
Incorporate NLP capabilities and detach wilhelm-vocabulary's database loading responsibility
Browse files- .github/load_all_in_parallel.py +0 -48
- .github/load_ancient_greek.py +0 -18
- .github/load_german.py +0 -18
- .github/load_latin.py +0 -18
- .github/workflows/ci-cd.yaml +62 -159
- .isort.cfg +2 -0
- .mdlrc +0 -2
- README.md +130 -39
- docs/data-pipeline.drawio +41 -26
- docs/data-pipeline.png +0 -0
- huggingface/__init__.py +0 -0
- huggingface/generate_ancient_greek_dataset.py +51 -0
- .github/cleanup_neo4j.py → huggingface/generate_datasets.py +6 -3
- huggingface/generate_german_dataset.py +60 -0
- huggingface/generate_latin_dataset.py +51 -0
- huggingface/german_parser.py +112 -0
- huggingface/vocabulary_parser.py +363 -0
- markdownlint.rb +0 -20
- setup.cfg +3 -0
- setup.py +19 -0
- tests/__init__.py +0 -0
- tests/test.yaml +9 -0
- tests/test_german_loader.py +133 -0
- tests/test_vocabulary_parser.py +337 -0
.github/load_all_in_parallel.py
DELETED
|
@@ -1,48 +0,0 @@
|
|
| 1 |
-
# Copyright Jiaqi Liu
|
| 2 |
-
#
|
| 3 |
-
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
-
# you may not use this file except in compliance with the License.
|
| 5 |
-
# You may obtain a copy of the License at
|
| 6 |
-
#
|
| 7 |
-
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
-
#
|
| 9 |
-
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
-
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
-
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
-
# See the License for the specific language governing permissions and
|
| 13 |
-
# limitations under the License.
|
| 14 |
-
|
| 15 |
-
from multiprocessing import Process, Queue
|
| 16 |
-
|
| 17 |
-
from wilhelm_python_sdk import latin_loader
|
| 18 |
-
from wilhelm_python_sdk import german_loader
|
| 19 |
-
from wilhelm_python_sdk import ancient_greek_loader
|
| 20 |
-
|
| 21 |
-
def load_latin(queue):
|
| 22 |
-
latin_loader.load_into_database("latin.yaml")
|
| 23 |
-
queue.put("Latin loads successfully")
|
| 24 |
-
|
| 25 |
-
|
| 26 |
-
def load_german(queue):
|
| 27 |
-
german_loader.load_into_database("german.yaml")
|
| 28 |
-
queue.put("German loads successfully")
|
| 29 |
-
|
| 30 |
-
|
| 31 |
-
def load_ancient_greek(queue):
|
| 32 |
-
ancient_greek_loader.load_into_database("ancient_greek.yaml")
|
| 33 |
-
queue.put("Ancient Greek loads successfully")
|
| 34 |
-
|
| 35 |
-
|
| 36 |
-
if __name__ == "__main__":
|
| 37 |
-
queue = Queue()
|
| 38 |
-
|
| 39 |
-
latin = Process(target=load_latin, args=(queue, ))
|
| 40 |
-
german = Process(target=load_german, args=(queue, ))
|
| 41 |
-
ancient_greek = Process(target=load_ancient_greek, args=(queue, ))
|
| 42 |
-
|
| 43 |
-
latin.start()
|
| 44 |
-
german.start()
|
| 45 |
-
ancient_greek.start()
|
| 46 |
-
|
| 47 |
-
# Blocking
|
| 48 |
-
result = queue.get()
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
.github/load_ancient_greek.py
DELETED
|
@@ -1,18 +0,0 @@
|
|
| 1 |
-
# Copyright Jiaqi Liu
|
| 2 |
-
#
|
| 3 |
-
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
-
# you may not use this file except in compliance with the License.
|
| 5 |
-
# You may obtain a copy of the License at
|
| 6 |
-
#
|
| 7 |
-
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
-
#
|
| 9 |
-
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
-
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
-
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
-
# See the License for the specific language governing permissions and
|
| 13 |
-
# limitations under the License.
|
| 14 |
-
|
| 15 |
-
from wilhelm_python_sdk.ancient_greek_loader import load_into_database
|
| 16 |
-
|
| 17 |
-
if __name__ == "__main__":
|
| 18 |
-
load_into_database("ancient-greek.yaml")
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
.github/load_german.py
DELETED
|
@@ -1,18 +0,0 @@
|
|
| 1 |
-
# Copyright Jiaqi Liu
|
| 2 |
-
#
|
| 3 |
-
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
-
# you may not use this file except in compliance with the License.
|
| 5 |
-
# You may obtain a copy of the License at
|
| 6 |
-
#
|
| 7 |
-
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
-
#
|
| 9 |
-
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
-
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
-
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
-
# See the License for the specific language governing permissions and
|
| 13 |
-
# limitations under the License.
|
| 14 |
-
|
| 15 |
-
from wilhelm_python_sdk.german_loader import load_into_database
|
| 16 |
-
|
| 17 |
-
if __name__ == "__main__":
|
| 18 |
-
load_into_database("german.yaml")
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
.github/load_latin.py
DELETED
|
@@ -1,18 +0,0 @@
|
|
| 1 |
-
# Copyright Jiaqi Liu
|
| 2 |
-
#
|
| 3 |
-
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
-
# you may not use this file except in compliance with the License.
|
| 5 |
-
# You may obtain a copy of the License at
|
| 6 |
-
#
|
| 7 |
-
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
-
#
|
| 9 |
-
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
-
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
-
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
-
# See the License for the specific language governing permissions and
|
| 13 |
-
# limitations under the License.
|
| 14 |
-
|
| 15 |
-
from wilhelm_python_sdk.latin_loader import load_into_database
|
| 16 |
-
|
| 17 |
-
if __name__ == "__main__":
|
| 18 |
-
load_into_database("latin.yaml")
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
.github/workflows/ci-cd.yaml
CHANGED
|
@@ -45,13 +45,6 @@ jobs:
|
|
| 45 |
- uses: actions/checkout@v3
|
| 46 |
- uses: actionshub/yamllint@main
|
| 47 |
|
| 48 |
-
markdown-lint:
|
| 49 |
-
name: Markdown Style Check
|
| 50 |
-
runs-on: ubuntu-latest
|
| 51 |
-
steps:
|
| 52 |
-
- uses: actions/checkout@v3
|
| 53 |
-
- uses: actionshub/markdownlint@main
|
| 54 |
-
|
| 55 |
linkChecker:
|
| 56 |
name: Link Check
|
| 57 |
runs-on: ubuntu-latest
|
|
@@ -62,97 +55,69 @@ jobs:
|
|
| 62 |
with:
|
| 63 |
fail: true
|
| 64 |
|
| 65 |
-
|
| 66 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 67 |
runs-on: ubuntu-latest
|
| 68 |
-
strategy:
|
| 69 |
-
fail-fast: false
|
| 70 |
-
matrix:
|
| 71 |
-
language: [
|
| 72 |
-
{
|
| 73 |
-
name: German,
|
| 74 |
-
load-script: .github/load_german.py
|
| 75 |
-
},
|
| 76 |
-
{
|
| 77 |
-
name: Ancient Greek,
|
| 78 |
-
load-script: .github/load_ancient_greek.py
|
| 79 |
-
},
|
| 80 |
-
{
|
| 81 |
-
name: Latin,
|
| 82 |
-
load-script: .github/load_latin.py
|
| 83 |
-
},
|
| 84 |
-
{
|
| 85 |
-
name: all languages (race condition test ①),
|
| 86 |
-
load-script: .github/load_all_in_parallel.py
|
| 87 |
-
},
|
| 88 |
-
{
|
| 89 |
-
name: all languages (race condition test ②),
|
| 90 |
-
load-script: .github/load_all_in_parallel.py
|
| 91 |
-
},
|
| 92 |
-
{
|
| 93 |
-
name: all languages (race condition test ③),
|
| 94 |
-
load-script: .github/load_all_in_parallel.py
|
| 95 |
-
},
|
| 96 |
-
{
|
| 97 |
-
name: all languages (race condition test ④),
|
| 98 |
-
load-script: .github/load_all_in_parallel.py
|
| 99 |
-
},
|
| 100 |
-
{
|
| 101 |
-
name: all languages (race condition test ⑤),
|
| 102 |
-
load-script: .github/load_all_in_parallel.py
|
| 103 |
-
},
|
| 104 |
-
{
|
| 105 |
-
name: all languages (race condition test ⑥),
|
| 106 |
-
load-script: .github/load_all_in_parallel.py
|
| 107 |
-
},
|
| 108 |
-
{
|
| 109 |
-
name: all languages (race condition test ⑦),
|
| 110 |
-
load-script: .github/load_all_in_parallel.py
|
| 111 |
-
},
|
| 112 |
-
{
|
| 113 |
-
name: all languages (race condition test ⑧),
|
| 114 |
-
load-script: .github/load_all_in_parallel.py
|
| 115 |
-
},
|
| 116 |
-
{
|
| 117 |
-
name: all languages (race condition test ⑨),
|
| 118 |
-
},
|
| 119 |
-
{
|
| 120 |
-
name: all languages (race condition test ⑩),
|
| 121 |
-
load-script: .github/load_all_in_parallel.py
|
| 122 |
-
}
|
| 123 |
-
]
|
| 124 |
steps:
|
| 125 |
- uses: actions/checkout@v3
|
| 126 |
with:
|
| 127 |
fetch-depth: 0
|
|
|
|
| 128 |
- name: Set up Python ${{ env.PYTHON_VERSION }}
|
| 129 |
uses: actions/setup-python@v4
|
| 130 |
with:
|
| 131 |
python-version: ${{ env.PYTHON_VERSION }}
|
| 132 |
-
- name:
|
|
|
|
|
|
|
| 133 |
run: |
|
| 134 |
-
|
| 135 |
-
|
| 136 |
-
|
| 137 |
-
|
| 138 |
-
--env=NEO4J_ACCEPT_LICENSE_AGREEMENT=yes neo4j:${{ env.NEO4J_ENTERPRISE_VERSION }} &
|
| 139 |
-
- name: Wait for database to be ready
|
| 140 |
-
uses: iFaxity/wait-on-action@v1
|
| 141 |
-
with:
|
| 142 |
-
resource: http://localhost:7474
|
| 143 |
-
- name: Test loading ${{ matrix.language.name }}
|
| 144 |
run: |
|
| 145 |
-
|
| 146 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 147 |
env:
|
| 148 |
-
|
| 149 |
-
NEO4J_DATABASE: ${{ env.NEO4J_DATABASE }}
|
| 150 |
-
NEO4J_USERNAME: ${{ env.NEO4J_USERNAME }}
|
| 151 |
-
NEO4J_PASSWORD: ${{ env.NEO4J_PASSWORD }}
|
| 152 |
|
| 153 |
docker:
|
| 154 |
-
name: Test Docker
|
| 155 |
-
needs: [
|
| 156 |
runs-on: ubuntu-latest
|
| 157 |
steps:
|
| 158 |
- uses: actions/checkout@v3
|
|
@@ -177,10 +142,11 @@ jobs:
|
|
| 177 |
resource: http://localhost:7474
|
| 178 |
- name: Load all languages into the intermediate container
|
| 179 |
run: |
|
| 180 |
-
|
| 181 |
-
|
| 182 |
-
|
| 183 |
-
|
|
|
|
| 184 |
env:
|
| 185 |
NEO4J_URI: ${{ env.NEO4J_URI }}
|
| 186 |
NEO4J_DATABASE: ${{ env.NEO4J_DATABASE }}
|
|
@@ -215,78 +181,15 @@ jobs:
|
|
| 215 |
repository: jack20191124/wilhelm-vocabulary
|
| 216 |
readme-filepath: README.md
|
| 217 |
|
| 218 |
-
|
| 219 |
-
|
| 220 |
-
needs: [
|
| 221 |
-
runs-on: ubuntu-latest
|
| 222 |
-
steps:
|
| 223 |
-
- uses: actions/checkout@v3
|
| 224 |
-
with:
|
| 225 |
-
fetch-depth: 0
|
| 226 |
-
- name: Set up Python ${{ env.PYTHON_VERSION }}
|
| 227 |
-
uses: actions/setup-python@v4
|
| 228 |
-
with:
|
| 229 |
-
python-version: ${{ env.PYTHON_VERSION }}
|
| 230 |
-
- name: Cleanup
|
| 231 |
-
run: |
|
| 232 |
-
pip3 install --upgrade --force-reinstall wilhelm-python-sdk
|
| 233 |
-
python3 .github/cleanup_neo4j.py
|
| 234 |
-
env:
|
| 235 |
-
NEO4J_URI: ${{ secrets.NEO4J_URI }}
|
| 236 |
-
NEO4J_DATABASE: ${{ secrets.NEO4J_DATABASE }}
|
| 237 |
-
NEO4J_USERNAME: ${{ secrets.NEO4J_USERNAME }}
|
| 238 |
-
NEO4J_PASSWORD: ${{ secrets.NEO4J_PASSWORD }}
|
| 239 |
-
|
| 240 |
-
load-vocabulary:
|
| 241 |
-
name: Load ${{ matrix.language.name }} vocabularies
|
| 242 |
if: github.ref == 'refs/heads/master'
|
| 243 |
-
needs: cleanup-neo4j
|
| 244 |
runs-on: ubuntu-latest
|
| 245 |
-
strategy:
|
| 246 |
-
fail-fast: false
|
| 247 |
-
matrix:
|
| 248 |
-
language: [
|
| 249 |
-
{
|
| 250 |
-
name: German,
|
| 251 |
-
load-script: .github/load_german.py
|
| 252 |
-
},
|
| 253 |
-
{
|
| 254 |
-
name: Ancient Greek,
|
| 255 |
-
load-script: .github/load_ancient_greek.py
|
| 256 |
-
},
|
| 257 |
-
{
|
| 258 |
-
name: Latin,
|
| 259 |
-
load-script: .github/load_latin.py
|
| 260 |
-
}
|
| 261 |
-
]
|
| 262 |
steps:
|
| 263 |
-
-
|
|
|
|
| 264 |
with:
|
| 265 |
-
|
| 266 |
-
|
| 267 |
-
|
| 268 |
-
with:
|
| 269 |
-
python-version: ${{ env.PYTHON_VERSION }}
|
| 270 |
-
- name: Load ${{ matrix.language.name }}
|
| 271 |
-
run: |
|
| 272 |
-
pip3 install --upgrade --force-reinstall wilhelm-python-sdk
|
| 273 |
-
python3 ${{ matrix.language.load-script }}
|
| 274 |
-
env:
|
| 275 |
-
NEO4J_URI: ${{ secrets.NEO4J_URI }}
|
| 276 |
-
NEO4J_DATABASE: ${{ secrets.NEO4J_DATABASE }}
|
| 277 |
-
NEO4J_USERNAME: ${{ secrets.NEO4J_USERNAME }}
|
| 278 |
-
NEO4J_PASSWORD: ${{ secrets.NEO4J_PASSWORD }}
|
| 279 |
-
|
| 280 |
-
sync-to-huggingface-space:
|
| 281 |
-
if: github.ref == 'refs/heads/master'
|
| 282 |
-
needs: tests
|
| 283 |
-
runs-on: ubuntu-latest
|
| 284 |
-
steps:
|
| 285 |
-
- uses: actions/checkout@v3
|
| 286 |
-
with:
|
| 287 |
-
fetch-depth: 0
|
| 288 |
-
lfs: true
|
| 289 |
-
- name: Push to hub
|
| 290 |
-
run: git push https://QubitPi:[email protected]/datasets/QubitPi/wilhelm-vocabulary master:main -f
|
| 291 |
-
env:
|
| 292 |
-
HF_TOKEN: ${{ secrets.HF_TOKEN }}
|
|
|
|
| 45 |
- uses: actions/checkout@v3
|
| 46 |
- uses: actionshub/yamllint@main
|
| 47 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 48 |
linkChecker:
|
| 49 |
name: Link Check
|
| 50 |
runs-on: ubuntu-latest
|
|
|
|
| 55 |
with:
|
| 56 |
fail: true
|
| 57 |
|
| 58 |
+
code-style:
|
| 59 |
+
name: Python Code Style Check
|
| 60 |
+
runs-on: ubuntu-latest
|
| 61 |
+
steps:
|
| 62 |
+
- uses: actions/checkout@v3
|
| 63 |
+
- name: Set up Python 3.10
|
| 64 |
+
uses: actions/setup-python@v5
|
| 65 |
+
with:
|
| 66 |
+
python-version: ${{ env.PYTHON_VERSION }}
|
| 67 |
+
- name: PEP 8 check
|
| 68 |
+
run: python setup.py pep8
|
| 69 |
+
- name: Check import orders
|
| 70 |
+
run: python setup.py isort
|
| 71 |
+
|
| 72 |
+
unit-tests:
|
| 73 |
+
name: Unit Tests
|
| 74 |
+
needs: [yaml-lint, linkChecker, code-style]
|
| 75 |
+
runs-on: ubuntu-latest
|
| 76 |
+
steps:
|
| 77 |
+
- uses: actions/checkout@v3
|
| 78 |
+
- name: Set up Python ${{ env.PYTHON_VERSION }}
|
| 79 |
+
uses: actions/setup-python@v5
|
| 80 |
+
with:
|
| 81 |
+
python-version: ${{ env.PYTHON_VERSION }}
|
| 82 |
+
- name: Run tests
|
| 83 |
+
run: python setup.py test
|
| 84 |
+
|
| 85 |
+
sync-to-huggingface-space:
|
| 86 |
+
needs: [yaml-lint, linkChecker, code-style]
|
| 87 |
runs-on: ubuntu-latest
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 88 |
steps:
|
| 89 |
- uses: actions/checkout@v3
|
| 90 |
with:
|
| 91 |
fetch-depth: 0
|
| 92 |
+
lfs: true
|
| 93 |
- name: Set up Python ${{ env.PYTHON_VERSION }}
|
| 94 |
uses: actions/setup-python@v4
|
| 95 |
with:
|
| 96 |
python-version: ${{ env.PYTHON_VERSION }}
|
| 97 |
+
- name: Install dependencies
|
| 98 |
+
run: pip3 install -e .
|
| 99 |
+
- name: Generate Hugging Face Datasets
|
| 100 |
run: |
|
| 101 |
+
cd huggingface
|
| 102 |
+
python3 ./generate_datasets.py
|
| 103 |
+
- name: Push to hub
|
| 104 |
+
if: github.ref == 'refs/heads/master'
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 105 |
run: |
|
| 106 |
+
git config --global user.name "QubitPi"
|
| 107 |
+
git config --global user.email "jack20220723@gmail.com"
|
| 108 |
+
|
| 109 |
+
git lfs install
|
| 110 |
+
git lfs track "*-graph-data.jsonl"
|
| 111 |
+
git add *-graph-data.jsonl
|
| 112 |
+
|
| 113 |
+
git commit -m "Generate Hugging Face Datasets"
|
| 114 |
+
git push https://QubitPi:[email protected]/datasets/QubitPi/wilhelm-vocabulary master:main -f
|
| 115 |
env:
|
| 116 |
+
HF_TOKEN: ${{ secrets.HF_TOKEN }}
|
|
|
|
|
|
|
|
|
|
| 117 |
|
| 118 |
docker:
|
| 119 |
+
name: Test Docker Build and Publish Data Image to DockerHub
|
| 120 |
+
needs: [sync-to-huggingface-space]
|
| 121 |
runs-on: ubuntu-latest
|
| 122 |
steps:
|
| 123 |
- uses: actions/checkout@v3
|
|
|
|
| 142 |
resource: http://localhost:7474
|
| 143 |
- name: Load all languages into the intermediate container
|
| 144 |
run: |
|
| 145 |
+
git clone https://github.com/QubitPi/wilhelm-data-loader.git ../wilhelm-data-loader
|
| 146 |
+
cd ../wilhelm-data-loader
|
| 147 |
+
pip3 install -r requirements.txt
|
| 148 |
+
pip3 install -e .
|
| 149 |
+
python3 wilhelm_vocabulary/load_all_in_parallel.py
|
| 150 |
env:
|
| 151 |
NEO4J_URI: ${{ env.NEO4J_URI }}
|
| 152 |
NEO4J_DATABASE: ${{ env.NEO4J_DATABASE }}
|
|
|
|
| 181 |
repository: jack20191124/wilhelm-vocabulary
|
| 182 |
readme-filepath: README.md
|
| 183 |
|
| 184 |
+
triggering:
|
| 185 |
+
name: Triggering data model acceptance tests CI/CD
|
| 186 |
+
needs: [sync-to-huggingface-space]
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 187 |
if: github.ref == 'refs/heads/master'
|
|
|
|
| 188 |
runs-on: ubuntu-latest
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 189 |
steps:
|
| 190 |
+
- name: Trigger wilhelm-data-loader to load all vocabularies into graph database
|
| 191 |
+
uses: peter-evans/repository-dispatch@v2
|
| 192 |
with:
|
| 193 |
+
token: ${{ secrets.QUBITPI_DOWNSTREAM_CICD_TRIGGERING_TOKEN }}
|
| 194 |
+
repository: QubitPi/wilhelm-data-loader
|
| 195 |
+
event-type: wilhelm-vocabulary-changes
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
.isort.cfg
ADDED
|
@@ -0,0 +1,2 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
[settings]
|
| 2 |
+
force_single_line = True
|
.mdlrc
DELETED
|
@@ -1,2 +0,0 @@
|
|
| 1 |
-
rules "~MD002", "~MD003", "~MD005", "~MD007", "~MD013", "~MD022", "~MD024", "~MD027", "~MD028", "~MD029", "~MD033", "~MD034", "~MD036", "~MD041", "~MD055", "~MD057"
|
| 2 |
-
style "#{File.dirname(__FILE__)}/markdownlint.rb"
|
|
|
|
|
|
|
|
|
README.md
CHANGED
|
@@ -1,51 +1,89 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
Wilhelm Vocabulary
|
| 2 |
==================
|
| 3 |
|
|
|
|
|
|
|
| 4 |
[![Vocabulary count - German]][Docker Hub URL]
|
| 5 |
[![Vocabulary count - Latin]][Docker Hub URL]
|
| 6 |
[![Vocabulary count - Ancient Greek]][Docker Hub URL]
|
| 7 |
[![Docker Hub][Docker Pulls Badge]][Docker Hub URL]
|
| 8 |
-
|
| 9 |
[![GitHub workflow status badge][GitHub workflow status badge]][GitHub workflow status URL]
|
| 10 |
[![Hugging Face sync status badge]][Hugging Face sync status URL]
|
| 11 |
-
[![Hugging Face dataset badge]][Hugging Face dataset URL]
|
| 12 |
[![Apache License Badge]][Apache License, Version 2.0]
|
| 13 |
|
| 14 |
<!-- TOC -->
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 15 |
|
| 16 |
-
- [
|
| 17 |
-
|
| 18 |
-
- [Interesting Queries](#interesting-queries)
|
| 19 |
-
- [Data Format](#data-format)
|
| 20 |
-
- [Encoding Table in YAML](#encoding-table-in-yaml)
|
| 21 |
-
- [Data Pipeline](#data-pipeline)
|
| 22 |
-
- [How Data (Vocabulary) is Stored in a Graph Database](#how-data-vocabulary-is-stored-in-a-graph-database)
|
| 23 |
-
- [Why Graph Database](#why-graph-database)
|
| 24 |
-
- [Base Schema](#base-schema)
|
| 25 |
-
- [Languages](#languages)
|
| 26 |
-
- [German](#german)
|
| 27 |
-
- [Pronoun](#pronoun)
|
| 28 |
-
- [Noun](#noun)
|
| 29 |
-
- [Ancient Greek](#ancient-greek)
|
| 30 |
-
- [Diacritic Mark Convention](#diacritic-mark-convention)
|
| 31 |
-
- [Pronoun](#pronoun-1)
|
| 32 |
-
- [Noun](#noun-1)
|
| 33 |
-
- [Adjective Declension](#adjective-declension)
|
| 34 |
-
- [Verb Conjugation](#verb-conjugation)
|
| 35 |
-
- [Latin](#latin)
|
| 36 |
-
- [Classical Hebrew (Coming Soon)](#classical-hebrew-coming-soon)
|
| 37 |
-
- [Korean](#korean)
|
| 38 |
-
- [License](#license)
|
| 39 |
|
| 40 |
-
|
| 41 |
|
| 42 |
-
|
|
|
|
|
|
|
|
|
|
| 43 |
|
| 44 |
-
|
| 45 |
-
|
|
|
|
|
|
|
| 46 |
|
| 47 |
-
|
| 48 |
-
|
| 49 |
|
| 50 |
```console
|
| 51 |
docker run \
|
|
@@ -70,10 +108,7 @@ docker run \
|
|
| 70 |
|
| 71 |

|
| 72 |
|
| 73 |
-
We have offered some queries that can be used to quickly explore
|
| 74 |
-
[next section](#interesting-queries)
|
| 75 |
-
|
| 76 |
-
### Interesting Queries
|
| 77 |
|
| 78 |
- Search for all Synonyms: `MATCH (term:Term)-[r]-(synonym:Term) WHERE r.name = "synonym" RETURN term, r, synonym`
|
| 79 |
- Finding all [gerunds](https://en.wiktionary.org/wiki/Appendix:Glossary#gerund):
|
|
@@ -104,15 +139,69 @@ We have offered some queries that can be used to quickly explore our language da
|
|
| 104 |
|
| 105 |
- `MATCH (term:Term{label:'die Schwester'}) CALL apoc.path.expand(term, "LINK", null, 1, -1) YIELD path RETURN path, length(path) AS hops ORDER BY hops;`
|
| 106 |
|
| 107 |
-
|
| 108 |
-----------
|
| 109 |
|
| 110 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 111 |
|
| 112 |
1. it is machine-readable so that it can be consumed quickly in data pipelines
|
| 113 |
2. it is human-readable and, thus, easy to read and modify
|
| 114 |
3. it supports multi-lines value which is very handy for language data
|
| 115 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 116 |
### Encoding Table in YAML
|
| 117 |
|
| 118 |
To encode the inflections which are common in most Indo-European languages, an
|
|
@@ -570,15 +659,17 @@ The use and distribution terms for [wilhelm-vocabulary]() are covered by the [Ap
|
|
| 570 |
[Docker Pulls Badge]: https://img.shields.io/docker/pulls/jack20191124/wilhelm-vocabulary?style=for-the-badge&logo=docker&color=2596EC
|
| 571 |
[Docker Hub URL]: https://hub.docker.com/r/jack20191124/wilhelm-vocabulary
|
| 572 |
|
| 573 |
-
[Hugging Face dataset badge]: https://img.shields.io/badge/
|
| 574 |
[Hugging Face dataset URL]: https://huggingface.co/datasets/QubitPi/wilhelm-vocabulary
|
| 575 |
|
| 576 |
[Hugging Face sync status badge]: https://img.shields.io/github/actions/workflow/status/QubitPi/wilhelm-vocabulary/ci-cd.yaml?branch=master&style=for-the-badge&logo=github&logoColor=white&label=Hugging%20Face%20Sync%20Up
|
| 577 |
[Hugging Face sync status URL]: https://github.com/QubitPi/wilhelm-vocabulary/actions/workflows/ci-cd.yaml
|
| 578 |
|
| 579 |
-
[GitHub workflow status badge]: https://img.shields.io/github/actions/workflow/status/QubitPi/wilhelm-vocabulary/ci-cd.yaml?branch=master&style=for-the-badge&logo=github&logoColor=white&label=
|
| 580 |
[GitHub workflow status URL]: https://github.com/QubitPi/wilhelm-vocabulary/actions/workflows/ci-cd.yaml
|
| 581 |
|
| 582 |
[Vocabulary count - German]: https://img.shields.io/badge/dynamic/json?url=https%3A%2F%2Fapi.paion-data.dev%2Fwilhelm%2Flanguages%2Fgerman%2Fcount&query=%24%5B0%5D.count&suffix=%20Words&style=for-the-badge&logo=neo4j&logoColor=white&label=German&color=4581C3
|
| 583 |
[Vocabulary count - Latin]: https://img.shields.io/badge/dynamic/json?url=https%3A%2F%2Fapi.paion-data.dev%2Fwilhelm%2Flanguages%2Flatin%2Fcount&query=%24%5B0%5D.count&suffix=%20Words&style=for-the-badge&logo=neo4j&logoColor=white&label=Latin&color=4581C3
|
| 584 |
[Vocabulary count - Ancient Greek]: https://img.shields.io/badge/dynamic/json?url=https%3A%2F%2Fapi.paion-data.dev%2Fwilhelm%2Flanguages%2FancientGreek%2Fcount&query=%24%5B0%5D.count&suffix=%20Words&style=for-the-badge&logo=neo4j&logoColor=white&label=Ancient%20Greek&color=4581C3
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
license: apache-2.0
|
| 3 |
+
pretty_name: Wilhelm Vocabulary
|
| 4 |
+
language:
|
| 5 |
+
- en
|
| 6 |
+
- de
|
| 7 |
+
- la
|
| 8 |
+
- grc
|
| 9 |
+
configs:
|
| 10 |
+
- config_name: Graph Data
|
| 11 |
+
data_files:
|
| 12 |
+
- split: German
|
| 13 |
+
path: german-graph-data.jsonl
|
| 14 |
+
- split: Latin
|
| 15 |
+
path: latin-graph-data.jsonl
|
| 16 |
+
- split: AncientGreek
|
| 17 |
+
path: ancient-greek-graph-data.jsonl
|
| 18 |
+
tags:
|
| 19 |
+
- Natural Language Processing
|
| 20 |
+
- NLP
|
| 21 |
+
- Vocabulary
|
| 22 |
+
- German
|
| 23 |
+
- Latin
|
| 24 |
+
- Ancient Greek
|
| 25 |
+
- Knowledge Graph
|
| 26 |
+
size_categories:
|
| 27 |
+
- 1K<n<10K
|
| 28 |
+
---
|
| 29 |
+
|
| 30 |
Wilhelm Vocabulary
|
| 31 |
==================
|
| 32 |
|
| 33 |
+
[![Hugging Face dataset badge]][Hugging Face dataset URL]
|
| 34 |
+
|
| 35 |
[![Vocabulary count - German]][Docker Hub URL]
|
| 36 |
[![Vocabulary count - Latin]][Docker Hub URL]
|
| 37 |
[![Vocabulary count - Ancient Greek]][Docker Hub URL]
|
| 38 |
[![Docker Hub][Docker Pulls Badge]][Docker Hub URL]
|
|
|
|
| 39 |
[![GitHub workflow status badge][GitHub workflow status badge]][GitHub workflow status URL]
|
| 40 |
[![Hugging Face sync status badge]][Hugging Face sync status URL]
|
|
|
|
| 41 |
[![Apache License Badge]][Apache License, Version 2.0]
|
| 42 |
|
| 43 |
<!-- TOC -->
|
| 44 |
+
* [Wilhelm Vocabulary](#wilhelm-vocabulary)
|
| 45 |
+
* [Development](#development)
|
| 46 |
+
* [Environment Setup](#environment-setup)
|
| 47 |
+
* [Installing Dependencies](#installing-dependencies)
|
| 48 |
+
* [Data Format](#data-format)
|
| 49 |
+
* [Encoding Table in YAML](#encoding-table-in-yaml)
|
| 50 |
+
* [Data Pipeline](#data-pipeline)
|
| 51 |
+
* [How Data (Vocabulary) is Stored in a Graph Database](#how-data-vocabulary-is-stored-in-a-graph-database)
|
| 52 |
+
* [Why Graph Database](#why-graph-database)
|
| 53 |
+
* [Base Schema](#base-schema)
|
| 54 |
+
* [Languages](#languages)
|
| 55 |
+
* [German](#german)
|
| 56 |
+
* [Pronoun](#pronoun)
|
| 57 |
+
* [Noun](#noun)
|
| 58 |
+
* [Ancient Greek](#ancient-greek)
|
| 59 |
+
* [Diacritic Mark Convention](#diacritic-mark-convention)
|
| 60 |
+
* [Pronoun](#pronoun-1)
|
| 61 |
+
* [Noun](#noun-1)
|
| 62 |
+
* [Adjective Declension](#adjective-declension)
|
| 63 |
+
* [Verb Conjugation](#verb-conjugation)
|
| 64 |
+
* [Latin](#latin)
|
| 65 |
+
* [Classical Hebrew (Coming Soon)](#classical-hebrew-coming-soon)
|
| 66 |
+
* [Korean](#korean)
|
| 67 |
+
* [License](#license)
|
| 68 |
+
<!-- TOC -->
|
| 69 |
|
| 70 |
+
__wilhelm-vocabulary__ is the data sources used for the flashcard contents on [wilhelmlang.com]. Specifically it's a
|
| 71 |
+
datasource manually made from the accumulation of the daily language studies of [myself](https://github.com/Qubitpi).
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 72 |
|
| 73 |
+
The data is available on 🤗 [Hugging Face Datasets][Hugging Face dataset URL]
|
| 74 |
|
| 75 |
+
```python
|
| 76 |
+
from datasets import load_dataset
|
| 77 |
+
dataset = load_dataset("QubitPi/wilhelm-vocabulary")
|
| 78 |
+
```
|
| 79 |
|
| 80 |
+
> [!TIP]
|
| 81 |
+
>
|
| 82 |
+
> If `dataset = load_dataset("QubitPi/wilhelm-vocabulary")` throws an error, please upgrade the `datasets` package to
|
| 83 |
+
> its _latest version_
|
| 84 |
|
| 85 |
+
In addition, a Docker image has been made to allow us exploring the vocabulary in Neo4J browser backed by a Neo4J
|
| 86 |
+
database. To get the image and run the container, simply do:
|
| 87 |
|
| 88 |
```console
|
| 89 |
docker run \
|
|
|
|
| 108 |
|
| 109 |

|
| 110 |
|
| 111 |
+
We have offered some queries that can be used to quickly explore the vocabulary in graph representations:
|
|
|
|
|
|
|
|
|
|
| 112 |
|
| 113 |
- Search for all Synonyms: `MATCH (term:Term)-[r]-(synonym:Term) WHERE r.name = "synonym" RETURN term, r, synonym`
|
| 114 |
- Finding all [gerunds](https://en.wiktionary.org/wiki/Appendix:Glossary#gerund):
|
|
|
|
| 139 |
|
| 140 |
- `MATCH (term:Term{label:'die Schwester'}) CALL apoc.path.expand(term, "LINK", null, 1, -1) YIELD path RETURN path, length(path) AS hops ORDER BY hops;`
|
| 141 |
|
| 142 |
+
Development
|
| 143 |
-----------
|
| 144 |
|
| 145 |
+
### Environment Setup
|
| 146 |
+
|
| 147 |
+
Get the source code:
|
| 148 |
+
|
| 149 |
+
```console
|
| 150 |
+
git clone [email protected]:QubitPi/wilhelm-vocabulary.git
|
| 151 |
+
cd wilhelm-vocabulary
|
| 152 |
+
```
|
| 153 |
+
|
| 154 |
+
It is strongly recommended to work in an isolated environment. Install virtualenv and create an isolated Python
|
| 155 |
+
environment by
|
| 156 |
+
|
| 157 |
+
```console
|
| 158 |
+
python3 -m pip install --user -U virtualenv
|
| 159 |
+
python3 -m virtualenv .venv
|
| 160 |
+
```
|
| 161 |
+
|
| 162 |
+
To activate this environment:
|
| 163 |
+
|
| 164 |
+
```console
|
| 165 |
+
source .venv/bin/activate
|
| 166 |
+
```
|
| 167 |
+
|
| 168 |
+
or, on Windows
|
| 169 |
+
|
| 170 |
+
```console
|
| 171 |
+
./venv\Scripts\activate
|
| 172 |
+
```
|
| 173 |
+
|
| 174 |
+
> [!TIP]
|
| 175 |
+
>
|
| 176 |
+
> To deactivate this environment, use
|
| 177 |
+
>
|
| 178 |
+
> ```console
|
| 179 |
+
> deactivate
|
| 180 |
+
> ```
|
| 181 |
+
|
| 182 |
+
### Installing Dependencies
|
| 183 |
+
|
| 184 |
+
```console
|
| 185 |
+
pip3 install -r requirements.txt
|
| 186 |
+
```
|
| 187 |
+
|
| 188 |
+
### Data Format
|
| 189 |
+
|
| 190 |
+
The raw data is written in YAML format, because
|
| 191 |
|
| 192 |
1. it is machine-readable so that it can be consumed quickly in data pipelines
|
| 193 |
2. it is human-readable and, thus, easy to read and modify
|
| 194 |
3. it supports multi-lines value which is very handy for language data
|
| 195 |
|
| 196 |
+
The YAML data files are
|
| 197 |
+
|
| 198 |
+
- [german.yaml](./german.yaml)
|
| 199 |
+
- [latin.yaml](./latin.yaml)
|
| 200 |
+
- [ancient-greek.yaml](./ancient-greek.yaml)
|
| 201 |
+
|
| 202 |
+
These YAML files are then [transformed](huggingface/generate_datasets.py) to Hugging Face Datasets formats in
|
| 203 |
+
[CI/CD](https://github.com/QubitPi/wilhelm-vocabulary/actions/workflows/ci-cd.yaml)
|
| 204 |
+
|
| 205 |
### Encoding Table in YAML
|
| 206 |
|
| 207 |
To encode the inflections which are common in most Indo-European languages, an
|
|
|
|
| 659 |
[Docker Pulls Badge]: https://img.shields.io/docker/pulls/jack20191124/wilhelm-vocabulary?style=for-the-badge&logo=docker&color=2596EC
|
| 660 |
[Docker Hub URL]: https://hub.docker.com/r/jack20191124/wilhelm-vocabulary
|
| 661 |
|
| 662 |
+
[Hugging Face dataset badge]: https://img.shields.io/badge/Datasets-wilhelm--vocabulary-FF9D00?style=for-the-badge&logo=huggingface&logoColor=white&labelColor=6B7280
|
| 663 |
[Hugging Face dataset URL]: https://huggingface.co/datasets/QubitPi/wilhelm-vocabulary
|
| 664 |
|
| 665 |
[Hugging Face sync status badge]: https://img.shields.io/github/actions/workflow/status/QubitPi/wilhelm-vocabulary/ci-cd.yaml?branch=master&style=for-the-badge&logo=github&logoColor=white&label=Hugging%20Face%20Sync%20Up
|
| 666 |
[Hugging Face sync status URL]: https://github.com/QubitPi/wilhelm-vocabulary/actions/workflows/ci-cd.yaml
|
| 667 |
|
| 668 |
+
[GitHub workflow status badge]: https://img.shields.io/github/actions/workflow/status/QubitPi/wilhelm-vocabulary/ci-cd.yaml?branch=master&style=for-the-badge&logo=github&logoColor=white&label=CI/CD
|
| 669 |
[GitHub workflow status URL]: https://github.com/QubitPi/wilhelm-vocabulary/actions/workflows/ci-cd.yaml
|
| 670 |
|
| 671 |
[Vocabulary count - German]: https://img.shields.io/badge/dynamic/json?url=https%3A%2F%2Fapi.paion-data.dev%2Fwilhelm%2Flanguages%2Fgerman%2Fcount&query=%24%5B0%5D.count&suffix=%20Words&style=for-the-badge&logo=neo4j&logoColor=white&label=German&color=4581C3
|
| 672 |
[Vocabulary count - Latin]: https://img.shields.io/badge/dynamic/json?url=https%3A%2F%2Fapi.paion-data.dev%2Fwilhelm%2Flanguages%2Flatin%2Fcount&query=%24%5B0%5D.count&suffix=%20Words&style=for-the-badge&logo=neo4j&logoColor=white&label=Latin&color=4581C3
|
| 673 |
[Vocabulary count - Ancient Greek]: https://img.shields.io/badge/dynamic/json?url=https%3A%2F%2Fapi.paion-data.dev%2Fwilhelm%2Flanguages%2FancientGreek%2Fcount&query=%24%5B0%5D.count&suffix=%20Words&style=for-the-badge&logo=neo4j&logoColor=white&label=Ancient%20Greek&color=4581C3
|
| 674 |
+
|
| 675 |
+
[wilhelmlang.com]: https://wilhelmlang.com/
|
docs/data-pipeline.drawio
CHANGED
|
@@ -1,62 +1,77 @@
|
|
| 1 |
-
<mxfile host="app.diagrams.net" agent="Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/
|
| 2 |
<diagram name="Page-1" id="-PRZJL_y_DcYyeR3ZVRW">
|
| 3 |
-
<mxGraphModel dx="
|
| 4 |
<root>
|
| 5 |
<mxCell id="0" />
|
| 6 |
<mxCell id="1" parent="0" />
|
| 7 |
-
<mxCell id="
|
| 8 |
-
<mxGeometry relative="1" as="geometry" />
|
| 9 |
-
</mxCell>
|
| 10 |
-
<mxCell id="CBPTevJeyTvfQtbZMOis-6" style="edgeStyle=orthogonalEdgeStyle;rounded=0;orthogonalLoop=1;jettySize=auto;html=1;strokeWidth=3;" edge="1" parent="1" source="jEus2W5ITfwieqKF0qT7-1">
|
| 11 |
<mxGeometry relative="1" as="geometry">
|
| 12 |
-
<mxPoint x="-
|
| 13 |
</mxGeometry>
|
| 14 |
</mxCell>
|
| 15 |
<mxCell id="jEus2W5ITfwieqKF0qT7-1" value="" style="shape=image;verticalLabelPosition=bottom;labelBackgroundColor=default;verticalAlign=top;aspect=fixed;imageAspect=0;image=https://upload.wikimedia.org/wikipedia/en/thumb/0/06/Wiktionary-logo-v2.svg/1200px-Wiktionary-logo-v2.svg.png;" parent="1" vertex="1">
|
| 16 |
-
<mxGeometry x="-
|
| 17 |
</mxCell>
|
| 18 |
<mxCell id="jEus2W5ITfwieqKF0qT7-7" value="" style="shape=image;verticalLabelPosition=bottom;labelBackgroundColor=default;verticalAlign=top;aspect=fixed;imageAspect=0;image=https://dist.neo4j.com/wp-content/uploads/20210616181554/neo4j-connects-data.svg;" parent="1" vertex="1">
|
| 19 |
-
<mxGeometry x="
|
| 20 |
</mxCell>
|
| 21 |
-
<mxCell id="jEus2W5ITfwieqKF0qT7-11" style="edgeStyle=orthogonalEdgeStyle;rounded=0;orthogonalLoop=1;jettySize=auto;html=1;strokeWidth=3;strokeColor=#
|
| 22 |
<mxGeometry relative="1" as="geometry">
|
| 23 |
-
<mxPoint x="
|
| 24 |
</mxGeometry>
|
| 25 |
</mxCell>
|
| 26 |
<mxCell id="jEus2W5ITfwieqKF0qT7-10" value="" style="shape=image;verticalLabelPosition=bottom;labelBackgroundColor=default;verticalAlign=top;aspect=fixed;imageAspect=0;image=https://upload.wikimedia.org/wikipedia/commons/9/91/Octicons-mark-github.svg;" parent="1" vertex="1">
|
| 27 |
-
<mxGeometry x="-
|
| 28 |
</mxCell>
|
| 29 |
<mxCell id="jEus2W5ITfwieqKF0qT7-30" style="edgeStyle=orthogonalEdgeStyle;rounded=0;orthogonalLoop=1;jettySize=auto;html=1;strokeWidth=3;" parent="1" edge="1">
|
| 30 |
<mxGeometry relative="1" as="geometry">
|
| 31 |
-
<mxPoint x="-
|
| 32 |
-
<mxPoint x="-
|
| 33 |
</mxGeometry>
|
| 34 |
</mxCell>
|
| 35 |
<mxCell id="jEus2W5ITfwieqKF0qT7-18" value="" style="shape=image;editableCssRules=.*;verticalLabelPosition=bottom;labelBackgroundColor=default;verticalAlign=top;aspect=fixed;imageAspect=0;image=data:image/svg+xml,PHN2ZyB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciIHZpZXdCb3g9Ii0wLjUgLTAuNSAyOCAyOCIgaGVpZ2h0PSIyOCIgd2lkdGg9IjI4Ij4mI3hhOwkgIDxzdHlsZSB0eXBlPSJ0ZXh0L2NzcyI+LnN0MCB7IHN0b3AtY29sb3I6IHJnYig5MSwgMTE1LCAxMzkpOyB9IC5zdDEgeyBzdG9wLWNvbG9yOiByZ2IoMzQsIDUzLCA3Mik7IH0gPC9zdHlsZT4mI3hhOwk8ZGVmcz4mI3hhOwkJPGxpbmVhckdyYWRpZW50IGdyYWRpZW50VW5pdHM9InVzZXJTcGFjZU9uVXNlIiB5Mj0iMjUuMzA5IiB4Mj0iMjMuNDU0IiB5MT0iMy40NzQiIHgxPSIyLjAzOSIgaWQ9IkEiPiYjeGE7CQkJPHN0b3AgY2xhc3M9InN0MCIvPiYjeGE7CQkJPHN0b3AgY2xhc3M9InN0MSIgb2Zmc2V0PSIxIi8+JiN4YTsJCTwvbGluZWFyR3JhZGllbnQ+JiN4YTsJPC9kZWZzPiYjeGE7CTxwYXRoIGZpbGw9InVybCgjQSkiIGQ9Ik0tLjUgMTMuNDcyYzAtMS45My4zNzEtMy43MyAxLjExMy01LjQuNzQyLTEuNzA3IDEuNzQ0LTMuMTkyIDMuMDA2LTQuNDUzUzYuMzY1IDEuMzU2IDguMDczLjYxMyAxMS41OTgtLjUgMTMuNTI4LS41czMuNzMuMzcxIDUuNCAxLjExM2MxLjcwNy43NDIgMy4xOTIgMS43NDQgNC40NTMgMy4wMDZzMi4yNjQgMi43NDYgMy4wMDYgNC40NTNjLjc0MiAxLjY3IDEuMTEzIDMuNDcgMS4xMTMgNS40cy0uMzcxIDMuNzQ4LTEuMTEzIDUuNDU1LTEuNzQ0IDMuMTkyLTMuMDA2IDQuNDUzYTE0LjI4IDE0LjI4IDAgMCAxLTQuNDUzIDMuMDA2Yy0xLjY3Ljc0Mi0zLjQ3IDEuMTEzLTUuNCAxLjExM3MtMy43NDgtLjM3MS01LjQ1NS0xLjExM2ExNC4yOCAxNC4yOCAwIDAgMS00LjQ1My0zLjAwNiAxNC4yOCAxNC4yOCAwIDAgMS0zLjAwNi00LjQ1M0MtLjEyOSAxNy4yMi0uNSAxNS40MDItLjUgMTMuNDcyem0xNi44MTEgNC4yMzFhNi42NSA2LjY1IDAgMCAxIDMuMjg0LjgzNWMxLjAwMi41MiAxLjgxOCAxLjI0MyAyLjQ0OSAyLjE3MWExMC4xNCAxMC4xNCAwIDAgMCAxLjk0OC0zLjI4NGMuNDgyLTEuMjI1LjcyNC0yLjU0Mi43MjQtMy45NTIgMC0xLjU1OS0uMjk3LTMuMDA2LS44OTEtNC4zNDItLjU5NC0xLjM3My0xLjM5Mi0yLjU2MS0yLjM5NC0zLjU2M3MtMi4xOS0xLjgtMy41NjMtMi4zOTRjLTEuMzM2LS41OTQtMi43ODMtLjg5MS00LjM0Mi0uODkxcy0zLjAyNC4yOTctNC4zOTguODkxYy0xLjMzNi41OTQtMi41MjQgMS4zOTItMy41NjMgMi4zOTRBMTEuMzUgMTEuMzUgMCAwIDAgMy4xNzQgOS4xM2MtLjU5NCAxLjMzNi0uODkxIDIuNzgzLS44OTEgNC4zNDIgMCAxLjQxLjIyMyAyLjcyOC42NjggMy45NTIuNDgyIDEuMjI1IDEuMTUgMi4zMTkgMi4wMDQgMy4yODQuNjMxLS45MjggMS40NDctMS42NTEgMi40NDktMi4xNzFhNi42NSA2LjY1IDAgMCAxIDMuMjg0LS44MzV6bTIuNzgzLTcuMDE0YTUuNjggNS42OCAwIDAgMS0uNDQ1IDIuMjI3IDUuODcgNS44NyAwIDAgMS0xLjIyNSAxLjc4MWMtLjQ4Mi40ODItMS4wNTguODcyLTEuNzI2IDEuMTY5cy0xLjM5Mi40NDUtMi4xNzEuNDQ1YTUuNjggNS42OCAwIDAgMS0yLjIyNy0uNDQ1IDYuNDQgNi40NCAwIDAgMS0xLjc4MS0xLjE2OSA2LjQ0IDYuNDQgMCAwIDEtMS4xNjktMS43ODEgNS42OCA1LjY4IDAgMCAxLS40NDUtMi4yMjdjMC0uNzc5LjE0OC0xLjUwMy40NDUtMi4xNzFBNi40NCA2LjQ0IDAgMCAxIDkuNTIgNi43MzdhNS44NyA1Ljg3IDAgMCAxIDEuNzgxLTEuMjI1IDUuNjggNS42OCAwIDAgMSAyLjIyNy0uNDQ1Yy43NzkgMCAxLjUwMy4xNDggMi4xNzEuNDQ1czEuMjQzLjcwNSAxLjcyNiAxLjIyNWE1Ljg3IDUuODcgMCAwIDEgMS4yMjUgMS43ODFjLjI5Ny42NjguNDQ1IDEuMzkyLjQ0NSAyLjE3MXptLTIuNzgzIDBjMC0uNzc5LS4yNzgtMS40MjktLjgzNS0xLjk0OC0uNTU3LS41NTctMS4yMDYtLjgzNS0xLjk0OC0uODM1YTIuNzMgMi43MyAwIDAgMC0yLjAwNC44MzVjLS41NTcuNTItLjgzNSAxLjE2OS0uODM1IDEuOTQ4YTIuNzMgMi43MyAwIDAgMCAuODM1IDIuMDA0Yy41NTcuNTIgMS4yMjUuNzc5IDIuMDA0Ljc3OS43NDIgMCAxLjM5Mi0uMjYgMS45NDgtLjc3OWEyLjczIDIuNzMgMCAwIDAgLjgzNS0yLjAwNHpNNy4wNzEgMjIuNjU3Yy44OTEuNjMxIDEuODc0IDEuMTMyIDIuOTUgMS41MDMgMS4xMTMuMzcxIDIuMjgyLjU1NyAzLjUwNy41NTcgMS4xODggMCAyLjMxOS0uMTg2IDMuMzk2LS41NTcgMS4xMTMtLjM3MSAyLjExNS0uODcyIDMuMDA2LTEuNTAzLS4zNzEtLjY2OC0uODkxLTEuMTg4LTEuNTU5LTEuNTU5LS42MzEtLjQwOC0xLjMxNy0uNjEyLTIuMDYtLjYxMmgtNS42MjJjLS43NDIgMC0xLjQ0Ny4yMDQtMi4xMTUuNjEyLS42MzEuMzcxLTEuMTMyLjg5MS0xLjUwMyAxLjU1OXoiLz4mI3hhOzwvc3ZnPg==;" parent="1" vertex="1">
|
| 36 |
-
<mxGeometry x="-
|
| 37 |
</mxCell>
|
| 38 |
-
<mxCell id="CBPTevJeyTvfQtbZMOis-7" style="edgeStyle=orthogonalEdgeStyle;rounded=0;orthogonalLoop=1;jettySize=auto;html=1;strokeWidth=3;"
|
| 39 |
<mxGeometry relative="1" as="geometry">
|
| 40 |
-
<mxPoint x="-
|
| 41 |
</mxGeometry>
|
| 42 |
</mxCell>
|
| 43 |
<mxCell id="jEus2W5ITfwieqKF0qT7-20" value="" style="shape=image;verticalLabelPosition=bottom;labelBackgroundColor=default;verticalAlign=top;aspect=fixed;imageAspect=0;image=https://cdn-icons-png.flaticon.com/512/8832/8832880.png;" parent="1" vertex="1">
|
| 44 |
-
<mxGeometry x="-
|
| 45 |
</mxCell>
|
| 46 |
-
<mxCell id="CBPTevJeyTvfQtbZMOis-8" style="rounded=0;orthogonalLoop=1;jettySize=auto;html=1;exitX=1;exitY=1;exitDx=0;exitDy=0;entryX=0;entryY=0;entryDx=0;entryDy=0;strokeWidth=3;"
|
| 47 |
<mxGeometry relative="1" as="geometry" />
|
| 48 |
</mxCell>
|
| 49 |
<mxCell id="jEus2W5ITfwieqKF0qT7-23" value="" style="shape=image;verticalLabelPosition=bottom;labelBackgroundColor=default;verticalAlign=top;aspect=fixed;imageAspect=0;image=data:image/png,iVBORw0KGgoAAAANSUhEUgAAAOEAAADhCAMAAAAJbSJIAAABL1BMVEX///8AAABU2fj/kae+2u5W3///lawAxPOamppS1vQveYsSLzaHh4fD4PX4+/1ldH6ES1aPUV3/VHcgICBNyOQDCgsscYEoaHYIFhrt7e1hNz//iqH/UHRhIC3Z2dmlpaV0dHQAaIFY4/9r3vmu7PvIyMieWmizZnXm5uZQUFD0i6DKc4RA1vcAwe8AzP1HuNLbfI90QkzDb4A5OTmC4fnL8vxzhJDQ0NBjY2MsLCw5lKkeTVhBqcENIichExZGKC5UMDe5ubkcSVONjY0/Pz89nrUjW2gAaYOEKz0xHCD/sL8AfpwuzfUAWG42i58VNz8AocgmFRl/0uY9Rk0AlrwAO0kAS10AHCInwOUAT2IAepcAsdsAm8BeXl5OTk4yEBeUqbnc6/auyNpWY2x9Vl5ipT6lAAASKklEQVR4nO2de0MbNxLAY6e2MRAXDptHegfUKZgYBzD0yvsd6HGhoWnT6/Vocu3dff/PcN7VjDSSRto1qwXceP5I2JW81k8jzYweKz95Ysn8ws5uo+CVuTjjij/TfUtjd2dh3sYxpbawleJhj5Iwlq2Fmh9waTfVcx4vYaGwe+oDXEz5lB++juSHXEt6d1l0t9CXaZ9RL0aynmcxs8hLV0tNDfjYCQsvecBxlWNsZtQn04KwPu3Ndd/y3ZgCGOcATzF19m21lCBFIUnZ7leu1169mUUIxtzU0IrOVBFg0KRSWXv1HVDs2l1xAZJGB5WvGCFW1r4FjgWLEBz9zAADFq8jRNDilgk4L+43qg9dykzSI6y8gojTDOBGxO23g6xCUOIbgTJiEH4QtwdbhTFh5ZVA+WAQCtXeDLYKi52IsCL8YsMg/APYmSIQoq1hCacfHeGLWNwXL7TcgvDLQSL8WpTu6/jihbj4Kr7oiIu/dmj2IeGQ8AFkSDj4hF/94QlffBXLC3ohcIvaBcgAEvYpQ8Ih4eOXIeGQ8PHLkLBHWKwOtHRe9aTiI/xDyZBw8GVIOPjyiRK+HBlw+SaSHz2E508GXJ5F8rmHkF0cHiCpfdaTIeFAy5BwSPj4ZUh4D4S12lwtYXtkpsf3R1ibT5LU37yyvTSyuPPh49bW7tTu1tbHDzuLI0vbKyGgNOmTcD4p8PuY6kuXzl9OOR4w9fL8dC4Y3pO+CRM3yDp2AFK6cRccwRxfCtZu75dw7nQnkQ5lJ5Aq75NwaSdhM7whjZ2lQSKsLSQ3TlumRjK31tCW5jX/NSvjzk80yL+cjGc0r30Szo0s+IXdFL/i3A1/uVcXu5XG6nv7rkyLmRjvwePXnPqbqZdKTSBslkr1GaceM7TV/AkXXMW+rDeLxWIJCKO1g2bdqUd782tayZtwXnvdpjF9Jv++aMbLCpSwd7Un08++1PrmVvpo6V4JtQY6tle9kH/XYcFHJyyW1g9lFVy/GaMfv2NBciWcp+8T3RyUmvJtjDO5Nd4gLJaqUs3rzev3P5En7N5Jjf0SztnitAIjpHRn681SsY7tbl+t2JmEvTvYGRv1Umfte8po7vHNgXCl0DDFpeQaCdDGDuL3MbDo+2R5zyZU+c56N6/X3pO2utO/UQ0Q0/CEKySEeVuMLeVbuLypJhBWb/CDPWvUWau8UY+a6ts35kW4pNL3wajU4bpRLyYQyqziZarrtVf/UI/rN1bNiVA5wcYFlh0Vs15KJCyhSbqJL68ra++V6+jTNeZDqGzMmfQK2EaNlxtYQjN3p7J2qyxOf+sMASJvm/Bcpo2qvgVKOCvqwhMWi+AzoElH2w2+lU/tC7HfyHtn0RKr1Sg3f9CUIBhz1g0SFyF2RXxVoNJrqb5mE4owjUgNHtZLVoGtF3BchLKdYpX0EG9/voMWwxPKPnhDAJuXAG1tznERFksQvu1jO4hefZGdMb3vD04oregZ9XpoGw/6IDyAz6zjHQ3R+3Z2noTSD+7TIpcumZsJhDJ6u5RJ0eYm6RnT+sXAhNKbXGqFxV643hchKl4qMX7T7hf8ipTRTWBCHExoTbRYmja1kYZQal7trOvQhrr7EIQYbI/pb/RVLWWkIpS9V3mYGBEj8Z37J0Qro0ee0vCfNfskbILbJy7mmrwRmi5+C0koO6HR3Zpg921DmkCI5vSQVE0Pce37frpiSMLX8L0XRmmhsc1yKvQSFpuzdvOukOjGMTubFyG6+mmDpAkB2x4PgbOJLD5MTM2Q1A59/zyF4w9HiG10rG4KdJt1KyGSKhBW2VRQf4Pe++ft7a20NsntNBwhvBddmDUFABtWghDXx7wf/hk/Zr67nCPhaeFhJDF6C0VYS3cQUXhhDrvIh9A5d5+7JDnFUIQPBmiVOifCEXcBcpcEjxGGsAZfdjljCUTPY3YKiLCKs870MfbR3/UERxn+nhiGEHrhYbFpHvLThLWYPSsFM6j1Qz4dnP6FnmGtJxWIBv09MQwhGFImasERkDkBlS5qiwTGlsbhFfTEEuvYmfCEp9ASuaBMJM06ARIJS+D0m/ptcp6H3ycGIYRwhjvIhtdAX4QzbCugSvQGNiEIMSJlDrLB8Q8fdacjhNGlMWLpkGNnvNFpCEKYIOXOy8L5C2c3TCYUg6/Z/QPjNn3pzucwQhA23BQwSp91n1OUTFi9HD2ol5rm7fjsoFvx1ebJOoEJYS2DPYuoKgw6M4uYnjA65I67HSsRpqU8698BCM89XQ3Gd573UFMQOoTaGs8sfwDCLXcjRUNjzmsEIeyQZupxidkJwZKyDRHtIDeNmJlQuESYA3db0+yEELGxp7o5fNldCJnOWCHN1O30sxMuetQESw+HvpKnICyVqusXb0fN29SaLuZHCIN7HgKmmW6amQghth0zXY44iU2sKW45BxiZCaEbXrIQELNx6xX9E9ptPW6mvyR0xMyEpyIXby3rnj7aB+Goj/B9QkfMTHju6YboDj3OIhXhheM74o4IU/xOj5iZEJab2AJi0dgFiz4IXV41JqyIROdCVGZCEZQ6JuWT3WEqW7ruaOziyAthaqZyIxSZ+PGfswP1SQjd2R68eA59DEa44qhejdBT+HQe30v4L5HqMqZZCZccXUSUHkKaZkbCpquh0KjGtXMhK+Gpr6fhbopAhLZbpcbU5S6yEi74eloJxr+ZCcWc6hlPCHGba04xKyG4Q34MXxIbLnlDi6X3rZDqeewxNj0j2OUQsxJC3M0ub9brYoR/w69+guA7Mx6BPcOHVkK0WHqbEHtnJQSHb+3+hj3g3tRQeUSiy+VnJcSV34cX16RpVsL0v3+Rt7jeCxwSDlvp4yHMy9KALZ3mRXjqw1FHMskz68syeujK82UkogiLORHCrnX+x1fQU7tWP9OskMZ5bhx5ruOFUn85sxLCAr43pqEb7+w8aaI2iBy8MU1eURvEpd7Iu5GZUDh1e9L5PuLSU5GJn6fASbLMhOIx9tginsVImIrKSrgtMvEroLh66J3tTTMjLB5jr+/Q8eF2ToRzIhP/a0I4xvf9ykkawqrrSypkJ6ZrSjjQPA27wVnORAWap3HMRP3EFj4c4WtPV8MNsIFmE62uIAhFonO7cGbCcY+aUiwf9jMjbFUUNaXOYmYmXPCpqe6o/D4J9xy1GBP+KhKdG6MyE867rAAh9B22nIbQtaGDTiY6V/IzE4Ix5RfQcKMCm5iaEDZ0HFommRoa53E92VdIxQixwdtLUTbfNFMaQpHlzLwvuqGId9wn/2QnPPd0RAhqPNtp0hBWxfDDCmloN3RvxshOCFENu3KBLj/bToV1R1enqxauiCYE4RysPnF6SrG8lkzo8jliZ5vo6Q33qVkB9tN88OjJVf19EToaAp3S9+xODEB4KvKxLgHel/Es5KcgFJ3ZsmV0655nh2kAQvAX7BoalP8m0849PkeHLAD7tnqH2Jv4ge8npP4z7b50bOi4JtsUfFtoQxBCM+WcfnLsnbyD1hF3U3fv2wYdZBc0vpzGlC/R1CQT8oamQ+yMb3tpGEIYX9C3BKWIJHvpLz3hGdvNqTP0nrAQhBA3ejO9DSYC3Uv5yf2Q7QN066X/JcQw71vAvDAT1+Aw39kRk1ZIsRsaA3z6M7/+d7rDEELkxr0mClHN9J1XSGHodKHfjVZG8YVnd8QWjlC+5GxLfwd6usX9nIRjbwMRbju/P3/xqzDY+4cfHwww6VzfUISJB5vmJkkH8QV709l5RGnOsphUsGCEc+5C5CqJxymHex8fX5S9GTUENrc1ps0EIbBCyidOgwmdIbemv+0JnjiQfKhCwFMj8H31urGQCT69sM4ugnpXSPGwTC01WhXFaCbFGTUBCdHYmLN+OL7gN7v7T/6AwRcdV8Tnt+ChXynO+wx5tgkeY2aO5PAAHnYY7CVkPtmhJymlOdQs6Ak86BRHdW3hMJgdQnnPpxm1q4yebJLuEP+QhPIIngsNEY+0YqdNfYRVPJ5GJdLTadKdhRX2nKhT/G5jKAFDKG6vtO8kLBiX3Khb0QlDv+KXpDuyLfBZX+csIk6b2isPXkJY9SATQNoRSilPFgx9Ip3cI6WdFYVlZZToOa/trVkvGmDyyTT5EKpxFEXEgxEYc+oeAaMh3cOkDgVMc0TUXQmZ46CJzMuBnDZmhXv2QNh9ihIMfdX+496gVxqZxry/GFkIa/5fcWiwQ1X+biq50wOn1BRxcMLHIUPCIeHjlyFhGsKriUcnf4vk38EIn5cfmzz9UyR/CUj49JHJF38eEg4JP2XCuJ9rV+a1XhZvfit72tz5Ebbbm8vdwpH8zuVYNvBysnCyvNluqzK2N1qTJ4UJ/PyGyC8fd1XoLq+2Se7lyePCpp67JZN7Xqu10c6XsNwV+bBQG+JysqwnK8KC9vleDcSCNdIWl90y/7QT9sta5VwJl7Ui4mUB06/iqyOpozLcwMt3IvuyjoSX7SPt24AfdVpukcv8CFe1MgGAJDZ00sswoakBiApXZa2CsFmWj0WqyF3eLGiP056VYz8U+aBjYYmRGPhbipDWu1I51IjBb/QBvMIWorWH/AjLVAlY/kLhWCNYVeZP0znoSNXBMSVQzxOfb7/D3KsiuUDKkiPhc5FRu0ClmHZIFUs0tLbMDg8UFyfy6Vp9yAYCpkezQzkSUlOjSiyUUhaWQvqSSIjtUSqHSjAMjd6PsQnLT0O33MybcFMRSVMgc1CFPdU6U1tXeVxOJCbdVlTRVXzxTuXeIMSiC+cY0xBTo0wBIBj+jOo86krgDGQtoHdUjRrrgDwslkjL4B2Pcvb4Uk+xaSFliJSiG04oszKv+KeQp8rw2PWxQe1uQfTU9pX8MwuhOXvOECpTo5W4pxTT+Btdi3SsQmwvwS6fEELVB6SrRWTQ6UQKwh9ZwtfsXZtQdQe9xAWpk3c6oShppPMjmr1XUr3MRh9o08w95LLuax2Ev0eEn4mc5lIAbKpcSiSUTRFUUIDeuFE2gi6tax21ywCE5qZMjZbRB67K+DUQmj4vGyGth/DZbyKn2eNOWXCmlUpzgiXeNG5M6IRYMvxjs2vc2KC5nyM+Rt1gUduGr3UQxo10i1WWPEp+IYkQNHWCpqAF9X6kOyyza22CJyg8bWGNGEMHrT6gkR5jV9gExwoRrYMwVuE3QGICyp+I204ghIJdoSVsY71vMDohOocyn5Rl4aGHsvUB/09g9+savpYnfKbaKLNQKNfllxIIobnAV59Iu94SCUeaoZE674Lqeq7tRHtAV1M54E+C6lZlb6eDQxfh7wSQW/eXi9aLZEGOIYSidmWJoVRXx6AbnRCHRGD927JGnutl1urjSo4jsEKxWjhCVMezZ//5L0Kw+6fUztidkaV5IcxMlOYG4zZ5TG90TULNqRw/1aMVOXDQ+4B6Fg0NC6rTaoSiqNu/ffOjzMevGnO/ylmwCTVPFYWQaB6EtEzCFk2NIjrdmeuNWq+PyGjpjpGbieLEscfPuW9UIyyTkFjEoJpSdJ2YqRtmjVzpFaLXR3yHxOuqIAmEzg1iK44fkNEJ6VeuWswmoBa+ilEDbefmVOyGmaYxL6ci3PXsLqrxe2N1QhoTl82mdWSUWA6JYhHRQJk8YNnITxtlyxgJE1/rI1z0/8rHNreJWyckfV+YFTpqMA2NPsgSppDe2TS7LemkMF9zbN7xEr5O2OweNdVxq63qTYlUM070qTumTnSdl606apu5Ff2J9fl3SYS75yl/kn1uewmEW7cgPHaxVm1CpWFUMKkjMzvpdsasqlYOzVtgYbcTd0kzwhKemN9IimXqRONBT6KM1YlFqOpDrhXIOxM84R24pLBrT8raS98nId7ZgDgbRfBVjUxaKpePupLfJw3ZJk/Y/6/MJxG2zBIrpdiGhrRha2LZjg+IxhS8VKsK6vMllOVTTUxC2zohOieTatjQ7UYtK4uEDnCHBPX3REjsJloD0/jHZUbTqVQg7SNDiEnkFjQCEtTnTIjjHzISRKdlDA41fDrqgFsndmasD9LemVs5E5Zb3W60p6Vs32JMaU/nE1Fil/a58kSUvWt3w17u53ESrat2/PAuabd567BsLm6zt+6an0mxbuVN+PAyJBwSfoqEjv1zsdx5+10G+YLfuXdnwqtJVpYFYItPzVf43Zd3JnSIGK5py4gPITkSwraQCV+ee5A8Cf8ey//uC8UhORLC7y6N+/Lcg+RP+FDvrqN88oT/B28HJZ+GpTewAAAAAElFTkSuQmCC;" parent="1" vertex="1">
|
| 50 |
-
<mxGeometry x="-
|
| 51 |
</mxCell>
|
| 52 |
-
<mxCell id="jEus2W5ITfwieqKF0qT7-49" value="wilhelm-
|
| 53 |
-
<mxGeometry x="
|
| 54 |
</mxCell>
|
| 55 |
-
<mxCell id="CBPTevJeyTvfQtbZMOis-4" style="edgeStyle=orthogonalEdgeStyle;rounded=0;orthogonalLoop=1;jettySize=auto;html=1;exitX=0.5;exitY=1;exitDx=0;exitDy=0;"
|
| 56 |
-
<mxGeometry relative="1" as="geometry"
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 57 |
</mxCell>
|
| 58 |
-
<mxCell id="
|
| 59 |
-
<mxGeometry x="-
|
| 60 |
</mxCell>
|
| 61 |
</root>
|
| 62 |
</mxGraphModel>
|
|
|
|
| 1 |
+
<mxfile host="app.diagrams.net" agent="Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36" version="25.0.1">
|
| 2 |
<diagram name="Page-1" id="-PRZJL_y_DcYyeR3ZVRW">
|
| 3 |
+
<mxGraphModel dx="2924" dy="1145" grid="1" gridSize="10" guides="1" tooltips="1" connect="1" arrows="1" fold="1" page="1" pageScale="1" pageWidth="850" pageHeight="1100" math="0" shadow="0">
|
| 4 |
<root>
|
| 5 |
<mxCell id="0" />
|
| 6 |
<mxCell id="1" parent="0" />
|
| 7 |
+
<mxCell id="lBE7YV5RTTJSdhW3G_g6-8" style="edgeStyle=orthogonalEdgeStyle;rounded=0;orthogonalLoop=1;jettySize=auto;html=1;exitX=0.5;exitY=1;exitDx=0;exitDy=0;fontSize=12;strokeWidth=3;" edge="1" parent="1" source="jEus2W5ITfwieqKF0qT7-1">
|
|
|
|
|
|
|
|
|
|
| 8 |
<mxGeometry relative="1" as="geometry">
|
| 9 |
+
<mxPoint x="-325" y="470" as="targetPoint" />
|
| 10 |
</mxGeometry>
|
| 11 |
</mxCell>
|
| 12 |
<mxCell id="jEus2W5ITfwieqKF0qT7-1" value="" style="shape=image;verticalLabelPosition=bottom;labelBackgroundColor=default;verticalAlign=top;aspect=fixed;imageAspect=0;image=https://upload.wikimedia.org/wikipedia/en/thumb/0/06/Wiktionary-logo-v2.svg/1200px-Wiktionary-logo-v2.svg.png;" parent="1" vertex="1">
|
| 13 |
+
<mxGeometry x="-375" y="263.25" width="100" height="100" as="geometry" />
|
| 14 |
</mxCell>
|
| 15 |
<mxCell id="jEus2W5ITfwieqKF0qT7-7" value="" style="shape=image;verticalLabelPosition=bottom;labelBackgroundColor=default;verticalAlign=top;aspect=fixed;imageAspect=0;image=https://dist.neo4j.com/wp-content/uploads/20210616181554/neo4j-connects-data.svg;" parent="1" vertex="1">
|
| 16 |
+
<mxGeometry x="300" y="441" width="256.2" height="137" as="geometry" />
|
| 17 |
</mxCell>
|
| 18 |
+
<mxCell id="jEus2W5ITfwieqKF0qT7-11" style="edgeStyle=orthogonalEdgeStyle;rounded=0;orthogonalLoop=1;jettySize=auto;html=1;strokeWidth=3;strokeColor=#FAA627;" parent="1" target="jEus2W5ITfwieqKF0qT7-7" edge="1">
|
| 19 |
<mxGeometry relative="1" as="geometry">
|
| 20 |
+
<mxPoint x="200" y="509" as="sourcePoint" />
|
| 21 |
</mxGeometry>
|
| 22 |
</mxCell>
|
| 23 |
<mxCell id="jEus2W5ITfwieqKF0qT7-10" value="" style="shape=image;verticalLabelPosition=bottom;labelBackgroundColor=default;verticalAlign=top;aspect=fixed;imageAspect=0;image=https://upload.wikimedia.org/wikipedia/commons/9/91/Octicons-mark-github.svg;" parent="1" vertex="1">
|
| 24 |
+
<mxGeometry x="-150" y="478" width="64" height="64" as="geometry" />
|
| 25 |
</mxCell>
|
| 26 |
<mxCell id="jEus2W5ITfwieqKF0qT7-30" style="edgeStyle=orthogonalEdgeStyle;rounded=0;orthogonalLoop=1;jettySize=auto;html=1;strokeWidth=3;" parent="1" edge="1">
|
| 27 |
<mxGeometry relative="1" as="geometry">
|
| 28 |
+
<mxPoint x="-275" y="509.75" as="sourcePoint" />
|
| 29 |
+
<mxPoint x="-165" y="509.75" as="targetPoint" />
|
| 30 |
</mxGeometry>
|
| 31 |
</mxCell>
|
| 32 |
<mxCell id="jEus2W5ITfwieqKF0qT7-18" value="" style="shape=image;editableCssRules=.*;verticalLabelPosition=bottom;labelBackgroundColor=default;verticalAlign=top;aspect=fixed;imageAspect=0;image=data:image/svg+xml,PHN2ZyB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciIHZpZXdCb3g9Ii0wLjUgLTAuNSAyOCAyOCIgaGVpZ2h0PSIyOCIgd2lkdGg9IjI4Ij4mI3hhOwkgIDxzdHlsZSB0eXBlPSJ0ZXh0L2NzcyI+LnN0MCB7IHN0b3AtY29sb3I6IHJnYig5MSwgMTE1LCAxMzkpOyB9IC5zdDEgeyBzdG9wLWNvbG9yOiByZ2IoMzQsIDUzLCA3Mik7IH0gPC9zdHlsZT4mI3hhOwk8ZGVmcz4mI3hhOwkJPGxpbmVhckdyYWRpZW50IGdyYWRpZW50VW5pdHM9InVzZXJTcGFjZU9uVXNlIiB5Mj0iMjUuMzA5IiB4Mj0iMjMuNDU0IiB5MT0iMy40NzQiIHgxPSIyLjAzOSIgaWQ9IkEiPiYjeGE7CQkJPHN0b3AgY2xhc3M9InN0MCIvPiYjeGE7CQkJPHN0b3AgY2xhc3M9InN0MSIgb2Zmc2V0PSIxIi8+JiN4YTsJCTwvbGluZWFyR3JhZGllbnQ+JiN4YTsJPC9kZWZzPiYjeGE7CTxwYXRoIGZpbGw9InVybCgjQSkiIGQ9Ik0tLjUgMTMuNDcyYzAtMS45My4zNzEtMy43MyAxLjExMy01LjQuNzQyLTEuNzA3IDEuNzQ0LTMuMTkyIDMuMDA2LTQuNDUzUzYuMzY1IDEuMzU2IDguMDczLjYxMyAxMS41OTgtLjUgMTMuNTI4LS41czMuNzMuMzcxIDUuNCAxLjExM2MxLjcwNy43NDIgMy4xOTIgMS43NDQgNC40NTMgMy4wMDZzMi4yNjQgMi43NDYgMy4wMDYgNC40NTNjLjc0MiAxLjY3IDEuMTEzIDMuNDcgMS4xMTMgNS40cy0uMzcxIDMuNzQ4LTEuMTEzIDUuNDU1LTEuNzQ0IDMuMTkyLTMuMDA2IDQuNDUzYTE0LjI4IDE0LjI4IDAgMCAxLTQuNDUzIDMuMDA2Yy0xLjY3Ljc0Mi0zLjQ3IDEuMTEzLTUuNCAxLjExM3MtMy43NDgtLjM3MS01LjQ1NS0xLjExM2ExNC4yOCAxNC4yOCAwIDAgMS00LjQ1My0zLjAwNiAxNC4yOCAxNC4yOCAwIDAgMS0zLjAwNi00LjQ1M0MtLjEyOSAxNy4yMi0uNSAxNS40MDItLjUgMTMuNDcyem0xNi44MTEgNC4yMzFhNi42NSA2LjY1IDAgMCAxIDMuMjg0LjgzNWMxLjAwMi41MiAxLjgxOCAxLjI0MyAyLjQ0OSAyLjE3MWExMC4xNCAxMC4xNCAwIDAgMCAxLjk0OC0zLjI4NGMuNDgyLTEuMjI1LjcyNC0yLjU0Mi43MjQtMy45NTIgMC0xLjU1OS0uMjk3LTMuMDA2LS44OTEtNC4zNDItLjU5NC0xLjM3My0xLjM5Mi0yLjU2MS0yLjM5NC0zLjU2M3MtMi4xOS0xLjgtMy41NjMtMi4zOTRjLTEuMzM2LS41OTQtMi43ODMtLjg5MS00LjM0Mi0uODkxcy0zLjAyNC4yOTctNC4zOTguODkxYy0xLjMzNi41OTQtMi41MjQgMS4zOTItMy41NjMgMi4zOTRBMTEuMzUgMTEuMzUgMCAwIDAgMy4xNzQgOS4xM2MtLjU5NCAxLjMzNi0uODkxIDIuNzgzLS44OTEgNC4zNDIgMCAxLjQxLjIyMyAyLjcyOC42NjggMy45NTIuNDgyIDEuMjI1IDEuMTUgMi4zMTkgMi4wMDQgMy4yODQuNjMxLS45MjggMS40NDctMS42NTEgMi40NDktMi4xNzFhNi42NSA2LjY1IDAgMCAxIDMuMjg0LS44MzV6bTIuNzgzLTcuMDE0YTUuNjggNS42OCAwIDAgMS0uNDQ1IDIuMjI3IDUuODcgNS44NyAwIDAgMS0xLjIyNSAxLjc4MWMtLjQ4Mi40ODItMS4wNTguODcyLTEuNzI2IDEuMTY5cy0xLjM5Mi40NDUtMi4xNzEuNDQ1YTUuNjggNS42OCAwIDAgMS0yLjIyNy0uNDQ1IDYuNDQgNi40NCAwIDAgMS0xLjc4MS0xLjE2OSA2LjQ0IDYuNDQgMCAwIDEtMS4xNjktMS43ODEgNS42OCA1LjY4IDAgMCAxLS40NDUtMi4yMjdjMC0uNzc5LjE0OC0xLjUwMy40NDUtMi4xNzFBNi40NCA2LjQ0IDAgMCAxIDkuNTIgNi43MzdhNS44NyA1Ljg3IDAgMCAxIDEuNzgxLTEuMjI1IDUuNjggNS42OCAwIDAgMSAyLjIyNy0uNDQ1Yy43NzkgMCAxLjUwMy4xNDggMi4xNzEuNDQ1czEuMjQzLjcwNSAxLjcyNiAxLjIyNWE1Ljg3IDUuODcgMCAwIDEgMS4yMjUgMS43ODFjLjI5Ny42NjguNDQ1IDEuMzkyLjQ0NSAyLjE3MXptLTIuNzgzIDBjMC0uNzc5LS4yNzgtMS40MjktLjgzNS0xLjk0OC0uNTU3LS41NTctMS4yMDYtLjgzNS0xLjk0OC0uODM1YTIuNzMgMi43MyAwIDAgMC0yLjAwNC44MzVjLS41NTcuNTItLjgzNSAxLjE2OS0uODM1IDEuOTQ4YTIuNzMgMi43MyAwIDAgMCAuODM1IDIuMDA0Yy41NTcuNTIgMS4yMjUuNzc5IDIuMDA0Ljc3OS43NDIgMCAxLjM5Mi0uMjYgMS45NDgtLjc3OWEyLjczIDIuNzMgMCAwIDAgLjgzNS0yLjAwNHpNNy4wNzEgMjIuNjU3Yy44OTEuNjMxIDEuODc0IDEuMTMyIDIuOTUgMS41MDMgMS4xMTMuMzcxIDIuMjgyLjU1NyAzLjUwNy41NTcgMS4xODggMCAyLjMxOS0uMTg2IDMuMzk2LS41NTcgMS4xMTMtLjM3MSAyLjExNS0uODcyIDMuMDA2LTEuNTAzLS4zNzEtLjY2OC0uODkxLTEuMTg4LTEuNTU5LTEuNTU5LS42MzEtLjQwOC0xLjMxNy0uNjEyLTIuMDYtLjYxMmgtNS42MjJjLS43NDIgMC0xLjQ0Ny4yMDQtMi4xMTUuNjEyLS42MzEuMzcxLTEuMTMyLjg5MS0xLjUwMyAxLjU1OXoiLz4mI3hhOzwvc3ZnPg==;" parent="1" vertex="1">
|
| 33 |
+
<mxGeometry x="-357.25" y="478" width="64.5" height="64.5" as="geometry" />
|
| 34 |
</mxCell>
|
| 35 |
+
<mxCell id="CBPTevJeyTvfQtbZMOis-7" style="edgeStyle=orthogonalEdgeStyle;rounded=0;orthogonalLoop=1;jettySize=auto;html=1;strokeWidth=3;" parent="1" source="jEus2W5ITfwieqKF0qT7-20" edge="1">
|
| 36 |
<mxGeometry relative="1" as="geometry">
|
| 37 |
+
<mxPoint x="-365" y="510.5" as="targetPoint" />
|
| 38 |
</mxGeometry>
|
| 39 |
</mxCell>
|
| 40 |
<mxCell id="jEus2W5ITfwieqKF0qT7-20" value="" style="shape=image;verticalLabelPosition=bottom;labelBackgroundColor=default;verticalAlign=top;aspect=fixed;imageAspect=0;image=https://cdn-icons-png.flaticon.com/512/8832/8832880.png;" parent="1" vertex="1">
|
| 41 |
+
<mxGeometry x="-536.25" y="474" width="73" height="73" as="geometry" />
|
| 42 |
</mxCell>
|
| 43 |
+
<mxCell id="CBPTevJeyTvfQtbZMOis-8" style="rounded=0;orthogonalLoop=1;jettySize=auto;html=1;exitX=1;exitY=1;exitDx=0;exitDy=0;entryX=0;entryY=0;entryDx=0;entryDy=0;strokeWidth=3;" parent="1" source="jEus2W5ITfwieqKF0qT7-23" target="jEus2W5ITfwieqKF0qT7-18" edge="1">
|
| 44 |
<mxGeometry relative="1" as="geometry" />
|
| 45 |
</mxCell>
|
| 46 |
<mxCell id="jEus2W5ITfwieqKF0qT7-23" value="" style="shape=image;verticalLabelPosition=bottom;labelBackgroundColor=default;verticalAlign=top;aspect=fixed;imageAspect=0;image=data:image/png,iVBORw0KGgoAAAANSUhEUgAAAOEAAADhCAMAAAAJbSJIAAABL1BMVEX///8AAABU2fj/kae+2u5W3///lawAxPOamppS1vQveYsSLzaHh4fD4PX4+/1ldH6ES1aPUV3/VHcgICBNyOQDCgsscYEoaHYIFhrt7e1hNz//iqH/UHRhIC3Z2dmlpaV0dHQAaIFY4/9r3vmu7PvIyMieWmizZnXm5uZQUFD0i6DKc4RA1vcAwe8AzP1HuNLbfI90QkzDb4A5OTmC4fnL8vxzhJDQ0NBjY2MsLCw5lKkeTVhBqcENIichExZGKC5UMDe5ubkcSVONjY0/Pz89nrUjW2gAaYOEKz0xHCD/sL8AfpwuzfUAWG42i58VNz8AocgmFRl/0uY9Rk0AlrwAO0kAS10AHCInwOUAT2IAepcAsdsAm8BeXl5OTk4yEBeUqbnc6/auyNpWY2x9Vl5ipT6lAAASKklEQVR4nO2de0MbNxLAY6e2MRAXDptHegfUKZgYBzD0yvsd6HGhoWnT6/Vocu3dff/PcN7VjDSSRto1qwXceP5I2JW81k8jzYweKz95Ysn8ws5uo+CVuTjjij/TfUtjd2dh3sYxpbawleJhj5Iwlq2Fmh9waTfVcx4vYaGwe+oDXEz5lB++juSHXEt6d1l0t9CXaZ9RL0aynmcxs8hLV0tNDfjYCQsvecBxlWNsZtQn04KwPu3Ndd/y3ZgCGOcATzF19m21lCBFIUnZ7leu1169mUUIxtzU0IrOVBFg0KRSWXv1HVDs2l1xAZJGB5WvGCFW1r4FjgWLEBz9zAADFq8jRNDilgk4L+43qg9dykzSI6y8gojTDOBGxO23g6xCUOIbgTJiEH4QtwdbhTFh5ZVA+WAQCtXeDLYKi52IsCL8YsMg/APYmSIQoq1hCacfHeGLWNwXL7TcgvDLQSL8WpTu6/jihbj4Kr7oiIu/dmj2IeGQ8AFkSDj4hF/94QlffBXLC3ohcIvaBcgAEvYpQ8Ih4eOXIeGQ8PHLkLBHWKwOtHRe9aTiI/xDyZBw8GVIOPjyiRK+HBlw+SaSHz2E508GXJ5F8rmHkF0cHiCpfdaTIeFAy5BwSPj4ZUh4D4S12lwtYXtkpsf3R1ibT5LU37yyvTSyuPPh49bW7tTu1tbHDzuLI0vbKyGgNOmTcD4p8PuY6kuXzl9OOR4w9fL8dC4Y3pO+CRM3yDp2AFK6cRccwRxfCtZu75dw7nQnkQ5lJ5Aq75NwaSdhM7whjZ2lQSKsLSQ3TlumRjK31tCW5jX/NSvjzk80yL+cjGc0r30Szo0s+IXdFL/i3A1/uVcXu5XG6nv7rkyLmRjvwePXnPqbqZdKTSBslkr1GaceM7TV/AkXXMW+rDeLxWIJCKO1g2bdqUd782tayZtwXnvdpjF9Jv++aMbLCpSwd7Un08++1PrmVvpo6V4JtQY6tle9kH/XYcFHJyyW1g9lFVy/GaMfv2NBciWcp+8T3RyUmvJtjDO5Nd4gLJaqUs3rzev3P5En7N5Jjf0SztnitAIjpHRn681SsY7tbl+t2JmEvTvYGRv1Umfte8po7vHNgXCl0DDFpeQaCdDGDuL3MbDo+2R5zyZU+c56N6/X3pO2utO/UQ0Q0/CEKySEeVuMLeVbuLypJhBWb/CDPWvUWau8UY+a6ts35kW4pNL3wajU4bpRLyYQyqziZarrtVf/UI/rN1bNiVA5wcYFlh0Vs15KJCyhSbqJL68ra++V6+jTNeZDqGzMmfQK2EaNlxtYQjN3p7J2qyxOf+sMASJvm/Bcpo2qvgVKOCvqwhMWi+AzoElH2w2+lU/tC7HfyHtn0RKr1Sg3f9CUIBhz1g0SFyF2RXxVoNJrqb5mE4owjUgNHtZLVoGtF3BchLKdYpX0EG9/voMWwxPKPnhDAJuXAG1tznERFksQvu1jO4hefZGdMb3vD04oregZ9XpoGw/6IDyAz6zjHQ3R+3Z2noTSD+7TIpcumZsJhDJ6u5RJ0eYm6RnT+sXAhNKbXGqFxV643hchKl4qMX7T7hf8ipTRTWBCHExoTbRYmja1kYZQal7trOvQhrr7EIQYbI/pb/RVLWWkIpS9V3mYGBEj8Z37J0Qro0ee0vCfNfskbILbJy7mmrwRmi5+C0koO6HR3Zpg921DmkCI5vSQVE0Pce37frpiSMLX8L0XRmmhsc1yKvQSFpuzdvOukOjGMTubFyG6+mmDpAkB2x4PgbOJLD5MTM2Q1A59/zyF4w9HiG10rG4KdJt1KyGSKhBW2VRQf4Pe++ft7a20NsntNBwhvBddmDUFABtWghDXx7wf/hk/Zr67nCPhaeFhJDF6C0VYS3cQUXhhDrvIh9A5d5+7JDnFUIQPBmiVOifCEXcBcpcEjxGGsAZfdjljCUTPY3YKiLCKs870MfbR3/UERxn+nhiGEHrhYbFpHvLThLWYPSsFM6j1Qz4dnP6FnmGtJxWIBv09MQwhGFImasERkDkBlS5qiwTGlsbhFfTEEuvYmfCEp9ASuaBMJM06ARIJS+D0m/ptcp6H3ycGIYRwhjvIhtdAX4QzbCugSvQGNiEIMSJlDrLB8Q8fdacjhNGlMWLpkGNnvNFpCEKYIOXOy8L5C2c3TCYUg6/Z/QPjNn3pzucwQhA23BQwSp91n1OUTFi9HD2ol5rm7fjsoFvx1ebJOoEJYS2DPYuoKgw6M4uYnjA65I67HSsRpqU8698BCM89XQ3Gd573UFMQOoTaGs8sfwDCLXcjRUNjzmsEIeyQZupxidkJwZKyDRHtIDeNmJlQuESYA3db0+yEELGxp7o5fNldCJnOWCHN1O30sxMuetQESw+HvpKnICyVqusXb0fN29SaLuZHCIN7HgKmmW6amQghth0zXY44iU2sKW45BxiZCaEbXrIQELNx6xX9E9ptPW6mvyR0xMyEpyIXby3rnj7aB+Goj/B9QkfMTHju6YboDj3OIhXhheM74o4IU/xOj5iZEJab2AJi0dgFiz4IXV41JqyIROdCVGZCEZQ6JuWT3WEqW7ruaOziyAthaqZyIxSZ+PGfswP1SQjd2R68eA59DEa44qhejdBT+HQe30v4L5HqMqZZCZccXUSUHkKaZkbCpquh0KjGtXMhK+Gpr6fhbopAhLZbpcbU5S6yEi74eloJxr+ZCcWc6hlPCHGba04xKyG4Q34MXxIbLnlDi6X3rZDqeewxNj0j2OUQsxJC3M0ub9brYoR/w69+guA7Mx6BPcOHVkK0WHqbEHtnJQSHb+3+hj3g3tRQeUSiy+VnJcSV34cX16RpVsL0v3+Rt7jeCxwSDlvp4yHMy9KALZ3mRXjqw1FHMskz68syeujK82UkogiLORHCrnX+x1fQU7tWP9OskMZ5bhx5ruOFUn85sxLCAr43pqEb7+w8aaI2iBy8MU1eURvEpd7Iu5GZUDh1e9L5PuLSU5GJn6fASbLMhOIx9tginsVImIrKSrgtMvEroLh66J3tTTMjLB5jr+/Q8eF2ToRzIhP/a0I4xvf9ykkawqrrSypkJ6ZrSjjQPA27wVnORAWap3HMRP3EFj4c4WtPV8MNsIFmE62uIAhFonO7cGbCcY+aUiwf9jMjbFUUNaXOYmYmXPCpqe6o/D4J9xy1GBP+KhKdG6MyE867rAAh9B22nIbQtaGDTiY6V/IzE4Ix5RfQcKMCm5iaEDZ0HFommRoa53E92VdIxQixwdtLUTbfNFMaQpHlzLwvuqGId9wn/2QnPPd0RAhqPNtp0hBWxfDDCmloN3RvxshOCFENu3KBLj/bToV1R1enqxauiCYE4RysPnF6SrG8lkzo8jliZ5vo6Q33qVkB9tN88OjJVf19EToaAp3S9+xODEB4KvKxLgHel/Es5KcgFJ3ZsmV0655nh2kAQvAX7BoalP8m0849PkeHLAD7tnqH2Jv4ge8npP4z7b50bOi4JtsUfFtoQxBCM+WcfnLsnbyD1hF3U3fv2wYdZBc0vpzGlC/R1CQT8oamQ+yMb3tpGEIYX9C3BKWIJHvpLz3hGdvNqTP0nrAQhBA3ejO9DSYC3Uv5yf2Q7QN066X/JcQw71vAvDAT1+Aw39kRk1ZIsRsaA3z6M7/+d7rDEELkxr0mClHN9J1XSGHodKHfjVZG8YVnd8QWjlC+5GxLfwd6usX9nIRjbwMRbju/P3/xqzDY+4cfHwww6VzfUISJB5vmJkkH8QV709l5RGnOsphUsGCEc+5C5CqJxymHex8fX5S9GTUENrc1ps0EIbBCyidOgwmdIbemv+0JnjiQfKhCwFMj8H31urGQCT69sM4ugnpXSPGwTC01WhXFaCbFGTUBCdHYmLN+OL7gN7v7T/6AwRcdV8Tnt+ChXynO+wx5tgkeY2aO5PAAHnYY7CVkPtmhJymlOdQs6Ak86BRHdW3hMJgdQnnPpxm1q4yebJLuEP+QhPIIngsNEY+0YqdNfYRVPJ5GJdLTadKdhRX2nKhT/G5jKAFDKG6vtO8kLBiX3Khb0QlDv+KXpDuyLfBZX+csIk6b2isPXkJY9SATQNoRSilPFgx9Ip3cI6WdFYVlZZToOa/trVkvGmDyyTT5EKpxFEXEgxEYc+oeAaMh3cOkDgVMc0TUXQmZ46CJzMuBnDZmhXv2QNh9ihIMfdX+496gVxqZxry/GFkIa/5fcWiwQ1X+biq50wOn1BRxcMLHIUPCIeHjlyFhGsKriUcnf4vk38EIn5cfmzz9UyR/CUj49JHJF38eEg4JP2XCuJ9rV+a1XhZvfit72tz5Ebbbm8vdwpH8zuVYNvBysnCyvNluqzK2N1qTJ4UJ/PyGyC8fd1XoLq+2Se7lyePCpp67JZN7Xqu10c6XsNwV+bBQG+JysqwnK8KC9vleDcSCNdIWl90y/7QT9sta5VwJl7Ui4mUB06/iqyOpozLcwMt3IvuyjoSX7SPt24AfdVpukcv8CFe1MgGAJDZ00sswoakBiApXZa2CsFmWj0WqyF3eLGiP056VYz8U+aBjYYmRGPhbipDWu1I51IjBb/QBvMIWorWH/AjLVAlY/kLhWCNYVeZP0znoSNXBMSVQzxOfb7/D3KsiuUDKkiPhc5FRu0ClmHZIFUs0tLbMDg8UFyfy6Vp9yAYCpkezQzkSUlOjSiyUUhaWQvqSSIjtUSqHSjAMjd6PsQnLT0O33MybcFMRSVMgc1CFPdU6U1tXeVxOJCbdVlTRVXzxTuXeIMSiC+cY0xBTo0wBIBj+jOo86krgDGQtoHdUjRrrgDwslkjL4B2Pcvb4Uk+xaSFliJSiG04oszKv+KeQp8rw2PWxQe1uQfTU9pX8MwuhOXvOECpTo5W4pxTT+Btdi3SsQmwvwS6fEELVB6SrRWTQ6UQKwh9ZwtfsXZtQdQe9xAWpk3c6oShppPMjmr1XUr3MRh9o08w95LLuax2Ev0eEn4mc5lIAbKpcSiSUTRFUUIDeuFE2gi6tax21ywCE5qZMjZbRB67K+DUQmj4vGyGth/DZbyKn2eNOWXCmlUpzgiXeNG5M6IRYMvxjs2vc2KC5nyM+Rt1gUduGr3UQxo10i1WWPEp+IYkQNHWCpqAF9X6kOyyza22CJyg8bWGNGEMHrT6gkR5jV9gExwoRrYMwVuE3QGICyp+I204ghIJdoSVsY71vMDohOocyn5Rl4aGHsvUB/09g9+savpYnfKbaKLNQKNfllxIIobnAV59Iu94SCUeaoZE674Lqeq7tRHtAV1M54E+C6lZlb6eDQxfh7wSQW/eXi9aLZEGOIYSidmWJoVRXx6AbnRCHRGD927JGnutl1urjSo4jsEKxWjhCVMezZ//5L0Kw+6fUztidkaV5IcxMlOYG4zZ5TG90TULNqRw/1aMVOXDQ+4B6Fg0NC6rTaoSiqNu/ffOjzMevGnO/ylmwCTVPFYWQaB6EtEzCFk2NIjrdmeuNWq+PyGjpjpGbieLEscfPuW9UIyyTkFjEoJpSdJ2YqRtmjVzpFaLXR3yHxOuqIAmEzg1iK44fkNEJ6VeuWswmoBa+ilEDbefmVOyGmaYxL6ci3PXsLqrxe2N1QhoTl82mdWSUWA6JYhHRQJk8YNnITxtlyxgJE1/rI1z0/8rHNreJWyckfV+YFTpqMA2NPsgSppDe2TS7LemkMF9zbN7xEr5O2OweNdVxq63qTYlUM070qTumTnSdl606apu5Ff2J9fl3SYS75yl/kn1uewmEW7cgPHaxVm1CpWFUMKkjMzvpdsasqlYOzVtgYbcTd0kzwhKemN9IimXqRONBT6KM1YlFqOpDrhXIOxM84R24pLBrT8raS98nId7ZgDgbRfBVjUxaKpePupLfJw3ZJk/Y/6/MJxG2zBIrpdiGhrRha2LZjg+IxhS8VKsK6vMllOVTTUxC2zohOieTatjQ7UYtK4uEDnCHBPX3REjsJloD0/jHZUbTqVQg7SNDiEnkFjQCEtTnTIjjHzISRKdlDA41fDrqgFsndmasD9LemVs5E5Zb3W60p6Vs32JMaU/nE1Fil/a58kSUvWt3w17u53ESrat2/PAuabd567BsLm6zt+6an0mxbuVN+PAyJBwSfoqEjv1zsdx5+10G+YLfuXdnwqtJVpYFYItPzVf43Zd3JnSIGK5py4gPITkSwraQCV+ee5A8Cf8ey//uC8UhORLC7y6N+/Lcg+RP+FDvrqN88oT/B28HJZ+GpTewAAAAAElFTkSuQmCC;" parent="1" vertex="1">
|
| 47 |
+
<mxGeometry x="-540" y="282.75" width="80.5" height="80.5" as="geometry" />
|
| 48 |
</mxCell>
|
| 49 |
+
<mxCell id="jEus2W5ITfwieqKF0qT7-49" value="<font color="#faa627">wilhelm-data-loader</font>" style="text;html=1;align=center;verticalAlign=middle;whiteSpace=wrap;rounded=0;fontColor=#2088FF;fontFamily=Ubuntu;fontStyle=1;fontSize=18;strokeColor=none;" parent="1" vertex="1">
|
| 50 |
+
<mxGeometry x="67" y="549" width="190" height="30" as="geometry" />
|
| 51 |
</mxCell>
|
| 52 |
+
<mxCell id="CBPTevJeyTvfQtbZMOis-4" style="edgeStyle=orthogonalEdgeStyle;rounded=0;orthogonalLoop=1;jettySize=auto;html=1;exitX=0.5;exitY=1;exitDx=0;exitDy=0;" parent="1" edge="1">
|
| 53 |
+
<mxGeometry relative="1" as="geometry">
|
| 54 |
+
<mxPoint x="162" y="578" as="sourcePoint" />
|
| 55 |
+
<mxPoint x="162" y="578" as="targetPoint" />
|
| 56 |
+
</mxGeometry>
|
| 57 |
+
</mxCell>
|
| 58 |
+
<mxCell id="CBPTevJeyTvfQtbZMOis-9" value="Pull Request" style="text;html=1;align=center;verticalAlign=middle;whiteSpace=wrap;rounded=0;fontColor=#000000;fontFamily=Ubuntu;fontStyle=1;fontSize=18;" parent="1" vertex="1">
|
| 59 |
+
<mxGeometry x="-320" y="517" width="190" height="30" as="geometry" />
|
| 60 |
+
</mxCell>
|
| 61 |
+
<mxCell id="lBE7YV5RTTJSdhW3G_g6-1" value="" style="shape=image;verticalLabelPosition=bottom;labelBackgroundColor=default;verticalAlign=top;aspect=fixed;imageAspect=0;image=https://upload.wikimedia.org/wikipedia/commons/9/91/Octicons-mark-github.svg;" vertex="1" parent="1">
|
| 62 |
+
<mxGeometry x="130" y="477" width="64" height="64" as="geometry" />
|
| 63 |
+
</mxCell>
|
| 64 |
+
<mxCell id="lBE7YV5RTTJSdhW3G_g6-2" style="edgeStyle=orthogonalEdgeStyle;rounded=0;orthogonalLoop=1;jettySize=auto;html=1;strokeWidth=3;" edge="1" parent="1">
|
| 65 |
+
<mxGeometry relative="1" as="geometry">
|
| 66 |
+
<mxPoint x="-70" y="510" as="sourcePoint" />
|
| 67 |
+
<mxPoint x="120" y="510" as="targetPoint" />
|
| 68 |
+
</mxGeometry>
|
| 69 |
+
</mxCell>
|
| 70 |
+
<mxCell id="lBE7YV5RTTJSdhW3G_g6-6" value="<font color="#60c203">wilhelm-vocabulary</font>" style="text;html=1;align=center;verticalAlign=middle;whiteSpace=wrap;rounded=0;fontColor=#2088FF;fontFamily=Ubuntu;fontStyle=1;fontSize=18;strokeColor=none;" vertex="1" parent="1">
|
| 71 |
+
<mxGeometry x="-200" y="549" width="190" height="30" as="geometry" />
|
| 72 |
</mxCell>
|
| 73 |
+
<mxCell id="lBE7YV5RTTJSdhW3G_g6-7" value="repository_dispatch" style="text;html=1;align=center;verticalAlign=middle;whiteSpace=wrap;rounded=0;fontColor=#000000;fontFamily=Ubuntu;fontStyle=1;fontSize=18;" vertex="1" parent="1">
|
| 74 |
+
<mxGeometry x="-70" y="470" width="190" height="30" as="geometry" />
|
| 75 |
</mxCell>
|
| 76 |
</root>
|
| 77 |
</mxGraphModel>
|
docs/data-pipeline.png
CHANGED
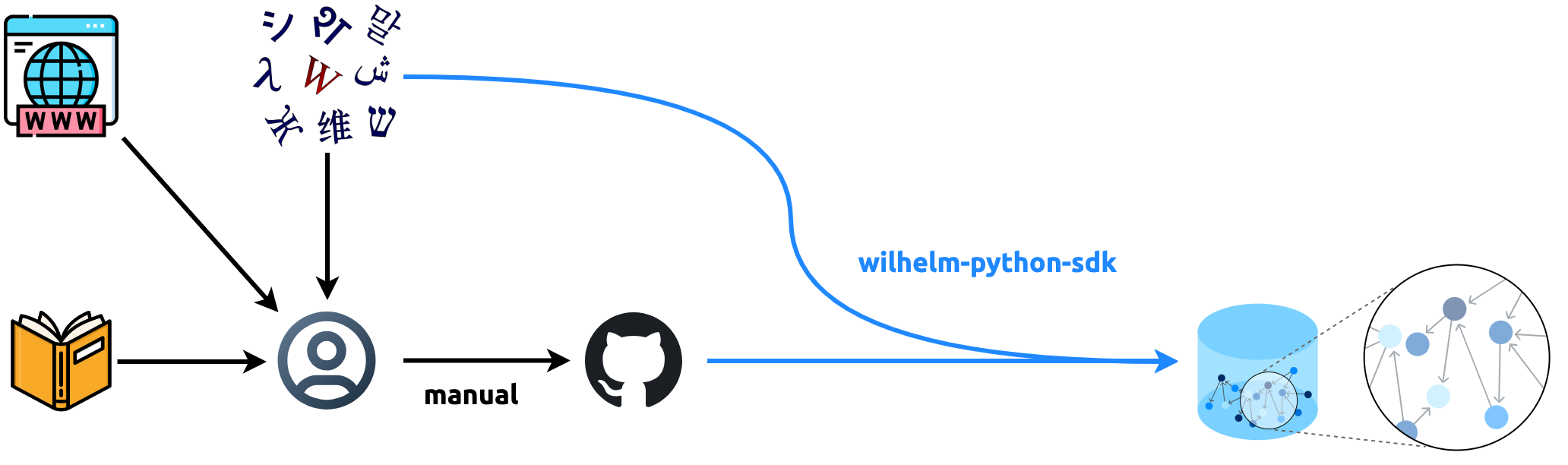
|
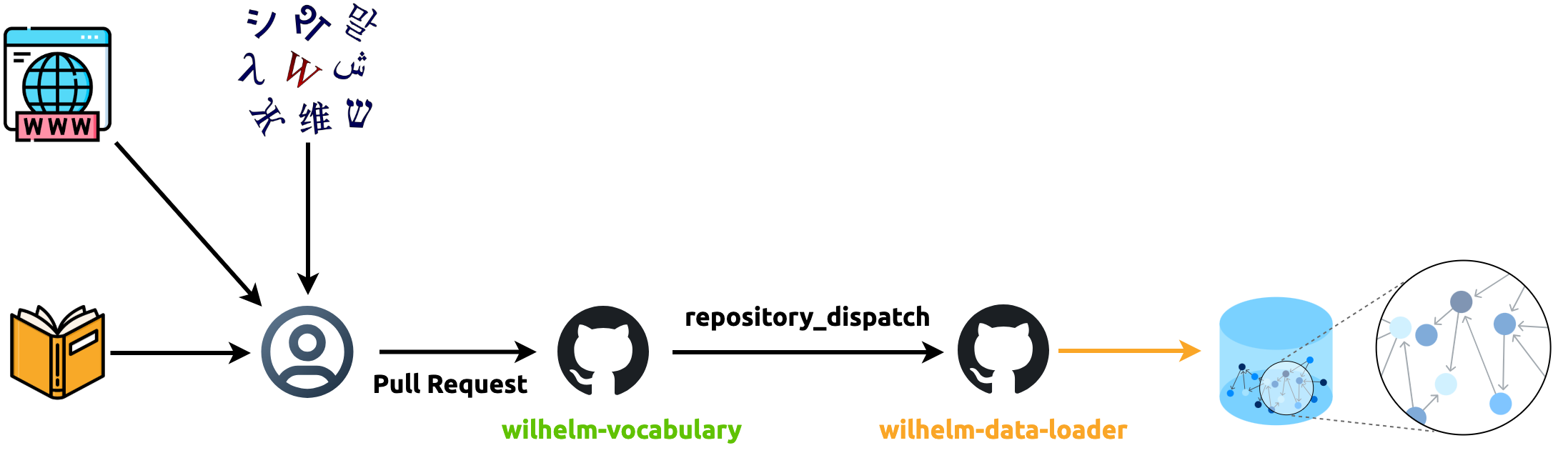
|
huggingface/__init__.py
ADDED
|
File without changes
|
huggingface/generate_ancient_greek_dataset.py
ADDED
|
@@ -0,0 +1,51 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright Jiaqi Liu
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
import json
|
| 15 |
+
|
| 16 |
+
from vocabulary_parser import ANCIENT_GREEK
|
| 17 |
+
from vocabulary_parser import get_attributes
|
| 18 |
+
from vocabulary_parser import get_definitions
|
| 19 |
+
from vocabulary_parser import get_vocabulary
|
| 20 |
+
from wilhelm_python_sdk.database_clients import get_node_label_attribute_key
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
def generate_dataset(yaml_path: str, dataset_path: str):
|
| 24 |
+
"""
|
| 25 |
+
Generates a Hugging Face Dataset from https://github.com/QubitPi/wilhelm-vocabulary/blob/master/ancient-greek.yaml
|
| 26 |
+
|
| 27 |
+
:param yaml_path: The absolute or relative path (to the invoking script) to the YAML file above
|
| 28 |
+
:param dataset_path: The absolute or relative path (to the invoking script) to the generated dataset file
|
| 29 |
+
"""
|
| 30 |
+
vocabulary = get_vocabulary(yaml_path)
|
| 31 |
+
label_key = get_node_label_attribute_key()
|
| 32 |
+
|
| 33 |
+
all_nodes = {}
|
| 34 |
+
|
| 35 |
+
with open(dataset_path, "w") as graph:
|
| 36 |
+
for word in vocabulary:
|
| 37 |
+
term = word["term"]
|
| 38 |
+
attributes = get_attributes(word, ANCIENT_GREEK, label_key)
|
| 39 |
+
source_node = attributes
|
| 40 |
+
|
| 41 |
+
all_nodes[term] = source_node
|
| 42 |
+
|
| 43 |
+
for definition_with_predicate in get_definitions(word):
|
| 44 |
+
predicate = definition_with_predicate[0]
|
| 45 |
+
definition = definition_with_predicate[1]
|
| 46 |
+
|
| 47 |
+
target_node = {label_key: definition}
|
| 48 |
+
label = {label_key: predicate if predicate else "definition"}
|
| 49 |
+
|
| 50 |
+
graph.write(json.dumps({"source": source_node, "target": target_node, label_key: label}))
|
| 51 |
+
graph.write("\n")
|
.github/cleanup_neo4j.py → huggingface/generate_datasets.py
RENAMED
|
@@ -11,8 +11,11 @@
|
|
| 11 |
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
# See the License for the specific language governing permissions and
|
| 13 |
# limitations under the License.
|
| 14 |
-
|
| 15 |
-
|
|
|
|
| 16 |
|
| 17 |
if __name__ == "__main__":
|
| 18 |
-
|
|
|
|
|
|
|
|
|
| 11 |
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
# See the License for the specific language governing permissions and
|
| 13 |
# limitations under the License.
|
| 14 |
+
import generate_ancient_greek_dataset
|
| 15 |
+
import generate_german_dataset
|
| 16 |
+
import generate_latin_dataset
|
| 17 |
|
| 18 |
if __name__ == "__main__":
|
| 19 |
+
generate_german_dataset.generate_dataset("../german.yaml", "../german-graph-data.jsonl")
|
| 20 |
+
generate_latin_dataset.generate_dataset("../latin.yaml", "../latin-graph-data.jsonl")
|
| 21 |
+
generate_ancient_greek_dataset.generate_dataset("../ancient-greek.yaml", "../ancient-greek-graph-data.jsonl")
|
huggingface/generate_german_dataset.py
ADDED
|
@@ -0,0 +1,60 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright Jiaqi Liu
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
import json
|
| 15 |
+
|
| 16 |
+
from german_parser import get_declension_attributes
|
| 17 |
+
from vocabulary_parser import GERMAN
|
| 18 |
+
from vocabulary_parser import get_attributes
|
| 19 |
+
from vocabulary_parser import get_definitions
|
| 20 |
+
from vocabulary_parser import get_inferred_links
|
| 21 |
+
from vocabulary_parser import get_vocabulary
|
| 22 |
+
from wilhelm_python_sdk.database_clients import get_node_label_attribute_key
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
def generate_dataset(yaml_path: str, dataset_path: str):
|
| 26 |
+
"""
|
| 27 |
+
Generates a Hugging Face Dataset from https://github.com/QubitPi/wilhelm-vocabulary/blob/master/german.yaml
|
| 28 |
+
|
| 29 |
+
:param yaml_path: The absolute or relative path (to the invoking script) to the YAML file above
|
| 30 |
+
:param dataset_path: The absolute or relative path (to the invoking script) to the generated dataset file
|
| 31 |
+
"""
|
| 32 |
+
vocabulary = get_vocabulary(yaml_path)
|
| 33 |
+
label_key = get_node_label_attribute_key()
|
| 34 |
+
|
| 35 |
+
all_nodes = {}
|
| 36 |
+
|
| 37 |
+
with open(dataset_path, "w") as graph:
|
| 38 |
+
for word in vocabulary:
|
| 39 |
+
term = word["term"]
|
| 40 |
+
attributes = get_attributes(word, GERMAN, label_key, get_declension_attributes)
|
| 41 |
+
source_node = attributes
|
| 42 |
+
all_nodes[term] = source_node
|
| 43 |
+
|
| 44 |
+
for definition_with_predicate in get_definitions(word):
|
| 45 |
+
predicate = definition_with_predicate[0]
|
| 46 |
+
definition = definition_with_predicate[1]
|
| 47 |
+
|
| 48 |
+
target_node = {label_key: definition}
|
| 49 |
+
label = {label_key: predicate if predicate else "definition"}
|
| 50 |
+
|
| 51 |
+
graph.write(json.dumps({"source": source_node, "target": target_node, label_key: label}))
|
| 52 |
+
graph.write("\n")
|
| 53 |
+
|
| 54 |
+
for link in get_inferred_links(vocabulary, label_key, get_declension_attributes):
|
| 55 |
+
source_node = all_nodes[link["source_label"]]
|
| 56 |
+
target_node = all_nodes[link["target_label"]]
|
| 57 |
+
label = link["attributes"]
|
| 58 |
+
|
| 59 |
+
graph.write(json.dumps({"source": source_node, "target": target_node, label_key: label}))
|
| 60 |
+
graph.write("\n")
|
huggingface/generate_latin_dataset.py
ADDED
|
@@ -0,0 +1,51 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright Jiaqi Liu
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
import json
|
| 15 |
+
|
| 16 |
+
from vocabulary_parser import LATIN
|
| 17 |
+
from vocabulary_parser import get_attributes
|
| 18 |
+
from vocabulary_parser import get_definitions
|
| 19 |
+
from vocabulary_parser import get_vocabulary
|
| 20 |
+
from wilhelm_python_sdk.database_clients import get_node_label_attribute_key
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
def generate_dataset(yaml_path: str, dataset_path: str):
|
| 24 |
+
"""
|
| 25 |
+
Generates a Hugging Face Dataset from https://github.com/QubitPi/wilhelm-vocabulary/blob/master/latin.yaml
|
| 26 |
+
|
| 27 |
+
:param yaml_path: The absolute or relative path (to the invoking script) to the YAML file above
|
| 28 |
+
:param dataset_path: The absolute or relative path (to the invoking script) to the generated dataset file
|
| 29 |
+
"""
|
| 30 |
+
vocabulary = get_vocabulary(yaml_path)
|
| 31 |
+
label_key = get_node_label_attribute_key()
|
| 32 |
+
|
| 33 |
+
all_nodes = {}
|
| 34 |
+
|
| 35 |
+
with open(dataset_path, "w") as graph:
|
| 36 |
+
for word in vocabulary:
|
| 37 |
+
term = word["term"]
|
| 38 |
+
attributes = get_attributes(word, LATIN, label_key)
|
| 39 |
+
source_node = attributes
|
| 40 |
+
|
| 41 |
+
all_nodes[term] = source_node
|
| 42 |
+
|
| 43 |
+
for definition_with_predicate in get_definitions(word):
|
| 44 |
+
predicate = definition_with_predicate[0]
|
| 45 |
+
definition = definition_with_predicate[1]
|
| 46 |
+
|
| 47 |
+
target_node = {label_key: definition}
|
| 48 |
+
label = {label_key: predicate if predicate else "definition"}
|
| 49 |
+
|
| 50 |
+
graph.write(json.dumps({"source": source_node, "target": target_node, label_key: label}))
|
| 51 |
+
graph.write("\n")
|
huggingface/german_parser.py
ADDED
|
@@ -0,0 +1,112 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright Jiaqi Liu
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
def get_declension_attributes(word: object) -> dict[str, str]:
|
| 17 |
+
"""
|
| 18 |
+
Returns the declension of a word.
|
| 19 |
+
|
| 20 |
+
If the word does not have a "declension" field or the noun's declension is, for some reasons, "Unknown", this
|
| 21 |
+
function returns an empty dictionary.
|
| 22 |
+
|
| 23 |
+
The declension table is flattened with "declension index" as the map key and the declined form as map value.
|
| 24 |
+
Specifically:
|
| 25 |
+
|
| 26 |
+
- A regular noun declension with a map structure of::
|
| 27 |
+
|
| 28 |
+
term: der Hut
|
| 29 |
+
definition: the hat
|
| 30 |
+
declension:
|
| 31 |
+
- ["", singular, plural]
|
| 32 |
+
- [nominative, Hut, Hüte ]
|
| 33 |
+
- [genitive, "Hutes, Huts", Hüte ]
|
| 34 |
+
- [dative, Hut, Hüten ]
|
| 35 |
+
- [accusative, Hut, Hüte ]
|
| 36 |
+
|
| 37 |
+
The returned map would be::
|
| 38 |
+
|
| 39 |
+
{
|
| 40 |
+
"declension-0-0": "",
|
| 41 |
+
"declension-0-1": "singular",
|
| 42 |
+
"declension-0-2": "plural",
|
| 43 |
+
"declension-1-0": "nominative",
|
| 44 |
+
"declension-1-1": "Hut",
|
| 45 |
+
"declension-1-2": "Hüte",
|
| 46 |
+
...
|
| 47 |
+
}
|
| 48 |
+
|
| 49 |
+
- A adjectival declension with a map structure of::
|
| 50 |
+
|
| 51 |
+
term: der Gefangener
|
| 52 |
+
definition: (adjectival, male) the prisoner
|
| 53 |
+
declension:
|
| 54 |
+
strong:
|
| 55 |
+
- ["", singular, plural ]
|
| 56 |
+
- [nominative, Gefangener, Gefangene ]
|
| 57 |
+
- [genitive, Gefangenen, Gefangener]
|
| 58 |
+
- [dative, Gefangenem, Gefangenen]
|
| 59 |
+
- [accusative, Gefangenen, Gefangene ]
|
| 60 |
+
weak:
|
| 61 |
+
- ["", singular, plural ]
|
| 62 |
+
- [nominative, Gefangene, Gefangenen]
|
| 63 |
+
- [genitive, Gefangenen, Gefangenen]
|
| 64 |
+
- [dative, Gefangenen, Gefangenen]
|
| 65 |
+
- [accusative, Gefangenen, Gefangenen]
|
| 66 |
+
mixed:
|
| 67 |
+
- ["", singular, plural ]
|
| 68 |
+
- [nominative, Gefangener, Gefangenen]
|
| 69 |
+
- [genitive, Gefangenen, Gefangenen]
|
| 70 |
+
- [dative, Gefangenen, Gefangenen]
|
| 71 |
+
- [accusative, Gefangenen, Gefangenen]
|
| 72 |
+
|
| 73 |
+
The returned map would be::
|
| 74 |
+
|
| 75 |
+
{
|
| 76 |
+
'strong-0-0': '',
|
| 77 |
+
'strong-0-1': 'singular',
|
| 78 |
+
'strong-0-2': 'plural',
|
| 79 |
+
'strong-1-0': 'nominative',
|
| 80 |
+
'strong-1-1': 'Gefangener',
|
| 81 |
+
'strong-1-2': 'Gefangene',
|
| 82 |
+
...
|
| 83 |
+
}
|
| 84 |
+
|
| 85 |
+
:param word: A vocabulary represented in YAML dictionary which has a "declension" key
|
| 86 |
+
|
| 87 |
+
:return: a flat map containing all the YAML encoded information about the noun excluding term and definition
|
| 88 |
+
"""
|
| 89 |
+
|
| 90 |
+
if "declension" not in word:
|
| 91 |
+
return {}
|
| 92 |
+
|
| 93 |
+
declension = word["declension"]
|
| 94 |
+
|
| 95 |
+
if declension == "Unknown":
|
| 96 |
+
return {}
|
| 97 |
+
|
| 98 |
+
declension_tables = {}
|
| 99 |
+
if "strong" in declension and "weak" in declension and "mixed" in declension:
|
| 100 |
+
declension_tables["strong"] = declension["strong"]
|
| 101 |
+
declension_tables["weak"] = declension["weak"]
|
| 102 |
+
declension_tables["mixed"] = declension["mixed"]
|
| 103 |
+
else:
|
| 104 |
+
declension_tables["declension"] = declension
|
| 105 |
+
|
| 106 |
+
declension_attributes = {}
|
| 107 |
+
for declension_type, declension_table in declension_tables.items():
|
| 108 |
+
for i, row in enumerate(declension_table):
|
| 109 |
+
for j, col in enumerate(row):
|
| 110 |
+
declension_attributes[f"{declension_type}-{i}-{j}"] = declension_table[i][j]
|
| 111 |
+
|
| 112 |
+
return declension_attributes
|
huggingface/vocabulary_parser.py
ADDED
|
@@ -0,0 +1,363 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright Jiaqi Liu
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
import logging
|
| 15 |
+
import re
|
| 16 |
+
from typing import Callable
|
| 17 |
+
|
| 18 |
+
import yaml
|
| 19 |
+
|
| 20 |
+
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
|
| 21 |
+
|
| 22 |
+
"""
|
| 23 |
+
The language identifier for German language.
|
| 24 |
+
|
| 25 |
+
.. py:data:: GERMAN
|
| 26 |
+
:value: German
|
| 27 |
+
:type: string
|
| 28 |
+
"""
|
| 29 |
+
GERMAN = "German"
|
| 30 |
+
|
| 31 |
+
"""
|
| 32 |
+
The language identifier for Latin language.
|
| 33 |
+
|
| 34 |
+
.. py:data:: LATIN
|
| 35 |
+
:value: Latin
|
| 36 |
+
:type: string
|
| 37 |
+
"""
|
| 38 |
+
LATIN = "Latin"
|
| 39 |
+
|
| 40 |
+
"""
|
| 41 |
+
The language identifier for Ancient Greek.
|
| 42 |
+
|
| 43 |
+
.. py:data:: ANCIENT_GREEK
|
| 44 |
+
:value: Ancient Greek
|
| 45 |
+
:type: string
|
| 46 |
+
"""
|
| 47 |
+
ANCIENT_GREEK = "Ancient Greek"
|
| 48 |
+
|
| 49 |
+
EXCLUDED_INFLECTION_ENTRIES = [
|
| 50 |
+
"",
|
| 51 |
+
"singular",
|
| 52 |
+
"plural",
|
| 53 |
+
"masculine",
|
| 54 |
+
"feminine",
|
| 55 |
+
"neuter",
|
| 56 |
+
"nominative",
|
| 57 |
+
"genitive",
|
| 58 |
+
"dative",
|
| 59 |
+
"accusative",
|
| 60 |
+
"N/A"
|
| 61 |
+
]
|
| 62 |
+
|
| 63 |
+
ENGLISH_PROPOSITIONS = {
|
| 64 |
+
"about", "above", "across", "after", "against", "along", "among", "around", "at", "before", "behind", "below",
|
| 65 |
+
"beneath", "beside", "between", "beyond", "by", "down", "during", "except", "for", "from", "in", "inside", "into",
|
| 66 |
+
"like", "near", "of", "off", "on", "onto", "out", "outside", "over", "past", "since", "through", "throughout", "to",
|
| 67 |
+
"toward", "under", "underneath", "until", "up", "upon", "with", "within", "without"
|
| 68 |
+
}
|
| 69 |
+
EXCLUDED_DEFINITION_TOKENS = {"the"} | ENGLISH_PROPOSITIONS
|
| 70 |
+
|
| 71 |
+
|
| 72 |
+
def get_vocabulary(yaml_path: str) -> list:
|
| 73 |
+
with open(yaml_path, "r") as f:
|
| 74 |
+
return yaml.safe_load(f)["vocabulary"]
|
| 75 |
+
|
| 76 |
+
|
| 77 |
+
def get_definitions(word) -> list[(str, str)]:
|
| 78 |
+
"""
|
| 79 |
+
Extract definitions from a word as a list of bi-tuples, with the first element being the predicate and the second
|
| 80 |
+
being the definition.
|
| 81 |
+
|
| 82 |
+
For example (in YAML)::
|
| 83 |
+
|
| 84 |
+
definition:
|
| 85 |
+
- term: nämlich
|
| 86 |
+
definition:
|
| 87 |
+
- (adj.) same
|
| 88 |
+
- (adv.) namely
|
| 89 |
+
- because
|
| 90 |
+
|
| 91 |
+
The method will return `[("adj.", "same"), ("adv.", "namely"), (None, "because")]`
|
| 92 |
+
|
| 93 |
+
The method works for the single-definition case, i.e.::
|
| 94 |
+
|
| 95 |
+
definition:
|
| 96 |
+
- term: na klar
|
| 97 |
+
definition: of course
|
| 98 |
+
|
| 99 |
+
returns a list of one tupple `[(None, "of course")]`
|
| 100 |
+
|
| 101 |
+
Note that any definition are converted to string. If the word does not contain a field named exactly "definition", a
|
| 102 |
+
ValueError is raised.
|
| 103 |
+
|
| 104 |
+
:param word: A dictionary that contains a "definition" key whose value is either a single-value or a list of
|
| 105 |
+
single-values
|
| 106 |
+
:return: a list of two-element tuples, where the first element being the predicate (can be `None`) and the second
|
| 107 |
+
being the definition
|
| 108 |
+
"""
|
| 109 |
+
logging.info("Extracting definitions from {}".format(word))
|
| 110 |
+
|
| 111 |
+
if "definition" not in word:
|
| 112 |
+
raise ValueError("{} does not contain 'definition' field. Maybe there is a typo".format(word))
|
| 113 |
+
|
| 114 |
+
predicate_with_definition = []
|
| 115 |
+
|
| 116 |
+
definitions = [word["definition"]] if not isinstance(word["definition"], list) else word["definition"]
|
| 117 |
+
|
| 118 |
+
for definition in definitions:
|
| 119 |
+
definition = str(definition)
|
| 120 |
+
|
| 121 |
+
definition = definition.strip()
|
| 122 |
+
|
| 123 |
+
match = re.match(r"\((.*?)\)", definition)
|
| 124 |
+
if match:
|
| 125 |
+
predicate_with_definition.append((match.group(1), re.sub(r'\(.*?\)', '', definition).strip()))
|
| 126 |
+
else:
|
| 127 |
+
predicate_with_definition.append((None, definition))
|
| 128 |
+
|
| 129 |
+
return predicate_with_definition
|
| 130 |
+
|
| 131 |
+
|
| 132 |
+
def get_attributes(
|
| 133 |
+
word: object,
|
| 134 |
+
language: str,
|
| 135 |
+
node_label_attribute_key: str,
|
| 136 |
+
inflection_supplier: Callable[[object], dict]=lambda word: {}
|
| 137 |
+
) -> dict[str, str]:
|
| 138 |
+
"""
|
| 139 |
+
Returns a flat map as the Term node properties stored in Neo4J.
|
| 140 |
+
|
| 141 |
+
:param word: A dict object representing a vocabulary
|
| 142 |
+
:param language: The language of the vocabulary. Can only be one of the constants defined in this file:
|
| 143 |
+
:py:data:`GERMAN` / :py:data:`LATIN` / :py:data:`ANCIENT_GREEK`
|
| 144 |
+
:param node_label_attribute_key: The attribute key in the returned map whose value contains the node caption
|
| 145 |
+
:param inflection_supplier: A functional object that, given a YAML dictionary, returns the inflection table of that
|
| 146 |
+
word. The key of the table can be arbitrary but the value must be a sole inflected word
|
| 147 |
+
|
| 148 |
+
:return: a flat map containing all the YAML encoded information about the vocabulary
|
| 149 |
+
"""
|
| 150 |
+
return {node_label_attribute_key: word["term"], "language": language} | inflection_supplier(word) | get_audio(word)
|
| 151 |
+
|
| 152 |
+
|
| 153 |
+
def get_audio(word: object) -> dict:
|
| 154 |
+
"""
|
| 155 |
+
Returns the pronunciation of a word in the form of a map with key being "audio" and value being a string pointing to
|
| 156 |
+
the URL of the audio file.
|
| 157 |
+
|
| 158 |
+
The word should be a dict object containing an "audio" string attribute, otherwise this function returns an empty
|
| 159 |
+
map
|
| 160 |
+
|
| 161 |
+
:param word: A dict object representing a vocabulary
|
| 162 |
+
|
| 163 |
+
:return: a single-entry map or empty map
|
| 164 |
+
"""
|
| 165 |
+
if "audio" not in word:
|
| 166 |
+
return {}
|
| 167 |
+
return {"audio": word["audio"]}
|
| 168 |
+
|
| 169 |
+
|
| 170 |
+
def get_inferred_links(
|
| 171 |
+
vocabulary: list[dict],
|
| 172 |
+
label_key: str,
|
| 173 |
+
inflection_supplier: Callable[[object], dict[str, str]]=lambda word: {}
|
| 174 |
+
) -> list[dict]:
|
| 175 |
+
"""
|
| 176 |
+
Return a list of inferred links between related vocabularies.
|
| 177 |
+
|
| 178 |
+
This function is the point of extending link inference capabilities. At this point, the link inference includes
|
| 179 |
+
|
| 180 |
+
- :py:meth:`token sharing <wilhelm_python_sdk.vocabulary_parser.get_inferred_tokenization_links>`
|
| 181 |
+
- :py:meth:`token sharing <wilhelm_python_sdk.vocabulary_parser.get_levenshtein_links>`
|
| 182 |
+
|
| 183 |
+
:param vocabulary: A wilhelm-vocabulary repo YAML file deserialized
|
| 184 |
+
:param label_key: The name of the node attribute that will be used as the label in displaying the node
|
| 185 |
+
:param inflection_supplier: A functional object that, given a YAML dictionary, returns the inflection table of that
|
| 186 |
+
word. The key of the table can be arbitrary but the value must be a sole inflected word
|
| 187 |
+
|
| 188 |
+
:return: a list of link object, each of which has a "source_label", a "target_label", and an "attributes" key
|
| 189 |
+
"""
|
| 190 |
+
return (get_inferred_tokenization_links(vocabulary, label_key, inflection_supplier) +
|
| 191 |
+
get_structurally_similar_links(vocabulary, label_key))
|
| 192 |
+
|
| 193 |
+
|
| 194 |
+
def get_definition_tokens(word: dict) -> set[str]:
|
| 195 |
+
definitions = [pair[1] for pair in get_definitions(word)]
|
| 196 |
+
tokens = set()
|
| 197 |
+
|
| 198 |
+
for token in set(sum([definition.split(" ") for definition in set().union(set(definitions))], [])):
|
| 199 |
+
cleansed = token.lower().strip()
|
| 200 |
+
if cleansed not in EXCLUDED_DEFINITION_TOKENS:
|
| 201 |
+
tokens.add(cleansed)
|
| 202 |
+
|
| 203 |
+
return tokens
|
| 204 |
+
|
| 205 |
+
|
| 206 |
+
def get_term_tokens(word: dict) -> set[str]:
|
| 207 |
+
term = word["term"]
|
| 208 |
+
tokens = set()
|
| 209 |
+
|
| 210 |
+
for token in term.split(" "):
|
| 211 |
+
cleansed = token.lower().strip()
|
| 212 |
+
if cleansed not in {"der", "die", "das"}:
|
| 213 |
+
tokens.add(cleansed)
|
| 214 |
+
|
| 215 |
+
return tokens
|
| 216 |
+
|
| 217 |
+
|
| 218 |
+
def get_inflection_tokens(
|
| 219 |
+
word: dict,
|
| 220 |
+
inflection_supplier: Callable[[object], dict[str, str]]=lambda word: {}
|
| 221 |
+
) -> set[str]:
|
| 222 |
+
tokens = set()
|
| 223 |
+
|
| 224 |
+
for key, value in inflection_supplier(word).items():
|
| 225 |
+
if value not in EXCLUDED_INFLECTION_ENTRIES:
|
| 226 |
+
for inflection in value.split(","):
|
| 227 |
+
cleansed = inflection.lower().strip()
|
| 228 |
+
tokens.add(cleansed)
|
| 229 |
+
|
| 230 |
+
return tokens
|
| 231 |
+
|
| 232 |
+
|
| 233 |
+
def get_tokens_of(word: dict, inflection_supplier: Callable[[object], dict[str, str]]=lambda word: {}) -> set[str]:
|
| 234 |
+
return get_inflection_tokens(word, inflection_supplier) | get_term_tokens(word) | get_definition_tokens(word)
|
| 235 |
+
|
| 236 |
+
|
| 237 |
+
def get_inferred_tokenization_links(
|
| 238 |
+
vocabulary: list[dict],
|
| 239 |
+
label_key: str,
|
| 240 |
+
inflection_supplier: Callable[[object], dict[str, str]]=lambda word: {}
|
| 241 |
+
) -> list[dict]:
|
| 242 |
+
"""
|
| 243 |
+
Return a list of inferred links between related vocabulary terms which are related to one another.
|
| 244 |
+
|
| 245 |
+
This mapping will be used to create more links in graph database.
|
| 246 |
+
|
| 247 |
+
This was inspired by the spotting the relationships among::
|
| 248 |
+
|
| 249 |
+
vocabulary:
|
| 250 |
+
- term: das Jahr
|
| 251 |
+
definition: the year
|
| 252 |
+
declension:
|
| 253 |
+
- ["", singular, plural ]
|
| 254 |
+
- [nominative, Jahr, "Jahre, Jahr" ]
|
| 255 |
+
- [genitive, "Jahres, Jahrs", "Jahre, Jahr" ]
|
| 256 |
+
- [dative, Jahr, "Jahren, Jahr"]
|
| 257 |
+
- [accusative, Jahr, "Jahre, Jahr" ]
|
| 258 |
+
- term: seit zwei Jahren
|
| 259 |
+
definition: for two years
|
| 260 |
+
- term: in den letzten Jahren
|
| 261 |
+
definition: in recent years
|
| 262 |
+
|
| 263 |
+
1. Both 2nd and 3rd are related to the 1st and the two links can be inferred by observing that "Jahren" in 2nd and
|
| 264 |
+
3rd match the declension table of the 1st
|
| 265 |
+
2. In addition, the 2nd and 3rd are related because they both have "Jahren".
|
| 266 |
+
|
| 267 |
+
Given the 2 observations above, this function tokenizes the "term" and the declension table of each word. If two
|
| 268 |
+
words share at least 1 token, they are defined to be "related"
|
| 269 |
+
|
| 270 |
+
:param vocabulary: A wilhelm-vocabulary repo YAML file deserialized
|
| 271 |
+
:param label_key: The name of the node attribute that will be used as the label in displaying the node
|
| 272 |
+
|
| 273 |
+
:return: a list of link object, each of which has a "source_label", a "target_label", and an "attributes" key
|
| 274 |
+
"""
|
| 275 |
+
all_vocabulary_tokenizations_by_term = dict(
|
| 276 |
+
[word["term"], get_tokens_of(word, inflection_supplier)] for word in vocabulary)
|
| 277 |
+
inferred_links = []
|
| 278 |
+
for this_word in vocabulary:
|
| 279 |
+
this_term = this_word["term"]
|
| 280 |
+
|
| 281 |
+
for that_term, that_term_tokens in all_vocabulary_tokenizations_by_term.items():
|
| 282 |
+
jump_to_next_term = False
|
| 283 |
+
|
| 284 |
+
if this_term == that_term:
|
| 285 |
+
continue
|
| 286 |
+
|
| 287 |
+
for this_token in get_term_tokens(this_word):
|
| 288 |
+
for that_token in that_term_tokens:
|
| 289 |
+
if this_token.lower().strip() == that_token:
|
| 290 |
+
inferred_links.append({
|
| 291 |
+
"source_label": this_term,
|
| 292 |
+
"target_label": that_term,
|
| 293 |
+
"attributes": {label_key: "term related"},
|
| 294 |
+
})
|
| 295 |
+
jump_to_next_term = True
|
| 296 |
+
break
|
| 297 |
+
|
| 298 |
+
if jump_to_next_term:
|
| 299 |
+
break
|
| 300 |
+
|
| 301 |
+
return inferred_links
|
| 302 |
+
|
| 303 |
+
|
| 304 |
+
def get_structurally_similar_links(vocabulary: list[dict], label_key: str) -> list[dict]:
|
| 305 |
+
"""
|
| 306 |
+
Return a list of inferred links between structurally-related vocabulary terms that are determined by the function
|
| 307 |
+
:py:meth:`token sharing <wilhelm_python_sdk.vocabulary_parser.is_structurally_similar>`.
|
| 308 |
+
|
| 309 |
+
This was inspired by the spotting the relationships among::
|
| 310 |
+
|
| 311 |
+
vocabulary:
|
| 312 |
+
- term: anschließen
|
| 313 |
+
definition: to connect
|
| 314 |
+
- term: anschließend
|
| 315 |
+
definition:
|
| 316 |
+
- (adj.) following
|
| 317 |
+
- (adv.) afterwards
|
| 318 |
+
- term: nachher
|
| 319 |
+
definition: (adv.) afterwards
|
| 320 |
+
|
| 321 |
+
:param vocabulary: A wilhelm-vocabulary repo YAML file deserialized
|
| 322 |
+
:param label_key: The name of the node attribute that will be used as the label in displaying the node
|
| 323 |
+
|
| 324 |
+
:return: a list of link object, each of which has a "source_label", a "target_label", and an "attributes" key
|
| 325 |
+
"""
|
| 326 |
+
inferred_links = []
|
| 327 |
+
|
| 328 |
+
for this in vocabulary:
|
| 329 |
+
for that in vocabulary:
|
| 330 |
+
this_term = this["term"]
|
| 331 |
+
that_term = that["term"]
|
| 332 |
+
if is_structurally_similar(this_term, that_term):
|
| 333 |
+
inferred_links.append({
|
| 334 |
+
"source_label": this_term,
|
| 335 |
+
"target_label": that_term,
|
| 336 |
+
"attributes": {label_key: "structurally similar"},
|
| 337 |
+
})
|
| 338 |
+
|
| 339 |
+
return inferred_links
|
| 340 |
+
|
| 341 |
+
|
| 342 |
+
def is_structurally_similar(this_word: str, that_word: str) -> bool:
|
| 343 |
+
"""
|
| 344 |
+
Returns whether or not two string words are structurally similar.
|
| 345 |
+
|
| 346 |
+
Two words are structurally similar iff the two share the same word stem. If two word strings are equal, this
|
| 347 |
+
function returns `False`.
|
| 348 |
+
|
| 349 |
+
:param this_word: The first word to compare structurally
|
| 350 |
+
:param that_word: The second word to compare structurally
|
| 351 |
+
|
| 352 |
+
:return: `True` if two words are structurally similar, or `False` otherwise
|
| 353 |
+
"""
|
| 354 |
+
if this_word is that_word:
|
| 355 |
+
return False
|
| 356 |
+
|
| 357 |
+
return get_stem(this_word) == get_stem(that_word)
|
| 358 |
+
|
| 359 |
+
|
| 360 |
+
def get_stem(word: str) -> str:
|
| 361 |
+
from nltk.stem.snowball import GermanStemmer
|
| 362 |
+
stemmer = GermanStemmer()
|
| 363 |
+
return stemmer.stem(word)
|
markdownlint.rb
DELETED
|
@@ -1,20 +0,0 @@
|
|
| 1 |
-
# Copyright Jiaqi Liu
|
| 2 |
-
#
|
| 3 |
-
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
-
# you may not use this file except in compliance with the License.
|
| 5 |
-
# You may obtain a copy of the License at
|
| 6 |
-
#
|
| 7 |
-
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
-
#
|
| 9 |
-
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
-
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
-
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
-
# See the License for the specific language governing permissions and
|
| 13 |
-
# limitations under the License.
|
| 14 |
-
|
| 15 |
-
all
|
| 16 |
-
rule 'MD003', style: :setext_with_atx
|
| 17 |
-
rule 'MD004', style: :sublist
|
| 18 |
-
rule 'MD013', line_length: 120
|
| 19 |
-
rule 'MD029', style: :ordered
|
| 20 |
-
rule 'MD026', punctuation: ".,;:!?"
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
setup.cfg
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
[pep8]
|
| 2 |
+
max-line-length = 120
|
| 3 |
+
exclude = ./.eggs
|
setup.py
ADDED
|
@@ -0,0 +1,19 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from setuptools import find_packages
|
| 2 |
+
from setuptools import setup
|
| 3 |
+
|
| 4 |
+
setup(
|
| 5 |
+
name="wilhelm-vocabulary",
|
| 6 |
+
version="0.0.1",
|
| 7 |
+
description="A vocabulary processor specifically designed for QubitPi",
|
| 8 |
+
url="https://github.com/QubitPi/wilhelm-vocabulary",
|
| 9 |
+
author="Jiaqi Liu",
|
| 10 |
+
author_email="[email protected]",
|
| 11 |
+
license="Apache-2.0",
|
| 12 |
+
packages=find_packages(),
|
| 13 |
+
python_requires='>=3.10',
|
| 14 |
+
install_requires=["pyyaml", "nltk", "wilhelm_python_sdk"],
|
| 15 |
+
zip_safe=False,
|
| 16 |
+
include_package_data=True,
|
| 17 |
+
setup_requires=["setuptools-pep8", "isort"],
|
| 18 |
+
test_suite='tests',
|
| 19 |
+
)
|
tests/__init__.py
ADDED
|
File without changes
|
tests/test.yaml
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
vocabulary:
|
| 2 |
+
- term: "null"
|
| 3 |
+
definition: 0
|
| 4 |
+
- term: eins
|
| 5 |
+
definition: 1
|
| 6 |
+
- term: Guten Tag
|
| 7 |
+
definition: Good day
|
| 8 |
+
- term: Hallo
|
| 9 |
+
definition: Hello
|
tests/test_german_loader.py
ADDED
|
@@ -0,0 +1,133 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright Jiaqi Liu
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
import unittest
|
| 15 |
+
|
| 16 |
+
import yaml
|
| 17 |
+
|
| 18 |
+
from huggingface.german_parser import get_declension_attributes
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
class TestGermanParser(unittest.TestCase):
|
| 22 |
+
|
| 23 |
+
def test_get_declension_attributes_on_regular_noun(self):
|
| 24 |
+
hut_yaml = """
|
| 25 |
+
term: der Hut
|
| 26 |
+
definition: the hat
|
| 27 |
+
declension:
|
| 28 |
+
- ["", singular, plural]
|
| 29 |
+
- [nominative, Hut, Hüte ]
|
| 30 |
+
- [genitive, "Hutes, Huts", Hüte ]
|
| 31 |
+
- [dative, Hut, Hüten ]
|
| 32 |
+
- [accusative, Hut, Hüte ]
|
| 33 |
+
"""
|
| 34 |
+
|
| 35 |
+
expected_declension_map = {
|
| 36 |
+
"declension-0-0": "",
|
| 37 |
+
"declension-0-1": "singular",
|
| 38 |
+
"declension-0-2": "plural",
|
| 39 |
+
|
| 40 |
+
"declension-1-0": "nominative",
|
| 41 |
+
"declension-1-1": "Hut",
|
| 42 |
+
"declension-1-2": "Hüte",
|
| 43 |
+
|
| 44 |
+
"declension-2-0": "genitive",
|
| 45 |
+
"declension-2-1": "Hutes, Huts",
|
| 46 |
+
"declension-2-2": "Hüte",
|
| 47 |
+
|
| 48 |
+
"declension-3-0": "dative",
|
| 49 |
+
"declension-3-1": "Hut",
|
| 50 |
+
"declension-3-2": "Hüten",
|
| 51 |
+
|
| 52 |
+
"declension-4-0": "accusative",
|
| 53 |
+
"declension-4-1": "Hut",
|
| 54 |
+
"declension-4-2": "Hüte",
|
| 55 |
+
}
|
| 56 |
+
|
| 57 |
+
self.assertEqual(expected_declension_map, get_declension_attributes(yaml.safe_load(hut_yaml)))
|
| 58 |
+
|
| 59 |
+
def test_get_declension_attributes_on_adjectival(self):
|
| 60 |
+
word_yaml = """
|
| 61 |
+
term: der Gefangener
|
| 62 |
+
definition: (adjectival, male) the prisoner
|
| 63 |
+
declension:
|
| 64 |
+
strong:
|
| 65 |
+
- ["", singular, plural ]
|
| 66 |
+
- [nominative, Gefangener, Gefangene ]
|
| 67 |
+
- [genitive, Gefangenen, Gefangener]
|
| 68 |
+
- [dative, Gefangenem, Gefangenen]
|
| 69 |
+
- [accusative, Gefangenen, Gefangene ]
|
| 70 |
+
weak:
|
| 71 |
+
- ["", singular, plural ]
|
| 72 |
+
- [nominative, Gefangene, Gefangenen]
|
| 73 |
+
- [genitive, Gefangenen, Gefangenen]
|
| 74 |
+
- [dative, Gefangenen, Gefangenen]
|
| 75 |
+
- [accusative, Gefangenen, Gefangenen]
|
| 76 |
+
mixed:
|
| 77 |
+
- ["", singular, plural ]
|
| 78 |
+
- [nominative, Gefangener, Gefangenen]
|
| 79 |
+
- [genitive, Gefangenen, Gefangenen]
|
| 80 |
+
- [dative, Gefangenen, Gefangenen]
|
| 81 |
+
- [accusative, Gefangenen, Gefangenen]
|
| 82 |
+
"""
|
| 83 |
+
|
| 84 |
+
self.assertEqual(
|
| 85 |
+
{
|
| 86 |
+
'mixed-0-0': '',
|
| 87 |
+
'mixed-0-1': 'singular',
|
| 88 |
+
'mixed-0-2': 'plural',
|
| 89 |
+
'mixed-1-0': 'nominative',
|
| 90 |
+
'mixed-1-1': 'Gefangener',
|
| 91 |
+
'mixed-1-2': 'Gefangenen',
|
| 92 |
+
'mixed-2-0': 'genitive',
|
| 93 |
+
'mixed-2-1': 'Gefangenen',
|
| 94 |
+
'mixed-2-2': 'Gefangenen',
|
| 95 |
+
'mixed-3-0': 'dative',
|
| 96 |
+
'mixed-3-1': 'Gefangenen',
|
| 97 |
+
'mixed-3-2': 'Gefangenen',
|
| 98 |
+
'mixed-4-0': 'accusative',
|
| 99 |
+
'mixed-4-1': 'Gefangenen',
|
| 100 |
+
'mixed-4-2': 'Gefangenen',
|
| 101 |
+
'strong-0-0': '',
|
| 102 |
+
'strong-0-1': 'singular',
|
| 103 |
+
'strong-0-2': 'plural',
|
| 104 |
+
'strong-1-0': 'nominative',
|
| 105 |
+
'strong-1-1': 'Gefangener',
|
| 106 |
+
'strong-1-2': 'Gefangene',
|
| 107 |
+
'strong-2-0': 'genitive',
|
| 108 |
+
'strong-2-1': 'Gefangenen',
|
| 109 |
+
'strong-2-2': 'Gefangener',
|
| 110 |
+
'strong-3-0': 'dative',
|
| 111 |
+
'strong-3-1': 'Gefangenem',
|
| 112 |
+
'strong-3-2': 'Gefangenen',
|
| 113 |
+
'strong-4-0': 'accusative',
|
| 114 |
+
'strong-4-1': 'Gefangenen',
|
| 115 |
+
'strong-4-2': 'Gefangene',
|
| 116 |
+
'weak-0-0': '',
|
| 117 |
+
'weak-0-1': 'singular',
|
| 118 |
+
'weak-0-2': 'plural',
|
| 119 |
+
'weak-1-0': 'nominative',
|
| 120 |
+
'weak-1-1': 'Gefangene',
|
| 121 |
+
'weak-1-2': 'Gefangenen',
|
| 122 |
+
'weak-2-0': 'genitive',
|
| 123 |
+
'weak-2-1': 'Gefangenen',
|
| 124 |
+
'weak-2-2': 'Gefangenen',
|
| 125 |
+
'weak-3-0': 'dative',
|
| 126 |
+
'weak-3-1': 'Gefangenen',
|
| 127 |
+
'weak-3-2': 'Gefangenen',
|
| 128 |
+
'weak-4-0': 'accusative',
|
| 129 |
+
'weak-4-1': 'Gefangenen',
|
| 130 |
+
'weak-4-2': 'Gefangenen'
|
| 131 |
+
},
|
| 132 |
+
get_declension_attributes(yaml.safe_load(word_yaml))
|
| 133 |
+
)
|
tests/test_vocabulary_parser.py
ADDED
|
@@ -0,0 +1,337 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright Jiaqi Liu
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
import unittest
|
| 15 |
+
|
| 16 |
+
import yaml
|
| 17 |
+
|
| 18 |
+
from huggingface.german_parser import get_declension_attributes
|
| 19 |
+
from huggingface.vocabulary_parser import GERMAN
|
| 20 |
+
from huggingface.vocabulary_parser import get_attributes
|
| 21 |
+
from huggingface.vocabulary_parser import get_definition_tokens
|
| 22 |
+
from huggingface.vocabulary_parser import get_definitions
|
| 23 |
+
from huggingface.vocabulary_parser import get_inferred_links
|
| 24 |
+
from huggingface.vocabulary_parser import get_inferred_tokenization_links
|
| 25 |
+
from huggingface.vocabulary_parser import get_inflection_tokens
|
| 26 |
+
from huggingface.vocabulary_parser import get_structurally_similar_links
|
| 27 |
+
from huggingface.vocabulary_parser import get_term_tokens
|
| 28 |
+
from huggingface.vocabulary_parser import is_structurally_similar
|
| 29 |
+
|
| 30 |
+
UNKOWN_DECLENSION_NOUN_YAML = """
|
| 31 |
+
term: die Grilltomate
|
| 32 |
+
definition: the grilled tomato
|
| 33 |
+
declension: Unknown
|
| 34 |
+
"""
|
| 35 |
+
|
| 36 |
+
LABEL_KEY = "label"
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
class TestVocabularyParser(unittest.TestCase):
|
| 40 |
+
|
| 41 |
+
def test_get_definitions(self):
|
| 42 |
+
self.assertEqual(
|
| 43 |
+
[("adj.", "same"), ("adv.", "namely"), (None, "because")],
|
| 44 |
+
get_definitions({
|
| 45 |
+
"definition": ["(adj.) same", "(adv.) namely", "because"]
|
| 46 |
+
}),
|
| 47 |
+
)
|
| 48 |
+
|
| 49 |
+
def test_single_definition_term(self):
|
| 50 |
+
self.assertEqual(
|
| 51 |
+
[(None, "one")],
|
| 52 |
+
get_definitions({
|
| 53 |
+
"definition": "one"
|
| 54 |
+
}),
|
| 55 |
+
)
|
| 56 |
+
|
| 57 |
+
def test_numerical_definition(self):
|
| 58 |
+
self.assertEqual(
|
| 59 |
+
[(None, "1")],
|
| 60 |
+
get_definitions({
|
| 61 |
+
"definition": 1
|
| 62 |
+
}),
|
| 63 |
+
)
|
| 64 |
+
|
| 65 |
+
def test_missing_definition(self):
|
| 66 |
+
with self.assertRaises(ValueError):
|
| 67 |
+
get_definitions({"defintion": "I'm 23 years old."})
|
| 68 |
+
|
| 69 |
+
def test_get_attributes_basic(self):
|
| 70 |
+
self.assertEqual(
|
| 71 |
+
{"label": "der Hut", "language": "German"},
|
| 72 |
+
get_attributes({"term": "der Hut", "definition": "the hat"}, GERMAN, LABEL_KEY),
|
| 73 |
+
)
|
| 74 |
+
|
| 75 |
+
def test_get_attributes_with_custom_inflection(self):
|
| 76 |
+
self.assertEqual(
|
| 77 |
+
{"label": "der Hut", "language": "German", "inflection": {"declension": "..."}},
|
| 78 |
+
get_attributes(
|
| 79 |
+
{
|
| 80 |
+
"term": "der Hut",
|
| 81 |
+
"definition": "the hat",
|
| 82 |
+
"inflection": {"declension": "...", "inflection": None}
|
| 83 |
+
},
|
| 84 |
+
GERMAN,
|
| 85 |
+
LABEL_KEY,
|
| 86 |
+
lambda word: {"inflection": {"declension": "..."}}
|
| 87 |
+
),
|
| 88 |
+
)
|
| 89 |
+
|
| 90 |
+
def test_get_attributes_with_audio(self):
|
| 91 |
+
self.assertEqual(
|
| 92 |
+
{
|
| 93 |
+
"label": "der Hut",
|
| 94 |
+
"language": "German",
|
| 95 |
+
"audio": "https://upload.wikimedia.org/wikipedia/commons/e/e9/De-Hut.ogg"
|
| 96 |
+
},
|
| 97 |
+
get_attributes(
|
| 98 |
+
{
|
| 99 |
+
"term": "der Hut",
|
| 100 |
+
"definition": "the hat",
|
| 101 |
+
"audio": "https://upload.wikimedia.org/wikipedia/commons/e/e9/De-Hut.ogg"
|
| 102 |
+
},
|
| 103 |
+
GERMAN,
|
| 104 |
+
LABEL_KEY
|
| 105 |
+
),
|
| 106 |
+
)
|
| 107 |
+
|
| 108 |
+
def test_get_inferred_links_on_unrelated_terms(self):
|
| 109 |
+
vocabulary = yaml.safe_load("""
|
| 110 |
+
vocabulary:
|
| 111 |
+
- term: der Beruf
|
| 112 |
+
definition: job
|
| 113 |
+
declension:
|
| 114 |
+
- ["", singular, plural ]
|
| 115 |
+
- [nominative, Beruf, Berufe ]
|
| 116 |
+
- [genitive, "Berufes, Berufs", Berufe ]
|
| 117 |
+
- [dative, Beruf, Berufen]
|
| 118 |
+
- [accusative, Beruf, Berufe ]
|
| 119 |
+
- term: der Qualitätswein
|
| 120 |
+
definition: The vintage wine
|
| 121 |
+
declension:
|
| 122 |
+
- ["", singular, plural ]
|
| 123 |
+
- [nominative, Qualitätswein, Qualitätsweine ]
|
| 124 |
+
- [genitive, "Qualitätsweines, Qualitätsweins", Qualitätsweine ]
|
| 125 |
+
- [dative, Qualitätswein, Qualitätsweinen]
|
| 126 |
+
- [accusative, Qualitätswein, Qualitätsweine ]
|
| 127 |
+
""")["vocabulary"]
|
| 128 |
+
label_key = LABEL_KEY
|
| 129 |
+
|
| 130 |
+
self.assertEqual(
|
| 131 |
+
[],
|
| 132 |
+
get_inferred_links(vocabulary, label_key, get_declension_attributes)
|
| 133 |
+
)
|
| 134 |
+
|
| 135 |
+
def test_get_inferred_links_on_unrelated_terms_with_same_definite_article(self):
|
| 136 |
+
vocabulary = yaml.safe_load("""
|
| 137 |
+
vocabulary:
|
| 138 |
+
- term: die Biographie
|
| 139 |
+
definition: (alternative spelling of) die Biografie
|
| 140 |
+
declension:
|
| 141 |
+
- ["", singular, plural ]
|
| 142 |
+
- [nominative, Biographie, Biographien]
|
| 143 |
+
- [genitive, Biographie, Biographien]
|
| 144 |
+
- [dative, Biographie, Biographien]
|
| 145 |
+
- [accusative, Biographie, Biographien]
|
| 146 |
+
- term: die Mittagspause
|
| 147 |
+
definition: the lunchbreak
|
| 148 |
+
declension:
|
| 149 |
+
- ["", singular, plural ]
|
| 150 |
+
- [nominative, Mittagspause, Mittagspausen]
|
| 151 |
+
- [genitive, Mittagspause, Mittagspausen]
|
| 152 |
+
- [dative, Mittagspause, Mittagspausen]
|
| 153 |
+
- [accusative, Mittagspause, Mittagspausen]
|
| 154 |
+
""")["vocabulary"] # "die Biographie" has "die" in its definition
|
| 155 |
+
label_key = LABEL_KEY
|
| 156 |
+
|
| 157 |
+
self.assertEqual(
|
| 158 |
+
[],
|
| 159 |
+
get_inferred_links(vocabulary, label_key, get_declension_attributes)
|
| 160 |
+
)
|
| 161 |
+
|
| 162 |
+
def test_get_definition_tokens(self):
|
| 163 |
+
vocabulary = yaml.safe_load("""
|
| 164 |
+
vocabulary:
|
| 165 |
+
- term: morgens
|
| 166 |
+
definition:
|
| 167 |
+
- (adv.) in the morning
|
| 168 |
+
- (adv.) a.m.
|
| 169 |
+
""")["vocabulary"]
|
| 170 |
+
self.assertEqual(
|
| 171 |
+
{"morning", "a.m."},
|
| 172 |
+
get_definition_tokens(vocabulary[0])
|
| 173 |
+
)
|
| 174 |
+
|
| 175 |
+
def test_get_term_tokens(self):
|
| 176 |
+
vocabulary = yaml.safe_load("""
|
| 177 |
+
vocabulary:
|
| 178 |
+
- term: Viertel vor sieben
|
| 179 |
+
definition: (clock time) a quarter before eight
|
| 180 |
+
""")["vocabulary"]
|
| 181 |
+
self.assertEqual(
|
| 182 |
+
{"sieben", "vor", "viertel"},
|
| 183 |
+
get_term_tokens(vocabulary[0])
|
| 184 |
+
)
|
| 185 |
+
|
| 186 |
+
def test_get_term_tokens_do_not_include_indefinite_articles(self):
|
| 187 |
+
vocabulary = yaml.safe_load("""
|
| 188 |
+
vocabulary:
|
| 189 |
+
- term: der Brief
|
| 190 |
+
- term: die Biographie
|
| 191 |
+
- term: das Jahr
|
| 192 |
+
""")["vocabulary"]
|
| 193 |
+
self.assertEqual({"brief"}, get_term_tokens(vocabulary[0]))
|
| 194 |
+
self.assertEqual({"biographie"}, get_term_tokens(vocabulary[1]))
|
| 195 |
+
self.assertEqual({"jahr"}, get_term_tokens(vocabulary[2]))
|
| 196 |
+
|
| 197 |
+
def test_get_declension_tokens(self):
|
| 198 |
+
vocabulary = yaml.safe_load("""
|
| 199 |
+
vocabulary:
|
| 200 |
+
- term: das Jahr
|
| 201 |
+
definition: the year
|
| 202 |
+
declension:
|
| 203 |
+
- ["", singular, plural ]
|
| 204 |
+
- [nominative, Jahr, "Jahre, Jahr" ]
|
| 205 |
+
- [genitive, "Jahres, Jahrs", "Jahre, Jahr" ]
|
| 206 |
+
- [dative, Jahr, "Jahren, Jahr"]
|
| 207 |
+
- [accusative, Jahr, "Jahre, Jahr" ]
|
| 208 |
+
""")["vocabulary"]
|
| 209 |
+
self.assertEqual(
|
| 210 |
+
{"jahres", "jahre", "jahr", "jahren", "jahrs"},
|
| 211 |
+
get_inflection_tokens(vocabulary[0], get_declension_attributes)
|
| 212 |
+
)
|
| 213 |
+
|
| 214 |
+
def test_two_words_shring_some_same_declension_table_entries(self):
|
| 215 |
+
vocabulary = yaml.safe_load("""
|
| 216 |
+
vocabulary:
|
| 217 |
+
- term: die Reise
|
| 218 |
+
definition: the travel
|
| 219 |
+
declension:
|
| 220 |
+
- ["", singular, plural]
|
| 221 |
+
- [nominative, Reise, Reisen]
|
| 222 |
+
- [genitive, Reise, Reisen]
|
| 223 |
+
- [dative, Reise, Reisen]
|
| 224 |
+
- [accusative, Reise, Reisen]
|
| 225 |
+
- term: der Reis
|
| 226 |
+
definition: the rice
|
| 227 |
+
declension:
|
| 228 |
+
- ["", singular, plural]
|
| 229 |
+
- [nominative, Reis, Reise ]
|
| 230 |
+
- [genitive, Reises, Reise ]
|
| 231 |
+
- [dative, Reis, Reisen]
|
| 232 |
+
- [accusative, Reis, Reise ]
|
| 233 |
+
""")["vocabulary"]
|
| 234 |
+
|
| 235 |
+
self.assertEqual(
|
| 236 |
+
[
|
| 237 |
+
{
|
| 238 |
+
'attributes': {LABEL_KEY: 'term related'},
|
| 239 |
+
'source_label': 'die Reise',
|
| 240 |
+
'target_label': 'der Reis'
|
| 241 |
+
}
|
| 242 |
+
],
|
| 243 |
+
get_inferred_tokenization_links(vocabulary, LABEL_KEY, get_declension_attributes)
|
| 244 |
+
)
|
| 245 |
+
|
| 246 |
+
def test_get_inferred_tokenization_links(self):
|
| 247 |
+
vocabulary = yaml.safe_load("""
|
| 248 |
+
vocabulary:
|
| 249 |
+
- term: das Jahr
|
| 250 |
+
definition: the year
|
| 251 |
+
declension:
|
| 252 |
+
- ["", singular, plural ]
|
| 253 |
+
- [nominative, Jahr, "Jahre, Jahr" ]
|
| 254 |
+
- [genitive, "Jahres, Jahrs", "Jahre, Jahr" ]
|
| 255 |
+
- [dative, Jahr, "Jahren, Jahr"]
|
| 256 |
+
- [accusative, Jahr, "Jahre, Jahr" ]
|
| 257 |
+
- term: seit zwei Jahren
|
| 258 |
+
definition: for two years
|
| 259 |
+
- term: letzte
|
| 260 |
+
definition: (adj.) last
|
| 261 |
+
- term: in den letzten Jahren
|
| 262 |
+
definition: in recent years
|
| 263 |
+
""")["vocabulary"]
|
| 264 |
+
|
| 265 |
+
self.assertEqual(
|
| 266 |
+
[
|
| 267 |
+
{
|
| 268 |
+
'attributes': {LABEL_KEY: 'term related'},
|
| 269 |
+
'source_label': 'seit zwei Jahren',
|
| 270 |
+
'target_label': 'das Jahr'
|
| 271 |
+
},
|
| 272 |
+
{
|
| 273 |
+
'attributes': {LABEL_KEY: 'term related'},
|
| 274 |
+
'source_label': 'seit zwei Jahren',
|
| 275 |
+
'target_label': 'in den letzten Jahren'
|
| 276 |
+
},
|
| 277 |
+
{
|
| 278 |
+
'attributes': {LABEL_KEY: 'term related'},
|
| 279 |
+
'source_label': 'in den letzten Jahren',
|
| 280 |
+
'target_label': 'das Jahr'
|
| 281 |
+
},
|
| 282 |
+
{
|
| 283 |
+
'attributes': {LABEL_KEY: 'term related'},
|
| 284 |
+
'source_label': 'in den letzten Jahren',
|
| 285 |
+
'target_label': 'seit zwei Jahren'
|
| 286 |
+
}
|
| 287 |
+
],
|
| 288 |
+
get_inferred_tokenization_links(vocabulary, LABEL_KEY, get_declension_attributes)
|
| 289 |
+
)
|
| 290 |
+
|
| 291 |
+
def test_get_structurally_similar_links(self):
|
| 292 |
+
vocabulary = yaml.safe_load("""
|
| 293 |
+
vocabulary:
|
| 294 |
+
- term: anschließen
|
| 295 |
+
definition: to connect
|
| 296 |
+
- term: anschließend
|
| 297 |
+
definition:
|
| 298 |
+
- (adj.) following
|
| 299 |
+
- (adv.) afterwards
|
| 300 |
+
- term: nachher
|
| 301 |
+
definition: (adv.) afterwards
|
| 302 |
+
""")["vocabulary"]
|
| 303 |
+
label_key = LABEL_KEY
|
| 304 |
+
|
| 305 |
+
self.assertEqual(
|
| 306 |
+
[
|
| 307 |
+
{
|
| 308 |
+
'attributes': {LABEL_KEY: 'structurally similar'},
|
| 309 |
+
'source_label': 'anschließen',
|
| 310 |
+
'target_label': 'anschließend'
|
| 311 |
+
},
|
| 312 |
+
{
|
| 313 |
+
'attributes': {LABEL_KEY: 'structurally similar'},
|
| 314 |
+
'source_label': 'anschließend',
|
| 315 |
+
'target_label': 'anschließen'
|
| 316 |
+
}
|
| 317 |
+
],
|
| 318 |
+
get_structurally_similar_links(vocabulary, label_key)
|
| 319 |
+
)
|
| 320 |
+
|
| 321 |
+
def test_get_structurally_similar_links_small_edit_distance_but_different_stem(self):
|
| 322 |
+
vocabulary = yaml.safe_load("""
|
| 323 |
+
vocabulary:
|
| 324 |
+
- term: die Bank
|
| 325 |
+
- term: die Sahne
|
| 326 |
+
""")["vocabulary"]
|
| 327 |
+
label_key = LABEL_KEY
|
| 328 |
+
|
| 329 |
+
self.assertEqual(
|
| 330 |
+
[],
|
| 331 |
+
get_structurally_similar_links(vocabulary, label_key)
|
| 332 |
+
)
|
| 333 |
+
|
| 334 |
+
def test_is_structurally_similar(self):
|
| 335 |
+
self.assertTrue(is_structurally_similar("anschließen", "anschließend"))
|
| 336 |
+
self.assertTrue(is_structurally_similar("anschließend", "anschließen"))
|
| 337 |
+
self.assertFalse(is_structurally_similar("die Bank", "die Sahne"))
|