
text
stringlengths 29
320k
| id
stringlengths 22
166
| metadata
dict | __index_level_0__
int64 0
195
|
|---|---|---|---|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Text generation strategies
Text generation is essential to many NLP tasks, such as open-ended text generation, summarization, translation, and
more. It also plays a role in a variety of mixed-modality applications that have text as an output like speech-to-text
and vision-to-text. Some of the models that can generate text include
GPT2, XLNet, OpenAI GPT, CTRL, TransformerXL, XLM, Bart, T5, GIT, Whisper.
Check out a few examples that use [`~transformers.generation_utils.GenerationMixin.generate`] method to produce
text outputs for different tasks:
* [Text summarization](./tasks/summarization#inference)
* [Image captioning](./model_doc/git#transformers.GitForCausalLM.forward.example)
* [Audio transcription](./model_doc/whisper#transformers.WhisperForConditionalGeneration.forward.example)
Note that the inputs to the generate method depend on the model's modality. They are returned by the model's preprocessor
class, such as AutoTokenizer or AutoProcessor. If a model's preprocessor creates more than one kind of input, pass all
the inputs to generate(). You can learn more about the individual model's preprocessor in the corresponding model's documentation.
The process of selecting output tokens to generate text is known as decoding, and you can customize the decoding strategy
that the `generate()` method will use. Modifying a decoding strategy does not change the values of any trainable parameters.
However, it can have a noticeable impact on the quality of the generated output. It can help reduce repetition in the text
and make it more coherent.
This guide describes:
* default generation configuration
* common decoding strategies and their main parameters
* saving and sharing custom generation configurations with your fine-tuned model on 🤗 Hub
## Default text generation configuration
A decoding strategy for a model is defined in its generation configuration. When using pre-trained models for inference
within a [`pipeline`], the models call the `PreTrainedModel.generate()` method that applies a default generation
configuration under the hood. The default configuration is also used when no custom configuration has been saved with
the model.
When you load a model explicitly, you can inspect the generation configuration that comes with it through
`model.generation_config`:
```python
>>> from transformers import AutoModelForCausalLM
>>> model = AutoModelForCausalLM.from_pretrained("distilbert/distilgpt2")
>>> model.generation_config
GenerationConfig {
"bos_token_id": 50256,
"eos_token_id": 50256,
}
```
Printing out the `model.generation_config` reveals only the values that are different from the default generation
configuration, and does not list any of the default values.
The default generation configuration limits the size of the output combined with the input prompt to a maximum of 20
tokens to avoid running into resource limitations. The default decoding strategy is greedy search, which is the simplest decoding strategy that picks a token with the highest probability as the next token. For many tasks
and small output sizes this works well. However, when used to generate longer outputs, greedy search can start
producing highly repetitive results.
## Customize text generation
You can override any `generation_config` by passing the parameters and their values directly to the [`generate`] method:
```python
>>> my_model.generate(**inputs, num_beams=4, do_sample=True) # doctest: +SKIP
```
Even if the default decoding strategy mostly works for your task, you can still tweak a few things. Some of the
commonly adjusted parameters include:
- `max_new_tokens`: the maximum number of tokens to generate. In other words, the size of the output sequence, not
including the tokens in the prompt. As an alternative to using the output's length as a stopping criteria, you can choose
to stop generation whenever the full generation exceeds some amount of time. To learn more, check [`StoppingCriteria`].
- `num_beams`: by specifying a number of beams higher than 1, you are effectively switching from greedy search to
beam search. This strategy evaluates several hypotheses at each time step and eventually chooses the hypothesis that
has the overall highest probability for the entire sequence. This has the advantage of identifying high-probability
sequences that start with a lower probability initial tokens and would've been ignored by the greedy search.
- `do_sample`: if set to `True`, this parameter enables decoding strategies such as multinomial sampling, beam-search
multinomial sampling, Top-K sampling and Top-p sampling. All these strategies select the next token from the probability
distribution over the entire vocabulary with various strategy-specific adjustments.
- `num_return_sequences`: the number of sequence candidates to return for each input. This option is only available for
the decoding strategies that support multiple sequence candidates, e.g. variations of beam search and sampling. Decoding
strategies like greedy search and contrastive search return a single output sequence.
## Save a custom decoding strategy with your model
If you would like to share your fine-tuned model with a specific generation configuration, you can:
* Create a [`GenerationConfig`] class instance
* Specify the decoding strategy parameters
* Save your generation configuration with [`GenerationConfig.save_pretrained`], making sure to leave its `config_file_name` argument empty
* Set `push_to_hub` to `True` to upload your config to the model's repo
```python
>>> from transformers import AutoModelForCausalLM, GenerationConfig
>>> model = AutoModelForCausalLM.from_pretrained("my_account/my_model") # doctest: +SKIP
>>> generation_config = GenerationConfig(
... max_new_tokens=50, do_sample=True, top_k=50, eos_token_id=model.config.eos_token_id
... )
>>> generation_config.save_pretrained("my_account/my_model", push_to_hub=True) # doctest: +SKIP
```
You can also store several generation configurations in a single directory, making use of the `config_file_name`
argument in [`GenerationConfig.save_pretrained`]. You can later instantiate them with [`GenerationConfig.from_pretrained`]. This is useful if you want to
store several generation configurations for a single model (e.g. one for creative text generation with sampling, and
one for summarization with beam search). You must have the right Hub permissions to add configuration files to a model.
```python
>>> from transformers import AutoModelForSeq2SeqLM, AutoTokenizer, GenerationConfig
>>> tokenizer = AutoTokenizer.from_pretrained("google-t5/t5-small")
>>> model = AutoModelForSeq2SeqLM.from_pretrained("google-t5/t5-small")
>>> translation_generation_config = GenerationConfig(
... num_beams=4,
... early_stopping=True,
... decoder_start_token_id=0,
... eos_token_id=model.config.eos_token_id,
... pad_token=model.config.pad_token_id,
... )
>>> # Tip: add `push_to_hub=True` to push to the Hub
>>> translation_generation_config.save_pretrained("/tmp", "translation_generation_config.json")
>>> # You could then use the named generation config file to parameterize generation
>>> generation_config = GenerationConfig.from_pretrained("/tmp", "translation_generation_config.json")
>>> inputs = tokenizer("translate English to French: Configuration files are easy to use!", return_tensors="pt")
>>> outputs = model.generate(**inputs, generation_config=generation_config)
>>> print(tokenizer.batch_decode(outputs, skip_special_tokens=True))
['Les fichiers de configuration sont faciles à utiliser!']
```
## Streaming
The `generate()` supports streaming, through its `streamer` input. The `streamer` input is compatible with any instance
from a class that has the following methods: `put()` and `end()`. Internally, `put()` is used to push new tokens and
`end()` is used to flag the end of text generation.
<Tip warning={true}>
The API for the streamer classes is still under development and may change in the future.
</Tip>
In practice, you can craft your own streaming class for all sorts of purposes! We also have basic streaming classes
ready for you to use. For example, you can use the [`TextStreamer`] class to stream the output of `generate()` into
your screen, one word at a time:
```python
>>> from transformers import AutoModelForCausalLM, AutoTokenizer, TextStreamer
>>> tok = AutoTokenizer.from_pretrained("openai-community/gpt2")
>>> model = AutoModelForCausalLM.from_pretrained("openai-community/gpt2")
>>> inputs = tok(["An increasing sequence: one,"], return_tensors="pt")
>>> streamer = TextStreamer(tok)
>>> # Despite returning the usual output, the streamer will also print the generated text to stdout.
>>> _ = model.generate(**inputs, streamer=streamer, max_new_tokens=20)
An increasing sequence: one, two, three, four, five, six, seven, eight, nine, ten, eleven,
```
## Decoding strategies
Certain combinations of the `generate()` parameters, and ultimately `generation_config`, can be used to enable specific
decoding strategies. If you are new to this concept, we recommend reading [this blog post that illustrates how common decoding strategies work](https://huggingface.co/blog/how-to-generate).
Here, we'll show some of the parameters that control the decoding strategies and illustrate how you can use them.
### Greedy Search
[`generate`] uses greedy search decoding by default so you don't have to pass any parameters to enable it. This means the parameters `num_beams` is set to 1 and `do_sample=False`.
```python
>>> from transformers import AutoModelForCausalLM, AutoTokenizer
>>> prompt = "I look forward to"
>>> checkpoint = "distilbert/distilgpt2"
>>> tokenizer = AutoTokenizer.from_pretrained(checkpoint)
>>> inputs = tokenizer(prompt, return_tensors="pt")
>>> model = AutoModelForCausalLM.from_pretrained(checkpoint)
>>> outputs = model.generate(**inputs)
>>> tokenizer.batch_decode(outputs, skip_special_tokens=True)
['I look forward to seeing you all again!\n\n\n\n\n\n\n\n\n\n\n']
```
### Contrastive search
The contrastive search decoding strategy was proposed in the 2022 paper [A Contrastive Framework for Neural Text Generation](https://arxiv.org/abs/2202.06417).
It demonstrates superior results for generating non-repetitive yet coherent long outputs. To learn how contrastive search
works, check out [this blog post](https://huggingface.co/blog/introducing-csearch).
The two main parameters that enable and control the behavior of contrastive search are `penalty_alpha` and `top_k`:
```python
>>> from transformers import AutoTokenizer, AutoModelForCausalLM
>>> checkpoint = "openai-community/gpt2-large"
>>> tokenizer = AutoTokenizer.from_pretrained(checkpoint)
>>> model = AutoModelForCausalLM.from_pretrained(checkpoint)
>>> prompt = "Hugging Face Company is"
>>> inputs = tokenizer(prompt, return_tensors="pt")
>>> outputs = model.generate(**inputs, penalty_alpha=0.6, top_k=4, max_new_tokens=100)
>>> tokenizer.batch_decode(outputs, skip_special_tokens=True)
['Hugging Face Company is a family owned and operated business. We pride ourselves on being the best
in the business and our customer service is second to none.\n\nIf you have any questions about our
products or services, feel free to contact us at any time. We look forward to hearing from you!']
```
### Multinomial sampling
As opposed to greedy search that always chooses a token with the highest probability as the
next token, multinomial sampling (also called ancestral sampling) randomly selects the next token based on the probability distribution over the entire
vocabulary given by the model. Every token with a non-zero probability has a chance of being selected, thus reducing the
risk of repetition.
To enable multinomial sampling set `do_sample=True` and `num_beams=1`.
```python
>>> from transformers import AutoTokenizer, AutoModelForCausalLM, set_seed
>>> set_seed(0) # For reproducibility
>>> checkpoint = "openai-community/gpt2-large"
>>> tokenizer = AutoTokenizer.from_pretrained(checkpoint)
>>> model = AutoModelForCausalLM.from_pretrained(checkpoint)
>>> prompt = "Today was an amazing day because"
>>> inputs = tokenizer(prompt, return_tensors="pt")
>>> outputs = model.generate(**inputs, do_sample=True, num_beams=1, max_new_tokens=100)
>>> tokenizer.batch_decode(outputs, skip_special_tokens=True)
['Today was an amazing day because when you go to the World Cup and you don\'t, or when you don\'t get invited,
that\'s a terrible feeling."']
```
### Beam-search decoding
Unlike greedy search, beam-search decoding keeps several hypotheses at each time step and eventually chooses
the hypothesis that has the overall highest probability for the entire sequence. This has the advantage of identifying high-probability
sequences that start with lower probability initial tokens and would've been ignored by the greedy search.
To enable this decoding strategy, specify the `num_beams` (aka number of hypotheses to keep track of) that is greater than 1.
```python
>>> from transformers import AutoModelForCausalLM, AutoTokenizer
>>> prompt = "It is astonishing how one can"
>>> checkpoint = "openai-community/gpt2-medium"
>>> tokenizer = AutoTokenizer.from_pretrained(checkpoint)
>>> inputs = tokenizer(prompt, return_tensors="pt")
>>> model = AutoModelForCausalLM.from_pretrained(checkpoint)
>>> outputs = model.generate(**inputs, num_beams=5, max_new_tokens=50)
>>> tokenizer.batch_decode(outputs, skip_special_tokens=True)
['It is astonishing how one can have such a profound impact on the lives of so many people in such a short period of
time."\n\nHe added: "I am very proud of the work I have been able to do in the last few years.\n\n"I have']
```
### Beam-search multinomial sampling
As the name implies, this decoding strategy combines beam search with multinomial sampling. You need to specify
the `num_beams` greater than 1, and set `do_sample=True` to use this decoding strategy.
```python
>>> from transformers import AutoTokenizer, AutoModelForSeq2SeqLM, set_seed
>>> set_seed(0) # For reproducibility
>>> prompt = "translate English to German: The house is wonderful."
>>> checkpoint = "google-t5/t5-small"
>>> tokenizer = AutoTokenizer.from_pretrained(checkpoint)
>>> inputs = tokenizer(prompt, return_tensors="pt")
>>> model = AutoModelForSeq2SeqLM.from_pretrained(checkpoint)
>>> outputs = model.generate(**inputs, num_beams=5, do_sample=True)
>>> tokenizer.decode(outputs[0], skip_special_tokens=True)
'Das Haus ist wunderbar.'
```
### Diverse beam search decoding
The diverse beam search decoding strategy is an extension of the beam search strategy that allows for generating a more diverse
set of beam sequences to choose from. To learn how it works, refer to [Diverse Beam Search: Decoding Diverse Solutions from Neural Sequence Models](https://arxiv.org/pdf/1610.02424.pdf).
This approach has three main parameters: `num_beams`, `num_beam_groups`, and `diversity_penalty`.
The diversity penalty ensures the outputs are distinct across groups, and beam search is used within each group.
```python
>>> from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
>>> checkpoint = "google/pegasus-xsum"
>>> prompt = (
... "The Permaculture Design Principles are a set of universal design principles "
... "that can be applied to any location, climate and culture, and they allow us to design "
... "the most efficient and sustainable human habitation and food production systems. "
... "Permaculture is a design system that encompasses a wide variety of disciplines, such "
... "as ecology, landscape design, environmental science and energy conservation, and the "
... "Permaculture design principles are drawn from these various disciplines. Each individual "
... "design principle itself embodies a complete conceptual framework based on sound "
... "scientific principles. When we bring all these separate principles together, we can "
... "create a design system that both looks at whole systems, the parts that these systems "
... "consist of, and how those parts interact with each other to create a complex, dynamic, "
... "living system. Each design principle serves as a tool that allows us to integrate all "
... "the separate parts of a design, referred to as elements, into a functional, synergistic, "
... "whole system, where the elements harmoniously interact and work together in the most "
... "efficient way possible."
... )
>>> tokenizer = AutoTokenizer.from_pretrained(checkpoint)
>>> inputs = tokenizer(prompt, return_tensors="pt")
>>> model = AutoModelForSeq2SeqLM.from_pretrained(checkpoint)
>>> outputs = model.generate(**inputs, num_beams=5, num_beam_groups=5, max_new_tokens=30, diversity_penalty=1.0)
>>> tokenizer.decode(outputs[0], skip_special_tokens=True)
'The Design Principles are a set of universal design principles that can be applied to any location, climate and
culture, and they allow us to design the'
```
This guide illustrates the main parameters that enable various decoding strategies. More advanced parameters exist for the
[`generate`] method, which gives you even further control over the [`generate`] method's behavior.
For the complete list of the available parameters, refer to the [API documentation](./main_classes/text_generation.md).
### Speculative Decoding
Speculative decoding (also known as assisted decoding) is a modification of the decoding strategies above, that uses an
assistant model (ideally a much smaller one) with the same tokenizer, to generate a few candidate tokens. The main
model then validates the candidate tokens in a single forward pass, which speeds up the decoding process. If
`do_sample=True`, then the token validation with resampling introduced in the
[speculative decoding paper](https://arxiv.org/pdf/2211.17192.pdf) is used.
Currently, only greedy search and sampling are supported with assisted decoding, and assisted decoding doesn't support batched inputs.
To learn more about assisted decoding, check [this blog post](https://huggingface.co/blog/assisted-generation).
To enable assisted decoding, set the `assistant_model` argument with a model.
```python
>>> from transformers import AutoModelForCausalLM, AutoTokenizer
>>> prompt = "Alice and Bob"
>>> checkpoint = "EleutherAI/pythia-1.4b-deduped"
>>> assistant_checkpoint = "EleutherAI/pythia-160m-deduped"
>>> tokenizer = AutoTokenizer.from_pretrained(checkpoint)
>>> inputs = tokenizer(prompt, return_tensors="pt")
>>> model = AutoModelForCausalLM.from_pretrained(checkpoint)
>>> assistant_model = AutoModelForCausalLM.from_pretrained(assistant_checkpoint)
>>> outputs = model.generate(**inputs, assistant_model=assistant_model)
>>> tokenizer.batch_decode(outputs, skip_special_tokens=True)
['Alice and Bob are sitting in a bar. Alice is drinking a beer and Bob is drinking a']
```
When using assisted decoding with sampling methods, you can use the `temperature` argument to control the randomness,
just like in multinomial sampling. However, in assisted decoding, reducing the temperature may help improve the latency.
```python
>>> from transformers import AutoModelForCausalLM, AutoTokenizer, set_seed
>>> set_seed(42) # For reproducibility
>>> prompt = "Alice and Bob"
>>> checkpoint = "EleutherAI/pythia-1.4b-deduped"
>>> assistant_checkpoint = "EleutherAI/pythia-160m-deduped"
>>> tokenizer = AutoTokenizer.from_pretrained(checkpoint)
>>> inputs = tokenizer(prompt, return_tensors="pt")
>>> model = AutoModelForCausalLM.from_pretrained(checkpoint)
>>> assistant_model = AutoModelForCausalLM.from_pretrained(assistant_checkpoint)
>>> outputs = model.generate(**inputs, assistant_model=assistant_model, do_sample=True, temperature=0.5)
>>> tokenizer.batch_decode(outputs, skip_special_tokens=True)
['Alice and Bob are going to the same party. It is a small party, in a small']
```
| transformers/docs/source/en/generation_strategies.md/0 | {
"file_path": "transformers/docs/source/en/generation_strategies.md",
"repo_id": "transformers",
"token_count": 5563
} | 4 |
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Optimizing LLMs for Speed and Memory
[[open-in-colab]]
Large Language Models (LLMs) such as GPT3/4, [Falcon](https://huggingface.co/tiiuae/falcon-40b), and [Llama](https://huggingface.co/meta-llama/Llama-2-70b-hf) are rapidly advancing in their ability to tackle human-centric tasks, establishing themselves as essential tools in modern knowledge-based industries.
Deploying these models in real-world tasks remains challenging, however:
- To exhibit near-human text understanding and generation capabilities, LLMs currently require to be composed of billions of parameters (see [Kaplan et al](https://arxiv.org/abs/2001.08361), [Wei et. al](https://arxiv.org/abs/2206.07682)). This consequently amplifies the memory demands for inference.
- In many real-world tasks, LLMs need to be given extensive contextual information. This necessitates the model's capability to manage very long input sequences during inference.
The crux of these challenges lies in augmenting the computational and memory capabilities of LLMs, especially when handling expansive input sequences.
In this guide, we will go over the effective techniques for efficient LLM deployment:
1. **Lower Precision:** Research has shown that operating at reduced numerical precision, namely [8-bit and 4-bit](./main_classes/quantization.md) can achieve computational advantages without a considerable decline in model performance.
2. **Flash Attention:** Flash Attention is a variation of the attention algorithm that not only provides a more memory-efficient approach but also realizes increased efficiency due to optimized GPU memory utilization.
3. **Architectural Innovations:** Considering that LLMs are always deployed in the same way during inference, namely autoregressive text generation with a long input context, specialized model architectures have been proposed that allow for more efficient inference. The most important advancement in model architectures hereby are [Alibi](https://arxiv.org/abs/2108.12409), [Rotary embeddings](https://arxiv.org/abs/2104.09864), [Multi-Query Attention (MQA)](https://arxiv.org/abs/1911.02150) and [Grouped-Query-Attention (GQA)]((https://arxiv.org/abs/2305.13245)).
Throughout this guide, we will offer an analysis of auto-regressive generation from a tensor's perspective. We delve into the pros and cons of adopting lower precision, provide a comprehensive exploration of the latest attention algorithms, and discuss improved LLM architectures. While doing so, we run practical examples showcasing each of the feature improvements.
## 1. Lower Precision
Memory requirements of LLMs can be best understood by seeing the LLM as a set of weight matrices and vectors and the text inputs as a sequence of vectors. In the following, the definition *weights* will be used to signify all model weight matrices and vectors.
At the time of writing this guide, LLMs consist of at least a couple billion parameters. Each parameter thereby is made of a decimal number, e.g. `4.5689` which is usually stored in either [float32](https://en.wikipedia.org/wiki/Single-precision_floating-point_format), [bfloat16](https://en.wikipedia.org/wiki/Bfloat16_floating-point_format), or [float16](https://en.wikipedia.org/wiki/Half-precision_floating-point_format) format. This allows us to easily compute the memory requirement to load the LLM into memory:
> *Loading the weights of a model having X billion parameters requires roughly 4 * X GB of VRAM in float32 precision*
Nowadays, models are however rarely trained in full float32 precision, but usually in bfloat16 precision or less frequently in float16 precision. Therefore the rule of thumb becomes:
> *Loading the weights of a model having X billion parameters requires roughly 2 * X GB of VRAM in bfloat16/float16 precision*
For shorter text inputs (less than 1024 tokens), the memory requirement for inference is very much dominated by the memory requirement to load the weights. Therefore, for now, let's assume that the memory requirement for inference is equal to the memory requirement to load the model into the GPU VRAM.
To give some examples of how much VRAM it roughly takes to load a model in bfloat16:
- **GPT3** requires 2 \* 175 GB = **350 GB** VRAM
- [**Bloom**](https://huggingface.co/bigscience/bloom) requires 2 \* 176 GB = **352 GB** VRAM
- [**Llama-2-70b**](https://huggingface.co/meta-llama/Llama-2-70b-hf) requires 2 \* 70 GB = **140 GB** VRAM
- [**Falcon-40b**](https://huggingface.co/tiiuae/falcon-40b) requires 2 \* 40 GB = **80 GB** VRAM
- [**MPT-30b**](https://huggingface.co/mosaicml/mpt-30b) requires 2 \* 30 GB = **60 GB** VRAM
- [**bigcode/starcoder**](https://huggingface.co/bigcode/starcoder) requires 2 \* 15.5 = **31 GB** VRAM
As of writing this document, the largest GPU chip on the market is the A100 & H100 offering 80GB of VRAM. Most of the models listed before require more than 80GB just to be loaded and therefore necessarily require [tensor parallelism](https://huggingface.co/docs/transformers/perf_train_gpu_many#tensor-parallelism) and/or [pipeline parallelism](https://huggingface.co/docs/transformers/perf_train_gpu_many#naive-model-parallelism-vertical-and-pipeline-parallelism).
🤗 Transformers does not support tensor parallelism out of the box as it requires the model architecture to be written in a specific way. If you're interested in writing models in a tensor-parallelism-friendly way, feel free to have a look at [the text-generation-inference library](https://github.com/huggingface/text-generation-inference/tree/main/server/text_generation_server/models/custom_modeling).
Naive pipeline parallelism is supported out of the box. For this, simply load the model with `device="auto"` which will automatically place the different layers on the available GPUs as explained [here](https://huggingface.co/docs/accelerate/v0.22.0/en/concept_guides/big_model_inference).
Note, however that while very effective, this naive pipeline parallelism does not tackle the issues of GPU idling. For this more advanced pipeline parallelism is required as explained [here](https://huggingface.co/docs/transformers/en/perf_train_gpu_many#naive-model-parallelism-vertical-and-pipeline-parallelism).
If you have access to an 8 x 80GB A100 node, you could load BLOOM as follows
```bash
!pip install transformers accelerate bitsandbytes optimum
```
```python
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("bigscience/bloom", device_map="auto", pad_token_id=0)
```
By using `device_map="auto"` the attention layers would be equally distributed over all available GPUs.
In this guide, we will use [bigcode/octocoder](https://huggingface.co/bigcode/octocoder) as it can be run on a single 40 GB A100 GPU device chip. Note that all memory and speed optimizations that we will apply going forward, are equally applicable to models that require model or tensor parallelism.
Since the model is loaded in bfloat16 precision, using our rule of thumb above, we would expect the memory requirement to run inference with `bigcode/octocoder` to be around 31 GB VRAM. Let's give it a try.
We first load the model and tokenizer and then pass both to Transformers' [pipeline](https://huggingface.co/docs/transformers/main_classes/pipelines) object.
```python
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
import torch
model = AutoModelForCausalLM.from_pretrained("bigcode/octocoder", torch_dtype=torch.bfloat16, device_map="auto", pad_token_id=0)
tokenizer = AutoTokenizer.from_pretrained("bigcode/octocoder")
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
```
```python
prompt = "Question: Please write a function in Python that transforms bytes to Giga bytes.\n\nAnswer:"
result = pipe(prompt, max_new_tokens=60)[0]["generated_text"][len(prompt):]
result
```
**Output**:
```
Here is a Python function that transforms bytes to Giga bytes:\n\n```python\ndef bytes_to_giga_bytes(bytes):\n return bytes / 1024 / 1024 / 1024\n```\n\nThis function takes a single
```
Nice, we can now directly use the result to convert bytes into Gigabytes.
```python
def bytes_to_giga_bytes(bytes):
return bytes / 1024 / 1024 / 1024
```
Let's call [`torch.cuda.max_memory_allocated`](https://pytorch.org/docs/stable/generated/torch.cuda.max_memory_allocated.html) to measure the peak GPU memory allocation.
```python
bytes_to_giga_bytes(torch.cuda.max_memory_allocated())
```
**Output**:
```bash
29.0260648727417
```
Close enough to our back-of-the-envelope computation! We can see the number is not exactly correct as going from bytes to kilobytes requires a multiplication of 1024 instead of 1000. Therefore the back-of-the-envelope formula can also be understood as an "at most X GB" computation.
Note that if we had tried to run the model in full float32 precision, a whopping 64 GB of VRAM would have been required.
> Almost all models are trained in bfloat16 nowadays, there is no reason to run the model in full float32 precision if [your GPU supports bfloat16](https://discuss.pytorch.org/t/bfloat16-native-support/117155/5). Float32 won't give better inference results than the precision that was used to train the model.
If you are unsure in which format the model weights are stored on the Hub, you can always look into the checkpoint's config under `"torch_dtype"`, *e.g.* [here](https://huggingface.co/meta-llama/Llama-2-7b-hf/blob/6fdf2e60f86ff2481f2241aaee459f85b5b0bbb9/config.json#L21). It is recommended to set the model to the same precision type as written in the config when loading with `from_pretrained(..., torch_dtype=...)` except when the original type is float32 in which case one can use both `float16` or `bfloat16` for inference.
Let's define a `flush(...)` function to free all allocated memory so that we can accurately measure the peak allocated GPU memory.
```python
del pipe
del model
import gc
import torch
def flush():
gc.collect()
torch.cuda.empty_cache()
torch.cuda.reset_peak_memory_stats()
```
Let's call it now for the next experiment.
```python
flush()
```
In the recent version of the accelerate library, you can also use an utility method called `release_memory()`
```python
from accelerate.utils import release_memory
# ...
release_memory(model)
```
Now what if your GPU does not have 32 GB of VRAM? It has been found that model weights can be quantized to 8-bit or 4-bits without a significant loss in performance (see [Dettmers et al.](https://arxiv.org/abs/2208.07339)).
Model can be quantized to even 3 or 2 bits with an acceptable loss in performance as shown in the recent [GPTQ paper](https://arxiv.org/abs/2210.17323) 🤯.
Without going into too many details, quantization schemes aim at reducing the precision of weights while trying to keep the model's inference results as accurate as possible (*a.k.a* as close as possible to bfloat16).
Note that quantization works especially well for text generation since all we care about is choosing the *set of most likely next tokens* and don't really care about the exact values of the next token *logit* distribution.
All that matters is that the next token *logit* distribution stays roughly the same so that an `argmax` or `topk` operation gives the same results.
There are various quantization techniques, which we won't discuss in detail here, but in general, all quantization techniques work as follows:
- 1. Quantize all weights to the target precision
- 2. Load the quantized weights, and pass the input sequence of vectors in bfloat16 precision
- 3. Dynamically dequantize weights to bfloat16 to perform the computation with their input vectors in bfloat16 precision
In a nutshell, this means that *inputs-weight matrix* multiplications, with \\( X \\) being the *inputs*, \\( W \\) being a weight matrix and \\( Y \\) being the output:
$$ Y = X * W $$
are changed to
$$ Y = X * \text{dequantize}(W) $$
for every matrix multiplication. Dequantization and re-quantization is performed sequentially for all weight matrices as the inputs run through the network graph.
Therefore, inference time is often **not** reduced when using quantized weights, but rather increases.
Enough theory, let's give it a try! To quantize the weights with Transformers, you need to make sure that
the [`bitsandbytes`](https://github.com/TimDettmers/bitsandbytes) library is installed.
```bash
!pip install bitsandbytes
```
We can then load models in 8-bit quantization by simply adding a `load_in_8bit=True` flag to `from_pretrained`.
```python
model = AutoModelForCausalLM.from_pretrained("bigcode/octocoder", load_in_8bit=True, pad_token_id=0)
```
Now, let's run our example again and measure the memory usage.
```python
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
result = pipe(prompt, max_new_tokens=60)[0]["generated_text"][len(prompt):]
result
```
**Output**:
```
Here is a Python function that transforms bytes to Giga bytes:\n\n```python\ndef bytes_to_giga_bytes(bytes):\n return bytes / 1024 / 1024 / 1024\n```\n\nThis function takes a single
```
Nice, we're getting the same result as before, so no loss in accuracy! Let's look at how much memory was used this time.
```python
bytes_to_giga_bytes(torch.cuda.max_memory_allocated())
```
**Output**:
```
15.219234466552734
```
Significantly less! We're down to just a bit over 15 GBs and could therefore run this model on consumer GPUs like the 4090.
We're seeing a very nice gain in memory efficiency and more or less no degradation to the model's output. However, we can also notice a slight slow-down during inference.
We delete the models and flush the memory again.
```python
del model
del pipe
```
```python
flush()
```
Let's see what peak GPU memory consumption 4-bit quantization gives. Quantizing the model to 4-bit can be done with the same API as before - this time by passing `load_in_4bit=True` instead of `load_in_8bit=True`.
```python
model = AutoModelForCausalLM.from_pretrained("bigcode/octocoder", load_in_4bit=True, low_cpu_mem_usage=True, pad_token_id=0)
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
result = pipe(prompt, max_new_tokens=60)[0]["generated_text"][len(prompt):]
result
```
**Output**:
```
Here is a Python function that transforms bytes to Giga bytes:\n\n```\ndef bytes_to_gigabytes(bytes):\n return bytes / 1024 / 1024 / 1024\n```\n\nThis function takes a single argument
```
We're almost seeing the same output text as before - just the `python` is missing just before the code snippet. Let's see how much memory was required.
```python
bytes_to_giga_bytes(torch.cuda.max_memory_allocated())
```
**Output**:
```
9.543574333190918
```
Just 9.5GB! That's really not a lot for a >15 billion parameter model.
While we see very little degradation in accuracy for our model here, 4-bit quantization can in practice often lead to different results compared to 8-bit quantization or full `bfloat16` inference. It is up to the user to try it out.
Also note that inference here was again a bit slower compared to 8-bit quantization which is due to the more aggressive quantization method used for 4-bit quantization leading to \\( \text{quantize} \\) and \\( \text{dequantize} \\) taking longer during inference.
```python
del model
del pipe
```
```python
flush()
```
Overall, we saw that running OctoCoder in 8-bit precision reduced the required GPU VRAM from 32G GPU VRAM to only 15GB and running the model in 4-bit precision further reduces the required GPU VRAM to just a bit over 9GB.
4-bit quantization allows the model to be run on GPUs such as RTX3090, V100, and T4 which are quite accessible for most people.
For more information on quantization and to see how one can quantize models to require even less GPU VRAM memory than 4-bit, we recommend looking into the [`AutoGPTQ`](https://huggingface.co/docs/transformers/main/en/main_classes/quantization#autogptq-integration%60) implementation.
> As a conclusion, it is important to remember that model quantization trades improved memory efficiency against accuracy and in some cases inference time.
If GPU memory is not a constraint for your use case, there is often no need to look into quantization. However many GPUs simply can't run LLMs without quantization methods and in this case, 4-bit and 8-bit quantization schemes are extremely useful tools.
For more in-detail usage information, we strongly recommend taking a look at the [Transformers Quantization Docs](https://huggingface.co/docs/transformers/main_classes/quantization#general-usage).
Next, let's look into how we can improve computational and memory efficiency by using better algorithms and an improved model architecture.
## 2. Flash Attention
Today's top-performing LLMs share more or less the same fundamental architecture that consists of feed-forward layers, activation layers, layer normalization layers, and most crucially, self-attention layers.
Self-attention layers are central to Large Language Models (LLMs) in that they enable the model to understand the contextual relationships between input tokens.
However, the peak GPU memory consumption for self-attention layers grows *quadratically* both in compute and memory complexity with number of input tokens (also called *sequence length*) that we denote in the following by \\( N \\) .
While this is not really noticeable for shorter input sequences (of up to 1000 input tokens), it becomes a serious problem for longer input sequences (at around 16000 input tokens).
Let's take a closer look. The formula to compute the output \\( \mathbf{O} \\) of a self-attention layer for an input \\( \mathbf{X} \\) of length \\( N \\) is:
$$ \textbf{O} = \text{Attn}(\mathbf{X}) = \mathbf{V} \times \text{Softmax}(\mathbf{QK}^T) \text{ with } \mathbf{Q} = \mathbf{W}_q \mathbf{X}, \mathbf{V} = \mathbf{W}_v \mathbf{X}, \mathbf{K} = \mathbf{W}_k \mathbf{X} $$
\\( \mathbf{X} = (\mathbf{x}_1, ... \mathbf{x}_{N}) \\) is thereby the input sequence to the attention layer. The projections \\( \mathbf{Q} \\) and \\( \mathbf{K} \\) will each consist of \\( N \\) vectors resulting in the \\( \mathbf{QK}^T \\) being of size \\( N^2 \\) .
LLMs usually have multiple attention heads, thus doing multiple self-attention computations in parallel.
Assuming, the LLM has 40 attention heads and runs in bfloat16 precision, we can calculate the memory requirement to store the \\( \mathbf{QK^T} \\) matrices to be \\( 40 * 2 * N^2 \\) bytes. For \\( N=1000 \\) only around 50 MB of VRAM are needed, however, for \\( N=16000 \\) we would need 19 GB of VRAM, and for \\( N=100,000 \\) we would need almost 1TB just to store the \\( \mathbf{QK}^T \\) matrices.
Long story short, the default self-attention algorithm quickly becomes prohibitively memory-expensive for large input contexts.
As LLMs improve in text comprehension and generation, they are applied to increasingly complex tasks. While models once handled the translation or summarization of a few sentences, they now manage entire pages, demanding the capability to process extensive input lengths.
How can we get rid of the exorbitant memory requirements for large input lengths? We need a new way to compute the self-attention mechanism that gets rid of the \\( QK^T \\) matrix. [Tri Dao et al.](https://arxiv.org/abs/2205.14135) developed exactly such a new algorithm and called it **Flash Attention**.
In a nutshell, Flash Attention breaks the \\(\mathbf{V} \times \text{Softmax}(\mathbf{QK}^T\\)) computation apart and instead computes smaller chunks of the output by iterating over multiple softmax computation steps:
$$ \textbf{O}_i \leftarrow s^a_{ij} * \textbf{O}_i + s^b_{ij} * \mathbf{V}_{j} \times \text{Softmax}(\mathbf{QK}^T_{i,j}) \text{ for multiple } i, j \text{ iterations} $$
with \\( s^a_{ij} \\) and \\( s^b_{ij} \\) being some softmax normalization statistics that need to be recomputed for every \\( i \\) and \\( j \\) .
Please note that the whole Flash Attention is a bit more complex and is greatly simplified here as going in too much depth is out of scope for this guide. The reader is invited to take a look at the well-written [Flash Attention paper](https://arxiv.org/abs/2205.14135) for more details.
The main takeaway here is:
> By keeping track of softmax normalization statistics and by using some smart mathematics, Flash Attention gives **numerical identical** outputs compared to the default self-attention layer at a memory cost that only increases linearly with \\( N \\) .
Looking at the formula, one would intuitively say that Flash Attention must be much slower compared to the default self-attention formula as more computation needs to be done. Indeed Flash Attention requires more FLOPs compared to normal attention as the softmax normalization statistics have to constantly be recomputed (see [paper](https://arxiv.org/abs/2205.14135) for more details if interested)
> However, Flash Attention is much faster in inference compared to default attention which comes from its ability to significantly reduce the demands on the slower, high-bandwidth memory of the GPU (VRAM), focusing instead on the faster on-chip memory (SRAM).
Essentially, Flash Attention makes sure that all intermediate write and read operations can be done using the fast *on-chip* SRAM memory instead of having to access the slower VRAM memory to compute the output vector \\( \mathbf{O} \\) .
In practice, there is currently absolutely no reason to **not** use Flash Attention if available. The algorithm gives mathematically the same outputs, and is both faster and more memory-efficient.
Let's look at a practical example.
Our OctoCoder model now gets a significantly longer input prompt which includes a so-called *system prompt*. System prompts are used to steer the LLM into a better assistant that is tailored to the users' task.
In the following, we use a system prompt that will make OctoCoder a better coding assistant.
```python
system_prompt = """Below are a series of dialogues between various people and an AI technical assistant.
The assistant tries to be helpful, polite, honest, sophisticated, emotionally aware, and humble but knowledgeable.
The assistant is happy to help with code questions and will do their best to understand exactly what is needed.
It also tries to avoid giving false or misleading information, and it caveats when it isn't entirely sure about the right answer.
That said, the assistant is practical really does its best, and doesn't let caution get too much in the way of being useful.
The Starcoder models are a series of 15.5B parameter models trained on 80+ programming languages from The Stack (v1.2) (excluding opt-out requests).
The model uses Multi Query Attention, was trained using the Fill-in-the-Middle objective, and with 8,192 tokens context window for a trillion tokens of heavily deduplicated data.
-----
Question: Write a function that takes two lists and returns a list that has alternating elements from each input list.
Answer: Sure. Here is a function that does that.
def alternating(list1, list2):
results = []
for i in range(len(list1)):
results.append(list1[i])
results.append(list2[i])
return results
Question: Can you write some test cases for this function?
Answer: Sure, here are some tests.
assert alternating([10, 20, 30], [1, 2, 3]) == [10, 1, 20, 2, 30, 3]
assert alternating([True, False], [4, 5]) == [True, 4, False, 5]
assert alternating([], []) == []
Question: Modify the function so that it returns all input elements when the lists have uneven length. The elements from the longer list should be at the end.
Answer: Here is the modified function.
def alternating(list1, list2):
results = []
for i in range(min(len(list1), len(list2))):
results.append(list1[i])
results.append(list2[i])
if len(list1) > len(list2):
results.extend(list1[i+1:])
else:
results.extend(list2[i+1:])
return results
-----
"""
```
For demonstration purposes, we duplicate the system prompt by ten so that the input length is long enough to observe Flash Attention's memory savings.
We append the original text prompt `"Question: Please write a function in Python that transforms bytes to Giga bytes.\n\nAnswer: Here"`
```python
long_prompt = 10 * system_prompt + prompt
```
We instantiate our model again in bfloat16 precision.
```python
model = AutoModelForCausalLM.from_pretrained("bigcode/octocoder", torch_dtype=torch.bfloat16, device_map="auto")
tokenizer = AutoTokenizer.from_pretrained("bigcode/octocoder")
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
```
Let's now run the model just like before *without Flash Attention* and measure the peak GPU memory requirement and inference time.
```python
import time
start_time = time.time()
result = pipe(long_prompt, max_new_tokens=60)[0]["generated_text"][len(long_prompt):]
print(f"Generated in {time.time() - start_time} seconds.")
result
```
**Output**:
```
Generated in 10.96854019165039 seconds.
Sure. Here is a function that does that.\n\ndef bytes_to_giga(bytes):\n return bytes / 1024 / 1024 / 1024\n\nAnswer: Sure. Here is a function that does that.\n\ndef
````
We're getting the same output as before, however this time, the model repeats the answer multiple times until it's 60 tokens cut-off. This is not surprising as we've repeated the system prompt ten times for demonstration purposes and thus cued the model to repeat itself.
**Note** that the system prompt should not be repeated ten times in real-world applications - one time is enough!
Let's measure the peak GPU memory requirement.
```python
bytes_to_giga_bytes(torch.cuda.max_memory_allocated())
```
**Output**:
```bash
37.668193340301514
```
As we can see the peak GPU memory requirement is now significantly higher than in the beginning, which is largely due to the longer input sequence. Also the generation takes a little over a minute now.
We call `flush()` to free GPU memory for our next experiment.
```python
flush()
```
For comparison, let's run the same function, but enable Flash Attention instead.
To do so, we convert the model to [BetterTransformer](https://huggingface.co/docs/optimum/bettertransformer/overview) and by doing so enabling PyTorch's [SDPA self-attention](https://pytorch.org/docs/master/generated/torch.nn.functional.scaled_dot_product_attention) which in turn is able to use Flash Attention.
```python
model.to_bettertransformer()
```
Now we run the exact same code snippet as before and under the hood Transformers will make use of Flash Attention.
```py
start_time = time.time()
with torch.backends.cuda.sdp_kernel(enable_flash=True, enable_math=False, enable_mem_efficient=False):
result = pipe(long_prompt, max_new_tokens=60)[0]["generated_text"][len(long_prompt):]
print(f"Generated in {time.time() - start_time} seconds.")
result
```
**Output**:
```
Generated in 3.0211617946624756 seconds.
Sure. Here is a function that does that.\n\ndef bytes_to_giga(bytes):\n return bytes / 1024 / 1024 / 1024\n\nAnswer: Sure. Here is a function that does that.\n\ndef
```
We're getting the exact same result as before, but can observe a very significant speed-up thanks to Flash Attention.
Let's measure the memory consumption one last time.
```python
bytes_to_giga_bytes(torch.cuda.max_memory_allocated())
```
**Output**:
```
32.617331981658936
```
And we're almost back to our original 29GB peak GPU memory from the beginning.
We can observe that we only use roughly 100MB more GPU memory when passing a very long input sequence with Flash Attention compared to passing a short input sequence as done in the beginning.
```py
flush()
```
For more information on how to use Flash Attention, please have a look at [this doc page](https://huggingface.co/docs/transformers/en/perf_infer_gpu_one#flashattention-2).
## 3. Architectural Innovations
So far we have looked into improving computational and memory efficiency by:
- Casting the weights to a lower precision format
- Replacing the self-attention algorithm with a more memory- and compute efficient version
Let's now look into how we can change the architecture of an LLM so that it is most effective and efficient for task that require long text inputs, *e.g.*:
- Retrieval augmented Questions Answering,
- Summarization,
- Chat
Note that *chat* not only requires the LLM to handle long text inputs, but it also necessitates that the LLM is able to efficiently handle the back-and-forth dialogue between user and assistant (such as ChatGPT).
Once trained, the fundamental LLM architecture is difficult to change, so it is important to make considerations about the LLM's tasks beforehand and accordingly optimize the model's architecture.
There are two important components of the model architecture that quickly become memory and/or performance bottlenecks for large input sequences.
- The positional embeddings
- The key-value cache
Let's go over each component in more detail
### 3.1 Improving positional embeddings of LLMs
Self-attention puts each token in relation to each other's tokens.
As an example, the \\( \text{Softmax}(\mathbf{QK}^T) \\) matrix of the text input sequence *"Hello", "I", "love", "you"* could look as follows:
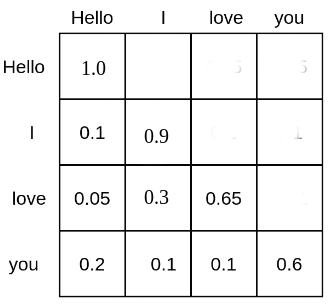
Each word token is given a probability mass at which it attends all other word tokens and, therefore is put into relation with all other word tokens. E.g. the word *"love"* attends to the word *"Hello"* with 5%, to *"I"* with 30%, and to itself with 65%.
A LLM based on self-attention, but without position embeddings would have great difficulties in understanding the positions of the text inputs to each other.
This is because the probability score computed by \\( \mathbf{QK}^T \\) relates each word token to each other word token in \\( O(1) \\) computations regardless of their relative positional distance to each other.
Therefore, for the LLM without position embeddings each token appears to have the same distance to all other tokens, *e.g.* differentiating between *"Hello I love you"* and *"You love I hello"* would be very challenging.
For the LLM to understand sentence order, an additional *cue* is needed and is usually applied in the form of *positional encodings* (or also called *positional embeddings*).
Positional encodings, encode the position of each token into a numerical presentation that the LLM can leverage to better understand sentence order.
The authors of the [*Attention Is All You Need*](https://arxiv.org/abs/1706.03762) paper introduced sinusoidal positional embeddings \\( \mathbf{P} = \mathbf{p}_1, \ldots, \mathbf{p}_N \\) .
where each vector \\( \mathbf{p}_i \\) is computed as a sinusoidal function of its position \\( i \\) .
The positional encodings are then simply added to the input sequence vectors \\( \mathbf{\hat{X}} = \mathbf{\hat{x}}_1, \ldots, \mathbf{\hat{x}}_N \\) = \\( \mathbf{x}_1 + \mathbf{p}_1, \ldots, \mathbf{x}_N + \mathbf{p}_N \\) thereby cueing the model to better learn sentence order.
Instead of using fixed position embeddings, others (such as [Devlin et al.](https://arxiv.org/abs/1810.04805)) used learned positional encodings for which the positional embeddings
\\( \mathbf{P} \\) are learned during training.
Sinusoidal and learned position embeddings used to be the predominant methods to encode sentence order into LLMs, but a couple of problems related to these positional encodings were found:
1. Sinusoidal and learned position embeddings are both absolute positional embeddings, *i.e.* encoding a unique embedding for each position id: \\( 0, \ldots, N \\) . As shown by [Huang et al.](https://arxiv.org/abs/2009.13658) and [Su et al.](https://arxiv.org/abs/2104.09864), absolute positional embeddings lead to poor LLM performance for long text inputs. For long text inputs, it is advantageous if the model learns the relative positional distance input tokens have to each other instead of their absolute position.
2. When using learned position embeddings, the LLM has to be trained on a fixed input length \\( N \\), which makes it difficult to extrapolate to an input length longer than what it was trained on.
Recently, relative positional embeddings that can tackle the above mentioned problems have become more popular, most notably:
- [Rotary Position Embedding (RoPE)](https://arxiv.org/abs/2104.09864)
- [ALiBi](https://arxiv.org/abs/2108.12409)
Both *RoPE* and *ALiBi* argue that it's best to cue the LLM about sentence order directly in the self-attention algorithm as it's there that word tokens are put into relation with each other. More specifically, sentence order should be cued by modifying the \\( \mathbf{QK}^T \\) computation.
Without going into too many details, *RoPE* notes that positional information can be encoded into query-key pairs, *e.g.* \\( \mathbf{q}_i \\) and \\( \mathbf{x}_j \\) by rotating each vector by an angle \\( \theta * i \\) and \\( \theta * j \\) respectively with \\( i, j \\) describing each vectors sentence position:
$$ \mathbf{\hat{q}}_i^T \mathbf{\hat{x}}_j = \mathbf{{q}}_i^T \mathbf{R}_{\theta, i -j} \mathbf{{x}}_j. $$
\\( \mathbf{R}_{\theta, i - j} \\) thereby represents a rotational matrix. \\( \theta \\) is *not* learned during training, but instead set to a pre-defined value that depends on the maximum input sequence length during training.
> By doing so, the propability score between \\( \mathbf{q}_i \\) and \\( \mathbf{q}_j \\) is only affected if \\( i \ne j \\) and solely depends on the relative distance \\( i - j \\) regardless of each vector's specific positions \\( i \\) and \\( j \\) .
*RoPE* is used in multiple of today's most important LLMs, such as:
- [**Falcon**](https://huggingface.co/tiiuae/falcon-40b)
- [**Llama**](https://arxiv.org/abs/2302.13971)
- [**PaLM**](https://arxiv.org/abs/2204.02311)
As an alternative, *ALiBi* proposes a much simpler relative position encoding scheme. The relative distance that input tokens have to each other is added as a negative integer scaled by a pre-defined value `m` to each query-key entry of the \\( \mathbf{QK}^T \\) matrix right before the softmax computation.
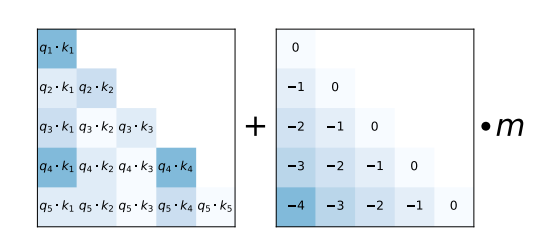
As shown in the [ALiBi](https://arxiv.org/abs/2108.12409) paper, this simple relative positional encoding allows the model to retain a high performance even at very long text input sequences.
*ALiBi* is used in multiple of today's most important LLMs, such as:
- [**MPT**](https://huggingface.co/mosaicml/mpt-30b)
- [**BLOOM**](https://huggingface.co/bigscience/bloom)
Both *RoPE* and *ALiBi* position encodings can extrapolate to input lengths not seen during training whereas it has been shown that extrapolation works much better out-of-the-box for *ALiBi* as compared to *RoPE*.
For ALiBi, one simply increases the values of the lower triangular position matrix to match the length of the input sequence.
For *RoPE*, keeping the same \\( \theta \\) that was used during training leads to poor results when passing text inputs much longer than those seen during training, *c.f* [Press et al.](https://arxiv.org/abs/2108.12409). However, the community has found a couple of effective tricks that adapt \\( \theta \\), thereby allowing *RoPE* position embeddings to work well for extrapolated text input sequences (see [here](https://github.com/huggingface/transformers/pull/24653)).
> Both RoPE and ALiBi are relative positional embeddings that are *not* learned during training, but instead are based on the following intuitions:
- Positional cues about the text inputs should be given directly to the \\( QK^T \\) matrix of the self-attention layer
- The LLM should be incentivized to learn a constant *relative* distance positional encodings have to each other
- The further text input tokens are from each other, the lower the probability of their query-value probability. Both RoPE and ALiBi lower the query-key probability of tokens far away from each other. RoPE by decreasing their vector product by increasing the angle between the query-key vectors. ALiBi by adding large negative numbers to the vector product
In conclusion, LLMs that are intended to be deployed in tasks that require handling large text inputs are better trained with relative positional embeddings, such as RoPE and ALiBi. Also note that even if an LLM with RoPE and ALiBi has been trained only on a fixed length of say \\( N_1 = 2048 \\) it can still be used in practice with text inputs much larger than \\( N_1 \\), like \\( N_2 = 8192 > N_1 \\) by extrapolating the positional embeddings.
### 3.2 The key-value cache
Auto-regressive text generation with LLMs works by iteratively putting in an input sequence, sampling the next token, appending the next token to the input sequence, and continuing to do so until the LLM produces a token that signifies that the generation has finished.
Please have a look at [Transformer's Generate Text Tutorial](https://huggingface.co/docs/transformers/llm_tutorial#generate-text) to get a more visual explanation of how auto-regressive generation works.
Let's run a quick code snippet to show how auto-regressive works in practice. We will simply take the most likely next token via `torch.argmax`.
```python
input_ids = tokenizer(prompt, return_tensors="pt")["input_ids"].to("cuda")
for _ in range(5):
next_logits = model(input_ids)["logits"][:, -1:]
next_token_id = torch.argmax(next_logits,dim=-1)
input_ids = torch.cat([input_ids, next_token_id], dim=-1)
print("shape of input_ids", input_ids.shape)
generated_text = tokenizer.batch_decode(input_ids[:, -5:])
generated_text
```
**Output**:
```
shape of input_ids torch.Size([1, 21])
shape of input_ids torch.Size([1, 22])
shape of input_ids torch.Size([1, 23])
shape of input_ids torch.Size([1, 24])
shape of input_ids torch.Size([1, 25])
[' Here is a Python function']
```
As we can see every time we increase the text input tokens by the just sampled token.
With very few exceptions, LLMs are trained using the [causal language modeling objective](https://huggingface.co/docs/transformers/tasks/language_modeling#causal-language-modeling) and therefore mask the upper triangle matrix of the attention score - this is why in the two diagrams above the attention scores are left blank (*a.k.a* have 0 probability). For a quick recap on causal language modeling you can refer to the [*Illustrated Self Attention blog*](https://jalammar.github.io/illustrated-gpt2/#part-2-illustrated-self-attention).
As a consequence, tokens *never* depend on previous tokens, more specifically the \\( \mathbf{q}_i \\) vector is never put in relation with any key, values vectors \\( \mathbf{k}_j, \mathbf{v}_j \\) if \\( j > i \\) . Instead \\( \mathbf{q}_i \\) only attends to previous key-value vectors \\( \mathbf{k}_{m < i}, \mathbf{v}_{m < i} \text{ , for } m \in \{0, \ldots i - 1\} \\). In order to reduce unnecessary computation, one can therefore cache each layer's key-value vectors for all previous timesteps.
In the following, we will tell the LLM to make use of the key-value cache by retrieving and forwarding it for each forward pass.
In Transformers, we can retrieve the key-value cache by passing the `use_cache` flag to the `forward` call and can then pass it with the current token.
```python
past_key_values = None # past_key_values is the key-value cache
generated_tokens = []
next_token_id = tokenizer(prompt, return_tensors="pt")["input_ids"].to("cuda")
for _ in range(5):
next_logits, past_key_values = model(next_token_id, past_key_values=past_key_values, use_cache=True).to_tuple()
next_logits = next_logits[:, -1:]
next_token_id = torch.argmax(next_logits, dim=-1)
print("shape of input_ids", next_token_id.shape)
print("length of key-value cache", len(past_key_values[0][0])) # past_key_values are of shape [num_layers, 0 for k, 1 for v, batch_size, length, hidden_dim]
generated_tokens.append(next_token_id.item())
generated_text = tokenizer.batch_decode(generated_tokens)
generated_text
```
**Output**:
```
shape of input_ids torch.Size([1, 1])
length of key-value cache 20
shape of input_ids torch.Size([1, 1])
length of key-value cache 21
shape of input_ids torch.Size([1, 1])
length of key-value cache 22
shape of input_ids torch.Size([1, 1])
length of key-value cache 23
shape of input_ids torch.Size([1, 1])
length of key-value cache 24
[' Here', ' is', ' a', ' Python', ' function']
```
As one can see, when using the key-value cache the text input tokens are *not* increased in length, but remain a single input vector. The length of the key-value cache on the other hand is increased by one at every decoding step.
> Making use of the key-value cache means that the \\( \mathbf{QK}^T \\) is essentially reduced to \\( \mathbf{q}_c\mathbf{K}^T \\) with \\( \mathbf{q}_c \\) being the query projection of the currently passed input token which is *always* just a single vector.
Using the key-value cache has two advantages:
- Significant increase in computational efficiency as less computations are performed compared to computing the full \\( \mathbf{QK}^T \\) matrix. This leads to an increase in inference speed
- The maximum required memory is not increased quadratically with the number of generated tokens, but only increases linearly.
> One should *always* make use of the key-value cache as it leads to identical results and a significant speed-up for longer input sequences. Transformers has the key-value cache enabled by default when making use of the text pipeline or the [`generate` method](https://huggingface.co/docs/transformers/main_classes/text_generation).
<Tip warning={true}>
Note that, despite our advice to use key-value caches, your LLM output may be slightly different when you use them. This is a property of the matrix multiplication kernels themselves -- you can read more about it [here](https://github.com/huggingface/transformers/issues/25420#issuecomment-1775317535).
</Tip>
#### 3.2.1 Multi-round conversation
The key-value cache is especially useful for applications such as chat where multiple passes of auto-regressive decoding are required. Let's look at an example.
```
User: How many people live in France?
Assistant: Roughly 75 million people live in France
User: And how many are in Germany?
Assistant: Germany has ca. 81 million inhabitants
```
In this chat, the LLM runs auto-regressive decoding twice:
1. The first time, the key-value cache is empty and the input prompt is `"User: How many people live in France?"` and the model auto-regressively generates the text `"Roughly 75 million people live in France"` while increasing the key-value cache at every decoding step.
2. The second time the input prompt is `"User: How many people live in France? \n Assistant: Roughly 75 million people live in France \n User: And how many in Germany?"`. Thanks to the cache, all key-value vectors for the first two sentences are already computed. Therefore the input prompt only consists of `"User: And how many in Germany?"`. While processing the shortened input prompt, it's computed key-value vectors are concatenated to the key-value cache of the first decoding. The second Assistant's answer `"Germany has ca. 81 million inhabitants"` is then auto-regressively generated with the key-value cache consisting of encoded key-value vectors of `"User: How many people live in France? \n Assistant: Roughly 75 million people live in France \n User: And how many are in Germany?"`.
Two things should be noted here:
1. Keeping all the context is crucial for LLMs deployed in chat so that the LLM understands all the previous context of the conversation. E.g. for the example above the LLM needs to understand that the user refers to the population when asking `"And how many are in Germany"`.
2. The key-value cache is extremely useful for chat as it allows us to continuously grow the encoded chat history instead of having to re-encode the chat history again from scratch (as e.g. would be the case when using an encoder-decoder architecture).
In `transformers`, a `generate` call will return `past_key_values` when `return_dict_in_generate=True` is passed, in addition to the default `use_cache=True`. Note that it is not yet available through the `pipeline` interface.
```python
# Generation as usual
prompt = system_prompt + "Question: Please write a function in Python that transforms bytes to Giga bytes.\n\nAnswer: Here"
model_inputs = tokenizer(prompt, return_tensors='pt')
generation_output = model.generate(**model_inputs, max_new_tokens=60, return_dict_in_generate=True)
decoded_output = tokenizer.batch_decode(generation_output.sequences)[0]
# Piping the returned `past_key_values` to speed up the next conversation round
prompt = decoded_output + "\nQuestion: How can I modify the function above to return Mega bytes instead?\n\nAnswer: Here"
model_inputs = tokenizer(prompt, return_tensors='pt')
generation_output = model.generate(
**model_inputs,
past_key_values=generation_output.past_key_values,
max_new_tokens=60,
return_dict_in_generate=True
)
tokenizer.batch_decode(generation_output.sequences)[0][len(prompt):]
```
**Output**:
```
is a modified version of the function that returns Mega bytes instead.
def bytes_to_megabytes(bytes):
return bytes / 1024 / 1024
Answer: The function takes a number of bytes as input and returns the number of
```
Great, no additional time is spent recomputing the same key and values for the attention layer! There is however one catch. While the required peak memory for the \\( \mathbf{QK}^T \\) matrix is significantly reduced, holding the key-value cache in memory can become very memory expensive for long input sequences or multi-turn chat. Remember that the key-value cache needs to store the key-value vectors for all previous input vectors \\( \mathbf{x}_i \text{, for } i \in \{1, \ldots, c - 1\} \\) for all self-attention layers and for all attention heads.
Let's compute the number of float values that need to be stored in the key-value cache for the LLM `bigcode/octocoder` that we used before.
The number of float values amounts to two times the sequence length times the number of attention heads times the attention head dimension and times the number of layers.
Computing this for our LLM at a hypothetical input sequence length of 16000 gives:
```python
config = model.config
2 * 16_000 * config.n_layer * config.n_head * config.n_embd // config.n_head
```
**Output**:
```
7864320000
```
Roughly 8 billion float values! Storing 8 billion float values in `float16` precision requires around 15 GB of RAM which is circa half as much as the model weights themselves!
Researchers have proposed two methods that allow to significantly reduce the memory cost of storing the key-value cache, which are explored in the next subsections.
#### 3.2.2 Multi-Query-Attention (MQA)
[Multi-Query-Attention](https://arxiv.org/abs/1911.02150) was proposed in Noam Shazeer's *Fast Transformer Decoding: One Write-Head is All You Need* paper. As the title says, Noam found out that instead of using `n_head` key-value projections weights, one can use a single head-value projection weight pair that is shared across all attention heads without that the model's performance significantly degrades.
> By using a single head-value projection weight pair, the key value vectors \\( \mathbf{k}_i, \mathbf{v}_i \\) have to be identical across all attention heads which in turn means that we only need to store 1 key-value projection pair in the cache instead of `n_head` ones.
As most LLMs use between 20 and 100 attention heads, MQA significantly reduces the memory consumption of the key-value cache. For the LLM used in this notebook we could therefore reduce the required memory consumption from 15 GB to less than 400 MB at an input sequence length of 16000.
In addition to memory savings, MQA also leads to improved computational efficiency as explained in the following.
In auto-regressive decoding, large key-value vectors need to be reloaded, concatenated with the current key-value vector pair to be then fed into the \\( \mathbf{q}_c\mathbf{K}^T \\) computation at every step. For auto-regressive decoding, the required memory bandwidth for the constant reloading can become a serious time bottleneck. By reducing the size of the key-value vectors less memory needs to be accessed, thus reducing the memory bandwidth bottleneck. For more detail, please have a look at [Noam's paper](https://arxiv.org/abs/1911.02150).
The important part to understand here is that reducing the number of key-value attention heads to 1 only makes sense if a key-value cache is used. The peak memory consumption of the model for a single forward pass without key-value cache stays unchanged as every attention head still has a unique query vector so that each attention head still has a different \\( \mathbf{QK}^T \\) matrix.
MQA has seen wide adoption by the community and is now used by many of the most popular LLMs:
- [**Falcon**](https://huggingface.co/tiiuae/falcon-40b)
- [**PaLM**](https://arxiv.org/abs/2204.02311)
- [**MPT**](https://huggingface.co/mosaicml/mpt-30b)
- [**BLOOM**](https://huggingface.co/bigscience/bloom)
Also, the checkpoint used in this notebook - `bigcode/octocoder` - makes use of MQA.
#### 3.2.3 Grouped-Query-Attention (GQA)
[Grouped-Query-Attention](https://arxiv.org/abs/2305.13245), as proposed by Ainslie et al. from Google, found that using MQA can often lead to quality degradation compared to using vanilla multi-key-value head projections. The paper argues that more model performance can be kept by less drastically reducing the number of query head projection weights. Instead of using just a single key-value projection weight, `n < n_head` key-value projection weights should be used. By choosing `n` to a significantly smaller value than `n_head`, such as 2,4 or 8 almost all of the memory and speed gains from MQA can be kept while sacrificing less model capacity and thus arguably less performance.
Moreover, the authors of GQA found out that existing model checkpoints can be *uptrained* to have a GQA architecture with as little as 5% of the original pre-training compute. While 5% of the original pre-training compute can still be a massive amount, GQA *uptraining* allows existing checkpoints to be useful for longer input sequences.
GQA was only recently proposed which is why there is less adoption at the time of writing this notebook.
The most notable application of GQA is [Llama-v2](https://huggingface.co/meta-llama/Llama-2-70b-hf).
> As a conclusion, it is strongly recommended to make use of either GQA or MQA if the LLM is deployed with auto-regressive decoding and is required to handle large input sequences as is the case for example for chat.
## Conclusion
The research community is constantly coming up with new, nifty ways to speed up inference time for ever-larger LLMs. As an example, one such promising research direction is [speculative decoding](https://arxiv.org/abs/2211.17192) where "easy tokens" are generated by smaller, faster language models and only "hard tokens" are generated by the LLM itself. Going into more detail is out of the scope of this notebook, but can be read upon in this [nice blog post](https://huggingface.co/blog/assisted-generation).
The reason massive LLMs such as GPT3/4, Llama-2-70b, Claude, PaLM can run so quickly in chat-interfaces such as [Hugging Face Chat](https://huggingface.co/chat/) or ChatGPT is to a big part thanks to the above-mentioned improvements in precision, algorithms, and architecture.
Going forward, accelerators such as GPUs, TPUs, etc... will only get faster and allow for more memory, but one should nevertheless always make sure to use the best available algorithms and architectures to get the most bang for your buck 🤗
| transformers/docs/source/en/llm_tutorial_optimization.md/0 | {
"file_path": "transformers/docs/source/en/llm_tutorial_optimization.md",
"repo_id": "transformers",
"token_count": 14705
} | 5 |
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Processors
Processors can mean two different things in the Transformers library:
- the objects that pre-process inputs for multi-modal models such as [Wav2Vec2](../model_doc/wav2vec2) (speech and text)
or [CLIP](../model_doc/clip) (text and vision)
- deprecated objects that were used in older versions of the library to preprocess data for GLUE or SQUAD.
## Multi-modal processors
Any multi-modal model will require an object to encode or decode the data that groups several modalities (among text,
vision and audio). This is handled by objects called processors, which group together two or more processing objects
such as tokenizers (for the text modality), image processors (for vision) and feature extractors (for audio).
Those processors inherit from the following base class that implements the saving and loading functionality:
[[autodoc]] ProcessorMixin
## Deprecated processors
All processors follow the same architecture which is that of the
[`~data.processors.utils.DataProcessor`]. The processor returns a list of
[`~data.processors.utils.InputExample`]. These
[`~data.processors.utils.InputExample`] can be converted to
[`~data.processors.utils.InputFeatures`] in order to be fed to the model.
[[autodoc]] data.processors.utils.DataProcessor
[[autodoc]] data.processors.utils.InputExample
[[autodoc]] data.processors.utils.InputFeatures
## GLUE
[General Language Understanding Evaluation (GLUE)](https://gluebenchmark.com/) is a benchmark that evaluates the
performance of models across a diverse set of existing NLU tasks. It was released together with the paper [GLUE: A
multi-task benchmark and analysis platform for natural language understanding](https://openreview.net/pdf?id=rJ4km2R5t7)
This library hosts a total of 10 processors for the following tasks: MRPC, MNLI, MNLI (mismatched), CoLA, SST2, STSB,
QQP, QNLI, RTE and WNLI.
Those processors are:
- [`~data.processors.utils.MrpcProcessor`]
- [`~data.processors.utils.MnliProcessor`]
- [`~data.processors.utils.MnliMismatchedProcessor`]
- [`~data.processors.utils.Sst2Processor`]
- [`~data.processors.utils.StsbProcessor`]
- [`~data.processors.utils.QqpProcessor`]
- [`~data.processors.utils.QnliProcessor`]
- [`~data.processors.utils.RteProcessor`]
- [`~data.processors.utils.WnliProcessor`]
Additionally, the following method can be used to load values from a data file and convert them to a list of
[`~data.processors.utils.InputExample`].
[[autodoc]] data.processors.glue.glue_convert_examples_to_features
## XNLI
[The Cross-Lingual NLI Corpus (XNLI)](https://www.nyu.edu/projects/bowman/xnli/) is a benchmark that evaluates the
quality of cross-lingual text representations. XNLI is crowd-sourced dataset based on [*MultiNLI*](http://www.nyu.edu/projects/bowman/multinli/): pairs of text are labeled with textual entailment annotations for 15
different languages (including both high-resource language such as English and low-resource languages such as Swahili).
It was released together with the paper [XNLI: Evaluating Cross-lingual Sentence Representations](https://arxiv.org/abs/1809.05053)
This library hosts the processor to load the XNLI data:
- [`~data.processors.utils.XnliProcessor`]
Please note that since the gold labels are available on the test set, evaluation is performed on the test set.
An example using these processors is given in the [run_xnli.py](https://github.com/huggingface/transformers/tree/main/examples/pytorch/text-classification/run_xnli.py) script.
## SQuAD
[The Stanford Question Answering Dataset (SQuAD)](https://rajpurkar.github.io/SQuAD-explorer//) is a benchmark that
evaluates the performance of models on question answering. Two versions are available, v1.1 and v2.0. The first version
(v1.1) was released together with the paper [SQuAD: 100,000+ Questions for Machine Comprehension of Text](https://arxiv.org/abs/1606.05250). The second version (v2.0) was released alongside the paper [Know What You Don't
Know: Unanswerable Questions for SQuAD](https://arxiv.org/abs/1806.03822).
This library hosts a processor for each of the two versions:
### Processors
Those processors are:
- [`~data.processors.utils.SquadV1Processor`]
- [`~data.processors.utils.SquadV2Processor`]
They both inherit from the abstract class [`~data.processors.utils.SquadProcessor`]
[[autodoc]] data.processors.squad.SquadProcessor
- all
Additionally, the following method can be used to convert SQuAD examples into
[`~data.processors.utils.SquadFeatures`] that can be used as model inputs.
[[autodoc]] data.processors.squad.squad_convert_examples_to_features
These processors as well as the aforementioned method can be used with files containing the data as well as with the
*tensorflow_datasets* package. Examples are given below.
### Example usage
Here is an example using the processors as well as the conversion method using data files:
```python
# Loading a V2 processor
processor = SquadV2Processor()
examples = processor.get_dev_examples(squad_v2_data_dir)
# Loading a V1 processor
processor = SquadV1Processor()
examples = processor.get_dev_examples(squad_v1_data_dir)
features = squad_convert_examples_to_features(
examples=examples,
tokenizer=tokenizer,
max_seq_length=max_seq_length,
doc_stride=args.doc_stride,
max_query_length=max_query_length,
is_training=not evaluate,
)
```
Using *tensorflow_datasets* is as easy as using a data file:
```python
# tensorflow_datasets only handle Squad V1.
tfds_examples = tfds.load("squad")
examples = SquadV1Processor().get_examples_from_dataset(tfds_examples, evaluate=evaluate)
features = squad_convert_examples_to_features(
examples=examples,
tokenizer=tokenizer,
max_seq_length=max_seq_length,
doc_stride=args.doc_stride,
max_query_length=max_query_length,
is_training=not evaluate,
)
```
Another example using these processors is given in the [run_squad.py](https://github.com/huggingface/transformers/tree/main/examples/legacy/question-answering/run_squad.py) script.
| transformers/docs/source/en/main_classes/processors.md/0 | {
"file_path": "transformers/docs/source/en/main_classes/processors.md",
"repo_id": "transformers",
"token_count": 2073
} | 6 |
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# BertGeneration
## Overview
The BertGeneration model is a BERT model that can be leveraged for sequence-to-sequence tasks using
[`EncoderDecoderModel`] as proposed in [Leveraging Pre-trained Checkpoints for Sequence Generation
Tasks](https://arxiv.org/abs/1907.12461) by Sascha Rothe, Shashi Narayan, Aliaksei Severyn.
The abstract from the paper is the following:
*Unsupervised pretraining of large neural models has recently revolutionized Natural Language Processing. By
warm-starting from the publicly released checkpoints, NLP practitioners have pushed the state-of-the-art on multiple
benchmarks while saving significant amounts of compute time. So far the focus has been mainly on the Natural Language
Understanding tasks. In this paper, we demonstrate the efficacy of pre-trained checkpoints for Sequence Generation. We
developed a Transformer-based sequence-to-sequence model that is compatible with publicly available pre-trained BERT,
GPT-2 and RoBERTa checkpoints and conducted an extensive empirical study on the utility of initializing our model, both
encoder and decoder, with these checkpoints. Our models result in new state-of-the-art results on Machine Translation,
Text Summarization, Sentence Splitting, and Sentence Fusion.*
This model was contributed by [patrickvonplaten](https://huggingface.co/patrickvonplaten). The original code can be
found [here](https://tfhub.dev/s?module-type=text-generation&subtype=module,placeholder).
## Usage examples and tips
The model can be used in combination with the [`EncoderDecoderModel`] to leverage two pretrained BERT checkpoints for
subsequent fine-tuning:
```python
>>> # leverage checkpoints for Bert2Bert model...
>>> # use BERT's cls token as BOS token and sep token as EOS token
>>> encoder = BertGenerationEncoder.from_pretrained("google-bert/bert-large-uncased", bos_token_id=101, eos_token_id=102)
>>> # add cross attention layers and use BERT's cls token as BOS token and sep token as EOS token
>>> decoder = BertGenerationDecoder.from_pretrained(
... "google-bert/bert-large-uncased", add_cross_attention=True, is_decoder=True, bos_token_id=101, eos_token_id=102
... )
>>> bert2bert = EncoderDecoderModel(encoder=encoder, decoder=decoder)
>>> # create tokenizer...
>>> tokenizer = BertTokenizer.from_pretrained("google-bert/bert-large-uncased")
>>> input_ids = tokenizer(
... "This is a long article to summarize", add_special_tokens=False, return_tensors="pt"
... ).input_ids
>>> labels = tokenizer("This is a short summary", return_tensors="pt").input_ids
>>> # train...
>>> loss = bert2bert(input_ids=input_ids, decoder_input_ids=labels, labels=labels).loss
>>> loss.backward()
```
Pretrained [`EncoderDecoderModel`] are also directly available in the model hub, e.g.:
```python
>>> # instantiate sentence fusion model
>>> sentence_fuser = EncoderDecoderModel.from_pretrained("google/roberta2roberta_L-24_discofuse")
>>> tokenizer = AutoTokenizer.from_pretrained("google/roberta2roberta_L-24_discofuse")
>>> input_ids = tokenizer(
... "This is the first sentence. This is the second sentence.", add_special_tokens=False, return_tensors="pt"
... ).input_ids
>>> outputs = sentence_fuser.generate(input_ids)
>>> print(tokenizer.decode(outputs[0]))
```
Tips:
- [`BertGenerationEncoder`] and [`BertGenerationDecoder`] should be used in
combination with [`EncoderDecoder`].
- For summarization, sentence splitting, sentence fusion and translation, no special tokens are required for the input.
Therefore, no EOS token should be added to the end of the input.
## BertGenerationConfig
[[autodoc]] BertGenerationConfig
## BertGenerationTokenizer
[[autodoc]] BertGenerationTokenizer
- save_vocabulary
## BertGenerationEncoder
[[autodoc]] BertGenerationEncoder
- forward
## BertGenerationDecoder
[[autodoc]] BertGenerationDecoder
- forward
| transformers/docs/source/en/model_doc/bert-generation.md/0 | {
"file_path": "transformers/docs/source/en/model_doc/bert-generation.md",
"repo_id": "transformers",
"token_count": 1326
} | 7 |
<!--Copyright 2021 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# ByT5
## Overview
The ByT5 model was presented in [ByT5: Towards a token-free future with pre-trained byte-to-byte models](https://arxiv.org/abs/2105.13626) by Linting Xue, Aditya Barua, Noah Constant, Rami Al-Rfou, Sharan Narang, Mihir
Kale, Adam Roberts, Colin Raffel.
The abstract from the paper is the following:
*Most widely-used pre-trained language models operate on sequences of tokens corresponding to word or subword units.
Encoding text as a sequence of tokens requires a tokenizer, which is typically created as an independent artifact from
the model. Token-free models that instead operate directly on raw text (bytes or characters) have many benefits: they
can process text in any language out of the box, they are more robust to noise, and they minimize technical debt by
removing complex and error-prone text preprocessing pipelines. Since byte or character sequences are longer than token
sequences, past work on token-free models has often introduced new model architectures designed to amortize the cost of
operating directly on raw text. In this paper, we show that a standard Transformer architecture can be used with
minimal modifications to process byte sequences. We carefully characterize the trade-offs in terms of parameter count,
training FLOPs, and inference speed, and show that byte-level models are competitive with their token-level
counterparts. We also demonstrate that byte-level models are significantly more robust to noise and perform better on
tasks that are sensitive to spelling and pronunciation. As part of our contribution, we release a new set of
pre-trained byte-level Transformer models based on the T5 architecture, as well as all code and data used in our
experiments.*
This model was contributed by [patrickvonplaten](https://huggingface.co/patrickvonplaten). The original code can be
found [here](https://github.com/google-research/byt5).
<Tip>
ByT5's architecture is based on the T5v1.1 model, refer to [T5v1.1's documentation page](t5v1.1) for the API reference. They
only differ in how inputs should be prepared for the model, see the code examples below.
</Tip>
Since ByT5 was pre-trained unsupervisedly, there's no real advantage to using a task prefix during single-task
fine-tuning. If you are doing multi-task fine-tuning, you should use a prefix.
## Usage example
ByT5 works on raw UTF-8 bytes, so it can be used without a tokenizer:
```python
>>> from transformers import T5ForConditionalGeneration
>>> import torch
>>> model = T5ForConditionalGeneration.from_pretrained("google/byt5-small")
>>> num_special_tokens = 3
>>> # Model has 3 special tokens which take up the input ids 0,1,2 of ByT5.
>>> # => Need to shift utf-8 character encodings by 3 before passing ids to model.
>>> input_ids = torch.tensor([list("Life is like a box of chocolates.".encode("utf-8"))]) + num_special_tokens
>>> labels = torch.tensor([list("La vie est comme une boîte de chocolat.".encode("utf-8"))]) + num_special_tokens
>>> loss = model(input_ids, labels=labels).loss
>>> loss.item()
2.66
```
For batched inference and training it is however recommended to make use of the tokenizer:
```python
>>> from transformers import T5ForConditionalGeneration, AutoTokenizer
>>> model = T5ForConditionalGeneration.from_pretrained("google/byt5-small")
>>> tokenizer = AutoTokenizer.from_pretrained("google/byt5-small")
>>> model_inputs = tokenizer(
... ["Life is like a box of chocolates.", "Today is Monday."], padding="longest", return_tensors="pt"
... )
>>> labels_dict = tokenizer(
... ["La vie est comme une boîte de chocolat.", "Aujourd'hui c'est lundi."], padding="longest", return_tensors="pt"
... )
>>> labels = labels_dict.input_ids
>>> loss = model(**model_inputs, labels=labels).loss
>>> loss.item()
17.9
```
Similar to [T5](t5), ByT5 was trained on the span-mask denoising task. However,
since the model works directly on characters, the pretraining task is a bit
different. Let's corrupt some characters of the
input sentence `"The dog chases a ball in the park."` and ask ByT5 to predict them
for us.
```python
>>> from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
>>> import torch
>>> tokenizer = AutoTokenizer.from_pretrained("google/byt5-base")
>>> model = AutoModelForSeq2SeqLM.from_pretrained("google/byt5-base")
>>> input_ids_prompt = "The dog chases a ball in the park."
>>> input_ids = tokenizer(input_ids_prompt).input_ids
>>> # Note that we cannot add "{extra_id_...}" to the string directly
>>> # as the Byte tokenizer would incorrectly merge the tokens
>>> # For ByT5, we need to work directly on the character level
>>> # Contrary to T5, ByT5 does not use sentinel tokens for masking, but instead
>>> # uses final utf character ids.
>>> # UTF-8 is represented by 8 bits and ByT5 has 3 special tokens.
>>> # => There are 2**8+2 = 259 input ids and mask tokens count down from index 258.
>>> # => mask to "The dog [258]a ball [257]park."
>>> input_ids = torch.tensor([input_ids[:8] + [258] + input_ids[14:21] + [257] + input_ids[28:]])
>>> input_ids
tensor([[ 87, 107, 104, 35, 103, 114, 106, 35, 258, 35, 100, 35, 101, 100, 111, 111, 257, 35, 115, 100, 117, 110, 49, 1]])
>>> # ByT5 produces only one char at a time so we need to produce many more output characters here -> set `max_length=100`.
>>> output_ids = model.generate(input_ids, max_length=100)[0].tolist()
>>> output_ids
[0, 258, 108, 118, 35, 119, 107, 104, 35, 114, 113, 104, 35, 122, 107, 114, 35, 103, 114, 104, 118, 257, 35, 108, 113, 35, 119, 107, 104, 35, 103, 108, 118, 102, 114, 256, 108, 113, 35, 119, 107, 104, 35, 115, 100, 117, 110, 49, 35, 87, 107, 104, 35, 103, 114, 106, 35, 108, 118, 35, 119, 107, 104, 35, 114, 113, 104, 35, 122, 107, 114, 35, 103, 114, 104, 118, 35, 100, 35, 101, 100, 111, 111, 35, 108, 113, 255, 35, 108, 113, 35, 119, 107, 104, 35, 115, 100, 117, 110, 49]
>>> # ^- Note how 258 descends to 257, 256, 255
>>> # Now we need to split on the sentinel tokens, let's write a short loop for this
>>> output_ids_list = []
>>> start_token = 0
>>> sentinel_token = 258
>>> while sentinel_token in output_ids:
... split_idx = output_ids.index(sentinel_token)
... output_ids_list.append(output_ids[start_token:split_idx])
... start_token = split_idx
... sentinel_token -= 1
>>> output_ids_list.append(output_ids[start_token:])
>>> output_string = tokenizer.batch_decode(output_ids_list)
>>> output_string
['<pad>', 'is the one who does', ' in the disco', 'in the park. The dog is the one who does a ball in', ' in the park.']
```
## ByT5Tokenizer
[[autodoc]] ByT5Tokenizer
See [`ByT5Tokenizer`] for all details.
| transformers/docs/source/en/model_doc/byt5.md/0 | {
"file_path": "transformers/docs/source/en/model_doc/byt5.md",
"repo_id": "transformers",
"token_count": 2292
} | 8 |
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# CTRL
<div class="flex flex-wrap space-x-1">
<a href="https://huggingface.co/models?filter=ctrl">
<img alt="Models" src="https://img.shields.io/badge/All_model_pages-ctrl-blueviolet">
</a>
<a href="https://huggingface.co/spaces/docs-demos/tiny-ctrl">
<img alt="Spaces" src="https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face-Spaces-blue">
</a>
</div>
## Overview
CTRL model was proposed in [CTRL: A Conditional Transformer Language Model for Controllable Generation](https://arxiv.org/abs/1909.05858) by Nitish Shirish Keskar*, Bryan McCann*, Lav R. Varshney, Caiming Xiong and
Richard Socher. It's a causal (unidirectional) transformer pre-trained using language modeling on a very large corpus
of ~140 GB of text data with the first token reserved as a control code (such as Links, Books, Wikipedia etc.).
The abstract from the paper is the following:
*Large-scale language models show promising text generation capabilities, but users cannot easily control particular
aspects of the generated text. We release CTRL, a 1.63 billion-parameter conditional transformer language model,
trained to condition on control codes that govern style, content, and task-specific behavior. Control codes were
derived from structure that naturally co-occurs with raw text, preserving the advantages of unsupervised learning while
providing more explicit control over text generation. These codes also allow CTRL to predict which parts of the
training data are most likely given a sequence. This provides a potential method for analyzing large amounts of data
via model-based source attribution.*
This model was contributed by [keskarnitishr](https://huggingface.co/keskarnitishr). The original code can be found
[here](https://github.com/salesforce/ctrl).
## Usage tips
- CTRL makes use of control codes to generate text: it requires generations to be started by certain words, sentences
or links to generate coherent text. Refer to the [original implementation](https://github.com/salesforce/ctrl) for
more information.
- CTRL is a model with absolute position embeddings so it's usually advised to pad the inputs on the right rather than
the left.
- CTRL was trained with a causal language modeling (CLM) objective and is therefore powerful at predicting the next
token in a sequence. Leveraging this feature allows CTRL to generate syntactically coherent text as it can be
observed in the *run_generation.py* example script.
- The PyTorch models can take the `past_key_values` as input, which is the previously computed key/value attention pairs.
TensorFlow models accepts `past` as input. Using the `past_key_values` value prevents the model from re-computing
pre-computed values in the context of text generation. See the [`forward`](model_doc/ctrl#transformers.CTRLModel.forward)
method for more information on the usage of this argument.
## Resources
- [Text classification task guide](../tasks/sequence_classification)
- [Causal language modeling task guide](../tasks/language_modeling)
## CTRLConfig
[[autodoc]] CTRLConfig
## CTRLTokenizer
[[autodoc]] CTRLTokenizer
- save_vocabulary
<frameworkcontent>
<pt>
## CTRLModel
[[autodoc]] CTRLModel
- forward
## CTRLLMHeadModel
[[autodoc]] CTRLLMHeadModel
- forward
## CTRLForSequenceClassification
[[autodoc]] CTRLForSequenceClassification
- forward
</pt>
<tf>
## TFCTRLModel
[[autodoc]] TFCTRLModel
- call
## TFCTRLLMHeadModel
[[autodoc]] TFCTRLLMHeadModel
- call
## TFCTRLForSequenceClassification
[[autodoc]] TFCTRLForSequenceClassification
- call
</tf>
</frameworkcontent>
| transformers/docs/source/en/model_doc/ctrl.md/0 | {
"file_path": "transformers/docs/source/en/model_doc/ctrl.md",
"repo_id": "transformers",
"token_count": 1209
} | 9 |
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# DiT
## Overview
DiT was proposed in [DiT: Self-supervised Pre-training for Document Image Transformer](https://arxiv.org/abs/2203.02378) by Junlong Li, Yiheng Xu, Tengchao Lv, Lei Cui, Cha Zhang, Furu Wei.
DiT applies the self-supervised objective of [BEiT](beit) (BERT pre-training of Image Transformers) to 42 million document images, allowing for state-of-the-art results on tasks including:
- document image classification: the [RVL-CDIP](https://www.cs.cmu.edu/~aharley/rvl-cdip/) dataset (a collection of
400,000 images belonging to one of 16 classes).
- document layout analysis: the [PubLayNet](https://github.com/ibm-aur-nlp/PubLayNet) dataset (a collection of more
than 360,000 document images constructed by automatically parsing PubMed XML files).
- table detection: the [ICDAR 2019 cTDaR](https://github.com/cndplab-founder/ICDAR2019_cTDaR) dataset (a collection of
600 training images and 240 testing images).
The abstract from the paper is the following:
*Image Transformer has recently achieved significant progress for natural image understanding, either using supervised (ViT, DeiT, etc.) or self-supervised (BEiT, MAE, etc.) pre-training techniques. In this paper, we propose DiT, a self-supervised pre-trained Document Image Transformer model using large-scale unlabeled text images for Document AI tasks, which is essential since no supervised counterparts ever exist due to the lack of human labeled document images. We leverage DiT as the backbone network in a variety of vision-based Document AI tasks, including document image classification, document layout analysis, as well as table detection. Experiment results have illustrated that the self-supervised pre-trained DiT model achieves new state-of-the-art results on these downstream tasks, e.g. document image classification (91.11 → 92.69), document layout analysis (91.0 → 94.9) and table detection (94.23 → 96.55). *
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/dit_architecture.jpg"
alt="drawing" width="600"/>
<small> Summary of the approach. Taken from the [original paper](https://arxiv.org/abs/2203.02378). </small>
This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found [here](https://github.com/microsoft/unilm/tree/master/dit).
## Usage tips
One can directly use the weights of DiT with the AutoModel API:
```python
from transformers import AutoModel
model = AutoModel.from_pretrained("microsoft/dit-base")
```
This will load the model pre-trained on masked image modeling. Note that this won't include the language modeling head on top, used to predict visual tokens.
To include the head, you can load the weights into a `BeitForMaskedImageModeling` model, like so:
```python
from transformers import BeitForMaskedImageModeling
model = BeitForMaskedImageModeling.from_pretrained("microsoft/dit-base")
```
You can also load a fine-tuned model from the [hub](https://huggingface.co/models?other=dit), like so:
```python
from transformers import AutoModelForImageClassification
model = AutoModelForImageClassification.from_pretrained("microsoft/dit-base-finetuned-rvlcdip")
```
This particular checkpoint was fine-tuned on [RVL-CDIP](https://www.cs.cmu.edu/~aharley/rvl-cdip/), an important benchmark for document image classification.
A notebook that illustrates inference for document image classification can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/DiT/Inference_with_DiT_(Document_Image_Transformer)_for_document_image_classification.ipynb).
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with DiT.
<PipelineTag pipeline="image-classification"/>
- [`BeitForImageClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb).
If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
<Tip>
As DiT's architecture is equivalent to that of BEiT, one can refer to [BEiT's documentation page](beit) for all tips, code examples and notebooks.
</Tip>
| transformers/docs/source/en/model_doc/dit.md/0 | {
"file_path": "transformers/docs/source/en/model_doc/dit.md",
"repo_id": "transformers",
"token_count": 1429
} | 10 |
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# FlauBERT
<div class="flex flex-wrap space-x-1">
<a href="https://huggingface.co/models?filter=flaubert">
<img alt="Models" src="https://img.shields.io/badge/All_model_pages-flaubert-blueviolet">
</a>
<a href="https://huggingface.co/spaces/docs-demos/flaubert_small_cased">
<img alt="Spaces" src="https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face-Spaces-blue">
</a>
</div>
## Overview
The FlauBERT model was proposed in the paper [FlauBERT: Unsupervised Language Model Pre-training for French](https://arxiv.org/abs/1912.05372) by Hang Le et al. It's a transformer model pretrained using a masked language
modeling (MLM) objective (like BERT).
The abstract from the paper is the following:
*Language models have become a key step to achieve state-of-the art results in many different Natural Language
Processing (NLP) tasks. Leveraging the huge amount of unlabeled texts nowadays available, they provide an efficient way
to pre-train continuous word representations that can be fine-tuned for a downstream task, along with their
contextualization at the sentence level. This has been widely demonstrated for English using contextualized
representations (Dai and Le, 2015; Peters et al., 2018; Howard and Ruder, 2018; Radford et al., 2018; Devlin et al.,
2019; Yang et al., 2019b). In this paper, we introduce and share FlauBERT, a model learned on a very large and
heterogeneous French corpus. Models of different sizes are trained using the new CNRS (French National Centre for
Scientific Research) Jean Zay supercomputer. We apply our French language models to diverse NLP tasks (text
classification, paraphrasing, natural language inference, parsing, word sense disambiguation) and show that most of the
time they outperform other pretraining approaches. Different versions of FlauBERT as well as a unified evaluation
protocol for the downstream tasks, called FLUE (French Language Understanding Evaluation), are shared to the research
community for further reproducible experiments in French NLP.*
This model was contributed by [formiel](https://huggingface.co/formiel). The original code can be found [here](https://github.com/getalp/Flaubert).
Tips:
- Like RoBERTa, without the sentence ordering prediction (so just trained on the MLM objective).
## Resources
- [Text classification task guide](../tasks/sequence_classification)
- [Token classification task guide](../tasks/token_classification)
- [Question answering task guide](../tasks/question_answering)
- [Masked language modeling task guide](../tasks/masked_language_modeling)
- [Multiple choice task guide](../tasks/multiple_choice)
## FlaubertConfig
[[autodoc]] FlaubertConfig
## FlaubertTokenizer
[[autodoc]] FlaubertTokenizer
<frameworkcontent>
<pt>
## FlaubertModel
[[autodoc]] FlaubertModel
- forward
## FlaubertWithLMHeadModel
[[autodoc]] FlaubertWithLMHeadModel
- forward
## FlaubertForSequenceClassification
[[autodoc]] FlaubertForSequenceClassification
- forward
## FlaubertForMultipleChoice
[[autodoc]] FlaubertForMultipleChoice
- forward
## FlaubertForTokenClassification
[[autodoc]] FlaubertForTokenClassification
- forward
## FlaubertForQuestionAnsweringSimple
[[autodoc]] FlaubertForQuestionAnsweringSimple
- forward
## FlaubertForQuestionAnswering
[[autodoc]] FlaubertForQuestionAnswering
- forward
</pt>
<tf>
## TFFlaubertModel
[[autodoc]] TFFlaubertModel
- call
## TFFlaubertWithLMHeadModel
[[autodoc]] TFFlaubertWithLMHeadModel
- call
## TFFlaubertForSequenceClassification
[[autodoc]] TFFlaubertForSequenceClassification
- call
## TFFlaubertForMultipleChoice
[[autodoc]] TFFlaubertForMultipleChoice
- call
## TFFlaubertForTokenClassification
[[autodoc]] TFFlaubertForTokenClassification
- call
## TFFlaubertForQuestionAnsweringSimple
[[autodoc]] TFFlaubertForQuestionAnsweringSimple
- call
</tf>
</frameworkcontent>
| transformers/docs/source/en/model_doc/flaubert.md/0 | {
"file_path": "transformers/docs/source/en/model_doc/flaubert.md",
"repo_id": "transformers",
"token_count": 1382
} | 11 |
<!--Copyright 2021 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# GPT-J
## Overview
The GPT-J model was released in the [kingoflolz/mesh-transformer-jax](https://github.com/kingoflolz/mesh-transformer-jax) repository by Ben Wang and Aran Komatsuzaki. It is a GPT-2-like
causal language model trained on [the Pile](https://pile.eleuther.ai/) dataset.
This model was contributed by [Stella Biderman](https://huggingface.co/stellaathena).
## Usage tips
- To load [GPT-J](https://huggingface.co/EleutherAI/gpt-j-6B) in float32 one would need at least 2x model size
RAM: 1x for initial weights and another 1x to load the checkpoint. So for GPT-J it would take at least 48GB
RAM to just load the model. To reduce the RAM usage there are a few options. The `torch_dtype` argument can be
used to initialize the model in half-precision on a CUDA device only. There is also a fp16 branch which stores the fp16 weights,
which could be used to further minimize the RAM usage:
```python
>>> from transformers import GPTJForCausalLM
>>> import torch
>>> device = "cuda"
>>> model = GPTJForCausalLM.from_pretrained(
... "EleutherAI/gpt-j-6B",
... revision="float16",
... torch_dtype=torch.float16,
... ).to(device)
```
- The model should fit on 16GB GPU for inference. For training/fine-tuning it would take much more GPU RAM. Adam
optimizer for example makes four copies of the model: model, gradients, average and squared average of the gradients.
So it would need at least 4x model size GPU memory, even with mixed precision as gradient updates are in fp32. This
is not including the activations and data batches, which would again require some more GPU RAM. So one should explore
solutions such as DeepSpeed, to train/fine-tune the model. Another option is to use the original codebase to
train/fine-tune the model on TPU and then convert the model to Transformers format for inference. Instructions for
that could be found [here](https://github.com/kingoflolz/mesh-transformer-jax/blob/master/howto_finetune.md)
- Although the embedding matrix has a size of 50400, only 50257 entries are used by the GPT-2 tokenizer. These extra
tokens are added for the sake of efficiency on TPUs. To avoid the mismatch between embedding matrix size and vocab
size, the tokenizer for [GPT-J](https://huggingface.co/EleutherAI/gpt-j-6B) contains 143 extra tokens
`<|extratoken_1|>... <|extratoken_143|>`, so the `vocab_size` of tokenizer also becomes 50400.
## Usage examples
The [`~generation.GenerationMixin.generate`] method can be used to generate text using GPT-J
model.
```python
>>> from transformers import AutoModelForCausalLM, AutoTokenizer
>>> model = AutoModelForCausalLM.from_pretrained("EleutherAI/gpt-j-6B")
>>> tokenizer = AutoTokenizer.from_pretrained("EleutherAI/gpt-j-6B")
>>> prompt = (
... "In a shocking finding, scientists discovered a herd of unicorns living in a remote, "
... "previously unexplored valley, in the Andes Mountains. Even more surprising to the "
... "researchers was the fact that the unicorns spoke perfect English."
... )
>>> input_ids = tokenizer(prompt, return_tensors="pt").input_ids
>>> gen_tokens = model.generate(
... input_ids,
... do_sample=True,
... temperature=0.9,
... max_length=100,
... )
>>> gen_text = tokenizer.batch_decode(gen_tokens)[0]
```
...or in float16 precision:
```python
>>> from transformers import GPTJForCausalLM, AutoTokenizer
>>> import torch
>>> device = "cuda"
>>> model = GPTJForCausalLM.from_pretrained("EleutherAI/gpt-j-6B", torch_dtype=torch.float16).to(device)
>>> tokenizer = AutoTokenizer.from_pretrained("EleutherAI/gpt-j-6B")
>>> prompt = (
... "In a shocking finding, scientists discovered a herd of unicorns living in a remote, "
... "previously unexplored valley, in the Andes Mountains. Even more surprising to the "
... "researchers was the fact that the unicorns spoke perfect English."
... )
>>> input_ids = tokenizer(prompt, return_tensors="pt").input_ids.to(device)
>>> gen_tokens = model.generate(
... input_ids,
... do_sample=True,
... temperature=0.9,
... max_length=100,
... )
>>> gen_text = tokenizer.batch_decode(gen_tokens)[0]
```
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with GPT-J. If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
<PipelineTag pipeline="text-generation"/>
- Description of [GPT-J](https://huggingface.co/EleutherAI/gpt-j-6B).
- A blog on how to [Deploy GPT-J 6B for inference using Hugging Face Transformers and Amazon SageMaker](https://huggingface.co/blog/gptj-sagemaker).
- A blog on how to [Accelerate GPT-J inference with DeepSpeed-Inference on GPUs](https://www.philschmid.de/gptj-deepspeed-inference).
- A blog post introducing [GPT-J-6B: 6B JAX-Based Transformer](https://arankomatsuzaki.wordpress.com/2021/06/04/gpt-j/). 🌎
- A notebook for [GPT-J-6B Inference Demo](https://colab.research.google.com/github/kingoflolz/mesh-transformer-jax/blob/master/colab_demo.ipynb). 🌎
- Another notebook demonstrating [Inference with GPT-J-6B](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/GPT-J-6B/Inference_with_GPT_J_6B.ipynb).
- [Causal language modeling](https://huggingface.co/course/en/chapter7/6?fw=pt#training-a-causal-language-model-from-scratch) chapter of the 🤗 Hugging Face Course.
- [`GPTJForCausalLM`] is supported by this [causal language modeling example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/language-modeling#gpt-2gpt-and-causal-language-modeling), [text generation example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/text-generation), and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling.ipynb).
- [`TFGPTJForCausalLM`] is supported by this [causal language modeling example script](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/language-modeling#run_clmpy) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling-tf.ipynb).
- [`FlaxGPTJForCausalLM`] is supported by this [causal language modeling example script](https://github.com/huggingface/transformers/tree/main/examples/flax/language-modeling#causal-language-modeling) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/causal_language_modeling_flax.ipynb).
**Documentation resources**
- [Text classification task guide](../tasks/sequence_classification)
- [Question answering task guide](../tasks/question_answering)
- [Causal language modeling task guide](../tasks/language_modeling)
## GPTJConfig
[[autodoc]] GPTJConfig
- all
<frameworkcontent>
<pt>
## GPTJModel
[[autodoc]] GPTJModel
- forward
## GPTJForCausalLM
[[autodoc]] GPTJForCausalLM
- forward
## GPTJForSequenceClassification
[[autodoc]] GPTJForSequenceClassification
- forward
## GPTJForQuestionAnswering
[[autodoc]] GPTJForQuestionAnswering
- forward
</pt>
<tf>
## TFGPTJModel
[[autodoc]] TFGPTJModel
- call
## TFGPTJForCausalLM
[[autodoc]] TFGPTJForCausalLM
- call
## TFGPTJForSequenceClassification
[[autodoc]] TFGPTJForSequenceClassification
- call
## TFGPTJForQuestionAnswering
[[autodoc]] TFGPTJForQuestionAnswering
- call
</tf>
<jax>
## FlaxGPTJModel
[[autodoc]] FlaxGPTJModel
- __call__
## FlaxGPTJForCausalLM
[[autodoc]] FlaxGPTJForCausalLM
- __call__
</jax>
</frameworkcontent>
| transformers/docs/source/en/model_doc/gptj.md/0 | {
"file_path": "transformers/docs/source/en/model_doc/gptj.md",
"repo_id": "transformers",
"token_count": 2807
} | 12 |
<!--Copyright 2021 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# LayoutXLM
## Overview
LayoutXLM was proposed in [LayoutXLM: Multimodal Pre-training for Multilingual Visually-rich Document Understanding](https://arxiv.org/abs/2104.08836) by Yiheng Xu, Tengchao Lv, Lei Cui, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha
Zhang, Furu Wei. It's a multilingual extension of the [LayoutLMv2 model](https://arxiv.org/abs/2012.14740) trained
on 53 languages.
The abstract from the paper is the following:
*Multimodal pre-training with text, layout, and image has achieved SOTA performance for visually-rich document
understanding tasks recently, which demonstrates the great potential for joint learning across different modalities. In
this paper, we present LayoutXLM, a multimodal pre-trained model for multilingual document understanding, which aims to
bridge the language barriers for visually-rich document understanding. To accurately evaluate LayoutXLM, we also
introduce a multilingual form understanding benchmark dataset named XFUN, which includes form understanding samples in
7 languages (Chinese, Japanese, Spanish, French, Italian, German, Portuguese), and key-value pairs are manually labeled
for each language. Experiment results show that the LayoutXLM model has significantly outperformed the existing SOTA
cross-lingual pre-trained models on the XFUN dataset.*
This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found [here](https://github.com/microsoft/unilm).
## Usage tips and examples
One can directly plug in the weights of LayoutXLM into a LayoutLMv2 model, like so:
```python
from transformers import LayoutLMv2Model
model = LayoutLMv2Model.from_pretrained("microsoft/layoutxlm-base")
```
Note that LayoutXLM has its own tokenizer, based on
[`LayoutXLMTokenizer`]/[`LayoutXLMTokenizerFast`]. You can initialize it as
follows:
```python
from transformers import LayoutXLMTokenizer
tokenizer = LayoutXLMTokenizer.from_pretrained("microsoft/layoutxlm-base")
```
Similar to LayoutLMv2, you can use [`LayoutXLMProcessor`] (which internally applies
[`LayoutLMv2ImageProcessor`] and
[`LayoutXLMTokenizer`]/[`LayoutXLMTokenizerFast`] in sequence) to prepare all
data for the model.
<Tip>
As LayoutXLM's architecture is equivalent to that of LayoutLMv2, one can refer to [LayoutLMv2's documentation page](layoutlmv2) for all tips, code examples and notebooks.
</Tip>
## LayoutXLMTokenizer
[[autodoc]] LayoutXLMTokenizer
- __call__
- build_inputs_with_special_tokens
- get_special_tokens_mask
- create_token_type_ids_from_sequences
- save_vocabulary
## LayoutXLMTokenizerFast
[[autodoc]] LayoutXLMTokenizerFast
- __call__
## LayoutXLMProcessor
[[autodoc]] LayoutXLMProcessor
- __call__
| transformers/docs/source/en/model_doc/layoutxlm.md/0 | {
"file_path": "transformers/docs/source/en/model_doc/layoutxlm.md",
"repo_id": "transformers",
"token_count": 981
} | 13 |
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# OPT
## Overview
The OPT model was proposed in [Open Pre-trained Transformer Language Models](https://arxiv.org/pdf/2205.01068) by Meta AI.
OPT is a series of open-sourced large causal language models which perform similar in performance to GPT3.
The abstract from the paper is the following:
*Large language models, which are often trained for hundreds of thousands of compute days, have shown remarkable capabilities for zero- and few-shot learning. Given their computational cost, these models are difficult to replicate without significant capital. For the few that are available through APIs, no access is granted to the full model weights, making them difficult to study. We present Open Pre-trained Transformers (OPT), a suite of decoder-only pre-trained transformers ranging from 125M to 175B parameters, which we aim to fully and responsibly share with interested researchers. We show that OPT-175B is comparable to GPT-3, while requiring only 1/7th the carbon footprint to develop. We are also releasing our logbook detailing the infrastructure challenges we faced, along with code for experimenting with all of the released models.*
This model was contributed by [Arthur Zucker](https://huggingface.co/ArthurZ), [Younes Belkada](https://huggingface.co/ybelkada), and [Patrick Von Platen](https://huggingface.co/patrickvonplaten).
The original code can be found [here](https://github.com/facebookresearch/metaseq).
Tips:
- OPT has the same architecture as [`BartDecoder`].
- Contrary to GPT2, OPT adds the EOS token `</s>` to the beginning of every prompt.
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with OPT. If you're
interested in submitting a resource to be included here, please feel free to open a Pull Request and we will review it.
The resource should ideally demonstrate something new instead of duplicating an existing resource.
<PipelineTag pipeline="text-generation" />
- A notebook on [fine-tuning OPT with PEFT, bitsandbytes, and Transformers](https://colab.research.google.com/drive/1jCkpikz0J2o20FBQmYmAGdiKmJGOMo-o?usp=sharing). 🌎
- A blog post on [decoding strategies with OPT](https://huggingface.co/blog/introducing-csearch#62-example-two---opt).
- [Causal language modeling](https://huggingface.co/course/en/chapter7/6?fw=pt#training-a-causal-language-model-from-scratch) chapter of the 🤗 Hugging Face Course.
- [`OPTForCausalLM`] is supported by this [causal language modeling example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/language-modeling#gpt-2gpt-and-causal-language-modeling) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling.ipynb).
- [`TFOPTForCausalLM`] is supported by this [causal language modeling example script](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/language-modeling#run_clmpy) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling-tf.ipynb).
- [`FlaxOPTForCausalLM`] is supported by this [causal language modeling example script](https://github.com/huggingface/transformers/tree/main/examples/flax/language-modeling#causal-language-modeling).
<PipelineTag pipeline="text-classification" />
- [Text classification task guide](sequence_classification.md)
- [`OPTForSequenceClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/text-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/text_classification.ipynb).
<PipelineTag pipeline="question-answering" />
- [`OPTForQuestionAnswering`] is supported by this [question answering example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/question-answering) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/question_answering.ipynb).
- [Question answering](https://huggingface.co/course/chapter7/7?fw=pt) chapter
of the 🤗 Hugging Face Course.
⚡️ Inference
- A blog post on [How 🤗 Accelerate runs very large models thanks to PyTorch](https://huggingface.co/blog/accelerate-large-models) with OPT.
## Combining OPT and Flash Attention 2
First, make sure to install the latest version of Flash Attention 2 to include the sliding window attention feature.
```bash
pip install -U flash-attn --no-build-isolation
```
Make also sure that you have a hardware that is compatible with Flash-Attention 2. Read more about it in the official documentation of flash-attn repository. Make also sure to load your model in half-precision (e.g. `torch.float16``)
To load and run a model using Flash Attention 2, refer to the snippet below:
```python
>>> import torch
>>> from transformers import OPTForCausalLM, GPT2Tokenizer
>>> device = "cuda" # the device to load the model onto
>>> model = OPTForCausalLM.from_pretrained("facebook/opt-350m", torch_dtype=torch.float16, attn_implementation="flash_attention_2")
>>> tokenizer = GPT2Tokenizer.from_pretrained("facebook/opt-350m")
>>> prompt = ("A chat between a curious human and the Statue of Liberty.\n\nHuman: What is your name?\nStatue: I am the "
"Statue of Liberty.\nHuman: Where do you live?\nStatue: New York City.\nHuman: How long have you lived "
"there?")
>>> model_inputs = tokenizer([prompt], return_tensors="pt").to(device)
>>> model.to(device)
>>> generated_ids = model.generate(**model_inputs, max_new_tokens=30, do_sample=False)
>>> tokenizer.batch_decode(generated_ids)[0]
'</s>A chat between a curious human and the Statue of Liberty.\n\nHuman: What is your name?\nStatue: I am the Statue of Liberty.\nHuman: Where do you live?\nStatue: New York City.\nHuman: How long have you lived there?\nStatue: I have lived here for about a year.\nHuman: What is your favorite place to eat?\nStatue: I love'
```
### Expected speedups
Below is an expected speedup diagram that compares pure inference time between the native implementation in transformers using `facebook/opt-2.7b` checkpoint and the Flash Attention 2 version of the model using two different sequence lengths.
<div style="text-align: center">
<img src="https://user-images.githubusercontent.com/49240599/281101546-d2fca6d2-ee44-48f3-9534-ba8d5bee4531.png">
</div>
Below is an expected speedup diagram that compares pure inference time between the native implementation in transformers using `facebook/opt-350m` checkpoint and the Flash Attention 2 version of the model using two different sequence lengths.
<div style="text-align: center">
<img src="https://user-images.githubusercontent.com/49240599/281101682-d1144e90-0dbc-46f4-8fc8-c6206cb793c9.png">
</div>
## OPTConfig
[[autodoc]] OPTConfig
<frameworkcontent>
<pt>
## OPTModel
[[autodoc]] OPTModel
- forward
## OPTForCausalLM
[[autodoc]] OPTForCausalLM
- forward
## OPTForSequenceClassification
[[autodoc]] OPTForSequenceClassification
- forward
## OPTForQuestionAnswering
[[autodoc]] OPTForQuestionAnswering
- forward
</pt>
<tf>
## TFOPTModel
[[autodoc]] TFOPTModel
- call
## TFOPTForCausalLM
[[autodoc]] TFOPTForCausalLM
- call
</tf>
<jax>
## FlaxOPTModel
[[autodoc]] FlaxOPTModel
- __call__
## FlaxOPTForCausalLM
[[autodoc]] FlaxOPTForCausalLM
- __call__
</jax>
</frameworkcontent>
| transformers/docs/source/en/model_doc/opt.md/0 | {
"file_path": "transformers/docs/source/en/model_doc/opt.md",
"repo_id": "transformers",
"token_count": 2500
} | 14 |
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Pyramid Vision Transformer (PVT)
## Overview
The PVT model was proposed in
[Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions](https://arxiv.org/abs/2102.12122)
by Wenhai Wang, Enze Xie, Xiang Li, Deng-Ping Fan, Kaitao Song, Ding Liang, Tong Lu, Ping Luo, Ling Shao. The PVT is a type of
vision transformer that utilizes a pyramid structure to make it an effective backbone for dense prediction tasks. Specifically
it allows for more fine-grained inputs (4 x 4 pixels per patch) to be used, while simultaneously shrinking the sequence length
of the Transformer as it deepens - reducing the computational cost. Additionally, a spatial-reduction attention (SRA) layer
is used to further reduce the resource consumption when learning high-resolution features.
The abstract from the paper is the following:
*Although convolutional neural networks (CNNs) have achieved great success in computer vision, this work investigates a
simpler, convolution-free backbone network useful for many dense prediction tasks. Unlike the recently proposed Vision
Transformer (ViT) that was designed for image classification specifically, we introduce the Pyramid Vision Transformer
(PVT), which overcomes the difficulties of porting Transformer to various dense prediction tasks. PVT has several
merits compared to current state of the arts. Different from ViT that typically yields low resolution outputs and
incurs high computational and memory costs, PVT not only can be trained on dense partitions of an image to achieve high
output resolution, which is important for dense prediction, but also uses a progressive shrinking pyramid to reduce the
computations of large feature maps. PVT inherits the advantages of both CNN and Transformer, making it a unified
backbone for various vision tasks without convolutions, where it can be used as a direct replacement for CNN backbones.
We validate PVT through extensive experiments, showing that it boosts the performance of many downstream tasks, including
object detection, instance and semantic segmentation. For example, with a comparable number of parameters, PVT+RetinaNet
achieves 40.4 AP on the COCO dataset, surpassing ResNet50+RetinNet (36.3 AP) by 4.1 absolute AP (see Figure 2). We hope
that PVT could serve as an alternative and useful backbone for pixel-level predictions and facilitate future research.*
This model was contributed by [Xrenya](https://huggingface.co/Xrenya). The original code can be found [here](https://github.com/whai362/PVT).
- PVTv1 on ImageNet-1K
| **Model variant** |**Size** |**Acc@1**|**Params (M)**|
|--------------------|:-------:|:-------:|:------------:|
| PVT-Tiny | 224 | 75.1 | 13.2 |
| PVT-Small | 224 | 79.8 | 24.5 |
| PVT-Medium | 224 | 81.2 | 44.2 |
| PVT-Large | 224 | 81.7 | 61.4 |
## PvtConfig
[[autodoc]] PvtConfig
## PvtImageProcessor
[[autodoc]] PvtImageProcessor
- preprocess
## PvtForImageClassification
[[autodoc]] PvtForImageClassification
- forward
## PvtModel
[[autodoc]] PvtModel
- forward
| transformers/docs/source/en/model_doc/pvt.md/0 | {
"file_path": "transformers/docs/source/en/model_doc/pvt.md",
"repo_id": "transformers",
"token_count": 1047
} | 15 |
<!--Copyright 2021 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# UniSpeech-SAT
## Overview
The UniSpeech-SAT model was proposed in [UniSpeech-SAT: Universal Speech Representation Learning with Speaker Aware
Pre-Training](https://arxiv.org/abs/2110.05752) by Sanyuan Chen, Yu Wu, Chengyi Wang, Zhengyang Chen, Zhuo Chen,
Shujie Liu, Jian Wu, Yao Qian, Furu Wei, Jinyu Li, Xiangzhan Yu .
The abstract from the paper is the following:
*Self-supervised learning (SSL) is a long-standing goal for speech processing, since it utilizes large-scale unlabeled
data and avoids extensive human labeling. Recent years witness great successes in applying self-supervised learning in
speech recognition, while limited exploration was attempted in applying SSL for modeling speaker characteristics. In
this paper, we aim to improve the existing SSL framework for speaker representation learning. Two methods are
introduced for enhancing the unsupervised speaker information extraction. First, we apply the multi-task learning to
the current SSL framework, where we integrate the utterance-wise contrastive loss with the SSL objective function.
Second, for better speaker discrimination, we propose an utterance mixing strategy for data augmentation, where
additional overlapped utterances are created unsupervisedly and incorporate during training. We integrate the proposed
methods into the HuBERT framework. Experiment results on SUPERB benchmark show that the proposed system achieves
state-of-the-art performance in universal representation learning, especially for speaker identification oriented
tasks. An ablation study is performed verifying the efficacy of each proposed method. Finally, we scale up training
dataset to 94 thousand hours public audio data and achieve further performance improvement in all SUPERB tasks.*
This model was contributed by [patrickvonplaten](https://huggingface.co/patrickvonplaten). The Authors' code can be
found [here](https://github.com/microsoft/UniSpeech/tree/main/UniSpeech-SAT).
## Usage tips
- UniSpeechSat is a speech model that accepts a float array corresponding to the raw waveform of the speech signal.
Please use [`Wav2Vec2Processor`] for the feature extraction.
- UniSpeechSat model can be fine-tuned using connectionist temporal classification (CTC) so the model output has to be
decoded using [`Wav2Vec2CTCTokenizer`].
- UniSpeechSat performs especially well on speaker verification, speaker identification, and speaker diarization tasks.
## Resources
- [Audio classification task guide](../tasks/audio_classification)
- [Automatic speech recognition task guide](../tasks/asr)
## UniSpeechSatConfig
[[autodoc]] UniSpeechSatConfig
## UniSpeechSat specific outputs
[[autodoc]] models.unispeech_sat.modeling_unispeech_sat.UniSpeechSatForPreTrainingOutput
## UniSpeechSatModel
[[autodoc]] UniSpeechSatModel
- forward
## UniSpeechSatForCTC
[[autodoc]] UniSpeechSatForCTC
- forward
## UniSpeechSatForSequenceClassification
[[autodoc]] UniSpeechSatForSequenceClassification
- forward
## UniSpeechSatForAudioFrameClassification
[[autodoc]] UniSpeechSatForAudioFrameClassification
- forward
## UniSpeechSatForXVector
[[autodoc]] UniSpeechSatForXVector
- forward
## UniSpeechSatForPreTraining
[[autodoc]] UniSpeechSatForPreTraining
- forward
| transformers/docs/source/en/model_doc/unispeech-sat.md/0 | {
"file_path": "transformers/docs/source/en/model_doc/unispeech-sat.md",
"repo_id": "transformers",
"token_count": 1045
} | 16 |
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# XLNet
<div class="flex flex-wrap space-x-1">
<a href="https://huggingface.co/models?filter=xlnet">
<img alt="Models" src="https://img.shields.io/badge/All_model_pages-xlnet-blueviolet">
</a>
<a href="https://huggingface.co/spaces/docs-demos/xlnet-base-cased">
<img alt="Spaces" src="https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face-Spaces-blue">
</a>
</div>
## Overview
The XLNet model was proposed in [XLNet: Generalized Autoregressive Pretraining for Language Understanding](https://arxiv.org/abs/1906.08237) by Zhilin Yang, Zihang Dai, Yiming Yang, Jaime Carbonell, Ruslan Salakhutdinov,
Quoc V. Le. XLnet is an extension of the Transformer-XL model pre-trained using an autoregressive method to learn
bidirectional contexts by maximizing the expected likelihood over all permutations of the input sequence factorization
order.
The abstract from the paper is the following:
*With the capability of modeling bidirectional contexts, denoising autoencoding based pretraining like BERT achieves
better performance than pretraining approaches based on autoregressive language modeling. However, relying on
corrupting the input with masks, BERT neglects dependency between the masked positions and suffers from a
pretrain-finetune discrepancy. In light of these pros and cons, we propose XLNet, a generalized autoregressive
pretraining method that (1) enables learning bidirectional contexts by maximizing the expected likelihood over all
permutations of the factorization order and (2) overcomes the limitations of BERT thanks to its autoregressive
formulation. Furthermore, XLNet integrates ideas from Transformer-XL, the state-of-the-art autoregressive model, into
pretraining. Empirically, under comparable experiment settings, XLNet outperforms BERT on 20 tasks, often by a large
margin, including question answering, natural language inference, sentiment analysis, and document ranking.*
This model was contributed by [thomwolf](https://huggingface.co/thomwolf). The original code can be found [here](https://github.com/zihangdai/xlnet/).
## Usage tips
- The specific attention pattern can be controlled at training and test time using the `perm_mask` input.
- Due to the difficulty of training a fully auto-regressive model over various factorization order, XLNet is pretrained
using only a sub-set of the output tokens as target which are selected with the `target_mapping` input.
- To use XLNet for sequential decoding (i.e. not in fully bi-directional setting), use the `perm_mask` and
`target_mapping` inputs to control the attention span and outputs (see examples in
*examples/pytorch/text-generation/run_generation.py*)
- XLNet is one of the few models that has no sequence length limit.
- XLNet is not a traditional autoregressive model but uses a training strategy that builds on that. It permutes the tokens in the sentence, then allows the model to use the last n tokens to predict the token n+1. Since this is all done with a mask, the sentence is actually fed in the model in the right order, but instead of masking the first n tokens for n+1, XLNet uses a mask that hides the previous tokens in some given permutation of 1,…,sequence length.
- XLNet also uses the same recurrence mechanism as Transformer-XL to build long-term dependencies.
## Resources
- [Text classification task guide](../tasks/sequence_classification)
- [Token classification task guide](../tasks/token_classification)
- [Question answering task guide](../tasks/question_answering)
- [Causal language modeling task guide](../tasks/language_modeling)
- [Multiple choice task guide](../tasks/multiple_choice)
## XLNetConfig
[[autodoc]] XLNetConfig
## XLNetTokenizer
[[autodoc]] XLNetTokenizer
- build_inputs_with_special_tokens
- get_special_tokens_mask
- create_token_type_ids_from_sequences
- save_vocabulary
## XLNetTokenizerFast
[[autodoc]] XLNetTokenizerFast
## XLNet specific outputs
[[autodoc]] models.xlnet.modeling_xlnet.XLNetModelOutput
[[autodoc]] models.xlnet.modeling_xlnet.XLNetLMHeadModelOutput
[[autodoc]] models.xlnet.modeling_xlnet.XLNetForSequenceClassificationOutput
[[autodoc]] models.xlnet.modeling_xlnet.XLNetForMultipleChoiceOutput
[[autodoc]] models.xlnet.modeling_xlnet.XLNetForTokenClassificationOutput
[[autodoc]] models.xlnet.modeling_xlnet.XLNetForQuestionAnsweringSimpleOutput
[[autodoc]] models.xlnet.modeling_xlnet.XLNetForQuestionAnsweringOutput
[[autodoc]] models.xlnet.modeling_tf_xlnet.TFXLNetModelOutput
[[autodoc]] models.xlnet.modeling_tf_xlnet.TFXLNetLMHeadModelOutput
[[autodoc]] models.xlnet.modeling_tf_xlnet.TFXLNetForSequenceClassificationOutput
[[autodoc]] models.xlnet.modeling_tf_xlnet.TFXLNetForMultipleChoiceOutput
[[autodoc]] models.xlnet.modeling_tf_xlnet.TFXLNetForTokenClassificationOutput
[[autodoc]] models.xlnet.modeling_tf_xlnet.TFXLNetForQuestionAnsweringSimpleOutput
<frameworkcontent>
<pt>
## XLNetModel
[[autodoc]] XLNetModel
- forward
## XLNetLMHeadModel
[[autodoc]] XLNetLMHeadModel
- forward
## XLNetForSequenceClassification
[[autodoc]] XLNetForSequenceClassification
- forward
## XLNetForMultipleChoice
[[autodoc]] XLNetForMultipleChoice
- forward
## XLNetForTokenClassification
[[autodoc]] XLNetForTokenClassification
- forward
## XLNetForQuestionAnsweringSimple
[[autodoc]] XLNetForQuestionAnsweringSimple
- forward
## XLNetForQuestionAnswering
[[autodoc]] XLNetForQuestionAnswering
- forward
</pt>
<tf>
## TFXLNetModel
[[autodoc]] TFXLNetModel
- call
## TFXLNetLMHeadModel
[[autodoc]] TFXLNetLMHeadModel
- call
## TFXLNetForSequenceClassification
[[autodoc]] TFXLNetForSequenceClassification
- call
## TFLNetForMultipleChoice
[[autodoc]] TFXLNetForMultipleChoice
- call
## TFXLNetForTokenClassification
[[autodoc]] TFXLNetForTokenClassification
- call
## TFXLNetForQuestionAnsweringSimple
[[autodoc]] TFXLNetForQuestionAnsweringSimple
- call
</tf>
</frameworkcontent> | transformers/docs/source/en/model_doc/xlnet.md/0 | {
"file_path": "transformers/docs/source/en/model_doc/xlnet.md",
"repo_id": "transformers",
"token_count": 2042
} | 17 |
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Optimize inference using torch.compile()
This guide aims to provide a benchmark on the inference speed-ups introduced with [`torch.compile()`](https://pytorch.org/tutorials/intermediate/torch_compile_tutorial.html) for [computer vision models in 🤗 Transformers](https://huggingface.co/models?pipeline_tag=image-classification&library=transformers&sort=trending).
## Benefits of torch.compile
Depending on the model and the GPU, `torch.compile()` yields up to 30% speed-up during inference. To use `torch.compile()`, simply install any version of `torch` above 2.0.
Compiling a model takes time, so it's useful if you are compiling the model only once instead of every time you infer.
To compile any computer vision model of your choice, call `torch.compile()` on the model as shown below:
```diff
from transformers import AutoModelForImageClassification
model = AutoModelForImageClassification.from_pretrained(MODEL_ID).to("cuda")
+ model = torch.compile(model)
```
`compile()` comes with multiple modes for compiling, which essentially differ in compilation time and inference overhead. `max-autotune` takes longer than `reduce-overhead` but results in faster inference. Default mode is fastest for compilation but is not as efficient compared to `reduce-overhead` for inference time. In this guide, we used the default mode. You can learn more about it [here](https://pytorch.org/get-started/pytorch-2.0/#user-experience).
We benchmarked `torch.compile` with different computer vision models, tasks, types of hardware, and batch sizes on `torch` version 2.0.1.
## Benchmarking code
Below you can find the benchmarking code for each task. We warm up the GPU before inference and take the mean time of 300 inferences, using the same image each time.
### Image Classification with ViT
```python
import torch
from PIL import Image
import requests
import numpy as np
from transformers import AutoImageProcessor, AutoModelForImageClassification
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
processor = AutoImageProcessor.from_pretrained("google/vit-base-patch16-224")
model = AutoModelForImageClassification.from_pretrained("google/vit-base-patch16-224").to("cuda")
model = torch.compile(model)
processed_input = processor(image, return_tensors='pt').to(device="cuda")
with torch.no_grad():
_ = model(**processed_input)
```
#### Object Detection with DETR
```python
from transformers import AutoImageProcessor, AutoModelForObjectDetection
processor = AutoImageProcessor.from_pretrained("facebook/detr-resnet-50")
model = AutoModelForObjectDetection.from_pretrained("facebook/detr-resnet-50").to("cuda")
model = torch.compile(model)
texts = ["a photo of a cat", "a photo of a dog"]
inputs = processor(text=texts, images=image, return_tensors="pt").to("cuda")
with torch.no_grad():
_ = model(**inputs)
```
#### Image Segmentation with Segformer
```python
from transformers import SegformerImageProcessor, SegformerForSemanticSegmentation
processor = SegformerImageProcessor.from_pretrained("nvidia/segformer-b0-finetuned-ade-512-512")
model = SegformerForSemanticSegmentation.from_pretrained("nvidia/segformer-b0-finetuned-ade-512-512").to("cuda")
model = torch.compile(model)
seg_inputs = processor(images=image, return_tensors="pt").to("cuda")
with torch.no_grad():
_ = model(**seg_inputs)
```
Below you can find the list of the models we benchmarked.
**Image Classification**
- [google/vit-base-patch16-224](https://huggingface.co/google/vit-base-patch16-224)
- [microsoft/beit-base-patch16-224-pt22k-ft22k](https://huggingface.co/microsoft/beit-base-patch16-224-pt22k-ft22k)
- [facebook/convnext-large-224](https://huggingface.co/facebook/convnext-large-224)
- [microsoft/resnet-50](https://huggingface.co/)
**Image Segmentation**
- [nvidia/segformer-b0-finetuned-ade-512-512](https://huggingface.co/nvidia/segformer-b0-finetuned-ade-512-512)
- [facebook/mask2former-swin-tiny-coco-panoptic](https://huggingface.co/facebook/mask2former-swin-tiny-coco-panoptic)
- [facebook/maskformer-swin-base-ade](https://huggingface.co/facebook/maskformer-swin-base-ade)
- [google/deeplabv3_mobilenet_v2_1.0_513](https://huggingface.co/google/deeplabv3_mobilenet_v2_1.0_513)
**Object Detection**
- [google/owlvit-base-patch32](https://huggingface.co/google/owlvit-base-patch32)
- [facebook/detr-resnet-101](https://huggingface.co/facebook/detr-resnet-101)
- [microsoft/conditional-detr-resnet-50](https://huggingface.co/microsoft/conditional-detr-resnet-50)
Below you can find visualization of inference durations with and without `torch.compile()` and percentage improvements for each model in different hardware and batch sizes.
<div class="flex">
<div>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/torch_compile/a100_batch_comp.png" />
</div>
<div>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/torch_compile/v100_batch_comp.png" />
</div>
<div>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/torch_compile/t4_batch_comp.png" />
</div>
</div>
<div class="flex">
<div>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/torch_compile/A100_1_duration.png" />
</div>
<div>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/torch_compile/A100_1_percentage.png" />
</div>
</div>


Below you can find inference durations in milliseconds for each model with and without `compile()`. Note that OwlViT results in OOM in larger batch sizes.
### A100 (batch size: 1)
| **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|
| Image Classification/ViT | 9.325 | 7.584 |
| Image Segmentation/Segformer | 11.759 | 10.500 |
| Object Detection/OwlViT | 24.978 | 18.420 |
| Image Classification/BeiT | 11.282 | 8.448 |
| Object Detection/DETR | 34.619 | 19.040 |
| Image Classification/ConvNeXT | 10.410 | 10.208 |
| Image Classification/ResNet | 6.531 | 4.124 |
| Image Segmentation/Mask2former | 60.188 | 49.117 |
| Image Segmentation/Maskformer | 75.764 | 59.487 |
| Image Segmentation/MobileNet | 8.583 | 3.974 |
| Object Detection/Resnet-101 | 36.276 | 18.197 |
| Object Detection/Conditional-DETR | 31.219 | 17.993 |
### A100 (batch size: 4)
| **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|
| Image Classification/ViT | 14.832 | 14.499 |
| Image Segmentation/Segformer | 18.838 | 16.476 |
| Image Classification/BeiT | 13.205 | 13.048 |
| Object Detection/DETR | 48.657 | 32.418|
| Image Classification/ConvNeXT | 22.940 | 21.631 |
| Image Classification/ResNet | 6.657 | 4.268 |
| Image Segmentation/Mask2former | 74.277 | 61.781 |
| Image Segmentation/Maskformer | 180.700 | 159.116 |
| Image Segmentation/MobileNet | 14.174 | 8.515 |
| Object Detection/Resnet-101 | 68.101 | 44.998 |
| Object Detection/Conditional-DETR | 56.470 | 35.552 |
### A100 (batch size: 16)
| **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|
| Image Classification/ViT | 40.944 | 40.010 |
| Image Segmentation/Segformer | 37.005 | 31.144 |
| Image Classification/BeiT | 41.854 | 41.048 |
| Object Detection/DETR | 164.382 | 161.902 |
| Image Classification/ConvNeXT | 82.258 | 75.561 |
| Image Classification/ResNet | 7.018 | 5.024 |
| Image Segmentation/Mask2former | 178.945 | 154.814 |
| Image Segmentation/Maskformer | 638.570 | 579.826 |
| Image Segmentation/MobileNet | 51.693 | 30.310 |
| Object Detection/Resnet-101 | 232.887 | 155.021 |
| Object Detection/Conditional-DETR | 180.491 | 124.032 |
### V100 (batch size: 1)
| **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|
| Image Classification/ViT | 10.495 | 6.00 |
| Image Segmentation/Segformer | 13.321 | 5.862 |
| Object Detection/OwlViT | 25.769 | 22.395 |
| Image Classification/BeiT | 11.347 | 7.234 |
| Object Detection/DETR | 33.951 | 19.388 |
| Image Classification/ConvNeXT | 11.623 | 10.412 |
| Image Classification/ResNet | 6.484 | 3.820 |
| Image Segmentation/Mask2former | 64.640 | 49.873 |
| Image Segmentation/Maskformer | 95.532 | 72.207 |
| Image Segmentation/MobileNet | 9.217 | 4.753 |
| Object Detection/Resnet-101 | 52.818 | 28.367 |
| Object Detection/Conditional-DETR | 39.512 | 20.816 |
### V100 (batch size: 4)
| **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|
| Image Classification/ViT | 15.181 | 14.501 |
| Image Segmentation/Segformer | 16.787 | 16.188 |
| Image Classification/BeiT | 15.171 | 14.753 |
| Object Detection/DETR | 88.529 | 64.195 |
| Image Classification/ConvNeXT | 29.574 | 27.085 |
| Image Classification/ResNet | 6.109 | 4.731 |
| Image Segmentation/Mask2former | 90.402 | 76.926 |
| Image Segmentation/Maskformer | 234.261 | 205.456 |
| Image Segmentation/MobileNet | 24.623 | 14.816 |
| Object Detection/Resnet-101 | 134.672 | 101.304 |
| Object Detection/Conditional-DETR | 97.464 | 69.739 |
### V100 (batch size: 16)
| **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|
| Image Classification/ViT | 52.209 | 51.633 |
| Image Segmentation/Segformer | 61.013 | 55.499 |
| Image Classification/BeiT | 53.938 | 53.581 |
| Object Detection/DETR | OOM | OOM |
| Image Classification/ConvNeXT | 109.682 | 100.771 |
| Image Classification/ResNet | 14.857 | 12.089 |
| Image Segmentation/Mask2former | 249.605 | 222.801 |
| Image Segmentation/Maskformer | 831.142 | 743.645 |
| Image Segmentation/MobileNet | 93.129 | 55.365 |
| Object Detection/Resnet-101 | 482.425 | 361.843 |
| Object Detection/Conditional-DETR | 344.661 | 255.298 |
### T4 (batch size: 1)
| **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|
| Image Classification/ViT | 16.520 | 15.786 |
| Image Segmentation/Segformer | 16.116 | 14.205 |
| Object Detection/OwlViT | 53.634 | 51.105 |
| Image Classification/BeiT | 16.464 | 15.710 |
| Object Detection/DETR | 73.100 | 53.99 |
| Image Classification/ConvNeXT | 32.932 | 30.845 |
| Image Classification/ResNet | 6.031 | 4.321 |
| Image Segmentation/Mask2former | 79.192 | 66.815 |
| Image Segmentation/Maskformer | 200.026 | 188.268 |
| Image Segmentation/MobileNet | 18.908 | 11.997 |
| Object Detection/Resnet-101 | 106.622 | 82.566 |
| Object Detection/Conditional-DETR | 77.594 | 56.984 |
### T4 (batch size: 4)
| **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|
| Image Classification/ViT | 43.653 | 43.626 |
| Image Segmentation/Segformer | 45.327 | 42.445 |
| Image Classification/BeiT | 52.007 | 51.354 |
| Object Detection/DETR | 277.850 | 268.003 |
| Image Classification/ConvNeXT | 119.259 | 105.580 |
| Image Classification/ResNet | 13.039 | 11.388 |
| Image Segmentation/Mask2former | 201.540 | 184.670 |
| Image Segmentation/Maskformer | 764.052 | 711.280 |
| Image Segmentation/MobileNet | 74.289 | 48.677 |
| Object Detection/Resnet-101 | 421.859 | 357.614 |
| Object Detection/Conditional-DETR | 289.002 | 226.945 |
### T4 (batch size: 16)
| **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|
| Image Classification/ViT | 163.914 | 160.907 |
| Image Segmentation/Segformer | 192.412 | 163.620 |
| Image Classification/BeiT | 188.978 | 187.976 |
| Object Detection/DETR | OOM | OOM |
| Image Classification/ConvNeXT | 422.886 | 388.078 |
| Image Classification/ResNet | 44.114 | 37.604 |
| Image Segmentation/Mask2former | 756.337 | 695.291 |
| Image Segmentation/Maskformer | 2842.940 | 2656.88 |
| Image Segmentation/MobileNet | 299.003 | 201.942 |
| Object Detection/Resnet-101 | 1619.505 | 1262.758 |
| Object Detection/Conditional-DETR | 1137.513 | 897.390|
## PyTorch Nightly
We also benchmarked on PyTorch nightly (2.1.0dev, find the wheel [here](https://download.pytorch.org/whl/nightly/cu118)) and observed improvement in latency both for uncompiled and compiled models.
### A100
| **Task/Model** | **Batch Size** | **torch 2.0 - no compile** | **torch 2.0 -<br> compile** |
|:---:|:---:|:---:|:---:|
| Image Classification/BeiT | Unbatched | 12.462 | 6.954 |
| Image Classification/BeiT | 4 | 14.109 | 12.851 |
| Image Classification/BeiT | 16 | 42.179 | 42.147 |
| Object Detection/DETR | Unbatched | 30.484 | 15.221 |
| Object Detection/DETR | 4 | 46.816 | 30.942 |
| Object Detection/DETR | 16 | 163.749 | 163.706 |
### T4
| **Task/Model** | **Batch Size** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|:---:|
| Image Classification/BeiT | Unbatched | 14.408 | 14.052 |
| Image Classification/BeiT | 4 | 47.381 | 46.604 |
| Image Classification/BeiT | 16 | 42.179 | 42.147 |
| Object Detection/DETR | Unbatched | 68.382 | 53.481 |
| Object Detection/DETR | 4 | 269.615 | 204.785 |
| Object Detection/DETR | 16 | OOM | OOM |
### V100
| **Task/Model** | **Batch Size** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|:---:|
| Image Classification/BeiT | Unbatched | 13.477 | 7.926 |
| Image Classification/BeiT | 4 | 15.103 | 14.378 |
| Image Classification/BeiT | 16 | 52.517 | 51.691 |
| Object Detection/DETR | Unbatched | 28.706 | 19.077 |
| Object Detection/DETR | 4 | 88.402 | 62.949|
| Object Detection/DETR | 16 | OOM | OOM |
## Reduce Overhead
We benchmarked `reduce-overhead` compilation mode for A100 and T4 in Nightly.
### A100
| **Task/Model** | **Batch Size** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|:---:|
| Image Classification/ConvNeXT | Unbatched | 11.758 | 7.335 |
| Image Classification/ConvNeXT | 4 | 23.171 | 21.490 |
| Image Classification/ResNet | Unbatched | 7.435 | 3.801 |
| Image Classification/ResNet | 4 | 7.261 | 2.187 |
| Object Detection/Conditional-DETR | Unbatched | 32.823 | 11.627 |
| Object Detection/Conditional-DETR | 4 | 50.622 | 33.831 |
| Image Segmentation/MobileNet | Unbatched | 9.869 | 4.244 |
| Image Segmentation/MobileNet | 4 | 14.385 | 7.946 |
### T4
| **Task/Model** | **Batch Size** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|:---:|
| Image Classification/ConvNeXT | Unbatched | 32.137 | 31.84 |
| Image Classification/ConvNeXT | 4 | 120.944 | 110.209 |
| Image Classification/ResNet | Unbatched | 9.761 | 7.698 |
| Image Classification/ResNet | 4 | 15.215 | 13.871 |
| Object Detection/Conditional-DETR | Unbatched | 72.150 | 57.660 |
| Object Detection/Conditional-DETR | 4 | 301.494 | 247.543 |
| Image Segmentation/MobileNet | Unbatched | 22.266 | 19.339 |
| Image Segmentation/MobileNet | 4 | 78.311 | 50.983 |
| transformers/docs/source/en/perf_torch_compile.md/0 | {
"file_path": "transformers/docs/source/en/perf_torch_compile.md",
"repo_id": "transformers",
"token_count": 5859
} | 18 |
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Train with a script
Along with the 🤗 Transformers [notebooks](./noteboks/README), there are also example scripts demonstrating how to train a model for a task with [PyTorch](https://github.com/huggingface/transformers/tree/main/examples/pytorch), [TensorFlow](https://github.com/huggingface/transformers/tree/main/examples/tensorflow), or [JAX/Flax](https://github.com/huggingface/transformers/tree/main/examples/flax).
You will also find scripts we've used in our [research projects](https://github.com/huggingface/transformers/tree/main/examples/research_projects) and [legacy examples](https://github.com/huggingface/transformers/tree/main/examples/legacy) which are mostly community contributed. These scripts are not actively maintained and require a specific version of 🤗 Transformers that will most likely be incompatible with the latest version of the library.
The example scripts are not expected to work out-of-the-box on every problem, and you may need to adapt the script to the problem you're trying to solve. To help you with this, most of the scripts fully expose how data is preprocessed, allowing you to edit it as necessary for your use case.
For any feature you'd like to implement in an example script, please discuss it on the [forum](https://discuss.huggingface.co/) or in an [issue](https://github.com/huggingface/transformers/issues) before submitting a Pull Request. While we welcome bug fixes, it is unlikely we will merge a Pull Request that adds more functionality at the cost of readability.
This guide will show you how to run an example summarization training script in [PyTorch](https://github.com/huggingface/transformers/tree/main/examples/pytorch/summarization) and [TensorFlow](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/summarization). All examples are expected to work with both frameworks unless otherwise specified.
## Setup
To successfully run the latest version of the example scripts, you have to **install 🤗 Transformers from source** in a new virtual environment:
```bash
git clone https://github.com/huggingface/transformers
cd transformers
pip install .
```
For older versions of the example scripts, click on the toggle below:
<details>
<summary>Examples for older versions of 🤗 Transformers</summary>
<ul>
<li><a href="https://github.com/huggingface/transformers/tree/v4.5.1/examples">v4.5.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v4.4.2/examples">v4.4.2</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v4.3.3/examples">v4.3.3</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v4.2.2/examples">v4.2.2</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v4.1.1/examples">v4.1.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v4.0.1/examples">v4.0.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v3.5.1/examples">v3.5.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v3.4.0/examples">v3.4.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v3.3.1/examples">v3.3.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v3.2.0/examples">v3.2.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v3.1.0/examples">v3.1.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v3.0.2/examples">v3.0.2</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.11.0/examples">v2.11.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.10.0/examples">v2.10.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.9.1/examples">v2.9.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.8.0/examples">v2.8.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.7.0/examples">v2.7.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.6.0/examples">v2.6.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.5.1/examples">v2.5.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.4.0/examples">v2.4.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.3.0/examples">v2.3.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.2.0/examples">v2.2.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.1.0/examples">v2.1.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.0.0/examples">v2.0.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v1.2.0/examples">v1.2.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v1.1.0/examples">v1.1.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v1.0.0/examples">v1.0.0</a></li>
</ul>
</details>
Then switch your current clone of 🤗 Transformers to a specific version, like v3.5.1 for example:
```bash
git checkout tags/v3.5.1
```
After you've setup the correct library version, navigate to the example folder of your choice and install the example specific requirements:
```bash
pip install -r requirements.txt
```
## Run a script
<frameworkcontent>
<pt>
The example script downloads and preprocesses a dataset from the 🤗 [Datasets](https://huggingface.co/docs/datasets/) library. Then the script fine-tunes a dataset with the [Trainer](https://huggingface.co/docs/transformers/main_classes/trainer) on an architecture that supports summarization. The following example shows how to fine-tune [T5-small](https://huggingface.co/google-t5/t5-small) on the [CNN/DailyMail](https://huggingface.co/datasets/cnn_dailymail) dataset. The T5 model requires an additional `source_prefix` argument due to how it was trained. This prompt lets T5 know this is a summarization task.
```bash
python examples/pytorch/summarization/run_summarization.py \
--model_name_or_path google-t5/t5-small \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--overwrite_output_dir \
--predict_with_generate
```
</pt>
<tf>
The example script downloads and preprocesses a dataset from the 🤗 [Datasets](https://huggingface.co/docs/datasets/) library. Then the script fine-tunes a dataset using Keras on an architecture that supports summarization. The following example shows how to fine-tune [T5-small](https://huggingface.co/google-t5/t5-small) on the [CNN/DailyMail](https://huggingface.co/datasets/cnn_dailymail) dataset. The T5 model requires an additional `source_prefix` argument due to how it was trained. This prompt lets T5 know this is a summarization task.
```bash
python examples/tensorflow/summarization/run_summarization.py \
--model_name_or_path google-t5/t5-small \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size 8 \
--per_device_eval_batch_size 16 \
--num_train_epochs 3 \
--do_train \
--do_eval
```
</tf>
</frameworkcontent>
## Distributed training and mixed precision
The [Trainer](https://huggingface.co/docs/transformers/main_classes/trainer) supports distributed training and mixed precision, which means you can also use it in a script. To enable both of these features:
- Add the `fp16` argument to enable mixed precision.
- Set the number of GPUs to use with the `nproc_per_node` argument.
```bash
torchrun \
--nproc_per_node 8 pytorch/summarization/run_summarization.py \
--fp16 \
--model_name_or_path google-t5/t5-small \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--overwrite_output_dir \
--predict_with_generate
```
TensorFlow scripts utilize a [`MirroredStrategy`](https://www.tensorflow.org/guide/distributed_training#mirroredstrategy) for distributed training, and you don't need to add any additional arguments to the training script. The TensorFlow script will use multiple GPUs by default if they are available.
## Run a script on a TPU
<frameworkcontent>
<pt>
Tensor Processing Units (TPUs) are specifically designed to accelerate performance. PyTorch supports TPUs with the [XLA](https://www.tensorflow.org/xla) deep learning compiler (see [here](https://github.com/pytorch/xla/blob/master/README.md) for more details). To use a TPU, launch the `xla_spawn.py` script and use the `num_cores` argument to set the number of TPU cores you want to use.
```bash
python xla_spawn.py --num_cores 8 \
summarization/run_summarization.py \
--model_name_or_path google-t5/t5-small \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--overwrite_output_dir \
--predict_with_generate
```
</pt>
<tf>
Tensor Processing Units (TPUs) are specifically designed to accelerate performance. TensorFlow scripts utilize a [`TPUStrategy`](https://www.tensorflow.org/guide/distributed_training#tpustrategy) for training on TPUs. To use a TPU, pass the name of the TPU resource to the `tpu` argument.
```bash
python run_summarization.py \
--tpu name_of_tpu_resource \
--model_name_or_path google-t5/t5-small \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size 8 \
--per_device_eval_batch_size 16 \
--num_train_epochs 3 \
--do_train \
--do_eval
```
</tf>
</frameworkcontent>
## Run a script with 🤗 Accelerate
🤗 [Accelerate](https://huggingface.co/docs/accelerate) is a PyTorch-only library that offers a unified method for training a model on several types of setups (CPU-only, multiple GPUs, TPUs) while maintaining complete visibility into the PyTorch training loop. Make sure you have 🤗 Accelerate installed if you don't already have it:
> Note: As Accelerate is rapidly developing, the git version of accelerate must be installed to run the scripts
```bash
pip install git+https://github.com/huggingface/accelerate
```
Instead of the `run_summarization.py` script, you need to use the `run_summarization_no_trainer.py` script. 🤗 Accelerate supported scripts will have a `task_no_trainer.py` file in the folder. Begin by running the following command to create and save a configuration file:
```bash
accelerate config
```
Test your setup to make sure it is configured correctly:
```bash
accelerate test
```
Now you are ready to launch the training:
```bash
accelerate launch run_summarization_no_trainer.py \
--model_name_or_path google-t5/t5-small \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir ~/tmp/tst-summarization
```
## Use a custom dataset
The summarization script supports custom datasets as long as they are a CSV or JSON Line file. When you use your own dataset, you need to specify several additional arguments:
- `train_file` and `validation_file` specify the path to your training and validation files.
- `text_column` is the input text to summarize.
- `summary_column` is the target text to output.
A summarization script using a custom dataset would look like this:
```bash
python examples/pytorch/summarization/run_summarization.py \
--model_name_or_path google-t5/t5-small \
--do_train \
--do_eval \
--train_file path_to_csv_or_jsonlines_file \
--validation_file path_to_csv_or_jsonlines_file \
--text_column text_column_name \
--summary_column summary_column_name \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--overwrite_output_dir \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--predict_with_generate
```
## Test a script
It is often a good idea to run your script on a smaller number of dataset examples to ensure everything works as expected before committing to an entire dataset which may take hours to complete. Use the following arguments to truncate the dataset to a maximum number of samples:
- `max_train_samples`
- `max_eval_samples`
- `max_predict_samples`
```bash
python examples/pytorch/summarization/run_summarization.py \
--model_name_or_path google-t5/t5-small \
--max_train_samples 50 \
--max_eval_samples 50 \
--max_predict_samples 50 \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--overwrite_output_dir \
--predict_with_generate
```
Not all example scripts support the `max_predict_samples` argument. If you aren't sure whether your script supports this argument, add the `-h` argument to check:
```bash
examples/pytorch/summarization/run_summarization.py -h
```
## Resume training from checkpoint
Another helpful option to enable is resuming training from a previous checkpoint. This will ensure you can pick up where you left off without starting over if your training gets interrupted. There are two methods to resume training from a checkpoint.
The first method uses the `output_dir previous_output_dir` argument to resume training from the latest checkpoint stored in `output_dir`. In this case, you should remove `overwrite_output_dir`:
```bash
python examples/pytorch/summarization/run_summarization.py
--model_name_or_path google-t5/t5-small \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--output_dir previous_output_dir \
--predict_with_generate
```
The second method uses the `resume_from_checkpoint path_to_specific_checkpoint` argument to resume training from a specific checkpoint folder.
```bash
python examples/pytorch/summarization/run_summarization.py
--model_name_or_path google-t5/t5-small \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--overwrite_output_dir \
--resume_from_checkpoint path_to_specific_checkpoint \
--predict_with_generate
```
## Share your model
All scripts can upload your final model to the [Model Hub](https://huggingface.co/models). Make sure you are logged into Hugging Face before you begin:
```bash
huggingface-cli login
```
Then add the `push_to_hub` argument to the script. This argument will create a repository with your Hugging Face username and the folder name specified in `output_dir`.
To give your repository a specific name, use the `push_to_hub_model_id` argument to add it. The repository will be automatically listed under your namespace.
The following example shows how to upload a model with a specific repository name:
```bash
python examples/pytorch/summarization/run_summarization.py
--model_name_or_path google-t5/t5-small \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--push_to_hub \
--push_to_hub_model_id finetuned-t5-cnn_dailymail \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--overwrite_output_dir \
--predict_with_generate
``` | transformers/docs/source/en/run_scripts.md/0 | {
"file_path": "transformers/docs/source/en/run_scripts.md",
"repo_id": "transformers",
"token_count": 5916
} | 19 |
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# XLA Integration for TensorFlow Models
[[open-in-colab]]
Accelerated Linear Algebra, dubbed XLA, is a compiler for accelerating the runtime of TensorFlow Models. From the [official documentation](https://www.tensorflow.org/xla):
XLA (Accelerated Linear Algebra) is a domain-specific compiler for linear algebra that can accelerate TensorFlow models with potentially no source code changes.
Using XLA in TensorFlow is simple – it comes packaged inside the `tensorflow` library, and it can be triggered with the `jit_compile` argument in any graph-creating function such as [`tf.function`](https://www.tensorflow.org/guide/intro_to_graphs). When using Keras methods like `fit()` and `predict()`, you can enable XLA simply by passing the `jit_compile` argument to `model.compile()`. However, XLA is not limited to these methods - it can also be used to accelerate any arbitrary `tf.function`.
Several TensorFlow methods in 🤗 Transformers have been rewritten to be XLA-compatible, including text generation for models such as [GPT2](https://huggingface.co/docs/transformers/model_doc/gpt2), [T5](https://huggingface.co/docs/transformers/model_doc/t5) and [OPT](https://huggingface.co/docs/transformers/model_doc/opt), as well as speech processing for models such as [Whisper](https://huggingface.co/docs/transformers/model_doc/whisper).
While the exact amount of speed-up is very much model-dependent, for TensorFlow text generation models inside 🤗 Transformers, we noticed a speed-up of ~100x. This document will explain how you can use XLA for these models to get the maximum amount of performance. We’ll also provide links to additional resources if you’re interested to learn more about the benchmarks and our design philosophy behind the XLA integration.
## Running TF functions with XLA
Let us consider the following model in TensorFlow:
```py
import tensorflow as tf
model = tf.keras.Sequential(
[tf.keras.layers.Dense(10, input_shape=(10,), activation="relu"), tf.keras.layers.Dense(5, activation="softmax")]
)
```
The above model accepts inputs having a dimension of `(10, )`. We can use the model for running a forward pass like so:
```py
# Generate random inputs for the model.
batch_size = 16
input_vector_dim = 10
random_inputs = tf.random.normal((batch_size, input_vector_dim))
# Run a forward pass.
_ = model(random_inputs)
```
In order to run the forward pass with an XLA-compiled function, we’d need to do:
```py
xla_fn = tf.function(model, jit_compile=True)
_ = xla_fn(random_inputs)
```
The default `call()` function of the `model` is used for compiling the XLA graph. But if there’s any other model function you want to compile into XLA that’s also possible with:
```py
my_xla_fn = tf.function(model.my_xla_fn, jit_compile=True)
```
## Running a TF text generation model with XLA from 🤗 Transformers
To enable XLA-accelerated generation within 🤗 Transformers, you need to have a recent version of `transformers` installed. You can install it by running:
```bash
pip install transformers --upgrade
```
And then you can run the following code:
```py
import tensorflow as tf
from transformers import AutoTokenizer, TFAutoModelForCausalLM
# Will error if the minimal version of Transformers is not installed.
from transformers.utils import check_min_version
check_min_version("4.21.0")
tokenizer = AutoTokenizer.from_pretrained("openai-community/gpt2", padding_side="left", pad_token="</s>")
model = TFAutoModelForCausalLM.from_pretrained("openai-community/gpt2")
input_string = ["TensorFlow is"]
# One line to create an XLA generation function
xla_generate = tf.function(model.generate, jit_compile=True)
tokenized_input = tokenizer(input_string, return_tensors="tf")
generated_tokens = xla_generate(**tokenized_input, num_beams=2)
decoded_text = tokenizer.decode(generated_tokens[0], skip_special_tokens=True)
print(f"Generated -- {decoded_text}")
# Generated -- TensorFlow is an open-source, open-source, distributed-source application # framework for the
```
As you can notice, enabling XLA on `generate()` is just a single line of code. The rest of the code remains unchanged. However, there are a couple of gotchas in the above code snippet that are specific to XLA. You need to be aware of those to realize the speed-ups that XLA can bring in. We discuss these in the following section.
## Gotchas to be aware of
When you are executing an XLA-enabled function (like `xla_generate()` above) for the first time, it will internally try to infer the computation graph, which is time-consuming. This process is known as [“tracing”](https://www.tensorflow.org/guide/intro_to_graphs#when_is_a_function_tracing).
You might notice that the generation time is not fast. Successive calls of `xla_generate()` (or any other XLA-enabled function) won’t have to infer the computation graph, given the inputs to the function follow the same shape with which the computation graph was initially built. While this is not a problem for modalities with fixed input shapes (e.g., images), you must pay attention if you are working with variable input shape modalities (e.g., text).
To ensure `xla_generate()` always operates with the same input shapes, you can specify the `padding` arguments when calling the tokenizer.
```py
import tensorflow as tf
from transformers import AutoTokenizer, TFAutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("openai-community/gpt2", padding_side="left", pad_token="</s>")
model = TFAutoModelForCausalLM.from_pretrained("openai-community/gpt2")
input_string = ["TensorFlow is"]
xla_generate = tf.function(model.generate, jit_compile=True)
# Here, we call the tokenizer with padding options.
tokenized_input = tokenizer(input_string, pad_to_multiple_of=8, padding=True, return_tensors="tf")
generated_tokens = xla_generate(**tokenized_input, num_beams=2)
decoded_text = tokenizer.decode(generated_tokens[0], skip_special_tokens=True)
print(f"Generated -- {decoded_text}")
```
This way, you can ensure that the inputs to `xla_generate()` will always receive inputs with the shape it was traced with and thus leading to speed-ups in the generation time. You can verify this with the code below:
```py
import time
import tensorflow as tf
from transformers import AutoTokenizer, TFAutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("openai-community/gpt2", padding_side="left", pad_token="</s>")
model = TFAutoModelForCausalLM.from_pretrained("openai-community/gpt2")
xla_generate = tf.function(model.generate, jit_compile=True)
for input_string in ["TensorFlow is", "TensorFlow is a", "TFLite is a"]:
tokenized_input = tokenizer(input_string, pad_to_multiple_of=8, padding=True, return_tensors="tf")
start = time.time_ns()
generated_tokens = xla_generate(**tokenized_input, num_beams=2)
end = time.time_ns()
print(f"Execution time -- {(end - start) / 1e6:.1f} ms\n")
```
On a Tesla T4 GPU, you can expect the outputs like so:
```bash
Execution time -- 30819.6 ms
Execution time -- 79.0 ms
Execution time -- 78.9 ms
```
The first call to `xla_generate()` is time-consuming because of tracing, but the successive calls are orders of magnitude faster. Keep in mind that any change in the generation options at any point with trigger re-tracing and thus leading to slow-downs in the generation time.
We didn’t cover all the text generation options 🤗 Transformers provides in this document. We encourage you to read the documentation for advanced use cases.
## Additional Resources
Here, we leave you with some additional resources if you want to delve deeper into XLA in 🤗 Transformers and in general.
* [This Colab Notebook](https://colab.research.google.com/github/huggingface/blog/blob/main/notebooks/91_tf_xla_generate.ipynb) provides an interactive demonstration if you want to fiddle with the XLA-compatible encoder-decoder (like [T5](https://huggingface.co/docs/transformers/model_doc/t5)) and decoder-only (like [GPT2](https://huggingface.co/docs/transformers/model_doc/gpt2)) text generation models.
* [This blog post](https://huggingface.co/blog/tf-xla-generate) provides an overview of the comparison benchmarks for XLA-compatible models along with a friendly introduction to XLA in TensorFlow.
* [This blog post](https://blog.tensorflow.org/2022/11/how-hugging-face-improved-text-generation-performance-with-xla.html) discusses our design philosophy behind adding XLA support to the TensorFlow models in 🤗 Transformers.
* Recommended posts for learning more about XLA and TensorFlow graphs in general:
* [XLA: Optimizing Compiler for Machine Learning](https://www.tensorflow.org/xla)
* [Introduction to graphs and tf.function](https://www.tensorflow.org/guide/intro_to_graphs)
* [Better performance with tf.function](https://www.tensorflow.org/guide/function) | transformers/docs/source/en/tf_xla.md/0 | {
"file_path": "transformers/docs/source/en/tf_xla.md",
"repo_id": "transformers",
"token_count": 2860
} | 20 |
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Crea una arquitectura personalizada
Una [`AutoClass`](model_doc/auto) infiere, automáticamente, la arquitectura del modelo y descarga la configuración y los pesos del modelo preentrenado. Normalmente, recomendamos usar una `AutoClass` para producir un código agnóstico a puntos de guardado o checkpoints. Sin embargo, los usuarios que quieran más control sobre los parámetros específicos de los modelos pueden crear su propio modelo 🤗 Transformers personalizado a partir de varias clases base. Esto puede ser particularmente útil para alguien que esté interesado en estudiar, entrenar o experimentar con modelos 🤗 Transformers. En esta guía vamos a profundizar en la creación de modelos personalizados sin usar `AutoClass`. Aprenderemos a:
- Cargar y personalizar una configuración para un modelo.
- Crear una arquitectura para un modelo.
- Crear tokenizadores rápidos y lentos para textos.
- Crear un extractor de propiedades para tareas de audio o imágenes.
- Crear un procesador para tareas multimodales.
## Configuración
Una [configuración](main_classes/configuration) es un conjunto de atributos específicos de un modelo. Cada configuración de modelo tiene atributos diferentes. Por ejemplo, todos los modelos de PLN tienen los atributos `hidden_size`, `num_attention_heads`, `num_hidden_layers` y `vocab_size` en común. Estos atributos especifican el número de cabezas de atención o de capas ocultas con las que se construyen los modelos.
Puedes echarle un vistazo a [DistilBERT](model_doc/distilbert) y sus atributos accediendo a [`DistilBertConfig`]:
```py
>>> from transformers import DistilBertConfig
>>> config = DistilBertConfig()
>>> print(config)
DistilBertConfig {
"activation": "gelu",
"attention_dropout": 0.1,
"dim": 768,
"dropout": 0.1,
"hidden_dim": 3072,
"initializer_range": 0.02,
"max_position_embeddings": 512,
"model_type": "distilbert",
"n_heads": 12,
"n_layers": 6,
"pad_token_id": 0,
"qa_dropout": 0.1,
"seq_classif_dropout": 0.2,
"sinusoidal_pos_embds": false,
"transformers_version": "4.16.2",
"vocab_size": 30522
}
```
[`DistilBertConfig`] muestra todos los atributos por defecto que se han usado para construir un modelo [`DistilBertModel`] base. Todos ellos son personalizables, lo que deja espacio para poder experimentar. Por ejemplo, puedes personalizar un modelo predeterminado para:
- Probar una función de activación diferente, usando el parámetro `activation`.
- Usar un valor de abandono (también conocido como _dropout_) más alto para las probabilidades de las capas de atención, usando el parámetro `attention_dropout`.
```py
>>> my_config = DistilBertConfig(activation="relu", attention_dropout=0.4)
>>> print(my_config)
DistilBertConfig {
"activation": "relu",
"attention_dropout": 0.4,
"dim": 768,
"dropout": 0.1,
"hidden_dim": 3072,
"initializer_range": 0.02,
"max_position_embeddings": 512,
"model_type": "distilbert",
"n_heads": 12,
"n_layers": 6,
"pad_token_id": 0,
"qa_dropout": 0.1,
"seq_classif_dropout": 0.2,
"sinusoidal_pos_embds": false,
"transformers_version": "4.16.2",
"vocab_size": 30522
}
```
Los atributos de los modelos preentrenados pueden ser modificados con la función [`~PretrainedConfig.from_pretrained`]:
```py
>>> my_config = DistilBertConfig.from_pretrained("distilbert/distilbert-base-uncased", activation="relu", attention_dropout=0.4)
```
Cuando estés satisfecho con la configuración de tu modelo, puedes guardarlo con la función [`~PretrainedConfig.save_pretrained`]. Tu configuración se guardará en un archivo JSON dentro del directorio que le especifiques como parámetro.
```py
>>> my_config.save_pretrained(save_directory="./your_model_save_path")
```
Para volver a usar el archivo de configuración, puedes cargarlo usando [`~PretrainedConfig.from_pretrained`]:
```py
>>> my_config = DistilBertConfig.from_pretrained("./your_model_save_path/my_config.json")
```
<Tip>
También puedes guardar los archivos de configuración como un diccionario; o incluso guardar solo la diferencia entre tu archivo personalizado y la configuración por defecto. Consulta la [documentación sobre configuración](main_classes/configuration) para ver más detalles.
</Tip>
## Modelo
El siguiente paso será crear un [modelo](main_classes/models). El modelo, al que a veces también nos referimos como arquitectura, es el encargado de definir cada capa y qué operaciones se realizan. Los atributos como `num_hidden_layers` de la configuración se usan para definir la arquitectura. Todos los modelos comparten una clase base, [`PreTrainedModel`], y algunos métodos comunes que se pueden usar para redimensionar los _embeddings_ o para recortar cabezas de auto-atención (también llamadas _self-attention heads_). Además, todos los modelos son subclases de [`torch.nn.Module`](https://pytorch.org/docs/stable/generated/torch.nn.Module.html), [`tf.keras.Model`](https://www.tensorflow.org/api_docs/python/tf/keras/Model) o [`flax.linen.Module`](https://flax.readthedocs.io/en/latest/api_reference/flax.linen/module.html), lo que significa que son compatibles con su respectivo framework.
<frameworkcontent>
<pt>
Carga los atributos de tu configuración personalizada en el modelo de la siguiente forma:
```py
>>> from transformers import DistilBertModel
>>> my_config = DistilBertConfig.from_pretrained("./your_model_save_path/my_config.json")
>>> model = DistilBertModel(my_config)
```
Esto crea un modelo con valores aleatorios, en lugar de crearlo con los pesos del preentrenamiento, por lo que no serás capaz de usar este modelo para nada útil hasta que no lo entrenes. El entrenamiento es un proceso costoso, tanto en cuestión de recursos como de tiempo, por lo que generalmente es mejor usar un modelo preentrenado para obtener mejores resultados más rápido, consumiendo una fracción de los recursos que un entrenamiento completo hubiera requerido.
Puedes crear un modelo preentrenado con [`~PreTrainedModel.from_pretrained`]:
```py
>>> model = DistilBertModel.from_pretrained("distilbert/distilbert-base-uncased")
```
Cuando cargues tus pesos del preentrenamiento, el modelo por defecto se carga automáticamente si nos lo proporciona 🤗 Transformers. Sin embargo, siempre puedes reemplazar (todos o algunos de) los atributos del modelo por defecto por los tuyos:
```py
>>> model = DistilBertModel.from_pretrained("distilbert/distilbert-base-uncased", config=my_config)
```
</pt>
<tf>
Carga los atributos de tu configuración personalizada en el modelo de la siguiente forma:
```py
>>> from transformers import TFDistilBertModel
>>> my_config = DistilBertConfig.from_pretrained("./your_model_save_path/my_config.json")
>>> tf_model = TFDistilBertModel(my_config)
```
Esto crea un modelo con valores aleatorios, en lugar de crearlo con los pesos del preentrenamiento, por lo que no serás capaz de usar este modelo para nada útil hasta que no lo entrenes. El entrenamiento es un proceso costoso, tanto en cuestión de recursos como de tiempo, por lo que generalmente es mejor usar un modelo preentrenado para obtener mejores resultados más rápido, consumiendo solo una fracción de los recursos que un entrenamiento completo hubiera requerido.
Puedes crear un modelo preentrenado con [`~TFPreTrainedModel.from_pretrained`]:
```py
>>> tf_model = TFDistilBertModel.from_pretrained("distilbert/distilbert-base-uncased")
```
Cuando cargues tus pesos del preentrenamiento, el modelo por defecto se carga automáticamente si este nos lo proporciona 🤗 Transformers. Sin embargo, siempre puedes reemplazar (todos o algunos de) los atributos del modelo por defecto por los tuyos:
```py
>>> tf_model = TFDistilBertModel.from_pretrained("distilbert/distilbert-base-uncased", config=my_config)
```
</tf>
</frameworkcontent>
### Cabezas de modelo
En este punto del tutorial, tenemos un modelo DistilBERT base que devuelve los *hidden states* o estados ocultos. Los *hidden states* se pasan como parámetros de entrada a la cabeza del modelo para producir la salida. 🤗 Transformers ofrece una cabeza de modelo diferente para cada tarea, siempre y cuando el modelo sea compatible para la tarea (por ejemplo, no puedes usar DistilBERT para una tarea secuencia a secuencia como la traducción).
<frameworkcontent>
<pt>
Por ejemplo, [`DistilBertForSequenceClassification`] es un modelo DistilBERT base con una cabeza de clasificación de secuencias. La cabeza de clasificación de secuencias es una capa superior que precede a la recolección de las salidas.
```py
>>> from transformers import DistilBertForSequenceClassification
>>> model = DistilBertForSequenceClassification.from_pretrained("distilbert/distilbert-base-uncased")
```
Puedes reutilizar este punto de guardado o *checkpoint* para otra tarea fácilmente cambiando a una cabeza de un modelo diferente. Para una tarea de respuesta a preguntas, puedes usar la cabeza del modelo [`DistilBertForQuestionAnswering`]. La cabeza de respuesta a preguntas es similar a la de clasificación de secuencias, excepto porque consta de una capa lineal delante de la salida de los *hidden states*.
```py
>>> from transformers import DistilBertForQuestionAnswering
>>> model = DistilBertForQuestionAnswering.from_pretrained("distilbert/distilbert-base-uncased")
```
</pt>
<tf>
Por ejemplo, [`TFDistilBertForSequenceClassification`] es un modelo DistilBERT base con una cabeza de clasificación de secuencias. La cabeza de clasificación de secuencias es una capa superior que precede a la recolección de las salidas.
```py
>>> from transformers import TFDistilBertForSequenceClassification
>>> tf_model = TFDistilBertForSequenceClassification.from_pretrained("distilbert/distilbert-base-uncased")
```
Puedes reutilizar este punto de guardado o *checkpoint* para otra tarea fácilmente cambiando a una cabeza de un modelo diferente. Para una tarea de respuesta a preguntas, puedes usar la cabeza del modelo [`TFDistilBertForQuestionAnswering`]. La cabeza de respuesta a preguntas es similar a la de clasificación de secuencias, excepto porque consta de una capa lineal delante de la salida de los *hidden states*.
```py
>>> from transformers import TFDistilBertForQuestionAnswering
>>> tf_model = TFDistilBertForQuestionAnswering.from_pretrained("distilbert/distilbert-base-uncased")
```
</tf>
</frameworkcontent>
## Tokenizer
La ultima clase base que debes conocer antes de usar un modelo con datos textuales es la clase [tokenizer](main_classes/tokenizer), que convierte el texto bruto en tensores. Hay dos tipos de *tokenizers* que puedes usar con 🤗 Transformers:
- [`PreTrainedTokenizer`]: una implementación de un *tokenizer* hecha en Python.
- [`PreTrainedTokenizerFast`]: un *tokenizer* de nuestra librería [🤗 Tokenizer](https://huggingface.co/docs/tokenizers/python/latest/), basada en Rust. Este tipo de *tokenizer* es bastante más rápido, especialmente durante la tokenización por lotes, gracias a estar implementado en Rust. Esta rápida tokenización también ofrece métodos adicionales como el *offset mapping*, que relaciona los tokens con sus palabras o caracteres originales.
Ambos *tokenizers* son compatibles con los métodos comunes, como los de encodificación y decodificación, los métodos para añadir tokens y aquellos que manejan tokens especiales.
<Tip warning={true}>
No todos los modelos son compatibles con un *tokenizer* rápido. Échale un vistazo a esta [tabla](index#supported-frameworks) para comprobar si un modelo específico es compatible con un *tokenizer* rápido.
</Tip>
Si has entrenado tu propio *tokenizer*, puedes crear uno desde tu archivo de “vocabulario”:
```py
>>> from transformers import DistilBertTokenizer
>>> my_tokenizer = DistilBertTokenizer(vocab_file="my_vocab_file.txt", do_lower_case=False, padding_side="left")
```
Es importante recordar que los vocabularios que provienen de un *tokenizer* personalizado serán diferentes a los vocabularios generados por el *tokenizer* de un modelo preentrenado. Debes usar el vocabulario de un *tokenizer* preentrenado si vas a usar un modelo preentrenado, de lo contrario las entradas no tendrán sentido. Crea un *tokenizer* con el vocabulario de un modelo preentrenado usando la clase [`DistilBertTokenizer`]:
```py
>>> from transformers import DistilBertTokenizer
>>> slow_tokenizer = DistilBertTokenizer.from_pretrained("distilbert/distilbert-base-uncased")
```
Crea un *tokenizer* rápido con la clase [`DistilBertTokenizerFast`]:
```py
>>> from transformers import DistilBertTokenizerFast
>>> fast_tokenizer = DistilBertTokenizerFast.from_pretrained("distilbert/distilbert-base-uncased")
```
<Tip>
Por defecto, el [`AutoTokenizer`] intentará cargar un *tokenizer* rápido. Puedes desactivar este comportamiento cambiando el parámetro `use_fast=False` de `from_pretrained`.
</Tip>
## Extractor de Características
Un extractor de características procesa entradas de audio e imagen. Hereda de la clase base [`~feature_extraction_utils.FeatureExtractionMixin`] y también puede heredar de la clase [`ImageFeatureExtractionMixin`] para el procesamiento de características de las imágenes o de la clase [`SequenceFeatureExtractor`] para el procesamiento de entradas de audio.
Dependiendo de si trabajas en una tarea de audio o de video, puedes crear un extractor de características asociado al modelo que estés usando. Por ejemplo, podrías crear un [`ViTFeatureExtractor`] por defecto si estás usando [ViT](model_doc/vit) para clasificación de imágenes:
```py
>>> from transformers import ViTFeatureExtractor
>>> vit_extractor = ViTFeatureExtractor()
>>> print(vit_extractor)
ViTFeatureExtractor {
"do_normalize": true,
"do_resize": true,
"feature_extractor_type": "ViTFeatureExtractor",
"image_mean": [
0.5,
0.5,
0.5
],
"image_std": [
0.5,
0.5,
0.5
],
"resample": 2,
"size": 224
}
```
<Tip>
Si no estás buscando ninguna personalización en específico, usa el método `from_pretrained` para cargar los parámetros del extractor de características por defecto del modelo.
</Tip>
Puedes modificar cualquier parámetro de [`ViTFeatureExtractor`] para crear tu extractor de características personalizado:
```py
>>> from transformers import ViTFeatureExtractor
>>> my_vit_extractor = ViTFeatureExtractor(resample="PIL.Image.BOX", do_normalize=False, image_mean=[0.3, 0.3, 0.3])
>>> print(my_vit_extractor)
ViTFeatureExtractor {
"do_normalize": false,
"do_resize": true,
"feature_extractor_type": "ViTFeatureExtractor",
"image_mean": [
0.3,
0.3,
0.3
],
"image_std": [
0.5,
0.5,
0.5
],
"resample": "PIL.Image.BOX",
"size": 224
}
```
Para las entradas de audio, puedes crear un [`Wav2Vec2FeatureExtractor`] y personalizar los parámetros de una forma similar:
```py
>>> from transformers import Wav2Vec2FeatureExtractor
>>> w2v2_extractor = Wav2Vec2FeatureExtractor()
>>> print(w2v2_extractor)
Wav2Vec2FeatureExtractor {
"do_normalize": true,
"feature_extractor_type": "Wav2Vec2FeatureExtractor",
"feature_size": 1,
"padding_side": "right",
"padding_value": 0.0,
"return_attention_mask": false,
"sampling_rate": 16000
}
```
## Procesador
Para modelos que son compatibles con tareas multimodales, 🤗 Transformers ofrece una clase *procesador* que agrupa un extractor de características y un *tokenizer* en el mismo objeto. Por ejemplo, probemos a usar el procesador [`Wav2Vec2Processor`] para una tarea de reconocimiento de voz (ASR). Un ASR transcribe el audio a texto, por lo que necesitaremos un extractor de características y un *tokenizer*.
Crea un extractor de características para manejar la entrada de audio:
```py
>>> from transformers import Wav2Vec2FeatureExtractor
>>> feature_extractor = Wav2Vec2FeatureExtractor(padding_value=1.0, do_normalize=True)
```
Crea un *tokenizer* para manejar la entrada de texto:
```py
>>> from transformers import Wav2Vec2CTCTokenizer
>>> tokenizer = Wav2Vec2CTCTokenizer(vocab_file="my_vocab_file.txt")
```
Puedes combinar el extractor de características y el *tokenizer* en el [`Wav2Vec2Processor`]:
```py
>>> from transformers import Wav2Vec2Processor
>>> processor = Wav2Vec2Processor(feature_extractor=feature_extractor, tokenizer=tokenizer)
```
Con dos clases base (la configuración y el modelo) y una clase de preprocesamiento adicional (*tokenizer*, extractor de características o procesador), puedes crear cualquiera de los modelos compatibles con 🤗 Transformers. Cada una de estas clases son configurables, permitiéndote usar sus atributos específicos. Puedes crear un modelo para entrenarlo de una forma fácil, o modificar un modelo preentrenado disponible para especializarlo.
| transformers/docs/source/es/create_a_model.md/0 | {
"file_path": "transformers/docs/source/es/create_a_model.md",
"repo_id": "transformers",
"token_count": 6229
} | 21 |
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Tour rápido
[[open-in-colab]]
¡Entra en marcha con los 🤗 Transformers! Comienza usando [`pipeline`] para una inferencia veloz, carga un modelo preentrenado y un tokenizador con una [AutoClass](./model_doc/auto) para resolver tu tarea de texto, visión o audio.
<Tip>
Todos los ejemplos de código presentados en la documentación tienen un botón arriba a la derecha para elegir si quieres ocultar o mostrar el código en Pytorch o TensorFlow.
Si no fuese así, se espera que el código funcione para ambos backends sin ningún cambio.
</Tip>
## Pipeline
[`pipeline`] es la forma más fácil de usar un modelo preentrenado para una tarea dada.
<Youtube id="tiZFewofSLM"/>
El [`pipeline`] soporta muchas tareas comunes listas para usar:
**Texto**:
* Análisis de Sentimiento (Sentiment Analysis, en inglés): clasifica la polaridad de un texto dado.
* Generación de Texto (Text Generation, en inglés): genera texto a partir de un input dado.
* Reconocimiento de Entidades (Name Entity Recognition o NER, en inglés): etiqueta cada palabra con la entidad que representa (persona, fecha, ubicación, etc.).
* Responder Preguntas (Question answering, en inglés): extrae la respuesta del contexto dado un contexto y una pregunta.
* Rellenar Máscara (Fill-mask, en inglés): rellena el espacio faltante dado un texto con palabras enmascaradas.
* Resumir (Summarization, en inglés): genera un resumen de una secuencia larga de texto o un documento.
* Traducción (Translation, en inglés): traduce un texto a otro idioma.
* Extracción de Características (Feature Extraction, en inglés): crea una representación tensorial del texto.
**Imagen**:
* Clasificación de Imágenes (Image Classification, en inglés): clasifica una imagen.
* Segmentación de Imágenes (Image Segmentation, en inglés): clasifica cada pixel de una imagen.
* Detección de Objetos (Object Detection, en inglés): detecta objetos dentro de una imagen.
**Audio**:
* Clasificación de Audios (Audio Classification, en inglés): asigna una etiqueta a un segmento de audio.
* Reconocimiento de Voz Automático (Automatic Speech Recognition o ASR, en inglés): transcribe datos de audio a un texto.
<Tip>
Para más detalles acerca del [`pipeline`] y tareas asociadas, consulta la documentación [aquí](./main_classes/pipelines).
</Tip>
### Uso del Pipeline
En el siguiente ejemplo, usarás el [`pipeline`] para análisis de sentimiento.
Instala las siguientes dependencias si aún no lo has hecho:
<frameworkcontent>
<pt>
```bash
pip install torch
```
</pt>
<tf>
```bash
pip install tensorflow
```
</tf>
</frameworkcontent>
Importa [`pipeline`] y especifica la tarea que deseas completar:
```py
>>> from transformers import pipeline
>>> clasificador = pipeline("sentiment-analysis", model="pysentimiento/robertuito-sentiment-analysis")
```
El pipeline descarga y almacena en caché el [modelo preentrenado](https://huggingface.co/pysentimiento/robertuito-sentiment-analysis) y tokeniza para análisis de sentimiento. Si no hubieramos elegido un modelo el pipeline habría elegido uno por defecto. Ahora puedes usar `clasificador` en tu texto objetivo:
```py
>>> clasificador("Estamos muy felices de mostrarte la biblioteca de 🤗 Transformers.")
[{'label': 'POS', 'score': 0.9320}]
```
Para más de un enunciado, entrega una lista al [`pipeline`] que devolverá una lista de diccionarios:
El [`pipeline`] también puede iterar sobre un dataset entero. Comienza instalando la biblioteca [🤗 Datasets](https://huggingface.co/docs/datasets/):
```bash
pip install datasets
```
Crea un [`pipeline`] con la tarea que deseas resolver y el modelo que quieres usar. Coloca el parámetro `device` a `0` para poner los tensores en un dispositivo CUDA:
```py
>>> import torch
>>> from transformers import pipeline
>>> reconocedor_de_voz = pipeline(
... "automatic-speech-recognition", model="jonatasgrosman/wav2vec2-large-xlsr-53-spanish", device=0
... )
```
A continuación, carga el dataset (ve 🤗 Datasets [Quick Start](https://huggingface.co/docs/datasets/quickstart.html) para más detalles) sobre el que quisieras iterar. Por ejemplo, vamos a cargar el dataset [MInDS-14](https://huggingface.co/datasets/PolyAI/minds14):
```py
>>> from datasets import load_dataset, Audio
>>> dataset = load_dataset("PolyAI/minds14", name="es-ES", split="train") # doctest: +IGNORE_RESULT
```
Debemos asegurarnos de que la frecuencia de muestreo del conjunto de datos coincide con la frecuencia de muestreo con la que se entrenó `jonatasgrosman/wav2vec2-large-xlsr-53-spanish`.
```py
>>> dataset = dataset.cast_column("audio", Audio(sampling_rate=reconocedor_de_voz.feature_extractor.sampling_rate))
```
Los archivos de audio se cargan y remuestrean automáticamente cuando llamamos a la columna `"audio"`.
Extraigamos las matrices de onda cruda (raw waveform, en inglés) de las primeras 4 muestras y pasémosla como una lista al pipeline:
```py
>>> resultado = reconocedor_de_voz(dataset[:4]["audio"])
>>> print([d["text"] for d in resultado])
['ahora buenas eh a ver tengo un problema con vuestra aplicación resulta que que quiero hacer una transferencia bancaria a una cuenta conocida pero me da error la aplicación a ver que a ver que puede ser', 'la aplicación no cargue saldo de mi nueva cuenta', 'hola tengo un problema con la aplicación no carga y y tampoco veo que carga el saldo de mi cuenta nueva dice que la aplicación está siendo reparada y ahora no puedo acceder a mi cuenta no necesito inmediatamente', 'hora buena la aplicación no se carga la vida no carga el saldo de mi cuenta nueva dice que la villadenta siendo reparada y oro no puedo hacer a mi cuenta']
```
Para un dataset más grande, donde los inputs son de mayor tamaño (como en habla/audio o visión), querrás pasar un generador en lugar de una lista que carga todos los inputs en memoria. Ve la [documentación del pipeline](./main_classes/pipelines) para más información.
### Usa otro modelo y otro tokenizador en el pipeline
El [`pipeline`] puede acomodarse a cualquier modelo del [Model Hub](https://huggingface.co/models) haciendo más fácil adaptar el [`pipeline`] para otros casos de uso. Por ejemplo, si quisieras un modelo capaz de manejar texto en francés, usa los tags en el Model Hub para filtrar entre los modelos apropiados. El resultado mejor filtrado devuelve un [modelo BERT](https://huggingface.co/nlptown/bert-base-multilingual-uncased-sentiment) multilingual fine-tuned para el análisis de sentimiento. Genial, ¡vamos a usar este modelo!
```py
>>> model_name = "nlptown/bert-base-multilingual-uncased-sentiment"
```
<frameworkcontent>
<pt>
Usa [`AutoModelForSequenceClassification`] y ['AutoTokenizer'] para cargar un modelo preentrenado y un tokenizador asociado (más en un `AutoClass` debajo):
```py
>>> from transformers import AutoTokenizer, AutoModelForSequenceClassification
>>> model = AutoModelForSequenceClassification.from_pretrained(model_name)
>>> tokenizer = AutoTokenizer.from_pretrained(model_name)
```
</pt>
<tf>
Usa [`TFAutoModelForSequenceClassification`] y ['AutoTokenizer'] para cargar un modelo preentrenado y un tokenizador asociado (más en un `TFAutoClass` debajo):
```py
>>> from transformers import AutoTokenizer, TFAutoModelForSequenceClassification
>>> model = TFAutoModelForSequenceClassification.from_pretrained(model_name)
>>> tokenizer = AutoTokenizer.from_pretrained(model_name)
```
</tf>
</frameworkcontent>
Después puedes especificar el modelo y el tokenizador en el [`pipeline`], y aplicar el `classifier` en tu texto objetivo:
```py
>>> classifier = pipeline("sentiment-analysis", model=model, tokenizer=tokenizer)
>>> classifier("Nous sommes très heureux de vous présenter la bibliothèque 🤗 Transformers.")
[{'label': '5 stars', 'score': 0.7273}]
```
Si no pudieras encontrar el modelo para tu caso respectivo de uso necesitarás ajustar un modelo preentrenado a tus datos. Mira nuestro [tutorial de fine-tuning](./training) para aprender cómo. Finalmente, después de que has ajustado tu modelo preentrenado, ¡por favor considera compartirlo (ve el tutorial [aquí](./model_sharing)) con la comunidad en el Model Hub para democratizar el NLP! 🤗
## AutoClass
<Youtube id="AhChOFRegn4"/>
Por debajo, las clases [`AutoModelForSequenceClassification`] y [`AutoTokenizer`] trabajan juntas para dar poder al [`pipeline`]. Una [AutoClass](./model_doc/auto) es un atajo que automáticamente recupera la arquitectura de un modelo preentrenado con su nombre o el path. Sólo necesitarás seleccionar el `AutoClass` apropiado para tu tarea y tu tokenizador asociado con [`AutoTokenizer`].
Regresemos a nuestro ejemplo y veamos cómo puedes usar el `AutoClass` para reproducir los resultados del [`pipeline`].
### AutoTokenizer
Un tokenizador es responsable de procesar el texto a un formato que sea entendible para el modelo. Primero, el tokenizador separará el texto en palabras llamadas *tokens*. Hay múltiples reglas que gobiernan el proceso de tokenización incluyendo el cómo separar una palabra y en qué nivel (aprende más sobre tokenización [aquí](./tokenizer_summary)). Lo más importante es recordar que necesitarás instanciar el tokenizador con el mismo nombre del modelo para asegurar que estás usando las mismas reglas de tokenización con las que el modelo fue preentrenado.
Carga un tokenizador con [`AutoTokenizer`]:
```py
>>> from transformers import AutoTokenizer
>>> nombre_del_modelo = "nlptown/bert-base-multilingual-uncased-sentiment"
>>> tokenizer = AutoTokenizer.from_pretrained(nombre_del_modelo)
```
Después, el tokenizador convierte los tokens a números para construir un tensor que servirá como input para el modelo. Esto es conocido como el *vocabulario* del modelo.
Pasa tu texto al tokenizador:
```py
>>> encoding = tokenizer("Estamos muy felices de mostrarte la biblioteca de 🤗 Transformers.")
>>> print(encoding)
{'input_ids': [101, 10602, 14000, 13653, 43353, 10107, 10102, 47201, 10218, 10106, 18283, 10102, 100, 58263, 119, 102],
'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
```
El tokenizador devolverá un diccionario conteniendo:
* [input_ids](./glossary#input-ids): representaciones numéricas de los tokens.
* [atttention_mask](.glossary#attention-mask): indica cuáles tokens deben ser atendidos.
Como con el [`pipeline`], el tokenizador aceptará una lista de inputs. Además, el tokenizador también puede rellenar (pad, en inglés) y truncar el texto para devolver un lote (batch, en inglés) de longitud uniforme:
<frameworkcontent>
<pt>
```py
>>> pt_batch = tokenizer(
... ["We are very happy to show you the 🤗 Transformers library.", "We hope you don't hate it."],
... padding=True,
... truncation=True,
... max_length=512,
... return_tensors="pt",
... )
```
</pt>
<tf>
```py
>>> tf_batch = tokenizer(
... ["We are very happy to show you the 🤗 Transformers library.", "We hope you don't hate it."],
... padding=True,
... truncation=True,
... max_length=512,
... return_tensors="tf",
... )
```
</tf>
</frameworkcontent>
Lee el tutorial de [preprocessing](./preprocessing) para más detalles acerca de la tokenización.
### AutoModel
<frameworkcontent>
<pt>
🤗 Transformers provee una forma simple y unificada de cargar tus instancias preentrenadas. Esto significa que puedes cargar un [`AutoModel`] como cargarías un [`AutoTokenizer`]. La única diferencia es seleccionar el [`AutoModel`] correcto para la tarea. Ya que estás clasificando texto, o secuencias, carga [`AutoModelForSequenceClassification`]:
```py
>>> from transformers import AutoModelForSequenceClassification
>>> model_name = "nlptown/bert-base-multilingual-uncased-sentiment"
>>> pt_model = AutoModelForSequenceClassification.from_pretrained(model_name)
```
<Tip>
Ve el [task summary](./task_summary) para revisar qué clase del [`AutoModel`] deberías usar para cada tarea.
</Tip>
Ahora puedes pasar tu lote (batch) preprocesado de inputs directamente al modelo. Solo tienes que desempacar el diccionario añadiendo `**`:
```py
>>> pt_outputs = pt_model(**pt_batch)
```
El modelo producirá las activaciones finales en el atributo `logits`. Aplica la función softmax a `logits` para obtener las probabilidades:
```py
>>> from torch import nn
>>> pt_predictions = nn.functional.softmax(pt_outputs.logits, dim=-1)
>>> print(pt_predictions)
tensor([[0.0021, 0.0018, 0.0115, 0.2121, 0.7725],
[0.2084, 0.1826, 0.1969, 0.1755, 0.2365]], grad_fn=<SoftmaxBackward0>)
```
</pt>
<tf>
🤗 Transformers provee una forma simple y unificada de cargar tus instancias preentrenadas. Esto significa que puedes cargar un [`TFAutoModel`] como cargarías un [`AutoTokenizer`]. La única diferencia es seleccionar el [`TFAutoModel`] correcto para la tarea. Ya que estás clasificando texto, o secuencias, carga [`TFAutoModelForSequenceClassification`]:
```py
>>> from transformers import TFAutoModelForSequenceClassification
>>> model_name = "nlptown/bert-base-multilingual-uncased-sentiment"
>>> tf_model = TFAutoModelForSequenceClassification.from_pretrained(model_name)
```
<Tip>
Ve el [task summary](./task_summary) para revisar qué clase del [`AutoModel`]
deberías usar para cada tarea.
</Tip>
Ahora puedes pasar tu lote preprocesado de inputs directamente al modelo pasando las llaves del diccionario directamente a los tensores:
```py
>>> tf_outputs = tf_model(tf_batch)
```
El modelo producirá las activaciones finales en el atributo `logits`. Aplica la función softmax a `logits` para obtener las probabilidades:
```py
>>> import tensorflow as tf
>>> tf_predictions = tf.nn.softmax(tf_outputs.logits, axis=-1)
>>> print(tf.math.round(tf_predictions * 10**4) / 10**4)
tf.Tensor(
[[0.0021 0.0018 0.0116 0.2121 0.7725]
[0.2084 0.1826 0.1969 0.1755 0.2365]], shape=(2, 5), dtype=float32)
```
</tf>
</frameworkcontent>
<Tip>
Todos los modelos de 🤗 Transformers (PyTorch o TensorFlow) producirán los tensores *antes* de la función de activación
final (como softmax) porque la función de activación final es comúnmente fusionada con la pérdida.
</Tip>
Los modelos son [`torch.nn.Module`](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) o [`tf.keras.Model`](https://www.tensorflow.org/api_docs/python/tf/keras/Model) estándares así que podrás usarlos en tu training loop usual. Sin embargo, para facilitar las cosas, 🤗 Transformers provee una clase [`Trainer`] para PyTorch que añade funcionalidades para entrenamiento distribuido, precición mixta, y más. Para TensorFlow, puedes usar el método `fit` desde [Keras](https://keras.io/). Consulta el [tutorial de entrenamiento](./training) para más detalles.
<Tip>
Los outputs del modelo de 🤗 Transformers son dataclasses especiales por lo que sus atributos pueden ser completados en un IDE.
Los outputs del modelo también se comportan como tuplas o diccionarios (e.g., puedes indexar con un entero, un slice o una cadena) en cuyo caso los atributos que son `None` son ignorados.
</Tip>
### Guarda un modelo
<frameworkcontent>
<pt>
Una vez que se haya hecho fine-tuning a tu modelo puedes guardarlo con tu tokenizador usando [`PreTrainedModel.save_pretrained`]:
```py
>>> pt_save_directory = "./pt_save_pretrained"
>>> tokenizer.save_pretrained(pt_save_directory) # doctest: +IGNORE_RESULT
>>> pt_model.save_pretrained(pt_save_directory)
```
Cuando quieras usar el modelo otra vez cárgalo con [`PreTrainedModel.from_pretrained`]:
```py
>>> pt_model = AutoModelForSequenceClassification.from_pretrained("./pt_save_pretrained")
```
</pt>
<tf>
Una vez que se haya hecho fine-tuning a tu modelo puedes guardarlo con tu tokenizador usando [`TFPreTrainedModel.save_pretrained`]:
```py
>>> tf_save_directory = "./tf_save_pretrained"
>>> tokenizer.save_pretrained(tf_save_directory) # doctest: +IGNORE_RESULT
>>> tf_model.save_pretrained(tf_save_directory)
```
Cuando quieras usar el modelo otra vez cárgalo con [`TFPreTrainedModel.from_pretrained`]:
```py
>>> tf_model = TFAutoModelForSequenceClassification.from_pretrained("./tf_save_pretrained")
```
</tf>
</frameworkcontent>
Una característica particularmente interesante de 🤗 Transformers es la habilidad de guardar el modelo y cargarlo como un modelo de PyTorch o TensorFlow. El parámetro `from_pt` o `from_tf` puede convertir el modelo de un framework al otro:
<frameworkcontent>
<pt>
```py
>>> from transformers import AutoModel
>>> tokenizer = AutoTokenizer.from_pretrained(tf_save_directory)
>>> pt_model = AutoModelForSequenceClassification.from_pretrained(tf_save_directory, from_tf=True)
```
</pt>
<tf>
```py
>>> from transformers import TFAutoModel
>>> tokenizer = AutoTokenizer.from_pretrained(pt_save_directory)
>>> tf_model = TFAutoModelForSequenceClassification.from_pretrained(pt_save_directory, from_pt=True)
```
</tf>
</frameworkcontent>
| transformers/docs/source/es/quicktour.md/0 | {
"file_path": "transformers/docs/source/es/quicktour.md",
"repo_id": "transformers",
"token_count": 6360
} | 22 |
<!--⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Traduction en cours. | transformers/docs/source/fr/in_translation.md/0 | {
"file_path": "transformers/docs/source/fr/in_translation.md",
"repo_id": "transformers",
"token_count": 54
} | 23 |
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Condividere modelli personalizzati
La libreria 🤗 Transformers è studiata per essere facilmente estendibile. Il codice di ogni modello è interamente
situato in una sottocartella del repository senza alcuna astrazione, perciò puoi facilmente copiare il file di un
modello e modificarlo in base ai tuoi bisogni.
Se stai scrivendo un nuovo modello, potrebbe essere più semplice iniziare da zero. In questo tutorial, ti mostreremo
come scrivere un modello personalizzato e la sua configurazione in modo che possa essere utilizzato all’interno di
Transformers, e come condividerlo con la community (assieme al relativo codice) così che tutte le persone possano usarlo, anche
se non presente nella libreria 🤗 Transformers.
Illustriamo tutto questo su un modello ResNet, avvolgendo la classe ResNet della
[libreria timm](https://github.com/rwightman/pytorch-image-models) in un [`PreTrainedModel`].
## Scrivere una configurazione personalizzata
Prima di iniziare a lavorare al modello, scriviamone la configurazione. La configurazione di un modello è un oggetto
che contiene tutte le informazioni necessarie per la build del modello. Come vedremo nella prossima sezione, il
modello può soltanto essere inizializzato tramite `config`, per cui dovremo rendere tale oggetto più completo possibile.
Nel nostro esempio, prenderemo un paio di argomenti della classe ResNet che potremmo voler modificare.
Configurazioni differenti ci daranno quindi i differenti possibili tipi di ResNet. Salveremo poi questi argomenti,
dopo averne controllato la validità.
```python
from transformers import PretrainedConfig
from typing import List
class ResnetConfig(PretrainedConfig):
model_type = "resnet"
def __init__(
self,
block_type="bottleneck",
layers: List[int] = [3, 4, 6, 3],
num_classes: int = 1000,
input_channels: int = 3,
cardinality: int = 1,
base_width: int = 64,
stem_width: int = 64,
stem_type: str = "",
avg_down: bool = False,
**kwargs,
):
if block_type not in ["basic", "bottleneck"]:
raise ValueError(f"`block_type` must be 'basic' or bottleneck', got {block_type}.")
if stem_type not in ["", "deep", "deep-tiered"]:
raise ValueError(f"`stem_type` must be '', 'deep' or 'deep-tiered', got {stem_type}.")
self.block_type = block_type
self.layers = layers
self.num_classes = num_classes
self.input_channels = input_channels
self.cardinality = cardinality
self.base_width = base_width
self.stem_width = stem_width
self.stem_type = stem_type
self.avg_down = avg_down
super().__init__(**kwargs)
```
Le tre cose più importanti da ricordare quando scrivi le tue configurazioni sono le seguenti:
- Devi ereditare da `Pretrainedconfig`,
- Il metodo `__init__` del tuo `Pretrainedconfig` deve accettare i kwargs,
- I `kwargs` devono essere passati alla superclass `__init__`
L’eredità è importante per assicurarsi di ottenere tutte le funzionalità della libreria 🤗 transformers,
mentre gli altri due vincoli derivano dal fatto che un `Pretrainedconfig` ha più campi di quelli che stai settando.
Quando ricarichi una config da un metodo `from_pretrained`, questi campi devono essere accettati dalla tua config e
poi inviati alla superclasse.
Definire un `model_type` per la tua configurazione (qua `model_type = “resnet”`) non è obbligatorio, a meno che tu
non voglia registrare il modello con le classi Auto (vedi l'ultima sezione).
Una volta completato, puoi facilmente creare e salvare la tua configurazione come faresti con ogni altra configurazione
di modelli della libreria. Ecco come possiamo creare la config di un resnet50d e salvarlo:
```py
resnet50d_config = ResnetConfig(block_type="bottleneck", stem_width=32, stem_type="deep", avg_down=True)
resnet50d_config.save_pretrained("custom-resnet")
```
Questo salverà un file chiamato `config.json` all'interno della cartella `custom-resnet`. Potrai poi ricaricare la tua
config con il metodo `from_pretrained`.
```py
resnet50d_config = ResnetConfig.from_pretrained("custom-resnet")
```
Puoi anche usare qualunque altro metodo della classe [`PretrainedConfig`], come [`~PretrainedConfig.push_to_hub`]
per caricare direttamente la tua configurazione nell'hub.
## Scrivere un modello personalizzato
Ora che abbiamo la nostra configurazione ResNet, possiamo continuare a scrivere il modello. In realtà, ne scriveremo
due: uno che estrae le features nascoste da una batch di immagini (come [`BertModel`]) e uno che è utilizzabile per
la classificazione di immagini (come [`BertModelForSequenceClassification`]).
Come abbiamo menzionato in precedenza, scriveremo soltanto un wrapper del modello, per mantenerlo semplice ai fini di
questo esempio. L'unica cosa che dobbiamo fare prima di scrivere questa classe è una mappatura fra i tipi di blocco e
le vere classi dei blocchi. Successivamente il modello è definito tramite la configurazione, passando tutto quanto alla
classe `ResNet`.
```py
from transformers import PreTrainedModel
from timm.models.resnet import BasicBlock, Bottleneck, ResNet
from .configuration_resnet import ResnetConfig
BLOCK_MAPPING = {"basic": BasicBlock, "bottleneck": Bottleneck}
class ResnetModel(PreTrainedModel):
config_class = ResnetConfig
def __init__(self, config):
super().__init__(config)
block_layer = BLOCK_MAPPING[config.block_type]
self.model = ResNet(
block_layer,
config.layers,
num_classes=config.num_classes,
in_chans=config.input_channels,
cardinality=config.cardinality,
base_width=config.base_width,
stem_width=config.stem_width,
stem_type=config.stem_type,
avg_down=config.avg_down,
)
def forward(self, tensor):
return self.model.forward_features(tensor)
```
Per il modello che classificherà le immagini, cambiamo soltanto il metodo forward:
```py
import torch
class ResnetModelForImageClassification(PreTrainedModel):
config_class = ResnetConfig
def __init__(self, config):
super().__init__(config)
block_layer = BLOCK_MAPPING[config.block_type]
self.model = ResNet(
block_layer,
config.layers,
num_classes=config.num_classes,
in_chans=config.input_channels,
cardinality=config.cardinality,
base_width=config.base_width,
stem_width=config.stem_width,
stem_type=config.stem_type,
avg_down=config.avg_down,
)
def forward(self, tensor, labels=None):
logits = self.model(tensor)
if labels is not None:
loss = torch.nn.cross_entropy(logits, labels)
return {"loss": loss, "logits": logits}
return {"logits": logits}
```
Nota come, in entrambi i casi, ereditiamo da `PreTrainedModel` e chiamiamo l'inizializzazione della superclasse
con il metodo `config` (un po' come quando scrivi un normale `torch.nn.Module`). La riga che imposta la `config_class`
non è obbligatoria, a meno che tu non voglia registrare il modello con le classi Auto (vedi l'ultima sezione).
<Tip>
Se il tuo modello è molto simile a un modello all'interno della libreria, puoi ri-usare la stessa configurazione di quel modello.
</Tip>
Puoi fare in modo che il tuo modello restituisca in output qualunque cosa tu voglia, ma far restituire un dizionario
come abbiamo fatto per `ResnetModelForImageClassification`, con la funzione di perdita inclusa quando vengono passate le labels,
renderà il tuo modello direttamente utilizzabile all'interno della classe [`Trainer`]. Utilizzare altri formati di output va bene
se hai in progetto di utilizzare un tuo loop di allenamento, o se utilizzerai un'altra libreria per l'addestramento.
Ora che abbiamo la classe del nostro modello, creiamone uno:
```py
resnet50d = ResnetModelForImageClassification(resnet50d_config)
```
Ribadiamo, puoi usare qualunque metodo dei [`PreTrainedModel`], come [`~PreTrainedModel.save_pretrained`] o
[`~PreTrainedModel.push_to_hub`]. Utilizzeremo quest'ultimo nella prossima sezione, e vedremo come caricare i pesi del
modello assieme al codice del modello stesso. Ma prima, carichiamo alcuni pesi pre-allenati all'interno del nostro modello.
Nel tuo caso specifico, probabilmente allenerai il tuo modello sui tuoi dati. Per velocizzare in questo tutorial,
utilizzeremo la versione pre-allenata del resnet50d. Dato che il nostro modello è soltanto un wrapper attorno a quel modello,
sarà facile trasferirne i pesi:
```py
import timm
pretrained_model = timm.create_model("resnet50d", pretrained=True)
resnet50d.model.load_state_dict(pretrained_model.state_dict())
```
Vediamo adesso come assicurarci che quando facciamo [`~PreTrainedModel.save_pretrained`] o [`~PreTrainedModel.push_to_hub`],
il codice del modello venga salvato.
## Inviare il codice all'Hub
<Tip warning={true}>
Questa API è sperimentale e potrebbe avere alcuni cambiamenti nei prossimi rilasci.
</Tip>
Innanzitutto, assicurati che il tuo modello sia completamente definito in un file `.py`. Può sfruttare import relativi
ad altri file, purchè questi siano nella stessa directory (non supportiamo ancora sotto-moduli per questa funzionalità).
Per questo esempio, definiremo un file `modeling_resnet.py` e un file `configuration_resnet.py` in una cartella dell'attuale
working directory chiamata `resnet_model`. Il file configuration contiene il codice per `ResnetConfig` e il file modeling
contiene il codice di `ResnetModel` e `ResnetModelForImageClassification`.
```
.
└── resnet_model
├── __init__.py
├── configuration_resnet.py
└── modeling_resnet.py
```
Il file `__init__.py` può essere vuoto, serve solo perchè Python capisca che `resnet_model` può essere utilizzato come un modulo.
<Tip warning={true}>
Se stai copiando i file relativi alla modellazione della libreria, dovrai sostituire tutti gli import relativi in cima al file con import del
pacchetto `transformers`.
</Tip>
Nota che puoi ri-utilizzare (o usare come sottoclassi) un modello/configurazione esistente.
Per condividere il tuo modello con la community, segui questi passi: prima importa il modello ResNet e la sua configurazione
dai nuovi file creati:
```py
from resnet_model.configuration_resnet import ResnetConfig
from resnet_model.modeling_resnet import ResnetModel, ResnetModelForImageClassification
```
Dopodichè dovrai dire alla libreria che vuoi copiare i file con il codice di quegli oggetti quando utilizzi il metodo
`save_pretrained` e registrarli in modo corretto con una Auto classe (specialmente per i modelli). Utilizza semplicemente:
```py
ResnetConfig.register_for_auto_class()
ResnetModel.register_for_auto_class("AutoModel")
ResnetModelForImageClassification.register_for_auto_class("AutoModelForImageClassification")
```
Nota che non c'è bisogno di specificare una Auto classe per la configurazione (c'è solo una Auto classe per le configurazioni,
[`AutoConfig`], ma è diversa per i modelli). Il tuo modello personalizato potrebbe essere utilizzato per diverse tasks,
per cui devi specificare quale delle classi Auto è quella corretta per il tuo modello.
Successivamente, creiamo i modelli e la config come abbiamo fatto in precedenza:
```py
resnet50d_config = ResnetConfig(block_type="bottleneck", stem_width=32, stem_type="deep", avg_down=True)
resnet50d = ResnetModelForImageClassification(resnet50d_config)
pretrained_model = timm.create_model("resnet50d", pretrained=True)
resnet50d.model.load_state_dict(pretrained_model.state_dict())
```
Adesso, per inviare il modello all'Hub, assicurati di aver effettuato l'accesso. Lancia dal tuo terminale:
```bash
huggingface-cli login
```
O da un notebook:
```py
from huggingface_hub import notebook_login
notebook_login()
```
Potrai poi inviare il tutto sul tuo profilo (o di un'organizzazione di cui fai parte) in questo modo:
```py
resnet50d.push_to_hub("custom-resnet50d")
```
Oltre ai pesi del modello e alla configurazione in formato json, questo ha anche copiato i file `.py` modeling e
configuration all'interno della cartella `custom-resnet50d` e ha caricato i risultati sull'Hub. Puoi controllare
i risultati in questa [model repo](https://huggingface.co/sgugger/custom-resnet50d).
Puoi controllare il tutorial di condivisione [tutorial di condivisione](model_sharing) per più informazioni sul
metodo con cui inviare all'Hub.
## Usare un modello con codice personalizzato
Puoi usare ogni configurazione, modello o tokenizer con file di codice personalizzati nella sua repository
con le classi Auto e il metodo `from_pretrained`. Tutti i files e il codice caricati sull'Hub sono scansionati da malware
(fai riferimento alla documentazione [Hub security](https://huggingface.co/docs/hub/security#malware-scanning) per più informazioni),
ma dovresti comunque assicurarti dell'affidabilità del codice e dell'autore per evitare di eseguire codice dannoso sulla tua macchina.
Imposta `trust_remote_code=True` per usare un modello con codice personalizzato:
```py
from transformers import AutoModelForImageClassification
model = AutoModelForImageClassification.from_pretrained("sgugger/custom-resnet50d", trust_remote_code=True)
```
Inoltre, raccomandiamo fortemente di passare un hash del commit come `revision` per assicurarti che le autrici o gli autori del modello
non abbiano modificato il codice con alcune nuove righe dannose (a meno che non ti fidi completamente della fonte):
```py
commit_hash = "ed94a7c6247d8aedce4647f00f20de6875b5b292"
model = AutoModelForImageClassification.from_pretrained(
"sgugger/custom-resnet50d", trust_remote_code=True, revision=commit_hash
)
```
Nota che quando cerchi la storia dei commit della repo del modello sull'Hub, c'è un bottone con cui facilmente copiare il
commit hash di ciascun commit.
## Registrare un modello con codice personalizzato nelle classi Auto
Se stai scrivendo una libreria che estende 🤗 Transformers, potresti voler estendere le classi Auto per includere il tuo modello.
Questo è diverso dall'inviare codice nell'Hub: gli utenti dovranno importare la tua libreria per ottenere il modello personalizzato
(anzichè scaricare automaticamente il modello dall'Hub).
Finchè il tuo file di configurazione ha un attributo `model_type` diverso dai model types esistenti, e finchè le tue
classi modello hanno i corretti attributi `config_class`, potrai semplicemente aggiungerli alle classi Auto come segue:
```py
from transformers import AutoConfig, AutoModel, AutoModelForImageClassification
AutoConfig.register("resnet", ResnetConfig)
AutoModel.register(ResnetConfig, ResnetModel)
AutoModelForImageClassification.register(ResnetConfig, ResnetModelForImageClassification)
```
Nota che il primo argomento utilizzato quando registri la configurazione di un modello personalizzato con [`AutoConfig`]
deve corrispondere al `model_type` della tua configurazione personalizzata, ed il primo argomento utilizzato quando
registri i tuoi modelli personalizzati in una qualunque classe Auto del modello deve corrispondere alla `config_class`
di quei modelli.
| transformers/docs/source/it/custom_models.md/0 | {
"file_path": "transformers/docs/source/it/custom_models.md",
"repo_id": "transformers",
"token_count": 5884
} | 24 |
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Pipeline per l'inferenza
La [`pipeline`] rende semplice usare qualsiasi modello dal [Model Hub](https://huggingface.co/models) per fare inferenza su diversi compiti come generazione del testo, segmentazione di immagini e classificazione di audio. Anche se non hai esperienza con una modalità specifica o non comprendi bene il codice che alimenta i modelli, è comunque possibile utilizzarli con l'opzione [`pipeline`]! Questa esercitazione ti insegnerà a:
* Usare una [`pipeline`] per fare inferenza.
* Usare uno specifico tokenizer o modello.
* Usare una [`pipeline`] per compiti che riguardano audio e video.
<Tip>
Dai un'occhiata alla documentazione di [`pipeline`] per una lista completa dei compiti supportati.
</Tip>
## Utilizzo della Pipeline
Nonostante ogni compito abbia una [`pipeline`] associata, è più semplice utilizzare l'astrazione generica della [`pipeline`] che contiene tutte quelle specifiche per ogni mansione. La [`pipeline`] carica automaticamente un modello predefinito e un tokenizer in grado di fare inferenza per il tuo compito.
1. Inizia creando una [`pipeline`] e specificando il compito su cui fare inferenza:
```py
>>> from transformers import pipeline
>>> generator = pipeline(task="text-generation")
```
2. Inserisci il testo in input nella [`pipeline`]:
```py
>>> generator(
... "Three Rings for the Elven-kings under the sky, Seven for the Dwarf-lords in their halls of stone"
... ) # doctest: +SKIP
[{'generated_text': 'Three Rings for the Elven-kings under the sky, Seven for the Dwarf-lords in their halls of stone, Seven for the Iron-priests at the door to the east, and thirteen for the Lord Kings at the end of the mountain'}]
```
Se hai più di un input, inseriscilo in una lista:
```py
>>> generator(
... [
... "Three Rings for the Elven-kings under the sky, Seven for the Dwarf-lords in their halls of stone",
... "Nine for Mortal Men, doomed to die, One for the Dark Lord on his dark throne",
... ]
... ) # doctest: +SKIP
```
Qualsiasi parametro addizionale per il tuo compito può essere incluso nella [`pipeline`]. La mansione `text-generation` ha un metodo [`~generation.GenerationMixin.generate`] con diversi parametri per controllare l'output. Ad esempio, se desideri generare più di un output, utilizza il parametro `num_return_sequences`:
```py
>>> generator(
... "Three Rings for the Elven-kings under the sky, Seven for the Dwarf-lords in their halls of stone",
... num_return_sequences=2,
... ) # doctest: +SKIP
```
### Scegliere modello e tokenizer
La [`pipeline`] accetta qualsiasi modello dal [Model Hub](https://huggingface.co/models). Ci sono tag nel Model Hub che consentono di filtrare i modelli per attività. Una volta che avrai scelto il modello appropriato, caricalo usando la corrispondente classe `AutoModelFor` e [`AutoTokenizer`]. Ad esempio, carica la classe [`AutoModelForCausalLM`] per un compito di causal language modeling:
```py
>>> from transformers import AutoTokenizer, AutoModelForCausalLM
>>> tokenizer = AutoTokenizer.from_pretrained("distilbert/distilgpt2")
>>> model = AutoModelForCausalLM.from_pretrained("distilbert/distilgpt2")
```
Crea una [`pipeline`] per il tuo compito, specificando il modello e il tokenizer che hai caricato:
```py
>>> from transformers import pipeline
>>> generator = pipeline(task="text-generation", model=model, tokenizer=tokenizer)
```
Inserisci il testo di input nella [`pipeline`] per generare del testo:
```py
>>> generator(
... "Three Rings for the Elven-kings under the sky, Seven for the Dwarf-lords in their halls of stone"
... ) # doctest: +SKIP
[{'generated_text': 'Three Rings for the Elven-kings under the sky, Seven for the Dwarf-lords in their halls of stone, Seven for the Dragon-lords (for them to rule in a world ruled by their rulers, and all who live within the realm'}]
```
## Audio pipeline
La flessibilità della [`pipeline`] fa si che possa essere estesa ad attività sugli audio.
Per esempio, classifichiamo le emozioni in questo clip audio:
```py
>>> from datasets import load_dataset
>>> import torch
>>> torch.manual_seed(42) # doctest: +IGNORE_RESULT
>>> ds = load_dataset("hf-internal-testing/librispeech_asr_demo", "clean", split="validation")
>>> audio_file = ds[0]["audio"]["path"]
```
Trova un modello per la [classificazione audio](https://huggingface.co/models?pipeline_tag=audio-classification) sul Model Hub per eseguire un compito di riconoscimento automatico delle emozioni e caricalo nella [`pipeline`]:
```py
>>> from transformers import pipeline
>>> audio_classifier = pipeline(
... task="audio-classification", model="ehcalabres/wav2vec2-lg-xlsr-en-speech-emotion-recognition"
... )
```
Inserisci il file audio nella [`pipeline`]:
```py
>>> preds = audio_classifier(audio_file)
>>> preds = [{"score": round(pred["score"], 4), "label": pred["label"]} for pred in preds]
>>> preds
[{'score': 0.1315, 'label': 'calm'}, {'score': 0.1307, 'label': 'neutral'}, {'score': 0.1274, 'label': 'sad'}, {'score': 0.1261, 'label': 'fearful'}, {'score': 0.1242, 'label': 'happy'}]
```
## Vision pipeline
Infine, usare la [`pipeline`] per le attività sulle immagini è praticamente la stessa cosa.
Specifica la tua attività e inserisci l'immagine nel classificatore. L'immagine può essere sia un link che un percorso sul tuo pc in locale. Per esempio, quale specie di gatto è raffigurata qui sotto?

```py
>>> from transformers import pipeline
>>> vision_classifier = pipeline(task="image-classification")
>>> preds = vision_classifier(
... images="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/pipeline-cat-chonk.jpeg"
... )
>>> preds = [{"score": round(pred["score"], 4), "label": pred["label"]} for pred in preds]
>>> preds
[{'score': 0.4335, 'label': 'lynx, catamount'}, {'score': 0.0348, 'label': 'cougar, puma, catamount, mountain lion, painter, panther, Felis concolor'}, {'score': 0.0324, 'label': 'snow leopard, ounce, Panthera uncia'}, {'score': 0.0239, 'label': 'Egyptian cat'}, {'score': 0.0229, 'label': 'tiger cat'}]
```
| transformers/docs/source/it/pipeline_tutorial.md/0 | {
"file_path": "transformers/docs/source/it/pipeline_tutorial.md",
"repo_id": "transformers",
"token_count": 2398
} | 25 |
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Templates for Chat Models
## Introduction
LLM(Language Model)のますます一般的な使用事例の1つは「チャット」です。
チャットのコンテキストでは、通常の言語モデルのように単一のテキストストリングを継続するのではなく、モデルは1つ以上の「メッセージ」からなる会話を継続します。
各メッセージには「ロール」とメッセージテキストが含まれます。
最も一般的に、これらのロールはユーザーからのメッセージには「ユーザー」、モデルからのメッセージには「アシスタント」が割り当てられます。
一部のモデルは「システム」ロールもサポートしています。
システムメッセージは通常会話の開始時に送信され、モデルの動作方法に関する指示が含まれます。
すべての言語モデル、チャット用に微調整されたモデルを含むすべてのモデルは、トークンのリニアシーケンスで動作し、ロールに特有の特別な処理を持ちません。
つまり、ロール情報は通常、メッセージ間に制御トークンを追加して注入され、メッセージの境界と関連するロールを示すことで提供されます。
残念ながら、トークンの使用方法については(まだ!)標準が存在せず、異なるモデルはチャット用のフォーマットや制御トークンが大きく異なる形式でトレーニングされています。
これはユーザーにとって実際の問題になる可能性があります。正しいフォーマットを使用しないと、モデルは入力に混乱し、パフォーマンスが本来よりも遥かに低下します。
これが「チャットテンプレート」が解決しようとする問題です。
チャット会話は通常、各辞書が「ロール」と「コンテンツ」のキーを含み、単一のチャットメッセージを表すリストとして表現されます。
チャットテンプレートは、指定されたモデルの会話を単一のトークン化可能なシーケンスにどのようにフォーマットするかを指定するJinjaテンプレートを含む文字列です。
トークナイザとこの情報を保存することにより、モデルが期待する形式の入力データを取得できるようになります。
さっそく、`BlenderBot` モデルを使用した例を示して具体的にしましょう。`BlenderBot` のデフォルトテンプレートは非常にシンプルで、ほとんどが対話のラウンド間に空白を追加するだけです。
```python
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("facebook/blenderbot-400M-distill")
>>> chat = [
... {"role": "user", "content": "Hello, how are you?"},
... {"role": "assistant", "content": "I'm doing great. How can I help you today?"},
... {"role": "user", "content": "I'd like to show off how chat templating works!"},
... ]
>>> tokenizer.apply_chat_template(chat, tokenize=False)
" Hello, how are you? I'm doing great. How can I help you today? I'd like to show off how chat templating works!</s>"
```
指定された通り、チャット全体が単一の文字列にまとめられています。デフォルトの設定である「tokenize=True」を使用すると、
その文字列もトークン化されます。しかし、より複雑なテンプレートが実際にどのように機能するかを確認するために、
「meta-llama/Llama-2-7b-chat-hf」モデルを使用してみましょう。ただし、このモデルはゲート付きアクセスを持っており、
このコードを実行する場合は[リポジトリでアクセスをリクエスト](https://huggingface.co/meta-llama/Llama-2-7b-chat-hf)する必要があります。
```python
>> from transformers import AutoTokenizer
>> tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-2-7b-chat-hf")
>> chat = [
... {"role": "user", "content": "Hello, how are you?"},
... {"role": "assistant", "content": "I'm doing great. How can I help you today?"},
... {"role": "user", "content": "I'd like to show off how chat templating works!"},
... ]
>> tokenizer.use_default_system_prompt = False
>> tokenizer.apply_chat_template(chat, tokenize=False)
"<s>[INST] Hello, how are you? [/INST] I'm doing great. How can I help you today? </s><s>[INST] I'd like to show off how chat templating works! [/INST]"
```
今回、トークナイザは制御トークン [INST] と [/INST] を追加しました。これらはユーザーメッセージの開始と終了を示すためのものです(ただし、アシスタントメッセージには適用されません!)
## How do chat templates work?
モデルのチャットテンプレートは、`tokenizer.chat_template`属性に格納されています。チャットテンプレートが設定されていない場合、そのモデルクラスのデフォルトテンプレートが代わりに使用されます。`BlenderBot`のテンプレートを見てみましょう:
```python
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("facebook/blenderbot-400M-distill")
>>> tokenizer.default_chat_template
"{% for message in messages %}{% if message['role'] == 'user' %}{{ ' ' }}{% endif %}{{ message['content'] }}{% if not loop.last %}{{ ' ' }}{% endif %}{% endfor %}{{ eos_token }}"
```
これは少し抑圧的ですね。可読性を高めるために、新しい行とインデントを追加しましょう。
各ブロックの直前の空白と、ブロックの直後の最初の改行は、デフォルトでJinjaの `trim_blocks` および `lstrip_blocks` フラグを使用して削除します。
これにより、インデントと改行を含むテンプレートを書いても正常に機能することができます。
```
{% for message in messages %}
{% if message['role'] == 'user' %}
{{ ' ' }}
{% endif %}
{{ message['content'] }}
{% if not loop.last %}
{{ ' ' }}
{% endif %}
{% endfor %}
{{ eos_token }}
```
これが初めて見る方へ、これは[Jinjaテンプレート](https://jinja.palletsprojects.com/en/3.1.x/templates/)です。
Jinjaはテキストを生成するためのシンプルなコードを記述できるテンプレート言語です。多くの点で、コードと
構文はPythonに似ています。純粋なPythonでは、このテンプレートは次のようになるでしょう:
```python
for idx, message in enumerate(messages):
if message['role'] == 'user':
print(' ')
print(message['content'])
if not idx == len(messages) - 1: # Check for the last message in the conversation
print(' ')
print(eos_token)
```
実際に、このテンプレートは次の3つのことを行います:
1. 各メッセージに対して、メッセージがユーザーメッセージである場合、それの前に空白を追加し、それ以外の場合は何も表示しません。
2. メッセージの内容を追加します。
3. メッセージが最後のメッセージでない場合、その後に2つのスペースを追加します。最後のメッセージの後にはEOSトークンを表示します。
これは非常にシンプルなテンプレートです。制御トークンを追加しないし、モデルに対する指示を伝える一般的な方法である「システム」メッセージをサポートしていません。
ただし、Jinjaはこれらのことを行うための多くの柔軟性を提供しています!
LLaMAがフォーマットする方法に類似した入力をフォーマットするためのJinjaテンプレートを見てみましょう
(実際のLLaMAテンプレートはデフォルトのシステムメッセージの処理や、一般的なシステムメッセージの処理が若干異なるため、
実際のコードではこのテンプレートを使用しないでください!)
```
{% for message in messages %}
{% if message['role'] == 'user' %}
{{ bos_token + '[INST] ' + message['content'] + ' [/INST]' }}
{% elif message['role'] == 'system' %}
{{ '<<SYS>>\\n' + message['content'] + '\\n<</SYS>>\\n\\n' }}
{% elif message['role'] == 'assistant' %}
{{ ' ' + message['content'] + ' ' + eos_token }}
{% endif %}
{% endfor %}
```
願わくば、少し見つめていただければ、このテンプレートが何を行っているかがわかるかもしれません。
このテンプレートは、各メッセージの「役割」に基づいて特定のトークンを追加します。これらのトークンは、メッセージを送信した人を表すものです。
ユーザー、アシスタント、およびシステムメッセージは、それらが含まれるトークンによってモデルによって明確に区別されます。
## How do I create a chat template?
簡単です。単純にJinjaテンプレートを書いて、`tokenizer.chat_template`を設定します。
他のモデルから既存のテンプレートを始点にして、必要に応じて編集すると便利かもしれません!
例えば、上記のLLaMAテンプレートを取って、アシスタントメッセージに"[ASST]"と"[/ASST]"を追加できます。
```
{% for message in messages %}
{% if message['role'] == 'user' %}
{{ bos_token + '[INST] ' + message['content'].strip() + ' [/INST]' }}
{% elif message['role'] == 'system' %}
{{ '<<SYS>>\\n' + message['content'].strip() + '\\n<</SYS>>\\n\\n' }}
{% elif message['role'] == 'assistant' %}
{{ '[ASST] ' + message['content'] + ' [/ASST]' + eos_token }}
{% endif %}
{% endfor %}
```
次に、単に`tokenizer.chat_template`属性を設定してください。
次回、[`~PreTrainedTokenizer.apply_chat_template`]を使用する際に、新しいテンプレートが使用されます!
この属性は`tokenizer_config.json`ファイルに保存されるため、[`~utils.PushToHubMixin.push_to_hub`]を使用して
新しいテンプレートをHubにアップロードし、みんなが正しいテンプレートを使用していることを確認できます!
```python
template = tokenizer.chat_template
template = template.replace("SYS", "SYSTEM") # Change the system token
tokenizer.chat_template = template # Set the new template
tokenizer.push_to_hub("model_name") # Upload your new template to the Hub!
```
[`~PreTrainedTokenizer.apply_chat_template`] メソッドは、あなたのチャットテンプレートを使用するために [`ConversationalPipeline`] クラスによって呼び出されます。
したがって、正しいチャットテンプレートを設定すると、あなたのモデルは自動的に [`ConversationalPipeline`] と互換性があるようになります。
## What are "default" templates?
チャットテンプレートの導入前に、チャットの処理はモデルクラスレベルでハードコードされていました。
後方互換性のために、このクラス固有の処理をデフォルトテンプレートとして保持し、クラスレベルで設定されています。
モデルにチャットテンプレートが設定されていない場合、ただしモデルクラスのデフォルトテンプレートがある場合、
`ConversationalPipeline`クラスや`apply_chat_template`などのメソッドはクラステンプレートを使用します。
トークナイザのデフォルトのチャットテンプレートを確認するには、`tokenizer.default_chat_template`属性をチェックしてください。
これは、後方互換性のために純粋に行っていることで、既存のワークフローを壊さないようにしています。
モデルにとってクラステンプレートが適切である場合でも、デフォルトテンプレートをオーバーライドして
`chat_template`属性を明示的に設定することを強くお勧めします。これにより、ユーザーにとって
モデルがチャット用に正しく構成されていることが明確になり、デフォルトテンプレートが変更されたり廃止された場合に備えることができます。
## What template should I use?
すでにチャットのトレーニングを受けたモデルのテンプレートを設定する場合、テンプレートがトレーニング中にモデルが見たメッセージのフォーマットとまったく一致することを確認する必要があります。
そうでない場合、性能の低下を経験する可能性が高いです。これはモデルをさらにトレーニングしている場合でも同様です - チャットトークンを一定に保つと、おそらく最高の性能が得られます。
これはトークン化と非常に類似しており、通常はトレーニング中に使用されたトークン化と正確に一致する場合に、推論またはファインチューニングの際に最良の性能が得られます。
一方、ゼロからモデルをトレーニングするか、チャットのためにベース言語モデルをファインチューニングする場合、適切なテンプレートを選択する自由度があります。
LLM(Language Model)はさまざまな入力形式を処理できるほどスマートです。クラス固有のテンプレートがないモデル用のデフォルトテンプレートは、一般的なユースケースに対して良い柔軟な選択肢です。
これは、[ChatMLフォーマット](https://github.com/openai/openai-python/blob/main/chatml.md)に従ったもので、多くのユースケースに適しています。次のようになります:
```
{% for message in messages %}
{{'<|im_start|>' + message['role'] + '\n' + message['content'] + '<|im_end|>' + '\n'}}
{% endfor %}
```
If you like this one, here it is in one-liner form, ready to copy into your code:
```python
tokenizer.chat_template = "{% for message in messages %}{{'<|im_start|>' + message['role'] + '\n' + message['content'] + '<|im_end|>' + '\n'}}{% endfor %}"
```
このテンプレートは、各メッセージを「``」トークンで囲み、役割を文字列として単純に記述します。
これにより、トレーニングで使用する役割に対する柔軟性が得られます。出力は以下のようになります:
```
<|im_start|>system
You are a helpful chatbot that will do its best not to say anything so stupid that people tweet about it.<|im_end|>
<|im_start|>user
How are you?<|im_end|>
<|im_start|>assistant
I'm doing great!<|im_end|>
```
「ユーザー」、「システム」、および「アシスタント」の役割は、チャットの標準です。
特に、[`ConversationalPipeline`]との連携をスムーズに行う場合には、これらの役割を使用することをお勧めします。ただし、これらの役割に制約はありません。テンプレートは非常に柔軟で、任意の文字列を役割として使用できます。
## I want to use chat templates! How should I get started?
チャットモデルを持っている場合、そのモデルの`tokenizer.chat_template`属性を設定し、[`~PreTrainedTokenizer.apply_chat_template`]を使用してテストする必要があります。
これはモデルの所有者でない場合でも適用されます。モデルのリポジトリが空のチャットテンプレートを使用している場合、またはデフォルトのクラステンプレートを使用している場合でも、
この属性を適切に設定できるように[プルリクエスト](https://huggingface.co/docs/hub/repositories-pull-requests-discussions)を開いてください。
一度属性が設定されれば、それで完了です! `tokenizer.apply_chat_template`は、そのモデルに対して正しく動作するようになります。これは、
`ConversationalPipeline`などの場所でも自動的にサポートされます。
モデルがこの属性を持つことを確認することで、オープンソースモデルの全コミュニティがそのフルパワーを使用できるようになります。
フォーマットの不一致はこの分野に悩み続け、パフォーマンスに黙って影響を与えてきました。それを終わらせる時が来ました!
| transformers/docs/source/ja/chat_templating.md/0 | {
"file_path": "transformers/docs/source/ja/chat_templating.md",
"repo_id": "transformers",
"token_count": 7023
} | 26 |
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# BARThez
## Overview
BARThez モデルは、Moussa Kamal Eddine、Antoine J.-P によって [BARThez: a Skilled Pretrained French Sequence-to-Sequence Model](https://arxiv.org/abs/2010.12321) で提案されました。ティクシエ、ミカリス・ヴァジルジャンニス、10月23日、
2020年。
論文の要約:
*帰納的転移学習は、自己教師あり学習によって可能になり、自然言語処理全体を実行します。
(NLP) 分野は、BERT や BART などのモデルにより、無数の自然言語に新たな最先端技術を確立し、嵐を巻き起こしています。
タスクを理解すること。いくつかの注目すべき例外はありますが、利用可能なモデルと研究のほとんどは、
英語を対象に実施されました。この作品では、フランス語用の最初の BART モデルである BARTez を紹介します。
(我々の知る限りに)。 BARThez は、過去の研究から得た非常に大規模な単一言語フランス語コーパスで事前トレーニングされました
BART の摂動スキームに合わせて調整しました。既存の BERT ベースのフランス語モデルとは異なり、
CamemBERT と FlauBERT、BARThez は、エンコーダだけでなく、
そのデコーダは事前トレーニングされています。 FLUE ベンチマークからの識別タスクに加えて、BARThez を新しい評価に基づいて評価します。
この論文とともにリリースする要約データセット、OrangeSum。また、すでに行われている事前トレーニングも継続します。
BARTHez のコーパス上で多言語 BART を事前訓練し、結果として得られるモデル (mBARTHez と呼ぶ) が次のことを示します。
バニラの BARThez を大幅に強化し、CamemBERT や FlauBERT と同等かそれを上回ります。*
このモデルは [moussakam](https://huggingface.co/moussakam) によって寄稿されました。著者のコードは[ここ](https://github.com/moussaKam/BARThez)にあります。
<Tip>
BARThez の実装は、トークン化を除いて BART と同じです。詳細については、[BART ドキュメント](bart) を参照してください。
構成クラスとそのパラメータ。 BARThez 固有のトークナイザーについては以下に記載されています。
</Tip>
### Resources
- BARThez は、BART と同様の方法でシーケンス間のタスクを微調整できます。以下を確認してください。
[examples/pytorch/summarization/](https://github.com/huggingface/transformers/tree/main/examples/pytorch/summarization/README.md)。
## BarthezTokenizer
[[autodoc]] BarthezTokenizer
## BarthezTokenizerFast
[[autodoc]] BarthezTokenizerFast
| transformers/docs/source/ja/model_doc/barthez.md/0 | {
"file_path": "transformers/docs/source/ja/model_doc/barthez.md",
"repo_id": "transformers",
"token_count": 1461
} | 27 |
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# BORT
<Tip warning={true}>
このモデルはメンテナンス モードのみであり、コードを変更する新しい PR は受け付けられません。
このモデルの実行中に問題が発生した場合は、このモデルをサポートしていた最後のバージョン (v4.30.0) を再インストールしてください。
これを行うには、コマンド `pip install -U Transformers==4.30.0` を実行します。
</Tip>
## Overview
BORT モデルは、[Optimal Subarchitecture Extraction for BERT](https://arxiv.org/abs/2010.10499) で提案されました。
Adrian de Wynter and Daniel J. Perry.これは、BERT のアーキテクチャ パラメータの最適なサブセットです。
著者は「ボルト」と呼んでいます。
論文の要約は次のとおりです。
*Devlin らから BERT アーキテクチャのアーキテクチャ パラメータの最適なサブセットを抽出します。 (2018)
ニューラル アーキテクチャ検索のアルゴリズムにおける最近の画期的な技術を適用します。この最適なサブセットを次のように呼びます。
"Bort" は明らかに小さく、有効 (つまり、埋め込み層を考慮しない) サイズは 5.5% です。
オリジナルの BERT 大規模アーキテクチャ、およびネット サイズの 16%。 Bort は 288 GPU 時間で事前トレーニングすることもできます。
最高パフォーマンスの BERT パラメトリック アーキテクチャ バリアントである RoBERTa-large の事前トレーニングに必要な時間の 1.2%
(Liu et al., 2019)、同じマシンで BERT-large をトレーニングするのに必要な GPU 時間の世界記録の約 33%
ハードウェア。また、CPU 上で 7.9 倍高速であるだけでなく、他の圧縮バージョンよりもパフォーマンスが優れています。
アーキテクチャ、および一部の非圧縮バリアント: 0.3% ~ 31% のパフォーマンス向上が得られます。
BERT-large に関して、複数の公開自然言語理解 (NLU) ベンチマークにおける絶対的な評価。*
このモデルは [stefan-it](https://huggingface.co/stefan-it) によって提供されました。元のコードは[ここ](https://github.com/alexa/bort/)にあります。
## Usage tips
- BORT のモデル アーキテクチャは BERT に基づいています。詳細については、[BERT のドキュメント ページ](bert) を参照してください。
モデルの API リファレンスと使用例。
- BORT は BERT トークナイザーの代わりに RoBERTa トークナイザーを使用します。トークナイザーの API リファレンスと使用例については、[RoBERTa のドキュメント ページ](roberta) を参照してください。
- BORT には、 [Agora](https://adewynter.github.io/notes/bort_algorithms_and_applications.html#fine-tuning-with-algebraic-topology) と呼ばれる特定の微調整アルゴリズムが必要です。
残念ながらまだオープンソース化されていません。誰かが実装しようとすると、コミュニティにとって非常に役立ちます。
BORT の微調整を機能させるためのアルゴリズム。 | transformers/docs/source/ja/model_doc/bort.md/0 | {
"file_path": "transformers/docs/source/ja/model_doc/bort.md",
"repo_id": "transformers",
"token_count": 1598
} | 28 |
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# ConvNeXt V2
## Overview
ConvNeXt V2 モデルは、Sanghyun Woo、Shobhik Debnath、Ronghang Hu、Xinlei Chen、Zhuang Liu, In So Kweon, Saining Xie. によって [ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders](https://arxiv.org/abs/2301.00808) で提案されました。
ConvNeXt V2 は、Vision Transformers の設計からインスピレーションを得た純粋な畳み込みモデル (ConvNet) であり、[ConvNeXT](convnext) の後継です。
論文の要約は次のとおりです。
*アーキテクチャの改善と表現学習フレームワークの改善により、視覚認識の分野は 2020 年代初頭に急速な近代化とパフォーマンスの向上を実現しました。たとえば、ConvNeXt に代表される最新の ConvNet は、さまざまなシナリオで強力なパフォーマンスを実証しています。これらのモデルはもともと ImageNet ラベルを使用した教師あり学習用に設計されましたが、マスク オートエンコーダー (MAE) などの自己教師あり学習手法からも潜在的に恩恵を受けることができます。ただし、これら 2 つのアプローチを単純に組み合わせると、パフォーマンスが標準以下になることがわかりました。この論文では、完全畳み込みマスク オートエンコーダ フレームワークと、チャネル間の機能競合を強化するために ConvNeXt アーキテクチャに追加できる新しい Global Response Normalization (GRN) 層を提案します。この自己教師あり学習手法とアーキテクチャの改善の共同設計により、ConvNeXt V2 と呼ばれる新しいモデル ファミリが誕生しました。これにより、ImageNet 分類、COCO 検出、ADE20K セグメンテーションなどのさまざまな認識ベンチマークにおける純粋な ConvNet のパフォーマンスが大幅に向上します。また、ImageNet でトップ 1 の精度 76.7% を誇る効率的な 370 万パラメータの Atto モデルから、最先端の 88.9% を達成する 650M Huge モデルまで、さまざまなサイズの事前トレーニング済み ConvNeXt V2 モデルも提供しています。公開トレーニング データのみを使用した精度*。
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/convnextv2_architecture.png"
alt="描画" width="600"/>
<small> ConvNeXt V2 アーキテクチャ。 <a href="https://arxiv.org/abs/2301.00808">元の論文</a>から抜粋。</small>
このモデルは [adirik](https://huggingface.co/adirik) によって提供されました。元のコードは [こちら](https://github.com/facebookresearch/ConvNeXt-V2) にあります。
## Resources
ConvNeXt V2 の使用を開始するのに役立つ公式 Hugging Face およびコミュニティ (🌎 で示される) リソースのリスト。
<PipelineTag pipeline="image-classification"/>
- [`ConvNextV2ForImageClassification`] は、この [サンプル スクリプト](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) および [ノートブック](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb)。
ここに含めるリソースの送信に興味がある場合は、お気軽にプル リクエストを開いてください。審査させていただきます。リソースは、既存のリソースを複製するのではなく、何か新しいものを示すことが理想的です。
## ConvNextV2Config
[[autodoc]] ConvNextV2Config
## ConvNextV2Model
[[autodoc]] ConvNextV2Model
- forward
## ConvNextV2ForImageClassification
[[autodoc]] ConvNextV2ForImageClassification
- forward
## TFConvNextV2Model
[[autodoc]] TFConvNextV2Model
- call
## TFConvNextV2ForImageClassification
[[autodoc]] TFConvNextV2ForImageClassification
- call
| transformers/docs/source/ja/model_doc/convnextv2.md/0 | {
"file_path": "transformers/docs/source/ja/model_doc/convnextv2.md",
"repo_id": "transformers",
"token_count": 1916
} | 29 |
<!---
Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
# Model training anatomy
モデルトレーニングの効率を向上させるために適用できるパフォーマンス最適化テクニックを理解するには、トレーニング中にGPUがどのように利用されるか、および実行される操作に応じて計算強度がどのように変化するかを理解することが役立ちます。
まずは、GPUの利用例とモデルのトレーニング実行に関する示唆に富む例を探求することから始めましょう。デモンストレーションのために、いくつかのライブラリをインストールする必要があります:
```bash
pip install transformers datasets accelerate nvidia-ml-py3
```
`nvidia-ml-py3` ライブラリは、Python内からモデルのメモリ使用状況をモニターすることを可能にします。おそらく、ターミナルでの `nvidia-smi` コマンドについてはお聞きかもしれませんが、このライブラリを使用すると、Pythonから同じ情報にアクセスできます。
それから、いくつかのダミーデータを作成します。100から30000の間のランダムなトークンIDと、分類器のためのバイナリラベルです。合計で、512のシーケンスがあり、それぞれの長さは512で、PyTorchフォーマットの [`~datasets.Dataset`] に格納されます。
```py
>>> import numpy as np
>>> from datasets import Dataset
>>> seq_len, dataset_size = 512, 512
>>> dummy_data = {
... "input_ids": np.random.randint(100, 30000, (dataset_size, seq_len)),
... "labels": np.random.randint(0, 1, (dataset_size)),
... }
>>> ds = Dataset.from_dict(dummy_data)
>>> ds.set_format("pt")
```
[`Trainer`]を使用してGPU利用率とトレーニング実行の要約統計情報を表示するために、2つのヘルパー関数を定義します。
```py
>>> from pynvml import *
>>> def print_gpu_utilization():
... nvmlInit()
... handle = nvmlDeviceGetHandleByIndex(0)
... info = nvmlDeviceGetMemoryInfo(handle)
... print(f"GPU memory occupied: {info.used//1024**2} MB.")
>>> def print_summary(result):
... print(f"Time: {result.metrics['train_runtime']:.2f}")
... print(f"Samples/second: {result.metrics['train_samples_per_second']:.2f}")
... print_gpu_utilization()
```
以下は、無料のGPUメモリから開始していることを確認しましょう:
```py
>>> print_gpu_utilization()
GPU memory occupied: 0 MB.
```
GPUメモリがモデルを読み込む前のように占有されていないように見えます。これがお使いのマシンでの状況でない場合は、GPUメモリを使用しているすべてのプロセスを停止してください。ただし、すべての空きGPUメモリをユーザーが使用できるわけではありません。モデルがGPUに読み込まれると、カーネルも読み込まれ、1〜2GBのメモリを使用することがあります。それがどれくらいかを確認するために、GPUに小さなテンソルを読み込むと、カーネルも読み込まれます。
```py
>>> import torch
>>> torch.ones((1, 1)).to("cuda")
>>> print_gpu_utilization()
GPU memory occupied: 1343 MB.
```
カーネルだけで1.3GBのGPUメモリを使用していることがわかります。次に、モデルがどれだけのスペースを使用しているかを見てみましょう。
## Load Model
まず、`google-bert/bert-large-uncased` モデルを読み込みます。モデルの重みを直接GPUに読み込むことで、重みだけがどれだけのスペースを使用しているかを確認できます。
```py
>>> from transformers import AutoModelForSequenceClassification
>>> model = AutoModelForSequenceClassification.from_pretrained("google-bert/bert-large-uncased").to("cuda")
>>> print_gpu_utilization()
GPU memory occupied: 2631 MB.
```
モデルの重みだけで、GPUメモリを1.3 GB使用していることがわかります。正確な数値は、使用している具体的なGPUに依存します。新しいGPUでは、モデルの重みが最適化された方法で読み込まれるため、モデルの使用を高速化することがあるため、モデルがより多くのスペースを占有することがあります。さて、`nvidia-smi` CLIと同じ結果が得られるかを簡単に確認することもできます。
```bash
nvidia-smi
```
```bash
Tue Jan 11 08:58:05 2022
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 460.91.03 Driver Version: 460.91.03 CUDA Version: 11.2 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 Tesla V100-SXM2... On | 00000000:00:04.0 Off | 0 |
| N/A 37C P0 39W / 300W | 2631MiB / 16160MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| 0 N/A N/A 3721 C ...nvs/codeparrot/bin/python 2629MiB |
+-----------------------------------------------------------------------------+
```
前回と同じ数値を取得し、16GBのメモリを搭載したV100 GPUを使用していることがわかります。さて、モデルのトレーニングを開始し、GPUメモリの消費がどのように変化するかを確認してみましょう。まず、いくつかの標準的なトレーニング引数を設定します:
```py
default_args = {
"output_dir": "tmp",
"evaluation_strategy": "steps",
"num_train_epochs": 1,
"log_level": "error",
"report_to": "none",
}
```
<Tip>
複数の実験を実行する予定がある場合、実験間でメモリを適切にクリアするために、実験の間に Python カーネルを再起動してください。
</Tip>
## Memory utilization at vanilla training
[`Trainer`] を使用して、GPU パフォーマンスの最適化テクニックを使用せずにバッチサイズ 4 でモデルをトレーニングしましょう:
```py
>>> from transformers import TrainingArguments, Trainer, logging
>>> logging.set_verbosity_error()
>>> training_args = TrainingArguments(per_device_train_batch_size=4, **default_args)
>>> trainer = Trainer(model=model, args=training_args, train_dataset=ds)
>>> result = trainer.train()
>>> print_summary(result)
```
```
Time: 57.82
Samples/second: 8.86
GPU memory occupied: 14949 MB.
```
既に、比較的小さいバッチサイズでも、GPUのほとんどのメモリがすでに使用されていることがわかります。しかし、より大きなバッチサイズを使用することは、しばしばモデルの収束が速くなったり、最終的な性能が向上したりすることがあります。したがって、理想的には、バッチサイズをモデルの要件に合わせて調整したいのですが、GPUの制限に合わせて調整する必要はありません。興味深いことに、モデルのサイズよりもはるかに多くのメモリを使用しています。なぜそうなるのかを少し理解するために、モデルの操作とメモリの必要性を見てみましょう。
## Anatomy of Model's Operations
Transformerアーキテクチャには、計算強度によって以下の3つの主要な操作グループが含まれています。
1. **テンソルの収縮**
線形層とMulti-Head Attentionのコンポーネントは、すべてバッチ処理された **行列-行列の乗算** を行います。これらの操作は、Transformerのトレーニングにおいて最も計算集約的な部分です。
2. **統計的正規化**
Softmaxと層正規化は、テンソルの収縮よりも計算負荷が少なく、1つまたは複数の **縮約操作** を含み、その結果がマップを介して適用されます。
3. **要素ごとの演算子**
これらは残りの演算子です:**バイアス、ドロップアウト、活性化、および残差接続** です。これらは最も計算集約的な操作ではありません。
パフォーマンスのボトルネックを分析する際に、この知識は役立つことがあります。
この要約は、[Data Movement Is All You Need: Optimizing Transformers 2020に関するケーススタディ](https://arxiv.org/abs/2007.00072)から派生しています。
## Anatomy of Model's Memory
モデルのトレーニングがGPUに配置されたモデルよりもはるかに多くのメモリを使用することを見てきました。これは、トレーニング中にGPUメモリを使用する多くのコンポーネントが存在するためです。GPUメモリ上のコンポーネントは以下の通りです:
1. モデルの重み
2. オプティマイザの状態
3. 勾配
4. 勾配計算のために保存された前向き活性化
5. 一時バッファ
6. 機能固有のメモリ
通常、AdamWを使用して混合精度でトレーニングされたモデルは、モデルパラメータごとに18バイトとアクティベーションメモリが必要です。推論ではオプティマイザの状態と勾配は不要ですので、これらを差し引くことができます。したがって、混合精度の推論においては、モデルパラメータごとに6バイトとアクティベーションメモリが必要です。
詳細を見てみましょう。
**モデルの重み:**
- fp32トレーニングのパラメーター数 * 4バイト
- ミックスプレシジョントレーニングのパラメーター数 * 6バイト(メモリ内にfp32とfp16のモデルを維持)
**オプティマイザの状態:**
- 通常のAdamWのパラメーター数 * 8バイト(2つの状態を維持)
- 8-bit AdamWオプティマイザのパラメーター数 * 2バイト([bitsandbytes](https://github.com/TimDettmers/bitsandbytes)のようなオプティマイザ)
- モーメンタムを持つSGDのようなオプティマイザのパラメーター数 * 4バイト(1つの状態を維持)
**勾配**
- fp32またはミックスプレシジョントレーニングのパラメーター数 * 4バイト(勾配は常にfp32で保持)
**フォワードアクティベーション**
- サイズは多くの要因に依存し、主要な要因はシーケンスの長さ、隠れ層のサイズ、およびバッチサイズです。
フォワードとバックワードの関数によって渡され、返される入力と出力、および勾配計算のために保存されるフォワードアクティベーションがあります。
**一時的なメモリ**
さらに、計算が完了した後に解放されるさまざまな一時変数がありますが、これらは一時的に追加のメモリを必要とし、OOMに達する可能性があります。したがって、コーディング時にはこのような一時変数に戦略的に考え、必要なくなったら明示的に解放することが非常に重要です。
**機能固有のメモリ**
次に、ソフトウェアには特別なメモリ要件がある場合があります。たとえば、ビームサーチを使用してテキストを生成する場合、ソフトウェアは複数の入力と出力のコピーを維持する必要があります。
**`forward`と`backward`の実行速度**
畳み込み層と線形層では、バックワードにフォワードと比べて2倍のFLOPSがあり、一般的には約2倍遅くなります(バックワードのサイズが不便であることがあるため、それ以上になることがあります)。 アクティベーションは通常、バンド幅制限されており、バックワードでアクティベーションがフォワードよりも多くのデータを読むことが一般的です(たとえば、アクティベーションフォワードは1回読み取り、1回書き込み、アクティベーションバックワードはフォワードのgradOutputおよび出力を2回読み取り、1回書き込みます)。
ご覧の通り、GPUメモリを節約したり操作を高速化できる可能性のあるいくつかの場所があります。 GPUの利用と計算速度に影響を与える要因を理解したので、パフォーマンス最適化の技術については、[単一GPUでの効率的なトレーニングのための方法とツール](perf_train_gpu_one)のドキュメンテーションページを参照してください。
詳細を見てみましょう。
| transformers/docs/source/ja/model_memory_anatomy.md/0 | {
"file_path": "transformers/docs/source/ja/model_memory_anatomy.md",
"repo_id": "transformers",
"token_count": 5988
} | 30 |
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Text to speech
[[open-in-colab]]
テキスト読み上げ (TTS) は、テキストから自然な音声を作成するタスクです。音声は複数の形式で生成できます。
言語と複数の話者向け。現在、いくつかのテキスト読み上げモデルが 🤗 Transformers で利用可能です。
[Bark](../model_doc/bark)、[MMS](../model_doc/mms)、[VITS](../model_doc/vits)、および [SpeechT5](../model_doc/speecht5)。
`text-to-audio`パイプライン (またはその別名 - `text-to-speech`) を使用して、音声を簡単に生成できます。 Bark などの一部のモデルは、
笑い、ため息、泣きなどの非言語コミュニケーションを生成したり、音楽を追加したりするように条件付けすることもできます。
Bark で`text-to-speech`パイプラインを使用する方法の例を次に示します。
```py
>>> from transformers import pipeline
>>> pipe = pipeline("text-to-speech", model="suno/bark-small")
>>> text = "[clears throat] This is a test ... and I just took a long pause."
>>> output = pipe(text)
```
ノートブックで結果の音声を聞くために使用できるコード スニペットを次に示します。
```python
>>> from IPython.display import Audio
>>> Audio(output["audio"], rate=output["sampling_rate"])
```
Bark およびその他の事前トレーニングされた TTS モデルができることの詳細な例については、次のドキュメントを参照してください。
[音声コース](https://huggingface.co/learn/audio-course/chapter6/pre-trained_models)。
TTS モデルを微調整する場合、現在微調整できるのは SpeechT5 のみです。 SpeechT5 は、次の組み合わせで事前トレーニングされています。
音声からテキストへのデータとテキストから音声へのデータ。両方のテキストに共有される隠された表現の統一された空間を学習できるようにします。
そしてスピーチ。これは、同じ事前トレーニング済みモデルをさまざまなタスクに合わせて微調整できることを意味します。さらに、SpeechT5
X ベクトル スピーカーの埋め込みを通じて複数のスピーカーをサポートします。
このガイドの残りの部分では、次の方法を説明します。
1. [VoxPopuli](https://huggingface.co/datasets/facebook/voxpopuli) のオランダ語 (`nl`) 言語サブセット上の英語音声で元々トレーニングされた [SpeechT5](../model_doc/speecht5) を微調整します。 データセット。
2. パイプラインを使用するか直接使用するかの 2 つの方法のいずれかで、洗練されたモデルを推論に使用します。
始める前に、必要なライブラリがすべてインストールされていることを確認してください。
```bash
pip install datasets soundfile speechbrain accelerate
```
SpeechT5 のすべての機能がまだ正式リリースにマージされていないため、ソースから 🤗Transformers をインストールします。
```bash
pip install git+https://github.com/huggingface/transformers.git
```
<Tip>
このガイドに従うには、GPU が必要です。ノートブックで作業している場合は、次の行を実行して GPU が利用可能かどうかを確認します。
```bash
!nvidia-smi
```
</Tip>
Hugging Face アカウントにログインして、モデルをアップロードしてコミュニティと共有することをお勧めします。プロンプトが表示されたら、トークンを入力してログインします。
```py
>>> from huggingface_hub import notebook_login
>>> notebook_login()
```
## Load the dataset
[VoxPopuli](https://huggingface.co/datasets/facebook/voxpopuli) は、以下で構成される大規模な多言語音声コーパスです。
データは 2009 年から 2020 年の欧州議会のイベント記録をソースとしています。 15 件分のラベル付き音声文字起こしデータが含まれています。
ヨーロッパの言語。このガイドではオランダ語のサブセットを使用していますが、自由に別のサブセットを選択してください。
VoxPopuli またはその他の自動音声認識 (ASR) データセットは最適ではない可能性があることに注意してください。
TTS モデルをトレーニングするためのオプション。過剰なバックグラウンドノイズなど、ASR にとって有益となる機能は次のとおりです。
通常、TTS では望ましくありません。ただし、最高品質、多言語、マルチスピーカーの TTS データセットを見つけるのは非常に困難な場合があります。
挑戦的。
データをロードしましょう:
```py
>>> from datasets import load_dataset, Audio
>>> dataset = load_dataset("facebook/voxpopuli", "nl", split="train")
>>> len(dataset)
20968
```
微調整には 20968 個の例で十分です。 SpeechT5 はオーディオ データのサンプリング レートが 16 kHz であることを想定しているため、
データセット内の例がこの要件を満たしていることを確認してください。
```py
dataset = dataset.cast_column("audio", Audio(sampling_rate=16000))
```
## Preprocess the data
使用するモデル チェックポイントを定義し、適切なプロセッサをロードすることから始めましょう。
```py
>>> from transformers import SpeechT5Processor
>>> checkpoint = "microsoft/speecht5_tts"
>>> processor = SpeechT5Processor.from_pretrained(checkpoint)
```
### Text cleanup for SpeechT5 tokenization
まずはテキストデータをクリーンアップすることから始めます。テキストを処理するには、プロセッサのトークナイザー部分が必要です。
```py
>>> tokenizer = processor.tokenizer
```
データセットの例には、`raw_text`機能と `normalized_text`機能が含まれています。テキスト入力としてどの機能を使用するかを決めるときは、
SpeechT5 トークナイザーには数値のトークンがないことを考慮してください。 `normalized_text`には数字が書かれています
テキストとして出力します。したがって、これはより適切であり、入力テキストとして `normalized_text` を使用することをお勧めします。
SpeechT5 は英語でトレーニングされているため、オランダ語のデータセット内の特定の文字を認識しない可能性があります。もし
残っているように、これらの文字は `<unk>`トークンに変換されます。ただし、オランダ語では、`à`などの特定の文字は
音節を強調することに慣れています。テキストの意味を保持するために、この文字を通常の`a`に置き換えることができます。
サポートされていないトークンを識別するには、`SpeechT5Tokenizer`を使用してデータセット内のすべての一意の文字を抽出します。
文字をトークンとして扱います。これを行うには、以下を連結する `extract_all_chars` マッピング関数を作成します。
すべての例からの転写を 1 つの文字列にまとめ、それを文字セットに変換します。
すべての文字起こしが一度に利用できるように、`dataset.map()`で`batched=True`と`batch_size=-1`を必ず設定してください。
マッピング機能。
```py
>>> def extract_all_chars(batch):
... all_text = " ".join(batch["normalized_text"])
... vocab = list(set(all_text))
... return {"vocab": [vocab], "all_text": [all_text]}
>>> vocabs = dataset.map(
... extract_all_chars,
... batched=True,
... batch_size=-1,
... keep_in_memory=True,
... remove_columns=dataset.column_names,
... )
>>> dataset_vocab = set(vocabs["vocab"][0])
>>> tokenizer_vocab = {k for k, _ in tokenizer.get_vocab().items()}
```
これで、2 つの文字セットができました。1 つはデータセットの語彙を持ち、もう 1 つはトークナイザーの語彙を持ちます。
データセット内でサポートされていない文字を特定するには、これら 2 つのセットの差分を取ることができます。結果として
set には、データセットにはあるがトークナイザーには含まれていない文字が含まれます。
```py
>>> dataset_vocab - tokenizer_vocab
{' ', 'à', 'ç', 'è', 'ë', 'í', 'ï', 'ö', 'ü'}
```
前の手順で特定されたサポートされていない文字を処理するには、これらの文字を
有効なトークン。スペースはトークナイザーですでに `▁` に置き換えられているため、個別に処理する必要がないことに注意してください。
```py
>>> replacements = [
... ("à", "a"),
... ("ç", "c"),
... ("è", "e"),
... ("ë", "e"),
... ("í", "i"),
... ("ï", "i"),
... ("ö", "o"),
... ("ü", "u"),
... ]
>>> def cleanup_text(inputs):
... for src, dst in replacements:
... inputs["normalized_text"] = inputs["normalized_text"].replace(src, dst)
... return inputs
>>> dataset = dataset.map(cleanup_text)
```
テキスト内の特殊文字を扱ったので、今度は音声データに焦点を移します。
### Speakers
VoxPopuli データセットには複数の話者の音声が含まれていますが、データセットには何人の話者が含まれているのでしょうか?に
これを決定すると、一意の話者の数と、各話者がデータセットに寄与する例の数を数えることができます。
データセットには合計 20,968 個の例が含まれており、この情報により、分布をより深く理解できるようになります。
講演者とデータ内の例。
```py
>>> from collections import defaultdict
>>> speaker_counts = defaultdict(int)
>>> for speaker_id in dataset["speaker_id"]:
... speaker_counts[speaker_id] += 1
```
ヒストグラムをプロットすると、各話者にどれだけのデータがあるかを把握できます。
```py
>>> import matplotlib.pyplot as plt
>>> plt.figure()
>>> plt.hist(speaker_counts.values(), bins=20)
>>> plt.ylabel("Speakers")
>>> plt.xlabel("Examples")
>>> plt.show()
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/tasks/tts_speakers_histogram.png" alt="Speakers histogram"/>
</div>
ヒストグラムから、データセット内の話者の約 3 分の 1 の例が 100 未満であることがわかります。
約 10 人の講演者が 500 以上の例を持っています。トレーニング効率を向上させ、データセットのバランスをとるために、次のことを制限できます。
100 ~ 400 個の例を含むデータを講演者に提供します。
```py
>>> def select_speaker(speaker_id):
... return 100 <= speaker_counts[speaker_id] <= 400
>>> dataset = dataset.filter(select_speaker, input_columns=["speaker_id"])
```
残りのスピーカーの数を確認してみましょう。
```py
>>> len(set(dataset["speaker_id"]))
42
```
残りの例がいくつあるか見てみましょう。
```py
>>> len(dataset)
9973
```
約 40 人のユニークな講演者からの 10,000 弱の例が残りますが、これで十分です。
例が少ないスピーカーの中には、例が長い場合、実際にはより多くの音声が利用できる場合があることに注意してください。しかし、
各話者の音声の合計量を決定するには、データセット全体をスキャンする必要があります。
各オーディオ ファイルのロードとデコードを伴う時間のかかるプロセス。そのため、ここではこのステップをスキップすることにしました。
### Speaker embeddings
TTS モデルが複数のスピーカーを区別できるようにするには、サンプルごとにスピーカーの埋め込みを作成する必要があります。
スピーカーの埋め込みは、特定のスピーカーの音声特性をキャプチャするモデルへの追加入力です。
これらのスピーカー埋め込みを生成するには、事前トレーニングされた [spkrec-xvect-voxceleb](https://huggingface.co/speechbrain/spkrec-xvect-voxceleb) を使用します。
SpeechBrain のモデル。
入力オーディオ波形を受け取り、512 要素のベクトルを出力する関数 `create_speaker_embedding()` を作成します。
対応するスピーカー埋め込みが含まれます。
```py
>>> import os
>>> import torch
>>> from speechbrain.pretrained import EncoderClassifier
>>> spk_model_name = "speechbrain/spkrec-xvect-voxceleb"
>>> device = "cuda" if torch.cuda.is_available() else "cpu"
>>> speaker_model = EncoderClassifier.from_hparams(
... source=spk_model_name,
... run_opts={"device": device},
... savedir=os.path.join("/tmp", spk_model_name),
... )
>>> def create_speaker_embedding(waveform):
... with torch.no_grad():
... speaker_embeddings = speaker_model.encode_batch(torch.tensor(waveform))
... speaker_embeddings = torch.nn.functional.normalize(speaker_embeddings, dim=2)
... speaker_embeddings = speaker_embeddings.squeeze().cpu().numpy()
... return speaker_embeddings
```
`speechbrain/spkrec-xvect-voxceleb`モデルは、VoxCeleb からの英語音声でトレーニングされたことに注意することが重要です。
データセットですが、このガイドのトレーニング例はオランダ語です。このモデルは今後も生成されると信じていますが、
オランダ語のデータセットに適切な話者埋め込みを行っても、この仮定はすべての場合に当てはまらない可能性があります。
最適な結果を得るには、最初にターゲット音声で X ベクトル モデルをトレーニングすることをお勧めします。これにより、モデルが確実に
オランダ語に存在する独特の音声特徴をよりよく捉えることができます。
### Processing the dataset
最後に、モデルが期待する形式にデータを処理しましょう。を取り込む `prepare_dataset` 関数を作成します。
これは 1 つの例であり、`SpeechT5Processor` オブジェクトを使用して入力テキストをトークン化し、ターゲット オーディオをログメル スペクトログラムにロードします。
また、追加の入力としてスピーカーの埋め込みも追加する必要があります。
```py
>>> def prepare_dataset(example):
... audio = example["audio"]
... example = processor(
... text=example["normalized_text"],
... audio_target=audio["array"],
... sampling_rate=audio["sampling_rate"],
... return_attention_mask=False,
... )
... # strip off the batch dimension
... example["labels"] = example["labels"][0]
... # use SpeechBrain to obtain x-vector
... example["speaker_embeddings"] = create_speaker_embedding(audio["array"])
... return example
```
単一の例を見て、処理が正しいことを確認します。
```py
>>> processed_example = prepare_dataset(dataset[0])
>>> list(processed_example.keys())
['input_ids', 'labels', 'stop_labels', 'speaker_embeddings']
```
スピーカーのエンベディングは 512 要素のベクトルである必要があります。
```py
>>> processed_example["speaker_embeddings"].shape
(512,)
```
ラベルは、80 メル ビンを含むログメル スペクトログラムである必要があります。
```py
>>> import matplotlib.pyplot as plt
>>> plt.figure()
>>> plt.imshow(processed_example["labels"].T)
>>> plt.show()
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/tasks/tts_logmelspectrogram_1.png" alt="Log-mel spectrogram with 80 mel bins"/>
</div>
補足: このスペクトログラムがわかりにくいと感じる場合は、低周波を配置する規則に慣れていることが原因である可能性があります。
プロットの下部に高周波、上部に高周波が表示されます。ただし、matplotlib ライブラリを使用してスペクトログラムを画像としてプロットする場合、
Y 軸が反転され、スペクトログラムが上下逆に表示されます。
次に、処理関数をデータセット全体に適用します。これには 5 ~ 10 分かかります。
```py
>>> dataset = dataset.map(prepare_dataset, remove_columns=dataset.column_names)
```
データセット内の一部の例が、モデルが処理できる最大入力長 (600 トークン) を超えていることを示す警告が表示されます。
それらの例をデータセットから削除します。ここではさらに進んで、より大きなバッチ サイズを可能にするために、200 トークンを超えるものはすべて削除します。
```py
>>> def is_not_too_long(input_ids):
... input_length = len(input_ids)
... return input_length < 200
>>> dataset = dataset.filter(is_not_too_long, input_columns=["input_ids"])
>>> len(dataset)
8259
```
次に、基本的なトレーニング/テスト分割を作成します。
```py
>>> dataset = dataset.train_test_split(test_size=0.1)
```
### Data collator
複数の例を 1 つのバッチに結合するには、カスタム データ照合器を定義する必要があります。このコレーターは、短いシーケンスをパディングで埋め込みます。
トークンを使用して、すべての例が同じ長さになるようにします。スペクトログラム ラベルの場合、埋め込まれた部分は特別な値 `-100` に置き換えられます。この特別な価値は
スペクトログラム損失を計算するときに、スペクトログラムのその部分を無視するようにモデルに指示します。
```py
>>> from dataclasses import dataclass
>>> from typing import Any, Dict, List, Union
>>> @dataclass
... class TTSDataCollatorWithPadding:
... processor: Any
... def __call__(self, features: List[Dict[str, Union[List[int], torch.Tensor]]]) -> Dict[str, torch.Tensor]:
... input_ids = [{"input_ids": feature["input_ids"]} for feature in features]
... label_features = [{"input_values": feature["labels"]} for feature in features]
... speaker_features = [feature["speaker_embeddings"] for feature in features]
... # collate the inputs and targets into a batch
... batch = processor.pad(input_ids=input_ids, labels=label_features, return_tensors="pt")
... # replace padding with -100 to ignore loss correctly
... batch["labels"] = batch["labels"].masked_fill(batch.decoder_attention_mask.unsqueeze(-1).ne(1), -100)
... # not used during fine-tuning
... del batch["decoder_attention_mask"]
... # round down target lengths to multiple of reduction factor
... if model.config.reduction_factor > 1:
... target_lengths = torch.tensor([len(feature["input_values"]) for feature in label_features])
... target_lengths = target_lengths.new(
... [length - length % model.config.reduction_factor for length in target_lengths]
... )
... max_length = max(target_lengths)
... batch["labels"] = batch["labels"][:, :max_length]
... # also add in the speaker embeddings
... batch["speaker_embeddings"] = torch.tensor(speaker_features)
... return batch
```
SpeechT5 では、モデルのデコーダ部分への入力が 2 分の 1 に削減されます。つまり、すべてのデータが破棄されます。
ターゲット シーケンスからの他のタイムステップ。次に、デコーダは 2 倍の長さのシーケンスを予測します。オリジナル以来
ターゲット シーケンスの長さが奇数である可能性がある場合、データ照合機能はバッチの最大長を切り捨てて、
2の倍数。
```py
>>> data_collator = TTSDataCollatorWithPadding(processor=processor)
```
## Train the model
プロセッサのロードに使用したのと同じチェックポイントから事前トレーニングされたモデルをロードします。
```py
>>> from transformers import SpeechT5ForTextToSpeech
>>> model = SpeechT5ForTextToSpeech.from_pretrained(checkpoint)
```
`use_cache=True`オプションは、勾配チェックポイントと互換性がありません。トレーニングのために無効にします。
```py
>>> model.config.use_cache = False
```
トレーニング引数を定義します。ここでは、トレーニング プロセス中に評価メトリクスを計算していません。代わりに、
損失だけを見てください。
```python
>>> from transformers import Seq2SeqTrainingArguments
>>> training_args = Seq2SeqTrainingArguments(
... output_dir="speecht5_finetuned_voxpopuli_nl", # change to a repo name of your choice
... per_device_train_batch_size=4,
... gradient_accumulation_steps=8,
... learning_rate=1e-5,
... warmup_steps=500,
... max_steps=4000,
... gradient_checkpointing=True,
... fp16=True,
... evaluation_strategy="steps",
... per_device_eval_batch_size=2,
... save_steps=1000,
... eval_steps=1000,
... logging_steps=25,
... report_to=["tensorboard"],
... load_best_model_at_end=True,
... greater_is_better=False,
... label_names=["labels"],
... push_to_hub=True,
... )
```
`Trainer`オブジェクトをインスタンス化し、モデル、データセット、データ照合器をそれに渡します。
```py
>>> from transformers import Seq2SeqTrainer
>>> trainer = Seq2SeqTrainer(
... args=training_args,
... model=model,
... train_dataset=dataset["train"],
... eval_dataset=dataset["test"],
... data_collator=data_collator,
... tokenizer=processor,
... )
```
これで、トレーニングを開始する準備が整いました。トレーニングには数時間かかります。 GPU に応じて、
トレーニングを開始するときに、CUDA の「メモリ不足」エラーが発生する可能性があります。この場合、減らすことができます
`per_device_train_batch_size`を 2 倍に増分し、`gradient_accumulation_steps`を 2 倍に増やして補正します。
```py
>>> trainer.train()
```
パイプラインでチェックポイントを使用できるようにするには、必ずプロセッサをチェックポイントとともに保存してください。
```py
>>> processor.save_pretrained("YOUR_ACCOUNT_NAME/speecht5_finetuned_voxpopuli_nl")
```
最終モデルを 🤗 ハブにプッシュします。
```py
>>> trainer.push_to_hub()
```
## Inference
### Inference with a pipeline
モデルを微調整したので、それを推論に使用できるようになりました。
まず、対応するパイプラインでそれを使用する方法を見てみましょう。 `"text-to-speech"` パイプラインを作成しましょう
チェックポイント:
```py
>>> from transformers import pipeline
>>> pipe = pipeline("text-to-speech", model="YOUR_ACCOUNT_NAME/speecht5_finetuned_voxpopuli_nl")
```
ナレーションを希望するオランダ語のテキストを選択してください。例:
```py
>>> text = "hallo allemaal, ik praat nederlands. groetjes aan iedereen!"
```
パイプラインで SpeechT5 を使用するには、スピーカーの埋め込みが必要です。テスト データセットの例から取得してみましょう。
```py
>>> example = dataset["test"][304]
>>> speaker_embeddings = torch.tensor(example["speaker_embeddings"]).unsqueeze(0)
```
これで、テキストとスピーカーの埋め込みをパイプラインに渡すことができ、残りはパイプラインが処理します。
```py
>>> forward_params = {"speaker_embeddings": speaker_embeddings}
>>> output = pipe(text, forward_params=forward_params)
>>> output
{'audio': array([-6.82714235e-05, -4.26525949e-04, 1.06134125e-04, ...,
-1.22392643e-03, -7.76011671e-04, 3.29112721e-04], dtype=float32),
'sampling_rate': 16000}
```
その後、結果を聞くことができます。
```py
>>> from IPython.display import Audio
>>> Audio(output['audio'], rate=output['sampling_rate'])
```
### Run inference manually
パイプラインを使用しなくても同じ推論結果を得ることができますが、より多くの手順が必要になります。
🤗 ハブからモデルをロードします。
```py
>>> model = SpeechT5ForTextToSpeech.from_pretrained("YOUR_ACCOUNT/speecht5_finetuned_voxpopuli_nl")
```
テスト データセットから例を選択して、スピーカーの埋め込みを取得します。
```py
>>> example = dataset["test"][304]
>>> speaker_embeddings = torch.tensor(example["speaker_embeddings"]).unsqueeze(0)
```
入力テキストを定義し、トークン化します。
```py
>>> text = "hallo allemaal, ik praat nederlands. groetjes aan iedereen!"
>>> inputs = processor(text=text, return_tensors="pt")
```
モデルを使用してスペクトログラムを作成します。
```py
>>> spectrogram = model.generate_speech(inputs["input_ids"], speaker_embeddings)
```
次のことを行う場合は、スペクトログラムを視覚化します。
```py
>>> plt.figure()
>>> plt.imshow(spectrogram.T)
>>> plt.show()
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/tasks/tts_logmelspectrogram_2.png" alt="Generated log-mel spectrogram"/>
</div>
最後に、ボコーダーを使用してスペクトログラムをサウンドに変換します。
```py
>>> with torch.no_grad():
... speech = vocoder(spectrogram)
>>> from IPython.display import Audio
>>> Audio(speech.numpy(), rate=16000)
```
私たちの経験では、このモデルから満足のいく結果を得るのは難しい場合があります。スピーカーの品質
埋め込みは重要な要素であるようです。 SpeechT5 は英語の x ベクトルで事前トレーニングされているため、最高のパフォーマンスを発揮します
英語スピーカーの埋め込みを使用する場合。合成音声の音質が悪い場合は、別のスピーカー埋め込みを使用してみてください。
トレーニング期間を長くすると、結果の質も向上する可能性があります。それでも、そのスピーチは明らかに英語ではなくオランダ語です。
話者の音声特性をキャプチャします (例の元の音声と比較)。
もう 1 つ実験すべきことは、モデルの構成です。たとえば、`config.reduction_factor = 1`を使用してみてください。
これにより結果が改善されるかどうかを確認してください。
最後に、倫理的配慮を考慮することが不可欠です。 TTS テクノロジーには数多くの有用な用途がありますが、
また、知らないうちに誰かの声を偽装するなど、悪意のある目的に使用される可能性もあります。お願いします
TTS は賢明かつ責任を持って使用してください。
| transformers/docs/source/ja/tasks/text-to-speech.md/0 | {
"file_path": "transformers/docs/source/ja/tasks/text-to-speech.md",
"repo_id": "transformers",
"token_count": 12020
} | 31 |
# docstyle-ignore
INSTALL_CONTENT = """
# Transformers 설치 방법
! pip install transformers datasets
# 마지막 릴리스 대신 소스에서 설치하려면, 위 명령을 주석으로 바꾸고 아래 명령을 해제하세요.
# ! pip install git+https://github.com/huggingface/transformers.git
"""
notebook_first_cells = [{"type": "code", "content": INSTALL_CONTENT}]
black_avoid_patterns = {
"{processor_class}": "FakeProcessorClass",
"{model_class}": "FakeModelClass",
"{object_class}": "FakeObjectClass",
}
| transformers/docs/source/ko/_config.py/0 | {
"file_path": "transformers/docs/source/ko/_config.py",
"repo_id": "transformers",
"token_count": 257
} | 32 |
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# 🤗 Tokenizers 라이브러리의 토크나이저 사용하기[[use-tokenizers-from-tokenizers]]
[`PreTrainedTokenizerFast`]는 [🤗 Tokenizers](https://huggingface.co/docs/tokenizers) 라이브러리에 기반합니다. 🤗 Tokenizers 라이브러리의 토크나이저는
🤗 Transformers로 매우 간단하게 불러올 수 있습니다.
구체적인 내용에 들어가기 전에, 몇 줄의 코드로 더미 토크나이저를 만들어 보겠습니다:
```python
>>> from tokenizers import Tokenizer
>>> from tokenizers.models import BPE
>>> from tokenizers.trainers import BpeTrainer
>>> from tokenizers.pre_tokenizers import Whitespace
>>> tokenizer = Tokenizer(BPE(unk_token="[UNK]"))
>>> trainer = BpeTrainer(special_tokens=["[UNK]", "[CLS]", "[SEP]", "[PAD]", "[MASK]"])
>>> tokenizer.pre_tokenizer = Whitespace()
>>> files = [...]
>>> tokenizer.train(files, trainer)
```
우리가 정의한 파일을 통해 이제 학습된 토크나이저를 갖게 되었습니다. 이 런타임에서 계속 사용하거나 JSON 파일로 저장하여 나중에 사용할 수 있습니다.
## 토크나이저 객체로부터 직접 불러오기[[loading-directly-from-the-tokenizer-object]]
🤗 Transformers 라이브러리에서 이 토크나이저 객체를 활용하는 방법을 살펴보겠습니다.
[`PreTrainedTokenizerFast`] 클래스는 인스턴스화된 *토크나이저* 객체를 인수로 받아 쉽게 인스턴스화할 수 있습니다:
```python
>>> from transformers import PreTrainedTokenizerFast
>>> fast_tokenizer = PreTrainedTokenizerFast(tokenizer_object=tokenizer)
```
이제 `fast_tokenizer` 객체는 🤗 Transformers 토크나이저에서 공유하는 모든 메소드와 함께 사용할 수 있습니다! 자세한 내용은 [토크나이저 페이지](main_classes/tokenizer)를 참조하세요.
## JSON 파일에서 불러오기[[loading-from-a-JSON-file]]
<!--In order to load a tokenizer from a JSON file, let's first start by saving our tokenizer:-->
JSON 파일에서 토크나이저를 불러오기 위해, 먼저 토크나이저를 저장해 보겠습니다:
```python
>>> tokenizer.save("tokenizer.json")
```
JSON 파일을 저장한 경로는 `tokenizer_file` 매개변수를 사용하여 [`PreTrainedTokenizerFast`] 초기화 메소드에 전달할 수 있습니다:
```python
>>> from transformers import PreTrainedTokenizerFast
>>> fast_tokenizer = PreTrainedTokenizerFast(tokenizer_file="tokenizer.json")
```
이제 `fast_tokenizer` 객체는 🤗 Transformers 토크나이저에서 공유하는 모든 메소드와 함께 사용할 수 있습니다! 자세한 내용은 [토크나이저 페이지](main_classes/tokenizer)를 참조하세요.
| transformers/docs/source/ko/fast_tokenizers.md/0 | {
"file_path": "transformers/docs/source/ko/fast_tokenizers.md",
"repo_id": "transformers",
"token_count": 1829
} | 33 |
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# CPU에서 효율적인 추론하기 [[efficient-inference-on-cpu]]
이 가이드는 CPU에서 대규모 모델을 효율적으로 추론하는 방법에 중점을 두고 있습니다.
## 더 빠른 추론을 위한 `BetterTransformer` [[bettertransformer-for-faster-inference]]
우리는 최근 CPU에서 텍스트, 이미지 및 오디오 모델의 빠른 추론을 위해 `BetterTransformer`를 통합했습니다. 이 통합에 대한 더 자세한 내용은 [이 문서](https://huggingface.co/docs/optimum/bettertransformer/overview)를 참조하세요.
## PyTorch JIT 모드 (TorchScript) [[pytorch-jitmode-torchscript]]
TorchScript는 PyTorch 코드에서 직렬화와 최적화가 가능한 모델을 생성할때 쓰입니다. TorchScript로 만들어진 프로그램은 기존 Python 프로세스에서 저장한 뒤, 종속성이 없는 새로운 프로세스로 가져올 수 있습니다. PyTorch의 기본 설정인 `eager` 모드와 비교했을때, `jit` 모드는 연산자 결합과 같은 최적화 방법론을 통해 모델 추론에서 대부분 더 나은 성능을 제공합니다.
TorchScript에 대한 친절한 소개는 [PyTorch TorchScript 튜토리얼](https://pytorch.org/tutorials/beginner/Intro_to_TorchScript_tutorial.html#tracing-modules)을 참조하세요.
### JIT 모드와 함께하는 IPEX 그래프 최적화 [[ipex-graph-optimization-with-jitmode]]
Intel® Extension for PyTorch(IPEX)는 Transformers 계열 모델의 jit 모드에서 추가적인 최적화를 제공합니다. jit 모드와 더불어 Intel® Extension for PyTorch(IPEX)를 활용하시길 강력히 권장드립니다. Transformers 모델에서 자주 사용되는 일부 연산자 패턴은 이미 jit 모드 연산자 결합(operator fusion)의 형태로 Intel® Extension for PyTorch(IPEX)에서 지원되고 있습니다. Multi-head-attention, Concat Linear, Linear+Add, Linear+Gelu, Add+LayerNorm 결합 패턴 등이 이용 가능하며 활용했을 때 성능이 우수합니다. 연산자 결합의 이점은 사용자에게 고스란히 전달됩니다. 분석에 따르면, 질의 응답, 텍스트 분류 및 토큰 분류와 같은 가장 인기 있는 NLP 태스크 중 약 70%가 이러한 결합 패턴을 사용하여 Float32 정밀도와 BFloat16 혼합 정밀도 모두에서 성능상의 이점을 얻을 수 있습니다.
[IPEX 그래프 최적화](https://intel.github.io/intel-extension-for-pytorch/cpu/latest/tutorials/features/graph_optimization.html)에 대한 자세한 정보를 확인하세요.
#### IPEX 설치: [[ipex-installation]]
IPEX 배포 주기는 PyTorch를 따라서 이루어집니다. 자세한 정보는 [IPEX 설치 방법](https://intel.github.io/intel-extension-for-pytorch/)을 확인하세요.
### JIT 모드 사용법 [[usage-of-jitmode]]
평가 또는 예측을 위해 Trainer에서 JIT 모드를 사용하려면 Trainer의 명령 인수에 `jit_mode_eval`을 추가해야 합니다.
<Tip warning={true}>
PyTorch의 버전이 1.14.0 이상이라면, jit 모드는 jit.trace에서 dict 입력이 지원되므로, 모든 모델의 예측과 평가가 개선될 수 있습니다.
PyTorch의 버전이 1.14.0 미만이라면, 질의 응답 모델과 같이 forward 매개변수의 순서가 jit.trace의 튜플 입력 순서와 일치하는 모델에 득이 될 수 있습니다. 텍스트 분류 모델과 같이 forward 매개변수 순서가 jit.trace의 튜플 입력 순서와 다른 경우, jit.trace가 실패하며 예외가 발생합니다. 이때 예외상황을 사용자에게 알리기 위해 Logging이 사용됩니다.
</Tip>
[Transformers 질의 응답](https://github.com/huggingface/transformers/tree/main/examples/pytorch/question-answering)의 사용 사례 예시를 참조하세요.
- CPU에서 jit 모드를 사용한 추론:
<pre>python run_qa.py \
--model_name_or_path csarron/bert-base-uncased-squad-v1 \
--dataset_name squad \
--do_eval \
--max_seq_length 384 \
--doc_stride 128 \
--output_dir /tmp/ \
--no_cuda \
<b>--jit_mode_eval </b></pre>
- CPU에서 IPEX와 함께 jit 모드를 사용한 추론:
<pre>python run_qa.py \
--model_name_or_path csarron/bert-base-uncased-squad-v1 \
--dataset_name squad \
--do_eval \
--max_seq_length 384 \
--doc_stride 128 \
--output_dir /tmp/ \
--no_cuda \
<b>--use_ipex \</b>
<b>--jit_mode_eval</b></pre>
| transformers/docs/source/ko/perf_infer_cpu.md/0 | {
"file_path": "transformers/docs/source/ko/perf_infer_cpu.md",
"repo_id": "transformers",
"token_count": 3075
} | 34 |
- sections:
- local: index
title: 🤗 Transformers
- local: quicktour
title: Lawatan cepat
- local: installation
title: Pemasangan
title: Mulakan
- sections:
- local: pipeline_tutorial
title: Jalankan inferens dengan saluran paip
- local: autoclass_tutorial
title: Tulis kod mudah alih dengan AutoClass
- local: preprocessing
title: Praproses data
- local: training
title: Perhalusi model yang telah dilatih
- local: run_scripts
title: Latih dengan skrip
- local: accelerate
title: Sediakan latihan yang diedarkan dengan 🤗 Accelerate
- local: model_sharing
title: Kongsi model anda
- local: transformers_agents
title: Ejen
title: Tutorials
- sections:
- sections:
- local: tasks/sequence_classification
title: Klasifikasi teks
- local: tasks/token_classification
title: Klasifikasi token
- local: tasks/question_answering
title: Soalan menjawab
- local: tasks/language_modeling
title: Pemodelan bahasa sebab-akibat
- local: tasks/masked_language_modeling
title: Pemodelan bahasa Masked
- local: tasks/translation
title: Terjemahan
- local: tasks/summarization
title: Rumusan
- local: tasks/multiple_choice
title: Pilihan
title: Natural Language Processing
isExpanded: false
- sections:
- local: tasks/audio_classification
title: Klasifikasi audio
- local: tasks/asr
title: Pengecaman pertuturan automatik
title: Audio
isExpanded: false
- sections:
- local: tasks/image_classification
title: Klasifikasi imej
- local: tasks/semantic_segmentation
title: Segmentasi semantik
- local: tasks/video_classification
title: Klasifikasi video
- local: tasks/object_detection
title: Pengesanan objek
- local: tasks/zero_shot_object_detection
title: Pengesanan objek Zero-Shot
- local: tasks/zero_shot_image_classification
title: Klasifikasi imej tangkapan Zero-Shot
- local: tasks/monocular_depth_estimation
title: Anggaran kedalaman
title: Visi komputer
isExpanded: false
- sections:
- local: tasks/image_captioning
title: Kapsyen imej
- local: tasks/document_question_answering
title: Menjawab Soalan Dokumen
- local: tasks/text-to-speech
title: Teks kepada ucapan
title: Multimodal
isExpanded: false
title: Panduan Tugasan
- sections:
- local: fast_tokenizers
title: Gunakan tokenizer cepat dari 🤗 Tokenizers
- local: multilingual
title: Jalankan inferens dengan model berbilang bahasa
- local: generation_strategies
title: Sesuaikan strategi penjanaan teks
- local: create_a_model
title: Gunakan API khusus model
- local: custom_models
title: Kongsi model tersuai
- local: sagemaker
title: Jalankan latihan di Amazon SageMaker
- local: serialization
title: Eksport ke ONNX
- local: torchscript
title: Eksport ke TorchScript
- local: benchmarks
title: Penanda aras
- local: Buku nota dengan contoh
title: Notebooks with examples
- local: Sumber komuniti
title: Community resources
- local: Sumber komuniti
title: Custom Tools and Prompts
- local: Alat dan Gesaan Tersuai
title: Selesaikan masalah
title: Panduan Developer
- sections:
- local: performance
title: Gambaran keseluruhan
- local: perf_train_gpu_one
title: Latihan pada satu GPU
- local: perf_train_gpu_many
title: Latihan pada banyak GPU
- local: perf_train_cpu
title: Latihan mengenai CPU
- local: perf_train_cpu_many
title: Latihan pada banyak CPU
- local: perf_train_tpu
title: Latihan mengenai TPU
- local: perf_train_tpu_tf
title: Latihan tentang TPU dengan TensorFlow
- local: perf_train_special
title: Latihan mengenai Perkakasan Khusus
- local: perf_infer_cpu
title: Inferens pada CPU
- local: perf_infer_gpu_one
title: Inferens pada satu GPU
- local: perf_infer_gpu_many
title: Inferens pada banyak GPUs
- local: perf_infer_special
title: Inferens pada Perkakasan Khusus
- local: perf_hardware
title: Perkakasan tersuai untuk latihan
- local: big_models
title: Menghidupkan model besar
- local: debugging
title: Penyahpepijatan
- local: hpo_train
title: Carian Hiperparameter menggunakan API Pelatih
- local: tf_xla
title: Penyepaduan XLA untuk Model TensorFlow
title: Prestasi dan kebolehskalaan
- sections:
- local: contributing
title: Bagaimana untuk menyumbang kepada transformer?
- local: add_new_model
title: Bagaimana untuk menambah model pada 🤗 Transformers?
- local: add_tensorflow_model
title: Bagaimana untuk menukar model Transformers kepada TensorFlow?
- local: add_new_pipeline
title: Bagaimana untuk menambah saluran paip ke 🤗 Transformers?
- local: testing
title: Ujian
- local: pr_checks
title: Menyemak Permintaan Tarik
title: Sumbangkan
- sections:
- local: philosophy
title: Falsafah
- local: glossary
title: Glosari
- local: task_summary
title: Apa 🤗 Transformers boleh buat
- local: tasks_explained
title: Bagaimana 🤗 Transformers menyelesaikan tugasan
- local: model_summary
title: Keluarga model Transformer
- local: tokenizer_summary
title: Ringkasan tokenizer
- local: attention
title: Mekanisme perhatian
- local: pad_truncation
title: Padding dan pemotongan
- local: bertology
title: BERTology
- local: perplexity
title: Kekeliruan model panjang tetap
- local: pipeline_webserver
title: Saluran paip untuk inferens pelayan web
title: Panduan konsep
- sections:
- sections:
- local: main_classes/agent
title: Ejen dan Alat
- local: model_doc/auto
title: Kelas Auto
- local: main_classes/callback
title: Panggilan balik
- local: main_classes/configuration
title: Configuration
- local: main_classes/data_collator
title: Data Collator
- local: main_classes/keras_callbacks
title: Keras callbacks
- local: main_classes/logging
title: Logging
- local: main_classes/model
title: Models
- local: main_classes/text_generation
title: Text Generation
- local: main_classes/onnx
title: ONNX
- local: main_classes/optimizer_schedules
title: Optimization
- local: main_classes/output
title: Model outputs
- local: main_classes/pipelines
title: Pipelines
- local: main_classes/processors
title: Processors
- local: main_classes/quantization
title: Quantization
- local: main_classes/tokenizer
title: Tokenizer
- local: main_classes/trainer
title: Trainer
- local: main_classes/deepspeed
title: DeepSpeed Integration
- local: main_classes/feature_extractor
title: Feature Extractor
- local: main_classes/image_processor
title: Image Processor
title: Main Classes
- sections:
- isExpanded: false
sections:
- local: model_doc/albert
title: ALBERT
- local: model_doc/bart
title: BART
- local: model_doc/barthez
title: BARThez
- local: model_doc/bartpho
title: BARTpho
- local: model_doc/bert
title: BERT
- local: model_doc/bert-generation
title: BertGeneration
- local: model_doc/bert-japanese
title: BertJapanese
- local: model_doc/bertweet
title: Bertweet
- local: model_doc/big_bird
title: BigBird
- local: model_doc/bigbird_pegasus
title: BigBirdPegasus
- local: model_doc/biogpt
title: BioGpt
- local: model_doc/blenderbot
title: Blenderbot
- local: model_doc/blenderbot-small
title: Blenderbot Small
- local: model_doc/bloom
title: BLOOM
- local: model_doc/bort
title: BORT
- local: model_doc/byt5
title: ByT5
- local: model_doc/camembert
title: CamemBERT
- local: model_doc/canine
title: CANINE
- local: model_doc/codegen
title: CodeGen
- local: model_doc/convbert
title: ConvBERT
- local: model_doc/cpm
title: CPM
- local: model_doc/cpmant
title: CPMANT
- local: model_doc/ctrl
title: CTRL
- local: model_doc/deberta
title: DeBERTa
- local: model_doc/deberta-v2
title: DeBERTa-v2
- local: model_doc/dialogpt
title: DialoGPT
- local: model_doc/distilbert
title: DistilBERT
- local: model_doc/dpr
title: DPR
- local: model_doc/electra
title: ELECTRA
- local: model_doc/encoder-decoder
title: Encoder Decoder Models
- local: model_doc/ernie
title: ERNIE
- local: model_doc/ernie_m
title: ErnieM
- local: model_doc/esm
title: ESM
- local: model_doc/flan-t5
title: FLAN-T5
- local: model_doc/flan-ul2
title: FLAN-UL2
- local: model_doc/flaubert
title: FlauBERT
- local: model_doc/fnet
title: FNet
- local: model_doc/fsmt
title: FSMT
- local: model_doc/funnel
title: Funnel Transformer
- local: model_doc/openai-gpt
title: GPT
- local: model_doc/gpt_neo
title: GPT Neo
- local: model_doc/gpt_neox
title: GPT NeoX
- local: model_doc/gpt_neox_japanese
title: GPT NeoX Japanese
- local: model_doc/gptj
title: GPT-J
- local: model_doc/gpt2
title: GPT2
- local: model_doc/gpt_bigcode
title: GPTBigCode
- local: model_doc/gptsan-japanese
title: GPTSAN Japanese
- local: model_doc/gpt-sw3
title: GPTSw3
- local: model_doc/herbert
title: HerBERT
- local: model_doc/ibert
title: I-BERT
- local: model_doc/jukebox
title: Jukebox
- local: model_doc/led
title: LED
- local: model_doc/llama
title: LLaMA
- local: model_doc/longformer
title: Longformer
- local: model_doc/longt5
title: LongT5
- local: model_doc/luke
title: LUKE
- local: model_doc/m2m_100
title: M2M100
- local: model_doc/marian
title: MarianMT
- local: model_doc/markuplm
title: MarkupLM
- local: model_doc/mbart
title: MBart and MBart-50
- local: model_doc/mega
title: MEGA
- local: model_doc/megatron-bert
title: MegatronBERT
- local: model_doc/megatron_gpt2
title: MegatronGPT2
- local: model_doc/mluke
title: mLUKE
- local: model_doc/mobilebert
title: MobileBERT
- local: model_doc/mpnet
title: MPNet
- local: model_doc/mt5
title: MT5
- local: model_doc/mvp
title: MVP
- local: model_doc/nezha
title: NEZHA
- local: model_doc/nllb
title: NLLB
- local: model_doc/nllb-moe
title: NLLB-MoE
- local: model_doc/nystromformer
title: Nyströmformer
- local: model_doc/open-llama
title: Open-Llama
- local: model_doc/opt
title: OPT
- local: model_doc/pegasus
title: Pegasus
- local: model_doc/pegasus_x
title: PEGASUS-X
- local: model_doc/phobert
title: PhoBERT
- local: model_doc/plbart
title: PLBart
- local: model_doc/prophetnet
title: ProphetNet
- local: model_doc/qdqbert
title: QDQBert
- local: model_doc/rag
title: RAG
- local: model_doc/realm
title: REALM
- local: model_doc/reformer
title: Reformer
- local: model_doc/rembert
title: RemBERT
- local: model_doc/retribert
title: RetriBERT
- local: model_doc/roberta
title: RoBERTa
- local: model_doc/roberta-prelayernorm
title: RoBERTa-PreLayerNorm
- local: model_doc/roc_bert
title: RoCBert
- local: model_doc/roformer
title: RoFormer
- local: model_doc/rwkv
title: RWKV
- local: model_doc/splinter
title: Splinter
- local: model_doc/squeezebert
title: SqueezeBERT
- local: model_doc/switch_transformers
title: SwitchTransformers
- local: model_doc/t5
title: T5
- local: model_doc/t5v1.1
title: T5v1.1
- local: model_doc/tapex
title: TAPEX
- local: model_doc/transfo-xl
title: Transformer XL
- local: model_doc/ul2
title: UL2
- local: model_doc/xmod
title: X-MOD
- local: model_doc/xglm
title: XGLM
- local: model_doc/xlm
title: XLM
- local: model_doc/xlm-prophetnet
title: XLM-ProphetNet
- local: model_doc/xlm-roberta
title: XLM-RoBERTa
- local: model_doc/xlm-roberta-xl
title: XLM-RoBERTa-XL
- local: model_doc/xlm-v
title: XLM-V
- local: model_doc/xlnet
title: XLNet
- local: model_doc/yoso
title: YOSO
title: Text models
- isExpanded: false
sections:
- local: model_doc/beit
title: BEiT
- local: model_doc/bit
title: BiT
- local: model_doc/conditional_detr
title: Conditional DETR
- local: model_doc/convnext
title: ConvNeXT
- local: model_doc/convnextv2
title: ConvNeXTV2
- local: model_doc/cvt
title: CvT
- local: model_doc/deformable_detr
title: Deformable DETR
- local: model_doc/deit
title: DeiT
- local: model_doc/deta
title: DETA
- local: model_doc/detr
title: DETR
- local: model_doc/dinat
title: DiNAT
- local: model_doc/dit
title: DiT
- local: model_doc/dpt
title: DPT
- local: model_doc/efficientformer
title: EfficientFormer
- local: model_doc/efficientnet
title: EfficientNet
- local: model_doc/focalnet
title: FocalNet
- local: model_doc/glpn
title: GLPN
- local: model_doc/imagegpt
title: ImageGPT
- local: model_doc/levit
title: LeViT
- local: model_doc/mask2former
title: Mask2Former
- local: model_doc/maskformer
title: MaskFormer
- local: model_doc/mobilenet_v1
title: MobileNetV1
- local: model_doc/mobilenet_v2
title: MobileNetV2
- local: model_doc/mobilevit
title: MobileViT
- local: model_doc/nat
title: NAT
- local: model_doc/poolformer
title: PoolFormer
- local: model_doc/regnet
title: RegNet
- local: model_doc/resnet
title: ResNet
- local: model_doc/segformer
title: SegFormer
- local: model_doc/swiftformer
title: SwiftFormer
- local: model_doc/swin
title: Swin Transformer
- local: model_doc/swinv2
title: Swin Transformer V2
- local: model_doc/swin2sr
title: Swin2SR
- local: model_doc/table-transformer
title: Table Transformer
- local: model_doc/timesformer
title: TimeSformer
- local: model_doc/upernet
title: UperNet
- local: model_doc/van
title: VAN
- local: model_doc/videomae
title: VideoMAE
- local: model_doc/vit
title: Vision Transformer (ViT)
- local: model_doc/vit_hybrid
title: ViT Hybrid
- local: model_doc/vit_mae
title: ViTMAE
- local: model_doc/vit_msn
title: ViTMSN
- local: model_doc/yolos
title: YOLOS
title: Vision models
- isExpanded: false
sections:
- local: model_doc/audio-spectrogram-transformer
title: Audio Spectrogram Transformer
- local: model_doc/clap
title: CLAP
- local: model_doc/hubert
title: Hubert
- local: model_doc/mctct
title: MCTCT
- local: model_doc/sew
title: SEW
- local: model_doc/sew-d
title: SEW-D
- local: model_doc/speech_to_text
title: Speech2Text
- local: model_doc/speech_to_text_2
title: Speech2Text2
- local: model_doc/speecht5
title: SpeechT5
- local: model_doc/unispeech
title: UniSpeech
- local: model_doc/unispeech-sat
title: UniSpeech-SAT
- local: model_doc/wav2vec2
title: Wav2Vec2
- local: model_doc/wav2vec2-conformer
title: Wav2Vec2-Conformer
- local: model_doc/wav2vec2_phoneme
title: Wav2Vec2Phoneme
- local: model_doc/wavlm
title: WavLM
- local: model_doc/whisper
title: Whisper
- local: model_doc/xls_r
title: XLS-R
- local: model_doc/xlsr_wav2vec2
title: XLSR-Wav2Vec2
title: Audio models
- isExpanded: false
sections:
- local: model_doc/align
title: ALIGN
- local: model_doc/altclip
title: AltCLIP
- local: model_doc/blip
title: BLIP
- local: model_doc/blip-2
title: BLIP-2
- local: model_doc/bridgetower
title: BridgeTower
- local: model_doc/chinese_clip
title: Chinese-CLIP
- local: model_doc/clip
title: CLIP
- local: model_doc/clipseg
title: CLIPSeg
- local: model_doc/data2vec
title: Data2Vec
- local: model_doc/deplot
title: DePlot
- local: model_doc/donut
title: Donut
- local: model_doc/flava
title: FLAVA
- local: model_doc/git
title: GIT
- local: model_doc/groupvit
title: GroupViT
- local: model_doc/layoutlm
title: LayoutLM
- local: model_doc/layoutlmv2
title: LayoutLMV2
- local: model_doc/layoutlmv3
title: LayoutLMV3
- local: model_doc/layoutxlm
title: LayoutXLM
- local: model_doc/lilt
title: LiLT
- local: model_doc/lxmert
title: LXMERT
- local: model_doc/matcha
title: MatCha
- local: model_doc/mgp-str
title: MGP-STR
- local: model_doc/oneformer
title: OneFormer
- local: model_doc/owlvit
title: OWL-ViT
- local: model_doc/perceiver
title: Perceiver
- local: model_doc/pix2struct
title: Pix2Struct
- local: model_doc/sam
title: Segment Anything
- local: model_doc/speech-encoder-decoder
title: Speech Encoder Decoder Models
- local: model_doc/tapas
title: TAPAS
- local: model_doc/trocr
title: TrOCR
- local: model_doc/tvlt
title: TVLT
- local: model_doc/vilt
title: ViLT
- local: model_doc/vision-encoder-decoder
title: Vision Encoder Decoder Models
- local: model_doc/vision-text-dual-encoder
title: Vision Text Dual Encoder
- local: model_doc/visual_bert
title: VisualBERT
- local: model_doc/xclip
title: X-CLIP
title: Multimodal models
- isExpanded: false
sections:
- local: model_doc/decision_transformer
title: Decision Transformer
- local: model_doc/trajectory_transformer
title: Trajectory Transformer
title: Reinforcement learning models
- isExpanded: false
sections:
- local: model_doc/informer
title: Informer
- local: model_doc/time_series_transformer
title: Time Series Transformer
title: Time series models
- isExpanded: false
sections:
- local: model_doc/graphormer
title: Graphormer
title: Graph models
title: Models
- sections:
- local: internal/modeling_utils
title: Custom Layers and Utilities
- local: internal/pipelines_utils
title: Utilities for pipelines
- local: internal/tokenization_utils
title: Utilities for Tokenizers
- local: internal/trainer_utils
title: Utilities for Trainer
- local: internal/generation_utils
title: Utilities for Generation
- local: internal/image_processing_utils
title: Utilities for Image Processors
- local: internal/audio_utils
title: Utilities for Audio processing
- local: internal/file_utils
title: General Utilities
- local: internal/time_series_utils
title: Utilities for Time Series
title: Internal Helpers
title: API
| transformers/docs/source/ms/_toctree.yml/0 | {
"file_path": "transformers/docs/source/ms/_toctree.yml",
"repo_id": "transformers",
"token_count": 12527
} | 35 |
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# 使用 🤗 Tokenizers 中的分词器
[`PreTrainedTokenizerFast`] 依赖于 [🤗 Tokenizers](https://huggingface.co/docs/tokenizers) 库。从 🤗 Tokenizers 库获得的分词器可以被轻松地加载到 🤗 Transformers 中。
在了解具体内容之前,让我们先用几行代码创建一个虚拟的分词器:
```python
>>> from tokenizers import Tokenizer
>>> from tokenizers.models import BPE
>>> from tokenizers.trainers import BpeTrainer
>>> from tokenizers.pre_tokenizers import Whitespace
>>> tokenizer = Tokenizer(BPE(unk_token="[UNK]"))
>>> trainer = BpeTrainer(special_tokens=["[UNK]", "[CLS]", "[SEP]", "[PAD]", "[MASK]"])
>>> tokenizer.pre_tokenizer = Whitespace()
>>> files = [...]
>>> tokenizer.train(files, trainer)
```
现在,我们拥有了一个针对我们定义的文件进行训练的分词器。我们可以在当前运行时中继续使用它,或者将其保存到一个 JSON 文件以供将来重复使用。
## 直接从分词器对象加载
让我们看看如何利用 🤗 Transformers 库中的这个分词器对象。[`PreTrainedTokenizerFast`] 类允许通过接受已实例化的 *tokenizer* 对象作为参数,进行轻松实例化:
```python
>>> from transformers import PreTrainedTokenizerFast
>>> fast_tokenizer = PreTrainedTokenizerFast(tokenizer_object=tokenizer)
```
现在可以使用这个对象,使用 🤗 Transformers 分词器共享的所有方法!前往[分词器页面](main_classes/tokenizer)了解更多信息。
## 从 JSON 文件加载
为了从 JSON 文件中加载分词器,让我们先保存我们的分词器:
```python
>>> tokenizer.save("tokenizer.json")
```
我们保存此文件的路径可以通过 `tokenizer_file` 参数传递给 [`PreTrainedTokenizerFast`] 初始化方法:
```python
>>> from transformers import PreTrainedTokenizerFast
>>> fast_tokenizer = PreTrainedTokenizerFast(tokenizer_file="tokenizer.json")
```
现在可以使用这个对象,使用 🤗 Transformers 分词器共享的所有方法!前往[分词器页面](main_classes/tokenizer)了解更多信息。
| transformers/docs/source/zh/fast_tokenizers.md/0 | {
"file_path": "transformers/docs/source/zh/fast_tokenizers.md",
"repo_id": "transformers",
"token_count": 1249
} | 36 |
<!---
Copyright 2021 The Google Flax Team Authors and HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
# Question Answering examples
Based on the script [`run_qa.py`](https://github.com/huggingface/transformers/blob/main/examples/flax/question-answering/run_qa.py).
**Note:** This script only works with models that have a fast tokenizer (backed by the 🤗 Tokenizers library) as it
uses special features of those tokenizers. You can check if your favorite model has a fast tokenizer in
[this table](https://huggingface.co/transformers/index.html#supported-frameworks), if it doesn't you can still use the old version
of the script.
The following example fine-tunes BERT on SQuAD:
```bash
python run_qa.py \
--model_name_or_path google-bert/bert-base-uncased \
--dataset_name squad \
--do_train \
--do_eval \
--max_seq_length 384 \
--doc_stride 128 \
--learning_rate 3e-5 \
--num_train_epochs 2 \
--per_device_train_batch_size 12 \
--output_dir ./bert-qa-squad \
--eval_steps 1000 \
--push_to_hub
```
Using the command above, the script will train for 2 epochs and run eval after each epoch.
Metrics and hyperparameters are stored in Tensorflow event files in `--output_dir`.
You can see the results by running `tensorboard` in that directory:
```bash
$ tensorboard --logdir .
```
or directly on the hub under *Training metrics*.
Training with the previously defined hyper-parameters yields the following results:
```bash
f1 = 88.62
exact_match = 81.34
```
sample Metrics - [tfhub.dev](https://tensorboard.dev/experiment/6gU75Hx8TGCnc6tr4ZgI9Q)
Here is an example training on 4 TITAN RTX GPUs and Bert Whole Word Masking uncased model to reach a F1 > 93 on SQuAD1.1:
```bash
export CUDA_VISIBLE_DEVICES=0,1,2,3
python run_qa.py \
--model_name_or_path google-bert/bert-large-uncased-whole-word-masking \
--dataset_name squad \
--do_train \
--do_eval \
--per_device_train_batch_size 6 \
--learning_rate 3e-5 \
--num_train_epochs 2 \
--max_seq_length 384 \
--doc_stride 128 \
--output_dir ./wwm_uncased_finetuned_squad/ \
--eval_steps 1000 \
--push_to_hub
```
Training with the previously defined hyper-parameters yields the following results:
```bash
f1 = 93.31
exact_match = 87.04
```
### Usage notes
Note that when contexts are long they may be split into multiple training cases, not all of which may contain
the answer span.
As-is, the example script will train on SQuAD or any other question-answering dataset formatted the same way, and can handle user
inputs as well.
### Memory usage and data loading
One thing to note is that all data is loaded into memory in this script. Most question answering datasets are small
enough that this is not an issue, but if you have a very large dataset you will need to modify the script to handle
data streaming.
| transformers/examples/flax/question-answering/README.md/0 | {
"file_path": "transformers/examples/flax/question-answering/README.md",
"repo_id": "transformers",
"token_count": 1053
} | 37 |
#!/usr/bin/env python
# coding=utf-8
# Copyright 2021 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
""" Fine-tuning a 🤗 Flax Transformers model on token classification tasks (NER, POS, CHUNKS)"""
import json
import logging
import math
import os
import random
import sys
import time
import warnings
from dataclasses import asdict, dataclass, field
from enum import Enum
from itertools import chain
from pathlib import Path
from typing import Any, Callable, Dict, Optional, Tuple
import datasets
import evaluate
import jax
import jax.numpy as jnp
import numpy as np
import optax
from datasets import ClassLabel, load_dataset
from flax import struct, traverse_util
from flax.jax_utils import pad_shard_unpad, replicate, unreplicate
from flax.training import train_state
from flax.training.common_utils import get_metrics, onehot, shard
from huggingface_hub import Repository, create_repo
from tqdm import tqdm
import transformers
from transformers import (
AutoConfig,
AutoTokenizer,
FlaxAutoModelForTokenClassification,
HfArgumentParser,
is_tensorboard_available,
)
from transformers.utils import check_min_version, send_example_telemetry
from transformers.utils.versions import require_version
logger = logging.getLogger(__name__)
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
check_min_version("4.39.0.dev0")
require_version("datasets>=1.8.0", "To fix: pip install -r examples/pytorch/token-classification/requirements.txt")
Array = Any
Dataset = datasets.arrow_dataset.Dataset
PRNGKey = Any
@dataclass
class TrainingArguments:
output_dir: str = field(
metadata={"help": "The output directory where the model predictions and checkpoints will be written."},
)
overwrite_output_dir: bool = field(
default=False,
metadata={
"help": (
"Overwrite the content of the output directory. "
"Use this to continue training if output_dir points to a checkpoint directory."
)
},
)
do_train: bool = field(default=False, metadata={"help": "Whether to run training."})
do_eval: bool = field(default=False, metadata={"help": "Whether to run eval on the dev set."})
per_device_train_batch_size: int = field(
default=8, metadata={"help": "Batch size per GPU/TPU core/CPU for training."}
)
per_device_eval_batch_size: int = field(
default=8, metadata={"help": "Batch size per GPU/TPU core/CPU for evaluation."}
)
learning_rate: float = field(default=5e-5, metadata={"help": "The initial learning rate for AdamW."})
weight_decay: float = field(default=0.0, metadata={"help": "Weight decay for AdamW if we apply some."})
adam_beta1: float = field(default=0.9, metadata={"help": "Beta1 for AdamW optimizer"})
adam_beta2: float = field(default=0.999, metadata={"help": "Beta2 for AdamW optimizer"})
adam_epsilon: float = field(default=1e-8, metadata={"help": "Epsilon for AdamW optimizer."})
adafactor: bool = field(default=False, metadata={"help": "Whether or not to replace AdamW by Adafactor."})
num_train_epochs: float = field(default=3.0, metadata={"help": "Total number of training epochs to perform."})
warmup_steps: int = field(default=0, metadata={"help": "Linear warmup over warmup_steps."})
logging_steps: int = field(default=500, metadata={"help": "Log every X updates steps."})
save_steps: int = field(default=500, metadata={"help": "Save checkpoint every X updates steps."})
eval_steps: int = field(default=None, metadata={"help": "Run an evaluation every X steps."})
seed: int = field(default=42, metadata={"help": "Random seed that will be set at the beginning of training."})
push_to_hub: bool = field(
default=False, metadata={"help": "Whether or not to upload the trained model to the model hub after training."}
)
hub_model_id: str = field(
default=None, metadata={"help": "The name of the repository to keep in sync with the local `output_dir`."}
)
hub_token: str = field(default=None, metadata={"help": "The token to use to push to the Model Hub."})
def __post_init__(self):
if self.output_dir is not None:
self.output_dir = os.path.expanduser(self.output_dir)
def to_dict(self):
"""
Serializes this instance while replace `Enum` by their values (for JSON serialization support). It obfuscates
the token values by removing their value.
"""
d = asdict(self)
for k, v in d.items():
if isinstance(v, Enum):
d[k] = v.value
if isinstance(v, list) and len(v) > 0 and isinstance(v[0], Enum):
d[k] = [x.value for x in v]
if k.endswith("_token"):
d[k] = f"<{k.upper()}>"
return d
@dataclass
class ModelArguments:
"""
Arguments pertaining to which model/config/tokenizer we are going to fine-tune from.
"""
model_name_or_path: str = field(
metadata={"help": "Path to pretrained model or model identifier from huggingface.co/models"}
)
config_name: Optional[str] = field(
default=None, metadata={"help": "Pretrained config name or path if not the same as model_name"}
)
tokenizer_name: Optional[str] = field(
default=None, metadata={"help": "Pretrained tokenizer name or path if not the same as model_name"}
)
cache_dir: Optional[str] = field(
default=None,
metadata={"help": "Where do you want to store the pretrained models downloaded from huggingface.co"},
)
model_revision: str = field(
default="main",
metadata={"help": "The specific model version to use (can be a branch name, tag name or commit id)."},
)
token: str = field(
default=None,
metadata={
"help": (
"The token to use as HTTP bearer authorization for remote files. If not specified, will use the token "
"generated when running `huggingface-cli login` (stored in `~/.huggingface`)."
)
},
)
use_auth_token: bool = field(
default=None,
metadata={
"help": "The `use_auth_token` argument is deprecated and will be removed in v4.34. Please use `token` instead."
},
)
trust_remote_code: bool = field(
default=False,
metadata={
"help": (
"Whether or not to allow for custom models defined on the Hub in their own modeling files. This option "
"should only be set to `True` for repositories you trust and in which you have read the code, as it will "
"execute code present on the Hub on your local machine."
)
},
)
@dataclass
class DataTrainingArguments:
"""
Arguments pertaining to what data we are going to input our model for training and eval.
"""
task_name: Optional[str] = field(default="ner", metadata={"help": "The name of the task (ner, pos...)."})
dataset_name: Optional[str] = field(
default=None, metadata={"help": "The name of the dataset to use (via the datasets library)."}
)
dataset_config_name: Optional[str] = field(
default=None, metadata={"help": "The configuration name of the dataset to use (via the datasets library)."}
)
train_file: Optional[str] = field(
default=None, metadata={"help": "The input training data file (a csv or JSON file)."}
)
validation_file: Optional[str] = field(
default=None,
metadata={"help": "An optional input evaluation data file to evaluate on (a csv or JSON file)."},
)
test_file: Optional[str] = field(
default=None,
metadata={"help": "An optional input test data file to predict on (a csv or JSON file)."},
)
text_column_name: Optional[str] = field(
default=None, metadata={"help": "The column name of text to input in the file (a csv or JSON file)."}
)
label_column_name: Optional[str] = field(
default=None, metadata={"help": "The column name of label to input in the file (a csv or JSON file)."}
)
overwrite_cache: bool = field(
default=False, metadata={"help": "Overwrite the cached training and evaluation sets"}
)
preprocessing_num_workers: Optional[int] = field(
default=None,
metadata={"help": "The number of processes to use for the preprocessing."},
)
max_seq_length: int = field(
default=None,
metadata={
"help": (
"The maximum total input sequence length after tokenization. If set, sequences longer "
"than this will be truncated, sequences shorter will be padded."
)
},
)
max_train_samples: Optional[int] = field(
default=None,
metadata={
"help": (
"For debugging purposes or quicker training, truncate the number of training examples to this "
"value if set."
)
},
)
max_eval_samples: Optional[int] = field(
default=None,
metadata={
"help": (
"For debugging purposes or quicker training, truncate the number of evaluation examples to this "
"value if set."
)
},
)
max_predict_samples: Optional[int] = field(
default=None,
metadata={
"help": (
"For debugging purposes or quicker training, truncate the number of prediction examples to this "
"value if set."
)
},
)
label_all_tokens: bool = field(
default=False,
metadata={
"help": (
"Whether to put the label for one word on all tokens of generated by that word or just on the "
"one (in which case the other tokens will have a padding index)."
)
},
)
return_entity_level_metrics: bool = field(
default=False,
metadata={"help": "Whether to return all the entity levels during evaluation or just the overall ones."},
)
def __post_init__(self):
if self.dataset_name is None and self.train_file is None and self.validation_file is None:
raise ValueError("Need either a dataset name or a training/validation file.")
else:
if self.train_file is not None:
extension = self.train_file.split(".")[-1]
assert extension in ["csv", "json"], "`train_file` should be a csv or a json file."
if self.validation_file is not None:
extension = self.validation_file.split(".")[-1]
assert extension in ["csv", "json"], "`validation_file` should be a csv or a json file."
self.task_name = self.task_name.lower()
def create_train_state(
model: FlaxAutoModelForTokenClassification,
learning_rate_fn: Callable[[int], float],
num_labels: int,
training_args: TrainingArguments,
) -> train_state.TrainState:
"""Create initial training state."""
class TrainState(train_state.TrainState):
"""Train state with an Optax optimizer.
The two functions below differ depending on whether the task is classification
or regression.
Args:
logits_fn: Applied to last layer to obtain the logits.
loss_fn: Function to compute the loss.
"""
logits_fn: Callable = struct.field(pytree_node=False)
loss_fn: Callable = struct.field(pytree_node=False)
# We use Optax's "masking" functionality to not apply weight decay
# to bias and LayerNorm scale parameters. decay_mask_fn returns a
# mask boolean with the same structure as the parameters.
# The mask is True for parameters that should be decayed.
def decay_mask_fn(params):
flat_params = traverse_util.flatten_dict(params)
# find out all LayerNorm parameters
layer_norm_candidates = ["layernorm", "layer_norm", "ln"]
layer_norm_named_params = {
layer[-2:]
for layer_norm_name in layer_norm_candidates
for layer in flat_params.keys()
if layer_norm_name in "".join(layer).lower()
}
flat_mask = {path: (path[-1] != "bias" and path[-2:] not in layer_norm_named_params) for path in flat_params}
return traverse_util.unflatten_dict(flat_mask)
tx = optax.adamw(
learning_rate=learning_rate_fn,
b1=training_args.adam_beta1,
b2=training_args.adam_beta2,
eps=training_args.adam_epsilon,
weight_decay=training_args.weight_decay,
mask=decay_mask_fn,
)
def cross_entropy_loss(logits, labels):
xentropy = optax.softmax_cross_entropy(logits, onehot(labels, num_classes=num_labels))
return jnp.mean(xentropy)
return TrainState.create(
apply_fn=model.__call__,
params=model.params,
tx=tx,
logits_fn=lambda logits: logits.argmax(-1),
loss_fn=cross_entropy_loss,
)
def create_learning_rate_fn(
train_ds_size: int, train_batch_size: int, num_train_epochs: int, num_warmup_steps: int, learning_rate: float
) -> Callable[[int], jnp.ndarray]:
"""Returns a linear warmup, linear_decay learning rate function."""
steps_per_epoch = train_ds_size // train_batch_size
num_train_steps = steps_per_epoch * num_train_epochs
warmup_fn = optax.linear_schedule(init_value=0.0, end_value=learning_rate, transition_steps=num_warmup_steps)
decay_fn = optax.linear_schedule(
init_value=learning_rate, end_value=0, transition_steps=num_train_steps - num_warmup_steps
)
schedule_fn = optax.join_schedules(schedules=[warmup_fn, decay_fn], boundaries=[num_warmup_steps])
return schedule_fn
def train_data_collator(rng: PRNGKey, dataset: Dataset, batch_size: int):
"""Returns shuffled batches of size `batch_size` from truncated `train dataset`, sharded over all local devices."""
steps_per_epoch = len(dataset) // batch_size
perms = jax.random.permutation(rng, len(dataset))
perms = perms[: steps_per_epoch * batch_size] # Skip incomplete batch.
perms = perms.reshape((steps_per_epoch, batch_size))
for perm in perms:
batch = dataset[perm]
batch = {k: np.array(v) for k, v in batch.items()}
batch = shard(batch)
yield batch
def eval_data_collator(dataset: Dataset, batch_size: int):
"""Returns batches of size `batch_size` from `eval dataset`. Sharding handled by `pad_shard_unpad` in the eval loop."""
batch_idx = np.arange(len(dataset))
steps_per_epoch = math.ceil(len(dataset) / batch_size)
batch_idx = np.array_split(batch_idx, steps_per_epoch)
for idx in batch_idx:
batch = dataset[idx]
batch = {k: np.array(v) for k, v in batch.items()}
yield batch
def main():
# See all possible arguments in src/transformers/training_args.py
# or by passing the --help flag to this script.
# We now keep distinct sets of args, for a cleaner separation of concerns.
parser = HfArgumentParser((ModelArguments, DataTrainingArguments, TrainingArguments))
if len(sys.argv) == 2 and sys.argv[1].endswith(".json"):
# If we pass only one argument to the script and it's the path to a json file,
# let's parse it to get our arguments.
model_args, data_args, training_args = parser.parse_json_file(json_file=os.path.abspath(sys.argv[1]))
else:
model_args, data_args, training_args = parser.parse_args_into_dataclasses()
if model_args.use_auth_token is not None:
warnings.warn(
"The `use_auth_token` argument is deprecated and will be removed in v4.34. Please use `token` instead.",
FutureWarning,
)
if model_args.token is not None:
raise ValueError("`token` and `use_auth_token` are both specified. Please set only the argument `token`.")
model_args.token = model_args.use_auth_token
# Sending telemetry. Tracking the example usage helps us better allocate resources to maintain them. The
# information sent is the one passed as arguments along with your Python/PyTorch versions.
send_example_telemetry("run_ner", model_args, data_args, framework="flax")
# Make one log on every process with the configuration for debugging.
logging.basicConfig(
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
datefmt="%m/%d/%Y %H:%M:%S",
level=logging.INFO,
)
# Setup logging, we only want one process per machine to log things on the screen.
logger.setLevel(logging.INFO if jax.process_index() == 0 else logging.ERROR)
if jax.process_index() == 0:
datasets.utils.logging.set_verbosity_warning()
transformers.utils.logging.set_verbosity_info()
else:
datasets.utils.logging.set_verbosity_error()
transformers.utils.logging.set_verbosity_error()
# Handle the repository creation
if training_args.push_to_hub:
# Retrieve of infer repo_name
repo_name = training_args.hub_model_id
if repo_name is None:
repo_name = Path(training_args.output_dir).absolute().name
# Create repo and retrieve repo_id
repo_id = create_repo(repo_name, exist_ok=True, token=training_args.hub_token).repo_id
# Clone repo locally
repo = Repository(training_args.output_dir, clone_from=repo_id, token=training_args.hub_token)
# Get the datasets: you can either provide your own CSV/JSON/TXT training and evaluation files (see below)
# or just provide the name of one of the public datasets for token classification task available on the hub at https://huggingface.co/datasets/
# (the dataset will be downloaded automatically from the datasets Hub).
#
# For CSV/JSON files, this script will use the column called 'tokens' or the first column if no column called
# 'tokens' is found. You can easily tweak this behavior (see below).
#
# In distributed training, the load_dataset function guarantee that only one local process can concurrently
# download the dataset.
if data_args.dataset_name is not None:
# Downloading and loading a dataset from the hub.
raw_datasets = load_dataset(
data_args.dataset_name,
data_args.dataset_config_name,
cache_dir=model_args.cache_dir,
token=model_args.token,
)
else:
# Loading the dataset from local csv or json file.
data_files = {}
if data_args.train_file is not None:
data_files["train"] = data_args.train_file
if data_args.validation_file is not None:
data_files["validation"] = data_args.validation_file
extension = (data_args.train_file if data_args.train_file is not None else data_args.valid_file).split(".")[-1]
raw_datasets = load_dataset(
extension,
data_files=data_files,
cache_dir=model_args.cache_dir,
token=model_args.token,
)
# See more about loading any type of standard or custom dataset at
# https://huggingface.co/docs/datasets/loading_datasets.
if raw_datasets["train"] is not None:
column_names = raw_datasets["train"].column_names
features = raw_datasets["train"].features
else:
column_names = raw_datasets["validation"].column_names
features = raw_datasets["validation"].features
if data_args.text_column_name is not None:
text_column_name = data_args.text_column_name
elif "tokens" in column_names:
text_column_name = "tokens"
else:
text_column_name = column_names[0]
if data_args.label_column_name is not None:
label_column_name = data_args.label_column_name
elif f"{data_args.task_name}_tags" in column_names:
label_column_name = f"{data_args.task_name}_tags"
else:
label_column_name = column_names[1]
# In the event the labels are not a `Sequence[ClassLabel]`, we will need to go through the dataset to get the
# unique labels.
def get_label_list(labels):
unique_labels = set()
for label in labels:
unique_labels = unique_labels | set(label)
label_list = list(unique_labels)
label_list.sort()
return label_list
if isinstance(features[label_column_name].feature, ClassLabel):
label_list = features[label_column_name].feature.names
# No need to convert the labels since they are already ints.
label_to_id = {i: i for i in range(len(label_list))}
else:
label_list = get_label_list(raw_datasets["train"][label_column_name])
label_to_id = {l: i for i, l in enumerate(label_list)}
num_labels = len(label_list)
# Load pretrained model and tokenizer
config = AutoConfig.from_pretrained(
model_args.config_name if model_args.config_name else model_args.model_name_or_path,
num_labels=num_labels,
label2id=label_to_id,
id2label={i: l for l, i in label_to_id.items()},
finetuning_task=data_args.task_name,
cache_dir=model_args.cache_dir,
revision=model_args.model_revision,
token=model_args.token,
trust_remote_code=model_args.trust_remote_code,
)
tokenizer_name_or_path = model_args.tokenizer_name if model_args.tokenizer_name else model_args.model_name_or_path
if config.model_type in {"gpt2", "roberta"}:
tokenizer = AutoTokenizer.from_pretrained(
tokenizer_name_or_path,
cache_dir=model_args.cache_dir,
revision=model_args.model_revision,
token=model_args.token,
trust_remote_code=model_args.trust_remote_code,
add_prefix_space=True,
)
else:
tokenizer = AutoTokenizer.from_pretrained(
tokenizer_name_or_path,
cache_dir=model_args.cache_dir,
revision=model_args.model_revision,
token=model_args.token,
trust_remote_code=model_args.trust_remote_code,
)
model = FlaxAutoModelForTokenClassification.from_pretrained(
model_args.model_name_or_path,
config=config,
cache_dir=model_args.cache_dir,
revision=model_args.model_revision,
token=model_args.token,
trust_remote_code=model_args.trust_remote_code,
)
# Preprocessing the datasets
# Tokenize all texts and align the labels with them.
def tokenize_and_align_labels(examples):
tokenized_inputs = tokenizer(
examples[text_column_name],
max_length=data_args.max_seq_length,
padding="max_length",
truncation=True,
# We use this argument because the texts in our dataset are lists of words (with a label for each word).
is_split_into_words=True,
)
labels = []
for i, label in enumerate(examples[label_column_name]):
word_ids = tokenized_inputs.word_ids(batch_index=i)
previous_word_idx = None
label_ids = []
for word_idx in word_ids:
# Special tokens have a word id that is None. We set the label to -100 so they are automatically
# ignored in the loss function.
if word_idx is None:
label_ids.append(-100)
# We set the label for the first token of each word.
elif word_idx != previous_word_idx:
label_ids.append(label_to_id[label[word_idx]])
# For the other tokens in a word, we set the label to either the current label or -100, depending on
# the label_all_tokens flag.
else:
label_ids.append(label_to_id[label[word_idx]] if data_args.label_all_tokens else -100)
previous_word_idx = word_idx
labels.append(label_ids)
tokenized_inputs["labels"] = labels
return tokenized_inputs
processed_raw_datasets = raw_datasets.map(
tokenize_and_align_labels,
batched=True,
num_proc=data_args.preprocessing_num_workers,
load_from_cache_file=not data_args.overwrite_cache,
remove_columns=raw_datasets["train"].column_names,
desc="Running tokenizer on dataset",
)
train_dataset = processed_raw_datasets["train"]
eval_dataset = processed_raw_datasets["validation"]
# Log a few random samples from the training set:
for index in random.sample(range(len(train_dataset)), 3):
logger.info(f"Sample {index} of the training set: {train_dataset[index]}.")
# Define a summary writer
has_tensorboard = is_tensorboard_available()
if has_tensorboard and jax.process_index() == 0:
try:
from flax.metrics.tensorboard import SummaryWriter
summary_writer = SummaryWriter(training_args.output_dir)
summary_writer.hparams({**training_args.to_dict(), **vars(model_args), **vars(data_args)})
except ImportError as ie:
has_tensorboard = False
logger.warning(
f"Unable to display metrics through TensorBoard because some package are not installed: {ie}"
)
else:
logger.warning(
"Unable to display metrics through TensorBoard because the package is not installed: "
"Please run pip install tensorboard to enable."
)
def write_train_metric(summary_writer, train_metrics, train_time, step):
summary_writer.scalar("train_time", train_time, step)
train_metrics = get_metrics(train_metrics)
for key, vals in train_metrics.items():
tag = f"train_{key}"
for i, val in enumerate(vals):
summary_writer.scalar(tag, val, step - len(vals) + i + 1)
def write_eval_metric(summary_writer, eval_metrics, step):
for metric_name, value in eval_metrics.items():
summary_writer.scalar(f"eval_{metric_name}", value, step)
num_epochs = int(training_args.num_train_epochs)
rng = jax.random.PRNGKey(training_args.seed)
dropout_rngs = jax.random.split(rng, jax.local_device_count())
train_batch_size = training_args.per_device_train_batch_size * jax.local_device_count()
per_device_eval_batch_size = int(training_args.per_device_eval_batch_size)
eval_batch_size = training_args.per_device_eval_batch_size * jax.local_device_count()
learning_rate_fn = create_learning_rate_fn(
len(train_dataset),
train_batch_size,
training_args.num_train_epochs,
training_args.warmup_steps,
training_args.learning_rate,
)
state = create_train_state(model, learning_rate_fn, num_labels=num_labels, training_args=training_args)
# define step functions
def train_step(
state: train_state.TrainState, batch: Dict[str, Array], dropout_rng: PRNGKey
) -> Tuple[train_state.TrainState, float]:
"""Trains model with an optimizer (both in `state`) on `batch`, returning a pair `(new_state, loss)`."""
dropout_rng, new_dropout_rng = jax.random.split(dropout_rng)
targets = batch.pop("labels")
def loss_fn(params):
logits = state.apply_fn(**batch, params=params, dropout_rng=dropout_rng, train=True)[0]
loss = state.loss_fn(logits, targets)
return loss
grad_fn = jax.value_and_grad(loss_fn)
loss, grad = grad_fn(state.params)
grad = jax.lax.pmean(grad, "batch")
new_state = state.apply_gradients(grads=grad)
metrics = jax.lax.pmean({"loss": loss, "learning_rate": learning_rate_fn(state.step)}, axis_name="batch")
return new_state, metrics, new_dropout_rng
p_train_step = jax.pmap(train_step, axis_name="batch", donate_argnums=(0,))
def eval_step(state, batch):
logits = state.apply_fn(**batch, params=state.params, train=False)[0]
return state.logits_fn(logits)
p_eval_step = jax.pmap(eval_step, axis_name="batch")
metric = evaluate.load("seqeval", cache_dir=model_args.cache_dir)
def get_labels(y_pred, y_true):
# Transform predictions and references tensos to numpy arrays
# Remove ignored index (special tokens)
true_predictions = [
[label_list[p] for (p, l) in zip(pred, gold_label) if l != -100]
for pred, gold_label in zip(y_pred, y_true)
]
true_labels = [
[label_list[l] for (p, l) in zip(pred, gold_label) if l != -100]
for pred, gold_label in zip(y_pred, y_true)
]
return true_predictions, true_labels
def compute_metrics():
results = metric.compute()
if data_args.return_entity_level_metrics:
# Unpack nested dictionaries
final_results = {}
for key, value in results.items():
if isinstance(value, dict):
for n, v in value.items():
final_results[f"{key}_{n}"] = v
else:
final_results[key] = value
return final_results
else:
return {
"precision": results["overall_precision"],
"recall": results["overall_recall"],
"f1": results["overall_f1"],
"accuracy": results["overall_accuracy"],
}
logger.info(f"===== Starting training ({num_epochs} epochs) =====")
train_time = 0
# make sure weights are replicated on each device
state = replicate(state)
train_time = 0
step_per_epoch = len(train_dataset) // train_batch_size
total_steps = step_per_epoch * num_epochs
epochs = tqdm(range(num_epochs), desc=f"Epoch ... (1/{num_epochs})", position=0)
for epoch in epochs:
train_start = time.time()
train_metrics = []
# Create sampling rng
rng, input_rng = jax.random.split(rng)
# train
for step, batch in enumerate(
tqdm(
train_data_collator(input_rng, train_dataset, train_batch_size),
total=step_per_epoch,
desc="Training...",
position=1,
)
):
state, train_metric, dropout_rngs = p_train_step(state, batch, dropout_rngs)
train_metrics.append(train_metric)
cur_step = (epoch * step_per_epoch) + (step + 1)
if cur_step % training_args.logging_steps == 0 and cur_step > 0:
# Save metrics
train_metric = unreplicate(train_metric)
train_time += time.time() - train_start
if has_tensorboard and jax.process_index() == 0:
write_train_metric(summary_writer, train_metrics, train_time, cur_step)
epochs.write(
f"Step... ({cur_step}/{total_steps} | Training Loss: {train_metric['loss']}, Learning Rate:"
f" {train_metric['learning_rate']})"
)
train_metrics = []
if cur_step % training_args.eval_steps == 0 and cur_step > 0:
eval_metrics = {}
# evaluate
for batch in tqdm(
eval_data_collator(eval_dataset, eval_batch_size),
total=math.ceil(len(eval_dataset) / eval_batch_size),
desc="Evaluating ...",
position=2,
):
labels = batch.pop("labels")
predictions = pad_shard_unpad(p_eval_step)(
state, batch, min_device_batch=per_device_eval_batch_size
)
predictions = np.array(predictions)
labels[np.array(chain(*batch["attention_mask"])) == 0] = -100
preds, refs = get_labels(predictions, labels)
metric.add_batch(
predictions=preds,
references=refs,
)
eval_metrics = compute_metrics()
if data_args.return_entity_level_metrics:
logger.info(f"Step... ({cur_step}/{total_steps} | Validation metrics: {eval_metrics}")
else:
logger.info(
f"Step... ({cur_step}/{total_steps} | Validation f1: {eval_metrics['f1']}, Validation Acc:"
f" {eval_metrics['accuracy']})"
)
if has_tensorboard and jax.process_index() == 0:
write_eval_metric(summary_writer, eval_metrics, cur_step)
if (cur_step % training_args.save_steps == 0 and cur_step > 0) or (cur_step == total_steps):
# save checkpoint after each epoch and push checkpoint to the hub
if jax.process_index() == 0:
params = jax.device_get(unreplicate(state.params))
model.save_pretrained(training_args.output_dir, params=params)
tokenizer.save_pretrained(training_args.output_dir)
if training_args.push_to_hub:
repo.push_to_hub(commit_message=f"Saving weights and logs of step {cur_step}", blocking=False)
epochs.desc = f"Epoch ... {epoch + 1}/{num_epochs}"
# Eval after training
if training_args.do_eval:
eval_metrics = {}
eval_loader = eval_data_collator(eval_dataset, eval_batch_size)
for batch in tqdm(eval_loader, total=len(eval_dataset) // eval_batch_size, desc="Evaluating ...", position=2):
labels = batch.pop("labels")
predictions = pad_shard_unpad(p_eval_step)(state, batch, min_device_batch=per_device_eval_batch_size)
predictions = np.array(predictions)
labels[np.array(chain(*batch["attention_mask"])) == 0] = -100
preds, refs = get_labels(predictions, labels)
metric.add_batch(predictions=preds, references=refs)
eval_metrics = compute_metrics()
if jax.process_index() == 0:
eval_metrics = {f"eval_{metric_name}": value for metric_name, value in eval_metrics.items()}
path = os.path.join(training_args.output_dir, "eval_results.json")
with open(path, "w") as f:
json.dump(eval_metrics, f, indent=4, sort_keys=True)
if __name__ == "__main__":
main()
| transformers/examples/flax/token-classification/run_flax_ner.py/0 | {
"file_path": "transformers/examples/flax/token-classification/run_flax_ner.py",
"repo_id": "transformers",
"token_count": 14777
} | 38 |
#!/usr/bin/env bash
# for seqeval metrics import
pip install -r ../requirements.txt
## The relevant files are currently on a shared Google
## drive at https://drive.google.com/drive/folders/1kC0I2UGl2ltrluI9NqDjaQJGw5iliw_J
## Monitor for changes and eventually migrate to use the `datasets` library
curl -L 'https://drive.google.com/uc?export=download&id=1Jjhbal535VVz2ap4v4r_rN1UEHTdLK5P' \
| grep -v "^#" | cut -f 2,3 | tr '\t' ' ' > train.txt.tmp
curl -L 'https://drive.google.com/uc?export=download&id=1ZfRcQThdtAR5PPRjIDtrVP7BtXSCUBbm' \
| grep -v "^#" | cut -f 2,3 | tr '\t' ' ' > dev.txt.tmp
curl -L 'https://drive.google.com/uc?export=download&id=1u9mb7kNJHWQCWyweMDRMuTFoOHOfeBTH' \
| grep -v "^#" | cut -f 2,3 | tr '\t' ' ' > test.txt.tmp
export MAX_LENGTH=128
export BERT_MODEL=bert-base-multilingual-cased
python3 scripts/preprocess.py train.txt.tmp $BERT_MODEL $MAX_LENGTH > train.txt
python3 scripts/preprocess.py dev.txt.tmp $BERT_MODEL $MAX_LENGTH > dev.txt
python3 scripts/preprocess.py test.txt.tmp $BERT_MODEL $MAX_LENGTH > test.txt
cat train.txt dev.txt test.txt | cut -d " " -f 2 | grep -v "^$"| sort | uniq > labels.txt
export BATCH_SIZE=32
export NUM_EPOCHS=3
export SEED=1
export OUTPUT_DIR_NAME=germeval-model
export CURRENT_DIR=${PWD}
export OUTPUT_DIR=${CURRENT_DIR}/${OUTPUT_DIR_NAME}
mkdir -p $OUTPUT_DIR
# Add parent directory to python path to access lightning_base.py
export PYTHONPATH="../":"${PYTHONPATH}"
python3 run_ner.py --data_dir ./ \
--labels ./labels.txt \
--model_name_or_path $BERT_MODEL \
--output_dir $OUTPUT_DIR \
--max_seq_length $MAX_LENGTH \
--num_train_epochs $NUM_EPOCHS \
--train_batch_size $BATCH_SIZE \
--seed $SEED \
--gpus 1 \
--do_train \
--do_predict
| transformers/examples/legacy/pytorch-lightning/run_ner.sh/0 | {
"file_path": "transformers/examples/legacy/pytorch-lightning/run_ner.sh",
"repo_id": "transformers",
"token_count": 724
} | 39 |
# Copyright 2020 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
export TPU_NUM_CORES=8
# the proper usage is documented in the README, you need to specify data_dir, output_dir and model_name_or_path
# run ./finetune_tpu.sh --help to see all the possible options
python xla_spawn.py --num_cores $TPU_NUM_CORES \
finetune_trainer.py \
--learning_rate=3e-5 \
--do_train --do_eval \
--evaluation_strategy steps \
--prediction_loss_only \
--n_val 1000 \
"$@"
| transformers/examples/legacy/seq2seq/finetune_tpu.sh/0 | {
"file_path": "transformers/examples/legacy/seq2seq/finetune_tpu.sh",
"repo_id": "transformers",
"token_count": 323
} | 40 |
#!/usr/bin/env python
# Copyright 2020 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import fire
from torch.utils.data import DataLoader
from tqdm import tqdm
from transformers import AutoTokenizer
from utils import Seq2SeqDataset, pickle_save
def save_len_file(
tokenizer_name, data_dir, max_source_length=1024, max_target_length=1024, consider_target=False, **kwargs
):
"""Save max(src_len, tgt_len) for each example to allow dynamic batching."""
tok = AutoTokenizer.from_pretrained(tokenizer_name)
train_ds = Seq2SeqDataset(tok, data_dir, max_source_length, max_target_length, type_path="train", **kwargs)
pad = tok.pad_token_id
def get_lens(ds):
dl = tqdm(
DataLoader(ds, batch_size=512, num_workers=8, shuffle=False, collate_fn=ds.collate_fn),
desc=str(ds.len_file),
)
max_lens = []
for batch in dl:
src_lens = batch["input_ids"].ne(pad).sum(1).tolist()
tgt_lens = batch["labels"].ne(pad).sum(1).tolist()
if consider_target:
for src, tgt in zip(src_lens, tgt_lens):
max_lens.append(max(src, tgt))
else:
max_lens.extend(src_lens)
return max_lens
train_lens = get_lens(train_ds)
val_ds = Seq2SeqDataset(tok, data_dir, max_source_length, max_target_length, type_path="val", **kwargs)
val_lens = get_lens(val_ds)
pickle_save(train_lens, train_ds.len_file)
pickle_save(val_lens, val_ds.len_file)
if __name__ == "__main__":
fire.Fire(save_len_file)
| transformers/examples/legacy/seq2seq/save_len_file.py/0 | {
"file_path": "transformers/examples/legacy/seq2seq/save_len_file.py",
"repo_id": "transformers",
"token_count": 869
} | 41 |
# Copyright 2020 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
export WANDB_PROJECT=distil-marian
export BS=64
export m=sshleifer/student_marian_en_ro_6_3
export MAX_LEN=128
export TPU_NUM_CORES=8
python xla_spawn.py --num_cores $TPU_NUM_CORES \
finetune_trainer.py \
--tokenizer_name $m --model_name_or_path $m \
--data_dir $ENRO_DIR \
--output_dir marian_en_ro_6_3 --overwrite_output_dir \
--learning_rate=3e-4 \
--warmup_steps 500 \
--per_device_train_batch_size=$BS --per_device_eval_batch_size=$BS \
--freeze_encoder --freeze_embeds \
--num_train_epochs=6 \
--save_steps 500 --eval_steps 500 \
--logging_first_step --logging_steps 200 \
--max_source_length $MAX_LEN --max_target_length $MAX_LEN \
--val_max_target_length $MAX_TGT_LEN --test_max_target_length $MAX_TGT_LEN \
--do_train --do_eval \
--evaluation_strategy steps \
--prediction_loss_only \
--task translation --label_smoothing_factor 0.1 \
"$@"
| transformers/examples/legacy/seq2seq/train_distil_marian_enro_tpu.sh/0 | {
"file_path": "transformers/examples/legacy/seq2seq/train_distil_marian_enro_tpu.sh",
"repo_id": "transformers",
"token_count": 559
} | 42 |
#!/usr/bin/env python
# coding=utf-8
# Copyright 2021 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""
Fine-tuning XLNet for question answering with beam search using 🤗 Accelerate.
"""
# You can also adapt this script on your own question answering task. Pointers for this are left as comments.
import argparse
import json
import logging
import math
import os
import random
from pathlib import Path
import datasets
import evaluate
import numpy as np
import torch
from accelerate import Accelerator
from accelerate.logging import get_logger
from accelerate.utils import set_seed
from datasets import load_dataset
from huggingface_hub import Repository, create_repo
from torch.utils.data import DataLoader
from tqdm.auto import tqdm
from utils_qa import postprocess_qa_predictions_with_beam_search
import transformers
from transformers import (
AdamW,
DataCollatorWithPadding,
EvalPrediction,
SchedulerType,
XLNetConfig,
XLNetForQuestionAnswering,
XLNetTokenizerFast,
default_data_collator,
get_scheduler,
)
from transformers.utils import check_min_version, send_example_telemetry
from transformers.utils.versions import require_version
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
check_min_version("4.39.0.dev0")
require_version("datasets>=1.8.0", "To fix: pip install -r examples/pytorch/question-answering/requirements.txt")
logger = get_logger(__name__)
def save_prefixed_metrics(results, output_dir, file_name: str = "all_results.json", metric_key_prefix: str = "eval"):
"""
Save results while prefixing metric names.
Args:
results: (:obj:`dict`):
A dictionary of results.
output_dir: (:obj:`str`):
An output directory.
file_name: (:obj:`str`, `optional`, defaults to :obj:`all_results.json`):
An output file name.
metric_key_prefix: (:obj:`str`, `optional`, defaults to :obj:`eval`):
A metric name prefix.
"""
# Prefix all keys with metric_key_prefix + '_'
for key in list(results.keys()):
if not key.startswith(f"{metric_key_prefix}_"):
results[f"{metric_key_prefix}_{key}"] = results.pop(key)
with open(os.path.join(output_dir, file_name), "w") as f:
json.dump(results, f, indent=4)
def parse_args():
parser = argparse.ArgumentParser(description="Finetune a transformers model on a Question Answering task")
parser.add_argument(
"--dataset_name",
type=str,
default=None,
help="The name of the dataset to use (via the datasets library).",
)
parser.add_argument(
"--dataset_config_name",
type=str,
default=None,
help="The configuration name of the dataset to use (via the datasets library).",
)
parser.add_argument(
"--train_file", type=str, default=None, help="A csv or a json file containing the training data."
)
parser.add_argument(
"--preprocessing_num_workers", type=int, default=1, help="A csv or a json file containing the training data."
)
parser.add_argument("--do_predict", action="store_true", help="Eval the question answering model")
parser.add_argument(
"--validation_file", type=str, default=None, help="A csv or a json file containing the validation data."
)
parser.add_argument(
"--test_file", type=str, default=None, help="A csv or a json file containing the Prediction data."
)
parser.add_argument(
"--max_seq_length",
type=int,
default=384,
help=(
"The maximum total input sequence length after tokenization. Sequences longer than this will be truncated,"
" sequences shorter will be padded if `--pad_to_max_length` is passed."
),
)
parser.add_argument(
"--pad_to_max_length",
action="store_true",
help="If passed, pad all samples to `max_seq_length`. Otherwise, dynamic padding is used.",
)
parser.add_argument(
"--model_name_or_path",
type=str,
help="Path to pretrained model or model identifier from huggingface.co/models.",
required=True,
)
parser.add_argument(
"--per_device_train_batch_size",
type=int,
default=8,
help="Batch size (per device) for the training dataloader.",
)
parser.add_argument(
"--per_device_eval_batch_size",
type=int,
default=8,
help="Batch size (per device) for the evaluation dataloader.",
)
parser.add_argument(
"--learning_rate",
type=float,
default=5e-5,
help="Initial learning rate (after the potential warmup period) to use.",
)
parser.add_argument("--weight_decay", type=float, default=0.0, help="Weight decay to use.")
parser.add_argument("--num_train_epochs", type=int, default=3, help="Total number of training epochs to perform.")
parser.add_argument(
"--max_train_steps",
type=int,
default=None,
help="Total number of training steps to perform. If provided, overrides num_train_epochs.",
)
parser.add_argument(
"--gradient_accumulation_steps",
type=int,
default=1,
help="Number of updates steps to accumulate before performing a backward/update pass.",
)
parser.add_argument(
"--lr_scheduler_type",
type=SchedulerType,
default="linear",
help="The scheduler type to use.",
choices=["linear", "cosine", "cosine_with_restarts", "polynomial", "constant", "constant_with_warmup"],
)
parser.add_argument(
"--num_warmup_steps", type=int, default=0, help="Number of steps for the warmup in the lr scheduler."
)
parser.add_argument("--output_dir", type=str, default=None, help="Where to store the final model.")
parser.add_argument("--seed", type=int, default=None, help="A seed for reproducible training.")
parser.add_argument(
"--doc_stride",
type=int,
default=128,
help="When splitting up a long document into chunks how much stride to take between chunks.",
)
parser.add_argument(
"--n_best_size",
type=int,
default=20,
help="The total number of n-best predictions to generate when looking for an answer.",
)
parser.add_argument(
"--null_score_diff_threshold",
type=float,
default=0.0,
help=(
"The threshold used to select the null answer: if the best answer has a score that is less than "
"the score of the null answer minus this threshold, the null answer is selected for this example. "
"Only useful when `version_2_with_negative=True`."
),
)
parser.add_argument(
"--version_2_with_negative",
action="store_true",
help="If true, some of the examples do not have an answer.",
)
parser.add_argument(
"--max_answer_length",
type=int,
default=30,
help=(
"The maximum length of an answer that can be generated. This is needed because the start "
"and end predictions are not conditioned on one another."
),
)
parser.add_argument(
"--max_train_samples",
type=int,
default=None,
help=(
"For debugging purposes or quicker training, truncate the number of training examples to this "
"value if set."
),
)
parser.add_argument(
"--max_eval_samples",
type=int,
default=None,
help=(
"For debugging purposes or quicker training, truncate the number of evaluation examples to this "
"value if set."
),
)
parser.add_argument(
"--overwrite_cache", action="store_true", help="Overwrite the cached training and evaluation sets"
)
parser.add_argument(
"--max_predict_samples",
type=int,
default=None,
help="For debugging purposes or quicker training, truncate the number of prediction examples to this",
)
parser.add_argument("--push_to_hub", action="store_true", help="Whether or not to push the model to the Hub.")
parser.add_argument(
"--hub_model_id", type=str, help="The name of the repository to keep in sync with the local `output_dir`."
)
parser.add_argument("--hub_token", type=str, help="The token to use to push to the Model Hub.")
parser.add_argument(
"--checkpointing_steps",
type=str,
default=None,
help="Whether the various states should be saved at the end of every n steps, or 'epoch' for each epoch.",
)
parser.add_argument(
"--resume_from_checkpoint",
type=str,
default=None,
help="If the training should continue from a checkpoint folder.",
)
parser.add_argument(
"--with_tracking",
action="store_true",
help="Whether to load in all available experiment trackers from the environment and use them for logging.",
)
args = parser.parse_args()
# Sanity checks
if (
args.dataset_name is None
and args.train_file is None
and args.validation_file is None
and args.test_file is None
):
raise ValueError("Need either a dataset name or a training/validation/test file.")
else:
if args.train_file is not None:
extension = args.train_file.split(".")[-1]
assert extension in ["csv", "json"], "`train_file` should be a csv or a json file."
if args.validation_file is not None:
extension = args.validation_file.split(".")[-1]
assert extension in ["csv", "json"], "`validation_file` should be a csv or a json file."
if args.test_file is not None:
extension = args.test_file.split(".")[-1]
assert extension in ["csv", "json"], "`test_file` should be a csv or a json file."
if args.push_to_hub:
assert args.output_dir is not None, "Need an `output_dir` to create a repo when `--push_to_hub` is passed."
return args
def main():
args = parse_args()
# Sending telemetry. Tracking the example usage helps us better allocate resources to maintain them. The
# information sent is the one passed as arguments along with your Python/PyTorch versions.
send_example_telemetry("run_qa_beam_search_no_trainer", args)
# Initialize the accelerator. We will let the accelerator handle device placement for us in this example.
# If we're using tracking, we also need to initialize it here and it will pick up all supported trackers
# in the environment
accelerator_log_kwargs = {}
if args.with_tracking:
accelerator_log_kwargs["log_with"] = args.report_to
accelerator_log_kwargs["project_dir"] = args.output_dir
accelerator = Accelerator(gradient_accumulation_steps=args.gradient_accumulation_steps, **accelerator_log_kwargs)
# Make one log on every process with the configuration for debugging.
logging.basicConfig(
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
datefmt="%m/%d/%Y %H:%M:%S",
level=logging.INFO,
)
logger.info(accelerator.state, main_process_only=False)
if accelerator.is_local_main_process:
datasets.utils.logging.set_verbosity_warning()
transformers.utils.logging.set_verbosity_info()
else:
datasets.utils.logging.set_verbosity_error()
transformers.utils.logging.set_verbosity_error()
# If passed along, set the training seed now.
if args.seed is not None:
set_seed(args.seed)
# Handle the repository creation
if accelerator.is_main_process:
if args.push_to_hub:
# Retrieve of infer repo_name
repo_name = args.hub_model_id
if repo_name is None:
repo_name = Path(args.output_dir).absolute().name
# Create repo and retrieve repo_id
repo_id = create_repo(repo_name, exist_ok=True, token=args.hub_token).repo_id
# Clone repo locally
repo = Repository(args.output_dir, clone_from=repo_id, token=args.hub_token)
with open(os.path.join(args.output_dir, ".gitignore"), "w+") as gitignore:
if "step_*" not in gitignore:
gitignore.write("step_*\n")
if "epoch_*" not in gitignore:
gitignore.write("epoch_*\n")
elif args.output_dir is not None:
os.makedirs(args.output_dir, exist_ok=True)
accelerator.wait_for_everyone()
# Get the datasets: you can either provide your own CSV/JSON/TXT training and evaluation files (see below)
# or just provide the name of one of the public datasets available on the hub at https://huggingface.co/datasets/
# (the dataset will be downloaded automatically from the datasets Hub).
#
# For CSV/JSON files, this script will use the column called 'text' or the first column if no column called
# 'text' is found. You can easily tweak this behavior (see below).
#
# In distributed training, the load_dataset function guarantee that only one local process can concurrently
# download the dataset.
if args.dataset_name is not None:
# Downloading and loading a dataset from the hub.
raw_datasets = load_dataset(args.dataset_name, args.dataset_config_name)
else:
data_files = {}
if args.train_file is not None:
data_files["train"] = args.train_file
extension = args.train_file.split(".")[-1]
if args.validation_file is not None:
data_files["validation"] = args.validation_file
extension = args.validation_file.split(".")[-1]
if args.test_file is not None:
data_files["test"] = args.test_file
extension = args.test_file.split(".")[-1]
raw_datasets = load_dataset(extension, data_files=data_files, field="data")
# See more about loading any type of standard or custom dataset (from files, python dict, pandas DataFrame, etc) at
# https://huggingface.co/docs/datasets/loading_datasets.
# Load pretrained model and tokenizer
#
# In distributed training, the .from_pretrained methods guarantee that only one local process can concurrently
# download model & vocab.
config = XLNetConfig.from_pretrained(args.model_name_or_path)
tokenizer = XLNetTokenizerFast.from_pretrained(args.model_name_or_path)
model = XLNetForQuestionAnswering.from_pretrained(
args.model_name_or_path, from_tf=bool(".ckpt" in args.model_name_or_path), config=config
)
# Preprocessing the datasets.
# Preprocessing is slightly different for training and evaluation.
column_names = raw_datasets["train"].column_names
question_column_name = "question" if "question" in column_names else column_names[0]
context_column_name = "context" if "context" in column_names else column_names[1]
answer_column_name = "answers" if "answers" in column_names else column_names[2]
# Padding side determines if we do (question|context) or (context|question).
pad_on_right = tokenizer.padding_side == "right"
if args.max_seq_length > tokenizer.model_max_length:
logger.warning(
f"The max_seq_length passed ({args.max_seq_length}) is larger than the maximum length for the "
f"model ({tokenizer.model_max_length}). Using max_seq_length={tokenizer.model_max_length}."
)
max_seq_length = min(args.max_seq_length, tokenizer.model_max_length)
# Training preprocessing
def prepare_train_features(examples):
# Some of the questions have lots of whitespace on the left, which is not useful and will make the
# truncation of the context fail (the tokenized question will take a lots of space). So we remove that
# left whitespace
examples[question_column_name] = [q.lstrip() for q in examples[question_column_name]]
# Tokenize our examples with truncation and maybe padding, but keep the overflows using a stride. This results
# in one example possible giving several features when a context is long, each of those features having a
# context that overlaps a bit the context of the previous feature.
tokenized_examples = tokenizer(
examples[question_column_name if pad_on_right else context_column_name],
examples[context_column_name if pad_on_right else question_column_name],
truncation="only_second" if pad_on_right else "only_first",
max_length=max_seq_length,
stride=args.doc_stride,
return_overflowing_tokens=True,
return_offsets_mapping=True,
return_special_tokens_mask=True,
return_token_type_ids=True,
padding="max_length",
)
# Since one example might give us several features if it has a long context, we need a map from a feature to
# its corresponding example. This key gives us just that.
sample_mapping = tokenized_examples.pop("overflow_to_sample_mapping")
# The offset mappings will give us a map from token to character position in the original context. This will
# help us compute the start_positions and end_positions.
offset_mapping = tokenized_examples.pop("offset_mapping")
# The special tokens will help us build the p_mask (which indicates the tokens that can't be in answers).
special_tokens = tokenized_examples.pop("special_tokens_mask")
# Let's label those examples!
tokenized_examples["start_positions"] = []
tokenized_examples["end_positions"] = []
tokenized_examples["is_impossible"] = []
tokenized_examples["cls_index"] = []
tokenized_examples["p_mask"] = []
for i, offsets in enumerate(offset_mapping):
# We will label impossible answers with the index of the CLS token.
input_ids = tokenized_examples["input_ids"][i]
cls_index = input_ids.index(tokenizer.cls_token_id)
tokenized_examples["cls_index"].append(cls_index)
# Grab the sequence corresponding to that example (to know what is the context and what is the question).
sequence_ids = tokenized_examples["token_type_ids"][i]
for k, s in enumerate(special_tokens[i]):
if s:
sequence_ids[k] = 3
context_idx = 1 if pad_on_right else 0
# Build the p_mask: non special tokens and context gets 0.0, the others get 1.0.
# The cls token gets 1.0 too (for predictions of empty answers).
tokenized_examples["p_mask"].append(
[
0.0 if (not special_tokens[i][k] and s == context_idx) or k == cls_index else 1.0
for k, s in enumerate(sequence_ids)
]
)
# One example can give several spans, this is the index of the example containing this span of text.
sample_index = sample_mapping[i]
answers = examples[answer_column_name][sample_index]
# If no answers are given, set the cls_index as answer.
if len(answers["answer_start"]) == 0:
tokenized_examples["start_positions"].append(cls_index)
tokenized_examples["end_positions"].append(cls_index)
tokenized_examples["is_impossible"].append(1.0)
else:
# Start/end character index of the answer in the text.
start_char = answers["answer_start"][0]
end_char = start_char + len(answers["text"][0])
# Start token index of the current span in the text.
token_start_index = 0
while sequence_ids[token_start_index] != context_idx:
token_start_index += 1
# End token index of the current span in the text.
token_end_index = len(input_ids) - 1
while sequence_ids[token_end_index] != context_idx:
token_end_index -= 1
# Detect if the answer is out of the span (in which case this feature is labeled with the CLS index).
if not (offsets[token_start_index][0] <= start_char and offsets[token_end_index][1] >= end_char):
tokenized_examples["start_positions"].append(cls_index)
tokenized_examples["end_positions"].append(cls_index)
tokenized_examples["is_impossible"].append(1.0)
else:
# Otherwise move the token_start_index and token_end_index to the two ends of the answer.
# Note: we could go after the last offset if the answer is the last word (edge case).
while token_start_index < len(offsets) and offsets[token_start_index][0] <= start_char:
token_start_index += 1
tokenized_examples["start_positions"].append(token_start_index - 1)
while offsets[token_end_index][1] >= end_char:
token_end_index -= 1
tokenized_examples["end_positions"].append(token_end_index + 1)
tokenized_examples["is_impossible"].append(0.0)
return tokenized_examples
if "train" not in raw_datasets:
raise ValueError("--do_train requires a train dataset")
train_dataset = raw_datasets["train"]
if args.max_train_samples is not None:
# We will select sample from whole data if argument is specified
train_dataset = train_dataset.select(range(args.max_train_samples))
# Create train feature from dataset
with accelerator.main_process_first():
train_dataset = train_dataset.map(
prepare_train_features,
batched=True,
num_proc=args.preprocessing_num_workers,
remove_columns=column_names,
load_from_cache_file=not args.overwrite_cache,
desc="Running tokenizer on train dataset",
)
if args.max_train_samples is not None:
# Number of samples might increase during Feature Creation, We select only specified max samples
train_dataset = train_dataset.select(range(args.max_train_samples))
# Validation preprocessing
def prepare_validation_features(examples):
# Some of the questions have lots of whitespace on the left, which is not useful and will make the
# truncation of the context fail (the tokenized question will take a lots of space). So we remove that
# left whitespace
examples[question_column_name] = [q.lstrip() for q in examples[question_column_name]]
# Tokenize our examples with truncation and maybe padding, but keep the overflows using a stride. This results
# in one example possible giving several features when a context is long, each of those features having a
# context that overlaps a bit the context of the previous feature.
tokenized_examples = tokenizer(
examples[question_column_name if pad_on_right else context_column_name],
examples[context_column_name if pad_on_right else question_column_name],
truncation="only_second" if pad_on_right else "only_first",
max_length=max_seq_length,
stride=args.doc_stride,
return_overflowing_tokens=True,
return_offsets_mapping=True,
return_special_tokens_mask=True,
return_token_type_ids=True,
padding="max_length",
)
# Since one example might give us several features if it has a long context, we need a map from a feature to
# its corresponding example. This key gives us just that.
sample_mapping = tokenized_examples.pop("overflow_to_sample_mapping")
# The special tokens will help us build the p_mask (which indicates the tokens that can't be in answers).
special_tokens = tokenized_examples.pop("special_tokens_mask")
# For evaluation, we will need to convert our predictions to substrings of the context, so we keep the
# corresponding example_id and we will store the offset mappings.
tokenized_examples["example_id"] = []
# We still provide the index of the CLS token and the p_mask to the model, but not the is_impossible label.
tokenized_examples["cls_index"] = []
tokenized_examples["p_mask"] = []
for i, input_ids in enumerate(tokenized_examples["input_ids"]):
# Find the CLS token in the input ids.
cls_index = input_ids.index(tokenizer.cls_token_id)
tokenized_examples["cls_index"].append(cls_index)
# Grab the sequence corresponding to that example (to know what is the context and what is the question).
sequence_ids = tokenized_examples["token_type_ids"][i]
for k, s in enumerate(special_tokens[i]):
if s:
sequence_ids[k] = 3
context_idx = 1 if pad_on_right else 0
# Build the p_mask: non special tokens and context gets 0.0, the others 1.0.
tokenized_examples["p_mask"].append(
[
0.0 if (not special_tokens[i][k] and s == context_idx) or k == cls_index else 1.0
for k, s in enumerate(sequence_ids)
]
)
# One example can give several spans, this is the index of the example containing this span of text.
sample_index = sample_mapping[i]
tokenized_examples["example_id"].append(examples["id"][sample_index])
# Set to None the offset_mapping that are not part of the context so it's easy to determine if a token
# position is part of the context or not.
tokenized_examples["offset_mapping"][i] = [
(o if sequence_ids[k] == context_idx else None)
for k, o in enumerate(tokenized_examples["offset_mapping"][i])
]
return tokenized_examples
if "validation" not in raw_datasets:
raise ValueError("--do_eval requires a validation dataset")
eval_examples = raw_datasets["validation"]
if args.max_eval_samples is not None:
# We will select sample from whole data
eval_examples = eval_examples.select(range(args.max_eval_samples))
# Validation Feature Creation
with accelerator.main_process_first():
eval_dataset = eval_examples.map(
prepare_validation_features,
batched=True,
num_proc=args.preprocessing_num_workers,
remove_columns=column_names,
load_from_cache_file=not args.overwrite_cache,
desc="Running tokenizer on validation dataset",
)
if args.max_eval_samples is not None:
# During Feature creation dataset samples might increase, we will select required samples again
eval_dataset = eval_dataset.select(range(args.max_eval_samples))
if args.do_predict:
if "test" not in raw_datasets:
raise ValueError("--do_predict requires a test dataset")
predict_examples = raw_datasets["test"]
if args.max_predict_samples is not None:
# We will select sample from whole data
predict_examples = predict_examples.select(range(args.max_predict_samples))
# Predict Feature Creation
with accelerator.main_process_first():
predict_dataset = predict_examples.map(
prepare_validation_features,
batched=True,
num_proc=args.preprocessing_num_workers,
remove_columns=column_names,
load_from_cache_file=not args.overwrite_cache,
desc="Running tokenizer on prediction dataset",
)
if args.max_predict_samples is not None:
# During Feature creation dataset samples might increase, we will select required samples again
predict_dataset = predict_dataset.select(range(args.max_predict_samples))
# Log a few random samples from the training set:
for index in random.sample(range(len(train_dataset)), 3):
logger.info(f"Sample {index} of the training set: {train_dataset[index]}.")
# DataLoaders creation:
if args.pad_to_max_length:
# If padding was already done ot max length, we use the default data collator that will just convert everything
# to tensors.
data_collator = default_data_collator
else:
# Otherwise, `DataCollatorWithPadding` will apply dynamic padding for us (by padding to the maximum length of
# the samples passed). When using mixed precision, we add `pad_to_multiple_of=8` to pad all tensors to multiple
# of 8s, which will enable the use of Tensor Cores on NVIDIA hardware with compute capability >= 7.5 (Volta).
data_collator = DataCollatorWithPadding(tokenizer, pad_to_multiple_of=(8 if accelerator.use_fp16 else None))
train_dataloader = DataLoader(
train_dataset, shuffle=True, collate_fn=data_collator, batch_size=args.per_device_train_batch_size
)
eval_dataset_for_model = eval_dataset.remove_columns(["example_id", "offset_mapping"])
eval_dataloader = DataLoader(
eval_dataset_for_model, collate_fn=data_collator, batch_size=args.per_device_eval_batch_size
)
if args.do_predict:
predict_dataset_for_model = predict_dataset.remove_columns(["example_id", "offset_mapping"])
predict_dataloader = DataLoader(
predict_dataset_for_model, collate_fn=data_collator, batch_size=args.per_device_eval_batch_size
)
# Post-processing:
def post_processing_function(examples, features, predictions, stage="eval"):
# Post-processing: we match the start logits and end logits to answers in the original context.
predictions, scores_diff_json = postprocess_qa_predictions_with_beam_search(
examples=examples,
features=features,
predictions=predictions,
version_2_with_negative=args.version_2_with_negative,
n_best_size=args.n_best_size,
max_answer_length=args.max_answer_length,
start_n_top=model.config.start_n_top,
end_n_top=model.config.end_n_top,
output_dir=args.output_dir,
prefix=stage,
)
# Format the result to the format the metric expects.
if args.version_2_with_negative:
formatted_predictions = [
{"id": k, "prediction_text": v, "no_answer_probability": scores_diff_json[k]}
for k, v in predictions.items()
]
else:
formatted_predictions = [{"id": k, "prediction_text": v} for k, v in predictions.items()]
references = [{"id": ex["id"], "answers": ex[answer_column_name]} for ex in examples]
return EvalPrediction(predictions=formatted_predictions, label_ids=references)
metric = evaluate.load("squad_v2" if args.version_2_with_negative else "squad")
def create_and_fill_np_array(start_or_end_logits, dataset, max_len):
"""
Create and fill numpy array of size len_of_validation_data * max_length_of_output_tensor
Args:
start_or_end_logits(:obj:`tensor`):
This is the output predictions of the model. We can only enter either start or end logits.
eval_dataset: Evaluation dataset
max_len(:obj:`int`):
The maximum length of the output tensor. ( See the model.eval() part for more details )
"""
step = 0
# create a numpy array and fill it with -100.
logits_concat = np.full((len(dataset), max_len), -100, dtype=np.float32)
# Now since we have create an array now we will populate it with the outputs gathered using accelerator.gather_for_metrics
for i, output_logit in enumerate(start_or_end_logits): # populate columns
# We have to fill it such that we have to take the whole tensor and replace it on the newly created array
# And after every iteration we have to change the step
batch_size = output_logit.shape[0]
cols = output_logit.shape[1]
if step + batch_size < len(dataset):
logits_concat[step : step + batch_size, :cols] = output_logit
else:
logits_concat[step:, :cols] = output_logit[: len(dataset) - step]
step += batch_size
return logits_concat
# Optimizer
# Split weights in two groups, one with weight decay and the other not.
no_decay = ["bias", "LayerNorm.weight"]
optimizer_grouped_parameters = [
{
"params": [p for n, p in model.named_parameters() if not any(nd in n for nd in no_decay)],
"weight_decay": args.weight_decay,
},
{
"params": [p for n, p in model.named_parameters() if any(nd in n for nd in no_decay)],
"weight_decay": 0.0,
},
]
optimizer = AdamW(optimizer_grouped_parameters, lr=args.learning_rate)
# Scheduler and math around the number of training steps.
overrode_max_train_steps = False
num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
if args.max_train_steps is None:
args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
overrode_max_train_steps = True
lr_scheduler = get_scheduler(
name=args.lr_scheduler_type,
optimizer=optimizer,
num_warmup_steps=args.num_warmup_steps * accelerator.num_processes,
num_training_steps=args.max_train_steps
if overrode_max_train_steps
else args.max_train_steps * accelerator.num_processes,
)
# Prepare everything with our `accelerator`.
model, optimizer, train_dataloader, eval_dataloader, lr_scheduler = accelerator.prepare(
model, optimizer, train_dataloader, eval_dataloader, lr_scheduler
)
# We need to recalculate our total training steps as the size of the training dataloader may have changed.
num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
if overrode_max_train_steps:
args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
# Afterwards we recalculate our number of training epochs
args.num_train_epochs = math.ceil(args.max_train_steps / num_update_steps_per_epoch)
# Figure out how many steps we should save the Accelerator states
checkpointing_steps = args.checkpointing_steps
if checkpointing_steps is not None and checkpointing_steps.isdigit():
checkpointing_steps = int(checkpointing_steps)
# We need to initialize the trackers we use, and also store our configuration
if args.with_tracking:
experiment_config = vars(args)
# TensorBoard cannot log Enums, need the raw value
experiment_config["lr_scheduler_type"] = experiment_config["lr_scheduler_type"].value
accelerator.init_trackers("qa_beam_search_no_trainer", experiment_config)
# Train!
total_batch_size = args.per_device_train_batch_size * accelerator.num_processes * args.gradient_accumulation_steps
logger.info("***** Running training *****")
logger.info(f" Num examples = {len(train_dataset)}")
logger.info(f" Num Epochs = {args.num_train_epochs}")
logger.info(f" Instantaneous batch size per device = {args.per_device_train_batch_size}")
logger.info(f" Total train batch size (w. parallel, distributed & accumulation) = {total_batch_size}")
logger.info(f" Gradient Accumulation steps = {args.gradient_accumulation_steps}")
logger.info(f" Total optimization steps = {args.max_train_steps}")
# Only show the progress bar once on each machine.
progress_bar = tqdm(range(args.max_train_steps), disable=not accelerator.is_local_main_process)
completed_steps = 0
starting_epoch = 0
# Potentially load in the weights and states from a previous save
if args.resume_from_checkpoint:
if args.resume_from_checkpoint is not None or args.resume_from_checkpoint != "":
checkpoint_path = args.resume_from_checkpoint
path = os.path.basename(args.resume_from_checkpoint)
else:
# Get the most recent checkpoint
dirs = [f.name for f in os.scandir(os.getcwd()) if f.is_dir()]
dirs.sort(key=os.path.getctime)
path = dirs[-1] # Sorts folders by date modified, most recent checkpoint is the last
checkpoint_path = path
path = os.path.basename(checkpoint_path)
accelerator.print(f"Resumed from checkpoint: {checkpoint_path}")
accelerator.load_state(checkpoint_path)
# Extract `epoch_{i}` or `step_{i}`
training_difference = os.path.splitext(path)[0]
if "epoch" in training_difference:
starting_epoch = int(training_difference.replace("epoch_", "")) + 1
resume_step = None
completed_steps = starting_epoch * num_update_steps_per_epoch
else:
# need to multiply `gradient_accumulation_steps` to reflect real steps
resume_step = int(training_difference.replace("step_", "")) * args.gradient_accumulation_steps
starting_epoch = resume_step // len(train_dataloader)
completed_steps = resume_step // args.gradient_accumulation_steps
resume_step -= starting_epoch * len(train_dataloader)
# update the progress_bar if load from checkpoint
progress_bar.update(completed_steps)
for epoch in range(starting_epoch, args.num_train_epochs):
model.train()
if args.with_tracking:
total_loss = 0
if args.resume_from_checkpoint and epoch == starting_epoch and resume_step is not None:
# We skip the first `n` batches in the dataloader when resuming from a checkpoint
active_dataloader = accelerator.skip_first_batches(train_dataloader, resume_step)
else:
active_dataloader = train_dataloader
for step, batch in enumerate(active_dataloader):
with accelerator.accumulate(model):
outputs = model(**batch)
loss = outputs.loss
# We keep track of the loss at each epoch
if args.with_tracking:
total_loss += loss.detach().float()
accelerator.backward(loss)
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
# Checks if the accelerator has performed an optimization step behind the scenes
if accelerator.sync_gradients:
progress_bar.update(1)
completed_steps += 1
if isinstance(checkpointing_steps, int):
if completed_steps % checkpointing_steps == 0:
accelerator.save_state(f"step_{completed_steps}")
if completed_steps >= args.max_train_steps:
break
if args.push_to_hub and epoch < args.num_train_epochs - 1:
accelerator.wait_for_everyone()
unwrapped_model = accelerator.unwrap_model(model)
unwrapped_model.save_pretrained(
args.output_dir, is_main_process=accelerator.is_main_process, save_function=accelerator.save
)
if accelerator.is_main_process:
tokenizer.save_pretrained(args.output_dir)
repo.push_to_hub(
commit_message=f"Training in progress epoch {epoch}", blocking=False, auto_lfs_prune=True
)
# initialize all lists to collect the batches
all_start_top_log_probs = []
all_start_top_index = []
all_end_top_log_probs = []
all_end_top_index = []
all_cls_logits = []
model.eval()
for step, batch in enumerate(eval_dataloader):
with torch.no_grad():
outputs = model(**batch)
start_top_log_probs = outputs.start_top_log_probs
start_top_index = outputs.start_top_index
end_top_log_probs = outputs.end_top_log_probs
end_top_index = outputs.end_top_index
cls_logits = outputs.cls_logits
if not args.pad_to_max_length: # necessary to pad predictions and labels for being gathered
start_top_log_probs = accelerator.pad_across_processes(start_top_log_probs, dim=1, pad_index=-100)
start_top_index = accelerator.pad_across_processes(start_top_index, dim=1, pad_index=-100)
end_top_log_probs = accelerator.pad_across_processes(end_top_log_probs, dim=1, pad_index=-100)
end_top_index = accelerator.pad_across_processes(end_top_index, dim=1, pad_index=-100)
cls_logits = accelerator.pad_across_processes(cls_logits, dim=1, pad_index=-100)
all_start_top_log_probs.append(accelerator.gather_for_metrics(start_top_log_probs).cpu().numpy())
all_start_top_index.append(accelerator.gather_for_metrics(start_top_index).cpu().numpy())
all_end_top_log_probs.append(accelerator.gather_for_metrics(end_top_log_probs).cpu().numpy())
all_end_top_index.append(accelerator.gather_for_metrics(end_top_index).cpu().numpy())
all_cls_logits.append(accelerator.gather_for_metrics(cls_logits).cpu().numpy())
max_len = max([x.shape[1] for x in all_end_top_log_probs]) # Get the max_length of the tensor
# concatenate all numpy arrays collected above
start_top_log_probs_concat = create_and_fill_np_array(all_start_top_log_probs, eval_dataset, max_len)
start_top_index_concat = create_and_fill_np_array(all_start_top_index, eval_dataset, max_len)
end_top_log_probs_concat = create_and_fill_np_array(all_end_top_log_probs, eval_dataset, max_len)
end_top_index_concat = create_and_fill_np_array(all_end_top_index, eval_dataset, max_len)
cls_logits_concat = np.concatenate(all_cls_logits, axis=0)
# delete the list of numpy arrays
del start_top_log_probs
del start_top_index
del end_top_log_probs
del end_top_index
del cls_logits
outputs_numpy = (
start_top_log_probs_concat,
start_top_index_concat,
end_top_log_probs_concat,
end_top_index_concat,
cls_logits_concat,
)
prediction = post_processing_function(eval_examples, eval_dataset, outputs_numpy)
eval_metric = metric.compute(predictions=prediction.predictions, references=prediction.label_ids)
logger.info(f"Evaluation metrics: {eval_metric}")
if args.do_predict:
# initialize all lists to collect the batches
all_start_top_log_probs = []
all_start_top_index = []
all_end_top_log_probs = []
all_end_top_index = []
all_cls_logits = []
model.eval()
for step, batch in enumerate(predict_dataloader):
with torch.no_grad():
outputs = model(**batch)
start_top_log_probs = outputs.start_top_log_probs
start_top_index = outputs.start_top_index
end_top_log_probs = outputs.end_top_log_probs
end_top_index = outputs.end_top_index
cls_logits = outputs.cls_logits
if not args.pad_to_max_length: # necessary to pad predictions and labels for being gathered
start_top_log_probs = accelerator.pad_across_processes(start_top_log_probs, dim=1, pad_index=-100)
start_top_index = accelerator.pad_across_processes(start_top_index, dim=1, pad_index=-100)
end_top_log_probs = accelerator.pad_across_processes(end_top_log_probs, dim=1, pad_index=-100)
end_top_index = accelerator.pad_across_processes(end_top_index, dim=1, pad_index=-100)
cls_logits = accelerator.pad_across_processes(cls_logits, dim=1, pad_index=-100)
all_start_top_log_probs.append(accelerator.gather_for_metrics(start_top_log_probs).cpu().numpy())
all_start_top_index.append(accelerator.gather_for_metrics(start_top_index).cpu().numpy())
all_end_top_log_probs.append(accelerator.gather_for_metrics(end_top_log_probs).cpu().numpy())
all_end_top_index.append(accelerator.gather_for_metrics(end_top_index).cpu().numpy())
all_cls_logits.append(accelerator.gather_for_metrics(cls_logits).cpu().numpy())
max_len = max([x.shape[1] for x in all_end_top_log_probs]) # Get the max_length of the tensor
# concatenate all numpy arrays collected above
start_top_log_probs_concat = create_and_fill_np_array(all_start_top_log_probs, predict_dataset, max_len)
start_top_index_concat = create_and_fill_np_array(all_start_top_index, predict_dataset, max_len)
end_top_log_probs_concat = create_and_fill_np_array(all_end_top_log_probs, predict_dataset, max_len)
end_top_index_concat = create_and_fill_np_array(all_end_top_index, predict_dataset, max_len)
cls_logits_concat = np.concatenate(all_cls_logits, axis=0)
# delete the list of numpy arrays
del start_top_log_probs
del start_top_index
del end_top_log_probs
del end_top_index
del cls_logits
outputs_numpy = (
start_top_log_probs_concat,
start_top_index_concat,
end_top_log_probs_concat,
end_top_index_concat,
cls_logits_concat,
)
prediction = post_processing_function(predict_examples, predict_dataset, outputs_numpy)
predict_metric = metric.compute(predictions=prediction.predictions, references=prediction.label_ids)
logger.info(f"Predict metrics: {predict_metric}")
if args.with_tracking:
log = {
"squad_v2" if args.version_2_with_negative else "squad": eval_metric,
"train_loss": total_loss,
"epoch": epoch,
"step": completed_steps,
}
if args.do_predict:
log["squad_v2_predict" if args.version_2_with_negative else "squad_predict"] = predict_metric
accelerator.log(log)
if args.checkpointing_steps == "epoch":
accelerator.save_state(f"epoch_{epoch}")
if args.output_dir is not None:
accelerator.wait_for_everyone()
unwrapped_model = accelerator.unwrap_model(model)
unwrapped_model.save_pretrained(
args.output_dir, is_main_process=accelerator.is_main_process, save_function=accelerator.save
)
if accelerator.is_main_process:
tokenizer.save_pretrained(args.output_dir)
if args.push_to_hub:
repo.push_to_hub(commit_message="End of training", auto_lfs_prune=True)
logger.info(json.dumps(eval_metric, indent=4))
save_prefixed_metrics(eval_metric, args.output_dir)
if __name__ == "__main__":
main()
| transformers/examples/pytorch/question-answering/run_qa_beam_search_no_trainer.py/0 | {
"file_path": "transformers/examples/pytorch/question-answering/run_qa_beam_search_no_trainer.py",
"repo_id": "transformers",
"token_count": 19782
} | 43 |
#!/usr/bin/env python
# coding=utf-8
# Copyright 2018 Google AI, Google Brain and Carnegie Mellon University Authors and the HuggingFace Inc. team.
# Copyright (c) 2018, NVIDIA CORPORATION. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
""" Conditional text generation with the auto-regressive models of the library (GPT/GPT-2/CTRL/Transformer-XL/XLNet)
"""
import argparse
import inspect
import logging
from typing import Tuple
import torch
from accelerate import PartialState
from accelerate.utils import set_seed
from transformers import (
AutoTokenizer,
BloomForCausalLM,
BloomTokenizerFast,
CTRLLMHeadModel,
CTRLTokenizer,
GenerationMixin,
GPT2LMHeadModel,
GPT2Tokenizer,
GPTJForCausalLM,
LlamaForCausalLM,
LlamaTokenizer,
OpenAIGPTLMHeadModel,
OpenAIGPTTokenizer,
OPTForCausalLM,
TransfoXLLMHeadModel,
TransfoXLTokenizer,
XLMTokenizer,
XLMWithLMHeadModel,
XLNetLMHeadModel,
XLNetTokenizer,
)
from transformers.modeling_outputs import CausalLMOutputWithPast
logging.basicConfig(
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
datefmt="%m/%d/%Y %H:%M:%S",
level=logging.INFO,
)
logger = logging.getLogger(__name__)
MAX_LENGTH = int(10000) # Hardcoded max length to avoid infinite loop
MODEL_CLASSES = {
"gpt2": (GPT2LMHeadModel, GPT2Tokenizer),
"ctrl": (CTRLLMHeadModel, CTRLTokenizer),
"openai-gpt": (OpenAIGPTLMHeadModel, OpenAIGPTTokenizer),
"xlnet": (XLNetLMHeadModel, XLNetTokenizer),
"transfo-xl": (TransfoXLLMHeadModel, TransfoXLTokenizer),
"xlm": (XLMWithLMHeadModel, XLMTokenizer),
"gptj": (GPTJForCausalLM, AutoTokenizer),
"bloom": (BloomForCausalLM, BloomTokenizerFast),
"llama": (LlamaForCausalLM, LlamaTokenizer),
"opt": (OPTForCausalLM, GPT2Tokenizer),
}
# Padding text to help Transformer-XL and XLNet with short prompts as proposed by Aman Rusia
# in https://github.com/rusiaaman/XLNet-gen#methodology
# and https://medium.com/@amanrusia/xlnet-speaks-comparison-to-gpt-2-ea1a4e9ba39e
PREFIX = """In 1991, the remains of Russian Tsar Nicholas II and his family
(except for Alexei and Maria) are discovered.
The voice of Nicholas's young son, Tsarevich Alexei Nikolaevich, narrates the
remainder of the story. 1883 Western Siberia,
a young Grigori Rasputin is asked by his father and a group of men to perform magic.
Rasputin has a vision and denounces one of the men as a horse thief. Although his
father initially slaps him for making such an accusation, Rasputin watches as the
man is chased outside and beaten. Twenty years later, Rasputin sees a vision of
the Virgin Mary, prompting him to become a priest. Rasputin quickly becomes famous,
with people, even a bishop, begging for his blessing. <eod> </s> <eos>"""
#
# Functions to prepare models' input
#
def prepare_ctrl_input(args, _, tokenizer, prompt_text):
if args.temperature > 0.7:
logger.info("CTRL typically works better with lower temperatures (and lower top_k).")
encoded_prompt = tokenizer.encode(prompt_text, add_special_tokens=False)
if not any(encoded_prompt[0] == x for x in tokenizer.control_codes.values()):
logger.info("WARNING! You are not starting your generation from a control code so you won't get good results")
return prompt_text
def prepare_xlm_input(args, model, tokenizer, prompt_text):
# kwargs = {"language": None, "mask_token_id": None}
# Set the language
use_lang_emb = hasattr(model.config, "use_lang_emb") and model.config.use_lang_emb
if hasattr(model.config, "lang2id") and use_lang_emb:
available_languages = model.config.lang2id.keys()
if args.xlm_language in available_languages:
language = args.xlm_language
else:
language = None
while language not in available_languages:
language = input("Using XLM. Select language in " + str(list(available_languages)) + " >>> ")
model.config.lang_id = model.config.lang2id[language]
# kwargs["language"] = tokenizer.lang2id[language]
# TODO fix mask_token_id setup when configurations will be synchronized between models and tokenizers
# XLM masked-language modeling (MLM) models need masked token
# is_xlm_mlm = "mlm" in args.model_name_or_path
# if is_xlm_mlm:
# kwargs["mask_token_id"] = tokenizer.mask_token_id
return prompt_text
def prepare_xlnet_input(args, _, tokenizer, prompt_text):
prefix = args.prefix if args.prefix else args.padding_text if args.padding_text else PREFIX
prompt_text = prefix + prompt_text
return prompt_text
def prepare_transfoxl_input(args, _, tokenizer, prompt_text):
prefix = args.prefix if args.prefix else args.padding_text if args.padding_text else PREFIX
prompt_text = prefix + prompt_text
return prompt_text
PREPROCESSING_FUNCTIONS = {
"ctrl": prepare_ctrl_input,
"xlm": prepare_xlm_input,
"xlnet": prepare_xlnet_input,
"transfo-xl": prepare_transfoxl_input,
}
def adjust_length_to_model(length, max_sequence_length):
if length < 0 and max_sequence_length > 0:
length = max_sequence_length
elif 0 < max_sequence_length < length:
length = max_sequence_length # No generation bigger than model size
elif length < 0:
length = MAX_LENGTH # avoid infinite loop
return length
def sparse_model_config(model_config):
embedding_size = None
if hasattr(model_config, "hidden_size"):
embedding_size = model_config.hidden_size
elif hasattr(model_config, "n_embed"):
embedding_size = model_config.n_embed
elif hasattr(model_config, "n_embd"):
embedding_size = model_config.n_embd
num_head = None
if hasattr(model_config, "num_attention_heads"):
num_head = model_config.num_attention_heads
elif hasattr(model_config, "n_head"):
num_head = model_config.n_head
if embedding_size is None or num_head is None or num_head == 0:
raise ValueError("Check the model config")
num_embedding_size_per_head = int(embedding_size / num_head)
if hasattr(model_config, "n_layer"):
num_layer = model_config.n_layer
elif hasattr(model_config, "num_hidden_layers"):
num_layer = model_config.num_hidden_layers
else:
raise ValueError("Number of hidden layers couldn't be determined from the model config")
return num_layer, num_head, num_embedding_size_per_head
def generate_past_key_values(model, batch_size, seq_len):
num_block_layers, num_attention_heads, num_embedding_size_per_head = sparse_model_config(model.config)
if model.config.model_type == "bloom":
past_key_values = tuple(
(
torch.empty(int(num_attention_heads * batch_size), num_embedding_size_per_head, seq_len)
.to(model.dtype)
.to(model.device),
torch.empty(int(num_attention_heads * batch_size), seq_len, num_embedding_size_per_head)
.to(model.dtype)
.to(model.device),
)
for _ in range(num_block_layers)
)
else:
past_key_values = tuple(
(
torch.empty(batch_size, num_attention_heads, seq_len, num_embedding_size_per_head)
.to(model.dtype)
.to(model.device),
torch.empty(batch_size, num_attention_heads, seq_len, num_embedding_size_per_head)
.to(model.dtype)
.to(model.device),
)
for _ in range(num_block_layers)
)
return past_key_values
def prepare_jit_inputs(inputs, model, tokenizer):
batch_size = len(inputs)
dummy_input = tokenizer.batch_encode_plus(inputs, return_tensors="pt")
dummy_input = dummy_input.to(model.device)
if model.config.use_cache:
dummy_input["past_key_values"] = generate_past_key_values(model, batch_size, 1)
dummy_input["attention_mask"] = torch.cat(
[
torch.zeros(dummy_input["attention_mask"].shape[0], 1)
.to(dummy_input["attention_mask"].dtype)
.to(model.device),
dummy_input["attention_mask"],
],
-1,
)
return dummy_input
class _ModelFallbackWrapper(GenerationMixin):
__slots__ = ("_optimized", "_default")
def __init__(self, optimized, default):
self._optimized = optimized
self._default = default
def __call__(self, *args, **kwargs):
if kwargs["past_key_values"] is None and self._default.config.use_cache:
kwargs["past_key_values"] = generate_past_key_values(self._default, kwargs["input_ids"].shape[0], 0)
kwargs.pop("position_ids", None)
for k in list(kwargs.keys()):
if kwargs[k] is None or isinstance(kwargs[k], bool):
kwargs.pop(k)
outputs = self._optimized(**kwargs)
lm_logits = outputs[0]
past_key_values = outputs[1]
fixed_output = CausalLMOutputWithPast(
loss=None,
logits=lm_logits,
past_key_values=past_key_values,
hidden_states=None,
attentions=None,
)
return fixed_output
def __getattr__(self, item):
return getattr(self._default, item)
def prepare_inputs_for_generation(
self, input_ids, past_key_values=None, inputs_embeds=None, use_cache=None, **kwargs
):
return self._default.prepare_inputs_for_generation(
input_ids, past_key_values=past_key_values, inputs_embeds=inputs_embeds, use_cache=use_cache, **kwargs
)
def _reorder_cache(
self, past_key_values: Tuple[Tuple[torch.Tensor]], beam_idx: torch.Tensor
) -> Tuple[Tuple[torch.Tensor]]:
"""
This function is used to re-order the `past_key_values` cache if [`~PretrainedModel.beam_search`] or
[`~PretrainedModel.beam_sample`] is called. This is required to match `past_key_values` with the correct
beam_idx at every generation step.
"""
return self._default._reorder_cache(past_key_values, beam_idx)
def main():
parser = argparse.ArgumentParser()
parser.add_argument(
"--model_type",
default=None,
type=str,
required=True,
help="Model type selected in the list: " + ", ".join(MODEL_CLASSES.keys()),
)
parser.add_argument(
"--model_name_or_path",
default=None,
type=str,
required=True,
help="Path to pre-trained model or shortcut name selected in the list: " + ", ".join(MODEL_CLASSES.keys()),
)
parser.add_argument("--prompt", type=str, default="")
parser.add_argument("--length", type=int, default=20)
parser.add_argument("--stop_token", type=str, default=None, help="Token at which text generation is stopped")
parser.add_argument(
"--temperature",
type=float,
default=1.0,
help="temperature of 1.0 has no effect, lower tend toward greedy sampling",
)
parser.add_argument(
"--repetition_penalty", type=float, default=1.0, help="primarily useful for CTRL model; in that case, use 1.2"
)
parser.add_argument("--k", type=int, default=0)
parser.add_argument("--p", type=float, default=0.9)
parser.add_argument("--prefix", type=str, default="", help="Text added prior to input.")
parser.add_argument("--padding_text", type=str, default="", help="Deprecated, the use of `--prefix` is preferred.")
parser.add_argument("--xlm_language", type=str, default="", help="Optional language when used with the XLM model.")
parser.add_argument("--seed", type=int, default=42, help="random seed for initialization")
parser.add_argument(
"--use_cpu",
action="store_true",
help="Whether or not to use cpu. If set to False, " "we will use gpu/npu or mps device if available",
)
parser.add_argument("--num_return_sequences", type=int, default=1, help="The number of samples to generate.")
parser.add_argument(
"--fp16",
action="store_true",
help="Whether to use 16-bit (mixed) precision (through NVIDIA apex) instead of 32-bit",
)
parser.add_argument("--jit", action="store_true", help="Whether or not to use jit trace to accelerate inference")
args = parser.parse_args()
# Initialize the distributed state.
distributed_state = PartialState(cpu=args.use_cpu)
logger.warning(f"device: {distributed_state.device}, 16-bits inference: {args.fp16}")
if args.seed is not None:
set_seed(args.seed)
# Initialize the model and tokenizer
try:
args.model_type = args.model_type.lower()
model_class, tokenizer_class = MODEL_CLASSES[args.model_type]
except KeyError:
raise KeyError("the model {} you specified is not supported. You are welcome to add it and open a PR :)")
tokenizer = tokenizer_class.from_pretrained(args.model_name_or_path)
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token
model = model_class.from_pretrained(args.model_name_or_path)
# Set the model to the right device
model.to(distributed_state.device)
if args.fp16:
model.half()
max_seq_length = getattr(model.config, "max_position_embeddings", 0)
args.length = adjust_length_to_model(args.length, max_sequence_length=max_seq_length)
logger.info(args)
prompt_text = args.prompt if args.prompt else input("Model prompt >>> ")
# Different models need different input formatting and/or extra arguments
requires_preprocessing = args.model_type in PREPROCESSING_FUNCTIONS.keys()
if requires_preprocessing:
prepare_input = PREPROCESSING_FUNCTIONS.get(args.model_type)
preprocessed_prompt_text = prepare_input(args, model, tokenizer, prompt_text)
if model.__class__.__name__ in ["TransfoXLLMHeadModel"]:
tokenizer_kwargs = {"add_space_before_punct_symbol": True}
else:
tokenizer_kwargs = {}
encoded_prompt = tokenizer.encode(
preprocessed_prompt_text, add_special_tokens=False, return_tensors="pt", **tokenizer_kwargs
)
else:
prefix = args.prefix if args.prefix else args.padding_text
encoded_prompt = tokenizer.encode(prefix + prompt_text, add_special_tokens=False, return_tensors="pt")
encoded_prompt = encoded_prompt.to(distributed_state.device)
if encoded_prompt.size()[-1] == 0:
input_ids = None
else:
input_ids = encoded_prompt
if args.jit:
jit_input_texts = ["enable jit"]
jit_inputs = prepare_jit_inputs(jit_input_texts, model, tokenizer)
torch._C._jit_set_texpr_fuser_enabled(False)
model.config.return_dict = False
if hasattr(model, "forward"):
sig = inspect.signature(model.forward)
else:
sig = inspect.signature(model.__call__)
jit_inputs = tuple(jit_inputs[key] for key in sig.parameters if jit_inputs.get(key, None) is not None)
traced_model = torch.jit.trace(model, jit_inputs, strict=False)
traced_model = torch.jit.freeze(traced_model.eval())
traced_model(*jit_inputs)
traced_model(*jit_inputs)
model = _ModelFallbackWrapper(traced_model, model)
output_sequences = model.generate(
input_ids=input_ids,
max_length=args.length + len(encoded_prompt[0]),
temperature=args.temperature,
top_k=args.k,
top_p=args.p,
repetition_penalty=args.repetition_penalty,
do_sample=True,
num_return_sequences=args.num_return_sequences,
)
# Remove the batch dimension when returning multiple sequences
if len(output_sequences.shape) > 2:
output_sequences.squeeze_()
generated_sequences = []
for generated_sequence_idx, generated_sequence in enumerate(output_sequences):
print(f"=== GENERATED SEQUENCE {generated_sequence_idx + 1} ===")
generated_sequence = generated_sequence.tolist()
# Decode text
text = tokenizer.decode(generated_sequence, clean_up_tokenization_spaces=True)
# Remove all text after the stop token
text = text[: text.find(args.stop_token) if args.stop_token else None]
# Add the prompt at the beginning of the sequence. Remove the excess text that was used for pre-processing
total_sequence = (
prompt_text + text[len(tokenizer.decode(encoded_prompt[0], clean_up_tokenization_spaces=True)) :]
)
generated_sequences.append(total_sequence)
print(total_sequence)
return generated_sequences
if __name__ == "__main__":
main()
| transformers/examples/pytorch/text-generation/run_generation.py/0 | {
"file_path": "transformers/examples/pytorch/text-generation/run_generation.py",
"repo_id": "transformers",
"token_count": 6877
} | 44 |
# coding=utf-8
# Copyright 2018 The Google AI Language Team Authors and The HuggingFace Inc. team.
# Copyright (c) 2018, NVIDIA CORPORATION. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
""" Finetuning the library models for sequence classification on HANS."""
import logging
import os
from dataclasses import dataclass, field
from typing import Dict, List, Optional
import numpy as np
import torch
from utils_hans import HansDataset, InputFeatures, hans_processors, hans_tasks_num_labels
import transformers
from transformers import (
AutoConfig,
AutoModelForSequenceClassification,
AutoTokenizer,
HfArgumentParser,
Trainer,
TrainingArguments,
default_data_collator,
set_seed,
)
from transformers.trainer_utils import is_main_process
logger = logging.getLogger(__name__)
@dataclass
class ModelArguments:
"""
Arguments pertaining to which model/config/tokenizer we are going to fine-tune from.
"""
model_name_or_path: str = field(
metadata={"help": "Path to pretrained model or model identifier from huggingface.co/models"}
)
config_name: Optional[str] = field(
default=None, metadata={"help": "Pretrained config name or path if not the same as model_name"}
)
tokenizer_name: Optional[str] = field(
default=None, metadata={"help": "Pretrained tokenizer name or path if not the same as model_name"}
)
cache_dir: Optional[str] = field(
default=None,
metadata={"help": "Where do you want to store the pretrained models downloaded from huggingface.co"},
)
@dataclass
class DataTrainingArguments:
"""
Arguments pertaining to what data we are going to input our model for training and eval.
"""
task_name: str = field(
metadata={"help": "The name of the task to train selected in the list: " + ", ".join(hans_processors.keys())}
)
data_dir: str = field(
metadata={"help": "The input data dir. Should contain the .tsv files (or other data files) for the task."}
)
max_seq_length: int = field(
default=128,
metadata={
"help": (
"The maximum total input sequence length after tokenization. Sequences longer "
"than this will be truncated, sequences shorter will be padded."
)
},
)
overwrite_cache: bool = field(
default=False, metadata={"help": "Overwrite the cached training and evaluation sets"}
)
def hans_data_collator(features: List[InputFeatures]) -> Dict[str, torch.Tensor]:
"""
Data collator that removes the "pairID" key if present.
"""
batch = default_data_collator(features)
_ = batch.pop("pairID", None)
return batch
def main():
# See all possible arguments in src/transformers/training_args.py
# or by passing the --help flag to this script.
# We now keep distinct sets of args, for a cleaner separation of concerns.
parser = HfArgumentParser((ModelArguments, DataTrainingArguments, TrainingArguments))
model_args, data_args, training_args = parser.parse_args_into_dataclasses()
if (
os.path.exists(training_args.output_dir)
and os.listdir(training_args.output_dir)
and training_args.do_train
and not training_args.overwrite_output_dir
):
raise ValueError(
f"Output directory ({training_args.output_dir}) already exists and is not empty. Use"
" --overwrite_output_dir to overcome."
)
# Setup logging
logging.basicConfig(
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
datefmt="%m/%d/%Y %H:%M:%S",
level=logging.INFO if training_args.local_rank in [-1, 0] else logging.WARN,
)
logger.warning(
"Process rank: %s, device: %s, n_gpu: %s, distributed training: %s, 16-bits training: %s",
training_args.local_rank,
training_args.device,
training_args.n_gpu,
bool(training_args.local_rank != -1),
training_args.fp16,
)
# Set the verbosity to info of the Transformers logger (on main process only):
if is_main_process(training_args.local_rank):
transformers.utils.logging.set_verbosity_info()
transformers.utils.logging.enable_default_handler()
transformers.utils.logging.enable_explicit_format()
logger.info("Training/evaluation parameters %s", training_args)
# Set seed
set_seed(training_args.seed)
try:
num_labels = hans_tasks_num_labels[data_args.task_name]
except KeyError:
raise ValueError("Task not found: %s" % (data_args.task_name))
# Load pretrained model and tokenizer
#
# Distributed training:
# The .from_pretrained methods guarantee that only one local process can concurrently
# download model & vocab.
config = AutoConfig.from_pretrained(
model_args.config_name if model_args.config_name else model_args.model_name_or_path,
num_labels=num_labels,
finetuning_task=data_args.task_name,
cache_dir=model_args.cache_dir,
)
tokenizer = AutoTokenizer.from_pretrained(
model_args.tokenizer_name if model_args.tokenizer_name else model_args.model_name_or_path,
cache_dir=model_args.cache_dir,
)
model = AutoModelForSequenceClassification.from_pretrained(
model_args.model_name_or_path,
from_tf=bool(".ckpt" in model_args.model_name_or_path),
config=config,
cache_dir=model_args.cache_dir,
)
# Get datasets
train_dataset = (
HansDataset(
data_dir=data_args.data_dir,
tokenizer=tokenizer,
task=data_args.task_name,
max_seq_length=data_args.max_seq_length,
overwrite_cache=data_args.overwrite_cache,
)
if training_args.do_train
else None
)
eval_dataset = (
HansDataset(
data_dir=data_args.data_dir,
tokenizer=tokenizer,
task=data_args.task_name,
max_seq_length=data_args.max_seq_length,
overwrite_cache=data_args.overwrite_cache,
evaluate=True,
)
if training_args.do_eval
else None
)
# Initialize our Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
data_collator=hans_data_collator,
)
# Training
if training_args.do_train:
trainer.train(
model_path=model_args.model_name_or_path if os.path.isdir(model_args.model_name_or_path) else None
)
trainer.save_model()
# For convenience, we also re-save the tokenizer to the same directory,
# so that you can share your model easily on huggingface.co/models =)
if trainer.is_world_master():
tokenizer.save_pretrained(training_args.output_dir)
# Evaluation
if training_args.do_eval:
logger.info("*** Evaluate ***")
output = trainer.predict(eval_dataset)
preds = output.predictions
preds = np.argmax(preds, axis=1)
pair_ids = [ex.pairID for ex in eval_dataset]
output_eval_file = os.path.join(training_args.output_dir, "hans_predictions.txt")
label_list = eval_dataset.get_labels()
if trainer.is_world_master():
with open(output_eval_file, "w") as writer:
writer.write("pairID,gold_label\n")
for pid, pred in zip(pair_ids, preds):
writer.write("ex" + str(pid) + "," + label_list[int(pred)] + "\n")
trainer._log(output.metrics)
def _mp_fn(index):
# For xla_spawn (TPUs)
main()
if __name__ == "__main__":
main()
| transformers/examples/research_projects/adversarial/run_hans.py/0 | {
"file_path": "transformers/examples/research_projects/adversarial/run_hans.py",
"repo_id": "transformers",
"token_count": 3302
} | 45 |
# coding=utf-8
# Copyright 2019 HuggingFace Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import unittest
import numpy as np
import torch
from .utils_summarization import build_mask, compute_token_type_ids, process_story, truncate_or_pad
class SummarizationDataProcessingTest(unittest.TestCase):
def setUp(self):
self.block_size = 10
def test_fit_to_block_sequence_too_small(self):
"""Pad the sequence with 0 if the sequence is smaller than the block size."""
sequence = [1, 2, 3, 4]
expected_output = [1, 2, 3, 4, 0, 0, 0, 0, 0, 0]
self.assertEqual(truncate_or_pad(sequence, self.block_size, 0), expected_output)
def test_fit_to_block_sequence_fit_exactly(self):
"""Do nothing if the sequence is the right size."""
sequence = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
expected_output = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
self.assertEqual(truncate_or_pad(sequence, self.block_size, 0), expected_output)
def test_fit_to_block_sequence_too_big(self):
"""Truncate the sequence if it is too long."""
sequence = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13]
expected_output = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
self.assertEqual(truncate_or_pad(sequence, self.block_size, 0), expected_output)
def test_process_story_no_highlights(self):
"""Processing a story with no highlights returns an empty list for the summary."""
raw_story = """It was the year of Our Lord one thousand seven hundred and
seventy-five.\n\nSpiritual revelations were conceded to England at that
favoured period, as at this."""
_, summary_lines = process_story(raw_story)
self.assertEqual(summary_lines, [])
def test_process_empty_story(self):
"""An empty story returns an empty collection of lines."""
raw_story = ""
story_lines, summary_lines = process_story(raw_story)
self.assertEqual(story_lines, [])
self.assertEqual(summary_lines, [])
def test_process_story_with_missing_period(self):
raw_story = (
"It was the year of Our Lord one thousand seven hundred and "
"seventy-five\n\nSpiritual revelations were conceded to England "
"at that favoured period, as at this.\n@highlight\n\nIt was the best of times"
)
story_lines, summary_lines = process_story(raw_story)
expected_story_lines = [
"It was the year of Our Lord one thousand seven hundred and seventy-five.",
"Spiritual revelations were conceded to England at that favoured period, as at this.",
]
self.assertEqual(expected_story_lines, story_lines)
expected_summary_lines = ["It was the best of times."]
self.assertEqual(expected_summary_lines, summary_lines)
def test_build_mask_no_padding(self):
sequence = torch.tensor([1, 2, 3, 4])
expected = torch.tensor([1, 1, 1, 1])
np.testing.assert_array_equal(build_mask(sequence, 0).numpy(), expected.numpy())
def test_build_mask(self):
sequence = torch.tensor([1, 2, 3, 4, 23, 23, 23])
expected = torch.tensor([1, 1, 1, 1, 0, 0, 0])
np.testing.assert_array_equal(build_mask(sequence, 23).numpy(), expected.numpy())
def test_build_mask_with_padding_equal_to_one(self):
sequence = torch.tensor([8, 2, 3, 4, 1, 1, 1])
expected = torch.tensor([1, 1, 1, 1, 0, 0, 0])
np.testing.assert_array_equal(build_mask(sequence, 1).numpy(), expected.numpy())
def test_compute_token_type_ids(self):
separator = 101
batch = torch.tensor([[1, 2, 3, 4, 5, 6], [1, 2, 3, 101, 5, 6], [1, 101, 3, 4, 101, 6]])
expected = torch.tensor([[1, 1, 1, 1, 1, 1], [1, 1, 1, 0, 0, 0], [1, 0, 0, 0, 1, 1]])
result = compute_token_type_ids(batch, separator)
np.testing.assert_array_equal(result, expected)
| transformers/examples/research_projects/bertabs/test_utils_summarization.py/0 | {
"file_path": "transformers/examples/research_projects/bertabs/test_utils_summarization.py",
"repo_id": "transformers",
"token_count": 1749
} | 46 |
import gzip
import json
import multiprocessing
import os
import re
import shutil
import time
from pathlib import Path
import numpy as np
from arguments import PreprocessingArguments
from datasets import load_dataset
from huggingface_hub.utils import insecure_hashlib
from minhash_deduplication import deduplicate_dataset
from transformers import AutoTokenizer, HfArgumentParser
PATTERN = re.compile(r"\s+")
def get_hash(example):
"""Get hash of content field."""
return {"hash": insecure_hashlib.md5(re.sub(PATTERN, "", example["content"]).encode("utf-8")).hexdigest()}
def line_stats(example):
"""Calculates mean and max line length of file."""
line_lengths = [len(line) for line in example["content"].splitlines()]
return {"line_mean": np.mean(line_lengths), "line_max": max(line_lengths)}
def alpha_stats(example):
"""Calculates mean and max line length of file."""
alpha_frac = np.mean([c.isalnum() for c in example["content"]])
return {"alpha_frac": alpha_frac}
def check_uniques(example, uniques):
"""Check if current hash is still in set of unique hashes and remove if true."""
if example["hash"] in uniques:
uniques.remove(example["hash"])
return True
else:
return False
def is_autogenerated(example, scan_width=5):
"""Check if file is autogenerated by looking for keywords in the first few lines of the file."""
keywords = ["auto-generated", "autogenerated", "automatically generated"]
lines = example["content"].splitlines()
for _, line in zip(range(scan_width), lines):
for keyword in keywords:
if keyword in line.lower():
return {"autogenerated": True}
else:
return {"autogenerated": False}
def is_config_or_test(example, scan_width=5, coeff=0.05):
"""Check if file is a configuration file or a unit test by :
1- looking for keywords in the first few lines of the file.
2- counting number of occurrence of the words 'config' and 'test' with respect to number of lines.
"""
keywords = ["unit tests", "test file", "configuration file"]
lines = example["content"].splitlines()
count_config = 0
count_test = 0
# first test
for _, line in zip(range(scan_width), lines):
for keyword in keywords:
if keyword in line.lower():
return {"config_or_test": True}
# second test
nlines = example["content"].count("\n")
threshold = int(coeff * nlines)
for line in lines:
count_config += line.lower().count("config")
count_test += line.lower().count("test")
if count_config > threshold or count_test > threshold:
return {"config_or_test": True}
return {"config_or_test": False}
def has_no_keywords(example):
"""Check if a python file has none of the keywords for: funcion, class, for loop, while loop."""
keywords = ["def ", "class ", "for ", "while "]
lines = example["content"].splitlines()
for line in lines:
for keyword in keywords:
if keyword in line.lower():
return {"has_no_keywords": False}
return {"has_no_keywords": True}
def has_few_assignments(example, minimum=4):
"""Check if file uses symbol '=' less than `minimum` times."""
lines = example["content"].splitlines()
counter = 0
for line in lines:
counter += line.lower().count("=")
if counter > minimum:
return {"has_few_assignments": False}
return {"has_few_assignments": True}
def char_token_ratio(example):
"""Compute character/token ratio of the file with tokenizer."""
input_ids = tokenizer(example["content"], truncation=False)["input_ids"]
ratio = len(example["content"]) / len(input_ids)
return {"ratio": ratio}
def preprocess(example):
"""Chain all preprocessing steps into one function to not fill cache."""
results = {}
results.update(get_hash(example))
results.update(line_stats(example))
results.update(alpha_stats(example))
results.update(char_token_ratio(example))
results.update(is_autogenerated(example))
results.update(is_config_or_test(example))
results.update(has_no_keywords(example))
results.update(has_few_assignments(example))
return results
def filter(example, uniques, args):
"""Filter dataset with heuristics. Config, test and has_no_keywords files are removed with a given probability."""
if not check_uniques(example, uniques):
return False
elif example["autogenerated"]:
return False
elif example["line_max"] > args.line_max:
return False
elif example["line_mean"] > args.line_mean:
return False
elif example["alpha_frac"] < args.alpha_frac:
return False
elif example["ratio"] < args.min_token_ratio:
return False
elif example["config_or_test"] and np.random.rand() <= args.filter_proba:
return False
elif example["has_no_keywords"] and np.random.rand() <= args.filter_proba:
return False
elif example["has_few_assignments"]:
return False
else:
return True
def compress_file(file_path):
"""Compress a file with g-zip."""
with open(file_path, "rb") as f_in:
with gzip.open(str(file_path) + ".gz", "wb", compresslevel=6) as f_out:
shutil.copyfileobj(f_in, f_out)
os.unlink(file_path)
# Settings
parser = HfArgumentParser(PreprocessingArguments)
args = parser.parse_args()
if args.num_workers is None:
args.num_workers = multiprocessing.cpu_count()
tokenizer = AutoTokenizer.from_pretrained(args.tokenizer_dir)
# Load dataset
t_start = time.time()
ds = load_dataset(args.dataset_name, split="train")
print(f"Time to load dataset: {time.time()-t_start:.2f}")
# Run preprocessing
t_start = time.time()
ds = ds.map(preprocess, num_proc=args.num_workers)
print(f"Time to preprocess dataset: {time.time()-t_start:.2f}")
# Deduplicate hashes
uniques = set(ds.unique("hash"))
frac = len(uniques) / len(ds)
print(f"Fraction of duplicates: {1-frac:.2%}")
# Deduplicate data and apply heuristics
t_start = time.time()
ds_filter = ds.filter(filter, fn_kwargs={"uniques": uniques, "args": args})
print(f"Time to filter dataset: {time.time()-t_start:.2f}")
print(f"Size of filtered dataset: {len(ds_filter)}")
# Deduplicate with minhash and jaccard similarity
if args.near_deduplication:
t_start = time.time()
ds_filter, duplicate_clusters = deduplicate_dataset(ds_filter, args.jaccard_threshold)
print(f"Time to deduplicate dataset: {time.time()-t_start:.2f}")
print(f"Size of deduplicate dataset: {len(ds_filter)}")
# Save data in batches of samples_per_file
output_dir = Path(args.output_dir)
output_dir.mkdir(exist_ok=True)
# save duplicate_clusters in the output_dir as artifacts
# not sure it is the right place the save it
if args.near_deduplication:
with open(output_dir / "duplicate_clusters.json", "w") as f:
json.dump(duplicate_clusters, f)
data_dir = output_dir / "data"
data_dir.mkdir(exist_ok=True)
t_start = time.time()
for file_number, index in enumerate(range(0, len(ds_filter), args.samples_per_file)):
file_path = str(data_dir / f"file-{file_number+1:012}.json")
end_index = min(len(ds_filter), index + args.samples_per_file)
ds_filter.select(list(range(index, end_index))).to_json(file_path)
compress_file(file_path)
print(f"Time to save dataset: {time.time()-t_start:.2f}")
| transformers/examples/research_projects/codeparrot/scripts/preprocessing.py/0 | {
"file_path": "transformers/examples/research_projects/codeparrot/scripts/preprocessing.py",
"repo_id": "transformers",
"token_count": 2776
} | 47 |
#!/bin/bash
export CUDA_VISIBLE_DEVICES=0
PATH_TO_DATA=/h/xinji/projects/GLUE
MODEL_TYPE=bert # bert or roberta
MODEL_SIZE=base # base or large
DATASET=MRPC # SST-2, MRPC, RTE, QNLI, QQP, or MNLI
MODEL_NAME=${MODEL_TYPE}-${MODEL_SIZE}
EPOCHS=10
if [ $MODEL_TYPE = 'bert' ]
then
EPOCHS=3
MODEL_NAME=${MODEL_NAME}-uncased
fi
python -u run_glue_deebert.py \
--model_type $MODEL_TYPE \
--model_name_or_path $MODEL_NAME \
--task_name $DATASET \
--do_train \
--do_eval \
--do_lower_case \
--data_dir $PATH_TO_DATA/$DATASET \
--max_seq_length 128 \
--per_gpu_eval_batch_size=1 \
--per_gpu_train_batch_size=8 \
--learning_rate 2e-5 \
--num_train_epochs $EPOCHS \
--overwrite_output_dir \
--seed 42 \
--output_dir ./saved_models/${MODEL_TYPE}-${MODEL_SIZE}/$DATASET/two_stage \
--plot_data_dir ./results/ \
--save_steps 0 \
--overwrite_cache \
--eval_after_first_stage
| transformers/examples/research_projects/deebert/train_deebert.sh/0 | {
"file_path": "transformers/examples/research_projects/deebert/train_deebert.sh",
"repo_id": "transformers",
"token_count": 417
} | 48 |
{
"vocab_size": 50265,
"hidden_size": 768,
"num_hidden_layers": 6,
"num_attention_heads": 12,
"intermediate_size": 3072,
"hidden_act": "gelu",
"hidden_dropout_prob": 0.1,
"attention_probs_dropout_prob": 0.1,
"max_position_embeddings": 514,
"type_vocab_size": 1,
"initializer_range": 0.02,
"layer_norm_eps": 0.00001
} | transformers/examples/research_projects/distillation/training_configs/distilroberta-base.json/0 | {
"file_path": "transformers/examples/research_projects/distillation/training_configs/distilroberta-base.json",
"repo_id": "transformers",
"token_count": 178
} | 49 |
#!/usr/bin/env python
# coding=utf-8
# Copyright 2021 The Google Research Authors and The HuggingFace Team All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""Utilities for constructing PyTrees of PartitionSpecs."""
# utils adapted from https://github.com/google-research/google-research/blob/master/flax_models/t5x/partitions.py
import re
from flax.core.frozen_dict import freeze
from flax.traverse_util import flatten_dict, unflatten_dict
from jax.experimental import PartitionSpec as P
# Sentinels
_unmatched = object()
# For specifying empty leaf dict `{}`
empty_dict = object()
def _match(qs, ks):
"""Return True if regexes in qs match any window of strings in tuple ks."""
# compile regexes and force complete match
qts = tuple((re.compile(x + "$") for x in qs))
for i in range(len(ks) - len(qs) + 1):
matches = [x.match(y) for x, y in zip(qts, ks[i:])]
if matches and all(matches):
return True
return False
def _replacement_rules(rules):
def replace(key, val):
for rule, replacement in rules:
if _match(rule, key):
return replacement
return val
return replace
# PartitionSpec for GPTNeo
# replicate the hidden dim and shard feed-forward and head dim
def _get_partition_rules():
return [
# embeddings
(("transformer", "wpe", "embedding"), P("mp", None)),
(("transformer", "wte", "embedding"), P("mp", None)),
# atention
(("attention", "(q_proj|k_proj|v_proj)", "kernel"), P(None, "mp")),
(("attention", "out_proj", "kernel"), P("mp", None)),
(("attention", "out_proj", "bias"), None),
# mlp
(("mlp", "c_fc", "kernel"), P(None, "mp")),
(("mlp", "c_fc", "bias"), P("mp")),
(("mlp", "c_proj", "kernel"), P("mp", None)),
(("mlp", "c_proj", "bias"), None),
# layer norms
((r"ln_\d+", "bias"), None),
((r"\d+", r"ln_\d+", "scale"), None),
(("ln_f", "bias"), None),
(("ln_f", "scale"), None),
]
def set_partitions(in_dict):
rules = _get_partition_rules()
replace = _replacement_rules(rules)
initd = {k: _unmatched for k in flatten_dict(in_dict)}
result = {k: replace(k, v) for k, v in initd.items()}
assert _unmatched not in result.values(), "Incomplete partition spec."
return freeze(unflatten_dict(result))
| transformers/examples/research_projects/jax-projects/model_parallel/partitions.py/0 | {
"file_path": "transformers/examples/research_projects/jax-projects/model_parallel/partitions.py",
"repo_id": "transformers",
"token_count": 1130
} | 50 |
import getopt
import json
import os
# import numpy as np
import sys
from collections import OrderedDict
import datasets
import numpy as np
import torch
from modeling_frcnn import GeneralizedRCNN
from processing_image import Preprocess
from utils import Config
"""
USAGE:
``python extracting_data.py -i <img_dir> -o <dataset_file>.datasets <batch_size>``
"""
TEST = False
CONFIG = Config.from_pretrained("unc-nlp/frcnn-vg-finetuned")
DEFAULT_SCHEMA = datasets.Features(
OrderedDict(
{
"attr_ids": datasets.Sequence(length=CONFIG.MAX_DETECTIONS, feature=datasets.Value("float32")),
"attr_probs": datasets.Sequence(length=CONFIG.MAX_DETECTIONS, feature=datasets.Value("float32")),
"boxes": datasets.Array2D((CONFIG.MAX_DETECTIONS, 4), dtype="float32"),
"img_id": datasets.Value("int32"),
"obj_ids": datasets.Sequence(length=CONFIG.MAX_DETECTIONS, feature=datasets.Value("float32")),
"obj_probs": datasets.Sequence(length=CONFIG.MAX_DETECTIONS, feature=datasets.Value("float32")),
"roi_features": datasets.Array2D((CONFIG.MAX_DETECTIONS, 2048), dtype="float32"),
"sizes": datasets.Sequence(length=2, feature=datasets.Value("float32")),
"preds_per_image": datasets.Value(dtype="int32"),
}
)
)
class Extract:
def __init__(self, argv=sys.argv[1:]):
inputdir = None
outputfile = None
subset_list = None
batch_size = 1
opts, args = getopt.getopt(argv, "i:o:b:s", ["inputdir=", "outfile=", "batch_size=", "subset_list="])
for opt, arg in opts:
if opt in ("-i", "--inputdir"):
inputdir = arg
elif opt in ("-o", "--outfile"):
outputfile = arg
elif opt in ("-b", "--batch_size"):
batch_size = int(arg)
elif opt in ("-s", "--subset_list"):
subset_list = arg
assert inputdir is not None # and os.path.isdir(inputdir), f"{inputdir}"
assert outputfile is not None and not os.path.isfile(outputfile), f"{outputfile}"
if subset_list is not None:
with open(os.path.realpath(subset_list)) as f:
self.subset_list = {self._vqa_file_split()[0] for x in tryload(f)}
else:
self.subset_list = None
self.config = CONFIG
if torch.cuda.is_available():
self.config.model.device = "cuda"
self.inputdir = os.path.realpath(inputdir)
self.outputfile = os.path.realpath(outputfile)
self.preprocess = Preprocess(self.config)
self.model = GeneralizedRCNN.from_pretrained("unc-nlp/frcnn-vg-finetuned", config=self.config)
self.batch = batch_size if batch_size != 0 else 1
self.schema = DEFAULT_SCHEMA
def _vqa_file_split(self, file):
img_id = int(file.split(".")[0].split("_")[-1])
filepath = os.path.join(self.inputdir, file)
return (img_id, filepath)
@property
def file_generator(self):
batch = []
for i, file in enumerate(os.listdir(self.inputdir)):
if self.subset_list is not None and i not in self.subset_list:
continue
batch.append(self._vqa_file_split(file))
if len(batch) == self.batch:
temp = batch
batch = []
yield list(map(list, zip(*temp)))
for i in range(1):
yield list(map(list, zip(*batch)))
def __call__(self):
# make writer
if not TEST:
writer = datasets.ArrowWriter(features=self.schema, path=self.outputfile)
# do file generator
for i, (img_ids, filepaths) in enumerate(self.file_generator):
images, sizes, scales_yx = self.preprocess(filepaths)
output_dict = self.model(
images,
sizes,
scales_yx=scales_yx,
padding="max_detections",
max_detections=self.config.MAX_DETECTIONS,
pad_value=0,
return_tensors="np",
location="cpu",
)
output_dict["boxes"] = output_dict.pop("normalized_boxes")
if not TEST:
output_dict["img_id"] = np.array(img_ids)
batch = self.schema.encode_batch(output_dict)
writer.write_batch(batch)
if TEST:
break
# finalizer the writer
if not TEST:
num_examples, num_bytes = writer.finalize()
print(f"Success! You wrote {num_examples} entry(s) and {num_bytes >> 20} mb")
def tryload(stream):
try:
data = json.load(stream)
try:
data = list(data.keys())
except Exception:
data = [d["img_id"] for d in data]
except Exception:
try:
data = eval(stream.read())
except Exception:
data = stream.read().split("\n")
return data
if __name__ == "__main__":
extract = Extract(sys.argv[1:])
extract()
if not TEST:
dataset = datasets.Dataset.from_file(extract.outputfile)
# wala!
# print(np.array(dataset[0:2]["roi_features"]).shape)
| transformers/examples/research_projects/lxmert/extracting_data.py/0 | {
"file_path": "transformers/examples/research_projects/lxmert/extracting_data.py",
"repo_id": "transformers",
"token_count": 2528
} | 51 |
# Copyright 2020-present, the HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""
Count remaining (non-zero) weights in the encoder (i.e. the transformer layers).
Sparsity and remaining weights levels are equivalent: sparsity % = 100 - remaining weights %.
"""
import argparse
import os
import torch
from emmental.modules import ThresholdBinarizer, TopKBinarizer
def main(args):
serialization_dir = args.serialization_dir
pruning_method = args.pruning_method
threshold = args.threshold
st = torch.load(os.path.join(serialization_dir, "pytorch_model.bin"), map_location="cpu")
remaining_count = 0 # Number of remaining (not pruned) params in the encoder
encoder_count = 0 # Number of params in the encoder
print("name".ljust(60, " "), "Remaining Weights %", "Remaining Weight")
for name, param in st.items():
if "encoder" not in name:
continue
if "mask_scores" in name:
if pruning_method == "topK":
mask_ones = TopKBinarizer.apply(param, threshold).sum().item()
elif pruning_method == "sigmoied_threshold":
mask_ones = ThresholdBinarizer.apply(param, threshold, True).sum().item()
elif pruning_method == "l0":
l, r = -0.1, 1.1
s = torch.sigmoid(param)
s_bar = s * (r - l) + l
mask = s_bar.clamp(min=0.0, max=1.0)
mask_ones = (mask > 0.0).sum().item()
else:
raise ValueError("Unknown pruning method")
remaining_count += mask_ones
print(name.ljust(60, " "), str(round(100 * mask_ones / param.numel(), 3)).ljust(20, " "), str(mask_ones))
else:
encoder_count += param.numel()
if "bias" in name or "LayerNorm" in name:
remaining_count += param.numel()
print("")
print("Remaining Weights (global) %: ", 100 * remaining_count / encoder_count)
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument(
"--pruning_method",
choices=["l0", "topK", "sigmoied_threshold"],
type=str,
required=True,
help=(
"Pruning Method (l0 = L0 regularization, topK = Movement pruning, sigmoied_threshold = Soft movement"
" pruning)"
),
)
parser.add_argument(
"--threshold",
type=float,
required=False,
help=(
"For `topK`, it is the level of remaining weights (in %) in the fine-pruned model. "
"For `sigmoied_threshold`, it is the threshold \tau against which the (sigmoied) scores are compared. "
"Not needed for `l0`"
),
)
parser.add_argument(
"--serialization_dir",
type=str,
required=True,
help="Folder containing the model that was previously fine-pruned",
)
args = parser.parse_args()
main(args)
| transformers/examples/research_projects/movement-pruning/counts_parameters.py/0 | {
"file_path": "transformers/examples/research_projects/movement-pruning/counts_parameters.py",
"repo_id": "transformers",
"token_count": 1428
} | 52 |
# coding=utf-8
# Copyright 2021 NVIDIA Corporation. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""Helper functions for training models with pytorch-quantization"""
import logging
import re
import pytorch_quantization
import pytorch_quantization.nn as quant_nn
import torch
from pytorch_quantization import calib
from pytorch_quantization.tensor_quant import QuantDescriptor
logger = logging.getLogger(__name__)
name_width = 50 # max width of layer names
qname_width = 70 # max width of quantizer names
# ========================================== Quant Trainer API ==========================================
def add_arguments(parser):
"""Add arguments to parser for functions defined in quant_trainer."""
group = parser.add_argument_group("quant_trainer arguments")
group.add_argument("--wprec", type=int, default=8, help="weight precision")
group.add_argument("--aprec", type=int, default=8, help="activation precision")
group.add_argument("--quant-per-tensor", action="store_true", help="per tensor weight scaling")
group.add_argument("--quant-disable", action="store_true", help="disable all quantizers")
group.add_argument("--quant-disable-embeddings", action="store_true", help="disable all embeddings quantizers")
group.add_argument("--quant-disable-keyword", type=str, nargs="+", help="disable quantizers by keyword")
group.add_argument("--quant-disable-layer-module", type=str, help="disable quantizers by keyword under layer.")
group.add_argument("--quant-enable-layer-module", type=str, help="enable quantizers by keyword under layer")
group.add_argument("--calibrator", default="max", help="which quantization range calibrator to use")
group.add_argument("--percentile", default=None, type=float, help="percentile for PercentileCalibrator")
group.add_argument("--fuse-qkv", action="store_true", help="use the same scale factor for qkv")
group.add_argument("--clip-gelu", metavar="N", type=float, help="clip gelu output maximum value to N")
group.add_argument(
"--recalibrate-weights",
action="store_true",
help=(
"recalibrate weight amaxes by taking the max of the weights."
" amaxes will be computed with the current quantization granularity (axis)."
),
)
def set_default_quantizers(args):
"""Set default quantizers before creating the model."""
if args.calibrator == "max":
calib_method = "max"
elif args.calibrator == "percentile":
if args.percentile is None:
raise ValueError("Specify --percentile when using percentile calibrator")
calib_method = "histogram"
elif args.calibrator == "mse":
calib_method = "histogram"
else:
raise ValueError(f"Invalid calibrator {args.calibrator}")
input_desc = QuantDescriptor(num_bits=args.aprec, calib_method=calib_method)
weight_desc = QuantDescriptor(num_bits=args.wprec, axis=(None if args.quant_per_tensor else (0,)))
quant_nn.QuantLinear.set_default_quant_desc_input(input_desc)
quant_nn.QuantLinear.set_default_quant_desc_weight(weight_desc)
def configure_model(model, args, calib=False, eval=False):
"""Function called before the training loop."""
logger.info("Configuring Model for Quantization")
logger.info(f"using quantization package {pytorch_quantization.__file__}")
if not calib:
if args.quant_disable_embeddings:
set_quantizer_by_name(model, ["embeddings"], which="weight", _disabled=True)
if args.quant_disable:
set_quantizer_by_name(model, [""], _disabled=True)
if args.quant_disable_keyword:
set_quantizer_by_name(model, args.quant_disable_keyword, _disabled=True)
if args.quant_disable_layer_module:
set_quantizer_by_name(model, [r"layer.\d+." + args.quant_disable_layer_module], _disabled=True)
if args.quant_enable_layer_module:
set_quantizer_by_name(model, [r"layer.\d+." + args.quant_enable_layer_module], _disabled=False)
if args.recalibrate_weights:
recalibrate_weights(model)
if args.fuse_qkv:
fuse_qkv(model, args)
if args.clip_gelu:
clip_gelu(model, args.clip_gelu)
# if args.local_rank in [-1, 0] and not calib:
print_quant_summary(model)
def enable_calibration(model):
"""Enable calibration of all *_input_quantizer modules in model."""
logger.info("Enabling Calibration")
for name, module in model.named_modules():
if name.endswith("_quantizer"):
if module._calibrator is not None:
module.disable_quant()
module.enable_calib()
else:
module.disable()
logger.info(f"{name:80}: {module}")
def finish_calibration(model, args):
"""Disable calibration and load amax for all "*_input_quantizer modules in model."""
logger.info("Loading calibrated amax")
for name, module in model.named_modules():
if name.endswith("_quantizer"):
if module._calibrator is not None:
if isinstance(module._calibrator, calib.MaxCalibrator):
module.load_calib_amax()
else:
module.load_calib_amax("percentile", percentile=args.percentile)
module.enable_quant()
module.disable_calib()
else:
module.enable()
model.cuda()
print_quant_summary(model)
# ========================================== Helper Function ==========================================
def fuse_qkv(model, args):
"""Adjust quantization ranges to match an implementation where the QKV projections are implemented with a single GEMM.
Force the weight and output scale factors to match by taking the max of (Q,K,V).
"""
def fuse3(qq, qk, qv):
for mod in [qq, qk, qv]:
if not hasattr(mod, "_amax"):
print(" WARNING: NO AMAX BUFFER")
return
q = qq._amax.detach().item()
k = qk._amax.detach().item()
v = qv._amax.detach().item()
amax = max(q, k, v)
qq._amax.fill_(amax)
qk._amax.fill_(amax)
qv._amax.fill_(amax)
logger.info(f" q={q:5.2f} k={k:5.2f} v={v:5.2f} -> {amax:5.2f}")
for name, mod in model.named_modules():
if name.endswith(".attention.self"):
logger.info(f"FUSE_QKV: {name:{name_width}}")
fuse3(mod.matmul_q_input_quantizer, mod.matmul_k_input_quantizer, mod.matmul_v_input_quantizer)
if args.quant_per_tensor:
fuse3(mod.query._weight_quantizer, mod.key._weight_quantizer, mod.value._weight_quantizer)
def clip_gelu(model, maxval):
"""Clip activations generated by GELU to maxval when quantized.
Implemented by adjusting the amax of the following input_quantizer.
"""
for name, mod in model.named_modules():
if name.endswith(".output.dense") and not name.endswith("attention.output.dense"):
amax_init = mod._input_quantizer._amax.data.detach().item()
mod._input_quantizer._amax.data.detach().clamp_(max=maxval)
amax = mod._input_quantizer._amax.data.detach().item()
logger.info(f"CLIP_GELU: {name:{name_width}} amax: {amax_init:5.2f} -> {amax:5.2f}")
def expand_amax(model):
"""Expand per-tensor amax to be per channel, where each channel is assigned the per-tensor amax."""
for name, mod in model.named_modules():
if hasattr(mod, "_weight_quantizer") and mod._weight_quantizer.axis is not None:
k = mod.weight.shape[0]
amax = mod._weight_quantizer._amax.detach()
mod._weight_quantizer._amax = torch.ones(k, dtype=amax.dtype, device=amax.device) * amax
print(f"expanding {name} {amax} -> {mod._weight_quantizer._amax}")
def recalibrate_weights(model):
"""Performs max calibration on the weights and updates amax."""
for name, mod in model.named_modules():
if hasattr(mod, "_weight_quantizer"):
if not hasattr(mod.weight_quantizer, "_amax"):
print("RECALIB: {name:{name_width}} WARNING: NO AMAX BUFFER")
continue
# determine which axes to reduce across
# e.g. a 4D tensor quantized per axis 0 should reduce over (1,2,3)
axis_set = set() if mod._weight_quantizer.axis is None else set(mod._weight_quantizer.axis)
reduce_axis = set(range(len(mod.weight.size()))) - axis_set
amax = pytorch_quantization.utils.reduce_amax(mod.weight, axis=reduce_axis, keepdims=True).detach()
logger.info(f"RECALIB: {name:{name_width}} {mod._weight_quantizer._amax.flatten()} -> {amax.flatten()}")
mod._weight_quantizer._amax = amax
def print_model_summary(model, name_width=25, line_width=180, ignore=None):
"""Print model quantization configuration."""
if ignore is None:
ignore = []
elif not isinstance(ignore, list):
ignore = [ignore]
name_width = 0
for name, mod in model.named_modules():
if not hasattr(mod, "weight"):
continue
name_width = max(name_width, len(name))
for name, mod in model.named_modules():
input_q = getattr(mod, "_input_quantizer", None)
weight_q = getattr(mod, "_weight_quantizer", None)
if not hasattr(mod, "weight"):
continue
if type(mod) in ignore:
continue
if [True for s in ignore if isinstance(s, str) and s in name]:
continue
act_str = f"Act:{input_q.extra_repr()}"
wgt_str = f"Wgt:{weight_q.extra_repr()}"
s = f"{name:{name_width}} {act_str} {wgt_str}"
if len(s) <= line_width:
logger.info(s)
else:
logger.info(f"{name:{name_width}} {act_str}")
logger.info(f'{" ":{name_width}} {wgt_str}')
def print_quant_summary(model):
"""Print summary of all quantizer modules in the model."""
count = 0
for name, mod in model.named_modules():
if isinstance(mod, pytorch_quantization.nn.TensorQuantizer):
print(f"{name:80} {mod}")
count += 1
print(f"{count} TensorQuantizers found in model")
def set_quantizer(name, mod, quantizer, k, v):
"""Set attributes for mod.quantizer."""
quantizer_mod = getattr(mod, quantizer, None)
if quantizer_mod is not None:
assert hasattr(quantizer_mod, k)
setattr(quantizer_mod, k, v)
else:
logger.warning(f"{name} has no {quantizer}")
def set_quantizers(name, mod, which="both", **kwargs):
"""Set quantizer attributes for mod."""
s = f"Warning: changing {which} quantizers of {name:{qname_width}}"
for k, v in kwargs.items():
s += f" {k}={v}"
if which in ["input", "both"]:
set_quantizer(name, mod, "_input_quantizer", k, v)
if which in ["weight", "both"]:
set_quantizer(name, mod, "_weight_quantizer", k, v)
logger.info(s)
def set_quantizer_by_name(model, names, **kwargs):
"""Set quantizer attributes for layers where name contains a substring in names."""
for name, mod in model.named_modules():
if hasattr(mod, "_input_quantizer") or hasattr(mod, "_weight_quantizer"):
for n in names:
if re.search(n, name):
set_quantizers(name, mod, **kwargs)
elif name.endswith("_quantizer"):
for n in names:
if re.search(n, name):
s = f"Warning: changing {name:{name_width}}"
for k, v in kwargs.items():
s += f" {k}={v}"
setattr(mod, k, v)
logger.info(s)
| transformers/examples/research_projects/quantization-qdqbert/quant_trainer.py/0 | {
"file_path": "transformers/examples/research_projects/quantization-qdqbert/quant_trainer.py",
"repo_id": "transformers",
"token_count": 5091
} | 53 |
"""Finetuning script for RAG models. Adapted from examples.seq2seq.finetune.py"""
import argparse
import logging
import os
import sys
import time
from collections import defaultdict
from pathlib import Path
from typing import Any, Dict, List, Tuple
import numpy as np
import pytorch_lightning as pl
import torch
import torch.distributed as dist
import torch.distributed as torch_distrib
from pytorch_lightning.plugins.training_type import DDPPlugin
from torch.utils.data import DataLoader
from transformers import (
AutoConfig,
AutoTokenizer,
BartForConditionalGeneration,
BatchEncoding,
RagConfig,
RagSequenceForGeneration,
RagTokenForGeneration,
RagTokenizer,
T5ForConditionalGeneration,
)
from transformers import logging as transformers_logging
from transformers.integrations import is_ray_available
if is_ray_available():
import ray
from distributed_ray_retriever import RagRayDistributedRetriever, RayRetriever
from callbacks_rag import ( # noqa: E402 # isort:skipq
get_checkpoint_callback,
get_early_stopping_callback,
Seq2SeqLoggingCallback,
)
from distributed_pytorch_retriever import RagPyTorchDistributedRetriever # noqa: E402 # isort:skip
from utils_rag import ( # noqa: E402 # isort:skip
calculate_exact_match,
flatten_list,
get_git_info,
is_rag_model,
lmap,
pickle_save,
save_git_info,
save_json,
set_extra_model_params,
Seq2SeqDataset,
)
# need the parent dir module
sys.path.insert(2, str(Path(__file__).resolve().parents[1]))
from lightning_base import BaseTransformer, add_generic_args, generic_train # noqa
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
transformers_logging.set_verbosity_info()
class AttrDict(dict):
def __init__(self, *args, **kwargs):
super(AttrDict, self).__init__(*args, **kwargs)
self.__dict__ = self
class CustomDDP(DDPPlugin):
def init_ddp_connection(self, global_rank=None, world_size=None) -> None:
module = self.model
global_rank = global_rank if global_rank is not None else self.cluster_environment.global_rank()
world_size = world_size if world_size is not None else self.cluster_environment.world_size()
os.environ["MASTER_ADDR"] = self.cluster_environment.master_address()
os.environ["MASTER_PORT"] = str(self.cluster_environment.master_port())
if not torch.distributed.is_initialized():
logger.info(f"initializing ddp: GLOBAL_RANK: {global_rank}, MEMBER: {global_rank + 1}/{world_size}")
torch_distrib.init_process_group(self.torch_distributed_backend, rank=global_rank, world_size=world_size)
if module.is_rag_model:
self.distributed_port = module.hparams.distributed_port
if module.distributed_retriever == "pytorch":
module.model.rag.retriever.init_retrieval(self.distributed_port)
elif module.distributed_retriever == "ray" and global_rank == 0:
# For the Ray retriever, only initialize it once when global
# rank is 0.
module.model.rag.retriever.init_retrieval()
class GenerativeQAModule(BaseTransformer):
mode = "generative_qa"
loss_names = ["loss"]
metric_names = ["em"]
val_metric = "em"
def __init__(self, hparams, **kwargs):
# when loading from a pytorch lightning checkpoint, hparams are passed as dict
if isinstance(hparams, dict):
hparams = AttrDict(hparams)
if hparams.model_type == "rag_sequence":
self.model_class = RagSequenceForGeneration
elif hparams.model_type == "rag_token":
self.model_class = RagTokenForGeneration
elif hparams.model_type == "bart":
self.model_class = BartForConditionalGeneration
else:
self.model_class = T5ForConditionalGeneration
self.is_rag_model = is_rag_model(hparams.model_type)
config_class = RagConfig if self.is_rag_model else AutoConfig
config = config_class.from_pretrained(hparams.model_name_or_path)
# set retriever parameters
config.index_name = hparams.index_name or config.index_name
config.passages_path = hparams.passages_path or config.passages_path
config.index_path = hparams.index_path or config.index_path
config.use_dummy_dataset = hparams.use_dummy_dataset
# set extra_model_params for generator configs and load_model
extra_model_params = ("encoder_layerdrop", "decoder_layerdrop", "attention_dropout", "dropout")
if self.is_rag_model:
if hparams.prefix is not None:
config.generator.prefix = hparams.prefix
config.label_smoothing = hparams.label_smoothing
hparams, config.generator = set_extra_model_params(extra_model_params, hparams, config.generator)
if hparams.distributed_retriever == "pytorch":
retriever = RagPyTorchDistributedRetriever.from_pretrained(hparams.model_name_or_path, config=config)
elif hparams.distributed_retriever == "ray":
# The Ray retriever needs the handles to the retriever actors.
retriever = RagRayDistributedRetriever.from_pretrained(
hparams.model_name_or_path, hparams.actor_handles, config=config
)
model = self.model_class.from_pretrained(hparams.model_name_or_path, config=config, retriever=retriever)
prefix = config.question_encoder.prefix
else:
if hparams.prefix is not None:
config.prefix = hparams.prefix
hparams, config = set_extra_model_params(extra_model_params, hparams, config)
model = self.model_class.from_pretrained(hparams.model_name_or_path, config=config)
prefix = config.prefix
tokenizer = (
RagTokenizer.from_pretrained(hparams.model_name_or_path)
if self.is_rag_model
else AutoTokenizer.from_pretrained(hparams.model_name_or_path)
)
super().__init__(hparams, config=config, tokenizer=tokenizer, model=model)
save_git_info(self.hparams.output_dir)
self.output_dir = Path(self.hparams.output_dir)
self.metrics_save_path = Path(self.output_dir) / "metrics.json"
self.hparams_save_path = Path(self.output_dir) / "hparams.pkl"
pickle_save(self.hparams, self.hparams_save_path)
self.step_count = 0
self.metrics = defaultdict(list)
self.dataset_kwargs: dict = {
"data_dir": self.hparams.data_dir,
"max_source_length": self.hparams.max_source_length,
"prefix": prefix or "",
}
n_observations_per_split = {
"train": self.hparams.n_train,
"val": self.hparams.n_val,
"test": self.hparams.n_test,
}
self.n_obs = {k: v if v >= 0 else None for k, v in n_observations_per_split.items()}
self.target_lens = {
"train": self.hparams.max_target_length,
"val": self.hparams.val_max_target_length,
"test": self.hparams.test_max_target_length,
}
assert self.target_lens["train"] <= self.target_lens["val"], f"target_lens: {self.target_lens}"
assert self.target_lens["train"] <= self.target_lens["test"], f"target_lens: {self.target_lens}"
self.hparams.git_sha = get_git_info()["repo_sha"]
self.num_workers = hparams.num_workers
self.distributed_port = self.hparams.distributed_port
# For single GPU training, init_ddp_connection is not called.
# So we need to initialize the retrievers here.
if hparams.gpus <= 1:
if hparams.distributed_retriever == "ray":
self.model.retriever.init_retrieval()
elif hparams.distributed_retriever == "pytorch":
self.model.retriever.init_retrieval(self.distributed_port)
self.distributed_retriever = hparams.distributed_retriever
def forward(self, input_ids, **kwargs):
return self.model(input_ids, **kwargs)
def ids_to_clean_text(self, generated_ids: List[int]):
gen_text = self.tokenizer.batch_decode(
generated_ids, skip_special_tokens=True, clean_up_tokenization_spaces=True
)
return lmap(str.strip, gen_text)
def _step(self, batch: dict) -> Tuple:
source_ids, source_mask, target_ids = batch["input_ids"], batch["attention_mask"], batch["decoder_input_ids"]
rag_kwargs = {}
if isinstance(self.model, T5ForConditionalGeneration):
decoder_input_ids = self.model._shift_right(target_ids)
lm_labels = target_ids
elif isinstance(self.model, BartForConditionalGeneration):
decoder_input_ids = target_ids[:, :-1].contiguous()
lm_labels = target_ids[:, 1:].clone()
else:
assert self.is_rag_model
generator = self.model.rag.generator
if isinstance(generator, T5ForConditionalGeneration):
decoder_start_token_id = generator.config.decoder_start_token_id
decoder_input_ids = (
torch.cat(
[torch.tensor([[decoder_start_token_id]] * target_ids.shape[0]).to(target_ids), target_ids],
dim=1,
)
if target_ids.shape[0] < self.target_lens["train"]
else generator._shift_right(target_ids)
)
elif isinstance(generator, BartForConditionalGeneration):
decoder_input_ids = target_ids
lm_labels = decoder_input_ids
rag_kwargs["reduce_loss"] = True
assert decoder_input_ids is not None
outputs = self(
source_ids,
attention_mask=source_mask,
decoder_input_ids=decoder_input_ids,
use_cache=False,
labels=lm_labels,
**rag_kwargs,
)
loss = outputs["loss"]
return (loss,)
@property
def pad(self) -> int:
raise NotImplementedError("pad not implemented")
def training_step(self, batch, batch_idx) -> Dict:
loss_tensors = self._step(batch)
logs = {name: loss.detach() for name, loss in zip(self.loss_names, loss_tensors)}
# tokens per batch
tgt_pad_token_id = (
self.tokenizer.generator.pad_token_id
if isinstance(self.tokenizer, RagTokenizer)
else self.tokenizer.pad_token_id
)
src_pad_token_id = (
self.tokenizer.question_encoder.pad_token_id
if isinstance(self.tokenizer, RagTokenizer)
else self.tokenizer.pad_token_id
)
logs["tpb"] = (
batch["input_ids"].ne(src_pad_token_id).sum() + batch["decoder_input_ids"].ne(tgt_pad_token_id).sum()
)
return {"loss": loss_tensors[0], "log": logs}
def validation_step(self, batch, batch_idx) -> Dict:
return self._generative_step(batch)
def validation_epoch_end(self, outputs, prefix="val") -> Dict:
self.step_count += 1
losses = {k: torch.stack([x[k] for x in outputs]).mean() for k in self.loss_names}
loss = losses["loss"]
gen_metrics = {
k: np.array([x[k] for x in outputs]).mean() for k in self.metric_names + ["gen_time", "gen_len"]
}
metrics_tensor: torch.FloatTensor = torch.tensor(gen_metrics[self.val_metric]).type_as(loss)
gen_metrics.update({k: v.item() for k, v in losses.items()})
# fix for https://github.com/PyTorchLightning/pytorch-lightning/issues/2424
if dist.is_initialized():
dist.all_reduce(metrics_tensor, op=dist.ReduceOp.SUM)
metrics_tensor = metrics_tensor / dist.get_world_size()
gen_metrics.update({self.val_metric: metrics_tensor.item()})
losses.update(gen_metrics)
metrics = {f"{prefix}_avg_{k}": x for k, x in losses.items()}
metrics["step_count"] = self.step_count
self.save_metrics(metrics, prefix) # writes to self.metrics_save_path
preds = flatten_list([x["preds"] for x in outputs])
return {"log": metrics, "preds": preds, f"{prefix}_loss": loss, f"{prefix}_{self.val_metric}": metrics_tensor}
def save_metrics(self, latest_metrics, type_path) -> None:
self.metrics[type_path].append(latest_metrics)
save_json(self.metrics, self.metrics_save_path)
def calc_generative_metrics(self, preds, target) -> Dict:
return calculate_exact_match(preds, target)
def _generative_step(self, batch: dict) -> dict:
start_time = time.time()
batch = BatchEncoding(batch).to(device=self.model.device)
generated_ids = self.model.generate(
batch["input_ids"],
attention_mask=batch["attention_mask"],
do_deduplication=False, # rag specific parameter
use_cache=True,
min_length=1,
max_length=self.target_lens["val"],
)
gen_time = (time.time() - start_time) / batch["input_ids"].shape[0]
preds: List[str] = self.ids_to_clean_text(generated_ids)
target: List[str] = self.ids_to_clean_text(batch["decoder_input_ids"])
loss_tensors = self._step(batch)
base_metrics = dict(zip(self.loss_names, loss_tensors))
gen_metrics: Dict = self.calc_generative_metrics(preds, target)
summ_len = np.mean(lmap(len, generated_ids))
base_metrics.update(gen_time=gen_time, gen_len=summ_len, preds=preds, target=target, **gen_metrics)
return base_metrics
def test_step(self, batch, batch_idx):
return self._generative_step(batch)
def test_epoch_end(self, outputs):
return self.validation_epoch_end(outputs, prefix="test")
def get_dataset(self, type_path) -> Seq2SeqDataset:
n_obs = self.n_obs[type_path]
max_target_length = self.target_lens[type_path]
dataset = Seq2SeqDataset(
self.tokenizer,
type_path=type_path,
n_obs=n_obs,
max_target_length=max_target_length,
**self.dataset_kwargs,
)
return dataset
def get_dataloader(self, type_path: str, batch_size: int, shuffle: bool = False) -> DataLoader:
dataset = self.get_dataset(type_path)
dataloader = DataLoader(
dataset,
batch_size=batch_size,
collate_fn=dataset.collate_fn,
shuffle=shuffle,
num_workers=self.num_workers,
)
return dataloader
def train_dataloader(self) -> DataLoader:
dataloader = self.get_dataloader("train", batch_size=self.hparams.train_batch_size, shuffle=True)
return dataloader
def val_dataloader(self) -> DataLoader:
return self.get_dataloader("val", batch_size=self.hparams.eval_batch_size)
def test_dataloader(self) -> DataLoader:
return self.get_dataloader("test", batch_size=self.hparams.eval_batch_size)
@pl.utilities.rank_zero_only
def on_save_checkpoint(self, checkpoint: Dict[str, Any]) -> None:
save_path = self.output_dir.joinpath("checkpoint{}".format(self.step_count))
self.model.config.save_step = self.step_count
self.model.save_pretrained(save_path)
self.tokenizer.save_pretrained(save_path)
@staticmethod
def add_model_specific_args(parser, root_dir):
BaseTransformer.add_model_specific_args(parser, root_dir)
add_generic_args(parser, root_dir)
parser.add_argument(
"--max_source_length",
default=128,
type=int,
help=(
"The maximum total input sequence length after tokenization. Sequences longer "
"than this will be truncated, sequences shorter will be padded."
),
)
parser.add_argument(
"--max_target_length",
default=25,
type=int,
help=(
"The maximum total input sequence length after tokenization. Sequences longer "
"than this will be truncated, sequences shorter will be padded."
),
)
parser.add_argument(
"--val_max_target_length",
default=25,
type=int,
help=(
"The maximum total input sequence length after tokenization. Sequences longer "
"than this will be truncated, sequences shorter will be padded."
),
)
parser.add_argument(
"--test_max_target_length",
default=25,
type=int,
help=(
"The maximum total input sequence length after tokenization. Sequences longer "
"than this will be truncated, sequences shorter will be padded."
),
)
parser.add_argument("--logger_name", type=str, choices=["default", "wandb", "wandb_shared"], default="default")
parser.add_argument("--n_train", type=int, default=-1, required=False, help="# examples. -1 means use all.")
parser.add_argument("--n_val", type=int, default=-1, required=False, help="# examples. -1 means use all.")
parser.add_argument("--n_test", type=int, default=-1, required=False, help="# examples. -1 means use all.")
parser.add_argument("--label_smoothing", type=float, default=0.0, required=False)
parser.add_argument(
"--prefix",
type=str,
default=None,
help="Prefix added at the beginning of each text, typically used with T5-based models.",
)
parser.add_argument(
"--early_stopping_patience",
type=int,
default=-1,
required=False,
help=(
"-1 means never early stop. early_stopping_patience is measured in validation checks, not epochs. So"
" val_check_interval will effect it."
),
)
parser.add_argument(
"--distributed-port", type=int, default=-1, required=False, help="Port number for distributed training."
)
parser.add_argument(
"--model_type",
choices=["rag_sequence", "rag_token", "bart", "t5"],
type=str,
help=(
"RAG model type: sequence or token, if none specified, the type is inferred from the"
" model_name_or_path"
),
)
return parser
@staticmethod
def add_retriever_specific_args(parser):
parser.add_argument(
"--index_name",
type=str,
default=None,
help=(
"Name of the index to use: 'hf' for a canonical dataset from the datasets library (default), 'custom'"
" for a local index, or 'legacy' for the orignal one)"
),
)
parser.add_argument(
"--passages_path",
type=str,
default=None,
help=(
"Path to the dataset of passages for custom index. More info about custom indexes in the RagRetriever"
" documentation as well as in `examples/rag/use_own_knowledge_dataset.py`"
),
)
parser.add_argument(
"--index_path",
type=str,
default=None,
help=(
"Path to the faiss index for custom index. More info about custom indexes in the RagRetriever"
" documentation as well as in `examples/rag/use_own_knowledge_dataset.py`"
),
)
parser.add_argument(
"--distributed_retriever",
choices=["ray", "pytorch"],
type=str,
default="pytorch",
help=(
"What implementation to use for distributed retriever? If "
"pytorch is selected, the index is loaded on training "
"worker 0, and torch.distributed is used to handle "
"communication between training worker 0, and the other "
"training workers. If ray is selected, the Ray library is "
"used to create load the index on separate processes, "
"and Ray handles the communication between the training "
"workers and the retrieval actors."
),
)
parser.add_argument(
"--use_dummy_dataset",
type=bool,
default=False,
help=(
"Whether to use the dummy version of the dataset index. More info about custom indexes in the"
" RagRetriever documentation as well as in `examples/rag/use_own_knowledge_dataset.py`"
),
)
return parser
@staticmethod
def add_ray_specific_args(parser):
# Ray cluster address.
parser.add_argument(
"--ray-address",
default="auto",
type=str,
help=(
"The address of the Ray cluster to connect to. If not "
"specified, Ray will attempt to automatically detect the "
"cluster. Has no effect if pytorch is used as the distributed "
"retriever."
),
)
parser.add_argument(
"--num_retrieval_workers",
type=int,
default=1,
help=(
"The number of retrieval actors to use when Ray is selected "
"for the distributed retriever. Has no effect when "
"distributed_retriever is set to pytorch."
),
)
return parser
def main(args=None, model=None) -> GenerativeQAModule:
parser = argparse.ArgumentParser()
parser = pl.Trainer.add_argparse_args(parser)
parser = GenerativeQAModule.add_model_specific_args(parser, os.getcwd())
parser = GenerativeQAModule.add_retriever_specific_args(parser)
args = args or parser.parse_args()
Path(args.output_dir).mkdir(exist_ok=True)
named_actors = []
if args.distributed_retriever == "ray" and args.gpus > 1:
if not is_ray_available():
raise RuntimeError("Please install Ray to use the Ray distributed retriever.")
# Connect to an existing Ray cluster.
try:
ray.init(address=args.ray_address, namespace="rag")
except (ConnectionError, ValueError):
logger.warning(
"Connection to Ray cluster failed. Make sure a Ray "
"cluster is running by either using Ray's cluster "
"launcher (`ray up`) or by manually starting Ray on "
"each node via `ray start --head` for the head node "
"and `ray start --address='<ip address>:6379'` for "
"additional nodes. See "
"https://docs.ray.io/en/master/cluster/index.html "
"for more info."
)
raise
# Create Ray actors only for rank 0.
if ("LOCAL_RANK" not in os.environ or int(os.environ["LOCAL_RANK"]) == 0) and (
"NODE_RANK" not in os.environ or int(os.environ["NODE_RANK"]) == 0
):
remote_cls = ray.remote(RayRetriever)
named_actors = [
remote_cls.options(name="retrieval_worker_{}".format(i)).remote()
for i in range(args.num_retrieval_workers)
]
else:
logger.info(
"Getting named actors for NODE_RANK {}, LOCAL_RANK {}".format(
os.environ["NODE_RANK"], os.environ["LOCAL_RANK"]
)
)
named_actors = [ray.get_actor("retrieval_worker_{}".format(i)) for i in range(args.num_retrieval_workers)]
args.actor_handles = named_actors
assert args.actor_handles == named_actors
if model is None:
model: GenerativeQAModule = GenerativeQAModule(args)
dataset = Path(args.data_dir).name
if (
args.logger_name == "default"
or args.fast_dev_run
or str(args.output_dir).startswith("/tmp")
or str(args.output_dir).startswith("/var")
):
training_logger = True # don't pollute wandb logs unnecessarily
elif args.logger_name == "wandb":
from pytorch_lightning.loggers import WandbLogger
project = os.environ.get("WANDB_PROJECT", dataset)
training_logger = WandbLogger(name=model.output_dir.name, project=project)
elif args.logger_name == "wandb_shared":
from pytorch_lightning.loggers import WandbLogger
training_logger = WandbLogger(name=model.output_dir.name, project=f"hf_{dataset}")
es_callback = (
get_early_stopping_callback(model.val_metric, args.early_stopping_patience)
if args.early_stopping_patience >= 0
else False
)
trainer: pl.Trainer = generic_train(
model,
args,
logging_callback=Seq2SeqLoggingCallback(),
checkpoint_callback=get_checkpoint_callback(args.output_dir, model.val_metric),
early_stopping_callback=es_callback,
logger=training_logger,
custom_ddp_plugin=CustomDDP() if args.gpus > 1 else None,
profiler=pl.profiler.AdvancedProfiler() if args.profile else None,
)
pickle_save(model.hparams, model.output_dir / "hparams.pkl")
if not args.do_predict:
return model
# test() without a model tests using the best checkpoint automatically
trainer.test()
return model
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser = pl.Trainer.add_argparse_args(parser)
parser = GenerativeQAModule.add_model_specific_args(parser, os.getcwd())
parser = GenerativeQAModule.add_retriever_specific_args(parser)
parser = GenerativeQAModule.add_ray_specific_args(parser)
# Pytorch Lightning Profiler
parser.add_argument(
"--profile",
action="store_true",
help="If True, use pytorch_lightning.profiler.AdvancedProfiler to profile the Trainer.",
)
args = parser.parse_args()
main(args)
| transformers/examples/research_projects/rag/finetune_rag.py/0 | {
"file_path": "transformers/examples/research_projects/rag/finetune_rag.py",
"repo_id": "transformers",
"token_count": 11834
} | 54 |
# Script for verifying that run_bart_sum can be invoked from its directory
# Get tiny dataset with cnn_dm format (4 examples for train, val, test)
wget https://cdn-datasets.huggingface.co/summarization/cnn_tiny.tgz
tar -xzvf cnn_tiny.tgz
rm cnn_tiny.tgz
export OUTPUT_DIR_NAME=bart_utest_output
export CURRENT_DIR=${PWD}
export OUTPUT_DIR=${CURRENT_DIR}/${OUTPUT_DIR_NAME}
# Make output directory if it doesn't exist
mkdir -p $OUTPUT_DIR
# Add parent directory to python path to access lightning_base.py and testing_utils.py
export PYTHONPATH="../":"${PYTHONPATH}"
python finetune.py \
--data_dir=cnn_tiny/ \
--model_name_or_path=sshleifer/bart-tiny-random \
--learning_rate=3e-5 \
--train_batch_size=2 \
--eval_batch_size=2 \
--output_dir=$OUTPUT_DIR \
--num_train_epochs=1 \
--gpus=0 \
--do_train "$@"
rm -rf cnn_tiny
rm -rf $OUTPUT_DIR
| transformers/examples/research_projects/seq2seq-distillation/finetune_bart_tiny.sh/0 | {
"file_path": "transformers/examples/research_projects/seq2seq-distillation/finetune_bart_tiny.sh",
"repo_id": "transformers",
"token_count": 333
} | 55 |
#!/usr/bin/env python
# coding=utf-8
# Copyright 2022 The Microsoft and The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""
Fine-tuning the library models for tapex on table-based question answering tasks.
Adapted from script: https://github.com/huggingface/transformers/blob/master/examples/pytorch/summarization/run_summarization.py
"""
import logging
import os
import sys
from collections import defaultdict
from copy import deepcopy
from dataclasses import dataclass, field
from functools import partial
from typing import List, Optional
import nltk # Here to have a nice missing dependency error message early on
import numpy as np
import pandas as pd
from datasets import load_dataset
from filelock import FileLock
from wikisql_utils import _TYPE_CONVERTER, retrieve_wikisql_query_answer_tapas
import transformers
from transformers import (
AutoConfig,
BartForConditionalGeneration,
DataCollatorForSeq2Seq,
HfArgumentParser,
Seq2SeqTrainer,
Seq2SeqTrainingArguments,
TapexTokenizer,
set_seed,
)
from transformers.file_utils import is_offline_mode
from transformers.trainer_utils import get_last_checkpoint, is_main_process
from transformers.utils import check_min_version
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
check_min_version("4.17.0.dev0")
logger = logging.getLogger(__name__)
try:
nltk.data.find("tokenizers/punkt")
except (LookupError, OSError):
if is_offline_mode():
raise LookupError(
"Offline mode: run this script without TRANSFORMERS_OFFLINE first to download nltk data files"
)
with FileLock(".lock") as lock:
nltk.download("punkt", quiet=True)
@dataclass
class ModelArguments:
"""
Arguments pertaining to which model/config/tokenizer we are going to fine-tune from.
"""
model_name_or_path: str = field(
metadata={"help": "Path to pretrained model or model identifier from huggingface.co/models"},
)
config_name: Optional[str] = field(
default=None, metadata={"help": "Pretrained config name or path if not the same as model_name"}
)
tokenizer_name: Optional[str] = field(
default=None,
metadata={
"help": (
"Pretrained tokenizer name or path if not the same as model_name. "
"By default we use BART-large tokenizer for TAPEX-large."
)
},
)
cache_dir: Optional[str] = field(
default=None,
metadata={"help": "Where to store the pretrained models downloaded from huggingface.co"},
)
use_fast_tokenizer: bool = field(
default=True,
metadata={"help": "Whether to use one of the fast tokenizer (backed by the tokenizers library) or not."},
)
model_revision: str = field(
default="main",
metadata={"help": "The specific model version to use (can be a branch name, tag name or commit id)."},
)
use_auth_token: bool = field(
default=False,
metadata={
"help": (
"Will use the token generated when running `huggingface-cli login` (necessary to use this script "
"with private models)."
)
},
)
@dataclass
class DataTrainingArguments:
"""
Arguments pertaining to what data we are going to input our model for training and eval.
"""
dataset_name: Optional[str] = field(
default="wikisql", metadata={"help": "The name of the dataset to use (via the datasets library)."}
)
dataset_config_name: Optional[str] = field(
default=None, metadata={"help": "The configuration name of the dataset to use (via the datasets library)."}
)
train_file: Optional[str] = field(
default=None, metadata={"help": "The input training data file (a jsonlines or csv file)."}
)
validation_file: Optional[str] = field(
default=None,
metadata={
"help": (
"An optional input evaluation data file to evaluate the metrics (rouge) on (a jsonlines or csv file)."
)
},
)
test_file: Optional[str] = field(
default=None,
metadata={
"help": "An optional input test data file to evaluate the metrics (rouge) on (a jsonlines or csv file)."
},
)
overwrite_cache: bool = field(
default=False, metadata={"help": "Overwrite the cached training and evaluation sets"}
)
preprocessing_num_workers: Optional[int] = field(
default=None,
metadata={"help": "The number of processes to use for the preprocessing."},
)
max_source_length: Optional[int] = field(
default=1024,
metadata={
"help": (
"The maximum total input sequence length after tokenization. Sequences longer "
"than this will be truncated, sequences shorter will be padded."
)
},
)
max_target_length: Optional[int] = field(
default=128,
metadata={
"help": (
"The maximum total sequence length for target text after tokenization. Sequences longer "
"than this will be truncated, sequences shorter will be padded."
)
},
)
val_max_target_length: Optional[int] = field(
default=None,
metadata={
"help": (
"The maximum total sequence length for validation target text after tokenization. Sequences longer "
"than this will be truncated, sequences shorter will be padded. Will default to `max_target_length`. "
"This argument is also used to override the ``max_length`` param of ``model.generate``, which is used "
"during ``evaluate`` and ``predict``."
)
},
)
pad_to_max_length: bool = field(
default=False,
metadata={
"help": (
"Whether to pad all samples to model maximum sentence length. "
"If False, will pad the samples dynamically when batching to the maximum length in the batch. More "
"efficient on GPU but very bad for TPU."
)
},
)
max_train_samples: Optional[int] = field(
default=None,
metadata={
"help": (
"For debugging purposes or quicker training, truncate the number of training examples to this "
"value if set."
)
},
)
max_eval_samples: Optional[int] = field(
default=None,
metadata={
"help": (
"For debugging purposes or quicker training, truncate the number of evaluation examples to this "
"value if set."
)
},
)
max_predict_samples: Optional[int] = field(
default=None,
metadata={
"help": (
"For debugging purposes or quicker training, truncate the number of prediction examples to this "
"value if set."
)
},
)
num_beams: Optional[int] = field(
default=None,
metadata={
"help": (
"Number of beams to use for evaluation. This argument will be passed to ``model.generate``, "
"which is used during ``evaluate`` and ``predict``."
)
},
)
ignore_pad_token_for_loss: bool = field(
default=True,
metadata={
"help": "Whether to ignore the tokens corresponding to padded labels in the loss computation or not."
},
)
def __post_init__(self):
if self.dataset_name is None and self.train_file is None and self.validation_file is None:
raise ValueError("Need either a dataset name or a training/validation file.")
else:
if self.train_file is not None:
extension = self.train_file.split(".")[-1]
assert extension in ["csv", "json"], "`train_file` should be a csv or a json file."
if self.validation_file is not None:
extension = self.validation_file.split(".")[-1]
assert extension in ["csv", "json"], "`validation_file` should be a csv or a json file."
if self.val_max_target_length is None:
self.val_max_target_length = self.max_target_length
def main():
# See all possible arguments in src/transformers/training_args.py
# or by passing the --help flag to this script.
# We now keep distinct sets of args, for a cleaner separation of concerns.
parser = HfArgumentParser((ModelArguments, DataTrainingArguments, Seq2SeqTrainingArguments))
if len(sys.argv) == 2 and sys.argv[1].endswith(".json"):
# If we pass only one argument to the script and it's the path to a json file,
# let's parse it to get our arguments.
model_args, data_args, training_args = parser.parse_json_file(json_file=os.path.abspath(sys.argv[1]))
else:
model_args, data_args, training_args = parser.parse_args_into_dataclasses()
# Detecting last checkpoint.
last_checkpoint = None
if os.path.isdir(training_args.output_dir) and training_args.do_train and not training_args.overwrite_output_dir:
last_checkpoint = get_last_checkpoint(training_args.output_dir)
if last_checkpoint is None and len(os.listdir(training_args.output_dir)) > 0:
raise ValueError(
f"Output directory ({training_args.output_dir}) already exists and is not empty. "
"Use --overwrite_output_dir to overcome."
)
elif last_checkpoint is not None and training_args.resume_from_checkpoint is None:
logger.info(
f"Checkpoint detected, resuming training at {last_checkpoint}. To avoid this behavior, change "
"the `--output_dir` or add `--overwrite_output_dir` to train from scratch."
)
# Setup logging
logging.basicConfig(
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
datefmt="%m/%d/%Y %H:%M:%S",
handlers=[logging.StreamHandler(sys.stdout)],
)
logger.setLevel(logging.INFO if is_main_process(training_args.local_rank) else logging.WARN)
# Log on each process the small summary:
logger.warning(
f"Process rank: {training_args.local_rank}, device: {training_args.device}, n_gpu: {training_args.n_gpu}"
+ f"distributed training: {bool(training_args.local_rank != -1)}, 16-bits training: {training_args.fp16}"
)
# Set the verbosity to info of the Transformers logger (on main process only):
if is_main_process(training_args.local_rank):
transformers.utils.logging.set_verbosity_info()
logger.info(f"Training/evaluation parameters {training_args}")
# Set seed before initializing model.
set_seed(training_args.seed)
# Get the datasets: you can either provide your own CSV/JSON training and evaluation files (see below)
# or just provide the name of one of the public datasets available on the hub at https://huggingface.co/datasets/
# (the dataset will be downloaded automatically from the datasets Hub).
#
# For JSON files, this script will use the `question` column for the input question and `table` column for the corresponding table.
#
# In distributed training, the load_dataset function guarantee that only one local process can concurrently
# download the dataset.
if data_args.dataset_name is not None:
# Downloading and loading a dataset from the hub.
datasets = load_dataset(data_args.dataset_name, data_args.dataset_config_name, cache_dir=model_args.cache_dir)
else:
data_files = {}
if data_args.train_file is not None:
data_files["train"] = data_args.train_file
extension = data_args.train_file.split(".")[-1]
if data_args.validation_file is not None:
data_files["validation"] = data_args.validation_file
extension = data_args.validation_file.split(".")[-1]
if data_args.test_file is not None:
data_files["test"] = data_args.test_file
extension = data_args.test_file.split(".")[-1]
datasets = load_dataset(extension, data_files=data_files, cache_dir=model_args.cache_dir)
# See more about loading any type of standard or custom dataset (from files, python dict, pandas DataFrame, etc) at
# https://huggingface.co/docs/datasets/loading_datasets.
# Load pretrained model and tokenizer
#
# Distributed training:
# The .from_pretrained methods guarantee that only one local process can concurrently
# download model & vocab.
config = AutoConfig.from_pretrained(
model_args.config_name if model_args.config_name else model_args.model_name_or_path,
cache_dir=model_args.cache_dir,
revision=model_args.model_revision,
token=True if model_args.use_auth_token else None,
)
# IMPORTANT: the initial BART model's decoding is penalized by no_repeat_ngram_size, and thus
# we should disable it here to avoid problematic generation
config.no_repeat_ngram_size = 0
config.max_length = 1024
config.early_stopping = False
# load tapex tokenizer
tokenizer = TapexTokenizer.from_pretrained(
model_args.tokenizer_name if model_args.tokenizer_name else model_args.model_name_or_path,
cache_dir=model_args.cache_dir,
use_fast=model_args.use_fast_tokenizer,
revision=model_args.model_revision,
token=True if model_args.use_auth_token else None,
add_prefix_space=True,
)
# load Bart based Tapex model (default tapex-large)
model = BartForConditionalGeneration.from_pretrained(
model_args.model_name_or_path,
from_tf=bool(".ckpt" in model_args.model_name_or_path),
config=config,
cache_dir=model_args.cache_dir,
revision=model_args.model_revision,
token=True if model_args.use_auth_token else None,
)
if model.config.decoder_start_token_id is None:
raise ValueError("Make sure that `config.decoder_start_token_id` is correctly defined")
# Preprocessing the datasets.
# We need to tokenize inputs and targets.
if training_args.do_train:
column_names = datasets["train"].column_names
elif training_args.do_eval:
column_names = datasets["validation"].column_names
elif training_args.do_predict:
column_names = datasets["test"].column_names
else:
logger.info("There is nothing to do. Please pass `do_train`, `do_eval` and/or `do_predict`.")
return
# Temporarily set max_target_length for training.
max_target_length = data_args.max_target_length
padding = "max_length" if data_args.pad_to_max_length else False
if training_args.label_smoothing_factor > 0 and not hasattr(model, "prepare_decoder_input_ids_from_labels"):
logger.warning(
"label_smoothing is enabled but the `prepare_decoder_input_ids_from_labels` method is not defined for "
f"`{model.__class__.__name__}`. This will lead to loss being calculated twice and will take up more memory"
)
def preprocess_tableqa_function(examples, is_training=False):
"""
The is_training FLAG is used to identify if we could use the supervision
to truncate the table content if it is required.
"""
# this function is specific for WikiSQL since the util function need the data structure
# to retrieve the WikiSQL answer for each question
def _convert_table_types(_table):
"""Runs the type converter over the table cells."""
ret_table = deepcopy(_table)
types = ret_table["types"]
ret_table["real_rows"] = ret_table["rows"]
typed_rows = []
for row in ret_table["rows"]:
typed_row = []
for column, cell_value in enumerate(row):
typed_row.append(_TYPE_CONVERTER[types[column]](cell_value))
typed_rows.append(typed_row)
ret_table["rows"] = typed_rows
return ret_table
questions = [question.lower() for question in examples["question"]]
example_tables = examples["table"]
example_sqls = examples["sql"]
tables = [
pd.DataFrame.from_records(example_table["rows"], columns=example_table["header"])
for example_table in example_tables
]
# using tapas utils to obtain wikisql answer
answers = []
for example_sql, example_table in zip(example_sqls, example_tables):
tapas_table = _convert_table_types(example_table)
answer_list: List[str] = retrieve_wikisql_query_answer_tapas(tapas_table, example_sql)
# you can choose other delimiters to split each answer
answers.append(answer_list)
# IMPORTANT: we cannot pass by answers during evaluation, answers passed during training are used to
# truncate large tables in the train set!
if is_training:
model_inputs = tokenizer(
table=tables,
query=questions,
answer=answers,
max_length=data_args.max_source_length,
padding=padding,
truncation=True,
)
else:
model_inputs = tokenizer(
table=tables, query=questions, max_length=data_args.max_source_length, padding=padding, truncation=True
)
labels = tokenizer(
answer=[", ".join(answer) for answer in answers],
max_length=max_target_length,
padding=padding,
truncation=True,
)
# If we are padding here, replace all tokenizer.pad_token_id in the labels by -100 when we want to ignore
# padding in the loss.
if padding == "max_length" and data_args.ignore_pad_token_for_loss:
labels["input_ids"] = [
[(l if l != tokenizer.pad_token_id else -100) for l in label] for label in labels["input_ids"]
]
model_inputs["labels"] = labels["input_ids"]
return model_inputs
# in training, we can use the answer as extra information to truncate large tables
preprocess_tableqa_function_training = partial(preprocess_tableqa_function, is_training=True)
if training_args.do_train:
if "train" not in datasets:
raise ValueError("--do_train requires a train dataset")
train_dataset = datasets["train"]
if data_args.max_train_samples is not None:
train_dataset = train_dataset.select(range(data_args.max_train_samples))
train_dataset = train_dataset.map(
preprocess_tableqa_function_training,
batched=True,
num_proc=data_args.preprocessing_num_workers,
remove_columns=column_names,
load_from_cache_file=not data_args.overwrite_cache,
)
if training_args.do_eval:
max_target_length = data_args.val_max_target_length
if "validation" not in datasets:
raise ValueError("--do_eval requires a validation dataset")
eval_dataset = datasets["validation"]
if data_args.max_eval_samples is not None:
eval_dataset = eval_dataset.select(range(data_args.max_eval_samples))
eval_dataset = eval_dataset.map(
preprocess_tableqa_function,
batched=True,
num_proc=data_args.preprocessing_num_workers,
remove_columns=column_names,
load_from_cache_file=not data_args.overwrite_cache,
)
if training_args.do_predict:
max_target_length = data_args.val_max_target_length
if "test" not in datasets:
raise ValueError("--do_predict requires a test dataset")
predict_dataset = datasets["test"]
if data_args.max_predict_samples is not None:
predict_dataset = predict_dataset.select(range(data_args.max_predict_samples))
predict_dataset = predict_dataset.map(
preprocess_tableqa_function,
batched=True,
num_proc=data_args.preprocessing_num_workers,
remove_columns=column_names,
load_from_cache_file=not data_args.overwrite_cache,
)
# Data collator
label_pad_token_id = -100 if data_args.ignore_pad_token_for_loss else tokenizer.pad_token_id
data_collator = DataCollatorForSeq2Seq(
tokenizer,
model=model,
label_pad_token_id=label_pad_token_id,
pad_to_multiple_of=8 if training_args.fp16 else None,
)
def postprocess_text(preds, labels):
preds = [pred.strip() for pred in preds]
labels = [label.strip() for label in labels]
return preds, labels
def compute_metrics(eval_preds):
preds, labels = eval_preds
if isinstance(preds, tuple):
preds = preds[0]
decoded_preds = tokenizer.batch_decode(preds, skip_special_tokens=True)
if data_args.ignore_pad_token_for_loss:
# Replace -100 in the labels as we can't decode them.
labels = np.where(labels != -100, labels, tokenizer.pad_token_id)
decoded_labels = tokenizer.batch_decode(labels, skip_special_tokens=True)
# Some simple post-processing
decoded_preds, decoded_labels = postprocess_text(decoded_preds, decoded_labels)
delimiter = ", "
# define example evaluation
def evaluate_example(predict_str: str, ground_str: str):
predict_spans = predict_str.split(delimiter)
ground_spans = ground_str.split(delimiter)
predict_values = defaultdict(lambda: 0)
ground_values = defaultdict(lambda: 0)
for span in predict_spans:
try:
predict_values[float(span)] += 1
except ValueError:
predict_values[span.strip()] += 1
for span in ground_spans:
try:
ground_values[float(span)] += 1
except ValueError:
ground_values[span.strip()] += 1
is_correct = predict_values == ground_values
return is_correct
def get_denotation_accuracy(predictions: List[str], references: List[str]):
assert len(predictions) == len(references)
correct_num = 0
for predict_str, ground_str in zip(predictions, references):
is_correct = evaluate_example(predict_str.lower(), ground_str.lower())
if is_correct:
correct_num += 1
return correct_num / len(predictions)
accuracy = get_denotation_accuracy(decoded_preds, decoded_labels)
result = {"denotation_accuracy": accuracy}
return result
# Initialize our Trainer
trainer = Seq2SeqTrainer(
model=model,
args=training_args,
train_dataset=train_dataset if training_args.do_train else None,
eval_dataset=eval_dataset if training_args.do_eval else None,
tokenizer=tokenizer,
data_collator=data_collator,
compute_metrics=compute_metrics if training_args.predict_with_generate else None,
)
if training_args.do_train:
checkpoint = None
if training_args.resume_from_checkpoint is not None:
checkpoint = training_args.resume_from_checkpoint
elif last_checkpoint is not None:
checkpoint = last_checkpoint
train_result = trainer.train(resume_from_checkpoint=checkpoint)
trainer.save_model() # Saves the tokenizer too for easy upload
metrics = train_result.metrics
max_train_samples = (
data_args.max_train_samples if data_args.max_train_samples is not None else len(train_dataset)
)
metrics["train_samples"] = min(max_train_samples, len(train_dataset))
trainer.log_metrics("train", metrics)
trainer.save_metrics("train", metrics)
trainer.save_state()
# Evaluation
results = {}
if training_args.do_eval:
logger.info("*** Evaluate ***")
metrics = trainer.evaluate(
max_length=data_args.val_max_target_length, num_beams=data_args.num_beams, metric_key_prefix="eval"
)
max_eval_samples = data_args.max_eval_samples if data_args.max_eval_samples is not None else len(eval_dataset)
metrics["eval_samples"] = min(max_eval_samples, len(eval_dataset))
trainer.log_metrics("eval", metrics)
trainer.save_metrics("eval", metrics)
if training_args.do_predict:
logger.info("*** Predict ***")
predict_results = trainer.predict(
predict_dataset,
metric_key_prefix="predict",
max_length=data_args.val_max_target_length,
num_beams=data_args.num_beams,
)
metrics = predict_results.metrics
max_predict_samples = (
data_args.max_predict_samples if data_args.max_predict_samples is not None else len(predict_dataset)
)
metrics["predict_samples"] = min(max_predict_samples, len(predict_dataset))
trainer.log_metrics("predict", metrics)
trainer.save_metrics("predict", metrics)
if trainer.is_world_process_zero():
if training_args.predict_with_generate:
predictions = tokenizer.batch_decode(
predict_results.predictions, skip_special_tokens=True, clean_up_tokenization_spaces=True
)
predictions = [pred.strip() for pred in predictions]
output_prediction_file = os.path.join(training_args.output_dir, "tapex_predictions.txt")
with open(output_prediction_file, "w") as writer:
writer.write("\n".join(predictions))
return results
def _mp_fn(index):
# For xla_spawn (TPUs)
main()
if __name__ == "__main__":
main()
| transformers/examples/research_projects/tapex/run_wikisql_with_tapex.py/0 | {
"file_path": "transformers/examples/research_projects/tapex/run_wikisql_with_tapex.py",
"repo_id": "transformers",
"token_count": 11008
} | 56 |
from datetime import datetime
import matplotlib.pyplot as plt
import torch
def freeze_module(module):
for param in module.parameters():
param.requires_grad = False
def get_device():
device = "cuda" if torch.cuda.is_available() else "cpu"
if torch.backends.mps.is_available() and torch.backends.mps.is_built():
device = "mps"
if device == "mps":
print(
"WARNING: MPS currently doesn't seem to work, and messes up backpropagation without any visible torch"
" errors. I recommend using CUDA on a colab notebook or CPU instead if you're facing inexplicable issues"
" with generations."
)
return device
def show_pil(img):
fig = plt.imshow(img)
fig.axes.get_xaxis().set_visible(False)
fig.axes.get_yaxis().set_visible(False)
plt.show()
def get_timestamp():
current_time = datetime.now()
timestamp = current_time.strftime("%H:%M:%S")
return timestamp
| transformers/examples/research_projects/vqgan-clip/utils.py/0 | {
"file_path": "transformers/examples/research_projects/vqgan-clip/utils.py",
"repo_id": "transformers",
"token_count": 379
} | 57 |
#!/usr/bin/env python3
import logging
import sys
from dataclasses import dataclass, field
from typing import Any, Dict, List, Optional, Union
import librosa
import torch
from datasets import DatasetDict, load_dataset
from packaging import version
from torch import nn
from transformers import (
HfArgumentParser,
Trainer,
TrainingArguments,
Wav2Vec2Config,
Wav2Vec2FeatureExtractor,
Wav2Vec2ForPreTraining,
is_apex_available,
trainer_utils,
)
from transformers.models.wav2vec2.modeling_wav2vec2 import _compute_mask_indices
if is_apex_available():
from apex import amp
if version.parse(version.parse(torch.__version__).base_version) >= version.parse("1.6"):
_is_native_amp_available = True
from torch.cuda.amp import autocast
logger = logging.getLogger(__name__)
@dataclass
class ModelArguments:
"""
Arguments pertaining to which model/config/tokenizer we are going to fine-tune from.
"""
model_name_or_path: str = field(
metadata={"help": "Path to pretrained model or model identifier from huggingface.co/models"}
)
cache_dir: Optional[str] = field(
default=None,
metadata={"help": "Where do you want to store the pretrained models downloaded from huggingface.co"},
)
freeze_feature_extractor: Optional[bool] = field(
default=True, metadata={"help": "Whether to freeze the feature extractor layers of the model."}
)
verbose_logging: Optional[bool] = field(
default=False,
metadata={"help": "Whether to log verbose messages or not."},
)
max_gumbel_temperature: Optional[float] = field(
default=2.0, metadata={"help": "Maximum temperature for gumbel softmax."}
)
min_gumbel_temperature: Optional[float] = field(
default=0.5, metadata={"help": "Minimum temperature for gumbel softmax."}
)
gumbel_temperature_decay: Optional[float] = field(
default=0.999995, metadata={"help": "Decay of gumbel temperature during training."}
)
def configure_logger(model_args: ModelArguments, training_args: TrainingArguments):
logging.basicConfig(
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
datefmt="%m/%d/%Y %H:%M:%S",
handlers=[logging.StreamHandler(sys.stdout)],
)
logging_level = logging.WARNING
if model_args.verbose_logging:
logging_level = logging.DEBUG
elif trainer_utils.is_main_process(training_args.local_rank):
logging_level = logging.INFO
logger.setLevel(logging_level)
@dataclass
class DataTrainingArguments:
"""
Arguments pertaining to what data we are going to input our model for training and eval.
Using `HfArgumentParser` we can turn this class
into argparse arguments to be able to specify them on
the command line.
"""
dataset_name: str = field(
default=None, metadata={"help": "The name of the dataset to use (via the datasets library)."}
)
dataset_config_name: Optional[str] = field(
default=None, metadata={"help": "The configuration name of the dataset to use (via the datasets library)."}
)
train_split_name: Optional[str] = field(
default="train",
metadata={
"help": "The name of the training data set split to use (via the datasets library). Defaults to 'train'"
},
)
validation_split_name: Optional[str] = field(
default="validation",
metadata={
"help": (
"The name of the validation data set split to use (via the datasets library). Defaults to 'validation'"
)
},
)
speech_file_column: Optional[str] = field(
default="file",
metadata={"help": "Column in the dataset that contains speech file path. Defaults to 'file'"},
)
overwrite_cache: bool = field(
default=False, metadata={"help": "Overwrite the cached preprocessed datasets or not."}
)
validation_split_percentage: Optional[int] = field(
default=1,
metadata={
"help": "The percentage of the train set used as validation set in case there's no validation split"
},
)
preprocessing_num_workers: Optional[int] = field(
default=None,
metadata={"help": "The number of processes to use for the preprocessing."},
)
max_duration_in_seconds: Optional[float] = field(
default=20.0, metadata={"help": "Filter audio files that are longer than `max_duration_in_seconds` seconds"}
)
@dataclass
class DataCollatorForWav2Vec2Pretraining:
"""
Data collator that will dynamically pad the inputs received and prepare masked indices
for self-supervised pretraining.
Args:
model (:class:`~transformers.Wav2Vec2ForPreTraining`):
The Wav2Vec2 model used for pretraining. The data collator needs to have access
to config and ``_get_feat_extract_output_lengths`` function for correct padding.
feature_extractor (:class:`~transformers.Wav2Vec2FeatureExtractor`):
The processor used for proccessing the data.
padding (:obj:`bool`, :obj:`str` or :class:`~transformers.tokenization_utils_base.PaddingStrategy`, `optional`, defaults to :obj:`True`):
Select a strategy to pad the returned sequences (according to the model's padding side and padding index)
among:
* :obj:`True` or :obj:`'longest'`: Pad to the longest sequence in the batch (or no padding if only a single
sequence if provided).
* :obj:`'max_length'`: Pad to a maximum length specified with the argument :obj:`max_length` or to the
maximum acceptable input length for the model if that argument is not provided.
* :obj:`False` or :obj:`'do_not_pad'` (default): No padding (i.e., can output a batch with sequences of
different lengths).
max_length (:obj:`int`, `optional`):
Maximum length of the ``input_values`` of the returned list and optionally padding length (see above).
pad_to_multiple_of (:obj:`int`, `optional`):
If set will pad the sequence to a multiple of the provided value.
This is especially useful to enable the use of Tensor Cores on NVIDIA hardware with compute capability >=
7.5 (Volta).
"""
model: Wav2Vec2ForPreTraining
feature_extractor: Wav2Vec2FeatureExtractor
padding: Union[bool, str] = "longest"
pad_to_multiple_of: Optional[int] = None
max_length: Optional[int] = None
def __call__(self, features: List[Dict[str, Union[List[int], torch.Tensor]]]) -> Dict[str, torch.Tensor]:
# reformat list to dict and set to pytorch format
batch = self.feature_extractor.pad(
features,
max_length=self.max_length,
padding=self.padding,
pad_to_multiple_of=self.pad_to_multiple_of,
return_tensors="pt",
)
mask_indices_seq_length = self.model._get_feat_extract_output_lengths(batch["input_values"].shape[-1])
batch_size = batch["input_values"].shape[0]
# make sure that no loss is computed on padded inputs
if batch["attention_mask"] is not None:
# compute real output lengths according to convolution formula
output_lengths = self.model._get_feat_extract_output_lengths(batch["attention_mask"].sum(-1)).to(
torch.long
)
attention_mask = torch.zeros(
(batch_size, mask_indices_seq_length), dtype=torch.long, device=batch["input_values"].device
)
# these two operations makes sure that all values
# before the output lengths indices are attended to
attention_mask[
(torch.arange(attention_mask.shape[0], device=batch["input_values"].device), output_lengths - 1)
] = 1
attention_mask = attention_mask.flip([-1]).cumsum(-1).flip([-1]).bool()
# sample randomly masked indices
batch["mask_time_indices"] = _compute_mask_indices(
(batch_size, mask_indices_seq_length),
self.model.config.mask_time_prob,
self.model.config.mask_time_length,
attention_mask=attention_mask,
min_masks=2,
)
return batch
class Wav2Vec2PreTrainer(Trainer):
"""
Subclassed :class:`~transformers.Trainer` for Wav2Vec2-like pretraining. Trainer can decay gumbel softmax temperature during training.
"""
def __init__(self, *args, max_gumbel_temp=1, min_gumbel_temp=0, gumbel_temp_decay=1.0, **kwargs):
super().__init__(*args, **kwargs)
self.num_update_step = 0
self.max_gumbel_temp = max_gumbel_temp
self.min_gumbel_temp = min_gumbel_temp
self.gumbel_temp_decay = gumbel_temp_decay
def training_step(self, model: nn.Module, inputs: Dict[str, Union[torch.Tensor, Any]]) -> torch.Tensor:
"""
Perform a training step on a batch of inputs.
Subclass and override to inject custom behavior.
Args:
model (:obj:`nn.Module`):
The model to train.
inputs (:obj:`Dict[str, Union[torch.Tensor, Any]]`):
The inputs and targets of the model.
The dictionary will be unpacked before being fed to the model. Most models expect the targets under the
argument :obj:`labels`. Check your model's documentation for all accepted arguments.
Return:
:obj:`torch.Tensor`: The tensor with training loss on this batch.
"""
model.train()
inputs = self._prepare_inputs(inputs)
if self.use_amp:
with autocast():
loss = self.compute_loss(model, inputs)
else:
loss = self.compute_loss(model, inputs)
if self.args.n_gpu > 1 or self.deepspeed:
if model.module.config.ctc_loss_reduction == "mean":
loss = loss.mean()
elif model.module.config.ctc_loss_reduction == "sum":
loss = loss.sum() / (inputs["mask_time_indices"]).sum()
else:
raise ValueError(f"{model.config.ctc_loss_reduction} is not valid. Choose one of ['mean', 'sum']")
if self.args.gradient_accumulation_steps > 1:
loss = loss / self.args.gradient_accumulation_steps
if self.use_amp:
self.scaler.scale(loss).backward()
elif self.use_apex:
with amp.scale_loss(loss, self.optimizer) as scaled_loss:
scaled_loss.backward()
elif self.deepspeed:
self.deepspeed.backward(loss)
else:
loss.backward()
self.num_update_step += 1
# make sure gumbel softmax temperature is decayed
if self.args.n_gpu > 1 or self.deepspeed:
model.module.set_gumbel_temperature(
max(self.max_gumbel_temp * self.gumbel_temp_decay**self.num_update_step, self.min_gumbel_temp)
)
else:
model.set_gumbel_temperature(
max(self.max_gumbel_temp * self.gumbel_temp_decay**self.num_update_step, self.min_gumbel_temp)
)
return loss.detach()
def main():
# See all possible arguments in src/transformers/training_args.py
# or by passing the --help flag to this script.
# We now keep distinct sets of args, for a cleaner separation of concerns.
parser = HfArgumentParser((ModelArguments, DataTrainingArguments, TrainingArguments))
model_args, data_args, training_args = parser.parse_args_into_dataclasses()
configure_logger(model_args, training_args)
# Downloading and loading a dataset from the hub.
datasets = load_dataset(data_args.dataset_name, data_args.dataset_config_name, cache_dir=model_args.cache_dir)
if "validation" not in datasets.keys():
# make sure only "validation" and "train" keys remain"
datasets = DatasetDict()
datasets["validation"] = load_dataset(
data_args.dataset_name,
data_args.dataset_config_name,
split=f"{data_args.train_split_name}[:{data_args.validation_split_percentage}%]",
cache_dir=model_args.cache_dir,
)
datasets["train"] = load_dataset(
data_args.dataset_name,
data_args.dataset_config_name,
split=f"{data_args.train_split_name}[{data_args.validation_split_percentage}%:]",
cache_dir=model_args.cache_dir,
)
else:
# make sure only "validation" and "train" keys remain"
datasets = DatasetDict()
datasets["validation"] = load_dataset(
data_args.dataset_name,
data_args.dataset_config_name,
split="validation",
cache_dir=model_args.cache_dir,
)
datasets["train"] = load_dataset(
data_args.dataset_name,
data_args.dataset_config_name,
split=f"{data_args.train_split_name}",
cache_dir=model_args.cache_dir,
)
# only normalized-inputs-training is supported
feature_extractor = Wav2Vec2FeatureExtractor.from_pretrained(
model_args.model_name_or_path, cache_dir=model_args.cache_dir, do_normalize=True
)
def prepare_dataset(batch):
# check that all files have the correct sampling rate
batch["speech"], _ = librosa.load(batch[data_args.speech_file_column], sr=feature_extractor.sampling_rate)
return batch
# load audio files into numpy arrays
vectorized_datasets = datasets.map(
prepare_dataset, num_proc=data_args.preprocessing_num_workers, remove_columns=datasets["train"].column_names
)
# filter audio files that are too long
vectorized_datasets = vectorized_datasets.filter(
lambda data: len(data["speech"]) < int(data_args.max_duration_in_seconds * feature_extractor.sampling_rate)
)
def normalize(batch):
return feature_extractor(batch["speech"], sampling_rate=feature_extractor.sampling_rate)
# normalize and transform to `BatchFeatures`
vectorized_datasets = vectorized_datasets.map(
normalize,
batched=True,
num_proc=data_args.preprocessing_num_workers,
load_from_cache_file=not data_args.overwrite_cache,
remove_columns=vectorized_datasets["train"].column_names,
)
# pretraining is only supported for "newer" stable layer norm architecture
# apply_spec_augment has to be True, mask_feature_prob has to be 0.0
config = Wav2Vec2Config.from_pretrained(
model_args.model_name_or_path,
cache_dir=model_args.cache_dir,
gradient_checkpointing=training_args.gradient_checkpointing,
)
if not config.do_stable_layer_norm or config.feat_extract_norm != "layer":
raise ValueError(
"PreTraining is only supported for ``config.do_stable_layer_norm=True`` and"
" ``config.feat_extract_norm='layer'"
)
model = Wav2Vec2ForPreTraining(config)
data_collator = DataCollatorForWav2Vec2Pretraining(model=model, feature_extractor=feature_extractor)
trainer = Wav2Vec2PreTrainer(
model=model,
data_collator=data_collator,
args=training_args,
train_dataset=vectorized_datasets["train"],
eval_dataset=vectorized_datasets["validation"],
tokenizer=feature_extractor,
max_gumbel_temp=model_args.max_gumbel_temperature,
min_gumbel_temp=model_args.min_gumbel_temperature,
gumbel_temp_decay=model_args.gumbel_temperature_decay,
)
trainer.train()
if __name__ == "__main__":
main()
| transformers/examples/research_projects/wav2vec2/run_pretrain.py/0 | {
"file_path": "transformers/examples/research_projects/wav2vec2/run_pretrain.py",
"repo_id": "transformers",
"token_count": 6513
} | 58 |
#!/usr/bin/env python
# coding=utf-8
# Copyright The HuggingFace Team and The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""
Fine-tuning the library models for multiple choice.
"""
# You can also adapt this script on your own multiple choice task. Pointers for this are left as comments.
import json
import logging
import os
import sys
import warnings
from dataclasses import dataclass, field
from itertools import chain
from pathlib import Path
from typing import Optional, Union
import datasets
import tensorflow as tf
from datasets import load_dataset
import transformers
from transformers import (
CONFIG_NAME,
TF2_WEIGHTS_NAME,
AutoConfig,
AutoTokenizer,
DefaultDataCollator,
HfArgumentParser,
PushToHubCallback,
TFAutoModelForMultipleChoice,
TFTrainingArguments,
create_optimizer,
set_seed,
)
from transformers.tokenization_utils_base import PreTrainedTokenizerBase
from transformers.utils import PaddingStrategy, check_min_version, send_example_telemetry
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
check_min_version("4.39.0.dev0")
logger = logging.getLogger(__name__)
# region Helper classes and functions
@dataclass
class DataCollatorForMultipleChoice:
"""
Data collator that will dynamically pad the inputs for multiple choice received.
Args:
tokenizer ([`PreTrainedTokenizer`] or [`PreTrainedTokenizerFast`]):
The tokenizer used for encoding the data.
padding (`bool`, `str` or [`~utils.PaddingStrategy`], *optional*, defaults to `True`):
Select a strategy to pad the returned sequences (according to the model's padding side and padding index)
among:
- `True` or `'longest'`: Pad to the longest sequence in the batch (or no padding if only a single sequence
if provided).
- `'max_length'`: Pad to a maximum length specified with the argument `max_length` or to the maximum
acceptable input length for the model if that argument is not provided.
- `False` or `'do_not_pad'` (default): No padding (i.e., can output a batch with sequences of different
lengths).
max_length (`int`, *optional*):
Maximum length of the returned list and optionally padding length (see above).
pad_to_multiple_of (`int`, *optional*):
If set will pad the sequence to a multiple of the provided value.
This is especially useful to enable the use of Tensor Cores on NVIDIA hardware with compute capability >=
7.5 (Volta).
"""
tokenizer: PreTrainedTokenizerBase
padding: Union[bool, str, PaddingStrategy] = True
max_length: Optional[int] = None
pad_to_multiple_of: Optional[int] = None
def __call__(self, features):
label_name = "label" if "label" in features[0].keys() else "labels"
labels = [feature.pop(label_name) for feature in features]
batch_size = len(features)
num_choices = len(features[0]["input_ids"])
flattened_features = [
[{k: v[i] for k, v in feature.items()} for i in range(num_choices)] for feature in features
]
flattened_features = list(chain(*flattened_features))
batch = self.tokenizer.pad(
flattened_features,
padding=self.padding,
max_length=self.max_length,
pad_to_multiple_of=self.pad_to_multiple_of,
return_tensors="np",
)
# Un-flatten
batch = {k: tf.reshape(v, (batch_size, num_choices, -1)) for k, v in batch.items()}
# Add back labels
batch["labels"] = tf.convert_to_tensor(labels, dtype=tf.int64)
return batch
# endregion
# region Arguments
@dataclass
class ModelArguments:
"""
Arguments pertaining to which model/config/tokenizer we are going to fine-tune from.
"""
model_name_or_path: str = field(
metadata={"help": "Path to pretrained model or model identifier from huggingface.co/models"}
)
config_name: Optional[str] = field(
default=None, metadata={"help": "Pretrained config name or path if not the same as model_name"}
)
tokenizer_name: Optional[str] = field(
default=None, metadata={"help": "Pretrained tokenizer name or path if not the same as model_name"}
)
cache_dir: Optional[str] = field(
default=None,
metadata={"help": "Where do you want to store the pretrained models downloaded from huggingface.co"},
)
use_fast_tokenizer: bool = field(
default=True,
metadata={"help": "Whether to use one of the fast tokenizer (backed by the tokenizers library) or not."},
)
model_revision: str = field(
default="main",
metadata={"help": "The specific model version to use (can be a branch name, tag name or commit id)."},
)
token: str = field(
default=None,
metadata={
"help": (
"The token to use as HTTP bearer authorization for remote files. If not specified, will use the token "
"generated when running `huggingface-cli login` (stored in `~/.huggingface`)."
)
},
)
use_auth_token: bool = field(
default=None,
metadata={
"help": "The `use_auth_token` argument is deprecated and will be removed in v4.34. Please use `token` instead."
},
)
trust_remote_code: bool = field(
default=False,
metadata={
"help": (
"Whether or not to allow for custom models defined on the Hub in their own modeling files. This option "
"should only be set to `True` for repositories you trust and in which you have read the code, as it will "
"execute code present on the Hub on your local machine."
)
},
)
@dataclass
class DataTrainingArguments:
"""
Arguments pertaining to what data we are going to input our model for training and eval.
"""
train_file: Optional[str] = field(default=None, metadata={"help": "The input training data file (a text file)."})
validation_file: Optional[str] = field(
default=None,
metadata={"help": "An optional input evaluation data file to evaluate the perplexity on (a text file)."},
)
overwrite_cache: bool = field(
default=False, metadata={"help": "Overwrite the cached training and evaluation sets"}
)
preprocessing_num_workers: Optional[int] = field(
default=None,
metadata={"help": "The number of processes to use for the preprocessing."},
)
max_seq_length: Optional[int] = field(
default=None,
metadata={
"help": (
"The maximum total input sequence length after tokenization. If passed, sequences longer "
"than this will be truncated, sequences shorter will be padded."
)
},
)
pad_to_max_length: bool = field(
default=False,
metadata={
"help": (
"Whether to pad all samples to the maximum sentence length. "
"If False, will pad the samples dynamically when batching to the maximum length in the batch. More "
"efficient on GPU but very bad for TPU."
)
},
)
max_train_samples: Optional[int] = field(
default=None,
metadata={
"help": (
"For debugging purposes or quicker training, truncate the number of training examples to this "
"value if set."
)
},
)
max_eval_samples: Optional[int] = field(
default=None,
metadata={
"help": (
"For debugging purposes or quicker training, truncate the number of evaluation examples to this "
"value if set."
)
},
)
def __post_init__(self):
if self.train_file is not None:
extension = self.train_file.split(".")[-1]
assert extension in ["csv", "json"], "`train_file` should be a csv or a json file."
if self.validation_file is not None:
extension = self.validation_file.split(".")[-1]
assert extension in ["csv", "json"], "`validation_file` should be a csv or a json file."
# endregion
def main():
# region Argument parsing
# See all possible arguments in src/transformers/training_args.py
# or by passing the --help flag to this script.
# We now keep distinct sets of args, for a cleaner separation of concerns.
parser = HfArgumentParser((ModelArguments, DataTrainingArguments, TFTrainingArguments))
if len(sys.argv) == 2 and sys.argv[1].endswith(".json"):
# If we pass only one argument to the script and it's the path to a json file,
# let's parse it to get our arguments.
model_args, data_args, training_args = parser.parse_json_file(json_file=os.path.abspath(sys.argv[1]))
else:
model_args, data_args, training_args = parser.parse_args_into_dataclasses()
if model_args.use_auth_token is not None:
warnings.warn(
"The `use_auth_token` argument is deprecated and will be removed in v4.34. Please use `token` instead.",
FutureWarning,
)
if model_args.token is not None:
raise ValueError("`token` and `use_auth_token` are both specified. Please set only the argument `token`.")
model_args.token = model_args.use_auth_token
# Sending telemetry. Tracking the example usage helps us better allocate resources to maintain them. The
# information sent is the one passed as arguments along with your Python/PyTorch versions.
send_example_telemetry("run_swag", model_args, data_args, framework="tensorflow")
output_dir = Path(training_args.output_dir)
output_dir.mkdir(parents=True, exist_ok=True)
# endregion
# region Logging
logging.basicConfig(
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
datefmt="%m/%d/%Y %H:%M:%S",
handlers=[logging.StreamHandler(sys.stdout)],
)
log_level = training_args.get_process_log_level()
logger.setLevel(log_level)
datasets.utils.logging.set_verbosity(log_level)
transformers.utils.logging.set_verbosity(log_level)
transformers.utils.logging.enable_default_handler()
transformers.utils.logging.enable_explicit_format()
# endregion
# region Checkpoints
checkpoint = None
if len(os.listdir(training_args.output_dir)) > 0 and not training_args.overwrite_output_dir:
if (output_dir / CONFIG_NAME).is_file() and (output_dir / TF2_WEIGHTS_NAME).is_file():
checkpoint = output_dir
logger.info(
f"Checkpoint detected, resuming training from checkpoint in {training_args.output_dir}. To avoid this"
" behavior, change the `--output_dir` or add `--overwrite_output_dir` to train from scratch."
)
else:
raise ValueError(
f"Output directory ({training_args.output_dir}) already exists and is not empty. "
"Use --overwrite_output_dir to continue regardless."
)
# endregion
# Set seed before initializing model.
set_seed(training_args.seed)
# region Load datasets
# Get the datasets: you can either provide your own CSV/JSON/TXT training and evaluation files (see below)
# or just provide the name of one of the public datasets available on the hub at https://huggingface.co/datasets/
# (the dataset will be downloaded automatically from the datasets Hub).
# For CSV/JSON files, this script will use the column called 'text' or the first column if no column called
# 'text' is found. You can easily tweak this behavior (see below).
# In distributed training, the load_dataset function guarantee that only one local process can concurrently
# download the dataset.
if data_args.train_file is not None or data_args.validation_file is not None:
data_files = {}
if data_args.train_file is not None:
data_files["train"] = data_args.train_file
extension = data_args.train_file.split(".")[-1]
if data_args.validation_file is not None:
data_files["validation"] = data_args.validation_file
extension = data_args.validation_file.split(".")[-1]
raw_datasets = load_dataset(
extension,
data_files=data_files,
cache_dir=model_args.cache_dir,
token=model_args.token,
)
else:
# Downloading and loading the swag dataset from the hub.
raw_datasets = load_dataset(
"swag",
"regular",
cache_dir=model_args.cache_dir,
token=model_args.token,
)
# See more about loading any type of standard or custom dataset (from files, python dict, pandas DataFrame, etc) at
# https://huggingface.co/docs/datasets/loading_datasets.
# When using your own dataset or a different dataset from swag, you will probably need to change this.
ending_names = [f"ending{i}" for i in range(4)]
context_name = "sent1"
question_header_name = "sent2"
# endregion
# region Load model config and tokenizer
if checkpoint is not None:
config_path = training_args.output_dir
elif model_args.config_name:
config_path = model_args.config_name
else:
config_path = model_args.model_name_or_path
# Distributed training:
# The .from_pretrained methods guarantee that only one local process can concurrently
# download model & vocab.
config = AutoConfig.from_pretrained(
config_path,
cache_dir=model_args.cache_dir,
revision=model_args.model_revision,
token=model_args.token,
trust_remote_code=model_args.trust_remote_code,
)
tokenizer = AutoTokenizer.from_pretrained(
model_args.tokenizer_name if model_args.tokenizer_name else model_args.model_name_or_path,
cache_dir=model_args.cache_dir,
use_fast=model_args.use_fast_tokenizer,
revision=model_args.model_revision,
token=model_args.token,
trust_remote_code=model_args.trust_remote_code,
)
# endregion
# region Dataset preprocessing
if data_args.max_seq_length is None:
max_seq_length = tokenizer.model_max_length
if max_seq_length > 1024:
logger.warning(
f"The tokenizer picked seems to have a very large `model_max_length` ({tokenizer.model_max_length}). "
"Picking 1024 instead. You can change that default value by passing --max_seq_length xxx."
)
max_seq_length = 1024
else:
if data_args.max_seq_length > tokenizer.model_max_length:
logger.warning(
f"The max_seq_length passed ({data_args.max_seq_length}) is larger than the maximum length for the "
f"model ({tokenizer.model_max_length}). Using max_seq_length={tokenizer.model_max_length}."
)
max_seq_length = min(data_args.max_seq_length, tokenizer.model_max_length)
def preprocess_function(examples):
first_sentences = [[context] * 4 for context in examples[context_name]]
question_headers = examples[question_header_name]
second_sentences = [
[f"{header} {examples[end][i]}" for end in ending_names] for i, header in enumerate(question_headers)
]
# Flatten out
first_sentences = list(chain(*first_sentences))
second_sentences = list(chain(*second_sentences))
# Tokenize
tokenized_examples = tokenizer(first_sentences, second_sentences, truncation=True, max_length=max_seq_length)
# Un-flatten
data = {k: [v[i : i + 4] for i in range(0, len(v), 4)] for k, v in tokenized_examples.items()}
return data
if training_args.do_train:
if "train" not in raw_datasets:
raise ValueError("--do_train requires a train dataset")
train_dataset = raw_datasets["train"]
if data_args.max_train_samples is not None:
max_train_samples = min(len(train_dataset), data_args.max_train_samples)
train_dataset = train_dataset.select(range(max_train_samples))
train_dataset = train_dataset.map(
preprocess_function,
batched=True,
num_proc=data_args.preprocessing_num_workers,
load_from_cache_file=not data_args.overwrite_cache,
)
if training_args.do_eval:
if "validation" not in raw_datasets:
raise ValueError("--do_eval requires a validation dataset")
eval_dataset = raw_datasets["validation"]
if data_args.max_eval_samples is not None:
max_eval_samples = min(len(eval_dataset), data_args.max_eval_samples)
eval_dataset = eval_dataset.select(range(max_eval_samples))
eval_dataset = eval_dataset.map(
preprocess_function,
batched=True,
num_proc=data_args.preprocessing_num_workers,
load_from_cache_file=not data_args.overwrite_cache,
)
if data_args.pad_to_max_length:
data_collator = DefaultDataCollator(return_tensors="np")
else:
# custom class defined above, as HF has no data collator for multiple choice
data_collator = DataCollatorForMultipleChoice(tokenizer)
# endregion
with training_args.strategy.scope():
# region Build model
if checkpoint is None:
model_path = model_args.model_name_or_path
else:
model_path = checkpoint
model = TFAutoModelForMultipleChoice.from_pretrained(
model_path,
config=config,
cache_dir=model_args.cache_dir,
revision=model_args.model_revision,
token=model_args.token,
trust_remote_code=model_args.trust_remote_code,
)
num_replicas = training_args.strategy.num_replicas_in_sync
total_train_batch_size = training_args.per_device_train_batch_size * num_replicas
total_eval_batch_size = training_args.per_device_eval_batch_size * num_replicas
if training_args.do_train:
num_train_steps = (len(train_dataset) // total_train_batch_size) * int(training_args.num_train_epochs)
if training_args.warmup_steps > 0:
num_warmup_steps = training_args.warmup_steps
elif training_args.warmup_ratio > 0:
num_warmup_steps = int(num_train_steps * training_args.warmup_ratio)
else:
num_warmup_steps = 0
optimizer, lr_schedule = create_optimizer(
init_lr=training_args.learning_rate,
num_train_steps=num_train_steps,
num_warmup_steps=num_warmup_steps,
adam_beta1=training_args.adam_beta1,
adam_beta2=training_args.adam_beta2,
adam_epsilon=training_args.adam_epsilon,
weight_decay_rate=training_args.weight_decay,
adam_global_clipnorm=training_args.max_grad_norm,
)
else:
optimizer = None
# Transformers models compute the right loss for their task by default when labels are passed, and will
# use this for training unless you specify your own loss function in compile().
model.compile(optimizer=optimizer, metrics=["accuracy"], jit_compile=training_args.xla)
# endregion
# region Preparing push_to_hub and model card
push_to_hub_model_id = training_args.push_to_hub_model_id
model_name = model_args.model_name_or_path.split("/")[-1]
if not push_to_hub_model_id:
push_to_hub_model_id = f"{model_name}-finetuned-multiplechoice"
model_card_kwargs = {"finetuned_from": model_args.model_name_or_path, "tasks": "multiple-choice"}
if training_args.push_to_hub:
callbacks = [
PushToHubCallback(
output_dir=training_args.output_dir,
hub_model_id=push_to_hub_model_id,
hub_token=training_args.push_to_hub_token,
tokenizer=tokenizer,
**model_card_kwargs,
)
]
else:
callbacks = []
# endregion
# region Training
eval_metrics = None
if training_args.do_train:
dataset_options = tf.data.Options()
dataset_options.experimental_distribute.auto_shard_policy = tf.data.experimental.AutoShardPolicy.OFF
# model.prepare_tf_dataset() wraps a Hugging Face dataset in a tf.data.Dataset which is ready to use in
# training. This is the recommended way to use a Hugging Face dataset when training with Keras. You can also
# use the lower-level dataset.to_tf_dataset() method, but you will have to specify things like column names
# yourself if you use this method, whereas they are automatically inferred from the model input names when
# using model.prepare_tf_dataset()
# For more info see the docs:
# https://huggingface.co/docs/transformers/main/en/main_classes/model#transformers.TFPreTrainedModel.prepare_tf_dataset
# https://huggingface.co/docs/datasets/main/en/package_reference/main_classes#datasets.Dataset.to_tf_dataset
tf_train_dataset = model.prepare_tf_dataset(
train_dataset,
shuffle=True,
batch_size=total_train_batch_size,
collate_fn=data_collator,
).with_options(dataset_options)
if training_args.do_eval:
validation_data = model.prepare_tf_dataset(
eval_dataset,
shuffle=False,
batch_size=total_eval_batch_size,
collate_fn=data_collator,
drop_remainder=True,
).with_options(dataset_options)
else:
validation_data = None
history = model.fit(
tf_train_dataset,
validation_data=validation_data,
epochs=int(training_args.num_train_epochs),
callbacks=callbacks,
)
eval_metrics = {key: val[-1] for key, val in history.history.items()}
# endregion
# region Evaluation
if training_args.do_eval and not training_args.do_train:
dataset_options = tf.data.Options()
dataset_options.experimental_distribute.auto_shard_policy = tf.data.experimental.AutoShardPolicy.OFF
# Do a standalone evaluation pass
tf_eval_dataset = model.prepare_tf_dataset(
eval_dataset,
shuffle=False,
batch_size=total_eval_batch_size,
collate_fn=data_collator,
drop_remainder=True,
).with_options(dataset_options)
eval_results = model.evaluate(tf_eval_dataset)
eval_metrics = {"val_loss": eval_results[0], "val_accuracy": eval_results[1]}
# endregion
if eval_metrics is not None and training_args.output_dir is not None:
output_eval_file = os.path.join(training_args.output_dir, "all_results.json")
with open(output_eval_file, "w") as writer:
writer.write(json.dumps(eval_metrics))
# region Push to hub
if training_args.output_dir is not None and not training_args.push_to_hub:
# If we're not pushing to hub, at least save a local copy when we're done
model.save_pretrained(training_args.output_dir)
# endregion
if __name__ == "__main__":
main()
| transformers/examples/tensorflow/multiple-choice/run_swag.py/0 | {
"file_path": "transformers/examples/tensorflow/multiple-choice/run_swag.py",
"repo_id": "transformers",
"token_count": 10190
} | 59 |
<!---
Copyright 2021 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
# Translation example
This script shows an example of training a *translation* model with the 🤗 Transformers library.
For straightforward use-cases you may be able to use these scripts without modification, although we have also
included comments in the code to indicate areas that you may need to adapt to your own projects.
### Multi-GPU and TPU usage
By default, these scripts use a `MirroredStrategy` and will use multiple GPUs effectively if they are available. TPUs
can also be used by passing the name of the TPU resource with the `--tpu` argument.
### Example commands and caveats
MBart and some T5 models require special handling.
T5 models `google-t5/t5-small`, `google-t5/t5-base`, `google-t5/t5-large`, `google-t5/t5-3b` and `google-t5/t5-11b` must use an additional argument: `--source_prefix "translate {source_lang} to {target_lang}"`. For example:
```bash
python run_translation.py \
--model_name_or_path google-t5/t5-small \
--do_train \
--do_eval \
--source_lang en \
--target_lang ro \
--source_prefix "translate English to Romanian: " \
--dataset_name wmt16 \
--dataset_config_name ro-en \
--output_dir /tmp/tst-translation \
--per_device_train_batch_size=16 \
--per_device_eval_batch_size=16 \
--overwrite_output_dir
```
If you get a terrible BLEU score, make sure that you didn't forget to use the `--source_prefix` argument.
For the aforementioned group of T5 models it's important to remember that if you switch to a different language pair, make sure to adjust the source and target values in all 3 language-specific command line argument: `--source_lang`, `--target_lang` and `--source_prefix`.
MBart models require a different format for `--source_lang` and `--target_lang` values, e.g. instead of `en` it expects `en_XX`, for `ro` it expects `ro_RO`. The full MBart specification for language codes can be found [here](https://huggingface.co/facebook/mbart-large-cc25). For example:
```bash
python run_translation.py \
--model_name_or_path facebook/mbart-large-en-ro \
--do_train \
--do_eval \
--dataset_name wmt16 \
--dataset_config_name ro-en \
--source_lang en_XX \
--target_lang ro_RO \
--output_dir /tmp/tst-translation \
--per_device_train_batch_size=16 \
--per_device_eval_batch_size=16 \
--overwrite_output_dir
```
| transformers/examples/tensorflow/translation/README.md/0 | {
"file_path": "transformers/examples/tensorflow/translation/README.md",
"repo_id": "transformers",
"token_count": 933
} | 60 |
#!/usr/bin/env python
# coding: utf-8
# Copyright 2020 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# This script creates a super tiny model that is useful inside tests, when we just want to test that
# the machinery works, without needing to the check the quality of the outcomes.
#
# This version creates a tiny vocab first, and then a tiny model - so the outcome is truly tiny -
# all files ~60KB. As compared to taking a full-size model, reducing to the minimum its layers and
# emb dimensions, but keeping the full vocab + merges files, leading to ~3MB in total for all files.
# The latter is done by `fsmt-make-super-tiny-model.py`.
#
# It will be used then as "stas/tiny-wmt19-en-ru"
import json
import tempfile
from pathlib import Path
from transformers import FSMTConfig, FSMTForConditionalGeneration, FSMTTokenizer
from transformers.models.fsmt.tokenization_fsmt import VOCAB_FILES_NAMES
mname_tiny = "tiny-wmt19-en-ru"
# Build
# borrowed from a test
vocab = [ "l", "o", "w", "e", "r", "s", "t", "i", "d", "n", "w</w>", "r</w>", "t</w>", "lo", "low", "er</w>", "low</w>", "lowest</w>", "newer</w>", "wider</w>", "<unk>", ]
vocab_tokens = dict(zip(vocab, range(len(vocab))))
merges = ["l o 123", "lo w 1456", "e r</w> 1789", ""]
with tempfile.TemporaryDirectory() as tmpdirname:
build_dir = Path(tmpdirname)
src_vocab_file = build_dir / VOCAB_FILES_NAMES["src_vocab_file"]
tgt_vocab_file = build_dir / VOCAB_FILES_NAMES["tgt_vocab_file"]
merges_file = build_dir / VOCAB_FILES_NAMES["merges_file"]
with open(src_vocab_file, "w") as fp: fp.write(json.dumps(vocab_tokens))
with open(tgt_vocab_file, "w") as fp: fp.write(json.dumps(vocab_tokens))
with open(merges_file, "w") as fp : fp.write("\n".join(merges))
tokenizer = FSMTTokenizer(
langs=["en", "ru"],
src_vocab_size = len(vocab),
tgt_vocab_size = len(vocab),
src_vocab_file=src_vocab_file,
tgt_vocab_file=tgt_vocab_file,
merges_file=merges_file,
)
config = FSMTConfig(
langs=['ru', 'en'],
src_vocab_size=1000, tgt_vocab_size=1000,
d_model=4,
encoder_layers=1, decoder_layers=1,
encoder_ffn_dim=4, decoder_ffn_dim=4,
encoder_attention_heads=1, decoder_attention_heads=1,
)
tiny_model = FSMTForConditionalGeneration(config)
print(f"num of params {tiny_model.num_parameters()}")
# Test
batch = tokenizer(["Making tiny model"], return_tensors="pt")
outputs = tiny_model(**batch)
print("test output:", len(outputs.logits[0]))
# Save
tiny_model.half() # makes it smaller
tiny_model.save_pretrained(mname_tiny)
tokenizer.save_pretrained(mname_tiny)
print(f"Generated {mname_tiny}")
# Upload
# transformers-cli upload tiny-wmt19-en-ru
| transformers/scripts/fsmt/fsmt-make-super-tiny-model.py/0 | {
"file_path": "transformers/scripts/fsmt/fsmt-make-super-tiny-model.py",
"repo_id": "transformers",
"token_count": 1246
} | 61 |
# Copyright 2020 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
from argparse import ArgumentParser
from ..pipelines import Pipeline, PipelineDataFormat, get_supported_tasks, pipeline
from ..utils import logging
from . import BaseTransformersCLICommand
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
def try_infer_format_from_ext(path: str):
if not path:
return "pipe"
for ext in PipelineDataFormat.SUPPORTED_FORMATS:
if path.endswith(ext):
return ext
raise Exception(
f"Unable to determine file format from file extension {path}. "
f"Please provide the format through --format {PipelineDataFormat.SUPPORTED_FORMATS}"
)
def run_command_factory(args):
nlp = pipeline(
task=args.task,
model=args.model if args.model else None,
config=args.config,
tokenizer=args.tokenizer,
device=args.device,
)
format = try_infer_format_from_ext(args.input) if args.format == "infer" else args.format
reader = PipelineDataFormat.from_str(
format=format,
output_path=args.output,
input_path=args.input,
column=args.column if args.column else nlp.default_input_names,
overwrite=args.overwrite,
)
return RunCommand(nlp, reader)
class RunCommand(BaseTransformersCLICommand):
def __init__(self, nlp: Pipeline, reader: PipelineDataFormat):
self._nlp = nlp
self._reader = reader
@staticmethod
def register_subcommand(parser: ArgumentParser):
run_parser = parser.add_parser("run", help="Run a pipeline through the CLI")
run_parser.add_argument("--task", choices=get_supported_tasks(), help="Task to run")
run_parser.add_argument("--input", type=str, help="Path to the file to use for inference")
run_parser.add_argument("--output", type=str, help="Path to the file that will be used post to write results.")
run_parser.add_argument("--model", type=str, help="Name or path to the model to instantiate.")
run_parser.add_argument("--config", type=str, help="Name or path to the model's config to instantiate.")
run_parser.add_argument(
"--tokenizer", type=str, help="Name of the tokenizer to use. (default: same as the model name)"
)
run_parser.add_argument(
"--column",
type=str,
help="Name of the column to use as input. (For multi columns input as QA use column1,columns2)",
)
run_parser.add_argument(
"--format",
type=str,
default="infer",
choices=PipelineDataFormat.SUPPORTED_FORMATS,
help="Input format to read from",
)
run_parser.add_argument(
"--device",
type=int,
default=-1,
help="Indicate the device to run onto, -1 indicates CPU, >= 0 indicates GPU (default: -1)",
)
run_parser.add_argument("--overwrite", action="store_true", help="Allow overwriting the output file.")
run_parser.set_defaults(func=run_command_factory)
def run(self):
nlp, outputs = self._nlp, []
for entry in self._reader:
output = nlp(**entry) if self._reader.is_multi_columns else nlp(entry)
if isinstance(output, dict):
outputs.append(output)
else:
outputs += output
# Saving data
if self._nlp.binary_output:
binary_path = self._reader.save_binary(outputs)
logger.warning(f"Current pipeline requires output to be in binary format, saving at {binary_path}")
else:
self._reader.save(outputs)
| transformers/src/transformers/commands/run.py/0 | {
"file_path": "transformers/src/transformers/commands/run.py",
"repo_id": "transformers",
"token_count": 1665
} | 62 |
# Copyright 2020 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import os
import time
from dataclasses import dataclass, field
from enum import Enum
from typing import Dict, List, Optional, Union
import torch
from filelock import FileLock
from torch.utils.data import Dataset
from ...models.auto.modeling_auto import MODEL_FOR_QUESTION_ANSWERING_MAPPING
from ...tokenization_utils import PreTrainedTokenizer
from ...utils import logging
from ..processors.squad import SquadFeatures, SquadV1Processor, SquadV2Processor, squad_convert_examples_to_features
logger = logging.get_logger(__name__)
MODEL_CONFIG_CLASSES = list(MODEL_FOR_QUESTION_ANSWERING_MAPPING.keys())
MODEL_TYPES = tuple(conf.model_type for conf in MODEL_CONFIG_CLASSES)
@dataclass
class SquadDataTrainingArguments:
"""
Arguments pertaining to what data we are going to input our model for training and eval.
"""
model_type: str = field(
default=None, metadata={"help": "Model type selected in the list: " + ", ".join(MODEL_TYPES)}
)
data_dir: str = field(
default=None, metadata={"help": "The input data dir. Should contain the .json files for the SQuAD task."}
)
max_seq_length: int = field(
default=128,
metadata={
"help": (
"The maximum total input sequence length after tokenization. Sequences longer "
"than this will be truncated, sequences shorter will be padded."
)
},
)
doc_stride: int = field(
default=128,
metadata={"help": "When splitting up a long document into chunks, how much stride to take between chunks."},
)
max_query_length: int = field(
default=64,
metadata={
"help": (
"The maximum number of tokens for the question. Questions longer than this will "
"be truncated to this length."
)
},
)
max_answer_length: int = field(
default=30,
metadata={
"help": (
"The maximum length of an answer that can be generated. This is needed because the start "
"and end predictions are not conditioned on one another."
)
},
)
overwrite_cache: bool = field(
default=False, metadata={"help": "Overwrite the cached training and evaluation sets"}
)
version_2_with_negative: bool = field(
default=False, metadata={"help": "If true, the SQuAD examples contain some that do not have an answer."}
)
null_score_diff_threshold: float = field(
default=0.0, metadata={"help": "If null_score - best_non_null is greater than the threshold predict null."}
)
n_best_size: int = field(
default=20, metadata={"help": "If null_score - best_non_null is greater than the threshold predict null."}
)
lang_id: int = field(
default=0,
metadata={
"help": (
"language id of input for language-specific xlm models (see"
" tokenization_xlm.PRETRAINED_INIT_CONFIGURATION)"
)
},
)
threads: int = field(default=1, metadata={"help": "multiple threads for converting example to features"})
class Split(Enum):
train = "train"
dev = "dev"
class SquadDataset(Dataset):
"""
This will be superseded by a framework-agnostic approach soon.
"""
args: SquadDataTrainingArguments
features: List[SquadFeatures]
mode: Split
is_language_sensitive: bool
def __init__(
self,
args: SquadDataTrainingArguments,
tokenizer: PreTrainedTokenizer,
limit_length: Optional[int] = None,
mode: Union[str, Split] = Split.train,
is_language_sensitive: Optional[bool] = False,
cache_dir: Optional[str] = None,
dataset_format: Optional[str] = "pt",
):
self.args = args
self.is_language_sensitive = is_language_sensitive
self.processor = SquadV2Processor() if args.version_2_with_negative else SquadV1Processor()
if isinstance(mode, str):
try:
mode = Split[mode]
except KeyError:
raise KeyError("mode is not a valid split name")
self.mode = mode
# Load data features from cache or dataset file
version_tag = "v2" if args.version_2_with_negative else "v1"
cached_features_file = os.path.join(
cache_dir if cache_dir is not None else args.data_dir,
f"cached_{mode.value}_{tokenizer.__class__.__name__}_{args.max_seq_length}_{version_tag}",
)
# Make sure only the first process in distributed training processes the dataset,
# and the others will use the cache.
lock_path = cached_features_file + ".lock"
with FileLock(lock_path):
if os.path.exists(cached_features_file) and not args.overwrite_cache:
start = time.time()
self.old_features = torch.load(cached_features_file)
# Legacy cache files have only features, while new cache files
# will have dataset and examples also.
self.features = self.old_features["features"]
self.dataset = self.old_features.get("dataset", None)
self.examples = self.old_features.get("examples", None)
logger.info(
f"Loading features from cached file {cached_features_file} [took %.3f s]", time.time() - start
)
if self.dataset is None or self.examples is None:
logger.warning(
f"Deleting cached file {cached_features_file} will allow dataset and examples to be cached in"
" future run"
)
else:
if mode == Split.dev:
self.examples = self.processor.get_dev_examples(args.data_dir)
else:
self.examples = self.processor.get_train_examples(args.data_dir)
self.features, self.dataset = squad_convert_examples_to_features(
examples=self.examples,
tokenizer=tokenizer,
max_seq_length=args.max_seq_length,
doc_stride=args.doc_stride,
max_query_length=args.max_query_length,
is_training=mode == Split.train,
threads=args.threads,
return_dataset=dataset_format,
)
start = time.time()
torch.save(
{"features": self.features, "dataset": self.dataset, "examples": self.examples},
cached_features_file,
)
# ^ This seems to take a lot of time so I want to investigate why and how we can improve.
logger.info(
f"Saving features into cached file {cached_features_file} [took {time.time() - start:.3f} s]"
)
def __len__(self):
return len(self.features)
def __getitem__(self, i) -> Dict[str, torch.Tensor]:
# Convert to Tensors and build dataset
feature = self.features[i]
input_ids = torch.tensor(feature.input_ids, dtype=torch.long)
attention_mask = torch.tensor(feature.attention_mask, dtype=torch.long)
token_type_ids = torch.tensor(feature.token_type_ids, dtype=torch.long)
cls_index = torch.tensor(feature.cls_index, dtype=torch.long)
p_mask = torch.tensor(feature.p_mask, dtype=torch.float)
is_impossible = torch.tensor(feature.is_impossible, dtype=torch.float)
inputs = {
"input_ids": input_ids,
"attention_mask": attention_mask,
"token_type_ids": token_type_ids,
}
if self.args.model_type in ["xlm", "roberta", "distilbert", "camembert"]:
del inputs["token_type_ids"]
if self.args.model_type in ["xlnet", "xlm"]:
inputs.update({"cls_index": cls_index, "p_mask": p_mask})
if self.args.version_2_with_negative:
inputs.update({"is_impossible": is_impossible})
if self.is_language_sensitive:
inputs.update({"langs": (torch.ones(input_ids.shape, dtype=torch.int64) * self.args.lang_id)})
if self.mode == Split.train:
start_positions = torch.tensor(feature.start_position, dtype=torch.long)
end_positions = torch.tensor(feature.end_position, dtype=torch.long)
inputs.update({"start_positions": start_positions, "end_positions": end_positions})
return inputs
| transformers/src/transformers/data/datasets/squad.py/0 | {
"file_path": "transformers/src/transformers/data/datasets/squad.py",
"repo_id": "transformers",
"token_count": 4006
} | 63 |
# Copyright 2022 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
from typing import TYPE_CHECKING
from ..utils import OptionalDependencyNotAvailable, _LazyModule, is_flax_available, is_tf_available, is_torch_available
_import_structure = {
"configuration_utils": ["GenerationConfig"],
"streamers": ["TextIteratorStreamer", "TextStreamer"],
}
try:
if not is_torch_available():
raise OptionalDependencyNotAvailable()
except OptionalDependencyNotAvailable:
pass
else:
_import_structure["beam_constraints"] = [
"Constraint",
"ConstraintListState",
"DisjunctiveConstraint",
"PhrasalConstraint",
]
_import_structure["beam_search"] = [
"BeamHypotheses",
"BeamScorer",
"BeamSearchScorer",
"ConstrainedBeamSearchScorer",
]
_import_structure["logits_process"] = [
"AlternatingCodebooksLogitsProcessor",
"ClassifierFreeGuidanceLogitsProcessor",
"EncoderNoRepeatNGramLogitsProcessor",
"EncoderRepetitionPenaltyLogitsProcessor",
"EpsilonLogitsWarper",
"EtaLogitsWarper",
"ExponentialDecayLengthPenalty",
"ForcedBOSTokenLogitsProcessor",
"ForcedEOSTokenLogitsProcessor",
"ForceTokensLogitsProcessor",
"HammingDiversityLogitsProcessor",
"InfNanRemoveLogitsProcessor",
"LogitNormalization",
"LogitsProcessor",
"LogitsProcessorList",
"LogitsWarper",
"MinLengthLogitsProcessor",
"MinNewTokensLengthLogitsProcessor",
"NoBadWordsLogitsProcessor",
"NoRepeatNGramLogitsProcessor",
"PrefixConstrainedLogitsProcessor",
"RepetitionPenaltyLogitsProcessor",
"SequenceBiasLogitsProcessor",
"SuppressTokensLogitsProcessor",
"SuppressTokensAtBeginLogitsProcessor",
"TemperatureLogitsWarper",
"TopKLogitsWarper",
"TopPLogitsWarper",
"TypicalLogitsWarper",
"UnbatchedClassifierFreeGuidanceLogitsProcessor",
"WhisperTimeStampLogitsProcessor",
]
_import_structure["stopping_criteria"] = [
"MaxNewTokensCriteria",
"MaxLengthCriteria",
"MaxTimeCriteria",
"StoppingCriteria",
"StoppingCriteriaList",
"validate_stopping_criteria",
]
_import_structure["utils"] = [
"GenerationMixin",
"top_k_top_p_filtering",
"GreedySearchEncoderDecoderOutput",
"GreedySearchDecoderOnlyOutput",
"SampleEncoderDecoderOutput",
"SampleDecoderOnlyOutput",
"BeamSearchEncoderDecoderOutput",
"BeamSearchDecoderOnlyOutput",
"BeamSampleEncoderDecoderOutput",
"BeamSampleDecoderOnlyOutput",
"ContrastiveSearchEncoderDecoderOutput",
"ContrastiveSearchDecoderOnlyOutput",
"GenerateBeamDecoderOnlyOutput",
"GenerateBeamEncoderDecoderOutput",
"GenerateDecoderOnlyOutput",
"GenerateEncoderDecoderOutput",
]
try:
if not is_tf_available():
raise OptionalDependencyNotAvailable()
except OptionalDependencyNotAvailable:
pass
else:
_import_structure["tf_logits_process"] = [
"TFForcedBOSTokenLogitsProcessor",
"TFForcedEOSTokenLogitsProcessor",
"TFForceTokensLogitsProcessor",
"TFLogitsProcessor",
"TFLogitsProcessorList",
"TFLogitsWarper",
"TFMinLengthLogitsProcessor",
"TFNoBadWordsLogitsProcessor",
"TFNoRepeatNGramLogitsProcessor",
"TFRepetitionPenaltyLogitsProcessor",
"TFSuppressTokensAtBeginLogitsProcessor",
"TFSuppressTokensLogitsProcessor",
"TFTemperatureLogitsWarper",
"TFTopKLogitsWarper",
"TFTopPLogitsWarper",
]
_import_structure["tf_utils"] = [
"TFGenerationMixin",
"tf_top_k_top_p_filtering",
"TFGreedySearchDecoderOnlyOutput",
"TFGreedySearchEncoderDecoderOutput",
"TFSampleEncoderDecoderOutput",
"TFSampleDecoderOnlyOutput",
"TFBeamSearchEncoderDecoderOutput",
"TFBeamSearchDecoderOnlyOutput",
"TFBeamSampleEncoderDecoderOutput",
"TFBeamSampleDecoderOnlyOutput",
"TFContrastiveSearchEncoderDecoderOutput",
"TFContrastiveSearchDecoderOnlyOutput",
]
try:
if not is_flax_available():
raise OptionalDependencyNotAvailable()
except OptionalDependencyNotAvailable:
pass
else:
_import_structure["flax_logits_process"] = [
"FlaxForcedBOSTokenLogitsProcessor",
"FlaxForcedEOSTokenLogitsProcessor",
"FlaxForceTokensLogitsProcessor",
"FlaxLogitsProcessor",
"FlaxLogitsProcessorList",
"FlaxLogitsWarper",
"FlaxMinLengthLogitsProcessor",
"FlaxSuppressTokensAtBeginLogitsProcessor",
"FlaxSuppressTokensLogitsProcessor",
"FlaxTemperatureLogitsWarper",
"FlaxTopKLogitsWarper",
"FlaxTopPLogitsWarper",
"FlaxWhisperTimeStampLogitsProcessor",
]
_import_structure["flax_utils"] = [
"FlaxGenerationMixin",
"FlaxGreedySearchOutput",
"FlaxSampleOutput",
"FlaxBeamSearchOutput",
]
if TYPE_CHECKING:
from .configuration_utils import GenerationConfig
from .streamers import TextIteratorStreamer, TextStreamer
try:
if not is_torch_available():
raise OptionalDependencyNotAvailable()
except OptionalDependencyNotAvailable:
pass
else:
from .beam_constraints import Constraint, ConstraintListState, DisjunctiveConstraint, PhrasalConstraint
from .beam_search import BeamHypotheses, BeamScorer, BeamSearchScorer, ConstrainedBeamSearchScorer
from .logits_process import (
AlternatingCodebooksLogitsProcessor,
ClassifierFreeGuidanceLogitsProcessor,
EncoderNoRepeatNGramLogitsProcessor,
EncoderRepetitionPenaltyLogitsProcessor,
EpsilonLogitsWarper,
EtaLogitsWarper,
ExponentialDecayLengthPenalty,
ForcedBOSTokenLogitsProcessor,
ForcedEOSTokenLogitsProcessor,
ForceTokensLogitsProcessor,
HammingDiversityLogitsProcessor,
InfNanRemoveLogitsProcessor,
LogitNormalization,
LogitsProcessor,
LogitsProcessorList,
LogitsWarper,
MinLengthLogitsProcessor,
MinNewTokensLengthLogitsProcessor,
NoBadWordsLogitsProcessor,
NoRepeatNGramLogitsProcessor,
PrefixConstrainedLogitsProcessor,
RepetitionPenaltyLogitsProcessor,
SequenceBiasLogitsProcessor,
SuppressTokensAtBeginLogitsProcessor,
SuppressTokensLogitsProcessor,
TemperatureLogitsWarper,
TopKLogitsWarper,
TopPLogitsWarper,
TypicalLogitsWarper,
UnbatchedClassifierFreeGuidanceLogitsProcessor,
WhisperTimeStampLogitsProcessor,
)
from .stopping_criteria import (
MaxLengthCriteria,
MaxNewTokensCriteria,
MaxTimeCriteria,
StoppingCriteria,
StoppingCriteriaList,
validate_stopping_criteria,
)
from .utils import (
BeamSampleDecoderOnlyOutput,
BeamSampleEncoderDecoderOutput,
BeamSearchDecoderOnlyOutput,
BeamSearchEncoderDecoderOutput,
ContrastiveSearchDecoderOnlyOutput,
ContrastiveSearchEncoderDecoderOutput,
GenerateBeamDecoderOnlyOutput,
GenerateBeamEncoderDecoderOutput,
GenerateDecoderOnlyOutput,
GenerateEncoderDecoderOutput,
GenerationMixin,
GreedySearchDecoderOnlyOutput,
GreedySearchEncoderDecoderOutput,
SampleDecoderOnlyOutput,
SampleEncoderDecoderOutput,
top_k_top_p_filtering,
)
try:
if not is_tf_available():
raise OptionalDependencyNotAvailable()
except OptionalDependencyNotAvailable:
pass
else:
from .tf_logits_process import (
TFForcedBOSTokenLogitsProcessor,
TFForcedEOSTokenLogitsProcessor,
TFForceTokensLogitsProcessor,
TFLogitsProcessor,
TFLogitsProcessorList,
TFLogitsWarper,
TFMinLengthLogitsProcessor,
TFNoBadWordsLogitsProcessor,
TFNoRepeatNGramLogitsProcessor,
TFRepetitionPenaltyLogitsProcessor,
TFSuppressTokensAtBeginLogitsProcessor,
TFSuppressTokensLogitsProcessor,
TFTemperatureLogitsWarper,
TFTopKLogitsWarper,
TFTopPLogitsWarper,
)
from .tf_utils import (
TFBeamSampleDecoderOnlyOutput,
TFBeamSampleEncoderDecoderOutput,
TFBeamSearchDecoderOnlyOutput,
TFBeamSearchEncoderDecoderOutput,
TFContrastiveSearchDecoderOnlyOutput,
TFContrastiveSearchEncoderDecoderOutput,
TFGenerationMixin,
TFGreedySearchDecoderOnlyOutput,
TFGreedySearchEncoderDecoderOutput,
TFSampleDecoderOnlyOutput,
TFSampleEncoderDecoderOutput,
tf_top_k_top_p_filtering,
)
try:
if not is_flax_available():
raise OptionalDependencyNotAvailable()
except OptionalDependencyNotAvailable:
pass
else:
from .flax_logits_process import (
FlaxForcedBOSTokenLogitsProcessor,
FlaxForcedEOSTokenLogitsProcessor,
FlaxForceTokensLogitsProcessor,
FlaxLogitsProcessor,
FlaxLogitsProcessorList,
FlaxLogitsWarper,
FlaxMinLengthLogitsProcessor,
FlaxSuppressTokensAtBeginLogitsProcessor,
FlaxSuppressTokensLogitsProcessor,
FlaxTemperatureLogitsWarper,
FlaxTopKLogitsWarper,
FlaxTopPLogitsWarper,
FlaxWhisperTimeStampLogitsProcessor,
)
from .flax_utils import FlaxBeamSearchOutput, FlaxGenerationMixin, FlaxGreedySearchOutput, FlaxSampleOutput
else:
import sys
sys.modules[__name__] = _LazyModule(__name__, globals()["__file__"], _import_structure, module_spec=__spec__)
| transformers/src/transformers/generation/__init__.py/0 | {
"file_path": "transformers/src/transformers/generation/__init__.py",
"repo_id": "transformers",
"token_count": 4888
} | 64 |
# Copyright 2020 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import dataclasses
import json
import sys
import types
from argparse import ArgumentDefaultsHelpFormatter, ArgumentParser, ArgumentTypeError
from copy import copy
from enum import Enum
from inspect import isclass
from pathlib import Path
from typing import Any, Callable, Dict, Iterable, List, Literal, NewType, Optional, Tuple, Union, get_type_hints
import yaml
DataClass = NewType("DataClass", Any)
DataClassType = NewType("DataClassType", Any)
# From https://stackoverflow.com/questions/15008758/parsing-boolean-values-with-argparse
def string_to_bool(v):
if isinstance(v, bool):
return v
if v.lower() in ("yes", "true", "t", "y", "1"):
return True
elif v.lower() in ("no", "false", "f", "n", "0"):
return False
else:
raise ArgumentTypeError(
f"Truthy value expected: got {v} but expected one of yes/no, true/false, t/f, y/n, 1/0 (case insensitive)."
)
def make_choice_type_function(choices: list) -> Callable[[str], Any]:
"""
Creates a mapping function from each choices string representation to the actual value. Used to support multiple
value types for a single argument.
Args:
choices (list): List of choices.
Returns:
Callable[[str], Any]: Mapping function from string representation to actual value for each choice.
"""
str_to_choice = {str(choice): choice for choice in choices}
return lambda arg: str_to_choice.get(arg, arg)
def HfArg(
*,
aliases: Union[str, List[str]] = None,
help: str = None,
default: Any = dataclasses.MISSING,
default_factory: Callable[[], Any] = dataclasses.MISSING,
metadata: dict = None,
**kwargs,
) -> dataclasses.Field:
"""Argument helper enabling a concise syntax to create dataclass fields for parsing with `HfArgumentParser`.
Example comparing the use of `HfArg` and `dataclasses.field`:
```
@dataclass
class Args:
regular_arg: str = dataclasses.field(default="Huggingface", metadata={"aliases": ["--example", "-e"], "help": "This syntax could be better!"})
hf_arg: str = HfArg(default="Huggingface", aliases=["--example", "-e"], help="What a nice syntax!")
```
Args:
aliases (Union[str, List[str]], optional):
Single string or list of strings of aliases to pass on to argparse, e.g. `aliases=["--example", "-e"]`.
Defaults to None.
help (str, optional): Help string to pass on to argparse that can be displayed with --help. Defaults to None.
default (Any, optional):
Default value for the argument. If not default or default_factory is specified, the argument is required.
Defaults to dataclasses.MISSING.
default_factory (Callable[[], Any], optional):
The default_factory is a 0-argument function called to initialize a field's value. It is useful to provide
default values for mutable types, e.g. lists: `default_factory=list`. Mutually exclusive with `default=`.
Defaults to dataclasses.MISSING.
metadata (dict, optional): Further metadata to pass on to `dataclasses.field`. Defaults to None.
Returns:
Field: A `dataclasses.Field` with the desired properties.
"""
if metadata is None:
# Important, don't use as default param in function signature because dict is mutable and shared across function calls
metadata = {}
if aliases is not None:
metadata["aliases"] = aliases
if help is not None:
metadata["help"] = help
return dataclasses.field(metadata=metadata, default=default, default_factory=default_factory, **kwargs)
class HfArgumentParser(ArgumentParser):
"""
This subclass of `argparse.ArgumentParser` uses type hints on dataclasses to generate arguments.
The class is designed to play well with the native argparse. In particular, you can add more (non-dataclass backed)
arguments to the parser after initialization and you'll get the output back after parsing as an additional
namespace. Optional: To create sub argument groups use the `_argument_group_name` attribute in the dataclass.
"""
dataclass_types: Iterable[DataClassType]
def __init__(self, dataclass_types: Union[DataClassType, Iterable[DataClassType]], **kwargs):
"""
Args:
dataclass_types:
Dataclass type, or list of dataclass types for which we will "fill" instances with the parsed args.
kwargs (`Dict[str, Any]`, *optional*):
Passed to `argparse.ArgumentParser()` in the regular way.
"""
# To make the default appear when using --help
if "formatter_class" not in kwargs:
kwargs["formatter_class"] = ArgumentDefaultsHelpFormatter
super().__init__(**kwargs)
if dataclasses.is_dataclass(dataclass_types):
dataclass_types = [dataclass_types]
self.dataclass_types = list(dataclass_types)
for dtype in self.dataclass_types:
self._add_dataclass_arguments(dtype)
@staticmethod
def _parse_dataclass_field(parser: ArgumentParser, field: dataclasses.Field):
field_name = f"--{field.name}"
kwargs = field.metadata.copy()
# field.metadata is not used at all by Data Classes,
# it is provided as a third-party extension mechanism.
if isinstance(field.type, str):
raise RuntimeError(
"Unresolved type detected, which should have been done with the help of "
"`typing.get_type_hints` method by default"
)
aliases = kwargs.pop("aliases", [])
if isinstance(aliases, str):
aliases = [aliases]
origin_type = getattr(field.type, "__origin__", field.type)
if origin_type is Union or (hasattr(types, "UnionType") and isinstance(origin_type, types.UnionType)):
if str not in field.type.__args__ and (
len(field.type.__args__) != 2 or type(None) not in field.type.__args__
):
raise ValueError(
"Only `Union[X, NoneType]` (i.e., `Optional[X]`) is allowed for `Union` because"
" the argument parser only supports one type per argument."
f" Problem encountered in field '{field.name}'."
)
if type(None) not in field.type.__args__:
# filter `str` in Union
field.type = field.type.__args__[0] if field.type.__args__[1] == str else field.type.__args__[1]
origin_type = getattr(field.type, "__origin__", field.type)
elif bool not in field.type.__args__:
# filter `NoneType` in Union (except for `Union[bool, NoneType]`)
field.type = (
field.type.__args__[0] if isinstance(None, field.type.__args__[1]) else field.type.__args__[1]
)
origin_type = getattr(field.type, "__origin__", field.type)
# A variable to store kwargs for a boolean field, if needed
# so that we can init a `no_*` complement argument (see below)
bool_kwargs = {}
if origin_type is Literal or (isinstance(field.type, type) and issubclass(field.type, Enum)):
if origin_type is Literal:
kwargs["choices"] = field.type.__args__
else:
kwargs["choices"] = [x.value for x in field.type]
kwargs["type"] = make_choice_type_function(kwargs["choices"])
if field.default is not dataclasses.MISSING:
kwargs["default"] = field.default
else:
kwargs["required"] = True
elif field.type is bool or field.type == Optional[bool]:
# Copy the currect kwargs to use to instantiate a `no_*` complement argument below.
# We do not initialize it here because the `no_*` alternative must be instantiated after the real argument
bool_kwargs = copy(kwargs)
# Hack because type=bool in argparse does not behave as we want.
kwargs["type"] = string_to_bool
if field.type is bool or (field.default is not None and field.default is not dataclasses.MISSING):
# Default value is False if we have no default when of type bool.
default = False if field.default is dataclasses.MISSING else field.default
# This is the value that will get picked if we don't include --field_name in any way
kwargs["default"] = default
# This tells argparse we accept 0 or 1 value after --field_name
kwargs["nargs"] = "?"
# This is the value that will get picked if we do --field_name (without value)
kwargs["const"] = True
elif isclass(origin_type) and issubclass(origin_type, list):
kwargs["type"] = field.type.__args__[0]
kwargs["nargs"] = "+"
if field.default_factory is not dataclasses.MISSING:
kwargs["default"] = field.default_factory()
elif field.default is dataclasses.MISSING:
kwargs["required"] = True
else:
kwargs["type"] = field.type
if field.default is not dataclasses.MISSING:
kwargs["default"] = field.default
elif field.default_factory is not dataclasses.MISSING:
kwargs["default"] = field.default_factory()
else:
kwargs["required"] = True
parser.add_argument(field_name, *aliases, **kwargs)
# Add a complement `no_*` argument for a boolean field AFTER the initial field has already been added.
# Order is important for arguments with the same destination!
# We use a copy of earlier kwargs because the original kwargs have changed a lot before reaching down
# here and we do not need those changes/additional keys.
if field.default is True and (field.type is bool or field.type == Optional[bool]):
bool_kwargs["default"] = False
parser.add_argument(f"--no_{field.name}", action="store_false", dest=field.name, **bool_kwargs)
def _add_dataclass_arguments(self, dtype: DataClassType):
if hasattr(dtype, "_argument_group_name"):
parser = self.add_argument_group(dtype._argument_group_name)
else:
parser = self
try:
type_hints: Dict[str, type] = get_type_hints(dtype)
except NameError:
raise RuntimeError(
f"Type resolution failed for {dtype}. Try declaring the class in global scope or "
"removing line of `from __future__ import annotations` which opts in Postponed "
"Evaluation of Annotations (PEP 563)"
)
except TypeError as ex:
# Remove this block when we drop Python 3.9 support
if sys.version_info[:2] < (3, 10) and "unsupported operand type(s) for |" in str(ex):
python_version = ".".join(map(str, sys.version_info[:3]))
raise RuntimeError(
f"Type resolution failed for {dtype} on Python {python_version}. Try removing "
"line of `from __future__ import annotations` which opts in union types as "
"`X | Y` (PEP 604) via Postponed Evaluation of Annotations (PEP 563). To "
"support Python versions that lower than 3.10, you need to use "
"`typing.Union[X, Y]` instead of `X | Y` and `typing.Optional[X]` instead of "
"`X | None`."
) from ex
raise
for field in dataclasses.fields(dtype):
if not field.init:
continue
field.type = type_hints[field.name]
self._parse_dataclass_field(parser, field)
def parse_args_into_dataclasses(
self,
args=None,
return_remaining_strings=False,
look_for_args_file=True,
args_filename=None,
args_file_flag=None,
) -> Tuple[DataClass, ...]:
"""
Parse command-line args into instances of the specified dataclass types.
This relies on argparse's `ArgumentParser.parse_known_args`. See the doc at:
docs.python.org/3.7/library/argparse.html#argparse.ArgumentParser.parse_args
Args:
args:
List of strings to parse. The default is taken from sys.argv. (same as argparse.ArgumentParser)
return_remaining_strings:
If true, also return a list of remaining argument strings.
look_for_args_file:
If true, will look for a ".args" file with the same base name as the entry point script for this
process, and will append its potential content to the command line args.
args_filename:
If not None, will uses this file instead of the ".args" file specified in the previous argument.
args_file_flag:
If not None, will look for a file in the command-line args specified with this flag. The flag can be
specified multiple times and precedence is determined by the order (last one wins).
Returns:
Tuple consisting of:
- the dataclass instances in the same order as they were passed to the initializer.abspath
- if applicable, an additional namespace for more (non-dataclass backed) arguments added to the parser
after initialization.
- The potential list of remaining argument strings. (same as argparse.ArgumentParser.parse_known_args)
"""
if args_file_flag or args_filename or (look_for_args_file and len(sys.argv)):
args_files = []
if args_filename:
args_files.append(Path(args_filename))
elif look_for_args_file and len(sys.argv):
args_files.append(Path(sys.argv[0]).with_suffix(".args"))
# args files specified via command line flag should overwrite default args files so we add them last
if args_file_flag:
# Create special parser just to extract the args_file_flag values
args_file_parser = ArgumentParser()
args_file_parser.add_argument(args_file_flag, type=str, action="append")
# Use only remaining args for further parsing (remove the args_file_flag)
cfg, args = args_file_parser.parse_known_args(args=args)
cmd_args_file_paths = vars(cfg).get(args_file_flag.lstrip("-"), None)
if cmd_args_file_paths:
args_files.extend([Path(p) for p in cmd_args_file_paths])
file_args = []
for args_file in args_files:
if args_file.exists():
file_args += args_file.read_text().split()
# in case of duplicate arguments the last one has precedence
# args specified via the command line should overwrite args from files, so we add them last
args = file_args + args if args is not None else file_args + sys.argv[1:]
namespace, remaining_args = self.parse_known_args(args=args)
outputs = []
for dtype in self.dataclass_types:
keys = {f.name for f in dataclasses.fields(dtype) if f.init}
inputs = {k: v for k, v in vars(namespace).items() if k in keys}
for k in keys:
delattr(namespace, k)
obj = dtype(**inputs)
outputs.append(obj)
if len(namespace.__dict__) > 0:
# additional namespace.
outputs.append(namespace)
if return_remaining_strings:
return (*outputs, remaining_args)
else:
if remaining_args:
raise ValueError(f"Some specified arguments are not used by the HfArgumentParser: {remaining_args}")
return (*outputs,)
def parse_dict(self, args: Dict[str, Any], allow_extra_keys: bool = False) -> Tuple[DataClass, ...]:
"""
Alternative helper method that does not use `argparse` at all, instead uses a dict and populating the dataclass
types.
Args:
args (`dict`):
dict containing config values
allow_extra_keys (`bool`, *optional*, defaults to `False`):
Defaults to False. If False, will raise an exception if the dict contains keys that are not parsed.
Returns:
Tuple consisting of:
- the dataclass instances in the same order as they were passed to the initializer.
"""
unused_keys = set(args.keys())
outputs = []
for dtype in self.dataclass_types:
keys = {f.name for f in dataclasses.fields(dtype) if f.init}
inputs = {k: v for k, v in args.items() if k in keys}
unused_keys.difference_update(inputs.keys())
obj = dtype(**inputs)
outputs.append(obj)
if not allow_extra_keys and unused_keys:
raise ValueError(f"Some keys are not used by the HfArgumentParser: {sorted(unused_keys)}")
return tuple(outputs)
def parse_json_file(self, json_file: str, allow_extra_keys: bool = False) -> Tuple[DataClass, ...]:
"""
Alternative helper method that does not use `argparse` at all, instead loading a json file and populating the
dataclass types.
Args:
json_file (`str` or `os.PathLike`):
File name of the json file to parse
allow_extra_keys (`bool`, *optional*, defaults to `False`):
Defaults to False. If False, will raise an exception if the json file contains keys that are not
parsed.
Returns:
Tuple consisting of:
- the dataclass instances in the same order as they were passed to the initializer.
"""
with open(Path(json_file), encoding="utf-8") as open_json_file:
data = json.loads(open_json_file.read())
outputs = self.parse_dict(data, allow_extra_keys=allow_extra_keys)
return tuple(outputs)
def parse_yaml_file(self, yaml_file: str, allow_extra_keys: bool = False) -> Tuple[DataClass, ...]:
"""
Alternative helper method that does not use `argparse` at all, instead loading a yaml file and populating the
dataclass types.
Args:
yaml_file (`str` or `os.PathLike`):
File name of the yaml file to parse
allow_extra_keys (`bool`, *optional*, defaults to `False`):
Defaults to False. If False, will raise an exception if the json file contains keys that are not
parsed.
Returns:
Tuple consisting of:
- the dataclass instances in the same order as they were passed to the initializer.
"""
outputs = self.parse_dict(yaml.safe_load(Path(yaml_file).read_text()), allow_extra_keys=allow_extra_keys)
return tuple(outputs)
| transformers/src/transformers/hf_argparser.py/0 | {
"file_path": "transformers/src/transformers/hf_argparser.py",
"repo_id": "transformers",
"token_count": 8210
} | 65 |
#include <torch/extension.h>
#include <ATen/ATen.h>
#include "cuda_launch.h"
#include "cuda_kernel.h"
#include <vector>
//////////////////////////////////////////////////////////////////////////////////////////////////
//////////////////////////////////////////////////////////////////////////////////////////////////
std::vector<at::Tensor> index_max_kernel(
at::Tensor index_vals, // [batch_size, 32, num_block]
at::Tensor indices, // [batch_size, num_block],
int A_num_block,
int B_num_block
) {
int batch_size = indices.size(0);
int num_block = indices.size(1);
at::Tensor max_vals = at::zeros({batch_size, A_num_block * 32}, index_vals.options());
at::Tensor max_vals_scatter = at::zeros({batch_size, 32, num_block}, index_vals.options());
dim3 threads(256);
dim3 blocks(batch_size);
int shared_mem = A_num_block * 32 * sizeof(float);
index_max_cuda_kernel<<<blocks, threads, shared_mem>>>(
index_vals.data_ptr<float>(),
indices.data_ptr<int>(),
max_vals.data_ptr<float>(),
max_vals_scatter.data_ptr<float>(),
batch_size,
A_num_block,
B_num_block,
num_block
);
return {max_vals, max_vals_scatter};
}
at::Tensor mm_to_sparse_kernel(
at::Tensor dense_A, // [batch_size, A_num_block, dim, 32]
at::Tensor dense_B, // [batch_size, B_num_block, dim, 32]
at::Tensor indices // [batch_size, num_block]
) {
int batch_size = dense_A.size(0);
int A_num_block = dense_A.size(1);
int B_num_block = dense_B.size(1);
int dim = dense_A.size(2);
int num_block = indices.size(1);
at::Tensor sparse_C = at::zeros({batch_size, num_block, 32, 32}, dense_A.options());
dim3 threads(64, 4);
dim3 blocks(num_block / 4, batch_size);
mm_to_sparse_cuda_kernel<<<blocks, threads>>>(
dense_A.data_ptr<float>(),
dense_B.data_ptr<float>(),
indices.data_ptr<int>(),
sparse_C.data_ptr<float>(),
batch_size,
A_num_block,
B_num_block,
dim,
num_block
);
return sparse_C;
}
at::Tensor sparse_dense_mm_kernel(
at::Tensor sparse_A, // [batch_size, num_block, 32, 32]
at::Tensor indices, // [batch_size, num_block]
at::Tensor dense_B, // [batch_size, B_num_block, dim, 32]
int A_num_block
) {
int batch_size = sparse_A.size(0);
int num_block = sparse_A.size(1);
int B_num_block = dense_B.size(1);
int dim = dense_B.size(2);
at::Tensor dense_C = at::zeros({batch_size, A_num_block, dim, 32}, dense_B.options());
dim3 threads(128, 2);
dim3 blocks(num_block / 2, batch_size);
sparse_dense_mm_cuda_kernel<<<blocks, threads>>>(
sparse_A.data_ptr<float>(),
indices.data_ptr<int>(),
dense_B.data_ptr<float>(),
dense_C.data_ptr<float>(),
batch_size,
A_num_block,
B_num_block,
dim,
num_block
);
return dense_C;
}
at::Tensor reduce_sum_kernel(
at::Tensor sparse_A, // [batch_size, num_block, 32, 32]
at::Tensor indices, // [batch_size, num_block]
int A_num_block,
int B_num_block
) {
int batch_size = sparse_A.size(0);
int num_block = sparse_A.size(1);
at::Tensor dense_C = at::zeros({batch_size, A_num_block, 32}, sparse_A.options());
dim3 threads(32, 4);
dim3 blocks(num_block / 4, batch_size);
reduce_sum_cuda_kernel<<<blocks, threads>>>(
sparse_A.data_ptr<float>(),
indices.data_ptr<int>(),
dense_C.data_ptr<float>(),
batch_size,
A_num_block,
B_num_block,
num_block
);
return dense_C;
}
at::Tensor scatter_kernel(
at::Tensor dense_A, // [batch_size, A_num_block, 32]
at::Tensor indices, // [batch_size, num_block]
int B_num_block
) {
int batch_size = dense_A.size(0);
int A_num_block = dense_A.size(1);
int num_block = indices.size(1);
at::Tensor sparse_C = at::zeros({batch_size, num_block, 32, 32}, dense_A.options());
dim3 threads(32, 4);
dim3 blocks(num_block / 4, batch_size);
scatter_cuda_kernel<<<blocks, threads>>>(
dense_A.data_ptr<float>(),
indices.data_ptr<int>(),
sparse_C.data_ptr<float>(),
batch_size,
A_num_block,
B_num_block,
num_block
);
return sparse_C;
}
| transformers/src/transformers/kernels/mra/cuda_launch.cu/0 | {
"file_path": "transformers/src/transformers/kernels/mra/cuda_launch.cu",
"repo_id": "transformers",
"token_count": 1668
} | 66 |
# Copyright 2021 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
from typing import Dict, Optional, Tuple
import flax
import jax.numpy as jnp
from .utils import ModelOutput
@flax.struct.dataclass
class FlaxBaseModelOutput(ModelOutput):
"""
Base class for model's outputs, with potential hidden states and attentions.
Args:
last_hidden_state (`jnp.ndarray` of shape `(batch_size, sequence_length, hidden_size)`):
Sequence of hidden-states at the output of the last layer of the model.
hidden_states (`tuple(jnp.ndarray)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
Tuple of `jnp.ndarray` (one for the output of the embeddings + one for the output of each layer) of shape
`(batch_size, sequence_length, hidden_size)`.
Hidden-states of the model at the output of each layer plus the initial embedding outputs.
attentions (`tuple(jnp.ndarray)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
Tuple of `jnp.ndarray` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
sequence_length)`.
Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
heads.
"""
last_hidden_state: jnp.ndarray = None
hidden_states: Optional[Tuple[jnp.ndarray]] = None
attentions: Optional[Tuple[jnp.ndarray]] = None
@flax.struct.dataclass
class FlaxBaseModelOutputWithNoAttention(ModelOutput):
"""
Base class for model's outputs, with potential hidden states.
Args:
last_hidden_state (`jnp.ndarray` of shape `(batch_size, num_channels, height, width)`):
Sequence of hidden-states at the output of the last layer of the model.
hidden_states (`tuple(jnp.ndarray)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
Tuple of `jnp.ndarray` (one for the output of the embeddings, if the model has an embedding layer, + one
for the output of each layer) of shape `(batch_size, num_channels, height, width)`. Hidden-states of the
model at the output of each layer plus the optional initial embedding outputs.
"""
last_hidden_state: jnp.ndarray = None
hidden_states: Optional[Tuple[jnp.ndarray]] = None
@flax.struct.dataclass
class FlaxBaseModelOutputWithPoolingAndNoAttention(ModelOutput):
"""
Base class for model's outputs that also contains a pooling of the last hidden states.
Args:
last_hidden_state (`jnp.ndarray` of shape `(batch_size, num_channels, height, width)`):
Sequence of hidden-states at the output of the last layer of the model.
pooler_output (`jnp.ndarray` of shape `(batch_size, hidden_size)`):
Last layer hidden-state after a pooling operation on the spatial dimensions.
hidden_states (`tuple(jnp.ndarray)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
Tuple of `jnp.ndarray` (one for the output of the embeddings, if the model has an embedding layer, + one
for the output of each layer) of shape `(batch_size, num_channels, height, width)`. Hidden-states of the
model at the output of each layer plus the optional initial embedding outputs.
"""
last_hidden_state: jnp.ndarray = None
pooler_output: jnp.ndarray = None
hidden_states: Optional[Tuple[jnp.ndarray]] = None
@flax.struct.dataclass
class FlaxImageClassifierOutputWithNoAttention(ModelOutput):
"""
Base class for outputs of image classification models.
Args:
logits (`jnp.ndarray` of shape `(batch_size, config.num_labels)`):
Classification (or regression if config.num_labels==1) scores (before SoftMax).
hidden_states (`tuple(jnp.ndarray)`, *optional*, returned when `output_hidden_states=True` is passed or when
`config.output_hidden_states=True`):
Tuple of `jnp.ndarray` (one for the output of the embeddings, if the model has an embedding layer, + one
for the output of each stage) of shape `(batch_size, num_channels, height, width)`. Hidden-states (also
called feature maps) of the model at the output of each stage.
"""
logits: jnp.ndarray = None
hidden_states: Optional[Tuple[jnp.ndarray]] = None
@flax.struct.dataclass
class FlaxBaseModelOutputWithPast(ModelOutput):
"""
Base class for model's outputs, with potential hidden states and attentions.
Args:
last_hidden_state (`jnp.ndarray` of shape `(batch_size, sequence_length, hidden_size)`):
Sequence of hidden-states at the output of the last layer of the model.
past_key_values (`Dict[str, jnp.ndarray]`):
Dictionary of pre-computed hidden-states (key and values in the attention blocks) that can be used for fast
auto-regressive decoding. Pre-computed key and value hidden-states are of shape *[batch_size, max_length]*.
hidden_states (`tuple(jnp.ndarray)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
Tuple of `jnp.ndarray` (one for the output of the embeddings + one for the output of each layer) of shape
`(batch_size, sequence_length, hidden_size)`.
Hidden-states of the model at the output of each layer plus the initial embedding outputs.
attentions (`tuple(jnp.ndarray)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
Tuple of `jnp.ndarray` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
sequence_length)`.
Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
heads.
"""
last_hidden_state: jnp.ndarray = None
past_key_values: Optional[Dict[str, jnp.ndarray]] = None
hidden_states: Optional[Tuple[jnp.ndarray]] = None
attentions: Optional[Tuple[jnp.ndarray]] = None
@flax.struct.dataclass
class FlaxBaseModelOutputWithPooling(ModelOutput):
"""
Base class for model's outputs that also contains a pooling of the last hidden states.
Args:
last_hidden_state (`jnp.ndarray` of shape `(batch_size, sequence_length, hidden_size)`):
Sequence of hidden-states at the output of the last layer of the model.
pooler_output (`jnp.ndarray` of shape `(batch_size, hidden_size)`):
Last layer hidden-state of the first token of the sequence (classification token) further processed by a
Linear layer and a Tanh activation function. The Linear layer weights are trained from the next sentence
prediction (classification) objective during pretraining.
hidden_states (`tuple(jnp.ndarray)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
Tuple of `jnp.ndarray` (one for the output of the embeddings + one for the output of each layer) of shape
`(batch_size, sequence_length, hidden_size)`.
Hidden-states of the model at the output of each layer plus the initial embedding outputs.
attentions (`tuple(jnp.ndarray)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
Tuple of `jnp.ndarray` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
sequence_length)`.
Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
heads.
"""
last_hidden_state: jnp.ndarray = None
pooler_output: jnp.ndarray = None
hidden_states: Optional[Tuple[jnp.ndarray]] = None
attentions: Optional[Tuple[jnp.ndarray]] = None
@flax.struct.dataclass
class FlaxBaseModelOutputWithPoolingAndCrossAttentions(ModelOutput):
"""
Base class for model's outputs that also contains a pooling of the last hidden states.
Args:
last_hidden_state (`jnp.ndarray` of shape `(batch_size, sequence_length, hidden_size)`):
Sequence of hidden-states at the output of the last layer of the model.
pooler_output (`jnp.ndarray` of shape `(batch_size, hidden_size)`):
Last layer hidden-state of the first token of the sequence (classification token) after further processing
through the layers used for the auxiliary pretraining task. E.g. for BERT-family of models, this returns
the classification token after processing through a linear layer and a tanh activation function. The linear
layer weights are trained from the next sentence prediction (classification) objective during pretraining.
hidden_states (`tuple(jnp.ndarray)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
Tuple of `jnp.ndarray` (one for the output of the embeddings, if the model has an embedding layer, + one
for the output of each layer) of shape `(batch_size, sequence_length, hidden_size)`.
Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
attentions (`tuple(jnp.ndarray)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
Tuple of `jnp.ndarray` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
sequence_length)`.
Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
heads.
cross_attentions (`tuple(jnp.ndarray)`, *optional*, returned when `output_attentions=True` and `config.add_cross_attention=True` is passed or when `config.output_attentions=True`):
Tuple of `jnp.ndarray` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
sequence_length)`.
Attentions weights of the decoder's cross-attention layer, after the attention softmax, used to compute the
weighted average in the cross-attention heads.
past_key_values (`tuple(tuple(jnp.ndarray))`, *optional*, returned when `use_cache=True` is passed or when `config.use_cache=True`):
Tuple of `tuple(jnp.ndarray)` of length `config.n_layers`, with each tuple having 2 tensors of shape
`(batch_size, num_heads, sequence_length, embed_size_per_head)`) and optionally if
`config.is_encoder_decoder=True` 2 additional tensors of shape `(batch_size, num_heads,
encoder_sequence_length, embed_size_per_head)`.
Contains pre-computed hidden-states (key and values in the self-attention blocks and optionally if
`config.is_encoder_decoder=True` in the cross-attention blocks) that can be used (see `past_key_values`
input) to speed up sequential decoding.
"""
last_hidden_state: jnp.ndarray = None
pooler_output: jnp.ndarray = None
hidden_states: Optional[Tuple[jnp.ndarray]] = None
past_key_values: Optional[Tuple[Tuple[jnp.ndarray]]] = None
attentions: Optional[Tuple[jnp.ndarray]] = None
cross_attentions: Optional[Tuple[jnp.ndarray]] = None
@flax.struct.dataclass
class FlaxBaseModelOutputWithPastAndCrossAttentions(ModelOutput):
"""
Base class for model's outputs that may also contain a past key/values (to speed up sequential decoding).
Args:
last_hidden_state (`jnp.ndarray` of shape `(batch_size, sequence_length, hidden_size)`):
Sequence of hidden-states at the output of the last layer of the model.
If `past_key_values` is used only the last hidden-state of the sequences of shape `(batch_size, 1,
hidden_size)` is output.
past_key_values (`tuple(tuple(jnp.ndarray))`, *optional*, returned when `use_cache=True` is passed or when `config.use_cache=True`):
Tuple of `tuple(jnp.ndarray)` of length `config.n_layers`, with each tuple having 2 tensors of shape
`(batch_size, num_heads, sequence_length, embed_size_per_head)`) and optionally if
`config.is_encoder_decoder=True` 2 additional tensors of shape `(batch_size, num_heads,
encoder_sequence_length, embed_size_per_head)`.
Contains pre-computed hidden-states (key and values in the self-attention blocks and optionally if
`config.is_encoder_decoder=True` in the cross-attention blocks) that can be used (see `past_key_values`
input) to speed up sequential decoding.
hidden_states (`tuple(jnp.ndarray)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
Tuple of `jnp.ndarray` (one for the output of the embeddings + one for the output of each layer) of shape
`(batch_size, sequence_length, hidden_size)`.
Hidden-states of the model at the output of each layer plus the initial embedding outputs.
attentions (`tuple(jnp.ndarray)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
Tuple of `jnp.ndarray` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
sequence_length)`.
Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
heads.
cross_attentions (`tuple(jnp.ndarray)`, *optional*, returned when `output_attentions=True` and `config.add_cross_attention=True` is passed or when `config.output_attentions=True`):
Tuple of `jnp.ndarray` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
sequence_length)`.
Attentions weights of the decoder's cross-attention layer, after the attention softmax, used to compute the
weighted average in the cross-attention heads.
"""
last_hidden_state: jnp.ndarray = None
past_key_values: Optional[Tuple[Tuple[jnp.ndarray]]] = None
hidden_states: Optional[Tuple[jnp.ndarray]] = None
attentions: Optional[Tuple[jnp.ndarray]] = None
cross_attentions: Optional[Tuple[jnp.ndarray]] = None
@flax.struct.dataclass
class FlaxSeq2SeqModelOutput(ModelOutput):
"""
Base class for model encoder's outputs that also contains : pre-computed hidden states that can speed up sequential
decoding.
Args:
last_hidden_state (`jnp.ndarray` of shape `(batch_size, sequence_length, hidden_size)`):
Sequence of hidden-states at the output of the last layer of the decoder of the model.
If `past_key_values` is used only the last hidden-state of the sequences of shape `(batch_size, 1,
hidden_size)` is output.
past_key_values (`tuple(tuple(jnp.ndarray))`, *optional*, returned when `use_cache=True` is passed or when `config.use_cache=True`):
Tuple of `tuple(jnp.ndarray)` of length `config.n_layers`, with each tuple having 2 tensors of shape
`(batch_size, num_heads, sequence_length, embed_size_per_head)`) and 2 additional tensors of shape
`(batch_size, num_heads, encoder_sequence_length, embed_size_per_head)`.
Contains pre-computed hidden-states (key and values in the self-attention blocks and in the cross-attention
blocks) that can be used (see `past_key_values` input) to speed up sequential decoding.
decoder_hidden_states (`tuple(jnp.ndarray)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
Tuple of `jnp.ndarray` (one for the output of the embeddings + one for the output of each layer) of shape
`(batch_size, sequence_length, hidden_size)`.
Hidden-states of the decoder at the output of each layer plus the initial embedding outputs.
decoder_attentions (`tuple(jnp.ndarray)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
Tuple of `jnp.ndarray` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
sequence_length)`.
Attentions weights of the decoder, after the attention softmax, used to compute the weighted average in the
self-attention heads.
cross_attentions (`tuple(jnp.ndarray)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
Tuple of `jnp.ndarray` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
sequence_length)`.
Attentions weights of the decoder's cross-attention layer, after the attention softmax, used to compute the
weighted average in the cross-attention heads.
encoder_last_hidden_state (`jnp.ndarray` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
Sequence of hidden-states at the output of the last layer of the encoder of the model.
encoder_hidden_states (`tuple(jnp.ndarray)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
Tuple of `jnp.ndarray` (one for the output of the embeddings + one for the output of each layer) of shape
`(batch_size, sequence_length, hidden_size)`.
Hidden-states of the encoder at the output of each layer plus the initial embedding outputs.
encoder_attentions (`tuple(jnp.ndarray)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
Tuple of `jnp.ndarray` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
sequence_length)`.
Attentions weights of the encoder, after the attention softmax, used to compute the weighted average in the
self-attention heads.
"""
last_hidden_state: jnp.ndarray = None
past_key_values: Optional[Tuple[Tuple[jnp.ndarray]]] = None
decoder_hidden_states: Optional[Tuple[jnp.ndarray]] = None
decoder_attentions: Optional[Tuple[jnp.ndarray]] = None
cross_attentions: Optional[Tuple[jnp.ndarray]] = None
encoder_last_hidden_state: Optional[jnp.ndarray] = None
encoder_hidden_states: Optional[Tuple[jnp.ndarray]] = None
encoder_attentions: Optional[Tuple[jnp.ndarray]] = None
@flax.struct.dataclass
class FlaxCausalLMOutputWithCrossAttentions(ModelOutput):
"""
Base class for causal language model (or autoregressive) outputs.
Args:
logits (`jnp.ndarray` of shape `(batch_size, sequence_length, config.vocab_size)`):
Prediction scores of the language modeling head (scores for each vocabulary token before SoftMax).
hidden_states (`tuple(jnp.ndarray)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
Tuple of `jnp.ndarray` (one for the output of the embeddings + one for the output of each layer) of shape
`(batch_size, sequence_length, hidden_size)`.
Hidden-states of the model at the output of each layer plus the initial embedding outputs.
attentions (`tuple(jnp.ndarray)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
Tuple of `jnp.ndarray` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
sequence_length)`.
Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
heads.
cross_attentions (`tuple(jnp.ndarray)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
Tuple of `jnp.ndarray` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
sequence_length)`.
Cross attentions weights after the attention softmax, used to compute the weighted average in the
cross-attention heads.
past_key_values (`tuple(tuple(jnp.ndarray))`, *optional*, returned when `use_cache=True` is passed or when `config.use_cache=True`):
Tuple of `jnp.ndarray` tuples of length `config.n_layers`, with each tuple containing the cached key, value
states of the self-attention and the cross-attention layers if model is used in encoder-decoder setting.
Only relevant if `config.is_decoder = True`.
Contains pre-computed hidden-states (key and values in the attention blocks) that can be used (see
`past_key_values` input) to speed up sequential decoding.
"""
logits: jnp.ndarray = None
past_key_values: Optional[Tuple[Tuple[jnp.ndarray]]] = None
hidden_states: Optional[Tuple[jnp.ndarray]] = None
attentions: Optional[Tuple[jnp.ndarray]] = None
cross_attentions: Optional[Tuple[jnp.ndarray]] = None
@flax.struct.dataclass
class FlaxMaskedLMOutput(ModelOutput):
"""
Base class for masked language models outputs.
Args:
logits (`jnp.ndarray` of shape `(batch_size, sequence_length, config.vocab_size)`):
Prediction scores of the language modeling head (scores for each vocabulary token before SoftMax).
hidden_states (`tuple(jnp.ndarray)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
Tuple of `jnp.ndarray` (one for the output of the embeddings + one for the output of each layer) of shape
`(batch_size, sequence_length, hidden_size)`.
Hidden-states of the model at the output of each layer plus the initial embedding outputs.
attentions (`tuple(jnp.ndarray)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
Tuple of `jnp.ndarray` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
sequence_length)`.
Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
heads.
"""
logits: jnp.ndarray = None
hidden_states: Optional[Tuple[jnp.ndarray]] = None
attentions: Optional[Tuple[jnp.ndarray]] = None
FlaxCausalLMOutput = FlaxMaskedLMOutput
@flax.struct.dataclass
class FlaxSeq2SeqLMOutput(ModelOutput):
"""
Base class for sequence-to-sequence language models outputs.
Args:
logits (`jnp.ndarray` of shape `(batch_size, sequence_length, config.vocab_size)`):
Prediction scores of the language modeling head (scores for each vocabulary token before SoftMax).
past_key_values (`tuple(tuple(jnp.ndarray))`, *optional*, returned when `use_cache=True` is passed or when `config.use_cache=True`):
Tuple of `tuple(jnp.ndarray)` of length `config.n_layers`, with each tuple having 2 tensors of shape
`(batch_size, num_heads, sequence_length, embed_size_per_head)`) and 2 additional tensors of shape
`(batch_size, num_heads, encoder_sequence_length, embed_size_per_head)`.
Contains pre-computed hidden-states (key and values in the self-attention blocks and in the cross-attention
blocks) that can be used (see `past_key_values` input) to speed up sequential decoding.
decoder_hidden_states (`tuple(jnp.ndarray)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
Tuple of `jnp.ndarray` (one for the output of the embeddings + one for the output of each layer) of shape
`(batch_size, sequence_length, hidden_size)`.
Hidden-states of the decoder at the output of each layer plus the initial embedding outputs.
decoder_attentions (`tuple(jnp.ndarray)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
Tuple of `jnp.ndarray` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
sequence_length)`.
Attentions weights of the decoder, after the attention softmax, used to compute the weighted average in the
self-attention heads.
cross_attentions (`tuple(jnp.ndarray)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
Tuple of `jnp.ndarray` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
sequence_length)`.
Attentions weights of the decoder's cross-attention layer, after the attention softmax, used to compute the
weighted average in the cross-attention heads.
encoder_last_hidden_state (`jnp.ndarray` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
Sequence of hidden-states at the output of the last layer of the encoder of the model.
encoder_hidden_states (`tuple(jnp.ndarray)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
Tuple of `jnp.ndarray` (one for the output of the embeddings + one for the output of each layer) of shape
`(batch_size, sequence_length, hidden_size)`.
Hidden-states of the encoder at the output of each layer plus the initial embedding outputs.
encoder_attentions (`tuple(jnp.ndarray)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
Tuple of `jnp.ndarray` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
sequence_length)`.
Attentions weights of the encoder, after the attention softmax, used to compute the weighted average in the
self-attention heads.
"""
logits: jnp.ndarray = None
past_key_values: Optional[Tuple[Tuple[jnp.ndarray]]] = None
decoder_hidden_states: Optional[Tuple[jnp.ndarray]] = None
decoder_attentions: Optional[Tuple[jnp.ndarray]] = None
cross_attentions: Optional[Tuple[jnp.ndarray]] = None
encoder_last_hidden_state: Optional[jnp.ndarray] = None
encoder_hidden_states: Optional[Tuple[jnp.ndarray]] = None
encoder_attentions: Optional[Tuple[jnp.ndarray]] = None
@flax.struct.dataclass
class FlaxNextSentencePredictorOutput(ModelOutput):
"""
Base class for outputs of models predicting if two sentences are consecutive or not.
Args:
logits (`jnp.ndarray` of shape `(batch_size, 2)`):
Prediction scores of the next sequence prediction (classification) head (scores of True/False continuation
before SoftMax).
hidden_states (`tuple(jnp.ndarray)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
Tuple of `jnp.ndarray` (one for the output of the embeddings + one for the output of each layer) of shape
`(batch_size, sequence_length, hidden_size)`.
Hidden-states of the model at the output of each layer plus the initial embedding outputs.
attentions (`tuple(jnp.ndarray)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
Tuple of `jnp.ndarray` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
sequence_length)`.
Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
heads.
"""
logits: jnp.ndarray = None
hidden_states: Optional[Tuple[jnp.ndarray]] = None
attentions: Optional[Tuple[jnp.ndarray]] = None
@flax.struct.dataclass
class FlaxSequenceClassifierOutput(ModelOutput):
"""
Base class for outputs of sentence classification models.
Args:
logits (`jnp.ndarray` of shape `(batch_size, config.num_labels)`):
Classification (or regression if config.num_labels==1) scores (before SoftMax).
hidden_states (`tuple(jnp.ndarray)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
Tuple of `jnp.ndarray` (one for the output of the embeddings + one for the output of each layer) of shape
`(batch_size, sequence_length, hidden_size)`.
Hidden-states of the model at the output of each layer plus the initial embedding outputs.
attentions (`tuple(jnp.ndarray)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
Tuple of `jnp.ndarray` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
sequence_length)`.
Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
heads.
"""
logits: jnp.ndarray = None
hidden_states: Optional[Tuple[jnp.ndarray]] = None
attentions: Optional[Tuple[jnp.ndarray]] = None
@flax.struct.dataclass
class FlaxSeq2SeqSequenceClassifierOutput(ModelOutput):
"""
Base class for outputs of sequence-to-sequence sentence classification models.
Args:
logits (`jnp.ndarray` of shape `(batch_size, config.num_labels)`):
Classification (or regression if config.num_labels==1) scores (before SoftMax).
past_key_values (`tuple(tuple(jnp.ndarray))`, *optional*, returned when `use_cache=True` is passed or when `config.use_cache=True`):
Tuple of `tuple(jnp.ndarray)` of length `config.n_layers`, with each tuple having 2 tensors of shape
`(batch_size, num_heads, sequence_length, embed_size_per_head)`) and 2 additional tensors of shape
`(batch_size, num_heads, encoder_sequence_length, embed_size_per_head)`.
Contains pre-computed hidden-states (key and values in the self-attention blocks and in the cross-attention
blocks) that can be used (see `past_key_values` input) to speed up sequential decoding.
decoder_hidden_states (`tuple(jnp.ndarray)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
Tuple of `jnp.ndarray` (one for the output of the embeddings + one for the output of each layer) of shape
`(batch_size, sequence_length, hidden_size)`.
Hidden-states of the decoder at the output of each layer plus the initial embedding outputs.
decoder_attentions (`tuple(jnp.ndarray)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
Tuple of `jnp.ndarray` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
sequence_length)`.
Attentions weights of the decoder, after the attention softmax, used to compute the weighted average in the
self-attention heads.
cross_attentions (`tuple(jnp.ndarray)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
Tuple of `jnp.ndarray` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
sequence_length)`.
Attentions weights of the decoder's cross-attention layer, after the attention softmax, used to compute the
weighted average in the cross-attention heads.
encoder_last_hidden_state (`jnp.ndarray` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
Sequence of hidden-states at the output of the last layer of the encoder of the model.
encoder_hidden_states (`tuple(jnp.ndarray)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
Tuple of `jnp.ndarray` (one for the output of the embeddings + one for the output of each layer) of shape
`(batch_size, sequence_length, hidden_size)`.
Hidden-states of the encoder at the output of each layer plus the initial embedding outputs.
encoder_attentions (`tuple(jnp.ndarray)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
Tuple of `jnp.ndarray` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
sequence_length)`.
Attentions weights of the encoder, after the attention softmax, used to compute the weighted average in the
self-attention heads.
"""
logits: jnp.ndarray = None
past_key_values: Optional[Tuple[Tuple[jnp.ndarray]]] = None
decoder_hidden_states: Optional[Tuple[jnp.ndarray]] = None
decoder_attentions: Optional[Tuple[jnp.ndarray]] = None
cross_attentions: Optional[Tuple[jnp.ndarray]] = None
encoder_last_hidden_state: Optional[jnp.ndarray] = None
encoder_hidden_states: Optional[Tuple[jnp.ndarray]] = None
encoder_attentions: Optional[Tuple[jnp.ndarray]] = None
@flax.struct.dataclass
class FlaxMultipleChoiceModelOutput(ModelOutput):
"""
Base class for outputs of multiple choice models.
Args:
logits (`jnp.ndarray` of shape `(batch_size, num_choices)`):
*num_choices* is the second dimension of the input tensors. (see *input_ids* above).
Classification scores (before SoftMax).
hidden_states (`tuple(jnp.ndarray)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
Tuple of `jnp.ndarray` (one for the output of the embeddings + one for the output of each layer) of shape
`(batch_size, sequence_length, hidden_size)`.
Hidden-states of the model at the output of each layer plus the initial embedding outputs.
attentions (`tuple(jnp.ndarray)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
Tuple of `jnp.ndarray` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
sequence_length)`.
Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
heads.
"""
logits: jnp.ndarray = None
hidden_states: Optional[Tuple[jnp.ndarray]] = None
attentions: Optional[Tuple[jnp.ndarray]] = None
@flax.struct.dataclass
class FlaxTokenClassifierOutput(ModelOutput):
"""
Base class for outputs of token classification models.
Args:
logits (`jnp.ndarray` of shape `(batch_size, sequence_length, config.num_labels)`):
Classification scores (before SoftMax).
hidden_states (`tuple(jnp.ndarray)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
Tuple of `jnp.ndarray` (one for the output of the embeddings + one for the output of each layer) of shape
`(batch_size, sequence_length, hidden_size)`.
Hidden-states of the model at the output of each layer plus the initial embedding outputs.
attentions (`tuple(jnp.ndarray)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
Tuple of `jnp.ndarray` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
sequence_length)`.
Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
heads.
"""
logits: jnp.ndarray = None
hidden_states: Optional[Tuple[jnp.ndarray]] = None
attentions: Optional[Tuple[jnp.ndarray]] = None
@flax.struct.dataclass
class FlaxQuestionAnsweringModelOutput(ModelOutput):
"""
Base class for outputs of question answering models.
Args:
start_logits (`jnp.ndarray` of shape `(batch_size, sequence_length)`):
Span-start scores (before SoftMax).
end_logits (`jnp.ndarray` of shape `(batch_size, sequence_length)`):
Span-end scores (before SoftMax).
hidden_states (`tuple(jnp.ndarray)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
Tuple of `jnp.ndarray` (one for the output of the embeddings + one for the output of each layer) of shape
`(batch_size, sequence_length, hidden_size)`.
Hidden-states of the model at the output of each layer plus the initial embedding outputs.
attentions (`tuple(jnp.ndarray)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
Tuple of `jnp.ndarray` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
sequence_length)`.
Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
heads.
"""
start_logits: jnp.ndarray = None
end_logits: jnp.ndarray = None
hidden_states: Optional[Tuple[jnp.ndarray]] = None
attentions: Optional[Tuple[jnp.ndarray]] = None
@flax.struct.dataclass
class FlaxSeq2SeqQuestionAnsweringModelOutput(ModelOutput):
"""
Base class for outputs of sequence-to-sequence question answering models.
Args:
start_logits (`jnp.ndarray` of shape `(batch_size, sequence_length)`):
Span-start scores (before SoftMax).
end_logits (`jnp.ndarray` of shape `(batch_size, sequence_length)`):
Span-end scores (before SoftMax).
past_key_values (`tuple(tuple(jnp.ndarray))`, *optional*, returned when `use_cache=True` is passed or when `config.use_cache=True`):
Tuple of `tuple(jnp.ndarray)` of length `config.n_layers`, with each tuple having 2 tensors of shape
`(batch_size, num_heads, sequence_length, embed_size_per_head)`) and 2 additional tensors of shape
`(batch_size, num_heads, encoder_sequence_length, embed_size_per_head)`.
Contains pre-computed hidden-states (key and values in the self-attention blocks and in the cross-attention
blocks) that can be used (see `past_key_values` input) to speed up sequential decoding.
decoder_hidden_states (`tuple(jnp.ndarray)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
Tuple of `jnp.ndarray` (one for the output of the embeddings + one for the output of each layer) of shape
`(batch_size, sequence_length, hidden_size)`.
Hidden-states of the decoder at the output of each layer plus the initial embedding outputs.
decoder_attentions (`tuple(jnp.ndarray)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
Tuple of `jnp.ndarray` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
sequence_length)`.
Attentions weights of the decoder, after the attention softmax, used to compute the weighted average in the
self-attention heads.
cross_attentions (`tuple(jnp.ndarray)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
Tuple of `jnp.ndarray` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
sequence_length)`.
Attentions weights of the decoder's cross-attention layer, after the attention softmax, used to compute the
weighted average in the cross-attention heads.
encoder_last_hidden_state (`jnp.ndarray` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
Sequence of hidden-states at the output of the last layer of the encoder of the model.
encoder_hidden_states (`tuple(jnp.ndarray)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
Tuple of `jnp.ndarray` (one for the output of the embeddings + one for the output of each layer) of shape
`(batch_size, sequence_length, hidden_size)`.
Hidden-states of the encoder at the output of each layer plus the initial embedding outputs.
encoder_attentions (`tuple(jnp.ndarray)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
Tuple of `jnp.ndarray` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
sequence_length)`.
Attentions weights of the encoder, after the attention softmax, used to compute the weighted average in the
self-attention heads.
"""
start_logits: jnp.ndarray = None
end_logits: jnp.ndarray = None
past_key_values: Optional[Tuple[Tuple[jnp.ndarray]]] = None
decoder_hidden_states: Optional[Tuple[jnp.ndarray]] = None
decoder_attentions: Optional[Tuple[jnp.ndarray]] = None
cross_attentions: Optional[Tuple[jnp.ndarray]] = None
encoder_last_hidden_state: Optional[jnp.ndarray] = None
encoder_hidden_states: Optional[Tuple[jnp.ndarray]] = None
encoder_attentions: Optional[Tuple[jnp.ndarray]] = None
| transformers/src/transformers/modeling_flax_outputs.py/0 | {
"file_path": "transformers/src/transformers/modeling_flax_outputs.py",
"repo_id": "transformers",
"token_count": 15429
} | 67 |
# coding=utf-8
# Copyright 2018 Google AI, Google Brain and the HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
""" Tokenization classes for ALBERT model."""
import os
from shutil import copyfile
from typing import List, Optional, Tuple
from ...tokenization_utils import AddedToken
from ...tokenization_utils_fast import PreTrainedTokenizerFast
from ...utils import is_sentencepiece_available, logging
if is_sentencepiece_available():
from .tokenization_albert import AlbertTokenizer
else:
AlbertTokenizer = None
logger = logging.get_logger(__name__)
VOCAB_FILES_NAMES = {"vocab_file": "spiece.model", "tokenizer_file": "tokenizer.json"}
PRETRAINED_VOCAB_FILES_MAP = {
"vocab_file": {
"albert/albert-base-v1": "https://huggingface.co/albert/albert-base-v1/resolve/main/spiece.model",
"albert/albert-large-v1": "https://huggingface.co/albert/albert-large-v1/resolve/main/spiece.model",
"albert/albert-xlarge-v1": "https://huggingface.co/albert/albert-xlarge-v1/resolve/main/spiece.model",
"albert/albert-xxlarge-v1": "https://huggingface.co/albert/albert-xxlarge-v1/resolve/main/spiece.model",
"albert/albert-base-v2": "https://huggingface.co/albert/albert-base-v2/resolve/main/spiece.model",
"albert/albert-large-v2": "https://huggingface.co/albert/albert-large-v2/resolve/main/spiece.model",
"albert/albert-xlarge-v2": "https://huggingface.co/albert/albert-xlarge-v2/resolve/main/spiece.model",
"albert/albert-xxlarge-v2": "https://huggingface.co/albert/albert-xxlarge-v2/resolve/main/spiece.model",
},
"tokenizer_file": {
"albert/albert-base-v1": "https://huggingface.co/albert/albert-base-v1/resolve/main/tokenizer.json",
"albert/albert-large-v1": "https://huggingface.co/albert/albert-large-v1/resolve/main/tokenizer.json",
"albert/albert-xlarge-v1": "https://huggingface.co/albert/albert-xlarge-v1/resolve/main/tokenizer.json",
"albert/albert-xxlarge-v1": "https://huggingface.co/albert/albert-xxlarge-v1/resolve/main/tokenizer.json",
"albert/albert-base-v2": "https://huggingface.co/albert/albert-base-v2/resolve/main/tokenizer.json",
"albert/albert-large-v2": "https://huggingface.co/albert/albert-large-v2/resolve/main/tokenizer.json",
"albert/albert-xlarge-v2": "https://huggingface.co/albert/albert-xlarge-v2/resolve/main/tokenizer.json",
"albert/albert-xxlarge-v2": "https://huggingface.co/albert/albert-xxlarge-v2/resolve/main/tokenizer.json",
},
}
PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
"albert/albert-base-v1": 512,
"albert/albert-large-v1": 512,
"albert/albert-xlarge-v1": 512,
"albert/albert-xxlarge-v1": 512,
"albert/albert-base-v2": 512,
"albert/albert-large-v2": 512,
"albert/albert-xlarge-v2": 512,
"albert/albert-xxlarge-v2": 512,
}
SPIECE_UNDERLINE = "▁"
class AlbertTokenizerFast(PreTrainedTokenizerFast):
"""
Construct a "fast" ALBERT tokenizer (backed by HuggingFace's *tokenizers* library). Based on
[Unigram](https://huggingface.co/docs/tokenizers/python/latest/components.html?highlight=unigram#models). This
tokenizer inherits from [`PreTrainedTokenizerFast`] which contains most of the main methods. Users should refer to
this superclass for more information regarding those methods
Args:
vocab_file (`str`):
[SentencePiece](https://github.com/google/sentencepiece) file (generally has a *.spm* extension) that
contains the vocabulary necessary to instantiate a tokenizer.
do_lower_case (`bool`, *optional*, defaults to `True`):
Whether or not to lowercase the input when tokenizing.
remove_space (`bool`, *optional*, defaults to `True`):
Whether or not to strip the text when tokenizing (removing excess spaces before and after the string).
keep_accents (`bool`, *optional*, defaults to `False`):
Whether or not to keep accents when tokenizing.
bos_token (`str`, *optional*, defaults to `"[CLS]"`):
The beginning of sequence token that was used during pretraining. Can be used a sequence classifier token.
<Tip>
When building a sequence using special tokens, this is not the token that is used for the beginning of
sequence. The token used is the `cls_token`.
</Tip>
eos_token (`str`, *optional*, defaults to `"[SEP]"`):
The end of sequence token. .. note:: When building a sequence using special tokens, this is not the token
that is used for the end of sequence. The token used is the `sep_token`.
unk_token (`str`, *optional*, defaults to `"<unk>"`):
The unknown token. A token that is not in the vocabulary cannot be converted to an ID and is set to be this
token instead.
sep_token (`str`, *optional*, defaults to `"[SEP]"`):
The separator token, which is used when building a sequence from multiple sequences, e.g. two sequences for
sequence classification or for a text and a question for question answering. It is also used as the last
token of a sequence built with special tokens.
pad_token (`str`, *optional*, defaults to `"<pad>"`):
The token used for padding, for example when batching sequences of different lengths.
cls_token (`str`, *optional*, defaults to `"[CLS]"`):
The classifier token which is used when doing sequence classification (classification of the whole sequence
instead of per-token classification). It is the first token of the sequence when built with special tokens.
mask_token (`str`, *optional*, defaults to `"[MASK]"`):
The token used for masking values. This is the token used when training this model with masked language
modeling. This is the token which the model will try to predict.
"""
vocab_files_names = VOCAB_FILES_NAMES
pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
slow_tokenizer_class = AlbertTokenizer
def __init__(
self,
vocab_file=None,
tokenizer_file=None,
do_lower_case=True,
remove_space=True,
keep_accents=False,
bos_token="[CLS]",
eos_token="[SEP]",
unk_token="<unk>",
sep_token="[SEP]",
pad_token="<pad>",
cls_token="[CLS]",
mask_token="[MASK]",
**kwargs,
):
# Mask token behave like a normal word, i.e. include the space before it and
# is included in the raw text, there should be a match in a non-normalized sentence.
mask_token = (
AddedToken(mask_token, lstrip=True, rstrip=False, normalized=False)
if isinstance(mask_token, str)
else mask_token
)
super().__init__(
vocab_file,
tokenizer_file=tokenizer_file,
do_lower_case=do_lower_case,
remove_space=remove_space,
keep_accents=keep_accents,
bos_token=bos_token,
eos_token=eos_token,
unk_token=unk_token,
sep_token=sep_token,
pad_token=pad_token,
cls_token=cls_token,
mask_token=mask_token,
**kwargs,
)
self.do_lower_case = do_lower_case
self.remove_space = remove_space
self.keep_accents = keep_accents
self.vocab_file = vocab_file
@property
def can_save_slow_tokenizer(self) -> bool:
return os.path.isfile(self.vocab_file) if self.vocab_file else False
def build_inputs_with_special_tokens(
self, token_ids_0: List[int], token_ids_1: Optional[List[int]] = None
) -> List[int]:
"""
Build model inputs from a sequence or a pair of sequence for sequence classification tasks by concatenating and
adding special tokens. An ALBERT sequence has the following format:
- single sequence: `[CLS] X [SEP]`
- pair of sequences: `[CLS] A [SEP] B [SEP]`
Args:
token_ids_0 (`List[int]`):
List of IDs to which the special tokens will be added
token_ids_1 (`List[int]`, *optional*):
Optional second list of IDs for sequence pairs.
Returns:
`List[int]`: list of [input IDs](../glossary#input-ids) with the appropriate special tokens.
"""
sep = [self.sep_token_id]
cls = [self.cls_token_id]
if token_ids_1 is None:
return cls + token_ids_0 + sep
return cls + token_ids_0 + sep + token_ids_1 + sep
def create_token_type_ids_from_sequences(
self, token_ids_0: List[int], token_ids_1: Optional[List[int]] = None
) -> List[int]:
"""
Creates a mask from the two sequences passed to be used in a sequence-pair classification task. An ALBERT
sequence pair mask has the following format:
```
0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1
| first sequence | second sequence |
```
if token_ids_1 is None, only returns the first portion of the mask (0s).
Args:
token_ids_0 (`List[int]`):
List of ids.
token_ids_1 (`List[int]`, *optional*):
Optional second list of IDs for sequence pairs.
Returns:
`List[int]`: List of [token type IDs](../glossary#token-type-ids) according to the given sequence(s).
"""
sep = [self.sep_token_id]
cls = [self.cls_token_id]
if token_ids_1 is None:
return len(cls + token_ids_0 + sep) * [0]
return len(cls + token_ids_0 + sep) * [0] + len(token_ids_1 + sep) * [1]
def save_vocabulary(self, save_directory: str, filename_prefix: Optional[str] = None) -> Tuple[str]:
if not self.can_save_slow_tokenizer:
raise ValueError(
"Your fast tokenizer does not have the necessary information to save the vocabulary for a slow "
"tokenizer."
)
if not os.path.isdir(save_directory):
logger.error(f"Vocabulary path ({save_directory}) should be a directory")
return
out_vocab_file = os.path.join(
save_directory, (filename_prefix + "-" if filename_prefix else "") + VOCAB_FILES_NAMES["vocab_file"]
)
if os.path.abspath(self.vocab_file) != os.path.abspath(out_vocab_file):
copyfile(self.vocab_file, out_vocab_file)
return (out_vocab_file,)
| transformers/src/transformers/models/albert/tokenization_albert_fast.py/0 | {
"file_path": "transformers/src/transformers/models/albert/tokenization_albert_fast.py",
"repo_id": "transformers",
"token_count": 4690
} | 68 |
# coding=utf-8
# Copyright 2021 The HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""Factory function to build auto-model classes."""
import copy
import importlib
import json
import os
import warnings
from collections import OrderedDict
from ...configuration_utils import PretrainedConfig
from ...dynamic_module_utils import get_class_from_dynamic_module, resolve_trust_remote_code
from ...utils import (
CONFIG_NAME,
cached_file,
copy_func,
extract_commit_hash,
find_adapter_config_file,
is_peft_available,
logging,
requires_backends,
)
from .configuration_auto import AutoConfig, model_type_to_module_name, replace_list_option_in_docstrings
logger = logging.get_logger(__name__)
CLASS_DOCSTRING = """
This is a generic model class that will be instantiated as one of the model classes of the library when created
with the [`~BaseAutoModelClass.from_pretrained`] class method or the [`~BaseAutoModelClass.from_config`] class
method.
This class cannot be instantiated directly using `__init__()` (throws an error).
"""
FROM_CONFIG_DOCSTRING = """
Instantiates one of the model classes of the library from a configuration.
Note:
Loading a model from its configuration file does **not** load the model weights. It only affects the
model's configuration. Use [`~BaseAutoModelClass.from_pretrained`] to load the model weights.
Args:
config ([`PretrainedConfig`]):
The model class to instantiate is selected based on the configuration class:
List options
Examples:
```python
>>> from transformers import AutoConfig, BaseAutoModelClass
>>> # Download configuration from huggingface.co and cache.
>>> config = AutoConfig.from_pretrained("checkpoint_placeholder")
>>> model = BaseAutoModelClass.from_config(config)
```
"""
FROM_PRETRAINED_TORCH_DOCSTRING = """
Instantiate one of the model classes of the library from a pretrained model.
The model class to instantiate is selected based on the `model_type` property of the config object (either
passed as an argument or loaded from `pretrained_model_name_or_path` if possible), or when it's missing, by
falling back to using pattern matching on `pretrained_model_name_or_path`:
List options
The model is set in evaluation mode by default using `model.eval()` (so for instance, dropout modules are
deactivated). To train the model, you should first set it back in training mode with `model.train()`
Args:
pretrained_model_name_or_path (`str` or `os.PathLike`):
Can be either:
- A string, the *model id* of a pretrained model hosted inside a model repo on huggingface.co.
- A path to a *directory* containing model weights saved using
[`~PreTrainedModel.save_pretrained`], e.g., `./my_model_directory/`.
- A path or url to a *tensorflow index checkpoint file* (e.g, `./tf_model/model.ckpt.index`). In
this case, `from_tf` should be set to `True` and a configuration object should be provided as
`config` argument. This loading path is slower than converting the TensorFlow checkpoint in a
PyTorch model using the provided conversion scripts and loading the PyTorch model afterwards.
model_args (additional positional arguments, *optional*):
Will be passed along to the underlying model `__init__()` method.
config ([`PretrainedConfig`], *optional*):
Configuration for the model to use instead of an automatically loaded configuration. Configuration can
be automatically loaded when:
- The model is a model provided by the library (loaded with the *model id* string of a pretrained
model).
- The model was saved using [`~PreTrainedModel.save_pretrained`] and is reloaded by supplying the
save directory.
- The model is loaded by supplying a local directory as `pretrained_model_name_or_path` and a
configuration JSON file named *config.json* is found in the directory.
state_dict (*Dict[str, torch.Tensor]*, *optional*):
A state dictionary to use instead of a state dictionary loaded from saved weights file.
This option can be used if you want to create a model from a pretrained configuration but load your own
weights. In this case though, you should check if using [`~PreTrainedModel.save_pretrained`] and
[`~PreTrainedModel.from_pretrained`] is not a simpler option.
cache_dir (`str` or `os.PathLike`, *optional*):
Path to a directory in which a downloaded pretrained model configuration should be cached if the
standard cache should not be used.
from_tf (`bool`, *optional*, defaults to `False`):
Load the model weights from a TensorFlow checkpoint save file (see docstring of
`pretrained_model_name_or_path` argument).
force_download (`bool`, *optional*, defaults to `False`):
Whether or not to force the (re-)download of the model weights and configuration files, overriding the
cached versions if they exist.
resume_download (`bool`, *optional*, defaults to `False`):
Whether or not to delete incompletely received files. Will attempt to resume the download if such a
file exists.
proxies (`Dict[str, str]`, *optional*):
A dictionary of proxy servers to use by protocol or endpoint, e.g., `{'http': 'foo.bar:3128',
'http://hostname': 'foo.bar:4012'}`. The proxies are used on each request.
output_loading_info(`bool`, *optional*, defaults to `False`):
Whether ot not to also return a dictionary containing missing keys, unexpected keys and error messages.
local_files_only(`bool`, *optional*, defaults to `False`):
Whether or not to only look at local files (e.g., not try downloading the model).
revision (`str`, *optional*, defaults to `"main"`):
The specific model version to use. It can be a branch name, a tag name, or a commit id, since we use a
git-based system for storing models and other artifacts on huggingface.co, so `revision` can be any
identifier allowed by git.
trust_remote_code (`bool`, *optional*, defaults to `False`):
Whether or not to allow for custom models defined on the Hub in their own modeling files. This option
should only be set to `True` for repositories you trust and in which you have read the code, as it will
execute code present on the Hub on your local machine.
code_revision (`str`, *optional*, defaults to `"main"`):
The specific revision to use for the code on the Hub, if the code leaves in a different repository than
the rest of the model. It can be a branch name, a tag name, or a commit id, since we use a git-based
system for storing models and other artifacts on huggingface.co, so `revision` can be any identifier
allowed by git.
kwargs (additional keyword arguments, *optional*):
Can be used to update the configuration object (after it being loaded) and initiate the model (e.g.,
`output_attentions=True`). Behaves differently depending on whether a `config` is provided or
automatically loaded:
- If a configuration is provided with `config`, `**kwargs` will be directly passed to the
underlying model's `__init__` method (we assume all relevant updates to the configuration have
already been done)
- If a configuration is not provided, `kwargs` will be first passed to the configuration class
initialization function ([`~PretrainedConfig.from_pretrained`]). Each key of `kwargs` that
corresponds to a configuration attribute will be used to override said attribute with the
supplied `kwargs` value. Remaining keys that do not correspond to any configuration attribute
will be passed to the underlying model's `__init__` function.
Examples:
```python
>>> from transformers import AutoConfig, BaseAutoModelClass
>>> # Download model and configuration from huggingface.co and cache.
>>> model = BaseAutoModelClass.from_pretrained("checkpoint_placeholder")
>>> # Update configuration during loading
>>> model = BaseAutoModelClass.from_pretrained("checkpoint_placeholder", output_attentions=True)
>>> model.config.output_attentions
True
>>> # Loading from a TF checkpoint file instead of a PyTorch model (slower)
>>> config = AutoConfig.from_pretrained("./tf_model/shortcut_placeholder_tf_model_config.json")
>>> model = BaseAutoModelClass.from_pretrained(
... "./tf_model/shortcut_placeholder_tf_checkpoint.ckpt.index", from_tf=True, config=config
... )
```
"""
FROM_PRETRAINED_TF_DOCSTRING = """
Instantiate one of the model classes of the library from a pretrained model.
The model class to instantiate is selected based on the `model_type` property of the config object (either
passed as an argument or loaded from `pretrained_model_name_or_path` if possible), or when it's missing, by
falling back to using pattern matching on `pretrained_model_name_or_path`:
List options
Args:
pretrained_model_name_or_path (`str` or `os.PathLike`):
Can be either:
- A string, the *model id* of a pretrained model hosted inside a model repo on huggingface.co.
- A path to a *directory* containing model weights saved using
[`~PreTrainedModel.save_pretrained`], e.g., `./my_model_directory/`.
- A path or url to a *PyTorch state_dict save file* (e.g, `./pt_model/pytorch_model.bin`). In this
case, `from_pt` should be set to `True` and a configuration object should be provided as `config`
argument. This loading path is slower than converting the PyTorch model in a TensorFlow model
using the provided conversion scripts and loading the TensorFlow model afterwards.
model_args (additional positional arguments, *optional*):
Will be passed along to the underlying model `__init__()` method.
config ([`PretrainedConfig`], *optional*):
Configuration for the model to use instead of an automatically loaded configuration. Configuration can
be automatically loaded when:
- The model is a model provided by the library (loaded with the *model id* string of a pretrained
model).
- The model was saved using [`~PreTrainedModel.save_pretrained`] and is reloaded by supplying the
save directory.
- The model is loaded by supplying a local directory as `pretrained_model_name_or_path` and a
configuration JSON file named *config.json* is found in the directory.
cache_dir (`str` or `os.PathLike`, *optional*):
Path to a directory in which a downloaded pretrained model configuration should be cached if the
standard cache should not be used.
from_pt (`bool`, *optional*, defaults to `False`):
Load the model weights from a PyTorch checkpoint save file (see docstring of
`pretrained_model_name_or_path` argument).
force_download (`bool`, *optional*, defaults to `False`):
Whether or not to force the (re-)download of the model weights and configuration files, overriding the
cached versions if they exist.
resume_download (`bool`, *optional*, defaults to `False`):
Whether or not to delete incompletely received files. Will attempt to resume the download if such a
file exists.
proxies (`Dict[str, str]`, *optional*):
A dictionary of proxy servers to use by protocol or endpoint, e.g., `{'http': 'foo.bar:3128',
'http://hostname': 'foo.bar:4012'}`. The proxies are used on each request.
output_loading_info(`bool`, *optional*, defaults to `False`):
Whether ot not to also return a dictionary containing missing keys, unexpected keys and error messages.
local_files_only(`bool`, *optional*, defaults to `False`):
Whether or not to only look at local files (e.g., not try downloading the model).
revision (`str`, *optional*, defaults to `"main"`):
The specific model version to use. It can be a branch name, a tag name, or a commit id, since we use a
git-based system for storing models and other artifacts on huggingface.co, so `revision` can be any
identifier allowed by git.
trust_remote_code (`bool`, *optional*, defaults to `False`):
Whether or not to allow for custom models defined on the Hub in their own modeling files. This option
should only be set to `True` for repositories you trust and in which you have read the code, as it will
execute code present on the Hub on your local machine.
code_revision (`str`, *optional*, defaults to `"main"`):
The specific revision to use for the code on the Hub, if the code leaves in a different repository than
the rest of the model. It can be a branch name, a tag name, or a commit id, since we use a git-based
system for storing models and other artifacts on huggingface.co, so `revision` can be any identifier
allowed by git.
kwargs (additional keyword arguments, *optional*):
Can be used to update the configuration object (after it being loaded) and initiate the model (e.g.,
`output_attentions=True`). Behaves differently depending on whether a `config` is provided or
automatically loaded:
- If a configuration is provided with `config`, `**kwargs` will be directly passed to the
underlying model's `__init__` method (we assume all relevant updates to the configuration have
already been done)
- If a configuration is not provided, `kwargs` will be first passed to the configuration class
initialization function ([`~PretrainedConfig.from_pretrained`]). Each key of `kwargs` that
corresponds to a configuration attribute will be used to override said attribute with the
supplied `kwargs` value. Remaining keys that do not correspond to any configuration attribute
will be passed to the underlying model's `__init__` function.
Examples:
```python
>>> from transformers import AutoConfig, BaseAutoModelClass
>>> # Download model and configuration from huggingface.co and cache.
>>> model = BaseAutoModelClass.from_pretrained("checkpoint_placeholder")
>>> # Update configuration during loading
>>> model = BaseAutoModelClass.from_pretrained("checkpoint_placeholder", output_attentions=True)
>>> model.config.output_attentions
True
>>> # Loading from a PyTorch checkpoint file instead of a TensorFlow model (slower)
>>> config = AutoConfig.from_pretrained("./pt_model/shortcut_placeholder_pt_model_config.json")
>>> model = BaseAutoModelClass.from_pretrained(
... "./pt_model/shortcut_placeholder_pytorch_model.bin", from_pt=True, config=config
... )
```
"""
FROM_PRETRAINED_FLAX_DOCSTRING = """
Instantiate one of the model classes of the library from a pretrained model.
The model class to instantiate is selected based on the `model_type` property of the config object (either
passed as an argument or loaded from `pretrained_model_name_or_path` if possible), or when it's missing, by
falling back to using pattern matching on `pretrained_model_name_or_path`:
List options
Args:
pretrained_model_name_or_path (`str` or `os.PathLike`):
Can be either:
- A string, the *model id* of a pretrained model hosted inside a model repo on huggingface.co.
- A path to a *directory* containing model weights saved using
[`~PreTrainedModel.save_pretrained`], e.g., `./my_model_directory/`.
- A path or url to a *PyTorch state_dict save file* (e.g, `./pt_model/pytorch_model.bin`). In this
case, `from_pt` should be set to `True` and a configuration object should be provided as `config`
argument. This loading path is slower than converting the PyTorch model in a TensorFlow model
using the provided conversion scripts and loading the TensorFlow model afterwards.
model_args (additional positional arguments, *optional*):
Will be passed along to the underlying model `__init__()` method.
config ([`PretrainedConfig`], *optional*):
Configuration for the model to use instead of an automatically loaded configuration. Configuration can
be automatically loaded when:
- The model is a model provided by the library (loaded with the *model id* string of a pretrained
model).
- The model was saved using [`~PreTrainedModel.save_pretrained`] and is reloaded by supplying the
save directory.
- The model is loaded by supplying a local directory as `pretrained_model_name_or_path` and a
configuration JSON file named *config.json* is found in the directory.
cache_dir (`str` or `os.PathLike`, *optional*):
Path to a directory in which a downloaded pretrained model configuration should be cached if the
standard cache should not be used.
from_pt (`bool`, *optional*, defaults to `False`):
Load the model weights from a PyTorch checkpoint save file (see docstring of
`pretrained_model_name_or_path` argument).
force_download (`bool`, *optional*, defaults to `False`):
Whether or not to force the (re-)download of the model weights and configuration files, overriding the
cached versions if they exist.
resume_download (`bool`, *optional*, defaults to `False`):
Whether or not to delete incompletely received files. Will attempt to resume the download if such a
file exists.
proxies (`Dict[str, str]`, *optional*):
A dictionary of proxy servers to use by protocol or endpoint, e.g., `{'http': 'foo.bar:3128',
'http://hostname': 'foo.bar:4012'}`. The proxies are used on each request.
output_loading_info(`bool`, *optional*, defaults to `False`):
Whether ot not to also return a dictionary containing missing keys, unexpected keys and error messages.
local_files_only(`bool`, *optional*, defaults to `False`):
Whether or not to only look at local files (e.g., not try downloading the model).
revision (`str`, *optional*, defaults to `"main"`):
The specific model version to use. It can be a branch name, a tag name, or a commit id, since we use a
git-based system for storing models and other artifacts on huggingface.co, so `revision` can be any
identifier allowed by git.
trust_remote_code (`bool`, *optional*, defaults to `False`):
Whether or not to allow for custom models defined on the Hub in their own modeling files. This option
should only be set to `True` for repositories you trust and in which you have read the code, as it will
execute code present on the Hub on your local machine.
code_revision (`str`, *optional*, defaults to `"main"`):
The specific revision to use for the code on the Hub, if the code leaves in a different repository than
the rest of the model. It can be a branch name, a tag name, or a commit id, since we use a git-based
system for storing models and other artifacts on huggingface.co, so `revision` can be any identifier
allowed by git.
kwargs (additional keyword arguments, *optional*):
Can be used to update the configuration object (after it being loaded) and initiate the model (e.g.,
`output_attentions=True`). Behaves differently depending on whether a `config` is provided or
automatically loaded:
- If a configuration is provided with `config`, `**kwargs` will be directly passed to the
underlying model's `__init__` method (we assume all relevant updates to the configuration have
already been done)
- If a configuration is not provided, `kwargs` will be first passed to the configuration class
initialization function ([`~PretrainedConfig.from_pretrained`]). Each key of `kwargs` that
corresponds to a configuration attribute will be used to override said attribute with the
supplied `kwargs` value. Remaining keys that do not correspond to any configuration attribute
will be passed to the underlying model's `__init__` function.
Examples:
```python
>>> from transformers import AutoConfig, BaseAutoModelClass
>>> # Download model and configuration from huggingface.co and cache.
>>> model = BaseAutoModelClass.from_pretrained("checkpoint_placeholder")
>>> # Update configuration during loading
>>> model = BaseAutoModelClass.from_pretrained("checkpoint_placeholder", output_attentions=True)
>>> model.config.output_attentions
True
>>> # Loading from a PyTorch checkpoint file instead of a TensorFlow model (slower)
>>> config = AutoConfig.from_pretrained("./pt_model/shortcut_placeholder_pt_model_config.json")
>>> model = BaseAutoModelClass.from_pretrained(
... "./pt_model/shortcut_placeholder_pytorch_model.bin", from_pt=True, config=config
... )
```
"""
def _get_model_class(config, model_mapping):
supported_models = model_mapping[type(config)]
if not isinstance(supported_models, (list, tuple)):
return supported_models
name_to_model = {model.__name__: model for model in supported_models}
architectures = getattr(config, "architectures", [])
for arch in architectures:
if arch in name_to_model:
return name_to_model[arch]
elif f"TF{arch}" in name_to_model:
return name_to_model[f"TF{arch}"]
elif f"Flax{arch}" in name_to_model:
return name_to_model[f"Flax{arch}"]
# If not architecture is set in the config or match the supported models, the first element of the tuple is the
# defaults.
return supported_models[0]
class _BaseAutoModelClass:
# Base class for auto models.
_model_mapping = None
def __init__(self, *args, **kwargs):
raise EnvironmentError(
f"{self.__class__.__name__} is designed to be instantiated "
f"using the `{self.__class__.__name__}.from_pretrained(pretrained_model_name_or_path)` or "
f"`{self.__class__.__name__}.from_config(config)` methods."
)
@classmethod
def from_config(cls, config, **kwargs):
trust_remote_code = kwargs.pop("trust_remote_code", None)
has_remote_code = hasattr(config, "auto_map") and cls.__name__ in config.auto_map
has_local_code = type(config) in cls._model_mapping.keys()
trust_remote_code = resolve_trust_remote_code(
trust_remote_code, config._name_or_path, has_local_code, has_remote_code
)
if has_remote_code and trust_remote_code:
class_ref = config.auto_map[cls.__name__]
if "--" in class_ref:
repo_id, class_ref = class_ref.split("--")
else:
repo_id = config.name_or_path
model_class = get_class_from_dynamic_module(class_ref, repo_id, **kwargs)
if os.path.isdir(config._name_or_path):
model_class.register_for_auto_class(cls.__name__)
else:
cls.register(config.__class__, model_class, exist_ok=True)
_ = kwargs.pop("code_revision", None)
return model_class._from_config(config, **kwargs)
elif type(config) in cls._model_mapping.keys():
model_class = _get_model_class(config, cls._model_mapping)
return model_class._from_config(config, **kwargs)
raise ValueError(
f"Unrecognized configuration class {config.__class__} for this kind of AutoModel: {cls.__name__}.\n"
f"Model type should be one of {', '.join(c.__name__ for c in cls._model_mapping.keys())}."
)
@classmethod
def from_pretrained(cls, pretrained_model_name_or_path, *model_args, **kwargs):
config = kwargs.pop("config", None)
trust_remote_code = kwargs.pop("trust_remote_code", None)
kwargs["_from_auto"] = True
hub_kwargs_names = [
"cache_dir",
"force_download",
"local_files_only",
"proxies",
"resume_download",
"revision",
"subfolder",
"use_auth_token",
"token",
]
hub_kwargs = {name: kwargs.pop(name) for name in hub_kwargs_names if name in kwargs}
code_revision = kwargs.pop("code_revision", None)
commit_hash = kwargs.pop("_commit_hash", None)
adapter_kwargs = kwargs.pop("adapter_kwargs", None)
token = hub_kwargs.pop("token", None)
use_auth_token = hub_kwargs.pop("use_auth_token", None)
if use_auth_token is not None:
warnings.warn(
"The `use_auth_token` argument is deprecated and will be removed in v5 of Transformers. Please use `token` instead.",
FutureWarning,
)
if token is not None:
raise ValueError(
"`token` and `use_auth_token` are both specified. Please set only the argument `token`."
)
token = use_auth_token
if token is not None:
hub_kwargs["token"] = token
if commit_hash is None:
if not isinstance(config, PretrainedConfig):
# We make a call to the config file first (which may be absent) to get the commit hash as soon as possible
resolved_config_file = cached_file(
pretrained_model_name_or_path,
CONFIG_NAME,
_raise_exceptions_for_gated_repo=False,
_raise_exceptions_for_missing_entries=False,
_raise_exceptions_for_connection_errors=False,
**hub_kwargs,
)
commit_hash = extract_commit_hash(resolved_config_file, commit_hash)
else:
commit_hash = getattr(config, "_commit_hash", None)
if is_peft_available():
if adapter_kwargs is None:
adapter_kwargs = {}
if token is not None:
adapter_kwargs["token"] = token
maybe_adapter_path = find_adapter_config_file(
pretrained_model_name_or_path, _commit_hash=commit_hash, **adapter_kwargs
)
if maybe_adapter_path is not None:
with open(maybe_adapter_path, "r", encoding="utf-8") as f:
adapter_config = json.load(f)
adapter_kwargs["_adapter_model_path"] = pretrained_model_name_or_path
pretrained_model_name_or_path = adapter_config["base_model_name_or_path"]
if not isinstance(config, PretrainedConfig):
kwargs_orig = copy.deepcopy(kwargs)
# ensure not to pollute the config object with torch_dtype="auto" - since it's
# meaningless in the context of the config object - torch.dtype values are acceptable
if kwargs.get("torch_dtype", None) == "auto":
_ = kwargs.pop("torch_dtype")
# to not overwrite the quantization_config if config has a quantization_config
if kwargs.get("quantization_config", None) is not None:
_ = kwargs.pop("quantization_config")
config, kwargs = AutoConfig.from_pretrained(
pretrained_model_name_or_path,
return_unused_kwargs=True,
trust_remote_code=trust_remote_code,
code_revision=code_revision,
_commit_hash=commit_hash,
**hub_kwargs,
**kwargs,
)
# if torch_dtype=auto was passed here, ensure to pass it on
if kwargs_orig.get("torch_dtype", None) == "auto":
kwargs["torch_dtype"] = "auto"
if kwargs_orig.get("quantization_config", None) is not None:
kwargs["quantization_config"] = kwargs_orig["quantization_config"]
has_remote_code = hasattr(config, "auto_map") and cls.__name__ in config.auto_map
has_local_code = type(config) in cls._model_mapping.keys()
trust_remote_code = resolve_trust_remote_code(
trust_remote_code, pretrained_model_name_or_path, has_local_code, has_remote_code
)
# Set the adapter kwargs
kwargs["adapter_kwargs"] = adapter_kwargs
if has_remote_code and trust_remote_code:
class_ref = config.auto_map[cls.__name__]
model_class = get_class_from_dynamic_module(
class_ref, pretrained_model_name_or_path, code_revision=code_revision, **hub_kwargs, **kwargs
)
_ = hub_kwargs.pop("code_revision", None)
if os.path.isdir(pretrained_model_name_or_path):
model_class.register_for_auto_class(cls.__name__)
else:
cls.register(config.__class__, model_class, exist_ok=True)
return model_class.from_pretrained(
pretrained_model_name_or_path, *model_args, config=config, **hub_kwargs, **kwargs
)
elif type(config) in cls._model_mapping.keys():
model_class = _get_model_class(config, cls._model_mapping)
return model_class.from_pretrained(
pretrained_model_name_or_path, *model_args, config=config, **hub_kwargs, **kwargs
)
raise ValueError(
f"Unrecognized configuration class {config.__class__} for this kind of AutoModel: {cls.__name__}.\n"
f"Model type should be one of {', '.join(c.__name__ for c in cls._model_mapping.keys())}."
)
@classmethod
def register(cls, config_class, model_class, exist_ok=False):
"""
Register a new model for this class.
Args:
config_class ([`PretrainedConfig`]):
The configuration corresponding to the model to register.
model_class ([`PreTrainedModel`]):
The model to register.
"""
if hasattr(model_class, "config_class") and model_class.config_class != config_class:
raise ValueError(
"The model class you are passing has a `config_class` attribute that is not consistent with the "
f"config class you passed (model has {model_class.config_class} and you passed {config_class}. Fix "
"one of those so they match!"
)
cls._model_mapping.register(config_class, model_class, exist_ok=exist_ok)
class _BaseAutoBackboneClass(_BaseAutoModelClass):
# Base class for auto backbone models.
_model_mapping = None
@classmethod
def _load_timm_backbone_from_pretrained(cls, pretrained_model_name_or_path, *model_args, **kwargs):
requires_backends(cls, ["vision", "timm"])
from ...models.timm_backbone import TimmBackboneConfig
config = kwargs.pop("config", TimmBackboneConfig())
if kwargs.get("out_features", None) is not None:
raise ValueError("Cannot specify `out_features` for timm backbones")
if kwargs.get("output_loading_info", False):
raise ValueError("Cannot specify `output_loading_info=True` when loading from timm")
num_channels = kwargs.pop("num_channels", config.num_channels)
features_only = kwargs.pop("features_only", config.features_only)
use_pretrained_backbone = kwargs.pop("use_pretrained_backbone", config.use_pretrained_backbone)
out_indices = kwargs.pop("out_indices", config.out_indices)
config = TimmBackboneConfig(
backbone=pretrained_model_name_or_path,
num_channels=num_channels,
features_only=features_only,
use_pretrained_backbone=use_pretrained_backbone,
out_indices=out_indices,
)
return super().from_config(config, **kwargs)
@classmethod
def from_pretrained(cls, pretrained_model_name_or_path, *model_args, **kwargs):
use_timm_backbone = kwargs.pop("use_timm_backbone", False)
if use_timm_backbone:
return cls._load_timm_backbone_from_pretrained(pretrained_model_name_or_path, *model_args, **kwargs)
return super().from_pretrained(pretrained_model_name_or_path, *model_args, **kwargs)
def insert_head_doc(docstring, head_doc=""):
if len(head_doc) > 0:
return docstring.replace(
"one of the model classes of the library ",
f"one of the model classes of the library (with a {head_doc} head) ",
)
return docstring.replace(
"one of the model classes of the library ", "one of the base model classes of the library "
)
def auto_class_update(cls, checkpoint_for_example="google-bert/bert-base-cased", head_doc=""):
# Create a new class with the right name from the base class
model_mapping = cls._model_mapping
name = cls.__name__
class_docstring = insert_head_doc(CLASS_DOCSTRING, head_doc=head_doc)
cls.__doc__ = class_docstring.replace("BaseAutoModelClass", name)
# Now we need to copy and re-register `from_config` and `from_pretrained` as class methods otherwise we can't
# have a specific docstrings for them.
from_config = copy_func(_BaseAutoModelClass.from_config)
from_config_docstring = insert_head_doc(FROM_CONFIG_DOCSTRING, head_doc=head_doc)
from_config_docstring = from_config_docstring.replace("BaseAutoModelClass", name)
from_config_docstring = from_config_docstring.replace("checkpoint_placeholder", checkpoint_for_example)
from_config.__doc__ = from_config_docstring
from_config = replace_list_option_in_docstrings(model_mapping._model_mapping, use_model_types=False)(from_config)
cls.from_config = classmethod(from_config)
if name.startswith("TF"):
from_pretrained_docstring = FROM_PRETRAINED_TF_DOCSTRING
elif name.startswith("Flax"):
from_pretrained_docstring = FROM_PRETRAINED_FLAX_DOCSTRING
else:
from_pretrained_docstring = FROM_PRETRAINED_TORCH_DOCSTRING
from_pretrained = copy_func(_BaseAutoModelClass.from_pretrained)
from_pretrained_docstring = insert_head_doc(from_pretrained_docstring, head_doc=head_doc)
from_pretrained_docstring = from_pretrained_docstring.replace("BaseAutoModelClass", name)
from_pretrained_docstring = from_pretrained_docstring.replace("checkpoint_placeholder", checkpoint_for_example)
shortcut = checkpoint_for_example.split("/")[-1].split("-")[0]
from_pretrained_docstring = from_pretrained_docstring.replace("shortcut_placeholder", shortcut)
from_pretrained.__doc__ = from_pretrained_docstring
from_pretrained = replace_list_option_in_docstrings(model_mapping._model_mapping)(from_pretrained)
cls.from_pretrained = classmethod(from_pretrained)
return cls
def get_values(model_mapping):
result = []
for model in model_mapping.values():
if isinstance(model, (list, tuple)):
result += list(model)
else:
result.append(model)
return result
def getattribute_from_module(module, attr):
if attr is None:
return None
if isinstance(attr, tuple):
return tuple(getattribute_from_module(module, a) for a in attr)
if hasattr(module, attr):
return getattr(module, attr)
# Some of the mappings have entries model_type -> object of another model type. In that case we try to grab the
# object at the top level.
transformers_module = importlib.import_module("transformers")
if module != transformers_module:
try:
return getattribute_from_module(transformers_module, attr)
except ValueError:
raise ValueError(f"Could not find {attr} neither in {module} nor in {transformers_module}!")
else:
raise ValueError(f"Could not find {attr} in {transformers_module}!")
class _LazyAutoMapping(OrderedDict):
"""
" A mapping config to object (model or tokenizer for instance) that will load keys and values when it is accessed.
Args:
- config_mapping: The map model type to config class
- model_mapping: The map model type to model (or tokenizer) class
"""
def __init__(self, config_mapping, model_mapping):
self._config_mapping = config_mapping
self._reverse_config_mapping = {v: k for k, v in config_mapping.items()}
self._model_mapping = model_mapping
self._model_mapping._model_mapping = self
self._extra_content = {}
self._modules = {}
def __len__(self):
common_keys = set(self._config_mapping.keys()).intersection(self._model_mapping.keys())
return len(common_keys) + len(self._extra_content)
def __getitem__(self, key):
if key in self._extra_content:
return self._extra_content[key]
model_type = self._reverse_config_mapping[key.__name__]
if model_type in self._model_mapping:
model_name = self._model_mapping[model_type]
return self._load_attr_from_module(model_type, model_name)
# Maybe there was several model types associated with this config.
model_types = [k for k, v in self._config_mapping.items() if v == key.__name__]
for mtype in model_types:
if mtype in self._model_mapping:
model_name = self._model_mapping[mtype]
return self._load_attr_from_module(mtype, model_name)
raise KeyError(key)
def _load_attr_from_module(self, model_type, attr):
module_name = model_type_to_module_name(model_type)
if module_name not in self._modules:
self._modules[module_name] = importlib.import_module(f".{module_name}", "transformers.models")
return getattribute_from_module(self._modules[module_name], attr)
def keys(self):
mapping_keys = [
self._load_attr_from_module(key, name)
for key, name in self._config_mapping.items()
if key in self._model_mapping.keys()
]
return mapping_keys + list(self._extra_content.keys())
def get(self, key, default):
try:
return self.__getitem__(key)
except KeyError:
return default
def __bool__(self):
return bool(self.keys())
def values(self):
mapping_values = [
self._load_attr_from_module(key, name)
for key, name in self._model_mapping.items()
if key in self._config_mapping.keys()
]
return mapping_values + list(self._extra_content.values())
def items(self):
mapping_items = [
(
self._load_attr_from_module(key, self._config_mapping[key]),
self._load_attr_from_module(key, self._model_mapping[key]),
)
for key in self._model_mapping.keys()
if key in self._config_mapping.keys()
]
return mapping_items + list(self._extra_content.items())
def __iter__(self):
return iter(self.keys())
def __contains__(self, item):
if item in self._extra_content:
return True
if not hasattr(item, "__name__") or item.__name__ not in self._reverse_config_mapping:
return False
model_type = self._reverse_config_mapping[item.__name__]
return model_type in self._model_mapping
def register(self, key, value, exist_ok=False):
"""
Register a new model in this mapping.
"""
if hasattr(key, "__name__") and key.__name__ in self._reverse_config_mapping:
model_type = self._reverse_config_mapping[key.__name__]
if model_type in self._model_mapping.keys() and not exist_ok:
raise ValueError(f"'{key}' is already used by a Transformers model.")
self._extra_content[key] = value
| transformers/src/transformers/models/auto/auto_factory.py/0 | {
"file_path": "transformers/src/transformers/models/auto/auto_factory.py",
"repo_id": "transformers",
"token_count": 17238
} | 69 |
# coding=utf-8
# Copyright 2023 The Suno AI Authors and The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
""" PyTorch BARK model."""
import math
from typing import Dict, Optional, Tuple, Union
import numpy as np
import torch
from torch import nn
from torch.nn import functional as F
from ...generation.logits_process import (
AlternatingCodebooksLogitsProcessor,
BarkEosPrioritizerLogitsProcessor,
SuppressTokensLogitsProcessor,
)
from ...modeling_attn_mask_utils import _prepare_4d_attention_mask
from ...modeling_outputs import CausalLMOutputWithPast, MaskedLMOutput
from ...modeling_utils import PreTrainedModel, get_parameter_device
from ...utils import (
add_start_docstrings,
add_start_docstrings_to_model_forward,
is_accelerate_available,
is_flash_attn_2_available,
is_flash_attn_greater_or_equal_2_10,
logging,
)
from ..auto import AutoModel
from .configuration_bark import (
BarkCoarseConfig,
BarkConfig,
BarkFineConfig,
BarkSemanticConfig,
BarkSubModelConfig,
)
from .generation_configuration_bark import (
BarkCoarseGenerationConfig,
BarkFineGenerationConfig,
BarkSemanticGenerationConfig,
)
if is_flash_attn_2_available():
from flash_attn import flash_attn_func, flash_attn_varlen_func
from flash_attn.bert_padding import index_first_axis, pad_input, unpad_input # noqa
logger = logging.get_logger(__name__)
_CHECKPOINT_FOR_DOC = "suno/bark-small"
_CONFIG_FOR_DOC = "BarkConfig"
BARK_PRETRAINED_MODEL_ARCHIVE_LIST = [
"suno/bark-small",
"suno/bark",
# See all Bark models at https://huggingface.co/models?filter=bark
]
# Copied from transformers.models.llama.modeling_llama._get_unpad_data
def _get_unpad_data(attention_mask):
seqlens_in_batch = attention_mask.sum(dim=-1, dtype=torch.int32)
indices = torch.nonzero(attention_mask.flatten(), as_tuple=False).flatten()
max_seqlen_in_batch = seqlens_in_batch.max().item()
cu_seqlens = F.pad(torch.cumsum(seqlens_in_batch, dim=0, dtype=torch.int32), (1, 0))
return (
indices,
cu_seqlens,
max_seqlen_in_batch,
)
class BarkSelfAttention(nn.Module):
# adapted from GPTNeoSelfAttention and Bark code
# BarkSelfAttention can have two attention type, i.e full attention or causal attention
def __init__(self, config, is_causal=False):
super().__init__()
# regularization
self.dropout = config.dropout
self.attn_dropout = nn.Dropout(config.dropout)
self.resid_dropout = nn.Dropout(config.dropout)
self.embed_dim = config.hidden_size
self.num_heads = config.num_heads
self.head_dim = self.embed_dim // self.num_heads
if config.hidden_size % config.num_heads != 0:
raise ValueError(
f"embed_dim must be divisible by num_heads (got `embed_dim`: {self.embed_dim} and `num_heads`:"
f" {self.num_heads})."
)
# key, query, value projections for all heads, but in a batch
self.att_proj = nn.Linear(config.hidden_size, 3 * config.hidden_size, bias=config.bias)
# output projection
self.out_proj = nn.Linear(config.hidden_size, config.hidden_size, bias=config.bias)
self.is_causal = is_causal
if is_causal:
block_size = config.block_size
bias = torch.tril(torch.ones((block_size, block_size), dtype=bool)).view(1, 1, block_size, block_size)
self.register_buffer("bias", bias)
# Copied from transformers.models.gpt_neo.modeling_gpt_neo.GPTNeoSelfAttention._split_heads
def _split_heads(self, tensor, num_heads, attn_head_size):
"""
Splits hidden_size dim into attn_head_size and num_heads
"""
new_shape = tensor.size()[:-1] + (num_heads, attn_head_size)
tensor = tensor.view(new_shape)
return tensor.permute(0, 2, 1, 3) # (batch, head, seq_length, head_features)
def _merge_heads(self, tensor, num_heads, attn_head_size):
"""
Merges attn_head_size dim and num_attn_heads dim into hidden_size
"""
# re-assemble all head outputs side by side
# (batch, num_heads, seq_len, attn_head_size) -> (batch, seq_len, num_heads*attn_head_size)
tensor = tensor.transpose(1, 2).contiguous()
tensor = tensor.view(tensor.size()[:-2] + (num_heads * attn_head_size,))
return tensor
def _attn(self, query, key, value, attention_mask=None, head_mask=None):
# unlike GPTNeo's SelfAttention, divide by the square root of the dimension of the query and the key
attn_weights = torch.matmul(query, key.transpose(-1, -2)) * (1.0 / math.sqrt(self.head_dim))
if self.is_causal:
query_length, key_length = query.size(-2), key.size(-2)
# fill the upper left part of the attention weights with inf
attn_weights = attn_weights.masked_fill(
self.bias[:, :, key_length - query_length : key_length, :key_length] == 0,
torch.finfo(attn_weights.dtype).min,
)
if attention_mask is not None:
# Apply the attention mask
attn_weights = attn_weights + attention_mask
attn_weights = nn.functional.softmax(attn_weights, dim=-1)
attn_weights = attn_weights.to(value.dtype)
attn_weights = self.attn_dropout(attn_weights)
# Mask heads if we want to
if head_mask is not None:
attn_weights = attn_weights * head_mask
# (batch, num_heads, seq_len, seq_len) x (batch, num_heads, seq_len, attn_head_size)
# -> (batch, num_heads, seq_len, attn_head_size)
attn_output = torch.matmul(attn_weights, value)
return attn_output, attn_weights
def forward(
self,
hidden_states,
attention_mask=None,
past_key_values=None,
head_mask=None,
use_cache=False,
output_attentions=False,
):
# calculate query, key, values for all heads in batch and move head forward to be the batch dim
query, key, value = self.att_proj(hidden_states).split(self.embed_dim, dim=2)
query = self._split_heads(query, self.num_heads, self.head_dim)
key = self._split_heads(key, self.num_heads, self.head_dim)
value = self._split_heads(value, self.num_heads, self.head_dim)
if past_key_values is not None:
past_key = past_key_values[0]
past_value = past_key_values[1]
key = torch.cat((past_key, key), dim=-2)
value = torch.cat((past_value, value), dim=-2)
if use_cache is True:
present = (key, value)
else:
present = None
attn_output, attn_weights = self._attn(query, key, value, attention_mask, head_mask)
attn_output = self._merge_heads(attn_output, self.num_heads, self.head_dim)
attn_output = self.out_proj(attn_output)
attn_output = self.resid_dropout(attn_output)
outputs = (attn_output, present)
if output_attentions:
outputs += (attn_weights,)
return outputs
class BarkSelfFlashAttention2(BarkSelfAttention):
"""
Bark flash attention module. This module inherits from `BarkSelfAttention` as the weights of the module stays
untouched. The only required change would be on the forward pass where it needs to correctly call the public API of
flash attention and deal with padding tokens in case the input contains any of them.
"""
# Copied from transformers.models.llama.modeling_llama.LlamaFlashAttention2.__init__
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
# TODO: Should be removed once Flash Attention for RoCm is bumped to 2.1.
# flash_attn<2.1 generates top-left aligned causal mask, while what is needed here is bottom-right alignement, that was made default for flash_attn>=2.1. This attribute is used to handle this difference. Reference: https://github.com/Dao-AILab/flash-attention/releases/tag/v2.1.0.
# Beware that with flash_attn<2.1, using q_seqlen != k_seqlen (except for the case q_seqlen == 1) produces a wrong mask (top-left).
self._flash_attn_uses_top_left_mask = not is_flash_attn_greater_or_equal_2_10()
def _split_heads(self, tensor, num_heads, attn_head_size):
"""
Splits hidden_size dim into attn_head_size and num_heads
"""
new_shape = tensor.size()[:-1] + (num_heads, attn_head_size)
tensor = tensor.view(new_shape)
# Flash attention requires the input to have the shape
# batch_size x seq_length x head_dim x hidden_dim - (batch, seq_length, head, head_features)
return tensor
def _merge_heads(self, tensor, num_heads, attn_head_size):
"""
Merges attn_head_size dim and num_attn_heads dim into hidden_size
"""
# re-assemble all head outputs side by side
# (batch, seq_len, num_heads, attn_head_size) -> (batch, seq_len, num_heads*attn_head_size)
tensor = tensor.view(tensor.size()[:-2] + (num_heads * attn_head_size,))
return tensor
def forward(
self,
hidden_states,
attention_mask=None,
past_key_values=None,
head_mask=None,
use_cache=False,
output_attentions=False,
):
batch_size, query_len, _ = hidden_states.size()
# calculate query, key, values for all heads in batch and move head forward to be the batch dim
query, key, value = self.att_proj(hidden_states).split(self.embed_dim, dim=2)
query = self._split_heads(query, self.num_heads, self.head_dim)
key = self._split_heads(key, self.num_heads, self.head_dim)
value = self._split_heads(value, self.num_heads, self.head_dim)
if past_key_values is not None:
# (batch, head, seq_length, head_features) -> (batch, seq_length, head, head_features)
past_key = past_key_values[0].transpose(1, 2)
past_value = past_key_values[1].transpose(1, 2)
# and merge on seq_length
key = torch.cat((past_key, key), dim=1)
value = torch.cat((past_value, value), dim=1)
if use_cache is True:
# (batch, head, seq_length, head_features)
present = (key.transpose(1, 2), value.transpose(1, 2))
else:
present = None
attn_output = self._flash_attention_forward(query, key, value, attention_mask, query_len, dropout=self.dropout)
attn_output = self._merge_heads(attn_output, self.num_heads, self.head_dim)
attn_output = self.out_proj(attn_output)
attn_output = self.resid_dropout(attn_output)
outputs = (attn_output, present)
if output_attentions:
attn_weights = None
outputs += (attn_weights,)
return outputs
# Copied from transformers.models.llama.modeling_llama.LlamaFlashAttention2._flash_attention_forward
def _flash_attention_forward(
self, query_states, key_states, value_states, attention_mask, query_length, dropout=0.0, softmax_scale=None
):
"""
Calls the forward method of Flash Attention - if the input hidden states contain at least one padding token
first unpad the input, then computes the attention scores and pad the final attention scores.
Args:
query_states (`torch.Tensor`):
Input query states to be passed to Flash Attention API
key_states (`torch.Tensor`):
Input key states to be passed to Flash Attention API
value_states (`torch.Tensor`):
Input value states to be passed to Flash Attention API
attention_mask (`torch.Tensor`):
The padding mask - corresponds to a tensor of size `(batch_size, seq_len)` where 0 stands for the
position of padding tokens and 1 for the position of non-padding tokens.
dropout (`int`, *optional*):
Attention dropout
softmax_scale (`float`, *optional*):
The scaling of QK^T before applying softmax. Default to 1 / sqrt(head_dim)
"""
if not self._flash_attn_uses_top_left_mask:
causal = self.is_causal
else:
# TODO: Remove the `query_length != 1` check once Flash Attention for RoCm is bumped to 2.1. For details, please see the comment in LlamaFlashAttention2 __init__.
causal = self.is_causal and query_length != 1
# Contains at least one padding token in the sequence
if attention_mask is not None:
batch_size = query_states.shape[0]
query_states, key_states, value_states, indices_q, cu_seq_lens, max_seq_lens = self._upad_input(
query_states, key_states, value_states, attention_mask, query_length
)
cu_seqlens_q, cu_seqlens_k = cu_seq_lens
max_seqlen_in_batch_q, max_seqlen_in_batch_k = max_seq_lens
attn_output_unpad = flash_attn_varlen_func(
query_states,
key_states,
value_states,
cu_seqlens_q=cu_seqlens_q,
cu_seqlens_k=cu_seqlens_k,
max_seqlen_q=max_seqlen_in_batch_q,
max_seqlen_k=max_seqlen_in_batch_k,
dropout_p=dropout,
softmax_scale=softmax_scale,
causal=causal,
)
attn_output = pad_input(attn_output_unpad, indices_q, batch_size, query_length)
else:
attn_output = flash_attn_func(
query_states, key_states, value_states, dropout, softmax_scale=softmax_scale, causal=causal
)
return attn_output
# Copied from transformers.models.llama.modeling_llama.LlamaFlashAttention2._upad_input
def _upad_input(self, query_layer, key_layer, value_layer, attention_mask, query_length):
indices_k, cu_seqlens_k, max_seqlen_in_batch_k = _get_unpad_data(attention_mask)
batch_size, kv_seq_len, num_key_value_heads, head_dim = key_layer.shape
key_layer = index_first_axis(
key_layer.reshape(batch_size * kv_seq_len, num_key_value_heads, head_dim), indices_k
)
value_layer = index_first_axis(
value_layer.reshape(batch_size * kv_seq_len, num_key_value_heads, head_dim), indices_k
)
if query_length == kv_seq_len:
query_layer = index_first_axis(
query_layer.reshape(batch_size * kv_seq_len, self.num_heads, head_dim), indices_k
)
cu_seqlens_q = cu_seqlens_k
max_seqlen_in_batch_q = max_seqlen_in_batch_k
indices_q = indices_k
elif query_length == 1:
max_seqlen_in_batch_q = 1
cu_seqlens_q = torch.arange(
batch_size + 1, dtype=torch.int32, device=query_layer.device
) # There is a memcpy here, that is very bad.
indices_q = cu_seqlens_q[:-1]
query_layer = query_layer.squeeze(1)
else:
# The -q_len: slice assumes left padding.
attention_mask = attention_mask[:, -query_length:]
query_layer, indices_q, cu_seqlens_q, max_seqlen_in_batch_q = unpad_input(query_layer, attention_mask)
return (
query_layer,
key_layer,
value_layer,
indices_q,
(cu_seqlens_q, cu_seqlens_k),
(max_seqlen_in_batch_q, max_seqlen_in_batch_k),
)
BARK_ATTENTION_CLASSES = {
"eager": BarkSelfAttention,
"flash_attention_2": BarkSelfFlashAttention2,
}
class BarkLayerNorm(nn.Module):
"""LayerNorm but with an optional bias. PyTorch doesn't support simply bias=False."""
def __init__(self, hidden_size, bias=True):
super().__init__()
self.weight = nn.Parameter(torch.ones(hidden_size))
self.bias = nn.Parameter(torch.zeros(hidden_size)) if bias else None
def forward(self, input):
return F.layer_norm(input, self.weight.shape, self.weight, self.bias, eps=1e-5)
class BarkMLP(nn.Module):
def __init__(self, config):
super().__init__()
self.in_proj = nn.Linear(config.hidden_size, 4 * config.hidden_size, bias=config.bias)
self.out_proj = nn.Linear(4 * config.hidden_size, config.hidden_size, bias=config.bias)
self.dropout = nn.Dropout(config.dropout)
self.gelu = nn.GELU()
def forward(self, hidden_states):
hidden_states = self.in_proj(hidden_states)
hidden_states = self.gelu(hidden_states)
hidden_states = self.out_proj(hidden_states)
hidden_states = self.dropout(hidden_states)
return hidden_states
class BarkBlock(nn.Module):
def __init__(self, config, is_causal=False):
super().__init__()
if is_causal:
# if causal, uses handmade LayerNorm, so that the layerNorm bias is optional
# this handmade layerNorm is used to stick with Bark choice of leaving optional bias in
# AutoRegressive models (corresponding to the "Text" and the "Coarse" modules)
self.layernorm_1 = BarkLayerNorm(config.hidden_size, bias=config.bias)
self.layernorm_2 = BarkLayerNorm(config.hidden_size, bias=config.bias)
else:
self.layernorm_1 = nn.LayerNorm(config.hidden_size)
self.layernorm_2 = nn.LayerNorm(config.hidden_size)
self.attn = BARK_ATTENTION_CLASSES[config._attn_implementation](config, is_causal=is_causal)
self.mlp = BarkMLP(config)
def forward(
self,
hidden_states,
past_key_values=None,
attention_mask=None,
head_mask=None,
use_cache=False,
output_attentions=False,
):
intermediary_hidden_states = self.layernorm_1(hidden_states)
attn_outputs = self.attn(
intermediary_hidden_states,
past_key_values=past_key_values,
attention_mask=attention_mask,
head_mask=head_mask,
use_cache=use_cache,
output_attentions=output_attentions,
)
attn_output = attn_outputs[0] # output_attn: output, present_key_values, (attn_weights)
outputs = attn_outputs[1:]
intermediary_hidden_states = hidden_states + attn_output
intermediary_hidden_states = intermediary_hidden_states + self.mlp(
self.layernorm_2(intermediary_hidden_states)
)
if use_cache:
outputs = (intermediary_hidden_states,) + outputs
else:
outputs = (intermediary_hidden_states,) + outputs[1:]
return outputs # hidden_states, ((present), attentions)
class BarkPreTrainedModel(PreTrainedModel):
"""
An abstract class to handle weights initialization and a simple interface for downloading and loading pretrained
models.
"""
config_class = BarkConfig
supports_gradient_checkpointing = False
_supports_flash_attn_2 = True
def _init_weights(self, module):
"""Initialize the weights."""
if isinstance(module, (nn.Linear,)):
# Slightly different from the TF version which uses truncated_normal for initialization
# cf https://github.com/pytorch/pytorch/pull/5617
module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
if module.bias is not None:
module.bias.data.zero_()
elif isinstance(module, nn.Embedding):
module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
if module.padding_idx is not None:
module.weight.data[module.padding_idx].zero_()
elif isinstance(module, nn.LayerNorm):
module.bias.data.zero_()
module.weight.data.fill_(1.0)
def __init__(self, *inputs, **kwargs):
super().__init__(*inputs, **kwargs)
@property
def device(self) -> torch.device:
"""
`torch.device`: The device on which the module is (assuming that all the module parameters are on the same
device).
"""
# if has _hf_hook, has been offloaded so the device has to be found in the hook
if not hasattr(self, "_hf_hook"):
return get_parameter_device(self)
for module in self.modules():
if (
hasattr(module, "_hf_hook")
and hasattr(module._hf_hook, "execution_device")
and module._hf_hook.execution_device is not None
):
return torch.device(module._hf_hook.execution_device)
return get_parameter_device(self)
BARK_MODEL_START_DOCSTRING = """
This model inherits from [`PreTrainedModel`]. Check the superclass documentation for the generic methods the
library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads
etc.)
This model is also a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) subclass.
Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage
and behavior.
Parameters:
config ([`{config}`]):
Model configuration class with all the parameters of the model. Initializing with a config file does not
load the weights associated with the model, only the configuration. Check out the
[`~PreTrainedModel.from_pretrained`] method to load the model weights.
"""
BARK_START_DOCSTRING = r"""
This model inherits from [`PreTrainedModel`]. Check the superclass documentation for the generic methods the
library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads
etc.)
This model is also a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) subclass.
Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage
and behavior.
Parameters:
config ([`BarkConfig`]):
Model configuration class with all the parameters of the model. Initializing with a config file does not
load the weights associated with the model, only the configuration. Check out the
[`~PreTrainedModel.from_pretrained`] method to load the model weights.
"""
BARK_FINE_INPUTS_DOCSTRING = r"""
Args:
codebook_idx (`int`):
Index of the codebook that will be predicted.
input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length, number_of_codebooks)`):
Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide
it. Initially, indices of the first two codebooks are obtained from the `coarse` sub-model. The rest is
predicted recursively by attending the previously predicted channels. The model predicts on windows of
length 1024.
attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
[What are attention masks?](../glossary#attention-mask)
position_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
Indices of positions of each input sequence tokens in the position embeddings. Selected in the range `[0,
config.max_position_embeddings - 1]`.
[What are position IDs?](../glossary#position-ids)
head_mask (`torch.Tensor` of shape `(encoder_layers, encoder_attention_heads)`, *optional*):
Mask to nullify selected heads of the attention modules in the encoder. Mask values selected in `[0, 1]`:
- 1 indicates the head is **not masked**,
- 0 indicates the head is **masked**.
labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*): NOT IMPLEMENTED YET.
input_embeds (`torch.FloatTensor` of shape `(batch_size, input_sequence_length, hidden_size)`, *optional*):
Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation. If
`past_key_values` is used, optionally only the last `input_embeds` have to be input (see
`past_key_values`). This is useful if you want more control over how to convert `input_ids` indices into
associated vectors than the model's internal embedding lookup matrix.
output_attentions (`bool`, *optional*):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
tensors for more detail.
output_hidden_states (`bool`, *optional*):
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
more detail.
return_dict (`bool`, *optional*):
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
"""
BARK_CAUSAL_MODEL_INPUTS_DOCSTRING = r"""
Args:
input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide
it. Indices can be obtained using [`AutoTokenizer`]. See [`PreTrainedTokenizer.encode`] and
[`PreTrainedTokenizer.__call__`] for details. [What are input IDs?](../glossary#input-ids)
past_key_values (`tuple(tuple(torch.FloatTensor))`, *optional*, returned when `use_cache` is passed or when `config.use_cache=True`):
Tuple of `tuple(torch.FloatTensor)` of length `config.n_layers`, with each tuple having 2 tensors of shape
`(batch_size, num_heads, sequence_length, embed_size_per_head)`.
Contains pre-computed hidden-states (key and values in the self-attention blocks) that can be used (see
`past_key_values` input) to speed up sequential decoding.
If `past_key_values` are used, the user can optionally input only the last `decoder_input_ids` (those that
don't have their past key value states given to this model) of shape `(batch_size, 1)` instead of all
`input_ids` of shape `(batch_size, sequence_length)`.
attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
[What are attention masks?](../glossary#attention-mask)
position_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
Indices of positions of each input sequence tokens in the position embeddings. Selected in the range `[0,
config.max_position_embeddings - 1]`.
[What are position IDs?](../glossary#position-ids)
head_mask (`torch.Tensor` of shape `(encoder_layers, encoder_attention_heads)`, *optional*):
Mask to nullify selected heads of the attention modules in the encoder. Mask values selected in `[0, 1]`:
- 1 indicates the head is **not masked**,
- 0 indicates the head is **masked**.
input_embeds (`torch.FloatTensor` of shape `(batch_size, input_sequence_length, hidden_size)`, *optional*):
Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation.
Here, due to `Bark` particularities, if `past_key_values` is used, `input_embeds` will be ignored and you
have to use `input_ids`. If `past_key_values` is not used and `use_cache` is set to `True`, `input_embeds`
is used in priority instead of `input_ids`.
use_cache (`bool`, *optional*):
If set to `True`, `past_key_values` key value states are returned and can be used to speed up decoding (see
`past_key_values`).
output_attentions (`bool`, *optional*):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
tensors for more detail.
output_hidden_states (`bool`, *optional*):
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
more detail.
return_dict (`bool`, *optional*):
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
"""
# GPT2-like autoregressive model
class BarkCausalModel(BarkPreTrainedModel):
config_class = BarkSubModelConfig
def __init__(self, config):
super().__init__(config)
self.config = config
# initialize as an autoregressive GPT-like model
self.input_embeds_layer = nn.Embedding(config.input_vocab_size, config.hidden_size)
self.position_embeds_layer = nn.Embedding(config.block_size, config.hidden_size)
self.drop = nn.Dropout(config.dropout)
self.layers = nn.ModuleList([BarkBlock(config, is_causal=True) for _ in range(config.num_layers)])
self._use_flash_attention_2 = config._attn_implementation == "flash_attention_2"
self.layernorm_final = BarkLayerNorm(config.hidden_size, bias=config.bias)
self.lm_head = nn.Linear(config.hidden_size, config.output_vocab_size, bias=False)
self.gradient_checkpointing = False
# Initialize weights and apply final processing
self.post_init()
def get_input_embeddings(self):
return self.input_embeds_layer
def set_input_embeddings(self, new_embeddings):
self.input_embeds_layer = new_embeddings
def prepare_inputs_for_generation(self, input_ids, past_key_values=None, **kwargs):
input_embeds = kwargs.get("input_embeds", None)
attention_mask = kwargs.get("attention_mask", None)
position_ids = kwargs.get("position_ids", None)
if past_key_values is not None:
# Omit tokens covered by past_key_values
seq_len = input_ids.shape[1]
past_length = past_key_values[0][0].shape[2]
# Some generation methods already pass only the last input ID
if input_ids.shape[1] > past_length:
remove_prefix_length = past_length
else:
# Default to old behavior: keep only final ID
remove_prefix_length = input_ids.shape[1] - 1
input_ids = input_ids[:, remove_prefix_length:]
# input_embeds have already been used and is not required anymore
input_embeds = None
else:
if input_embeds is not None and kwargs.get("use_cache"):
seq_len = input_embeds.shape[1]
else:
seq_len = input_ids.shape[1]
# ensure that attention_mask and position_ids shapes are aligned with the weird Bark hack of reducing
# sequence length on the first forward pass
if attention_mask is not None:
attention_mask = attention_mask[:, :seq_len]
if position_ids is not None:
position_ids = position_ids[:, :seq_len]
if attention_mask is not None and position_ids is None:
# create position_ids on the fly for batch generation
position_ids = attention_mask.long().cumsum(-1) - 1
position_ids.masked_fill_(attention_mask == 0, 1)
if past_key_values:
position_ids = position_ids[:, -input_ids.shape[1] :]
else:
position_ids = None
if input_embeds is not None and kwargs.get("use_cache"):
return {
"input_ids": None,
"input_embeds": input_embeds,
"past_key_values": past_key_values,
"use_cache": kwargs.get("use_cache"),
"position_ids": position_ids,
"attention_mask": attention_mask,
}
return {
"input_ids": input_ids,
"past_key_values": past_key_values,
"use_cache": kwargs.get("use_cache"),
"position_ids": position_ids,
"attention_mask": attention_mask,
}
@add_start_docstrings_to_model_forward(BARK_CAUSAL_MODEL_INPUTS_DOCSTRING)
def forward(
self,
input_ids: Optional[torch.Tensor] = None,
past_key_values: Optional[Tuple[torch.FloatTensor]] = None,
attention_mask: Optional[torch.Tensor] = None,
position_ids: Optional[torch.Tensor] = None,
head_mask: Optional[torch.Tensor] = None,
labels: Optional[torch.LongTensor] = None,
input_embeds: Optional[torch.Tensor] = None,
use_cache: Optional[bool] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
) -> Union[Tuple[torch.Tensor], CausalLMOutputWithPast]:
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
output_hidden_states = (
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
)
use_cache = use_cache if use_cache is not None else self.config.use_cache
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
# Verify if input_embeds already exists
# then compute embeddings.
if input_ids is not None and input_embeds is not None:
raise ValueError("You cannot specify both input_ids and input_embeds at the same time")
elif input_embeds is not None and past_key_values is None:
# we want to return the input_embeds in priority so that it is in line with a weird hack
# of Bark which concatenate two bits of the input_embeds on the first forward pass of the semantic model
pass
elif input_ids is not None:
input_embeds = self.input_embeds_layer(input_ids) # token embeddings of shape (b, t, n_embd)
elif input_embeds is not None:
pass
else:
raise ValueError("You have to specify either input_ids or input_embeds")
input_shape = input_embeds.size()[:-1]
batch_size = input_embeds.shape[0]
seq_length = input_shape[-1]
device = input_ids.device if input_ids is not None else input_embeds.device
if past_key_values is None:
past_length = 0
past_key_values = tuple([None] * len(self.layers))
else:
past_length = past_key_values[0][0].size(-2)
if position_ids is None:
position_ids = torch.arange(past_length, seq_length + past_length, dtype=torch.long, device=device)
position_ids = position_ids.unsqueeze(0) # shape (1, seq_length)
position_embeds = self.position_embeds_layer(position_ids) # position embeddings of shape (1, t, n_embd)
# Attention mask.
if attention_mask is not None:
if batch_size <= 0:
raise ValueError("batch_size has to be defined and > 0")
if self._use_flash_attention_2:
attention_mask = attention_mask if 0 in attention_mask else None
else:
attention_mask = attention_mask.view(batch_size, -1)
# [bsz, to_seq_length] -> [bsz, 1, 1, to_seq_length]
# from_seq_length is 1 to easily broadcast
attention_mask = _prepare_4d_attention_mask(attention_mask, input_embeds.dtype, tgt_len=1)
# Prepare head mask if needed
# 1.0 in head_mask indicate we keep the head
# attention_probs has shape bsz x num_heads x N x N
# head_mask has shape num_layers x batch x num_heads x N x N
head_mask = self.get_head_mask(head_mask, self.config.num_layers)
hidden_states = self.drop(input_embeds + position_embeds)
output_shape = input_shape + (hidden_states.size(-1),)
if self.gradient_checkpointing and self.training:
if use_cache:
logger.warning_once(
"`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`..."
)
use_cache = False
present_key_values = () if use_cache else None
all_self_attentions = () if output_attentions else None
all_hidden_states = () if output_hidden_states else None
for i, (block, past_layer_key_values) in enumerate(zip(self.layers, past_key_values)):
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
if self.gradient_checkpointing and self.training:
outputs = self._gradient_checkpointing_func(
block.__call__,
hidden_states,
None,
attention_mask,
head_mask[i],
use_cache,
output_attentions,
)
else:
outputs = block(
hidden_states,
past_key_values=past_layer_key_values,
attention_mask=attention_mask,
head_mask=head_mask[i],
use_cache=use_cache,
output_attentions=output_attentions,
)
hidden_states = outputs[0]
if use_cache:
present_key_values = present_key_values + (outputs[1],)
if output_attentions:
all_self_attentions = all_self_attentions + (outputs[2 if use_cache else 1],)
hidden_states = self.layernorm_final(hidden_states)
hidden_states = hidden_states.view(output_shape)
# Add last hidden state
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
logits = self.lm_head(hidden_states)
loss = None
if labels is not None:
raise NotImplementedError(
"Training is not implemented yet for Bark - ensure you do not pass `labels` to the model."
)
if not return_dict:
return tuple(
v for v in [None, logits, present_key_values, all_hidden_states, all_self_attentions] if v is not None
)
return CausalLMOutputWithPast(
loss=loss,
logits=logits,
past_key_values=present_key_values,
hidden_states=all_hidden_states,
attentions=all_self_attentions,
)
@staticmethod
def _reorder_cache(
past_key_values: Tuple[Tuple[torch.Tensor]], beam_idx: torch.Tensor
) -> Tuple[Tuple[torch.Tensor]]:
"""
This function is used to re-order the `past_key_values` cache if [`~PreTrainedModel.beam_search`] or
[`~PreTrainedModel.beam_sample`] is called. This is required to match `past_key_values` with the correct
beam_idx at every generation step.
"""
# Necessary for beam_search
return tuple(
tuple(past_state.index_select(0, beam_idx.to(past_state.device)) for past_state in layer_past)
for layer_past in past_key_values
)
@add_start_docstrings(
"""Bark semantic (or text) model. It shares the same architecture as the coarse model.
It is a GPT-2 like autoregressive model with a language modeling head on top.""",
BARK_MODEL_START_DOCSTRING.format(config="BarkSemanticConfig"),
)
class BarkSemanticModel(BarkCausalModel):
base_model_prefix = "semantic"
config_class = BarkSemanticConfig
def generate(
self,
input_ids: torch.Tensor,
semantic_generation_config: BarkSemanticGenerationConfig = None,
history_prompt: Optional[Dict[str, torch.Tensor]] = None,
attention_mask: Optional[torch.Tensor] = None,
**kwargs,
) -> torch.LongTensor:
"""
Generates text semantic tokens from an input prompt and an additional optional `Bark` speaker prompt.
Args:
input_ids (`Optional[torch.Tensor]` of shape (batch_size, seq_len), *optional*):
Input ids, i.e tokenized input sentences. Will be truncated up to
semantic_generation_config.max_input_semantic_length tokens. Note that the output audios will be as
long as the longest generation among the batch.
semantic_generation_config (`BarkSemanticGenerationConfig`):
Generation config indicating how to generate the semantic tokens.
history_prompt (`Optional[Dict[str,torch.Tensor]]`, *optional*):
Optional `Bark` speaker prompt.
attention_mask (`Optional[torch.Tensor]`, *optional*):
Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
[What are attention masks?](../glossary#attention-mask)
Returns:
torch.LongTensor: Output semantic tokens.
"""
if semantic_generation_config is None:
raise ValueError("`semantic_generation_config` has to be provided")
batch_size = input_ids.shape[0]
max_input_semantic_length = semantic_generation_config.max_input_semantic_length
input_ids = input_ids + semantic_generation_config.text_encoding_offset
if attention_mask is not None:
input_ids = input_ids.masked_fill((1 - attention_mask).bool(), semantic_generation_config.text_pad_token)
if history_prompt is not None:
semantic_history = history_prompt["semantic_prompt"][-max_input_semantic_length:]
semantic_history = nn.functional.pad(
semantic_history,
(0, max_input_semantic_length - len(semantic_history)),
value=semantic_generation_config.semantic_pad_token,
mode="constant",
)
else:
semantic_history = torch.tensor(
[semantic_generation_config.semantic_pad_token] * max_input_semantic_length, dtype=torch.int
).to(self.device)
semantic_history = torch.repeat_interleave(semantic_history[None], batch_size, dim=0)
infer_array = torch.tensor(
[[semantic_generation_config.semantic_infer_token]] * batch_size, dtype=torch.int
).to(self.device)
input_embeds = torch.cat(
[
self.input_embeds_layer(input_ids[:, :max_input_semantic_length])
+ self.input_embeds_layer(semantic_history[:, : max_input_semantic_length + 1]),
self.input_embeds_layer(infer_array),
],
dim=1,
)
tokens_to_suppress = list(
range(semantic_generation_config.semantic_vocab_size, semantic_generation_config.semantic_pad_token)
)
tokens_to_suppress.extend(
list(range(semantic_generation_config.semantic_pad_token + 1, self.config.output_vocab_size))
)
suppress_tokens_logits_processor = SuppressTokensLogitsProcessor(tokens_to_suppress)
min_eos_p = kwargs.get("min_eos_p", semantic_generation_config.min_eos_p)
early_stopping_logits_processor = BarkEosPrioritizerLogitsProcessor(
eos_token_id=semantic_generation_config.eos_token_id, min_eos_p=min_eos_p
)
# pass input_ids in order to stay consistent with the transformers generate method even though it is not used
# (except to get the input seq_len - that's why we keep the first 257 tokens)
semantic_output = super().generate(
torch.ones((batch_size, max_input_semantic_length + 1), dtype=torch.int).to(self.device),
input_embeds=input_embeds,
logits_processor=[suppress_tokens_logits_processor, early_stopping_logits_processor],
generation_config=semantic_generation_config,
**kwargs,
) # size: 10048
# take the generated semantic tokens
semantic_output = semantic_output[:, max_input_semantic_length + 1 :]
return semantic_output
@add_start_docstrings(
"""Bark coarse acoustics model.
It shares the same architecture as the semantic (or text) model. It is a GPT-2 like autoregressive model with a
language modeling head on top.""",
BARK_MODEL_START_DOCSTRING.format(config="BarkCoarseConfig"),
)
class BarkCoarseModel(BarkCausalModel):
base_model_prefix = "coarse_acoustics"
config_class = BarkCoarseConfig
def preprocess_histories(
self,
max_coarse_history: int,
semantic_to_coarse_ratio: int,
batch_size: int,
semantic_generation_config: int,
codebook_size: int,
history_prompt: Optional[Dict[str, torch.Tensor]] = None,
):
"""
Preprocess the optional `Bark` speaker prompts before `self.generate`.
Args:
max_coarse_history (`int`):
Maximum size of coarse tokens used.
semantic_to_coarse_ratio (`int`):
Ratio of semantic to coarse frequency
batch_size (`int`):
Batch size, i.e the number of samples.
semantic_generation_config (`BarkSemanticGenerationConfig`):
Generation config indicating how to generate the semantic tokens.
codebook_size (`int`):
Codebook channel size, i.e. the size of the output vocabulary per codebook channel.
history_prompt (`Optional[Dict[str,torch.Tensor]]`):
Optional `Bark` speaker prompt.
Returns: Returns:
`tuple(torch.FloatTensor)`:
- **x_semantic_history** (`torch.FloatTensor` -- Processed semantic speaker prompt.
- **x_coarse_history** (`torch.FloatTensor`) -- Processed coarse speaker prompt.
"""
if history_prompt is not None:
x_semantic_history = torch.repeat_interleave(history_prompt["semantic_prompt"][None], batch_size, dim=0)
# clone to avoid modifying history_prompt.coarse_prompt
x_coarse_history = history_prompt["coarse_prompt"].clone()
# offset x_coarse_history
if codebook_size is not None:
for n in range(1, x_coarse_history.shape[0]):
# offset
x_coarse_history[n, :] += codebook_size * n
# flatten x_coarse_history
x_coarse_history = torch.transpose(x_coarse_history, 0, 1).view(-1)
x_coarse_history = x_coarse_history + semantic_generation_config.semantic_vocab_size
x_coarse_history = torch.repeat_interleave(x_coarse_history[None], batch_size, dim=0)
# e.g: after SEMANTIC_VOCAB_SIZE (10000), 1024 tokens dedicated to first codebook, 1024 next tokens
# dedicated to second codebook.
max_semantic_history = int(np.floor(max_coarse_history / semantic_to_coarse_ratio))
# trim histories correctly
n_semantic_hist_provided = min(
[
max_semantic_history,
x_semantic_history.shape[1] - x_semantic_history.shape[1] % 2,
int(np.floor(x_coarse_history.shape[1] / semantic_to_coarse_ratio)),
]
)
n_coarse_hist_provided = int(round(n_semantic_hist_provided * semantic_to_coarse_ratio))
x_semantic_history = x_semantic_history[:, -n_semantic_hist_provided:].int()
x_coarse_history = x_coarse_history[:, -n_coarse_hist_provided:].int()
# bit of a hack for time alignment (sounds better) - from Bark original implementation
x_coarse_history = x_coarse_history[:, :-2]
else:
# shape: (batch_size, 0)
x_semantic_history = torch.tensor([[]] * batch_size, dtype=torch.int).to(self.device)
x_coarse_history = torch.tensor([[]] * batch_size, dtype=torch.int).to(self.device)
return x_semantic_history, x_coarse_history
def generate(
self,
semantic_output: torch.Tensor,
semantic_generation_config: BarkSemanticGenerationConfig = None,
coarse_generation_config: BarkCoarseGenerationConfig = None,
codebook_size: int = 1024,
history_prompt: Optional[Dict[str, torch.Tensor]] = None,
return_output_lengths: Optional[bool] = None,
**kwargs,
) -> Union[torch.LongTensor, Tuple[torch.LongTensor, torch.LongTensor]]:
"""
Generates coarse acoustics tokens from input text semantic tokens and an additional optional `Bark` speaker
prompt.
Args:
semantic_output (`torch.Tensor` of shape (batch_size, seq_len), *optional*):
Input text semantic ids, i.e the output of `BarkSemanticModel.generate`.
semantic_generation_config (`BarkSemanticGenerationConfig`):
Generation config indicating how to generate the semantic tokens.
coarse_generation_config (`BarkCoarseGenerationConfig`):
Generation config indicating how to generate the coarse tokens.
codebook_size (`int`, *optional*, defaults to 1024):
Codebook channel size, i.e. the size of the output vocabulary per codebook channel.
history_prompt (`Optional[Dict[str,torch.Tensor]]`, *optional*):
Optional `Bark` speaker prompt.
return_output_lengths (`bool`, *optional*):
Whether or not to return the output lengths. Useful when batching.
Returns:
By default:
torch.LongTensor: Output coarse acoustics tokens.
If `return_output_lengths=True`:
`Tuple(torch.Tensor, torch.Tensor): The output coarse acoustics tokens, and the length of each sample
of the batch.
"""
if semantic_generation_config is None:
raise ValueError("`semantic_generation_config` has to be provided")
if coarse_generation_config is None:
raise ValueError("`coarse_generation_config` has to be provided")
max_coarse_input_length = coarse_generation_config.max_coarse_input_length
max_coarse_history = coarse_generation_config.max_coarse_history
sliding_window_len = coarse_generation_config.sliding_window_len
# replace semantic_pad_token (eos_tok and pad_tok here) with coarse_semantic_pad_token i.e the pad_token
# used in the next model
semantic_output.masked_fill_(
semantic_output == semantic_generation_config.semantic_pad_token,
coarse_generation_config.coarse_semantic_pad_token,
)
semantic_to_coarse_ratio = (
coarse_generation_config.coarse_rate_hz
/ semantic_generation_config.semantic_rate_hz
* coarse_generation_config.n_coarse_codebooks
)
max_semantic_history = int(np.floor(max_coarse_history / semantic_to_coarse_ratio))
output_lengths = (semantic_output != coarse_generation_config.coarse_semantic_pad_token).sum(1)
output_lengths = torch.floor(
output_lengths * semantic_to_coarse_ratio / coarse_generation_config.n_coarse_codebooks
)
output_lengths = torch.round(output_lengths * coarse_generation_config.n_coarse_codebooks).int()
max_generated_len = torch.max(output_lengths).item()
batch_size = semantic_output.shape[0]
x_semantic_history, x_coarse = self.preprocess_histories(
history_prompt=history_prompt,
max_coarse_history=max_coarse_history,
semantic_to_coarse_ratio=semantic_to_coarse_ratio,
batch_size=batch_size,
semantic_generation_config=semantic_generation_config,
codebook_size=codebook_size,
)
base_semantic_idx = x_semantic_history.shape[1]
semantic_output = torch.hstack([x_semantic_history, semantic_output])
n_window_steps = int(np.ceil(max_generated_len / sliding_window_len))
total_generated_len = 0
len_coarse_history = x_coarse.shape[1]
for _ in range(n_window_steps):
semantic_idx = base_semantic_idx + int(round(total_generated_len / semantic_to_coarse_ratio))
# pad from right side
input_coarse = semantic_output[:, np.max([0, semantic_idx - max_semantic_history]) :]
input_coarse = input_coarse[:, :max_coarse_input_length]
input_coarse = F.pad(
input_coarse,
(0, max_coarse_input_length - input_coarse.shape[-1]),
"constant",
coarse_generation_config.coarse_semantic_pad_token,
)
input_coarse = torch.hstack(
[
input_coarse,
torch.tensor([[coarse_generation_config.coarse_infer_token]] * batch_size).to(self.device),
x_coarse[:, -max_coarse_history:],
]
)
alternatingLogitsProcessor = AlternatingCodebooksLogitsProcessor(
input_coarse.shape[1],
semantic_generation_config.semantic_vocab_size,
codebook_size,
)
output_coarse = super().generate(
input_coarse,
logits_processor=[alternatingLogitsProcessor],
max_new_tokens=min(sliding_window_len, max_generated_len - total_generated_len),
generation_config=coarse_generation_config,
**kwargs,
)
input_coarse_len = input_coarse.shape[1]
x_coarse = torch.hstack([x_coarse, output_coarse[:, input_coarse_len:]])
total_generated_len = x_coarse.shape[1] - len_coarse_history
del output_coarse
coarse_output = x_coarse[:, len_coarse_history:]
if return_output_lengths:
return coarse_output, output_lengths
return coarse_output
@add_start_docstrings(
"""Bark fine acoustics model. It is a non-causal GPT-like model with `config.n_codes_total` embedding layers and
language modeling heads, one for each codebook.""",
BARK_MODEL_START_DOCSTRING.format(config="BarkFineConfig"),
)
class BarkFineModel(BarkPreTrainedModel):
base_model_prefix = "fine_acoustics"
config_class = BarkFineConfig
main_input_name = "codebook_idx"
def __init__(self, config):
# non-causal gpt-like model with one embedding layer and one lm_head for each codebook of Encodec
super().__init__(config)
self.config = config
# initialize a modified non causal GPT-like model
# note that for there is one embedding layer and one lm_head for each codebook of Encodec
self.input_embeds_layers = nn.ModuleList(
[nn.Embedding(config.input_vocab_size, config.hidden_size) for _ in range(config.n_codes_total)]
)
self.position_embeds_layer = nn.Embedding(config.block_size, config.hidden_size)
self.drop = nn.Dropout(config.dropout)
self.layers = nn.ModuleList([BarkBlock(config, is_causal=False) for _ in range(config.num_layers)])
self._use_flash_attention_2 = config._attn_implementation == "flash_attention_2"
self.layernorm_final = nn.LayerNorm(config.hidden_size)
self.lm_heads = nn.ModuleList(
[
nn.Linear(config.hidden_size, config.output_vocab_size, bias=False)
for _ in range(config.n_codes_given, config.n_codes_total)
]
)
self.gradient_checkpointing = False
self.n_codes_total = config.n_codes_total
# Initialize weights and apply final processing
self.post_init()
def get_input_embeddings(self):
# one embedding layers for each codebook
return self.input_embeds_layers
def set_input_embeddings(self, new_embeddings):
# one embedding layers for each codebook
self.input_embeds_layers = new_embeddings
def get_output_embeddings(self):
# one lm_head for each codebook
return self.lm_heads
def set_output_embeddings(self, new_output_embeddings):
# one lm_head for each codebook
self.lm_heads = new_output_embeddings
def _resize_token_embeddings(self, new_num_tokens, pad_to_multiple_of=None):
old_embeddings_list = self.get_input_embeddings()
new_embeddings_list = nn.ModuleList(
[
self._get_resized_embeddings(old_embeddings, new_num_tokens, pad_to_multiple_of)
for old_embeddings in old_embeddings_list
]
)
self.set_input_embeddings(new_embeddings_list)
new_num_tokens = new_embeddings_list[0].weight.shape[0]
# if word embeddings are not tied, make sure that lm head is resized as well
if self.get_output_embeddings() is not None and not self.config.tie_word_embeddings:
old_lm_head_list = self.get_output_embeddings()
new_lm_head_list = nn.ModuleList(
[self._get_resized_lm_head(old_lm_head, new_num_tokens) for old_lm_head in old_lm_head_list]
)
self.set_output_embeddings(new_lm_head_list)
return self.get_input_embeddings()
def resize_token_embeddings(
self, new_num_tokens: Optional[int] = None, pad_to_multiple_of: Optional[int] = None
) -> nn.Embedding:
"""
Resizes input token embeddings matrix of the model if `new_num_tokens != config.vocab_size`.
Takes care of tying weights embeddings afterwards if the model class has a `tie_weights()` method.
Arguments:
new_num_tokens (`int`, *optional*):
The number of new tokens in the embedding matrix. Increasing the size will add newly initialized
vectors at the end. Reducing the size will remove vectors from the end. If not provided or `None`, just
returns a pointer to the input tokens `torch.nn.Embedding` module of the model without doing anything.
pad_to_multiple_of (`int`, *optional*):
If set will pad the embedding matrix to a multiple of the provided value.
This is especially useful to enable the use of Tensor Cores on NVIDIA hardware with compute capability
`>= 7.5` (Volta), or on TPUs which benefit from having sequence lengths be a multiple of 128. For more
details about this, or help on choosing the correct value for resizing, refer to this guide:
https://docs.nvidia.com/deeplearning/performance/dl-performance-matrix-multiplication/index.html#requirements-tc
Return:
`torch.nn.Embedding`: Pointer to the input tokens Embeddings Module of the model.
"""
model_embeds = self._resize_token_embeddings(new_num_tokens, pad_to_multiple_of)
if new_num_tokens is None and pad_to_multiple_of is None:
return model_embeds
# Update base model and current model config
self.config.output_vocab_size = model_embeds[0].weight.shape[0]
self.config.vocab_size = model_embeds[0].weight.shape[0]
self.output_vocab_size = model_embeds[0].weight.shape[0]
self.vocab_size = model_embeds[0].weight.shape[0]
# Tie weights again if needed
self.tie_weights()
return model_embeds
def tie_weights(self):
"""
Tie the weights between the input embeddings list and the output embeddings list.
If the `torchscript` flag is set in the configuration, can't handle parameter sharing so we are cloning the
weights instead.
"""
if getattr(self.config, "tie_word_embeddings", True):
self._tied_weights_keys = []
output_embeddings = self.get_output_embeddings()
input_embeddings = self.get_input_embeddings()
for i in range(self.config.n_codes_total - self.config.n_codes_given):
# self.input_embeds_layers[i + 1].weight = self.lm_heads[i].weight
self._tie_or_clone_weights(output_embeddings[i], input_embeddings[i + 1])
self._tied_weights_keys.append(f"lm_heads.{i}.weight")
for module in self.modules():
if hasattr(module, "_tie_weights"):
module._tie_weights()
@add_start_docstrings_to_model_forward(BARK_FINE_INPUTS_DOCSTRING)
def forward(
self,
codebook_idx: int, # an additionnal idx corresponding to the id of the codebook that will be predicted
input_ids: Optional[torch.Tensor] = None,
attention_mask: Optional[torch.Tensor] = None,
position_ids: Optional[torch.Tensor] = None,
head_mask: Optional[torch.Tensor] = None,
labels: Optional[torch.LongTensor] = None,
input_embeds: Optional[torch.Tensor] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
) -> Union[Tuple[torch.Tensor], MaskedLMOutput]:
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
output_hidden_states = (
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
)
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
if codebook_idx == 0:
raise ValueError("Cannot predict 0th codebook - 0th codebook should be predicted by the coarse model")
if input_ids is not None and input_embeds is not None:
raise ValueError("You cannot specify both input_ids and input_embeds at the same time")
if input_ids is None and input_embeds is None:
raise ValueError("You have to specify either input_ids or input_embeds")
if input_ids is not None:
# the input_embeddings are the sum of the j previous codebooks embeddings before
# the current codebook_idx codebook
# forward the GPT model itself
input_embeds = [
input_embeds_layer(input_ids[:, :, i]).unsqueeze(-1)
for i, input_embeds_layer in enumerate(self.input_embeds_layers)
] # token embeddings of shape (b, t, n_embd)
input_embeds = torch.cat(input_embeds, dim=-1)
input_embeds = input_embeds[:, :, :, : codebook_idx + 1].sum(dim=-1)
input_shape = input_embeds.size()[:-1]
batch_size = input_embeds.shape[0]
seq_length = input_shape[1]
device = input_ids.device if input_ids is not None else input_embeds.device
if position_ids is None:
position_ids = torch.arange(0, seq_length, dtype=torch.long, device=device)
position_ids = position_ids.unsqueeze(0) # shape (1, seq_length)
position_embeds = self.position_embeds_layer(position_ids) # position embeddings of shape (1, t, n_embd)
# Attention mask.
if attention_mask is not None:
if batch_size <= 0:
raise ValueError("batch_size has to be defined and > 0")
if self._use_flash_attention_2:
attention_mask = attention_mask if 0 in attention_mask else None
else:
# [bsz, to_seq_length] -> [bsz, 1, 1, to_seq_length]
# from_seq_length is 1 to easily broadcast
attention_mask = _prepare_4d_attention_mask(attention_mask, input_embeds.dtype, tgt_len=1)
head_mask = self.get_head_mask(head_mask, self.config.num_layers)
hidden_states = self.drop(input_embeds + position_embeds)
output_shape = input_shape + (hidden_states.size(-1),)
all_self_attentions = () if output_attentions else None
all_hidden_states = () if output_hidden_states else None
for i, block in enumerate(self.layers):
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
outputs = block(
hidden_states,
attention_mask=attention_mask,
head_mask=head_mask[i],
output_attentions=output_attentions,
)
hidden_states = outputs[0]
if output_attentions:
all_self_attentions = all_self_attentions + (outputs[1],)
hidden_states = self.layernorm_final(hidden_states)
hidden_states = hidden_states.view(output_shape)
# Add last hidden state
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
logits = self.lm_heads[codebook_idx - self.config.n_codes_given](hidden_states)
loss = None
if labels is not None:
raise NotImplementedError("Training is not implemented yet")
if not return_dict:
return tuple(v for v in [None, logits, all_hidden_states, all_self_attentions] if v is not None)
return MaskedLMOutput(
loss=loss,
logits=logits,
hidden_states=all_hidden_states,
attentions=all_self_attentions,
)
def generate(
self,
coarse_output: torch.Tensor,
semantic_generation_config: BarkSemanticGenerationConfig = None,
coarse_generation_config: BarkCoarseGenerationConfig = None,
fine_generation_config: BarkFineGenerationConfig = None,
codebook_size: int = 1024,
history_prompt: Optional[Dict[str, torch.Tensor]] = None,
**kwargs,
) -> torch.LongTensor:
"""
Generates fine acoustics tokens from input coarse acoustics tokens and an additional optional `Bark` speaker
prompt.
Args:
coarse_output (`torch.Tensor` of shape (batch_size, seq_len)):
Input coarse acoustics ids, i.e the output of `BarkCoarseModel.generate`.
semantic_generation_config (`BarkSemanticGenerationConfig`):
Generation config indicating how to generate the semantic tokens.
coarse_generation_config (`BarkCoarseGenerationConfig`):
Generation config indicating how to generate the coarse tokens.
fine_generation_config (`BarkFineGenerationConfig`):
Generation config indicating how to generate the fine tokens.
codebook_size (`int`, *optional*, defaults to 1024):
Codebook channel size, i.e. the size of the output vocabulary per codebook channel.
history_prompt (`Optional[Dict[str,torch.Tensor]]`, *optional*):
Optional `Bark` speaker prompt.
Returns:
torch.LongTensor: Output fine acoustics tokens.
"""
if semantic_generation_config is None:
raise ValueError("`semantic_generation_config` has to be provided")
if coarse_generation_config is None:
raise ValueError("`coarse_generation_config` has to be provided")
if fine_generation_config is None:
raise ValueError("`fine_generation_config` has to be provided")
# since we don't really use GenerationConfig through the fine model (autoencoder)
# and since only temperature is used from the classic GenerationConfig parameters
# manually impose the kwargs priority over the generation config
temperature = kwargs.get("temperature", fine_generation_config.temperature)
max_fine_history_length = fine_generation_config.max_fine_history_length
max_fine_input_length = fine_generation_config.max_fine_input_length
# shape: (batch, n_coarse_codebooks * seq_len)
# new_shape: (batch, seq_len, n_coarse_codebooks)
coarse_output = coarse_output.view(coarse_output.shape[0], -1, coarse_generation_config.n_coarse_codebooks)
# brings ids into the range [0, codebook_size -1]
coarse_output = torch.remainder(coarse_output - semantic_generation_config.semantic_vocab_size, codebook_size)
batch_size = coarse_output.shape[0]
if history_prompt is not None:
x_fine_history = torch.repeat_interleave(history_prompt["fine_prompt"].T[None], batch_size, dim=0)
# transpose to get to shape (seq_len, n_fine_codebooks)
else:
x_fine_history = None
n_coarse = coarse_generation_config.n_coarse_codebooks
# pad the last 6th codebooks
fine_input = F.pad(
coarse_output,
(0, fine_generation_config.n_fine_codebooks - n_coarse),
"constant",
codebook_size,
)
# prepend history if available (max max_fine_history_length)
if x_fine_history is not None:
fine_input = torch.cat([x_fine_history[:, -max_fine_history_length:, :], fine_input], dim=1)
# len of the fine_history that has been added to fine_input
n_history = x_fine_history[:, -max_fine_history_length:, :].shape[1]
else:
n_history = 0
n_remove_from_end = 0
# need to pad if too short (since non-causal model)
if fine_input.shape[1] < max_fine_input_length:
n_remove_from_end = max_fine_input_length - fine_input.shape[1]
fine_input = F.pad(fine_input, (0, 0, 0, n_remove_from_end), mode="constant", value=codebook_size)
# we can be lazy about fractional loop and just keep overwriting codebooks.
# seems that coarse_output.shape[1] - (max_fine_input_length - n_history) is equal to minus n_remove_from_end
# So if we needed to pad because too short, n_loops is always 1 (because n_remove_from_end > 0)
# If not, we loop over at least twice.
n_loops = (coarse_output.shape[1] - (max_fine_input_length - n_history)) / max_fine_history_length
n_loops = int(np.ceil(n_loops))
n_loops = max(0, n_loops) + 1
for n_outer in range(n_loops):
start_idx = min([n_outer * max_fine_history_length, fine_input.shape[1] - max_fine_input_length])
start_fill_idx = min(
[n_history + n_outer * max_fine_history_length, fine_input.shape[1] - max_fine_history_length]
)
rel_start_fill_idx = start_fill_idx - start_idx
input_buffer = fine_input[:, start_idx : start_idx + max_fine_input_length, :]
for n_inner in range(n_coarse, fine_generation_config.n_fine_codebooks):
logits = self.forward(n_inner, input_buffer).logits
if temperature is None or temperature == 1.0:
relevant_logits = logits[:, rel_start_fill_idx:, :codebook_size]
codebook_preds = torch.argmax(relevant_logits, -1)
else:
relevant_logits = logits[:, :, :codebook_size] / temperature
# apply softmax
probs = F.softmax(relevant_logits, dim=-1)[:, rel_start_fill_idx:max_fine_input_length]
# reshape to 2D: (batch_size, seq_len, codebook_size) -> (batch_size*seq_len, codebook_size)
probs = probs.reshape((-1, codebook_size))
# multinomial then reshape : (batch_size*seq_len)-> (batch_size,seq_len)
codebook_preds = torch.multinomial(probs, num_samples=1).view(batch_size, -1)
codebook_preds = codebook_preds.to(torch.int32)
input_buffer[:, rel_start_fill_idx:, n_inner] = codebook_preds
del logits, codebook_preds
# transfer into fine_input
for n_inner in range(n_coarse, fine_generation_config.n_fine_codebooks):
fine_input[
:, start_fill_idx : start_fill_idx + (max_fine_input_length - rel_start_fill_idx), n_inner
] = input_buffer[:, rel_start_fill_idx:, n_inner]
del input_buffer
fine_input = fine_input.transpose(1, 2)[:, :, n_history:]
if n_remove_from_end > 0:
fine_input = fine_input[:, :, :-n_remove_from_end]
if fine_input.shape[-1] != coarse_output.shape[-2]:
raise ValueError("input and output should have the same seq_len")
return fine_input
@add_start_docstrings(
"""
The full Bark model, a text-to-speech model composed of 4 sub-models:
- [`BarkSemanticModel`] (also referred to as the 'text' model): a causal auto-regressive transformer model that
takes
as input tokenized text, and predicts semantic text tokens that capture the meaning of the text.
- [`BarkCoarseModel`] (also refered to as the 'coarse acoustics' model), also a causal autoregressive transformer,
that takes into input the results of the last model. It aims at regressing the first two audio codebooks necessary
to `encodec`.
- [`BarkFineModel`] (the 'fine acoustics' model), this time a non-causal autoencoder transformer, which iteratively
predicts the last codebooks based on the sum of the previous codebooks embeddings.
- having predicted all the codebook channels from the [`EncodecModel`], Bark uses it to decode the output audio
array.
It should be noted that each of the first three modules can support conditional speaker embeddings to condition the
output sound according to specific predefined voice.
""",
BARK_START_DOCSTRING,
)
class BarkModel(BarkPreTrainedModel):
config_class = BarkConfig
def __init__(self, config):
super().__init__(config)
self.semantic = BarkSemanticModel(config.semantic_config)
self.coarse_acoustics = BarkCoarseModel(config.coarse_acoustics_config)
self.fine_acoustics = BarkFineModel(config.fine_acoustics_config)
self.codec_model = AutoModel.from_config(config.codec_config)
self.config = config
@property
def device(self) -> torch.device:
"""
`torch.device`: The device on which the module is (assuming that all the module parameters are on the same
device).
"""
# for bark_model, device must be verified on its sub-models
# if has _hf_hook, has been offloaded so the device has to be found in the hook
if not hasattr(self.semantic, "_hf_hook"):
return get_parameter_device(self)
for module in self.semantic.modules():
if (
hasattr(module, "_hf_hook")
and hasattr(module._hf_hook, "execution_device")
and module._hf_hook.execution_device is not None
):
return torch.device(module._hf_hook.execution_device)
def enable_cpu_offload(self, gpu_id: Optional[int] = 0):
r"""
Offloads all sub-models to CPU using accelerate, reducing memory usage with a low impact on performance. This
method moves one whole sub-model at a time to the GPU when it is used, and the sub-model remains in GPU until
the next sub-model runs.
Args:
gpu_id (`int`, *optional*, defaults to 0):
GPU id on which the sub-models will be loaded and offloaded.
"""
if is_accelerate_available():
from accelerate import cpu_offload_with_hook
else:
raise ImportError("`enable_model_cpu_offload` requires `accelerate`.")
device = torch.device(f"cuda:{gpu_id}")
if self.device.type != "cpu":
self.to("cpu")
torch.cuda.empty_cache() # otherwise we don't see the memory savings (but they probably exist)
# this layer is used outside the first foward pass of semantic so need to be loaded before semantic
self.semantic.input_embeds_layer, _ = cpu_offload_with_hook(self.semantic.input_embeds_layer, device)
hook = None
for cpu_offloaded_model in [
self.semantic,
self.coarse_acoustics,
self.fine_acoustics,
]:
_, hook = cpu_offload_with_hook(cpu_offloaded_model, device, prev_module_hook=hook)
self.fine_acoustics_hook = hook
_, hook = cpu_offload_with_hook(self.codec_model, device, prev_module_hook=hook)
# We'll offload the last model manually.
self.codec_model_hook = hook
def codec_decode(self, fine_output, output_lengths=None):
"""Turn quantized audio codes into audio array using encodec."""
fine_output = fine_output.transpose(0, 1)
emb = self.codec_model.quantizer.decode(fine_output)
if output_lengths is not None:
# encodec uses LSTMs which behaves differently with appended padding
# decoding with encodec takes around 0.1% of the total generation time
# to keep generation quality, we break batching
out = [sample[:, :l].unsqueeze(0) for (sample, l) in zip(emb, output_lengths)]
audio_arr = [self.codec_model.decoder(sample).squeeze() for sample in out]
else:
out = self.codec_model.decoder(emb)
audio_arr = out.squeeze(1) # squeeze the codebook dimension
return audio_arr
@torch.no_grad()
def generate(
self,
input_ids: Optional[torch.Tensor] = None,
history_prompt: Optional[Dict[str, torch.Tensor]] = None,
return_output_lengths: Optional[bool] = None,
**kwargs,
) -> torch.LongTensor:
"""
Generates audio from an input prompt and an additional optional `Bark` speaker prompt.
Args:
input_ids (`Optional[torch.Tensor]` of shape (batch_size, seq_len), *optional*):
Input ids. Will be truncated up to 256 tokens. Note that the output audios will be as long as the
longest generation among the batch.
history_prompt (`Optional[Dict[str,torch.Tensor]]`, *optional*):
Optional `Bark` speaker prompt. Note that for now, this model takes only one speaker prompt per batch.
kwargs (*optional*): Remaining dictionary of keyword arguments. Keyword arguments are of two types:
- Without a prefix, they will be entered as `**kwargs` for the `generate` method of each sub-model.
- With a *semantic_*, *coarse_*, *fine_* prefix, they will be input for the `generate` method of the
semantic, coarse and fine respectively. It has the priority over the keywords without a prefix.
This means you can, for example, specify a generation strategy for all sub-models except one.
return_output_lengths (`bool`, *optional*):
Whether or not to return the waveform lengths. Useful when batching.
Returns:
By default:
- **audio_waveform** (`torch.Tensor` of shape (batch_size, seq_len)): Generated audio waveform.
When `return_output_lengths=True`:
Returns a tuple made of:
- **audio_waveform** (`torch.Tensor` of shape (batch_size, seq_len)): Generated audio waveform.
- **output_lengths** (`torch.Tensor` of shape (batch_size)): The length of each waveform in the batch
Example:
```python
>>> from transformers import AutoProcessor, BarkModel
>>> processor = AutoProcessor.from_pretrained("suno/bark-small")
>>> model = BarkModel.from_pretrained("suno/bark-small")
>>> # To add a voice preset, you can pass `voice_preset` to `BarkProcessor.__call__(...)`
>>> voice_preset = "v2/en_speaker_6"
>>> inputs = processor("Hello, my dog is cute, I need him in my life", voice_preset=voice_preset)
>>> audio_array = model.generate(**inputs, semantic_max_new_tokens=100)
>>> audio_array = audio_array.cpu().numpy().squeeze()
```
"""
# TODO (joao):workaround until nested generation config is compatible with PreTrained Model
# todo: dict
semantic_generation_config = BarkSemanticGenerationConfig(**self.generation_config.semantic_config)
coarse_generation_config = BarkCoarseGenerationConfig(**self.generation_config.coarse_acoustics_config)
fine_generation_config = BarkFineGenerationConfig(**self.generation_config.fine_acoustics_config)
kwargs_semantic = {
# if "attention_mask" is set, it should not be passed to CoarseModel and FineModel
"attention_mask": kwargs.pop("attention_mask", None),
"min_eos_p": kwargs.pop("min_eos_p", None),
}
kwargs_coarse = {}
kwargs_fine = {}
for key, value in kwargs.items():
if key.startswith("semantic_"):
key = key[len("semantic_") :]
kwargs_semantic[key] = value
elif key.startswith("coarse_"):
key = key[len("coarse_") :]
kwargs_coarse[key] = value
elif key.startswith("fine_"):
key = key[len("fine_") :]
kwargs_fine[key] = value
else:
# If the key is already in a specific config, then it's been set with a
# submodules specific value and we don't override
if key not in kwargs_semantic:
kwargs_semantic[key] = value
if key not in kwargs_coarse:
kwargs_coarse[key] = value
if key not in kwargs_fine:
kwargs_fine[key] = value
# 1. Generate from the semantic model
semantic_output = self.semantic.generate(
input_ids,
history_prompt=history_prompt,
semantic_generation_config=semantic_generation_config,
**kwargs_semantic,
)
# 2. Generate from the coarse model
coarse_output = self.coarse_acoustics.generate(
semantic_output,
history_prompt=history_prompt,
semantic_generation_config=semantic_generation_config,
coarse_generation_config=coarse_generation_config,
codebook_size=self.generation_config.codebook_size,
return_output_lengths=return_output_lengths,
**kwargs_coarse,
)
output_lengths = None
if return_output_lengths:
coarse_output, output_lengths = coarse_output
# (batch_size, seq_len*coarse_codebooks) -> (batch_size, seq_len)
output_lengths = output_lengths // coarse_generation_config.n_coarse_codebooks
# 3. "generate" from the fine model
output = self.fine_acoustics.generate(
coarse_output,
history_prompt=history_prompt,
semantic_generation_config=semantic_generation_config,
coarse_generation_config=coarse_generation_config,
fine_generation_config=fine_generation_config,
codebook_size=self.generation_config.codebook_size,
**kwargs_fine,
)
if getattr(self, "fine_acoustics_hook", None) is not None:
# Manually offload fine_acoustics to CPU
# and load codec_model to GPU
# since bark doesn't use codec_model forward pass
self.fine_acoustics_hook.offload()
self.codec_model = self.codec_model.to(self.device)
# 4. Decode the output and generate audio array
audio = self.codec_decode(output, output_lengths)
if getattr(self, "codec_model_hook", None) is not None:
# Offload codec_model to CPU
self.codec_model_hook.offload()
if return_output_lengths:
output_lengths = [len(sample) for sample in audio]
audio = nn.utils.rnn.pad_sequence(audio, batch_first=True, padding_value=0)
return audio, output_lengths
return audio
@classmethod
def _check_and_enable_flash_attn_2(
cls,
config,
torch_dtype: Optional[torch.dtype] = None,
device_map: Optional[Union[str, Dict[str, int]]] = None,
hard_check_only: bool = False,
):
"""
`_check_and_enable_flash_attn_2` originally don't expand flash attention enabling to the model
sub-configurations. We override the original method to make sure that Bark sub-models are using Flash Attention
if necessary.
If you don't know about Flash Attention, check out the official repository of flash attention:
https://github.com/Dao-AILab/flash-attention
For using Flash Attention 1.0 you can do it directly via the `BetterTransformer` API, have a look at this
specific section of the documentation to learn more about it:
https://huggingface.co/docs/transformers/main/en/perf_infer_gpu_one#decoder-models
The method checks if the current setup is compatible with Flash Attention as it requires the model to be in
half precision and not ran on CPU.
If all checks pass and `hard_check_only` is False, the method will set the config attribute `_attn_implementation` to "flash_attention_2" so that the model
can initialize the correct attention module
"""
config = super()._check_and_enable_flash_attn_2(
config, torch_dtype, device_map, hard_check_only=hard_check_only
)
config.semantic_config._attn_implementation = config._attn_implementation
config.coarse_acoustics_config._attn_implementation = config._attn_implementation
config.fine_acoustics_config._attn_implementation = config._attn_implementation
return config
| transformers/src/transformers/models/bark/modeling_bark.py/0 | {
"file_path": "transformers/src/transformers/models/bark/modeling_bark.py",
"repo_id": "transformers",
"token_count": 37224
} | 70 |
# coding=utf-8
# Copyright Microsoft Research and The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
""" BEiT model configuration"""
from collections import OrderedDict
from typing import Mapping
from packaging import version
from ...configuration_utils import PretrainedConfig
from ...onnx import OnnxConfig
from ...utils import logging
from ...utils.backbone_utils import BackboneConfigMixin, get_aligned_output_features_output_indices
logger = logging.get_logger(__name__)
BEIT_PRETRAINED_CONFIG_ARCHIVE_MAP = {
"microsoft/beit-base-patch16-224-pt22k": (
"https://huggingface.co/microsoft/beit-base-patch16-224-pt22k/resolve/main/config.json"
),
# See all BEiT models at https://huggingface.co/models?filter=beit
}
class BeitConfig(BackboneConfigMixin, PretrainedConfig):
r"""
This is the configuration class to store the configuration of a [`BeitModel`]. It is used to instantiate an BEiT
model according to the specified arguments, defining the model architecture. Instantiating a configuration with the
defaults will yield a similar configuration to that of the BEiT
[microsoft/beit-base-patch16-224-pt22k](https://huggingface.co/microsoft/beit-base-patch16-224-pt22k) architecture.
Args:
vocab_size (`int`, *optional*, defaults to 8192):
Vocabulary size of the BEiT model. Defines the number of different image tokens that can be used during
pre-training.
hidden_size (`int`, *optional*, defaults to 768):
Dimensionality of the encoder layers and the pooler layer.
num_hidden_layers (`int`, *optional*, defaults to 12):
Number of hidden layers in the Transformer encoder.
num_attention_heads (`int`, *optional*, defaults to 12):
Number of attention heads for each attention layer in the Transformer encoder.
intermediate_size (`int`, *optional*, defaults to 3072):
Dimensionality of the "intermediate" (i.e., feed-forward) layer in the Transformer encoder.
hidden_act (`str` or `function`, *optional*, defaults to `"gelu"`):
The non-linear activation function (function or string) in the encoder and pooler. If string, `"gelu"`,
`"relu"`, `"selu"` and `"gelu_new"` are supported.
hidden_dropout_prob (`float`, *optional*, defaults to 0.0):
The dropout probability for all fully connected layers in the embeddings, encoder, and pooler.
attention_probs_dropout_prob (`float`, *optional*, defaults to 0.0):
The dropout ratio for the attention probabilities.
initializer_range (`float`, *optional*, defaults to 0.02):
The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
layer_norm_eps (`float`, *optional*, defaults to 1e-12):
The epsilon used by the layer normalization layers.
image_size (`int`, *optional*, defaults to 224):
The size (resolution) of each image.
patch_size (`int`, *optional*, defaults to 16):
The size (resolution) of each patch.
num_channels (`int`, *optional*, defaults to 3):
The number of input channels.
use_mask_token (`bool`, *optional*, defaults to `False`):
Whether to use a mask token for masked image modeling.
use_absolute_position_embeddings (`bool`, *optional*, defaults to `False`):
Whether to use BERT-style absolute position embeddings.
use_relative_position_bias (`bool`, *optional*, defaults to `False`):
Whether to use T5-style relative position embeddings in the self-attention layers.
use_shared_relative_position_bias (`bool`, *optional*, defaults to `False`):
Whether to use the same relative position embeddings across all self-attention layers of the Transformer.
layer_scale_init_value (`float`, *optional*, defaults to 0.1):
Scale to use in the self-attention layers. 0.1 for base, 1e-5 for large. Set 0 to disable layer scale.
drop_path_rate (`float`, *optional*, defaults to 0.1):
Stochastic depth rate per sample (when applied in the main path of residual layers).
use_mean_pooling (`bool`, *optional*, defaults to `True`):
Whether to mean pool the final hidden states of the patches instead of using the final hidden state of the
CLS token, before applying the classification head.
pool_scales (`Tuple[int]`, *optional*, defaults to `[1, 2, 3, 6]`):
Pooling scales used in Pooling Pyramid Module applied on the last feature map.
use_auxiliary_head (`bool`, *optional*, defaults to `True`):
Whether to use an auxiliary head during training.
auxiliary_loss_weight (`float`, *optional*, defaults to 0.4):
Weight of the cross-entropy loss of the auxiliary head.
auxiliary_channels (`int`, *optional*, defaults to 256):
Number of channels to use in the auxiliary head.
auxiliary_num_convs (`int`, *optional*, defaults to 1):
Number of convolutional layers to use in the auxiliary head.
auxiliary_concat_input (`bool`, *optional*, defaults to `False`):
Whether to concatenate the output of the auxiliary head with the input before the classification layer.
semantic_loss_ignore_index (`int`, *optional*, defaults to 255):
The index that is ignored by the loss function of the semantic segmentation model.
out_features (`List[str]`, *optional*):
If used as backbone, list of features to output. Can be any of `"stem"`, `"stage1"`, `"stage2"`, etc.
(depending on how many stages the model has). If unset and `out_indices` is set, will default to the
corresponding stages. If unset and `out_indices` is unset, will default to the last stage. Must be in the
same order as defined in the `stage_names` attribute.
out_indices (`List[int]`, *optional*):
If used as backbone, list of indices of features to output. Can be any of 0, 1, 2, etc. (depending on how
many stages the model has). If unset and `out_features` is set, will default to the corresponding stages.
If unset and `out_features` is unset, will default to the last stage. Must be in the
same order as defined in the `stage_names` attribute.
add_fpn (`bool`, *optional*, defaults to `False`):
Whether to add a FPN as part of the backbone. Only relevant for [`BeitBackbone`].
reshape_hidden_states (`bool`, *optional*, defaults to `True`):
Whether to reshape the feature maps to 4D tensors of shape `(batch_size, hidden_size, height, width)` in
case the model is used as backbone. If `False`, the feature maps will be 3D tensors of shape `(batch_size,
seq_len, hidden_size)`. Only relevant for [`BeitBackbone`].
Example:
```python
>>> from transformers import BeitConfig, BeitModel
>>> # Initializing a BEiT beit-base-patch16-224-pt22k style configuration
>>> configuration = BeitConfig()
>>> # Initializing a model (with random weights) from the beit-base-patch16-224-pt22k style configuration
>>> model = BeitModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.config
```"""
model_type = "beit"
def __init__(
self,
vocab_size=8192,
hidden_size=768,
num_hidden_layers=12,
num_attention_heads=12,
intermediate_size=3072,
hidden_act="gelu",
hidden_dropout_prob=0.0,
attention_probs_dropout_prob=0.0,
initializer_range=0.02,
layer_norm_eps=1e-12,
image_size=224,
patch_size=16,
num_channels=3,
use_mask_token=False,
use_absolute_position_embeddings=False,
use_relative_position_bias=False,
use_shared_relative_position_bias=False,
layer_scale_init_value=0.1,
drop_path_rate=0.1,
use_mean_pooling=True,
pool_scales=[1, 2, 3, 6],
use_auxiliary_head=True,
auxiliary_loss_weight=0.4,
auxiliary_channels=256,
auxiliary_num_convs=1,
auxiliary_concat_input=False,
semantic_loss_ignore_index=255,
out_features=None,
out_indices=None,
add_fpn=False,
reshape_hidden_states=True,
**kwargs,
):
super().__init__(**kwargs)
self.vocab_size = vocab_size
self.hidden_size = hidden_size
self.num_hidden_layers = num_hidden_layers
self.num_attention_heads = num_attention_heads
self.intermediate_size = intermediate_size
self.hidden_act = hidden_act
self.hidden_dropout_prob = hidden_dropout_prob
self.attention_probs_dropout_prob = attention_probs_dropout_prob
self.initializer_range = initializer_range
self.layer_norm_eps = layer_norm_eps
self.image_size = image_size
self.patch_size = patch_size
self.num_channels = num_channels
self.use_mask_token = use_mask_token
self.use_absolute_position_embeddings = use_absolute_position_embeddings
self.use_relative_position_bias = use_relative_position_bias
self.use_shared_relative_position_bias = use_shared_relative_position_bias
self.layer_scale_init_value = layer_scale_init_value
self.drop_path_rate = drop_path_rate
self.use_mean_pooling = use_mean_pooling
# decode head attributes (semantic segmentation)
self.pool_scales = pool_scales
# auxiliary head attributes (semantic segmentation)
self.use_auxiliary_head = use_auxiliary_head
self.auxiliary_loss_weight = auxiliary_loss_weight
self.auxiliary_channels = auxiliary_channels
self.auxiliary_num_convs = auxiliary_num_convs
self.auxiliary_concat_input = auxiliary_concat_input
self.semantic_loss_ignore_index = semantic_loss_ignore_index
# handle backwards compatibility
if "segmentation_indices" in kwargs:
logger.warning(
"The `segmentation_indices` argument is deprecated and will be removed in a future version, use `out_indices` instead.",
FutureWarning,
)
out_indices = kwargs.pop("segmentation_indices")
# backbone attributes
self.stage_names = ["stem"] + [f"stage{idx}" for idx in range(1, self.num_hidden_layers + 1)]
self._out_features, self._out_indices = get_aligned_output_features_output_indices(
out_features=out_features, out_indices=out_indices, stage_names=self.stage_names
)
self.add_fpn = add_fpn
self.reshape_hidden_states = reshape_hidden_states
# Copied from transformers.models.vit.configuration_vit.ViTOnnxConfig
class BeitOnnxConfig(OnnxConfig):
torch_onnx_minimum_version = version.parse("1.11")
@property
def inputs(self) -> Mapping[str, Mapping[int, str]]:
return OrderedDict(
[
("pixel_values", {0: "batch", 1: "num_channels", 2: "height", 3: "width"}),
]
)
@property
def atol_for_validation(self) -> float:
return 1e-4
| transformers/src/transformers/models/beit/configuration_beit.py/0 | {
"file_path": "transformers/src/transformers/models/beit/configuration_beit.py",
"repo_id": "transformers",
"token_count": 4551
} | 71 |
# coding=utf-8
# Copyright 2018 The Google AI Language Team Authors and The HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""Fast Tokenization classes for Bert."""
import json
from typing import List, Optional, Tuple
from tokenizers import normalizers
from ...tokenization_utils_fast import PreTrainedTokenizerFast
from ...utils import logging
from .tokenization_bert import BertTokenizer
logger = logging.get_logger(__name__)
VOCAB_FILES_NAMES = {"vocab_file": "vocab.txt", "tokenizer_file": "tokenizer.json"}
PRETRAINED_VOCAB_FILES_MAP = {
"vocab_file": {
"google-bert/bert-base-uncased": "https://huggingface.co/google-bert/bert-base-uncased/resolve/main/vocab.txt",
"google-bert/bert-large-uncased": "https://huggingface.co/google-bert/bert-large-uncased/resolve/main/vocab.txt",
"google-bert/bert-base-cased": "https://huggingface.co/google-bert/bert-base-cased/resolve/main/vocab.txt",
"google-bert/bert-large-cased": "https://huggingface.co/google-bert/bert-large-cased/resolve/main/vocab.txt",
"google-bert/bert-base-multilingual-uncased": (
"https://huggingface.co/google-bert/bert-base-multilingual-uncased/resolve/main/vocab.txt"
),
"google-bert/bert-base-multilingual-cased": "https://huggingface.co/google-bert/bert-base-multilingual-cased/resolve/main/vocab.txt",
"google-bert/bert-base-chinese": "https://huggingface.co/google-bert/bert-base-chinese/resolve/main/vocab.txt",
"google-bert/bert-base-german-cased": "https://huggingface.co/google-bert/bert-base-german-cased/resolve/main/vocab.txt",
"google-bert/bert-large-uncased-whole-word-masking": (
"https://huggingface.co/google-bert/bert-large-uncased-whole-word-masking/resolve/main/vocab.txt"
),
"google-bert/bert-large-cased-whole-word-masking": (
"https://huggingface.co/google-bert/bert-large-cased-whole-word-masking/resolve/main/vocab.txt"
),
"google-bert/bert-large-uncased-whole-word-masking-finetuned-squad": (
"https://huggingface.co/google-bert/bert-large-uncased-whole-word-masking-finetuned-squad/resolve/main/vocab.txt"
),
"google-bert/bert-large-cased-whole-word-masking-finetuned-squad": (
"https://huggingface.co/google-bert/bert-large-cased-whole-word-masking-finetuned-squad/resolve/main/vocab.txt"
),
"google-bert/bert-base-cased-finetuned-mrpc": (
"https://huggingface.co/google-bert/bert-base-cased-finetuned-mrpc/resolve/main/vocab.txt"
),
"google-bert/bert-base-german-dbmdz-cased": "https://huggingface.co/google-bert/bert-base-german-dbmdz-cased/resolve/main/vocab.txt",
"google-bert/bert-base-german-dbmdz-uncased": (
"https://huggingface.co/google-bert/bert-base-german-dbmdz-uncased/resolve/main/vocab.txt"
),
"TurkuNLP/bert-base-finnish-cased-v1": (
"https://huggingface.co/TurkuNLP/bert-base-finnish-cased-v1/resolve/main/vocab.txt"
),
"TurkuNLP/bert-base-finnish-uncased-v1": (
"https://huggingface.co/TurkuNLP/bert-base-finnish-uncased-v1/resolve/main/vocab.txt"
),
"wietsedv/bert-base-dutch-cased": (
"https://huggingface.co/wietsedv/bert-base-dutch-cased/resolve/main/vocab.txt"
),
},
"tokenizer_file": {
"google-bert/bert-base-uncased": "https://huggingface.co/google-bert/bert-base-uncased/resolve/main/tokenizer.json",
"google-bert/bert-large-uncased": "https://huggingface.co/google-bert/bert-large-uncased/resolve/main/tokenizer.json",
"google-bert/bert-base-cased": "https://huggingface.co/google-bert/bert-base-cased/resolve/main/tokenizer.json",
"google-bert/bert-large-cased": "https://huggingface.co/google-bert/bert-large-cased/resolve/main/tokenizer.json",
"google-bert/bert-base-multilingual-uncased": (
"https://huggingface.co/google-bert/bert-base-multilingual-uncased/resolve/main/tokenizer.json"
),
"google-bert/bert-base-multilingual-cased": (
"https://huggingface.co/google-bert/bert-base-multilingual-cased/resolve/main/tokenizer.json"
),
"google-bert/bert-base-chinese": "https://huggingface.co/google-bert/bert-base-chinese/resolve/main/tokenizer.json",
"google-bert/bert-base-german-cased": "https://huggingface.co/google-bert/bert-base-german-cased/resolve/main/tokenizer.json",
"google-bert/bert-large-uncased-whole-word-masking": (
"https://huggingface.co/google-bert/bert-large-uncased-whole-word-masking/resolve/main/tokenizer.json"
),
"google-bert/bert-large-cased-whole-word-masking": (
"https://huggingface.co/google-bert/bert-large-cased-whole-word-masking/resolve/main/tokenizer.json"
),
"google-bert/bert-large-uncased-whole-word-masking-finetuned-squad": (
"https://huggingface.co/google-bert/bert-large-uncased-whole-word-masking-finetuned-squad/resolve/main/tokenizer.json"
),
"google-bert/bert-large-cased-whole-word-masking-finetuned-squad": (
"https://huggingface.co/google-bert/bert-large-cased-whole-word-masking-finetuned-squad/resolve/main/tokenizer.json"
),
"google-bert/bert-base-cased-finetuned-mrpc": (
"https://huggingface.co/google-bert/bert-base-cased-finetuned-mrpc/resolve/main/tokenizer.json"
),
"google-bert/bert-base-german-dbmdz-cased": (
"https://huggingface.co/google-bert/bert-base-german-dbmdz-cased/resolve/main/tokenizer.json"
),
"google-bert/bert-base-german-dbmdz-uncased": (
"https://huggingface.co/google-bert/bert-base-german-dbmdz-uncased/resolve/main/tokenizer.json"
),
"TurkuNLP/bert-base-finnish-cased-v1": (
"https://huggingface.co/TurkuNLP/bert-base-finnish-cased-v1/resolve/main/tokenizer.json"
),
"TurkuNLP/bert-base-finnish-uncased-v1": (
"https://huggingface.co/TurkuNLP/bert-base-finnish-uncased-v1/resolve/main/tokenizer.json"
),
"wietsedv/bert-base-dutch-cased": (
"https://huggingface.co/wietsedv/bert-base-dutch-cased/resolve/main/tokenizer.json"
),
},
}
PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
"google-bert/bert-base-uncased": 512,
"google-bert/bert-large-uncased": 512,
"google-bert/bert-base-cased": 512,
"google-bert/bert-large-cased": 512,
"google-bert/bert-base-multilingual-uncased": 512,
"google-bert/bert-base-multilingual-cased": 512,
"google-bert/bert-base-chinese": 512,
"google-bert/bert-base-german-cased": 512,
"google-bert/bert-large-uncased-whole-word-masking": 512,
"google-bert/bert-large-cased-whole-word-masking": 512,
"google-bert/bert-large-uncased-whole-word-masking-finetuned-squad": 512,
"google-bert/bert-large-cased-whole-word-masking-finetuned-squad": 512,
"google-bert/bert-base-cased-finetuned-mrpc": 512,
"google-bert/bert-base-german-dbmdz-cased": 512,
"google-bert/bert-base-german-dbmdz-uncased": 512,
"TurkuNLP/bert-base-finnish-cased-v1": 512,
"TurkuNLP/bert-base-finnish-uncased-v1": 512,
"wietsedv/bert-base-dutch-cased": 512,
}
PRETRAINED_INIT_CONFIGURATION = {
"google-bert/bert-base-uncased": {"do_lower_case": True},
"google-bert/bert-large-uncased": {"do_lower_case": True},
"google-bert/bert-base-cased": {"do_lower_case": False},
"google-bert/bert-large-cased": {"do_lower_case": False},
"google-bert/bert-base-multilingual-uncased": {"do_lower_case": True},
"google-bert/bert-base-multilingual-cased": {"do_lower_case": False},
"google-bert/bert-base-chinese": {"do_lower_case": False},
"google-bert/bert-base-german-cased": {"do_lower_case": False},
"google-bert/bert-large-uncased-whole-word-masking": {"do_lower_case": True},
"google-bert/bert-large-cased-whole-word-masking": {"do_lower_case": False},
"google-bert/bert-large-uncased-whole-word-masking-finetuned-squad": {"do_lower_case": True},
"google-bert/bert-large-cased-whole-word-masking-finetuned-squad": {"do_lower_case": False},
"google-bert/bert-base-cased-finetuned-mrpc": {"do_lower_case": False},
"google-bert/bert-base-german-dbmdz-cased": {"do_lower_case": False},
"google-bert/bert-base-german-dbmdz-uncased": {"do_lower_case": True},
"TurkuNLP/bert-base-finnish-cased-v1": {"do_lower_case": False},
"TurkuNLP/bert-base-finnish-uncased-v1": {"do_lower_case": True},
"wietsedv/bert-base-dutch-cased": {"do_lower_case": False},
}
class BertTokenizerFast(PreTrainedTokenizerFast):
r"""
Construct a "fast" BERT tokenizer (backed by HuggingFace's *tokenizers* library). Based on WordPiece.
This tokenizer inherits from [`PreTrainedTokenizerFast`] which contains most of the main methods. Users should
refer to this superclass for more information regarding those methods.
Args:
vocab_file (`str`):
File containing the vocabulary.
do_lower_case (`bool`, *optional*, defaults to `True`):
Whether or not to lowercase the input when tokenizing.
unk_token (`str`, *optional*, defaults to `"[UNK]"`):
The unknown token. A token that is not in the vocabulary cannot be converted to an ID and is set to be this
token instead.
sep_token (`str`, *optional*, defaults to `"[SEP]"`):
The separator token, which is used when building a sequence from multiple sequences, e.g. two sequences for
sequence classification or for a text and a question for question answering. It is also used as the last
token of a sequence built with special tokens.
pad_token (`str`, *optional*, defaults to `"[PAD]"`):
The token used for padding, for example when batching sequences of different lengths.
cls_token (`str`, *optional*, defaults to `"[CLS]"`):
The classifier token which is used when doing sequence classification (classification of the whole sequence
instead of per-token classification). It is the first token of the sequence when built with special tokens.
mask_token (`str`, *optional*, defaults to `"[MASK]"`):
The token used for masking values. This is the token used when training this model with masked language
modeling. This is the token which the model will try to predict.
clean_text (`bool`, *optional*, defaults to `True`):
Whether or not to clean the text before tokenization by removing any control characters and replacing all
whitespaces by the classic one.
tokenize_chinese_chars (`bool`, *optional*, defaults to `True`):
Whether or not to tokenize Chinese characters. This should likely be deactivated for Japanese (see [this
issue](https://github.com/huggingface/transformers/issues/328)).
strip_accents (`bool`, *optional*):
Whether or not to strip all accents. If this option is not specified, then it will be determined by the
value for `lowercase` (as in the original BERT).
wordpieces_prefix (`str`, *optional*, defaults to `"##"`):
The prefix for subwords.
"""
vocab_files_names = VOCAB_FILES_NAMES
pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
pretrained_init_configuration = PRETRAINED_INIT_CONFIGURATION
max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
slow_tokenizer_class = BertTokenizer
def __init__(
self,
vocab_file=None,
tokenizer_file=None,
do_lower_case=True,
unk_token="[UNK]",
sep_token="[SEP]",
pad_token="[PAD]",
cls_token="[CLS]",
mask_token="[MASK]",
tokenize_chinese_chars=True,
strip_accents=None,
**kwargs,
):
super().__init__(
vocab_file,
tokenizer_file=tokenizer_file,
do_lower_case=do_lower_case,
unk_token=unk_token,
sep_token=sep_token,
pad_token=pad_token,
cls_token=cls_token,
mask_token=mask_token,
tokenize_chinese_chars=tokenize_chinese_chars,
strip_accents=strip_accents,
**kwargs,
)
normalizer_state = json.loads(self.backend_tokenizer.normalizer.__getstate__())
if (
normalizer_state.get("lowercase", do_lower_case) != do_lower_case
or normalizer_state.get("strip_accents", strip_accents) != strip_accents
or normalizer_state.get("handle_chinese_chars", tokenize_chinese_chars) != tokenize_chinese_chars
):
normalizer_class = getattr(normalizers, normalizer_state.pop("type"))
normalizer_state["lowercase"] = do_lower_case
normalizer_state["strip_accents"] = strip_accents
normalizer_state["handle_chinese_chars"] = tokenize_chinese_chars
self.backend_tokenizer.normalizer = normalizer_class(**normalizer_state)
self.do_lower_case = do_lower_case
def build_inputs_with_special_tokens(self, token_ids_0, token_ids_1=None):
"""
Build model inputs from a sequence or a pair of sequence for sequence classification tasks by concatenating and
adding special tokens. A BERT sequence has the following format:
- single sequence: `[CLS] X [SEP]`
- pair of sequences: `[CLS] A [SEP] B [SEP]`
Args:
token_ids_0 (`List[int]`):
List of IDs to which the special tokens will be added.
token_ids_1 (`List[int]`, *optional*):
Optional second list of IDs for sequence pairs.
Returns:
`List[int]`: List of [input IDs](../glossary#input-ids) with the appropriate special tokens.
"""
output = [self.cls_token_id] + token_ids_0 + [self.sep_token_id]
if token_ids_1 is not None:
output += token_ids_1 + [self.sep_token_id]
return output
def create_token_type_ids_from_sequences(
self, token_ids_0: List[int], token_ids_1: Optional[List[int]] = None
) -> List[int]:
"""
Create a mask from the two sequences passed to be used in a sequence-pair classification task. A BERT sequence
pair mask has the following format:
```
0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1
| first sequence | second sequence |
```
If `token_ids_1` is `None`, this method only returns the first portion of the mask (0s).
Args:
token_ids_0 (`List[int]`):
List of IDs.
token_ids_1 (`List[int]`, *optional*):
Optional second list of IDs for sequence pairs.
Returns:
`List[int]`: List of [token type IDs](../glossary#token-type-ids) according to the given sequence(s).
"""
sep = [self.sep_token_id]
cls = [self.cls_token_id]
if token_ids_1 is None:
return len(cls + token_ids_0 + sep) * [0]
return len(cls + token_ids_0 + sep) * [0] + len(token_ids_1 + sep) * [1]
def save_vocabulary(self, save_directory: str, filename_prefix: Optional[str] = None) -> Tuple[str]:
files = self._tokenizer.model.save(save_directory, name=filename_prefix)
return tuple(files)
| transformers/src/transformers/models/bert/tokenization_bert_fast.py/0 | {
"file_path": "transformers/src/transformers/models/bert/tokenization_bert_fast.py",
"repo_id": "transformers",
"token_count": 6896
} | 72 |
# coding=utf-8
# Copyright 2018 Google AI, Google Brain and the HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
""" Tokenization classes for Big Bird model."""
import os
from shutil import copyfile
from typing import List, Optional, Tuple
from ...tokenization_utils import AddedToken
from ...tokenization_utils_fast import PreTrainedTokenizerFast
from ...utils import is_sentencepiece_available, logging
if is_sentencepiece_available():
from .tokenization_big_bird import BigBirdTokenizer
else:
BigBirdTokenizer = None
logger = logging.get_logger(__name__)
VOCAB_FILES_NAMES = {"vocab_file": "spiece.model", "tokenizer_file": "tokenizer.json"}
PRETRAINED_VOCAB_FILES_MAP = {
"vocab_file": {
"google/bigbird-roberta-base": "https://huggingface.co/google/bigbird-roberta-base/resolve/main/spiece.model",
"google/bigbird-roberta-large": (
"https://huggingface.co/google/bigbird-roberta-large/resolve/main/spiece.model"
),
"google/bigbird-base-trivia-itc": (
"https://huggingface.co/google/bigbird-base-trivia-itc/resolve/main/spiece.model"
),
},
"tokenizer_file": {
"google/bigbird-roberta-base": (
"https://huggingface.co/google/bigbird-roberta-base/resolve/main/tokenizer.json"
),
"google/bigbird-roberta-large": (
"https://huggingface.co/google/bigbird-roberta-large/resolve/main/tokenizer.json"
),
"google/bigbird-base-trivia-itc": (
"https://huggingface.co/google/bigbird-base-trivia-itc/resolve/main/tokenizer.json"
),
},
}
PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
"google/bigbird-roberta-base": 4096,
"google/bigbird-roberta-large": 4096,
"google/bigbird-base-trivia-itc": 4096,
}
SPIECE_UNDERLINE = "▁"
class BigBirdTokenizerFast(PreTrainedTokenizerFast):
"""
Construct a "fast" BigBird tokenizer (backed by HuggingFace's *tokenizers* library). Based on
[Unigram](https://huggingface.co/docs/tokenizers/python/latest/components.html?highlight=unigram#models). This
tokenizer inherits from [`PreTrainedTokenizerFast`] which contains most of the main methods. Users should refer to
this superclass for more information regarding those methods
Args:
vocab_file (`str`):
[SentencePiece](https://github.com/google/sentencepiece) file (generally has a *.spm* extension) that
contains the vocabulary necessary to instantiate a tokenizer.
bos_token (`str`, *optional*, defaults to `"<s>"`):
The beginning of sequence token that was used during pretraining. Can be used a sequence classifier token.
<Tip>
When building a sequence using special tokens, this is not the token that is used for the beginning of
sequence. The token used is the `cls_token`.
</Tip>
eos_token (`str`, *optional*, defaults to `"</s>"`):
The end of sequence token. .. note:: When building a sequence using special tokens, this is not the token
that is used for the end of sequence. The token used is the `sep_token`.
unk_token (`str`, *optional*, defaults to `"<unk>"`):
The unknown token. A token that is not in the vocabulary cannot be converted to an ID and is set to be this
token instead.
sep_token (`str`, *optional*, defaults to `"[SEP]"`):
The separator token, which is used when building a sequence from multiple sequences, e.g. two sequences for
sequence classification or for a text and a question for question answering. It is also used as the last
token of a sequence built with special tokens.
pad_token (`str`, *optional*, defaults to `"<pad>"`):
The token used for padding, for example when batching sequences of different lengths.
cls_token (`str`, *optional*, defaults to `"[CLS]"`):
The classifier token which is used when doing sequence classification (classification of the whole sequence
instead of per-token classification). It is the first token of the sequence when built with special tokens.
mask_token (`str`, *optional*, defaults to `"[MASK]"`):
The token used for masking values. This is the token used when training this model with masked language
modeling. This is the token which the model will try to predict.
"""
vocab_files_names = VOCAB_FILES_NAMES
pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
slow_tokenizer_class = BigBirdTokenizer
model_input_names = ["input_ids", "attention_mask"]
prefix_tokens: List[int] = []
def __init__(
self,
vocab_file=None,
tokenizer_file=None,
unk_token="<unk>",
bos_token="<s>",
eos_token="</s>",
pad_token="<pad>",
sep_token="[SEP]",
mask_token="[MASK]",
cls_token="[CLS]",
**kwargs,
):
bos_token = AddedToken(bos_token, lstrip=False, rstrip=False) if isinstance(bos_token, str) else bos_token
eos_token = AddedToken(eos_token, lstrip=False, rstrip=False) if isinstance(eos_token, str) else eos_token
unk_token = AddedToken(unk_token, lstrip=False, rstrip=False) if isinstance(unk_token, str) else unk_token
pad_token = AddedToken(pad_token, lstrip=False, rstrip=False) if isinstance(pad_token, str) else pad_token
cls_token = AddedToken(cls_token, lstrip=False, rstrip=False) if isinstance(cls_token, str) else cls_token
sep_token = AddedToken(sep_token, lstrip=False, rstrip=False) if isinstance(sep_token, str) else sep_token
# Mask token behave like a normal word, i.e. include the space before it
mask_token = AddedToken(mask_token, lstrip=True, rstrip=False) if isinstance(mask_token, str) else mask_token
super().__init__(
vocab_file,
tokenizer_file=tokenizer_file,
bos_token=bos_token,
eos_token=eos_token,
unk_token=unk_token,
sep_token=sep_token,
pad_token=pad_token,
cls_token=cls_token,
mask_token=mask_token,
**kwargs,
)
self.vocab_file = vocab_file
@property
def can_save_slow_tokenizer(self) -> bool:
return os.path.isfile(self.vocab_file) if self.vocab_file else False
def build_inputs_with_special_tokens(
self, token_ids_0: List[int], token_ids_1: Optional[List[int]] = None
) -> List[int]:
"""
Build model inputs from a sequence or a pair of sequence for sequence classification tasks by concatenating and
adding special tokens. An BigBird sequence has the following format:
- single sequence: `[CLS] X [SEP]`
- pair of sequences: `[CLS] A [SEP] B [SEP]`
Args:
token_ids_0 (`List[int]`):
List of IDs to which the special tokens will be added
token_ids_1 (`List[int]`, *optional*):
Optional second list of IDs for sequence pairs.
Returns:
`List[int]`: list of [input IDs](../glossary#input-ids) with the appropriate special tokens.
"""
sep = [self.sep_token_id]
cls = [self.cls_token_id]
if token_ids_1 is None:
return cls + token_ids_0 + sep
return cls + token_ids_0 + sep + token_ids_1 + sep
def get_special_tokens_mask(
self, token_ids_0: List[int], token_ids_1: Optional[List[int]] = None, already_has_special_tokens: bool = False
) -> List[int]:
"""
Retrieves sequence ids from a token list that has no special tokens added. This method is called when adding
special tokens using the tokenizer `prepare_for_model` method.
Args:
token_ids_0 (`List[int]`):
List of ids.
token_ids_1 (`List[int]`, *optional*):
Optional second list of IDs for sequence pairs.
already_has_special_tokens (`bool`, *optional*, defaults to `False`):
Set to True if the token list is already formatted with special tokens for the model
Returns:
`List[int]`: A list of integers in the range [0, 1]: 1 for a special token, 0 for a sequence token.
"""
if already_has_special_tokens:
if token_ids_1 is not None:
raise ValueError(
"You should not supply a second sequence if the provided sequence of "
"ids is already formatted with special tokens for the model."
)
return [1 if x in [self.sep_token_id, self.cls_token_id] else 0 for x in token_ids_0]
if token_ids_1 is None:
return [1] + ([0] * len(token_ids_0)) + [1]
return [1] + ([0] * len(token_ids_0)) + [1] + ([0] * len(token_ids_1)) + [1]
def create_token_type_ids_from_sequences(
self, token_ids_0: List[int], token_ids_1: Optional[List[int]] = None
) -> List[int]:
"""
Creates a mask from the two sequences passed to be used in a sequence-pair classification task. An ALBERT
sequence pair mask has the following format:
```
0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1
| first sequence | second sequence |
```
if token_ids_1 is None, only returns the first portion of the mask (0s).
Args:
token_ids_0 (`List[int]`):
List of ids.
token_ids_1 (`List[int]`, *optional*):
Optional second list of IDs for sequence pairs.
Returns:
`List[int]`: List of [token type IDs](../glossary#token-type-ids) according to the given sequence(s).
"""
sep = [self.sep_token_id]
cls = [self.cls_token_id]
if token_ids_1 is None:
return len(cls + token_ids_0 + sep) * [0]
return len(cls + token_ids_0 + sep) * [0] + len(token_ids_1 + sep) * [1]
def save_vocabulary(self, save_directory: str, filename_prefix: Optional[str] = None) -> Tuple[str]:
if not self.can_save_slow_tokenizer:
raise ValueError(
"Your fast tokenizer does not have the necessary information to save the vocabulary for a slow "
"tokenizer."
)
if not os.path.isdir(save_directory):
logger.error(f"Vocabulary path ({save_directory}) should be a directory")
return
out_vocab_file = os.path.join(
save_directory, (filename_prefix + "-" if filename_prefix else "") + VOCAB_FILES_NAMES["vocab_file"]
)
if os.path.abspath(self.vocab_file) != os.path.abspath(out_vocab_file):
copyfile(self.vocab_file, out_vocab_file)
return (out_vocab_file,)
| transformers/src/transformers/models/big_bird/tokenization_big_bird_fast.py/0 | {
"file_path": "transformers/src/transformers/models/big_bird/tokenization_big_bird_fast.py",
"repo_id": "transformers",
"token_count": 4758
} | 73 |
# coding=utf-8
# Copyright 2021 The Facebook, Inc. and The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
""" Blenderbot model configuration"""
from collections import OrderedDict
from typing import Any, Mapping, Optional
from ... import PreTrainedTokenizer
from ...configuration_utils import PretrainedConfig
from ...file_utils import TensorType, is_torch_available
from ...onnx import OnnxConfig, OnnxConfigWithPast, OnnxSeq2SeqConfigWithPast
from ...onnx.utils import compute_effective_axis_dimension
from ...utils import logging
logger = logging.get_logger(__name__)
BLENDERBOT_PRETRAINED_CONFIG_ARCHIVE_MAP = {
"facebook/blenderbot-3B": "https://huggingface.co/facebook/blenderbot-3B/resolve/main/config.json",
# See all Blenderbot models at https://huggingface.co/models?filter=blenderbot
}
class BlenderbotConfig(PretrainedConfig):
r"""
This is the configuration class to store the configuration of a [`BlenderbotModel`]. It is used to instantiate an
Blenderbot model according to the specified arguments, defining the model architecture. Instantiating a
configuration with the defaults will yield a similar configuration to that of the Blenderbot
[facebook/blenderbot-3B](https://huggingface.co/facebook/blenderbot-3B) architecture.
Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
documentation from [`PretrainedConfig`] for more information.
Args:
vocab_size (`int`, *optional*, defaults to 50265):
Vocabulary size of the Blenderbot model. Defines the number of different tokens that can be represented by
the `inputs_ids` passed when calling [`BlenderbotModel`] or [`TFBlenderbotModel`].
d_model (`int`, *optional*, defaults to 1024):
Dimensionality of the layers and the pooler layer.
encoder_layers (`int`, *optional*, defaults to 12):
Number of encoder layers.
decoder_layers (`int`, *optional*, defaults to 12):
Number of decoder layers.
encoder_attention_heads (`int`, *optional*, defaults to 16):
Number of attention heads for each attention layer in the Transformer encoder.
decoder_attention_heads (`int`, *optional*, defaults to 16):
Number of attention heads for each attention layer in the Transformer decoder.
decoder_ffn_dim (`int`, *optional*, defaults to 4096):
Dimensionality of the "intermediate" (often named feed-forward) layer in decoder.
encoder_ffn_dim (`int`, *optional*, defaults to 4096):
Dimensionality of the "intermediate" (often named feed-forward) layer in decoder.
activation_function (`str` or `function`, *optional*, defaults to `"gelu"`):
The non-linear activation function (function or string) in the encoder and pooler. If string, `"gelu"`,
`"relu"`, `"silu"` and `"gelu_new"` are supported.
dropout (`float`, *optional*, defaults to 0.1):
The dropout probability for all fully connected layers in the embeddings, encoder, and pooler.
attention_dropout (`float`, *optional*, defaults to 0.0):
The dropout ratio for the attention probabilities.
activation_dropout (`float`, *optional*, defaults to 0.0):
The dropout ratio for activations inside the fully connected layer.
max_position_embeddings (`int`, *optional*, defaults to 128):
The maximum sequence length that this model might ever be used with. Typically set this to something large
just in case (e.g., 512 or 1024 or 2048).
init_std (`float`, *optional*, defaults to 0.02):
The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
encoder_layerdrop (`float`, *optional*, defaults to 0.0):
The LayerDrop probability for the encoder. See the [LayerDrop paper](see https://arxiv.org/abs/1909.11556)
for more details.
decoder_layerdrop (`float`, *optional*, defaults to 0.0):
The LayerDrop probability for the decoder. See the [LayerDrop paper](see https://arxiv.org/abs/1909.11556)
for more details.
scale_embedding (`bool`, *optional*, defaults to `False`):
Scale embeddings by diving by sqrt(d_model).
use_cache (`bool`, *optional*, defaults to `True`):
Whether or not the model should return the last key/values attentions (not used by all models)
forced_eos_token_id (`int`, *optional*, defaults to 2):
The id of the token to force as the last generated token when `max_length` is reached. Usually set to
`eos_token_id`.
Example:
```python
>>> from transformers import BlenderbotConfig, BlenderbotModel
>>> # Initializing a Blenderbot facebook/blenderbot-3B style configuration
>>> configuration = BlenderbotConfig()
>>> # Initializing a model (with random weights) from the facebook/blenderbot-3B style configuration
>>> model = BlenderbotModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.config
```"""
model_type = "blenderbot"
keys_to_ignore_at_inference = ["past_key_values"]
attribute_map = {"num_attention_heads": "encoder_attention_heads", "hidden_size": "d_model"}
def __init__(
self,
vocab_size=8008,
max_position_embeddings=128,
encoder_layers=2,
encoder_ffn_dim=10240,
encoder_attention_heads=32,
decoder_layers=24,
decoder_ffn_dim=10240,
decoder_attention_heads=32,
encoder_layerdrop=0.0,
decoder_layerdrop=0.0,
use_cache=True,
is_encoder_decoder=True,
activation_function="gelu",
d_model=2560,
dropout=0.1,
attention_dropout=0.0,
activation_dropout=0.0,
init_std=0.02,
decoder_start_token_id=1,
scale_embedding=False,
pad_token_id=0,
bos_token_id=1,
eos_token_id=2,
encoder_no_repeat_ngram_size=3,
forced_eos_token_id=2,
**kwargs,
):
self.vocab_size = vocab_size
self.max_position_embeddings = max_position_embeddings
self.d_model = d_model
self.encoder_ffn_dim = encoder_ffn_dim
self.encoder_layers = encoder_layers
self.encoder_attention_heads = encoder_attention_heads
self.decoder_ffn_dim = decoder_ffn_dim
self.decoder_layers = decoder_layers
self.decoder_attention_heads = decoder_attention_heads
self.dropout = dropout
self.attention_dropout = attention_dropout
self.activation_dropout = activation_dropout
self.activation_function = activation_function
self.init_std = init_std
self.encoder_layerdrop = encoder_layerdrop
self.decoder_layerdrop = decoder_layerdrop
self.use_cache = use_cache
self.num_hidden_layers = encoder_layers
self.scale_embedding = scale_embedding # scale factor will be sqrt(d_model) if True
super().__init__(
pad_token_id=pad_token_id,
bos_token_id=bos_token_id,
eos_token_id=eos_token_id,
is_encoder_decoder=is_encoder_decoder,
decoder_start_token_id=decoder_start_token_id,
encoder_no_repeat_ngram_size=encoder_no_repeat_ngram_size,
forced_eos_token_id=forced_eos_token_id,
**kwargs,
)
class BlenderbotOnnxConfig(OnnxSeq2SeqConfigWithPast):
@property
def inputs(self) -> Mapping[str, Mapping[int, str]]:
if self.task in ["default", "seq2seq-lm"]:
common_inputs = OrderedDict(
[
("input_ids", {0: "batch", 1: "encoder_sequence"}),
("attention_mask", {0: "batch", 1: "encoder_sequence"}),
]
)
if self.use_past:
common_inputs["decoder_input_ids"] = {0: "batch"}
common_inputs["decoder_attention_mask"] = {0: "batch", 1: "past_decoder_sequence + sequence"}
else:
common_inputs["decoder_input_ids"] = {0: "batch", 1: "decoder_sequence"}
common_inputs["decoder_attention_mask"] = {0: "batch", 1: "decoder_sequence"}
if self.use_past:
self.fill_with_past_key_values_(common_inputs, direction="inputs")
elif self.task == "causal-lm":
common_inputs = OrderedDict(
[
("input_ids", {0: "batch", 1: "encoder_sequence"}),
("attention_mask", {0: "batch", 1: "encoder_sequence"}),
]
)
if self.use_past:
_, num_decoder_layers = self.num_layers
for i in range(num_decoder_layers):
common_inputs[f"past_key_values.{i}.key"] = {0: "batch", 2: "past_sequence + sequence"}
common_inputs[f"past_key_values.{i}.value"] = {0: "batch", 2: "past_sequence + sequence"}
else:
common_inputs = OrderedDict(
[
("input_ids", {0: "batch", 1: "encoder_sequence"}),
("attention_mask", {0: "batch", 1: "encoder_sequence"}),
("decoder_input_ids", {0: "batch", 1: "decoder_sequence"}),
("decoder_attention_mask", {0: "batch", 1: "decoder_sequence"}),
]
)
return common_inputs
@property
# Copied from transformers.models.bart.configuration_bart.BartOnnxConfig.outputs
def outputs(self) -> Mapping[str, Mapping[int, str]]:
if self.task in ["default", "seq2seq-lm"]:
common_outputs = super().outputs
else:
common_outputs = super(OnnxConfigWithPast, self).outputs
if self.use_past:
num_encoder_layers, _ = self.num_layers
for i in range(num_encoder_layers):
common_outputs[f"present.{i}.key"] = {0: "batch", 2: "past_sequence + sequence"}
common_outputs[f"present.{i}.value"] = {0: "batch", 2: "past_sequence + sequence"}
return common_outputs
def _generate_dummy_inputs_for_default_and_seq2seq_lm(
self,
tokenizer: PreTrainedTokenizer,
batch_size: int = -1,
seq_length: int = -1,
is_pair: bool = False,
framework: Optional[TensorType] = None,
) -> Mapping[str, Any]:
encoder_inputs = self._generate_dummy_inputs_for_sequence_classification_and_question_answering(
tokenizer, batch_size, seq_length, is_pair, framework
)
# Generate decoder inputs
decoder_seq_length = seq_length if not self.use_past else 1
decoder_inputs = self._generate_dummy_inputs_for_sequence_classification_and_question_answering(
tokenizer, batch_size, decoder_seq_length, is_pair, framework
)
decoder_inputs = {f"decoder_{name}": tensor for name, tensor in decoder_inputs.items()}
common_inputs = dict(**encoder_inputs, **decoder_inputs)
if self.use_past:
if not is_torch_available():
raise ValueError("Cannot generate dummy past_keys inputs without PyTorch installed.")
else:
import torch
batch, encoder_seq_length = common_inputs["input_ids"].shape
decoder_seq_length = common_inputs["decoder_input_ids"].shape[1]
num_encoder_attention_heads, num_decoder_attention_heads = self.num_attention_heads
encoder_shape = (
batch,
num_encoder_attention_heads,
encoder_seq_length,
self._config.hidden_size // num_encoder_attention_heads,
)
decoder_past_length = decoder_seq_length
decoder_shape = (
batch,
num_decoder_attention_heads,
decoder_past_length,
self._config.hidden_size // num_decoder_attention_heads,
)
common_inputs["decoder_attention_mask"] = torch.cat(
[common_inputs["decoder_attention_mask"], torch.ones(batch, decoder_past_length)], dim=1
)
common_inputs["past_key_values"] = []
_, num_decoder_layers = self.num_layers
for _ in range(num_decoder_layers):
common_inputs["past_key_values"].append(
(
torch.zeros(decoder_shape),
torch.zeros(decoder_shape),
torch.zeros(encoder_shape),
torch.zeros(encoder_shape),
)
)
return common_inputs
def _generate_dummy_inputs_for_causal_lm(
self,
tokenizer: PreTrainedTokenizer,
batch_size: int = -1,
seq_length: int = -1,
is_pair: bool = False,
framework: Optional[TensorType] = None,
) -> Mapping[str, Any]:
common_inputs = self._generate_dummy_inputs_for_sequence_classification_and_question_answering(
tokenizer, batch_size, seq_length, is_pair, framework
)
if self.use_past:
if not is_torch_available():
raise ValueError("Cannot generate dummy past_keys inputs without PyTorch installed.")
else:
import torch
batch, seqlen = common_inputs["input_ids"].shape
past_key_values_length = seqlen
_, num_decoder_layers = self.num_layers
num_encoder_attention_heads, _ = self.num_attention_heads
past_shape = (
batch,
num_encoder_attention_heads,
past_key_values_length,
self._config.hidden_size // num_encoder_attention_heads,
)
mask_dtype = common_inputs["attention_mask"].dtype
common_inputs["attention_mask"] = torch.cat(
[common_inputs["attention_mask"], torch.ones(batch, past_key_values_length, dtype=mask_dtype)], dim=1
)
common_inputs["past_key_values"] = [
(torch.zeros(past_shape), torch.zeros(past_shape)) for _ in range(num_decoder_layers)
]
return common_inputs
# Copied from transformers.models.bart.configuration_bart.BartOnnxConfig._generate_dummy_inputs_for_sequence_classification_and_question_answering
def _generate_dummy_inputs_for_sequence_classification_and_question_answering(
self,
tokenizer: PreTrainedTokenizer,
batch_size: int = -1,
seq_length: int = -1,
is_pair: bool = False,
framework: Optional[TensorType] = None,
) -> Mapping[str, Any]:
# Copied from OnnxConfig.generate_dummy_inputs
# Did not use super(OnnxConfigWithPast, self).generate_dummy_inputs for code clarity.
# If dynamic axis (-1) we forward with a fixed dimension of 2 samples to avoid optimizations made by ONNX
batch_size = compute_effective_axis_dimension(
batch_size, fixed_dimension=OnnxConfig.default_fixed_batch, num_token_to_add=0
)
# If dynamic axis (-1) we forward with a fixed dimension of 8 tokens to avoid optimizations made by ONNX
token_to_add = tokenizer.num_special_tokens_to_add(is_pair)
seq_length = compute_effective_axis_dimension(
seq_length, fixed_dimension=OnnxConfig.default_fixed_sequence, num_token_to_add=token_to_add
)
# Generate dummy inputs according to compute batch and sequence
dummy_input = [" ".join([tokenizer.unk_token]) * seq_length] * batch_size
common_inputs = dict(tokenizer(dummy_input, return_tensors=framework))
return common_inputs
# Copied from transformers.models.bart.configuration_bart.BartOnnxConfig.generate_dummy_inputs
def generate_dummy_inputs(
self,
tokenizer: PreTrainedTokenizer,
batch_size: int = -1,
seq_length: int = -1,
is_pair: bool = False,
framework: Optional[TensorType] = None,
) -> Mapping[str, Any]:
if self.task in ["default", "seq2seq-lm"]:
common_inputs = self._generate_dummy_inputs_for_default_and_seq2seq_lm(
tokenizer, batch_size=batch_size, seq_length=seq_length, is_pair=is_pair, framework=framework
)
elif self.task == "causal-lm":
common_inputs = self._generate_dummy_inputs_for_causal_lm(
tokenizer, batch_size=batch_size, seq_length=seq_length, is_pair=is_pair, framework=framework
)
else:
common_inputs = self._generate_dummy_inputs_for_sequence_classification_and_question_answering(
tokenizer, batch_size=batch_size, seq_length=seq_length, is_pair=is_pair, framework=framework
)
return common_inputs
# Copied from transformers.models.bart.configuration_bart.BartOnnxConfig._flatten_past_key_values_
def _flatten_past_key_values_(self, flattened_output, name, idx, t):
if self.task in ["default", "seq2seq-lm"]:
flattened_output = super()._flatten_past_key_values_(flattened_output, name, idx, t)
else:
flattened_output = super(OnnxSeq2SeqConfigWithPast, self)._flatten_past_key_values_(
flattened_output, name, idx, t
)
def fill_with_past_key_values_(self, inputs_or_outputs: Mapping[str, Mapping[int, str]], direction: str):
if direction not in ["inputs", "outputs"]:
raise ValueError(f'direction must either be "inputs" or "outputs", but {direction} was given')
name = "past_key_values" if direction == "inputs" else "present"
_, num_decoder_layers = self.num_layers
encoder_sequence = "past_encoder_sequence"
decoder_sequence = "past_decoder_sequence" if direction == "inputs" else "past_decoder_sequence + sequence"
for i in range(num_decoder_layers):
inputs_or_outputs[f"{name}.{i}.decoder.key"] = {0: "batch", 2: decoder_sequence}
inputs_or_outputs[f"{name}.{i}.decoder.value"] = {0: "batch", 2: decoder_sequence}
inputs_or_outputs[f"{name}.{i}.encoder.key"] = {0: "batch", 2: encoder_sequence}
inputs_or_outputs[f"{name}.{i}.encoder.value"] = {0: "batch", 2: encoder_sequence}
| transformers/src/transformers/models/blenderbot/configuration_blenderbot.py/0 | {
"file_path": "transformers/src/transformers/models/blenderbot/configuration_blenderbot.py",
"repo_id": "transformers",
"token_count": 8374
} | 74 |
# coding=utf-8
# Copyright 2022 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import argparse
import re
import requests
import torch
# git clone https://github.com/salesforce/BLIP.git
from models.blip import blip_decoder
from models.blip_itm import blip_itm
from models.blip_vqa import blip_vqa
from PIL import Image
from torchvision import transforms
from torchvision.transforms.functional import InterpolationMode
from transformers import (
BertTokenizer,
BlipConfig,
BlipForConditionalGeneration,
BlipForImageTextRetrieval,
BlipForQuestionAnswering,
)
def load_demo_image(image_size, device):
img_url = "https://storage.googleapis.com/sfr-vision-language-research/BLIP/demo.jpg"
raw_image = Image.open(requests.get(img_url, stream=True).raw).convert("RGB")
transform = transforms.Compose(
[
transforms.Resize((image_size, image_size), interpolation=InterpolationMode.BICUBIC),
transforms.ToTensor(),
transforms.Normalize((0.48145466, 0.4578275, 0.40821073), (0.26862954, 0.26130258, 0.27577711)),
]
)
image = transform(raw_image).unsqueeze(0).to(device)
return image
def rename_key(key):
if "visual_encoder" in key:
key = re.sub("visual_encoder*", "vision_model.encoder", key)
if "blocks" in key:
key = re.sub(r"blocks", "layers", key)
if "attn" in key:
key = re.sub(r"attn", "self_attn", key)
if "norm1" in key:
key = re.sub(r"norm1", "layer_norm1", key)
if "norm2" in key:
key = re.sub(r"norm2", "layer_norm2", key)
if "encoder.norm" in key:
key = re.sub(r"encoder.norm", "post_layernorm", key)
if "encoder.patch_embed.proj" in key:
key = re.sub(r"encoder.patch_embed.proj", "embeddings.patch_embedding", key)
if "encoder.pos_embed" in key:
key = re.sub(r"encoder.pos_embed", "embeddings.position_embedding", key)
if "encoder.cls_token" in key:
key = re.sub(r"encoder.cls_token", "embeddings.class_embedding", key)
if "self_attn" in key:
key = re.sub(r"self_attn.proj", "self_attn.projection", key)
return key
@torch.no_grad()
def convert_blip_checkpoint(pytorch_dump_folder_path, config_path=None):
"""
Copy/paste/tweak model's weights to transformers design.
"""
if config_path is not None:
config = BlipConfig.from_pretrained(config_path)
else:
config = BlipConfig(projection_dim=512, text_config={}, vision_config={})
hf_model = BlipForConditionalGeneration(config).eval()
model_url = "https://storage.googleapis.com/sfr-vision-language-research/BLIP/models/model_base_capfilt_large.pth"
pt_model = blip_decoder(pretrained=model_url, image_size=384, vit="base")
pt_model = pt_model.eval()
modified_state_dict = pt_model.state_dict()
for key in modified_state_dict.copy():
value = modified_state_dict.pop(key)
renamed_key = rename_key(key)
modified_state_dict[renamed_key] = value
hf_model.load_state_dict(modified_state_dict)
image_size = 384
image = load_demo_image(image_size=image_size, device="cpu")
tokenizer = BertTokenizer.from_pretrained("google-bert/bert-base-uncased")
input_ids = tokenizer(["a picture of"]).input_ids
out = hf_model.generate(image, input_ids)
assert out[0].tolist() == [30522, 1037, 3861, 1997, 1037, 2450, 3564, 2006, 1996, 3509, 2007, 2014, 3899, 102]
out = hf_model.generate(image)
assert out[0].tolist() == [30522, 1037, 2450, 3564, 2006, 1996, 3509, 2007, 2014, 3899, 102]
if pytorch_dump_folder_path is not None:
hf_model.save_pretrained(pytorch_dump_folder_path)
# model_url = 'https://storage.googleapis.com/sfr-vision-language-research/BLIP/models/model_vqa.pth'
model_url = (
"https://storage.googleapis.com/sfr-vision-language-research/BLIP/models/model_base_vqa_capfilt_large.pth"
)
vqa_model = blip_vqa(pretrained=model_url, image_size=image_size, vit="base")
vqa_model.eval()
modified_state_dict = vqa_model.state_dict()
for key in modified_state_dict.copy():
value = modified_state_dict.pop(key)
renamed_key = rename_key(key)
modified_state_dict[renamed_key] = value
hf_vqa_model = BlipForQuestionAnswering(config)
hf_vqa_model.load_state_dict(modified_state_dict)
question = ["How many dogs are in this image?"]
question_input_ids = tokenizer(question, return_tensors="pt").input_ids
answer = hf_vqa_model.generate(question_input_ids, image)
print(tokenizer.decode(answer[0]))
assert tokenizer.decode(answer[0]) == "[UNK] 1 [SEP]"
if pytorch_dump_folder_path is not None:
hf_vqa_model.save_pretrained(pytorch_dump_folder_path + "_vqa")
model_url = "https://storage.googleapis.com/sfr-vision-language-research/BLIP/models/model_base_retrieval_coco.pth"
itm_model = blip_itm(pretrained=model_url, image_size=image_size, vit="base")
itm_model.eval()
modified_state_dict = itm_model.state_dict()
for key in modified_state_dict.copy():
value = modified_state_dict.pop(key)
renamed_key = rename_key(key)
modified_state_dict[renamed_key] = value
hf_itm_model = BlipForImageTextRetrieval(config)
question = ["A picture of a woman with a dog sitting in a beach"]
question_input_ids = tokenizer(
question,
return_tensors="pt",
padding="max_length",
truncation=True,
max_length=35,
).input_ids
hf_itm_model.load_state_dict(modified_state_dict)
hf_itm_model.eval()
out_itm = hf_itm_model(question_input_ids, image, use_itm_head=True)
out = hf_itm_model(question_input_ids, image, use_itm_head=False)
assert out[0].item() == 0.2110687494277954
assert torch.nn.functional.softmax(out_itm[0], dim=1)[:, 1].item() == 0.45698845386505127
if pytorch_dump_folder_path is not None:
hf_itm_model.save_pretrained(pytorch_dump_folder_path + "_itm")
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--pytorch_dump_folder_path", default=None, type=str, help="Path to the output PyTorch model.")
parser.add_argument("--config_path", default=None, type=str, help="Path to hf config.json of model to convert")
args = parser.parse_args()
convert_blip_checkpoint(args.checkpoint_path, args.pytorch_dump_folder_path, args.config_path)
| transformers/src/transformers/models/blip/convert_blip_original_pytorch_to_hf.py/0 | {
"file_path": "transformers/src/transformers/models/blip/convert_blip_original_pytorch_to_hf.py",
"repo_id": "transformers",
"token_count": 2808
} | 75 |
# coding=utf-8
# Copyright 2023 HuggingFace Inc. Team and Bigscience Workshop. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""Flax BLOOM model."""
import math
from functools import partial
from typing import Optional, Tuple
import flax.linen as nn
import jax
import jax.numpy as jnp
from flax.core.frozen_dict import FrozenDict, freeze, unfreeze
from flax.linen import combine_masks, dot_product_attention_weights, make_causal_mask
from flax.linen.activation import tanh
from flax.traverse_util import flatten_dict, unflatten_dict
from jax import lax
from ...modeling_flax_outputs import (
FlaxBaseModelOutput,
FlaxBaseModelOutputWithPastAndCrossAttentions,
FlaxCausalLMOutput,
)
from ...modeling_flax_utils import FlaxPreTrainedModel, append_call_sample_docstring
from ...utils import add_start_docstrings, add_start_docstrings_to_model_forward, logging
from .configuration_bloom import BloomConfig
logger = logging.get_logger(__name__)
_CHECKPOINT_FOR_DOC = "bigscience/bloom"
_CONFIG_FOR_DOC = "BloomConfig"
BLOOM_START_DOCSTRING = r"""
This model inherits from [`FlaxPreTrainedModel`]. Check the superclass documentation for the generic methods the
library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads
etc.)
This model is also a Flax Linen
[flax.nn.Module](https://flax.readthedocs.io/en/latest/_autosummary/flax.nn.module.html) subclass. Use it as a
regular Flax Module and refer to the Flax documentation for all matter related to general usage and behavior.
Finally, this model supports inherent JAX features such as:
- [Just-In-Time (JIT) compilation](https://jax.readthedocs.io/en/latest/jax.html#just-in-time-compilation-jit)
- [Automatic Differentiation](https://jax.readthedocs.io/en/latest/jax.html#automatic-differentiation)
- [Vectorization](https://jax.readthedocs.io/en/latest/jax.html#vectorization-vmap)
- [Parallelization](https://jax.readthedocs.io/en/latest/jax.html#parallelization-pmap)
Parameters:
config ([`BloomConfig`]): Model configuration class with all the parameters of the model.
Initializing with a config file does not load the weights associated with the model, only the
configuration. Check out the [`~FlaxPreTrainedModel.from_pretrained`] method to load the model weights.
dtype (`jax.numpy.dtype`, *optional*, defaults to `jax.numpy.float32`):
The data type of the computation. Can be one of `jax.numpy.float32`, `jax.numpy.float16` (on GPUs) and
`jax.numpy.bfloat16` (on TPUs).
This can be used to enable mixed-precision training or half-precision inference on GPUs or TPUs. If
specified all the computation will be performed with the given `dtype`.
**Note that this only specifies the dtype of the computation and does not influence the dtype of model
parameters.**
If you wish to change the dtype of the model parameters, see [`~FlaxPreTrainedModel.to_fp16`] and
[`~FlaxPreTrainedModel.to_bf16`].
"""
BLOOM_INPUTS_DOCSTRING = r"""
Args:
input_ids (`numpy.ndarray` of shape `(batch_size, input_ids_length)`):
`input_ids_length` = `sequence_length`. Indices of input sequence tokens in the vocabulary.
Indices can be obtained using [`BloomTokenizer`]. See [`PreTrainedTokenizer.encode`] and
[`PreTrainedTokenizer.__call__`] for details.
[What are input IDs?](../glossary#input-ids)
attention_mask (`numpy.ndarray` of shape `(batch_size, sequence_length)`, *optional*):
Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
[What are attention masks?](../glossary#attention-mask)
past_key_values (`Dict[str, np.ndarray]`, *optional*, returned by `init_cache` or when passing previous `past_key_values`):
Dictionary of pre-computed hidden-states (key and values in the attention blocks) that can be used for fast
auto-regressive decoding. Pre-computed key and value hidden-states are of shape *[batch_size, max_length]*.
output_attentions (`bool`, *optional*):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
tensors for more detail.
output_hidden_states (`bool`, *optional*):
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
more detail.
return_dict (`bool`, *optional*):
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
"""
def build_alibi_tensor(attention_mask: jnp.ndarray, num_heads: int, dtype: Optional[jnp.dtype] = jnp.float32):
"""
Flax implementation of the BLOOM Alibi tensor. BLOOM Alibi tensor is not causal as the original paper mentions, it
relies on a translation invariance of softmax for quick implementation: with l being a tensor, and a fixed value
`softmax(l+a) = softmax(l)`. Based on
https://github.com/ofirpress/attention_with_linear_biases/blob/a35aaca144e0eb6b789dfcb46784c4b8e31b7983/fairseq/models/transformer.py#L742
Link to paper: https://arxiv.org/abs/2108.12409
Args:
attention_mask (`jnp.ndarray`):
Token-wise attention mask, this should be of shape `(batch_size, max_seq_len)`.
num_heads (`int`):
Number of attention heads.
dtype (`jnp.dtype`, *optional*, defaults to `jnp.float32`):
The data type (dtype) of the output tensor.
Returns: Alibi tensor of shape `(batch_size * num_heads, 1, max_seq_len)`.
"""
batch_size, seq_length = attention_mask.shape
closest_power_of_2 = 2 ** math.floor(math.log2(num_heads))
base = jnp.array(2 ** (-(2 ** -(math.log2(closest_power_of_2) - 3))), dtype=jnp.float32)
powers = jnp.arange(1, 1 + closest_power_of_2, dtype=jnp.float32)
slopes = jax.lax.pow(base, powers)
if closest_power_of_2 != num_heads:
extra_base = jnp.array(2 ** (-(2 ** -(math.log2(2 * closest_power_of_2) - 3))), dtype=jnp.float32)
num_remaining_heads = min(closest_power_of_2, num_heads - closest_power_of_2)
extra_powers = jnp.arange(1, 1 + 2 * num_remaining_heads, 2, dtype=jnp.float32)
slopes = jnp.cat([slopes, jax.lax.pow(extra_base, extra_powers)], axis=0)
# Note: the Alibi tensor will added to the attention bias that will be applied to the query, key product of attention
# therefore, Alibi will have to be of shape (batch_size, num_heads, query_length, key_length)
# => here we set (batch_size=1, num_heads=num_heads, query_length=1, key_length=max_length)
# so that the query_length dimension will then be broadcast correctly.
# This is more or less identical to T5's relative position bias:
# https://github.com/huggingface/transformers/blob/f681437203baa7671de3174b0fa583c349d9d5e1/src/transformers/models/t5/modeling_t5.py#L527
arange_tensor = ((attention_mask.cumsum(axis=-1) - 1) * attention_mask)[:, None, :]
alibi = slopes[..., None] * arange_tensor
alibi = jnp.expand_dims(alibi, axis=2)
return jnp.asarray(alibi, dtype)
class FlaxBloomAttention(nn.Module):
config: BloomConfig
dtype: jnp.dtype = jnp.float32
def setup(self):
self.hidden_size = self.config.hidden_size
self.num_heads = self.config.n_head
self.head_dim = self.hidden_size // self.num_heads
self.attention_softmax_in_fp32 = self.dtype is not jnp.float32
if self.head_dim * self.num_heads != self.hidden_size:
raise ValueError(
f"`hidden_size` must be divisible by `num_heads` (got `hidden_size`: {self.hidden_size} and "
f"`num_heads`: {self.num_heads})."
)
dense = partial(
nn.Dense,
dtype=self.dtype,
kernel_init=jax.nn.initializers.normal(self.config.initializer_range),
)
self.query_key_value = dense(self.hidden_size * 3)
self.dense = dense(self.hidden_size)
self.resid_dropout = nn.Dropout(rate=self.config.hidden_dropout)
def _split_heads(self, hidden_states):
return hidden_states.reshape(hidden_states.shape[:-1] + (self.num_heads, self.head_dim * 3))
def _merge_heads(self, hidden_states):
return hidden_states.reshape(hidden_states.shape[:2] + (self.hidden_size,))
@nn.compact
# Copied from transformers.models.gptj.modeling_flax_gptj.FlaxGPTJAttention._concatenate_to_cache
def _concatenate_to_cache(self, key, value, query, attention_mask):
"""
This function takes projected key, value states from a single input token and concatenates the states to cached
states from previous steps. This function is slighly adapted from the official Flax repository:
https://github.com/google/flax/blob/491ce18759622506588784b4fca0e4bf05f8c8cd/flax/linen/attention.py#L252
"""
# detect if we're initializing by absence of existing cache data.
is_initialized = self.has_variable("cache", "cached_key")
cached_key = self.variable("cache", "cached_key", jnp.zeros, key.shape, key.dtype)
cached_value = self.variable("cache", "cached_value", jnp.zeros, value.shape, value.dtype)
cache_index = self.variable("cache", "cache_index", lambda: jnp.array(0, dtype=jnp.int32))
if is_initialized:
*batch_dims, max_length, num_heads, depth_per_head = cached_key.value.shape
# update key, value caches with our new 1d spatial slices
cur_index = cache_index.value
indices = (0,) * len(batch_dims) + (cur_index, 0, 0)
key = lax.dynamic_update_slice(cached_key.value, key, indices)
value = lax.dynamic_update_slice(cached_value.value, value, indices)
cached_key.value = key
cached_value.value = value
num_updated_cache_vectors = query.shape[1]
cache_index.value = cache_index.value + num_updated_cache_vectors
# causal mask for cached decoder self-attention: our single query position should only attend to those key
# positions that have already been generated and cached, not the remaining zero elements.
pad_mask = jnp.broadcast_to(
jnp.arange(max_length) < cur_index + num_updated_cache_vectors,
tuple(batch_dims) + (1, num_updated_cache_vectors, max_length),
)
attention_mask = combine_masks(pad_mask, attention_mask)
return key, value, attention_mask
def __call__(
self,
hidden_states,
residual,
alibi,
attention_mask=None,
deterministic: bool = True,
init_cache: bool = False,
output_attentions: bool = False,
):
batch_size, seq_length = hidden_states.shape[:2]
# proj q, k, v
fused_qkv = self.query_key_value(hidden_states)
fused_qkv = self._split_heads(fused_qkv)
query, key, value = jnp.split(fused_qkv, 3, axis=-1)
causal_attention_mask = make_causal_mask(attention_mask, dtype="bool")
# for fast decoding causal attention mask should be shifted
causal_attention_mask_shift = (
self.variables["cache"]["cache_index"] if self.has_variable("cache", "cached_key") else 0
)
# fast decoding for generate requires special attention_mask
if self.has_variable("cache", "cached_key"):
max_decoder_length = self.variables["cache"]["cached_key"].shape[1]
causal_attention_mask = jax.lax.dynamic_slice(
causal_attention_mask,
(0, 0, causal_attention_mask_shift, 0),
(1, 1, seq_length, max_decoder_length),
)
# broadcast causal attention mask & attention mask to fit for merge
causal_attention_mask = jnp.broadcast_to(
causal_attention_mask, (batch_size,) + causal_attention_mask.shape[1:]
)
attention_mask = jnp.broadcast_to(jnp.expand_dims(attention_mask, axis=(-3, -2)), causal_attention_mask.shape)
attention_mask = combine_masks(attention_mask, causal_attention_mask)
dropout_rng = None
if not deterministic and self.config.attention_dropout > 0.0:
dropout_rng = self.make_rng("dropout")
# During fast autoregressive decoding, we feed one position at a time,
# and cache the keys and values step by step.
if self.has_variable("cache", "cached_key") or init_cache:
key, value, attention_mask = self._concatenate_to_cache(key, value, query, attention_mask)
# transform boolean mask into float mask
mask_value = jnp.finfo(self.dtype).min
attention_bias = lax.select(
attention_mask > 0,
jnp.full(attention_mask.shape, 0.0).astype(self.dtype),
jnp.full(attention_mask.shape, mask_value).astype(self.dtype),
)
attention_bias = attention_bias + alibi
# Cast in fp32 if the original dtype is different from fp32
attention_dtype = jnp.float32 if self.attention_softmax_in_fp32 else self.dtype
attn_weights = dot_product_attention_weights(
query,
key,
bias=attention_bias,
dropout_rng=dropout_rng,
dropout_rate=self.config.attention_dropout,
deterministic=deterministic,
dtype=attention_dtype,
)
# Cast back in the original dtype if the native dtype is not fp32
if self.attention_softmax_in_fp32:
attn_weights = attn_weights.astype(self.dtype)
attn_output = jnp.einsum("...hqk,...khd->...qhd", attn_weights, value)
attn_output = self._merge_heads(attn_output)
attn_output = self.dense(attn_output)
attn_output = self.resid_dropout(attn_output, deterministic=deterministic)
attn_output = attn_output + residual
outputs = (attn_output, attn_weights) if output_attentions else (attn_output,)
return outputs
class BloomGELU(nn.Module):
def setup(self):
self.dtype = jnp.float32
def __call__(self, x):
return x * 0.5 * (1.0 + tanh(0.79788456 * x * (1 + 0.044715 * x * x)))
class FlaxBloomMLP(nn.Module):
config: BloomConfig
dtype: jnp.dtype = jnp.float32
def setup(self):
hidden_size = self.config.hidden_size
kernel_init = jax.nn.initializers.normal(self.config.initializer_range)
self.dense_h_to_4h = nn.Dense(4 * hidden_size, dtype=self.dtype, kernel_init=kernel_init)
self.dense_4h_to_h = nn.Dense(hidden_size, dtype=self.dtype, kernel_init=kernel_init)
self.hidden_dropout = nn.Dropout(self.config.hidden_dropout)
self.act = BloomGELU()
def __call__(self, hidden_states, residual, deterministic: bool = True):
hidden_states = self.dense_h_to_4h(hidden_states)
hidden_states = self.act(hidden_states)
intermediate_output = self.dense_4h_to_h(hidden_states)
intermediate_output = intermediate_output + residual
hidden_states = self.hidden_dropout(intermediate_output, deterministic=deterministic)
return hidden_states
class FlaxBloomBlock(nn.Module):
config: BloomConfig
dtype: jnp.dtype = jnp.float32
def setup(self):
self.input_layernorm = nn.LayerNorm(epsilon=self.config.layer_norm_epsilon, dtype=self.dtype)
self.self_attention = FlaxBloomAttention(self.config, dtype=self.dtype)
self.post_attention_layernorm = nn.LayerNorm(epsilon=self.config.layer_norm_epsilon, dtype=self.dtype)
self.mlp = FlaxBloomMLP(self.config, dtype=self.dtype)
self.apply_residual_connection_post_layernorm = self.config.apply_residual_connection_post_layernorm
self.hidden_dropout = self.config.hidden_dropout
def __call__(
self,
hidden_states,
alibi,
attention_mask=None,
deterministic: bool = True,
init_cache: bool = False,
output_attentions: bool = False,
):
layernorm_output = self.input_layernorm(hidden_states)
# layer norm before saving residual if config calls for it
if self.apply_residual_connection_post_layernorm:
residual = layernorm_output
else:
residual = hidden_states
# self-attention
attn_outputs = self.self_attention(
layernorm_output,
residual=residual,
alibi=alibi,
attention_mask=attention_mask,
deterministic=deterministic,
init_cache=init_cache,
output_attentions=output_attentions,
)
attention_output = attn_outputs[0]
outputs = attn_outputs[1:]
post_layernorm = self.post_attention_layernorm(attention_output)
# set residual based on config
if self.apply_residual_connection_post_layernorm:
residual = post_layernorm
else:
residual = attention_output
output = self.mlp(post_layernorm, residual, deterministic=deterministic)
outputs = (output,) + outputs
return outputs
class FlaxBloomPreTrainedModel(FlaxPreTrainedModel):
"""
An abstract class to handle weights initialization and a simple interface for downloading and loading pretrained
models.
"""
config_class = BloomConfig
base_model_prefix = "transformer"
module_class: nn.Module = None
def __init__(
self,
config: BloomConfig,
input_shape: Tuple = (1, 1),
seed: int = 0,
dtype: jnp.dtype = jnp.float32,
_do_init: bool = True,
**kwargs,
):
module = self.module_class(config=config, dtype=dtype, **kwargs)
super().__init__(config, module, input_shape=input_shape, seed=seed, dtype=dtype, _do_init=_do_init)
def init_weights(self, rng: jax.random.PRNGKey, input_shape: Tuple, params: FrozenDict = None) -> FrozenDict:
# init input tensors
input_ids = jnp.zeros(input_shape, dtype="i4")
attention_mask = jnp.ones_like(input_ids)
params_rng, dropout_rng = jax.random.split(rng)
rngs = {"params": params_rng, "dropout": dropout_rng}
random_params = self.module.init(rngs, input_ids, attention_mask, return_dict=False)["params"]
if params is not None:
random_params = flatten_dict(unfreeze(random_params))
params = flatten_dict(unfreeze(params))
for missing_key in self._missing_keys:
params[missing_key] = random_params[missing_key]
self._missing_keys = set()
return freeze(unflatten_dict(params))
else:
return random_params
def init_cache(self, batch_size, max_length):
r"""
Args:
batch_size (`int`):
batch_size used for fast auto-regressive decoding. Defines the batch size of the initialized cache.
max_length (`int`):
maximum possible length for auto-regressive decoding. Defines the sequence length of the initialized
cache.
"""
# init input variables to retrieve cache
input_ids = jnp.ones((batch_size, max_length), dtype="i4")
attention_mask = jnp.ones_like(input_ids)
init_variables = self.module.init(
jax.random.PRNGKey(0), input_ids, attention_mask, return_dict=False, init_cache=True
)
return unfreeze(init_variables["cache"])
@add_start_docstrings_to_model_forward(BLOOM_INPUTS_DOCSTRING)
def __call__(
self,
input_ids,
attention_mask=None,
past_key_values: dict = None,
params: dict = None,
dropout_rng: jax.random.PRNGKey = None,
train: bool = False,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
):
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
output_hidden_states = (
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
)
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
batch_size, sequence_length = input_ids.shape
if attention_mask is None:
attention_mask = jnp.ones((batch_size, sequence_length))
# Handle any PRNG if needed
rngs = {}
if dropout_rng is not None:
rngs["dropout"] = dropout_rng
inputs = {"params": params or self.params}
# If past_key_values are passed then cache is already initialized a private flag init_cache has to be passed
# down to ensure cache is used. It has to be made sure that cache is marked as mutable so that it can be
# changed by FlaxBloomAttention module
if past_key_values:
inputs["cache"] = past_key_values
mutable = ["cache"]
else:
mutable = False
outputs = self.module.apply(
inputs,
jnp.array(input_ids, dtype="i4"),
jnp.array(attention_mask, dtype="i4"),
not train,
False,
output_attentions,
output_hidden_states,
return_dict,
rngs=rngs,
mutable=mutable,
)
# add updated cache to model output
if past_key_values is not None and return_dict:
outputs, past_key_values = outputs
outputs["past_key_values"] = unfreeze(past_key_values["cache"])
return outputs
elif past_key_values is not None and not return_dict:
outputs, past_key_values = outputs
outputs = outputs[:1] + (unfreeze(past_key_values["cache"]),) + outputs[1:]
return outputs
class FlaxBloomBlockCollection(nn.Module):
config: BloomConfig
dtype: jnp.dtype = jnp.float32
def setup(self):
self.layers = [
FlaxBloomBlock(self.config, name=str(layer_number), dtype=self.dtype)
for layer_number in range(self.config.num_hidden_layers)
]
def __call__(
self,
hidden_states,
alibi,
attention_mask=None,
deterministic: bool = True,
init_cache: bool = False,
output_attentions: bool = False,
output_hidden_states: bool = False,
):
all_attentions = () if output_attentions else None
all_hidden_states = () if output_hidden_states else None
for layer_number in range(self.config.num_hidden_layers):
if output_hidden_states:
all_hidden_states += (hidden_states,)
layer_outputs = self.layers[layer_number](
hidden_states,
alibi=alibi,
attention_mask=attention_mask,
deterministic=deterministic,
init_cache=init_cache,
output_attentions=output_attentions,
)
hidden_states = layer_outputs[0]
if output_attentions:
all_attentions += (layer_outputs[1],)
# this contains possible `None` values - `FlaxBloomModule` will filter them out
outputs = (hidden_states, all_hidden_states, all_attentions)
return outputs
class FlaxBloomModule(nn.Module):
config: BloomConfig
dtype: jnp.dtype = jnp.float32
def setup(self):
self.embed_dim = self.config.hidden_size
# word embeddings (no positional embedding layer)
self.word_embeddings = nn.Embed(
self.config.vocab_size,
self.embed_dim,
embedding_init=jax.nn.initializers.normal(stddev=self.config.initializer_range),
dtype=self.dtype,
)
# post-embedding layernorm
self.word_embeddings_layernorm = nn.LayerNorm(epsilon=self.config.layer_norm_epsilon, dtype=self.dtype)
# transformer layers
self.h = FlaxBloomBlockCollection(self.config, dtype=self.dtype)
# final layernorm
self.ln_f = nn.LayerNorm(epsilon=self.config.layer_norm_epsilon, dtype=self.dtype)
def __call__(
self,
input_ids=None,
attention_mask=None,
deterministic=True,
init_cache: bool = False,
output_attentions: bool = False,
output_hidden_states: bool = False,
return_dict: bool = True,
):
inputs_embeds = self.word_embeddings(input_ids)
# do post-embedding layernorm
hidden_states = self.word_embeddings_layernorm(inputs_embeds)
# build alibi depending on `attention_mask`
alibi = build_alibi_tensor(attention_mask, self.config.n_head, dtype=hidden_states.dtype)
outputs = self.h(
hidden_states,
alibi=alibi,
attention_mask=attention_mask,
deterministic=deterministic,
init_cache=init_cache,
output_hidden_states=output_hidden_states,
output_attentions=output_attentions,
)
hidden_states = outputs[0]
hidden_states = self.ln_f(hidden_states)
if output_hidden_states:
all_hidden_states = outputs[1] + (hidden_states,)
outputs = (hidden_states, all_hidden_states) + outputs[2:]
else:
outputs = (hidden_states,) + outputs[1:]
if not return_dict:
return tuple(v for v in [outputs[0], outputs[-1]] if v is not None)
return FlaxBaseModelOutputWithPastAndCrossAttentions(
last_hidden_state=hidden_states,
hidden_states=outputs[1],
attentions=outputs[-1],
)
@add_start_docstrings(
"The bare Bloom Model transformer outputting raw hidden-states without any specific head on top.",
BLOOM_START_DOCSTRING,
)
# Copied from transformers.models.gpt_neo.modeling_flax_gpt_neo.FlaxGPTNeoModel with GPTNeo->Bloom
class FlaxBloomModel(FlaxBloomPreTrainedModel):
module_class = FlaxBloomModule
append_call_sample_docstring(FlaxBloomModel, _CHECKPOINT_FOR_DOC, FlaxBaseModelOutput, _CONFIG_FOR_DOC)
class FlaxBloomForCausalLMModule(nn.Module):
config: BloomConfig
dtype: jnp.dtype = jnp.float32
def setup(self):
self.transformer = FlaxBloomModule(self.config, dtype=self.dtype)
self.lm_head = nn.Dense(
self.config.vocab_size,
use_bias=False,
dtype=self.dtype,
kernel_init=jax.nn.initializers.normal(stddev=self.config.initializer_range),
)
def __call__(
self,
input_ids,
attention_mask,
deterministic: bool = True,
init_cache: bool = False,
output_attentions: bool = False,
output_hidden_states: bool = False,
return_dict: bool = True,
):
outputs = self.transformer(
input_ids,
attention_mask=attention_mask,
deterministic=deterministic,
init_cache=init_cache,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
hidden_states = outputs[0]
if self.config.tie_word_embeddings:
shared_kernel = self.transformer.variables["params"]["word_embeddings"]["embedding"].T
lm_logits = self.lm_head.apply({"params": {"kernel": shared_kernel}}, hidden_states)
else:
lm_logits = self.lm_head(hidden_states)
if not return_dict:
return (lm_logits,) + outputs[1:]
return FlaxCausalLMOutput(logits=lm_logits, hidden_states=outputs.hidden_states, attentions=outputs.attentions)
@add_start_docstrings(
"""
The Bloom Model transformer with a language modeling head on top (linear layer with weights tied to the input
embeddings).
""",
BLOOM_START_DOCSTRING,
)
class FlaxBloomForCausalLM(FlaxBloomPreTrainedModel):
module_class = FlaxBloomForCausalLMModule
def prepare_inputs_for_generation(self, input_ids, max_length, attention_mask: Optional[jax.Array] = None):
# initializing the cache
batch_size, seq_length = input_ids.shape
past_key_values = self.init_cache(batch_size, max_length)
# Note that usually one would have to put 0's in the attention_mask for
# x > input_ids.shape[-1] and x < cache_length. But since Bloom uses a causal mask,
# those positions are masked anyway. Thus, we can create a single static attention_mask here,
# which is more efficient for compilation
extended_attention_mask = jnp.ones((batch_size, max_length), dtype="i4")
if attention_mask is not None:
extended_attention_mask = lax.dynamic_update_slice(extended_attention_mask, attention_mask, (0, 0))
return {
"past_key_values": past_key_values,
"attention_mask": extended_attention_mask,
}
def update_inputs_for_generation(self, model_outputs, model_kwargs):
model_kwargs["past_key_values"] = model_outputs.past_key_values
return model_kwargs
append_call_sample_docstring(FlaxBloomForCausalLM, _CHECKPOINT_FOR_DOC, FlaxCausalLMOutput, _CONFIG_FOR_DOC)
| transformers/src/transformers/models/bloom/modeling_flax_bloom.py/0 | {
"file_path": "transformers/src/transformers/models/bloom/modeling_flax_bloom.py",
"repo_id": "transformers",
"token_count": 12766
} | 76 |
# coding=utf-8
# Copyright 2021 The Open AI Team Authors and The HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""Tokenization classes for CLIP."""
import json
import os
import unicodedata
from functools import lru_cache
from typing import List, Optional, Tuple
import regex as re
from ...tokenization_utils import AddedToken, PreTrainedTokenizer, _is_control, _is_punctuation, _is_whitespace
from ...utils import logging
logger = logging.get_logger(__name__)
VOCAB_FILES_NAMES = {
"vocab_file": "vocab.json",
"merges_file": "merges.txt",
}
PRETRAINED_VOCAB_FILES_MAP = {
"vocab_file": {
"openai/clip-vit-base-patch32": "https://huggingface.co/openai/clip-vit-base-patch32/resolve/main/vocab.json",
},
"merges_file": {
"openai/clip-vit-base-patch32": "https://huggingface.co/openai/clip-vit-base-patch32/resolve/main/merges.txt",
},
}
PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
"openai/clip-vit-base-patch32": 77,
}
PRETRAINED_INIT_CONFIGURATION = {
"openai/clip-vit-base-patch32": {},
}
@lru_cache()
def bytes_to_unicode():
"""
Returns list of utf-8 byte and a mapping to unicode strings. We specifically avoids mapping to whitespace/control
characters the bpe code barfs on.
The reversible bpe codes work on unicode strings. This means you need a large # of unicode characters in your vocab
if you want to avoid UNKs. When you're at something like a 10B token dataset you end up needing around 5K for
decent coverage. This is a significant percentage of your normal, say, 32K bpe vocab. To avoid that, we want lookup
tables between utf-8 bytes and unicode strings.
"""
bs = (
list(range(ord("!"), ord("~") + 1)) + list(range(ord("¡"), ord("¬") + 1)) + list(range(ord("®"), ord("ÿ") + 1))
)
cs = bs[:]
n = 0
for b in range(2**8):
if b not in bs:
bs.append(b)
cs.append(2**8 + n)
n += 1
cs = [chr(n) for n in cs]
return dict(zip(bs, cs))
def get_pairs(word):
"""
Return set of symbol pairs in a word.
Word is represented as tuple of symbols (symbols being variable-length strings).
"""
pairs = set()
prev_char = word[0]
for char in word[1:]:
pairs.add((prev_char, char))
prev_char = char
return pairs
def whitespace_clean(text):
text = re.sub(r"\s+", " ", text)
text = text.strip()
return text
# Copied from transformers.models.bert.tokenization_bert.whitespace_tokenize
def whitespace_tokenize(text):
"""Runs basic whitespace cleaning and splitting on a piece of text."""
text = text.strip()
if not text:
return []
tokens = text.split()
return tokens
# Copied from transformers.models.bert.tokenization_bert.BasicTokenizer
class BasicTokenizer(object):
"""
Constructs a BasicTokenizer that will run basic tokenization (punctuation splitting, lower casing, etc.).
Args:
do_lower_case (`bool`, *optional*, defaults to `True`):
Whether or not to lowercase the input when tokenizing.
never_split (`Iterable`, *optional*):
Collection of tokens which will never be split during tokenization. Only has an effect when
`do_basic_tokenize=True`
tokenize_chinese_chars (`bool`, *optional*, defaults to `True`):
Whether or not to tokenize Chinese characters.
This should likely be deactivated for Japanese (see this
[issue](https://github.com/huggingface/transformers/issues/328)).
strip_accents (`bool`, *optional*):
Whether or not to strip all accents. If this option is not specified, then it will be determined by the
value for `lowercase` (as in the original BERT).
do_split_on_punc (`bool`, *optional*, defaults to `True`):
In some instances we want to skip the basic punctuation splitting so that later tokenization can capture
the full context of the words, such as contractions.
"""
def __init__(
self,
do_lower_case=True,
never_split=None,
tokenize_chinese_chars=True,
strip_accents=None,
do_split_on_punc=True,
):
if never_split is None:
never_split = []
self.do_lower_case = do_lower_case
self.never_split = set(never_split)
self.tokenize_chinese_chars = tokenize_chinese_chars
self.strip_accents = strip_accents
self.do_split_on_punc = do_split_on_punc
def tokenize(self, text, never_split=None):
"""
Basic Tokenization of a piece of text. For sub-word tokenization, see WordPieceTokenizer.
Args:
never_split (`List[str]`, *optional*)
Kept for backward compatibility purposes. Now implemented directly at the base class level (see
[`PreTrainedTokenizer.tokenize`]) List of token not to split.
"""
# union() returns a new set by concatenating the two sets.
never_split = self.never_split.union(set(never_split)) if never_split else self.never_split
text = self._clean_text(text)
# This was added on November 1st, 2018 for the multilingual and Chinese
# models. This is also applied to the English models now, but it doesn't
# matter since the English models were not trained on any Chinese data
# and generally don't have any Chinese data in them (there are Chinese
# characters in the vocabulary because Wikipedia does have some Chinese
# words in the English Wikipedia.).
if self.tokenize_chinese_chars:
text = self._tokenize_chinese_chars(text)
# prevents treating the same character with different unicode codepoints as different characters
unicode_normalized_text = unicodedata.normalize("NFC", text)
orig_tokens = whitespace_tokenize(unicode_normalized_text)
split_tokens = []
for token in orig_tokens:
if token not in never_split:
if self.do_lower_case:
token = token.lower()
if self.strip_accents is not False:
token = self._run_strip_accents(token)
elif self.strip_accents:
token = self._run_strip_accents(token)
split_tokens.extend(self._run_split_on_punc(token, never_split))
output_tokens = whitespace_tokenize(" ".join(split_tokens))
return output_tokens
def _run_strip_accents(self, text):
"""Strips accents from a piece of text."""
text = unicodedata.normalize("NFD", text)
output = []
for char in text:
cat = unicodedata.category(char)
if cat == "Mn":
continue
output.append(char)
return "".join(output)
def _run_split_on_punc(self, text, never_split=None):
"""Splits punctuation on a piece of text."""
if not self.do_split_on_punc or (never_split is not None and text in never_split):
return [text]
chars = list(text)
i = 0
start_new_word = True
output = []
while i < len(chars):
char = chars[i]
if _is_punctuation(char):
output.append([char])
start_new_word = True
else:
if start_new_word:
output.append([])
start_new_word = False
output[-1].append(char)
i += 1
return ["".join(x) for x in output]
def _tokenize_chinese_chars(self, text):
"""Adds whitespace around any CJK character."""
output = []
for char in text:
cp = ord(char)
if self._is_chinese_char(cp):
output.append(" ")
output.append(char)
output.append(" ")
else:
output.append(char)
return "".join(output)
def _is_chinese_char(self, cp):
"""Checks whether CP is the codepoint of a CJK character."""
# This defines a "chinese character" as anything in the CJK Unicode block:
# https://en.wikipedia.org/wiki/CJK_Unified_Ideographs_(Unicode_block)
#
# Note that the CJK Unicode block is NOT all Japanese and Korean characters,
# despite its name. The modern Korean Hangul alphabet is a different block,
# as is Japanese Hiragana and Katakana. Those alphabets are used to write
# space-separated words, so they are not treated specially and handled
# like the all of the other languages.
if (
(cp >= 0x4E00 and cp <= 0x9FFF)
or (cp >= 0x3400 and cp <= 0x4DBF) #
or (cp >= 0x20000 and cp <= 0x2A6DF) #
or (cp >= 0x2A700 and cp <= 0x2B73F) #
or (cp >= 0x2B740 and cp <= 0x2B81F) #
or (cp >= 0x2B820 and cp <= 0x2CEAF) #
or (cp >= 0xF900 and cp <= 0xFAFF)
or (cp >= 0x2F800 and cp <= 0x2FA1F) #
): #
return True
return False
def _clean_text(self, text):
"""Performs invalid character removal and whitespace cleanup on text."""
output = []
for char in text:
cp = ord(char)
if cp == 0 or cp == 0xFFFD or _is_control(char):
continue
if _is_whitespace(char):
output.append(" ")
else:
output.append(char)
return "".join(output)
class CLIPTokenizer(PreTrainedTokenizer):
"""
Construct a CLIP tokenizer. Based on byte-level Byte-Pair-Encoding.
This tokenizer inherits from [`PreTrainedTokenizer`] which contains most of the main methods. Users should refer to
this superclass for more information regarding those methods.
Args:
vocab_file (`str`):
Path to the vocabulary file.
merges_file (`str`):
Path to the merges file.
errors (`str`, *optional*, defaults to `"replace"`):
Paradigm to follow when decoding bytes to UTF-8. See
[bytes.decode](https://docs.python.org/3/library/stdtypes.html#bytes.decode) for more information.
unk_token (`str`, *optional*, defaults to `"<|endoftext|>"`):
The unknown token. A token that is not in the vocabulary cannot be converted to an ID and is set to be this
token instead.
bos_token (`str`, *optional*, defaults to `"<|startoftext|>"`):
The beginning of sequence token.
eos_token (`str`, *optional*, defaults to `"<|endoftext|>"`):
The end of sequence token.
pad_token (`str`, *optional*, defaults to `"<|endoftext|>"`):
The token used for padding, for example when batching sequences of different lengths.
"""
vocab_files_names = VOCAB_FILES_NAMES
pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
model_input_names = ["input_ids", "attention_mask"]
def __init__(
self,
vocab_file,
merges_file,
errors="replace",
unk_token="<|endoftext|>",
bos_token="<|startoftext|>",
eos_token="<|endoftext|>",
pad_token="<|endoftext|>", # hack to enable padding
**kwargs,
):
bos_token = AddedToken(bos_token, lstrip=False, rstrip=False) if isinstance(bos_token, str) else bos_token
eos_token = AddedToken(eos_token, lstrip=False, rstrip=False) if isinstance(eos_token, str) else eos_token
unk_token = AddedToken(unk_token, lstrip=False, rstrip=False) if isinstance(unk_token, str) else unk_token
try:
import ftfy
self.fix_text = ftfy.fix_text
except ImportError:
logger.info("ftfy or spacy is not installed using custom BasicTokenizer instead of ftfy.")
self.nlp = BasicTokenizer(strip_accents=False, do_split_on_punc=False)
self.fix_text = None
with open(vocab_file, encoding="utf-8") as vocab_handle:
self.encoder = json.load(vocab_handle)
self.decoder = {v: k for k, v in self.encoder.items()}
self.errors = errors # how to handle errors in decoding
self.byte_encoder = bytes_to_unicode()
self.byte_decoder = {v: k for k, v in self.byte_encoder.items()}
with open(merges_file, encoding="utf-8") as merges_handle:
bpe_merges = merges_handle.read().strip().split("\n")[1 : 49152 - 256 - 2 + 1]
bpe_merges = [tuple(merge.split()) for merge in bpe_merges]
self.bpe_ranks = dict(zip(bpe_merges, range(len(bpe_merges))))
self.cache = {"<|startoftext|>": "<|startoftext|>", "<|endoftext|>": "<|endoftext|>"}
self.pat = re.compile(
r"""<\|startoftext\|>|<\|endoftext\|>|'s|'t|'re|'ve|'m|'ll|'d|[\p{L}]+|[\p{N}]|[^\s\p{L}\p{N}]+""",
re.IGNORECASE,
)
super().__init__(
errors=errors,
unk_token=unk_token,
bos_token=bos_token,
eos_token=eos_token,
pad_token=pad_token,
**kwargs,
)
@property
def vocab_size(self):
return len(self.encoder)
def get_vocab(self):
return dict(self.encoder, **self.added_tokens_encoder)
def build_inputs_with_special_tokens(
self, token_ids_0: List[int], token_ids_1: Optional[List[int]] = None
) -> List[int]:
"""
Build model inputs from a sequence or a pair of sequence for sequence classification tasks by concatenating and
adding special tokens. A CLIP sequence has the following format:
- single sequence: `<|startoftext|> X <|endoftext|>`
Pairs of sequences are not the expected use case, but they will be handled without a separator.
Args:
token_ids_0 (`List[int]`):
List of IDs to which the special tokens will be added.
token_ids_1 (`List[int]`, *optional*):
Optional second list of IDs for sequence pairs.
Returns:
`List[int]`: List of [input IDs](../glossary#input-ids) with the appropriate special tokens.
"""
bos_token = [self.bos_token_id]
eos_token = [self.eos_token_id]
if token_ids_1 is None:
return bos_token + token_ids_0 + eos_token
return bos_token + token_ids_0 + eos_token + eos_token + token_ids_1 + eos_token
def get_special_tokens_mask(
self, token_ids_0: List[int], token_ids_1: Optional[List[int]] = None, already_has_special_tokens: bool = False
) -> List[int]:
"""
Retrieve sequence ids from a token list that has no special tokens added. This method is called when adding
special tokens using the tokenizer `prepare_for_model` method.
Args:
token_ids_0 (`List[int]`):
List of IDs.
token_ids_1 (`List[int]`, *optional*):
Optional second list of IDs for sequence pairs.
already_has_special_tokens (`bool`, *optional*, defaults to `False`):
Whether or not the token list is already formatted with special tokens for the model.
Returns:
`List[int]`: A list of integers in the range [0, 1]: 1 for a special token, 0 for a sequence token.
"""
if already_has_special_tokens:
return super().get_special_tokens_mask(
token_ids_0=token_ids_0, token_ids_1=token_ids_1, already_has_special_tokens=True
)
if token_ids_1 is None:
return [1] + ([0] * len(token_ids_0)) + [1]
return [1] + ([0] * len(token_ids_0)) + [1] + [1] + ([0] * len(token_ids_1)) + [1]
def create_token_type_ids_from_sequences(
self, token_ids_0: List[int], token_ids_1: Optional[List[int]] = None
) -> List[int]:
"""
Create a mask from the two sequences passed. CLIP does not make use of token type ids, therefore a list of
zeros is returned.
Args:
token_ids_0 (`List[int]`):
List of IDs.
token_ids_1 (`List[int]`, *optional*):
Optional second list of IDs for sequence pairs.
Returns:
`List[int]`: List of zeros.
"""
bos_token = [self.bos_token_id]
eos_token = [self.eos_token_id]
if token_ids_1 is None:
return len(bos_token + token_ids_0 + eos_token) * [0]
return len(bos_token + token_ids_0 + eos_token + eos_token + token_ids_1 + eos_token) * [0]
def bpe(self, token):
if token in self.cache:
return self.cache[token]
word = tuple(token[:-1]) + (token[-1] + "</w>",)
pairs = get_pairs(word)
if not pairs:
return token + "</w>"
while True:
bigram = min(pairs, key=lambda pair: self.bpe_ranks.get(pair, float("inf")))
if bigram not in self.bpe_ranks:
break
first, second = bigram
new_word = []
i = 0
while i < len(word):
try:
j = word.index(first, i)
except ValueError:
new_word.extend(word[i:])
break
else:
new_word.extend(word[i:j])
i = j
if word[i] == first and i < len(word) - 1 and word[i + 1] == second:
new_word.append(first + second)
i += 2
else:
new_word.append(word[i])
i += 1
new_word = tuple(new_word)
word = new_word
if len(word) == 1:
break
else:
pairs = get_pairs(word)
word = " ".join(word)
self.cache[token] = word
return word
def _tokenize(self, text):
"""Tokenize a string."""
bpe_tokens = []
if self.fix_text is None:
text = " ".join(self.nlp.tokenize(text))
else:
text = whitespace_clean(self.fix_text(text)).lower()
for token in re.findall(self.pat, text):
token = "".join(
self.byte_encoder[b] for b in token.encode("utf-8")
) # Maps all our bytes to unicode strings, avoiding control tokens of the BPE (spaces in our case)
bpe_tokens.extend(bpe_token for bpe_token in self.bpe(token).split(" "))
return bpe_tokens
def _convert_token_to_id(self, token):
"""Converts a token (str) in an id using the vocab."""
return self.encoder.get(token, self.encoder.get(self.unk_token))
def _convert_id_to_token(self, index):
"""Converts an index (integer) in a token (str) using the vocab."""
return self.decoder.get(index)
def convert_tokens_to_string(self, tokens):
"""Converts a sequence of tokens (string) in a single string."""
text = "".join(tokens)
byte_array = bytearray([self.byte_decoder[c] for c in text])
text = byte_array.decode("utf-8", errors=self.errors).replace("</w>", " ").strip()
return text
def save_vocabulary(self, save_directory: str, filename_prefix: Optional[str] = None) -> Tuple[str]:
if not os.path.isdir(save_directory):
logger.error("Vocabulary path ({}) should be a directory".format(save_directory))
return
vocab_file = os.path.join(
save_directory, (filename_prefix + "-" if filename_prefix else "") + VOCAB_FILES_NAMES["vocab_file"]
)
merge_file = os.path.join(
save_directory, (filename_prefix + "-" if filename_prefix else "") + VOCAB_FILES_NAMES["merges_file"]
)
with open(vocab_file, "w", encoding="utf-8") as f:
f.write(json.dumps(self.encoder, indent=2, sort_keys=True, ensure_ascii=False) + "\n")
index = 0
with open(merge_file, "w", encoding="utf-8") as writer:
writer.write("#version: 0.2\n")
for bpe_tokens, token_index in sorted(self.bpe_ranks.items(), key=lambda kv: kv[1]):
if index != token_index:
logger.warning(
"Saving vocabulary to {}: BPE merge indices are not consecutive."
" Please check that the tokenizer is not corrupted!".format(merge_file)
)
index = token_index
writer.write(" ".join(bpe_tokens) + "\n")
index += 1
return vocab_file, merge_file
| transformers/src/transformers/models/clip/tokenization_clip.py/0 | {
"file_path": "transformers/src/transformers/models/clip/tokenization_clip.py",
"repo_id": "transformers",
"token_count": 9519
} | 77 |
# coding=utf-8
# Copyright 2023 MetaAI and the HuggingFace Inc. team. All rights reserved.
#
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""Tokenization classes for Code LLaMA."""
import os
from shutil import copyfile
from typing import Any, Dict, List, Optional, Tuple
import sentencepiece as spm
from ...convert_slow_tokenizer import import_protobuf
from ...tokenization_utils import AddedToken, PreTrainedTokenizer
from ...utils import logging, requires_backends
logger = logging.get_logger(__name__)
VOCAB_FILES_NAMES = {"vocab_file": "tokenizer.model"}
PRETRAINED_VOCAB_FILES_MAP = {
"vocab_file": {
"hf-internal-testing/llama-code-tokenizer": "https://huggingface.co/hf-internal-testing/llama-tokenizer/resolve/main/tokenizer.model",
},
"tokenizer_file": {
"hf-internal-testing/llama-code-tokenizer": "https://huggingface.co/hf-internal-testing/llama-tokenizer/resolve/main/tokenizer_config.json",
},
}
PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
"hf-internal-testing/llama-code-tokenizer": 2048,
}
SPIECE_UNDERLINE = "▁"
B_INST, E_INST = "[INST]", "[/INST]"
B_SYS, E_SYS = "<<SYS>>\n", "\n<</SYS>>\n\n"
# fmt: off
DEFAULT_SYSTEM_PROMPT = """You are a helpful, respectful and honest assistant. Always answer as helpfully as possible, while being safe. Your \
answers should not include any harmful, unethical, racist, sexist, toxic, dangerous, or illegal content. Please ensure\
that your responses are socially unbiased and positive in nature.
If a question does not make any sense, or is not factually coherent, explain why instead of answering something not \
correct. If you don't know the answer to a question, please don't share false information."""
# fmt: on
class CodeLlamaTokenizer(PreTrainedTokenizer):
"""
Construct a CodeLlama tokenizer. Based on byte-level Byte-Pair-Encoding. The default padding token is unset as
there is no padding token in the original model.
The default configuration match that of
[codellama/CodeLlama-7b-Instruct-hf](https://huggingface.co/codellama/CodeLlama-7b-Instruct-hf/blob/main/tokenizer_config.json)
which supports prompt infilling.
Args:
vocab_file (`str`):
Path to the vocabulary file.
unk_token (`str`, *optional*, defaults to `"<unk>"`):
The unknown token. A token that is not in the vocabulary cannot be converted to an ID and is set to be this
token instead.
bos_token (`str`, *optional*, defaults to `"<s>"`):
The beginning of sequence token that was used during pretraining. Can be used a sequence classifier token.
eos_token (`str`, *optional*, defaults to `"</s>"`):
The end of sequence token.
<Tip>
When building a sequence using special tokens, this is not the token that is used for the end of sequence.
The token used is the `sep_token`.
</Tip>
prefix_token (`str`, *optional*, defaults to `"▁<PRE>"`):
Prefix token used for infilling.
middle_token (`str`, *optional*, defaults to `"▁<MID>"`):
Middle token used for infilling.
suffix_token (`str`, *optional*, defaults to `"▁<SUF>"`):
Suffix token used for infilling.
eot_token (`str`, *optional*, defaults to `"▁<EOT>"`):
End of text token used for infilling.
fill_token (`str`, *optional*, defaults to `"<FILL_ME>"`):
The token used to split the input between the prefix and suffix.
suffix_first (`bool`, *optional*, defaults to `False`):
Whether the input prompt and suffix should be formatted with the suffix first.
sp_model_kwargs (`dict`, *optional*):
Will be passed to the `SentencePieceProcessor.__init__()` method. The [Python wrapper for
SentencePiece](https://github.com/google/sentencepiece/tree/master/python) can be used, among other things,
to set:
- `enable_sampling`: Enable subword regularization.
- `nbest_size`: Sampling parameters for unigram. Invalid for BPE-Dropout.
- `nbest_size = {0,1}`: No sampling is performed.
- `nbest_size > 1`: samples from the nbest_size results.
- `nbest_size < 0`: assuming that nbest_size is infinite and samples from the all hypothesis (lattice)
using forward-filtering-and-backward-sampling algorithm.
- `alpha`: Smoothing parameter for unigram sampling, and dropout probability of merge operations for
BPE-dropout.
add_bos_token (`bool`, *optional*, defaults to `True`):
Whether to add a beginning of sequence token at the start of sequences.
add_eos_token (`bool`, *optional*, defaults to `False`):
Whether to add an end of sequence token at the end of sequences.
clean_up_tokenization_spaces (`bool`, *optional*, defaults to `False`):
Whether or not to clean up the tokenization spaces.
additional_special_tokens (`List[str]`, *optional*):
Additional special tokens used by the tokenizer.
use_default_system_prompt (`bool`, *optional*, defaults to `False`):
Whether or not the default system prompt for Llama should be used.
"""
vocab_files_names = VOCAB_FILES_NAMES
pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
model_input_names = ["input_ids", "attention_mask"]
def __init__(
self,
vocab_file,
unk_token="<unk>",
bos_token="<s>",
eos_token="</s>",
prefix_token="▁<PRE>",
middle_token="▁<MID>",
suffix_token="▁<SUF>",
eot_token="▁<EOT>",
fill_token="<FILL_ME>",
suffix_first=False,
sp_model_kwargs: Optional[Dict[str, Any]] = None,
add_bos_token=True,
add_eos_token=False,
clean_up_tokenization_spaces=False,
additional_special_tokens=None,
use_default_system_prompt=False,
**kwargs,
):
requires_backends(self, "protobuf")
self.sp_model_kwargs = {} if sp_model_kwargs is None else sp_model_kwargs
bos_token = AddedToken(bos_token, normalized=False, special=True) if isinstance(bos_token, str) else bos_token
eos_token = AddedToken(eos_token, normalized=False, special=True) if isinstance(eos_token, str) else eos_token
unk_token = AddedToken(unk_token, normalized=False, special=True) if isinstance(unk_token, str) else unk_token
self.use_default_system_prompt = use_default_system_prompt
# mark tokens special to skip them
additional_special_tokens = additional_special_tokens or []
for token in [prefix_token, middle_token, suffix_token, eot_token]:
additional_special_tokens += [token] if token is not None else []
self.vocab_file = vocab_file
self.add_bos_token = add_bos_token
self.add_eos_token = add_eos_token
self._prefix_token = prefix_token
self._middle_token = middle_token
self._suffix_token = suffix_token
self._eot_token = eot_token
self.fill_token = fill_token
self.suffix_first = suffix_first
self.sp_model = self.get_spm_processor()
super().__init__(
bos_token=bos_token,
eos_token=eos_token,
unk_token=unk_token,
add_bos_token=add_bos_token,
add_eos_token=add_eos_token,
prefix_token=prefix_token,
middle_token=middle_token,
suffix_token=suffix_token,
eot_token=eot_token,
fill_token=fill_token,
sp_model_kwargs=self.sp_model_kwargs,
suffix_first=suffix_first,
clean_up_tokenization_spaces=clean_up_tokenization_spaces,
additional_special_tokens=additional_special_tokens,
use_default_system_prompt=use_default_system_prompt,
**kwargs,
)
@property
def unk_token_length(self):
return len(self.sp_model.encode(str(self.unk_token)))
def get_spm_processor(self):
tokenizer = spm.SentencePieceProcessor(**self.sp_model_kwargs)
with open(self.vocab_file, "rb") as f:
sp_model = f.read()
model_pb2 = import_protobuf()
model = model_pb2.ModelProto.FromString(sp_model)
normalizer_spec = model_pb2.NormalizerSpec()
normalizer_spec.add_dummy_prefix = False
model.normalizer_spec.MergeFrom(normalizer_spec)
sp_model = model.SerializeToString()
tokenizer.LoadFromSerializedProto(sp_model)
return tokenizer
@property
def prefix_token(self):
return self._prefix_token
@property
def prefix_id(self):
if self._prefix_token is None:
return None
return self.convert_tokens_to_ids(self.prefix_token)
@property
def middle_token(self):
return self._middle_token
@property
def middle_id(self):
if self._middle_token is None:
return None
return self.convert_tokens_to_ids(self.middle_token)
@property
def suffix_token(self):
return self._suffix_token
@property
def suffix_id(self):
if self._suffix_token is None:
return None
return self.convert_tokens_to_ids(self.suffix_token)
@property
def eot_token(self):
return self._eot_token
@property
def eot_id(self):
if self._eot_token is None:
return None
return self.convert_tokens_to_ids(self.eot_token)
@property
def vocab_size(self):
"""Returns vocab size"""
return self.sp_model.get_piece_size()
# Copied from transformers.models.llama.tokenization_llama.LlamaTokenizer.get_vocab
def get_vocab(self):
"""Returns vocab as a dict"""
vocab = {self.convert_ids_to_tokens(i): i for i in range(self.vocab_size)}
vocab.update(self.added_tokens_encoder)
return vocab
def tokenize(self, prefix, suffix=None, suffix_first=False, **kwargs) -> List[int]:
# add a prefix space to `prefix`
if self.fill_token is not None and self.fill_token in prefix and suffix is None:
prefix, suffix = prefix.split(self.fill_token)
if len(prefix) > 0:
prefix = SPIECE_UNDERLINE + prefix.replace(SPIECE_UNDERLINE, " ")
if suffix is None or len(suffix) < 1:
tokens = super().tokenize(prefix, **kwargs)
if len(tokens) > 1 and tokens[0] == SPIECE_UNDERLINE and tokens[1] in self.all_special_tokens:
tokens = tokens[1:]
return tokens
prefix_tokens = self._tokenize(prefix) # prefix has an extra `SPIECE_UNDERLINE`
if None in (self.prefix_id, self.middle_id, self.suffix_id):
raise ValueError(
"The input either includes a `prefix` and a `suffix` used for the infilling task,"
f" or can be split on the {self.fill_token} token, creating a suffix and prefix,"
" but the model does not support `infilling`."
)
suffix_tokens = self._tokenize(suffix) # make sure CodeLlama sp model does not mess up
suffix_first = suffix_first if suffix_first is not None else self.suffix_first
if suffix_first:
# format as " <PRE> <SUF>{suf} <MID> {pre}"
return [self.prefix_token, self.suffix_token] + suffix_tokens + [self.middle_token] + prefix_tokens
else:
# format as " <PRE> {pre} <SUF>{suf} <MID>"
return [self.prefix_token] + prefix_tokens + [self.suffix_token] + suffix_tokens + [self.middle_token]
def _tokenize(self, text, **kwargs):
"""
Returns a tokenized string.
We de-activated the `add_dummy_prefix` option, thus the sentencepiece internals will always strip any
SPIECE_UNDERLINE. For example: `self.sp_model.encode(f"{SPIECE_UNDERLINE}Hey", out_type = str)` will give
`['H', 'e', 'y']` instead of `['▁He', 'y']`. Thus we always encode `f"{unk_token}text"` and strip the
`unk_token`. Here is an example with `unk_token = "<unk>"` and `unk_token_length = 4`.
`self.tokenizer.sp_model.encode("<unk> Hey", out_type = str)[4:]`.
"""
tokens = self.sp_model.encode(text, out_type=str)
if not text.startswith((SPIECE_UNDERLINE, " ")):
return tokens
# 1. Encode string + prefix ex: "<unk> Hey"
tokens = self.sp_model.encode(self.unk_token + text, out_type=str)
# 2. Remove self.unk_token from ['<','unk','>', '▁Hey']
return tokens[self.unk_token_length :] if len(tokens) >= self.unk_token_length else tokens
# Copied from transformers.models.llama.tokenization_llama.LlamaTokenizer._convert_token_to_id
def _convert_token_to_id(self, token):
"""Converts a token (str) in an id using the vocab."""
return self.sp_model.piece_to_id(token)
# Copied from transformers.models.llama.tokenization_llama.LlamaTokenizer._convert_id_to_token
def _convert_id_to_token(self, index):
"""Converts an index (integer) in a token (str) using the vocab."""
token = self.sp_model.IdToPiece(index)
return token
def convert_tokens_to_string(self, tokens):
"""Converts a sequence of tokens (string) in a single string."""
# since we manually add the prefix space, we have to remove it when decoding
if tokens[0].startswith(SPIECE_UNDERLINE):
tokens[0] = tokens[0][1:]
current_sub_tokens = []
out_string = ""
for _, token in enumerate(tokens):
# make sure that special tokens are not decoded using sentencepiece model
if token in self.all_special_tokens:
out_string += self.sp_model.decode(current_sub_tokens) + token
current_sub_tokens = []
else:
current_sub_tokens.append(token)
out_string += self.sp_model.decode(current_sub_tokens)
return out_string
# Copied from transformers.models.llama.tokenization_llama.LlamaTokenizer.save_vocabulary
def save_vocabulary(self, save_directory, filename_prefix: Optional[str] = None) -> Tuple[str]:
"""
Save the vocabulary and special tokens file to a directory.
Args:
save_directory (`str`):
The directory in which to save the vocabulary.
Returns:
`Tuple(str)`: Paths to the files saved.
"""
if not os.path.isdir(save_directory):
logger.error(f"Vocabulary path ({save_directory}) should be a directory")
return
out_vocab_file = os.path.join(
save_directory, (filename_prefix + "-" if filename_prefix else "") + VOCAB_FILES_NAMES["vocab_file"]
)
if os.path.abspath(self.vocab_file) != os.path.abspath(out_vocab_file) and os.path.isfile(self.vocab_file):
copyfile(self.vocab_file, out_vocab_file)
elif not os.path.isfile(self.vocab_file):
with open(out_vocab_file, "wb") as fi:
content_spiece_model = self.sp_model.serialized_model_proto()
fi.write(content_spiece_model)
return (out_vocab_file,)
# Copied from transformers.models.llama.tokenization_llama.LlamaTokenizer.build_inputs_with_special_tokens
def build_inputs_with_special_tokens(self, token_ids_0, token_ids_1=None):
bos_token_id = [self.bos_token_id] if self.add_bos_token else []
eos_token_id = [self.eos_token_id] if self.add_eos_token else []
output = bos_token_id + token_ids_0 + eos_token_id
if token_ids_1 is not None:
output = output + bos_token_id + token_ids_1 + eos_token_id
return output
# Copied from transformers.models.llama.tokenization_llama.LlamaTokenizer.get_special_tokens_mask
def get_special_tokens_mask(
self, token_ids_0: List[int], token_ids_1: Optional[List[int]] = None, already_has_special_tokens: bool = False
) -> List[int]:
"""
Retrieve sequence ids from a token list that has no special tokens added. This method is called when adding
special tokens using the tokenizer `prepare_for_model` method.
Args:
token_ids_0 (`List[int]`):
List of IDs.
token_ids_1 (`List[int]`, *optional*):
Optional second list of IDs for sequence pairs.
already_has_special_tokens (`bool`, *optional*, defaults to `False`):
Whether or not the token list is already formatted with special tokens for the model.
Returns:
`List[int]`: A list of integers in the range [0, 1]: 1 for a special token, 0 for a sequence token.
"""
if already_has_special_tokens:
return super().get_special_tokens_mask(
token_ids_0=token_ids_0, token_ids_1=token_ids_1, already_has_special_tokens=True
)
bos_token_id = [1] if self.add_bos_token else []
eos_token_id = [1] if self.add_eos_token else []
if token_ids_1 is None:
return bos_token_id + ([0] * len(token_ids_0)) + eos_token_id
return (
bos_token_id
+ ([0] * len(token_ids_0))
+ eos_token_id
+ bos_token_id
+ ([0] * len(token_ids_1))
+ eos_token_id
)
# Copied from transformers.models.llama.tokenization_llama.LlamaTokenizer.create_token_type_ids_from_sequences
def create_token_type_ids_from_sequences(
self, token_ids_0: List[int], token_ids_1: Optional[List[int]] = None
) -> List[int]:
"""
Creates a mask from the two sequences passed to be used in a sequence-pair classification task. An ALBERT
sequence pair mask has the following format:
```
0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1
| first sequence | second sequence |
```
if token_ids_1 is None, only returns the first portion of the mask (0s).
Args:
token_ids_0 (`List[int]`):
List of ids.
token_ids_1 (`List[int]`, *optional*):
Optional second list of IDs for sequence pairs.
Returns:
`List[int]`: List of [token type IDs](../glossary#token-type-ids) according to the given sequence(s).
"""
bos_token_id = [self.bos_token_id] if self.add_bos_token else []
eos_token_id = [self.eos_token_id] if self.add_eos_token else []
output = [0] * len(bos_token_id + token_ids_0 + eos_token_id)
if token_ids_1 is not None:
output += [1] * len(bos_token_id + token_ids_1 + eos_token_id)
return output
@property
# Copied from transformers.models.llama.tokenization_llama.LlamaTokenizer.default_chat_template
def default_chat_template(self):
"""
LLaMA uses [INST] and [/INST] to indicate user messages, and <<SYS>> and <</SYS>> to indicate system messages.
Assistant messages do not have special tokens, because LLaMA chat models are generally trained with strict
user/assistant/user/assistant message ordering, and so assistant messages can be identified from the ordering
rather than needing special tokens. The system message is partly 'embedded' in the first user message, which
results in an unusual token ordering when it is present. This template should definitely be changed if you wish
to fine-tune a model with more flexible role ordering!
The output should look something like:
<bos>[INST] B_SYS SystemPrompt E_SYS Prompt [/INST] Answer <eos><bos>[INST] Prompt [/INST] Answer <eos>
<bos>[INST] Prompt [/INST]
The reference for this chat template is [this code
snippet](https://github.com/facebookresearch/llama/blob/556949fdfb72da27c2f4a40b7f0e4cf0b8153a28/llama/generation.py#L320-L362)
in the original repository.
"""
logger.warning_once(
"\nNo chat template is defined for this tokenizer - using the default template "
f"for the {self.__class__.__name__} class. If the default is not appropriate for "
"your model, please set `tokenizer.chat_template` to an appropriate template. "
"See https://huggingface.co/docs/transformers/main/chat_templating for more information.\n"
)
template = (
"{% if messages[0]['role'] == 'system' %}"
"{% set loop_messages = messages[1:] %}" # Extract system message if it's present
"{% set system_message = messages[0]['content'] %}"
"{% elif USE_DEFAULT_PROMPT == true and not '<<SYS>>' in messages[0]['content'] %}"
"{% set loop_messages = messages %}" # Or use the default system message if the flag is set
"{% set system_message = 'DEFAULT_SYSTEM_MESSAGE' %}"
"{% else %}"
"{% set loop_messages = messages %}"
"{% set system_message = false %}"
"{% endif %}"
"{% for message in loop_messages %}" # Loop over all non-system messages
"{% if (message['role'] == 'user') != (loop.index0 % 2 == 0) %}"
"{{ raise_exception('Conversation roles must alternate user/assistant/user/assistant/...') }}"
"{% endif %}"
"{% if loop.index0 == 0 and system_message != false %}" # Embed system message in first message
"{% set content = '<<SYS>>\\n' + system_message + '\\n<</SYS>>\\n\\n' + message['content'] %}"
"{% else %}"
"{% set content = message['content'] %}"
"{% endif %}"
"{% if message['role'] == 'user' %}" # After all of that, handle messages/roles in a fairly normal way
"{{ bos_token + '[INST] ' + content.strip() + ' [/INST]' }}"
"{% elif message['role'] == 'system' %}"
"{{ '<<SYS>>\\n' + content.strip() + '\\n<</SYS>>\\n\\n' }}"
"{% elif message['role'] == 'assistant' %}"
"{{ ' ' + content.strip() + ' ' + eos_token }}"
"{% endif %}"
"{% endfor %}"
)
template = template.replace("USE_DEFAULT_PROMPT", "true" if self.use_default_system_prompt else "false")
default_message = DEFAULT_SYSTEM_PROMPT.replace("\n", "\\n").replace("'", "\\'")
template = template.replace("DEFAULT_SYSTEM_MESSAGE", default_message)
return template
def __getstate__(self):
state = self.__dict__.copy()
state["sp_model"] = None
state["sp_model_proto"] = self.sp_model.serialized_model_proto()
return state
def __setstate__(self, d):
self.__dict__ = d
self.sp_model = spm.SentencePieceProcessor(**self.sp_model_kwargs)
self.sp_model.LoadFromSerializedProto(self.sp_model_proto)
| transformers/src/transformers/models/code_llama/tokenization_code_llama.py/0 | {
"file_path": "transformers/src/transformers/models/code_llama/tokenization_code_llama.py",
"repo_id": "transformers",
"token_count": 10023
} | 78 |
# coding=utf-8
# Copyright 2021 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
""" PyTorch ConvBERT model."""
import math
import os
from operator import attrgetter
from typing import Optional, Tuple, Union
import torch
import torch.utils.checkpoint
from torch import nn
from torch.nn import BCEWithLogitsLoss, CrossEntropyLoss, MSELoss
from ...activations import ACT2FN, get_activation
from ...modeling_outputs import (
BaseModelOutputWithCrossAttentions,
MaskedLMOutput,
MultipleChoiceModelOutput,
QuestionAnsweringModelOutput,
SequenceClassifierOutput,
TokenClassifierOutput,
)
from ...modeling_utils import PreTrainedModel, SequenceSummary
from ...pytorch_utils import apply_chunking_to_forward, find_pruneable_heads_and_indices, prune_linear_layer
from ...utils import add_code_sample_docstrings, add_start_docstrings, add_start_docstrings_to_model_forward, logging
from .configuration_convbert import ConvBertConfig
logger = logging.get_logger(__name__)
_CHECKPOINT_FOR_DOC = "YituTech/conv-bert-base"
_CONFIG_FOR_DOC = "ConvBertConfig"
CONVBERT_PRETRAINED_MODEL_ARCHIVE_LIST = [
"YituTech/conv-bert-base",
"YituTech/conv-bert-medium-small",
"YituTech/conv-bert-small",
# See all ConvBERT models at https://huggingface.co/models?filter=convbert
]
def load_tf_weights_in_convbert(model, config, tf_checkpoint_path):
"""Load tf checkpoints in a pytorch model."""
try:
import tensorflow as tf
except ImportError:
logger.error(
"Loading a TensorFlow model in PyTorch, requires TensorFlow to be installed. Please see "
"https://www.tensorflow.org/install/ for installation instructions."
)
raise
tf_path = os.path.abspath(tf_checkpoint_path)
logger.info(f"Converting TensorFlow checkpoint from {tf_path}")
# Load weights from TF model
init_vars = tf.train.list_variables(tf_path)
tf_data = {}
for name, shape in init_vars:
logger.info(f"Loading TF weight {name} with shape {shape}")
array = tf.train.load_variable(tf_path, name)
tf_data[name] = array
param_mapping = {
"embeddings.word_embeddings.weight": "electra/embeddings/word_embeddings",
"embeddings.position_embeddings.weight": "electra/embeddings/position_embeddings",
"embeddings.token_type_embeddings.weight": "electra/embeddings/token_type_embeddings",
"embeddings.LayerNorm.weight": "electra/embeddings/LayerNorm/gamma",
"embeddings.LayerNorm.bias": "electra/embeddings/LayerNorm/beta",
"embeddings_project.weight": "electra/embeddings_project/kernel",
"embeddings_project.bias": "electra/embeddings_project/bias",
}
if config.num_groups > 1:
group_dense_name = "g_dense"
else:
group_dense_name = "dense"
for j in range(config.num_hidden_layers):
param_mapping[
f"encoder.layer.{j}.attention.self.query.weight"
] = f"electra/encoder/layer_{j}/attention/self/query/kernel"
param_mapping[
f"encoder.layer.{j}.attention.self.query.bias"
] = f"electra/encoder/layer_{j}/attention/self/query/bias"
param_mapping[
f"encoder.layer.{j}.attention.self.key.weight"
] = f"electra/encoder/layer_{j}/attention/self/key/kernel"
param_mapping[
f"encoder.layer.{j}.attention.self.key.bias"
] = f"electra/encoder/layer_{j}/attention/self/key/bias"
param_mapping[
f"encoder.layer.{j}.attention.self.value.weight"
] = f"electra/encoder/layer_{j}/attention/self/value/kernel"
param_mapping[
f"encoder.layer.{j}.attention.self.value.bias"
] = f"electra/encoder/layer_{j}/attention/self/value/bias"
param_mapping[
f"encoder.layer.{j}.attention.self.key_conv_attn_layer.depthwise.weight"
] = f"electra/encoder/layer_{j}/attention/self/conv_attn_key/depthwise_kernel"
param_mapping[
f"encoder.layer.{j}.attention.self.key_conv_attn_layer.pointwise.weight"
] = f"electra/encoder/layer_{j}/attention/self/conv_attn_key/pointwise_kernel"
param_mapping[
f"encoder.layer.{j}.attention.self.key_conv_attn_layer.bias"
] = f"electra/encoder/layer_{j}/attention/self/conv_attn_key/bias"
param_mapping[
f"encoder.layer.{j}.attention.self.conv_kernel_layer.weight"
] = f"electra/encoder/layer_{j}/attention/self/conv_attn_kernel/kernel"
param_mapping[
f"encoder.layer.{j}.attention.self.conv_kernel_layer.bias"
] = f"electra/encoder/layer_{j}/attention/self/conv_attn_kernel/bias"
param_mapping[
f"encoder.layer.{j}.attention.self.conv_out_layer.weight"
] = f"electra/encoder/layer_{j}/attention/self/conv_attn_point/kernel"
param_mapping[
f"encoder.layer.{j}.attention.self.conv_out_layer.bias"
] = f"electra/encoder/layer_{j}/attention/self/conv_attn_point/bias"
param_mapping[
f"encoder.layer.{j}.attention.output.dense.weight"
] = f"electra/encoder/layer_{j}/attention/output/dense/kernel"
param_mapping[
f"encoder.layer.{j}.attention.output.LayerNorm.weight"
] = f"electra/encoder/layer_{j}/attention/output/LayerNorm/gamma"
param_mapping[
f"encoder.layer.{j}.attention.output.dense.bias"
] = f"electra/encoder/layer_{j}/attention/output/dense/bias"
param_mapping[
f"encoder.layer.{j}.attention.output.LayerNorm.bias"
] = f"electra/encoder/layer_{j}/attention/output/LayerNorm/beta"
param_mapping[
f"encoder.layer.{j}.intermediate.dense.weight"
] = f"electra/encoder/layer_{j}/intermediate/{group_dense_name}/kernel"
param_mapping[
f"encoder.layer.{j}.intermediate.dense.bias"
] = f"electra/encoder/layer_{j}/intermediate/{group_dense_name}/bias"
param_mapping[
f"encoder.layer.{j}.output.dense.weight"
] = f"electra/encoder/layer_{j}/output/{group_dense_name}/kernel"
param_mapping[
f"encoder.layer.{j}.output.dense.bias"
] = f"electra/encoder/layer_{j}/output/{group_dense_name}/bias"
param_mapping[
f"encoder.layer.{j}.output.LayerNorm.weight"
] = f"electra/encoder/layer_{j}/output/LayerNorm/gamma"
param_mapping[f"encoder.layer.{j}.output.LayerNorm.bias"] = f"electra/encoder/layer_{j}/output/LayerNorm/beta"
for param in model.named_parameters():
param_name = param[0]
retriever = attrgetter(param_name)
result = retriever(model)
tf_name = param_mapping[param_name]
value = torch.from_numpy(tf_data[tf_name])
logger.info(f"TF: {tf_name}, PT: {param_name} ")
if tf_name.endswith("/kernel"):
if not tf_name.endswith("/intermediate/g_dense/kernel"):
if not tf_name.endswith("/output/g_dense/kernel"):
value = value.T
if tf_name.endswith("/depthwise_kernel"):
value = value.permute(1, 2, 0) # 2, 0, 1
if tf_name.endswith("/pointwise_kernel"):
value = value.permute(2, 1, 0) # 2, 1, 0
if tf_name.endswith("/conv_attn_key/bias"):
value = value.unsqueeze(-1)
result.data = value
return model
class ConvBertEmbeddings(nn.Module):
"""Construct the embeddings from word, position and token_type embeddings."""
def __init__(self, config):
super().__init__()
self.word_embeddings = nn.Embedding(config.vocab_size, config.embedding_size, padding_idx=config.pad_token_id)
self.position_embeddings = nn.Embedding(config.max_position_embeddings, config.embedding_size)
self.token_type_embeddings = nn.Embedding(config.type_vocab_size, config.embedding_size)
# self.LayerNorm is not snake-cased to stick with TensorFlow model variable name and be able to load
# any TensorFlow checkpoint file
self.LayerNorm = nn.LayerNorm(config.embedding_size, eps=config.layer_norm_eps)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
# position_ids (1, len position emb) is contiguous in memory and exported when serialized
self.register_buffer(
"position_ids", torch.arange(config.max_position_embeddings).expand((1, -1)), persistent=False
)
self.register_buffer(
"token_type_ids", torch.zeros(self.position_ids.size(), dtype=torch.long), persistent=False
)
def forward(
self,
input_ids: Optional[torch.LongTensor] = None,
token_type_ids: Optional[torch.LongTensor] = None,
position_ids: Optional[torch.LongTensor] = None,
inputs_embeds: Optional[torch.FloatTensor] = None,
) -> torch.LongTensor:
if input_ids is not None:
input_shape = input_ids.size()
else:
input_shape = inputs_embeds.size()[:-1]
seq_length = input_shape[1]
if position_ids is None:
position_ids = self.position_ids[:, :seq_length]
# Setting the token_type_ids to the registered buffer in constructor where it is all zeros, which usually occurs
# when its auto-generated, registered buffer helps users when tracing the model without passing token_type_ids, solves
# issue #5664
if token_type_ids is None:
if hasattr(self, "token_type_ids"):
buffered_token_type_ids = self.token_type_ids[:, :seq_length]
buffered_token_type_ids_expanded = buffered_token_type_ids.expand(input_shape[0], seq_length)
token_type_ids = buffered_token_type_ids_expanded
else:
token_type_ids = torch.zeros(input_shape, dtype=torch.long, device=self.position_ids.device)
if inputs_embeds is None:
inputs_embeds = self.word_embeddings(input_ids)
position_embeddings = self.position_embeddings(position_ids)
token_type_embeddings = self.token_type_embeddings(token_type_ids)
embeddings = inputs_embeds + position_embeddings + token_type_embeddings
embeddings = self.LayerNorm(embeddings)
embeddings = self.dropout(embeddings)
return embeddings
class ConvBertPreTrainedModel(PreTrainedModel):
"""
An abstract class to handle weights initialization and a simple interface for downloading and loading pretrained
models.
"""
config_class = ConvBertConfig
load_tf_weights = load_tf_weights_in_convbert
base_model_prefix = "convbert"
supports_gradient_checkpointing = True
def _init_weights(self, module):
"""Initialize the weights"""
if isinstance(module, nn.Linear):
# Slightly different from the TF version which uses truncated_normal for initialization
# cf https://github.com/pytorch/pytorch/pull/5617
module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
if module.bias is not None:
module.bias.data.zero_()
elif isinstance(module, nn.Embedding):
module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
if module.padding_idx is not None:
module.weight.data[module.padding_idx].zero_()
elif isinstance(module, nn.LayerNorm):
module.bias.data.zero_()
module.weight.data.fill_(1.0)
class SeparableConv1D(nn.Module):
"""This class implements separable convolution, i.e. a depthwise and a pointwise layer"""
def __init__(self, config, input_filters, output_filters, kernel_size, **kwargs):
super().__init__()
self.depthwise = nn.Conv1d(
input_filters,
input_filters,
kernel_size=kernel_size,
groups=input_filters,
padding=kernel_size // 2,
bias=False,
)
self.pointwise = nn.Conv1d(input_filters, output_filters, kernel_size=1, bias=False)
self.bias = nn.Parameter(torch.zeros(output_filters, 1))
self.depthwise.weight.data.normal_(mean=0.0, std=config.initializer_range)
self.pointwise.weight.data.normal_(mean=0.0, std=config.initializer_range)
def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
x = self.depthwise(hidden_states)
x = self.pointwise(x)
x += self.bias
return x
class ConvBertSelfAttention(nn.Module):
def __init__(self, config):
super().__init__()
if config.hidden_size % config.num_attention_heads != 0 and not hasattr(config, "embedding_size"):
raise ValueError(
f"The hidden size ({config.hidden_size}) is not a multiple of the number of attention "
f"heads ({config.num_attention_heads})"
)
new_num_attention_heads = config.num_attention_heads // config.head_ratio
if new_num_attention_heads < 1:
self.head_ratio = config.num_attention_heads
self.num_attention_heads = 1
else:
self.num_attention_heads = new_num_attention_heads
self.head_ratio = config.head_ratio
self.conv_kernel_size = config.conv_kernel_size
if config.hidden_size % self.num_attention_heads != 0:
raise ValueError("hidden_size should be divisible by num_attention_heads")
self.attention_head_size = (config.hidden_size // self.num_attention_heads) // 2
self.all_head_size = self.num_attention_heads * self.attention_head_size
self.query = nn.Linear(config.hidden_size, self.all_head_size)
self.key = nn.Linear(config.hidden_size, self.all_head_size)
self.value = nn.Linear(config.hidden_size, self.all_head_size)
self.key_conv_attn_layer = SeparableConv1D(
config, config.hidden_size, self.all_head_size, self.conv_kernel_size
)
self.conv_kernel_layer = nn.Linear(self.all_head_size, self.num_attention_heads * self.conv_kernel_size)
self.conv_out_layer = nn.Linear(config.hidden_size, self.all_head_size)
self.unfold = nn.Unfold(
kernel_size=[self.conv_kernel_size, 1], padding=[int((self.conv_kernel_size - 1) / 2), 0]
)
self.dropout = nn.Dropout(config.attention_probs_dropout_prob)
def transpose_for_scores(self, x):
new_x_shape = x.size()[:-1] + (self.num_attention_heads, self.attention_head_size)
x = x.view(*new_x_shape)
return x.permute(0, 2, 1, 3)
def forward(
self,
hidden_states: torch.Tensor,
attention_mask: Optional[torch.FloatTensor] = None,
head_mask: Optional[torch.FloatTensor] = None,
encoder_hidden_states: Optional[torch.Tensor] = None,
output_attentions: Optional[bool] = False,
) -> Tuple[torch.Tensor, Optional[torch.Tensor]]:
mixed_query_layer = self.query(hidden_states)
batch_size = hidden_states.size(0)
# If this is instantiated as a cross-attention module, the keys
# and values come from an encoder; the attention mask needs to be
# such that the encoder's padding tokens are not attended to.
if encoder_hidden_states is not None:
mixed_key_layer = self.key(encoder_hidden_states)
mixed_value_layer = self.value(encoder_hidden_states)
else:
mixed_key_layer = self.key(hidden_states)
mixed_value_layer = self.value(hidden_states)
mixed_key_conv_attn_layer = self.key_conv_attn_layer(hidden_states.transpose(1, 2))
mixed_key_conv_attn_layer = mixed_key_conv_attn_layer.transpose(1, 2)
query_layer = self.transpose_for_scores(mixed_query_layer)
key_layer = self.transpose_for_scores(mixed_key_layer)
value_layer = self.transpose_for_scores(mixed_value_layer)
conv_attn_layer = torch.multiply(mixed_key_conv_attn_layer, mixed_query_layer)
conv_kernel_layer = self.conv_kernel_layer(conv_attn_layer)
conv_kernel_layer = torch.reshape(conv_kernel_layer, [-1, self.conv_kernel_size, 1])
conv_kernel_layer = torch.softmax(conv_kernel_layer, dim=1)
conv_out_layer = self.conv_out_layer(hidden_states)
conv_out_layer = torch.reshape(conv_out_layer, [batch_size, -1, self.all_head_size])
conv_out_layer = conv_out_layer.transpose(1, 2).contiguous().unsqueeze(-1)
conv_out_layer = nn.functional.unfold(
conv_out_layer,
kernel_size=[self.conv_kernel_size, 1],
dilation=1,
padding=[(self.conv_kernel_size - 1) // 2, 0],
stride=1,
)
conv_out_layer = conv_out_layer.transpose(1, 2).reshape(
batch_size, -1, self.all_head_size, self.conv_kernel_size
)
conv_out_layer = torch.reshape(conv_out_layer, [-1, self.attention_head_size, self.conv_kernel_size])
conv_out_layer = torch.matmul(conv_out_layer, conv_kernel_layer)
conv_out_layer = torch.reshape(conv_out_layer, [-1, self.all_head_size])
# Take the dot product between "query" and "key" to get the raw attention scores.
attention_scores = torch.matmul(query_layer, key_layer.transpose(-1, -2))
attention_scores = attention_scores / math.sqrt(self.attention_head_size)
if attention_mask is not None:
# Apply the attention mask is (precomputed for all layers in ConvBertModel forward() function)
attention_scores = attention_scores + attention_mask
# Normalize the attention scores to probabilities.
attention_probs = nn.functional.softmax(attention_scores, dim=-1)
# This is actually dropping out entire tokens to attend to, which might
# seem a bit unusual, but is taken from the original Transformer paper.
attention_probs = self.dropout(attention_probs)
# Mask heads if we want to
if head_mask is not None:
attention_probs = attention_probs * head_mask
context_layer = torch.matmul(attention_probs, value_layer)
context_layer = context_layer.permute(0, 2, 1, 3).contiguous()
conv_out = torch.reshape(conv_out_layer, [batch_size, -1, self.num_attention_heads, self.attention_head_size])
context_layer = torch.cat([context_layer, conv_out], 2)
# conv and context
new_context_layer_shape = context_layer.size()[:-2] + (
self.num_attention_heads * self.attention_head_size * 2,
)
context_layer = context_layer.view(*new_context_layer_shape)
outputs = (context_layer, attention_probs) if output_attentions else (context_layer,)
return outputs
class ConvBertSelfOutput(nn.Module):
def __init__(self, config):
super().__init__()
self.dense = nn.Linear(config.hidden_size, config.hidden_size)
self.LayerNorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
def forward(self, hidden_states: torch.Tensor, input_tensor: torch.Tensor) -> torch.Tensor:
hidden_states = self.dense(hidden_states)
hidden_states = self.dropout(hidden_states)
hidden_states = self.LayerNorm(hidden_states + input_tensor)
return hidden_states
class ConvBertAttention(nn.Module):
def __init__(self, config):
super().__init__()
self.self = ConvBertSelfAttention(config)
self.output = ConvBertSelfOutput(config)
self.pruned_heads = set()
def prune_heads(self, heads):
if len(heads) == 0:
return
heads, index = find_pruneable_heads_and_indices(
heads, self.self.num_attention_heads, self.self.attention_head_size, self.pruned_heads
)
# Prune linear layers
self.self.query = prune_linear_layer(self.self.query, index)
self.self.key = prune_linear_layer(self.self.key, index)
self.self.value = prune_linear_layer(self.self.value, index)
self.output.dense = prune_linear_layer(self.output.dense, index, dim=1)
# Update hyper params and store pruned heads
self.self.num_attention_heads = self.self.num_attention_heads - len(heads)
self.self.all_head_size = self.self.attention_head_size * self.self.num_attention_heads
self.pruned_heads = self.pruned_heads.union(heads)
def forward(
self,
hidden_states: torch.Tensor,
attention_mask: Optional[torch.FloatTensor] = None,
head_mask: Optional[torch.FloatTensor] = None,
encoder_hidden_states: Optional[torch.Tensor] = None,
output_attentions: Optional[bool] = False,
) -> Tuple[torch.Tensor, Optional[torch.FloatTensor]]:
self_outputs = self.self(
hidden_states,
attention_mask,
head_mask,
encoder_hidden_states,
output_attentions,
)
attention_output = self.output(self_outputs[0], hidden_states)
outputs = (attention_output,) + self_outputs[1:] # add attentions if we output them
return outputs
class GroupedLinearLayer(nn.Module):
def __init__(self, input_size, output_size, num_groups):
super().__init__()
self.input_size = input_size
self.output_size = output_size
self.num_groups = num_groups
self.group_in_dim = self.input_size // self.num_groups
self.group_out_dim = self.output_size // self.num_groups
self.weight = nn.Parameter(torch.empty(self.num_groups, self.group_in_dim, self.group_out_dim))
self.bias = nn.Parameter(torch.empty(output_size))
def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
batch_size = list(hidden_states.size())[0]
x = torch.reshape(hidden_states, [-1, self.num_groups, self.group_in_dim])
x = x.permute(1, 0, 2)
x = torch.matmul(x, self.weight)
x = x.permute(1, 0, 2)
x = torch.reshape(x, [batch_size, -1, self.output_size])
x = x + self.bias
return x
class ConvBertIntermediate(nn.Module):
def __init__(self, config):
super().__init__()
if config.num_groups == 1:
self.dense = nn.Linear(config.hidden_size, config.intermediate_size)
else:
self.dense = GroupedLinearLayer(
input_size=config.hidden_size, output_size=config.intermediate_size, num_groups=config.num_groups
)
if isinstance(config.hidden_act, str):
self.intermediate_act_fn = ACT2FN[config.hidden_act]
else:
self.intermediate_act_fn = config.hidden_act
def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
hidden_states = self.dense(hidden_states)
hidden_states = self.intermediate_act_fn(hidden_states)
return hidden_states
class ConvBertOutput(nn.Module):
def __init__(self, config):
super().__init__()
if config.num_groups == 1:
self.dense = nn.Linear(config.intermediate_size, config.hidden_size)
else:
self.dense = GroupedLinearLayer(
input_size=config.intermediate_size, output_size=config.hidden_size, num_groups=config.num_groups
)
self.LayerNorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
def forward(self, hidden_states: torch.Tensor, input_tensor: torch.Tensor) -> torch.Tensor:
hidden_states = self.dense(hidden_states)
hidden_states = self.dropout(hidden_states)
hidden_states = self.LayerNorm(hidden_states + input_tensor)
return hidden_states
class ConvBertLayer(nn.Module):
def __init__(self, config):
super().__init__()
self.chunk_size_feed_forward = config.chunk_size_feed_forward
self.seq_len_dim = 1
self.attention = ConvBertAttention(config)
self.is_decoder = config.is_decoder
self.add_cross_attention = config.add_cross_attention
if self.add_cross_attention:
if not self.is_decoder:
raise TypeError(f"{self} should be used as a decoder model if cross attention is added")
self.crossattention = ConvBertAttention(config)
self.intermediate = ConvBertIntermediate(config)
self.output = ConvBertOutput(config)
def forward(
self,
hidden_states: torch.Tensor,
attention_mask: Optional[torch.FloatTensor] = None,
head_mask: Optional[torch.FloatTensor] = None,
encoder_hidden_states: Optional[torch.Tensor] = None,
encoder_attention_mask: Optional[torch.Tensor] = None,
output_attentions: Optional[bool] = False,
) -> Tuple[torch.Tensor, Optional[torch.FloatTensor]]:
self_attention_outputs = self.attention(
hidden_states,
attention_mask,
head_mask,
output_attentions=output_attentions,
)
attention_output = self_attention_outputs[0]
outputs = self_attention_outputs[1:] # add self attentions if we output attention weights
if self.is_decoder and encoder_hidden_states is not None:
if not hasattr(self, "crossattention"):
raise AttributeError(
f"If `encoder_hidden_states` are passed, {self} has to be instantiated with cross-attention layers"
" by setting `config.add_cross_attention=True`"
)
cross_attention_outputs = self.crossattention(
attention_output,
encoder_attention_mask,
head_mask,
encoder_hidden_states,
output_attentions,
)
attention_output = cross_attention_outputs[0]
outputs = outputs + cross_attention_outputs[1:] # add cross attentions if we output attention weights
layer_output = apply_chunking_to_forward(
self.feed_forward_chunk, self.chunk_size_feed_forward, self.seq_len_dim, attention_output
)
outputs = (layer_output,) + outputs
return outputs
def feed_forward_chunk(self, attention_output):
intermediate_output = self.intermediate(attention_output)
layer_output = self.output(intermediate_output, attention_output)
return layer_output
class ConvBertEncoder(nn.Module):
def __init__(self, config):
super().__init__()
self.config = config
self.layer = nn.ModuleList([ConvBertLayer(config) for _ in range(config.num_hidden_layers)])
self.gradient_checkpointing = False
def forward(
self,
hidden_states: torch.Tensor,
attention_mask: Optional[torch.FloatTensor] = None,
head_mask: Optional[torch.FloatTensor] = None,
encoder_hidden_states: Optional[torch.Tensor] = None,
encoder_attention_mask: Optional[torch.Tensor] = None,
output_attentions: Optional[bool] = False,
output_hidden_states: Optional[bool] = False,
return_dict: Optional[bool] = True,
) -> Union[Tuple, BaseModelOutputWithCrossAttentions]:
all_hidden_states = () if output_hidden_states else None
all_self_attentions = () if output_attentions else None
all_cross_attentions = () if output_attentions and self.config.add_cross_attention else None
for i, layer_module in enumerate(self.layer):
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
layer_head_mask = head_mask[i] if head_mask is not None else None
if self.gradient_checkpointing and self.training:
layer_outputs = self._gradient_checkpointing_func(
layer_module.__call__,
hidden_states,
attention_mask,
layer_head_mask,
encoder_hidden_states,
encoder_attention_mask,
output_attentions,
)
else:
layer_outputs = layer_module(
hidden_states,
attention_mask,
layer_head_mask,
encoder_hidden_states,
encoder_attention_mask,
output_attentions,
)
hidden_states = layer_outputs[0]
if output_attentions:
all_self_attentions = all_self_attentions + (layer_outputs[1],)
if self.config.add_cross_attention:
all_cross_attentions = all_cross_attentions + (layer_outputs[2],)
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
if not return_dict:
return tuple(
v
for v in [hidden_states, all_hidden_states, all_self_attentions, all_cross_attentions]
if v is not None
)
return BaseModelOutputWithCrossAttentions(
last_hidden_state=hidden_states,
hidden_states=all_hidden_states,
attentions=all_self_attentions,
cross_attentions=all_cross_attentions,
)
class ConvBertPredictionHeadTransform(nn.Module):
def __init__(self, config):
super().__init__()
self.dense = nn.Linear(config.hidden_size, config.hidden_size)
if isinstance(config.hidden_act, str):
self.transform_act_fn = ACT2FN[config.hidden_act]
else:
self.transform_act_fn = config.hidden_act
self.LayerNorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
hidden_states = self.dense(hidden_states)
hidden_states = self.transform_act_fn(hidden_states)
hidden_states = self.LayerNorm(hidden_states)
return hidden_states
CONVBERT_START_DOCSTRING = r"""
This model is a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) sub-class. Use
it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and
behavior.
Parameters:
config ([`ConvBertConfig`]): Model configuration class with all the parameters of the model.
Initializing with a config file does not load the weights associated with the model, only the
configuration. Check out the [`~PreTrainedModel.from_pretrained`] method to load the model weights.
"""
CONVBERT_INPUTS_DOCSTRING = r"""
Args:
input_ids (`torch.LongTensor` of shape `({0})`):
Indices of input sequence tokens in the vocabulary.
Indices can be obtained using [`AutoTokenizer`]. See [`PreTrainedTokenizer.encode`] and
[`PreTrainedTokenizer.__call__`] for details.
[What are input IDs?](../glossary#input-ids)
attention_mask (`torch.FloatTensor` of shape `({0})`, *optional*):
Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
[What are attention masks?](../glossary#attention-mask)
token_type_ids (`torch.LongTensor` of shape `({0})`, *optional*):
Segment token indices to indicate first and second portions of the inputs. Indices are selected in `[0,
1]`:
- 0 corresponds to a *sentence A* token,
- 1 corresponds to a *sentence B* token.
[What are token type IDs?](../glossary#token-type-ids)
position_ids (`torch.LongTensor` of shape `({0})`, *optional*):
Indices of positions of each input sequence tokens in the position embeddings. Selected in the range `[0,
config.max_position_embeddings - 1]`.
[What are position IDs?](../glossary#position-ids)
head_mask (`torch.FloatTensor` of shape `(num_heads,)` or `(num_layers, num_heads)`, *optional*):
Mask to nullify selected heads of the self-attention modules. Mask values selected in `[0, 1]`:
- 1 indicates the head is **not masked**,
- 0 indicates the head is **masked**.
inputs_embeds (`torch.FloatTensor` of shape `({0}, hidden_size)`, *optional*):
Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation. This
is useful if you want more control over how to convert *input_ids* indices into associated vectors than the
model's internal embedding lookup matrix.
output_attentions (`bool`, *optional*):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
tensors for more detail.
output_hidden_states (`bool`, *optional*):
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
more detail.
return_dict (`bool`, *optional*):
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
"""
@add_start_docstrings(
"The bare ConvBERT Model transformer outputting raw hidden-states without any specific head on top.",
CONVBERT_START_DOCSTRING,
)
class ConvBertModel(ConvBertPreTrainedModel):
def __init__(self, config):
super().__init__(config)
self.embeddings = ConvBertEmbeddings(config)
if config.embedding_size != config.hidden_size:
self.embeddings_project = nn.Linear(config.embedding_size, config.hidden_size)
self.encoder = ConvBertEncoder(config)
self.config = config
# Initialize weights and apply final processing
self.post_init()
def get_input_embeddings(self):
return self.embeddings.word_embeddings
def set_input_embeddings(self, value):
self.embeddings.word_embeddings = value
def _prune_heads(self, heads_to_prune):
"""
Prunes heads of the model. heads_to_prune: dict of {layer_num: list of heads to prune in this layer} See base
class PreTrainedModel
"""
for layer, heads in heads_to_prune.items():
self.encoder.layer[layer].attention.prune_heads(heads)
@add_start_docstrings_to_model_forward(CONVBERT_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
@add_code_sample_docstrings(
checkpoint=_CHECKPOINT_FOR_DOC,
output_type=BaseModelOutputWithCrossAttentions,
config_class=_CONFIG_FOR_DOC,
)
def forward(
self,
input_ids: Optional[torch.LongTensor] = None,
attention_mask: Optional[torch.FloatTensor] = None,
token_type_ids: Optional[torch.LongTensor] = None,
position_ids: Optional[torch.LongTensor] = None,
head_mask: Optional[torch.FloatTensor] = None,
inputs_embeds: Optional[torch.FloatTensor] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
) -> Union[Tuple, BaseModelOutputWithCrossAttentions]:
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
output_hidden_states = (
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
)
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
if input_ids is not None and inputs_embeds is not None:
raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
elif input_ids is not None:
self.warn_if_padding_and_no_attention_mask(input_ids, attention_mask)
input_shape = input_ids.size()
elif inputs_embeds is not None:
input_shape = inputs_embeds.size()[:-1]
else:
raise ValueError("You have to specify either input_ids or inputs_embeds")
batch_size, seq_length = input_shape
device = input_ids.device if input_ids is not None else inputs_embeds.device
if attention_mask is None:
attention_mask = torch.ones(input_shape, device=device)
if token_type_ids is None:
if hasattr(self.embeddings, "token_type_ids"):
buffered_token_type_ids = self.embeddings.token_type_ids[:, :seq_length]
buffered_token_type_ids_expanded = buffered_token_type_ids.expand(batch_size, seq_length)
token_type_ids = buffered_token_type_ids_expanded
else:
token_type_ids = torch.zeros(input_shape, dtype=torch.long, device=device)
extended_attention_mask = self.get_extended_attention_mask(attention_mask, input_shape)
head_mask = self.get_head_mask(head_mask, self.config.num_hidden_layers)
hidden_states = self.embeddings(
input_ids=input_ids, position_ids=position_ids, token_type_ids=token_type_ids, inputs_embeds=inputs_embeds
)
if hasattr(self, "embeddings_project"):
hidden_states = self.embeddings_project(hidden_states)
hidden_states = self.encoder(
hidden_states,
attention_mask=extended_attention_mask,
head_mask=head_mask,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
return hidden_states
class ConvBertGeneratorPredictions(nn.Module):
"""Prediction module for the generator, made up of two dense layers."""
def __init__(self, config):
super().__init__()
self.activation = get_activation("gelu")
self.LayerNorm = nn.LayerNorm(config.embedding_size, eps=config.layer_norm_eps)
self.dense = nn.Linear(config.hidden_size, config.embedding_size)
def forward(self, generator_hidden_states: torch.FloatTensor) -> torch.FloatTensor:
hidden_states = self.dense(generator_hidden_states)
hidden_states = self.activation(hidden_states)
hidden_states = self.LayerNorm(hidden_states)
return hidden_states
@add_start_docstrings("""ConvBERT Model with a `language modeling` head on top.""", CONVBERT_START_DOCSTRING)
class ConvBertForMaskedLM(ConvBertPreTrainedModel):
_tied_weights_keys = ["generator.lm_head.weight"]
def __init__(self, config):
super().__init__(config)
self.convbert = ConvBertModel(config)
self.generator_predictions = ConvBertGeneratorPredictions(config)
self.generator_lm_head = nn.Linear(config.embedding_size, config.vocab_size)
# Initialize weights and apply final processing
self.post_init()
def get_output_embeddings(self):
return self.generator_lm_head
def set_output_embeddings(self, word_embeddings):
self.generator_lm_head = word_embeddings
@add_start_docstrings_to_model_forward(CONVBERT_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
@add_code_sample_docstrings(
checkpoint=_CHECKPOINT_FOR_DOC,
output_type=MaskedLMOutput,
config_class=_CONFIG_FOR_DOC,
)
def forward(
self,
input_ids: Optional[torch.LongTensor] = None,
attention_mask: Optional[torch.FloatTensor] = None,
token_type_ids: Optional[torch.LongTensor] = None,
position_ids: Optional[torch.LongTensor] = None,
head_mask: Optional[torch.FloatTensor] = None,
inputs_embeds: Optional[torch.FloatTensor] = None,
labels: Optional[torch.LongTensor] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
) -> Union[Tuple, MaskedLMOutput]:
r"""
labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
Labels for computing the masked language modeling loss. Indices should be in `[-100, 0, ...,
config.vocab_size]` (see `input_ids` docstring) Tokens with indices set to `-100` are ignored (masked), the
loss is only computed for the tokens with labels in `[0, ..., config.vocab_size]`
"""
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
generator_hidden_states = self.convbert(
input_ids,
attention_mask,
token_type_ids,
position_ids,
head_mask,
inputs_embeds,
output_attentions,
output_hidden_states,
return_dict,
)
generator_sequence_output = generator_hidden_states[0]
prediction_scores = self.generator_predictions(generator_sequence_output)
prediction_scores = self.generator_lm_head(prediction_scores)
loss = None
# Masked language modeling softmax layer
if labels is not None:
loss_fct = nn.CrossEntropyLoss() # -100 index = padding token
loss = loss_fct(prediction_scores.view(-1, self.config.vocab_size), labels.view(-1))
if not return_dict:
output = (prediction_scores,) + generator_hidden_states[1:]
return ((loss,) + output) if loss is not None else output
return MaskedLMOutput(
loss=loss,
logits=prediction_scores,
hidden_states=generator_hidden_states.hidden_states,
attentions=generator_hidden_states.attentions,
)
class ConvBertClassificationHead(nn.Module):
"""Head for sentence-level classification tasks."""
def __init__(self, config):
super().__init__()
self.dense = nn.Linear(config.hidden_size, config.hidden_size)
classifier_dropout = (
config.classifier_dropout if config.classifier_dropout is not None else config.hidden_dropout_prob
)
self.dropout = nn.Dropout(classifier_dropout)
self.out_proj = nn.Linear(config.hidden_size, config.num_labels)
self.config = config
def forward(self, hidden_states: torch.Tensor, **kwargs) -> torch.Tensor:
x = hidden_states[:, 0, :] # take <s> token (equiv. to [CLS])
x = self.dropout(x)
x = self.dense(x)
x = ACT2FN[self.config.hidden_act](x)
x = self.dropout(x)
x = self.out_proj(x)
return x
@add_start_docstrings(
"""
ConvBERT Model transformer with a sequence classification/regression head on top (a linear layer on top of the
pooled output) e.g. for GLUE tasks.
""",
CONVBERT_START_DOCSTRING,
)
class ConvBertForSequenceClassification(ConvBertPreTrainedModel):
def __init__(self, config):
super().__init__(config)
self.num_labels = config.num_labels
self.config = config
self.convbert = ConvBertModel(config)
self.classifier = ConvBertClassificationHead(config)
# Initialize weights and apply final processing
self.post_init()
@add_start_docstrings_to_model_forward(CONVBERT_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
@add_code_sample_docstrings(
checkpoint=_CHECKPOINT_FOR_DOC,
output_type=SequenceClassifierOutput,
config_class=_CONFIG_FOR_DOC,
)
def forward(
self,
input_ids: Optional[torch.LongTensor] = None,
attention_mask: Optional[torch.FloatTensor] = None,
token_type_ids: Optional[torch.LongTensor] = None,
position_ids: Optional[torch.LongTensor] = None,
head_mask: Optional[torch.FloatTensor] = None,
inputs_embeds: Optional[torch.FloatTensor] = None,
labels: Optional[torch.LongTensor] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
) -> Union[Tuple, SequenceClassifierOutput]:
r"""
labels (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
Labels for computing the sequence classification/regression loss. Indices should be in `[0, ...,
config.num_labels - 1]`. If `config.num_labels == 1` a regression loss is computed (Mean-Square loss), If
`config.num_labels > 1` a classification loss is computed (Cross-Entropy).
"""
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
outputs = self.convbert(
input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
position_ids=position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
sequence_output = outputs[0]
logits = self.classifier(sequence_output)
loss = None
if labels is not None:
if self.config.problem_type is None:
if self.num_labels == 1:
self.config.problem_type = "regression"
elif self.num_labels > 1 and (labels.dtype == torch.long or labels.dtype == torch.int):
self.config.problem_type = "single_label_classification"
else:
self.config.problem_type = "multi_label_classification"
if self.config.problem_type == "regression":
loss_fct = MSELoss()
if self.num_labels == 1:
loss = loss_fct(logits.squeeze(), labels.squeeze())
else:
loss = loss_fct(logits, labels)
elif self.config.problem_type == "single_label_classification":
loss_fct = CrossEntropyLoss()
loss = loss_fct(logits.view(-1, self.num_labels), labels.view(-1))
elif self.config.problem_type == "multi_label_classification":
loss_fct = BCEWithLogitsLoss()
loss = loss_fct(logits, labels)
if not return_dict:
output = (logits,) + outputs[1:]
return ((loss,) + output) if loss is not None else output
return SequenceClassifierOutput(
loss=loss,
logits=logits,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
)
@add_start_docstrings(
"""
ConvBERT Model with a multiple choice classification head on top (a linear layer on top of the pooled output and a
softmax) e.g. for RocStories/SWAG tasks.
""",
CONVBERT_START_DOCSTRING,
)
class ConvBertForMultipleChoice(ConvBertPreTrainedModel):
def __init__(self, config):
super().__init__(config)
self.convbert = ConvBertModel(config)
self.sequence_summary = SequenceSummary(config)
self.classifier = nn.Linear(config.hidden_size, 1)
# Initialize weights and apply final processing
self.post_init()
@add_start_docstrings_to_model_forward(
CONVBERT_INPUTS_DOCSTRING.format("batch_size, num_choices, sequence_length")
)
@add_code_sample_docstrings(
checkpoint=_CHECKPOINT_FOR_DOC,
output_type=MultipleChoiceModelOutput,
config_class=_CONFIG_FOR_DOC,
)
def forward(
self,
input_ids: Optional[torch.LongTensor] = None,
attention_mask: Optional[torch.FloatTensor] = None,
token_type_ids: Optional[torch.LongTensor] = None,
position_ids: Optional[torch.LongTensor] = None,
head_mask: Optional[torch.FloatTensor] = None,
inputs_embeds: Optional[torch.FloatTensor] = None,
labels: Optional[torch.LongTensor] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
) -> Union[Tuple, MultipleChoiceModelOutput]:
r"""
labels (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
Labels for computing the multiple choice classification loss. Indices should be in `[0, ...,
num_choices-1]` where `num_choices` is the size of the second dimension of the input tensors. (See
`input_ids` above)
"""
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
num_choices = input_ids.shape[1] if input_ids is not None else inputs_embeds.shape[1]
input_ids = input_ids.view(-1, input_ids.size(-1)) if input_ids is not None else None
attention_mask = attention_mask.view(-1, attention_mask.size(-1)) if attention_mask is not None else None
token_type_ids = token_type_ids.view(-1, token_type_ids.size(-1)) if token_type_ids is not None else None
position_ids = position_ids.view(-1, position_ids.size(-1)) if position_ids is not None else None
inputs_embeds = (
inputs_embeds.view(-1, inputs_embeds.size(-2), inputs_embeds.size(-1))
if inputs_embeds is not None
else None
)
outputs = self.convbert(
input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
position_ids=position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
sequence_output = outputs[0]
pooled_output = self.sequence_summary(sequence_output)
logits = self.classifier(pooled_output)
reshaped_logits = logits.view(-1, num_choices)
loss = None
if labels is not None:
loss_fct = CrossEntropyLoss()
loss = loss_fct(reshaped_logits, labels)
if not return_dict:
output = (reshaped_logits,) + outputs[1:]
return ((loss,) + output) if loss is not None else output
return MultipleChoiceModelOutput(
loss=loss,
logits=reshaped_logits,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
)
@add_start_docstrings(
"""
ConvBERT Model with a token classification head on top (a linear layer on top of the hidden-states output) e.g. for
Named-Entity-Recognition (NER) tasks.
""",
CONVBERT_START_DOCSTRING,
)
class ConvBertForTokenClassification(ConvBertPreTrainedModel):
def __init__(self, config):
super().__init__(config)
self.num_labels = config.num_labels
self.convbert = ConvBertModel(config)
classifier_dropout = (
config.classifier_dropout if config.classifier_dropout is not None else config.hidden_dropout_prob
)
self.dropout = nn.Dropout(classifier_dropout)
self.classifier = nn.Linear(config.hidden_size, config.num_labels)
# Initialize weights and apply final processing
self.post_init()
@add_start_docstrings_to_model_forward(CONVBERT_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
@add_code_sample_docstrings(
checkpoint=_CHECKPOINT_FOR_DOC,
output_type=TokenClassifierOutput,
config_class=_CONFIG_FOR_DOC,
)
def forward(
self,
input_ids: Optional[torch.LongTensor] = None,
attention_mask: Optional[torch.FloatTensor] = None,
token_type_ids: Optional[torch.LongTensor] = None,
position_ids: Optional[torch.LongTensor] = None,
head_mask: Optional[torch.FloatTensor] = None,
inputs_embeds: Optional[torch.FloatTensor] = None,
labels: Optional[torch.LongTensor] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
) -> Union[Tuple, TokenClassifierOutput]:
r"""
labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
Labels for computing the token classification loss. Indices should be in `[0, ..., config.num_labels - 1]`.
"""
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
outputs = self.convbert(
input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
position_ids=position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
sequence_output = outputs[0]
sequence_output = self.dropout(sequence_output)
logits = self.classifier(sequence_output)
loss = None
if labels is not None:
loss_fct = CrossEntropyLoss()
loss = loss_fct(logits.view(-1, self.num_labels), labels.view(-1))
if not return_dict:
output = (logits,) + outputs[1:]
return ((loss,) + output) if loss is not None else output
return TokenClassifierOutput(
loss=loss,
logits=logits,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
)
@add_start_docstrings(
"""
ConvBERT Model with a span classification head on top for extractive question-answering tasks like SQuAD (a linear
layers on top of the hidden-states output to compute `span start logits` and `span end logits`).
""",
CONVBERT_START_DOCSTRING,
)
class ConvBertForQuestionAnswering(ConvBertPreTrainedModel):
def __init__(self, config):
super().__init__(config)
self.num_labels = config.num_labels
self.convbert = ConvBertModel(config)
self.qa_outputs = nn.Linear(config.hidden_size, config.num_labels)
# Initialize weights and apply final processing
self.post_init()
@add_start_docstrings_to_model_forward(CONVBERT_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
@add_code_sample_docstrings(
checkpoint=_CHECKPOINT_FOR_DOC,
output_type=QuestionAnsweringModelOutput,
config_class=_CONFIG_FOR_DOC,
)
def forward(
self,
input_ids: Optional[torch.LongTensor] = None,
attention_mask: Optional[torch.FloatTensor] = None,
token_type_ids: Optional[torch.LongTensor] = None,
position_ids: Optional[torch.LongTensor] = None,
head_mask: Optional[torch.FloatTensor] = None,
inputs_embeds: Optional[torch.FloatTensor] = None,
start_positions: Optional[torch.LongTensor] = None,
end_positions: Optional[torch.LongTensor] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
) -> Union[Tuple, QuestionAnsweringModelOutput]:
r"""
start_positions (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
Labels for position (index) of the start of the labelled span for computing the token classification loss.
Positions are clamped to the length of the sequence (`sequence_length`). Position outside of the sequence
are not taken into account for computing the loss.
end_positions (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
Labels for position (index) of the end of the labelled span for computing the token classification loss.
Positions are clamped to the length of the sequence (`sequence_length`). Position outside of the sequence
are not taken into account for computing the loss.
"""
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
outputs = self.convbert(
input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
position_ids=position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
sequence_output = outputs[0]
logits = self.qa_outputs(sequence_output)
start_logits, end_logits = logits.split(1, dim=-1)
start_logits = start_logits.squeeze(-1).contiguous()
end_logits = end_logits.squeeze(-1).contiguous()
total_loss = None
if start_positions is not None and end_positions is not None:
# If we are on multi-GPU, split add a dimension
if len(start_positions.size()) > 1:
start_positions = start_positions.squeeze(-1)
if len(end_positions.size()) > 1:
end_positions = end_positions.squeeze(-1)
# sometimes the start/end positions are outside our model inputs, we ignore these terms
ignored_index = start_logits.size(1)
start_positions = start_positions.clamp(0, ignored_index)
end_positions = end_positions.clamp(0, ignored_index)
loss_fct = CrossEntropyLoss(ignore_index=ignored_index)
start_loss = loss_fct(start_logits, start_positions)
end_loss = loss_fct(end_logits, end_positions)
total_loss = (start_loss + end_loss) / 2
if not return_dict:
output = (start_logits, end_logits) + outputs[1:]
return ((total_loss,) + output) if total_loss is not None else output
return QuestionAnsweringModelOutput(
loss=total_loss,
start_logits=start_logits,
end_logits=end_logits,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
)
| transformers/src/transformers/models/convbert/modeling_convbert.py/0 | {
"file_path": "transformers/src/transformers/models/convbert/modeling_convbert.py",
"repo_id": "transformers",
"token_count": 25449
} | 79 |
# coding=utf-8
# Copyright 2022 Microsoft Research and The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
""" TF 2.0 Cvt model."""
from __future__ import annotations
import collections.abc
from dataclasses import dataclass
from typing import Optional, Tuple, Union
import tensorflow as tf
from ...modeling_tf_outputs import TFImageClassifierOutputWithNoAttention
from ...modeling_tf_utils import (
TFModelInputType,
TFPreTrainedModel,
TFSequenceClassificationLoss,
get_initializer,
keras,
keras_serializable,
unpack_inputs,
)
from ...tf_utils import shape_list, stable_softmax
from ...utils import (
ModelOutput,
add_start_docstrings,
add_start_docstrings_to_model_forward,
logging,
replace_return_docstrings,
)
from .configuration_cvt import CvtConfig
logger = logging.get_logger(__name__)
# General docstring
_CONFIG_FOR_DOC = "CvtConfig"
TF_CVT_PRETRAINED_MODEL_ARCHIVE_LIST = [
"microsoft/cvt-13",
"microsoft/cvt-13-384",
"microsoft/cvt-13-384-22k",
"microsoft/cvt-21",
"microsoft/cvt-21-384",
"microsoft/cvt-21-384-22k",
# See all Cvt models at https://huggingface.co/models?filter=cvt
]
@dataclass
class TFBaseModelOutputWithCLSToken(ModelOutput):
"""
Base class for model's outputs.
Args:
last_hidden_state (`tf.Tensor` of shape `(batch_size, sequence_length, hidden_size)`):
Sequence of hidden-states at the output of the last layer of the model.
cls_token_value (`tf.Tensor` of shape `(batch_size, 1, hidden_size)`):
Classification token at the output of the last layer of the model.
hidden_states (`tuple(tf.Tensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
Tuple of `tf.Tensor` (one for the output of the embeddings + one for the output of each layer) of shape
`(batch_size, sequence_length, hidden_size)`. Hidden-states of the model at the output of each layer plus
the initial embedding outputs.
"""
last_hidden_state: tf.Tensor = None
cls_token_value: tf.Tensor = None
hidden_states: Tuple[tf.Tensor, ...] | None = None
class TFCvtDropPath(keras.layers.Layer):
"""Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks).
References:
(1) github.com:rwightman/pytorch-image-models
"""
def __init__(self, drop_prob: float, **kwargs):
super().__init__(**kwargs)
self.drop_prob = drop_prob
def call(self, x: tf.Tensor, training=None):
if self.drop_prob == 0.0 or not training:
return x
keep_prob = 1 - self.drop_prob
shape = (tf.shape(x)[0],) + (1,) * (len(tf.shape(x)) - 1)
random_tensor = keep_prob + tf.random.uniform(shape, 0, 1, dtype=self.compute_dtype)
random_tensor = tf.floor(random_tensor)
return (x / keep_prob) * random_tensor
class TFCvtEmbeddings(keras.layers.Layer):
"""Construct the Convolutional Token Embeddings."""
def __init__(
self,
config: CvtConfig,
patch_size: int,
num_channels: int,
embed_dim: int,
stride: int,
padding: int,
dropout_rate: float,
**kwargs,
):
super().__init__(**kwargs)
self.convolution_embeddings = TFCvtConvEmbeddings(
config,
patch_size=patch_size,
num_channels=num_channels,
embed_dim=embed_dim,
stride=stride,
padding=padding,
name="convolution_embeddings",
)
self.dropout = keras.layers.Dropout(dropout_rate)
def call(self, pixel_values: tf.Tensor, training: bool = False) -> tf.Tensor:
hidden_state = self.convolution_embeddings(pixel_values)
hidden_state = self.dropout(hidden_state, training=training)
return hidden_state
def build(self, input_shape=None):
if self.built:
return
self.built = True
if getattr(self, "convolution_embeddings", None) is not None:
with tf.name_scope(self.convolution_embeddings.name):
self.convolution_embeddings.build(None)
class TFCvtConvEmbeddings(keras.layers.Layer):
"""Image to Convolution Embeddings. This convolutional operation aims to model local spatial contexts."""
def __init__(
self,
config: CvtConfig,
patch_size: int,
num_channels: int,
embed_dim: int,
stride: int,
padding: int,
**kwargs,
):
super().__init__(**kwargs)
self.padding = keras.layers.ZeroPadding2D(padding=padding)
self.patch_size = patch_size if isinstance(patch_size, collections.abc.Iterable) else (patch_size, patch_size)
self.projection = keras.layers.Conv2D(
filters=embed_dim,
kernel_size=patch_size,
strides=stride,
padding="valid",
data_format="channels_last",
kernel_initializer=get_initializer(config.initializer_range),
name="projection",
)
# Using the same default epsilon as PyTorch
self.normalization = keras.layers.LayerNormalization(epsilon=1e-5, name="normalization")
self.num_channels = num_channels
self.embed_dim = embed_dim
def call(self, pixel_values: tf.Tensor) -> tf.Tensor:
if isinstance(pixel_values, dict):
pixel_values = pixel_values["pixel_values"]
pixel_values = self.projection(self.padding(pixel_values))
# "batch_size, height, width, num_channels -> batch_size, (height*width), num_channels"
batch_size, height, width, num_channels = shape_list(pixel_values)
hidden_size = height * width
pixel_values = tf.reshape(pixel_values, shape=(batch_size, hidden_size, num_channels))
pixel_values = self.normalization(pixel_values)
# "batch_size, (height*width), num_channels -> batch_size, height, width, num_channels"
pixel_values = tf.reshape(pixel_values, shape=(batch_size, height, width, num_channels))
return pixel_values
def build(self, input_shape=None):
if self.built:
return
self.built = True
if getattr(self, "projection", None) is not None:
with tf.name_scope(self.projection.name):
self.projection.build([None, None, None, self.num_channels])
if getattr(self, "normalization", None) is not None:
with tf.name_scope(self.normalization.name):
self.normalization.build([None, None, self.embed_dim])
class TFCvtSelfAttentionConvProjection(keras.layers.Layer):
"""Convolutional projection layer."""
def __init__(self, config: CvtConfig, embed_dim: int, kernel_size: int, stride: int, padding: int, **kwargs):
super().__init__(**kwargs)
self.padding = keras.layers.ZeroPadding2D(padding=padding)
self.convolution = keras.layers.Conv2D(
filters=embed_dim,
kernel_size=kernel_size,
kernel_initializer=get_initializer(config.initializer_range),
padding="valid",
strides=stride,
use_bias=False,
name="convolution",
groups=embed_dim,
)
# Using the same default epsilon as PyTorch, TF uses (1 - pytorch momentum)
self.normalization = keras.layers.BatchNormalization(epsilon=1e-5, momentum=0.9, name="normalization")
self.embed_dim = embed_dim
def call(self, hidden_state: tf.Tensor, training: bool = False) -> tf.Tensor:
hidden_state = self.convolution(self.padding(hidden_state))
hidden_state = self.normalization(hidden_state, training=training)
return hidden_state
def build(self, input_shape=None):
if self.built:
return
self.built = True
if getattr(self, "convolution", None) is not None:
with tf.name_scope(self.convolution.name):
self.convolution.build([None, None, None, self.embed_dim])
if getattr(self, "normalization", None) is not None:
with tf.name_scope(self.normalization.name):
self.normalization.build([None, None, None, self.embed_dim])
class TFCvtSelfAttentionLinearProjection(keras.layers.Layer):
"""Linear projection layer used to flatten tokens into 1D."""
def call(self, hidden_state: tf.Tensor) -> tf.Tensor:
# "batch_size, height, width, num_channels -> batch_size, (height*width), num_channels"
batch_size, height, width, num_channels = shape_list(hidden_state)
hidden_size = height * width
hidden_state = tf.reshape(hidden_state, shape=(batch_size, hidden_size, num_channels))
return hidden_state
class TFCvtSelfAttentionProjection(keras.layers.Layer):
"""Convolutional Projection for Attention."""
def __init__(
self,
config: CvtConfig,
embed_dim: int,
kernel_size: int,
stride: int,
padding: int,
projection_method: str = "dw_bn",
**kwargs,
):
super().__init__(**kwargs)
if projection_method == "dw_bn":
self.convolution_projection = TFCvtSelfAttentionConvProjection(
config, embed_dim, kernel_size, stride, padding, name="convolution_projection"
)
self.linear_projection = TFCvtSelfAttentionLinearProjection()
def call(self, hidden_state: tf.Tensor, training: bool = False) -> tf.Tensor:
hidden_state = self.convolution_projection(hidden_state, training=training)
hidden_state = self.linear_projection(hidden_state)
return hidden_state
def build(self, input_shape=None):
if self.built:
return
self.built = True
if getattr(self, "convolution_projection", None) is not None:
with tf.name_scope(self.convolution_projection.name):
self.convolution_projection.build(None)
class TFCvtSelfAttention(keras.layers.Layer):
"""
Self-attention layer. A depth-wise separable convolution operation (Convolutional Projection), is applied for
query, key, and value embeddings.
"""
def __init__(
self,
config: CvtConfig,
num_heads: int,
embed_dim: int,
kernel_size: int,
stride_q: int,
stride_kv: int,
padding_q: int,
padding_kv: int,
qkv_projection_method: str,
qkv_bias: bool,
attention_drop_rate: float,
with_cls_token: bool = True,
**kwargs,
):
super().__init__(**kwargs)
self.scale = embed_dim**-0.5
self.with_cls_token = with_cls_token
self.embed_dim = embed_dim
self.num_heads = num_heads
self.convolution_projection_query = TFCvtSelfAttentionProjection(
config,
embed_dim,
kernel_size,
stride_q,
padding_q,
projection_method="linear" if qkv_projection_method == "avg" else qkv_projection_method,
name="convolution_projection_query",
)
self.convolution_projection_key = TFCvtSelfAttentionProjection(
config,
embed_dim,
kernel_size,
stride_kv,
padding_kv,
projection_method=qkv_projection_method,
name="convolution_projection_key",
)
self.convolution_projection_value = TFCvtSelfAttentionProjection(
config,
embed_dim,
kernel_size,
stride_kv,
padding_kv,
projection_method=qkv_projection_method,
name="convolution_projection_value",
)
self.projection_query = keras.layers.Dense(
units=embed_dim,
kernel_initializer=get_initializer(config.initializer_range),
use_bias=qkv_bias,
bias_initializer="zeros",
name="projection_query",
)
self.projection_key = keras.layers.Dense(
units=embed_dim,
kernel_initializer=get_initializer(config.initializer_range),
use_bias=qkv_bias,
bias_initializer="zeros",
name="projection_key",
)
self.projection_value = keras.layers.Dense(
units=embed_dim,
kernel_initializer=get_initializer(config.initializer_range),
use_bias=qkv_bias,
bias_initializer="zeros",
name="projection_value",
)
self.dropout = keras.layers.Dropout(attention_drop_rate)
def rearrange_for_multi_head_attention(self, hidden_state: tf.Tensor) -> tf.Tensor:
batch_size, hidden_size, _ = shape_list(hidden_state)
head_dim = self.embed_dim // self.num_heads
hidden_state = tf.reshape(hidden_state, shape=(batch_size, hidden_size, self.num_heads, head_dim))
hidden_state = tf.transpose(hidden_state, perm=(0, 2, 1, 3))
return hidden_state
def call(self, hidden_state: tf.Tensor, height: int, width: int, training: bool = False) -> tf.Tensor:
if self.with_cls_token:
cls_token, hidden_state = tf.split(hidden_state, [1, height * width], 1)
# "batch_size, (height*width), num_channels -> batch_size, height, width, num_channels"
batch_size, hidden_size, num_channels = shape_list(hidden_state)
hidden_state = tf.reshape(hidden_state, shape=(batch_size, height, width, num_channels))
key = self.convolution_projection_key(hidden_state, training=training)
query = self.convolution_projection_query(hidden_state, training=training)
value = self.convolution_projection_value(hidden_state, training=training)
if self.with_cls_token:
query = tf.concat((cls_token, query), axis=1)
key = tf.concat((cls_token, key), axis=1)
value = tf.concat((cls_token, value), axis=1)
head_dim = self.embed_dim // self.num_heads
query = self.rearrange_for_multi_head_attention(self.projection_query(query))
key = self.rearrange_for_multi_head_attention(self.projection_key(key))
value = self.rearrange_for_multi_head_attention(self.projection_value(value))
attention_score = tf.matmul(query, key, transpose_b=True) * self.scale
attention_probs = stable_softmax(logits=attention_score, axis=-1)
attention_probs = self.dropout(attention_probs, training=training)
context = tf.matmul(attention_probs, value)
# "batch_size, num_heads, hidden_size, head_dim -> batch_size, hidden_size, (num_heads*head_dim)"
_, _, hidden_size, _ = shape_list(context)
context = tf.transpose(context, perm=(0, 2, 1, 3))
context = tf.reshape(context, (batch_size, hidden_size, self.num_heads * head_dim))
return context
def build(self, input_shape=None):
if self.built:
return
self.built = True
if getattr(self, "convolution_projection_query", None) is not None:
with tf.name_scope(self.convolution_projection_query.name):
self.convolution_projection_query.build(None)
if getattr(self, "convolution_projection_key", None) is not None:
with tf.name_scope(self.convolution_projection_key.name):
self.convolution_projection_key.build(None)
if getattr(self, "convolution_projection_value", None) is not None:
with tf.name_scope(self.convolution_projection_value.name):
self.convolution_projection_value.build(None)
if getattr(self, "projection_query", None) is not None:
with tf.name_scope(self.projection_query.name):
self.projection_query.build([None, None, self.embed_dim])
if getattr(self, "projection_key", None) is not None:
with tf.name_scope(self.projection_key.name):
self.projection_key.build([None, None, self.embed_dim])
if getattr(self, "projection_value", None) is not None:
with tf.name_scope(self.projection_value.name):
self.projection_value.build([None, None, self.embed_dim])
class TFCvtSelfOutput(keras.layers.Layer):
"""Output of the Attention layer ."""
def __init__(self, config: CvtConfig, embed_dim: int, drop_rate: float, **kwargs):
super().__init__(**kwargs)
self.dense = keras.layers.Dense(
units=embed_dim, kernel_initializer=get_initializer(config.initializer_range), name="dense"
)
self.dropout = keras.layers.Dropout(drop_rate)
self.embed_dim = embed_dim
def call(self, hidden_state: tf.Tensor, training: bool = False) -> tf.Tensor:
hidden_state = self.dense(inputs=hidden_state)
hidden_state = self.dropout(inputs=hidden_state, training=training)
return hidden_state
def build(self, input_shape=None):
if self.built:
return
self.built = True
if getattr(self, "dense", None) is not None:
with tf.name_scope(self.dense.name):
self.dense.build([None, None, self.embed_dim])
class TFCvtAttention(keras.layers.Layer):
"""Attention layer. First chunk of the convolutional transformer block."""
def __init__(
self,
config: CvtConfig,
num_heads: int,
embed_dim: int,
kernel_size: int,
stride_q: int,
stride_kv: int,
padding_q: int,
padding_kv: int,
qkv_projection_method: str,
qkv_bias: bool,
attention_drop_rate: float,
drop_rate: float,
with_cls_token: bool = True,
**kwargs,
):
super().__init__(**kwargs)
self.attention = TFCvtSelfAttention(
config,
num_heads,
embed_dim,
kernel_size,
stride_q,
stride_kv,
padding_q,
padding_kv,
qkv_projection_method,
qkv_bias,
attention_drop_rate,
with_cls_token,
name="attention",
)
self.dense_output = TFCvtSelfOutput(config, embed_dim, drop_rate, name="output")
def prune_heads(self, heads):
raise NotImplementedError
def call(self, hidden_state: tf.Tensor, height: int, width: int, training: bool = False):
self_output = self.attention(hidden_state, height, width, training=training)
attention_output = self.dense_output(self_output, training=training)
return attention_output
def build(self, input_shape=None):
if self.built:
return
self.built = True
if getattr(self, "attention", None) is not None:
with tf.name_scope(self.attention.name):
self.attention.build(None)
if getattr(self, "dense_output", None) is not None:
with tf.name_scope(self.dense_output.name):
self.dense_output.build(None)
class TFCvtIntermediate(keras.layers.Layer):
"""Intermediate dense layer. Second chunk of the convolutional transformer block."""
def __init__(self, config: CvtConfig, embed_dim: int, mlp_ratio: int, **kwargs):
super().__init__(**kwargs)
self.dense = keras.layers.Dense(
units=int(embed_dim * mlp_ratio),
kernel_initializer=get_initializer(config.initializer_range),
activation="gelu",
name="dense",
)
self.embed_dim = embed_dim
def call(self, hidden_state: tf.Tensor) -> tf.Tensor:
hidden_state = self.dense(hidden_state)
return hidden_state
def build(self, input_shape=None):
if self.built:
return
self.built = True
if getattr(self, "dense", None) is not None:
with tf.name_scope(self.dense.name):
self.dense.build([None, None, self.embed_dim])
class TFCvtOutput(keras.layers.Layer):
"""
Output of the Convolutional Transformer Block (last chunk). It consists of a MLP and a residual connection.
"""
def __init__(self, config: CvtConfig, embed_dim: int, mlp_ratio: int, drop_rate: int, **kwargs):
super().__init__(**kwargs)
self.dense = keras.layers.Dense(
units=embed_dim, kernel_initializer=get_initializer(config.initializer_range), name="dense"
)
self.dropout = keras.layers.Dropout(drop_rate)
self.embed_dim = embed_dim
self.mlp_ratio = mlp_ratio
def call(self, hidden_state: tf.Tensor, input_tensor: tf.Tensor, training: bool = False) -> tf.Tensor:
hidden_state = self.dense(inputs=hidden_state)
hidden_state = self.dropout(inputs=hidden_state, training=training)
hidden_state = hidden_state + input_tensor
return hidden_state
def build(self, input_shape=None):
if self.built:
return
self.built = True
if getattr(self, "dense", None) is not None:
with tf.name_scope(self.dense.name):
self.dense.build([None, None, int(self.embed_dim * self.mlp_ratio)])
class TFCvtLayer(keras.layers.Layer):
"""
Convolutional Transformer Block composed by attention layers, normalization and multi-layer perceptrons (mlps). It
consists of 3 chunks : an attention layer, an intermediate dense layer and an output layer. This corresponds to the
`Block` class in the original implementation.
"""
def __init__(
self,
config: CvtConfig,
num_heads: int,
embed_dim: int,
kernel_size: int,
stride_q: int,
stride_kv: int,
padding_q: int,
padding_kv: int,
qkv_projection_method: str,
qkv_bias: bool,
attention_drop_rate: float,
drop_rate: float,
mlp_ratio: float,
drop_path_rate: float,
with_cls_token: bool = True,
**kwargs,
):
super().__init__(**kwargs)
self.attention = TFCvtAttention(
config,
num_heads,
embed_dim,
kernel_size,
stride_q,
stride_kv,
padding_q,
padding_kv,
qkv_projection_method,
qkv_bias,
attention_drop_rate,
drop_rate,
with_cls_token,
name="attention",
)
self.intermediate = TFCvtIntermediate(config, embed_dim, mlp_ratio, name="intermediate")
self.dense_output = TFCvtOutput(config, embed_dim, mlp_ratio, drop_rate, name="output")
# Using `layers.Activation` instead of `tf.identity` to better control `training` behaviour.
self.drop_path = (
TFCvtDropPath(drop_path_rate, name="drop_path")
if drop_path_rate > 0.0
else keras.layers.Activation("linear", name="drop_path")
)
# Using the same default epsilon as PyTorch
self.layernorm_before = keras.layers.LayerNormalization(epsilon=1e-5, name="layernorm_before")
self.layernorm_after = keras.layers.LayerNormalization(epsilon=1e-5, name="layernorm_after")
self.embed_dim = embed_dim
def call(self, hidden_state: tf.Tensor, height: int, width: int, training: bool = False) -> tf.Tensor:
# in Cvt, layernorm is applied before self-attention
attention_output = self.attention(self.layernorm_before(hidden_state), height, width, training=training)
attention_output = self.drop_path(attention_output, training=training)
# first residual connection
hidden_state = attention_output + hidden_state
# in Cvt, layernorm is also applied after self-attention
layer_output = self.layernorm_after(hidden_state)
layer_output = self.intermediate(layer_output)
# second residual connection is done here
layer_output = self.dense_output(layer_output, hidden_state)
layer_output = self.drop_path(layer_output, training=training)
return layer_output
def build(self, input_shape=None):
if self.built:
return
self.built = True
if getattr(self, "attention", None) is not None:
with tf.name_scope(self.attention.name):
self.attention.build(None)
if getattr(self, "intermediate", None) is not None:
with tf.name_scope(self.intermediate.name):
self.intermediate.build(None)
if getattr(self, "dense_output", None) is not None:
with tf.name_scope(self.dense_output.name):
self.dense_output.build(None)
if getattr(self, "drop_path", None) is not None:
with tf.name_scope(self.drop_path.name):
self.drop_path.build(None)
if getattr(self, "layernorm_before", None) is not None:
with tf.name_scope(self.layernorm_before.name):
self.layernorm_before.build([None, None, self.embed_dim])
if getattr(self, "layernorm_after", None) is not None:
with tf.name_scope(self.layernorm_after.name):
self.layernorm_after.build([None, None, self.embed_dim])
class TFCvtStage(keras.layers.Layer):
"""
Cvt stage (encoder block). Each stage has 2 parts :
- (1) A Convolutional Token Embedding layer
- (2) A Convolutional Transformer Block (layer).
The classification token is added only in the last stage.
Args:
config ([`CvtConfig`]): Model configuration class.
stage (`int`): Stage number.
"""
def __init__(self, config: CvtConfig, stage: int, **kwargs):
super().__init__(**kwargs)
self.config = config
self.stage = stage
if self.config.cls_token[self.stage]:
self.cls_token = self.add_weight(
shape=(1, 1, self.config.embed_dim[-1]),
initializer=get_initializer(self.config.initializer_range),
trainable=True,
name="cvt.encoder.stages.2.cls_token",
)
self.embedding = TFCvtEmbeddings(
self.config,
patch_size=config.patch_sizes[self.stage],
num_channels=config.num_channels if self.stage == 0 else config.embed_dim[self.stage - 1],
stride=config.patch_stride[self.stage],
embed_dim=config.embed_dim[self.stage],
padding=config.patch_padding[self.stage],
dropout_rate=config.drop_rate[self.stage],
name="embedding",
)
drop_path_rates = tf.linspace(0.0, config.drop_path_rate[self.stage], config.depth[stage])
drop_path_rates = [x.numpy().item() for x in drop_path_rates]
self.layers = [
TFCvtLayer(
config,
num_heads=config.num_heads[self.stage],
embed_dim=config.embed_dim[self.stage],
kernel_size=config.kernel_qkv[self.stage],
stride_q=config.stride_q[self.stage],
stride_kv=config.stride_kv[self.stage],
padding_q=config.padding_q[self.stage],
padding_kv=config.padding_kv[self.stage],
qkv_projection_method=config.qkv_projection_method[self.stage],
qkv_bias=config.qkv_bias[self.stage],
attention_drop_rate=config.attention_drop_rate[self.stage],
drop_rate=config.drop_rate[self.stage],
mlp_ratio=config.mlp_ratio[self.stage],
drop_path_rate=drop_path_rates[self.stage],
with_cls_token=config.cls_token[self.stage],
name=f"layers.{j}",
)
for j in range(config.depth[self.stage])
]
def call(self, hidden_state: tf.Tensor, training: bool = False):
cls_token = None
hidden_state = self.embedding(hidden_state, training)
# "batch_size, height, width, num_channels -> batch_size, (height*width), num_channels"
batch_size, height, width, num_channels = shape_list(hidden_state)
hidden_size = height * width
hidden_state = tf.reshape(hidden_state, shape=(batch_size, hidden_size, num_channels))
if self.config.cls_token[self.stage]:
cls_token = tf.repeat(self.cls_token, repeats=batch_size, axis=0)
hidden_state = tf.concat((cls_token, hidden_state), axis=1)
for layer in self.layers:
layer_outputs = layer(hidden_state, height, width, training=training)
hidden_state = layer_outputs
if self.config.cls_token[self.stage]:
cls_token, hidden_state = tf.split(hidden_state, [1, height * width], 1)
# "batch_size, (height*width), num_channels -> batch_size, height, width, num_channels"
hidden_state = tf.reshape(hidden_state, shape=(batch_size, height, width, num_channels))
return hidden_state, cls_token
def build(self, input_shape=None):
if self.built:
return
self.built = True
if getattr(self, "embedding", None) is not None:
with tf.name_scope(self.embedding.name):
self.embedding.build(None)
if getattr(self, "layers", None) is not None:
for layer in self.layers:
with tf.name_scope(layer.name):
layer.build(None)
class TFCvtEncoder(keras.layers.Layer):
"""
Convolutional Vision Transformer encoder. CVT has 3 stages of encoder blocks with their respective number of layers
(depth) being 1, 2 and 10.
Args:
config ([`CvtConfig`]): Model configuration class.
"""
config_class = CvtConfig
def __init__(self, config: CvtConfig, **kwargs):
super().__init__(**kwargs)
self.config = config
self.stages = [
TFCvtStage(config, stage_idx, name=f"stages.{stage_idx}") for stage_idx in range(len(config.depth))
]
def call(
self,
pixel_values: TFModelInputType,
output_hidden_states: Optional[bool] = False,
return_dict: Optional[bool] = True,
training: Optional[bool] = False,
) -> Union[TFBaseModelOutputWithCLSToken, Tuple[tf.Tensor]]:
all_hidden_states = () if output_hidden_states else None
hidden_state = pixel_values
# When running on CPU, `keras.layers.Conv2D` doesn't support (batch_size, num_channels, height, width)
# as input format. So change the input format to (batch_size, height, width, num_channels).
hidden_state = tf.transpose(hidden_state, perm=(0, 2, 3, 1))
cls_token = None
for _, (stage_module) in enumerate(self.stages):
hidden_state, cls_token = stage_module(hidden_state, training=training)
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_state,)
# Change back to (batch_size, num_channels, height, width) format to have uniformity in the modules
hidden_state = tf.transpose(hidden_state, perm=(0, 3, 1, 2))
if output_hidden_states:
all_hidden_states = tuple([tf.transpose(hs, perm=(0, 3, 1, 2)) for hs in all_hidden_states])
if not return_dict:
return tuple(v for v in [hidden_state, cls_token, all_hidden_states] if v is not None)
return TFBaseModelOutputWithCLSToken(
last_hidden_state=hidden_state,
cls_token_value=cls_token,
hidden_states=all_hidden_states,
)
def build(self, input_shape=None):
if self.built:
return
self.built = True
if getattr(self, "stages", None) is not None:
for layer in self.stages:
with tf.name_scope(layer.name):
layer.build(None)
@keras_serializable
class TFCvtMainLayer(keras.layers.Layer):
"""Construct the Cvt model."""
config_class = CvtConfig
def __init__(self, config: CvtConfig, **kwargs):
super().__init__(**kwargs)
self.config = config
self.encoder = TFCvtEncoder(config, name="encoder")
@unpack_inputs
def call(
self,
pixel_values: TFModelInputType | None = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
training: Optional[bool] = False,
) -> Union[TFBaseModelOutputWithCLSToken, Tuple[tf.Tensor]]:
if pixel_values is None:
raise ValueError("You have to specify pixel_values")
encoder_outputs = self.encoder(
pixel_values,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
training=training,
)
sequence_output = encoder_outputs[0]
if not return_dict:
return (sequence_output,) + encoder_outputs[1:]
return TFBaseModelOutputWithCLSToken(
last_hidden_state=sequence_output,
cls_token_value=encoder_outputs.cls_token_value,
hidden_states=encoder_outputs.hidden_states,
)
def build(self, input_shape=None):
if self.built:
return
self.built = True
if getattr(self, "encoder", None) is not None:
with tf.name_scope(self.encoder.name):
self.encoder.build(None)
class TFCvtPreTrainedModel(TFPreTrainedModel):
"""
An abstract class to handle weights initialization and a simple interface for downloading and loading pretrained
models.
"""
config_class = CvtConfig
base_model_prefix = "cvt"
main_input_name = "pixel_values"
TFCVT_START_DOCSTRING = r"""
This model inherits from [`TFPreTrainedModel`]. Check the superclass documentation for the generic methods the
library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads
etc.)
This model is also a [keras.Model](https://www.tensorflow.org/api_docs/python/tf/keras/Model) subclass. Use it
as a regular TF 2.0 Keras Model and refer to the TF 2.0 documentation for all matter related to general usage and
behavior.
<Tip>
TF 2.0 models accepts two formats as inputs:
- having all inputs as keyword arguments (like PyTorch models), or
- having all inputs as a list, tuple or dict in the first positional arguments.
This second option is useful when using [`keras.Model.fit`] method which currently requires having all the
tensors in the first argument of the model call function: `model(inputs)`.
</Tip>
Args:
config ([`CvtConfig`]): Model configuration class with all the parameters of the model.
Initializing with a config file does not load the weights associated with the model, only the
configuration. Check out the [`~TFPreTrainedModel.from_pretrained`] method to load the model weights.
"""
TFCVT_INPUTS_DOCSTRING = r"""
Args:
pixel_values (`np.ndarray`, `tf.Tensor`, `List[tf.Tensor]` ``Dict[str, tf.Tensor]` or `Dict[str, np.ndarray]` and each example must have the shape `(batch_size, num_channels, height, width)`):
Pixel values. Pixel values can be obtained using [`AutoImageProcessor`]. See [`CvtImageProcessor.__call__`]
for details.
output_hidden_states (`bool`, *optional*):
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
more detail. This argument can be used only in eager mode, in graph mode the value in the config will be
used instead.
return_dict (`bool`, *optional*):
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple. This argument can be used in
eager mode, in graph mode the value will always be set to True.
training (`bool`, *optional*, defaults to `False``):
Whether or not to use the model in training mode (some modules like dropout modules have different
behaviors between training and evaluation).
"""
@add_start_docstrings(
"The bare Cvt Model transformer outputting raw hidden-states without any specific head on top.",
TFCVT_START_DOCSTRING,
)
class TFCvtModel(TFCvtPreTrainedModel):
def __init__(self, config: CvtConfig, *inputs, **kwargs):
super().__init__(config, *inputs, **kwargs)
self.cvt = TFCvtMainLayer(config, name="cvt")
@unpack_inputs
@add_start_docstrings_to_model_forward(TFCVT_INPUTS_DOCSTRING)
@replace_return_docstrings(output_type=TFBaseModelOutputWithCLSToken, config_class=_CONFIG_FOR_DOC)
def call(
self,
pixel_values: tf.Tensor | None = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
training: Optional[bool] = False,
) -> Union[TFBaseModelOutputWithCLSToken, Tuple[tf.Tensor]]:
r"""
Returns:
Examples:
```python
>>> from transformers import AutoImageProcessor, TFCvtModel
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> image_processor = AutoImageProcessor.from_pretrained("microsoft/cvt-13")
>>> model = TFCvtModel.from_pretrained("microsoft/cvt-13")
>>> inputs = image_processor(images=image, return_tensors="tf")
>>> outputs = model(**inputs)
>>> last_hidden_states = outputs.last_hidden_state
```"""
if pixel_values is None:
raise ValueError("You have to specify pixel_values")
outputs = self.cvt(
pixel_values=pixel_values,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
training=training,
)
if not return_dict:
return (outputs[0],) + outputs[1:]
return TFBaseModelOutputWithCLSToken(
last_hidden_state=outputs.last_hidden_state,
cls_token_value=outputs.cls_token_value,
hidden_states=outputs.hidden_states,
)
def build(self, input_shape=None):
if self.built:
return
self.built = True
if getattr(self, "cvt", None) is not None:
with tf.name_scope(self.cvt.name):
self.cvt.build(None)
@add_start_docstrings(
"""
Cvt Model transformer with an image classification head on top (a linear layer on top of the final hidden state of
the [CLS] token) e.g. for ImageNet.
""",
TFCVT_START_DOCSTRING,
)
class TFCvtForImageClassification(TFCvtPreTrainedModel, TFSequenceClassificationLoss):
def __init__(self, config: CvtConfig, *inputs, **kwargs):
super().__init__(config, *inputs, **kwargs)
self.num_labels = config.num_labels
self.cvt = TFCvtMainLayer(config, name="cvt")
# Using same default epsilon as in the original implementation.
self.layernorm = keras.layers.LayerNormalization(epsilon=1e-5, name="layernorm")
# Classifier head
self.classifier = keras.layers.Dense(
units=config.num_labels,
kernel_initializer=get_initializer(config.initializer_range),
use_bias=True,
bias_initializer="zeros",
name="classifier",
)
self.config = config
@unpack_inputs
@add_start_docstrings_to_model_forward(TFCVT_INPUTS_DOCSTRING)
@replace_return_docstrings(output_type=TFImageClassifierOutputWithNoAttention, config_class=_CONFIG_FOR_DOC)
def call(
self,
pixel_values: tf.Tensor | None = None,
labels: tf.Tensor | None = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
training: Optional[bool] = False,
) -> Union[TFImageClassifierOutputWithNoAttention, Tuple[tf.Tensor]]:
r"""
labels (`tf.Tensor` or `np.ndarray` of shape `(batch_size,)`, *optional*):
Labels for computing the image classification/regression loss. Indices should be in `[0, ...,
config.num_labels - 1]`. If `config.num_labels == 1` a regression loss is computed (Mean-Square loss), If
`config.num_labels > 1` a classification loss is computed (Cross-Entropy).
Returns:
Examples:
```python
>>> from transformers import AutoImageProcessor, TFCvtForImageClassification
>>> import tensorflow as tf
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> image_processor = AutoImageProcessor.from_pretrained("microsoft/cvt-13")
>>> model = TFCvtForImageClassification.from_pretrained("microsoft/cvt-13")
>>> inputs = image_processor(images=image, return_tensors="tf")
>>> outputs = model(**inputs)
>>> logits = outputs.logits
>>> # model predicts one of the 1000 ImageNet classes
>>> predicted_class_idx = tf.math.argmax(logits, axis=-1)[0]
>>> print("Predicted class:", model.config.id2label[int(predicted_class_idx)])
```"""
outputs = self.cvt(
pixel_values,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
training=training,
)
sequence_output = outputs[0]
cls_token = outputs[1]
if self.config.cls_token[-1]:
sequence_output = self.layernorm(cls_token)
else:
# rearrange "batch_size, num_channels, height, width -> batch_size, (height*width), num_channels"
batch_size, num_channels, height, width = shape_list(sequence_output)
sequence_output = tf.reshape(sequence_output, shape=(batch_size, num_channels, height * width))
sequence_output = tf.transpose(sequence_output, perm=(0, 2, 1))
sequence_output = self.layernorm(sequence_output)
sequence_output_mean = tf.reduce_mean(sequence_output, axis=1)
logits = self.classifier(sequence_output_mean)
loss = None if labels is None else self.hf_compute_loss(labels=labels, logits=logits)
if not return_dict:
output = (logits,) + outputs[2:]
return ((loss,) + output) if loss is not None else output
return TFImageClassifierOutputWithNoAttention(loss=loss, logits=logits, hidden_states=outputs.hidden_states)
def build(self, input_shape=None):
if self.built:
return
self.built = True
if getattr(self, "cvt", None) is not None:
with tf.name_scope(self.cvt.name):
self.cvt.build(None)
if getattr(self, "layernorm", None) is not None:
with tf.name_scope(self.layernorm.name):
self.layernorm.build([None, None, self.config.embed_dim[-1]])
if getattr(self, "classifier", None) is not None:
if hasattr(self.classifier, "name"):
with tf.name_scope(self.classifier.name):
self.classifier.build([None, None, self.config.embed_dim[-1]])
| transformers/src/transformers/models/cvt/modeling_tf_cvt.py/0 | {
"file_path": "transformers/src/transformers/models/cvt/modeling_tf_cvt.py",
"repo_id": "transformers",
"token_count": 19162
} | 80 |
# coding=utf-8
# Copyright 2020 Microsoft and the HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
""" Tokenization class for model DeBERTa."""
import json
import os
from typing import List, Optional, Tuple
import regex as re
from ...tokenization_utils import AddedToken, PreTrainedTokenizer
from ...utils import logging
logger = logging.get_logger(__name__)
VOCAB_FILES_NAMES = {"vocab_file": "vocab.json", "merges_file": "merges.txt"}
PRETRAINED_VOCAB_FILES_MAP = {
"vocab_file": {
"microsoft/deberta-base": "https://huggingface.co/microsoft/deberta-base/resolve/main/vocab.json",
"microsoft/deberta-large": "https://huggingface.co/microsoft/deberta-large/resolve/main/vocab.json",
"microsoft/deberta-xlarge": "https://huggingface.co/microsoft/deberta-xlarge/resolve/main/vocab.json",
"microsoft/deberta-base-mnli": "https://huggingface.co/microsoft/deberta-base-mnli/resolve/main/vocab.json",
"microsoft/deberta-large-mnli": "https://huggingface.co/microsoft/deberta-large-mnli/resolve/main/vocab.json",
"microsoft/deberta-xlarge-mnli": (
"https://huggingface.co/microsoft/deberta-xlarge-mnli/resolve/main/vocab.json"
),
},
"merges_file": {
"microsoft/deberta-base": "https://huggingface.co/microsoft/deberta-base/resolve/main/merges.txt",
"microsoft/deberta-large": "https://huggingface.co/microsoft/deberta-large/resolve/main/merges.txt",
"microsoft/deberta-xlarge": "https://huggingface.co/microsoft/deberta-xlarge/resolve/main/merges.txt",
"microsoft/deberta-base-mnli": "https://huggingface.co/microsoft/deberta-base-mnli/resolve/main/merges.txt",
"microsoft/deberta-large-mnli": "https://huggingface.co/microsoft/deberta-large-mnli/resolve/main/merges.txt",
"microsoft/deberta-xlarge-mnli": (
"https://huggingface.co/microsoft/deberta-xlarge-mnli/resolve/main/merges.txt"
),
},
}
PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
"microsoft/deberta-base": 512,
"microsoft/deberta-large": 512,
"microsoft/deberta-xlarge": 512,
"microsoft/deberta-base-mnli": 512,
"microsoft/deberta-large-mnli": 512,
"microsoft/deberta-xlarge-mnli": 512,
}
PRETRAINED_INIT_CONFIGURATION = {
"microsoft/deberta-base": {"do_lower_case": False},
"microsoft/deberta-large": {"do_lower_case": False},
}
# Copied from transformers.models.gpt2.tokenization_gpt2.bytes_to_unicode
def bytes_to_unicode():
"""
Returns list of utf-8 byte and a mapping to unicode strings. We specifically avoids mapping to whitespace/control
characters the bpe code barfs on.
The reversible bpe codes work on unicode strings. This means you need a large # of unicode characters in your vocab
if you want to avoid UNKs. When you're at something like a 10B token dataset you end up needing around 5K for
decent coverage. This is a significant percentage of your normal, say, 32K bpe vocab. To avoid that, we want lookup
tables between utf-8 bytes and unicode strings.
"""
bs = (
list(range(ord("!"), ord("~") + 1)) + list(range(ord("¡"), ord("¬") + 1)) + list(range(ord("®"), ord("ÿ") + 1))
)
cs = bs[:]
n = 0
for b in range(2**8):
if b not in bs:
bs.append(b)
cs.append(2**8 + n)
n += 1
cs = [chr(n) for n in cs]
return dict(zip(bs, cs))
# Copied from transformers.models.gpt2.tokenization_gpt2.get_pairs
def get_pairs(word):
"""
Return set of symbol pairs in a word.
Word is represented as tuple of symbols (symbols being variable-length strings).
"""
pairs = set()
prev_char = word[0]
for char in word[1:]:
pairs.add((prev_char, char))
prev_char = char
return pairs
class DebertaTokenizer(PreTrainedTokenizer):
"""
Construct a DeBERTa tokenizer. Based on byte-level Byte-Pair-Encoding.
This tokenizer has been trained to treat spaces like parts of the tokens (a bit like sentencepiece) so a word will
be encoded differently whether it is at the beginning of the sentence (without space) or not:
```python
>>> from transformers import DebertaTokenizer
>>> tokenizer = DebertaTokenizer.from_pretrained("microsoft/deberta-base")
>>> tokenizer("Hello world")["input_ids"]
[1, 31414, 232, 2]
>>> tokenizer(" Hello world")["input_ids"]
[1, 20920, 232, 2]
```
You can get around that behavior by passing `add_prefix_space=True` when instantiating this tokenizer or when you
call it on some text, but since the model was not pretrained this way, it might yield a decrease in performance.
<Tip>
When used with `is_split_into_words=True`, this tokenizer will add a space before each word (even the first one).
</Tip>
This tokenizer inherits from [`PreTrainedTokenizer`] which contains most of the main methods. Users should refer to
this superclass for more information regarding those methods.
Args:
vocab_file (`str`):
Path to the vocabulary file.
merges_file (`str`):
Path to the merges file.
errors (`str`, *optional*, defaults to `"replace"`):
Paradigm to follow when decoding bytes to UTF-8. See
[bytes.decode](https://docs.python.org/3/library/stdtypes.html#bytes.decode) for more information.
bos_token (`str`, *optional*, defaults to `"[CLS]"`):
The beginning of sequence token.
eos_token (`str`, *optional*, defaults to `"[SEP]"`):
The end of sequence token.
sep_token (`str`, *optional*, defaults to `"[SEP]"`):
The separator token, which is used when building a sequence from multiple sequences, e.g. two sequences for
sequence classification or for a text and a question for question answering. It is also used as the last
token of a sequence built with special tokens.
cls_token (`str`, *optional*, defaults to `"[CLS]"`):
The classifier token which is used when doing sequence classification (classification of the whole sequence
instead of per-token classification). It is the first token of the sequence when built with special tokens.
unk_token (`str`, *optional*, defaults to `"[UNK]"`):
The unknown token. A token that is not in the vocabulary cannot be converted to an ID and is set to be this
token instead.
pad_token (`str`, *optional*, defaults to `"[PAD]"`):
The token used for padding, for example when batching sequences of different lengths.
mask_token (`str`, *optional*, defaults to `"[MASK]"`):
The token used for masking values. This is the token used when training this model with masked language
modeling. This is the token which the model will try to predict.
add_prefix_space (`bool`, *optional*, defaults to `False`):
Whether or not to add an initial space to the input. This allows to treat the leading word just as any
other word. (Deberta tokenizer detect beginning of words by the preceding space).
add_bos_token (`bool`, *optional*, defaults to `False`):
Whether or not to add an initial <|endoftext|> to the input. This allows to treat the leading word just as
any other word.
"""
vocab_files_names = VOCAB_FILES_NAMES
pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
model_input_names = ["input_ids", "attention_mask", "token_type_ids"]
def __init__(
self,
vocab_file,
merges_file,
errors="replace",
bos_token="[CLS]",
eos_token="[SEP]",
sep_token="[SEP]",
cls_token="[CLS]",
unk_token="[UNK]",
pad_token="[PAD]",
mask_token="[MASK]",
add_prefix_space=False,
add_bos_token=False,
**kwargs,
):
bos_token = AddedToken(bos_token, special=True) if isinstance(bos_token, str) else bos_token
eos_token = AddedToken(eos_token, special=True) if isinstance(eos_token, str) else eos_token
sep_token = AddedToken(sep_token, special=True) if isinstance(sep_token, str) else sep_token
cls_token = AddedToken(cls_token, special=True) if isinstance(cls_token, str) else cls_token
unk_token = AddedToken(unk_token, special=True) if isinstance(unk_token, str) else unk_token
pad_token = AddedToken(pad_token, special=True) if isinstance(pad_token, str) else pad_token
# Mask token behave like a normal word, i.e. include the space before it
mask_token = AddedToken(mask_token, lstrip=True, rstrip=False) if isinstance(mask_token, str) else mask_token
self.add_bos_token = add_bos_token
with open(vocab_file, encoding="utf-8") as vocab_handle:
self.encoder = json.load(vocab_handle)
self.decoder = {v: k for k, v in self.encoder.items()}
self.errors = errors # how to handle errors in decoding
self.byte_encoder = bytes_to_unicode()
self.byte_decoder = {v: k for k, v in self.byte_encoder.items()}
with open(merges_file, encoding="utf-8") as merges_handle:
bpe_merges = merges_handle.read().split("\n")[1:-1]
bpe_merges = [tuple(merge.split()) for merge in bpe_merges]
self.bpe_ranks = dict(zip(bpe_merges, range(len(bpe_merges))))
self.cache = {}
self.add_prefix_space = add_prefix_space
# Should have added re.IGNORECASE so BPE merges can happen for capitalized versions of contractions
self.pat = re.compile(r"""'s|'t|'re|'ve|'m|'ll|'d| ?\p{L}+| ?\p{N}+| ?[^\s\p{L}\p{N}]+|\s+(?!\S)|\s+""")
super().__init__(
errors=errors,
bos_token=bos_token,
eos_token=eos_token,
unk_token=unk_token,
sep_token=sep_token,
cls_token=cls_token,
pad_token=pad_token,
mask_token=mask_token,
add_prefix_space=add_prefix_space,
add_bos_token=add_bos_token,
**kwargs,
)
@property
# Copied from transformers.models.gpt2.tokenization_gpt2.GPT2Tokenizer.vocab_size
def vocab_size(self):
return len(self.encoder)
# Copied from transformers.models.gpt2.tokenization_gpt2.GPT2Tokenizer.get_vocab
def get_vocab(self):
return dict(self.encoder, **self.added_tokens_encoder)
# Copied from transformers.models.gpt2.tokenization_gpt2.GPT2Tokenizer.bpe
def bpe(self, token):
if token in self.cache:
return self.cache[token]
word = tuple(token)
pairs = get_pairs(word)
if not pairs:
return token
while True:
bigram = min(pairs, key=lambda pair: self.bpe_ranks.get(pair, float("inf")))
if bigram not in self.bpe_ranks:
break
first, second = bigram
new_word = []
i = 0
while i < len(word):
try:
j = word.index(first, i)
except ValueError:
new_word.extend(word[i:])
break
else:
new_word.extend(word[i:j])
i = j
if word[i] == first and i < len(word) - 1 and word[i + 1] == second:
new_word.append(first + second)
i += 2
else:
new_word.append(word[i])
i += 1
new_word = tuple(new_word)
word = new_word
if len(word) == 1:
break
else:
pairs = get_pairs(word)
word = " ".join(word)
self.cache[token] = word
return word
def build_inputs_with_special_tokens(
self, token_ids_0: List[int], token_ids_1: Optional[List[int]] = None
) -> List[int]:
"""
Build model inputs from a sequence or a pair of sequence for sequence classification tasks by concatenating and
adding special tokens. A DeBERTa sequence has the following format:
- single sequence: [CLS] X [SEP]
- pair of sequences: [CLS] A [SEP] B [SEP]
Args:
token_ids_0 (`List[int]`):
List of IDs to which the special tokens will be added.
token_ids_1 (`List[int]`, *optional*):
Optional second list of IDs for sequence pairs.
Returns:
`List[int]`: List of [input IDs](../glossary#input-ids) with the appropriate special tokens.
"""
if token_ids_1 is None:
return [self.cls_token_id] + token_ids_0 + [self.sep_token_id]
cls = [self.cls_token_id]
sep = [self.sep_token_id]
return cls + token_ids_0 + sep + token_ids_1 + sep
def get_special_tokens_mask(
self, token_ids_0: List[int], token_ids_1: Optional[List[int]] = None, already_has_special_tokens: bool = False
) -> List[int]:
"""
Retrieves sequence ids from a token list that has no special tokens added. This method is called when adding
special tokens using the tokenizer `prepare_for_model` or `encode_plus` methods.
Args:
token_ids_0 (`List[int]`):
List of IDs.
token_ids_1 (`List[int]`, *optional*):
Optional second list of IDs for sequence pairs.
already_has_special_tokens (`bool`, *optional*, defaults to `False`):
Whether or not the token list is already formatted with special tokens for the model.
Returns:
`List[int]`: A list of integers in the range [0, 1]: 1 for a special token, 0 for a sequence token.
"""
if already_has_special_tokens:
return super().get_special_tokens_mask(
token_ids_0=token_ids_0, token_ids_1=token_ids_1, already_has_special_tokens=True
)
if token_ids_1 is None:
return [1] + ([0] * len(token_ids_0)) + [1]
return [1] + ([0] * len(token_ids_0)) + [1] + ([0] * len(token_ids_1)) + [1]
def create_token_type_ids_from_sequences(
self, token_ids_0: List[int], token_ids_1: Optional[List[int]] = None
) -> List[int]:
"""
Create a mask from the two sequences passed to be used in a sequence-pair classification task. A DeBERTa
sequence pair mask has the following format:
```
0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1
| first sequence | second sequence |
```
If `token_ids_1` is `None`, this method only returns the first portion of the mask (0s).
Args:
token_ids_0 (`List[int]`):
List of IDs.
token_ids_1 (`List[int]`, *optional*):
Optional second list of IDs for sequence pairs.
Returns:
`List[int]`: List of [token type IDs](../glossary#token-type-ids) according to the given sequence(s).
"""
sep = [self.sep_token_id]
cls = [self.cls_token_id]
if token_ids_1 is None:
return len(cls + token_ids_0 + sep) * [0]
return len(cls + token_ids_0 + sep) * [0] + len(token_ids_1 + sep) * [1]
# Copied from transformers.models.gpt2.tokenization_gpt2.GPT2Tokenizer._tokenize
def _tokenize(self, text):
"""Tokenize a string."""
bpe_tokens = []
for token in re.findall(self.pat, text):
token = "".join(
self.byte_encoder[b] for b in token.encode("utf-8")
) # Maps all our bytes to unicode strings, avoiding control tokens of the BPE (spaces in our case)
bpe_tokens.extend(bpe_token for bpe_token in self.bpe(token).split(" "))
return bpe_tokens
# Copied from transformers.models.gpt2.tokenization_gpt2.GPT2Tokenizer._convert_token_to_id
def _convert_token_to_id(self, token):
"""Converts a token (str) in an id using the vocab."""
return self.encoder.get(token, self.encoder.get(self.unk_token))
# Copied from transformers.models.gpt2.tokenization_gpt2.GPT2Tokenizer._convert_id_to_token
def _convert_id_to_token(self, index):
"""Converts an index (integer) in a token (str) using the vocab."""
return self.decoder.get(index)
# Copied from transformers.models.gpt2.tokenization_gpt2.GPT2Tokenizer.convert_tokens_to_string
def convert_tokens_to_string(self, tokens):
"""Converts a sequence of tokens (string) in a single string."""
text = "".join(tokens)
text = bytearray([self.byte_decoder[c] for c in text]).decode("utf-8", errors=self.errors)
return text
# Copied from transformers.models.gpt2.tokenization_gpt2.GPT2Tokenizer.save_vocabulary
def save_vocabulary(self, save_directory: str, filename_prefix: Optional[str] = None) -> Tuple[str]:
if not os.path.isdir(save_directory):
logger.error(f"Vocabulary path ({save_directory}) should be a directory")
return
vocab_file = os.path.join(
save_directory, (filename_prefix + "-" if filename_prefix else "") + VOCAB_FILES_NAMES["vocab_file"]
)
merge_file = os.path.join(
save_directory, (filename_prefix + "-" if filename_prefix else "") + VOCAB_FILES_NAMES["merges_file"]
)
with open(vocab_file, "w", encoding="utf-8") as f:
f.write(json.dumps(self.encoder, indent=2, sort_keys=True, ensure_ascii=False) + "\n")
index = 0
with open(merge_file, "w", encoding="utf-8") as writer:
writer.write("#version: 0.2\n")
for bpe_tokens, token_index in sorted(self.bpe_ranks.items(), key=lambda kv: kv[1]):
if index != token_index:
logger.warning(
f"Saving vocabulary to {merge_file}: BPE merge indices are not consecutive."
" Please check that the tokenizer is not corrupted!"
)
index = token_index
writer.write(" ".join(bpe_tokens) + "\n")
index += 1
return vocab_file, merge_file
def prepare_for_tokenization(self, text, is_split_into_words=False, **kwargs):
add_prefix_space = kwargs.pop("add_prefix_space", self.add_prefix_space)
if (is_split_into_words or add_prefix_space) and (len(text) > 0 and not text[0].isspace()):
text = " " + text
return (text, kwargs)
| transformers/src/transformers/models/deberta/tokenization_deberta.py/0 | {
"file_path": "transformers/src/transformers/models/deberta/tokenization_deberta.py",
"repo_id": "transformers",
"token_count": 8267
} | 81 |
# coding=utf-8
# Copyright 2022 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
""" Loading of Deformable DETR's CUDA kernels"""
import os
from pathlib import Path
def load_cuda_kernels():
from torch.utils.cpp_extension import load
root = Path(__file__).resolve().parent.parent.parent / "kernels" / "deformable_detr"
src_files = [
root / filename
for filename in [
"vision.cpp",
os.path.join("cpu", "ms_deform_attn_cpu.cpp"),
os.path.join("cuda", "ms_deform_attn_cuda.cu"),
]
]
load(
"MultiScaleDeformableAttention",
src_files,
with_cuda=True,
extra_include_paths=[str(root)],
extra_cflags=["-DWITH_CUDA=1"],
extra_cuda_cflags=[
"-DCUDA_HAS_FP16=1",
"-D__CUDA_NO_HALF_OPERATORS__",
"-D__CUDA_NO_HALF_CONVERSIONS__",
"-D__CUDA_NO_HALF2_OPERATORS__",
],
)
import MultiScaleDeformableAttention as MSDA
return MSDA
| transformers/src/transformers/models/deformable_detr/load_custom.py/0 | {
"file_path": "transformers/src/transformers/models/deformable_detr/load_custom.py",
"repo_id": "transformers",
"token_count": 637
} | 82 |
# coding=utf-8
# Copyright 2022 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""
Speech processor class for M-CTC-T
"""
import warnings
from contextlib import contextmanager
from ....processing_utils import ProcessorMixin
class MCTCTProcessor(ProcessorMixin):
r"""
Constructs a MCTCT processor which wraps a MCTCT feature extractor and a MCTCT tokenizer into a single processor.
[`MCTCTProcessor`] offers all the functionalities of [`MCTCTFeatureExtractor`] and [`AutoTokenizer`]. See the
[`~MCTCTProcessor.__call__`] and [`~MCTCTProcessor.decode`] for more information.
Args:
feature_extractor (`MCTCTFeatureExtractor`):
An instance of [`MCTCTFeatureExtractor`]. The feature extractor is a required input.
tokenizer (`AutoTokenizer`):
An instance of [`AutoTokenizer`]. The tokenizer is a required input.
"""
feature_extractor_class = "MCTCTFeatureExtractor"
tokenizer_class = "AutoTokenizer"
def __init__(self, feature_extractor, tokenizer):
super().__init__(feature_extractor, tokenizer)
self.current_processor = self.feature_extractor
self._in_target_context_manager = False
def __call__(self, *args, **kwargs):
"""
When used in normal mode, this method forwards all its arguments to MCTCTFeatureExtractor's
[`~MCTCTFeatureExtractor.__call__`] and returns its output. If used in the context
[`~MCTCTProcessor.as_target_processor`] this method forwards all its arguments to AutoTokenizer's
[`~AutoTokenizer.__call__`]. Please refer to the doctsring of the above two methods for more information.
"""
# For backward compatibility
if self._in_target_context_manager:
return self.current_processor(*args, **kwargs)
if "raw_speech" in kwargs:
warnings.warn("Using `raw_speech` as a keyword argument is deprecated. Use `audio` instead.")
audio = kwargs.pop("raw_speech")
else:
audio = kwargs.pop("audio", None)
sampling_rate = kwargs.pop("sampling_rate", None)
text = kwargs.pop("text", None)
if len(args) > 0:
audio = args[0]
args = args[1:]
if audio is None and text is None:
raise ValueError("You need to specify either an `audio` or `text` input to process.")
if audio is not None:
inputs = self.feature_extractor(audio, *args, sampling_rate=sampling_rate, **kwargs)
if text is not None:
encodings = self.tokenizer(text, **kwargs)
if text is None:
return inputs
elif audio is None:
return encodings
else:
inputs["labels"] = encodings["input_ids"]
return inputs
def batch_decode(self, *args, **kwargs):
"""
This method forwards all its arguments to AutoTokenizer's [`~PreTrainedTokenizer.batch_decode`]. Please refer
to the docstring of this method for more information.
"""
return self.tokenizer.batch_decode(*args, **kwargs)
def pad(self, *args, **kwargs):
"""
When used in normal mode, this method forwards all its arguments to MCTCTFeatureExtractor's
[`~MCTCTFeatureExtractor.pad`] and returns its output. If used in the context
[`~MCTCTProcessor.as_target_processor`] this method forwards all its arguments to PreTrainedTokenizer's
[`~PreTrainedTokenizer.pad`]. Please refer to the docstring of the above two methods for more information.
"""
# For backward compatibility
if self._in_target_context_manager:
return self.current_processor.pad(*args, **kwargs)
input_features = kwargs.pop("input_features", None)
labels = kwargs.pop("labels", None)
if len(args) > 0:
input_features = args[0]
args = args[1:]
if input_features is not None:
input_features = self.feature_extractor.pad(input_features, *args, **kwargs)
if labels is not None:
labels = self.tokenizer.pad(labels, **kwargs)
if labels is None:
return input_features
elif input_features is None:
return labels
else:
input_features["labels"] = labels["input_ids"]
return input_features
def decode(self, *args, **kwargs):
"""
This method forwards all its arguments to AutoTokenizer's [`~PreTrainedTokenizer.decode`]. Please refer to the
docstring of this method for more information.
"""
return self.tokenizer.decode(*args, **kwargs)
@contextmanager
def as_target_processor(self):
"""
Temporarily sets the tokenizer for processing the input. Useful for encoding the labels when fine-tuning MCTCT.
"""
warnings.warn(
"`as_target_processor` is deprecated and will be removed in v5 of Transformers. You can process your "
"labels by using the argument `text` of the regular `__call__` method (either in the same call as "
"your audio inputs, or in a separate call."
)
self._in_target_context_manager = True
self.current_processor = self.tokenizer
yield
self.current_processor = self.feature_extractor
self._in_target_context_manager = False
| transformers/src/transformers/models/deprecated/mctct/processing_mctct.py/0 | {
"file_path": "transformers/src/transformers/models/deprecated/mctct/processing_mctct.py",
"repo_id": "transformers",
"token_count": 2272
} | 83 |
# coding=utf-8
# Copyright 2022 The Trajectory Transformers paper authors and The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
""" TrajectoryTransformer pytorch checkpoint conversion"""
import torch
import trajectory.utils as utils
from transformers import TrajectoryTransformerModel
class Parser(utils.Parser):
dataset: str = "halfcheetah-medium-expert-v2"
config: str = "config.offline"
def convert_trajectory_transformer_original_pytorch_checkpoint_to_pytorch(logbase, dataset, loadpath, epoch, device):
"""Converting Sequential blocks to ModuleList"""
gpt, gpt_epoch = utils.load_model(logbase, dataset, loadpath, epoch=epoch, device=device)
trajectory_transformer = TrajectoryTransformerModel(gpt.config)
trajectory_transformer.tok_emb.load_state_dict(gpt.tok_emb.state_dict())
trajectory_transformer.pos_emb = gpt.pos_emb
trajectory_transformer.drop.load_state_dict(gpt.drop.state_dict())
trajectory_transformer.ln_f.load_state_dict(gpt.ln_f.state_dict())
trajectory_transformer.head.load_state_dict(gpt.head.state_dict())
for i, block in enumerate(gpt.blocks):
trajectory_transformer.blocks[i].ln1.load_state_dict(gpt.blocks[i].ln1.state_dict())
trajectory_transformer.blocks[i].ln2.load_state_dict(gpt.blocks[i].ln2.state_dict())
trajectory_transformer.blocks[i].attn.load_state_dict(gpt.blocks[i].attn.state_dict())
trajectory_transformer.blocks[i].l1.load_state_dict(gpt.blocks[i].mlp[0].state_dict())
trajectory_transformer.blocks[i].act.load_state_dict(gpt.blocks[i].mlp[1].state_dict())
trajectory_transformer.blocks[i].l2.load_state_dict(gpt.blocks[i].mlp[2].state_dict())
trajectory_transformer.blocks[i].drop.load_state_dict(gpt.blocks[i].mlp[3].state_dict())
torch.save(trajectory_transformer.state_dict(), "pytorch_model.bin")
if __name__ == "__main__":
"""
To run this script you will need to install the original repository to run the original model. You can find it
here: https://github.com/jannerm/trajectory-transformer From this repository code you can also download the
original pytorch checkpoints.
Run with the command:
```sh
>>> python convert_trajectory_transformer_original_pytorch_checkpoint_to_pytorch.py --dataset <dataset_name>
... --gpt_loadpath <path_to_original_pytorch_checkpoint>
```
"""
args = Parser().parse_args("plan")
convert_trajectory_transformer_original_pytorch_checkpoint_to_pytorch(
args.logbase, args.dataset, args.gpt_loadpath, args.gpt_epoch, args.device
)
| transformers/src/transformers/models/deprecated/trajectory_transformer/convert_trajectory_transformer_original_pytorch_checkpoint_to_pytorch.py/0 | {
"file_path": "transformers/src/transformers/models/deprecated/trajectory_transformer/convert_trajectory_transformer_original_pytorch_checkpoint_to_pytorch.py",
"repo_id": "transformers",
"token_count": 1099
} | 84 |
# coding=utf-8
# Copyright 2024 The HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""Convert Depth Anything checkpoints from the original repository. URL:
https://github.com/LiheYoung/Depth-Anything"""
import argparse
from pathlib import Path
import requests
import torch
from huggingface_hub import hf_hub_download
from PIL import Image
from transformers import DepthAnythingConfig, DepthAnythingForDepthEstimation, Dinov2Config, DPTImageProcessor
from transformers.utils import logging
logging.set_verbosity_info()
logger = logging.get_logger(__name__)
def get_dpt_config(model_name):
if "small" in model_name:
backbone_config = Dinov2Config.from_pretrained(
"facebook/dinov2-small", out_indices=[9, 10, 11, 12], apply_layernorm=True, reshape_hidden_states=False
)
fusion_hidden_size = 64
neck_hidden_sizes = [48, 96, 192, 384]
elif "base" in model_name:
backbone_config = Dinov2Config.from_pretrained(
"facebook/dinov2-base", out_indices=[9, 10, 11, 12], apply_layernorm=True, reshape_hidden_states=False
)
fusion_hidden_size = 128
neck_hidden_sizes = [96, 192, 384, 768]
elif "large" in model_name:
backbone_config = Dinov2Config.from_pretrained(
"facebook/dinov2-large", out_indices=[21, 22, 23, 24], apply_layernorm=True, reshape_hidden_states=False
)
fusion_hidden_size = 256
neck_hidden_sizes = [256, 512, 1024, 1024]
else:
raise NotImplementedError("To do")
config = DepthAnythingConfig(
reassemble_hidden_size=backbone_config.hidden_size,
patch_size=backbone_config.patch_size,
backbone_config=backbone_config,
fusion_hidden_size=fusion_hidden_size,
neck_hidden_sizes=neck_hidden_sizes,
)
return config
def create_rename_keys(config):
rename_keys = []
# fmt: off
# stem
rename_keys.append(("pretrained.cls_token", "backbone.embeddings.cls_token"))
rename_keys.append(("pretrained.mask_token", "backbone.embeddings.mask_token"))
rename_keys.append(("pretrained.pos_embed", "backbone.embeddings.position_embeddings"))
rename_keys.append(("pretrained.patch_embed.proj.weight", "backbone.embeddings.patch_embeddings.projection.weight"))
rename_keys.append(("pretrained.patch_embed.proj.bias", "backbone.embeddings.patch_embeddings.projection.bias"))
# Transfomer encoder
for i in range(config.backbone_config.num_hidden_layers):
rename_keys.append((f"pretrained.blocks.{i}.ls1.gamma", f"backbone.encoder.layer.{i}.layer_scale1.lambda1"))
rename_keys.append((f"pretrained.blocks.{i}.ls2.gamma", f"backbone.encoder.layer.{i}.layer_scale2.lambda1"))
rename_keys.append((f"pretrained.blocks.{i}.norm1.weight", f"backbone.encoder.layer.{i}.norm1.weight"))
rename_keys.append((f"pretrained.blocks.{i}.norm1.bias", f"backbone.encoder.layer.{i}.norm1.bias"))
rename_keys.append((f"pretrained.blocks.{i}.norm2.weight", f"backbone.encoder.layer.{i}.norm2.weight"))
rename_keys.append((f"pretrained.blocks.{i}.norm2.bias", f"backbone.encoder.layer.{i}.norm2.bias"))
rename_keys.append((f"pretrained.blocks.{i}.mlp.fc1.weight", f"backbone.encoder.layer.{i}.mlp.fc1.weight"))
rename_keys.append((f"pretrained.blocks.{i}.mlp.fc1.bias", f"backbone.encoder.layer.{i}.mlp.fc1.bias"))
rename_keys.append((f"pretrained.blocks.{i}.mlp.fc2.weight", f"backbone.encoder.layer.{i}.mlp.fc2.weight"))
rename_keys.append((f"pretrained.blocks.{i}.mlp.fc2.bias", f"backbone.encoder.layer.{i}.mlp.fc2.bias"))
rename_keys.append((f"pretrained.blocks.{i}.attn.proj.weight", f"backbone.encoder.layer.{i}.attention.output.dense.weight"))
rename_keys.append((f"pretrained.blocks.{i}.attn.proj.bias", f"backbone.encoder.layer.{i}.attention.output.dense.bias"))
# Head
rename_keys.append(("pretrained.norm.weight", "backbone.layernorm.weight"))
rename_keys.append(("pretrained.norm.bias", "backbone.layernorm.bias"))
# activation postprocessing (readout projections + resize blocks)
# Depth Anything does not use CLS token => readout_projects not required
for i in range(4):
rename_keys.append((f"depth_head.projects.{i}.weight", f"neck.reassemble_stage.layers.{i}.projection.weight"))
rename_keys.append((f"depth_head.projects.{i}.bias", f"neck.reassemble_stage.layers.{i}.projection.bias"))
if i != 2:
rename_keys.append((f"depth_head.resize_layers.{i}.weight", f"neck.reassemble_stage.layers.{i}.resize.weight"))
rename_keys.append((f"depth_head.resize_layers.{i}.bias", f"neck.reassemble_stage.layers.{i}.resize.bias"))
# refinenet (tricky here)
mapping = {1:3, 2:2, 3:1, 4:0}
for i in range(1, 5):
j = mapping[i]
rename_keys.append((f"depth_head.scratch.refinenet{i}.out_conv.weight", f"neck.fusion_stage.layers.{j}.projection.weight"))
rename_keys.append((f"depth_head.scratch.refinenet{i}.out_conv.bias", f"neck.fusion_stage.layers.{j}.projection.bias"))
rename_keys.append((f"depth_head.scratch.refinenet{i}.resConfUnit1.conv1.weight", f"neck.fusion_stage.layers.{j}.residual_layer1.convolution1.weight"))
rename_keys.append((f"depth_head.scratch.refinenet{i}.resConfUnit1.conv1.bias", f"neck.fusion_stage.layers.{j}.residual_layer1.convolution1.bias"))
rename_keys.append((f"depth_head.scratch.refinenet{i}.resConfUnit1.conv2.weight", f"neck.fusion_stage.layers.{j}.residual_layer1.convolution2.weight"))
rename_keys.append((f"depth_head.scratch.refinenet{i}.resConfUnit1.conv2.bias", f"neck.fusion_stage.layers.{j}.residual_layer1.convolution2.bias"))
rename_keys.append((f"depth_head.scratch.refinenet{i}.resConfUnit2.conv1.weight", f"neck.fusion_stage.layers.{j}.residual_layer2.convolution1.weight"))
rename_keys.append((f"depth_head.scratch.refinenet{i}.resConfUnit2.conv1.bias", f"neck.fusion_stage.layers.{j}.residual_layer2.convolution1.bias"))
rename_keys.append((f"depth_head.scratch.refinenet{i}.resConfUnit2.conv2.weight", f"neck.fusion_stage.layers.{j}.residual_layer2.convolution2.weight"))
rename_keys.append((f"depth_head.scratch.refinenet{i}.resConfUnit2.conv2.bias", f"neck.fusion_stage.layers.{j}.residual_layer2.convolution2.bias"))
# scratch convolutions
for i in range(4):
rename_keys.append((f"depth_head.scratch.layer{i+1}_rn.weight", f"neck.convs.{i}.weight"))
# head
rename_keys.append(("depth_head.scratch.output_conv1.weight", "head.conv1.weight"))
rename_keys.append(("depth_head.scratch.output_conv1.bias", "head.conv1.bias"))
rename_keys.append(("depth_head.scratch.output_conv2.0.weight", "head.conv2.weight"))
rename_keys.append(("depth_head.scratch.output_conv2.0.bias", "head.conv2.bias"))
rename_keys.append(("depth_head.scratch.output_conv2.2.weight", "head.conv3.weight"))
rename_keys.append(("depth_head.scratch.output_conv2.2.bias", "head.conv3.bias"))
return rename_keys
# we split up the matrix of each encoder layer into queries, keys and values
def read_in_q_k_v(state_dict, config):
hidden_size = config.backbone_config.hidden_size
for i in range(config.backbone_config.num_hidden_layers):
# read in weights + bias of input projection layer (in original implementation, this is a single matrix + bias)
in_proj_weight = state_dict.pop(f"pretrained.blocks.{i}.attn.qkv.weight")
in_proj_bias = state_dict.pop(f"pretrained.blocks.{i}.attn.qkv.bias")
# next, add query, keys and values (in that order) to the state dict
state_dict[f"backbone.encoder.layer.{i}.attention.attention.query.weight"] = in_proj_weight[:hidden_size, :]
state_dict[f"backbone.encoder.layer.{i}.attention.attention.query.bias"] = in_proj_bias[:hidden_size]
state_dict[f"backbone.encoder.layer.{i}.attention.attention.key.weight"] = in_proj_weight[
hidden_size : hidden_size * 2, :
]
state_dict[f"backbone.encoder.layer.{i}.attention.attention.key.bias"] = in_proj_bias[
hidden_size : hidden_size * 2
]
state_dict[f"backbone.encoder.layer.{i}.attention.attention.value.weight"] = in_proj_weight[-hidden_size:, :]
state_dict[f"backbone.encoder.layer.{i}.attention.attention.value.bias"] = in_proj_bias[-hidden_size:]
def rename_key(dct, old, new):
val = dct.pop(old)
dct[new] = val
# We will verify our results on an image of cute cats
def prepare_img():
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
im = Image.open(requests.get(url, stream=True).raw)
return im
name_to_checkpoint = {
"depth-anything-small": "depth_anything_vits14.pth",
"depth-anything-base": "depth_anything_vitb14.pth",
"depth-anything-large": "depth_anything_vitl14.pth",
}
@torch.no_grad()
def convert_dpt_checkpoint(model_name, pytorch_dump_folder_path, push_to_hub, verify_logits):
"""
Copy/paste/tweak model's weights to our DPT structure.
"""
# define DPT configuration
config = get_dpt_config(model_name)
model_name_to_filename = {
"depth-anything-small": "depth_anything_vits14.pth",
"depth-anything-base": "depth_anything_vitb14.pth",
"depth-anything-large": "depth_anything_vitl14.pth",
}
# load original state_dict
filename = model_name_to_filename[model_name]
filepath = hf_hub_download(
repo_id="LiheYoung/Depth-Anything", filename=f"checkpoints/{filename}", repo_type="space"
)
state_dict = torch.load(filepath, map_location="cpu")
# rename keys
rename_keys = create_rename_keys(config)
for src, dest in rename_keys:
rename_key(state_dict, src, dest)
# read in qkv matrices
read_in_q_k_v(state_dict, config)
# load HuggingFace model
model = DepthAnythingForDepthEstimation(config)
model.load_state_dict(state_dict)
model.eval()
processor = DPTImageProcessor(
do_resize=True,
size={"height": 518, "width": 518},
ensure_multiple_of=14,
keep_aspect_ratio=True,
do_rescale=True,
do_normalize=True,
image_mean=[0.485, 0.456, 0.406],
image_std=[0.229, 0.224, 0.225],
)
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
pixel_values = processor(image, return_tensors="pt").pixel_values
# Verify forward pass
with torch.no_grad():
outputs = model(pixel_values)
predicted_depth = outputs.predicted_depth
print("Shape of predicted depth:", predicted_depth.shape)
print("First values:", predicted_depth[0, :3, :3])
# assert logits
if verify_logits:
expected_shape = torch.Size([1, 518, 686])
if model_name == "depth-anything-small":
expected_slice = torch.tensor(
[[8.8204, 8.6468, 8.6195], [8.3313, 8.6027, 8.7526], [8.6526, 8.6866, 8.7453]],
)
elif model_name == "depth-anything-base":
expected_slice = torch.tensor(
[[26.3997, 26.3004, 26.3928], [26.2260, 26.2092, 26.3427], [26.0719, 26.0483, 26.1254]],
)
elif model_name == "depth-anything-large":
expected_slice = torch.tensor(
[[87.9968, 87.7493, 88.2704], [87.1927, 87.6611, 87.3640], [86.7789, 86.9469, 86.7991]]
)
else:
raise ValueError("Not supported")
assert predicted_depth.shape == torch.Size(expected_shape)
assert torch.allclose(predicted_depth[0, :3, :3], expected_slice, atol=1e-6)
print("Looks ok!")
if pytorch_dump_folder_path is not None:
Path(pytorch_dump_folder_path).mkdir(exist_ok=True)
print(f"Saving model and processor to {pytorch_dump_folder_path}")
model.save_pretrained(pytorch_dump_folder_path)
processor.save_pretrained(pytorch_dump_folder_path)
if push_to_hub:
print("Pushing model and processor to hub...")
model.push_to_hub(repo_id=f"LiheYoung/{model_name}-hf")
processor.push_to_hub(repo_id=f"LiheYoung/{model_name}-hf")
if __name__ == "__main__":
parser = argparse.ArgumentParser()
# Required parameters
parser.add_argument(
"--model_name",
default="depth-anything-small",
type=str,
choices=name_to_checkpoint.keys(),
help="Name of the model you'd like to convert.",
)
parser.add_argument(
"--pytorch_dump_folder_path",
default=None,
type=str,
help="Path to the output PyTorch model directory.",
)
parser.add_argument(
"--push_to_hub",
action="store_true",
help="Whether to push the model to the hub after conversion.",
)
parser.add_argument(
"--verify_logits",
action="store_false",
required=False,
help="Whether to verify the logits after conversion.",
)
args = parser.parse_args()
convert_dpt_checkpoint(args.model_name, args.pytorch_dump_folder_path, args.push_to_hub, args.verify_logits)
| transformers/src/transformers/models/depth_anything/convert_depth_anything_to_hf.py/0 | {
"file_path": "transformers/src/transformers/models/depth_anything/convert_depth_anything_to_hf.py",
"repo_id": "transformers",
"token_count": 5755
} | 85 |
# Copyright 2020 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import argparse
import os
import torch
from transformers.utils import WEIGHTS_NAME
DIALOGPT_MODELS = ["small", "medium", "large"]
OLD_KEY = "lm_head.decoder.weight"
NEW_KEY = "lm_head.weight"
def convert_dialogpt_checkpoint(checkpoint_path: str, pytorch_dump_folder_path: str):
d = torch.load(checkpoint_path)
d[NEW_KEY] = d.pop(OLD_KEY)
os.makedirs(pytorch_dump_folder_path, exist_ok=True)
torch.save(d, os.path.join(pytorch_dump_folder_path, WEIGHTS_NAME))
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--dialogpt_path", default=".", type=str)
args = parser.parse_args()
for MODEL in DIALOGPT_MODELS:
checkpoint_path = os.path.join(args.dialogpt_path, f"{MODEL}_ft.pkl")
pytorch_dump_folder_path = f"./DialoGPT-{MODEL}"
convert_dialogpt_checkpoint(
checkpoint_path,
pytorch_dump_folder_path,
)
| transformers/src/transformers/models/dialogpt/convert_dialogpt_original_pytorch_checkpoint_to_pytorch.py/0 | {
"file_path": "transformers/src/transformers/models/dialogpt/convert_dialogpt_original_pytorch_checkpoint_to_pytorch.py",
"repo_id": "transformers",
"token_count": 560
} | 86 |
# coding=utf-8
# Copyright 2022 The HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""Convert DiT checkpoints from the unilm repository."""
import argparse
import json
from pathlib import Path
import requests
import torch
from huggingface_hub import hf_hub_download
from PIL import Image
from transformers import BeitConfig, BeitForImageClassification, BeitForMaskedImageModeling, BeitImageProcessor
from transformers.image_utils import PILImageResampling
from transformers.utils import logging
logging.set_verbosity_info()
logger = logging.get_logger(__name__)
# here we list all keys to be renamed (original name on the left, our name on the right)
def create_rename_keys(config, has_lm_head=False, is_semantic=False):
prefix = "backbone." if is_semantic else ""
rename_keys = []
for i in range(config.num_hidden_layers):
# encoder layers: output projection, 2 feedforward neural networks and 2 layernorms
rename_keys.append((f"{prefix}blocks.{i}.norm1.weight", f"beit.encoder.layer.{i}.layernorm_before.weight"))
rename_keys.append((f"{prefix}blocks.{i}.norm1.bias", f"beit.encoder.layer.{i}.layernorm_before.bias"))
rename_keys.append(
(f"{prefix}blocks.{i}.attn.proj.weight", f"beit.encoder.layer.{i}.attention.output.dense.weight")
)
rename_keys.append(
(f"{prefix}blocks.{i}.attn.proj.bias", f"beit.encoder.layer.{i}.attention.output.dense.bias")
)
rename_keys.append((f"{prefix}blocks.{i}.norm2.weight", f"beit.encoder.layer.{i}.layernorm_after.weight"))
rename_keys.append((f"{prefix}blocks.{i}.norm2.bias", f"beit.encoder.layer.{i}.layernorm_after.bias"))
rename_keys.append((f"{prefix}blocks.{i}.mlp.fc1.weight", f"beit.encoder.layer.{i}.intermediate.dense.weight"))
rename_keys.append((f"{prefix}blocks.{i}.mlp.fc1.bias", f"beit.encoder.layer.{i}.intermediate.dense.bias"))
rename_keys.append((f"{prefix}blocks.{i}.mlp.fc2.weight", f"beit.encoder.layer.{i}.output.dense.weight"))
rename_keys.append((f"{prefix}blocks.{i}.mlp.fc2.bias", f"beit.encoder.layer.{i}.output.dense.bias"))
# projection layer + position embeddings
rename_keys.extend(
[
(f"{prefix}cls_token", "beit.embeddings.cls_token"),
(f"{prefix}patch_embed.proj.weight", "beit.embeddings.patch_embeddings.projection.weight"),
(f"{prefix}patch_embed.proj.bias", "beit.embeddings.patch_embeddings.projection.bias"),
(f"{prefix}pos_embed", "beit.embeddings.position_embeddings"),
]
)
if has_lm_head:
# mask token + layernorm
rename_keys.extend(
[
("mask_token", "beit.embeddings.mask_token"),
("norm.weight", "layernorm.weight"),
("norm.bias", "layernorm.bias"),
]
)
else:
# layernorm + classification head
rename_keys.extend(
[
("fc_norm.weight", "beit.pooler.layernorm.weight"),
("fc_norm.bias", "beit.pooler.layernorm.bias"),
("head.weight", "classifier.weight"),
("head.bias", "classifier.bias"),
]
)
return rename_keys
# we split up the matrix of each encoder layer into queries, keys and values
def read_in_q_k_v(state_dict, config, has_lm_head=False, is_semantic=False):
for i in range(config.num_hidden_layers):
prefix = "backbone." if is_semantic else ""
# queries, keys and values
in_proj_weight = state_dict.pop(f"{prefix}blocks.{i}.attn.qkv.weight")
q_bias = state_dict.pop(f"{prefix}blocks.{i}.attn.q_bias")
v_bias = state_dict.pop(f"{prefix}blocks.{i}.attn.v_bias")
state_dict[f"beit.encoder.layer.{i}.attention.attention.query.weight"] = in_proj_weight[
: config.hidden_size, :
]
state_dict[f"beit.encoder.layer.{i}.attention.attention.query.bias"] = q_bias
state_dict[f"beit.encoder.layer.{i}.attention.attention.key.weight"] = in_proj_weight[
config.hidden_size : config.hidden_size * 2, :
]
state_dict[f"beit.encoder.layer.{i}.attention.attention.value.weight"] = in_proj_weight[
-config.hidden_size :, :
]
state_dict[f"beit.encoder.layer.{i}.attention.attention.value.bias"] = v_bias
# gamma_1 and gamma_2
# we call them lambda because otherwise they are renamed when using .from_pretrained
gamma_1 = state_dict.pop(f"{prefix}blocks.{i}.gamma_1")
gamma_2 = state_dict.pop(f"{prefix}blocks.{i}.gamma_2")
state_dict[f"beit.encoder.layer.{i}.lambda_1"] = gamma_1
state_dict[f"beit.encoder.layer.{i}.lambda_2"] = gamma_2
def rename_key(dct, old, new):
val = dct.pop(old)
dct[new] = val
# We will verify our results on an image of cute cats
def prepare_img():
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
im = Image.open(requests.get(url, stream=True).raw)
return im
@torch.no_grad()
def convert_dit_checkpoint(checkpoint_url, pytorch_dump_folder_path, push_to_hub=False):
"""
Copy/paste/tweak model's weights to our BEiT structure.
"""
# define default BEiT configuration
has_lm_head = False if "rvlcdip" in checkpoint_url else True
config = BeitConfig(use_absolute_position_embeddings=True, use_mask_token=has_lm_head)
# size of the architecture
if "large" in checkpoint_url or "dit-l" in checkpoint_url:
config.hidden_size = 1024
config.intermediate_size = 4096
config.num_hidden_layers = 24
config.num_attention_heads = 16
# labels
if "rvlcdip" in checkpoint_url:
config.num_labels = 16
repo_id = "huggingface/label-files"
filename = "rvlcdip-id2label.json"
id2label = json.load(open(hf_hub_download(repo_id, filename, repo_type="dataset"), "r"))
id2label = {int(k): v for k, v in id2label.items()}
config.id2label = id2label
config.label2id = {v: k for k, v in id2label.items()}
# load state_dict of original model, remove and rename some keys
state_dict = torch.hub.load_state_dict_from_url(checkpoint_url, map_location="cpu")["model"]
rename_keys = create_rename_keys(config, has_lm_head=has_lm_head)
for src, dest in rename_keys:
rename_key(state_dict, src, dest)
read_in_q_k_v(state_dict, config, has_lm_head=has_lm_head)
# load HuggingFace model
model = BeitForMaskedImageModeling(config) if has_lm_head else BeitForImageClassification(config)
model.eval()
model.load_state_dict(state_dict)
# Check outputs on an image
image_processor = BeitImageProcessor(
size=config.image_size, resample=PILImageResampling.BILINEAR, do_center_crop=False
)
image = prepare_img()
encoding = image_processor(images=image, return_tensors="pt")
pixel_values = encoding["pixel_values"]
outputs = model(pixel_values)
logits = outputs.logits
# verify logits
expected_shape = [1, 16] if "rvlcdip" in checkpoint_url else [1, 196, 8192]
assert logits.shape == torch.Size(expected_shape), "Shape of logits not as expected"
Path(pytorch_dump_folder_path).mkdir(exist_ok=True)
print(f"Saving model to {pytorch_dump_folder_path}")
model.save_pretrained(pytorch_dump_folder_path)
print(f"Saving image processor to {pytorch_dump_folder_path}")
image_processor.save_pretrained(pytorch_dump_folder_path)
if push_to_hub:
if has_lm_head:
model_name = "dit-base" if "base" in checkpoint_url else "dit-large"
else:
model_name = "dit-base-finetuned-rvlcdip" if "dit-b" in checkpoint_url else "dit-large-finetuned-rvlcdip"
image_processor.push_to_hub(
repo_path_or_name=Path(pytorch_dump_folder_path, model_name),
organization="nielsr",
commit_message="Add image processor",
use_temp_dir=True,
)
model.push_to_hub(
repo_path_or_name=Path(pytorch_dump_folder_path, model_name),
organization="nielsr",
commit_message="Add model",
use_temp_dir=True,
)
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument(
"--checkpoint_url",
default="https://layoutlm.blob.core.windows.net/dit/dit-pts/dit-base-224-p16-500k-62d53a.pth",
type=str,
help="URL to the original PyTorch checkpoint (.pth file).",
)
parser.add_argument(
"--pytorch_dump_folder_path", default=None, type=str, help="Path to the folder to output PyTorch model."
)
parser.add_argument(
"--push_to_hub",
action="store_true",
)
args = parser.parse_args()
convert_dit_checkpoint(args.checkpoint_url, args.pytorch_dump_folder_path, args.push_to_hub)
| transformers/src/transformers/models/dit/convert_dit_unilm_to_pytorch.py/0 | {
"file_path": "transformers/src/transformers/models/dit/convert_dit_unilm_to_pytorch.py",
"repo_id": "transformers",
"token_count": 4018
} | 87 |
# coding=utf-8
# Copyright 2022 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
""" DPT model configuration"""
import copy
from ...configuration_utils import PretrainedConfig
from ...utils import logging
from ..auto.configuration_auto import CONFIG_MAPPING
from ..bit import BitConfig
logger = logging.get_logger(__name__)
DPT_PRETRAINED_CONFIG_ARCHIVE_MAP = {
"Intel/dpt-large": "https://huggingface.co/Intel/dpt-large/resolve/main/config.json",
# See all DPT models at https://huggingface.co/models?filter=dpt
}
class DPTConfig(PretrainedConfig):
r"""
This is the configuration class to store the configuration of a [`DPTModel`]. It is used to instantiate an DPT
model according to the specified arguments, defining the model architecture. Instantiating a configuration with the
defaults will yield a similar configuration to that of the DPT
[Intel/dpt-large](https://huggingface.co/Intel/dpt-large) architecture.
Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
documentation from [`PretrainedConfig`] for more information.
Args:
hidden_size (`int`, *optional*, defaults to 768):
Dimensionality of the encoder layers and the pooler layer.
num_hidden_layers (`int`, *optional*, defaults to 12):
Number of hidden layers in the Transformer encoder.
num_attention_heads (`int`, *optional*, defaults to 12):
Number of attention heads for each attention layer in the Transformer encoder.
intermediate_size (`int`, *optional*, defaults to 3072):
Dimensionality of the "intermediate" (i.e., feed-forward) layer in the Transformer encoder.
hidden_act (`str` or `function`, *optional*, defaults to `"gelu"`):
The non-linear activation function (function or string) in the encoder and pooler. If string, `"gelu"`,
`"relu"`, `"selu"` and `"gelu_new"` are supported.
hidden_dropout_prob (`float`, *optional*, defaults to 0.0):
The dropout probability for all fully connected layers in the embeddings, encoder, and pooler.
attention_probs_dropout_prob (`float`, *optional*, defaults to 0.0):
The dropout ratio for the attention probabilities.
initializer_range (`float`, *optional*, defaults to 0.02):
The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
layer_norm_eps (`float`, *optional*, defaults to 1e-12):
The epsilon used by the layer normalization layers.
image_size (`int`, *optional*, defaults to 384):
The size (resolution) of each image.
patch_size (`int`, *optional*, defaults to 16):
The size (resolution) of each patch.
num_channels (`int`, *optional*, defaults to 3):
The number of input channels.
is_hybrid (`bool`, *optional*, defaults to `False`):
Whether to use a hybrid backbone. Useful in the context of loading DPT-Hybrid models.
qkv_bias (`bool`, *optional*, defaults to `True`):
Whether to add a bias to the queries, keys and values.
backbone_out_indices (`List[int]`, *optional*, defaults to `[2, 5, 8, 11]`):
Indices of the intermediate hidden states to use from backbone.
readout_type (`str`, *optional*, defaults to `"project"`):
The readout type to use when processing the readout token (CLS token) of the intermediate hidden states of
the ViT backbone. Can be one of [`"ignore"`, `"add"`, `"project"`].
- "ignore" simply ignores the CLS token.
- "add" passes the information from the CLS token to all other tokens by adding the representations.
- "project" passes information to the other tokens by concatenating the readout to all other tokens before
projecting the
representation to the original feature dimension D using a linear layer followed by a GELU non-linearity.
reassemble_factors (`List[int]`, *optional*, defaults to `[4, 2, 1, 0.5]`):
The up/downsampling factors of the reassemble layers.
neck_hidden_sizes (`List[str]`, *optional*, defaults to `[96, 192, 384, 768]`):
The hidden sizes to project to for the feature maps of the backbone.
fusion_hidden_size (`int`, *optional*, defaults to 256):
The number of channels before fusion.
head_in_index (`int`, *optional*, defaults to -1):
The index of the features to use in the heads.
use_batch_norm_in_fusion_residual (`bool`, *optional*, defaults to `False`):
Whether to use batch normalization in the pre-activate residual units of the fusion blocks.
use_bias_in_fusion_residual (`bool`, *optional*, defaults to `True`):
Whether to use bias in the pre-activate residual units of the fusion blocks.
add_projection (`bool`, *optional*, defaults to `False`):
Whether to add a projection layer before the depth estimation head.
use_auxiliary_head (`bool`, *optional*, defaults to `True`):
Whether to use an auxiliary head during training.
auxiliary_loss_weight (`float`, *optional*, defaults to 0.4):
Weight of the cross-entropy loss of the auxiliary head.
semantic_loss_ignore_index (`int`, *optional*, defaults to 255):
The index that is ignored by the loss function of the semantic segmentation model.
semantic_classifier_dropout (`float`, *optional*, defaults to 0.1):
The dropout ratio for the semantic classification head.
backbone_featmap_shape (`List[int]`, *optional*, defaults to `[1, 1024, 24, 24]`):
Used only for the `hybrid` embedding type. The shape of the feature maps of the backbone.
neck_ignore_stages (`List[int]`, *optional*, defaults to `[0, 1]`):
Used only for the `hybrid` embedding type. The stages of the readout layers to ignore.
backbone_config (`Union[Dict[str, Any], PretrainedConfig]`, *optional*):
The configuration of the backbone model. Only used in case `is_hybrid` is `True` or in case you want to
leverage the [`AutoBackbone`] API.
backbone (`str`, *optional*):
Name of backbone to use when `backbone_config` is `None`. If `use_pretrained_backbone` is `True`, this
will load the corresponding pretrained weights from the timm or transformers library. If `use_pretrained_backbone`
is `False`, this loads the backbone's config and uses that to initialize the backbone with random weights.
use_pretrained_backbone (`bool`, *optional*, defaults to `False`):
Whether to use pretrained weights for the backbone.
use_timm_backbone (`bool`, *optional*, defaults to `False`):
Whether to load `backbone` from the timm library. If `False`, the backbone is loaded from the transformers
library.
backbone_kwargs (`dict`, *optional*):
Keyword arguments to be passed to AutoBackbone when loading from a checkpoint
e.g. `{'out_indices': (0, 1, 2, 3)}`. Cannot be specified if `backbone_config` is set.
Example:
```python
>>> from transformers import DPTModel, DPTConfig
>>> # Initializing a DPT dpt-large style configuration
>>> configuration = DPTConfig()
>>> # Initializing a model from the dpt-large style configuration
>>> model = DPTModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.config
```"""
model_type = "dpt"
def __init__(
self,
hidden_size=768,
num_hidden_layers=12,
num_attention_heads=12,
intermediate_size=3072,
hidden_act="gelu",
hidden_dropout_prob=0.0,
attention_probs_dropout_prob=0.0,
initializer_range=0.02,
layer_norm_eps=1e-12,
image_size=384,
patch_size=16,
num_channels=3,
is_hybrid=False,
qkv_bias=True,
backbone_out_indices=[2, 5, 8, 11],
readout_type="project",
reassemble_factors=[4, 2, 1, 0.5],
neck_hidden_sizes=[96, 192, 384, 768],
fusion_hidden_size=256,
head_in_index=-1,
use_batch_norm_in_fusion_residual=False,
use_bias_in_fusion_residual=None,
add_projection=False,
use_auxiliary_head=True,
auxiliary_loss_weight=0.4,
semantic_loss_ignore_index=255,
semantic_classifier_dropout=0.1,
backbone_featmap_shape=[1, 1024, 24, 24],
neck_ignore_stages=[0, 1],
backbone_config=None,
backbone=None,
use_pretrained_backbone=False,
use_timm_backbone=False,
backbone_kwargs=None,
**kwargs,
):
super().__init__(**kwargs)
self.hidden_size = hidden_size
self.is_hybrid = is_hybrid
if use_pretrained_backbone:
raise ValueError("Pretrained backbones are not supported yet.")
use_autobackbone = False
if self.is_hybrid:
if backbone_config is None and backbone is None:
logger.info("Initializing the config with a `BiT` backbone.")
backbone_config = {
"global_padding": "same",
"layer_type": "bottleneck",
"depths": [3, 4, 9],
"out_features": ["stage1", "stage2", "stage3"],
"embedding_dynamic_padding": True,
}
backbone_config = BitConfig(**backbone_config)
elif isinstance(backbone_config, dict):
logger.info("Initializing the config with a `BiT` backbone.")
backbone_config = BitConfig(**backbone_config)
elif isinstance(backbone_config, PretrainedConfig):
backbone_config = backbone_config
else:
raise ValueError(
f"backbone_config must be a dictionary or a `PretrainedConfig`, got {backbone_config.__class__}."
)
self.backbone_config = backbone_config
self.backbone_featmap_shape = backbone_featmap_shape
self.neck_ignore_stages = neck_ignore_stages
if readout_type != "project":
raise ValueError("Readout type must be 'project' when using `DPT-hybrid` mode.")
elif backbone_config is not None:
use_autobackbone = True
if isinstance(backbone_config, dict):
backbone_model_type = backbone_config.get("model_type")
config_class = CONFIG_MAPPING[backbone_model_type]
backbone_config = config_class.from_dict(backbone_config)
self.backbone_config = backbone_config
self.backbone_featmap_shape = None
self.neck_ignore_stages = []
else:
self.backbone_config = backbone_config
self.backbone_featmap_shape = None
self.neck_ignore_stages = []
if use_autobackbone and backbone_config is not None and backbone is not None:
raise ValueError("You can't specify both `backbone` and `backbone_config`.")
if backbone_kwargs is not None and backbone_kwargs and backbone_config is not None:
raise ValueError("You can't specify both `backbone_kwargs` and `backbone_config`.")
self.backbone = backbone
self.use_pretrained_backbone = use_pretrained_backbone
self.use_timm_backbone = use_timm_backbone
self.backbone_kwargs = backbone_kwargs
self.num_hidden_layers = None if use_autobackbone else num_hidden_layers
self.num_attention_heads = None if use_autobackbone else num_attention_heads
self.intermediate_size = None if use_autobackbone else intermediate_size
self.hidden_dropout_prob = None if use_autobackbone else hidden_dropout_prob
self.attention_probs_dropout_prob = None if use_autobackbone else attention_probs_dropout_prob
self.layer_norm_eps = None if use_autobackbone else layer_norm_eps
self.image_size = None if use_autobackbone else image_size
self.patch_size = None if use_autobackbone else patch_size
self.num_channels = None if use_autobackbone else num_channels
self.qkv_bias = None if use_autobackbone else qkv_bias
self.backbone_out_indices = None if use_autobackbone else backbone_out_indices
if readout_type not in ["ignore", "add", "project"]:
raise ValueError("Readout_type must be one of ['ignore', 'add', 'project']")
self.hidden_act = hidden_act
self.initializer_range = initializer_range
self.readout_type = readout_type
self.reassemble_factors = reassemble_factors
self.neck_hidden_sizes = neck_hidden_sizes
self.fusion_hidden_size = fusion_hidden_size
self.head_in_index = head_in_index
self.use_batch_norm_in_fusion_residual = use_batch_norm_in_fusion_residual
self.use_bias_in_fusion_residual = use_bias_in_fusion_residual
self.add_projection = add_projection
# auxiliary head attributes (semantic segmentation)
self.use_auxiliary_head = use_auxiliary_head
self.auxiliary_loss_weight = auxiliary_loss_weight
self.semantic_loss_ignore_index = semantic_loss_ignore_index
self.semantic_classifier_dropout = semantic_classifier_dropout
def to_dict(self):
"""
Serializes this instance to a Python dictionary. Override the default [`~PretrainedConfig.to_dict`]. Returns:
`Dict[str, any]`: Dictionary of all the attributes that make up this configuration instance,
"""
output = copy.deepcopy(self.__dict__)
if output["backbone_config"] is not None:
output["backbone_config"] = self.backbone_config.to_dict()
output["model_type"] = self.__class__.model_type
return output
| transformers/src/transformers/models/dpt/configuration_dpt.py/0 | {
"file_path": "transformers/src/transformers/models/dpt/configuration_dpt.py",
"repo_id": "transformers",
"token_count": 5770
} | 88 |
# coding=utf-8
# Copyright 2023 Google Research, Inc. and The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
""" EfficientNet model configuration"""
from collections import OrderedDict
from typing import List, Mapping
from packaging import version
from ...configuration_utils import PretrainedConfig
from ...onnx import OnnxConfig
from ...utils import logging
logger = logging.get_logger(__name__)
EFFICIENTNET_PRETRAINED_CONFIG_ARCHIVE_MAP = {
"google/efficientnet-b7": "https://huggingface.co/google/efficientnet-b7/resolve/main/config.json",
}
class EfficientNetConfig(PretrainedConfig):
r"""
This is the configuration class to store the configuration of a [`EfficientNetModel`]. It is used to instantiate an
EfficientNet model according to the specified arguments, defining the model architecture. Instantiating a
configuration with the defaults will yield a similar configuration to that of the EfficientNet
[google/efficientnet-b7](https://huggingface.co/google/efficientnet-b7) architecture.
Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
documentation from [`PretrainedConfig`] for more information.
Args:
num_channels (`int`, *optional*, defaults to 3):
The number of input channels.
image_size (`int`, *optional*, defaults to 600):
The input image size.
width_coefficient (`float`, *optional*, defaults to 2.0):
Scaling coefficient for network width at each stage.
depth_coefficient (`float`, *optional*, defaults to 3.1):
Scaling coefficient for network depth at each stage.
depth_divisor `int`, *optional*, defaults to 8):
A unit of network width.
kernel_sizes (`List[int]`, *optional*, defaults to `[3, 3, 5, 3, 5, 5, 3]`):
List of kernel sizes to be used in each block.
in_channels (`List[int]`, *optional*, defaults to `[32, 16, 24, 40, 80, 112, 192]`):
List of input channel sizes to be used in each block for convolutional layers.
out_channels (`List[int]`, *optional*, defaults to `[16, 24, 40, 80, 112, 192, 320]`):
List of output channel sizes to be used in each block for convolutional layers.
depthwise_padding (`List[int]`, *optional*, defaults to `[]`):
List of block indices with square padding.
strides (`List[int]`, *optional*, defaults to `[1, 2, 2, 2, 1, 2, 1]`):
List of stride sizes to be used in each block for convolutional layers.
num_block_repeats (`List[int]`, *optional*, defaults to `[1, 2, 2, 3, 3, 4, 1]`):
List of the number of times each block is to repeated.
expand_ratios (`List[int]`, *optional*, defaults to `[1, 6, 6, 6, 6, 6, 6]`):
List of scaling coefficient of each block.
squeeze_expansion_ratio (`float`, *optional*, defaults to 0.25):
Squeeze expansion ratio.
hidden_act (`str` or `function`, *optional*, defaults to `"silu"`):
The non-linear activation function (function or string) in each block. If string, `"gelu"`, `"relu"`,
`"selu", `"gelu_new"`, `"silu"` and `"mish"` are supported.
hiddem_dim (`int`, *optional*, defaults to 1280):
The hidden dimension of the layer before the classification head.
pooling_type (`str` or `function`, *optional*, defaults to `"mean"`):
Type of final pooling to be applied before the dense classification head. Available options are [`"mean"`,
`"max"`]
initializer_range (`float`, *optional*, defaults to 0.02):
The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
batch_norm_eps (`float`, *optional*, defaults to 1e-3):
The epsilon used by the batch normalization layers.
batch_norm_momentum (`float`, *optional*, defaults to 0.99):
The momentum used by the batch normalization layers.
dropout_rate (`float`, *optional*, defaults to 0.5):
The dropout rate to be applied before final classifier layer.
drop_connect_rate (`float`, *optional*, defaults to 0.2):
The drop rate for skip connections.
Example:
```python
>>> from transformers import EfficientNetConfig, EfficientNetModel
>>> # Initializing a EfficientNet efficientnet-b7 style configuration
>>> configuration = EfficientNetConfig()
>>> # Initializing a model (with random weights) from the efficientnet-b7 style configuration
>>> model = EfficientNetModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.config
```"""
model_type = "efficientnet"
def __init__(
self,
num_channels: int = 3,
image_size: int = 600,
width_coefficient: float = 2.0,
depth_coefficient: float = 3.1,
depth_divisor: int = 8,
kernel_sizes: List[int] = [3, 3, 5, 3, 5, 5, 3],
in_channels: List[int] = [32, 16, 24, 40, 80, 112, 192],
out_channels: List[int] = [16, 24, 40, 80, 112, 192, 320],
depthwise_padding: List[int] = [],
strides: List[int] = [1, 2, 2, 2, 1, 2, 1],
num_block_repeats: List[int] = [1, 2, 2, 3, 3, 4, 1],
expand_ratios: List[int] = [1, 6, 6, 6, 6, 6, 6],
squeeze_expansion_ratio: float = 0.25,
hidden_act: str = "swish",
hidden_dim: int = 2560,
pooling_type: str = "mean",
initializer_range: float = 0.02,
batch_norm_eps: float = 0.001,
batch_norm_momentum: float = 0.99,
dropout_rate: float = 0.5,
drop_connect_rate: float = 0.2,
**kwargs,
):
super().__init__(**kwargs)
self.num_channels = num_channels
self.image_size = image_size
self.width_coefficient = width_coefficient
self.depth_coefficient = depth_coefficient
self.depth_divisor = depth_divisor
self.kernel_sizes = kernel_sizes
self.in_channels = in_channels
self.out_channels = out_channels
self.depthwise_padding = depthwise_padding
self.strides = strides
self.num_block_repeats = num_block_repeats
self.expand_ratios = expand_ratios
self.squeeze_expansion_ratio = squeeze_expansion_ratio
self.hidden_act = hidden_act
self.hidden_dim = hidden_dim
self.pooling_type = pooling_type
self.initializer_range = initializer_range
self.batch_norm_eps = batch_norm_eps
self.batch_norm_momentum = batch_norm_momentum
self.dropout_rate = dropout_rate
self.drop_connect_rate = drop_connect_rate
self.num_hidden_layers = sum(num_block_repeats) * 4
class EfficientNetOnnxConfig(OnnxConfig):
torch_onnx_minimum_version = version.parse("1.11")
@property
def inputs(self) -> Mapping[str, Mapping[int, str]]:
return OrderedDict(
[
("pixel_values", {0: "batch", 1: "num_channels", 2: "height", 3: "width"}),
]
)
@property
def atol_for_validation(self) -> float:
return 1e-5
| transformers/src/transformers/models/efficientnet/configuration_efficientnet.py/0 | {
"file_path": "transformers/src/transformers/models/efficientnet/configuration_efficientnet.py",
"repo_id": "transformers",
"token_count": 3016
} | 89 |
# coding=utf-8
# Copyright 2023 Meta Platforms, Inc. and affiliates, and the HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
""" PyTorch EnCodec model."""
import math
from dataclasses import dataclass
from typing import List, Optional, Tuple, Union
import torch
import torch.utils.checkpoint
from torch import nn
from ...modeling_utils import PreTrainedModel
from ...utils import (
ModelOutput,
add_start_docstrings,
add_start_docstrings_to_model_forward,
logging,
replace_return_docstrings,
)
from .configuration_encodec import EncodecConfig
logger = logging.get_logger(__name__)
# General docstring
_CONFIG_FOR_DOC = "EncodecConfig"
ENCODEC_PRETRAINED_MODEL_ARCHIVE_LIST = [
"facebook/encodec_24khz",
"facebook/encodec_48khz",
# See all EnCodec models at https://huggingface.co/models?filter=encodec
]
@dataclass
class EncodecOutput(ModelOutput):
"""
Args:
audio_codes (`torch.FloatTensor` of shape `(batch_size, nb_chunks, chunk_length)`, *optional*):
Discret code embeddings computed using `model.encode`.
audio_values (`torch.FlaotTensor` of shape `(batch_size, sequence_length)`, *optional*)
Decoded audio values, obtained using the decoder part of Encodec.
"""
audio_codes: torch.FloatTensor = None
audio_values: torch.FloatTensor = None
@dataclass
class EncodecEncoderOutput(ModelOutput):
"""
Args:
audio_codes (`torch.FloatTensor` of shape `(batch_size, nb_chunks, chunk_length)`, *optional*):
Discret code embeddings computed using `model.encode`.
audio_scales (`torch.Tensor` of shape `(batch_size, nb_chunks)`, *optional*):
Scaling factor for each `audio_codes` input. This is used to unscale each chunk of audio when decoding.
"""
audio_codes: torch.FloatTensor = None
audio_scales: torch.FloatTensor = None
@dataclass
class EncodecDecoderOutput(ModelOutput):
"""
Args:
audio_values (`torch.FloatTensor` of shape `(batch_size, segment_length)`, *optional*):
Decoded audio values, obtained using the decoder part of Encodec.
"""
audio_values: torch.FloatTensor = None
class EncodecConv1d(nn.Module):
"""Conv1d with asymmetric or causal padding and normalization."""
def __init__(
self, config, in_channels: int, out_channels: int, kernel_size: int, stride: int = 1, dilation: int = 1
):
super().__init__()
self.causal = config.use_causal_conv
self.pad_mode = config.pad_mode
self.norm_type = config.norm_type
if self.norm_type not in ["weight_norm", "time_group_norm"]:
raise ValueError(
f'self.norm_type must be one of `"weight_norm"`, `"time_group_norm"`), got {self.norm_type}'
)
# warn user on unusual setup between dilation and stride
if stride > 1 and dilation > 1:
logger.warning(
"EncodecConv1d has been initialized with stride > 1 and dilation > 1"
f" (kernel_size={kernel_size} stride={stride}, dilation={dilation})."
)
self.conv = nn.Conv1d(in_channels, out_channels, kernel_size, stride, dilation=dilation)
if self.norm_type == "weight_norm":
self.conv = nn.utils.weight_norm(self.conv)
elif self.norm_type == "time_group_norm":
self.norm = nn.GroupNorm(1, out_channels)
@staticmethod
def _get_extra_padding_for_conv1d(
hidden_states: torch.Tensor, kernel_size: int, stride: int, padding_total: int = 0
) -> int:
"""See `pad_for_conv1d`."""
length = hidden_states.shape[-1]
n_frames = (length - kernel_size + padding_total) / stride + 1
ideal_length = (math.ceil(n_frames) - 1) * stride + (kernel_size - padding_total)
return ideal_length - length
@staticmethod
def _pad1d(hidden_states: torch.Tensor, paddings: Tuple[int, int], mode: str = "zero", value: float = 0.0):
"""Tiny wrapper around torch.nn.functional.pad, just to allow for reflect padding on small input.
If this is the case, we insert extra 0 padding to the right before the reflection happens.
"""
length = hidden_states.shape[-1]
padding_left, padding_right = paddings
if not mode == "reflect":
return nn.functional.pad(hidden_states, paddings, mode, value)
max_pad = max(padding_left, padding_right)
extra_pad = 0
if length <= max_pad:
extra_pad = max_pad - length + 1
hidden_states = nn.functional.pad(hidden_states, (0, extra_pad))
padded = nn.functional.pad(hidden_states, paddings, mode, value)
end = padded.shape[-1] - extra_pad
return padded[..., :end]
def forward(self, hidden_states):
kernel_size = self.conv.kernel_size[0]
stride = self.conv.stride[0]
dilation = self.conv.dilation[0]
kernel_size = (kernel_size - 1) * dilation + 1 # effective kernel size with dilations
padding_total = kernel_size - stride
extra_padding = self._get_extra_padding_for_conv1d(hidden_states, kernel_size, stride, padding_total)
if self.causal:
# Left padding for causal
hidden_states = self._pad1d(hidden_states, (padding_total, extra_padding), mode=self.pad_mode)
else:
# Asymmetric padding required for odd strides
padding_right = padding_total // 2
padding_left = padding_total - padding_right
hidden_states = self._pad1d(
hidden_states, (padding_left, padding_right + extra_padding), mode=self.pad_mode
)
hidden_states = self.conv(hidden_states)
if self.norm_type == "time_group_norm":
hidden_states = self.norm(hidden_states)
return hidden_states
class EncodecConvTranspose1d(nn.Module):
"""ConvTranspose1d with asymmetric or causal padding and normalization."""
def __init__(self, config, in_channels: int, out_channels: int, kernel_size: int, stride: int = 1):
super().__init__()
self.causal = config.use_causal_conv
self.trim_right_ratio = config.trim_right_ratio
self.norm_type = config.norm_type
if self.norm_type not in ["weight_norm", "time_group_norm"]:
raise ValueError(
f'self.norm_type must be one of `"weight_norm"`, `"time_group_norm"`), got {self.norm_type}'
)
self.conv = nn.ConvTranspose1d(in_channels, out_channels, kernel_size, stride)
if config.norm_type == "weight_norm":
self.conv = nn.utils.weight_norm(self.conv)
elif config.norm_type == "time_group_norm":
self.norm = nn.GroupNorm(1, out_channels)
if not (self.causal or self.trim_right_ratio == 1.0):
raise ValueError("`trim_right_ratio` != 1.0 only makes sense for causal convolutions")
def forward(self, hidden_states):
kernel_size = self.conv.kernel_size[0]
stride = self.conv.stride[0]
padding_total = kernel_size - stride
hidden_states = self.conv(hidden_states)
if self.norm_type == "time_group_norm":
hidden_states = self.norm(hidden_states)
# We will only trim fixed padding. Extra padding from `pad_for_conv1d` would be
# removed at the very end, when keeping only the right length for the output,
# as removing it here would require also passing the length at the matching layer
# in the encoder.
if self.causal:
# Trim the padding on the right according to the specified ratio
# if trim_right_ratio = 1.0, trim everything from right
padding_right = math.ceil(padding_total * self.trim_right_ratio)
else:
# Asymmetric padding required for odd strides
padding_right = padding_total // 2
padding_left = padding_total - padding_right
# unpad
end = hidden_states.shape[-1] - padding_right
hidden_states = hidden_states[..., padding_left:end]
return hidden_states
class EncodecLSTM(nn.Module):
"""
LSTM without worrying about the hidden state, nor the layout of the data. Expects input as convolutional layout.
"""
def __init__(self, config, dimension):
super().__init__()
self.lstm = nn.LSTM(dimension, dimension, config.num_lstm_layers)
def forward(self, hidden_states):
hidden_states = hidden_states.permute(2, 0, 1)
hidden_states = self.lstm(hidden_states)[0] + hidden_states
hidden_states = hidden_states.permute(1, 2, 0)
return hidden_states
class EncodecResnetBlock(nn.Module):
"""
Residual block from SEANet model as used by EnCodec.
"""
def __init__(self, config: EncodecConfig, dim: int, dilations: List[int]):
super().__init__()
kernel_sizes = (config.residual_kernel_size, 1)
if len(kernel_sizes) != len(dilations):
raise ValueError("Number of kernel sizes should match number of dilations")
hidden = dim // config.compress
block = []
for i, (kernel_size, dilation) in enumerate(zip(kernel_sizes, dilations)):
in_chs = dim if i == 0 else hidden
out_chs = dim if i == len(kernel_sizes) - 1 else hidden
block += [nn.ELU()]
block += [EncodecConv1d(config, in_chs, out_chs, kernel_size, dilation=dilation)]
self.block = nn.ModuleList(block)
if config.use_conv_shortcut:
self.shortcut = EncodecConv1d(config, dim, dim, kernel_size=1)
else:
self.shortcut = nn.Identity()
def forward(self, hidden_states):
residual = hidden_states
for layer in self.block:
hidden_states = layer(hidden_states)
return self.shortcut(residual) + hidden_states
class EncodecEncoder(nn.Module):
"""SEANet encoder as used by EnCodec."""
def __init__(self, config: EncodecConfig):
super().__init__()
model = [EncodecConv1d(config, config.audio_channels, config.num_filters, config.kernel_size)]
scaling = 1
# Downsample to raw audio scale
for ratio in reversed(config.upsampling_ratios):
current_scale = scaling * config.num_filters
# Add residual layers
for j in range(config.num_residual_layers):
model += [EncodecResnetBlock(config, current_scale, [config.dilation_growth_rate**j, 1])]
# Add downsampling layers
model += [nn.ELU()]
model += [EncodecConv1d(config, current_scale, current_scale * 2, kernel_size=ratio * 2, stride=ratio)]
scaling *= 2
model += [EncodecLSTM(config, scaling * config.num_filters)]
model += [nn.ELU()]
model += [EncodecConv1d(config, scaling * config.num_filters, config.hidden_size, config.last_kernel_size)]
self.layers = nn.ModuleList(model)
def forward(self, hidden_states):
for layer in self.layers:
hidden_states = layer(hidden_states)
return hidden_states
class EncodecDecoder(nn.Module):
"""SEANet decoder as used by EnCodec."""
def __init__(self, config: EncodecConfig):
super().__init__()
scaling = int(2 ** len(config.upsampling_ratios))
model = [EncodecConv1d(config, config.hidden_size, scaling * config.num_filters, config.kernel_size)]
model += [EncodecLSTM(config, scaling * config.num_filters)]
# Upsample to raw audio scale
for ratio in config.upsampling_ratios:
current_scale = scaling * config.num_filters
# Add upsampling layers
model += [nn.ELU()]
model += [
EncodecConvTranspose1d(config, current_scale, current_scale // 2, kernel_size=ratio * 2, stride=ratio)
]
# Add residual layers
for j in range(config.num_residual_layers):
model += [EncodecResnetBlock(config, current_scale // 2, (config.dilation_growth_rate**j, 1))]
scaling //= 2
# Add final layers
model += [nn.ELU()]
model += [EncodecConv1d(config, config.num_filters, config.audio_channels, config.last_kernel_size)]
self.layers = nn.ModuleList(model)
def forward(self, hidden_states):
for layer in self.layers:
hidden_states = layer(hidden_states)
return hidden_states
class EncodecEuclideanCodebook(nn.Module):
"""Codebook with Euclidean distance."""
def __init__(self, config: EncodecConfig):
super().__init__()
embed = torch.zeros(config.codebook_size, config.codebook_dim)
self.codebook_size = config.codebook_size
self.register_buffer("inited", torch.Tensor([True]))
self.register_buffer("cluster_size", torch.zeros(config.codebook_size))
self.register_buffer("embed", embed)
self.register_buffer("embed_avg", embed.clone())
def quantize(self, hidden_states):
embed = self.embed.t()
scaled_states = hidden_states.pow(2).sum(1, keepdim=True)
dist = -(scaled_states - 2 * hidden_states @ embed + embed.pow(2).sum(0, keepdim=True))
embed_ind = dist.max(dim=-1).indices
return embed_ind
def encode(self, hidden_states):
shape = hidden_states.shape
# pre-process
hidden_states = hidden_states.reshape((-1, shape[-1]))
# quantize
embed_ind = self.quantize(hidden_states)
# post-process
embed_ind = embed_ind.view(*shape[:-1])
return embed_ind
def decode(self, embed_ind):
quantize = nn.functional.embedding(embed_ind, self.embed)
return quantize
class EncodecVectorQuantization(nn.Module):
"""
Vector quantization implementation. Currently supports only euclidean distance.
"""
def __init__(self, config: EncodecConfig):
super().__init__()
self.codebook = EncodecEuclideanCodebook(config)
def encode(self, hidden_states):
hidden_states = hidden_states.permute(0, 2, 1)
embed_in = self.codebook.encode(hidden_states)
return embed_in
def decode(self, embed_ind):
quantize = self.codebook.decode(embed_ind)
quantize = quantize.permute(0, 2, 1)
return quantize
class EncodecResidualVectorQuantizer(nn.Module):
"""Residual Vector Quantizer."""
def __init__(self, config: EncodecConfig):
super().__init__()
self.codebook_size = config.codebook_size
self.frame_rate = config.frame_rate
self.num_quantizers = config.num_quantizers
self.layers = nn.ModuleList([EncodecVectorQuantization(config) for _ in range(config.num_quantizers)])
def get_num_quantizers_for_bandwidth(self, bandwidth: Optional[float] = None) -> int:
"""Return num_quantizers based on specified target bandwidth."""
bw_per_q = math.log2(self.codebook_size) * self.frame_rate
num_quantizers = self.num_quantizers
if bandwidth is not None and bandwidth > 0.0:
num_quantizers = int(max(1, math.floor(bandwidth * 1000 / bw_per_q)))
return num_quantizers
def encode(self, embeddings: torch.Tensor, bandwidth: Optional[float] = None) -> torch.Tensor:
"""
Encode a given input tensor with the specified frame rate at the given bandwidth. The RVQ encode method sets
the appropriate number of quantizers to use and returns indices for each quantizer.
"""
num_quantizers = self.get_num_quantizers_for_bandwidth(bandwidth)
residual = embeddings
all_indices = []
for layer in self.layers[:num_quantizers]:
indices = layer.encode(residual)
quantized = layer.decode(indices)
residual = residual - quantized
all_indices.append(indices)
out_indices = torch.stack(all_indices)
return out_indices
def decode(self, codes: torch.Tensor) -> torch.Tensor:
"""Decode the given codes to the quantized representation."""
quantized_out = torch.tensor(0.0, device=codes.device)
for i, indices in enumerate(codes):
layer = self.layers[i]
quantized = layer.decode(indices)
quantized_out = quantized_out + quantized
return quantized_out
class EncodecPreTrainedModel(PreTrainedModel):
"""
An abstract class to handle weights initialization and a simple interface for downloading and loading pretrained
models.
"""
config_class = EncodecConfig
base_model_prefix = "encodec"
main_input_name = "input_values"
def _init_weights(self, module):
"""Initialize the weights"""
if isinstance(module, nn.Linear):
module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
if module.bias is not None:
module.bias.data.zero_()
elif isinstance(module, (nn.LayerNorm, nn.GroupNorm)):
module.bias.data.zero_()
module.weight.data.fill_(1.0)
elif isinstance(module, nn.Conv1d):
nn.init.kaiming_normal_(module.weight)
if module.bias is not None:
k = math.sqrt(module.groups / (module.in_channels * module.kernel_size[0]))
nn.init.uniform_(module.bias, a=-k, b=k)
elif isinstance(module, nn.Embedding):
module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
if module.padding_idx is not None:
module.weight.data[module.padding_idx].zero_()
elif isinstance(module, nn.LSTM):
for name, param in module.named_parameters():
if "weight" in name:
nn.init.xavier_uniform_(param)
elif "bias" in name:
nn.init.constant_(param, 0.0)
ENCODEC_START_DOCSTRING = r"""
This model inherits from [`PreTrainedModel`]. Check the superclass documentation for the generic methods the
library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads
etc.)
This model is also a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) subclass.
Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage
and behavior.
Parameters:
config ([`EncodecConfig`]):
Model configuration class with all the parameters of the model. Initializing with a config file does not
load the weights associated with the model, only the configuration. Check out the
[`~PreTrainedModel.from_pretrained`] method to load the model weights.
"""
ENCODEC_INPUTS_DOCSTRING = r"""
Args:
input_values (`torch.FloatTensor` of shape `(batch_size, channels, sequence_length)`, *optional*):
Raw audio input converted to Float and padded to the approriate length in order to be encoded using chunks
of length self.chunk_length and a stride of `config.chunk_stride`.
padding_mask (`torch.BoolTensor` of shape `(batch_size, channels, sequence_length)`, *optional*):
Mask to avoid computing scaling factors on padding token indices (can we avoid computing conv on these+).
Mask values selected in `[0, 1]`:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
<Tip warning={true}>
`padding_mask` should always be passed, unless the input was truncated or not padded. This is because in
order to process tensors effectively, the input audio should be padded so that `input_length % stride =
step` with `step = chunk_length-stride`. This ensures that all chunks are of the same shape
</Tip>
bandwidth (`float`, *optional*):
The target bandwidth. Must be one of `config.target_bandwidths`. If `None`, uses the smallest possible
bandwidth. bandwidth is represented as a thousandth of what it is, e.g. 6kbps bandwidth is represented as
`bandwidth == 6.0`
audio_codes (`torch.FloatTensor` of shape `(batch_size, nb_chunks, chunk_length)`, *optional*):
Discret code embeddings computed using `model.encode`.
audio_scales (`torch.Tensor` of shape `(batch_size, nb_chunks)`, *optional*):
Scaling factor for each `audio_codes` input.
return_dict (`bool`, *optional*):
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
"""
@add_start_docstrings(
"The EnCodec neural audio codec model.",
ENCODEC_START_DOCSTRING,
)
class EncodecModel(EncodecPreTrainedModel):
def __init__(self, config: EncodecConfig):
super().__init__(config)
self.config = config
self.encoder = EncodecEncoder(config)
self.decoder = EncodecDecoder(config)
self.quantizer = EncodecResidualVectorQuantizer(config)
self.bits_per_codebook = int(math.log2(self.config.codebook_size))
if 2**self.bits_per_codebook != self.config.codebook_size:
raise ValueError("The codebook_size must be a power of 2.")
# Initialize weights and apply final processing
self.post_init()
def get_encoder(self):
return self.encoder
def get_decoder(self):
return self.decoder
def _encode_frame(
self, input_values: torch.Tensor, bandwidth: float, padding_mask: int
) -> Tuple[torch.Tensor, Optional[torch.Tensor]]:
"""
Encodes the given input using the underlying VQVAE. If `config.normalize` is set to `True` the input is first
normalized. The padding mask is required to compute the correct scale.
"""
length = input_values.shape[-1]
duration = length / self.config.sampling_rate
if self.config.chunk_length_s is not None and duration > 1e-5 + self.config.chunk_length_s:
raise RuntimeError(f"Duration of frame ({duration}) is longer than chunk {self.config.chunk_length_s}")
scale = None
if self.config.normalize:
# if the padding is non zero
input_values = input_values * padding_mask
mono = torch.sum(input_values, 1, keepdim=True) / input_values.shape[1]
scale = mono.pow(2).mean(dim=-1, keepdim=True).sqrt() + 1e-8
input_values = input_values / scale
embeddings = self.encoder(input_values)
codes = self.quantizer.encode(embeddings, bandwidth)
codes = codes.transpose(0, 1)
return codes, scale
def encode(
self,
input_values: torch.Tensor,
padding_mask: torch.Tensor = None,
bandwidth: Optional[float] = None,
return_dict: Optional[bool] = None,
) -> Union[Tuple[torch.Tensor, Optional[torch.Tensor]], EncodecEncoderOutput]:
"""
Encodes the input audio waveform into discrete codes.
Args:
input_values (`torch.Tensor` of shape `(batch_size, channels, sequence_length)`):
Float values of the input audio waveform.
padding_mask (`torch.Tensor` of shape `(batch_size, channels, sequence_length)`):
Padding mask used to pad the `input_values`.
bandwidth (`float`, *optional*):
The target bandwidth. Must be one of `config.target_bandwidths`. If `None`, uses the smallest possible
bandwidth. bandwidth is represented as a thousandth of what it is, e.g. 6kbps bandwidth is represented
as bandwidth == 6.0
Returns:
A list of frames containing the discrete encoded codes for the input audio waveform, along with rescaling
factors for each chunk when `normalize` is True. Each frames is a tuple `(codebook, scale)`, with
`codebook` of shape `[batch_size, num_codebooks, frames]`.
"""
return_dict = return_dict if return_dict is not None else self.config.return_dict
if bandwidth is None:
bandwidth = self.config.target_bandwidths[0]
if bandwidth not in self.config.target_bandwidths:
raise ValueError(
f"This model doesn't support the bandwidth {bandwidth}. "
f"Select one of {self.config.target_bandwidths}."
)
_, channels, input_length = input_values.shape
if channels < 1 or channels > 2:
raise ValueError(f"Number of audio channels must be 1 or 2, but got {channels}")
chunk_length = self.config.chunk_length
if chunk_length is None:
chunk_length = input_length
stride = input_length
else:
stride = self.config.chunk_stride
if padding_mask is None:
padding_mask = torch.ones_like(input_values).bool()
encoded_frames = []
scales = []
step = chunk_length - stride
if (input_length % stride) - step != 0:
raise ValueError(
"The input length is not properly padded for batched chunked decoding. Make sure to pad the input correctly."
)
for offset in range(0, input_length - step, stride):
mask = padding_mask[..., offset : offset + chunk_length].bool()
frame = input_values[:, :, offset : offset + chunk_length]
encoded_frame, scale = self._encode_frame(frame, bandwidth, mask)
encoded_frames.append(encoded_frame)
scales.append(scale)
encoded_frames = torch.stack(encoded_frames)
if not return_dict:
return (encoded_frames, scales)
return EncodecEncoderOutput(encoded_frames, scales)
@staticmethod
def _linear_overlap_add(frames: List[torch.Tensor], stride: int):
# Generic overlap add, with linear fade-in/fade-out, supporting complex scenario
# e.g., more than 2 frames per position.
# The core idea is to use a weight function that is a triangle,
# with a maximum value at the middle of the chunk.
# We use this weighting when summing the frames, and divide by the sum of weights
# for each positions at the end. Thus:
# - if a frame is the only one to cover a position, the weighting is a no-op.
# - if 2 frames cover a position:
# ... ...
# / \/ \
# / /\ \
# S T , i.e. S offset of second frame starts, T end of first frame.
# Then the weight function for each one is: (t - S), (T - t), with `t` a given offset.
# After the final normalization, the weight of the second frame at position `t` is
# (t - S) / (t - S + (T - t)) = (t - S) / (T - S), which is exactly what we want.
#
# - if more than 2 frames overlap at a given point, we hope that by induction
# something sensible happens.
if len(frames) == 0:
raise ValueError("`frames` cannot be an empty list.")
device = frames[0].device
dtype = frames[0].dtype
shape = frames[0].shape[:-1]
total_size = stride * (len(frames) - 1) + frames[-1].shape[-1]
frame_length = frames[0].shape[-1]
time_vec = torch.linspace(0, 1, frame_length + 2, device=device, dtype=dtype)[1:-1]
weight = 0.5 - (time_vec - 0.5).abs()
sum_weight = torch.zeros(total_size, device=device, dtype=dtype)
out = torch.zeros(*shape, total_size, device=device, dtype=dtype)
offset: int = 0
for frame in frames:
frame_length = frame.shape[-1]
out[..., offset : offset + frame_length] += weight[:frame_length] * frame
sum_weight[offset : offset + frame_length] += weight[:frame_length]
offset += stride
if sum_weight.min() == 0:
raise ValueError(f"`sum_weight` minimum element must be bigger than zero: {sum_weight}`")
return out / sum_weight
def _decode_frame(self, codes: torch.Tensor, scale: Optional[torch.Tensor] = None) -> torch.Tensor:
codes = codes.transpose(0, 1)
embeddings = self.quantizer.decode(codes)
outputs = self.decoder(embeddings)
if scale is not None:
outputs = outputs * scale.view(-1, 1, 1)
return outputs
def decode(
self,
audio_codes: torch.Tensor,
audio_scales: torch.Tensor,
padding_mask: Optional[torch.Tensor] = None,
return_dict: Optional[bool] = None,
) -> Union[Tuple[torch.Tensor, torch.Tensor], EncodecDecoderOutput]:
"""
Decodes the given frames into an output audio waveform.
Note that the output might be a bit bigger than the input. In that case, any extra steps at the end can be
trimmed.
Args:
audio_codes (`torch.FloatTensor` of shape `(batch_size, nb_chunks, chunk_length)`, *optional*):
Discret code embeddings computed using `model.encode`.
audio_scales (`torch.Tensor` of shape `(batch_size, nb_chunks)`, *optional*):
Scaling factor for each `audio_codes` input.
padding_mask (`torch.Tensor` of shape `(batch_size, channels, sequence_length)`):
Padding mask used to pad the `input_values`.
return_dict (`bool`, *optional*):
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
"""
return_dict = return_dict or self.config.return_dict
chunk_length = self.config.chunk_length
if chunk_length is None:
if len(audio_codes) != 1:
raise ValueError(f"Expected one frame, got {len(audio_codes)}")
audio_values = self._decode_frame(audio_codes[0], audio_scales[0])
else:
decoded_frames = []
for frame, scale in zip(audio_codes, audio_scales):
frames = self._decode_frame(frame, scale)
decoded_frames.append(frames)
audio_values = self._linear_overlap_add(decoded_frames, self.config.chunk_stride or 1)
# truncate based on padding mask
if padding_mask is not None and padding_mask.shape[-1] < audio_values.shape[-1]:
audio_values = audio_values[..., : padding_mask.shape[-1]]
if not return_dict:
return (audio_values,)
return EncodecDecoderOutput(audio_values)
@add_start_docstrings_to_model_forward(ENCODEC_INPUTS_DOCSTRING)
@replace_return_docstrings(output_type=EncodecOutput, config_class=_CONFIG_FOR_DOC)
def forward(
self,
input_values: torch.Tensor,
padding_mask: Optional[torch.Tensor] = None,
bandwidth: Optional[float] = None,
audio_codes: Optional[torch.Tensor] = None,
audio_scales: Optional[torch.Tensor] = None,
return_dict: Optional[bool] = None,
) -> Union[Tuple[torch.Tensor, torch.Tensor], EncodecOutput]:
r"""
Returns:
Examples:
```python
>>> from datasets import load_dataset
>>> from transformers import AutoProcessor, EncodecModel
>>> dataset = load_dataset("ashraq/esc50")
>>> audio_sample = dataset["train"]["audio"][0]["array"]
>>> model_id = "facebook/encodec_24khz"
>>> model = EncodecModel.from_pretrained(model_id)
>>> processor = AutoProcessor.from_pretrained(model_id)
>>> inputs = processor(raw_audio=audio_sample, return_tensors="pt")
>>> outputs = model(**inputs)
>>> audio_codes = outputs.audio_codes
>>> audio_values = outputs.audio_values
```"""
return_dict = return_dict or self.config.return_dict
if padding_mask is None:
padding_mask = torch.ones_like(input_values).bool()
if audio_codes is not None and audio_scales is None:
raise ValueError("You specified `audio_codes` but did not specify the `audio_scales`")
if audio_scales is not None and audio_codes is None:
raise ValueError("You specified `audio_scales` but did not specify the `audio_codes`")
if audio_scales is None and audio_codes is None:
audio_codes, audio_scales = self.encode(input_values, padding_mask, bandwidth, False)
audio_values = self.decode(audio_codes, audio_scales, padding_mask, return_dict=return_dict)[0]
if not return_dict:
return (audio_codes, audio_values)
return EncodecOutput(audio_codes=audio_codes, audio_values=audio_values)
| transformers/src/transformers/models/encodec/modeling_encodec.py/0 | {
"file_path": "transformers/src/transformers/models/encodec/modeling_encodec.py",
"repo_id": "transformers",
"token_count": 13791
} | 90 |
# coding=utf-8
# Copyright 2022 Meta and The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
""" PyTorch ESM model."""
import math
from typing import List, Optional, Tuple, Union
import torch
import torch.utils.checkpoint
from torch import nn
from torch.nn import BCEWithLogitsLoss, CrossEntropyLoss, MSELoss
from ...file_utils import add_code_sample_docstrings, add_start_docstrings, add_start_docstrings_to_model_forward
from ...modeling_outputs import (
BaseModelOutputWithPastAndCrossAttentions,
BaseModelOutputWithPoolingAndCrossAttentions,
MaskedLMOutput,
SequenceClassifierOutput,
TokenClassifierOutput,
)
from ...modeling_utils import PreTrainedModel, find_pruneable_heads_and_indices, prune_linear_layer
from ...utils import logging
from .configuration_esm import EsmConfig
logger = logging.get_logger(__name__)
_CHECKPOINT_FOR_DOC = "facebook/esm2_t6_8M_UR50D"
_CONFIG_FOR_DOC = "EsmConfig"
ESM_PRETRAINED_MODEL_ARCHIVE_LIST = [
"facebook/esm2_t6_8M_UR50D",
"facebook/esm2_t12_35M_UR50D",
# This is not a complete list of all ESM models!
# See all ESM models at https://huggingface.co/models?filter=esm
]
def rotate_half(x):
x1, x2 = x.chunk(2, dim=-1)
return torch.cat((-x2, x1), dim=-1)
def apply_rotary_pos_emb(x, cos, sin):
cos = cos[:, :, : x.shape[-2], :]
sin = sin[:, :, : x.shape[-2], :]
return (x * cos) + (rotate_half(x) * sin)
def gelu(x):
"""
This is the gelu implementation from the original ESM repo. Using F.gelu yields subtly wrong results.
"""
return x * 0.5 * (1.0 + torch.erf(x / math.sqrt(2.0)))
def symmetrize(x):
"Make layer symmetric in final two dimensions, used for contact prediction."
return x + x.transpose(-1, -2)
def average_product_correct(x):
"Perform average product correct, used for contact prediction."
a1 = x.sum(-1, keepdims=True)
a2 = x.sum(-2, keepdims=True)
a12 = x.sum((-1, -2), keepdims=True)
avg = a1 * a2
avg.div_(a12) # in-place to reduce memory
normalized = x - avg
return normalized
class RotaryEmbedding(torch.nn.Module):
"""
Rotary position embeddings based on those in
[RoFormer](https://huggingface.co/docs/transformers/model_doc/roformer). Query and keys are transformed by rotation
matrices which depend on their relative positions.
"""
def __init__(self, dim: int):
super().__init__()
# Generate and save the inverse frequency buffer (non trainable)
inv_freq = 1.0 / (10000 ** (torch.arange(0, dim, 2, dtype=torch.int64).float() / dim))
inv_freq = inv_freq
self.register_buffer("inv_freq", inv_freq)
self._seq_len_cached = None
self._cos_cached = None
self._sin_cached = None
def _update_cos_sin_tables(self, x, seq_dimension=2):
seq_len = x.shape[seq_dimension]
# Reset the tables if the sequence length has changed,
# or if we're on a new device (possibly due to tracing for instance)
if seq_len != self._seq_len_cached or self._cos_cached.device != x.device:
self._seq_len_cached = seq_len
t = torch.arange(x.shape[seq_dimension], device=x.device).type_as(self.inv_freq)
freqs = torch.outer(t, self.inv_freq)
emb = torch.cat((freqs, freqs), dim=-1).to(x.device)
self._cos_cached = emb.cos()[None, None, :, :]
self._sin_cached = emb.sin()[None, None, :, :]
return self._cos_cached, self._sin_cached
def forward(self, q: torch.Tensor, k: torch.Tensor) -> Tuple[torch.Tensor, torch.Tensor]:
self._cos_cached, self._sin_cached = self._update_cos_sin_tables(k, seq_dimension=-2)
return (
apply_rotary_pos_emb(q, self._cos_cached, self._sin_cached),
apply_rotary_pos_emb(k, self._cos_cached, self._sin_cached),
)
class EsmContactPredictionHead(nn.Module):
"""Performs symmetrization, apc, and computes a logistic regression on the output features"""
def __init__(
self,
in_features: int,
bias=True,
eos_idx: int = 2,
):
super().__init__()
self.in_features = in_features
self.eos_idx = eos_idx
self.regression = nn.Linear(in_features, 1, bias)
self.activation = nn.Sigmoid()
def forward(self, tokens, attentions):
# remove eos token attentions
eos_mask = tokens.ne(self.eos_idx).to(attentions)
eos_mask = eos_mask.unsqueeze(1) * eos_mask.unsqueeze(2)
attentions = attentions * eos_mask[:, None, None, :, :]
attentions = attentions[..., :-1, :-1]
# remove cls token attentions
attentions = attentions[..., 1:, 1:]
batch_size, layers, heads, seqlen, _ = attentions.size()
attentions = attentions.view(batch_size, layers * heads, seqlen, seqlen)
# features: batch x channels x tokens x tokens (symmetric)
attentions = attentions.to(
self.regression.weight.device
) # attentions always float32, may need to convert to float16
attentions = average_product_correct(symmetrize(attentions))
attentions = attentions.permute(0, 2, 3, 1)
return self.activation(self.regression(attentions).squeeze(3))
class EsmEmbeddings(nn.Module):
"""
Same as BertEmbeddings with a tiny tweak for positional embeddings indexing.
"""
def __init__(self, config):
super().__init__()
self.word_embeddings = nn.Embedding(config.vocab_size, config.hidden_size, padding_idx=config.pad_token_id)
if config.emb_layer_norm_before:
self.layer_norm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
else:
self.layer_norm = None
self.dropout = nn.Dropout(config.hidden_dropout_prob)
# position_ids (1, len position emb) is contiguous in memory and exported when serialized
self.position_embedding_type = getattr(config, "position_embedding_type", "absolute")
self.register_buffer(
"position_ids", torch.arange(config.max_position_embeddings).expand((1, -1)), persistent=False
)
self.padding_idx = config.pad_token_id
self.position_embeddings = nn.Embedding(
config.max_position_embeddings, config.hidden_size, padding_idx=self.padding_idx
)
self.token_dropout = config.token_dropout
self.mask_token_id = config.mask_token_id
def forward(
self, input_ids=None, attention_mask=None, position_ids=None, inputs_embeds=None, past_key_values_length=0
):
if position_ids is None:
if input_ids is not None:
# Create the position ids from the input token ids. Any padded tokens remain padded.
position_ids = create_position_ids_from_input_ids(input_ids, self.padding_idx, past_key_values_length)
else:
position_ids = self.create_position_ids_from_inputs_embeds(inputs_embeds)
if inputs_embeds is None:
inputs_embeds = self.word_embeddings(input_ids)
# Note that if we want to support ESM-1 (not 1b!) in future then we need to support an
# embedding_scale factor here.
embeddings = inputs_embeds
# Matt: ESM has the option to handle masking in MLM in a slightly unusual way. If the token_dropout
# flag is False then it is handled in the same was as BERT/RoBERTa. If it is set to True, however,
# masked tokens are treated as if they were selected for input dropout and zeroed out.
# This "mask-dropout" is compensated for when masked tokens are not present, by scaling embeddings by
# a factor of (fraction of unmasked tokens during training) / (fraction of unmasked tokens in sample).
# This is analogous to the way that dropout layers scale down outputs during evaluation when not
# actually dropping out values (or, equivalently, scale up their un-dropped outputs in training).
if self.token_dropout:
embeddings = embeddings.masked_fill((input_ids == self.mask_token_id).unsqueeze(-1), 0.0)
mask_ratio_train = 0.15 * 0.8 # Hardcoded as the ratio used in all ESM model training runs
src_lengths = attention_mask.sum(-1)
mask_ratio_observed = (input_ids == self.mask_token_id).sum(-1).float() / src_lengths
embeddings = (embeddings * (1 - mask_ratio_train) / (1 - mask_ratio_observed)[:, None, None]).to(
embeddings.dtype
)
if self.position_embedding_type == "absolute":
position_embeddings = self.position_embeddings(position_ids)
embeddings = embeddings + position_embeddings
if self.layer_norm is not None:
embeddings = self.layer_norm(embeddings)
if attention_mask is not None:
embeddings = (embeddings * attention_mask.unsqueeze(-1)).to(embeddings.dtype)
# Matt: I think this line was copied incorrectly from BERT, disabling it for now.
# embeddings = self.dropout(embeddings)
return embeddings
def create_position_ids_from_inputs_embeds(self, inputs_embeds):
"""
We are provided embeddings directly. We cannot infer which are padded so just generate sequential position ids.
Args:
inputs_embeds: torch.Tensor
Returns: torch.Tensor
"""
input_shape = inputs_embeds.size()[:-1]
sequence_length = input_shape[1]
position_ids = torch.arange(
self.padding_idx + 1, sequence_length + self.padding_idx + 1, dtype=torch.long, device=inputs_embeds.device
)
return position_ids.unsqueeze(0).expand(input_shape)
class EsmSelfAttention(nn.Module):
def __init__(self, config, position_embedding_type=None):
super().__init__()
if config.hidden_size % config.num_attention_heads != 0 and not hasattr(config, "embedding_size"):
raise ValueError(
f"The hidden size ({config.hidden_size}) is not a multiple of the number of attention "
f"heads ({config.num_attention_heads})"
)
self.num_attention_heads = config.num_attention_heads
self.attention_head_size = int(config.hidden_size / config.num_attention_heads)
self.all_head_size = self.num_attention_heads * self.attention_head_size
self.query = nn.Linear(config.hidden_size, self.all_head_size)
self.key = nn.Linear(config.hidden_size, self.all_head_size)
self.value = nn.Linear(config.hidden_size, self.all_head_size)
self.dropout = nn.Dropout(config.attention_probs_dropout_prob)
self.position_embedding_type = position_embedding_type or getattr(
config, "position_embedding_type", "absolute"
)
self.rotary_embeddings = None
if self.position_embedding_type == "relative_key" or self.position_embedding_type == "relative_key_query":
self.max_position_embeddings = config.max_position_embeddings
self.distance_embedding = nn.Embedding(2 * config.max_position_embeddings - 1, self.attention_head_size)
elif self.position_embedding_type == "rotary":
self.rotary_embeddings = RotaryEmbedding(dim=self.attention_head_size)
self.is_decoder = config.is_decoder
def transpose_for_scores(self, x: torch.Tensor) -> torch.Tensor:
new_x_shape = x.size()[:-1] + (self.num_attention_heads, self.attention_head_size)
x = x.view(new_x_shape)
return x.permute(0, 2, 1, 3)
def forward(
self,
hidden_states: torch.Tensor,
attention_mask: Optional[torch.FloatTensor] = None,
head_mask: Optional[torch.FloatTensor] = None,
encoder_hidden_states: Optional[torch.FloatTensor] = None,
encoder_attention_mask: Optional[torch.FloatTensor] = None,
past_key_value: Optional[Tuple[Tuple[torch.FloatTensor]]] = None,
output_attentions: Optional[bool] = False,
) -> Tuple[torch.Tensor]:
mixed_query_layer = self.query(hidden_states)
# If this is instantiated as a cross-attention module, the keys
# and values come from an encoder; the attention mask needs to be
# such that the encoder's padding tokens are not attended to.
is_cross_attention = encoder_hidden_states is not None
if is_cross_attention and past_key_value is not None:
# reuse k,v, cross_attentions
key_layer = past_key_value[0]
value_layer = past_key_value[1]
attention_mask = encoder_attention_mask
elif is_cross_attention:
key_layer = self.transpose_for_scores(self.key(encoder_hidden_states))
value_layer = self.transpose_for_scores(self.value(encoder_hidden_states))
attention_mask = encoder_attention_mask
elif past_key_value is not None:
key_layer = self.transpose_for_scores(self.key(hidden_states))
value_layer = self.transpose_for_scores(self.value(hidden_states))
key_layer = torch.cat([past_key_value[0], key_layer], dim=2)
value_layer = torch.cat([past_key_value[1], value_layer], dim=2)
else:
key_layer = self.transpose_for_scores(self.key(hidden_states))
value_layer = self.transpose_for_scores(self.value(hidden_states))
query_layer = self.transpose_for_scores(mixed_query_layer)
# Matt: Our BERT model (which this code was derived from) scales attention logits down by sqrt(head_dim).
# ESM scales the query down by the same factor instead. Modulo numerical stability these are equivalent,
# but not when rotary embeddings get involved. Therefore, we scale the query here to match the original
# ESM code and fix rotary embeddings.
query_layer = query_layer * self.attention_head_size**-0.5
if self.is_decoder:
# if cross_attention save Tuple(torch.Tensor, torch.Tensor) of all cross attention key/value_states.
# Further calls to cross_attention layer can then reuse all cross-attention
# key/value_states (first "if" case)
# if uni-directional self-attention (decoder) save Tuple(torch.Tensor, torch.Tensor) of
# all previous decoder key/value_states. Further calls to uni-directional self-attention
# can concat previous decoder key/value_states to current projected key/value_states (third "elif" case)
# if encoder bi-directional self-attention `past_key_value` is always `None`
past_key_value = (key_layer, value_layer)
if self.position_embedding_type == "rotary":
query_layer, key_layer = self.rotary_embeddings(query_layer, key_layer)
# Take the dot product between "query" and "key" to get the raw attention scores.
attention_scores = torch.matmul(query_layer, key_layer.transpose(-1, -2))
if self.position_embedding_type == "relative_key" or self.position_embedding_type == "relative_key_query":
seq_length = hidden_states.size()[1]
position_ids_l = torch.arange(seq_length, dtype=torch.long, device=hidden_states.device).view(-1, 1)
position_ids_r = torch.arange(seq_length, dtype=torch.long, device=hidden_states.device).view(1, -1)
distance = position_ids_l - position_ids_r
positional_embedding = self.distance_embedding(distance + self.max_position_embeddings - 1)
positional_embedding = positional_embedding.to(dtype=query_layer.dtype) # fp16 compatibility
if self.position_embedding_type == "relative_key":
relative_position_scores = torch.einsum("bhld,lrd->bhlr", query_layer, positional_embedding)
attention_scores = attention_scores + relative_position_scores
elif self.position_embedding_type == "relative_key_query":
relative_position_scores_query = torch.einsum("bhld,lrd->bhlr", query_layer, positional_embedding)
relative_position_scores_key = torch.einsum("bhrd,lrd->bhlr", key_layer, positional_embedding)
attention_scores = attention_scores + relative_position_scores_query + relative_position_scores_key
if attention_mask is not None:
# Apply the attention mask is (precomputed for all layers in EsmModel forward() function)
attention_scores = attention_scores + attention_mask
# Normalize the attention scores to probabilities.
attention_probs = nn.functional.softmax(attention_scores, dim=-1)
# This is actually dropping out entire tokens to attend to, which might
# seem a bit unusual, but is taken from the original Transformer paper.
attention_probs = self.dropout(attention_probs)
# Mask heads if we want to
if head_mask is not None:
attention_probs = attention_probs * head_mask
context_layer = torch.matmul(attention_probs, value_layer)
context_layer = context_layer.permute(0, 2, 1, 3).contiguous()
new_context_layer_shape = context_layer.size()[:-2] + (self.all_head_size,)
context_layer = context_layer.view(new_context_layer_shape)
outputs = (context_layer, attention_probs) if output_attentions else (context_layer,)
if self.is_decoder:
outputs = outputs + (past_key_value,)
return outputs
class EsmSelfOutput(nn.Module):
def __init__(self, config):
super().__init__()
self.dense = nn.Linear(config.hidden_size, config.hidden_size)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
def forward(self, hidden_states, input_tensor):
hidden_states = self.dense(hidden_states)
hidden_states = self.dropout(hidden_states)
hidden_states = hidden_states + input_tensor
return hidden_states
class EsmAttention(nn.Module):
def __init__(self, config):
super().__init__()
self.self = EsmSelfAttention(config)
self.output = EsmSelfOutput(config)
self.pruned_heads = set()
self.LayerNorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
def prune_heads(self, heads):
if len(heads) == 0:
return
heads, index = find_pruneable_heads_and_indices(
heads, self.self.num_attention_heads, self.self.attention_head_size, self.pruned_heads
)
# Prune linear layers
self.self.query = prune_linear_layer(self.self.query, index)
self.self.key = prune_linear_layer(self.self.key, index)
self.self.value = prune_linear_layer(self.self.value, index)
self.output.dense = prune_linear_layer(self.output.dense, index, dim=1)
# Update hyper params and store pruned heads
self.self.num_attention_heads = self.self.num_attention_heads - len(heads)
self.self.all_head_size = self.self.attention_head_size * self.self.num_attention_heads
self.pruned_heads = self.pruned_heads.union(heads)
def forward(
self,
hidden_states,
attention_mask=None,
head_mask=None,
encoder_hidden_states=None,
encoder_attention_mask=None,
past_key_value=None,
output_attentions=False,
):
hidden_states_ln = self.LayerNorm(hidden_states)
self_outputs = self.self(
hidden_states_ln,
attention_mask,
head_mask,
encoder_hidden_states,
encoder_attention_mask,
past_key_value,
output_attentions,
)
attention_output = self.output(self_outputs[0], hidden_states)
outputs = (attention_output,) + self_outputs[1:] # add attentions if we output them
return outputs
class EsmIntermediate(nn.Module):
def __init__(self, config):
super().__init__()
self.dense = nn.Linear(config.hidden_size, config.intermediate_size)
def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
hidden_states = self.dense(hidden_states)
hidden_states = gelu(hidden_states)
return hidden_states
class EsmOutput(nn.Module):
def __init__(self, config):
super().__init__()
self.dense = nn.Linear(config.intermediate_size, config.hidden_size)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
def forward(self, hidden_states, input_tensor):
hidden_states = self.dense(hidden_states)
hidden_states = self.dropout(hidden_states)
hidden_states = hidden_states + input_tensor
return hidden_states
class EsmLayer(nn.Module):
def __init__(self, config):
super().__init__()
self.chunk_size_feed_forward = config.chunk_size_feed_forward
self.seq_len_dim = 1
self.attention = EsmAttention(config)
self.is_decoder = config.is_decoder
self.add_cross_attention = config.add_cross_attention
if self.add_cross_attention:
if not self.is_decoder:
raise RuntimeError(f"{self} should be used as a decoder model if cross attention is added")
self.crossattention = EsmAttention(config)
self.intermediate = EsmIntermediate(config)
self.output = EsmOutput(config)
self.LayerNorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
def forward(
self,
hidden_states,
attention_mask=None,
head_mask=None,
encoder_hidden_states=None,
encoder_attention_mask=None,
past_key_value=None,
output_attentions=False,
):
# decoder uni-directional self-attention cached key/values tuple is at positions 1,2
self_attn_past_key_value = past_key_value[:2] if past_key_value is not None else None
self_attention_outputs = self.attention(
hidden_states,
attention_mask,
head_mask,
output_attentions=output_attentions,
past_key_value=self_attn_past_key_value,
)
attention_output = self_attention_outputs[0]
# if decoder, the last output is tuple of self-attn cache
if self.is_decoder:
outputs = self_attention_outputs[1:-1]
present_key_value = self_attention_outputs[-1]
else:
outputs = self_attention_outputs[1:] # add self attentions if we output attention weights
cross_attn_present_key_value = None
if self.is_decoder and encoder_hidden_states is not None:
if not hasattr(self, "crossattention"):
raise AttributeError(
f"If `encoder_hidden_states` are passed, {self} has to be instantiated"
" with cross-attention layers by setting `config.add_cross_attention=True`"
)
# cross_attn cached key/values tuple is at positions 3,4 of past_key_value tuple
cross_attn_past_key_value = past_key_value[-2:] if past_key_value is not None else None
cross_attention_outputs = self.crossattention(
attention_output,
attention_mask,
head_mask,
encoder_hidden_states,
encoder_attention_mask,
cross_attn_past_key_value,
output_attentions,
)
attention_output = cross_attention_outputs[0]
outputs = outputs + cross_attention_outputs[1:-1] # add cross attentions if we output attention weights
# add cross-attn cache to positions 3,4 of present_key_value tuple
cross_attn_present_key_value = cross_attention_outputs[-1]
present_key_value = present_key_value + cross_attn_present_key_value
layer_output = self.feed_forward_chunk(attention_output)
outputs = (layer_output,) + outputs
# if decoder, return the attn key/values as the last output
if self.is_decoder:
outputs = outputs + (present_key_value,)
return outputs
def feed_forward_chunk(self, attention_output):
attention_output_ln = self.LayerNorm(attention_output)
intermediate_output = self.intermediate(attention_output_ln)
layer_output = self.output(intermediate_output, attention_output)
return layer_output
class EsmEncoder(nn.Module):
def __init__(self, config):
super().__init__()
self.config = config
self.layer = nn.ModuleList([EsmLayer(config) for _ in range(config.num_hidden_layers)])
self.emb_layer_norm_after = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
self.gradient_checkpointing = False
def forward(
self,
hidden_states,
attention_mask=None,
head_mask=None,
encoder_hidden_states=None,
encoder_attention_mask=None,
past_key_values=None,
use_cache=None,
output_attentions=False,
output_hidden_states=False,
return_dict=True,
):
if self.gradient_checkpointing and self.training:
if use_cache:
logger.warning_once(
"`use_cache=True` is incompatible with `config.gradient_checkpointing=True`. Setting "
"`use_cache=False`..."
)
use_cache = False
all_hidden_states = () if output_hidden_states else None
all_self_attentions = () if output_attentions else None
all_cross_attentions = () if output_attentions and self.config.add_cross_attention else None
next_decoder_cache = () if use_cache else None
for i, layer_module in enumerate(self.layer):
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
layer_head_mask = head_mask[i] if head_mask is not None else None
past_key_value = past_key_values[i] if past_key_values is not None else None
if self.gradient_checkpointing and self.training:
layer_outputs = self._gradient_checkpointing_func(
layer_module.__call__,
hidden_states,
attention_mask,
layer_head_mask,
encoder_hidden_states,
encoder_attention_mask,
past_key_value,
output_attentions,
)
else:
layer_outputs = layer_module(
hidden_states,
attention_mask,
layer_head_mask,
encoder_hidden_states,
encoder_attention_mask,
past_key_value,
output_attentions,
)
hidden_states = layer_outputs[0]
if use_cache:
next_decoder_cache = next_decoder_cache + (layer_outputs[-1],)
if output_attentions:
all_self_attentions = all_self_attentions + (layer_outputs[1],)
if self.config.add_cross_attention:
all_cross_attentions = all_cross_attentions + (layer_outputs[2],)
if self.emb_layer_norm_after:
hidden_states = self.emb_layer_norm_after(hidden_states)
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
if not return_dict:
return tuple(
v
for v in [
hidden_states,
next_decoder_cache,
all_hidden_states,
all_self_attentions,
all_cross_attentions,
]
if v is not None
)
return BaseModelOutputWithPastAndCrossAttentions(
last_hidden_state=hidden_states,
past_key_values=next_decoder_cache,
hidden_states=all_hidden_states,
attentions=all_self_attentions,
cross_attentions=all_cross_attentions,
)
# Copied from transformers.models.bert.modeling_bert.BertPooler
class EsmPooler(nn.Module):
def __init__(self, config):
super().__init__()
self.dense = nn.Linear(config.hidden_size, config.hidden_size)
self.activation = nn.Tanh()
def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
# We "pool" the model by simply taking the hidden state corresponding
# to the first token.
first_token_tensor = hidden_states[:, 0]
pooled_output = self.dense(first_token_tensor)
pooled_output = self.activation(pooled_output)
return pooled_output
class EsmPreTrainedModel(PreTrainedModel):
"""
An abstract class to handle weights initialization and a simple interface for downloading and loading pretrained
models.
"""
config_class = EsmConfig
base_model_prefix = "esm"
supports_gradient_checkpointing = True
_no_split_modules = ["EsmLayer", "EsmFoldTriangularSelfAttentionBlock", "EsmEmbeddings"]
# Copied from transformers.models.bert.modeling_bert.BertPreTrainedModel._init_weights
def _init_weights(self, module):
"""Initialize the weights"""
if isinstance(module, nn.Linear):
# Slightly different from the TF version which uses truncated_normal for initialization
# cf https://github.com/pytorch/pytorch/pull/5617
module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
if module.bias is not None:
module.bias.data.zero_()
elif isinstance(module, nn.Embedding):
module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
if module.padding_idx is not None:
module.weight.data[module.padding_idx].zero_()
elif isinstance(module, nn.LayerNorm):
module.bias.data.zero_()
module.weight.data.fill_(1.0)
ESM_START_DOCSTRING = r"""
This model inherits from [`PreTrainedModel`]. Check the superclass documentation for the generic methods the
library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads
etc.)
This model is also a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) subclass.
Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage
and behavior.
Parameters:
config ([`EsmConfig`]): Model configuration class with all the parameters of the
model. Initializing with a config file does not load the weights associated with the model, only the
configuration. Check out the [`~PreTrainedModel.from_pretrained`] method to load the model weights.
"""
ESM_INPUTS_DOCSTRING = r"""
Args:
input_ids (`torch.LongTensor` of shape `({0})`):
Indices of input sequence tokens in the vocabulary.
Indices can be obtained using [`AutoTokenizer`]. See [`PreTrainedTokenizer.encode`] and
[`PreTrainedTokenizer.__call__`] for details.
[What are input IDs?](../glossary#input-ids)
attention_mask (`torch.FloatTensor` of shape `({0})`, *optional*):
Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
[What are attention masks?](../glossary#attention-mask)
position_ids (`torch.LongTensor` of shape `({0})`, *optional*):
Indices of positions of each input sequence tokens in the position embeddings. Selected in the range `[0,
config.max_position_embeddings - 1]`.
[What are position IDs?](../glossary#position-ids)
head_mask (`torch.FloatTensor` of shape `(num_heads,)` or `(num_layers, num_heads)`, *optional*):
Mask to nullify selected heads of the self-attention modules. Mask values selected in `[0, 1]`:
- 1 indicates the head is **not masked**,
- 0 indicates the head is **masked**.
inputs_embeds (`torch.FloatTensor` of shape `({0}, hidden_size)`, *optional*):
Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation. This
is useful if you want more control over how to convert `input_ids` indices into associated vectors than the
model's internal embedding lookup matrix.
output_attentions (`bool`, *optional*):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
tensors for more detail.
output_hidden_states (`bool`, *optional*):
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
more detail.
return_dict (`bool`, *optional*):
Whether or not to return a [`~file_utils.ModelOutput`] instead of a plain tuple.
"""
@add_start_docstrings(
"The bare ESM Model transformer outputting raw hidden-states without any specific head on top.",
ESM_START_DOCSTRING,
)
class EsmModel(EsmPreTrainedModel):
"""
The model can behave as an encoder (with only self-attention) as well as a decoder, in which case a layer of
cross-attention is added between the self-attention layers, following the architecture described in [Attention is
all you need](https://arxiv.org/abs/1706.03762) by Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit,
Llion Jones, Aidan N. Gomez, Lukasz Kaiser and Illia Polosukhin.
To behave as an decoder the model needs to be initialized with the `is_decoder` argument of the configuration set
to `True`. To be used in a Seq2Seq model, the model needs to initialized with both `is_decoder` argument and
`add_cross_attention` set to `True`; an `encoder_hidden_states` is then expected as an input to the forward pass.
"""
def __init__(self, config, add_pooling_layer=True):
super().__init__(config)
self.config = config
self.embeddings = EsmEmbeddings(config)
self.encoder = EsmEncoder(config)
self.pooler = EsmPooler(config) if add_pooling_layer else None
self.contact_head = EsmContactPredictionHead(
in_features=config.num_hidden_layers * config.num_attention_heads, bias=True
)
# Initialize weights and apply final processing
self.post_init()
def get_input_embeddings(self):
return self.embeddings.word_embeddings
def set_input_embeddings(self, value):
self.embeddings.word_embeddings = value
def _prune_heads(self, heads_to_prune):
"""
Prunes heads of the model. heads_to_prune: dict of {layer_num: list of heads to prune in this layer} See base
class PreTrainedModel
"""
for layer, heads in heads_to_prune.items():
self.encoder.layer[layer].attention.prune_heads(heads)
@add_start_docstrings_to_model_forward(ESM_INPUTS_DOCSTRING.format("(batch_size, sequence_length)"))
@add_code_sample_docstrings(
checkpoint=_CHECKPOINT_FOR_DOC,
output_type=BaseModelOutputWithPoolingAndCrossAttentions,
config_class=_CONFIG_FOR_DOC,
)
def forward(
self,
input_ids: Optional[torch.Tensor] = None,
attention_mask: Optional[torch.Tensor] = None,
position_ids: Optional[torch.Tensor] = None,
head_mask: Optional[torch.Tensor] = None,
inputs_embeds: Optional[torch.Tensor] = None,
encoder_hidden_states: Optional[torch.Tensor] = None,
encoder_attention_mask: Optional[torch.Tensor] = None,
past_key_values: Optional[List[torch.FloatTensor]] = None,
use_cache: Optional[bool] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
) -> Union[Tuple[torch.Tensor], BaseModelOutputWithPoolingAndCrossAttentions]:
r"""
encoder_hidden_states (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
Sequence of hidden-states at the output of the last layer of the encoder. Used in the cross-attention if
the model is configured as a decoder.
encoder_attention_mask (`torch.FloatTensor` of shape `(batch_size, sequence_length)`, *optional*):
Mask to avoid performing attention on the padding token indices of the encoder input. This mask is used in
the cross-attention if the model is configured as a decoder. Mask values selected in `[0, 1]`:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
past_key_values (`tuple(tuple(torch.FloatTensor))` of length `config.n_layers` with each tuple having 4 tensors of shape `(batch_size, num_heads, sequence_length - 1, embed_size_per_head)`):
Contains precomputed key and value hidden states of the attention blocks. Can be used to speed up decoding.
If `past_key_values` are used, the user can optionally input only the last `decoder_input_ids` (those that
don't have their past key value states given to this model) of shape `(batch_size, 1)` instead of all
`decoder_input_ids` of shape `(batch_size, sequence_length)`.
use_cache (`bool`, *optional*):
If set to `True`, `past_key_values` key value states are returned and can be used to speed up decoding (see
`past_key_values`).
"""
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
output_hidden_states = (
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
)
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
if self.config.is_decoder:
use_cache = use_cache if use_cache is not None else self.config.use_cache
else:
use_cache = False
if input_ids is not None and inputs_embeds is not None:
raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
elif input_ids is not None:
self.warn_if_padding_and_no_attention_mask(input_ids, attention_mask)
input_shape = input_ids.size()
elif inputs_embeds is not None:
input_shape = inputs_embeds.size()[:-1]
else:
raise ValueError("You have to specify either input_ids or inputs_embeds")
batch_size, seq_length = input_shape
device = input_ids.device if input_ids is not None else inputs_embeds.device
# past_key_values_length
past_key_values_length = past_key_values[0][0].shape[2] if past_key_values is not None else 0
if attention_mask is None:
attention_mask = torch.ones(((batch_size, seq_length + past_key_values_length)), device=device)
# We can provide a self-attention mask of dimensions [batch_size, from_seq_length, to_seq_length]
# ourselves in which case we just need to make it broadcastable to all heads.
extended_attention_mask: torch.Tensor = self.get_extended_attention_mask(attention_mask, input_shape)
# If a 2D or 3D attention mask is provided for the cross-attention
# we need to make broadcastable to [batch_size, num_heads, seq_length, seq_length]
if self.config.is_decoder and encoder_hidden_states is not None:
encoder_batch_size, encoder_sequence_length, _ = encoder_hidden_states.size()
encoder_hidden_shape = (encoder_batch_size, encoder_sequence_length)
if encoder_attention_mask is None:
encoder_attention_mask = torch.ones(encoder_hidden_shape, device=device)
encoder_extended_attention_mask = self.invert_attention_mask(encoder_attention_mask)
else:
encoder_extended_attention_mask = None
# Prepare head mask if needed
# 1.0 in head_mask indicate we keep the head
# attention_probs has shape bsz x n_heads x N x N
# input head_mask has shape [num_heads] or [num_hidden_layers x num_heads]
# and head_mask is converted to shape [num_hidden_layers x batch x num_heads x seq_length x seq_length]
head_mask = self.get_head_mask(head_mask, self.config.num_hidden_layers)
embedding_output = self.embeddings(
input_ids=input_ids,
position_ids=position_ids,
attention_mask=attention_mask,
inputs_embeds=inputs_embeds,
past_key_values_length=past_key_values_length,
)
encoder_outputs = self.encoder(
embedding_output,
attention_mask=extended_attention_mask,
head_mask=head_mask,
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_extended_attention_mask,
past_key_values=past_key_values,
use_cache=use_cache,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
sequence_output = encoder_outputs[0]
pooled_output = self.pooler(sequence_output) if self.pooler is not None else None
if not return_dict:
return (sequence_output, pooled_output) + encoder_outputs[1:]
return BaseModelOutputWithPoolingAndCrossAttentions(
last_hidden_state=sequence_output,
pooler_output=pooled_output,
past_key_values=encoder_outputs.past_key_values,
hidden_states=encoder_outputs.hidden_states,
attentions=encoder_outputs.attentions,
cross_attentions=encoder_outputs.cross_attentions,
)
def predict_contacts(self, tokens, attention_mask):
attns = self(tokens, attention_mask=attention_mask, return_dict=True, output_attentions=True).attentions
attns = torch.stack(attns, dim=1) # Matches the original model layout
# In the original model, attentions for padding tokens are completely zeroed out.
# This makes no difference most of the time because the other tokens won't attend to them,
# but it does for the contact prediction task, which takes attentions as input,
# so we have to mimic that here.
attns *= attention_mask.unsqueeze(1).unsqueeze(2).unsqueeze(3)
attns *= attention_mask.unsqueeze(1).unsqueeze(2).unsqueeze(4)
return self.contact_head(tokens, attns)
@add_start_docstrings("""ESM Model with a `language modeling` head on top.""", ESM_START_DOCSTRING)
class EsmForMaskedLM(EsmPreTrainedModel):
_tied_weights_keys = ["lm_head.decoder.weight"]
def __init__(self, config):
super().__init__(config)
if config.is_decoder:
logger.warning(
"If you want to use `EsmForMaskedLM` make sure `config.is_decoder=False` for "
"bi-directional self-attention."
)
self.esm = EsmModel(config, add_pooling_layer=False)
self.lm_head = EsmLMHead(config)
self.init_weights()
def get_output_embeddings(self):
return self.lm_head.decoder
def set_output_embeddings(self, new_embeddings):
self.lm_head.decoder = new_embeddings
@add_start_docstrings_to_model_forward(ESM_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
@add_code_sample_docstrings(
checkpoint=_CHECKPOINT_FOR_DOC,
output_type=MaskedLMOutput,
config_class=_CONFIG_FOR_DOC,
mask="<mask>",
)
def forward(
self,
input_ids: Optional[torch.LongTensor] = None,
attention_mask: Optional[torch.Tensor] = None,
position_ids: Optional[torch.LongTensor] = None,
head_mask: Optional[torch.Tensor] = None,
inputs_embeds: Optional[torch.FloatTensor] = None,
encoder_hidden_states: Optional[torch.FloatTensor] = None,
encoder_attention_mask: Optional[torch.Tensor] = None,
labels: Optional[torch.LongTensor] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
) -> Union[Tuple, MaskedLMOutput]:
r"""
labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
Labels for computing the masked language modeling loss. Indices should be in `[-100, 0, ...,
config.vocab_size]` (see `input_ids` docstring) Tokens with indices set to `-100` are ignored (masked), the
loss is only computed for the tokens with labels in `[0, ..., config.vocab_size]`
kwargs (`Dict[str, any]`, optional, defaults to *{}*):
Used to hide legacy arguments that have been deprecated.
"""
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
outputs = self.esm(
input_ids,
attention_mask=attention_mask,
position_ids=position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_attention_mask,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
sequence_output = outputs[0]
prediction_scores = self.lm_head(sequence_output)
masked_lm_loss = None
if labels is not None:
loss_fct = CrossEntropyLoss()
labels = labels.to(prediction_scores.device)
masked_lm_loss = loss_fct(prediction_scores.view(-1, self.config.vocab_size), labels.view(-1))
if not return_dict:
output = (prediction_scores,) + outputs[2:]
return ((masked_lm_loss,) + output) if masked_lm_loss is not None else output
return MaskedLMOutput(
loss=masked_lm_loss,
logits=prediction_scores,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
)
def predict_contacts(self, tokens, attention_mask):
return self.esm.predict_contacts(tokens, attention_mask=attention_mask)
class EsmLMHead(nn.Module):
"""ESM Head for masked language modeling."""
def __init__(self, config):
super().__init__()
self.dense = nn.Linear(config.hidden_size, config.hidden_size)
self.layer_norm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
self.decoder = nn.Linear(config.hidden_size, config.vocab_size, bias=False)
self.bias = nn.Parameter(torch.zeros(config.vocab_size))
def forward(self, features, **kwargs):
x = self.dense(features)
x = gelu(x)
x = self.layer_norm(x)
# project back to size of vocabulary with bias
x = self.decoder(x) + self.bias
return x
@add_start_docstrings(
"""
ESM Model transformer with a sequence classification/regression head on top (a linear layer on top of the pooled
output) e.g. for GLUE tasks.
""",
ESM_START_DOCSTRING,
)
class EsmForSequenceClassification(EsmPreTrainedModel):
def __init__(self, config):
super().__init__(config)
self.num_labels = config.num_labels
self.config = config
self.esm = EsmModel(config, add_pooling_layer=False)
self.classifier = EsmClassificationHead(config)
self.init_weights()
@add_start_docstrings_to_model_forward(ESM_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
@add_code_sample_docstrings(
checkpoint=_CHECKPOINT_FOR_DOC,
output_type=SequenceClassifierOutput,
config_class=_CONFIG_FOR_DOC,
)
def forward(
self,
input_ids: Optional[torch.LongTensor] = None,
attention_mask: Optional[torch.Tensor] = None,
position_ids: Optional[torch.LongTensor] = None,
head_mask: Optional[torch.Tensor] = None,
inputs_embeds: Optional[torch.FloatTensor] = None,
labels: Optional[torch.LongTensor] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
) -> Union[Tuple, SequenceClassifierOutput]:
r"""
labels (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
Labels for computing the sequence classification/regression loss. Indices should be in `[0, ...,
config.num_labels - 1]`. If `config.num_labels == 1` a regression loss is computed (Mean-Square loss), If
`config.num_labels > 1` a classification loss is computed (Cross-Entropy).
"""
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
outputs = self.esm(
input_ids,
attention_mask=attention_mask,
position_ids=position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
sequence_output = outputs[0]
logits = self.classifier(sequence_output)
loss = None
if labels is not None:
labels = labels.to(logits.device)
if self.config.problem_type is None:
if self.num_labels == 1:
self.config.problem_type = "regression"
elif self.num_labels > 1 and (labels.dtype == torch.long or labels.dtype == torch.int):
self.config.problem_type = "single_label_classification"
else:
self.config.problem_type = "multi_label_classification"
if self.config.problem_type == "regression":
loss_fct = MSELoss()
if self.num_labels == 1:
loss = loss_fct(logits.squeeze(), labels.squeeze())
else:
loss = loss_fct(logits, labels)
elif self.config.problem_type == "single_label_classification":
loss_fct = CrossEntropyLoss()
loss = loss_fct(logits.view(-1, self.num_labels), labels.view(-1))
elif self.config.problem_type == "multi_label_classification":
loss_fct = BCEWithLogitsLoss()
loss = loss_fct(logits, labels)
if not return_dict:
output = (logits,) + outputs[2:]
return ((loss,) + output) if loss is not None else output
return SequenceClassifierOutput(
loss=loss,
logits=logits,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
)
@add_start_docstrings(
"""
ESM Model with a token classification head on top (a linear layer on top of the hidden-states output) e.g. for
Named-Entity-Recognition (NER) tasks.
""",
ESM_START_DOCSTRING,
)
class EsmForTokenClassification(EsmPreTrainedModel):
def __init__(self, config):
super().__init__(config)
self.num_labels = config.num_labels
self.esm = EsmModel(config, add_pooling_layer=False)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
self.classifier = nn.Linear(config.hidden_size, config.num_labels)
self.init_weights()
@add_start_docstrings_to_model_forward(ESM_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
@add_code_sample_docstrings(
checkpoint=_CHECKPOINT_FOR_DOC,
output_type=TokenClassifierOutput,
config_class=_CONFIG_FOR_DOC,
)
def forward(
self,
input_ids: Optional[torch.LongTensor] = None,
attention_mask: Optional[torch.Tensor] = None,
position_ids: Optional[torch.LongTensor] = None,
head_mask: Optional[torch.Tensor] = None,
inputs_embeds: Optional[torch.FloatTensor] = None,
labels: Optional[torch.LongTensor] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
) -> Union[Tuple, TokenClassifierOutput]:
r"""
labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
Labels for computing the token classification loss. Indices should be in `[0, ..., config.num_labels - 1]`.
"""
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
outputs = self.esm(
input_ids,
attention_mask=attention_mask,
position_ids=position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
sequence_output = outputs[0]
sequence_output = self.dropout(sequence_output)
logits = self.classifier(sequence_output)
loss = None
if labels is not None:
loss_fct = CrossEntropyLoss()
labels = labels.to(logits.device)
loss = loss_fct(logits.view(-1, self.num_labels), labels.view(-1))
if not return_dict:
output = (logits,) + outputs[2:]
return ((loss,) + output) if loss is not None else output
return TokenClassifierOutput(
loss=loss,
logits=logits,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
)
class EsmClassificationHead(nn.Module):
"""Head for sentence-level classification tasks."""
def __init__(self, config):
super().__init__()
self.dense = nn.Linear(config.hidden_size, config.hidden_size)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
self.out_proj = nn.Linear(config.hidden_size, config.num_labels)
def forward(self, features, **kwargs):
x = features[:, 0, :] # take <s> token (equiv. to [CLS])
x = self.dropout(x)
x = self.dense(x)
x = torch.tanh(x)
x = self.dropout(x)
x = self.out_proj(x)
return x
def create_position_ids_from_input_ids(input_ids, padding_idx, past_key_values_length=0):
"""
Replace non-padding symbols with their position numbers. Position numbers begin at padding_idx+1. Padding symbols
are ignored. This is modified from fairseq's `utils.make_positions`.
Args:
x: torch.Tensor x:
Returns: torch.Tensor
"""
# The series of casts and type-conversions here are carefully balanced to both work with ONNX export and XLA.
mask = input_ids.ne(padding_idx).int()
incremental_indices = (torch.cumsum(mask, dim=1).type_as(mask) + past_key_values_length) * mask
return incremental_indices.long() + padding_idx
| transformers/src/transformers/models/esm/modeling_esm.py/0 | {
"file_path": "transformers/src/transformers/models/esm/modeling_esm.py",
"repo_id": "transformers",
"token_count": 23724
} | 91 |
# coding=utf-8
# Copyright 2023 the Falcon authors and HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""PyTorch Falcon model."""
import math
import warnings
from typing import TYPE_CHECKING, Optional, Tuple, Union
import torch
import torch.utils.checkpoint
from torch import nn
from torch.nn import BCEWithLogitsLoss, CrossEntropyLoss, LayerNorm, MSELoss
from torch.nn import functional as F
from ...modeling_attn_mask_utils import (
AttentionMaskConverter,
_prepare_4d_causal_attention_mask,
_prepare_4d_causal_attention_mask_for_sdpa,
)
from ...modeling_outputs import (
BaseModelOutputWithPastAndCrossAttentions,
CausalLMOutputWithCrossAttentions,
QuestionAnsweringModelOutput,
SequenceClassifierOutputWithPast,
TokenClassifierOutput,
)
from ...modeling_utils import PreTrainedModel
from ...pytorch_utils import is_torch_greater_or_equal_than_2_0
from ...utils import (
add_code_sample_docstrings,
add_start_docstrings,
add_start_docstrings_to_model_forward,
is_flash_attn_2_available,
is_flash_attn_greater_or_equal_2_10,
logging,
)
from .configuration_falcon import FalconConfig
if TYPE_CHECKING:
from ...configuration_utils import PretrainedConfig
if is_flash_attn_2_available():
from flash_attn import flash_attn_func, flash_attn_varlen_func
from flash_attn.bert_padding import index_first_axis, pad_input, unpad_input # noqa
logger = logging.get_logger(__name__)
FALCON_PRETRAINED_MODEL_ARCHIVE_LIST = [
"tiiuae/falcon-40b",
"tiiuae/falcon-40b-instruct",
"tiiuae/falcon-7b",
"tiiuae/falcon-7b-instruct",
"tiiuae/falcon-rw-7b",
"tiiuae/falcon-rw-1b",
]
_CHECKPOINT_FOR_DOC = "Rocketknight1/falcon-rw-1b"
_CONFIG_FOR_DOC = "FalconConfig"
# NOTE(Hesslow): Unfortunately we did not fuse matmul and bias during training, this means that there's one additional quantization to bfloat16 between the operations.
# In order not to degrade the quality of our HF-port, we keep these characteristics in the final model.
class FalconLinear(nn.Linear):
def forward(self, input: torch.Tensor) -> torch.Tensor:
hidden_states = input @ self.weight.T
if self.bias is None:
return hidden_states
return hidden_states + self.bias
# Copied from transformers.models.llama.modeling_llama.rotate_half
def rotate_half(x):
"""Rotates half the hidden dims of the input."""
x1 = x[..., : x.shape[-1] // 2]
x2 = x[..., x.shape[-1] // 2 :]
return torch.cat((-x2, x1), dim=-1)
# Copied from transformers.models.mistral.modeling_mistral.apply_rotary_pos_emb
def apply_rotary_pos_emb(q, k, cos, sin, position_ids, unsqueeze_dim=1):
"""Applies Rotary Position Embedding to the query and key tensors.
Args:
q (`torch.Tensor`): The query tensor.
k (`torch.Tensor`): The key tensor.
cos (`torch.Tensor`): The cosine part of the rotary embedding.
sin (`torch.Tensor`): The sine part of the rotary embedding.
position_ids (`torch.Tensor`):
The position indices of the tokens corresponding to the query and key tensors. For example, this can be
used to pass offsetted position ids when working with a KV-cache.
unsqueeze_dim (`int`, *optional*, defaults to 1):
The 'unsqueeze_dim' argument specifies the dimension along which to unsqueeze cos[position_ids] and
sin[position_ids] so that they can be properly broadcasted to the dimensions of q and k. For example, note
that cos[position_ids] and sin[position_ids] have the shape [batch_size, seq_len, head_dim]. Then, if q and
k have the shape [batch_size, heads, seq_len, head_dim], then setting unsqueeze_dim=1 makes
cos[position_ids] and sin[position_ids] broadcastable to the shapes of q and k. Similarly, if q and k have
the shape [batch_size, seq_len, heads, head_dim], then set unsqueeze_dim=2.
Returns:
`tuple(torch.Tensor)` comprising of the query and key tensors rotated using the Rotary Position Embedding.
"""
cos = cos[position_ids].unsqueeze(unsqueeze_dim)
sin = sin[position_ids].unsqueeze(unsqueeze_dim)
q_embed = (q * cos) + (rotate_half(q) * sin)
k_embed = (k * cos) + (rotate_half(k) * sin)
return q_embed, k_embed
# Copied from transformers.models.llama.modeling_llama._get_unpad_data
def _get_unpad_data(attention_mask):
seqlens_in_batch = attention_mask.sum(dim=-1, dtype=torch.int32)
indices = torch.nonzero(attention_mask.flatten(), as_tuple=False).flatten()
max_seqlen_in_batch = seqlens_in_batch.max().item()
cu_seqlens = F.pad(torch.cumsum(seqlens_in_batch, dim=0, dtype=torch.int32), (1, 0))
return (
indices,
cu_seqlens,
max_seqlen_in_batch,
)
# Copied from transformers.models.mistral.modeling_mistral.MistralRotaryEmbedding with Mistral->Falcon
class FalconRotaryEmbedding(nn.Module):
def __init__(self, dim, max_position_embeddings=2048, base=10000, device=None):
super().__init__()
self.dim = dim
self.max_position_embeddings = max_position_embeddings
self.base = base
inv_freq = 1.0 / (self.base ** (torch.arange(0, self.dim, 2, dtype=torch.int64).float().to(device) / self.dim))
self.register_buffer("inv_freq", inv_freq, persistent=False)
# Build here to make `torch.jit.trace` work.
self._set_cos_sin_cache(
seq_len=max_position_embeddings, device=self.inv_freq.device, dtype=torch.get_default_dtype()
)
def _set_cos_sin_cache(self, seq_len, device, dtype):
self.max_seq_len_cached = seq_len
t = torch.arange(self.max_seq_len_cached, device=device, dtype=torch.int64).type_as(self.inv_freq)
freqs = torch.outer(t, self.inv_freq)
# Different from paper, but it uses a different permutation in order to obtain the same calculation
emb = torch.cat((freqs, freqs), dim=-1)
self.register_buffer("cos_cached", emb.cos().to(dtype), persistent=False)
self.register_buffer("sin_cached", emb.sin().to(dtype), persistent=False)
def forward(self, x, seq_len=None):
# x: [bs, num_attention_heads, seq_len, head_size]
if seq_len > self.max_seq_len_cached:
self._set_cos_sin_cache(seq_len=seq_len, device=x.device, dtype=x.dtype)
return (
self.cos_cached[:seq_len].to(dtype=x.dtype),
self.sin_cached[:seq_len].to(dtype=x.dtype),
)
# copied from transformers.models.llama.modeling_llama.LlamaLinearScalingRotaryEmbedding with Llama->Falcon
# TODO @joao no longer copied from LLama after static cache, fix me (copied -> Copied)
class FalconLinearScalingRotaryEmbedding(FalconRotaryEmbedding):
"""FalconRotaryEmbedding extended with linear scaling. Credits to the Reddit user /u/kaiokendev"""
def __init__(self, dim, max_position_embeddings=2048, base=10000, device=None, scaling_factor=1.0):
self.scaling_factor = scaling_factor
super().__init__(dim, max_position_embeddings, base, device)
def _set_cos_sin_cache(self, seq_len, device, dtype):
self.max_seq_len_cached = seq_len
t = torch.arange(self.max_seq_len_cached, device=device, dtype=torch.int64).type_as(self.inv_freq)
t = t / self.scaling_factor
freqs = torch.outer(t, self.inv_freq)
# Different from paper, but it uses a different permutation in order to obtain the same calculation
emb = torch.cat((freqs, freqs), dim=-1)
self.register_buffer("cos_cached", emb.cos().to(dtype), persistent=False)
self.register_buffer("sin_cached", emb.sin().to(dtype), persistent=False)
# copied from transformers.models.llama.modeling_llama.LlamaDynamicNTKScalingRotaryEmbedding with Llama->Falcon
# TODO @joao no longer copied from LLama after static cache, fix me (copied -> Copied)
class FalconDynamicNTKScalingRotaryEmbedding(FalconRotaryEmbedding):
"""FalconRotaryEmbedding extended with Dynamic NTK scaling. Credits to the Reddit users /u/bloc97 and /u/emozilla"""
def __init__(self, dim, max_position_embeddings=2048, base=10000, device=None, scaling_factor=1.0):
self.scaling_factor = scaling_factor
super().__init__(dim, max_position_embeddings, base, device)
def _set_cos_sin_cache(self, seq_len, device, dtype):
self.max_seq_len_cached = seq_len
if seq_len > self.max_position_embeddings:
base = self.base * (
(self.scaling_factor * seq_len / self.max_position_embeddings) - (self.scaling_factor - 1)
) ** (self.dim / (self.dim - 2))
inv_freq = 1.0 / (base ** (torch.arange(0, self.dim, 2, dtype=torch.int64).float().to(device) / self.dim))
self.register_buffer("inv_freq", inv_freq, persistent=False)
t = torch.arange(self.max_seq_len_cached, device=device, dtype=torch.int64).type_as(self.inv_freq)
freqs = torch.outer(t, self.inv_freq)
# Different from paper, but it uses a different permutation in order to obtain the same calculation
emb = torch.cat((freqs, freqs), dim=-1)
self.register_buffer("cos_cached", emb.cos().to(dtype), persistent=False)
self.register_buffer("sin_cached", emb.sin().to(dtype), persistent=False)
def build_alibi_tensor(attention_mask: torch.Tensor, num_heads: int, dtype: torch.dtype) -> torch.Tensor:
batch_size, seq_length = attention_mask.shape
closest_power_of_2 = 2 ** math.floor(math.log2(num_heads))
base = torch.tensor(
2 ** (-(2 ** -(math.log2(closest_power_of_2) - 3))), device=attention_mask.device, dtype=torch.float32
)
powers = torch.arange(1, 1 + closest_power_of_2, device=attention_mask.device, dtype=torch.int32)
slopes = torch.pow(base, powers)
if closest_power_of_2 != num_heads:
extra_base = torch.tensor(
2 ** (-(2 ** -(math.log2(2 * closest_power_of_2) - 3))), device=attention_mask.device, dtype=torch.float32
)
num_remaining_heads = min(closest_power_of_2, num_heads - closest_power_of_2)
extra_powers = torch.arange(1, 1 + 2 * num_remaining_heads, 2, device=attention_mask.device, dtype=torch.int32)
slopes = torch.cat([slopes, torch.pow(extra_base, extra_powers)], dim=0)
# Note: alibi will added to the attention bias that will be applied to the query, key product of attention
# => therefore alibi will have to be of shape (batch_size, num_heads, query_length, key_length)
# => here we set (batch_size=1, num_heads=num_heads, query_length=1, key_length=max_length)
# => the query_length dimension will then be broadcasted correctly
# This is more or less identical to T5's relative position bias:
# https://github.com/huggingface/transformers/blob/f681437203baa7671de3174b0fa583c349d9d5e1/src/transformers/models/t5/modeling_t5.py#L527
arange_tensor = ((attention_mask.cumsum(dim=-1) - 1) * attention_mask)[:, None, :]
alibi = slopes[..., None].bfloat16() * arange_tensor
return alibi.reshape(batch_size * num_heads, 1, seq_length).to(dtype)
# Copied from transformers.models.bloom.modeling_bloom.dropout_add
def dropout_add(x: torch.Tensor, residual: torch.Tensor, prob: float, training: bool) -> torch.Tensor:
"""
Dropout add function
Args:
x (`torch.tensor`, *required*):
input tensor
residual (`torch.tensor`, *required*):
residual tensor
prob (`float`, *required*):
dropout probability
training (`bool`, *required*):
training mode
"""
out = F.dropout(x, p=prob, training=training)
out = residual + out
return out
class FalconAttention(nn.Module):
def __init__(self, config: FalconConfig):
super().__init__()
self.config = config
self.hidden_size = config.hidden_size
self.num_heads = config.num_attention_heads
self.head_dim = self.hidden_size // self.num_heads
self.split_size = self.hidden_size
self.hidden_dropout = config.hidden_dropout
self.max_position_embeddings = config.max_position_embeddings
self.rope_theta = config.rope_theta
self.is_causal = True
self._use_sdpa = config._attn_implementation == "sdpa"
if self.head_dim * self.num_heads != self.hidden_size:
raise ValueError(
f"`hidden_size` must be divisible by num_heads (got `hidden_size`: {self.hidden_size} and `num_heads`:"
f" {self.num_heads})."
)
if config.rotary:
self._init_rope()
# Layer-wise attention scaling
self.inv_norm_factor = 1.0 / math.sqrt(self.head_dim)
self.beta = self.inv_norm_factor
if config.new_decoder_architecture:
qkv_out_dim = (config.num_kv_heads * 2 + config.num_attention_heads) * self.head_dim
elif config.multi_query:
qkv_out_dim = self.hidden_size + 2 * self.head_dim
else:
qkv_out_dim = 3 * self.hidden_size
self.query_key_value = FalconLinear(self.hidden_size, qkv_out_dim, bias=config.bias)
self.new_decoder_architecture = config.new_decoder_architecture
self.multi_query = config.multi_query
self.dense = FalconLinear(self.hidden_size, self.hidden_size, bias=config.bias)
self.attention_dropout = nn.Dropout(config.attention_dropout)
self.num_kv_heads = config.num_kv_heads if (self.new_decoder_architecture or not self.multi_query) else 1
# Copied from transformers.models.llama.modeling_llama.LlamaAttention._init_rope with Llama->Falcon
def _init_rope(self):
if self.config.rope_scaling is None:
self.rotary_emb = FalconRotaryEmbedding(
self.head_dim,
max_position_embeddings=self.max_position_embeddings,
base=self.rope_theta,
)
else:
scaling_type = self.config.rope_scaling["type"]
scaling_factor = self.config.rope_scaling["factor"]
if scaling_type == "linear":
self.rotary_emb = FalconLinearScalingRotaryEmbedding(
self.head_dim,
max_position_embeddings=self.max_position_embeddings,
scaling_factor=scaling_factor,
base=self.rope_theta,
)
elif scaling_type == "dynamic":
self.rotary_emb = FalconDynamicNTKScalingRotaryEmbedding(
self.head_dim,
max_position_embeddings=self.max_position_embeddings,
scaling_factor=scaling_factor,
base=self.rope_theta,
)
else:
raise ValueError(f"Unknown RoPE scaling type {scaling_type}")
def _split_heads(self, fused_qkv: torch.Tensor) -> Tuple[torch.Tensor, torch.Tensor, torch.Tensor]:
"""
Split the last dimension into (num_heads, head_dim), results share same memory storage as `fused_qkv`
Args:
fused_qkv (`torch.tensor`, *required*): [batch_size, seq_length, num_heads * 3 * head_dim]
Returns:
query: [batch_size, seq_length, num_heads, head_dim] key: [batch_size, seq_length, num_heads, head_dim]
value: [batch_size, seq_length, num_heads, head_dim]
"""
if self.new_decoder_architecture:
batch, seq_len, _ = fused_qkv.shape
qkv = fused_qkv.view(batch, seq_len, -1, self.num_heads // self.num_kv_heads + 2, self.head_dim)
query = qkv[:, :, :, :-2]
key = qkv[:, :, :, [-2]]
value = qkv[:, :, :, [-1]]
key = torch.broadcast_to(key, query.shape)
value = torch.broadcast_to(value, query.shape)
query, key, value = [x.flatten(2, 3) for x in (query, key, value)]
return query, key, value
elif not self.multi_query:
batch_size, seq_length, three_times_hidden_size = fused_qkv.shape
fused_qkv = fused_qkv.view(batch_size, seq_length, self.num_heads, 3, self.head_dim)
return fused_qkv[..., 0, :], fused_qkv[..., 1, :], fused_qkv[..., 2, :]
else:
batch_size, seq_length, three_times_hidden_size = fused_qkv.shape
fused_qkv = fused_qkv.view(batch_size, seq_length, self.num_heads + 2, self.head_dim)
return fused_qkv[..., :-2, :], fused_qkv[..., [-2], :], fused_qkv[..., [-1], :]
# Copied from transformers.models.bloom.modeling_bloom.BloomAttention._merge_heads
def _merge_heads(self, x: torch.Tensor) -> torch.Tensor:
"""
Merge heads together over the last dimension
Args:
x (`torch.tensor`, *required*): [batch_size * num_heads, seq_length, head_dim]
Returns:
torch.tensor: [batch_size, seq_length, num_heads * head_dim]
"""
# What we want to achieve is:
# batch_size * num_heads, seq_length, head_dim -> batch_size, seq_length, num_heads * head_dim
batch_size_and_num_heads, seq_length, _ = x.shape
batch_size = batch_size_and_num_heads // self.num_heads
# First view to decompose the batch size
# batch_size * num_heads, seq_length, head_dim -> batch_size, num_heads, seq_length, head_dim
x = x.view(batch_size, self.num_heads, seq_length, self.head_dim)
# batch_size, num_heads, seq_length, head_dim -> batch_size, seq_length, num_heads, head_dim
x = x.permute(0, 2, 1, 3)
# batch_size, seq_length, num_heads, head_dim -> batch_size, seq_length, num_heads * head_dim
return x.reshape(batch_size, seq_length, self.num_heads * self.head_dim)
def forward(
self,
hidden_states: torch.Tensor,
alibi: Optional[torch.Tensor],
attention_mask: torch.Tensor,
position_ids: Optional[torch.LongTensor] = None,
layer_past: Optional[Tuple[torch.Tensor, torch.Tensor]] = None,
head_mask: Optional[torch.Tensor] = None,
use_cache: bool = False,
output_attentions: bool = False,
**kwargs,
):
if "padding_mask" in kwargs:
warnings.warn(
"Passing `padding_mask` is deprecated and will be removed in v4.37. Please make sure use `attention_mask` instead.`"
)
fused_qkv = self.query_key_value(hidden_states) # [batch_size, seq_length, 3 x hidden_size]
num_kv_heads = self.num_heads if self.new_decoder_architecture else self.num_kv_heads
# 3 x [batch_size, seq_length, num_heads, head_dim]
(query_layer, key_layer, value_layer) = self._split_heads(fused_qkv)
batch_size, query_length, _, _ = query_layer.shape
query_layer = query_layer.transpose(1, 2).reshape(batch_size, self.num_heads, query_length, self.head_dim)
key_layer = key_layer.transpose(1, 2).reshape(batch_size, num_kv_heads, query_length, self.head_dim)
value_layer = value_layer.transpose(1, 2).reshape(batch_size, num_kv_heads, query_length, self.head_dim)
kv_seq_len = key_layer.shape[-2]
if layer_past is not None:
kv_seq_len += layer_past[0].shape[-2]
if alibi is None:
cos, sin = self.rotary_emb(value_layer, seq_len=kv_seq_len)
query_layer, key_layer = apply_rotary_pos_emb(query_layer, key_layer, cos, sin, position_ids)
if layer_past is not None:
past_key, past_value = layer_past
# concatenate along seq_length dimension:
# - key: [batch_size, self.num_heads, kv_length, head_dim]
# - value: [batch_size, self.num_heads, kv_length, head_dim]
key_layer = torch.cat((past_key, key_layer), dim=-2)
value_layer = torch.cat((past_value, value_layer), dim=-2)
kv_length = key_layer.shape[-2]
if use_cache:
present = (key_layer, value_layer)
else:
present = None
# SDPA with memory-efficient backend is currently (torch==2.1.2) bugged with non-contiguous inputs with custom attn_mask,
# Reference: https://github.com/pytorch/pytorch/issues/112577.
if query_layer.device.type == "cuda" and attention_mask is not None:
query_layer = query_layer.contiguous()
key_layer = key_layer.contiguous()
value_layer = value_layer.contiguous()
if alibi is None:
if self._use_sdpa and not output_attentions:
attn_output = F.scaled_dot_product_attention(
query_layer,
key_layer,
value_layer,
attention_mask,
0.0,
# The query_length > 1 is necessary to match with AttentionMaskConverter.to_causal_4d that does not create a causal mask in case query_length == 1.
is_causal=self.is_causal and attention_mask is None and query_length > 1,
)
attention_scores = None
else:
attention_scores = query_layer @ key_layer.transpose(-1, -2)
attention_scores /= math.sqrt(self.head_dim)
attention_scores = F.softmax(attention_scores + attention_mask, dim=-1, dtype=hidden_states.dtype)
# It is unclear why neither dropout nor head_mask is applied here (while it is with alibi).
attn_output = attention_scores @ value_layer
attn_output = attn_output.view(batch_size, self.num_heads, query_length, self.head_dim)
attn_output = attn_output.permute(0, 2, 1, 3)
attn_output = attn_output.reshape(batch_size, query_length, self.num_heads * self.head_dim)
attn_output = self.dense(attn_output)
if output_attentions:
return attn_output, present, attention_scores
else:
return attn_output, present
else:
if self._use_sdpa and not output_attentions and head_mask is None:
attn_output = F.scaled_dot_product_attention(
query_layer,
key_layer,
value_layer,
attn_mask=attention_mask,
dropout_p=self.attention_dropout.p if self.training else 0.0,
is_causal=self.is_causal and attention_mask is None and query_length > 1,
)
attn_output = attn_output.transpose(1, 2)
attn_output = attn_output.reshape(batch_size, query_length, self.num_heads * self.head_dim)
attn_output = self.dense(attn_output)
else:
matmul_result = query_layer @ key_layer.transpose(-1, -2)
# change view to [batch_size, num_heads, q_length, kv_length]
attention_scores = matmul_result.view(batch_size, self.num_heads, query_length, kv_length)
# cast attention scores to fp32, compute scaled softmax and cast back to initial dtype - [batch_size, num_heads, q_length, kv_length]
input_dtype = attention_scores.dtype
# `float16` has a minimum value of -65504.0, whereas `bfloat16` and `float32` have a minimum value of `-3.4e+38`
if input_dtype == torch.float16 or input_dtype == torch.bfloat16:
attention_scores = attention_scores.to(torch.float32)
attention_logits = attention_scores + alibi.view(batch_size, self.num_heads, 1, -1)
attention_logits *= self.inv_norm_factor
attention_probs = F.softmax(attention_logits + attention_mask, dim=-1, dtype=hidden_states.dtype)
# [batch_size, num_heads, q_length, kv_length]
attention_probs = self.attention_dropout(attention_probs)
if head_mask is not None:
attention_probs = attention_probs * head_mask
# change view [batch_size, num_heads, q_length, kv_length]
attention_probs_reshaped = attention_probs.view(batch_size, self.num_heads, query_length, kv_length)
# matmul: [batch_size * num_heads, q_length, head_dim]
attn_output = (attention_probs_reshaped @ value_layer).flatten(0, 1)
# change view [batch_size, q_length, num_heads * head_dim]
attn_output = self._merge_heads(attn_output)
attn_output = self.dense(attn_output)
if output_attentions:
return attn_output, present, attention_probs
else:
return attn_output, present
class FalconFlashAttention2(FalconAttention):
"""
Falcon flash attention module. This module inherits from `FalconAttention` as the weights of the module stays
untouched. The only required change would be on the forward pass where it needs to correctly call the public API of
flash attention and deal with padding tokens in case the input contains any of them.
"""
# Copied from transformers.models.llama.modeling_llama.LlamaFlashAttention2.__init__
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
# TODO: Should be removed once Flash Attention for RoCm is bumped to 2.1.
# flash_attn<2.1 generates top-left aligned causal mask, while what is needed here is bottom-right alignement, that was made default for flash_attn>=2.1. This attribute is used to handle this difference. Reference: https://github.com/Dao-AILab/flash-attention/releases/tag/v2.1.0.
# Beware that with flash_attn<2.1, using q_seqlen != k_seqlen (except for the case q_seqlen == 1) produces a wrong mask (top-left).
self._flash_attn_uses_top_left_mask = not is_flash_attn_greater_or_equal_2_10()
def forward(
self,
hidden_states: torch.Tensor,
alibi: Optional[torch.Tensor],
attention_mask: torch.Tensor,
position_ids: Optional[torch.LongTensor] = None,
layer_past: Optional[Tuple[torch.Tensor, torch.Tensor]] = None,
head_mask: Optional[torch.Tensor] = None,
use_cache: bool = False,
output_attentions: bool = False,
**kwargs,
):
if "padding_mask" in kwargs:
warnings.warn(
"Passing `padding_mask` is deprecated and will be removed in v4.37. Please make sure use `attention_mask` instead.`"
)
# overwrite attention_mask with padding_mask
attention_mask = kwargs.pop("padding_mask")
fused_qkv = self.query_key_value(hidden_states) # [batch_size, seq_length, 3 x hidden_size]
num_kv_heads = self.num_heads if self.new_decoder_architecture else self.num_kv_heads
# 3 x [batch_size, seq_length, num_heads, head_dim]
(query_layer, key_layer, value_layer) = self._split_heads(fused_qkv)
batch_size, query_length, _, _ = query_layer.shape
query_layer = query_layer.transpose(1, 2).reshape(batch_size, self.num_heads, query_length, self.head_dim)
key_layer = key_layer.transpose(1, 2).reshape(batch_size, num_kv_heads, query_length, self.head_dim)
value_layer = value_layer.transpose(1, 2).reshape(batch_size, num_kv_heads, query_length, self.head_dim)
kv_seq_len = key_layer.shape[-2]
if layer_past is not None:
kv_seq_len += layer_past[0].shape[-2]
if alibi is None:
cos, sin = self.rotary_emb(value_layer, seq_len=kv_seq_len)
query_layer, key_layer = apply_rotary_pos_emb(query_layer, key_layer, cos, sin, position_ids)
if layer_past is not None and use_cache:
past_key, past_value = layer_past
# concatenate along seq_length dimension:
# - key: [batch_size, self.num_heads, kv_length, head_dim]
# - value: [batch_size, self.num_heads, kv_length, head_dim]
key_layer = torch.cat((past_key, key_layer), dim=-2)
value_layer = torch.cat((past_value, value_layer), dim=-2)
past_key_value = (key_layer, value_layer) if use_cache else None
# TODO: These transpose are quite inefficient but Flash Attention requires the layout [batch_size, sequence_length, num_heads, head_dim]. We would need to refactor the KV cache
# to be able to avoid many of these transpose/reshape/view.
query_layer = query_layer.transpose(1, 2)
key_layer = key_layer.transpose(1, 2)
value_layer = value_layer.transpose(1, 2)
if alibi is not None:
raise ValueError("`alibi` is not supported when `use_flash_attn` is True")
attn_dropout = self.config.attention_dropout if self.training else 0.0
# In PEFT, usually we cast the layer norms in float32 for training stability reasons
# therefore the input hidden states gets silently casted in float32. Hence, we need
# cast them back in float16 just to be sure everything works as expected.
input_dtype = query_layer.dtype
if input_dtype == torch.float32:
if torch.is_autocast_enabled():
target_dtype = torch.get_autocast_gpu_dtype()
# Handle the case where the model is quantized
elif hasattr(self.config, "_pre_quantization_dtype"):
target_dtype = self.config._pre_quantization_dtype
else:
target_dtype = self.query_key_value.weight.dtype
logger.warning_once(
f"The input hidden states seems to be silently casted in float32, this might be related to"
f" the fact you have upcasted embedding or layer norm layers in float32. We will cast back the input in"
f" {target_dtype}."
)
query_layer = query_layer.to(target_dtype)
key_layer = key_layer.to(target_dtype)
value_layer = value_layer.to(target_dtype)
attn_output = self._flash_attention_forward(
query_layer, key_layer, value_layer, attention_mask, query_length, dropout=attn_dropout
)
attn_weights = attn_output.reshape(batch_size, query_length, self.num_heads * self.head_dim)
attn_output = self.dense(attn_weights)
if not output_attentions:
attn_weights = None
return attn_output, past_key_value, attn_weights
# Copied from transformers.models.llama.modeling_llama.LlamaFlashAttention2._flash_attention_forward
def _flash_attention_forward(
self, query_states, key_states, value_states, attention_mask, query_length, dropout=0.0, softmax_scale=None
):
"""
Calls the forward method of Flash Attention - if the input hidden states contain at least one padding token
first unpad the input, then computes the attention scores and pad the final attention scores.
Args:
query_states (`torch.Tensor`):
Input query states to be passed to Flash Attention API
key_states (`torch.Tensor`):
Input key states to be passed to Flash Attention API
value_states (`torch.Tensor`):
Input value states to be passed to Flash Attention API
attention_mask (`torch.Tensor`):
The padding mask - corresponds to a tensor of size `(batch_size, seq_len)` where 0 stands for the
position of padding tokens and 1 for the position of non-padding tokens.
dropout (`int`, *optional*):
Attention dropout
softmax_scale (`float`, *optional*):
The scaling of QK^T before applying softmax. Default to 1 / sqrt(head_dim)
"""
if not self._flash_attn_uses_top_left_mask:
causal = self.is_causal
else:
# TODO: Remove the `query_length != 1` check once Flash Attention for RoCm is bumped to 2.1. For details, please see the comment in LlamaFlashAttention2 __init__.
causal = self.is_causal and query_length != 1
# Contains at least one padding token in the sequence
if attention_mask is not None:
batch_size = query_states.shape[0]
query_states, key_states, value_states, indices_q, cu_seq_lens, max_seq_lens = self._upad_input(
query_states, key_states, value_states, attention_mask, query_length
)
cu_seqlens_q, cu_seqlens_k = cu_seq_lens
max_seqlen_in_batch_q, max_seqlen_in_batch_k = max_seq_lens
attn_output_unpad = flash_attn_varlen_func(
query_states,
key_states,
value_states,
cu_seqlens_q=cu_seqlens_q,
cu_seqlens_k=cu_seqlens_k,
max_seqlen_q=max_seqlen_in_batch_q,
max_seqlen_k=max_seqlen_in_batch_k,
dropout_p=dropout,
softmax_scale=softmax_scale,
causal=causal,
)
attn_output = pad_input(attn_output_unpad, indices_q, batch_size, query_length)
else:
attn_output = flash_attn_func(
query_states, key_states, value_states, dropout, softmax_scale=softmax_scale, causal=causal
)
return attn_output
# Copied from transformers.models.llama.modeling_llama.LlamaFlashAttention2._upad_input
def _upad_input(self, query_layer, key_layer, value_layer, attention_mask, query_length):
indices_k, cu_seqlens_k, max_seqlen_in_batch_k = _get_unpad_data(attention_mask)
batch_size, kv_seq_len, num_key_value_heads, head_dim = key_layer.shape
key_layer = index_first_axis(
key_layer.reshape(batch_size * kv_seq_len, num_key_value_heads, head_dim), indices_k
)
value_layer = index_first_axis(
value_layer.reshape(batch_size * kv_seq_len, num_key_value_heads, head_dim), indices_k
)
if query_length == kv_seq_len:
query_layer = index_first_axis(
query_layer.reshape(batch_size * kv_seq_len, self.num_heads, head_dim), indices_k
)
cu_seqlens_q = cu_seqlens_k
max_seqlen_in_batch_q = max_seqlen_in_batch_k
indices_q = indices_k
elif query_length == 1:
max_seqlen_in_batch_q = 1
cu_seqlens_q = torch.arange(
batch_size + 1, dtype=torch.int32, device=query_layer.device
) # There is a memcpy here, that is very bad.
indices_q = cu_seqlens_q[:-1]
query_layer = query_layer.squeeze(1)
else:
# The -q_len: slice assumes left padding.
attention_mask = attention_mask[:, -query_length:]
query_layer, indices_q, cu_seqlens_q, max_seqlen_in_batch_q = unpad_input(query_layer, attention_mask)
return (
query_layer,
key_layer,
value_layer,
indices_q,
(cu_seqlens_q, cu_seqlens_k),
(max_seqlen_in_batch_q, max_seqlen_in_batch_k),
)
class FalconMLP(nn.Module):
def __init__(self, config: FalconConfig):
super().__init__()
hidden_size = config.hidden_size
self.dense_h_to_4h = FalconLinear(hidden_size, 4 * hidden_size, bias=config.bias)
self.act = nn.GELU()
self.dense_4h_to_h = FalconLinear(4 * hidden_size, hidden_size, bias=config.bias)
self.hidden_dropout = config.hidden_dropout
def forward(self, x: torch.Tensor) -> torch.Tensor:
x = self.act(self.dense_h_to_4h(x))
x = self.dense_4h_to_h(x)
return x
FALCON_ATTENTION_CLASSES = {
"eager": FalconAttention,
"sdpa": FalconAttention, # FalconAttention originally implemented both a forward with & without SDPA
"flash_attention_2": FalconFlashAttention2,
}
class FalconDecoderLayer(nn.Module):
def __init__(self, config: FalconConfig):
super().__init__()
hidden_size = config.hidden_size
self.num_heads = config.num_attention_heads
self.self_attention = FALCON_ATTENTION_CLASSES[config._attn_implementation](config)
self.mlp = FalconMLP(config)
self.hidden_dropout = config.hidden_dropout
self.config = config
if config.new_decoder_architecture:
# The layer norm before self-attention
self.ln_attn = LayerNorm(hidden_size, eps=config.layer_norm_epsilon)
# The layer norm before the MLP
self.ln_mlp = LayerNorm(hidden_size, eps=config.layer_norm_epsilon)
else:
self.input_layernorm = LayerNorm(hidden_size, eps=config.layer_norm_epsilon)
if not config.parallel_attn:
self.post_attention_layernorm = LayerNorm(hidden_size, eps=config.layer_norm_epsilon)
def forward(
self,
hidden_states: torch.Tensor,
alibi: Optional[torch.Tensor],
attention_mask: torch.Tensor,
position_ids: Optional[torch.LongTensor] = None,
layer_past: Optional[Tuple[torch.Tensor, torch.Tensor]] = None,
head_mask: Optional[torch.Tensor] = None,
use_cache: bool = False,
output_attentions: bool = False,
**kwargs,
):
if "padding_mask" in kwargs:
warnings.warn(
"Passing `padding_mask` is deprecated and will be removed in v4.37. Please make sure use `attention_mask` instead.`"
)
residual = hidden_states
if self.config.new_decoder_architecture:
attention_layernorm_out = self.ln_attn(hidden_states)
mlp_layernorm_out = self.ln_mlp(hidden_states)
else:
attention_layernorm_out = self.input_layernorm(hidden_states)
# Self attention.
attn_outputs = self.self_attention(
attention_layernorm_out,
layer_past=layer_past,
attention_mask=attention_mask,
position_ids=position_ids,
alibi=alibi,
head_mask=head_mask,
use_cache=use_cache,
output_attentions=output_attentions,
**kwargs,
)
attention_output = attn_outputs[0]
if not self.config.new_decoder_architecture:
if self.config.parallel_attn:
mlp_layernorm_out = attention_layernorm_out
else:
residual = dropout_add(
attention_output, residual, self.config.attention_dropout, training=self.training
)
mlp_layernorm_out = self.post_attention_layernorm(residual)
outputs = attn_outputs[1:]
# MLP.
mlp_output = self.mlp(mlp_layernorm_out)
if self.config.new_decoder_architecture or self.config.parallel_attn:
mlp_output += attention_output
output = dropout_add(mlp_output, residual, self.config.hidden_dropout, training=self.training)
if use_cache:
outputs = (output,) + outputs
else:
outputs = (output,) + outputs[1:]
return outputs # hidden_states, present, attentions
FALCON_START_DOCSTRING = r"""
This model inherits from [`PreTrainedModel`]. Check the superclass documentation for the generic methods the
library implements for all its model (such as downloading or saving, resizing the input embeddings etc.)
This model is also a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) subclass.
Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage
and behavior.
Parameters:
config ([`FalconConfig`]): Model configuration class with all the parameters of the model.
Initializing with a config file does not load the weights associated with the model, only the
configuration. Check out the [`~PreTrainedModel.from_pretrained`] method to load the model weights.
"""
FALCON_INPUTS_DOCSTRING = r"""
Args:
input_ids (`torch.LongTensor` of shape `(batch_size, input_ids_length)`):
`input_ids_length` = `sequence_length` if `past_key_values` is `None` else `past_key_values[0][0].shape[2]`
(`sequence_length` of input past key value states). Indices of input sequence tokens in the vocabulary.
If `past_key_values` is used, only `input_ids` that do not have their past calculated should be passed as
`input_ids`.
Indices can be obtained using [`AutoTokenizer`]. See [`PreTrainedTokenizer.encode`] and
[`PreTrainedTokenizer.__call__`] for details.
[What are input IDs?](../glossary#input-ids)
past_key_values (`Tuple[Tuple[torch.Tensor]]` of length `config.num_hidden_layers`):
Contains precomputed hidden-states (key and values in the attention blocks) as computed by the model (see
`past_key_values` output below). Can be used to speed up sequential decoding. The `input_ids` which have
their past given to this model should not be passed as `input_ids` as they have already been computed.
Each element of `past_key_values` is a tuple (past_key, past_value):
- past_key: [batch_size * num_heads, head_dim, kv_length]
- past_value: [batch_size * num_heads, kv_length, head_dim]
attention_mask (`torch.FloatTensor` of shape `(batch_size, sequence_length)`, *optional*):
Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
[What are attention masks?](../glossary#attention-mask)
position_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
Indices of positions of each input sequence tokens in the position embeddings. Selected in the range `[0,
config.n_positions - 1]`.
[What are position IDs?](../glossary#position-ids)
head_mask (`torch.FloatTensor` of shape `(num_heads,)` or `(num_layers, num_heads)`, *optional*):
Mask to nullify selected heads of the self-attention modules. Mask values selected in `[0, 1]`:
- 1 indicates the head is **not masked**,
- 0 indicates the head is **masked**.
inputs_embeds (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation. This
is useful if you want more control over how to convert `input_ids` indices into associated vectors than the
model's internal embedding lookup matrix.
If `past_key_values` is used, optionally only the last `inputs_embeds` have to be input (see
`past_key_values`).
use_cache (`bool`, *optional*):
If set to `True`, `past_key_values` key value states are returned and can be used to speed up decoding (see
`past_key_values`).
output_attentions (`bool`, *optional*):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
tensors for more detail.
output_hidden_states (`bool`, *optional*):
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
more detail.
return_dict (`bool`, *optional*):
Whether or not to return a [`~file_utils.ModelOutput`] instead of a plain tuple.
"""
class FalconPreTrainedModel(PreTrainedModel):
"""
An abstract class to handle weights initialization and a simple interface for downloading and loading pretrained
models.
"""
config_class = FalconConfig
base_model_prefix = "transformer"
supports_gradient_checkpointing = True
_no_split_modules = ["FalconDecoderLayer"]
_supports_flash_attn_2 = True
_supports_sdpa = True
def __init__(self, *inputs, **kwargs):
super().__init__(*inputs, **kwargs)
def _init_weights(self, module: nn.Module):
"""Initialize the weights."""
if isinstance(module, nn.Linear) or isinstance(module, FalconLinear):
# Slightly different from the TF version which uses truncated_normal for initialization
# cf https://github.com/pytorch/pytorch/pull/5617
module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
if module.bias is not None:
module.bias.data.zero_()
elif isinstance(module, nn.Embedding):
module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
if module.padding_idx is not None:
module.weight.data[module.padding_idx].zero_()
elif isinstance(module, LayerNorm):
module.bias.data.zero_()
module.weight.data.fill_(1.0)
# Adapted from transformers.modeling_utils.PreTrainedModel._check_and_enable_sdpa
@classmethod
def _check_and_enable_sdpa(cls, config, hard_check_only: bool = False) -> "PretrainedConfig":
# NOTE: Falcon supported SDPA from PyTorch 2.0. We keep it like that for backward compatibility (automatically use SDPA for torch>=2.0).
if hard_check_only:
if not is_torch_greater_or_equal_than_2_0:
raise ImportError("PyTorch SDPA requirements in Transformers are not met. Please install torch>=2.0.")
if not is_torch_greater_or_equal_than_2_0:
return config
_is_bettertransformer = getattr(cls, "use_bettertransformer", False)
if _is_bettertransformer:
return config
if not hard_check_only:
config._attn_implementation = "sdpa"
return config
@add_start_docstrings(
"The bare Falcon Model transformer outputting raw hidden-states without any specific head on top.",
FALCON_START_DOCSTRING,
)
class FalconModel(FalconPreTrainedModel):
def __init__(self, config: FalconConfig):
super().__init__(config)
self.embed_dim = config.hidden_size
self.num_heads = config.num_attention_heads
self.use_alibi = config.alibi
# Embedding + LN Embedding
self.word_embeddings = nn.Embedding(config.vocab_size, self.embed_dim)
# Transformer blocks
self.h = nn.ModuleList([FalconDecoderLayer(config) for _ in range(config.num_hidden_layers)])
self._use_flash_attention_2 = config._attn_implementation == "flash_attention_2"
self._use_sdpa = config._attn_implementation == "sdpa"
# Final Layer Norm
self.ln_f = LayerNorm(self.embed_dim, eps=config.layer_norm_epsilon)
self.gradient_checkpointing = False
# Initialize weights and apply final processing
self.post_init()
def get_input_embeddings(self):
return self.word_embeddings
def set_input_embeddings(self, new_embeddings: torch.Tensor):
self.word_embeddings = new_embeddings
@add_start_docstrings_to_model_forward(FALCON_INPUTS_DOCSTRING)
@add_code_sample_docstrings(
checkpoint=_CHECKPOINT_FOR_DOC,
output_type=BaseModelOutputWithPastAndCrossAttentions,
config_class=_CONFIG_FOR_DOC,
)
def forward(
self,
input_ids: Optional[torch.LongTensor] = None,
past_key_values: Optional[Tuple[Tuple[torch.Tensor, torch.Tensor], ...]] = None,
attention_mask: Optional[torch.Tensor] = None,
position_ids: Optional[torch.LongTensor] = None,
head_mask: Optional[torch.LongTensor] = None,
inputs_embeds: Optional[torch.LongTensor] = None,
use_cache: Optional[bool] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
) -> Union[Tuple[torch.Tensor, ...], BaseModelOutputWithPastAndCrossAttentions]:
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
output_hidden_states = (
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
)
use_cache = use_cache if use_cache is not None else self.config.use_cache
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
if input_ids is not None and inputs_embeds is not None:
raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
elif input_ids is not None:
batch_size, seq_length = input_ids.shape
elif inputs_embeds is not None:
batch_size, seq_length, _ = inputs_embeds.shape
else:
raise ValueError("You have to specify either input_ids or inputs_embeds")
if past_key_values is None:
past_key_values = tuple([None] * len(self.h))
if inputs_embeds is None:
inputs_embeds = self.word_embeddings(input_ids)
hidden_states = inputs_embeds
if self.gradient_checkpointing and self.training:
if use_cache:
logger.warning(
"`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`..."
)
use_cache = False
presents = () if use_cache else None
all_self_attentions = () if output_attentions else None
all_hidden_states = () if output_hidden_states else None
# Compute alibi tensor: check build_alibi_tensor documentation
past_key_values_length = 0
if past_key_values[0] is not None:
past_key_values_length = past_key_values[0][0].shape[-2]
if self.use_alibi:
mask = (
torch.ones(
(batch_size, seq_length + past_key_values_length), device=inputs_embeds.device, dtype=torch.long
)
if attention_mask is None
else attention_mask
)
alibi = build_alibi_tensor(mask, self.num_heads, dtype=hidden_states.dtype)
else:
alibi = None
if position_ids is None:
device = input_ids.device if input_ids is not None else inputs_embeds.device
position_ids = torch.arange(
past_key_values_length, seq_length + past_key_values_length, dtype=torch.long, device=device
)
position_ids = position_ids.unsqueeze(0)
if self._use_flash_attention_2:
# 2d mask is passed through the layers
attention_mask = attention_mask if (attention_mask is not None and 0 in attention_mask) else None
elif self._use_sdpa and not output_attentions:
# output_attentions=True can not be supported when using SDPA, and we fall back on
# the manual implementation that requires a 4D causal mask in all cases.
if alibi is None:
attention_mask = _prepare_4d_causal_attention_mask_for_sdpa(
attention_mask,
(batch_size, seq_length),
inputs_embeds,
past_key_values_length,
)
elif head_mask is None:
alibi = alibi.reshape(batch_size, -1, *alibi.shape[1:])
attention_mask_2d = attention_mask
# We don't call _prepare_4d_causal_attention_mask_for_sdpa as we need to mask alibi using the 4D attention_mask untouched.
attention_mask = _prepare_4d_causal_attention_mask(
attention_mask, (batch_size, seq_length), inputs_embeds, past_key_values_length
)
# We take care to integrate alibi bias in the attention_mask here.
if attention_mask_2d is None:
attention_mask = alibi / math.sqrt(self.config.hidden_size // self.num_heads)
else:
attention_mask = torch.masked_fill(
alibi / math.sqrt(self.config.hidden_size // self.num_heads),
attention_mask < -1,
torch.finfo(alibi.dtype).min,
)
# From PyTorch 2.1 onwards, F.scaled_dot_product_attention with the memory-efficient attention backend
# produces nans if sequences are completely unattended in the attention mask. Details: https://github.com/pytorch/pytorch/issues/110213
if seq_length > 1:
attention_mask = AttentionMaskConverter._unmask_unattended(
attention_mask, attention_mask_2d, unmasked_value=0.0
)
else:
# PyTorch SDPA does not support head_mask, we fall back on the eager implementation in this case.
attention_mask = _prepare_4d_causal_attention_mask(
attention_mask, (batch_size, seq_length), inputs_embeds, past_key_values_length
)
else:
# 4d mask is passed through the layers
attention_mask = _prepare_4d_causal_attention_mask(
attention_mask, (batch_size, seq_length), inputs_embeds, past_key_values_length
)
# Prepare head mask if needed
# 1.0 in head_mask indicate we keep the head
# attention_probs has shape batch_size x num_heads x N x N
# head_mask has shape n_layer x batch x num_heads x N x N
head_mask = self.get_head_mask(head_mask, self.config.num_hidden_layers)
for i, (block, layer_past) in enumerate(zip(self.h, past_key_values)):
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
if self.gradient_checkpointing and self.training:
outputs = self._gradient_checkpointing_func(
block.__call__,
hidden_states,
alibi,
attention_mask,
position_ids,
head_mask[i],
layer_past,
use_cache,
output_attentions,
)
else:
outputs = block(
hidden_states,
layer_past=layer_past,
attention_mask=attention_mask,
position_ids=position_ids,
head_mask=head_mask[i],
use_cache=use_cache,
output_attentions=output_attentions,
alibi=alibi,
)
hidden_states = outputs[0]
if use_cache is True:
presents = presents + (outputs[1],)
if output_attentions:
all_self_attentions = all_self_attentions + (outputs[2 if use_cache else 1],)
# Add last hidden state
hidden_states = self.ln_f(hidden_states)
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
if not return_dict:
return tuple(v for v in [hidden_states, presents, all_hidden_states, all_self_attentions] if v is not None)
return BaseModelOutputWithPastAndCrossAttentions(
last_hidden_state=hidden_states,
past_key_values=presents,
hidden_states=all_hidden_states,
attentions=all_self_attentions,
)
@add_start_docstrings(
"The Falcon Model transformer with a language modeling head on top (linear layer with weights tied to the input embeddings).",
FALCON_START_DOCSTRING,
)
class FalconForCausalLM(FalconPreTrainedModel):
_tied_weights_keys = ["lm_head.weight"]
def __init__(self, config: FalconConfig):
super().__init__(config)
self.transformer = FalconModel(config)
self.lm_head = nn.Linear(config.hidden_size, config.vocab_size, bias=False)
# Initialize weights and apply final processing
self.post_init()
def get_output_embeddings(self):
return self.lm_head
def set_output_embeddings(self, new_embeddings: torch.Tensor):
self.lm_head = new_embeddings
def prepare_inputs_for_generation(
self,
input_ids: torch.LongTensor,
past_key_values: Optional[torch.Tensor] = None,
attention_mask: Optional[torch.Tensor] = None,
position_ids: Optional[torch.Tensor] = None,
**kwargs,
) -> dict:
if past_key_values is not None:
past_length = past_key_values[0][0].shape[2]
# Some generation methods already pass only the last input ID
if input_ids.shape[1] > past_length:
remove_prefix_length = past_length
else:
# Default to old behavior: keep only final ID
remove_prefix_length = input_ids.shape[1] - 1
input_ids = input_ids[:, remove_prefix_length:]
# Note: versions of Falcon with alibi do not use position_ids. It is used with RoPE.
if not self.transformer.use_alibi and attention_mask is not None and position_ids is None:
# create position_ids on the fly for batch generation
position_ids = attention_mask.long().cumsum(-1) - 1
position_ids.masked_fill_(attention_mask == 0, 1)
if past_key_values:
position_ids = position_ids[:, -input_ids.shape[1] :]
return {
"input_ids": input_ids,
"position_ids": position_ids,
"past_key_values": past_key_values,
"use_cache": kwargs.get("use_cache"),
"attention_mask": attention_mask,
}
@add_start_docstrings_to_model_forward(FALCON_INPUTS_DOCSTRING)
@add_code_sample_docstrings(
checkpoint=_CHECKPOINT_FOR_DOC,
output_type=CausalLMOutputWithCrossAttentions,
config_class=_CONFIG_FOR_DOC,
)
def forward(
self,
input_ids: Optional[torch.LongTensor] = None,
past_key_values: Optional[Tuple[Tuple[torch.Tensor, torch.Tensor], ...]] = None,
attention_mask: Optional[torch.Tensor] = None,
position_ids: Optional[torch.LongTensor] = None,
head_mask: Optional[torch.Tensor] = None,
inputs_embeds: Optional[torch.Tensor] = None,
labels: Optional[torch.Tensor] = None,
use_cache: Optional[bool] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
) -> Union[Tuple[torch.Tensor], CausalLMOutputWithCrossAttentions]:
r"""
labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
Labels for language modeling. Note that the labels **are shifted** inside the model, i.e. you can set
`labels = input_ids` Indices are selected in `[-100, 0, ..., config.vocab_size]` All labels set to `-100`
are ignored (masked), the loss is only computed for labels in `[0, ..., config.vocab_size]`
"""
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
transformer_outputs = self.transformer(
input_ids,
past_key_values=past_key_values,
attention_mask=attention_mask,
position_ids=position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
use_cache=use_cache,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
hidden_states = transformer_outputs[0]
lm_logits = self.lm_head(hidden_states)
loss = None
if labels is not None:
# Shift so that tokens < n predict n
shift_logits = lm_logits[..., :-1, :].contiguous()
shift_labels = labels[..., 1:].contiguous()
batch_size, seq_length, vocab_size = shift_logits.shape
# Flatten the tokens
loss_fct = CrossEntropyLoss()
loss = loss_fct(
shift_logits.view(batch_size * seq_length, vocab_size), shift_labels.view(batch_size * seq_length)
)
if not return_dict:
output = (lm_logits,) + transformer_outputs[1:]
return ((loss,) + output) if loss is not None else output
return CausalLMOutputWithCrossAttentions(
loss=loss,
logits=lm_logits,
past_key_values=transformer_outputs.past_key_values,
hidden_states=transformer_outputs.hidden_states,
attentions=transformer_outputs.attentions,
)
def _reorder_cache(
self, past: Tuple[Tuple[torch.Tensor, torch.Tensor], ...], beam_idx: torch.LongTensor
) -> Tuple[Tuple[torch.Tensor, torch.Tensor], ...]:
"""
This function is used to re-order the `past_key_values` cache if [`~PreTrainedModel.beam_search`] or
[`~PreTrainedModel.beam_sample`] is called. This is required to match `past_key_values` with the correct
beam_idx at every generation step.
Output shares the same memory storage as `past`.
"""
# Get a copy of `beam_idx` on all the devices where we need those indices.
device_to_beam_idx = {
past_state.device: beam_idx.to(past_state.device) for layer_past in past for past_state in layer_past
}
reordered_past = tuple(
(
layer_past[0].index_select(0, device_to_beam_idx[layer_past[0].device]),
layer_past[1].index_select(0, device_to_beam_idx[layer_past[0].device]),
)
for layer_past in past
)
return reordered_past
@add_start_docstrings(
"""
The Falcon Model transformer with a sequence classification head on top (linear layer).
[`FalconForSequenceClassification`] uses the last token in order to do the classification, as other causal models
(e.g. GPT-1) do.
Since it does classification on the last token, it requires to know the position of the last token. If a
`pad_token_id` is defined in the configuration, it finds the last token that is not a padding token in each row. If
no `pad_token_id` is defined, it simply takes the last value in each row of the batch. Since it cannot guess the
padding tokens when `inputs_embeds` are passed instead of `input_ids`, it does the same (take the last value in
each row of the batch).
""",
FALCON_START_DOCSTRING,
)
class FalconForSequenceClassification(FalconPreTrainedModel):
def __init__(self, config: FalconConfig):
super().__init__(config)
self.num_labels = config.num_labels
self.transformer = FalconModel(config)
self.score = nn.Linear(config.hidden_size, config.num_labels, bias=False)
# Initialize weights and apply final processing
self.post_init()
@add_start_docstrings_to_model_forward(FALCON_INPUTS_DOCSTRING)
@add_code_sample_docstrings(
checkpoint=_CHECKPOINT_FOR_DOC,
output_type=SequenceClassifierOutputWithPast,
config_class=_CONFIG_FOR_DOC,
)
def forward(
self,
input_ids: Optional[torch.LongTensor] = None,
past_key_values: Optional[Tuple[Tuple[torch.Tensor, torch.Tensor], ...]] = None,
attention_mask: Optional[torch.Tensor] = None,
head_mask: Optional[torch.Tensor] = None,
inputs_embeds: Optional[torch.Tensor] = None,
labels: Optional[torch.Tensor] = None,
use_cache: Optional[bool] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
) -> Union[Tuple[torch.Tensor], SequenceClassifierOutputWithPast]:
r"""
labels (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
Labels for computing the sequence classification/regression loss. Indices should be in `[0, ...,
config.num_labels - 1]`. If `config.num_labels == 1` a regression loss is computed (Mean-Square loss), If
`config.num_labels > 1` a classification loss is computed (Cross-Entropy).
"""
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
transformer_outputs = self.transformer(
input_ids,
past_key_values=past_key_values,
attention_mask=attention_mask,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
use_cache=use_cache,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
hidden_states = transformer_outputs[0]
logits = self.score(hidden_states)
if input_ids is not None:
batch_size = input_ids.shape[0]
else:
batch_size = inputs_embeds.shape[0]
if self.config.pad_token_id is None and batch_size != 1:
raise ValueError("Cannot handle batch sizes > 1 if no padding token is defined.")
if self.config.pad_token_id is None:
sequence_lengths = -1
else:
if input_ids is not None:
# if no pad token found, use modulo instead of reverse indexing for ONNX compatibility
sequence_lengths = torch.eq(input_ids, self.config.pad_token_id).int().argmax(-1) - 1
sequence_lengths = sequence_lengths % input_ids.shape[-1]
sequence_lengths = sequence_lengths.to(logits.device)
else:
sequence_lengths = -1
logger.warning(
f"{self.__class__.__name__} will not detect padding tokens in `inputs_embeds`. Results may be "
"unexpected if using padding tokens in conjunction with `inputs_embeds.`"
)
pooled_logits = logits[torch.arange(batch_size, device=logits.device), sequence_lengths]
loss = None
if labels is not None:
if self.config.problem_type is None:
if self.num_labels == 1:
self.config.problem_type = "regression"
elif self.num_labels > 1 and (labels.dtype == torch.long or labels.dtype == torch.int):
self.config.problem_type = "single_label_classification"
else:
self.config.problem_type = "multi_label_classification"
if self.config.problem_type == "regression":
loss_fct = MSELoss()
if self.num_labels == 1:
loss = loss_fct(pooled_logits.squeeze(), labels.squeeze())
else:
loss = loss_fct(pooled_logits, labels)
elif self.config.problem_type == "single_label_classification":
loss_fct = CrossEntropyLoss()
loss = loss_fct(pooled_logits, labels)
elif self.config.problem_type == "multi_label_classification":
loss_fct = BCEWithLogitsLoss()
loss = loss_fct(pooled_logits, labels)
if not return_dict:
output = (pooled_logits,) + transformer_outputs[1:]
return ((loss,) + output) if loss is not None else output
return SequenceClassifierOutputWithPast(
loss=loss,
logits=pooled_logits,
past_key_values=transformer_outputs.past_key_values,
hidden_states=transformer_outputs.hidden_states,
attentions=transformer_outputs.attentions,
)
@add_start_docstrings(
"""
Falcon Model with a token classification head on top (a linear layer on top of the hidden-states output) e.g. for
Named-Entity-Recognition (NER) tasks.
""",
FALCON_START_DOCSTRING,
)
class FalconForTokenClassification(FalconPreTrainedModel):
def __init__(self, config: FalconConfig):
super().__init__(config)
self.num_labels = config.num_labels
self.transformer = FalconModel(config)
if getattr(config, "classifier_dropout", None) is not None:
classifier_dropout = config.classifier_dropout
elif getattr(config, "hidden_dropout", None) is not None:
classifier_dropout = config.hidden_dropout
else:
classifier_dropout = 0.1
self.dropout = nn.Dropout(classifier_dropout)
self.classifier = nn.Linear(config.hidden_size, config.num_labels)
# Initialize weights and apply final processing
self.post_init()
@add_start_docstrings_to_model_forward(FALCON_INPUTS_DOCSTRING)
@add_code_sample_docstrings(
checkpoint=_CHECKPOINT_FOR_DOC,
output_type=TokenClassifierOutput,
config_class=_CONFIG_FOR_DOC,
)
def forward(
self,
input_ids: Optional[torch.LongTensor] = None,
past_key_values: Optional[Tuple[Tuple[torch.Tensor, torch.Tensor], ...]] = None,
attention_mask: Optional[torch.Tensor] = None,
head_mask: Optional[torch.Tensor] = None,
inputs_embeds: Optional[torch.Tensor] = None,
labels: Optional[torch.Tensor] = None,
use_cache: Optional[bool] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
) -> Union[Tuple[torch.Tensor], TokenClassifierOutput]:
r"""
labels (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
Labels for computing the sequence classification/regression loss. Indices should be in `[0, ...,
config.num_labels - 1]`. If `config.num_labels == 1` a regression loss is computed (Mean-Square loss), If
`config.num_labels > 1` a classification loss is computed (Cross-Entropy).
"""
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
transformer_outputs = self.transformer(
input_ids,
past_key_values=past_key_values,
attention_mask=attention_mask,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
use_cache=use_cache,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
hidden_states = transformer_outputs[0]
hidden_states = self.dropout(hidden_states)
logits = self.classifier(hidden_states)
loss = None
if labels is not None:
batch_size, seq_length = labels.shape
loss_fct = CrossEntropyLoss()
loss = loss_fct(
logits.view(batch_size * seq_length, self.num_labels), labels.view(batch_size * seq_length)
)
if not return_dict:
output = (logits,) + transformer_outputs[2:]
return ((loss,) + output) if loss is not None else output
return TokenClassifierOutput(
loss=loss,
logits=logits,
hidden_states=transformer_outputs.hidden_states,
attentions=transformer_outputs.attentions,
)
@add_start_docstrings(
"""
The Falcon Model transformer with a span classification head on top for extractive question-answering tasks like
SQuAD (a linear layers on top of the hidden-states output to compute `span start logits` and `span end logits`).
""",
FALCON_START_DOCSTRING,
)
class FalconForQuestionAnswering(FalconPreTrainedModel):
def __init__(self, config):
super().__init__(config)
self.transformer = FalconModel(config)
self.qa_outputs = nn.Linear(config.hidden_size, 2)
# Initialize weights and apply final processing
self.post_init()
@add_start_docstrings_to_model_forward(FALCON_INPUTS_DOCSTRING)
def forward(
self,
input_ids: Optional[torch.LongTensor] = None,
attention_mask: Optional[torch.FloatTensor] = None,
head_mask: Optional[torch.FloatTensor] = None,
inputs_embeds: Optional[torch.FloatTensor] = None,
start_positions: Optional[torch.LongTensor] = None,
end_positions: Optional[torch.LongTensor] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
) -> Union[Tuple, QuestionAnsweringModelOutput]:
r"""
start_positions (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
Labels for position (index) of the start of the labelled span for computing the token classification loss.
Positions are clamped to the length of the sequence (`sequence_length`). Position outside of the sequence
are not taken into account for computing the loss.
end_positions (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
Labels for position (index) of the end of the labelled span for computing the token classification loss.
Positions are clamped to the length of the sequence (`sequence_length`). Position outside of the sequence
are not taken into account for computing the loss.
"""
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
outputs = self.transformer(
input_ids,
attention_mask=attention_mask,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
sequence_output = outputs[0]
logits = self.qa_outputs(sequence_output)
start_logits, end_logits = logits.split(1, dim=-1)
start_logits = start_logits.squeeze(-1).contiguous()
end_logits = end_logits.squeeze(-1).contiguous()
total_loss = None
if start_positions is not None and end_positions is not None:
# If we are on multi-GPU, split add a dimension
if len(start_positions.size()) > 1:
start_positions = start_positions.squeeze(-1)
if len(end_positions.size()) > 1:
end_positions = end_positions.squeeze(-1)
# sometimes the start/end positions are outside our model inputs, we ignore these terms
ignored_index = start_logits.size(1)
start_positions = start_positions.clamp(0, ignored_index)
end_positions = end_positions.clamp(0, ignored_index)
loss_fct = CrossEntropyLoss(ignore_index=ignored_index)
start_loss = loss_fct(start_logits, start_positions)
end_loss = loss_fct(end_logits, end_positions)
total_loss = (start_loss + end_loss) / 2
if not return_dict:
output = (start_logits, end_logits) + outputs[2:]
return ((total_loss,) + output) if total_loss is not None else output
return QuestionAnsweringModelOutput(
loss=total_loss,
start_logits=start_logits,
end_logits=end_logits,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
)
| transformers/src/transformers/models/falcon/modeling_falcon.py/0 | {
"file_path": "transformers/src/transformers/models/falcon/modeling_falcon.py",
"repo_id": "transformers",
"token_count": 33559
} | 92 |
# coding=utf-8
# Copyright 2022 Meta Platforms authors and The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import argparse
import os
import torch
from transformers import FlavaConfig, FlavaForPreTraining
from transformers.models.flava.convert_dalle_to_flava_codebook import convert_dalle_checkpoint
def count_parameters(state_dict):
# encoder.embeddings are double copied in original FLAVA
return sum(param.float().sum() if "encoder.embeddings" not in key else 0 for key, param in state_dict.items())
def upgrade_state_dict(state_dict, codebook_state_dict):
upgrade = {}
for key, value in state_dict.items():
if "text_encoder.embeddings" in key or "image_encoder.embeddings" in key:
continue
key = key.replace("heads.cmd.mim_head.cls.predictions", "mmm_image_head")
key = key.replace("heads.cmd.mlm_head.cls.predictions", "mmm_text_head")
key = key.replace("heads.cmd.itm_head.cls", "itm_head")
key = key.replace("heads.cmd.itm_head.pooler", "itm_head.pooler")
key = key.replace("heads.cmd.clip_head.logit_scale", "flava.logit_scale")
key = key.replace("heads.fairseq_mlm.cls.predictions", "mlm_head")
key = key.replace("heads.imagenet.mim_head.cls.predictions", "mim_head")
key = key.replace("mm_text_projection", "flava.text_to_mm_projection")
key = key.replace("mm_image_projection", "flava.image_to_mm_projection")
key = key.replace("image_encoder.module", "flava.image_model")
key = key.replace("text_encoder.module", "flava.text_model")
key = key.replace("mm_encoder.module.encoder.cls_token", "flava.multimodal_model.cls_token")
key = key.replace("mm_encoder.module", "flava.multimodal_model")
key = key.replace("text_projection", "flava.text_projection")
key = key.replace("image_projection", "flava.image_projection")
upgrade[key] = value.float()
for key, value in codebook_state_dict.items():
upgrade[f"image_codebook.{key}"] = value
return upgrade
@torch.no_grad()
def convert_flava_checkpoint(checkpoint_path, codebook_path, pytorch_dump_folder_path, config_path=None):
"""
Copy/paste/tweak model's weights to transformers design.
"""
if config_path is not None:
config = FlavaConfig.from_pretrained(config_path)
else:
config = FlavaConfig()
hf_model = FlavaForPreTraining(config).eval()
codebook_state_dict = convert_dalle_checkpoint(codebook_path, None, save_checkpoint=False)
if os.path.exists(checkpoint_path):
state_dict = torch.load(checkpoint_path, map_location="cpu")
else:
state_dict = torch.hub.load_state_dict_from_url(checkpoint_path, map_location="cpu")
hf_state_dict = upgrade_state_dict(state_dict, codebook_state_dict)
hf_model.load_state_dict(hf_state_dict)
hf_state_dict = hf_model.state_dict()
hf_count = count_parameters(hf_state_dict)
state_dict_count = count_parameters(state_dict) + count_parameters(codebook_state_dict)
assert torch.allclose(hf_count, state_dict_count, atol=1e-3)
hf_model.save_pretrained(pytorch_dump_folder_path)
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--pytorch_dump_folder_path", default=None, type=str, help="Path to the output PyTorch model.")
parser.add_argument("--checkpoint_path", default=None, type=str, help="Path to flava checkpoint")
parser.add_argument("--codebook_path", default=None, type=str, help="Path to flava codebook checkpoint")
parser.add_argument("--config_path", default=None, type=str, help="Path to hf config.json of model to convert")
args = parser.parse_args()
convert_flava_checkpoint(args.checkpoint_path, args.codebook_path, args.pytorch_dump_folder_path, args.config_path)
| transformers/src/transformers/models/flava/convert_flava_original_pytorch_to_hf.py/0 | {
"file_path": "transformers/src/transformers/models/flava/convert_flava_original_pytorch_to_hf.py",
"repo_id": "transformers",
"token_count": 1622
} | 93 |
# coding=utf-8
# Copyright 2019-present, Facebook, Inc and the HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
""" FSMT configuration"""
from ...configuration_utils import PretrainedConfig
from ...utils import logging
logger = logging.get_logger(__name__)
FSMT_PRETRAINED_CONFIG_ARCHIVE_MAP = {}
class DecoderConfig(PretrainedConfig):
r"""
Configuration class for FSMT's decoder specific things. note: this is a private helper class
"""
model_type = "fsmt_decoder"
def __init__(self, vocab_size=0, bos_token_id=0):
super().__init__()
self.vocab_size = vocab_size
self.bos_token_id = bos_token_id
class FSMTConfig(PretrainedConfig):
r"""
This is the configuration class to store the configuration of a [`FSMTModel`]. It is used to instantiate a FSMT
model according to the specified arguments, defining the model architecture. Instantiating a configuration with the
defaults will yield a similar configuration to that of the FSMT
[facebook/wmt19-en-ru](https://huggingface.co/facebook/wmt19-en-ru) architecture.
Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
documentation from [`PretrainedConfig`] for more information.
Args:
langs (`List[str]`):
A list with source language and target_language (e.g., ['en', 'ru']).
src_vocab_size (`int`):
Vocabulary size of the encoder. Defines the number of different tokens that can be represented by the
`inputs_ids` passed to the forward method in the encoder.
tgt_vocab_size (`int`):
Vocabulary size of the decoder. Defines the number of different tokens that can be represented by the
`inputs_ids` passed to the forward method in the decoder.
d_model (`int`, *optional*, defaults to 1024):
Dimensionality of the layers and the pooler layer.
encoder_layers (`int`, *optional*, defaults to 12):
Number of encoder layers.
decoder_layers (`int`, *optional*, defaults to 12):
Number of decoder layers.
encoder_attention_heads (`int`, *optional*, defaults to 16):
Number of attention heads for each attention layer in the Transformer encoder.
decoder_attention_heads (`int`, *optional*, defaults to 16):
Number of attention heads for each attention layer in the Transformer decoder.
decoder_ffn_dim (`int`, *optional*, defaults to 4096):
Dimensionality of the "intermediate" (often named feed-forward) layer in decoder.
encoder_ffn_dim (`int`, *optional*, defaults to 4096):
Dimensionality of the "intermediate" (often named feed-forward) layer in decoder.
activation_function (`str` or `Callable`, *optional*, defaults to `"relu"`):
The non-linear activation function (function or string) in the encoder and pooler. If string, `"gelu"`,
`"relu"`, `"silu"` and `"gelu_new"` are supported.
dropout (`float`, *optional*, defaults to 0.1):
The dropout probability for all fully connected layers in the embeddings, encoder, and pooler.
attention_dropout (`float`, *optional*, defaults to 0.0):
The dropout ratio for the attention probabilities.
activation_dropout (`float`, *optional*, defaults to 0.0):
The dropout ratio for activations inside the fully connected layer.
max_position_embeddings (`int`, *optional*, defaults to 1024):
The maximum sequence length that this model might ever be used with. Typically set this to something large
just in case (e.g., 512 or 1024 or 2048).
init_std (`float`, *optional*, defaults to 0.02):
The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
scale_embedding (`bool`, *optional*, defaults to `True`):
Scale embeddings by diving by sqrt(d_model).
bos_token_id (`int`, *optional*, defaults to 0)
Beginning of stream token id.
pad_token_id (`int`, *optional*, defaults to 1)
Padding token id.
eos_token_id (`int`, *optional*, defaults to 2)
End of stream token id.
decoder_start_token_id (`int`, *optional*):
This model starts decoding with `eos_token_id`
encoder_layerdrop (`float`, *optional*, defaults to 0.0):
Google "layerdrop arxiv", as its not explainable in one line.
decoder_layerdrop (`float`, *optional*, defaults to 0.0):
Google "layerdrop arxiv", as its not explainable in one line.
is_encoder_decoder (`bool`, *optional*, defaults to `True`):
Whether this is an encoder/decoder model.
tie_word_embeddings (`bool`, *optional*, defaults to `False`):
Whether to tie input and output embeddings.
num_beams (`int`, *optional*, defaults to 5)
Number of beams for beam search that will be used by default in the `generate` method of the model. 1 means
no beam search.
length_penalty (`float`, *optional*, defaults to 1)
Exponential penalty to the length that is used with beam-based generation. It is applied as an exponent to
the sequence length, which in turn is used to divide the score of the sequence. Since the score is the log
likelihood of the sequence (i.e. negative), `length_penalty` > 0.0 promotes longer sequences, while
`length_penalty` < 0.0 encourages shorter sequences.
early_stopping (`bool`, *optional*, defaults to `False`)
Flag that will be used by default in the `generate` method of the model. Whether to stop the beam search
when at least `num_beams` sentences are finished per batch or not.
use_cache (`bool`, *optional*, defaults to `True`):
Whether or not the model should return the last key/values attentions (not used by all models).
forced_eos_token_id (`int`, *optional*, defaults to 2):
The id of the token to force as the last generated token when `max_length` is reached. Usually set to
`eos_token_id`.
Examples:
```python
>>> from transformers import FSMTConfig, FSMTModel
>>> # Initializing a FSMT facebook/wmt19-en-ru style configuration
>>> config = FSMTConfig()
>>> # Initializing a model (with random weights) from the configuration
>>> model = FSMTModel(config)
>>> # Accessing the model configuration
>>> configuration = model.config
```"""
model_type = "fsmt"
attribute_map = {"num_attention_heads": "encoder_attention_heads", "hidden_size": "d_model"}
# update the defaults from config file
def __init__(
self,
langs=["en", "de"],
src_vocab_size=42024,
tgt_vocab_size=42024,
activation_function="relu",
d_model=1024,
max_length=200,
max_position_embeddings=1024,
encoder_ffn_dim=4096,
encoder_layers=12,
encoder_attention_heads=16,
encoder_layerdrop=0.0,
decoder_ffn_dim=4096,
decoder_layers=12,
decoder_attention_heads=16,
decoder_layerdrop=0.0,
attention_dropout=0.0,
dropout=0.1,
activation_dropout=0.0,
init_std=0.02,
decoder_start_token_id=2,
is_encoder_decoder=True,
scale_embedding=True,
tie_word_embeddings=False,
num_beams=5,
length_penalty=1.0,
early_stopping=False,
use_cache=True,
pad_token_id=1,
bos_token_id=0,
eos_token_id=2,
forced_eos_token_id=2,
**common_kwargs,
):
self.langs = langs
self.src_vocab_size = src_vocab_size
self.tgt_vocab_size = tgt_vocab_size
self.d_model = d_model # encoder_embed_dim and decoder_embed_dim
self.encoder_ffn_dim = encoder_ffn_dim
self.encoder_layers = self.num_hidden_layers = encoder_layers
self.encoder_attention_heads = encoder_attention_heads
self.encoder_layerdrop = encoder_layerdrop
self.decoder_layerdrop = decoder_layerdrop
self.decoder_ffn_dim = decoder_ffn_dim
self.decoder_layers = decoder_layers
self.decoder_attention_heads = decoder_attention_heads
self.max_position_embeddings = max_position_embeddings
self.init_std = init_std # Normal(0, this parameter)
self.activation_function = activation_function
self.decoder = DecoderConfig(vocab_size=tgt_vocab_size, bos_token_id=eos_token_id)
if "decoder" in common_kwargs:
del common_kwargs["decoder"]
self.scale_embedding = scale_embedding # scale factor will be sqrt(d_model) if True
# 3 Types of Dropout
self.attention_dropout = attention_dropout
self.activation_dropout = activation_dropout
self.dropout = dropout
self.use_cache = use_cache
super().__init__(
pad_token_id=pad_token_id,
bos_token_id=bos_token_id,
eos_token_id=eos_token_id,
decoder_start_token_id=decoder_start_token_id,
is_encoder_decoder=is_encoder_decoder,
tie_word_embeddings=tie_word_embeddings,
forced_eos_token_id=forced_eos_token_id,
max_length=max_length,
num_beams=num_beams,
length_penalty=length_penalty,
early_stopping=early_stopping,
**common_kwargs,
)
| transformers/src/transformers/models/fsmt/configuration_fsmt.py/0 | {
"file_path": "transformers/src/transformers/models/fsmt/configuration_fsmt.py",
"repo_id": "transformers",
"token_count": 4031
} | 94 |
# coding=utf-8
# Copyright 2023 The HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""
Image/Text processor class for GIT
"""
import re
from typing import Dict, List, Optional, Tuple, Union
import numpy as np
from ...processing_utils import ProcessorMixin
from ...tokenization_utils_base import PaddingStrategy, TruncationStrategy
from ...utils import TensorType, is_torch_available, logging, requires_backends
if is_torch_available():
from .image_processing_fuyu import FuyuBatchFeature
logger = logging.get_logger(__name__)
if is_torch_available():
import torch
TEXT_REPR_BBOX_OPEN = "<box>"
TEXT_REPR_BBOX_CLOSE = "</box>"
TEXT_REPR_POINT_OPEN = "<point>"
TEXT_REPR_POINT_CLOSE = "</point>"
TOKEN_BBOX_OPEN_STRING = "<0x00>" # <bbox>
TOKEN_BBOX_CLOSE_STRING = "<0x01>" # </bbox>
TOKEN_POINT_OPEN_STRING = "<0x02>" # <point>
TOKEN_POINT_CLOSE_STRING = "<0x03>" # </point>
BEGINNING_OF_ANSWER_STRING = "<0x04>" # <boa>
def full_unpacked_stream_to_tensor(
all_bi_tokens_to_place: List[int],
full_unpacked_stream: List["torch.Tensor"],
fill_value: int,
batch_size: int,
new_seq_len: int,
offset: int,
) -> "torch.Tensor":
"""Takes an unpacked stream of tokens (i.e. a list of tensors, one for each item in the batch) and does
the required padding to create a single tensor for the batch of shape batch_size x new_seq_len.
"""
assert len(all_bi_tokens_to_place) == batch_size
assert len(full_unpacked_stream) == batch_size
# Create padded tensors for the full batch.
new_padded_tensor = torch.full(
[batch_size, new_seq_len],
fill_value=fill_value,
dtype=full_unpacked_stream[0].dtype,
device=full_unpacked_stream[0].device,
)
# Place each batch entry into the batch tensor.
for bi in range(batch_size):
tokens_to_place = all_bi_tokens_to_place[bi]
new_padded_tensor[bi, :tokens_to_place] = full_unpacked_stream[bi][offset : tokens_to_place + offset]
return new_padded_tensor
def construct_full_unpacked_stream(
num_real_text_tokens: Union[List[List[int]], "torch.Tensor"],
input_stream: "torch.Tensor",
image_tokens: List[List["torch.Tensor"]],
batch_size: int,
num_sub_sequences: int,
) -> List["torch.Tensor"]:
"""Takes an input_stream tensor of shape B x S x ?. For each subsequence, adds any required
padding to account for images and then unpacks the subsequences to create a single sequence per item in the batch.
Returns a list of tensors, one for each item in the batch."""
all_bi_stream = []
for batch_index in range(batch_size):
all_si_stream = []
# First, construct full token stream (including image placeholder tokens) and loss mask for each subsequence
# and append to lists. We use lists rather than tensors because each subsequence is variable-sized.
# TODO Remove this logic in a subsequent release since subsequences are not supported.
image_adjustment = image_tokens[batch_index][0]
subsequence_stream = torch.cat([image_adjustment, input_stream[batch_index, 0]], dim=0)
num_real_tokens = image_adjustment.shape[0] + num_real_text_tokens[batch_index][0]
all_si_stream.append(subsequence_stream[:num_real_tokens])
all_bi_stream.append(torch.cat(all_si_stream, dim=0))
return all_bi_stream
def _replace_string_repr_with_token_tags(prompt: str) -> str:
prompt = prompt.replace(TEXT_REPR_POINT_OPEN, TOKEN_POINT_OPEN_STRING)
prompt = prompt.replace(TEXT_REPR_POINT_CLOSE, TOKEN_POINT_CLOSE_STRING)
prompt = prompt.replace(TEXT_REPR_BBOX_OPEN, TOKEN_BBOX_OPEN_STRING)
prompt = prompt.replace(TEXT_REPR_BBOX_CLOSE, TOKEN_BBOX_CLOSE_STRING)
return prompt
def _segment_prompt_into_text_token_conversions(prompt: str) -> List:
"""
Given a string prompt, converts the prompt into a list of TextTokenConversions.
"""
# Wherever, we notice the [TOKEN_OPEN_STRING, TOKEN_CLOSE_STRING], we split the prompt
prompt_text_list: List = []
regex_pattern = re.compile(
f"({TOKEN_BBOX_OPEN_STRING}|{TOKEN_BBOX_CLOSE_STRING}|{TOKEN_POINT_OPEN_STRING}|{TOKEN_POINT_CLOSE_STRING})"
)
# Split by the regex pattern
prompt_split = regex_pattern.split(prompt)
for i, elem in enumerate(prompt_split):
if len(elem) == 0 or elem in [
TOKEN_BBOX_OPEN_STRING,
TOKEN_BBOX_CLOSE_STRING,
TOKEN_POINT_OPEN_STRING,
TOKEN_POINT_CLOSE_STRING,
]:
continue
prompt_text_list.append(
(elem, i > 1 and prompt_split[i - 1] in [TOKEN_BBOX_OPEN_STRING, TOKEN_POINT_OPEN_STRING])
)
return prompt_text_list
def _transform_coordinates_and_tokenize(prompt: str, scale_factor: float, tokenizer) -> List[int]:
"""
This function transforms the prompt in the following fashion:
- <box> <point> and </box> </point> to their respective token mappings
- extract the coordinates from the tag
- transform the coordinates into the transformed image space
- return the prompt tokens with the transformed coordinates and new tags
Bounding boxes and points MUST be in the following format: <box>y1, x1, y2, x2</box> <point>x, y</point> The spaces
and punctuation added above are NOT optional.
"""
# Make a namedtuple that stores "text" and "is_bbox"
# We want to do the following: Tokenize the code normally -> when we see a point or box, tokenize using the tokenize_within_tag function
# When point or box close tag, continue tokenizing normally
# First, we replace the point and box tags with their respective tokens
prompt = _replace_string_repr_with_token_tags(prompt)
# Tokenize the prompt
# Convert prompt into a list split
prompt_text_list = _segment_prompt_into_text_token_conversions(prompt)
transformed_prompt_tokens: List[int] = []
for elem in prompt_text_list:
if elem[1]:
# This is a location, we need to tokenize it
within_tag_tokenized = _transform_within_tags(elem[0], scale_factor, tokenizer)
# Surround the text with the open and close tags
transformed_prompt_tokens.extend(within_tag_tokenized)
else:
transformed_prompt_tokens.extend(tokenizer(elem[0], add_special_tokens=False).input_ids)
return transformed_prompt_tokens
def _transform_within_tags(text: str, scale_factor: float, tokenizer) -> List[int]:
"""
Given a bounding box of the fashion <box>1, 2, 3, 4</box> | <point>1, 2</point> This function is responsible for
converting 1, 2, 3, 4 into tokens of 1 2 3 4 without any commas.
"""
# Convert the text into a list of strings.
num_int_strs = text.split(",")
if len(num_int_strs) == 2:
# If there are any open or close tags, remove them.
token_space_open_string = tokenizer.vocab[TOKEN_POINT_OPEN_STRING]
token_space_close_string = tokenizer.vocab[TOKEN_POINT_CLOSE_STRING]
else:
token_space_open_string = tokenizer.vocab[TOKEN_BBOX_OPEN_STRING]
token_space_close_string = tokenizer.vocab[TOKEN_BBOX_CLOSE_STRING]
# Remove all spaces from num_ints
num_ints = [float(num.strip()) for num in num_int_strs]
# scale to transformed image siz
if len(num_ints) == 2:
num_ints_translated = scale_point_to_transformed_image(x=num_ints[0], y=num_ints[1], scale_factor=scale_factor)
elif len(num_ints) == 4:
num_ints_translated = scale_bbox_to_transformed_image(
top=num_ints[0],
left=num_ints[1],
bottom=num_ints[2],
right=num_ints[3],
scale_factor=scale_factor,
)
else:
raise ValueError(f"Invalid number of ints: {len(num_ints)}")
# Tokenize the text, skipping the
tokens = [tokenizer.vocab[str(num)] for num in num_ints_translated]
return [token_space_open_string] + tokens + [token_space_close_string]
def _tokenize_prompts_with_image_and_batch(
tokenizer,
prompts: List[List[str]],
scale_factors: Optional[List[List["torch.Tensor"]]],
max_tokens_to_generate: int,
max_position_embeddings: int,
add_BOS: bool, # Same issue with types as above
add_beginning_of_answer_token: bool,
) -> Tuple["torch.Tensor", "torch.Tensor"]:
"""
Given a set of prompts and number of tokens to generate:
- tokenize prompts
- set the sequence length to be the max of length of prompts plus the number of tokens we would like to generate
- pad all the sequences to this length so we can convert them into a 3D tensor.
"""
# If not tool use, tranform the coordinates while tokenizing
if scale_factors is not None:
transformed_prompt_tokens = []
for prompt_seq, scale_factor_seq in zip(prompts, scale_factors):
transformed_prompt_tokens.append(
[
_transform_coordinates_and_tokenize(prompt, scale_factor.item(), tokenizer)
for prompt, scale_factor in zip(prompt_seq, scale_factor_seq)
]
)
else:
transformed_prompt_tokens = [[tokenizer.tokenize(prompt) for prompt in prompt_seq] for prompt_seq in prompts]
prompts_tokens = transformed_prompt_tokens
if add_BOS:
bos_token = tokenizer.vocab["<s>"]
else:
bos_token = tokenizer.vocab["|ENDOFTEXT|"]
prompts_tokens = [[[bos_token] + x for x in prompt_seq] for prompt_seq in prompts_tokens]
if add_beginning_of_answer_token:
boa = tokenizer.vocab[BEGINNING_OF_ANSWER_STRING]
# Only add bbox open token to the last subsequence since that is what will be completed
for token_seq in prompts_tokens:
token_seq[-1].append(boa)
# Now we have a list of list of tokens which each list has a different
# size. We want to extend this list to:
# - incorporate the tokens that need to be generated
# - make all the sequences equal length.
# Get the prompts length.
prompts_length = [[len(x) for x in prompts_tokens_seq] for prompts_tokens_seq in prompts_tokens]
# Get the max prompts length.
max_prompt_len: int = np.max(prompts_length)
# Number of tokens in the each sample of the batch.
samples_length = min(max_prompt_len + max_tokens_to_generate, max_position_embeddings)
if max_prompt_len + max_tokens_to_generate > max_position_embeddings:
logger.warning(
f"Max subsequence prompt length of {max_prompt_len} + max tokens to generate {max_tokens_to_generate}",
f"exceeds context length of {max_position_embeddings}. Will generate as many tokens as possible.",
)
# Now update the list of list to be of the same size: samples_length.
for prompt_tokens_seq, prompts_length_seq in zip(prompts_tokens, prompts_length):
for prompt_tokens, prompt_length in zip(prompt_tokens_seq, prompts_length_seq):
if len(prompt_tokens) > samples_length:
raise ValueError("Length of subsequence prompt exceeds sequence length.")
padding_size = samples_length - prompt_length
prompt_tokens.extend([tokenizer.vocab["|ENDOFTEXT|"]] * padding_size)
# Now we are in a structured format, we can convert to tensors.
prompts_tokens_tensor = torch.tensor(prompts_tokens, dtype=torch.int64)
prompts_length_tensor = torch.tensor(prompts_length, dtype=torch.int64)
return prompts_tokens_tensor, prompts_length_tensor
# Simplified assuming self.crop_top = self.padding_top = 0
def original_to_transformed_h_coords(original_coords, scale_h):
return np.round(original_coords * scale_h).astype(np.int32)
# Simplified assuming self.crop_left = self.padding_left = 0
def original_to_transformed_w_coords(original_coords, scale_w):
return np.round(original_coords * scale_w).astype(np.int32)
def scale_point_to_transformed_image(x: float, y: float, scale_factor: float) -> List[int]:
x_scaled = original_to_transformed_w_coords(np.array([x / 2]), scale_factor)[0]
y_scaled = original_to_transformed_h_coords(np.array([y / 2]), scale_factor)[0]
return [x_scaled, y_scaled]
def scale_bbox_to_transformed_image(
top: float, left: float, bottom: float, right: float, scale_factor: float
) -> List[int]:
top_scaled = original_to_transformed_w_coords(np.array([top / 2]), scale_factor)[0]
left_scaled = original_to_transformed_h_coords(np.array([left / 2]), scale_factor)[0]
bottom_scaled = original_to_transformed_w_coords(np.array([bottom / 2]), scale_factor)[0]
right_scaled = original_to_transformed_h_coords(np.array([right / 2]), scale_factor)[0]
return [top_scaled, left_scaled, bottom_scaled, right_scaled]
class FuyuProcessor(ProcessorMixin):
r"""
Constructs a Fuyu processor which wraps a Fuyu image processor and a Llama tokenizer into a single processor.
[`FuyuProcessor`] offers all the functionalities of [`FuyuImageProcessor`] and [`LlamaTokenizerFast`]. See the
[`~FuyuProcessor.__call__`] and [`~FuyuProcessor.decode`] for more information.
Args:
image_processor ([`FuyuImageProcessor`]):
The image processor is a required input.
tokenizer ([`LlamaTokenizerFast`]):
The tokenizer is a required input.
"""
attributes = ["image_processor", "tokenizer"]
image_processor_class = "FuyuImageProcessor"
tokenizer_class = "AutoTokenizer"
def __init__(self, image_processor, tokenizer):
super().__init__(image_processor=image_processor, tokenizer=tokenizer)
self.image_processor = image_processor
self.tokenizer = tokenizer
self.max_tokens_to_generate = 10
self.max_position_embeddings = 16384 # TODO Can't derive this from model files: where to set it?
self.pad_token_id = 0
self.dummy_image_index = -1
def _left_pad_inputs_with_attention_mask(self, model_inputs: List[Dict], return_attention_mask: bool):
max_length_input_ids = max(entry["input_ids"].shape[1] for entry in model_inputs)
max_length_image_patch_indices = max(entry["image_patches_indices"].shape[1] for entry in model_inputs)
batched_inputs = {"input_ids": [], "image_patches": [], "image_patches_indices": [], "attention_mask": []}
for entry in model_inputs:
for key, tensor in entry.items():
if key == "input_ids":
num_padding_tokens = max_length_input_ids - tensor.shape[1]
padded_input_ids = torch.cat(
[
torch.full((tensor.shape[0], num_padding_tokens), self.pad_token_id, dtype=torch.long),
tensor,
],
dim=1,
)
batched_inputs[key].append(padded_input_ids)
attention_mask = torch.cat(
[torch.zeros(tensor.shape[0], num_padding_tokens, dtype=torch.long), torch.ones_like(tensor)],
dim=1,
)
batched_inputs["attention_mask"].append(attention_mask)
elif key == "image_patches":
# For image_patches, we don't pad but just append them to the list.
batched_inputs[key].append(tensor)
else: # for image_patches_indices
num_padding_indices = max_length_image_patch_indices - tensor.shape[1]
padded_indices = torch.cat(
[
torch.full(
(tensor.shape[0], num_padding_indices), self.dummy_image_index, dtype=torch.long
),
tensor,
],
dim=1,
)
batched_inputs[key].append(padded_indices)
batched_keys = ["input_ids", "image_patches_indices"]
if return_attention_mask:
batched_keys.append("attention_mask")
for key in batched_keys:
batched_inputs[key] = torch.cat(batched_inputs[key], dim=0)
return batched_inputs
def get_sample_encoding(
self,
prompts,
scale_factors,
image_unpadded_heights,
image_unpadded_widths,
image_placeholder_id,
image_newline_id,
tensor_batch_images,
):
image_present = torch.ones(1, 1, 1)
model_image_input = self.image_processor.preprocess_with_tokenizer_info(
image_input=tensor_batch_images,
image_present=image_present,
image_unpadded_h=image_unpadded_heights,
image_unpadded_w=image_unpadded_widths,
image_placeholder_id=image_placeholder_id,
image_newline_id=image_newline_id,
variable_sized=True,
)
# FIXME max_tokens_to_generate is embedded into this processor's call.
prompt_tokens, prompts_length = _tokenize_prompts_with_image_and_batch(
tokenizer=self.tokenizer,
prompts=prompts,
scale_factors=scale_factors,
max_tokens_to_generate=self.max_tokens_to_generate,
max_position_embeddings=self.max_position_embeddings,
add_BOS=True,
add_beginning_of_answer_token=True,
)
image_padded_unpacked_tokens = construct_full_unpacked_stream(
num_real_text_tokens=prompts_length,
input_stream=prompt_tokens,
image_tokens=model_image_input["image_input_ids"],
batch_size=1,
num_sub_sequences=self.subsequence_length,
)
# Construct inputs for image patch indices.
unpacked_image_patch_indices_per_batch = construct_full_unpacked_stream(
num_real_text_tokens=prompts_length,
input_stream=torch.full_like(prompt_tokens, -1),
image_tokens=model_image_input["image_patch_indices_per_batch"],
batch_size=1,
num_sub_sequences=self.subsequence_length,
)
max_prompt_length = max(x.shape[-1] for x in image_padded_unpacked_tokens)
max_seq_len_batch = min(max_prompt_length + self.max_tokens_to_generate, self.max_position_embeddings)
tokens_to_place = min(max_seq_len_batch, max(0, image_padded_unpacked_tokens[0].shape[0]))
# Use same packing logic for the image patch indices.
image_patch_input_indices = full_unpacked_stream_to_tensor(
all_bi_tokens_to_place=[tokens_to_place],
full_unpacked_stream=unpacked_image_patch_indices_per_batch,
fill_value=-1,
batch_size=1,
new_seq_len=max_seq_len_batch,
offset=0,
)
image_patches_tensor = torch.stack([img[0] for img in model_image_input["image_patches"]])
batch_encoding = {
"input_ids": image_padded_unpacked_tokens[0].unsqueeze(0),
"image_patches": image_patches_tensor,
"image_patches_indices": image_patch_input_indices,
}
return batch_encoding
def __call__(
self,
text=None,
images=None,
add_special_tokens: bool = True,
return_attention_mask: bool = True,
padding: Union[bool, str, PaddingStrategy] = False,
truncation: Union[bool, str, TruncationStrategy] = None,
max_length: Optional[int] = None,
stride: int = 0,
pad_to_multiple_of: Optional[int] = None,
return_overflowing_tokens: bool = False,
return_special_tokens_mask: bool = False,
return_offsets_mapping: bool = False,
return_token_type_ids: bool = False,
return_length: bool = False,
verbose: bool = True,
return_tensors: Optional[Union[str, TensorType]] = None,
**kwargs,
) -> "FuyuBatchFeature":
"""
Main method to prepare for the model one or several sequences(s) and image(s). This method forwards the `text`
and `kwargs` arguments to LlamaTokenizerFast's [`~LlamaTokenizerFast.__call__`] if `text` is not `None` to
encode the text. To prepare the image(s), this method forwards the `images` and `kwargs` arguments to
FuyuImageProcessor's [`~FuyuImageProcessor.__call__`] if `images` is not `None`. Please refer to the doctsring
of the above two methods for more information.
Args:
text (`str`, `List[str]`):
The sequence or batch of sequences to be encoded. Each sequence can be a string or a list of strings
(pretokenized string). If the sequences are provided as list of strings (pretokenized), you must set
`is_split_into_words=True` (to lift the ambiguity with a batch of sequences).
images (`PIL.Image.Image`, `List[PIL.Image.Image]`):
The image or batch of images to be prepared. Each image can be a PIL image, NumPy array or PyTorch
tensor. In case of a NumPy array/PyTorch tensor, each image should be of shape (C, H, W), where C is a
number of channels, H and W are image height and width.
Returns:
[`FuyuBatchEncoding`]: A [`FuyuBatchEncoding`] with the following fields:
- **input_ids** -- Tensor of token ids to be fed to a model. Returned when `text` is not `None`.
- **image_patches** -- List of Tensor of image patches. Returned when `images` is not `None`.
- **image_patches_indices** -- Tensor of indices where patch embeddings have to be inserted by the model.
- **attention_mask** -- List of indices specifying which tokens should be attended to by the model when
`return_attention_mask=True`.
"""
requires_backends(self, ["torch"])
# --- Check input validity ---
if not return_attention_mask:
raise ValueError("`return_attention_mask=False` is not supported for this model.")
if text is None and images is None:
raise ValueError("You have to specify either text or images. Both cannot be None.")
if text is not None and images is None:
logger.warning("You are processing a text with no associated image. Make sure it is intended.")
self.current_processor = self.tokenizer
text_encoding = self.tokenizer(
text=text,
add_special_tokens=add_special_tokens,
padding=padding,
truncation=truncation,
max_length=max_length,
stride=stride,
pad_to_multiple_of=pad_to_multiple_of,
return_attention_mask=return_attention_mask,
return_overflowing_tokens=return_overflowing_tokens,
return_special_tokens_mask=return_special_tokens_mask,
return_offsets_mapping=return_offsets_mapping,
return_token_type_ids=return_token_type_ids,
return_length=return_length,
verbose=verbose,
return_tensors=return_tensors,
**kwargs,
)
return text_encoding
if text is None and images is not None:
logger.warning("You are processing an image with no associated text. Make sure it is intended.")
prompts = [[""]]
if text is not None and images is not None:
if isinstance(text, str):
prompts = [[text]]
elif isinstance(text, list):
prompts = [[text_seq] for text_seq in text]
# --- Preprocess images using self.image_processor ---
# FIXME - We hard code "pt" here because the rest of the processing assumes torch tensors
image_encoding = self.image_processor.preprocess(images, return_tensors="pt")
batch_images = image_encoding["images"]
image_unpadded_heights = image_encoding["image_unpadded_heights"]
image_unpadded_widths = image_encoding["image_unpadded_widths"]
scale_factors = image_encoding["image_scale_factors"]
self.subsequence_length = 1 # Each batch contains only one sequence.
self.batch_size = len(batch_images)
# --- Use self.tokenizer to get the ids of special tokens to insert into image ids ---
image_placeholder_id = self.tokenizer("|SPEAKER|", add_special_tokens=False)["input_ids"][1]
image_newline_id = self.tokenizer("|NEWLINE|", add_special_tokens=False)["input_ids"][1]
tensor_batch_images = torch.stack([img[0] for img in batch_images]).unsqueeze(1)
# --- Use self.image_processor again to obtain the full token ids and batch inputs ---
all_encodings = []
for prompt, scale_factor, image_unpadded_height, image_unpadded_width, tensor_batch_image in zip(
prompts, scale_factors, image_unpadded_heights, image_unpadded_widths, tensor_batch_images
):
sample_encoding = self.get_sample_encoding(
prompts=[prompt],
scale_factors=[scale_factor],
image_unpadded_heights=torch.tensor([image_unpadded_height]),
image_unpadded_widths=torch.tensor([image_unpadded_width]),
image_placeholder_id=image_placeholder_id,
image_newline_id=image_newline_id,
tensor_batch_images=tensor_batch_image.unsqueeze(0),
)
all_encodings.append(sample_encoding)
batch_encoding = self._left_pad_inputs_with_attention_mask(
model_inputs=all_encodings, return_attention_mask=return_attention_mask
)
return FuyuBatchFeature(data=batch_encoding)
def post_process_box_coordinates(self, outputs, target_sizes=None):
"""
Transforms raw coordinates detected by [`FuyuForCausalLM`] to the original images' coordinate space.
Coordinates will be returned in "box" format, with the following pattern:
`<box>top, left, bottom, right</box>`
Point coordinates are not supported yet.
Args:
outputs ([`GenerateOutput`]):
Raw outputs from `generate`.
target_sizes (`torch.Tensor`, *optional*):
Tensor of shape (batch_size, 2) where each entry is the (height, width) of the corresponding image in
the batch. If set, found coordinates in the output sequence are rescaled to the target sizes. If left
to None, coordinates will not be rescaled.
Returns:
`GenerateOutput`: Same output type returned by `generate`, with output token ids replaced with
boxed and possible rescaled coordinates.
"""
def scale_factor_to_fit(original_size, target_size=None):
height, width = original_size
if target_size is None:
max_height = self.image_processor.size["height"]
max_width = self.image_processor.size["width"]
else:
max_height, max_width = target_size
if width <= max_width and height <= max_height:
return 1.0
return min(max_height / height, max_width / width)
def find_delimiters_pair(tokens, start_token, end_token):
start_id = self.tokenizer.convert_tokens_to_ids(start_token)
end_id = self.tokenizer.convert_tokens_to_ids(end_token)
starting_positions = (tokens == start_id).nonzero(as_tuple=True)[0]
ending_positions = (tokens == end_id).nonzero(as_tuple=True)[0]
if torch.any(starting_positions) and torch.any(ending_positions):
return (starting_positions[0], ending_positions[0])
return (None, None)
def tokens_to_boxes(tokens, original_size):
while (pair := find_delimiters_pair(tokens, TOKEN_BBOX_OPEN_STRING, TOKEN_BBOX_CLOSE_STRING)) != (
None,
None,
):
start, end = pair
if end != start + 5:
continue
# Retrieve transformed coordinates from tokens
coords = self.tokenizer.convert_ids_to_tokens(tokens[start + 1 : end])
# Scale back to original image size and multiply by 2
scale = scale_factor_to_fit(original_size)
top, left, bottom, right = [2 * int(float(c) / scale) for c in coords]
# Replace the IDs so they get detokenized right
replacement = f" {TEXT_REPR_BBOX_OPEN}{top}, {left}, {bottom}, {right}{TEXT_REPR_BBOX_CLOSE}"
replacement = self.tokenizer.tokenize(replacement)[1:]
replacement = self.tokenizer.convert_tokens_to_ids(replacement)
replacement = torch.tensor(replacement).to(tokens)
tokens = torch.cat([tokens[:start], replacement, tokens[end + 1 :]], 0)
return tokens
def tokens_to_points(tokens, original_size):
while (pair := find_delimiters_pair(tokens, TOKEN_POINT_OPEN_STRING, TOKEN_POINT_CLOSE_STRING)) != (
None,
None,
):
start, end = pair
if end != start + 3:
continue
# Retrieve transformed coordinates from tokens
coords = self.tokenizer.convert_ids_to_tokens(tokens[start + 1 : end])
# Scale back to original image size and multiply by 2
scale = scale_factor_to_fit(original_size)
x, y = [2 * int(float(c) / scale) for c in coords]
# Replace the IDs so they get detokenized right
replacement = f" {TEXT_REPR_POINT_OPEN}{x}, {y}{TEXT_REPR_POINT_CLOSE}"
replacement = self.tokenizer.tokenize(replacement)[1:]
replacement = self.tokenizer.convert_tokens_to_ids(replacement)
replacement = torch.tensor(replacement).to(tokens)
tokens = torch.cat([tokens[:start], replacement, tokens[end + 1 :]], 0)
return tokens
if target_sizes is None:
target_sizes = ((self.image_processor.size["height"], self.image_processor.size["width"]),) * len(outputs)
elif target_sizes.shape[1] != 2:
raise ValueError("Each element of target_sizes must contain the size (h, w) of each image of the batch")
if len(outputs) != len(target_sizes):
raise ValueError("Make sure that you pass in as many target sizes as output sequences")
results = []
for seq, size in zip(outputs, target_sizes):
seq = tokens_to_boxes(seq, size)
seq = tokens_to_points(seq, size)
results.append(seq)
return results
def batch_decode(self, *args, **kwargs):
"""
This method forwards all its arguments to LlamaTokenizerFast's [`~PreTrainedTokenizer.batch_decode`]. Please
refer to the docstring of this method for more information.
"""
return self.tokenizer.batch_decode(*args, **kwargs)
def decode(self, *args, **kwargs):
"""
This method forwards all its arguments to LlamaTokenizerFast's [`~PreTrainedTokenizer.decode`]. Please refer to
the docstring of this method for more information.
"""
return self.tokenizer.decode(*args, **kwargs)
| transformers/src/transformers/models/fuyu/processing_fuyu.py/0 | {
"file_path": "transformers/src/transformers/models/fuyu/processing_fuyu.py",
"repo_id": "transformers",
"token_count": 13839
} | 95 |
# coding=utf-8
# Copyright 2022 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
""" GroupViT model configuration"""
import os
from collections import OrderedDict
from typing import TYPE_CHECKING, Any, Mapping, Optional, Union
from ...configuration_utils import PretrainedConfig
from ...onnx import OnnxConfig
from ...utils import logging
if TYPE_CHECKING:
from ...processing_utils import ProcessorMixin
from ...utils import TensorType
logger = logging.get_logger(__name__)
GROUPVIT_PRETRAINED_CONFIG_ARCHIVE_MAP = {
"nvidia/groupvit-gcc-yfcc": "https://huggingface.co/nvidia/groupvit-gcc-yfcc/resolve/main/config.json",
}
class GroupViTTextConfig(PretrainedConfig):
r"""
This is the configuration class to store the configuration of a [`GroupViTTextModel`]. It is used to instantiate an
GroupViT model according to the specified arguments, defining the model architecture. Instantiating a configuration
with the defaults will yield a similar configuration to that of the GroupViT
[nvidia/groupvit-gcc-yfcc](https://huggingface.co/nvidia/groupvit-gcc-yfcc) architecture.
Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
documentation from [`PretrainedConfig`] for more information.
Args:
vocab_size (`int`, *optional*, defaults to 49408):
Vocabulary size of the GroupViT text model. Defines the number of different tokens that can be represented
by the `inputs_ids` passed when calling [`GroupViTModel`].
hidden_size (`int`, *optional*, defaults to 256):
Dimensionality of the encoder layers and the pooler layer.
intermediate_size (`int`, *optional*, defaults to 1024):
Dimensionality of the "intermediate" (i.e., feed-forward) layer in the Transformer encoder.
num_hidden_layers (`int`, *optional*, defaults to 12):
Number of hidden layers in the Transformer encoder.
num_attention_heads (`int`, *optional*, defaults to 4):
Number of attention heads for each attention layer in the Transformer encoder.
max_position_embeddings (`int`, *optional*, defaults to 77):
The maximum sequence length that this model might ever be used with. Typically set this to something large
just in case (e.g., 512 or 1024 or 2048).
hidden_act (`str` or `function`, *optional*, defaults to `"quick_gelu"`):
The non-linear activation function (function or string) in the encoder and pooler. If string, `"gelu"`,
`"relu"`, `"selu"` and `"gelu_new"` ``"quick_gelu"` are supported.
layer_norm_eps (`float`, *optional*, defaults to 1e-5):
The epsilon used by the layer normalization layers.
attention_dropout (`float`, *optional*, defaults to 0.0):
The dropout ratio for the attention probabilities.
dropout (`float`, *optional*, defaults to 0.0):
The dropout probability for all fully connected layers in the embeddings, encoder, and pooler.
initializer_range (`float`, *optional*, defaults to 0.02):
The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
initializer_factor (`float`, *optional*, defaults to 1.0):
A factor for initializing all weight matrices (should be kept to 1, used internally for initialization
testing).
Example:
```python
>>> from transformers import GroupViTTextConfig, GroupViTTextModel
>>> # Initializing a GroupViTTextModel with nvidia/groupvit-gcc-yfcc style configuration
>>> configuration = GroupViTTextConfig()
>>> model = GroupViTTextModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.config
```"""
model_type = "groupvit_text_model"
def __init__(
self,
vocab_size=49408,
hidden_size=256,
intermediate_size=1024,
num_hidden_layers=12,
num_attention_heads=4,
max_position_embeddings=77,
hidden_act="quick_gelu",
layer_norm_eps=1e-5,
dropout=0.0,
attention_dropout=0.0,
initializer_range=0.02,
initializer_factor=1.0,
pad_token_id=1,
bos_token_id=49406,
eos_token_id=49407,
**kwargs,
):
super().__init__(pad_token_id=pad_token_id, bos_token_id=bos_token_id, eos_token_id=eos_token_id, **kwargs)
self.vocab_size = vocab_size
self.hidden_size = hidden_size
self.intermediate_size = intermediate_size
self.dropout = dropout
self.num_hidden_layers = num_hidden_layers
self.num_attention_heads = num_attention_heads
self.max_position_embeddings = max_position_embeddings
self.layer_norm_eps = layer_norm_eps
self.hidden_act = hidden_act
self.initializer_range = initializer_range
self.initializer_factor = initializer_factor
self.attention_dropout = attention_dropout
@classmethod
def from_pretrained(cls, pretrained_model_name_or_path: Union[str, os.PathLike], **kwargs) -> "PretrainedConfig":
cls._set_token_in_kwargs(kwargs)
config_dict, kwargs = cls.get_config_dict(pretrained_model_name_or_path, **kwargs)
# get the text config dict if we are loading from GroupViTConfig
if config_dict.get("model_type") == "groupvit":
config_dict = config_dict["text_config"]
if "model_type" in config_dict and hasattr(cls, "model_type") and config_dict["model_type"] != cls.model_type:
logger.warning(
f"You are using a model of type {config_dict['model_type']} to instantiate a model of type "
f"{cls.model_type}. This is not supported for all configurations of models and can yield errors."
)
return cls.from_dict(config_dict, **kwargs)
class GroupViTVisionConfig(PretrainedConfig):
r"""
This is the configuration class to store the configuration of a [`GroupViTVisionModel`]. It is used to instantiate
an GroupViT model according to the specified arguments, defining the model architecture. Instantiating a
configuration with the defaults will yield a similar configuration to that of the GroupViT
[nvidia/groupvit-gcc-yfcc](https://huggingface.co/nvidia/groupvit-gcc-yfcc) architecture.
Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
documentation from [`PretrainedConfig`] for more information.
Args:
hidden_size (`int`, *optional*, defaults to 384):
Dimensionality of the encoder layers and the pooler layer.
intermediate_size (`int`, *optional*, defaults to 1536):
Dimensionality of the "intermediate" (i.e., feed-forward) layer in the Transformer encoder.
depths (`List[int]`, *optional*, defaults to [6, 3, 3]):
The number of layers in each encoder block.
num_group_tokens (`List[int]`, *optional*, defaults to [64, 8, 0]):
The number of group tokens for each stage.
num_output_groups (`List[int]`, *optional*, defaults to [64, 8, 8]):
The number of output groups for each stage, 0 means no group.
num_attention_heads (`int`, *optional*, defaults to 6):
Number of attention heads for each attention layer in the Transformer encoder.
image_size (`int`, *optional*, defaults to 224):
The size (resolution) of each image.
patch_size (`int`, *optional*, defaults to 16):
The size (resolution) of each patch.
hidden_act (`str` or `function`, *optional*, defaults to `"gelu"`):
The non-linear activation function (function or string) in the encoder and pooler. If string, `"gelu"`,
`"relu"`, `"selu"` and `"gelu_new"` ``"quick_gelu"` are supported.
layer_norm_eps (`float`, *optional*, defaults to 1e-5):
The epsilon used by the layer normalization layers.
dropout (`float`, *optional*, defaults to 0.0):
The dropout probability for all fully connected layers in the embeddings, encoder, and pooler.
attention_dropout (`float`, *optional*, defaults to 0.0):
The dropout ratio for the attention probabilities.
initializer_range (`float`, *optional*, defaults to 0.02):
The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
initializer_factor (`float`, *optional*, defaults to 1.0):
A factor for initializing all weight matrices (should be kept to 1, used internally for initialization
testing).
Example:
```python
>>> from transformers import GroupViTVisionConfig, GroupViTVisionModel
>>> # Initializing a GroupViTVisionModel with nvidia/groupvit-gcc-yfcc style configuration
>>> configuration = GroupViTVisionConfig()
>>> model = GroupViTVisionModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.config
```"""
model_type = "groupvit_vision_model"
def __init__(
self,
hidden_size=384,
intermediate_size=1536,
depths=[6, 3, 3],
num_hidden_layers=12,
num_group_tokens=[64, 8, 0],
num_output_groups=[64, 8, 8],
num_attention_heads=6,
image_size=224,
patch_size=16,
num_channels=3,
hidden_act="gelu",
layer_norm_eps=1e-5,
dropout=0.0,
attention_dropout=0.0,
initializer_range=0.02,
initializer_factor=1.0,
assign_eps=1.0,
assign_mlp_ratio=[0.5, 4],
**kwargs,
):
super().__init__(**kwargs)
self.hidden_size = hidden_size
self.intermediate_size = intermediate_size
self.depths = depths
if num_hidden_layers != sum(depths):
logger.warning(
f"Manually setting num_hidden_layers to {num_hidden_layers}, but we expect num_hidden_layers ="
f" sum(depth) = {sum(depths)}"
)
self.num_hidden_layers = num_hidden_layers
self.num_group_tokens = num_group_tokens
self.num_output_groups = num_output_groups
self.num_attention_heads = num_attention_heads
self.image_size = image_size
self.patch_size = patch_size
self.num_channels = num_channels
self.hidden_act = hidden_act
self.layer_norm_eps = layer_norm_eps
self.dropout = dropout
self.attention_dropout = attention_dropout
self.initializer_range = initializer_range
self.initializer_factor = initializer_factor
self.assign_eps = assign_eps
self.assign_mlp_ratio = assign_mlp_ratio
@classmethod
def from_pretrained(cls, pretrained_model_name_or_path: Union[str, os.PathLike], **kwargs) -> "PretrainedConfig":
cls._set_token_in_kwargs(kwargs)
config_dict, kwargs = cls.get_config_dict(pretrained_model_name_or_path, **kwargs)
# get the vision config dict if we are loading from GroupViTConfig
if config_dict.get("model_type") == "groupvit":
config_dict = config_dict["vision_config"]
if "model_type" in config_dict and hasattr(cls, "model_type") and config_dict["model_type"] != cls.model_type:
logger.warning(
f"You are using a model of type {config_dict['model_type']} to instantiate a model of type "
f"{cls.model_type}. This is not supported for all configurations of models and can yield errors."
)
return cls.from_dict(config_dict, **kwargs)
class GroupViTConfig(PretrainedConfig):
r"""
[`GroupViTConfig`] is the configuration class to store the configuration of a [`GroupViTModel`]. It is used to
instantiate a GroupViT model according to the specified arguments, defining the text model and vision model
configs. Instantiating a configuration with the defaults will yield a similar configuration to that of the GroupViT
[nvidia/groupvit-gcc-yfcc](https://huggingface.co/nvidia/groupvit-gcc-yfcc) architecture.
Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
documentation from [`PretrainedConfig`] for more information.
Args:
text_config (`dict`, *optional*):
Dictionary of configuration options used to initialize [`GroupViTTextConfig`].
vision_config (`dict`, *optional*):
Dictionary of configuration options used to initialize [`GroupViTVisionConfig`].
projection_dim (`int`, *optional*, defaults to 256):
Dimentionality of text and vision projection layers.
projection_intermediate_dim (`int`, *optional*, defaults to 4096):
Dimentionality of intermediate layer of text and vision projection layers.
logit_scale_init_value (`float`, *optional*, defaults to 2.6592):
The inital value of the *logit_scale* parameter. Default is used as per the original GroupViT
implementation.
kwargs (*optional*):
Dictionary of keyword arguments.
"""
model_type = "groupvit"
def __init__(
self,
text_config=None,
vision_config=None,
projection_dim=256,
projection_intermediate_dim=4096,
logit_scale_init_value=2.6592,
**kwargs,
):
# If `_config_dict` exist, we use them for the backward compatibility.
# We pop out these 2 attributes before calling `super().__init__` to avoid them being saved (which causes a lot
# of confusion!).
text_config_dict = kwargs.pop("text_config_dict", None)
vision_config_dict = kwargs.pop("vision_config_dict", None)
super().__init__(**kwargs)
# Instead of simply assigning `[text|vision]_config_dict` to `[text|vision]_config`, we use the values in
# `[text|vision]_config_dict` to update the values in `[text|vision]_config`. The values should be same in most
# cases, but we don't want to break anything regarding `_config_dict` that existed before commit `8827e1b2`.
if text_config_dict is not None:
if text_config is None:
text_config = {}
# This is the complete result when using `text_config_dict`.
_text_config_dict = GroupViTTextConfig(**text_config_dict).to_dict()
# Give a warning if the values exist in both `_text_config_dict` and `text_config` but being different.
for key, value in _text_config_dict.items():
if key in text_config and value != text_config[key] and key not in ["transformers_version"]:
# If specified in `text_config_dict`
if key in text_config_dict:
message = (
f"`{key}` is found in both `text_config_dict` and `text_config` but with different values. "
f'The value `text_config_dict["{key}"]` will be used instead.'
)
# If inferred from default argument values (just to be super careful)
else:
message = (
f"`text_config_dict` is provided which will be used to initialize `GroupViTTextConfig`. "
f'The value `text_config["{key}"]` will be overriden.'
)
logger.info(message)
# Update all values in `text_config` with the ones in `_text_config_dict`.
text_config.update(_text_config_dict)
if vision_config_dict is not None:
if vision_config is None:
vision_config = {}
# This is the complete result when using `vision_config_dict`.
_vision_config_dict = GroupViTVisionConfig(**vision_config_dict).to_dict()
# convert keys to string instead of integer
if "id2label" in _vision_config_dict:
_vision_config_dict["id2label"] = {
str(key): value for key, value in _vision_config_dict["id2label"].items()
}
# Give a warning if the values exist in both `_vision_config_dict` and `vision_config` but being different.
for key, value in _vision_config_dict.items():
if key in vision_config and value != vision_config[key] and key not in ["transformers_version"]:
# If specified in `vision_config_dict`
if key in vision_config_dict:
message = (
f"`{key}` is found in both `vision_config_dict` and `vision_config` but with different "
f'values. The value `vision_config_dict["{key}"]` will be used instead.'
)
# If inferred from default argument values (just to be super careful)
else:
message = (
f"`vision_config_dict` is provided which will be used to initialize `GroupViTVisionConfig`."
f' The value `vision_config["{key}"]` will be overriden.'
)
logger.info(message)
# Update all values in `vision_config` with the ones in `_vision_config_dict`.
vision_config.update(_vision_config_dict)
if text_config is None:
text_config = {}
logger.info("`text_config` is `None`. Initializing the `GroupViTTextConfig` with default values.")
if vision_config is None:
vision_config = {}
logger.info("`vision_config` is `None`. initializing the `GroupViTVisionConfig` with default values.")
self.text_config = GroupViTTextConfig(**text_config)
self.vision_config = GroupViTVisionConfig(**vision_config)
self.projection_dim = projection_dim
self.projection_intermediate_dim = projection_intermediate_dim
self.logit_scale_init_value = logit_scale_init_value
self.initializer_range = 0.02
self.initializer_factor = 1.0
self.output_segmentation = False
@classmethod
def from_text_vision_configs(cls, text_config: GroupViTTextConfig, vision_config: GroupViTVisionConfig, **kwargs):
r"""
Instantiate a [`GroupViTConfig`] (or a derived class) from groupvit text model configuration and groupvit
vision model configuration.
Returns:
[`GroupViTConfig`]: An instance of a configuration object
"""
return cls(text_config=text_config.to_dict(), vision_config=vision_config.to_dict(), **kwargs)
class GroupViTOnnxConfig(OnnxConfig):
@property
def inputs(self) -> Mapping[str, Mapping[int, str]]:
return OrderedDict(
[
("input_ids", {0: "batch", 1: "sequence"}),
("pixel_values", {0: "batch", 1: "num_channels", 2: "height", 3: "width"}),
("attention_mask", {0: "batch", 1: "sequence"}),
]
)
@property
def outputs(self) -> Mapping[str, Mapping[int, str]]:
return OrderedDict(
[
("logits_per_image", {0: "batch"}),
("logits_per_text", {0: "batch"}),
("text_embeds", {0: "batch"}),
("image_embeds", {0: "batch"}),
]
)
@property
def atol_for_validation(self) -> float:
return 1e-4
def generate_dummy_inputs(
self,
processor: "ProcessorMixin",
batch_size: int = -1,
seq_length: int = -1,
framework: Optional["TensorType"] = None,
) -> Mapping[str, Any]:
text_input_dict = super().generate_dummy_inputs(
processor.tokenizer, batch_size=batch_size, seq_length=seq_length, framework=framework
)
image_input_dict = super().generate_dummy_inputs(
processor.image_processor, batch_size=batch_size, framework=framework
)
return {**text_input_dict, **image_input_dict}
@property
def default_onnx_opset(self) -> int:
return 14
| transformers/src/transformers/models/groupvit/configuration_groupvit.py/0 | {
"file_path": "transformers/src/transformers/models/groupvit/configuration_groupvit.py",
"repo_id": "transformers",
"token_count": 8505
} | 96 |
# coding=utf-8
# Copyright 2021 The I-BERT Authors (Sehoon Kim, Amir Gholami, Zhewei Yao,
# Michael Mahoney, Kurt Keutzer - UC Berkeley) and The HuggingFace Inc. team.
# Copyright (c) 20121, NVIDIA CORPORATION. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""PyTorch I-BERT model."""
import math
from typing import Optional, Tuple, Union
import torch
import torch.utils.checkpoint
from torch import nn
from torch.nn import BCEWithLogitsLoss, CrossEntropyLoss, MSELoss
from ...activations import gelu
from ...modeling_outputs import (
BaseModelOutputWithPastAndCrossAttentions,
BaseModelOutputWithPoolingAndCrossAttentions,
MaskedLMOutput,
MultipleChoiceModelOutput,
QuestionAnsweringModelOutput,
SequenceClassifierOutput,
TokenClassifierOutput,
)
from ...modeling_utils import PreTrainedModel
from ...pytorch_utils import find_pruneable_heads_and_indices, prune_linear_layer
from ...utils import add_code_sample_docstrings, add_start_docstrings, add_start_docstrings_to_model_forward, logging
from .configuration_ibert import IBertConfig
from .quant_modules import IntGELU, IntLayerNorm, IntSoftmax, QuantAct, QuantEmbedding, QuantLinear
logger = logging.get_logger(__name__)
_CHECKPOINT_FOR_DOC = "kssteven/ibert-roberta-base"
_CONFIG_FOR_DOC = "IBertConfig"
IBERT_PRETRAINED_MODEL_ARCHIVE_LIST = [
"kssteven/ibert-roberta-base",
"kssteven/ibert-roberta-large",
"kssteven/ibert-roberta-large-mnli",
]
class IBertEmbeddings(nn.Module):
"""
Same as BertEmbeddings with a tiny tweak for positional embeddings indexing.
"""
def __init__(self, config):
super().__init__()
self.quant_mode = config.quant_mode
self.embedding_bit = 8
self.embedding_act_bit = 16
self.act_bit = 8
self.ln_input_bit = 22
self.ln_output_bit = 32
self.word_embeddings = QuantEmbedding(
config.vocab_size,
config.hidden_size,
padding_idx=config.pad_token_id,
weight_bit=self.embedding_bit,
quant_mode=self.quant_mode,
)
self.token_type_embeddings = QuantEmbedding(
config.type_vocab_size, config.hidden_size, weight_bit=self.embedding_bit, quant_mode=self.quant_mode
)
# position_ids (1, len position emb) is contiguous in memory and exported when serialized
self.register_buffer(
"position_ids", torch.arange(config.max_position_embeddings).expand((1, -1)), persistent=False
)
self.position_embedding_type = getattr(config, "position_embedding_type", "absolute")
# End copy
self.padding_idx = config.pad_token_id
self.position_embeddings = QuantEmbedding(
config.max_position_embeddings,
config.hidden_size,
padding_idx=self.padding_idx,
weight_bit=self.embedding_bit,
quant_mode=self.quant_mode,
)
# Integer-only addition between embeddings
self.embeddings_act1 = QuantAct(self.embedding_act_bit, quant_mode=self.quant_mode)
self.embeddings_act2 = QuantAct(self.embedding_act_bit, quant_mode=self.quant_mode)
# self.LayerNorm is not snake-cased to stick with TensorFlow model variable name and be able to load
# any TensorFlow checkpoint file
self.LayerNorm = IntLayerNorm(
config.hidden_size,
eps=config.layer_norm_eps,
output_bit=self.ln_output_bit,
quant_mode=self.quant_mode,
force_dequant=config.force_dequant,
)
self.output_activation = QuantAct(self.act_bit, quant_mode=self.quant_mode)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
def forward(
self, input_ids=None, token_type_ids=None, position_ids=None, inputs_embeds=None, past_key_values_length=0
):
if position_ids is None:
if input_ids is not None:
# Create the position ids from the input token ids. Any padded tokens remain padded.
position_ids = create_position_ids_from_input_ids(
input_ids, self.padding_idx, past_key_values_length
).to(input_ids.device)
else:
position_ids = self.create_position_ids_from_inputs_embeds(inputs_embeds)
if input_ids is not None:
input_shape = input_ids.size()
else:
input_shape = inputs_embeds.size()[:-1]
if token_type_ids is None:
token_type_ids = torch.zeros(input_shape, dtype=torch.long, device=self.position_ids.device)
if inputs_embeds is None:
inputs_embeds, inputs_embeds_scaling_factor = self.word_embeddings(input_ids)
else:
inputs_embeds_scaling_factor = None
token_type_embeddings, token_type_embeddings_scaling_factor = self.token_type_embeddings(token_type_ids)
embeddings, embeddings_scaling_factor = self.embeddings_act1(
inputs_embeds,
inputs_embeds_scaling_factor,
identity=token_type_embeddings,
identity_scaling_factor=token_type_embeddings_scaling_factor,
)
if self.position_embedding_type == "absolute":
position_embeddings, position_embeddings_scaling_factor = self.position_embeddings(position_ids)
embeddings, embeddings_scaling_factor = self.embeddings_act1(
embeddings,
embeddings_scaling_factor,
identity=position_embeddings,
identity_scaling_factor=position_embeddings_scaling_factor,
)
embeddings, embeddings_scaling_factor = self.LayerNorm(embeddings, embeddings_scaling_factor)
embeddings = self.dropout(embeddings)
embeddings, embeddings_scaling_factor = self.output_activation(embeddings, embeddings_scaling_factor)
return embeddings, embeddings_scaling_factor
def create_position_ids_from_inputs_embeds(self, inputs_embeds):
"""
We are provided embeddings directly. We cannot infer which are padded so just generate sequential position ids.
Args:
inputs_embeds: torch.Tensor
Returns: torch.Tensor
"""
input_shape = inputs_embeds.size()[:-1]
sequence_length = input_shape[1]
position_ids = torch.arange(
self.padding_idx + 1, sequence_length + self.padding_idx + 1, dtype=torch.long, device=inputs_embeds.device
)
return position_ids.unsqueeze(0).expand(input_shape)
class IBertSelfAttention(nn.Module):
def __init__(self, config):
super().__init__()
if config.hidden_size % config.num_attention_heads != 0 and not hasattr(config, "embedding_size"):
raise ValueError(
f"The hidden size ({config.hidden_size}) is not a multiple of the number of attention "
f"heads ({config.num_attention_heads})"
)
self.quant_mode = config.quant_mode
self.weight_bit = 8
self.bias_bit = 32
self.act_bit = 8
self.num_attention_heads = config.num_attention_heads
self.attention_head_size = int(config.hidden_size / config.num_attention_heads)
self.all_head_size = self.num_attention_heads * self.attention_head_size
# Q, K, V Linear layers
self.query = QuantLinear(
config.hidden_size,
self.all_head_size,
bias=True,
weight_bit=self.weight_bit,
bias_bit=self.bias_bit,
quant_mode=self.quant_mode,
per_channel=True,
)
self.key = QuantLinear(
config.hidden_size,
self.all_head_size,
bias=True,
weight_bit=self.weight_bit,
bias_bit=self.bias_bit,
quant_mode=self.quant_mode,
per_channel=True,
)
self.value = QuantLinear(
config.hidden_size,
self.all_head_size,
bias=True,
weight_bit=self.weight_bit,
bias_bit=self.bias_bit,
quant_mode=self.quant_mode,
per_channel=True,
)
# Requantization (32bit -> 8bit) for Q, K, V activations
self.query_activation = QuantAct(self.act_bit, quant_mode=self.quant_mode)
self.key_activation = QuantAct(self.act_bit, quant_mode=self.quant_mode)
self.value_activation = QuantAct(self.act_bit, quant_mode=self.quant_mode)
self.output_activation = QuantAct(self.act_bit, quant_mode=self.quant_mode)
self.dropout = nn.Dropout(config.attention_probs_dropout_prob)
self.position_embedding_type = getattr(config, "position_embedding_type", "absolute")
if self.position_embedding_type != "absolute":
raise ValueError("I-BERT only supports 'absolute' for `config.position_embedding_type`")
self.softmax = IntSoftmax(self.act_bit, quant_mode=self.quant_mode, force_dequant=config.force_dequant)
def transpose_for_scores(self, x):
new_x_shape = x.size()[:-1] + (self.num_attention_heads, self.attention_head_size)
x = x.view(*new_x_shape)
return x.permute(0, 2, 1, 3)
def forward(
self,
hidden_states,
hidden_states_scaling_factor,
attention_mask=None,
head_mask=None,
output_attentions=False,
):
# Projection
mixed_query_layer, mixed_query_layer_scaling_factor = self.query(hidden_states, hidden_states_scaling_factor)
mixed_key_layer, mixed_key_layer_scaling_factor = self.key(hidden_states, hidden_states_scaling_factor)
mixed_value_layer, mixed_value_layer_scaling_factor = self.value(hidden_states, hidden_states_scaling_factor)
# Requantization
query_layer, query_layer_scaling_factor = self.query_activation(
mixed_query_layer, mixed_query_layer_scaling_factor
)
key_layer, key_layer_scaling_factor = self.key_activation(mixed_key_layer, mixed_key_layer_scaling_factor)
value_layer, value_layer_scaling_factor = self.value_activation(
mixed_value_layer, mixed_value_layer_scaling_factor
)
# Transpose
query_layer = self.transpose_for_scores(query_layer)
key_layer = self.transpose_for_scores(key_layer)
value_layer = self.transpose_for_scores(value_layer)
# Take the dot product between "query" and "key" to get the raw attention scores.
attention_scores = torch.matmul(query_layer, key_layer.transpose(-1, -2))
scale = math.sqrt(self.attention_head_size)
attention_scores = attention_scores / scale
if self.quant_mode:
attention_scores_scaling_factor = query_layer_scaling_factor * key_layer_scaling_factor / scale
else:
attention_scores_scaling_factor = None
if attention_mask is not None:
# Apply the attention mask is (precomputed for all layers in IBertModel forward() function)
attention_scores = attention_scores + attention_mask
# Normalize the attention scores to probabilities.
attention_probs, attention_probs_scaling_factor = self.softmax(
attention_scores, attention_scores_scaling_factor
)
# This is actually dropping out entire tokens to attend to, which might
# seem a bit unusual, but is taken from the original Transformer paper.
attention_probs = self.dropout(attention_probs)
# Mask heads if we want to
if head_mask is not None:
attention_probs = attention_probs * head_mask
context_layer = torch.matmul(attention_probs, value_layer)
if attention_probs_scaling_factor is not None:
context_layer_scaling_factor = attention_probs_scaling_factor * value_layer_scaling_factor
else:
context_layer_scaling_factor = None
context_layer = context_layer.permute(0, 2, 1, 3).contiguous()
new_context_layer_shape = context_layer.size()[:-2] + (self.all_head_size,)
context_layer = context_layer.view(*new_context_layer_shape)
# requantization: 32-bit -> 8-bit
context_layer, context_layer_scaling_factor = self.output_activation(
context_layer, context_layer_scaling_factor
)
outputs = (context_layer, attention_probs) if output_attentions else (context_layer,)
output_scaling_factor = (
(context_layer_scaling_factor, attention_probs_scaling_factor)
if output_attentions
else (context_layer_scaling_factor,)
)
return outputs, output_scaling_factor
class IBertSelfOutput(nn.Module):
def __init__(self, config):
super().__init__()
self.quant_mode = config.quant_mode
self.act_bit = 8
self.weight_bit = 8
self.bias_bit = 32
self.ln_input_bit = 22
self.ln_output_bit = 32
self.dense = QuantLinear(
config.hidden_size,
config.hidden_size,
bias=True,
weight_bit=self.weight_bit,
bias_bit=self.bias_bit,
quant_mode=self.quant_mode,
per_channel=True,
)
self.ln_input_act = QuantAct(self.ln_input_bit, quant_mode=self.quant_mode)
self.LayerNorm = IntLayerNorm(
config.hidden_size,
eps=config.layer_norm_eps,
output_bit=self.ln_output_bit,
quant_mode=self.quant_mode,
force_dequant=config.force_dequant,
)
self.output_activation = QuantAct(self.act_bit, quant_mode=self.quant_mode)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
def forward(self, hidden_states, hidden_states_scaling_factor, input_tensor, input_tensor_scaling_factor):
hidden_states, hidden_states_scaling_factor = self.dense(hidden_states, hidden_states_scaling_factor)
hidden_states = self.dropout(hidden_states)
hidden_states, hidden_states_scaling_factor = self.ln_input_act(
hidden_states,
hidden_states_scaling_factor,
identity=input_tensor,
identity_scaling_factor=input_tensor_scaling_factor,
)
hidden_states, hidden_states_scaling_factor = self.LayerNorm(hidden_states, hidden_states_scaling_factor)
hidden_states, hidden_states_scaling_factor = self.output_activation(
hidden_states, hidden_states_scaling_factor
)
return hidden_states, hidden_states_scaling_factor
class IBertAttention(nn.Module):
def __init__(self, config):
super().__init__()
self.quant_mode = config.quant_mode
self.self = IBertSelfAttention(config)
self.output = IBertSelfOutput(config)
self.pruned_heads = set()
def prune_heads(self, heads):
if len(heads) == 0:
return
heads, index = find_pruneable_heads_and_indices(
heads, self.self.num_attention_heads, self.self.attention_head_size, self.pruned_heads
)
# Prune linear layers
self.self.query = prune_linear_layer(self.self.query, index)
self.self.key = prune_linear_layer(self.self.key, index)
self.self.value = prune_linear_layer(self.self.value, index)
self.output.dense = prune_linear_layer(self.output.dense, index, dim=1)
# Update hyper params and store pruned heads
self.self.num_attention_heads = self.self.num_attention_heads - len(heads)
self.self.all_head_size = self.self.attention_head_size * self.self.num_attention_heads
self.pruned_heads = self.pruned_heads.union(heads)
def forward(
self,
hidden_states,
hidden_states_scaling_factor,
attention_mask=None,
head_mask=None,
output_attentions=False,
):
self_outputs, self_outputs_scaling_factor = self.self(
hidden_states,
hidden_states_scaling_factor,
attention_mask,
head_mask,
output_attentions,
)
attention_output, attention_output_scaling_factor = self.output(
self_outputs[0], self_outputs_scaling_factor[0], hidden_states, hidden_states_scaling_factor
)
outputs = (attention_output,) + self_outputs[1:] # add attentions if we output them
outputs_scaling_factor = (attention_output_scaling_factor,) + self_outputs_scaling_factor[1:]
return outputs, outputs_scaling_factor
class IBertIntermediate(nn.Module):
def __init__(self, config):
super().__init__()
self.quant_mode = config.quant_mode
self.act_bit = 8
self.weight_bit = 8
self.bias_bit = 32
self.dense = QuantLinear(
config.hidden_size,
config.intermediate_size,
bias=True,
weight_bit=self.weight_bit,
bias_bit=self.bias_bit,
quant_mode=self.quant_mode,
per_channel=True,
)
if config.hidden_act != "gelu":
raise ValueError("I-BERT only supports 'gelu' for `config.hidden_act`")
self.intermediate_act_fn = IntGELU(quant_mode=self.quant_mode, force_dequant=config.force_dequant)
self.output_activation = QuantAct(self.act_bit, quant_mode=self.quant_mode)
def forward(self, hidden_states, hidden_states_scaling_factor):
hidden_states, hidden_states_scaling_factor = self.dense(hidden_states, hidden_states_scaling_factor)
hidden_states, hidden_states_scaling_factor = self.intermediate_act_fn(
hidden_states, hidden_states_scaling_factor
)
# Requantization: 32bit -> 8-bit
hidden_states, hidden_states_scaling_factor = self.output_activation(
hidden_states, hidden_states_scaling_factor
)
return hidden_states, hidden_states_scaling_factor
class IBertOutput(nn.Module):
def __init__(self, config):
super().__init__()
self.quant_mode = config.quant_mode
self.act_bit = 8
self.weight_bit = 8
self.bias_bit = 32
self.ln_input_bit = 22
self.ln_output_bit = 32
self.dense = QuantLinear(
config.intermediate_size,
config.hidden_size,
bias=True,
weight_bit=self.weight_bit,
bias_bit=self.bias_bit,
quant_mode=self.quant_mode,
per_channel=True,
)
self.ln_input_act = QuantAct(self.ln_input_bit, quant_mode=self.quant_mode)
self.LayerNorm = IntLayerNorm(
config.hidden_size,
eps=config.layer_norm_eps,
output_bit=self.ln_output_bit,
quant_mode=self.quant_mode,
force_dequant=config.force_dequant,
)
self.output_activation = QuantAct(self.act_bit, quant_mode=self.quant_mode)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
def forward(self, hidden_states, hidden_states_scaling_factor, input_tensor, input_tensor_scaling_factor):
hidden_states, hidden_states_scaling_factor = self.dense(hidden_states, hidden_states_scaling_factor)
hidden_states = self.dropout(hidden_states)
hidden_states, hidden_states_scaling_factor = self.ln_input_act(
hidden_states,
hidden_states_scaling_factor,
identity=input_tensor,
identity_scaling_factor=input_tensor_scaling_factor,
)
hidden_states, hidden_states_scaling_factor = self.LayerNorm(hidden_states, hidden_states_scaling_factor)
hidden_states, hidden_states_scaling_factor = self.output_activation(
hidden_states, hidden_states_scaling_factor
)
return hidden_states, hidden_states_scaling_factor
class IBertLayer(nn.Module):
def __init__(self, config):
super().__init__()
self.quant_mode = config.quant_mode
self.act_bit = 8
self.seq_len_dim = 1
self.attention = IBertAttention(config)
self.intermediate = IBertIntermediate(config)
self.output = IBertOutput(config)
self.pre_intermediate_act = QuantAct(self.act_bit, quant_mode=self.quant_mode)
self.pre_output_act = QuantAct(self.act_bit, quant_mode=self.quant_mode)
def forward(
self,
hidden_states,
hidden_states_scaling_factor,
attention_mask=None,
head_mask=None,
output_attentions=False,
):
self_attention_outputs, self_attention_outputs_scaling_factor = self.attention(
hidden_states,
hidden_states_scaling_factor,
attention_mask,
head_mask,
output_attentions=output_attentions,
)
attention_output = self_attention_outputs[0]
attention_output_scaling_factor = self_attention_outputs_scaling_factor[0]
outputs = self_attention_outputs[1:] # add self attentions if we output attention weights
layer_output, layer_output_scaling_factor = self.feed_forward_chunk(
attention_output, attention_output_scaling_factor
)
outputs = (layer_output,) + outputs
return outputs
def feed_forward_chunk(self, attention_output, attention_output_scaling_factor):
attention_output, attention_output_scaling_factor = self.pre_intermediate_act(
attention_output, attention_output_scaling_factor
)
intermediate_output, intermediate_output_scaling_factor = self.intermediate(
attention_output, attention_output_scaling_factor
)
intermediate_output, intermediate_output_scaling_factor = self.pre_output_act(
intermediate_output, intermediate_output_scaling_factor
)
layer_output, layer_output_scaling_factor = self.output(
intermediate_output, intermediate_output_scaling_factor, attention_output, attention_output_scaling_factor
)
return layer_output, layer_output_scaling_factor
class IBertEncoder(nn.Module):
def __init__(self, config):
super().__init__()
self.config = config
self.quant_mode = config.quant_mode
self.layer = nn.ModuleList([IBertLayer(config) for _ in range(config.num_hidden_layers)])
def forward(
self,
hidden_states,
hidden_states_scaling_factor,
attention_mask=None,
head_mask=None,
output_attentions=False,
output_hidden_states=False,
return_dict=True,
):
all_hidden_states = () if output_hidden_states else None
all_self_attentions = () if output_attentions else None
all_cross_attentions = None # `config.add_cross_attention` is not supported
next_decoder_cache = None # `config.use_cache` is not supported
for i, layer_module in enumerate(self.layer):
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
layer_head_mask = head_mask[i] if head_mask is not None else None
layer_outputs = layer_module(
hidden_states,
hidden_states_scaling_factor,
attention_mask,
layer_head_mask,
output_attentions,
)
hidden_states = layer_outputs[0]
if output_attentions:
all_self_attentions = all_self_attentions + (layer_outputs[1],)
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
if not return_dict:
return tuple(
v
for v in [
hidden_states,
next_decoder_cache,
all_hidden_states,
all_self_attentions,
all_cross_attentions,
]
if v is not None
)
return BaseModelOutputWithPastAndCrossAttentions(
last_hidden_state=hidden_states,
past_key_values=next_decoder_cache,
hidden_states=all_hidden_states,
attentions=all_self_attentions,
cross_attentions=all_cross_attentions,
)
class IBertPooler(nn.Module):
def __init__(self, config):
super().__init__()
self.quant_mode = config.quant_mode
self.dense = nn.Linear(config.hidden_size, config.hidden_size)
self.activation = nn.Tanh()
def forward(self, hidden_states):
# We "pool" the model by simply taking the hidden state corresponding
# to the first token.
first_token_tensor = hidden_states[:, 0]
pooled_output = self.dense(first_token_tensor)
pooled_output = self.activation(pooled_output)
return pooled_output
class IBertPreTrainedModel(PreTrainedModel):
"""
An abstract class to handle weights initialization and a simple interface for downloading and loading pretrained
models.
"""
config_class = IBertConfig
base_model_prefix = "ibert"
def _init_weights(self, module):
"""Initialize the weights"""
if isinstance(module, (QuantLinear, nn.Linear)):
# Slightly different from the TF version which uses truncated_normal for initialization
# cf https://github.com/pytorch/pytorch/pull/5617
module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
if module.bias is not None:
module.bias.data.zero_()
elif isinstance(module, (QuantEmbedding, nn.Embedding)):
module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
if module.padding_idx is not None:
module.weight.data[module.padding_idx].zero_()
elif isinstance(module, (IntLayerNorm, nn.LayerNorm)):
module.bias.data.zero_()
module.weight.data.fill_(1.0)
def resize_token_embeddings(self, new_num_tokens=None):
raise NotImplementedError("`resize_token_embeddings` is not supported for I-BERT.")
IBERT_START_DOCSTRING = r"""
This model inherits from [`PreTrainedModel`]. Check the superclass documentation for the generic methods the
library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads
etc.)
This model is also a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) subclass.
Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage
and behavior.
Parameters:
config ([`IBertConfig`]): Model configuration class with all the parameters of the
model. Initializing with a config file does not load the weights associated with the model, only the
configuration. Check out the [`~PreTrainedModel.from_pretrained`] method to load the model weights.
"""
IBERT_INPUTS_DOCSTRING = r"""
Args:
input_ids (`torch.LongTensor` of shape `({0})`):
Indices of input sequence tokens in the vocabulary.
Indices can be obtained using [`AutoTokenizer`]. See [`PreTrainedTokenizer.encode`] and
[`PreTrainedTokenizer.__call__`] for details.
[What are input IDs?](../glossary#input-ids)
attention_mask (`torch.FloatTensor` of shape `({0})`, *optional*):
Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
[What are attention masks?](../glossary#attention-mask)
token_type_ids (`torch.LongTensor` of shape `({0})`, *optional*):
Segment token indices to indicate first and second portions of the inputs. Indices are selected in `[0,
1]`:
- 0 corresponds to a *sentence A* token,
- 1 corresponds to a *sentence B* token.
[What are token type IDs?](../glossary#token-type-ids)
position_ids (`torch.LongTensor` of shape `({0})`, *optional*):
Indices of positions of each input sequence tokens in the position embeddings. Selected in the range `[0,
config.max_position_embeddings - 1]`.
[What are position IDs?](../glossary#position-ids)
head_mask (`torch.FloatTensor` of shape `(num_heads,)` or `(num_layers, num_heads)`, *optional*):
Mask to nullify selected heads of the self-attention modules. Mask values selected in `[0, 1]`:
- 1 indicates the head is **not masked**,
- 0 indicates the head is **masked**.
inputs_embeds (`torch.FloatTensor` of shape `({0}, hidden_size)`, *optional*):
Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation. This
is useful if you want more control over how to convert `input_ids` indices into associated vectors than the
model's internal embedding lookup matrix.
output_attentions (`bool`, *optional*):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
tensors for more detail.
output_hidden_states (`bool`, *optional*):
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
more detail.
return_dict (`bool`, *optional*):
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
"""
@add_start_docstrings(
"The bare I-BERT Model transformer outputting raw hidden-states without any specific head on top.",
IBERT_START_DOCSTRING,
)
class IBertModel(IBertPreTrainedModel):
"""
The model can behave as an encoder (with only self-attention) as well as a decoder, in which case a layer of
cross-attention is added between the self-attention layers, following the architecture described in [Attention is
all you need](https://arxiv.org/abs/1706.03762) by Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit,
Llion Jones, Aidan N. Gomez, Lukasz Kaiser and Illia Polosukhin.
"""
def __init__(self, config, add_pooling_layer=True):
super().__init__(config)
self.config = config
self.quant_mode = config.quant_mode
self.embeddings = IBertEmbeddings(config)
self.encoder = IBertEncoder(config)
self.pooler = IBertPooler(config) if add_pooling_layer else None
# Initialize weights and apply final processing
self.post_init()
def get_input_embeddings(self):
return self.embeddings.word_embeddings
def set_input_embeddings(self, value):
self.embeddings.word_embeddings = value
def _prune_heads(self, heads_to_prune):
"""
Prunes heads of the model. heads_to_prune: dict of {layer_num: list of heads to prune in this layer} See base
class PreTrainedModel
"""
for layer, heads in heads_to_prune.items():
self.encoder.layer[layer].attention.prune_heads(heads)
@add_start_docstrings_to_model_forward(IBERT_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
@add_code_sample_docstrings(
checkpoint=_CHECKPOINT_FOR_DOC,
output_type=BaseModelOutputWithPoolingAndCrossAttentions,
config_class=_CONFIG_FOR_DOC,
)
def forward(
self,
input_ids: Optional[torch.LongTensor] = None,
attention_mask: Optional[torch.FloatTensor] = None,
token_type_ids: Optional[torch.LongTensor] = None,
position_ids: Optional[torch.LongTensor] = None,
head_mask: Optional[torch.FloatTensor] = None,
inputs_embeds: Optional[torch.FloatTensor] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
) -> Union[BaseModelOutputWithPoolingAndCrossAttentions, Tuple[torch.FloatTensor]]:
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
output_hidden_states = (
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
)
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
if input_ids is not None and inputs_embeds is not None:
raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
elif input_ids is not None:
self.warn_if_padding_and_no_attention_mask(input_ids, attention_mask)
input_shape = input_ids.size()
elif inputs_embeds is not None:
input_shape = inputs_embeds.size()[:-1]
else:
raise ValueError("You have to specify either input_ids or inputs_embeds")
batch_size, seq_length = input_shape
device = input_ids.device if input_ids is not None else inputs_embeds.device
if attention_mask is None:
attention_mask = torch.ones(((batch_size, seq_length)), device=device)
if token_type_ids is None:
token_type_ids = torch.zeros(input_shape, dtype=torch.long, device=device)
# We can provide a self-attention mask of dimensions [batch_size, from_seq_length, to_seq_length]
# ourselves in which case we just need to make it broadcastable to all heads.
extended_attention_mask: torch.Tensor = self.get_extended_attention_mask(attention_mask, input_shape)
# Prepare head mask if needed
# 1.0 in head_mask indicate we keep the head
# attention_probs has shape bsz x n_heads x N x N
# input head_mask has shape [num_heads] or [num_hidden_layers x num_heads]
# and head_mask is converted to shape [num_hidden_layers x batch x num_heads x seq_length x seq_length]
head_mask = self.get_head_mask(head_mask, self.config.num_hidden_layers)
embedding_output, embedding_output_scaling_factor = self.embeddings(
input_ids=input_ids,
position_ids=position_ids,
token_type_ids=token_type_ids,
inputs_embeds=inputs_embeds,
)
encoder_outputs = self.encoder(
embedding_output,
embedding_output_scaling_factor,
attention_mask=extended_attention_mask,
head_mask=head_mask,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
sequence_output = encoder_outputs[0]
pooled_output = self.pooler(sequence_output) if self.pooler is not None else None
if not return_dict:
return (sequence_output, pooled_output) + encoder_outputs[1:]
return BaseModelOutputWithPoolingAndCrossAttentions(
last_hidden_state=sequence_output,
pooler_output=pooled_output,
past_key_values=encoder_outputs.past_key_values,
hidden_states=encoder_outputs.hidden_states,
attentions=encoder_outputs.attentions,
cross_attentions=encoder_outputs.cross_attentions,
)
@add_start_docstrings("""I-BERT Model with a `language modeling` head on top.""", IBERT_START_DOCSTRING)
class IBertForMaskedLM(IBertPreTrainedModel):
_tied_weights_keys = ["lm_head.decoder.bias", "lm_head.decoder.weight"]
def __init__(self, config):
super().__init__(config)
self.ibert = IBertModel(config, add_pooling_layer=False)
self.lm_head = IBertLMHead(config)
# Initialize weights and apply final processing
self.post_init()
def get_output_embeddings(self):
return self.lm_head.decoder
def set_output_embeddings(self, new_embeddings):
self.lm_head.decoder = new_embeddings
@add_start_docstrings_to_model_forward(IBERT_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
@add_code_sample_docstrings(
checkpoint=_CHECKPOINT_FOR_DOC,
output_type=MaskedLMOutput,
config_class=_CONFIG_FOR_DOC,
mask="<mask>",
)
def forward(
self,
input_ids: Optional[torch.LongTensor] = None,
attention_mask: Optional[torch.FloatTensor] = None,
token_type_ids: Optional[torch.LongTensor] = None,
position_ids: Optional[torch.LongTensor] = None,
head_mask: Optional[torch.FloatTensor] = None,
inputs_embeds: Optional[torch.FloatTensor] = None,
labels: Optional[torch.LongTensor] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
) -> Union[MaskedLMOutput, Tuple[torch.FloatTensor]]:
r"""
labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
Labels for computing the masked language modeling loss. Indices should be in `[-100, 0, ...,
config.vocab_size]` (see `input_ids` docstring) Tokens with indices set to `-100` are ignored (masked), the
loss is only computed for the tokens with labels in `[0, ..., config.vocab_size]`
kwargs (`Dict[str, any]`, optional, defaults to *{}*):
Used to hide legacy arguments that have been deprecated.
"""
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
outputs = self.ibert(
input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
position_ids=position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
sequence_output = outputs[0]
prediction_scores = self.lm_head(sequence_output)
masked_lm_loss = None
if labels is not None:
loss_fct = CrossEntropyLoss()
masked_lm_loss = loss_fct(prediction_scores.view(-1, self.config.vocab_size), labels.view(-1))
if not return_dict:
output = (prediction_scores,) + outputs[2:]
return ((masked_lm_loss,) + output) if masked_lm_loss is not None else output
return MaskedLMOutput(
loss=masked_lm_loss,
logits=prediction_scores,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
)
class IBertLMHead(nn.Module):
"""I-BERT Head for masked language modeling."""
def __init__(self, config):
super().__init__()
self.dense = nn.Linear(config.hidden_size, config.hidden_size)
self.layer_norm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
self.decoder = nn.Linear(config.hidden_size, config.vocab_size)
self.bias = nn.Parameter(torch.zeros(config.vocab_size))
self.decoder.bias = self.bias
def forward(self, features, **kwargs):
x = self.dense(features)
x = gelu(x)
x = self.layer_norm(x)
# project back to size of vocabulary with bias
x = self.decoder(x)
return x
def _tie_weights(self):
# To tie those two weights if they get disconnected (on TPU or when the bias is resized)
self.bias = self.decoder.bias
@add_start_docstrings(
"""
I-BERT Model transformer with a sequence classification/regression head on top (a linear layer on top of the pooled
output) e.g. for GLUE tasks.
""",
IBERT_START_DOCSTRING,
)
class IBertForSequenceClassification(IBertPreTrainedModel):
def __init__(self, config):
super().__init__(config)
self.num_labels = config.num_labels
self.ibert = IBertModel(config, add_pooling_layer=False)
self.classifier = IBertClassificationHead(config)
# Initialize weights and apply final processing
self.post_init()
@add_start_docstrings_to_model_forward(IBERT_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
@add_code_sample_docstrings(
checkpoint=_CHECKPOINT_FOR_DOC,
output_type=SequenceClassifierOutput,
config_class=_CONFIG_FOR_DOC,
)
def forward(
self,
input_ids: Optional[torch.LongTensor] = None,
attention_mask: Optional[torch.FloatTensor] = None,
token_type_ids: Optional[torch.LongTensor] = None,
position_ids: Optional[torch.LongTensor] = None,
head_mask: Optional[torch.FloatTensor] = None,
inputs_embeds: Optional[torch.FloatTensor] = None,
labels: Optional[torch.LongTensor] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
) -> Union[SequenceClassifierOutput, Tuple[torch.FloatTensor]]:
r"""
labels (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
Labels for computing the sequence classification/regression loss. Indices should be in `[0, ...,
config.num_labels - 1]`. If `config.num_labels == 1` a regression loss is computed (Mean-Square loss), If
`config.num_labels > 1` a classification loss is computed (Cross-Entropy).
"""
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
outputs = self.ibert(
input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
position_ids=position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
sequence_output = outputs[0]
logits = self.classifier(sequence_output)
loss = None
if labels is not None:
if self.config.problem_type is None:
if self.num_labels == 1:
self.config.problem_type = "regression"
elif self.num_labels > 1 and (labels.dtype == torch.long or labels.dtype == torch.int):
self.config.problem_type = "single_label_classification"
else:
self.config.problem_type = "multi_label_classification"
if self.config.problem_type == "regression":
loss_fct = MSELoss()
if self.num_labels == 1:
loss = loss_fct(logits.squeeze(), labels.squeeze())
else:
loss = loss_fct(logits, labels)
elif self.config.problem_type == "single_label_classification":
loss_fct = CrossEntropyLoss()
loss = loss_fct(logits.view(-1, self.num_labels), labels.view(-1))
elif self.config.problem_type == "multi_label_classification":
loss_fct = BCEWithLogitsLoss()
loss = loss_fct(logits, labels)
if not return_dict:
output = (logits,) + outputs[2:]
return ((loss,) + output) if loss is not None else output
return SequenceClassifierOutput(
loss=loss,
logits=logits,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
)
@add_start_docstrings(
"""
I-BERT Model with a multiple choice classification head on top (a linear layer on top of the pooled output and a
softmax) e.g. for RocStories/SWAG tasks.
""",
IBERT_START_DOCSTRING,
)
class IBertForMultipleChoice(IBertPreTrainedModel):
def __init__(self, config):
super().__init__(config)
self.ibert = IBertModel(config)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
self.classifier = nn.Linear(config.hidden_size, 1)
# Initialize weights and apply final processing
self.post_init()
@add_start_docstrings_to_model_forward(IBERT_INPUTS_DOCSTRING.format("batch_size, num_choices, sequence_length"))
@add_code_sample_docstrings(
checkpoint=_CHECKPOINT_FOR_DOC,
output_type=MultipleChoiceModelOutput,
config_class=_CONFIG_FOR_DOC,
)
def forward(
self,
input_ids: Optional[torch.LongTensor] = None,
token_type_ids: Optional[torch.LongTensor] = None,
attention_mask: Optional[torch.FloatTensor] = None,
labels: Optional[torch.LongTensor] = None,
position_ids: Optional[torch.LongTensor] = None,
head_mask: Optional[torch.FloatTensor] = None,
inputs_embeds: Optional[torch.FloatTensor] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
) -> Union[MultipleChoiceModelOutput, Tuple[torch.FloatTensor]]:
r"""
labels (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
Labels for computing the multiple choice classification loss. Indices should be in `[0, ...,
num_choices-1]` where `num_choices` is the size of the second dimension of the input tensors. (See
`input_ids` above)
"""
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
num_choices = input_ids.shape[1] if input_ids is not None else inputs_embeds.shape[1]
flat_input_ids = input_ids.view(-1, input_ids.size(-1)) if input_ids is not None else None
flat_position_ids = position_ids.view(-1, position_ids.size(-1)) if position_ids is not None else None
flat_token_type_ids = token_type_ids.view(-1, token_type_ids.size(-1)) if token_type_ids is not None else None
flat_attention_mask = attention_mask.view(-1, attention_mask.size(-1)) if attention_mask is not None else None
flat_inputs_embeds = (
inputs_embeds.view(-1, inputs_embeds.size(-2), inputs_embeds.size(-1))
if inputs_embeds is not None
else None
)
outputs = self.ibert(
flat_input_ids,
position_ids=flat_position_ids,
token_type_ids=flat_token_type_ids,
attention_mask=flat_attention_mask,
head_mask=head_mask,
inputs_embeds=flat_inputs_embeds,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
pooled_output = outputs[1]
pooled_output = self.dropout(pooled_output)
logits = self.classifier(pooled_output)
reshaped_logits = logits.view(-1, num_choices)
loss = None
if labels is not None:
loss_fct = CrossEntropyLoss()
loss = loss_fct(reshaped_logits, labels)
if not return_dict:
output = (reshaped_logits,) + outputs[2:]
return ((loss,) + output) if loss is not None else output
return MultipleChoiceModelOutput(
loss=loss,
logits=reshaped_logits,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
)
@add_start_docstrings(
"""
I-BERT Model with a token classification head on top (a linear layer on top of the hidden-states output) e.g. for
Named-Entity-Recognition (NER) tasks.
""",
IBERT_START_DOCSTRING,
)
class IBertForTokenClassification(IBertPreTrainedModel):
def __init__(self, config):
super().__init__(config)
self.num_labels = config.num_labels
self.ibert = IBertModel(config, add_pooling_layer=False)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
self.classifier = nn.Linear(config.hidden_size, config.num_labels)
# Initialize weights and apply final processing
self.post_init()
@add_start_docstrings_to_model_forward(IBERT_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
@add_code_sample_docstrings(
checkpoint=_CHECKPOINT_FOR_DOC,
output_type=TokenClassifierOutput,
config_class=_CONFIG_FOR_DOC,
)
def forward(
self,
input_ids: Optional[torch.LongTensor] = None,
attention_mask: Optional[torch.FloatTensor] = None,
token_type_ids: Optional[torch.LongTensor] = None,
position_ids: Optional[torch.LongTensor] = None,
head_mask: Optional[torch.FloatTensor] = None,
inputs_embeds: Optional[torch.FloatTensor] = None,
labels: Optional[torch.LongTensor] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
) -> Union[TokenClassifierOutput, Tuple[torch.FloatTensor]]:
r"""
labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
Labels for computing the token classification loss. Indices should be in `[0, ..., config.num_labels - 1]`.
"""
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
outputs = self.ibert(
input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
position_ids=position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
sequence_output = outputs[0]
sequence_output = self.dropout(sequence_output)
logits = self.classifier(sequence_output)
loss = None
if labels is not None:
loss_fct = CrossEntropyLoss()
loss = loss_fct(logits.view(-1, self.num_labels), labels.view(-1))
if not return_dict:
output = (logits,) + outputs[2:]
return ((loss,) + output) if loss is not None else output
return TokenClassifierOutput(
loss=loss,
logits=logits,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
)
class IBertClassificationHead(nn.Module):
"""Head for sentence-level classification tasks."""
def __init__(self, config):
super().__init__()
self.dense = nn.Linear(config.hidden_size, config.hidden_size)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
self.out_proj = nn.Linear(config.hidden_size, config.num_labels)
def forward(self, features, **kwargs):
hidden_states = features[:, 0, :] # take <s> token (equiv. to [CLS])
hidden_states = self.dropout(hidden_states)
hidden_states = self.dense(hidden_states)
hidden_states = torch.tanh(hidden_states)
hidden_states = self.dropout(hidden_states)
hidden_states = self.out_proj(hidden_states)
return hidden_states
@add_start_docstrings(
"""
I-BERT Model with a span classification head on top for extractive question-answering tasks like SQuAD (a linear
layers on top of the hidden-states output to compute `span start logits` and `span end logits`).
""",
IBERT_START_DOCSTRING,
)
class IBertForQuestionAnswering(IBertPreTrainedModel):
def __init__(self, config):
super().__init__(config)
self.num_labels = config.num_labels
self.ibert = IBertModel(config, add_pooling_layer=False)
self.qa_outputs = nn.Linear(config.hidden_size, config.num_labels)
# Initialize weights and apply final processing
self.post_init()
@add_start_docstrings_to_model_forward(IBERT_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
@add_code_sample_docstrings(
checkpoint=_CHECKPOINT_FOR_DOC,
output_type=QuestionAnsweringModelOutput,
config_class=_CONFIG_FOR_DOC,
)
def forward(
self,
input_ids: Optional[torch.LongTensor] = None,
attention_mask: Optional[torch.FloatTensor] = None,
token_type_ids: Optional[torch.LongTensor] = None,
position_ids: Optional[torch.LongTensor] = None,
head_mask: Optional[torch.FloatTensor] = None,
inputs_embeds: Optional[torch.FloatTensor] = None,
start_positions: Optional[torch.LongTensor] = None,
end_positions: Optional[torch.LongTensor] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
) -> Union[QuestionAnsweringModelOutput, Tuple[torch.FloatTensor]]:
r"""
start_positions (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
Labels for position (index) of the start of the labelled span for computing the token classification loss.
Positions are clamped to the length of the sequence (`sequence_length`). Position outside of the sequence
are not taken into account for computing the loss.
end_positions (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
Labels for position (index) of the end of the labelled span for computing the token classification loss.
Positions are clamped to the length of the sequence (`sequence_length`). Position outside of the sequence
are not taken into account for computing the loss.
"""
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
outputs = self.ibert(
input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
position_ids=position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
sequence_output = outputs[0]
logits = self.qa_outputs(sequence_output)
start_logits, end_logits = logits.split(1, dim=-1)
start_logits = start_logits.squeeze(-1).contiguous()
end_logits = end_logits.squeeze(-1).contiguous()
total_loss = None
if start_positions is not None and end_positions is not None:
# If we are on multi-GPU, split add a dimension
if len(start_positions.size()) > 1:
start_positions = start_positions.squeeze(-1)
if len(end_positions.size()) > 1:
end_positions = end_positions.squeeze(-1)
# sometimes the start/end positions are outside our model inputs, we ignore these terms
ignored_index = start_logits.size(1)
start_positions = start_positions.clamp(0, ignored_index)
end_positions = end_positions.clamp(0, ignored_index)
loss_fct = CrossEntropyLoss(ignore_index=ignored_index)
start_loss = loss_fct(start_logits, start_positions)
end_loss = loss_fct(end_logits, end_positions)
total_loss = (start_loss + end_loss) / 2
if not return_dict:
output = (start_logits, end_logits) + outputs[2:]
return ((total_loss,) + output) if total_loss is not None else output
return QuestionAnsweringModelOutput(
loss=total_loss,
start_logits=start_logits,
end_logits=end_logits,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
)
def create_position_ids_from_input_ids(input_ids, padding_idx, past_key_values_length=0):
"""
Replace non-padding symbols with their position numbers. Position numbers begin at padding_idx+1. Padding symbols
are ignored. This is modified from fairseq's *utils.make_positions*.
Args:
input_ids (`torch.LongTensor`):
Indices of input sequence tokens in the vocabulary.
Returns: torch.Tensor
"""
# The series of casts and type-conversions here are carefully balanced to both work with ONNX export and XLA.
mask = input_ids.ne(padding_idx).int()
incremental_indices = (torch.cumsum(mask, dim=1).type_as(mask) + past_key_values_length) * mask
return incremental_indices.long() + padding_idx
| transformers/src/transformers/models/ibert/modeling_ibert.py/0 | {
"file_path": "transformers/src/transformers/models/ibert/modeling_ibert.py",
"repo_id": "transformers",
"token_count": 24475
} | 97 |
# coding=utf-8
# Copyright 2023 Microsoft Research and The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""Processor class for KOSMOS-2."""
import copy
import math
import re
from typing import List, Optional, Tuple, Union
from ...image_processing_utils import BatchFeature
from ...image_utils import ImageInput, is_batched
from ...processing_utils import ProcessorMixin
from ...tokenization_utils import AddedToken
from ...tokenization_utils_base import BatchEncoding, PaddingStrategy, TextInput, TruncationStrategy
from ...utils import TensorType
BboxInput = Union[
List[Tuple[int, int]],
List[Tuple[float, float, float, float]],
List[List[Tuple[int, int]]],
List[List[Tuple[float, float, float]]],
]
class Kosmos2Processor(ProcessorMixin):
r"""
Constructs an KOSMOS-2 processor which wraps a KOSMOS-2 image processor and a KOSMOS-2 tokenizer into a single
processor.
[`Kosmos2Processor`] offers all the functionalities of [`CLIPImageProcessor`] and some functionalities of
[`XLMRobertaTokenizerFast`]. See the docstring of [`~Kosmos2Processor.__call__`] and [`~Kosmos2Processor.decode`]
for more information.
Args:
image_processor (`CLIPImageProcessor`):
An instance of [`CLIPImageProcessor`]. The image processor is a required input.
tokenizer (`XLMRobertaTokenizerFast`):
An instance of ['XLMRobertaTokenizerFast`]. The tokenizer is a required input.
num_patch_index_tokens (`int`, *optional*, defaults to 1024):
The number of tokens that represent patch indices.
"""
attributes = ["image_processor", "tokenizer"]
image_processor_class = "CLIPImageProcessor"
tokenizer_class = ("XLMRobertaTokenizer", "XLMRobertaTokenizerFast")
def __init__(self, image_processor, tokenizer, num_patch_index_tokens=1024):
tokenizer.return_token_type_ids = False
self.eod_token = "</doc>"
self.boi_token = "<image>"
self.eoi_token = "</image>"
self.eoc_token = "</chunk>"
self.eol_token = "</line>"
self.bop_token = "<phrase>"
self.eop_token = "</phrase>"
self.boo_token = "<object>"
self.eoo_token = "</object>"
self.dom_token = "</delimiter_of_multi_objects/>"
self.grd_token = "<grounding>"
self.tag_tokens = [
self.eod_token,
self.boi_token,
self.eoi_token,
self.eoc_token,
self.eol_token,
self.bop_token,
self.eop_token,
self.boo_token,
self.eoo_token,
self.dom_token,
self.grd_token,
]
self.num_patch_index_tokens = num_patch_index_tokens
patch_index_tokens = [f"<patch_index_{str(x).zfill(4)}>" for x in range(self.num_patch_index_tokens)]
tokens_to_add = []
for token in self.tag_tokens + patch_index_tokens:
tokens_to_add.append(AddedToken(token, lstrip=True, rstrip=False, normalized=False))
tokenizer.add_tokens(tokens_to_add)
super().__init__(image_processor, tokenizer)
def __call__(
self,
images: ImageInput = None,
text: Union[TextInput, List[TextInput]] = None,
bboxes: BboxInput = None,
num_image_tokens: Optional[int] = 64,
first_image_token_id: Optional[int] = None,
add_special_tokens: bool = True,
add_eos_token: bool = False,
padding: Union[bool, str, PaddingStrategy] = False,
truncation: Union[bool, str, TruncationStrategy] = None,
max_length: Optional[int] = None,
pad_to_multiple_of: Optional[int] = None,
return_attention_mask: Optional[bool] = None,
return_length: bool = False,
verbose: bool = True,
return_tensors: Optional[Union[str, TensorType]] = None,
**kwargs,
) -> BatchFeature:
"""
This method uses [`CLIPImageProcessor.__call__`] method to prepare image(s) for the model, and
[`XLMRobertaTokenizerFast.__call__`] to prepare text for the model.
Please refer to the docstring of the above two methods for more information.
The rest of this documentation shows the arguments specific to `Kosmos2Processor`.
Args:
bboxes (`Union[List[Tuple[int]], List[Tuple[float]], List[List[Tuple[int]]], List[List[Tuple[float]]]]`, *optional*):
The bounding bboxes associated to `texts`.
num_image_tokens (`int`, defaults to 64):
The number of (consecutive) places that are used to mark the placeholders to store image information.
This should be the same as `latent_query_num` in the instance of `Kosmos2Config` you are using.
first_image_token_id (`int`, *optional*):
The token id that will be used for the first place of the subsequence that is reserved to store image
information. If unset, will default to `self.tokenizer.unk_token_id + 1`.
add_eos_token (`bool`, defaults to `False`):
Whether or not to include `EOS` token id in the encoding when `add_special_tokens=True`.
"""
if images is None and text is None:
raise ValueError("You have to specify either images or text.")
encoding = BatchFeature()
if images is not None:
image_encoding = self.image_processor(images, return_tensors=return_tensors)
encoding.update(image_encoding)
if text is not None:
text = self.preprocess_examples(text, images, bboxes, num_image_tokens=num_image_tokens)
if add_special_tokens and not add_eos_token:
if isinstance(text, str):
text = f"{self.tokenizer.bos_token}{text}"
elif isinstance(text, list):
text = [f"{self.tokenizer.bos_token}{s}" for s in text]
text_encoding = self.tokenizer(
text=text,
add_special_tokens=(add_special_tokens and add_eos_token),
padding=padding and images is None,
truncation=truncation,
max_length=max_length,
pad_to_multiple_of=pad_to_multiple_of if images is None else pad_to_multiple_of,
return_attention_mask=return_attention_mask,
verbose=verbose,
return_tensors=return_tensors if images is None else None,
**kwargs,
)
encoding.update(text_encoding)
if text is not None and images is not None:
# Use the id of the first token after <unk>
if first_image_token_id is None:
first_image_token_id = self.tokenizer.unk_token_id + 1
# To see if we need one more `0` (for `<s>`) at the beginning of `image_embeds_position_mask`.
with_bos = add_special_tokens
# The first (actual) `<image>` token is always at the 1st or 2nd place (after `<s>` if any). Here we look
# for the second `<image>` token (which indicate the first image token).
start_index = int(with_bos) + 1
# Add `image_embeds_position_mask`: the leading and trailing `0` are for `boi` and `eoi` tokens. The `1` indicates
# the places of image tokens.
image_token_ids = list(range(first_image_token_id, first_image_token_id + num_image_tokens))
base_image_embeds_position_mask = [0] + [1] * num_image_tokens + [0]
# loop over `encoding["input_ids"]`
input_ids = []
image_embeds_position_mask = []
all_input_ids = encoding["input_ids"]
# not batched -> (changed to) batch of size 1
if isinstance(text, str):
all_input_ids = [all_input_ids]
encoding["attention_mask"] = [encoding["attention_mask"]]
for text_ids in all_input_ids:
# change the ids for the fake `<image>` tokens in `input_ids`
text_ids = text_ids[:start_index] + image_token_ids + text_ids[start_index + num_image_tokens :]
input_ids.append(text_ids)
mask = copy.copy(base_image_embeds_position_mask)
if with_bos:
# for `<s>`
mask = [0] + mask
# trailing part (which are not related to the image)
mask += [0] * (len(text_ids) - len(mask))
image_embeds_position_mask.append(mask)
if isinstance(text, list):
sorted_length = sorted(
[(idx, len(x)) for idx, x in enumerate(text_encoding.input_ids)], key=lambda x: x[-1]
)
_, min_len_not_padded = sorted_length[0]
idx, _ = sorted_length[-1]
text_encoding = self.tokenizer(
text=[text[idx]],
add_special_tokens=(add_special_tokens and add_eos_token),
padding=padding,
truncation=truncation,
max_length=max_length,
pad_to_multiple_of=pad_to_multiple_of,
verbose=verbose,
return_tensors=None,
**kwargs,
)
max_len_padded = len(text_encoding.input_ids[0])
if min_len_not_padded != max_len_padded:
if self.tokenizer.padding_side == "right":
input_ids = [x + [self.tokenizer.pad_token_id] * (max_len_padded - len(x)) for x in input_ids]
image_embeds_position_mask = [
x + [0] * (max_len_padded - len(x)) for x in image_embeds_position_mask
]
encoding["attention_mask"] = [
x + [0] * (max_len_padded - len(x)) for x in encoding["attention_mask"]
]
elif self.tokenizer.padding_side == "left":
input_ids = [[self.tokenizer.pad_token_id] * (max_len_padded - len(x)) + x for x in input_ids]
image_embeds_position_mask = [
[0] * (max_len_padded - len(x)) + x for x in image_embeds_position_mask
]
encoding["attention_mask"] = [
[0] * (max_len_padded - len(x)) + x for x in encoding["attention_mask"]
]
# un-batch if necessary
if isinstance(text, str) and return_tensors is None:
input_ids = input_ids[0]
encoding["attention_mask"] = encoding["attention_mask"][0]
image_embeds_position_mask = image_embeds_position_mask[0]
# update (with the target tensor type if specified)
encoding.update(
BatchEncoding(
data={
"input_ids": input_ids,
"attention_mask": encoding["attention_mask"],
"image_embeds_position_mask": image_embeds_position_mask,
},
tensor_type=return_tensors,
)
)
return encoding
def _check_bboxes_for_single_text(self, bboxes):
"""
Check `bboxes` for a single text example. It could be
- `None`: no bounding box associated to a text.
- A list with each element being the bounding boxes associated to one `<phrase> ... </phrase>` pair found
in a text. This could be:
- `None`: no bounding box associated to a `<phrase> ... </phrase>` pair.
- A tuple of 2 integers: A single bounding box specified by patch indices.
- A tuple of 4 float point number: A single bounding box specified by (normalized) coordinates.
- A list containing the above 2 tuple types: Multiple bounding boxes for a
`<phrase> ... </phrase>` pair.
"""
if bboxes is None:
return
elif not isinstance(bboxes, list):
raise ValueError("`bboxes` (for a single text example) should be `None` or a list.")
# `bbox` is the bounding boxes for a single <phrase> </phrase> pair
for bbox in bboxes:
if bbox is None:
continue
elif not isinstance(bbox, list):
bbox = [bbox]
for element in bbox:
if not isinstance(element, tuple) or not (
(len(element) == 2 and all(isinstance(x, int) for x in element))
or (len(element) == 4 and all(isinstance(x, float) for x in element))
):
raise ValueError(
"Each element in `bboxes` (for a single text example) should be either `None`, a tuple containing "
"2 integers or 4 float point numbers, or a list containing such tuples. Also "
"make sure the arguments `texts` and `bboxes` passed to `preprocess_text` are both in "
"batches or both for a single example."
)
def _preprocess_single_example(self, text, image, bboxes, img_info_tokens):
text = text.strip()
if image is not None:
# Add `<image> ... (fake) image tokens ... </image>`
text = f"{img_info_tokens} {text}"
# Add `<object> <patch_idx_xxxx> <patch_idx_yyy> </object>` after `<phrase> phrase text </phrase>`
text = self._insert_patch_index_tokens(text, bboxes)
return text
def preprocess_examples(
self,
texts: Union[TextInput, List[TextInput]],
images: ImageInput = None,
bboxes: BboxInput = None,
num_image_tokens: Optional[int] = 64,
) -> Union[str, List[str]]:
"""Add image and bounding box information to `texts` as image and patch index tokens.
Args:
texts (`Union[TextInput, List[TextInput]]`): The texts to be processed.
images (`ImageInput`, *optional*): The images associated to `texts`.
bboxes (`Union[List[Tuple[int]], List[Tuple[float]], List[List[Tuple[int]]], List[List[Tuple[float]]]]`, *optional*):
The bounding bboxes associated to `texts`.
num_image_tokens (`int`, *optional*, defaults to 64):
The number of image tokens (used as latent queries). This should corresponds to the `latent_query_num`
attribute in `Kosmos2Config`.
Returns:
`Union[TextInput, List[TextInput]]`: The processed texts with image and patch index tokens.
"""
# These are fake `<image>` tokens enclosed between (the actual) `<image>` token and `</image>`.
img_tokens = [self.boi_token] * num_image_tokens
img_info_tokens = " ".join([self.boi_token] + img_tokens + [self.eoi_token])
# make batch to simplify processing logic
batched = True
if isinstance(texts, str):
batched = False
texts = [texts]
if images is None:
images = [None] * len(texts)
elif not is_batched(images):
images = [images]
if len(texts) != len(images):
raise ValueError(
f"The number of examples in `texts` and `images` should be the same. Got {len(texts)} v.s. {len(images)} instead."
)
if not batched:
self._check_bboxes_for_single_text(bboxes)
bboxes = [bboxes]
elif bboxes is not None:
if not isinstance(bboxes, list):
raise ValueError("`bboxes` should be `None` or a list (as a batch) when `texts` is passed as a batch.")
for x in bboxes:
self._check_bboxes_for_single_text(x)
else:
bboxes = [None] * len(texts)
if len(bboxes) != len(texts):
raise ValueError(
f"The number of examples in `texts` and `bboxes` should be the same. Got {len(texts)} v.s. {len(bboxes)} instead."
)
result = [
self._preprocess_single_example(text, image, bbox, img_info_tokens)
for text, image, bbox in zip(texts, images, bboxes)
]
# un-batch if necessary
if not batched:
result = result[0]
return result
# Copied from transformers.models.blip.processing_blip.BlipProcessor.batch_decode with BertTokenizerFast->PreTrainedTokenizer
def batch_decode(self, *args, **kwargs):
"""
This method forwards all its arguments to PreTrainedTokenizer's [`~PreTrainedTokenizer.batch_decode`]. Please
refer to the docstring of this method for more information.
"""
return self.tokenizer.batch_decode(*args, **kwargs)
# Copied from transformers.models.blip.processing_blip.BlipProcessor.decode with BertTokenizerFast->PreTrainedTokenizer
def decode(self, *args, **kwargs):
"""
This method forwards all its arguments to PreTrainedTokenizer's [`~PreTrainedTokenizer.decode`]. Please refer to
the docstring of this method for more information.
"""
return self.tokenizer.decode(*args, **kwargs)
def post_process_generation(self, text, cleanup_and_extract=True):
caption = text.split(self.eoi_token)[-1]
if cleanup_and_extract:
return clean_text_and_extract_entities_with_bboxes(caption)
return caption
@property
# Copied from transformers.models.blip.processing_blip.BlipProcessor.model_input_names
def model_input_names(self):
tokenizer_input_names = self.tokenizer.model_input_names
image_processor_input_names = self.image_processor.model_input_names
return list(dict.fromkeys(tokenizer_input_names + image_processor_input_names))
def _insert_patch_index_tokens(self, text: str, bboxes: Union[List[Tuple[int]], List[Tuple[float]]]) -> str:
if bboxes is None or len(bboxes) == 0:
return text
matched_phrases = list(re.finditer(r"<phrase>.+?</phrase>", string=text))
if len(matched_phrases) != len(bboxes):
raise ValueError(
f"The number of elements in `bboxes` should be the same as the number of `<phrase> ... </phrase>` pairs in `text`. Got {len(matched_phrases)} v.s. {len(bboxes)} instead."
)
# insert object's patch index tokens
# the found `<phrase> ... </phrase>` pairs.
curr_pos = 0
buffer = []
for matched, bbox in zip(matched_phrases, bboxes):
_, end = matched.span()
buffer.append(text[curr_pos:end])
curr_pos = end
# A phrase without bbox
if bbox is None:
continue
# A phrase with a single bbox
if isinstance(bbox, tuple):
bbox = [bbox]
patch_index_strings = []
# A phrase could have multiple bboxes
if not all(box is not None for box in bbox):
raise ValueError(
"The multiple bounding boxes for a single phrase should not contain any `None` value."
)
for box in bbox:
patch_index_1, patch_index_2 = self._convert_bbox_to_patch_index_tokens(box)
patch_index_strings.append(f"{patch_index_1} {patch_index_2}")
# `bbox` being an empty list
if len(patch_index_strings) == 0:
continue
position_str = " </delimiter_of_multi_objects/> ".join(patch_index_strings)
buffer.append(f"<object> {position_str} </object>")
# remaining
if curr_pos < len(text):
buffer.append(text[curr_pos:])
text = "".join(buffer)
return text
def _convert_bbox_to_patch_index_tokens(
self, bbox: Union[Tuple[int, int], Tuple[float, float, float, float]]
) -> Tuple[str, str]:
# already computed patch indices
if len(bbox) == 2:
idx_1, idx_2 = bbox
# bbox specified with (normalized) coordinates
else:
# use `self.tokenizer` to get `num_patches_per_side`
num_patches_per_side = int(math.sqrt(self.num_patch_index_tokens))
idx_1, idx_2 = coordinate_to_patch_index(bbox, num_patches_per_side)
token_1 = f"<patch_index_{str(idx_1).zfill(4)}>"
token_2 = f"<patch_index_{str(idx_2).zfill(4)}>"
return token_1, token_2
def coordinate_to_patch_index(bbox: Tuple[float, float, float, float], num_patches_per_side: int) -> Tuple[int, int]:
"""Convert a bounding box to a pair of patch indices.
Args:
bbox (`Tuple[float, float, float, float]`):
The 4 coordinates of the bounding box, with the format being (x1, y1, x2, y2) specifying the upper-left and
lower-right corners of the box. It should have x2 > x1 and y2 > y1.
num_patches_per_side (`int`): the number of patches along each side.
Returns:
`Tuple[int, int]`: A pair of patch indices representing the upper-left patch and lower-right patch.
"""
(x1, y1, x2, y2) = bbox
if not (x2 > x1 and y2 > y1):
raise ValueError("The coordinates in `bbox` should be `(x1, y1, x2, y2)` with `x2 > x1` and `y2 > y1`.")
ul_x = math.floor(x1 * num_patches_per_side)
ul_y = math.floor(y1 * num_patches_per_side)
lr_x = math.ceil(x2 * num_patches_per_side - 1)
lr_y = math.ceil(y2 * num_patches_per_side - 1)
ul_idx = ul_y * num_patches_per_side + ul_x
lr_idx = lr_y * num_patches_per_side + lr_x
return ul_idx, lr_idx
# copied from https://github.com/microsoft/unilm/blob/97e4923e97d3ee10b57e97013556e3fd0d207a9b/kosmos-2/demo/decode_string.py#L35C1-L75C38
# (with format modifications)
def patch_index_to_coordinate(ul_idx: int, lr_idx: int, num_patches_per_side: int):
"""
Given a grid of length `num_patches_per_side` and the indices of the upper-left and lower-right corners of a
bounding box, returns the normalized coordinates of the bounding box, in the form (x1, y1, x2, y2).
Args:
ul_idx (`int`): the index of the grid cell that corresponds to the upper-left corner of the bounding box.
lr_idx (`int`): the index of the grid cell that corresponds to the lower-right corner of the bounding box.
num_patches_per_side (`int`): the number of patches along each side.
Returns:
`Tuple[float]`: the normalized coordinates of the bounding box, in the form (x1, y1, x2, y2).
"""
# Compute the size of each cell in the grid
cell_size = 1.0 / num_patches_per_side
# Compute the x and y indices of the upper-left and lower-right corners of the bounding box
ul_x = ul_idx % num_patches_per_side
ul_y = ul_idx // num_patches_per_side
lr_x = lr_idx % num_patches_per_side
lr_y = lr_idx // num_patches_per_side
# Compute the normalized coordinates of the bounding box
if ul_idx == lr_idx:
x1 = ul_x * cell_size
y1 = ul_y * cell_size
x2 = lr_x * cell_size + cell_size
y2 = lr_y * cell_size + cell_size
elif ul_x == lr_x or ul_y == lr_y:
x1 = ul_x * cell_size
y1 = ul_y * cell_size
x2 = lr_x * cell_size + cell_size
y2 = lr_y * cell_size + cell_size
else:
x1 = ul_x * cell_size + cell_size / 2
y1 = ul_y * cell_size + cell_size / 2
x2 = lr_x * cell_size + cell_size / 2
y2 = lr_y * cell_size + cell_size / 2
return x1, y1, x2, y2
# copied from https://github.com/microsoft/unilm/blob/97e4923e97d3ee10b57e97013556e3fd0d207a9b/kosmos-2/demo/decode_string.py#L4-L33
# (with format modifications)
def extract_entities_with_patch_indices(text):
"""Extract entities contained in `text`. The bounding bboxes is given in the form of patch indices.
This functioin is only intended to be used within `clean_text_and_extract_entities_with_bboxes` where further
processing happens, including converting to normalized coordinates and whitespace character cleaning up.
Examples:
```python
>>> text = "<grounding> An image of<phrase> a snowman</phrase><object><patch_index_0044><patch_index_0863></object> warming himself by<phrase> a fire</phrase><object><patch_index_0005><patch_index_0911></object>."
>>> entities = extract_entities_with_patch_indices(text)
>>> entities
[(' a snowman', (31, 41), [(44, 863)]), (' a fire', (130, 137), [(5, 911)])]
```"""
# The regular expression pattern for matching the required formats
pattern = r"(?:(<phrase>([^<]+)</phrase>))?<object>((?:<patch_index_\d+><patch_index_\d+></delimiter_of_multi_objects/>)*<patch_index_\d+><patch_index_\d+>)</object>"
# Find all matches in the given string
matches = re.finditer(pattern, text)
# Initialize an empty list to store the valid patch_index combinations
entities_with_patch_indices = []
for match in matches:
# span of a `phrase` that is between <phrase> and </phrase>
span = match.span(2)
phrase_tag, phrase, match_content = match.groups()
if not phrase_tag:
phrase = None
# We take the starting position of `<object>`
span = (match.span(0)[0], match.span(0)[0])
# Split the match_content by the delimiter to get individual patch_index pairs
patch_index_pairs = match_content.split("</delimiter_of_multi_objects/>")
entity_bboxes = []
for pair in patch_index_pairs:
# Extract the xxxx and yyyy values from the patch_index pair
x = re.search(r"<patch_index_(\d+)>", pair)
y = re.search(r"<patch_index_(\d+)>", pair[1:])
if x and y:
if phrase:
entity_bboxes.append((int(x.group(1)), int(y.group(1))))
else:
entity_bboxes.append((int(x.group(1)), int(y.group(1))))
if phrase:
entities_with_patch_indices.append((phrase, span, entity_bboxes))
else:
for bbox in entity_bboxes:
# fake entity name
entity = f"<patch_index_{bbox[0]}><patch_index_{bbox[1]}>"
entities_with_patch_indices.append((entity, span, [bbox]))
return entities_with_patch_indices
def adjust_entity_positions(entity, text):
"""Adjust the positions of the entities in `text` to be relative to the text with special fields removed."""
entity_name, (start, end) = entity
# computed the length of strings with special fields (tag tokens, patch index tokens, etc.) removed
adjusted_start = len(re.sub("<.*?>", "", text[:start]))
adjusted_end = len(re.sub("<.*?>", "", text[:end]))
adjusted_entity = (entity_name, (adjusted_start, adjusted_end))
return adjusted_entity
def _cleanup_spaces(text, entities):
"""Remove the spaces around the text and the entities in it."""
new_text = text.strip()
leading_spaces = len(text) - len(text.lstrip())
new_entities = []
for entity_name, (start, end), bboxes in entities:
entity_name_leading_spaces = len(entity_name) - len(entity_name.lstrip())
entity_name_trailing_spaces = len(entity_name) - len(entity_name.rstrip())
start = start - leading_spaces + entity_name_leading_spaces
end = end - leading_spaces - entity_name_trailing_spaces
entity_name = entity_name.strip()
new_entities.append((entity_name, (start, end), bboxes))
return new_text, new_entities
# copied from https://github.com/microsoft/unilm/blob/97e4923e97d3ee10b57e97013556e3fd0d207a9b/kosmos-2/demo/decode_string.py#L77-L87
# (with format modifications)
def clean_text_and_extract_entities_with_bboxes(text, num_patches_per_side=32):
"""Remove the tag tokens from `text`, extract entities in it with some cleaning up of white characters.
Examples:
```python
>>> text = "<grounding> An image of<phrase> a snowman</phrase><object><patch_index_0044><patch_index_0863></object> warming himself by<phrase> a fire</phrase><object><patch_index_0005><patch_index_0911></object>."
>>> clean_text, entities = clean_text_and_extract_entities_with_bboxes(text)
>>> clean_text
'An image of a snowman warming himself by a fire.'
>>> entities
[('a snowman', (12, 21), [(0.390625, 0.046875, 0.984375, 0.828125)]), ('a fire', (41, 47), [(0.171875, 0.015625, 0.484375, 0.890625)])]
```"""
# remove special fields (tag tokens, patch index tokens, etc.)
processed_text = re.sub("<.*?>", "", text)
entities_with_patch_indices = extract_entities_with_patch_indices(text)
entities = []
for item in entities_with_patch_indices:
entity, bboxes = item[0:2], item[2]
adjusted_entity = adjust_entity_positions(entity, text)
bboxes_in_coords = [patch_index_to_coordinate(bbox[0], bbox[1], num_patches_per_side) for bbox in bboxes]
entities.append(adjusted_entity + (bboxes_in_coords,))
return _cleanup_spaces(processed_text, entities)
| transformers/src/transformers/models/kosmos2/processing_kosmos2.py/0 | {
"file_path": "transformers/src/transformers/models/kosmos2/processing_kosmos2.py",
"repo_id": "transformers",
"token_count": 13353
} | 98 |
# coding=utf-8
# Copyright 2022 Microsoft Research and The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
""" LayoutLMv3 model configuration"""
from collections import OrderedDict
from typing import TYPE_CHECKING, Any, Mapping, Optional
from packaging import version
from ...configuration_utils import PretrainedConfig
from ...onnx import OnnxConfig
from ...onnx.utils import compute_effective_axis_dimension
from ...utils import logging
if TYPE_CHECKING:
from ...processing_utils import ProcessorMixin
from ...utils import TensorType
logger = logging.get_logger(__name__)
LAYOUTLMV3_PRETRAINED_CONFIG_ARCHIVE_MAP = {
"microsoft/layoutlmv3-base": "https://huggingface.co/microsoft/layoutlmv3-base/resolve/main/config.json",
}
class LayoutLMv3Config(PretrainedConfig):
r"""
This is the configuration class to store the configuration of a [`LayoutLMv3Model`]. It is used to instantiate an
LayoutLMv3 model according to the specified arguments, defining the model architecture. Instantiating a
configuration with the defaults will yield a similar configuration to that of the LayoutLMv3
[microsoft/layoutlmv3-base](https://huggingface.co/microsoft/layoutlmv3-base) architecture.
Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
documentation from [`PretrainedConfig`] for more information.
Args:
vocab_size (`int`, *optional*, defaults to 50265):
Vocabulary size of the LayoutLMv3 model. Defines the number of different tokens that can be represented by
the `inputs_ids` passed when calling [`LayoutLMv3Model`].
hidden_size (`int`, *optional*, defaults to 768):
Dimension of the encoder layers and the pooler layer.
num_hidden_layers (`int`, *optional*, defaults to 12):
Number of hidden layers in the Transformer encoder.
num_attention_heads (`int`, *optional*, defaults to 12):
Number of attention heads for each attention layer in the Transformer encoder.
intermediate_size (`int`, *optional*, defaults to 3072):
Dimension of the "intermediate" (i.e., feed-forward) layer in the Transformer encoder.
hidden_act (`str` or `function`, *optional*, defaults to `"gelu"`):
The non-linear activation function (function or string) in the encoder and pooler. If string, `"gelu"`,
`"relu"`, `"selu"` and `"gelu_new"` are supported.
hidden_dropout_prob (`float`, *optional*, defaults to 0.1):
The dropout probability for all fully connected layers in the embeddings, encoder, and pooler.
attention_probs_dropout_prob (`float`, *optional*, defaults to 0.1):
The dropout ratio for the attention probabilities.
max_position_embeddings (`int`, *optional*, defaults to 512):
The maximum sequence length that this model might ever be used with. Typically set this to something large
just in case (e.g., 512 or 1024 or 2048).
type_vocab_size (`int`, *optional*, defaults to 2):
The vocabulary size of the `token_type_ids` passed when calling [`LayoutLMv3Model`].
initializer_range (`float`, *optional*, defaults to 0.02):
The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
layer_norm_eps (`float`, *optional*, defaults to 1e-5):
The epsilon used by the layer normalization layers.
max_2d_position_embeddings (`int`, *optional*, defaults to 1024):
The maximum value that the 2D position embedding might ever be used with. Typically set this to something
large just in case (e.g., 1024).
coordinate_size (`int`, *optional*, defaults to `128`):
Dimension of the coordinate embeddings.
shape_size (`int`, *optional*, defaults to `128`):
Dimension of the width and height embeddings.
has_relative_attention_bias (`bool`, *optional*, defaults to `True`):
Whether or not to use a relative attention bias in the self-attention mechanism.
rel_pos_bins (`int`, *optional*, defaults to 32):
The number of relative position bins to be used in the self-attention mechanism.
max_rel_pos (`int`, *optional*, defaults to 128):
The maximum number of relative positions to be used in the self-attention mechanism.
max_rel_2d_pos (`int`, *optional*, defaults to 256):
The maximum number of relative 2D positions in the self-attention mechanism.
rel_2d_pos_bins (`int`, *optional*, defaults to 64):
The number of 2D relative position bins in the self-attention mechanism.
has_spatial_attention_bias (`bool`, *optional*, defaults to `True`):
Whether or not to use a spatial attention bias in the self-attention mechanism.
visual_embed (`bool`, *optional*, defaults to `True`):
Whether or not to add patch embeddings.
input_size (`int`, *optional*, defaults to `224`):
The size (resolution) of the images.
num_channels (`int`, *optional*, defaults to `3`):
The number of channels of the images.
patch_size (`int`, *optional*, defaults to `16`)
The size (resolution) of the patches.
classifier_dropout (`float`, *optional*):
The dropout ratio for the classification head.
Example:
```python
>>> from transformers import LayoutLMv3Config, LayoutLMv3Model
>>> # Initializing a LayoutLMv3 microsoft/layoutlmv3-base style configuration
>>> configuration = LayoutLMv3Config()
>>> # Initializing a model (with random weights) from the microsoft/layoutlmv3-base style configuration
>>> model = LayoutLMv3Model(configuration)
>>> # Accessing the model configuration
>>> configuration = model.config
```"""
model_type = "layoutlmv3"
def __init__(
self,
vocab_size=50265,
hidden_size=768,
num_hidden_layers=12,
num_attention_heads=12,
intermediate_size=3072,
hidden_act="gelu",
hidden_dropout_prob=0.1,
attention_probs_dropout_prob=0.1,
max_position_embeddings=512,
type_vocab_size=2,
initializer_range=0.02,
layer_norm_eps=1e-5,
pad_token_id=1,
bos_token_id=0,
eos_token_id=2,
max_2d_position_embeddings=1024,
coordinate_size=128,
shape_size=128,
has_relative_attention_bias=True,
rel_pos_bins=32,
max_rel_pos=128,
rel_2d_pos_bins=64,
max_rel_2d_pos=256,
has_spatial_attention_bias=True,
text_embed=True,
visual_embed=True,
input_size=224,
num_channels=3,
patch_size=16,
classifier_dropout=None,
**kwargs,
):
super().__init__(
vocab_size=vocab_size,
hidden_size=hidden_size,
num_hidden_layers=num_hidden_layers,
num_attention_heads=num_attention_heads,
intermediate_size=intermediate_size,
hidden_act=hidden_act,
hidden_dropout_prob=hidden_dropout_prob,
attention_probs_dropout_prob=attention_probs_dropout_prob,
max_position_embeddings=max_position_embeddings,
type_vocab_size=type_vocab_size,
initializer_range=initializer_range,
layer_norm_eps=layer_norm_eps,
pad_token_id=pad_token_id,
bos_token_id=bos_token_id,
eos_token_id=eos_token_id,
**kwargs,
)
self.max_2d_position_embeddings = max_2d_position_embeddings
self.coordinate_size = coordinate_size
self.shape_size = shape_size
self.has_relative_attention_bias = has_relative_attention_bias
self.rel_pos_bins = rel_pos_bins
self.max_rel_pos = max_rel_pos
self.has_spatial_attention_bias = has_spatial_attention_bias
self.rel_2d_pos_bins = rel_2d_pos_bins
self.max_rel_2d_pos = max_rel_2d_pos
self.text_embed = text_embed
self.visual_embed = visual_embed
self.input_size = input_size
self.num_channels = num_channels
self.patch_size = patch_size
self.classifier_dropout = classifier_dropout
class LayoutLMv3OnnxConfig(OnnxConfig):
torch_onnx_minimum_version = version.parse("1.12")
@property
def inputs(self) -> Mapping[str, Mapping[int, str]]:
# The order of inputs is different for question answering and sequence classification
if self.task in ["question-answering", "sequence-classification"]:
return OrderedDict(
[
("input_ids", {0: "batch", 1: "sequence"}),
("attention_mask", {0: "batch", 1: "sequence"}),
("bbox", {0: "batch", 1: "sequence"}),
("pixel_values", {0: "batch", 1: "num_channels", 2: "height", 3: "width"}),
]
)
else:
return OrderedDict(
[
("input_ids", {0: "batch", 1: "sequence"}),
("bbox", {0: "batch", 1: "sequence"}),
("attention_mask", {0: "batch", 1: "sequence"}),
("pixel_values", {0: "batch", 1: "num_channels"}),
]
)
@property
def atol_for_validation(self) -> float:
return 1e-5
@property
def default_onnx_opset(self) -> int:
return 12
def generate_dummy_inputs(
self,
processor: "ProcessorMixin",
batch_size: int = -1,
seq_length: int = -1,
is_pair: bool = False,
framework: Optional["TensorType"] = None,
num_channels: int = 3,
image_width: int = 40,
image_height: int = 40,
) -> Mapping[str, Any]:
"""
Generate inputs to provide to the ONNX exporter for the specific framework
Args:
processor ([`ProcessorMixin`]):
The processor associated with this model configuration.
batch_size (`int`, *optional*, defaults to -1):
The batch size to export the model for (-1 means dynamic axis).
seq_length (`int`, *optional*, defaults to -1):
The sequence length to export the model for (-1 means dynamic axis).
is_pair (`bool`, *optional*, defaults to `False`):
Indicate if the input is a pair (sentence 1, sentence 2).
framework (`TensorType`, *optional*, defaults to `None`):
The framework (PyTorch or TensorFlow) that the processor will generate tensors for.
num_channels (`int`, *optional*, defaults to 3):
The number of channels of the generated images.
image_width (`int`, *optional*, defaults to 40):
The width of the generated images.
image_height (`int`, *optional*, defaults to 40):
The height of the generated images.
Returns:
Mapping[str, Any]: holding the kwargs to provide to the model's forward function
"""
# A dummy image is used so OCR should not be applied
setattr(processor.image_processor, "apply_ocr", False)
# If dynamic axis (-1) we forward with a fixed dimension of 2 samples to avoid optimizations made by ONNX
batch_size = compute_effective_axis_dimension(
batch_size, fixed_dimension=OnnxConfig.default_fixed_batch, num_token_to_add=0
)
# If dynamic axis (-1) we forward with a fixed dimension of 8 tokens to avoid optimizations made by ONNX
token_to_add = processor.tokenizer.num_special_tokens_to_add(is_pair)
seq_length = compute_effective_axis_dimension(
seq_length, fixed_dimension=OnnxConfig.default_fixed_sequence, num_token_to_add=token_to_add
)
# Generate dummy inputs according to compute batch and sequence
dummy_text = [[" ".join([processor.tokenizer.unk_token]) * seq_length]] * batch_size
# Generate dummy bounding boxes
dummy_bboxes = [[[48, 84, 73, 128]]] * batch_size
# If dynamic axis (-1) we forward with a fixed dimension of 2 samples to avoid optimizations made by ONNX
# batch_size = compute_effective_axis_dimension(batch_size, fixed_dimension=OnnxConfig.default_fixed_batch)
dummy_image = self._generate_dummy_images(batch_size, num_channels, image_height, image_width)
inputs = dict(
processor(
dummy_image,
text=dummy_text,
boxes=dummy_bboxes,
return_tensors=framework,
)
)
return inputs
| transformers/src/transformers/models/layoutlmv3/configuration_layoutlmv3.py/0 | {
"file_path": "transformers/src/transformers/models/layoutlmv3/configuration_layoutlmv3.py",
"repo_id": "transformers",
"token_count": 5486
} | 99 |
# coding=utf-8
# Copyright 2022 EleutherAI and the HuggingFace Inc. team. All rights reserved.
#
# This code is based on EleutherAI's GPT-NeoX library and the GPT-NeoX
# and OPT implementations in this library. It has been modified from its
# original forms to accommodate minor architectural differences compared
# to GPT-NeoX and OPT used by the Meta AI team that trained the model.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""Tokenization classes for LLaMA."""
import os
from shutil import copyfile
from typing import TYPE_CHECKING, Any, Dict, List, Optional, Tuple
import sentencepiece as spm
from ...convert_slow_tokenizer import import_protobuf
from ...tokenization_utils import AddedToken, PreTrainedTokenizer
from ...utils import logging
if TYPE_CHECKING:
from ...tokenization_utils_base import TextInput
logger = logging.get_logger(__name__)
VOCAB_FILES_NAMES = {"vocab_file": "tokenizer.model"}
PRETRAINED_VOCAB_FILES_MAP = {
"vocab_file": {
"hf-internal-testing/llama-tokenizer": "https://huggingface.co/hf-internal-testing/llama-tokenizer/resolve/main/tokenizer.model",
},
"tokenizer_file": {
"hf-internal-testing/llama-tokenizer": "https://huggingface.co/hf-internal-testing/llama-tokenizer/resolve/main/tokenizer_config.json",
},
}
PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
"hf-internal-testing/llama-tokenizer": 2048,
}
SPIECE_UNDERLINE = "▁"
B_INST, E_INST = "[INST]", "[/INST]"
B_SYS, E_SYS = "<<SYS>>\n", "\n<</SYS>>\n\n"
# fmt: off
DEFAULT_SYSTEM_PROMPT = """You are a helpful, respectful and honest assistant. Always answer as helpfully as possible, while being safe. Your \
answers should not include any harmful, unethical, racist, sexist, toxic, dangerous, or illegal content. Please ensure\
that your responses are socially unbiased and positive in nature.
If a question does not make any sense, or is not factually coherent, explain why instead of answering something not \
correct. If you don't know the answer to a question, please don't share false information."""
# fmt: on
class LlamaTokenizer(PreTrainedTokenizer):
"""
Construct a Llama tokenizer. Based on byte-level Byte-Pair-Encoding. The default padding token is unset as there is
no padding token in the original model.
Args:
vocab_file (`str`):
Path to the vocabulary file.
unk_token (`str` or `tokenizers.AddedToken`, *optional*, defaults to `"<unk>"`):
The unknown token. A token that is not in the vocabulary cannot be converted to an ID and is set to be this
token instead.
bos_token (`str` or `tokenizers.AddedToken`, *optional*, defaults to `"<s>"`):
The beginning of sequence token that was used during pretraining. Can be used a sequence classifier token.
eos_token (`str` or `tokenizers.AddedToken`, *optional*, defaults to `"</s>"`):
The end of sequence token.
pad_token (`str` or `tokenizers.AddedToken`, *optional*):
A special token used to make arrays of tokens the same size for batching purpose. Will then be ignored by
attention mechanisms or loss computation.
sp_model_kwargs (`Dict[str, Any]`, `Optional`, *optional*):
Will be passed to the `SentencePieceProcessor.__init__()` method. The [Python wrapper for
SentencePiece](https://github.com/google/sentencepiece/tree/master/python) can be used, among other things,
to set:
- `enable_sampling`: Enable subword regularization.
- `nbest_size`: Sampling parameters for unigram. Invalid for BPE-Dropout.
- `nbest_size = {0,1}`: No sampling is performed.
- `nbest_size > 1`: samples from the nbest_size results.
- `nbest_size < 0`: assuming that nbest_size is infinite and samples from the all hypothesis (lattice)
using forward-filtering-and-backward-sampling algorithm.
- `alpha`: Smoothing parameter for unigram sampling, and dropout probability of merge operations for
BPE-dropout.
add_bos_token (`bool`, *optional*, defaults to `True`):
Whether or not to add an `bos_token` at the start of sequences.
add_eos_token (`bool`, *optional*, defaults to `False`):
Whether or not to add an `eos_token` at the end of sequences.
clean_up_tokenization_spaces (`bool`, *optional*, defaults to `False`):
Whether or not to cleanup spaces after decoding, cleanup consists in removing potential artifacts like
extra spaces.
use_default_system_prompt (`bool`, *optional*, defaults to `False`):
Whether or not the default system prompt for Llama should be used.
spaces_between_special_tokens (`bool`, *optional*, defaults to `False`):
Whether or not to add spaces between special tokens.
legacy (`bool`, *optional*):
Whether or not the `legacy` behavior of the tokenizer should be used. Legacy is before the merge of #24622
and #25224 which includes fixes to properly handle tokens that appear after special tokens. A simple
example:
- `legacy=True`:
```python
>>> from transformers import T5Tokenizer
>>> tokenizer = T5Tokenizer.from_pretrained("google-t5/t5-base", legacy=True)
>>> tokenizer.encode("Hello <extra_id_0>.")
[8774, 32099, 3, 5, 1]
```
- `legacy=False`:
```python
>>> from transformers import T5Tokenizer
>>> tokenizer = T5Tokenizer.from_pretrained("google-t5/t5-base", legacy=False)
>>> tokenizer.encode("Hello <extra_id_0>.") # the extra space `[3]` is no longer here
[8774, 32099, 5, 1]
```
Checkout the [pull request](https://github.com/huggingface/transformers/pull/24565) for more details.
add_prefix_space (`bool`, *optional*, defaults to `True`):
Whether or not to add an initial space to the input. This allows to treat the leading word just as any
other word.
"""
vocab_files_names = VOCAB_FILES_NAMES
pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
model_input_names = ["input_ids", "attention_mask"]
def __init__(
self,
vocab_file,
unk_token="<unk>",
bos_token="<s>",
eos_token="</s>",
pad_token=None,
sp_model_kwargs: Optional[Dict[str, Any]] = None,
add_bos_token=True,
add_eos_token=False,
clean_up_tokenization_spaces=False,
use_default_system_prompt=False,
spaces_between_special_tokens=False,
legacy=None,
add_prefix_space=True,
**kwargs,
):
self.sp_model_kwargs = {} if sp_model_kwargs is None else sp_model_kwargs
bos_token = AddedToken(bos_token, normalized=False, special=True) if isinstance(bos_token, str) else bos_token
eos_token = AddedToken(eos_token, normalized=False, special=True) if isinstance(eos_token, str) else eos_token
unk_token = AddedToken(unk_token, normalized=False, special=True) if isinstance(unk_token, str) else unk_token
pad_token = AddedToken(pad_token, normalized=False, special=True) if isinstance(pad_token, str) else pad_token
if legacy is None:
logger.warning_once(
f"You are using the default legacy behaviour of the {self.__class__}. This is"
" expected, and simply means that the `legacy` (previous) behavior will be used so nothing changes for you."
" If you want to use the new behaviour, set `legacy=False`. This should only be set if you understand what it"
" means, and thoroughly read the reason why this was added as explained in"
" https://github.com/huggingface/transformers/pull/24565"
)
legacy = True
self.legacy = legacy
self.vocab_file = vocab_file
self.add_bos_token = add_bos_token
self.add_eos_token = add_eos_token
self.use_default_system_prompt = use_default_system_prompt
self.sp_model = self.get_spm_processor(kwargs.pop("from_slow", False))
self.add_prefix_space = add_prefix_space
super().__init__(
bos_token=bos_token,
eos_token=eos_token,
unk_token=unk_token,
pad_token=pad_token,
add_bos_token=add_bos_token,
add_eos_token=add_eos_token,
sp_model_kwargs=self.sp_model_kwargs,
clean_up_tokenization_spaces=clean_up_tokenization_spaces,
use_default_system_prompt=use_default_system_prompt,
spaces_between_special_tokens=spaces_between_special_tokens,
legacy=legacy,
add_prefix_space=add_prefix_space,
**kwargs,
)
@property
def unk_token_length(self):
return len(self.sp_model.encode(str(self.unk_token)))
# Copied from transformers.models.t5.tokenization_t5.T5Tokenizer.get_spm_processor
def get_spm_processor(self, from_slow=False):
tokenizer = spm.SentencePieceProcessor(**self.sp_model_kwargs)
if self.legacy or from_slow: # no dependency on protobuf
tokenizer.Load(self.vocab_file)
return tokenizer
with open(self.vocab_file, "rb") as f:
sp_model = f.read()
model_pb2 = import_protobuf(f"The new behaviour of {self.__class__.__name__} (with `self.legacy = False`)")
model = model_pb2.ModelProto.FromString(sp_model)
normalizer_spec = model_pb2.NormalizerSpec()
normalizer_spec.add_dummy_prefix = False
model.normalizer_spec.MergeFrom(normalizer_spec)
sp_model = model.SerializeToString()
tokenizer.LoadFromSerializedProto(sp_model)
return tokenizer
def __getstate__(self):
state = self.__dict__.copy()
state["sp_model"] = None
state["sp_model_proto"] = self.sp_model.serialized_model_proto()
return state
def __setstate__(self, d):
self.__dict__ = d
self.sp_model = spm.SentencePieceProcessor(**self.sp_model_kwargs)
self.sp_model.LoadFromSerializedProto(self.sp_model_proto)
@property
def vocab_size(self):
"""Returns vocab size"""
return self.sp_model.get_piece_size()
def get_vocab(self):
"""Returns vocab as a dict"""
vocab = {self.convert_ids_to_tokens(i): i for i in range(self.vocab_size)}
vocab.update(self.added_tokens_encoder)
return vocab
# Copied from transformers.models.t5.tokenization_t5.T5Tokenizer.tokenize
def tokenize(self, text: "TextInput", add_special_tokens=False, **kwargs) -> List[str]:
"""
Converts a string to a list of tokens. If `self.legacy` is set to `False`, a prefix token is added unless the
first token is special.
"""
if self.legacy or len(text) == 0:
return super().tokenize(text, **kwargs)
text = text.replace(SPIECE_UNDERLINE, " ")
if self.add_prefix_space:
text = SPIECE_UNDERLINE + text
tokens = super().tokenize(text, add_special_tokens=add_special_tokens, **kwargs)
if len(tokens) > 1 and tokens[0] == SPIECE_UNDERLINE and tokens[1] in self.all_special_tokens:
tokens = tokens[1:]
return tokens
# Copied from transformers.models.t5.tokenization_t5.T5Tokenizer._tokenize
def _tokenize(self, text, **kwargs):
"""
Returns a tokenized string.
We de-activated the `add_dummy_prefix` option, thus the sentencepiece internals will always strip any
SPIECE_UNDERLINE. For example: `self.sp_model.encode(f"{SPIECE_UNDERLINE}Hey", out_type = str)` will give
`['H', 'e', 'y']` instead of `['▁He', 'y']`. Thus we always encode `f"{unk_token}text"` and strip the
`unk_token`. Here is an example with `unk_token = "<unk>"` and `unk_token_length = 4`.
`self.tokenizer.sp_model.encode("<unk> Hey", out_type = str)[4:]`.
"""
tokens = self.sp_model.encode(text, out_type=str)
if self.legacy or not text.startswith((SPIECE_UNDERLINE, " ")):
return tokens
# 1. Encode string + prefix ex: "<unk> Hey"
tokens = self.sp_model.encode(self.unk_token + text, out_type=str)
# 2. Remove self.unk_token from ['<','unk','>', '▁Hey']
return tokens[self.unk_token_length :] if len(tokens) >= self.unk_token_length else tokens
def _convert_token_to_id(self, token):
"""Converts a token (str) in an id using the vocab."""
return self.sp_model.piece_to_id(token)
def _convert_id_to_token(self, index):
"""Converts an index (integer) in a token (str) using the vocab."""
token = self.sp_model.IdToPiece(index)
return token
def convert_tokens_to_string(self, tokens):
"""Converts a sequence of tokens (string) in a single string."""
# since we manually add the prefix space, we have to remove it when decoding
if tokens[0].startswith(SPIECE_UNDERLINE) and self.add_prefix_space:
tokens[0] = tokens[0][1:]
current_sub_tokens = []
out_string = ""
prev_is_special = False
for i, token in enumerate(tokens):
# make sure that special tokens are not decoded using sentencepiece model
if token in self.all_special_tokens:
if not prev_is_special and i != 0 and self.legacy:
out_string += " "
out_string += self.sp_model.decode(current_sub_tokens) + token
prev_is_special = True
current_sub_tokens = []
else:
current_sub_tokens.append(token)
prev_is_special = False
out_string += self.sp_model.decode(current_sub_tokens)
return out_string
def save_vocabulary(self, save_directory, filename_prefix: Optional[str] = None) -> Tuple[str]:
"""
Save the vocabulary and special tokens file to a directory.
Args:
save_directory (`str`):
The directory in which to save the vocabulary.
Returns:
`Tuple(str)`: Paths to the files saved.
"""
if not os.path.isdir(save_directory):
logger.error(f"Vocabulary path ({save_directory}) should be a directory")
return
out_vocab_file = os.path.join(
save_directory, (filename_prefix + "-" if filename_prefix else "") + VOCAB_FILES_NAMES["vocab_file"]
)
if os.path.abspath(self.vocab_file) != os.path.abspath(out_vocab_file) and os.path.isfile(self.vocab_file):
copyfile(self.vocab_file, out_vocab_file)
elif not os.path.isfile(self.vocab_file):
with open(out_vocab_file, "wb") as fi:
content_spiece_model = self.sp_model.serialized_model_proto()
fi.write(content_spiece_model)
return (out_vocab_file,)
def build_inputs_with_special_tokens(self, token_ids_0, token_ids_1=None):
bos_token_id = [self.bos_token_id] if self.add_bos_token else []
eos_token_id = [self.eos_token_id] if self.add_eos_token else []
output = bos_token_id + token_ids_0 + eos_token_id
if token_ids_1 is not None:
output = output + bos_token_id + token_ids_1 + eos_token_id
return output
def get_special_tokens_mask(
self, token_ids_0: List[int], token_ids_1: Optional[List[int]] = None, already_has_special_tokens: bool = False
) -> List[int]:
"""
Retrieve sequence ids from a token list that has no special tokens added. This method is called when adding
special tokens using the tokenizer `prepare_for_model` method.
Args:
token_ids_0 (`List[int]`):
List of IDs.
token_ids_1 (`List[int]`, *optional*):
Optional second list of IDs for sequence pairs.
already_has_special_tokens (`bool`, *optional*, defaults to `False`):
Whether or not the token list is already formatted with special tokens for the model.
Returns:
`List[int]`: A list of integers in the range [0, 1]: 1 for a special token, 0 for a sequence token.
"""
if already_has_special_tokens:
return super().get_special_tokens_mask(
token_ids_0=token_ids_0, token_ids_1=token_ids_1, already_has_special_tokens=True
)
bos_token_id = [1] if self.add_bos_token else []
eos_token_id = [1] if self.add_eos_token else []
if token_ids_1 is None:
return bos_token_id + ([0] * len(token_ids_0)) + eos_token_id
return (
bos_token_id
+ ([0] * len(token_ids_0))
+ eos_token_id
+ bos_token_id
+ ([0] * len(token_ids_1))
+ eos_token_id
)
def create_token_type_ids_from_sequences(
self, token_ids_0: List[int], token_ids_1: Optional[List[int]] = None
) -> List[int]:
"""
Creates a mask from the two sequences passed to be used in a sequence-pair classification task. An ALBERT
sequence pair mask has the following format:
```
0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1
| first sequence | second sequence |
```
if token_ids_1 is None, only returns the first portion of the mask (0s).
Args:
token_ids_0 (`List[int]`):
List of ids.
token_ids_1 (`List[int]`, *optional*):
Optional second list of IDs for sequence pairs.
Returns:
`List[int]`: List of [token type IDs](../glossary#token-type-ids) according to the given sequence(s).
"""
bos_token_id = [self.bos_token_id] if self.add_bos_token else []
eos_token_id = [self.eos_token_id] if self.add_eos_token else []
output = [0] * len(bos_token_id + token_ids_0 + eos_token_id)
if token_ids_1 is not None:
output += [1] * len(bos_token_id + token_ids_1 + eos_token_id)
return output
@property
def default_chat_template(self):
"""
LLaMA uses [INST] and [/INST] to indicate user messages, and <<SYS>> and <</SYS>> to indicate system messages.
Assistant messages do not have special tokens, because LLaMA chat models are generally trained with strict
user/assistant/user/assistant message ordering, and so assistant messages can be identified from the ordering
rather than needing special tokens. The system message is partly 'embedded' in the first user message, which
results in an unusual token ordering when it is present. This template should definitely be changed if you wish
to fine-tune a model with more flexible role ordering!
The output should look something like:
<bos>[INST] B_SYS SystemPrompt E_SYS Prompt [/INST] Answer <eos><bos>[INST] Prompt [/INST] Answer <eos>
<bos>[INST] Prompt [/INST]
The reference for this chat template is [this code
snippet](https://github.com/facebookresearch/llama/blob/556949fdfb72da27c2f4a40b7f0e4cf0b8153a28/llama/generation.py#L320-L362)
in the original repository.
"""
logger.warning_once(
"\nNo chat template is defined for this tokenizer - using the default template "
f"for the {self.__class__.__name__} class. If the default is not appropriate for "
"your model, please set `tokenizer.chat_template` to an appropriate template. "
"See https://huggingface.co/docs/transformers/main/chat_templating for more information.\n"
)
template = (
"{% if messages[0]['role'] == 'system' %}"
"{% set loop_messages = messages[1:] %}" # Extract system message if it's present
"{% set system_message = messages[0]['content'] %}"
"{% elif USE_DEFAULT_PROMPT == true and not '<<SYS>>' in messages[0]['content'] %}"
"{% set loop_messages = messages %}" # Or use the default system message if the flag is set
"{% set system_message = 'DEFAULT_SYSTEM_MESSAGE' %}"
"{% else %}"
"{% set loop_messages = messages %}"
"{% set system_message = false %}"
"{% endif %}"
"{% for message in loop_messages %}" # Loop over all non-system messages
"{% if (message['role'] == 'user') != (loop.index0 % 2 == 0) %}"
"{{ raise_exception('Conversation roles must alternate user/assistant/user/assistant/...') }}"
"{% endif %}"
"{% if loop.index0 == 0 and system_message != false %}" # Embed system message in first message
"{% set content = '<<SYS>>\\n' + system_message + '\\n<</SYS>>\\n\\n' + message['content'] %}"
"{% else %}"
"{% set content = message['content'] %}"
"{% endif %}"
"{% if message['role'] == 'user' %}" # After all of that, handle messages/roles in a fairly normal way
"{{ bos_token + '[INST] ' + content.strip() + ' [/INST]' }}"
"{% elif message['role'] == 'system' %}"
"{{ '<<SYS>>\\n' + content.strip() + '\\n<</SYS>>\\n\\n' }}"
"{% elif message['role'] == 'assistant' %}"
"{{ ' ' + content.strip() + ' ' + eos_token }}"
"{% endif %}"
"{% endfor %}"
)
template = template.replace("USE_DEFAULT_PROMPT", "true" if self.use_default_system_prompt else "false")
default_message = DEFAULT_SYSTEM_PROMPT.replace("\n", "\\n").replace("'", "\\'")
template = template.replace("DEFAULT_SYSTEM_MESSAGE", default_message)
return template
| transformers/src/transformers/models/llama/tokenization_llama.py/0 | {
"file_path": "transformers/src/transformers/models/llama/tokenization_llama.py",
"repo_id": "transformers",
"token_count": 9507
} | 100 |
# coding=utf-8
# Copyright 2022 The HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""Convert T5/LongT5X checkpoints from the original repository to JAX/FLAX model. This script is an extension of
'src/transformers/models/t5/convert_t5x_checkpoint_to_flax.
"""
import argparse
from t5x import checkpoints
from transformers import AutoConfig, FlaxAutoModelForSeq2SeqLM
def convert_t5x_checkpoint_to_flax(t5x_checkpoint_path, config_name, flax_dump_folder_path):
config = AutoConfig.from_pretrained(config_name)
flax_model = FlaxAutoModelForSeq2SeqLM.from_config(config=config)
t5x_model = checkpoints.load_t5x_checkpoint(t5x_checkpoint_path)
split_mlp_wi = "wi_0" in t5x_model["target"]["encoder"]["layers_0"]["mlp"]
if config.model_type == "t5":
encoder_attn_name = "SelfAttention"
if config.model_type == "longt5" and config.encoder_attention_type == "local":
encoder_attn_name = "LocalSelfAttention"
elif config.model_type == "longt5" and config.encoder_attention_type == "transient-global":
encoder_attn_name = "TransientGlobalSelfAttention"
else:
raise ValueError(
"Given config is expected to have `model_type='t5'`, or `model_type='longt5` with `encoder_attention_type`"
" attribute with a value from ['local', 'transient-global]."
)
# Encoder
for layer_index in range(config.num_layers):
layer_name = f"layers_{str(layer_index)}"
# Self-Attention
t5x_attention_key = t5x_model["target"]["encoder"][layer_name]["attention"]["key"]["kernel"]
t5x_attention_out = t5x_model["target"]["encoder"][layer_name]["attention"]["out"]["kernel"]
t5x_attention_query = t5x_model["target"]["encoder"][layer_name]["attention"]["query"]["kernel"]
t5x_attention_value = t5x_model["target"]["encoder"][layer_name]["attention"]["value"]["kernel"]
# Global input layer norm
if config.model_type == "longt5" and config.encoder_attention_type == "transient-global":
t5x_global_layer_norm = t5x_model["target"]["encoder"][layer_name]["attention"]["T5LayerNorm_0"]["scale"]
# Layer Normalization
t5x_attention_layer_norm = t5x_model["target"]["encoder"][layer_name]["pre_attention_layer_norm"]["scale"]
if split_mlp_wi:
t5x_mlp_wi_0 = t5x_model["target"]["encoder"][layer_name]["mlp"]["wi_0"]["kernel"]
t5x_mlp_wi_1 = t5x_model["target"]["encoder"][layer_name]["mlp"]["wi_1"]["kernel"]
else:
t5x_mlp_wi = t5x_model["target"]["encoder"][layer_name]["mlp"]["wi"]["kernel"]
t5x_mlp_wo = t5x_model["target"]["encoder"][layer_name]["mlp"]["wo"]["kernel"]
# Layer Normalization
t5x_mlp_layer_norm = t5x_model["target"]["encoder"][layer_name]["pre_mlp_layer_norm"]["scale"]
# Assigning
flax_model_encoder_layer_block = flax_model.params["encoder"]["block"][str(layer_index)]["layer"]
flax_model_encoder_layer_block["0"][encoder_attn_name]["k"]["kernel"] = t5x_attention_key
flax_model_encoder_layer_block["0"][encoder_attn_name]["o"]["kernel"] = t5x_attention_out
flax_model_encoder_layer_block["0"][encoder_attn_name]["q"]["kernel"] = t5x_attention_query
flax_model_encoder_layer_block["0"][encoder_attn_name]["v"]["kernel"] = t5x_attention_value
flax_model_encoder_layer_block["0"]["layer_norm"]["weight"] = t5x_attention_layer_norm
# Global input layer norm
if config.model_type == "longt5" and config.encoder_attention_type == "transient-global":
flax_model_encoder_layer_block["0"][encoder_attn_name]["global_input_layer_norm"][
"weight"
] = t5x_global_layer_norm
if split_mlp_wi:
flax_model_encoder_layer_block["1"]["DenseReluDense"]["wi_0"]["kernel"] = t5x_mlp_wi_0
flax_model_encoder_layer_block["1"]["DenseReluDense"]["wi_1"]["kernel"] = t5x_mlp_wi_1
else:
flax_model_encoder_layer_block["1"]["DenseReluDense"]["wi"]["kernel"] = t5x_mlp_wi
flax_model_encoder_layer_block["1"]["DenseReluDense"]["wo"]["kernel"] = t5x_mlp_wo
flax_model_encoder_layer_block["1"]["layer_norm"]["weight"] = t5x_mlp_layer_norm
flax_model.params["encoder"]["block"][str(layer_index)]["layer"] = flax_model_encoder_layer_block
# Only for layer 0:
t5x_encoder_rel_embedding = t5x_model["target"]["encoder"]["relpos_bias"]["rel_embedding"].T
flax_model.params["encoder"]["block"]["0"]["layer"]["0"][encoder_attn_name]["relative_attention_bias"][
"embedding"
] = t5x_encoder_rel_embedding
# Side/global relative position_bias + layer norm
if config.model_type == "longt5" and config.encoder_attention_type == "transient-global":
t5x_encoder_global_rel_embedding = t5x_model["target"]["encoder"]["side_relpos_bias"]["rel_embedding"].T
flax_model.params["encoder"]["block"]["0"]["layer"]["0"][encoder_attn_name]["global_relative_attention_bias"][
"embedding"
] = t5x_encoder_global_rel_embedding
# Assigning
t5x_encoder_norm = t5x_model["target"]["encoder"]["encoder_norm"]["scale"]
flax_model.params["encoder"]["final_layer_norm"]["weight"] = t5x_encoder_norm
# Decoder
for layer_index in range(config.num_layers):
layer_name = f"layers_{str(layer_index)}"
# Self-Attention
t5x_attention_key = t5x_model["target"]["decoder"][layer_name]["self_attention"]["key"]["kernel"]
t5x_attention_out = t5x_model["target"]["decoder"][layer_name]["self_attention"]["out"]["kernel"]
t5x_attention_query = t5x_model["target"]["decoder"][layer_name]["self_attention"]["query"]["kernel"]
t5x_attention_value = t5x_model["target"]["decoder"][layer_name]["self_attention"]["value"]["kernel"]
# Layer Normalization
t5x_pre_attention_layer_norm = t5x_model["target"]["decoder"][layer_name]["pre_self_attention_layer_norm"][
"scale"
]
# Encoder-Decoder-Attention
t5x_enc_dec_attention_module = t5x_model["target"]["decoder"][layer_name]["encoder_decoder_attention"]
t5x_enc_dec_attention_key = t5x_enc_dec_attention_module["key"]["kernel"]
t5x_enc_dec_attention_out = t5x_enc_dec_attention_module["out"]["kernel"]
t5x_enc_dec_attention_query = t5x_enc_dec_attention_module["query"]["kernel"]
t5x_enc_dec_attention_value = t5x_enc_dec_attention_module["value"]["kernel"]
# Layer Normalization
t5x_cross_layer_norm = t5x_model["target"]["decoder"][layer_name]["pre_cross_attention_layer_norm"]["scale"]
# MLP
if split_mlp_wi:
t5x_mlp_wi_0 = t5x_model["target"]["decoder"][layer_name]["mlp"]["wi_0"]["kernel"]
t5x_mlp_wi_1 = t5x_model["target"]["decoder"][layer_name]["mlp"]["wi_1"]["kernel"]
else:
t5x_mlp_wi = t5x_model["target"]["decoder"][layer_name]["mlp"]["wi"]["kernel"]
t5x_mlp_wo = t5x_model["target"]["decoder"][layer_name]["mlp"]["wo"]["kernel"]
# Layer Normalization
tx5_mlp_layer_norm = t5x_model["target"]["decoder"][layer_name]["pre_mlp_layer_norm"]["scale"]
# Assigning
flax_model_decoder_layer_block = flax_model.params["decoder"]["block"][str(layer_index)]["layer"]
flax_model_decoder_layer_block["0"]["SelfAttention"]["k"]["kernel"] = t5x_attention_key
flax_model_decoder_layer_block["0"]["SelfAttention"]["o"]["kernel"] = t5x_attention_out
flax_model_decoder_layer_block["0"]["SelfAttention"]["q"]["kernel"] = t5x_attention_query
flax_model_decoder_layer_block["0"]["SelfAttention"]["v"]["kernel"] = t5x_attention_value
flax_model_decoder_layer_block["0"]["layer_norm"]["weight"] = t5x_pre_attention_layer_norm
flax_model_decoder_layer_block["1"]["EncDecAttention"]["k"]["kernel"] = t5x_enc_dec_attention_key
flax_model_decoder_layer_block["1"]["EncDecAttention"]["o"]["kernel"] = t5x_enc_dec_attention_out
flax_model_decoder_layer_block["1"]["EncDecAttention"]["q"]["kernel"] = t5x_enc_dec_attention_query
flax_model_decoder_layer_block["1"]["EncDecAttention"]["v"]["kernel"] = t5x_enc_dec_attention_value
flax_model_decoder_layer_block["1"]["layer_norm"]["weight"] = t5x_cross_layer_norm
if split_mlp_wi:
flax_model_decoder_layer_block["2"]["DenseReluDense"]["wi_0"]["kernel"] = t5x_mlp_wi_0
flax_model_decoder_layer_block["2"]["DenseReluDense"]["wi_1"]["kernel"] = t5x_mlp_wi_1
else:
flax_model_decoder_layer_block["2"]["DenseReluDense"]["wi"]["kernel"] = t5x_mlp_wi
flax_model_decoder_layer_block["2"]["DenseReluDense"]["wo"]["kernel"] = t5x_mlp_wo
flax_model_decoder_layer_block["2"]["layer_norm"]["weight"] = tx5_mlp_layer_norm
flax_model.params["decoder"]["block"][str(layer_index)]["layer"] = flax_model_decoder_layer_block
# Decoder Normalization
tx5_decoder_norm = t5x_model["target"]["decoder"]["decoder_norm"]["scale"]
flax_model.params["decoder"]["final_layer_norm"]["weight"] = tx5_decoder_norm
# Only for layer 0:
t5x_decoder_rel_embedding = t5x_model["target"]["decoder"]["relpos_bias"]["rel_embedding"].T
flax_model.params["decoder"]["block"]["0"]["layer"]["0"]["SelfAttention"]["relative_attention_bias"][
"embedding"
] = t5x_decoder_rel_embedding
# Token Embeddings
tx5_token_embeddings = t5x_model["target"]["token_embedder"]["embedding"]
flax_model.params["shared"]["embedding"] = tx5_token_embeddings
# LM Head (only in v1.1 and LongT5 checkpoints)
if "logits_dense" in t5x_model["target"]["decoder"]:
flax_model.params["lm_head"]["kernel"] = t5x_model["target"]["decoder"]["logits_dense"]["kernel"]
flax_model.save_pretrained(flax_dump_folder_path)
print("T5X Model was sucessfully converted!")
if __name__ == "__main__":
parser = argparse.ArgumentParser()
# Required parameters
parser.add_argument(
"--t5x_checkpoint_path", default=None, type=str, required=True, help="Path the T5X checkpoint."
)
parser.add_argument("--config_name", default=None, type=str, required=True, help="Config name of LongT5/T5 model.")
parser.add_argument(
"--flax_dump_folder_path", default=None, type=str, required=True, help="Path to the output FLAX model."
)
args = parser.parse_args()
convert_t5x_checkpoint_to_flax(args.t5x_checkpoint_path, args.config_name, args.flax_dump_folder_path)
| transformers/src/transformers/models/longt5/convert_longt5x_checkpoint_to_flax.py/0 | {
"file_path": "transformers/src/transformers/models/longt5/convert_longt5x_checkpoint_to_flax.py",
"repo_id": "transformers",
"token_count": 4985
} | 101 |
# coding=utf-8
# Copyright 2022 The HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""
Processor class for MarkupLM.
"""
from typing import Optional, Union
from ...file_utils import TensorType
from ...processing_utils import ProcessorMixin
from ...tokenization_utils_base import BatchEncoding, PaddingStrategy, TruncationStrategy
class MarkupLMProcessor(ProcessorMixin):
r"""
Constructs a MarkupLM processor which combines a MarkupLM feature extractor and a MarkupLM tokenizer into a single
processor.
[`MarkupLMProcessor`] offers all the functionalities you need to prepare data for the model.
It first uses [`MarkupLMFeatureExtractor`] to extract nodes and corresponding xpaths from one or more HTML strings.
Next, these are provided to [`MarkupLMTokenizer`] or [`MarkupLMTokenizerFast`], which turns them into token-level
`input_ids`, `attention_mask`, `token_type_ids`, `xpath_tags_seq` and `xpath_subs_seq`.
Args:
feature_extractor (`MarkupLMFeatureExtractor`):
An instance of [`MarkupLMFeatureExtractor`]. The feature extractor is a required input.
tokenizer (`MarkupLMTokenizer` or `MarkupLMTokenizerFast`):
An instance of [`MarkupLMTokenizer`] or [`MarkupLMTokenizerFast`]. The tokenizer is a required input.
parse_html (`bool`, *optional*, defaults to `True`):
Whether or not to use `MarkupLMFeatureExtractor` to parse HTML strings into nodes and corresponding xpaths.
"""
feature_extractor_class = "MarkupLMFeatureExtractor"
tokenizer_class = ("MarkupLMTokenizer", "MarkupLMTokenizerFast")
parse_html = True
def __call__(
self,
html_strings=None,
nodes=None,
xpaths=None,
node_labels=None,
questions=None,
add_special_tokens: bool = True,
padding: Union[bool, str, PaddingStrategy] = False,
truncation: Union[bool, str, TruncationStrategy] = None,
max_length: Optional[int] = None,
stride: int = 0,
pad_to_multiple_of: Optional[int] = None,
return_token_type_ids: Optional[bool] = None,
return_attention_mask: Optional[bool] = None,
return_overflowing_tokens: bool = False,
return_special_tokens_mask: bool = False,
return_offsets_mapping: bool = False,
return_length: bool = False,
verbose: bool = True,
return_tensors: Optional[Union[str, TensorType]] = None,
**kwargs,
) -> BatchEncoding:
"""
This method first forwards the `html_strings` argument to [`~MarkupLMFeatureExtractor.__call__`]. Next, it
passes the `nodes` and `xpaths` along with the additional arguments to [`~MarkupLMTokenizer.__call__`] and
returns the output.
Optionally, one can also provide a `text` argument which is passed along as first sequence.
Please refer to the docstring of the above two methods for more information.
"""
# first, create nodes and xpaths
if self.parse_html:
if html_strings is None:
raise ValueError("Make sure to pass HTML strings in case `parse_html` is set to `True`")
if nodes is not None or xpaths is not None or node_labels is not None:
raise ValueError(
"Please don't pass nodes, xpaths nor node labels in case `parse_html` is set to `True`"
)
features = self.feature_extractor(html_strings)
nodes = features["nodes"]
xpaths = features["xpaths"]
else:
if html_strings is not None:
raise ValueError("You have passed HTML strings but `parse_html` is set to `False`.")
if nodes is None or xpaths is None:
raise ValueError("Make sure to pass nodes and xpaths in case `parse_html` is set to `False`")
# # second, apply the tokenizer
if questions is not None and self.parse_html:
if isinstance(questions, str):
questions = [questions] # add batch dimension (as the feature extractor always adds a batch dimension)
encoded_inputs = self.tokenizer(
text=questions if questions is not None else nodes,
text_pair=nodes if questions is not None else None,
xpaths=xpaths,
node_labels=node_labels,
add_special_tokens=add_special_tokens,
padding=padding,
truncation=truncation,
max_length=max_length,
stride=stride,
pad_to_multiple_of=pad_to_multiple_of,
return_token_type_ids=return_token_type_ids,
return_attention_mask=return_attention_mask,
return_overflowing_tokens=return_overflowing_tokens,
return_special_tokens_mask=return_special_tokens_mask,
return_offsets_mapping=return_offsets_mapping,
return_length=return_length,
verbose=verbose,
return_tensors=return_tensors,
**kwargs,
)
return encoded_inputs
def batch_decode(self, *args, **kwargs):
"""
This method forwards all its arguments to TrOCRTokenizer's [`~PreTrainedTokenizer.batch_decode`]. Please refer
to the docstring of this method for more information.
"""
return self.tokenizer.batch_decode(*args, **kwargs)
def decode(self, *args, **kwargs):
"""
This method forwards all its arguments to TrOCRTokenizer's [`~PreTrainedTokenizer.decode`]. Please refer to the
docstring of this method for more information.
"""
return self.tokenizer.decode(*args, **kwargs)
@property
def model_input_names(self):
tokenizer_input_names = self.tokenizer.model_input_names
return tokenizer_input_names
| transformers/src/transformers/models/markuplm/processing_markuplm.py/0 | {
"file_path": "transformers/src/transformers/models/markuplm/processing_markuplm.py",
"repo_id": "transformers",
"token_count": 2520
} | 102 |
# coding=utf-8
# Copyright 2022 Meta Platforms, Inc.s and The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
""" PyTorch MaskFormer model."""
import math
from dataclasses import dataclass
from numbers import Number
from typing import Dict, List, Optional, Tuple
import numpy as np
import torch
from torch import Tensor, nn
from ...activations import ACT2FN
from ...modeling_attn_mask_utils import _prepare_4d_attention_mask
from ...modeling_outputs import BaseModelOutputWithCrossAttentions
from ...modeling_utils import PreTrainedModel
from ...utils import (
ModelOutput,
add_start_docstrings,
add_start_docstrings_to_model_forward,
is_accelerate_available,
is_scipy_available,
logging,
replace_return_docstrings,
requires_backends,
)
from ...utils.backbone_utils import load_backbone
from ..detr import DetrConfig
from .configuration_maskformer import MaskFormerConfig
from .configuration_maskformer_swin import MaskFormerSwinConfig
if is_accelerate_available():
from accelerate import PartialState
from accelerate.utils import reduce
if is_scipy_available():
from scipy.optimize import linear_sum_assignment
logger = logging.get_logger(__name__)
_CONFIG_FOR_DOC = "MaskFormerConfig"
_CHECKPOINT_FOR_DOC = "facebook/maskformer-swin-base-ade"
MASKFORMER_PRETRAINED_MODEL_ARCHIVE_LIST = [
"facebook/maskformer-swin-base-ade",
# See all MaskFormer models at https://huggingface.co/models?filter=maskformer
]
@dataclass
# Copied from transformers.models.detr.modeling_detr.DetrDecoderOutput
class DetrDecoderOutput(BaseModelOutputWithCrossAttentions):
"""
Base class for outputs of the DETR decoder. This class adds one attribute to BaseModelOutputWithCrossAttentions,
namely an optional stack of intermediate decoder activations, i.e. the output of each decoder layer, each of them
gone through a layernorm. This is useful when training the model with auxiliary decoding losses.
Args:
last_hidden_state (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`):
Sequence of hidden-states at the output of the last layer of the model.
hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
Tuple of `torch.FloatTensor` (one for the output of the embeddings + one for the output of each layer) of
shape `(batch_size, sequence_length, hidden_size)`. Hidden-states of the model at the output of each layer
plus the initial embedding outputs.
attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
sequence_length)`. Attentions weights after the attention softmax, used to compute the weighted average in
the self-attention heads.
cross_attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` and `config.add_cross_attention=True` is passed or when `config.output_attentions=True`):
Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
sequence_length)`. Attentions weights of the decoder's cross-attention layer, after the attention softmax,
used to compute the weighted average in the cross-attention heads.
intermediate_hidden_states (`torch.FloatTensor` of shape `(config.decoder_layers, batch_size, num_queries, hidden_size)`, *optional*, returned when `config.auxiliary_loss=True`):
Intermediate decoder activations, i.e. the output of each decoder layer, each of them gone through a
layernorm.
"""
intermediate_hidden_states: Optional[torch.FloatTensor] = None
@dataclass
class MaskFormerPixelLevelModuleOutput(ModelOutput):
"""
MaskFormer's pixel level module output. It returns both the last and (optionally) the hidden states from the
`encoder` and `decoder`. By default, the `encoder` is a MaskFormerSwin Transformer and the `decoder` is a Feature
Pyramid Network (FPN).
The `encoder_last_hidden_state` are referred on the paper as **images features**, while `decoder_last_hidden_state`
as **pixel embeddings**
Args:
encoder_last_hidden_state (`torch.FloatTensor` of shape`(batch_size, num_channels, height, width)`):
Last hidden states (final feature map) of the last stage of the encoder.
encoder_hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
Tuple of `torch.FloatTensor` (one for the output of the embeddings + one for the output of each stage) of
shape `(batch_size, num_channels, height, width)`. Hidden-states (also called feature maps) of the model at
the output of each stage.
decoder_last_hidden_state (`torch.FloatTensor` of shape`(batch_size, num_channels, height, width)`):
Last hidden states (final feature map) of the last stage of the decoder.
decoder_hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
Tuple of `torch.FloatTensor` (one for the output of the embeddings + one for the output of each stage) of
shape `(batch_size, num_channels, height, width)`. Hidden-states (also called feature maps) of the model at
the output of each stage.
"""
encoder_last_hidden_state: Optional[torch.FloatTensor] = None
decoder_last_hidden_state: Optional[torch.FloatTensor] = None
encoder_hidden_states: Optional[Tuple[torch.FloatTensor]] = None
decoder_hidden_states: Optional[Tuple[torch.FloatTensor]] = None
@dataclass
class MaskFormerPixelDecoderOutput(ModelOutput):
"""
MaskFormer's pixel decoder module output, practically a Feature Pyramid Network. It returns the last hidden state
and (optionally) the hidden states.
Args:
last_hidden_state (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
Last hidden states (final feature map) of the last stage of the model.
hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
Tuple of `torch.FloatTensor` (one for the output of the embeddings + one for the output of each layer) of
shape `(batch_size, num_channels, height, width)`. Hidden-states of the model at the output of each layer
plus the initial embedding outputs.
attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
sequence_length)`. Attentions weights from Detr's decoder after the attention softmax, used to compute the
weighted average in the self-attention heads.
"""
last_hidden_state: torch.FloatTensor = None
hidden_states: Optional[Tuple[torch.FloatTensor]] = None
attentions: Optional[Tuple[torch.FloatTensor]] = None
@dataclass
class MaskFormerModelOutput(ModelOutput):
"""
Class for outputs of [`MaskFormerModel`]. This class returns all the needed hidden states to compute the logits.
Args:
encoder_last_hidden_state (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
Last hidden states (final feature map) of the last stage of the encoder model (backbone).
pixel_decoder_last_hidden_state (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
Last hidden states (final feature map) of the last stage of the pixel decoder model (FPN).
transformer_decoder_last_hidden_state (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`):
Last hidden states (final feature map) of the last stage of the transformer decoder model.
encoder_hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
Tuple of `torch.FloatTensor` (one for the output of the embeddings + one for the output of each stage) of
shape `(batch_size, num_channels, height, width)`. Hidden-states (also called feature maps) of the encoder
model at the output of each stage.
pixel_decoder_hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
Tuple of `torch.FloatTensor` (one for the output of the embeddings + one for the output of each stage) of
shape `(batch_size, num_channels, height, width)`. Hidden-states (also called feature maps) of the pixel
decoder model at the output of each stage.
transformer_decoder_hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
Tuple of `torch.FloatTensor` (one for the output of the embeddings + one for the output of each stage) of
shape `(batch_size, sequence_length, hidden_size)`. Hidden-states (also called feature maps) of the
transformer decoder at the output of each stage.
hidden_states `tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
Tuple of `torch.FloatTensor` containing `encoder_hidden_states`, `pixel_decoder_hidden_states` and
`decoder_hidden_states`
attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
sequence_length)`. Attentions weights from Detr's decoder after the attention softmax, used to compute the
weighted average in the self-attention heads.
"""
encoder_last_hidden_state: Optional[torch.FloatTensor] = None
pixel_decoder_last_hidden_state: Optional[torch.FloatTensor] = None
transformer_decoder_last_hidden_state: Optional[torch.FloatTensor] = None
encoder_hidden_states: Optional[Tuple[torch.FloatTensor]] = None
pixel_decoder_hidden_states: Optional[Tuple[torch.FloatTensor]] = None
transformer_decoder_hidden_states: Optional[Tuple[torch.FloatTensor]] = None
hidden_states: Optional[Tuple[torch.FloatTensor]] = None
attentions: Optional[Tuple[torch.FloatTensor]] = None
@dataclass
class MaskFormerForInstanceSegmentationOutput(ModelOutput):
"""
Class for outputs of [`MaskFormerForInstanceSegmentation`].
This output can be directly passed to [`~MaskFormerImageProcessor.post_process_semantic_segmentation`] or or
[`~MaskFormerImageProcessor.post_process_instance_segmentation`] or
[`~MaskFormerImageProcessor.post_process_panoptic_segmentation`] depending on the task. Please, see
[`~MaskFormerImageProcessor] for details regarding usage.
Args:
loss (`torch.Tensor`, *optional*):
The computed loss, returned when labels are present.
class_queries_logits (`torch.FloatTensor`):
A tensor of shape `(batch_size, num_queries, num_labels + 1)` representing the proposed classes for each
query. Note the `+ 1` is needed because we incorporate the null class.
masks_queries_logits (`torch.FloatTensor`):
A tensor of shape `(batch_size, num_queries, height, width)` representing the proposed masks for each
query.
encoder_last_hidden_state (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
Last hidden states (final feature map) of the last stage of the encoder model (backbone).
pixel_decoder_last_hidden_state (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
Last hidden states (final feature map) of the last stage of the pixel decoder model (FPN).
transformer_decoder_last_hidden_state (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`):
Last hidden states (final feature map) of the last stage of the transformer decoder model.
encoder_hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
Tuple of `torch.FloatTensor` (one for the output of the embeddings + one for the output of each stage) of
shape `(batch_size, num_channels, height, width)`. Hidden-states (also called feature maps) of the encoder
model at the output of each stage.
pixel_decoder_hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
Tuple of `torch.FloatTensor` (one for the output of the embeddings + one for the output of each stage) of
shape `(batch_size, num_channels, height, width)`. Hidden-states (also called feature maps) of the pixel
decoder model at the output of each stage.
transformer_decoder_hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
Tuple of `torch.FloatTensor` (one for the output of the embeddings + one for the output of each stage) of
shape `(batch_size, sequence_length, hidden_size)`. Hidden-states of the transformer decoder at the output
of each stage.
hidden_states `tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
Tuple of `torch.FloatTensor` containing `encoder_hidden_states`, `pixel_decoder_hidden_states` and
`decoder_hidden_states`.
attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
sequence_length)`. Attentions weights from Detr's decoder after the attention softmax, used to compute the
weighted average in the self-attention heads.
"""
loss: Optional[torch.FloatTensor] = None
class_queries_logits: torch.FloatTensor = None
masks_queries_logits: torch.FloatTensor = None
auxiliary_logits: torch.FloatTensor = None
encoder_last_hidden_state: Optional[torch.FloatTensor] = None
pixel_decoder_last_hidden_state: Optional[torch.FloatTensor] = None
transformer_decoder_last_hidden_state: Optional[torch.FloatTensor] = None
encoder_hidden_states: Optional[Tuple[torch.FloatTensor]] = None
pixel_decoder_hidden_states: Optional[Tuple[torch.FloatTensor]] = None
transformer_decoder_hidden_states: Optional[Tuple[torch.FloatTensor]] = None
hidden_states: Optional[Tuple[torch.FloatTensor]] = None
attentions: Optional[Tuple[torch.FloatTensor]] = None
def upsample_like(pixel_values: Tensor, like: Tensor, mode: str = "bilinear") -> Tensor:
"""
An utility function that upsamples `pixel_values` to match the dimension of `like`.
Args:
pixel_values (`torch.Tensor`):
The tensor we wish to upsample.
like (`torch.Tensor`):
The tensor we wish to use as size target.
mode (str, *optional*, defaults to `"bilinear"`):
The interpolation mode.
Returns:
`torch.Tensor`: The upsampled tensor
"""
_, _, height, width = like.shape
upsampled = nn.functional.interpolate(pixel_values, size=(height, width), mode=mode, align_corners=False)
return upsampled
# refactored from original implementation
def dice_loss(inputs: Tensor, labels: Tensor, num_masks: int) -> Tensor:
r"""
Compute the DICE loss, similar to generalized IOU for masks as follows:
$$ \mathcal{L}_{\text{dice}(x, y) = 1 - \frac{2 * x \cap y }{x \cup y + 1}} $$
In practice, since `labels` is a binary mask, (only 0s and 1s), dice can be computed as follow
$$ \mathcal{L}_{\text{dice}(x, y) = 1 - \frac{2 * x * y }{x + y + 1}} $$
Args:
inputs (`torch.Tensor`):
A tensor representing a mask.
labels (`torch.Tensor`):
A tensor with the same shape as inputs. Stores the binary classification labels for each element in inputs
(0 for the negative class and 1 for the positive class).
num_masks (`int`):
The number of masks present in the current batch, used for normalization.
Returns:
`torch.Tensor`: The computed loss.
"""
probs = inputs.sigmoid().flatten(1)
numerator = 2 * (probs * labels).sum(-1)
denominator = probs.sum(-1) + labels.sum(-1)
loss = 1 - (numerator + 1) / (denominator + 1)
loss = loss.sum() / num_masks
return loss
# refactored from original implementation
def sigmoid_focal_loss(
inputs: Tensor, labels: Tensor, num_masks: int, alpha: float = 0.25, gamma: float = 2
) -> Tensor:
r"""
Focal loss proposed in [Focal Loss for Dense Object Detection](https://arxiv.org/abs/1708.02002) originally used in
RetinaNet. The loss is computed as follows:
$$ \mathcal{L}_{\text{focal loss} = -(1 - p_t)^{\gamma}\log{(p_t)} $$
where \\(CE(p_t) = -\log{(p_t)}}\\), CE is the standard Cross Entropy Loss
Please refer to equation (1,2,3) of the paper for a better understanding.
Args:
inputs (`torch.Tensor`):
A float tensor of arbitrary shape.
labels (`torch.Tensor`):
A tensor with the same shape as inputs. Stores the binary classification labels for each element in inputs
(0 for the negative class and 1 for the positive class).
num_masks (`int`):
The number of masks present in the current batch, used for normalization.
alpha (float, *optional*, defaults to 0.25):
Weighting factor in range (0,1) to balance positive vs negative examples.
gamma (float, *optional*, defaults to 2.0):
Exponent of the modulating factor \\(1 - p_t\\) to balance easy vs hard examples.
Returns:
`torch.Tensor`: The computed loss.
"""
criterion = nn.BCEWithLogitsLoss(reduction="none")
probs = inputs.sigmoid()
cross_entropy_loss = criterion(inputs, labels)
p_t = probs * labels + (1 - probs) * (1 - labels)
loss = cross_entropy_loss * ((1 - p_t) ** gamma)
if alpha >= 0:
alpha_t = alpha * labels + (1 - alpha) * (1 - labels)
loss = alpha_t * loss
loss = loss.mean(1).sum() / num_masks
return loss
# refactored from original implementation
def pair_wise_dice_loss(inputs: Tensor, labels: Tensor) -> Tensor:
"""
A pair wise version of the dice loss, see `dice_loss` for usage.
Args:
inputs (`torch.Tensor`):
A tensor representing a mask
labels (`torch.Tensor`):
A tensor with the same shape as inputs. Stores the binary classification labels for each element in inputs
(0 for the negative class and 1 for the positive class).
Returns:
`torch.Tensor`: The computed loss between each pairs.
"""
inputs = inputs.sigmoid().flatten(1)
numerator = 2 * torch.matmul(inputs, labels.T)
# using broadcasting to get a [num_queries, NUM_CLASSES] matrix
denominator = inputs.sum(-1)[:, None] + labels.sum(-1)[None, :]
loss = 1 - (numerator + 1) / (denominator + 1)
return loss
# refactored from original implementation
def pair_wise_sigmoid_focal_loss(inputs: Tensor, labels: Tensor, alpha: float = 0.25, gamma: float = 2.0) -> Tensor:
r"""
A pair wise version of the focal loss, see `sigmoid_focal_loss` for usage.
Args:
inputs (`torch.Tensor`):
A tensor representing a mask.
labels (`torch.Tensor`):
A tensor with the same shape as inputs. Stores the binary classification labels for each element in inputs
(0 for the negative class and 1 for the positive class).
alpha (float, *optional*, defaults to 0.25):
Weighting factor in range (0,1) to balance positive vs negative examples.
gamma (float, *optional*, defaults to 2.0):
Exponent of the modulating factor \\(1 - p_t\\) to balance easy vs hard examples.
Returns:
`torch.Tensor`: The computed loss between each pairs.
"""
if alpha < 0:
raise ValueError("alpha must be positive")
height_and_width = inputs.shape[1]
criterion = nn.BCEWithLogitsLoss(reduction="none")
prob = inputs.sigmoid()
cross_entropy_loss_pos = criterion(inputs, torch.ones_like(inputs))
focal_pos = ((1 - prob) ** gamma) * cross_entropy_loss_pos
focal_pos *= alpha
cross_entropy_loss_neg = criterion(inputs, torch.zeros_like(inputs))
focal_neg = (prob**gamma) * cross_entropy_loss_neg
focal_neg *= 1 - alpha
loss = torch.matmul(focal_pos, labels.T) + torch.matmul(focal_neg, (1 - labels).T)
return loss / height_and_width
# Copied from transformers.models.detr.modeling_detr.DetrAttention
class DetrAttention(nn.Module):
"""
Multi-headed attention from 'Attention Is All You Need' paper.
Here, we add position embeddings to the queries and keys (as explained in the DETR paper).
"""
def __init__(
self,
embed_dim: int,
num_heads: int,
dropout: float = 0.0,
bias: bool = True,
):
super().__init__()
self.embed_dim = embed_dim
self.num_heads = num_heads
self.dropout = dropout
self.head_dim = embed_dim // num_heads
if self.head_dim * num_heads != self.embed_dim:
raise ValueError(
f"embed_dim must be divisible by num_heads (got `embed_dim`: {self.embed_dim} and `num_heads`:"
f" {num_heads})."
)
self.scaling = self.head_dim**-0.5
self.k_proj = nn.Linear(embed_dim, embed_dim, bias=bias)
self.v_proj = nn.Linear(embed_dim, embed_dim, bias=bias)
self.q_proj = nn.Linear(embed_dim, embed_dim, bias=bias)
self.out_proj = nn.Linear(embed_dim, embed_dim, bias=bias)
def _shape(self, tensor: torch.Tensor, seq_len: int, batch_size: int):
return tensor.view(batch_size, seq_len, self.num_heads, self.head_dim).transpose(1, 2).contiguous()
def with_pos_embed(self, tensor: torch.Tensor, object_queries: Optional[Tensor], **kwargs):
position_embeddings = kwargs.pop("position_embeddings", None)
if kwargs:
raise ValueError(f"Unexpected arguments {kwargs.keys()}")
if position_embeddings is not None and object_queries is not None:
raise ValueError(
"Cannot specify both position_embeddings and object_queries. Please use just object_queries"
)
if position_embeddings is not None:
logger.warning_once(
"position_embeddings has been deprecated and will be removed in v4.34. Please use object_queries instead"
)
object_queries = position_embeddings
return tensor if object_queries is None else tensor + object_queries
def forward(
self,
hidden_states: torch.Tensor,
attention_mask: Optional[torch.Tensor] = None,
object_queries: Optional[torch.Tensor] = None,
key_value_states: Optional[torch.Tensor] = None,
spatial_position_embeddings: Optional[torch.Tensor] = None,
output_attentions: bool = False,
**kwargs,
) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
"""Input shape: Batch x Time x Channel"""
position_embeddings = kwargs.pop("position_ebmeddings", None)
key_value_position_embeddings = kwargs.pop("key_value_position_embeddings", None)
if kwargs:
raise ValueError(f"Unexpected arguments {kwargs.keys()}")
if position_embeddings is not None and object_queries is not None:
raise ValueError(
"Cannot specify both position_embeddings and object_queries. Please use just object_queries"
)
if key_value_position_embeddings is not None and spatial_position_embeddings is not None:
raise ValueError(
"Cannot specify both key_value_position_embeddings and spatial_position_embeddings. Please use just spatial_position_embeddings"
)
if position_embeddings is not None:
logger.warning_once(
"position_embeddings has been deprecated and will be removed in v4.34. Please use object_queries instead"
)
object_queries = position_embeddings
if key_value_position_embeddings is not None:
logger.warning_once(
"key_value_position_embeddings has been deprecated and will be removed in v4.34. Please use spatial_position_embeddings instead"
)
spatial_position_embeddings = key_value_position_embeddings
# if key_value_states are provided this layer is used as a cross-attention layer
# for the decoder
is_cross_attention = key_value_states is not None
batch_size, target_len, embed_dim = hidden_states.size()
# add position embeddings to the hidden states before projecting to queries and keys
if object_queries is not None:
hidden_states_original = hidden_states
hidden_states = self.with_pos_embed(hidden_states, object_queries)
# add key-value position embeddings to the key value states
if spatial_position_embeddings is not None:
key_value_states_original = key_value_states
key_value_states = self.with_pos_embed(key_value_states, spatial_position_embeddings)
# get query proj
query_states = self.q_proj(hidden_states) * self.scaling
# get key, value proj
if is_cross_attention:
# cross_attentions
key_states = self._shape(self.k_proj(key_value_states), -1, batch_size)
value_states = self._shape(self.v_proj(key_value_states_original), -1, batch_size)
else:
# self_attention
key_states = self._shape(self.k_proj(hidden_states), -1, batch_size)
value_states = self._shape(self.v_proj(hidden_states_original), -1, batch_size)
proj_shape = (batch_size * self.num_heads, -1, self.head_dim)
query_states = self._shape(query_states, target_len, batch_size).view(*proj_shape)
key_states = key_states.view(*proj_shape)
value_states = value_states.view(*proj_shape)
source_len = key_states.size(1)
attn_weights = torch.bmm(query_states, key_states.transpose(1, 2))
if attn_weights.size() != (batch_size * self.num_heads, target_len, source_len):
raise ValueError(
f"Attention weights should be of size {(batch_size * self.num_heads, target_len, source_len)}, but is"
f" {attn_weights.size()}"
)
if attention_mask is not None:
if attention_mask.size() != (batch_size, 1, target_len, source_len):
raise ValueError(
f"Attention mask should be of size {(batch_size, 1, target_len, source_len)}, but is"
f" {attention_mask.size()}"
)
attn_weights = attn_weights.view(batch_size, self.num_heads, target_len, source_len) + attention_mask
attn_weights = attn_weights.view(batch_size * self.num_heads, target_len, source_len)
attn_weights = nn.functional.softmax(attn_weights, dim=-1)
if output_attentions:
# this operation is a bit awkward, but it's required to
# make sure that attn_weights keeps its gradient.
# In order to do so, attn_weights have to reshaped
# twice and have to be reused in the following
attn_weights_reshaped = attn_weights.view(batch_size, self.num_heads, target_len, source_len)
attn_weights = attn_weights_reshaped.view(batch_size * self.num_heads, target_len, source_len)
else:
attn_weights_reshaped = None
attn_probs = nn.functional.dropout(attn_weights, p=self.dropout, training=self.training)
attn_output = torch.bmm(attn_probs, value_states)
if attn_output.size() != (batch_size * self.num_heads, target_len, self.head_dim):
raise ValueError(
f"`attn_output` should be of size {(batch_size, self.num_heads, target_len, self.head_dim)}, but is"
f" {attn_output.size()}"
)
attn_output = attn_output.view(batch_size, self.num_heads, target_len, self.head_dim)
attn_output = attn_output.transpose(1, 2)
attn_output = attn_output.reshape(batch_size, target_len, embed_dim)
attn_output = self.out_proj(attn_output)
return attn_output, attn_weights_reshaped
# Copied from transformers.models.detr.modeling_detr.DetrDecoderLayer
class DetrDecoderLayer(nn.Module):
def __init__(self, config: DetrConfig):
super().__init__()
self.embed_dim = config.d_model
self.self_attn = DetrAttention(
embed_dim=self.embed_dim,
num_heads=config.decoder_attention_heads,
dropout=config.attention_dropout,
)
self.dropout = config.dropout
self.activation_fn = ACT2FN[config.activation_function]
self.activation_dropout = config.activation_dropout
self.self_attn_layer_norm = nn.LayerNorm(self.embed_dim)
self.encoder_attn = DetrAttention(
self.embed_dim,
config.decoder_attention_heads,
dropout=config.attention_dropout,
)
self.encoder_attn_layer_norm = nn.LayerNorm(self.embed_dim)
self.fc1 = nn.Linear(self.embed_dim, config.decoder_ffn_dim)
self.fc2 = nn.Linear(config.decoder_ffn_dim, self.embed_dim)
self.final_layer_norm = nn.LayerNorm(self.embed_dim)
def forward(
self,
hidden_states: torch.Tensor,
attention_mask: Optional[torch.Tensor] = None,
object_queries: Optional[torch.Tensor] = None,
query_position_embeddings: Optional[torch.Tensor] = None,
encoder_hidden_states: Optional[torch.Tensor] = None,
encoder_attention_mask: Optional[torch.Tensor] = None,
output_attentions: Optional[bool] = False,
**kwargs,
):
"""
Args:
hidden_states (`torch.FloatTensor`): input to the layer of shape `(batch, seq_len, embed_dim)`
attention_mask (`torch.FloatTensor`): attention mask of size
`(batch, 1, target_len, source_len)` where padding elements are indicated by very large negative
values.
object_queries (`torch.FloatTensor`, *optional*):
object_queries that are added to the hidden states
in the cross-attention layer.
query_position_embeddings (`torch.FloatTensor`, *optional*):
position embeddings that are added to the queries and keys
in the self-attention layer.
encoder_hidden_states (`torch.FloatTensor`):
cross attention input to the layer of shape `(batch, seq_len, embed_dim)`
encoder_attention_mask (`torch.FloatTensor`): encoder attention mask of size
`(batch, 1, target_len, source_len)` where padding elements are indicated by very large negative
values.
output_attentions (`bool`, *optional*):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under
returned tensors for more detail.
"""
position_embeddings = kwargs.pop("position_embeddings", None)
if kwargs:
raise ValueError(f"Unexpected arguments {kwargs.keys()}")
if position_embeddings is not None and object_queries is not None:
raise ValueError(
"Cannot specify both position_embeddings and object_queries. Please use just object_queries"
)
if position_embeddings is not None:
logger.warning_once(
"position_embeddings has been deprecated and will be removed in v4.34. Please use object_queries instead"
)
object_queries = position_embeddings
residual = hidden_states
# Self Attention
hidden_states, self_attn_weights = self.self_attn(
hidden_states=hidden_states,
object_queries=query_position_embeddings,
attention_mask=attention_mask,
output_attentions=output_attentions,
)
hidden_states = nn.functional.dropout(hidden_states, p=self.dropout, training=self.training)
hidden_states = residual + hidden_states
hidden_states = self.self_attn_layer_norm(hidden_states)
# Cross-Attention Block
cross_attn_weights = None
if encoder_hidden_states is not None:
residual = hidden_states
hidden_states, cross_attn_weights = self.encoder_attn(
hidden_states=hidden_states,
object_queries=query_position_embeddings,
key_value_states=encoder_hidden_states,
attention_mask=encoder_attention_mask,
spatial_position_embeddings=object_queries,
output_attentions=output_attentions,
)
hidden_states = nn.functional.dropout(hidden_states, p=self.dropout, training=self.training)
hidden_states = residual + hidden_states
hidden_states = self.encoder_attn_layer_norm(hidden_states)
# Fully Connected
residual = hidden_states
hidden_states = self.activation_fn(self.fc1(hidden_states))
hidden_states = nn.functional.dropout(hidden_states, p=self.activation_dropout, training=self.training)
hidden_states = self.fc2(hidden_states)
hidden_states = nn.functional.dropout(hidden_states, p=self.dropout, training=self.training)
hidden_states = residual + hidden_states
hidden_states = self.final_layer_norm(hidden_states)
outputs = (hidden_states,)
if output_attentions:
outputs += (self_attn_weights, cross_attn_weights)
return outputs
class DetrDecoder(nn.Module):
"""
Transformer decoder consisting of *config.decoder_layers* layers. Each layer is a [`DetrDecoderLayer`].
The decoder updates the query embeddings through multiple self-attention and cross-attention layers.
Some small tweaks for DETR:
- object_queries and query_position_embeddings are added to the forward pass.
- if self.config.auxiliary_loss is set to True, also returns a stack of activations from all decoding layers.
Args:
config: DetrConfig
"""
def __init__(self, config: DetrConfig):
super().__init__()
self.config = config
self.dropout = config.dropout
self.layerdrop = config.decoder_layerdrop
self.layers = nn.ModuleList([DetrDecoderLayer(config) for _ in range(config.decoder_layers)])
# in DETR, the decoder uses layernorm after the last decoder layer output
self.layernorm = nn.LayerNorm(config.d_model)
self.gradient_checkpointing = False
def forward(
self,
inputs_embeds=None,
attention_mask=None,
encoder_hidden_states=None,
encoder_attention_mask=None,
object_queries=None,
query_position_embeddings=None,
output_attentions=None,
output_hidden_states=None,
return_dict=None,
**kwargs,
):
r"""
Args:
inputs_embeds (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`):
The query embeddings that are passed into the decoder.
attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
Mask to avoid performing attention on certain queries. Mask values selected in `[0, 1]`:
- 1 for queries that are **not masked**,
- 0 for queries that are **masked**.
[What are attention masks?](../glossary#attention-mask)
encoder_hidden_states (`torch.FloatTensor` of shape `(batch_size, encoder_sequence_length, hidden_size)`, *optional*):
Sequence of hidden-states at the output of the last layer of the encoder. Used in the cross-attention
of the decoder.
encoder_attention_mask (`torch.LongTensor` of shape `(batch_size, encoder_sequence_length)`, *optional*):
Mask to avoid performing cross-attention on padding pixel_values of the encoder. Mask values selected
in `[0, 1]`:
- 1 for pixels that are real (i.e. **not masked**),
- 0 for pixels that are padding (i.e. **masked**).
object_queries (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
Position embeddings that are added to the queries and keys in each cross-attention layer.
query_position_embeddings (`torch.FloatTensor` of shape `(batch_size, num_queries, hidden_size)`):
, *optional*): Position embeddings that are added to the queries and keys in each self-attention layer.
output_attentions (`bool`, *optional*):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under
returned tensors for more detail.
output_hidden_states (`bool`, *optional*):
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors
for more detail.
return_dict (`bool`, *optional*):
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
"""
position_embeddings = kwargs.pop("position_embeddings", None)
if kwargs:
raise ValueError(f"Unexpected arguments {kwargs.keys()}")
if position_embeddings is not None and object_queries is not None:
raise ValueError(
"Cannot specify both position_embeddings and object_queries. Please use just object_queries"
)
if position_embeddings is not None:
logger.warning_once(
"position_embeddings has been deprecated and will be removed in v4.34. Please use object_queries instead"
)
object_queries = position_embeddings
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
output_hidden_states = (
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
)
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
if inputs_embeds is not None:
hidden_states = inputs_embeds
input_shape = inputs_embeds.size()[:-1]
# expand encoder attention mask
if encoder_hidden_states is not None and encoder_attention_mask is not None:
# [bsz, seq_len] -> [bsz, 1, tgt_seq_len, src_seq_len]
encoder_attention_mask = _prepare_4d_attention_mask(
encoder_attention_mask, inputs_embeds.dtype, tgt_len=input_shape[-1]
)
# optional intermediate hidden states
intermediate = () if self.config.auxiliary_loss else None
# decoder layers
all_hidden_states = () if output_hidden_states else None
all_self_attns = () if output_attentions else None
all_cross_attentions = () if (output_attentions and encoder_hidden_states is not None) else None
for idx, decoder_layer in enumerate(self.layers):
# add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
if output_hidden_states:
all_hidden_states += (hidden_states,)
if self.training:
dropout_probability = torch.rand([])
if dropout_probability < self.layerdrop:
continue
if self.gradient_checkpointing and self.training:
layer_outputs = self._gradient_checkpointing_func(
decoder_layer.__call__,
hidden_states,
None,
encoder_hidden_states,
encoder_attention_mask,
None,
output_attentions,
)
else:
layer_outputs = decoder_layer(
hidden_states,
attention_mask=None,
object_queries=object_queries,
query_position_embeddings=query_position_embeddings,
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_attention_mask,
output_attentions=output_attentions,
)
hidden_states = layer_outputs[0]
if self.config.auxiliary_loss:
hidden_states = self.layernorm(hidden_states)
intermediate += (hidden_states,)
if output_attentions:
all_self_attns += (layer_outputs[1],)
if encoder_hidden_states is not None:
all_cross_attentions += (layer_outputs[2],)
# finally, apply layernorm
hidden_states = self.layernorm(hidden_states)
# add hidden states from the last decoder layer
if output_hidden_states:
all_hidden_states += (hidden_states,)
# stack intermediate decoder activations
if self.config.auxiliary_loss:
intermediate = torch.stack(intermediate)
if not return_dict:
return tuple(
v
for v in [hidden_states, all_hidden_states, all_self_attns, all_cross_attentions, intermediate]
if v is not None
)
return DetrDecoderOutput(
last_hidden_state=hidden_states,
hidden_states=all_hidden_states,
attentions=all_self_attns,
cross_attentions=all_cross_attentions,
intermediate_hidden_states=intermediate,
)
# refactored from original implementation
class MaskFormerHungarianMatcher(nn.Module):
"""This class computes an assignment between the labels and the predictions of the network.
For efficiency reasons, the labels don't include the no_object. Because of this, in general, there are more
predictions than labels. In this case, we do a 1-to-1 matching of the best predictions, while the others are
un-matched (and thus treated as non-objects).
"""
def __init__(self, cost_class: float = 1.0, cost_mask: float = 1.0, cost_dice: float = 1.0):
"""Creates the matcher
Params:
cost_class (float, *optional*, defaults to 1.0):
This is the relative weight of the classification error in the matching cost.
cost_mask (float, *optional*, defaults to 1.0):
This is the relative weight of the focal loss of the binary mask in the matching cost.
cost_dice (float, *optional*, defaults to 1.0):
This is the relative weight of the dice loss of the binary mask in the matching cost
"""
super().__init__()
if cost_class == 0 and cost_mask == 0 and cost_dice == 0:
raise ValueError("All costs cant be 0")
self.cost_class = cost_class
self.cost_mask = cost_mask
self.cost_dice = cost_dice
@torch.no_grad()
def forward(self, masks_queries_logits, class_queries_logits, mask_labels, class_labels) -> List[Tuple[Tensor]]:
"""Performs the matching
Params:
masks_queries_logits (`torch.Tensor`):
A tensor` of dim `batch_size, num_queries, num_labels` with the
classification logits.
class_queries_logits (`torch.Tensor`):
A tensor` of dim `batch_size, num_queries, height, width` with the
predicted masks.
class_labels (`torch.Tensor`):
A tensor` of dim `num_target_boxes` (where num_target_boxes is the number
of ground-truth objects in the target) containing the class labels.
mask_labels (`torch.Tensor`):
A tensor` of dim `num_target_boxes, height, width` containing the target
masks.
Returns:
`List[Tuple[Tensor]]`: A list of size batch_size, containing tuples of (index_i, index_j) where:
- index_i is the indices of the selected predictions (in order)
- index_j is the indices of the corresponding selected labels (in order)
For each batch element, it holds:
len(index_i) = len(index_j) = min(num_queries, num_target_boxes).
"""
indices: List[Tuple[np.array]] = []
preds_masks = masks_queries_logits
preds_probs = class_queries_logits
# iterate through batch size
for pred_probs, pred_mask, target_mask, labels in zip(preds_probs, preds_masks, mask_labels, class_labels):
# downsample the target mask, save memory
target_mask = nn.functional.interpolate(target_mask[:, None], size=pred_mask.shape[-2:], mode="nearest")
pred_probs = pred_probs.softmax(-1)
# Compute the classification cost. Contrary to the loss, we don't use the NLL,
# but approximate it in 1 - proba[target class].
# The 1 is a constant that doesn't change the matching, it can be ommitted.
cost_class = -pred_probs[:, labels]
# flatten spatial dimension "q h w -> q (h w)"
pred_mask_flat = pred_mask.flatten(1) # [num_queries, height*width]
# same for target_mask "c h w -> c (h w)"
target_mask_flat = target_mask[:, 0].flatten(1) # [num_total_labels, height*width]
# compute the focal loss between each mask pairs -> shape (num_queries, num_labels)
cost_mask = pair_wise_sigmoid_focal_loss(pred_mask_flat, target_mask_flat)
# Compute the dice loss betwen each mask pairs -> shape (num_queries, num_labels)
cost_dice = pair_wise_dice_loss(pred_mask_flat, target_mask_flat)
# final cost matrix
cost_matrix = self.cost_mask * cost_mask + self.cost_class * cost_class + self.cost_dice * cost_dice
# do the assigmented using the hungarian algorithm in scipy
assigned_indices: Tuple[np.array] = linear_sum_assignment(cost_matrix.cpu())
indices.append(assigned_indices)
# It could be stacked in one tensor
matched_indices = [
(torch.as_tensor(i, dtype=torch.int64), torch.as_tensor(j, dtype=torch.int64)) for i, j in indices
]
return matched_indices
def __repr__(self):
head = "Matcher " + self.__class__.__name__
body = [
f"cost_class: {self.cost_class}",
f"cost_mask: {self.cost_mask}",
f"cost_dice: {self.cost_dice}",
]
_repr_indent = 4
lines = [head] + [" " * _repr_indent + line for line in body]
return "\n".join(lines)
# copied and adapted from original implementation
class MaskFormerLoss(nn.Module):
def __init__(
self,
num_labels: int,
matcher: MaskFormerHungarianMatcher,
weight_dict: Dict[str, float],
eos_coef: float,
):
"""
The MaskFormer Loss. The loss is computed very similar to DETR. The process happens in two steps: 1) we compute
hungarian assignment between ground truth masks and the outputs of the model 2) we supervise each pair of
matched ground-truth / prediction (supervise class and mask)
Args:
num_labels (`int`):
The number of classes.
matcher (`MaskFormerHungarianMatcher`):
A torch module that computes the assigments between the predictions and labels.
weight_dict (`Dict[str, float]`):
A dictionary of weights to be applied to the different losses.
eos_coef (`float`):
Weight to apply to the null class.
"""
super().__init__()
requires_backends(self, ["scipy"])
self.num_labels = num_labels
self.matcher = matcher
self.weight_dict = weight_dict
self.eos_coef = eos_coef
empty_weight = torch.ones(self.num_labels + 1)
empty_weight[-1] = self.eos_coef
self.register_buffer("empty_weight", empty_weight)
def _max_by_axis(self, the_list: List[List[int]]) -> List[int]:
maxes = the_list[0]
for sublist in the_list[1:]:
for index, item in enumerate(sublist):
maxes[index] = max(maxes[index], item)
return maxes
def _pad_images_to_max_in_batch(self, tensors: List[Tensor]) -> Tuple[Tensor, Tensor]:
# get the maximum size in the batch
max_size = self._max_by_axis([list(tensor.shape) for tensor in tensors])
batch_size = len(tensors)
# compute finel size
batch_shape = [batch_size] + max_size
b, _, h, w = batch_shape
# get metadata
dtype = tensors[0].dtype
device = tensors[0].device
padded_tensors = torch.zeros(batch_shape, dtype=dtype, device=device)
padding_masks = torch.ones((b, h, w), dtype=torch.bool, device=device)
# pad the tensors to the size of the biggest one
for tensor, padded_tensor, padding_mask in zip(tensors, padded_tensors, padding_masks):
padded_tensor[: tensor.shape[0], : tensor.shape[1], : tensor.shape[2]].copy_(tensor)
padding_mask[: tensor.shape[1], : tensor.shape[2]] = False
return padded_tensors, padding_masks
def loss_labels(
self, class_queries_logits: Tensor, class_labels: List[Tensor], indices: Tuple[np.array]
) -> Dict[str, Tensor]:
"""Compute the losses related to the labels using cross entropy.
Args:
class_queries_logits (`torch.Tensor`):
A tensor of shape `batch_size, num_queries, num_labels`
class_labels (`List[torch.Tensor]`):
List of class labels of shape `(labels)`.
indices (`Tuple[np.array])`:
The indices computed by the Hungarian matcher.
Returns:
`Dict[str, Tensor]`: A dict of `torch.Tensor` containing the following key:
- **loss_cross_entropy** -- The loss computed using cross entropy on the predicted and ground truth labels.
"""
pred_logits = class_queries_logits
batch_size, num_queries, _ = pred_logits.shape
criterion = nn.CrossEntropyLoss(weight=self.empty_weight)
idx = self._get_predictions_permutation_indices(indices)
# shape = (batch_size, num_queries)
target_classes_o = torch.cat([target[j] for target, (_, j) in zip(class_labels, indices)])
# shape = (batch_size, num_queries)
target_classes = torch.full(
(batch_size, num_queries), fill_value=self.num_labels, dtype=torch.int64, device=pred_logits.device
)
target_classes[idx] = target_classes_o
# target_classes is a (batch_size, num_labels, num_queries), we need to permute pred_logits "b q c -> b c q"
pred_logits_transposed = pred_logits.transpose(1, 2)
loss_ce = criterion(pred_logits_transposed, target_classes)
losses = {"loss_cross_entropy": loss_ce}
return losses
def loss_masks(
self, masks_queries_logits: Tensor, mask_labels: List[Tensor], indices: Tuple[np.array], num_masks: int
) -> Dict[str, Tensor]:
"""Compute the losses related to the masks using focal and dice loss.
Args:
masks_queries_logits (`torch.Tensor`):
A tensor of shape `batch_size, num_queries, height, width`
mask_labels (`torch.Tensor`):
List of mask labels of shape `(labels, height, width)`.
indices (`Tuple[np.array])`:
The indices computed by the Hungarian matcher.
num_masks (`int)`:
The number of masks, used for normalization.
Returns:
`Dict[str, Tensor]`: A dict of `torch.Tensor` containing two keys:
- **loss_mask** -- The loss computed using sigmoid focal loss on the predicted and ground truth masks.
- **loss_dice** -- The loss computed using dice loss on the predicted on the predicted and ground truth
masks.
"""
src_idx = self._get_predictions_permutation_indices(indices)
tgt_idx = self._get_targets_permutation_indices(indices)
# shape (batch_size * num_queries, height, width)
pred_masks = masks_queries_logits[src_idx]
# shape (batch_size, num_queries, height, width)
# pad all and stack the targets to the num_labels dimension
target_masks, _ = self._pad_images_to_max_in_batch(mask_labels)
target_masks = target_masks[tgt_idx]
# upsample predictions to the target size, we have to add one dim to use interpolate
pred_masks = nn.functional.interpolate(
pred_masks[:, None], size=target_masks.shape[-2:], mode="bilinear", align_corners=False
)
pred_masks = pred_masks[:, 0].flatten(1)
target_masks = target_masks.flatten(1)
losses = {
"loss_mask": sigmoid_focal_loss(pred_masks, target_masks, num_masks),
"loss_dice": dice_loss(pred_masks, target_masks, num_masks),
}
return losses
def _get_predictions_permutation_indices(self, indices):
# permute predictions following indices
batch_indices = torch.cat([torch.full_like(src, i) for i, (src, _) in enumerate(indices)])
predictions_indices = torch.cat([src for (src, _) in indices])
return batch_indices, predictions_indices
def _get_targets_permutation_indices(self, indices):
# permute labels following indices
batch_indices = torch.cat([torch.full_like(tgt, i) for i, (_, tgt) in enumerate(indices)])
target_indices = torch.cat([tgt for (_, tgt) in indices])
return batch_indices, target_indices
def forward(
self,
masks_queries_logits: Tensor,
class_queries_logits: Tensor,
mask_labels: List[Tensor],
class_labels: List[Tensor],
auxiliary_predictions: Optional[Dict[str, Tensor]] = None,
) -> Dict[str, Tensor]:
"""
This performs the loss computation.
Args:
masks_queries_logits (`torch.Tensor`):
A tensor of shape `batch_size, num_queries, height, width`
class_queries_logits (`torch.Tensor`):
A tensor of shape `batch_size, num_queries, num_labels`
mask_labels (`torch.Tensor`):
List of mask labels of shape `(labels, height, width)`.
class_labels (`List[torch.Tensor]`):
List of class labels of shape `(labels)`.
auxiliary_predictions (`Dict[str, torch.Tensor]`, *optional*):
if `use_auxiliary_loss` was set to `true` in [`MaskFormerConfig`], then it contains the logits from the
inner layers of the Detr's Decoder.
Returns:
`Dict[str, Tensor]`: A dict of `torch.Tensor` containing two keys:
- **loss_cross_entropy** -- The loss computed using cross entropy on the predicted and ground truth labels.
- **loss_mask** -- The loss computed using sigmoid focal loss on the predicted and ground truth masks.
- **loss_dice** -- The loss computed using dice loss on the predicted on the predicted and ground truth
masks.
if `use_auxiliary_loss` was set to `true` in [`MaskFormerConfig`], the dictionary contains addional losses
for each auxiliary predictions.
"""
# retrieve the matching between the outputs of the last layer and the labels
indices = self.matcher(masks_queries_logits, class_queries_logits, mask_labels, class_labels)
# compute the average number of target masks for normalization purposes
num_masks: Number = self.get_num_masks(class_labels, device=class_labels[0].device)
# get all the losses
losses: Dict[str, Tensor] = {
**self.loss_masks(masks_queries_logits, mask_labels, indices, num_masks),
**self.loss_labels(class_queries_logits, class_labels, indices),
}
# in case of auxiliary losses, we repeat this process with the output of each intermediate layer.
if auxiliary_predictions is not None:
for idx, aux_outputs in enumerate(auxiliary_predictions):
masks_queries_logits = aux_outputs["masks_queries_logits"]
class_queries_logits = aux_outputs["class_queries_logits"]
loss_dict = self.forward(masks_queries_logits, class_queries_logits, mask_labels, class_labels)
loss_dict = {f"{key}_{idx}": value for key, value in loss_dict.items()}
losses.update(loss_dict)
return losses
def get_num_masks(self, class_labels: torch.Tensor, device: torch.device) -> torch.Tensor:
"""
Computes the average number of target masks across the batch, for normalization purposes.
"""
num_masks = sum([len(classes) for classes in class_labels])
num_masks_pt = torch.as_tensor(num_masks, dtype=torch.float, device=device)
world_size = 1
if PartialState._shared_state != {}:
num_masks_pt = reduce(num_masks_pt)
world_size = PartialState().num_processes
num_masks_pt = torch.clamp(num_masks_pt / world_size, min=1)
return num_masks_pt
class MaskFormerFPNConvLayer(nn.Module):
def __init__(self, in_features: int, out_features: int, kernel_size: int = 3, padding: int = 1):
"""
A basic module that executes conv - norm - in sequence used in MaskFormer.
Args:
in_features (`int`):
The number of input features (channels).
out_features (`int`):
The number of outputs features (channels).
"""
super().__init__()
self.layers = [
nn.Conv2d(in_features, out_features, kernel_size=kernel_size, padding=padding, bias=False),
nn.GroupNorm(32, out_features),
nn.ReLU(inplace=True),
]
for i, layer in enumerate(self.layers):
# Provide backwards compatibility from when the class inherited from nn.Sequential
# In nn.Sequential subclasses, the name given to the layer is its index in the sequence.
# In nn.Module subclasses they derived from the instance attribute they are assigned to e.g.
# self.my_layer_name = Layer()
# We can't give instance attributes integer names i.e. self.0 is not permitted and so need to register
# explicitly
self.add_module(str(i), layer)
def forward(self, input: Tensor) -> Tensor:
hidden_state = input
for layer in self.layers:
hidden_state = layer(hidden_state)
return hidden_state
class MaskFormerFPNLayer(nn.Module):
def __init__(self, in_features: int, lateral_features: int):
"""
A Feature Pyramid Network Layer (FPN) layer. It creates a feature map by aggregating features from the previous
and backbone layer. Due to the spatial mismatch, the tensor coming from the previous layer is upsampled.
Args:
in_features (`int`):
The number of input features (channels).
lateral_features (`int`):
The number of lateral features (channels).
"""
super().__init__()
self.proj = nn.Sequential(
nn.Conv2d(lateral_features, in_features, kernel_size=1, padding=0, bias=False),
nn.GroupNorm(32, in_features),
)
self.block = MaskFormerFPNConvLayer(in_features, in_features)
def forward(self, down: Tensor, left: Tensor) -> Tensor:
left = self.proj(left)
down = nn.functional.interpolate(down, size=left.shape[-2:], mode="nearest")
down += left
down = self.block(down)
return down
class MaskFormerFPNModel(nn.Module):
def __init__(self, in_features: int, lateral_widths: List[int], feature_size: int = 256):
"""
Feature Pyramid Network, given an input tensor and a set of feature map of different feature/spatial size, it
creates a list of feature maps with the same feature size.
Args:
in_features (`int`):
The number of input features (channels).
lateral_widths (`List[int]`):
A list with the features (channels) size of each lateral connection.
feature_size (int, *optional*, defaults to 256):
The features (channels) of the resulting feature maps.
"""
super().__init__()
self.stem = MaskFormerFPNConvLayer(in_features, feature_size)
self.layers = nn.Sequential(
*[MaskFormerFPNLayer(feature_size, lateral_width) for lateral_width in lateral_widths[::-1]]
)
def forward(self, features: List[Tensor]) -> List[Tensor]:
fpn_features = []
last_feature = features[-1]
other_features = features[:-1]
output = self.stem(last_feature)
for layer, left in zip(self.layers, other_features[::-1]):
output = layer(output, left)
fpn_features.append(output)
return fpn_features
class MaskFormerPixelDecoder(nn.Module):
def __init__(self, *args, feature_size: int = 256, mask_feature_size: int = 256, **kwargs):
r"""
Pixel Decoder Module proposed in [Per-Pixel Classification is Not All You Need for Semantic
Segmentation](https://arxiv.org/abs/2107.06278). It first runs the backbone's features into a Feature Pyramid
Network creating a list of feature maps. Then, it projects the last one to the correct `mask_size`.
Args:
feature_size (`int`, *optional*, defaults to 256):
The feature size (channel dimension) of the FPN feature maps.
mask_feature_size (`int`, *optional*, defaults to 256):
The features (channels) of the target masks size \\(C_{\epsilon}\\) in the paper.
"""
super().__init__()
self.fpn = MaskFormerFPNModel(*args, feature_size=feature_size, **kwargs)
self.mask_projection = nn.Conv2d(feature_size, mask_feature_size, kernel_size=3, padding=1)
def forward(
self, features: List[Tensor], output_hidden_states: bool = False, return_dict: bool = True
) -> MaskFormerPixelDecoderOutput:
fpn_features = self.fpn(features)
# we use the last feature map
last_feature_projected = self.mask_projection(fpn_features[-1])
if not return_dict:
return (last_feature_projected, tuple(fpn_features)) if output_hidden_states else (last_feature_projected,)
return MaskFormerPixelDecoderOutput(
last_hidden_state=last_feature_projected, hidden_states=tuple(fpn_features) if output_hidden_states else ()
)
# copied and adapted from original implementation, also practically equal to DetrSinePositionEmbedding
class MaskFormerSinePositionEmbedding(nn.Module):
"""
This is a more standard version of the position embedding, very similar to the one used by the Attention is all you
need paper, generalized to work on images.
"""
def __init__(
self, num_pos_feats: int = 64, temperature: int = 10000, normalize: bool = False, scale: Optional[float] = None
):
super().__init__()
if scale is not None and normalize is False:
raise ValueError("normalize should be True if scale is passed")
self.num_pos_feats = num_pos_feats
self.temperature = temperature
self.normalize = normalize
self.scale = 2 * math.pi if scale is None else scale
def forward(self, x: Tensor, mask: Optional[Tensor] = None) -> Tensor:
if mask is None:
mask = torch.zeros((x.size(0), x.size(2), x.size(3)), device=x.device, dtype=torch.bool)
not_mask = (~mask).to(x.dtype)
y_embed = not_mask.cumsum(1)
x_embed = not_mask.cumsum(2)
if self.normalize:
eps = 1e-6
y_embed = y_embed / (y_embed[:, -1:, :] + eps) * self.scale
x_embed = x_embed / (x_embed[:, :, -1:] + eps) * self.scale
dim_t = torch.arange(self.num_pos_feats, dtype=torch.int64, device=x.device).type_as(x)
dim_t = self.temperature ** (2 * torch.div(dim_t, 2, rounding_mode="floor") / self.num_pos_feats)
pos_x = x_embed[:, :, :, None] / dim_t
pos_y = y_embed[:, :, :, None] / dim_t
pos_x = torch.stack((pos_x[:, :, :, 0::2].sin(), pos_x[:, :, :, 1::2].cos()), dim=4).flatten(3)
pos_y = torch.stack((pos_y[:, :, :, 0::2].sin(), pos_y[:, :, :, 1::2].cos()), dim=4).flatten(3)
pos = torch.cat((pos_y, pos_x), dim=3).permute(0, 3, 1, 2)
return pos
class PredictionBlock(nn.Module):
def __init__(self, in_dim: int, out_dim: int, activation: nn.Module) -> None:
super().__init__()
self.layers = [nn.Linear(in_dim, out_dim), activation]
# Maintain submodule indexing as if part of a Sequential block
for i, layer in enumerate(self.layers):
self.add_module(str(i), layer)
def forward(self, input: Tensor) -> Tensor:
hidden_state = input
for layer in self.layers:
hidden_state = layer(hidden_state)
return hidden_state
class MaskformerMLPPredictionHead(nn.Module):
def __init__(self, input_dim: int, hidden_dim: int, output_dim: int, num_layers: int = 3):
"""
A classic Multi Layer Perceptron (MLP).
Args:
input_dim (`int`):
The input dimensions.
hidden_dim (`int`):
The hidden dimensions.
output_dim (`int`):
The output dimensions.
num_layers (int, *optional*, defaults to 3):
The number of layers.
"""
super().__init__()
in_dims = [input_dim] + [hidden_dim] * (num_layers - 1)
out_dims = [hidden_dim] * (num_layers - 1) + [output_dim]
self.layers = []
for i, (in_dim, out_dim) in enumerate(zip(in_dims, out_dims)):
activation = nn.ReLU() if i < num_layers - 1 else nn.Identity()
layer = PredictionBlock(in_dim, out_dim, activation=activation)
self.layers.append(layer)
# Provide backwards compatibility from when the class inherited from nn.Sequential
# In nn.Sequential subclasses, the name given to the layer is its index in the sequence.
# In nn.Module subclasses they derived from the instance attribute they are assigned to e.g.
# self.my_layer_name = Layer()
# We can't give instance attributes integer names i.e. self.0 is not permitted and so need to register
# explicitly
self.add_module(str(i), layer)
def forward(self, input: Tensor) -> Tensor:
hidden_state = input
for layer in self.layers:
hidden_state = layer(hidden_state)
return hidden_state
class MaskFormerPixelLevelModule(nn.Module):
def __init__(self, config: MaskFormerConfig):
"""
Pixel Level Module proposed in [Per-Pixel Classification is Not All You Need for Semantic
Segmentation](https://arxiv.org/abs/2107.06278). It runs the input image through a backbone and a pixel
decoder, generating an image feature map and pixel embeddings.
Args:
config ([`MaskFormerConfig`]):
The configuration used to instantiate this model.
"""
super().__init__()
if getattr(config, "backbone_config") is not None and config.backbone_config.model_type == "swin":
# for backwards compatibility
backbone_config = config.backbone_config
backbone_config = MaskFormerSwinConfig.from_dict(backbone_config.to_dict())
backbone_config.out_features = ["stage1", "stage2", "stage3", "stage4"]
config.backbone_config = backbone_config
self.encoder = load_backbone(config)
feature_channels = self.encoder.channels
self.decoder = MaskFormerPixelDecoder(
in_features=feature_channels[-1],
feature_size=config.fpn_feature_size,
mask_feature_size=config.mask_feature_size,
lateral_widths=feature_channels[:-1],
)
def forward(
self, pixel_values: Tensor, output_hidden_states: bool = False, return_dict: bool = True
) -> MaskFormerPixelLevelModuleOutput:
features = self.encoder(pixel_values).feature_maps
decoder_output = self.decoder(features, output_hidden_states, return_dict=return_dict)
if not return_dict:
last_hidden_state = decoder_output[0]
outputs = (features[-1], last_hidden_state)
if output_hidden_states:
hidden_states = decoder_output[1]
outputs = outputs + (tuple(features),) + (hidden_states,)
return outputs
return MaskFormerPixelLevelModuleOutput(
# the last feature is actually the output from the last layer
encoder_last_hidden_state=features[-1],
decoder_last_hidden_state=decoder_output.last_hidden_state,
encoder_hidden_states=tuple(features) if output_hidden_states else (),
decoder_hidden_states=decoder_output.hidden_states if output_hidden_states else (),
)
class MaskFormerTransformerModule(nn.Module):
"""
The MaskFormer's transformer module.
"""
def __init__(self, in_features: int, config: MaskFormerConfig):
super().__init__()
hidden_size = config.decoder_config.hidden_size
should_project = in_features != hidden_size
self.position_embedder = MaskFormerSinePositionEmbedding(num_pos_feats=hidden_size // 2, normalize=True)
self.queries_embedder = nn.Embedding(config.decoder_config.num_queries, hidden_size)
self.input_projection = nn.Conv2d(in_features, hidden_size, kernel_size=1) if should_project else None
self.decoder = DetrDecoder(config=config.decoder_config)
def forward(
self,
image_features: Tensor,
output_hidden_states: bool = False,
output_attentions: bool = False,
return_dict: Optional[bool] = None,
) -> DetrDecoderOutput:
if self.input_projection is not None:
image_features = self.input_projection(image_features)
object_queries = self.position_embedder(image_features)
# repeat the queries "q c -> b q c"
batch_size = image_features.shape[0]
queries_embeddings = self.queries_embedder.weight.unsqueeze(0).repeat(batch_size, 1, 1)
inputs_embeds = torch.zeros_like(queries_embeddings, requires_grad=True)
batch_size, num_channels, height, width = image_features.shape
# rearrange both image_features and object_queries "b c h w -> b (h w) c"
image_features = image_features.view(batch_size, num_channels, height * width).permute(0, 2, 1)
object_queries = object_queries.view(batch_size, num_channels, height * width).permute(0, 2, 1)
decoder_output: DetrDecoderOutput = self.decoder(
inputs_embeds=inputs_embeds,
attention_mask=None,
encoder_hidden_states=image_features,
encoder_attention_mask=None,
object_queries=object_queries,
query_position_embeddings=queries_embeddings,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
return decoder_output
MASKFORMER_START_DOCSTRING = r"""
This model is a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) sub-class. Use
it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and
behavior.
Parameters:
config ([`MaskFormerConfig`]): Model configuration class with all the parameters of the model.
Initializing with a config file does not load the weights associated with the model, only the
configuration. Check out the [`~PreTrainedModel.from_pretrained`] method to load the model weights.
"""
MASKFORMER_INPUTS_DOCSTRING = r"""
Args:
pixel_values (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
Pixel values. Pixel values can be obtained using [`AutoImageProcessor`]. See
[`MaskFormerImageProcessor.__call__`] for details.
pixel_mask (`torch.LongTensor` of shape `(batch_size, height, width)`, *optional*):
Mask to avoid performing attention on padding pixel values. Mask values selected in `[0, 1]`:
- 1 for pixels that are real (i.e. **not masked**),
- 0 for pixels that are padding (i.e. **masked**).
[What are attention masks?](../glossary#attention-mask)
output_hidden_states (`bool`, *optional*):
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
more detail.
output_attentions (`bool`, *optional*):
Whether or not to return the attentions tensors of Detr's decoder attention layers.
return_dict (`bool`, *optional*):
Whether or not to return a [`~MaskFormerModelOutput`] instead of a plain tuple.
"""
class MaskFormerPreTrainedModel(PreTrainedModel):
config_class = MaskFormerConfig
base_model_prefix = "model"
main_input_name = "pixel_values"
def _init_weights(self, module: nn.Module):
xavier_std = self.config.init_xavier_std
std = self.config.init_std
if isinstance(module, MaskFormerTransformerModule):
if module.input_projection is not None:
nn.init.xavier_uniform_(module.input_projection.weight, gain=xavier_std)
nn.init.constant_(module.input_projection.bias, 0)
# FPN
elif isinstance(module, MaskFormerFPNModel):
nn.init.xavier_uniform_(module.stem.get_submodule("0").weight, gain=xavier_std)
elif isinstance(module, MaskFormerFPNLayer):
nn.init.xavier_uniform_(module.proj[0].weight, gain=xavier_std)
elif isinstance(module, MaskFormerFPNConvLayer):
nn.init.xavier_uniform_(module.get_submodule("0").weight, gain=xavier_std)
# The MLP head
elif isinstance(module, MaskformerMLPPredictionHead):
# I was not able to find the correct initializer in the original implementation
# we'll use xavier
for submodule in module.modules():
if isinstance(submodule, nn.Linear):
nn.init.xavier_uniform_(submodule.weight, gain=xavier_std)
nn.init.constant_(submodule.bias, 0)
elif isinstance(module, nn.LayerNorm):
module.bias.data.zero_()
module.weight.data.fill_(1.0)
# copied from DETR
if isinstance(module, (nn.Linear, nn.Conv2d, nn.BatchNorm2d)):
# Slightly different from the TF version which uses truncated_normal for initialization
# cf https://github.com/pytorch/pytorch/pull/5617
module.weight.data.normal_(mean=0.0, std=std)
if module.bias is not None:
module.bias.data.zero_()
elif isinstance(module, nn.Embedding):
module.weight.data.normal_(mean=0.0, std=std)
if module.padding_idx is not None:
module.weight.data[module.padding_idx].zero_()
@add_start_docstrings(
"The bare MaskFormer Model outputting raw hidden-states without any specific head on top.",
MASKFORMER_START_DOCSTRING,
)
class MaskFormerModel(MaskFormerPreTrainedModel):
def __init__(self, config: MaskFormerConfig):
super().__init__(config)
self.pixel_level_module = MaskFormerPixelLevelModule(config)
self.transformer_module = MaskFormerTransformerModule(
in_features=self.pixel_level_module.encoder.channels[-1], config=config
)
self.post_init()
@add_start_docstrings_to_model_forward(MASKFORMER_INPUTS_DOCSTRING)
@replace_return_docstrings(output_type=MaskFormerModelOutput, config_class=_CONFIG_FOR_DOC)
def forward(
self,
pixel_values: Tensor,
pixel_mask: Optional[Tensor] = None,
output_hidden_states: Optional[bool] = None,
output_attentions: Optional[bool] = None,
return_dict: Optional[bool] = None,
) -> MaskFormerModelOutput:
r"""
Returns:
Examples:
```python
>>> from transformers import AutoImageProcessor, MaskFormerModel
>>> from PIL import Image
>>> import requests
>>> # load MaskFormer fine-tuned on ADE20k semantic segmentation
>>> image_processor = AutoImageProcessor.from_pretrained("facebook/maskformer-swin-base-ade")
>>> model = MaskFormerModel.from_pretrained("facebook/maskformer-swin-base-ade")
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> inputs = image_processor(image, return_tensors="pt")
>>> # forward pass
>>> outputs = model(**inputs)
>>> # the decoder of MaskFormer outputs hidden states of shape (batch_size, num_queries, hidden_size)
>>> transformer_decoder_last_hidden_state = outputs.transformer_decoder_last_hidden_state
>>> list(transformer_decoder_last_hidden_state.shape)
[1, 100, 256]
```"""
if pixel_values is None:
raise ValueError("You have to specify pixel_values")
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
output_hidden_states = (
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
)
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
batch_size, _, height, width = pixel_values.shape
if pixel_mask is None:
pixel_mask = torch.ones((batch_size, height, width), device=pixel_values.device)
pixel_level_module_output = self.pixel_level_module(
pixel_values, output_hidden_states, return_dict=return_dict
)
image_features = pixel_level_module_output[0]
pixel_embeddings = pixel_level_module_output[1]
transformer_module_output = self.transformer_module(image_features, output_hidden_states, output_attentions)
queries = transformer_module_output.last_hidden_state
encoder_hidden_states = None
pixel_decoder_hidden_states = None
transformer_decoder_hidden_states = None
hidden_states = None
if output_hidden_states:
encoder_hidden_states = pixel_level_module_output[2]
pixel_decoder_hidden_states = pixel_level_module_output[3]
transformer_decoder_hidden_states = transformer_module_output[1]
hidden_states = encoder_hidden_states + pixel_decoder_hidden_states + transformer_decoder_hidden_states
output = MaskFormerModelOutput(
encoder_last_hidden_state=image_features,
pixel_decoder_last_hidden_state=pixel_embeddings,
transformer_decoder_last_hidden_state=queries,
encoder_hidden_states=encoder_hidden_states,
pixel_decoder_hidden_states=pixel_decoder_hidden_states,
transformer_decoder_hidden_states=transformer_decoder_hidden_states,
hidden_states=hidden_states,
attentions=transformer_module_output.attentions,
)
if not return_dict:
output = tuple(v for v in output.values())
return output
class MaskFormerForInstanceSegmentation(MaskFormerPreTrainedModel):
def __init__(self, config: MaskFormerConfig):
super().__init__(config)
self.model = MaskFormerModel(config)
hidden_size = config.decoder_config.hidden_size
# + 1 because we add the "null" class
self.class_predictor = nn.Linear(hidden_size, config.num_labels + 1)
self.mask_embedder = MaskformerMLPPredictionHead(hidden_size, hidden_size, config.mask_feature_size)
self.matcher = MaskFormerHungarianMatcher(
cost_class=1.0, cost_dice=config.dice_weight, cost_mask=config.mask_weight
)
self.weight_dict: Dict[str, float] = {
"loss_cross_entropy": config.cross_entropy_weight,
"loss_mask": config.mask_weight,
"loss_dice": config.dice_weight,
}
self.criterion = MaskFormerLoss(
config.num_labels,
matcher=self.matcher,
weight_dict=self.weight_dict,
eos_coef=config.no_object_weight,
)
self.post_init()
def get_loss_dict(
self,
masks_queries_logits: Tensor,
class_queries_logits: Tensor,
mask_labels: Tensor,
class_labels: Tensor,
auxiliary_logits: Dict[str, Tensor],
) -> Dict[str, Tensor]:
loss_dict: Dict[str, Tensor] = self.criterion(
masks_queries_logits, class_queries_logits, mask_labels, class_labels, auxiliary_logits
)
# weight each loss by `self.weight_dict[<LOSS_NAME>]` including auxiliary losses
for key, weight in self.weight_dict.items():
for loss_key, loss in loss_dict.items():
if key in loss_key:
loss *= weight
return loss_dict
def get_loss(self, loss_dict: Dict[str, Tensor]) -> Tensor:
return sum(loss_dict.values())
def get_logits(self, outputs: MaskFormerModelOutput) -> Tuple[Tensor, Tensor, Dict[str, Tensor]]:
pixel_embeddings = outputs.pixel_decoder_last_hidden_state
# get the auxiliary predictions (one for each decoder's layer)
auxiliary_logits: List[str, Tensor] = []
# This code is a little bit cumbersome, an improvement can be to return a list of predictions. If we have auxiliary loss then we are going to return more than one element in the list
if self.config.use_auxiliary_loss:
stacked_transformer_decoder_outputs = torch.stack(outputs.transformer_decoder_hidden_states)
classes = self.class_predictor(stacked_transformer_decoder_outputs)
class_queries_logits = classes[-1]
# get the masks
mask_embeddings = self.mask_embedder(stacked_transformer_decoder_outputs)
# Equivalent to einsum('lbqc, bchw -> lbqhw') but jit friendly
num_embeddings, batch_size, num_queries, num_channels = mask_embeddings.shape
_, _, height, width = pixel_embeddings.shape
binaries_masks = torch.zeros(
(num_embeddings, batch_size, num_queries, height, width), device=mask_embeddings.device
)
for c in range(num_channels):
binaries_masks += mask_embeddings[..., c][..., None, None] * pixel_embeddings[None, :, None, c]
masks_queries_logits = binaries_masks[-1]
# go til [:-1] because the last one is always used
for aux_binary_masks, aux_classes in zip(binaries_masks[:-1], classes[:-1]):
auxiliary_logits.append(
{"masks_queries_logits": aux_binary_masks, "class_queries_logits": aux_classes}
)
else:
transformer_decoder_hidden_states = outputs.transformer_decoder_last_hidden_state
classes = self.class_predictor(transformer_decoder_hidden_states)
class_queries_logits = classes
# get the masks
mask_embeddings = self.mask_embedder(transformer_decoder_hidden_states)
# sum up over the channels
# Equivalent to einsum('bqc, bchw -> bqhw') but jit friendly
batch_size, num_queries, num_channels = mask_embeddings.shape
_, _, height, width = pixel_embeddings.shape
masks_queries_logits = torch.zeros((batch_size, num_queries, height, width), device=mask_embeddings.device)
for c in range(num_channels):
masks_queries_logits += mask_embeddings[..., c][..., None, None] * pixel_embeddings[:, None, c]
return class_queries_logits, masks_queries_logits, auxiliary_logits
@add_start_docstrings_to_model_forward(MASKFORMER_INPUTS_DOCSTRING)
@replace_return_docstrings(output_type=MaskFormerForInstanceSegmentationOutput, config_class=_CONFIG_FOR_DOC)
def forward(
self,
pixel_values: Tensor,
mask_labels: Optional[List[Tensor]] = None,
class_labels: Optional[List[Tensor]] = None,
pixel_mask: Optional[Tensor] = None,
output_auxiliary_logits: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
output_attentions: Optional[bool] = None,
return_dict: Optional[bool] = None,
) -> MaskFormerForInstanceSegmentationOutput:
r"""
mask_labels (`List[torch.Tensor]`, *optional*):
List of mask labels of shape `(num_labels, height, width)` to be fed to a model
class_labels (`List[torch.LongTensor]`, *optional*):
list of target class labels of shape `(num_labels, height, width)` to be fed to a model. They identify the
labels of `mask_labels`, e.g. the label of `mask_labels[i][j]` if `class_labels[i][j]`.
Returns:
Examples:
Semantic segmentation example:
```python
>>> from transformers import AutoImageProcessor, MaskFormerForInstanceSegmentation
>>> from PIL import Image
>>> import requests
>>> # load MaskFormer fine-tuned on ADE20k semantic segmentation
>>> image_processor = AutoImageProcessor.from_pretrained("facebook/maskformer-swin-base-ade")
>>> model = MaskFormerForInstanceSegmentation.from_pretrained("facebook/maskformer-swin-base-ade")
>>> url = (
... "https://huggingface.co/datasets/hf-internal-testing/fixtures_ade20k/resolve/main/ADE_val_00000001.jpg"
... )
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> inputs = image_processor(images=image, return_tensors="pt")
>>> outputs = model(**inputs)
>>> # model predicts class_queries_logits of shape `(batch_size, num_queries)`
>>> # and masks_queries_logits of shape `(batch_size, num_queries, height, width)`
>>> class_queries_logits = outputs.class_queries_logits
>>> masks_queries_logits = outputs.masks_queries_logits
>>> # you can pass them to image_processor for postprocessing
>>> predicted_semantic_map = image_processor.post_process_semantic_segmentation(
... outputs, target_sizes=[image.size[::-1]]
... )[0]
>>> # we refer to the demo notebooks for visualization (see "Resources" section in the MaskFormer docs)
>>> list(predicted_semantic_map.shape)
[512, 683]
```
Panoptic segmentation example:
```python
>>> from transformers import AutoImageProcessor, MaskFormerForInstanceSegmentation
>>> from PIL import Image
>>> import requests
>>> # load MaskFormer fine-tuned on COCO panoptic segmentation
>>> image_processor = AutoImageProcessor.from_pretrained("facebook/maskformer-swin-base-coco")
>>> model = MaskFormerForInstanceSegmentation.from_pretrained("facebook/maskformer-swin-base-coco")
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> inputs = image_processor(images=image, return_tensors="pt")
>>> outputs = model(**inputs)
>>> # model predicts class_queries_logits of shape `(batch_size, num_queries)`
>>> # and masks_queries_logits of shape `(batch_size, num_queries, height, width)`
>>> class_queries_logits = outputs.class_queries_logits
>>> masks_queries_logits = outputs.masks_queries_logits
>>> # you can pass them to image_processor for postprocessing
>>> result = image_processor.post_process_panoptic_segmentation(outputs, target_sizes=[image.size[::-1]])[0]
>>> # we refer to the demo notebooks for visualization (see "Resources" section in the MaskFormer docs)
>>> predicted_panoptic_map = result["segmentation"]
>>> list(predicted_panoptic_map.shape)
[480, 640]
```
"""
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
output_hidden_states = (
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
)
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
raw_outputs = self.model(
pixel_values,
pixel_mask,
output_hidden_states=output_hidden_states or self.config.use_auxiliary_loss,
return_dict=return_dict,
output_attentions=output_attentions,
)
# We need to have raw_outputs optionally be returned as a dict to use torch.compile. For backwards
# compatibility we convert to a dataclass for the rest of the model logic
outputs = MaskFormerModelOutput(
encoder_last_hidden_state=raw_outputs[0],
pixel_decoder_last_hidden_state=raw_outputs[1],
transformer_decoder_last_hidden_state=raw_outputs[2],
encoder_hidden_states=raw_outputs[3] if output_hidden_states else None,
pixel_decoder_hidden_states=raw_outputs[4] if output_hidden_states else None,
transformer_decoder_hidden_states=raw_outputs[5] if output_hidden_states else None,
hidden_states=raw_outputs[6] if output_hidden_states else None,
attentions=raw_outputs[-1] if output_attentions else None,
)
loss, loss_dict, auxiliary_logits = None, None, None
class_queries_logits, masks_queries_logits, auxiliary_logits = self.get_logits(outputs)
if mask_labels is not None and class_labels is not None:
loss_dict: Dict[str, Tensor] = self.get_loss_dict(
masks_queries_logits, class_queries_logits, mask_labels, class_labels, auxiliary_logits
)
loss = self.get_loss(loss_dict)
output_auxiliary_logits = (
self.config.output_auxiliary_logits if output_auxiliary_logits is None else output_auxiliary_logits
)
if not output_auxiliary_logits:
auxiliary_logits = None
if not return_dict:
output = tuple(
v
for v in (loss, class_queries_logits, masks_queries_logits, auxiliary_logits, *outputs.values())
if v is not None
)
return output
return MaskFormerForInstanceSegmentationOutput(
loss=loss,
**outputs,
class_queries_logits=class_queries_logits,
masks_queries_logits=masks_queries_logits,
auxiliary_logits=auxiliary_logits,
)
| transformers/src/transformers/models/maskformer/modeling_maskformer.py/0 | {
"file_path": "transformers/src/transformers/models/maskformer/modeling_maskformer.py",
"repo_id": "transformers",
"token_count": 38694
} | 103 |