
GGUF quantized and fp8 scaled version of hyvid with lora anime adapter

- Prompt
- anime style anime girl with massive fennec ears and one big fluffy tail, she has blonde long hair blue eyes wearing a maid outfit with a long black gold leaf pattern dress, walking slowly to the front with sweetie smile, holding a fancy black forest cake with candles on top in the kitchen of an old dark Victorian mansion lit by candlelight with a bright window to the foggy

- Prompt
- anime scene of a vibrant carnival with colorful rides, games, and food stalls, and a cute anime girl with multicolored hair, holding a melting ice-cream, wearing a fluffy white hoodie and blue mini shorts, winking her eye, smiling to the camera

- Prompt
- anime girl with pink twin tails and green eyes, wearing a school uniform, holding a stack of books in a bustling library filled with sunlight streaming through tall windows

- Prompt
- anime boy with silver hair and blue eyes, wearing a casual hoodie, sitting on a park bench, feeding pigeons with a gentle smile

- Prompt
- anime style anime girl with massive fennec ears and one big fluffy tail, she has blonde long hair blue eyes wearing a maid outfit with a long black gold leaf pattern dress, walking slowly to the front with sweetie smile, holding a fancy black forest cake with candles on top in the kitchen of an old dark Victorian mansion lit by candlelight with a bright window to the foggy forest

- Prompt
- anime style anime girl with massive fennec ears and one big fluffy tail, she has blonde hair long hair blue eyes wearing a pink sweater and a long blue skirt walking in a beautiful outdoor scenery with snow mountains in the background
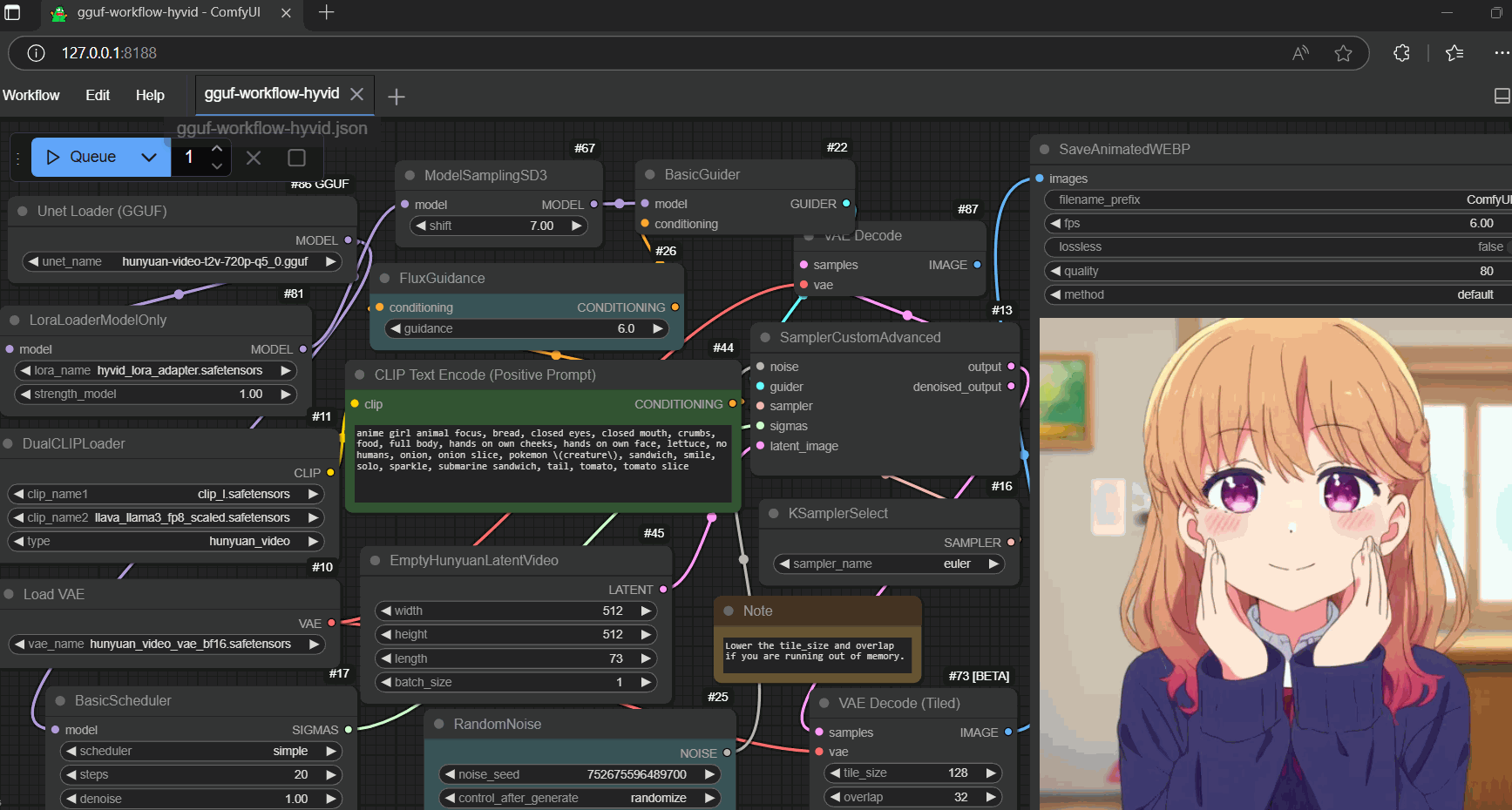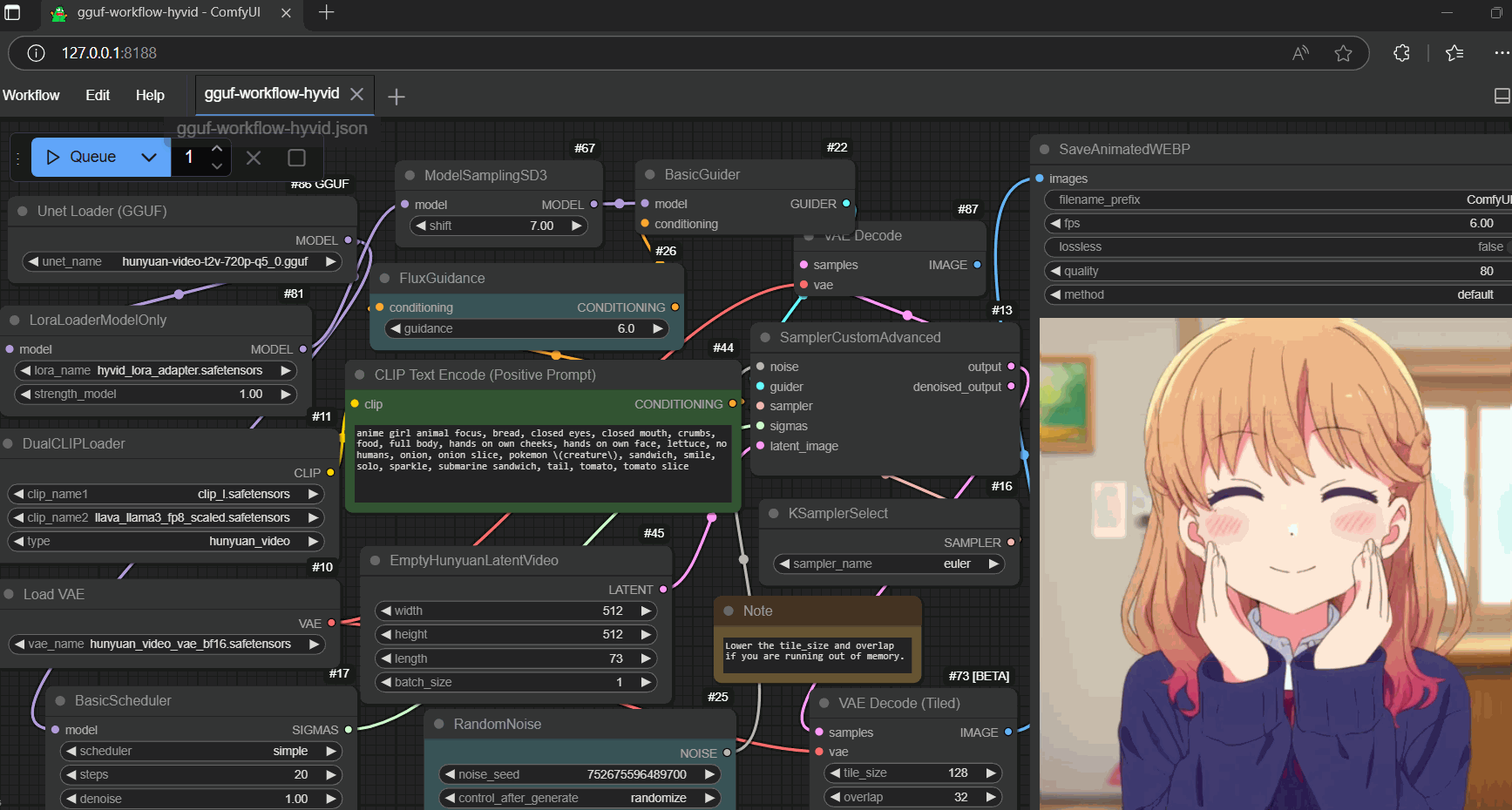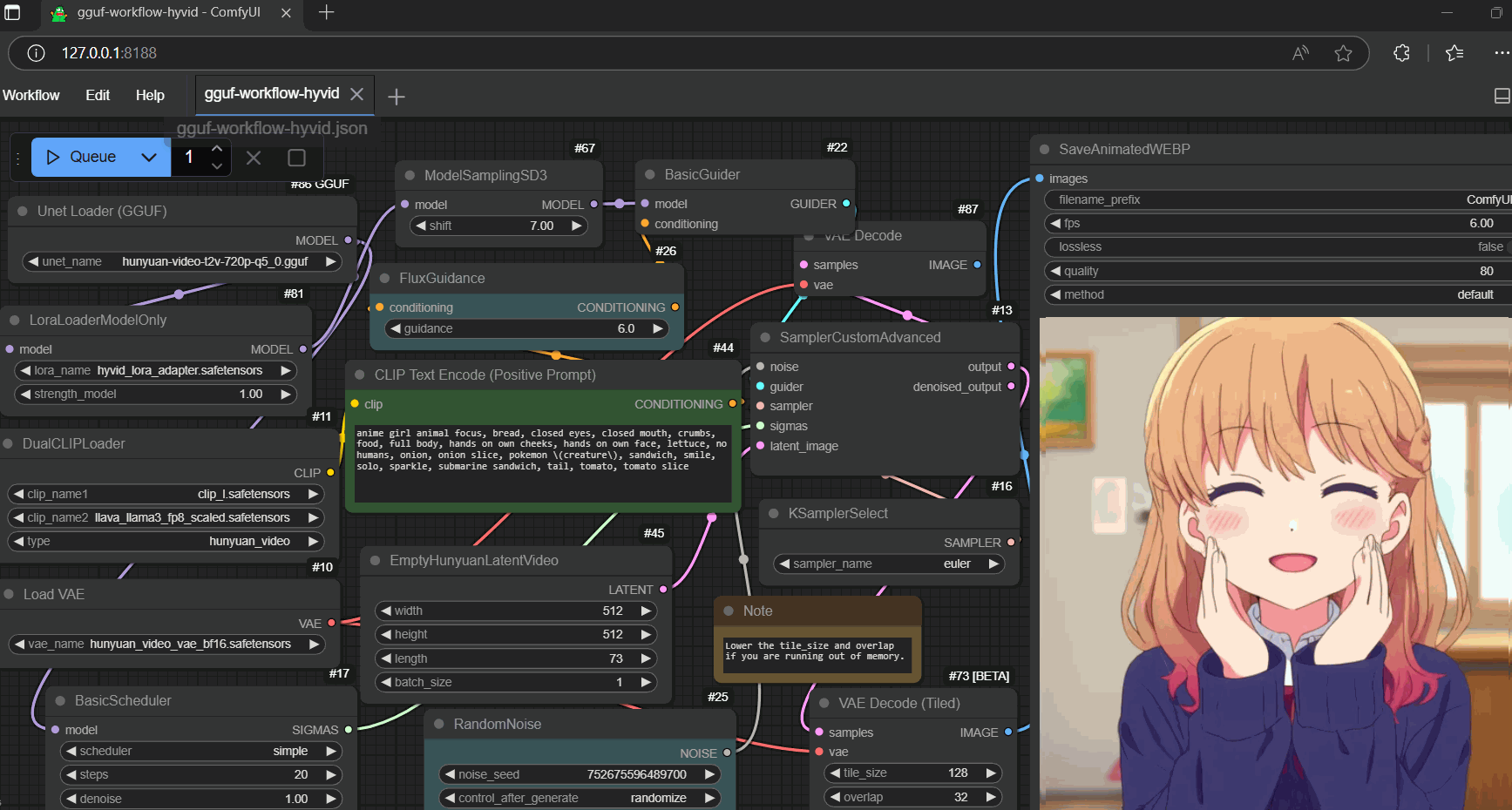
setup (once)
- drag hyvid_lora_adapter.safetensors [323MB] to > ./ComfyUI/models/loras
- drag hunyuan-video-t2v-720p-q4_0.gguf [7.74GB] to > ./ComfyUI/models/diffusion_models
- drag llava_llama3-q4_0.gguf [4.68GB] to > ./ComfyUI/models/text_encoders
- drag clip_l_fp8_e4m3fn.safetensors [123MB] to > ./ComfyUI/models/text_encoders
- drag hunyuan_video_vae_fp8_e4m3fn.safetensors [247MB] to > ./ComfyUI/models/vae
run it straight (no installation needed way)
- run the .bat file in the main directory (assuming you are using the gguf-node pack below)
- drag the demo clip or the workflow json file (below) to > your browser
{kind=link}
workflows
- example workflow for gguf (upgrade your node for llava gguf support)
- example workflow for safetensors (fp8 scaled version [13.2GB] is recommended)
review
- more stable output if adapter applied
- working good even with fp8_e4m3fn scaled clip and vae
- significant changes in loading speed while using the new quantized/scaled file(s) with revised workflow (see above)
references
- lora adapter from trojblue
- base model from tencent
- fast model from fastvideo
- comfyui from comfyanonymous
- comfyui-gguf city96
- gguf-comfy pack
- gguf-node (pypi|repo|pack)
appendices
- Downloads last month
- 819
Model tree for calcuis/hyvid
Base model
tencent/HunyuanVideo