

Update README.md
Browse files
README.md
CHANGED
|
@@ -1,57 +1,72 @@
|
|
| 1 |
---
|
| 2 |
tags:
|
| 3 |
-
-
|
|
|
|
|
|
|
|
|
|
|
|
|
| 4 |
base_model: llava-hf/bakLlava-v1-hf
|
| 5 |
model-index:
|
| 6 |
-
- name:
|
| 7 |
results: []
|
|
|
|
|
|
|
|
|
|
| 8 |
---
|
| 9 |
|
| 10 |
-
|
| 11 |
-
should probably proofread and complete it, then remove this comment. -->
|
| 12 |
|
| 13 |
-
|
| 14 |
|
| 15 |
-
|
| 16 |
|
| 17 |
-
|
| 18 |
|
| 19 |
-
|
| 20 |
|
| 21 |
-
|
| 22 |
|
| 23 |
-
|
| 24 |
|
| 25 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
| 26 |
|
| 27 |
-
|
|
|
|
|
|
|
|
|
|
| 28 |
|
| 29 |
-
## Training procedure
|
| 30 |
|
| 31 |
-
|
|
|
|
|
|
|
| 32 |
|
| 33 |
-
|
| 34 |
-
|
| 35 |
-
|
| 36 |
-
-
|
| 37 |
-
- seed: 42
|
| 38 |
-
- distributed_type: multi-GPU
|
| 39 |
-
- num_devices: 32
|
| 40 |
-
- gradient_accumulation_steps: 4
|
| 41 |
-
- total_train_batch_size: 128
|
| 42 |
-
- total_eval_batch_size: 32
|
| 43 |
-
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
|
| 44 |
-
- lr_scheduler_type: cosine
|
| 45 |
-
- lr_scheduler_warmup_ratio: 0.03
|
| 46 |
-
- num_epochs: 1.0
|
| 47 |
|
| 48 |
-
|
|
|
|
|
|
|
| 49 |
|
|
|
|
|
|
|
|
|
|
| 50 |
|
|
|
|
|
|
|
| 51 |
|
| 52 |
-
|
|
|
|
|
|
|
|
|
|
| 53 |
|
| 54 |
-
-
|
| 55 |
-
|
| 56 |
-
|
| 57 |
-
|
|
|
|
|
|
| 1 |
---
|
| 2 |
tags:
|
| 3 |
+
- Mantis
|
| 4 |
+
- VLM
|
| 5 |
+
- LMM
|
| 6 |
+
- Multimodal LLM
|
| 7 |
+
- bakllava
|
| 8 |
base_model: llava-hf/bakLlava-v1-hf
|
| 9 |
model-index:
|
| 10 |
+
- name: Mantis-bakllava-7b
|
| 11 |
results: []
|
| 12 |
+
license: apache-2.0
|
| 13 |
+
language:
|
| 14 |
+
- en
|
| 15 |
---
|
| 16 |
|
| 17 |
+
# Mantis: Interleaved Multi-Image Instruction Tuning
|
|
|
|
| 18 |
|
| 19 |
+
**Mantis** is a multimodal conversational AI model that can chat with users about images and text. It's optimized for multi-image reasoning, where interleaved text and images can be used to generate responses.
|
| 20 |
|
| 21 |
+
Mantis is trained on the newly curated dataset **Mantis-Instruct**, a large-scale multi-image QA dataset that covers various multi-image reasoning tasks.
|
| 22 |
|
| 23 |
+
Mantis is an active work in progress. Check our [Blog](https://tiger-ai-lab.github.io/Blog/mantis) for more details!
|
| 24 |
|
| 25 |
+
|[Demo](https://huggingface.co/spaces/TIGER-Lab/Mantis) | [Blog](https://tiger-ai-lab.github.io/Blog/mantis) | [Github](https://github.com/TIGER-AI-Lab/Mantis) | [Models](https://huggingface.co/collections/TIGER-Lab/mantis-6619b0834594c878cdb1d6e4) |
|
| 26 |
|
| 27 |
+
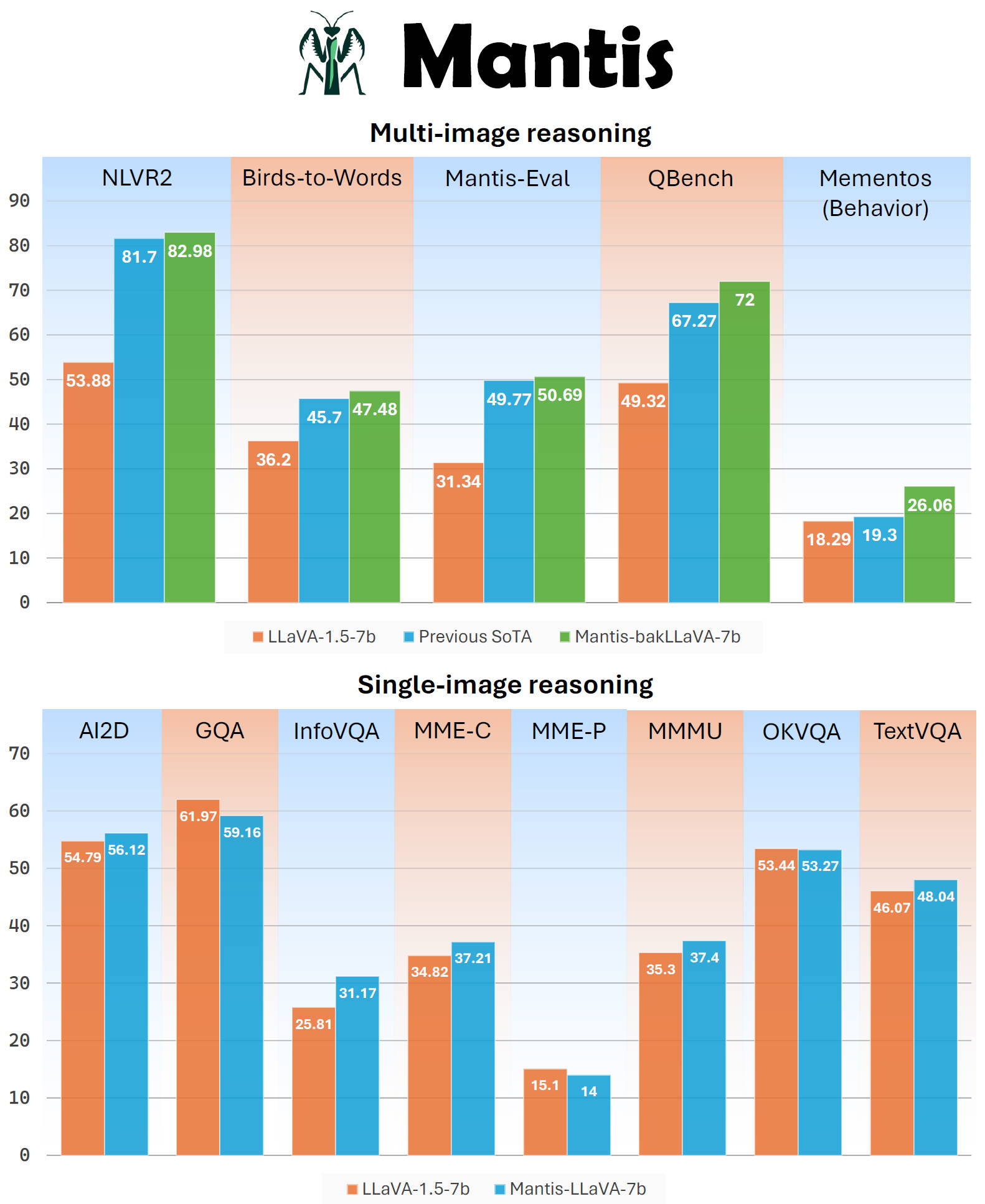
|
| 28 |
|
| 29 |
+
## Inference
|
| 30 |
|
| 31 |
+
You can install Mantis's GitHub codes as a Python package
|
| 32 |
+
```bash
|
| 33 |
+
pip install git+https://github.com/TIGER-AI-Lab/Mantis.git
|
| 34 |
+
```
|
| 35 |
+
then run inference with codes here: [examples/run_mantis.py](https://github.com/TIGER-AI-Lab/Mantis/blob/main/examples/run_mantis_hf.py)
|
| 36 |
|
| 37 |
+
```python
|
| 38 |
+
from mantis.models.mllava import chat_mllava
|
| 39 |
+
from PIL import Image
|
| 40 |
+
import torch
|
| 41 |
|
|
|
|
| 42 |
|
| 43 |
+
image1 = "image1.jpg"
|
| 44 |
+
image2 = "image2.jpg"
|
| 45 |
+
images = [Image.open(image1), Image.open(image2)]
|
| 46 |
|
| 47 |
+
# load processor and model
|
| 48 |
+
from mantis.models.mllava import MLlavaProcessor, LlavaForConditionalGeneration
|
| 49 |
+
processor = MLlavaProcessor.from_pretrained("TIGER-Lab/Mantis-bakllava-7b")
|
| 50 |
+
model = LlavaForConditionalGeneration.from_pretrained("TIGER-Lab/Mantis-bakllava-7b", device_map="auto", torch_dtype=torch.bfloat16, attn_implementation="flash_attention_2")
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 51 |
|
| 52 |
+
# chat
|
| 53 |
+
text = "<image> <image> What's the difference between these two images? Please describe as much as you can."
|
| 54 |
+
response, history = chat_mllava(text, images, model, processor)
|
| 55 |
|
| 56 |
+
print("USER: ", text)
|
| 57 |
+
print("ASSISTANT: ", response)
|
| 58 |
+
# The image on the right has a larger number of wallets displayed compared to the image on the left. The wallets in the right image are arranged in a grid pattern, while the wallets in the left image are displayed in a more scattered manner. The wallets in the right image have various colors, including red, purple, and brown, while the wallets in the left image are primarily brown.
|
| 59 |
|
| 60 |
+
text = "How many items are there in image 1 and image 2 respectively?"
|
| 61 |
+
response, history = chat_mllava(text, images, model, processor, history=history)
|
| 62 |
|
| 63 |
+
print("USER: ", text)
|
| 64 |
+
print("ASSISTANT: ", response)
|
| 65 |
+
# There are two items in image 1 and four items in image 2.
|
| 66 |
+
```
|
| 67 |
|
| 68 |
+
Or, you can run the model without relying on the mantis codes, using pure hugging face transformers. See [examples/run_mantis_hf.py](https://github.com/TIGER-AI-Lab/Mantis/blob/main/examples/run_mantis_hf.py) for details.
|
| 69 |
+
|
| 70 |
+
|
| 71 |
+
## Training
|
| 72 |
+
Training codes will be released soon.
|