
Update README.md
Browse files
README.md
CHANGED
|
@@ -1,134 +1,134 @@
|
|
| 1 |
-
---
|
| 2 |
-
license: apache-2.0
|
| 3 |
-
pipeline_tag: text-to-video
|
| 4 |
-
---
|
| 5 |
-
|
| 6 |
-
|
| 7 |
-
<h1 align="center">
|
| 8 |
-
<a href="https://yhzhai.github.io/mcm/"><b>Motion Consistency Model: Accelerating Video Diffusion with Disentangled Motion-Appearance Distillation</b></a>
|
| 9 |
-
</h1>
|
| 10 |
-
|
| 11 |
-
[[Project page]](https://yhzhai.github.io/mcm/) [[Code]](https://github.com/yhZhai/mcm) [[arXiv]](https://arxiv.org/abs/2406.06890) [[Demo]](https://huggingface.co/spaces/yhzhai/mcm)
|
| 12 |
-
|
| 13 |
-
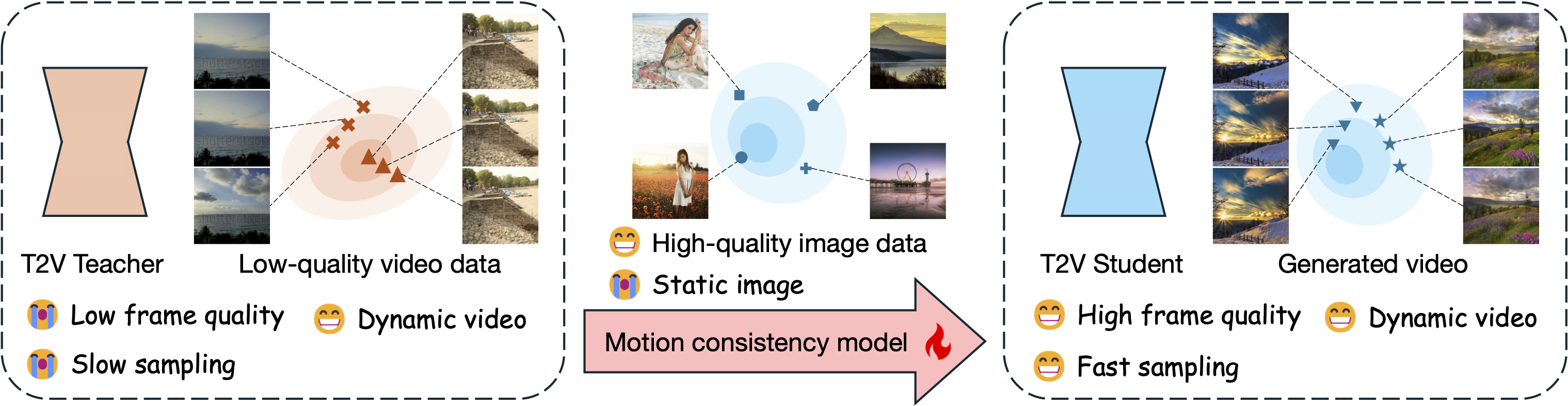
**TL;DR**: Our motion consistency model not only accelerates text2video diffusion model sampling process, but also can benefit from an additional high-quality image dataset to improve the frame quality of generated videos.
|
| 14 |
-
|
| 15 |
-
|
| 16 |
-
|
| 17 |
-
## Usage
|
| 18 |
-
|
| 19 |
-
```python
|
| 20 |
-
from typing import Optional
|
| 21 |
-
|
| 22 |
-
import torch
|
| 23 |
-
from diffusers import (
|
| 24 |
-
AnimateDiffPipeline,
|
| 25 |
-
DiffusionPipeline,
|
| 26 |
-
LCMScheduler,
|
| 27 |
-
MotionAdapter,
|
| 28 |
-
)
|
| 29 |
-
from diffusers.utils import export_to_video
|
| 30 |
-
from peft import PeftModel
|
| 31 |
-
|
| 32 |
-
|
| 33 |
-
def main():
|
| 34 |
-
# select model_path from ["animatediff-webvid", "animatediff-
|
| 35 |
-
# "modelscopet2v-webvid", "modelscopet2v-laion", "modelscopet2v-anime",
|
| 36 |
-
# "modelscopet2v-real", "modelscopet2v-3d-cartoon"]
|
| 37 |
-
model_path = "modelscopet2v-laion"
|
| 38 |
-
prompts = ["A cat walking on a treadmill", "A dog walking on a treadmill"]
|
| 39 |
-
num_inference_steps = 4
|
| 40 |
-
|
| 41 |
-
model_id = "yhzhai/mcm"
|
| 42 |
-
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
|
| 43 |
-
if "animatediff" in model_path:
|
| 44 |
-
pipeline = get_animatediff_pipeline()
|
| 45 |
-
elif "modelscope" in model_path:
|
| 46 |
-
pipeline = get_modelscope_pipeline()
|
| 47 |
-
else:
|
| 48 |
-
raise ValueError(f"Unknown pipeline {model_path}")
|
| 49 |
-
|
| 50 |
-
lora = PeftModel.from_pretrained(
|
| 51 |
-
pipeline.unet,
|
| 52 |
-
model_id,
|
| 53 |
-
subfolder=model_path,
|
| 54 |
-
adapter_name="pretrained_lora",
|
| 55 |
-
torch_device="cpu",
|
| 56 |
-
)
|
| 57 |
-
lora.merge_and_unload()
|
| 58 |
-
pipeline.unet = lora
|
| 59 |
-
|
| 60 |
-
pipeline = pipeline.to(device)
|
| 61 |
-
output = pipeline(
|
| 62 |
-
prompt=prompts,
|
| 63 |
-
num_frames=16,
|
| 64 |
-
guidance_scale=1.0,
|
| 65 |
-
num_inference_steps=num_inference_steps,
|
| 66 |
-
generator=torch.Generator("cpu").manual_seed(42),
|
| 67 |
-
).frames
|
| 68 |
-
if not isinstance(output, list):
|
| 69 |
-
output = [output[i] for i in range(output.shape[0])]
|
| 70 |
-
|
| 71 |
-
for j in range(len(prompts)):
|
| 72 |
-
export_to_video(
|
| 73 |
-
output[j],
|
| 74 |
-
f"{j}-{model_path}.mp4",
|
| 75 |
-
fps=7,
|
| 76 |
-
)
|
| 77 |
-
|
| 78 |
-
|
| 79 |
-
def get_animatediff_pipeline(
|
| 80 |
-
real_variant: Optional[str] = "realvision",
|
| 81 |
-
motion_module_path: str = "guoyww/animatediff-motion-adapter-v1-5-2",
|
| 82 |
-
):
|
| 83 |
-
if real_variant is None:
|
| 84 |
-
model_id = "runwayml/stable-diffusion-v1-5"
|
| 85 |
-
elif real_variant == "epicrealism":
|
| 86 |
-
model_id = "emilianJR/epiCRealism"
|
| 87 |
-
elif real_variant == "realvision":
|
| 88 |
-
model_id = "SG161222/Realistic_Vision_V6.0_B1_noVAE"
|
| 89 |
-
else:
|
| 90 |
-
raise ValueError(f"Unknown real_variant {real_variant}")
|
| 91 |
-
|
| 92 |
-
adapter = MotionAdapter.from_pretrained(
|
| 93 |
-
motion_module_path, torch_dtype=torch.float16
|
| 94 |
-
)
|
| 95 |
-
pipe = AnimateDiffPipeline.from_pretrained(
|
| 96 |
-
model_id,
|
| 97 |
-
motion_adapter=adapter,
|
| 98 |
-
torch_dtype=torch.float16,
|
| 99 |
-
)
|
| 100 |
-
scheduler = LCMScheduler.from_pretrained(
|
| 101 |
-
model_id,
|
| 102 |
-
subfolder="scheduler",
|
| 103 |
-
timestep_scaling=4.0,
|
| 104 |
-
clip_sample=False,
|
| 105 |
-
timestep_spacing="linspace",
|
| 106 |
-
beta_schedule="linear",
|
| 107 |
-
beta_start=0.00085,
|
| 108 |
-
beta_end=0.012,
|
| 109 |
-
steps_offset=1,
|
| 110 |
-
)
|
| 111 |
-
pipe.scheduler = scheduler
|
| 112 |
-
pipe.enable_vae_slicing()
|
| 113 |
-
return pipe
|
| 114 |
-
|
| 115 |
-
|
| 116 |
-
def get_modelscope_pipeline():
|
| 117 |
-
model_id = "ali-vilab/text-to-video-ms-1.7b"
|
| 118 |
-
pipe = DiffusionPipeline.from_pretrained(
|
| 119 |
-
model_id, torch_dtype=torch.float16, variant="fp16"
|
| 120 |
-
)
|
| 121 |
-
scheduler = LCMScheduler.from_pretrained(
|
| 122 |
-
model_id,
|
| 123 |
-
subfolder="scheduler",
|
| 124 |
-
timestep_scaling=4.0,
|
| 125 |
-
)
|
| 126 |
-
pipe.scheduler = scheduler
|
| 127 |
-
pipe.enable_vae_slicing()
|
| 128 |
-
|
| 129 |
-
return pipe
|
| 130 |
-
|
| 131 |
-
|
| 132 |
-
if __name__ == "__main__":
|
| 133 |
-
main()
|
| 134 |
```
|
|
|
|
| 1 |
+
---
|
| 2 |
+
license: apache-2.0
|
| 3 |
+
pipeline_tag: text-to-video
|
| 4 |
+
---
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
<h1 align="center">
|
| 8 |
+
<a href="https://yhzhai.github.io/mcm/"><b>Motion Consistency Model: Accelerating Video Diffusion with Disentangled Motion-Appearance Distillation</b></a>
|
| 9 |
+
</h1>
|
| 10 |
+
|
| 11 |
+
[[Project page]](https://yhzhai.github.io/mcm/) [[Code]](https://github.com/yhZhai/mcm) [[arXiv]](https://arxiv.org/abs/2406.06890) [[Demo]](https://huggingface.co/spaces/yhzhai/mcm)
|
| 12 |
+
|
| 13 |
+
**TL;DR**: Our motion consistency model not only accelerates text2video diffusion model sampling process, but also can benefit from an additional high-quality image dataset to improve the frame quality of generated videos.
|
| 14 |
+
|
| 15 |
+

|
| 16 |
+
|
| 17 |
+
## Usage
|
| 18 |
+
|
| 19 |
+
```python
|
| 20 |
+
from typing import Optional
|
| 21 |
+
|
| 22 |
+
import torch
|
| 23 |
+
from diffusers import (
|
| 24 |
+
AnimateDiffPipeline,
|
| 25 |
+
DiffusionPipeline,
|
| 26 |
+
LCMScheduler,
|
| 27 |
+
MotionAdapter,
|
| 28 |
+
)
|
| 29 |
+
from diffusers.utils import export_to_video
|
| 30 |
+
from peft import PeftModel
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
def main():
|
| 34 |
+
# select model_path from ["animatediff-webvid", "animatediff-webvid",
|
| 35 |
+
# "modelscopet2v-webvid", "modelscopet2v-laion", "modelscopet2v-anime",
|
| 36 |
+
# "modelscopet2v-real", "modelscopet2v-3d-cartoon"]
|
| 37 |
+
model_path = "modelscopet2v-laion"
|
| 38 |
+
prompts = ["A cat walking on a treadmill", "A dog walking on a treadmill"]
|
| 39 |
+
num_inference_steps = 4
|
| 40 |
+
|
| 41 |
+
model_id = "yhzhai/mcm"
|
| 42 |
+
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
|
| 43 |
+
if "animatediff" in model_path:
|
| 44 |
+
pipeline = get_animatediff_pipeline()
|
| 45 |
+
elif "modelscope" in model_path:
|
| 46 |
+
pipeline = get_modelscope_pipeline()
|
| 47 |
+
else:
|
| 48 |
+
raise ValueError(f"Unknown pipeline {model_path}")
|
| 49 |
+
|
| 50 |
+
lora = PeftModel.from_pretrained(
|
| 51 |
+
pipeline.unet,
|
| 52 |
+
model_id,
|
| 53 |
+
subfolder=model_path,
|
| 54 |
+
adapter_name="pretrained_lora",
|
| 55 |
+
torch_device="cpu",
|
| 56 |
+
)
|
| 57 |
+
lora.merge_and_unload()
|
| 58 |
+
pipeline.unet = lora
|
| 59 |
+
|
| 60 |
+
pipeline = pipeline.to(device)
|
| 61 |
+
output = pipeline(
|
| 62 |
+
prompt=prompts,
|
| 63 |
+
num_frames=16,
|
| 64 |
+
guidance_scale=1.0,
|
| 65 |
+
num_inference_steps=num_inference_steps,
|
| 66 |
+
generator=torch.Generator("cpu").manual_seed(42),
|
| 67 |
+
).frames
|
| 68 |
+
if not isinstance(output, list):
|
| 69 |
+
output = [output[i] for i in range(output.shape[0])]
|
| 70 |
+
|
| 71 |
+
for j in range(len(prompts)):
|
| 72 |
+
export_to_video(
|
| 73 |
+
output[j],
|
| 74 |
+
f"{j}-{model_path}.mp4",
|
| 75 |
+
fps=7,
|
| 76 |
+
)
|
| 77 |
+
|
| 78 |
+
|
| 79 |
+
def get_animatediff_pipeline(
|
| 80 |
+
real_variant: Optional[str] = "realvision",
|
| 81 |
+
motion_module_path: str = "guoyww/animatediff-motion-adapter-v1-5-2",
|
| 82 |
+
):
|
| 83 |
+
if real_variant is None:
|
| 84 |
+
model_id = "runwayml/stable-diffusion-v1-5"
|
| 85 |
+
elif real_variant == "epicrealism":
|
| 86 |
+
model_id = "emilianJR/epiCRealism"
|
| 87 |
+
elif real_variant == "realvision":
|
| 88 |
+
model_id = "SG161222/Realistic_Vision_V6.0_B1_noVAE"
|
| 89 |
+
else:
|
| 90 |
+
raise ValueError(f"Unknown real_variant {real_variant}")
|
| 91 |
+
|
| 92 |
+
adapter = MotionAdapter.from_pretrained(
|
| 93 |
+
motion_module_path, torch_dtype=torch.float16
|
| 94 |
+
)
|
| 95 |
+
pipe = AnimateDiffPipeline.from_pretrained(
|
| 96 |
+
model_id,
|
| 97 |
+
motion_adapter=adapter,
|
| 98 |
+
torch_dtype=torch.float16,
|
| 99 |
+
)
|
| 100 |
+
scheduler = LCMScheduler.from_pretrained(
|
| 101 |
+
model_id,
|
| 102 |
+
subfolder="scheduler",
|
| 103 |
+
timestep_scaling=4.0,
|
| 104 |
+
clip_sample=False,
|
| 105 |
+
timestep_spacing="linspace",
|
| 106 |
+
beta_schedule="linear",
|
| 107 |
+
beta_start=0.00085,
|
| 108 |
+
beta_end=0.012,
|
| 109 |
+
steps_offset=1,
|
| 110 |
+
)
|
| 111 |
+
pipe.scheduler = scheduler
|
| 112 |
+
pipe.enable_vae_slicing()
|
| 113 |
+
return pipe
|
| 114 |
+
|
| 115 |
+
|
| 116 |
+
def get_modelscope_pipeline():
|
| 117 |
+
model_id = "ali-vilab/text-to-video-ms-1.7b"
|
| 118 |
+
pipe = DiffusionPipeline.from_pretrained(
|
| 119 |
+
model_id, torch_dtype=torch.float16, variant="fp16"
|
| 120 |
+
)
|
| 121 |
+
scheduler = LCMScheduler.from_pretrained(
|
| 122 |
+
model_id,
|
| 123 |
+
subfolder="scheduler",
|
| 124 |
+
timestep_scaling=4.0,
|
| 125 |
+
)
|
| 126 |
+
pipe.scheduler = scheduler
|
| 127 |
+
pipe.enable_vae_slicing()
|
| 128 |
+
|
| 129 |
+
return pipe
|
| 130 |
+
|
| 131 |
+
|
| 132 |
+
if __name__ == "__main__":
|
| 133 |
+
main()
|
| 134 |
```
|