

readme: add initial version
Browse files- README.md +174 -0
- stats/Corpus_Stats.ipynb +0 -0
- stats/bl_stats.pickle +0 -0
- stats/figures/all_corpus_stats.png +0 -0
- stats/figures/bl_corpus_stats.png +0 -0
- stats/figures/finnish_europeana_corpus_stats.png +0 -0
- stats/figures/french_europeana_corpus_stats.png +0 -0
- stats/figures/german_europeana_corpus_stats.png +0 -0
- stats/figures/pretraining_loss.png +0 -0
- stats/figures/swedish_europeana_corpus_stats.png +0 -0
- stats/finnish_europeana_stats.pickle +0 -0
- stats/french_europeana_stats.pickle +0 -0
- stats/german_europeana_stats.pickle +0 -0
- stats/swedish_europeana_stats.pickle +0 -0
README.md
ADDED
|
@@ -0,0 +1,174 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Historic Language Models (HLMs)
|
| 2 |
+
|
| 3 |
+
Our Historic Language Models Zoo contains support for the following languages - incl. their training data source:
|
| 4 |
+
|
| 5 |
+
| Language | Training data | Size
|
| 6 |
+
| -------- | ------------- | ----
|
| 7 |
+
| German | [Europeana](http://www.europeana-newspapers.eu/) | 13-28GB (filtered)
|
| 8 |
+
| French | [Europeana](http://www.europeana-newspapers.eu/) | 11-31GB (filtered)
|
| 9 |
+
| English | [British Library](https://data.bl.uk/digbks/db14.html) | 24GB (year filtered)
|
| 10 |
+
| Finnish | [Europeana](http://www.europeana-newspapers.eu/) | 1.2GB
|
| 11 |
+
| Swedish | [Europeana](http://www.europeana-newspapers.eu/) | 1.1GB
|
| 12 |
+
|
| 13 |
+
# Corpora Stats
|
| 14 |
+
|
| 15 |
+
## German Europeana Corpus
|
| 16 |
+
|
| 17 |
+
We provide some statistics using different thresholds of ocr confidences, in order to shrink down the corpus size
|
| 18 |
+
and use less-noisier data:
|
| 19 |
+
|
| 20 |
+
| OCR confidence | Size
|
| 21 |
+
| -------------- | ----
|
| 22 |
+
| **0.60** | 28GB
|
| 23 |
+
| 0.65 | 18GB
|
| 24 |
+
| 0.70 | 13GB
|
| 25 |
+
|
| 26 |
+
For the final corpus we use a OCR confidence of 0.6 (28GB). The following plot shows a tokens per year distribution:
|
| 27 |
+
|
| 28 |
+

|
| 29 |
+
|
| 30 |
+
## French Europeana Corpus
|
| 31 |
+
|
| 32 |
+
Like German, we use different ocr confidence thresholds:
|
| 33 |
+
|
| 34 |
+
| OCR confidence | Size
|
| 35 |
+
| -------------- | ----
|
| 36 |
+
| 0.60 | 31GB
|
| 37 |
+
| 0.65 | 27GB
|
| 38 |
+
| **0.70** | 27GB
|
| 39 |
+
| 0.75 | 23GB
|
| 40 |
+
| 0.80 | 11GB
|
| 41 |
+
|
| 42 |
+
For the final corpus we use a OCR confidence of 0.7 (27GB). The following plot shows a tokens per year distribution:
|
| 43 |
+
|
| 44 |
+

|
| 45 |
+
|
| 46 |
+
## British Library Corpus
|
| 47 |
+
|
| 48 |
+
Metadata is taken from [here](https://data.bl.uk/digbks/DB21.html). Stats incl. year filtering:
|
| 49 |
+
|
| 50 |
+
| Years | Size
|
| 51 |
+
| ----------------- | ----
|
| 52 |
+
| ALL | 24GB
|
| 53 |
+
| >= 1800 && < 1900 | 24GB
|
| 54 |
+
|
| 55 |
+
We use the year filtered variant. The following plot shows a tokens per year distribution:
|
| 56 |
+
|
| 57 |
+

|
| 58 |
+
|
| 59 |
+
## Finnish Europeana Corpus
|
| 60 |
+
|
| 61 |
+
| OCR confidence | Size
|
| 62 |
+
| -------------- | ----
|
| 63 |
+
| 0.60 | 1.2GB
|
| 64 |
+
|
| 65 |
+
The following plot shows a tokens per year distribution:
|
| 66 |
+
|
| 67 |
+

|
| 68 |
+
|
| 69 |
+
## Swedish Europeana Corpus
|
| 70 |
+
|
| 71 |
+
| OCR confidence | Size
|
| 72 |
+
| -------------- | ----
|
| 73 |
+
| 0.60 | 1.1GB
|
| 74 |
+
|
| 75 |
+
The following plot shows a tokens per year distribution:
|
| 76 |
+
|
| 77 |
+

|
| 78 |
+
|
| 79 |
+
## All Corpora
|
| 80 |
+
|
| 81 |
+
The following plot shows a tokens per year distribution of the complete training corpus:
|
| 82 |
+
|
| 83 |
+

|
| 84 |
+
|
| 85 |
+
# Multilingual Vocab generation
|
| 86 |
+
|
| 87 |
+
For the first attempt, we use the first 10GB of each pretraining corpus. We upsample both Finnish and Swedish to ~10GB.
|
| 88 |
+
The following tables shows the exact size that is used for generating a 32k and 64k subword vocabs:
|
| 89 |
+
|
| 90 |
+
| Language | Size
|
| 91 |
+
| -------- | ----
|
| 92 |
+
| German | 10GB
|
| 93 |
+
| French | 10GB
|
| 94 |
+
| English | 10GB
|
| 95 |
+
| Finnish | 9.5GB
|
| 96 |
+
| Swedish | 9.7GB
|
| 97 |
+
|
| 98 |
+
We then calculate the subword fertility rate and portion of `[UNK]`s over the following NER corpora:
|
| 99 |
+
|
| 100 |
+
| Language | NER corpora
|
| 101 |
+
| -------- | ------------------
|
| 102 |
+
| German | CLEF-HIPE, NewsEye
|
| 103 |
+
| French | CLEF-HIPE, NewsEye
|
| 104 |
+
| English | CLEF-HIPE
|
| 105 |
+
| Finnish | NewsEye
|
| 106 |
+
| Swedish | NewsEye
|
| 107 |
+
|
| 108 |
+
Breakdown of subword fertility rate and unknown portion per language for the 32k vocab:
|
| 109 |
+
|
| 110 |
+
| Language | Subword fertility | Unknown portion
|
| 111 |
+
| -------- | ------------------ | ---------------
|
| 112 |
+
| German | 1.43 | 0.0004
|
| 113 |
+
| French | 1.25 | 0.0001
|
| 114 |
+
| English | 1.25 | 0.0
|
| 115 |
+
| Finnish | 1.69 | 0.0007
|
| 116 |
+
| Swedish | 1.43 | 0.0
|
| 117 |
+
|
| 118 |
+
Breakdown of subword fertility rate and unknown portion per language for the 64k vocab:
|
| 119 |
+
|
| 120 |
+
| Language | Subword fertility | Unknown portion
|
| 121 |
+
| -------- | ------------------ | ---------------
|
| 122 |
+
| German | 1.31 | 0.0004
|
| 123 |
+
| French | 1.16 | 0.0001
|
| 124 |
+
| English | 1.17 | 0.0
|
| 125 |
+
| Finnish | 1.54 | 0.0007
|
| 126 |
+
| Swedish | 1.32 | 0.0
|
| 127 |
+
|
| 128 |
+
# Final pretraining corpora
|
| 129 |
+
|
| 130 |
+
We upsample Swedish and Finnish to ~27GB. The final stats for all pretraining corpora can be seen here:
|
| 131 |
+
|
| 132 |
+
| Language | Size
|
| 133 |
+
| -------- | ----
|
| 134 |
+
| German | 28GB
|
| 135 |
+
| French | 27GB
|
| 136 |
+
| English | 24GB
|
| 137 |
+
| Finnish | 27GB
|
| 138 |
+
| Swedish | 27GB
|
| 139 |
+
|
| 140 |
+
Total size is 130GB.
|
| 141 |
+
|
| 142 |
+
# Pretraining
|
| 143 |
+
|
| 144 |
+
We train a multilingual BERT model using the 32k vocab with the official BERT implementation
|
| 145 |
+
on a v3-32 TPU using the following parameters:
|
| 146 |
+
|
| 147 |
+
```bash
|
| 148 |
+
python3 run_pretraining.py --input_file gs://histolectra/historic-multilingual-tfrecords/*.tfrecord \
|
| 149 |
+
--output_dir gs://histolectra/bert-base-historic-multilingual-cased \
|
| 150 |
+
--bert_config_file ./config.json \
|
| 151 |
+
--max_seq_length=512 \
|
| 152 |
+
--max_predictions_per_seq=75 \
|
| 153 |
+
--do_train=True \
|
| 154 |
+
--train_batch_size=128 \
|
| 155 |
+
--num_train_steps=3000000 \
|
| 156 |
+
--learning_rate=1e-4 \
|
| 157 |
+
--save_checkpoints_steps=100000 \
|
| 158 |
+
--keep_checkpoint_max=20 \
|
| 159 |
+
--use_tpu=True \
|
| 160 |
+
--tpu_name=electra-2 \
|
| 161 |
+
--num_tpu_cores=32
|
| 162 |
+
```
|
| 163 |
+
|
| 164 |
+
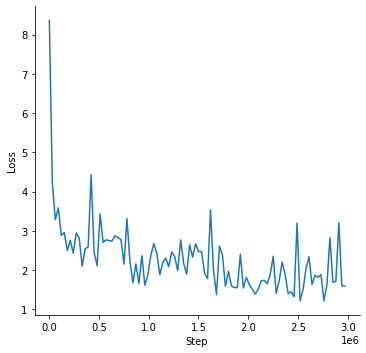
The following plot shows the pretraining loss curve:
|
| 165 |
+
|
| 166 |
+

|
| 167 |
+
|
| 168 |
+
# Acknowledgments
|
| 169 |
+
|
| 170 |
+
Research supported with Cloud TPUs from Google's TPU Research Cloud (TRC) program, previously known as
|
| 171 |
+
TensorFlow Research Cloud (TFRC). Many thanks for providing access to the TRC ❤️
|
| 172 |
+
|
| 173 |
+
Thanks to the generous support from the [Hugging Face](https://huggingface.co/) team,
|
| 174 |
+
it is possible to download both cased and uncased models from their S3 storage 🤗
|
stats/Corpus_Stats.ipynb
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
stats/bl_stats.pickle
ADDED
|
Binary file (3.93 kB). View file
|
|
|
stats/figures/all_corpus_stats.png
ADDED

|
stats/figures/bl_corpus_stats.png
ADDED

|
stats/figures/finnish_europeana_corpus_stats.png
ADDED

|
stats/figures/french_europeana_corpus_stats.png
ADDED

|
stats/figures/german_europeana_corpus_stats.png
ADDED

|
stats/figures/pretraining_loss.png
ADDED
|
stats/figures/swedish_europeana_corpus_stats.png
ADDED

|
stats/finnish_europeana_stats.pickle
ADDED
|
Binary file (199 Bytes). View file
|
|
|
stats/french_europeana_stats.pickle
ADDED
|
Binary file (1.64 kB). View file
|
|
|
stats/german_europeana_stats.pickle
ADDED
|
Binary file (1.99 kB). View file
|
|
|
stats/swedish_europeana_stats.pickle
ADDED
|
Binary file (199 Bytes). View file
|
|
|