

Duplicate from yixin6178/ChatPaper
Browse filesCo-authored-by: Yixin Liu <[email protected]>
- .gitattributes +34 -0
- .gitignore +2 -0
- .streamlit/config.toml +4 -0
- Dockerfile +65 -0
- LICENSE +25 -0
- README.md +66 -0
- __pycache__/base_class.cpython-39.pyc +0 -0
- __pycache__/chat_pdf.cpython-39.pyc +0 -0
- __pycache__/chatbot.cpython-39.pyc +0 -0
- __pycache__/config.cpython-39.pyc +0 -0
- __pycache__/embedding_model.cpython-39.pyc +0 -0
- __pycache__/pdf_parser.cpython-39.pyc +0 -0
- __pycache__/scipdf_utils.cpython-39.pyc +0 -0
- __pycache__/similarity_metric.cpython-39.pyc +0 -0
- __pycache__/utils.cpython-39.pyc +0 -0
- backend.py +81 -0
- base_class.py +106 -0
- chat_pdf.py +83 -0
- chatbot.py +320 -0
- config.py +15 -0
- embedding_model.py +47 -0
- frontend.py +87 -0
- pdf_parser.py +148 -0
- requirements.txt +13 -0
- run.sh +5 -0
- scipdf_utils.py +424 -0
- serve_grobid.sh +14 -0
- similarity_metric.py +13 -0
- utils.py +24 -0
.gitattributes
ADDED
|
@@ -0,0 +1,34 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
*.7z filter=lfs diff=lfs merge=lfs -text
|
| 2 |
+
*.arrow filter=lfs diff=lfs merge=lfs -text
|
| 3 |
+
*.bin filter=lfs diff=lfs merge=lfs -text
|
| 4 |
+
*.bz2 filter=lfs diff=lfs merge=lfs -text
|
| 5 |
+
*.ckpt filter=lfs diff=lfs merge=lfs -text
|
| 6 |
+
*.ftz filter=lfs diff=lfs merge=lfs -text
|
| 7 |
+
*.gz filter=lfs diff=lfs merge=lfs -text
|
| 8 |
+
*.h5 filter=lfs diff=lfs merge=lfs -text
|
| 9 |
+
*.joblib filter=lfs diff=lfs merge=lfs -text
|
| 10 |
+
*.lfs.* filter=lfs diff=lfs merge=lfs -text
|
| 11 |
+
*.mlmodel filter=lfs diff=lfs merge=lfs -text
|
| 12 |
+
*.model filter=lfs diff=lfs merge=lfs -text
|
| 13 |
+
*.msgpack filter=lfs diff=lfs merge=lfs -text
|
| 14 |
+
*.npy filter=lfs diff=lfs merge=lfs -text
|
| 15 |
+
*.npz filter=lfs diff=lfs merge=lfs -text
|
| 16 |
+
*.onnx filter=lfs diff=lfs merge=lfs -text
|
| 17 |
+
*.ot filter=lfs diff=lfs merge=lfs -text
|
| 18 |
+
*.parquet filter=lfs diff=lfs merge=lfs -text
|
| 19 |
+
*.pb filter=lfs diff=lfs merge=lfs -text
|
| 20 |
+
*.pickle filter=lfs diff=lfs merge=lfs -text
|
| 21 |
+
*.pkl filter=lfs diff=lfs merge=lfs -text
|
| 22 |
+
*.pt filter=lfs diff=lfs merge=lfs -text
|
| 23 |
+
*.pth filter=lfs diff=lfs merge=lfs -text
|
| 24 |
+
*.rar filter=lfs diff=lfs merge=lfs -text
|
| 25 |
+
*.safetensors filter=lfs diff=lfs merge=lfs -text
|
| 26 |
+
saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
| 27 |
+
*.tar.* filter=lfs diff=lfs merge=lfs -text
|
| 28 |
+
*.tflite filter=lfs diff=lfs merge=lfs -text
|
| 29 |
+
*.tgz filter=lfs diff=lfs merge=lfs -text
|
| 30 |
+
*.wasm filter=lfs diff=lfs merge=lfs -text
|
| 31 |
+
*.xz filter=lfs diff=lfs merge=lfs -text
|
| 32 |
+
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 33 |
+
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 34 |
+
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
.gitignore
ADDED
|
@@ -0,0 +1,2 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
grobid-0.6.2
|
| 2 |
+
__pycache__
|
.streamlit/config.toml
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
[server]
|
| 2 |
+
port = 7860
|
| 3 |
+
enableXsrfProtection = false
|
| 4 |
+
gatherUsageStats = false
|
Dockerfile
ADDED
|
@@ -0,0 +1,65 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Use an official Python runtime as a parent image
|
| 2 |
+
FROM python:3.9-slim
|
| 3 |
+
USER root
|
| 4 |
+
|
| 5 |
+
# Set the working directory to /app
|
| 6 |
+
RUN mkdir -m 777 -p /app/
|
| 7 |
+
WORKDIR /app
|
| 8 |
+
|
| 9 |
+
# make directory /app/files/
|
| 10 |
+
RUN mkdir -m 777 -p /app/files/
|
| 11 |
+
RUN mkdir -m 777 -p /app/ckpt/
|
| 12 |
+
RUN mkdir -m 777 -p /.cache/huggingface/hub/
|
| 13 |
+
RUN mkdir -m 777 -p /.config/matplotlib/
|
| 14 |
+
RUN mkdir -m 777 -p /.gradle/
|
| 15 |
+
RUN mkdir -m 777 -p /opt/grobid/grobid-home/tmp
|
| 16 |
+
RUN mkdir -m 777 -p /opt/grobid/logs
|
| 17 |
+
|
| 18 |
+
# Copy the requirements file into the container
|
| 19 |
+
COPY requirements.txt .
|
| 20 |
+
COPY serve_grobid.sh .
|
| 21 |
+
|
| 22 |
+
# JAVA
|
| 23 |
+
RUN apt-get update && \
|
| 24 |
+
apt-get install -y openjdk-11-jre-headless && \
|
| 25 |
+
apt-get clean;
|
| 26 |
+
ENV JAVA_HOME /usr/lib/jvm/java-11-openjdk-amd64/
|
| 27 |
+
ENV PATH $JAVA_HOME/bin:$PATH
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
# Install any needed packages specified in requirements.txt
|
| 31 |
+
RUN pip install --no-cache-dir -r requirements.txt
|
| 32 |
+
|
| 33 |
+
# open the grobid server
|
| 34 |
+
RUN apt-get update && \
|
| 35 |
+
apt-get install -y wget unzip
|
| 36 |
+
RUN chmod +x serve_grobid.sh
|
| 37 |
+
RUN ./serve_grobid.sh
|
| 38 |
+
|
| 39 |
+
# Copy the current directory contents into the container at /app
|
| 40 |
+
COPY . /app
|
| 41 |
+
|
| 42 |
+
# Expose port
|
| 43 |
+
EXPOSE 5000
|
| 44 |
+
EXPOSE 7860
|
| 45 |
+
EXPOSE 8070
|
| 46 |
+
|
| 47 |
+
|
| 48 |
+
RUN chmod +x /app/grobid-0.6.2/gradlew
|
| 49 |
+
RUN mkdir -m 777 -p /app/.gradle/
|
| 50 |
+
RUN mkdir -m 777 -p /app/?/.gradle/
|
| 51 |
+
RUN mkdir -m 777 -p /app/grobid-0.6.2/
|
| 52 |
+
RUN mkdir -m 777 -p /app/grobid-0.6.2/?/.gradle/
|
| 53 |
+
RUN mkdir -m 777 -p /app/grobid-0.6.2/6.5.1/
|
| 54 |
+
RUN mkdir -m 777 -p /app/grobid-0.6.2/.gradle/
|
| 55 |
+
RUN mkdir -m 777 -p /app/grobid-0.6.2/.gradle/6.5.1/
|
| 56 |
+
RUN mkdir -m 777 -p /app/grobid-0.6.2/gradle-core/
|
| 57 |
+
RUN mkdir -m 777 -p /app/grobid-0.6.2/gradle-core/build/
|
| 58 |
+
RUN mkdir -m 777 -p /app/grobid-0.6.2/.gradle/6.5.1/fileHashes/
|
| 59 |
+
RUN chmod 777 /app/grobid-0.6.2/.gradle/6.5.1/fileHashes/fileHashes.lock
|
| 60 |
+
RUN chmod -R 777 /app/grobid-0.6.2/
|
| 61 |
+
|
| 62 |
+
# open the backend server and streamlit app
|
| 63 |
+
RUN chmod +x run.sh
|
| 64 |
+
CMD ["bash" ,"run.sh"]
|
| 65 |
+
|
LICENSE
ADDED
|
@@ -0,0 +1,25 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
BSD 2-Clause License
|
| 2 |
+
|
| 3 |
+
Copyright (c) 2023, Yixin Liu
|
| 4 |
+
All rights reserved.
|
| 5 |
+
|
| 6 |
+
Redistribution and use in source and binary forms, with or without
|
| 7 |
+
modification, are permitted provided that the following conditions are met:
|
| 8 |
+
|
| 9 |
+
* Redistributions of source code must retain the above copyright notice, this
|
| 10 |
+
list of conditions and the following disclaimer.
|
| 11 |
+
|
| 12 |
+
* Redistributions in binary form must reproduce the above copyright notice,
|
| 13 |
+
this list of conditions and the following disclaimer in the documentation
|
| 14 |
+
and/or other materials provided with the distribution.
|
| 15 |
+
|
| 16 |
+
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
|
| 17 |
+
AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
|
| 18 |
+
IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
|
| 19 |
+
DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE
|
| 20 |
+
FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
|
| 21 |
+
DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR
|
| 22 |
+
SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
|
| 23 |
+
CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,
|
| 24 |
+
OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
|
| 25 |
+
OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
|
README.md
ADDED
|
@@ -0,0 +1,66 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
title: ChatPaper
|
| 3 |
+
emoji: 📕
|
| 4 |
+
colorFrom: pink
|
| 5 |
+
colorTo: purple
|
| 6 |
+
sdk: docker
|
| 7 |
+
sdk_version: 20.10.23
|
| 8 |
+
app_file: frontend.py
|
| 9 |
+
pinned: false
|
| 10 |
+
license: gpl-3.0
|
| 11 |
+
duplicated_from: yixin6178/ChatPaper
|
| 12 |
+
---
|
| 13 |
+
|
| 14 |
+
# ChatPaper
|
| 15 |
+
|
| 16 |
+
Yet another paper reading assistant, similar as [ChatPDF](https://www.chatpdf.com/).
|
| 17 |
+
|
| 18 |
+
## Setup
|
| 19 |
+
|
| 20 |
+
1. Install dependencies (tested on Python 3.9)
|
| 21 |
+
|
| 22 |
+
```bash
|
| 23 |
+
pip install -r requirements.txt
|
| 24 |
+
```
|
| 25 |
+
|
| 26 |
+
2. Setup GROBID local server
|
| 27 |
+
|
| 28 |
+
```bash
|
| 29 |
+
bash serve_grobid.sh
|
| 30 |
+
```
|
| 31 |
+
|
| 32 |
+
3. Setup backend
|
| 33 |
+
|
| 34 |
+
```bash
|
| 35 |
+
python backend.py --port 5000 --host localhost
|
| 36 |
+
```
|
| 37 |
+
|
| 38 |
+
4. Frontend
|
| 39 |
+
|
| 40 |
+
```bash
|
| 41 |
+
streamlit run frontend.py --server.port 8502 --server.host localhost
|
| 42 |
+
```
|
| 43 |
+
|
| 44 |
+
## Demo Example
|
| 45 |
+
|
| 46 |
+
- Prepare an [OpenAI API key](https://platform.openai.com/account/api-keys) and then upload a PDF to start chatting with the paper.
|
| 47 |
+
|
| 48 |
+
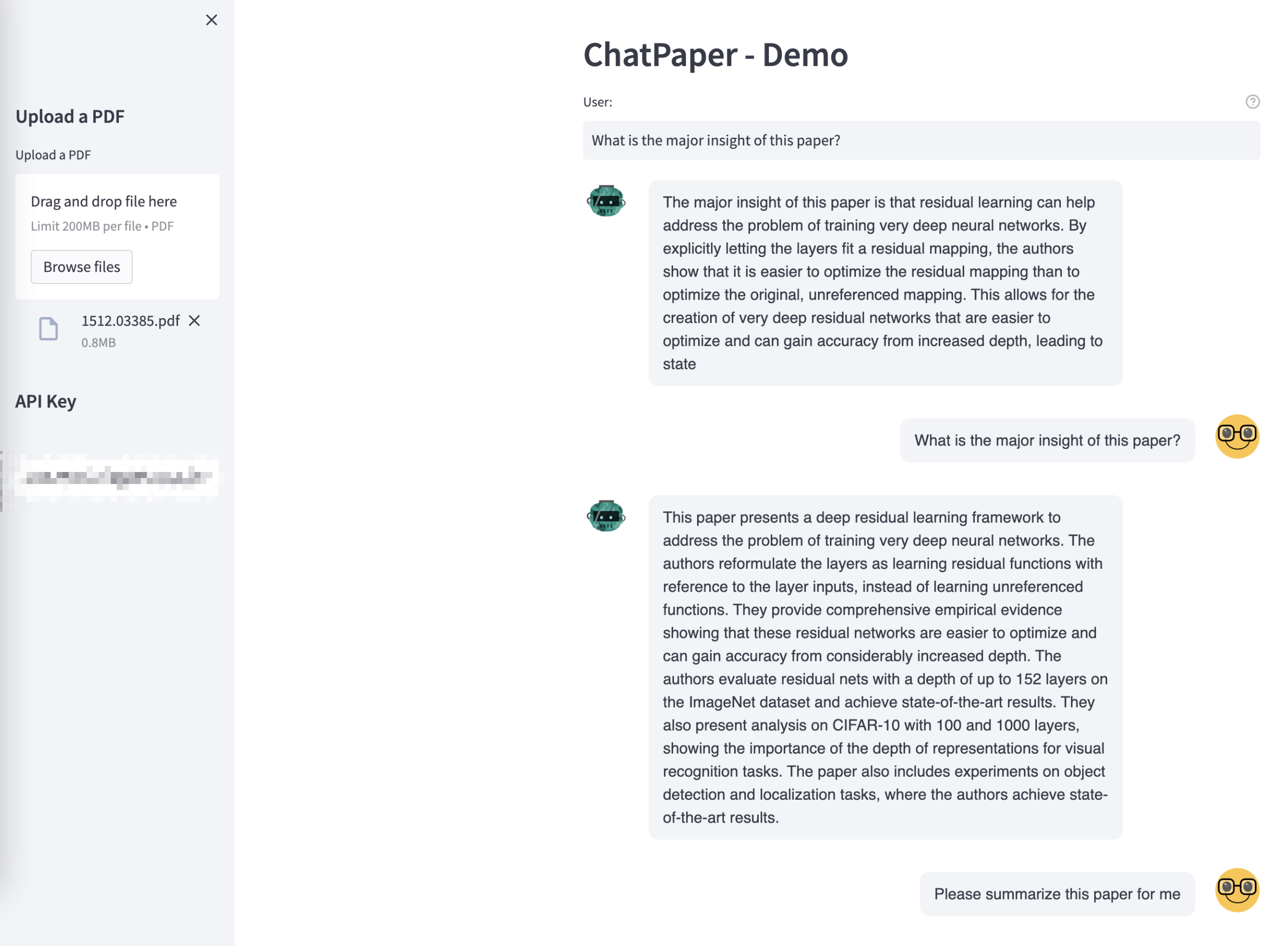
|
| 49 |
+
|
| 50 |
+
## Implementation Details
|
| 51 |
+
|
| 52 |
+
- Greedy Dynamic Context: Since the max token limit, we select the most relevant paragraphs in the pdf for each user query. Our model split the text input and output by the chatbot into four part: system_prompt (S), dynamic_source (D), user_query (Q), and model_answer(A). So upon each query, we first rank all the paragraphs by using a sentence_embedding model to calculate the similarity distance between the query embedding and all source embeddings. Then we compose the dynamic_source using a greedy method by to gradually push all relevant paragraphs (maintaing D <= MAX_TOKEN_LIMIT - Q - S - A - SOME_OVERHEAD).
|
| 53 |
+
|
| 54 |
+
- Context Truncating: When context is too long, we now we simply pop out the first QA-pair.
|
| 55 |
+
|
| 56 |
+
## TODO
|
| 57 |
+
|
| 58 |
+
- [ ] **Context Condense**: how to deal with long context? maybe we can tune a soft prompt to condense the context
|
| 59 |
+
- [ ] **Poping context out based on similarity**
|
| 60 |
+
|
| 61 |
+
## References
|
| 62 |
+
|
| 63 |
+
1. SciPDF Parser: https://github.com/titipata/scipdf_parser
|
| 64 |
+
2. St-chat: https://github.com/AI-Yash/st-chat
|
| 65 |
+
3. Sentence-transformers: https://github.com/UKPLab/sentence-transformers
|
| 66 |
+
4. ChatGPT Chatbot Wrapper: https://github.com/acheong08/ChatGPT
|
__pycache__/base_class.cpython-39.pyc
ADDED
|
Binary file (4.25 kB). View file
|
|
|
__pycache__/chat_pdf.cpython-39.pyc
ADDED
|
Binary file (3.98 kB). View file
|
|
|
__pycache__/chatbot.cpython-39.pyc
ADDED
|
Binary file (8.1 kB). View file
|
|
|
__pycache__/config.cpython-39.pyc
ADDED
|
Binary file (419 Bytes). View file
|
|
|
__pycache__/embedding_model.cpython-39.pyc
ADDED
|
Binary file (2.04 kB). View file
|
|
|
__pycache__/pdf_parser.cpython-39.pyc
ADDED
|
Binary file (5.23 kB). View file
|
|
|
__pycache__/scipdf_utils.cpython-39.pyc
ADDED
|
Binary file (11.2 kB). View file
|
|
|
__pycache__/similarity_metric.cpython-39.pyc
ADDED
|
Binary file (810 Bytes). View file
|
|
|
__pycache__/utils.cpython-39.pyc
ADDED
|
Binary file (1.05 kB). View file
|
|
|
backend.py
ADDED
|
@@ -0,0 +1,81 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from flask import jsonify, Flask, request
|
| 2 |
+
from embedding_model import HuggingfaceSentenceTransformerModel
|
| 3 |
+
from similarity_metric import CosineSimilarity
|
| 4 |
+
from pdf_parser import GrobidSciPDFPaser
|
| 5 |
+
from chatbot import OpenAIChatbot
|
| 6 |
+
from chat_pdf import ChatPDF
|
| 7 |
+
from config import DEFAULT_ENGINE, MAX_TOKEN_MODEL_MAP, DEFAULT_TEMPERATURE, DEFAULT_TOP_P, DEFAULT_PRESENCE_PENALTY, DEFAULT_FREQUENCY_PENALTY, DEFAULT_REPLY_COUNT
|
| 8 |
+
app = Flask(__name__)
|
| 9 |
+
chatpdf_pool = {}
|
| 10 |
+
|
| 11 |
+
embedding_model = HuggingfaceSentenceTransformerModel()
|
| 12 |
+
simi_metric = CosineSimilarity()
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
@app.route("/query/", methods=['POST', 'GET'])
|
| 16 |
+
def query():
|
| 17 |
+
api_key = request.headers.get('Api-Key')
|
| 18 |
+
pdf_link = request.json['pdf_link']
|
| 19 |
+
user_stamp = request.json['user_stamp']
|
| 20 |
+
user_query = request.json['user_query']
|
| 21 |
+
print(
|
| 22 |
+
"api_key", api_key,
|
| 23 |
+
"pdf_link", pdf_link,
|
| 24 |
+
"user_stamp", user_stamp,
|
| 25 |
+
"user_query", user_query
|
| 26 |
+
)
|
| 27 |
+
|
| 28 |
+
chat_pdf = None
|
| 29 |
+
if user_stamp not in chatpdf_pool:
|
| 30 |
+
print(f"User {user_stamp} not in pool, creating new chatpdf")
|
| 31 |
+
# Initialize the ChatPDF
|
| 32 |
+
bot = OpenAIChatbot(
|
| 33 |
+
api_key=api_key,
|
| 34 |
+
engine=DEFAULT_ENGINE,
|
| 35 |
+
proxy=None,
|
| 36 |
+
max_tokens=4000,
|
| 37 |
+
temperature=DEFAULT_TEMPERATURE,
|
| 38 |
+
top_p=DEFAULT_TOP_P,
|
| 39 |
+
presence_penalty=DEFAULT_PRESENCE_PENALTY,
|
| 40 |
+
frequency_penalty=DEFAULT_FREQUENCY_PENALTY,
|
| 41 |
+
reply_count=DEFAULT_REPLY_COUNT
|
| 42 |
+
)
|
| 43 |
+
|
| 44 |
+
pdf = GrobidSciPDFPaser(
|
| 45 |
+
pdf_link=pdf_link
|
| 46 |
+
)
|
| 47 |
+
chat_pdf = ChatPDF(
|
| 48 |
+
pdf=pdf,
|
| 49 |
+
bot=bot,
|
| 50 |
+
embedding_model=embedding_model,
|
| 51 |
+
similarity_metric=simi_metric,
|
| 52 |
+
user_stamp=user_stamp
|
| 53 |
+
)
|
| 54 |
+
chatpdf_pool[user_stamp] = chat_pdf
|
| 55 |
+
else:
|
| 56 |
+
print("user_stamp", user_stamp, "already exists")
|
| 57 |
+
chat_pdf = chatpdf_pool[user_stamp]
|
| 58 |
+
|
| 59 |
+
try:
|
| 60 |
+
response = chat_pdf.chat(user_query)
|
| 61 |
+
code = 200
|
| 62 |
+
json_dict = {
|
| 63 |
+
"code": code,
|
| 64 |
+
"response": response
|
| 65 |
+
}
|
| 66 |
+
except Exception as e:
|
| 67 |
+
code = 500
|
| 68 |
+
json_dict = {
|
| 69 |
+
"code": code,
|
| 70 |
+
"response": str(e)
|
| 71 |
+
}
|
| 72 |
+
return jsonify(json_dict)
|
| 73 |
+
|
| 74 |
+
|
| 75 |
+
# @app.route("/", methods=['GET'])
|
| 76 |
+
# def index():
|
| 77 |
+
# return "Hello World!"
|
| 78 |
+
|
| 79 |
+
|
| 80 |
+
if __name__ == '__main__':
|
| 81 |
+
app.run(host='0.0.0.0', port=5000, debug=False)
|
base_class.py
ADDED
|
@@ -0,0 +1,106 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import abc
|
| 2 |
+
import pandas as pd
|
| 3 |
+
import pickle
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
class SimilarityAlg(metaclass=abc.ABCMeta):
|
| 7 |
+
"""Similarity Algorithm to compute similarity between query_embedding and embeddings"""
|
| 8 |
+
|
| 9 |
+
def __init__(self) -> None:
|
| 10 |
+
pass
|
| 11 |
+
|
| 12 |
+
@abc.abstractmethod
|
| 13 |
+
def __call__(self, query_embedding, embeddings) -> None:
|
| 14 |
+
pass
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
class Embedding_Model(metaclass=abc.ABCMeta):
|
| 18 |
+
"""Embedding Model to compute embedding of a text"""
|
| 19 |
+
|
| 20 |
+
def __init__(self, model_name) -> None:
|
| 21 |
+
"""Initialize the embedding model"""
|
| 22 |
+
embedding_cache_path = f"/app/ckpt/embedding_cache_{model_name}.pkl"
|
| 23 |
+
self.embedding_cache_path = embedding_cache_path
|
| 24 |
+
|
| 25 |
+
# load the cache if it exists, and save a copy to disk
|
| 26 |
+
try:
|
| 27 |
+
embedding_cache = pd.read_pickle(embedding_cache_path)
|
| 28 |
+
except FileNotFoundError:
|
| 29 |
+
embedding_cache = {}
|
| 30 |
+
with open(embedding_cache_path, "wb") as embedding_cache_file:
|
| 31 |
+
pickle.dump(embedding_cache, embedding_cache_file)
|
| 32 |
+
self.embedding_cache = embedding_cache
|
| 33 |
+
self.model_name = model_name
|
| 34 |
+
|
| 35 |
+
@abc.abstractmethod
|
| 36 |
+
def __call__(self, text) -> None:
|
| 37 |
+
"""Compute the embedding of the text"""
|
| 38 |
+
pass
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
class AbstractPDFParser(metaclass=abc.ABCMeta):
|
| 42 |
+
""" PDF parser to parse a PDF file"""
|
| 43 |
+
|
| 44 |
+
def __init__(self, db_name) -> None:
|
| 45 |
+
"""Initialize the pdf database"""
|
| 46 |
+
db_cache_path = f"/app/ckpt/pdf_parser_{db_name}.pkl"
|
| 47 |
+
self.db_cache_path = db_cache_path
|
| 48 |
+
|
| 49 |
+
# load the cache if it exists, and save a copy to disk
|
| 50 |
+
try:
|
| 51 |
+
db_cache = pd.read_pickle(db_cache_path)
|
| 52 |
+
except FileNotFoundError:
|
| 53 |
+
db_cache = {}
|
| 54 |
+
with open(db_cache_path, "wb") as cache_file:
|
| 55 |
+
pickle.dump(db_cache, cache_file)
|
| 56 |
+
self.db_cache = db_cache
|
| 57 |
+
self.db_name = db_name
|
| 58 |
+
|
| 59 |
+
@abc.abstractmethod
|
| 60 |
+
def parse_pdf(self,) -> None:
|
| 61 |
+
"""Parse the PDF file"""
|
| 62 |
+
pass
|
| 63 |
+
|
| 64 |
+
@abc.abstractmethod
|
| 65 |
+
def _get_metadata(self, ) -> None:
|
| 66 |
+
"""Get the metadata of the PDF file"""
|
| 67 |
+
pass
|
| 68 |
+
|
| 69 |
+
def get_paragraphs(self, ) -> None:
|
| 70 |
+
"""Get the paragraphs of the PDF file"""
|
| 71 |
+
pass
|
| 72 |
+
|
| 73 |
+
@abc.abstractmethod
|
| 74 |
+
def get_split_paragraphs(self, ) -> None:
|
| 75 |
+
"""
|
| 76 |
+
Get the split paragraphs of the PDF file
|
| 77 |
+
Return:
|
| 78 |
+
split_paragraphs: dict of metadata and corresponding list of split paragraphs
|
| 79 |
+
"""
|
| 80 |
+
pass
|
| 81 |
+
|
| 82 |
+
def _determine_metadata_of_paragraph(self, paragraph) -> None:
|
| 83 |
+
"""
|
| 84 |
+
Determine the metadata of a paragraph
|
| 85 |
+
Return:
|
| 86 |
+
metadata: metadata of the paragraph
|
| 87 |
+
"""
|
| 88 |
+
pass
|
| 89 |
+
|
| 90 |
+
# @abc.abstractmethod
|
| 91 |
+
# def _determine_optimal_split_of_pargraphs(self, ) -> None:
|
| 92 |
+
# """
|
| 93 |
+
# Determine the optimal split of paragraphs
|
| 94 |
+
# Return:
|
| 95 |
+
# split_paragraphs: dict of metadata and corresponding list of split paragraphs
|
| 96 |
+
# """
|
| 97 |
+
# pass
|
| 98 |
+
|
| 99 |
+
|
| 100 |
+
class ChatbotEngine(metaclass=abc.ABCMeta):
|
| 101 |
+
def __init__(self,) -> None:
|
| 102 |
+
pass
|
| 103 |
+
|
| 104 |
+
@abc.abstractmethod
|
| 105 |
+
def query(self, user_query):
|
| 106 |
+
pass
|
chat_pdf.py
ADDED
|
@@ -0,0 +1,83 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
class ChatPDF():
|
| 3 |
+
"""ChatPDF enables us to chat with a PDF file
|
| 4 |
+
"""
|
| 5 |
+
|
| 6 |
+
def __init__(self, pdf, bot, embedding_model, similarity_metric, expect_answer_token_length_max=100, expect_q_token_length_max=100, user_stamp=None) -> None:
|
| 7 |
+
self.pdf = pdf
|
| 8 |
+
self.bot = bot
|
| 9 |
+
self.embedding_model = embedding_model
|
| 10 |
+
self.similarity_metric = similarity_metric
|
| 11 |
+
self.user_stamp = user_stamp
|
| 12 |
+
|
| 13 |
+
self.system_task_prompt = f"You are a helpful PDF file. Your task is to provide information and answer any questions related to the topic of {self.pdf.metadata['title']}. You should use the sections of the PDF as your source of information and try to provide concise and accurate answers to any questions asked by the user. If you are unable to find relevant information in the given sections, you will need to let the user know that the source does not contain relevant information but still try to provide an answer based on your general knowledge. You must refer to the corresponding section name and page that you refer to when answering. The following is the related information about the PDF file that will help you answer users' questions:\n\n"
|
| 14 |
+
self.system_information_prompt = "Title:\n" + self.pdf.metadata['title'] + "\n\nAbstract:\n" + self.pdf.metadata["abstract"] + \
|
| 15 |
+
"\n\nFiltered paragraphs from each sections (the section titles are enclosed in asterisks**):\n\n"
|
| 16 |
+
|
| 17 |
+
self.system_token_length = self.bot.encode_length(
|
| 18 |
+
self.system_task_prompt) + self.bot.encode_length(self.system_information_prompt)
|
| 19 |
+
self.expect_answer_token_length_max = expect_answer_token_length_max
|
| 20 |
+
self.expect_q_token_length_max = expect_q_token_length_max
|
| 21 |
+
self.context_max_length = self.bot.max_tokens - self.system_token_length - \
|
| 22 |
+
self.bot.overhead_token - self.expect_answer_token_length_max - \
|
| 23 |
+
self.expect_q_token_length_max
|
| 24 |
+
|
| 25 |
+
def _get_related_context(self, user_query):
|
| 26 |
+
all_contextes = [user_query]+self.pdf.flattn_paragraphs
|
| 27 |
+
rank_indices = self.rank_indices(all_contextes, 0,)
|
| 28 |
+
rank_indices = list(rank_indices)
|
| 29 |
+
rank_indices.remove(0)
|
| 30 |
+
inital_context = ":\n\n".join(self.pdf.section_names_with_page_index)
|
| 31 |
+
context_dict = {section_name: []
|
| 32 |
+
for section_name in self.pdf.section_names}
|
| 33 |
+
inital_context_token_length = self.bot.encode_length(inital_context)
|
| 34 |
+
running_length = inital_context_token_length
|
| 35 |
+
for idx in rank_indices:
|
| 36 |
+
text_to_insert = all_contextes[idx]
|
| 37 |
+
text_to_insert_token_length = self.bot.encode_length(
|
| 38 |
+
text_to_insert)
|
| 39 |
+
if running_length + text_to_insert_token_length < self.context_max_length:
|
| 40 |
+
running_length += text_to_insert_token_length
|
| 41 |
+
section = self.pdf.content2section[text_to_insert]
|
| 42 |
+
context_dict[section].append(text_to_insert)
|
| 43 |
+
else:
|
| 44 |
+
break
|
| 45 |
+
composed_context = ""
|
| 46 |
+
for i, section_name in enumerate(self.pdf.section_names):
|
| 47 |
+
if len(context_dict[section_name]) > 0:
|
| 48 |
+
section_name_with_page_index = self.pdf.section_names_with_page_index[i]
|
| 49 |
+
composed_context += "**"+section_name_with_page_index + "**" + \
|
| 50 |
+
":\n" + "\n".join(context_dict[section_name]) + "\n\n"
|
| 51 |
+
return composed_context
|
| 52 |
+
|
| 53 |
+
def chat(self, user_query):
|
| 54 |
+
"""Chat with the PDF file
|
| 55 |
+
"""
|
| 56 |
+
context_data = self._get_related_context(user_query)
|
| 57 |
+
dynamic_system_context = self.system_task_prompt + \
|
| 58 |
+
self.system_information_prompt + context_data
|
| 59 |
+
print(
|
| 60 |
+
"************ Start of Composed Context ************\n",
|
| 61 |
+
dynamic_system_context,
|
| 62 |
+
"\n************ End of Composed Context ************\n"
|
| 63 |
+
)
|
| 64 |
+
response = self.bot.query(
|
| 65 |
+
context=dynamic_system_context, questions=user_query, convo_id=self.user_stamp)
|
| 66 |
+
return response
|
| 67 |
+
|
| 68 |
+
def rank_indices(
|
| 69 |
+
self,
|
| 70 |
+
strings: list[str],
|
| 71 |
+
index_of_source_string: int,
|
| 72 |
+
) -> list[int]:
|
| 73 |
+
"""Rank the indices of the strings in the list based on their similarity to the source string."""
|
| 74 |
+
# get embeddings for all strings
|
| 75 |
+
embeddings = [self.embedding_model(string) for string in strings]
|
| 76 |
+
# get the embedding of the source string
|
| 77 |
+
query_embedding = embeddings[index_of_source_string]
|
| 78 |
+
# get distances between the source embedding and other embeddings (function from embeddings_utils.py)
|
| 79 |
+
distances = self.similarity_metric(query_embedding, embeddings)
|
| 80 |
+
# get rank of indices based on distances
|
| 81 |
+
import numpy as np
|
| 82 |
+
indices_of_nearest_neighbors = np.argsort(distances, )
|
| 83 |
+
return indices_of_nearest_neighbors
|
chatbot.py
ADDED
|
@@ -0,0 +1,320 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from base_class import ChatbotEngine
|
| 2 |
+
import os
|
| 3 |
+
import openai
|
| 4 |
+
import json
|
| 5 |
+
import os
|
| 6 |
+
import requests
|
| 7 |
+
import tiktoken
|
| 8 |
+
from config import MAX_TOKEN_MODEL_MAP
|
| 9 |
+
from utils import get_filtered_keys_from_object
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
class ChatbotWrapper:
|
| 13 |
+
"""
|
| 14 |
+
Wrapper of Official ChatGPT API,
|
| 15 |
+
# base on https://github.com/ChatGPT-Hackers/revChatGPT
|
| 16 |
+
"""
|
| 17 |
+
|
| 18 |
+
def __init__(
|
| 19 |
+
self,
|
| 20 |
+
api_key: str,
|
| 21 |
+
engine: str = os.environ.get("GPT_ENGINE") or "gpt-3.5-turbo",
|
| 22 |
+
proxy: str = None,
|
| 23 |
+
max_tokens: int = 3000,
|
| 24 |
+
temperature: float = 0.5,
|
| 25 |
+
top_p: float = 1.0,
|
| 26 |
+
presence_penalty: float = 0.0,
|
| 27 |
+
frequency_penalty: float = 0.0,
|
| 28 |
+
reply_count: int = 1,
|
| 29 |
+
system_prompt: str = "You are ChatGPT, a large language model trained by OpenAI. Respond conversationally",
|
| 30 |
+
overhead_token=96,
|
| 31 |
+
) -> None:
|
| 32 |
+
"""
|
| 33 |
+
Initialize Chatbot with API key (from https://platform.openai.com/account/api-keys)
|
| 34 |
+
"""
|
| 35 |
+
self.engine = engine
|
| 36 |
+
self.session = requests.Session()
|
| 37 |
+
self.api_key = api_key
|
| 38 |
+
self.system_prompt = system_prompt
|
| 39 |
+
self.max_tokens = max_tokens
|
| 40 |
+
self.temperature = temperature
|
| 41 |
+
self.top_p = top_p
|
| 42 |
+
self.presence_penalty = presence_penalty
|
| 43 |
+
self.frequency_penalty = frequency_penalty
|
| 44 |
+
self.reply_count = reply_count
|
| 45 |
+
self.max_limit = MAX_TOKEN_MODEL_MAP[self.engine]
|
| 46 |
+
self.overhead_token = overhead_token
|
| 47 |
+
|
| 48 |
+
if proxy:
|
| 49 |
+
self.session.proxies = {
|
| 50 |
+
"http": proxy,
|
| 51 |
+
"https": proxy,
|
| 52 |
+
}
|
| 53 |
+
|
| 54 |
+
self.conversation: dict = {
|
| 55 |
+
"default": [
|
| 56 |
+
{
|
| 57 |
+
"role": "system",
|
| 58 |
+
"content": system_prompt,
|
| 59 |
+
},
|
| 60 |
+
],
|
| 61 |
+
}
|
| 62 |
+
|
| 63 |
+
if max_tokens > self.max_limit - self.overhead_token:
|
| 64 |
+
raise Exception(
|
| 65 |
+
f"Max tokens cannot be greater than {self.max_limit- self.overhead_token}")
|
| 66 |
+
|
| 67 |
+
if self.get_token_count("default") > self.max_tokens:
|
| 68 |
+
raise Exception("System prompt is too long")
|
| 69 |
+
|
| 70 |
+
def add_to_conversation(
|
| 71 |
+
self,
|
| 72 |
+
message: str,
|
| 73 |
+
role: str,
|
| 74 |
+
convo_id: str = "default",
|
| 75 |
+
) -> None:
|
| 76 |
+
"""
|
| 77 |
+
Add a message to the conversation
|
| 78 |
+
"""
|
| 79 |
+
self.conversation[convo_id].append({"role": role, "content": message})
|
| 80 |
+
|
| 81 |
+
def __truncate_conversation(self, convo_id: str = "default") -> None:
|
| 82 |
+
"""
|
| 83 |
+
Truncate the conversation
|
| 84 |
+
"""
|
| 85 |
+
# TODO: context condense with soft prompt tuning
|
| 86 |
+
while True:
|
| 87 |
+
if (
|
| 88 |
+
self.get_token_count(convo_id) > self.max_tokens
|
| 89 |
+
and len(self.conversation[convo_id]) > 1
|
| 90 |
+
):
|
| 91 |
+
# Don't remove the first message and remove the first QA pair
|
| 92 |
+
self.conversation[convo_id].pop(1)
|
| 93 |
+
self.conversation[convo_id].pop(1)
|
| 94 |
+
# TODO: optimal pop out based on similarity distance
|
| 95 |
+
else:
|
| 96 |
+
break
|
| 97 |
+
|
| 98 |
+
# https://github.com/openai/openai-cookbook/blob/main/examples/How_to_count_tokens_with_tiktoken.ipynb
|
| 99 |
+
def get_token_count(self, convo_id: str = "default") -> int:
|
| 100 |
+
"""
|
| 101 |
+
Get token count
|
| 102 |
+
"""
|
| 103 |
+
if self.engine not in ["gpt-3.5-turbo", "gpt-3.5-turbo-0301"]:
|
| 104 |
+
raise NotImplementedError("Unsupported engine {self.engine}")
|
| 105 |
+
|
| 106 |
+
encoding = tiktoken.encoding_for_model(self.engine)
|
| 107 |
+
|
| 108 |
+
num_tokens = 0
|
| 109 |
+
for message in self.conversation[convo_id]:
|
| 110 |
+
# every message follows <im_start>{role/name}\n{content}<im_end>\n
|
| 111 |
+
num_tokens += 4
|
| 112 |
+
for key, value in message.items():
|
| 113 |
+
num_tokens += len(encoding.encode(value))
|
| 114 |
+
if key == "name": # if there's a name, the role is omitted
|
| 115 |
+
num_tokens += 1 # role is always required and always 1 token
|
| 116 |
+
num_tokens += 2 # every reply is primed with <im_start>assistant
|
| 117 |
+
return num_tokens
|
| 118 |
+
|
| 119 |
+
def get_max_tokens(self, convo_id: str) -> int:
|
| 120 |
+
"""
|
| 121 |
+
Get max tokens
|
| 122 |
+
"""
|
| 123 |
+
return self.max_tokens - self.get_token_count(convo_id)
|
| 124 |
+
|
| 125 |
+
def ask_stream(
|
| 126 |
+
self,
|
| 127 |
+
prompt: str,
|
| 128 |
+
role: str = "user",
|
| 129 |
+
convo_id: str = "default",
|
| 130 |
+
dynamic_system_prompt=None,
|
| 131 |
+
**kwargs,
|
| 132 |
+
) -> str:
|
| 133 |
+
"""
|
| 134 |
+
Ask a question
|
| 135 |
+
"""
|
| 136 |
+
# Make conversation if it doesn't exist
|
| 137 |
+
if convo_id not in self.conversation:
|
| 138 |
+
self.reset(convo_id=convo_id, system_prompt=dynamic_system_prompt)
|
| 139 |
+
|
| 140 |
+
# adjust system prompt
|
| 141 |
+
assert dynamic_system_prompt is not None
|
| 142 |
+
self.conversation[convo_id][0]["content"] = dynamic_system_prompt
|
| 143 |
+
|
| 144 |
+
self.add_to_conversation(prompt, "user", convo_id=convo_id)
|
| 145 |
+
print(" total tokens:")
|
| 146 |
+
print(self.get_token_count(convo_id))
|
| 147 |
+
self.__truncate_conversation(convo_id=convo_id)
|
| 148 |
+
# Get response
|
| 149 |
+
response = self.session.post(
|
| 150 |
+
os.environ.get(
|
| 151 |
+
"API_URL") or "https://api.openai.com/v1/chat/completions",
|
| 152 |
+
headers={
|
| 153 |
+
"Authorization": f"Bearer {kwargs.get('api_key', self.api_key)}"},
|
| 154 |
+
json={
|
| 155 |
+
"model": self.engine,
|
| 156 |
+
"messages": self.conversation[convo_id],
|
| 157 |
+
"stream": True,
|
| 158 |
+
# kwargs
|
| 159 |
+
"temperature": kwargs.get("temperature", self.temperature),
|
| 160 |
+
"top_p": kwargs.get("top_p", self.top_p),
|
| 161 |
+
"presence_penalty": kwargs.get(
|
| 162 |
+
"presence_penalty",
|
| 163 |
+
self.presence_penalty,
|
| 164 |
+
),
|
| 165 |
+
"frequency_penalty": kwargs.get(
|
| 166 |
+
"frequency_penalty",
|
| 167 |
+
self.frequency_penalty,
|
| 168 |
+
),
|
| 169 |
+
"n": kwargs.get("n", self.reply_count),
|
| 170 |
+
"user": role,
|
| 171 |
+
"max_tokens": self. get_max_tokens(convo_id=convo_id),
|
| 172 |
+
},
|
| 173 |
+
stream=True,
|
| 174 |
+
)
|
| 175 |
+
if response.status_code != 200:
|
| 176 |
+
raise Exception(
|
| 177 |
+
f"Error: {response.status_code} {response.reason} {response.text}",
|
| 178 |
+
)
|
| 179 |
+
response_role: str = None
|
| 180 |
+
full_response: str = ""
|
| 181 |
+
for line in response.iter_lines():
|
| 182 |
+
if not line:
|
| 183 |
+
continue
|
| 184 |
+
# Remove "data: "
|
| 185 |
+
line = line.decode("utf-8")[6:]
|
| 186 |
+
if line == "[DONE]":
|
| 187 |
+
break
|
| 188 |
+
resp: dict = json.loads(line)
|
| 189 |
+
choices = resp.get("choices")
|
| 190 |
+
if not choices:
|
| 191 |
+
continue
|
| 192 |
+
delta = choices[0].get("delta")
|
| 193 |
+
if not delta:
|
| 194 |
+
continue
|
| 195 |
+
if "role" in delta:
|
| 196 |
+
response_role = delta["role"]
|
| 197 |
+
if "content" in delta:
|
| 198 |
+
content = delta["content"]
|
| 199 |
+
full_response += content
|
| 200 |
+
yield content
|
| 201 |
+
self.add_to_conversation(
|
| 202 |
+
full_response, response_role, convo_id=convo_id)
|
| 203 |
+
|
| 204 |
+
def ask(
|
| 205 |
+
self,
|
| 206 |
+
prompt: str,
|
| 207 |
+
role: str = "user",
|
| 208 |
+
convo_id: str = "default",
|
| 209 |
+
dynamic_system_prompt: str = None,
|
| 210 |
+
**kwargs,
|
| 211 |
+
) -> str:
|
| 212 |
+
"""
|
| 213 |
+
Non-streaming ask
|
| 214 |
+
"""
|
| 215 |
+
response = self.ask_stream(
|
| 216 |
+
prompt=prompt,
|
| 217 |
+
role=role,
|
| 218 |
+
convo_id=convo_id,
|
| 219 |
+
dynamic_system_prompt=dynamic_system_prompt,
|
| 220 |
+
**kwargs,
|
| 221 |
+
)
|
| 222 |
+
full_response: str = "".join(response)
|
| 223 |
+
return full_response
|
| 224 |
+
|
| 225 |
+
def rollback(self, n: int = 1, convo_id: str = "default") -> None:
|
| 226 |
+
"""
|
| 227 |
+
Rollback the conversation
|
| 228 |
+
"""
|
| 229 |
+
for _ in range(n):
|
| 230 |
+
self.conversation[convo_id].pop()
|
| 231 |
+
|
| 232 |
+
def reset(self, convo_id: str = "default", system_prompt: str = None) -> None:
|
| 233 |
+
"""
|
| 234 |
+
Reset the conversation
|
| 235 |
+
"""
|
| 236 |
+
self.conversation[convo_id] = [
|
| 237 |
+
{"role": "system", "content": system_prompt or self.system_prompt},
|
| 238 |
+
]
|
| 239 |
+
|
| 240 |
+
def save(self, file: str, *keys: str) -> None:
|
| 241 |
+
"""
|
| 242 |
+
Save the Chatbot configuration to a JSON file
|
| 243 |
+
"""
|
| 244 |
+
with open(file, "w", encoding="utf-8") as f:
|
| 245 |
+
json.dump(
|
| 246 |
+
{
|
| 247 |
+
key: self.__dict__[key]
|
| 248 |
+
for key in get_filtered_keys_from_object(self, *keys)
|
| 249 |
+
},
|
| 250 |
+
f,
|
| 251 |
+
indent=2,
|
| 252 |
+
# saves session.proxies dict as session
|
| 253 |
+
default=lambda o: o.__dict__["proxies"],
|
| 254 |
+
)
|
| 255 |
+
|
| 256 |
+
def load(self, file: str, *keys: str) -> None:
|
| 257 |
+
"""
|
| 258 |
+
Load the Chatbot configuration from a JSON file
|
| 259 |
+
"""
|
| 260 |
+
with open(file, encoding="utf-8") as f:
|
| 261 |
+
# load json, if session is in keys, load proxies
|
| 262 |
+
loaded_config = json.load(f)
|
| 263 |
+
keys = get_filtered_keys_from_object(self, *keys)
|
| 264 |
+
|
| 265 |
+
if "session" in keys and loaded_config["session"]:
|
| 266 |
+
self.session.proxies = loaded_config["session"]
|
| 267 |
+
keys = keys - {"session"}
|
| 268 |
+
self.__dict__.update({key: loaded_config[key] for key in keys})
|
| 269 |
+
|
| 270 |
+
|
| 271 |
+
class OpenAIChatbot(ChatbotEngine):
|
| 272 |
+
def __init__(self, api_key: str,
|
| 273 |
+
engine: str = os.environ.get("GPT_ENGINE") or "gpt-3.5-turbo",
|
| 274 |
+
proxy: str = None,
|
| 275 |
+
max_tokens: int = 3000,
|
| 276 |
+
temperature: float = 0.5,
|
| 277 |
+
top_p: float = 1.0,
|
| 278 |
+
presence_penalty: float = 0.0,
|
| 279 |
+
frequency_penalty: float = 0.0,
|
| 280 |
+
reply_count: int = 1,
|
| 281 |
+
system_prompt: str = "You are ChatGPT, a large language model trained by OpenAI. Respond conversationally",
|
| 282 |
+
overhead_token=96) -> None:
|
| 283 |
+
openai.api_key = api_key
|
| 284 |
+
self.api_key = api_key
|
| 285 |
+
self.engine = engine
|
| 286 |
+
self.proxy = proxy
|
| 287 |
+
self.max_tokens = max_tokens
|
| 288 |
+
self.temperature = temperature
|
| 289 |
+
self.top_p = top_p
|
| 290 |
+
self.presence_penalty = presence_penalty
|
| 291 |
+
self.frequency_penalty = frequency_penalty
|
| 292 |
+
self.reply_count = reply_count
|
| 293 |
+
self.system_prompt = system_prompt
|
| 294 |
+
|
| 295 |
+
self.bot = ChatbotWrapper(
|
| 296 |
+
api_key=self.api_key,
|
| 297 |
+
engine=self.engine,
|
| 298 |
+
proxy=self.proxy,
|
| 299 |
+
max_tokens=self.max_tokens,
|
| 300 |
+
temperature=self.temperature,
|
| 301 |
+
top_p=self.top_p,
|
| 302 |
+
presence_penalty=self.presence_penalty,
|
| 303 |
+
frequency_penalty=self.frequency_penalty,
|
| 304 |
+
reply_count=self.reply_count,
|
| 305 |
+
system_prompt=self.system_prompt,
|
| 306 |
+
overhead_token=overhead_token
|
| 307 |
+
)
|
| 308 |
+
self.overhead_token = overhead_token
|
| 309 |
+
import tiktoken
|
| 310 |
+
self.encoding = tiktoken.encoding_for_model(self.engine)
|
| 311 |
+
|
| 312 |
+
def encode_length(self, text: str) -> int:
|
| 313 |
+
return len(self.encoding.encode(text))
|
| 314 |
+
|
| 315 |
+
def query(self, questions: str,
|
| 316 |
+
role: str = "user",
|
| 317 |
+
convo_id: str = "default",
|
| 318 |
+
context: str = None,
|
| 319 |
+
**kwargs,):
|
| 320 |
+
return self.bot.ask(prompt=questions, role=role, convo_id=convo_id, dynamic_system_prompt=context, **kwargs)
|
config.py
ADDED
|
@@ -0,0 +1,15 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
|
| 3 |
+
MAX_TOKEN_MODEL_MAP = {
|
| 4 |
+
"gpt-3.5-turbo": 4096,
|
| 5 |
+
}
|
| 6 |
+
|
| 7 |
+
PDF_SAVE_DIR = "/app/files/"
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
DEFAULT_ENGINE = "gpt-3.5-turbo"
|
| 11 |
+
DEFAULT_TEMPERATURE = 0.5
|
| 12 |
+
DEFAULT_TOP_P = 1
|
| 13 |
+
DEFAULT_PRESENCE_PENALTY = 0
|
| 14 |
+
DEFAULT_FREQUENCY_PENALTY = 0
|
| 15 |
+
DEFAULT_REPLY_COUNT = 1
|
embedding_model.py
ADDED
|
@@ -0,0 +1,47 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
from base_class import Embedding_Model
|
| 3 |
+
import pickle
|
| 4 |
+
from sentence_transformers import SentenceTransformer
|
| 5 |
+
|
| 6 |
+
from openai.embeddings_utils import (
|
| 7 |
+
get_embedding,
|
| 8 |
+
)
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
class HuggingfaceSentenceTransformerModel(Embedding_Model):
|
| 12 |
+
EMBEDDING_MODEL = "distiluse-base-multilingual-cased-v2"
|
| 13 |
+
|
| 14 |
+
def __init__(self, model_name=EMBEDDING_MODEL) -> None:
|
| 15 |
+
super().__init__(model_name)
|
| 16 |
+
|
| 17 |
+
self.model = SentenceTransformer(model_name, cache_folder="/app/ckpt/")
|
| 18 |
+
|
| 19 |
+
def __call__(self, text) -> None:
|
| 20 |
+
return self.model.encode(text)
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
class OpenAIEmbeddingModel(Embedding_Model):
|
| 24 |
+
# constants
|
| 25 |
+
EMBEDDING_MODEL = "text-embedding-ada-002"
|
| 26 |
+
# establish a cache of embeddings to avoid recomputing
|
| 27 |
+
# cache is a dict of tuples (text, model) -> embedding, saved as a pickle file
|
| 28 |
+
|
| 29 |
+
def __init__(self, model_name=EMBEDDING_MODEL) -> None:
|
| 30 |
+
super().__init__(model_name)
|
| 31 |
+
self.model_name = model_name
|
| 32 |
+
|
| 33 |
+
# define a function to retrieve embeddings from the cache if present, and otherwise request via the API
|
| 34 |
+
def embedding_from_string(self,
|
| 35 |
+
string: str,
|
| 36 |
+
) -> list:
|
| 37 |
+
"""Return embedding of given string, using a cache to avoid recomputing."""
|
| 38 |
+
model = self.model_name
|
| 39 |
+
if (string, model) not in self.embedding_cache.keys():
|
| 40 |
+
self.embedding_cache[(string, model)] = get_embedding(
|
| 41 |
+
string, model)
|
| 42 |
+
with open(self.embedding_cache_path, "wb") as embedding_cache_file:
|
| 43 |
+
pickle.dump(self.embedding_cache, embedding_cache_file)
|
| 44 |
+
return self.embedding_cache[(string, model)]
|
| 45 |
+
|
| 46 |
+
def __call__(self, text) -> None:
|
| 47 |
+
return self.embedding_from_string(text)
|
frontend.py
ADDED
|
@@ -0,0 +1,87 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import datetime
|
| 2 |
+
import os
|
| 3 |
+
import streamlit as st
|
| 4 |
+
from streamlit_chat import message
|
| 5 |
+
import requests
|
| 6 |
+
from config import PDF_SAVE_DIR
|
| 7 |
+
|
| 8 |
+
st.set_page_config(
|
| 9 |
+
page_title="ChatPaper - Demo",
|
| 10 |
+
page_icon=":robot:"
|
| 11 |
+
)
|
| 12 |
+
|
| 13 |
+
pdf_uploaded = False
|
| 14 |
+
|
| 15 |
+
if pdf_uploaded is False:
|
| 16 |
+
st.sidebar.markdown("## Upload a PDF")
|
| 17 |
+
pdf_uploader = st.sidebar.file_uploader("Upload a PDF", type="pdf", )
|
| 18 |
+
|
| 19 |
+
st.sidebar.markdown("## API Key")
|
| 20 |
+
api_key = st.sidebar.text_input(
|
| 21 |
+
"OpenAI API Key", value="", label_visibility="hidden", help="Please enter your API key.")
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
def get_text():
|
| 25 |
+
input_text = st.text_input(
|
| 26 |
+
"User: ", "", help="Please ask any questions about the paper.")
|
| 27 |
+
return input_text
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
st.header("ChatPaper - Demo")
|
| 31 |
+
|
| 32 |
+
API_URL = "http://localhost:5000/query/"
|
| 33 |
+
header = {"api_key": ""}
|
| 34 |
+
|
| 35 |
+
if 'generated' not in st.session_state:
|
| 36 |
+
st.session_state['generated'] = []
|
| 37 |
+
|
| 38 |
+
if 'past' not in st.session_state:
|
| 39 |
+
st.session_state['past'] = []
|
| 40 |
+
|
| 41 |
+
if "user_stamp" not in st.session_state:
|
| 42 |
+
import datetime
|
| 43 |
+
user_stamp = datetime.datetime.now().strftime("%Y%m%d_%H%M%S")
|
| 44 |
+
st.session_state['user_stamp'] = user_stamp
|
| 45 |
+
|
| 46 |
+
|
| 47 |
+
if pdf_uploader is not None:
|
| 48 |
+
if api_key:
|
| 49 |
+
header['api_key'] = api_key
|
| 50 |
+
pdf_name = pdf_uploader.name.replace(' ', '_')
|
| 51 |
+
|
| 52 |
+
file_name = f"{st.session_state.user_stamp}_{pdf_name}"
|
| 53 |
+
|
| 54 |
+
# check PDF_SAVE_DIR
|
| 55 |
+
if not os.path.exists(PDF_SAVE_DIR):
|
| 56 |
+
os.makedirs(PDF_SAVE_DIR)
|
| 57 |
+
|
| 58 |
+
filepath = os.path.join(PDF_SAVE_DIR, file_name)
|
| 59 |
+
with open(filepath, "wb") as f:
|
| 60 |
+
f.write(pdf_uploader.getbuffer())
|
| 61 |
+
user_query = get_text()
|
| 62 |
+
|
| 63 |
+
if user_query:
|
| 64 |
+
st.session_state.past.append(user_query)
|
| 65 |
+
query_data = {"pdf_link": filepath,
|
| 66 |
+
"user_stamp": st.session_state.user_stamp, "user_query": user_query}
|
| 67 |
+
print(query_data)
|
| 68 |
+
response = requests.post(
|
| 69 |
+
API_URL, headers=header, json=query_data, timeout=300)
|
| 70 |
+
output = response.json()
|
| 71 |
+
code = output['code']
|
| 72 |
+
response = output['response']
|
| 73 |
+
if code == 200:
|
| 74 |
+
st.session_state.generated.append(response)
|
| 75 |
+
|
| 76 |
+
if st.session_state['generated']:
|
| 77 |
+
for i in range(len(st.session_state['generated'])-1, -1, -1):
|
| 78 |
+
message(st.session_state["generated"][i],
|
| 79 |
+
key=str(i), avatar_style="fun-emoji")
|
| 80 |
+
message(st.session_state['past'][i], is_user=True, key=str(
|
| 81 |
+
i) + '_user', avatar_style="personas")
|
| 82 |
+
else:
|
| 83 |
+
st.markdown(
|
| 84 |
+
"<span style='color:red'>Please enter your API key.</span>", unsafe_allow_html=True)
|
| 85 |
+
else:
|
| 86 |
+
st.markdown("<span style='color:red'>Please upload a PDF file.</span>",
|
| 87 |
+
unsafe_allow_html=True)
|
pdf_parser.py
ADDED
|
@@ -0,0 +1,148 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from base_class import AbstractPDFParser
|
| 2 |
+
import pickle
|
| 3 |
+
from scipdf_utils import parse_pdf_to_dict
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
class GrobidSciPDFPaser(AbstractPDFParser):
|
| 7 |
+
# import pysbd
|
| 8 |
+
# seg_en = pysbd.Segmenter(language="en", clean=False)
|
| 9 |
+
# seg_chinese = pysbd.Segmenter(language="zh", clean=False)
|
| 10 |
+
|
| 11 |
+
def __init__(self, pdf_link, db_name="grobid_scipdf", short_thereshold=30) -> None:
|
| 12 |
+
"""Initialize the PDF parser
|
| 13 |
+
|
| 14 |
+
Args:
|
| 15 |
+
pdf_link: link to the PDF file, the pdf link can be a web link or local file path
|
| 16 |
+
metadata: metadata of the PDF file, like authors, title, abstract, etc.
|
| 17 |
+
paragraphs: list of paragraphs of the PDF file, all paragraphs are concatenated together
|
| 18 |
+
split_paragraphs: dict of section name and corresponding list of split paragraphs
|
| 19 |
+
"""
|
| 20 |
+
super().__init__(db_name=db_name)
|
| 21 |
+
self.db_name = db_name
|
| 22 |
+
self.pdf_link = pdf_link
|
| 23 |
+
self.pdf = None
|
| 24 |
+
self.metadata = {}
|
| 25 |
+
self.flattn_paragraphs = None
|
| 26 |
+
self.split_paragraphs = None
|
| 27 |
+
self.short_thereshold = short_thereshold
|
| 28 |
+
self.parse_pdf()
|
| 29 |
+
|
| 30 |
+
def _contact_too_short_paragraphs(self, ):
|
| 31 |
+
"""Contact too short paragraphs or discard them"""
|
| 32 |
+
for i, section in enumerate(self.split_paragraphs):
|
| 33 |
+
# section_name = section['heading']
|
| 34 |
+
paragraphs = section['texts']
|
| 35 |
+
new_paragraphs = []
|
| 36 |
+
for paragraph in paragraphs:
|
| 37 |
+
if len(paragraph) <= self.short_thereshold and len(paragraph.strip()) != 0:
|
| 38 |
+
if len(new_paragraphs) != 0:
|
| 39 |
+
new_paragraphs[-1] += paragraph
|
| 40 |
+
else:
|
| 41 |
+
new_paragraphs.append(paragraph)
|
| 42 |
+
else:
|
| 43 |
+
new_paragraphs.append(paragraph)
|
| 44 |
+
self.split_paragraphs[i]['texts'] = new_paragraphs
|
| 45 |
+
|
| 46 |
+
@staticmethod
|
| 47 |
+
def _find_largest_font_string(file_name, search_string):
|
| 48 |
+
search_string = search_string.strip()
|
| 49 |
+
max_font_size = -1
|
| 50 |
+
page_number = -1
|
| 51 |
+
import PyPDF2
|
| 52 |
+
from pdfminer.high_level import extract_pages
|
| 53 |
+
from pdfminer.layout import LTTextContainer, LTChar
|
| 54 |
+
try:
|
| 55 |
+
with open(file_name, 'rb') as file:
|
| 56 |
+
pdf_reader = PyPDF2.PdfReader(file)
|
| 57 |
+
|
| 58 |
+
for index, page_layout in enumerate(extract_pages(file_name)):
|
| 59 |
+
for element in page_layout:
|
| 60 |
+
if isinstance(element, LTTextContainer):
|
| 61 |
+
for text_line in element:
|
| 62 |
+
if search_string in text_line.get_text():
|
| 63 |
+
for character in text_line:
|
| 64 |
+
if isinstance(character, LTChar):
|
| 65 |
+
if character.size > max_font_size:
|
| 66 |
+
max_font_size = character.size
|
| 67 |
+
page_number = index
|
| 68 |
+
return page_number + 1 if page_number != -1 else -1
|
| 69 |
+
except Exception as e:
|
| 70 |
+
return -1
|
| 71 |
+
|
| 72 |
+
|
| 73 |
+
def _find_section_page(self, section_name) -> None:
|
| 74 |
+
return GrobidSciPDFPaser._find_largest_font_string(self.pdf_link, section_name)
|
| 75 |
+
|
| 76 |
+
def _retrive_or_parse(self, ):
|
| 77 |
+
"""Return pdf dict from cache if present, otherwise parse the pdf"""
|
| 78 |
+
db_name = self.db_name
|
| 79 |
+
if (self.pdf_link, db_name) not in self.db_cache.keys():
|
| 80 |
+
self.db_cache[(self.pdf_link, db_name)
|
| 81 |
+
] = parse_pdf_to_dict(self.pdf_link)
|
| 82 |
+
with open(self.db_cache_path, "wb") as db_cache_file:
|
| 83 |
+
pickle.dump(self.db_cache, db_cache_file)
|
| 84 |
+
return self.db_cache[(self.pdf_link, db_name)]
|
| 85 |
+
|
| 86 |
+
@staticmethod
|
| 87 |
+
def _check_chinese(text) -> None:
|
| 88 |
+
return any(u'\u4e00' <= char <= u'\u9fff' for char in text)
|
| 89 |
+
|
| 90 |
+
def parse_pdf(self) -> None:
|
| 91 |
+
"""Parse the PDF file
|
| 92 |
+
"""
|
| 93 |
+
article_dict = self._retrive_or_parse()
|
| 94 |
+
self.article_dict = article_dict
|
| 95 |
+
self._get_metadata()
|
| 96 |
+
self.split_paragraphs = self.get_split_paragraphs()
|
| 97 |
+
self._contact_too_short_paragraphs()
|
| 98 |
+
|
| 99 |
+
self.flattn_paragraphs = self.get_paragraphs()
|
| 100 |
+
|
| 101 |
+
def get_paragraphs(self) -> None:
|
| 102 |
+
"""Get the paragraphs of the PDF file
|
| 103 |
+
"""
|
| 104 |
+
paragraphs = []
|
| 105 |
+
self.content2section = {}
|
| 106 |
+
for section in self.split_paragraphs:
|
| 107 |
+
# paragraphs+=[section["heading"]]
|
| 108 |
+
paragraphs += section["texts"]
|
| 109 |
+
for para in section["texts"]:
|
| 110 |
+
self.content2section[para] = section["heading"]
|
| 111 |
+
return paragraphs
|
| 112 |
+
|
| 113 |
+
def _get_metadata(self) -> None:
|
| 114 |
+
for meta in ['authors', "pub_date", "abstract", "references", "doi", 'title',]:
|
| 115 |
+
self.metadata[meta] = self.article_dict[meta]
|
| 116 |
+
self.section_names = [section["heading"]
|
| 117 |
+
for section in self.article_dict['sections']]
|
| 118 |
+
self.section_names2page = {}
|
| 119 |
+
for section_name in self.section_names:
|
| 120 |
+
section_page_index = self._find_section_page(section_name)
|
| 121 |
+
self.section_names2page.update({section_name: section_page_index})
|
| 122 |
+
self.section_names_with_page_index = [section_name + " (Page {})".format(
|
| 123 |
+
self.section_names2page[section_name]) for section_name in self.section_names]
|
| 124 |
+
|
| 125 |
+
def get_split_paragraphs(self, ) -> None:
|
| 126 |
+
section_pair_list = []
|
| 127 |
+
for section in self.article_dict['sections']:
|
| 128 |
+
section_pair_list.append({
|
| 129 |
+
"heading": section["heading"],
|
| 130 |
+
"texts": section["all_paragraphs"],
|
| 131 |
+
})
|
| 132 |
+
return section_pair_list
|
| 133 |
+
|
| 134 |
+
# @staticmethod
|
| 135 |
+
# def _determine_optimal_split_of_pargraphs(section_pair_list) -> None:
|
| 136 |
+
# """
|
| 137 |
+
# split based on the some magic rules
|
| 138 |
+
# """
|
| 139 |
+
# import pysbd
|
| 140 |
+
# for section_pair in section_pair_list:
|
| 141 |
+
# if GrobidSciPDFPaser._check_chinese(section_pair["text"]):
|
| 142 |
+
# seg = GrobidSciPDFPaser.seg_chinese
|
| 143 |
+
# else:
|
| 144 |
+
# seg = GrobidSciPDFPaser.seg_en
|
| 145 |
+
# section_pair["texts"] = seg.segment(section_pair["texts"])
|
| 146 |
+
# section_pair["texts"] = [
|
| 147 |
+
# para for para in section_pair["text"] if len(para) > 2]
|
| 148 |
+
# return section_pair_list
|
requirements.txt
ADDED
|
@@ -0,0 +1,13 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Flask==2.2.3
|
| 2 |
+
streamlit
|
| 3 |
+
streamlit-chat
|
| 4 |
+
torch
|
| 5 |
+
sentence_transformers
|
| 6 |
+
bs4
|
| 7 |
+
openai
|
| 8 |
+
matplotlib
|
| 9 |
+
plotly
|
| 10 |
+
tiktoken
|
| 11 |
+
lxml
|
| 12 |
+
PyPDF2
|
| 13 |
+
pdfminer.six
|
run.sh
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
cd /app/grobid-0.6.2
|
| 2 |
+
./gradlew run &
|
| 3 |
+
cd /app/
|
| 4 |
+
nohup python backend.py &
|
| 5 |
+
streamlit run frontend.py --server.address 0.0.0.0 --server.port 7860 --server.enableCORS true --server.enableXsrfProtection false
|
scipdf_utils.py
ADDED
|
@@ -0,0 +1,424 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import re
|
| 2 |
+
import os
|
| 3 |
+
import os.path as op
|
| 4 |
+
from glob import glob
|
| 5 |
+
import urllib
|
| 6 |
+
import subprocess
|
| 7 |
+
import requests
|
| 8 |
+
from bs4 import BeautifulSoup, NavigableString
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
# or https://cloud.science-miner.com/grobid/ for cloud service
|
| 12 |
+
GROBID_URL = "http://localhost:8070"
|
| 13 |
+
DIR_PATH = op.dirname(op.abspath(__file__))
|
| 14 |
+
PDF_FIGURES_JAR_PATH = op.join(
|
| 15 |
+
DIR_PATH, "pdffigures2", "pdffigures2-assembly-0.0.12-SNAPSHOT.jar"
|
| 16 |
+
)
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
def list_pdf_paths(pdf_folder: str):
|
| 20 |
+
"""
|
| 21 |
+
list of pdf paths in pdf folder
|
| 22 |
+
"""
|
| 23 |
+
return glob(op.join(pdf_folder, "*", "*", "*.pdf"))
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
def validate_url(path: str):
|
| 27 |
+
"""
|
| 28 |
+
Validate a given ``path`` if it is URL or not
|
| 29 |
+
"""
|
| 30 |
+
regex = re.compile(
|
| 31 |
+
r"^(?:http|ftp)s?://" # http:// or https://
|
| 32 |
+
# domain...
|
| 33 |
+
r"(?:(?:[A-Z0-9](?:[A-Z0-9-]{0,61}[A-Z0-9])?\.)+(?:[A-Z]{2,6}\.?|[A-Z0-9-]{2,}\.?)|"
|
| 34 |
+
r"localhost|" # localhost...
|
| 35 |
+
r"\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3})" # ...or ip
|
| 36 |
+
r"(?::\d+)?" # optional port
|
| 37 |
+
r"(?:/?|[/?]\S+)$",
|
| 38 |
+
re.IGNORECASE,
|
| 39 |
+
)
|
| 40 |
+
return re.match(regex, path) is not None
|
| 41 |
+
|
| 42 |
+
|
| 43 |
+
def parse_pdf(
|
| 44 |
+
pdf_path: str,
|
| 45 |
+
fulltext: bool = True,
|
| 46 |
+
soup: bool = False,
|
| 47 |
+
grobid_url: str = GROBID_URL,
|
| 48 |
+
):
|
| 49 |
+
"""
|
| 50 |
+
Function to parse PDF to XML or BeautifulSoup using GROBID tool
|
| 51 |
+
|
| 52 |
+
You can see http://grobid.readthedocs.io/en/latest/Install-Grobid/ on how to run GROBID locally
|
| 53 |
+
After loading GROBID zip file, you can run GROBID by using the following
|
| 54 |
+
>> ./gradlew run
|
| 55 |
+
|
| 56 |
+
Parameters
|
| 57 |
+
==========
|
| 58 |
+
pdf_path: str or bytes, path or URL to publication or article or bytes string of PDF
|
| 59 |
+
fulltext: bool, option for parsing, if True, parse full text of the article
|
| 60 |
+
if False, parse only header
|
| 61 |
+
grobid_url: str, url to GROBID parser, default at 'http://localhost:8070'
|
| 62 |
+
This could be changed to "https://cloud.science-miner.com/grobid/" for the cloud service
|
| 63 |
+
soup: bool, if True, return BeautifulSoup of the article
|
| 64 |
+
|
| 65 |
+
Output
|
| 66 |
+
======
|
| 67 |
+
parsed_article: if soup is False, return parsed XML in text format,
|
| 68 |
+
else return BeautifulSoup of the XML
|
| 69 |
+
Example
|
| 70 |
+
=======
|
| 71 |
+
>> parsed_article = parse_pdf(pdf_path, fulltext=True, soup=True)
|
| 72 |
+
"""
|
| 73 |
+
# GROBID URL
|
| 74 |
+
if fulltext:
|
| 75 |
+
url = "%s/api/processFulltextDocument" % grobid_url
|
| 76 |
+
else:
|
| 77 |
+
url = "%s/api/processHeaderDocument" % grobid_url
|
| 78 |
+
|
| 79 |
+
if isinstance(pdf_path, str):
|
| 80 |
+
if validate_url(pdf_path) and op.splitext(pdf_path)[-1].lower() != ".pdf":
|
| 81 |
+
print("The input URL has to end with ``.pdf``")
|
| 82 |
+
parsed_article = None
|
| 83 |
+
elif validate_url(pdf_path) and op.splitext(pdf_path)[-1] == ".pdf":
|
| 84 |
+
page = urllib.request.urlopen(pdf_path).read()
|
| 85 |
+
parsed_article = requests.post(url, files={"input": page}).text
|
| 86 |
+
elif op.exists(pdf_path):
|
| 87 |
+
parsed_article = requests.post(
|
| 88 |
+
url, files={"input": open(pdf_path, "rb")}
|
| 89 |
+
).text
|
| 90 |
+
else:
|
| 91 |
+
parsed_article = None
|
| 92 |
+
elif isinstance(pdf_path, bytes):
|
| 93 |
+
# assume that incoming is byte string
|
| 94 |
+
parsed_article = requests.post(url, files={"input": pdf_path}).text
|
| 95 |
+
else:
|
| 96 |
+
parsed_article = None
|
| 97 |
+
|
| 98 |
+
if soup and parsed_article is not None:
|
| 99 |
+
parsed_article = BeautifulSoup(parsed_article, "lxml")
|
| 100 |
+
return parsed_article
|
| 101 |
+
|
| 102 |
+
|
| 103 |
+
def parse_authors(article):
|
| 104 |
+
"""
|
| 105 |
+
Parse authors from a given BeautifulSoup of an article
|
| 106 |
+
"""
|
| 107 |
+
author_names = article.find("sourcedesc").findAll("persname")
|
| 108 |
+
authors = []
|
| 109 |
+
for author in author_names:
|
| 110 |
+
firstname = author.find("forename", {"type": "first"})
|
| 111 |
+
firstname = firstname.text.strip() if firstname is not None else ""
|
| 112 |
+
middlename = author.find("forename", {"type": "middle"})
|
| 113 |
+
middlename = middlename.text.strip() if middlename is not None else ""
|
| 114 |
+
lastname = author.find("surname")
|
| 115 |
+
lastname = lastname.text.strip() if lastname is not None else ""
|
| 116 |
+
if middlename != "":
|
| 117 |
+
authors.append(firstname + " " + middlename + " " + lastname)
|
| 118 |
+
else:
|
| 119 |
+
authors.append(firstname + " " + lastname)
|
| 120 |
+
authors = "; ".join(authors)
|
| 121 |
+
return authors
|
| 122 |
+
|
| 123 |
+
|
| 124 |
+
def parse_date(article):
|
| 125 |
+
"""
|
| 126 |
+
Parse date from a given BeautifulSoup of an article
|
| 127 |
+
"""
|
| 128 |
+
pub_date = article.find("publicationstmt")
|
| 129 |
+
year = pub_date.find("date")
|
| 130 |
+
year = year.attrs.get("when") if year is not None else ""
|
| 131 |
+
return year
|
| 132 |
+
|
| 133 |
+
|
| 134 |
+
def parse_abstract(article):
|
| 135 |
+
"""
|
| 136 |
+
Parse abstract from a given BeautifulSoup of an article
|
| 137 |
+
"""
|
| 138 |
+
div = article.find("abstract")
|
| 139 |
+
abstract = ""
|
| 140 |
+
for p in list(div.children):
|
| 141 |
+
if not isinstance(p, NavigableString) and len(list(p)) > 0:
|
| 142 |
+
abstract += " ".join(
|
| 143 |
+
[elem.text for elem in p if not isinstance(
|
| 144 |
+
elem, NavigableString)]
|
| 145 |
+
)
|
| 146 |
+
return abstract
|
| 147 |
+
|
| 148 |
+
|
| 149 |
+
def calculate_number_of_references(div):
|
| 150 |
+
"""
|
| 151 |
+
For a given section, calculate number of references made in the section
|
| 152 |
+
"""
|
| 153 |
+
n_publication_ref = len(
|
| 154 |
+
[ref for ref in div.find_all("ref") if ref.attrs.get("type") == "bibr"]
|
| 155 |
+
)
|
| 156 |
+
n_figure_ref = len(
|
| 157 |
+
[ref for ref in div.find_all(
|
| 158 |
+
"ref") if ref.attrs.get("type") == "figure"]
|
| 159 |
+
)
|
| 160 |
+
return {"n_publication_ref": n_publication_ref, "n_figure_ref": n_figure_ref}
|
| 161 |
+
|
| 162 |
+
|
| 163 |
+
def parse_sections(article, as_list: bool = False):
|
| 164 |
+
"""
|
| 165 |
+
Parse list of sections from a given BeautifulSoup of an article
|
| 166 |
+
|
| 167 |
+
Parameters
|
| 168 |
+
==========
|
| 169 |
+
as_list: bool, if True, output text as a list of paragraph instead
|
| 170 |
+
of joining it together as one single text
|
| 171 |
+
"""
|
| 172 |
+
article_text = article.find("text")
|
| 173 |
+
divs = article_text.find_all(
|
| 174 |
+
"div", attrs={"xmlns": "http://www.tei-c.org/ns/1.0"})
|
| 175 |
+
sections = []
|
| 176 |
+
for div in divs:
|
| 177 |
+
div_list = list(div.children)
|
| 178 |
+
if len(div_list) == 0:
|
| 179 |
+
heading = ""
|
| 180 |
+
text = ""
|
| 181 |
+
all_paragraphs = []
|
| 182 |
+
elif len(div_list) == 1:
|
| 183 |
+
if isinstance(div_list[0], NavigableString):
|
| 184 |
+
heading = str(div_list[0])
|
| 185 |
+
text = ""
|
| 186 |
+
all_paragraphs = []
|
| 187 |
+
else:
|
| 188 |
+
heading = ""
|
| 189 |
+
text = div_list[0].text
|
| 190 |
+
all_paragraphs = [text]
|
| 191 |
+
else:
|
| 192 |
+
text = []
|
| 193 |
+
heading = div_list[0]
|
| 194 |
+
all_paragraphs = []
|
| 195 |
+
if isinstance(heading, NavigableString):
|
| 196 |
+
heading = str(heading)
|
| 197 |
+
p_all = list(div.children)[1:]
|
| 198 |
+
else:
|
| 199 |
+
heading = ""
|
| 200 |
+
p_all = list(div.children)
|
| 201 |
+
for p in p_all:
|
| 202 |
+
if p is not None:
|
| 203 |
+
try:
|
| 204 |
+
text.append(p.text)
|
| 205 |
+
all_paragraphs.append(p.text)
|
| 206 |
+
except:
|
| 207 |
+
pass
|
| 208 |
+
if not as_list:
|
| 209 |
+
text = "\n".join(text)
|
| 210 |
+
if heading != "" or text != "":
|
| 211 |
+
ref_dict = calculate_number_of_references(div)
|
| 212 |
+
sections.append(
|
| 213 |
+
{
|
| 214 |
+
"heading": heading,
|
| 215 |
+
"text": text,
|
| 216 |
+
"all_paragraphs": all_paragraphs,
|
| 217 |
+
"n_publication_ref": ref_dict["n_publication_ref"],
|
| 218 |
+
"n_figure_ref": ref_dict["n_figure_ref"],
|
| 219 |
+
}
|
| 220 |
+
)
|
| 221 |
+
return sections
|
| 222 |
+
|
| 223 |
+
|
| 224 |
+
def parse_references(article):
|
| 225 |
+
"""
|
| 226 |
+
Parse list of references from a given BeautifulSoup of an article
|
| 227 |
+
"""
|
| 228 |
+
reference_list = []
|
| 229 |
+
references = article.find("text").find("div", attrs={"type": "references"})
|
| 230 |
+
references = references.find_all(
|
| 231 |
+
"biblstruct") if references is not None else []
|
| 232 |
+
reference_list = []
|
| 233 |
+
for reference in references:
|
| 234 |
+
title = reference.find("title", attrs={"level": "a"})
|
| 235 |
+
if title is None:
|
| 236 |
+
title = reference.find("title", attrs={"level": "m"})
|
| 237 |
+
title = title.text if title is not None else ""
|
| 238 |
+
journal = reference.find("title", attrs={"level": "j"})
|
| 239 |
+
journal = journal.text if journal is not None else ""
|
| 240 |
+
if journal == "":
|
| 241 |
+
journal = reference.find("publisher")
|
| 242 |
+
journal = journal.text if journal is not None else ""
|
| 243 |
+
year = reference.find("date")
|
| 244 |
+
year = year.attrs.get("when") if year is not None else ""
|
| 245 |
+
authors = []
|
| 246 |
+
for author in reference.find_all("author"):
|
| 247 |
+
firstname = author.find("forename", {"type": "first"})
|
| 248 |
+
firstname = firstname.text.strip() if firstname is not None else ""
|
| 249 |
+
middlename = author.find("forename", {"type": "middle"})
|
| 250 |
+
middlename = middlename.text.strip() if middlename is not None else ""
|
| 251 |
+
lastname = author.find("surname")
|
| 252 |
+
lastname = lastname.text.strip() if lastname is not None else ""
|
| 253 |
+
if middlename != "":
|
| 254 |
+
authors.append(firstname + " " + middlename + " " + lastname)
|
| 255 |
+
else:
|
| 256 |
+
authors.append(firstname + " " + lastname)
|
| 257 |
+
authors = "; ".join(authors)
|
| 258 |
+
reference_list.append(
|
| 259 |
+
{"title": title, "journal": journal, "year": year, "authors": authors}
|
| 260 |
+
)
|
| 261 |
+
return reference_list
|
| 262 |
+
|
| 263 |
+
|
| 264 |
+
def parse_figure_caption(article):
|
| 265 |
+
"""
|
| 266 |
+
Parse list of figures/tables from a given BeautifulSoup of an article
|
| 267 |
+
"""
|
| 268 |
+
figures_list = []
|
| 269 |
+
figures = article.find_all("figure")
|
| 270 |
+
for figure in figures:
|
| 271 |
+
figure_type = figure.attrs.get("type") or ""
|
| 272 |
+
figure_id = figure.attrs["xml:id"] or ""
|
| 273 |
+
label = figure.find("label").text
|
| 274 |
+
if figure_type == "table":
|
| 275 |
+
caption = figure.find("figdesc").text
|
| 276 |
+
data = figure.table.text
|
| 277 |
+
else:
|
| 278 |
+
caption = figure.text
|
| 279 |
+
data = ""
|
| 280 |
+
figures_list.append(
|
| 281 |
+
{
|
| 282 |
+
"figure_label": label,
|
| 283 |
+
"figure_type": figure_type,
|
| 284 |
+
"figure_id": figure_id,
|
| 285 |
+
"figure_caption": caption,
|
| 286 |
+
"figure_data": data,
|
| 287 |
+
}
|
| 288 |
+
)
|
| 289 |
+
return figures_list
|
| 290 |
+
|
| 291 |
+
|
| 292 |
+
def convert_article_soup_to_dict(article, as_list: bool = False):
|
| 293 |
+
"""
|
| 294 |
+
Function to convert BeautifulSoup to JSON format
|
| 295 |
+
similar to the output from https://github.com/allenai/science-parse/
|
| 296 |
+
|
| 297 |
+
Parameters
|
| 298 |
+
==========
|
| 299 |
+
article: BeautifulSoup
|
| 300 |
+
|
| 301 |
+
Output
|
| 302 |
+
======
|
| 303 |
+
article_json: dict, parsed dictionary of a given article in the following format
|
| 304 |
+
{
|
| 305 |
+
'title': ...,
|
| 306 |
+
'abstract': ...,
|
| 307 |
+
'sections': [
|
| 308 |
+
{'heading': ..., 'text': ...},
|
| 309 |
+
{'heading': ..., 'text': ...},
|
| 310 |
+
...
|
| 311 |
+
],
|
| 312 |
+
'references': [
|
| 313 |
+
{'title': ..., 'journal': ..., 'year': ..., 'authors': ...},
|
| 314 |
+
{'title': ..., 'journal': ..., 'year': ..., 'authors': ...},
|
| 315 |
+
...
|
| 316 |
+
],
|
| 317 |
+
'figures': [
|
| 318 |
+
{'figure_label': ..., 'figure_type': ..., 'figure_id': ..., 'figure_caption': ..., 'figure_data': ...},
|
| 319 |
+
...
|
| 320 |
+
]
|
| 321 |
+
}
|
| 322 |
+
"""
|
| 323 |
+
article_dict = {}
|
| 324 |
+
if article is not None:
|
| 325 |
+
title = article.find("title", attrs={"type": "main"})
|
| 326 |
+
title = title.text.strip() if title is not None else ""
|
| 327 |
+
article_dict["authors"] = parse_authors(article)
|
| 328 |
+
article_dict["pub_date"] = parse_date(article)
|
| 329 |
+
article_dict["title"] = title
|
| 330 |
+
article_dict["abstract"] = parse_abstract(article)
|
| 331 |
+
article_dict["sections"] = parse_sections(article, as_list=as_list)
|
| 332 |
+
article_dict["references"] = parse_references(article)
|
| 333 |
+
article_dict["figures"] = parse_figure_caption(article)
|
| 334 |
+
|
| 335 |
+
doi = article.find("idno", attrs={"type": "DOI"})
|
| 336 |
+
doi = doi.text if doi is not None else ""
|
| 337 |
+
article_dict["doi"] = doi
|
| 338 |
+
|
| 339 |
+
return article_dict
|
| 340 |
+
else:
|
| 341 |
+
return None
|
| 342 |
+
|
| 343 |
+
|
| 344 |
+
def parse_pdf_to_dict(
|
| 345 |
+
pdf_path: str,
|
| 346 |
+
fulltext: bool = True,
|
| 347 |
+
soup: bool = True,
|
| 348 |
+
as_list: bool = False,
|
| 349 |
+
grobid_url: str = GROBID_URL,
|
| 350 |
+
):
|
| 351 |
+
"""
|
| 352 |
+
Parse the given PDF and return dictionary of the parsed article
|
| 353 |
+
|
| 354 |
+
Parameters
|
| 355 |
+
==========
|
| 356 |
+
pdf_path: str, path to publication or article
|
| 357 |
+
fulltext: bool, whether to extract fulltext or not
|
| 358 |
+
soup: bool, whether to return BeautifulSoup or not
|
| 359 |
+
as_list: bool, whether to return list of sections or not
|
| 360 |
+
grobid_url: str, url to grobid server, default is `GROBID_URL`
|
| 361 |
+
This could be changed to "https://cloud.science-miner.com/grobid/" for the cloud service
|
| 362 |
+
|
| 363 |
+
Ouput
|
| 364 |
+
=====
|
| 365 |
+
article_dict: dict, dictionary of an article
|
| 366 |
+
"""
|
| 367 |
+
parsed_article = parse_pdf(
|
| 368 |
+
pdf_path, fulltext=fulltext, soup=soup, grobid_url=grobid_url
|
| 369 |
+
)
|
| 370 |
+
article_dict = convert_article_soup_to_dict(
|
| 371 |
+
parsed_article, as_list=as_list)
|
| 372 |
+
return article_dict
|
| 373 |
+
|
| 374 |
+
|
| 375 |
+
def parse_figures(
|
| 376 |
+
pdf_folder: str,
|
| 377 |
+
jar_path: str = PDF_FIGURES_JAR_PATH,
|
| 378 |
+
resolution: int = 300,
|
| 379 |
+
output_folder: str = "figures",
|
| 380 |
+
):
|
| 381 |
+
"""
|
| 382 |
+
Parse figures from the given scientific PDF using pdffigures2
|
| 383 |
+
|
| 384 |
+
Parameters
|
| 385 |
+
==========
|
| 386 |
+
pdf_folder: str, path to a folder that contains PDF files. A folder must contains only PDF files
|
| 387 |
+
jar_path: str, default path to pdffigures2-assembly-0.0.12-SNAPSHOT.jar file
|
| 388 |
+
resolution: int, resolution of the output figures
|
| 389 |
+
output_folder: str, path to folder that we want to save parsed data (related to figures) and figures
|
| 390 |
+
|
| 391 |
+
Output
|
| 392 |
+
======
|
| 393 |
+
folder: making a folder of output_folder/data and output_folder/figures of parsed data and figures relatively
|
| 394 |
+
"""
|
| 395 |
+
if not op.isdir(output_folder):
|
| 396 |
+
os.makedirs(output_folder)
|
| 397 |
+
|
| 398 |
+
# create ``data`` and ``figures`` subfolder within ``output_folder``
|
| 399 |
+
data_path = op.join(output_folder, "data")
|
| 400 |
+
figure_path = op.join(output_folder, "figures")
|
| 401 |
+
if not op.exists(data_path):
|
| 402 |
+
os.makedirs(data_path)
|
| 403 |
+
if not op.exists(figure_path):
|
| 404 |
+
os.makedirs(figure_path)
|
| 405 |
+
|
| 406 |
+
if op.isdir(data_path) and op.isdir(figure_path):
|
| 407 |
+
args = [
|
| 408 |
+
"java",
|
| 409 |
+
"-jar",
|
| 410 |
+
jar_path,
|
| 411 |
+
pdf_folder,
|
| 412 |
+
"-i",
|
| 413 |
+
str(resolution),
|
| 414 |
+
"-d",
|
| 415 |
+
os.path.join(os.path.abspath(data_path), ""),
|
| 416 |
+
"-m",
|
| 417 |
+
op.join(os.path.abspath(figure_path), ""), # end path with "/"
|
| 418 |
+
]
|
| 419 |
+
_ = subprocess.run(
|
| 420 |
+
args, stdout=subprocess.PIPE, stderr=subprocess.PIPE, timeout=20
|
| 421 |
+
)
|
| 422 |
+
print("Done parsing figures from PDFs!")
|
| 423 |
+
else:
|
| 424 |
+
print("You may have to check of ``data`` and ``figures`` in the the output folder path.")
|
serve_grobid.sh
ADDED
|
@@ -0,0 +1,14 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/bin/bash
|
| 2 |
+
|
| 3 |
+
# download GROBID if directory does not exist
|
| 4 |
+
declare -r GROBID_VERSION="0.6.2" # or change to current stable version
|
| 5 |
+
|
| 6 |
+
if [ ! -d grobid-${GROBID_VERSION} ]; then
|
| 7 |
+
wget https://github.com/kermitt2/grobid/archive/${GROBID_VERSION}.zip
|
| 8 |
+
sudo chmod 777 "${GROBID_VERSION}.zip"
|
| 9 |
+
unzip "${GROBID_VERSION}.zip"
|
| 10 |
+
rm "${GROBID_VERSION}.zip"
|
| 11 |
+
fi
|
| 12 |
+
cd grobid-${GROBID_VERSION} || exit
|
| 13 |
+
sudo chmod 777 gradlew
|
| 14 |
+
./gradlew
|
similarity_metric.py
ADDED
|
@@ -0,0 +1,13 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from base_class import SimilarityAlg
|
| 2 |
+
from openai.embeddings_utils import (
|
| 3 |
+
distances_from_embeddings,
|
| 4 |
+
)
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
class CosineSimilarity(SimilarityAlg):
|
| 8 |
+
def __init__(self) -> None:
|
| 9 |
+
pass
|
| 10 |
+
|
| 11 |
+
@staticmethod
|
| 12 |
+
def __call__(query_embedding, embeddings) -> None:
|
| 13 |
+
return distances_from_embeddings(query_embedding, embeddings, distance_metric="cosine")
|
utils.py
ADDED
|
@@ -0,0 +1,24 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
from typing import Set
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
def get_filtered_keys_from_object(obj: object, *keys: str) -> Set[str]:
|
| 6 |
+
"""
|
| 7 |
+
Get filtered list of object variable names.
|
| 8 |
+
:param keys: List of keys to include. If the first key is "not", the remaining keys will be removed from the class keys.
|
| 9 |
+
:return: List of class keys.
|
| 10 |
+
"""
|
| 11 |
+
class_keys = obj.__dict__.keys()
|
| 12 |
+
if not keys:
|
| 13 |
+
return class_keys
|
| 14 |
+
|
| 15 |
+
# Remove the passed keys from the class keys.
|
| 16 |
+
if keys[0] == "not":
|
| 17 |
+
return {key for key in class_keys if key not in keys[1:]}
|
| 18 |
+
# Check if all passed keys are valid
|
| 19 |
+
if invalid_keys := set(keys) - class_keys:
|
| 20 |
+
raise ValueError(
|
| 21 |
+
f"Invalid keys: {invalid_keys}",
|
| 22 |
+
)
|
| 23 |
+
# Only return specified keys that are in class_keys
|
| 24 |
+
return {key for key in keys if key in class_keys}
|