
NExtLong: Toward Effective Long-Context Training without Long Documents
This repository contains the code ,models and datasets for our paper NExtLong: Toward Effective Long-Context Training without Long Documents.
[Github]
Quick Links
Overview
Large language models (LLMs) with extended context windows have made significant strides yet remain a challenge due to the scarcity of long documents. Existing methods tend to synthesize long-context data but lack a clear mechanism to reinforce the long-range dependency modeling. To address this limitation, we propose NExtLong, a novel framework for synthesizing long-context data through Negative document Extension. NExtLong decomposes a document into multiple meta-chunks and extends the context by interleaving hard negative distractors retrieved from pretraining corpora. This approach compels the model to discriminate long-range dependent context from distracting content, enhancing its ability to model long-range dependencies. Extensive experiments demonstrate that NExtLong achieves significant performance improvements on the HELMET and RULER benchmarks compared to existing long-context synthesis approaches and leading models, which are trained on non-synthetic long documents.
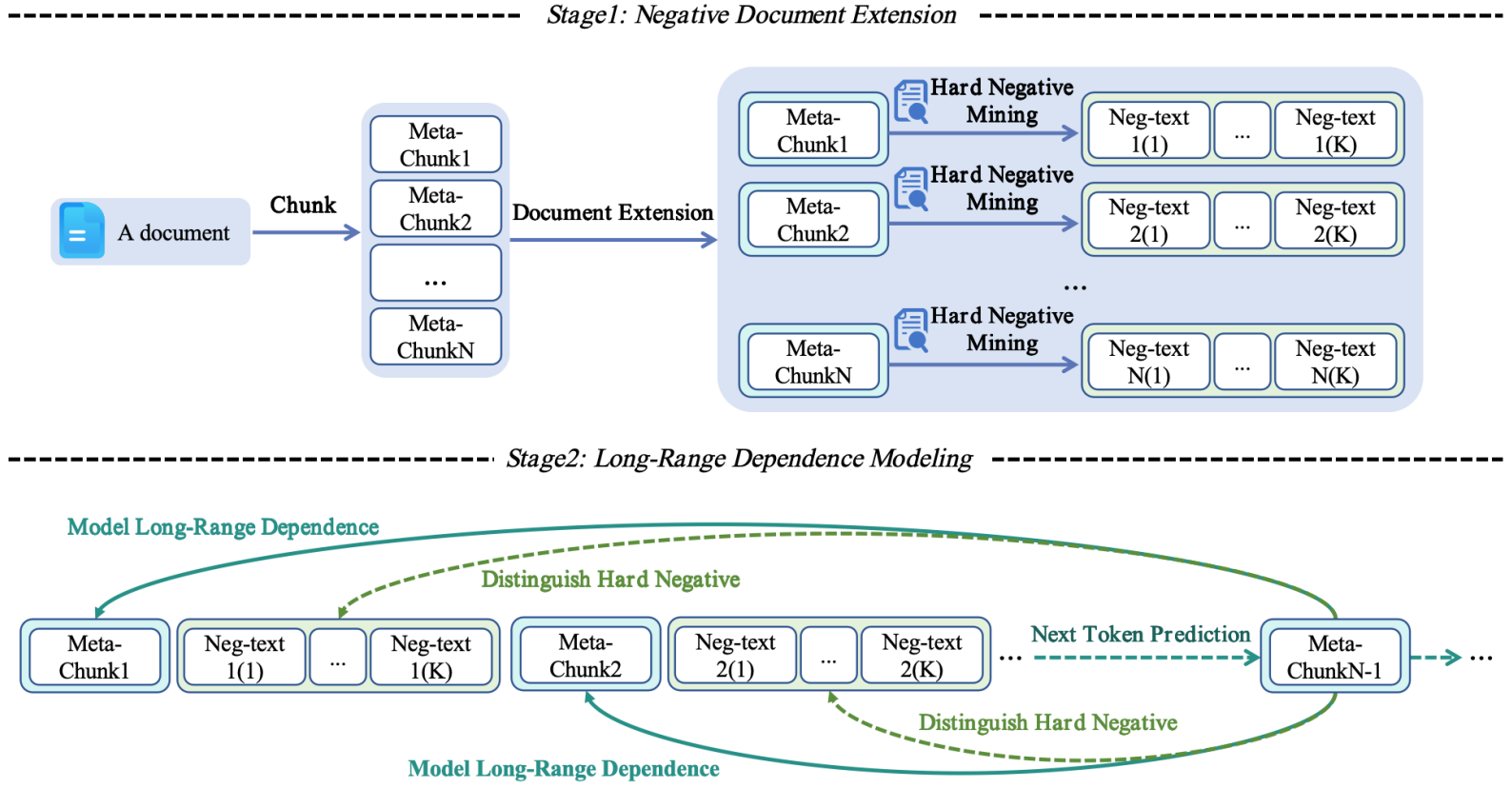
NExtLong Models
Our released models are listed as follows. You can import these models by using HuggingFace's Transformers. All models are trained on long-context data synthesized by fineweb-edu and Cosmopedia v2.
| Model | Avg. | Recall | RAG | ICL | Re-rank | LongQA | RULER |
|---|---|---|---|---|---|---|---|
| Llama-3-8B-NExtLong-128K-Base | 62.58 | 82.56 | 60.91 | 81.76 | 31.47 | 37.30 | 81.50 |
| Llama-3-8B-NExtLong-512K-Base | 65.76 | 91.58 | 63.68 | 84.08 | 31.27 | 38.42 | 85.52 |
We released our Instruct model, which is based on our Llama-3-8B-NExtLong-512K-Base model, fine-tuned using the Magpie-Align/Magpie-Llama-3.3-Pro-1M-v0.1 dataset. We evaluated our model on the Longbench V2 benchmark and achieved the top ranking (2025-01-23) among models of the comparable size (under 10B).
| Model | Overall (%) | Easy (%) | Hard (%) | Short (%) | Medium (%) | Long (%) |
|---|---|---|---|---|---|---|
| Llama-3-8B-NExtLong-512K-Instruct | 30.8 | 33.9 | 28.9 | 37.8 | 27.4 | 25.9 |
| Llama-3-8B-NExtLong-512K-Instruct + cot | 32 | 36.5 | 29.3 | 37.2 | 31.2 | 25 |
In addition, fine-tuning using the ultrachat dataset can also yield good results, as we reported in Section 5.2 of the NExtLong paper.
NExtLong Datasets
Datasets list
Our released datasets are listed as follows. All datasets are synthesized from the short-text datasets fineweb-edu and Cosmopedia v2.
| Dataset | Description |
|---|---|
| NExtLong-64K-dataset | Completely composed of 64K synthetic data. |
| NExtLong-512K-dataset | Completely composed of 512K synthetic data. |
| NExtLong-128K-dataset | Completely composed of 128K synthetic data. The NExtLong-128K-dataset is used to produce the Llama-3-8B-NExtLong-128K-Base model. |
| NExtLong-512K-dataset-subset | A subset randomly selected from the NExtLong-64K-dataset and NExtLong-512K-dataset. It is used to produce the Llama-3-8B-NExtLong-512K-Base model. |
| NExtLong-Instruct-dataset-Magpie-Llama-3.3-Pro-1M-v0.1 | We transformed the Magpie-Align/Magpie-Llama-3.3-Pro-1M-v0.1 dataset and produce the Llama-3-8B-NExtLong-512K-Instruct model. |
How to use NExtLong datasets
Due to differences in model tokenizers, the number of tokens after encoding each piece of data may not meet expectations. Therefore, for data that exceeds the target length after tokenization, truncation is necessary. Additionally, a small portion of the data may fall short of the target length and should be discarded.
Given the abundance of data, we recommend discarding data that does not meet the target length or using document mask techniques for concatenation. The implementation of document mask can be referenced in ProLong. If document mask is not used, please avoid randomly concatenating such data.
Since our data is solely sourced from fineweb-edu and Cosmopedia v2, we recommend using 4B NExtLong data for long context training. If a larger volume of data is desired for training, it is advisable to incorporate more data sources to prevent the model from overfitting to these two datasets.
Bugs or questions?
If you have any questions related to the code or the paper, feel free to email Chaochen ([email protected]) and XingWu ([email protected]). If you encounter any problems when using the code, or want to report a bug, you can open an issue. Please try to specify the problem with details so we can help you better and quicker!
- Downloads last month
- 3