
Upload 9 files
Browse files- README.md +68 -0
- cocom.png +0 -0
- config.json +25 -0
- generation_config.json +5 -0
- model-00001-of-00003.safetensors +3 -0
- model-00002-of-00003.safetensors +3 -0
- model-00003-of-00003.safetensors +3 -0
- model.safetensors.index.json +746 -0
- modeling_cocom.py +306 -0
README.md
ADDED
|
@@ -0,0 +1,68 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
library_name: transformers
|
| 3 |
+
language:
|
| 4 |
+
- en
|
| 5 |
+
base_model:
|
| 6 |
+
- mistralai/Mistral-7B-Instruct-v0.2
|
| 7 |
+
---
|
| 8 |
+
|
| 9 |
+
# Summary
|
| 10 |
+
|
| 11 |
+
<!-- Provide a quick summary of what the model is/does. -->
|
| 12 |
+
|
| 13 |
+
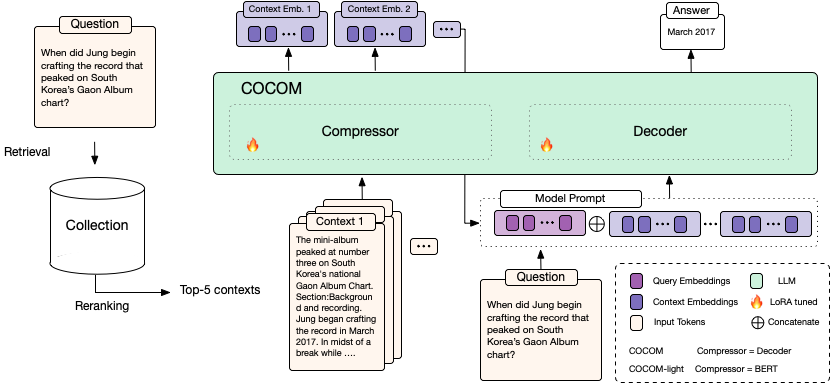
COCOM is an effective context compression method, reducing long contexts to only a handful of Context Embeddings speeding up the generation time for Question Answering
|
| 14 |
+
|
| 15 |
+

|
| 16 |
+
|
| 17 |
+
## Context Embeddings for Efficient Answer Generation in RAG
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
*Retrieval-Augmented Generation* (RAG) allows overcoming the limited knowledge of LLMs by extending the input with external context. A major drawback in RAG is the considerable increase in decoding time with longer inputs. We address this challenge by presenting **COCOM**, an effective context compression method, reducing long contexts to only a handful of *Context Embeddings* speeding up the generation time. Our method allows for different compression rates trading off decoding time for answer quality. Compared to earlier methods, COCOM allows for handling multiple contexts more effectively, significantly reducing decoding time for long inputs. Our method demonstrates a speed-up of up to 5.69 times while achieving higher performance compared to existing efficient context compression methods.
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
## Model Inference
|
| 24 |
+
|
| 25 |
+
For batch processing, the model takes as input
|
| 26 |
+
|
| 27 |
+
- `questions` (`list`): A list containing questions
|
| 28 |
+
- `contexts` (`list of lists`). For each question a list of contexts, where the number of contexts is fixed throughout questions. The models have been fine-tuned (and should be inferenced) with `5` contexts.
|
| 29 |
+
|
| 30 |
+
The model compresses the questions into context embeddings and answers the question based on the provided context embeddings.
|
| 31 |
+
|
| 32 |
+
```python
|
| 33 |
+
from transformers import AutoModel
|
| 34 |
+
|
| 35 |
+
model = AutoModel.from_pretrained('naver/cocom-v1-4-mistral-7b', trust_remote_code=True)
|
| 36 |
+
model = model.to('cuda')
|
| 37 |
+
contexts = [[
|
| 38 |
+
'Rosalind Bailey. Rosalind Bailey Rosalind Bailey (born 1946) is a British actress, known for her portrayal of Sarah Headley ("née" Lytton) in the 1970s and 1980s BBC television drama “When the Boat Comes In". Bailey has appeared in numerous British television drama series, including "Byker Grove", “Distant Shores" and "Burn Up". Her stage work includes playing Miss Mary Shepherd in Alan Bennett’s play "The Lady in the Van”.',
|
| 39 |
+
'Malcolm Terris. Malcolm Terris Malcolm Terris (born 11 January 1941 in Sunderland, County Durham) is a British actor. He had a lengthy career in a large number of television programmes. Possibly his best-known role was in "When the Boat Comes In", a popular 1970s series, where he played the part of Matt Headley. His film career includes appearances in "The First Great Train Robbery" (1978), "McVicar" (1980), "The Plague Dogs" (1982, voice only), "Slayground" (1983), “The Bounty" (1984) as Thomas Huggan, ship’s surgeon, "Mata Hari" (1985), "Revolution" (1985), “Scandal" (1989), and “Chaplin” (1992). His TV appearances include: One episode of',
|
| 40 |
+
'When the Boat Comes In. When the Boat Comes In When the Boat Comes In is a British television period drama produced by the BBC between 1976 and 1981. The series stars James Bolam as Jack Ford, a First World War veteran who returns to his poverty-stricken (fictional) town of Gallowshield in the North East of England. The series dramatises the political struggles of the 1920s and 1930s and explores the impact of national and international politics upon Ford and the people around him. Section:Production. The majority of episodes were written by creator James Mitchell, but in Series 1 north-eastern',
|
| 41 |
+
'Susie Youssef. Youssef began her comedy career as a writer for "The Ronnie Johns Half Hour" in 2006, and made her acting debut in the short film "Clicked" in the role of Lina in 2011. In 2014, she played Jane in the short film "Kevin Needs to Make New Friends: Because Everyone Hates Him for Some Reason" and then turned to television where she appeared in "The Chaser’s Media Circus". In 2014, Youssef played the lead role of Sarah in the Hayloft Project’s stage play "The Boat People" which won the Best On Stage award at the FBi SMAC Awards',
|
| 42 |
+
'Madelaine Newton. Madelaine Newton Madelaine Newton is a British actress best known for her portrayal of Dolly in 1970s BBC television drama "When the Boat Comes In". She is married to actor Kevin Whately, known for his role as Robert "Robbie" Lewis in both "Inspector Morse” and its spin-off "Lewis". They have two children. She starred alongside her husband in the “Inspector Morse" episode "Masonic Mysteries" as Beryl Newsome - the love-interest of Morse - whom Morse was wrongly suspected of murdering. She played Whately’s on-screen wife in the 1988 Look and Read children’s serial, Geordie Racer. She also made'
|
| 43 |
+
]]
|
| 44 |
+
questions = ['who played sarah hedley in when the boat comes in?']
|
| 45 |
+
|
| 46 |
+
answers = model.generate_from_text(contexts=contexts, questions=questions, max_new_tokens=128)
|
| 47 |
+
|
| 48 |
+
print(answers)
|
| 49 |
+
```
|
| 50 |
+
|
| 51 |
+
|
| 52 |
+
|
| 53 |
+
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
|
| 54 |
+
|
| 55 |
+
**References:**
|
| 56 |
+
|
| 57 |
+
**Paper**: https://arxiv.org/pdf/2407.09252
|
| 58 |
+
```
|
| 59 |
+
@misc{rau2024contextembeddingsefficientanswer,
|
| 60 |
+
title={Context Embeddings for Efficient Answer Generation in RAG},
|
| 61 |
+
author={David Rau and Shuai Wang and Hervé Déjean and Stéphane Clinchant},
|
| 62 |
+
year={2024},
|
| 63 |
+
eprint={2407.09252},
|
| 64 |
+
archivePrefix={arXiv},
|
| 65 |
+
primaryClass={cs.CL},
|
| 66 |
+
url={https://arxiv.org/abs/2407.09252},
|
| 67 |
+
}
|
| 68 |
+
```
|
cocom.png
ADDED
|
config.json
ADDED
|
@@ -0,0 +1,25 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_name_or_path": "/scratch/1/user/sclincha/cocom_release/cocom-v1-4-mistral-7b/",
|
| 3 |
+
"architectures": [
|
| 4 |
+
"COCOM"
|
| 5 |
+
],
|
| 6 |
+
"auto_map": {
|
| 7 |
+
"AutoConfig": "modeling_cocom.COCOMConfig",
|
| 8 |
+
"AutoModel": "modeling_cocom.COCOM",
|
| 9 |
+
"AutoModelForCausalLM": "modeling_cocom.COCOM"
|
| 10 |
+
},
|
| 11 |
+
"compr_linear_type": "concat",
|
| 12 |
+
"compr_model_name": null,
|
| 13 |
+
"compr_rate": 4,
|
| 14 |
+
"decoder_model_name": "mistralai/Mistral-7B-Instruct-v0.2",
|
| 15 |
+
"generation_top_k": 5,
|
| 16 |
+
"lora": true,
|
| 17 |
+
"lora_r": 16,
|
| 18 |
+
"max_new_tokens": 128,
|
| 19 |
+
"model_type": "COCOM",
|
| 20 |
+
"quantization": "no",
|
| 21 |
+
"sep": false,
|
| 22 |
+
"torch_dtype": "bfloat16",
|
| 23 |
+
"training_form": "both",
|
| 24 |
+
"transformers_version": "4.45.2"
|
| 25 |
+
}
|
generation_config.json
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_from_model_config": true,
|
| 3 |
+
"max_new_tokens": 128,
|
| 4 |
+
"transformers_version": "4.45.2"
|
| 5 |
+
}
|
model-00001-of-00003.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:0fe5aba54200930a590d773567a042402a03f6e313f6bdfa19b7c7aeb7014b06
|
| 3 |
+
size 4971467720
|
model-00002-of-00003.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:502881d0b08de90d4a8e29665b253a4dd691a71c769a19e77b2de1cd9686a987
|
| 3 |
+
size 4996308792
|
model-00003-of-00003.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:4dd7504c0fe0be1055012a2a8eb5f728e23c9240bbf6c8381c20fcf31585d440
|
| 3 |
+
size 4599751896
|
model.safetensors.index.json
ADDED
|
@@ -0,0 +1,746 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"metadata": {
|
| 3 |
+
"total_size": 14567415808
|
| 4 |
+
},
|
| 5 |
+
"weight_map": {
|
| 6 |
+
"decoder.base_model.model.lm_head.weight": "model-00003-of-00003.safetensors",
|
| 7 |
+
"decoder.base_model.model.model.embed_tokens.weight": "model-00001-of-00003.safetensors",
|
| 8 |
+
"decoder.base_model.model.model.layers.0.input_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 9 |
+
"decoder.base_model.model.model.layers.0.mlp.down_proj.base_layer.weight": "model-00001-of-00003.safetensors",
|
| 10 |
+
"decoder.base_model.model.model.layers.0.mlp.down_proj.lora_A.default.weight": "model-00001-of-00003.safetensors",
|
| 11 |
+
"decoder.base_model.model.model.layers.0.mlp.down_proj.lora_B.default.weight": "model-00001-of-00003.safetensors",
|
| 12 |
+
"decoder.base_model.model.model.layers.0.mlp.gate_proj.base_layer.weight": "model-00001-of-00003.safetensors",
|
| 13 |
+
"decoder.base_model.model.model.layers.0.mlp.gate_proj.lora_A.default.weight": "model-00001-of-00003.safetensors",
|
| 14 |
+
"decoder.base_model.model.model.layers.0.mlp.gate_proj.lora_B.default.weight": "model-00001-of-00003.safetensors",
|
| 15 |
+
"decoder.base_model.model.model.layers.0.mlp.up_proj.base_layer.weight": "model-00001-of-00003.safetensors",
|
| 16 |
+
"decoder.base_model.model.model.layers.0.mlp.up_proj.lora_A.default.weight": "model-00001-of-00003.safetensors",
|
| 17 |
+
"decoder.base_model.model.model.layers.0.mlp.up_proj.lora_B.default.weight": "model-00001-of-00003.safetensors",
|
| 18 |
+
"decoder.base_model.model.model.layers.0.post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 19 |
+
"decoder.base_model.model.model.layers.0.self_attn.k_proj.base_layer.weight": "model-00001-of-00003.safetensors",
|
| 20 |
+
"decoder.base_model.model.model.layers.0.self_attn.k_proj.lora_A.default.weight": "model-00001-of-00003.safetensors",
|
| 21 |
+
"decoder.base_model.model.model.layers.0.self_attn.k_proj.lora_B.default.weight": "model-00001-of-00003.safetensors",
|
| 22 |
+
"decoder.base_model.model.model.layers.0.self_attn.o_proj.base_layer.weight": "model-00001-of-00003.safetensors",
|
| 23 |
+
"decoder.base_model.model.model.layers.0.self_attn.o_proj.lora_A.default.weight": "model-00001-of-00003.safetensors",
|
| 24 |
+
"decoder.base_model.model.model.layers.0.self_attn.o_proj.lora_B.default.weight": "model-00001-of-00003.safetensors",
|
| 25 |
+
"decoder.base_model.model.model.layers.0.self_attn.q_proj.base_layer.weight": "model-00001-of-00003.safetensors",
|
| 26 |
+
"decoder.base_model.model.model.layers.0.self_attn.q_proj.lora_A.default.weight": "model-00001-of-00003.safetensors",
|
| 27 |
+
"decoder.base_model.model.model.layers.0.self_attn.q_proj.lora_B.default.weight": "model-00001-of-00003.safetensors",
|
| 28 |
+
"decoder.base_model.model.model.layers.0.self_attn.v_proj.base_layer.weight": "model-00001-of-00003.safetensors",
|
| 29 |
+
"decoder.base_model.model.model.layers.0.self_attn.v_proj.lora_A.default.weight": "model-00001-of-00003.safetensors",
|
| 30 |
+
"decoder.base_model.model.model.layers.0.self_attn.v_proj.lora_B.default.weight": "model-00001-of-00003.safetensors",
|
| 31 |
+
"decoder.base_model.model.model.layers.1.input_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 32 |
+
"decoder.base_model.model.model.layers.1.mlp.down_proj.base_layer.weight": "model-00001-of-00003.safetensors",
|
| 33 |
+
"decoder.base_model.model.model.layers.1.mlp.down_proj.lora_A.default.weight": "model-00001-of-00003.safetensors",
|
| 34 |
+
"decoder.base_model.model.model.layers.1.mlp.down_proj.lora_B.default.weight": "model-00001-of-00003.safetensors",
|
| 35 |
+
"decoder.base_model.model.model.layers.1.mlp.gate_proj.base_layer.weight": "model-00001-of-00003.safetensors",
|
| 36 |
+
"decoder.base_model.model.model.layers.1.mlp.gate_proj.lora_A.default.weight": "model-00001-of-00003.safetensors",
|
| 37 |
+
"decoder.base_model.model.model.layers.1.mlp.gate_proj.lora_B.default.weight": "model-00001-of-00003.safetensors",
|
| 38 |
+
"decoder.base_model.model.model.layers.1.mlp.up_proj.base_layer.weight": "model-00001-of-00003.safetensors",
|
| 39 |
+
"decoder.base_model.model.model.layers.1.mlp.up_proj.lora_A.default.weight": "model-00001-of-00003.safetensors",
|
| 40 |
+
"decoder.base_model.model.model.layers.1.mlp.up_proj.lora_B.default.weight": "model-00001-of-00003.safetensors",
|
| 41 |
+
"decoder.base_model.model.model.layers.1.post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 42 |
+
"decoder.base_model.model.model.layers.1.self_attn.k_proj.base_layer.weight": "model-00001-of-00003.safetensors",
|
| 43 |
+
"decoder.base_model.model.model.layers.1.self_attn.k_proj.lora_A.default.weight": "model-00001-of-00003.safetensors",
|
| 44 |
+
"decoder.base_model.model.model.layers.1.self_attn.k_proj.lora_B.default.weight": "model-00001-of-00003.safetensors",
|
| 45 |
+
"decoder.base_model.model.model.layers.1.self_attn.o_proj.base_layer.weight": "model-00001-of-00003.safetensors",
|
| 46 |
+
"decoder.base_model.model.model.layers.1.self_attn.o_proj.lora_A.default.weight": "model-00001-of-00003.safetensors",
|
| 47 |
+
"decoder.base_model.model.model.layers.1.self_attn.o_proj.lora_B.default.weight": "model-00001-of-00003.safetensors",
|
| 48 |
+
"decoder.base_model.model.model.layers.1.self_attn.q_proj.base_layer.weight": "model-00001-of-00003.safetensors",
|
| 49 |
+
"decoder.base_model.model.model.layers.1.self_attn.q_proj.lora_A.default.weight": "model-00001-of-00003.safetensors",
|
| 50 |
+
"decoder.base_model.model.model.layers.1.self_attn.q_proj.lora_B.default.weight": "model-00001-of-00003.safetensors",
|
| 51 |
+
"decoder.base_model.model.model.layers.1.self_attn.v_proj.base_layer.weight": "model-00001-of-00003.safetensors",
|
| 52 |
+
"decoder.base_model.model.model.layers.1.self_attn.v_proj.lora_A.default.weight": "model-00001-of-00003.safetensors",
|
| 53 |
+
"decoder.base_model.model.model.layers.1.self_attn.v_proj.lora_B.default.weight": "model-00001-of-00003.safetensors",
|
| 54 |
+
"decoder.base_model.model.model.layers.10.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 55 |
+
"decoder.base_model.model.model.layers.10.mlp.down_proj.base_layer.weight": "model-00002-of-00003.safetensors",
|
| 56 |
+
"decoder.base_model.model.model.layers.10.mlp.down_proj.lora_A.default.weight": "model-00002-of-00003.safetensors",
|
| 57 |
+
"decoder.base_model.model.model.layers.10.mlp.down_proj.lora_B.default.weight": "model-00002-of-00003.safetensors",
|
| 58 |
+
"decoder.base_model.model.model.layers.10.mlp.gate_proj.base_layer.weight": "model-00001-of-00003.safetensors",
|
| 59 |
+
"decoder.base_model.model.model.layers.10.mlp.gate_proj.lora_A.default.weight": "model-00001-of-00003.safetensors",
|
| 60 |
+
"decoder.base_model.model.model.layers.10.mlp.gate_proj.lora_B.default.weight": "model-00001-of-00003.safetensors",
|
| 61 |
+
"decoder.base_model.model.model.layers.10.mlp.up_proj.base_layer.weight": "model-00001-of-00003.safetensors",
|
| 62 |
+
"decoder.base_model.model.model.layers.10.mlp.up_proj.lora_A.default.weight": "model-00001-of-00003.safetensors",
|
| 63 |
+
"decoder.base_model.model.model.layers.10.mlp.up_proj.lora_B.default.weight": "model-00001-of-00003.safetensors",
|
| 64 |
+
"decoder.base_model.model.model.layers.10.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 65 |
+
"decoder.base_model.model.model.layers.10.self_attn.k_proj.base_layer.weight": "model-00001-of-00003.safetensors",
|
| 66 |
+
"decoder.base_model.model.model.layers.10.self_attn.k_proj.lora_A.default.weight": "model-00001-of-00003.safetensors",
|
| 67 |
+
"decoder.base_model.model.model.layers.10.self_attn.k_proj.lora_B.default.weight": "model-00001-of-00003.safetensors",
|
| 68 |
+
"decoder.base_model.model.model.layers.10.self_attn.o_proj.base_layer.weight": "model-00001-of-00003.safetensors",
|
| 69 |
+
"decoder.base_model.model.model.layers.10.self_attn.o_proj.lora_A.default.weight": "model-00001-of-00003.safetensors",
|
| 70 |
+
"decoder.base_model.model.model.layers.10.self_attn.o_proj.lora_B.default.weight": "model-00001-of-00003.safetensors",
|
| 71 |
+
"decoder.base_model.model.model.layers.10.self_attn.q_proj.base_layer.weight": "model-00001-of-00003.safetensors",
|
| 72 |
+
"decoder.base_model.model.model.layers.10.self_attn.q_proj.lora_A.default.weight": "model-00001-of-00003.safetensors",
|
| 73 |
+
"decoder.base_model.model.model.layers.10.self_attn.q_proj.lora_B.default.weight": "model-00001-of-00003.safetensors",
|
| 74 |
+
"decoder.base_model.model.model.layers.10.self_attn.v_proj.base_layer.weight": "model-00001-of-00003.safetensors",
|
| 75 |
+
"decoder.base_model.model.model.layers.10.self_attn.v_proj.lora_A.default.weight": "model-00001-of-00003.safetensors",
|
| 76 |
+
"decoder.base_model.model.model.layers.10.self_attn.v_proj.lora_B.default.weight": "model-00001-of-00003.safetensors",
|
| 77 |
+
"decoder.base_model.model.model.layers.11.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 78 |
+
"decoder.base_model.model.model.layers.11.mlp.down_proj.base_layer.weight": "model-00002-of-00003.safetensors",
|
| 79 |
+
"decoder.base_model.model.model.layers.11.mlp.down_proj.lora_A.default.weight": "model-00002-of-00003.safetensors",
|
| 80 |
+
"decoder.base_model.model.model.layers.11.mlp.down_proj.lora_B.default.weight": "model-00002-of-00003.safetensors",
|
| 81 |
+
"decoder.base_model.model.model.layers.11.mlp.gate_proj.base_layer.weight": "model-00002-of-00003.safetensors",
|
| 82 |
+
"decoder.base_model.model.model.layers.11.mlp.gate_proj.lora_A.default.weight": "model-00002-of-00003.safetensors",
|
| 83 |
+
"decoder.base_model.model.model.layers.11.mlp.gate_proj.lora_B.default.weight": "model-00002-of-00003.safetensors",
|
| 84 |
+
"decoder.base_model.model.model.layers.11.mlp.up_proj.base_layer.weight": "model-00002-of-00003.safetensors",
|
| 85 |
+
"decoder.base_model.model.model.layers.11.mlp.up_proj.lora_A.default.weight": "model-00002-of-00003.safetensors",
|
| 86 |
+
"decoder.base_model.model.model.layers.11.mlp.up_proj.lora_B.default.weight": "model-00002-of-00003.safetensors",
|
| 87 |
+
"decoder.base_model.model.model.layers.11.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 88 |
+
"decoder.base_model.model.model.layers.11.self_attn.k_proj.base_layer.weight": "model-00002-of-00003.safetensors",
|
| 89 |
+
"decoder.base_model.model.model.layers.11.self_attn.k_proj.lora_A.default.weight": "model-00002-of-00003.safetensors",
|
| 90 |
+
"decoder.base_model.model.model.layers.11.self_attn.k_proj.lora_B.default.weight": "model-00002-of-00003.safetensors",
|
| 91 |
+
"decoder.base_model.model.model.layers.11.self_attn.o_proj.base_layer.weight": "model-00002-of-00003.safetensors",
|
| 92 |
+
"decoder.base_model.model.model.layers.11.self_attn.o_proj.lora_A.default.weight": "model-00002-of-00003.safetensors",
|
| 93 |
+
"decoder.base_model.model.model.layers.11.self_attn.o_proj.lora_B.default.weight": "model-00002-of-00003.safetensors",
|
| 94 |
+
"decoder.base_model.model.model.layers.11.self_attn.q_proj.base_layer.weight": "model-00002-of-00003.safetensors",
|
| 95 |
+
"decoder.base_model.model.model.layers.11.self_attn.q_proj.lora_A.default.weight": "model-00002-of-00003.safetensors",
|
| 96 |
+
"decoder.base_model.model.model.layers.11.self_attn.q_proj.lora_B.default.weight": "model-00002-of-00003.safetensors",
|
| 97 |
+
"decoder.base_model.model.model.layers.11.self_attn.v_proj.base_layer.weight": "model-00002-of-00003.safetensors",
|
| 98 |
+
"decoder.base_model.model.model.layers.11.self_attn.v_proj.lora_A.default.weight": "model-00002-of-00003.safetensors",
|
| 99 |
+
"decoder.base_model.model.model.layers.11.self_attn.v_proj.lora_B.default.weight": "model-00002-of-00003.safetensors",
|
| 100 |
+
"decoder.base_model.model.model.layers.12.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 101 |
+
"decoder.base_model.model.model.layers.12.mlp.down_proj.base_layer.weight": "model-00002-of-00003.safetensors",
|
| 102 |
+
"decoder.base_model.model.model.layers.12.mlp.down_proj.lora_A.default.weight": "model-00002-of-00003.safetensors",
|
| 103 |
+
"decoder.base_model.model.model.layers.12.mlp.down_proj.lora_B.default.weight": "model-00002-of-00003.safetensors",
|
| 104 |
+
"decoder.base_model.model.model.layers.12.mlp.gate_proj.base_layer.weight": "model-00002-of-00003.safetensors",
|
| 105 |
+
"decoder.base_model.model.model.layers.12.mlp.gate_proj.lora_A.default.weight": "model-00002-of-00003.safetensors",
|
| 106 |
+
"decoder.base_model.model.model.layers.12.mlp.gate_proj.lora_B.default.weight": "model-00002-of-00003.safetensors",
|
| 107 |
+
"decoder.base_model.model.model.layers.12.mlp.up_proj.base_layer.weight": "model-00002-of-00003.safetensors",
|
| 108 |
+
"decoder.base_model.model.model.layers.12.mlp.up_proj.lora_A.default.weight": "model-00002-of-00003.safetensors",
|
| 109 |
+
"decoder.base_model.model.model.layers.12.mlp.up_proj.lora_B.default.weight": "model-00002-of-00003.safetensors",
|
| 110 |
+
"decoder.base_model.model.model.layers.12.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 111 |
+
"decoder.base_model.model.model.layers.12.self_attn.k_proj.base_layer.weight": "model-00002-of-00003.safetensors",
|
| 112 |
+
"decoder.base_model.model.model.layers.12.self_attn.k_proj.lora_A.default.weight": "model-00002-of-00003.safetensors",
|
| 113 |
+
"decoder.base_model.model.model.layers.12.self_attn.k_proj.lora_B.default.weight": "model-00002-of-00003.safetensors",
|
| 114 |
+
"decoder.base_model.model.model.layers.12.self_attn.o_proj.base_layer.weight": "model-00002-of-00003.safetensors",
|
| 115 |
+
"decoder.base_model.model.model.layers.12.self_attn.o_proj.lora_A.default.weight": "model-00002-of-00003.safetensors",
|
| 116 |
+
"decoder.base_model.model.model.layers.12.self_attn.o_proj.lora_B.default.weight": "model-00002-of-00003.safetensors",
|
| 117 |
+
"decoder.base_model.model.model.layers.12.self_attn.q_proj.base_layer.weight": "model-00002-of-00003.safetensors",
|
| 118 |
+
"decoder.base_model.model.model.layers.12.self_attn.q_proj.lora_A.default.weight": "model-00002-of-00003.safetensors",
|
| 119 |
+
"decoder.base_model.model.model.layers.12.self_attn.q_proj.lora_B.default.weight": "model-00002-of-00003.safetensors",
|
| 120 |
+
"decoder.base_model.model.model.layers.12.self_attn.v_proj.base_layer.weight": "model-00002-of-00003.safetensors",
|
| 121 |
+
"decoder.base_model.model.model.layers.12.self_attn.v_proj.lora_A.default.weight": "model-00002-of-00003.safetensors",
|
| 122 |
+
"decoder.base_model.model.model.layers.12.self_attn.v_proj.lora_B.default.weight": "model-00002-of-00003.safetensors",
|
| 123 |
+
"decoder.base_model.model.model.layers.13.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 124 |
+
"decoder.base_model.model.model.layers.13.mlp.down_proj.base_layer.weight": "model-00002-of-00003.safetensors",
|
| 125 |
+
"decoder.base_model.model.model.layers.13.mlp.down_proj.lora_A.default.weight": "model-00002-of-00003.safetensors",
|
| 126 |
+
"decoder.base_model.model.model.layers.13.mlp.down_proj.lora_B.default.weight": "model-00002-of-00003.safetensors",
|
| 127 |
+
"decoder.base_model.model.model.layers.13.mlp.gate_proj.base_layer.weight": "model-00002-of-00003.safetensors",
|
| 128 |
+
"decoder.base_model.model.model.layers.13.mlp.gate_proj.lora_A.default.weight": "model-00002-of-00003.safetensors",
|
| 129 |
+
"decoder.base_model.model.model.layers.13.mlp.gate_proj.lora_B.default.weight": "model-00002-of-00003.safetensors",
|
| 130 |
+
"decoder.base_model.model.model.layers.13.mlp.up_proj.base_layer.weight": "model-00002-of-00003.safetensors",
|
| 131 |
+
"decoder.base_model.model.model.layers.13.mlp.up_proj.lora_A.default.weight": "model-00002-of-00003.safetensors",
|
| 132 |
+
"decoder.base_model.model.model.layers.13.mlp.up_proj.lora_B.default.weight": "model-00002-of-00003.safetensors",
|
| 133 |
+
"decoder.base_model.model.model.layers.13.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 134 |
+
"decoder.base_model.model.model.layers.13.self_attn.k_proj.base_layer.weight": "model-00002-of-00003.safetensors",
|
| 135 |
+
"decoder.base_model.model.model.layers.13.self_attn.k_proj.lora_A.default.weight": "model-00002-of-00003.safetensors",
|
| 136 |
+
"decoder.base_model.model.model.layers.13.self_attn.k_proj.lora_B.default.weight": "model-00002-of-00003.safetensors",
|
| 137 |
+
"decoder.base_model.model.model.layers.13.self_attn.o_proj.base_layer.weight": "model-00002-of-00003.safetensors",
|
| 138 |
+
"decoder.base_model.model.model.layers.13.self_attn.o_proj.lora_A.default.weight": "model-00002-of-00003.safetensors",
|
| 139 |
+
"decoder.base_model.model.model.layers.13.self_attn.o_proj.lora_B.default.weight": "model-00002-of-00003.safetensors",
|
| 140 |
+
"decoder.base_model.model.model.layers.13.self_attn.q_proj.base_layer.weight": "model-00002-of-00003.safetensors",
|
| 141 |
+
"decoder.base_model.model.model.layers.13.self_attn.q_proj.lora_A.default.weight": "model-00002-of-00003.safetensors",
|
| 142 |
+
"decoder.base_model.model.model.layers.13.self_attn.q_proj.lora_B.default.weight": "model-00002-of-00003.safetensors",
|
| 143 |
+
"decoder.base_model.model.model.layers.13.self_attn.v_proj.base_layer.weight": "model-00002-of-00003.safetensors",
|
| 144 |
+
"decoder.base_model.model.model.layers.13.self_attn.v_proj.lora_A.default.weight": "model-00002-of-00003.safetensors",
|
| 145 |
+
"decoder.base_model.model.model.layers.13.self_attn.v_proj.lora_B.default.weight": "model-00002-of-00003.safetensors",
|
| 146 |
+
"decoder.base_model.model.model.layers.14.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 147 |
+
"decoder.base_model.model.model.layers.14.mlp.down_proj.base_layer.weight": "model-00002-of-00003.safetensors",
|
| 148 |
+
"decoder.base_model.model.model.layers.14.mlp.down_proj.lora_A.default.weight": "model-00002-of-00003.safetensors",
|
| 149 |
+
"decoder.base_model.model.model.layers.14.mlp.down_proj.lora_B.default.weight": "model-00002-of-00003.safetensors",
|
| 150 |
+
"decoder.base_model.model.model.layers.14.mlp.gate_proj.base_layer.weight": "model-00002-of-00003.safetensors",
|
| 151 |
+
"decoder.base_model.model.model.layers.14.mlp.gate_proj.lora_A.default.weight": "model-00002-of-00003.safetensors",
|
| 152 |
+
"decoder.base_model.model.model.layers.14.mlp.gate_proj.lora_B.default.weight": "model-00002-of-00003.safetensors",
|
| 153 |
+
"decoder.base_model.model.model.layers.14.mlp.up_proj.base_layer.weight": "model-00002-of-00003.safetensors",
|
| 154 |
+
"decoder.base_model.model.model.layers.14.mlp.up_proj.lora_A.default.weight": "model-00002-of-00003.safetensors",
|
| 155 |
+
"decoder.base_model.model.model.layers.14.mlp.up_proj.lora_B.default.weight": "model-00002-of-00003.safetensors",
|
| 156 |
+
"decoder.base_model.model.model.layers.14.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 157 |
+
"decoder.base_model.model.model.layers.14.self_attn.k_proj.base_layer.weight": "model-00002-of-00003.safetensors",
|
| 158 |
+
"decoder.base_model.model.model.layers.14.self_attn.k_proj.lora_A.default.weight": "model-00002-of-00003.safetensors",
|
| 159 |
+
"decoder.base_model.model.model.layers.14.self_attn.k_proj.lora_B.default.weight": "model-00002-of-00003.safetensors",
|
| 160 |
+
"decoder.base_model.model.model.layers.14.self_attn.o_proj.base_layer.weight": "model-00002-of-00003.safetensors",
|
| 161 |
+
"decoder.base_model.model.model.layers.14.self_attn.o_proj.lora_A.default.weight": "model-00002-of-00003.safetensors",
|
| 162 |
+
"decoder.base_model.model.model.layers.14.self_attn.o_proj.lora_B.default.weight": "model-00002-of-00003.safetensors",
|
| 163 |
+
"decoder.base_model.model.model.layers.14.self_attn.q_proj.base_layer.weight": "model-00002-of-00003.safetensors",
|
| 164 |
+
"decoder.base_model.model.model.layers.14.self_attn.q_proj.lora_A.default.weight": "model-00002-of-00003.safetensors",
|
| 165 |
+
"decoder.base_model.model.model.layers.14.self_attn.q_proj.lora_B.default.weight": "model-00002-of-00003.safetensors",
|
| 166 |
+
"decoder.base_model.model.model.layers.14.self_attn.v_proj.base_layer.weight": "model-00002-of-00003.safetensors",
|
| 167 |
+
"decoder.base_model.model.model.layers.14.self_attn.v_proj.lora_A.default.weight": "model-00002-of-00003.safetensors",
|
| 168 |
+
"decoder.base_model.model.model.layers.14.self_attn.v_proj.lora_B.default.weight": "model-00002-of-00003.safetensors",
|
| 169 |
+
"decoder.base_model.model.model.layers.15.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 170 |
+
"decoder.base_model.model.model.layers.15.mlp.down_proj.base_layer.weight": "model-00002-of-00003.safetensors",
|
| 171 |
+
"decoder.base_model.model.model.layers.15.mlp.down_proj.lora_A.default.weight": "model-00002-of-00003.safetensors",
|
| 172 |
+
"decoder.base_model.model.model.layers.15.mlp.down_proj.lora_B.default.weight": "model-00002-of-00003.safetensors",
|
| 173 |
+
"decoder.base_model.model.model.layers.15.mlp.gate_proj.base_layer.weight": "model-00002-of-00003.safetensors",
|
| 174 |
+
"decoder.base_model.model.model.layers.15.mlp.gate_proj.lora_A.default.weight": "model-00002-of-00003.safetensors",
|
| 175 |
+
"decoder.base_model.model.model.layers.15.mlp.gate_proj.lora_B.default.weight": "model-00002-of-00003.safetensors",
|
| 176 |
+
"decoder.base_model.model.model.layers.15.mlp.up_proj.base_layer.weight": "model-00002-of-00003.safetensors",
|
| 177 |
+
"decoder.base_model.model.model.layers.15.mlp.up_proj.lora_A.default.weight": "model-00002-of-00003.safetensors",
|
| 178 |
+
"decoder.base_model.model.model.layers.15.mlp.up_proj.lora_B.default.weight": "model-00002-of-00003.safetensors",
|
| 179 |
+
"decoder.base_model.model.model.layers.15.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 180 |
+
"decoder.base_model.model.model.layers.15.self_attn.k_proj.base_layer.weight": "model-00002-of-00003.safetensors",
|
| 181 |
+
"decoder.base_model.model.model.layers.15.self_attn.k_proj.lora_A.default.weight": "model-00002-of-00003.safetensors",
|
| 182 |
+
"decoder.base_model.model.model.layers.15.self_attn.k_proj.lora_B.default.weight": "model-00002-of-00003.safetensors",
|
| 183 |
+
"decoder.base_model.model.model.layers.15.self_attn.o_proj.base_layer.weight": "model-00002-of-00003.safetensors",
|
| 184 |
+
"decoder.base_model.model.model.layers.15.self_attn.o_proj.lora_A.default.weight": "model-00002-of-00003.safetensors",
|
| 185 |
+
"decoder.base_model.model.model.layers.15.self_attn.o_proj.lora_B.default.weight": "model-00002-of-00003.safetensors",
|
| 186 |
+
"decoder.base_model.model.model.layers.15.self_attn.q_proj.base_layer.weight": "model-00002-of-00003.safetensors",
|
| 187 |
+
"decoder.base_model.model.model.layers.15.self_attn.q_proj.lora_A.default.weight": "model-00002-of-00003.safetensors",
|
| 188 |
+
"decoder.base_model.model.model.layers.15.self_attn.q_proj.lora_B.default.weight": "model-00002-of-00003.safetensors",
|
| 189 |
+
"decoder.base_model.model.model.layers.15.self_attn.v_proj.base_layer.weight": "model-00002-of-00003.safetensors",
|
| 190 |
+
"decoder.base_model.model.model.layers.15.self_attn.v_proj.lora_A.default.weight": "model-00002-of-00003.safetensors",
|
| 191 |
+
"decoder.base_model.model.model.layers.15.self_attn.v_proj.lora_B.default.weight": "model-00002-of-00003.safetensors",
|
| 192 |
+
"decoder.base_model.model.model.layers.16.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 193 |
+
"decoder.base_model.model.model.layers.16.mlp.down_proj.base_layer.weight": "model-00002-of-00003.safetensors",
|
| 194 |
+
"decoder.base_model.model.model.layers.16.mlp.down_proj.lora_A.default.weight": "model-00002-of-00003.safetensors",
|
| 195 |
+
"decoder.base_model.model.model.layers.16.mlp.down_proj.lora_B.default.weight": "model-00002-of-00003.safetensors",
|
| 196 |
+
"decoder.base_model.model.model.layers.16.mlp.gate_proj.base_layer.weight": "model-00002-of-00003.safetensors",
|
| 197 |
+
"decoder.base_model.model.model.layers.16.mlp.gate_proj.lora_A.default.weight": "model-00002-of-00003.safetensors",
|
| 198 |
+
"decoder.base_model.model.model.layers.16.mlp.gate_proj.lora_B.default.weight": "model-00002-of-00003.safetensors",
|
| 199 |
+
"decoder.base_model.model.model.layers.16.mlp.up_proj.base_layer.weight": "model-00002-of-00003.safetensors",
|
| 200 |
+
"decoder.base_model.model.model.layers.16.mlp.up_proj.lora_A.default.weight": "model-00002-of-00003.safetensors",
|
| 201 |
+
"decoder.base_model.model.model.layers.16.mlp.up_proj.lora_B.default.weight": "model-00002-of-00003.safetensors",
|
| 202 |
+
"decoder.base_model.model.model.layers.16.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 203 |
+
"decoder.base_model.model.model.layers.16.self_attn.k_proj.base_layer.weight": "model-00002-of-00003.safetensors",
|
| 204 |
+
"decoder.base_model.model.model.layers.16.self_attn.k_proj.lora_A.default.weight": "model-00002-of-00003.safetensors",
|
| 205 |
+
"decoder.base_model.model.model.layers.16.self_attn.k_proj.lora_B.default.weight": "model-00002-of-00003.safetensors",
|
| 206 |
+
"decoder.base_model.model.model.layers.16.self_attn.o_proj.base_layer.weight": "model-00002-of-00003.safetensors",
|
| 207 |
+
"decoder.base_model.model.model.layers.16.self_attn.o_proj.lora_A.default.weight": "model-00002-of-00003.safetensors",
|
| 208 |
+
"decoder.base_model.model.model.layers.16.self_attn.o_proj.lora_B.default.weight": "model-00002-of-00003.safetensors",
|
| 209 |
+
"decoder.base_model.model.model.layers.16.self_attn.q_proj.base_layer.weight": "model-00002-of-00003.safetensors",
|
| 210 |
+
"decoder.base_model.model.model.layers.16.self_attn.q_proj.lora_A.default.weight": "model-00002-of-00003.safetensors",
|
| 211 |
+
"decoder.base_model.model.model.layers.16.self_attn.q_proj.lora_B.default.weight": "model-00002-of-00003.safetensors",
|
| 212 |
+
"decoder.base_model.model.model.layers.16.self_attn.v_proj.base_layer.weight": "model-00002-of-00003.safetensors",
|
| 213 |
+
"decoder.base_model.model.model.layers.16.self_attn.v_proj.lora_A.default.weight": "model-00002-of-00003.safetensors",
|
| 214 |
+
"decoder.base_model.model.model.layers.16.self_attn.v_proj.lora_B.default.weight": "model-00002-of-00003.safetensors",
|
| 215 |
+
"decoder.base_model.model.model.layers.17.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 216 |
+
"decoder.base_model.model.model.layers.17.mlp.down_proj.base_layer.weight": "model-00002-of-00003.safetensors",
|
| 217 |
+
"decoder.base_model.model.model.layers.17.mlp.down_proj.lora_A.default.weight": "model-00002-of-00003.safetensors",
|
| 218 |
+
"decoder.base_model.model.model.layers.17.mlp.down_proj.lora_B.default.weight": "model-00002-of-00003.safetensors",
|
| 219 |
+
"decoder.base_model.model.model.layers.17.mlp.gate_proj.base_layer.weight": "model-00002-of-00003.safetensors",
|
| 220 |
+
"decoder.base_model.model.model.layers.17.mlp.gate_proj.lora_A.default.weight": "model-00002-of-00003.safetensors",
|
| 221 |
+
"decoder.base_model.model.model.layers.17.mlp.gate_proj.lora_B.default.weight": "model-00002-of-00003.safetensors",
|
| 222 |
+
"decoder.base_model.model.model.layers.17.mlp.up_proj.base_layer.weight": "model-00002-of-00003.safetensors",
|
| 223 |
+
"decoder.base_model.model.model.layers.17.mlp.up_proj.lora_A.default.weight": "model-00002-of-00003.safetensors",
|
| 224 |
+
"decoder.base_model.model.model.layers.17.mlp.up_proj.lora_B.default.weight": "model-00002-of-00003.safetensors",
|
| 225 |
+
"decoder.base_model.model.model.layers.17.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 226 |
+
"decoder.base_model.model.model.layers.17.self_attn.k_proj.base_layer.weight": "model-00002-of-00003.safetensors",
|
| 227 |
+
"decoder.base_model.model.model.layers.17.self_attn.k_proj.lora_A.default.weight": "model-00002-of-00003.safetensors",
|
| 228 |
+
"decoder.base_model.model.model.layers.17.self_attn.k_proj.lora_B.default.weight": "model-00002-of-00003.safetensors",
|
| 229 |
+
"decoder.base_model.model.model.layers.17.self_attn.o_proj.base_layer.weight": "model-00002-of-00003.safetensors",
|
| 230 |
+
"decoder.base_model.model.model.layers.17.self_attn.o_proj.lora_A.default.weight": "model-00002-of-00003.safetensors",
|
| 231 |
+
"decoder.base_model.model.model.layers.17.self_attn.o_proj.lora_B.default.weight": "model-00002-of-00003.safetensors",
|
| 232 |
+
"decoder.base_model.model.model.layers.17.self_attn.q_proj.base_layer.weight": "model-00002-of-00003.safetensors",
|
| 233 |
+
"decoder.base_model.model.model.layers.17.self_attn.q_proj.lora_A.default.weight": "model-00002-of-00003.safetensors",
|
| 234 |
+
"decoder.base_model.model.model.layers.17.self_attn.q_proj.lora_B.default.weight": "model-00002-of-00003.safetensors",
|
| 235 |
+
"decoder.base_model.model.model.layers.17.self_attn.v_proj.base_layer.weight": "model-00002-of-00003.safetensors",
|
| 236 |
+
"decoder.base_model.model.model.layers.17.self_attn.v_proj.lora_A.default.weight": "model-00002-of-00003.safetensors",
|
| 237 |
+
"decoder.base_model.model.model.layers.17.self_attn.v_proj.lora_B.default.weight": "model-00002-of-00003.safetensors",
|
| 238 |
+
"decoder.base_model.model.model.layers.18.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 239 |
+
"decoder.base_model.model.model.layers.18.mlp.down_proj.base_layer.weight": "model-00002-of-00003.safetensors",
|
| 240 |
+
"decoder.base_model.model.model.layers.18.mlp.down_proj.lora_A.default.weight": "model-00002-of-00003.safetensors",
|
| 241 |
+
"decoder.base_model.model.model.layers.18.mlp.down_proj.lora_B.default.weight": "model-00002-of-00003.safetensors",
|
| 242 |
+
"decoder.base_model.model.model.layers.18.mlp.gate_proj.base_layer.weight": "model-00002-of-00003.safetensors",
|
| 243 |
+
"decoder.base_model.model.model.layers.18.mlp.gate_proj.lora_A.default.weight": "model-00002-of-00003.safetensors",
|
| 244 |
+
"decoder.base_model.model.model.layers.18.mlp.gate_proj.lora_B.default.weight": "model-00002-of-00003.safetensors",
|
| 245 |
+
"decoder.base_model.model.model.layers.18.mlp.up_proj.base_layer.weight": "model-00002-of-00003.safetensors",
|
| 246 |
+
"decoder.base_model.model.model.layers.18.mlp.up_proj.lora_A.default.weight": "model-00002-of-00003.safetensors",
|
| 247 |
+
"decoder.base_model.model.model.layers.18.mlp.up_proj.lora_B.default.weight": "model-00002-of-00003.safetensors",
|
| 248 |
+
"decoder.base_model.model.model.layers.18.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 249 |
+
"decoder.base_model.model.model.layers.18.self_attn.k_proj.base_layer.weight": "model-00002-of-00003.safetensors",
|
| 250 |
+
"decoder.base_model.model.model.layers.18.self_attn.k_proj.lora_A.default.weight": "model-00002-of-00003.safetensors",
|
| 251 |
+
"decoder.base_model.model.model.layers.18.self_attn.k_proj.lora_B.default.weight": "model-00002-of-00003.safetensors",
|
| 252 |
+
"decoder.base_model.model.model.layers.18.self_attn.o_proj.base_layer.weight": "model-00002-of-00003.safetensors",
|
| 253 |
+
"decoder.base_model.model.model.layers.18.self_attn.o_proj.lora_A.default.weight": "model-00002-of-00003.safetensors",
|
| 254 |
+
"decoder.base_model.model.model.layers.18.self_attn.o_proj.lora_B.default.weight": "model-00002-of-00003.safetensors",
|
| 255 |
+
"decoder.base_model.model.model.layers.18.self_attn.q_proj.base_layer.weight": "model-00002-of-00003.safetensors",
|
| 256 |
+
"decoder.base_model.model.model.layers.18.self_attn.q_proj.lora_A.default.weight": "model-00002-of-00003.safetensors",
|
| 257 |
+
"decoder.base_model.model.model.layers.18.self_attn.q_proj.lora_B.default.weight": "model-00002-of-00003.safetensors",
|
| 258 |
+
"decoder.base_model.model.model.layers.18.self_attn.v_proj.base_layer.weight": "model-00002-of-00003.safetensors",
|
| 259 |
+
"decoder.base_model.model.model.layers.18.self_attn.v_proj.lora_A.default.weight": "model-00002-of-00003.safetensors",
|
| 260 |
+
"decoder.base_model.model.model.layers.18.self_attn.v_proj.lora_B.default.weight": "model-00002-of-00003.safetensors",
|
| 261 |
+
"decoder.base_model.model.model.layers.19.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 262 |
+
"decoder.base_model.model.model.layers.19.mlp.down_proj.base_layer.weight": "model-00002-of-00003.safetensors",
|
| 263 |
+
"decoder.base_model.model.model.layers.19.mlp.down_proj.lora_A.default.weight": "model-00002-of-00003.safetensors",
|
| 264 |
+
"decoder.base_model.model.model.layers.19.mlp.down_proj.lora_B.default.weight": "model-00002-of-00003.safetensors",
|
| 265 |
+
"decoder.base_model.model.model.layers.19.mlp.gate_proj.base_layer.weight": "model-00002-of-00003.safetensors",
|
| 266 |
+
"decoder.base_model.model.model.layers.19.mlp.gate_proj.lora_A.default.weight": "model-00002-of-00003.safetensors",
|
| 267 |
+
"decoder.base_model.model.model.layers.19.mlp.gate_proj.lora_B.default.weight": "model-00002-of-00003.safetensors",
|
| 268 |
+
"decoder.base_model.model.model.layers.19.mlp.up_proj.base_layer.weight": "model-00002-of-00003.safetensors",
|
| 269 |
+
"decoder.base_model.model.model.layers.19.mlp.up_proj.lora_A.default.weight": "model-00002-of-00003.safetensors",
|
| 270 |
+
"decoder.base_model.model.model.layers.19.mlp.up_proj.lora_B.default.weight": "model-00002-of-00003.safetensors",
|
| 271 |
+
"decoder.base_model.model.model.layers.19.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 272 |
+
"decoder.base_model.model.model.layers.19.self_attn.k_proj.base_layer.weight": "model-00002-of-00003.safetensors",
|
| 273 |
+
"decoder.base_model.model.model.layers.19.self_attn.k_proj.lora_A.default.weight": "model-00002-of-00003.safetensors",
|
| 274 |
+
"decoder.base_model.model.model.layers.19.self_attn.k_proj.lora_B.default.weight": "model-00002-of-00003.safetensors",
|
| 275 |
+
"decoder.base_model.model.model.layers.19.self_attn.o_proj.base_layer.weight": "model-00002-of-00003.safetensors",
|
| 276 |
+
"decoder.base_model.model.model.layers.19.self_attn.o_proj.lora_A.default.weight": "model-00002-of-00003.safetensors",
|
| 277 |
+
"decoder.base_model.model.model.layers.19.self_attn.o_proj.lora_B.default.weight": "model-00002-of-00003.safetensors",
|
| 278 |
+
"decoder.base_model.model.model.layers.19.self_attn.q_proj.base_layer.weight": "model-00002-of-00003.safetensors",
|
| 279 |
+
"decoder.base_model.model.model.layers.19.self_attn.q_proj.lora_A.default.weight": "model-00002-of-00003.safetensors",
|
| 280 |
+
"decoder.base_model.model.model.layers.19.self_attn.q_proj.lora_B.default.weight": "model-00002-of-00003.safetensors",
|
| 281 |
+
"decoder.base_model.model.model.layers.19.self_attn.v_proj.base_layer.weight": "model-00002-of-00003.safetensors",
|
| 282 |
+
"decoder.base_model.model.model.layers.19.self_attn.v_proj.lora_A.default.weight": "model-00002-of-00003.safetensors",
|
| 283 |
+
"decoder.base_model.model.model.layers.19.self_attn.v_proj.lora_B.default.weight": "model-00002-of-00003.safetensors",
|
| 284 |
+
"decoder.base_model.model.model.layers.2.input_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 285 |
+
"decoder.base_model.model.model.layers.2.mlp.down_proj.base_layer.weight": "model-00001-of-00003.safetensors",
|
| 286 |
+
"decoder.base_model.model.model.layers.2.mlp.down_proj.lora_A.default.weight": "model-00001-of-00003.safetensors",
|
| 287 |
+
"decoder.base_model.model.model.layers.2.mlp.down_proj.lora_B.default.weight": "model-00001-of-00003.safetensors",
|
| 288 |
+
"decoder.base_model.model.model.layers.2.mlp.gate_proj.base_layer.weight": "model-00001-of-00003.safetensors",
|
| 289 |
+
"decoder.base_model.model.model.layers.2.mlp.gate_proj.lora_A.default.weight": "model-00001-of-00003.safetensors",
|
| 290 |
+
"decoder.base_model.model.model.layers.2.mlp.gate_proj.lora_B.default.weight": "model-00001-of-00003.safetensors",
|
| 291 |
+
"decoder.base_model.model.model.layers.2.mlp.up_proj.base_layer.weight": "model-00001-of-00003.safetensors",
|
| 292 |
+
"decoder.base_model.model.model.layers.2.mlp.up_proj.lora_A.default.weight": "model-00001-of-00003.safetensors",
|
| 293 |
+
"decoder.base_model.model.model.layers.2.mlp.up_proj.lora_B.default.weight": "model-00001-of-00003.safetensors",
|
| 294 |
+
"decoder.base_model.model.model.layers.2.post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 295 |
+
"decoder.base_model.model.model.layers.2.self_attn.k_proj.base_layer.weight": "model-00001-of-00003.safetensors",
|
| 296 |
+
"decoder.base_model.model.model.layers.2.self_attn.k_proj.lora_A.default.weight": "model-00001-of-00003.safetensors",
|
| 297 |
+
"decoder.base_model.model.model.layers.2.self_attn.k_proj.lora_B.default.weight": "model-00001-of-00003.safetensors",
|
| 298 |
+
"decoder.base_model.model.model.layers.2.self_attn.o_proj.base_layer.weight": "model-00001-of-00003.safetensors",
|
| 299 |
+
"decoder.base_model.model.model.layers.2.self_attn.o_proj.lora_A.default.weight": "model-00001-of-00003.safetensors",
|
| 300 |
+
"decoder.base_model.model.model.layers.2.self_attn.o_proj.lora_B.default.weight": "model-00001-of-00003.safetensors",
|
| 301 |
+
"decoder.base_model.model.model.layers.2.self_attn.q_proj.base_layer.weight": "model-00001-of-00003.safetensors",
|
| 302 |
+
"decoder.base_model.model.model.layers.2.self_attn.q_proj.lora_A.default.weight": "model-00001-of-00003.safetensors",
|
| 303 |
+
"decoder.base_model.model.model.layers.2.self_attn.q_proj.lora_B.default.weight": "model-00001-of-00003.safetensors",
|
| 304 |
+
"decoder.base_model.model.model.layers.2.self_attn.v_proj.base_layer.weight": "model-00001-of-00003.safetensors",
|
| 305 |
+
"decoder.base_model.model.model.layers.2.self_attn.v_proj.lora_A.default.weight": "model-00001-of-00003.safetensors",
|
| 306 |
+
"decoder.base_model.model.model.layers.2.self_attn.v_proj.lora_B.default.weight": "model-00001-of-00003.safetensors",
|
| 307 |
+
"decoder.base_model.model.model.layers.20.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 308 |
+
"decoder.base_model.model.model.layers.20.mlp.down_proj.base_layer.weight": "model-00002-of-00003.safetensors",
|
| 309 |
+
"decoder.base_model.model.model.layers.20.mlp.down_proj.lora_A.default.weight": "model-00002-of-00003.safetensors",
|
| 310 |
+
"decoder.base_model.model.model.layers.20.mlp.down_proj.lora_B.default.weight": "model-00002-of-00003.safetensors",
|
| 311 |
+
"decoder.base_model.model.model.layers.20.mlp.gate_proj.base_layer.weight": "model-00002-of-00003.safetensors",
|
| 312 |
+
"decoder.base_model.model.model.layers.20.mlp.gate_proj.lora_A.default.weight": "model-00002-of-00003.safetensors",
|
| 313 |
+
"decoder.base_model.model.model.layers.20.mlp.gate_proj.lora_B.default.weight": "model-00002-of-00003.safetensors",
|
| 314 |
+
"decoder.base_model.model.model.layers.20.mlp.up_proj.base_layer.weight": "model-00002-of-00003.safetensors",
|
| 315 |
+
"decoder.base_model.model.model.layers.20.mlp.up_proj.lora_A.default.weight": "model-00002-of-00003.safetensors",
|
| 316 |
+
"decoder.base_model.model.model.layers.20.mlp.up_proj.lora_B.default.weight": "model-00002-of-00003.safetensors",
|
| 317 |
+
"decoder.base_model.model.model.layers.20.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 318 |
+
"decoder.base_model.model.model.layers.20.self_attn.k_proj.base_layer.weight": "model-00002-of-00003.safetensors",
|
| 319 |
+
"decoder.base_model.model.model.layers.20.self_attn.k_proj.lora_A.default.weight": "model-00002-of-00003.safetensors",
|
| 320 |
+
"decoder.base_model.model.model.layers.20.self_attn.k_proj.lora_B.default.weight": "model-00002-of-00003.safetensors",
|
| 321 |
+
"decoder.base_model.model.model.layers.20.self_attn.o_proj.base_layer.weight": "model-00002-of-00003.safetensors",
|
| 322 |
+
"decoder.base_model.model.model.layers.20.self_attn.o_proj.lora_A.default.weight": "model-00002-of-00003.safetensors",
|
| 323 |
+
"decoder.base_model.model.model.layers.20.self_attn.o_proj.lora_B.default.weight": "model-00002-of-00003.safetensors",
|
| 324 |
+
"decoder.base_model.model.model.layers.20.self_attn.q_proj.base_layer.weight": "model-00002-of-00003.safetensors",
|
| 325 |
+
"decoder.base_model.model.model.layers.20.self_attn.q_proj.lora_A.default.weight": "model-00002-of-00003.safetensors",
|
| 326 |
+
"decoder.base_model.model.model.layers.20.self_attn.q_proj.lora_B.default.weight": "model-00002-of-00003.safetensors",
|
| 327 |
+
"decoder.base_model.model.model.layers.20.self_attn.v_proj.base_layer.weight": "model-00002-of-00003.safetensors",
|
| 328 |
+
"decoder.base_model.model.model.layers.20.self_attn.v_proj.lora_A.default.weight": "model-00002-of-00003.safetensors",
|
| 329 |
+
"decoder.base_model.model.model.layers.20.self_attn.v_proj.lora_B.default.weight": "model-00002-of-00003.safetensors",
|
| 330 |
+
"decoder.base_model.model.model.layers.21.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 331 |
+
"decoder.base_model.model.model.layers.21.mlp.down_proj.base_layer.weight": "model-00002-of-00003.safetensors",
|
| 332 |
+
"decoder.base_model.model.model.layers.21.mlp.down_proj.lora_A.default.weight": "model-00002-of-00003.safetensors",
|
| 333 |
+
"decoder.base_model.model.model.layers.21.mlp.down_proj.lora_B.default.weight": "model-00002-of-00003.safetensors",
|
| 334 |
+
"decoder.base_model.model.model.layers.21.mlp.gate_proj.base_layer.weight": "model-00002-of-00003.safetensors",
|
| 335 |
+
"decoder.base_model.model.model.layers.21.mlp.gate_proj.lora_A.default.weight": "model-00002-of-00003.safetensors",
|
| 336 |
+
"decoder.base_model.model.model.layers.21.mlp.gate_proj.lora_B.default.weight": "model-00002-of-00003.safetensors",
|
| 337 |
+
"decoder.base_model.model.model.layers.21.mlp.up_proj.base_layer.weight": "model-00002-of-00003.safetensors",
|
| 338 |
+
"decoder.base_model.model.model.layers.21.mlp.up_proj.lora_A.default.weight": "model-00002-of-00003.safetensors",
|
| 339 |
+
"decoder.base_model.model.model.layers.21.mlp.up_proj.lora_B.default.weight": "model-00002-of-00003.safetensors",
|
| 340 |
+
"decoder.base_model.model.model.layers.21.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 341 |
+
"decoder.base_model.model.model.layers.21.self_attn.k_proj.base_layer.weight": "model-00002-of-00003.safetensors",
|
| 342 |
+
"decoder.base_model.model.model.layers.21.self_attn.k_proj.lora_A.default.weight": "model-00002-of-00003.safetensors",
|
| 343 |
+
"decoder.base_model.model.model.layers.21.self_attn.k_proj.lora_B.default.weight": "model-00002-of-00003.safetensors",
|
| 344 |
+
"decoder.base_model.model.model.layers.21.self_attn.o_proj.base_layer.weight": "model-00002-of-00003.safetensors",
|
| 345 |
+
"decoder.base_model.model.model.layers.21.self_attn.o_proj.lora_A.default.weight": "model-00002-of-00003.safetensors",
|
| 346 |
+
"decoder.base_model.model.model.layers.21.self_attn.o_proj.lora_B.default.weight": "model-00002-of-00003.safetensors",
|
| 347 |
+
"decoder.base_model.model.model.layers.21.self_attn.q_proj.base_layer.weight": "model-00002-of-00003.safetensors",
|
| 348 |
+
"decoder.base_model.model.model.layers.21.self_attn.q_proj.lora_A.default.weight": "model-00002-of-00003.safetensors",
|
| 349 |
+
"decoder.base_model.model.model.layers.21.self_attn.q_proj.lora_B.default.weight": "model-00002-of-00003.safetensors",
|
| 350 |
+
"decoder.base_model.model.model.layers.21.self_attn.v_proj.base_layer.weight": "model-00002-of-00003.safetensors",
|
| 351 |
+
"decoder.base_model.model.model.layers.21.self_attn.v_proj.lora_A.default.weight": "model-00002-of-00003.safetensors",
|
| 352 |
+
"decoder.base_model.model.model.layers.21.self_attn.v_proj.lora_B.default.weight": "model-00002-of-00003.safetensors",
|
| 353 |
+
"decoder.base_model.model.model.layers.22.input_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 354 |
+
"decoder.base_model.model.model.layers.22.mlp.down_proj.base_layer.weight": "model-00003-of-00003.safetensors",
|
| 355 |
+
"decoder.base_model.model.model.layers.22.mlp.down_proj.lora_A.default.weight": "model-00003-of-00003.safetensors",
|
| 356 |
+
"decoder.base_model.model.model.layers.22.mlp.down_proj.lora_B.default.weight": "model-00003-of-00003.safetensors",
|
| 357 |
+
"decoder.base_model.model.model.layers.22.mlp.gate_proj.base_layer.weight": "model-00003-of-00003.safetensors",
|
| 358 |
+
"decoder.base_model.model.model.layers.22.mlp.gate_proj.lora_A.default.weight": "model-00003-of-00003.safetensors",
|
| 359 |
+
"decoder.base_model.model.model.layers.22.mlp.gate_proj.lora_B.default.weight": "model-00003-of-00003.safetensors",
|
| 360 |
+
"decoder.base_model.model.model.layers.22.mlp.up_proj.base_layer.weight": "model-00003-of-00003.safetensors",
|
| 361 |
+
"decoder.base_model.model.model.layers.22.mlp.up_proj.lora_A.default.weight": "model-00003-of-00003.safetensors",
|
| 362 |
+
"decoder.base_model.model.model.layers.22.mlp.up_proj.lora_B.default.weight": "model-00003-of-00003.safetensors",
|
| 363 |
+
"decoder.base_model.model.model.layers.22.post_attention_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 364 |
+
"decoder.base_model.model.model.layers.22.self_attn.k_proj.base_layer.weight": "model-00002-of-00003.safetensors",
|
| 365 |
+
"decoder.base_model.model.model.layers.22.self_attn.k_proj.lora_A.default.weight": "model-00002-of-00003.safetensors",
|
| 366 |
+
"decoder.base_model.model.model.layers.22.self_attn.k_proj.lora_B.default.weight": "model-00002-of-00003.safetensors",
|
| 367 |
+
"decoder.base_model.model.model.layers.22.self_attn.o_proj.base_layer.weight": "model-00003-of-00003.safetensors",
|
| 368 |
+
"decoder.base_model.model.model.layers.22.self_attn.o_proj.lora_A.default.weight": "model-00003-of-00003.safetensors",
|
| 369 |
+
"decoder.base_model.model.model.layers.22.self_attn.o_proj.lora_B.default.weight": "model-00003-of-00003.safetensors",
|
| 370 |
+
"decoder.base_model.model.model.layers.22.self_attn.q_proj.base_layer.weight": "model-00002-of-00003.safetensors",
|
| 371 |
+
"decoder.base_model.model.model.layers.22.self_attn.q_proj.lora_A.default.weight": "model-00002-of-00003.safetensors",
|
| 372 |
+
"decoder.base_model.model.model.layers.22.self_attn.q_proj.lora_B.default.weight": "model-00002-of-00003.safetensors",
|
| 373 |
+
"decoder.base_model.model.model.layers.22.self_attn.v_proj.base_layer.weight": "model-00002-of-00003.safetensors",
|
| 374 |
+
"decoder.base_model.model.model.layers.22.self_attn.v_proj.lora_A.default.weight": "model-00002-of-00003.safetensors",
|
| 375 |
+
"decoder.base_model.model.model.layers.22.self_attn.v_proj.lora_B.default.weight": "model-00002-of-00003.safetensors",
|
| 376 |
+
"decoder.base_model.model.model.layers.23.input_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 377 |
+
"decoder.base_model.model.model.layers.23.mlp.down_proj.base_layer.weight": "model-00003-of-00003.safetensors",
|
| 378 |
+
"decoder.base_model.model.model.layers.23.mlp.down_proj.lora_A.default.weight": "model-00003-of-00003.safetensors",
|
| 379 |
+
"decoder.base_model.model.model.layers.23.mlp.down_proj.lora_B.default.weight": "model-00003-of-00003.safetensors",
|
| 380 |
+
"decoder.base_model.model.model.layers.23.mlp.gate_proj.base_layer.weight": "model-00003-of-00003.safetensors",
|
| 381 |
+
"decoder.base_model.model.model.layers.23.mlp.gate_proj.lora_A.default.weight": "model-00003-of-00003.safetensors",
|
| 382 |
+
"decoder.base_model.model.model.layers.23.mlp.gate_proj.lora_B.default.weight": "model-00003-of-00003.safetensors",
|
| 383 |
+
"decoder.base_model.model.model.layers.23.mlp.up_proj.base_layer.weight": "model-00003-of-00003.safetensors",
|
| 384 |
+
"decoder.base_model.model.model.layers.23.mlp.up_proj.lora_A.default.weight": "model-00003-of-00003.safetensors",
|
| 385 |
+
"decoder.base_model.model.model.layers.23.mlp.up_proj.lora_B.default.weight": "model-00003-of-00003.safetensors",
|
| 386 |
+
"decoder.base_model.model.model.layers.23.post_attention_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 387 |
+
"decoder.base_model.model.model.layers.23.self_attn.k_proj.base_layer.weight": "model-00003-of-00003.safetensors",
|
| 388 |
+
"decoder.base_model.model.model.layers.23.self_attn.k_proj.lora_A.default.weight": "model-00003-of-00003.safetensors",
|
| 389 |
+
"decoder.base_model.model.model.layers.23.self_attn.k_proj.lora_B.default.weight": "model-00003-of-00003.safetensors",
|
| 390 |
+
"decoder.base_model.model.model.layers.23.self_attn.o_proj.base_layer.weight": "model-00003-of-00003.safetensors",
|
| 391 |
+
"decoder.base_model.model.model.layers.23.self_attn.o_proj.lora_A.default.weight": "model-00003-of-00003.safetensors",
|
| 392 |
+
"decoder.base_model.model.model.layers.23.self_attn.o_proj.lora_B.default.weight": "model-00003-of-00003.safetensors",
|
| 393 |
+
"decoder.base_model.model.model.layers.23.self_attn.q_proj.base_layer.weight": "model-00003-of-00003.safetensors",
|
| 394 |
+
"decoder.base_model.model.model.layers.23.self_attn.q_proj.lora_A.default.weight": "model-00003-of-00003.safetensors",
|
| 395 |
+
"decoder.base_model.model.model.layers.23.self_attn.q_proj.lora_B.default.weight": "model-00003-of-00003.safetensors",
|
| 396 |
+
"decoder.base_model.model.model.layers.23.self_attn.v_proj.base_layer.weight": "model-00003-of-00003.safetensors",
|
| 397 |
+
"decoder.base_model.model.model.layers.23.self_attn.v_proj.lora_A.default.weight": "model-00003-of-00003.safetensors",
|
| 398 |
+
"decoder.base_model.model.model.layers.23.self_attn.v_proj.lora_B.default.weight": "model-00003-of-00003.safetensors",
|
| 399 |
+
"decoder.base_model.model.model.layers.24.input_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 400 |
+
"decoder.base_model.model.model.layers.24.mlp.down_proj.base_layer.weight": "model-00003-of-00003.safetensors",
|
| 401 |
+
"decoder.base_model.model.model.layers.24.mlp.down_proj.lora_A.default.weight": "model-00003-of-00003.safetensors",
|
| 402 |
+
"decoder.base_model.model.model.layers.24.mlp.down_proj.lora_B.default.weight": "model-00003-of-00003.safetensors",
|
| 403 |
+
"decoder.base_model.model.model.layers.24.mlp.gate_proj.base_layer.weight": "model-00003-of-00003.safetensors",
|
| 404 |
+
"decoder.base_model.model.model.layers.24.mlp.gate_proj.lora_A.default.weight": "model-00003-of-00003.safetensors",
|
| 405 |
+
"decoder.base_model.model.model.layers.24.mlp.gate_proj.lora_B.default.weight": "model-00003-of-00003.safetensors",
|
| 406 |
+
"decoder.base_model.model.model.layers.24.mlp.up_proj.base_layer.weight": "model-00003-of-00003.safetensors",
|
| 407 |
+
"decoder.base_model.model.model.layers.24.mlp.up_proj.lora_A.default.weight": "model-00003-of-00003.safetensors",
|
| 408 |
+
"decoder.base_model.model.model.layers.24.mlp.up_proj.lora_B.default.weight": "model-00003-of-00003.safetensors",
|
| 409 |
+
"decoder.base_model.model.model.layers.24.post_attention_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 410 |
+
"decoder.base_model.model.model.layers.24.self_attn.k_proj.base_layer.weight": "model-00003-of-00003.safetensors",
|
| 411 |
+
"decoder.base_model.model.model.layers.24.self_attn.k_proj.lora_A.default.weight": "model-00003-of-00003.safetensors",
|
| 412 |
+
"decoder.base_model.model.model.layers.24.self_attn.k_proj.lora_B.default.weight": "model-00003-of-00003.safetensors",
|
| 413 |
+
"decoder.base_model.model.model.layers.24.self_attn.o_proj.base_layer.weight": "model-00003-of-00003.safetensors",
|
| 414 |
+
"decoder.base_model.model.model.layers.24.self_attn.o_proj.lora_A.default.weight": "model-00003-of-00003.safetensors",
|
| 415 |
+
"decoder.base_model.model.model.layers.24.self_attn.o_proj.lora_B.default.weight": "model-00003-of-00003.safetensors",
|
| 416 |
+
"decoder.base_model.model.model.layers.24.self_attn.q_proj.base_layer.weight": "model-00003-of-00003.safetensors",
|
| 417 |
+
"decoder.base_model.model.model.layers.24.self_attn.q_proj.lora_A.default.weight": "model-00003-of-00003.safetensors",
|
| 418 |
+
"decoder.base_model.model.model.layers.24.self_attn.q_proj.lora_B.default.weight": "model-00003-of-00003.safetensors",
|
| 419 |
+
"decoder.base_model.model.model.layers.24.self_attn.v_proj.base_layer.weight": "model-00003-of-00003.safetensors",
|
| 420 |
+
"decoder.base_model.model.model.layers.24.self_attn.v_proj.lora_A.default.weight": "model-00003-of-00003.safetensors",
|
| 421 |
+
"decoder.base_model.model.model.layers.24.self_attn.v_proj.lora_B.default.weight": "model-00003-of-00003.safetensors",
|
| 422 |
+
"decoder.base_model.model.model.layers.25.input_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 423 |
+
"decoder.base_model.model.model.layers.25.mlp.down_proj.base_layer.weight": "model-00003-of-00003.safetensors",
|
| 424 |
+
"decoder.base_model.model.model.layers.25.mlp.down_proj.lora_A.default.weight": "model-00003-of-00003.safetensors",
|
| 425 |
+
"decoder.base_model.model.model.layers.25.mlp.down_proj.lora_B.default.weight": "model-00003-of-00003.safetensors",
|
| 426 |
+
"decoder.base_model.model.model.layers.25.mlp.gate_proj.base_layer.weight": "model-00003-of-00003.safetensors",
|
| 427 |
+
"decoder.base_model.model.model.layers.25.mlp.gate_proj.lora_A.default.weight": "model-00003-of-00003.safetensors",
|
| 428 |
+
"decoder.base_model.model.model.layers.25.mlp.gate_proj.lora_B.default.weight": "model-00003-of-00003.safetensors",
|
| 429 |
+
"decoder.base_model.model.model.layers.25.mlp.up_proj.base_layer.weight": "model-00003-of-00003.safetensors",
|
| 430 |
+
"decoder.base_model.model.model.layers.25.mlp.up_proj.lora_A.default.weight": "model-00003-of-00003.safetensors",
|
| 431 |
+
"decoder.base_model.model.model.layers.25.mlp.up_proj.lora_B.default.weight": "model-00003-of-00003.safetensors",
|
| 432 |
+
"decoder.base_model.model.model.layers.25.post_attention_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 433 |
+
"decoder.base_model.model.model.layers.25.self_attn.k_proj.base_layer.weight": "model-00003-of-00003.safetensors",
|
| 434 |
+
"decoder.base_model.model.model.layers.25.self_attn.k_proj.lora_A.default.weight": "model-00003-of-00003.safetensors",
|
| 435 |
+
"decoder.base_model.model.model.layers.25.self_attn.k_proj.lora_B.default.weight": "model-00003-of-00003.safetensors",
|
| 436 |
+
"decoder.base_model.model.model.layers.25.self_attn.o_proj.base_layer.weight": "model-00003-of-00003.safetensors",
|
| 437 |
+
"decoder.base_model.model.model.layers.25.self_attn.o_proj.lora_A.default.weight": "model-00003-of-00003.safetensors",
|
| 438 |
+
"decoder.base_model.model.model.layers.25.self_attn.o_proj.lora_B.default.weight": "model-00003-of-00003.safetensors",
|
| 439 |
+
"decoder.base_model.model.model.layers.25.self_attn.q_proj.base_layer.weight": "model-00003-of-00003.safetensors",
|
| 440 |
+
"decoder.base_model.model.model.layers.25.self_attn.q_proj.lora_A.default.weight": "model-00003-of-00003.safetensors",
|
| 441 |
+
"decoder.base_model.model.model.layers.25.self_attn.q_proj.lora_B.default.weight": "model-00003-of-00003.safetensors",
|
| 442 |
+
"decoder.base_model.model.model.layers.25.self_attn.v_proj.base_layer.weight": "model-00003-of-00003.safetensors",
|
| 443 |
+
"decoder.base_model.model.model.layers.25.self_attn.v_proj.lora_A.default.weight": "model-00003-of-00003.safetensors",
|
| 444 |
+
"decoder.base_model.model.model.layers.25.self_attn.v_proj.lora_B.default.weight": "model-00003-of-00003.safetensors",
|
| 445 |
+
"decoder.base_model.model.model.layers.26.input_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 446 |
+
"decoder.base_model.model.model.layers.26.mlp.down_proj.base_layer.weight": "model-00003-of-00003.safetensors",
|
| 447 |
+
"decoder.base_model.model.model.layers.26.mlp.down_proj.lora_A.default.weight": "model-00003-of-00003.safetensors",
|
| 448 |
+
"decoder.base_model.model.model.layers.26.mlp.down_proj.lora_B.default.weight": "model-00003-of-00003.safetensors",
|
| 449 |
+
"decoder.base_model.model.model.layers.26.mlp.gate_proj.base_layer.weight": "model-00003-of-00003.safetensors",
|
| 450 |
+
"decoder.base_model.model.model.layers.26.mlp.gate_proj.lora_A.default.weight": "model-00003-of-00003.safetensors",
|
| 451 |
+
"decoder.base_model.model.model.layers.26.mlp.gate_proj.lora_B.default.weight": "model-00003-of-00003.safetensors",
|
| 452 |
+
"decoder.base_model.model.model.layers.26.mlp.up_proj.base_layer.weight": "model-00003-of-00003.safetensors",
|
| 453 |
+
"decoder.base_model.model.model.layers.26.mlp.up_proj.lora_A.default.weight": "model-00003-of-00003.safetensors",
|
| 454 |
+
"decoder.base_model.model.model.layers.26.mlp.up_proj.lora_B.default.weight": "model-00003-of-00003.safetensors",
|
| 455 |
+
"decoder.base_model.model.model.layers.26.post_attention_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 456 |
+
"decoder.base_model.model.model.layers.26.self_attn.k_proj.base_layer.weight": "model-00003-of-00003.safetensors",
|
| 457 |
+
"decoder.base_model.model.model.layers.26.self_attn.k_proj.lora_A.default.weight": "model-00003-of-00003.safetensors",
|
| 458 |
+
"decoder.base_model.model.model.layers.26.self_attn.k_proj.lora_B.default.weight": "model-00003-of-00003.safetensors",
|
| 459 |
+
"decoder.base_model.model.model.layers.26.self_attn.o_proj.base_layer.weight": "model-00003-of-00003.safetensors",
|
| 460 |
+
"decoder.base_model.model.model.layers.26.self_attn.o_proj.lora_A.default.weight": "model-00003-of-00003.safetensors",
|
| 461 |
+
"decoder.base_model.model.model.layers.26.self_attn.o_proj.lora_B.default.weight": "model-00003-of-00003.safetensors",
|
| 462 |
+
"decoder.base_model.model.model.layers.26.self_attn.q_proj.base_layer.weight": "model-00003-of-00003.safetensors",
|
| 463 |
+
"decoder.base_model.model.model.layers.26.self_attn.q_proj.lora_A.default.weight": "model-00003-of-00003.safetensors",
|
| 464 |
+
"decoder.base_model.model.model.layers.26.self_attn.q_proj.lora_B.default.weight": "model-00003-of-00003.safetensors",
|
| 465 |
+
"decoder.base_model.model.model.layers.26.self_attn.v_proj.base_layer.weight": "model-00003-of-00003.safetensors",
|
| 466 |
+
"decoder.base_model.model.model.layers.26.self_attn.v_proj.lora_A.default.weight": "model-00003-of-00003.safetensors",
|
| 467 |
+
"decoder.base_model.model.model.layers.26.self_attn.v_proj.lora_B.default.weight": "model-00003-of-00003.safetensors",
|
| 468 |
+
"decoder.base_model.model.model.layers.27.input_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 469 |
+
"decoder.base_model.model.model.layers.27.mlp.down_proj.base_layer.weight": "model-00003-of-00003.safetensors",
|
| 470 |
+
"decoder.base_model.model.model.layers.27.mlp.down_proj.lora_A.default.weight": "model-00003-of-00003.safetensors",
|
| 471 |
+
"decoder.base_model.model.model.layers.27.mlp.down_proj.lora_B.default.weight": "model-00003-of-00003.safetensors",
|
| 472 |
+
"decoder.base_model.model.model.layers.27.mlp.gate_proj.base_layer.weight": "model-00003-of-00003.safetensors",
|
| 473 |
+
"decoder.base_model.model.model.layers.27.mlp.gate_proj.lora_A.default.weight": "model-00003-of-00003.safetensors",
|
| 474 |
+
"decoder.base_model.model.model.layers.27.mlp.gate_proj.lora_B.default.weight": "model-00003-of-00003.safetensors",
|
| 475 |
+
"decoder.base_model.model.model.layers.27.mlp.up_proj.base_layer.weight": "model-00003-of-00003.safetensors",
|
| 476 |
+
"decoder.base_model.model.model.layers.27.mlp.up_proj.lora_A.default.weight": "model-00003-of-00003.safetensors",
|
| 477 |
+
"decoder.base_model.model.model.layers.27.mlp.up_proj.lora_B.default.weight": "model-00003-of-00003.safetensors",
|
| 478 |
+
"decoder.base_model.model.model.layers.27.post_attention_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 479 |
+
"decoder.base_model.model.model.layers.27.self_attn.k_proj.base_layer.weight": "model-00003-of-00003.safetensors",
|
| 480 |
+
"decoder.base_model.model.model.layers.27.self_attn.k_proj.lora_A.default.weight": "model-00003-of-00003.safetensors",
|
| 481 |
+
"decoder.base_model.model.model.layers.27.self_attn.k_proj.lora_B.default.weight": "model-00003-of-00003.safetensors",
|
| 482 |
+
"decoder.base_model.model.model.layers.27.self_attn.o_proj.base_layer.weight": "model-00003-of-00003.safetensors",
|
| 483 |
+
"decoder.base_model.model.model.layers.27.self_attn.o_proj.lora_A.default.weight": "model-00003-of-00003.safetensors",
|
| 484 |
+
"decoder.base_model.model.model.layers.27.self_attn.o_proj.lora_B.default.weight": "model-00003-of-00003.safetensors",
|
| 485 |
+
"decoder.base_model.model.model.layers.27.self_attn.q_proj.base_layer.weight": "model-00003-of-00003.safetensors",
|
| 486 |
+
"decoder.base_model.model.model.layers.27.self_attn.q_proj.lora_A.default.weight": "model-00003-of-00003.safetensors",
|
| 487 |
+
"decoder.base_model.model.model.layers.27.self_attn.q_proj.lora_B.default.weight": "model-00003-of-00003.safetensors",
|
| 488 |
+
"decoder.base_model.model.model.layers.27.self_attn.v_proj.base_layer.weight": "model-00003-of-00003.safetensors",
|
| 489 |
+
"decoder.base_model.model.model.layers.27.self_attn.v_proj.lora_A.default.weight": "model-00003-of-00003.safetensors",
|
| 490 |
+
"decoder.base_model.model.model.layers.27.self_attn.v_proj.lora_B.default.weight": "model-00003-of-00003.safetensors",
|
| 491 |
+
"decoder.base_model.model.model.layers.28.input_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 492 |
+
"decoder.base_model.model.model.layers.28.mlp.down_proj.base_layer.weight": "model-00003-of-00003.safetensors",
|
| 493 |
+
"decoder.base_model.model.model.layers.28.mlp.down_proj.lora_A.default.weight": "model-00003-of-00003.safetensors",
|
| 494 |
+
"decoder.base_model.model.model.layers.28.mlp.down_proj.lora_B.default.weight": "model-00003-of-00003.safetensors",
|
| 495 |
+
"decoder.base_model.model.model.layers.28.mlp.gate_proj.base_layer.weight": "model-00003-of-00003.safetensors",
|
| 496 |
+
"decoder.base_model.model.model.layers.28.mlp.gate_proj.lora_A.default.weight": "model-00003-of-00003.safetensors",
|
| 497 |
+
"decoder.base_model.model.model.layers.28.mlp.gate_proj.lora_B.default.weight": "model-00003-of-00003.safetensors",
|
| 498 |
+
"decoder.base_model.model.model.layers.28.mlp.up_proj.base_layer.weight": "model-00003-of-00003.safetensors",
|
| 499 |
+
"decoder.base_model.model.model.layers.28.mlp.up_proj.lora_A.default.weight": "model-00003-of-00003.safetensors",
|
| 500 |
+
"decoder.base_model.model.model.layers.28.mlp.up_proj.lora_B.default.weight": "model-00003-of-00003.safetensors",
|
| 501 |
+
"decoder.base_model.model.model.layers.28.post_attention_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 502 |
+
"decoder.base_model.model.model.layers.28.self_attn.k_proj.base_layer.weight": "model-00003-of-00003.safetensors",
|
| 503 |
+
"decoder.base_model.model.model.layers.28.self_attn.k_proj.lora_A.default.weight": "model-00003-of-00003.safetensors",
|
| 504 |
+
"decoder.base_model.model.model.layers.28.self_attn.k_proj.lora_B.default.weight": "model-00003-of-00003.safetensors",
|
| 505 |
+
"decoder.base_model.model.model.layers.28.self_attn.o_proj.base_layer.weight": "model-00003-of-00003.safetensors",
|
| 506 |
+
"decoder.base_model.model.model.layers.28.self_attn.o_proj.lora_A.default.weight": "model-00003-of-00003.safetensors",
|
| 507 |
+
"decoder.base_model.model.model.layers.28.self_attn.o_proj.lora_B.default.weight": "model-00003-of-00003.safetensors",
|
| 508 |
+
"decoder.base_model.model.model.layers.28.self_attn.q_proj.base_layer.weight": "model-00003-of-00003.safetensors",
|
| 509 |
+
"decoder.base_model.model.model.layers.28.self_attn.q_proj.lora_A.default.weight": "model-00003-of-00003.safetensors",
|
| 510 |
+
"decoder.base_model.model.model.layers.28.self_attn.q_proj.lora_B.default.weight": "model-00003-of-00003.safetensors",
|
| 511 |
+
"decoder.base_model.model.model.layers.28.self_attn.v_proj.base_layer.weight": "model-00003-of-00003.safetensors",
|
| 512 |
+
"decoder.base_model.model.model.layers.28.self_attn.v_proj.lora_A.default.weight": "model-00003-of-00003.safetensors",
|
| 513 |
+
"decoder.base_model.model.model.layers.28.self_attn.v_proj.lora_B.default.weight": "model-00003-of-00003.safetensors",
|
| 514 |
+
"decoder.base_model.model.model.layers.29.input_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 515 |
+
"decoder.base_model.model.model.layers.29.mlp.down_proj.base_layer.weight": "model-00003-of-00003.safetensors",
|
| 516 |
+
"decoder.base_model.model.model.layers.29.mlp.down_proj.lora_A.default.weight": "model-00003-of-00003.safetensors",
|
| 517 |
+
"decoder.base_model.model.model.layers.29.mlp.down_proj.lora_B.default.weight": "model-00003-of-00003.safetensors",
|
| 518 |
+
"decoder.base_model.model.model.layers.29.mlp.gate_proj.base_layer.weight": "model-00003-of-00003.safetensors",
|
| 519 |
+
"decoder.base_model.model.model.layers.29.mlp.gate_proj.lora_A.default.weight": "model-00003-of-00003.safetensors",
|
| 520 |
+
"decoder.base_model.model.model.layers.29.mlp.gate_proj.lora_B.default.weight": "model-00003-of-00003.safetensors",
|
| 521 |
+
"decoder.base_model.model.model.layers.29.mlp.up_proj.base_layer.weight": "model-00003-of-00003.safetensors",
|
| 522 |
+
"decoder.base_model.model.model.layers.29.mlp.up_proj.lora_A.default.weight": "model-00003-of-00003.safetensors",
|
| 523 |
+
"decoder.base_model.model.model.layers.29.mlp.up_proj.lora_B.default.weight": "model-00003-of-00003.safetensors",
|
| 524 |
+
"decoder.base_model.model.model.layers.29.post_attention_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 525 |
+
"decoder.base_model.model.model.layers.29.self_attn.k_proj.base_layer.weight": "model-00003-of-00003.safetensors",
|
| 526 |
+
"decoder.base_model.model.model.layers.29.self_attn.k_proj.lora_A.default.weight": "model-00003-of-00003.safetensors",
|
| 527 |
+
"decoder.base_model.model.model.layers.29.self_attn.k_proj.lora_B.default.weight": "model-00003-of-00003.safetensors",
|
| 528 |
+
"decoder.base_model.model.model.layers.29.self_attn.o_proj.base_layer.weight": "model-00003-of-00003.safetensors",
|
| 529 |
+
"decoder.base_model.model.model.layers.29.self_attn.o_proj.lora_A.default.weight": "model-00003-of-00003.safetensors",
|
| 530 |
+
"decoder.base_model.model.model.layers.29.self_attn.o_proj.lora_B.default.weight": "model-00003-of-00003.safetensors",
|
| 531 |
+
"decoder.base_model.model.model.layers.29.self_attn.q_proj.base_layer.weight": "model-00003-of-00003.safetensors",
|
| 532 |
+
"decoder.base_model.model.model.layers.29.self_attn.q_proj.lora_A.default.weight": "model-00003-of-00003.safetensors",
|
| 533 |
+
"decoder.base_model.model.model.layers.29.self_attn.q_proj.lora_B.default.weight": "model-00003-of-00003.safetensors",
|
| 534 |
+
"decoder.base_model.model.model.layers.29.self_attn.v_proj.base_layer.weight": "model-00003-of-00003.safetensors",
|
| 535 |
+
"decoder.base_model.model.model.layers.29.self_attn.v_proj.lora_A.default.weight": "model-00003-of-00003.safetensors",
|
| 536 |
+
"decoder.base_model.model.model.layers.29.self_attn.v_proj.lora_B.default.weight": "model-00003-of-00003.safetensors",
|
| 537 |
+
"decoder.base_model.model.model.layers.3.input_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 538 |
+
"decoder.base_model.model.model.layers.3.mlp.down_proj.base_layer.weight": "model-00001-of-00003.safetensors",
|
| 539 |
+
"decoder.base_model.model.model.layers.3.mlp.down_proj.lora_A.default.weight": "model-00001-of-00003.safetensors",
|
| 540 |
+
"decoder.base_model.model.model.layers.3.mlp.down_proj.lora_B.default.weight": "model-00001-of-00003.safetensors",
|
| 541 |
+
"decoder.base_model.model.model.layers.3.mlp.gate_proj.base_layer.weight": "model-00001-of-00003.safetensors",
|
| 542 |
+
"decoder.base_model.model.model.layers.3.mlp.gate_proj.lora_A.default.weight": "model-00001-of-00003.safetensors",
|
| 543 |
+
"decoder.base_model.model.model.layers.3.mlp.gate_proj.lora_B.default.weight": "model-00001-of-00003.safetensors",
|
| 544 |
+
"decoder.base_model.model.model.layers.3.mlp.up_proj.base_layer.weight": "model-00001-of-00003.safetensors",
|
| 545 |
+
"decoder.base_model.model.model.layers.3.mlp.up_proj.lora_A.default.weight": "model-00001-of-00003.safetensors",
|
| 546 |
+
"decoder.base_model.model.model.layers.3.mlp.up_proj.lora_B.default.weight": "model-00001-of-00003.safetensors",
|
| 547 |
+
"decoder.base_model.model.model.layers.3.post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 548 |
+
"decoder.base_model.model.model.layers.3.self_attn.k_proj.base_layer.weight": "model-00001-of-00003.safetensors",
|
| 549 |
+
"decoder.base_model.model.model.layers.3.self_attn.k_proj.lora_A.default.weight": "model-00001-of-00003.safetensors",
|
| 550 |
+
"decoder.base_model.model.model.layers.3.self_attn.k_proj.lora_B.default.weight": "model-00001-of-00003.safetensors",
|
| 551 |
+
"decoder.base_model.model.model.layers.3.self_attn.o_proj.base_layer.weight": "model-00001-of-00003.safetensors",
|
| 552 |
+
"decoder.base_model.model.model.layers.3.self_attn.o_proj.lora_A.default.weight": "model-00001-of-00003.safetensors",
|
| 553 |
+
"decoder.base_model.model.model.layers.3.self_attn.o_proj.lora_B.default.weight": "model-00001-of-00003.safetensors",
|
| 554 |
+
"decoder.base_model.model.model.layers.3.self_attn.q_proj.base_layer.weight": "model-00001-of-00003.safetensors",
|
| 555 |
+
"decoder.base_model.model.model.layers.3.self_attn.q_proj.lora_A.default.weight": "model-00001-of-00003.safetensors",
|
| 556 |
+
"decoder.base_model.model.model.layers.3.self_attn.q_proj.lora_B.default.weight": "model-00001-of-00003.safetensors",
|
| 557 |
+
"decoder.base_model.model.model.layers.3.self_attn.v_proj.base_layer.weight": "model-00001-of-00003.safetensors",
|
| 558 |
+
"decoder.base_model.model.model.layers.3.self_attn.v_proj.lora_A.default.weight": "model-00001-of-00003.safetensors",
|
| 559 |
+
"decoder.base_model.model.model.layers.3.self_attn.v_proj.lora_B.default.weight": "model-00001-of-00003.safetensors",
|
| 560 |
+
"decoder.base_model.model.model.layers.30.input_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 561 |
+
"decoder.base_model.model.model.layers.30.mlp.down_proj.base_layer.weight": "model-00003-of-00003.safetensors",
|
| 562 |
+
"decoder.base_model.model.model.layers.30.mlp.down_proj.lora_A.default.weight": "model-00003-of-00003.safetensors",
|
| 563 |
+
"decoder.base_model.model.model.layers.30.mlp.down_proj.lora_B.default.weight": "model-00003-of-00003.safetensors",
|
| 564 |
+
"decoder.base_model.model.model.layers.30.mlp.gate_proj.base_layer.weight": "model-00003-of-00003.safetensors",
|
| 565 |
+
"decoder.base_model.model.model.layers.30.mlp.gate_proj.lora_A.default.weight": "model-00003-of-00003.safetensors",
|
| 566 |
+
"decoder.base_model.model.model.layers.30.mlp.gate_proj.lora_B.default.weight": "model-00003-of-00003.safetensors",
|
| 567 |
+
"decoder.base_model.model.model.layers.30.mlp.up_proj.base_layer.weight": "model-00003-of-00003.safetensors",
|
| 568 |
+
"decoder.base_model.model.model.layers.30.mlp.up_proj.lora_A.default.weight": "model-00003-of-00003.safetensors",
|
| 569 |
+
"decoder.base_model.model.model.layers.30.mlp.up_proj.lora_B.default.weight": "model-00003-of-00003.safetensors",
|
| 570 |
+
"decoder.base_model.model.model.layers.30.post_attention_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 571 |
+
"decoder.base_model.model.model.layers.30.self_attn.k_proj.base_layer.weight": "model-00003-of-00003.safetensors",
|
| 572 |
+
"decoder.base_model.model.model.layers.30.self_attn.k_proj.lora_A.default.weight": "model-00003-of-00003.safetensors",
|
| 573 |
+
"decoder.base_model.model.model.layers.30.self_attn.k_proj.lora_B.default.weight": "model-00003-of-00003.safetensors",
|
| 574 |
+
"decoder.base_model.model.model.layers.30.self_attn.o_proj.base_layer.weight": "model-00003-of-00003.safetensors",
|
| 575 |
+
"decoder.base_model.model.model.layers.30.self_attn.o_proj.lora_A.default.weight": "model-00003-of-00003.safetensors",
|
| 576 |
+
"decoder.base_model.model.model.layers.30.self_attn.o_proj.lora_B.default.weight": "model-00003-of-00003.safetensors",
|
| 577 |
+
"decoder.base_model.model.model.layers.30.self_attn.q_proj.base_layer.weight": "model-00003-of-00003.safetensors",
|
| 578 |
+
"decoder.base_model.model.model.layers.30.self_attn.q_proj.lora_A.default.weight": "model-00003-of-00003.safetensors",
|
| 579 |
+
"decoder.base_model.model.model.layers.30.self_attn.q_proj.lora_B.default.weight": "model-00003-of-00003.safetensors",
|
| 580 |
+
"decoder.base_model.model.model.layers.30.self_attn.v_proj.base_layer.weight": "model-00003-of-00003.safetensors",
|
| 581 |
+
"decoder.base_model.model.model.layers.30.self_attn.v_proj.lora_A.default.weight": "model-00003-of-00003.safetensors",
|
| 582 |
+
"decoder.base_model.model.model.layers.30.self_attn.v_proj.lora_B.default.weight": "model-00003-of-00003.safetensors",
|
| 583 |
+
"decoder.base_model.model.model.layers.31.input_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 584 |
+
"decoder.base_model.model.model.layers.31.mlp.down_proj.base_layer.weight": "model-00003-of-00003.safetensors",
|
| 585 |
+
"decoder.base_model.model.model.layers.31.mlp.down_proj.lora_A.default.weight": "model-00003-of-00003.safetensors",
|
| 586 |
+
"decoder.base_model.model.model.layers.31.mlp.down_proj.lora_B.default.weight": "model-00003-of-00003.safetensors",
|
| 587 |
+
"decoder.base_model.model.model.layers.31.mlp.gate_proj.base_layer.weight": "model-00003-of-00003.safetensors",
|
| 588 |
+
"decoder.base_model.model.model.layers.31.mlp.gate_proj.lora_A.default.weight": "model-00003-of-00003.safetensors",
|
| 589 |
+
"decoder.base_model.model.model.layers.31.mlp.gate_proj.lora_B.default.weight": "model-00003-of-00003.safetensors",
|
| 590 |
+
"decoder.base_model.model.model.layers.31.mlp.up_proj.base_layer.weight": "model-00003-of-00003.safetensors",
|
| 591 |
+
"decoder.base_model.model.model.layers.31.mlp.up_proj.lora_A.default.weight": "model-00003-of-00003.safetensors",
|
| 592 |
+
"decoder.base_model.model.model.layers.31.mlp.up_proj.lora_B.default.weight": "model-00003-of-00003.safetensors",
|
| 593 |
+
"decoder.base_model.model.model.layers.31.post_attention_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 594 |
+
"decoder.base_model.model.model.layers.31.self_attn.k_proj.base_layer.weight": "model-00003-of-00003.safetensors",
|
| 595 |
+
"decoder.base_model.model.model.layers.31.self_attn.k_proj.lora_A.default.weight": "model-00003-of-00003.safetensors",
|
| 596 |
+
"decoder.base_model.model.model.layers.31.self_attn.k_proj.lora_B.default.weight": "model-00003-of-00003.safetensors",
|
| 597 |
+
"decoder.base_model.model.model.layers.31.self_attn.o_proj.base_layer.weight": "model-00003-of-00003.safetensors",
|
| 598 |
+
"decoder.base_model.model.model.layers.31.self_attn.o_proj.lora_A.default.weight": "model-00003-of-00003.safetensors",
|
| 599 |
+
"decoder.base_model.model.model.layers.31.self_attn.o_proj.lora_B.default.weight": "model-00003-of-00003.safetensors",
|
| 600 |
+
"decoder.base_model.model.model.layers.31.self_attn.q_proj.base_layer.weight": "model-00003-of-00003.safetensors",
|
| 601 |
+
"decoder.base_model.model.model.layers.31.self_attn.q_proj.lora_A.default.weight": "model-00003-of-00003.safetensors",
|
| 602 |
+
"decoder.base_model.model.model.layers.31.self_attn.q_proj.lora_B.default.weight": "model-00003-of-00003.safetensors",
|
| 603 |
+
"decoder.base_model.model.model.layers.31.self_attn.v_proj.base_layer.weight": "model-00003-of-00003.safetensors",
|
| 604 |
+
"decoder.base_model.model.model.layers.31.self_attn.v_proj.lora_A.default.weight": "model-00003-of-00003.safetensors",
|
| 605 |
+
"decoder.base_model.model.model.layers.31.self_attn.v_proj.lora_B.default.weight": "model-00003-of-00003.safetensors",
|
| 606 |
+
"decoder.base_model.model.model.layers.4.input_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 607 |
+
"decoder.base_model.model.model.layers.4.mlp.down_proj.base_layer.weight": "model-00001-of-00003.safetensors",
|
| 608 |
+
"decoder.base_model.model.model.layers.4.mlp.down_proj.lora_A.default.weight": "model-00001-of-00003.safetensors",
|
| 609 |
+
"decoder.base_model.model.model.layers.4.mlp.down_proj.lora_B.default.weight": "model-00001-of-00003.safetensors",
|
| 610 |
+
"decoder.base_model.model.model.layers.4.mlp.gate_proj.base_layer.weight": "model-00001-of-00003.safetensors",
|
| 611 |
+
"decoder.base_model.model.model.layers.4.mlp.gate_proj.lora_A.default.weight": "model-00001-of-00003.safetensors",
|
| 612 |
+
"decoder.base_model.model.model.layers.4.mlp.gate_proj.lora_B.default.weight": "model-00001-of-00003.safetensors",
|
| 613 |
+
"decoder.base_model.model.model.layers.4.mlp.up_proj.base_layer.weight": "model-00001-of-00003.safetensors",
|
| 614 |
+
"decoder.base_model.model.model.layers.4.mlp.up_proj.lora_A.default.weight": "model-00001-of-00003.safetensors",
|
| 615 |
+
"decoder.base_model.model.model.layers.4.mlp.up_proj.lora_B.default.weight": "model-00001-of-00003.safetensors",
|
| 616 |
+
"decoder.base_model.model.model.layers.4.post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 617 |
+
"decoder.base_model.model.model.layers.4.self_attn.k_proj.base_layer.weight": "model-00001-of-00003.safetensors",
|
| 618 |
+
"decoder.base_model.model.model.layers.4.self_attn.k_proj.lora_A.default.weight": "model-00001-of-00003.safetensors",
|
| 619 |
+
"decoder.base_model.model.model.layers.4.self_attn.k_proj.lora_B.default.weight": "model-00001-of-00003.safetensors",
|
| 620 |
+
"decoder.base_model.model.model.layers.4.self_attn.o_proj.base_layer.weight": "model-00001-of-00003.safetensors",
|
| 621 |
+
"decoder.base_model.model.model.layers.4.self_attn.o_proj.lora_A.default.weight": "model-00001-of-00003.safetensors",
|
| 622 |
+
"decoder.base_model.model.model.layers.4.self_attn.o_proj.lora_B.default.weight": "model-00001-of-00003.safetensors",
|
| 623 |
+
"decoder.base_model.model.model.layers.4.self_attn.q_proj.base_layer.weight": "model-00001-of-00003.safetensors",
|
| 624 |
+
"decoder.base_model.model.model.layers.4.self_attn.q_proj.lora_A.default.weight": "model-00001-of-00003.safetensors",
|
| 625 |
+
"decoder.base_model.model.model.layers.4.self_attn.q_proj.lora_B.default.weight": "model-00001-of-00003.safetensors",
|
| 626 |
+
"decoder.base_model.model.model.layers.4.self_attn.v_proj.base_layer.weight": "model-00001-of-00003.safetensors",
|
| 627 |
+
"decoder.base_model.model.model.layers.4.self_attn.v_proj.lora_A.default.weight": "model-00001-of-00003.safetensors",
|
| 628 |
+
"decoder.base_model.model.model.layers.4.self_attn.v_proj.lora_B.default.weight": "model-00001-of-00003.safetensors",
|
| 629 |
+
"decoder.base_model.model.model.layers.5.input_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 630 |
+
"decoder.base_model.model.model.layers.5.mlp.down_proj.base_layer.weight": "model-00001-of-00003.safetensors",
|
| 631 |
+
"decoder.base_model.model.model.layers.5.mlp.down_proj.lora_A.default.weight": "model-00001-of-00003.safetensors",
|
| 632 |
+
"decoder.base_model.model.model.layers.5.mlp.down_proj.lora_B.default.weight": "model-00001-of-00003.safetensors",
|
| 633 |
+
"decoder.base_model.model.model.layers.5.mlp.gate_proj.base_layer.weight": "model-00001-of-00003.safetensors",
|
| 634 |
+
"decoder.base_model.model.model.layers.5.mlp.gate_proj.lora_A.default.weight": "model-00001-of-00003.safetensors",
|
| 635 |
+
"decoder.base_model.model.model.layers.5.mlp.gate_proj.lora_B.default.weight": "model-00001-of-00003.safetensors",
|
| 636 |
+
"decoder.base_model.model.model.layers.5.mlp.up_proj.base_layer.weight": "model-00001-of-00003.safetensors",
|
| 637 |
+
"decoder.base_model.model.model.layers.5.mlp.up_proj.lora_A.default.weight": "model-00001-of-00003.safetensors",
|
| 638 |
+
"decoder.base_model.model.model.layers.5.mlp.up_proj.lora_B.default.weight": "model-00001-of-00003.safetensors",
|
| 639 |
+
"decoder.base_model.model.model.layers.5.post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 640 |
+
"decoder.base_model.model.model.layers.5.self_attn.k_proj.base_layer.weight": "model-00001-of-00003.safetensors",
|
| 641 |
+
"decoder.base_model.model.model.layers.5.self_attn.k_proj.lora_A.default.weight": "model-00001-of-00003.safetensors",
|
| 642 |
+
"decoder.base_model.model.model.layers.5.self_attn.k_proj.lora_B.default.weight": "model-00001-of-00003.safetensors",
|
| 643 |
+
"decoder.base_model.model.model.layers.5.self_attn.o_proj.base_layer.weight": "model-00001-of-00003.safetensors",
|
| 644 |
+
"decoder.base_model.model.model.layers.5.self_attn.o_proj.lora_A.default.weight": "model-00001-of-00003.safetensors",
|
| 645 |
+
"decoder.base_model.model.model.layers.5.self_attn.o_proj.lora_B.default.weight": "model-00001-of-00003.safetensors",
|
| 646 |
+
"decoder.base_model.model.model.layers.5.self_attn.q_proj.base_layer.weight": "model-00001-of-00003.safetensors",
|
| 647 |
+
"decoder.base_model.model.model.layers.5.self_attn.q_proj.lora_A.default.weight": "model-00001-of-00003.safetensors",
|
| 648 |
+
"decoder.base_model.model.model.layers.5.self_attn.q_proj.lora_B.default.weight": "model-00001-of-00003.safetensors",
|
| 649 |
+
"decoder.base_model.model.model.layers.5.self_attn.v_proj.base_layer.weight": "model-00001-of-00003.safetensors",
|
| 650 |
+
"decoder.base_model.model.model.layers.5.self_attn.v_proj.lora_A.default.weight": "model-00001-of-00003.safetensors",
|
| 651 |
+
"decoder.base_model.model.model.layers.5.self_attn.v_proj.lora_B.default.weight": "model-00001-of-00003.safetensors",
|
| 652 |
+
"decoder.base_model.model.model.layers.6.input_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 653 |
+
"decoder.base_model.model.model.layers.6.mlp.down_proj.base_layer.weight": "model-00001-of-00003.safetensors",
|
| 654 |
+
"decoder.base_model.model.model.layers.6.mlp.down_proj.lora_A.default.weight": "model-00001-of-00003.safetensors",
|
| 655 |
+
"decoder.base_model.model.model.layers.6.mlp.down_proj.lora_B.default.weight": "model-00001-of-00003.safetensors",
|
| 656 |
+
"decoder.base_model.model.model.layers.6.mlp.gate_proj.base_layer.weight": "model-00001-of-00003.safetensors",
|
| 657 |
+
"decoder.base_model.model.model.layers.6.mlp.gate_proj.lora_A.default.weight": "model-00001-of-00003.safetensors",
|
| 658 |
+
"decoder.base_model.model.model.layers.6.mlp.gate_proj.lora_B.default.weight": "model-00001-of-00003.safetensors",
|
| 659 |
+
"decoder.base_model.model.model.layers.6.mlp.up_proj.base_layer.weight": "model-00001-of-00003.safetensors",
|
| 660 |
+
"decoder.base_model.model.model.layers.6.mlp.up_proj.lora_A.default.weight": "model-00001-of-00003.safetensors",
|
| 661 |
+
"decoder.base_model.model.model.layers.6.mlp.up_proj.lora_B.default.weight": "model-00001-of-00003.safetensors",
|
| 662 |
+
"decoder.base_model.model.model.layers.6.post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 663 |
+
"decoder.base_model.model.model.layers.6.self_attn.k_proj.base_layer.weight": "model-00001-of-00003.safetensors",
|
| 664 |
+
"decoder.base_model.model.model.layers.6.self_attn.k_proj.lora_A.default.weight": "model-00001-of-00003.safetensors",
|
| 665 |
+
"decoder.base_model.model.model.layers.6.self_attn.k_proj.lora_B.default.weight": "model-00001-of-00003.safetensors",
|
| 666 |
+
"decoder.base_model.model.model.layers.6.self_attn.o_proj.base_layer.weight": "model-00001-of-00003.safetensors",
|
| 667 |
+
"decoder.base_model.model.model.layers.6.self_attn.o_proj.lora_A.default.weight": "model-00001-of-00003.safetensors",
|
| 668 |
+
"decoder.base_model.model.model.layers.6.self_attn.o_proj.lora_B.default.weight": "model-00001-of-00003.safetensors",
|
| 669 |
+
"decoder.base_model.model.model.layers.6.self_attn.q_proj.base_layer.weight": "model-00001-of-00003.safetensors",
|
| 670 |
+
"decoder.base_model.model.model.layers.6.self_attn.q_proj.lora_A.default.weight": "model-00001-of-00003.safetensors",
|
| 671 |
+
"decoder.base_model.model.model.layers.6.self_attn.q_proj.lora_B.default.weight": "model-00001-of-00003.safetensors",
|
| 672 |
+
"decoder.base_model.model.model.layers.6.self_attn.v_proj.base_layer.weight": "model-00001-of-00003.safetensors",
|
| 673 |
+
"decoder.base_model.model.model.layers.6.self_attn.v_proj.lora_A.default.weight": "model-00001-of-00003.safetensors",
|
| 674 |
+
"decoder.base_model.model.model.layers.6.self_attn.v_proj.lora_B.default.weight": "model-00001-of-00003.safetensors",
|
| 675 |
+
"decoder.base_model.model.model.layers.7.input_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 676 |
+
"decoder.base_model.model.model.layers.7.mlp.down_proj.base_layer.weight": "model-00001-of-00003.safetensors",
|
| 677 |
+
"decoder.base_model.model.model.layers.7.mlp.down_proj.lora_A.default.weight": "model-00001-of-00003.safetensors",
|
| 678 |
+
"decoder.base_model.model.model.layers.7.mlp.down_proj.lora_B.default.weight": "model-00001-of-00003.safetensors",
|
| 679 |
+
"decoder.base_model.model.model.layers.7.mlp.gate_proj.base_layer.weight": "model-00001-of-00003.safetensors",
|
| 680 |
+
"decoder.base_model.model.model.layers.7.mlp.gate_proj.lora_A.default.weight": "model-00001-of-00003.safetensors",
|
| 681 |
+
"decoder.base_model.model.model.layers.7.mlp.gate_proj.lora_B.default.weight": "model-00001-of-00003.safetensors",
|
| 682 |
+
"decoder.base_model.model.model.layers.7.mlp.up_proj.base_layer.weight": "model-00001-of-00003.safetensors",
|
| 683 |
+
"decoder.base_model.model.model.layers.7.mlp.up_proj.lora_A.default.weight": "model-00001-of-00003.safetensors",
|
| 684 |
+
"decoder.base_model.model.model.layers.7.mlp.up_proj.lora_B.default.weight": "model-00001-of-00003.safetensors",
|
| 685 |
+
"decoder.base_model.model.model.layers.7.post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 686 |
+
"decoder.base_model.model.model.layers.7.self_attn.k_proj.base_layer.weight": "model-00001-of-00003.safetensors",
|
| 687 |
+
"decoder.base_model.model.model.layers.7.self_attn.k_proj.lora_A.default.weight": "model-00001-of-00003.safetensors",
|
| 688 |
+
"decoder.base_model.model.model.layers.7.self_attn.k_proj.lora_B.default.weight": "model-00001-of-00003.safetensors",
|
| 689 |
+
"decoder.base_model.model.model.layers.7.self_attn.o_proj.base_layer.weight": "model-00001-of-00003.safetensors",
|
| 690 |
+
"decoder.base_model.model.model.layers.7.self_attn.o_proj.lora_A.default.weight": "model-00001-of-00003.safetensors",
|
| 691 |
+
"decoder.base_model.model.model.layers.7.self_attn.o_proj.lora_B.default.weight": "model-00001-of-00003.safetensors",
|
| 692 |
+
"decoder.base_model.model.model.layers.7.self_attn.q_proj.base_layer.weight": "model-00001-of-00003.safetensors",
|
| 693 |
+
"decoder.base_model.model.model.layers.7.self_attn.q_proj.lora_A.default.weight": "model-00001-of-00003.safetensors",
|
| 694 |
+
"decoder.base_model.model.model.layers.7.self_attn.q_proj.lora_B.default.weight": "model-00001-of-00003.safetensors",
|
| 695 |
+
"decoder.base_model.model.model.layers.7.self_attn.v_proj.base_layer.weight": "model-00001-of-00003.safetensors",
|
| 696 |
+
"decoder.base_model.model.model.layers.7.self_attn.v_proj.lora_A.default.weight": "model-00001-of-00003.safetensors",
|
| 697 |
+
"decoder.base_model.model.model.layers.7.self_attn.v_proj.lora_B.default.weight": "model-00001-of-00003.safetensors",
|
| 698 |
+
"decoder.base_model.model.model.layers.8.input_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 699 |
+
"decoder.base_model.model.model.layers.8.mlp.down_proj.base_layer.weight": "model-00001-of-00003.safetensors",
|
| 700 |
+
"decoder.base_model.model.model.layers.8.mlp.down_proj.lora_A.default.weight": "model-00001-of-00003.safetensors",
|
| 701 |
+
"decoder.base_model.model.model.layers.8.mlp.down_proj.lora_B.default.weight": "model-00001-of-00003.safetensors",
|
| 702 |
+
"decoder.base_model.model.model.layers.8.mlp.gate_proj.base_layer.weight": "model-00001-of-00003.safetensors",
|
| 703 |
+
"decoder.base_model.model.model.layers.8.mlp.gate_proj.lora_A.default.weight": "model-00001-of-00003.safetensors",
|
| 704 |
+
"decoder.base_model.model.model.layers.8.mlp.gate_proj.lora_B.default.weight": "model-00001-of-00003.safetensors",
|
| 705 |
+
"decoder.base_model.model.model.layers.8.mlp.up_proj.base_layer.weight": "model-00001-of-00003.safetensors",
|
| 706 |
+
"decoder.base_model.model.model.layers.8.mlp.up_proj.lora_A.default.weight": "model-00001-of-00003.safetensors",
|
| 707 |
+
"decoder.base_model.model.model.layers.8.mlp.up_proj.lora_B.default.weight": "model-00001-of-00003.safetensors",
|
| 708 |
+
"decoder.base_model.model.model.layers.8.post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 709 |
+
"decoder.base_model.model.model.layers.8.self_attn.k_proj.base_layer.weight": "model-00001-of-00003.safetensors",
|
| 710 |
+
"decoder.base_model.model.model.layers.8.self_attn.k_proj.lora_A.default.weight": "model-00001-of-00003.safetensors",
|
| 711 |
+
"decoder.base_model.model.model.layers.8.self_attn.k_proj.lora_B.default.weight": "model-00001-of-00003.safetensors",
|
| 712 |
+
"decoder.base_model.model.model.layers.8.self_attn.o_proj.base_layer.weight": "model-00001-of-00003.safetensors",
|
| 713 |
+
"decoder.base_model.model.model.layers.8.self_attn.o_proj.lora_A.default.weight": "model-00001-of-00003.safetensors",
|
| 714 |
+
"decoder.base_model.model.model.layers.8.self_attn.o_proj.lora_B.default.weight": "model-00001-of-00003.safetensors",
|
| 715 |
+
"decoder.base_model.model.model.layers.8.self_attn.q_proj.base_layer.weight": "model-00001-of-00003.safetensors",
|
| 716 |
+
"decoder.base_model.model.model.layers.8.self_attn.q_proj.lora_A.default.weight": "model-00001-of-00003.safetensors",
|
| 717 |
+
"decoder.base_model.model.model.layers.8.self_attn.q_proj.lora_B.default.weight": "model-00001-of-00003.safetensors",
|
| 718 |
+
"decoder.base_model.model.model.layers.8.self_attn.v_proj.base_layer.weight": "model-00001-of-00003.safetensors",
|
| 719 |
+
"decoder.base_model.model.model.layers.8.self_attn.v_proj.lora_A.default.weight": "model-00001-of-00003.safetensors",
|
| 720 |
+
"decoder.base_model.model.model.layers.8.self_attn.v_proj.lora_B.default.weight": "model-00001-of-00003.safetensors",
|
| 721 |
+
"decoder.base_model.model.model.layers.9.input_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 722 |
+
"decoder.base_model.model.model.layers.9.mlp.down_proj.base_layer.weight": "model-00001-of-00003.safetensors",
|
| 723 |
+
"decoder.base_model.model.model.layers.9.mlp.down_proj.lora_A.default.weight": "model-00001-of-00003.safetensors",
|
| 724 |
+
"decoder.base_model.model.model.layers.9.mlp.down_proj.lora_B.default.weight": "model-00001-of-00003.safetensors",
|
| 725 |
+
"decoder.base_model.model.model.layers.9.mlp.gate_proj.base_layer.weight": "model-00001-of-00003.safetensors",
|
| 726 |
+
"decoder.base_model.model.model.layers.9.mlp.gate_proj.lora_A.default.weight": "model-00001-of-00003.safetensors",
|
| 727 |
+
"decoder.base_model.model.model.layers.9.mlp.gate_proj.lora_B.default.weight": "model-00001-of-00003.safetensors",
|
| 728 |
+
"decoder.base_model.model.model.layers.9.mlp.up_proj.base_layer.weight": "model-00001-of-00003.safetensors",
|
| 729 |
+
"decoder.base_model.model.model.layers.9.mlp.up_proj.lora_A.default.weight": "model-00001-of-00003.safetensors",
|
| 730 |
+
"decoder.base_model.model.model.layers.9.mlp.up_proj.lora_B.default.weight": "model-00001-of-00003.safetensors",
|
| 731 |
+
"decoder.base_model.model.model.layers.9.post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 732 |
+
"decoder.base_model.model.model.layers.9.self_attn.k_proj.base_layer.weight": "model-00001-of-00003.safetensors",
|
| 733 |
+
"decoder.base_model.model.model.layers.9.self_attn.k_proj.lora_A.default.weight": "model-00001-of-00003.safetensors",
|
| 734 |
+
"decoder.base_model.model.model.layers.9.self_attn.k_proj.lora_B.default.weight": "model-00001-of-00003.safetensors",
|
| 735 |
+
"decoder.base_model.model.model.layers.9.self_attn.o_proj.base_layer.weight": "model-00001-of-00003.safetensors",
|
| 736 |
+
"decoder.base_model.model.model.layers.9.self_attn.o_proj.lora_A.default.weight": "model-00001-of-00003.safetensors",
|
| 737 |
+
"decoder.base_model.model.model.layers.9.self_attn.o_proj.lora_B.default.weight": "model-00001-of-00003.safetensors",
|
| 738 |
+
"decoder.base_model.model.model.layers.9.self_attn.q_proj.base_layer.weight": "model-00001-of-00003.safetensors",
|
| 739 |
+
"decoder.base_model.model.model.layers.9.self_attn.q_proj.lora_A.default.weight": "model-00001-of-00003.safetensors",
|
| 740 |
+
"decoder.base_model.model.model.layers.9.self_attn.q_proj.lora_B.default.weight": "model-00001-of-00003.safetensors",
|
| 741 |
+
"decoder.base_model.model.model.layers.9.self_attn.v_proj.base_layer.weight": "model-00001-of-00003.safetensors",
|
| 742 |
+
"decoder.base_model.model.model.layers.9.self_attn.v_proj.lora_A.default.weight": "model-00001-of-00003.safetensors",
|
| 743 |
+
"decoder.base_model.model.model.layers.9.self_attn.v_proj.lora_B.default.weight": "model-00001-of-00003.safetensors",
|
| 744 |
+
"decoder.base_model.model.model.norm.weight": "model-00003-of-00003.safetensors"
|
| 745 |
+
}
|
| 746 |
+
}
|
modeling_cocom.py
ADDED
|
@@ -0,0 +1,306 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig, PreTrainedModel, PretrainedConfig, AutoModel
|
| 2 |
+
import torch
|
| 3 |
+
import math
|
| 4 |
+
from peft import get_peft_model, LoraConfig, TaskType
|
| 5 |
+
import os
|
| 6 |
+
|
| 7 |
+
def freeze_model(model):
|
| 8 |
+
for param in model.parameters():
|
| 9 |
+
param.requires_grad = False
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
class BERT_Compressor(torch.nn.Module):
|
| 13 |
+
def __init__(self, compr_model_name, compr_rate, compr_linear_type, decoder_hidden_size):
|
| 14 |
+
super().__init__()
|
| 15 |
+
# init model
|
| 16 |
+
self.model_name = compr_model_name # base model name of BERT; example: bert-base-ucased
|
| 17 |
+
self.model = AutoModel.from_pretrained(compr_model_name, torch_dtype=torch.bfloat16)
|
| 18 |
+
self.tokenizer = AutoTokenizer.from_pretrained(compr_model_name, use_fast=True)
|
| 19 |
+
self.compr_rate = compr_rate # compression rate
|
| 20 |
+
self.compressing_mode = compr_linear_type # linear layer type, could be either concat or mean.
|
| 21 |
+
|
| 22 |
+
if self.compressing_mode == 'concat': # default setting in paper
|
| 23 |
+
self.linear = torch.nn.Linear(self.model.config.hidden_size*self.compr_rate, decoder_hidden_size)
|
| 24 |
+
elif self.compressing_mode == 'mean':
|
| 25 |
+
self.linear = torch.nn.Linear(self.model.config.hidden_size, decoder_hidden_size)
|
| 26 |
+
self.linear = self.linear.bfloat16()
|
| 27 |
+
|
| 28 |
+
def forward(self, input_ids, attention_mask):
|
| 29 |
+
# compressing context using BERT
|
| 30 |
+
segment_compress_outputs = self.model(input_ids=input_ids, attention_mask=attention_mask, output_hidden_states=True)
|
| 31 |
+
num_embs = math.ceil(input_ids.size(1) / self.compr_rate)
|
| 32 |
+
all_hidden_states_emb = list()
|
| 33 |
+
if self.compressing_mode == 'concat':
|
| 34 |
+
for segment_idx in range(num_embs):
|
| 35 |
+
start_idx = segment_idx * self.compr_rate
|
| 36 |
+
end_idx = (segment_idx + 1) * self.compr_rate
|
| 37 |
+
hidden_state = segment_compress_outputs.hidden_states[-1][:, start_idx:end_idx, :]
|
| 38 |
+
hidden_state_concat = torch.flatten(hidden_state, start_dim=1) #batch_size, hidden_state_dim * compression_rate
|
| 39 |
+
all_hidden_states_emb.append(hidden_state_concat)
|
| 40 |
+
elif self.compressing_mode == "mean":
|
| 41 |
+
for segment_idx in range(num_embs):
|
| 42 |
+
start_idx = segment_idx * self.compr_rate
|
| 43 |
+
end_idx = (segment_idx + 1) * self.compr_rate
|
| 44 |
+
hidden_state = segment_compress_outputs.hidden_states[-1][:, start_idx:end_idx, :]
|
| 45 |
+
# Apply mean pooling to get the final embedding for the segment
|
| 46 |
+
all_hidden_states_emb.append(hidden_state)
|
| 47 |
+
else:
|
| 48 |
+
raise NotImplementedError()
|
| 49 |
+
|
| 50 |
+
all_hidden_states_emb_cat = torch.stack(all_hidden_states_emb, dim=1)
|
| 51 |
+
transformed_embeds = self.linear(all_hidden_states_emb_cat)
|
| 52 |
+
|
| 53 |
+
|
| 54 |
+
if self.compressing_mode == "mean":
|
| 55 |
+
transformed_embeds = torch.mean(transformed_embeds, dim=2)
|
| 56 |
+
|
| 57 |
+
# dimention of transformed_embeds: (batch_size*generation_top_k, num_embs, decoder_hidden_size)
|
| 58 |
+
return transformed_embeds
|
| 59 |
+
|
| 60 |
+
class COCOMConfig(PretrainedConfig):
|
| 61 |
+
|
| 62 |
+
model_type = "COCOM"
|
| 63 |
+
def __init__(self,
|
| 64 |
+
decoder_model_name="meta-llama/Llama-2-7b-chat-hf",
|
| 65 |
+
quantization = 'no',
|
| 66 |
+
generation_top_k = 1,
|
| 67 |
+
sep = False,
|
| 68 |
+
compr_model_name = "bert-base-uncased",
|
| 69 |
+
compr_rate = 64,
|
| 70 |
+
compr_linear_type = 'concat',
|
| 71 |
+
lora = False,
|
| 72 |
+
training_form="both",
|
| 73 |
+
lora_r=16,
|
| 74 |
+
**kwargs):
|
| 75 |
+
super().__init__(**kwargs)
|
| 76 |
+
|
| 77 |
+
self.decoder_model_name = decoder_model_name # model name of decoder
|
| 78 |
+
self.quantization = quantization # quantization, could be no, int4, int8
|
| 79 |
+
self.generation_top_k = generation_top_k # top k for each query, for pretraining, set to 1
|
| 80 |
+
self.sep = sep # boolean type, whether to use sep token
|
| 81 |
+
self.compr_model_name = compr_model_name # model name of compressor
|
| 82 |
+
self.compr_rate = compr_rate # compression rate
|
| 83 |
+
self.compr_linear_type = compr_linear_type # linear layer type, could be either concat or mean
|
| 84 |
+
self.lora = lora # boolean type, whether to use lora trsining
|
| 85 |
+
self.training_form = training_form # training form, could be compressor: training only comprssor; both:
|
| 86 |
+
self.lora_r = lora_r # lora_r for lora training, we use 16 throughout the experiment.
|
| 87 |
+
|
| 88 |
+
class COCOM(PreTrainedModel):
|
| 89 |
+
config_class = COCOMConfig
|
| 90 |
+
def __init__(self, cfg):
|
| 91 |
+
super().__init__(cfg)
|
| 92 |
+
# define models
|
| 93 |
+
# model could be loaded in three quantization modes: no, int4, int8
|
| 94 |
+
if cfg.quantization == "no":
|
| 95 |
+
self.decoder = AutoModelForCausalLM.from_pretrained(
|
| 96 |
+
cfg.decoder_model_name,
|
| 97 |
+
torch_dtype=torch.bfloat16,
|
| 98 |
+
attn_implementation="flash_attention_2",
|
| 99 |
+
low_cpu_mem_usage = True,
|
| 100 |
+
)
|
| 101 |
+
elif cfg.quantization == "int4":
|
| 102 |
+
quant_config = BitsAndBytesConfig(
|
| 103 |
+
load_in_4bit=True,
|
| 104 |
+
bnb_4bit_quant_type='nf4',
|
| 105 |
+
bnb_4bit_compute_dtype='bfloat16',
|
| 106 |
+
low_cpu_mem_usage = True,
|
| 107 |
+
)
|
| 108 |
+
self.decoder = AutoModelForCausalLM.from_pretrained(
|
| 109 |
+
cfg.decoder_model_name,
|
| 110 |
+
quantization_config=quant_config,
|
| 111 |
+
attn_implementation="flash_attention_2",
|
| 112 |
+
torch_dtype=torch.bfloat16,
|
| 113 |
+
resume_download=True,
|
| 114 |
+
low_cpu_mem_usage = True,
|
| 115 |
+
trust_remote_code=True,
|
| 116 |
+
)
|
| 117 |
+
elif cfg.quantization == "int8":
|
| 118 |
+
quant_config = BitsAndBytesConfig(
|
| 119 |
+
load_in_8bit=True,
|
| 120 |
+
llm_int8_enable_fp32_cpu_offload=True,
|
| 121 |
+
bnb_4bit_compute_dtype='bfloat16',
|
| 122 |
+
low_cpu_mem_usage = True,
|
| 123 |
+
)
|
| 124 |
+
self.decoder = AutoModelForCausalLM.from_pretrained(
|
| 125 |
+
cfg.decoder_model_name,
|
| 126 |
+
quantization_config=quant_config,
|
| 127 |
+
attn_implementation="flash_attention_2",
|
| 128 |
+
torch_dtype=torch.bfloat16,
|
| 129 |
+
resume_download=True,
|
| 130 |
+
low_cpu_mem_usage = True,
|
| 131 |
+
trust_remote_code=True,
|
| 132 |
+
)
|
| 133 |
+
else:
|
| 134 |
+
raise NotImplementedError()
|
| 135 |
+
|
| 136 |
+
# when compr_model_name is not set, then means using a decoder-based compressor, otherwise a bert based compressor
|
| 137 |
+
if cfg.compr_model_name is not None:
|
| 138 |
+
# case bert based compressor
|
| 139 |
+
self.compr = BERT_Compressor(cfg.compr_model_name, cfg.compr_rate, cfg.compr_linear_type, self.decoder.config.hidden_size)
|
| 140 |
+
else:
|
| 141 |
+
# case decoder based compressor
|
| 142 |
+
self.compr = None
|
| 143 |
+
|
| 144 |
+
# set lora adaptors
|
| 145 |
+
if cfg.lora:
|
| 146 |
+
peft_config = LoraConfig(
|
| 147 |
+
task_type="CAUSAL_LM",
|
| 148 |
+
r=cfg.lora_r,
|
| 149 |
+
lora_alpha=2* cfg.lora_r,
|
| 150 |
+
target_modules='all-linear',
|
| 151 |
+
lora_dropout=0.1,
|
| 152 |
+
)
|
| 153 |
+
self.decoder = get_peft_model(self.decoder, peft_config)
|
| 154 |
+
self.decoder.print_trainable_parameters()
|
| 155 |
+
|
| 156 |
+
# for training_form=compressor, then freeze the decoder for BERT-based
|
| 157 |
+
self.training_form = cfg.training_form
|
| 158 |
+
if self.training_form == "compressor" and self.compr is not None:
|
| 159 |
+
freeze_model(self.decoder)
|
| 160 |
+
|
| 161 |
+
self.decoder_tokenizer = AutoTokenizer.from_pretrained(cfg.decoder_model_name, use_fast=True, padding_side='left')
|
| 162 |
+
|
| 163 |
+
# define special tokens
|
| 164 |
+
self.decoder_tokenizer.add_special_tokens({'additional_special_tokens': ['<MEM>', '<AE>', '<ENC>', '<SEP>']})
|
| 165 |
+
self.decoder_tokenizer.mem_token = '<MEM>' # Memory token
|
| 166 |
+
self.decoder_tokenizer.ae_token = '<AE>' # token for autoencoding on decoder side
|
| 167 |
+
self.decoder_tokenizer.enc_token = '<ENC>' # token for autoencoding on compressor side
|
| 168 |
+
self.decoder_tokenizer.sep_token = '<SEP>' # sep token between document
|
| 169 |
+
|
| 170 |
+
self.decoder_tokenizer.mem_token_id = self.decoder_tokenizer.convert_tokens_to_ids('<MEM>')
|
| 171 |
+
self.decoder_tokenizer.ae_token_id = self.decoder_tokenizer.convert_tokens_to_ids('<AE>')
|
| 172 |
+
self.decoder_tokenizer.sep_token_id = self.decoder_tokenizer.convert_tokens_to_ids('<SEP>')
|
| 173 |
+
# if pad token ecist then use pad token, othrwise bos token
|
| 174 |
+
if self.decoder_tokenizer.pad_token_id is None:
|
| 175 |
+
self.decoder_tokenizer.pad_token_id = self.decoder_tokenizer.bos_token_id
|
| 176 |
+
|
| 177 |
+
# resize the tokenizer embedding
|
| 178 |
+
self.decoder.resize_token_embeddings(len(self.decoder_tokenizer))
|
| 179 |
+
self.decoder.generation_config.top_p=None
|
| 180 |
+
self.decoder.generation_config.temperature=None
|
| 181 |
+
self.compr_model_name = cfg.compr_model_name
|
| 182 |
+
# other settings
|
| 183 |
+
self.generation_top_k = cfg.generation_top_k
|
| 184 |
+
self.sep = cfg.sep
|
| 185 |
+
self.compr_rate = cfg.compr_rate
|
| 186 |
+
self.local_rank = os.getenv('LOCAL_RANK', '0')
|
| 187 |
+
|
| 188 |
+
def compress_and_replace_emb(self, enc_input_ids, enc_attention_mask, dec_input_ids):
|
| 189 |
+
indices = range(0, enc_input_ids.size(0) + 1, self.generation_top_k)
|
| 190 |
+
if self.compr:
|
| 191 |
+
compressed_embs = self.compr(enc_input_ids, enc_attention_mask)
|
| 192 |
+
input_embeds = self.replace_embeddings(compressed_embs, dec_input_ids, indices)
|
| 193 |
+
else:
|
| 194 |
+
compressed_embs = self.compr_decoder(enc_input_ids, enc_attention_mask)
|
| 195 |
+
input_embeds = self.replace_embeddings(compressed_embs, dec_input_ids, indices)
|
| 196 |
+
return input_embeds
|
| 197 |
+
|
| 198 |
+
def compr_decoder(self, input_ids, attention_mask):
|
| 199 |
+
emb = self.decoder(input_ids=input_ids, attention_mask=attention_mask, output_hidden_states=True).hidden_states[-1]
|
| 200 |
+
mask = input_ids == self.decoder_tokenizer.mem_token_id
|
| 201 |
+
return emb[mask].reshape(emb.size(0), -1, emb.size(-1))
|
| 202 |
+
|
| 203 |
+
|
| 204 |
+
def replace_embeddings(self, compressed_embs, dec_input_ids, indices):
|
| 205 |
+
# Embed the decoder input
|
| 206 |
+
inputs_embeds = self.decoder.get_input_embeddings()(dec_input_ids)
|
| 207 |
+
num_embs = compressed_embs.size(1)
|
| 208 |
+
if self.sep:
|
| 209 |
+
slot_len = num_embs + 1
|
| 210 |
+
else:
|
| 211 |
+
slot_len = num_embs
|
| 212 |
+
# get first mem_token inidices
|
| 213 |
+
first_mem_token_indices = torch.argmax((dec_input_ids == self.decoder_tokenizer.mem_token_id).int(), dim=1)
|
| 214 |
+
batch_size = inputs_embeds.size(0)
|
| 215 |
+
# for each example in batch, replace them with compressed embeddings
|
| 216 |
+
for i in range(batch_size):
|
| 217 |
+
for j in range(indices[i], indices[i + 1]):
|
| 218 |
+
start_idx = first_mem_token_indices[i].item() + (j-indices[i]) * slot_len
|
| 219 |
+
inputs_embeds[i, start_idx:start_idx + num_embs, :] = compressed_embs[j]
|
| 220 |
+
return inputs_embeds
|
| 221 |
+
|
| 222 |
+
|
| 223 |
+
def forward(self,
|
| 224 |
+
enc_input_ids: torch.LongTensor = None,
|
| 225 |
+
enc_attention_mask: torch.LongTensor = None,
|
| 226 |
+
dec_input_ids: torch.LongTensor = None,
|
| 227 |
+
dec_attention_mask: torch.LongTensor = None,
|
| 228 |
+
labels: torch.LongTensor = None):
|
| 229 |
+
|
| 230 |
+
# enc_input_ids: stores the contexts, should be flattened from all queries before input, dimention (batch_size*generation_top_k, token_length)
|
| 231 |
+
# enc_attention_mask: attention mask of enc_input_ids
|
| 232 |
+
# dec_input_ids: stores the prompts (including mem tokens), dimention (batch_size, token_length)
|
| 233 |
+
# dec_attention_mask: attention mask of dec_input_ids
|
| 234 |
+
|
| 235 |
+
# Perform compression with gradient tracking
|
| 236 |
+
inputs_embeds = self.compress_and_replace_emb(enc_input_ids, enc_attention_mask, dec_input_ids)
|
| 237 |
+
|
| 238 |
+
# if training_form is compressor, then detach the inputs_embeds, to make gradient not count in decoder
|
| 239 |
+
if (self.training_form == "compressor") and (self.compr is None):
|
| 240 |
+
inputs_embeds = inputs_embeds.detach()
|
| 241 |
+
|
| 242 |
+
# decoding
|
| 243 |
+
decoder_outputs = self.decoder(inputs_embeds=inputs_embeds, attention_mask=dec_attention_mask, labels=labels)
|
| 244 |
+
|
| 245 |
+
return {"loss": decoder_outputs.loss, "logits": decoder_outputs.logits}
|
| 246 |
+
|
| 247 |
+
|
| 248 |
+
|
| 249 |
+
def generate(self, model_input, max_new_tokens=128):
|
| 250 |
+
device = self.decoder.device
|
| 251 |
+
enc_input_ids, enc_attention_mask, dec_input_ids, dec_attention_mask = model_input['enc_input_ids'], model_input['enc_attention_mask'], model_input['dec_input_ids'], model_input['dec_attention_mask']
|
| 252 |
+
inputs_embeds = self.compress_and_replace_emb(enc_input_ids.to(device), enc_attention_mask.to(device), dec_input_ids.to(device))
|
| 253 |
+
output_ids = self.decoder.generate(
|
| 254 |
+
inputs_embeds=inputs_embeds.to(device),
|
| 255 |
+
attention_mask=dec_attention_mask.to(device),
|
| 256 |
+
do_sample=False,
|
| 257 |
+
top_p=None,
|
| 258 |
+
max_new_tokens=max_new_tokens
|
| 259 |
+
)
|
| 260 |
+
decoded = self.decoder_tokenizer.batch_decode(output_ids, skip_special_tokens=True)
|
| 261 |
+
return decoded
|
| 262 |
+
|
| 263 |
+
def generate_from_text(self, contexts, questions, max_new_tokens=128):
|
| 264 |
+
# for each question in list give input a list of contexts of equal length
|
| 265 |
+
# first make sure that every list in contexts are having the same length
|
| 266 |
+
assert len(contexts) == len(questions)
|
| 267 |
+
assert all([len(context) == len(contexts[0]) for context in contexts])
|
| 268 |
+
|
| 269 |
+
# prepare inp_enc for compression
|
| 270 |
+
# first flatten the contexts
|
| 271 |
+
self.generation_top_k = len(contexts[0])
|
| 272 |
+
flat_contexts = sum(contexts, [])
|
| 273 |
+
#tokenize the contexts, depending if compr exist or not
|
| 274 |
+
if self.compr is not None:
|
| 275 |
+
enc_input = self.compr.tokenizer(flat_contexts, padding=True, truncation=True, return_tensors='pt', pad_to_multiple_of=self.compr_rate)
|
| 276 |
+
num_mem_tokens = math.ceil(enc_input['input_ids'].size(1) / self.compr_rate)
|
| 277 |
+
else:
|
| 278 |
+
# first need to add special token in flat_contexts
|
| 279 |
+
flat_contexts = [self.decoder_tokenizer.enc_token + self.decoder_tokenizer.bos_token + context + self.decoder_tokenizer.bos_token for context in flat_contexts]
|
| 280 |
+
enc_input = self.decoder_tokenizer(flat_contexts, truncation=True, return_tensors='pt', padding="longest")
|
| 281 |
+
num_mem_tokens = math.ceil((enc_input['input_ids'].size(1)-3) / self.compr_rate)
|
| 282 |
+
mem_tokens = torch.full((enc_input['input_ids'].size(0), num_mem_tokens), self.decoder_tokenizer.mem_token_id, dtype=torch.long)
|
| 283 |
+
enc_input['input_ids'] = torch.cat([mem_tokens, enc_input['input_ids']], dim=1)
|
| 284 |
+
enc_input['attention_mask'] = torch.cat([torch.ones_like(mem_tokens), enc_input['attention_mask']], dim=1)
|
| 285 |
+
|
| 286 |
+
|
| 287 |
+
# prepare inp_dec
|
| 288 |
+
mem_tokens = self.decoder_tokenizer.mem_token * num_mem_tokens
|
| 289 |
+
if self.sep:
|
| 290 |
+
mem_tokens += self.decoder_tokenizer.sep_token
|
| 291 |
+
|
| 292 |
+
instr = [self.decoder_tokenizer.bos_token + mem_tokens* self.generation_top_k + '[INST]' + question + '\n[/INST]\n' for question in questions]
|
| 293 |
+
inp_dec = self.decoder_tokenizer(instr, truncation=True, return_tensors='pt', padding="longest")
|
| 294 |
+
|
| 295 |
+
# generate
|
| 296 |
+
model_input = {
|
| 297 |
+
'enc_input_ids': enc_input['input_ids'],
|
| 298 |
+
'enc_attention_mask': enc_input['attention_mask'],
|
| 299 |
+
'dec_input_ids': inp_dec['input_ids'],
|
| 300 |
+
'dec_attention_mask': inp_dec['attention_mask']
|
| 301 |
+
}
|
| 302 |
+
|
| 303 |
+
return self.generate(model_input, max_new_tokens)
|
| 304 |
+
|
| 305 |
+
|
| 306 |
+
|