
Add files using upload-large-folder tool
Browse files- extras/check_drum_channel_slakh.py +24 -0
- extras/dataset_mutable_var_sanity_check.py +81 -0
- extras/demo_intra_augmentation.py +52 -0
- extras/examples/singing_note_events.npy +3 -0
- extras/examples/singing_notes.npy +3 -0
- extras/fig/label_smooth_interval_of_interest.png +0 -0
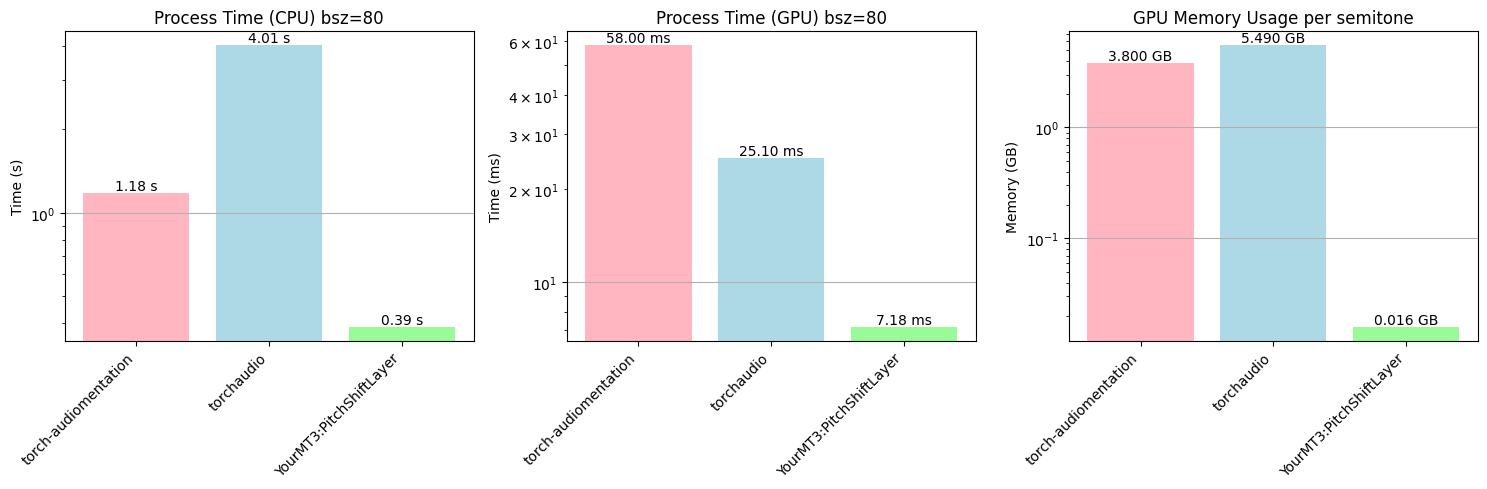
- extras/fig/pitchshift_benchnmark.png +0 -0
- extras/fig/pitchshift_stretch_and_resampler_process_time.png +0 -0
- extras/label_smoothing.py +67 -0
- extras/npy_speed_benchmark.py +187 -0
- extras/perceivertf_inspect.py +640 -0
- extras/perceivertf_multi_inspect.py +778 -0
- extras/pitch_shift_benchmark.py +167 -0
- extras/run_spleeter_mir1k.sh +17 -0
- extras/run_spleeter_mirst500.sh +13 -0
- model/__pycache__/conformer_mod.cpython-310.pyc +0 -0
extras/check_drum_channel_slakh.py
ADDED
|
@@ -0,0 +1,24 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from utils.mirdata_dev.datasets import slakh16k
|
| 2 |
+
|
| 3 |
+
|
| 4 |
+
def check_drum_channel_slakh(data_home: str):
|
| 5 |
+
ds = slakh16k.Dataset(data_home, version='default')
|
| 6 |
+
for track_id in ds.track_ids:
|
| 7 |
+
is_drum = ds.track(track_id).is_drum
|
| 8 |
+
midi = MidiFile(ds.track(track_id).midi_path)
|
| 9 |
+
cnt = 0
|
| 10 |
+
for msg in midi:
|
| 11 |
+
if 'note' in msg.type:
|
| 12 |
+
if is_drum and (msg.channel != 9):
|
| 13 |
+
print('found drum track with channel != 9 in track_id: ',
|
| 14 |
+
track_id)
|
| 15 |
+
if not is_drum and (msg.channel == 9):
|
| 16 |
+
print(
|
| 17 |
+
'found non-drum track with channel == 9 in track_id: ',
|
| 18 |
+
track_id)
|
| 19 |
+
if is_drum and (msg.channel == 9):
|
| 20 |
+
cnt += 1
|
| 21 |
+
if cnt > 0:
|
| 22 |
+
print(f'found {cnt} notes in drum track with ch 9 in track_id: ',
|
| 23 |
+
track_id)
|
| 24 |
+
return
|
extras/dataset_mutable_var_sanity_check.py
ADDED
|
@@ -0,0 +1,81 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
for n in range(1000):
|
| 2 |
+
sampled_data = ds.__getitem__(n)
|
| 3 |
+
|
| 4 |
+
a = deepcopy(sampled_data['note_event_segments'])
|
| 5 |
+
b = deepcopy(sampled_data['note_event_segments'])
|
| 6 |
+
|
| 7 |
+
for (note_events, tie_note_events, start_time) in list(zip(*b.values())):
|
| 8 |
+
note_events = pitch_shift_note_events(note_events, 2)
|
| 9 |
+
tie_note_events = pitch_shift_note_events(tie_note_events, 2)
|
| 10 |
+
|
| 11 |
+
# compare
|
| 12 |
+
for i, (note_events, tie_note_events, start_time) in enumerate(list(zip(*b.values()))):
|
| 13 |
+
for j, ne in enumerate(note_events):
|
| 14 |
+
if ne.is_drum is False:
|
| 15 |
+
if ne.pitch != a['note_events'][i][j].pitch + 2:
|
| 16 |
+
print(i, j)
|
| 17 |
+
assert ne.pitch == a['note_events'][i][j].pitch + 2
|
| 18 |
+
|
| 19 |
+
for k, tne in enumerate(tie_note_events):
|
| 20 |
+
assert tne.pitch == a['tie_note_events'][i][k].pitch + 2
|
| 21 |
+
|
| 22 |
+
print('test {} passed'.format(n))
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
def assert_note_events_almost_equal(actual_note_events,
|
| 26 |
+
predicted_note_events,
|
| 27 |
+
ignore_time=False,
|
| 28 |
+
ignore_activity=True,
|
| 29 |
+
delta=5.1e-3):
|
| 30 |
+
"""
|
| 31 |
+
Asserts that the given lists of Note instances are equal up to a small
|
| 32 |
+
floating-point tolerance, similar to `assertAlmostEqual` of `unittest`.
|
| 33 |
+
Tolerance is 5e-3 by default, which is 5 ms for 100 ticks-per-second.
|
| 34 |
+
|
| 35 |
+
If `ignore_time` is True, then the time field is ignored. (useful for
|
| 36 |
+
comparing tie note events, default is False)
|
| 37 |
+
|
| 38 |
+
If `ignore_activity` is True, then the activity field is ignored (default
|
| 39 |
+
is True).
|
| 40 |
+
"""
|
| 41 |
+
assert len(actual_note_events) == len(predicted_note_events)
|
| 42 |
+
for j, (actual_note_event,
|
| 43 |
+
predicted_note_event) in enumerate(zip(actual_note_events, predicted_note_events)):
|
| 44 |
+
if ignore_time is False:
|
| 45 |
+
assert abs(actual_note_event.time - predicted_note_event.time) <= delta
|
| 46 |
+
assert actual_note_event.is_drum == predicted_note_event.is_drum
|
| 47 |
+
if actual_note_event.is_drum is False and predicted_note_event.is_drum is False:
|
| 48 |
+
assert actual_note_event.program == predicted_note_event.program
|
| 49 |
+
assert actual_note_event.pitch == predicted_note_event.pitch
|
| 50 |
+
assert actual_note_event.velocity == predicted_note_event.velocity
|
| 51 |
+
if ignore_activity is False:
|
| 52 |
+
assert actual_note_event.activity == predicted_note_event.activity
|
| 53 |
+
|
| 54 |
+
|
| 55 |
+
cache_old = deepcopy(dict(ds.cache))
|
| 56 |
+
for n in range(500):
|
| 57 |
+
sampled_data = ds.__getitem__(n)
|
| 58 |
+
cache_new = ds.cache
|
| 59 |
+
cnt = 0
|
| 60 |
+
for k, v in cache_new.items():
|
| 61 |
+
if k in cache_old:
|
| 62 |
+
cnt += 1
|
| 63 |
+
assert (cache_new[k]['programs'] == cache_old[k]['programs']).all()
|
| 64 |
+
assert (cache_new[k]['is_drum'] == cache_old[k]['is_drum']).all()
|
| 65 |
+
assert (cache_new[k]['has_stems'] == cache_old[k]['has_stems'])
|
| 66 |
+
assert (cache_new[k]['has_unannotated'] == cache_old[k]['has_unannotated'])
|
| 67 |
+
assert (cache_new[k]['audio_array'] == cache_old[k]['audio_array']).all()
|
| 68 |
+
|
| 69 |
+
for nes_new, nes_old in zip(cache_new[k]['note_event_segments']['note_events'],
|
| 70 |
+
cache_old[k]['note_event_segments']['note_events']):
|
| 71 |
+
assert_note_events_almost_equal(nes_new, nes_old)
|
| 72 |
+
|
| 73 |
+
for tnes_new, tnes_old in zip(cache_new[k]['note_event_segments']['tie_note_events'],
|
| 74 |
+
cache_old[k]['note_event_segments']['tie_note_events']):
|
| 75 |
+
assert_note_events_almost_equal(tnes_new, tnes_old, ignore_time=True)
|
| 76 |
+
|
| 77 |
+
for s_new, s_old in zip(cache_new[k]['note_event_segments']['start_times'],
|
| 78 |
+
cache_old[k]['note_event_segments']['start_times']):
|
| 79 |
+
assert s_new == s_old
|
| 80 |
+
cache_old = deepcopy(dict(ds.cache))
|
| 81 |
+
print(n, cnt)
|
extras/demo_intra_augmentation.py
ADDED
|
@@ -0,0 +1,52 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2024 The YourMT3 Authors.
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Please see the details in the LICENSE file.
|
| 10 |
+
import numpy as np
|
| 11 |
+
import torch
|
| 12 |
+
import json
|
| 13 |
+
import soundfile as sf
|
| 14 |
+
from utils.datasets_train import get_cache_data_loader
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
def get_filelist(track_id: int) -> dict:
|
| 18 |
+
filelist = '../../data/yourmt3_indexes/slakh_train_file_list.json'
|
| 19 |
+
with open(filelist, 'r') as f:
|
| 20 |
+
fl = json.load(f)
|
| 21 |
+
new_filelist = dict()
|
| 22 |
+
for key, value in fl.items():
|
| 23 |
+
if int(key) == track_id:
|
| 24 |
+
new_filelist[0] = value
|
| 25 |
+
return new_filelist
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
def get_ds(track_id: int, random_amp_range: list = [1., 1.], stem_aug_prob: float = 0.8):
|
| 29 |
+
filelist = get_filelist(track_id)
|
| 30 |
+
dl = get_cache_data_loader(filelist,
|
| 31 |
+
'train',
|
| 32 |
+
1,
|
| 33 |
+
1,
|
| 34 |
+
random_amp_range=random_amp_range,
|
| 35 |
+
stem_aug_prob=stem_aug_prob,
|
| 36 |
+
shuffle=False)
|
| 37 |
+
ds = dl.dataset
|
| 38 |
+
return ds
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
def gen_audio(track_id: int, n_segments: int = 30, random_amp_range: list = [1., 1.], stem_aug_prob: float = 0.8):
|
| 42 |
+
ds = get_ds(track_id, random_amp_range, stem_aug_prob)
|
| 43 |
+
audio = []
|
| 44 |
+
for i in range(n_segments):
|
| 45 |
+
audio.append(ds.__getitem__(0)[0])
|
| 46 |
+
# audio.append(ds.__getitem__(i)[0])
|
| 47 |
+
|
| 48 |
+
audio = torch.concat(audio, dim=2).numpy()[0, 0, :]
|
| 49 |
+
sf.write('audio.wav', audio, 16000, subtype='PCM_16')
|
| 50 |
+
|
| 51 |
+
|
| 52 |
+
gen_audio(1, 20)
|
extras/examples/singing_note_events.npy
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:8eabaecc837fb052fba68483b965a59d40220fdf2a91a57b5155849c72306ba0
|
| 3 |
+
size 37504
|
extras/examples/singing_notes.npy
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:aa8ebde37531514ea145063af32543f8e520a6c34525c98e863e152b66119be8
|
| 3 |
+
size 15085
|
extras/fig/label_smooth_interval_of_interest.png
ADDED

|
extras/fig/pitchshift_benchnmark.png
ADDED
|
extras/fig/pitchshift_stretch_and_resampler_process_time.png
ADDED

|
extras/label_smoothing.py
ADDED
|
@@ -0,0 +1,67 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import numpy as np
|
| 3 |
+
import matplotlib.pyplot as plt
|
| 4 |
+
|
| 5 |
+
a = torch.signal.windows.gaussian(11, sym=True, std=3)
|
| 6 |
+
plt.plot(a)
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
def gaussian_smoothing(y_hot, mu=5, sigma=0.865):
|
| 10 |
+
"""
|
| 11 |
+
y_hot: one-hot encoded array
|
| 12 |
+
"""
|
| 13 |
+
#sigma = np.sqrt(np.abs(np.log(0.05) / ((4 - mu)**2))) / 2
|
| 14 |
+
|
| 15 |
+
# Generate index array
|
| 16 |
+
i = np.arange(len(y_hot))
|
| 17 |
+
|
| 18 |
+
# Gaussian function
|
| 19 |
+
y_smooth = np.exp(-(i - mu)**2 / (2 * sigma**2))
|
| 20 |
+
|
| 21 |
+
# Normalize the resulting array
|
| 22 |
+
y_smooth /= y_smooth.sum()
|
| 23 |
+
return y_smooth, sigma
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
# y_ls = (1 - α) * y_hot + α / K, where K is the number of classes, alpha is the smoothing parameter
|
| 27 |
+
|
| 28 |
+
y_hot = torch.zeros(11)
|
| 29 |
+
y_hot[5] = 1
|
| 30 |
+
plt.plot(y_hot, 'b.-')
|
| 31 |
+
|
| 32 |
+
alpha = 0.3
|
| 33 |
+
y_ls = (1 - alpha) * y_hot + alpha / 10
|
| 34 |
+
plt.plot(y_ls, 'r.-')
|
| 35 |
+
|
| 36 |
+
y_gs, std = gaussian_smoothing(y_hot, A=0.5)
|
| 37 |
+
plt.plot(y_gs, 'g.-')
|
| 38 |
+
|
| 39 |
+
y_gst_a, std = gaussian_smoothing(y_hot, A=0.5, mu=5.5)
|
| 40 |
+
plt.plot(y_gst_a, 'y.-')
|
| 41 |
+
|
| 42 |
+
y_gst_b, std = gaussian_smoothing(y_hot, A=0.5, mu=5.8)
|
| 43 |
+
plt.plot(y_gst_b, 'c.-')
|
| 44 |
+
|
| 45 |
+
plt.legend([
|
| 46 |
+
'y_hot', 'label smoothing' + '\n' + '(alpha=0.3)',
|
| 47 |
+
'gaussian smoothing' + '\n' + 'for interval of interest' + '\n' + 'mu=5',
|
| 48 |
+
'gaussian smoothing' + '\n' + 'mu=5.5', 'gaussian smoothing' + '\n' + 'mu=5.8'
|
| 49 |
+
])
|
| 50 |
+
|
| 51 |
+
plt.grid()
|
| 52 |
+
plt.xticks(np.arange(11), np.arange(0, 110, 10))
|
| 53 |
+
plt.xlabel('''Time (ms)
|
| 54 |
+
original (quantized) one hot label:
|
| 55 |
+
[0,0,0,0,0,1,0,0,0,0,0]
|
| 56 |
+
\n
|
| 57 |
+
label smooting is defined as:
|
| 58 |
+
y_ls = (1 - α) * y_hot + α / K,
|
| 59 |
+
where K is the number of classes, α is the smoothing parameter
|
| 60 |
+
\n
|
| 61 |
+
gaussian smoothing for the interval (± 10ms) of interest:
|
| 62 |
+
y_gs = A * exp(-(i - mu)**2 / (2 * sigma**2))
|
| 63 |
+
with sigma = 0.865 an mu = 5
|
| 64 |
+
\n
|
| 65 |
+
gaussian smoothing with unqunatized target timing:
|
| 66 |
+
mu = 5.5 for 55ms target timing
|
| 67 |
+
''')
|
extras/npy_speed_benchmark.py
ADDED
|
@@ -0,0 +1,187 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
from tasks.utils.event_codec import Event, EventRange
|
| 3 |
+
from tasks.utils import event_codec
|
| 4 |
+
|
| 5 |
+
ec = event_codec.Codec(
|
| 6 |
+
max_shift_steps=1000, # this means 0,1,...,1000
|
| 7 |
+
steps_per_second=100,
|
| 8 |
+
event_ranges=[
|
| 9 |
+
EventRange('pitch', min_value=0, max_value=127),
|
| 10 |
+
EventRange('velocity', min_value=0, max_value=1),
|
| 11 |
+
EventRange('tie', min_value=0, max_value=0),
|
| 12 |
+
EventRange('program', min_value=0, max_value=127),
|
| 13 |
+
EventRange('drum', min_value=0, max_value=127),
|
| 14 |
+
],
|
| 15 |
+
)
|
| 16 |
+
|
| 17 |
+
events = [
|
| 18 |
+
Event(type='shift', value=0), # actually not needed
|
| 19 |
+
Event(type='shift', value=1), # 10 ms shift
|
| 20 |
+
Event(type='shift', value=1000), # 10 s shift
|
| 21 |
+
Event(type='pitch', value=0), # lowest pitch 8.18 Hz
|
| 22 |
+
Event(type='pitch', value=60), # C4 or 261.63 Hz
|
| 23 |
+
Event(type='pitch', value=127), # highest pitch G9 or 12543.85 Hz
|
| 24 |
+
Event(type='velocity', value=0), # lowest velocity)
|
| 25 |
+
Event(type='velocity', value=1), # lowest velocity)
|
| 26 |
+
Event(type='tie', value=0), # tie
|
| 27 |
+
Event(type='program', value=0), # program
|
| 28 |
+
Event(type='program', value=127), # program
|
| 29 |
+
Event(type='drum', value=0), # drum
|
| 30 |
+
Event(type='drum', value=127), # drum
|
| 31 |
+
]
|
| 32 |
+
|
| 33 |
+
events = events * 100
|
| 34 |
+
tokens = [ec.encode_event(e) for e in events]
|
| 35 |
+
tokens = np.array(tokens, dtype=np.int16)
|
| 36 |
+
|
| 37 |
+
import csv
|
| 38 |
+
# Save events to a CSV file
|
| 39 |
+
with open('events.csv', 'w', newline='') as file:
|
| 40 |
+
writer = csv.writer(file)
|
| 41 |
+
for event in events:
|
| 42 |
+
writer.writerow([event.type, event.value])
|
| 43 |
+
|
| 44 |
+
# Load events from a CSV file
|
| 45 |
+
with open('events.csv', 'r') as file:
|
| 46 |
+
reader = csv.reader(file)
|
| 47 |
+
events2 = [Event(row[0], int(row[1])) for row in reader]
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
import json
|
| 51 |
+
# Save events to a JSON file
|
| 52 |
+
with open('events.json', 'w') as file:
|
| 53 |
+
json.dump([event.__dict__ for event in events], file)
|
| 54 |
+
|
| 55 |
+
# Load events from a JSON file
|
| 56 |
+
with open('events.json', 'r') as file:
|
| 57 |
+
events = [Event(**event_dict) for event_dict in json.load(file)]
|
| 58 |
+
|
| 59 |
+
|
| 60 |
+
|
| 61 |
+
|
| 62 |
+
"""----------------------------"""
|
| 63 |
+
# Write the tokens to a npy file
|
| 64 |
+
import numpy as np
|
| 65 |
+
np.save('tokens.npy', tokens)
|
| 66 |
+
|
| 67 |
+
def t_npy():
|
| 68 |
+
t = np.load('tokens.npy', allow_pickle=True) # allow pickle doesn't affect speed
|
| 69 |
+
|
| 70 |
+
os.makedirs('temp', exist_ok=True)
|
| 71 |
+
for i in range(2400):
|
| 72 |
+
np.save(f'temp/tokens{i}.npy', tokens)
|
| 73 |
+
|
| 74 |
+
def t_npy2400():
|
| 75 |
+
for i in range(2400):
|
| 76 |
+
t = np.load(f'temp/tokens{i}.npy')
|
| 77 |
+
def t_npy2400_take200():
|
| 78 |
+
for i in range(200):
|
| 79 |
+
t = np.load(f'temp/tokens{i}.npy')
|
| 80 |
+
|
| 81 |
+
import shutil
|
| 82 |
+
shutil.rmtree('temp', ignore_errors=True)
|
| 83 |
+
|
| 84 |
+
# Write the 2400 tokens to a single npy file
|
| 85 |
+
data = dict()
|
| 86 |
+
for i in range(2400):
|
| 87 |
+
data[f'arr{i}'] = tokens.copy()
|
| 88 |
+
np.save(f'tokens_2400x.npy', data)
|
| 89 |
+
def t_npy2400single():
|
| 90 |
+
t = np.load('tokens_2400x.npy', allow_pickle=True).item()
|
| 91 |
+
|
| 92 |
+
def t_mmap2400single():
|
| 93 |
+
t = np.load('tokens_2400x.npy', mmap_mode='r')
|
| 94 |
+
|
| 95 |
+
# Write the tokens to a npz file
|
| 96 |
+
np.savez('tokens.npz', arr0=tokens)
|
| 97 |
+
def t_npz():
|
| 98 |
+
npz_file = np.load('tokens.npz')
|
| 99 |
+
tt = npz_file['arr0']
|
| 100 |
+
|
| 101 |
+
data = dict()
|
| 102 |
+
for i in range(2400):
|
| 103 |
+
data[f'arr{i}'] = tokens
|
| 104 |
+
np.savez('tokens.npz', **data )
|
| 105 |
+
def t_npz2400():
|
| 106 |
+
npz_file = np.load('tokens.npz')
|
| 107 |
+
for i in range(2400):
|
| 108 |
+
tt = npz_file[f'arr{i}']
|
| 109 |
+
|
| 110 |
+
def t_npz2400_take200():
|
| 111 |
+
npz_file = np.load('tokens.npz')
|
| 112 |
+
# npz_file.files
|
| 113 |
+
for i in range(200):
|
| 114 |
+
tt = npz_file[f'arr{i}']
|
| 115 |
+
|
| 116 |
+
|
| 117 |
+
# Write the tokens to a txt file
|
| 118 |
+
with open('tokens.txt', 'w') as file:
|
| 119 |
+
file.write(' '.join(map(str, tokens)))
|
| 120 |
+
|
| 121 |
+
def t_txt():
|
| 122 |
+
# Read the tokens from the file
|
| 123 |
+
with open('tokens.txt', 'r') as file:
|
| 124 |
+
t = list(map(int, file.read().split()))
|
| 125 |
+
t = np.array(t)
|
| 126 |
+
|
| 127 |
+
|
| 128 |
+
# Write the tokens to a CSV file
|
| 129 |
+
with open('tokens.csv', 'w', newline='') as file:
|
| 130 |
+
writer = csv.writer(file)
|
| 131 |
+
writer.writerow(tokens)
|
| 132 |
+
|
| 133 |
+
def t_csv():
|
| 134 |
+
# Read the tokens from the CSV file
|
| 135 |
+
with open('tokens.csv', 'r') as file:
|
| 136 |
+
reader = csv.reader(file)
|
| 137 |
+
t = list(map(int, next(reader)))
|
| 138 |
+
t = np.array(t)
|
| 139 |
+
|
| 140 |
+
|
| 141 |
+
# Write the tokens to a JSON file
|
| 142 |
+
with open('tokens.json', 'w') as file:
|
| 143 |
+
json.dump(tokens, file)
|
| 144 |
+
|
| 145 |
+
def t_json():
|
| 146 |
+
# Read the tokens from the JSON file
|
| 147 |
+
with open('tokens.json', 'r') as file:
|
| 148 |
+
t = json.load(file)
|
| 149 |
+
t = np.array(t)
|
| 150 |
+
|
| 151 |
+
with open('tokens_2400x.json', 'w') as file:
|
| 152 |
+
json.dump(data, file)
|
| 153 |
+
|
| 154 |
+
def t_json2400single():
|
| 155 |
+
# Read the tokens from the JSON file
|
| 156 |
+
with open('tokens_2400x.json', 'r') as file:
|
| 157 |
+
t = json.load(file)
|
| 158 |
+
|
| 159 |
+
def t_mmap():
|
| 160 |
+
t = np.load('tokens.npy', mmap_mode='r')
|
| 161 |
+
|
| 162 |
+
# Write the tokens to bytes file
|
| 163 |
+
|
| 164 |
+
|
| 165 |
+
|
| 166 |
+
|
| 167 |
+
np.savetxt('tokens.ntxt', tokens)
|
| 168 |
+
def t_ntxt():
|
| 169 |
+
t = np.loadtxt('tokens.ntxt').astype(np.int32)
|
| 170 |
+
|
| 171 |
+
%timeit t_npz() # 139 us
|
| 172 |
+
%timeit t_mmap() # 3.12 ms
|
| 173 |
+
%timeit t_npy() # 87.8 us
|
| 174 |
+
%timeit t_txt() # 109 152 us
|
| 175 |
+
%timeit t_csv() # 145 190 us
|
| 176 |
+
%timeit t_json() # 72.8 119 us
|
| 177 |
+
%timeit t_ntxt() # 878 us
|
| 178 |
+
|
| 179 |
+
%timeit t_npy2400() # 212 ms; 2400 files in a folder
|
| 180 |
+
%timeit t_npz2400() # 296 ms; uncompreesed 1000 arrays in a single file
|
| 181 |
+
|
| 182 |
+
%timeit t_npy2400_take200() # 17.4 ms; 25 Mb
|
| 183 |
+
%timeit t_npz2400_take200() # 28.8 ms; 3.72 ms for 10 arrays; 25 Mb
|
| 184 |
+
%timeit t_npy2400single() # 4 ms; frozen dictionary containing 2400 arrays; 6.4 Mb; int16
|
| 185 |
+
%timeit t_mmap2400single() # dictionary is not supported
|
| 186 |
+
%timeit t_json2400single() # 175 ms; 17 Mb
|
| 187 |
+
# 2400 files from 100ms hop for 4 minutes
|
extras/perceivertf_inspect.py
ADDED
|
@@ -0,0 +1,640 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import numpy as np
|
| 2 |
+
import torch
|
| 3 |
+
import torch.nn.functional as F
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
def l2_normalize(matrix):
|
| 7 |
+
"""
|
| 8 |
+
L2 Normalize the matrix along its rows.
|
| 9 |
+
|
| 10 |
+
Parameters:
|
| 11 |
+
matrix (numpy.ndarray): The input matrix.
|
| 12 |
+
|
| 13 |
+
Returns:
|
| 14 |
+
numpy.ndarray: The L2 normalized matrix.
|
| 15 |
+
"""
|
| 16 |
+
l2_norms = np.linalg.norm(matrix, axis=1, keepdims=True)
|
| 17 |
+
normalized_matrix = matrix / l2_norms
|
| 18 |
+
return normalized_matrix
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
def z_normalize(matrix):
|
| 22 |
+
"""
|
| 23 |
+
Z-normalize the matrix along its rows (mean=0 and std=1).
|
| 24 |
+
Z-normalization is also known as "standardization", and derives from z-score.
|
| 25 |
+
Z = (X - mean) / std
|
| 26 |
+
Z-nomarlized, each row has mean=0 and std=1.
|
| 27 |
+
|
| 28 |
+
Parameters:
|
| 29 |
+
matrix (numpy.ndarray): The input matrix.
|
| 30 |
+
|
| 31 |
+
Returns:
|
| 32 |
+
numpy.ndarray: The Z normalized matrix.
|
| 33 |
+
"""
|
| 34 |
+
mean = np.mean(matrix, axis=1, keepdims=True)
|
| 35 |
+
std = np.std(matrix, axis=1, keepdims=True)
|
| 36 |
+
normalized_matrix = (matrix - mean) / std
|
| 37 |
+
return normalized_matrix
|
| 38 |
+
|
| 39 |
+
|
| 40 |
+
def l2_normalize_tensors(tensor_tuple):
|
| 41 |
+
"""
|
| 42 |
+
Applies L2 normalization on the last two dimensions for each tensor in a tuple.
|
| 43 |
+
|
| 44 |
+
Parameters:
|
| 45 |
+
tensor_tuple (tuple of torch.Tensor): A tuple containing N tensors, each of shape (1, k, 30, 30).
|
| 46 |
+
|
| 47 |
+
Returns:
|
| 48 |
+
tuple of torch.Tensor: A tuple containing N L2-normalized tensors.
|
| 49 |
+
"""
|
| 50 |
+
normalized_tensors = []
|
| 51 |
+
for tensor in tensor_tuple:
|
| 52 |
+
# Ensure the tensor is a floating-point type
|
| 53 |
+
tensor = tensor.float()
|
| 54 |
+
|
| 55 |
+
# Calculate L2 norm on the last two dimensions, keeping the dimensions using keepdim=True
|
| 56 |
+
l2_norm = torch.linalg.norm(tensor, dim=(-2, -1), keepdim=True)
|
| 57 |
+
|
| 58 |
+
# Apply L2 normalization
|
| 59 |
+
normalized_tensor = tensor / (
|
| 60 |
+
l2_norm + 1e-7) # Small value to avoid division by zero
|
| 61 |
+
|
| 62 |
+
normalized_tensors.append(normalized_tensor)
|
| 63 |
+
|
| 64 |
+
return tuple(normalized_tensors)
|
| 65 |
+
|
| 66 |
+
|
| 67 |
+
def z_normalize_tensors(tensor_tuple):
|
| 68 |
+
"""
|
| 69 |
+
Applies Z-normalization on the last two dimensions for each tensor in a tuple.
|
| 70 |
+
|
| 71 |
+
Parameters:
|
| 72 |
+
tensor_tuple (tuple of torch.Tensor): A tuple containing N tensors, each of shape (1, k, 30, 30).
|
| 73 |
+
|
| 74 |
+
Returns:
|
| 75 |
+
tuple of torch.Tensor: A tuple containing N Z-normalized tensors.
|
| 76 |
+
"""
|
| 77 |
+
normalized_tensors = []
|
| 78 |
+
for tensor in tensor_tuple:
|
| 79 |
+
# Ensure the tensor is a floating-point type
|
| 80 |
+
tensor = tensor.float()
|
| 81 |
+
|
| 82 |
+
# Calculate mean and std on the last two dimensions
|
| 83 |
+
mean = tensor.mean(dim=(-2, -1), keepdim=True)
|
| 84 |
+
std = tensor.std(dim=(-2, -1), keepdim=True)
|
| 85 |
+
|
| 86 |
+
# Apply Z-normalization
|
| 87 |
+
normalized_tensor = (tensor - mean) / (
|
| 88 |
+
std + 1e-7) # Small value to avoid division by zero
|
| 89 |
+
|
| 90 |
+
normalized_tensors.append(normalized_tensor)
|
| 91 |
+
|
| 92 |
+
return tuple(normalized_tensors)
|
| 93 |
+
|
| 94 |
+
|
| 95 |
+
def apply_temperature_to_attention_tensors(tensor_tuple, temperature=1.0):
|
| 96 |
+
"""
|
| 97 |
+
Applies temperature scaling to the attention weights in each tensor in a tuple.
|
| 98 |
+
|
| 99 |
+
Parameters:
|
| 100 |
+
tensor_tuple (tuple of torch.Tensor): A tuple containing N tensors,
|
| 101 |
+
each of shape (1, k, 30, 30).
|
| 102 |
+
temperature (float): Temperature parameter to control the sharpness
|
| 103 |
+
of the attention weights. Default is 1.0.
|
| 104 |
+
|
| 105 |
+
Returns:
|
| 106 |
+
tuple of torch.Tensor: A tuple containing N tensors with scaled attention weights.
|
| 107 |
+
"""
|
| 108 |
+
scaled_attention_tensors = []
|
| 109 |
+
|
| 110 |
+
for tensor in tensor_tuple:
|
| 111 |
+
# Ensure the tensor is a floating-point type
|
| 112 |
+
tensor = tensor.float()
|
| 113 |
+
|
| 114 |
+
# Flatten the last two dimensions
|
| 115 |
+
flattened_tensor = tensor.reshape(1, tensor.shape[1],
|
| 116 |
+
-1) # Modified line here
|
| 117 |
+
|
| 118 |
+
# Apply temperature scaling and softmax along the last dimension
|
| 119 |
+
scaled_attention = flattened_tensor / temperature
|
| 120 |
+
scaled_attention = F.softmax(scaled_attention, dim=-1)
|
| 121 |
+
|
| 122 |
+
# Reshape to original shape
|
| 123 |
+
scaled_attention = scaled_attention.view_as(tensor)
|
| 124 |
+
|
| 125 |
+
scaled_attention_tensors.append(scaled_attention)
|
| 126 |
+
|
| 127 |
+
return tuple(scaled_attention_tensors)
|
| 128 |
+
|
| 129 |
+
|
| 130 |
+
def shorten_att(tensor_tuple, length=30):
|
| 131 |
+
shortend_tensors = []
|
| 132 |
+
for tensor in tensor_tuple:
|
| 133 |
+
shortend_tensors.append(tensor[:, :, :length, :length])
|
| 134 |
+
return tuple(shortend_tensors)
|
| 135 |
+
|
| 136 |
+
|
| 137 |
+
def keep_top_k(matrix, k=6):
|
| 138 |
+
"""
|
| 139 |
+
Keep only the top k values in each row, set the rest to 0.
|
| 140 |
+
|
| 141 |
+
Parameters:
|
| 142 |
+
matrix (numpy.ndarray): The input matrix.
|
| 143 |
+
k (int): The number of top values to keep in each row.
|
| 144 |
+
|
| 145 |
+
Returns:
|
| 146 |
+
numpy.ndarray: The transformed matrix.
|
| 147 |
+
"""
|
| 148 |
+
topk_indices_per_row = np.argpartition(matrix, -k, axis=1)[:, -k:]
|
| 149 |
+
result_matrix = np.zeros_like(matrix)
|
| 150 |
+
|
| 151 |
+
for i in range(matrix.shape[0]):
|
| 152 |
+
result_matrix[i, topk_indices_per_row[i]] = matrix[
|
| 153 |
+
i, topk_indices_per_row[i]]
|
| 154 |
+
return result_matrix
|
| 155 |
+
|
| 156 |
+
|
| 157 |
+
def test_case_forward_enc_perceiver_tf_dec_t5():
|
| 158 |
+
import torch
|
| 159 |
+
from model.ymt3 import YourMT3
|
| 160 |
+
from config.config import audio_cfg, model_cfg, shared_cfg
|
| 161 |
+
model_cfg["encoder_type"] = "perceiver-tf"
|
| 162 |
+
model_cfg["encoder"]["perceiver-tf"]["attention_to_channel"] = True
|
| 163 |
+
model_cfg["encoder"]["perceiver-tf"]["num_latents"] = 24
|
| 164 |
+
model_cfg["decoder_type"] = "t5"
|
| 165 |
+
model_cfg["pre_decoder_type"] = "default"
|
| 166 |
+
|
| 167 |
+
audio_cfg["codec"] = "spec"
|
| 168 |
+
audio_cfg["hop_length"] = 300
|
| 169 |
+
model = YourMT3(audio_cfg=audio_cfg, model_cfg=model_cfg)
|
| 170 |
+
model.eval()
|
| 171 |
+
|
| 172 |
+
# x = torch.randn(2, 1, 32767)
|
| 173 |
+
# labels = torch.randint(0, 400, (2, 1024), requires_grad=False)
|
| 174 |
+
|
| 175 |
+
# # forward
|
| 176 |
+
# output = model.forward(x, labels)
|
| 177 |
+
|
| 178 |
+
# # inference
|
| 179 |
+
# result = model.inference(x, None)
|
| 180 |
+
|
| 181 |
+
# display latents
|
| 182 |
+
checkpoint = torch.load(
|
| 183 |
+
"../logs/ymt3/ptf_all_cross_rebal5_spec300_xk2_amp0811_edr_005_attend_c_full_plus_b52/checkpoints/model.ckpt",
|
| 184 |
+
map_location="cpu")
|
| 185 |
+
state_dict = checkpoint['state_dict']
|
| 186 |
+
new_state_dict = {
|
| 187 |
+
k: v
|
| 188 |
+
for k, v in state_dict.items() if 'pitchshift' not in k
|
| 189 |
+
}
|
| 190 |
+
model.load_state_dict(new_state_dict, strict=False)
|
| 191 |
+
|
| 192 |
+
latents = model.encoder.latent_array.latents.detach().numpy()
|
| 193 |
+
import matplotlib.pyplot as plt
|
| 194 |
+
import numpy as np
|
| 195 |
+
from sklearn.metrics.pairwise import cosine_similarity
|
| 196 |
+
cos = cosine_similarity(latents)
|
| 197 |
+
|
| 198 |
+
from utils.data_modules import AMTDataModule
|
| 199 |
+
from einops import rearrange
|
| 200 |
+
dm = AMTDataModule(data_preset_multi={"presets": ["slakh"]})
|
| 201 |
+
dm.setup("test")
|
| 202 |
+
dl = dm.test_dataloader()
|
| 203 |
+
ds = list(dl.values())[0].dataset
|
| 204 |
+
audio, notes, tokens, _ = ds.__getitem__(7)
|
| 205 |
+
x = audio[[16], ::]
|
| 206 |
+
label = tokens[[16], :]
|
| 207 |
+
# spectrogram
|
| 208 |
+
x_spec = model.spectrogram(x)
|
| 209 |
+
plt.imshow(x_spec[0].detach().numpy().T, aspect='auto', origin='lower')
|
| 210 |
+
plt.title("spectrogram")
|
| 211 |
+
plt.xlabel('time step')
|
| 212 |
+
plt.ylabel('frequency bin')
|
| 213 |
+
plt.show()
|
| 214 |
+
x_conv = model.pre_encoder(x_spec)
|
| 215 |
+
# Create a larger figure
|
| 216 |
+
plt.figure(
|
| 217 |
+
figsize=(15,
|
| 218 |
+
10)) # Adjust these numbers as needed for width and height
|
| 219 |
+
plt.subplot(2, 4, 1)
|
| 220 |
+
plt.imshow(x_spec[0].detach().numpy().T, aspect='auto', origin='lower')
|
| 221 |
+
plt.title("spectrogram")
|
| 222 |
+
plt.xlabel('time step')
|
| 223 |
+
plt.ylabel('frequency bin')
|
| 224 |
+
plt.subplot(2, 4, 2)
|
| 225 |
+
plt.imshow(x_conv[0][:, :, 0].detach().numpy().T,
|
| 226 |
+
aspect='auto',
|
| 227 |
+
origin='lower')
|
| 228 |
+
plt.title("conv(spec), ch=0")
|
| 229 |
+
plt.xlabel('time step')
|
| 230 |
+
plt.ylabel('F')
|
| 231 |
+
plt.subplot(2, 4, 3)
|
| 232 |
+
plt.imshow(x_conv[0][:, :, 42].detach().numpy().T,
|
| 233 |
+
aspect='auto',
|
| 234 |
+
origin='lower')
|
| 235 |
+
plt.title("ch=42")
|
| 236 |
+
plt.xlabel('time step')
|
| 237 |
+
plt.ylabel('F')
|
| 238 |
+
plt.subplot(2, 4, 4)
|
| 239 |
+
plt.imshow(x_conv[0][:, :, 80].detach().numpy().T,
|
| 240 |
+
aspect='auto',
|
| 241 |
+
origin='lower')
|
| 242 |
+
plt.title("ch=80")
|
| 243 |
+
plt.xlabel('time step')
|
| 244 |
+
plt.ylabel('F')
|
| 245 |
+
plt.subplot(2, 4, 5)
|
| 246 |
+
plt.imshow(x_conv[0][:, :, 11].detach().numpy().T,
|
| 247 |
+
aspect='auto',
|
| 248 |
+
origin='lower')
|
| 249 |
+
plt.title("ch=11")
|
| 250 |
+
plt.xlabel('time step')
|
| 251 |
+
plt.ylabel('F')
|
| 252 |
+
plt.subplot(2, 4, 6)
|
| 253 |
+
plt.imshow(x_conv[0][:, :, 20].detach().numpy().T,
|
| 254 |
+
aspect='auto',
|
| 255 |
+
origin='lower')
|
| 256 |
+
plt.title("ch=20")
|
| 257 |
+
plt.xlabel('time step')
|
| 258 |
+
plt.ylabel('F')
|
| 259 |
+
plt.subplot(2, 4, 7)
|
| 260 |
+
plt.imshow(x_conv[0][:, :, 77].detach().numpy().T,
|
| 261 |
+
aspect='auto',
|
| 262 |
+
origin='lower')
|
| 263 |
+
plt.title("ch=77")
|
| 264 |
+
plt.xlabel('time step')
|
| 265 |
+
plt.ylabel('F')
|
| 266 |
+
plt.subplot(2, 4, 8)
|
| 267 |
+
plt.imshow(x_conv[0][:, :, 90].detach().numpy().T,
|
| 268 |
+
aspect='auto',
|
| 269 |
+
origin='lower')
|
| 270 |
+
plt.title("ch=90")
|
| 271 |
+
plt.xlabel('time step')
|
| 272 |
+
plt.ylabel('F')
|
| 273 |
+
plt.tight_layout()
|
| 274 |
+
plt.show()
|
| 275 |
+
|
| 276 |
+
# encoding
|
| 277 |
+
output = model.encoder(inputs_embeds=x_conv,
|
| 278 |
+
output_hidden_states=True,
|
| 279 |
+
output_attentions=True)
|
| 280 |
+
enc_hs_all, att, catt = output["hidden_states"], output[
|
| 281 |
+
"attentions"], output["cross_attentions"]
|
| 282 |
+
enc_hs_last = enc_hs_all[2]
|
| 283 |
+
|
| 284 |
+
# enc_hs: time-varying encoder hidden state
|
| 285 |
+
plt.subplot(2, 3, 1)
|
| 286 |
+
plt.imshow(enc_hs_all[0][0][:, :, 21].detach().numpy().T)
|
| 287 |
+
plt.title('ENC_HS B0, d21')
|
| 288 |
+
plt.colorbar(orientation='horizontal')
|
| 289 |
+
plt.ylabel('latent k')
|
| 290 |
+
plt.xlabel('t')
|
| 291 |
+
plt.subplot(2, 3, 4)
|
| 292 |
+
plt.imshow(enc_hs_all[0][0][:, :, 127].detach().numpy().T)
|
| 293 |
+
plt.colorbar(orientation='horizontal')
|
| 294 |
+
plt.title('B0, d127')
|
| 295 |
+
plt.ylabel('latent k')
|
| 296 |
+
plt.xlabel('t')
|
| 297 |
+
plt.subplot(2, 3, 2)
|
| 298 |
+
plt.imshow(enc_hs_all[1][0][:, :, 21].detach().numpy().T)
|
| 299 |
+
plt.colorbar(orientation='horizontal')
|
| 300 |
+
plt.title('B1, d21')
|
| 301 |
+
plt.ylabel('latent k')
|
| 302 |
+
plt.xlabel('t')
|
| 303 |
+
plt.subplot(2, 3, 5)
|
| 304 |
+
plt.imshow(enc_hs_all[1][0][:, :, 127].detach().numpy().T)
|
| 305 |
+
plt.colorbar(orientation='horizontal')
|
| 306 |
+
plt.title('B1, d127')
|
| 307 |
+
plt.ylabel('latent k')
|
| 308 |
+
plt.xlabel('t')
|
| 309 |
+
plt.subplot(2, 3, 3)
|
| 310 |
+
plt.imshow(enc_hs_all[2][0][:, :, 21].detach().numpy().T)
|
| 311 |
+
plt.colorbar(orientation='horizontal')
|
| 312 |
+
plt.title('B2, d21')
|
| 313 |
+
plt.ylabel('latent k')
|
| 314 |
+
plt.xlabel('t')
|
| 315 |
+
plt.subplot(2, 3, 6)
|
| 316 |
+
plt.imshow(enc_hs_all[2][0][:, :, 127].detach().numpy().T)
|
| 317 |
+
plt.colorbar(orientation='horizontal')
|
| 318 |
+
plt.title('B2, d127')
|
| 319 |
+
plt.ylabel('latent k')
|
| 320 |
+
plt.xlabel('t')
|
| 321 |
+
plt.tight_layout()
|
| 322 |
+
plt.show()
|
| 323 |
+
|
| 324 |
+
enc_hs_proj = model.pre_decoder(enc_hs_last)
|
| 325 |
+
plt.imshow(enc_hs_proj[0].detach().numpy())
|
| 326 |
+
plt.title(
|
| 327 |
+
'ENC_HS_PROJ: linear projection of encoder output, which is used for enc-dec cross attention'
|
| 328 |
+
)
|
| 329 |
+
plt.colorbar(orientation='horizontal')
|
| 330 |
+
plt.ylabel('latent k')
|
| 331 |
+
plt.xlabel('d')
|
| 332 |
+
plt.show()
|
| 333 |
+
|
| 334 |
+
plt.subplot(221)
|
| 335 |
+
plt.imshow(enc_hs_all[2][0][0, :, :].detach().numpy(), aspect='auto')
|
| 336 |
+
plt.title('enc_hs, t=0')
|
| 337 |
+
plt.ylabel('latent k')
|
| 338 |
+
plt.xlabel('d')
|
| 339 |
+
plt.subplot(222)
|
| 340 |
+
plt.imshow(enc_hs_all[2][0][10, :, :].detach().numpy(), aspect='auto')
|
| 341 |
+
plt.title('enc_hs, t=10')
|
| 342 |
+
plt.ylabel('latent k')
|
| 343 |
+
plt.xlabel('d')
|
| 344 |
+
plt.subplot(223)
|
| 345 |
+
plt.imshow(enc_hs_all[2][0][20, :, :].detach().numpy(), aspect='auto')
|
| 346 |
+
plt.title('enc_hs, t=20')
|
| 347 |
+
plt.ylabel('latent k')
|
| 348 |
+
plt.xlabel('d')
|
| 349 |
+
plt.subplot(224)
|
| 350 |
+
plt.imshow(enc_hs_all[2][0][30, :, :].detach().numpy(), aspect='auto')
|
| 351 |
+
plt.title('enc_hs, t=30')
|
| 352 |
+
plt.ylabel('latent k')
|
| 353 |
+
plt.xlabel('d')
|
| 354 |
+
plt.tight_layout()
|
| 355 |
+
plt.show()
|
| 356 |
+
|
| 357 |
+
# enc_hs correlation: which dim has most unique info?
|
| 358 |
+
plt.subplot(1, 3, 1)
|
| 359 |
+
a = rearrange(enc_hs_last, '1 t k d -> t (k d)').detach().numpy()
|
| 360 |
+
plt.imshow(cosine_similarity(a))
|
| 361 |
+
plt.title("enc hs, t x t cos_sim")
|
| 362 |
+
plt.subplot(1, 3, 2)
|
| 363 |
+
b = rearrange(enc_hs_last, '1 t k d -> k (t d)').detach().numpy()
|
| 364 |
+
plt.imshow(cosine_similarity(b))
|
| 365 |
+
plt.title("enc hs, k x k cos_sim")
|
| 366 |
+
plt.subplot(1, 3, 3)
|
| 367 |
+
c = rearrange(enc_hs_last, '1 t k d -> d (k t)').detach().numpy()
|
| 368 |
+
plt.imshow(cosine_similarity(c))
|
| 369 |
+
plt.title("cross att, d x d cos_sim")
|
| 370 |
+
plt.tight_layout()
|
| 371 |
+
plt.show()
|
| 372 |
+
|
| 373 |
+
# enc latent
|
| 374 |
+
plt.imshow(model.encoder.latent_array.latents.detach().numpy())
|
| 375 |
+
plt.title('latent array')
|
| 376 |
+
plt.xlabel('d')
|
| 377 |
+
plt.ylabel('latent k')
|
| 378 |
+
plt.show()
|
| 379 |
+
|
| 380 |
+
# enc Spectral Cross Attention: (T x head x K x D). How latent K attends to conv channel C?
|
| 381 |
+
plt.subplot(311)
|
| 382 |
+
plt.imshow(
|
| 383 |
+
torch.sum(torch.sum(catt[0][0], axis=0), axis=0).detach().numpy())
|
| 384 |
+
plt.title('block=0')
|
| 385 |
+
plt.ylabel('latent k')
|
| 386 |
+
plt.xlabel('conv channel')
|
| 387 |
+
plt.subplot(312)
|
| 388 |
+
plt.imshow(
|
| 389 |
+
torch.sum(torch.sum(catt[1][0], axis=0), axis=0).detach().numpy())
|
| 390 |
+
plt.title('block=1')
|
| 391 |
+
plt.ylabel('latent k')
|
| 392 |
+
plt.xlabel('conv channel')
|
| 393 |
+
plt.subplot(313)
|
| 394 |
+
plt.imshow(
|
| 395 |
+
torch.sum(torch.sum(catt[2][0], axis=0), axis=0).detach().numpy())
|
| 396 |
+
plt.title('block=2')
|
| 397 |
+
plt.ylabel('latent k')
|
| 398 |
+
plt.xlabel('conv channel')
|
| 399 |
+
plt.tight_layout()
|
| 400 |
+
plt.show()
|
| 401 |
+
# enc Latent Self-attention: How latent K attends to K?
|
| 402 |
+
plt.subplot(231)
|
| 403 |
+
plt.imshow(torch.sum(torch.sum(att[0][0], axis=1),
|
| 404 |
+
axis=0).detach().numpy(),
|
| 405 |
+
origin='upper')
|
| 406 |
+
plt.title('B0L0')
|
| 407 |
+
plt.xlabel('latent k')
|
| 408 |
+
plt.ylabel('latent k')
|
| 409 |
+
plt.subplot(234)
|
| 410 |
+
plt.imshow(torch.sum(torch.sum(att[0][1], axis=1),
|
| 411 |
+
axis=0).detach().numpy(),
|
| 412 |
+
origin='upper')
|
| 413 |
+
plt.title('B0L1')
|
| 414 |
+
plt.xlabel('latent k')
|
| 415 |
+
plt.ylabel('latent k')
|
| 416 |
+
plt.subplot(232)
|
| 417 |
+
plt.imshow(torch.sum(torch.sum(att[1][0], axis=1),
|
| 418 |
+
axis=0).detach().numpy(),
|
| 419 |
+
origin='upper')
|
| 420 |
+
plt.title('B1L0')
|
| 421 |
+
plt.xlabel('latent k')
|
| 422 |
+
plt.ylabel('latent k')
|
| 423 |
+
plt.subplot(235)
|
| 424 |
+
plt.imshow(torch.sum(torch.sum(att[1][1], axis=1),
|
| 425 |
+
axis=0).detach().numpy(),
|
| 426 |
+
origin='upper')
|
| 427 |
+
plt.title('B1L1')
|
| 428 |
+
plt.xlabel('latent k')
|
| 429 |
+
plt.ylabel('latent k')
|
| 430 |
+
plt.subplot(233)
|
| 431 |
+
plt.imshow(torch.sum(torch.sum(att[2][0], axis=1),
|
| 432 |
+
axis=0).detach().numpy(),
|
| 433 |
+
origin='upper')
|
| 434 |
+
plt.title('B2L0')
|
| 435 |
+
plt.xlabel('latent k')
|
| 436 |
+
plt.ylabel('latent k')
|
| 437 |
+
plt.subplot(236)
|
| 438 |
+
plt.imshow(torch.sum(torch.sum(att[2][1], axis=1),
|
| 439 |
+
axis=0).detach().numpy(),
|
| 440 |
+
origin='upper')
|
| 441 |
+
plt.title('B2L1')
|
| 442 |
+
plt.xlabel('latent k')
|
| 443 |
+
plt.ylabel('latent k')
|
| 444 |
+
plt.tight_layout()
|
| 445 |
+
plt.show()
|
| 446 |
+
# Time varying, different head for latent self-attention
|
| 447 |
+
plt.subplot(231)
|
| 448 |
+
plt.imshow(att[0][0][30, 3, :, :].detach().numpy())
|
| 449 |
+
plt.title('B0L0, t=30, Head=3')
|
| 450 |
+
plt.colorbar(orientation='horizontal')
|
| 451 |
+
plt.xlabel('k')
|
| 452 |
+
plt.ylabel('k')
|
| 453 |
+
plt.subplot(234)
|
| 454 |
+
plt.imshow(att[0][1][30, 3, :, :].detach().numpy())
|
| 455 |
+
plt.title('B0L1, t=30, Head=3')
|
| 456 |
+
plt.colorbar(orientation='horizontal')
|
| 457 |
+
plt.xlabel('k')
|
| 458 |
+
plt.ylabel('k')
|
| 459 |
+
plt.subplot(232)
|
| 460 |
+
plt.imshow(att[1][0][30, 3, :, :].detach().numpy())
|
| 461 |
+
plt.title('B1L0, t=30, Head=3')
|
| 462 |
+
plt.colorbar(orientation='horizontal')
|
| 463 |
+
plt.xlabel('k')
|
| 464 |
+
plt.ylabel('k')
|
| 465 |
+
plt.subplot(235)
|
| 466 |
+
plt.imshow(att[1][1][30, 3, :, :].detach().numpy())
|
| 467 |
+
plt.title('B1L1, t=30, Head=3')
|
| 468 |
+
plt.colorbar(orientation='horizontal')
|
| 469 |
+
plt.xlabel('k')
|
| 470 |
+
plt.ylabel('k')
|
| 471 |
+
plt.subplot(233)
|
| 472 |
+
plt.imshow(att[2][0][30, 3, :, :].detach().numpy())
|
| 473 |
+
plt.title('B2L0, t=30, Head=3')
|
| 474 |
+
plt.colorbar(orientation='horizontal')
|
| 475 |
+
plt.xlabel('k')
|
| 476 |
+
plt.ylabel('k')
|
| 477 |
+
plt.subplot(236)
|
| 478 |
+
plt.imshow(att[2][1][30, 3, :, :].detach().numpy())
|
| 479 |
+
plt.title('B2L1, t=30, Head=3')
|
| 480 |
+
plt.colorbar(orientation='horizontal')
|
| 481 |
+
plt.xlabel('k')
|
| 482 |
+
plt.ylabel('k')
|
| 483 |
+
plt.tight_layout()
|
| 484 |
+
plt.show()
|
| 485 |
+
plt.subplot(231)
|
| 486 |
+
plt.imshow(att[0][0][30, 5, :, :].detach().numpy())
|
| 487 |
+
plt.title('B0L0, t=30, Head=5')
|
| 488 |
+
plt.colorbar(orientation='horizontal')
|
| 489 |
+
plt.xlabel('k')
|
| 490 |
+
plt.ylabel('k')
|
| 491 |
+
plt.subplot(234)
|
| 492 |
+
plt.imshow(att[0][1][30, 5, :, :].detach().numpy())
|
| 493 |
+
plt.title('B0L1, t=30, Head=5')
|
| 494 |
+
plt.colorbar(orientation='horizontal')
|
| 495 |
+
plt.xlabel('k')
|
| 496 |
+
plt.ylabel('k')
|
| 497 |
+
plt.subplot(232)
|
| 498 |
+
plt.imshow(att[1][0][30, 5, :, :].detach().numpy())
|
| 499 |
+
plt.title('B1L0, t=30, Head=5')
|
| 500 |
+
plt.colorbar(orientation='horizontal')
|
| 501 |
+
plt.xlabel('k')
|
| 502 |
+
plt.ylabel('k')
|
| 503 |
+
plt.subplot(235)
|
| 504 |
+
plt.imshow(att[1][1][30, 5, :, :].detach().numpy())
|
| 505 |
+
plt.title('B1L1, t=30, Head=5')
|
| 506 |
+
plt.colorbar(orientation='horizontal')
|
| 507 |
+
plt.xlabel('k')
|
| 508 |
+
plt.ylabel('k')
|
| 509 |
+
plt.subplot(233)
|
| 510 |
+
plt.imshow(att[2][0][30, 5, :, :].detach().numpy())
|
| 511 |
+
plt.title('B2L0, t=30, Head=5')
|
| 512 |
+
plt.colorbar(orientation='horizontal')
|
| 513 |
+
plt.xlabel('k')
|
| 514 |
+
plt.ylabel('k')
|
| 515 |
+
plt.subplot(236)
|
| 516 |
+
plt.imshow(att[2][1][30, 5, :, :].detach().numpy())
|
| 517 |
+
plt.title('B2L1, t=30, Head=5')
|
| 518 |
+
plt.colorbar(orientation='horizontal')
|
| 519 |
+
plt.xlabel('k')
|
| 520 |
+
plt.ylabel('k')
|
| 521 |
+
plt.tight_layout()
|
| 522 |
+
plt.show()
|
| 523 |
+
|
| 524 |
+
# Temporal Self-attention: (K x H x T x T) How time t attends to time t?
|
| 525 |
+
plt.subplot(231)
|
| 526 |
+
plt.imshow(torch.sum(torch.sum(att[0][2], axis=1),
|
| 527 |
+
axis=0).detach().numpy(),
|
| 528 |
+
origin='upper')
|
| 529 |
+
plt.title('B0L2')
|
| 530 |
+
plt.xlabel('t')
|
| 531 |
+
plt.ylabel('t')
|
| 532 |
+
plt.subplot(234)
|
| 533 |
+
plt.imshow(torch.sum(torch.sum(att[0][3], axis=1),
|
| 534 |
+
axis=0).detach().numpy(),
|
| 535 |
+
origin='upper')
|
| 536 |
+
plt.title('B0L3')
|
| 537 |
+
plt.xlabel('t')
|
| 538 |
+
plt.ylabel('t')
|
| 539 |
+
plt.subplot(232)
|
| 540 |
+
plt.imshow(torch.sum(torch.sum(att[1][2], axis=1),
|
| 541 |
+
axis=0).detach().numpy(),
|
| 542 |
+
origin='upper')
|
| 543 |
+
plt.title('B1L2')
|
| 544 |
+
plt.xlabel('t')
|
| 545 |
+
plt.ylabel('t')
|
| 546 |
+
plt.subplot(235)
|
| 547 |
+
plt.imshow(torch.sum(torch.sum(att[1][3], axis=1),
|
| 548 |
+
axis=0).detach().numpy(),
|
| 549 |
+
origin='upper')
|
| 550 |
+
plt.title('B1L3')
|
| 551 |
+
plt.xlabel('t')
|
| 552 |
+
plt.ylabel('t')
|
| 553 |
+
plt.subplot(233)
|
| 554 |
+
plt.imshow(torch.sum(torch.sum(att[2][2], axis=1),
|
| 555 |
+
axis=0).detach().numpy(),
|
| 556 |
+
origin='upper')
|
| 557 |
+
plt.title('B2L2')
|
| 558 |
+
plt.xlabel('t')
|
| 559 |
+
plt.ylabel('t')
|
| 560 |
+
plt.subplot(236)
|
| 561 |
+
plt.imshow(torch.sum(torch.sum(att[2][3], axis=1),
|
| 562 |
+
axis=0).detach().numpy(),
|
| 563 |
+
origin='upper')
|
| 564 |
+
plt.title('B2L3')
|
| 565 |
+
plt.xlabel('t')
|
| 566 |
+
plt.ylabel('t')
|
| 567 |
+
plt.tight_layout()
|
| 568 |
+
plt.show()
|
| 569 |
+
|
| 570 |
+
# decoding
|
| 571 |
+
dec_input_ids = model.shift_right_fn(label)
|
| 572 |
+
dec_inputs_embeds = model.embed_tokens(dec_input_ids)
|
| 573 |
+
dec_output = model.decoder(inputs_embeds=dec_inputs_embeds,
|
| 574 |
+
encoder_hidden_states=enc_hs_proj,
|
| 575 |
+
output_attentions=True,
|
| 576 |
+
output_hidden_states=True,
|
| 577 |
+
return_dict=True)
|
| 578 |
+
dec_att, dec_catt = dec_output.attentions, dec_output.cross_attentions
|
| 579 |
+
dec_hs_all = dec_output.hidden_states
|
| 580 |
+
|
| 581 |
+
# dec att
|
| 582 |
+
plt.subplot(1, 2, 1)
|
| 583 |
+
plt.imshow(torch.sum(dec_att[0][0], axis=0).detach().numpy())
|
| 584 |
+
plt.title('decoder attention, layer0')
|
| 585 |
+
plt.xlabel('decoder time step')
|
| 586 |
+
plt.ylabel('decoder time step')
|
| 587 |
+
plt.subplot(1, 2, 2)
|
| 588 |
+
plt.imshow(torch.sum(dec_att[7][0], axis=0).detach().numpy())
|
| 589 |
+
plt.title('decoder attention, layer8')
|
| 590 |
+
plt.xlabel('decoder time step')
|
| 591 |
+
plt.show()
|
| 592 |
+
# dec catt
|
| 593 |
+
plt.imshow(np.rot90((torch.sum(dec_catt[7][0],
|
| 594 |
+
axis=0))[:1000, :].detach().numpy()),
|
| 595 |
+
origin='upper',
|
| 596 |
+
aspect='auto')
|
| 597 |
+
plt.colorbar()
|
| 598 |
+
plt.title('decoder cross att, layer8')
|
| 599 |
+
plt.xlabel('decoder time step')
|
| 600 |
+
plt.ylabel('encoder frame')
|
| 601 |
+
plt.show()
|
| 602 |
+
# dec catt by head with xxx
|
| 603 |
+
dec_att_z = z_normalize_tensors(shorten_att(dec_att))
|
| 604 |
+
plt.imshow(dec_att_z[0][0, 0, :, :].detach().numpy())
|
| 605 |
+
from bertviz import head_view
|
| 606 |
+
token = []
|
| 607 |
+
for i in label[0, :30]:
|
| 608 |
+
token.append(str(i))
|
| 609 |
+
head_view(dec_att_z, tokens)
|
| 610 |
+
|
| 611 |
+
# dec_hs
|
| 612 |
+
plt.subplot(1, 2, 1)
|
| 613 |
+
plt.imshow(dec_hs_all[0][0].detach().numpy(), origin='upper')
|
| 614 |
+
plt.colorbar(orientation='horizontal')
|
| 615 |
+
plt.title('decoder hidden state, layer1')
|
| 616 |
+
plt.xlabel('hidden dim')
|
| 617 |
+
plt.ylabel('time step')
|
| 618 |
+
plt.subplot(1, 2, 2)
|
| 619 |
+
plt.imshow(dec_hs_all[7][0].detach().numpy(), origin='upper')
|
| 620 |
+
plt.colorbar(orientation='horizontal')
|
| 621 |
+
plt.title('decoder hidden state, layer8')
|
| 622 |
+
plt.xlabel('hidden dim')
|
| 623 |
+
plt.show()
|
| 624 |
+
|
| 625 |
+
# lm head
|
| 626 |
+
logits = model.lm_head(dec_hs_all[0])
|
| 627 |
+
plt.imshow(logits[0][0:200, :].detach().numpy(), origin='upper')
|
| 628 |
+
plt.title('lm head softmax')
|
| 629 |
+
plt.xlabel('vocab dim')
|
| 630 |
+
plt.ylabel('time step')
|
| 631 |
+
plt.xlim([1000, 1350])
|
| 632 |
+
plt.show()
|
| 633 |
+
softmax = torch.nn.Softmax(dim=2)
|
| 634 |
+
logits_sm = softmax(logits)
|
| 635 |
+
plt.imshow(logits_sm[0][0:200, :].detach().numpy(), origin='upper')
|
| 636 |
+
plt.title('lm head softmax')
|
| 637 |
+
plt.xlabel('vocab dim')
|
| 638 |
+
plt.ylabel('time step')
|
| 639 |
+
plt.xlim([1000, 1350])
|
| 640 |
+
plt.show()
|
extras/perceivertf_multi_inspect.py
ADDED
|
@@ -0,0 +1,778 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import numpy as np
|
| 2 |
+
import torch
|
| 3 |
+
import torch.nn.functional as F
|
| 4 |
+
import torchaudio
|
| 5 |
+
from matplotlib.animation import FuncAnimation
|
| 6 |
+
|
| 7 |
+
def l2_normalize(matrix):
|
| 8 |
+
"""
|
| 9 |
+
L2 Normalize the matrix along its rows.
|
| 10 |
+
|
| 11 |
+
Parameters:
|
| 12 |
+
matrix (numpy.ndarray): The input matrix.
|
| 13 |
+
|
| 14 |
+
Returns:
|
| 15 |
+
numpy.ndarray: The L2 normalized matrix.
|
| 16 |
+
"""
|
| 17 |
+
l2_norms = np.linalg.norm(matrix, axis=1, keepdims=True)
|
| 18 |
+
normalized_matrix = matrix / l2_norms
|
| 19 |
+
return normalized_matrix
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
def z_normalize(matrix):
|
| 23 |
+
"""
|
| 24 |
+
Z-normalize the matrix along its rows (mean=0 and std=1).
|
| 25 |
+
Z-normalization is also known as "standardization", and derives from z-score.
|
| 26 |
+
Z = (X - mean) / std
|
| 27 |
+
Z-nomarlized, each row has mean=0 and std=1.
|
| 28 |
+
|
| 29 |
+
Parameters:
|
| 30 |
+
matrix (numpy.ndarray): The input matrix.
|
| 31 |
+
|
| 32 |
+
Returns:
|
| 33 |
+
numpy.ndarray: The Z normalized matrix.
|
| 34 |
+
"""
|
| 35 |
+
mean = np.mean(matrix, axis=1, keepdims=True)
|
| 36 |
+
std = np.std(matrix, axis=1, keepdims=True)
|
| 37 |
+
normalized_matrix = (matrix - mean) / std
|
| 38 |
+
return normalized_matrix
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
def l2_normalize_tensors(tensor_tuple):
|
| 42 |
+
"""
|
| 43 |
+
Applies L2 normalization on the last two dimensions for each tensor in a tuple.
|
| 44 |
+
|
| 45 |
+
Parameters:
|
| 46 |
+
tensor_tuple (tuple of torch.Tensor): A tuple containing N tensors, each of shape (1, k, 30, 30).
|
| 47 |
+
|
| 48 |
+
Returns:
|
| 49 |
+
tuple of torch.Tensor: A tuple containing N L2-normalized tensors.
|
| 50 |
+
"""
|
| 51 |
+
normalized_tensors = []
|
| 52 |
+
for tensor in tensor_tuple:
|
| 53 |
+
# Ensure the tensor is a floating-point type
|
| 54 |
+
tensor = tensor.float()
|
| 55 |
+
|
| 56 |
+
# Calculate L2 norm on the last two dimensions, keeping the dimensions using keepdim=True
|
| 57 |
+
l2_norm = torch.linalg.norm(tensor, dim=(-2, -1), keepdim=True)
|
| 58 |
+
|
| 59 |
+
# Apply L2 normalization
|
| 60 |
+
normalized_tensor = tensor / (
|
| 61 |
+
l2_norm + 1e-7) # Small value to avoid division by zero
|
| 62 |
+
|
| 63 |
+
normalized_tensors.append(normalized_tensor)
|
| 64 |
+
|
| 65 |
+
return tuple(normalized_tensors)
|
| 66 |
+
|
| 67 |
+
|
| 68 |
+
def z_normalize_tensors(tensor_tuple):
|
| 69 |
+
"""
|
| 70 |
+
Applies Z-normalization on the last two dimensions for each tensor in a tuple.
|
| 71 |
+
|
| 72 |
+
Parameters:
|
| 73 |
+
tensor_tuple (tuple of torch.Tensor): A tuple containing N tensors, each of shape (1, k, 30, 30).
|
| 74 |
+
|
| 75 |
+
Returns:
|
| 76 |
+
tuple of torch.Tensor: A tuple containing N Z-normalized tensors.
|
| 77 |
+
"""
|
| 78 |
+
normalized_tensors = []
|
| 79 |
+
for tensor in tensor_tuple:
|
| 80 |
+
# Ensure the tensor is a floating-point type
|
| 81 |
+
tensor = tensor.float()
|
| 82 |
+
|
| 83 |
+
# Calculate mean and std on the last two dimensions
|
| 84 |
+
mean = tensor.mean(dim=(-2, -1), keepdim=True)
|
| 85 |
+
std = tensor.std(dim=(-2, -1), keepdim=True)
|
| 86 |
+
|
| 87 |
+
# Apply Z-normalization
|
| 88 |
+
normalized_tensor = (tensor - mean) / (
|
| 89 |
+
std + 1e-7) # Small value to avoid division by zero
|
| 90 |
+
|
| 91 |
+
normalized_tensors.append(normalized_tensor)
|
| 92 |
+
|
| 93 |
+
return tuple(normalized_tensors)
|
| 94 |
+
|
| 95 |
+
|
| 96 |
+
def apply_temperature_to_attention_tensors(tensor_tuple, temperature=1.0):
|
| 97 |
+
"""
|
| 98 |
+
Applies temperature scaling to the attention weights in each tensor in a tuple.
|
| 99 |
+
|
| 100 |
+
Parameters:
|
| 101 |
+
tensor_tuple (tuple of torch.Tensor): A tuple containing N tensors,
|
| 102 |
+
each of shape (1, k, 30, 30).
|
| 103 |
+
temperature (float): Temperature parameter to control the sharpness
|
| 104 |
+
of the attention weights. Default is 1.0.
|
| 105 |
+
|
| 106 |
+
Returns:
|
| 107 |
+
tuple of torch.Tensor: A tuple containing N tensors with scaled attention weights.
|
| 108 |
+
"""
|
| 109 |
+
scaled_attention_tensors = []
|
| 110 |
+
|
| 111 |
+
for tensor in tensor_tuple:
|
| 112 |
+
# Ensure the tensor is a floating-point type
|
| 113 |
+
tensor = tensor.float()
|
| 114 |
+
|
| 115 |
+
# Flatten the last two dimensions
|
| 116 |
+
flattened_tensor = tensor.reshape(1, tensor.shape[1],
|
| 117 |
+
-1) # Modified line here
|
| 118 |
+
|
| 119 |
+
# Apply temperature scaling and softmax along the last dimension
|
| 120 |
+
scaled_attention = flattened_tensor / temperature
|
| 121 |
+
scaled_attention = F.softmax(scaled_attention, dim=-1)
|
| 122 |
+
|
| 123 |
+
# Reshape to original shape
|
| 124 |
+
scaled_attention = scaled_attention.view_as(tensor)
|
| 125 |
+
|
| 126 |
+
scaled_attention_tensors.append(scaled_attention)
|
| 127 |
+
|
| 128 |
+
return tuple(scaled_attention_tensors)
|
| 129 |
+
|
| 130 |
+
|
| 131 |
+
def shorten_att(tensor_tuple, length=30):
|
| 132 |
+
shortend_tensors = []
|
| 133 |
+
for tensor in tensor_tuple:
|
| 134 |
+
shortend_tensors.append(tensor[:, :, :length, :length])
|
| 135 |
+
return tuple(shortend_tensors)
|
| 136 |
+
|
| 137 |
+
|
| 138 |
+
def keep_top_k(matrix, k=6):
|
| 139 |
+
"""
|
| 140 |
+
Keep only the top k values in each row, set the rest to 0.
|
| 141 |
+
|
| 142 |
+
Parameters:
|
| 143 |
+
matrix (numpy.ndarray): The input matrix.
|
| 144 |
+
k (int): The number of top values to keep in each row.
|
| 145 |
+
|
| 146 |
+
Returns:
|
| 147 |
+
numpy.ndarray: The transformed matrix.
|
| 148 |
+
"""
|
| 149 |
+
topk_indices_per_row = np.argpartition(matrix, -k, axis=1)[:, -k:]
|
| 150 |
+
result_matrix = np.zeros_like(matrix)
|
| 151 |
+
|
| 152 |
+
for i in range(matrix.shape[0]):
|
| 153 |
+
result_matrix[i, topk_indices_per_row[i]] = matrix[
|
| 154 |
+
i, topk_indices_per_row[i]]
|
| 155 |
+
return result_matrix
|
| 156 |
+
|
| 157 |
+
|
| 158 |
+
def test_case_forward_enc_perceiver_tf_dec_multi_t5():
|
| 159 |
+
import torch
|
| 160 |
+
from model.ymt3 import YourMT3
|
| 161 |
+
from config.config import audio_cfg, model_cfg, shared_cfg
|
| 162 |
+
model_cfg["encoder_type"] = "perceiver-tf"
|
| 163 |
+
|
| 164 |
+
model_cfg["encoder"]["perceiver-tf"]["attention_to_channel"] = True
|
| 165 |
+
model_cfg["encoder"]["perceiver-tf"]["num_latents"] = 26
|
| 166 |
+
|
| 167 |
+
model_cfg["decoder_type"] = "multi-t5"
|
| 168 |
+
|
| 169 |
+
audio_cfg["codec"] = "spec"
|
| 170 |
+
audio_cfg["hop_length"] = 300
|
| 171 |
+
model = YourMT3(audio_cfg=audio_cfg, model_cfg=model_cfg)
|
| 172 |
+
model.eval()
|
| 173 |
+
|
| 174 |
+
# x = torch.randn(2, 1, 32767)
|
| 175 |
+
# labels = torch.randint(0, 400, (2, 1024), requires_grad=False)
|
| 176 |
+
|
| 177 |
+
# # forward
|
| 178 |
+
# output = model.forward(x, labels)
|
| 179 |
+
|
| 180 |
+
# # inference
|
| 181 |
+
# result = model.inference(x, None)
|
| 182 |
+
|
| 183 |
+
# display latents
|
| 184 |
+
checkpoint = torch.load(
|
| 185 |
+
"../logs/ymt3/ptf_mc13_256_all_cross_v6_xk5_amp0811_edr005_attend_c_full_plus_2psn_nl26_sb_b26r_800k/checkpoints/model.ckpt",
|
| 186 |
+
map_location="cpu")
|
| 187 |
+
state_dict = checkpoint['state_dict']
|
| 188 |
+
new_state_dict = {
|
| 189 |
+
k: v
|
| 190 |
+
for k, v in state_dict.items() if 'pitchshift' not in k
|
| 191 |
+
}
|
| 192 |
+
model.load_state_dict(new_state_dict, strict=False)
|
| 193 |
+
|
| 194 |
+
latents = model.encoder.latent_array.latents.detach().numpy()
|
| 195 |
+
import matplotlib.pyplot as plt
|
| 196 |
+
import numpy as np
|
| 197 |
+
from sklearn.metrics.pairwise import cosine_similarity
|
| 198 |
+
cos = cosine_similarity(latents)
|
| 199 |
+
|
| 200 |
+
from utils.data_modules import AMTDataModule
|
| 201 |
+
from einops import rearrange
|
| 202 |
+
# dm = AMTDataModule(data_preset_multi={"presets": ["slakh"]})
|
| 203 |
+
#dm.setup("test")
|
| 204 |
+
# dl = dm.test_dataloader()
|
| 205 |
+
# ds = list(dl.values())[0].dataset
|
| 206 |
+
# audio, notes, tokens, _ = ds.__getitem__(7)
|
| 207 |
+
# x = audio[[16], ::]
|
| 208 |
+
# label = tokens[[16], :]
|
| 209 |
+
|
| 210 |
+
# from utils.task_manager import TaskManager
|
| 211 |
+
# tm = TaskManager(task_name='mc13_256')
|
| 212 |
+
# dm = AMTDataModule(data_preset_multi={"presets": ["slakh"]},
|
| 213 |
+
# task_manager=tm,
|
| 214 |
+
# train_stem_iaug_prob=None,
|
| 215 |
+
# train_stem_xaug_policy=None)
|
| 216 |
+
# dm.setup('fit')
|
| 217 |
+
# dl = dm.train_dataloader()
|
| 218 |
+
# ds = dl.flattened[0].dataset
|
| 219 |
+
# audio,tokens, _, _ = ds.__getitem__(67)
|
| 220 |
+
# x = audio[[5], ::]
|
| 221 |
+
# label = tokens[[5], :]
|
| 222 |
+
# save audio
|
| 223 |
+
# torchaudio.save("singing.wav", x[0, :, :], 16000)
|
| 224 |
+
|
| 225 |
+
x, _ = torchaudio.load('piano.wav')#'test.wav')
|
| 226 |
+
x = x.unsqueeze(0)
|
| 227 |
+
|
| 228 |
+
# spectrogram
|
| 229 |
+
x_spec = model.spectrogram(x)
|
| 230 |
+
x_conv = model.pre_encoder(x_spec)
|
| 231 |
+
# Create a larger figure
|
| 232 |
+
plt.figure(
|
| 233 |
+
figsize=(15,
|
| 234 |
+
10)) # Adjust these numbers as needed for width and height
|
| 235 |
+
plt.subplot(2, 4, 1)
|
| 236 |
+
plt.imshow(x_spec[0].detach().numpy().T, aspect='auto', origin='lower')
|
| 237 |
+
plt.title("spectrogram")
|
| 238 |
+
plt.xlabel('time step')
|
| 239 |
+
plt.ylabel('frequency bin')
|
| 240 |
+
plt.subplot(2, 4, 2)
|
| 241 |
+
plt.imshow(x_conv[0][:, :, 0].detach().numpy().T,
|
| 242 |
+
aspect='auto',
|
| 243 |
+
origin='lower')
|
| 244 |
+
plt.title("conv(spec), ch=0")
|
| 245 |
+
plt.xlabel('time step')
|
| 246 |
+
plt.ylabel('F')
|
| 247 |
+
plt.subplot(2, 4, 3)
|
| 248 |
+
plt.imshow(x_conv[0][:, :, 42].detach().numpy().T,
|
| 249 |
+
aspect='auto',
|
| 250 |
+
origin='lower')
|
| 251 |
+
plt.title("ch=42")
|
| 252 |
+
plt.xlabel('time step')
|
| 253 |
+
plt.ylabel('F')
|
| 254 |
+
plt.subplot(2, 4, 4)
|
| 255 |
+
plt.imshow(x_conv[0][:, :, 80].detach().numpy().T,
|
| 256 |
+
aspect='auto',
|
| 257 |
+
origin='lower')
|
| 258 |
+
plt.title("ch=80")
|
| 259 |
+
plt.xlabel('time step')
|
| 260 |
+
plt.ylabel('F')
|
| 261 |
+
plt.subplot(2, 4, 5)
|
| 262 |
+
plt.imshow(x_conv[0][:, :, 11].detach().numpy().T,
|
| 263 |
+
aspect='auto',
|
| 264 |
+
origin='lower')
|
| 265 |
+
plt.title("ch=11")
|
| 266 |
+
plt.xlabel('time step')
|
| 267 |
+
plt.ylabel('F')
|
| 268 |
+
plt.subplot(2, 4, 6)
|
| 269 |
+
plt.imshow(x_conv[0][:, :, 20].detach().numpy().T,
|
| 270 |
+
aspect='auto',
|
| 271 |
+
origin='lower')
|
| 272 |
+
plt.title("ch=20")
|
| 273 |
+
plt.xlabel('time step')
|
| 274 |
+
plt.ylabel('F')
|
| 275 |
+
plt.subplot(2, 4, 7)
|
| 276 |
+
plt.imshow(x_conv[0][:, :, 77].detach().numpy().T,
|
| 277 |
+
aspect='auto',
|
| 278 |
+
origin='lower')
|
| 279 |
+
plt.title("ch=77")
|
| 280 |
+
plt.xlabel('time step')
|
| 281 |
+
plt.ylabel('F')
|
| 282 |
+
plt.subplot(2, 4, 8)
|
| 283 |
+
plt.imshow(x_conv[0][:, :, 90].detach().numpy().T,
|
| 284 |
+
aspect='auto',
|
| 285 |
+
origin='lower')
|
| 286 |
+
plt.title("ch=90")
|
| 287 |
+
plt.xlabel('time step')
|
| 288 |
+
plt.ylabel('F')
|
| 289 |
+
plt.tight_layout()
|
| 290 |
+
plt.show()
|
| 291 |
+
|
| 292 |
+
# encoding
|
| 293 |
+
output = model.encoder(inputs_embeds=x_conv,
|
| 294 |
+
output_hidden_states=True,
|
| 295 |
+
output_attentions=True)
|
| 296 |
+
enc_hs_all, att, catt = output["hidden_states"], output[
|
| 297 |
+
"attentions"], output["cross_attentions"]
|
| 298 |
+
enc_hs_last = enc_hs_all[2]
|
| 299 |
+
|
| 300 |
+
# enc_hs: time-varying encoder hidden state
|
| 301 |
+
plt.subplot(2, 3, 1)
|
| 302 |
+
plt.imshow(enc_hs_all[0][0][:, :, 21].detach().numpy().T)
|
| 303 |
+
plt.title('ENC_HS B0, d21')
|
| 304 |
+
plt.colorbar(orientation='horizontal')
|
| 305 |
+
plt.ylabel('latent k')
|
| 306 |
+
plt.xlabel('t')
|
| 307 |
+
plt.subplot(2, 3, 4)
|
| 308 |
+
plt.imshow(enc_hs_all[0][0][:, :, 127].detach().numpy().T)
|
| 309 |
+
plt.colorbar(orientation='horizontal')
|
| 310 |
+
plt.title('B0, d127')
|
| 311 |
+
plt.ylabel('latent k')
|
| 312 |
+
plt.xlabel('t')
|
| 313 |
+
plt.subplot(2, 3, 2)
|
| 314 |
+
plt.imshow(enc_hs_all[1][0][:, :, 21].detach().numpy().T)
|
| 315 |
+
plt.colorbar(orientation='horizontal')
|
| 316 |
+
plt.title('B1, d21')
|
| 317 |
+
plt.ylabel('latent k')
|
| 318 |
+
plt.xlabel('t')
|
| 319 |
+
plt.subplot(2, 3, 5)
|
| 320 |
+
plt.imshow(enc_hs_all[1][0][:, :, 127].detach().numpy().T)
|
| 321 |
+
plt.colorbar(orientation='horizontal')
|
| 322 |
+
plt.title('B1, d127')
|
| 323 |
+
plt.ylabel('latent k')
|
| 324 |
+
plt.xlabel('t')
|
| 325 |
+
plt.subplot(2, 3, 3)
|
| 326 |
+
plt.imshow(enc_hs_all[2][0][:, :, 21].detach().numpy().T)
|
| 327 |
+
plt.colorbar(orientation='horizontal')
|
| 328 |
+
plt.title('B2, d21')
|
| 329 |
+
plt.ylabel('latent k')
|
| 330 |
+
plt.xlabel('t')
|
| 331 |
+
plt.subplot(2, 3, 6)
|
| 332 |
+
plt.imshow(enc_hs_all[2][0][:, :, 127].detach().numpy().T)
|
| 333 |
+
plt.colorbar(orientation='horizontal')
|
| 334 |
+
plt.title('B2, d127')
|
| 335 |
+
plt.ylabel('latent k')
|
| 336 |
+
plt.xlabel('t')
|
| 337 |
+
plt.tight_layout()
|
| 338 |
+
plt.show()
|
| 339 |
+
|
| 340 |
+
# enc_hs: time-varying encoder hidden state by k (block, 1, t, k, d)
|
| 341 |
+
# --> (t, d) for each k in last block
|
| 342 |
+
data = enc_hs_all[2][0].detach().numpy() # (T, K, D)
|
| 343 |
+
fig, axs = plt.subplots(
|
| 344 |
+
5, 5, figsize=(10, 9)) # 25 subplots arranged in 5 rows and 5 columns
|
| 345 |
+
axs = axs.flatten(
|
| 346 |
+
) # Flatten the 2D array of axes to 1D for easy iteration
|
| 347 |
+
|
| 348 |
+
for k in range(25): # Iterating through K indices from 0 to 24
|
| 349 |
+
axs[k].imshow(data[:, k, :].T,
|
| 350 |
+
cmap='viridis') # Transposing the matrix to swap T and D
|
| 351 |
+
axs[k].set_title(f'k={k}')
|
| 352 |
+
axs[k].set_xlabel('Time step')
|
| 353 |
+
axs[k].set_ylabel('Dim')
|
| 354 |
+
|
| 355 |
+
# Adjusting layout for better visibility
|
| 356 |
+
plt.tight_layout()
|
| 357 |
+
plt.show()
|
| 358 |
+
|
| 359 |
+
#!! Projected encoder hidden state for 13 channels, that is conditioning for decoder
|
| 360 |
+
enc_hs_proj = model.pre_decoder(enc_hs_last)
|
| 361 |
+
fig, axs = plt.subplots(1, 13, figsize=(26, 8)) # 13 subplots in a row
|
| 362 |
+
data = enc_hs_proj[0].detach().numpy()
|
| 363 |
+
for ch in range(13):
|
| 364 |
+
axs[ch].imshow(np.rot90(data[ch]), cmap='viridis') # Rotate 90 degrees
|
| 365 |
+
axs[ch].set_title(f'ch: {ch}')
|
| 366 |
+
axs[ch].set_xlabel('Time step')
|
| 367 |
+
axs[ch].set_ylabel('Dim')
|
| 368 |
+
plt.suptitle(
|
| 369 |
+
'linear projection of encoder outputs by channel, which is conditioning for enc-dec cross attention',
|
| 370 |
+
y=0.1,
|
| 371 |
+
fontsize=12)
|
| 372 |
+
plt.tight_layout(rect=[0, 0.1, 1, 1])
|
| 373 |
+
plt.show()
|
| 374 |
+
|
| 375 |
+
plt.subplot(221)
|
| 376 |
+
plt.imshow(enc_hs_all[2][0][0, :, :].detach().numpy(), aspect='auto')
|
| 377 |
+
plt.title('enc_hs, t=0')
|
| 378 |
+
plt.ylabel('latent k')
|
| 379 |
+
plt.xlabel('d')
|
| 380 |
+
plt.subplot(222)
|
| 381 |
+
plt.imshow(enc_hs_all[2][0][10, :, :].detach().numpy(), aspect='auto')
|
| 382 |
+
plt.title('enc_hs, t=10')
|
| 383 |
+
plt.ylabel('latent k')
|
| 384 |
+
plt.xlabel('d')
|
| 385 |
+
plt.subplot(223)
|
| 386 |
+
plt.imshow(enc_hs_all[2][0][20, :, :].detach().numpy(), aspect='auto')
|
| 387 |
+
plt.title('enc_hs, t=20')
|
| 388 |
+
plt.ylabel('latent k')
|
| 389 |
+
plt.xlabel('d')
|
| 390 |
+
plt.subplot(224)
|
| 391 |
+
plt.imshow(enc_hs_all[2][0][30, :, :].detach().numpy(), aspect='auto')
|
| 392 |
+
plt.title('enc_hs, t=30')
|
| 393 |
+
plt.ylabel('latent k')
|
| 394 |
+
plt.xlabel('d')
|
| 395 |
+
plt.tight_layout()
|
| 396 |
+
plt.show()
|
| 397 |
+
|
| 398 |
+
# enc_hs correlation: which dim has most unique info?
|
| 399 |
+
plt.subplot(1, 3, 1)
|
| 400 |
+
a = rearrange(enc_hs_last, '1 t k d -> t (k d)').detach().numpy()
|
| 401 |
+
plt.imshow(cosine_similarity(a))
|
| 402 |
+
plt.title("enc hs, t x t cos_sim")
|
| 403 |
+
plt.subplot(1, 3, 2)
|
| 404 |
+
b = rearrange(enc_hs_last, '1 t k d -> k (t d)').detach().numpy()
|
| 405 |
+
plt.imshow(cosine_similarity(b))
|
| 406 |
+
plt.title("enc hs, k x k cos_sim")
|
| 407 |
+
plt.subplot(1, 3, 3)
|
| 408 |
+
c = rearrange(enc_hs_last, '1 t k d -> d (k t)').detach().numpy()
|
| 409 |
+
plt.imshow(cosine_similarity(c))
|
| 410 |
+
plt.title("cross att, d x d cos_sim")
|
| 411 |
+
plt.tight_layout()
|
| 412 |
+
plt.show()
|
| 413 |
+
|
| 414 |
+
#!! enc latent
|
| 415 |
+
plt.imshow(model.encoder.latent_array.latents.detach().numpy())
|
| 416 |
+
plt.title('latent array')
|
| 417 |
+
plt.xlabel('d')
|
| 418 |
+
plt.ylabel('latent k')
|
| 419 |
+
plt.show()
|
| 420 |
+
|
| 421 |
+
#!! enc Spectral Cross Attention: (T x head x K x D). How latent K attends to conv channel C?
|
| 422 |
+
plt.subplot(311)
|
| 423 |
+
plt.imshow(
|
| 424 |
+
torch.sum(torch.sum(catt[0][0], axis=0), axis=0).detach().numpy())
|
| 425 |
+
plt.title('block=0')
|
| 426 |
+
plt.ylabel('latent k')
|
| 427 |
+
plt.xlabel('conv channel')
|
| 428 |
+
plt.subplot(312)
|
| 429 |
+
plt.imshow(
|
| 430 |
+
torch.sum(torch.sum(catt[1][0], axis=0), axis=0).detach().numpy())
|
| 431 |
+
plt.title('block=1')
|
| 432 |
+
plt.ylabel('latent k')
|
| 433 |
+
plt.xlabel('conv channel')
|
| 434 |
+
plt.subplot(313)
|
| 435 |
+
plt.imshow(
|
| 436 |
+
torch.sum(torch.sum(catt[2][0], axis=0), axis=0).detach().numpy())
|
| 437 |
+
plt.title('block=2')
|
| 438 |
+
plt.ylabel('latent k')
|
| 439 |
+
plt.xlabel('conv channel')
|
| 440 |
+
# f'spectral cross attention. T-C-F Model',
|
| 441 |
+
# y=0,
|
| 442 |
+
# fontsize=12)
|
| 443 |
+
plt.tight_layout()
|
| 444 |
+
plt.show()
|
| 445 |
+
|
| 446 |
+
#!! Animation of SCA for varying time, head in last block
|
| 447 |
+
fig, (ax1, ax2) = plt.subplots(2, 1, figsize=(10, 6)) # Adjusted figsize for better layout
|
| 448 |
+
|
| 449 |
+
# Function to update the plots for each frame in the animation
|
| 450 |
+
def update(t):
|
| 451 |
+
# Clear previous images
|
| 452 |
+
ax1.clear()
|
| 453 |
+
ax2.clear()
|
| 454 |
+
|
| 455 |
+
# Update subplot for h=3
|
| 456 |
+
ax1.imshow(catt[2][0][t, 3, :, :].detach().numpy())
|
| 457 |
+
ax1.set_title(f'block=2, t={t}, head=3')
|
| 458 |
+
ax1.set_ylabel('latent k'); ax1.set_xlabel('conv channel')
|
| 459 |
+
|
| 460 |
+
# Update subplot for h=5
|
| 461 |
+
ax2.imshow(catt[2][0][t, 5, :, :].detach().numpy())
|
| 462 |
+
ax2.set_title(f'block=2, t={t}, head=5')
|
| 463 |
+
ax2.set_ylabel('latent k'); ax2.set_xlabel('conv channel')
|
| 464 |
+
|
| 465 |
+
# Adjust layout
|
| 466 |
+
fig.tight_layout()
|
| 467 |
+
|
| 468 |
+
# Create the animation
|
| 469 |
+
anim = FuncAnimation(fig, update, frames=range(0, 110), interval=200)
|
| 470 |
+
anim.save('animation.gif', writer='pillow', fps=5)
|
| 471 |
+
|
| 472 |
+
|
| 473 |
+
|
| 474 |
+
fig, axs = plt.subplots(3, 1, figsize=(12, 18), gridspec_kw={'height_ratios': [1, 1, 0.5]}) # Adjusted for different subplot sizes
|
| 475 |
+
|
| 476 |
+
# Subplots for catt visualization (h=3 and h=5)
|
| 477 |
+
ax_catt3, ax_catt5, ax_att_row = axs
|
| 478 |
+
|
| 479 |
+
# Creating 8 subplots for att visualization within the third row
|
| 480 |
+
for i in range(8):
|
| 481 |
+
ax_att_row = fig.add_subplot(3, 8, 17 + i) # Adding subplots in the third row
|
| 482 |
+
|
| 483 |
+
# Update function for the combined animation
|
| 484 |
+
def combined_update_smaller_att(t):
|
| 485 |
+
# Update subplot for catt with h=3
|
| 486 |
+
ax_catt3.clear()
|
| 487 |
+
ax_catt3.imshow(catt[2][0][t, 3, :, :].detach().numpy())
|
| 488 |
+
ax_catt3.set_title(f'block=2, t={t}, head=3')
|
| 489 |
+
ax_catt3.set_ylabel('latent k'); ax_catt3.set_xlabel('conv channel')
|
| 490 |
+
|
| 491 |
+
# Update subplot for catt with h=5
|
| 492 |
+
ax_catt5.clear()
|
| 493 |
+
ax_catt5.imshow(catt[2][0][t, 5, :, :].detach().numpy())
|
| 494 |
+
ax_catt5.set_title(f'block=2, t={t}, head=5')
|
| 495 |
+
ax_catt5.set_ylabel('latent k'); ax_catt5.set_xlabel('conv channel')
|
| 496 |
+
|
| 497 |
+
# Update subplots for att (8 heads in one row)
|
| 498 |
+
for i in range(8):
|
| 499 |
+
ax = fig.add_subplot(3, 8, 17 + i)
|
| 500 |
+
ax.clear()
|
| 501 |
+
ax.imshow(att[0][1][t, i, :, :].detach().numpy(), cmap='viridis')
|
| 502 |
+
ax.set_title(f't={t}, head={i}')
|
| 503 |
+
ax.set_xlabel('k')
|
| 504 |
+
ax.set_ylabel('k')
|
| 505 |
+
ax.axis('square') # Make each subplot square-shaped
|
| 506 |
+
|
| 507 |
+
# Adjust layout
|
| 508 |
+
fig.tight_layout()
|
| 509 |
+
combined_anim_smaller_att = FuncAnimation(fig, combined_update_smaller_att, frames=range(0, 110), interval=200)
|
| 510 |
+
combined_anim_smaller_att.save('combined_animation_smaller_att.gif', writer='pillow', fps=5)
|
| 511 |
+
|
| 512 |
+
|
| 513 |
+
|
| 514 |
+
|
| 515 |
+
|
| 516 |
+
# enc Latent Self-attention: How latent K attends to K?
|
| 517 |
+
plt.subplot(231)
|
| 518 |
+
plt.imshow(torch.sum(torch.sum(att[0][0], axis=1),
|
| 519 |
+
axis=0).detach().numpy(),
|
| 520 |
+
origin='upper')
|
| 521 |
+
plt.title('B0L0')
|
| 522 |
+
plt.xlabel('latent k')
|
| 523 |
+
plt.ylabel('latent k')
|
| 524 |
+
plt.subplot(234)
|
| 525 |
+
plt.imshow(torch.sum(torch.sum(att[0][1], axis=1),
|
| 526 |
+
axis=0).detach().numpy(),
|
| 527 |
+
origin='upper')
|
| 528 |
+
plt.title('B0L1')
|
| 529 |
+
plt.xlabel('latent k')
|
| 530 |
+
plt.ylabel('latent k')
|
| 531 |
+
plt.subplot(232)
|
| 532 |
+
plt.imshow(torch.sum(torch.sum(att[1][0], axis=1),
|
| 533 |
+
axis=0).detach().numpy(),
|
| 534 |
+
origin='upper')
|
| 535 |
+
plt.title('B1L0')
|
| 536 |
+
plt.xlabel('latent k')
|
| 537 |
+
plt.ylabel('latent k')
|
| 538 |
+
plt.subplot(235)
|
| 539 |
+
plt.imshow(torch.sum(torch.sum(att[1][1], axis=1),
|
| 540 |
+
axis=0).detach().numpy(),
|
| 541 |
+
origin='upper')
|
| 542 |
+
plt.title('B1L1')
|
| 543 |
+
plt.xlabel('latent k')
|
| 544 |
+
plt.ylabel('latent k')
|
| 545 |
+
plt.subplot(233)
|
| 546 |
+
plt.imshow(torch.sum(torch.sum(att[2][0], axis=1),
|
| 547 |
+
axis=0).detach().numpy(),
|
| 548 |
+
origin='upper')
|
| 549 |
+
plt.title('B2L0')
|
| 550 |
+
plt.xlabel('latent k')
|
| 551 |
+
plt.ylabel('latent k')
|
| 552 |
+
plt.subplot(236)
|
| 553 |
+
plt.imshow(torch.sum(torch.sum(att[2][1], axis=1),
|
| 554 |
+
axis=0).detach().numpy(),
|
| 555 |
+
origin='upper')
|
| 556 |
+
plt.title('B2L1')
|
| 557 |
+
plt.xlabel('latent k')
|
| 558 |
+
plt.ylabel('latent k')
|
| 559 |
+
plt.tight_layout()
|
| 560 |
+
plt.show()
|
| 561 |
+
# Time varying, different head for latent self-attention
|
| 562 |
+
#!!! Display latent self-attention for each head
|
| 563 |
+
bl = 0 # first latent transformer block, last layer att
|
| 564 |
+
data = att[bl][1].detach().numpy()
|
| 565 |
+
time_steps = [30, 50, 100]
|
| 566 |
+
fig, axs = plt.subplots(
|
| 567 |
+
len(time_steps), 8,
|
| 568 |
+
figsize=(16, 6)) # Subplots for each time step and head
|
| 569 |
+
for i, t in enumerate(time_steps):
|
| 570 |
+
for head in range(8):
|
| 571 |
+
axs[i, head].imshow(data[t, head, :, :], cmap='viridis')
|
| 572 |
+
axs[i, head].set_title(f't={t}, head={head}')
|
| 573 |
+
axs[i, head].set_xlabel('k')
|
| 574 |
+
axs[i, head].set_ylabel('k')
|
| 575 |
+
plt.suptitle(
|
| 576 |
+
f'latent transformer block={bl}, last layer self-attention over time',
|
| 577 |
+
y=0,
|
| 578 |
+
fontsize=12)
|
| 579 |
+
plt.tight_layout()
|
| 580 |
+
plt.show()
|
| 581 |
+
|
| 582 |
+
bl = 1 # second latent transformer block, last layer att
|
| 583 |
+
data = att[bl][1].detach().numpy()
|
| 584 |
+
time_steps = [30, 50, 100]
|
| 585 |
+
fig, axs = plt.subplots(
|
| 586 |
+
len(time_steps), 8,
|
| 587 |
+
figsize=(16, 6)) # Subplots for each time step and head
|
| 588 |
+
for i, t in enumerate(time_steps):
|
| 589 |
+
for head in range(8):
|
| 590 |
+
axs[i, head].imshow(data[t, head, :, :], cmap='viridis')
|
| 591 |
+
axs[i, head].set_title(f't={t}, head={head}')
|
| 592 |
+
axs[i, head].set_xlabel('k')
|
| 593 |
+
axs[i, head].set_ylabel('k')
|
| 594 |
+
plt.suptitle(
|
| 595 |
+
f'latent transformer block={bl}, last layer self-attention over time',
|
| 596 |
+
y=0,
|
| 597 |
+
fontsize=12)
|
| 598 |
+
plt.tight_layout()
|
| 599 |
+
plt.show()
|
| 600 |
+
|
| 601 |
+
bl = 2 # last latent transformer block, last layer att
|
| 602 |
+
data = att[bl][1].detach().numpy()
|
| 603 |
+
time_steps = [30, 50, 100]
|
| 604 |
+
fig, axs = plt.subplots(
|
| 605 |
+
len(time_steps), 8,
|
| 606 |
+
figsize=(16, 6)) # Subplots for each time step and head
|
| 607 |
+
for i, t in enumerate(time_steps):
|
| 608 |
+
for head in range(8):
|
| 609 |
+
axs[i, head].imshow(data[t, head, :, :], cmap='viridis')
|
| 610 |
+
axs[i, head].set_title(f't={t}, head={head}')
|
| 611 |
+
axs[i, head].set_xlabel('k')
|
| 612 |
+
axs[i, head].set_ylabel('k')
|
| 613 |
+
plt.suptitle(
|
| 614 |
+
f'latent transformer block={bl}, last layer self-attention over time',
|
| 615 |
+
y=0,
|
| 616 |
+
fontsize=12)
|
| 617 |
+
plt.tight_layout()
|
| 618 |
+
plt.show()
|
| 619 |
+
|
| 620 |
+
# Temporal Self-attention: (K x H x T x T) How time t attends to time t?
|
| 621 |
+
plt.subplot(231)
|
| 622 |
+
plt.imshow(torch.sum(torch.sum(att[0][2], axis=1),
|
| 623 |
+
axis=0).detach().numpy(),
|
| 624 |
+
origin='upper')
|
| 625 |
+
plt.title('B0L2')
|
| 626 |
+
plt.xlabel('t')
|
| 627 |
+
plt.ylabel('t')
|
| 628 |
+
plt.subplot(234)
|
| 629 |
+
plt.imshow(torch.sum(torch.sum(att[0][3], axis=1),
|
| 630 |
+
axis=0).detach().numpy(),
|
| 631 |
+
origin='upper')
|
| 632 |
+
plt.title('B0L3')
|
| 633 |
+
plt.xlabel('t')
|
| 634 |
+
plt.ylabel('t')
|
| 635 |
+
plt.subplot(232)
|
| 636 |
+
plt.imshow(torch.sum(torch.sum(att[1][2], axis=1),
|
| 637 |
+
axis=0).detach().numpy(),
|
| 638 |
+
origin='upper')
|
| 639 |
+
plt.title('B1L2')
|
| 640 |
+
plt.xlabel('t')
|
| 641 |
+
plt.ylabel('t')
|
| 642 |
+
plt.subplot(235)
|
| 643 |
+
plt.imshow(torch.sum(torch.sum(att[1][3], axis=1),
|
| 644 |
+
axis=0).detach().numpy(),
|
| 645 |
+
origin='upper')
|
| 646 |
+
plt.title('B1L3')
|
| 647 |
+
plt.xlabel('t')
|
| 648 |
+
plt.ylabel('t')
|
| 649 |
+
plt.subplot(233)
|
| 650 |
+
plt.imshow(torch.sum(torch.sum(att[2][2], axis=1),
|
| 651 |
+
axis=0).detach().numpy(),
|
| 652 |
+
origin='upper')
|
| 653 |
+
plt.title('B2L2')
|
| 654 |
+
plt.xlabel('t')
|
| 655 |
+
plt.ylabel('t')
|
| 656 |
+
plt.subplot(236)
|
| 657 |
+
plt.imshow(torch.sum(torch.sum(att[2][3], axis=1),
|
| 658 |
+
axis=0).detach().numpy(),
|
| 659 |
+
origin='upper')
|
| 660 |
+
plt.title('B2L3')
|
| 661 |
+
plt.xlabel('t')
|
| 662 |
+
plt.ylabel('t')
|
| 663 |
+
plt.tight_layout()
|
| 664 |
+
plt.show()
|
| 665 |
+
|
| 666 |
+
# decoding
|
| 667 |
+
dec_input_ids = model.shift_right_fn(label)
|
| 668 |
+
dec_inputs_embeds = model.embed_tokens(dec_input_ids)
|
| 669 |
+
dec_output = model.decoder(inputs_embeds=dec_inputs_embeds,
|
| 670 |
+
encoder_hidden_states=enc_hs_proj,
|
| 671 |
+
output_attentions=True,
|
| 672 |
+
output_hidden_states=True,
|
| 673 |
+
return_dict=True)
|
| 674 |
+
dec_att, dec_catt = dec_output.attentions, dec_output.cross_attentions
|
| 675 |
+
dec_hs_all = dec_output.hidden_states
|
| 676 |
+
dec_last_hs = dec_output.last_hidden_state
|
| 677 |
+
|
| 678 |
+
# lm head
|
| 679 |
+
logits = model.lm_head(dec_last_hs)
|
| 680 |
+
|
| 681 |
+
# pred ids
|
| 682 |
+
pred_ids = torch.argmax(logits, dim=3)
|
| 683 |
+
|
| 684 |
+
# dec att
|
| 685 |
+
plt.subplot(1, 2, 1)
|
| 686 |
+
plt.imshow(torch.sum(dec_att[5][0], axis=0).detach().numpy())
|
| 687 |
+
plt.title('decoder attention, layer0')
|
| 688 |
+
plt.xlabel('decoder time step')
|
| 689 |
+
plt.ylabel('decoder time step')
|
| 690 |
+
plt.subplot(1, 2, 2)
|
| 691 |
+
plt.imshow(torch.sum(dec_att[7][0], axis=0).detach().numpy())
|
| 692 |
+
plt.title('decoder attention, final layer')
|
| 693 |
+
plt.xlabel('decoder step')
|
| 694 |
+
plt.show()
|
| 695 |
+
|
| 696 |
+
|
| 697 |
+
# dec catt
|
| 698 |
+
def remove_values_after_eos(catt_np, pred_ids, max_k):
|
| 699 |
+
# catt_np: (k, head, t, t)
|
| 700 |
+
# pred_ids: (1, k, t))
|
| 701 |
+
max_length = pred_ids.shape[-1]
|
| 702 |
+
seq_lengths = np.zeros((max_k), dtype=np.int32)
|
| 703 |
+
for k in range(max_k):
|
| 704 |
+
for t in range(max_length):
|
| 705 |
+
if pred_ids[0, k, t] == 1:
|
| 706 |
+
break
|
| 707 |
+
catt_np[k, :, t+1:, :] = 0
|
| 708 |
+
# catt_np[k, :, :, t+1:] = 0
|
| 709 |
+
seq_lengths[k] = t+1
|
| 710 |
+
return catt_np, seq_lengths
|
| 711 |
+
|
| 712 |
+
# data = dec_catt[1].detach().numpy() # last layer's cross attention
|
| 713 |
+
l = 4
|
| 714 |
+
data = dec_catt[l].detach().numpy()
|
| 715 |
+
data, seq_lengths = remove_values_after_eos(data, pred_ids, max_k=13)
|
| 716 |
+
seq_lengths[:]= 256
|
| 717 |
+
|
| 718 |
+
fig, axs = plt.subplots(13, 6, figsize=(21, 39)) # 13 rows (for k=0:12) and 7 columns (for head=0:6)
|
| 719 |
+
for k in range(13):
|
| 720 |
+
s = seq_lengths[k]
|
| 721 |
+
for head in range(6):
|
| 722 |
+
axs[k, head].imshow(data[k, head, :s, :].T, aspect='auto', cmap='viridis')
|
| 723 |
+
axs[k, head].set_title(f'Layer {l}, k={k}, head={head}')
|
| 724 |
+
axs[k, head].set_xlabel('Decoder step')
|
| 725 |
+
axs[k, head].set_ylabel('Encoder frame')
|
| 726 |
+
plt.tight_layout()
|
| 727 |
+
plt.show()
|
| 728 |
+
|
| 729 |
+
|
| 730 |
+
# # dec catt by head with xxx
|
| 731 |
+
# dec_att_z = z_normalize_tensors(shorten_att(dec_att))
|
| 732 |
+
# plt.imshow(dec_att_z[0][0, 0, :, :].detach().numpy())
|
| 733 |
+
# from bertviz import head_view
|
| 734 |
+
# token = []
|
| 735 |
+
# for i in label[0, :30]:
|
| 736 |
+
# token.append(str(i))
|
| 737 |
+
# head_view(dec_att_z, tokens)
|
| 738 |
+
|
| 739 |
+
# dec_hs
|
| 740 |
+
plt.subplot(1, 2, 1)
|
| 741 |
+
k=2
|
| 742 |
+
plt.imshow(dec_last_hs[0][k].detach().numpy(), origin='upper')
|
| 743 |
+
plt.colorbar(orientation='horizontal')
|
| 744 |
+
plt.title('decoder last hidden state, k=0')
|
| 745 |
+
plt.xlabel('hidden dim')
|
| 746 |
+
plt.ylabel('time step')
|
| 747 |
+
plt.subplot(1, 2, 2)
|
| 748 |
+
k=12
|
| 749 |
+
plt.imshow(dec_last_hs[0][k].detach().numpy(), origin='upper')
|
| 750 |
+
plt.colorbar(orientation='horizontal')
|
| 751 |
+
plt.title('decoder last hidden state, k=12')
|
| 752 |
+
plt.xlabel('hidden dim')
|
| 753 |
+
plt.show()
|
| 754 |
+
|
| 755 |
+
# lm head
|
| 756 |
+
logits = model.lm_head(dec_last_hs)
|
| 757 |
+
k=6
|
| 758 |
+
plt.imshow(logits[0][k][0:200, :].detach().numpy().T, origin='upper')
|
| 759 |
+
plt.title('lm head output')
|
| 760 |
+
plt.xlabel('vocab dim')
|
| 761 |
+
plt.ylabel('time step')
|
| 762 |
+
plt.show()
|
| 763 |
+
softmax = torch.nn.Softmax(dim=3)
|
| 764 |
+
logits_sm = softmax(logits) # B, K, T, V
|
| 765 |
+
k=6
|
| 766 |
+
plt.imshow(logits_sm[0][k][:255, :].detach().numpy().T, origin='upper')
|
| 767 |
+
plt.title('lm head softmax')
|
| 768 |
+
plt.xlabel('vocab dim')
|
| 769 |
+
plt.ylabel('time step')
|
| 770 |
+
# plt.xlim([1000, 1350])
|
| 771 |
+
plt.show()
|
| 772 |
+
|
| 773 |
+
k = 10
|
| 774 |
+
print(torch.argmax(logits, dim=3)[0,k,:])
|
| 775 |
+
|
| 776 |
+
|
| 777 |
+
|
| 778 |
+
|
extras/pitch_shift_benchmark.py
ADDED
|
@@ -0,0 +1,167 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
""" Test the speed of the augmentation """
|
| 2 |
+
import torch
|
| 3 |
+
import torchaudio
|
| 4 |
+
|
| 5 |
+
# Device
|
| 6 |
+
device = torch.device("cuda")
|
| 7 |
+
# device = torch.device("cpu")
|
| 8 |
+
|
| 9 |
+
# Music
|
| 10 |
+
# x, _ = torchaudio.load("music.wav")
|
| 11 |
+
# slice_length = 32767
|
| 12 |
+
# n_slices = 80
|
| 13 |
+
# slices = [x[0, i * slice_length:(i + 1) * slice_length] for i in range(n_slices)]
|
| 14 |
+
# x = torch.stack(slices) # (80, 32767)
|
| 15 |
+
# Sine wave
|
| 16 |
+
t = torch.arange(0, 2.0479, 1 / 16000) # 2.05 seconds at 16kHz
|
| 17 |
+
x = torch.sin(2 * torch.pi * 440 * t) * 0.5
|
| 18 |
+
x = x.reshape(1, 1, 32767).tile(80, 1, 1)
|
| 19 |
+
x = x.to(device)
|
| 20 |
+
|
| 21 |
+
############################################################################################
|
| 22 |
+
# torch-audiomentation: https://github.com/asteroid-team/torch-audiomentation
|
| 23 |
+
#
|
| 24 |
+
# process time <CPU>: 1.18 s ± 5.35 ms
|
| 25 |
+
# process time <GPU>: 58 ms
|
| 26 |
+
# GPU memory usage: 3.8 GB per 1 semitone
|
| 27 |
+
############################################################################################
|
| 28 |
+
import torch
|
| 29 |
+
from torch_audiomentations import Compose, PitchShift, Gain, PolarityInversion
|
| 30 |
+
|
| 31 |
+
apply_augmentation = Compose(transforms=[
|
| 32 |
+
# Gain(
|
| 33 |
+
# min_gain_in_db=-15.0,
|
| 34 |
+
# max_gain_in_db=5.0,
|
| 35 |
+
# p=0.5,
|
| 36 |
+
# ),
|
| 37 |
+
# PolarityInversion(p=0.5)
|
| 38 |
+
PitchShift(
|
| 39 |
+
min_transpose_semitones=0,
|
| 40 |
+
max_transpose_semitones=2.2,
|
| 41 |
+
mode="per_batch", #"per_example",
|
| 42 |
+
p=1.0,
|
| 43 |
+
p_mode="per_batch",
|
| 44 |
+
sample_rate=16000,
|
| 45 |
+
target_rate=16000)
|
| 46 |
+
])
|
| 47 |
+
x_am = apply_augmentation(x, sample_rate=16000)
|
| 48 |
+
|
| 49 |
+
############################################################################################
|
| 50 |
+
# torchaudio:
|
| 51 |
+
#
|
| 52 |
+
# process time <CPU>: 4.01 s ± 19.6 ms per loop
|
| 53 |
+
# process time <GPU>: 25.1 ms ± 161 µs per loop
|
| 54 |
+
# memory usage <GPU>: 1.2 (growth to 5.49) GB per 1 semitone
|
| 55 |
+
############################################################################################
|
| 56 |
+
from torchaudio import transforms
|
| 57 |
+
|
| 58 |
+
ta_transform = transforms.PitchShift(16000, n_steps=2).to(device)
|
| 59 |
+
x_ta = ta_transform(x)
|
| 60 |
+
|
| 61 |
+
############################################################################################
|
| 62 |
+
# YourMT3 pitch_shift_layer:
|
| 63 |
+
#
|
| 64 |
+
# process time <CPU>: 389ms ± 22ms, (stretch=143 ms, resampler=245 ms)
|
| 65 |
+
# process time <GPU>: 7.18 ms ± 17.3 µs (stretch=6.47 ms, resampler=0.71 ms)
|
| 66 |
+
# memory usage: 16 MB per 1 semitone (average)
|
| 67 |
+
############################################################################################
|
| 68 |
+
from model.pitchshift_layer import PitchShiftLayer
|
| 69 |
+
|
| 70 |
+
ps_ymt3 = PitchShiftLayer(pshift_range=[2, 2], fs=16000, min_gcd=16, n_fft=2048).to(device)
|
| 71 |
+
x_ymt3 = ps_ymt3(x, 2)
|
| 72 |
+
|
| 73 |
+
############################################################################################
|
| 74 |
+
# Plot 1: Comparison of Process Time and GPU Memory Usage for 3 Pitch Shifting Methods
|
| 75 |
+
############################################################################################
|
| 76 |
+
import matplotlib.pyplot as plt
|
| 77 |
+
|
| 78 |
+
# Model names
|
| 79 |
+
models = ['torch-audiomentation', 'torchaudio', 'YourMT3:PitchShiftLayer']
|
| 80 |
+
|
| 81 |
+
# Process time (CPU) in seconds
|
| 82 |
+
cpu_time = [1.18, 4.01, 0.389]
|
| 83 |
+
|
| 84 |
+
# Process time (GPU) in milliseconds
|
| 85 |
+
gpu_time = [58, 25.1, 7.18]
|
| 86 |
+
|
| 87 |
+
# GPU memory usage in GB
|
| 88 |
+
gpu_memory = [3.8, 5.49, 0.016]
|
| 89 |
+
|
| 90 |
+
# Creating subplots
|
| 91 |
+
fig, axs = plt.subplots(1, 3, figsize=(15, 5))
|
| 92 |
+
|
| 93 |
+
# Creating bar charts
|
| 94 |
+
bar1 = axs[0].bar(models, cpu_time, color=['#FFB6C1', '#ADD8E6', '#98FB98'])
|
| 95 |
+
bar2 = axs[1].bar(models, gpu_time, color=['#FFB6C1', '#ADD8E6', '#98FB98'])
|
| 96 |
+
bar3 = axs[2].bar(models, gpu_memory, color=['#FFB6C1', '#ADD8E6', '#98FB98'])
|
| 97 |
+
|
| 98 |
+
# Adding labels and titles
|
| 99 |
+
axs[0].set_ylabel('Time (s)')
|
| 100 |
+
axs[0].set_title('Process Time (CPU) bsz=80')
|
| 101 |
+
axs[1].set_ylabel('Time (ms)')
|
| 102 |
+
axs[1].set_title('Process Time (GPU) bsz=80')
|
| 103 |
+
axs[2].set_ylabel('Memory (GB)')
|
| 104 |
+
axs[2].set_title('GPU Memory Usage per semitone')
|
| 105 |
+
|
| 106 |
+
# Adding grid for better readability of the plots
|
| 107 |
+
for ax in axs:
|
| 108 |
+
ax.grid(axis='y')
|
| 109 |
+
ax.set_yscale('log')
|
| 110 |
+
ax.set_xticklabels(models, rotation=45, ha="right")
|
| 111 |
+
|
| 112 |
+
# Adding text labels above the bars
|
| 113 |
+
for i, rect in enumerate(bar1):
|
| 114 |
+
axs[0].text(
|
| 115 |
+
rect.get_x() + rect.get_width() / 2,
|
| 116 |
+
rect.get_height(),
|
| 117 |
+
f'{cpu_time[i]:.2f} s',
|
| 118 |
+
ha='center',
|
| 119 |
+
va='bottom')
|
| 120 |
+
for i, rect in enumerate(bar2):
|
| 121 |
+
axs[1].text(
|
| 122 |
+
rect.get_x() + rect.get_width() / 2,
|
| 123 |
+
rect.get_height(),
|
| 124 |
+
f'{gpu_time[i]:.2f} ms',
|
| 125 |
+
ha='center',
|
| 126 |
+
va='bottom')
|
| 127 |
+
for i, rect in enumerate(bar3):
|
| 128 |
+
axs[2].text(
|
| 129 |
+
rect.get_x() + rect.get_width() / 2,
|
| 130 |
+
rect.get_height(),
|
| 131 |
+
f'{gpu_memory[i]:.3f} GB',
|
| 132 |
+
ha='center',
|
| 133 |
+
va='bottom')
|
| 134 |
+
plt.tight_layout()
|
| 135 |
+
plt.show()
|
| 136 |
+
|
| 137 |
+
############################################################################################
|
| 138 |
+
# Plot 2: Stretch and Resampler Processing Time Contribution
|
| 139 |
+
############################################################################################
|
| 140 |
+
# Data
|
| 141 |
+
processing_type = ['Stretch (Phase Vocoder)', 'Resampler (Conv1D)']
|
| 142 |
+
cpu_times = [143, 245] # [Stretch, Resampler] times for CPU in milliseconds
|
| 143 |
+
gpu_times = [6.47, 0.71] # [Stretch, Resampler] times for GPU in milliseconds
|
| 144 |
+
|
| 145 |
+
# Creating subplots
|
| 146 |
+
fig, axs = plt.subplots(1, 2, figsize=(12, 6))
|
| 147 |
+
|
| 148 |
+
# Plotting bar charts
|
| 149 |
+
axs[0].bar(processing_type, cpu_times, color=['#ADD8E6', '#98FB98'])
|
| 150 |
+
axs[1].bar(processing_type, gpu_times, color=['#ADD8E6', '#98FB98'])
|
| 151 |
+
|
| 152 |
+
# Adding labels and titles
|
| 153 |
+
axs[0].set_ylabel('Time (ms)')
|
| 154 |
+
axs[0].set_title('Contribution of CPU Processing Time: YMT3-PS (BSZ=80)')
|
| 155 |
+
axs[1].set_title('Contribution of GPU Processing Time: YMT3-PS (BSZ=80)')
|
| 156 |
+
|
| 157 |
+
# Adding grid for better readability of the plots
|
| 158 |
+
for ax in axs:
|
| 159 |
+
ax.grid(axis='y')
|
| 160 |
+
ax.set_yscale('log') # Log scale to better visualize the smaller values
|
| 161 |
+
|
| 162 |
+
# Adding values on top of the bars
|
| 163 |
+
for ax, times in zip(axs, [cpu_times, gpu_times]):
|
| 164 |
+
for idx, time in enumerate(times):
|
| 165 |
+
ax.text(idx, time, f"{time:.2f} ms", ha='center', va='bottom', fontsize=8)
|
| 166 |
+
plt.tight_layout()
|
| 167 |
+
plt.show()
|
extras/run_spleeter_mir1k.sh
ADDED
|
@@ -0,0 +1,17 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/bin/bash
|
| 2 |
+
shopt -s globstar
|
| 3 |
+
for file in "$1"/**/*.wav; do
|
| 4 |
+
echo $file
|
| 5 |
+
output_dir="tmp"
|
| 6 |
+
spleeter separate -b 256k -B tensorflow -p spleeter:2stems -o $output_dir $file -f {instrument}.{codec}
|
| 7 |
+
sox --ignore-length tmp/accompaniment.wav -r 16000 -c 1 -b 16 tmp/accompaniment_16k.wav
|
| 8 |
+
sox --ignore-length tmp/vocals.wav -r 16000 -c 1 -b 16 tmp/vocals_16k.wav
|
| 9 |
+
acc_file="${file//.wav/_accompaniment.wav}"
|
| 10 |
+
voc_file="${file//.wav/_vocals.wav}"
|
| 11 |
+
mv -f "tmp/accompaniment_16k.wav" $acc_file
|
| 12 |
+
mv -f "tmp/vocals_16k.wav" $voc_file
|
| 13 |
+
echo $acc_file
|
| 14 |
+
echo $voc_file
|
| 15 |
+
rm -rf tmp
|
| 16 |
+
done
|
| 17 |
+
rm -rf pretrained_models
|
extras/run_spleeter_mirst500.sh
ADDED
|
@@ -0,0 +1,13 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/bin/bash
|
| 2 |
+
shopt -s globstar
|
| 3 |
+
for file in "$1"/**/*.wav; do
|
| 4 |
+
output_dir="${file%/*}"
|
| 5 |
+
input_file="$output_dir/converted_Mixture.wav"
|
| 6 |
+
spleeter separate -p spleeter:2stems -o $output_dir $input_file -f {instrument}.{codec}
|
| 7 |
+
ffmpeg -i "$output_dir/vocals.wav" -acodec pcm_s16le -ac 1 -ar 16000 -y "$output_dir/vocals_16k.wav"
|
| 8 |
+
ffmpeg -i "$output_dir/accompaniment.wav" -acodec pcm_s16le -ac 1 -ar 16000 -y "$output_dir/accompaniment_16k.wav"
|
| 9 |
+
rm "$output_dir/vocals.wav"
|
| 10 |
+
rm "$output_dir/accompaniment.wav"
|
| 11 |
+
mv "$output_dir/vocals_16k.wav" "$output_dir/vocals.wav"
|
| 12 |
+
mv "$output_dir/accompaniment_16k.wav" "$output_dir/accompaniment.wav"
|
| 13 |
+
done
|
model/__pycache__/conformer_mod.cpython-310.pyc
ADDED
|
Binary file (10.7 kB). View file
|
|
|