
Commit
•
58cfd1b
1
Parent(s):
dcd70f4
Upload folder using huggingface_hub
Browse files- README.md +50 -0
- __pycache__/models.cpython-310.pyc +0 -0
- __pycache__/predict.cpython-310.pyc +0 -0
- captioner.pt +3 -0
- imagecaptioning.ipynb +0 -0
- images/loss.png +0 -0
- images/model.png +0 -0
- images/perplexity.png +0 -0
- images/test1.png +0 -0
- images/test2.png +0 -0
- images/test3.png +0 -0
- images/test4.png +0 -0
- images/test5.png +0 -0
- images/test6.png +0 -0
- images/test7.png +0 -0
- images/test8.png +0 -0
- images/test9.png +0 -0
- models.py +265 -0
- predict.py +98 -0
- requirements.txt +7 -0
README.md
ADDED
|
@@ -0,0 +1,50 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Image Captioning using ViT and GPT2 architecture
|
| 2 |
+
|
| 3 |
+
This is my attempt to make a transformer model which takes image as the input and provides a caption for the image
|
| 4 |
+
|
| 5 |
+
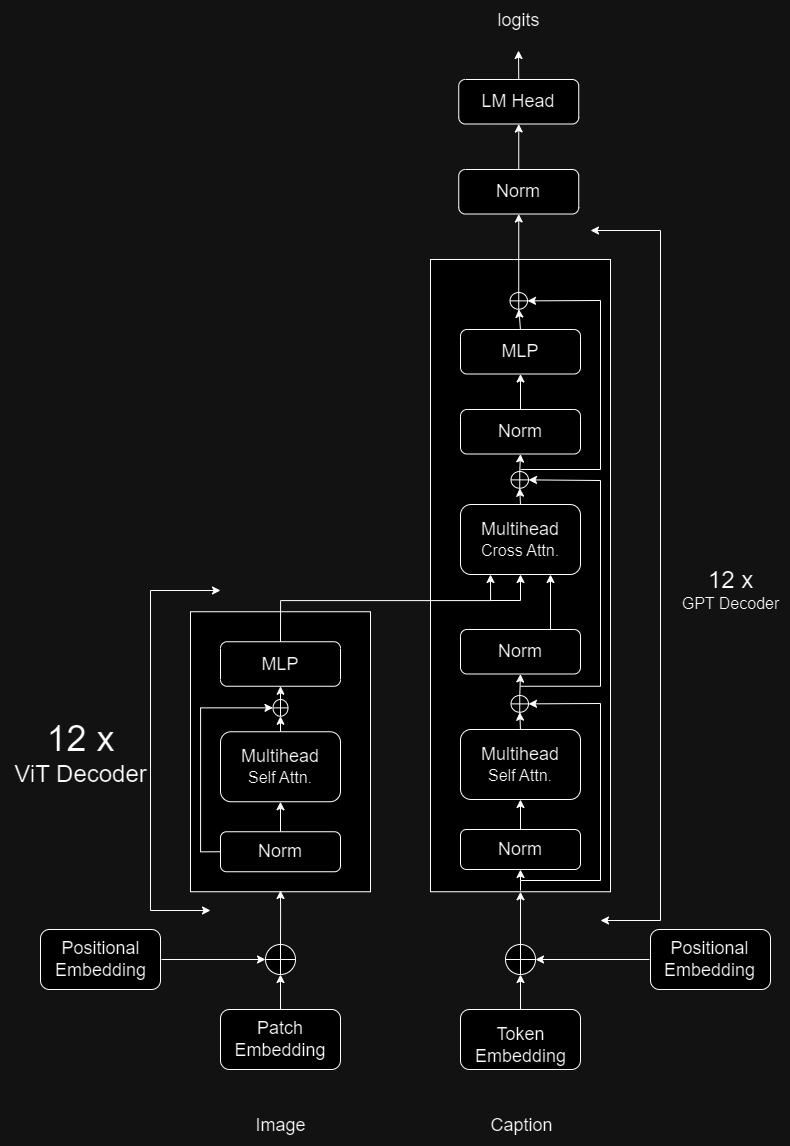
## Model Architecture
|
| 6 |
+
It comprises of 12 ViT encoder and 12 GPT2 decoders
|
| 7 |
+
|
| 8 |
+

|
| 9 |
+
|
| 10 |
+
## Training
|
| 11 |
+
The model was trained on the dataset Flickr30k which comprises of 30k images and 5 captions for each image
|
| 12 |
+
The model was trained for 8 epochs (which took 10hrs on kaggle's P100 GPU)
|
| 13 |
+
|
| 14 |
+
## Results
|
| 15 |
+
The model acieved a BLEU-4 score of 0.2115, CIDEr score of 0.4, METEOR score of 0.25, and SPICE score of 0.19 on the Flickr8k dataset
|
| 16 |
+
|
| 17 |
+
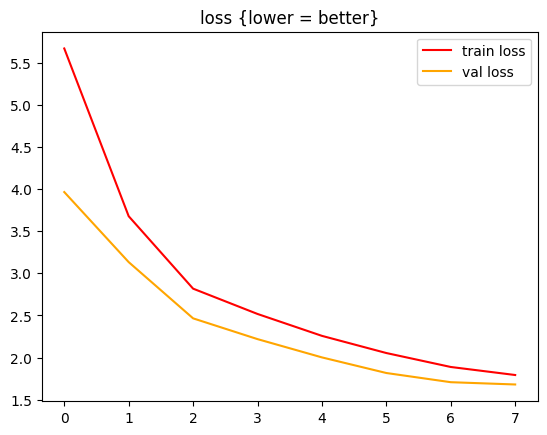
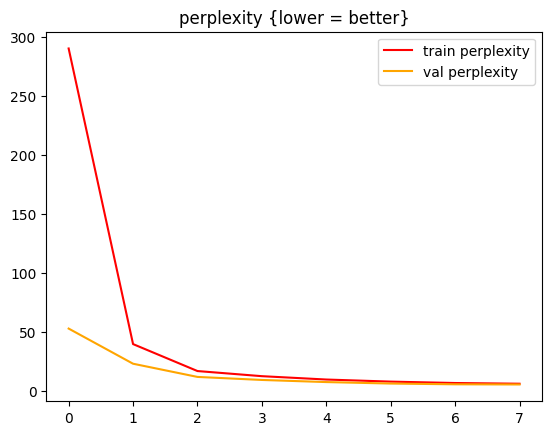
These are the loss curves.
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+

|
| 21 |
+

|
| 22 |
+
|
| 23 |
+
## Predictions
|
| 24 |
+
To predict your own images download the models.py, predict.py and the requirements.txt and then run the following commands->
|
| 25 |
+
|
| 26 |
+
`pip install -r requirements.txt`
|
| 27 |
+
|
| 28 |
+
`python predict.py`
|
| 29 |
+
|
| 30 |
+
*Predicting for the first time will take time as it has to download the model weights (1GB)*
|
| 31 |
+
|
| 32 |
+
Here are a few examples of the prediction done on the Validation dataset
|
| 33 |
+
|
| 34 |
+

|
| 35 |
+

|
| 36 |
+

|
| 37 |
+

|
| 38 |
+

|
| 39 |
+

|
| 40 |
+

|
| 41 |
+

|
| 42 |
+

|
| 43 |
+
|
| 44 |
+
As we can see these are not the most amazing predictions. The performance could be improved by training it further and using an even bigger dataset like MS COCO (500k captioned images)
|
| 45 |
+
|
| 46 |
+
## FAQ
|
| 47 |
+
|
| 48 |
+
Check the [full notebook](./imagecaptioning.ipynb) or [Kaggle](https://www.kaggle.com/code/ayushman72/imagecaptioning)
|
| 49 |
+
|
| 50 |
+
Download the [weights](https://drive.google.com/file/d/1X51wAI7Bsnrhd2Pa4WUoHIXvvhIcRH7Y/view?usp=drive_link) of the model
|
__pycache__/models.cpython-310.pyc
ADDED
|
Binary file (10.9 kB). View file
|
|
|
__pycache__/predict.cpython-310.pyc
ADDED
|
Binary file (3.32 kB). View file
|
|
|
captioner.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:854d3b80d6720ccdb1750b6a38a7bba5ea6ce3be96e8bc3ebad68a508884fc17
|
| 3 |
+
size 1004907962
|
imagecaptioning.ipynb
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
images/loss.png
ADDED
|
images/model.png
ADDED
|
images/perplexity.png
ADDED
|
images/test1.png
ADDED

|
images/test2.png
ADDED

|
images/test3.png
ADDED

|
images/test4.png
ADDED

|
images/test5.png
ADDED

|
images/test6.png
ADDED

|
images/test7.png
ADDED

|
images/test8.png
ADDED

|
images/test9.png
ADDED

|
models.py
ADDED
|
@@ -0,0 +1,265 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import torch.nn as nn
|
| 3 |
+
import torch.nn.functional as F
|
| 4 |
+
from transformers import GPT2LMHeadModel, GPT2TokenizerFast
|
| 5 |
+
from timm import create_model
|
| 6 |
+
from types import SimpleNamespace
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
tokenizer = GPT2TokenizerFast.from_pretrained('gpt2')
|
| 10 |
+
tokenizer.pad_token = tokenizer.eos_token
|
| 11 |
+
|
| 12 |
+
class GPT2Attention(nn.Module):
|
| 13 |
+
def __init__(self,config:SimpleNamespace):
|
| 14 |
+
super(GPT2Attention,self).__init__()
|
| 15 |
+
self.embed_dim = config.embed_dim
|
| 16 |
+
self.n_heads = config.num_heads
|
| 17 |
+
assert self.embed_dim % self.n_heads == 0, "embedding dim must be divisible by num heads"
|
| 18 |
+
self.head_size = self.embed_dim // self.n_heads
|
| 19 |
+
self.seq_len = config.seq_len
|
| 20 |
+
self.c_attn = nn.Linear(self.embed_dim,self.embed_dim*3)
|
| 21 |
+
self.scale = self.head_size ** -0.5
|
| 22 |
+
|
| 23 |
+
self.register_buffer('mask',torch.tril(torch.ones(1,1,self.seq_len,self.seq_len)))
|
| 24 |
+
self.c_proj = nn.Linear(self.embed_dim,self.embed_dim)
|
| 25 |
+
self.attn_dropout = nn.Dropout(config.attention_dropout)
|
| 26 |
+
self.resid_dropout = nn.Dropout(config.residual_dropout)
|
| 27 |
+
|
| 28 |
+
def forward(self,x:torch.Tensor)-> torch.Tensor:
|
| 29 |
+
b,t,c = x.shape
|
| 30 |
+
|
| 31 |
+
q,k,v = self.c_attn(x).chunk(3,dim=-1)
|
| 32 |
+
q = q.view(b,t,self.n_heads,self.head_size).permute(0,2,1,3)
|
| 33 |
+
k = k.view(b,t,self.n_heads,self.head_size).permute(0,2,1,3)
|
| 34 |
+
v = v.view(b,t,self.n_heads,self.head_size).permute(0,2,1,3)
|
| 35 |
+
|
| 36 |
+
qk_t = ([email protected](-2,-1))*self.scale
|
| 37 |
+
qk_t = qk_t.masked_fill(self.mask[:,:,:t,:t]==0,float('-inf'))
|
| 38 |
+
qk_t = F.softmax(qk_t,dim=-1)
|
| 39 |
+
weights = self.attn_dropout(qk_t)
|
| 40 |
+
|
| 41 |
+
attention = weights@v
|
| 42 |
+
attention = attention.permute(0,2,1,3).contiguous().view(b,t,c)
|
| 43 |
+
|
| 44 |
+
out = self.c_proj(attention)
|
| 45 |
+
return self.resid_dropout(out)
|
| 46 |
+
|
| 47 |
+
class GPT2CrossAttention(nn.Module):
|
| 48 |
+
def __init__(self,config:SimpleNamespace):
|
| 49 |
+
super(GPT2CrossAttention,self).__init__()
|
| 50 |
+
self.embed_dim = config.embed_dim
|
| 51 |
+
self.n_heads = config.num_heads
|
| 52 |
+
assert self.embed_dim %self.n_heads == 0, "embedding dim must be divisible by num heads"
|
| 53 |
+
self.head_size = self.embed_dim // self.n_heads
|
| 54 |
+
self.seq_len = config.seq_len
|
| 55 |
+
|
| 56 |
+
self.q = nn.Linear(self.embed_dim,self.embed_dim)
|
| 57 |
+
self.k = nn.Linear(self.embed_dim,self.embed_dim)
|
| 58 |
+
self.v = nn.Linear(self.embed_dim,self.embed_dim)
|
| 59 |
+
self.scale = self.head_size ** -0.5
|
| 60 |
+
|
| 61 |
+
self.c_proj = nn.Linear(self.embed_dim,self.embed_dim)
|
| 62 |
+
self.attn_dropout = nn.Dropout(config.attention_dropout)
|
| 63 |
+
self.resid_dropout = nn.Dropout(config.residual_dropout)
|
| 64 |
+
self.apply(self._init_weights)
|
| 65 |
+
|
| 66 |
+
def _init_weights(self,module):
|
| 67 |
+
if isinstance(module,nn.Linear):
|
| 68 |
+
nn.init.normal_(module.weight,mean=0.0,std=0.02)
|
| 69 |
+
|
| 70 |
+
if module.bias is not None:
|
| 71 |
+
nn.init.zeros_(module.bias)
|
| 72 |
+
|
| 73 |
+
def forward(self,q:torch.Tensor,k:torch.Tensor,v:torch.Tensor)->torch.Tensor:
|
| 74 |
+
b,t,c = q.shape
|
| 75 |
+
|
| 76 |
+
q,k,v = self.q(q),self.k(k),self.v(v)
|
| 77 |
+
|
| 78 |
+
q = q.view(b,q.size(1),self.n_heads,self.head_size).permute(0,2,1,3)
|
| 79 |
+
k = k.view(b,k.size(1),self.n_heads,self.head_size).permute(0,2,1,3)
|
| 80 |
+
v = v.view(b,v.size(1),self.n_heads,self.head_size).permute(0,2,1,3)
|
| 81 |
+
|
| 82 |
+
qk_t = ([email protected](-2,-1))*self.scale
|
| 83 |
+
qk_t = F.softmax(qk_t,dim=-1)
|
| 84 |
+
weights = self.attn_dropout(qk_t)
|
| 85 |
+
|
| 86 |
+
attention = weights@v
|
| 87 |
+
attention = attention.permute(0,2,1,3).contiguous().view(b,t,c)
|
| 88 |
+
|
| 89 |
+
out = self.c_proj(attention)
|
| 90 |
+
return self.resid_dropout(out)
|
| 91 |
+
|
| 92 |
+
class GPT2MLP(nn.Module):
|
| 93 |
+
def __init__(self,config:SimpleNamespace):
|
| 94 |
+
super().__init__()
|
| 95 |
+
self.embed_dim = config.embed_dim
|
| 96 |
+
self.mlp_ratio = config.mlp_ratio
|
| 97 |
+
self.mlp_dropout = config.mlp_dropout
|
| 98 |
+
self.c_fc = nn.Linear(self.embed_dim,self.embed_dim*self.mlp_ratio)
|
| 99 |
+
self.c_proj = nn.Linear(self.embed_dim*self.mlp_ratio,self.embed_dim)
|
| 100 |
+
self.act = nn.GELU()
|
| 101 |
+
self.dropout = nn.Dropout(self.mlp_dropout)
|
| 102 |
+
|
| 103 |
+
def forward(self,x:torch.Tensor)->torch.Tensor:
|
| 104 |
+
x = self.c_fc(x)
|
| 105 |
+
x = self.act(x)
|
| 106 |
+
x = self.c_proj(x)
|
| 107 |
+
return self.dropout(x)
|
| 108 |
+
|
| 109 |
+
class GPT2Block(nn.Module):
|
| 110 |
+
def __init__(self,config:SimpleNamespace):
|
| 111 |
+
super(GPT2Block,self).__init__()
|
| 112 |
+
self.embed_dim = config.embed_dim
|
| 113 |
+
self.ln_1 = nn.LayerNorm(self.embed_dim)
|
| 114 |
+
self.attn = GPT2Attention(config)
|
| 115 |
+
self.ln_2 = nn.LayerNorm(self.embed_dim)
|
| 116 |
+
self.mlp = GPT2MLP(config)
|
| 117 |
+
self.ln_3 = nn.LayerNorm(self.embed_dim)
|
| 118 |
+
self.cross_attn = GPT2CrossAttention(config)
|
| 119 |
+
|
| 120 |
+
def forward(self,x:torch.Tensor,enc_out:torch.Tensor)->torch.Tensor:
|
| 121 |
+
x = x+self.attn(self.ln_1(x))
|
| 122 |
+
x = x+self.cross_attn(self.ln_2(x),enc_out,enc_out)
|
| 123 |
+
x = x+self.mlp(self.ln_3(x))
|
| 124 |
+
return x
|
| 125 |
+
|
| 126 |
+
class VisionGPT2Model(nn.Module):
|
| 127 |
+
def __init__(self,config:SimpleNamespace):
|
| 128 |
+
super(VisionGPT2Model,self).__init__()
|
| 129 |
+
self.config = config
|
| 130 |
+
vit = create_model('vit_base_patch16_224',pretrained=True,num_classes=0)
|
| 131 |
+
self.patch_embed = vit.patch_embed
|
| 132 |
+
num_patches = self.patch_embed.num_patches
|
| 133 |
+
self.cls_token = vit.cls_token
|
| 134 |
+
embed_len = num_patches + vit.num_prefix_tokens
|
| 135 |
+
self.pos_embed = vit.pos_embed
|
| 136 |
+
self.blocks = nn.ModuleList([vit.blocks[i] for i in range(config.depth)])
|
| 137 |
+
self.transformer = nn.ModuleDict(dict(
|
| 138 |
+
wte = nn.Embedding(config.vocab_size,config.embed_dim),
|
| 139 |
+
wpe = nn.Embedding(config.seq_len,config.embed_dim),
|
| 140 |
+
drop = nn.Dropout(config.emb_dropout),
|
| 141 |
+
h = nn.ModuleList([GPT2Block(config) for _ in range(config.depth)]),
|
| 142 |
+
ln_f = nn.LayerNorm(config.embed_dim),
|
| 143 |
+
))
|
| 144 |
+
self.lm_head = nn.Linear(config.embed_dim,config.vocab_size,bias= False)
|
| 145 |
+
self.transformer.wte.weight = self.lm_head.weight
|
| 146 |
+
|
| 147 |
+
def _pos_embed(self,x:torch.Tensor)->torch.Tensor:
|
| 148 |
+
pos_embed = self.pos_embed
|
| 149 |
+
x = torch.cat((self.cls_token.expand(x.shape[0],-1,-1),x),dim =1)
|
| 150 |
+
x = x+pos_embed
|
| 151 |
+
return x
|
| 152 |
+
|
| 153 |
+
def pretrained_layers_trainable(self,t:bool = False)->None:
|
| 154 |
+
layers =[
|
| 155 |
+
self.cls_token,self.patch_embed,self.pos_embed,self.blocks,
|
| 156 |
+
self.transformer.wte,self.transformer.wpe,
|
| 157 |
+
self.transformer.ln_f,self.lm_head
|
| 158 |
+
]
|
| 159 |
+
gpt_layers = [[
|
| 160 |
+
self.transformer.h[i].ln_1,self.transformer.h[i].ln_2,
|
| 161 |
+
self.transformer.h[i].attn,self.transformer.h[i].mlp
|
| 162 |
+
]for i in range(self.config.depth)]
|
| 163 |
+
|
| 164 |
+
for l in gpt_layers:
|
| 165 |
+
layers.extend(l)
|
| 166 |
+
|
| 167 |
+
for layer in layers:
|
| 168 |
+
if not isinstance(layer,nn.Parameter):
|
| 169 |
+
for p in layer.parameters():
|
| 170 |
+
p.requires_grad = t
|
| 171 |
+
else:
|
| 172 |
+
layer.requires_grad = t
|
| 173 |
+
|
| 174 |
+
total_frozen_params = sum([p.numel() for p in self.parameters() if not p.requires_grad])
|
| 175 |
+
print(f"{total_frozen_params =}")
|
| 176 |
+
|
| 177 |
+
def unfreeze_gpt_layers(self)->None:
|
| 178 |
+
gpt_layers = [[
|
| 179 |
+
self.transformer.h[i].ln_1,self.transformer.h[i].ln_2,
|
| 180 |
+
self.transformer.h[i].attn,self.transformer.h[i].mlp
|
| 181 |
+
]for i in range(self.config.depth)]
|
| 182 |
+
|
| 183 |
+
flatten = []
|
| 184 |
+
|
| 185 |
+
for l in gpt_layers:
|
| 186 |
+
flatten.extend(l)
|
| 187 |
+
|
| 188 |
+
for layer in flatten:
|
| 189 |
+
if not isinstance(layer,nn.Parameter):
|
| 190 |
+
for p in layer.parameters():
|
| 191 |
+
p.requires_grad = True
|
| 192 |
+
else:
|
| 193 |
+
layer.requires_grad = True
|
| 194 |
+
|
| 195 |
+
@classmethod
|
| 196 |
+
def from_pretrained(self,config:SimpleNamespace):
|
| 197 |
+
model = VisionGPT2Model(config)
|
| 198 |
+
sd = model.state_dict()
|
| 199 |
+
keys = sd.keys()
|
| 200 |
+
ignore_matches = ['blocks.','cross_attn.','ln_3','cls_token',
|
| 201 |
+
'pos_embed','patch_embed.','.attn.mask']
|
| 202 |
+
vit_keys = [key for key in keys if any(match in key for match in ignore_matches)]
|
| 203 |
+
gpt_keys = [key for key in keys if key not in vit_keys]
|
| 204 |
+
gpt2_small = GPT2LMHeadModel.from_pretrained('gpt2')
|
| 205 |
+
sd_hf = gpt2_small.state_dict()
|
| 206 |
+
hf_keys = sd_hf.keys()
|
| 207 |
+
hf_keys = [k for k in hf_keys if not k.endswith('.attn.masked_bias')]
|
| 208 |
+
hf_keys = [k for k in hf_keys if not k.endswith('.attn.bias')]
|
| 209 |
+
transposed = ['attn.c_attn.weight','attn.c_proj.weight',
|
| 210 |
+
'mlp.c_fc.weight','mlp.c_proj.weight']
|
| 211 |
+
|
| 212 |
+
for k in hf_keys:
|
| 213 |
+
if any(match in k for match in ignore_matches):
|
| 214 |
+
continue
|
| 215 |
+
if any(k.endswith(w) for w in transposed):
|
| 216 |
+
assert sd_hf[k].shape[::-1] == sd[k].shape
|
| 217 |
+
with torch.no_grad():
|
| 218 |
+
sd[k].copy_(sd_hf[k].t())
|
| 219 |
+
else:
|
| 220 |
+
assert sd_hf[k].shape == sd[k].shape
|
| 221 |
+
with torch.no_grad():
|
| 222 |
+
sd[k].copy_(sd_hf[k])
|
| 223 |
+
|
| 224 |
+
model.load_state_dict(sd)
|
| 225 |
+
return model
|
| 226 |
+
|
| 227 |
+
def forward(self,image:torch.Tensor,input_ids:torch.Tensor,labels:None|torch.Tensor=None)->torch.Tensor:
|
| 228 |
+
image = self.patch_embed(image)
|
| 229 |
+
image = self._pos_embed(image)
|
| 230 |
+
token_embeddings = self.transformer.wte(input_ids)
|
| 231 |
+
pos_embs = torch.arange(0,input_ids.size(1)).to(input_ids.device)
|
| 232 |
+
positional_embeddings = self.transformer.wpe(pos_embs)
|
| 233 |
+
input_ids = self.transformer.drop(token_embeddings+positional_embeddings)
|
| 234 |
+
|
| 235 |
+
for i in range(self.config.depth):
|
| 236 |
+
image = self.blocks[i](image)
|
| 237 |
+
input_ids = self.transformer.h[i](input_ids,image)
|
| 238 |
+
input_ids = self.transformer.ln_f(input_ids)
|
| 239 |
+
|
| 240 |
+
if labels is not None:
|
| 241 |
+
lm_logits = self.lm_head(input_ids)
|
| 242 |
+
loss = F.cross_entropy(lm_logits.view(-1,lm_logits.shape[-1]),labels.view(-1))
|
| 243 |
+
return loss
|
| 244 |
+
lm_logits = self.lm_head(input_ids[:,[-1],:])
|
| 245 |
+
return lm_logits
|
| 246 |
+
|
| 247 |
+
def generate(self,image:torch.Tensor,
|
| 248 |
+
sequence:torch.Tensor,
|
| 249 |
+
max_tokens:int =50,
|
| 250 |
+
temp:float =1.0,
|
| 251 |
+
deter:bool =False) -> torch.Tensor:
|
| 252 |
+
|
| 253 |
+
for _ in range(max_tokens):
|
| 254 |
+
out = self(image,sequence)
|
| 255 |
+
out = out[:,-1,:]/temp
|
| 256 |
+
probs = F.softmax(out,dim=-1)
|
| 257 |
+
if deter:
|
| 258 |
+
next_token = torch.argmax(probs,dim=-1,keepdim=True)
|
| 259 |
+
else:
|
| 260 |
+
next_token = torch.multinomial(probs,num_samples=1)
|
| 261 |
+
|
| 262 |
+
sequence = torch.cat([sequence,next_token],dim=1)
|
| 263 |
+
if next_token.item() == tokenizer.eos_token_id:
|
| 264 |
+
break
|
| 265 |
+
return sequence.cpu().flatten()
|
predict.py
ADDED
|
@@ -0,0 +1,98 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import numpy as np
|
| 2 |
+
|
| 3 |
+
import torch
|
| 4 |
+
from transformers import GPT2TokenizerFast
|
| 5 |
+
from .models import VisionGPT2Model
|
| 6 |
+
|
| 7 |
+
import albumentations as A
|
| 8 |
+
from albumentations.pytorch import ToTensorV2
|
| 9 |
+
|
| 10 |
+
from PIL import Image
|
| 11 |
+
import matplotlib.pyplot as plt
|
| 12 |
+
from types import SimpleNamespace
|
| 13 |
+
import pathlib
|
| 14 |
+
from tkinter import filedialog
|
| 15 |
+
|
| 16 |
+
def download(url:str, filename:str)->pathlib.Path:
|
| 17 |
+
import functools
|
| 18 |
+
import shutil
|
| 19 |
+
import requests
|
| 20 |
+
from tqdm.auto import tqdm
|
| 21 |
+
|
| 22 |
+
r = requests.get(url, stream=True, allow_redirects=True)
|
| 23 |
+
if r.status_code != 200:
|
| 24 |
+
r.raise_for_status() # Will only raise for 4xx codes, so...
|
| 25 |
+
raise RuntimeError(f"Request to {url} returned status code {r.status_code}\n Please download the captioner.pt file manually from the link provided in the README.md file.")
|
| 26 |
+
file_size = int(r.headers.get('Content-Length', 0))
|
| 27 |
+
|
| 28 |
+
path = pathlib.Path(filename).expanduser().resolve()
|
| 29 |
+
path.parent.mkdir(parents=True, exist_ok=True)
|
| 30 |
+
|
| 31 |
+
desc = "(Unknown total file size)" if file_size == 0 else ""
|
| 32 |
+
r.raw.read = functools.partial(r.raw.read, decode_content=True) # Decompress if needed
|
| 33 |
+
with tqdm.wrapattr(r.raw, "read", total=file_size, desc=desc) as r_raw:
|
| 34 |
+
with path.open("wb") as f:
|
| 35 |
+
shutil.copyfileobj(r_raw, f)
|
| 36 |
+
|
| 37 |
+
return path
|
| 38 |
+
|
| 39 |
+
def main():
|
| 40 |
+
model_config = SimpleNamespace(
|
| 41 |
+
vocab_size = 50257, # GPT2 vocb size
|
| 42 |
+
embed_dim = 768, # dim same for both VIT and GPT2
|
| 43 |
+
num_heads = 12,
|
| 44 |
+
seq_len = 1024,
|
| 45 |
+
depth = 12,
|
| 46 |
+
attention_dropout = 0.1,
|
| 47 |
+
residual_dropout = 0.1,
|
| 48 |
+
mlp_ratio = 4,
|
| 49 |
+
mlp_dropout = 0.1,
|
| 50 |
+
emb_dropout = 0.1,
|
| 51 |
+
)
|
| 52 |
+
|
| 53 |
+
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
|
| 54 |
+
|
| 55 |
+
model = VisionGPT2Model(model_config).to(device)
|
| 56 |
+
try:
|
| 57 |
+
sd = torch.load("captioner.pt", map_location=device)
|
| 58 |
+
except:
|
| 59 |
+
print("Model not found. Downloading Model ")
|
| 60 |
+
url = "https://drive.usercontent.google.com/download?id=1X51wAI7Bsnrhd2Pa4WUoHIXvvhIcRH7Y&export=download&authuser=0&confirm=t&uuid=ae5c4861-4411-4f81-88cd-66ea30b6fe2b&at=APZUnTWodeDt1upcQVMej2TDcADs%3A1722666079498"
|
| 61 |
+
path = download(url, "captioner.pt")
|
| 62 |
+
sd = torch.load(path, map_location=device)
|
| 63 |
+
|
| 64 |
+
model.load_state_dict(sd)
|
| 65 |
+
model.eval()
|
| 66 |
+
tokenizer = GPT2TokenizerFast.from_pretrained("gpt2")
|
| 67 |
+
|
| 68 |
+
tfms = A.Compose([
|
| 69 |
+
A.Resize(224, 224),
|
| 70 |
+
A.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5],always_apply=True),
|
| 71 |
+
ToTensorV2()
|
| 72 |
+
])
|
| 73 |
+
|
| 74 |
+
test_img:str = filedialog.askopenfilename(title = "Select an image",
|
| 75 |
+
filetypes = (("jpeg files","*.jpg"),("png files",'*.png'),("all files","*.*")))
|
| 76 |
+
|
| 77 |
+
im = Image.open(test_img).convert("RGB")
|
| 78 |
+
|
| 79 |
+
det = True #generates deterministic results
|
| 80 |
+
temp = 1.0 #when det is true, temp has no effect
|
| 81 |
+
max_tokens = 50
|
| 82 |
+
|
| 83 |
+
image = np.array(im)
|
| 84 |
+
image:torch.Tensor = tfms(image=image)['image']
|
| 85 |
+
image = image.unsqueeze(0).to(device)
|
| 86 |
+
seq = torch.ones(1,1).to(device).long()*tokenizer.bos_token_id
|
| 87 |
+
|
| 88 |
+
caption = model.generate(image, seq, max_tokens, temp, det)
|
| 89 |
+
caption = tokenizer.decode(caption.numpy(), skip_special_tokens=True)
|
| 90 |
+
|
| 91 |
+
plt.imshow(im)
|
| 92 |
+
plt.title(f"Predicted : {caption}")
|
| 93 |
+
plt.axis('off')
|
| 94 |
+
plt.show()
|
| 95 |
+
|
| 96 |
+
|
| 97 |
+
if __name__ == "__main__":
|
| 98 |
+
main()
|
requirements.txt
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
numpy
|
| 2 |
+
torch
|
| 3 |
+
transformers
|
| 4 |
+
timm
|
| 5 |
+
matplotlib
|
| 6 |
+
albumentations
|
| 7 |
+
tqdm
|