Spaces:
Runtime error

Runtime error
Upload folder using huggingface_hub
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- .dockerignore +1 -0
- .gitattributes +9 -0
- .gitignore +11 -0
- .gradio/certificate.pem +31 -0
- .python-version +1 -0
- .vscode/settings.json +3 -0
- =0.6.0 +0 -0
- Dockerfile +22 -0
- README.md +43 -8
- app.py +381 -0
- backup_001.py +330 -0
- configs/sam2.1_hiera_b+.yaml +116 -0
- configs/sam2.1_hiera_s.yaml +119 -0
- configs/sam2.1_hiera_t.yaml +121 -0
- configs/sam2_configs_sam2.1_sam2.1_hiera_l.yaml +120 -0
- gradio_app.py +379 -0
- hello.py +6 -0
- pyproject.toml +21 -0
- ref.py +265 -0
- reference_code.py +776 -0
- requirements.txt +5 -0
- sam2-repo/.clang-format +85 -0
- sam2-repo/.github/workflows/check_fmt.yml +17 -0
- sam2-repo/.gitignore +11 -0
- sam2-repo/.watchmanconfig +1 -0
- sam2-repo/CODE_OF_CONDUCT.md +80 -0
- sam2-repo/CONTRIBUTING.md +31 -0
- sam2-repo/INSTALL.md +189 -0
- sam2-repo/LICENSE +201 -0
- sam2-repo/LICENSE_cctorch +29 -0
- sam2-repo/MANIFEST.in +7 -0
- sam2-repo/README.md +224 -0
- sam2-repo/RELEASE_NOTES.md +27 -0
- sam2-repo/assets/model_diagram.png +0 -0
- sam2-repo/assets/sa_v_dataset.jpg +0 -0
- sam2-repo/backend.Dockerfile +64 -0
- sam2-repo/checkpoints/download_ckpts.sh +59 -0
- sam2-repo/demo/.gitignore +2 -0
- sam2-repo/demo/README.md +173 -0
- sam2-repo/demo/backend/server/app.py +140 -0
- sam2-repo/demo/backend/server/app_conf.py +55 -0
- sam2-repo/demo/backend/server/data/data_types.py +154 -0
- sam2-repo/demo/backend/server/data/loader.py +92 -0
- sam2-repo/demo/backend/server/data/resolver.py +18 -0
- sam2-repo/demo/backend/server/data/schema.py +357 -0
- sam2-repo/demo/backend/server/data/store.py +28 -0
- sam2-repo/demo/backend/server/data/transcoder.py +186 -0
- sam2-repo/demo/backend/server/inference/data_types.py +191 -0
- sam2-repo/demo/backend/server/inference/multipart.py +48 -0
- sam2-repo/demo/backend/server/inference/predictor.py +427 -0
.dockerignore
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
.venv
|
.gitattributes
CHANGED
|
@@ -33,3 +33,12 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
sam2-repo/demo/data/gallery/01_dog.mp4 filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
sam2-repo/demo/data/gallery/02_cups.mp4 filter=lfs diff=lfs merge=lfs -text
|
| 38 |
+
sam2-repo/demo/data/gallery/03_blocks.mp4 filter=lfs diff=lfs merge=lfs -text
|
| 39 |
+
sam2-repo/demo/data/gallery/04_coffee.mp4 filter=lfs diff=lfs merge=lfs -text
|
| 40 |
+
sam2-repo/demo/data/gallery/05_default_juggle.mp4 filter=lfs diff=lfs merge=lfs -text
|
| 41 |
+
sam2-repo/demo/frontend/src/assets/videos/sam2_720px_dark.mp4 filter=lfs diff=lfs merge=lfs -text
|
| 42 |
+
sam2-repo/notebooks/images/cars.jpg filter=lfs diff=lfs merge=lfs -text
|
| 43 |
+
sam2-repo/notebooks/videos/bedroom.mp4 filter=lfs diff=lfs merge=lfs -text
|
| 44 |
+
sam2-repo/sav_dataset/example/sav_000001.mp4 filter=lfs diff=lfs merge=lfs -text
|
.gitignore
ADDED
|
@@ -0,0 +1,11 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Python-generated files
|
| 2 |
+
__pycache__/
|
| 3 |
+
*.py[oc]
|
| 4 |
+
build/
|
| 5 |
+
dist/
|
| 6 |
+
wheels/
|
| 7 |
+
*.egg-info
|
| 8 |
+
|
| 9 |
+
# Virtual environments
|
| 10 |
+
.venv
|
| 11 |
+
models/
|
.gradio/certificate.pem
ADDED
|
@@ -0,0 +1,31 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
-----BEGIN CERTIFICATE-----
|
| 2 |
+
MIIFazCCA1OgAwIBAgIRAIIQz7DSQONZRGPgu2OCiwAwDQYJKoZIhvcNAQELBQAw
|
| 3 |
+
TzELMAkGA1UEBhMCVVMxKTAnBgNVBAoTIEludGVybmV0IFNlY3VyaXR5IFJlc2Vh
|
| 4 |
+
cmNoIEdyb3VwMRUwEwYDVQQDEwxJU1JHIFJvb3QgWDEwHhcNMTUwNjA0MTEwNDM4
|
| 5 |
+
WhcNMzUwNjA0MTEwNDM4WjBPMQswCQYDVQQGEwJVUzEpMCcGA1UEChMgSW50ZXJu
|
| 6 |
+
ZXQgU2VjdXJpdHkgUmVzZWFyY2ggR3JvdXAxFTATBgNVBAMTDElTUkcgUm9vdCBY
|
| 7 |
+
MTCCAiIwDQYJKoZIhvcNAQEBBQADggIPADCCAgoCggIBAK3oJHP0FDfzm54rVygc
|
| 8 |
+
h77ct984kIxuPOZXoHj3dcKi/vVqbvYATyjb3miGbESTtrFj/RQSa78f0uoxmyF+
|
| 9 |
+
0TM8ukj13Xnfs7j/EvEhmkvBioZxaUpmZmyPfjxwv60pIgbz5MDmgK7iS4+3mX6U
|
| 10 |
+
A5/TR5d8mUgjU+g4rk8Kb4Mu0UlXjIB0ttov0DiNewNwIRt18jA8+o+u3dpjq+sW
|
| 11 |
+
T8KOEUt+zwvo/7V3LvSye0rgTBIlDHCNAymg4VMk7BPZ7hm/ELNKjD+Jo2FR3qyH
|
| 12 |
+
B5T0Y3HsLuJvW5iB4YlcNHlsdu87kGJ55tukmi8mxdAQ4Q7e2RCOFvu396j3x+UC
|
| 13 |
+
B5iPNgiV5+I3lg02dZ77DnKxHZu8A/lJBdiB3QW0KtZB6awBdpUKD9jf1b0SHzUv
|
| 14 |
+
KBds0pjBqAlkd25HN7rOrFleaJ1/ctaJxQZBKT5ZPt0m9STJEadao0xAH0ahmbWn
|
| 15 |
+
OlFuhjuefXKnEgV4We0+UXgVCwOPjdAvBbI+e0ocS3MFEvzG6uBQE3xDk3SzynTn
|
| 16 |
+
jh8BCNAw1FtxNrQHusEwMFxIt4I7mKZ9YIqioymCzLq9gwQbooMDQaHWBfEbwrbw
|
| 17 |
+
qHyGO0aoSCqI3Haadr8faqU9GY/rOPNk3sgrDQoo//fb4hVC1CLQJ13hef4Y53CI
|
| 18 |
+
rU7m2Ys6xt0nUW7/vGT1M0NPAgMBAAGjQjBAMA4GA1UdDwEB/wQEAwIBBjAPBgNV
|
| 19 |
+
HRMBAf8EBTADAQH/MB0GA1UdDgQWBBR5tFnme7bl5AFzgAiIyBpY9umbbjANBgkq
|
| 20 |
+
hkiG9w0BAQsFAAOCAgEAVR9YqbyyqFDQDLHYGmkgJykIrGF1XIpu+ILlaS/V9lZL
|
| 21 |
+
ubhzEFnTIZd+50xx+7LSYK05qAvqFyFWhfFQDlnrzuBZ6brJFe+GnY+EgPbk6ZGQ
|
| 22 |
+
3BebYhtF8GaV0nxvwuo77x/Py9auJ/GpsMiu/X1+mvoiBOv/2X/qkSsisRcOj/KK
|
| 23 |
+
NFtY2PwByVS5uCbMiogziUwthDyC3+6WVwW6LLv3xLfHTjuCvjHIInNzktHCgKQ5
|
| 24 |
+
ORAzI4JMPJ+GslWYHb4phowim57iaztXOoJwTdwJx4nLCgdNbOhdjsnvzqvHu7Ur
|
| 25 |
+
TkXWStAmzOVyyghqpZXjFaH3pO3JLF+l+/+sKAIuvtd7u+Nxe5AW0wdeRlN8NwdC
|
| 26 |
+
jNPElpzVmbUq4JUagEiuTDkHzsxHpFKVK7q4+63SM1N95R1NbdWhscdCb+ZAJzVc
|
| 27 |
+
oyi3B43njTOQ5yOf+1CceWxG1bQVs5ZufpsMljq4Ui0/1lvh+wjChP4kqKOJ2qxq
|
| 28 |
+
4RgqsahDYVvTH9w7jXbyLeiNdd8XM2w9U/t7y0Ff/9yi0GE44Za4rF2LN9d11TPA
|
| 29 |
+
mRGunUHBcnWEvgJBQl9nJEiU0Zsnvgc/ubhPgXRR4Xq37Z0j4r7g1SgEEzwxA57d
|
| 30 |
+
emyPxgcYxn/eR44/KJ4EBs+lVDR3veyJm+kXQ99b21/+jh5Xos1AnX5iItreGCc=
|
| 31 |
+
-----END CERTIFICATE-----
|
.python-version
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
3.12
|
.vscode/settings.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"python.languageServer": "None"
|
| 3 |
+
}
|
=0.6.0
ADDED
|
File without changes
|
Dockerfile
ADDED
|
@@ -0,0 +1,22 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Use an official Python runtime as a parent image
|
| 2 |
+
FROM python:3.9-slim
|
| 3 |
+
|
| 4 |
+
# Set the working directory in the container
|
| 5 |
+
WORKDIR /app
|
| 6 |
+
|
| 7 |
+
# Copy the current directory contents into the container at /app
|
| 8 |
+
COPY . /app
|
| 9 |
+
|
| 10 |
+
# Install any needed packages specified in requirements.txt
|
| 11 |
+
RUN pip install --no-cache-dir -r requirements.txt
|
| 12 |
+
|
| 13 |
+
# Install additional dependencies
|
| 14 |
+
RUN apt-get update && apt-get install -y \
|
| 15 |
+
ffmpeg \
|
| 16 |
+
&& rm -rf /var/lib/apt/lists/*
|
| 17 |
+
|
| 18 |
+
# Expose port 7860 for Gradio
|
| 19 |
+
EXPOSE 7860
|
| 20 |
+
|
| 21 |
+
# Run the application
|
| 22 |
+
CMD ["python", "app.py"]
|
README.md
CHANGED
|
@@ -1,12 +1,47 @@
|
|
| 1 |
---
|
| 2 |
-
title:
|
| 3 |
-
|
| 4 |
-
colorFrom: yellow
|
| 5 |
-
colorTo: green
|
| 6 |
sdk: gradio
|
| 7 |
-
sdk_version: 5.
|
| 8 |
-
app_file: app.py
|
| 9 |
-
pinned: false
|
| 10 |
---
|
|
|
|
| 11 |
|
| 12 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
---
|
| 2 |
+
title: golf_tracking
|
| 3 |
+
app_file: gradio_app.py
|
|
|
|
|
|
|
| 4 |
sdk: gradio
|
| 5 |
+
sdk_version: 5.10.0
|
|
|
|
|
|
|
| 6 |
---
|
| 7 |
+
# Golf Ball Trajectory Tracker
|
| 8 |
|
| 9 |
+
This application uses Meta's Segment Anything Model (SAM) 2.1 and physics-based trajectory fitting to track and analyze golf ball trajectories from videos.
|
| 10 |
+
|
| 11 |
+
## Setup
|
| 12 |
+
|
| 13 |
+
1. Download the SAM model checkpoint:
|
| 14 |
+
- Visit: https://dl.fbaipublicfiles.com/segment_anything/sam_vit_b_01ec64.pth
|
| 15 |
+
- Save the file in the project directory
|
| 16 |
+
|
| 17 |
+
2. Install dependencies:
|
| 18 |
+
```bash
|
| 19 |
+
pip install -r requirements.txt
|
| 20 |
+
```
|
| 21 |
+
|
| 22 |
+
## Usage
|
| 23 |
+
|
| 24 |
+
1. Run the application:
|
| 25 |
+
```bash
|
| 26 |
+
python app.py
|
| 27 |
+
```
|
| 28 |
+
|
| 29 |
+
2. Using the interface:
|
| 30 |
+
- Upload a golf swing video
|
| 31 |
+
- Click "Process Video" to load the video
|
| 32 |
+
- Click on the golf ball position in key frames (at least 3 points recommended)
|
| 33 |
+
- The application will fit and display the trajectory
|
| 34 |
+
- Use "Clear Points" to start over
|
| 35 |
+
|
| 36 |
+
## Features
|
| 37 |
+
|
| 38 |
+
- Interactive point selection for trajectory tracking
|
| 39 |
+
- Physics-based trajectory fitting
|
| 40 |
+
- Real-time visualization of predicted path
|
| 41 |
+
- CPU-optimized for Intel UHD 630 graphics
|
| 42 |
+
|
| 43 |
+
## Notes
|
| 44 |
+
|
| 45 |
+
- The application uses the SAM base model optimized for CPU usage
|
| 46 |
+
- For best results, provide clear video footage with visible golf ball
|
| 47 |
+
- Select points at different stages of the ball's flight for better trajectory fitting
|
app.py
ADDED
|
@@ -0,0 +1,381 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import gradio as gr
|
| 2 |
+
import numpy as np
|
| 3 |
+
import cv2
|
| 4 |
+
import torch
|
| 5 |
+
import os
|
| 6 |
+
import logging
|
| 7 |
+
import contextlib
|
| 8 |
+
from sam2.build_sam import build_sam2_video_predictor
|
| 9 |
+
|
| 10 |
+
# Add current directory to path
|
| 11 |
+
import sys
|
| 12 |
+
|
| 13 |
+
sys.path.append(os.getcwd())
|
| 14 |
+
sys.path.append(os.path.join(os.getcwd(), "sam2")) # Add sam2 directory to path
|
| 15 |
+
print(f"current dir is {os.getcwd()}")
|
| 16 |
+
|
| 17 |
+
# Ensure device setup matches the official code
|
| 18 |
+
force_cpu_device = os.environ.get("SAM2_DEMO_FORCE_CPU_DEVICE", "0") == "1"
|
| 19 |
+
if force_cpu_device:
|
| 20 |
+
logging.info("forcing CPU device for SAM 2 demo")
|
| 21 |
+
if torch.cuda.is_available() and not force_cpu_device:
|
| 22 |
+
DEVICE = torch.device("cuda")
|
| 23 |
+
elif torch.backends.mps.is_available() and not force_cpu_device:
|
| 24 |
+
DEVICE = torch.device("mps")
|
| 25 |
+
else:
|
| 26 |
+
DEVICE = torch.device("cpu")
|
| 27 |
+
logging.info(f"using device: {DEVICE}")
|
| 28 |
+
|
| 29 |
+
if DEVICE.type == "cuda":
|
| 30 |
+
if torch.cuda.get_device_properties(0).major >= 8:
|
| 31 |
+
torch.backends.cuda.matmul.allow_tf32 = True
|
| 32 |
+
torch.backends.cudnn.allow_tf32 = True
|
| 33 |
+
elif DEVICE.type == "mps":
|
| 34 |
+
logging.warning(
|
| 35 |
+
"\nSupport for MPS devices is preliminary. SAM 2 is trained with CUDA and might "
|
| 36 |
+
"give numerically different outputs and sometimes degraded performance on MPS. "
|
| 37 |
+
"See e.g. https://github.com/pytorch/pytorch/issues/84936 for a discussion."
|
| 38 |
+
)
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
def load_model_paths(checkpoint_name):
|
| 42 |
+
"""Get model checkpoint and config paths"""
|
| 43 |
+
if checkpoint_name == "SAM2-T":
|
| 44 |
+
sam2_checkpoint = "models/sam2.1_hiera_tiny.pt"
|
| 45 |
+
model_cfg = "configs/sam2.1/sam2.1_hiera_t.yaml"
|
| 46 |
+
elif checkpoint_name == "SAM2-S":
|
| 47 |
+
sam2_checkpoint = "models/sam2.1_hiera_small.pt"
|
| 48 |
+
model_cfg = "configs/sam2.1/sam2.1_hiera_s.yaml"
|
| 49 |
+
elif checkpoint_name == "SAM2-B_PLUS":
|
| 50 |
+
sam2_checkpoint = "models/sam2.1_hiera_base_plus.pt"
|
| 51 |
+
model_cfg = "configs/sam2.1/sam2.1_hiera_b+.yaml"
|
| 52 |
+
else:
|
| 53 |
+
raise ValueError(f"Invalid checkpoint name: {checkpoint_name}")
|
| 54 |
+
|
| 55 |
+
return sam2_checkpoint, model_cfg
|
| 56 |
+
|
| 57 |
+
|
| 58 |
+
# Available checkpoints
|
| 59 |
+
CHECKPOINTS = {
|
| 60 |
+
"SAM2-B_PLUS": "Base Plus Model",
|
| 61 |
+
"SAM2-S": "Small Model",
|
| 62 |
+
"SAM2-T": "Tiny Model",
|
| 63 |
+
}
|
| 64 |
+
|
| 65 |
+
|
| 66 |
+
class GolfTracker:
|
| 67 |
+
def __init__(self, checkpoint="SAM2-T"):
|
| 68 |
+
"""Initialize with specified checkpoint model"""
|
| 69 |
+
self.current_checkpoint = checkpoint
|
| 70 |
+
self.predictor = None
|
| 71 |
+
self.points = []
|
| 72 |
+
self.frames = []
|
| 73 |
+
self.current_frame_idx = 0
|
| 74 |
+
self.video_info = None
|
| 75 |
+
self.state = None
|
| 76 |
+
self.obj_id = 1 # Track single object (golf ball)
|
| 77 |
+
self.device = DEVICE
|
| 78 |
+
self.out_mask_logits = None
|
| 79 |
+
self.load_model(checkpoint)
|
| 80 |
+
|
| 81 |
+
def load_model(self, checkpoint_name):
|
| 82 |
+
"""Load specified checkpoint model"""
|
| 83 |
+
if checkpoint_name not in CHECKPOINTS:
|
| 84 |
+
raise ValueError(f"Invalid checkpoint: {checkpoint_name}")
|
| 85 |
+
|
| 86 |
+
print(f"Loading checkpoint: {checkpoint_name}")
|
| 87 |
+
sam2_checkpoint, model_cfg = load_model_paths(checkpoint_name)
|
| 88 |
+
|
| 89 |
+
# Build predictor with model config and checkpoint
|
| 90 |
+
self.predictor = build_sam2_video_predictor(
|
| 91 |
+
model_cfg, sam2_checkpoint, self.device
|
| 92 |
+
)
|
| 93 |
+
print(f"Model loaded successfully: {CHECKPOINTS[checkpoint_name]}")
|
| 94 |
+
self.current_checkpoint = checkpoint_name
|
| 95 |
+
|
| 96 |
+
def process_video(self, video_path):
|
| 97 |
+
"""Process the video and initialize tracking"""
|
| 98 |
+
if not os.path.exists(video_path):
|
| 99 |
+
return None, None, None, "Video file not found"
|
| 100 |
+
|
| 101 |
+
# Reset state
|
| 102 |
+
self.points = []
|
| 103 |
+
self.frames = []
|
| 104 |
+
self.current_frame_idx = 0
|
| 105 |
+
self.state = None
|
| 106 |
+
|
| 107 |
+
# Read video frames
|
| 108 |
+
cap = cv2.VideoCapture(video_path)
|
| 109 |
+
while True:
|
| 110 |
+
ret, frame = cap.read()
|
| 111 |
+
if not ret:
|
| 112 |
+
break
|
| 113 |
+
self.frames.append(frame)
|
| 114 |
+
|
| 115 |
+
if not self.frames:
|
| 116 |
+
return None, None, None, "Failed to read video"
|
| 117 |
+
|
| 118 |
+
# Store video info
|
| 119 |
+
self.video_info = {
|
| 120 |
+
"path": video_path,
|
| 121 |
+
"height": int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT)),
|
| 122 |
+
"width": int(cap.get(cv2.CAP_PROP_FRAME_WIDTH)),
|
| 123 |
+
"fps": cap.get(cv2.CAP_PROP_FPS),
|
| 124 |
+
"total_frames": len(self.frames),
|
| 125 |
+
}
|
| 126 |
+
|
| 127 |
+
cap.release()
|
| 128 |
+
|
| 129 |
+
# Initialize SAM2 state
|
| 130 |
+
with self.autocast_context(), torch.inference_mode():
|
| 131 |
+
self.state = self.predictor.init_state(video_path)
|
| 132 |
+
|
| 133 |
+
return (
|
| 134 |
+
self.frames[0], # First frame
|
| 135 |
+
self.current_checkpoint,
|
| 136 |
+
gr.Slider(minimum=0, maximum=len(self.frames) - 1, step=1, value=0),
|
| 137 |
+
"Navigate through frames and click on the golf ball to track",
|
| 138 |
+
)
|
| 139 |
+
|
| 140 |
+
def update_frame(self, frame_idx):
|
| 141 |
+
"""Update displayed frame"""
|
| 142 |
+
if not self.frames or frame_idx >= len(self.frames):
|
| 143 |
+
return None
|
| 144 |
+
|
| 145 |
+
self.current_frame_idx = int(frame_idx)
|
| 146 |
+
frame = self.frames[self.current_frame_idx].copy()
|
| 147 |
+
|
| 148 |
+
# Draw existing points and trajectory
|
| 149 |
+
self._draw_tracking(frame)
|
| 150 |
+
return frame
|
| 151 |
+
|
| 152 |
+
def add_point(self, frame, evt: gr.SelectData):
|
| 153 |
+
"""Add a point and get ball prediction with enhanced mask visualization"""
|
| 154 |
+
if self.state is None:
|
| 155 |
+
return frame
|
| 156 |
+
|
| 157 |
+
x, y = evt.index[0], evt.index[1]
|
| 158 |
+
self.points.append((self.current_frame_idx, x, y))
|
| 159 |
+
|
| 160 |
+
frame_with_points = frame.copy()
|
| 161 |
+
|
| 162 |
+
# Get ball prediction using SAM2.1
|
| 163 |
+
with self.autocast_context(), torch.inference_mode():
|
| 164 |
+
# Convert points and labels to numpy arrays
|
| 165 |
+
points = np.array([(x, y)], dtype=np.float32)
|
| 166 |
+
labels = np.array([1], dtype=np.int32) # 1 for positive click
|
| 167 |
+
|
| 168 |
+
# Add point and get mask
|
| 169 |
+
_, out_obj_ids, out_mask_logits = self.predictor.add_new_points(
|
| 170 |
+
inference_state=self.state,
|
| 171 |
+
frame_idx=self.current_frame_idx,
|
| 172 |
+
obj_id=self.obj_id,
|
| 173 |
+
points=points,
|
| 174 |
+
labels=labels,
|
| 175 |
+
)
|
| 176 |
+
|
| 177 |
+
if out_mask_logits is not None and len(out_mask_logits) > 0:
|
| 178 |
+
self.out_mask_logits = out_mask_logits
|
| 179 |
+
|
| 180 |
+
# Draw tracking visualization
|
| 181 |
+
self._draw_tracking(frame_with_points)
|
| 182 |
+
return frame_with_points
|
| 183 |
+
|
| 184 |
+
def propagate_masks(self):
|
| 185 |
+
"""Propagate masks to the entire video after user selection"""
|
| 186 |
+
if self.state is None:
|
| 187 |
+
return "No state initialized"
|
| 188 |
+
|
| 189 |
+
logging.info(f"Propagating masks in video with state: {self.state}")
|
| 190 |
+
|
| 191 |
+
# Propagate the masks across the video
|
| 192 |
+
with self.autocast_context(), torch.inference_mode():
|
| 193 |
+
frame_idx, obj_ids, video_res_masks = self.predictor.propagate_in_video(
|
| 194 |
+
inference_state=self.state,
|
| 195 |
+
start_frame_idx=0,
|
| 196 |
+
reverse=False,
|
| 197 |
+
)
|
| 198 |
+
|
| 199 |
+
self.out_mask_logits = video_res_masks
|
| 200 |
+
|
| 201 |
+
return "Propagation complete"
|
| 202 |
+
|
| 203 |
+
def autocast_context(self):
|
| 204 |
+
if self.device.type == "cuda":
|
| 205 |
+
return torch.autocast("cuda", dtype=torch.bfloat16)
|
| 206 |
+
else:
|
| 207 |
+
return contextlib.nullcontext()
|
| 208 |
+
|
| 209 |
+
def _draw_tracking(self, frame):
|
| 210 |
+
"""Draw object mask on frame with enhanced visualization"""
|
| 211 |
+
# Assuming out_mask_logits is available from propagate_masks
|
| 212 |
+
if self.current_frame_idx < len(self.frames):
|
| 213 |
+
mask_np = (self.out_mask_logits[self.current_frame_idx] > 0.0).cpu().numpy()
|
| 214 |
+
if mask_np.shape[:2] == frame.shape[:2]:
|
| 215 |
+
overlay = frame.copy()
|
| 216 |
+
overlay[mask_np > 0] = [0, 0, 255] # Red color for mask
|
| 217 |
+
alpha = 0.5 # Transparency factor
|
| 218 |
+
frame = cv2.addWeighted(overlay, alpha, frame, 1 - alpha, 0)
|
| 219 |
+
return frame
|
| 220 |
+
|
| 221 |
+
def clear_points(self):
|
| 222 |
+
"""Clear all tracked points"""
|
| 223 |
+
self.points = []
|
| 224 |
+
if self.frames:
|
| 225 |
+
return self.frames[self.current_frame_idx].copy()
|
| 226 |
+
return None
|
| 227 |
+
|
| 228 |
+
def change_model(self, checkpoint_name):
|
| 229 |
+
"""Change the current model checkpoint"""
|
| 230 |
+
if checkpoint_name != self.current_checkpoint:
|
| 231 |
+
self.load_model(checkpoint_name)
|
| 232 |
+
return f"Loaded {CHECKPOINTS[checkpoint_name]}"
|
| 233 |
+
|
| 234 |
+
def save_output_video(self):
|
| 235 |
+
"""Save the processed video with tracking visualization"""
|
| 236 |
+
if not self.frames or not self.video_info:
|
| 237 |
+
return None, "No video loaded"
|
| 238 |
+
|
| 239 |
+
output_path = "output_tracked.mp4"
|
| 240 |
+
|
| 241 |
+
# Initialize video writer
|
| 242 |
+
fourcc = cv2.VideoWriter_fourcc(*"mp4v")
|
| 243 |
+
out = cv2.VideoWriter(
|
| 244 |
+
output_path,
|
| 245 |
+
fourcc,
|
| 246 |
+
self.video_info["fps"],
|
| 247 |
+
(self.video_info["width"], self.video_info["height"]),
|
| 248 |
+
)
|
| 249 |
+
|
| 250 |
+
# Process each frame
|
| 251 |
+
for frame_idx in range(len(self.frames)):
|
| 252 |
+
frame = self.frames[frame_idx].copy()
|
| 253 |
+
|
| 254 |
+
# Draw tracking for this frame
|
| 255 |
+
frame_points = [(x, y) for f, x, y in self.points if f == frame_idx]
|
| 256 |
+
if frame_points:
|
| 257 |
+
# Draw points
|
| 258 |
+
for x, y in frame_points:
|
| 259 |
+
cv2.circle(frame, (int(x), int(y)), 5, (255, 0, 0), -1)
|
| 260 |
+
|
| 261 |
+
# Fit and draw trajectory if enough points
|
| 262 |
+
if len(frame_points) >= 3:
|
| 263 |
+
points_arr = np.array(frame_points)
|
| 264 |
+
# fit_results = self.trajectory_fitter.fit_trajectory(points_arr)
|
| 265 |
+
|
| 266 |
+
# if fit_results is not None:
|
| 267 |
+
# trajectory = fit_results["trajectory"]
|
| 268 |
+
# points = trajectory.astype(np.int32)
|
| 269 |
+
# for i in range(len(points) - 1):
|
| 270 |
+
# cv2.line(
|
| 271 |
+
# frame,
|
| 272 |
+
# tuple(points[i]),
|
| 273 |
+
# tuple(points[i + 1]),
|
| 274 |
+
# (0, 255, 0),
|
| 275 |
+
# 2,
|
| 276 |
+
# )
|
| 277 |
+
|
| 278 |
+
# # Calculate and display metrics
|
| 279 |
+
# metrics = self.trajectory_fitter.calculate_metrics(fit_results)
|
| 280 |
+
# cv2.putText(
|
| 281 |
+
# frame,
|
| 282 |
+
# f"Speed: {metrics['initial_velocity_mph']:.1f} mph",
|
| 283 |
+
# (10, 30),
|
| 284 |
+
# cv2.FONT_HERSHEY_SIMPLEX,
|
| 285 |
+
# 1,
|
| 286 |
+
# (255, 255, 255),
|
| 287 |
+
# 2,
|
| 288 |
+
# )
|
| 289 |
+
# cv2.putText(
|
| 290 |
+
# frame,
|
| 291 |
+
# f"Height: {metrics['max_height']:.1f} m",
|
| 292 |
+
# (10, 70),
|
| 293 |
+
# cv2.FONT_HERSHEY_SIMPLEX,
|
| 294 |
+
# 1,
|
| 295 |
+
# (255, 255, 255),
|
| 296 |
+
# 2,
|
| 297 |
+
# )
|
| 298 |
+
|
| 299 |
+
out.write(frame)
|
| 300 |
+
|
| 301 |
+
out.release()
|
| 302 |
+
return output_path, "Video saved successfully!"
|
| 303 |
+
|
| 304 |
+
|
| 305 |
+
def create_ui():
|
| 306 |
+
tracker = GolfTracker()
|
| 307 |
+
|
| 308 |
+
with gr.Blocks() as app:
|
| 309 |
+
gr.Markdown("# Golf Ball Trajectory Tracker")
|
| 310 |
+
gr.Markdown(
|
| 311 |
+
"Upload a video and click on the golf ball positions to track its trajectory"
|
| 312 |
+
)
|
| 313 |
+
|
| 314 |
+
with gr.Row():
|
| 315 |
+
with gr.Column():
|
| 316 |
+
video_input = gr.Video(label="Input Video")
|
| 317 |
+
model_dropdown = gr.Dropdown(
|
| 318 |
+
choices=list(CHECKPOINTS.keys()),
|
| 319 |
+
value="SAM2-T",
|
| 320 |
+
label="Select Model",
|
| 321 |
+
)
|
| 322 |
+
upload_button = gr.Button("Process Video")
|
| 323 |
+
clear_button = gr.Button("Clear Points")
|
| 324 |
+
save_button = gr.Button("Save Output Video")
|
| 325 |
+
propagate_button = gr.Button("Propagate Masks")
|
| 326 |
+
|
| 327 |
+
with gr.Column():
|
| 328 |
+
image_output = gr.Image(label="Click on golf ball positions")
|
| 329 |
+
frame_slider = gr.Slider(
|
| 330 |
+
minimum=0,
|
| 331 |
+
maximum=0,
|
| 332 |
+
step=1,
|
| 333 |
+
value=0,
|
| 334 |
+
label="Frame",
|
| 335 |
+
interactive=True,
|
| 336 |
+
)
|
| 337 |
+
current_model = gr.Textbox(label="Current Model", interactive=False)
|
| 338 |
+
status_text = gr.Textbox(label="Status", interactive=False)
|
| 339 |
+
output_video = gr.Video(label="Output Video")
|
| 340 |
+
|
| 341 |
+
# Event handlers
|
| 342 |
+
model_dropdown.change(
|
| 343 |
+
fn=tracker.change_model, inputs=[model_dropdown], outputs=[status_text]
|
| 344 |
+
)
|
| 345 |
+
|
| 346 |
+
video_input.change(
|
| 347 |
+
fn=tracker.process_video,
|
| 348 |
+
inputs=[video_input],
|
| 349 |
+
outputs=[image_output, current_model, frame_slider, status_text],
|
| 350 |
+
)
|
| 351 |
+
|
| 352 |
+
upload_button.click(
|
| 353 |
+
fn=tracker.process_video,
|
| 354 |
+
inputs=[video_input],
|
| 355 |
+
outputs=[image_output, current_model, frame_slider, status_text],
|
| 356 |
+
)
|
| 357 |
+
|
| 358 |
+
clear_button.click(fn=tracker.clear_points, inputs=[], outputs=[image_output])
|
| 359 |
+
|
| 360 |
+
frame_slider.change(
|
| 361 |
+
fn=tracker.update_frame, inputs=[frame_slider], outputs=[image_output]
|
| 362 |
+
)
|
| 363 |
+
|
| 364 |
+
image_output.select(
|
| 365 |
+
fn=tracker.add_point, inputs=[image_output], outputs=[image_output]
|
| 366 |
+
)
|
| 367 |
+
|
| 368 |
+
save_button.click(
|
| 369 |
+
fn=tracker.save_output_video, inputs=[], outputs=[output_video, status_text]
|
| 370 |
+
)
|
| 371 |
+
|
| 372 |
+
propagate_button.click(
|
| 373 |
+
fn=tracker.propagate_masks, inputs=[], outputs=[status_text]
|
| 374 |
+
)
|
| 375 |
+
|
| 376 |
+
return app
|
| 377 |
+
|
| 378 |
+
|
| 379 |
+
if __name__ == "__main__":
|
| 380 |
+
app = create_ui()
|
| 381 |
+
app.launch()
|
backup_001.py
ADDED
|
@@ -0,0 +1,330 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import gradio as gr
|
| 2 |
+
import torch
|
| 3 |
+
import numpy as np
|
| 4 |
+
import cv2
|
| 5 |
+
from sam2.build_sam import build_sam2_video_predictor
|
| 6 |
+
import tempfile
|
| 7 |
+
import os
|
| 8 |
+
import contextlib
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
class VideoTracker:
|
| 12 |
+
def __init__(self):
|
| 13 |
+
self.checkpoint = "./models/sam2.1_hiera_tiny.pt"
|
| 14 |
+
self.model_cfg = "configs/sam2.1/sam2.1_hiera_t.yaml"
|
| 15 |
+
self.predictor = build_sam2_video_predictor(
|
| 16 |
+
self.model_cfg, self.checkpoint, device="cpu", mode="eval"
|
| 17 |
+
)
|
| 18 |
+
self.state = None
|
| 19 |
+
self.video_frames = None
|
| 20 |
+
self.current_frame_idx = 0
|
| 21 |
+
self.masks = []
|
| 22 |
+
self.points = []
|
| 23 |
+
self.frame_count = 0
|
| 24 |
+
self.video_info = None
|
| 25 |
+
self.obj_id = 1
|
| 26 |
+
self.out_mask_logits = None
|
| 27 |
+
self.frame_masks = {} # Store masks for each frame
|
| 28 |
+
|
| 29 |
+
def load_video(self, video_path):
|
| 30 |
+
if video_path is None:
|
| 31 |
+
return None, gr.Slider(minimum=0, maximum=0, step=1, value=0)
|
| 32 |
+
|
| 33 |
+
# Create a temporary file for the video
|
| 34 |
+
temp_file = tempfile.NamedTemporaryFile(delete=False, suffix=".mp4")
|
| 35 |
+
temp_file.close()
|
| 36 |
+
|
| 37 |
+
# Copy the uploaded video to the temporary file
|
| 38 |
+
with open(video_path, "rb") as f_src, open(temp_file.name, "wb") as f_dst:
|
| 39 |
+
f_dst.write(f_src.read())
|
| 40 |
+
|
| 41 |
+
# Load video frames using OpenCV
|
| 42 |
+
cap = cv2.VideoCapture(temp_file.name)
|
| 43 |
+
frames = []
|
| 44 |
+
while True:
|
| 45 |
+
ret, frame = cap.read()
|
| 46 |
+
if not ret:
|
| 47 |
+
break
|
| 48 |
+
frames.append(frame)
|
| 49 |
+
|
| 50 |
+
if not frames:
|
| 51 |
+
cap.release()
|
| 52 |
+
os.unlink(temp_file.name)
|
| 53 |
+
return None, gr.Slider(minimum=0, maximum=0, step=1, value=0)
|
| 54 |
+
|
| 55 |
+
# Store video info
|
| 56 |
+
self.video_info = {
|
| 57 |
+
"path": temp_file.name,
|
| 58 |
+
"height": int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT)),
|
| 59 |
+
"width": int(cap.get(cv2.CAP_PROP_FRAME_WIDTH)),
|
| 60 |
+
"fps": cap.get(cv2.CAP_PROP_FPS),
|
| 61 |
+
"total_frames": len(frames),
|
| 62 |
+
}
|
| 63 |
+
cap.release()
|
| 64 |
+
|
| 65 |
+
self.video_frames = frames
|
| 66 |
+
self.frame_count = len(frames)
|
| 67 |
+
|
| 68 |
+
# Initialize SAM2 state with video path
|
| 69 |
+
with torch.inference_mode():
|
| 70 |
+
self.state = self.predictor.init_state(temp_file.name)
|
| 71 |
+
|
| 72 |
+
# Now we can remove the temp file
|
| 73 |
+
os.unlink(temp_file.name)
|
| 74 |
+
|
| 75 |
+
return frames[0], gr.Slider(minimum=0, maximum=len(frames) - 1, step=1, value=0)
|
| 76 |
+
|
| 77 |
+
def update_frame(self, frame_number):
|
| 78 |
+
if self.video_frames is None:
|
| 79 |
+
return None
|
| 80 |
+
|
| 81 |
+
self.current_frame_idx = frame_number
|
| 82 |
+
frame = self.video_frames[frame_number].copy()
|
| 83 |
+
|
| 84 |
+
# Apply any existing mask for this frame
|
| 85 |
+
if frame_number in self.frame_masks:
|
| 86 |
+
self.out_mask_logits = self.frame_masks[frame_number]
|
| 87 |
+
frame = self._draw_tracking(frame)
|
| 88 |
+
|
| 89 |
+
# Draw points
|
| 90 |
+
for point in self.points:
|
| 91 |
+
if point[0] == frame_number:
|
| 92 |
+
cv2.circle(
|
| 93 |
+
frame, (int(point[1]), int(point[2])), 5, (255, 255, 0), -1
|
| 94 |
+
) # Yellow dot
|
| 95 |
+
cv2.circle(
|
| 96 |
+
frame, (int(point[1]), int(point[2])), 7, (0, 0, 0), 1
|
| 97 |
+
) # Black border
|
| 98 |
+
|
| 99 |
+
return frame
|
| 100 |
+
|
| 101 |
+
def add_point(self, frame, evt: gr.SelectData):
|
| 102 |
+
"""Add a point and get ball prediction with enhanced mask visualization"""
|
| 103 |
+
if self.state is None:
|
| 104 |
+
return frame
|
| 105 |
+
|
| 106 |
+
x, y = evt.index[0], evt.index[1]
|
| 107 |
+
self.points.append((self.current_frame_idx, x, y))
|
| 108 |
+
|
| 109 |
+
frame_with_points = frame.copy()
|
| 110 |
+
|
| 111 |
+
# Get ball prediction using SAM2.1
|
| 112 |
+
with torch.inference_mode():
|
| 113 |
+
# Convert points and labels to numpy arrays
|
| 114 |
+
points = np.array([(x, y)], dtype=np.float32)
|
| 115 |
+
labels = np.array([1], dtype=np.int32) # 1 for positive click
|
| 116 |
+
|
| 117 |
+
# Add point and get mask
|
| 118 |
+
_, out_obj_ids, out_mask_logits = self.predictor.add_new_points(
|
| 119 |
+
inference_state=self.state,
|
| 120 |
+
frame_idx=self.current_frame_idx,
|
| 121 |
+
obj_id=self.obj_id,
|
| 122 |
+
points=points,
|
| 123 |
+
labels=labels,
|
| 124 |
+
)
|
| 125 |
+
|
| 126 |
+
if out_mask_logits is not None and len(out_mask_logits) > 0:
|
| 127 |
+
self.out_mask_logits = (
|
| 128 |
+
out_mask_logits[0]
|
| 129 |
+
if isinstance(out_mask_logits, list)
|
| 130 |
+
else out_mask_logits
|
| 131 |
+
)
|
| 132 |
+
# Store mask for this frame
|
| 133 |
+
self.frame_masks[self.current_frame_idx] = self.out_mask_logits
|
| 134 |
+
|
| 135 |
+
# Draw tracking visualization with enhanced mask
|
| 136 |
+
frame_with_points = self._draw_tracking(frame_with_points)
|
| 137 |
+
|
| 138 |
+
# Draw point on top of mask
|
| 139 |
+
cv2.circle(
|
| 140 |
+
frame_with_points, (int(x), int(y)), 5, (255, 255, 0), -1
|
| 141 |
+
) # Yellow dot
|
| 142 |
+
cv2.circle(frame_with_points, (int(x), int(y)), 7, (0, 0, 0), 1) # Black border
|
| 143 |
+
|
| 144 |
+
return frame_with_points
|
| 145 |
+
|
| 146 |
+
def propagate_video(self):
|
| 147 |
+
if self.state is None:
|
| 148 |
+
return None
|
| 149 |
+
|
| 150 |
+
output_frames = self.video_frames.copy()
|
| 151 |
+
|
| 152 |
+
# Store all masks for smoother visualization
|
| 153 |
+
all_masks = []
|
| 154 |
+
|
| 155 |
+
# First pass: collect all masks
|
| 156 |
+
with torch.inference_mode():
|
| 157 |
+
for frame_idx, obj_ids, masks in self.predictor.propagate_in_video(
|
| 158 |
+
self.state,
|
| 159 |
+
start_frame_idx=0,
|
| 160 |
+
reverse=False,
|
| 161 |
+
):
|
| 162 |
+
if masks is not None and len(masks) > 0:
|
| 163 |
+
mask = masks[0] if isinstance(masks, list) else masks
|
| 164 |
+
all_masks.append((frame_idx, mask))
|
| 165 |
+
# Store mask for each frame
|
| 166 |
+
self.frame_masks[frame_idx] = mask
|
| 167 |
+
|
| 168 |
+
# Second pass: apply visualization with temporal smoothing
|
| 169 |
+
for i, frame in enumerate(output_frames):
|
| 170 |
+
frame = frame.copy()
|
| 171 |
+
|
| 172 |
+
# Find masks for this frame
|
| 173 |
+
current_masks = [m[1] for m in all_masks if m[0] == i]
|
| 174 |
+
|
| 175 |
+
if current_masks:
|
| 176 |
+
self.out_mask_logits = current_masks[0]
|
| 177 |
+
|
| 178 |
+
# Get binary mask and ensure correct dimensions
|
| 179 |
+
mask_np = (current_masks[0] > 0.0).cpu().numpy()
|
| 180 |
+
mask_np = self._handle_mask_dimensions(mask_np)
|
| 181 |
+
|
| 182 |
+
# Convert to proper format for OpenCV
|
| 183 |
+
mask_np = mask_np.astype(np.uint8)
|
| 184 |
+
|
| 185 |
+
# Enhanced visualization for video
|
| 186 |
+
frame = self._draw_tracking(frame, alpha=0.6)
|
| 187 |
+
|
| 188 |
+
# Create glowing effect
|
| 189 |
+
try:
|
| 190 |
+
# Create kernel for dilation
|
| 191 |
+
kernel = np.ones((5, 5), np.uint8)
|
| 192 |
+
|
| 193 |
+
# Dilate mask for glow effect
|
| 194 |
+
dilated_mask = cv2.dilate(mask_np, kernel, iterations=2)
|
| 195 |
+
|
| 196 |
+
# Create glow overlay
|
| 197 |
+
glow = frame.copy()
|
| 198 |
+
glow[dilated_mask > 0] = [0, 255, 255] # Yellow glow
|
| 199 |
+
|
| 200 |
+
# Blend glow with frame
|
| 201 |
+
frame = cv2.addWeighted(frame, 0.7, glow, 0.3, 0)
|
| 202 |
+
except cv2.error as e:
|
| 203 |
+
print(
|
| 204 |
+
f"Warning: Could not apply glow effect. Mask shape: {mask_np.shape}, Frame shape: {frame.shape}"
|
| 205 |
+
)
|
| 206 |
+
# Continue without glow effect if there's an error
|
| 207 |
+
|
| 208 |
+
output_frames[i] = frame
|
| 209 |
+
|
| 210 |
+
# Save as video with higher quality
|
| 211 |
+
temp_output = tempfile.NamedTemporaryFile(suffix=".mp4", delete=False).name
|
| 212 |
+
height, width = output_frames[0].shape[:2]
|
| 213 |
+
|
| 214 |
+
# Use higher bitrate for better quality
|
| 215 |
+
writer = cv2.VideoWriter(
|
| 216 |
+
temp_output, cv2.VideoWriter_fourcc(*"mp4v"), 30, (width, height), True
|
| 217 |
+
)
|
| 218 |
+
|
| 219 |
+
for frame in output_frames:
|
| 220 |
+
writer.write(frame)
|
| 221 |
+
writer.release()
|
| 222 |
+
|
| 223 |
+
return temp_output
|
| 224 |
+
|
| 225 |
+
def _handle_mask_dimensions(self, mask_np):
|
| 226 |
+
"""Helper function to handle various mask dimensions"""
|
| 227 |
+
# Handle 4D tensor (1, 1, H, W)
|
| 228 |
+
if len(mask_np.shape) == 4:
|
| 229 |
+
mask_np = mask_np[0, 0]
|
| 230 |
+
# Handle 3D tensor (1, H, W) or (H, W, 1)
|
| 231 |
+
elif len(mask_np.shape) == 3:
|
| 232 |
+
if mask_np.shape[0] == 1: # (1, H, W) format
|
| 233 |
+
mask_np = mask_np[0]
|
| 234 |
+
elif mask_np.shape[2] == 1: # (H, W, 1) format
|
| 235 |
+
mask_np = mask_np[:, :, 0]
|
| 236 |
+
return mask_np
|
| 237 |
+
|
| 238 |
+
def _draw_tracking(self, frame, alpha=0.5):
|
| 239 |
+
"""Draw object mask on frame with enhanced visualization"""
|
| 240 |
+
if self.out_mask_logits is not None:
|
| 241 |
+
# Convert logits to binary mask
|
| 242 |
+
if isinstance(self.out_mask_logits, list):
|
| 243 |
+
mask = self.out_mask_logits[0]
|
| 244 |
+
else:
|
| 245 |
+
mask = self.out_mask_logits
|
| 246 |
+
|
| 247 |
+
# Get binary mask and handle dimensions
|
| 248 |
+
mask_np = (mask > 0.0).cpu().numpy()
|
| 249 |
+
mask_np = self._handle_mask_dimensions(mask_np)
|
| 250 |
+
|
| 251 |
+
if mask_np.shape[:2] == frame.shape[:2]:
|
| 252 |
+
# Create a red overlay for the mask
|
| 253 |
+
overlay = frame.copy()
|
| 254 |
+
overlay[mask_np > 0] = [0, 0, 255] # BGR format: Red color
|
| 255 |
+
|
| 256 |
+
# Add a border around the mask for better visibility
|
| 257 |
+
contours, _ = cv2.findContours(
|
| 258 |
+
mask_np.astype(np.uint8), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE
|
| 259 |
+
)
|
| 260 |
+
|
| 261 |
+
# Draw thicker contours for better visibility
|
| 262 |
+
cv2.drawContours(
|
| 263 |
+
overlay, contours, -1, (0, 255, 255), 3
|
| 264 |
+
) # Thicker yellow border
|
| 265 |
+
|
| 266 |
+
# Add a second contour for emphasis
|
| 267 |
+
cv2.drawContours(
|
| 268 |
+
frame, contours, -1, (255, 255, 0), 1
|
| 269 |
+
) # Thin bright border
|
| 270 |
+
|
| 271 |
+
# Blend the overlay with original frame
|
| 272 |
+
frame = cv2.addWeighted(overlay, alpha, frame, 1 - alpha, 0)
|
| 273 |
+
|
| 274 |
+
return frame
|
| 275 |
+
|
| 276 |
+
|
| 277 |
+
def create_interface():
|
| 278 |
+
tracker = VideoTracker()
|
| 279 |
+
|
| 280 |
+
with gr.Blocks() as interface:
|
| 281 |
+
gr.Markdown("# Object Tracking with SAM2")
|
| 282 |
+
gr.Markdown("Upload a video and click on objects to track them")
|
| 283 |
+
|
| 284 |
+
with gr.Row():
|
| 285 |
+
with gr.Column(scale=2):
|
| 286 |
+
video_input = gr.Video(label="Input Video")
|
| 287 |
+
image_output = gr.Image(label="Current Frame", interactive=True)
|
| 288 |
+
frame_slider = gr.Slider(
|
| 289 |
+
minimum=0,
|
| 290 |
+
maximum=0,
|
| 291 |
+
step=1,
|
| 292 |
+
value=0,
|
| 293 |
+
label="Frame Selection",
|
| 294 |
+
interactive=True,
|
| 295 |
+
)
|
| 296 |
+
|
| 297 |
+
with gr.Column(scale=1):
|
| 298 |
+
propagate_btn = gr.Button("Propagate Through Video", variant="primary")
|
| 299 |
+
video_output = gr.Video(label="Output Video")
|
| 300 |
+
|
| 301 |
+
video_input.change(
|
| 302 |
+
fn=tracker.load_video,
|
| 303 |
+
inputs=[video_input],
|
| 304 |
+
outputs=[image_output, frame_slider],
|
| 305 |
+
)
|
| 306 |
+
|
| 307 |
+
frame_slider.change(
|
| 308 |
+
fn=tracker.update_frame,
|
| 309 |
+
inputs=[frame_slider],
|
| 310 |
+
outputs=[image_output],
|
| 311 |
+
)
|
| 312 |
+
|
| 313 |
+
image_output.select(
|
| 314 |
+
fn=tracker.add_point,
|
| 315 |
+
inputs=[image_output],
|
| 316 |
+
outputs=[image_output],
|
| 317 |
+
)
|
| 318 |
+
|
| 319 |
+
propagate_btn.click(
|
| 320 |
+
fn=tracker.propagate_video,
|
| 321 |
+
inputs=[],
|
| 322 |
+
outputs=[video_output],
|
| 323 |
+
)
|
| 324 |
+
|
| 325 |
+
return interface
|
| 326 |
+
|
| 327 |
+
|
| 328 |
+
if __name__ == "__main__":
|
| 329 |
+
interface = create_interface()
|
| 330 |
+
interface.launch(share=True)
|
configs/sam2.1_hiera_b+.yaml
ADDED
|
@@ -0,0 +1,116 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# @package _global_
|
| 2 |
+
|
| 3 |
+
# Model
|
| 4 |
+
model:
|
| 5 |
+
_target_: sam2.modeling.sam2_base.SAM2Base
|
| 6 |
+
image_encoder:
|
| 7 |
+
_target_: sam2.modeling.backbones.image_encoder.ImageEncoder
|
| 8 |
+
scalp: 1
|
| 9 |
+
trunk:
|
| 10 |
+
_target_: sam2.modeling.backbones.hieradet.Hiera
|
| 11 |
+
embed_dim: 112
|
| 12 |
+
num_heads: 2
|
| 13 |
+
neck:
|
| 14 |
+
_target_: sam2.modeling.backbones.image_encoder.FpnNeck
|
| 15 |
+
position_encoding:
|
| 16 |
+
_target_: sam2.modeling.position_encoding.PositionEmbeddingSine
|
| 17 |
+
num_pos_feats: 256
|
| 18 |
+
normalize: true
|
| 19 |
+
scale: null
|
| 20 |
+
temperature: 10000
|
| 21 |
+
d_model: 256
|
| 22 |
+
backbone_channel_list: [896, 448, 224, 112]
|
| 23 |
+
fpn_top_down_levels: [2, 3] # output level 0 and 1 directly use the backbone features
|
| 24 |
+
fpn_interp_model: nearest
|
| 25 |
+
|
| 26 |
+
memory_attention:
|
| 27 |
+
_target_: sam2.modeling.memory_attention.MemoryAttention
|
| 28 |
+
d_model: 256
|
| 29 |
+
pos_enc_at_input: true
|
| 30 |
+
layer:
|
| 31 |
+
_target_: sam2.modeling.memory_attention.MemoryAttentionLayer
|
| 32 |
+
activation: relu
|
| 33 |
+
dim_feedforward: 2048
|
| 34 |
+
dropout: 0.1
|
| 35 |
+
pos_enc_at_attn: false
|
| 36 |
+
self_attention:
|
| 37 |
+
_target_: sam2.modeling.sam.transformer.RoPEAttention
|
| 38 |
+
rope_theta: 10000.0
|
| 39 |
+
feat_sizes: [32, 32]
|
| 40 |
+
embedding_dim: 256
|
| 41 |
+
num_heads: 1
|
| 42 |
+
downsample_rate: 1
|
| 43 |
+
dropout: 0.1
|
| 44 |
+
d_model: 256
|
| 45 |
+
pos_enc_at_cross_attn_keys: true
|
| 46 |
+
pos_enc_at_cross_attn_queries: false
|
| 47 |
+
cross_attention:
|
| 48 |
+
_target_: sam2.modeling.sam.transformer.RoPEAttention
|
| 49 |
+
rope_theta: 10000.0
|
| 50 |
+
feat_sizes: [32, 32]
|
| 51 |
+
rope_k_repeat: True
|
| 52 |
+
embedding_dim: 256
|
| 53 |
+
num_heads: 1
|
| 54 |
+
downsample_rate: 1
|
| 55 |
+
dropout: 0.1
|
| 56 |
+
kv_in_dim: 64
|
| 57 |
+
num_layers: 4
|
| 58 |
+
|
| 59 |
+
memory_encoder:
|
| 60 |
+
_target_: sam2.modeling.memory_encoder.MemoryEncoder
|
| 61 |
+
out_dim: 64
|
| 62 |
+
position_encoding:
|
| 63 |
+
_target_: sam2.modeling.position_encoding.PositionEmbeddingSine
|
| 64 |
+
num_pos_feats: 64
|
| 65 |
+
normalize: true
|
| 66 |
+
scale: null
|
| 67 |
+
temperature: 10000
|
| 68 |
+
mask_downsampler:
|
| 69 |
+
_target_: sam2.modeling.memory_encoder.MaskDownSampler
|
| 70 |
+
kernel_size: 3
|
| 71 |
+
stride: 2
|
| 72 |
+
padding: 1
|
| 73 |
+
fuser:
|
| 74 |
+
_target_: sam2.modeling.memory_encoder.Fuser
|
| 75 |
+
layer:
|
| 76 |
+
_target_: sam2.modeling.memory_encoder.CXBlock
|
| 77 |
+
dim: 256
|
| 78 |
+
kernel_size: 7
|
| 79 |
+
padding: 3
|
| 80 |
+
layer_scale_init_value: 1e-6
|
| 81 |
+
use_dwconv: True # depth-wise convs
|
| 82 |
+
num_layers: 2
|
| 83 |
+
|
| 84 |
+
num_maskmem: 7
|
| 85 |
+
image_size: 1024
|
| 86 |
+
# apply scaled sigmoid on mask logits for memory encoder, and directly feed input mask as output mask
|
| 87 |
+
sigmoid_scale_for_mem_enc: 20.0
|
| 88 |
+
sigmoid_bias_for_mem_enc: -10.0
|
| 89 |
+
use_mask_input_as_output_without_sam: true
|
| 90 |
+
# Memory
|
| 91 |
+
directly_add_no_mem_embed: true
|
| 92 |
+
no_obj_embed_spatial: true
|
| 93 |
+
# use high-resolution feature map in the SAM mask decoder
|
| 94 |
+
use_high_res_features_in_sam: true
|
| 95 |
+
# output 3 masks on the first click on initial conditioning frames
|
| 96 |
+
multimask_output_in_sam: true
|
| 97 |
+
# SAM heads
|
| 98 |
+
iou_prediction_use_sigmoid: True
|
| 99 |
+
# cross-attend to object pointers from other frames (based on SAM output tokens) in the encoder
|
| 100 |
+
use_obj_ptrs_in_encoder: true
|
| 101 |
+
add_tpos_enc_to_obj_ptrs: true
|
| 102 |
+
proj_tpos_enc_in_obj_ptrs: true
|
| 103 |
+
use_signed_tpos_enc_to_obj_ptrs: true
|
| 104 |
+
only_obj_ptrs_in_the_past_for_eval: true
|
| 105 |
+
# object occlusion prediction
|
| 106 |
+
pred_obj_scores: true
|
| 107 |
+
pred_obj_scores_mlp: true
|
| 108 |
+
fixed_no_obj_ptr: true
|
| 109 |
+
# multimask tracking settings
|
| 110 |
+
multimask_output_for_tracking: true
|
| 111 |
+
use_multimask_token_for_obj_ptr: true
|
| 112 |
+
multimask_min_pt_num: 0
|
| 113 |
+
multimask_max_pt_num: 1
|
| 114 |
+
use_mlp_for_obj_ptr_proj: true
|
| 115 |
+
# Compilation flag
|
| 116 |
+
compile_image_encoder: False
|
configs/sam2.1_hiera_s.yaml
ADDED
|
@@ -0,0 +1,119 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# @package _global_
|
| 2 |
+
|
| 3 |
+
# Model
|
| 4 |
+
model:
|
| 5 |
+
_target_: sam2.modeling.sam2_base.SAM2Base
|
| 6 |
+
image_encoder:
|
| 7 |
+
_target_: sam2.modeling.backbones.image_encoder.ImageEncoder
|
| 8 |
+
scalp: 1
|
| 9 |
+
trunk:
|
| 10 |
+
_target_: sam2.modeling.backbones.hieradet.Hiera
|
| 11 |
+
embed_dim: 96
|
| 12 |
+
num_heads: 1
|
| 13 |
+
stages: [1, 2, 11, 2]
|
| 14 |
+
global_att_blocks: [7, 10, 13]
|
| 15 |
+
window_pos_embed_bkg_spatial_size: [7, 7]
|
| 16 |
+
neck:
|
| 17 |
+
_target_: sam2.modeling.backbones.image_encoder.FpnNeck
|
| 18 |
+
position_encoding:
|
| 19 |
+
_target_: sam2.modeling.position_encoding.PositionEmbeddingSine
|
| 20 |
+
num_pos_feats: 256
|
| 21 |
+
normalize: true
|
| 22 |
+
scale: null
|
| 23 |
+
temperature: 10000
|
| 24 |
+
d_model: 256
|
| 25 |
+
backbone_channel_list: [768, 384, 192, 96]
|
| 26 |
+
fpn_top_down_levels: [2, 3] # output level 0 and 1 directly use the backbone features
|
| 27 |
+
fpn_interp_model: nearest
|
| 28 |
+
|
| 29 |
+
memory_attention:
|
| 30 |
+
_target_: sam2.modeling.memory_attention.MemoryAttention
|
| 31 |
+
d_model: 256
|
| 32 |
+
pos_enc_at_input: true
|
| 33 |
+
layer:
|
| 34 |
+
_target_: sam2.modeling.memory_attention.MemoryAttentionLayer
|
| 35 |
+
activation: relu
|
| 36 |
+
dim_feedforward: 2048
|
| 37 |
+
dropout: 0.1
|
| 38 |
+
pos_enc_at_attn: false
|
| 39 |
+
self_attention:
|
| 40 |
+
_target_: sam2.modeling.sam.transformer.RoPEAttention
|
| 41 |
+
rope_theta: 10000.0
|
| 42 |
+
feat_sizes: [32, 32]
|
| 43 |
+
embedding_dim: 256
|
| 44 |
+
num_heads: 1
|
| 45 |
+
downsample_rate: 1
|
| 46 |
+
dropout: 0.1
|
| 47 |
+
d_model: 256
|
| 48 |
+
pos_enc_at_cross_attn_keys: true
|
| 49 |
+
pos_enc_at_cross_attn_queries: false
|
| 50 |
+
cross_attention:
|
| 51 |
+
_target_: sam2.modeling.sam.transformer.RoPEAttention
|
| 52 |
+
rope_theta: 10000.0
|
| 53 |
+
feat_sizes: [32, 32]
|
| 54 |
+
rope_k_repeat: True
|
| 55 |
+
embedding_dim: 256
|
| 56 |
+
num_heads: 1
|
| 57 |
+
downsample_rate: 1
|
| 58 |
+
dropout: 0.1
|
| 59 |
+
kv_in_dim: 64
|
| 60 |
+
num_layers: 4
|
| 61 |
+
|
| 62 |
+
memory_encoder:
|
| 63 |
+
_target_: sam2.modeling.memory_encoder.MemoryEncoder
|
| 64 |
+
out_dim: 64
|
| 65 |
+
position_encoding:
|
| 66 |
+
_target_: sam2.modeling.position_encoding.PositionEmbeddingSine
|
| 67 |
+
num_pos_feats: 64
|
| 68 |
+
normalize: true
|
| 69 |
+
scale: null
|
| 70 |
+
temperature: 10000
|
| 71 |
+
mask_downsampler:
|
| 72 |
+
_target_: sam2.modeling.memory_encoder.MaskDownSampler
|
| 73 |
+
kernel_size: 3
|
| 74 |
+
stride: 2
|
| 75 |
+
padding: 1
|
| 76 |
+
fuser:
|
| 77 |
+
_target_: sam2.modeling.memory_encoder.Fuser
|
| 78 |
+
layer:
|
| 79 |
+
_target_: sam2.modeling.memory_encoder.CXBlock
|
| 80 |
+
dim: 256
|
| 81 |
+
kernel_size: 7
|
| 82 |
+
padding: 3
|
| 83 |
+
layer_scale_init_value: 1e-6
|
| 84 |
+
use_dwconv: True # depth-wise convs
|
| 85 |
+
num_layers: 2
|
| 86 |
+
|
| 87 |
+
num_maskmem: 7
|
| 88 |
+
image_size: 1024
|
| 89 |
+
# apply scaled sigmoid on mask logits for memory encoder, and directly feed input mask as output mask
|
| 90 |
+
sigmoid_scale_for_mem_enc: 20.0
|
| 91 |
+
sigmoid_bias_for_mem_enc: -10.0
|
| 92 |
+
use_mask_input_as_output_without_sam: true
|
| 93 |
+
# Memory
|
| 94 |
+
directly_add_no_mem_embed: true
|
| 95 |
+
no_obj_embed_spatial: true
|
| 96 |
+
# use high-resolution feature map in the SAM mask decoder
|
| 97 |
+
use_high_res_features_in_sam: true
|
| 98 |
+
# output 3 masks on the first click on initial conditioning frames
|
| 99 |
+
multimask_output_in_sam: true
|
| 100 |
+
# SAM heads
|
| 101 |
+
iou_prediction_use_sigmoid: True
|
| 102 |
+
# cross-attend to object pointers from other frames (based on SAM output tokens) in the encoder
|
| 103 |
+
use_obj_ptrs_in_encoder: true
|
| 104 |
+
add_tpos_enc_to_obj_ptrs: true
|
| 105 |
+
proj_tpos_enc_in_obj_ptrs: true
|
| 106 |
+
use_signed_tpos_enc_to_obj_ptrs: true
|
| 107 |
+
only_obj_ptrs_in_the_past_for_eval: true
|
| 108 |
+
# object occlusion prediction
|
| 109 |
+
pred_obj_scores: true
|
| 110 |
+
pred_obj_scores_mlp: true
|
| 111 |
+
fixed_no_obj_ptr: true
|
| 112 |
+
# multimask tracking settings
|
| 113 |
+
multimask_output_for_tracking: true
|
| 114 |
+
use_multimask_token_for_obj_ptr: true
|
| 115 |
+
multimask_min_pt_num: 0
|
| 116 |
+
multimask_max_pt_num: 1
|
| 117 |
+
use_mlp_for_obj_ptr_proj: true
|
| 118 |
+
# Compilation flag
|
| 119 |
+
compile_image_encoder: False
|
configs/sam2.1_hiera_t.yaml
ADDED
|
@@ -0,0 +1,121 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# @package _global_
|
| 2 |
+
|
| 3 |
+
# Model
|
| 4 |
+
model:
|
| 5 |
+
_target_: sam2.modeling.sam2_base.SAM2Base
|
| 6 |
+
image_encoder:
|
| 7 |
+
_target_: sam2.modeling.backbones.image_encoder.ImageEncoder
|
| 8 |
+
scalp: 1
|
| 9 |
+
trunk:
|
| 10 |
+
_target_: sam2.modeling.backbones.hieradet.Hiera
|
| 11 |
+
embed_dim: 96
|
| 12 |
+
num_heads: 1
|
| 13 |
+
stages: [1, 2, 7, 2]
|
| 14 |
+
global_att_blocks: [5, 7, 9]
|
| 15 |
+
window_pos_embed_bkg_spatial_size: [7, 7]
|
| 16 |
+
neck:
|
| 17 |
+
_target_: sam2.modeling.backbones.image_encoder.FpnNeck
|
| 18 |
+
position_encoding:
|
| 19 |
+
_target_: sam2.modeling.position_encoding.PositionEmbeddingSine
|
| 20 |
+
num_pos_feats: 256
|
| 21 |
+
normalize: true
|
| 22 |
+
scale: null
|
| 23 |
+
temperature: 10000
|
| 24 |
+
d_model: 256
|
| 25 |
+
backbone_channel_list: [768, 384, 192, 96]
|
| 26 |
+
fpn_top_down_levels: [2, 3] # output level 0 and 1 directly use the backbone features
|
| 27 |
+
fpn_interp_model: nearest
|
| 28 |
+
|
| 29 |
+
memory_attention:
|
| 30 |
+
_target_: sam2.modeling.memory_attention.MemoryAttention
|
| 31 |
+
d_model: 256
|
| 32 |
+
pos_enc_at_input: true
|
| 33 |
+
layer:
|
| 34 |
+
_target_: sam2.modeling.memory_attention.MemoryAttentionLayer
|
| 35 |
+
activation: relu
|
| 36 |
+
dim_feedforward: 2048
|
| 37 |
+
dropout: 0.1
|
| 38 |
+
pos_enc_at_attn: false
|
| 39 |
+
self_attention:
|
| 40 |
+
_target_: sam2.modeling.sam.transformer.RoPEAttention
|
| 41 |
+
rope_theta: 10000.0
|
| 42 |
+
feat_sizes: [32, 32]
|
| 43 |
+
embedding_dim: 256
|
| 44 |
+
num_heads: 1
|
| 45 |
+
downsample_rate: 1
|
| 46 |
+
dropout: 0.1
|
| 47 |
+
d_model: 256
|
| 48 |
+
pos_enc_at_cross_attn_keys: true
|
| 49 |
+
pos_enc_at_cross_attn_queries: false
|
| 50 |
+
cross_attention:
|
| 51 |
+
_target_: sam2.modeling.sam.transformer.RoPEAttention
|
| 52 |
+
rope_theta: 10000.0
|
| 53 |
+
feat_sizes: [32, 32]
|
| 54 |
+
rope_k_repeat: True
|
| 55 |
+
embedding_dim: 256
|
| 56 |
+
num_heads: 1
|
| 57 |
+
downsample_rate: 1
|
| 58 |
+
dropout: 0.1
|
| 59 |
+
kv_in_dim: 64
|
| 60 |
+
num_layers: 4
|
| 61 |
+
|
| 62 |
+
memory_encoder:
|
| 63 |
+
_target_: sam2.modeling.memory_encoder.MemoryEncoder
|
| 64 |
+
out_dim: 64
|
| 65 |
+
position_encoding:
|
| 66 |
+
_target_: sam2.modeling.position_encoding.PositionEmbeddingSine
|
| 67 |
+
num_pos_feats: 64
|
| 68 |
+
normalize: true
|
| 69 |
+
scale: null
|
| 70 |
+
temperature: 10000
|
| 71 |
+
mask_downsampler:
|
| 72 |
+
_target_: sam2.modeling.memory_encoder.MaskDownSampler
|
| 73 |
+
kernel_size: 3
|
| 74 |
+
stride: 2
|
| 75 |
+
padding: 1
|
| 76 |
+
fuser:
|
| 77 |
+
_target_: sam2.modeling.memory_encoder.Fuser
|
| 78 |
+
layer:
|
| 79 |
+
_target_: sam2.modeling.memory_encoder.CXBlock
|
| 80 |
+
dim: 256
|
| 81 |
+
kernel_size: 7
|
| 82 |
+
padding: 3
|
| 83 |
+
layer_scale_init_value: 1e-6
|
| 84 |
+
use_dwconv: True # depth-wise convs
|
| 85 |
+
num_layers: 2
|
| 86 |
+
|
| 87 |
+
num_maskmem: 7
|
| 88 |
+
image_size: 1024
|
| 89 |
+
# apply scaled sigmoid on mask logits for memory encoder, and directly feed input mask as output mask
|
| 90 |
+
# SAM decoder
|
| 91 |
+
sigmoid_scale_for_mem_enc: 20.0
|
| 92 |
+
sigmoid_bias_for_mem_enc: -10.0
|
| 93 |
+
use_mask_input_as_output_without_sam: true
|
| 94 |
+
# Memory
|
| 95 |
+
directly_add_no_mem_embed: true
|
| 96 |
+
no_obj_embed_spatial: true
|
| 97 |
+
# use high-resolution feature map in the SAM mask decoder
|
| 98 |
+
use_high_res_features_in_sam: true
|
| 99 |
+
# output 3 masks on the first click on initial conditioning frames
|
| 100 |
+
multimask_output_in_sam: true
|
| 101 |
+
# SAM heads
|
| 102 |
+
iou_prediction_use_sigmoid: True
|
| 103 |
+
# cross-attend to object pointers from other frames (based on SAM output tokens) in the encoder
|
| 104 |
+
use_obj_ptrs_in_encoder: true
|
| 105 |
+
add_tpos_enc_to_obj_ptrs: true
|
| 106 |
+
proj_tpos_enc_in_obj_ptrs: true
|
| 107 |
+
use_signed_tpos_enc_to_obj_ptrs: true
|
| 108 |
+
only_obj_ptrs_in_the_past_for_eval: true
|
| 109 |
+
# object occlusion prediction
|
| 110 |
+
pred_obj_scores: true
|
| 111 |
+
pred_obj_scores_mlp: true
|
| 112 |
+
fixed_no_obj_ptr: true
|
| 113 |
+
# multimask tracking settings
|
| 114 |
+
multimask_output_for_tracking: true
|
| 115 |
+
use_multimask_token_for_obj_ptr: true
|
| 116 |
+
multimask_min_pt_num: 0
|
| 117 |
+
multimask_max_pt_num: 1
|
| 118 |
+
use_mlp_for_obj_ptr_proj: true
|
| 119 |
+
# Compilation flag
|
| 120 |
+
# HieraT does not currently support compilation, should always be set to False
|
| 121 |
+
compile_image_encoder: False
|
configs/sam2_configs_sam2.1_sam2.1_hiera_l.yaml
ADDED
|
@@ -0,0 +1,120 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# @package _global_
|
| 2 |
+
|
| 3 |
+
# Model
|
| 4 |
+
model:
|
| 5 |
+
_target_: sam2.modeling.sam2_base.SAM2Base
|
| 6 |
+
image_encoder:
|
| 7 |
+
_target_: sam2.modeling.backbones.image_encoder.ImageEncoder
|
| 8 |
+
scalp: 1
|
| 9 |
+
trunk:
|
| 10 |
+
_target_: sam2.modeling.backbones.hieradet.Hiera
|
| 11 |
+
embed_dim: 144
|
| 12 |
+
num_heads: 2
|
| 13 |
+
stages: [2, 6, 36, 4]
|
| 14 |
+
global_att_blocks: [23, 33, 43]
|
| 15 |
+
window_pos_embed_bkg_spatial_size: [7, 7]
|
| 16 |
+
window_spec: [8, 4, 16, 8]
|
| 17 |
+
neck:
|
| 18 |
+
_target_: sam2.modeling.backbones.image_encoder.FpnNeck
|
| 19 |
+
position_encoding:
|
| 20 |
+
_target_: sam2.modeling.position_encoding.PositionEmbeddingSine
|
| 21 |
+
num_pos_feats: 256
|
| 22 |
+
normalize: true
|
| 23 |
+
scale: null
|
| 24 |
+
temperature: 10000
|
| 25 |
+
d_model: 256
|
| 26 |
+
backbone_channel_list: [1152, 576, 288, 144]
|
| 27 |
+
fpn_top_down_levels: [2, 3] # output level 0 and 1 directly use the backbone features
|
| 28 |
+
fpn_interp_model: nearest
|
| 29 |
+
|
| 30 |
+
memory_attention:
|
| 31 |
+
_target_: sam2.modeling.memory_attention.MemoryAttention
|
| 32 |
+
d_model: 256
|
| 33 |
+
pos_enc_at_input: true
|
| 34 |
+
layer:
|
| 35 |
+
_target_: sam2.modeling.memory_attention.MemoryAttentionLayer
|
| 36 |
+
activation: relu
|
| 37 |
+
dim_feedforward: 2048
|
| 38 |
+
dropout: 0.1
|
| 39 |
+
pos_enc_at_attn: false
|
| 40 |
+
self_attention:
|
| 41 |
+
_target_: sam2.modeling.sam.transformer.RoPEAttention
|
| 42 |
+
rope_theta: 10000.0
|
| 43 |
+
feat_sizes: [32, 32]
|
| 44 |
+
embedding_dim: 256
|
| 45 |
+
num_heads: 1
|
| 46 |
+
downsample_rate: 1
|
| 47 |
+
dropout: 0.1
|
| 48 |
+
d_model: 256
|
| 49 |
+
pos_enc_at_cross_attn_keys: true
|
| 50 |
+
pos_enc_at_cross_attn_queries: false
|
| 51 |
+
cross_attention:
|
| 52 |
+
_target_: sam2.modeling.sam.transformer.RoPEAttention
|
| 53 |
+
rope_theta: 10000.0
|
| 54 |
+
feat_sizes: [32, 32]
|
| 55 |
+
rope_k_repeat: True
|
| 56 |
+
embedding_dim: 256
|
| 57 |
+
num_heads: 1
|
| 58 |
+
downsample_rate: 1
|
| 59 |
+
dropout: 0.1
|
| 60 |
+
kv_in_dim: 64
|
| 61 |
+
num_layers: 4
|
| 62 |
+
|
| 63 |
+
memory_encoder:
|
| 64 |
+
_target_: sam2.modeling.memory_encoder.MemoryEncoder
|
| 65 |
+
out_dim: 64
|
| 66 |
+
position_encoding:
|
| 67 |
+
_target_: sam2.modeling.position_encoding.PositionEmbeddingSine
|
| 68 |
+
num_pos_feats: 64
|
| 69 |
+
normalize: true
|
| 70 |
+
scale: null
|
| 71 |
+
temperature: 10000
|
| 72 |
+
mask_downsampler:
|
| 73 |
+
_target_: sam2.modeling.memory_encoder.MaskDownSampler
|
| 74 |
+
kernel_size: 3
|
| 75 |
+
stride: 2
|
| 76 |
+
padding: 1
|
| 77 |
+
fuser:
|
| 78 |
+
_target_: sam2.modeling.memory_encoder.Fuser
|
| 79 |
+
layer:
|
| 80 |
+
_target_: sam2.modeling.memory_encoder.CXBlock
|
| 81 |
+
dim: 256
|
| 82 |
+
kernel_size: 7
|
| 83 |
+
padding: 3
|
| 84 |
+
layer_scale_init_value: 1e-6
|
| 85 |
+
use_dwconv: True # depth-wise convs
|
| 86 |
+
num_layers: 2
|
| 87 |
+
|
| 88 |
+
num_maskmem: 7
|
| 89 |
+
image_size: 1024
|
| 90 |
+
# apply scaled sigmoid on mask logits for memory encoder, and directly feed input mask as output mask
|
| 91 |
+
sigmoid_scale_for_mem_enc: 20.0
|
| 92 |
+
sigmoid_bias_for_mem_enc: -10.0
|
| 93 |
+
use_mask_input_as_output_without_sam: true
|
| 94 |
+
# Memory
|
| 95 |
+
directly_add_no_mem_embed: true
|
| 96 |
+
no_obj_embed_spatial: true
|
| 97 |
+
# use high-resolution feature map in the SAM mask decoder
|
| 98 |
+
use_high_res_features_in_sam: true
|
| 99 |
+
# output 3 masks on the first click on initial conditioning frames
|
| 100 |
+
multimask_output_in_sam: true
|
| 101 |
+
# SAM heads
|
| 102 |
+
iou_prediction_use_sigmoid: True
|
| 103 |
+
# cross-attend to object pointers from other frames (based on SAM output tokens) in the encoder
|
| 104 |
+
use_obj_ptrs_in_encoder: true
|
| 105 |
+
add_tpos_enc_to_obj_ptrs: true
|
| 106 |
+
proj_tpos_enc_in_obj_ptrs: true
|
| 107 |
+
use_signed_tpos_enc_to_obj_ptrs: true
|
| 108 |
+
only_obj_ptrs_in_the_past_for_eval: true
|
| 109 |
+
# object occlusion prediction
|
| 110 |
+
pred_obj_scores: true
|
| 111 |
+
pred_obj_scores_mlp: true
|
| 112 |
+
fixed_no_obj_ptr: true
|
| 113 |
+
# multimask tracking settings
|
| 114 |
+
multimask_output_for_tracking: true
|
| 115 |
+
use_multimask_token_for_obj_ptr: true
|
| 116 |
+
multimask_min_pt_num: 0
|
| 117 |
+
multimask_max_pt_num: 1
|
| 118 |
+
use_mlp_for_obj_ptr_proj: true
|
| 119 |
+
# Compilation flag
|
| 120 |
+
compile_image_encoder: False
|
gradio_app.py
ADDED
|
@@ -0,0 +1,379 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import gradio as gr
|
| 2 |
+
import torch
|
| 3 |
+
import numpy as np
|
| 4 |
+
import cv2
|
| 5 |
+
from sam2.build_sam import build_sam2_video_predictor
|
| 6 |
+
import tempfile
|
| 7 |
+
import os
|
| 8 |
+
import contextlib
|
| 9 |
+
from trajectory_service import TrajectoryService
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
class VideoTracker:
|
| 13 |
+
def __init__(self):
|
| 14 |
+
self.checkpoint = "./models/sam2.1_hiera_tiny.pt"
|
| 15 |
+
self.model_cfg = "configs/sam2.1/sam2.1_hiera_t.yaml"
|
| 16 |
+
self.predictor = build_sam2_video_predictor(
|
| 17 |
+
self.model_cfg, self.checkpoint, device="cpu", mode="eval"
|
| 18 |
+
)
|
| 19 |
+
self.state = None
|
| 20 |
+
self.video_frames = None
|
| 21 |
+
self.current_frame_idx = 0
|
| 22 |
+
self.masks = []
|
| 23 |
+
self.points = []
|
| 24 |
+
self.frame_count = 0
|
| 25 |
+
self.video_info = None
|
| 26 |
+
self.obj_id = 1
|
| 27 |
+
self.out_mask_logits = None
|
| 28 |
+
self.frame_masks = {} # Store masks for each frame
|
| 29 |
+
self.trajectory_service = None
|
| 30 |
+
|
| 31 |
+
def load_video(self, video_path):
|
| 32 |
+
if video_path is None:
|
| 33 |
+
return None, gr.Slider(minimum=0, maximum=0, step=1, value=0)
|
| 34 |
+
|
| 35 |
+
# Create a temporary file for the video
|
| 36 |
+
temp_file = tempfile.NamedTemporaryFile(delete=False, suffix=".mp4")
|
| 37 |
+
temp_file.close()
|
| 38 |
+
|
| 39 |
+
# Copy the uploaded video to the temporary file
|
| 40 |
+
with open(video_path, "rb") as f_src, open(temp_file.name, "wb") as f_dst:
|
| 41 |
+
f_dst.write(f_src.read())
|
| 42 |
+
|
| 43 |
+
# Load video frames using OpenCV
|
| 44 |
+
cap = cv2.VideoCapture(temp_file.name)
|
| 45 |
+
frames = []
|
| 46 |
+
while True:
|
| 47 |
+
ret, frame = cap.read()
|
| 48 |
+
if not ret:
|
| 49 |
+
break
|
| 50 |
+
frames.append(frame)
|
| 51 |
+
|
| 52 |
+
if not frames:
|
| 53 |
+
cap.release()
|
| 54 |
+
os.unlink(temp_file.name)
|
| 55 |
+
return None, gr.Slider(minimum=0, maximum=0, step=1, value=0)
|
| 56 |
+
|
| 57 |
+
# Store video info
|
| 58 |
+
fps = cap.get(cv2.CAP_PROP_FPS)
|
| 59 |
+
self.video_info = {
|
| 60 |
+
"path": temp_file.name,
|
| 61 |
+
"height": int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT)),
|
| 62 |
+
"width": int(cap.get(cv2.CAP_PROP_FRAME_WIDTH)),
|
| 63 |
+
"fps": fps,
|
| 64 |
+
"total_frames": len(frames),
|
| 65 |
+
}
|
| 66 |
+
cap.release()
|
| 67 |
+
|
| 68 |
+
self.video_frames = frames
|
| 69 |
+
self.frame_count = len(frames)
|
| 70 |
+
self.trajectory_service = TrajectoryService(fps=fps)
|
| 71 |
+
|
| 72 |
+
# Initialize SAM2 state with video path
|
| 73 |
+
with torch.inference_mode():
|
| 74 |
+
self.state = self.predictor.init_state(temp_file.name)
|
| 75 |
+
|
| 76 |
+
# Now we can remove the temp file
|
| 77 |
+
os.unlink(temp_file.name)
|
| 78 |
+
|
| 79 |
+
return frames[0], gr.Slider(minimum=0, maximum=len(frames) - 1, step=1, value=0)
|
| 80 |
+
|
| 81 |
+
def update_frame(self, frame_number):
|
| 82 |
+
if self.video_frames is None:
|
| 83 |
+
return None
|
| 84 |
+
|
| 85 |
+
self.current_frame_idx = frame_number
|
| 86 |
+
frame = self.video_frames[frame_number].copy()
|
| 87 |
+
|
| 88 |
+
# Apply any existing mask for this frame
|
| 89 |
+
if frame_number in self.frame_masks:
|
| 90 |
+
self.out_mask_logits = self.frame_masks[frame_number]
|
| 91 |
+
frame = self._draw_tracking(frame)
|
| 92 |
+
|
| 93 |
+
# Draw points (just the points, no trajectory)
|
| 94 |
+
for point in self.points:
|
| 95 |
+
if point[0] == frame_number:
|
| 96 |
+
cv2.circle(
|
| 97 |
+
frame, (int(point[1]), int(point[2])), 5, (255, 255, 0), -1
|
| 98 |
+
) # Yellow dot
|
| 99 |
+
cv2.circle(
|
| 100 |
+
frame, (int(point[1]), int(point[2])), 7, (0, 0, 0), 1
|
| 101 |
+
) # Black border
|
| 102 |
+
|
| 103 |
+
return frame
|
| 104 |
+
|
| 105 |
+
def add_point(self, frame, evt: gr.SelectData):
|
| 106 |
+
"""Add a point and get ball prediction with enhanced mask visualization"""
|
| 107 |
+
if self.state is None:
|
| 108 |
+
return frame
|
| 109 |
+
|
| 110 |
+
x, y = evt.index[0], evt.index[1]
|
| 111 |
+
self.points.append((self.current_frame_idx, x, y))
|
| 112 |
+
|
| 113 |
+
# Add point to trajectory service for later use
|
| 114 |
+
if self.trajectory_service:
|
| 115 |
+
self.trajectory_service.add_point(self.current_frame_idx, x, y)
|
| 116 |
+
|
| 117 |
+
frame_with_points = frame.copy()
|
| 118 |
+
|
| 119 |
+
# Get ball prediction using SAM2.1
|
| 120 |
+
with torch.inference_mode():
|
| 121 |
+
# Convert points and labels to numpy arrays
|
| 122 |
+
points = np.array([(x, y)], dtype=np.float32)
|
| 123 |
+
labels = np.array([1], dtype=np.int32) # 1 for positive click
|
| 124 |
+
|
| 125 |
+
# Add point and get mask
|
| 126 |
+
_, out_obj_ids, out_mask_logits = self.predictor.add_new_points(
|
| 127 |
+
inference_state=self.state,
|
| 128 |
+
frame_idx=self.current_frame_idx,
|
| 129 |
+
obj_id=self.obj_id,
|
| 130 |
+
points=points,
|
| 131 |
+
labels=labels,
|
| 132 |
+
)
|
| 133 |
+
|
| 134 |
+
if out_mask_logits is not None and len(out_mask_logits) > 0:
|
| 135 |
+
self.out_mask_logits = (
|
| 136 |
+
out_mask_logits[0]
|
| 137 |
+
if isinstance(out_mask_logits, list)
|
| 138 |
+
else out_mask_logits
|
| 139 |
+
)
|
| 140 |
+
# Store mask for this frame
|
| 141 |
+
self.frame_masks[self.current_frame_idx] = self.out_mask_logits
|
| 142 |
+
|
| 143 |
+
# Draw tracking visualization with enhanced mask
|
| 144 |
+
frame_with_points = self._draw_tracking(frame_with_points)
|
| 145 |
+
|
| 146 |
+
# Draw point on top of mask (just the point, no trajectory)
|
| 147 |
+
cv2.circle(
|
| 148 |
+
frame_with_points, (int(x), int(y)), 5, (255, 255, 0), -1
|
| 149 |
+
) # Yellow dot
|
| 150 |
+
cv2.circle(frame_with_points, (int(x), int(y)), 7, (0, 0, 0), 1) # Black border
|
| 151 |
+
|
| 152 |
+
return frame_with_points
|
| 153 |
+
|
| 154 |
+
def propagate_video(self):
|
| 155 |
+
if self.state is None:
|
| 156 |
+
return None
|
| 157 |
+
|
| 158 |
+
output_frames = self.video_frames.copy()
|
| 159 |
+
|
| 160 |
+
# Store all masks and their centers for trajectory calculation
|
| 161 |
+
all_masks = []
|
| 162 |
+
mask_centers = []
|
| 163 |
+
|
| 164 |
+
# First pass: collect all masks and calculate centers
|
| 165 |
+
with torch.inference_mode():
|
| 166 |
+
for frame_idx, obj_ids, masks in self.predictor.propagate_in_video(
|
| 167 |
+
self.state,
|
| 168 |
+
start_frame_idx=0,
|
| 169 |
+
reverse=False,
|
| 170 |
+
):
|
| 171 |
+
if masks is not None and len(masks) > 0:
|
| 172 |
+
mask = masks[0] if isinstance(masks, list) else masks
|
| 173 |
+
all_masks.append((frame_idx, mask))
|
| 174 |
+
|
| 175 |
+
# Get mask center
|
| 176 |
+
mask_np = (mask > 0.0).cpu().numpy()
|
| 177 |
+
center = self._get_mask_center(mask_np)
|
| 178 |
+
if center is not None:
|
| 179 |
+
mask_centers.append((frame_idx, center[0], center[1]))
|
| 180 |
+
|
| 181 |
+
# Store mask for each frame
|
| 182 |
+
self.frame_masks[frame_idx] = mask
|
| 183 |
+
|
| 184 |
+
# Add detected centers to trajectory service
|
| 185 |
+
if self.trajectory_service:
|
| 186 |
+
# Clear existing points and add user-selected points first
|
| 187 |
+
self.trajectory_service.clear_points()
|
| 188 |
+
for point in self.points:
|
| 189 |
+
self.trajectory_service.add_point(point[0], point[1], point[2])
|
| 190 |
+
|
| 191 |
+
# Add centers from mask detection
|
| 192 |
+
for center in mask_centers:
|
| 193 |
+
if center[0] not in [
|
| 194 |
+
p[0] for p in self.points
|
| 195 |
+
]: # Don't duplicate user points
|
| 196 |
+
self.trajectory_service.add_point(center[0], center[1], center[2])
|
| 197 |
+
|
| 198 |
+
# Calculate trajectory with all points
|
| 199 |
+
trajectory_points = self.trajectory_service.get_trajectory()
|
| 200 |
+
|
| 201 |
+
# Second pass: apply visualization with temporal smoothing and trajectory
|
| 202 |
+
for i, frame in enumerate(output_frames):
|
| 203 |
+
frame = frame.copy()
|
| 204 |
+
|
| 205 |
+
# Find masks for this frame
|
| 206 |
+
current_masks = [m[1] for m in all_masks if m[0] == i]
|
| 207 |
+
|
| 208 |
+
if current_masks:
|
| 209 |
+
self.out_mask_logits = current_masks[0]
|
| 210 |
+
mask_np = (current_masks[0] > 0.0).cpu().numpy()
|
| 211 |
+
mask_np = self._handle_mask_dimensions(mask_np)
|
| 212 |
+
mask_np = mask_np.astype(np.uint8)
|
| 213 |
+
frame = self._draw_tracking(frame, alpha=0.6)
|
| 214 |
+
|
| 215 |
+
try:
|
| 216 |
+
kernel = np.ones((5, 5), np.uint8)
|
| 217 |
+
dilated_mask = cv2.dilate(mask_np, kernel, iterations=2)
|
| 218 |
+
glow = frame.copy()
|
| 219 |
+
glow[dilated_mask > 0] = [0, 255, 255] # Yellow glow
|
| 220 |
+
frame = cv2.addWeighted(frame, 0.7, glow, 0.3, 0)
|
| 221 |
+
except cv2.error as e:
|
| 222 |
+
print(
|
| 223 |
+
f"Warning: Could not apply glow effect. Mask shape: {mask_np.shape}, Frame shape: {frame.shape}"
|
| 224 |
+
)
|
| 225 |
+
|
| 226 |
+
# Draw trajectory
|
| 227 |
+
if self.trajectory_service and trajectory_points:
|
| 228 |
+
frame = self.trajectory_service.draw_trajectory(frame, i)
|
| 229 |
+
|
| 230 |
+
output_frames[i] = frame
|
| 231 |
+
|
| 232 |
+
# Save as video with higher quality
|
| 233 |
+
temp_output = tempfile.NamedTemporaryFile(suffix=".mp4", delete=False).name
|
| 234 |
+
height, width = output_frames[0].shape[:2]
|
| 235 |
+
writer = cv2.VideoWriter(
|
| 236 |
+
temp_output, cv2.VideoWriter_fourcc(*"mp4v"), 30, (width, height), True
|
| 237 |
+
)
|
| 238 |
+
|
| 239 |
+
for frame in output_frames:
|
| 240 |
+
writer.write(frame)
|
| 241 |
+
writer.release()
|
| 242 |
+
|
| 243 |
+
return temp_output
|
| 244 |
+
|
| 245 |
+
def _get_mask_center(self, mask_np):
|
| 246 |
+
"""Get the center point of a mask"""
|
| 247 |
+
if mask_np is None:
|
| 248 |
+
return None
|
| 249 |
+
|
| 250 |
+
# Ensure mask is 2D
|
| 251 |
+
mask_np = self._handle_mask_dimensions(mask_np)
|
| 252 |
+
mask_np = (mask_np > 0.0).astype(np.uint8)
|
| 253 |
+
|
| 254 |
+
# Find contours
|
| 255 |
+
contours, _ = cv2.findContours(
|
| 256 |
+
mask_np, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE
|
| 257 |
+
)
|
| 258 |
+
if not contours:
|
| 259 |
+
return None
|
| 260 |
+
|
| 261 |
+
# Get largest contour
|
| 262 |
+
largest_contour = max(contours, key=cv2.contourArea)
|
| 263 |
+
|
| 264 |
+
# Calculate centroid
|
| 265 |
+
M = cv2.moments(largest_contour)
|
| 266 |
+
if M["m00"] == 0:
|
| 267 |
+
return None
|
| 268 |
+
|
| 269 |
+
cx = int(M["m10"] / M["m00"])
|
| 270 |
+
cy = int(M["m01"] / M["m00"])
|
| 271 |
+
|
| 272 |
+
return (cx, cy)
|
| 273 |
+
|
| 274 |
+
def _handle_mask_dimensions(self, mask_np):
|
| 275 |
+
"""Helper function to handle various mask dimensions"""
|
| 276 |
+
# Handle 4D tensor (1, 1, H, W)
|
| 277 |
+
if len(mask_np.shape) == 4:
|
| 278 |
+
mask_np = mask_np[0, 0]
|
| 279 |
+
# Handle 3D tensor (1, H, W) or (H, W, 1)
|
| 280 |
+
elif len(mask_np.shape) == 3:
|
| 281 |
+
if mask_np.shape[0] == 1: # (1, H, W) format
|
| 282 |
+
mask_np = mask_np[0]
|
| 283 |
+
elif mask_np.shape[2] == 1: # (H, W, 1) format
|
| 284 |
+
mask_np = mask_np[:, :, 0]
|
| 285 |
+
return mask_np
|
| 286 |
+
|
| 287 |
+
def _draw_tracking(self, frame, alpha=0.5):
|
| 288 |
+
"""Draw object mask on frame with enhanced visualization"""
|
| 289 |
+
if self.out_mask_logits is not None:
|
| 290 |
+
# Convert logits to binary mask
|
| 291 |
+
if isinstance(self.out_mask_logits, list):
|
| 292 |
+
mask = self.out_mask_logits[0]
|
| 293 |
+
else:
|
| 294 |
+
mask = self.out_mask_logits
|
| 295 |
+
|
| 296 |
+
# Get binary mask and handle dimensions
|
| 297 |
+
mask_np = (mask > 0.0).cpu().numpy()
|
| 298 |
+
mask_np = self._handle_mask_dimensions(mask_np)
|
| 299 |
+
|
| 300 |
+
if mask_np.shape[:2] == frame.shape[:2]:
|
| 301 |
+
# Create a red overlay for the mask
|
| 302 |
+
overlay = frame.copy()
|
| 303 |
+
overlay[mask_np > 0] = [0, 0, 255] # BGR format: Red color
|
| 304 |
+
|
| 305 |
+
# Add a border around the mask for better visibility
|
| 306 |
+
contours, _ = cv2.findContours(
|
| 307 |
+
mask_np.astype(np.uint8), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE
|
| 308 |
+
)
|
| 309 |
+
|
| 310 |
+
# Draw thicker contours for better visibility
|
| 311 |
+
cv2.drawContours(
|
| 312 |
+
overlay, contours, -1, (0, 255, 255), 3
|
| 313 |
+
) # Thicker yellow border
|
| 314 |
+
|
| 315 |
+
# Draw a second contour for emphasis
|
| 316 |
+
cv2.drawContours(
|
| 317 |
+
frame, contours, -1, (255, 255, 0), 1
|
| 318 |
+
) # Thin bright border
|
| 319 |
+
|
| 320 |
+
# Blend the overlay with original frame
|
| 321 |
+
frame = cv2.addWeighted(overlay, alpha, frame, 1 - alpha, 0)
|
| 322 |
+
|
| 323 |
+
return frame
|
| 324 |
+
|
| 325 |
+
|
| 326 |
+
def create_interface():
|
| 327 |
+
tracker = VideoTracker()
|
| 328 |
+
|
| 329 |
+
with gr.Blocks() as interface:
|
| 330 |
+
gr.Markdown("# Object Tracking with SAM2")
|
| 331 |
+
gr.Markdown("Upload a video and click on objects to track them")
|
| 332 |
+
|
| 333 |
+
with gr.Row():
|
| 334 |
+
with gr.Column(scale=2):
|
| 335 |
+
video_input = gr.Video(label="Input Video")
|
| 336 |
+
image_output = gr.Image(label="Current Frame", interactive=True)
|
| 337 |
+
frame_slider = gr.Slider(
|
| 338 |
+
minimum=0,
|
| 339 |
+
maximum=0,
|
| 340 |
+
step=1,
|
| 341 |
+
value=0,
|
| 342 |
+
label="Frame Selection",
|
| 343 |
+
interactive=True,
|
| 344 |
+
)
|
| 345 |
+
|
| 346 |
+
with gr.Column(scale=1):
|
| 347 |
+
propagate_btn = gr.Button("Propagate Through Video", variant="primary")
|
| 348 |
+
video_output = gr.Video(label="Output Video")
|
| 349 |
+
|
| 350 |
+
video_input.change(
|
| 351 |
+
fn=tracker.load_video,
|
| 352 |
+
inputs=[video_input],
|
| 353 |
+
outputs=[image_output, frame_slider],
|
| 354 |
+
)
|
| 355 |
+
|
| 356 |
+
frame_slider.change(
|
| 357 |
+
fn=tracker.update_frame,
|
| 358 |
+
inputs=[frame_slider],
|
| 359 |
+
outputs=[image_output],
|
| 360 |
+
)
|
| 361 |
+
|
| 362 |
+
image_output.select(
|
| 363 |
+
fn=tracker.add_point,
|
| 364 |
+
inputs=[image_output],
|
| 365 |
+
outputs=[image_output],
|
| 366 |
+
)
|
| 367 |
+
|
| 368 |
+
propagate_btn.click(
|
| 369 |
+
fn=tracker.propagate_video,
|
| 370 |
+
inputs=[],
|
| 371 |
+
outputs=[video_output],
|
| 372 |
+
)
|
| 373 |
+
|
| 374 |
+
return interface
|
| 375 |
+
|
| 376 |
+
|
| 377 |
+
if __name__ == "__main__":
|
| 378 |
+
interface = create_interface()
|
| 379 |
+
interface.launch(share=True)
|
hello.py
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
def main():
|
| 2 |
+
print("Hello from golf-tracking!")
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
if __name__ == "__main__":
|
| 6 |
+
main()
|
pyproject.toml
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
[project]
|
| 2 |
+
name = "golf-tracking"
|
| 3 |
+
version = "0.1.0"
|
| 4 |
+
description = "Add your description here"
|
| 5 |
+
readme = "README.md"
|
| 6 |
+
requires-python = ">=3.12"
|
| 7 |
+
dependencies = [
|
| 8 |
+
"decord>=0.6.0",
|
| 9 |
+
"gradio>=4.0.0",
|
| 10 |
+
"hydra-core>=1.3.2",
|
| 11 |
+
"iopath>=0.1.10",
|
| 12 |
+
"matplotlib>=3.9.1",
|
| 13 |
+
"moviepy==1.0.3",
|
| 14 |
+
"numpy>=1.24.4",
|
| 15 |
+
"opencv-python>=4.7.0",
|
| 16 |
+
"pillow>=9.4.0",
|
| 17 |
+
"sam2>=1.1.0",
|
| 18 |
+
"scipy>=1.7.0",
|
| 19 |
+
"torch>=2.0.0",
|
| 20 |
+
"tqdm>=4.66.1",
|
| 21 |
+
]
|
ref.py
ADDED
|
@@ -0,0 +1,265 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import gradio as gr
|
| 2 |
+
from gradio_image_prompter import ImagePrompter
|
| 3 |
+
import torch
|
| 4 |
+
import numpy as np
|
| 5 |
+
from sam2.sam2_image_predictor import SAM2ImagePredictor
|
| 6 |
+
from uuid import uuid4
|
| 7 |
+
import os
|
| 8 |
+
from huggingface_hub import upload_folder, login
|
| 9 |
+
from PIL import Image as PILImage
|
| 10 |
+
from datasets import Dataset, Features, Array2D, Image
|
| 11 |
+
import shutil
|
| 12 |
+
import random
|
| 13 |
+
from datasets import load_dataset
|
| 14 |
+
|
| 15 |
+
MODEL = "facebook/sam2-hiera-large"
|
| 16 |
+
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
|
| 17 |
+
PREDICTOR = SAM2ImagePredictor.from_pretrained(MODEL, device=DEVICE)
|
| 18 |
+
|
| 19 |
+
DESTINATION_DS = "amaye15/object-segmentation"
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
token = os.getenv("TOKEN")
|
| 23 |
+
if token:
|
| 24 |
+
login(token)
|
| 25 |
+
|
| 26 |
+
IMAGE = None
|
| 27 |
+
MASKS = None
|
| 28 |
+
MASKED_IMAGES = None
|
| 29 |
+
INDEX = None
|
| 30 |
+
|
| 31 |
+
|
| 32 |
+
ds_name = ["amaye15/product_labels"] # "amaye15/Products-10k", "amaye15/receipts"
|
| 33 |
+
choices = ["test", "train"]
|
| 34 |
+
max_len = None
|
| 35 |
+
|
| 36 |
+
ds_stream = load_dataset(random.choice(ds_name), streaming=True)
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
ds_split = ds_stream[random.choice(choices)]
|
| 40 |
+
|
| 41 |
+
ds_iter = ds_split.iter(batch_size=1)
|
| 42 |
+
|
| 43 |
+
for idx, val in enumerate(ds_iter):
|
| 44 |
+
max_len = idx
|
| 45 |
+
|
| 46 |
+
|
| 47 |
+
def prompter(prompts):
|
| 48 |
+
image = np.array(prompts["image"]) # Convert the image to a numpy array
|
| 49 |
+
points = prompts["points"] # Get the points from prompts
|
| 50 |
+
|
| 51 |
+
# Perform inference with multimask_output=True
|
| 52 |
+
with torch.inference_mode():
|
| 53 |
+
PREDICTOR.set_image(image)
|
| 54 |
+
input_point = [[point[0], point[1]] for point in points]
|
| 55 |
+
input_label = [1] * len(points) # Assuming all points are foreground
|
| 56 |
+
masks, _, _ = PREDICTOR.predict(
|
| 57 |
+
point_coords=input_point, point_labels=input_label, multimask_output=True
|
| 58 |
+
)
|
| 59 |
+
|
| 60 |
+
# Prepare individual images with separate overlays
|
| 61 |
+
overlay_images = []
|
| 62 |
+
for i, mask in enumerate(masks):
|
| 63 |
+
print(f"Predicted Mask {i+1}:", mask.shape)
|
| 64 |
+
red_mask = np.zeros_like(image)
|
| 65 |
+
red_mask[:, :, 0] = mask.astype(np.uint8) * 255 # Apply the red channel
|
| 66 |
+
red_mask = PILImage.fromarray(red_mask)
|
| 67 |
+
|
| 68 |
+
# Convert the original image to a PIL image
|
| 69 |
+
original_image = PILImage.fromarray(image)
|
| 70 |
+
|
| 71 |
+
# Blend the original image with the red mask
|
| 72 |
+
blended_image = PILImage.blend(original_image, red_mask, alpha=0.5)
|
| 73 |
+
|
| 74 |
+
# Add the blended image to the list
|
| 75 |
+
overlay_images.append(blended_image)
|
| 76 |
+
|
| 77 |
+
global IMAGE, MASKS, MASKED_IMAGES
|
| 78 |
+
IMAGE, MASKS = image, masks
|
| 79 |
+
MASKED_IMAGES = [np.array(img) for img in overlay_images]
|
| 80 |
+
|
| 81 |
+
return overlay_images[0], overlay_images[1], overlay_images[2], masks
|
| 82 |
+
|
| 83 |
+
|
| 84 |
+
def select_mask(
|
| 85 |
+
selected_mask_index,
|
| 86 |
+
mask1,
|
| 87 |
+
mask2,
|
| 88 |
+
mask3,
|
| 89 |
+
):
|
| 90 |
+
masks = [mask1, mask2, mask3]
|
| 91 |
+
global INDEX
|
| 92 |
+
INDEX = selected_mask_index
|
| 93 |
+
return masks[selected_mask_index]
|
| 94 |
+
|
| 95 |
+
|
| 96 |
+
def save_selected_mask(image, mask, output_dir="output"):
|
| 97 |
+
output_dir = os.path.join(os.getcwd(), output_dir)
|
| 98 |
+
|
| 99 |
+
os.makedirs(output_dir, exist_ok=True)
|
| 100 |
+
|
| 101 |
+
folder_id = str(uuid4())
|
| 102 |
+
|
| 103 |
+
folder_path = os.path.join(output_dir, folder_id)
|
| 104 |
+
|
| 105 |
+
os.makedirs(folder_path, exist_ok=True)
|
| 106 |
+
|
| 107 |
+
data_path = os.path.join(folder_path, "data.parquet")
|
| 108 |
+
|
| 109 |
+
data = {
|
| 110 |
+
"image": IMAGE,
|
| 111 |
+
"masked_image": MASKED_IMAGES[INDEX],
|
| 112 |
+
"mask": MASKS[INDEX],
|
| 113 |
+
}
|
| 114 |
+
|
| 115 |
+
features = Features(
|
| 116 |
+
{
|
| 117 |
+
"image": Image(),
|
| 118 |
+
"masked_image": Image(),
|
| 119 |
+
"mask": Array2D(
|
| 120 |
+
dtype="int64", shape=(MASKS[INDEX].shape[0], MASKS[INDEX].shape[1])
|
| 121 |
+
),
|
| 122 |
+
}
|
| 123 |
+
)
|
| 124 |
+
|
| 125 |
+
ds = Dataset.from_list([data], features=features)
|
| 126 |
+
ds.to_parquet(data_path)
|
| 127 |
+
|
| 128 |
+
upload_folder(
|
| 129 |
+
folder_path=output_dir,
|
| 130 |
+
repo_id=DESTINATION_DS,
|
| 131 |
+
repo_type="dataset",
|
| 132 |
+
)
|
| 133 |
+
|
| 134 |
+
shutil.rmtree(folder_path)
|
| 135 |
+
|
| 136 |
+
iframe_code = """## Success! 🎉🤖✅
|
| 137 |
+
You've successfully contributed to the dataset.
|
| 138 |
+
Please note that because new data has been added to the dataset, it may take a couple of minutes to render.
|
| 139 |
+
Check it out here:
|
| 140 |
+
[Object Segmentation Dataset](https://huggingface.co/datasets/amaye15/object-segmentation)
|
| 141 |
+
"""
|
| 142 |
+
|
| 143 |
+
return iframe_code
|
| 144 |
+
|
| 145 |
+
|
| 146 |
+
def get_random_image():
|
| 147 |
+
"""Get a random image from the dataset."""
|
| 148 |
+
global max_len
|
| 149 |
+
random_idx = random.choice(range(max_len))
|
| 150 |
+
image_data = list(ds_split.skip(random_idx).take(1))[0]["pixel_values"]
|
| 151 |
+
formatted_image = {
|
| 152 |
+
"image": np.array(image_data),
|
| 153 |
+
"points": [],
|
| 154 |
+
} # Create the correct format
|
| 155 |
+
return formatted_image
|
| 156 |
+
|
| 157 |
+
|
| 158 |
+
# Define the Gradio Blocks app
|
| 159 |
+
with gr.Blocks() as demo:
|
| 160 |
+
gr.Markdown("# Object Segmentation- Image Point Collector and Mask Overlay Tool")
|
| 161 |
+
gr.Markdown(
|
| 162 |
+
"""
|
| 163 |
+
This application utilizes **Segment Anything V2 (SAM2)** to allow you to upload an image or select a random image from a dataset and interactively generate segmentation masks based on multiple points you select on the image.
|
| 164 |
+
### How It Works:
|
| 165 |
+
1. **Upload or Select an Image**: You can either upload your own image or use a random image from the dataset.
|
| 166 |
+
2. **Point Selection**: Click on the image to indicate points of interest. You can add multiple points, and these will be used collectively to generate segmentation masks using SAM2.
|
| 167 |
+
3. **Mask Generation**: The app will generate up to three different segmentation masks for the selected points, each displayed separately with a red overlay.
|
| 168 |
+
4. **Mask Selection**: Carefully review the generated masks and select the one that best fits your needs. **It's important to choose the correct mask, as your selection will be saved and used for further processing.**
|
| 169 |
+
5. **Save and Contribute**: Save the selected mask along with the image to a dataset, contributing to a shared dataset on Hugging Face.
|
| 170 |
+
**Disclaimer**: All images and masks you work with will be collected and stored in a public dataset. Please ensure that you are comfortable with your selections and the data you provide before saving.
|
| 171 |
+
|
| 172 |
+
This tool is particularly useful for creating precise object segmentation masks for computer vision tasks, such as training models or generating labeled datasets.
|
| 173 |
+
"""
|
| 174 |
+
)
|
| 175 |
+
|
| 176 |
+
with gr.Row():
|
| 177 |
+
with gr.Column():
|
| 178 |
+
image_input = gr.State()
|
| 179 |
+
# Input: ImagePrompter for uploaded image
|
| 180 |
+
upload_image_input = ImagePrompter(show_label=False)
|
| 181 |
+
|
| 182 |
+
random_image_button = gr.Button("Use Random Image")
|
| 183 |
+
|
| 184 |
+
submit_button = gr.Button("Submit")
|
| 185 |
+
|
| 186 |
+
with gr.Row():
|
| 187 |
+
with gr.Column():
|
| 188 |
+
# Outputs: Up to 3 overlay images
|
| 189 |
+
image_output_1 = gr.Image(show_label=False)
|
| 190 |
+
with gr.Column():
|
| 191 |
+
image_output_2 = gr.Image(show_label=False)
|
| 192 |
+
with gr.Column():
|
| 193 |
+
image_output_3 = gr.Image(show_label=False)
|
| 194 |
+
|
| 195 |
+
# Dropdown for selecting the correct mask
|
| 196 |
+
with gr.Row():
|
| 197 |
+
mask_selector = gr.Radio(
|
| 198 |
+
label="Select the correct mask",
|
| 199 |
+
choices=["Mask 1", "Mask 2", "Mask 3"],
|
| 200 |
+
type="index",
|
| 201 |
+
)
|
| 202 |
+
# selected_mask_output = gr.Image(show_label=False)
|
| 203 |
+
|
| 204 |
+
save_button = gr.Button("Save Selected Mask and Image")
|
| 205 |
+
iframe_display = gr.Markdown()
|
| 206 |
+
|
| 207 |
+
# Logic for the random image button
|
| 208 |
+
random_image_button.click(
|
| 209 |
+
fn=get_random_image,
|
| 210 |
+
inputs=None,
|
| 211 |
+
outputs=upload_image_input, # Pass the formatted random image to ImagePrompter
|
| 212 |
+
)
|
| 213 |
+
|
| 214 |
+
# Logic to use uploaded image
|
| 215 |
+
upload_image_input.change(
|
| 216 |
+
fn=lambda img: img, inputs=upload_image_input, outputs=image_input
|
| 217 |
+
)
|
| 218 |
+
# Define the action triggered by the submit button
|
| 219 |
+
submit_button.click(
|
| 220 |
+
fn=prompter,
|
| 221 |
+
inputs=upload_image_input, # The final image input (whether uploaded or random)
|
| 222 |
+
outputs=[image_output_1, image_output_2, image_output_3, gr.State()],
|
| 223 |
+
show_progress=True,
|
| 224 |
+
)
|
| 225 |
+
|
| 226 |
+
# Define the action triggered by mask selection
|
| 227 |
+
mask_selector.change(
|
| 228 |
+
fn=select_mask,
|
| 229 |
+
inputs=[mask_selector, image_output_1, image_output_2, image_output_3],
|
| 230 |
+
outputs=gr.State(),
|
| 231 |
+
)
|
| 232 |
+
|
| 233 |
+
# Define the action triggered by the save button
|
| 234 |
+
save_button.click(
|
| 235 |
+
fn=save_selected_mask,
|
| 236 |
+
inputs=[gr.State(), gr.State()],
|
| 237 |
+
outputs=iframe_display,
|
| 238 |
+
show_progress=True,
|
| 239 |
+
)
|
| 240 |
+
|
| 241 |
+
# Launch the Gradio app
|
| 242 |
+
demo.launch()
|
| 243 |
+
|
| 244 |
+
|
| 245 |
+
# with gr.Column():
|
| 246 |
+
# source = gr.Textbox(label="Source Dataset")
|
| 247 |
+
# source_display = gr.Markdown()
|
| 248 |
+
# iframe_display = gr.HTML()
|
| 249 |
+
|
| 250 |
+
# source.change(
|
| 251 |
+
# save_dataset_name,
|
| 252 |
+
# inputs=(gr.State("source_dataset"), source),
|
| 253 |
+
# outputs=(source_display, iframe_display),
|
| 254 |
+
# )
|
| 255 |
+
|
| 256 |
+
# with gr.Column():
|
| 257 |
+
|
| 258 |
+
# destination = gr.Textbox(label="Destination Dataset")
|
| 259 |
+
# destination_display = gr.Markdown()
|
| 260 |
+
|
| 261 |
+
# destination.change(
|
| 262 |
+
# save_dataset_name,
|
| 263 |
+
# inputs=(gr.State("destination_dataset"), destination),
|
| 264 |
+
# outputs=destination_display,
|
| 265 |
+
# )
|
reference_code.py
ADDED
|
@@ -0,0 +1,776 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import subprocess
|
| 2 |
+
import re
|
| 3 |
+
from typing import List, Tuple, Optional
|
| 4 |
+
import spaces
|
| 5 |
+
|
| 6 |
+
# Define the command to be executed
|
| 7 |
+
command = ["python", "setup.py", "build_ext", "--inplace"]
|
| 8 |
+
|
| 9 |
+
# Execute the command
|
| 10 |
+
result = subprocess.run(command, capture_output=True, text=True)
|
| 11 |
+
|
| 12 |
+
css = """
|
| 13 |
+
div#component-18, div#component-25, div#component-35, div#component-41{
|
| 14 |
+
align-items: stretch!important;
|
| 15 |
+
}
|
| 16 |
+
"""
|
| 17 |
+
|
| 18 |
+
# Print the output and error (if any)
|
| 19 |
+
print("Output:\n", result.stdout)
|
| 20 |
+
print("Errors:\n", result.stderr)
|
| 21 |
+
|
| 22 |
+
# Check if the command was successful
|
| 23 |
+
if result.returncode == 0:
|
| 24 |
+
print("Command executed successfully.")
|
| 25 |
+
else:
|
| 26 |
+
print("Command failed with return code:", result.returncode)
|
| 27 |
+
|
| 28 |
+
import gradio as gr
|
| 29 |
+
from datetime import datetime
|
| 30 |
+
import os
|
| 31 |
+
|
| 32 |
+
os.environ["TORCH_CUDNN_SDPA_ENABLED"] = "1"
|
| 33 |
+
import torch
|
| 34 |
+
import numpy as np
|
| 35 |
+
import cv2
|
| 36 |
+
import matplotlib.pyplot as plt
|
| 37 |
+
from PIL import Image, ImageFilter
|
| 38 |
+
from sam2.build_sam import build_sam2_video_predictor
|
| 39 |
+
|
| 40 |
+
from moviepy.editor import ImageSequenceClip
|
| 41 |
+
|
| 42 |
+
|
| 43 |
+
def sparse_sampling(jpeg_images, original_fps, target_fps=6):
|
| 44 |
+
# Calculate the frame interval for sampling based on the target fps
|
| 45 |
+
frame_interval = int(original_fps // target_fps)
|
| 46 |
+
|
| 47 |
+
# Sparse sample the jpeg_images by selecting every 'frame_interval' frame
|
| 48 |
+
sampled_images = [
|
| 49 |
+
jpeg_images[i] for i in range(0, len(jpeg_images), frame_interval)
|
| 50 |
+
]
|
| 51 |
+
|
| 52 |
+
return sampled_images
|
| 53 |
+
|
| 54 |
+
|
| 55 |
+
def get_video_fps(video_path):
|
| 56 |
+
# Open the video file
|
| 57 |
+
cap = cv2.VideoCapture(video_path)
|
| 58 |
+
|
| 59 |
+
if not cap.isOpened():
|
| 60 |
+
print("Error: Could not open video.")
|
| 61 |
+
return None
|
| 62 |
+
|
| 63 |
+
# Get the FPS of the video
|
| 64 |
+
fps = cap.get(cv2.CAP_PROP_FPS)
|
| 65 |
+
|
| 66 |
+
return fps
|
| 67 |
+
|
| 68 |
+
|
| 69 |
+
def clear_points(image):
|
| 70 |
+
# we clean all
|
| 71 |
+
return [
|
| 72 |
+
image, # first_frame_path
|
| 73 |
+
[], # tracking_points
|
| 74 |
+
[], # trackings_input_label
|
| 75 |
+
image, # points_map
|
| 76 |
+
# gr.State() # stored_inference_state
|
| 77 |
+
]
|
| 78 |
+
|
| 79 |
+
|
| 80 |
+
def preprocess_video_in(video_path):
|
| 81 |
+
# Generate a unique ID based on the current date and time
|
| 82 |
+
unique_id = datetime.now().strftime("%Y%m%d%H%M%S")
|
| 83 |
+
|
| 84 |
+
# Set directory with this ID to store video frames
|
| 85 |
+
extracted_frames_output_dir = f"frames_{unique_id}"
|
| 86 |
+
|
| 87 |
+
# Create the output directory
|
| 88 |
+
os.makedirs(extracted_frames_output_dir, exist_ok=True)
|
| 89 |
+
|
| 90 |
+
### Process video frames ###
|
| 91 |
+
# Open the video file
|
| 92 |
+
cap = cv2.VideoCapture(video_path)
|
| 93 |
+
|
| 94 |
+
if not cap.isOpened():
|
| 95 |
+
print("Error: Could not open video.")
|
| 96 |
+
return None
|
| 97 |
+
|
| 98 |
+
# Get the frames per second (FPS) of the video
|
| 99 |
+
fps = cap.get(cv2.CAP_PROP_FPS)
|
| 100 |
+
|
| 101 |
+
# Calculate the number of frames to process (60 seconds of video)
|
| 102 |
+
max_frames = int(fps * 60)
|
| 103 |
+
|
| 104 |
+
frame_number = 0
|
| 105 |
+
first_frame = None
|
| 106 |
+
|
| 107 |
+
while True:
|
| 108 |
+
ret, frame = cap.read()
|
| 109 |
+
if not ret or frame_number >= max_frames:
|
| 110 |
+
break
|
| 111 |
+
if frame_number % 6 == 0:
|
| 112 |
+
# Format the frame filename as '00000.jpg'
|
| 113 |
+
frame_filename = os.path.join(
|
| 114 |
+
extracted_frames_output_dir, f"{frame_number:05d}.jpg"
|
| 115 |
+
)
|
| 116 |
+
|
| 117 |
+
# Save the frame as a JPEG file
|
| 118 |
+
cv2.imwrite(frame_filename, frame)
|
| 119 |
+
|
| 120 |
+
# Store the first frame
|
| 121 |
+
if frame_number == 0:
|
| 122 |
+
first_frame = frame_filename
|
| 123 |
+
|
| 124 |
+
frame_number += 1
|
| 125 |
+
|
| 126 |
+
# Release the video capture object
|
| 127 |
+
cap.release()
|
| 128 |
+
|
| 129 |
+
# scan all the JPEG frame names in this directory
|
| 130 |
+
scanned_frames = [
|
| 131 |
+
p
|
| 132 |
+
for p in os.listdir(extracted_frames_output_dir)
|
| 133 |
+
if os.path.splitext(p)[-1] in [".jpg", ".jpeg", ".JPG", ".JPEG"]
|
| 134 |
+
]
|
| 135 |
+
scanned_frames.sort(key=lambda p: int(os.path.splitext(p)[0]))
|
| 136 |
+
# print(f"SCANNED_FRAMES: {scanned_frames}")
|
| 137 |
+
|
| 138 |
+
return [
|
| 139 |
+
first_frame, # first_frame_path
|
| 140 |
+
[], # tracking_points
|
| 141 |
+
[], # trackings_input_label
|
| 142 |
+
first_frame, # input_first_frame_image
|
| 143 |
+
first_frame, # points_map
|
| 144 |
+
extracted_frames_output_dir, # video_frames_dir
|
| 145 |
+
scanned_frames, # scanned_frames
|
| 146 |
+
None, # stored_inference_state
|
| 147 |
+
None, # stored_frame_names
|
| 148 |
+
gr.update(open=False), # video_in_drawer
|
| 149 |
+
]
|
| 150 |
+
|
| 151 |
+
|
| 152 |
+
def get_point(
|
| 153 |
+
point_type,
|
| 154 |
+
tracking_points,
|
| 155 |
+
trackings_input_label,
|
| 156 |
+
input_first_frame_image,
|
| 157 |
+
evt: gr.SelectData,
|
| 158 |
+
):
|
| 159 |
+
print(f"You selected {evt.value} at {evt.index} from {evt.target}")
|
| 160 |
+
|
| 161 |
+
tracking_points.append(evt.index)
|
| 162 |
+
# tracking_points.value.append(evt.index)
|
| 163 |
+
print(f"TRACKING POINT: {tracking_points}")
|
| 164 |
+
|
| 165 |
+
if point_type == "include":
|
| 166 |
+
trackings_input_label.append(1)
|
| 167 |
+
# trackings_input_label.value.append(1)
|
| 168 |
+
elif point_type == "exclude":
|
| 169 |
+
trackings_input_label.append(0)
|
| 170 |
+
# trackings_input_label.value.append(0)
|
| 171 |
+
print(f"TRACKING INPUT LABEL: {trackings_input_label}")
|
| 172 |
+
|
| 173 |
+
# Open the image and get its dimensions
|
| 174 |
+
transparent_background = Image.open(input_first_frame_image).convert("RGBA")
|
| 175 |
+
w, h = transparent_background.size
|
| 176 |
+
|
| 177 |
+
# Define the circle radius as a fraction of the smaller dimension
|
| 178 |
+
fraction = 0.02 # You can adjust this value as needed
|
| 179 |
+
radius = int(fraction * min(w, h))
|
| 180 |
+
|
| 181 |
+
# Create a transparent layer to draw on
|
| 182 |
+
transparent_layer = np.zeros((h, w, 4), dtype=np.uint8)
|
| 183 |
+
|
| 184 |
+
for index, track in enumerate(tracking_points):
|
| 185 |
+
if trackings_input_label[index] == 1:
|
| 186 |
+
cv2.circle(transparent_layer, track, radius, (0, 255, 0, 255), -1)
|
| 187 |
+
else:
|
| 188 |
+
cv2.circle(transparent_layer, track, radius, (255, 0, 0, 255), -1)
|
| 189 |
+
|
| 190 |
+
# Convert the transparent layer back to an image
|
| 191 |
+
transparent_layer = Image.fromarray(transparent_layer, "RGBA")
|
| 192 |
+
selected_point_map = Image.alpha_composite(
|
| 193 |
+
transparent_background, transparent_layer
|
| 194 |
+
)
|
| 195 |
+
|
| 196 |
+
return tracking_points, trackings_input_label, selected_point_map
|
| 197 |
+
|
| 198 |
+
|
| 199 |
+
def show_mask(mask, ax, obj_id=None, random_color=False):
|
| 200 |
+
if random_color:
|
| 201 |
+
color = np.concatenate([np.random.random(3), np.array([0.6])], axis=0)
|
| 202 |
+
else:
|
| 203 |
+
cmap = plt.get_cmap("tab10")
|
| 204 |
+
cmap_idx = 0 if obj_id is None else obj_id
|
| 205 |
+
color = np.array([*cmap(cmap_idx)[:3], 0.6])
|
| 206 |
+
h, w = mask.shape[-2:]
|
| 207 |
+
mask_image = mask.reshape(h, w, 1) * color.reshape(1, 1, -1)
|
| 208 |
+
ax.imshow(mask_image)
|
| 209 |
+
|
| 210 |
+
|
| 211 |
+
def show_points(coords, labels, ax, marker_size=200):
|
| 212 |
+
pos_points = coords[labels == 1]
|
| 213 |
+
neg_points = coords[labels == 0]
|
| 214 |
+
ax.scatter(
|
| 215 |
+
pos_points[:, 0],
|
| 216 |
+
pos_points[:, 1],
|
| 217 |
+
color="green",
|
| 218 |
+
marker="*",
|
| 219 |
+
s=marker_size,
|
| 220 |
+
edgecolor="white",
|
| 221 |
+
linewidth=1.25,
|
| 222 |
+
)
|
| 223 |
+
ax.scatter(
|
| 224 |
+
neg_points[:, 0],
|
| 225 |
+
neg_points[:, 1],
|
| 226 |
+
color="red",
|
| 227 |
+
marker="*",
|
| 228 |
+
s=marker_size,
|
| 229 |
+
edgecolor="white",
|
| 230 |
+
linewidth=1.25,
|
| 231 |
+
)
|
| 232 |
+
|
| 233 |
+
|
| 234 |
+
def show_box(box, ax):
|
| 235 |
+
x0, y0 = box[0], box[1]
|
| 236 |
+
w, h = box[2] - box[0], box[3] - box[1]
|
| 237 |
+
ax.add_patch(
|
| 238 |
+
plt.Rectangle((x0, y0), w, h, edgecolor="green", facecolor=(0, 0, 0, 0), lw=2)
|
| 239 |
+
)
|
| 240 |
+
|
| 241 |
+
|
| 242 |
+
def load_model(checkpoint):
|
| 243 |
+
# Load model accordingly to user's choice
|
| 244 |
+
if checkpoint == "tiny":
|
| 245 |
+
sam2_checkpoint = "./checkpoints/sam2.1_hiera_tiny.pt"
|
| 246 |
+
model_cfg = "configs/sam2.1/sam2.1_hiera_t.yaml"
|
| 247 |
+
return [sam2_checkpoint, model_cfg]
|
| 248 |
+
elif checkpoint == "samll":
|
| 249 |
+
sam2_checkpoint = "./checkpoints/sam2.1_hiera_small.pt"
|
| 250 |
+
model_cfg = "configs/sam2.1/sam2.1_hiera_s.yaml"
|
| 251 |
+
return [sam2_checkpoint, model_cfg]
|
| 252 |
+
elif checkpoint == "base-plus":
|
| 253 |
+
sam2_checkpoint = "./checkpoints/sam2.1_hiera_base_plus.pt"
|
| 254 |
+
model_cfg = "configs/sam2.1/sam2.1_hiera_b+.yaml"
|
| 255 |
+
return [sam2_checkpoint, model_cfg]
|
| 256 |
+
# elif checkpoint == "large":
|
| 257 |
+
# sam2_checkpoint = "./checkpoints/sam2.1_hiera_large.pt"
|
| 258 |
+
# model_cfg = "configs/sam2.1/sam2.1_hiera_l.yaml"
|
| 259 |
+
# return [sam2_checkpoint, model_cfg]
|
| 260 |
+
|
| 261 |
+
|
| 262 |
+
def get_mask_sam_process(
|
| 263 |
+
stored_inference_state,
|
| 264 |
+
input_first_frame_image,
|
| 265 |
+
checkpoint,
|
| 266 |
+
tracking_points,
|
| 267 |
+
trackings_input_label,
|
| 268 |
+
video_frames_dir, # extracted_frames_output_dir defined in 'preprocess_video_in' function
|
| 269 |
+
scanned_frames,
|
| 270 |
+
working_frame: str = None, # current frame being added points
|
| 271 |
+
available_frames_to_check: List[str] = [],
|
| 272 |
+
# progress=gr.Progress(track_tqdm=True)
|
| 273 |
+
):
|
| 274 |
+
# get model and model config paths
|
| 275 |
+
print(f"USER CHOSEN CHECKPOINT: {checkpoint}")
|
| 276 |
+
sam2_checkpoint, model_cfg = load_model(checkpoint)
|
| 277 |
+
print("MODEL LOADED")
|
| 278 |
+
|
| 279 |
+
# set predictor
|
| 280 |
+
|
| 281 |
+
predictor = build_sam2_video_predictor(model_cfg, sam2_checkpoint, device="cpu")
|
| 282 |
+
|
| 283 |
+
print("PREDICTOR READY")
|
| 284 |
+
|
| 285 |
+
# `video_dir` a directory of JPEG frames with filenames like `<frame_index>.jpg`
|
| 286 |
+
# print(f"STATE FRAME OUTPUT DIRECTORY: {video_frames_dir}")
|
| 287 |
+
video_dir = video_frames_dir
|
| 288 |
+
|
| 289 |
+
# scan all the JPEG frame names in this directory
|
| 290 |
+
frame_names = scanned_frames
|
| 291 |
+
|
| 292 |
+
# print(f"STORED INFERENCE STEP: {stored_inference_state}")
|
| 293 |
+
if stored_inference_state is None:
|
| 294 |
+
# Init SAM2 inference_state
|
| 295 |
+
inference_state = predictor.init_state(video_path=video_dir)
|
| 296 |
+
inference_state["num_pathway"] = 3
|
| 297 |
+
inference_state["iou_thre"] = 0.3
|
| 298 |
+
inference_state["uncertainty"] = 2
|
| 299 |
+
print("NEW INFERENCE_STATE INITIATED")
|
| 300 |
+
else:
|
| 301 |
+
inference_state = stored_inference_state
|
| 302 |
+
|
| 303 |
+
inference_state["device"] = "cpu"
|
| 304 |
+
|
| 305 |
+
# segment and track one object
|
| 306 |
+
# predictor.reset_state(inference_state) # if any previous tracking, reset
|
| 307 |
+
|
| 308 |
+
### HANDLING WORKING FRAME
|
| 309 |
+
# new_working_frame = None
|
| 310 |
+
# Add new point
|
| 311 |
+
if working_frame is None:
|
| 312 |
+
ann_frame_idx = (
|
| 313 |
+
0 # the frame index we interact with, 0 if it is the first frame
|
| 314 |
+
)
|
| 315 |
+
working_frame = "00000.jpg"
|
| 316 |
+
else:
|
| 317 |
+
# Use a regular expression to find the integer
|
| 318 |
+
match = re.search(r"frame_(\d+)", working_frame)
|
| 319 |
+
if match:
|
| 320 |
+
# Extract the integer from the match
|
| 321 |
+
frame_number = int(match.group(1))
|
| 322 |
+
ann_frame_idx = frame_number
|
| 323 |
+
|
| 324 |
+
print(f"NEW_WORKING_FRAME PATH: {working_frame}")
|
| 325 |
+
|
| 326 |
+
ann_obj_id = (
|
| 327 |
+
1 # give a unique id to each object we interact with (it can be any integers)
|
| 328 |
+
)
|
| 329 |
+
|
| 330 |
+
# Let's add a positive click at (x, y) = (210, 350) to get started
|
| 331 |
+
points = np.array(tracking_points, dtype=np.float32)
|
| 332 |
+
# for labels, `1` means positive click and `0` means negative click
|
| 333 |
+
labels = np.array(trackings_input_label, np.int32)
|
| 334 |
+
|
| 335 |
+
_, out_obj_ids, out_mask_logits = predictor.add_new_points(
|
| 336 |
+
inference_state=inference_state,
|
| 337 |
+
frame_idx=ann_frame_idx,
|
| 338 |
+
obj_id=ann_obj_id,
|
| 339 |
+
points=points,
|
| 340 |
+
labels=labels,
|
| 341 |
+
)
|
| 342 |
+
|
| 343 |
+
# Create the plot
|
| 344 |
+
plt.figure(figsize=(12, 8))
|
| 345 |
+
plt.title(f"frame {ann_frame_idx}")
|
| 346 |
+
plt.imshow(Image.open(os.path.join(video_dir, frame_names[ann_frame_idx])))
|
| 347 |
+
show_points(points, labels, plt.gca())
|
| 348 |
+
show_mask(
|
| 349 |
+
(out_mask_logits[0] > 0.0).cpu().numpy(), plt.gca(), obj_id=out_obj_ids[0]
|
| 350 |
+
)
|
| 351 |
+
|
| 352 |
+
# Save the plot as a JPG file
|
| 353 |
+
first_frame_output_filename = "output_first_frame.jpg"
|
| 354 |
+
plt.savefig(first_frame_output_filename, format="jpg")
|
| 355 |
+
plt.close()
|
| 356 |
+
# torch.cuda.empty_cache()
|
| 357 |
+
|
| 358 |
+
# Assuming available_frames_to_check.value is a list
|
| 359 |
+
if working_frame not in available_frames_to_check:
|
| 360 |
+
available_frames_to_check.append(working_frame)
|
| 361 |
+
print(available_frames_to_check)
|
| 362 |
+
|
| 363 |
+
# return gr.update(visible=True), "output_first_frame.jpg", frame_names, predictor, inference_state, gr.update(choices=available_frames_to_check, value=working_frame, visible=True)
|
| 364 |
+
return (
|
| 365 |
+
"output_first_frame.jpg",
|
| 366 |
+
frame_names,
|
| 367 |
+
predictor,
|
| 368 |
+
inference_state,
|
| 369 |
+
gr.update(
|
| 370 |
+
choices=available_frames_to_check, value=working_frame, visible=False
|
| 371 |
+
),
|
| 372 |
+
)
|
| 373 |
+
|
| 374 |
+
|
| 375 |
+
@spaces.GPU
|
| 376 |
+
def propagate_to_all(
|
| 377 |
+
video_in,
|
| 378 |
+
checkpoint,
|
| 379 |
+
stored_inference_state,
|
| 380 |
+
stored_frame_names,
|
| 381 |
+
video_frames_dir,
|
| 382 |
+
vis_frame_type,
|
| 383 |
+
available_frames_to_check,
|
| 384 |
+
working_frame,
|
| 385 |
+
progress=gr.Progress(track_tqdm=True),
|
| 386 |
+
):
|
| 387 |
+
# use bfloat16 for the entire notebook
|
| 388 |
+
torch.autocast(device_type="cuda", dtype=torch.bfloat16).__enter__()
|
| 389 |
+
|
| 390 |
+
if torch.cuda.get_device_properties(0).major >= 8:
|
| 391 |
+
# turn on tfloat32 for Ampere GPUs (https://pytorch.org/docs/stable/notes/cuda.html#tensorfloat-32-tf32-on-ampere-devices)
|
| 392 |
+
torch.backends.cuda.matmul.allow_tf32 = True
|
| 393 |
+
torch.backends.cudnn.allow_tf32 = True
|
| 394 |
+
|
| 395 |
+
#### PROPAGATION ####
|
| 396 |
+
sam2_checkpoint, model_cfg = load_model(checkpoint)
|
| 397 |
+
# set predictor
|
| 398 |
+
|
| 399 |
+
inference_state = stored_inference_state
|
| 400 |
+
|
| 401 |
+
if torch.cuda.is_available():
|
| 402 |
+
inference_state["device"] = "cuda"
|
| 403 |
+
predictor = build_sam2_video_predictor(model_cfg, sam2_checkpoint)
|
| 404 |
+
else:
|
| 405 |
+
inference_state["device"] = "cpu"
|
| 406 |
+
predictor = build_sam2_video_predictor(model_cfg, sam2_checkpoint, device="cpu")
|
| 407 |
+
|
| 408 |
+
frame_names = stored_frame_names
|
| 409 |
+
video_dir = video_frames_dir
|
| 410 |
+
|
| 411 |
+
# Define a directory to save the JPEG images
|
| 412 |
+
frames_output_dir = "frames_output_images"
|
| 413 |
+
os.makedirs(frames_output_dir, exist_ok=True)
|
| 414 |
+
|
| 415 |
+
# Initialize a list to store file paths of saved images
|
| 416 |
+
jpeg_images = []
|
| 417 |
+
|
| 418 |
+
# run propagation throughout the video and collect the results in a dict
|
| 419 |
+
video_segments = {} # video_segments contains the per-frame segmentation results
|
| 420 |
+
# for out_frame_idx, out_obj_ids, out_mask_logits in predictor.propagate_in_video(inference_state):
|
| 421 |
+
# video_segments[out_frame_idx] = {
|
| 422 |
+
# out_obj_id: (out_mask_logits[i] > 0.0).cpu().numpy()
|
| 423 |
+
# for i, out_obj_id in enumerate(out_obj_ids)
|
| 424 |
+
# }
|
| 425 |
+
|
| 426 |
+
out_obj_ids, out_mask_logits = predictor.propagate_in_video(
|
| 427 |
+
inference_state,
|
| 428 |
+
start_frame_idx=0,
|
| 429 |
+
reverse=False,
|
| 430 |
+
)
|
| 431 |
+
print(out_obj_ids)
|
| 432 |
+
for frame_idx in range(0, inference_state["num_frames"]):
|
| 433 |
+
video_segments[frame_idx] = {
|
| 434 |
+
out_obj_ids[0]: (out_mask_logits[frame_idx] > 0.0).cpu().numpy()
|
| 435 |
+
}
|
| 436 |
+
# output_scores_per_object[object_id][frame_idx] = out_mask_logits[frame_idx].cpu().numpy()
|
| 437 |
+
|
| 438 |
+
# render the segmentation results every few frames
|
| 439 |
+
if vis_frame_type == "check":
|
| 440 |
+
vis_frame_stride = 15
|
| 441 |
+
elif vis_frame_type == "render":
|
| 442 |
+
vis_frame_stride = 1
|
| 443 |
+
|
| 444 |
+
plt.close("all")
|
| 445 |
+
for out_frame_idx in range(0, len(frame_names), vis_frame_stride):
|
| 446 |
+
plt.figure(figsize=(6, 4))
|
| 447 |
+
plt.title(f"frame {out_frame_idx}")
|
| 448 |
+
plt.imshow(Image.open(os.path.join(video_dir, frame_names[out_frame_idx])))
|
| 449 |
+
for out_obj_id, out_mask in video_segments[out_frame_idx].items():
|
| 450 |
+
show_mask(out_mask, plt.gca(), obj_id=out_obj_id)
|
| 451 |
+
|
| 452 |
+
# Define the output filename and save the figure as a JPEG file
|
| 453 |
+
output_filename = os.path.join(frames_output_dir, f"frame_{out_frame_idx}.jpg")
|
| 454 |
+
plt.savefig(output_filename, format="jpg")
|
| 455 |
+
|
| 456 |
+
# Close the plot
|
| 457 |
+
plt.close()
|
| 458 |
+
|
| 459 |
+
# Append the file path to the list
|
| 460 |
+
jpeg_images.append(output_filename)
|
| 461 |
+
|
| 462 |
+
if f"frame_{out_frame_idx}.jpg" not in available_frames_to_check:
|
| 463 |
+
available_frames_to_check.append(f"frame_{out_frame_idx}.jpg")
|
| 464 |
+
|
| 465 |
+
torch.cuda.empty_cache()
|
| 466 |
+
print(f"JPEG_IMAGES: {jpeg_images}")
|
| 467 |
+
|
| 468 |
+
if vis_frame_type == "check":
|
| 469 |
+
return (
|
| 470 |
+
gr.update(value=jpeg_images),
|
| 471 |
+
gr.update(value=None),
|
| 472 |
+
gr.update(
|
| 473 |
+
choices=available_frames_to_check, value=working_frame, visible=True
|
| 474 |
+
),
|
| 475 |
+
available_frames_to_check,
|
| 476 |
+
gr.update(visible=True),
|
| 477 |
+
)
|
| 478 |
+
elif vis_frame_type == "render":
|
| 479 |
+
# Create a video clip from the image sequence
|
| 480 |
+
original_fps = get_video_fps(video_in)
|
| 481 |
+
# sampled_images = sparse_sampling(jpeg_images, original_fps, target_fps=6)
|
| 482 |
+
clip = ImageSequenceClip(jpeg_images, fps=original_fps // 6)
|
| 483 |
+
# clip = ImageSequenceClip(jpeg_images, fps=fps)
|
| 484 |
+
# Write the result to a file
|
| 485 |
+
final_vid_output_path = "output_video.mp4"
|
| 486 |
+
|
| 487 |
+
# Write the result to a file
|
| 488 |
+
clip.write_videofile(final_vid_output_path, codec="libx264")
|
| 489 |
+
|
| 490 |
+
return (
|
| 491 |
+
gr.update(value=None),
|
| 492 |
+
gr.update(value=final_vid_output_path),
|
| 493 |
+
working_frame,
|
| 494 |
+
available_frames_to_check,
|
| 495 |
+
gr.update(visible=True),
|
| 496 |
+
)
|
| 497 |
+
|
| 498 |
+
|
| 499 |
+
def update_ui(vis_frame_type):
|
| 500 |
+
if vis_frame_type == "check":
|
| 501 |
+
return gr.update(visible=True), gr.update(visible=False)
|
| 502 |
+
elif vis_frame_type == "render":
|
| 503 |
+
return gr.update(visible=False), gr.update(visible=True)
|
| 504 |
+
|
| 505 |
+
|
| 506 |
+
def switch_working_frame(working_frame, scanned_frames, video_frames_dir):
|
| 507 |
+
new_working_frame = None
|
| 508 |
+
if working_frame == None:
|
| 509 |
+
new_working_frame = os.path.join(video_frames_dir, scanned_frames[0])
|
| 510 |
+
|
| 511 |
+
else:
|
| 512 |
+
# Use a regular expression to find the integer
|
| 513 |
+
match = re.search(r"frame_(\d+)", working_frame)
|
| 514 |
+
if match:
|
| 515 |
+
# Extract the integer from the match
|
| 516 |
+
frame_number = int(match.group(1))
|
| 517 |
+
ann_frame_idx = frame_number
|
| 518 |
+
new_working_frame = os.path.join(
|
| 519 |
+
video_frames_dir, scanned_frames[ann_frame_idx]
|
| 520 |
+
)
|
| 521 |
+
return gr.State([]), gr.State([]), new_working_frame, new_working_frame
|
| 522 |
+
|
| 523 |
+
|
| 524 |
+
def reset_propagation(first_frame_path, predictor, stored_inference_state):
|
| 525 |
+
predictor.reset_state(stored_inference_state)
|
| 526 |
+
# print(f"RESET State: {stored_inference_state} ")
|
| 527 |
+
return (
|
| 528 |
+
first_frame_path,
|
| 529 |
+
[],
|
| 530 |
+
[],
|
| 531 |
+
gr.update(value=None, visible=False),
|
| 532 |
+
stored_inference_state,
|
| 533 |
+
None,
|
| 534 |
+
["frame_0.jpg"],
|
| 535 |
+
first_frame_path,
|
| 536 |
+
"frame_0.jpg",
|
| 537 |
+
gr.update(visible=False),
|
| 538 |
+
)
|
| 539 |
+
|
| 540 |
+
|
| 541 |
+
with gr.Blocks(css=css) as demo:
|
| 542 |
+
first_frame_path = gr.State()
|
| 543 |
+
tracking_points = gr.State([])
|
| 544 |
+
trackings_input_label = gr.State([])
|
| 545 |
+
video_frames_dir = gr.State()
|
| 546 |
+
scanned_frames = gr.State()
|
| 547 |
+
loaded_predictor = gr.State()
|
| 548 |
+
stored_inference_state = gr.State()
|
| 549 |
+
stored_frame_names = gr.State()
|
| 550 |
+
available_frames_to_check = gr.State([])
|
| 551 |
+
with gr.Column():
|
| 552 |
+
gr.Markdown(
|
| 553 |
+
"""
|
| 554 |
+
<h1 style="text-align: center;">🔥 SAM2Long Demo 🔥</h1>
|
| 555 |
+
"""
|
| 556 |
+
)
|
| 557 |
+
gr.Markdown(
|
| 558 |
+
"""
|
| 559 |
+
This is a simple demo for video segmentation with [SAM2Long](https://github.com/Mark12Ding/SAM2Long).
|
| 560 |
+
"""
|
| 561 |
+
)
|
| 562 |
+
gr.Markdown(
|
| 563 |
+
"""
|
| 564 |
+
### 📋 Instructions:
|
| 565 |
+
It is largely built on the [SAM2-Video-Predictor](https://huggingface.co/spaces/fffiloni/SAM2-Video-Predictor).
|
| 566 |
+
1. **Upload your video** [MP4-24fps]
|
| 567 |
+
2. With **'include' point type** selected, click on the object to mask on the first frame
|
| 568 |
+
3. Switch to **'exclude' point type** if you want to specify an area to avoid
|
| 569 |
+
4. **Get Mask!**
|
| 570 |
+
5. **Check Propagation** every 15 frames
|
| 571 |
+
6. **Propagate with "render"** to render the final masked video
|
| 572 |
+
7. **Hit Reset** button if you want to refresh and start again
|
| 573 |
+
|
| 574 |
+
*Note: Input video will be processed for up to 60 seconds only for demo purposes.*
|
| 575 |
+
"""
|
| 576 |
+
)
|
| 577 |
+
with gr.Row():
|
| 578 |
+
with gr.Column():
|
| 579 |
+
with gr.Group():
|
| 580 |
+
with gr.Group():
|
| 581 |
+
with gr.Row():
|
| 582 |
+
point_type = gr.Radio(
|
| 583 |
+
label="point type",
|
| 584 |
+
choices=["include", "exclude"],
|
| 585 |
+
value="include",
|
| 586 |
+
scale=2,
|
| 587 |
+
)
|
| 588 |
+
clear_points_btn = gr.Button("Clear Points", scale=1)
|
| 589 |
+
|
| 590 |
+
input_first_frame_image = gr.Image(
|
| 591 |
+
label="input image",
|
| 592 |
+
interactive=False,
|
| 593 |
+
type="filepath",
|
| 594 |
+
visible=False,
|
| 595 |
+
)
|
| 596 |
+
|
| 597 |
+
points_map = gr.Image(
|
| 598 |
+
label="Point n Click map", type="filepath", interactive=False
|
| 599 |
+
)
|
| 600 |
+
|
| 601 |
+
with gr.Group():
|
| 602 |
+
with gr.Row():
|
| 603 |
+
checkpoint = gr.Dropdown(
|
| 604 |
+
label="Checkpoint",
|
| 605 |
+
choices=["tiny", "small", "base-plus"],
|
| 606 |
+
value="tiny",
|
| 607 |
+
)
|
| 608 |
+
submit_btn = gr.Button("Get Mask", size="lg")
|
| 609 |
+
|
| 610 |
+
with gr.Accordion("Your video IN", open=True) as video_in_drawer:
|
| 611 |
+
video_in = gr.Video(label="Video IN", format="mp4")
|
| 612 |
+
|
| 613 |
+
gr.HTML("""
|
| 614 |
+
|
| 615 |
+
<a href="https://huggingface.co/spaces/{os.environ['SPACE_ID']}?duplicate=true">
|
| 616 |
+
<img src="https://huggingface.co/datasets/huggingface/badges/resolve/main/duplicate-this-space-lg-dark.svg" alt="Duplicate this Space" />
|
| 617 |
+
</a> to skip queue and avoid OOM errors from heavy public load
|
| 618 |
+
""")
|
| 619 |
+
|
| 620 |
+
with gr.Column():
|
| 621 |
+
with gr.Group():
|
| 622 |
+
# with gr.Group():
|
| 623 |
+
# with gr.Row():
|
| 624 |
+
working_frame = gr.Dropdown(
|
| 625 |
+
label="working frame ID",
|
| 626 |
+
choices=["frame_0.jpg"],
|
| 627 |
+
value="frame_0.jpg",
|
| 628 |
+
visible=False,
|
| 629 |
+
allow_custom_value=False,
|
| 630 |
+
interactive=True,
|
| 631 |
+
)
|
| 632 |
+
# change_current = gr.Button("change current", visible=False)
|
| 633 |
+
# working_frame = []
|
| 634 |
+
output_result = gr.Image(label="current working mask ref")
|
| 635 |
+
with gr.Group():
|
| 636 |
+
with gr.Row():
|
| 637 |
+
vis_frame_type = gr.Radio(
|
| 638 |
+
label="Propagation level",
|
| 639 |
+
choices=["check", "render"],
|
| 640 |
+
value="check",
|
| 641 |
+
scale=2,
|
| 642 |
+
)
|
| 643 |
+
propagate_btn = gr.Button("Propagate", scale=2)
|
| 644 |
+
|
| 645 |
+
reset_prpgt_brn = gr.Button("Reset", visible=False)
|
| 646 |
+
output_propagated = gr.Gallery(
|
| 647 |
+
label="Propagated Mask samples gallery", columns=4, visible=False
|
| 648 |
+
)
|
| 649 |
+
output_video = gr.Video(visible=False)
|
| 650 |
+
# output_result_mask = gr.Image()
|
| 651 |
+
|
| 652 |
+
# When new video is uploaded
|
| 653 |
+
video_in.upload(
|
| 654 |
+
fn=preprocess_video_in,
|
| 655 |
+
inputs=[video_in],
|
| 656 |
+
outputs=[
|
| 657 |
+
first_frame_path,
|
| 658 |
+
tracking_points, # update Tracking Points in the gr.State([]) object
|
| 659 |
+
trackings_input_label, # update Tracking Labels in the gr.State([]) object
|
| 660 |
+
input_first_frame_image, # hidden component used as ref when clearing points
|
| 661 |
+
points_map, # Image component where we add new tracking points
|
| 662 |
+
video_frames_dir, # Array where frames from video_in are deep stored
|
| 663 |
+
scanned_frames, # Scanned frames by SAM2
|
| 664 |
+
stored_inference_state, # Sam2 inference state
|
| 665 |
+
stored_frame_names, #
|
| 666 |
+
video_in_drawer, # Accordion to hide uploaded video player
|
| 667 |
+
],
|
| 668 |
+
queue=False,
|
| 669 |
+
)
|
| 670 |
+
|
| 671 |
+
# triggered when we click on image to add new points
|
| 672 |
+
points_map.select(
|
| 673 |
+
fn=get_point,
|
| 674 |
+
inputs=[
|
| 675 |
+
point_type, # "include" or "exclude"
|
| 676 |
+
tracking_points, # get tracking_points values
|
| 677 |
+
trackings_input_label, # get tracking label values
|
| 678 |
+
input_first_frame_image, # gr.State() first frame path
|
| 679 |
+
],
|
| 680 |
+
outputs=[
|
| 681 |
+
tracking_points, # updated with new points
|
| 682 |
+
trackings_input_label, # updated with corresponding labels
|
| 683 |
+
points_map, # updated image with points
|
| 684 |
+
],
|
| 685 |
+
queue=False,
|
| 686 |
+
)
|
| 687 |
+
|
| 688 |
+
# Clear every points clicked and added to the map
|
| 689 |
+
clear_points_btn.click(
|
| 690 |
+
fn=clear_points,
|
| 691 |
+
inputs=input_first_frame_image, # we get the untouched hidden image
|
| 692 |
+
outputs=[
|
| 693 |
+
first_frame_path,
|
| 694 |
+
tracking_points,
|
| 695 |
+
trackings_input_label,
|
| 696 |
+
points_map,
|
| 697 |
+
# stored_inference_state,
|
| 698 |
+
],
|
| 699 |
+
queue=False,
|
| 700 |
+
)
|
| 701 |
+
|
| 702 |
+
# change_current.click(
|
| 703 |
+
# fn = switch_working_frame,
|
| 704 |
+
# inputs = [working_frame, scanned_frames, video_frames_dir],
|
| 705 |
+
# outputs = [tracking_points, trackings_input_label, input_first_frame_image, points_map],
|
| 706 |
+
# queue=False
|
| 707 |
+
# )
|
| 708 |
+
|
| 709 |
+
submit_btn.click(
|
| 710 |
+
fn=get_mask_sam_process,
|
| 711 |
+
inputs=[
|
| 712 |
+
stored_inference_state,
|
| 713 |
+
input_first_frame_image,
|
| 714 |
+
checkpoint,
|
| 715 |
+
tracking_points,
|
| 716 |
+
trackings_input_label,
|
| 717 |
+
video_frames_dir,
|
| 718 |
+
scanned_frames,
|
| 719 |
+
working_frame,
|
| 720 |
+
available_frames_to_check,
|
| 721 |
+
],
|
| 722 |
+
outputs=[
|
| 723 |
+
output_result,
|
| 724 |
+
stored_frame_names,
|
| 725 |
+
loaded_predictor,
|
| 726 |
+
stored_inference_state,
|
| 727 |
+
working_frame,
|
| 728 |
+
],
|
| 729 |
+
queue=False,
|
| 730 |
+
)
|
| 731 |
+
|
| 732 |
+
reset_prpgt_brn.click(
|
| 733 |
+
fn=reset_propagation,
|
| 734 |
+
inputs=[first_frame_path, loaded_predictor, stored_inference_state],
|
| 735 |
+
outputs=[
|
| 736 |
+
points_map,
|
| 737 |
+
tracking_points,
|
| 738 |
+
trackings_input_label,
|
| 739 |
+
output_propagated,
|
| 740 |
+
stored_inference_state,
|
| 741 |
+
output_result,
|
| 742 |
+
available_frames_to_check,
|
| 743 |
+
input_first_frame_image,
|
| 744 |
+
working_frame,
|
| 745 |
+
reset_prpgt_brn,
|
| 746 |
+
],
|
| 747 |
+
queue=False,
|
| 748 |
+
)
|
| 749 |
+
|
| 750 |
+
propagate_btn.click(
|
| 751 |
+
fn=update_ui,
|
| 752 |
+
inputs=[vis_frame_type],
|
| 753 |
+
outputs=[output_propagated, output_video],
|
| 754 |
+
queue=False,
|
| 755 |
+
).then(
|
| 756 |
+
fn=propagate_to_all,
|
| 757 |
+
inputs=[
|
| 758 |
+
video_in,
|
| 759 |
+
checkpoint,
|
| 760 |
+
stored_inference_state,
|
| 761 |
+
stored_frame_names,
|
| 762 |
+
video_frames_dir,
|
| 763 |
+
vis_frame_type,
|
| 764 |
+
available_frames_to_check,
|
| 765 |
+
working_frame,
|
| 766 |
+
],
|
| 767 |
+
outputs=[
|
| 768 |
+
output_propagated,
|
| 769 |
+
output_video,
|
| 770 |
+
working_frame,
|
| 771 |
+
available_frames_to_check,
|
| 772 |
+
reset_prpgt_brn,
|
| 773 |
+
],
|
| 774 |
+
)
|
| 775 |
+
|
| 776 |
+
demo.launch()
|
requirements.txt
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
gradio>=5.0.0
|
| 2 |
+
torch>=2.0.0
|
| 3 |
+
numpy>=1.24.0
|
| 4 |
+
opencv-python>=4.8.0
|
| 5 |
+
decord>=0.6.0
|
sam2-repo/.clang-format
ADDED
|
@@ -0,0 +1,85 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
AccessModifierOffset: -1
|
| 2 |
+
AlignAfterOpenBracket: AlwaysBreak
|
| 3 |
+
AlignConsecutiveAssignments: false
|
| 4 |
+
AlignConsecutiveDeclarations: false
|
| 5 |
+
AlignEscapedNewlinesLeft: true
|
| 6 |
+
AlignOperands: false
|
| 7 |
+
AlignTrailingComments: false
|
| 8 |
+
AllowAllParametersOfDeclarationOnNextLine: false
|
| 9 |
+
AllowShortBlocksOnASingleLine: false
|
| 10 |
+
AllowShortCaseLabelsOnASingleLine: false
|
| 11 |
+
AllowShortFunctionsOnASingleLine: Empty
|
| 12 |
+
AllowShortIfStatementsOnASingleLine: false
|
| 13 |
+
AllowShortLoopsOnASingleLine: false
|
| 14 |
+
AlwaysBreakAfterReturnType: None
|
| 15 |
+
AlwaysBreakBeforeMultilineStrings: true
|
| 16 |
+
AlwaysBreakTemplateDeclarations: true
|
| 17 |
+
BinPackArguments: false
|
| 18 |
+
BinPackParameters: false
|
| 19 |
+
BraceWrapping:
|
| 20 |
+
AfterClass: false
|
| 21 |
+
AfterControlStatement: false
|
| 22 |
+
AfterEnum: false
|
| 23 |
+
AfterFunction: false
|
| 24 |
+
AfterNamespace: false
|
| 25 |
+
AfterObjCDeclaration: false
|
| 26 |
+
AfterStruct: false
|
| 27 |
+
AfterUnion: false
|
| 28 |
+
BeforeCatch: false
|
| 29 |
+
BeforeElse: false
|
| 30 |
+
IndentBraces: false
|
| 31 |
+
BreakBeforeBinaryOperators: None
|
| 32 |
+
BreakBeforeBraces: Attach
|
| 33 |
+
BreakBeforeTernaryOperators: true
|
| 34 |
+
BreakConstructorInitializersBeforeComma: false
|
| 35 |
+
BreakAfterJavaFieldAnnotations: false
|
| 36 |
+
BreakStringLiterals: false
|
| 37 |
+
ColumnLimit: 80
|
| 38 |
+
CommentPragmas: '^ IWYU pragma:'
|
| 39 |
+
ConstructorInitializerAllOnOneLineOrOnePerLine: true
|
| 40 |
+
ConstructorInitializerIndentWidth: 4
|
| 41 |
+
ContinuationIndentWidth: 4
|
| 42 |
+
Cpp11BracedListStyle: true
|
| 43 |
+
DerivePointerAlignment: false
|
| 44 |
+
DisableFormat: false
|
| 45 |
+
ForEachMacros: [ FOR_EACH, FOR_EACH_R, FOR_EACH_RANGE, ]
|
| 46 |
+
IncludeCategories:
|
| 47 |
+
- Regex: '^<.*\.h(pp)?>'
|
| 48 |
+
Priority: 1
|
| 49 |
+
- Regex: '^<.*'
|
| 50 |
+
Priority: 2
|
| 51 |
+
- Regex: '.*'
|
| 52 |
+
Priority: 3
|
| 53 |
+
IndentCaseLabels: true
|
| 54 |
+
IndentWidth: 2
|
| 55 |
+
IndentWrappedFunctionNames: false
|
| 56 |
+
KeepEmptyLinesAtTheStartOfBlocks: false
|
| 57 |
+
MacroBlockBegin: ''
|
| 58 |
+
MacroBlockEnd: ''
|
| 59 |
+
MaxEmptyLinesToKeep: 1
|
| 60 |
+
NamespaceIndentation: None
|
| 61 |
+
ObjCBlockIndentWidth: 2
|
| 62 |
+
ObjCSpaceAfterProperty: false
|
| 63 |
+
ObjCSpaceBeforeProtocolList: false
|
| 64 |
+
PenaltyBreakBeforeFirstCallParameter: 1
|
| 65 |
+
PenaltyBreakComment: 300
|
| 66 |
+
PenaltyBreakFirstLessLess: 120
|
| 67 |
+
PenaltyBreakString: 1000
|
| 68 |
+
PenaltyExcessCharacter: 1000000
|
| 69 |
+
PenaltyReturnTypeOnItsOwnLine: 200
|
| 70 |
+
PointerAlignment: Left
|
| 71 |
+
ReflowComments: true
|
| 72 |
+
SortIncludes: true
|
| 73 |
+
SpaceAfterCStyleCast: false
|
| 74 |
+
SpaceBeforeAssignmentOperators: true
|
| 75 |
+
SpaceBeforeParens: ControlStatements
|
| 76 |
+
SpaceInEmptyParentheses: false
|
| 77 |
+
SpacesBeforeTrailingComments: 1
|
| 78 |
+
SpacesInAngles: false
|
| 79 |
+
SpacesInContainerLiterals: true
|
| 80 |
+
SpacesInCStyleCastParentheses: false
|
| 81 |
+
SpacesInParentheses: false
|
| 82 |
+
SpacesInSquareBrackets: false
|
| 83 |
+
Standard: Cpp11
|
| 84 |
+
TabWidth: 8
|
| 85 |
+
UseTab: Never
|
sam2-repo/.github/workflows/check_fmt.yml
ADDED
|
@@ -0,0 +1,17 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
name: SAM2/fmt
|
| 2 |
+
on:
|
| 3 |
+
pull_request:
|
| 4 |
+
branches:
|
| 5 |
+
- main
|
| 6 |
+
jobs:
|
| 7 |
+
ufmt_check:
|
| 8 |
+
runs-on: ubuntu-latest
|
| 9 |
+
steps:
|
| 10 |
+
- name: Check formatting
|
| 11 |
+
uses: omnilib/ufmt@action-v1
|
| 12 |
+
with:
|
| 13 |
+
path: sam2 tools
|
| 14 |
+
version: "2.0.0b2"
|
| 15 |
+
python-version: "3.10"
|
| 16 |
+
black-version: "24.2.0"
|
| 17 |
+
usort-version: "1.0.2"
|
sam2-repo/.gitignore
ADDED
|
@@ -0,0 +1,11 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
.vscode/
|
| 2 |
+
.DS_Store
|
| 3 |
+
__pycache__/
|
| 4 |
+
*-checkpoint.ipynb
|
| 5 |
+
.venv
|
| 6 |
+
*.egg*
|
| 7 |
+
build/*
|
| 8 |
+
_C.*
|
| 9 |
+
outputs/*
|
| 10 |
+
checkpoints/*.pt
|
| 11 |
+
demo/backend/checkpoints/*.pt
|
sam2-repo/.watchmanconfig
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
{}
|
sam2-repo/CODE_OF_CONDUCT.md
ADDED
|
@@ -0,0 +1,80 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Code of Conduct
|
| 2 |
+
|
| 3 |
+
## Our Pledge
|
| 4 |
+
|
| 5 |
+
In the interest of fostering an open and welcoming environment, we as
|
| 6 |
+
contributors and maintainers pledge to make participation in our project and
|
| 7 |
+
our community a harassment-free experience for everyone, regardless of age, body
|
| 8 |
+
size, disability, ethnicity, sex characteristics, gender identity and expression,
|
| 9 |
+
level of experience, education, socio-economic status, nationality, personal
|
| 10 |
+
appearance, race, religion, or sexual identity and orientation.
|
| 11 |
+
|
| 12 |
+
## Our Standards
|
| 13 |
+
|
| 14 |
+
Examples of behavior that contributes to creating a positive environment
|
| 15 |
+
include:
|
| 16 |
+
|
| 17 |
+
* Using welcoming and inclusive language
|
| 18 |
+
* Being respectful of differing viewpoints and experiences
|
| 19 |
+
* Gracefully accepting constructive criticism
|
| 20 |
+
* Focusing on what is best for the community
|
| 21 |
+
* Showing empathy towards other community members
|
| 22 |
+
|
| 23 |
+
Examples of unacceptable behavior by participants include:
|
| 24 |
+
|
| 25 |
+
* The use of sexualized language or imagery and unwelcome sexual attention or
|
| 26 |
+
advances
|
| 27 |
+
* Trolling, insulting/derogatory comments, and personal or political attacks
|
| 28 |
+
* Public or private harassment
|
| 29 |
+
* Publishing others' private information, such as a physical or electronic
|
| 30 |
+
address, without explicit permission
|
| 31 |
+
* Other conduct which could reasonably be considered inappropriate in a
|
| 32 |
+
professional setting
|
| 33 |
+
|
| 34 |
+
## Our Responsibilities
|
| 35 |
+
|
| 36 |
+
Project maintainers are responsible for clarifying the standards of acceptable
|
| 37 |
+
behavior and are expected to take appropriate and fair corrective action in
|
| 38 |
+
response to any instances of unacceptable behavior.
|
| 39 |
+
|
| 40 |
+
Project maintainers have the right and responsibility to remove, edit, or
|
| 41 |
+
reject comments, commits, code, wiki edits, issues, and other contributions
|
| 42 |
+
that are not aligned to this Code of Conduct, or to ban temporarily or
|
| 43 |
+
permanently any contributor for other behaviors that they deem inappropriate,
|
| 44 |
+
threatening, offensive, or harmful.
|
| 45 |
+
|
| 46 |
+
## Scope
|
| 47 |
+
|
| 48 |
+
This Code of Conduct applies within all project spaces, and it also applies when
|
| 49 |
+
an individual is representing the project or its community in public spaces.
|
| 50 |
+
Examples of representing a project or community include using an official
|
| 51 |
+
project e-mail address, posting via an official social media account, or acting
|
| 52 |
+
as an appointed representative at an online or offline event. Representation of
|
| 53 |
+
a project may be further defined and clarified by project maintainers.
|
| 54 |
+
|
| 55 |
+
This Code of Conduct also applies outside the project spaces when there is a
|
| 56 |
+
reasonable belief that an individual's behavior may have a negative impact on
|
| 57 |
+
the project or its community.
|
| 58 |
+
|
| 59 |
+
## Enforcement
|
| 60 |
+
|
| 61 |
+
Instances of abusive, harassing, or otherwise unacceptable behavior may be
|
| 62 |
+
reported by contacting the project team at <[email protected]>. All
|
| 63 |
+
complaints will be reviewed and investigated and will result in a response that
|
| 64 |
+
is deemed necessary and appropriate to the circumstances. The project team is
|
| 65 |
+
obligated to maintain confidentiality with regard to the reporter of an incident.
|
| 66 |
+
Further details of specific enforcement policies may be posted separately.
|
| 67 |
+
|
| 68 |
+
Project maintainers who do not follow or enforce the Code of Conduct in good
|
| 69 |
+
faith may face temporary or permanent repercussions as determined by other
|
| 70 |
+
members of the project's leadership.
|
| 71 |
+
|
| 72 |
+
## Attribution
|
| 73 |
+
|
| 74 |
+
This Code of Conduct is adapted from the [Contributor Covenant][homepage], version 1.4,
|
| 75 |
+
available at https://www.contributor-covenant.org/version/1/4/code-of-conduct.html
|
| 76 |
+
|
| 77 |
+
[homepage]: https://www.contributor-covenant.org
|
| 78 |
+
|
| 79 |
+
For answers to common questions about this code of conduct, see
|
| 80 |
+
https://www.contributor-covenant.org/faq
|
sam2-repo/CONTRIBUTING.md
ADDED
|
@@ -0,0 +1,31 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Contributing to segment-anything
|
| 2 |
+
We want to make contributing to this project as easy and transparent as
|
| 3 |
+
possible.
|
| 4 |
+
|
| 5 |
+
## Pull Requests
|
| 6 |
+
We actively welcome your pull requests.
|
| 7 |
+
|
| 8 |
+
1. Fork the repo and create your branch from `main`.
|
| 9 |
+
2. If you've added code that should be tested, add tests.
|
| 10 |
+
3. If you've changed APIs, update the documentation.
|
| 11 |
+
4. Ensure the test suite passes.
|
| 12 |
+
5. Make sure your code lints, using the `ufmt format` command. Linting requires `black==24.2.0`, `usort==1.0.2`, and `ufmt==2.0.0b2`, which can be installed via `pip install -e ".[dev]"`.
|
| 13 |
+
6. If you haven't already, complete the Contributor License Agreement ("CLA").
|
| 14 |
+
|
| 15 |
+
## Contributor License Agreement ("CLA")
|
| 16 |
+
In order to accept your pull request, we need you to submit a CLA. You only need
|
| 17 |
+
to do this once to work on any of Facebook's open source projects.
|
| 18 |
+
|
| 19 |
+
Complete your CLA here: <https://code.facebook.com/cla>
|
| 20 |
+
|
| 21 |
+
## Issues
|
| 22 |
+
We use GitHub issues to track public bugs. Please ensure your description is
|
| 23 |
+
clear and has sufficient instructions to be able to reproduce the issue.
|
| 24 |
+
|
| 25 |
+
Facebook has a [bounty program](https://www.facebook.com/whitehat/) for the safe
|
| 26 |
+
disclosure of security bugs. In those cases, please go through the process
|
| 27 |
+
outlined on that page and do not file a public issue.
|
| 28 |
+
|
| 29 |
+
## License
|
| 30 |
+
By contributing to segment-anything, you agree that your contributions will be licensed
|
| 31 |
+
under the LICENSE file in the root directory of this source tree.
|
sam2-repo/INSTALL.md
ADDED
|
@@ -0,0 +1,189 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## Installation
|
| 2 |
+
|
| 3 |
+
### Requirements
|
| 4 |
+
|
| 5 |
+
- Linux with Python ≥ 3.10, PyTorch ≥ 2.5.1 and [torchvision](https://github.com/pytorch/vision/) that matches the PyTorch installation. Install them together at https://pytorch.org to ensure this.
|
| 6 |
+
* Note older versions of Python or PyTorch may also work. However, the versions above are strongly recommended to provide all features such as `torch.compile`.
|
| 7 |
+
- [CUDA toolkits](https://developer.nvidia.com/cuda-toolkit-archive) that match the CUDA version for your PyTorch installation. This should typically be CUDA 12.1 if you follow the default installation command.
|
| 8 |
+
- If you are installing on Windows, it's strongly recommended to use [Windows Subsystem for Linux (WSL)](https://learn.microsoft.com/en-us/windows/wsl/install) with Ubuntu.
|
| 9 |
+
|
| 10 |
+
Then, install SAM 2 from the root of this repository via
|
| 11 |
+
```bash
|
| 12 |
+
pip install -e ".[notebooks]"
|
| 13 |
+
```
|
| 14 |
+
|
| 15 |
+
Note that you may skip building the SAM 2 CUDA extension during installation via environment variable `SAM2_BUILD_CUDA=0`, as follows:
|
| 16 |
+
```bash
|
| 17 |
+
# skip the SAM 2 CUDA extension
|
| 18 |
+
SAM2_BUILD_CUDA=0 pip install -e ".[notebooks]"
|
| 19 |
+
```
|
| 20 |
+
This would also skip the post-processing step at runtime (removing small holes and sprinkles in the output masks, which requires the CUDA extension), but shouldn't affect the results in most cases.
|
| 21 |
+
|
| 22 |
+
### Building the SAM 2 CUDA extension
|
| 23 |
+
|
| 24 |
+
By default, we allow the installation to proceed even if the SAM 2 CUDA extension fails to build. (In this case, the build errors are hidden unless using `-v` for verbose output in `pip install`.)
|
| 25 |
+
|
| 26 |
+
If you see a message like `Skipping the post-processing step due to the error above` at runtime or `Failed to build the SAM 2 CUDA extension due to the error above` during installation, it indicates that the SAM 2 CUDA extension failed to build in your environment. In this case, **you can still use SAM 2 for both image and video applications**. The post-processing step (removing small holes and sprinkles in the output masks) will be skipped, but this shouldn't affect the results in most cases.
|
| 27 |
+
|
| 28 |
+
If you would like to enable this post-processing step, you can reinstall SAM 2 on a GPU machine with environment variable `SAM2_BUILD_ALLOW_ERRORS=0` to force building the CUDA extension (and raise errors if it fails to build), as follows
|
| 29 |
+
```bash
|
| 30 |
+
pip uninstall -y SAM-2 && \
|
| 31 |
+
rm -f ./sam2/*.so && \
|
| 32 |
+
SAM2_BUILD_ALLOW_ERRORS=0 pip install -v -e ".[notebooks]"
|
| 33 |
+
```
|
| 34 |
+
|
| 35 |
+
Note that PyTorch needs to be installed first before building the SAM 2 CUDA extension. It's also necessary to install [CUDA toolkits](https://developer.nvidia.com/cuda-toolkit-archive) that match the CUDA version for your PyTorch installation. (This should typically be CUDA 12.1 if you follow the default installation command.) After installing the CUDA toolkits, you can check its version via `nvcc --version`.
|
| 36 |
+
|
| 37 |
+
Please check the section below on common installation issues if the CUDA extension fails to build during installation or load at runtime.
|
| 38 |
+
|
| 39 |
+
### Common Installation Issues
|
| 40 |
+
|
| 41 |
+
Click each issue for its solutions:
|
| 42 |
+
|
| 43 |
+
<details>
|
| 44 |
+
<summary>
|
| 45 |
+
I got `ImportError: cannot import name '_C' from 'sam2'`
|
| 46 |
+
</summary>
|
| 47 |
+
<br/>
|
| 48 |
+
|
| 49 |
+
This is usually because you haven't run the `pip install -e ".[notebooks]"` step above or the installation failed. Please install SAM 2 first, and see the other issues if your installation fails.
|
| 50 |
+
|
| 51 |
+
In some systems, you may need to run `python setup.py build_ext --inplace` in the SAM 2 repo root as suggested in https://github.com/facebookresearch/sam2/issues/77.
|
| 52 |
+
</details>
|
| 53 |
+
|
| 54 |
+
<details>
|
| 55 |
+
<summary>
|
| 56 |
+
I got `MissingConfigException: Cannot find primary config 'configs/sam2.1/sam2.1_hiera_l.yaml'`
|
| 57 |
+
</summary>
|
| 58 |
+
<br/>
|
| 59 |
+
|
| 60 |
+
This is usually because you haven't run the `pip install -e .` step above, so `sam2` isn't in your Python's `sys.path`. Please run this installation step. In case it still fails after the installation step, you may try manually adding the root of this repo to `PYTHONPATH` via
|
| 61 |
+
```bash
|
| 62 |
+
export SAM2_REPO_ROOT=/path/to/sam2 # path to this repo
|
| 63 |
+
export PYTHONPATH="${SAM2_REPO_ROOT}:${PYTHONPATH}"
|
| 64 |
+
```
|
| 65 |
+
to manually add `sam2_configs` into your Python's `sys.path`.
|
| 66 |
+
|
| 67 |
+
</details>
|
| 68 |
+
|
| 69 |
+
<details>
|
| 70 |
+
<summary>
|
| 71 |
+
I got `RuntimeError: Error(s) in loading state_dict for SAM2Base` when loading the new SAM 2.1 checkpoints
|
| 72 |
+
</summary>
|
| 73 |
+
<br/>
|
| 74 |
+
|
| 75 |
+
This is likely because you have installed a previous version of this repo, which doesn't have the new modules to support the SAM 2.1 checkpoints yet. Please try the following steps:
|
| 76 |
+
|
| 77 |
+
1. pull the latest code from the `main` branch of this repo
|
| 78 |
+
2. run `pip uninstall -y SAM-2` to uninstall any previous installations
|
| 79 |
+
3. then install the latest repo again using `pip install -e ".[notebooks]"`
|
| 80 |
+
|
| 81 |
+
In case the steps above still don't resolve the error, please try running in your Python environment the following
|
| 82 |
+
```python
|
| 83 |
+
from sam2.modeling import sam2_base
|
| 84 |
+
|
| 85 |
+
print(sam2_base.__file__)
|
| 86 |
+
```
|
| 87 |
+
and check whether the content in the printed local path of `sam2/modeling/sam2_base.py` matches the latest one in https://github.com/facebookresearch/sam2/blob/main/sam2/modeling/sam2_base.py (e.g. whether your local file has `no_obj_embed_spatial`) to indentify if you're still using a previous installation.
|
| 88 |
+
|
| 89 |
+
</details>
|
| 90 |
+
|
| 91 |
+
<details>
|
| 92 |
+
<summary>
|
| 93 |
+
My installation failed with `CUDA_HOME environment variable is not set`
|
| 94 |
+
</summary>
|
| 95 |
+
<br/>
|
| 96 |
+
|
| 97 |
+
This usually happens because the installation step cannot find the CUDA toolkits (that contain the NVCC compiler) to build a custom CUDA kernel in SAM 2. Please install [CUDA toolkits](https://developer.nvidia.com/cuda-toolkit-archive) or the version that matches the CUDA version for your PyTorch installation. If the error persists after installing CUDA toolkits, you may explicitly specify `CUDA_HOME` via
|
| 98 |
+
```
|
| 99 |
+
export CUDA_HOME=/usr/local/cuda # change to your CUDA toolkit path
|
| 100 |
+
```
|
| 101 |
+
and rerun the installation.
|
| 102 |
+
|
| 103 |
+
Also, you should make sure
|
| 104 |
+
```
|
| 105 |
+
python -c 'import torch; from torch.utils.cpp_extension import CUDA_HOME; print(torch.cuda.is_available(), CUDA_HOME)'
|
| 106 |
+
```
|
| 107 |
+
print `(True, a directory with cuda)` to verify that the CUDA toolkits are correctly set up.
|
| 108 |
+
|
| 109 |
+
If you are still having problems after verifying that the CUDA toolkit is installed and the `CUDA_HOME` environment variable is set properly, you may have to add the `--no-build-isolation` flag to the pip command:
|
| 110 |
+
```
|
| 111 |
+
pip install --no-build-isolation -e .
|
| 112 |
+
```
|
| 113 |
+
|
| 114 |
+
</details>
|
| 115 |
+
|
| 116 |
+
<details>
|
| 117 |
+
<summary>
|
| 118 |
+
I got `undefined symbol: _ZN3c1015SmallVectorBaseIjE8grow_podEPKvmm` (or similar errors)
|
| 119 |
+
</summary>
|
| 120 |
+
<br/>
|
| 121 |
+
|
| 122 |
+
This usually happens because you have multiple versions of dependencies (PyTorch or CUDA) in your environment. During installation, the SAM 2 library is compiled against one version library while at run time it links against another version. This might be due to that you have different versions of PyTorch or CUDA installed separately via `pip` or `conda`. You may delete one of the duplicates to only keep a single PyTorch and CUDA version.
|
| 123 |
+
|
| 124 |
+
In particular, if you have a lower PyTorch version than 2.5.1, it's recommended to upgrade to PyTorch 2.5.1 or higher first. Otherwise, the installation script will try to upgrade to the latest PyTorch using `pip`, which could sometimes lead to duplicated PyTorch installation if you have previously installed another PyTorch version using `conda`.
|
| 125 |
+
|
| 126 |
+
We have been building SAM 2 against PyTorch 2.5.1 internally. However, a few user comments (e.g. https://github.com/facebookresearch/sam2/issues/22, https://github.com/facebookresearch/sam2/issues/14) suggested that downgrading to PyTorch 2.1.0 might resolve this problem. In case the error persists, you may try changing the restriction from `torch>=2.5.1` to `torch==2.1.0` in both [`pyproject.toml`](pyproject.toml) and [`setup.py`](setup.py) to allow PyTorch 2.1.0.
|
| 127 |
+
</details>
|
| 128 |
+
|
| 129 |
+
<details>
|
| 130 |
+
<summary>
|
| 131 |
+
I got `CUDA error: no kernel image is available for execution on the device`
|
| 132 |
+
</summary>
|
| 133 |
+
<br/>
|
| 134 |
+
|
| 135 |
+
A possible cause could be that the CUDA kernel is somehow not compiled towards your GPU's CUDA [capability](https://developer.nvidia.com/cuda-gpus). This could happen if the installation is done in an environment different from the runtime (e.g. in a slurm system).
|
| 136 |
+
|
| 137 |
+
You can try pulling the latest code from the SAM 2 repo and running the following
|
| 138 |
+
```
|
| 139 |
+
export TORCH_CUDA_ARCH_LIST=9.0 8.0 8.6 8.9 7.0 7.2 7.5 6.0`
|
| 140 |
+
```
|
| 141 |
+
to manually specify the CUDA capability in the compilation target that matches your GPU.
|
| 142 |
+
</details>
|
| 143 |
+
|
| 144 |
+
<details>
|
| 145 |
+
<summary>
|
| 146 |
+
I got `RuntimeError: No available kernel. Aborting execution.` (or similar errors)
|
| 147 |
+
</summary>
|
| 148 |
+
<br/>
|
| 149 |
+
|
| 150 |
+
This is probably because your machine doesn't have a GPU or a compatible PyTorch version for Flash Attention (see also https://discuss.pytorch.org/t/using-f-scaled-dot-product-attention-gives-the-error-runtimeerror-no-available-kernel-aborting-execution/180900 for a discussion in PyTorch forum). You may be able to resolve this error by replacing the line
|
| 151 |
+
```python
|
| 152 |
+
OLD_GPU, USE_FLASH_ATTN, MATH_KERNEL_ON = get_sdpa_settings()
|
| 153 |
+
```
|
| 154 |
+
in [`sam2/modeling/sam/transformer.py`](sam2/modeling/sam/transformer.py) with
|
| 155 |
+
```python
|
| 156 |
+
OLD_GPU, USE_FLASH_ATTN, MATH_KERNEL_ON = True, True, True
|
| 157 |
+
```
|
| 158 |
+
to relax the attention kernel setting and use other kernels than Flash Attention.
|
| 159 |
+
</details>
|
| 160 |
+
|
| 161 |
+
<details>
|
| 162 |
+
<summary>
|
| 163 |
+
I got `Error compiling objects for extension`
|
| 164 |
+
</summary>
|
| 165 |
+
<br/>
|
| 166 |
+
|
| 167 |
+
You may see error log of:
|
| 168 |
+
> unsupported Microsoft Visual Studio version! Only the versions between 2017 and 2022 (inclusive) are supported! The nvcc flag '-allow-unsupported-compiler' can be used to override this version check; however, using an unsupported host compiler may cause compilation failure or incorrect run time execution. Use at your own risk.
|
| 169 |
+
|
| 170 |
+
This is probably because your versions of CUDA and Visual Studio are incompatible. (see also https://stackoverflow.com/questions/78515942/cuda-compatibility-with-visual-studio-2022-version-17-10 for a discussion in stackoverflow).<br>
|
| 171 |
+
You may be able to fix this by adding the `-allow-unsupported-compiler` argument to `nvcc` after L48 in the [setup.py](https://github.com/facebookresearch/sam2/blob/main/setup.py). <br>
|
| 172 |
+
After adding the argument, `get_extension()` will look like this:
|
| 173 |
+
```python
|
| 174 |
+
def get_extensions():
|
| 175 |
+
srcs = ["sam2/csrc/connected_components.cu"]
|
| 176 |
+
compile_args = {
|
| 177 |
+
"cxx": [],
|
| 178 |
+
"nvcc": [
|
| 179 |
+
"-DCUDA_HAS_FP16=1",
|
| 180 |
+
"-D__CUDA_NO_HALF_OPERATORS__",
|
| 181 |
+
"-D__CUDA_NO_HALF_CONVERSIONS__",
|
| 182 |
+
"-D__CUDA_NO_HALF2_OPERATORS__",
|
| 183 |
+
"-allow-unsupported-compiler" # Add this argument
|
| 184 |
+
],
|
| 185 |
+
}
|
| 186 |
+
ext_modules = [CUDAExtension("sam2._C", srcs, extra_compile_args=compile_args)]
|
| 187 |
+
return ext_modules
|
| 188 |
+
```
|
| 189 |
+
</details>
|
sam2-repo/LICENSE
ADDED
|
@@ -0,0 +1,201 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Apache License
|
| 2 |
+
Version 2.0, January 2004
|
| 3 |
+
http://www.apache.org/licenses/
|
| 4 |
+
|
| 5 |
+
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
|
| 6 |
+
|
| 7 |
+
1. Definitions.
|
| 8 |
+
|
| 9 |
+
"License" shall mean the terms and conditions for use, reproduction,
|
| 10 |
+
and distribution as defined by Sections 1 through 9 of this document.
|
| 11 |
+
|
| 12 |
+
"Licensor" shall mean the copyright owner or entity authorized by
|
| 13 |
+
the copyright owner that is granting the License.
|
| 14 |
+
|
| 15 |
+
"Legal Entity" shall mean the union of the acting entity and all
|
| 16 |
+
other entities that control, are controlled by, or are under common
|
| 17 |
+
control with that entity. For the purposes of this definition,
|
| 18 |
+
"control" means (i) the power, direct or indirect, to cause the
|
| 19 |
+
direction or management of such entity, whether by contract or
|
| 20 |
+
otherwise, or (ii) ownership of fifty percent (50%) or more of the
|
| 21 |
+
outstanding shares, or (iii) beneficial ownership of such entity.
|
| 22 |
+
|
| 23 |
+
"You" (or "Your") shall mean an individual or Legal Entity
|
| 24 |
+
exercising permissions granted by this License.
|
| 25 |
+
|
| 26 |
+
"Source" form shall mean the preferred form for making modifications,
|
| 27 |
+
including but not limited to software source code, documentation
|
| 28 |
+
source, and configuration files.
|
| 29 |
+
|
| 30 |
+
"Object" form shall mean any form resulting from mechanical
|
| 31 |
+
transformation or translation of a Source form, including but
|
| 32 |
+
not limited to compiled object code, generated documentation,
|
| 33 |
+
and conversions to other media types.
|
| 34 |
+
|
| 35 |
+
"Work" shall mean the work of authorship, whether in Source or
|
| 36 |
+
Object form, made available under the License, as indicated by a
|
| 37 |
+
copyright notice that is included in or attached to the work
|
| 38 |
+
(an example is provided in the Appendix below).
|
| 39 |
+
|
| 40 |
+
"Derivative Works" shall mean any work, whether in Source or Object
|
| 41 |
+
form, that is based on (or derived from) the Work and for which the
|
| 42 |
+
editorial revisions, annotations, elaborations, or other modifications
|
| 43 |
+
represent, as a whole, an original work of authorship. For the purposes
|
| 44 |
+
of this License, Derivative Works shall not include works that remain
|
| 45 |
+
separable from, or merely link (or bind by name) to the interfaces of,
|
| 46 |
+
the Work and Derivative Works thereof.
|
| 47 |
+
|
| 48 |
+
"Contribution" shall mean any work of authorship, including
|
| 49 |
+
the original version of the Work and any modifications or additions
|
| 50 |
+
to that Work or Derivative Works thereof, that is intentionally
|
| 51 |
+
submitted to Licensor for inclusion in the Work by the copyright owner
|
| 52 |
+
or by an individual or Legal Entity authorized to submit on behalf of
|
| 53 |
+
the copyright owner. For the purposes of this definition, "submitted"
|
| 54 |
+
means any form of electronic, verbal, or written communication sent
|
| 55 |
+
to the Licensor or its representatives, including but not limited to
|
| 56 |
+
communication on electronic mailing lists, source code control systems,
|
| 57 |
+
and issue tracking systems that are managed by, or on behalf of, the
|
| 58 |
+
Licensor for the purpose of discussing and improving the Work, but
|
| 59 |
+
excluding communication that is conspicuously marked or otherwise
|
| 60 |
+
designated in writing by the copyright owner as "Not a Contribution."
|
| 61 |
+
|
| 62 |
+
"Contributor" shall mean Licensor and any individual or Legal Entity
|
| 63 |
+
on behalf of whom a Contribution has been received by Licensor and
|
| 64 |
+
subsequently incorporated within the Work.
|
| 65 |
+
|
| 66 |
+
2. Grant of Copyright License. Subject to the terms and conditions of
|
| 67 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 68 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 69 |
+
copyright license to reproduce, prepare Derivative Works of,
|
| 70 |
+
publicly display, publicly perform, sublicense, and distribute the
|
| 71 |
+
Work and such Derivative Works in Source or Object form.
|
| 72 |
+
|
| 73 |
+
3. Grant of Patent License. Subject to the terms and conditions of
|
| 74 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 75 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 76 |
+
(except as stated in this section) patent license to make, have made,
|
| 77 |
+
use, offer to sell, sell, import, and otherwise transfer the Work,
|
| 78 |
+
where such license applies only to those patent claims licensable
|
| 79 |
+
by such Contributor that are necessarily infringed by their
|
| 80 |
+
Contribution(s) alone or by combination of their Contribution(s)
|
| 81 |
+
with the Work to which such Contribution(s) was submitted. If You
|
| 82 |
+
institute patent litigation against any entity (including a
|
| 83 |
+
cross-claim or counterclaim in a lawsuit) alleging that the Work
|
| 84 |
+
or a Contribution incorporated within the Work constitutes direct
|
| 85 |
+
or contributory patent infringement, then any patent licenses
|
| 86 |
+
granted to You under this License for that Work shall terminate
|
| 87 |
+
as of the date such litigation is filed.
|
| 88 |
+
|
| 89 |
+
4. Redistribution. You may reproduce and distribute copies of the
|
| 90 |
+
Work or Derivative Works thereof in any medium, with or without
|
| 91 |
+
modifications, and in Source or Object form, provided that You
|
| 92 |
+
meet the following conditions:
|
| 93 |
+
|
| 94 |
+
(a) You must give any other recipients of the Work or
|
| 95 |
+
Derivative Works a copy of this License; and
|
| 96 |
+
|
| 97 |
+
(b) You must cause any modified files to carry prominent notices
|
| 98 |
+
stating that You changed the files; and
|
| 99 |
+
|
| 100 |
+
(c) You must retain, in the Source form of any Derivative Works
|
| 101 |
+
that You distribute, all copyright, patent, trademark, and
|
| 102 |
+
attribution notices from the Source form of the Work,
|
| 103 |
+
excluding those notices that do not pertain to any part of
|
| 104 |
+
the Derivative Works; and
|
| 105 |
+
|
| 106 |
+
(d) If the Work includes a "NOTICE" text file as part of its
|
| 107 |
+
distribution, then any Derivative Works that You distribute must
|
| 108 |
+
include a readable copy of the attribution notices contained
|
| 109 |
+
within such NOTICE file, excluding those notices that do not
|
| 110 |
+
pertain to any part of the Derivative Works, in at least one
|
| 111 |
+
of the following places: within a NOTICE text file distributed
|
| 112 |
+
as part of the Derivative Works; within the Source form or
|
| 113 |
+
documentation, if provided along with the Derivative Works; or,
|
| 114 |
+
within a display generated by the Derivative Works, if and
|
| 115 |
+
wherever such third-party notices normally appear. The contents
|
| 116 |
+
of the NOTICE file are for informational purposes only and
|
| 117 |
+
do not modify the License. You may add Your own attribution
|
| 118 |
+
notices within Derivative Works that You distribute, alongside
|
| 119 |
+
or as an addendum to the NOTICE text from the Work, provided
|
| 120 |
+
that such additional attribution notices cannot be construed
|
| 121 |
+
as modifying the License.
|
| 122 |
+
|
| 123 |
+
You may add Your own copyright statement to Your modifications and
|
| 124 |
+
may provide additional or different license terms and conditions
|
| 125 |
+
for use, reproduction, or distribution of Your modifications, or
|
| 126 |
+
for any such Derivative Works as a whole, provided Your use,
|
| 127 |
+
reproduction, and distribution of the Work otherwise complies with
|
| 128 |
+
the conditions stated in this License.
|
| 129 |
+
|
| 130 |
+
5. Submission of Contributions. Unless You explicitly state otherwise,
|
| 131 |
+
any Contribution intentionally submitted for inclusion in the Work
|
| 132 |
+
by You to the Licensor shall be under the terms and conditions of
|
| 133 |
+
this License, without any additional terms or conditions.
|
| 134 |
+
Notwithstanding the above, nothing herein shall supersede or modify
|
| 135 |
+
the terms of any separate license agreement you may have executed
|
| 136 |
+
with Licensor regarding such Contributions.
|
| 137 |
+
|
| 138 |
+
6. Trademarks. This License does not grant permission to use the trade
|
| 139 |
+
names, trademarks, service marks, or product names of the Licensor,
|
| 140 |
+
except as required for reasonable and customary use in describing the
|
| 141 |
+
origin of the Work and reproducing the content of the NOTICE file.
|
| 142 |
+
|
| 143 |
+
7. Disclaimer of Warranty. Unless required by applicable law or
|
| 144 |
+
agreed to in writing, Licensor provides the Work (and each
|
| 145 |
+
Contributor provides its Contributions) on an "AS IS" BASIS,
|
| 146 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
|
| 147 |
+
implied, including, without limitation, any warranties or conditions
|
| 148 |
+
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
|
| 149 |
+
PARTICULAR PURPOSE. You are solely responsible for determining the
|
| 150 |
+
appropriateness of using or redistributing the Work and assume any
|
| 151 |
+
risks associated with Your exercise of permissions under this License.
|
| 152 |
+
|
| 153 |
+
8. Limitation of Liability. In no event and under no legal theory,
|
| 154 |
+
whether in tort (including negligence), contract, or otherwise,
|
| 155 |
+
unless required by applicable law (such as deliberate and grossly
|
| 156 |
+
negligent acts) or agreed to in writing, shall any Contributor be
|
| 157 |
+
liable to You for damages, including any direct, indirect, special,
|
| 158 |
+
incidental, or consequential damages of any character arising as a
|
| 159 |
+
result of this License or out of the use or inability to use the
|
| 160 |
+
Work (including but not limited to damages for loss of goodwill,
|
| 161 |
+
work stoppage, computer failure or malfunction, or any and all
|
| 162 |
+
other commercial damages or losses), even if such Contributor
|
| 163 |
+
has been advised of the possibility of such damages.
|
| 164 |
+
|
| 165 |
+
9. Accepting Warranty or Additional Liability. While redistributing
|
| 166 |
+
the Work or Derivative Works thereof, You may choose to offer,
|
| 167 |
+
and charge a fee for, acceptance of support, warranty, indemnity,
|
| 168 |
+
or other liability obligations and/or rights consistent with this
|
| 169 |
+
License. However, in accepting such obligations, You may act only
|
| 170 |
+
on Your own behalf and on Your sole responsibility, not on behalf
|
| 171 |
+
of any other Contributor, and only if You agree to indemnify,
|
| 172 |
+
defend, and hold each Contributor harmless for any liability
|
| 173 |
+
incurred by, or claims asserted against, such Contributor by reason
|
| 174 |
+
of your accepting any such warranty or additional liability.
|
| 175 |
+
|
| 176 |
+
END OF TERMS AND CONDITIONS
|
| 177 |
+
|
| 178 |
+
APPENDIX: How to apply the Apache License to your work.
|
| 179 |
+
|
| 180 |
+
To apply the Apache License to your work, attach the following
|
| 181 |
+
boilerplate notice, with the fields enclosed by brackets "[]"
|
| 182 |
+
replaced with your own identifying information. (Don't include
|
| 183 |
+
the brackets!) The text should be enclosed in the appropriate
|
| 184 |
+
comment syntax for the file format. We also recommend that a
|
| 185 |
+
file or class name and description of purpose be included on the
|
| 186 |
+
same "printed page" as the copyright notice for easier
|
| 187 |
+
identification within third-party archives.
|
| 188 |
+
|
| 189 |
+
Copyright [yyyy] [name of copyright owner]
|
| 190 |
+
|
| 191 |
+
Licensed under the Apache License, Version 2.0 (the "License");
|
| 192 |
+
you may not use this file except in compliance with the License.
|
| 193 |
+
You may obtain a copy of the License at
|
| 194 |
+
|
| 195 |
+
http://www.apache.org/licenses/LICENSE-2.0
|
| 196 |
+
|
| 197 |
+
Unless required by applicable law or agreed to in writing, software
|
| 198 |
+
distributed under the License is distributed on an "AS IS" BASIS,
|
| 199 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 200 |
+
See the License for the specific language governing permissions and
|
| 201 |
+
limitations under the License.
|
sam2-repo/LICENSE_cctorch
ADDED
|
@@ -0,0 +1,29 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
BSD 3-Clause License
|
| 2 |
+
|
| 3 |
+
Copyright (c) 2020, the respective contributors, as shown by the AUTHORS file.
|
| 4 |
+
All rights reserved.
|
| 5 |
+
|
| 6 |
+
Redistribution and use in source and binary forms, with or without
|
| 7 |
+
modification, are permitted provided that the following conditions are met:
|
| 8 |
+
|
| 9 |
+
1. Redistributions of source code must retain the above copyright notice, this
|
| 10 |
+
list of conditions and the following disclaimer.
|
| 11 |
+
|
| 12 |
+
2. Redistributions in binary form must reproduce the above copyright notice,
|
| 13 |
+
this list of conditions and the following disclaimer in the documentation
|
| 14 |
+
and/or other materials provided with the distribution.
|
| 15 |
+
|
| 16 |
+
3. Neither the name of the copyright holder nor the names of its
|
| 17 |
+
contributors may be used to endorse or promote products derived from
|
| 18 |
+
this software without specific prior written permission.
|
| 19 |
+
|
| 20 |
+
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
|
| 21 |
+
AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
|
| 22 |
+
IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
|
| 23 |
+
DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE
|
| 24 |
+
FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
|
| 25 |
+
DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR
|
| 26 |
+
SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
|
| 27 |
+
CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,
|
| 28 |
+
OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
|
| 29 |
+
OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
|
sam2-repo/MANIFEST.in
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
|
| 4 |
+
# This source code is licensed under the license found in the
|
| 5 |
+
# LICENSE file in the root directory of this source tree.
|
| 6 |
+
|
| 7 |
+
recursive-include sam2 *.yaml #include all config files
|
sam2-repo/README.md
ADDED
|
@@ -0,0 +1,224 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# SAM 2: Segment Anything in Images and Videos
|
| 2 |
+
|
| 3 |
+
**[AI at Meta, FAIR](https://ai.meta.com/research/)**
|
| 4 |
+
|
| 5 |
+
[Nikhila Ravi](https://nikhilaravi.com/), [Valentin Gabeur](https://gabeur.github.io/), [Yuan-Ting Hu](https://scholar.google.com/citations?user=E8DVVYQAAAAJ&hl=en), [Ronghang Hu](https://ronghanghu.com/), [Chaitanya Ryali](https://scholar.google.com/citations?user=4LWx24UAAAAJ&hl=en), [Tengyu Ma](https://scholar.google.com/citations?user=VeTSl0wAAAAJ&hl=en), [Haitham Khedr](https://hkhedr.com/), [Roman Rädle](https://scholar.google.de/citations?user=Tpt57v0AAAAJ&hl=en), [Chloe Rolland](https://scholar.google.com/citations?hl=fr&user=n-SnMhoAAAAJ), [Laura Gustafson](https://scholar.google.com/citations?user=c8IpF9gAAAAJ&hl=en), [Eric Mintun](https://ericmintun.github.io/), [Junting Pan](https://junting.github.io/), [Kalyan Vasudev Alwala](https://scholar.google.co.in/citations?user=m34oaWEAAAAJ&hl=en), [Nicolas Carion](https://www.nicolascarion.com/), [Chao-Yuan Wu](https://chaoyuan.org/), [Ross Girshick](https://www.rossgirshick.info/), [Piotr Dollár](https://pdollar.github.io/), [Christoph Feichtenhofer](https://feichtenhofer.github.io/)
|
| 6 |
+
|
| 7 |
+
[[`Paper`](https://ai.meta.com/research/publications/sam-2-segment-anything-in-images-and-videos/)] [[`Project`](https://ai.meta.com/sam2)] [[`Demo`](https://sam2.metademolab.com/)] [[`Dataset`](https://ai.meta.com/datasets/segment-anything-video)] [[`Blog`](https://ai.meta.com/blog/segment-anything-2)] [[`BibTeX`](#citing-sam-2)]
|
| 8 |
+
|
| 9 |
+

|
| 10 |
+
|
| 11 |
+
**Segment Anything Model 2 (SAM 2)** is a foundation model towards solving promptable visual segmentation in images and videos. We extend SAM to video by considering images as a video with a single frame. The model design is a simple transformer architecture with streaming memory for real-time video processing. We build a model-in-the-loop data engine, which improves model and data via user interaction, to collect [**our SA-V dataset**](https://ai.meta.com/datasets/segment-anything-video), the largest video segmentation dataset to date. SAM 2 trained on our data provides strong performance across a wide range of tasks and visual domains.
|
| 12 |
+
|
| 13 |
+

|
| 14 |
+
|
| 15 |
+
## Latest updates
|
| 16 |
+
|
| 17 |
+
**12/11/2024 -- full model compilation for a major VOS speedup and a new `SAM2VideoPredictor` to better handle multi-object tracking**
|
| 18 |
+
|
| 19 |
+
- We now support `torch.compile` of the entire SAM 2 model on videos, which can be turned on by setting `vos_optimized=True` in `build_sam2_video_predictor`, leading to a major speedup for VOS inference.
|
| 20 |
+
- We update the implementation of `SAM2VideoPredictor` to support independent per-object inference, allowing us to relax the assumption of prompting for multi-object tracking and adding new objects after tracking starts.
|
| 21 |
+
- See [`RELEASE_NOTES.md`](RELEASE_NOTES.md) for full details.
|
| 22 |
+
|
| 23 |
+
**09/30/2024 -- SAM 2.1 Developer Suite (new checkpoints, training code, web demo) is released**
|
| 24 |
+
|
| 25 |
+
- A new suite of improved model checkpoints (denoted as **SAM 2.1**) are released. See [Model Description](#model-description) for details.
|
| 26 |
+
* To use the new SAM 2.1 checkpoints, you need the latest model code from this repo. If you have installed an earlier version of this repo, please first uninstall the previous version via `pip uninstall SAM-2`, pull the latest code from this repo (with `git pull`), and then reinstall the repo following [Installation](#installation) below.
|
| 27 |
+
- The training (and fine-tuning) code has been released. See [`training/README.md`](training/README.md) on how to get started.
|
| 28 |
+
- The frontend + backend code for the SAM 2 web demo has been released. See [`demo/README.md`](demo/README.md) for details.
|
| 29 |
+
|
| 30 |
+
## Installation
|
| 31 |
+
|
| 32 |
+
SAM 2 needs to be installed first before use. The code requires `python>=3.10`, as well as `torch>=2.5.1` and `torchvision>=0.20.1`. Please follow the instructions [here](https://pytorch.org/get-started/locally/) to install both PyTorch and TorchVision dependencies. You can install SAM 2 on a GPU machine using:
|
| 33 |
+
|
| 34 |
+
```bash
|
| 35 |
+
git clone https://github.com/facebookresearch/sam2.git && cd sam2
|
| 36 |
+
|
| 37 |
+
pip install -e .
|
| 38 |
+
```
|
| 39 |
+
If you are installing on Windows, it's strongly recommended to use [Windows Subsystem for Linux (WSL)](https://learn.microsoft.com/en-us/windows/wsl/install) with Ubuntu.
|
| 40 |
+
|
| 41 |
+
To use the SAM 2 predictor and run the example notebooks, `jupyter` and `matplotlib` are required and can be installed by:
|
| 42 |
+
|
| 43 |
+
```bash
|
| 44 |
+
pip install -e ".[notebooks]"
|
| 45 |
+
```
|
| 46 |
+
|
| 47 |
+
Note:
|
| 48 |
+
1. It's recommended to create a new Python environment via [Anaconda](https://www.anaconda.com/) for this installation and install PyTorch 2.5.1 (or higher) via `pip` following https://pytorch.org/. If you have a PyTorch version lower than 2.5.1 in your current environment, the installation command above will try to upgrade it to the latest PyTorch version using `pip`.
|
| 49 |
+
2. The step above requires compiling a custom CUDA kernel with the `nvcc` compiler. If it isn't already available on your machine, please install the [CUDA toolkits](https://developer.nvidia.com/cuda-toolkit-archive) with a version that matches your PyTorch CUDA version.
|
| 50 |
+
3. If you see a message like `Failed to build the SAM 2 CUDA extension` during installation, you can ignore it and still use SAM 2 (some post-processing functionality may be limited, but it doesn't affect the results in most cases).
|
| 51 |
+
|
| 52 |
+
Please see [`INSTALL.md`](./INSTALL.md) for FAQs on potential issues and solutions.
|
| 53 |
+
|
| 54 |
+
## Getting Started
|
| 55 |
+
|
| 56 |
+
### Download Checkpoints
|
| 57 |
+
|
| 58 |
+
First, we need to download a model checkpoint. All the model checkpoints can be downloaded by running:
|
| 59 |
+
|
| 60 |
+
```bash
|
| 61 |
+
cd checkpoints && \
|
| 62 |
+
./download_ckpts.sh && \
|
| 63 |
+
cd ..
|
| 64 |
+
```
|
| 65 |
+
|
| 66 |
+
or individually from:
|
| 67 |
+
|
| 68 |
+
- [sam2.1_hiera_tiny.pt](https://dl.fbaipublicfiles.com/segment_anything_2/092824/sam2.1_hiera_tiny.pt)
|
| 69 |
+
- [sam2.1_hiera_small.pt](https://dl.fbaipublicfiles.com/segment_anything_2/092824/sam2.1_hiera_small.pt)
|
| 70 |
+
- [sam2.1_hiera_base_plus.pt](https://dl.fbaipublicfiles.com/segment_anything_2/092824/sam2.1_hiera_base_plus.pt)
|
| 71 |
+
- [sam2.1_hiera_large.pt](https://dl.fbaipublicfiles.com/segment_anything_2/092824/sam2.1_hiera_large.pt)
|
| 72 |
+
|
| 73 |
+
(note that these are the improved checkpoints denoted as SAM 2.1; see [Model Description](#model-description) for details.)
|
| 74 |
+
|
| 75 |
+
Then SAM 2 can be used in a few lines as follows for image and video prediction.
|
| 76 |
+
|
| 77 |
+
### Image prediction
|
| 78 |
+
|
| 79 |
+
SAM 2 has all the capabilities of [SAM](https://github.com/facebookresearch/segment-anything) on static images, and we provide image prediction APIs that closely resemble SAM for image use cases. The `SAM2ImagePredictor` class has an easy interface for image prompting.
|
| 80 |
+
|
| 81 |
+
```python
|
| 82 |
+
import torch
|
| 83 |
+
from sam2.build_sam import build_sam2
|
| 84 |
+
from sam2.sam2_image_predictor import SAM2ImagePredictor
|
| 85 |
+
|
| 86 |
+
checkpoint = "./checkpoints/sam2.1_hiera_large.pt"
|
| 87 |
+
model_cfg = "configs/sam2.1/sam2.1_hiera_l.yaml"
|
| 88 |
+
predictor = SAM2ImagePredictor(build_sam2(model_cfg, checkpoint))
|
| 89 |
+
|
| 90 |
+
with torch.inference_mode(), torch.autocast("cuda", dtype=torch.bfloat16):
|
| 91 |
+
predictor.set_image(<your_image>)
|
| 92 |
+
masks, _, _ = predictor.predict(<input_prompts>)
|
| 93 |
+
```
|
| 94 |
+
|
| 95 |
+
Please refer to the examples in [image_predictor_example.ipynb](./notebooks/image_predictor_example.ipynb) (also in Colab [here](https://colab.research.google.com/github/facebookresearch/sam2/blob/main/notebooks/image_predictor_example.ipynb)) for static image use cases.
|
| 96 |
+
|
| 97 |
+
SAM 2 also supports automatic mask generation on images just like SAM. Please see [automatic_mask_generator_example.ipynb](./notebooks/automatic_mask_generator_example.ipynb) (also in Colab [here](https://colab.research.google.com/github/facebookresearch/sam2/blob/main/notebooks/automatic_mask_generator_example.ipynb)) for automatic mask generation in images.
|
| 98 |
+
|
| 99 |
+
### Video prediction
|
| 100 |
+
|
| 101 |
+
For promptable segmentation and tracking in videos, we provide a video predictor with APIs for example to add prompts and propagate masklets throughout a video. SAM 2 supports video inference on multiple objects and uses an inference state to keep track of the interactions in each video.
|
| 102 |
+
|
| 103 |
+
```python
|
| 104 |
+
import torch
|
| 105 |
+
from sam2.build_sam import build_sam2_video_predictor
|
| 106 |
+
|
| 107 |
+
checkpoint = "./checkpoints/sam2.1_hiera_large.pt"
|
| 108 |
+
model_cfg = "configs/sam2.1/sam2.1_hiera_l.yaml"
|
| 109 |
+
predictor = build_sam2_video_predictor(model_cfg, checkpoint)
|
| 110 |
+
|
| 111 |
+
with torch.inference_mode(), torch.autocast("cuda", dtype=torch.bfloat16):
|
| 112 |
+
state = predictor.init_state(<your_video>)
|
| 113 |
+
|
| 114 |
+
# add new prompts and instantly get the output on the same frame
|
| 115 |
+
frame_idx, object_ids, masks = predictor.add_new_points_or_box(state, <your_prompts>):
|
| 116 |
+
|
| 117 |
+
# propagate the prompts to get masklets throughout the video
|
| 118 |
+
for frame_idx, object_ids, masks in predictor.propagate_in_video(state):
|
| 119 |
+
...
|
| 120 |
+
```
|
| 121 |
+
|
| 122 |
+
Please refer to the examples in [video_predictor_example.ipynb](./notebooks/video_predictor_example.ipynb) (also in Colab [here](https://colab.research.google.com/github/facebookresearch/sam2/blob/main/notebooks/video_predictor_example.ipynb)) for details on how to add click or box prompts, make refinements, and track multiple objects in videos.
|
| 123 |
+
|
| 124 |
+
## Load from 🤗 Hugging Face
|
| 125 |
+
|
| 126 |
+
Alternatively, models can also be loaded from [Hugging Face](https://huggingface.co/models?search=facebook/sam2) (requires `pip install huggingface_hub`).
|
| 127 |
+
|
| 128 |
+
For image prediction:
|
| 129 |
+
|
| 130 |
+
```python
|
| 131 |
+
import torch
|
| 132 |
+
from sam2.sam2_image_predictor import SAM2ImagePredictor
|
| 133 |
+
|
| 134 |
+
predictor = SAM2ImagePredictor.from_pretrained("facebook/sam2-hiera-large")
|
| 135 |
+
|
| 136 |
+
with torch.inference_mode(), torch.autocast("cuda", dtype=torch.bfloat16):
|
| 137 |
+
predictor.set_image(<your_image>)
|
| 138 |
+
masks, _, _ = predictor.predict(<input_prompts>)
|
| 139 |
+
```
|
| 140 |
+
|
| 141 |
+
For video prediction:
|
| 142 |
+
|
| 143 |
+
```python
|
| 144 |
+
import torch
|
| 145 |
+
from sam2.sam2_video_predictor import SAM2VideoPredictor
|
| 146 |
+
|
| 147 |
+
predictor = SAM2VideoPredictor.from_pretrained("facebook/sam2-hiera-large")
|
| 148 |
+
|
| 149 |
+
with torch.inference_mode(), torch.autocast("cuda", dtype=torch.bfloat16):
|
| 150 |
+
state = predictor.init_state(<your_video>)
|
| 151 |
+
|
| 152 |
+
# add new prompts and instantly get the output on the same frame
|
| 153 |
+
frame_idx, object_ids, masks = predictor.add_new_points_or_box(state, <your_prompts>):
|
| 154 |
+
|
| 155 |
+
# propagate the prompts to get masklets throughout the video
|
| 156 |
+
for frame_idx, object_ids, masks in predictor.propagate_in_video(state):
|
| 157 |
+
...
|
| 158 |
+
```
|
| 159 |
+
|
| 160 |
+
## Model Description
|
| 161 |
+
|
| 162 |
+
### SAM 2.1 checkpoints
|
| 163 |
+
|
| 164 |
+
The table below shows the improved SAM 2.1 checkpoints released on September 29, 2024.
|
| 165 |
+
| **Model** | **Size (M)** | **Speed (FPS)** | **SA-V test (J&F)** | **MOSE val (J&F)** | **LVOS v2 (J&F)** |
|
| 166 |
+
| :------------------: | :----------: | :--------------------: | :-----------------: | :----------------: | :---------------: |
|
| 167 |
+
| sam2.1_hiera_tiny <br /> ([config](sam2/configs/sam2.1/sam2.1_hiera_t.yaml), [checkpoint](https://dl.fbaipublicfiles.com/segment_anything_2/092824/sam2.1_hiera_tiny.pt)) | 38.9 | 91.2 | 76.5 | 71.8 | 77.3 |
|
| 168 |
+
| sam2.1_hiera_small <br /> ([config](sam2/configs/sam2.1/sam2.1_hiera_s.yaml), [checkpoint](https://dl.fbaipublicfiles.com/segment_anything_2/092824/sam2.1_hiera_small.pt)) | 46 | 84.8 | 76.6 | 73.5 | 78.3 |
|
| 169 |
+
| sam2.1_hiera_base_plus <br /> ([config](sam2/configs/sam2.1/sam2.1_hiera_b+.yaml), [checkpoint](https://dl.fbaipublicfiles.com/segment_anything_2/092824/sam2.1_hiera_base_plus.pt)) | 80.8 | 64.1 | 78.2 | 73.7 | 78.2 |
|
| 170 |
+
| sam2.1_hiera_large <br /> ([config](sam2/configs/sam2.1/sam2.1_hiera_l.yaml), [checkpoint](https://dl.fbaipublicfiles.com/segment_anything_2/092824/sam2.1_hiera_large.pt)) | 224.4 | 39.5 | 79.5 | 74.6 | 80.6 |
|
| 171 |
+
|
| 172 |
+
### SAM 2 checkpoints
|
| 173 |
+
|
| 174 |
+
The previous SAM 2 checkpoints released on July 29, 2024 can be found as follows:
|
| 175 |
+
|
| 176 |
+
| **Model** | **Size (M)** | **Speed (FPS)** | **SA-V test (J&F)** | **MOSE val (J&F)** | **LVOS v2 (J&F)** |
|
| 177 |
+
| :------------------: | :----------: | :--------------------: | :-----------------: | :----------------: | :---------------: |
|
| 178 |
+
| sam2_hiera_tiny <br /> ([config](sam2/configs/sam2/sam2_hiera_t.yaml), [checkpoint](https://dl.fbaipublicfiles.com/segment_anything_2/072824/sam2_hiera_tiny.pt)) | 38.9 | 91.5 | 75.0 | 70.9 | 75.3 |
|
| 179 |
+
| sam2_hiera_small <br /> ([config](sam2/configs/sam2/sam2_hiera_s.yaml), [checkpoint](https://dl.fbaipublicfiles.com/segment_anything_2/072824/sam2_hiera_small.pt)) | 46 | 85.6 | 74.9 | 71.5 | 76.4 |
|
| 180 |
+
| sam2_hiera_base_plus <br /> ([config](sam2/configs/sam2/sam2_hiera_b+.yaml), [checkpoint](https://dl.fbaipublicfiles.com/segment_anything_2/072824/sam2_hiera_base_plus.pt)) | 80.8 | 64.8 | 74.7 | 72.8 | 75.8 |
|
| 181 |
+
| sam2_hiera_large <br /> ([config](sam2/configs/sam2/sam2_hiera_l.yaml), [checkpoint](https://dl.fbaipublicfiles.com/segment_anything_2/072824/sam2_hiera_large.pt)) | 224.4 | 39.7 | 76.0 | 74.6 | 79.8 |
|
| 182 |
+
|
| 183 |
+
Speed measured on an A100 with `torch 2.5.1, cuda 12.4`. See `benchmark.py` for an example on benchmarking (compiling all the model components). Compiling only the image encoder can be more flexible and also provide (a smaller) speed-up (set `compile_image_encoder: True` in the config).
|
| 184 |
+
## Segment Anything Video Dataset
|
| 185 |
+
|
| 186 |
+
See [sav_dataset/README.md](sav_dataset/README.md) for details.
|
| 187 |
+
|
| 188 |
+
## Training SAM 2
|
| 189 |
+
|
| 190 |
+
You can train or fine-tune SAM 2 on custom datasets of images, videos, or both. Please check the training [README](training/README.md) on how to get started.
|
| 191 |
+
|
| 192 |
+
## Web demo for SAM 2
|
| 193 |
+
|
| 194 |
+
We have released the frontend + backend code for the SAM 2 web demo (a locally deployable version similar to https://sam2.metademolab.com/demo). Please see the web demo [README](demo/README.md) for details.
|
| 195 |
+
|
| 196 |
+
## License
|
| 197 |
+
|
| 198 |
+
The SAM 2 model checkpoints, SAM 2 demo code (front-end and back-end), and SAM 2 training code are licensed under [Apache 2.0](./LICENSE), however the [Inter Font](https://github.com/rsms/inter?tab=OFL-1.1-1-ov-file) and [Noto Color Emoji](https://github.com/googlefonts/noto-emoji) used in the SAM 2 demo code are made available under the [SIL Open Font License, version 1.1](https://openfontlicense.org/open-font-license-official-text/).
|
| 199 |
+
|
| 200 |
+
## Contributing
|
| 201 |
+
|
| 202 |
+
See [contributing](CONTRIBUTING.md) and the [code of conduct](CODE_OF_CONDUCT.md).
|
| 203 |
+
|
| 204 |
+
## Contributors
|
| 205 |
+
|
| 206 |
+
The SAM 2 project was made possible with the help of many contributors (alphabetical):
|
| 207 |
+
|
| 208 |
+
Karen Bergan, Daniel Bolya, Alex Bosenberg, Kai Brown, Vispi Cassod, Christopher Chedeau, Ida Cheng, Luc Dahlin, Shoubhik Debnath, Rene Martinez Doehner, Grant Gardner, Sahir Gomez, Rishi Godugu, Baishan Guo, Caleb Ho, Andrew Huang, Somya Jain, Bob Kamma, Amanda Kallet, Jake Kinney, Alexander Kirillov, Shiva Koduvayur, Devansh Kukreja, Robert Kuo, Aohan Lin, Parth Malani, Jitendra Malik, Mallika Malhotra, Miguel Martin, Alexander Miller, Sasha Mitts, William Ngan, George Orlin, Joelle Pineau, Kate Saenko, Rodrick Shepard, Azita Shokrpour, David Soofian, Jonathan Torres, Jenny Truong, Sagar Vaze, Meng Wang, Claudette Ward, Pengchuan Zhang.
|
| 209 |
+
|
| 210 |
+
Third-party code: we use a GPU-based connected component algorithm adapted from [`cc_torch`](https://github.com/zsef123/Connected_components_PyTorch) (with its license in [`LICENSE_cctorch`](./LICENSE_cctorch)) as an optional post-processing step for the mask predictions.
|
| 211 |
+
|
| 212 |
+
## Citing SAM 2
|
| 213 |
+
|
| 214 |
+
If you use SAM 2 or the SA-V dataset in your research, please use the following BibTeX entry.
|
| 215 |
+
|
| 216 |
+
```bibtex
|
| 217 |
+
@article{ravi2024sam2,
|
| 218 |
+
title={SAM 2: Segment Anything in Images and Videos},
|
| 219 |
+
author={Ravi, Nikhila and Gabeur, Valentin and Hu, Yuan-Ting and Hu, Ronghang and Ryali, Chaitanya and Ma, Tengyu and Khedr, Haitham and R{\"a}dle, Roman and Rolland, Chloe and Gustafson, Laura and Mintun, Eric and Pan, Junting and Alwala, Kalyan Vasudev and Carion, Nicolas and Wu, Chao-Yuan and Girshick, Ross and Doll{\'a}r, Piotr and Feichtenhofer, Christoph},
|
| 220 |
+
journal={arXiv preprint arXiv:2408.00714},
|
| 221 |
+
url={https://arxiv.org/abs/2408.00714},
|
| 222 |
+
year={2024}
|
| 223 |
+
}
|
| 224 |
+
```
|
sam2-repo/RELEASE_NOTES.md
ADDED
|
@@ -0,0 +1,27 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## SAM 2 release notes
|
| 2 |
+
|
| 3 |
+
### 12/11/2024 -- full model compilation for a major VOS speedup and a new `SAM2VideoPredictor` to better handle multi-object tracking
|
| 4 |
+
|
| 5 |
+
- We now support `torch.compile` of the entire SAM 2 model on videos, which can be turned on by setting `vos_optimized=True` in `build_sam2_video_predictor` (it uses the new `SAM2VideoPredictorVOS` predictor class in `sam2/sam2_video_predictor.py`).
|
| 6 |
+
* Compared to the previous setting (which only compiles the image encoder backbone), the new full model compilation gives a major speedup in inference FPS.
|
| 7 |
+
* In the VOS prediction script `tools/vos_inference.py`, you can specify this option in `tools/vos_inference.py` via the `--use_vos_optimized_video_predictor` flag.
|
| 8 |
+
* Note that turning on this flag might introduce a small variance in the predictions due to numerical differences caused by `torch.compile` of the full model.
|
| 9 |
+
* **PyTorch 2.5.1 is the minimum version for full support of this feature**. (Earlier PyTorch versions might run into compilation errors in some cases.) Therefore, we have updated the minimum PyTorch version to 2.5.1 accordingly in the installation scripts.
|
| 10 |
+
- We also update the implementation of the `SAM2VideoPredictor` class for the SAM 2 video prediction in `sam2/sam2_video_predictor.py`, which allows for independent per-object inference. Specifically, in the new `SAM2VideoPredictor`:
|
| 11 |
+
* Now **we handle the inference of each object independently** (as if we are opening a separate session for each object) while sharing their backbone features.
|
| 12 |
+
* This change allows us to relax the assumption of prompting for multi-object tracking. Previously (due to the batching behavior in inference), if a video frame receives clicks for only a subset of objects, the rest of the (non-prompted) objects are assumed to be non-existent in this frame (i.e., in such frames, the user is telling SAM 2 that the rest of the objects don't appear). Now, if a frame receives clicks for only a subset of objects, we do not make any assumptions about the remaining (non-prompted) objects (i.e., now each object is handled independently and is not affected by how other objects are prompted). As a result, **we allow adding new objects after tracking starts** after this change (which was previously a restriction on usage).
|
| 13 |
+
* We believe that the new version is a more natural inference behavior and therefore switched to it as the default behavior. The previous implementation of `SAM2VideoPredictor` is backed up to in `sam2/sam2_video_predictor_legacy.py`. All the VOS inference results using `tools/vos_inference.py` should remain the same after this change to the `SAM2VideoPredictor` class.
|
| 14 |
+
|
| 15 |
+
### 09/30/2024 -- SAM 2.1 Developer Suite (new checkpoints, training code, web demo) is released
|
| 16 |
+
|
| 17 |
+
- A new suite of improved model checkpoints (denoted as **SAM 2.1**) are released. See [Model Description](#model-description) for details.
|
| 18 |
+
* To use the new SAM 2.1 checkpoints, you need the latest model code from this repo. If you have installed an earlier version of this repo, please first uninstall the previous version via `pip uninstall SAM-2`, pull the latest code from this repo (with `git pull`), and then reinstall the repo following [Installation](#installation) below.
|
| 19 |
+
- The training (and fine-tuning) code has been released. See [`training/README.md`](training/README.md) on how to get started.
|
| 20 |
+
- The frontend + backend code for the SAM 2 web demo has been released. See [`demo/README.md`](demo/README.md) for details.
|
| 21 |
+
|
| 22 |
+
### 07/29/2024 -- SAM 2 is released
|
| 23 |
+
|
| 24 |
+
- We release Segment Anything Model 2 (SAM 2), a foundation model towards solving promptable visual segmentation in images and videos.
|
| 25 |
+
* SAM 2 code: https://github.com/facebookresearch/sam2
|
| 26 |
+
* SAM 2 demo: https://sam2.metademolab.com/
|
| 27 |
+
* SAM 2 paper: https://arxiv.org/abs/2408.00714
|
sam2-repo/assets/model_diagram.png
ADDED
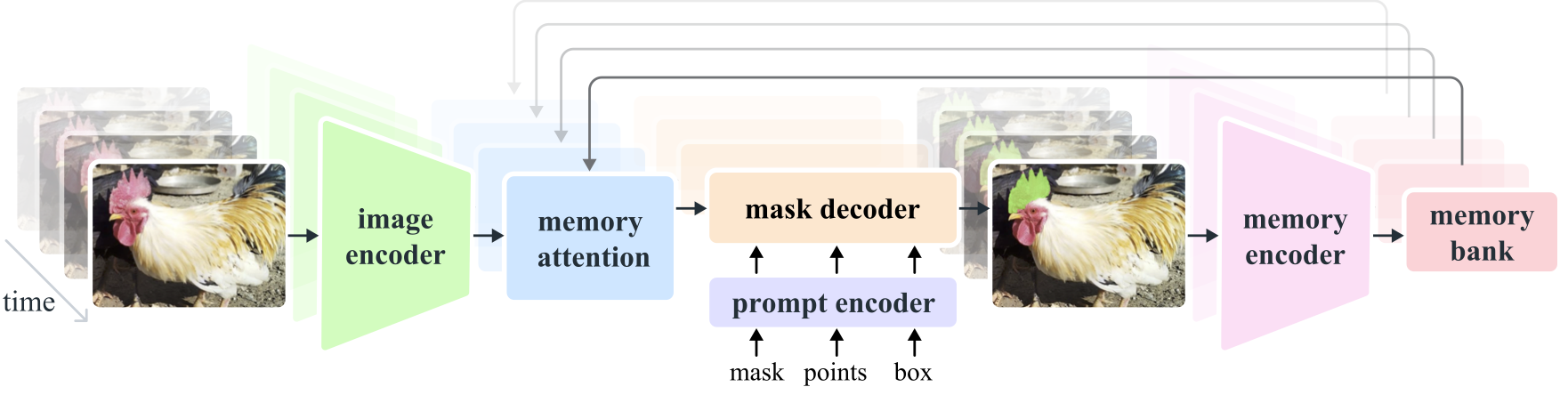
|
sam2-repo/assets/sa_v_dataset.jpg
ADDED

|
sam2-repo/backend.Dockerfile
ADDED
|
@@ -0,0 +1,64 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
ARG BASE_IMAGE=pytorch/pytorch:2.5.1-cuda12.1-cudnn9-runtime
|
| 2 |
+
ARG MODEL_SIZE=base_plus
|
| 3 |
+
|
| 4 |
+
FROM ${BASE_IMAGE}
|
| 5 |
+
|
| 6 |
+
# Gunicorn environment variables
|
| 7 |
+
ENV GUNICORN_WORKERS=1
|
| 8 |
+
ENV GUNICORN_THREADS=2
|
| 9 |
+
ENV GUNICORN_PORT=5000
|
| 10 |
+
|
| 11 |
+
# SAM 2 environment variables
|
| 12 |
+
ENV APP_ROOT=/opt/sam2
|
| 13 |
+
ENV PYTHONUNBUFFERED=1
|
| 14 |
+
ENV SAM2_BUILD_CUDA=0
|
| 15 |
+
ENV MODEL_SIZE=${MODEL_SIZE}
|
| 16 |
+
|
| 17 |
+
# Install system requirements
|
| 18 |
+
RUN apt-get update && apt-get install -y --no-install-recommends \
|
| 19 |
+
ffmpeg \
|
| 20 |
+
libavutil-dev \
|
| 21 |
+
libavcodec-dev \
|
| 22 |
+
libavformat-dev \
|
| 23 |
+
libswscale-dev \
|
| 24 |
+
pkg-config \
|
| 25 |
+
build-essential \
|
| 26 |
+
libffi-dev
|
| 27 |
+
|
| 28 |
+
COPY setup.py .
|
| 29 |
+
COPY README.md .
|
| 30 |
+
|
| 31 |
+
RUN pip install --upgrade pip setuptools
|
| 32 |
+
RUN pip install -e ".[interactive-demo]"
|
| 33 |
+
|
| 34 |
+
# https://github.com/Kosinkadink/ComfyUI-VideoHelperSuite/issues/69#issuecomment-1826764707
|
| 35 |
+
RUN rm /opt/conda/bin/ffmpeg && ln -s /bin/ffmpeg /opt/conda/bin/ffmpeg
|
| 36 |
+
|
| 37 |
+
# Make app directory. This directory will host all files required for the
|
| 38 |
+
# backend and SAM 2 inference files.
|
| 39 |
+
RUN mkdir ${APP_ROOT}
|
| 40 |
+
|
| 41 |
+
# Copy backend server files
|
| 42 |
+
COPY demo/backend/server ${APP_ROOT}/server
|
| 43 |
+
|
| 44 |
+
# Copy SAM 2 inference files
|
| 45 |
+
COPY sam2 ${APP_ROOT}/server/sam2
|
| 46 |
+
|
| 47 |
+
# Download SAM 2.1 checkpoints
|
| 48 |
+
ADD https://dl.fbaipublicfiles.com/segment_anything_2/092824/sam2.1_hiera_tiny.pt ${APP_ROOT}/checkpoints/sam2.1_hiera_tiny.pt
|
| 49 |
+
ADD https://dl.fbaipublicfiles.com/segment_anything_2/092824/sam2.1_hiera_small.pt ${APP_ROOT}/checkpoints/sam2.1_hiera_small.pt
|
| 50 |
+
ADD https://dl.fbaipublicfiles.com/segment_anything_2/092824/sam2.1_hiera_base_plus.pt ${APP_ROOT}/checkpoints/sam2.1_hiera_base_plus.pt
|
| 51 |
+
ADD https://dl.fbaipublicfiles.com/segment_anything_2/092824/sam2.1_hiera_large.pt ${APP_ROOT}/checkpoints/sam2.1_hiera_large.pt
|
| 52 |
+
|
| 53 |
+
WORKDIR ${APP_ROOT}/server
|
| 54 |
+
|
| 55 |
+
# https://pythonspeed.com/articles/gunicorn-in-docker/
|
| 56 |
+
CMD gunicorn --worker-tmp-dir /dev/shm \
|
| 57 |
+
--worker-class gthread app:app \
|
| 58 |
+
--log-level info \
|
| 59 |
+
--access-logfile /dev/stdout \
|
| 60 |
+
--log-file /dev/stderr \
|
| 61 |
+
--workers ${GUNICORN_WORKERS} \
|
| 62 |
+
--threads ${GUNICORN_THREADS} \
|
| 63 |
+
--bind 0.0.0.0:${GUNICORN_PORT} \
|
| 64 |
+
--timeout 60
|
sam2-repo/checkpoints/download_ckpts.sh
ADDED
|
@@ -0,0 +1,59 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/bin/bash
|
| 2 |
+
|
| 3 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 4 |
+
# All rights reserved.
|
| 5 |
+
|
| 6 |
+
# This source code is licensed under the license found in the
|
| 7 |
+
# LICENSE file in the root directory of this source tree.
|
| 8 |
+
|
| 9 |
+
# Use either wget or curl to download the checkpoints
|
| 10 |
+
if command -v wget &> /dev/null; then
|
| 11 |
+
CMD="wget"
|
| 12 |
+
elif command -v curl &> /dev/null; then
|
| 13 |
+
CMD="curl -L -O"
|
| 14 |
+
else
|
| 15 |
+
echo "Please install wget or curl to download the checkpoints."
|
| 16 |
+
exit 1
|
| 17 |
+
fi
|
| 18 |
+
|
| 19 |
+
# Define the URLs for SAM 2 checkpoints
|
| 20 |
+
# SAM2_BASE_URL="https://dl.fbaipublicfiles.com/segment_anything_2/072824"
|
| 21 |
+
# sam2_hiera_t_url="${SAM2_BASE_URL}/sam2_hiera_tiny.pt"
|
| 22 |
+
# sam2_hiera_s_url="${SAM2_BASE_URL}/sam2_hiera_small.pt"
|
| 23 |
+
# sam2_hiera_b_plus_url="${SAM2_BASE_URL}/sam2_hiera_base_plus.pt"
|
| 24 |
+
# sam2_hiera_l_url="${SAM2_BASE_URL}/sam2_hiera_large.pt"
|
| 25 |
+
|
| 26 |
+
# Download each of the four checkpoints using wget
|
| 27 |
+
# echo "Downloading sam2_hiera_tiny.pt checkpoint..."
|
| 28 |
+
# $CMD $sam2_hiera_t_url || { echo "Failed to download checkpoint from $sam2_hiera_t_url"; exit 1; }
|
| 29 |
+
|
| 30 |
+
# echo "Downloading sam2_hiera_small.pt checkpoint..."
|
| 31 |
+
# $CMD $sam2_hiera_s_url || { echo "Failed to download checkpoint from $sam2_hiera_s_url"; exit 1; }
|
| 32 |
+
|
| 33 |
+
# echo "Downloading sam2_hiera_base_plus.pt checkpoint..."
|
| 34 |
+
# $CMD $sam2_hiera_b_plus_url || { echo "Failed to download checkpoint from $sam2_hiera_b_plus_url"; exit 1; }
|
| 35 |
+
|
| 36 |
+
# echo "Downloading sam2_hiera_large.pt checkpoint..."
|
| 37 |
+
# $CMD $sam2_hiera_l_url || { echo "Failed to download checkpoint from $sam2_hiera_l_url"; exit 1; }
|
| 38 |
+
|
| 39 |
+
# Define the URLs for SAM 2.1 checkpoints
|
| 40 |
+
SAM2p1_BASE_URL="https://dl.fbaipublicfiles.com/segment_anything_2/092824"
|
| 41 |
+
sam2p1_hiera_t_url="${SAM2p1_BASE_URL}/sam2.1_hiera_tiny.pt"
|
| 42 |
+
sam2p1_hiera_s_url="${SAM2p1_BASE_URL}/sam2.1_hiera_small.pt"
|
| 43 |
+
sam2p1_hiera_b_plus_url="${SAM2p1_BASE_URL}/sam2.1_hiera_base_plus.pt"
|
| 44 |
+
sam2p1_hiera_l_url="${SAM2p1_BASE_URL}/sam2.1_hiera_large.pt"
|
| 45 |
+
|
| 46 |
+
# SAM 2.1 checkpoints
|
| 47 |
+
echo "Downloading sam2.1_hiera_tiny.pt checkpoint..."
|
| 48 |
+
$CMD $sam2p1_hiera_t_url || { echo "Failed to download checkpoint from $sam2p1_hiera_t_url"; exit 1; }
|
| 49 |
+
|
| 50 |
+
echo "Downloading sam2.1_hiera_small.pt checkpoint..."
|
| 51 |
+
$CMD $sam2p1_hiera_s_url || { echo "Failed to download checkpoint from $sam2p1_hiera_s_url"; exit 1; }
|
| 52 |
+
|
| 53 |
+
echo "Downloading sam2.1_hiera_base_plus.pt checkpoint..."
|
| 54 |
+
$CMD $sam2p1_hiera_b_plus_url || { echo "Failed to download checkpoint from $sam2p1_hiera_b_plus_url"; exit 1; }
|
| 55 |
+
|
| 56 |
+
echo "Downloading sam2.1_hiera_large.pt checkpoint..."
|
| 57 |
+
$CMD $sam2p1_hiera_l_url || { echo "Failed to download checkpoint from $sam2p1_hiera_l_url"; exit 1; }
|
| 58 |
+
|
| 59 |
+
echo "All checkpoints are downloaded successfully."
|
sam2-repo/demo/.gitignore
ADDED
|
@@ -0,0 +1,2 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
data/uploads
|
| 2 |
+
data/posters
|
sam2-repo/demo/README.md
ADDED
|
@@ -0,0 +1,173 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# SAM 2 Demo
|
| 2 |
+
|
| 3 |
+
Welcome to the SAM 2 Demo! This project consists of a frontend built with React TypeScript and Vite and a backend service using Python Flask and Strawberry GraphQL. Both components can be run in Docker containers or locally on MPS (Metal Performance Shaders) or CPU. However, running the backend service on MPS or CPU devices may result in significantly slower performance (FPS).
|
| 4 |
+
|
| 5 |
+
## Prerequisites
|
| 6 |
+
|
| 7 |
+
Before you begin, ensure you have the following installed on your system:
|
| 8 |
+
|
| 9 |
+
- Docker and Docker Compose
|
| 10 |
+
- [OPTIONAL] Node.js and Yarn for running frontend locally
|
| 11 |
+
- [OPTIONAL] Anaconda for running backend locally
|
| 12 |
+
|
| 13 |
+
### Installing Docker
|
| 14 |
+
|
| 15 |
+
To install Docker, follow these steps:
|
| 16 |
+
|
| 17 |
+
1. Go to the [Docker website](https://www.docker.com/get-started)
|
| 18 |
+
2. Follow the installation instructions for your operating system.
|
| 19 |
+
|
| 20 |
+
### [OPTIONAL] Installing Node.js and Yarn
|
| 21 |
+
|
| 22 |
+
To install Node.js and Yarn, follow these steps:
|
| 23 |
+
|
| 24 |
+
1. Go to the [Node.js website](https://nodejs.org/en/download/).
|
| 25 |
+
2. Follow the installation instructions for your operating system.
|
| 26 |
+
3. Once Node.js is installed, open a terminal or command prompt and run the following command to install Yarn:
|
| 27 |
+
|
| 28 |
+
```
|
| 29 |
+
npm install -g yarn
|
| 30 |
+
```
|
| 31 |
+
|
| 32 |
+
### [OPTIONAL] Installing Anaconda
|
| 33 |
+
|
| 34 |
+
To install Anaconda, follow these steps:
|
| 35 |
+
|
| 36 |
+
1. Go to the [Anaconda website](https://www.anaconda.com/products/distribution).
|
| 37 |
+
2. Follow the installation instructions for your operating system.
|
| 38 |
+
|
| 39 |
+
## Quick Start
|
| 40 |
+
|
| 41 |
+
To get both the frontend and backend running quickly using Docker, you can use the following command:
|
| 42 |
+
|
| 43 |
+
```bash
|
| 44 |
+
docker compose up --build
|
| 45 |
+
```
|
| 46 |
+
|
| 47 |
+
> [!WARNING]
|
| 48 |
+
> On macOS, Docker containers only support running on CPU. MPS is not supported through Docker. If you want to run the demo backend service on MPS, you will need to run it locally (see "Running the Backend Locally" below).
|
| 49 |
+
|
| 50 |
+
This will build and start both services. You can access them at:
|
| 51 |
+
|
| 52 |
+
- **Frontend:** [http://localhost:7262](http://localhost:7262)
|
| 53 |
+
- **Backend:** [http://localhost:7263/graphql](http://localhost:7263/graphql)
|
| 54 |
+
|
| 55 |
+
## Running Backend with MPS Support
|
| 56 |
+
|
| 57 |
+
MPS (Metal Performance Shaders) is not supported with Docker. To use MPS, you need to run the backend on your local machine.
|
| 58 |
+
|
| 59 |
+
### Setting Up Your Environment
|
| 60 |
+
|
| 61 |
+
1. **Create Conda environment**
|
| 62 |
+
|
| 63 |
+
Create a new Conda environment for this project by running the following command or use your existing conda environment for SAM 2:
|
| 64 |
+
|
| 65 |
+
```
|
| 66 |
+
conda create --name sam2-demo python=3.10 --yes
|
| 67 |
+
```
|
| 68 |
+
|
| 69 |
+
This will create a new environment named `sam2-demo` with Python 3.10 as the interpreter.
|
| 70 |
+
|
| 71 |
+
2. **Activate the Conda environment:**
|
| 72 |
+
|
| 73 |
+
```bash
|
| 74 |
+
conda activate sam2-demo
|
| 75 |
+
```
|
| 76 |
+
|
| 77 |
+
3. **Install ffmpeg**
|
| 78 |
+
|
| 79 |
+
```bash
|
| 80 |
+
conda install -c conda-forge ffmpeg
|
| 81 |
+
```
|
| 82 |
+
|
| 83 |
+
4. **Install SAM 2 demo dependencies:**
|
| 84 |
+
|
| 85 |
+
Install project dependencies by running the following command in the SAM 2 checkout root directory:
|
| 86 |
+
|
| 87 |
+
```bash
|
| 88 |
+
pip install -e '.[interactive-demo]'
|
| 89 |
+
```
|
| 90 |
+
|
| 91 |
+
### Running the Backend Locally
|
| 92 |
+
|
| 93 |
+
Download the SAM 2 checkpoints:
|
| 94 |
+
|
| 95 |
+
```bash
|
| 96 |
+
(cd ./checkpoints && ./download_ckpts.sh)
|
| 97 |
+
```
|
| 98 |
+
|
| 99 |
+
Use the following command to start the backend with MPS support:
|
| 100 |
+
|
| 101 |
+
```bash
|
| 102 |
+
cd demo/backend/server/
|
| 103 |
+
```
|
| 104 |
+
|
| 105 |
+
```bash
|
| 106 |
+
PYTORCH_ENABLE_MPS_FALLBACK=1 \
|
| 107 |
+
APP_ROOT="$(pwd)/../../../" \
|
| 108 |
+
API_URL=http://localhost:7263 \
|
| 109 |
+
MODEL_SIZE=base_plus \
|
| 110 |
+
DATA_PATH="$(pwd)/../../data" \
|
| 111 |
+
DEFAULT_VIDEO_PATH=gallery/05_default_juggle.mp4 \
|
| 112 |
+
gunicorn \
|
| 113 |
+
--worker-class gthread app:app \
|
| 114 |
+
--workers 1 \
|
| 115 |
+
--threads 2 \
|
| 116 |
+
--bind 0.0.0.0:7263 \
|
| 117 |
+
--timeout 60
|
| 118 |
+
```
|
| 119 |
+
|
| 120 |
+
Options for the `MODEL_SIZE` argument are "tiny", "small", "base_plus" (default), and "large".
|
| 121 |
+
|
| 122 |
+
> [!WARNING]
|
| 123 |
+
> Running the backend service on MPS devices can cause fatal crashes with the Gunicorn worker due to insufficient MPS memory. Try switching to CPU devices by setting the `SAM2_DEMO_FORCE_CPU_DEVICE=1` environment variable.
|
| 124 |
+
|
| 125 |
+
### Starting the Frontend
|
| 126 |
+
|
| 127 |
+
If you wish to run the frontend separately (useful for development), follow these steps:
|
| 128 |
+
|
| 129 |
+
1. **Navigate to demo frontend directory:**
|
| 130 |
+
|
| 131 |
+
```bash
|
| 132 |
+
cd demo/frontend
|
| 133 |
+
```
|
| 134 |
+
|
| 135 |
+
2. **Install dependencies:**
|
| 136 |
+
|
| 137 |
+
```bash
|
| 138 |
+
yarn install
|
| 139 |
+
```
|
| 140 |
+
|
| 141 |
+
3. **Start the development server:**
|
| 142 |
+
|
| 143 |
+
```bash
|
| 144 |
+
yarn dev --port 7262
|
| 145 |
+
```
|
| 146 |
+
|
| 147 |
+
This will start the frontend development server on [http://localhost:7262](http://localhost:7262).
|
| 148 |
+
|
| 149 |
+
## Docker Tips
|
| 150 |
+
|
| 151 |
+
- To rebuild the Docker containers (useful if you've made changes to the Dockerfile or dependencies):
|
| 152 |
+
|
| 153 |
+
```bash
|
| 154 |
+
docker compose up --build
|
| 155 |
+
```
|
| 156 |
+
|
| 157 |
+
- To stop the Docker containers:
|
| 158 |
+
|
| 159 |
+
```bash
|
| 160 |
+
docker compose down
|
| 161 |
+
```
|
| 162 |
+
|
| 163 |
+
## Contributing
|
| 164 |
+
|
| 165 |
+
Contributions are welcome! Please read our contributing guidelines to get started.
|
| 166 |
+
|
| 167 |
+
## License
|
| 168 |
+
|
| 169 |
+
See the LICENSE file for details.
|
| 170 |
+
|
| 171 |
+
---
|
| 172 |
+
|
| 173 |
+
By following these instructions, you should have a fully functional development environment for both the frontend and backend of the SAM 2 Demo. Happy coding!
|
sam2-repo/demo/backend/server/app.py
ADDED
|
@@ -0,0 +1,140 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
# This source code is licensed under the license found in the
|
| 4 |
+
# LICENSE file in the root directory of this source tree.
|
| 5 |
+
|
| 6 |
+
import logging
|
| 7 |
+
from typing import Any, Generator
|
| 8 |
+
|
| 9 |
+
from app_conf import (
|
| 10 |
+
GALLERY_PATH,
|
| 11 |
+
GALLERY_PREFIX,
|
| 12 |
+
POSTERS_PATH,
|
| 13 |
+
POSTERS_PREFIX,
|
| 14 |
+
UPLOADS_PATH,
|
| 15 |
+
UPLOADS_PREFIX,
|
| 16 |
+
)
|
| 17 |
+
from data.loader import preload_data
|
| 18 |
+
from data.schema import schema
|
| 19 |
+
from data.store import set_videos
|
| 20 |
+
from flask import Flask, make_response, Request, request, Response, send_from_directory
|
| 21 |
+
from flask_cors import CORS
|
| 22 |
+
from inference.data_types import PropagateDataResponse, PropagateInVideoRequest
|
| 23 |
+
from inference.multipart import MultipartResponseBuilder
|
| 24 |
+
from inference.predictor import InferenceAPI
|
| 25 |
+
from strawberry.flask.views import GraphQLView
|
| 26 |
+
|
| 27 |
+
logger = logging.getLogger(__name__)
|
| 28 |
+
|
| 29 |
+
app = Flask(__name__)
|
| 30 |
+
cors = CORS(app, supports_credentials=True)
|
| 31 |
+
|
| 32 |
+
videos = preload_data()
|
| 33 |
+
set_videos(videos)
|
| 34 |
+
|
| 35 |
+
inference_api = InferenceAPI()
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
@app.route("/healthy")
|
| 39 |
+
def healthy() -> Response:
|
| 40 |
+
return make_response("OK", 200)
|
| 41 |
+
|
| 42 |
+
|
| 43 |
+
@app.route(f"/{GALLERY_PREFIX}/<path:path>", methods=["GET"])
|
| 44 |
+
def send_gallery_video(path: str) -> Response:
|
| 45 |
+
try:
|
| 46 |
+
return send_from_directory(
|
| 47 |
+
GALLERY_PATH,
|
| 48 |
+
path,
|
| 49 |
+
)
|
| 50 |
+
except:
|
| 51 |
+
raise ValueError("resource not found")
|
| 52 |
+
|
| 53 |
+
|
| 54 |
+
@app.route(f"/{POSTERS_PREFIX}/<path:path>", methods=["GET"])
|
| 55 |
+
def send_poster_image(path: str) -> Response:
|
| 56 |
+
try:
|
| 57 |
+
return send_from_directory(
|
| 58 |
+
POSTERS_PATH,
|
| 59 |
+
path,
|
| 60 |
+
)
|
| 61 |
+
except:
|
| 62 |
+
raise ValueError("resource not found")
|
| 63 |
+
|
| 64 |
+
|
| 65 |
+
@app.route(f"/{UPLOADS_PREFIX}/<path:path>", methods=["GET"])
|
| 66 |
+
def send_uploaded_video(path: str):
|
| 67 |
+
try:
|
| 68 |
+
return send_from_directory(
|
| 69 |
+
UPLOADS_PATH,
|
| 70 |
+
path,
|
| 71 |
+
)
|
| 72 |
+
except:
|
| 73 |
+
raise ValueError("resource not found")
|
| 74 |
+
|
| 75 |
+
|
| 76 |
+
# TOOD: Protect route with ToS permission check
|
| 77 |
+
@app.route("/propagate_in_video", methods=["POST"])
|
| 78 |
+
def propagate_in_video() -> Response:
|
| 79 |
+
data = request.json
|
| 80 |
+
args = {
|
| 81 |
+
"session_id": data["session_id"],
|
| 82 |
+
"start_frame_index": data.get("start_frame_index", 0),
|
| 83 |
+
}
|
| 84 |
+
|
| 85 |
+
boundary = "frame"
|
| 86 |
+
frame = gen_track_with_mask_stream(boundary, **args)
|
| 87 |
+
return Response(frame, mimetype="multipart/x-savi-stream; boundary=" + boundary)
|
| 88 |
+
|
| 89 |
+
|
| 90 |
+
def gen_track_with_mask_stream(
|
| 91 |
+
boundary: str,
|
| 92 |
+
session_id: str,
|
| 93 |
+
start_frame_index: int,
|
| 94 |
+
) -> Generator[bytes, None, None]:
|
| 95 |
+
with inference_api.autocast_context():
|
| 96 |
+
request = PropagateInVideoRequest(
|
| 97 |
+
type="propagate_in_video",
|
| 98 |
+
session_id=session_id,
|
| 99 |
+
start_frame_index=start_frame_index,
|
| 100 |
+
)
|
| 101 |
+
|
| 102 |
+
for chunk in inference_api.propagate_in_video(request=request):
|
| 103 |
+
yield MultipartResponseBuilder.build(
|
| 104 |
+
boundary=boundary,
|
| 105 |
+
headers={
|
| 106 |
+
"Content-Type": "application/json; charset=utf-8",
|
| 107 |
+
"Frame-Current": "-1",
|
| 108 |
+
# Total frames minus the reference frame
|
| 109 |
+
"Frame-Total": "-1",
|
| 110 |
+
"Mask-Type": "RLE[]",
|
| 111 |
+
},
|
| 112 |
+
body=chunk.to_json().encode("UTF-8"),
|
| 113 |
+
).get_message()
|
| 114 |
+
|
| 115 |
+
|
| 116 |
+
class MyGraphQLView(GraphQLView):
|
| 117 |
+
def get_context(self, request: Request, response: Response) -> Any:
|
| 118 |
+
return {"inference_api": inference_api}
|
| 119 |
+
|
| 120 |
+
|
| 121 |
+
# Add GraphQL route to Flask app.
|
| 122 |
+
app.add_url_rule(
|
| 123 |
+
"/graphql",
|
| 124 |
+
view_func=MyGraphQLView.as_view(
|
| 125 |
+
"graphql_view",
|
| 126 |
+
schema=schema,
|
| 127 |
+
# Disable GET queries
|
| 128 |
+
# https://strawberry.rocks/docs/operations/deployment
|
| 129 |
+
# https://strawberry.rocks/docs/integrations/flask
|
| 130 |
+
allow_queries_via_get=False,
|
| 131 |
+
# Strawberry recently changed multipart request handling, which now
|
| 132 |
+
# requires enabling support explicitly for views.
|
| 133 |
+
# https://github.com/strawberry-graphql/strawberry/issues/3655
|
| 134 |
+
multipart_uploads_enabled=True,
|
| 135 |
+
),
|
| 136 |
+
)
|
| 137 |
+
|
| 138 |
+
|
| 139 |
+
if __name__ == "__main__":
|
| 140 |
+
app.run(host="0.0.0.0", port=5000)
|
sam2-repo/demo/backend/server/app_conf.py
ADDED
|
@@ -0,0 +1,55 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
# This source code is licensed under the license found in the
|
| 4 |
+
# LICENSE file in the root directory of this source tree.
|
| 5 |
+
|
| 6 |
+
import logging
|
| 7 |
+
import os
|
| 8 |
+
from pathlib import Path
|
| 9 |
+
|
| 10 |
+
logger = logging.getLogger(__name__)
|
| 11 |
+
|
| 12 |
+
APP_ROOT = os.getenv("APP_ROOT", "/opt/sam2")
|
| 13 |
+
|
| 14 |
+
API_URL = os.getenv("API_URL", "http://localhost:7263")
|
| 15 |
+
|
| 16 |
+
MODEL_SIZE = os.getenv("MODEL_SIZE", "base_plus")
|
| 17 |
+
|
| 18 |
+
logger.info(f"using model size {MODEL_SIZE}")
|
| 19 |
+
|
| 20 |
+
FFMPEG_NUM_THREADS = int(os.getenv("FFMPEG_NUM_THREADS", "1"))
|
| 21 |
+
|
| 22 |
+
# Path for all data used in API
|
| 23 |
+
DATA_PATH = Path(os.getenv("DATA_PATH", "/data"))
|
| 24 |
+
|
| 25 |
+
# Max duration an uploaded video can have in seconds. The default is 10
|
| 26 |
+
# seconds.
|
| 27 |
+
MAX_UPLOAD_VIDEO_DURATION = float(os.environ.get("MAX_UPLOAD_VIDEO_DURATION", "10"))
|
| 28 |
+
|
| 29 |
+
# If set, it will define which video is returned by the default video query for
|
| 30 |
+
# desktop
|
| 31 |
+
DEFAULT_VIDEO_PATH = os.getenv("DEFAULT_VIDEO_PATH")
|
| 32 |
+
|
| 33 |
+
# Prefix for gallery videos
|
| 34 |
+
GALLERY_PREFIX = "gallery"
|
| 35 |
+
|
| 36 |
+
# Path where all gallery videos are stored
|
| 37 |
+
GALLERY_PATH = DATA_PATH / GALLERY_PREFIX
|
| 38 |
+
|
| 39 |
+
# Prefix for uploaded videos
|
| 40 |
+
UPLOADS_PREFIX = "uploads"
|
| 41 |
+
|
| 42 |
+
# Path where all uploaded videos are stored
|
| 43 |
+
UPLOADS_PATH = DATA_PATH / UPLOADS_PREFIX
|
| 44 |
+
|
| 45 |
+
# Prefix for video posters (1st frame of video)
|
| 46 |
+
POSTERS_PREFIX = "posters"
|
| 47 |
+
|
| 48 |
+
# Path where all posters are stored
|
| 49 |
+
POSTERS_PATH = DATA_PATH / POSTERS_PREFIX
|
| 50 |
+
|
| 51 |
+
# Make sure any of those paths exist
|
| 52 |
+
os.makedirs(DATA_PATH, exist_ok=True)
|
| 53 |
+
os.makedirs(GALLERY_PATH, exist_ok=True)
|
| 54 |
+
os.makedirs(UPLOADS_PATH, exist_ok=True)
|
| 55 |
+
os.makedirs(POSTERS_PATH, exist_ok=True)
|
sam2-repo/demo/backend/server/data/data_types.py
ADDED
|
@@ -0,0 +1,154 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
# This source code is licensed under the license found in the
|
| 4 |
+
# LICENSE file in the root directory of this source tree.
|
| 5 |
+
|
| 6 |
+
from dataclasses import dataclass
|
| 7 |
+
from typing import Iterable, List, Optional
|
| 8 |
+
|
| 9 |
+
import strawberry
|
| 10 |
+
from app_conf import API_URL
|
| 11 |
+
from data.resolver import resolve_videos
|
| 12 |
+
from dataclasses_json import dataclass_json
|
| 13 |
+
from strawberry import relay
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
@strawberry.type
|
| 17 |
+
class Video(relay.Node):
|
| 18 |
+
"""Core type for video."""
|
| 19 |
+
|
| 20 |
+
code: relay.NodeID[str]
|
| 21 |
+
path: str
|
| 22 |
+
poster_path: Optional[str]
|
| 23 |
+
width: int
|
| 24 |
+
height: int
|
| 25 |
+
|
| 26 |
+
@strawberry.field
|
| 27 |
+
def url(self) -> str:
|
| 28 |
+
return f"{API_URL}/{self.path}"
|
| 29 |
+
|
| 30 |
+
@strawberry.field
|
| 31 |
+
def poster_url(self) -> str:
|
| 32 |
+
return f"{API_URL}/{self.poster_path}"
|
| 33 |
+
|
| 34 |
+
@classmethod
|
| 35 |
+
def resolve_nodes(
|
| 36 |
+
cls,
|
| 37 |
+
*,
|
| 38 |
+
info: relay.PageInfo,
|
| 39 |
+
node_ids: Iterable[str],
|
| 40 |
+
required: bool = False,
|
| 41 |
+
):
|
| 42 |
+
return resolve_videos(node_ids, required)
|
| 43 |
+
|
| 44 |
+
|
| 45 |
+
@strawberry.type
|
| 46 |
+
class RLEMask:
|
| 47 |
+
"""Core type for Onevision GraphQL RLE mask."""
|
| 48 |
+
|
| 49 |
+
size: List[int]
|
| 50 |
+
counts: str
|
| 51 |
+
order: str
|
| 52 |
+
|
| 53 |
+
|
| 54 |
+
@strawberry.type
|
| 55 |
+
class RLEMaskForObject:
|
| 56 |
+
"""Type for RLE mask associated with a specific object id."""
|
| 57 |
+
|
| 58 |
+
object_id: int
|
| 59 |
+
rle_mask: RLEMask
|
| 60 |
+
|
| 61 |
+
|
| 62 |
+
@strawberry.type
|
| 63 |
+
class RLEMaskListOnFrame:
|
| 64 |
+
"""Type for a list of object-associated RLE masks on a specific video frame."""
|
| 65 |
+
|
| 66 |
+
frame_index: int
|
| 67 |
+
rle_mask_list: List[RLEMaskForObject]
|
| 68 |
+
|
| 69 |
+
|
| 70 |
+
@strawberry.input
|
| 71 |
+
class StartSessionInput:
|
| 72 |
+
path: str
|
| 73 |
+
|
| 74 |
+
|
| 75 |
+
@strawberry.type
|
| 76 |
+
class StartSession:
|
| 77 |
+
session_id: str
|
| 78 |
+
|
| 79 |
+
|
| 80 |
+
@strawberry.input
|
| 81 |
+
class PingInput:
|
| 82 |
+
session_id: str
|
| 83 |
+
|
| 84 |
+
|
| 85 |
+
@strawberry.type
|
| 86 |
+
class Pong:
|
| 87 |
+
success: bool
|
| 88 |
+
|
| 89 |
+
|
| 90 |
+
@strawberry.input
|
| 91 |
+
class CloseSessionInput:
|
| 92 |
+
session_id: str
|
| 93 |
+
|
| 94 |
+
|
| 95 |
+
@strawberry.type
|
| 96 |
+
class CloseSession:
|
| 97 |
+
success: bool
|
| 98 |
+
|
| 99 |
+
|
| 100 |
+
@strawberry.input
|
| 101 |
+
class AddPointsInput:
|
| 102 |
+
session_id: str
|
| 103 |
+
frame_index: int
|
| 104 |
+
clear_old_points: bool
|
| 105 |
+
object_id: int
|
| 106 |
+
labels: List[int]
|
| 107 |
+
points: List[List[float]]
|
| 108 |
+
|
| 109 |
+
|
| 110 |
+
@strawberry.input
|
| 111 |
+
class ClearPointsInFrameInput:
|
| 112 |
+
session_id: str
|
| 113 |
+
frame_index: int
|
| 114 |
+
object_id: int
|
| 115 |
+
|
| 116 |
+
|
| 117 |
+
@strawberry.input
|
| 118 |
+
class ClearPointsInVideoInput:
|
| 119 |
+
session_id: str
|
| 120 |
+
|
| 121 |
+
|
| 122 |
+
@strawberry.type
|
| 123 |
+
class ClearPointsInVideo:
|
| 124 |
+
success: bool
|
| 125 |
+
|
| 126 |
+
|
| 127 |
+
@strawberry.input
|
| 128 |
+
class RemoveObjectInput:
|
| 129 |
+
session_id: str
|
| 130 |
+
object_id: int
|
| 131 |
+
|
| 132 |
+
|
| 133 |
+
@strawberry.input
|
| 134 |
+
class PropagateInVideoInput:
|
| 135 |
+
session_id: str
|
| 136 |
+
start_frame_index: int
|
| 137 |
+
|
| 138 |
+
|
| 139 |
+
@strawberry.input
|
| 140 |
+
class CancelPropagateInVideoInput:
|
| 141 |
+
session_id: str
|
| 142 |
+
|
| 143 |
+
|
| 144 |
+
@strawberry.type
|
| 145 |
+
class CancelPropagateInVideo:
|
| 146 |
+
success: bool
|
| 147 |
+
|
| 148 |
+
|
| 149 |
+
@strawberry.type
|
| 150 |
+
class SessionExpiration:
|
| 151 |
+
session_id: str
|
| 152 |
+
expiration_time: int
|
| 153 |
+
max_expiration_time: int
|
| 154 |
+
ttl: int
|
sam2-repo/demo/backend/server/data/loader.py
ADDED
|
@@ -0,0 +1,92 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
# This source code is licensed under the license found in the
|
| 4 |
+
# LICENSE file in the root directory of this source tree.
|
| 5 |
+
|
| 6 |
+
import os
|
| 7 |
+
import shutil
|
| 8 |
+
import subprocess
|
| 9 |
+
from glob import glob
|
| 10 |
+
from pathlib import Path
|
| 11 |
+
from typing import Dict, Optional
|
| 12 |
+
|
| 13 |
+
import imagesize
|
| 14 |
+
from app_conf import GALLERY_PATH, POSTERS_PATH, POSTERS_PREFIX
|
| 15 |
+
from data.data_types import Video
|
| 16 |
+
from tqdm import tqdm
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
def preload_data() -> Dict[str, Video]:
|
| 20 |
+
"""
|
| 21 |
+
Preload data including gallery videos and their posters.
|
| 22 |
+
"""
|
| 23 |
+
# Dictionaries for videos and datasets on the backend.
|
| 24 |
+
# Note that since Python 3.7, dictionaries preserve their insert order, so
|
| 25 |
+
# when looping over its `.values()`, elements inserted first also appear first.
|
| 26 |
+
# https://stackoverflow.com/questions/39980323/are-dictionaries-ordered-in-python-3-6
|
| 27 |
+
all_videos = {}
|
| 28 |
+
|
| 29 |
+
video_path_pattern = os.path.join(GALLERY_PATH, "**/*.mp4")
|
| 30 |
+
video_paths = glob(video_path_pattern, recursive=True)
|
| 31 |
+
|
| 32 |
+
for p in tqdm(video_paths):
|
| 33 |
+
video = get_video(p, GALLERY_PATH)
|
| 34 |
+
all_videos[video.code] = video
|
| 35 |
+
|
| 36 |
+
return all_videos
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
def get_video(
|
| 40 |
+
filepath: os.PathLike,
|
| 41 |
+
absolute_path: Path,
|
| 42 |
+
file_key: Optional[str] = None,
|
| 43 |
+
generate_poster: bool = True,
|
| 44 |
+
width: Optional[int] = None,
|
| 45 |
+
height: Optional[int] = None,
|
| 46 |
+
verbose: Optional[bool] = False,
|
| 47 |
+
) -> Video:
|
| 48 |
+
"""
|
| 49 |
+
Get video object given
|
| 50 |
+
"""
|
| 51 |
+
# Use absolute_path to include the parent directory in the video
|
| 52 |
+
video_path = os.path.relpath(filepath, absolute_path.parent)
|
| 53 |
+
poster_path = None
|
| 54 |
+
if generate_poster:
|
| 55 |
+
poster_id = os.path.splitext(os.path.basename(filepath))[0]
|
| 56 |
+
poster_filename = f"{str(poster_id)}.jpg"
|
| 57 |
+
poster_path = f"{POSTERS_PREFIX}/{poster_filename}"
|
| 58 |
+
|
| 59 |
+
# Extract the first frame from video
|
| 60 |
+
poster_output_path = os.path.join(POSTERS_PATH, poster_filename)
|
| 61 |
+
ffmpeg = shutil.which("ffmpeg")
|
| 62 |
+
subprocess.call(
|
| 63 |
+
[
|
| 64 |
+
ffmpeg,
|
| 65 |
+
"-y",
|
| 66 |
+
"-i",
|
| 67 |
+
str(filepath),
|
| 68 |
+
"-pix_fmt",
|
| 69 |
+
"yuv420p",
|
| 70 |
+
"-frames:v",
|
| 71 |
+
"1",
|
| 72 |
+
"-update",
|
| 73 |
+
"1",
|
| 74 |
+
"-strict",
|
| 75 |
+
"unofficial",
|
| 76 |
+
str(poster_output_path),
|
| 77 |
+
],
|
| 78 |
+
stdout=None if verbose else subprocess.DEVNULL,
|
| 79 |
+
stderr=None if verbose else subprocess.DEVNULL,
|
| 80 |
+
)
|
| 81 |
+
|
| 82 |
+
# Extract video width and height from poster. This is important to optimize
|
| 83 |
+
# rendering previews in the mosaic video preview.
|
| 84 |
+
width, height = imagesize.get(poster_output_path)
|
| 85 |
+
|
| 86 |
+
return Video(
|
| 87 |
+
code=video_path,
|
| 88 |
+
path=video_path if file_key is None else file_key,
|
| 89 |
+
poster_path=poster_path,
|
| 90 |
+
width=width,
|
| 91 |
+
height=height,
|
| 92 |
+
)
|
sam2-repo/demo/backend/server/data/resolver.py
ADDED
|
@@ -0,0 +1,18 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
# This source code is licensed under the license found in the
|
| 4 |
+
# LICENSE file in the root directory of this source tree.
|
| 5 |
+
|
| 6 |
+
from typing import Iterable
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
def resolve_videos(node_ids: Iterable[str], required: bool = False):
|
| 10 |
+
"""
|
| 11 |
+
Resolve videos given node ids.
|
| 12 |
+
"""
|
| 13 |
+
from data.store import get_videos
|
| 14 |
+
|
| 15 |
+
all_videos = get_videos()
|
| 16 |
+
return [
|
| 17 |
+
all_videos[nid] if required else all_videos.get(nid, None) for nid in node_ids
|
| 18 |
+
]
|
sam2-repo/demo/backend/server/data/schema.py
ADDED
|
@@ -0,0 +1,357 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
# This source code is licensed under the license found in the
|
| 4 |
+
# LICENSE file in the root directory of this source tree.
|
| 5 |
+
|
| 6 |
+
import hashlib
|
| 7 |
+
import os
|
| 8 |
+
import shutil
|
| 9 |
+
import tempfile
|
| 10 |
+
from pathlib import Path
|
| 11 |
+
from typing import Iterable, List, Optional, Tuple, Union
|
| 12 |
+
|
| 13 |
+
import av
|
| 14 |
+
import strawberry
|
| 15 |
+
from app_conf import (
|
| 16 |
+
DATA_PATH,
|
| 17 |
+
DEFAULT_VIDEO_PATH,
|
| 18 |
+
MAX_UPLOAD_VIDEO_DURATION,
|
| 19 |
+
UPLOADS_PATH,
|
| 20 |
+
UPLOADS_PREFIX,
|
| 21 |
+
)
|
| 22 |
+
from data.data_types import (
|
| 23 |
+
AddPointsInput,
|
| 24 |
+
CancelPropagateInVideo,
|
| 25 |
+
CancelPropagateInVideoInput,
|
| 26 |
+
ClearPointsInFrameInput,
|
| 27 |
+
ClearPointsInVideo,
|
| 28 |
+
ClearPointsInVideoInput,
|
| 29 |
+
CloseSession,
|
| 30 |
+
CloseSessionInput,
|
| 31 |
+
RemoveObjectInput,
|
| 32 |
+
RLEMask,
|
| 33 |
+
RLEMaskForObject,
|
| 34 |
+
RLEMaskListOnFrame,
|
| 35 |
+
StartSession,
|
| 36 |
+
StartSessionInput,
|
| 37 |
+
Video,
|
| 38 |
+
)
|
| 39 |
+
from data.loader import get_video
|
| 40 |
+
from data.store import get_videos
|
| 41 |
+
from data.transcoder import get_video_metadata, transcode, VideoMetadata
|
| 42 |
+
from inference.data_types import (
|
| 43 |
+
AddPointsRequest,
|
| 44 |
+
CancelPropagateInVideoRequest,
|
| 45 |
+
CancelPropagateInVideoRequest,
|
| 46 |
+
ClearPointsInFrameRequest,
|
| 47 |
+
ClearPointsInVideoRequest,
|
| 48 |
+
CloseSessionRequest,
|
| 49 |
+
RemoveObjectRequest,
|
| 50 |
+
StartSessionRequest,
|
| 51 |
+
)
|
| 52 |
+
from inference.predictor import InferenceAPI
|
| 53 |
+
from strawberry import relay
|
| 54 |
+
from strawberry.file_uploads import Upload
|
| 55 |
+
|
| 56 |
+
|
| 57 |
+
@strawberry.type
|
| 58 |
+
class Query:
|
| 59 |
+
|
| 60 |
+
@strawberry.field
|
| 61 |
+
def default_video(self) -> Video:
|
| 62 |
+
"""
|
| 63 |
+
Return the default video.
|
| 64 |
+
|
| 65 |
+
The default video can be set with the DEFAULT_VIDEO_PATH environment
|
| 66 |
+
variable. It will return the video that matches this path. If no video
|
| 67 |
+
is found, it will return the first video.
|
| 68 |
+
"""
|
| 69 |
+
all_videos = get_videos()
|
| 70 |
+
|
| 71 |
+
# Find the video that matches the default path and return that as
|
| 72 |
+
# default video.
|
| 73 |
+
for _, v in all_videos.items():
|
| 74 |
+
if v.path == DEFAULT_VIDEO_PATH:
|
| 75 |
+
return v
|
| 76 |
+
|
| 77 |
+
# Fallback is returning the first video
|
| 78 |
+
return next(iter(all_videos.values()))
|
| 79 |
+
|
| 80 |
+
@relay.connection(relay.ListConnection[Video])
|
| 81 |
+
def videos(
|
| 82 |
+
self,
|
| 83 |
+
) -> Iterable[Video]:
|
| 84 |
+
"""
|
| 85 |
+
Return all available videos.
|
| 86 |
+
"""
|
| 87 |
+
all_videos = get_videos()
|
| 88 |
+
return all_videos.values()
|
| 89 |
+
|
| 90 |
+
|
| 91 |
+
@strawberry.type
|
| 92 |
+
class Mutation:
|
| 93 |
+
|
| 94 |
+
@strawberry.mutation
|
| 95 |
+
def upload_video(
|
| 96 |
+
self,
|
| 97 |
+
file: Upload,
|
| 98 |
+
start_time_sec: Optional[float] = None,
|
| 99 |
+
duration_time_sec: Optional[float] = None,
|
| 100 |
+
) -> Video:
|
| 101 |
+
"""
|
| 102 |
+
Receive a video file and store it in the configured S3 bucket.
|
| 103 |
+
"""
|
| 104 |
+
max_time = MAX_UPLOAD_VIDEO_DURATION
|
| 105 |
+
filepath, file_key, vm = process_video(
|
| 106 |
+
file,
|
| 107 |
+
max_time=max_time,
|
| 108 |
+
start_time_sec=start_time_sec,
|
| 109 |
+
duration_time_sec=duration_time_sec,
|
| 110 |
+
)
|
| 111 |
+
|
| 112 |
+
video = get_video(
|
| 113 |
+
filepath,
|
| 114 |
+
UPLOADS_PATH,
|
| 115 |
+
file_key=file_key,
|
| 116 |
+
width=vm.width,
|
| 117 |
+
height=vm.height,
|
| 118 |
+
generate_poster=False,
|
| 119 |
+
)
|
| 120 |
+
return video
|
| 121 |
+
|
| 122 |
+
@strawberry.mutation
|
| 123 |
+
def start_session(
|
| 124 |
+
self, input: StartSessionInput, info: strawberry.Info
|
| 125 |
+
) -> StartSession:
|
| 126 |
+
inference_api: InferenceAPI = info.context["inference_api"]
|
| 127 |
+
|
| 128 |
+
request = StartSessionRequest(
|
| 129 |
+
type="start_session",
|
| 130 |
+
path=f"{DATA_PATH}/{input.path}",
|
| 131 |
+
)
|
| 132 |
+
|
| 133 |
+
response = inference_api.start_session(request=request)
|
| 134 |
+
|
| 135 |
+
return StartSession(session_id=response.session_id)
|
| 136 |
+
|
| 137 |
+
@strawberry.mutation
|
| 138 |
+
def close_session(
|
| 139 |
+
self, input: CloseSessionInput, info: strawberry.Info
|
| 140 |
+
) -> CloseSession:
|
| 141 |
+
inference_api: InferenceAPI = info.context["inference_api"]
|
| 142 |
+
|
| 143 |
+
request = CloseSessionRequest(
|
| 144 |
+
type="close_session",
|
| 145 |
+
session_id=input.session_id,
|
| 146 |
+
)
|
| 147 |
+
response = inference_api.close_session(request)
|
| 148 |
+
return CloseSession(success=response.success)
|
| 149 |
+
|
| 150 |
+
@strawberry.mutation
|
| 151 |
+
def add_points(
|
| 152 |
+
self, input: AddPointsInput, info: strawberry.Info
|
| 153 |
+
) -> RLEMaskListOnFrame:
|
| 154 |
+
inference_api: InferenceAPI = info.context["inference_api"]
|
| 155 |
+
|
| 156 |
+
request = AddPointsRequest(
|
| 157 |
+
type="add_points",
|
| 158 |
+
session_id=input.session_id,
|
| 159 |
+
frame_index=input.frame_index,
|
| 160 |
+
object_id=input.object_id,
|
| 161 |
+
points=input.points,
|
| 162 |
+
labels=input.labels,
|
| 163 |
+
clear_old_points=input.clear_old_points,
|
| 164 |
+
)
|
| 165 |
+
reponse = inference_api.add_points(request)
|
| 166 |
+
|
| 167 |
+
return RLEMaskListOnFrame(
|
| 168 |
+
frame_index=reponse.frame_index,
|
| 169 |
+
rle_mask_list=[
|
| 170 |
+
RLEMaskForObject(
|
| 171 |
+
object_id=r.object_id,
|
| 172 |
+
rle_mask=RLEMask(counts=r.mask.counts, size=r.mask.size, order="F"),
|
| 173 |
+
)
|
| 174 |
+
for r in reponse.results
|
| 175 |
+
],
|
| 176 |
+
)
|
| 177 |
+
|
| 178 |
+
@strawberry.mutation
|
| 179 |
+
def remove_object(
|
| 180 |
+
self, input: RemoveObjectInput, info: strawberry.Info
|
| 181 |
+
) -> List[RLEMaskListOnFrame]:
|
| 182 |
+
inference_api: InferenceAPI = info.context["inference_api"]
|
| 183 |
+
|
| 184 |
+
request = RemoveObjectRequest(
|
| 185 |
+
type="remove_object", session_id=input.session_id, object_id=input.object_id
|
| 186 |
+
)
|
| 187 |
+
|
| 188 |
+
response = inference_api.remove_object(request)
|
| 189 |
+
|
| 190 |
+
return [
|
| 191 |
+
RLEMaskListOnFrame(
|
| 192 |
+
frame_index=res.frame_index,
|
| 193 |
+
rle_mask_list=[
|
| 194 |
+
RLEMaskForObject(
|
| 195 |
+
object_id=r.object_id,
|
| 196 |
+
rle_mask=RLEMask(
|
| 197 |
+
counts=r.mask.counts, size=r.mask.size, order="F"
|
| 198 |
+
),
|
| 199 |
+
)
|
| 200 |
+
for r in res.results
|
| 201 |
+
],
|
| 202 |
+
)
|
| 203 |
+
for res in response.results
|
| 204 |
+
]
|
| 205 |
+
|
| 206 |
+
@strawberry.mutation
|
| 207 |
+
def clear_points_in_frame(
|
| 208 |
+
self, input: ClearPointsInFrameInput, info: strawberry.Info
|
| 209 |
+
) -> RLEMaskListOnFrame:
|
| 210 |
+
inference_api: InferenceAPI = info.context["inference_api"]
|
| 211 |
+
|
| 212 |
+
request = ClearPointsInFrameRequest(
|
| 213 |
+
type="clear_points_in_frame",
|
| 214 |
+
session_id=input.session_id,
|
| 215 |
+
frame_index=input.frame_index,
|
| 216 |
+
object_id=input.object_id,
|
| 217 |
+
)
|
| 218 |
+
|
| 219 |
+
response = inference_api.clear_points_in_frame(request)
|
| 220 |
+
|
| 221 |
+
return RLEMaskListOnFrame(
|
| 222 |
+
frame_index=response.frame_index,
|
| 223 |
+
rle_mask_list=[
|
| 224 |
+
RLEMaskForObject(
|
| 225 |
+
object_id=r.object_id,
|
| 226 |
+
rle_mask=RLEMask(counts=r.mask.counts, size=r.mask.size, order="F"),
|
| 227 |
+
)
|
| 228 |
+
for r in response.results
|
| 229 |
+
],
|
| 230 |
+
)
|
| 231 |
+
|
| 232 |
+
@strawberry.mutation
|
| 233 |
+
def clear_points_in_video(
|
| 234 |
+
self, input: ClearPointsInVideoInput, info: strawberry.Info
|
| 235 |
+
) -> ClearPointsInVideo:
|
| 236 |
+
inference_api: InferenceAPI = info.context["inference_api"]
|
| 237 |
+
|
| 238 |
+
request = ClearPointsInVideoRequest(
|
| 239 |
+
type="clear_points_in_video",
|
| 240 |
+
session_id=input.session_id,
|
| 241 |
+
)
|
| 242 |
+
response = inference_api.clear_points_in_video(request)
|
| 243 |
+
return ClearPointsInVideo(success=response.success)
|
| 244 |
+
|
| 245 |
+
@strawberry.mutation
|
| 246 |
+
def cancel_propagate_in_video(
|
| 247 |
+
self, input: CancelPropagateInVideoInput, info: strawberry.Info
|
| 248 |
+
) -> CancelPropagateInVideo:
|
| 249 |
+
inference_api: InferenceAPI = info.context["inference_api"]
|
| 250 |
+
|
| 251 |
+
request = CancelPropagateInVideoRequest(
|
| 252 |
+
type="cancel_propagate_in_video",
|
| 253 |
+
session_id=input.session_id,
|
| 254 |
+
)
|
| 255 |
+
response = inference_api.cancel_propagate_in_video(request)
|
| 256 |
+
return CancelPropagateInVideo(success=response.success)
|
| 257 |
+
|
| 258 |
+
|
| 259 |
+
def get_file_hash(video_path_or_file) -> str:
|
| 260 |
+
if isinstance(video_path_or_file, str):
|
| 261 |
+
with open(video_path_or_file, "rb") as in_f:
|
| 262 |
+
result = hashlib.sha256(in_f.read()).hexdigest()
|
| 263 |
+
else:
|
| 264 |
+
video_path_or_file.seek(0)
|
| 265 |
+
result = hashlib.sha256(video_path_or_file.read()).hexdigest()
|
| 266 |
+
return result
|
| 267 |
+
|
| 268 |
+
|
| 269 |
+
def _get_start_sec_duration_sec(
|
| 270 |
+
start_time_sec: Union[float, None],
|
| 271 |
+
duration_time_sec: Union[float, None],
|
| 272 |
+
max_time: float,
|
| 273 |
+
) -> Tuple[float, float]:
|
| 274 |
+
default_seek_t = int(os.environ.get("VIDEO_ENCODE_SEEK_TIME", "0"))
|
| 275 |
+
if start_time_sec is None:
|
| 276 |
+
start_time_sec = default_seek_t
|
| 277 |
+
|
| 278 |
+
if duration_time_sec is not None:
|
| 279 |
+
duration_time_sec = min(duration_time_sec, max_time)
|
| 280 |
+
else:
|
| 281 |
+
duration_time_sec = max_time
|
| 282 |
+
return start_time_sec, duration_time_sec
|
| 283 |
+
|
| 284 |
+
|
| 285 |
+
def process_video(
|
| 286 |
+
file: Upload,
|
| 287 |
+
max_time: float,
|
| 288 |
+
start_time_sec: Optional[float] = None,
|
| 289 |
+
duration_time_sec: Optional[float] = None,
|
| 290 |
+
) -> Tuple[Optional[str], str, str, VideoMetadata]:
|
| 291 |
+
"""
|
| 292 |
+
Process file upload including video trimming and content moderation checks.
|
| 293 |
+
|
| 294 |
+
Returns the filepath, s3_file_key, hash & video metaedata as a tuple.
|
| 295 |
+
"""
|
| 296 |
+
with tempfile.TemporaryDirectory() as tempdir:
|
| 297 |
+
in_path = f"{tempdir}/in.mp4"
|
| 298 |
+
out_path = f"{tempdir}/out.mp4"
|
| 299 |
+
with open(in_path, "wb") as in_f:
|
| 300 |
+
in_f.write(file.read())
|
| 301 |
+
|
| 302 |
+
try:
|
| 303 |
+
video_metadata = get_video_metadata(in_path)
|
| 304 |
+
except av.InvalidDataError:
|
| 305 |
+
raise Exception("not valid video file")
|
| 306 |
+
|
| 307 |
+
if video_metadata.num_video_streams == 0:
|
| 308 |
+
raise Exception("video container does not contain a video stream")
|
| 309 |
+
if video_metadata.width is None or video_metadata.height is None:
|
| 310 |
+
raise Exception("video container does not contain width or height metadata")
|
| 311 |
+
|
| 312 |
+
if video_metadata.duration_sec in (None, 0):
|
| 313 |
+
raise Exception("video container does time duration metadata")
|
| 314 |
+
|
| 315 |
+
start_time_sec, duration_time_sec = _get_start_sec_duration_sec(
|
| 316 |
+
max_time=max_time,
|
| 317 |
+
start_time_sec=start_time_sec,
|
| 318 |
+
duration_time_sec=duration_time_sec,
|
| 319 |
+
)
|
| 320 |
+
|
| 321 |
+
# Transcode video to make sure videos returned to the app are all in
|
| 322 |
+
# the same format, duration, resolution, fps.
|
| 323 |
+
transcode(
|
| 324 |
+
in_path,
|
| 325 |
+
out_path,
|
| 326 |
+
video_metadata,
|
| 327 |
+
seek_t=start_time_sec,
|
| 328 |
+
duration_time_sec=duration_time_sec,
|
| 329 |
+
)
|
| 330 |
+
|
| 331 |
+
os.remove(in_path) # don't need original video now
|
| 332 |
+
|
| 333 |
+
out_video_metadata = get_video_metadata(out_path)
|
| 334 |
+
if out_video_metadata.num_video_frames == 0:
|
| 335 |
+
raise Exception(
|
| 336 |
+
"transcode produced empty video; check seek time or your input video"
|
| 337 |
+
)
|
| 338 |
+
|
| 339 |
+
filepath = None
|
| 340 |
+
file_key = None
|
| 341 |
+
with open(out_path, "rb") as file_data:
|
| 342 |
+
file_hash = get_file_hash(file_data)
|
| 343 |
+
file_data.seek(0)
|
| 344 |
+
|
| 345 |
+
file_key = UPLOADS_PREFIX + "/" + f"{file_hash}.mp4"
|
| 346 |
+
filepath = os.path.join(UPLOADS_PATH, f"{file_hash}.mp4")
|
| 347 |
+
|
| 348 |
+
assert filepath is not None and file_key is not None
|
| 349 |
+
shutil.move(out_path, filepath)
|
| 350 |
+
|
| 351 |
+
return filepath, file_key, out_video_metadata
|
| 352 |
+
|
| 353 |
+
|
| 354 |
+
schema = strawberry.Schema(
|
| 355 |
+
query=Query,
|
| 356 |
+
mutation=Mutation,
|
| 357 |
+
)
|
sam2-repo/demo/backend/server/data/store.py
ADDED
|
@@ -0,0 +1,28 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
# This source code is licensed under the license found in the
|
| 4 |
+
# LICENSE file in the root directory of this source tree.
|
| 5 |
+
|
| 6 |
+
from typing import Dict
|
| 7 |
+
|
| 8 |
+
from data.data_types import Video
|
| 9 |
+
|
| 10 |
+
ALL_VIDEOS: Dict[str, Video] = []
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
def set_videos(videos: Dict[str, Video]) -> None:
|
| 14 |
+
"""
|
| 15 |
+
Set the videos available in the backend. The data is kept in-memory, but a future change could replace the
|
| 16 |
+
in-memory storage with a database backend. This would also be more efficient when querying videos given a
|
| 17 |
+
dataset name etc.
|
| 18 |
+
"""
|
| 19 |
+
global ALL_VIDEOS
|
| 20 |
+
ALL_VIDEOS = videos
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
def get_videos() -> Dict[str, Video]:
|
| 24 |
+
"""
|
| 25 |
+
Return the videos available in the backend.
|
| 26 |
+
"""
|
| 27 |
+
global ALL_VIDEOS
|
| 28 |
+
return ALL_VIDEOS
|
sam2-repo/demo/backend/server/data/transcoder.py
ADDED
|
@@ -0,0 +1,186 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
# This source code is licensed under the license found in the
|
| 4 |
+
# LICENSE file in the root directory of this source tree.
|
| 5 |
+
|
| 6 |
+
import ast
|
| 7 |
+
import math
|
| 8 |
+
import os
|
| 9 |
+
import shutil
|
| 10 |
+
import subprocess
|
| 11 |
+
from dataclasses import dataclass
|
| 12 |
+
from typing import Optional
|
| 13 |
+
|
| 14 |
+
import av
|
| 15 |
+
from app_conf import FFMPEG_NUM_THREADS
|
| 16 |
+
from dataclasses_json import dataclass_json
|
| 17 |
+
|
| 18 |
+
TRANSCODE_VERSION = 1
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
@dataclass_json
|
| 22 |
+
@dataclass
|
| 23 |
+
class VideoMetadata:
|
| 24 |
+
duration_sec: Optional[float]
|
| 25 |
+
video_duration_sec: Optional[float]
|
| 26 |
+
container_duration_sec: Optional[float]
|
| 27 |
+
fps: Optional[float]
|
| 28 |
+
width: Optional[int]
|
| 29 |
+
height: Optional[int]
|
| 30 |
+
num_video_frames: int
|
| 31 |
+
num_video_streams: int
|
| 32 |
+
video_start_time: float
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
def transcode(
|
| 36 |
+
in_path: str,
|
| 37 |
+
out_path: str,
|
| 38 |
+
in_metadata: Optional[VideoMetadata],
|
| 39 |
+
seek_t: float,
|
| 40 |
+
duration_time_sec: float,
|
| 41 |
+
):
|
| 42 |
+
codec = os.environ.get("VIDEO_ENCODE_CODEC", "libx264")
|
| 43 |
+
crf = int(os.environ.get("VIDEO_ENCODE_CRF", "23"))
|
| 44 |
+
fps = int(os.environ.get("VIDEO_ENCODE_FPS", "24"))
|
| 45 |
+
max_w = int(os.environ.get("VIDEO_ENCODE_MAX_WIDTH", "1280"))
|
| 46 |
+
max_h = int(os.environ.get("VIDEO_ENCODE_MAX_HEIGHT", "720"))
|
| 47 |
+
verbose = ast.literal_eval(os.environ.get("VIDEO_ENCODE_VERBOSE", "False"))
|
| 48 |
+
|
| 49 |
+
normalize_video(
|
| 50 |
+
in_path=in_path,
|
| 51 |
+
out_path=out_path,
|
| 52 |
+
max_w=max_w,
|
| 53 |
+
max_h=max_h,
|
| 54 |
+
seek_t=seek_t,
|
| 55 |
+
max_time=duration_time_sec,
|
| 56 |
+
in_metadata=in_metadata,
|
| 57 |
+
codec=codec,
|
| 58 |
+
crf=crf,
|
| 59 |
+
fps=fps,
|
| 60 |
+
verbose=verbose,
|
| 61 |
+
)
|
| 62 |
+
|
| 63 |
+
|
| 64 |
+
def get_video_metadata(path: str) -> VideoMetadata:
|
| 65 |
+
with av.open(path) as cont:
|
| 66 |
+
num_video_streams = len(cont.streams.video)
|
| 67 |
+
width, height, fps = None, None, None
|
| 68 |
+
video_duration_sec = 0
|
| 69 |
+
container_duration_sec = float((cont.duration or 0) / av.time_base)
|
| 70 |
+
video_start_time = 0.0
|
| 71 |
+
rotation_deg = 0
|
| 72 |
+
num_video_frames = 0
|
| 73 |
+
if num_video_streams > 0:
|
| 74 |
+
video_stream = cont.streams.video[0]
|
| 75 |
+
assert video_stream.time_base is not None
|
| 76 |
+
|
| 77 |
+
# for rotation, see: https://github.com/PyAV-Org/PyAV/pull/1249
|
| 78 |
+
rotation_deg = video_stream.side_data.get("DISPLAYMATRIX", 0)
|
| 79 |
+
num_video_frames = video_stream.frames
|
| 80 |
+
video_start_time = float(video_stream.start_time * video_stream.time_base)
|
| 81 |
+
width, height = video_stream.width, video_stream.height
|
| 82 |
+
fps = float(video_stream.guessed_rate)
|
| 83 |
+
fps_avg = video_stream.average_rate
|
| 84 |
+
if video_stream.duration is not None:
|
| 85 |
+
video_duration_sec = float(
|
| 86 |
+
video_stream.duration * video_stream.time_base
|
| 87 |
+
)
|
| 88 |
+
if fps is None:
|
| 89 |
+
fps = float(fps_avg)
|
| 90 |
+
|
| 91 |
+
if not math.isnan(rotation_deg) and int(rotation_deg) in (
|
| 92 |
+
90,
|
| 93 |
+
-90,
|
| 94 |
+
270,
|
| 95 |
+
-270,
|
| 96 |
+
):
|
| 97 |
+
width, height = height, width
|
| 98 |
+
|
| 99 |
+
duration_sec = max(container_duration_sec, video_duration_sec)
|
| 100 |
+
|
| 101 |
+
return VideoMetadata(
|
| 102 |
+
duration_sec=duration_sec,
|
| 103 |
+
container_duration_sec=container_duration_sec,
|
| 104 |
+
video_duration_sec=video_duration_sec,
|
| 105 |
+
video_start_time=video_start_time,
|
| 106 |
+
fps=fps,
|
| 107 |
+
width=width,
|
| 108 |
+
height=height,
|
| 109 |
+
num_video_streams=num_video_streams,
|
| 110 |
+
num_video_frames=num_video_frames,
|
| 111 |
+
)
|
| 112 |
+
|
| 113 |
+
|
| 114 |
+
def normalize_video(
|
| 115 |
+
in_path: str,
|
| 116 |
+
out_path: str,
|
| 117 |
+
max_w: int,
|
| 118 |
+
max_h: int,
|
| 119 |
+
seek_t: float,
|
| 120 |
+
max_time: float,
|
| 121 |
+
in_metadata: Optional[VideoMetadata],
|
| 122 |
+
codec: str = "libx264",
|
| 123 |
+
crf: int = 23,
|
| 124 |
+
fps: int = 24,
|
| 125 |
+
verbose: bool = False,
|
| 126 |
+
):
|
| 127 |
+
if in_metadata is None:
|
| 128 |
+
in_metadata = get_video_metadata(in_path)
|
| 129 |
+
|
| 130 |
+
assert in_metadata.num_video_streams > 0, "no video stream present"
|
| 131 |
+
|
| 132 |
+
w, h = in_metadata.width, in_metadata.height
|
| 133 |
+
assert w is not None, "width not available"
|
| 134 |
+
assert h is not None, "height not available"
|
| 135 |
+
|
| 136 |
+
# rescale to max_w:max_h if needed & preserve aspect ratio
|
| 137 |
+
r = w / h
|
| 138 |
+
if r < 1:
|
| 139 |
+
h = min(720, h)
|
| 140 |
+
w = h * r
|
| 141 |
+
else:
|
| 142 |
+
w = min(1280, w)
|
| 143 |
+
h = w / r
|
| 144 |
+
|
| 145 |
+
# h264 cannot encode w/ odd dimensions
|
| 146 |
+
w = int(w)
|
| 147 |
+
h = int(h)
|
| 148 |
+
if w % 2 != 0:
|
| 149 |
+
w += 1
|
| 150 |
+
if h % 2 != 0:
|
| 151 |
+
h += 1
|
| 152 |
+
|
| 153 |
+
ffmpeg = shutil.which("ffmpeg")
|
| 154 |
+
cmd = [
|
| 155 |
+
ffmpeg,
|
| 156 |
+
"-threads",
|
| 157 |
+
f"{FFMPEG_NUM_THREADS}", # global threads
|
| 158 |
+
"-ss",
|
| 159 |
+
f"{seek_t:.2f}",
|
| 160 |
+
"-t",
|
| 161 |
+
f"{max_time:.2f}",
|
| 162 |
+
"-i",
|
| 163 |
+
in_path,
|
| 164 |
+
"-threads",
|
| 165 |
+
f"{FFMPEG_NUM_THREADS}", # decode (or filter..?) threads
|
| 166 |
+
"-vf",
|
| 167 |
+
f"fps={fps},scale={w}:{h},setsar=1:1",
|
| 168 |
+
"-c:v",
|
| 169 |
+
codec,
|
| 170 |
+
"-crf",
|
| 171 |
+
f"{crf}",
|
| 172 |
+
"-pix_fmt",
|
| 173 |
+
"yuv420p",
|
| 174 |
+
"-threads",
|
| 175 |
+
f"{FFMPEG_NUM_THREADS}", # encode threads
|
| 176 |
+
out_path,
|
| 177 |
+
"-y",
|
| 178 |
+
]
|
| 179 |
+
if verbose:
|
| 180 |
+
print(" ".join(cmd))
|
| 181 |
+
|
| 182 |
+
subprocess.call(
|
| 183 |
+
cmd,
|
| 184 |
+
stdout=None if verbose else subprocess.DEVNULL,
|
| 185 |
+
stderr=None if verbose else subprocess.DEVNULL,
|
| 186 |
+
)
|
sam2-repo/demo/backend/server/inference/data_types.py
ADDED
|
@@ -0,0 +1,191 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
# This source code is licensed under the license found in the
|
| 4 |
+
# LICENSE file in the root directory of this source tree.
|
| 5 |
+
|
| 6 |
+
from dataclasses import dataclass
|
| 7 |
+
from typing import Dict, List, Optional, Union
|
| 8 |
+
|
| 9 |
+
from dataclasses_json import dataclass_json
|
| 10 |
+
from torch import Tensor
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
@dataclass_json
|
| 14 |
+
@dataclass
|
| 15 |
+
class Mask:
|
| 16 |
+
size: List[int]
|
| 17 |
+
counts: str
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
@dataclass_json
|
| 21 |
+
@dataclass
|
| 22 |
+
class BaseRequest:
|
| 23 |
+
type: str
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
@dataclass_json
|
| 27 |
+
@dataclass
|
| 28 |
+
class StartSessionRequest(BaseRequest):
|
| 29 |
+
type: str
|
| 30 |
+
path: str
|
| 31 |
+
session_id: Optional[str] = None
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
@dataclass_json
|
| 35 |
+
@dataclass
|
| 36 |
+
class SaveSessionRequest(BaseRequest):
|
| 37 |
+
type: str
|
| 38 |
+
session_id: str
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
@dataclass_json
|
| 42 |
+
@dataclass
|
| 43 |
+
class LoadSessionRequest(BaseRequest):
|
| 44 |
+
type: str
|
| 45 |
+
session_id: str
|
| 46 |
+
|
| 47 |
+
|
| 48 |
+
@dataclass_json
|
| 49 |
+
@dataclass
|
| 50 |
+
class RenewSessionRequest(BaseRequest):
|
| 51 |
+
type: str
|
| 52 |
+
session_id: str
|
| 53 |
+
|
| 54 |
+
|
| 55 |
+
@dataclass_json
|
| 56 |
+
@dataclass
|
| 57 |
+
class CloseSessionRequest(BaseRequest):
|
| 58 |
+
type: str
|
| 59 |
+
session_id: str
|
| 60 |
+
|
| 61 |
+
|
| 62 |
+
@dataclass_json
|
| 63 |
+
@dataclass
|
| 64 |
+
class AddPointsRequest(BaseRequest):
|
| 65 |
+
type: str
|
| 66 |
+
session_id: str
|
| 67 |
+
frame_index: int
|
| 68 |
+
clear_old_points: bool
|
| 69 |
+
object_id: int
|
| 70 |
+
labels: List[int]
|
| 71 |
+
points: List[List[float]]
|
| 72 |
+
|
| 73 |
+
|
| 74 |
+
@dataclass_json
|
| 75 |
+
@dataclass
|
| 76 |
+
class AddMaskRequest(BaseRequest):
|
| 77 |
+
type: str
|
| 78 |
+
session_id: str
|
| 79 |
+
frame_index: int
|
| 80 |
+
object_id: int
|
| 81 |
+
mask: Mask
|
| 82 |
+
|
| 83 |
+
|
| 84 |
+
@dataclass_json
|
| 85 |
+
@dataclass
|
| 86 |
+
class ClearPointsInFrameRequest(BaseRequest):
|
| 87 |
+
type: str
|
| 88 |
+
session_id: str
|
| 89 |
+
frame_index: int
|
| 90 |
+
object_id: int
|
| 91 |
+
|
| 92 |
+
|
| 93 |
+
@dataclass_json
|
| 94 |
+
@dataclass
|
| 95 |
+
class ClearPointsInVideoRequest(BaseRequest):
|
| 96 |
+
type: str
|
| 97 |
+
session_id: str
|
| 98 |
+
|
| 99 |
+
|
| 100 |
+
@dataclass_json
|
| 101 |
+
@dataclass
|
| 102 |
+
class RemoveObjectRequest(BaseRequest):
|
| 103 |
+
type: str
|
| 104 |
+
session_id: str
|
| 105 |
+
object_id: int
|
| 106 |
+
|
| 107 |
+
|
| 108 |
+
@dataclass_json
|
| 109 |
+
@dataclass
|
| 110 |
+
class PropagateInVideoRequest(BaseRequest):
|
| 111 |
+
type: str
|
| 112 |
+
session_id: str
|
| 113 |
+
start_frame_index: int
|
| 114 |
+
|
| 115 |
+
|
| 116 |
+
@dataclass_json
|
| 117 |
+
@dataclass
|
| 118 |
+
class CancelPropagateInVideoRequest(BaseRequest):
|
| 119 |
+
type: str
|
| 120 |
+
session_id: str
|
| 121 |
+
|
| 122 |
+
|
| 123 |
+
@dataclass_json
|
| 124 |
+
@dataclass
|
| 125 |
+
class StartSessionResponse:
|
| 126 |
+
session_id: str
|
| 127 |
+
|
| 128 |
+
|
| 129 |
+
@dataclass_json
|
| 130 |
+
@dataclass
|
| 131 |
+
class SaveSessionResponse:
|
| 132 |
+
session_id: str
|
| 133 |
+
|
| 134 |
+
|
| 135 |
+
@dataclass_json
|
| 136 |
+
@dataclass
|
| 137 |
+
class LoadSessionResponse:
|
| 138 |
+
session_id: str
|
| 139 |
+
|
| 140 |
+
|
| 141 |
+
@dataclass_json
|
| 142 |
+
@dataclass
|
| 143 |
+
class RenewSessionResponse:
|
| 144 |
+
session_id: str
|
| 145 |
+
|
| 146 |
+
|
| 147 |
+
@dataclass_json
|
| 148 |
+
@dataclass
|
| 149 |
+
class CloseSessionResponse:
|
| 150 |
+
success: bool
|
| 151 |
+
|
| 152 |
+
|
| 153 |
+
@dataclass_json
|
| 154 |
+
@dataclass
|
| 155 |
+
class ClearPointsInVideoResponse:
|
| 156 |
+
success: bool
|
| 157 |
+
|
| 158 |
+
|
| 159 |
+
@dataclass_json
|
| 160 |
+
@dataclass
|
| 161 |
+
class PropagateDataValue:
|
| 162 |
+
object_id: int
|
| 163 |
+
mask: Mask
|
| 164 |
+
|
| 165 |
+
|
| 166 |
+
@dataclass_json
|
| 167 |
+
@dataclass
|
| 168 |
+
class PropagateDataResponse:
|
| 169 |
+
frame_index: int
|
| 170 |
+
results: List[PropagateDataValue]
|
| 171 |
+
|
| 172 |
+
|
| 173 |
+
@dataclass_json
|
| 174 |
+
@dataclass
|
| 175 |
+
class RemoveObjectResponse:
|
| 176 |
+
results: List[PropagateDataResponse]
|
| 177 |
+
|
| 178 |
+
|
| 179 |
+
@dataclass_json
|
| 180 |
+
@dataclass
|
| 181 |
+
class CancelPorpagateResponse:
|
| 182 |
+
success: bool
|
| 183 |
+
|
| 184 |
+
|
| 185 |
+
@dataclass_json
|
| 186 |
+
@dataclass
|
| 187 |
+
class InferenceSession:
|
| 188 |
+
start_time: float
|
| 189 |
+
last_use_time: float
|
| 190 |
+
session_id: str
|
| 191 |
+
state: Dict[str, Dict[str, Union[Tensor, Dict[int, Tensor]]]]
|
sam2-repo/demo/backend/server/inference/multipart.py
ADDED
|
@@ -0,0 +1,48 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
# This source code is licensed under the license found in the
|
| 4 |
+
# LICENSE file in the root directory of this source tree.
|
| 5 |
+
|
| 6 |
+
from typing import Dict, Union
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
class MultipartResponseBuilder:
|
| 10 |
+
message: bytes
|
| 11 |
+
|
| 12 |
+
def __init__(self, boundary: str) -> None:
|
| 13 |
+
self.message = b"--" + boundary.encode("utf-8") + b"\r\n"
|
| 14 |
+
|
| 15 |
+
@classmethod
|
| 16 |
+
def build(
|
| 17 |
+
cls, boundary: str, headers: Dict[str, str], body: Union[str, bytes]
|
| 18 |
+
) -> "MultipartResponseBuilder":
|
| 19 |
+
builder = cls(boundary=boundary)
|
| 20 |
+
for k, v in headers.items():
|
| 21 |
+
builder.__append_header(key=k, value=v)
|
| 22 |
+
if isinstance(body, bytes):
|
| 23 |
+
builder.__append_body(body)
|
| 24 |
+
elif isinstance(body, str):
|
| 25 |
+
builder.__append_body(body.encode("utf-8"))
|
| 26 |
+
else:
|
| 27 |
+
raise ValueError(
|
| 28 |
+
f"body needs to be of type bytes or str but got {type(body)}"
|
| 29 |
+
)
|
| 30 |
+
|
| 31 |
+
return builder
|
| 32 |
+
|
| 33 |
+
def get_message(self) -> bytes:
|
| 34 |
+
return self.message
|
| 35 |
+
|
| 36 |
+
def __append_header(self, key: str, value: str) -> "MultipartResponseBuilder":
|
| 37 |
+
self.message += key.encode("utf-8") + b": " + value.encode("utf-8") + b"\r\n"
|
| 38 |
+
return self
|
| 39 |
+
|
| 40 |
+
def __close_header(self) -> "MultipartResponseBuilder":
|
| 41 |
+
self.message += b"\r\n"
|
| 42 |
+
return self
|
| 43 |
+
|
| 44 |
+
def __append_body(self, body: bytes) -> "MultipartResponseBuilder":
|
| 45 |
+
self.__append_header(key="Content-Length", value=str(len(body)))
|
| 46 |
+
self.__close_header()
|
| 47 |
+
self.message += body
|
| 48 |
+
return self
|
sam2-repo/demo/backend/server/inference/predictor.py
ADDED
|
@@ -0,0 +1,427 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
# This source code is licensed under the license found in the
|
| 4 |
+
# LICENSE file in the root directory of this source tree.
|
| 5 |
+
|
| 6 |
+
import contextlib
|
| 7 |
+
import logging
|
| 8 |
+
import os
|
| 9 |
+
import uuid
|
| 10 |
+
from pathlib import Path
|
| 11 |
+
from threading import Lock
|
| 12 |
+
from typing import Any, Dict, Generator, List
|
| 13 |
+
|
| 14 |
+
import numpy as np
|
| 15 |
+
import torch
|
| 16 |
+
from app_conf import APP_ROOT, MODEL_SIZE
|
| 17 |
+
from inference.data_types import (
|
| 18 |
+
AddMaskRequest,
|
| 19 |
+
AddPointsRequest,
|
| 20 |
+
CancelPorpagateResponse,
|
| 21 |
+
CancelPropagateInVideoRequest,
|
| 22 |
+
ClearPointsInFrameRequest,
|
| 23 |
+
ClearPointsInVideoRequest,
|
| 24 |
+
ClearPointsInVideoResponse,
|
| 25 |
+
CloseSessionRequest,
|
| 26 |
+
CloseSessionResponse,
|
| 27 |
+
Mask,
|
| 28 |
+
PropagateDataResponse,
|
| 29 |
+
PropagateDataValue,
|
| 30 |
+
PropagateInVideoRequest,
|
| 31 |
+
RemoveObjectRequest,
|
| 32 |
+
RemoveObjectResponse,
|
| 33 |
+
StartSessionRequest,
|
| 34 |
+
StartSessionResponse,
|
| 35 |
+
)
|
| 36 |
+
from pycocotools.mask import decode as decode_masks, encode as encode_masks
|
| 37 |
+
from sam2.build_sam import build_sam2_video_predictor
|
| 38 |
+
|
| 39 |
+
|
| 40 |
+
logger = logging.getLogger(__name__)
|
| 41 |
+
|
| 42 |
+
|
| 43 |
+
class InferenceAPI:
|
| 44 |
+
|
| 45 |
+
def __init__(self) -> None:
|
| 46 |
+
super(InferenceAPI, self).__init__()
|
| 47 |
+
|
| 48 |
+
self.session_states: Dict[str, Any] = {}
|
| 49 |
+
self.score_thresh = 0
|
| 50 |
+
|
| 51 |
+
if MODEL_SIZE == "tiny":
|
| 52 |
+
checkpoint = Path(APP_ROOT) / "checkpoints/sam2.1_hiera_tiny.pt"
|
| 53 |
+
model_cfg = "configs/sam2.1/sam2.1_hiera_t.yaml"
|
| 54 |
+
elif MODEL_SIZE == "small":
|
| 55 |
+
checkpoint = Path(APP_ROOT) / "checkpoints/sam2.1_hiera_small.pt"
|
| 56 |
+
model_cfg = "configs/sam2.1/sam2.1_hiera_s.yaml"
|
| 57 |
+
elif MODEL_SIZE == "large":
|
| 58 |
+
checkpoint = Path(APP_ROOT) / "checkpoints/sam2.1_hiera_large.pt"
|
| 59 |
+
model_cfg = "configs/sam2.1/sam2.1_hiera_l.yaml"
|
| 60 |
+
else: # base_plus (default)
|
| 61 |
+
checkpoint = Path(APP_ROOT) / "checkpoints/sam2.1_hiera_base_plus.pt"
|
| 62 |
+
model_cfg = "configs/sam2.1/sam2.1_hiera_b+.yaml"
|
| 63 |
+
|
| 64 |
+
# select the device for computation
|
| 65 |
+
force_cpu_device = os.environ.get("SAM2_DEMO_FORCE_CPU_DEVICE", "0") == "1"
|
| 66 |
+
if force_cpu_device:
|
| 67 |
+
logger.info("forcing CPU device for SAM 2 demo")
|
| 68 |
+
if torch.cuda.is_available() and not force_cpu_device:
|
| 69 |
+
device = torch.device("cuda")
|
| 70 |
+
elif torch.backends.mps.is_available() and not force_cpu_device:
|
| 71 |
+
device = torch.device("mps")
|
| 72 |
+
else:
|
| 73 |
+
device = torch.device("cpu")
|
| 74 |
+
logger.info(f"using device: {device}")
|
| 75 |
+
|
| 76 |
+
if device.type == "cuda":
|
| 77 |
+
# turn on tfloat32 for Ampere GPUs (https://pytorch.org/docs/stable/notes/cuda.html#tensorfloat-32-tf32-on-ampere-devices)
|
| 78 |
+
if torch.cuda.get_device_properties(0).major >= 8:
|
| 79 |
+
torch.backends.cuda.matmul.allow_tf32 = True
|
| 80 |
+
torch.backends.cudnn.allow_tf32 = True
|
| 81 |
+
elif device.type == "mps":
|
| 82 |
+
logging.warning(
|
| 83 |
+
"\nSupport for MPS devices is preliminary. SAM 2 is trained with CUDA and might "
|
| 84 |
+
"give numerically different outputs and sometimes degraded performance on MPS. "
|
| 85 |
+
"See e.g. https://github.com/pytorch/pytorch/issues/84936 for a discussion."
|
| 86 |
+
)
|
| 87 |
+
|
| 88 |
+
self.device = device
|
| 89 |
+
self.predictor = build_sam2_video_predictor(
|
| 90 |
+
model_cfg, checkpoint, device=device
|
| 91 |
+
)
|
| 92 |
+
self.inference_lock = Lock()
|
| 93 |
+
|
| 94 |
+
def autocast_context(self):
|
| 95 |
+
if self.device.type == "cuda":
|
| 96 |
+
return torch.autocast("cuda", dtype=torch.bfloat16)
|
| 97 |
+
else:
|
| 98 |
+
return contextlib.nullcontext()
|
| 99 |
+
|
| 100 |
+
def start_session(self, request: StartSessionRequest) -> StartSessionResponse:
|
| 101 |
+
with self.autocast_context(), self.inference_lock:
|
| 102 |
+
session_id = str(uuid.uuid4())
|
| 103 |
+
# for MPS devices, we offload the video frames to CPU by default to avoid
|
| 104 |
+
# memory fragmentation in MPS (which sometimes crashes the entire process)
|
| 105 |
+
offload_video_to_cpu = self.device.type == "mps"
|
| 106 |
+
inference_state = self.predictor.init_state(
|
| 107 |
+
request.path,
|
| 108 |
+
offload_video_to_cpu=offload_video_to_cpu,
|
| 109 |
+
)
|
| 110 |
+
self.session_states[session_id] = {
|
| 111 |
+
"canceled": False,
|
| 112 |
+
"state": inference_state,
|
| 113 |
+
}
|
| 114 |
+
return StartSessionResponse(session_id=session_id)
|
| 115 |
+
|
| 116 |
+
def close_session(self, request: CloseSessionRequest) -> CloseSessionResponse:
|
| 117 |
+
is_successful = self.__clear_session_state(request.session_id)
|
| 118 |
+
return CloseSessionResponse(success=is_successful)
|
| 119 |
+
|
| 120 |
+
def add_points(
|
| 121 |
+
self, request: AddPointsRequest, test: str = ""
|
| 122 |
+
) -> PropagateDataResponse:
|
| 123 |
+
with self.autocast_context(), self.inference_lock:
|
| 124 |
+
session = self.__get_session(request.session_id)
|
| 125 |
+
inference_state = session["state"]
|
| 126 |
+
|
| 127 |
+
frame_idx = request.frame_index
|
| 128 |
+
obj_id = request.object_id
|
| 129 |
+
points = request.points
|
| 130 |
+
labels = request.labels
|
| 131 |
+
clear_old_points = request.clear_old_points
|
| 132 |
+
|
| 133 |
+
# add new prompts and instantly get the output on the same frame
|
| 134 |
+
frame_idx, object_ids, masks = self.predictor.add_new_points_or_box(
|
| 135 |
+
inference_state=inference_state,
|
| 136 |
+
frame_idx=frame_idx,
|
| 137 |
+
obj_id=obj_id,
|
| 138 |
+
points=points,
|
| 139 |
+
labels=labels,
|
| 140 |
+
clear_old_points=clear_old_points,
|
| 141 |
+
normalize_coords=False,
|
| 142 |
+
)
|
| 143 |
+
|
| 144 |
+
masks_binary = (masks > self.score_thresh)[:, 0].cpu().numpy()
|
| 145 |
+
|
| 146 |
+
rle_mask_list = self.__get_rle_mask_list(
|
| 147 |
+
object_ids=object_ids, masks=masks_binary
|
| 148 |
+
)
|
| 149 |
+
|
| 150 |
+
return PropagateDataResponse(
|
| 151 |
+
frame_index=frame_idx,
|
| 152 |
+
results=rle_mask_list,
|
| 153 |
+
)
|
| 154 |
+
|
| 155 |
+
def add_mask(self, request: AddMaskRequest) -> PropagateDataResponse:
|
| 156 |
+
"""
|
| 157 |
+
Add new points on a specific video frame.
|
| 158 |
+
- mask is a numpy array of shape [H_im, W_im] (containing 1 for foreground and 0 for background).
|
| 159 |
+
Note: providing an input mask would overwrite any previous input points on this frame.
|
| 160 |
+
"""
|
| 161 |
+
with self.autocast_context(), self.inference_lock:
|
| 162 |
+
session_id = request.session_id
|
| 163 |
+
frame_idx = request.frame_index
|
| 164 |
+
obj_id = request.object_id
|
| 165 |
+
rle_mask = {
|
| 166 |
+
"counts": request.mask.counts,
|
| 167 |
+
"size": request.mask.size,
|
| 168 |
+
}
|
| 169 |
+
|
| 170 |
+
mask = decode_masks(rle_mask)
|
| 171 |
+
|
| 172 |
+
logger.info(
|
| 173 |
+
f"add mask on frame {frame_idx} in session {session_id}: {obj_id=}, {mask.shape=}"
|
| 174 |
+
)
|
| 175 |
+
session = self.__get_session(session_id)
|
| 176 |
+
inference_state = session["state"]
|
| 177 |
+
|
| 178 |
+
frame_idx, obj_ids, video_res_masks = self.model.add_new_mask(
|
| 179 |
+
inference_state=inference_state,
|
| 180 |
+
frame_idx=frame_idx,
|
| 181 |
+
obj_id=obj_id,
|
| 182 |
+
mask=torch.tensor(mask > 0),
|
| 183 |
+
)
|
| 184 |
+
masks_binary = (video_res_masks > self.score_thresh)[:, 0].cpu().numpy()
|
| 185 |
+
|
| 186 |
+
rle_mask_list = self.__get_rle_mask_list(
|
| 187 |
+
object_ids=obj_ids, masks=masks_binary
|
| 188 |
+
)
|
| 189 |
+
|
| 190 |
+
return PropagateDataResponse(
|
| 191 |
+
frame_index=frame_idx,
|
| 192 |
+
results=rle_mask_list,
|
| 193 |
+
)
|
| 194 |
+
|
| 195 |
+
def clear_points_in_frame(
|
| 196 |
+
self, request: ClearPointsInFrameRequest
|
| 197 |
+
) -> PropagateDataResponse:
|
| 198 |
+
"""
|
| 199 |
+
Remove all input points in a specific frame.
|
| 200 |
+
"""
|
| 201 |
+
with self.autocast_context(), self.inference_lock:
|
| 202 |
+
session_id = request.session_id
|
| 203 |
+
frame_idx = request.frame_index
|
| 204 |
+
obj_id = request.object_id
|
| 205 |
+
|
| 206 |
+
logger.info(
|
| 207 |
+
f"clear inputs on frame {frame_idx} in session {session_id}: {obj_id=}"
|
| 208 |
+
)
|
| 209 |
+
session = self.__get_session(session_id)
|
| 210 |
+
inference_state = session["state"]
|
| 211 |
+
frame_idx, obj_ids, video_res_masks = (
|
| 212 |
+
self.predictor.clear_all_prompts_in_frame(
|
| 213 |
+
inference_state, frame_idx, obj_id
|
| 214 |
+
)
|
| 215 |
+
)
|
| 216 |
+
masks_binary = (video_res_masks > self.score_thresh)[:, 0].cpu().numpy()
|
| 217 |
+
|
| 218 |
+
rle_mask_list = self.__get_rle_mask_list(
|
| 219 |
+
object_ids=obj_ids, masks=masks_binary
|
| 220 |
+
)
|
| 221 |
+
|
| 222 |
+
return PropagateDataResponse(
|
| 223 |
+
frame_index=frame_idx,
|
| 224 |
+
results=rle_mask_list,
|
| 225 |
+
)
|
| 226 |
+
|
| 227 |
+
def clear_points_in_video(
|
| 228 |
+
self, request: ClearPointsInVideoRequest
|
| 229 |
+
) -> ClearPointsInVideoResponse:
|
| 230 |
+
"""
|
| 231 |
+
Remove all input points in all frames throughout the video.
|
| 232 |
+
"""
|
| 233 |
+
with self.autocast_context(), self.inference_lock:
|
| 234 |
+
session_id = request.session_id
|
| 235 |
+
logger.info(f"clear all inputs across the video in session {session_id}")
|
| 236 |
+
session = self.__get_session(session_id)
|
| 237 |
+
inference_state = session["state"]
|
| 238 |
+
self.predictor.reset_state(inference_state)
|
| 239 |
+
return ClearPointsInVideoResponse(success=True)
|
| 240 |
+
|
| 241 |
+
def remove_object(self, request: RemoveObjectRequest) -> RemoveObjectResponse:
|
| 242 |
+
"""
|
| 243 |
+
Remove an object id from the tracking state.
|
| 244 |
+
"""
|
| 245 |
+
with self.autocast_context(), self.inference_lock:
|
| 246 |
+
session_id = request.session_id
|
| 247 |
+
obj_id = request.object_id
|
| 248 |
+
logger.info(f"remove object in session {session_id}: {obj_id=}")
|
| 249 |
+
session = self.__get_session(session_id)
|
| 250 |
+
inference_state = session["state"]
|
| 251 |
+
new_obj_ids, updated_frames = self.predictor.remove_object(
|
| 252 |
+
inference_state, obj_id
|
| 253 |
+
)
|
| 254 |
+
|
| 255 |
+
results = []
|
| 256 |
+
for frame_index, video_res_masks in updated_frames:
|
| 257 |
+
masks = (video_res_masks > self.score_thresh)[:, 0].cpu().numpy()
|
| 258 |
+
rle_mask_list = self.__get_rle_mask_list(
|
| 259 |
+
object_ids=new_obj_ids, masks=masks
|
| 260 |
+
)
|
| 261 |
+
results.append(
|
| 262 |
+
PropagateDataResponse(
|
| 263 |
+
frame_index=frame_index,
|
| 264 |
+
results=rle_mask_list,
|
| 265 |
+
)
|
| 266 |
+
)
|
| 267 |
+
|
| 268 |
+
return RemoveObjectResponse(results=results)
|
| 269 |
+
|
| 270 |
+
def propagate_in_video(
|
| 271 |
+
self, request: PropagateInVideoRequest
|
| 272 |
+
) -> Generator[PropagateDataResponse, None, None]:
|
| 273 |
+
session_id = request.session_id
|
| 274 |
+
start_frame_idx = request.start_frame_index
|
| 275 |
+
propagation_direction = "both"
|
| 276 |
+
max_frame_num_to_track = None
|
| 277 |
+
|
| 278 |
+
"""
|
| 279 |
+
Propagate existing input points in all frames to track the object across video.
|
| 280 |
+
"""
|
| 281 |
+
|
| 282 |
+
# Note that as this method is a generator, we also need to use autocast_context
|
| 283 |
+
# in caller to this method to ensure that it's called under the correct context
|
| 284 |
+
# (we've added `autocast_context` to `gen_track_with_mask_stream` in app.py).
|
| 285 |
+
with self.autocast_context(), self.inference_lock:
|
| 286 |
+
logger.info(
|
| 287 |
+
f"propagate in video in session {session_id}: "
|
| 288 |
+
f"{propagation_direction=}, {start_frame_idx=}, {max_frame_num_to_track=}"
|
| 289 |
+
)
|
| 290 |
+
|
| 291 |
+
try:
|
| 292 |
+
session = self.__get_session(session_id)
|
| 293 |
+
session["canceled"] = False
|
| 294 |
+
|
| 295 |
+
inference_state = session["state"]
|
| 296 |
+
if propagation_direction not in ["both", "forward", "backward"]:
|
| 297 |
+
raise ValueError(
|
| 298 |
+
f"invalid propagation direction: {propagation_direction}"
|
| 299 |
+
)
|
| 300 |
+
|
| 301 |
+
# First doing the forward propagation
|
| 302 |
+
if propagation_direction in ["both", "forward"]:
|
| 303 |
+
for outputs in self.predictor.propagate_in_video(
|
| 304 |
+
inference_state=inference_state,
|
| 305 |
+
start_frame_idx=start_frame_idx,
|
| 306 |
+
max_frame_num_to_track=max_frame_num_to_track,
|
| 307 |
+
reverse=False,
|
| 308 |
+
):
|
| 309 |
+
if session["canceled"]:
|
| 310 |
+
return None
|
| 311 |
+
|
| 312 |
+
frame_idx, obj_ids, video_res_masks = outputs
|
| 313 |
+
masks_binary = (
|
| 314 |
+
(video_res_masks > self.score_thresh)[:, 0].cpu().numpy()
|
| 315 |
+
)
|
| 316 |
+
|
| 317 |
+
rle_mask_list = self.__get_rle_mask_list(
|
| 318 |
+
object_ids=obj_ids, masks=masks_binary
|
| 319 |
+
)
|
| 320 |
+
|
| 321 |
+
yield PropagateDataResponse(
|
| 322 |
+
frame_index=frame_idx,
|
| 323 |
+
results=rle_mask_list,
|
| 324 |
+
)
|
| 325 |
+
|
| 326 |
+
# Then doing the backward propagation (reverse in time)
|
| 327 |
+
if propagation_direction in ["both", "backward"]:
|
| 328 |
+
for outputs in self.predictor.propagate_in_video(
|
| 329 |
+
inference_state=inference_state,
|
| 330 |
+
start_frame_idx=start_frame_idx,
|
| 331 |
+
max_frame_num_to_track=max_frame_num_to_track,
|
| 332 |
+
reverse=True,
|
| 333 |
+
):
|
| 334 |
+
if session["canceled"]:
|
| 335 |
+
return None
|
| 336 |
+
|
| 337 |
+
frame_idx, obj_ids, video_res_masks = outputs
|
| 338 |
+
masks_binary = (
|
| 339 |
+
(video_res_masks > self.score_thresh)[:, 0].cpu().numpy()
|
| 340 |
+
)
|
| 341 |
+
|
| 342 |
+
rle_mask_list = self.__get_rle_mask_list(
|
| 343 |
+
object_ids=obj_ids, masks=masks_binary
|
| 344 |
+
)
|
| 345 |
+
|
| 346 |
+
yield PropagateDataResponse(
|
| 347 |
+
frame_index=frame_idx,
|
| 348 |
+
results=rle_mask_list,
|
| 349 |
+
)
|
| 350 |
+
finally:
|
| 351 |
+
# Log upon completion (so that e.g. we can see if two propagations happen in parallel).
|
| 352 |
+
# Using `finally` here to log even when the tracking is aborted with GeneratorExit.
|
| 353 |
+
logger.info(
|
| 354 |
+
f"propagation ended in session {session_id}; {self.__get_session_stats()}"
|
| 355 |
+
)
|
| 356 |
+
|
| 357 |
+
def cancel_propagate_in_video(
|
| 358 |
+
self, request: CancelPropagateInVideoRequest
|
| 359 |
+
) -> CancelPorpagateResponse:
|
| 360 |
+
session = self.__get_session(request.session_id)
|
| 361 |
+
session["canceled"] = True
|
| 362 |
+
return CancelPorpagateResponse(success=True)
|
| 363 |
+
|
| 364 |
+
def __get_rle_mask_list(
|
| 365 |
+
self, object_ids: List[int], masks: np.ndarray
|
| 366 |
+
) -> List[PropagateDataValue]:
|
| 367 |
+
"""
|
| 368 |
+
Return a list of data values, i.e. list of object/mask combos.
|
| 369 |
+
"""
|
| 370 |
+
return [
|
| 371 |
+
self.__get_mask_for_object(object_id=object_id, mask=mask)
|
| 372 |
+
for object_id, mask in zip(object_ids, masks)
|
| 373 |
+
]
|
| 374 |
+
|
| 375 |
+
def __get_mask_for_object(
|
| 376 |
+
self, object_id: int, mask: np.ndarray
|
| 377 |
+
) -> PropagateDataValue:
|
| 378 |
+
"""
|
| 379 |
+
Create a data value for an object/mask combo.
|
| 380 |
+
"""
|
| 381 |
+
mask_rle = encode_masks(np.array(mask, dtype=np.uint8, order="F"))
|
| 382 |
+
mask_rle["counts"] = mask_rle["counts"].decode()
|
| 383 |
+
return PropagateDataValue(
|
| 384 |
+
object_id=object_id,
|
| 385 |
+
mask=Mask(
|
| 386 |
+
size=mask_rle["size"],
|
| 387 |
+
counts=mask_rle["counts"],
|
| 388 |
+
),
|
| 389 |
+
)
|
| 390 |
+
|
| 391 |
+
def __get_session(self, session_id: str):
|
| 392 |
+
session = self.session_states.get(session_id, None)
|
| 393 |
+
if session is None:
|
| 394 |
+
raise RuntimeError(
|
| 395 |
+
f"Cannot find session {session_id}; it might have expired"
|
| 396 |
+
)
|
| 397 |
+
return session
|
| 398 |
+
|
| 399 |
+
def __get_session_stats(self):
|
| 400 |
+
"""Get a statistics string for live sessions and their GPU usage."""
|
| 401 |
+
# print both the session ids and their video frame numbers
|
| 402 |
+
live_session_strs = [
|
| 403 |
+
f"'{session_id}' ({session['state']['num_frames']} frames, "
|
| 404 |
+
f"{len(session['state']['obj_ids'])} objects)"
|
| 405 |
+
for session_id, session in self.session_states.items()
|
| 406 |
+
]
|
| 407 |
+
session_stats_str = (
|
| 408 |
+
"Test String Here - -"
|
| 409 |
+
f"live sessions: [{', '.join(live_session_strs)}], GPU memory: "
|
| 410 |
+
f"{torch.cuda.memory_allocated() // 1024**2} MiB used and "
|
| 411 |
+
f"{torch.cuda.memory_reserved() // 1024**2} MiB reserved"
|
| 412 |
+
f" (max over time: {torch.cuda.max_memory_allocated() // 1024**2} MiB used "
|
| 413 |
+
f"and {torch.cuda.max_memory_reserved() // 1024**2} MiB reserved)"
|
| 414 |
+
)
|
| 415 |
+
return session_stats_str
|
| 416 |
+
|
| 417 |
+
def __clear_session_state(self, session_id: str) -> bool:
|
| 418 |
+
session = self.session_states.pop(session_id, None)
|
| 419 |
+
if session is None:
|
| 420 |
+
logger.warning(
|
| 421 |
+
f"cannot close session {session_id} as it does not exist (it might have expired); "
|
| 422 |
+
f"{self.__get_session_stats()}"
|
| 423 |
+
)
|
| 424 |
+
return False
|
| 425 |
+
else:
|
| 426 |
+
logger.info(f"removed session {session_id}; {self.__get_session_stats()}")
|
| 427 |
+
return True
|