
Upload 8 files
Browse files- README.md +36 -3
- adapter_config.json +32 -0
- adapter_model.safetensors +3 -0
- merges.txt +0 -0
- special_tokens_map.json +24 -0
- tokenizer.json +0 -0
- tokenizer_config.json +24 -0
- vocab.json +0 -0
README.md
CHANGED
|
@@ -1,3 +1,36 @@
|
|
| 1 |
-
---
|
| 2 |
-
license: apache-2.0
|
| 3 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
license: apache-2.0
|
| 3 |
+
language:
|
| 4 |
+
- en
|
| 5 |
+
metrics:
|
| 6 |
+
- roc_auc
|
| 7 |
+
base_model:
|
| 8 |
+
- EleutherAI/gpt-neo-2.7B
|
| 9 |
+
pipeline_tag: text-classification
|
| 10 |
+
tags:
|
| 11 |
+
- machine-text-detection
|
| 12 |
+
- machine-revised-text-detection
|
| 13 |
+
---
|
| 14 |
+
|
| 15 |
+
<h1 align="center">Imitate Before Detect: Aligning Machine Stylistic Preference for Machine-Revised Text Detection</h1>
|
| 16 |
+
|
| 17 |
+
<p align="center">
|
| 18 |
+
<a href="https://scholar.google.com/citations?user=Au_y5poAAAAJ">Jiaqi Chen</a><sup>*</sup>, <a href="https://xyzhu1225.github.io/">Xiaoye Zhu</a><sup>*</sup>, <a href="https://leolty.github.io/">Tianyang Liu</a><sup>*</sup>, Ying Chen, <a href="https://xinhuichen-02.github.io/">Xinhui Chen</a>,<br> <a href="https://scholar.google.com/citations?user=koA9QbMAAAAJ">Yiwen Yuan</a>, <a href="https://cooperleong00.github.io/">Chak Tou Leong</a>, <a href="https://zcli-charlie.github.io/">Zuchao Li</a><sup>†</sup>, Tang Long, <a href="https://yusalei.github.io/">Lei Zhang</a>, <br><a href="https://scholar.google.com/citations?user=281EWzQAAAAJ">Chenyu Yan</a>, <a href="https://scholar.google.com/citations?user=mliv6KEAAAAJ">Guanghao Mei</a>, <a href="https://scholar.google.com/citations?user=epTfECgAAAAJ">Jie Zhang</a><sup>†</sup>, <a href="https://scholar.google.com/citations?user=BLKHwNwAAAAJ">Lefei Zhang</a><sup>†</sup>
|
| 19 |
+
</p>
|
| 20 |
+
|
| 21 |
+
<p align="center">
|
| 22 |
+
*Equal contribution.<br> †Equal contribution of corresponding author.
|
| 23 |
+
</p>
|
| 24 |
+
|
| 25 |
+
Detecting **machine-revised text** remains a challenging task as it often involves subtle style changes embedded within human-originated content. The ImBD framework introduces a novel approach to tackle this problem, leveraging **style preference optimization (SPO)** and **Style-CPC** to effectively capture machine-style phrasing. Our method achieves state-of-the-art performance in detecting revisions by open-source and proprietary LLMs like GPT-3.5 and GPT-4o, demonstrating significant efficiency with minimal training data.
|
| 26 |
+
|
| 27 |
+
We are excited to share our code and data to support further exploration in detecting machine-revised text. We welcome your feedback and invite collaborations to advance this field together!
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
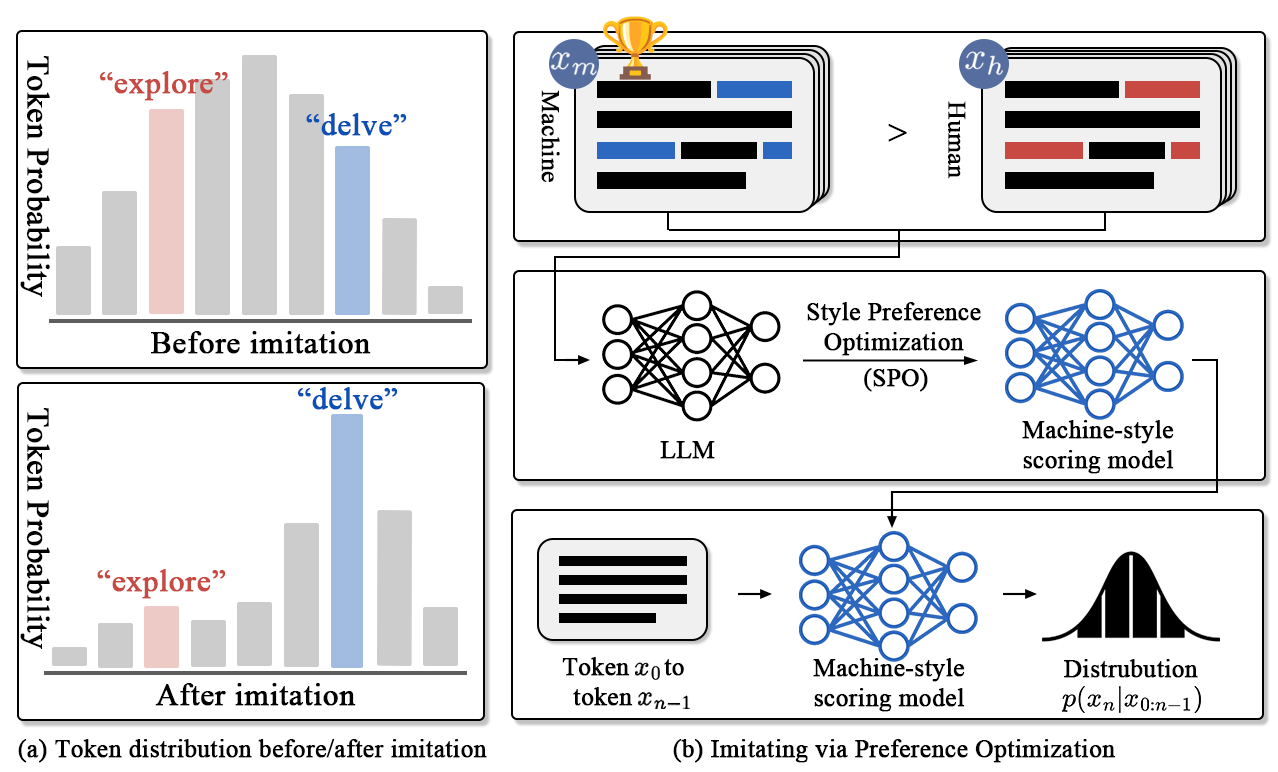
|
| 31 |
+
|
| 32 |
+
## 🔥 News
|
| 33 |
+
- **[2024, Dec 16]** Our online [demo](https://huggingface.co/spaces/machine-text-detection/ImBD) is available on hugging-face now!
|
| 34 |
+
- **[2024, Dec 13]** Our [model](https://huggingface.co/xyzhu1225/ImBD/tree/main) and local inference code are available.
|
| 35 |
+
- **[2024, Dec 9]** 🎉🎉 Our paper has been accepted by AAAI 25!
|
| 36 |
+
- **[2024, Dec 7]** We've released our [website](https://machine-text-detection.github.io/ImBD).
|
adapter_config.json
ADDED
|
@@ -0,0 +1,32 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"alpha_pattern": {},
|
| 3 |
+
"auto_mapping": null,
|
| 4 |
+
"base_model_name_or_path": "./models/gpt-neo-2.7B",
|
| 5 |
+
"bias": "none",
|
| 6 |
+
"eva_config": null,
|
| 7 |
+
"exclude_modules": null,
|
| 8 |
+
"fan_in_fan_out": false,
|
| 9 |
+
"inference_mode": true,
|
| 10 |
+
"init_lora_weights": true,
|
| 11 |
+
"layer_replication": null,
|
| 12 |
+
"layers_pattern": null,
|
| 13 |
+
"layers_to_transform": null,
|
| 14 |
+
"loftq_config": {},
|
| 15 |
+
"lora_alpha": 32,
|
| 16 |
+
"lora_bias": false,
|
| 17 |
+
"lora_dropout": 0.1,
|
| 18 |
+
"megatron_config": null,
|
| 19 |
+
"megatron_core": "megatron.core",
|
| 20 |
+
"modules_to_save": null,
|
| 21 |
+
"peft_type": "LORA",
|
| 22 |
+
"r": 8,
|
| 23 |
+
"rank_pattern": {},
|
| 24 |
+
"revision": null,
|
| 25 |
+
"target_modules": [
|
| 26 |
+
"v_proj",
|
| 27 |
+
"q_proj"
|
| 28 |
+
],
|
| 29 |
+
"task_type": "CAUSAL_LM",
|
| 30 |
+
"use_dora": false,
|
| 31 |
+
"use_rslora": false
|
| 32 |
+
}
|
adapter_model.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:77d90811cd85cf114444c8df70fc092d3cfedb1c9d12243618e5ed5fa45b3c75
|
| 3 |
+
size 10503408
|
merges.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
special_tokens_map.json
ADDED
|
@@ -0,0 +1,24 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"bos_token": {
|
| 3 |
+
"content": "<|endoftext|>",
|
| 4 |
+
"lstrip": false,
|
| 5 |
+
"normalized": true,
|
| 6 |
+
"rstrip": false,
|
| 7 |
+
"single_word": false
|
| 8 |
+
},
|
| 9 |
+
"eos_token": {
|
| 10 |
+
"content": "<|endoftext|>",
|
| 11 |
+
"lstrip": false,
|
| 12 |
+
"normalized": true,
|
| 13 |
+
"rstrip": false,
|
| 14 |
+
"single_word": false
|
| 15 |
+
},
|
| 16 |
+
"pad_token": "<|endoftext|>",
|
| 17 |
+
"unk_token": {
|
| 18 |
+
"content": "<|endoftext|>",
|
| 19 |
+
"lstrip": false,
|
| 20 |
+
"normalized": true,
|
| 21 |
+
"rstrip": false,
|
| 22 |
+
"single_word": false
|
| 23 |
+
}
|
| 24 |
+
}
|
tokenizer.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
tokenizer_config.json
ADDED
|
@@ -0,0 +1,24 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"add_bos_token": false,
|
| 3 |
+
"add_prefix_space": false,
|
| 4 |
+
"added_tokens_decoder": {
|
| 5 |
+
"50256": {
|
| 6 |
+
"content": "<|endoftext|>",
|
| 7 |
+
"lstrip": false,
|
| 8 |
+
"normalized": true,
|
| 9 |
+
"rstrip": false,
|
| 10 |
+
"single_word": false,
|
| 11 |
+
"special": true
|
| 12 |
+
}
|
| 13 |
+
},
|
| 14 |
+
"bos_token": "<|endoftext|>",
|
| 15 |
+
"clean_up_tokenization_spaces": false,
|
| 16 |
+
"eos_token": "<|endoftext|>",
|
| 17 |
+
"errors": "replace",
|
| 18 |
+
"extra_special_tokens": {},
|
| 19 |
+
"model_max_length": 2048,
|
| 20 |
+
"pad_token": "<|endoftext|>",
|
| 21 |
+
"padding_side": "right",
|
| 22 |
+
"tokenizer_class": "GPT2Tokenizer",
|
| 23 |
+
"unk_token": "<|endoftext|>"
|
| 24 |
+
}
|
vocab.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|