
repo_id
stringlengths 1
51
| file_structure
stringlengths 56
247k
| readme_content
stringlengths 0
287k
| key_code_snippets
stringlengths 1.04k
16.8M
| __index_level_0__
float64 0
7
⌀ |
|---|---|---|---|---|
100-times-faster-nlp | {"type": "directory", "name": "100-times-faster-nlp", "children": [{"type": "file", "name": "100-times-faster-nlp-in-python.html"}, {"type": "file", "name": "100-times-faster-nlp-in-python.ipynb"}, {"type": "file", "name": "README.md"}]} | # 🚀 100 Times Faster Natural Language Processing in Python
This repository contains an iPython notebook accompanying the post [🚀100 Times Faster Natural Language Processing in Python](https://medium.com/huggingface/100-times-faster-natural-language-processing-in-python-ee32033bdced).
The notebook contains all the examples of the post running in a iPython session.
Online, the notebook can be better visualized [on nbviewer](https://nbviewer.jupyter.org/github/huggingface/100-times-faster-nlp/blob/master/100-times-faster-nlp-in-python.ipynb) (Github's ipynb visualizer doesn't render well Cython interactive annotations).
| {".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n"} | 0 |
accelerate | {"type": "directory", "name": "accelerate", "children": [{"type": "directory", "name": ".devcontainer", "children": [{"type": "file", "name": "devcontainer.json"}]}, {"type": "file", "name": ".pre-commit-config.yaml"}, {"type": "directory", "name": "benchmarks", "children": [{"type": "directory", "name": "big_model_inference", "children": [{"type": "file", "name": "big_model_inference.py"}, {"type": "file", "name": "measures_util.py"}, {"type": "file", "name": "README.md"}]}, {"type": "directory", "name": "fp8", "children": [{"type": "directory", "name": "ms_amp", "children": [{"type": "file", "name": "ddp.py"}, {"type": "file", "name": "distrib_deepspeed.py"}, {"type": "file", "name": "Dockerfile"}, {"type": "file", "name": "fp8_utils.py"}, {"type": "file", "name": "non_distributed.py"}]}, {"type": "directory", "name": "transformer_engine", "children": [{"type": "file", "name": "ddp.py"}, {"type": "file", "name": "distrib_deepspeed.py"}, {"type": "file", "name": "Dockerfile"}, {"type": "file", "name": "fp8_utils.py"}, {"type": "file", "name": "fsdp.py"}, {"type": "file", "name": "non_distributed.py"}, {"type": "file", "name": "README.md"}]}]}, {"type": "file", "name": "README.md"}]}, {"type": "file", "name": "CODE_OF_CONDUCT.md"}, {"type": "file", "name": "CONTRIBUTING.md"}, {"type": "directory", "name": "docker", "children": [{"type": "directory", "name": "accelerate-cpu", "children": [{"type": "file", "name": "Dockerfile"}]}, {"type": "directory", "name": "accelerate-gpu", "children": [{"type": "file", "name": "Dockerfile"}]}, {"type": "directory", "name": "accelerate-gpu-deepspeed", "children": [{"type": "file", "name": "Dockerfile"}]}, {"type": "file", "name": "README.md"}]}, {"type": "directory", "name": "docs", "children": [{"type": "file", "name": "Makefile"}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "source", "children": [{"type": "directory", "name": "basic_tutorials", "children": [{"type": "file", "name": "execution.md"}, {"type": "file", "name": "install.md"}, {"type": "file", "name": "launch.md"}, {"type": "file", "name": "migration.md"}, {"type": "file", "name": "notebook.md"}, {"type": "file", "name": "overview.md"}, {"type": "file", "name": "tpu.md"}, {"type": "file", "name": "troubleshooting.md"}]}, {"type": "directory", "name": "concept_guides", "children": [{"type": "file", "name": "big_model_inference.md"}, {"type": "file", "name": "deferring_execution.md"}, {"type": "file", "name": "fsdp_and_deepspeed.md"}, {"type": "file", "name": "gradient_synchronization.md"}, {"type": "file", "name": "internal_mechanism.md"}, {"type": "file", "name": "low_precision_training.md"}, {"type": "file", "name": "performance.md"}, {"type": "file", "name": "training_tpu.md"}]}, {"type": "directory", "name": "imgs", "children": []}, {"type": "file", "name": "index.md"}, {"type": "directory", "name": "package_reference", "children": [{"type": "file", "name": "accelerator.md"}, {"type": "file", "name": "big_modeling.md"}, {"type": "file", "name": "cli.md"}, {"type": "file", "name": "deepspeed.md"}, {"type": "file", "name": "fp8.md"}, {"type": "file", "name": "fsdp.md"}, {"type": "file", "name": "inference.md"}, {"type": "file", "name": "kwargs.md"}, {"type": "file", "name": "launchers.md"}, {"type": "file", "name": "logging.md"}, {"type": "file", "name": "megatron_lm.md"}, {"type": "file", "name": "state.md"}, {"type": "file", "name": "torch_wrappers.md"}, {"type": "file", "name": "tracking.md"}, {"type": "file", "name": "utilities.md"}]}, {"type": "file", "name": "quicktour.md"}, {"type": "directory", "name": "usage_guides", "children": [{"type": "file", "name": "big_modeling.md"}, {"type": "file", "name": "checkpoint.md"}, {"type": "file", "name": "ddp_comm_hook.md"}, {"type": "file", "name": "deepspeed.md"}, {"type": "file", "name": "deepspeed_multiple_model.md"}, {"type": "file", "name": "distributed_inference.md"}, {"type": "file", "name": "explore.md"}, {"type": "file", "name": "fsdp.md"}, {"type": "file", "name": "gradient_accumulation.md"}, {"type": "file", "name": "ipex.md"}, {"type": "file", "name": "local_sgd.md"}, {"type": "file", "name": "low_precision_training.md"}, {"type": "file", "name": "megatron_lm.md"}, {"type": "file", "name": "model_size_estimator.md"}, {"type": "file", "name": "mps.md"}, {"type": "file", "name": "profiler.md"}, {"type": "file", "name": "quantization.md"}, {"type": "file", "name": "sagemaker.md"}, {"type": "file", "name": "tracking.md"}, {"type": "file", "name": "training_zoo.md"}]}, {"type": "file", "name": "_toctree.yml"}]}]}, {"type": "directory", "name": "examples", "children": [{"type": "directory", "name": "by_feature", "children": [{"type": "file", "name": "automatic_gradient_accumulation.py"}, {"type": "file", "name": "checkpointing.py"}, {"type": "file", "name": "cross_validation.py"}, {"type": "file", "name": "ddp_comm_hook.py"}, {"type": "file", "name": "deepspeed_with_config_support.py"}, {"type": "file", "name": "early_stopping.py"}, {"type": "file", "name": "fsdp_with_peak_mem_tracking.py"}, {"type": "file", "name": "gradient_accumulation.py"}, {"type": "file", "name": "local_sgd.py"}, {"type": "file", "name": "megatron_lm_gpt_pretraining.py"}, {"type": "file", "name": "memory.py"}, {"type": "file", "name": "multi_process_metrics.py"}, {"type": "file", "name": "profiler.py"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "schedule_free.py"}, {"type": "file", "name": "tracking.py"}]}, {"type": "file", "name": "complete_cv_example.py"}, {"type": "file", "name": "complete_nlp_example.py"}, {"type": "directory", "name": "config_yaml_templates", "children": [{"type": "file", "name": "deepspeed.yaml"}, {"type": "file", "name": "fp8.yaml"}, {"type": "file", "name": "fsdp.yaml"}, {"type": "file", "name": "multi_gpu.yaml"}, {"type": "file", "name": "multi_node.yaml"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "run_me.py"}, {"type": "file", "name": "single_gpu.yaml"}]}, {"type": "file", "name": "cv_example.py"}, {"type": "directory", "name": "deepspeed_config_templates", "children": [{"type": "file", "name": "zero_stage1_config.json"}, {"type": "file", "name": "zero_stage2_config.json"}, {"type": "file", "name": "zero_stage2_offload_config.json"}, {"type": "file", "name": "zero_stage3_config.json"}, {"type": "file", "name": "zero_stage3_offload_config.json"}]}, {"type": "directory", "name": "inference", "children": [{"type": "directory", "name": "distributed", "children": [{"type": "file", "name": "distributed_image_generation.py"}, {"type": "file", "name": "phi2.py"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "stable_diffusion.py"}]}, {"type": "directory", "name": "pippy", "children": [{"type": "file", "name": "bert.py"}, {"type": "file", "name": "gpt2.py"}, {"type": "file", "name": "llama.py"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "t5.py"}]}]}, {"type": "file", "name": "multigpu_remote_launcher.py"}, {"type": "file", "name": "nlp_example.py"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "directory", "name": "slurm", "children": [{"type": "file", "name": "fsdp_config.yaml"}, {"type": "file", "name": "submit_multicpu.sh"}, {"type": "file", "name": "submit_multigpu.sh"}, {"type": "file", "name": "submit_multinode.sh"}, {"type": "file", "name": "submit_multinode_fsdp.sh"}]}]}, {"type": "file", "name": "LICENSE"}, {"type": "file", "name": "Makefile"}, {"type": "directory", "name": "manim_animations", "children": [{"type": "directory", "name": "big_model_inference", "children": [{"type": "file", "name": "stage_1.py"}, {"type": "file", "name": "stage_2.py"}, {"type": "file", "name": "stage_3.py"}, {"type": "file", "name": "stage_4.py"}, {"type": "file", "name": "stage_5.py"}]}, {"type": "directory", "name": "dataloaders", "children": [{"type": "file", "name": "stage_0.py"}, {"type": "file", "name": "stage_1.py"}, {"type": "file", "name": "stage_2.py"}, {"type": "file", "name": "stage_3.py"}, {"type": "file", "name": "stage_4.py"}, {"type": "file", "name": "stage_5.py"}, {"type": "file", "name": "stage_6.py"}, {"type": "file", "name": "stage_7.py"}]}]}, {"type": "file", "name": "pyproject.toml"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "setup.py"}, {"type": "directory", "name": "src", "children": [{"type": "directory", "name": "accelerate", "children": [{"type": "file", "name": "accelerator.py"}, {"type": "file", "name": "big_modeling.py"}, {"type": "file", "name": "checkpointing.py"}, {"type": "directory", "name": "commands", "children": [{"type": "file", "name": "accelerate_cli.py"}, {"type": "directory", "name": "config", "children": [{"type": "file", "name": "cluster.py"}, {"type": "file", "name": "config.py"}, {"type": "file", "name": "config_args.py"}, {"type": "file", "name": "config_utils.py"}, {"type": "file", "name": "default.py"}, {"type": "file", "name": "sagemaker.py"}, {"type": "file", "name": "update.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "env.py"}, {"type": "file", "name": "estimate.py"}, {"type": "file", "name": "launch.py"}, {"type": "directory", "name": "menu", "children": [{"type": "file", "name": "cursor.py"}, {"type": "file", "name": "helpers.py"}, {"type": "file", "name": "input.py"}, {"type": "file", "name": "keymap.py"}, {"type": "file", "name": "selection_menu.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "merge.py"}, {"type": "file", "name": "test.py"}, {"type": "file", "name": "tpu.py"}, {"type": "file", "name": "utils.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "data_loader.py"}, {"type": "file", "name": "hooks.py"}, {"type": "file", "name": "inference.py"}, {"type": "file", "name": "launchers.py"}, {"type": "file", "name": "local_sgd.py"}, {"type": "file", "name": "logging.py"}, {"type": "file", "name": "memory_utils.py"}, {"type": "file", "name": "optimizer.py"}, {"type": "file", "name": "scheduler.py"}, {"type": "file", "name": "state.py"}, {"type": "directory", "name": "test_utils", "children": [{"type": "file", "name": "examples.py"}, {"type": "directory", "name": "scripts", "children": [{"type": "directory", "name": "external_deps", "children": [{"type": "file", "name": "test_checkpointing.py"}, {"type": "file", "name": "test_ds_multiple_model.py"}, {"type": "file", "name": "test_metrics.py"}, {"type": "file", "name": "test_peak_memory_usage.py"}, {"type": "file", "name": "test_performance.py"}, {"type": "file", "name": "test_pippy.py"}, {"type": "file", "name": "test_zero3_integration.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "test_cli.py"}, {"type": "file", "name": "test_ddp_comm_hook.py"}, {"type": "file", "name": "test_distributed_data_loop.py"}, {"type": "file", "name": "test_merge_weights.py"}, {"type": "file", "name": "test_notebook.py"}, {"type": "file", "name": "test_ops.py"}, {"type": "file", "name": "test_script.py"}, {"type": "file", "name": "test_sync.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "testing.py"}, {"type": "file", "name": "training.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "tracking.py"}, {"type": "directory", "name": "utils", "children": [{"type": "file", "name": "bnb.py"}, {"type": "file", "name": "constants.py"}, {"type": "file", "name": "dataclasses.py"}, {"type": "file", "name": "deepspeed.py"}, {"type": "file", "name": "environment.py"}, {"type": "file", "name": "fsdp_utils.py"}, {"type": "file", "name": "imports.py"}, {"type": "file", "name": "launch.py"}, {"type": "file", "name": "megatron_lm.py"}, {"type": "file", "name": "memory.py"}, {"type": "file", "name": "modeling.py"}, {"type": "file", "name": "offload.py"}, {"type": "file", "name": "operations.py"}, {"type": "file", "name": "other.py"}, {"type": "file", "name": "random.py"}, {"type": "file", "name": "rich.py"}, {"type": "file", "name": "torch_xla.py"}, {"type": "file", "name": "tqdm.py"}, {"type": "file", "name": "transformer_engine.py"}, {"type": "file", "name": "versions.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "__init__.py"}]}]}, {"type": "directory", "name": "tests", "children": [{"type": "directory", "name": "deepspeed", "children": [{"type": "file", "name": "ds_config_zero2.json"}, {"type": "file", "name": "ds_config_zero2_model_only.json"}, {"type": "file", "name": "ds_config_zero3.json"}, {"type": "file", "name": "ds_config_zero3_model_only.json"}, {"type": "file", "name": "test_deepspeed.py"}, {"type": "file", "name": "test_deepspeed_multiple_model.py"}]}, {"type": "directory", "name": "fsdp", "children": [{"type": "file", "name": "test_fsdp.py"}]}, {"type": "file", "name": "test_accelerator.py"}, {"type": "file", "name": "test_big_modeling.py"}, {"type": "file", "name": "test_cli.py"}, {"type": "directory", "name": "test_configs", "children": [{"type": "file", "name": "0_11_0.yaml"}, {"type": "file", "name": "0_12_0.yaml"}, {"type": "file", "name": "0_28_0_mpi.yaml"}, {"type": "file", "name": "0_30_0_sagemaker.yaml"}, {"type": "file", "name": "0_34_0_fp8.yaml"}, {"type": "file", "name": "invalid_keys.yaml"}, {"type": "file", "name": "latest.yaml"}, {"type": "file", "name": "README.md"}]}, {"type": "file", "name": "test_cpu.py"}, {"type": "file", "name": "test_data_loader.py"}, {"type": "file", "name": "test_examples.py"}, {"type": "file", "name": "test_grad_sync.py"}, {"type": "file", "name": "test_hooks.py"}, {"type": "file", "name": "test_imports.py"}, {"type": "file", "name": "test_kwargs_handlers.py"}, {"type": "file", "name": "test_logging.py"}, {"type": "file", "name": "test_memory_utils.py"}, {"type": "file", "name": "test_metrics.py"}, {"type": "file", "name": "test_modeling_utils.py"}, {"type": "file", "name": "test_multigpu.py"}, {"type": "file", "name": "test_offload.py"}, {"type": "file", "name": "test_optimizer.py"}, {"type": "file", "name": "test_quantization.py"}, {"type": "file", "name": "test_sagemaker.py"}, {"type": "directory", "name": "test_samples", "children": [{"type": "directory", "name": "MRPC", "children": [{"type": "file", "name": "dev.csv"}, {"type": "file", "name": "train.csv"}]}, {"type": "file", "name": "test_command_file.sh"}]}, {"type": "file", "name": "test_scheduler.py"}, {"type": "file", "name": "test_state_checkpointing.py"}, {"type": "file", "name": "test_tpu.py"}, {"type": "file", "name": "test_tracking.py"}, {"type": "file", "name": "test_utils.py"}, {"type": "file", "name": "xla_spawn.py"}]}, {"type": "directory", "name": "utils", "children": [{"type": "file", "name": "log_reports.py"}, {"type": "file", "name": "stale.py"}]}]} | This folder contains test configs for `accelerate config`. These should be generated for each major version
and are written based on `accelerate config` and selecting the "No distributed training" option. | {"setup.py": "# Copyright 2021 The HuggingFace Team. All rights reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom setuptools import find_packages, setup\n\n\nextras = {}\nextras[\"quality\"] = [\n \"black ~= 23.1\", # hf-doc-builder has a hidden dependency on `black`\n \"hf-doc-builder >= 0.3.0\",\n \"ruff ~= 0.6.4\",\n]\nextras[\"docs\"] = []\nextras[\"test_prod\"] = [\"pytest>=7.2.0,<=8.0.0\", \"pytest-xdist\", \"pytest-subtests\", \"parameterized\"]\nextras[\"test_dev\"] = [\n \"datasets\",\n \"diffusers\",\n \"evaluate\",\n \"torchdata>=0.8.0\",\n \"torchpippy>=0.2.0\",\n \"transformers\",\n \"scipy\",\n \"scikit-learn\",\n \"tqdm\",\n \"bitsandbytes\",\n \"timm\",\n]\nextras[\"testing\"] = extras[\"test_prod\"] + extras[\"test_dev\"]\nextras[\"deepspeed\"] = [\"deepspeed\"]\nextras[\"rich\"] = [\"rich\"]\n\nextras[\"test_trackers\"] = [\"wandb\", \"comet-ml\", \"tensorboard\", \"dvclive\"]\nextras[\"dev\"] = extras[\"quality\"] + extras[\"testing\"] + extras[\"rich\"]\n\nextras[\"sagemaker\"] = [\n \"sagemaker\", # boto3 is a required package in sagemaker\n]\n\nsetup(\n name=\"accelerate\",\n version=\"0.35.0.dev0\",\n description=\"Accelerate\",\n long_description=open(\"README.md\", encoding=\"utf-8\").read(),\n long_description_content_type=\"text/markdown\",\n keywords=\"deep learning\",\n license=\"Apache\",\n author=\"The HuggingFace team\",\n author_email=\"[email protected]\",\n url=\"https://github.com/huggingface/accelerate\",\n package_dir={\"\": \"src\"},\n packages=find_packages(\"src\"),\n entry_points={\n \"console_scripts\": [\n \"accelerate=accelerate.commands.accelerate_cli:main\",\n \"accelerate-config=accelerate.commands.config:main\",\n \"accelerate-estimate-memory=accelerate.commands.estimate:main\",\n \"accelerate-launch=accelerate.commands.launch:main\",\n \"accelerate-merge-weights=accelerate.commands.merge:main\",\n ]\n },\n python_requires=\">=3.8.0\",\n install_requires=[\n \"numpy>=1.17,<3.0.0\",\n \"packaging>=20.0\",\n \"psutil\",\n \"pyyaml\",\n \"torch>=1.10.0\",\n \"huggingface_hub>=0.21.0\",\n \"safetensors>=0.4.3\",\n ],\n extras_require=extras,\n classifiers=[\n \"Development Status :: 5 - Production/Stable\",\n \"Intended Audience :: Developers\",\n \"Intended Audience :: Education\",\n \"Intended Audience :: Science/Research\",\n \"License :: OSI Approved :: Apache Software License\",\n \"Operating System :: OS Independent\",\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.8\",\n \"Topic :: Scientific/Engineering :: Artificial Intelligence\",\n ],\n)\n\n# Release checklist\n# 1. Checkout the release branch (for a patch the current release branch, for a new minor version, create one):\n# git checkout -b vXX.xx-release\n# The -b is only necessary for creation (so remove it when doing a patch)\n# 2. Change the version in __init__.py and setup.py to the proper value.\n# 3. Commit these changes with the message: \"Release: v<VERSION>\"\n# 4. Add a tag in git to mark the release:\n# git tag v<VERSION> -m 'Adds tag v<VERSION> for pypi'\n# Push the tag and release commit to git: git push --tags origin vXX.xx-release\n# 5. Run the following commands in the top-level directory:\n# rm -rf dist\n# rm -rf build\n# python setup.py bdist_wheel\n# python setup.py sdist\n# 6. Upload the package to the pypi test server first:\n# twine upload dist/* -r testpypi\n# 7. Check that you can install it in a virtualenv by running:\n# pip install accelerate\n# pip uninstall accelerate\n# pip install -i https://testpypi.python.org/pypi accelerate\n# accelerate env\n# accelerate test\n# 8. Upload the final version to actual pypi:\n# twine upload dist/* -r pypi\n# 9. Add release notes to the tag in github once everything is looking hunky-dory.\n# 10. Go back to the main branch and update the version in __init__.py, setup.py to the new version \".dev\" and push to\n# main.\n", ".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 4305033f8035defad0a87cd38e5c918e78510ba5 Hamza Amin <[email protected]> 1727369074 +0500\tclone: from https://github.com/huggingface/accelerate.git\n", ".git\\refs\\heads\\main": "4305033f8035defad0a87cd38e5c918e78510ba5\n", "benchmarks\\fp8\\ms_amp\\Dockerfile": "FROM ghcr.io/azure/msamp\n\nRUN pip install transformers evaluate datasets\nRUN git clone https://github.com/huggingface/accelerate\n\nRUN cd accelerate && \\\n pip install -e . && \\\n cd benchmarks/fp8\n\nCMD [\"bash\"]\n\n\n", "benchmarks\\fp8\\transformer_engine\\Dockerfile": "FROM nvcr.io/nvidia/pytorch:24.07-py3\n\nRUN pip install transformers evaluate datasets\nRUN git clone https://github.com/huggingface/accelerate.git\n\nRUN cd accelerate && \\\n pip install -e . && \\\n cd benchmarks/fp8\n\nRUN /bin/bash\n\n\n", "docker\\accelerate-cpu\\Dockerfile": "# Builds CPU-only Docker image of PyTorch\n# Uses multi-staged approach to reduce size\n# Stage 1\nFROM python:3.8-slim as compile-image\n\nARG DEBIAN_FRONTEND=noninteractive\n\nRUN apt update\nRUN apt-get install -y --no-install-recommends \\\n build-essential \\\n git \\\n gcc\n\n# Setup virtual environment for Docker\nENV VIRTUAL_ENV=/opt/venv\nRUN python3 -m venv ${VIRTUAL_ENV}\n# Make sure we use the virtualenv\nENV PATH=\"${VIRTUAL_ENV}/bin:$PATH\"\nWORKDIR /workspace\n# Install specific CPU torch wheel to save on space\nRUN python3 -m pip install --upgrade --no-cache-dir pip\nRUN python3 -m pip install --no-cache-dir \\\n jupyter \\\n git+https://github.com/huggingface/accelerate#egg=accelerate[testing,test_trackers] \\\n --extra-index-url https://download.pytorch.org/whl/cpu\n \n# Stage 2\nFROM python:3.8-slim AS build-image\nCOPY --from=compile-image /opt/venv /opt/venv\nRUN useradd -ms /bin/bash user\nUSER user\n\n# Make sure we use the virtualenv\nENV PATH=\"/opt/venv/bin:$PATH\"\nCMD [\"/bin/bash\"]", "docker\\accelerate-gpu\\Dockerfile": "# Builds GPU docker image of PyTorch specifically\n# Uses multi-staged approach to reduce size\n# Stage 1\n# Use base conda image to reduce time\nFROM continuumio/miniconda3:latest AS compile-image\n# Specify py version\nENV PYTHON_VERSION=3.9\n# Install apt libs\nRUN apt-get update && \\\n apt-get install -y curl git wget && \\\n apt-get clean && \\\n rm -rf /var/lib/apt/lists*\n\n# Create our conda env\nRUN conda create --name accelerate python=${PYTHON_VERSION} ipython jupyter pip\n# We don't install pytorch here yet since CUDA isn't available\n# instead we use the direct torch wheel\nENV PATH /opt/conda/envs/accelerate/bin:$PATH\n# Activate our bash shell\nRUN chsh -s /bin/bash\nSHELL [\"/bin/bash\", \"-c\"]\n# Activate the conda env, install mpy4pi, and install torch + accelerate\nRUN source activate accelerate && conda install -c conda-forge mpi4py\nRUN source activate accelerate && \\\n python3 -m pip install --no-cache-dir \\\n git+https://github.com/huggingface/accelerate#egg=accelerate[testing,test_trackers] \\\n --extra-index-url https://download.pytorch.org/whl/cu117\n\nRUN python3 -m pip install --no-cache-dir bitsandbytes\n\n# Stage 2\nFROM nvidia/cuda:12.1.0-cudnn8-devel-ubuntu20.04 AS build-image\nCOPY --from=compile-image /opt/conda /opt/conda\nENV PATH /opt/conda/bin:$PATH\n\n# Install apt libs\nRUN apt-get update && \\\n apt-get install -y curl git wget && \\\n apt-get clean && \\\n rm -rf /var/lib/apt/lists*\n\nRUN echo \"source activate accelerate\" >> ~/.profile\n\n# Activate the virtualenv\nCMD [\"/bin/bash\"]", "docker\\accelerate-gpu-deepspeed\\Dockerfile": "# Builds GPU docker image of PyTorch specifically\n# Uses multi-staged approach to reduce size\n# Stage 1\n# Use base conda image to reduce time\nFROM continuumio/miniconda3:latest AS compile-image\n# Specify py version\n# Note: DeepSpeed beyond v0.12.6 requires py 3.10\nENV PYTHON_VERSION=3.10\n# Install apt libs\nRUN apt-get update && \\\n apt-get install -y curl git wget && \\\n apt-get clean && \\\n rm -rf /var/lib/apt/lists*\n\n# Create our conda env\nRUN conda create --name accelerate python=${PYTHON_VERSION} ipython jupyter pip\n# We don't install pytorch here yet since CUDA isn't available\n# instead we use the direct torch wheel\nENV PATH /opt/conda/envs/accelerate/bin:$PATH\n# Activate our bash shell\nRUN chsh -s /bin/bash\nSHELL [\"/bin/bash\", \"-c\"]\n# Activate the conda env, install mpy4pi, and install torch + accelerate\nRUN source activate accelerate && conda install -c conda-forge mpi4py\nRUN source activate accelerate && \\\n python3 -m pip install --no-cache-dir \\\n git+https://github.com/huggingface/accelerate#egg=accelerate[testing,test_trackers,deepspeed] \\\n --extra-index-url https://download.pytorch.org/whl/cu117\n\nRUN python3 -m pip install --no-cache-dir bitsandbytes\n\n# Stage 2\nFROM nvidia/cuda:12.1.0-cudnn8-devel-ubuntu20.04 AS build-image\nCOPY --from=compile-image /opt/conda /opt/conda\nENV PATH /opt/conda/bin:$PATH\n\n# Install apt libs\nRUN apt-get update && \\\n apt-get install -y curl git wget && \\\n apt-get clean && \\\n rm -rf /var/lib/apt/lists*\n\nRUN echo \"source activate accelerate\" >> ~/.profile\n\n# Activate the virtualenv\nCMD [\"/bin/bash\"]", "docs\\source\\index.md": "<!--Copyright 2022 The HuggingFace Team. All rights reserved.\n\nLicensed under the Apache License, Version 2.0 (the \"License\"); you may not use this file except in compliance with\nthe License. You may obtain a copy of the License at\n\nhttp://www.apache.org/licenses/LICENSE-2.0\n\nUnless required by applicable law or agreed to in writing, software distributed under the License is distributed on\nan \"AS IS\" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the\nspecific language governing permissions and limitations under the License.\n\n\u26a0\ufe0f Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be\nrendered properly in your Markdown viewer.\n-->\n\n# Accelerate\n\nAccelerate is a library that enables the same PyTorch code to be run across any distributed configuration by adding just four lines of code! In short, training and inference at scale made simple, efficient and adaptable.\n\n```diff\n+ from accelerate import Accelerator\n+ accelerator = Accelerator()\n\n+ model, optimizer, training_dataloader, scheduler = accelerator.prepare(\n+ model, optimizer, training_dataloader, scheduler\n+ )\n\n for batch in training_dataloader:\n optimizer.zero_grad()\n inputs, targets = batch\n inputs = inputs.to(device)\n targets = targets.to(device)\n outputs = model(inputs)\n loss = loss_function(outputs, targets)\n+ accelerator.backward(loss)\n optimizer.step()\n scheduler.step()\n```\n\nBuilt on `torch_xla` and `torch.distributed`, Accelerate takes care of the heavy lifting, so you don't have to write any custom code to adapt to these platforms.\nConvert existing codebases to utilize [DeepSpeed](usage_guides/deepspeed), perform [fully sharded data parallelism](usage_guides/fsdp), and have automatic support for mixed-precision training! \n\n<Tip> \n\n To get a better idea of this process, make sure to check out the [Tutorials](basic_tutorials/overview)! \n\n</Tip>\n\n\nThis code can then be launched on any system through Accelerate's CLI interface:\n```bash\naccelerate launch {my_script.py}\n```\n\n<div class=\"mt-10\">\n <div class=\"w-full flex flex-col space-y-4 md:space-y-0 md:grid md:grid-cols-2 md:gap-y-4 md:gap-x-5\">\n <a class=\"!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg\" href=\"./basic_tutorials/overview\"\n ><div class=\"w-full text-center bg-gradient-to-br from-blue-400 to-blue-500 rounded-lg py-1.5 font-semibold mb-5 text-white text-lg leading-relaxed\">Tutorials</div>\n <p class=\"text-gray-700\">Learn the basics and become familiar with using Accelerate. Start here if you are using Accelerate for the first time!</p>\n </a>\n <a class=\"!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg\" href=\"./usage_guides/explore\"\n ><div class=\"w-full text-center bg-gradient-to-br from-indigo-400 to-indigo-500 rounded-lg py-1.5 font-semibold mb-5 text-white text-lg leading-relaxed\">How-to guides</div>\n <p class=\"text-gray-700\">Practical guides to help you achieve a specific goal. Take a look at these guides to learn how to use Accelerate to solve real-world problems.</p>\n </a>\n <a class=\"!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg\" href=\"./concept_guides/gradient_synchronization\"\n ><div class=\"w-full text-center bg-gradient-to-br from-pink-400 to-pink-500 rounded-lg py-1.5 font-semibold mb-5 text-white text-lg leading-relaxed\">Conceptual guides</div>\n <p class=\"text-gray-700\">High-level explanations for building a better understanding of important topics such as avoiding subtle nuances and pitfalls in distributed training and DeepSpeed.</p>\n </a>\n <a class=\"!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg\" href=\"./package_reference/accelerator\"\n ><div class=\"w-full text-center bg-gradient-to-br from-purple-400 to-purple-500 rounded-lg py-1.5 font-semibold mb-5 text-white text-lg leading-relaxed\">Reference</div>\n <p class=\"text-gray-700\">Technical descriptions of how Accelerate classes and methods work.</p>\n </a>\n </div>\n</div>\n", "docs\\source\\package_reference\\torch_wrappers.md": "<!--Copyright 2021 The HuggingFace Team. All rights reserved.\n\nLicensed under the Apache License, Version 2.0 (the \"License\"); you may not use this file except in compliance with\nthe License. You may obtain a copy of the License at\n\nhttp://www.apache.org/licenses/LICENSE-2.0\n\nUnless required by applicable law or agreed to in writing, software distributed under the License is distributed on\nan \"AS IS\" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the\nspecific language governing permissions and limitations under the License.\n\n\u26a0\ufe0f Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be\nrendered properly in your Markdown viewer.\n-->\n\n# DataLoaders, Optimizers, and Schedulers\n\nThe internal classes Accelerate uses to prepare objects for distributed training\nwhen calling [`~Accelerator.prepare`].\n\n## DataLoader utilities\n\n[[autodoc]] data_loader.prepare_data_loader\n[[autodoc]] data_loader.skip_first_batches\n\n## BatchSamplerShard\n\n[[autodoc]] data_loader.BatchSamplerShard\n\n## IterableDatasetShard\n\n[[autodoc]] data_loader.IterableDatasetShard\n\n## DataLoaderShard\n\n[[autodoc]] data_loader.DataLoaderShard\n\n## DataLoaderDispatcher\n\n[[autodoc]] data_loader.DataLoaderDispatcher\n\n## AcceleratedOptimizer\n\n[[autodoc]] optimizer.AcceleratedOptimizer\n\n## AcceleratedScheduler\n\n[[autodoc]] scheduler.AcceleratedScheduler", "examples\\requirements.txt": "accelerate # used to be installed in Amazon SageMaker environment\nevaluate\ndatasets==2.3.2\nschedulefree\nhuggingface_hub>=0.20.0\n", "examples\\inference\\pippy\\requirements.txt": "accelerate\npippy>=0.2.0"} | 1 |
action-check-commits | {"type": "directory", "name": "action-check-commits", "children": [{"type": "file", "name": ".prettierrc.js"}, {"type": "file", "name": "action.yml"}, {"type": "file", "name": "babel.config.js"}, {"type": "file", "name": "CONTRIBUTING.md"}, {"type": "directory", "name": "dist", "children": [{"type": "directory", "name": "main", "children": [{"type": "file", "name": "index.js"}]}]}, {"type": "file", "name": "index.js"}, {"type": "file", "name": "jest.config.js"}, {"type": "file", "name": "package.json"}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "src", "children": [{"type": "file", "name": "extractCommits.ts"}, {"type": "file", "name": "isValidCommitMessage.ts"}, {"type": "file", "name": "main.ts"}, {"type": "directory", "name": "__tests__", "children": [{"type": "file", "name": "isValidCommitMessage.test.ts"}]}]}, {"type": "file", "name": "tsconfig.json"}]} | # Check Commit Messages GitHub Action
A simple GitHub action that checks the list of commits in a pull-request:
- the number of commits shall not be higher than `max-commits` (defaults to 10),
- each commit message must at least contain `min-words` (defaults to 3),
- each commit message must not contain any `forbidden-words` (like `fixup`).
Heavily inspired by [webiny/action-conventional-commits](https://github.com/webiny/action-conventional-commits).
### Usage
Latest version: `v0.0.1`
```yml
name: Check commit messages
on:
pull_request:
branches: [ master ]
jobs:
build:
name: Check Commits
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- uses: huggingface/[email protected]
with:
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }} # Optional, for private repositories.
max-commits: "15" # Optional, defaults to 10.
min-words: "5" # Optional, defaults to 3.
forbidden-words: ["fixup', "wip"] # Optional, defaults to ["fixup"].
```
| {"index.js": "const got = require(\"got\");\n\ngot.get(\"https://api.github.com/repos/doitadrian/contreebutors-action/pulls/2/commits\", {\n responseType: \"json\",\n}).then((response) => {\n console.log(response.body);\n});\n", "package.json": "{\n \"name\": \"action-check-commits\",\n \"version\": \"0.0.1\",\n \"main\": \"index.js\",\n \"repository\": \"[email protected]:huggingface/action-check-commits.git\",\n \"author\": \"David Corvoysier\",\n \"license\": \"MIT\",\n \"dependencies\": {\n \"@actions/core\": \"^1.2.3\",\n \"@actions/exec\": \"^1.0.3\",\n \"@actions/github\": \"^2.1.1\",\n \"got\": \"^11.3.0\",\n \"lodash.get\": \"^4.4.2\"\n },\n \"devDependencies\": {\n \"@vercel/ncc\": \"^0.38.1\",\n \"@babel/core\": \"^7.10.2\",\n \"@babel/preset-env\": \"^7.10.2\",\n \"@babel/preset-typescript\": \"^7.10.1\",\n \"@types/jest\": \"^26.0.0\",\n \"babel-jest\": \"^26.0.1\",\n \"jest\": \"^26.0.1\",\n \"prettier\": \"^2.0.2\",\n \"typescript\": \"^5.3.2\"\n },\n \"scripts\": {\n \"build\": \"ncc build src/main.ts --out dist/main\",\n \"watch\": \"ncc build src/main.ts --out dist/main --watch\",\n \"test\": \"jest\"\n }\n}\n", ".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 7546dfa9ac8bd8270ea7ca5f137319aaa62e1599 Hamza Amin <[email protected]> 1727369077 +0500\tclone: from https://github.com/huggingface/action-check-commits.git\n", ".git\\refs\\heads\\main": "7546dfa9ac8bd8270ea7ca5f137319aaa62e1599\n", "dist\\main\\index.js": "/******/ (() => { // webpackBootstrap\n/******/ \tvar __webpack_modules__ = ({\n\n/***/ 7351:\n/***/ (function(__unused_webpack_module, exports, __nccwpck_require__) {\n\n\"use strict\";\n\nvar __createBinding = (this && this.__createBinding) || (Object.create ? (function(o, m, k, k2) {\n if (k2 === undefined) k2 = k;\n Object.defineProperty(o, k2, { enumerable: true, get: function() { return m[k]; } });\n}) : (function(o, m, k, k2) {\n if (k2 === undefined) k2 = k;\n o[k2] = m[k];\n}));\nvar __setModuleDefault = (this && this.__setModuleDefault) || (Object.create ? (function(o, v) {\n Object.defineProperty(o, \"default\", { enumerable: true, value: v });\n}) : function(o, v) {\n o[\"default\"] = v;\n});\nvar __importStar = (this && this.__importStar) || function (mod) {\n if (mod && mod.__esModule) return mod;\n var result = {};\n if (mod != null) for (var k in mod) if (k !== \"default\" && Object.hasOwnProperty.call(mod, k)) __createBinding(result, mod, k);\n __setModuleDefault(result, mod);\n return result;\n};\nObject.defineProperty(exports, \"__esModule\", ({ value: true }));\nexports.issue = exports.issueCommand = void 0;\nconst os = __importStar(__nccwpck_require__(2037));\nconst utils_1 = __nccwpck_require__(5278);\n/**\n * Commands\n *\n * Command Format:\n * ::name key=value,key=value::message\n *\n * Examples:\n * ::warning::This is the message\n * ::set-env name=MY_VAR::some value\n */\nfunction issueCommand(command, properties, message) {\n const cmd = new Command(command, properties, message);\n process.stdout.write(cmd.toString() + os.EOL);\n}\nexports.issueCommand = issueCommand;\nfunction issue(name, message = '') {\n issueCommand(name, {}, message);\n}\nexports.issue = issue;\nconst CMD_STRING = '::';\nclass Command {\n constructor(command, properties, message) {\n if (!command) {\n command = 'missing.command';\n }\n this.command = command;\n this.properties = properties;\n this.message = message;\n }\n toString() {\n let cmdStr = CMD_STRING + this.command;\n if (this.properties && Object.keys(this.properties).length > 0) {\n cmdStr += ' ';\n let first = true;\n for (const key in this.properties) {\n if (this.properties.hasOwnProperty(key)) {\n const val = this.properties[key];\n if (val) {\n if (first) {\n first = false;\n }\n else {\n cmdStr += ',';\n }\n cmdStr += `${key}=${escapeProperty(val)}`;\n }\n }\n }\n }\n cmdStr += `${CMD_STRING}${escapeData(this.message)}`;\n return cmdStr;\n }\n}\nfunction escapeData(s) {\n return utils_1.toCommandValue(s)\n .replace(/%/g, '%25')\n .replace(/\\r/g, '%0D')\n .replace(/\\n/g, '%0A');\n}\nfunction escapeProperty(s) {\n return utils_1.toCommandValue(s)\n .replace(/%/g, '%25')\n .replace(/\\r/g, '%0D')\n .replace(/\\n/g, '%0A')\n .replace(/:/g, '%3A')\n .replace(/,/g, '%2C');\n}\n//# sourceMappingURL=command.js.map\n\n/***/ }),\n\n/***/ 2186:\n/***/ (function(__unused_webpack_module, exports, __nccwpck_require__) {\n\n\"use strict\";\n\nvar __createBinding = (this && this.__createBinding) || (Object.create ? (function(o, m, k, k2) {\n if (k2 === undefined) k2 = k;\n Object.defineProperty(o, k2, { enumerable: true, get: function() { return m[k]; } });\n}) : (function(o, m, k, k2) {\n if (k2 === undefined) k2 = k;\n o[k2] = m[k];\n}));\nvar __setModuleDefault = (this && this.__setModuleDefault) || (Object.create ? (function(o, v) {\n Object.defineProperty(o, \"default\", { enumerable: true, value: v });\n}) : function(o, v) {\n o[\"default\"] = v;\n});\nvar __importStar = (this && this.__importStar) || function (mod) {\n if (mod && mod.__esModule) return mod;\n var result = {};\n if (mod != null) for (var k in mod) if (k !== \"default\" && Object.hasOwnProperty.call(mod, k)) __createBinding(result, mod, k);\n __setModuleDefault(result, mod);\n return result;\n};\nvar __awaiter = (this && this.__awaiter) || function (thisArg, _arguments, P, generator) {\n function adopt(value) { return value instanceof P ? value : new P(function (resolve) { resolve(value); }); }\n return new (P || (P = Promise))(function (resolve, reject) {\n function fulfilled(value) { try { step(generator.next(value)); } catch (e) { reject(e); } }\n function rejected(value) { try { step(generator[\"throw\"](value)); } catch (e) { reject(e); } }\n function step(result) { result.done ? resolve(result.value) : adopt(result.value).then(fulfilled, rejected); }\n step((generator = generator.apply(thisArg, _arguments || [])).next());\n });\n};\nObject.defineProperty(exports, \"__esModule\", ({ value: true }));\nexports.getIDToken = exports.getState = exports.saveState = exports.group = exports.endGroup = exports.startGroup = exports.info = exports.notice = exports.warning = exports.error = exports.debug = exports.isDebug = exports.setFailed = exports.setCommandEcho = exports.setOutput = exports.getBooleanInput = exports.getMultilineInput = exports.getInput = exports.addPath = exports.setSecret = exports.exportVariable = exports.ExitCode = void 0;\nconst command_1 = __nccwpck_require__(7351);\nconst file_command_1 = __nccwpck_require__(717);\nconst utils_1 = __nccwpck_require__(5278);\nconst os = __importStar(__nccwpck_require__(2037));\nconst path = __importStar(__nccwpck_require__(1017));\nconst oidc_utils_1 = __nccwpck_require__(8041);\n/**\n * The code to exit an action\n */\nvar ExitCode;\n(function (ExitCode) {\n /**\n * A code indicating that the action was successful\n */\n ExitCode[ExitCode[\"Success\"] = 0] = \"Success\";\n /**\n * A code indicating that the action was a failure\n */\n ExitCode[ExitCode[\"Failure\"] = 1] = \"Failure\";\n})(ExitCode = exports.ExitCode || (exports.ExitCode = {}));\n//-----------------------------------------------------------------------\n// Variables\n//-----------------------------------------------------------------------\n/**\n * Sets env variable for this action and future actions in the job\n * @param name the name of the variable to set\n * @param val the value of the variable. Non-string values will be converted to a string via JSON.stringify\n */\n// eslint-disable-next-line @typescript-eslint/no-explicit-any\nfunction exportVariable(name, val) {\n const convertedVal = utils_1.toCommandValue(val);\n process.env[name] = convertedVal;\n const filePath = process.env['GITHUB_ENV'] || '';\n if (filePath) {\n return file_command_1.issueFileCommand('ENV', file_command_1.prepareKeyValueMessage(name, val));\n }\n command_1.issueCommand('set-env', { name }, convertedVal);\n}\nexports.exportVariable = exportVariable;\n/**\n * Registers a secret which will get masked from logs\n * @param secret value of the secret\n */\nfunction setSecret(secret) {\n command_1.issueCommand('add-mask', {}, secret);\n}\nexports.setSecret = setSecret;\n/**\n * Prepends inputPath to the PATH (for this action and future actions)\n * @param inputPath\n */\nfunction addPath(inputPath) {\n const filePath = process.env['GITHUB_PATH'] || '';\n if (filePath) {\n file_command_1.issueFileCommand('PATH', inputPath);\n }\n else {\n command_1.issueCommand('add-path', {}, inputPath);\n }\n process.env['PATH'] = `${inputPath}${path.delimiter}${process.env['PATH']}`;\n}\nexports.addPath = addPath;\n/**\n * Gets the value of an input.\n * Unless trimWhitespace is set to false in InputOptions, the value is also trimmed.\n * Returns an empty string if the value is not defined.\n *\n * @param name name of the input to get\n * @param options optional. See InputOptions.\n * @returns string\n */\nfunction getInput(name, options) {\n const val = process.env[`INPUT_${name.replace(/ /g, '_').toUpperCase()}`] || '';\n if (options && options.required && !val) {\n throw new Error(`Input required and not supplied: ${name}`);\n }\n if (options && options.trimWhitespace === false) {\n return val;\n }\n return val.trim();\n}\nexports.getInput = getInput;\n/**\n * Gets the values of an multiline input. Each value is also trimmed.\n *\n * @param name name of the input to get\n * @param options optional. See InputOptions.\n * @returns string[]\n *\n */\nfunction getMultilineInput(name, options) {\n const inputs = getInput(name, options)\n .split('\\n')\n .filter(x => x !== '');\n if (options && options.trimWhitespace === false) {\n return inputs;\n }\n return inputs.map(input => input.trim());\n}\nexports.getMultilineInput = getMultilineInput;\n/**\n * Gets the input value of the boolean type in the YAML 1.2 \"core schema\" specification.\n * Support boolean input list: `true | True | TRUE | false | False | FALSE` .\n * The return value is also in boolean type.\n * ref: https://yaml.org/spec/1.2/spec.html#id2804923\n *\n * @param name name of the input to get\n * @param options optional. See InputOptions.\n * @returns boolean\n */\nfunction getBooleanInput(name, options) {\n const trueValue = ['true', 'True', 'TRUE'];\n const falseValue = ['false', 'False', 'FALSE'];\n const val = getInput(name, options);\n if (trueValue.includes(val))\n return true;\n if (falseValue.includes(val))\n return false;\n throw new TypeError(`Input does not meet YAML 1.2 \"Core Schema\" specification: ${name}\\n` +\n `Support boolean input list: \\`true | True | TRUE | false | False | FALSE\\``);\n}\nexports.getBooleanInput = getBooleanInput;\n/**\n * Sets the value of an output.\n *\n * @param name name of the output to set\n * @param value value to store. Non-string values will be converted to a string via JSON.stringify\n */\n// eslint-disable-next-line @typescript-eslint/no-explicit-any\nfunction setOutput(name, value) {\n const filePath = process.env['GITHUB_OUTPUT'] || '';\n if (filePath) {\n return file_command_1.issueFileCommand('OUTPUT', file_command_1.prepareKeyValueMessage(name, value));\n }\n process.stdout.write(os.EOL);\n command_1.issueCommand('set-output', { name }, utils_1.toCommandValue(value));\n}\nexports.setOutput = setOutput;\n/**\n * Enables or disables the echoing of commands into stdout for the rest of the step.\n * Echoing is disabled by default if ACTIONS_STEP_DEBUG is not set.\n *\n */\nfunction setCommandEcho(enabled) {\n command_1.issue('echo', enabled ? 'on' : 'off');\n}\nexports.setCommandEcho = setCommandEcho;\n//-----------------------------------------------------------------------\n// Results\n//-----------------------------------------------------------------------\n/**\n * Sets the action status to failed.\n * When the action exits it will be with an exit code of 1\n * @param message add error issue message\n */\nfunction setFailed(message) {\n process.exitCode = ExitCode.Failure;\n error(message);\n}\nexports.setFailed = setFailed;\n//-----------------------------------------------------------------------\n// Logging Commands\n//-----------------------------------------------------------------------\n/**\n * Gets whether Actions Step Debug is on or not\n */\nfunction isDebug() {\n return process.env['RUNNER_DEBUG'] === '1';\n}\nexports.isDebug = isDebug;\n/**\n * Writes debug message to user log\n * @param message debug message\n */\nfunction debug(message) {\n command_1.issueCommand('debug', {}, message);\n}\nexports.debug = debug;\n/**\n * Adds an error issue\n * @param message error issue message. Errors will be converted to string via toString()\n * @param properties optional properties to add to the annotation.\n */\nfunction error(message, properties = {}) {\n command_1.issueCommand('error', utils_1.toCommandProperties(properties), message instanceof Error ? message.toString() : message);\n}\nexports.error = error;\n/**\n * Adds a warning issue\n * @param message warning issue message. Errors will be converted to string via toString()\n * @param properties optional properties to add to the annotation.\n */\nfunction warning(message, properties = {}) {\n command_1.issueCommand('warning', utils_1.toCommandProperties(properties), message instanceof Error ? message.toString() : message);\n}\nexports.warning = warning;\n/**\n * Adds a notice issue\n * @param message notice issue message. Errors will be converted to string via toString()\n * @param properties optional properties to add to the annotation.\n */\nfunction notice(message, properties = {}) {\n command_1.issueCommand('notice', utils_1.toCommandProperties(properties), message instanceof Error ? message.toString() : message);\n}\nexports.notice = notice;\n/**\n * Writes info to log with console.log.\n * @param message info message\n */\nfunction info(message) {\n process.stdout.write(message + os.EOL);\n}\nexports.info = info;\n/**\n * Begin an output group.\n *\n * Output until the next `groupEnd` will be foldable in this group\n *\n * @param name The name of the output group\n */\nfunction startGroup(name) {\n command_1.issue('group', name);\n}\nexports.startGroup = startGroup;\n/**\n * End an output group.\n */\nfunction endGroup() {\n command_1.issue('endgroup');\n}\nexports.endGroup = endGroup;\n/**\n * Wrap an asynchronous function call in a group.\n *\n * Returns the same type as the function itself.\n *\n * @param name The name of the group\n * @param fn The function to wrap in the group\n */\nfunction group(name, fn) {\n return __awaiter(this, void 0, void 0, function* () {\n startGroup(name);\n let result;\n try {\n result = yield fn();\n }\n finally {\n endGroup();\n }\n return result;\n });\n}\nexports.group = group;\n//-----------------------------------------------------------------------\n// Wrapper action state\n//-----------------------------------------------------------------------\n/**\n * Saves state for current action, the state can only be retrieved by this action's post job execution.\n *\n * @param name name of the state to store\n * @param value value to store. Non-string values will be converted to a string via JSON.stringify\n */\n// eslint-disable-next-line @typescript-eslint/no-explicit-any\nfunction saveState(name, value) {\n const filePath = process.env['GITHUB_STATE'] || '';\n if (filePath) {\n return file_command_1.issueFileCommand('STATE', file_command_1.prepareKeyValueMessage(name, value));\n }\n command_1.issueCommand('save-state', { name }, utils_1.toCommandValue(value));\n}\nexports.saveState = saveState;\n/**\n * Gets the value of an state set by this action's main execution.\n *\n * @param name name of the state to get\n * @returns string\n */\nfunction getState(name) {\n return process.env[`STATE_${name}`] || '';\n}\nexports.getState = getState;\nfunction getIDToken(aud) {\n return __awaiter(this, void 0, void 0, function* () {\n return yield oidc_utils_1.OidcClient.getIDToken(aud);\n });\n}\nexports.getIDToken = getIDToken;\n/**\n * Summary exports\n */\nvar summary_1 = __nccwpck_require__(1327);\nObject.defineProperty(exports, \"summary\", ({ enumerable: true, get: function () { return summary_1.summary; } }));\n/**\n * @deprecated use core.summary\n */\nvar summary_2 = __nccwpck_require__(1327);\nObject.defineProperty(exports, \"markdownSummary\", ({ enumerable: true, get: function () { return summary_2.markdownSummary; } }));\n/**\n * Path exports\n */\nvar path_utils_1 = __nccwpck_require__(2981);\nObject.defineProperty(exports, \"toPosixPath\", ({ enumerable: true, get: function () { return path_utils_1.toPosixPath; } }));\nObject.defineProperty(exports, \"toWin32Path\", ({ enumerable: true, get: function () { return path_utils_1.toWin32Path; } }));\nObject.defineProperty(exports, \"toPlatformPath\", ({ enumerable: true, get: function () { return path_utils_1.toPlatformPath; } }));\n//# sourceMappingURL=core.js.map\n\n/***/ }),\n\n/***/ 717:\n/***/ (function(__unused_webpack_module, exports, __nccwpck_require__) {\n\n\"use strict\";\n\n// For internal use, subject to change.\nvar __createBinding = (this && this.__createBinding) || (Object.create ? (function(o, m, k, k2) {\n if (k2 === undefined) k2 = k;\n Object.defineProperty(o, k2, { enumerable: true, get: function() { return m[k]; } });\n}) : (function(o, m, k, k2) {\n if (k2 === undefined) k2 = k;\n o[k2] = m[k];\n}));\nvar __setModuleDefault = (this && this.__setModuleDefault) || (Object.create ? (function(o, v) {\n Object.defineProperty(o, \"default\", { enumerable: true, value: v });\n}) : function(o, v) {\n o[\"default\"] = v;\n});\nvar __importStar = (this && this.__importStar) || function (mod) {\n if (mod && mod.__esModule) return mod;\n var result = {};\n if (mod != null) for (var k in mod) if (k !== \"default\" && Object.hasOwnProperty.call(mod, k)) __createBinding(result, mod, k);\n __setModuleDefault(result, mod);\n return result;\n};\nObject.defineProperty(exports, \"__esModule\", ({ value: true }));\nexports.prepareKeyValueMessage = exports.issueFileCommand = void 0;\n// We use any as a valid input type\n/* eslint-disable @typescript-eslint/no-explicit-any */\nconst fs = __importStar(__nccwpck_require__(7147));\nconst os = __importStar(__nccwpck_require__(2037));\nconst uuid_1 = __nccwpck_require__(5840);\nconst utils_1 = __nccwpck_require__(5278);\nfunction issueFileCommand(command, message) {\n const filePath = process.env[`GITHUB_${command}`];\n if (!filePath) {\n throw new Error(`Unable to find environment variable for file command ${command}`);\n }\n if (!fs.existsSync(filePath)) {\n throw new Error(`Missing file at path: ${filePath}`);\n }\n fs.appendFileSync(filePath, `${utils_1.toCommandValue(message)}${os.EOL}`, {\n encoding: 'utf8'\n });\n}\nexports.issueFileCommand = issueFileCommand;\nfunction prepareKeyValueMessage(key, value) {\n const delimiter = `ghadelimiter_${uuid_1.v4()}`;\n const convertedValue = utils_1.toCommandValue(value);\n // These should realistically never happen, but just in case someone finds a\n // way to exploit uuid generation let's not allow keys or values that contain\n // the delimiter.\n if (key.includes(delimiter)) {\n throw new Error(`Unexpected input: name should not contain the delimiter \"${delimiter}\"`);\n }\n if (convertedValue.includes(delimiter)) {\n throw new Error(`Unexpected input: value should not contain the delimiter \"${delimiter}\"`);\n }\n return `${key}<<${delimiter}${os.EOL}${convertedValue}${os.EOL}${delimiter}`;\n}\nexports.prepareKeyValueMessage = prepareKeyValueMessage;\n//# sourceMappingURL=file-command.js.map\n\n/***/ }),\n\n/***/ 8041:\n/***/ (function(__unused_webpack_module, exports, __nccwpck_require__) {\n\n\"use strict\";\n\nvar __awaiter = (this && this.__awaiter) || function (thisArg, _arguments, P, generator) {\n function adopt(value) { return value instanceof P ? value : new P(function (resolve) { resolve(value); }); }\n return new (P || (P = Promise))(function (resolve, reject) {\n function fulfilled(value) { try { step(generator.next(value)); } catch (e) { reject(e); } }\n function rejected(value) { try { step(generator[\"throw\"](value)); } catch (e) { reject(e); } }\n function step(result) { result.done ? resolve(result.value) : adopt(result.value).then(fulfilled, rejected); }\n step((generator = generator.apply(thisArg, _arguments || [])).next());\n });\n};\nObject.defineProperty(exports, \"__esModule\", ({ value: true }));\nexports.OidcClient = void 0;\nconst http_client_1 = __nccwpck_require__(1404);\nconst auth_1 = __nccwpck_require__(6758);\nconst core_1 = __nccwpck_require__(2186);\nclass OidcClient {\n static createHttpClient(allowRetry = true, maxRetry = 10) {\n const requestOptions = {\n allowRetries: allowRetry,\n maxRetries: maxRetry\n };\n return new http_client_1.HttpClient('actions/oidc-client', [new auth_1.BearerCredentialHandler(OidcClient.getRequestToken())], requestOptions);\n }\n static getRequestToken() {\n const token = process.env['ACTIONS_ID_TOKEN_REQUEST_TOKEN'];\n if (!token) {\n throw new Error('Unable to get ACTIONS_ID_TOKEN_REQUEST_TOKEN env variable');\n }\n return token;\n }\n static getIDTokenUrl() {\n const runtimeUrl = process.env['ACTIONS_ID_TOKEN_REQUEST_URL'];\n if (!runtimeUrl) {\n throw new Error('Unable to get ACTIONS_ID_TOKEN_REQUEST_URL env variable');\n }\n return runtimeUrl;\n }\n static getCall(id_token_url) {\n var _a;\n return __awaiter(this, void 0, void 0, function* () {\n const httpclient = OidcClient.createHttpClient();\n const res = yield httpclient\n .getJson(id_token_url)\n .catch(error => {\n throw new Error(`Failed to get ID Token. \\n \n Error Code : ${error.statusCode}\\n \n Error Message: ${error.message}`);\n });\n const id_token = (_a = res.result) === null || _a === void 0 ? void 0 : _a.value;\n if (!id_token) {\n throw new Error('Response json body do not have ID Token field');\n }\n return id_token;\n });\n }\n static getIDToken(audience) {\n return __awaiter(this, void 0, void 0, function* () {\n try {\n // New ID Token is requested from action service\n let id_token_url = OidcClient.getIDTokenUrl();\n if (audience) {\n const encodedAudience = encodeURIComponent(audience);\n id_token_url = `${id_token_url}&audience=${encodedAudience}`;\n }\n core_1.debug(`ID token url is ${id_token_url}`);\n const id_token = yield OidcClient.getCall(id_token_url);\n core_1.setSecret(id_token);\n return id_token;\n }\n catch (error) {\n throw new Error(`Error message: ${error.message}`);\n }\n });\n }\n}\nexports.OidcClient = OidcClient;\n//# sourceMappingURL=oidc-utils.js.map\n\n/***/ }),\n\n/***/ 2981:\n/***/ (function(__unused_webpack_module, exports, __nccwpck_require__) {\n\n\"use strict\";\n\nvar __createBinding = (this && this.__createBinding) || (Object.create ? (function(o, m, k, k2) {\n if (k2 === undefined) k2 = k;\n Object.defineProperty(o, k2, { enumerable: true, get: function() { return m[k]; } });\n}) : (function(o, m, k, k2) {\n if (k2 === undefined) k2 = k;\n o[k2] = m[k];\n}));\nvar __setModuleDefault = (this && this.__setModuleDefault) || (Object.create ? (function(o, v) {\n Object.defineProperty(o, \"default\", { enumerable: true, value: v });\n}) : function(o, v) {\n o[\"default\"] = v;\n});\nvar __importStar = (this && this.__importStar) || function (mod) {\n if (mod && mod.__esModule) return mod;\n var result = {};\n if (mod != null) for (var k in mod) if (k !== \"default\" && Object.hasOwnProperty.call(mod, k)) __createBinding(result, mod, k);\n __setModuleDefault(result, mod);\n return result;\n};\nObject.defineProperty(exports, \"__esModule\", ({ value: true }));\nexports.toPlatformPath = exports.toWin32Path = exports.toPosixPath = void 0;\nconst path = __importStar(__nccwpck_require__(1017));\n/**\n * toPosixPath converts the given path to the posix form. On Windows, \\\\ will be\n * replaced with /.\n *\n * @param pth. Path to transform.\n * @return string Posix path.\n */\nfunction toPosixPath(pth) {\n return pth.replace(/[\\\\]/g, '/');\n}\nexports.toPosixPath = toPosixPath;\n/**\n * toWin32Path converts the given path to the win32 form. On Linux, / will be\n * replaced with \\\\.\n *\n * @param pth. Path to transform.\n * @return string Win32 path.\n */\nfunction toWin32Path(pth) {\n return pth.replace(/[/]/g, '\\\\');\n}\nexports.toWin32Path = toWin32Path;\n/**\n * toPlatformPath converts the given path to a platform-specific path. It does\n * this by replacing instances of / and \\ with the platform-specific path\n * separator.\n *\n * @param pth The path to platformize.\n * @return string The platform-specific path.\n */\nfunction toPlatformPath(pth) {\n return pth.replace(/[/\\\\]/g, path.sep);\n}\nexports.toPlatformPath = toPlatformPath;\n//# sourceMappingURL=path-utils.js.map\n\n/***/ }),\n\n/***/ 1327:\n/***/ (function(__unused_webpack_module, exports, __nccwpck_require__) {\n\n\"use strict\";\n\nvar __awaiter = (this && this.__awaiter) || function (thisArg, _arguments, P, generator) {\n function adopt(value) { return value instanceof P ? value : new P(function (resolve) { resolve(value); }); }\n return new (P || (P = Promise))(function (resolve, reject) {\n function fulfilled(value) { try { step(generator.next(value)); } catch (e) { reject(e); } }\n function rejected(value) { try { step(generator[\"throw\"](value)); } catch (e) { reject(e); } }\n function step(result) { result.done ? resolve(result.value) : adopt(result.value).then(fulfilled, rejected); }\n step((generator = generator.apply(thisArg, _arguments || [])).next());\n });\n};\nObject.defineProperty(exports, \"__esModule\", ({ value: true }));\nexports.summary = exports.markdownSummary = exports.SUMMARY_DOCS_URL = exports.SUMMARY_ENV_VAR = void 0;\nconst os_1 = __nccwpck_require__(2037);\nconst fs_1 = __nccwpck_require__(7147);\nconst { access, appendFile, writeFile } = fs_1.promises;\nexports.SUMMARY_ENV_VAR = 'GITHUB_STEP_SUMMARY';\nexports.SUMMARY_DOCS_URL = 'https://docs.github.com/actions/using-workflows/workflow-commands-for-github-actions#adding-a-job-summary';\nclass Summary {\n constructor() {\n this._buffer = '';\n }\n /**\n * Finds the summary file path from the environment, rejects if env var is not found or file does not exist\n * Also checks r/w permissions.\n *\n * @returns step summary file path\n */\n filePath() {\n return __awaiter(this, void 0, void 0, function* () {\n if (this._filePath) {\n return this._filePath;\n }\n const pathFromEnv = process.env[exports.SUMMARY_ENV_VAR];\n if (!pathFromEnv) {\n throw new Error(`Unable to find environment variable for $${exports.SUMMARY_ENV_VAR}. Check if your runtime environment supports job summaries.`);\n }\n try {\n yield access(pathFromEnv, fs_1.constants.R_OK | fs_1.constants.W_OK);\n }\n catch (_a) {\n throw new Error(`Unable to access summary file: '${pathFromEnv}'. Check if the file has correct read/write permissions.`);\n }\n this._filePath = pathFromEnv;\n return this._filePath;\n });\n }\n /**\n * Wraps content in an HTML tag, adding any HTML attributes\n *\n * @param {string} tag HTML tag to wrap\n * @param {string | null} content content within the tag\n * @param {[attribute: string]: string} attrs key-value list of HTML attributes to add\n *\n * @returns {string} content wrapped in HTML element\n */\n wrap(tag, content, attrs = {}) {\n const htmlAttrs = Object.entries(attrs)\n .map(([key, value]) => ` ${key}=\"${value}\"`)\n .join('');\n if (!content) {\n return `<${tag}${htmlAttrs}>`;\n }\n return `<${tag}${htmlAttrs}>${content}</${tag}>`;\n }\n /**\n * Writes text in the buffer to the summary buffer file and empties buffer. Will append by default.\n *\n * @param {SummaryWriteOptions} [options] (optional) options for write operation\n *\n * @returns {Promise<Summary>} summary instance\n */\n write(options) {\n return __awaiter(this, void 0, void 0, function* () {\n const overwrite = !!(options === null || options === void 0 ? void 0 : options.overwrite);\n const filePath = yield this.filePath();\n const writeFunc = overwrite ? writeFile : appendFile;\n yield writeFunc(filePath, this._buffer, { encoding: 'utf8' });\n return this.emptyBuffer();\n });\n }\n /**\n * Clears the summary buffer and wipes the summary file\n *\n * @returns {Summary} summary instance\n */\n clear() {\n return __awaiter(this, void 0, void 0, function* () {\n return this.emptyBuffer().write({ overwrite: true });\n });\n }\n /**\n * Returns the current summary buffer as a string\n *\n * @returns {string} string of summary buffer\n */\n stringify() {\n return this._buffer;\n }\n /**\n * If the summary buffer is empty\n *\n * @returns {boolen} true if the buffer is empty\n */\n isEmptyBuffer() {\n return this._buffer.length === 0;\n }\n /**\n * Resets the summary buffer without writing to summary file\n *\n * @returns {Summary} summary instance\n */\n emptyBuffer() {\n this._buffer = '';\n return this;\n }\n /**\n * Adds raw text to the summary buffer\n *\n * @param {string} text content to add\n * @param {boolean} [addEOL=false] (optional) append an EOL to the raw text (default: false)\n *\n * @returns {Summary} summary instance\n */\n addRaw(text, addEOL = false) {\n this._buffer += text;\n return addEOL ? this.addEOL() : this;\n }\n /**\n * Adds the operating system-specific end-of-line marker to the buffer\n *\n * @returns {Summary} summary instance\n */\n addEOL() {\n return this.addRaw(os_1.EOL);\n }\n /**\n * Adds an HTML codeblock to the summary buffer\n *\n * @param {string} code content to render within fenced code block\n * @param {string} lang (optional) language to syntax highlight code\n *\n * @returns {Summary} summary instance\n */\n addCodeBlock(code, lang) {\n const attrs = Object.assign({}, (lang && { lang }));\n const element = this.wrap('pre', this.wrap('code', code), attrs);\n return this.addRaw(element).addEOL();\n }\n /**\n * Adds an HTML list to the summary buffer\n *\n * @param {string[]} items list of items to render\n * @param {boolean} [ordered=false] (optional) if the rendered list should be ordered or not (default: false)\n *\n * @returns {Summary} summary instance\n */\n addList(items, ordered = false) {\n const tag = ordered ? 'ol' : 'ul';\n const listItems = items.map(item => this.wrap('li', item)).join('');\n const element = this.wrap(tag, listItems);\n return this.addRaw(element).addEOL();\n }\n /**\n * Adds an HTML table to the summary buffer\n *\n * @param {SummaryTableCell[]} rows table rows\n *\n * @returns {Summary} summary instance\n */\n addTable(rows) {\n const tableBody = rows\n .map(row => {\n const cells = row\n .map(cell => {\n if (typeof cell === 'string') {\n return this.wrap('td', cell);\n }\n const { header, data, colspan, rowspan } = cell;\n const tag = header ? 'th' : 'td';\n const attrs = Object.assign(Object.assign({}, (colspan && { colspan })), (rowspan && { rowspan }));\n return this.wrap(tag, data, attrs);\n })\n .join('');\n return this.wrap('tr', cells);\n })\n .join('');\n const element = this.wrap('table', tableBody);\n return this.addRaw(element).addEOL();\n }\n /**\n * Adds a collapsable HTML details element to the summary buffer\n *\n * @param {string} label text for the closed state\n * @param {string} content collapsable content\n *\n * @returns {Summary} summary instance\n */\n addDetails(label, content) {\n const element = this.wrap('details', this.wrap('summary', label) + content);\n return this.addRaw(element).addEOL();\n }\n /**\n * Adds an HTML image tag to the summary buffer\n *\n * @param {string} src path to the image you to embed\n * @param {string} alt text description of the image\n * @param {SummaryImageOptions} options (optional) addition image attributes\n *\n * @returns {Summary} summary instance\n */\n addImage(src, alt, options) {\n const { width, height } = options || {};\n const attrs = Object.assign(Object.assign({}, (width && { width })), (height && { height }));\n const element = this.wrap('img', null, Object.assign({ src, alt }, attrs));\n return this.addRaw(element).addEOL();\n }\n /**\n * Adds an HTML section heading element\n *\n * @param {string} text heading text\n * @param {number | string} [level=1] (optional) the heading level, default: 1\n *\n * @returns {Summary} summary instance\n */\n addHeading(text, level) {\n const tag = `h${level}`;\n const allowedTag = ['h1', 'h2', 'h3', 'h4', 'h5', 'h6'].includes(tag)\n ? tag\n : 'h1';\n const element = this.wrap(allowedTag, text);\n return this.addRaw(element).addEOL();\n }\n /**\n * Adds an HTML thematic break (<hr>) to the summary buffer\n *\n * @returns {Summary} summary instance\n */\n addSeparator() {\n const element = this.wrap('hr', null);\n return this.addRaw(element).addEOL();\n }\n /**\n * Adds an HTML line break (<br>) to the summary buffer\n *\n * @returns {Summary} summary instance\n */\n addBreak() {\n const element = this.wrap('br', null);\n return this.addRaw(element).addEOL();\n }\n /**\n * Adds an HTML blockquote to the summary buffer\n *\n * @param {string} text quote text\n * @param {string} cite (optional) citation url\n *\n * @returns {Summary} summary instance\n */\n addQuote(text, cite) {\n const attrs = Object.assign({}, (cite && { cite }));\n const element = this.wrap('blockquote', text, attrs);\n return this.addRaw(element).addEOL();\n }\n /**\n * Adds an HTML anchor tag to the summary buffer\n *\n * @param {string} text link text/content\n * @param {string} href hyperlink\n *\n * @returns {Summary} summary instance\n */\n addLink(text, href) {\n const element = this.wrap('a', text, { href });\n return this.addRaw(element).addEOL();\n }\n}\nconst _summary = new Summary();\n/**\n * @deprecated use `core.summary`\n */\nexports.markdownSummary = _summary;\nexports.summary = _summary;\n//# sourceMappingURL=summary.js.map\n\n/***/ }),\n\n/***/ 5278:\n/***/ ((__unused_webpack_module, exports) => {\n\n\"use strict\";\n\n// We use any as a valid input type\n/* eslint-disable @typescript-eslint/no-explicit-any */\nObject.defineProperty(exports, \"__esModule\", ({ value: true }));\nexports.toCommandProperties = exports.toCommandValue = void 0;\n/**\n * Sanitizes an input into a string so it can be passed into issueCommand safely\n * @param input input to sanitize into a string\n */\nfunction toCommandValue(input) {\n if (input === null || input === undefined) {\n return '';\n }\n else if (typeof input === 'string' || input instanceof String) {\n return input;\n }\n return JSON.stringify(input);\n}\nexports.toCommandValue = toCommandValue;\n/**\n *\n * @param annotationProperties\n * @returns The command properties to send with the actual annotation command\n * See IssueCommandProperties: https://github.com/actions/runner/blob/main/src/Runner.Worker/ActionCommandManager.cs#L646\n */\nfunction toCommandProperties(annotationProperties) {\n if (!Object.keys(annotationProperties).length) {\n return {};\n }\n return {\n title: annotationProperties.title,\n file: annotationProperties.file,\n line: annotationProperties.startLine,\n endLine: annotationProperties.endLine,\n col: annotationProperties.startColumn,\n endColumn: annotationProperties.endColumn\n };\n}\nexports.toCommandProperties = toCommandProperties;\n//# sourceMappingURL=utils.js.map\n\n/***/ }),\n\n/***/ 6758:\n/***/ (function(__unused_webpack_module, exports) {\n\n\"use strict\";\n\nvar __awaiter = (this && this.__awaiter) || function (thisArg, _arguments, P, generator) {\n function adopt(value) { return value instanceof P ? value : new P(function (resolve) { resolve(value); }); }\n return new (P || (P = Promise))(function (resolve, reject) {\n function fulfilled(value) { try { step(generator.next(value)); } catch (e) { reject(e); } }\n function rejected(value) { try { step(generator[\"throw\"](value)); } catch (e) { reject(e); } }\n function step(result) { result.done ? resolve(result.value) : adopt(result.value).then(fulfilled, rejected); }\n step((generator = generator.apply(thisArg, _arguments || [])).next());\n });\n};\nObject.defineProperty(exports, \"__esModule\", ({ value: true }));\nexports.PersonalAccessTokenCredentialHandler = exports.BearerCredentialHandler = exports.BasicCredentialHandler = void 0;\nclass BasicCredentialHandler {\n constructor(username, password) {\n this.username = username;\n this.password = password;\n }\n prepareRequest(options) {\n if (!options.headers) {\n throw Error('The request has no headers');\n }\n options.headers['Authorization'] = `Basic ${Buffer.from(`${this.username}:${this.password}`).toString('base64')}`;\n }\n // This handler cannot handle 401\n canHandleAuthentication() {\n return false;\n }\n handleAuthentication() {\n return __awaiter(this, void 0, void 0, function* () {\n throw new Error('not implemented');\n });\n }\n}\nexports.BasicCredentialHandler = BasicCredentialHandler;\nclass BearerCredentialHandler {\n constructor(token) {\n this.token = token;\n }\n // currently implements pre-authorization\n // TODO: support preAuth = false where it hooks on 401\n prepareRequest(options) {\n if (!options.headers) {\n throw Error('The request has no headers');\n }\n options.headers['Authorization'] = `Bearer ${this.token}`;\n }\n // This handler cannot handle 401\n canHandleAuthentication() {\n return false;\n }\n handleAuthentication() {\n return __awaiter(this, void 0, void 0, function* () {\n throw new Error('not implemented');\n });\n }\n}\nexports.BearerCredentialHandler = BearerCredentialHandler;\nclass PersonalAccessTokenCredentialHandler {\n constructor(token) {\n this.token = token;\n }\n // currently implements pre-authorization\n // TODO: support preAuth = false where it hooks on 401\n prepareRequest(options) {\n if (!options.headers) {\n throw Error('The request has no headers');\n }\n options.headers['Authorization'] = `Basic ${Buffer.from(`PAT:${this.token}`).toString('base64')}`;\n }\n // This handler cannot handle 401\n canHandleAuthentication() {\n return false;\n }\n handleAuthentication() {\n return __awaiter(this, void 0, void 0, function* () {\n throw new Error('not implemented');\n });\n }\n}\nexports.PersonalAccessTokenCredentialHandler = PersonalAccessTokenCredentialHandler;\n//# sourceMappingURL=auth.js.map\n\n/***/ }),\n\n/***/ 1404:\n/***/ (function(__unused_webpack_module, exports, __nccwpck_require__) {\n\n\"use strict\";\n\n/* eslint-disable @typescript-eslint/no-explicit-any */\nvar __createBinding = (this && this.__createBinding) || (Object.create ? (function(o, m, k, k2) {\n if (k2 === undefined) k2 = k;\n var desc = Object.getOwnPropertyDescriptor(m, k);\n if (!desc || (\"get\" in desc ? !m.__esModule : desc.writable || desc.configurable)) {\n desc = { enumerable: true, get: function() { return m[k]; } };\n }\n Object.defineProperty(o, k2, desc);\n}) : (function(o, m, k, k2) {\n if (k2 === undefined) k2 = k;\n o[k2] = m[k];\n}));\nvar __setModuleDefault = (this && this.__setModuleDefault) || (Object.create ? (function(o, v) {\n Object.defineProperty(o, \"default\", { enumerable: true, value: v });\n}) : function(o, v) {\n o[\"default\"] = v;\n});\nvar __importStar = (this && this.__importStar) || function (mod) {\n if (mod && mod.__esModule) return mod;\n var result = {};\n if (mod != null) for (var k in mod) if (k !== \"default\" && Object.prototype.hasOwnProperty.call(mod, k)) __createBinding(result, mod, k);\n __setModuleDefault(result, mod);\n return result;\n};\nvar __awaiter = (this && this.__awaiter) || function (thisArg, _arguments, P, generator) {\n function adopt(value) { return value instanceof P ? value : new P(function (resolve) { resolve(value); }); }\n return new (P || (P = Promise))(function (resolve, reject) {\n function fulfilled(value) { try { step(generator.next(value)); } catch (e) { reject(e); } }\n function rejected(value) { try { step(generator[\"throw\"](value)); } catch (e) { reject(e); } }\n function step(result) { result.done ? resolve(result.value) : adopt(result.value).then(fulfilled, rejected); }\n step((generator = generator.apply(thisArg, _arguments || [])).next());\n });\n};\nObject.defineProperty(exports, \"__esModule\", ({ value: true }));\nexports.HttpClient = exports.isHttps = exports.HttpClientResponse = exports.HttpClientError = exports.getProxyUrl = exports.MediaTypes = exports.Headers = exports.HttpCodes = void 0;\nconst http = __importStar(__nccwpck_require__(3685));\nconst https = __importStar(__nccwpck_require__(5687));\nconst pm = __importStar(__nccwpck_require__(2843));\nconst tunnel = __importStar(__nccwpck_require__(4294));\nconst undici_1 = __nccwpck_require__(1773);\nvar HttpCodes;\n(function (HttpCodes) {\n HttpCodes[HttpCodes[\"OK\"] = 200] = \"OK\";\n HttpCodes[HttpCodes[\"MultipleChoices\"] = 300] = \"MultipleChoices\";\n HttpCodes[HttpCodes[\"MovedPermanently\"] = 301] = \"MovedPermanently\";\n HttpCodes[HttpCodes[\"ResourceMoved\"] = 302] = \"ResourceMoved\";\n HttpCodes[HttpCodes[\"SeeOther\"] = 303] = \"SeeOther\";\n HttpCodes[HttpCodes[\"NotModified\"] = 304] = \"NotModified\";\n HttpCodes[HttpCodes[\"UseProxy\"] = 305] = \"UseProxy\";\n HttpCodes[HttpCodes[\"SwitchProxy\"] = 306] = \"SwitchProxy\";\n HttpCodes[HttpCodes[\"TemporaryRedirect\"] = 307] = \"TemporaryRedirect\";\n HttpCodes[HttpCodes[\"PermanentRedirect\"] = 308] = \"PermanentRedirect\";\n HttpCodes[HttpCodes[\"BadRequest\"] = 400] = \"BadRequest\";\n HttpCodes[HttpCodes[\"Unauthorized\"] = 401] = \"Unauthorized\";\n HttpCodes[HttpCodes[\"PaymentRequired\"] = 402] = \"PaymentRequired\";\n HttpCodes[HttpCodes[\"Forbidden\"] = 403] = \"Forbidden\";\n HttpCodes[HttpCodes[\"NotFound\"] = 404] = \"NotFound\";\n HttpCodes[HttpCodes[\"MethodNotAllowed\"] = 405] = \"MethodNotAllowed\";\n HttpCodes[HttpCodes[\"NotAcceptable\"] = 406] = \"NotAcceptable\";\n HttpCodes[HttpCodes[\"ProxyAuthenticationRequired\"] = 407] = \"ProxyAuthenticationRequired\";\n HttpCodes[HttpCodes[\"RequestTimeout\"] = 408] = \"RequestTimeout\";\n HttpCodes[HttpCodes[\"Conflict\"] = 409] = \"Conflict\";\n HttpCodes[HttpCodes[\"Gone\"] = 410] = \"Gone\";\n HttpCodes[HttpCodes[\"TooManyRequests\"] = 429] = \"TooManyRequests\";\n HttpCodes[HttpCodes[\"InternalServerError\"] = 500] = \"InternalServerError\";\n HttpCodes[HttpCodes[\"NotImplemented\"] = 501] = \"NotImplemented\";\n HttpCodes[HttpCodes[\"BadGateway\"] = 502] = \"BadGateway\";\n HttpCodes[HttpCodes[\"ServiceUnavailable\"] = 503] = \"ServiceUnavailable\";\n HttpCodes[HttpCodes[\"GatewayTimeout\"] = 504] = \"GatewayTimeout\";\n})(HttpCodes || (exports.HttpCodes = HttpCodes = {}));\nvar Headers;\n(function (Headers) {\n Headers[\"Accept\"] = \"accept\";\n Headers[\"ContentType\"] = \"content-type\";\n})(Headers || (exports.Headers = Headers = {}));\nvar MediaTypes;\n(function (MediaTypes) {\n MediaTypes[\"ApplicationJson\"] = \"application/json\";\n})(MediaTypes || (exports.MediaTypes = MediaTypes = {}));\n/**\n * Returns the proxy URL, depending upon the supplied url and proxy environment variables.\n * @param serverUrl The server URL where the request will be sent. For example, https://api.github.com\n */\nfunction getProxyUrl(serverUrl) {\n const proxyUrl = pm.getProxyUrl(new URL(serverUrl));\n return proxyUrl ? proxyUrl.href : '';\n}\nexports.getProxyUrl = getProxyUrl;\nconst HttpRedirectCodes = [\n HttpCodes.MovedPermanently,\n HttpCodes.ResourceMoved,\n HttpCodes.SeeOther,\n HttpCodes.TemporaryRedirect,\n HttpCodes.PermanentRedirect\n];\nconst HttpResponseRetryCodes = [\n HttpCodes.BadGateway,\n HttpCodes.ServiceUnavailable,\n HttpCodes.GatewayTimeout\n];\nconst RetryableHttpVerbs = ['OPTIONS', 'GET', 'DELETE', 'HEAD'];\nconst ExponentialBackoffCeiling = 10;\nconst ExponentialBackoffTimeSlice = 5;\nclass HttpClientError extends Error {\n constructor(message, statusCode) {\n super(message);\n this.name = 'HttpClientError';\n this.statusCode = statusCode;\n Object.setPrototypeOf(this, HttpClientError.prototype);\n }\n}\nexports.HttpClientError = HttpClientError;\nclass HttpClientResponse {\n constructor(message) {\n this.message = message;\n }\n readBody() {\n return __awaiter(this, void 0, void 0, function* () {\n return new Promise((resolve) => __awaiter(this, void 0, void 0, function* () {\n let output = Buffer.alloc(0);\n this.message.on('data', (chunk) => {\n output = Buffer.concat([output, chunk]);\n });\n this.message.on('end', () => {\n resolve(output.toString());\n });\n }));\n });\n }\n readBodyBuffer() {\n return __awaiter(this, void 0, void 0, function* () {\n return new Promise((resolve) => __awaiter(this, void 0, void 0, function* () {\n const chunks = [];\n this.message.on('data', (chunk) => {\n chunks.push(chunk);\n });\n this.message.on('end', () => {\n resolve(Buffer.concat(chunks));\n });\n }));\n });\n }\n}\nexports.HttpClientResponse = HttpClientResponse;\nfunction isHttps(requestUrl) {\n const parsedUrl = new URL(requestUrl);\n return parsedUrl.protocol === 'https:';\n}\nexports.isHttps = isHttps;\nclass HttpClient {\n constructor(userAgent, handlers, requestOptions) {\n this._ignoreSslError = false;\n this._allowRedirects = true;\n this._allowRedirectDowngrade = false;\n this._maxRedirects = 50;\n this._allowRetries = false;\n this._maxRetries = 1;\n this._keepAlive = false;\n this._disposed = false;\n this.userAgent = userAgent;\n this.handlers = handlers || [];\n this.requestOptions = requestOptions;\n if (requestOptions) {\n if (requestOptions.ignoreSslError != null) {\n this._ignoreSslError = requestOptions.ignoreSslError;\n }\n this._socketTimeout = requestOptions.socketTimeout;\n if (requestOptions.allowRedirects != null) {\n this._allowRedirects = requestOptions.allowRedirects;\n }\n if (requestOptions.allowRedirectDowngrade != null) {\n this._allowRedirectDowngrade = requestOptions.allowRedirectDowngrade;\n }\n if (requestOptions.maxRedirects != null) {\n this._maxRedirects = Math.max(requestOptions.maxRedirects, 0);\n }\n if (requestOptions.keepAlive != null) {\n this._keepAlive = requestOptions.keepAlive;\n }\n if (requestOptions.allowRetries != null) {\n this._allowRetries = requestOptions.allowRetries;\n }\n if (requestOptions.maxRetries != null) {\n this._maxRetries = requestOptions.maxRetries;\n }\n }\n }\n options(requestUrl, additionalHeaders) {\n return __awaiter(this, void 0, void 0, function* () {\n return this.request('OPTIONS', requestUrl, null, additionalHeaders || {});\n });\n }\n get(requestUrl, additionalHeaders) {\n return __awaiter(this, void 0, void 0, function* () {\n return this.request('GET', requestUrl, null, additionalHeaders || {});\n });\n }\n del(requestUrl, additionalHeaders) {\n return __awaiter(this, void 0, void 0, function* () {\n return this.request('DELETE', requestUrl, null, additionalHeaders || {});\n });\n }\n post(requestUrl, data, additionalHeaders) {\n return __awaiter(this, void 0, void 0, function* () {\n return this.request('POST', requestUrl, data, additionalHeaders || {});\n });\n }\n patch(requestUrl, data, additionalHeaders) {\n return __awaiter(this, void 0, void 0, function* () {\n return this.request('PATCH', requestUrl, data, additionalHeaders || {});\n });\n }\n put(requestUrl, data, additionalHeaders) {\n return __awaiter(this, void 0, void 0, function* () {\n return this.request('PUT', requestUrl, data, additionalHeaders || {});\n });\n }\n head(requestUrl, additionalHeaders) {\n return __awaiter(this, void 0, void 0, function* () {\n return this.request('HEAD', requestUrl, null, additionalHeaders || {});\n });\n }\n sendStream(verb, requestUrl, stream, additionalHeaders) {\n return __awaiter(this, void 0, void 0, function* () {\n return this.request(verb, requestUrl, stream, additionalHeaders);\n });\n }\n /**\n * Gets a typed object from an endpoint\n * Be aware that not found returns a null. Other errors (4xx, 5xx) reject the promise\n */\n getJson(requestUrl, additionalHeaders = {}) {\n return __awaiter(this, void 0, void 0, function* () {\n additionalHeaders[Headers.Accept] = this._getExistingOrDefaultHeader(additionalHeaders, Headers.Accept, MediaTypes.ApplicationJson);\n const res = yield this.get(requestUrl, additionalHeaders);\n return this._processResponse(res, this.requestOptions);\n });\n }\n postJson(requestUrl, obj, additionalHeaders = {}) {\n return __awaiter(this, void 0, void 0, function* () {\n const data = JSON.stringify(obj, null, 2);\n additionalHeaders[Headers.Accept] = this._getExistingOrDefaultHeader(additionalHeaders, Headers.Accept, MediaTypes.ApplicationJson);\n additionalHeaders[Headers.ContentType] = this._getExistingOrDefaultHeader(additionalHeaders, Headers.ContentType, MediaTypes.ApplicationJson);\n const res = yield this.post(requestUrl, data, additionalHeaders);\n return this._processResponse(res, this.requestOptions);\n });\n }\n putJson(requestUrl, obj, additionalHeaders = {}) {\n return __awaiter(this, void 0, void 0, function* () {\n const data = JSON.stringify(obj, null, 2);\n additionalHeaders[Headers.Accept] = this._getExistingOrDefaultHeader(additionalHeaders, Headers.Accept, MediaTypes.ApplicationJson);\n additionalHeaders[Headers.ContentType] = this._getExistingOrDefaultHeader(additionalHeaders, Headers.ContentType, MediaTypes.ApplicationJson);\n const res = yield this.put(requestUrl, data, additionalHeaders);\n return this._processResponse(res, this.requestOptions);\n });\n }\n patchJson(requestUrl, obj, additionalHeaders = {}) {\n return __awaiter(this, void 0, void 0, function* () {\n const data = JSON.stringify(obj, null, 2);\n additionalHeaders[Headers.Accept] = this._getExistingOrDefaultHeader(additionalHeaders, Headers.Accept, MediaTypes.ApplicationJson);\n additionalHeaders[Headers.ContentType] = this._getExistingOrDefaultHeader(additionalHeaders, Headers.ContentType, MediaTypes.ApplicationJson);\n const res = yield this.patch(requestUrl, data, additionalHeaders);\n return this._processResponse(res, this.requestOptions);\n });\n }\n /**\n * Makes a raw http request.\n * All other methods such as get, post, patch, and request ultimately call this.\n * Prefer get, del, post and patch\n */\n request(verb, requestUrl, data, headers) {\n return __awaiter(this, void 0, void 0, function* () {\n if (this._disposed) {\n throw new Error('Client has already been disposed.');\n }\n const parsedUrl = new URL(requestUrl);\n let info = this._prepareRequest(verb, parsedUrl, headers);\n // Only perform retries on reads since writes may not be idempotent.\n const maxTries = this._allowRetries && RetryableHttpVerbs.includes(verb)\n ? this._maxRetries + 1\n : 1;\n let numTries = 0;\n let response;\n do {\n response = yield this.requestRaw(info, data);\n // Check if it's an authentication challenge\n if (response &&\n response.message &&\n response.message.statusCode === HttpCodes.Unauthorized) {\n let authenticationHandler;\n for (const handler of this.handlers) {\n if (handler.canHandleAuthentication(response)) {\n authenticationHandler = handler;\n break;\n }\n }\n if (authenticationHandler) {\n return authenticationHandler.handleAuthentication(this, info, data);\n }\n else {\n // We have received an unauthorized response but have no handlers to handle it.\n // Let the response return to the caller.\n return response;\n }\n }\n let redirectsRemaining = this._maxRedirects;\n while (response.message.statusCode &&\n HttpRedirectCodes.includes(response.message.statusCode) &&\n this._allowRedirects &&\n redirectsRemaining > 0) {\n const redirectUrl = response.message.headers['location'];\n if (!redirectUrl) {\n // if there's no location to redirect to, we won't\n break;\n }\n const parsedRedirectUrl = new URL(redirectUrl);\n if (parsedUrl.protocol === 'https:' &&\n parsedUrl.protocol !== parsedRedirectUrl.protocol &&\n !this._allowRedirectDowngrade) {\n throw new Error('Redirect from HTTPS to HTTP protocol. This downgrade is not allowed for security reasons. If you want to allow this behavior, set the allowRedirectDowngrade option to true.');\n }\n // we need to finish reading the response before reassigning response\n // which will leak the open socket.\n yield response.readBody();\n // strip authorization header if redirected to a different hostname\n if (parsedRedirectUrl.hostname !== parsedUrl.hostname) {\n for (const header in headers) {\n // header names are case insensitive\n if (header.toLowerCase() === 'authorization') {\n delete headers[header];\n }\n }\n }\n // let's make the request with the new redirectUrl\n info = this._prepareRequest(verb, parsedRedirectUrl, headers);\n response = yield this.requestRaw(info, data);\n redirectsRemaining--;\n }\n if (!response.message.statusCode ||\n !HttpResponseRetryCodes.includes(response.message.statusCode)) {\n // If not a retry code, return immediately instead of retrying\n return response;\n }\n numTries += 1;\n if (numTries < maxTries) {\n yield response.readBody();\n yield this._performExponentialBackoff(numTries);\n }\n } while (numTries < maxTries);\n return response;\n });\n }\n /**\n * Needs to be called if keepAlive is set to true in request options.\n */\n dispose() {\n if (this._agent) {\n this._agent.destroy();\n }\n this._disposed = true;\n }\n /**\n * Raw request.\n * @param info\n * @param data\n */\n requestRaw(info, data) {\n return __awaiter(this, void 0, void 0, function* () {\n return new Promise((resolve, reject) => {\n function callbackForResult(err, res) {\n if (err) {\n reject(err);\n }\n else if (!res) {\n // If `err` is not passed, then `res` must be passed.\n reject(new Error('Unknown error'));\n }\n else {\n resolve(res);\n }\n }\n this.requestRawWithCallback(info, data, callbackForResult);\n });\n });\n }\n /**\n * Raw request with callback.\n * @param info\n * @param data\n * @param onResult\n */\n requestRawWithCallback(info, data, onResult) {\n if (typeof data === 'string') {\n if (!info.options.headers) {\n info.options.headers = {};\n }\n info.options.headers['Content-Length'] = Buffer.byteLength(data, 'utf8');\n }\n let callbackCalled = false;\n function handleResult(err, res) {\n if (!callbackCalled) {\n callbackCalled = true;\n onResult(err, res);\n }\n }\n const req = info.httpModule.request(info.options, (msg) => {\n const res = new HttpClientResponse(msg);\n handleResult(undefined, res);\n });\n let socket;\n req.on('socket', sock => {\n socket = sock;\n });\n // If we ever get disconnected, we want the socket to timeout eventually\n req.setTimeout(this._socketTimeout || 3 * 60000, () => {\n if (socket) {\n socket.end();\n }\n handleResult(new Error(`Request timeout: ${info.options.path}`));\n });\n req.on('error', function (err) {\n // err has statusCode property\n // res should have headers\n handleResult(err);\n });\n if (data && typeof data === 'string') {\n req.write(data, 'utf8');\n }\n if (data && typeof data !== 'string') {\n data.on('close', function () {\n req.end();\n });\n data.pipe(req);\n }\n else {\n req.end();\n }\n }\n /**\n * Gets an http agent. This function is useful when you need an http agent that handles\n * routing through a proxy server - depending upon the url and proxy environment variables.\n * @param serverUrl The server URL where the request will be sent. For example, https://api.github.com\n */\n getAgent(serverUrl) {\n const parsedUrl = new URL(serverUrl);\n return this._getAgent(parsedUrl);\n }\n getAgentDispatcher(serverUrl) {\n const parsedUrl = new URL(serverUrl);\n const proxyUrl = pm.getProxyUrl(parsedUrl);\n const useProxy = proxyUrl && proxyUrl.hostname;\n if (!useProxy) {\n return;\n }\n return this._getProxyAgentDispatcher(parsedUrl, proxyUrl);\n }\n _prepareRequest(method, requestUrl, headers) {\n const info = {};\n info.parsedUrl = requestUrl;\n const usingSsl = info.parsedUrl.protocol === 'https:';\n info.httpModule = usingSsl ? https : http;\n const defaultPort = usingSsl ? 443 : 80;\n info.options = {};\n info.options.host = info.parsedUrl.hostname;\n info.options.port = info.parsedUrl.port\n ? parseInt(info.parsedUrl.port)\n : defaultPort;\n info.options.path =\n (info.parsedUrl.pathname || '') + (info.parsedUrl.search || '');\n info.options.method = method;\n info.options.headers = this._mergeHeaders(headers);\n if (this.userAgent != null) {\n info.options.headers['user-agent'] = this.userAgent;\n }\n info.options.agent = this._getAgent(info.parsedUrl);\n // gives handlers an opportunity to participate\n if (this.handlers) {\n for (const handler of this.handlers) {\n handler.prepareRequest(info.options);\n }\n }\n return info;\n }\n _mergeHeaders(headers) {\n if (this.requestOptions && this.requestOptions.headers) {\n return Object.assign({}, lowercaseKeys(this.requestOptions.headers), lowercaseKeys(headers || {}));\n }\n return lowercaseKeys(headers || {});\n }\n _getExistingOrDefaultHeader(additionalHeaders, header, _default) {\n let clientHeader;\n if (this.requestOptions && this.requestOptions.headers) {\n clientHeader = lowercaseKeys(this.requestOptions.headers)[header];\n }\n return additionalHeaders[header] || clientHeader || _default;\n }\n _getAgent(parsedUrl) {\n let agent;\n const proxyUrl = pm.getProxyUrl(parsedUrl);\n const useProxy = proxyUrl && proxyUrl.hostname;\n if (this._keepAlive && useProxy) {\n agent = this._proxyAgent;\n }\n if (!useProxy) {\n agent = this._agent;\n }\n // if agent is already assigned use that agent.\n if (agent) {\n return agent;\n }\n const usingSsl = parsedUrl.protocol === 'https:';\n let maxSockets = 100;\n if (this.requestOptions) {\n maxSockets = this.requestOptions.maxSockets || http.globalAgent.maxSockets;\n }\n // This is `useProxy` again, but we need to check `proxyURl` directly for TypeScripts's flow analysis.\n if (proxyUrl && proxyUrl.hostname) {\n const agentOptions = {\n maxSockets,\n keepAlive: this._keepAlive,\n proxy: Object.assign(Object.assign({}, ((proxyUrl.username || proxyUrl.password) && {\n proxyAuth: `${proxyUrl.username}:${proxyUrl.password}`\n })), { host: proxyUrl.hostname, port: proxyUrl.port })\n };\n let tunnelAgent;\n const overHttps = proxyUrl.protocol === 'https:';\n if (usingSsl) {\n tunnelAgent = overHttps ? tunnel.httpsOverHttps : tunnel.httpsOverHttp;\n }\n else {\n tunnelAgent = overHttps ? tunnel.httpOverHttps : tunnel.httpOverHttp;\n }\n agent = tunnelAgent(agentOptions);\n this._proxyAgent = agent;\n }\n // if tunneling agent isn't assigned create a new agent\n if (!agent) {\n const options = { keepAlive: this._keepAlive, maxSockets };\n agent = usingSsl ? new https.Agent(options) : new http.Agent(options);\n this._agent = agent;\n }\n if (usingSsl && this._ignoreSslError) {\n // we don't want to set NODE_TLS_REJECT_UNAUTHORIZED=0 since that will affect request for entire process\n // http.RequestOptions doesn't expose a way to modify RequestOptions.agent.options\n // we have to cast it to any and change it directly\n agent.options = Object.assign(agent.options || {}, {\n rejectUnauthorized: false\n });\n }\n return agent;\n }\n _getProxyAgentDispatcher(parsedUrl, proxyUrl) {\n let proxyAgent;\n if (this._keepAlive) {\n proxyAgent = this._proxyAgentDispatcher;\n }\n // if agent is already assigned use that agent.\n if (proxyAgent) {\n return proxyAgent;\n }\n const usingSsl = parsedUrl.protocol === 'https:';\n proxyAgent = new undici_1.ProxyAgent(Object.assign({ uri: proxyUrl.href, pipelining: !this._keepAlive ? 0 : 1 }, ((proxyUrl.username || proxyUrl.password) && {\n token: `Basic ${Buffer.from(`${proxyUrl.username}:${proxyUrl.password}`).toString('base64')}`\n })));\n this._proxyAgentDispatcher = proxyAgent;\n if (usingSsl && this._ignoreSslError) {\n // we don't want to set NODE_TLS_REJECT_UNAUTHORIZED=0 since that will affect request for entire process\n // http.RequestOptions doesn't expose a way to modify RequestOptions.agent.options\n // we have to cast it to any and change it directly\n proxyAgent.options = Object.assign(proxyAgent.options.requestTls || {}, {\n rejectUnauthorized: false\n });\n }\n return proxyAgent;\n }\n _performExponentialBackoff(retryNumber) {\n return __awaiter(this, void 0, void 0, function* () {\n retryNumber = Math.min(ExponentialBackoffCeiling, retryNumber);\n const ms = ExponentialBackoffTimeSlice * Math.pow(2, retryNumber);\n return new Promise(resolve => setTimeout(() => resolve(), ms));\n });\n }\n _processResponse(res, options) {\n return __awaiter(this, void 0, void 0, function* () {\n return new Promise((resolve, reject) => __awaiter(this, void 0, void 0, function* () {\n const statusCode = res.message.statusCode || 0;\n const response = {\n statusCode,\n result: null,\n headers: {}\n };\n // not found leads to null obj returned\n if (statusCode === HttpCodes.NotFound) {\n resolve(response);\n }\n // get the result from the body\n function dateTimeDeserializer(key, value) {\n if (typeof value === 'string') {\n const a = new Date(value);\n if (!isNaN(a.valueOf())) {\n return a;\n }\n }\n return value;\n }\n let obj;\n let contents;\n try {\n contents = yield res.readBody();\n if (contents && contents.length > 0) {\n if (options && options.deserializeDates) {\n obj = JSON.parse(contents, dateTimeDeserializer);\n }\n else {\n obj = JSON.parse(contents);\n }\n response.result = obj;\n }\n response.headers = res.message.headers;\n }\n catch (err) {\n // Invalid resource (contents not json); leaving result obj null\n }\n // note that 3xx redirects are handled by the http layer.\n if (statusCode > 299) {\n let msg;\n // if exception/error in body, attempt to get better error\n if (obj && obj.message) {\n msg = obj.message;\n }\n else if (contents && contents.length > 0) {\n // it may be the case that the exception is in the body message as string\n msg = contents;\n }\n else {\n msg = `Failed request: (${statusCode})`;\n }\n const err = new HttpClientError(msg, statusCode);\n err.result = response.result;\n reject(err);\n }\n else {\n resolve(response);\n }\n }));\n });\n }\n}\nexports.HttpClient = HttpClient;\nconst lowercaseKeys = (obj) => Object.keys(obj).reduce((c, k) => ((c[k.toLowerCase()] = obj[k]), c), {});\n//# sourceMappingURL=index.js.map\n\n/***/ }),\n\n/***/ 2843:\n/***/ ((__unused_webpack_module, exports) => {\n\n\"use strict\";\n\nObject.defineProperty(exports, \"__esModule\", ({ value: true }));\nexports.checkBypass = exports.getProxyUrl = void 0;\nfunction getProxyUrl(reqUrl) {\n const usingSsl = reqUrl.protocol === 'https:';\n if (checkBypass(reqUrl)) {\n return undefined;\n }\n const proxyVar = (() => {\n if (usingSsl) {\n return process.env['https_proxy'] || process.env['HTTPS_PROXY'];\n }\n else {\n return process.env['http_proxy'] || process.env['HTTP_PROXY'];\n }\n })();\n if (proxyVar) {\n try {\n return new DecodedURL(proxyVar);\n }\n catch (_a) {\n if (!proxyVar.startsWith('http://') && !proxyVar.startsWith('https://'))\n return new DecodedURL(`http://${proxyVar}`);\n }\n }\n else {\n return undefined;\n }\n}\nexports.getProxyUrl = getProxyUrl;\nfunction checkBypass(reqUrl) {\n if (!reqUrl.hostname) {\n return false;\n }\n const reqHost = reqUrl.hostname;\n if (isLoopbackAddress(reqHost)) {\n return true;\n }\n const noProxy = process.env['no_proxy'] || process.env['NO_PROXY'] || '';\n if (!noProxy) {\n return false;\n }\n // Determine the request port\n let reqPort;\n if (reqUrl.port) {\n reqPort = Number(reqUrl.port);\n }\n else if (reqUrl.protocol === 'http:') {\n reqPort = 80;\n }\n else if (reqUrl.protocol === 'https:') {\n reqPort = 443;\n }\n // Format the request hostname and hostname with port\n const upperReqHosts = [reqUrl.hostname.toUpperCase()];\n if (typeof reqPort === 'number') {\n upperReqHosts.push(`${upperReqHosts[0]}:${reqPort}`);\n }\n // Compare request host against noproxy\n for (const upperNoProxyItem of noProxy\n .split(',')\n .map(x => x.trim().toUpperCase())\n .filter(x => x)) {\n if (upperNoProxyItem === '*' ||\n upperReqHosts.some(x => x === upperNoProxyItem ||\n x.endsWith(`.${upperNoProxyItem}`) ||\n (upperNoProxyItem.startsWith('.') &&\n x.endsWith(`${upperNoProxyItem}`)))) {\n return true;\n }\n }\n return false;\n}\nexports.checkBypass = checkBypass;\nfunction isLoopbackAddress(host) {\n const hostLower = host.toLowerCase();\n return (hostLower === 'localhost' ||\n hostLower.startsWith('127.') ||\n hostLower.startsWith('[::1]') ||\n hostLower.startsWith('[0:0:0:0:0:0:0:1]'));\n}\nclass DecodedURL extends URL {\n constructor(url, base) {\n super(url, base);\n this._decodedUsername = decodeURIComponent(super.username);\n this._decodedPassword = decodeURIComponent(super.password);\n }\n get username() {\n return this._decodedUsername;\n }\n get password() {\n return this._decodedPassword;\n }\n}\n//# sourceMappingURL=proxy.js.map\n\n/***/ }),\n\n/***/ 4087:\n/***/ ((__unused_webpack_module, exports, __nccwpck_require__) => {\n\n\"use strict\";\n\nObject.defineProperty(exports, \"__esModule\", ({ value: true }));\nconst fs_1 = __nccwpck_require__(7147);\nconst os_1 = __nccwpck_require__(2037);\nclass Context {\n /**\n * Hydrate the context from the environment\n */\n constructor() {\n this.payload = {};\n if (process.env.GITHUB_EVENT_PATH) {\n if (fs_1.existsSync(process.env.GITHUB_EVENT_PATH)) {\n this.payload = JSON.parse(fs_1.readFileSync(process.env.GITHUB_EVENT_PATH, { encoding: 'utf8' }));\n }\n else {\n const path = process.env.GITHUB_EVENT_PATH;\n process.stdout.write(`GITHUB_EVENT_PATH ${path} does not exist${os_1.EOL}`);\n }\n }\n this.eventName = process.env.GITHUB_EVENT_NAME;\n this.sha = process.env.GITHUB_SHA;\n this.ref = process.env.GITHUB_REF;\n this.workflow = process.env.GITHUB_WORKFLOW;\n this.action = process.env.GITHUB_ACTION;\n this.actor = process.env.GITHUB_ACTOR;\n }\n get issue() {\n const payload = this.payload;\n return Object.assign(Object.assign({}, this.repo), { number: (payload.issue || payload.pull_request || payload).number });\n }\n get repo() {\n if (process.env.GITHUB_REPOSITORY) {\n const [owner, repo] = process.env.GITHUB_REPOSITORY.split('/');\n return { owner, repo };\n }\n if (this.payload.repository) {\n return {\n owner: this.payload.repository.owner.login,\n repo: this.payload.repository.name\n };\n }\n throw new Error(\"context.repo requires a GITHUB_REPOSITORY environment variable like 'owner/repo'\");\n }\n}\nexports.Context = Context;\n//# sourceMappingURL=context.js.map\n\n/***/ }),\n\n/***/ 5438:\n/***/ (function(__unused_webpack_module, exports, __nccwpck_require__) {\n\n\"use strict\";\n\nvar __importStar = (this && this.__importStar) || function (mod) {\n if (mod && mod.__esModule) return mod;\n var result = {};\n if (mod != null) for (var k in mod) if (Object.hasOwnProperty.call(mod, k)) result[k] = mod[k];\n result[\"default\"] = mod;\n return result;\n};\nObject.defineProperty(exports, \"__esModule\", ({ value: true }));\n// Originally pulled from https://github.com/JasonEtco/actions-toolkit/blob/master/src/github.ts\nconst graphql_1 = __nccwpck_require__(8467);\nconst rest_1 = __nccwpck_require__(9351);\nconst Context = __importStar(__nccwpck_require__(4087));\nconst httpClient = __importStar(__nccwpck_require__(9925));\n// We need this in order to extend Octokit\nrest_1.Octokit.prototype = new rest_1.Octokit();\nexports.context = new Context.Context();\nclass GitHub extends rest_1.Octokit {\n constructor(token, opts) {\n super(GitHub.getOctokitOptions(GitHub.disambiguate(token, opts)));\n this.graphql = GitHub.getGraphQL(GitHub.disambiguate(token, opts));\n }\n /**\n * Disambiguates the constructor overload parameters\n */\n static disambiguate(token, opts) {\n return [\n typeof token === 'string' ? token : '',\n typeof token === 'object' ? token : opts || {}\n ];\n }\n static getOctokitOptions(args) {\n const token = args[0];\n const options = Object.assign({}, args[1]); // Shallow clone - don't mutate the object provided by the caller\n // Base URL - GHES or Dotcom\n options.baseUrl = options.baseUrl || this.getApiBaseUrl();\n // Auth\n const auth = GitHub.getAuthString(token, options);\n if (auth) {\n options.auth = auth;\n }\n // Proxy\n const agent = GitHub.getProxyAgent(options.baseUrl, options);\n if (agent) {\n // Shallow clone - don't mutate the object provided by the caller\n options.request = options.request ? Object.assign({}, options.request) : {};\n // Set the agent\n options.request.agent = agent;\n }\n return options;\n }\n static getGraphQL(args) {\n const defaults = {};\n defaults.baseUrl = this.getGraphQLBaseUrl();\n const token = args[0];\n const options = args[1];\n // Authorization\n const auth = this.getAuthString(token, options);\n if (auth) {\n defaults.headers = {\n authorization: auth\n };\n }\n // Proxy\n const agent = GitHub.getProxyAgent(defaults.baseUrl, options);\n if (agent) {\n defaults.request = { agent };\n }\n return graphql_1.graphql.defaults(defaults);\n }\n static getAuthString(token, options) {\n // Validate args\n if (!token && !options.auth) {\n throw new Error('Parameter token or opts.auth is required');\n }\n else if (token && options.auth) {\n throw new Error('Parameters token and opts.auth may not both be specified');\n }\n return typeof options.auth === 'string' ? options.auth : `token ${token}`;\n }\n static getProxyAgent(destinationUrl, options) {\n var _a;\n if (!((_a = options.request) === null || _a === void 0 ? void 0 : _a.agent)) {\n if (httpClient.getProxyUrl(destinationUrl)) {\n const hc = new httpClient.HttpClient();\n return hc.getAgent(destinationUrl);\n }\n }\n return undefined;\n }\n static getApiBaseUrl() {\n return process.env['GITHUB_API_URL'] || 'https://api.github.com';\n }\n static getGraphQLBaseUrl() {\n let url = process.env['GITHUB_GRAPHQL_URL'] || 'https://api.github.com/graphql';\n // Shouldn't be a trailing slash, but remove if so\n if (url.endsWith('/')) {\n url = url.substr(0, url.length - 1);\n }\n // Remove trailing \"/graphql\"\n if (url.toUpperCase().endsWith('/GRAPHQL')) {\n url = url.substr(0, url.length - '/graphql'.length);\n }\n return url;\n }\n}\nexports.GitHub = GitHub;\n//# sourceMappingURL=github.js.map\n\n/***/ }),\n\n/***/ 9925:\n/***/ ((__unused_webpack_module, exports, __nccwpck_require__) => {\n\n\"use strict\";\n\nObject.defineProperty(exports, \"__esModule\", ({ value: true }));\nconst http = __nccwpck_require__(3685);\nconst https = __nccwpck_require__(5687);\nconst pm = __nccwpck_require__(6443);\nlet tunnel;\nvar HttpCodes;\n(function (HttpCodes) {\n HttpCodes[HttpCodes[\"OK\"] = 200] = \"OK\";\n HttpCodes[HttpCodes[\"MultipleChoices\"] = 300] = \"MultipleChoices\";\n HttpCodes[HttpCodes[\"MovedPermanently\"] = 301] = \"MovedPermanently\";\n HttpCodes[HttpCodes[\"ResourceMoved\"] = 302] = \"ResourceMoved\";\n HttpCodes[HttpCodes[\"SeeOther\"] = 303] = \"SeeOther\";\n HttpCodes[HttpCodes[\"NotModified\"] = 304] = \"NotModified\";\n HttpCodes[HttpCodes[\"UseProxy\"] = 305] = \"UseProxy\";\n HttpCodes[HttpCodes[\"SwitchProxy\"] = 306] = \"SwitchProxy\";\n HttpCodes[HttpCodes[\"TemporaryRedirect\"] = 307] = \"TemporaryRedirect\";\n HttpCodes[HttpCodes[\"PermanentRedirect\"] = 308] = \"PermanentRedirect\";\n HttpCodes[HttpCodes[\"BadRequest\"] = 400] = \"BadRequest\";\n HttpCodes[HttpCodes[\"Unauthorized\"] = 401] = \"Unauthorized\";\n HttpCodes[HttpCodes[\"PaymentRequired\"] = 402] = \"PaymentRequired\";\n HttpCodes[HttpCodes[\"Forbidden\"] = 403] = \"Forbidden\";\n HttpCodes[HttpCodes[\"NotFound\"] = 404] = \"NotFound\";\n HttpCodes[HttpCodes[\"MethodNotAllowed\"] = 405] = \"MethodNotAllowed\";\n HttpCodes[HttpCodes[\"NotAcceptable\"] = 406] = \"NotAcceptable\";\n HttpCodes[HttpCodes[\"ProxyAuthenticationRequired\"] = 407] = \"ProxyAuthenticationRequired\";\n HttpCodes[HttpCodes[\"RequestTimeout\"] = 408] = \"RequestTimeout\";\n HttpCodes[HttpCodes[\"Conflict\"] = 409] = \"Conflict\";\n HttpCodes[HttpCodes[\"Gone\"] = 410] = \"Gone\";\n HttpCodes[HttpCodes[\"TooManyRequests\"] = 429] = \"TooManyRequests\";\n HttpCodes[HttpCodes[\"InternalServerError\"] = 500] = \"InternalServerError\";\n HttpCodes[HttpCodes[\"NotImplemented\"] = 501] = \"NotImplemented\";\n HttpCodes[HttpCodes[\"BadGateway\"] = 502] = \"BadGateway\";\n HttpCodes[HttpCodes[\"ServiceUnavailable\"] = 503] = \"ServiceUnavailable\";\n HttpCodes[HttpCodes[\"GatewayTimeout\"] = 504] = \"GatewayTimeout\";\n})(HttpCodes = exports.HttpCodes || (exports.HttpCodes = {}));\nvar Headers;\n(function (Headers) {\n Headers[\"Accept\"] = \"accept\";\n Headers[\"ContentType\"] = \"content-type\";\n})(Headers = exports.Headers || (exports.Headers = {}));\nvar MediaTypes;\n(function (MediaTypes) {\n MediaTypes[\"ApplicationJson\"] = \"application/json\";\n})(MediaTypes = exports.MediaTypes || (exports.MediaTypes = {}));\n/**\n * Returns the proxy URL, depending upon the supplied url and proxy environment variables.\n * @param serverUrl The server URL where the request will be sent. For example, https://api.github.com\n */\nfunction getProxyUrl(serverUrl) {\n let proxyUrl = pm.getProxyUrl(new URL(serverUrl));\n return proxyUrl ? proxyUrl.href : '';\n}\nexports.getProxyUrl = getProxyUrl;\nconst HttpRedirectCodes = [\n HttpCodes.MovedPermanently,\n HttpCodes.ResourceMoved,\n HttpCodes.SeeOther,\n HttpCodes.TemporaryRedirect,\n HttpCodes.PermanentRedirect\n];\nconst HttpResponseRetryCodes = [\n HttpCodes.BadGateway,\n HttpCodes.ServiceUnavailable,\n HttpCodes.GatewayTimeout\n];\nconst RetryableHttpVerbs = ['OPTIONS', 'GET', 'DELETE', 'HEAD'];\nconst ExponentialBackoffCeiling = 10;\nconst ExponentialBackoffTimeSlice = 5;\nclass HttpClientError extends Error {\n constructor(message, statusCode) {\n super(message);\n this.name = 'HttpClientError';\n this.statusCode = statusCode;\n Object.setPrototypeOf(this, HttpClientError.prototype);\n }\n}\nexports.HttpClientError = HttpClientError;\nclass HttpClientResponse {\n constructor(message) {\n this.message = message;\n }\n readBody() {\n return new Promise(async (resolve, reject) => {\n let output = Buffer.alloc(0);\n this.message.on('data', (chunk) => {\n output = Buffer.concat([output, chunk]);\n });\n this.message.on('end', () => {\n resolve(output.toString());\n });\n });\n }\n}\nexports.HttpClientResponse = HttpClientResponse;\nfunction isHttps(requestUrl) {\n let parsedUrl = new URL(requestUrl);\n return parsedUrl.protocol === 'https:';\n}\nexports.isHttps = isHttps;\nclass HttpClient {\n constructor(userAgent, handlers, requestOptions) {\n this._ignoreSslError = false;\n this._allowRedirects = true;\n this._allowRedirectDowngrade = false;\n this._maxRedirects = 50;\n this._allowRetries = false;\n this._maxRetries = 1;\n this._keepAlive = false;\n this._disposed = false;\n this.userAgent = userAgent;\n this.handlers = handlers || [];\n this.requestOptions = requestOptions;\n if (requestOptions) {\n if (requestOptions.ignoreSslError != null) {\n this._ignoreSslError = requestOptions.ignoreSslError;\n }\n this._socketTimeout = requestOptions.socketTimeout;\n if (requestOptions.allowRedirects != null) {\n this._allowRedirects = requestOptions.allowRedirects;\n }\n if (requestOptions.allowRedirectDowngrade != null) {\n this._allowRedirectDowngrade = requestOptions.allowRedirectDowngrade;\n }\n if (requestOptions.maxRedirects != null) {\n this._maxRedirects = Math.max(requestOptions.maxRedirects, 0);\n }\n if (requestOptions.keepAlive != null) {\n this._keepAlive = requestOptions.keepAlive;\n }\n if (requestOptions.allowRetries != null) {\n this._allowRetries = requestOptions.allowRetries;\n }\n if (requestOptions.maxRetries != null) {\n this._maxRetries = requestOptions.maxRetries;\n }\n }\n }\n options(requestUrl, additionalHeaders) {\n return this.request('OPTIONS', requestUrl, null, additionalHeaders || {});\n }\n get(requestUrl, additionalHeaders) {\n return this.request('GET', requestUrl, null, additionalHeaders || {});\n }\n del(requestUrl, additionalHeaders) {\n return this.request('DELETE', requestUrl, null, additionalHeaders || {});\n }\n post(requestUrl, data, additionalHeaders) {\n return this.request('POST', requestUrl, data, additionalHeaders || {});\n }\n patch(requestUrl, data, additionalHeaders) {\n return this.request('PATCH', requestUrl, data, additionalHeaders || {});\n }\n put(requestUrl, data, additionalHeaders) {\n return this.request('PUT', requestUrl, data, additionalHeaders || {});\n }\n head(requestUrl, additionalHeaders) {\n return this.request('HEAD', requestUrl, null, additionalHeaders || {});\n }\n sendStream(verb, requestUrl, stream, additionalHeaders) {\n return this.request(verb, requestUrl, stream, additionalHeaders);\n }\n /**\n * Gets a typed object from an endpoint\n * Be aware that not found returns a null. Other errors (4xx, 5xx) reject the promise\n */\n async getJson(requestUrl, additionalHeaders = {}) {\n additionalHeaders[Headers.Accept] = this._getExistingOrDefaultHeader(additionalHeaders, Headers.Accept, MediaTypes.ApplicationJson);\n let res = await this.get(requestUrl, additionalHeaders);\n return this._processResponse(res, this.requestOptions);\n }\n async postJson(requestUrl, obj, additionalHeaders = {}) {\n let data = JSON.stringify(obj, null, 2);\n additionalHeaders[Headers.Accept] = this._getExistingOrDefaultHeader(additionalHeaders, Headers.Accept, MediaTypes.ApplicationJson);\n additionalHeaders[Headers.ContentType] = this._getExistingOrDefaultHeader(additionalHeaders, Headers.ContentType, MediaTypes.ApplicationJson);\n let res = await this.post(requestUrl, data, additionalHeaders);\n return this._processResponse(res, this.requestOptions);\n }\n async putJson(requestUrl, obj, additionalHeaders = {}) {\n let data = JSON.stringify(obj, null, 2);\n additionalHeaders[Headers.Accept] = this._getExistingOrDefaultHeader(additionalHeaders, Headers.Accept, MediaTypes.ApplicationJson);\n additionalHeaders[Headers.ContentType] = this._getExistingOrDefaultHeader(additionalHeaders, Headers.ContentType, MediaTypes.ApplicationJson);\n let res = await this.put(requestUrl, data, additionalHeaders);\n return this._processResponse(res, this.requestOptions);\n }\n async patchJson(requestUrl, obj, additionalHeaders = {}) {\n let data = JSON.stringify(obj, null, 2);\n additionalHeaders[Headers.Accept] = this._getExistingOrDefaultHeader(additionalHeaders, Headers.Accept, MediaTypes.ApplicationJson);\n additionalHeaders[Headers.ContentType] = this._getExistingOrDefaultHeader(additionalHeaders, Headers.ContentType, MediaTypes.ApplicationJson);\n let res = await this.patch(requestUrl, data, additionalHeaders);\n return this._processResponse(res, this.requestOptions);\n }\n /**\n * Makes a raw http request.\n * All other methods such as get, post, patch, and request ultimately call this.\n * Prefer get, del, post and patch\n */\n async request(verb, requestUrl, data, headers) {\n if (this._disposed) {\n throw new Error('Client has already been disposed.');\n }\n let parsedUrl = new URL(requestUrl);\n let info = this._prepareRequest(verb, parsedUrl, headers);\n // Only perform retries on reads since writes may not be idempotent.\n let maxTries = this._allowRetries && RetryableHttpVerbs.indexOf(verb) != -1\n ? this._maxRetries + 1\n : 1;\n let numTries = 0;\n let response;\n while (numTries < maxTries) {\n response = await this.requestRaw(info, data);\n // Check if it's an authentication challenge\n if (response &&\n response.message &&\n response.message.statusCode === HttpCodes.Unauthorized) {\n let authenticationHandler;\n for (let i = 0; i < this.handlers.length; i++) {\n if (this.handlers[i].canHandleAuthentication(response)) {\n authenticationHandler = this.handlers[i];\n break;\n }\n }\n if (authenticationHandler) {\n return authenticationHandler.handleAuthentication(this, info, data);\n }\n else {\n // We have received an unauthorized response but have no handlers to handle it.\n // Let the response return to the caller.\n return response;\n }\n }\n let redirectsRemaining = this._maxRedirects;\n while (HttpRedirectCodes.indexOf(response.message.statusCode) != -1 &&\n this._allowRedirects &&\n redirectsRemaining > 0) {\n const redirectUrl = response.message.headers['location'];\n if (!redirectUrl) {\n // if there's no location to redirect to, we won't\n break;\n }\n let parsedRedirectUrl = new URL(redirectUrl);\n if (parsedUrl.protocol == 'https:' &&\n parsedUrl.protocol != parsedRedirectUrl.protocol &&\n !this._allowRedirectDowngrade) {\n throw new Error('Redirect from HTTPS to HTTP protocol. This downgrade is not allowed for security reasons. If you want to allow this behavior, set the allowRedirectDowngrade option to true.');\n }\n // we need to finish reading the response before reassigning response\n // which will leak the open socket.\n await response.readBody();\n // strip authorization header if redirected to a different hostname\n if (parsedRedirectUrl.hostname !== parsedUrl.hostname) {\n for (let header in headers) {\n // header names are case insensitive\n if (header.toLowerCase() === 'authorization') {\n delete headers[header];\n }\n }\n }\n // let's make the request with the new redirectUrl\n info = this._prepareRequest(verb, parsedRedirectUrl, headers);\n response = await this.requestRaw(info, data);\n redirectsRemaining--;\n }\n if (HttpResponseRetryCodes.indexOf(response.message.statusCode) == -1) {\n // If not a retry code, return immediately instead of retrying\n return response;\n }\n numTries += 1;\n if (numTries < maxTries) {\n await response.readBody();\n await this._performExponentialBackoff(numTries);\n }\n }\n return response;\n }\n /**\n * Needs to be called if keepAlive is set to true in request options.\n */\n dispose() {\n if (this._agent) {\n this._agent.destroy();\n }\n this._disposed = true;\n }\n /**\n * Raw request.\n * @param info\n * @param data\n */\n requestRaw(info, data) {\n return new Promise((resolve, reject) => {\n let callbackForResult = function (err, res) {\n if (err) {\n reject(err);\n }\n resolve(res);\n };\n this.requestRawWithCallback(info, data, callbackForResult);\n });\n }\n /**\n * Raw request with callback.\n * @param info\n * @param data\n * @param onResult\n */\n requestRawWithCallback(info, data, onResult) {\n let socket;\n if (typeof data === 'string') {\n info.options.headers['Content-Length'] = Buffer.byteLength(data, 'utf8');\n }\n let callbackCalled = false;\n let handleResult = (err, res) => {\n if (!callbackCalled) {\n callbackCalled = true;\n onResult(err, res);\n }\n };\n let req = info.httpModule.request(info.options, (msg) => {\n let res = new HttpClientResponse(msg);\n handleResult(null, res);\n });\n req.on('socket', sock => {\n socket = sock;\n });\n // If we ever get disconnected, we want the socket to timeout eventually\n req.setTimeout(this._socketTimeout || 3 * 60000, () => {\n if (socket) {\n socket.end();\n }\n handleResult(new Error('Request timeout: ' + info.options.path), null);\n });\n req.on('error', function (err) {\n // err has statusCode property\n // res should have headers\n handleResult(err, null);\n });\n if (data && typeof data === 'string') {\n req.write(data, 'utf8');\n }\n if (data && typeof data !== 'string') {\n data.on('close', function () {\n req.end();\n });\n data.pipe(req);\n }\n else {\n req.end();\n }\n }\n /**\n * Gets an http agent. This function is useful when you need an http agent that handles\n * routing through a proxy server - depending upon the url and proxy environment variables.\n * @param serverUrl The server URL where the request will be sent. For example, https://api.github.com\n */\n getAgent(serverUrl) {\n let parsedUrl = new URL(serverUrl);\n return this._getAgent(parsedUrl);\n }\n _prepareRequest(method, requestUrl, headers) {\n const info = {};\n info.parsedUrl = requestUrl;\n const usingSsl = info.parsedUrl.protocol === 'https:';\n info.httpModule = usingSsl ? https : http;\n const defaultPort = usingSsl ? 443 : 80;\n info.options = {};\n info.options.host = info.parsedUrl.hostname;\n info.options.port = info.parsedUrl.port\n ? parseInt(info.parsedUrl.port)\n : defaultPort;\n info.options.path =\n (info.parsedUrl.pathname || '') + (info.parsedUrl.search || '');\n info.options.method = method;\n info.options.headers = this._mergeHeaders(headers);\n if (this.userAgent != null) {\n info.options.headers['user-agent'] = this.userAgent;\n }\n info.options.agent = this._getAgent(info.parsedUrl);\n // gives handlers an opportunity to participate\n if (this.handlers) {\n this.handlers.forEach(handler => {\n handler.prepareRequest(info.options);\n });\n }\n return info;\n }\n _mergeHeaders(headers) {\n const lowercaseKeys = obj => Object.keys(obj).reduce((c, k) => ((c[k.toLowerCase()] = obj[k]), c), {});\n if (this.requestOptions && this.requestOptions.headers) {\n return Object.assign({}, lowercaseKeys(this.requestOptions.headers), lowercaseKeys(headers));\n }\n return lowercaseKeys(headers || {});\n }\n _getExistingOrDefaultHeader(additionalHeaders, header, _default) {\n const lowercaseKeys = obj => Object.keys(obj).reduce((c, k) => ((c[k.toLowerCase()] = obj[k]), c), {});\n let clientHeader;\n if (this.requestOptions && this.requestOptions.headers) {\n clientHeader = lowercaseKeys(this.requestOptions.headers)[header];\n }\n return additionalHeaders[header] || clientHeader || _default;\n }\n _getAgent(parsedUrl) {\n let agent;\n let proxyUrl = pm.getProxyUrl(parsedUrl);\n let useProxy = proxyUrl && proxyUrl.hostname;\n if (this._keepAlive && useProxy) {\n agent = this._proxyAgent;\n }\n if (this._keepAlive && !useProxy) {\n agent = this._agent;\n }\n // if agent is already assigned use that agent.\n if (!!agent) {\n return agent;\n }\n const usingSsl = parsedUrl.protocol === 'https:';\n let maxSockets = 100;\n if (!!this.requestOptions) {\n maxSockets = this.requestOptions.maxSockets || http.globalAgent.maxSockets;\n }\n if (useProxy) {\n // If using proxy, need tunnel\n if (!tunnel) {\n tunnel = __nccwpck_require__(4294);\n }\n const agentOptions = {\n maxSockets: maxSockets,\n keepAlive: this._keepAlive,\n proxy: {\n ...((proxyUrl.username || proxyUrl.password) && {\n proxyAuth: `${proxyUrl.username}:${proxyUrl.password}`\n }),\n host: proxyUrl.hostname,\n port: proxyUrl.port\n }\n };\n let tunnelAgent;\n const overHttps = proxyUrl.protocol === 'https:';\n if (usingSsl) {\n tunnelAgent = overHttps ? tunnel.httpsOverHttps : tunnel.httpsOverHttp;\n }\n else {\n tunnelAgent = overHttps ? tunnel.httpOverHttps : tunnel.httpOverHttp;\n }\n agent = tunnelAgent(agentOptions);\n this._proxyAgent = agent;\n }\n // if reusing agent across request and tunneling agent isn't assigned create a new agent\n if (this._keepAlive && !agent) {\n const options = { keepAlive: this._keepAlive, maxSockets: maxSockets };\n agent = usingSsl ? new https.Agent(options) : new http.Agent(options);\n this._agent = agent;\n }\n // if not using private agent and tunnel agent isn't setup then use global agent\n if (!agent) {\n agent = usingSsl ? https.globalAgent : http.globalAgent;\n }\n if (usingSsl && this._ignoreSslError) {\n // we don't want to set NODE_TLS_REJECT_UNAUTHORIZED=0 since that will affect request for entire process\n // http.RequestOptions doesn't expose a way to modify RequestOptions.agent.options\n // we have to cast it to any and change it directly\n agent.options = Object.assign(agent.options || {}, {\n rejectUnauthorized: false\n });\n }\n return agent;\n }\n _performExponentialBackoff(retryNumber) {\n retryNumber = Math.min(ExponentialBackoffCeiling, retryNumber);\n const ms = ExponentialBackoffTimeSlice * Math.pow(2, retryNumber);\n return new Promise(resolve => setTimeout(() => resolve(), ms));\n }\n static dateTimeDeserializer(key, value) {\n if (typeof value === 'string') {\n let a = new Date(value);\n if (!isNaN(a.valueOf())) {\n return a;\n }\n }\n return value;\n }\n async _processResponse(res, options) {\n return new Promise(async (resolve, reject) => {\n const statusCode = res.message.statusCode;\n const response = {\n statusCode: statusCode,\n result: null,\n headers: {}\n };\n // not found leads to null obj returned\n if (statusCode == HttpCodes.NotFound) {\n resolve(response);\n }\n let obj;\n let contents;\n // get the result from the body\n try {\n contents = await res.readBody();\n if (contents && contents.length > 0) {\n if (options && options.deserializeDates) {\n obj = JSON.parse(contents, HttpClient.dateTimeDeserializer);\n }\n else {\n obj = JSON.parse(contents);\n }\n response.result = obj;\n }\n response.headers = res.message.headers;\n }\n catch (err) {\n // Invalid resource (contents not json); leaving result obj null\n }\n // note that 3xx redirects are handled by the http layer.\n if (statusCode > 299) {\n let msg;\n // if exception/error in body, attempt to get better error\n if (obj && obj.message) {\n msg = obj.message;\n }\n else if (contents && contents.length > 0) {\n // it may be the case that the exception is in the body message as string\n msg = contents;\n }\n else {\n msg = 'Failed request: (' + statusCode + ')';\n }\n let err = new HttpClientError(msg, statusCode);\n err.result = response.result;\n reject(err);\n }\n else {\n resolve(response);\n }\n });\n }\n}\nexports.HttpClient = HttpClient;\n\n\n/***/ }),\n\n/***/ 6443:\n/***/ ((__unused_webpack_module, exports) => {\n\n\"use strict\";\n\nObject.defineProperty(exports, \"__esModule\", ({ value: true }));\nfunction getProxyUrl(reqUrl) {\n let usingSsl = reqUrl.protocol === 'https:';\n let proxyUrl;\n if (checkBypass(reqUrl)) {\n return proxyUrl;\n }\n let proxyVar;\n if (usingSsl) {\n proxyVar = process.env['https_proxy'] || process.env['HTTPS_PROXY'];\n }\n else {\n proxyVar = process.env['http_proxy'] || process.env['HTTP_PROXY'];\n }\n if (proxyVar) {\n proxyUrl = new URL(proxyVar);\n }\n return proxyUrl;\n}\nexports.getProxyUrl = getProxyUrl;\nfunction checkBypass(reqUrl) {\n if (!reqUrl.hostname) {\n return false;\n }\n let noProxy = process.env['no_proxy'] || process.env['NO_PROXY'] || '';\n if (!noProxy) {\n return false;\n }\n // Determine the request port\n let reqPort;\n if (reqUrl.port) {\n reqPort = Number(reqUrl.port);\n }\n else if (reqUrl.protocol === 'http:') {\n reqPort = 80;\n }\n else if (reqUrl.protocol === 'https:') {\n reqPort = 443;\n }\n // Format the request hostname and hostname with port\n let upperReqHosts = [reqUrl.hostname.toUpperCase()];\n if (typeof reqPort === 'number') {\n upperReqHosts.push(`${upperReqHosts[0]}:${reqPort}`);\n }\n // Compare request host against noproxy\n for (let upperNoProxyItem of noProxy\n .split(',')\n .map(x => x.trim().toUpperCase())\n .filter(x => x)) {\n if (upperReqHosts.some(x => x === upperNoProxyItem)) {\n return true;\n }\n }\n return false;\n}\nexports.checkBypass = checkBypass;\n\n\n/***/ }),\n\n/***/ 334:\n/***/ ((__unused_webpack_module, exports) => {\n\n\"use strict\";\n\n\nObject.defineProperty(exports, \"__esModule\", ({ value: true }));\n\nconst REGEX_IS_INSTALLATION_LEGACY = /^v1\\./;\nconst REGEX_IS_INSTALLATION = /^ghs_/;\nconst REGEX_IS_USER_TO_SERVER = /^ghu_/;\nasync function auth(token) {\n const isApp = token.split(/\\./).length === 3;\n const isInstallation = REGEX_IS_INSTALLATION_LEGACY.test(token) || REGEX_IS_INSTALLATION.test(token);\n const isUserToServer = REGEX_IS_USER_TO_SERVER.test(token);\n const tokenType = isApp ? \"app\" : isInstallation ? \"installation\" : isUserToServer ? \"user-to-server\" : \"oauth\";\n return {\n type: \"token\",\n token: token,\n tokenType\n };\n}\n\n/**\n * Prefix token for usage in the Authorization header\n *\n * @param token OAuth token or JSON Web Token\n */\nfunction withAuthorizationPrefix(token) {\n if (token.split(/\\./).length === 3) {\n return `bearer ${token}`;\n }\n\n return `token ${token}`;\n}\n\nasync function hook(token, request, route, parameters) {\n const endpoint = request.endpoint.merge(route, parameters);\n endpoint.headers.authorization = withAuthorizationPrefix(token);\n return request(endpoint);\n}\n\nconst createTokenAuth = function createTokenAuth(token) {\n if (!token) {\n throw new Error(\"[@octokit/auth-token] No token passed to createTokenAuth\");\n }\n\n if (typeof token !== \"string\") {\n throw new Error(\"[@octokit/auth-token] Token passed to createTokenAuth is not a string\");\n }\n\n token = token.replace(/^(token|bearer) +/i, \"\");\n return Object.assign(auth.bind(null, token), {\n hook: hook.bind(null, token)\n });\n};\n\nexports.createTokenAuth = createTokenAuth;\n//# sourceMappingURL=index.js.map\n\n\n/***/ }),\n\n/***/ 9440:\n/***/ ((__unused_webpack_module, exports, __nccwpck_require__) => {\n\n\"use strict\";\n\n\nObject.defineProperty(exports, \"__esModule\", ({ value: true }));\n\nvar isPlainObject = __nccwpck_require__(558);\nvar universalUserAgent = __nccwpck_require__(5030);\n\nfunction lowercaseKeys(object) {\n if (!object) {\n return {};\n }\n\n return Object.keys(object).reduce((newObj, key) => {\n newObj[key.toLowerCase()] = object[key];\n return newObj;\n }, {});\n}\n\nfunction mergeDeep(defaults, options) {\n const result = Object.assign({}, defaults);\n Object.keys(options).forEach(key => {\n if (isPlainObject.isPlainObject(options[key])) {\n if (!(key in defaults)) Object.assign(result, {\n [key]: options[key]\n });else result[key] = mergeDeep(defaults[key], options[key]);\n } else {\n Object.assign(result, {\n [key]: options[key]\n });\n }\n });\n return result;\n}\n\nfunction removeUndefinedProperties(obj) {\n for (const key in obj) {\n if (obj[key] === undefined) {\n delete obj[key];\n }\n }\n\n return obj;\n}\n\nfunction merge(defaults, route, options) {\n if (typeof route === \"string\") {\n let [method, url] = route.split(\" \");\n options = Object.assign(url ? {\n method,\n url\n } : {\n url: method\n }, options);\n } else {\n options = Object.assign({}, route);\n } // lowercase header names before merging with defaults to avoid duplicates\n\n\n options.headers = lowercaseKeys(options.headers); // remove properties with undefined values before merging\n\n removeUndefinedProperties(options);\n removeUndefinedProperties(options.headers);\n const mergedOptions = mergeDeep(defaults || {}, options); // mediaType.previews arrays are merged, instead of overwritten\n\n if (defaults && defaults.mediaType.previews.length) {\n mergedOptions.mediaType.previews = defaults.mediaType.previews.filter(preview => !mergedOptions.mediaType.previews.includes(preview)).concat(mergedOptions.mediaType.previews);\n }\n\n mergedOptions.mediaType.previews = mergedOptions.mediaType.previews.map(preview => preview.replace(/-preview/, \"\"));\n return mergedOptions;\n}\n\nfunction addQueryParameters(url, parameters) {\n const separator = /\\?/.test(url) ? \"&\" : \"?\";\n const names = Object.keys(parameters);\n\n if (names.length === 0) {\n return url;\n }\n\n return url + separator + names.map(name => {\n if (name === \"q\") {\n return \"q=\" + parameters.q.split(\"+\").map(encodeURIComponent).join(\"+\");\n }\n\n return `${name}=${encodeURIComponent(parameters[name])}`;\n }).join(\"&\");\n}\n\nconst urlVariableRegex = /\\{[^}]+\\}/g;\n\nfunction removeNonChars(variableName) {\n return variableName.replace(/^\\W+|\\W+$/g, \"\").split(/,/);\n}\n\nfunction extractUrlVariableNames(url) {\n const matches = url.match(urlVariableRegex);\n\n if (!matches) {\n return [];\n }\n\n return matches.map(removeNonChars).reduce((a, b) => a.concat(b), []);\n}\n\nfunction omit(object, keysToOmit) {\n return Object.keys(object).filter(option => !keysToOmit.includes(option)).reduce((obj, key) => {\n obj[key] = object[key];\n return obj;\n }, {});\n}\n\n// Based on https://github.com/bramstein/url-template, licensed under BSD\n// TODO: create separate package.\n//\n// Copyright (c) 2012-2014, Bram Stein\n// All rights reserved.\n// Redistribution and use in source and binary forms, with or without\n// modification, are permitted provided that the following conditions\n// are met:\n// 1. Redistributions of source code must retain the above copyright\n// notice, this list of conditions and the following disclaimer.\n// 2. Redistributions in binary form must reproduce the above copyright\n// notice, this list of conditions and the following disclaimer in the\n// documentation and/or other materials provided with the distribution.\n// 3. The name of the author may not be used to endorse or promote products\n// derived from this software without specific prior written permission.\n// THIS SOFTWARE IS PROVIDED BY THE AUTHOR \"AS IS\" AND ANY EXPRESS OR IMPLIED\n// WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF\n// MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO\n// EVENT SHALL THE COPYRIGHT OWNER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT,\n// INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING,\n// BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE,\n// DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY\n// OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING\n// NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS SOFTWARE,\n// EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.\n\n/* istanbul ignore file */\nfunction encodeReserved(str) {\n return str.split(/(%[0-9A-Fa-f]{2})/g).map(function (part) {\n if (!/%[0-9A-Fa-f]/.test(part)) {\n part = encodeURI(part).replace(/%5B/g, \"[\").replace(/%5D/g, \"]\");\n }\n\n return part;\n }).join(\"\");\n}\n\nfunction encodeUnreserved(str) {\n return encodeURIComponent(str).replace(/[!'()*]/g, function (c) {\n return \"%\" + c.charCodeAt(0).toString(16).toUpperCase();\n });\n}\n\nfunction encodeValue(operator, value, key) {\n value = operator === \"+\" || operator === \"#\" ? encodeReserved(value) : encodeUnreserved(value);\n\n if (key) {\n return encodeUnreserved(key) + \"=\" + value;\n } else {\n return value;\n }\n}\n\nfunction isDefined(value) {\n return value !== undefined && value !== null;\n}\n\nfunction isKeyOperator(operator) {\n return operator === \";\" || operator === \"&\" || operator === \"?\";\n}\n\nfunction getValues(context, operator, key, modifier) {\n var value = context[key],\n result = [];\n\n if (isDefined(value) && value !== \"\") {\n if (typeof value === \"string\" || typeof value === \"number\" || typeof value === \"boolean\") {\n value = value.toString();\n\n if (modifier && modifier !== \"*\") {\n value = value.substring(0, parseInt(modifier, 10));\n }\n\n result.push(encodeValue(operator, value, isKeyOperator(operator) ? key : \"\"));\n } else {\n if (modifier === \"*\") {\n if (Array.isArray(value)) {\n value.filter(isDefined).forEach(function (value) {\n result.push(encodeValue(operator, value, isKeyOperator(operator) ? key : \"\"));\n });\n } else {\n Object.keys(value).forEach(function (k) {\n if (isDefined(value[k])) {\n result.push(encodeValue(operator, value[k], k));\n }\n });\n }\n } else {\n const tmp = [];\n\n if (Array.isArray(value)) {\n value.filter(isDefined).forEach(function (value) {\n tmp.push(encodeValue(operator, value));\n });\n } else {\n Object.keys(value).forEach(function (k) {\n if (isDefined(value[k])) {\n tmp.push(encodeUnreserved(k));\n tmp.push(encodeValue(operator, value[k].toString()));\n }\n });\n }\n\n if (isKeyOperator(operator)) {\n result.push(encodeUnreserved(key) + \"=\" + tmp.join(\",\"));\n } else if (tmp.length !== 0) {\n result.push(tmp.join(\",\"));\n }\n }\n }\n } else {\n if (operator === \";\") {\n if (isDefined(value)) {\n result.push(encodeUnreserved(key));\n }\n } else if (value === \"\" && (operator === \"&\" || operator === \"?\")) {\n result.push(encodeUnreserved(key) + \"=\");\n } else if (value === \"\") {\n result.push(\"\");\n }\n }\n\n return result;\n}\n\nfunction parseUrl(template) {\n return {\n expand: expand.bind(null, template)\n };\n}\n\nfunction expand(template, context) {\n var operators = [\"+\", \"#\", \".\", \"/\", \";\", \"?\", \"&\"];\n return template.replace(/\\{([^\\{\\}]+)\\}|([^\\{\\}]+)/g, function (_, expression, literal) {\n if (expression) {\n let operator = \"\";\n const values = [];\n\n if (operators.indexOf(expression.charAt(0)) !== -1) {\n operator = expression.charAt(0);\n expression = expression.substr(1);\n }\n\n expression.split(/,/g).forEach(function (variable) {\n var tmp = /([^:\\*]*)(?::(\\d+)|(\\*))?/.exec(variable);\n values.push(getValues(context, operator, tmp[1], tmp[2] || tmp[3]));\n });\n\n if (operator && operator !== \"+\") {\n var separator = \",\";\n\n if (operator === \"?\") {\n separator = \"&\";\n } else if (operator !== \"#\") {\n separator = operator;\n }\n\n return (values.length !== 0 ? operator : \"\") + values.join(separator);\n } else {\n return values.join(\",\");\n }\n } else {\n return encodeReserved(literal);\n }\n });\n}\n\nfunction parse(options) {\n // https://fetch.spec.whatwg.org/#methods\n let method = options.method.toUpperCase(); // replace :varname with {varname} to make it RFC 6570 compatible\n\n let url = (options.url || \"/\").replace(/:([a-z]\\w+)/g, \"{$1}\");\n let headers = Object.assign({}, options.headers);\n let body;\n let parameters = omit(options, [\"method\", \"baseUrl\", \"url\", \"headers\", \"request\", \"mediaType\"]); // extract variable names from URL to calculate remaining variables later\n\n const urlVariableNames = extractUrlVariableNames(url);\n url = parseUrl(url).expand(parameters);\n\n if (!/^http/.test(url)) {\n url = options.baseUrl + url;\n }\n\n const omittedParameters = Object.keys(options).filter(option => urlVariableNames.includes(option)).concat(\"baseUrl\");\n const remainingParameters = omit(parameters, omittedParameters);\n const isBinaryRequest = /application\\/octet-stream/i.test(headers.accept);\n\n if (!isBinaryRequest) {\n if (options.mediaType.format) {\n // e.g. application/vnd.github.v3+json => application/vnd.github.v3.raw\n headers.accept = headers.accept.split(/,/).map(preview => preview.replace(/application\\/vnd(\\.\\w+)(\\.v3)?(\\.\\w+)?(\\+json)?$/, `application/vnd$1$2.${options.mediaType.format}`)).join(\",\");\n }\n\n if (options.mediaType.previews.length) {\n const previewsFromAcceptHeader = headers.accept.match(/[\\w-]+(?=-preview)/g) || [];\n headers.accept = previewsFromAcceptHeader.concat(options.mediaType.previews).map(preview => {\n const format = options.mediaType.format ? `.${options.mediaType.format}` : \"+json\";\n return `application/vnd.github.${preview}-preview${format}`;\n }).join(\",\");\n }\n } // for GET/HEAD requests, set URL query parameters from remaining parameters\n // for PATCH/POST/PUT/DELETE requests, set request body from remaining parameters\n\n\n if ([\"GET\", \"HEAD\"].includes(method)) {\n url = addQueryParameters(url, remainingParameters);\n } else {\n if (\"data\" in remainingParameters) {\n body = remainingParameters.data;\n } else {\n if (Object.keys(remainingParameters).length) {\n body = remainingParameters;\n } else {\n headers[\"content-length\"] = 0;\n }\n }\n } // default content-type for JSON if body is set\n\n\n if (!headers[\"content-type\"] && typeof body !== \"undefined\") {\n headers[\"content-type\"] = \"application/json; charset=utf-8\";\n } // GitHub expects 'content-length: 0' header for PUT/PATCH requests without body.\n // fetch does not allow to set `content-length` header, but we can set body to an empty string\n\n\n if ([\"PATCH\", \"PUT\"].includes(method) && typeof body === \"undefined\") {\n body = \"\";\n } // Only return body/request keys if present\n\n\n return Object.assign({\n method,\n url,\n headers\n }, typeof body !== \"undefined\" ? {\n body\n } : null, options.request ? {\n request: options.request\n } : null);\n}\n\nfunction endpointWithDefaults(defaults, route, options) {\n return parse(merge(defaults, route, options));\n}\n\nfunction withDefaults(oldDefaults, newDefaults) {\n const DEFAULTS = merge(oldDefaults, newDefaults);\n const endpoint = endpointWithDefaults.bind(null, DEFAULTS);\n return Object.assign(endpoint, {\n DEFAULTS,\n defaults: withDefaults.bind(null, DEFAULTS),\n merge: merge.bind(null, DEFAULTS),\n parse\n });\n}\n\nconst VERSION = \"6.0.12\";\n\nconst userAgent = `octokit-endpoint.js/${VERSION} ${universalUserAgent.getUserAgent()}`; // DEFAULTS has all properties set that EndpointOptions has, except url.\n// So we use RequestParameters and add method as additional required property.\n\nconst DEFAULTS = {\n method: \"GET\",\n baseUrl: \"https://api.github.com\",\n headers: {\n accept: \"application/vnd.github.v3+json\",\n \"user-agent\": userAgent\n },\n mediaType: {\n format: \"\",\n previews: []\n }\n};\n\nconst endpoint = withDefaults(null, DEFAULTS);\n\nexports.endpoint = endpoint;\n//# sourceMappingURL=index.js.map\n\n\n/***/ }),\n\n/***/ 558:\n/***/ ((__unused_webpack_module, exports) => {\n\n\"use strict\";\n\n\nObject.defineProperty(exports, \"__esModule\", ({ value: true }));\n\n/*!\n * is-plain-object <https://github.com/jonschlinkert/is-plain-object>\n *\n * Copyright (c) 2014-2017, Jon Schlinkert.\n * Released under the MIT License.\n */\n\nfunction isObject(o) {\n return Object.prototype.toString.call(o) === '[object Object]';\n}\n\nfunction isPlainObject(o) {\n var ctor,prot;\n\n if (isObject(o) === false) return false;\n\n // If has modified constructor\n ctor = o.constructor;\n if (ctor === undefined) return true;\n\n // If has modified prototype\n prot = ctor.prototype;\n if (isObject(prot) === false) return false;\n\n // If constructor does not have an Object-specific method\n if (prot.hasOwnProperty('isPrototypeOf') === false) {\n return false;\n }\n\n // Most likely a plain Object\n return true;\n}\n\nexports.isPlainObject = isPlainObject;\n\n\n/***/ }),\n\n/***/ 8467:\n/***/ ((__unused_webpack_module, exports, __nccwpck_require__) => {\n\n\"use strict\";\n\n\nObject.defineProperty(exports, \"__esModule\", ({ value: true }));\n\nvar request = __nccwpck_require__(6234);\nvar universalUserAgent = __nccwpck_require__(5030);\n\nconst VERSION = \"4.8.0\";\n\nfunction _buildMessageForResponseErrors(data) {\n return `Request failed due to following response errors:\\n` + data.errors.map(e => ` - ${e.message}`).join(\"\\n\");\n}\n\nclass GraphqlResponseError extends Error {\n constructor(request, headers, response) {\n super(_buildMessageForResponseErrors(response));\n this.request = request;\n this.headers = headers;\n this.response = response;\n this.name = \"GraphqlResponseError\"; // Expose the errors and response data in their shorthand properties.\n\n this.errors = response.errors;\n this.data = response.data; // Maintains proper stack trace (only available on V8)\n\n /* istanbul ignore next */\n\n if (Error.captureStackTrace) {\n Error.captureStackTrace(this, this.constructor);\n }\n }\n\n}\n\nconst NON_VARIABLE_OPTIONS = [\"method\", \"baseUrl\", \"url\", \"headers\", \"request\", \"query\", \"mediaType\"];\nconst FORBIDDEN_VARIABLE_OPTIONS = [\"query\", \"method\", \"url\"];\nconst GHES_V3_SUFFIX_REGEX = /\\/api\\/v3\\/?$/;\nfunction graphql(request, query, options) {\n if (options) {\n if (typeof query === \"string\" && \"query\" in options) {\n return Promise.reject(new Error(`[@octokit/graphql] \"query\" cannot be used as variable name`));\n }\n\n for (const key in options) {\n if (!FORBIDDEN_VARIABLE_OPTIONS.includes(key)) continue;\n return Promise.reject(new Error(`[@octokit/graphql] \"${key}\" cannot be used as variable name`));\n }\n }\n\n const parsedOptions = typeof query === \"string\" ? Object.assign({\n query\n }, options) : query;\n const requestOptions = Object.keys(parsedOptions).reduce((result, key) => {\n if (NON_VARIABLE_OPTIONS.includes(key)) {\n result[key] = parsedOptions[key];\n return result;\n }\n\n if (!result.variables) {\n result.variables = {};\n }\n\n result.variables[key] = parsedOptions[key];\n return result;\n }, {}); // workaround for GitHub Enterprise baseUrl set with /api/v3 suffix\n // https://github.com/octokit/auth-app.js/issues/111#issuecomment-657610451\n\n const baseUrl = parsedOptions.baseUrl || request.endpoint.DEFAULTS.baseUrl;\n\n if (GHES_V3_SUFFIX_REGEX.test(baseUrl)) {\n requestOptions.url = baseUrl.replace(GHES_V3_SUFFIX_REGEX, \"/api/graphql\");\n }\n\n return request(requestOptions).then(response => {\n if (response.data.errors) {\n const headers = {};\n\n for (const key of Object.keys(response.headers)) {\n headers[key] = response.headers[key];\n }\n\n throw new GraphqlResponseError(requestOptions, headers, response.data);\n }\n\n return response.data.data;\n });\n}\n\nfunction withDefaults(request$1, newDefaults) {\n const newRequest = request$1.defaults(newDefaults);\n\n const newApi = (query, options) => {\n return graphql(newRequest, query, options);\n };\n\n return Object.assign(newApi, {\n defaults: withDefaults.bind(null, newRequest),\n endpoint: request.request.endpoint\n });\n}\n\nconst graphql$1 = withDefaults(request.request, {\n headers: {\n \"user-agent\": `octokit-graphql.js/${VERSION} ${universalUserAgent.getUserAgent()}`\n },\n method: \"POST\",\n url: \"/graphql\"\n});\nfunction withCustomRequest(customRequest) {\n return withDefaults(customRequest, {\n method: \"POST\",\n url: \"/graphql\"\n });\n}\n\nexports.GraphqlResponseError = GraphqlResponseError;\nexports.graphql = graphql$1;\nexports.withCustomRequest = withCustomRequest;\n//# sourceMappingURL=index.js.map\n\n\n/***/ }),\n\n/***/ 4193:\n/***/ ((__unused_webpack_module, exports) => {\n\n\"use strict\";\n\n\nObject.defineProperty(exports, \"__esModule\", ({ value: true }));\n\nconst VERSION = \"1.1.2\";\n\n/**\n * Some \u201clist\u201d response that can be paginated have a different response structure\n *\n * They have a `total_count` key in the response (search also has `incomplete_results`,\n * /installation/repositories also has `repository_selection`), as well as a key with\n * the list of the items which name varies from endpoint to endpoint:\n *\n * - https://developer.github.com/v3/search/#example (key `items`)\n * - https://developer.github.com/v3/checks/runs/#response-3 (key: `check_runs`)\n * - https://developer.github.com/v3/checks/suites/#response-1 (key: `check_suites`)\n * - https://developer.github.com/v3/apps/installations/#list-repositories (key: `repositories`)\n * - https://developer.github.com/v3/apps/installations/#list-installations-for-a-user (key `installations`)\n *\n * Octokit normalizes these responses so that paginated results are always returned following\n * the same structure. One challenge is that if the list response has only one page, no Link\n * header is provided, so this header alone is not sufficient to check wether a response is\n * paginated or not. For the exceptions with the namespace, a fallback check for the route\n * paths has to be added in order to normalize the response. We cannot check for the total_count\n * property because it also exists in the response of Get the combined status for a specific ref.\n */\nconst REGEX = [/^\\/search\\//, /^\\/repos\\/[^/]+\\/[^/]+\\/commits\\/[^/]+\\/(check-runs|check-suites)([^/]|$)/, /^\\/installation\\/repositories([^/]|$)/, /^\\/user\\/installations([^/]|$)/, /^\\/repos\\/[^/]+\\/[^/]+\\/actions\\/secrets([^/]|$)/, /^\\/repos\\/[^/]+\\/[^/]+\\/actions\\/workflows(\\/[^/]+\\/runs)?([^/]|$)/, /^\\/repos\\/[^/]+\\/[^/]+\\/actions\\/runs(\\/[^/]+\\/(artifacts|jobs))?([^/]|$)/];\nfunction normalizePaginatedListResponse(octokit, url, response) {\n const path = url.replace(octokit.request.endpoint.DEFAULTS.baseUrl, \"\");\n const responseNeedsNormalization = REGEX.find(regex => regex.test(path));\n if (!responseNeedsNormalization) return; // keep the additional properties intact as there is currently no other way\n // to retrieve the same information.\n\n const incompleteResults = response.data.incomplete_results;\n const repositorySelection = response.data.repository_selection;\n const totalCount = response.data.total_count;\n delete response.data.incomplete_results;\n delete response.data.repository_selection;\n delete response.data.total_count;\n const namespaceKey = Object.keys(response.data)[0];\n const data = response.data[namespaceKey];\n response.data = data;\n\n if (typeof incompleteResults !== \"undefined\") {\n response.data.incomplete_results = incompleteResults;\n }\n\n if (typeof repositorySelection !== \"undefined\") {\n response.data.repository_selection = repositorySelection;\n }\n\n response.data.total_count = totalCount;\n Object.defineProperty(response.data, namespaceKey, {\n get() {\n octokit.log.warn(`[@octokit/paginate-rest] \"response.data.${namespaceKey}\" is deprecated for \"GET ${path}\". Get the results directly from \"response.data\"`);\n return Array.from(data);\n }\n\n });\n}\n\nfunction iterator(octokit, route, parameters) {\n const options = octokit.request.endpoint(route, parameters);\n const method = options.method;\n const headers = options.headers;\n let url = options.url;\n return {\n [Symbol.asyncIterator]: () => ({\n next() {\n if (!url) {\n return Promise.resolve({\n done: true\n });\n }\n\n return octokit.request({\n method,\n url,\n headers\n }).then(response => {\n normalizePaginatedListResponse(octokit, url, response); // `response.headers.link` format:\n // '<https://api.github.com/users/aseemk/followers?page=2>; rel=\"next\", <https://api.github.com/users/aseemk/followers?page=2>; rel=\"last\"'\n // sets `url` to undefined if \"next\" URL is not present or `link` header is not set\n\n url = ((response.headers.link || \"\").match(/<([^>]+)>;\\s*rel=\"next\"/) || [])[1];\n return {\n value: response\n };\n });\n }\n\n })\n };\n}\n\nfunction paginate(octokit, route, parameters, mapFn) {\n if (typeof parameters === \"function\") {\n mapFn = parameters;\n parameters = undefined;\n }\n\n return gather(octokit, [], iterator(octokit, route, parameters)[Symbol.asyncIterator](), mapFn);\n}\n\nfunction gather(octokit, results, iterator, mapFn) {\n return iterator.next().then(result => {\n if (result.done) {\n return results;\n }\n\n let earlyExit = false;\n\n function done() {\n earlyExit = true;\n }\n\n results = results.concat(mapFn ? mapFn(result.value, done) : result.value.data);\n\n if (earlyExit) {\n return results;\n }\n\n return gather(octokit, results, iterator, mapFn);\n });\n}\n\n/**\n * @param octokit Octokit instance\n * @param options Options passed to Octokit constructor\n */\n\nfunction paginateRest(octokit) {\n return {\n paginate: Object.assign(paginate.bind(null, octokit), {\n iterator: iterator.bind(null, octokit)\n })\n };\n}\npaginateRest.VERSION = VERSION;\n\nexports.paginateRest = paginateRest;\n//# sourceMappingURL=index.js.map\n\n\n/***/ }),\n\n/***/ 8883:\n/***/ ((__unused_webpack_module, exports) => {\n\n\"use strict\";\n\n\nObject.defineProperty(exports, \"__esModule\", ({ value: true }));\n\nconst VERSION = \"1.0.4\";\n\n/**\n * @param octokit Octokit instance\n * @param options Options passed to Octokit constructor\n */\n\nfunction requestLog(octokit) {\n octokit.hook.wrap(\"request\", (request, options) => {\n octokit.log.debug(\"request\", options);\n const start = Date.now();\n const requestOptions = octokit.request.endpoint.parse(options);\n const path = requestOptions.url.replace(options.baseUrl, \"\");\n return request(options).then(response => {\n octokit.log.info(`${requestOptions.method} ${path} - ${response.status} in ${Date.now() - start}ms`);\n return response;\n }).catch(error => {\n octokit.log.info(`${requestOptions.method} ${path} - ${error.status} in ${Date.now() - start}ms`);\n throw error;\n });\n });\n}\nrequestLog.VERSION = VERSION;\n\nexports.requestLog = requestLog;\n//# sourceMappingURL=index.js.map\n\n\n/***/ }),\n\n/***/ 3044:\n/***/ ((__unused_webpack_module, exports, __nccwpck_require__) => {\n\n\"use strict\";\n\n\nObject.defineProperty(exports, \"__esModule\", ({ value: true }));\n\nvar deprecation = __nccwpck_require__(8932);\n\nvar endpointsByScope = {\n actions: {\n cancelWorkflowRun: {\n method: \"POST\",\n params: {\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n },\n run_id: {\n required: true,\n type: \"integer\"\n }\n },\n url: \"/repos/:owner/:repo/actions/runs/:run_id/cancel\"\n },\n createOrUpdateSecretForRepo: {\n method: \"PUT\",\n params: {\n encrypted_value: {\n type: \"string\"\n },\n key_id: {\n type: \"string\"\n },\n name: {\n required: true,\n type: \"string\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/actions/secrets/:name\"\n },\n createRegistrationToken: {\n method: \"POST\",\n params: {\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/actions/runners/registration-token\"\n },\n createRemoveToken: {\n method: \"POST\",\n params: {\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/actions/runners/remove-token\"\n },\n deleteArtifact: {\n method: \"DELETE\",\n params: {\n artifact_id: {\n required: true,\n type: \"integer\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/actions/artifacts/:artifact_id\"\n },\n deleteSecretFromRepo: {\n method: \"DELETE\",\n params: {\n name: {\n required: true,\n type: \"string\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/actions/secrets/:name\"\n },\n downloadArtifact: {\n method: \"GET\",\n params: {\n archive_format: {\n required: true,\n type: \"string\"\n },\n artifact_id: {\n required: true,\n type: \"integer\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/actions/artifacts/:artifact_id/:archive_format\"\n },\n getArtifact: {\n method: \"GET\",\n params: {\n artifact_id: {\n required: true,\n type: \"integer\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/actions/artifacts/:artifact_id\"\n },\n getPublicKey: {\n method: \"GET\",\n params: {\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/actions/secrets/public-key\"\n },\n getSecret: {\n method: \"GET\",\n params: {\n name: {\n required: true,\n type: \"string\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/actions/secrets/:name\"\n },\n getSelfHostedRunner: {\n method: \"GET\",\n params: {\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n },\n runner_id: {\n required: true,\n type: \"integer\"\n }\n },\n url: \"/repos/:owner/:repo/actions/runners/:runner_id\"\n },\n getWorkflow: {\n method: \"GET\",\n params: {\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n },\n workflow_id: {\n required: true,\n type: \"integer\"\n }\n },\n url: \"/repos/:owner/:repo/actions/workflows/:workflow_id\"\n },\n getWorkflowJob: {\n method: \"GET\",\n params: {\n job_id: {\n required: true,\n type: \"integer\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/actions/jobs/:job_id\"\n },\n getWorkflowRun: {\n method: \"GET\",\n params: {\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n },\n run_id: {\n required: true,\n type: \"integer\"\n }\n },\n url: \"/repos/:owner/:repo/actions/runs/:run_id\"\n },\n listDownloadsForSelfHostedRunnerApplication: {\n method: \"GET\",\n params: {\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/actions/runners/downloads\"\n },\n listJobsForWorkflowRun: {\n method: \"GET\",\n params: {\n owner: {\n required: true,\n type: \"string\"\n },\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n repo: {\n required: true,\n type: \"string\"\n },\n run_id: {\n required: true,\n type: \"integer\"\n }\n },\n url: \"/repos/:owner/:repo/actions/runs/:run_id/jobs\"\n },\n listRepoWorkflowRuns: {\n method: \"GET\",\n params: {\n actor: {\n type: \"string\"\n },\n branch: {\n type: \"string\"\n },\n event: {\n type: \"string\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n repo: {\n required: true,\n type: \"string\"\n },\n status: {\n enum: [\"completed\", \"status\", \"conclusion\"],\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/actions/runs\"\n },\n listRepoWorkflows: {\n method: \"GET\",\n params: {\n owner: {\n required: true,\n type: \"string\"\n },\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/actions/workflows\"\n },\n listSecretsForRepo: {\n method: \"GET\",\n params: {\n owner: {\n required: true,\n type: \"string\"\n },\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/actions/secrets\"\n },\n listSelfHostedRunnersForRepo: {\n method: \"GET\",\n params: {\n owner: {\n required: true,\n type: \"string\"\n },\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/actions/runners\"\n },\n listWorkflowJobLogs: {\n method: \"GET\",\n params: {\n job_id: {\n required: true,\n type: \"integer\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/actions/jobs/:job_id/logs\"\n },\n listWorkflowRunArtifacts: {\n method: \"GET\",\n params: {\n owner: {\n required: true,\n type: \"string\"\n },\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n repo: {\n required: true,\n type: \"string\"\n },\n run_id: {\n required: true,\n type: \"integer\"\n }\n },\n url: \"/repos/:owner/:repo/actions/runs/:run_id/artifacts\"\n },\n listWorkflowRunLogs: {\n method: \"GET\",\n params: {\n owner: {\n required: true,\n type: \"string\"\n },\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n repo: {\n required: true,\n type: \"string\"\n },\n run_id: {\n required: true,\n type: \"integer\"\n }\n },\n url: \"/repos/:owner/:repo/actions/runs/:run_id/logs\"\n },\n listWorkflowRuns: {\n method: \"GET\",\n params: {\n actor: {\n type: \"string\"\n },\n branch: {\n type: \"string\"\n },\n event: {\n type: \"string\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n repo: {\n required: true,\n type: \"string\"\n },\n status: {\n enum: [\"completed\", \"status\", \"conclusion\"],\n type: \"string\"\n },\n workflow_id: {\n required: true,\n type: \"integer\"\n }\n },\n url: \"/repos/:owner/:repo/actions/workflows/:workflow_id/runs\"\n },\n reRunWorkflow: {\n method: \"POST\",\n params: {\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n },\n run_id: {\n required: true,\n type: \"integer\"\n }\n },\n url: \"/repos/:owner/:repo/actions/runs/:run_id/rerun\"\n },\n removeSelfHostedRunner: {\n method: \"DELETE\",\n params: {\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n },\n runner_id: {\n required: true,\n type: \"integer\"\n }\n },\n url: \"/repos/:owner/:repo/actions/runners/:runner_id\"\n }\n },\n activity: {\n checkStarringRepo: {\n method: \"GET\",\n params: {\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/user/starred/:owner/:repo\"\n },\n deleteRepoSubscription: {\n method: \"DELETE\",\n params: {\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/subscription\"\n },\n deleteThreadSubscription: {\n method: \"DELETE\",\n params: {\n thread_id: {\n required: true,\n type: \"integer\"\n }\n },\n url: \"/notifications/threads/:thread_id/subscription\"\n },\n getRepoSubscription: {\n method: \"GET\",\n params: {\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/subscription\"\n },\n getThread: {\n method: \"GET\",\n params: {\n thread_id: {\n required: true,\n type: \"integer\"\n }\n },\n url: \"/notifications/threads/:thread_id\"\n },\n getThreadSubscription: {\n method: \"GET\",\n params: {\n thread_id: {\n required: true,\n type: \"integer\"\n }\n },\n url: \"/notifications/threads/:thread_id/subscription\"\n },\n listEventsForOrg: {\n method: \"GET\",\n params: {\n org: {\n required: true,\n type: \"string\"\n },\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n username: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/users/:username/events/orgs/:org\"\n },\n listEventsForUser: {\n method: \"GET\",\n params: {\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n username: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/users/:username/events\"\n },\n listFeeds: {\n method: \"GET\",\n params: {},\n url: \"/feeds\"\n },\n listNotifications: {\n method: \"GET\",\n params: {\n all: {\n type: \"boolean\"\n },\n before: {\n type: \"string\"\n },\n page: {\n type: \"integer\"\n },\n participating: {\n type: \"boolean\"\n },\n per_page: {\n type: \"integer\"\n },\n since: {\n type: \"string\"\n }\n },\n url: \"/notifications\"\n },\n listNotificationsForRepo: {\n method: \"GET\",\n params: {\n all: {\n type: \"boolean\"\n },\n before: {\n type: \"string\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n page: {\n type: \"integer\"\n },\n participating: {\n type: \"boolean\"\n },\n per_page: {\n type: \"integer\"\n },\n repo: {\n required: true,\n type: \"string\"\n },\n since: {\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/notifications\"\n },\n listPublicEvents: {\n method: \"GET\",\n params: {\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n }\n },\n url: \"/events\"\n },\n listPublicEventsForOrg: {\n method: \"GET\",\n params: {\n org: {\n required: true,\n type: \"string\"\n },\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n }\n },\n url: \"/orgs/:org/events\"\n },\n listPublicEventsForRepoNetwork: {\n method: \"GET\",\n params: {\n owner: {\n required: true,\n type: \"string\"\n },\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/networks/:owner/:repo/events\"\n },\n listPublicEventsForUser: {\n method: \"GET\",\n params: {\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n username: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/users/:username/events/public\"\n },\n listReceivedEventsForUser: {\n method: \"GET\",\n params: {\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n username: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/users/:username/received_events\"\n },\n listReceivedPublicEventsForUser: {\n method: \"GET\",\n params: {\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n username: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/users/:username/received_events/public\"\n },\n listRepoEvents: {\n method: \"GET\",\n params: {\n owner: {\n required: true,\n type: \"string\"\n },\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/events\"\n },\n listReposStarredByAuthenticatedUser: {\n method: \"GET\",\n params: {\n direction: {\n enum: [\"asc\", \"desc\"],\n type: \"string\"\n },\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n sort: {\n enum: [\"created\", \"updated\"],\n type: \"string\"\n }\n },\n url: \"/user/starred\"\n },\n listReposStarredByUser: {\n method: \"GET\",\n params: {\n direction: {\n enum: [\"asc\", \"desc\"],\n type: \"string\"\n },\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n sort: {\n enum: [\"created\", \"updated\"],\n type: \"string\"\n },\n username: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/users/:username/starred\"\n },\n listReposWatchedByUser: {\n method: \"GET\",\n params: {\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n username: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/users/:username/subscriptions\"\n },\n listStargazersForRepo: {\n method: \"GET\",\n params: {\n owner: {\n required: true,\n type: \"string\"\n },\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/stargazers\"\n },\n listWatchedReposForAuthenticatedUser: {\n method: \"GET\",\n params: {\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n }\n },\n url: \"/user/subscriptions\"\n },\n listWatchersForRepo: {\n method: \"GET\",\n params: {\n owner: {\n required: true,\n type: \"string\"\n },\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/subscribers\"\n },\n markAsRead: {\n method: \"PUT\",\n params: {\n last_read_at: {\n type: \"string\"\n }\n },\n url: \"/notifications\"\n },\n markNotificationsAsReadForRepo: {\n method: \"PUT\",\n params: {\n last_read_at: {\n type: \"string\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/notifications\"\n },\n markThreadAsRead: {\n method: \"PATCH\",\n params: {\n thread_id: {\n required: true,\n type: \"integer\"\n }\n },\n url: \"/notifications/threads/:thread_id\"\n },\n setRepoSubscription: {\n method: \"PUT\",\n params: {\n ignored: {\n type: \"boolean\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n },\n subscribed: {\n type: \"boolean\"\n }\n },\n url: \"/repos/:owner/:repo/subscription\"\n },\n setThreadSubscription: {\n method: \"PUT\",\n params: {\n ignored: {\n type: \"boolean\"\n },\n thread_id: {\n required: true,\n type: \"integer\"\n }\n },\n url: \"/notifications/threads/:thread_id/subscription\"\n },\n starRepo: {\n method: \"PUT\",\n params: {\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/user/starred/:owner/:repo\"\n },\n unstarRepo: {\n method: \"DELETE\",\n params: {\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/user/starred/:owner/:repo\"\n }\n },\n apps: {\n addRepoToInstallation: {\n headers: {\n accept: \"application/vnd.github.machine-man-preview+json\"\n },\n method: \"PUT\",\n params: {\n installation_id: {\n required: true,\n type: \"integer\"\n },\n repository_id: {\n required: true,\n type: \"integer\"\n }\n },\n url: \"/user/installations/:installation_id/repositories/:repository_id\"\n },\n checkAccountIsAssociatedWithAny: {\n method: \"GET\",\n params: {\n account_id: {\n required: true,\n type: \"integer\"\n }\n },\n url: \"/marketplace_listing/accounts/:account_id\"\n },\n checkAccountIsAssociatedWithAnyStubbed: {\n method: \"GET\",\n params: {\n account_id: {\n required: true,\n type: \"integer\"\n }\n },\n url: \"/marketplace_listing/stubbed/accounts/:account_id\"\n },\n checkAuthorization: {\n deprecated: \"octokit.apps.checkAuthorization() is deprecated, see https://developer.github.com/v3/apps/oauth_applications/#check-an-authorization\",\n method: \"GET\",\n params: {\n access_token: {\n required: true,\n type: \"string\"\n },\n client_id: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/applications/:client_id/tokens/:access_token\"\n },\n checkToken: {\n headers: {\n accept: \"application/vnd.github.doctor-strange-preview+json\"\n },\n method: \"POST\",\n params: {\n access_token: {\n type: \"string\"\n },\n client_id: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/applications/:client_id/token\"\n },\n createContentAttachment: {\n headers: {\n accept: \"application/vnd.github.corsair-preview+json\"\n },\n method: \"POST\",\n params: {\n body: {\n required: true,\n type: \"string\"\n },\n content_reference_id: {\n required: true,\n type: \"integer\"\n },\n title: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/content_references/:content_reference_id/attachments\"\n },\n createFromManifest: {\n headers: {\n accept: \"application/vnd.github.fury-preview+json\"\n },\n method: \"POST\",\n params: {\n code: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/app-manifests/:code/conversions\"\n },\n createInstallationToken: {\n headers: {\n accept: \"application/vnd.github.machine-man-preview+json\"\n },\n method: \"POST\",\n params: {\n installation_id: {\n required: true,\n type: \"integer\"\n },\n permissions: {\n type: \"object\"\n },\n repository_ids: {\n type: \"integer[]\"\n }\n },\n url: \"/app/installations/:installation_id/access_tokens\"\n },\n deleteAuthorization: {\n headers: {\n accept: \"application/vnd.github.doctor-strange-preview+json\"\n },\n method: \"DELETE\",\n params: {\n access_token: {\n type: \"string\"\n },\n client_id: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/applications/:client_id/grant\"\n },\n deleteInstallation: {\n headers: {\n accept: \"application/vnd.github.gambit-preview+json,application/vnd.github.machine-man-preview+json\"\n },\n method: \"DELETE\",\n params: {\n installation_id: {\n required: true,\n type: \"integer\"\n }\n },\n url: \"/app/installations/:installation_id\"\n },\n deleteToken: {\n headers: {\n accept: \"application/vnd.github.doctor-strange-preview+json\"\n },\n method: \"DELETE\",\n params: {\n access_token: {\n type: \"string\"\n },\n client_id: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/applications/:client_id/token\"\n },\n findOrgInstallation: {\n deprecated: \"octokit.apps.findOrgInstallation() has been renamed to octokit.apps.getOrgInstallation() (2019-04-10)\",\n headers: {\n accept: \"application/vnd.github.machine-man-preview+json\"\n },\n method: \"GET\",\n params: {\n org: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/orgs/:org/installation\"\n },\n findRepoInstallation: {\n deprecated: \"octokit.apps.findRepoInstallation() has been renamed to octokit.apps.getRepoInstallation() (2019-04-10)\",\n headers: {\n accept: \"application/vnd.github.machine-man-preview+json\"\n },\n method: \"GET\",\n params: {\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/installation\"\n },\n findUserInstallation: {\n deprecated: \"octokit.apps.findUserInstallation() has been renamed to octokit.apps.getUserInstallation() (2019-04-10)\",\n headers: {\n accept: \"application/vnd.github.machine-man-preview+json\"\n },\n method: \"GET\",\n params: {\n username: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/users/:username/installation\"\n },\n getAuthenticated: {\n headers: {\n accept: \"application/vnd.github.machine-man-preview+json\"\n },\n method: \"GET\",\n params: {},\n url: \"/app\"\n },\n getBySlug: {\n headers: {\n accept: \"application/vnd.github.machine-man-preview+json\"\n },\n method: \"GET\",\n params: {\n app_slug: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/apps/:app_slug\"\n },\n getInstallation: {\n headers: {\n accept: \"application/vnd.github.machine-man-preview+json\"\n },\n method: \"GET\",\n params: {\n installation_id: {\n required: true,\n type: \"integer\"\n }\n },\n url: \"/app/installations/:installation_id\"\n },\n getOrgInstallation: {\n headers: {\n accept: \"application/vnd.github.machine-man-preview+json\"\n },\n method: \"GET\",\n params: {\n org: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/orgs/:org/installation\"\n },\n getRepoInstallation: {\n headers: {\n accept: \"application/vnd.github.machine-man-preview+json\"\n },\n method: \"GET\",\n params: {\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/installation\"\n },\n getUserInstallation: {\n headers: {\n accept: \"application/vnd.github.machine-man-preview+json\"\n },\n method: \"GET\",\n params: {\n username: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/users/:username/installation\"\n },\n listAccountsUserOrOrgOnPlan: {\n method: \"GET\",\n params: {\n direction: {\n enum: [\"asc\", \"desc\"],\n type: \"string\"\n },\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n plan_id: {\n required: true,\n type: \"integer\"\n },\n sort: {\n enum: [\"created\", \"updated\"],\n type: \"string\"\n }\n },\n url: \"/marketplace_listing/plans/:plan_id/accounts\"\n },\n listAccountsUserOrOrgOnPlanStubbed: {\n method: \"GET\",\n params: {\n direction: {\n enum: [\"asc\", \"desc\"],\n type: \"string\"\n },\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n plan_id: {\n required: true,\n type: \"integer\"\n },\n sort: {\n enum: [\"created\", \"updated\"],\n type: \"string\"\n }\n },\n url: \"/marketplace_listing/stubbed/plans/:plan_id/accounts\"\n },\n listInstallationReposForAuthenticatedUser: {\n headers: {\n accept: \"application/vnd.github.machine-man-preview+json\"\n },\n method: \"GET\",\n params: {\n installation_id: {\n required: true,\n type: \"integer\"\n },\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n }\n },\n url: \"/user/installations/:installation_id/repositories\"\n },\n listInstallations: {\n headers: {\n accept: \"application/vnd.github.machine-man-preview+json\"\n },\n method: \"GET\",\n params: {\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n }\n },\n url: \"/app/installations\"\n },\n listInstallationsForAuthenticatedUser: {\n headers: {\n accept: \"application/vnd.github.machine-man-preview+json\"\n },\n method: \"GET\",\n params: {\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n }\n },\n url: \"/user/installations\"\n },\n listMarketplacePurchasesForAuthenticatedUser: {\n method: \"GET\",\n params: {\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n }\n },\n url: \"/user/marketplace_purchases\"\n },\n listMarketplacePurchasesForAuthenticatedUserStubbed: {\n method: \"GET\",\n params: {\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n }\n },\n url: \"/user/marketplace_purchases/stubbed\"\n },\n listPlans: {\n method: \"GET\",\n params: {\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n }\n },\n url: \"/marketplace_listing/plans\"\n },\n listPlansStubbed: {\n method: \"GET\",\n params: {\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n }\n },\n url: \"/marketplace_listing/stubbed/plans\"\n },\n listRepos: {\n headers: {\n accept: \"application/vnd.github.machine-man-preview+json\"\n },\n method: \"GET\",\n params: {\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n }\n },\n url: \"/installation/repositories\"\n },\n removeRepoFromInstallation: {\n headers: {\n accept: \"application/vnd.github.machine-man-preview+json\"\n },\n method: \"DELETE\",\n params: {\n installation_id: {\n required: true,\n type: \"integer\"\n },\n repository_id: {\n required: true,\n type: \"integer\"\n }\n },\n url: \"/user/installations/:installation_id/repositories/:repository_id\"\n },\n resetAuthorization: {\n deprecated: \"octokit.apps.resetAuthorization() is deprecated, see https://developer.github.com/v3/apps/oauth_applications/#reset-an-authorization\",\n method: \"POST\",\n params: {\n access_token: {\n required: true,\n type: \"string\"\n },\n client_id: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/applications/:client_id/tokens/:access_token\"\n },\n resetToken: {\n headers: {\n accept: \"application/vnd.github.doctor-strange-preview+json\"\n },\n method: \"PATCH\",\n params: {\n access_token: {\n type: \"string\"\n },\n client_id: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/applications/:client_id/token\"\n },\n revokeAuthorizationForApplication: {\n deprecated: \"octokit.apps.revokeAuthorizationForApplication() is deprecated, see https://developer.github.com/v3/apps/oauth_applications/#revoke-an-authorization-for-an-application\",\n method: \"DELETE\",\n params: {\n access_token: {\n required: true,\n type: \"string\"\n },\n client_id: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/applications/:client_id/tokens/:access_token\"\n },\n revokeGrantForApplication: {\n deprecated: \"octokit.apps.revokeGrantForApplication() is deprecated, see https://developer.github.com/v3/apps/oauth_applications/#revoke-a-grant-for-an-application\",\n method: \"DELETE\",\n params: {\n access_token: {\n required: true,\n type: \"string\"\n },\n client_id: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/applications/:client_id/grants/:access_token\"\n },\n revokeInstallationToken: {\n headers: {\n accept: \"application/vnd.github.gambit-preview+json\"\n },\n method: \"DELETE\",\n params: {},\n url: \"/installation/token\"\n }\n },\n checks: {\n create: {\n headers: {\n accept: \"application/vnd.github.antiope-preview+json\"\n },\n method: \"POST\",\n params: {\n actions: {\n type: \"object[]\"\n },\n \"actions[].description\": {\n required: true,\n type: \"string\"\n },\n \"actions[].identifier\": {\n required: true,\n type: \"string\"\n },\n \"actions[].label\": {\n required: true,\n type: \"string\"\n },\n completed_at: {\n type: \"string\"\n },\n conclusion: {\n enum: [\"success\", \"failure\", \"neutral\", \"cancelled\", \"timed_out\", \"action_required\"],\n type: \"string\"\n },\n details_url: {\n type: \"string\"\n },\n external_id: {\n type: \"string\"\n },\n head_sha: {\n required: true,\n type: \"string\"\n },\n name: {\n required: true,\n type: \"string\"\n },\n output: {\n type: \"object\"\n },\n \"output.annotations\": {\n type: \"object[]\"\n },\n \"output.annotations[].annotation_level\": {\n enum: [\"notice\", \"warning\", \"failure\"],\n required: true,\n type: \"string\"\n },\n \"output.annotations[].end_column\": {\n type: \"integer\"\n },\n \"output.annotations[].end_line\": {\n required: true,\n type: \"integer\"\n },\n \"output.annotations[].message\": {\n required: true,\n type: \"string\"\n },\n \"output.annotations[].path\": {\n required: true,\n type: \"string\"\n },\n \"output.annotations[].raw_details\": {\n type: \"string\"\n },\n \"output.annotations[].start_column\": {\n type: \"integer\"\n },\n \"output.annotations[].start_line\": {\n required: true,\n type: \"integer\"\n },\n \"output.annotations[].title\": {\n type: \"string\"\n },\n \"output.images\": {\n type: \"object[]\"\n },\n \"output.images[].alt\": {\n required: true,\n type: \"string\"\n },\n \"output.images[].caption\": {\n type: \"string\"\n },\n \"output.images[].image_url\": {\n required: true,\n type: \"string\"\n },\n \"output.summary\": {\n required: true,\n type: \"string\"\n },\n \"output.text\": {\n type: \"string\"\n },\n \"output.title\": {\n required: true,\n type: \"string\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n },\n started_at: {\n type: \"string\"\n },\n status: {\n enum: [\"queued\", \"in_progress\", \"completed\"],\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/check-runs\"\n },\n createSuite: {\n headers: {\n accept: \"application/vnd.github.antiope-preview+json\"\n },\n method: \"POST\",\n params: {\n head_sha: {\n required: true,\n type: \"string\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/check-suites\"\n },\n get: {\n headers: {\n accept: \"application/vnd.github.antiope-preview+json\"\n },\n method: \"GET\",\n params: {\n check_run_id: {\n required: true,\n type: \"integer\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/check-runs/:check_run_id\"\n },\n getSuite: {\n headers: {\n accept: \"application/vnd.github.antiope-preview+json\"\n },\n method: \"GET\",\n params: {\n check_suite_id: {\n required: true,\n type: \"integer\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/check-suites/:check_suite_id\"\n },\n listAnnotations: {\n headers: {\n accept: \"application/vnd.github.antiope-preview+json\"\n },\n method: \"GET\",\n params: {\n check_run_id: {\n required: true,\n type: \"integer\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/check-runs/:check_run_id/annotations\"\n },\n listForRef: {\n headers: {\n accept: \"application/vnd.github.antiope-preview+json\"\n },\n method: \"GET\",\n params: {\n check_name: {\n type: \"string\"\n },\n filter: {\n enum: [\"latest\", \"all\"],\n type: \"string\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n ref: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n },\n status: {\n enum: [\"queued\", \"in_progress\", \"completed\"],\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/commits/:ref/check-runs\"\n },\n listForSuite: {\n headers: {\n accept: \"application/vnd.github.antiope-preview+json\"\n },\n method: \"GET\",\n params: {\n check_name: {\n type: \"string\"\n },\n check_suite_id: {\n required: true,\n type: \"integer\"\n },\n filter: {\n enum: [\"latest\", \"all\"],\n type: \"string\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n repo: {\n required: true,\n type: \"string\"\n },\n status: {\n enum: [\"queued\", \"in_progress\", \"completed\"],\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/check-suites/:check_suite_id/check-runs\"\n },\n listSuitesForRef: {\n headers: {\n accept: \"application/vnd.github.antiope-preview+json\"\n },\n method: \"GET\",\n params: {\n app_id: {\n type: \"integer\"\n },\n check_name: {\n type: \"string\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n ref: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/commits/:ref/check-suites\"\n },\n rerequestSuite: {\n headers: {\n accept: \"application/vnd.github.antiope-preview+json\"\n },\n method: \"POST\",\n params: {\n check_suite_id: {\n required: true,\n type: \"integer\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/check-suites/:check_suite_id/rerequest\"\n },\n setSuitesPreferences: {\n headers: {\n accept: \"application/vnd.github.antiope-preview+json\"\n },\n method: \"PATCH\",\n params: {\n auto_trigger_checks: {\n type: \"object[]\"\n },\n \"auto_trigger_checks[].app_id\": {\n required: true,\n type: \"integer\"\n },\n \"auto_trigger_checks[].setting\": {\n required: true,\n type: \"boolean\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/check-suites/preferences\"\n },\n update: {\n headers: {\n accept: \"application/vnd.github.antiope-preview+json\"\n },\n method: \"PATCH\",\n params: {\n actions: {\n type: \"object[]\"\n },\n \"actions[].description\": {\n required: true,\n type: \"string\"\n },\n \"actions[].identifier\": {\n required: true,\n type: \"string\"\n },\n \"actions[].label\": {\n required: true,\n type: \"string\"\n },\n check_run_id: {\n required: true,\n type: \"integer\"\n },\n completed_at: {\n type: \"string\"\n },\n conclusion: {\n enum: [\"success\", \"failure\", \"neutral\", \"cancelled\", \"timed_out\", \"action_required\"],\n type: \"string\"\n },\n details_url: {\n type: \"string\"\n },\n external_id: {\n type: \"string\"\n },\n name: {\n type: \"string\"\n },\n output: {\n type: \"object\"\n },\n \"output.annotations\": {\n type: \"object[]\"\n },\n \"output.annotations[].annotation_level\": {\n enum: [\"notice\", \"warning\", \"failure\"],\n required: true,\n type: \"string\"\n },\n \"output.annotations[].end_column\": {\n type: \"integer\"\n },\n \"output.annotations[].end_line\": {\n required: true,\n type: \"integer\"\n },\n \"output.annotations[].message\": {\n required: true,\n type: \"string\"\n },\n \"output.annotations[].path\": {\n required: true,\n type: \"string\"\n },\n \"output.annotations[].raw_details\": {\n type: \"string\"\n },\n \"output.annotations[].start_column\": {\n type: \"integer\"\n },\n \"output.annotations[].start_line\": {\n required: true,\n type: \"integer\"\n },\n \"output.annotations[].title\": {\n type: \"string\"\n },\n \"output.images\": {\n type: \"object[]\"\n },\n \"output.images[].alt\": {\n required: true,\n type: \"string\"\n },\n \"output.images[].caption\": {\n type: \"string\"\n },\n \"output.images[].image_url\": {\n required: true,\n type: \"string\"\n },\n \"output.summary\": {\n required: true,\n type: \"string\"\n },\n \"output.text\": {\n type: \"string\"\n },\n \"output.title\": {\n type: \"string\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n },\n started_at: {\n type: \"string\"\n },\n status: {\n enum: [\"queued\", \"in_progress\", \"completed\"],\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/check-runs/:check_run_id\"\n }\n },\n codesOfConduct: {\n getConductCode: {\n headers: {\n accept: \"application/vnd.github.scarlet-witch-preview+json\"\n },\n method: \"GET\",\n params: {\n key: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/codes_of_conduct/:key\"\n },\n getForRepo: {\n headers: {\n accept: \"application/vnd.github.scarlet-witch-preview+json\"\n },\n method: \"GET\",\n params: {\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/community/code_of_conduct\"\n },\n listConductCodes: {\n headers: {\n accept: \"application/vnd.github.scarlet-witch-preview+json\"\n },\n method: \"GET\",\n params: {},\n url: \"/codes_of_conduct\"\n }\n },\n emojis: {\n get: {\n method: \"GET\",\n params: {},\n url: \"/emojis\"\n }\n },\n gists: {\n checkIsStarred: {\n method: \"GET\",\n params: {\n gist_id: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/gists/:gist_id/star\"\n },\n create: {\n method: \"POST\",\n params: {\n description: {\n type: \"string\"\n },\n files: {\n required: true,\n type: \"object\"\n },\n \"files.content\": {\n type: \"string\"\n },\n public: {\n type: \"boolean\"\n }\n },\n url: \"/gists\"\n },\n createComment: {\n method: \"POST\",\n params: {\n body: {\n required: true,\n type: \"string\"\n },\n gist_id: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/gists/:gist_id/comments\"\n },\n delete: {\n method: \"DELETE\",\n params: {\n gist_id: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/gists/:gist_id\"\n },\n deleteComment: {\n method: \"DELETE\",\n params: {\n comment_id: {\n required: true,\n type: \"integer\"\n },\n gist_id: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/gists/:gist_id/comments/:comment_id\"\n },\n fork: {\n method: \"POST\",\n params: {\n gist_id: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/gists/:gist_id/forks\"\n },\n get: {\n method: \"GET\",\n params: {\n gist_id: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/gists/:gist_id\"\n },\n getComment: {\n method: \"GET\",\n params: {\n comment_id: {\n required: true,\n type: \"integer\"\n },\n gist_id: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/gists/:gist_id/comments/:comment_id\"\n },\n getRevision: {\n method: \"GET\",\n params: {\n gist_id: {\n required: true,\n type: \"string\"\n },\n sha: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/gists/:gist_id/:sha\"\n },\n list: {\n method: \"GET\",\n params: {\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n since: {\n type: \"string\"\n }\n },\n url: \"/gists\"\n },\n listComments: {\n method: \"GET\",\n params: {\n gist_id: {\n required: true,\n type: \"string\"\n },\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n }\n },\n url: \"/gists/:gist_id/comments\"\n },\n listCommits: {\n method: \"GET\",\n params: {\n gist_id: {\n required: true,\n type: \"string\"\n },\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n }\n },\n url: \"/gists/:gist_id/commits\"\n },\n listForks: {\n method: \"GET\",\n params: {\n gist_id: {\n required: true,\n type: \"string\"\n },\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n }\n },\n url: \"/gists/:gist_id/forks\"\n },\n listPublic: {\n method: \"GET\",\n params: {\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n since: {\n type: \"string\"\n }\n },\n url: \"/gists/public\"\n },\n listPublicForUser: {\n method: \"GET\",\n params: {\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n since: {\n type: \"string\"\n },\n username: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/users/:username/gists\"\n },\n listStarred: {\n method: \"GET\",\n params: {\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n since: {\n type: \"string\"\n }\n },\n url: \"/gists/starred\"\n },\n star: {\n method: \"PUT\",\n params: {\n gist_id: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/gists/:gist_id/star\"\n },\n unstar: {\n method: \"DELETE\",\n params: {\n gist_id: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/gists/:gist_id/star\"\n },\n update: {\n method: \"PATCH\",\n params: {\n description: {\n type: \"string\"\n },\n files: {\n type: \"object\"\n },\n \"files.content\": {\n type: \"string\"\n },\n \"files.filename\": {\n type: \"string\"\n },\n gist_id: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/gists/:gist_id\"\n },\n updateComment: {\n method: \"PATCH\",\n params: {\n body: {\n required: true,\n type: \"string\"\n },\n comment_id: {\n required: true,\n type: \"integer\"\n },\n gist_id: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/gists/:gist_id/comments/:comment_id\"\n }\n },\n git: {\n createBlob: {\n method: \"POST\",\n params: {\n content: {\n required: true,\n type: \"string\"\n },\n encoding: {\n type: \"string\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/git/blobs\"\n },\n createCommit: {\n method: \"POST\",\n params: {\n author: {\n type: \"object\"\n },\n \"author.date\": {\n type: \"string\"\n },\n \"author.email\": {\n type: \"string\"\n },\n \"author.name\": {\n type: \"string\"\n },\n committer: {\n type: \"object\"\n },\n \"committer.date\": {\n type: \"string\"\n },\n \"committer.email\": {\n type: \"string\"\n },\n \"committer.name\": {\n type: \"string\"\n },\n message: {\n required: true,\n type: \"string\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n parents: {\n required: true,\n type: \"string[]\"\n },\n repo: {\n required: true,\n type: \"string\"\n },\n signature: {\n type: \"string\"\n },\n tree: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/git/commits\"\n },\n createRef: {\n method: \"POST\",\n params: {\n owner: {\n required: true,\n type: \"string\"\n },\n ref: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n },\n sha: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/git/refs\"\n },\n createTag: {\n method: \"POST\",\n params: {\n message: {\n required: true,\n type: \"string\"\n },\n object: {\n required: true,\n type: \"string\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n },\n tag: {\n required: true,\n type: \"string\"\n },\n tagger: {\n type: \"object\"\n },\n \"tagger.date\": {\n type: \"string\"\n },\n \"tagger.email\": {\n type: \"string\"\n },\n \"tagger.name\": {\n type: \"string\"\n },\n type: {\n enum: [\"commit\", \"tree\", \"blob\"],\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/git/tags\"\n },\n createTree: {\n method: \"POST\",\n params: {\n base_tree: {\n type: \"string\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n },\n tree: {\n required: true,\n type: \"object[]\"\n },\n \"tree[].content\": {\n type: \"string\"\n },\n \"tree[].mode\": {\n enum: [\"100644\", \"100755\", \"040000\", \"160000\", \"120000\"],\n type: \"string\"\n },\n \"tree[].path\": {\n type: \"string\"\n },\n \"tree[].sha\": {\n allowNull: true,\n type: \"string\"\n },\n \"tree[].type\": {\n enum: [\"blob\", \"tree\", \"commit\"],\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/git/trees\"\n },\n deleteRef: {\n method: \"DELETE\",\n params: {\n owner: {\n required: true,\n type: \"string\"\n },\n ref: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/git/refs/:ref\"\n },\n getBlob: {\n method: \"GET\",\n params: {\n file_sha: {\n required: true,\n type: \"string\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/git/blobs/:file_sha\"\n },\n getCommit: {\n method: \"GET\",\n params: {\n commit_sha: {\n required: true,\n type: \"string\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/git/commits/:commit_sha\"\n },\n getRef: {\n method: \"GET\",\n params: {\n owner: {\n required: true,\n type: \"string\"\n },\n ref: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/git/ref/:ref\"\n },\n getTag: {\n method: \"GET\",\n params: {\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n },\n tag_sha: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/git/tags/:tag_sha\"\n },\n getTree: {\n method: \"GET\",\n params: {\n owner: {\n required: true,\n type: \"string\"\n },\n recursive: {\n enum: [\"1\"],\n type: \"integer\"\n },\n repo: {\n required: true,\n type: \"string\"\n },\n tree_sha: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/git/trees/:tree_sha\"\n },\n listMatchingRefs: {\n method: \"GET\",\n params: {\n owner: {\n required: true,\n type: \"string\"\n },\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n ref: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/git/matching-refs/:ref\"\n },\n listRefs: {\n method: \"GET\",\n params: {\n namespace: {\n type: \"string\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/git/refs/:namespace\"\n },\n updateRef: {\n method: \"PATCH\",\n params: {\n force: {\n type: \"boolean\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n ref: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n },\n sha: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/git/refs/:ref\"\n }\n },\n gitignore: {\n getTemplate: {\n method: \"GET\",\n params: {\n name: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/gitignore/templates/:name\"\n },\n listTemplates: {\n method: \"GET\",\n params: {},\n url: \"/gitignore/templates\"\n }\n },\n interactions: {\n addOrUpdateRestrictionsForOrg: {\n headers: {\n accept: \"application/vnd.github.sombra-preview+json\"\n },\n method: \"PUT\",\n params: {\n limit: {\n enum: [\"existing_users\", \"contributors_only\", \"collaborators_only\"],\n required: true,\n type: \"string\"\n },\n org: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/orgs/:org/interaction-limits\"\n },\n addOrUpdateRestrictionsForRepo: {\n headers: {\n accept: \"application/vnd.github.sombra-preview+json\"\n },\n method: \"PUT\",\n params: {\n limit: {\n enum: [\"existing_users\", \"contributors_only\", \"collaborators_only\"],\n required: true,\n type: \"string\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/interaction-limits\"\n },\n getRestrictionsForOrg: {\n headers: {\n accept: \"application/vnd.github.sombra-preview+json\"\n },\n method: \"GET\",\n params: {\n org: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/orgs/:org/interaction-limits\"\n },\n getRestrictionsForRepo: {\n headers: {\n accept: \"application/vnd.github.sombra-preview+json\"\n },\n method: \"GET\",\n params: {\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/interaction-limits\"\n },\n removeRestrictionsForOrg: {\n headers: {\n accept: \"application/vnd.github.sombra-preview+json\"\n },\n method: \"DELETE\",\n params: {\n org: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/orgs/:org/interaction-limits\"\n },\n removeRestrictionsForRepo: {\n headers: {\n accept: \"application/vnd.github.sombra-preview+json\"\n },\n method: \"DELETE\",\n params: {\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/interaction-limits\"\n }\n },\n issues: {\n addAssignees: {\n method: \"POST\",\n params: {\n assignees: {\n type: \"string[]\"\n },\n issue_number: {\n required: true,\n type: \"integer\"\n },\n number: {\n alias: \"issue_number\",\n deprecated: true,\n type: \"integer\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/issues/:issue_number/assignees\"\n },\n addLabels: {\n method: \"POST\",\n params: {\n issue_number: {\n required: true,\n type: \"integer\"\n },\n labels: {\n required: true,\n type: \"string[]\"\n },\n number: {\n alias: \"issue_number\",\n deprecated: true,\n type: \"integer\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/issues/:issue_number/labels\"\n },\n checkAssignee: {\n method: \"GET\",\n params: {\n assignee: {\n required: true,\n type: \"string\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/assignees/:assignee\"\n },\n create: {\n method: \"POST\",\n params: {\n assignee: {\n type: \"string\"\n },\n assignees: {\n type: \"string[]\"\n },\n body: {\n type: \"string\"\n },\n labels: {\n type: \"string[]\"\n },\n milestone: {\n type: \"integer\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n },\n title: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/issues\"\n },\n createComment: {\n method: \"POST\",\n params: {\n body: {\n required: true,\n type: \"string\"\n },\n issue_number: {\n required: true,\n type: \"integer\"\n },\n number: {\n alias: \"issue_number\",\n deprecated: true,\n type: \"integer\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/issues/:issue_number/comments\"\n },\n createLabel: {\n method: \"POST\",\n params: {\n color: {\n required: true,\n type: \"string\"\n },\n description: {\n type: \"string\"\n },\n name: {\n required: true,\n type: \"string\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/labels\"\n },\n createMilestone: {\n method: \"POST\",\n params: {\n description: {\n type: \"string\"\n },\n due_on: {\n type: \"string\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n },\n state: {\n enum: [\"open\", \"closed\"],\n type: \"string\"\n },\n title: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/milestones\"\n },\n deleteComment: {\n method: \"DELETE\",\n params: {\n comment_id: {\n required: true,\n type: \"integer\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/issues/comments/:comment_id\"\n },\n deleteLabel: {\n method: \"DELETE\",\n params: {\n name: {\n required: true,\n type: \"string\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/labels/:name\"\n },\n deleteMilestone: {\n method: \"DELETE\",\n params: {\n milestone_number: {\n required: true,\n type: \"integer\"\n },\n number: {\n alias: \"milestone_number\",\n deprecated: true,\n type: \"integer\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/milestones/:milestone_number\"\n },\n get: {\n method: \"GET\",\n params: {\n issue_number: {\n required: true,\n type: \"integer\"\n },\n number: {\n alias: \"issue_number\",\n deprecated: true,\n type: \"integer\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/issues/:issue_number\"\n },\n getComment: {\n method: \"GET\",\n params: {\n comment_id: {\n required: true,\n type: \"integer\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/issues/comments/:comment_id\"\n },\n getEvent: {\n method: \"GET\",\n params: {\n event_id: {\n required: true,\n type: \"integer\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/issues/events/:event_id\"\n },\n getLabel: {\n method: \"GET\",\n params: {\n name: {\n required: true,\n type: \"string\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/labels/:name\"\n },\n getMilestone: {\n method: \"GET\",\n params: {\n milestone_number: {\n required: true,\n type: \"integer\"\n },\n number: {\n alias: \"milestone_number\",\n deprecated: true,\n type: \"integer\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/milestones/:milestone_number\"\n },\n list: {\n method: \"GET\",\n params: {\n direction: {\n enum: [\"asc\", \"desc\"],\n type: \"string\"\n },\n filter: {\n enum: [\"assigned\", \"created\", \"mentioned\", \"subscribed\", \"all\"],\n type: \"string\"\n },\n labels: {\n type: \"string\"\n },\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n since: {\n type: \"string\"\n },\n sort: {\n enum: [\"created\", \"updated\", \"comments\"],\n type: \"string\"\n },\n state: {\n enum: [\"open\", \"closed\", \"all\"],\n type: \"string\"\n }\n },\n url: \"/issues\"\n },\n listAssignees: {\n method: \"GET\",\n params: {\n owner: {\n required: true,\n type: \"string\"\n },\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/assignees\"\n },\n listComments: {\n method: \"GET\",\n params: {\n issue_number: {\n required: true,\n type: \"integer\"\n },\n number: {\n alias: \"issue_number\",\n deprecated: true,\n type: \"integer\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n repo: {\n required: true,\n type: \"string\"\n },\n since: {\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/issues/:issue_number/comments\"\n },\n listCommentsForRepo: {\n method: \"GET\",\n params: {\n direction: {\n enum: [\"asc\", \"desc\"],\n type: \"string\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n },\n since: {\n type: \"string\"\n },\n sort: {\n enum: [\"created\", \"updated\"],\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/issues/comments\"\n },\n listEvents: {\n method: \"GET\",\n params: {\n issue_number: {\n required: true,\n type: \"integer\"\n },\n number: {\n alias: \"issue_number\",\n deprecated: true,\n type: \"integer\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/issues/:issue_number/events\"\n },\n listEventsForRepo: {\n method: \"GET\",\n params: {\n owner: {\n required: true,\n type: \"string\"\n },\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/issues/events\"\n },\n listEventsForTimeline: {\n headers: {\n accept: \"application/vnd.github.mockingbird-preview+json\"\n },\n method: \"GET\",\n params: {\n issue_number: {\n required: true,\n type: \"integer\"\n },\n number: {\n alias: \"issue_number\",\n deprecated: true,\n type: \"integer\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/issues/:issue_number/timeline\"\n },\n listForAuthenticatedUser: {\n method: \"GET\",\n params: {\n direction: {\n enum: [\"asc\", \"desc\"],\n type: \"string\"\n },\n filter: {\n enum: [\"assigned\", \"created\", \"mentioned\", \"subscribed\", \"all\"],\n type: \"string\"\n },\n labels: {\n type: \"string\"\n },\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n since: {\n type: \"string\"\n },\n sort: {\n enum: [\"created\", \"updated\", \"comments\"],\n type: \"string\"\n },\n state: {\n enum: [\"open\", \"closed\", \"all\"],\n type: \"string\"\n }\n },\n url: \"/user/issues\"\n },\n listForOrg: {\n method: \"GET\",\n params: {\n direction: {\n enum: [\"asc\", \"desc\"],\n type: \"string\"\n },\n filter: {\n enum: [\"assigned\", \"created\", \"mentioned\", \"subscribed\", \"all\"],\n type: \"string\"\n },\n labels: {\n type: \"string\"\n },\n org: {\n required: true,\n type: \"string\"\n },\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n since: {\n type: \"string\"\n },\n sort: {\n enum: [\"created\", \"updated\", \"comments\"],\n type: \"string\"\n },\n state: {\n enum: [\"open\", \"closed\", \"all\"],\n type: \"string\"\n }\n },\n url: \"/orgs/:org/issues\"\n },\n listForRepo: {\n method: \"GET\",\n params: {\n assignee: {\n type: \"string\"\n },\n creator: {\n type: \"string\"\n },\n direction: {\n enum: [\"asc\", \"desc\"],\n type: \"string\"\n },\n labels: {\n type: \"string\"\n },\n mentioned: {\n type: \"string\"\n },\n milestone: {\n type: \"string\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n repo: {\n required: true,\n type: \"string\"\n },\n since: {\n type: \"string\"\n },\n sort: {\n enum: [\"created\", \"updated\", \"comments\"],\n type: \"string\"\n },\n state: {\n enum: [\"open\", \"closed\", \"all\"],\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/issues\"\n },\n listLabelsForMilestone: {\n method: \"GET\",\n params: {\n milestone_number: {\n required: true,\n type: \"integer\"\n },\n number: {\n alias: \"milestone_number\",\n deprecated: true,\n type: \"integer\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/milestones/:milestone_number/labels\"\n },\n listLabelsForRepo: {\n method: \"GET\",\n params: {\n owner: {\n required: true,\n type: \"string\"\n },\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/labels\"\n },\n listLabelsOnIssue: {\n method: \"GET\",\n params: {\n issue_number: {\n required: true,\n type: \"integer\"\n },\n number: {\n alias: \"issue_number\",\n deprecated: true,\n type: \"integer\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/issues/:issue_number/labels\"\n },\n listMilestonesForRepo: {\n method: \"GET\",\n params: {\n direction: {\n enum: [\"asc\", \"desc\"],\n type: \"string\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n repo: {\n required: true,\n type: \"string\"\n },\n sort: {\n enum: [\"due_on\", \"completeness\"],\n type: \"string\"\n },\n state: {\n enum: [\"open\", \"closed\", \"all\"],\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/milestones\"\n },\n lock: {\n method: \"PUT\",\n params: {\n issue_number: {\n required: true,\n type: \"integer\"\n },\n lock_reason: {\n enum: [\"off-topic\", \"too heated\", \"resolved\", \"spam\"],\n type: \"string\"\n },\n number: {\n alias: \"issue_number\",\n deprecated: true,\n type: \"integer\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/issues/:issue_number/lock\"\n },\n removeAssignees: {\n method: \"DELETE\",\n params: {\n assignees: {\n type: \"string[]\"\n },\n issue_number: {\n required: true,\n type: \"integer\"\n },\n number: {\n alias: \"issue_number\",\n deprecated: true,\n type: \"integer\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/issues/:issue_number/assignees\"\n },\n removeLabel: {\n method: \"DELETE\",\n params: {\n issue_number: {\n required: true,\n type: \"integer\"\n },\n name: {\n required: true,\n type: \"string\"\n },\n number: {\n alias: \"issue_number\",\n deprecated: true,\n type: \"integer\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/issues/:issue_number/labels/:name\"\n },\n removeLabels: {\n method: \"DELETE\",\n params: {\n issue_number: {\n required: true,\n type: \"integer\"\n },\n number: {\n alias: \"issue_number\",\n deprecated: true,\n type: \"integer\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/issues/:issue_number/labels\"\n },\n replaceLabels: {\n method: \"PUT\",\n params: {\n issue_number: {\n required: true,\n type: \"integer\"\n },\n labels: {\n type: \"string[]\"\n },\n number: {\n alias: \"issue_number\",\n deprecated: true,\n type: \"integer\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/issues/:issue_number/labels\"\n },\n unlock: {\n method: \"DELETE\",\n params: {\n issue_number: {\n required: true,\n type: \"integer\"\n },\n number: {\n alias: \"issue_number\",\n deprecated: true,\n type: \"integer\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/issues/:issue_number/lock\"\n },\n update: {\n method: \"PATCH\",\n params: {\n assignee: {\n type: \"string\"\n },\n assignees: {\n type: \"string[]\"\n },\n body: {\n type: \"string\"\n },\n issue_number: {\n required: true,\n type: \"integer\"\n },\n labels: {\n type: \"string[]\"\n },\n milestone: {\n allowNull: true,\n type: \"integer\"\n },\n number: {\n alias: \"issue_number\",\n deprecated: true,\n type: \"integer\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n },\n state: {\n enum: [\"open\", \"closed\"],\n type: \"string\"\n },\n title: {\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/issues/:issue_number\"\n },\n updateComment: {\n method: \"PATCH\",\n params: {\n body: {\n required: true,\n type: \"string\"\n },\n comment_id: {\n required: true,\n type: \"integer\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/issues/comments/:comment_id\"\n },\n updateLabel: {\n method: \"PATCH\",\n params: {\n color: {\n type: \"string\"\n },\n current_name: {\n required: true,\n type: \"string\"\n },\n description: {\n type: \"string\"\n },\n name: {\n type: \"string\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/labels/:current_name\"\n },\n updateMilestone: {\n method: \"PATCH\",\n params: {\n description: {\n type: \"string\"\n },\n due_on: {\n type: \"string\"\n },\n milestone_number: {\n required: true,\n type: \"integer\"\n },\n number: {\n alias: \"milestone_number\",\n deprecated: true,\n type: \"integer\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n },\n state: {\n enum: [\"open\", \"closed\"],\n type: \"string\"\n },\n title: {\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/milestones/:milestone_number\"\n }\n },\n licenses: {\n get: {\n method: \"GET\",\n params: {\n license: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/licenses/:license\"\n },\n getForRepo: {\n method: \"GET\",\n params: {\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/license\"\n },\n list: {\n deprecated: \"octokit.licenses.list() has been renamed to octokit.licenses.listCommonlyUsed() (2019-03-05)\",\n method: \"GET\",\n params: {},\n url: \"/licenses\"\n },\n listCommonlyUsed: {\n method: \"GET\",\n params: {},\n url: \"/licenses\"\n }\n },\n markdown: {\n render: {\n method: \"POST\",\n params: {\n context: {\n type: \"string\"\n },\n mode: {\n enum: [\"markdown\", \"gfm\"],\n type: \"string\"\n },\n text: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/markdown\"\n },\n renderRaw: {\n headers: {\n \"content-type\": \"text/plain; charset=utf-8\"\n },\n method: \"POST\",\n params: {\n data: {\n mapTo: \"data\",\n required: true,\n type: \"string\"\n }\n },\n url: \"/markdown/raw\"\n }\n },\n meta: {\n get: {\n method: \"GET\",\n params: {},\n url: \"/meta\"\n }\n },\n migrations: {\n cancelImport: {\n method: \"DELETE\",\n params: {\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/import\"\n },\n deleteArchiveForAuthenticatedUser: {\n headers: {\n accept: \"application/vnd.github.wyandotte-preview+json\"\n },\n method: \"DELETE\",\n params: {\n migration_id: {\n required: true,\n type: \"integer\"\n }\n },\n url: \"/user/migrations/:migration_id/archive\"\n },\n deleteArchiveForOrg: {\n headers: {\n accept: \"application/vnd.github.wyandotte-preview+json\"\n },\n method: \"DELETE\",\n params: {\n migration_id: {\n required: true,\n type: \"integer\"\n },\n org: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/orgs/:org/migrations/:migration_id/archive\"\n },\n downloadArchiveForOrg: {\n headers: {\n accept: \"application/vnd.github.wyandotte-preview+json\"\n },\n method: \"GET\",\n params: {\n migration_id: {\n required: true,\n type: \"integer\"\n },\n org: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/orgs/:org/migrations/:migration_id/archive\"\n },\n getArchiveForAuthenticatedUser: {\n headers: {\n accept: \"application/vnd.github.wyandotte-preview+json\"\n },\n method: \"GET\",\n params: {\n migration_id: {\n required: true,\n type: \"integer\"\n }\n },\n url: \"/user/migrations/:migration_id/archive\"\n },\n getArchiveForOrg: {\n deprecated: \"octokit.migrations.getArchiveForOrg() has been renamed to octokit.migrations.downloadArchiveForOrg() (2020-01-27)\",\n headers: {\n accept: \"application/vnd.github.wyandotte-preview+json\"\n },\n method: \"GET\",\n params: {\n migration_id: {\n required: true,\n type: \"integer\"\n },\n org: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/orgs/:org/migrations/:migration_id/archive\"\n },\n getCommitAuthors: {\n method: \"GET\",\n params: {\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n },\n since: {\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/import/authors\"\n },\n getImportProgress: {\n method: \"GET\",\n params: {\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/import\"\n },\n getLargeFiles: {\n method: \"GET\",\n params: {\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/import/large_files\"\n },\n getStatusForAuthenticatedUser: {\n headers: {\n accept: \"application/vnd.github.wyandotte-preview+json\"\n },\n method: \"GET\",\n params: {\n migration_id: {\n required: true,\n type: \"integer\"\n }\n },\n url: \"/user/migrations/:migration_id\"\n },\n getStatusForOrg: {\n headers: {\n accept: \"application/vnd.github.wyandotte-preview+json\"\n },\n method: \"GET\",\n params: {\n migration_id: {\n required: true,\n type: \"integer\"\n },\n org: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/orgs/:org/migrations/:migration_id\"\n },\n listForAuthenticatedUser: {\n headers: {\n accept: \"application/vnd.github.wyandotte-preview+json\"\n },\n method: \"GET\",\n params: {\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n }\n },\n url: \"/user/migrations\"\n },\n listForOrg: {\n headers: {\n accept: \"application/vnd.github.wyandotte-preview+json\"\n },\n method: \"GET\",\n params: {\n org: {\n required: true,\n type: \"string\"\n },\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n }\n },\n url: \"/orgs/:org/migrations\"\n },\n listReposForOrg: {\n headers: {\n accept: \"application/vnd.github.wyandotte-preview+json\"\n },\n method: \"GET\",\n params: {\n migration_id: {\n required: true,\n type: \"integer\"\n },\n org: {\n required: true,\n type: \"string\"\n },\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n }\n },\n url: \"/orgs/:org/migrations/:migration_id/repositories\"\n },\n listReposForUser: {\n headers: {\n accept: \"application/vnd.github.wyandotte-preview+json\"\n },\n method: \"GET\",\n params: {\n migration_id: {\n required: true,\n type: \"integer\"\n },\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n }\n },\n url: \"/user/:migration_id/repositories\"\n },\n mapCommitAuthor: {\n method: \"PATCH\",\n params: {\n author_id: {\n required: true,\n type: \"integer\"\n },\n email: {\n type: \"string\"\n },\n name: {\n type: \"string\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/import/authors/:author_id\"\n },\n setLfsPreference: {\n method: \"PATCH\",\n params: {\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n },\n use_lfs: {\n enum: [\"opt_in\", \"opt_out\"],\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/import/lfs\"\n },\n startForAuthenticatedUser: {\n method: \"POST\",\n params: {\n exclude_attachments: {\n type: \"boolean\"\n },\n lock_repositories: {\n type: \"boolean\"\n },\n repositories: {\n required: true,\n type: \"string[]\"\n }\n },\n url: \"/user/migrations\"\n },\n startForOrg: {\n method: \"POST\",\n params: {\n exclude_attachments: {\n type: \"boolean\"\n },\n lock_repositories: {\n type: \"boolean\"\n },\n org: {\n required: true,\n type: \"string\"\n },\n repositories: {\n required: true,\n type: \"string[]\"\n }\n },\n url: \"/orgs/:org/migrations\"\n },\n startImport: {\n method: \"PUT\",\n params: {\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n },\n tfvc_project: {\n type: \"string\"\n },\n vcs: {\n enum: [\"subversion\", \"git\", \"mercurial\", \"tfvc\"],\n type: \"string\"\n },\n vcs_password: {\n type: \"string\"\n },\n vcs_url: {\n required: true,\n type: \"string\"\n },\n vcs_username: {\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/import\"\n },\n unlockRepoForAuthenticatedUser: {\n headers: {\n accept: \"application/vnd.github.wyandotte-preview+json\"\n },\n method: \"DELETE\",\n params: {\n migration_id: {\n required: true,\n type: \"integer\"\n },\n repo_name: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/user/migrations/:migration_id/repos/:repo_name/lock\"\n },\n unlockRepoForOrg: {\n headers: {\n accept: \"application/vnd.github.wyandotte-preview+json\"\n },\n method: \"DELETE\",\n params: {\n migration_id: {\n required: true,\n type: \"integer\"\n },\n org: {\n required: true,\n type: \"string\"\n },\n repo_name: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/orgs/:org/migrations/:migration_id/repos/:repo_name/lock\"\n },\n updateImport: {\n method: \"PATCH\",\n params: {\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n },\n vcs_password: {\n type: \"string\"\n },\n vcs_username: {\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/import\"\n }\n },\n oauthAuthorizations: {\n checkAuthorization: {\n deprecated: \"octokit.oauthAuthorizations.checkAuthorization() has been renamed to octokit.apps.checkAuthorization() (2019-11-05)\",\n method: \"GET\",\n params: {\n access_token: {\n required: true,\n type: \"string\"\n },\n client_id: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/applications/:client_id/tokens/:access_token\"\n },\n createAuthorization: {\n deprecated: \"octokit.oauthAuthorizations.createAuthorization() is deprecated, see https://developer.github.com/v3/oauth_authorizations/#create-a-new-authorization\",\n method: \"POST\",\n params: {\n client_id: {\n type: \"string\"\n },\n client_secret: {\n type: \"string\"\n },\n fingerprint: {\n type: \"string\"\n },\n note: {\n required: true,\n type: \"string\"\n },\n note_url: {\n type: \"string\"\n },\n scopes: {\n type: \"string[]\"\n }\n },\n url: \"/authorizations\"\n },\n deleteAuthorization: {\n deprecated: \"octokit.oauthAuthorizations.deleteAuthorization() is deprecated, see https://developer.github.com/v3/oauth_authorizations/#delete-an-authorization\",\n method: \"DELETE\",\n params: {\n authorization_id: {\n required: true,\n type: \"integer\"\n }\n },\n url: \"/authorizations/:authorization_id\"\n },\n deleteGrant: {\n deprecated: \"octokit.oauthAuthorizations.deleteGrant() is deprecated, see https://developer.github.com/v3/oauth_authorizations/#delete-a-grant\",\n method: \"DELETE\",\n params: {\n grant_id: {\n required: true,\n type: \"integer\"\n }\n },\n url: \"/applications/grants/:grant_id\"\n },\n getAuthorization: {\n deprecated: \"octokit.oauthAuthorizations.getAuthorization() is deprecated, see https://developer.github.com/v3/oauth_authorizations/#get-a-single-authorization\",\n method: \"GET\",\n params: {\n authorization_id: {\n required: true,\n type: \"integer\"\n }\n },\n url: \"/authorizations/:authorization_id\"\n },\n getGrant: {\n deprecated: \"octokit.oauthAuthorizations.getGrant() is deprecated, see https://developer.github.com/v3/oauth_authorizations/#get-a-single-grant\",\n method: \"GET\",\n params: {\n grant_id: {\n required: true,\n type: \"integer\"\n }\n },\n url: \"/applications/grants/:grant_id\"\n },\n getOrCreateAuthorizationForApp: {\n deprecated: \"octokit.oauthAuthorizations.getOrCreateAuthorizationForApp() is deprecated, see https://developer.github.com/v3/oauth_authorizations/#get-or-create-an-authorization-for-a-specific-app\",\n method: \"PUT\",\n params: {\n client_id: {\n required: true,\n type: \"string\"\n },\n client_secret: {\n required: true,\n type: \"string\"\n },\n fingerprint: {\n type: \"string\"\n },\n note: {\n type: \"string\"\n },\n note_url: {\n type: \"string\"\n },\n scopes: {\n type: \"string[]\"\n }\n },\n url: \"/authorizations/clients/:client_id\"\n },\n getOrCreateAuthorizationForAppAndFingerprint: {\n deprecated: \"octokit.oauthAuthorizations.getOrCreateAuthorizationForAppAndFingerprint() is deprecated, see https://developer.github.com/v3/oauth_authorizations/#get-or-create-an-authorization-for-a-specific-app-and-fingerprint\",\n method: \"PUT\",\n params: {\n client_id: {\n required: true,\n type: \"string\"\n },\n client_secret: {\n required: true,\n type: \"string\"\n },\n fingerprint: {\n required: true,\n type: \"string\"\n },\n note: {\n type: \"string\"\n },\n note_url: {\n type: \"string\"\n },\n scopes: {\n type: \"string[]\"\n }\n },\n url: \"/authorizations/clients/:client_id/:fingerprint\"\n },\n getOrCreateAuthorizationForAppFingerprint: {\n deprecated: \"octokit.oauthAuthorizations.getOrCreateAuthorizationForAppFingerprint() has been renamed to octokit.oauthAuthorizations.getOrCreateAuthorizationForAppAndFingerprint() (2018-12-27)\",\n method: \"PUT\",\n params: {\n client_id: {\n required: true,\n type: \"string\"\n },\n client_secret: {\n required: true,\n type: \"string\"\n },\n fingerprint: {\n required: true,\n type: \"string\"\n },\n note: {\n type: \"string\"\n },\n note_url: {\n type: \"string\"\n },\n scopes: {\n type: \"string[]\"\n }\n },\n url: \"/authorizations/clients/:client_id/:fingerprint\"\n },\n listAuthorizations: {\n deprecated: \"octokit.oauthAuthorizations.listAuthorizations() is deprecated, see https://developer.github.com/v3/oauth_authorizations/#list-your-authorizations\",\n method: \"GET\",\n params: {\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n }\n },\n url: \"/authorizations\"\n },\n listGrants: {\n deprecated: \"octokit.oauthAuthorizations.listGrants() is deprecated, see https://developer.github.com/v3/oauth_authorizations/#list-your-grants\",\n method: \"GET\",\n params: {\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n }\n },\n url: \"/applications/grants\"\n },\n resetAuthorization: {\n deprecated: \"octokit.oauthAuthorizations.resetAuthorization() has been renamed to octokit.apps.resetAuthorization() (2019-11-05)\",\n method: \"POST\",\n params: {\n access_token: {\n required: true,\n type: \"string\"\n },\n client_id: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/applications/:client_id/tokens/:access_token\"\n },\n revokeAuthorizationForApplication: {\n deprecated: \"octokit.oauthAuthorizations.revokeAuthorizationForApplication() has been renamed to octokit.apps.revokeAuthorizationForApplication() (2019-11-05)\",\n method: \"DELETE\",\n params: {\n access_token: {\n required: true,\n type: \"string\"\n },\n client_id: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/applications/:client_id/tokens/:access_token\"\n },\n revokeGrantForApplication: {\n deprecated: \"octokit.oauthAuthorizations.revokeGrantForApplication() has been renamed to octokit.apps.revokeGrantForApplication() (2019-11-05)\",\n method: \"DELETE\",\n params: {\n access_token: {\n required: true,\n type: \"string\"\n },\n client_id: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/applications/:client_id/grants/:access_token\"\n },\n updateAuthorization: {\n deprecated: \"octokit.oauthAuthorizations.updateAuthorization() is deprecated, see https://developer.github.com/v3/oauth_authorizations/#update-an-existing-authorization\",\n method: \"PATCH\",\n params: {\n add_scopes: {\n type: \"string[]\"\n },\n authorization_id: {\n required: true,\n type: \"integer\"\n },\n fingerprint: {\n type: \"string\"\n },\n note: {\n type: \"string\"\n },\n note_url: {\n type: \"string\"\n },\n remove_scopes: {\n type: \"string[]\"\n },\n scopes: {\n type: \"string[]\"\n }\n },\n url: \"/authorizations/:authorization_id\"\n }\n },\n orgs: {\n addOrUpdateMembership: {\n method: \"PUT\",\n params: {\n org: {\n required: true,\n type: \"string\"\n },\n role: {\n enum: [\"admin\", \"member\"],\n type: \"string\"\n },\n username: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/orgs/:org/memberships/:username\"\n },\n blockUser: {\n method: \"PUT\",\n params: {\n org: {\n required: true,\n type: \"string\"\n },\n username: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/orgs/:org/blocks/:username\"\n },\n checkBlockedUser: {\n method: \"GET\",\n params: {\n org: {\n required: true,\n type: \"string\"\n },\n username: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/orgs/:org/blocks/:username\"\n },\n checkMembership: {\n method: \"GET\",\n params: {\n org: {\n required: true,\n type: \"string\"\n },\n username: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/orgs/:org/members/:username\"\n },\n checkPublicMembership: {\n method: \"GET\",\n params: {\n org: {\n required: true,\n type: \"string\"\n },\n username: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/orgs/:org/public_members/:username\"\n },\n concealMembership: {\n method: \"DELETE\",\n params: {\n org: {\n required: true,\n type: \"string\"\n },\n username: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/orgs/:org/public_members/:username\"\n },\n convertMemberToOutsideCollaborator: {\n method: \"PUT\",\n params: {\n org: {\n required: true,\n type: \"string\"\n },\n username: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/orgs/:org/outside_collaborators/:username\"\n },\n createHook: {\n method: \"POST\",\n params: {\n active: {\n type: \"boolean\"\n },\n config: {\n required: true,\n type: \"object\"\n },\n \"config.content_type\": {\n type: \"string\"\n },\n \"config.insecure_ssl\": {\n type: \"string\"\n },\n \"config.secret\": {\n type: \"string\"\n },\n \"config.url\": {\n required: true,\n type: \"string\"\n },\n events: {\n type: \"string[]\"\n },\n name: {\n required: true,\n type: \"string\"\n },\n org: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/orgs/:org/hooks\"\n },\n createInvitation: {\n method: \"POST\",\n params: {\n email: {\n type: \"string\"\n },\n invitee_id: {\n type: \"integer\"\n },\n org: {\n required: true,\n type: \"string\"\n },\n role: {\n enum: [\"admin\", \"direct_member\", \"billing_manager\"],\n type: \"string\"\n },\n team_ids: {\n type: \"integer[]\"\n }\n },\n url: \"/orgs/:org/invitations\"\n },\n deleteHook: {\n method: \"DELETE\",\n params: {\n hook_id: {\n required: true,\n type: \"integer\"\n },\n org: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/orgs/:org/hooks/:hook_id\"\n },\n get: {\n method: \"GET\",\n params: {\n org: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/orgs/:org\"\n },\n getHook: {\n method: \"GET\",\n params: {\n hook_id: {\n required: true,\n type: \"integer\"\n },\n org: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/orgs/:org/hooks/:hook_id\"\n },\n getMembership: {\n method: \"GET\",\n params: {\n org: {\n required: true,\n type: \"string\"\n },\n username: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/orgs/:org/memberships/:username\"\n },\n getMembershipForAuthenticatedUser: {\n method: \"GET\",\n params: {\n org: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/user/memberships/orgs/:org\"\n },\n list: {\n method: \"GET\",\n params: {\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n since: {\n type: \"integer\"\n }\n },\n url: \"/organizations\"\n },\n listBlockedUsers: {\n method: \"GET\",\n params: {\n org: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/orgs/:org/blocks\"\n },\n listForAuthenticatedUser: {\n method: \"GET\",\n params: {\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n }\n },\n url: \"/user/orgs\"\n },\n listForUser: {\n method: \"GET\",\n params: {\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n username: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/users/:username/orgs\"\n },\n listHooks: {\n method: \"GET\",\n params: {\n org: {\n required: true,\n type: \"string\"\n },\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n }\n },\n url: \"/orgs/:org/hooks\"\n },\n listInstallations: {\n headers: {\n accept: \"application/vnd.github.machine-man-preview+json\"\n },\n method: \"GET\",\n params: {\n org: {\n required: true,\n type: \"string\"\n },\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n }\n },\n url: \"/orgs/:org/installations\"\n },\n listInvitationTeams: {\n method: \"GET\",\n params: {\n invitation_id: {\n required: true,\n type: \"integer\"\n },\n org: {\n required: true,\n type: \"string\"\n },\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n }\n },\n url: \"/orgs/:org/invitations/:invitation_id/teams\"\n },\n listMembers: {\n method: \"GET\",\n params: {\n filter: {\n enum: [\"2fa_disabled\", \"all\"],\n type: \"string\"\n },\n org: {\n required: true,\n type: \"string\"\n },\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n role: {\n enum: [\"all\", \"admin\", \"member\"],\n type: \"string\"\n }\n },\n url: \"/orgs/:org/members\"\n },\n listMemberships: {\n method: \"GET\",\n params: {\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n state: {\n enum: [\"active\", \"pending\"],\n type: \"string\"\n }\n },\n url: \"/user/memberships/orgs\"\n },\n listOutsideCollaborators: {\n method: \"GET\",\n params: {\n filter: {\n enum: [\"2fa_disabled\", \"all\"],\n type: \"string\"\n },\n org: {\n required: true,\n type: \"string\"\n },\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n }\n },\n url: \"/orgs/:org/outside_collaborators\"\n },\n listPendingInvitations: {\n method: \"GET\",\n params: {\n org: {\n required: true,\n type: \"string\"\n },\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n }\n },\n url: \"/orgs/:org/invitations\"\n },\n listPublicMembers: {\n method: \"GET\",\n params: {\n org: {\n required: true,\n type: \"string\"\n },\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n }\n },\n url: \"/orgs/:org/public_members\"\n },\n pingHook: {\n method: \"POST\",\n params: {\n hook_id: {\n required: true,\n type: \"integer\"\n },\n org: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/orgs/:org/hooks/:hook_id/pings\"\n },\n publicizeMembership: {\n method: \"PUT\",\n params: {\n org: {\n required: true,\n type: \"string\"\n },\n username: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/orgs/:org/public_members/:username\"\n },\n removeMember: {\n method: \"DELETE\",\n params: {\n org: {\n required: true,\n type: \"string\"\n },\n username: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/orgs/:org/members/:username\"\n },\n removeMembership: {\n method: \"DELETE\",\n params: {\n org: {\n required: true,\n type: \"string\"\n },\n username: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/orgs/:org/memberships/:username\"\n },\n removeOutsideCollaborator: {\n method: \"DELETE\",\n params: {\n org: {\n required: true,\n type: \"string\"\n },\n username: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/orgs/:org/outside_collaborators/:username\"\n },\n unblockUser: {\n method: \"DELETE\",\n params: {\n org: {\n required: true,\n type: \"string\"\n },\n username: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/orgs/:org/blocks/:username\"\n },\n update: {\n method: \"PATCH\",\n params: {\n billing_email: {\n type: \"string\"\n },\n company: {\n type: \"string\"\n },\n default_repository_permission: {\n enum: [\"read\", \"write\", \"admin\", \"none\"],\n type: \"string\"\n },\n description: {\n type: \"string\"\n },\n email: {\n type: \"string\"\n },\n has_organization_projects: {\n type: \"boolean\"\n },\n has_repository_projects: {\n type: \"boolean\"\n },\n location: {\n type: \"string\"\n },\n members_allowed_repository_creation_type: {\n enum: [\"all\", \"private\", \"none\"],\n type: \"string\"\n },\n members_can_create_internal_repositories: {\n type: \"boolean\"\n },\n members_can_create_private_repositories: {\n type: \"boolean\"\n },\n members_can_create_public_repositories: {\n type: \"boolean\"\n },\n members_can_create_repositories: {\n type: \"boolean\"\n },\n name: {\n type: \"string\"\n },\n org: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/orgs/:org\"\n },\n updateHook: {\n method: \"PATCH\",\n params: {\n active: {\n type: \"boolean\"\n },\n config: {\n type: \"object\"\n },\n \"config.content_type\": {\n type: \"string\"\n },\n \"config.insecure_ssl\": {\n type: \"string\"\n },\n \"config.secret\": {\n type: \"string\"\n },\n \"config.url\": {\n required: true,\n type: \"string\"\n },\n events: {\n type: \"string[]\"\n },\n hook_id: {\n required: true,\n type: \"integer\"\n },\n org: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/orgs/:org/hooks/:hook_id\"\n },\n updateMembership: {\n method: \"PATCH\",\n params: {\n org: {\n required: true,\n type: \"string\"\n },\n state: {\n enum: [\"active\"],\n required: true,\n type: \"string\"\n }\n },\n url: \"/user/memberships/orgs/:org\"\n }\n },\n projects: {\n addCollaborator: {\n headers: {\n accept: \"application/vnd.github.inertia-preview+json\"\n },\n method: \"PUT\",\n params: {\n permission: {\n enum: [\"read\", \"write\", \"admin\"],\n type: \"string\"\n },\n project_id: {\n required: true,\n type: \"integer\"\n },\n username: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/projects/:project_id/collaborators/:username\"\n },\n createCard: {\n headers: {\n accept: \"application/vnd.github.inertia-preview+json\"\n },\n method: \"POST\",\n params: {\n column_id: {\n required: true,\n type: \"integer\"\n },\n content_id: {\n type: \"integer\"\n },\n content_type: {\n type: \"string\"\n },\n note: {\n type: \"string\"\n }\n },\n url: \"/projects/columns/:column_id/cards\"\n },\n createColumn: {\n headers: {\n accept: \"application/vnd.github.inertia-preview+json\"\n },\n method: \"POST\",\n params: {\n name: {\n required: true,\n type: \"string\"\n },\n project_id: {\n required: true,\n type: \"integer\"\n }\n },\n url: \"/projects/:project_id/columns\"\n },\n createForAuthenticatedUser: {\n headers: {\n accept: \"application/vnd.github.inertia-preview+json\"\n },\n method: \"POST\",\n params: {\n body: {\n type: \"string\"\n },\n name: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/user/projects\"\n },\n createForOrg: {\n headers: {\n accept: \"application/vnd.github.inertia-preview+json\"\n },\n method: \"POST\",\n params: {\n body: {\n type: \"string\"\n },\n name: {\n required: true,\n type: \"string\"\n },\n org: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/orgs/:org/projects\"\n },\n createForRepo: {\n headers: {\n accept: \"application/vnd.github.inertia-preview+json\"\n },\n method: \"POST\",\n params: {\n body: {\n type: \"string\"\n },\n name: {\n required: true,\n type: \"string\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/projects\"\n },\n delete: {\n headers: {\n accept: \"application/vnd.github.inertia-preview+json\"\n },\n method: \"DELETE\",\n params: {\n project_id: {\n required: true,\n type: \"integer\"\n }\n },\n url: \"/projects/:project_id\"\n },\n deleteCard: {\n headers: {\n accept: \"application/vnd.github.inertia-preview+json\"\n },\n method: \"DELETE\",\n params: {\n card_id: {\n required: true,\n type: \"integer\"\n }\n },\n url: \"/projects/columns/cards/:card_id\"\n },\n deleteColumn: {\n headers: {\n accept: \"application/vnd.github.inertia-preview+json\"\n },\n method: \"DELETE\",\n params: {\n column_id: {\n required: true,\n type: \"integer\"\n }\n },\n url: \"/projects/columns/:column_id\"\n },\n get: {\n headers: {\n accept: \"application/vnd.github.inertia-preview+json\"\n },\n method: \"GET\",\n params: {\n project_id: {\n required: true,\n type: \"integer\"\n }\n },\n url: \"/projects/:project_id\"\n },\n getCard: {\n headers: {\n accept: \"application/vnd.github.inertia-preview+json\"\n },\n method: \"GET\",\n params: {\n card_id: {\n required: true,\n type: \"integer\"\n }\n },\n url: \"/projects/columns/cards/:card_id\"\n },\n getColumn: {\n headers: {\n accept: \"application/vnd.github.inertia-preview+json\"\n },\n method: \"GET\",\n params: {\n column_id: {\n required: true,\n type: \"integer\"\n }\n },\n url: \"/projects/columns/:column_id\"\n },\n listCards: {\n headers: {\n accept: \"application/vnd.github.inertia-preview+json\"\n },\n method: \"GET\",\n params: {\n archived_state: {\n enum: [\"all\", \"archived\", \"not_archived\"],\n type: \"string\"\n },\n column_id: {\n required: true,\n type: \"integer\"\n },\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n }\n },\n url: \"/projects/columns/:column_id/cards\"\n },\n listCollaborators: {\n headers: {\n accept: \"application/vnd.github.inertia-preview+json\"\n },\n method: \"GET\",\n params: {\n affiliation: {\n enum: [\"outside\", \"direct\", \"all\"],\n type: \"string\"\n },\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n project_id: {\n required: true,\n type: \"integer\"\n }\n },\n url: \"/projects/:project_id/collaborators\"\n },\n listColumns: {\n headers: {\n accept: \"application/vnd.github.inertia-preview+json\"\n },\n method: \"GET\",\n params: {\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n project_id: {\n required: true,\n type: \"integer\"\n }\n },\n url: \"/projects/:project_id/columns\"\n },\n listForOrg: {\n headers: {\n accept: \"application/vnd.github.inertia-preview+json\"\n },\n method: \"GET\",\n params: {\n org: {\n required: true,\n type: \"string\"\n },\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n state: {\n enum: [\"open\", \"closed\", \"all\"],\n type: \"string\"\n }\n },\n url: \"/orgs/:org/projects\"\n },\n listForRepo: {\n headers: {\n accept: \"application/vnd.github.inertia-preview+json\"\n },\n method: \"GET\",\n params: {\n owner: {\n required: true,\n type: \"string\"\n },\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n repo: {\n required: true,\n type: \"string\"\n },\n state: {\n enum: [\"open\", \"closed\", \"all\"],\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/projects\"\n },\n listForUser: {\n headers: {\n accept: \"application/vnd.github.inertia-preview+json\"\n },\n method: \"GET\",\n params: {\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n state: {\n enum: [\"open\", \"closed\", \"all\"],\n type: \"string\"\n },\n username: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/users/:username/projects\"\n },\n moveCard: {\n headers: {\n accept: \"application/vnd.github.inertia-preview+json\"\n },\n method: \"POST\",\n params: {\n card_id: {\n required: true,\n type: \"integer\"\n },\n column_id: {\n type: \"integer\"\n },\n position: {\n required: true,\n type: \"string\",\n validation: \"^(top|bottom|after:\\\\d+)$\"\n }\n },\n url: \"/projects/columns/cards/:card_id/moves\"\n },\n moveColumn: {\n headers: {\n accept: \"application/vnd.github.inertia-preview+json\"\n },\n method: \"POST\",\n params: {\n column_id: {\n required: true,\n type: \"integer\"\n },\n position: {\n required: true,\n type: \"string\",\n validation: \"^(first|last|after:\\\\d+)$\"\n }\n },\n url: \"/projects/columns/:column_id/moves\"\n },\n removeCollaborator: {\n headers: {\n accept: \"application/vnd.github.inertia-preview+json\"\n },\n method: \"DELETE\",\n params: {\n project_id: {\n required: true,\n type: \"integer\"\n },\n username: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/projects/:project_id/collaborators/:username\"\n },\n reviewUserPermissionLevel: {\n headers: {\n accept: \"application/vnd.github.inertia-preview+json\"\n },\n method: \"GET\",\n params: {\n project_id: {\n required: true,\n type: \"integer\"\n },\n username: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/projects/:project_id/collaborators/:username/permission\"\n },\n update: {\n headers: {\n accept: \"application/vnd.github.inertia-preview+json\"\n },\n method: \"PATCH\",\n params: {\n body: {\n type: \"string\"\n },\n name: {\n type: \"string\"\n },\n organization_permission: {\n type: \"string\"\n },\n private: {\n type: \"boolean\"\n },\n project_id: {\n required: true,\n type: \"integer\"\n },\n state: {\n enum: [\"open\", \"closed\"],\n type: \"string\"\n }\n },\n url: \"/projects/:project_id\"\n },\n updateCard: {\n headers: {\n accept: \"application/vnd.github.inertia-preview+json\"\n },\n method: \"PATCH\",\n params: {\n archived: {\n type: \"boolean\"\n },\n card_id: {\n required: true,\n type: \"integer\"\n },\n note: {\n type: \"string\"\n }\n },\n url: \"/projects/columns/cards/:card_id\"\n },\n updateColumn: {\n headers: {\n accept: \"application/vnd.github.inertia-preview+json\"\n },\n method: \"PATCH\",\n params: {\n column_id: {\n required: true,\n type: \"integer\"\n },\n name: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/projects/columns/:column_id\"\n }\n },\n pulls: {\n checkIfMerged: {\n method: \"GET\",\n params: {\n number: {\n alias: \"pull_number\",\n deprecated: true,\n type: \"integer\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n pull_number: {\n required: true,\n type: \"integer\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/pulls/:pull_number/merge\"\n },\n create: {\n method: \"POST\",\n params: {\n base: {\n required: true,\n type: \"string\"\n },\n body: {\n type: \"string\"\n },\n draft: {\n type: \"boolean\"\n },\n head: {\n required: true,\n type: \"string\"\n },\n maintainer_can_modify: {\n type: \"boolean\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n },\n title: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/pulls\"\n },\n createComment: {\n method: \"POST\",\n params: {\n body: {\n required: true,\n type: \"string\"\n },\n commit_id: {\n required: true,\n type: \"string\"\n },\n in_reply_to: {\n deprecated: true,\n description: \"The comment ID to reply to. **Note**: This must be the ID of a top-level comment, not a reply to that comment. Replies to replies are not supported.\",\n type: \"integer\"\n },\n line: {\n type: \"integer\"\n },\n number: {\n alias: \"pull_number\",\n deprecated: true,\n type: \"integer\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n path: {\n required: true,\n type: \"string\"\n },\n position: {\n type: \"integer\"\n },\n pull_number: {\n required: true,\n type: \"integer\"\n },\n repo: {\n required: true,\n type: \"string\"\n },\n side: {\n enum: [\"LEFT\", \"RIGHT\"],\n type: \"string\"\n },\n start_line: {\n type: \"integer\"\n },\n start_side: {\n enum: [\"LEFT\", \"RIGHT\", \"side\"],\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/pulls/:pull_number/comments\"\n },\n createCommentReply: {\n deprecated: \"octokit.pulls.createCommentReply() has been renamed to octokit.pulls.createComment() (2019-09-09)\",\n method: \"POST\",\n params: {\n body: {\n required: true,\n type: \"string\"\n },\n commit_id: {\n required: true,\n type: \"string\"\n },\n in_reply_to: {\n deprecated: true,\n description: \"The comment ID to reply to. **Note**: This must be the ID of a top-level comment, not a reply to that comment. Replies to replies are not supported.\",\n type: \"integer\"\n },\n line: {\n type: \"integer\"\n },\n number: {\n alias: \"pull_number\",\n deprecated: true,\n type: \"integer\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n path: {\n required: true,\n type: \"string\"\n },\n position: {\n type: \"integer\"\n },\n pull_number: {\n required: true,\n type: \"integer\"\n },\n repo: {\n required: true,\n type: \"string\"\n },\n side: {\n enum: [\"LEFT\", \"RIGHT\"],\n type: \"string\"\n },\n start_line: {\n type: \"integer\"\n },\n start_side: {\n enum: [\"LEFT\", \"RIGHT\", \"side\"],\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/pulls/:pull_number/comments\"\n },\n createFromIssue: {\n deprecated: \"octokit.pulls.createFromIssue() is deprecated, see https://developer.github.com/v3/pulls/#create-a-pull-request\",\n method: \"POST\",\n params: {\n base: {\n required: true,\n type: \"string\"\n },\n draft: {\n type: \"boolean\"\n },\n head: {\n required: true,\n type: \"string\"\n },\n issue: {\n required: true,\n type: \"integer\"\n },\n maintainer_can_modify: {\n type: \"boolean\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/pulls\"\n },\n createReview: {\n method: \"POST\",\n params: {\n body: {\n type: \"string\"\n },\n comments: {\n type: \"object[]\"\n },\n \"comments[].body\": {\n required: true,\n type: \"string\"\n },\n \"comments[].path\": {\n required: true,\n type: \"string\"\n },\n \"comments[].position\": {\n required: true,\n type: \"integer\"\n },\n commit_id: {\n type: \"string\"\n },\n event: {\n enum: [\"APPROVE\", \"REQUEST_CHANGES\", \"COMMENT\"],\n type: \"string\"\n },\n number: {\n alias: \"pull_number\",\n deprecated: true,\n type: \"integer\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n pull_number: {\n required: true,\n type: \"integer\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/pulls/:pull_number/reviews\"\n },\n createReviewCommentReply: {\n method: \"POST\",\n params: {\n body: {\n required: true,\n type: \"string\"\n },\n comment_id: {\n required: true,\n type: \"integer\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n pull_number: {\n required: true,\n type: \"integer\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/pulls/:pull_number/comments/:comment_id/replies\"\n },\n createReviewRequest: {\n method: \"POST\",\n params: {\n number: {\n alias: \"pull_number\",\n deprecated: true,\n type: \"integer\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n pull_number: {\n required: true,\n type: \"integer\"\n },\n repo: {\n required: true,\n type: \"string\"\n },\n reviewers: {\n type: \"string[]\"\n },\n team_reviewers: {\n type: \"string[]\"\n }\n },\n url: \"/repos/:owner/:repo/pulls/:pull_number/requested_reviewers\"\n },\n deleteComment: {\n method: \"DELETE\",\n params: {\n comment_id: {\n required: true,\n type: \"integer\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/pulls/comments/:comment_id\"\n },\n deletePendingReview: {\n method: \"DELETE\",\n params: {\n number: {\n alias: \"pull_number\",\n deprecated: true,\n type: \"integer\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n pull_number: {\n required: true,\n type: \"integer\"\n },\n repo: {\n required: true,\n type: \"string\"\n },\n review_id: {\n required: true,\n type: \"integer\"\n }\n },\n url: \"/repos/:owner/:repo/pulls/:pull_number/reviews/:review_id\"\n },\n deleteReviewRequest: {\n method: \"DELETE\",\n params: {\n number: {\n alias: \"pull_number\",\n deprecated: true,\n type: \"integer\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n pull_number: {\n required: true,\n type: \"integer\"\n },\n repo: {\n required: true,\n type: \"string\"\n },\n reviewers: {\n type: \"string[]\"\n },\n team_reviewers: {\n type: \"string[]\"\n }\n },\n url: \"/repos/:owner/:repo/pulls/:pull_number/requested_reviewers\"\n },\n dismissReview: {\n method: \"PUT\",\n params: {\n message: {\n required: true,\n type: \"string\"\n },\n number: {\n alias: \"pull_number\",\n deprecated: true,\n type: \"integer\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n pull_number: {\n required: true,\n type: \"integer\"\n },\n repo: {\n required: true,\n type: \"string\"\n },\n review_id: {\n required: true,\n type: \"integer\"\n }\n },\n url: \"/repos/:owner/:repo/pulls/:pull_number/reviews/:review_id/dismissals\"\n },\n get: {\n method: \"GET\",\n params: {\n number: {\n alias: \"pull_number\",\n deprecated: true,\n type: \"integer\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n pull_number: {\n required: true,\n type: \"integer\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/pulls/:pull_number\"\n },\n getComment: {\n method: \"GET\",\n params: {\n comment_id: {\n required: true,\n type: \"integer\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/pulls/comments/:comment_id\"\n },\n getCommentsForReview: {\n method: \"GET\",\n params: {\n number: {\n alias: \"pull_number\",\n deprecated: true,\n type: \"integer\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n pull_number: {\n required: true,\n type: \"integer\"\n },\n repo: {\n required: true,\n type: \"string\"\n },\n review_id: {\n required: true,\n type: \"integer\"\n }\n },\n url: \"/repos/:owner/:repo/pulls/:pull_number/reviews/:review_id/comments\"\n },\n getReview: {\n method: \"GET\",\n params: {\n number: {\n alias: \"pull_number\",\n deprecated: true,\n type: \"integer\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n pull_number: {\n required: true,\n type: \"integer\"\n },\n repo: {\n required: true,\n type: \"string\"\n },\n review_id: {\n required: true,\n type: \"integer\"\n }\n },\n url: \"/repos/:owner/:repo/pulls/:pull_number/reviews/:review_id\"\n },\n list: {\n method: \"GET\",\n params: {\n base: {\n type: \"string\"\n },\n direction: {\n enum: [\"asc\", \"desc\"],\n type: \"string\"\n },\n head: {\n type: \"string\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n repo: {\n required: true,\n type: \"string\"\n },\n sort: {\n enum: [\"created\", \"updated\", \"popularity\", \"long-running\"],\n type: \"string\"\n },\n state: {\n enum: [\"open\", \"closed\", \"all\"],\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/pulls\"\n },\n listComments: {\n method: \"GET\",\n params: {\n direction: {\n enum: [\"asc\", \"desc\"],\n type: \"string\"\n },\n number: {\n alias: \"pull_number\",\n deprecated: true,\n type: \"integer\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n pull_number: {\n required: true,\n type: \"integer\"\n },\n repo: {\n required: true,\n type: \"string\"\n },\n since: {\n type: \"string\"\n },\n sort: {\n enum: [\"created\", \"updated\"],\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/pulls/:pull_number/comments\"\n },\n listCommentsForRepo: {\n method: \"GET\",\n params: {\n direction: {\n enum: [\"asc\", \"desc\"],\n type: \"string\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n repo: {\n required: true,\n type: \"string\"\n },\n since: {\n type: \"string\"\n },\n sort: {\n enum: [\"created\", \"updated\"],\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/pulls/comments\"\n },\n listCommits: {\n method: \"GET\",\n params: {\n number: {\n alias: \"pull_number\",\n deprecated: true,\n type: \"integer\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n pull_number: {\n required: true,\n type: \"integer\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/pulls/:pull_number/commits\"\n },\n listFiles: {\n method: \"GET\",\n params: {\n number: {\n alias: \"pull_number\",\n deprecated: true,\n type: \"integer\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n pull_number: {\n required: true,\n type: \"integer\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/pulls/:pull_number/files\"\n },\n listReviewRequests: {\n method: \"GET\",\n params: {\n number: {\n alias: \"pull_number\",\n deprecated: true,\n type: \"integer\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n pull_number: {\n required: true,\n type: \"integer\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/pulls/:pull_number/requested_reviewers\"\n },\n listReviews: {\n method: \"GET\",\n params: {\n number: {\n alias: \"pull_number\",\n deprecated: true,\n type: \"integer\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n pull_number: {\n required: true,\n type: \"integer\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/pulls/:pull_number/reviews\"\n },\n merge: {\n method: \"PUT\",\n params: {\n commit_message: {\n type: \"string\"\n },\n commit_title: {\n type: \"string\"\n },\n merge_method: {\n enum: [\"merge\", \"squash\", \"rebase\"],\n type: \"string\"\n },\n number: {\n alias: \"pull_number\",\n deprecated: true,\n type: \"integer\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n pull_number: {\n required: true,\n type: \"integer\"\n },\n repo: {\n required: true,\n type: \"string\"\n },\n sha: {\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/pulls/:pull_number/merge\"\n },\n submitReview: {\n method: \"POST\",\n params: {\n body: {\n type: \"string\"\n },\n event: {\n enum: [\"APPROVE\", \"REQUEST_CHANGES\", \"COMMENT\"],\n required: true,\n type: \"string\"\n },\n number: {\n alias: \"pull_number\",\n deprecated: true,\n type: \"integer\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n pull_number: {\n required: true,\n type: \"integer\"\n },\n repo: {\n required: true,\n type: \"string\"\n },\n review_id: {\n required: true,\n type: \"integer\"\n }\n },\n url: \"/repos/:owner/:repo/pulls/:pull_number/reviews/:review_id/events\"\n },\n update: {\n method: \"PATCH\",\n params: {\n base: {\n type: \"string\"\n },\n body: {\n type: \"string\"\n },\n maintainer_can_modify: {\n type: \"boolean\"\n },\n number: {\n alias: \"pull_number\",\n deprecated: true,\n type: \"integer\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n pull_number: {\n required: true,\n type: \"integer\"\n },\n repo: {\n required: true,\n type: \"string\"\n },\n state: {\n enum: [\"open\", \"closed\"],\n type: \"string\"\n },\n title: {\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/pulls/:pull_number\"\n },\n updateBranch: {\n headers: {\n accept: \"application/vnd.github.lydian-preview+json\"\n },\n method: \"PUT\",\n params: {\n expected_head_sha: {\n type: \"string\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n pull_number: {\n required: true,\n type: \"integer\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/pulls/:pull_number/update-branch\"\n },\n updateComment: {\n method: \"PATCH\",\n params: {\n body: {\n required: true,\n type: \"string\"\n },\n comment_id: {\n required: true,\n type: \"integer\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/pulls/comments/:comment_id\"\n },\n updateReview: {\n method: \"PUT\",\n params: {\n body: {\n required: true,\n type: \"string\"\n },\n number: {\n alias: \"pull_number\",\n deprecated: true,\n type: \"integer\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n pull_number: {\n required: true,\n type: \"integer\"\n },\n repo: {\n required: true,\n type: \"string\"\n },\n review_id: {\n required: true,\n type: \"integer\"\n }\n },\n url: \"/repos/:owner/:repo/pulls/:pull_number/reviews/:review_id\"\n }\n },\n rateLimit: {\n get: {\n method: \"GET\",\n params: {},\n url: \"/rate_limit\"\n }\n },\n reactions: {\n createForCommitComment: {\n headers: {\n accept: \"application/vnd.github.squirrel-girl-preview+json\"\n },\n method: \"POST\",\n params: {\n comment_id: {\n required: true,\n type: \"integer\"\n },\n content: {\n enum: [\"+1\", \"-1\", \"laugh\", \"confused\", \"heart\", \"hooray\", \"rocket\", \"eyes\"],\n required: true,\n type: \"string\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/comments/:comment_id/reactions\"\n },\n createForIssue: {\n headers: {\n accept: \"application/vnd.github.squirrel-girl-preview+json\"\n },\n method: \"POST\",\n params: {\n content: {\n enum: [\"+1\", \"-1\", \"laugh\", \"confused\", \"heart\", \"hooray\", \"rocket\", \"eyes\"],\n required: true,\n type: \"string\"\n },\n issue_number: {\n required: true,\n type: \"integer\"\n },\n number: {\n alias: \"issue_number\",\n deprecated: true,\n type: \"integer\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/issues/:issue_number/reactions\"\n },\n createForIssueComment: {\n headers: {\n accept: \"application/vnd.github.squirrel-girl-preview+json\"\n },\n method: \"POST\",\n params: {\n comment_id: {\n required: true,\n type: \"integer\"\n },\n content: {\n enum: [\"+1\", \"-1\", \"laugh\", \"confused\", \"heart\", \"hooray\", \"rocket\", \"eyes\"],\n required: true,\n type: \"string\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/issues/comments/:comment_id/reactions\"\n },\n createForPullRequestReviewComment: {\n headers: {\n accept: \"application/vnd.github.squirrel-girl-preview+json\"\n },\n method: \"POST\",\n params: {\n comment_id: {\n required: true,\n type: \"integer\"\n },\n content: {\n enum: [\"+1\", \"-1\", \"laugh\", \"confused\", \"heart\", \"hooray\", \"rocket\", \"eyes\"],\n required: true,\n type: \"string\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/pulls/comments/:comment_id/reactions\"\n },\n createForTeamDiscussion: {\n deprecated: \"octokit.reactions.createForTeamDiscussion() has been renamed to octokit.reactions.createForTeamDiscussionLegacy() (2020-01-16)\",\n headers: {\n accept: \"application/vnd.github.squirrel-girl-preview+json\"\n },\n method: \"POST\",\n params: {\n content: {\n enum: [\"+1\", \"-1\", \"laugh\", \"confused\", \"heart\", \"hooray\", \"rocket\", \"eyes\"],\n required: true,\n type: \"string\"\n },\n discussion_number: {\n required: true,\n type: \"integer\"\n },\n team_id: {\n required: true,\n type: \"integer\"\n }\n },\n url: \"/teams/:team_id/discussions/:discussion_number/reactions\"\n },\n createForTeamDiscussionComment: {\n deprecated: \"octokit.reactions.createForTeamDiscussionComment() has been renamed to octokit.reactions.createForTeamDiscussionCommentLegacy() (2020-01-16)\",\n headers: {\n accept: \"application/vnd.github.squirrel-girl-preview+json\"\n },\n method: \"POST\",\n params: {\n comment_number: {\n required: true,\n type: \"integer\"\n },\n content: {\n enum: [\"+1\", \"-1\", \"laugh\", \"confused\", \"heart\", \"hooray\", \"rocket\", \"eyes\"],\n required: true,\n type: \"string\"\n },\n discussion_number: {\n required: true,\n type: \"integer\"\n },\n team_id: {\n required: true,\n type: \"integer\"\n }\n },\n url: \"/teams/:team_id/discussions/:discussion_number/comments/:comment_number/reactions\"\n },\n createForTeamDiscussionCommentInOrg: {\n headers: {\n accept: \"application/vnd.github.squirrel-girl-preview+json\"\n },\n method: \"POST\",\n params: {\n comment_number: {\n required: true,\n type: \"integer\"\n },\n content: {\n enum: [\"+1\", \"-1\", \"laugh\", \"confused\", \"heart\", \"hooray\", \"rocket\", \"eyes\"],\n required: true,\n type: \"string\"\n },\n discussion_number: {\n required: true,\n type: \"integer\"\n },\n org: {\n required: true,\n type: \"string\"\n },\n team_slug: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/orgs/:org/teams/:team_slug/discussions/:discussion_number/comments/:comment_number/reactions\"\n },\n createForTeamDiscussionCommentLegacy: {\n deprecated: \"octokit.reactions.createForTeamDiscussionCommentLegacy() is deprecated, see https://developer.github.com/v3/reactions/#create-reaction-for-a-team-discussion-comment-legacy\",\n headers: {\n accept: \"application/vnd.github.squirrel-girl-preview+json\"\n },\n method: \"POST\",\n params: {\n comment_number: {\n required: true,\n type: \"integer\"\n },\n content: {\n enum: [\"+1\", \"-1\", \"laugh\", \"confused\", \"heart\", \"hooray\", \"rocket\", \"eyes\"],\n required: true,\n type: \"string\"\n },\n discussion_number: {\n required: true,\n type: \"integer\"\n },\n team_id: {\n required: true,\n type: \"integer\"\n }\n },\n url: \"/teams/:team_id/discussions/:discussion_number/comments/:comment_number/reactions\"\n },\n createForTeamDiscussionInOrg: {\n headers: {\n accept: \"application/vnd.github.squirrel-girl-preview+json\"\n },\n method: \"POST\",\n params: {\n content: {\n enum: [\"+1\", \"-1\", \"laugh\", \"confused\", \"heart\", \"hooray\", \"rocket\", \"eyes\"],\n required: true,\n type: \"string\"\n },\n discussion_number: {\n required: true,\n type: \"integer\"\n },\n org: {\n required: true,\n type: \"string\"\n },\n team_slug: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/orgs/:org/teams/:team_slug/discussions/:discussion_number/reactions\"\n },\n createForTeamDiscussionLegacy: {\n deprecated: \"octokit.reactions.createForTeamDiscussionLegacy() is deprecated, see https://developer.github.com/v3/reactions/#create-reaction-for-a-team-discussion-legacy\",\n headers: {\n accept: \"application/vnd.github.squirrel-girl-preview+json\"\n },\n method: \"POST\",\n params: {\n content: {\n enum: [\"+1\", \"-1\", \"laugh\", \"confused\", \"heart\", \"hooray\", \"rocket\", \"eyes\"],\n required: true,\n type: \"string\"\n },\n discussion_number: {\n required: true,\n type: \"integer\"\n },\n team_id: {\n required: true,\n type: \"integer\"\n }\n },\n url: \"/teams/:team_id/discussions/:discussion_number/reactions\"\n },\n delete: {\n headers: {\n accept: \"application/vnd.github.squirrel-girl-preview+json\"\n },\n method: \"DELETE\",\n params: {\n reaction_id: {\n required: true,\n type: \"integer\"\n }\n },\n url: \"/reactions/:reaction_id\"\n },\n listForCommitComment: {\n headers: {\n accept: \"application/vnd.github.squirrel-girl-preview+json\"\n },\n method: \"GET\",\n params: {\n comment_id: {\n required: true,\n type: \"integer\"\n },\n content: {\n enum: [\"+1\", \"-1\", \"laugh\", \"confused\", \"heart\", \"hooray\", \"rocket\", \"eyes\"],\n type: \"string\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/comments/:comment_id/reactions\"\n },\n listForIssue: {\n headers: {\n accept: \"application/vnd.github.squirrel-girl-preview+json\"\n },\n method: \"GET\",\n params: {\n content: {\n enum: [\"+1\", \"-1\", \"laugh\", \"confused\", \"heart\", \"hooray\", \"rocket\", \"eyes\"],\n type: \"string\"\n },\n issue_number: {\n required: true,\n type: \"integer\"\n },\n number: {\n alias: \"issue_number\",\n deprecated: true,\n type: \"integer\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/issues/:issue_number/reactions\"\n },\n listForIssueComment: {\n headers: {\n accept: \"application/vnd.github.squirrel-girl-preview+json\"\n },\n method: \"GET\",\n params: {\n comment_id: {\n required: true,\n type: \"integer\"\n },\n content: {\n enum: [\"+1\", \"-1\", \"laugh\", \"confused\", \"heart\", \"hooray\", \"rocket\", \"eyes\"],\n type: \"string\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/issues/comments/:comment_id/reactions\"\n },\n listForPullRequestReviewComment: {\n headers: {\n accept: \"application/vnd.github.squirrel-girl-preview+json\"\n },\n method: \"GET\",\n params: {\n comment_id: {\n required: true,\n type: \"integer\"\n },\n content: {\n enum: [\"+1\", \"-1\", \"laugh\", \"confused\", \"heart\", \"hooray\", \"rocket\", \"eyes\"],\n type: \"string\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/pulls/comments/:comment_id/reactions\"\n },\n listForTeamDiscussion: {\n deprecated: \"octokit.reactions.listForTeamDiscussion() has been renamed to octokit.reactions.listForTeamDiscussionLegacy() (2020-01-16)\",\n headers: {\n accept: \"application/vnd.github.squirrel-girl-preview+json\"\n },\n method: \"GET\",\n params: {\n content: {\n enum: [\"+1\", \"-1\", \"laugh\", \"confused\", \"heart\", \"hooray\", \"rocket\", \"eyes\"],\n type: \"string\"\n },\n discussion_number: {\n required: true,\n type: \"integer\"\n },\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n team_id: {\n required: true,\n type: \"integer\"\n }\n },\n url: \"/teams/:team_id/discussions/:discussion_number/reactions\"\n },\n listForTeamDiscussionComment: {\n deprecated: \"octokit.reactions.listForTeamDiscussionComment() has been renamed to octokit.reactions.listForTeamDiscussionCommentLegacy() (2020-01-16)\",\n headers: {\n accept: \"application/vnd.github.squirrel-girl-preview+json\"\n },\n method: \"GET\",\n params: {\n comment_number: {\n required: true,\n type: \"integer\"\n },\n content: {\n enum: [\"+1\", \"-1\", \"laugh\", \"confused\", \"heart\", \"hooray\", \"rocket\", \"eyes\"],\n type: \"string\"\n },\n discussion_number: {\n required: true,\n type: \"integer\"\n },\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n team_id: {\n required: true,\n type: \"integer\"\n }\n },\n url: \"/teams/:team_id/discussions/:discussion_number/comments/:comment_number/reactions\"\n },\n listForTeamDiscussionCommentInOrg: {\n headers: {\n accept: \"application/vnd.github.squirrel-girl-preview+json\"\n },\n method: \"GET\",\n params: {\n comment_number: {\n required: true,\n type: \"integer\"\n },\n content: {\n enum: [\"+1\", \"-1\", \"laugh\", \"confused\", \"heart\", \"hooray\", \"rocket\", \"eyes\"],\n type: \"string\"\n },\n discussion_number: {\n required: true,\n type: \"integer\"\n },\n org: {\n required: true,\n type: \"string\"\n },\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n team_slug: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/orgs/:org/teams/:team_slug/discussions/:discussion_number/comments/:comment_number/reactions\"\n },\n listForTeamDiscussionCommentLegacy: {\n deprecated: \"octokit.reactions.listForTeamDiscussionCommentLegacy() is deprecated, see https://developer.github.com/v3/reactions/#list-reactions-for-a-team-discussion-comment-legacy\",\n headers: {\n accept: \"application/vnd.github.squirrel-girl-preview+json\"\n },\n method: \"GET\",\n params: {\n comment_number: {\n required: true,\n type: \"integer\"\n },\n content: {\n enum: [\"+1\", \"-1\", \"laugh\", \"confused\", \"heart\", \"hooray\", \"rocket\", \"eyes\"],\n type: \"string\"\n },\n discussion_number: {\n required: true,\n type: \"integer\"\n },\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n team_id: {\n required: true,\n type: \"integer\"\n }\n },\n url: \"/teams/:team_id/discussions/:discussion_number/comments/:comment_number/reactions\"\n },\n listForTeamDiscussionInOrg: {\n headers: {\n accept: \"application/vnd.github.squirrel-girl-preview+json\"\n },\n method: \"GET\",\n params: {\n content: {\n enum: [\"+1\", \"-1\", \"laugh\", \"confused\", \"heart\", \"hooray\", \"rocket\", \"eyes\"],\n type: \"string\"\n },\n discussion_number: {\n required: true,\n type: \"integer\"\n },\n org: {\n required: true,\n type: \"string\"\n },\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n team_slug: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/orgs/:org/teams/:team_slug/discussions/:discussion_number/reactions\"\n },\n listForTeamDiscussionLegacy: {\n deprecated: \"octokit.reactions.listForTeamDiscussionLegacy() is deprecated, see https://developer.github.com/v3/reactions/#list-reactions-for-a-team-discussion-legacy\",\n headers: {\n accept: \"application/vnd.github.squirrel-girl-preview+json\"\n },\n method: \"GET\",\n params: {\n content: {\n enum: [\"+1\", \"-1\", \"laugh\", \"confused\", \"heart\", \"hooray\", \"rocket\", \"eyes\"],\n type: \"string\"\n },\n discussion_number: {\n required: true,\n type: \"integer\"\n },\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n team_id: {\n required: true,\n type: \"integer\"\n }\n },\n url: \"/teams/:team_id/discussions/:discussion_number/reactions\"\n }\n },\n repos: {\n acceptInvitation: {\n method: \"PATCH\",\n params: {\n invitation_id: {\n required: true,\n type: \"integer\"\n }\n },\n url: \"/user/repository_invitations/:invitation_id\"\n },\n addCollaborator: {\n method: \"PUT\",\n params: {\n owner: {\n required: true,\n type: \"string\"\n },\n permission: {\n enum: [\"pull\", \"push\", \"admin\"],\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n },\n username: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/collaborators/:username\"\n },\n addDeployKey: {\n method: \"POST\",\n params: {\n key: {\n required: true,\n type: \"string\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n read_only: {\n type: \"boolean\"\n },\n repo: {\n required: true,\n type: \"string\"\n },\n title: {\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/keys\"\n },\n addProtectedBranchAdminEnforcement: {\n method: \"POST\",\n params: {\n branch: {\n required: true,\n type: \"string\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/branches/:branch/protection/enforce_admins\"\n },\n addProtectedBranchAppRestrictions: {\n method: \"POST\",\n params: {\n apps: {\n mapTo: \"data\",\n required: true,\n type: \"string[]\"\n },\n branch: {\n required: true,\n type: \"string\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/branches/:branch/protection/restrictions/apps\"\n },\n addProtectedBranchRequiredSignatures: {\n headers: {\n accept: \"application/vnd.github.zzzax-preview+json\"\n },\n method: \"POST\",\n params: {\n branch: {\n required: true,\n type: \"string\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/branches/:branch/protection/required_signatures\"\n },\n addProtectedBranchRequiredStatusChecksContexts: {\n method: \"POST\",\n params: {\n branch: {\n required: true,\n type: \"string\"\n },\n contexts: {\n mapTo: \"data\",\n required: true,\n type: \"string[]\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/branches/:branch/protection/required_status_checks/contexts\"\n },\n addProtectedBranchTeamRestrictions: {\n method: \"POST\",\n params: {\n branch: {\n required: true,\n type: \"string\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n },\n teams: {\n mapTo: \"data\",\n required: true,\n type: \"string[]\"\n }\n },\n url: \"/repos/:owner/:repo/branches/:branch/protection/restrictions/teams\"\n },\n addProtectedBranchUserRestrictions: {\n method: \"POST\",\n params: {\n branch: {\n required: true,\n type: \"string\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n },\n users: {\n mapTo: \"data\",\n required: true,\n type: \"string[]\"\n }\n },\n url: \"/repos/:owner/:repo/branches/:branch/protection/restrictions/users\"\n },\n checkCollaborator: {\n method: \"GET\",\n params: {\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n },\n username: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/collaborators/:username\"\n },\n checkVulnerabilityAlerts: {\n headers: {\n accept: \"application/vnd.github.dorian-preview+json\"\n },\n method: \"GET\",\n params: {\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/vulnerability-alerts\"\n },\n compareCommits: {\n method: \"GET\",\n params: {\n base: {\n required: true,\n type: \"string\"\n },\n head: {\n required: true,\n type: \"string\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/compare/:base...:head\"\n },\n createCommitComment: {\n method: \"POST\",\n params: {\n body: {\n required: true,\n type: \"string\"\n },\n commit_sha: {\n required: true,\n type: \"string\"\n },\n line: {\n type: \"integer\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n path: {\n type: \"string\"\n },\n position: {\n type: \"integer\"\n },\n repo: {\n required: true,\n type: \"string\"\n },\n sha: {\n alias: \"commit_sha\",\n deprecated: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/commits/:commit_sha/comments\"\n },\n createDeployment: {\n method: \"POST\",\n params: {\n auto_merge: {\n type: \"boolean\"\n },\n description: {\n type: \"string\"\n },\n environment: {\n type: \"string\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n payload: {\n type: \"string\"\n },\n production_environment: {\n type: \"boolean\"\n },\n ref: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n },\n required_contexts: {\n type: \"string[]\"\n },\n task: {\n type: \"string\"\n },\n transient_environment: {\n type: \"boolean\"\n }\n },\n url: \"/repos/:owner/:repo/deployments\"\n },\n createDeploymentStatus: {\n method: \"POST\",\n params: {\n auto_inactive: {\n type: \"boolean\"\n },\n deployment_id: {\n required: true,\n type: \"integer\"\n },\n description: {\n type: \"string\"\n },\n environment: {\n enum: [\"production\", \"staging\", \"qa\"],\n type: \"string\"\n },\n environment_url: {\n type: \"string\"\n },\n log_url: {\n type: \"string\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n },\n state: {\n enum: [\"error\", \"failure\", \"inactive\", \"in_progress\", \"queued\", \"pending\", \"success\"],\n required: true,\n type: \"string\"\n },\n target_url: {\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/deployments/:deployment_id/statuses\"\n },\n createDispatchEvent: {\n method: \"POST\",\n params: {\n client_payload: {\n type: \"object\"\n },\n event_type: {\n type: \"string\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/dispatches\"\n },\n createFile: {\n deprecated: \"octokit.repos.createFile() has been renamed to octokit.repos.createOrUpdateFile() (2019-06-07)\",\n method: \"PUT\",\n params: {\n author: {\n type: \"object\"\n },\n \"author.email\": {\n required: true,\n type: \"string\"\n },\n \"author.name\": {\n required: true,\n type: \"string\"\n },\n branch: {\n type: \"string\"\n },\n committer: {\n type: \"object\"\n },\n \"committer.email\": {\n required: true,\n type: \"string\"\n },\n \"committer.name\": {\n required: true,\n type: \"string\"\n },\n content: {\n required: true,\n type: \"string\"\n },\n message: {\n required: true,\n type: \"string\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n path: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n },\n sha: {\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/contents/:path\"\n },\n createForAuthenticatedUser: {\n method: \"POST\",\n params: {\n allow_merge_commit: {\n type: \"boolean\"\n },\n allow_rebase_merge: {\n type: \"boolean\"\n },\n allow_squash_merge: {\n type: \"boolean\"\n },\n auto_init: {\n type: \"boolean\"\n },\n delete_branch_on_merge: {\n type: \"boolean\"\n },\n description: {\n type: \"string\"\n },\n gitignore_template: {\n type: \"string\"\n },\n has_issues: {\n type: \"boolean\"\n },\n has_projects: {\n type: \"boolean\"\n },\n has_wiki: {\n type: \"boolean\"\n },\n homepage: {\n type: \"string\"\n },\n is_template: {\n type: \"boolean\"\n },\n license_template: {\n type: \"string\"\n },\n name: {\n required: true,\n type: \"string\"\n },\n private: {\n type: \"boolean\"\n },\n team_id: {\n type: \"integer\"\n },\n visibility: {\n enum: [\"public\", \"private\", \"visibility\", \"internal\"],\n type: \"string\"\n }\n },\n url: \"/user/repos\"\n },\n createFork: {\n method: \"POST\",\n params: {\n organization: {\n type: \"string\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/forks\"\n },\n createHook: {\n method: \"POST\",\n params: {\n active: {\n type: \"boolean\"\n },\n config: {\n required: true,\n type: \"object\"\n },\n \"config.content_type\": {\n type: \"string\"\n },\n \"config.insecure_ssl\": {\n type: \"string\"\n },\n \"config.secret\": {\n type: \"string\"\n },\n \"config.url\": {\n required: true,\n type: \"string\"\n },\n events: {\n type: \"string[]\"\n },\n name: {\n type: \"string\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/hooks\"\n },\n createInOrg: {\n method: \"POST\",\n params: {\n allow_merge_commit: {\n type: \"boolean\"\n },\n allow_rebase_merge: {\n type: \"boolean\"\n },\n allow_squash_merge: {\n type: \"boolean\"\n },\n auto_init: {\n type: \"boolean\"\n },\n delete_branch_on_merge: {\n type: \"boolean\"\n },\n description: {\n type: \"string\"\n },\n gitignore_template: {\n type: \"string\"\n },\n has_issues: {\n type: \"boolean\"\n },\n has_projects: {\n type: \"boolean\"\n },\n has_wiki: {\n type: \"boolean\"\n },\n homepage: {\n type: \"string\"\n },\n is_template: {\n type: \"boolean\"\n },\n license_template: {\n type: \"string\"\n },\n name: {\n required: true,\n type: \"string\"\n },\n org: {\n required: true,\n type: \"string\"\n },\n private: {\n type: \"boolean\"\n },\n team_id: {\n type: \"integer\"\n },\n visibility: {\n enum: [\"public\", \"private\", \"visibility\", \"internal\"],\n type: \"string\"\n }\n },\n url: \"/orgs/:org/repos\"\n },\n createOrUpdateFile: {\n method: \"PUT\",\n params: {\n author: {\n type: \"object\"\n },\n \"author.email\": {\n required: true,\n type: \"string\"\n },\n \"author.name\": {\n required: true,\n type: \"string\"\n },\n branch: {\n type: \"string\"\n },\n committer: {\n type: \"object\"\n },\n \"committer.email\": {\n required: true,\n type: \"string\"\n },\n \"committer.name\": {\n required: true,\n type: \"string\"\n },\n content: {\n required: true,\n type: \"string\"\n },\n message: {\n required: true,\n type: \"string\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n path: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n },\n sha: {\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/contents/:path\"\n },\n createRelease: {\n method: \"POST\",\n params: {\n body: {\n type: \"string\"\n },\n draft: {\n type: \"boolean\"\n },\n name: {\n type: \"string\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n prerelease: {\n type: \"boolean\"\n },\n repo: {\n required: true,\n type: \"string\"\n },\n tag_name: {\n required: true,\n type: \"string\"\n },\n target_commitish: {\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/releases\"\n },\n createStatus: {\n method: \"POST\",\n params: {\n context: {\n type: \"string\"\n },\n description: {\n type: \"string\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n },\n sha: {\n required: true,\n type: \"string\"\n },\n state: {\n enum: [\"error\", \"failure\", \"pending\", \"success\"],\n required: true,\n type: \"string\"\n },\n target_url: {\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/statuses/:sha\"\n },\n createUsingTemplate: {\n headers: {\n accept: \"application/vnd.github.baptiste-preview+json\"\n },\n method: \"POST\",\n params: {\n description: {\n type: \"string\"\n },\n name: {\n required: true,\n type: \"string\"\n },\n owner: {\n type: \"string\"\n },\n private: {\n type: \"boolean\"\n },\n template_owner: {\n required: true,\n type: \"string\"\n },\n template_repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:template_owner/:template_repo/generate\"\n },\n declineInvitation: {\n method: \"DELETE\",\n params: {\n invitation_id: {\n required: true,\n type: \"integer\"\n }\n },\n url: \"/user/repository_invitations/:invitation_id\"\n },\n delete: {\n method: \"DELETE\",\n params: {\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo\"\n },\n deleteCommitComment: {\n method: \"DELETE\",\n params: {\n comment_id: {\n required: true,\n type: \"integer\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/comments/:comment_id\"\n },\n deleteDownload: {\n method: \"DELETE\",\n params: {\n download_id: {\n required: true,\n type: \"integer\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/downloads/:download_id\"\n },\n deleteFile: {\n method: \"DELETE\",\n params: {\n author: {\n type: \"object\"\n },\n \"author.email\": {\n type: \"string\"\n },\n \"author.name\": {\n type: \"string\"\n },\n branch: {\n type: \"string\"\n },\n committer: {\n type: \"object\"\n },\n \"committer.email\": {\n type: \"string\"\n },\n \"committer.name\": {\n type: \"string\"\n },\n message: {\n required: true,\n type: \"string\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n path: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n },\n sha: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/contents/:path\"\n },\n deleteHook: {\n method: \"DELETE\",\n params: {\n hook_id: {\n required: true,\n type: \"integer\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/hooks/:hook_id\"\n },\n deleteInvitation: {\n method: \"DELETE\",\n params: {\n invitation_id: {\n required: true,\n type: \"integer\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/invitations/:invitation_id\"\n },\n deleteRelease: {\n method: \"DELETE\",\n params: {\n owner: {\n required: true,\n type: \"string\"\n },\n release_id: {\n required: true,\n type: \"integer\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/releases/:release_id\"\n },\n deleteReleaseAsset: {\n method: \"DELETE\",\n params: {\n asset_id: {\n required: true,\n type: \"integer\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/releases/assets/:asset_id\"\n },\n disableAutomatedSecurityFixes: {\n headers: {\n accept: \"application/vnd.github.london-preview+json\"\n },\n method: \"DELETE\",\n params: {\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/automated-security-fixes\"\n },\n disablePagesSite: {\n headers: {\n accept: \"application/vnd.github.switcheroo-preview+json\"\n },\n method: \"DELETE\",\n params: {\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/pages\"\n },\n disableVulnerabilityAlerts: {\n headers: {\n accept: \"application/vnd.github.dorian-preview+json\"\n },\n method: \"DELETE\",\n params: {\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/vulnerability-alerts\"\n },\n enableAutomatedSecurityFixes: {\n headers: {\n accept: \"application/vnd.github.london-preview+json\"\n },\n method: \"PUT\",\n params: {\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/automated-security-fixes\"\n },\n enablePagesSite: {\n headers: {\n accept: \"application/vnd.github.switcheroo-preview+json\"\n },\n method: \"POST\",\n params: {\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n },\n source: {\n type: \"object\"\n },\n \"source.branch\": {\n enum: [\"master\", \"gh-pages\"],\n type: \"string\"\n },\n \"source.path\": {\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/pages\"\n },\n enableVulnerabilityAlerts: {\n headers: {\n accept: \"application/vnd.github.dorian-preview+json\"\n },\n method: \"PUT\",\n params: {\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/vulnerability-alerts\"\n },\n get: {\n method: \"GET\",\n params: {\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo\"\n },\n getAppsWithAccessToProtectedBranch: {\n method: \"GET\",\n params: {\n branch: {\n required: true,\n type: \"string\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/branches/:branch/protection/restrictions/apps\"\n },\n getArchiveLink: {\n method: \"GET\",\n params: {\n archive_format: {\n required: true,\n type: \"string\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n ref: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/:archive_format/:ref\"\n },\n getBranch: {\n method: \"GET\",\n params: {\n branch: {\n required: true,\n type: \"string\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/branches/:branch\"\n },\n getBranchProtection: {\n method: \"GET\",\n params: {\n branch: {\n required: true,\n type: \"string\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/branches/:branch/protection\"\n },\n getClones: {\n method: \"GET\",\n params: {\n owner: {\n required: true,\n type: \"string\"\n },\n per: {\n enum: [\"day\", \"week\"],\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/traffic/clones\"\n },\n getCodeFrequencyStats: {\n method: \"GET\",\n params: {\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/stats/code_frequency\"\n },\n getCollaboratorPermissionLevel: {\n method: \"GET\",\n params: {\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n },\n username: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/collaborators/:username/permission\"\n },\n getCombinedStatusForRef: {\n method: \"GET\",\n params: {\n owner: {\n required: true,\n type: \"string\"\n },\n ref: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/commits/:ref/status\"\n },\n getCommit: {\n method: \"GET\",\n params: {\n commit_sha: {\n alias: \"ref\",\n deprecated: true,\n type: \"string\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n ref: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n },\n sha: {\n alias: \"ref\",\n deprecated: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/commits/:ref\"\n },\n getCommitActivityStats: {\n method: \"GET\",\n params: {\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/stats/commit_activity\"\n },\n getCommitComment: {\n method: \"GET\",\n params: {\n comment_id: {\n required: true,\n type: \"integer\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/comments/:comment_id\"\n },\n getCommitRefSha: {\n deprecated: \"octokit.repos.getCommitRefSha() is deprecated, see https://developer.github.com/v3/repos/commits/#get-a-single-commit\",\n headers: {\n accept: \"application/vnd.github.v3.sha\"\n },\n method: \"GET\",\n params: {\n owner: {\n required: true,\n type: \"string\"\n },\n ref: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/commits/:ref\"\n },\n getContents: {\n method: \"GET\",\n params: {\n owner: {\n required: true,\n type: \"string\"\n },\n path: {\n required: true,\n type: \"string\"\n },\n ref: {\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/contents/:path\"\n },\n getContributorsStats: {\n method: \"GET\",\n params: {\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/stats/contributors\"\n },\n getDeployKey: {\n method: \"GET\",\n params: {\n key_id: {\n required: true,\n type: \"integer\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/keys/:key_id\"\n },\n getDeployment: {\n method: \"GET\",\n params: {\n deployment_id: {\n required: true,\n type: \"integer\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/deployments/:deployment_id\"\n },\n getDeploymentStatus: {\n method: \"GET\",\n params: {\n deployment_id: {\n required: true,\n type: \"integer\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n },\n status_id: {\n required: true,\n type: \"integer\"\n }\n },\n url: \"/repos/:owner/:repo/deployments/:deployment_id/statuses/:status_id\"\n },\n getDownload: {\n method: \"GET\",\n params: {\n download_id: {\n required: true,\n type: \"integer\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/downloads/:download_id\"\n },\n getHook: {\n method: \"GET\",\n params: {\n hook_id: {\n required: true,\n type: \"integer\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/hooks/:hook_id\"\n },\n getLatestPagesBuild: {\n method: \"GET\",\n params: {\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/pages/builds/latest\"\n },\n getLatestRelease: {\n method: \"GET\",\n params: {\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/releases/latest\"\n },\n getPages: {\n method: \"GET\",\n params: {\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/pages\"\n },\n getPagesBuild: {\n method: \"GET\",\n params: {\n build_id: {\n required: true,\n type: \"integer\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/pages/builds/:build_id\"\n },\n getParticipationStats: {\n method: \"GET\",\n params: {\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/stats/participation\"\n },\n getProtectedBranchAdminEnforcement: {\n method: \"GET\",\n params: {\n branch: {\n required: true,\n type: \"string\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/branches/:branch/protection/enforce_admins\"\n },\n getProtectedBranchPullRequestReviewEnforcement: {\n method: \"GET\",\n params: {\n branch: {\n required: true,\n type: \"string\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/branches/:branch/protection/required_pull_request_reviews\"\n },\n getProtectedBranchRequiredSignatures: {\n headers: {\n accept: \"application/vnd.github.zzzax-preview+json\"\n },\n method: \"GET\",\n params: {\n branch: {\n required: true,\n type: \"string\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/branches/:branch/protection/required_signatures\"\n },\n getProtectedBranchRequiredStatusChecks: {\n method: \"GET\",\n params: {\n branch: {\n required: true,\n type: \"string\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/branches/:branch/protection/required_status_checks\"\n },\n getProtectedBranchRestrictions: {\n method: \"GET\",\n params: {\n branch: {\n required: true,\n type: \"string\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/branches/:branch/protection/restrictions\"\n },\n getPunchCardStats: {\n method: \"GET\",\n params: {\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/stats/punch_card\"\n },\n getReadme: {\n method: \"GET\",\n params: {\n owner: {\n required: true,\n type: \"string\"\n },\n ref: {\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/readme\"\n },\n getRelease: {\n method: \"GET\",\n params: {\n owner: {\n required: true,\n type: \"string\"\n },\n release_id: {\n required: true,\n type: \"integer\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/releases/:release_id\"\n },\n getReleaseAsset: {\n method: \"GET\",\n params: {\n asset_id: {\n required: true,\n type: \"integer\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/releases/assets/:asset_id\"\n },\n getReleaseByTag: {\n method: \"GET\",\n params: {\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n },\n tag: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/releases/tags/:tag\"\n },\n getTeamsWithAccessToProtectedBranch: {\n method: \"GET\",\n params: {\n branch: {\n required: true,\n type: \"string\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/branches/:branch/protection/restrictions/teams\"\n },\n getTopPaths: {\n method: \"GET\",\n params: {\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/traffic/popular/paths\"\n },\n getTopReferrers: {\n method: \"GET\",\n params: {\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/traffic/popular/referrers\"\n },\n getUsersWithAccessToProtectedBranch: {\n method: \"GET\",\n params: {\n branch: {\n required: true,\n type: \"string\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/branches/:branch/protection/restrictions/users\"\n },\n getViews: {\n method: \"GET\",\n params: {\n owner: {\n required: true,\n type: \"string\"\n },\n per: {\n enum: [\"day\", \"week\"],\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/traffic/views\"\n },\n list: {\n method: \"GET\",\n params: {\n affiliation: {\n type: \"string\"\n },\n direction: {\n enum: [\"asc\", \"desc\"],\n type: \"string\"\n },\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n sort: {\n enum: [\"created\", \"updated\", \"pushed\", \"full_name\"],\n type: \"string\"\n },\n type: {\n enum: [\"all\", \"owner\", \"public\", \"private\", \"member\"],\n type: \"string\"\n },\n visibility: {\n enum: [\"all\", \"public\", \"private\"],\n type: \"string\"\n }\n },\n url: \"/user/repos\"\n },\n listAppsWithAccessToProtectedBranch: {\n deprecated: \"octokit.repos.listAppsWithAccessToProtectedBranch() has been renamed to octokit.repos.getAppsWithAccessToProtectedBranch() (2019-09-13)\",\n method: \"GET\",\n params: {\n branch: {\n required: true,\n type: \"string\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/branches/:branch/protection/restrictions/apps\"\n },\n listAssetsForRelease: {\n method: \"GET\",\n params: {\n owner: {\n required: true,\n type: \"string\"\n },\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n release_id: {\n required: true,\n type: \"integer\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/releases/:release_id/assets\"\n },\n listBranches: {\n method: \"GET\",\n params: {\n owner: {\n required: true,\n type: \"string\"\n },\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n protected: {\n type: \"boolean\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/branches\"\n },\n listBranchesForHeadCommit: {\n headers: {\n accept: \"application/vnd.github.groot-preview+json\"\n },\n method: \"GET\",\n params: {\n commit_sha: {\n required: true,\n type: \"string\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/commits/:commit_sha/branches-where-head\"\n },\n listCollaborators: {\n method: \"GET\",\n params: {\n affiliation: {\n enum: [\"outside\", \"direct\", \"all\"],\n type: \"string\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/collaborators\"\n },\n listCommentsForCommit: {\n method: \"GET\",\n params: {\n commit_sha: {\n required: true,\n type: \"string\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n ref: {\n alias: \"commit_sha\",\n deprecated: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/commits/:commit_sha/comments\"\n },\n listCommitComments: {\n method: \"GET\",\n params: {\n owner: {\n required: true,\n type: \"string\"\n },\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/comments\"\n },\n listCommits: {\n method: \"GET\",\n params: {\n author: {\n type: \"string\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n page: {\n type: \"integer\"\n },\n path: {\n type: \"string\"\n },\n per_page: {\n type: \"integer\"\n },\n repo: {\n required: true,\n type: \"string\"\n },\n sha: {\n type: \"string\"\n },\n since: {\n type: \"string\"\n },\n until: {\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/commits\"\n },\n listContributors: {\n method: \"GET\",\n params: {\n anon: {\n type: \"string\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/contributors\"\n },\n listDeployKeys: {\n method: \"GET\",\n params: {\n owner: {\n required: true,\n type: \"string\"\n },\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/keys\"\n },\n listDeploymentStatuses: {\n method: \"GET\",\n params: {\n deployment_id: {\n required: true,\n type: \"integer\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/deployments/:deployment_id/statuses\"\n },\n listDeployments: {\n method: \"GET\",\n params: {\n environment: {\n type: \"string\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n ref: {\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n },\n sha: {\n type: \"string\"\n },\n task: {\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/deployments\"\n },\n listDownloads: {\n method: \"GET\",\n params: {\n owner: {\n required: true,\n type: \"string\"\n },\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/downloads\"\n },\n listForOrg: {\n method: \"GET\",\n params: {\n direction: {\n enum: [\"asc\", \"desc\"],\n type: \"string\"\n },\n org: {\n required: true,\n type: \"string\"\n },\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n sort: {\n enum: [\"created\", \"updated\", \"pushed\", \"full_name\"],\n type: \"string\"\n },\n type: {\n enum: [\"all\", \"public\", \"private\", \"forks\", \"sources\", \"member\", \"internal\"],\n type: \"string\"\n }\n },\n url: \"/orgs/:org/repos\"\n },\n listForUser: {\n method: \"GET\",\n params: {\n direction: {\n enum: [\"asc\", \"desc\"],\n type: \"string\"\n },\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n sort: {\n enum: [\"created\", \"updated\", \"pushed\", \"full_name\"],\n type: \"string\"\n },\n type: {\n enum: [\"all\", \"owner\", \"member\"],\n type: \"string\"\n },\n username: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/users/:username/repos\"\n },\n listForks: {\n method: \"GET\",\n params: {\n owner: {\n required: true,\n type: \"string\"\n },\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n repo: {\n required: true,\n type: \"string\"\n },\n sort: {\n enum: [\"newest\", \"oldest\", \"stargazers\"],\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/forks\"\n },\n listHooks: {\n method: \"GET\",\n params: {\n owner: {\n required: true,\n type: \"string\"\n },\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/hooks\"\n },\n listInvitations: {\n method: \"GET\",\n params: {\n owner: {\n required: true,\n type: \"string\"\n },\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/invitations\"\n },\n listInvitationsForAuthenticatedUser: {\n method: \"GET\",\n params: {\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n }\n },\n url: \"/user/repository_invitations\"\n },\n listLanguages: {\n method: \"GET\",\n params: {\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/languages\"\n },\n listPagesBuilds: {\n method: \"GET\",\n params: {\n owner: {\n required: true,\n type: \"string\"\n },\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/pages/builds\"\n },\n listProtectedBranchRequiredStatusChecksContexts: {\n method: \"GET\",\n params: {\n branch: {\n required: true,\n type: \"string\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/branches/:branch/protection/required_status_checks/contexts\"\n },\n listProtectedBranchTeamRestrictions: {\n deprecated: \"octokit.repos.listProtectedBranchTeamRestrictions() has been renamed to octokit.repos.getTeamsWithAccessToProtectedBranch() (2019-09-09)\",\n method: \"GET\",\n params: {\n branch: {\n required: true,\n type: \"string\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/branches/:branch/protection/restrictions/teams\"\n },\n listProtectedBranchUserRestrictions: {\n deprecated: \"octokit.repos.listProtectedBranchUserRestrictions() has been renamed to octokit.repos.getUsersWithAccessToProtectedBranch() (2019-09-09)\",\n method: \"GET\",\n params: {\n branch: {\n required: true,\n type: \"string\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/branches/:branch/protection/restrictions/users\"\n },\n listPublic: {\n method: \"GET\",\n params: {\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n since: {\n type: \"integer\"\n }\n },\n url: \"/repositories\"\n },\n listPullRequestsAssociatedWithCommit: {\n headers: {\n accept: \"application/vnd.github.groot-preview+json\"\n },\n method: \"GET\",\n params: {\n commit_sha: {\n required: true,\n type: \"string\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/commits/:commit_sha/pulls\"\n },\n listReleases: {\n method: \"GET\",\n params: {\n owner: {\n required: true,\n type: \"string\"\n },\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/releases\"\n },\n listStatusesForRef: {\n method: \"GET\",\n params: {\n owner: {\n required: true,\n type: \"string\"\n },\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n ref: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/commits/:ref/statuses\"\n },\n listTags: {\n method: \"GET\",\n params: {\n owner: {\n required: true,\n type: \"string\"\n },\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/tags\"\n },\n listTeams: {\n method: \"GET\",\n params: {\n owner: {\n required: true,\n type: \"string\"\n },\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/teams\"\n },\n listTeamsWithAccessToProtectedBranch: {\n deprecated: \"octokit.repos.listTeamsWithAccessToProtectedBranch() has been renamed to octokit.repos.getTeamsWithAccessToProtectedBranch() (2019-09-13)\",\n method: \"GET\",\n params: {\n branch: {\n required: true,\n type: \"string\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/branches/:branch/protection/restrictions/teams\"\n },\n listTopics: {\n headers: {\n accept: \"application/vnd.github.mercy-preview+json\"\n },\n method: \"GET\",\n params: {\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/topics\"\n },\n listUsersWithAccessToProtectedBranch: {\n deprecated: \"octokit.repos.listUsersWithAccessToProtectedBranch() has been renamed to octokit.repos.getUsersWithAccessToProtectedBranch() (2019-09-13)\",\n method: \"GET\",\n params: {\n branch: {\n required: true,\n type: \"string\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/branches/:branch/protection/restrictions/users\"\n },\n merge: {\n method: \"POST\",\n params: {\n base: {\n required: true,\n type: \"string\"\n },\n commit_message: {\n type: \"string\"\n },\n head: {\n required: true,\n type: \"string\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/merges\"\n },\n pingHook: {\n method: \"POST\",\n params: {\n hook_id: {\n required: true,\n type: \"integer\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/hooks/:hook_id/pings\"\n },\n removeBranchProtection: {\n method: \"DELETE\",\n params: {\n branch: {\n required: true,\n type: \"string\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/branches/:branch/protection\"\n },\n removeCollaborator: {\n method: \"DELETE\",\n params: {\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n },\n username: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/collaborators/:username\"\n },\n removeDeployKey: {\n method: \"DELETE\",\n params: {\n key_id: {\n required: true,\n type: \"integer\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/keys/:key_id\"\n },\n removeProtectedBranchAdminEnforcement: {\n method: \"DELETE\",\n params: {\n branch: {\n required: true,\n type: \"string\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/branches/:branch/protection/enforce_admins\"\n },\n removeProtectedBranchAppRestrictions: {\n method: \"DELETE\",\n params: {\n apps: {\n mapTo: \"data\",\n required: true,\n type: \"string[]\"\n },\n branch: {\n required: true,\n type: \"string\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/branches/:branch/protection/restrictions/apps\"\n },\n removeProtectedBranchPullRequestReviewEnforcement: {\n method: \"DELETE\",\n params: {\n branch: {\n required: true,\n type: \"string\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/branches/:branch/protection/required_pull_request_reviews\"\n },\n removeProtectedBranchRequiredSignatures: {\n headers: {\n accept: \"application/vnd.github.zzzax-preview+json\"\n },\n method: \"DELETE\",\n params: {\n branch: {\n required: true,\n type: \"string\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/branches/:branch/protection/required_signatures\"\n },\n removeProtectedBranchRequiredStatusChecks: {\n method: \"DELETE\",\n params: {\n branch: {\n required: true,\n type: \"string\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/branches/:branch/protection/required_status_checks\"\n },\n removeProtectedBranchRequiredStatusChecksContexts: {\n method: \"DELETE\",\n params: {\n branch: {\n required: true,\n type: \"string\"\n },\n contexts: {\n mapTo: \"data\",\n required: true,\n type: \"string[]\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/branches/:branch/protection/required_status_checks/contexts\"\n },\n removeProtectedBranchRestrictions: {\n method: \"DELETE\",\n params: {\n branch: {\n required: true,\n type: \"string\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/branches/:branch/protection/restrictions\"\n },\n removeProtectedBranchTeamRestrictions: {\n method: \"DELETE\",\n params: {\n branch: {\n required: true,\n type: \"string\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n },\n teams: {\n mapTo: \"data\",\n required: true,\n type: \"string[]\"\n }\n },\n url: \"/repos/:owner/:repo/branches/:branch/protection/restrictions/teams\"\n },\n removeProtectedBranchUserRestrictions: {\n method: \"DELETE\",\n params: {\n branch: {\n required: true,\n type: \"string\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n },\n users: {\n mapTo: \"data\",\n required: true,\n type: \"string[]\"\n }\n },\n url: \"/repos/:owner/:repo/branches/:branch/protection/restrictions/users\"\n },\n replaceProtectedBranchAppRestrictions: {\n method: \"PUT\",\n params: {\n apps: {\n mapTo: \"data\",\n required: true,\n type: \"string[]\"\n },\n branch: {\n required: true,\n type: \"string\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/branches/:branch/protection/restrictions/apps\"\n },\n replaceProtectedBranchRequiredStatusChecksContexts: {\n method: \"PUT\",\n params: {\n branch: {\n required: true,\n type: \"string\"\n },\n contexts: {\n mapTo: \"data\",\n required: true,\n type: \"string[]\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/branches/:branch/protection/required_status_checks/contexts\"\n },\n replaceProtectedBranchTeamRestrictions: {\n method: \"PUT\",\n params: {\n branch: {\n required: true,\n type: \"string\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n },\n teams: {\n mapTo: \"data\",\n required: true,\n type: \"string[]\"\n }\n },\n url: \"/repos/:owner/:repo/branches/:branch/protection/restrictions/teams\"\n },\n replaceProtectedBranchUserRestrictions: {\n method: \"PUT\",\n params: {\n branch: {\n required: true,\n type: \"string\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n },\n users: {\n mapTo: \"data\",\n required: true,\n type: \"string[]\"\n }\n },\n url: \"/repos/:owner/:repo/branches/:branch/protection/restrictions/users\"\n },\n replaceTopics: {\n headers: {\n accept: \"application/vnd.github.mercy-preview+json\"\n },\n method: \"PUT\",\n params: {\n names: {\n required: true,\n type: \"string[]\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/topics\"\n },\n requestPageBuild: {\n method: \"POST\",\n params: {\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/pages/builds\"\n },\n retrieveCommunityProfileMetrics: {\n method: \"GET\",\n params: {\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/community/profile\"\n },\n testPushHook: {\n method: \"POST\",\n params: {\n hook_id: {\n required: true,\n type: \"integer\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/hooks/:hook_id/tests\"\n },\n transfer: {\n method: \"POST\",\n params: {\n new_owner: {\n type: \"string\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n },\n team_ids: {\n type: \"integer[]\"\n }\n },\n url: \"/repos/:owner/:repo/transfer\"\n },\n update: {\n method: \"PATCH\",\n params: {\n allow_merge_commit: {\n type: \"boolean\"\n },\n allow_rebase_merge: {\n type: \"boolean\"\n },\n allow_squash_merge: {\n type: \"boolean\"\n },\n archived: {\n type: \"boolean\"\n },\n default_branch: {\n type: \"string\"\n },\n delete_branch_on_merge: {\n type: \"boolean\"\n },\n description: {\n type: \"string\"\n },\n has_issues: {\n type: \"boolean\"\n },\n has_projects: {\n type: \"boolean\"\n },\n has_wiki: {\n type: \"boolean\"\n },\n homepage: {\n type: \"string\"\n },\n is_template: {\n type: \"boolean\"\n },\n name: {\n type: \"string\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n private: {\n type: \"boolean\"\n },\n repo: {\n required: true,\n type: \"string\"\n },\n visibility: {\n enum: [\"public\", \"private\", \"visibility\", \"internal\"],\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo\"\n },\n updateBranchProtection: {\n method: \"PUT\",\n params: {\n allow_deletions: {\n type: \"boolean\"\n },\n allow_force_pushes: {\n allowNull: true,\n type: \"boolean\"\n },\n branch: {\n required: true,\n type: \"string\"\n },\n enforce_admins: {\n allowNull: true,\n required: true,\n type: \"boolean\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n },\n required_linear_history: {\n type: \"boolean\"\n },\n required_pull_request_reviews: {\n allowNull: true,\n required: true,\n type: \"object\"\n },\n \"required_pull_request_reviews.dismiss_stale_reviews\": {\n type: \"boolean\"\n },\n \"required_pull_request_reviews.dismissal_restrictions\": {\n type: \"object\"\n },\n \"required_pull_request_reviews.dismissal_restrictions.teams\": {\n type: \"string[]\"\n },\n \"required_pull_request_reviews.dismissal_restrictions.users\": {\n type: \"string[]\"\n },\n \"required_pull_request_reviews.require_code_owner_reviews\": {\n type: \"boolean\"\n },\n \"required_pull_request_reviews.required_approving_review_count\": {\n type: \"integer\"\n },\n required_status_checks: {\n allowNull: true,\n required: true,\n type: \"object\"\n },\n \"required_status_checks.contexts\": {\n required: true,\n type: \"string[]\"\n },\n \"required_status_checks.strict\": {\n required: true,\n type: \"boolean\"\n },\n restrictions: {\n allowNull: true,\n required: true,\n type: \"object\"\n },\n \"restrictions.apps\": {\n type: \"string[]\"\n },\n \"restrictions.teams\": {\n required: true,\n type: \"string[]\"\n },\n \"restrictions.users\": {\n required: true,\n type: \"string[]\"\n }\n },\n url: \"/repos/:owner/:repo/branches/:branch/protection\"\n },\n updateCommitComment: {\n method: \"PATCH\",\n params: {\n body: {\n required: true,\n type: \"string\"\n },\n comment_id: {\n required: true,\n type: \"integer\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/comments/:comment_id\"\n },\n updateFile: {\n deprecated: \"octokit.repos.updateFile() has been renamed to octokit.repos.createOrUpdateFile() (2019-06-07)\",\n method: \"PUT\",\n params: {\n author: {\n type: \"object\"\n },\n \"author.email\": {\n required: true,\n type: \"string\"\n },\n \"author.name\": {\n required: true,\n type: \"string\"\n },\n branch: {\n type: \"string\"\n },\n committer: {\n type: \"object\"\n },\n \"committer.email\": {\n required: true,\n type: \"string\"\n },\n \"committer.name\": {\n required: true,\n type: \"string\"\n },\n content: {\n required: true,\n type: \"string\"\n },\n message: {\n required: true,\n type: \"string\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n path: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n },\n sha: {\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/contents/:path\"\n },\n updateHook: {\n method: \"PATCH\",\n params: {\n active: {\n type: \"boolean\"\n },\n add_events: {\n type: \"string[]\"\n },\n config: {\n type: \"object\"\n },\n \"config.content_type\": {\n type: \"string\"\n },\n \"config.insecure_ssl\": {\n type: \"string\"\n },\n \"config.secret\": {\n type: \"string\"\n },\n \"config.url\": {\n required: true,\n type: \"string\"\n },\n events: {\n type: \"string[]\"\n },\n hook_id: {\n required: true,\n type: \"integer\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n remove_events: {\n type: \"string[]\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/hooks/:hook_id\"\n },\n updateInformationAboutPagesSite: {\n method: \"PUT\",\n params: {\n cname: {\n type: \"string\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n },\n source: {\n enum: ['\"gh-pages\"', '\"master\"', '\"master /docs\"'],\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/pages\"\n },\n updateInvitation: {\n method: \"PATCH\",\n params: {\n invitation_id: {\n required: true,\n type: \"integer\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n permissions: {\n enum: [\"read\", \"write\", \"admin\"],\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/invitations/:invitation_id\"\n },\n updateProtectedBranchPullRequestReviewEnforcement: {\n method: \"PATCH\",\n params: {\n branch: {\n required: true,\n type: \"string\"\n },\n dismiss_stale_reviews: {\n type: \"boolean\"\n },\n dismissal_restrictions: {\n type: \"object\"\n },\n \"dismissal_restrictions.teams\": {\n type: \"string[]\"\n },\n \"dismissal_restrictions.users\": {\n type: \"string[]\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n },\n require_code_owner_reviews: {\n type: \"boolean\"\n },\n required_approving_review_count: {\n type: \"integer\"\n }\n },\n url: \"/repos/:owner/:repo/branches/:branch/protection/required_pull_request_reviews\"\n },\n updateProtectedBranchRequiredStatusChecks: {\n method: \"PATCH\",\n params: {\n branch: {\n required: true,\n type: \"string\"\n },\n contexts: {\n type: \"string[]\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n },\n strict: {\n type: \"boolean\"\n }\n },\n url: \"/repos/:owner/:repo/branches/:branch/protection/required_status_checks\"\n },\n updateRelease: {\n method: \"PATCH\",\n params: {\n body: {\n type: \"string\"\n },\n draft: {\n type: \"boolean\"\n },\n name: {\n type: \"string\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n prerelease: {\n type: \"boolean\"\n },\n release_id: {\n required: true,\n type: \"integer\"\n },\n repo: {\n required: true,\n type: \"string\"\n },\n tag_name: {\n type: \"string\"\n },\n target_commitish: {\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/releases/:release_id\"\n },\n updateReleaseAsset: {\n method: \"PATCH\",\n params: {\n asset_id: {\n required: true,\n type: \"integer\"\n },\n label: {\n type: \"string\"\n },\n name: {\n type: \"string\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/repos/:owner/:repo/releases/assets/:asset_id\"\n },\n uploadReleaseAsset: {\n method: \"POST\",\n params: {\n data: {\n mapTo: \"data\",\n required: true,\n type: \"string | object\"\n },\n file: {\n alias: \"data\",\n deprecated: true,\n type: \"string | object\"\n },\n headers: {\n required: true,\n type: \"object\"\n },\n \"headers.content-length\": {\n required: true,\n type: \"integer\"\n },\n \"headers.content-type\": {\n required: true,\n type: \"string\"\n },\n label: {\n type: \"string\"\n },\n name: {\n required: true,\n type: \"string\"\n },\n url: {\n required: true,\n type: \"string\"\n }\n },\n url: \":url\"\n }\n },\n search: {\n code: {\n method: \"GET\",\n params: {\n order: {\n enum: [\"desc\", \"asc\"],\n type: \"string\"\n },\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n q: {\n required: true,\n type: \"string\"\n },\n sort: {\n enum: [\"indexed\"],\n type: \"string\"\n }\n },\n url: \"/search/code\"\n },\n commits: {\n headers: {\n accept: \"application/vnd.github.cloak-preview+json\"\n },\n method: \"GET\",\n params: {\n order: {\n enum: [\"desc\", \"asc\"],\n type: \"string\"\n },\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n q: {\n required: true,\n type: \"string\"\n },\n sort: {\n enum: [\"author-date\", \"committer-date\"],\n type: \"string\"\n }\n },\n url: \"/search/commits\"\n },\n issues: {\n deprecated: \"octokit.search.issues() has been renamed to octokit.search.issuesAndPullRequests() (2018-12-27)\",\n method: \"GET\",\n params: {\n order: {\n enum: [\"desc\", \"asc\"],\n type: \"string\"\n },\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n q: {\n required: true,\n type: \"string\"\n },\n sort: {\n enum: [\"comments\", \"reactions\", \"reactions-+1\", \"reactions--1\", \"reactions-smile\", \"reactions-thinking_face\", \"reactions-heart\", \"reactions-tada\", \"interactions\", \"created\", \"updated\"],\n type: \"string\"\n }\n },\n url: \"/search/issues\"\n },\n issuesAndPullRequests: {\n method: \"GET\",\n params: {\n order: {\n enum: [\"desc\", \"asc\"],\n type: \"string\"\n },\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n q: {\n required: true,\n type: \"string\"\n },\n sort: {\n enum: [\"comments\", \"reactions\", \"reactions-+1\", \"reactions--1\", \"reactions-smile\", \"reactions-thinking_face\", \"reactions-heart\", \"reactions-tada\", \"interactions\", \"created\", \"updated\"],\n type: \"string\"\n }\n },\n url: \"/search/issues\"\n },\n labels: {\n method: \"GET\",\n params: {\n order: {\n enum: [\"desc\", \"asc\"],\n type: \"string\"\n },\n q: {\n required: true,\n type: \"string\"\n },\n repository_id: {\n required: true,\n type: \"integer\"\n },\n sort: {\n enum: [\"created\", \"updated\"],\n type: \"string\"\n }\n },\n url: \"/search/labels\"\n },\n repos: {\n method: \"GET\",\n params: {\n order: {\n enum: [\"desc\", \"asc\"],\n type: \"string\"\n },\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n q: {\n required: true,\n type: \"string\"\n },\n sort: {\n enum: [\"stars\", \"forks\", \"help-wanted-issues\", \"updated\"],\n type: \"string\"\n }\n },\n url: \"/search/repositories\"\n },\n topics: {\n method: \"GET\",\n params: {\n q: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/search/topics\"\n },\n users: {\n method: \"GET\",\n params: {\n order: {\n enum: [\"desc\", \"asc\"],\n type: \"string\"\n },\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n q: {\n required: true,\n type: \"string\"\n },\n sort: {\n enum: [\"followers\", \"repositories\", \"joined\"],\n type: \"string\"\n }\n },\n url: \"/search/users\"\n }\n },\n teams: {\n addMember: {\n deprecated: \"octokit.teams.addMember() has been renamed to octokit.teams.addMemberLegacy() (2020-01-16)\",\n method: \"PUT\",\n params: {\n team_id: {\n required: true,\n type: \"integer\"\n },\n username: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/teams/:team_id/members/:username\"\n },\n addMemberLegacy: {\n deprecated: \"octokit.teams.addMemberLegacy() is deprecated, see https://developer.github.com/v3/teams/members/#add-team-member-legacy\",\n method: \"PUT\",\n params: {\n team_id: {\n required: true,\n type: \"integer\"\n },\n username: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/teams/:team_id/members/:username\"\n },\n addOrUpdateMembership: {\n deprecated: \"octokit.teams.addOrUpdateMembership() has been renamed to octokit.teams.addOrUpdateMembershipLegacy() (2020-01-16)\",\n method: \"PUT\",\n params: {\n role: {\n enum: [\"member\", \"maintainer\"],\n type: \"string\"\n },\n team_id: {\n required: true,\n type: \"integer\"\n },\n username: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/teams/:team_id/memberships/:username\"\n },\n addOrUpdateMembershipInOrg: {\n method: \"PUT\",\n params: {\n org: {\n required: true,\n type: \"string\"\n },\n role: {\n enum: [\"member\", \"maintainer\"],\n type: \"string\"\n },\n team_slug: {\n required: true,\n type: \"string\"\n },\n username: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/orgs/:org/teams/:team_slug/memberships/:username\"\n },\n addOrUpdateMembershipLegacy: {\n deprecated: \"octokit.teams.addOrUpdateMembershipLegacy() is deprecated, see https://developer.github.com/v3/teams/members/#add-or-update-team-membership-legacy\",\n method: \"PUT\",\n params: {\n role: {\n enum: [\"member\", \"maintainer\"],\n type: \"string\"\n },\n team_id: {\n required: true,\n type: \"integer\"\n },\n username: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/teams/:team_id/memberships/:username\"\n },\n addOrUpdateProject: {\n deprecated: \"octokit.teams.addOrUpdateProject() has been renamed to octokit.teams.addOrUpdateProjectLegacy() (2020-01-16)\",\n headers: {\n accept: \"application/vnd.github.inertia-preview+json\"\n },\n method: \"PUT\",\n params: {\n permission: {\n enum: [\"read\", \"write\", \"admin\"],\n type: \"string\"\n },\n project_id: {\n required: true,\n type: \"integer\"\n },\n team_id: {\n required: true,\n type: \"integer\"\n }\n },\n url: \"/teams/:team_id/projects/:project_id\"\n },\n addOrUpdateProjectInOrg: {\n headers: {\n accept: \"application/vnd.github.inertia-preview+json\"\n },\n method: \"PUT\",\n params: {\n org: {\n required: true,\n type: \"string\"\n },\n permission: {\n enum: [\"read\", \"write\", \"admin\"],\n type: \"string\"\n },\n project_id: {\n required: true,\n type: \"integer\"\n },\n team_slug: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/orgs/:org/teams/:team_slug/projects/:project_id\"\n },\n addOrUpdateProjectLegacy: {\n deprecated: \"octokit.teams.addOrUpdateProjectLegacy() is deprecated, see https://developer.github.com/v3/teams/#add-or-update-team-project-legacy\",\n headers: {\n accept: \"application/vnd.github.inertia-preview+json\"\n },\n method: \"PUT\",\n params: {\n permission: {\n enum: [\"read\", \"write\", \"admin\"],\n type: \"string\"\n },\n project_id: {\n required: true,\n type: \"integer\"\n },\n team_id: {\n required: true,\n type: \"integer\"\n }\n },\n url: \"/teams/:team_id/projects/:project_id\"\n },\n addOrUpdateRepo: {\n deprecated: \"octokit.teams.addOrUpdateRepo() has been renamed to octokit.teams.addOrUpdateRepoLegacy() (2020-01-16)\",\n method: \"PUT\",\n params: {\n owner: {\n required: true,\n type: \"string\"\n },\n permission: {\n enum: [\"pull\", \"push\", \"admin\"],\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n },\n team_id: {\n required: true,\n type: \"integer\"\n }\n },\n url: \"/teams/:team_id/repos/:owner/:repo\"\n },\n addOrUpdateRepoInOrg: {\n method: \"PUT\",\n params: {\n org: {\n required: true,\n type: \"string\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n permission: {\n enum: [\"pull\", \"push\", \"admin\"],\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n },\n team_slug: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/orgs/:org/teams/:team_slug/repos/:owner/:repo\"\n },\n addOrUpdateRepoLegacy: {\n deprecated: \"octokit.teams.addOrUpdateRepoLegacy() is deprecated, see https://developer.github.com/v3/teams/#add-or-update-team-repository-legacy\",\n method: \"PUT\",\n params: {\n owner: {\n required: true,\n type: \"string\"\n },\n permission: {\n enum: [\"pull\", \"push\", \"admin\"],\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n },\n team_id: {\n required: true,\n type: \"integer\"\n }\n },\n url: \"/teams/:team_id/repos/:owner/:repo\"\n },\n checkManagesRepo: {\n deprecated: \"octokit.teams.checkManagesRepo() has been renamed to octokit.teams.checkManagesRepoLegacy() (2020-01-16)\",\n method: \"GET\",\n params: {\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n },\n team_id: {\n required: true,\n type: \"integer\"\n }\n },\n url: \"/teams/:team_id/repos/:owner/:repo\"\n },\n checkManagesRepoInOrg: {\n method: \"GET\",\n params: {\n org: {\n required: true,\n type: \"string\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n },\n team_slug: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/orgs/:org/teams/:team_slug/repos/:owner/:repo\"\n },\n checkManagesRepoLegacy: {\n deprecated: \"octokit.teams.checkManagesRepoLegacy() is deprecated, see https://developer.github.com/v3/teams/#check-if-a-team-manages-a-repository-legacy\",\n method: \"GET\",\n params: {\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n },\n team_id: {\n required: true,\n type: \"integer\"\n }\n },\n url: \"/teams/:team_id/repos/:owner/:repo\"\n },\n create: {\n method: \"POST\",\n params: {\n description: {\n type: \"string\"\n },\n maintainers: {\n type: \"string[]\"\n },\n name: {\n required: true,\n type: \"string\"\n },\n org: {\n required: true,\n type: \"string\"\n },\n parent_team_id: {\n type: \"integer\"\n },\n permission: {\n enum: [\"pull\", \"push\", \"admin\"],\n type: \"string\"\n },\n privacy: {\n enum: [\"secret\", \"closed\"],\n type: \"string\"\n },\n repo_names: {\n type: \"string[]\"\n }\n },\n url: \"/orgs/:org/teams\"\n },\n createDiscussion: {\n deprecated: \"octokit.teams.createDiscussion() has been renamed to octokit.teams.createDiscussionLegacy() (2020-01-16)\",\n method: \"POST\",\n params: {\n body: {\n required: true,\n type: \"string\"\n },\n private: {\n type: \"boolean\"\n },\n team_id: {\n required: true,\n type: \"integer\"\n },\n title: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/teams/:team_id/discussions\"\n },\n createDiscussionComment: {\n deprecated: \"octokit.teams.createDiscussionComment() has been renamed to octokit.teams.createDiscussionCommentLegacy() (2020-01-16)\",\n method: \"POST\",\n params: {\n body: {\n required: true,\n type: \"string\"\n },\n discussion_number: {\n required: true,\n type: \"integer\"\n },\n team_id: {\n required: true,\n type: \"integer\"\n }\n },\n url: \"/teams/:team_id/discussions/:discussion_number/comments\"\n },\n createDiscussionCommentInOrg: {\n method: \"POST\",\n params: {\n body: {\n required: true,\n type: \"string\"\n },\n discussion_number: {\n required: true,\n type: \"integer\"\n },\n org: {\n required: true,\n type: \"string\"\n },\n team_slug: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/orgs/:org/teams/:team_slug/discussions/:discussion_number/comments\"\n },\n createDiscussionCommentLegacy: {\n deprecated: \"octokit.teams.createDiscussionCommentLegacy() is deprecated, see https://developer.github.com/v3/teams/discussion_comments/#create-a-comment-legacy\",\n method: \"POST\",\n params: {\n body: {\n required: true,\n type: \"string\"\n },\n discussion_number: {\n required: true,\n type: \"integer\"\n },\n team_id: {\n required: true,\n type: \"integer\"\n }\n },\n url: \"/teams/:team_id/discussions/:discussion_number/comments\"\n },\n createDiscussionInOrg: {\n method: \"POST\",\n params: {\n body: {\n required: true,\n type: \"string\"\n },\n org: {\n required: true,\n type: \"string\"\n },\n private: {\n type: \"boolean\"\n },\n team_slug: {\n required: true,\n type: \"string\"\n },\n title: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/orgs/:org/teams/:team_slug/discussions\"\n },\n createDiscussionLegacy: {\n deprecated: \"octokit.teams.createDiscussionLegacy() is deprecated, see https://developer.github.com/v3/teams/discussions/#create-a-discussion-legacy\",\n method: \"POST\",\n params: {\n body: {\n required: true,\n type: \"string\"\n },\n private: {\n type: \"boolean\"\n },\n team_id: {\n required: true,\n type: \"integer\"\n },\n title: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/teams/:team_id/discussions\"\n },\n delete: {\n deprecated: \"octokit.teams.delete() has been renamed to octokit.teams.deleteLegacy() (2020-01-16)\",\n method: \"DELETE\",\n params: {\n team_id: {\n required: true,\n type: \"integer\"\n }\n },\n url: \"/teams/:team_id\"\n },\n deleteDiscussion: {\n deprecated: \"octokit.teams.deleteDiscussion() has been renamed to octokit.teams.deleteDiscussionLegacy() (2020-01-16)\",\n method: \"DELETE\",\n params: {\n discussion_number: {\n required: true,\n type: \"integer\"\n },\n team_id: {\n required: true,\n type: \"integer\"\n }\n },\n url: \"/teams/:team_id/discussions/:discussion_number\"\n },\n deleteDiscussionComment: {\n deprecated: \"octokit.teams.deleteDiscussionComment() has been renamed to octokit.teams.deleteDiscussionCommentLegacy() (2020-01-16)\",\n method: \"DELETE\",\n params: {\n comment_number: {\n required: true,\n type: \"integer\"\n },\n discussion_number: {\n required: true,\n type: \"integer\"\n },\n team_id: {\n required: true,\n type: \"integer\"\n }\n },\n url: \"/teams/:team_id/discussions/:discussion_number/comments/:comment_number\"\n },\n deleteDiscussionCommentInOrg: {\n method: \"DELETE\",\n params: {\n comment_number: {\n required: true,\n type: \"integer\"\n },\n discussion_number: {\n required: true,\n type: \"integer\"\n },\n org: {\n required: true,\n type: \"string\"\n },\n team_slug: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/orgs/:org/teams/:team_slug/discussions/:discussion_number/comments/:comment_number\"\n },\n deleteDiscussionCommentLegacy: {\n deprecated: \"octokit.teams.deleteDiscussionCommentLegacy() is deprecated, see https://developer.github.com/v3/teams/discussion_comments/#delete-a-comment-legacy\",\n method: \"DELETE\",\n params: {\n comment_number: {\n required: true,\n type: \"integer\"\n },\n discussion_number: {\n required: true,\n type: \"integer\"\n },\n team_id: {\n required: true,\n type: \"integer\"\n }\n },\n url: \"/teams/:team_id/discussions/:discussion_number/comments/:comment_number\"\n },\n deleteDiscussionInOrg: {\n method: \"DELETE\",\n params: {\n discussion_number: {\n required: true,\n type: \"integer\"\n },\n org: {\n required: true,\n type: \"string\"\n },\n team_slug: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/orgs/:org/teams/:team_slug/discussions/:discussion_number\"\n },\n deleteDiscussionLegacy: {\n deprecated: \"octokit.teams.deleteDiscussionLegacy() is deprecated, see https://developer.github.com/v3/teams/discussions/#delete-a-discussion-legacy\",\n method: \"DELETE\",\n params: {\n discussion_number: {\n required: true,\n type: \"integer\"\n },\n team_id: {\n required: true,\n type: \"integer\"\n }\n },\n url: \"/teams/:team_id/discussions/:discussion_number\"\n },\n deleteInOrg: {\n method: \"DELETE\",\n params: {\n org: {\n required: true,\n type: \"string\"\n },\n team_slug: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/orgs/:org/teams/:team_slug\"\n },\n deleteLegacy: {\n deprecated: \"octokit.teams.deleteLegacy() is deprecated, see https://developer.github.com/v3/teams/#delete-team-legacy\",\n method: \"DELETE\",\n params: {\n team_id: {\n required: true,\n type: \"integer\"\n }\n },\n url: \"/teams/:team_id\"\n },\n get: {\n deprecated: \"octokit.teams.get() has been renamed to octokit.teams.getLegacy() (2020-01-16)\",\n method: \"GET\",\n params: {\n team_id: {\n required: true,\n type: \"integer\"\n }\n },\n url: \"/teams/:team_id\"\n },\n getByName: {\n method: \"GET\",\n params: {\n org: {\n required: true,\n type: \"string\"\n },\n team_slug: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/orgs/:org/teams/:team_slug\"\n },\n getDiscussion: {\n deprecated: \"octokit.teams.getDiscussion() has been renamed to octokit.teams.getDiscussionLegacy() (2020-01-16)\",\n method: \"GET\",\n params: {\n discussion_number: {\n required: true,\n type: \"integer\"\n },\n team_id: {\n required: true,\n type: \"integer\"\n }\n },\n url: \"/teams/:team_id/discussions/:discussion_number\"\n },\n getDiscussionComment: {\n deprecated: \"octokit.teams.getDiscussionComment() has been renamed to octokit.teams.getDiscussionCommentLegacy() (2020-01-16)\",\n method: \"GET\",\n params: {\n comment_number: {\n required: true,\n type: \"integer\"\n },\n discussion_number: {\n required: true,\n type: \"integer\"\n },\n team_id: {\n required: true,\n type: \"integer\"\n }\n },\n url: \"/teams/:team_id/discussions/:discussion_number/comments/:comment_number\"\n },\n getDiscussionCommentInOrg: {\n method: \"GET\",\n params: {\n comment_number: {\n required: true,\n type: \"integer\"\n },\n discussion_number: {\n required: true,\n type: \"integer\"\n },\n org: {\n required: true,\n type: \"string\"\n },\n team_slug: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/orgs/:org/teams/:team_slug/discussions/:discussion_number/comments/:comment_number\"\n },\n getDiscussionCommentLegacy: {\n deprecated: \"octokit.teams.getDiscussionCommentLegacy() is deprecated, see https://developer.github.com/v3/teams/discussion_comments/#get-a-single-comment-legacy\",\n method: \"GET\",\n params: {\n comment_number: {\n required: true,\n type: \"integer\"\n },\n discussion_number: {\n required: true,\n type: \"integer\"\n },\n team_id: {\n required: true,\n type: \"integer\"\n }\n },\n url: \"/teams/:team_id/discussions/:discussion_number/comments/:comment_number\"\n },\n getDiscussionInOrg: {\n method: \"GET\",\n params: {\n discussion_number: {\n required: true,\n type: \"integer\"\n },\n org: {\n required: true,\n type: \"string\"\n },\n team_slug: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/orgs/:org/teams/:team_slug/discussions/:discussion_number\"\n },\n getDiscussionLegacy: {\n deprecated: \"octokit.teams.getDiscussionLegacy() is deprecated, see https://developer.github.com/v3/teams/discussions/#get-a-single-discussion-legacy\",\n method: \"GET\",\n params: {\n discussion_number: {\n required: true,\n type: \"integer\"\n },\n team_id: {\n required: true,\n type: \"integer\"\n }\n },\n url: \"/teams/:team_id/discussions/:discussion_number\"\n },\n getLegacy: {\n deprecated: \"octokit.teams.getLegacy() is deprecated, see https://developer.github.com/v3/teams/#get-team-legacy\",\n method: \"GET\",\n params: {\n team_id: {\n required: true,\n type: \"integer\"\n }\n },\n url: \"/teams/:team_id\"\n },\n getMember: {\n deprecated: \"octokit.teams.getMember() has been renamed to octokit.teams.getMemberLegacy() (2020-01-16)\",\n method: \"GET\",\n params: {\n team_id: {\n required: true,\n type: \"integer\"\n },\n username: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/teams/:team_id/members/:username\"\n },\n getMemberLegacy: {\n deprecated: \"octokit.teams.getMemberLegacy() is deprecated, see https://developer.github.com/v3/teams/members/#get-team-member-legacy\",\n method: \"GET\",\n params: {\n team_id: {\n required: true,\n type: \"integer\"\n },\n username: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/teams/:team_id/members/:username\"\n },\n getMembership: {\n deprecated: \"octokit.teams.getMembership() has been renamed to octokit.teams.getMembershipLegacy() (2020-01-16)\",\n method: \"GET\",\n params: {\n team_id: {\n required: true,\n type: \"integer\"\n },\n username: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/teams/:team_id/memberships/:username\"\n },\n getMembershipInOrg: {\n method: \"GET\",\n params: {\n org: {\n required: true,\n type: \"string\"\n },\n team_slug: {\n required: true,\n type: \"string\"\n },\n username: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/orgs/:org/teams/:team_slug/memberships/:username\"\n },\n getMembershipLegacy: {\n deprecated: \"octokit.teams.getMembershipLegacy() is deprecated, see https://developer.github.com/v3/teams/members/#get-team-membership-legacy\",\n method: \"GET\",\n params: {\n team_id: {\n required: true,\n type: \"integer\"\n },\n username: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/teams/:team_id/memberships/:username\"\n },\n list: {\n method: \"GET\",\n params: {\n org: {\n required: true,\n type: \"string\"\n },\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n }\n },\n url: \"/orgs/:org/teams\"\n },\n listChild: {\n deprecated: \"octokit.teams.listChild() has been renamed to octokit.teams.listChildLegacy() (2020-01-16)\",\n method: \"GET\",\n params: {\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n team_id: {\n required: true,\n type: \"integer\"\n }\n },\n url: \"/teams/:team_id/teams\"\n },\n listChildInOrg: {\n method: \"GET\",\n params: {\n org: {\n required: true,\n type: \"string\"\n },\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n team_slug: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/orgs/:org/teams/:team_slug/teams\"\n },\n listChildLegacy: {\n deprecated: \"octokit.teams.listChildLegacy() is deprecated, see https://developer.github.com/v3/teams/#list-child-teams-legacy\",\n method: \"GET\",\n params: {\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n team_id: {\n required: true,\n type: \"integer\"\n }\n },\n url: \"/teams/:team_id/teams\"\n },\n listDiscussionComments: {\n deprecated: \"octokit.teams.listDiscussionComments() has been renamed to octokit.teams.listDiscussionCommentsLegacy() (2020-01-16)\",\n method: \"GET\",\n params: {\n direction: {\n enum: [\"asc\", \"desc\"],\n type: \"string\"\n },\n discussion_number: {\n required: true,\n type: \"integer\"\n },\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n team_id: {\n required: true,\n type: \"integer\"\n }\n },\n url: \"/teams/:team_id/discussions/:discussion_number/comments\"\n },\n listDiscussionCommentsInOrg: {\n method: \"GET\",\n params: {\n direction: {\n enum: [\"asc\", \"desc\"],\n type: \"string\"\n },\n discussion_number: {\n required: true,\n type: \"integer\"\n },\n org: {\n required: true,\n type: \"string\"\n },\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n team_slug: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/orgs/:org/teams/:team_slug/discussions/:discussion_number/comments\"\n },\n listDiscussionCommentsLegacy: {\n deprecated: \"octokit.teams.listDiscussionCommentsLegacy() is deprecated, see https://developer.github.com/v3/teams/discussion_comments/#list-comments-legacy\",\n method: \"GET\",\n params: {\n direction: {\n enum: [\"asc\", \"desc\"],\n type: \"string\"\n },\n discussion_number: {\n required: true,\n type: \"integer\"\n },\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n team_id: {\n required: true,\n type: \"integer\"\n }\n },\n url: \"/teams/:team_id/discussions/:discussion_number/comments\"\n },\n listDiscussions: {\n deprecated: \"octokit.teams.listDiscussions() has been renamed to octokit.teams.listDiscussionsLegacy() (2020-01-16)\",\n method: \"GET\",\n params: {\n direction: {\n enum: [\"asc\", \"desc\"],\n type: \"string\"\n },\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n team_id: {\n required: true,\n type: \"integer\"\n }\n },\n url: \"/teams/:team_id/discussions\"\n },\n listDiscussionsInOrg: {\n method: \"GET\",\n params: {\n direction: {\n enum: [\"asc\", \"desc\"],\n type: \"string\"\n },\n org: {\n required: true,\n type: \"string\"\n },\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n team_slug: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/orgs/:org/teams/:team_slug/discussions\"\n },\n listDiscussionsLegacy: {\n deprecated: \"octokit.teams.listDiscussionsLegacy() is deprecated, see https://developer.github.com/v3/teams/discussions/#list-discussions-legacy\",\n method: \"GET\",\n params: {\n direction: {\n enum: [\"asc\", \"desc\"],\n type: \"string\"\n },\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n team_id: {\n required: true,\n type: \"integer\"\n }\n },\n url: \"/teams/:team_id/discussions\"\n },\n listForAuthenticatedUser: {\n method: \"GET\",\n params: {\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n }\n },\n url: \"/user/teams\"\n },\n listMembers: {\n deprecated: \"octokit.teams.listMembers() has been renamed to octokit.teams.listMembersLegacy() (2020-01-16)\",\n method: \"GET\",\n params: {\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n role: {\n enum: [\"member\", \"maintainer\", \"all\"],\n type: \"string\"\n },\n team_id: {\n required: true,\n type: \"integer\"\n }\n },\n url: \"/teams/:team_id/members\"\n },\n listMembersInOrg: {\n method: \"GET\",\n params: {\n org: {\n required: true,\n type: \"string\"\n },\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n role: {\n enum: [\"member\", \"maintainer\", \"all\"],\n type: \"string\"\n },\n team_slug: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/orgs/:org/teams/:team_slug/members\"\n },\n listMembersLegacy: {\n deprecated: \"octokit.teams.listMembersLegacy() is deprecated, see https://developer.github.com/v3/teams/members/#list-team-members-legacy\",\n method: \"GET\",\n params: {\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n role: {\n enum: [\"member\", \"maintainer\", \"all\"],\n type: \"string\"\n },\n team_id: {\n required: true,\n type: \"integer\"\n }\n },\n url: \"/teams/:team_id/members\"\n },\n listPendingInvitations: {\n deprecated: \"octokit.teams.listPendingInvitations() has been renamed to octokit.teams.listPendingInvitationsLegacy() (2020-01-16)\",\n method: \"GET\",\n params: {\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n team_id: {\n required: true,\n type: \"integer\"\n }\n },\n url: \"/teams/:team_id/invitations\"\n },\n listPendingInvitationsInOrg: {\n method: \"GET\",\n params: {\n org: {\n required: true,\n type: \"string\"\n },\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n team_slug: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/orgs/:org/teams/:team_slug/invitations\"\n },\n listPendingInvitationsLegacy: {\n deprecated: \"octokit.teams.listPendingInvitationsLegacy() is deprecated, see https://developer.github.com/v3/teams/members/#list-pending-team-invitations-legacy\",\n method: \"GET\",\n params: {\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n team_id: {\n required: true,\n type: \"integer\"\n }\n },\n url: \"/teams/:team_id/invitations\"\n },\n listProjects: {\n deprecated: \"octokit.teams.listProjects() has been renamed to octokit.teams.listProjectsLegacy() (2020-01-16)\",\n headers: {\n accept: \"application/vnd.github.inertia-preview+json\"\n },\n method: \"GET\",\n params: {\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n team_id: {\n required: true,\n type: \"integer\"\n }\n },\n url: \"/teams/:team_id/projects\"\n },\n listProjectsInOrg: {\n headers: {\n accept: \"application/vnd.github.inertia-preview+json\"\n },\n method: \"GET\",\n params: {\n org: {\n required: true,\n type: \"string\"\n },\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n team_slug: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/orgs/:org/teams/:team_slug/projects\"\n },\n listProjectsLegacy: {\n deprecated: \"octokit.teams.listProjectsLegacy() is deprecated, see https://developer.github.com/v3/teams/#list-team-projects-legacy\",\n headers: {\n accept: \"application/vnd.github.inertia-preview+json\"\n },\n method: \"GET\",\n params: {\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n team_id: {\n required: true,\n type: \"integer\"\n }\n },\n url: \"/teams/:team_id/projects\"\n },\n listRepos: {\n deprecated: \"octokit.teams.listRepos() has been renamed to octokit.teams.listReposLegacy() (2020-01-16)\",\n method: \"GET\",\n params: {\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n team_id: {\n required: true,\n type: \"integer\"\n }\n },\n url: \"/teams/:team_id/repos\"\n },\n listReposInOrg: {\n method: \"GET\",\n params: {\n org: {\n required: true,\n type: \"string\"\n },\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n team_slug: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/orgs/:org/teams/:team_slug/repos\"\n },\n listReposLegacy: {\n deprecated: \"octokit.teams.listReposLegacy() is deprecated, see https://developer.github.com/v3/teams/#list-team-repos-legacy\",\n method: \"GET\",\n params: {\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n team_id: {\n required: true,\n type: \"integer\"\n }\n },\n url: \"/teams/:team_id/repos\"\n },\n removeMember: {\n deprecated: \"octokit.teams.removeMember() has been renamed to octokit.teams.removeMemberLegacy() (2020-01-16)\",\n method: \"DELETE\",\n params: {\n team_id: {\n required: true,\n type: \"integer\"\n },\n username: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/teams/:team_id/members/:username\"\n },\n removeMemberLegacy: {\n deprecated: \"octokit.teams.removeMemberLegacy() is deprecated, see https://developer.github.com/v3/teams/members/#remove-team-member-legacy\",\n method: \"DELETE\",\n params: {\n team_id: {\n required: true,\n type: \"integer\"\n },\n username: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/teams/:team_id/members/:username\"\n },\n removeMembership: {\n deprecated: \"octokit.teams.removeMembership() has been renamed to octokit.teams.removeMembershipLegacy() (2020-01-16)\",\n method: \"DELETE\",\n params: {\n team_id: {\n required: true,\n type: \"integer\"\n },\n username: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/teams/:team_id/memberships/:username\"\n },\n removeMembershipInOrg: {\n method: \"DELETE\",\n params: {\n org: {\n required: true,\n type: \"string\"\n },\n team_slug: {\n required: true,\n type: \"string\"\n },\n username: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/orgs/:org/teams/:team_slug/memberships/:username\"\n },\n removeMembershipLegacy: {\n deprecated: \"octokit.teams.removeMembershipLegacy() is deprecated, see https://developer.github.com/v3/teams/members/#remove-team-membership-legacy\",\n method: \"DELETE\",\n params: {\n team_id: {\n required: true,\n type: \"integer\"\n },\n username: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/teams/:team_id/memberships/:username\"\n },\n removeProject: {\n deprecated: \"octokit.teams.removeProject() has been renamed to octokit.teams.removeProjectLegacy() (2020-01-16)\",\n method: \"DELETE\",\n params: {\n project_id: {\n required: true,\n type: \"integer\"\n },\n team_id: {\n required: true,\n type: \"integer\"\n }\n },\n url: \"/teams/:team_id/projects/:project_id\"\n },\n removeProjectInOrg: {\n method: \"DELETE\",\n params: {\n org: {\n required: true,\n type: \"string\"\n },\n project_id: {\n required: true,\n type: \"integer\"\n },\n team_slug: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/orgs/:org/teams/:team_slug/projects/:project_id\"\n },\n removeProjectLegacy: {\n deprecated: \"octokit.teams.removeProjectLegacy() is deprecated, see https://developer.github.com/v3/teams/#remove-team-project-legacy\",\n method: \"DELETE\",\n params: {\n project_id: {\n required: true,\n type: \"integer\"\n },\n team_id: {\n required: true,\n type: \"integer\"\n }\n },\n url: \"/teams/:team_id/projects/:project_id\"\n },\n removeRepo: {\n deprecated: \"octokit.teams.removeRepo() has been renamed to octokit.teams.removeRepoLegacy() (2020-01-16)\",\n method: \"DELETE\",\n params: {\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n },\n team_id: {\n required: true,\n type: \"integer\"\n }\n },\n url: \"/teams/:team_id/repos/:owner/:repo\"\n },\n removeRepoInOrg: {\n method: \"DELETE\",\n params: {\n org: {\n required: true,\n type: \"string\"\n },\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n },\n team_slug: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/orgs/:org/teams/:team_slug/repos/:owner/:repo\"\n },\n removeRepoLegacy: {\n deprecated: \"octokit.teams.removeRepoLegacy() is deprecated, see https://developer.github.com/v3/teams/#remove-team-repository-legacy\",\n method: \"DELETE\",\n params: {\n owner: {\n required: true,\n type: \"string\"\n },\n repo: {\n required: true,\n type: \"string\"\n },\n team_id: {\n required: true,\n type: \"integer\"\n }\n },\n url: \"/teams/:team_id/repos/:owner/:repo\"\n },\n reviewProject: {\n deprecated: \"octokit.teams.reviewProject() has been renamed to octokit.teams.reviewProjectLegacy() (2020-01-16)\",\n headers: {\n accept: \"application/vnd.github.inertia-preview+json\"\n },\n method: \"GET\",\n params: {\n project_id: {\n required: true,\n type: \"integer\"\n },\n team_id: {\n required: true,\n type: \"integer\"\n }\n },\n url: \"/teams/:team_id/projects/:project_id\"\n },\n reviewProjectInOrg: {\n headers: {\n accept: \"application/vnd.github.inertia-preview+json\"\n },\n method: \"GET\",\n params: {\n org: {\n required: true,\n type: \"string\"\n },\n project_id: {\n required: true,\n type: \"integer\"\n },\n team_slug: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/orgs/:org/teams/:team_slug/projects/:project_id\"\n },\n reviewProjectLegacy: {\n deprecated: \"octokit.teams.reviewProjectLegacy() is deprecated, see https://developer.github.com/v3/teams/#review-a-team-project-legacy\",\n headers: {\n accept: \"application/vnd.github.inertia-preview+json\"\n },\n method: \"GET\",\n params: {\n project_id: {\n required: true,\n type: \"integer\"\n },\n team_id: {\n required: true,\n type: \"integer\"\n }\n },\n url: \"/teams/:team_id/projects/:project_id\"\n },\n update: {\n deprecated: \"octokit.teams.update() has been renamed to octokit.teams.updateLegacy() (2020-01-16)\",\n method: \"PATCH\",\n params: {\n description: {\n type: \"string\"\n },\n name: {\n required: true,\n type: \"string\"\n },\n parent_team_id: {\n type: \"integer\"\n },\n permission: {\n enum: [\"pull\", \"push\", \"admin\"],\n type: \"string\"\n },\n privacy: {\n enum: [\"secret\", \"closed\"],\n type: \"string\"\n },\n team_id: {\n required: true,\n type: \"integer\"\n }\n },\n url: \"/teams/:team_id\"\n },\n updateDiscussion: {\n deprecated: \"octokit.teams.updateDiscussion() has been renamed to octokit.teams.updateDiscussionLegacy() (2020-01-16)\",\n method: \"PATCH\",\n params: {\n body: {\n type: \"string\"\n },\n discussion_number: {\n required: true,\n type: \"integer\"\n },\n team_id: {\n required: true,\n type: \"integer\"\n },\n title: {\n type: \"string\"\n }\n },\n url: \"/teams/:team_id/discussions/:discussion_number\"\n },\n updateDiscussionComment: {\n deprecated: \"octokit.teams.updateDiscussionComment() has been renamed to octokit.teams.updateDiscussionCommentLegacy() (2020-01-16)\",\n method: \"PATCH\",\n params: {\n body: {\n required: true,\n type: \"string\"\n },\n comment_number: {\n required: true,\n type: \"integer\"\n },\n discussion_number: {\n required: true,\n type: \"integer\"\n },\n team_id: {\n required: true,\n type: \"integer\"\n }\n },\n url: \"/teams/:team_id/discussions/:discussion_number/comments/:comment_number\"\n },\n updateDiscussionCommentInOrg: {\n method: \"PATCH\",\n params: {\n body: {\n required: true,\n type: \"string\"\n },\n comment_number: {\n required: true,\n type: \"integer\"\n },\n discussion_number: {\n required: true,\n type: \"integer\"\n },\n org: {\n required: true,\n type: \"string\"\n },\n team_slug: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/orgs/:org/teams/:team_slug/discussions/:discussion_number/comments/:comment_number\"\n },\n updateDiscussionCommentLegacy: {\n deprecated: \"octokit.teams.updateDiscussionCommentLegacy() is deprecated, see https://developer.github.com/v3/teams/discussion_comments/#edit-a-comment-legacy\",\n method: \"PATCH\",\n params: {\n body: {\n required: true,\n type: \"string\"\n },\n comment_number: {\n required: true,\n type: \"integer\"\n },\n discussion_number: {\n required: true,\n type: \"integer\"\n },\n team_id: {\n required: true,\n type: \"integer\"\n }\n },\n url: \"/teams/:team_id/discussions/:discussion_number/comments/:comment_number\"\n },\n updateDiscussionInOrg: {\n method: \"PATCH\",\n params: {\n body: {\n type: \"string\"\n },\n discussion_number: {\n required: true,\n type: \"integer\"\n },\n org: {\n required: true,\n type: \"string\"\n },\n team_slug: {\n required: true,\n type: \"string\"\n },\n title: {\n type: \"string\"\n }\n },\n url: \"/orgs/:org/teams/:team_slug/discussions/:discussion_number\"\n },\n updateDiscussionLegacy: {\n deprecated: \"octokit.teams.updateDiscussionLegacy() is deprecated, see https://developer.github.com/v3/teams/discussions/#edit-a-discussion-legacy\",\n method: \"PATCH\",\n params: {\n body: {\n type: \"string\"\n },\n discussion_number: {\n required: true,\n type: \"integer\"\n },\n team_id: {\n required: true,\n type: \"integer\"\n },\n title: {\n type: \"string\"\n }\n },\n url: \"/teams/:team_id/discussions/:discussion_number\"\n },\n updateInOrg: {\n method: \"PATCH\",\n params: {\n description: {\n type: \"string\"\n },\n name: {\n required: true,\n type: \"string\"\n },\n org: {\n required: true,\n type: \"string\"\n },\n parent_team_id: {\n type: \"integer\"\n },\n permission: {\n enum: [\"pull\", \"push\", \"admin\"],\n type: \"string\"\n },\n privacy: {\n enum: [\"secret\", \"closed\"],\n type: \"string\"\n },\n team_slug: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/orgs/:org/teams/:team_slug\"\n },\n updateLegacy: {\n deprecated: \"octokit.teams.updateLegacy() is deprecated, see https://developer.github.com/v3/teams/#edit-team-legacy\",\n method: \"PATCH\",\n params: {\n description: {\n type: \"string\"\n },\n name: {\n required: true,\n type: \"string\"\n },\n parent_team_id: {\n type: \"integer\"\n },\n permission: {\n enum: [\"pull\", \"push\", \"admin\"],\n type: \"string\"\n },\n privacy: {\n enum: [\"secret\", \"closed\"],\n type: \"string\"\n },\n team_id: {\n required: true,\n type: \"integer\"\n }\n },\n url: \"/teams/:team_id\"\n }\n },\n users: {\n addEmails: {\n method: \"POST\",\n params: {\n emails: {\n required: true,\n type: \"string[]\"\n }\n },\n url: \"/user/emails\"\n },\n block: {\n method: \"PUT\",\n params: {\n username: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/user/blocks/:username\"\n },\n checkBlocked: {\n method: \"GET\",\n params: {\n username: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/user/blocks/:username\"\n },\n checkFollowing: {\n method: \"GET\",\n params: {\n username: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/user/following/:username\"\n },\n checkFollowingForUser: {\n method: \"GET\",\n params: {\n target_user: {\n required: true,\n type: \"string\"\n },\n username: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/users/:username/following/:target_user\"\n },\n createGpgKey: {\n method: \"POST\",\n params: {\n armored_public_key: {\n type: \"string\"\n }\n },\n url: \"/user/gpg_keys\"\n },\n createPublicKey: {\n method: \"POST\",\n params: {\n key: {\n type: \"string\"\n },\n title: {\n type: \"string\"\n }\n },\n url: \"/user/keys\"\n },\n deleteEmails: {\n method: \"DELETE\",\n params: {\n emails: {\n required: true,\n type: \"string[]\"\n }\n },\n url: \"/user/emails\"\n },\n deleteGpgKey: {\n method: \"DELETE\",\n params: {\n gpg_key_id: {\n required: true,\n type: \"integer\"\n }\n },\n url: \"/user/gpg_keys/:gpg_key_id\"\n },\n deletePublicKey: {\n method: \"DELETE\",\n params: {\n key_id: {\n required: true,\n type: \"integer\"\n }\n },\n url: \"/user/keys/:key_id\"\n },\n follow: {\n method: \"PUT\",\n params: {\n username: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/user/following/:username\"\n },\n getAuthenticated: {\n method: \"GET\",\n params: {},\n url: \"/user\"\n },\n getByUsername: {\n method: \"GET\",\n params: {\n username: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/users/:username\"\n },\n getContextForUser: {\n method: \"GET\",\n params: {\n subject_id: {\n type: \"string\"\n },\n subject_type: {\n enum: [\"organization\", \"repository\", \"issue\", \"pull_request\"],\n type: \"string\"\n },\n username: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/users/:username/hovercard\"\n },\n getGpgKey: {\n method: \"GET\",\n params: {\n gpg_key_id: {\n required: true,\n type: \"integer\"\n }\n },\n url: \"/user/gpg_keys/:gpg_key_id\"\n },\n getPublicKey: {\n method: \"GET\",\n params: {\n key_id: {\n required: true,\n type: \"integer\"\n }\n },\n url: \"/user/keys/:key_id\"\n },\n list: {\n method: \"GET\",\n params: {\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n since: {\n type: \"string\"\n }\n },\n url: \"/users\"\n },\n listBlocked: {\n method: \"GET\",\n params: {},\n url: \"/user/blocks\"\n },\n listEmails: {\n method: \"GET\",\n params: {\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n }\n },\n url: \"/user/emails\"\n },\n listFollowersForAuthenticatedUser: {\n method: \"GET\",\n params: {\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n }\n },\n url: \"/user/followers\"\n },\n listFollowersForUser: {\n method: \"GET\",\n params: {\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n username: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/users/:username/followers\"\n },\n listFollowingForAuthenticatedUser: {\n method: \"GET\",\n params: {\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n }\n },\n url: \"/user/following\"\n },\n listFollowingForUser: {\n method: \"GET\",\n params: {\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n username: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/users/:username/following\"\n },\n listGpgKeys: {\n method: \"GET\",\n params: {\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n }\n },\n url: \"/user/gpg_keys\"\n },\n listGpgKeysForUser: {\n method: \"GET\",\n params: {\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n username: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/users/:username/gpg_keys\"\n },\n listPublicEmails: {\n method: \"GET\",\n params: {\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n }\n },\n url: \"/user/public_emails\"\n },\n listPublicKeys: {\n method: \"GET\",\n params: {\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n }\n },\n url: \"/user/keys\"\n },\n listPublicKeysForUser: {\n method: \"GET\",\n params: {\n page: {\n type: \"integer\"\n },\n per_page: {\n type: \"integer\"\n },\n username: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/users/:username/keys\"\n },\n togglePrimaryEmailVisibility: {\n method: \"PATCH\",\n params: {\n email: {\n required: true,\n type: \"string\"\n },\n visibility: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/user/email/visibility\"\n },\n unblock: {\n method: \"DELETE\",\n params: {\n username: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/user/blocks/:username\"\n },\n unfollow: {\n method: \"DELETE\",\n params: {\n username: {\n required: true,\n type: \"string\"\n }\n },\n url: \"/user/following/:username\"\n },\n updateAuthenticated: {\n method: \"PATCH\",\n params: {\n bio: {\n type: \"string\"\n },\n blog: {\n type: \"string\"\n },\n company: {\n type: \"string\"\n },\n email: {\n type: \"string\"\n },\n hireable: {\n type: \"boolean\"\n },\n location: {\n type: \"string\"\n },\n name: {\n type: \"string\"\n }\n },\n url: \"/user\"\n }\n }\n};\n\nconst VERSION = \"2.4.0\";\n\nfunction registerEndpoints(octokit, routes) {\n Object.keys(routes).forEach(namespaceName => {\n if (!octokit[namespaceName]) {\n octokit[namespaceName] = {};\n }\n\n Object.keys(routes[namespaceName]).forEach(apiName => {\n const apiOptions = routes[namespaceName][apiName];\n const endpointDefaults = [\"method\", \"url\", \"headers\"].reduce((map, key) => {\n if (typeof apiOptions[key] !== \"undefined\") {\n map[key] = apiOptions[key];\n }\n\n return map;\n }, {});\n endpointDefaults.request = {\n validate: apiOptions.params\n };\n let request = octokit.request.defaults(endpointDefaults); // patch request & endpoint methods to support deprecated parameters.\n // Not the most elegant solution, but we don\u2019t want to move deprecation\n // logic into octokit/endpoint.js as it\u2019s out of scope\n\n const hasDeprecatedParam = Object.keys(apiOptions.params || {}).find(key => apiOptions.params[key].deprecated);\n\n if (hasDeprecatedParam) {\n const patch = patchForDeprecation.bind(null, octokit, apiOptions);\n request = patch(octokit.request.defaults(endpointDefaults), `.${namespaceName}.${apiName}()`);\n request.endpoint = patch(request.endpoint, `.${namespaceName}.${apiName}.endpoint()`);\n request.endpoint.merge = patch(request.endpoint.merge, `.${namespaceName}.${apiName}.endpoint.merge()`);\n }\n\n if (apiOptions.deprecated) {\n octokit[namespaceName][apiName] = Object.assign(function deprecatedEndpointMethod() {\n octokit.log.warn(new deprecation.Deprecation(`[@octokit/rest] ${apiOptions.deprecated}`));\n octokit[namespaceName][apiName] = request;\n return request.apply(null, arguments);\n }, request);\n return;\n }\n\n octokit[namespaceName][apiName] = request;\n });\n });\n}\n\nfunction patchForDeprecation(octokit, apiOptions, method, methodName) {\n const patchedMethod = options => {\n options = Object.assign({}, options);\n Object.keys(options).forEach(key => {\n if (apiOptions.params[key] && apiOptions.params[key].deprecated) {\n const aliasKey = apiOptions.params[key].alias;\n octokit.log.warn(new deprecation.Deprecation(`[@octokit/rest] \"${key}\" parameter is deprecated for \"${methodName}\". Use \"${aliasKey}\" instead`));\n\n if (!(aliasKey in options)) {\n options[aliasKey] = options[key];\n }\n\n delete options[key];\n }\n });\n return method(options);\n };\n\n Object.keys(method).forEach(key => {\n patchedMethod[key] = method[key];\n });\n return patchedMethod;\n}\n\n/**\n * This plugin is a 1:1 copy of internal @octokit/rest plugins. The primary\n * goal is to rebuild @octokit/rest on top of @octokit/core. Once that is\n * done, we will remove the registerEndpoints methods and return the methods\n * directly as with the other plugins. At that point we will also remove the\n * legacy workarounds and deprecations.\n *\n * See the plan at\n * https://github.com/octokit/plugin-rest-endpoint-methods.js/pull/1\n */\n\nfunction restEndpointMethods(octokit) {\n // @ts-ignore\n octokit.registerEndpoints = registerEndpoints.bind(null, octokit);\n registerEndpoints(octokit, endpointsByScope); // Aliasing scopes for backward compatibility\n // See https://github.com/octokit/rest.js/pull/1134\n\n [[\"gitdata\", \"git\"], [\"authorization\", \"oauthAuthorizations\"], [\"pullRequests\", \"pulls\"]].forEach(([deprecatedScope, scope]) => {\n Object.defineProperty(octokit, deprecatedScope, {\n get() {\n octokit.log.warn( // @ts-ignore\n new deprecation.Deprecation(`[@octokit/plugin-rest-endpoint-methods] \"octokit.${deprecatedScope}.*\" methods are deprecated, use \"octokit.${scope}.*\" instead`)); // @ts-ignore\n\n return octokit[scope];\n }\n\n });\n });\n return {};\n}\nrestEndpointMethods.VERSION = VERSION;\n\nexports.restEndpointMethods = restEndpointMethods;\n//# sourceMappingURL=index.js.map\n\n\n/***/ }),\n\n/***/ 537:\n/***/ ((__unused_webpack_module, exports, __nccwpck_require__) => {\n\n\"use strict\";\n\n\nObject.defineProperty(exports, \"__esModule\", ({ value: true }));\n\nfunction _interopDefault (ex) { return (ex && (typeof ex === 'object') && 'default' in ex) ? ex['default'] : ex; }\n\nvar deprecation = __nccwpck_require__(8932);\nvar once = _interopDefault(__nccwpck_require__(1223));\n\nconst logOnce = once(deprecation => console.warn(deprecation));\n/**\n * Error with extra properties to help with debugging\n */\n\nclass RequestError extends Error {\n constructor(message, statusCode, options) {\n super(message); // Maintains proper stack trace (only available on V8)\n\n /* istanbul ignore next */\n\n if (Error.captureStackTrace) {\n Error.captureStackTrace(this, this.constructor);\n }\n\n this.name = \"HttpError\";\n this.status = statusCode;\n Object.defineProperty(this, \"code\", {\n get() {\n logOnce(new deprecation.Deprecation(\"[@octokit/request-error] `error.code` is deprecated, use `error.status`.\"));\n return statusCode;\n }\n\n });\n this.headers = options.headers || {}; // redact request credentials without mutating original request options\n\n const requestCopy = Object.assign({}, options.request);\n\n if (options.request.headers.authorization) {\n requestCopy.headers = Object.assign({}, options.request.headers, {\n authorization: options.request.headers.authorization.replace(/ .*$/, \" [REDACTED]\")\n });\n }\n\n requestCopy.url = requestCopy.url // client_id & client_secret can be passed as URL query parameters to increase rate limit\n // see https://developer.github.com/v3/#increasing-the-unauthenticated-rate-limit-for-oauth-applications\n .replace(/\\bclient_secret=\\w+/g, \"client_secret=[REDACTED]\") // OAuth tokens can be passed as URL query parameters, although it is not recommended\n // see https://developer.github.com/v3/#oauth2-token-sent-in-a-header\n .replace(/\\baccess_token=\\w+/g, \"access_token=[REDACTED]\");\n this.request = requestCopy;\n }\n\n}\n\nexports.RequestError = RequestError;\n//# sourceMappingURL=index.js.map\n\n\n/***/ }),\n\n/***/ 6234:\n/***/ ((__unused_webpack_module, exports, __nccwpck_require__) => {\n\n\"use strict\";\n\n\nObject.defineProperty(exports, \"__esModule\", ({ value: true }));\n\nfunction _interopDefault (ex) { return (ex && (typeof ex === 'object') && 'default' in ex) ? ex['default'] : ex; }\n\nvar endpoint = __nccwpck_require__(9440);\nvar universalUserAgent = __nccwpck_require__(5030);\nvar isPlainObject = __nccwpck_require__(9062);\nvar nodeFetch = _interopDefault(__nccwpck_require__(467));\nvar requestError = __nccwpck_require__(13);\n\nconst VERSION = \"5.6.3\";\n\nfunction getBufferResponse(response) {\n return response.arrayBuffer();\n}\n\nfunction fetchWrapper(requestOptions) {\n const log = requestOptions.request && requestOptions.request.log ? requestOptions.request.log : console;\n\n if (isPlainObject.isPlainObject(requestOptions.body) || Array.isArray(requestOptions.body)) {\n requestOptions.body = JSON.stringify(requestOptions.body);\n }\n\n let headers = {};\n let status;\n let url;\n const fetch = requestOptions.request && requestOptions.request.fetch || nodeFetch;\n return fetch(requestOptions.url, Object.assign({\n method: requestOptions.method,\n body: requestOptions.body,\n headers: requestOptions.headers,\n redirect: requestOptions.redirect\n }, // `requestOptions.request.agent` type is incompatible\n // see https://github.com/octokit/types.ts/pull/264\n requestOptions.request)).then(async response => {\n url = response.url;\n status = response.status;\n\n for (const keyAndValue of response.headers) {\n headers[keyAndValue[0]] = keyAndValue[1];\n }\n\n if (\"deprecation\" in headers) {\n const matches = headers.link && headers.link.match(/<([^>]+)>; rel=\"deprecation\"/);\n const deprecationLink = matches && matches.pop();\n log.warn(`[@octokit/request] \"${requestOptions.method} ${requestOptions.url}\" is deprecated. It is scheduled to be removed on ${headers.sunset}${deprecationLink ? `. See ${deprecationLink}` : \"\"}`);\n }\n\n if (status === 204 || status === 205) {\n return;\n } // GitHub API returns 200 for HEAD requests\n\n\n if (requestOptions.method === \"HEAD\") {\n if (status < 400) {\n return;\n }\n\n throw new requestError.RequestError(response.statusText, status, {\n response: {\n url,\n status,\n headers,\n data: undefined\n },\n request: requestOptions\n });\n }\n\n if (status === 304) {\n throw new requestError.RequestError(\"Not modified\", status, {\n response: {\n url,\n status,\n headers,\n data: await getResponseData(response)\n },\n request: requestOptions\n });\n }\n\n if (status >= 400) {\n const data = await getResponseData(response);\n const error = new requestError.RequestError(toErrorMessage(data), status, {\n response: {\n url,\n status,\n headers,\n data\n },\n request: requestOptions\n });\n throw error;\n }\n\n return getResponseData(response);\n }).then(data => {\n return {\n status,\n url,\n headers,\n data\n };\n }).catch(error => {\n if (error instanceof requestError.RequestError) throw error;\n throw new requestError.RequestError(error.message, 500, {\n request: requestOptions\n });\n });\n}\n\nasync function getResponseData(response) {\n const contentType = response.headers.get(\"content-type\");\n\n if (/application\\/json/.test(contentType)) {\n return response.json();\n }\n\n if (!contentType || /^text\\/|charset=utf-8$/.test(contentType)) {\n return response.text();\n }\n\n return getBufferResponse(response);\n}\n\nfunction toErrorMessage(data) {\n if (typeof data === \"string\") return data; // istanbul ignore else - just in case\n\n if (\"message\" in data) {\n if (Array.isArray(data.errors)) {\n return `${data.message}: ${data.errors.map(JSON.stringify).join(\", \")}`;\n }\n\n return data.message;\n } // istanbul ignore next - just in case\n\n\n return `Unknown error: ${JSON.stringify(data)}`;\n}\n\nfunction withDefaults(oldEndpoint, newDefaults) {\n const endpoint = oldEndpoint.defaults(newDefaults);\n\n const newApi = function (route, parameters) {\n const endpointOptions = endpoint.merge(route, parameters);\n\n if (!endpointOptions.request || !endpointOptions.request.hook) {\n return fetchWrapper(endpoint.parse(endpointOptions));\n }\n\n const request = (route, parameters) => {\n return fetchWrapper(endpoint.parse(endpoint.merge(route, parameters)));\n };\n\n Object.assign(request, {\n endpoint,\n defaults: withDefaults.bind(null, endpoint)\n });\n return endpointOptions.request.hook(request, endpointOptions);\n };\n\n return Object.assign(newApi, {\n endpoint,\n defaults: withDefaults.bind(null, endpoint)\n });\n}\n\nconst request = withDefaults(endpoint.endpoint, {\n headers: {\n \"user-agent\": `octokit-request.js/${VERSION} ${universalUserAgent.getUserAgent()}`\n }\n});\n\nexports.request = request;\n//# sourceMappingURL=index.js.map\n\n\n/***/ }),\n\n/***/ 13:\n/***/ ((__unused_webpack_module, exports, __nccwpck_require__) => {\n\n\"use strict\";\n\n\nObject.defineProperty(exports, \"__esModule\", ({ value: true }));\n\nfunction _interopDefault (ex) { return (ex && (typeof ex === 'object') && 'default' in ex) ? ex['default'] : ex; }\n\nvar deprecation = __nccwpck_require__(8932);\nvar once = _interopDefault(__nccwpck_require__(1223));\n\nconst logOnceCode = once(deprecation => console.warn(deprecation));\nconst logOnceHeaders = once(deprecation => console.warn(deprecation));\n/**\n * Error with extra properties to help with debugging\n */\n\nclass RequestError extends Error {\n constructor(message, statusCode, options) {\n super(message); // Maintains proper stack trace (only available on V8)\n\n /* istanbul ignore next */\n\n if (Error.captureStackTrace) {\n Error.captureStackTrace(this, this.constructor);\n }\n\n this.name = \"HttpError\";\n this.status = statusCode;\n let headers;\n\n if (\"headers\" in options && typeof options.headers !== \"undefined\") {\n headers = options.headers;\n }\n\n if (\"response\" in options) {\n this.response = options.response;\n headers = options.response.headers;\n } // redact request credentials without mutating original request options\n\n\n const requestCopy = Object.assign({}, options.request);\n\n if (options.request.headers.authorization) {\n requestCopy.headers = Object.assign({}, options.request.headers, {\n authorization: options.request.headers.authorization.replace(/ .*$/, \" [REDACTED]\")\n });\n }\n\n requestCopy.url = requestCopy.url // client_id & client_secret can be passed as URL query parameters to increase rate limit\n // see https://developer.github.com/v3/#increasing-the-unauthenticated-rate-limit-for-oauth-applications\n .replace(/\\bclient_secret=\\w+/g, \"client_secret=[REDACTED]\") // OAuth tokens can be passed as URL query parameters, although it is not recommended\n // see https://developer.github.com/v3/#oauth2-token-sent-in-a-header\n .replace(/\\baccess_token=\\w+/g, \"access_token=[REDACTED]\");\n this.request = requestCopy; // deprecations\n\n Object.defineProperty(this, \"code\", {\n get() {\n logOnceCode(new deprecation.Deprecation(\"[@octokit/request-error] `error.code` is deprecated, use `error.status`.\"));\n return statusCode;\n }\n\n });\n Object.defineProperty(this, \"headers\", {\n get() {\n logOnceHeaders(new deprecation.Deprecation(\"[@octokit/request-error] `error.headers` is deprecated, use `error.response.headers`.\"));\n return headers || {};\n }\n\n });\n }\n\n}\n\nexports.RequestError = RequestError;\n//# sourceMappingURL=index.js.map\n\n\n/***/ }),\n\n/***/ 9062:\n/***/ ((__unused_webpack_module, exports) => {\n\n\"use strict\";\n\n\nObject.defineProperty(exports, \"__esModule\", ({ value: true }));\n\n/*!\n * is-plain-object <https://github.com/jonschlinkert/is-plain-object>\n *\n * Copyright (c) 2014-2017, Jon Schlinkert.\n * Released under the MIT License.\n */\n\nfunction isObject(o) {\n return Object.prototype.toString.call(o) === '[object Object]';\n}\n\nfunction isPlainObject(o) {\n var ctor,prot;\n\n if (isObject(o) === false) return false;\n\n // If has modified constructor\n ctor = o.constructor;\n if (ctor === undefined) return true;\n\n // If has modified prototype\n prot = ctor.prototype;\n if (isObject(prot) === false) return false;\n\n // If constructor does not have an Object-specific method\n if (prot.hasOwnProperty('isPrototypeOf') === false) {\n return false;\n }\n\n // Most likely a plain Object\n return true;\n}\n\nexports.isPlainObject = isPlainObject;\n\n\n/***/ }),\n\n/***/ 9351:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\nconst { requestLog } = __nccwpck_require__(8883);\nconst {\n restEndpointMethods\n} = __nccwpck_require__(3044);\n\nconst Core = __nccwpck_require__(9833);\n\nconst CORE_PLUGINS = [\n __nccwpck_require__(4555),\n __nccwpck_require__(3691), // deprecated: remove in v17\n requestLog,\n __nccwpck_require__(8579),\n restEndpointMethods,\n __nccwpck_require__(2657),\n\n __nccwpck_require__(2072) // deprecated: remove in v17\n];\n\nconst OctokitRest = Core.plugin(CORE_PLUGINS);\n\nfunction DeprecatedOctokit(options) {\n const warn =\n options && options.log && options.log.warn\n ? options.log.warn\n : console.warn;\n warn(\n '[@octokit/rest] `const Octokit = require(\"@octokit/rest\")` is deprecated. Use `const { Octokit } = require(\"@octokit/rest\")` instead'\n );\n return new OctokitRest(options);\n}\n\nconst Octokit = Object.assign(DeprecatedOctokit, {\n Octokit: OctokitRest\n});\n\nObject.keys(OctokitRest).forEach(key => {\n /* istanbul ignore else */\n if (OctokitRest.hasOwnProperty(key)) {\n Octokit[key] = OctokitRest[key];\n }\n});\n\nmodule.exports = Octokit;\n\n\n/***/ }),\n\n/***/ 823:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\nmodule.exports = Octokit;\n\nconst { request } = __nccwpck_require__(6234);\nconst Hook = __nccwpck_require__(3682);\n\nconst parseClientOptions = __nccwpck_require__(4613);\n\nfunction Octokit(plugins, options) {\n options = options || {};\n const hook = new Hook.Collection();\n const log = Object.assign(\n {\n debug: () => {},\n info: () => {},\n warn: console.warn,\n error: console.error\n },\n options && options.log\n );\n const api = {\n hook,\n log,\n request: request.defaults(parseClientOptions(options, log, hook))\n };\n\n plugins.forEach(pluginFunction => pluginFunction(api, options));\n\n return api;\n}\n\n\n/***/ }),\n\n/***/ 9833:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\nconst factory = __nccwpck_require__(5320);\n\nmodule.exports = factory();\n\n\n/***/ }),\n\n/***/ 5320:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\nmodule.exports = factory;\n\nconst Octokit = __nccwpck_require__(823);\nconst registerPlugin = __nccwpck_require__(7826);\n\nfunction factory(plugins) {\n const Api = Octokit.bind(null, plugins || []);\n Api.plugin = registerPlugin.bind(null, plugins || []);\n return Api;\n}\n\n\n/***/ }),\n\n/***/ 4613:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\nmodule.exports = parseOptions;\n\nconst { Deprecation } = __nccwpck_require__(8932);\nconst { getUserAgent } = __nccwpck_require__(3318);\nconst once = __nccwpck_require__(1223);\n\nconst pkg = __nccwpck_require__(1322);\n\nconst deprecateOptionsTimeout = once((log, deprecation) =>\n log.warn(deprecation)\n);\nconst deprecateOptionsAgent = once((log, deprecation) => log.warn(deprecation));\nconst deprecateOptionsHeaders = once((log, deprecation) =>\n log.warn(deprecation)\n);\n\nfunction parseOptions(options, log, hook) {\n if (options.headers) {\n options.headers = Object.keys(options.headers).reduce((newObj, key) => {\n newObj[key.toLowerCase()] = options.headers[key];\n return newObj;\n }, {});\n }\n\n const clientDefaults = {\n headers: options.headers || {},\n request: options.request || {},\n mediaType: {\n previews: [],\n format: \"\"\n }\n };\n\n if (options.baseUrl) {\n clientDefaults.baseUrl = options.baseUrl;\n }\n\n if (options.userAgent) {\n clientDefaults.headers[\"user-agent\"] = options.userAgent;\n }\n\n if (options.previews) {\n clientDefaults.mediaType.previews = options.previews;\n }\n\n if (options.timeZone) {\n clientDefaults.headers[\"time-zone\"] = options.timeZone;\n }\n\n if (options.timeout) {\n deprecateOptionsTimeout(\n log,\n new Deprecation(\n \"[@octokit/rest] new Octokit({timeout}) is deprecated. Use {request: {timeout}} instead. See https://github.com/octokit/request.js#request\"\n )\n );\n clientDefaults.request.timeout = options.timeout;\n }\n\n if (options.agent) {\n deprecateOptionsAgent(\n log,\n new Deprecation(\n \"[@octokit/rest] new Octokit({agent}) is deprecated. Use {request: {agent}} instead. See https://github.com/octokit/request.js#request\"\n )\n );\n clientDefaults.request.agent = options.agent;\n }\n\n if (options.headers) {\n deprecateOptionsHeaders(\n log,\n new Deprecation(\n \"[@octokit/rest] new Octokit({headers}) is deprecated. Use {userAgent, previews} instead. See https://github.com/octokit/request.js#request\"\n )\n );\n }\n\n const userAgentOption = clientDefaults.headers[\"user-agent\"];\n const defaultUserAgent = `octokit.js/${pkg.version} ${getUserAgent()}`;\n\n clientDefaults.headers[\"user-agent\"] = [userAgentOption, defaultUserAgent]\n .filter(Boolean)\n .join(\" \");\n\n clientDefaults.request.hook = hook.bind(null, \"request\");\n\n return clientDefaults;\n}\n\n\n/***/ }),\n\n/***/ 7826:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\nmodule.exports = registerPlugin;\n\nconst factory = __nccwpck_require__(5320);\n\nfunction registerPlugin(plugins, pluginFunction) {\n return factory(\n plugins.includes(pluginFunction) ? plugins : plugins.concat(pluginFunction)\n );\n}\n\n\n/***/ }),\n\n/***/ 3318:\n/***/ ((__unused_webpack_module, exports, __nccwpck_require__) => {\n\n\"use strict\";\n\n\nObject.defineProperty(exports, \"__esModule\", ({ value: true }));\n\nfunction _interopDefault (ex) { return (ex && (typeof ex === 'object') && 'default' in ex) ? ex['default'] : ex; }\n\nvar osName = _interopDefault(__nccwpck_require__(4824));\n\nfunction getUserAgent() {\n try {\n return `Node.js/${process.version.substr(1)} (${osName()}; ${process.arch})`;\n } catch (error) {\n if (/wmic os get Caption/.test(error.message)) {\n return \"Windows <version undetectable>\";\n }\n\n throw error;\n }\n}\n\nexports.getUserAgent = getUserAgent;\n//# sourceMappingURL=index.js.map\n\n\n/***/ }),\n\n/***/ 795:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\nmodule.exports = authenticate;\n\nconst { Deprecation } = __nccwpck_require__(8932);\nconst once = __nccwpck_require__(1223);\n\nconst deprecateAuthenticate = once((log, deprecation) => log.warn(deprecation));\n\nfunction authenticate(state, options) {\n deprecateAuthenticate(\n state.octokit.log,\n new Deprecation(\n '[@octokit/rest] octokit.authenticate() is deprecated. Use \"auth\" constructor option instead.'\n )\n );\n\n if (!options) {\n state.auth = false;\n return;\n }\n\n switch (options.type) {\n case \"basic\":\n if (!options.username || !options.password) {\n throw new Error(\n \"Basic authentication requires both a username and password to be set\"\n );\n }\n break;\n\n case \"oauth\":\n if (!options.token && !(options.key && options.secret)) {\n throw new Error(\n \"OAuth2 authentication requires a token or key & secret to be set\"\n );\n }\n break;\n\n case \"token\":\n case \"app\":\n if (!options.token) {\n throw new Error(\"Token authentication requires a token to be set\");\n }\n break;\n\n default:\n throw new Error(\n \"Invalid authentication type, must be 'basic', 'oauth', 'token' or 'app'\"\n );\n }\n\n state.auth = options;\n}\n\n\n/***/ }),\n\n/***/ 7578:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\nmodule.exports = authenticationBeforeRequest;\n\nconst btoa = __nccwpck_require__(2358);\nconst uniq = __nccwpck_require__(8216);\n\nfunction authenticationBeforeRequest(state, options) {\n if (!state.auth.type) {\n return;\n }\n\n if (state.auth.type === \"basic\") {\n const hash = btoa(`${state.auth.username}:${state.auth.password}`);\n options.headers.authorization = `Basic ${hash}`;\n return;\n }\n\n if (state.auth.type === \"token\") {\n options.headers.authorization = `token ${state.auth.token}`;\n return;\n }\n\n if (state.auth.type === \"app\") {\n options.headers.authorization = `Bearer ${state.auth.token}`;\n const acceptHeaders = options.headers.accept\n .split(\",\")\n .concat(\"application/vnd.github.machine-man-preview+json\");\n options.headers.accept = uniq(acceptHeaders)\n .filter(Boolean)\n .join(\",\");\n return;\n }\n\n options.url += options.url.indexOf(\"?\") === -1 ? \"?\" : \"&\";\n\n if (state.auth.token) {\n options.url += `access_token=${encodeURIComponent(state.auth.token)}`;\n return;\n }\n\n const key = encodeURIComponent(state.auth.key);\n const secret = encodeURIComponent(state.auth.secret);\n options.url += `client_id=${key}&client_secret=${secret}`;\n}\n\n\n/***/ }),\n\n/***/ 3691:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\nmodule.exports = authenticationPlugin;\n\nconst { Deprecation } = __nccwpck_require__(8932);\nconst once = __nccwpck_require__(1223);\n\nconst deprecateAuthenticate = once((log, deprecation) => log.warn(deprecation));\n\nconst authenticate = __nccwpck_require__(795);\nconst beforeRequest = __nccwpck_require__(7578);\nconst requestError = __nccwpck_require__(4275);\n\nfunction authenticationPlugin(octokit, options) {\n if (options.auth) {\n octokit.authenticate = () => {\n deprecateAuthenticate(\n octokit.log,\n new Deprecation(\n '[@octokit/rest] octokit.authenticate() is deprecated and has no effect when \"auth\" option is set on Octokit constructor'\n )\n );\n };\n return;\n }\n const state = {\n octokit,\n auth: false\n };\n octokit.authenticate = authenticate.bind(null, state);\n octokit.hook.before(\"request\", beforeRequest.bind(null, state));\n octokit.hook.error(\"request\", requestError.bind(null, state));\n}\n\n\n/***/ }),\n\n/***/ 4275:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\nmodule.exports = authenticationRequestError;\n\nconst { RequestError } = __nccwpck_require__(537);\n\nfunction authenticationRequestError(state, error, options) {\n /* istanbul ignore next */\n if (!error.headers) throw error;\n\n const otpRequired = /required/.test(error.headers[\"x-github-otp\"] || \"\");\n // handle \"2FA required\" error only\n if (error.status !== 401 || !otpRequired) {\n throw error;\n }\n\n if (\n error.status === 401 &&\n otpRequired &&\n error.request &&\n error.request.headers[\"x-github-otp\"]\n ) {\n throw new RequestError(\n \"Invalid one-time password for two-factor authentication\",\n 401,\n {\n headers: error.headers,\n request: options\n }\n );\n }\n\n if (typeof state.auth.on2fa !== \"function\") {\n throw new RequestError(\n \"2FA required, but options.on2fa is not a function. See https://github.com/octokit/rest.js#authentication\",\n 401,\n {\n headers: error.headers,\n request: options\n }\n );\n }\n\n return Promise.resolve()\n .then(() => {\n return state.auth.on2fa();\n })\n .then(oneTimePassword => {\n const newOptions = Object.assign(options, {\n headers: Object.assign(\n { \"x-github-otp\": oneTimePassword },\n options.headers\n )\n });\n return state.octokit.request(newOptions);\n });\n}\n\n\n/***/ }),\n\n/***/ 9733:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\nmodule.exports = authenticationBeforeRequest;\n\nconst btoa = __nccwpck_require__(2358);\n\nconst withAuthorizationPrefix = __nccwpck_require__(9603);\n\nfunction authenticationBeforeRequest(state, options) {\n if (typeof state.auth === \"string\") {\n options.headers.authorization = withAuthorizationPrefix(state.auth);\n return;\n }\n\n if (state.auth.username) {\n const hash = btoa(`${state.auth.username}:${state.auth.password}`);\n options.headers.authorization = `Basic ${hash}`;\n if (state.otp) {\n options.headers[\"x-github-otp\"] = state.otp;\n }\n return;\n }\n\n if (state.auth.clientId) {\n // There is a special case for OAuth applications, when `clientId` and `clientSecret` is passed as\n // Basic Authorization instead of query parameters. The only routes where that applies share the same\n // URL though: `/applications/:client_id/tokens/:access_token`.\n //\n // 1. [Check an authorization](https://developer.github.com/v3/oauth_authorizations/#check-an-authorization)\n // 2. [Reset an authorization](https://developer.github.com/v3/oauth_authorizations/#reset-an-authorization)\n // 3. [Revoke an authorization for an application](https://developer.github.com/v3/oauth_authorizations/#revoke-an-authorization-for-an-application)\n //\n // We identify by checking the URL. It must merge both \"/applications/:client_id/tokens/:access_token\"\n // as well as \"/applications/123/tokens/token456\"\n if (/\\/applications\\/:?[\\w_]+\\/tokens\\/:?[\\w_]+($|\\?)/.test(options.url)) {\n const hash = btoa(`${state.auth.clientId}:${state.auth.clientSecret}`);\n options.headers.authorization = `Basic ${hash}`;\n return;\n }\n\n options.url += options.url.indexOf(\"?\") === -1 ? \"?\" : \"&\";\n options.url += `client_id=${state.auth.clientId}&client_secret=${state.auth.clientSecret}`;\n return;\n }\n\n return Promise.resolve()\n\n .then(() => {\n return state.auth();\n })\n\n .then(authorization => {\n options.headers.authorization = withAuthorizationPrefix(authorization);\n });\n}\n\n\n/***/ }),\n\n/***/ 4555:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\nmodule.exports = authenticationPlugin;\n\nconst { createTokenAuth } = __nccwpck_require__(334);\nconst { Deprecation } = __nccwpck_require__(8932);\nconst once = __nccwpck_require__(1223);\n\nconst beforeRequest = __nccwpck_require__(9733);\nconst requestError = __nccwpck_require__(3217);\nconst validate = __nccwpck_require__(8997);\nconst withAuthorizationPrefix = __nccwpck_require__(9603);\n\nconst deprecateAuthBasic = once((log, deprecation) => log.warn(deprecation));\nconst deprecateAuthObject = once((log, deprecation) => log.warn(deprecation));\n\nfunction authenticationPlugin(octokit, options) {\n // If `options.authStrategy` is set then use it and pass in `options.auth`\n if (options.authStrategy) {\n const auth = options.authStrategy(options.auth);\n octokit.hook.wrap(\"request\", auth.hook);\n octokit.auth = auth;\n return;\n }\n\n // If neither `options.authStrategy` nor `options.auth` are set, the `octokit` instance\n // is unauthenticated. The `octokit.auth()` method is a no-op and no request hook is registred.\n if (!options.auth) {\n octokit.auth = () =>\n Promise.resolve({\n type: \"unauthenticated\"\n });\n return;\n }\n\n const isBasicAuthString =\n typeof options.auth === \"string\" &&\n /^basic/.test(withAuthorizationPrefix(options.auth));\n\n // If only `options.auth` is set to a string, use the default token authentication strategy.\n if (typeof options.auth === \"string\" && !isBasicAuthString) {\n const auth = createTokenAuth(options.auth);\n octokit.hook.wrap(\"request\", auth.hook);\n octokit.auth = auth;\n return;\n }\n\n // Otherwise log a deprecation message\n const [deprecationMethod, deprecationMessapge] = isBasicAuthString\n ? [\n deprecateAuthBasic,\n 'Setting the \"new Octokit({ auth })\" option to a Basic Auth string is deprecated. Use https://github.com/octokit/auth-basic.js instead. See (https://octokit.github.io/rest.js/#authentication)'\n ]\n : [\n deprecateAuthObject,\n 'Setting the \"new Octokit({ auth })\" option to an object without also setting the \"authStrategy\" option is deprecated and will be removed in v17. See (https://octokit.github.io/rest.js/#authentication)'\n ];\n deprecationMethod(\n octokit.log,\n new Deprecation(\"[@octokit/rest] \" + deprecationMessapge)\n );\n\n octokit.auth = () =>\n Promise.resolve({\n type: \"deprecated\",\n message: deprecationMessapge\n });\n\n validate(options.auth);\n\n const state = {\n octokit,\n auth: options.auth\n };\n\n octokit.hook.before(\"request\", beforeRequest.bind(null, state));\n octokit.hook.error(\"request\", requestError.bind(null, state));\n}\n\n\n/***/ }),\n\n/***/ 3217:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\nmodule.exports = authenticationRequestError;\n\nconst { RequestError } = __nccwpck_require__(537);\n\nfunction authenticationRequestError(state, error, options) {\n if (!error.headers) throw error;\n\n const otpRequired = /required/.test(error.headers[\"x-github-otp\"] || \"\");\n // handle \"2FA required\" error only\n if (error.status !== 401 || !otpRequired) {\n throw error;\n }\n\n if (\n error.status === 401 &&\n otpRequired &&\n error.request &&\n error.request.headers[\"x-github-otp\"]\n ) {\n if (state.otp) {\n delete state.otp; // no longer valid, request again\n } else {\n throw new RequestError(\n \"Invalid one-time password for two-factor authentication\",\n 401,\n {\n headers: error.headers,\n request: options\n }\n );\n }\n }\n\n if (typeof state.auth.on2fa !== \"function\") {\n throw new RequestError(\n \"2FA required, but options.on2fa is not a function. See https://github.com/octokit/rest.js#authentication\",\n 401,\n {\n headers: error.headers,\n request: options\n }\n );\n }\n\n return Promise.resolve()\n .then(() => {\n return state.auth.on2fa();\n })\n .then(oneTimePassword => {\n const newOptions = Object.assign(options, {\n headers: Object.assign(options.headers, {\n \"x-github-otp\": oneTimePassword\n })\n });\n return state.octokit.request(newOptions).then(response => {\n // If OTP still valid, then persist it for following requests\n state.otp = oneTimePassword;\n return response;\n });\n });\n}\n\n\n/***/ }),\n\n/***/ 8997:\n/***/ ((module) => {\n\nmodule.exports = validateAuth;\n\nfunction validateAuth(auth) {\n if (typeof auth === \"string\") {\n return;\n }\n\n if (typeof auth === \"function\") {\n return;\n }\n\n if (auth.username && auth.password) {\n return;\n }\n\n if (auth.clientId && auth.clientSecret) {\n return;\n }\n\n throw new Error(`Invalid \"auth\" option: ${JSON.stringify(auth)}`);\n}\n\n\n/***/ }),\n\n/***/ 9603:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\nmodule.exports = withAuthorizationPrefix;\n\nconst atob = __nccwpck_require__(5224);\n\nconst REGEX_IS_BASIC_AUTH = /^[\\w-]+:/;\n\nfunction withAuthorizationPrefix(authorization) {\n if (/^(basic|bearer|token) /i.test(authorization)) {\n return authorization;\n }\n\n try {\n if (REGEX_IS_BASIC_AUTH.test(atob(authorization))) {\n return `basic ${authorization}`;\n }\n } catch (error) {}\n\n if (authorization.split(/\\./).length === 3) {\n return `bearer ${authorization}`;\n }\n\n return `token ${authorization}`;\n}\n\n\n/***/ }),\n\n/***/ 8579:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\nmodule.exports = paginatePlugin;\n\nconst { paginateRest } = __nccwpck_require__(4193);\n\nfunction paginatePlugin(octokit) {\n Object.assign(octokit, paginateRest(octokit));\n}\n\n\n/***/ }),\n\n/***/ 2657:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\nmodule.exports = octokitValidate;\n\nconst validate = __nccwpck_require__(6132);\n\nfunction octokitValidate(octokit) {\n octokit.hook.before(\"request\", validate.bind(null, octokit));\n}\n\n\n/***/ }),\n\n/***/ 6132:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\n\"use strict\";\n\n\nmodule.exports = validate;\n\nconst { RequestError } = __nccwpck_require__(537);\nconst get = __nccwpck_require__(9197);\nconst set = __nccwpck_require__(1552);\n\nfunction validate(octokit, options) {\n if (!options.request.validate) {\n return;\n }\n const { validate: params } = options.request;\n\n Object.keys(params).forEach(parameterName => {\n const parameter = get(params, parameterName);\n\n const expectedType = parameter.type;\n let parentParameterName;\n let parentValue;\n let parentParamIsPresent = true;\n let parentParameterIsArray = false;\n\n if (/\\./.test(parameterName)) {\n parentParameterName = parameterName.replace(/\\.[^.]+$/, \"\");\n parentParameterIsArray = parentParameterName.slice(-2) === \"[]\";\n if (parentParameterIsArray) {\n parentParameterName = parentParameterName.slice(0, -2);\n }\n parentValue = get(options, parentParameterName);\n parentParamIsPresent =\n parentParameterName === \"headers\" ||\n (typeof parentValue === \"object\" && parentValue !== null);\n }\n\n const values = parentParameterIsArray\n ? (get(options, parentParameterName) || []).map(\n value => value[parameterName.split(/\\./).pop()]\n )\n : [get(options, parameterName)];\n\n values.forEach((value, i) => {\n const valueIsPresent = typeof value !== \"undefined\";\n const valueIsNull = value === null;\n const currentParameterName = parentParameterIsArray\n ? parameterName.replace(/\\[\\]/, `[${i}]`)\n : parameterName;\n\n if (!parameter.required && !valueIsPresent) {\n return;\n }\n\n // if the parent parameter is of type object but allows null\n // then the child parameters can be ignored\n if (!parentParamIsPresent) {\n return;\n }\n\n if (parameter.allowNull && valueIsNull) {\n return;\n }\n\n if (!parameter.allowNull && valueIsNull) {\n throw new RequestError(\n `'${currentParameterName}' cannot be null`,\n 400,\n {\n request: options\n }\n );\n }\n\n if (parameter.required && !valueIsPresent) {\n throw new RequestError(\n `Empty value for parameter '${currentParameterName}': ${JSON.stringify(\n value\n )}`,\n 400,\n {\n request: options\n }\n );\n }\n\n // parse to integer before checking for enum\n // so that string \"1\" will match enum with number 1\n if (expectedType === \"integer\") {\n const unparsedValue = value;\n value = parseInt(value, 10);\n if (isNaN(value)) {\n throw new RequestError(\n `Invalid value for parameter '${currentParameterName}': ${JSON.stringify(\n unparsedValue\n )} is NaN`,\n 400,\n {\n request: options\n }\n );\n }\n }\n\n if (parameter.enum && parameter.enum.indexOf(String(value)) === -1) {\n throw new RequestError(\n `Invalid value for parameter '${currentParameterName}': ${JSON.stringify(\n value\n )}`,\n 400,\n {\n request: options\n }\n );\n }\n\n if (parameter.validation) {\n const regex = new RegExp(parameter.validation);\n if (!regex.test(value)) {\n throw new RequestError(\n `Invalid value for parameter '${currentParameterName}': ${JSON.stringify(\n value\n )}`,\n 400,\n {\n request: options\n }\n );\n }\n }\n\n if (expectedType === \"object\" && typeof value === \"string\") {\n try {\n value = JSON.parse(value);\n } catch (exception) {\n throw new RequestError(\n `JSON parse error of value for parameter '${currentParameterName}': ${JSON.stringify(\n value\n )}`,\n 400,\n {\n request: options\n }\n );\n }\n }\n\n set(options, parameter.mapTo || currentParameterName, value);\n });\n });\n\n return options;\n}\n\n\n/***/ }),\n\n/***/ 7678:\n/***/ ((module, exports) => {\n\n\"use strict\";\n\n/// <reference lib=\"es2018\"/>\n/// <reference lib=\"dom\"/>\n/// <reference types=\"node\"/>\nObject.defineProperty(exports, \"__esModule\", ({ value: true }));\nconst typedArrayTypeNames = [\n 'Int8Array',\n 'Uint8Array',\n 'Uint8ClampedArray',\n 'Int16Array',\n 'Uint16Array',\n 'Int32Array',\n 'Uint32Array',\n 'Float32Array',\n 'Float64Array',\n 'BigInt64Array',\n 'BigUint64Array'\n];\nfunction isTypedArrayName(name) {\n return typedArrayTypeNames.includes(name);\n}\nconst objectTypeNames = [\n 'Function',\n 'Generator',\n 'AsyncGenerator',\n 'GeneratorFunction',\n 'AsyncGeneratorFunction',\n 'AsyncFunction',\n 'Observable',\n 'Array',\n 'Buffer',\n 'Blob',\n 'Object',\n 'RegExp',\n 'Date',\n 'Error',\n 'Map',\n 'Set',\n 'WeakMap',\n 'WeakSet',\n 'ArrayBuffer',\n 'SharedArrayBuffer',\n 'DataView',\n 'Promise',\n 'URL',\n 'FormData',\n 'URLSearchParams',\n 'HTMLElement',\n ...typedArrayTypeNames\n];\nfunction isObjectTypeName(name) {\n return objectTypeNames.includes(name);\n}\nconst primitiveTypeNames = [\n 'null',\n 'undefined',\n 'string',\n 'number',\n 'bigint',\n 'boolean',\n 'symbol'\n];\nfunction isPrimitiveTypeName(name) {\n return primitiveTypeNames.includes(name);\n}\n// eslint-disable-next-line @typescript-eslint/ban-types\nfunction isOfType(type) {\n return (value) => typeof value === type;\n}\nconst { toString } = Object.prototype;\nconst getObjectType = (value) => {\n const objectTypeName = toString.call(value).slice(8, -1);\n if (/HTML\\w+Element/.test(objectTypeName) && is.domElement(value)) {\n return 'HTMLElement';\n }\n if (isObjectTypeName(objectTypeName)) {\n return objectTypeName;\n }\n return undefined;\n};\nconst isObjectOfType = (type) => (value) => getObjectType(value) === type;\nfunction is(value) {\n if (value === null) {\n return 'null';\n }\n switch (typeof value) {\n case 'undefined':\n return 'undefined';\n case 'string':\n return 'string';\n case 'number':\n return 'number';\n case 'boolean':\n return 'boolean';\n case 'function':\n return 'Function';\n case 'bigint':\n return 'bigint';\n case 'symbol':\n return 'symbol';\n default:\n }\n if (is.observable(value)) {\n return 'Observable';\n }\n if (is.array(value)) {\n return 'Array';\n }\n if (is.buffer(value)) {\n return 'Buffer';\n }\n const tagType = getObjectType(value);\n if (tagType) {\n return tagType;\n }\n if (value instanceof String || value instanceof Boolean || value instanceof Number) {\n throw new TypeError('Please don\\'t use object wrappers for primitive types');\n }\n return 'Object';\n}\nis.undefined = isOfType('undefined');\nis.string = isOfType('string');\nconst isNumberType = isOfType('number');\nis.number = (value) => isNumberType(value) && !is.nan(value);\nis.bigint = isOfType('bigint');\n// eslint-disable-next-line @typescript-eslint/ban-types\nis.function_ = isOfType('function');\nis.null_ = (value) => value === null;\nis.class_ = (value) => is.function_(value) && value.toString().startsWith('class ');\nis.boolean = (value) => value === true || value === false;\nis.symbol = isOfType('symbol');\nis.numericString = (value) => is.string(value) && !is.emptyStringOrWhitespace(value) && !Number.isNaN(Number(value));\nis.array = (value, assertion) => {\n if (!Array.isArray(value)) {\n return false;\n }\n if (!is.function_(assertion)) {\n return true;\n }\n return value.every(assertion);\n};\nis.buffer = (value) => { var _a, _b, _c, _d; return (_d = (_c = (_b = (_a = value) === null || _a === void 0 ? void 0 : _a.constructor) === null || _b === void 0 ? void 0 : _b.isBuffer) === null || _c === void 0 ? void 0 : _c.call(_b, value)) !== null && _d !== void 0 ? _d : false; };\nis.blob = (value) => isObjectOfType('Blob')(value);\nis.nullOrUndefined = (value) => is.null_(value) || is.undefined(value);\nis.object = (value) => !is.null_(value) && (typeof value === 'object' || is.function_(value));\nis.iterable = (value) => { var _a; return is.function_((_a = value) === null || _a === void 0 ? void 0 : _a[Symbol.iterator]); };\nis.asyncIterable = (value) => { var _a; return is.function_((_a = value) === null || _a === void 0 ? void 0 : _a[Symbol.asyncIterator]); };\nis.generator = (value) => { var _a, _b; return is.iterable(value) && is.function_((_a = value) === null || _a === void 0 ? void 0 : _a.next) && is.function_((_b = value) === null || _b === void 0 ? void 0 : _b.throw); };\nis.asyncGenerator = (value) => is.asyncIterable(value) && is.function_(value.next) && is.function_(value.throw);\nis.nativePromise = (value) => isObjectOfType('Promise')(value);\nconst hasPromiseAPI = (value) => {\n var _a, _b;\n return is.function_((_a = value) === null || _a === void 0 ? void 0 : _a.then) &&\n is.function_((_b = value) === null || _b === void 0 ? void 0 : _b.catch);\n};\nis.promise = (value) => is.nativePromise(value) || hasPromiseAPI(value);\nis.generatorFunction = isObjectOfType('GeneratorFunction');\nis.asyncGeneratorFunction = (value) => getObjectType(value) === 'AsyncGeneratorFunction';\nis.asyncFunction = (value) => getObjectType(value) === 'AsyncFunction';\n// eslint-disable-next-line no-prototype-builtins, @typescript-eslint/ban-types\nis.boundFunction = (value) => is.function_(value) && !value.hasOwnProperty('prototype');\nis.regExp = isObjectOfType('RegExp');\nis.date = isObjectOfType('Date');\nis.error = isObjectOfType('Error');\nis.map = (value) => isObjectOfType('Map')(value);\nis.set = (value) => isObjectOfType('Set')(value);\nis.weakMap = (value) => isObjectOfType('WeakMap')(value);\nis.weakSet = (value) => isObjectOfType('WeakSet')(value);\nis.int8Array = isObjectOfType('Int8Array');\nis.uint8Array = isObjectOfType('Uint8Array');\nis.uint8ClampedArray = isObjectOfType('Uint8ClampedArray');\nis.int16Array = isObjectOfType('Int16Array');\nis.uint16Array = isObjectOfType('Uint16Array');\nis.int32Array = isObjectOfType('Int32Array');\nis.uint32Array = isObjectOfType('Uint32Array');\nis.float32Array = isObjectOfType('Float32Array');\nis.float64Array = isObjectOfType('Float64Array');\nis.bigInt64Array = isObjectOfType('BigInt64Array');\nis.bigUint64Array = isObjectOfType('BigUint64Array');\nis.arrayBuffer = isObjectOfType('ArrayBuffer');\nis.sharedArrayBuffer = isObjectOfType('SharedArrayBuffer');\nis.dataView = isObjectOfType('DataView');\nis.enumCase = (value, targetEnum) => Object.values(targetEnum).includes(value);\nis.directInstanceOf = (instance, class_) => Object.getPrototypeOf(instance) === class_.prototype;\nis.urlInstance = (value) => isObjectOfType('URL')(value);\nis.urlString = (value) => {\n if (!is.string(value)) {\n return false;\n }\n try {\n new URL(value); // eslint-disable-line no-new\n return true;\n }\n catch (_a) {\n return false;\n }\n};\n// Example: `is.truthy = (value: unknown): value is (not false | not 0 | not '' | not undefined | not null) => Boolean(value);`\nis.truthy = (value) => Boolean(value);\n// Example: `is.falsy = (value: unknown): value is (not true | 0 | '' | undefined | null) => Boolean(value);`\nis.falsy = (value) => !value;\nis.nan = (value) => Number.isNaN(value);\nis.primitive = (value) => is.null_(value) || isPrimitiveTypeName(typeof value);\nis.integer = (value) => Number.isInteger(value);\nis.safeInteger = (value) => Number.isSafeInteger(value);\nis.plainObject = (value) => {\n // From: https://github.com/sindresorhus/is-plain-obj/blob/main/index.js\n if (toString.call(value) !== '[object Object]') {\n return false;\n }\n const prototype = Object.getPrototypeOf(value);\n return prototype === null || prototype === Object.getPrototypeOf({});\n};\nis.typedArray = (value) => isTypedArrayName(getObjectType(value));\nconst isValidLength = (value) => is.safeInteger(value) && value >= 0;\nis.arrayLike = (value) => !is.nullOrUndefined(value) && !is.function_(value) && isValidLength(value.length);\nis.inRange = (value, range) => {\n if (is.number(range)) {\n return value >= Math.min(0, range) && value <= Math.max(range, 0);\n }\n if (is.array(range) && range.length === 2) {\n return value >= Math.min(...range) && value <= Math.max(...range);\n }\n throw new TypeError(`Invalid range: ${JSON.stringify(range)}`);\n};\nconst NODE_TYPE_ELEMENT = 1;\nconst DOM_PROPERTIES_TO_CHECK = [\n 'innerHTML',\n 'ownerDocument',\n 'style',\n 'attributes',\n 'nodeValue'\n];\nis.domElement = (value) => {\n return is.object(value) &&\n value.nodeType === NODE_TYPE_ELEMENT &&\n is.string(value.nodeName) &&\n !is.plainObject(value) &&\n DOM_PROPERTIES_TO_CHECK.every(property => property in value);\n};\nis.observable = (value) => {\n var _a, _b, _c, _d;\n if (!value) {\n return false;\n }\n // eslint-disable-next-line no-use-extend-native/no-use-extend-native\n if (value === ((_b = (_a = value)[Symbol.observable]) === null || _b === void 0 ? void 0 : _b.call(_a))) {\n return true;\n }\n if (value === ((_d = (_c = value)['@@observable']) === null || _d === void 0 ? void 0 : _d.call(_c))) {\n return true;\n }\n return false;\n};\nis.nodeStream = (value) => is.object(value) && is.function_(value.pipe) && !is.observable(value);\nis.infinite = (value) => value === Infinity || value === -Infinity;\nconst isAbsoluteMod2 = (remainder) => (value) => is.integer(value) && Math.abs(value % 2) === remainder;\nis.evenInteger = isAbsoluteMod2(0);\nis.oddInteger = isAbsoluteMod2(1);\nis.emptyArray = (value) => is.array(value) && value.length === 0;\nis.nonEmptyArray = (value) => is.array(value) && value.length > 0;\nis.emptyString = (value) => is.string(value) && value.length === 0;\nconst isWhiteSpaceString = (value) => is.string(value) && !/\\S/.test(value);\nis.emptyStringOrWhitespace = (value) => is.emptyString(value) || isWhiteSpaceString(value);\n// TODO: Use `not ''` when the `not` operator is available.\nis.nonEmptyString = (value) => is.string(value) && value.length > 0;\n// TODO: Use `not ''` when the `not` operator is available.\nis.nonEmptyStringAndNotWhitespace = (value) => is.string(value) && !is.emptyStringOrWhitespace(value);\nis.emptyObject = (value) => is.object(value) && !is.map(value) && !is.set(value) && Object.keys(value).length === 0;\n// TODO: Use `not` operator here to remove `Map` and `Set` from type guard:\n// - https://github.com/Microsoft/TypeScript/pull/29317\nis.nonEmptyObject = (value) => is.object(value) && !is.map(value) && !is.set(value) && Object.keys(value).length > 0;\nis.emptySet = (value) => is.set(value) && value.size === 0;\nis.nonEmptySet = (value) => is.set(value) && value.size > 0;\nis.emptyMap = (value) => is.map(value) && value.size === 0;\nis.nonEmptyMap = (value) => is.map(value) && value.size > 0;\n// `PropertyKey` is any value that can be used as an object key (string, number, or symbol)\nis.propertyKey = (value) => is.any([is.string, is.number, is.symbol], value);\nis.formData = (value) => isObjectOfType('FormData')(value);\nis.urlSearchParams = (value) => isObjectOfType('URLSearchParams')(value);\nconst predicateOnArray = (method, predicate, values) => {\n if (!is.function_(predicate)) {\n throw new TypeError(`Invalid predicate: ${JSON.stringify(predicate)}`);\n }\n if (values.length === 0) {\n throw new TypeError('Invalid number of values');\n }\n return method.call(values, predicate);\n};\nis.any = (predicate, ...values) => {\n const predicates = is.array(predicate) ? predicate : [predicate];\n return predicates.some(singlePredicate => predicateOnArray(Array.prototype.some, singlePredicate, values));\n};\nis.all = (predicate, ...values) => predicateOnArray(Array.prototype.every, predicate, values);\nconst assertType = (condition, description, value, options = {}) => {\n if (!condition) {\n const { multipleValues } = options;\n const valuesMessage = multipleValues ?\n `received values of types ${[\n ...new Set(value.map(singleValue => `\\`${is(singleValue)}\\``))\n ].join(', ')}` :\n `received value of type \\`${is(value)}\\``;\n throw new TypeError(`Expected value which is \\`${description}\\`, ${valuesMessage}.`);\n }\n};\nexports.assert = {\n // Unknowns.\n undefined: (value) => assertType(is.undefined(value), 'undefined', value),\n string: (value) => assertType(is.string(value), 'string', value),\n number: (value) => assertType(is.number(value), 'number', value),\n bigint: (value) => assertType(is.bigint(value), 'bigint', value),\n // eslint-disable-next-line @typescript-eslint/ban-types\n function_: (value) => assertType(is.function_(value), 'Function', value),\n null_: (value) => assertType(is.null_(value), 'null', value),\n class_: (value) => assertType(is.class_(value), \"Class\" /* class_ */, value),\n boolean: (value) => assertType(is.boolean(value), 'boolean', value),\n symbol: (value) => assertType(is.symbol(value), 'symbol', value),\n numericString: (value) => assertType(is.numericString(value), \"string with a number\" /* numericString */, value),\n array: (value, assertion) => {\n const assert = assertType;\n assert(is.array(value), 'Array', value);\n if (assertion) {\n value.forEach(assertion);\n }\n },\n buffer: (value) => assertType(is.buffer(value), 'Buffer', value),\n blob: (value) => assertType(is.blob(value), 'Blob', value),\n nullOrUndefined: (value) => assertType(is.nullOrUndefined(value), \"null or undefined\" /* nullOrUndefined */, value),\n object: (value) => assertType(is.object(value), 'Object', value),\n iterable: (value) => assertType(is.iterable(value), \"Iterable\" /* iterable */, value),\n asyncIterable: (value) => assertType(is.asyncIterable(value), \"AsyncIterable\" /* asyncIterable */, value),\n generator: (value) => assertType(is.generator(value), 'Generator', value),\n asyncGenerator: (value) => assertType(is.asyncGenerator(value), 'AsyncGenerator', value),\n nativePromise: (value) => assertType(is.nativePromise(value), \"native Promise\" /* nativePromise */, value),\n promise: (value) => assertType(is.promise(value), 'Promise', value),\n generatorFunction: (value) => assertType(is.generatorFunction(value), 'GeneratorFunction', value),\n asyncGeneratorFunction: (value) => assertType(is.asyncGeneratorFunction(value), 'AsyncGeneratorFunction', value),\n // eslint-disable-next-line @typescript-eslint/ban-types\n asyncFunction: (value) => assertType(is.asyncFunction(value), 'AsyncFunction', value),\n // eslint-disable-next-line @typescript-eslint/ban-types\n boundFunction: (value) => assertType(is.boundFunction(value), 'Function', value),\n regExp: (value) => assertType(is.regExp(value), 'RegExp', value),\n date: (value) => assertType(is.date(value), 'Date', value),\n error: (value) => assertType(is.error(value), 'Error', value),\n map: (value) => assertType(is.map(value), 'Map', value),\n set: (value) => assertType(is.set(value), 'Set', value),\n weakMap: (value) => assertType(is.weakMap(value), 'WeakMap', value),\n weakSet: (value) => assertType(is.weakSet(value), 'WeakSet', value),\n int8Array: (value) => assertType(is.int8Array(value), 'Int8Array', value),\n uint8Array: (value) => assertType(is.uint8Array(value), 'Uint8Array', value),\n uint8ClampedArray: (value) => assertType(is.uint8ClampedArray(value), 'Uint8ClampedArray', value),\n int16Array: (value) => assertType(is.int16Array(value), 'Int16Array', value),\n uint16Array: (value) => assertType(is.uint16Array(value), 'Uint16Array', value),\n int32Array: (value) => assertType(is.int32Array(value), 'Int32Array', value),\n uint32Array: (value) => assertType(is.uint32Array(value), 'Uint32Array', value),\n float32Array: (value) => assertType(is.float32Array(value), 'Float32Array', value),\n float64Array: (value) => assertType(is.float64Array(value), 'Float64Array', value),\n bigInt64Array: (value) => assertType(is.bigInt64Array(value), 'BigInt64Array', value),\n bigUint64Array: (value) => assertType(is.bigUint64Array(value), 'BigUint64Array', value),\n arrayBuffer: (value) => assertType(is.arrayBuffer(value), 'ArrayBuffer', value),\n sharedArrayBuffer: (value) => assertType(is.sharedArrayBuffer(value), 'SharedArrayBuffer', value),\n dataView: (value) => assertType(is.dataView(value), 'DataView', value),\n enumCase: (value, targetEnum) => assertType(is.enumCase(value, targetEnum), 'EnumCase', value),\n urlInstance: (value) => assertType(is.urlInstance(value), 'URL', value),\n urlString: (value) => assertType(is.urlString(value), \"string with a URL\" /* urlString */, value),\n truthy: (value) => assertType(is.truthy(value), \"truthy\" /* truthy */, value),\n falsy: (value) => assertType(is.falsy(value), \"falsy\" /* falsy */, value),\n nan: (value) => assertType(is.nan(value), \"NaN\" /* nan */, value),\n primitive: (value) => assertType(is.primitive(value), \"primitive\" /* primitive */, value),\n integer: (value) => assertType(is.integer(value), \"integer\" /* integer */, value),\n safeInteger: (value) => assertType(is.safeInteger(value), \"integer\" /* safeInteger */, value),\n plainObject: (value) => assertType(is.plainObject(value), \"plain object\" /* plainObject */, value),\n typedArray: (value) => assertType(is.typedArray(value), \"TypedArray\" /* typedArray */, value),\n arrayLike: (value) => assertType(is.arrayLike(value), \"array-like\" /* arrayLike */, value),\n domElement: (value) => assertType(is.domElement(value), \"HTMLElement\" /* domElement */, value),\n observable: (value) => assertType(is.observable(value), 'Observable', value),\n nodeStream: (value) => assertType(is.nodeStream(value), \"Node.js Stream\" /* nodeStream */, value),\n infinite: (value) => assertType(is.infinite(value), \"infinite number\" /* infinite */, value),\n emptyArray: (value) => assertType(is.emptyArray(value), \"empty array\" /* emptyArray */, value),\n nonEmptyArray: (value) => assertType(is.nonEmptyArray(value), \"non-empty array\" /* nonEmptyArray */, value),\n emptyString: (value) => assertType(is.emptyString(value), \"empty string\" /* emptyString */, value),\n emptyStringOrWhitespace: (value) => assertType(is.emptyStringOrWhitespace(value), \"empty string or whitespace\" /* emptyStringOrWhitespace */, value),\n nonEmptyString: (value) => assertType(is.nonEmptyString(value), \"non-empty string\" /* nonEmptyString */, value),\n nonEmptyStringAndNotWhitespace: (value) => assertType(is.nonEmptyStringAndNotWhitespace(value), \"non-empty string and not whitespace\" /* nonEmptyStringAndNotWhitespace */, value),\n emptyObject: (value) => assertType(is.emptyObject(value), \"empty object\" /* emptyObject */, value),\n nonEmptyObject: (value) => assertType(is.nonEmptyObject(value), \"non-empty object\" /* nonEmptyObject */, value),\n emptySet: (value) => assertType(is.emptySet(value), \"empty set\" /* emptySet */, value),\n nonEmptySet: (value) => assertType(is.nonEmptySet(value), \"non-empty set\" /* nonEmptySet */, value),\n emptyMap: (value) => assertType(is.emptyMap(value), \"empty map\" /* emptyMap */, value),\n nonEmptyMap: (value) => assertType(is.nonEmptyMap(value), \"non-empty map\" /* nonEmptyMap */, value),\n propertyKey: (value) => assertType(is.propertyKey(value), 'PropertyKey', value),\n formData: (value) => assertType(is.formData(value), 'FormData', value),\n urlSearchParams: (value) => assertType(is.urlSearchParams(value), 'URLSearchParams', value),\n // Numbers.\n evenInteger: (value) => assertType(is.evenInteger(value), \"even integer\" /* evenInteger */, value),\n oddInteger: (value) => assertType(is.oddInteger(value), \"odd integer\" /* oddInteger */, value),\n // Two arguments.\n directInstanceOf: (instance, class_) => assertType(is.directInstanceOf(instance, class_), \"T\" /* directInstanceOf */, instance),\n inRange: (value, range) => assertType(is.inRange(value, range), \"in range\" /* inRange */, value),\n // Variadic functions.\n any: (predicate, ...values) => {\n return assertType(is.any(predicate, ...values), \"predicate returns truthy for any value\" /* any */, values, { multipleValues: true });\n },\n all: (predicate, ...values) => assertType(is.all(predicate, ...values), \"predicate returns truthy for all values\" /* all */, values, { multipleValues: true })\n};\n// Some few keywords are reserved, but we'll populate them for Node.js users\n// See https://github.com/Microsoft/TypeScript/issues/2536\nObject.defineProperties(is, {\n class: {\n value: is.class_\n },\n function: {\n value: is.function_\n },\n null: {\n value: is.null_\n }\n});\nObject.defineProperties(exports.assert, {\n class: {\n value: exports.assert.class_\n },\n function: {\n value: exports.assert.function_\n },\n null: {\n value: exports.assert.null_\n }\n});\nexports[\"default\"] = is;\n// For CommonJS default export support\nmodule.exports = is;\nmodule.exports[\"default\"] = is;\nmodule.exports.assert = exports.assert;\n\n\n/***/ }),\n\n/***/ 8097:\n/***/ ((module, exports, __nccwpck_require__) => {\n\n\"use strict\";\n\nObject.defineProperty(exports, \"__esModule\", ({ value: true }));\nconst defer_to_connect_1 = __nccwpck_require__(6214);\nconst util_1 = __nccwpck_require__(3837);\nconst nodejsMajorVersion = Number(process.versions.node.split('.')[0]);\nconst timer = (request) => {\n if (request.timings) {\n return request.timings;\n }\n const timings = {\n start: Date.now(),\n socket: undefined,\n lookup: undefined,\n connect: undefined,\n secureConnect: undefined,\n upload: undefined,\n response: undefined,\n end: undefined,\n error: undefined,\n abort: undefined,\n phases: {\n wait: undefined,\n dns: undefined,\n tcp: undefined,\n tls: undefined,\n request: undefined,\n firstByte: undefined,\n download: undefined,\n total: undefined\n }\n };\n request.timings = timings;\n const handleError = (origin) => {\n const emit = origin.emit.bind(origin);\n origin.emit = (event, ...args) => {\n // Catches the `error` event\n if (event === 'error') {\n timings.error = Date.now();\n timings.phases.total = timings.error - timings.start;\n origin.emit = emit;\n }\n // Saves the original behavior\n return emit(event, ...args);\n };\n };\n handleError(request);\n const onAbort = () => {\n timings.abort = Date.now();\n // Let the `end` response event be responsible for setting the total phase,\n // unless the Node.js major version is >= 13.\n if (!timings.response || nodejsMajorVersion >= 13) {\n timings.phases.total = Date.now() - timings.start;\n }\n };\n request.prependOnceListener('abort', onAbort);\n const onSocket = (socket) => {\n timings.socket = Date.now();\n timings.phases.wait = timings.socket - timings.start;\n if (util_1.types.isProxy(socket)) {\n return;\n }\n const lookupListener = () => {\n timings.lookup = Date.now();\n timings.phases.dns = timings.lookup - timings.socket;\n };\n socket.prependOnceListener('lookup', lookupListener);\n defer_to_connect_1.default(socket, {\n connect: () => {\n timings.connect = Date.now();\n if (timings.lookup === undefined) {\n socket.removeListener('lookup', lookupListener);\n timings.lookup = timings.connect;\n timings.phases.dns = timings.lookup - timings.socket;\n }\n timings.phases.tcp = timings.connect - timings.lookup;\n // This callback is called before flushing any data,\n // so we don't need to set `timings.phases.request` here.\n },\n secureConnect: () => {\n timings.secureConnect = Date.now();\n timings.phases.tls = timings.secureConnect - timings.connect;\n }\n });\n };\n if (request.socket) {\n onSocket(request.socket);\n }\n else {\n request.prependOnceListener('socket', onSocket);\n }\n const onUpload = () => {\n var _a;\n timings.upload = Date.now();\n timings.phases.request = timings.upload - ((_a = timings.secureConnect) !== null && _a !== void 0 ? _a : timings.connect);\n };\n const writableFinished = () => {\n if (typeof request.writableFinished === 'boolean') {\n return request.writableFinished;\n }\n // Node.js doesn't have `request.writableFinished` property\n return request.finished && request.outputSize === 0 && (!request.socket || request.socket.writableLength === 0);\n };\n if (writableFinished()) {\n onUpload();\n }\n else {\n request.prependOnceListener('finish', onUpload);\n }\n request.prependOnceListener('response', (response) => {\n timings.response = Date.now();\n timings.phases.firstByte = timings.response - timings.upload;\n response.timings = timings;\n handleError(response);\n response.prependOnceListener('end', () => {\n timings.end = Date.now();\n timings.phases.download = timings.end - timings.response;\n timings.phases.total = timings.end - timings.start;\n });\n response.prependOnceListener('aborted', onAbort);\n });\n return timings;\n};\nexports[\"default\"] = timer;\n// For CommonJS default export support\nmodule.exports = timer;\nmodule.exports[\"default\"] = timer;\n\n\n/***/ }),\n\n/***/ 5224:\n/***/ ((module) => {\n\nmodule.exports = function atob(str) {\n return Buffer.from(str, 'base64').toString('binary')\n}\n\n\n/***/ }),\n\n/***/ 3682:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\nvar register = __nccwpck_require__(4670);\nvar addHook = __nccwpck_require__(5549);\nvar removeHook = __nccwpck_require__(6819);\n\n// bind with array of arguments: https://stackoverflow.com/a/21792913\nvar bind = Function.bind;\nvar bindable = bind.bind(bind);\n\nfunction bindApi(hook, state, name) {\n var removeHookRef = bindable(removeHook, null).apply(\n null,\n name ? [state, name] : [state]\n );\n hook.api = { remove: removeHookRef };\n hook.remove = removeHookRef;\n [\"before\", \"error\", \"after\", \"wrap\"].forEach(function (kind) {\n var args = name ? [state, kind, name] : [state, kind];\n hook[kind] = hook.api[kind] = bindable(addHook, null).apply(null, args);\n });\n}\n\nfunction HookSingular() {\n var singularHookName = \"h\";\n var singularHookState = {\n registry: {},\n };\n var singularHook = register.bind(null, singularHookState, singularHookName);\n bindApi(singularHook, singularHookState, singularHookName);\n return singularHook;\n}\n\nfunction HookCollection() {\n var state = {\n registry: {},\n };\n\n var hook = register.bind(null, state);\n bindApi(hook, state);\n\n return hook;\n}\n\nvar collectionHookDeprecationMessageDisplayed = false;\nfunction Hook() {\n if (!collectionHookDeprecationMessageDisplayed) {\n console.warn(\n '[before-after-hook]: \"Hook()\" repurposing warning, use \"Hook.Collection()\". Read more: https://git.io/upgrade-before-after-hook-to-1.4'\n );\n collectionHookDeprecationMessageDisplayed = true;\n }\n return HookCollection();\n}\n\nHook.Singular = HookSingular.bind();\nHook.Collection = HookCollection.bind();\n\nmodule.exports = Hook;\n// expose constructors as a named property for TypeScript\nmodule.exports.Hook = Hook;\nmodule.exports.Singular = Hook.Singular;\nmodule.exports.Collection = Hook.Collection;\n\n\n/***/ }),\n\n/***/ 5549:\n/***/ ((module) => {\n\nmodule.exports = addHook;\n\nfunction addHook(state, kind, name, hook) {\n var orig = hook;\n if (!state.registry[name]) {\n state.registry[name] = [];\n }\n\n if (kind === \"before\") {\n hook = function (method, options) {\n return Promise.resolve()\n .then(orig.bind(null, options))\n .then(method.bind(null, options));\n };\n }\n\n if (kind === \"after\") {\n hook = function (method, options) {\n var result;\n return Promise.resolve()\n .then(method.bind(null, options))\n .then(function (result_) {\n result = result_;\n return orig(result, options);\n })\n .then(function () {\n return result;\n });\n };\n }\n\n if (kind === \"error\") {\n hook = function (method, options) {\n return Promise.resolve()\n .then(method.bind(null, options))\n .catch(function (error) {\n return orig(error, options);\n });\n };\n }\n\n state.registry[name].push({\n hook: hook,\n orig: orig,\n });\n}\n\n\n/***/ }),\n\n/***/ 4670:\n/***/ ((module) => {\n\nmodule.exports = register;\n\nfunction register(state, name, method, options) {\n if (typeof method !== \"function\") {\n throw new Error(\"method for before hook must be a function\");\n }\n\n if (!options) {\n options = {};\n }\n\n if (Array.isArray(name)) {\n return name.reverse().reduce(function (callback, name) {\n return register.bind(null, state, name, callback, options);\n }, method)();\n }\n\n return Promise.resolve().then(function () {\n if (!state.registry[name]) {\n return method(options);\n }\n\n return state.registry[name].reduce(function (method, registered) {\n return registered.hook.bind(null, method, options);\n }, method)();\n });\n}\n\n\n/***/ }),\n\n/***/ 6819:\n/***/ ((module) => {\n\nmodule.exports = removeHook;\n\nfunction removeHook(state, name, method) {\n if (!state.registry[name]) {\n return;\n }\n\n var index = state.registry[name]\n .map(function (registered) {\n return registered.orig;\n })\n .indexOf(method);\n\n if (index === -1) {\n return;\n }\n\n state.registry[name].splice(index, 1);\n}\n\n\n/***/ }),\n\n/***/ 2358:\n/***/ ((module) => {\n\nmodule.exports = function btoa(str) {\n return new Buffer(str).toString('base64')\n}\n\n\n/***/ }),\n\n/***/ 8367:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\n\"use strict\";\n\nconst {\n\tV4MAPPED,\n\tADDRCONFIG,\n\tALL,\n\tpromises: {\n\t\tResolver: AsyncResolver\n\t},\n\tlookup: dnsLookup\n} = __nccwpck_require__(9523);\nconst {promisify} = __nccwpck_require__(3837);\nconst os = __nccwpck_require__(2037);\n\nconst kCacheableLookupCreateConnection = Symbol('cacheableLookupCreateConnection');\nconst kCacheableLookupInstance = Symbol('cacheableLookupInstance');\nconst kExpires = Symbol('expires');\n\nconst supportsALL = typeof ALL === 'number';\n\nconst verifyAgent = agent => {\n\tif (!(agent && typeof agent.createConnection === 'function')) {\n\t\tthrow new Error('Expected an Agent instance as the first argument');\n\t}\n};\n\nconst map4to6 = entries => {\n\tfor (const entry of entries) {\n\t\tif (entry.family === 6) {\n\t\t\tcontinue;\n\t\t}\n\n\t\tentry.address = `::ffff:${entry.address}`;\n\t\tentry.family = 6;\n\t}\n};\n\nconst getIfaceInfo = () => {\n\tlet has4 = false;\n\tlet has6 = false;\n\n\tfor (const device of Object.values(os.networkInterfaces())) {\n\t\tfor (const iface of device) {\n\t\t\tif (iface.internal) {\n\t\t\t\tcontinue;\n\t\t\t}\n\n\t\t\tif (iface.family === 'IPv6') {\n\t\t\t\thas6 = true;\n\t\t\t} else {\n\t\t\t\thas4 = true;\n\t\t\t}\n\n\t\t\tif (has4 && has6) {\n\t\t\t\treturn {has4, has6};\n\t\t\t}\n\t\t}\n\t}\n\n\treturn {has4, has6};\n};\n\nconst isIterable = map => {\n\treturn Symbol.iterator in map;\n};\n\nconst ttl = {ttl: true};\nconst all = {all: true};\n\nclass CacheableLookup {\n\tconstructor({\n\t\tcache = new Map(),\n\t\tmaxTtl = Infinity,\n\t\tfallbackDuration = 3600,\n\t\terrorTtl = 0.15,\n\t\tresolver = new AsyncResolver(),\n\t\tlookup = dnsLookup\n\t} = {}) {\n\t\tthis.maxTtl = maxTtl;\n\t\tthis.errorTtl = errorTtl;\n\n\t\tthis._cache = cache;\n\t\tthis._resolver = resolver;\n\t\tthis._dnsLookup = promisify(lookup);\n\n\t\tif (this._resolver instanceof AsyncResolver) {\n\t\t\tthis._resolve4 = this._resolver.resolve4.bind(this._resolver);\n\t\t\tthis._resolve6 = this._resolver.resolve6.bind(this._resolver);\n\t\t} else {\n\t\t\tthis._resolve4 = promisify(this._resolver.resolve4.bind(this._resolver));\n\t\t\tthis._resolve6 = promisify(this._resolver.resolve6.bind(this._resolver));\n\t\t}\n\n\t\tthis._iface = getIfaceInfo();\n\n\t\tthis._pending = {};\n\t\tthis._nextRemovalTime = false;\n\t\tthis._hostnamesToFallback = new Set();\n\n\t\tif (fallbackDuration < 1) {\n\t\t\tthis._fallback = false;\n\t\t} else {\n\t\t\tthis._fallback = true;\n\n\t\t\tconst interval = setInterval(() => {\n\t\t\t\tthis._hostnamesToFallback.clear();\n\t\t\t}, fallbackDuration * 1000);\n\n\t\t\t/* istanbul ignore next: There is no `interval.unref()` when running inside an Electron renderer */\n\t\t\tif (interval.unref) {\n\t\t\t\tinterval.unref();\n\t\t\t}\n\t\t}\n\n\t\tthis.lookup = this.lookup.bind(this);\n\t\tthis.lookupAsync = this.lookupAsync.bind(this);\n\t}\n\n\tset servers(servers) {\n\t\tthis.clear();\n\n\t\tthis._resolver.setServers(servers);\n\t}\n\n\tget servers() {\n\t\treturn this._resolver.getServers();\n\t}\n\n\tlookup(hostname, options, callback) {\n\t\tif (typeof options === 'function') {\n\t\t\tcallback = options;\n\t\t\toptions = {};\n\t\t} else if (typeof options === 'number') {\n\t\t\toptions = {\n\t\t\t\tfamily: options\n\t\t\t};\n\t\t}\n\n\t\tif (!callback) {\n\t\t\tthrow new Error('Callback must be a function.');\n\t\t}\n\n\t\t// eslint-disable-next-line promise/prefer-await-to-then\n\t\tthis.lookupAsync(hostname, options).then(result => {\n\t\t\tif (options.all) {\n\t\t\t\tcallback(null, result);\n\t\t\t} else {\n\t\t\t\tcallback(null, result.address, result.family, result.expires, result.ttl);\n\t\t\t}\n\t\t}, callback);\n\t}\n\n\tasync lookupAsync(hostname, options = {}) {\n\t\tif (typeof options === 'number') {\n\t\t\toptions = {\n\t\t\t\tfamily: options\n\t\t\t};\n\t\t}\n\n\t\tlet cached = await this.query(hostname);\n\n\t\tif (options.family === 6) {\n\t\t\tconst filtered = cached.filter(entry => entry.family === 6);\n\n\t\t\tif (options.hints & V4MAPPED) {\n\t\t\t\tif ((supportsALL && options.hints & ALL) || filtered.length === 0) {\n\t\t\t\t\tmap4to6(cached);\n\t\t\t\t} else {\n\t\t\t\t\tcached = filtered;\n\t\t\t\t}\n\t\t\t} else {\n\t\t\t\tcached = filtered;\n\t\t\t}\n\t\t} else if (options.family === 4) {\n\t\t\tcached = cached.filter(entry => entry.family === 4);\n\t\t}\n\n\t\tif (options.hints & ADDRCONFIG) {\n\t\t\tconst {_iface} = this;\n\t\t\tcached = cached.filter(entry => entry.family === 6 ? _iface.has6 : _iface.has4);\n\t\t}\n\n\t\tif (cached.length === 0) {\n\t\t\tconst error = new Error(`cacheableLookup ENOTFOUND ${hostname}`);\n\t\t\terror.code = 'ENOTFOUND';\n\t\t\terror.hostname = hostname;\n\n\t\t\tthrow error;\n\t\t}\n\n\t\tif (options.all) {\n\t\t\treturn cached;\n\t\t}\n\n\t\treturn cached[0];\n\t}\n\n\tasync query(hostname) {\n\t\tlet cached = await this._cache.get(hostname);\n\n\t\tif (!cached) {\n\t\t\tconst pending = this._pending[hostname];\n\n\t\t\tif (pending) {\n\t\t\t\tcached = await pending;\n\t\t\t} else {\n\t\t\t\tconst newPromise = this.queryAndCache(hostname);\n\t\t\t\tthis._pending[hostname] = newPromise;\n\n\t\t\t\ttry {\n\t\t\t\t\tcached = await newPromise;\n\t\t\t\t} finally {\n\t\t\t\t\tdelete this._pending[hostname];\n\t\t\t\t}\n\t\t\t}\n\t\t}\n\n\t\tcached = cached.map(entry => {\n\t\t\treturn {...entry};\n\t\t});\n\n\t\treturn cached;\n\t}\n\n\tasync _resolve(hostname) {\n\t\tconst wrap = async promise => {\n\t\t\ttry {\n\t\t\t\treturn await promise;\n\t\t\t} catch (error) {\n\t\t\t\tif (error.code === 'ENODATA' || error.code === 'ENOTFOUND') {\n\t\t\t\t\treturn [];\n\t\t\t\t}\n\n\t\t\t\tthrow error;\n\t\t\t}\n\t\t};\n\n\t\t// ANY is unsafe as it doesn't trigger new queries in the underlying server.\n\t\tconst [A, AAAA] = await Promise.all([\n\t\t\tthis._resolve4(hostname, ttl),\n\t\t\tthis._resolve6(hostname, ttl)\n\t\t].map(promise => wrap(promise)));\n\n\t\tlet aTtl = 0;\n\t\tlet aaaaTtl = 0;\n\t\tlet cacheTtl = 0;\n\n\t\tconst now = Date.now();\n\n\t\tfor (const entry of A) {\n\t\t\tentry.family = 4;\n\t\t\tentry.expires = now + (entry.ttl * 1000);\n\n\t\t\taTtl = Math.max(aTtl, entry.ttl);\n\t\t}\n\n\t\tfor (const entry of AAAA) {\n\t\t\tentry.family = 6;\n\t\t\tentry.expires = now + (entry.ttl * 1000);\n\n\t\t\taaaaTtl = Math.max(aaaaTtl, entry.ttl);\n\t\t}\n\n\t\tif (A.length > 0) {\n\t\t\tif (AAAA.length > 0) {\n\t\t\t\tcacheTtl = Math.min(aTtl, aaaaTtl);\n\t\t\t} else {\n\t\t\t\tcacheTtl = aTtl;\n\t\t\t}\n\t\t} else {\n\t\t\tcacheTtl = aaaaTtl;\n\t\t}\n\n\t\treturn {\n\t\t\tentries: [\n\t\t\t\t...A,\n\t\t\t\t...AAAA\n\t\t\t],\n\t\t\tcacheTtl\n\t\t};\n\t}\n\n\tasync _lookup(hostname) {\n\t\ttry {\n\t\t\tconst entries = await this._dnsLookup(hostname, {\n\t\t\t\tall: true\n\t\t\t});\n\n\t\t\treturn {\n\t\t\t\tentries,\n\t\t\t\tcacheTtl: 0\n\t\t\t};\n\t\t} catch (_) {\n\t\t\treturn {\n\t\t\t\tentries: [],\n\t\t\t\tcacheTtl: 0\n\t\t\t};\n\t\t}\n\t}\n\n\tasync _set(hostname, data, cacheTtl) {\n\t\tif (this.maxTtl > 0 && cacheTtl > 0) {\n\t\t\tcacheTtl = Math.min(cacheTtl, this.maxTtl) * 1000;\n\t\t\tdata[kExpires] = Date.now() + cacheTtl;\n\n\t\t\ttry {\n\t\t\t\tawait this._cache.set(hostname, data, cacheTtl);\n\t\t\t} catch (error) {\n\t\t\t\tthis.lookupAsync = async () => {\n\t\t\t\t\tconst cacheError = new Error('Cache Error. Please recreate the CacheableLookup instance.');\n\t\t\t\t\tcacheError.cause = error;\n\n\t\t\t\t\tthrow cacheError;\n\t\t\t\t};\n\t\t\t}\n\n\t\t\tif (isIterable(this._cache)) {\n\t\t\t\tthis._tick(cacheTtl);\n\t\t\t}\n\t\t}\n\t}\n\n\tasync queryAndCache(hostname) {\n\t\tif (this._hostnamesToFallback.has(hostname)) {\n\t\t\treturn this._dnsLookup(hostname, all);\n\t\t}\n\n\t\tlet query = await this._resolve(hostname);\n\n\t\tif (query.entries.length === 0 && this._fallback) {\n\t\t\tquery = await this._lookup(hostname);\n\n\t\t\tif (query.entries.length !== 0) {\n\t\t\t\t// Use `dns.lookup(...)` for that particular hostname\n\t\t\t\tthis._hostnamesToFallback.add(hostname);\n\t\t\t}\n\t\t}\n\n\t\tconst cacheTtl = query.entries.length === 0 ? this.errorTtl : query.cacheTtl;\n\t\tawait this._set(hostname, query.entries, cacheTtl);\n\n\t\treturn query.entries;\n\t}\n\n\t_tick(ms) {\n\t\tconst nextRemovalTime = this._nextRemovalTime;\n\n\t\tif (!nextRemovalTime || ms < nextRemovalTime) {\n\t\t\tclearTimeout(this._removalTimeout);\n\n\t\t\tthis._nextRemovalTime = ms;\n\n\t\t\tthis._removalTimeout = setTimeout(() => {\n\t\t\t\tthis._nextRemovalTime = false;\n\n\t\t\t\tlet nextExpiry = Infinity;\n\n\t\t\t\tconst now = Date.now();\n\n\t\t\t\tfor (const [hostname, entries] of this._cache) {\n\t\t\t\t\tconst expires = entries[kExpires];\n\n\t\t\t\t\tif (now >= expires) {\n\t\t\t\t\t\tthis._cache.delete(hostname);\n\t\t\t\t\t} else if (expires < nextExpiry) {\n\t\t\t\t\t\tnextExpiry = expires;\n\t\t\t\t\t}\n\t\t\t\t}\n\n\t\t\t\tif (nextExpiry !== Infinity) {\n\t\t\t\t\tthis._tick(nextExpiry - now);\n\t\t\t\t}\n\t\t\t}, ms);\n\n\t\t\t/* istanbul ignore next: There is no `timeout.unref()` when running inside an Electron renderer */\n\t\t\tif (this._removalTimeout.unref) {\n\t\t\t\tthis._removalTimeout.unref();\n\t\t\t}\n\t\t}\n\t}\n\n\tinstall(agent) {\n\t\tverifyAgent(agent);\n\n\t\tif (kCacheableLookupCreateConnection in agent) {\n\t\t\tthrow new Error('CacheableLookup has been already installed');\n\t\t}\n\n\t\tagent[kCacheableLookupCreateConnection] = agent.createConnection;\n\t\tagent[kCacheableLookupInstance] = this;\n\n\t\tagent.createConnection = (options, callback) => {\n\t\t\tif (!('lookup' in options)) {\n\t\t\t\toptions.lookup = this.lookup;\n\t\t\t}\n\n\t\t\treturn agent[kCacheableLookupCreateConnection](options, callback);\n\t\t};\n\t}\n\n\tuninstall(agent) {\n\t\tverifyAgent(agent);\n\n\t\tif (agent[kCacheableLookupCreateConnection]) {\n\t\t\tif (agent[kCacheableLookupInstance] !== this) {\n\t\t\t\tthrow new Error('The agent is not owned by this CacheableLookup instance');\n\t\t\t}\n\n\t\t\tagent.createConnection = agent[kCacheableLookupCreateConnection];\n\n\t\t\tdelete agent[kCacheableLookupCreateConnection];\n\t\t\tdelete agent[kCacheableLookupInstance];\n\t\t}\n\t}\n\n\tupdateInterfaceInfo() {\n\t\tconst {_iface} = this;\n\n\t\tthis._iface = getIfaceInfo();\n\n\t\tif ((_iface.has4 && !this._iface.has4) || (_iface.has6 && !this._iface.has6)) {\n\t\t\tthis._cache.clear();\n\t\t}\n\t}\n\n\tclear(hostname) {\n\t\tif (hostname) {\n\t\t\tthis._cache.delete(hostname);\n\t\t\treturn;\n\t\t}\n\n\t\tthis._cache.clear();\n\t}\n}\n\nmodule.exports = CacheableLookup;\nmodule.exports[\"default\"] = CacheableLookup;\n\n\n/***/ }),\n\n/***/ 8116:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\n\"use strict\";\n\n\nconst EventEmitter = __nccwpck_require__(2361);\nconst urlLib = __nccwpck_require__(7310);\nconst normalizeUrl = __nccwpck_require__(7952);\nconst getStream = __nccwpck_require__(1766);\nconst CachePolicy = __nccwpck_require__(1002);\nconst Response = __nccwpck_require__(9004);\nconst lowercaseKeys = __nccwpck_require__(9662);\nconst cloneResponse = __nccwpck_require__(1312);\nconst Keyv = __nccwpck_require__(1531);\n\nclass CacheableRequest {\n\tconstructor(request, cacheAdapter) {\n\t\tif (typeof request !== 'function') {\n\t\t\tthrow new TypeError('Parameter `request` must be a function');\n\t\t}\n\n\t\tthis.cache = new Keyv({\n\t\t\turi: typeof cacheAdapter === 'string' && cacheAdapter,\n\t\t\tstore: typeof cacheAdapter !== 'string' && cacheAdapter,\n\t\t\tnamespace: 'cacheable-request'\n\t\t});\n\n\t\treturn this.createCacheableRequest(request);\n\t}\n\n\tcreateCacheableRequest(request) {\n\t\treturn (opts, cb) => {\n\t\t\tlet url;\n\t\t\tif (typeof opts === 'string') {\n\t\t\t\turl = normalizeUrlObject(urlLib.parse(opts));\n\t\t\t\topts = {};\n\t\t\t} else if (opts instanceof urlLib.URL) {\n\t\t\t\turl = normalizeUrlObject(urlLib.parse(opts.toString()));\n\t\t\t\topts = {};\n\t\t\t} else {\n\t\t\t\tconst [pathname, ...searchParts] = (opts.path || '').split('?');\n\t\t\t\tconst search = searchParts.length > 0 ?\n\t\t\t\t\t`?${searchParts.join('?')}` :\n\t\t\t\t\t'';\n\t\t\t\turl = normalizeUrlObject({ ...opts, pathname, search });\n\t\t\t}\n\n\t\t\topts = {\n\t\t\t\theaders: {},\n\t\t\t\tmethod: 'GET',\n\t\t\t\tcache: true,\n\t\t\t\tstrictTtl: false,\n\t\t\t\tautomaticFailover: false,\n\t\t\t\t...opts,\n\t\t\t\t...urlObjectToRequestOptions(url)\n\t\t\t};\n\t\t\topts.headers = lowercaseKeys(opts.headers);\n\n\t\t\tconst ee = new EventEmitter();\n\t\t\tconst normalizedUrlString = normalizeUrl(\n\t\t\t\turlLib.format(url),\n\t\t\t\t{\n\t\t\t\t\tstripWWW: false,\n\t\t\t\t\tremoveTrailingSlash: false,\n\t\t\t\t\tstripAuthentication: false\n\t\t\t\t}\n\t\t\t);\n\t\t\tconst key = `${opts.method}:${normalizedUrlString}`;\n\t\t\tlet revalidate = false;\n\t\t\tlet madeRequest = false;\n\n\t\t\tconst makeRequest = opts => {\n\t\t\t\tmadeRequest = true;\n\t\t\t\tlet requestErrored = false;\n\t\t\t\tlet requestErrorCallback;\n\n\t\t\t\tconst requestErrorPromise = new Promise(resolve => {\n\t\t\t\t\trequestErrorCallback = () => {\n\t\t\t\t\t\tif (!requestErrored) {\n\t\t\t\t\t\t\trequestErrored = true;\n\t\t\t\t\t\t\tresolve();\n\t\t\t\t\t\t}\n\t\t\t\t\t};\n\t\t\t\t});\n\n\t\t\t\tconst handler = response => {\n\t\t\t\t\tif (revalidate && !opts.forceRefresh) {\n\t\t\t\t\t\tresponse.status = response.statusCode;\n\t\t\t\t\t\tconst revalidatedPolicy = CachePolicy.fromObject(revalidate.cachePolicy).revalidatedPolicy(opts, response);\n\t\t\t\t\t\tif (!revalidatedPolicy.modified) {\n\t\t\t\t\t\t\tconst headers = revalidatedPolicy.policy.responseHeaders();\n\t\t\t\t\t\t\tresponse = new Response(revalidate.statusCode, headers, revalidate.body, revalidate.url);\n\t\t\t\t\t\t\tresponse.cachePolicy = revalidatedPolicy.policy;\n\t\t\t\t\t\t\tresponse.fromCache = true;\n\t\t\t\t\t\t}\n\t\t\t\t\t}\n\n\t\t\t\t\tif (!response.fromCache) {\n\t\t\t\t\t\tresponse.cachePolicy = new CachePolicy(opts, response, opts);\n\t\t\t\t\t\tresponse.fromCache = false;\n\t\t\t\t\t}\n\n\t\t\t\t\tlet clonedResponse;\n\t\t\t\t\tif (opts.cache && response.cachePolicy.storable()) {\n\t\t\t\t\t\tclonedResponse = cloneResponse(response);\n\n\t\t\t\t\t\t(async () => {\n\t\t\t\t\t\t\ttry {\n\t\t\t\t\t\t\t\tconst bodyPromise = getStream.buffer(response);\n\n\t\t\t\t\t\t\t\tawait Promise.race([\n\t\t\t\t\t\t\t\t\trequestErrorPromise,\n\t\t\t\t\t\t\t\t\tnew Promise(resolve => response.once('end', resolve))\n\t\t\t\t\t\t\t\t]);\n\n\t\t\t\t\t\t\t\tif (requestErrored) {\n\t\t\t\t\t\t\t\t\treturn;\n\t\t\t\t\t\t\t\t}\n\n\t\t\t\t\t\t\t\tconst body = await bodyPromise;\n\n\t\t\t\t\t\t\t\tconst value = {\n\t\t\t\t\t\t\t\t\tcachePolicy: response.cachePolicy.toObject(),\n\t\t\t\t\t\t\t\t\turl: response.url,\n\t\t\t\t\t\t\t\t\tstatusCode: response.fromCache ? revalidate.statusCode : response.statusCode,\n\t\t\t\t\t\t\t\t\tbody\n\t\t\t\t\t\t\t\t};\n\n\t\t\t\t\t\t\t\tlet ttl = opts.strictTtl ? response.cachePolicy.timeToLive() : undefined;\n\t\t\t\t\t\t\t\tif (opts.maxTtl) {\n\t\t\t\t\t\t\t\t\tttl = ttl ? Math.min(ttl, opts.maxTtl) : opts.maxTtl;\n\t\t\t\t\t\t\t\t}\n\n\t\t\t\t\t\t\t\tawait this.cache.set(key, value, ttl);\n\t\t\t\t\t\t\t} catch (error) {\n\t\t\t\t\t\t\t\tee.emit('error', new CacheableRequest.CacheError(error));\n\t\t\t\t\t\t\t}\n\t\t\t\t\t\t})();\n\t\t\t\t\t} else if (opts.cache && revalidate) {\n\t\t\t\t\t\t(async () => {\n\t\t\t\t\t\t\ttry {\n\t\t\t\t\t\t\t\tawait this.cache.delete(key);\n\t\t\t\t\t\t\t} catch (error) {\n\t\t\t\t\t\t\t\tee.emit('error', new CacheableRequest.CacheError(error));\n\t\t\t\t\t\t\t}\n\t\t\t\t\t\t})();\n\t\t\t\t\t}\n\n\t\t\t\t\tee.emit('response', clonedResponse || response);\n\t\t\t\t\tif (typeof cb === 'function') {\n\t\t\t\t\t\tcb(clonedResponse || response);\n\t\t\t\t\t}\n\t\t\t\t};\n\n\t\t\t\ttry {\n\t\t\t\t\tconst req = request(opts, handler);\n\t\t\t\t\treq.once('error', requestErrorCallback);\n\t\t\t\t\treq.once('abort', requestErrorCallback);\n\t\t\t\t\tee.emit('request', req);\n\t\t\t\t} catch (error) {\n\t\t\t\t\tee.emit('error', new CacheableRequest.RequestError(error));\n\t\t\t\t}\n\t\t\t};\n\n\t\t\t(async () => {\n\t\t\t\tconst get = async opts => {\n\t\t\t\t\tawait Promise.resolve();\n\n\t\t\t\t\tconst cacheEntry = opts.cache ? await this.cache.get(key) : undefined;\n\t\t\t\t\tif (typeof cacheEntry === 'undefined') {\n\t\t\t\t\t\treturn makeRequest(opts);\n\t\t\t\t\t}\n\n\t\t\t\t\tconst policy = CachePolicy.fromObject(cacheEntry.cachePolicy);\n\t\t\t\t\tif (policy.satisfiesWithoutRevalidation(opts) && !opts.forceRefresh) {\n\t\t\t\t\t\tconst headers = policy.responseHeaders();\n\t\t\t\t\t\tconst response = new Response(cacheEntry.statusCode, headers, cacheEntry.body, cacheEntry.url);\n\t\t\t\t\t\tresponse.cachePolicy = policy;\n\t\t\t\t\t\tresponse.fromCache = true;\n\n\t\t\t\t\t\tee.emit('response', response);\n\t\t\t\t\t\tif (typeof cb === 'function') {\n\t\t\t\t\t\t\tcb(response);\n\t\t\t\t\t\t}\n\t\t\t\t\t} else {\n\t\t\t\t\t\trevalidate = cacheEntry;\n\t\t\t\t\t\topts.headers = policy.revalidationHeaders(opts);\n\t\t\t\t\t\tmakeRequest(opts);\n\t\t\t\t\t}\n\t\t\t\t};\n\n\t\t\t\tconst errorHandler = error => ee.emit('error', new CacheableRequest.CacheError(error));\n\t\t\t\tthis.cache.once('error', errorHandler);\n\t\t\t\tee.on('response', () => this.cache.removeListener('error', errorHandler));\n\n\t\t\t\ttry {\n\t\t\t\t\tawait get(opts);\n\t\t\t\t} catch (error) {\n\t\t\t\t\tif (opts.automaticFailover && !madeRequest) {\n\t\t\t\t\t\tmakeRequest(opts);\n\t\t\t\t\t}\n\n\t\t\t\t\tee.emit('error', new CacheableRequest.CacheError(error));\n\t\t\t\t}\n\t\t\t})();\n\n\t\t\treturn ee;\n\t\t};\n\t}\n}\n\nfunction urlObjectToRequestOptions(url) {\n\tconst options = { ...url };\n\toptions.path = `${url.pathname || '/'}${url.search || ''}`;\n\tdelete options.pathname;\n\tdelete options.search;\n\treturn options;\n}\n\nfunction normalizeUrlObject(url) {\n\t// If url was parsed by url.parse or new URL:\n\t// - hostname will be set\n\t// - host will be hostname[:port]\n\t// - port will be set if it was explicit in the parsed string\n\t// Otherwise, url was from request options:\n\t// - hostname or host may be set\n\t// - host shall not have port encoded\n\treturn {\n\t\tprotocol: url.protocol,\n\t\tauth: url.auth,\n\t\thostname: url.hostname || url.host || 'localhost',\n\t\tport: url.port,\n\t\tpathname: url.pathname,\n\t\tsearch: url.search\n\t};\n}\n\nCacheableRequest.RequestError = class extends Error {\n\tconstructor(error) {\n\t\tsuper(error.message);\n\t\tthis.name = 'RequestError';\n\t\tObject.assign(this, error);\n\t}\n};\n\nCacheableRequest.CacheError = class extends Error {\n\tconstructor(error) {\n\t\tsuper(error.message);\n\t\tthis.name = 'CacheError';\n\t\tObject.assign(this, error);\n\t}\n};\n\nmodule.exports = CacheableRequest;\n\n\n/***/ }),\n\n/***/ 9372:\n/***/ ((module) => {\n\n\"use strict\";\n\n\n// We define these manually to ensure they're always copied\n// even if they would move up the prototype chain\n// https://nodejs.org/api/http.html#http_class_http_incomingmessage\nconst knownProps = [\n\t'destroy',\n\t'setTimeout',\n\t'socket',\n\t'headers',\n\t'trailers',\n\t'rawHeaders',\n\t'statusCode',\n\t'httpVersion',\n\t'httpVersionMinor',\n\t'httpVersionMajor',\n\t'rawTrailers',\n\t'statusMessage'\n];\n\nmodule.exports = (fromStream, toStream) => {\n\tconst fromProps = new Set(Object.keys(fromStream).concat(knownProps));\n\n\tfor (const prop of fromProps) {\n\t\t// Don't overwrite existing properties\n\t\tif (prop in toStream) {\n\t\t\tcontinue;\n\t\t}\n\n\t\ttoStream[prop] = typeof fromStream[prop] === 'function' ? fromStream[prop].bind(fromStream) : fromStream[prop];\n\t}\n};\n\n\n/***/ }),\n\n/***/ 1312:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\n\"use strict\";\n\n\nconst PassThrough = (__nccwpck_require__(2781).PassThrough);\nconst mimicResponse = __nccwpck_require__(9372);\n\nconst cloneResponse = response => {\n\tif (!(response && response.pipe)) {\n\t\tthrow new TypeError('Parameter `response` must be a response stream.');\n\t}\n\n\tconst clone = new PassThrough();\n\tmimicResponse(response, clone);\n\n\treturn response.pipe(clone);\n};\n\nmodule.exports = cloneResponse;\n\n\n/***/ }),\n\n/***/ 2746:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\n\"use strict\";\n\n\nconst cp = __nccwpck_require__(2081);\nconst parse = __nccwpck_require__(6855);\nconst enoent = __nccwpck_require__(4101);\n\nfunction spawn(command, args, options) {\n // Parse the arguments\n const parsed = parse(command, args, options);\n\n // Spawn the child process\n const spawned = cp.spawn(parsed.command, parsed.args, parsed.options);\n\n // Hook into child process \"exit\" event to emit an error if the command\n // does not exists, see: https://github.com/IndigoUnited/node-cross-spawn/issues/16\n enoent.hookChildProcess(spawned, parsed);\n\n return spawned;\n}\n\nfunction spawnSync(command, args, options) {\n // Parse the arguments\n const parsed = parse(command, args, options);\n\n // Spawn the child process\n const result = cp.spawnSync(parsed.command, parsed.args, parsed.options);\n\n // Analyze if the command does not exist, see: https://github.com/IndigoUnited/node-cross-spawn/issues/16\n result.error = result.error || enoent.verifyENOENTSync(result.status, parsed);\n\n return result;\n}\n\nmodule.exports = spawn;\nmodule.exports.spawn = spawn;\nmodule.exports.sync = spawnSync;\n\nmodule.exports._parse = parse;\nmodule.exports._enoent = enoent;\n\n\n/***/ }),\n\n/***/ 4101:\n/***/ ((module) => {\n\n\"use strict\";\n\n\nconst isWin = process.platform === 'win32';\n\nfunction notFoundError(original, syscall) {\n return Object.assign(new Error(`${syscall} ${original.command} ENOENT`), {\n code: 'ENOENT',\n errno: 'ENOENT',\n syscall: `${syscall} ${original.command}`,\n path: original.command,\n spawnargs: original.args,\n });\n}\n\nfunction hookChildProcess(cp, parsed) {\n if (!isWin) {\n return;\n }\n\n const originalEmit = cp.emit;\n\n cp.emit = function (name, arg1) {\n // If emitting \"exit\" event and exit code is 1, we need to check if\n // the command exists and emit an \"error\" instead\n // See https://github.com/IndigoUnited/node-cross-spawn/issues/16\n if (name === 'exit') {\n const err = verifyENOENT(arg1, parsed, 'spawn');\n\n if (err) {\n return originalEmit.call(cp, 'error', err);\n }\n }\n\n return originalEmit.apply(cp, arguments); // eslint-disable-line prefer-rest-params\n };\n}\n\nfunction verifyENOENT(status, parsed) {\n if (isWin && status === 1 && !parsed.file) {\n return notFoundError(parsed.original, 'spawn');\n }\n\n return null;\n}\n\nfunction verifyENOENTSync(status, parsed) {\n if (isWin && status === 1 && !parsed.file) {\n return notFoundError(parsed.original, 'spawnSync');\n }\n\n return null;\n}\n\nmodule.exports = {\n hookChildProcess,\n verifyENOENT,\n verifyENOENTSync,\n notFoundError,\n};\n\n\n/***/ }),\n\n/***/ 6855:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\n\"use strict\";\n\n\nconst path = __nccwpck_require__(1017);\nconst niceTry = __nccwpck_require__(8560);\nconst resolveCommand = __nccwpck_require__(7274);\nconst escape = __nccwpck_require__(4274);\nconst readShebang = __nccwpck_require__(1252);\nconst semver = __nccwpck_require__(1129);\n\nconst isWin = process.platform === 'win32';\nconst isExecutableRegExp = /\\.(?:com|exe)$/i;\nconst isCmdShimRegExp = /node_modules[\\\\/].bin[\\\\/][^\\\\/]+\\.cmd$/i;\n\n// `options.shell` is supported in Node ^4.8.0, ^5.7.0 and >= 6.0.0\nconst supportsShellOption = niceTry(() => semver.satisfies(process.version, '^4.8.0 || ^5.7.0 || >= 6.0.0', true)) || false;\n\nfunction detectShebang(parsed) {\n parsed.file = resolveCommand(parsed);\n\n const shebang = parsed.file && readShebang(parsed.file);\n\n if (shebang) {\n parsed.args.unshift(parsed.file);\n parsed.command = shebang;\n\n return resolveCommand(parsed);\n }\n\n return parsed.file;\n}\n\nfunction parseNonShell(parsed) {\n if (!isWin) {\n return parsed;\n }\n\n // Detect & add support for shebangs\n const commandFile = detectShebang(parsed);\n\n // We don't need a shell if the command filename is an executable\n const needsShell = !isExecutableRegExp.test(commandFile);\n\n // If a shell is required, use cmd.exe and take care of escaping everything correctly\n // Note that `forceShell` is an hidden option used only in tests\n if (parsed.options.forceShell || needsShell) {\n // Need to double escape meta chars if the command is a cmd-shim located in `node_modules/.bin/`\n // The cmd-shim simply calls execute the package bin file with NodeJS, proxying any argument\n // Because the escape of metachars with ^ gets interpreted when the cmd.exe is first called,\n // we need to double escape them\n const needsDoubleEscapeMetaChars = isCmdShimRegExp.test(commandFile);\n\n // Normalize posix paths into OS compatible paths (e.g.: foo/bar -> foo\\bar)\n // This is necessary otherwise it will always fail with ENOENT in those cases\n parsed.command = path.normalize(parsed.command);\n\n // Escape command & arguments\n parsed.command = escape.command(parsed.command);\n parsed.args = parsed.args.map((arg) => escape.argument(arg, needsDoubleEscapeMetaChars));\n\n const shellCommand = [parsed.command].concat(parsed.args).join(' ');\n\n parsed.args = ['/d', '/s', '/c', `\"${shellCommand}\"`];\n parsed.command = process.env.comspec || 'cmd.exe';\n parsed.options.windowsVerbatimArguments = true; // Tell node's spawn that the arguments are already escaped\n }\n\n return parsed;\n}\n\nfunction parseShell(parsed) {\n // If node supports the shell option, there's no need to mimic its behavior\n if (supportsShellOption) {\n return parsed;\n }\n\n // Mimic node shell option\n // See https://github.com/nodejs/node/blob/b9f6a2dc059a1062776133f3d4fd848c4da7d150/lib/child_process.js#L335\n const shellCommand = [parsed.command].concat(parsed.args).join(' ');\n\n if (isWin) {\n parsed.command = typeof parsed.options.shell === 'string' ? parsed.options.shell : process.env.comspec || 'cmd.exe';\n parsed.args = ['/d', '/s', '/c', `\"${shellCommand}\"`];\n parsed.options.windowsVerbatimArguments = true; // Tell node's spawn that the arguments are already escaped\n } else {\n if (typeof parsed.options.shell === 'string') {\n parsed.command = parsed.options.shell;\n } else if (process.platform === 'android') {\n parsed.command = '/system/bin/sh';\n } else {\n parsed.command = '/bin/sh';\n }\n\n parsed.args = ['-c', shellCommand];\n }\n\n return parsed;\n}\n\nfunction parse(command, args, options) {\n // Normalize arguments, similar to nodejs\n if (args && !Array.isArray(args)) {\n options = args;\n args = null;\n }\n\n args = args ? args.slice(0) : []; // Clone array to avoid changing the original\n options = Object.assign({}, options); // Clone object to avoid changing the original\n\n // Build our parsed object\n const parsed = {\n command,\n args,\n options,\n file: undefined,\n original: {\n command,\n args,\n },\n };\n\n // Delegate further parsing to shell or non-shell\n return options.shell ? parseShell(parsed) : parseNonShell(parsed);\n}\n\nmodule.exports = parse;\n\n\n/***/ }),\n\n/***/ 4274:\n/***/ ((module) => {\n\n\"use strict\";\n\n\n// See http://www.robvanderwoude.com/escapechars.php\nconst metaCharsRegExp = /([()\\][%!^\"`<>&|;, *?])/g;\n\nfunction escapeCommand(arg) {\n // Escape meta chars\n arg = arg.replace(metaCharsRegExp, '^$1');\n\n return arg;\n}\n\nfunction escapeArgument(arg, doubleEscapeMetaChars) {\n // Convert to string\n arg = `${arg}`;\n\n // Algorithm below is based on https://qntm.org/cmd\n\n // Sequence of backslashes followed by a double quote:\n // double up all the backslashes and escape the double quote\n arg = arg.replace(/(\\\\*)\"/g, '$1$1\\\\\"');\n\n // Sequence of backslashes followed by the end of the string\n // (which will become a double quote later):\n // double up all the backslashes\n arg = arg.replace(/(\\\\*)$/, '$1$1');\n\n // All other backslashes occur literally\n\n // Quote the whole thing:\n arg = `\"${arg}\"`;\n\n // Escape meta chars\n arg = arg.replace(metaCharsRegExp, '^$1');\n\n // Double escape meta chars if necessary\n if (doubleEscapeMetaChars) {\n arg = arg.replace(metaCharsRegExp, '^$1');\n }\n\n return arg;\n}\n\nmodule.exports.command = escapeCommand;\nmodule.exports.argument = escapeArgument;\n\n\n/***/ }),\n\n/***/ 1252:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\n\"use strict\";\n\n\nconst fs = __nccwpck_require__(7147);\nconst shebangCommand = __nccwpck_require__(7032);\n\nfunction readShebang(command) {\n // Read the first 150 bytes from the file\n const size = 150;\n let buffer;\n\n if (Buffer.alloc) {\n // Node.js v4.5+ / v5.10+\n buffer = Buffer.alloc(size);\n } else {\n // Old Node.js API\n buffer = new Buffer(size);\n buffer.fill(0); // zero-fill\n }\n\n let fd;\n\n try {\n fd = fs.openSync(command, 'r');\n fs.readSync(fd, buffer, 0, size, 0);\n fs.closeSync(fd);\n } catch (e) { /* Empty */ }\n\n // Attempt to extract shebang (null is returned if not a shebang)\n return shebangCommand(buffer.toString());\n}\n\nmodule.exports = readShebang;\n\n\n/***/ }),\n\n/***/ 7274:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\n\"use strict\";\n\n\nconst path = __nccwpck_require__(1017);\nconst which = __nccwpck_require__(9383);\nconst pathKey = __nccwpck_require__(539)();\n\nfunction resolveCommandAttempt(parsed, withoutPathExt) {\n const cwd = process.cwd();\n const hasCustomCwd = parsed.options.cwd != null;\n\n // If a custom `cwd` was specified, we need to change the process cwd\n // because `which` will do stat calls but does not support a custom cwd\n if (hasCustomCwd) {\n try {\n process.chdir(parsed.options.cwd);\n } catch (err) {\n /* Empty */\n }\n }\n\n let resolved;\n\n try {\n resolved = which.sync(parsed.command, {\n path: (parsed.options.env || process.env)[pathKey],\n pathExt: withoutPathExt ? path.delimiter : undefined,\n });\n } catch (e) {\n /* Empty */\n } finally {\n process.chdir(cwd);\n }\n\n // If we successfully resolved, ensure that an absolute path is returned\n // Note that when a custom `cwd` was used, we need to resolve to an absolute path based on it\n if (resolved) {\n resolved = path.resolve(hasCustomCwd ? parsed.options.cwd : '', resolved);\n }\n\n return resolved;\n}\n\nfunction resolveCommand(parsed) {\n return resolveCommandAttempt(parsed) || resolveCommandAttempt(parsed, true);\n}\n\nmodule.exports = resolveCommand;\n\n\n/***/ }),\n\n/***/ 1129:\n/***/ ((module, exports) => {\n\nexports = module.exports = SemVer\n\nvar debug\n/* istanbul ignore next */\nif (typeof process === 'object' &&\n process.env &&\n process.env.NODE_DEBUG &&\n /\\bsemver\\b/i.test(process.env.NODE_DEBUG)) {\n debug = function () {\n var args = Array.prototype.slice.call(arguments, 0)\n args.unshift('SEMVER')\n console.log.apply(console, args)\n }\n} else {\n debug = function () {}\n}\n\n// Note: this is the semver.org version of the spec that it implements\n// Not necessarily the package version of this code.\nexports.SEMVER_SPEC_VERSION = '2.0.0'\n\nvar MAX_LENGTH = 256\nvar MAX_SAFE_INTEGER = Number.MAX_SAFE_INTEGER ||\n /* istanbul ignore next */ 9007199254740991\n\n// Max safe segment length for coercion.\nvar MAX_SAFE_COMPONENT_LENGTH = 16\n\nvar MAX_SAFE_BUILD_LENGTH = MAX_LENGTH - 6\n\n// The actual regexps go on exports.re\nvar re = exports.re = []\nvar safeRe = exports.safeRe = []\nvar src = exports.src = []\nvar R = 0\n\nvar LETTERDASHNUMBER = '[a-zA-Z0-9-]'\n\n// Replace some greedy regex tokens to prevent regex dos issues. These regex are\n// used internally via the safeRe object since all inputs in this library get\n// normalized first to trim and collapse all extra whitespace. The original\n// regexes are exported for userland consumption and lower level usage. A\n// future breaking change could export the safer regex only with a note that\n// all input should have extra whitespace removed.\nvar safeRegexReplacements = [\n ['\\\\s', 1],\n ['\\\\d', MAX_LENGTH],\n [LETTERDASHNUMBER, MAX_SAFE_BUILD_LENGTH],\n]\n\nfunction makeSafeRe (value) {\n for (var i = 0; i < safeRegexReplacements.length; i++) {\n var token = safeRegexReplacements[i][0]\n var max = safeRegexReplacements[i][1]\n value = value\n .split(token + '*').join(token + '{0,' + max + '}')\n .split(token + '+').join(token + '{1,' + max + '}')\n }\n return value\n}\n\n// The following Regular Expressions can be used for tokenizing,\n// validating, and parsing SemVer version strings.\n\n// ## Numeric Identifier\n// A single `0`, or a non-zero digit followed by zero or more digits.\n\nvar NUMERICIDENTIFIER = R++\nsrc[NUMERICIDENTIFIER] = '0|[1-9]\\\\d*'\nvar NUMERICIDENTIFIERLOOSE = R++\nsrc[NUMERICIDENTIFIERLOOSE] = '\\\\d+'\n\n// ## Non-numeric Identifier\n// Zero or more digits, followed by a letter or hyphen, and then zero or\n// more letters, digits, or hyphens.\n\nvar NONNUMERICIDENTIFIER = R++\nsrc[NONNUMERICIDENTIFIER] = '\\\\d*[a-zA-Z-]' + LETTERDASHNUMBER + '*'\n\n// ## Main Version\n// Three dot-separated numeric identifiers.\n\nvar MAINVERSION = R++\nsrc[MAINVERSION] = '(' + src[NUMERICIDENTIFIER] + ')\\\\.' +\n '(' + src[NUMERICIDENTIFIER] + ')\\\\.' +\n '(' + src[NUMERICIDENTIFIER] + ')'\n\nvar MAINVERSIONLOOSE = R++\nsrc[MAINVERSIONLOOSE] = '(' + src[NUMERICIDENTIFIERLOOSE] + ')\\\\.' +\n '(' + src[NUMERICIDENTIFIERLOOSE] + ')\\\\.' +\n '(' + src[NUMERICIDENTIFIERLOOSE] + ')'\n\n// ## Pre-release Version Identifier\n// A numeric identifier, or a non-numeric identifier.\n\nvar PRERELEASEIDENTIFIER = R++\nsrc[PRERELEASEIDENTIFIER] = '(?:' + src[NUMERICIDENTIFIER] +\n '|' + src[NONNUMERICIDENTIFIER] + ')'\n\nvar PRERELEASEIDENTIFIERLOOSE = R++\nsrc[PRERELEASEIDENTIFIERLOOSE] = '(?:' + src[NUMERICIDENTIFIERLOOSE] +\n '|' + src[NONNUMERICIDENTIFIER] + ')'\n\n// ## Pre-release Version\n// Hyphen, followed by one or more dot-separated pre-release version\n// identifiers.\n\nvar PRERELEASE = R++\nsrc[PRERELEASE] = '(?:-(' + src[PRERELEASEIDENTIFIER] +\n '(?:\\\\.' + src[PRERELEASEIDENTIFIER] + ')*))'\n\nvar PRERELEASELOOSE = R++\nsrc[PRERELEASELOOSE] = '(?:-?(' + src[PRERELEASEIDENTIFIERLOOSE] +\n '(?:\\\\.' + src[PRERELEASEIDENTIFIERLOOSE] + ')*))'\n\n// ## Build Metadata Identifier\n// Any combination of digits, letters, or hyphens.\n\nvar BUILDIDENTIFIER = R++\nsrc[BUILDIDENTIFIER] = LETTERDASHNUMBER + '+'\n\n// ## Build Metadata\n// Plus sign, followed by one or more period-separated build metadata\n// identifiers.\n\nvar BUILD = R++\nsrc[BUILD] = '(?:\\\\+(' + src[BUILDIDENTIFIER] +\n '(?:\\\\.' + src[BUILDIDENTIFIER] + ')*))'\n\n// ## Full Version String\n// A main version, followed optionally by a pre-release version and\n// build metadata.\n\n// Note that the only major, minor, patch, and pre-release sections of\n// the version string are capturing groups. The build metadata is not a\n// capturing group, because it should not ever be used in version\n// comparison.\n\nvar FULL = R++\nvar FULLPLAIN = 'v?' + src[MAINVERSION] +\n src[PRERELEASE] + '?' +\n src[BUILD] + '?'\n\nsrc[FULL] = '^' + FULLPLAIN + '$'\n\n// like full, but allows v1.2.3 and =1.2.3, which people do sometimes.\n// also, 1.0.0alpha1 (prerelease without the hyphen) which is pretty\n// common in the npm registry.\nvar LOOSEPLAIN = '[v=\\\\s]*' + src[MAINVERSIONLOOSE] +\n src[PRERELEASELOOSE] + '?' +\n src[BUILD] + '?'\n\nvar LOOSE = R++\nsrc[LOOSE] = '^' + LOOSEPLAIN + '$'\n\nvar GTLT = R++\nsrc[GTLT] = '((?:<|>)?=?)'\n\n// Something like \"2.*\" or \"1.2.x\".\n// Note that \"x.x\" is a valid xRange identifer, meaning \"any version\"\n// Only the first item is strictly required.\nvar XRANGEIDENTIFIERLOOSE = R++\nsrc[XRANGEIDENTIFIERLOOSE] = src[NUMERICIDENTIFIERLOOSE] + '|x|X|\\\\*'\nvar XRANGEIDENTIFIER = R++\nsrc[XRANGEIDENTIFIER] = src[NUMERICIDENTIFIER] + '|x|X|\\\\*'\n\nvar XRANGEPLAIN = R++\nsrc[XRANGEPLAIN] = '[v=\\\\s]*(' + src[XRANGEIDENTIFIER] + ')' +\n '(?:\\\\.(' + src[XRANGEIDENTIFIER] + ')' +\n '(?:\\\\.(' + src[XRANGEIDENTIFIER] + ')' +\n '(?:' + src[PRERELEASE] + ')?' +\n src[BUILD] + '?' +\n ')?)?'\n\nvar XRANGEPLAINLOOSE = R++\nsrc[XRANGEPLAINLOOSE] = '[v=\\\\s]*(' + src[XRANGEIDENTIFIERLOOSE] + ')' +\n '(?:\\\\.(' + src[XRANGEIDENTIFIERLOOSE] + ')' +\n '(?:\\\\.(' + src[XRANGEIDENTIFIERLOOSE] + ')' +\n '(?:' + src[PRERELEASELOOSE] + ')?' +\n src[BUILD] + '?' +\n ')?)?'\n\nvar XRANGE = R++\nsrc[XRANGE] = '^' + src[GTLT] + '\\\\s*' + src[XRANGEPLAIN] + '$'\nvar XRANGELOOSE = R++\nsrc[XRANGELOOSE] = '^' + src[GTLT] + '\\\\s*' + src[XRANGEPLAINLOOSE] + '$'\n\n// Coercion.\n// Extract anything that could conceivably be a part of a valid semver\nvar COERCE = R++\nsrc[COERCE] = '(?:^|[^\\\\d])' +\n '(\\\\d{1,' + MAX_SAFE_COMPONENT_LENGTH + '})' +\n '(?:\\\\.(\\\\d{1,' + MAX_SAFE_COMPONENT_LENGTH + '}))?' +\n '(?:\\\\.(\\\\d{1,' + MAX_SAFE_COMPONENT_LENGTH + '}))?' +\n '(?:$|[^\\\\d])'\n\n// Tilde ranges.\n// Meaning is \"reasonably at or greater than\"\nvar LONETILDE = R++\nsrc[LONETILDE] = '(?:~>?)'\n\nvar TILDETRIM = R++\nsrc[TILDETRIM] = '(\\\\s*)' + src[LONETILDE] + '\\\\s+'\nre[TILDETRIM] = new RegExp(src[TILDETRIM], 'g')\nsafeRe[TILDETRIM] = new RegExp(makeSafeRe(src[TILDETRIM]), 'g')\nvar tildeTrimReplace = '$1~'\n\nvar TILDE = R++\nsrc[TILDE] = '^' + src[LONETILDE] + src[XRANGEPLAIN] + '$'\nvar TILDELOOSE = R++\nsrc[TILDELOOSE] = '^' + src[LONETILDE] + src[XRANGEPLAINLOOSE] + '$'\n\n// Caret ranges.\n// Meaning is \"at least and backwards compatible with\"\nvar LONECARET = R++\nsrc[LONECARET] = '(?:\\\\^)'\n\nvar CARETTRIM = R++\nsrc[CARETTRIM] = '(\\\\s*)' + src[LONECARET] + '\\\\s+'\nre[CARETTRIM] = new RegExp(src[CARETTRIM], 'g')\nsafeRe[CARETTRIM] = new RegExp(makeSafeRe(src[CARETTRIM]), 'g')\nvar caretTrimReplace = '$1^'\n\nvar CARET = R++\nsrc[CARET] = '^' + src[LONECARET] + src[XRANGEPLAIN] + '$'\nvar CARETLOOSE = R++\nsrc[CARETLOOSE] = '^' + src[LONECARET] + src[XRANGEPLAINLOOSE] + '$'\n\n// A simple gt/lt/eq thing, or just \"\" to indicate \"any version\"\nvar COMPARATORLOOSE = R++\nsrc[COMPARATORLOOSE] = '^' + src[GTLT] + '\\\\s*(' + LOOSEPLAIN + ')$|^$'\nvar COMPARATOR = R++\nsrc[COMPARATOR] = '^' + src[GTLT] + '\\\\s*(' + FULLPLAIN + ')$|^$'\n\n// An expression to strip any whitespace between the gtlt and the thing\n// it modifies, so that `> 1.2.3` ==> `>1.2.3`\nvar COMPARATORTRIM = R++\nsrc[COMPARATORTRIM] = '(\\\\s*)' + src[GTLT] +\n '\\\\s*(' + LOOSEPLAIN + '|' + src[XRANGEPLAIN] + ')'\n\n// this one has to use the /g flag\nre[COMPARATORTRIM] = new RegExp(src[COMPARATORTRIM], 'g')\nsafeRe[COMPARATORTRIM] = new RegExp(makeSafeRe(src[COMPARATORTRIM]), 'g')\nvar comparatorTrimReplace = '$1$2$3'\n\n// Something like `1.2.3 - 1.2.4`\n// Note that these all use the loose form, because they'll be\n// checked against either the strict or loose comparator form\n// later.\nvar HYPHENRANGE = R++\nsrc[HYPHENRANGE] = '^\\\\s*(' + src[XRANGEPLAIN] + ')' +\n '\\\\s+-\\\\s+' +\n '(' + src[XRANGEPLAIN] + ')' +\n '\\\\s*$'\n\nvar HYPHENRANGELOOSE = R++\nsrc[HYPHENRANGELOOSE] = '^\\\\s*(' + src[XRANGEPLAINLOOSE] + ')' +\n '\\\\s+-\\\\s+' +\n '(' + src[XRANGEPLAINLOOSE] + ')' +\n '\\\\s*$'\n\n// Star ranges basically just allow anything at all.\nvar STAR = R++\nsrc[STAR] = '(<|>)?=?\\\\s*\\\\*'\n\n// Compile to actual regexp objects.\n// All are flag-free, unless they were created above with a flag.\nfor (var i = 0; i < R; i++) {\n debug(i, src[i])\n if (!re[i]) {\n re[i] = new RegExp(src[i])\n\n // Replace all greedy whitespace to prevent regex dos issues. These regex are\n // used internally via the safeRe object since all inputs in this library get\n // normalized first to trim and collapse all extra whitespace. The original\n // regexes are exported for userland consumption and lower level usage. A\n // future breaking change could export the safer regex only with a note that\n // all input should have extra whitespace removed.\n safeRe[i] = new RegExp(makeSafeRe(src[i]))\n }\n}\n\nexports.parse = parse\nfunction parse (version, options) {\n if (!options || typeof options !== 'object') {\n options = {\n loose: !!options,\n includePrerelease: false\n }\n }\n\n if (version instanceof SemVer) {\n return version\n }\n\n if (typeof version !== 'string') {\n return null\n }\n\n if (version.length > MAX_LENGTH) {\n return null\n }\n\n var r = options.loose ? safeRe[LOOSE] : safeRe[FULL]\n if (!r.test(version)) {\n return null\n }\n\n try {\n return new SemVer(version, options)\n } catch (er) {\n return null\n }\n}\n\nexports.valid = valid\nfunction valid (version, options) {\n var v = parse(version, options)\n return v ? v.version : null\n}\n\nexports.clean = clean\nfunction clean (version, options) {\n var s = parse(version.trim().replace(/^[=v]+/, ''), options)\n return s ? s.version : null\n}\n\nexports.SemVer = SemVer\n\nfunction SemVer (version, options) {\n if (!options || typeof options !== 'object') {\n options = {\n loose: !!options,\n includePrerelease: false\n }\n }\n if (version instanceof SemVer) {\n if (version.loose === options.loose) {\n return version\n } else {\n version = version.version\n }\n } else if (typeof version !== 'string') {\n throw new TypeError('Invalid Version: ' + version)\n }\n\n if (version.length > MAX_LENGTH) {\n throw new TypeError('version is longer than ' + MAX_LENGTH + ' characters')\n }\n\n if (!(this instanceof SemVer)) {\n return new SemVer(version, options)\n }\n\n debug('SemVer', version, options)\n this.options = options\n this.loose = !!options.loose\n\n var m = version.trim().match(options.loose ? safeRe[LOOSE] : safeRe[FULL])\n\n if (!m) {\n throw new TypeError('Invalid Version: ' + version)\n }\n\n this.raw = version\n\n // these are actually numbers\n this.major = +m[1]\n this.minor = +m[2]\n this.patch = +m[3]\n\n if (this.major > MAX_SAFE_INTEGER || this.major < 0) {\n throw new TypeError('Invalid major version')\n }\n\n if (this.minor > MAX_SAFE_INTEGER || this.minor < 0) {\n throw new TypeError('Invalid minor version')\n }\n\n if (this.patch > MAX_SAFE_INTEGER || this.patch < 0) {\n throw new TypeError('Invalid patch version')\n }\n\n // numberify any prerelease numeric ids\n if (!m[4]) {\n this.prerelease = []\n } else {\n this.prerelease = m[4].split('.').map(function (id) {\n if (/^[0-9]+$/.test(id)) {\n var num = +id\n if (num >= 0 && num < MAX_SAFE_INTEGER) {\n return num\n }\n }\n return id\n })\n }\n\n this.build = m[5] ? m[5].split('.') : []\n this.format()\n}\n\nSemVer.prototype.format = function () {\n this.version = this.major + '.' + this.minor + '.' + this.patch\n if (this.prerelease.length) {\n this.version += '-' + this.prerelease.join('.')\n }\n return this.version\n}\n\nSemVer.prototype.toString = function () {\n return this.version\n}\n\nSemVer.prototype.compare = function (other) {\n debug('SemVer.compare', this.version, this.options, other)\n if (!(other instanceof SemVer)) {\n other = new SemVer(other, this.options)\n }\n\n return this.compareMain(other) || this.comparePre(other)\n}\n\nSemVer.prototype.compareMain = function (other) {\n if (!(other instanceof SemVer)) {\n other = new SemVer(other, this.options)\n }\n\n return compareIdentifiers(this.major, other.major) ||\n compareIdentifiers(this.minor, other.minor) ||\n compareIdentifiers(this.patch, other.patch)\n}\n\nSemVer.prototype.comparePre = function (other) {\n if (!(other instanceof SemVer)) {\n other = new SemVer(other, this.options)\n }\n\n // NOT having a prerelease is > having one\n if (this.prerelease.length && !other.prerelease.length) {\n return -1\n } else if (!this.prerelease.length && other.prerelease.length) {\n return 1\n } else if (!this.prerelease.length && !other.prerelease.length) {\n return 0\n }\n\n var i = 0\n do {\n var a = this.prerelease[i]\n var b = other.prerelease[i]\n debug('prerelease compare', i, a, b)\n if (a === undefined && b === undefined) {\n return 0\n } else if (b === undefined) {\n return 1\n } else if (a === undefined) {\n return -1\n } else if (a === b) {\n continue\n } else {\n return compareIdentifiers(a, b)\n }\n } while (++i)\n}\n\n// preminor will bump the version up to the next minor release, and immediately\n// down to pre-release. premajor and prepatch work the same way.\nSemVer.prototype.inc = function (release, identifier) {\n switch (release) {\n case 'premajor':\n this.prerelease.length = 0\n this.patch = 0\n this.minor = 0\n this.major++\n this.inc('pre', identifier)\n break\n case 'preminor':\n this.prerelease.length = 0\n this.patch = 0\n this.minor++\n this.inc('pre', identifier)\n break\n case 'prepatch':\n // If this is already a prerelease, it will bump to the next version\n // drop any prereleases that might already exist, since they are not\n // relevant at this point.\n this.prerelease.length = 0\n this.inc('patch', identifier)\n this.inc('pre', identifier)\n break\n // If the input is a non-prerelease version, this acts the same as\n // prepatch.\n case 'prerelease':\n if (this.prerelease.length === 0) {\n this.inc('patch', identifier)\n }\n this.inc('pre', identifier)\n break\n\n case 'major':\n // If this is a pre-major version, bump up to the same major version.\n // Otherwise increment major.\n // 1.0.0-5 bumps to 1.0.0\n // 1.1.0 bumps to 2.0.0\n if (this.minor !== 0 ||\n this.patch !== 0 ||\n this.prerelease.length === 0) {\n this.major++\n }\n this.minor = 0\n this.patch = 0\n this.prerelease = []\n break\n case 'minor':\n // If this is a pre-minor version, bump up to the same minor version.\n // Otherwise increment minor.\n // 1.2.0-5 bumps to 1.2.0\n // 1.2.1 bumps to 1.3.0\n if (this.patch !== 0 || this.prerelease.length === 0) {\n this.minor++\n }\n this.patch = 0\n this.prerelease = []\n break\n case 'patch':\n // If this is not a pre-release version, it will increment the patch.\n // If it is a pre-release it will bump up to the same patch version.\n // 1.2.0-5 patches to 1.2.0\n // 1.2.0 patches to 1.2.1\n if (this.prerelease.length === 0) {\n this.patch++\n }\n this.prerelease = []\n break\n // This probably shouldn't be used publicly.\n // 1.0.0 \"pre\" would become 1.0.0-0 which is the wrong direction.\n case 'pre':\n if (this.prerelease.length === 0) {\n this.prerelease = [0]\n } else {\n var i = this.prerelease.length\n while (--i >= 0) {\n if (typeof this.prerelease[i] === 'number') {\n this.prerelease[i]++\n i = -2\n }\n }\n if (i === -1) {\n // didn't increment anything\n this.prerelease.push(0)\n }\n }\n if (identifier) {\n // 1.2.0-beta.1 bumps to 1.2.0-beta.2,\n // 1.2.0-beta.fooblz or 1.2.0-beta bumps to 1.2.0-beta.0\n if (this.prerelease[0] === identifier) {\n if (isNaN(this.prerelease[1])) {\n this.prerelease = [identifier, 0]\n }\n } else {\n this.prerelease = [identifier, 0]\n }\n }\n break\n\n default:\n throw new Error('invalid increment argument: ' + release)\n }\n this.format()\n this.raw = this.version\n return this\n}\n\nexports.inc = inc\nfunction inc (version, release, loose, identifier) {\n if (typeof (loose) === 'string') {\n identifier = loose\n loose = undefined\n }\n\n try {\n return new SemVer(version, loose).inc(release, identifier).version\n } catch (er) {\n return null\n }\n}\n\nexports.diff = diff\nfunction diff (version1, version2) {\n if (eq(version1, version2)) {\n return null\n } else {\n var v1 = parse(version1)\n var v2 = parse(version2)\n var prefix = ''\n if (v1.prerelease.length || v2.prerelease.length) {\n prefix = 'pre'\n var defaultResult = 'prerelease'\n }\n for (var key in v1) {\n if (key === 'major' || key === 'minor' || key === 'patch') {\n if (v1[key] !== v2[key]) {\n return prefix + key\n }\n }\n }\n return defaultResult // may be undefined\n }\n}\n\nexports.compareIdentifiers = compareIdentifiers\n\nvar numeric = /^[0-9]+$/\nfunction compareIdentifiers (a, b) {\n var anum = numeric.test(a)\n var bnum = numeric.test(b)\n\n if (anum && bnum) {\n a = +a\n b = +b\n }\n\n return a === b ? 0\n : (anum && !bnum) ? -1\n : (bnum && !anum) ? 1\n : a < b ? -1\n : 1\n}\n\nexports.rcompareIdentifiers = rcompareIdentifiers\nfunction rcompareIdentifiers (a, b) {\n return compareIdentifiers(b, a)\n}\n\nexports.major = major\nfunction major (a, loose) {\n return new SemVer(a, loose).major\n}\n\nexports.minor = minor\nfunction minor (a, loose) {\n return new SemVer(a, loose).minor\n}\n\nexports.patch = patch\nfunction patch (a, loose) {\n return new SemVer(a, loose).patch\n}\n\nexports.compare = compare\nfunction compare (a, b, loose) {\n return new SemVer(a, loose).compare(new SemVer(b, loose))\n}\n\nexports.compareLoose = compareLoose\nfunction compareLoose (a, b) {\n return compare(a, b, true)\n}\n\nexports.rcompare = rcompare\nfunction rcompare (a, b, loose) {\n return compare(b, a, loose)\n}\n\nexports.sort = sort\nfunction sort (list, loose) {\n return list.sort(function (a, b) {\n return exports.compare(a, b, loose)\n })\n}\n\nexports.rsort = rsort\nfunction rsort (list, loose) {\n return list.sort(function (a, b) {\n return exports.rcompare(a, b, loose)\n })\n}\n\nexports.gt = gt\nfunction gt (a, b, loose) {\n return compare(a, b, loose) > 0\n}\n\nexports.lt = lt\nfunction lt (a, b, loose) {\n return compare(a, b, loose) < 0\n}\n\nexports.eq = eq\nfunction eq (a, b, loose) {\n return compare(a, b, loose) === 0\n}\n\nexports.neq = neq\nfunction neq (a, b, loose) {\n return compare(a, b, loose) !== 0\n}\n\nexports.gte = gte\nfunction gte (a, b, loose) {\n return compare(a, b, loose) >= 0\n}\n\nexports.lte = lte\nfunction lte (a, b, loose) {\n return compare(a, b, loose) <= 0\n}\n\nexports.cmp = cmp\nfunction cmp (a, op, b, loose) {\n switch (op) {\n case '===':\n if (typeof a === 'object')\n a = a.version\n if (typeof b === 'object')\n b = b.version\n return a === b\n\n case '!==':\n if (typeof a === 'object')\n a = a.version\n if (typeof b === 'object')\n b = b.version\n return a !== b\n\n case '':\n case '=':\n case '==':\n return eq(a, b, loose)\n\n case '!=':\n return neq(a, b, loose)\n\n case '>':\n return gt(a, b, loose)\n\n case '>=':\n return gte(a, b, loose)\n\n case '<':\n return lt(a, b, loose)\n\n case '<=':\n return lte(a, b, loose)\n\n default:\n throw new TypeError('Invalid operator: ' + op)\n }\n}\n\nexports.Comparator = Comparator\nfunction Comparator (comp, options) {\n if (!options || typeof options !== 'object') {\n options = {\n loose: !!options,\n includePrerelease: false\n }\n }\n\n if (comp instanceof Comparator) {\n if (comp.loose === !!options.loose) {\n return comp\n } else {\n comp = comp.value\n }\n }\n\n if (!(this instanceof Comparator)) {\n return new Comparator(comp, options)\n }\n\n comp = comp.trim().split(/\\s+/).join(' ')\n debug('comparator', comp, options)\n this.options = options\n this.loose = !!options.loose\n this.parse(comp)\n\n if (this.semver === ANY) {\n this.value = ''\n } else {\n this.value = this.operator + this.semver.version\n }\n\n debug('comp', this)\n}\n\nvar ANY = {}\nComparator.prototype.parse = function (comp) {\n var r = this.options.loose ? safeRe[COMPARATORLOOSE] : safeRe[COMPARATOR]\n var m = comp.match(r)\n\n if (!m) {\n throw new TypeError('Invalid comparator: ' + comp)\n }\n\n this.operator = m[1]\n if (this.operator === '=') {\n this.operator = ''\n }\n\n // if it literally is just '>' or '' then allow anything.\n if (!m[2]) {\n this.semver = ANY\n } else {\n this.semver = new SemVer(m[2], this.options.loose)\n }\n}\n\nComparator.prototype.toString = function () {\n return this.value\n}\n\nComparator.prototype.test = function (version) {\n debug('Comparator.test', version, this.options.loose)\n\n if (this.semver === ANY) {\n return true\n }\n\n if (typeof version === 'string') {\n version = new SemVer(version, this.options)\n }\n\n return cmp(version, this.operator, this.semver, this.options)\n}\n\nComparator.prototype.intersects = function (comp, options) {\n if (!(comp instanceof Comparator)) {\n throw new TypeError('a Comparator is required')\n }\n\n if (!options || typeof options !== 'object') {\n options = {\n loose: !!options,\n includePrerelease: false\n }\n }\n\n var rangeTmp\n\n if (this.operator === '') {\n rangeTmp = new Range(comp.value, options)\n return satisfies(this.value, rangeTmp, options)\n } else if (comp.operator === '') {\n rangeTmp = new Range(this.value, options)\n return satisfies(comp.semver, rangeTmp, options)\n }\n\n var sameDirectionIncreasing =\n (this.operator === '>=' || this.operator === '>') &&\n (comp.operator === '>=' || comp.operator === '>')\n var sameDirectionDecreasing =\n (this.operator === '<=' || this.operator === '<') &&\n (comp.operator === '<=' || comp.operator === '<')\n var sameSemVer = this.semver.version === comp.semver.version\n var differentDirectionsInclusive =\n (this.operator === '>=' || this.operator === '<=') &&\n (comp.operator === '>=' || comp.operator === '<=')\n var oppositeDirectionsLessThan =\n cmp(this.semver, '<', comp.semver, options) &&\n ((this.operator === '>=' || this.operator === '>') &&\n (comp.operator === '<=' || comp.operator === '<'))\n var oppositeDirectionsGreaterThan =\n cmp(this.semver, '>', comp.semver, options) &&\n ((this.operator === '<=' || this.operator === '<') &&\n (comp.operator === '>=' || comp.operator === '>'))\n\n return sameDirectionIncreasing || sameDirectionDecreasing ||\n (sameSemVer && differentDirectionsInclusive) ||\n oppositeDirectionsLessThan || oppositeDirectionsGreaterThan\n}\n\nexports.Range = Range\nfunction Range (range, options) {\n if (!options || typeof options !== 'object') {\n options = {\n loose: !!options,\n includePrerelease: false\n }\n }\n\n if (range instanceof Range) {\n if (range.loose === !!options.loose &&\n range.includePrerelease === !!options.includePrerelease) {\n return range\n } else {\n return new Range(range.raw, options)\n }\n }\n\n if (range instanceof Comparator) {\n return new Range(range.value, options)\n }\n\n if (!(this instanceof Range)) {\n return new Range(range, options)\n }\n\n this.options = options\n this.loose = !!options.loose\n this.includePrerelease = !!options.includePrerelease\n\n // First reduce all whitespace as much as possible so we do not have to rely\n // on potentially slow regexes like \\s*. This is then stored and used for\n // future error messages as well.\n this.raw = range\n .trim()\n .split(/\\s+/)\n .join(' ')\n\n // First, split based on boolean or ||\n this.set = this.raw.split('||').map(function (range) {\n return this.parseRange(range.trim())\n }, this).filter(function (c) {\n // throw out any that are not relevant for whatever reason\n return c.length\n })\n\n if (!this.set.length) {\n throw new TypeError('Invalid SemVer Range: ' + this.raw)\n }\n\n this.format()\n}\n\nRange.prototype.format = function () {\n this.range = this.set.map(function (comps) {\n return comps.join(' ').trim()\n }).join('||').trim()\n return this.range\n}\n\nRange.prototype.toString = function () {\n return this.range\n}\n\nRange.prototype.parseRange = function (range) {\n var loose = this.options.loose\n // `1.2.3 - 1.2.4` => `>=1.2.3 <=1.2.4`\n var hr = loose ? safeRe[HYPHENRANGELOOSE] : safeRe[HYPHENRANGE]\n range = range.replace(hr, hyphenReplace)\n debug('hyphen replace', range)\n // `> 1.2.3 < 1.2.5` => `>1.2.3 <1.2.5`\n range = range.replace(safeRe[COMPARATORTRIM], comparatorTrimReplace)\n debug('comparator trim', range, safeRe[COMPARATORTRIM])\n\n // `~ 1.2.3` => `~1.2.3`\n range = range.replace(safeRe[TILDETRIM], tildeTrimReplace)\n\n // `^ 1.2.3` => `^1.2.3`\n range = range.replace(safeRe[CARETTRIM], caretTrimReplace)\n\n // At this point, the range is completely trimmed and\n // ready to be split into comparators.\n var compRe = loose ? safeRe[COMPARATORLOOSE] : safeRe[COMPARATOR]\n var set = range.split(' ').map(function (comp) {\n return parseComparator(comp, this.options)\n }, this).join(' ').split(/\\s+/)\n if (this.options.loose) {\n // in loose mode, throw out any that are not valid comparators\n set = set.filter(function (comp) {\n return !!comp.match(compRe)\n })\n }\n set = set.map(function (comp) {\n return new Comparator(comp, this.options)\n }, this)\n\n return set\n}\n\nRange.prototype.intersects = function (range, options) {\n if (!(range instanceof Range)) {\n throw new TypeError('a Range is required')\n }\n\n return this.set.some(function (thisComparators) {\n return thisComparators.every(function (thisComparator) {\n return range.set.some(function (rangeComparators) {\n return rangeComparators.every(function (rangeComparator) {\n return thisComparator.intersects(rangeComparator, options)\n })\n })\n })\n })\n}\n\n// Mostly just for testing and legacy API reasons\nexports.toComparators = toComparators\nfunction toComparators (range, options) {\n return new Range(range, options).set.map(function (comp) {\n return comp.map(function (c) {\n return c.value\n }).join(' ').trim().split(' ')\n })\n}\n\n// comprised of xranges, tildes, stars, and gtlt's at this point.\n// already replaced the hyphen ranges\n// turn into a set of JUST comparators.\nfunction parseComparator (comp, options) {\n debug('comp', comp, options)\n comp = replaceCarets(comp, options)\n debug('caret', comp)\n comp = replaceTildes(comp, options)\n debug('tildes', comp)\n comp = replaceXRanges(comp, options)\n debug('xrange', comp)\n comp = replaceStars(comp, options)\n debug('stars', comp)\n return comp\n}\n\nfunction isX (id) {\n return !id || id.toLowerCase() === 'x' || id === '*'\n}\n\n// ~, ~> --> * (any, kinda silly)\n// ~2, ~2.x, ~2.x.x, ~>2, ~>2.x ~>2.x.x --> >=2.0.0 <3.0.0\n// ~2.0, ~2.0.x, ~>2.0, ~>2.0.x --> >=2.0.0 <2.1.0\n// ~1.2, ~1.2.x, ~>1.2, ~>1.2.x --> >=1.2.0 <1.3.0\n// ~1.2.3, ~>1.2.3 --> >=1.2.3 <1.3.0\n// ~1.2.0, ~>1.2.0 --> >=1.2.0 <1.3.0\nfunction replaceTildes (comp, options) {\n return comp.trim().split(/\\s+/).map(function (comp) {\n return replaceTilde(comp, options)\n }).join(' ')\n}\n\nfunction replaceTilde (comp, options) {\n var r = options.loose ? safeRe[TILDELOOSE] : safeRe[TILDE]\n return comp.replace(r, function (_, M, m, p, pr) {\n debug('tilde', comp, _, M, m, p, pr)\n var ret\n\n if (isX(M)) {\n ret = ''\n } else if (isX(m)) {\n ret = '>=' + M + '.0.0 <' + (+M + 1) + '.0.0'\n } else if (isX(p)) {\n // ~1.2 == >=1.2.0 <1.3.0\n ret = '>=' + M + '.' + m + '.0 <' + M + '.' + (+m + 1) + '.0'\n } else if (pr) {\n debug('replaceTilde pr', pr)\n ret = '>=' + M + '.' + m + '.' + p + '-' + pr +\n ' <' + M + '.' + (+m + 1) + '.0'\n } else {\n // ~1.2.3 == >=1.2.3 <1.3.0\n ret = '>=' + M + '.' + m + '.' + p +\n ' <' + M + '.' + (+m + 1) + '.0'\n }\n\n debug('tilde return', ret)\n return ret\n })\n}\n\n// ^ --> * (any, kinda silly)\n// ^2, ^2.x, ^2.x.x --> >=2.0.0 <3.0.0\n// ^2.0, ^2.0.x --> >=2.0.0 <3.0.0\n// ^1.2, ^1.2.x --> >=1.2.0 <2.0.0\n// ^1.2.3 --> >=1.2.3 <2.0.0\n// ^1.2.0 --> >=1.2.0 <2.0.0\nfunction replaceCarets (comp, options) {\n return comp.trim().split(/\\s+/).map(function (comp) {\n return replaceCaret(comp, options)\n }).join(' ')\n}\n\nfunction replaceCaret (comp, options) {\n debug('caret', comp, options)\n var r = options.loose ? safeRe[CARETLOOSE] : safeRe[CARET]\n return comp.replace(r, function (_, M, m, p, pr) {\n debug('caret', comp, _, M, m, p, pr)\n var ret\n\n if (isX(M)) {\n ret = ''\n } else if (isX(m)) {\n ret = '>=' + M + '.0.0 <' + (+M + 1) + '.0.0'\n } else if (isX(p)) {\n if (M === '0') {\n ret = '>=' + M + '.' + m + '.0 <' + M + '.' + (+m + 1) + '.0'\n } else {\n ret = '>=' + M + '.' + m + '.0 <' + (+M + 1) + '.0.0'\n }\n } else if (pr) {\n debug('replaceCaret pr', pr)\n if (M === '0') {\n if (m === '0') {\n ret = '>=' + M + '.' + m + '.' + p + '-' + pr +\n ' <' + M + '.' + m + '.' + (+p + 1)\n } else {\n ret = '>=' + M + '.' + m + '.' + p + '-' + pr +\n ' <' + M + '.' + (+m + 1) + '.0'\n }\n } else {\n ret = '>=' + M + '.' + m + '.' + p + '-' + pr +\n ' <' + (+M + 1) + '.0.0'\n }\n } else {\n debug('no pr')\n if (M === '0') {\n if (m === '0') {\n ret = '>=' + M + '.' + m + '.' + p +\n ' <' + M + '.' + m + '.' + (+p + 1)\n } else {\n ret = '>=' + M + '.' + m + '.' + p +\n ' <' + M + '.' + (+m + 1) + '.0'\n }\n } else {\n ret = '>=' + M + '.' + m + '.' + p +\n ' <' + (+M + 1) + '.0.0'\n }\n }\n\n debug('caret return', ret)\n return ret\n })\n}\n\nfunction replaceXRanges (comp, options) {\n debug('replaceXRanges', comp, options)\n return comp.split(/\\s+/).map(function (comp) {\n return replaceXRange(comp, options)\n }).join(' ')\n}\n\nfunction replaceXRange (comp, options) {\n comp = comp.trim()\n var r = options.loose ? safeRe[XRANGELOOSE] : safeRe[XRANGE]\n return comp.replace(r, function (ret, gtlt, M, m, p, pr) {\n debug('xRange', comp, ret, gtlt, M, m, p, pr)\n var xM = isX(M)\n var xm = xM || isX(m)\n var xp = xm || isX(p)\n var anyX = xp\n\n if (gtlt === '=' && anyX) {\n gtlt = ''\n }\n\n if (xM) {\n if (gtlt === '>' || gtlt === '<') {\n // nothing is allowed\n ret = '<0.0.0'\n } else {\n // nothing is forbidden\n ret = '*'\n }\n } else if (gtlt && anyX) {\n // we know patch is an x, because we have any x at all.\n // replace X with 0\n if (xm) {\n m = 0\n }\n p = 0\n\n if (gtlt === '>') {\n // >1 => >=2.0.0\n // >1.2 => >=1.3.0\n // >1.2.3 => >= 1.2.4\n gtlt = '>='\n if (xm) {\n M = +M + 1\n m = 0\n p = 0\n } else {\n m = +m + 1\n p = 0\n }\n } else if (gtlt === '<=') {\n // <=0.7.x is actually <0.8.0, since any 0.7.x should\n // pass. Similarly, <=7.x is actually <8.0.0, etc.\n gtlt = '<'\n if (xm) {\n M = +M + 1\n } else {\n m = +m + 1\n }\n }\n\n ret = gtlt + M + '.' + m + '.' + p\n } else if (xm) {\n ret = '>=' + M + '.0.0 <' + (+M + 1) + '.0.0'\n } else if (xp) {\n ret = '>=' + M + '.' + m + '.0 <' + M + '.' + (+m + 1) + '.0'\n }\n\n debug('xRange return', ret)\n\n return ret\n })\n}\n\n// Because * is AND-ed with everything else in the comparator,\n// and '' means \"any version\", just remove the *s entirely.\nfunction replaceStars (comp, options) {\n debug('replaceStars', comp, options)\n // Looseness is ignored here. star is always as loose as it gets!\n return comp.trim().replace(safeRe[STAR], '')\n}\n\n// This function is passed to string.replace(safeRe[HYPHENRANGE])\n// M, m, patch, prerelease, build\n// 1.2 - 3.4.5 => >=1.2.0 <=3.4.5\n// 1.2.3 - 3.4 => >=1.2.0 <3.5.0 Any 3.4.x will do\n// 1.2 - 3.4 => >=1.2.0 <3.5.0\nfunction hyphenReplace ($0,\n from, fM, fm, fp, fpr, fb,\n to, tM, tm, tp, tpr, tb) {\n if (isX(fM)) {\n from = ''\n } else if (isX(fm)) {\n from = '>=' + fM + '.0.0'\n } else if (isX(fp)) {\n from = '>=' + fM + '.' + fm + '.0'\n } else {\n from = '>=' + from\n }\n\n if (isX(tM)) {\n to = ''\n } else if (isX(tm)) {\n to = '<' + (+tM + 1) + '.0.0'\n } else if (isX(tp)) {\n to = '<' + tM + '.' + (+tm + 1) + '.0'\n } else if (tpr) {\n to = '<=' + tM + '.' + tm + '.' + tp + '-' + tpr\n } else {\n to = '<=' + to\n }\n\n return (from + ' ' + to).trim()\n}\n\n// if ANY of the sets match ALL of its comparators, then pass\nRange.prototype.test = function (version) {\n if (!version) {\n return false\n }\n\n if (typeof version === 'string') {\n version = new SemVer(version, this.options)\n }\n\n for (var i = 0; i < this.set.length; i++) {\n if (testSet(this.set[i], version, this.options)) {\n return true\n }\n }\n return false\n}\n\nfunction testSet (set, version, options) {\n for (var i = 0; i < set.length; i++) {\n if (!set[i].test(version)) {\n return false\n }\n }\n\n if (version.prerelease.length && !options.includePrerelease) {\n // Find the set of versions that are allowed to have prereleases\n // For example, ^1.2.3-pr.1 desugars to >=1.2.3-pr.1 <2.0.0\n // That should allow `1.2.3-pr.2` to pass.\n // However, `1.2.4-alpha.notready` should NOT be allowed,\n // even though it's within the range set by the comparators.\n for (i = 0; i < set.length; i++) {\n debug(set[i].semver)\n if (set[i].semver === ANY) {\n continue\n }\n\n if (set[i].semver.prerelease.length > 0) {\n var allowed = set[i].semver\n if (allowed.major === version.major &&\n allowed.minor === version.minor &&\n allowed.patch === version.patch) {\n return true\n }\n }\n }\n\n // Version has a -pre, but it's not one of the ones we like.\n return false\n }\n\n return true\n}\n\nexports.satisfies = satisfies\nfunction satisfies (version, range, options) {\n try {\n range = new Range(range, options)\n } catch (er) {\n return false\n }\n return range.test(version)\n}\n\nexports.maxSatisfying = maxSatisfying\nfunction maxSatisfying (versions, range, options) {\n var max = null\n var maxSV = null\n try {\n var rangeObj = new Range(range, options)\n } catch (er) {\n return null\n }\n versions.forEach(function (v) {\n if (rangeObj.test(v)) {\n // satisfies(v, range, options)\n if (!max || maxSV.compare(v) === -1) {\n // compare(max, v, true)\n max = v\n maxSV = new SemVer(max, options)\n }\n }\n })\n return max\n}\n\nexports.minSatisfying = minSatisfying\nfunction minSatisfying (versions, range, options) {\n var min = null\n var minSV = null\n try {\n var rangeObj = new Range(range, options)\n } catch (er) {\n return null\n }\n versions.forEach(function (v) {\n if (rangeObj.test(v)) {\n // satisfies(v, range, options)\n if (!min || minSV.compare(v) === 1) {\n // compare(min, v, true)\n min = v\n minSV = new SemVer(min, options)\n }\n }\n })\n return min\n}\n\nexports.minVersion = minVersion\nfunction minVersion (range, loose) {\n range = new Range(range, loose)\n\n var minver = new SemVer('0.0.0')\n if (range.test(minver)) {\n return minver\n }\n\n minver = new SemVer('0.0.0-0')\n if (range.test(minver)) {\n return minver\n }\n\n minver = null\n for (var i = 0; i < range.set.length; ++i) {\n var comparators = range.set[i]\n\n comparators.forEach(function (comparator) {\n // Clone to avoid manipulating the comparator's semver object.\n var compver = new SemVer(comparator.semver.version)\n switch (comparator.operator) {\n case '>':\n if (compver.prerelease.length === 0) {\n compver.patch++\n } else {\n compver.prerelease.push(0)\n }\n compver.raw = compver.format()\n /* fallthrough */\n case '':\n case '>=':\n if (!minver || gt(minver, compver)) {\n minver = compver\n }\n break\n case '<':\n case '<=':\n /* Ignore maximum versions */\n break\n /* istanbul ignore next */\n default:\n throw new Error('Unexpected operation: ' + comparator.operator)\n }\n })\n }\n\n if (minver && range.test(minver)) {\n return minver\n }\n\n return null\n}\n\nexports.validRange = validRange\nfunction validRange (range, options) {\n try {\n // Return '*' instead of '' so that truthiness works.\n // This will throw if it's invalid anyway\n return new Range(range, options).range || '*'\n } catch (er) {\n return null\n }\n}\n\n// Determine if version is less than all the versions possible in the range\nexports.ltr = ltr\nfunction ltr (version, range, options) {\n return outside(version, range, '<', options)\n}\n\n// Determine if version is greater than all the versions possible in the range.\nexports.gtr = gtr\nfunction gtr (version, range, options) {\n return outside(version, range, '>', options)\n}\n\nexports.outside = outside\nfunction outside (version, range, hilo, options) {\n version = new SemVer(version, options)\n range = new Range(range, options)\n\n var gtfn, ltefn, ltfn, comp, ecomp\n switch (hilo) {\n case '>':\n gtfn = gt\n ltefn = lte\n ltfn = lt\n comp = '>'\n ecomp = '>='\n break\n case '<':\n gtfn = lt\n ltefn = gte\n ltfn = gt\n comp = '<'\n ecomp = '<='\n break\n default:\n throw new TypeError('Must provide a hilo val of \"<\" or \">\"')\n }\n\n // If it satisifes the range it is not outside\n if (satisfies(version, range, options)) {\n return false\n }\n\n // From now on, variable terms are as if we're in \"gtr\" mode.\n // but note that everything is flipped for the \"ltr\" function.\n\n for (var i = 0; i < range.set.length; ++i) {\n var comparators = range.set[i]\n\n var high = null\n var low = null\n\n comparators.forEach(function (comparator) {\n if (comparator.semver === ANY) {\n comparator = new Comparator('>=0.0.0')\n }\n high = high || comparator\n low = low || comparator\n if (gtfn(comparator.semver, high.semver, options)) {\n high = comparator\n } else if (ltfn(comparator.semver, low.semver, options)) {\n low = comparator\n }\n })\n\n // If the edge version comparator has a operator then our version\n // isn't outside it\n if (high.operator === comp || high.operator === ecomp) {\n return false\n }\n\n // If the lowest version comparator has an operator and our version\n // is less than it then it isn't higher than the range\n if ((!low.operator || low.operator === comp) &&\n ltefn(version, low.semver)) {\n return false\n } else if (low.operator === ecomp && ltfn(version, low.semver)) {\n return false\n }\n }\n return true\n}\n\nexports.prerelease = prerelease\nfunction prerelease (version, options) {\n var parsed = parse(version, options)\n return (parsed && parsed.prerelease.length) ? parsed.prerelease : null\n}\n\nexports.intersects = intersects\nfunction intersects (r1, r2, options) {\n r1 = new Range(r1, options)\n r2 = new Range(r2, options)\n return r1.intersects(r2)\n}\n\nexports.coerce = coerce\nfunction coerce (version) {\n if (version instanceof SemVer) {\n return version\n }\n\n if (typeof version !== 'string') {\n return null\n }\n\n var match = version.match(safeRe[COERCE])\n\n if (match == null) {\n return null\n }\n\n return parse(match[1] +\n '.' + (match[2] || '0') +\n '.' + (match[3] || '0'))\n}\n\n\n/***/ }),\n\n/***/ 9383:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\nmodule.exports = which\nwhich.sync = whichSync\n\nvar isWindows = process.platform === 'win32' ||\n process.env.OSTYPE === 'cygwin' ||\n process.env.OSTYPE === 'msys'\n\nvar path = __nccwpck_require__(1017)\nvar COLON = isWindows ? ';' : ':'\nvar isexe = __nccwpck_require__(7126)\n\nfunction getNotFoundError (cmd) {\n var er = new Error('not found: ' + cmd)\n er.code = 'ENOENT'\n\n return er\n}\n\nfunction getPathInfo (cmd, opt) {\n var colon = opt.colon || COLON\n var pathEnv = opt.path || process.env.PATH || ''\n var pathExt = ['']\n\n pathEnv = pathEnv.split(colon)\n\n var pathExtExe = ''\n if (isWindows) {\n pathEnv.unshift(process.cwd())\n pathExtExe = (opt.pathExt || process.env.PATHEXT || '.EXE;.CMD;.BAT;.COM')\n pathExt = pathExtExe.split(colon)\n\n\n // Always test the cmd itself first. isexe will check to make sure\n // it's found in the pathExt set.\n if (cmd.indexOf('.') !== -1 && pathExt[0] !== '')\n pathExt.unshift('')\n }\n\n // If it has a slash, then we don't bother searching the pathenv.\n // just check the file itself, and that's it.\n if (cmd.match(/\\//) || isWindows && cmd.match(/\\\\/))\n pathEnv = ['']\n\n return {\n env: pathEnv,\n ext: pathExt,\n extExe: pathExtExe\n }\n}\n\nfunction which (cmd, opt, cb) {\n if (typeof opt === 'function') {\n cb = opt\n opt = {}\n }\n\n var info = getPathInfo(cmd, opt)\n var pathEnv = info.env\n var pathExt = info.ext\n var pathExtExe = info.extExe\n var found = []\n\n ;(function F (i, l) {\n if (i === l) {\n if (opt.all && found.length)\n return cb(null, found)\n else\n return cb(getNotFoundError(cmd))\n }\n\n var pathPart = pathEnv[i]\n if (pathPart.charAt(0) === '\"' && pathPart.slice(-1) === '\"')\n pathPart = pathPart.slice(1, -1)\n\n var p = path.join(pathPart, cmd)\n if (!pathPart && (/^\\.[\\\\\\/]/).test(cmd)) {\n p = cmd.slice(0, 2) + p\n }\n ;(function E (ii, ll) {\n if (ii === ll) return F(i + 1, l)\n var ext = pathExt[ii]\n isexe(p + ext, { pathExt: pathExtExe }, function (er, is) {\n if (!er && is) {\n if (opt.all)\n found.push(p + ext)\n else\n return cb(null, p + ext)\n }\n return E(ii + 1, ll)\n })\n })(0, pathExt.length)\n })(0, pathEnv.length)\n}\n\nfunction whichSync (cmd, opt) {\n opt = opt || {}\n\n var info = getPathInfo(cmd, opt)\n var pathEnv = info.env\n var pathExt = info.ext\n var pathExtExe = info.extExe\n var found = []\n\n for (var i = 0, l = pathEnv.length; i < l; i ++) {\n var pathPart = pathEnv[i]\n if (pathPart.charAt(0) === '\"' && pathPart.slice(-1) === '\"')\n pathPart = pathPart.slice(1, -1)\n\n var p = path.join(pathPart, cmd)\n if (!pathPart && /^\\.[\\\\\\/]/.test(cmd)) {\n p = cmd.slice(0, 2) + p\n }\n for (var j = 0, ll = pathExt.length; j < ll; j ++) {\n var cur = p + pathExt[j]\n var is\n try {\n is = isexe.sync(cur, { pathExt: pathExtExe })\n if (is) {\n if (opt.all)\n found.push(cur)\n else\n return cur\n }\n } catch (ex) {}\n }\n }\n\n if (opt.all && found.length)\n return found\n\n if (opt.nothrow)\n return null\n\n throw getNotFoundError(cmd)\n}\n\n\n/***/ }),\n\n/***/ 2391:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\n\"use strict\";\n\nconst {Transform, PassThrough} = __nccwpck_require__(2781);\nconst zlib = __nccwpck_require__(9796);\nconst mimicResponse = __nccwpck_require__(2610);\n\nmodule.exports = response => {\n\tconst contentEncoding = (response.headers['content-encoding'] || '').toLowerCase();\n\n\tif (!['gzip', 'deflate', 'br'].includes(contentEncoding)) {\n\t\treturn response;\n\t}\n\n\t// TODO: Remove this when targeting Node.js 12.\n\tconst isBrotli = contentEncoding === 'br';\n\tif (isBrotli && typeof zlib.createBrotliDecompress !== 'function') {\n\t\tresponse.destroy(new Error('Brotli is not supported on Node.js < 12'));\n\t\treturn response;\n\t}\n\n\tlet isEmpty = true;\n\n\tconst checker = new Transform({\n\t\ttransform(data, _encoding, callback) {\n\t\t\tisEmpty = false;\n\n\t\t\tcallback(null, data);\n\t\t},\n\n\t\tflush(callback) {\n\t\t\tcallback();\n\t\t}\n\t});\n\n\tconst finalStream = new PassThrough({\n\t\tautoDestroy: false,\n\t\tdestroy(error, callback) {\n\t\t\tresponse.destroy();\n\n\t\t\tcallback(error);\n\t\t}\n\t});\n\n\tconst decompressStream = isBrotli ? zlib.createBrotliDecompress() : zlib.createUnzip();\n\n\tdecompressStream.once('error', error => {\n\t\tif (isEmpty && !response.readable) {\n\t\t\tfinalStream.end();\n\t\t\treturn;\n\t\t}\n\n\t\tfinalStream.destroy(error);\n\t});\n\n\tmimicResponse(response, finalStream);\n\tresponse.pipe(checker).pipe(decompressStream).pipe(finalStream);\n\n\treturn finalStream;\n};\n\n\n/***/ }),\n\n/***/ 6214:\n/***/ ((module, exports) => {\n\n\"use strict\";\n\nObject.defineProperty(exports, \"__esModule\", ({ value: true }));\nfunction isTLSSocket(socket) {\n return socket.encrypted;\n}\nconst deferToConnect = (socket, fn) => {\n let listeners;\n if (typeof fn === 'function') {\n const connect = fn;\n listeners = { connect };\n }\n else {\n listeners = fn;\n }\n const hasConnectListener = typeof listeners.connect === 'function';\n const hasSecureConnectListener = typeof listeners.secureConnect === 'function';\n const hasCloseListener = typeof listeners.close === 'function';\n const onConnect = () => {\n if (hasConnectListener) {\n listeners.connect();\n }\n if (isTLSSocket(socket) && hasSecureConnectListener) {\n if (socket.authorized) {\n listeners.secureConnect();\n }\n else if (!socket.authorizationError) {\n socket.once('secureConnect', listeners.secureConnect);\n }\n }\n if (hasCloseListener) {\n socket.once('close', listeners.close);\n }\n };\n if (socket.writable && !socket.connecting) {\n onConnect();\n }\n else if (socket.connecting) {\n socket.once('connect', onConnect);\n }\n else if (socket.destroyed && hasCloseListener) {\n listeners.close(socket._hadError);\n }\n};\nexports[\"default\"] = deferToConnect;\n// For CommonJS default export support\nmodule.exports = deferToConnect;\nmodule.exports[\"default\"] = deferToConnect;\n\n\n/***/ }),\n\n/***/ 8932:\n/***/ ((__unused_webpack_module, exports) => {\n\n\"use strict\";\n\n\nObject.defineProperty(exports, \"__esModule\", ({ value: true }));\n\nclass Deprecation extends Error {\n constructor(message) {\n super(message); // Maintains proper stack trace (only available on V8)\n\n /* istanbul ignore next */\n\n if (Error.captureStackTrace) {\n Error.captureStackTrace(this, this.constructor);\n }\n\n this.name = 'Deprecation';\n }\n\n}\n\nexports.Deprecation = Deprecation;\n\n\n/***/ }),\n\n/***/ 1205:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\nvar once = __nccwpck_require__(1223);\n\nvar noop = function() {};\n\nvar isRequest = function(stream) {\n\treturn stream.setHeader && typeof stream.abort === 'function';\n};\n\nvar isChildProcess = function(stream) {\n\treturn stream.stdio && Array.isArray(stream.stdio) && stream.stdio.length === 3\n};\n\nvar eos = function(stream, opts, callback) {\n\tif (typeof opts === 'function') return eos(stream, null, opts);\n\tif (!opts) opts = {};\n\n\tcallback = once(callback || noop);\n\n\tvar ws = stream._writableState;\n\tvar rs = stream._readableState;\n\tvar readable = opts.readable || (opts.readable !== false && stream.readable);\n\tvar writable = opts.writable || (opts.writable !== false && stream.writable);\n\tvar cancelled = false;\n\n\tvar onlegacyfinish = function() {\n\t\tif (!stream.writable) onfinish();\n\t};\n\n\tvar onfinish = function() {\n\t\twritable = false;\n\t\tif (!readable) callback.call(stream);\n\t};\n\n\tvar onend = function() {\n\t\treadable = false;\n\t\tif (!writable) callback.call(stream);\n\t};\n\n\tvar onexit = function(exitCode) {\n\t\tcallback.call(stream, exitCode ? new Error('exited with error code: ' + exitCode) : null);\n\t};\n\n\tvar onerror = function(err) {\n\t\tcallback.call(stream, err);\n\t};\n\n\tvar onclose = function() {\n\t\tprocess.nextTick(onclosenexttick);\n\t};\n\n\tvar onclosenexttick = function() {\n\t\tif (cancelled) return;\n\t\tif (readable && !(rs && (rs.ended && !rs.destroyed))) return callback.call(stream, new Error('premature close'));\n\t\tif (writable && !(ws && (ws.ended && !ws.destroyed))) return callback.call(stream, new Error('premature close'));\n\t};\n\n\tvar onrequest = function() {\n\t\tstream.req.on('finish', onfinish);\n\t};\n\n\tif (isRequest(stream)) {\n\t\tstream.on('complete', onfinish);\n\t\tstream.on('abort', onclose);\n\t\tif (stream.req) onrequest();\n\t\telse stream.on('request', onrequest);\n\t} else if (writable && !ws) { // legacy streams\n\t\tstream.on('end', onlegacyfinish);\n\t\tstream.on('close', onlegacyfinish);\n\t}\n\n\tif (isChildProcess(stream)) stream.on('exit', onexit);\n\n\tstream.on('end', onend);\n\tstream.on('finish', onfinish);\n\tif (opts.error !== false) stream.on('error', onerror);\n\tstream.on('close', onclose);\n\n\treturn function() {\n\t\tcancelled = true;\n\t\tstream.removeListener('complete', onfinish);\n\t\tstream.removeListener('abort', onclose);\n\t\tstream.removeListener('request', onrequest);\n\t\tif (stream.req) stream.req.removeListener('finish', onfinish);\n\t\tstream.removeListener('end', onlegacyfinish);\n\t\tstream.removeListener('close', onlegacyfinish);\n\t\tstream.removeListener('finish', onfinish);\n\t\tstream.removeListener('exit', onexit);\n\t\tstream.removeListener('end', onend);\n\t\tstream.removeListener('error', onerror);\n\t\tstream.removeListener('close', onclose);\n\t};\n};\n\nmodule.exports = eos;\n\n\n/***/ }),\n\n/***/ 5447:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\n\"use strict\";\n\nconst path = __nccwpck_require__(1017);\nconst childProcess = __nccwpck_require__(2081);\nconst crossSpawn = __nccwpck_require__(2746);\nconst stripEof = __nccwpck_require__(5515);\nconst npmRunPath = __nccwpck_require__(502);\nconst isStream = __nccwpck_require__(1554);\nconst _getStream = __nccwpck_require__(1336);\nconst pFinally = __nccwpck_require__(1330);\nconst onExit = __nccwpck_require__(4931);\nconst errname = __nccwpck_require__(4689);\nconst stdio = __nccwpck_require__(166);\n\nconst TEN_MEGABYTES = 1000 * 1000 * 10;\n\nfunction handleArgs(cmd, args, opts) {\n\tlet parsed;\n\n\topts = Object.assign({\n\t\textendEnv: true,\n\t\tenv: {}\n\t}, opts);\n\n\tif (opts.extendEnv) {\n\t\topts.env = Object.assign({}, process.env, opts.env);\n\t}\n\n\tif (opts.__winShell === true) {\n\t\tdelete opts.__winShell;\n\t\tparsed = {\n\t\t\tcommand: cmd,\n\t\t\targs,\n\t\t\toptions: opts,\n\t\t\tfile: cmd,\n\t\t\toriginal: {\n\t\t\t\tcmd,\n\t\t\t\targs\n\t\t\t}\n\t\t};\n\t} else {\n\t\tparsed = crossSpawn._parse(cmd, args, opts);\n\t}\n\n\topts = Object.assign({\n\t\tmaxBuffer: TEN_MEGABYTES,\n\t\tbuffer: true,\n\t\tstripEof: true,\n\t\tpreferLocal: true,\n\t\tlocalDir: parsed.options.cwd || process.cwd(),\n\t\tencoding: 'utf8',\n\t\treject: true,\n\t\tcleanup: true\n\t}, parsed.options);\n\n\topts.stdio = stdio(opts);\n\n\tif (opts.preferLocal) {\n\t\topts.env = npmRunPath.env(Object.assign({}, opts, {cwd: opts.localDir}));\n\t}\n\n\tif (opts.detached) {\n\t\t// #115\n\t\topts.cleanup = false;\n\t}\n\n\tif (process.platform === 'win32' && path.basename(parsed.command) === 'cmd.exe') {\n\t\t// #116\n\t\tparsed.args.unshift('/q');\n\t}\n\n\treturn {\n\t\tcmd: parsed.command,\n\t\targs: parsed.args,\n\t\topts,\n\t\tparsed\n\t};\n}\n\nfunction handleInput(spawned, input) {\n\tif (input === null || input === undefined) {\n\t\treturn;\n\t}\n\n\tif (isStream(input)) {\n\t\tinput.pipe(spawned.stdin);\n\t} else {\n\t\tspawned.stdin.end(input);\n\t}\n}\n\nfunction handleOutput(opts, val) {\n\tif (val && opts.stripEof) {\n\t\tval = stripEof(val);\n\t}\n\n\treturn val;\n}\n\nfunction handleShell(fn, cmd, opts) {\n\tlet file = '/bin/sh';\n\tlet args = ['-c', cmd];\n\n\topts = Object.assign({}, opts);\n\n\tif (process.platform === 'win32') {\n\t\topts.__winShell = true;\n\t\tfile = process.env.comspec || 'cmd.exe';\n\t\targs = ['/s', '/c', `\"${cmd}\"`];\n\t\topts.windowsVerbatimArguments = true;\n\t}\n\n\tif (opts.shell) {\n\t\tfile = opts.shell;\n\t\tdelete opts.shell;\n\t}\n\n\treturn fn(file, args, opts);\n}\n\nfunction getStream(process, stream, {encoding, buffer, maxBuffer}) {\n\tif (!process[stream]) {\n\t\treturn null;\n\t}\n\n\tlet ret;\n\n\tif (!buffer) {\n\t\t// TODO: Use `ret = util.promisify(stream.finished)(process[stream]);` when targeting Node.js 10\n\t\tret = new Promise((resolve, reject) => {\n\t\t\tprocess[stream]\n\t\t\t\t.once('end', resolve)\n\t\t\t\t.once('error', reject);\n\t\t});\n\t} else if (encoding) {\n\t\tret = _getStream(process[stream], {\n\t\t\tencoding,\n\t\t\tmaxBuffer\n\t\t});\n\t} else {\n\t\tret = _getStream.buffer(process[stream], {maxBuffer});\n\t}\n\n\treturn ret.catch(err => {\n\t\terr.stream = stream;\n\t\terr.message = `${stream} ${err.message}`;\n\t\tthrow err;\n\t});\n}\n\nfunction makeError(result, options) {\n\tconst {stdout, stderr} = result;\n\n\tlet err = result.error;\n\tconst {code, signal} = result;\n\n\tconst {parsed, joinedCmd} = options;\n\tconst timedOut = options.timedOut || false;\n\n\tif (!err) {\n\t\tlet output = '';\n\n\t\tif (Array.isArray(parsed.opts.stdio)) {\n\t\t\tif (parsed.opts.stdio[2] !== 'inherit') {\n\t\t\t\toutput += output.length > 0 ? stderr : `\\n${stderr}`;\n\t\t\t}\n\n\t\t\tif (parsed.opts.stdio[1] !== 'inherit') {\n\t\t\t\toutput += `\\n${stdout}`;\n\t\t\t}\n\t\t} else if (parsed.opts.stdio !== 'inherit') {\n\t\t\toutput = `\\n${stderr}${stdout}`;\n\t\t}\n\n\t\terr = new Error(`Command failed: ${joinedCmd}${output}`);\n\t\terr.code = code < 0 ? errname(code) : code;\n\t}\n\n\terr.stdout = stdout;\n\terr.stderr = stderr;\n\terr.failed = true;\n\terr.signal = signal || null;\n\terr.cmd = joinedCmd;\n\terr.timedOut = timedOut;\n\n\treturn err;\n}\n\nfunction joinCmd(cmd, args) {\n\tlet joinedCmd = cmd;\n\n\tif (Array.isArray(args) && args.length > 0) {\n\t\tjoinedCmd += ' ' + args.join(' ');\n\t}\n\n\treturn joinedCmd;\n}\n\nmodule.exports = (cmd, args, opts) => {\n\tconst parsed = handleArgs(cmd, args, opts);\n\tconst {encoding, buffer, maxBuffer} = parsed.opts;\n\tconst joinedCmd = joinCmd(cmd, args);\n\n\tlet spawned;\n\ttry {\n\t\tspawned = childProcess.spawn(parsed.cmd, parsed.args, parsed.opts);\n\t} catch (err) {\n\t\treturn Promise.reject(err);\n\t}\n\n\tlet removeExitHandler;\n\tif (parsed.opts.cleanup) {\n\t\tremoveExitHandler = onExit(() => {\n\t\t\tspawned.kill();\n\t\t});\n\t}\n\n\tlet timeoutId = null;\n\tlet timedOut = false;\n\n\tconst cleanup = () => {\n\t\tif (timeoutId) {\n\t\t\tclearTimeout(timeoutId);\n\t\t\ttimeoutId = null;\n\t\t}\n\n\t\tif (removeExitHandler) {\n\t\t\tremoveExitHandler();\n\t\t}\n\t};\n\n\tif (parsed.opts.timeout > 0) {\n\t\ttimeoutId = setTimeout(() => {\n\t\t\ttimeoutId = null;\n\t\t\ttimedOut = true;\n\t\t\tspawned.kill(parsed.opts.killSignal);\n\t\t}, parsed.opts.timeout);\n\t}\n\n\tconst processDone = new Promise(resolve => {\n\t\tspawned.on('exit', (code, signal) => {\n\t\t\tcleanup();\n\t\t\tresolve({code, signal});\n\t\t});\n\n\t\tspawned.on('error', err => {\n\t\t\tcleanup();\n\t\t\tresolve({error: err});\n\t\t});\n\n\t\tif (spawned.stdin) {\n\t\t\tspawned.stdin.on('error', err => {\n\t\t\t\tcleanup();\n\t\t\t\tresolve({error: err});\n\t\t\t});\n\t\t}\n\t});\n\n\tfunction destroy() {\n\t\tif (spawned.stdout) {\n\t\t\tspawned.stdout.destroy();\n\t\t}\n\n\t\tif (spawned.stderr) {\n\t\t\tspawned.stderr.destroy();\n\t\t}\n\t}\n\n\tconst handlePromise = () => pFinally(Promise.all([\n\t\tprocessDone,\n\t\tgetStream(spawned, 'stdout', {encoding, buffer, maxBuffer}),\n\t\tgetStream(spawned, 'stderr', {encoding, buffer, maxBuffer})\n\t]).then(arr => {\n\t\tconst result = arr[0];\n\t\tresult.stdout = arr[1];\n\t\tresult.stderr = arr[2];\n\n\t\tif (result.error || result.code !== 0 || result.signal !== null) {\n\t\t\tconst err = makeError(result, {\n\t\t\t\tjoinedCmd,\n\t\t\t\tparsed,\n\t\t\t\ttimedOut\n\t\t\t});\n\n\t\t\t// TODO: missing some timeout logic for killed\n\t\t\t// https://github.com/nodejs/node/blob/master/lib/child_process.js#L203\n\t\t\t// err.killed = spawned.killed || killed;\n\t\t\terr.killed = err.killed || spawned.killed;\n\n\t\t\tif (!parsed.opts.reject) {\n\t\t\t\treturn err;\n\t\t\t}\n\n\t\t\tthrow err;\n\t\t}\n\n\t\treturn {\n\t\t\tstdout: handleOutput(parsed.opts, result.stdout),\n\t\t\tstderr: handleOutput(parsed.opts, result.stderr),\n\t\t\tcode: 0,\n\t\t\tfailed: false,\n\t\t\tkilled: false,\n\t\t\tsignal: null,\n\t\t\tcmd: joinedCmd,\n\t\t\ttimedOut: false\n\t\t};\n\t}), destroy);\n\n\tcrossSpawn._enoent.hookChildProcess(spawned, parsed.parsed);\n\n\thandleInput(spawned, parsed.opts.input);\n\n\tspawned.then = (onfulfilled, onrejected) => handlePromise().then(onfulfilled, onrejected);\n\tspawned.catch = onrejected => handlePromise().catch(onrejected);\n\n\treturn spawned;\n};\n\n// TODO: set `stderr: 'ignore'` when that option is implemented\nmodule.exports.stdout = (...args) => module.exports(...args).then(x => x.stdout);\n\n// TODO: set `stdout: 'ignore'` when that option is implemented\nmodule.exports.stderr = (...args) => module.exports(...args).then(x => x.stderr);\n\nmodule.exports.shell = (cmd, opts) => handleShell(module.exports, cmd, opts);\n\nmodule.exports.sync = (cmd, args, opts) => {\n\tconst parsed = handleArgs(cmd, args, opts);\n\tconst joinedCmd = joinCmd(cmd, args);\n\n\tif (isStream(parsed.opts.input)) {\n\t\tthrow new TypeError('The `input` option cannot be a stream in sync mode');\n\t}\n\n\tconst result = childProcess.spawnSync(parsed.cmd, parsed.args, parsed.opts);\n\tresult.code = result.status;\n\n\tif (result.error || result.status !== 0 || result.signal !== null) {\n\t\tconst err = makeError(result, {\n\t\t\tjoinedCmd,\n\t\t\tparsed\n\t\t});\n\n\t\tif (!parsed.opts.reject) {\n\t\t\treturn err;\n\t\t}\n\n\t\tthrow err;\n\t}\n\n\treturn {\n\t\tstdout: handleOutput(parsed.opts, result.stdout),\n\t\tstderr: handleOutput(parsed.opts, result.stderr),\n\t\tcode: 0,\n\t\tfailed: false,\n\t\tsignal: null,\n\t\tcmd: joinedCmd,\n\t\ttimedOut: false\n\t};\n};\n\nmodule.exports.shellSync = (cmd, opts) => handleShell(module.exports.sync, cmd, opts);\n\n\n/***/ }),\n\n/***/ 4689:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\n\"use strict\";\n\n// Older verions of Node.js might not have `util.getSystemErrorName()`.\n// In that case, fall back to a deprecated internal.\nconst util = __nccwpck_require__(3837);\n\nlet uv;\n\nif (typeof util.getSystemErrorName === 'function') {\n\tmodule.exports = util.getSystemErrorName;\n} else {\n\ttry {\n\t\tuv = process.binding('uv');\n\n\t\tif (typeof uv.errname !== 'function') {\n\t\t\tthrow new TypeError('uv.errname is not a function');\n\t\t}\n\t} catch (err) {\n\t\tconsole.error('execa/lib/errname: unable to establish process.binding(\\'uv\\')', err);\n\t\tuv = null;\n\t}\n\n\tmodule.exports = code => errname(uv, code);\n}\n\n// Used for testing the fallback behavior\nmodule.exports.__test__ = errname;\n\nfunction errname(uv, code) {\n\tif (uv) {\n\t\treturn uv.errname(code);\n\t}\n\n\tif (!(code < 0)) {\n\t\tthrow new Error('err >= 0');\n\t}\n\n\treturn `Unknown system error ${code}`;\n}\n\n\n\n/***/ }),\n\n/***/ 166:\n/***/ ((module) => {\n\n\"use strict\";\n\nconst alias = ['stdin', 'stdout', 'stderr'];\n\nconst hasAlias = opts => alias.some(x => Boolean(opts[x]));\n\nmodule.exports = opts => {\n\tif (!opts) {\n\t\treturn null;\n\t}\n\n\tif (opts.stdio && hasAlias(opts)) {\n\t\tthrow new Error(`It's not possible to provide \\`stdio\\` in combination with one of ${alias.map(x => `\\`${x}\\``).join(', ')}`);\n\t}\n\n\tif (typeof opts.stdio === 'string') {\n\t\treturn opts.stdio;\n\t}\n\n\tconst stdio = opts.stdio || [];\n\n\tif (!Array.isArray(stdio)) {\n\t\tthrow new TypeError(`Expected \\`stdio\\` to be of type \\`string\\` or \\`Array\\`, got \\`${typeof stdio}\\``);\n\t}\n\n\tconst result = [];\n\tconst len = Math.max(stdio.length, alias.length);\n\n\tfor (let i = 0; i < len; i++) {\n\t\tlet value = null;\n\n\t\tif (stdio[i] !== undefined) {\n\t\t\tvalue = stdio[i];\n\t\t} else if (opts[alias[i]] !== undefined) {\n\t\t\tvalue = opts[alias[i]];\n\t\t}\n\n\t\tresult[i] = value;\n\t}\n\n\treturn result;\n};\n\n\n/***/ }),\n\n/***/ 7740:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\n\"use strict\";\n\nconst {PassThrough} = __nccwpck_require__(2781);\n\nmodule.exports = options => {\n\toptions = Object.assign({}, options);\n\n\tconst {array} = options;\n\tlet {encoding} = options;\n\tconst buffer = encoding === 'buffer';\n\tlet objectMode = false;\n\n\tif (array) {\n\t\tobjectMode = !(encoding || buffer);\n\t} else {\n\t\tencoding = encoding || 'utf8';\n\t}\n\n\tif (buffer) {\n\t\tencoding = null;\n\t}\n\n\tlet len = 0;\n\tconst ret = [];\n\tconst stream = new PassThrough({objectMode});\n\n\tif (encoding) {\n\t\tstream.setEncoding(encoding);\n\t}\n\n\tstream.on('data', chunk => {\n\t\tret.push(chunk);\n\n\t\tif (objectMode) {\n\t\t\tlen = ret.length;\n\t\t} else {\n\t\t\tlen += chunk.length;\n\t\t}\n\t});\n\n\tstream.getBufferedValue = () => {\n\t\tif (array) {\n\t\t\treturn ret;\n\t\t}\n\n\t\treturn buffer ? Buffer.concat(ret, len) : ret.join('');\n\t};\n\n\tstream.getBufferedLength = () => len;\n\n\treturn stream;\n};\n\n\n/***/ }),\n\n/***/ 1336:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\n\"use strict\";\n\nconst pump = __nccwpck_require__(8341);\nconst bufferStream = __nccwpck_require__(7740);\n\nclass MaxBufferError extends Error {\n\tconstructor() {\n\t\tsuper('maxBuffer exceeded');\n\t\tthis.name = 'MaxBufferError';\n\t}\n}\n\nfunction getStream(inputStream, options) {\n\tif (!inputStream) {\n\t\treturn Promise.reject(new Error('Expected a stream'));\n\t}\n\n\toptions = Object.assign({maxBuffer: Infinity}, options);\n\n\tconst {maxBuffer} = options;\n\n\tlet stream;\n\treturn new Promise((resolve, reject) => {\n\t\tconst rejectPromise = error => {\n\t\t\tif (error) { // A null check\n\t\t\t\terror.bufferedData = stream.getBufferedValue();\n\t\t\t}\n\t\t\treject(error);\n\t\t};\n\n\t\tstream = pump(inputStream, bufferStream(options), error => {\n\t\t\tif (error) {\n\t\t\t\trejectPromise(error);\n\t\t\t\treturn;\n\t\t\t}\n\n\t\t\tresolve();\n\t\t});\n\n\t\tstream.on('data', () => {\n\t\t\tif (stream.getBufferedLength() > maxBuffer) {\n\t\t\t\trejectPromise(new MaxBufferError());\n\t\t\t}\n\t\t});\n\t}).then(() => stream.getBufferedValue());\n}\n\nmodule.exports = getStream;\nmodule.exports.buffer = (stream, options) => getStream(stream, Object.assign({}, options, {encoding: 'buffer'}));\nmodule.exports.array = (stream, options) => getStream(stream, Object.assign({}, options, {array: true}));\nmodule.exports.MaxBufferError = MaxBufferError;\n\n\n/***/ }),\n\n/***/ 1585:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\n\"use strict\";\n\nconst {PassThrough: PassThroughStream} = __nccwpck_require__(2781);\n\nmodule.exports = options => {\n\toptions = {...options};\n\n\tconst {array} = options;\n\tlet {encoding} = options;\n\tconst isBuffer = encoding === 'buffer';\n\tlet objectMode = false;\n\n\tif (array) {\n\t\tobjectMode = !(encoding || isBuffer);\n\t} else {\n\t\tencoding = encoding || 'utf8';\n\t}\n\n\tif (isBuffer) {\n\t\tencoding = null;\n\t}\n\n\tconst stream = new PassThroughStream({objectMode});\n\n\tif (encoding) {\n\t\tstream.setEncoding(encoding);\n\t}\n\n\tlet length = 0;\n\tconst chunks = [];\n\n\tstream.on('data', chunk => {\n\t\tchunks.push(chunk);\n\n\t\tif (objectMode) {\n\t\t\tlength = chunks.length;\n\t\t} else {\n\t\t\tlength += chunk.length;\n\t\t}\n\t});\n\n\tstream.getBufferedValue = () => {\n\t\tif (array) {\n\t\t\treturn chunks;\n\t\t}\n\n\t\treturn isBuffer ? Buffer.concat(chunks, length) : chunks.join('');\n\t};\n\n\tstream.getBufferedLength = () => length;\n\n\treturn stream;\n};\n\n\n/***/ }),\n\n/***/ 1766:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\n\"use strict\";\n\nconst {constants: BufferConstants} = __nccwpck_require__(4300);\nconst pump = __nccwpck_require__(8341);\nconst bufferStream = __nccwpck_require__(1585);\n\nclass MaxBufferError extends Error {\n\tconstructor() {\n\t\tsuper('maxBuffer exceeded');\n\t\tthis.name = 'MaxBufferError';\n\t}\n}\n\nasync function getStream(inputStream, options) {\n\tif (!inputStream) {\n\t\treturn Promise.reject(new Error('Expected a stream'));\n\t}\n\n\toptions = {\n\t\tmaxBuffer: Infinity,\n\t\t...options\n\t};\n\n\tconst {maxBuffer} = options;\n\n\tlet stream;\n\tawait new Promise((resolve, reject) => {\n\t\tconst rejectPromise = error => {\n\t\t\t// Don't retrieve an oversized buffer.\n\t\t\tif (error && stream.getBufferedLength() <= BufferConstants.MAX_LENGTH) {\n\t\t\t\terror.bufferedData = stream.getBufferedValue();\n\t\t\t}\n\n\t\t\treject(error);\n\t\t};\n\n\t\tstream = pump(inputStream, bufferStream(options), error => {\n\t\t\tif (error) {\n\t\t\t\trejectPromise(error);\n\t\t\t\treturn;\n\t\t\t}\n\n\t\t\tresolve();\n\t\t});\n\n\t\tstream.on('data', () => {\n\t\t\tif (stream.getBufferedLength() > maxBuffer) {\n\t\t\t\trejectPromise(new MaxBufferError());\n\t\t\t}\n\t\t});\n\t});\n\n\treturn stream.getBufferedValue();\n}\n\nmodule.exports = getStream;\n// TODO: Remove this for the next major release\nmodule.exports[\"default\"] = getStream;\nmodule.exports.buffer = (stream, options) => getStream(stream, {...options, encoding: 'buffer'});\nmodule.exports.array = (stream, options) => getStream(stream, {...options, array: true});\nmodule.exports.MaxBufferError = MaxBufferError;\n\n\n/***/ }),\n\n/***/ 6457:\n/***/ ((__unused_webpack_module, exports, __nccwpck_require__) => {\n\n\"use strict\";\n\nObject.defineProperty(exports, \"__esModule\", ({ value: true }));\nconst types_1 = __nccwpck_require__(4597);\nfunction createRejection(error, ...beforeErrorGroups) {\n const promise = (async () => {\n if (error instanceof types_1.RequestError) {\n try {\n for (const hooks of beforeErrorGroups) {\n if (hooks) {\n for (const hook of hooks) {\n // eslint-disable-next-line no-await-in-loop\n error = await hook(error);\n }\n }\n }\n }\n catch (error_) {\n error = error_;\n }\n }\n throw error;\n })();\n const returnPromise = () => promise;\n promise.json = returnPromise;\n promise.text = returnPromise;\n promise.buffer = returnPromise;\n promise.on = returnPromise;\n return promise;\n}\nexports[\"default\"] = createRejection;\n\n\n/***/ }),\n\n/***/ 6056:\n/***/ (function(__unused_webpack_module, exports, __nccwpck_require__) {\n\n\"use strict\";\n\nvar __createBinding = (this && this.__createBinding) || (Object.create ? (function(o, m, k, k2) {\n if (k2 === undefined) k2 = k;\n Object.defineProperty(o, k2, { enumerable: true, get: function() { return m[k]; } });\n}) : (function(o, m, k, k2) {\n if (k2 === undefined) k2 = k;\n o[k2] = m[k];\n}));\nvar __exportStar = (this && this.__exportStar) || function(m, exports) {\n for (var p in m) if (p !== \"default\" && !Object.prototype.hasOwnProperty.call(exports, p)) __createBinding(exports, m, p);\n};\nObject.defineProperty(exports, \"__esModule\", ({ value: true }));\nconst events_1 = __nccwpck_require__(2361);\nconst is_1 = __nccwpck_require__(7678);\nconst PCancelable = __nccwpck_require__(9072);\nconst types_1 = __nccwpck_require__(4597);\nconst parse_body_1 = __nccwpck_require__(8220);\nconst core_1 = __nccwpck_require__(94);\nconst proxy_events_1 = __nccwpck_require__(3021);\nconst get_buffer_1 = __nccwpck_require__(4500);\nconst is_response_ok_1 = __nccwpck_require__(9298);\nconst proxiedRequestEvents = [\n 'request',\n 'response',\n 'redirect',\n 'uploadProgress',\n 'downloadProgress'\n];\nfunction asPromise(normalizedOptions) {\n let globalRequest;\n let globalResponse;\n const emitter = new events_1.EventEmitter();\n const promise = new PCancelable((resolve, reject, onCancel) => {\n const makeRequest = (retryCount) => {\n const request = new core_1.default(undefined, normalizedOptions);\n request.retryCount = retryCount;\n request._noPipe = true;\n onCancel(() => request.destroy());\n onCancel.shouldReject = false;\n onCancel(() => reject(new types_1.CancelError(request)));\n globalRequest = request;\n request.once('response', async (response) => {\n var _a;\n response.retryCount = retryCount;\n if (response.request.aborted) {\n // Canceled while downloading - will throw a `CancelError` or `TimeoutError` error\n return;\n }\n // Download body\n let rawBody;\n try {\n rawBody = await get_buffer_1.default(request);\n response.rawBody = rawBody;\n }\n catch (_b) {\n // The same error is caught below.\n // See request.once('error')\n return;\n }\n if (request._isAboutToError) {\n return;\n }\n // Parse body\n const contentEncoding = ((_a = response.headers['content-encoding']) !== null && _a !== void 0 ? _a : '').toLowerCase();\n const isCompressed = ['gzip', 'deflate', 'br'].includes(contentEncoding);\n const { options } = request;\n if (isCompressed && !options.decompress) {\n response.body = rawBody;\n }\n else {\n try {\n response.body = parse_body_1.default(response, options.responseType, options.parseJson, options.encoding);\n }\n catch (error) {\n // Fallback to `utf8`\n response.body = rawBody.toString();\n if (is_response_ok_1.isResponseOk(response)) {\n request._beforeError(error);\n return;\n }\n }\n }\n try {\n for (const [index, hook] of options.hooks.afterResponse.entries()) {\n // @ts-expect-error TS doesn't notice that CancelableRequest is a Promise\n // eslint-disable-next-line no-await-in-loop\n response = await hook(response, async (updatedOptions) => {\n const typedOptions = core_1.default.normalizeArguments(undefined, {\n ...updatedOptions,\n retry: {\n calculateDelay: () => 0\n },\n throwHttpErrors: false,\n resolveBodyOnly: false\n }, options);\n // Remove any further hooks for that request, because we'll call them anyway.\n // The loop continues. We don't want duplicates (asPromise recursion).\n typedOptions.hooks.afterResponse = typedOptions.hooks.afterResponse.slice(0, index);\n for (const hook of typedOptions.hooks.beforeRetry) {\n // eslint-disable-next-line no-await-in-loop\n await hook(typedOptions);\n }\n const promise = asPromise(typedOptions);\n onCancel(() => {\n promise.catch(() => { });\n promise.cancel();\n });\n return promise;\n });\n }\n }\n catch (error) {\n request._beforeError(new types_1.RequestError(error.message, error, request));\n return;\n }\n globalResponse = response;\n if (!is_response_ok_1.isResponseOk(response)) {\n request._beforeError(new types_1.HTTPError(response));\n return;\n }\n request.destroy();\n resolve(request.options.resolveBodyOnly ? response.body : response);\n });\n const onError = (error) => {\n if (promise.isCanceled) {\n return;\n }\n const { options } = request;\n if (error instanceof types_1.HTTPError && !options.throwHttpErrors) {\n const { response } = error;\n resolve(request.options.resolveBodyOnly ? response.body : response);\n return;\n }\n reject(error);\n };\n request.once('error', onError);\n const previousBody = request.options.body;\n request.once('retry', (newRetryCount, error) => {\n var _a, _b;\n if (previousBody === ((_a = error.request) === null || _a === void 0 ? void 0 : _a.options.body) && is_1.default.nodeStream((_b = error.request) === null || _b === void 0 ? void 0 : _b.options.body)) {\n onError(error);\n return;\n }\n makeRequest(newRetryCount);\n });\n proxy_events_1.default(request, emitter, proxiedRequestEvents);\n };\n makeRequest(0);\n });\n promise.on = (event, fn) => {\n emitter.on(event, fn);\n return promise;\n };\n const shortcut = (responseType) => {\n const newPromise = (async () => {\n // Wait until downloading has ended\n await promise;\n const { options } = globalResponse.request;\n return parse_body_1.default(globalResponse, responseType, options.parseJson, options.encoding);\n })();\n Object.defineProperties(newPromise, Object.getOwnPropertyDescriptors(promise));\n return newPromise;\n };\n promise.json = () => {\n const { headers } = globalRequest.options;\n if (!globalRequest.writableFinished && headers.accept === undefined) {\n headers.accept = 'application/json';\n }\n return shortcut('json');\n };\n promise.buffer = () => shortcut('buffer');\n promise.text = () => shortcut('text');\n return promise;\n}\nexports[\"default\"] = asPromise;\n__exportStar(__nccwpck_require__(4597), exports);\n\n\n/***/ }),\n\n/***/ 1048:\n/***/ ((__unused_webpack_module, exports, __nccwpck_require__) => {\n\n\"use strict\";\n\nObject.defineProperty(exports, \"__esModule\", ({ value: true }));\nconst is_1 = __nccwpck_require__(7678);\nconst normalizeArguments = (options, defaults) => {\n if (is_1.default.null_(options.encoding)) {\n throw new TypeError('To get a Buffer, set `options.responseType` to `buffer` instead');\n }\n is_1.assert.any([is_1.default.string, is_1.default.undefined], options.encoding);\n is_1.assert.any([is_1.default.boolean, is_1.default.undefined], options.resolveBodyOnly);\n is_1.assert.any([is_1.default.boolean, is_1.default.undefined], options.methodRewriting);\n is_1.assert.any([is_1.default.boolean, is_1.default.undefined], options.isStream);\n is_1.assert.any([is_1.default.string, is_1.default.undefined], options.responseType);\n // `options.responseType`\n if (options.responseType === undefined) {\n options.responseType = 'text';\n }\n // `options.retry`\n const { retry } = options;\n if (defaults) {\n options.retry = { ...defaults.retry };\n }\n else {\n options.retry = {\n calculateDelay: retryObject => retryObject.computedValue,\n limit: 0,\n methods: [],\n statusCodes: [],\n errorCodes: [],\n maxRetryAfter: undefined\n };\n }\n if (is_1.default.object(retry)) {\n options.retry = {\n ...options.retry,\n ...retry\n };\n options.retry.methods = [...new Set(options.retry.methods.map(method => method.toUpperCase()))];\n options.retry.statusCodes = [...new Set(options.retry.statusCodes)];\n options.retry.errorCodes = [...new Set(options.retry.errorCodes)];\n }\n else if (is_1.default.number(retry)) {\n options.retry.limit = retry;\n }\n if (is_1.default.undefined(options.retry.maxRetryAfter)) {\n options.retry.maxRetryAfter = Math.min(\n // TypeScript is not smart enough to handle `.filter(x => is.number(x))`.\n // eslint-disable-next-line unicorn/no-fn-reference-in-iterator\n ...[options.timeout.request, options.timeout.connect].filter(is_1.default.number));\n }\n // `options.pagination`\n if (is_1.default.object(options.pagination)) {\n if (defaults) {\n options.pagination = {\n ...defaults.pagination,\n ...options.pagination\n };\n }\n const { pagination } = options;\n if (!is_1.default.function_(pagination.transform)) {\n throw new Error('`options.pagination.transform` must be implemented');\n }\n if (!is_1.default.function_(pagination.shouldContinue)) {\n throw new Error('`options.pagination.shouldContinue` must be implemented');\n }\n if (!is_1.default.function_(pagination.filter)) {\n throw new TypeError('`options.pagination.filter` must be implemented');\n }\n if (!is_1.default.function_(pagination.paginate)) {\n throw new Error('`options.pagination.paginate` must be implemented');\n }\n }\n // JSON mode\n if (options.responseType === 'json' && options.headers.accept === undefined) {\n options.headers.accept = 'application/json';\n }\n return options;\n};\nexports[\"default\"] = normalizeArguments;\n\n\n/***/ }),\n\n/***/ 8220:\n/***/ ((__unused_webpack_module, exports, __nccwpck_require__) => {\n\n\"use strict\";\n\nObject.defineProperty(exports, \"__esModule\", ({ value: true }));\nconst types_1 = __nccwpck_require__(4597);\nconst parseBody = (response, responseType, parseJson, encoding) => {\n const { rawBody } = response;\n try {\n if (responseType === 'text') {\n return rawBody.toString(encoding);\n }\n if (responseType === 'json') {\n return rawBody.length === 0 ? '' : parseJson(rawBody.toString());\n }\n if (responseType === 'buffer') {\n return rawBody;\n }\n throw new types_1.ParseError({\n message: `Unknown body type '${responseType}'`,\n name: 'Error'\n }, response);\n }\n catch (error) {\n throw new types_1.ParseError(error, response);\n }\n};\nexports[\"default\"] = parseBody;\n\n\n/***/ }),\n\n/***/ 4597:\n/***/ (function(__unused_webpack_module, exports, __nccwpck_require__) {\n\n\"use strict\";\n\nvar __createBinding = (this && this.__createBinding) || (Object.create ? (function(o, m, k, k2) {\n if (k2 === undefined) k2 = k;\n Object.defineProperty(o, k2, { enumerable: true, get: function() { return m[k]; } });\n}) : (function(o, m, k, k2) {\n if (k2 === undefined) k2 = k;\n o[k2] = m[k];\n}));\nvar __exportStar = (this && this.__exportStar) || function(m, exports) {\n for (var p in m) if (p !== \"default\" && !Object.prototype.hasOwnProperty.call(exports, p)) __createBinding(exports, m, p);\n};\nObject.defineProperty(exports, \"__esModule\", ({ value: true }));\nexports.CancelError = exports.ParseError = void 0;\nconst core_1 = __nccwpck_require__(94);\n/**\nAn error to be thrown when server response code is 2xx, and parsing body fails.\nIncludes a `response` property.\n*/\nclass ParseError extends core_1.RequestError {\n constructor(error, response) {\n const { options } = response.request;\n super(`${error.message} in \"${options.url.toString()}\"`, error, response.request);\n this.name = 'ParseError';\n this.code = this.code === 'ERR_GOT_REQUEST_ERROR' ? 'ERR_BODY_PARSE_FAILURE' : this.code;\n }\n}\nexports.ParseError = ParseError;\n/**\nAn error to be thrown when the request is aborted with `.cancel()`.\n*/\nclass CancelError extends core_1.RequestError {\n constructor(request) {\n super('Promise was canceled', {}, request);\n this.name = 'CancelError';\n this.code = 'ERR_CANCELED';\n }\n get isCanceled() {\n return true;\n }\n}\nexports.CancelError = CancelError;\n__exportStar(__nccwpck_require__(94), exports);\n\n\n/***/ }),\n\n/***/ 3462:\n/***/ ((__unused_webpack_module, exports) => {\n\n\"use strict\";\n\nObject.defineProperty(exports, \"__esModule\", ({ value: true }));\nexports.retryAfterStatusCodes = void 0;\nexports.retryAfterStatusCodes = new Set([413, 429, 503]);\nconst calculateRetryDelay = ({ attemptCount, retryOptions, error, retryAfter }) => {\n if (attemptCount > retryOptions.limit) {\n return 0;\n }\n const hasMethod = retryOptions.methods.includes(error.options.method);\n const hasErrorCode = retryOptions.errorCodes.includes(error.code);\n const hasStatusCode = error.response && retryOptions.statusCodes.includes(error.response.statusCode);\n if (!hasMethod || (!hasErrorCode && !hasStatusCode)) {\n return 0;\n }\n if (error.response) {\n if (retryAfter) {\n if (retryOptions.maxRetryAfter === undefined || retryAfter > retryOptions.maxRetryAfter) {\n return 0;\n }\n return retryAfter;\n }\n if (error.response.statusCode === 413) {\n return 0;\n }\n }\n const noise = Math.random() * 100;\n return ((2 ** (attemptCount - 1)) * 1000) + noise;\n};\nexports[\"default\"] = calculateRetryDelay;\n\n\n/***/ }),\n\n/***/ 94:\n/***/ ((__unused_webpack_module, exports, __nccwpck_require__) => {\n\n\"use strict\";\n\nObject.defineProperty(exports, \"__esModule\", ({ value: true }));\nexports.UnsupportedProtocolError = exports.ReadError = exports.TimeoutError = exports.UploadError = exports.CacheError = exports.HTTPError = exports.MaxRedirectsError = exports.RequestError = exports.setNonEnumerableProperties = exports.knownHookEvents = exports.withoutBody = exports.kIsNormalizedAlready = void 0;\nconst util_1 = __nccwpck_require__(3837);\nconst stream_1 = __nccwpck_require__(2781);\nconst fs_1 = __nccwpck_require__(7147);\nconst url_1 = __nccwpck_require__(7310);\nconst http = __nccwpck_require__(3685);\nconst http_1 = __nccwpck_require__(3685);\nconst https = __nccwpck_require__(5687);\nconst http_timer_1 = __nccwpck_require__(8097);\nconst cacheable_lookup_1 = __nccwpck_require__(8367);\nconst CacheableRequest = __nccwpck_require__(8116);\nconst decompressResponse = __nccwpck_require__(2391);\n// @ts-expect-error Missing types\nconst http2wrapper = __nccwpck_require__(4645);\nconst lowercaseKeys = __nccwpck_require__(9662);\nconst is_1 = __nccwpck_require__(7678);\nconst get_body_size_1 = __nccwpck_require__(4564);\nconst is_form_data_1 = __nccwpck_require__(40);\nconst proxy_events_1 = __nccwpck_require__(3021);\nconst timed_out_1 = __nccwpck_require__(2454);\nconst url_to_options_1 = __nccwpck_require__(8026);\nconst options_to_url_1 = __nccwpck_require__(9219);\nconst weakable_map_1 = __nccwpck_require__(7288);\nconst get_buffer_1 = __nccwpck_require__(4500);\nconst dns_ip_version_1 = __nccwpck_require__(4993);\nconst is_response_ok_1 = __nccwpck_require__(9298);\nconst deprecation_warning_1 = __nccwpck_require__(397);\nconst normalize_arguments_1 = __nccwpck_require__(1048);\nconst calculate_retry_delay_1 = __nccwpck_require__(3462);\nlet globalDnsCache;\nconst kRequest = Symbol('request');\nconst kResponse = Symbol('response');\nconst kResponseSize = Symbol('responseSize');\nconst kDownloadedSize = Symbol('downloadedSize');\nconst kBodySize = Symbol('bodySize');\nconst kUploadedSize = Symbol('uploadedSize');\nconst kServerResponsesPiped = Symbol('serverResponsesPiped');\nconst kUnproxyEvents = Symbol('unproxyEvents');\nconst kIsFromCache = Symbol('isFromCache');\nconst kCancelTimeouts = Symbol('cancelTimeouts');\nconst kStartedReading = Symbol('startedReading');\nconst kStopReading = Symbol('stopReading');\nconst kTriggerRead = Symbol('triggerRead');\nconst kBody = Symbol('body');\nconst kJobs = Symbol('jobs');\nconst kOriginalResponse = Symbol('originalResponse');\nconst kRetryTimeout = Symbol('retryTimeout');\nexports.kIsNormalizedAlready = Symbol('isNormalizedAlready');\nconst supportsBrotli = is_1.default.string(process.versions.brotli);\nexports.withoutBody = new Set(['GET', 'HEAD']);\nexports.knownHookEvents = [\n 'init',\n 'beforeRequest',\n 'beforeRedirect',\n 'beforeError',\n 'beforeRetry',\n // Promise-Only\n 'afterResponse'\n];\nfunction validateSearchParameters(searchParameters) {\n // eslint-disable-next-line guard-for-in\n for (const key in searchParameters) {\n const value = searchParameters[key];\n if (!is_1.default.string(value) && !is_1.default.number(value) && !is_1.default.boolean(value) && !is_1.default.null_(value) && !is_1.default.undefined(value)) {\n throw new TypeError(`The \\`searchParams\\` value '${String(value)}' must be a string, number, boolean or null`);\n }\n }\n}\nfunction isClientRequest(clientRequest) {\n return is_1.default.object(clientRequest) && !('statusCode' in clientRequest);\n}\nconst cacheableStore = new weakable_map_1.default();\nconst waitForOpenFile = async (file) => new Promise((resolve, reject) => {\n const onError = (error) => {\n reject(error);\n };\n // Node.js 12 has incomplete types\n if (!file.pending) {\n resolve();\n }\n file.once('error', onError);\n file.once('ready', () => {\n file.off('error', onError);\n resolve();\n });\n});\nconst redirectCodes = new Set([300, 301, 302, 303, 304, 307, 308]);\nconst nonEnumerableProperties = [\n 'context',\n 'body',\n 'json',\n 'form'\n];\nexports.setNonEnumerableProperties = (sources, to) => {\n // Non enumerable properties shall not be merged\n const properties = {};\n for (const source of sources) {\n if (!source) {\n continue;\n }\n for (const name of nonEnumerableProperties) {\n if (!(name in source)) {\n continue;\n }\n properties[name] = {\n writable: true,\n configurable: true,\n enumerable: false,\n // @ts-expect-error TS doesn't see the check above\n value: source[name]\n };\n }\n }\n Object.defineProperties(to, properties);\n};\n/**\nAn error to be thrown when a request fails.\nContains a `code` property with error class code, like `ECONNREFUSED`.\n*/\nclass RequestError extends Error {\n constructor(message, error, self) {\n var _a, _b;\n super(message);\n Error.captureStackTrace(this, this.constructor);\n this.name = 'RequestError';\n this.code = (_a = error.code) !== null && _a !== void 0 ? _a : 'ERR_GOT_REQUEST_ERROR';\n if (self instanceof Request) {\n Object.defineProperty(this, 'request', {\n enumerable: false,\n value: self\n });\n Object.defineProperty(this, 'response', {\n enumerable: false,\n value: self[kResponse]\n });\n Object.defineProperty(this, 'options', {\n // This fails because of TS 3.7.2 useDefineForClassFields\n // Ref: https://github.com/microsoft/TypeScript/issues/34972\n enumerable: false,\n value: self.options\n });\n }\n else {\n Object.defineProperty(this, 'options', {\n // This fails because of TS 3.7.2 useDefineForClassFields\n // Ref: https://github.com/microsoft/TypeScript/issues/34972\n enumerable: false,\n value: self\n });\n }\n this.timings = (_b = this.request) === null || _b === void 0 ? void 0 : _b.timings;\n // Recover the original stacktrace\n if (is_1.default.string(error.stack) && is_1.default.string(this.stack)) {\n const indexOfMessage = this.stack.indexOf(this.message) + this.message.length;\n const thisStackTrace = this.stack.slice(indexOfMessage).split('\\n').reverse();\n const errorStackTrace = error.stack.slice(error.stack.indexOf(error.message) + error.message.length).split('\\n').reverse();\n // Remove duplicated traces\n while (errorStackTrace.length !== 0 && errorStackTrace[0] === thisStackTrace[0]) {\n thisStackTrace.shift();\n }\n this.stack = `${this.stack.slice(0, indexOfMessage)}${thisStackTrace.reverse().join('\\n')}${errorStackTrace.reverse().join('\\n')}`;\n }\n }\n}\nexports.RequestError = RequestError;\n/**\nAn error to be thrown when the server redirects you more than ten times.\nIncludes a `response` property.\n*/\nclass MaxRedirectsError extends RequestError {\n constructor(request) {\n super(`Redirected ${request.options.maxRedirects} times. Aborting.`, {}, request);\n this.name = 'MaxRedirectsError';\n this.code = 'ERR_TOO_MANY_REDIRECTS';\n }\n}\nexports.MaxRedirectsError = MaxRedirectsError;\n/**\nAn error to be thrown when the server response code is not 2xx nor 3xx if `options.followRedirect` is `true`, but always except for 304.\nIncludes a `response` property.\n*/\nclass HTTPError extends RequestError {\n constructor(response) {\n super(`Response code ${response.statusCode} (${response.statusMessage})`, {}, response.request);\n this.name = 'HTTPError';\n this.code = 'ERR_NON_2XX_3XX_RESPONSE';\n }\n}\nexports.HTTPError = HTTPError;\n/**\nAn error to be thrown when a cache method fails.\nFor example, if the database goes down or there's a filesystem error.\n*/\nclass CacheError extends RequestError {\n constructor(error, request) {\n super(error.message, error, request);\n this.name = 'CacheError';\n this.code = this.code === 'ERR_GOT_REQUEST_ERROR' ? 'ERR_CACHE_ACCESS' : this.code;\n }\n}\nexports.CacheError = CacheError;\n/**\nAn error to be thrown when the request body is a stream and an error occurs while reading from that stream.\n*/\nclass UploadError extends RequestError {\n constructor(error, request) {\n super(error.message, error, request);\n this.name = 'UploadError';\n this.code = this.code === 'ERR_GOT_REQUEST_ERROR' ? 'ERR_UPLOAD' : this.code;\n }\n}\nexports.UploadError = UploadError;\n/**\nAn error to be thrown when the request is aborted due to a timeout.\nIncludes an `event` and `timings` property.\n*/\nclass TimeoutError extends RequestError {\n constructor(error, timings, request) {\n super(error.message, error, request);\n this.name = 'TimeoutError';\n this.event = error.event;\n this.timings = timings;\n }\n}\nexports.TimeoutError = TimeoutError;\n/**\nAn error to be thrown when reading from response stream fails.\n*/\nclass ReadError extends RequestError {\n constructor(error, request) {\n super(error.message, error, request);\n this.name = 'ReadError';\n this.code = this.code === 'ERR_GOT_REQUEST_ERROR' ? 'ERR_READING_RESPONSE_STREAM' : this.code;\n }\n}\nexports.ReadError = ReadError;\n/**\nAn error to be thrown when given an unsupported protocol.\n*/\nclass UnsupportedProtocolError extends RequestError {\n constructor(options) {\n super(`Unsupported protocol \"${options.url.protocol}\"`, {}, options);\n this.name = 'UnsupportedProtocolError';\n this.code = 'ERR_UNSUPPORTED_PROTOCOL';\n }\n}\nexports.UnsupportedProtocolError = UnsupportedProtocolError;\nconst proxiedRequestEvents = [\n 'socket',\n 'connect',\n 'continue',\n 'information',\n 'upgrade',\n 'timeout'\n];\nclass Request extends stream_1.Duplex {\n constructor(url, options = {}, defaults) {\n super({\n // This must be false, to enable throwing after destroy\n // It is used for retry logic in Promise API\n autoDestroy: false,\n // It needs to be zero because we're just proxying the data to another stream\n highWaterMark: 0\n });\n this[kDownloadedSize] = 0;\n this[kUploadedSize] = 0;\n this.requestInitialized = false;\n this[kServerResponsesPiped] = new Set();\n this.redirects = [];\n this[kStopReading] = false;\n this[kTriggerRead] = false;\n this[kJobs] = [];\n this.retryCount = 0;\n // TODO: Remove this when targeting Node.js >= 12\n this._progressCallbacks = [];\n const unlockWrite = () => this._unlockWrite();\n const lockWrite = () => this._lockWrite();\n this.on('pipe', (source) => {\n source.prependListener('data', unlockWrite);\n source.on('data', lockWrite);\n source.prependListener('end', unlockWrite);\n source.on('end', lockWrite);\n });\n this.on('unpipe', (source) => {\n source.off('data', unlockWrite);\n source.off('data', lockWrite);\n source.off('end', unlockWrite);\n source.off('end', lockWrite);\n });\n this.on('pipe', source => {\n if (source instanceof http_1.IncomingMessage) {\n this.options.headers = {\n ...source.headers,\n ...this.options.headers\n };\n }\n });\n const { json, body, form } = options;\n if (json || body || form) {\n this._lockWrite();\n }\n if (exports.kIsNormalizedAlready in options) {\n this.options = options;\n }\n else {\n try {\n // @ts-expect-error Common TypeScript bug saying that `this.constructor` is not accessible\n this.options = this.constructor.normalizeArguments(url, options, defaults);\n }\n catch (error) {\n // TODO: Move this to `_destroy()`\n if (is_1.default.nodeStream(options.body)) {\n options.body.destroy();\n }\n this.destroy(error);\n return;\n }\n }\n (async () => {\n var _a;\n try {\n if (this.options.body instanceof fs_1.ReadStream) {\n await waitForOpenFile(this.options.body);\n }\n const { url: normalizedURL } = this.options;\n if (!normalizedURL) {\n throw new TypeError('Missing `url` property');\n }\n this.requestUrl = normalizedURL.toString();\n decodeURI(this.requestUrl);\n await this._finalizeBody();\n await this._makeRequest();\n if (this.destroyed) {\n (_a = this[kRequest]) === null || _a === void 0 ? void 0 : _a.destroy();\n return;\n }\n // Queued writes etc.\n for (const job of this[kJobs]) {\n job();\n }\n // Prevent memory leak\n this[kJobs].length = 0;\n this.requestInitialized = true;\n }\n catch (error) {\n if (error instanceof RequestError) {\n this._beforeError(error);\n return;\n }\n // This is a workaround for https://github.com/nodejs/node/issues/33335\n if (!this.destroyed) {\n this.destroy(error);\n }\n }\n })();\n }\n static normalizeArguments(url, options, defaults) {\n var _a, _b, _c, _d, _e;\n const rawOptions = options;\n if (is_1.default.object(url) && !is_1.default.urlInstance(url)) {\n options = { ...defaults, ...url, ...options };\n }\n else {\n if (url && options && options.url !== undefined) {\n throw new TypeError('The `url` option is mutually exclusive with the `input` argument');\n }\n options = { ...defaults, ...options };\n if (url !== undefined) {\n options.url = url;\n }\n if (is_1.default.urlInstance(options.url)) {\n options.url = new url_1.URL(options.url.toString());\n }\n }\n // TODO: Deprecate URL options in Got 12.\n // Support extend-specific options\n if (options.cache === false) {\n options.cache = undefined;\n }\n if (options.dnsCache === false) {\n options.dnsCache = undefined;\n }\n // Nice type assertions\n is_1.assert.any([is_1.default.string, is_1.default.undefined], options.method);\n is_1.assert.any([is_1.default.object, is_1.default.undefined], options.headers);\n is_1.assert.any([is_1.default.string, is_1.default.urlInstance, is_1.default.undefined], options.prefixUrl);\n is_1.assert.any([is_1.default.object, is_1.default.undefined], options.cookieJar);\n is_1.assert.any([is_1.default.object, is_1.default.string, is_1.default.undefined], options.searchParams);\n is_1.assert.any([is_1.default.object, is_1.default.string, is_1.default.undefined], options.cache);\n is_1.assert.any([is_1.default.object, is_1.default.number, is_1.default.undefined], options.timeout);\n is_1.assert.any([is_1.default.object, is_1.default.undefined], options.context);\n is_1.assert.any([is_1.default.object, is_1.default.undefined], options.hooks);\n is_1.assert.any([is_1.default.boolean, is_1.default.undefined], options.decompress);\n is_1.assert.any([is_1.default.boolean, is_1.default.undefined], options.ignoreInvalidCookies);\n is_1.assert.any([is_1.default.boolean, is_1.default.undefined], options.followRedirect);\n is_1.assert.any([is_1.default.number, is_1.default.undefined], options.maxRedirects);\n is_1.assert.any([is_1.default.boolean, is_1.default.undefined], options.throwHttpErrors);\n is_1.assert.any([is_1.default.boolean, is_1.default.undefined], options.http2);\n is_1.assert.any([is_1.default.boolean, is_1.default.undefined], options.allowGetBody);\n is_1.assert.any([is_1.default.string, is_1.default.undefined], options.localAddress);\n is_1.assert.any([dns_ip_version_1.isDnsLookupIpVersion, is_1.default.undefined], options.dnsLookupIpVersion);\n is_1.assert.any([is_1.default.object, is_1.default.undefined], options.https);\n is_1.assert.any([is_1.default.boolean, is_1.default.undefined], options.rejectUnauthorized);\n if (options.https) {\n is_1.assert.any([is_1.default.boolean, is_1.default.undefined], options.https.rejectUnauthorized);\n is_1.assert.any([is_1.default.function_, is_1.default.undefined], options.https.checkServerIdentity);\n is_1.assert.any([is_1.default.string, is_1.default.object, is_1.default.array, is_1.default.undefined], options.https.certificateAuthority);\n is_1.assert.any([is_1.default.string, is_1.default.object, is_1.default.array, is_1.default.undefined], options.https.key);\n is_1.assert.any([is_1.default.string, is_1.default.object, is_1.default.array, is_1.default.undefined], options.https.certificate);\n is_1.assert.any([is_1.default.string, is_1.default.undefined], options.https.passphrase);\n is_1.assert.any([is_1.default.string, is_1.default.buffer, is_1.default.array, is_1.default.undefined], options.https.pfx);\n }\n is_1.assert.any([is_1.default.object, is_1.default.undefined], options.cacheOptions);\n // `options.method`\n if (is_1.default.string(options.method)) {\n options.method = options.method.toUpperCase();\n }\n else {\n options.method = 'GET';\n }\n // `options.headers`\n if (options.headers === (defaults === null || defaults === void 0 ? void 0 : defaults.headers)) {\n options.headers = { ...options.headers };\n }\n else {\n options.headers = lowercaseKeys({ ...(defaults === null || defaults === void 0 ? void 0 : defaults.headers), ...options.headers });\n }\n // Disallow legacy `url.Url`\n if ('slashes' in options) {\n throw new TypeError('The legacy `url.Url` has been deprecated. Use `URL` instead.');\n }\n // `options.auth`\n if ('auth' in options) {\n throw new TypeError('Parameter `auth` is deprecated. Use `username` / `password` instead.');\n }\n // `options.searchParams`\n if ('searchParams' in options) {\n if (options.searchParams && options.searchParams !== (defaults === null || defaults === void 0 ? void 0 : defaults.searchParams)) {\n let searchParameters;\n if (is_1.default.string(options.searchParams) || (options.searchParams instanceof url_1.URLSearchParams)) {\n searchParameters = new url_1.URLSearchParams(options.searchParams);\n }\n else {\n validateSearchParameters(options.searchParams);\n searchParameters = new url_1.URLSearchParams();\n // eslint-disable-next-line guard-for-in\n for (const key in options.searchParams) {\n const value = options.searchParams[key];\n if (value === null) {\n searchParameters.append(key, '');\n }\n else if (value !== undefined) {\n searchParameters.append(key, value);\n }\n }\n }\n // `normalizeArguments()` is also used to merge options\n (_a = defaults === null || defaults === void 0 ? void 0 : defaults.searchParams) === null || _a === void 0 ? void 0 : _a.forEach((value, key) => {\n // Only use default if one isn't already defined\n if (!searchParameters.has(key)) {\n searchParameters.append(key, value);\n }\n });\n options.searchParams = searchParameters;\n }\n }\n // `options.username` & `options.password`\n options.username = (_b = options.username) !== null && _b !== void 0 ? _b : '';\n options.password = (_c = options.password) !== null && _c !== void 0 ? _c : '';\n // `options.prefixUrl` & `options.url`\n if (is_1.default.undefined(options.prefixUrl)) {\n options.prefixUrl = (_d = defaults === null || defaults === void 0 ? void 0 : defaults.prefixUrl) !== null && _d !== void 0 ? _d : '';\n }\n else {\n options.prefixUrl = options.prefixUrl.toString();\n if (options.prefixUrl !== '' && !options.prefixUrl.endsWith('/')) {\n options.prefixUrl += '/';\n }\n }\n if (is_1.default.string(options.url)) {\n if (options.url.startsWith('/')) {\n throw new Error('`input` must not start with a slash when using `prefixUrl`');\n }\n options.url = options_to_url_1.default(options.prefixUrl + options.url, options);\n }\n else if ((is_1.default.undefined(options.url) && options.prefixUrl !== '') || options.protocol) {\n options.url = options_to_url_1.default(options.prefixUrl, options);\n }\n if (options.url) {\n if ('port' in options) {\n delete options.port;\n }\n // Make it possible to change `options.prefixUrl`\n let { prefixUrl } = options;\n Object.defineProperty(options, 'prefixUrl', {\n set: (value) => {\n const url = options.url;\n if (!url.href.startsWith(value)) {\n throw new Error(`Cannot change \\`prefixUrl\\` from ${prefixUrl} to ${value}: ${url.href}`);\n }\n options.url = new url_1.URL(value + url.href.slice(prefixUrl.length));\n prefixUrl = value;\n },\n get: () => prefixUrl\n });\n // Support UNIX sockets\n let { protocol } = options.url;\n if (protocol === 'unix:') {\n protocol = 'http:';\n options.url = new url_1.URL(`http://unix${options.url.pathname}${options.url.search}`);\n }\n // Set search params\n if (options.searchParams) {\n // eslint-disable-next-line @typescript-eslint/no-base-to-string\n options.url.search = options.searchParams.toString();\n }\n // Protocol check\n if (protocol !== 'http:' && protocol !== 'https:') {\n throw new UnsupportedProtocolError(options);\n }\n // Update `username`\n if (options.username === '') {\n options.username = options.url.username;\n }\n else {\n options.url.username = options.username;\n }\n // Update `password`\n if (options.password === '') {\n options.password = options.url.password;\n }\n else {\n options.url.password = options.password;\n }\n }\n // `options.cookieJar`\n const { cookieJar } = options;\n if (cookieJar) {\n let { setCookie, getCookieString } = cookieJar;\n is_1.assert.function_(setCookie);\n is_1.assert.function_(getCookieString);\n /* istanbul ignore next: Horrible `tough-cookie` v3 check */\n if (setCookie.length === 4 && getCookieString.length === 0) {\n setCookie = util_1.promisify(setCookie.bind(options.cookieJar));\n getCookieString = util_1.promisify(getCookieString.bind(options.cookieJar));\n options.cookieJar = {\n setCookie,\n getCookieString: getCookieString\n };\n }\n }\n // `options.cache`\n const { cache } = options;\n if (cache) {\n if (!cacheableStore.has(cache)) {\n cacheableStore.set(cache, new CacheableRequest(((requestOptions, handler) => {\n const result = requestOptions[kRequest](requestOptions, handler);\n // TODO: remove this when `cacheable-request` supports async request functions.\n if (is_1.default.promise(result)) {\n // @ts-expect-error\n // We only need to implement the error handler in order to support HTTP2 caching.\n // The result will be a promise anyway.\n result.once = (event, handler) => {\n if (event === 'error') {\n result.catch(handler);\n }\n else if (event === 'abort') {\n // The empty catch is needed here in case when\n // it rejects before it's `await`ed in `_makeRequest`.\n (async () => {\n try {\n const request = (await result);\n request.once('abort', handler);\n }\n catch (_a) { }\n })();\n }\n else {\n /* istanbul ignore next: safety check */\n throw new Error(`Unknown HTTP2 promise event: ${event}`);\n }\n return result;\n };\n }\n return result;\n }), cache));\n }\n }\n // `options.cacheOptions`\n options.cacheOptions = { ...options.cacheOptions };\n // `options.dnsCache`\n if (options.dnsCache === true) {\n if (!globalDnsCache) {\n globalDnsCache = new cacheable_lookup_1.default();\n }\n options.dnsCache = globalDnsCache;\n }\n else if (!is_1.default.undefined(options.dnsCache) && !options.dnsCache.lookup) {\n throw new TypeError(`Parameter \\`dnsCache\\` must be a CacheableLookup instance or a boolean, got ${is_1.default(options.dnsCache)}`);\n }\n // `options.timeout`\n if (is_1.default.number(options.timeout)) {\n options.timeout = { request: options.timeout };\n }\n else if (defaults && options.timeout !== defaults.timeout) {\n options.timeout = {\n ...defaults.timeout,\n ...options.timeout\n };\n }\n else {\n options.timeout = { ...options.timeout };\n }\n // `options.context`\n if (!options.context) {\n options.context = {};\n }\n // `options.hooks`\n const areHooksDefault = options.hooks === (defaults === null || defaults === void 0 ? void 0 : defaults.hooks);\n options.hooks = { ...options.hooks };\n for (const event of exports.knownHookEvents) {\n if (event in options.hooks) {\n if (is_1.default.array(options.hooks[event])) {\n // See https://github.com/microsoft/TypeScript/issues/31445#issuecomment-576929044\n options.hooks[event] = [...options.hooks[event]];\n }\n else {\n throw new TypeError(`Parameter \\`${event}\\` must be an Array, got ${is_1.default(options.hooks[event])}`);\n }\n }\n else {\n options.hooks[event] = [];\n }\n }\n if (defaults && !areHooksDefault) {\n for (const event of exports.knownHookEvents) {\n const defaultHooks = defaults.hooks[event];\n if (defaultHooks.length > 0) {\n // See https://github.com/microsoft/TypeScript/issues/31445#issuecomment-576929044\n options.hooks[event] = [\n ...defaults.hooks[event],\n ...options.hooks[event]\n ];\n }\n }\n }\n // DNS options\n if ('family' in options) {\n deprecation_warning_1.default('\"options.family\" was never documented, please use \"options.dnsLookupIpVersion\"');\n }\n // HTTPS options\n if (defaults === null || defaults === void 0 ? void 0 : defaults.https) {\n options.https = { ...defaults.https, ...options.https };\n }\n if ('rejectUnauthorized' in options) {\n deprecation_warning_1.default('\"options.rejectUnauthorized\" is now deprecated, please use \"options.https.rejectUnauthorized\"');\n }\n if ('checkServerIdentity' in options) {\n deprecation_warning_1.default('\"options.checkServerIdentity\" was never documented, please use \"options.https.checkServerIdentity\"');\n }\n if ('ca' in options) {\n deprecation_warning_1.default('\"options.ca\" was never documented, please use \"options.https.certificateAuthority\"');\n }\n if ('key' in options) {\n deprecation_warning_1.default('\"options.key\" was never documented, please use \"options.https.key\"');\n }\n if ('cert' in options) {\n deprecation_warning_1.default('\"options.cert\" was never documented, please use \"options.https.certificate\"');\n }\n if ('passphrase' in options) {\n deprecation_warning_1.default('\"options.passphrase\" was never documented, please use \"options.https.passphrase\"');\n }\n if ('pfx' in options) {\n deprecation_warning_1.default('\"options.pfx\" was never documented, please use \"options.https.pfx\"');\n }\n // Other options\n if ('followRedirects' in options) {\n throw new TypeError('The `followRedirects` option does not exist. Use `followRedirect` instead.');\n }\n if (options.agent) {\n for (const key in options.agent) {\n if (key !== 'http' && key !== 'https' && key !== 'http2') {\n throw new TypeError(`Expected the \\`options.agent\\` properties to be \\`http\\`, \\`https\\` or \\`http2\\`, got \\`${key}\\``);\n }\n }\n }\n options.maxRedirects = (_e = options.maxRedirects) !== null && _e !== void 0 ? _e : 0;\n // Set non-enumerable properties\n exports.setNonEnumerableProperties([defaults, rawOptions], options);\n return normalize_arguments_1.default(options, defaults);\n }\n _lockWrite() {\n const onLockedWrite = () => {\n throw new TypeError('The payload has been already provided');\n };\n this.write = onLockedWrite;\n this.end = onLockedWrite;\n }\n _unlockWrite() {\n this.write = super.write;\n this.end = super.end;\n }\n async _finalizeBody() {\n const { options } = this;\n const { headers } = options;\n const isForm = !is_1.default.undefined(options.form);\n const isJSON = !is_1.default.undefined(options.json);\n const isBody = !is_1.default.undefined(options.body);\n const hasPayload = isForm || isJSON || isBody;\n const cannotHaveBody = exports.withoutBody.has(options.method) && !(options.method === 'GET' && options.allowGetBody);\n this._cannotHaveBody = cannotHaveBody;\n if (hasPayload) {\n if (cannotHaveBody) {\n throw new TypeError(`The \\`${options.method}\\` method cannot be used with a body`);\n }\n if ([isBody, isForm, isJSON].filter(isTrue => isTrue).length > 1) {\n throw new TypeError('The `body`, `json` and `form` options are mutually exclusive');\n }\n if (isBody &&\n !(options.body instanceof stream_1.Readable) &&\n !is_1.default.string(options.body) &&\n !is_1.default.buffer(options.body) &&\n !is_form_data_1.default(options.body)) {\n throw new TypeError('The `body` option must be a stream.Readable, string or Buffer');\n }\n if (isForm && !is_1.default.object(options.form)) {\n throw new TypeError('The `form` option must be an Object');\n }\n {\n // Serialize body\n const noContentType = !is_1.default.string(headers['content-type']);\n if (isBody) {\n // Special case for https://github.com/form-data/form-data\n if (is_form_data_1.default(options.body) && noContentType) {\n headers['content-type'] = `multipart/form-data; boundary=${options.body.getBoundary()}`;\n }\n this[kBody] = options.body;\n }\n else if (isForm) {\n if (noContentType) {\n headers['content-type'] = 'application/x-www-form-urlencoded';\n }\n this[kBody] = (new url_1.URLSearchParams(options.form)).toString();\n }\n else {\n if (noContentType) {\n headers['content-type'] = 'application/json';\n }\n this[kBody] = options.stringifyJson(options.json);\n }\n const uploadBodySize = await get_body_size_1.default(this[kBody], options.headers);\n // See https://tools.ietf.org/html/rfc7230#section-3.3.2\n // A user agent SHOULD send a Content-Length in a request message when\n // no Transfer-Encoding is sent and the request method defines a meaning\n // for an enclosed payload body. For example, a Content-Length header\n // field is normally sent in a POST request even when the value is 0\n // (indicating an empty payload body). A user agent SHOULD NOT send a\n // Content-Length header field when the request message does not contain\n // a payload body and the method semantics do not anticipate such a\n // body.\n if (is_1.default.undefined(headers['content-length']) && is_1.default.undefined(headers['transfer-encoding'])) {\n if (!cannotHaveBody && !is_1.default.undefined(uploadBodySize)) {\n headers['content-length'] = String(uploadBodySize);\n }\n }\n }\n }\n else if (cannotHaveBody) {\n this._lockWrite();\n }\n else {\n this._unlockWrite();\n }\n this[kBodySize] = Number(headers['content-length']) || undefined;\n }\n async _onResponseBase(response) {\n const { options } = this;\n const { url } = options;\n this[kOriginalResponse] = response;\n if (options.decompress) {\n response = decompressResponse(response);\n }\n const statusCode = response.statusCode;\n const typedResponse = response;\n typedResponse.statusMessage = typedResponse.statusMessage ? typedResponse.statusMessage : http.STATUS_CODES[statusCode];\n typedResponse.url = options.url.toString();\n typedResponse.requestUrl = this.requestUrl;\n typedResponse.redirectUrls = this.redirects;\n typedResponse.request = this;\n typedResponse.isFromCache = response.fromCache || false;\n typedResponse.ip = this.ip;\n typedResponse.retryCount = this.retryCount;\n this[kIsFromCache] = typedResponse.isFromCache;\n this[kResponseSize] = Number(response.headers['content-length']) || undefined;\n this[kResponse] = response;\n response.once('end', () => {\n this[kResponseSize] = this[kDownloadedSize];\n this.emit('downloadProgress', this.downloadProgress);\n });\n response.once('error', (error) => {\n // Force clean-up, because some packages don't do this.\n // TODO: Fix decompress-response\n response.destroy();\n this._beforeError(new ReadError(error, this));\n });\n response.once('aborted', () => {\n this._beforeError(new ReadError({\n name: 'Error',\n message: 'The server aborted pending request',\n code: 'ECONNRESET'\n }, this));\n });\n this.emit('downloadProgress', this.downloadProgress);\n const rawCookies = response.headers['set-cookie'];\n if (is_1.default.object(options.cookieJar) && rawCookies) {\n let promises = rawCookies.map(async (rawCookie) => options.cookieJar.setCookie(rawCookie, url.toString()));\n if (options.ignoreInvalidCookies) {\n promises = promises.map(async (p) => p.catch(() => { }));\n }\n try {\n await Promise.all(promises);\n }\n catch (error) {\n this._beforeError(error);\n return;\n }\n }\n if (options.followRedirect && response.headers.location && redirectCodes.has(statusCode)) {\n // We're being redirected, we don't care about the response.\n // It'd be best to abort the request, but we can't because\n // we would have to sacrifice the TCP connection. We don't want that.\n response.resume();\n if (this[kRequest]) {\n this[kCancelTimeouts]();\n // eslint-disable-next-line @typescript-eslint/no-dynamic-delete\n delete this[kRequest];\n this[kUnproxyEvents]();\n }\n const shouldBeGet = statusCode === 303 && options.method !== 'GET' && options.method !== 'HEAD';\n if (shouldBeGet || !options.methodRewriting) {\n // Server responded with \"see other\", indicating that the resource exists at another location,\n // and the client should request it from that location via GET or HEAD.\n options.method = 'GET';\n if ('body' in options) {\n delete options.body;\n }\n if ('json' in options) {\n delete options.json;\n }\n if ('form' in options) {\n delete options.form;\n }\n this[kBody] = undefined;\n delete options.headers['content-length'];\n }\n if (this.redirects.length >= options.maxRedirects) {\n this._beforeError(new MaxRedirectsError(this));\n return;\n }\n try {\n // Do not remove. See https://github.com/sindresorhus/got/pull/214\n const redirectBuffer = Buffer.from(response.headers.location, 'binary').toString();\n // Handles invalid URLs. See https://github.com/sindresorhus/got/issues/604\n const redirectUrl = new url_1.URL(redirectBuffer, url);\n const redirectString = redirectUrl.toString();\n decodeURI(redirectString);\n // eslint-disable-next-line no-inner-declarations\n function isUnixSocketURL(url) {\n return url.protocol === 'unix:' || url.hostname === 'unix';\n }\n if (!isUnixSocketURL(url) && isUnixSocketURL(redirectUrl)) {\n this._beforeError(new RequestError('Cannot redirect to UNIX socket', {}, this));\n return;\n }\n // Redirecting to a different site, clear sensitive data.\n if (redirectUrl.hostname !== url.hostname || redirectUrl.port !== url.port) {\n if ('host' in options.headers) {\n delete options.headers.host;\n }\n if ('cookie' in options.headers) {\n delete options.headers.cookie;\n }\n if ('authorization' in options.headers) {\n delete options.headers.authorization;\n }\n if (options.username || options.password) {\n options.username = '';\n options.password = '';\n }\n }\n else {\n redirectUrl.username = options.username;\n redirectUrl.password = options.password;\n }\n this.redirects.push(redirectString);\n options.url = redirectUrl;\n for (const hook of options.hooks.beforeRedirect) {\n // eslint-disable-next-line no-await-in-loop\n await hook(options, typedResponse);\n }\n this.emit('redirect', typedResponse, options);\n await this._makeRequest();\n }\n catch (error) {\n this._beforeError(error);\n return;\n }\n return;\n }\n if (options.isStream && options.throwHttpErrors && !is_response_ok_1.isResponseOk(typedResponse)) {\n this._beforeError(new HTTPError(typedResponse));\n return;\n }\n response.on('readable', () => {\n if (this[kTriggerRead]) {\n this._read();\n }\n });\n this.on('resume', () => {\n response.resume();\n });\n this.on('pause', () => {\n response.pause();\n });\n response.once('end', () => {\n this.push(null);\n });\n this.emit('response', response);\n for (const destination of this[kServerResponsesPiped]) {\n if (destination.headersSent) {\n continue;\n }\n // eslint-disable-next-line guard-for-in\n for (const key in response.headers) {\n const isAllowed = options.decompress ? key !== 'content-encoding' : true;\n const value = response.headers[key];\n if (isAllowed) {\n destination.setHeader(key, value);\n }\n }\n destination.statusCode = statusCode;\n }\n }\n async _onResponse(response) {\n try {\n await this._onResponseBase(response);\n }\n catch (error) {\n /* istanbul ignore next: better safe than sorry */\n this._beforeError(error);\n }\n }\n _onRequest(request) {\n const { options } = this;\n const { timeout, url } = options;\n http_timer_1.default(request);\n this[kCancelTimeouts] = timed_out_1.default(request, timeout, url);\n const responseEventName = options.cache ? 'cacheableResponse' : 'response';\n request.once(responseEventName, (response) => {\n void this._onResponse(response);\n });\n request.once('error', (error) => {\n var _a;\n // Force clean-up, because some packages (e.g. nock) don't do this.\n request.destroy();\n // Node.js <= 12.18.2 mistakenly emits the response `end` first.\n (_a = request.res) === null || _a === void 0 ? void 0 : _a.removeAllListeners('end');\n error = error instanceof timed_out_1.TimeoutError ? new TimeoutError(error, this.timings, this) : new RequestError(error.message, error, this);\n this._beforeError(error);\n });\n this[kUnproxyEvents] = proxy_events_1.default(request, this, proxiedRequestEvents);\n this[kRequest] = request;\n this.emit('uploadProgress', this.uploadProgress);\n // Send body\n const body = this[kBody];\n const currentRequest = this.redirects.length === 0 ? this : request;\n if (is_1.default.nodeStream(body)) {\n body.pipe(currentRequest);\n body.once('error', (error) => {\n this._beforeError(new UploadError(error, this));\n });\n }\n else {\n this._unlockWrite();\n if (!is_1.default.undefined(body)) {\n this._writeRequest(body, undefined, () => { });\n currentRequest.end();\n this._lockWrite();\n }\n else if (this._cannotHaveBody || this._noPipe) {\n currentRequest.end();\n this._lockWrite();\n }\n }\n this.emit('request', request);\n }\n async _createCacheableRequest(url, options) {\n return new Promise((resolve, reject) => {\n // TODO: Remove `utils/url-to-options.ts` when `cacheable-request` is fixed\n Object.assign(options, url_to_options_1.default(url));\n // `http-cache-semantics` checks this\n // TODO: Fix this ignore.\n // @ts-expect-error\n delete options.url;\n let request;\n // This is ugly\n const cacheRequest = cacheableStore.get(options.cache)(options, async (response) => {\n // TODO: Fix `cacheable-response`\n response._readableState.autoDestroy = false;\n if (request) {\n (await request).emit('cacheableResponse', response);\n }\n resolve(response);\n });\n // Restore options\n options.url = url;\n cacheRequest.once('error', reject);\n cacheRequest.once('request', async (requestOrPromise) => {\n request = requestOrPromise;\n resolve(request);\n });\n });\n }\n async _makeRequest() {\n var _a, _b, _c, _d, _e;\n const { options } = this;\n const { headers } = options;\n for (const key in headers) {\n if (is_1.default.undefined(headers[key])) {\n // eslint-disable-next-line @typescript-eslint/no-dynamic-delete\n delete headers[key];\n }\n else if (is_1.default.null_(headers[key])) {\n throw new TypeError(`Use \\`undefined\\` instead of \\`null\\` to delete the \\`${key}\\` header`);\n }\n }\n if (options.decompress && is_1.default.undefined(headers['accept-encoding'])) {\n headers['accept-encoding'] = supportsBrotli ? 'gzip, deflate, br' : 'gzip, deflate';\n }\n // Set cookies\n if (options.cookieJar) {\n const cookieString = await options.cookieJar.getCookieString(options.url.toString());\n if (is_1.default.nonEmptyString(cookieString)) {\n options.headers.cookie = cookieString;\n }\n }\n for (const hook of options.hooks.beforeRequest) {\n // eslint-disable-next-line no-await-in-loop\n const result = await hook(options);\n if (!is_1.default.undefined(result)) {\n // @ts-expect-error Skip the type mismatch to support abstract responses\n options.request = () => result;\n break;\n }\n }\n if (options.body && this[kBody] !== options.body) {\n this[kBody] = options.body;\n }\n const { agent, request, timeout, url } = options;\n if (options.dnsCache && !('lookup' in options)) {\n options.lookup = options.dnsCache.lookup;\n }\n // UNIX sockets\n if (url.hostname === 'unix') {\n const matches = /(?<socketPath>.+?):(?<path>.+)/.exec(`${url.pathname}${url.search}`);\n if (matches === null || matches === void 0 ? void 0 : matches.groups) {\n const { socketPath, path } = matches.groups;\n Object.assign(options, {\n socketPath,\n path,\n host: ''\n });\n }\n }\n const isHttps = url.protocol === 'https:';\n // Fallback function\n let fallbackFn;\n if (options.http2) {\n fallbackFn = http2wrapper.auto;\n }\n else {\n fallbackFn = isHttps ? https.request : http.request;\n }\n const realFn = (_a = options.request) !== null && _a !== void 0 ? _a : fallbackFn;\n // Cache support\n const fn = options.cache ? this._createCacheableRequest : realFn;\n // Pass an agent directly when HTTP2 is disabled\n if (agent && !options.http2) {\n options.agent = agent[isHttps ? 'https' : 'http'];\n }\n // Prepare plain HTTP request options\n options[kRequest] = realFn;\n delete options.request;\n // TODO: Fix this ignore.\n // @ts-expect-error\n delete options.timeout;\n const requestOptions = options;\n requestOptions.shared = (_b = options.cacheOptions) === null || _b === void 0 ? void 0 : _b.shared;\n requestOptions.cacheHeuristic = (_c = options.cacheOptions) === null || _c === void 0 ? void 0 : _c.cacheHeuristic;\n requestOptions.immutableMinTimeToLive = (_d = options.cacheOptions) === null || _d === void 0 ? void 0 : _d.immutableMinTimeToLive;\n requestOptions.ignoreCargoCult = (_e = options.cacheOptions) === null || _e === void 0 ? void 0 : _e.ignoreCargoCult;\n // If `dnsLookupIpVersion` is not present do not override `family`\n if (options.dnsLookupIpVersion !== undefined) {\n try {\n requestOptions.family = dns_ip_version_1.dnsLookupIpVersionToFamily(options.dnsLookupIpVersion);\n }\n catch (_f) {\n throw new Error('Invalid `dnsLookupIpVersion` option value');\n }\n }\n // HTTPS options remapping\n if (options.https) {\n if ('rejectUnauthorized' in options.https) {\n requestOptions.rejectUnauthorized = options.https.rejectUnauthorized;\n }\n if (options.https.checkServerIdentity) {\n requestOptions.checkServerIdentity = options.https.checkServerIdentity;\n }\n if (options.https.certificateAuthority) {\n requestOptions.ca = options.https.certificateAuthority;\n }\n if (options.https.certificate) {\n requestOptions.cert = options.https.certificate;\n }\n if (options.https.key) {\n requestOptions.key = options.https.key;\n }\n if (options.https.passphrase) {\n requestOptions.passphrase = options.https.passphrase;\n }\n if (options.https.pfx) {\n requestOptions.pfx = options.https.pfx;\n }\n }\n try {\n let requestOrResponse = await fn(url, requestOptions);\n if (is_1.default.undefined(requestOrResponse)) {\n requestOrResponse = fallbackFn(url, requestOptions);\n }\n // Restore options\n options.request = request;\n options.timeout = timeout;\n options.agent = agent;\n // HTTPS options restore\n if (options.https) {\n if ('rejectUnauthorized' in options.https) {\n delete requestOptions.rejectUnauthorized;\n }\n if (options.https.checkServerIdentity) {\n // @ts-expect-error - This one will be removed when we remove the alias.\n delete requestOptions.checkServerIdentity;\n }\n if (options.https.certificateAuthority) {\n delete requestOptions.ca;\n }\n if (options.https.certificate) {\n delete requestOptions.cert;\n }\n if (options.https.key) {\n delete requestOptions.key;\n }\n if (options.https.passphrase) {\n delete requestOptions.passphrase;\n }\n if (options.https.pfx) {\n delete requestOptions.pfx;\n }\n }\n if (isClientRequest(requestOrResponse)) {\n this._onRequest(requestOrResponse);\n // Emit the response after the stream has been ended\n }\n else if (this.writable) {\n this.once('finish', () => {\n void this._onResponse(requestOrResponse);\n });\n this._unlockWrite();\n this.end();\n this._lockWrite();\n }\n else {\n void this._onResponse(requestOrResponse);\n }\n }\n catch (error) {\n if (error instanceof CacheableRequest.CacheError) {\n throw new CacheError(error, this);\n }\n throw new RequestError(error.message, error, this);\n }\n }\n async _error(error) {\n try {\n for (const hook of this.options.hooks.beforeError) {\n // eslint-disable-next-line no-await-in-loop\n error = await hook(error);\n }\n }\n catch (error_) {\n error = new RequestError(error_.message, error_, this);\n }\n this.destroy(error);\n }\n _beforeError(error) {\n if (this[kStopReading]) {\n return;\n }\n const { options } = this;\n const retryCount = this.retryCount + 1;\n this[kStopReading] = true;\n if (!(error instanceof RequestError)) {\n error = new RequestError(error.message, error, this);\n }\n const typedError = error;\n const { response } = typedError;\n void (async () => {\n if (response && !response.body) {\n response.setEncoding(this._readableState.encoding);\n try {\n response.rawBody = await get_buffer_1.default(response);\n response.body = response.rawBody.toString();\n }\n catch (_a) { }\n }\n if (this.listenerCount('retry') !== 0) {\n let backoff;\n try {\n let retryAfter;\n if (response && 'retry-after' in response.headers) {\n retryAfter = Number(response.headers['retry-after']);\n if (Number.isNaN(retryAfter)) {\n retryAfter = Date.parse(response.headers['retry-after']) - Date.now();\n if (retryAfter <= 0) {\n retryAfter = 1;\n }\n }\n else {\n retryAfter *= 1000;\n }\n }\n backoff = await options.retry.calculateDelay({\n attemptCount: retryCount,\n retryOptions: options.retry,\n error: typedError,\n retryAfter,\n computedValue: calculate_retry_delay_1.default({\n attemptCount: retryCount,\n retryOptions: options.retry,\n error: typedError,\n retryAfter,\n computedValue: 0\n })\n });\n }\n catch (error_) {\n void this._error(new RequestError(error_.message, error_, this));\n return;\n }\n if (backoff) {\n const retry = async () => {\n try {\n for (const hook of this.options.hooks.beforeRetry) {\n // eslint-disable-next-line no-await-in-loop\n await hook(this.options, typedError, retryCount);\n }\n }\n catch (error_) {\n void this._error(new RequestError(error_.message, error, this));\n return;\n }\n // Something forced us to abort the retry\n if (this.destroyed) {\n return;\n }\n this.destroy();\n this.emit('retry', retryCount, error);\n };\n this[kRetryTimeout] = setTimeout(retry, backoff);\n return;\n }\n }\n void this._error(typedError);\n })();\n }\n _read() {\n this[kTriggerRead] = true;\n const response = this[kResponse];\n if (response && !this[kStopReading]) {\n // We cannot put this in the `if` above\n // because `.read()` also triggers the `end` event\n if (response.readableLength) {\n this[kTriggerRead] = false;\n }\n let data;\n while ((data = response.read()) !== null) {\n this[kDownloadedSize] += data.length;\n this[kStartedReading] = true;\n const progress = this.downloadProgress;\n if (progress.percent < 1) {\n this.emit('downloadProgress', progress);\n }\n this.push(data);\n }\n }\n }\n // Node.js 12 has incorrect types, so the encoding must be a string\n _write(chunk, encoding, callback) {\n const write = () => {\n this._writeRequest(chunk, encoding, callback);\n };\n if (this.requestInitialized) {\n write();\n }\n else {\n this[kJobs].push(write);\n }\n }\n _writeRequest(chunk, encoding, callback) {\n if (this[kRequest].destroyed) {\n // Probably the `ClientRequest` instance will throw\n return;\n }\n this._progressCallbacks.push(() => {\n this[kUploadedSize] += Buffer.byteLength(chunk, encoding);\n const progress = this.uploadProgress;\n if (progress.percent < 1) {\n this.emit('uploadProgress', progress);\n }\n });\n // TODO: What happens if it's from cache? Then this[kRequest] won't be defined.\n this[kRequest].write(chunk, encoding, (error) => {\n if (!error && this._progressCallbacks.length > 0) {\n this._progressCallbacks.shift()();\n }\n callback(error);\n });\n }\n _final(callback) {\n const endRequest = () => {\n // FIX: Node.js 10 calls the write callback AFTER the end callback!\n while (this._progressCallbacks.length !== 0) {\n this._progressCallbacks.shift()();\n }\n // We need to check if `this[kRequest]` is present,\n // because it isn't when we use cache.\n if (!(kRequest in this)) {\n callback();\n return;\n }\n if (this[kRequest].destroyed) {\n callback();\n return;\n }\n this[kRequest].end((error) => {\n if (!error) {\n this[kBodySize] = this[kUploadedSize];\n this.emit('uploadProgress', this.uploadProgress);\n this[kRequest].emit('upload-complete');\n }\n callback(error);\n });\n };\n if (this.requestInitialized) {\n endRequest();\n }\n else {\n this[kJobs].push(endRequest);\n }\n }\n _destroy(error, callback) {\n var _a;\n this[kStopReading] = true;\n // Prevent further retries\n clearTimeout(this[kRetryTimeout]);\n if (kRequest in this) {\n this[kCancelTimeouts]();\n // TODO: Remove the next `if` when these get fixed:\n // - https://github.com/nodejs/node/issues/32851\n if (!((_a = this[kResponse]) === null || _a === void 0 ? void 0 : _a.complete)) {\n this[kRequest].destroy();\n }\n }\n if (error !== null && !is_1.default.undefined(error) && !(error instanceof RequestError)) {\n error = new RequestError(error.message, error, this);\n }\n callback(error);\n }\n get _isAboutToError() {\n return this[kStopReading];\n }\n /**\n The remote IP address.\n */\n get ip() {\n var _a;\n return (_a = this.socket) === null || _a === void 0 ? void 0 : _a.remoteAddress;\n }\n /**\n Indicates whether the request has been aborted or not.\n */\n get aborted() {\n var _a, _b, _c;\n return ((_b = (_a = this[kRequest]) === null || _a === void 0 ? void 0 : _a.destroyed) !== null && _b !== void 0 ? _b : this.destroyed) && !((_c = this[kOriginalResponse]) === null || _c === void 0 ? void 0 : _c.complete);\n }\n get socket() {\n var _a, _b;\n return (_b = (_a = this[kRequest]) === null || _a === void 0 ? void 0 : _a.socket) !== null && _b !== void 0 ? _b : undefined;\n }\n /**\n Progress event for downloading (receiving a response).\n */\n get downloadProgress() {\n let percent;\n if (this[kResponseSize]) {\n percent = this[kDownloadedSize] / this[kResponseSize];\n }\n else if (this[kResponseSize] === this[kDownloadedSize]) {\n percent = 1;\n }\n else {\n percent = 0;\n }\n return {\n percent,\n transferred: this[kDownloadedSize],\n total: this[kResponseSize]\n };\n }\n /**\n Progress event for uploading (sending a request).\n */\n get uploadProgress() {\n let percent;\n if (this[kBodySize]) {\n percent = this[kUploadedSize] / this[kBodySize];\n }\n else if (this[kBodySize] === this[kUploadedSize]) {\n percent = 1;\n }\n else {\n percent = 0;\n }\n return {\n percent,\n transferred: this[kUploadedSize],\n total: this[kBodySize]\n };\n }\n /**\n The object contains the following properties:\n\n - `start` - Time when the request started.\n - `socket` - Time when a socket was assigned to the request.\n - `lookup` - Time when the DNS lookup finished.\n - `connect` - Time when the socket successfully connected.\n - `secureConnect` - Time when the socket securely connected.\n - `upload` - Time when the request finished uploading.\n - `response` - Time when the request fired `response` event.\n - `end` - Time when the response fired `end` event.\n - `error` - Time when the request fired `error` event.\n - `abort` - Time when the request fired `abort` event.\n - `phases`\n - `wait` - `timings.socket - timings.start`\n - `dns` - `timings.lookup - timings.socket`\n - `tcp` - `timings.connect - timings.lookup`\n - `tls` - `timings.secureConnect - timings.connect`\n - `request` - `timings.upload - (timings.secureConnect || timings.connect)`\n - `firstByte` - `timings.response - timings.upload`\n - `download` - `timings.end - timings.response`\n - `total` - `(timings.end || timings.error || timings.abort) - timings.start`\n\n If something has not been measured yet, it will be `undefined`.\n\n __Note__: The time is a `number` representing the milliseconds elapsed since the UNIX epoch.\n */\n get timings() {\n var _a;\n return (_a = this[kRequest]) === null || _a === void 0 ? void 0 : _a.timings;\n }\n /**\n Whether the response was retrieved from the cache.\n */\n get isFromCache() {\n return this[kIsFromCache];\n }\n pipe(destination, options) {\n if (this[kStartedReading]) {\n throw new Error('Failed to pipe. The response has been emitted already.');\n }\n if (destination instanceof http_1.ServerResponse) {\n this[kServerResponsesPiped].add(destination);\n }\n return super.pipe(destination, options);\n }\n unpipe(destination) {\n if (destination instanceof http_1.ServerResponse) {\n this[kServerResponsesPiped].delete(destination);\n }\n super.unpipe(destination);\n return this;\n }\n}\nexports[\"default\"] = Request;\n\n\n/***/ }),\n\n/***/ 4993:\n/***/ ((__unused_webpack_module, exports) => {\n\n\"use strict\";\n\nObject.defineProperty(exports, \"__esModule\", ({ value: true }));\nexports.dnsLookupIpVersionToFamily = exports.isDnsLookupIpVersion = void 0;\nconst conversionTable = {\n auto: 0,\n ipv4: 4,\n ipv6: 6\n};\nexports.isDnsLookupIpVersion = (value) => {\n return value in conversionTable;\n};\nexports.dnsLookupIpVersionToFamily = (dnsLookupIpVersion) => {\n if (exports.isDnsLookupIpVersion(dnsLookupIpVersion)) {\n return conversionTable[dnsLookupIpVersion];\n }\n throw new Error('Invalid DNS lookup IP version');\n};\n\n\n/***/ }),\n\n/***/ 4564:\n/***/ ((__unused_webpack_module, exports, __nccwpck_require__) => {\n\n\"use strict\";\n\nObject.defineProperty(exports, \"__esModule\", ({ value: true }));\nconst fs_1 = __nccwpck_require__(7147);\nconst util_1 = __nccwpck_require__(3837);\nconst is_1 = __nccwpck_require__(7678);\nconst is_form_data_1 = __nccwpck_require__(40);\nconst statAsync = util_1.promisify(fs_1.stat);\nexports[\"default\"] = async (body, headers) => {\n if (headers && 'content-length' in headers) {\n return Number(headers['content-length']);\n }\n if (!body) {\n return 0;\n }\n if (is_1.default.string(body)) {\n return Buffer.byteLength(body);\n }\n if (is_1.default.buffer(body)) {\n return body.length;\n }\n if (is_form_data_1.default(body)) {\n return util_1.promisify(body.getLength.bind(body))();\n }\n if (body instanceof fs_1.ReadStream) {\n const { size } = await statAsync(body.path);\n if (size === 0) {\n return undefined;\n }\n return size;\n }\n return undefined;\n};\n\n\n/***/ }),\n\n/***/ 4500:\n/***/ ((__unused_webpack_module, exports) => {\n\n\"use strict\";\n\nObject.defineProperty(exports, \"__esModule\", ({ value: true }));\n// TODO: Update https://github.com/sindresorhus/get-stream\nconst getBuffer = async (stream) => {\n const chunks = [];\n let length = 0;\n for await (const chunk of stream) {\n chunks.push(chunk);\n length += Buffer.byteLength(chunk);\n }\n if (Buffer.isBuffer(chunks[0])) {\n return Buffer.concat(chunks, length);\n }\n return Buffer.from(chunks.join(''));\n};\nexports[\"default\"] = getBuffer;\n\n\n/***/ }),\n\n/***/ 40:\n/***/ ((__unused_webpack_module, exports, __nccwpck_require__) => {\n\n\"use strict\";\n\nObject.defineProperty(exports, \"__esModule\", ({ value: true }));\nconst is_1 = __nccwpck_require__(7678);\nexports[\"default\"] = (body) => is_1.default.nodeStream(body) && is_1.default.function_(body.getBoundary);\n\n\n/***/ }),\n\n/***/ 9298:\n/***/ ((__unused_webpack_module, exports) => {\n\n\"use strict\";\n\nObject.defineProperty(exports, \"__esModule\", ({ value: true }));\nexports.isResponseOk = void 0;\nexports.isResponseOk = (response) => {\n const { statusCode } = response;\n const limitStatusCode = response.request.options.followRedirect ? 299 : 399;\n return (statusCode >= 200 && statusCode <= limitStatusCode) || statusCode === 304;\n};\n\n\n/***/ }),\n\n/***/ 9219:\n/***/ ((__unused_webpack_module, exports, __nccwpck_require__) => {\n\n\"use strict\";\n\nObject.defineProperty(exports, \"__esModule\", ({ value: true }));\n/* istanbul ignore file: deprecated */\nconst url_1 = __nccwpck_require__(7310);\nconst keys = [\n 'protocol',\n 'host',\n 'hostname',\n 'port',\n 'pathname',\n 'search'\n];\nexports[\"default\"] = (origin, options) => {\n var _a, _b;\n if (options.path) {\n if (options.pathname) {\n throw new TypeError('Parameters `path` and `pathname` are mutually exclusive.');\n }\n if (options.search) {\n throw new TypeError('Parameters `path` and `search` are mutually exclusive.');\n }\n if (options.searchParams) {\n throw new TypeError('Parameters `path` and `searchParams` are mutually exclusive.');\n }\n }\n if (options.search && options.searchParams) {\n throw new TypeError('Parameters `search` and `searchParams` are mutually exclusive.');\n }\n if (!origin) {\n if (!options.protocol) {\n throw new TypeError('No URL protocol specified');\n }\n origin = `${options.protocol}//${(_b = (_a = options.hostname) !== null && _a !== void 0 ? _a : options.host) !== null && _b !== void 0 ? _b : ''}`;\n }\n const url = new url_1.URL(origin);\n if (options.path) {\n const searchIndex = options.path.indexOf('?');\n if (searchIndex === -1) {\n options.pathname = options.path;\n }\n else {\n options.pathname = options.path.slice(0, searchIndex);\n options.search = options.path.slice(searchIndex + 1);\n }\n delete options.path;\n }\n for (const key of keys) {\n if (options[key]) {\n url[key] = options[key].toString();\n }\n }\n return url;\n};\n\n\n/***/ }),\n\n/***/ 3021:\n/***/ ((__unused_webpack_module, exports) => {\n\n\"use strict\";\n\nObject.defineProperty(exports, \"__esModule\", ({ value: true }));\nfunction default_1(from, to, events) {\n const fns = {};\n for (const event of events) {\n fns[event] = (...args) => {\n to.emit(event, ...args);\n };\n from.on(event, fns[event]);\n }\n return () => {\n for (const event of events) {\n from.off(event, fns[event]);\n }\n };\n}\nexports[\"default\"] = default_1;\n\n\n/***/ }),\n\n/***/ 2454:\n/***/ ((__unused_webpack_module, exports, __nccwpck_require__) => {\n\n\"use strict\";\n\nObject.defineProperty(exports, \"__esModule\", ({ value: true }));\nexports.TimeoutError = void 0;\nconst net = __nccwpck_require__(1808);\nconst unhandle_1 = __nccwpck_require__(1593);\nconst reentry = Symbol('reentry');\nconst noop = () => { };\nclass TimeoutError extends Error {\n constructor(threshold, event) {\n super(`Timeout awaiting '${event}' for ${threshold}ms`);\n this.event = event;\n this.name = 'TimeoutError';\n this.code = 'ETIMEDOUT';\n }\n}\nexports.TimeoutError = TimeoutError;\nexports[\"default\"] = (request, delays, options) => {\n if (reentry in request) {\n return noop;\n }\n request[reentry] = true;\n const cancelers = [];\n const { once, unhandleAll } = unhandle_1.default();\n const addTimeout = (delay, callback, event) => {\n var _a;\n const timeout = setTimeout(callback, delay, delay, event);\n (_a = timeout.unref) === null || _a === void 0 ? void 0 : _a.call(timeout);\n const cancel = () => {\n clearTimeout(timeout);\n };\n cancelers.push(cancel);\n return cancel;\n };\n const { host, hostname } = options;\n const timeoutHandler = (delay, event) => {\n request.destroy(new TimeoutError(delay, event));\n };\n const cancelTimeouts = () => {\n for (const cancel of cancelers) {\n cancel();\n }\n unhandleAll();\n };\n request.once('error', error => {\n cancelTimeouts();\n // Save original behavior\n /* istanbul ignore next */\n if (request.listenerCount('error') === 0) {\n throw error;\n }\n });\n request.once('close', cancelTimeouts);\n once(request, 'response', (response) => {\n once(response, 'end', cancelTimeouts);\n });\n if (typeof delays.request !== 'undefined') {\n addTimeout(delays.request, timeoutHandler, 'request');\n }\n if (typeof delays.socket !== 'undefined') {\n const socketTimeoutHandler = () => {\n timeoutHandler(delays.socket, 'socket');\n };\n request.setTimeout(delays.socket, socketTimeoutHandler);\n // `request.setTimeout(0)` causes a memory leak.\n // We can just remove the listener and forget about the timer - it's unreffed.\n // See https://github.com/sindresorhus/got/issues/690\n cancelers.push(() => {\n request.removeListener('timeout', socketTimeoutHandler);\n });\n }\n once(request, 'socket', (socket) => {\n var _a;\n const { socketPath } = request;\n /* istanbul ignore next: hard to test */\n if (socket.connecting) {\n const hasPath = Boolean(socketPath !== null && socketPath !== void 0 ? socketPath : net.isIP((_a = hostname !== null && hostname !== void 0 ? hostname : host) !== null && _a !== void 0 ? _a : '') !== 0);\n if (typeof delays.lookup !== 'undefined' && !hasPath && typeof socket.address().address === 'undefined') {\n const cancelTimeout = addTimeout(delays.lookup, timeoutHandler, 'lookup');\n once(socket, 'lookup', cancelTimeout);\n }\n if (typeof delays.connect !== 'undefined') {\n const timeConnect = () => addTimeout(delays.connect, timeoutHandler, 'connect');\n if (hasPath) {\n once(socket, 'connect', timeConnect());\n }\n else {\n once(socket, 'lookup', (error) => {\n if (error === null) {\n once(socket, 'connect', timeConnect());\n }\n });\n }\n }\n if (typeof delays.secureConnect !== 'undefined' && options.protocol === 'https:') {\n once(socket, 'connect', () => {\n const cancelTimeout = addTimeout(delays.secureConnect, timeoutHandler, 'secureConnect');\n once(socket, 'secureConnect', cancelTimeout);\n });\n }\n }\n if (typeof delays.send !== 'undefined') {\n const timeRequest = () => addTimeout(delays.send, timeoutHandler, 'send');\n /* istanbul ignore next: hard to test */\n if (socket.connecting) {\n once(socket, 'connect', () => {\n once(request, 'upload-complete', timeRequest());\n });\n }\n else {\n once(request, 'upload-complete', timeRequest());\n }\n }\n });\n if (typeof delays.response !== 'undefined') {\n once(request, 'upload-complete', () => {\n const cancelTimeout = addTimeout(delays.response, timeoutHandler, 'response');\n once(request, 'response', cancelTimeout);\n });\n }\n return cancelTimeouts;\n};\n\n\n/***/ }),\n\n/***/ 1593:\n/***/ ((__unused_webpack_module, exports) => {\n\n\"use strict\";\n\nObject.defineProperty(exports, \"__esModule\", ({ value: true }));\n// When attaching listeners, it's very easy to forget about them.\n// Especially if you do error handling and set timeouts.\n// So instead of checking if it's proper to throw an error on every timeout ever,\n// use this simple tool which will remove all listeners you have attached.\nexports[\"default\"] = () => {\n const handlers = [];\n return {\n once(origin, event, fn) {\n origin.once(event, fn);\n handlers.push({ origin, event, fn });\n },\n unhandleAll() {\n for (const handler of handlers) {\n const { origin, event, fn } = handler;\n origin.removeListener(event, fn);\n }\n handlers.length = 0;\n }\n };\n};\n\n\n/***/ }),\n\n/***/ 8026:\n/***/ ((__unused_webpack_module, exports, __nccwpck_require__) => {\n\n\"use strict\";\n\nObject.defineProperty(exports, \"__esModule\", ({ value: true }));\nconst is_1 = __nccwpck_require__(7678);\nexports[\"default\"] = (url) => {\n // Cast to URL\n url = url;\n const options = {\n protocol: url.protocol,\n hostname: is_1.default.string(url.hostname) && url.hostname.startsWith('[') ? url.hostname.slice(1, -1) : url.hostname,\n host: url.host,\n hash: url.hash,\n search: url.search,\n pathname: url.pathname,\n href: url.href,\n path: `${url.pathname || ''}${url.search || ''}`\n };\n if (is_1.default.string(url.port) && url.port.length > 0) {\n options.port = Number(url.port);\n }\n if (url.username || url.password) {\n options.auth = `${url.username || ''}:${url.password || ''}`;\n }\n return options;\n};\n\n\n/***/ }),\n\n/***/ 7288:\n/***/ ((__unused_webpack_module, exports) => {\n\n\"use strict\";\n\nObject.defineProperty(exports, \"__esModule\", ({ value: true }));\nclass WeakableMap {\n constructor() {\n this.weakMap = new WeakMap();\n this.map = new Map();\n }\n set(key, value) {\n if (typeof key === 'object') {\n this.weakMap.set(key, value);\n }\n else {\n this.map.set(key, value);\n }\n }\n get(key) {\n if (typeof key === 'object') {\n return this.weakMap.get(key);\n }\n return this.map.get(key);\n }\n has(key) {\n if (typeof key === 'object') {\n return this.weakMap.has(key);\n }\n return this.map.has(key);\n }\n}\nexports[\"default\"] = WeakableMap;\n\n\n/***/ }),\n\n/***/ 4337:\n/***/ (function(__unused_webpack_module, exports, __nccwpck_require__) {\n\n\"use strict\";\n\nvar __createBinding = (this && this.__createBinding) || (Object.create ? (function(o, m, k, k2) {\n if (k2 === undefined) k2 = k;\n Object.defineProperty(o, k2, { enumerable: true, get: function() { return m[k]; } });\n}) : (function(o, m, k, k2) {\n if (k2 === undefined) k2 = k;\n o[k2] = m[k];\n}));\nvar __exportStar = (this && this.__exportStar) || function(m, exports) {\n for (var p in m) if (p !== \"default\" && !Object.prototype.hasOwnProperty.call(exports, p)) __createBinding(exports, m, p);\n};\nObject.defineProperty(exports, \"__esModule\", ({ value: true }));\nexports.defaultHandler = void 0;\nconst is_1 = __nccwpck_require__(7678);\nconst as_promise_1 = __nccwpck_require__(6056);\nconst create_rejection_1 = __nccwpck_require__(6457);\nconst core_1 = __nccwpck_require__(94);\nconst deep_freeze_1 = __nccwpck_require__(285);\nconst errors = {\n RequestError: as_promise_1.RequestError,\n CacheError: as_promise_1.CacheError,\n ReadError: as_promise_1.ReadError,\n HTTPError: as_promise_1.HTTPError,\n MaxRedirectsError: as_promise_1.MaxRedirectsError,\n TimeoutError: as_promise_1.TimeoutError,\n ParseError: as_promise_1.ParseError,\n CancelError: as_promise_1.CancelError,\n UnsupportedProtocolError: as_promise_1.UnsupportedProtocolError,\n UploadError: as_promise_1.UploadError\n};\n// The `delay` package weighs 10KB (!)\nconst delay = async (ms) => new Promise(resolve => {\n setTimeout(resolve, ms);\n});\nconst { normalizeArguments } = core_1.default;\nconst mergeOptions = (...sources) => {\n let mergedOptions;\n for (const source of sources) {\n mergedOptions = normalizeArguments(undefined, source, mergedOptions);\n }\n return mergedOptions;\n};\nconst getPromiseOrStream = (options) => options.isStream ? new core_1.default(undefined, options) : as_promise_1.default(options);\nconst isGotInstance = (value) => ('defaults' in value && 'options' in value.defaults);\nconst aliases = [\n 'get',\n 'post',\n 'put',\n 'patch',\n 'head',\n 'delete'\n];\nexports.defaultHandler = (options, next) => next(options);\nconst callInitHooks = (hooks, options) => {\n if (hooks) {\n for (const hook of hooks) {\n hook(options);\n }\n }\n};\nconst create = (defaults) => {\n // Proxy properties from next handlers\n defaults._rawHandlers = defaults.handlers;\n defaults.handlers = defaults.handlers.map(fn => ((options, next) => {\n // This will be assigned by assigning result\n let root;\n const result = fn(options, newOptions => {\n root = next(newOptions);\n return root;\n });\n if (result !== root && !options.isStream && root) {\n const typedResult = result;\n const { then: promiseThen, catch: promiseCatch, finally: promiseFianlly } = typedResult;\n Object.setPrototypeOf(typedResult, Object.getPrototypeOf(root));\n Object.defineProperties(typedResult, Object.getOwnPropertyDescriptors(root));\n // These should point to the new promise\n // eslint-disable-next-line promise/prefer-await-to-then\n typedResult.then = promiseThen;\n typedResult.catch = promiseCatch;\n typedResult.finally = promiseFianlly;\n }\n return result;\n }));\n // Got interface\n const got = ((url, options = {}, _defaults) => {\n var _a, _b;\n let iteration = 0;\n const iterateHandlers = (newOptions) => {\n return defaults.handlers[iteration++](newOptions, iteration === defaults.handlers.length ? getPromiseOrStream : iterateHandlers);\n };\n // TODO: Remove this in Got 12.\n if (is_1.default.plainObject(url)) {\n const mergedOptions = {\n ...url,\n ...options\n };\n core_1.setNonEnumerableProperties([url, options], mergedOptions);\n options = mergedOptions;\n url = undefined;\n }\n try {\n // Call `init` hooks\n let initHookError;\n try {\n callInitHooks(defaults.options.hooks.init, options);\n callInitHooks((_a = options.hooks) === null || _a === void 0 ? void 0 : _a.init, options);\n }\n catch (error) {\n initHookError = error;\n }\n // Normalize options & call handlers\n const normalizedOptions = normalizeArguments(url, options, _defaults !== null && _defaults !== void 0 ? _defaults : defaults.options);\n normalizedOptions[core_1.kIsNormalizedAlready] = true;\n if (initHookError) {\n throw new as_promise_1.RequestError(initHookError.message, initHookError, normalizedOptions);\n }\n return iterateHandlers(normalizedOptions);\n }\n catch (error) {\n if (options.isStream) {\n throw error;\n }\n else {\n return create_rejection_1.default(error, defaults.options.hooks.beforeError, (_b = options.hooks) === null || _b === void 0 ? void 0 : _b.beforeError);\n }\n }\n });\n got.extend = (...instancesOrOptions) => {\n const optionsArray = [defaults.options];\n let handlers = [...defaults._rawHandlers];\n let isMutableDefaults;\n for (const value of instancesOrOptions) {\n if (isGotInstance(value)) {\n optionsArray.push(value.defaults.options);\n handlers.push(...value.defaults._rawHandlers);\n isMutableDefaults = value.defaults.mutableDefaults;\n }\n else {\n optionsArray.push(value);\n if ('handlers' in value) {\n handlers.push(...value.handlers);\n }\n isMutableDefaults = value.mutableDefaults;\n }\n }\n handlers = handlers.filter(handler => handler !== exports.defaultHandler);\n if (handlers.length === 0) {\n handlers.push(exports.defaultHandler);\n }\n return create({\n options: mergeOptions(...optionsArray),\n handlers,\n mutableDefaults: Boolean(isMutableDefaults)\n });\n };\n // Pagination\n const paginateEach = (async function* (url, options) {\n // TODO: Remove this `@ts-expect-error` when upgrading to TypeScript 4.\n // Error: Argument of type 'Merge<Options, PaginationOptions<T, R>> | undefined' is not assignable to parameter of type 'Options | undefined'.\n // @ts-expect-error\n let normalizedOptions = normalizeArguments(url, options, defaults.options);\n normalizedOptions.resolveBodyOnly = false;\n const pagination = normalizedOptions.pagination;\n if (!is_1.default.object(pagination)) {\n throw new TypeError('`options.pagination` must be implemented');\n }\n const all = [];\n let { countLimit } = pagination;\n let numberOfRequests = 0;\n while (numberOfRequests < pagination.requestLimit) {\n if (numberOfRequests !== 0) {\n // eslint-disable-next-line no-await-in-loop\n await delay(pagination.backoff);\n }\n // @ts-expect-error FIXME!\n // TODO: Throw when result is not an instance of Response\n // eslint-disable-next-line no-await-in-loop\n const result = (await got(undefined, undefined, normalizedOptions));\n // eslint-disable-next-line no-await-in-loop\n const parsed = await pagination.transform(result);\n const current = [];\n for (const item of parsed) {\n if (pagination.filter(item, all, current)) {\n if (!pagination.shouldContinue(item, all, current)) {\n return;\n }\n yield item;\n if (pagination.stackAllItems) {\n all.push(item);\n }\n current.push(item);\n if (--countLimit <= 0) {\n return;\n }\n }\n }\n const optionsToMerge = pagination.paginate(result, all, current);\n if (optionsToMerge === false) {\n return;\n }\n if (optionsToMerge === result.request.options) {\n normalizedOptions = result.request.options;\n }\n else if (optionsToMerge !== undefined) {\n normalizedOptions = normalizeArguments(undefined, optionsToMerge, normalizedOptions);\n }\n numberOfRequests++;\n }\n });\n got.paginate = paginateEach;\n got.paginate.all = (async (url, options) => {\n const results = [];\n for await (const item of paginateEach(url, options)) {\n results.push(item);\n }\n return results;\n });\n // For those who like very descriptive names\n got.paginate.each = paginateEach;\n // Stream API\n got.stream = ((url, options) => got(url, { ...options, isStream: true }));\n // Shortcuts\n for (const method of aliases) {\n got[method] = ((url, options) => got(url, { ...options, method }));\n got.stream[method] = ((url, options) => {\n return got(url, { ...options, method, isStream: true });\n });\n }\n Object.assign(got, errors);\n Object.defineProperty(got, 'defaults', {\n value: defaults.mutableDefaults ? defaults : deep_freeze_1.default(defaults),\n writable: defaults.mutableDefaults,\n configurable: defaults.mutableDefaults,\n enumerable: true\n });\n got.mergeOptions = mergeOptions;\n return got;\n};\nexports[\"default\"] = create;\n__exportStar(__nccwpck_require__(2613), exports);\n\n\n/***/ }),\n\n/***/ 3061:\n/***/ (function(module, exports, __nccwpck_require__) {\n\n\"use strict\";\n\nvar __createBinding = (this && this.__createBinding) || (Object.create ? (function(o, m, k, k2) {\n if (k2 === undefined) k2 = k;\n Object.defineProperty(o, k2, { enumerable: true, get: function() { return m[k]; } });\n}) : (function(o, m, k, k2) {\n if (k2 === undefined) k2 = k;\n o[k2] = m[k];\n}));\nvar __exportStar = (this && this.__exportStar) || function(m, exports) {\n for (var p in m) if (p !== \"default\" && !Object.prototype.hasOwnProperty.call(exports, p)) __createBinding(exports, m, p);\n};\nObject.defineProperty(exports, \"__esModule\", ({ value: true }));\nconst url_1 = __nccwpck_require__(7310);\nconst create_1 = __nccwpck_require__(4337);\nconst defaults = {\n options: {\n method: 'GET',\n retry: {\n limit: 2,\n methods: [\n 'GET',\n 'PUT',\n 'HEAD',\n 'DELETE',\n 'OPTIONS',\n 'TRACE'\n ],\n statusCodes: [\n 408,\n 413,\n 429,\n 500,\n 502,\n 503,\n 504,\n 521,\n 522,\n 524\n ],\n errorCodes: [\n 'ETIMEDOUT',\n 'ECONNRESET',\n 'EADDRINUSE',\n 'ECONNREFUSED',\n 'EPIPE',\n 'ENOTFOUND',\n 'ENETUNREACH',\n 'EAI_AGAIN'\n ],\n maxRetryAfter: undefined,\n calculateDelay: ({ computedValue }) => computedValue\n },\n timeout: {},\n headers: {\n 'user-agent': 'got (https://github.com/sindresorhus/got)'\n },\n hooks: {\n init: [],\n beforeRequest: [],\n beforeRedirect: [],\n beforeRetry: [],\n beforeError: [],\n afterResponse: []\n },\n cache: undefined,\n dnsCache: undefined,\n decompress: true,\n throwHttpErrors: true,\n followRedirect: true,\n isStream: false,\n responseType: 'text',\n resolveBodyOnly: false,\n maxRedirects: 10,\n prefixUrl: '',\n methodRewriting: true,\n ignoreInvalidCookies: false,\n context: {},\n // TODO: Set this to `true` when Got 12 gets released\n http2: false,\n allowGetBody: false,\n https: undefined,\n pagination: {\n transform: (response) => {\n if (response.request.options.responseType === 'json') {\n return response.body;\n }\n return JSON.parse(response.body);\n },\n paginate: response => {\n if (!Reflect.has(response.headers, 'link')) {\n return false;\n }\n const items = response.headers.link.split(',');\n let next;\n for (const item of items) {\n const parsed = item.split(';');\n if (parsed[1].includes('next')) {\n next = parsed[0].trimStart().trim();\n next = next.slice(1, -1);\n break;\n }\n }\n if (next) {\n const options = {\n url: new url_1.URL(next)\n };\n return options;\n }\n return false;\n },\n filter: () => true,\n shouldContinue: () => true,\n countLimit: Infinity,\n backoff: 0,\n requestLimit: 10000,\n stackAllItems: true\n },\n parseJson: (text) => JSON.parse(text),\n stringifyJson: (object) => JSON.stringify(object),\n cacheOptions: {}\n },\n handlers: [create_1.defaultHandler],\n mutableDefaults: false\n};\nconst got = create_1.default(defaults);\nexports[\"default\"] = got;\n// For CommonJS default export support\nmodule.exports = got;\nmodule.exports[\"default\"] = got;\nmodule.exports.__esModule = true; // Workaround for TS issue: https://github.com/sindresorhus/got/pull/1267\n__exportStar(__nccwpck_require__(4337), exports);\n__exportStar(__nccwpck_require__(6056), exports);\n\n\n/***/ }),\n\n/***/ 2613:\n/***/ ((__unused_webpack_module, exports) => {\n\n\"use strict\";\n\nObject.defineProperty(exports, \"__esModule\", ({ value: true }));\n\n\n/***/ }),\n\n/***/ 285:\n/***/ ((__unused_webpack_module, exports, __nccwpck_require__) => {\n\n\"use strict\";\n\nObject.defineProperty(exports, \"__esModule\", ({ value: true }));\nconst is_1 = __nccwpck_require__(7678);\nfunction deepFreeze(object) {\n for (const value of Object.values(object)) {\n if (is_1.default.plainObject(value) || is_1.default.array(value)) {\n deepFreeze(value);\n }\n }\n return Object.freeze(object);\n}\nexports[\"default\"] = deepFreeze;\n\n\n/***/ }),\n\n/***/ 397:\n/***/ ((__unused_webpack_module, exports) => {\n\n\"use strict\";\n\nObject.defineProperty(exports, \"__esModule\", ({ value: true }));\nconst alreadyWarned = new Set();\nexports[\"default\"] = (message) => {\n if (alreadyWarned.has(message)) {\n return;\n }\n alreadyWarned.add(message);\n // @ts-expect-error Missing types.\n process.emitWarning(`Got: ${message}`, {\n type: 'DeprecationWarning'\n });\n};\n\n\n/***/ }),\n\n/***/ 1002:\n/***/ ((module) => {\n\n\"use strict\";\n\n// rfc7231 6.1\nconst statusCodeCacheableByDefault = new Set([\n 200,\n 203,\n 204,\n 206,\n 300,\n 301,\n 308,\n 404,\n 405,\n 410,\n 414,\n 501,\n]);\n\n// This implementation does not understand partial responses (206)\nconst understoodStatuses = new Set([\n 200,\n 203,\n 204,\n 300,\n 301,\n 302,\n 303,\n 307,\n 308,\n 404,\n 405,\n 410,\n 414,\n 501,\n]);\n\nconst errorStatusCodes = new Set([\n 500,\n 502,\n 503, \n 504,\n]);\n\nconst hopByHopHeaders = {\n date: true, // included, because we add Age update Date\n connection: true,\n 'keep-alive': true,\n 'proxy-authenticate': true,\n 'proxy-authorization': true,\n te: true,\n trailer: true,\n 'transfer-encoding': true,\n upgrade: true,\n};\n\nconst excludedFromRevalidationUpdate = {\n // Since the old body is reused, it doesn't make sense to change properties of the body\n 'content-length': true,\n 'content-encoding': true,\n 'transfer-encoding': true,\n 'content-range': true,\n};\n\nfunction toNumberOrZero(s) {\n const n = parseInt(s, 10);\n return isFinite(n) ? n : 0;\n}\n\n// RFC 5861\nfunction isErrorResponse(response) {\n // consider undefined response as faulty\n if(!response) {\n return true\n }\n return errorStatusCodes.has(response.status);\n}\n\nfunction parseCacheControl(header) {\n const cc = {};\n if (!header) return cc;\n\n // TODO: When there is more than one value present for a given directive (e.g., two Expires header fields, multiple Cache-Control: max-age directives),\n // the directive's value is considered invalid. Caches are encouraged to consider responses that have invalid freshness information to be stale\n const parts = header.trim().split(/,/);\n for (const part of parts) {\n const [k, v] = part.split(/=/, 2);\n cc[k.trim()] = v === undefined ? true : v.trim().replace(/^\"|\"$/g, '');\n }\n\n return cc;\n}\n\nfunction formatCacheControl(cc) {\n let parts = [];\n for (const k in cc) {\n const v = cc[k];\n parts.push(v === true ? k : k + '=' + v);\n }\n if (!parts.length) {\n return undefined;\n }\n return parts.join(', ');\n}\n\nmodule.exports = class CachePolicy {\n constructor(\n req,\n res,\n {\n shared,\n cacheHeuristic,\n immutableMinTimeToLive,\n ignoreCargoCult,\n _fromObject,\n } = {}\n ) {\n if (_fromObject) {\n this._fromObject(_fromObject);\n return;\n }\n\n if (!res || !res.headers) {\n throw Error('Response headers missing');\n }\n this._assertRequestHasHeaders(req);\n\n this._responseTime = this.now();\n this._isShared = shared !== false;\n this._cacheHeuristic =\n undefined !== cacheHeuristic ? cacheHeuristic : 0.1; // 10% matches IE\n this._immutableMinTtl =\n undefined !== immutableMinTimeToLive\n ? immutableMinTimeToLive\n : 24 * 3600 * 1000;\n\n this._status = 'status' in res ? res.status : 200;\n this._resHeaders = res.headers;\n this._rescc = parseCacheControl(res.headers['cache-control']);\n this._method = 'method' in req ? req.method : 'GET';\n this._url = req.url;\n this._host = req.headers.host;\n this._noAuthorization = !req.headers.authorization;\n this._reqHeaders = res.headers.vary ? req.headers : null; // Don't keep all request headers if they won't be used\n this._reqcc = parseCacheControl(req.headers['cache-control']);\n\n // Assume that if someone uses legacy, non-standard uncecessary options they don't understand caching,\n // so there's no point stricly adhering to the blindly copy&pasted directives.\n if (\n ignoreCargoCult &&\n 'pre-check' in this._rescc &&\n 'post-check' in this._rescc\n ) {\n delete this._rescc['pre-check'];\n delete this._rescc['post-check'];\n delete this._rescc['no-cache'];\n delete this._rescc['no-store'];\n delete this._rescc['must-revalidate'];\n this._resHeaders = Object.assign({}, this._resHeaders, {\n 'cache-control': formatCacheControl(this._rescc),\n });\n delete this._resHeaders.expires;\n delete this._resHeaders.pragma;\n }\n\n // When the Cache-Control header field is not present in a request, caches MUST consider the no-cache request pragma-directive\n // as having the same effect as if \"Cache-Control: no-cache\" were present (see Section 5.2.1).\n if (\n res.headers['cache-control'] == null &&\n /no-cache/.test(res.headers.pragma)\n ) {\n this._rescc['no-cache'] = true;\n }\n }\n\n now() {\n return Date.now();\n }\n\n storable() {\n // The \"no-store\" request directive indicates that a cache MUST NOT store any part of either this request or any response to it.\n return !!(\n !this._reqcc['no-store'] &&\n // A cache MUST NOT store a response to any request, unless:\n // The request method is understood by the cache and defined as being cacheable, and\n ('GET' === this._method ||\n 'HEAD' === this._method ||\n ('POST' === this._method && this._hasExplicitExpiration())) &&\n // the response status code is understood by the cache, and\n understoodStatuses.has(this._status) &&\n // the \"no-store\" cache directive does not appear in request or response header fields, and\n !this._rescc['no-store'] &&\n // the \"private\" response directive does not appear in the response, if the cache is shared, and\n (!this._isShared || !this._rescc.private) &&\n // the Authorization header field does not appear in the request, if the cache is shared,\n (!this._isShared ||\n this._noAuthorization ||\n this._allowsStoringAuthenticated()) &&\n // the response either:\n // contains an Expires header field, or\n (this._resHeaders.expires ||\n // contains a max-age response directive, or\n // contains a s-maxage response directive and the cache is shared, or\n // contains a public response directive.\n this._rescc['max-age'] ||\n (this._isShared && this._rescc['s-maxage']) ||\n this._rescc.public ||\n // has a status code that is defined as cacheable by default\n statusCodeCacheableByDefault.has(this._status))\n );\n }\n\n _hasExplicitExpiration() {\n // 4.2.1 Calculating Freshness Lifetime\n return (\n (this._isShared && this._rescc['s-maxage']) ||\n this._rescc['max-age'] ||\n this._resHeaders.expires\n );\n }\n\n _assertRequestHasHeaders(req) {\n if (!req || !req.headers) {\n throw Error('Request headers missing');\n }\n }\n\n satisfiesWithoutRevalidation(req) {\n this._assertRequestHasHeaders(req);\n\n // When presented with a request, a cache MUST NOT reuse a stored response, unless:\n // the presented request does not contain the no-cache pragma (Section 5.4), nor the no-cache cache directive,\n // unless the stored response is successfully validated (Section 4.3), and\n const requestCC = parseCacheControl(req.headers['cache-control']);\n if (requestCC['no-cache'] || /no-cache/.test(req.headers.pragma)) {\n return false;\n }\n\n if (requestCC['max-age'] && this.age() > requestCC['max-age']) {\n return false;\n }\n\n if (\n requestCC['min-fresh'] &&\n this.timeToLive() < 1000 * requestCC['min-fresh']\n ) {\n return false;\n }\n\n // the stored response is either:\n // fresh, or allowed to be served stale\n if (this.stale()) {\n const allowsStale =\n requestCC['max-stale'] &&\n !this._rescc['must-revalidate'] &&\n (true === requestCC['max-stale'] ||\n requestCC['max-stale'] > this.age() - this.maxAge());\n if (!allowsStale) {\n return false;\n }\n }\n\n return this._requestMatches(req, false);\n }\n\n _requestMatches(req, allowHeadMethod) {\n // The presented effective request URI and that of the stored response match, and\n return (\n (!this._url || this._url === req.url) &&\n this._host === req.headers.host &&\n // the request method associated with the stored response allows it to be used for the presented request, and\n (!req.method ||\n this._method === req.method ||\n (allowHeadMethod && 'HEAD' === req.method)) &&\n // selecting header fields nominated by the stored response (if any) match those presented, and\n this._varyMatches(req)\n );\n }\n\n _allowsStoringAuthenticated() {\n // following Cache-Control response directives (Section 5.2.2) have such an effect: must-revalidate, public, and s-maxage.\n return (\n this._rescc['must-revalidate'] ||\n this._rescc.public ||\n this._rescc['s-maxage']\n );\n }\n\n _varyMatches(req) {\n if (!this._resHeaders.vary) {\n return true;\n }\n\n // A Vary header field-value of \"*\" always fails to match\n if (this._resHeaders.vary === '*') {\n return false;\n }\n\n const fields = this._resHeaders.vary\n .trim()\n .toLowerCase()\n .split(/\\s*,\\s*/);\n for (const name of fields) {\n if (req.headers[name] !== this._reqHeaders[name]) return false;\n }\n return true;\n }\n\n _copyWithoutHopByHopHeaders(inHeaders) {\n const headers = {};\n for (const name in inHeaders) {\n if (hopByHopHeaders[name]) continue;\n headers[name] = inHeaders[name];\n }\n // 9.1. Connection\n if (inHeaders.connection) {\n const tokens = inHeaders.connection.trim().split(/\\s*,\\s*/);\n for (const name of tokens) {\n delete headers[name];\n }\n }\n if (headers.warning) {\n const warnings = headers.warning.split(/,/).filter(warning => {\n return !/^\\s*1[0-9][0-9]/.test(warning);\n });\n if (!warnings.length) {\n delete headers.warning;\n } else {\n headers.warning = warnings.join(',').trim();\n }\n }\n return headers;\n }\n\n responseHeaders() {\n const headers = this._copyWithoutHopByHopHeaders(this._resHeaders);\n const age = this.age();\n\n // A cache SHOULD generate 113 warning if it heuristically chose a freshness\n // lifetime greater than 24 hours and the response's age is greater than 24 hours.\n if (\n age > 3600 * 24 &&\n !this._hasExplicitExpiration() &&\n this.maxAge() > 3600 * 24\n ) {\n headers.warning =\n (headers.warning ? `${headers.warning}, ` : '') +\n '113 - \"rfc7234 5.5.4\"';\n }\n headers.age = `${Math.round(age)}`;\n headers.date = new Date(this.now()).toUTCString();\n return headers;\n }\n\n /**\n * Value of the Date response header or current time if Date was invalid\n * @return timestamp\n */\n date() {\n const serverDate = Date.parse(this._resHeaders.date);\n if (isFinite(serverDate)) {\n return serverDate;\n }\n return this._responseTime;\n }\n\n /**\n * Value of the Age header, in seconds, updated for the current time.\n * May be fractional.\n *\n * @return Number\n */\n age() {\n let age = this._ageValue();\n\n const residentTime = (this.now() - this._responseTime) / 1000;\n return age + residentTime;\n }\n\n _ageValue() {\n return toNumberOrZero(this._resHeaders.age);\n }\n\n /**\n * Value of applicable max-age (or heuristic equivalent) in seconds. This counts since response's `Date`.\n *\n * For an up-to-date value, see `timeToLive()`.\n *\n * @return Number\n */\n maxAge() {\n if (!this.storable() || this._rescc['no-cache']) {\n return 0;\n }\n\n // Shared responses with cookies are cacheable according to the RFC, but IMHO it'd be unwise to do so by default\n // so this implementation requires explicit opt-in via public header\n if (\n this._isShared &&\n (this._resHeaders['set-cookie'] &&\n !this._rescc.public &&\n !this._rescc.immutable)\n ) {\n return 0;\n }\n\n if (this._resHeaders.vary === '*') {\n return 0;\n }\n\n if (this._isShared) {\n if (this._rescc['proxy-revalidate']) {\n return 0;\n }\n // if a response includes the s-maxage directive, a shared cache recipient MUST ignore the Expires field.\n if (this._rescc['s-maxage']) {\n return toNumberOrZero(this._rescc['s-maxage']);\n }\n }\n\n // If a response includes a Cache-Control field with the max-age directive, a recipient MUST ignore the Expires field.\n if (this._rescc['max-age']) {\n return toNumberOrZero(this._rescc['max-age']);\n }\n\n const defaultMinTtl = this._rescc.immutable ? this._immutableMinTtl : 0;\n\n const serverDate = this.date();\n if (this._resHeaders.expires) {\n const expires = Date.parse(this._resHeaders.expires);\n // A cache recipient MUST interpret invalid date formats, especially the value \"0\", as representing a time in the past (i.e., \"already expired\").\n if (Number.isNaN(expires) || expires < serverDate) {\n return 0;\n }\n return Math.max(defaultMinTtl, (expires - serverDate) / 1000);\n }\n\n if (this._resHeaders['last-modified']) {\n const lastModified = Date.parse(this._resHeaders['last-modified']);\n if (isFinite(lastModified) && serverDate > lastModified) {\n return Math.max(\n defaultMinTtl,\n ((serverDate - lastModified) / 1000) * this._cacheHeuristic\n );\n }\n }\n\n return defaultMinTtl;\n }\n\n timeToLive() {\n const age = this.maxAge() - this.age();\n const staleIfErrorAge = age + toNumberOrZero(this._rescc['stale-if-error']);\n const staleWhileRevalidateAge = age + toNumberOrZero(this._rescc['stale-while-revalidate']);\n return Math.max(0, age, staleIfErrorAge, staleWhileRevalidateAge) * 1000;\n }\n\n stale() {\n return this.maxAge() <= this.age();\n }\n\n _useStaleIfError() {\n return this.maxAge() + toNumberOrZero(this._rescc['stale-if-error']) > this.age();\n }\n\n useStaleWhileRevalidate() {\n return this.maxAge() + toNumberOrZero(this._rescc['stale-while-revalidate']) > this.age();\n }\n\n static fromObject(obj) {\n return new this(undefined, undefined, { _fromObject: obj });\n }\n\n _fromObject(obj) {\n if (this._responseTime) throw Error('Reinitialized');\n if (!obj || obj.v !== 1) throw Error('Invalid serialization');\n\n this._responseTime = obj.t;\n this._isShared = obj.sh;\n this._cacheHeuristic = obj.ch;\n this._immutableMinTtl =\n obj.imm !== undefined ? obj.imm : 24 * 3600 * 1000;\n this._status = obj.st;\n this._resHeaders = obj.resh;\n this._rescc = obj.rescc;\n this._method = obj.m;\n this._url = obj.u;\n this._host = obj.h;\n this._noAuthorization = obj.a;\n this._reqHeaders = obj.reqh;\n this._reqcc = obj.reqcc;\n }\n\n toObject() {\n return {\n v: 1,\n t: this._responseTime,\n sh: this._isShared,\n ch: this._cacheHeuristic,\n imm: this._immutableMinTtl,\n st: this._status,\n resh: this._resHeaders,\n rescc: this._rescc,\n m: this._method,\n u: this._url,\n h: this._host,\n a: this._noAuthorization,\n reqh: this._reqHeaders,\n reqcc: this._reqcc,\n };\n }\n\n /**\n * Headers for sending to the origin server to revalidate stale response.\n * Allows server to return 304 to allow reuse of the previous response.\n *\n * Hop by hop headers are always stripped.\n * Revalidation headers may be added or removed, depending on request.\n */\n revalidationHeaders(incomingReq) {\n this._assertRequestHasHeaders(incomingReq);\n const headers = this._copyWithoutHopByHopHeaders(incomingReq.headers);\n\n // This implementation does not understand range requests\n delete headers['if-range'];\n\n if (!this._requestMatches(incomingReq, true) || !this.storable()) {\n // revalidation allowed via HEAD\n // not for the same resource, or wasn't allowed to be cached anyway\n delete headers['if-none-match'];\n delete headers['if-modified-since'];\n return headers;\n }\n\n /* MUST send that entity-tag in any cache validation request (using If-Match or If-None-Match) if an entity-tag has been provided by the origin server. */\n if (this._resHeaders.etag) {\n headers['if-none-match'] = headers['if-none-match']\n ? `${headers['if-none-match']}, ${this._resHeaders.etag}`\n : this._resHeaders.etag;\n }\n\n // Clients MAY issue simple (non-subrange) GET requests with either weak validators or strong validators. Clients MUST NOT use weak validators in other forms of request.\n const forbidsWeakValidators =\n headers['accept-ranges'] ||\n headers['if-match'] ||\n headers['if-unmodified-since'] ||\n (this._method && this._method != 'GET');\n\n /* SHOULD send the Last-Modified value in non-subrange cache validation requests (using If-Modified-Since) if only a Last-Modified value has been provided by the origin server.\n Note: This implementation does not understand partial responses (206) */\n if (forbidsWeakValidators) {\n delete headers['if-modified-since'];\n\n if (headers['if-none-match']) {\n const etags = headers['if-none-match']\n .split(/,/)\n .filter(etag => {\n return !/^\\s*W\\//.test(etag);\n });\n if (!etags.length) {\n delete headers['if-none-match'];\n } else {\n headers['if-none-match'] = etags.join(',').trim();\n }\n }\n } else if (\n this._resHeaders['last-modified'] &&\n !headers['if-modified-since']\n ) {\n headers['if-modified-since'] = this._resHeaders['last-modified'];\n }\n\n return headers;\n }\n\n /**\n * Creates new CachePolicy with information combined from the previews response,\n * and the new revalidation response.\n *\n * Returns {policy, modified} where modified is a boolean indicating\n * whether the response body has been modified, and old cached body can't be used.\n *\n * @return {Object} {policy: CachePolicy, modified: Boolean}\n */\n revalidatedPolicy(request, response) {\n this._assertRequestHasHeaders(request);\n if(this._useStaleIfError() && isErrorResponse(response)) { // I consider the revalidation request unsuccessful\n return {\n modified: false,\n matches: false,\n policy: this,\n };\n }\n if (!response || !response.headers) {\n throw Error('Response headers missing');\n }\n\n // These aren't going to be supported exactly, since one CachePolicy object\n // doesn't know about all the other cached objects.\n let matches = false;\n if (response.status !== undefined && response.status != 304) {\n matches = false;\n } else if (\n response.headers.etag &&\n !/^\\s*W\\//.test(response.headers.etag)\n ) {\n // \"All of the stored responses with the same strong validator are selected.\n // If none of the stored responses contain the same strong validator,\n // then the cache MUST NOT use the new response to update any stored responses.\"\n matches =\n this._resHeaders.etag &&\n this._resHeaders.etag.replace(/^\\s*W\\//, '') ===\n response.headers.etag;\n } else if (this._resHeaders.etag && response.headers.etag) {\n // \"If the new response contains a weak validator and that validator corresponds\n // to one of the cache's stored responses,\n // then the most recent of those matching stored responses is selected for update.\"\n matches =\n this._resHeaders.etag.replace(/^\\s*W\\//, '') ===\n response.headers.etag.replace(/^\\s*W\\//, '');\n } else if (this._resHeaders['last-modified']) {\n matches =\n this._resHeaders['last-modified'] ===\n response.headers['last-modified'];\n } else {\n // If the new response does not include any form of validator (such as in the case where\n // a client generates an If-Modified-Since request from a source other than the Last-Modified\n // response header field), and there is only one stored response, and that stored response also\n // lacks a validator, then that stored response is selected for update.\n if (\n !this._resHeaders.etag &&\n !this._resHeaders['last-modified'] &&\n !response.headers.etag &&\n !response.headers['last-modified']\n ) {\n matches = true;\n }\n }\n\n if (!matches) {\n return {\n policy: new this.constructor(request, response),\n // Client receiving 304 without body, even if it's invalid/mismatched has no option\n // but to reuse a cached body. We don't have a good way to tell clients to do\n // error recovery in such case.\n modified: response.status != 304,\n matches: false,\n };\n }\n\n // use other header fields provided in the 304 (Not Modified) response to replace all instances\n // of the corresponding header fields in the stored response.\n const headers = {};\n for (const k in this._resHeaders) {\n headers[k] =\n k in response.headers && !excludedFromRevalidationUpdate[k]\n ? response.headers[k]\n : this._resHeaders[k];\n }\n\n const newResponse = Object.assign({}, response, {\n status: this._status,\n method: this._method,\n headers,\n });\n return {\n policy: new this.constructor(request, newResponse, {\n shared: this._isShared,\n cacheHeuristic: this._cacheHeuristic,\n immutableMinTimeToLive: this._immutableMinTtl,\n }),\n modified: false,\n matches: true,\n };\n }\n};\n\n\n/***/ }),\n\n/***/ 9898:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\n\"use strict\";\n\nconst EventEmitter = __nccwpck_require__(2361);\nconst tls = __nccwpck_require__(4404);\nconst http2 = __nccwpck_require__(5158);\nconst QuickLRU = __nccwpck_require__(9273);\n\nconst kCurrentStreamsCount = Symbol('currentStreamsCount');\nconst kRequest = Symbol('request');\nconst kOriginSet = Symbol('cachedOriginSet');\nconst kGracefullyClosing = Symbol('gracefullyClosing');\n\nconst nameKeys = [\n\t// `http2.connect()` options\n\t'maxDeflateDynamicTableSize',\n\t'maxSessionMemory',\n\t'maxHeaderListPairs',\n\t'maxOutstandingPings',\n\t'maxReservedRemoteStreams',\n\t'maxSendHeaderBlockLength',\n\t'paddingStrategy',\n\n\t// `tls.connect()` options\n\t'localAddress',\n\t'path',\n\t'rejectUnauthorized',\n\t'minDHSize',\n\n\t// `tls.createSecureContext()` options\n\t'ca',\n\t'cert',\n\t'clientCertEngine',\n\t'ciphers',\n\t'key',\n\t'pfx',\n\t'servername',\n\t'minVersion',\n\t'maxVersion',\n\t'secureProtocol',\n\t'crl',\n\t'honorCipherOrder',\n\t'ecdhCurve',\n\t'dhparam',\n\t'secureOptions',\n\t'sessionIdContext'\n];\n\nconst getSortedIndex = (array, value, compare) => {\n\tlet low = 0;\n\tlet high = array.length;\n\n\twhile (low < high) {\n\t\tconst mid = (low + high) >>> 1;\n\n\t\t/* istanbul ignore next */\n\t\tif (compare(array[mid], value)) {\n\t\t\t// This never gets called because we use descending sort. Better to have this anyway.\n\t\t\tlow = mid + 1;\n\t\t} else {\n\t\t\thigh = mid;\n\t\t}\n\t}\n\n\treturn low;\n};\n\nconst compareSessions = (a, b) => {\n\treturn a.remoteSettings.maxConcurrentStreams > b.remoteSettings.maxConcurrentStreams;\n};\n\n// See https://tools.ietf.org/html/rfc8336\nconst closeCoveredSessions = (where, session) => {\n\t// Clients SHOULD NOT emit new requests on any connection whose Origin\n\t// Set is a proper subset of another connection's Origin Set, and they\n\t// SHOULD close it once all outstanding requests are satisfied.\n\tfor (const coveredSession of where) {\n\t\tif (\n\t\t\t// The set is a proper subset when its length is less than the other set.\n\t\t\tcoveredSession[kOriginSet].length < session[kOriginSet].length &&\n\n\t\t\t// And the other set includes all elements of the subset.\n\t\t\tcoveredSession[kOriginSet].every(origin => session[kOriginSet].includes(origin)) &&\n\n\t\t\t// Makes sure that the session can handle all requests from the covered session.\n\t\t\tcoveredSession[kCurrentStreamsCount] + session[kCurrentStreamsCount] <= session.remoteSettings.maxConcurrentStreams\n\t\t) {\n\t\t\t// This allows pending requests to finish and prevents making new requests.\n\t\t\tgracefullyClose(coveredSession);\n\t\t}\n\t}\n};\n\n// This is basically inverted `closeCoveredSessions(...)`.\nconst closeSessionIfCovered = (where, coveredSession) => {\n\tfor (const session of where) {\n\t\tif (\n\t\t\tcoveredSession[kOriginSet].length < session[kOriginSet].length &&\n\t\t\tcoveredSession[kOriginSet].every(origin => session[kOriginSet].includes(origin)) &&\n\t\t\tcoveredSession[kCurrentStreamsCount] + session[kCurrentStreamsCount] <= session.remoteSettings.maxConcurrentStreams\n\t\t) {\n\t\t\tgracefullyClose(coveredSession);\n\t\t}\n\t}\n};\n\nconst getSessions = ({agent, isFree}) => {\n\tconst result = {};\n\n\t// eslint-disable-next-line guard-for-in\n\tfor (const normalizedOptions in agent.sessions) {\n\t\tconst sessions = agent.sessions[normalizedOptions];\n\n\t\tconst filtered = sessions.filter(session => {\n\t\t\tconst result = session[Agent.kCurrentStreamsCount] < session.remoteSettings.maxConcurrentStreams;\n\n\t\t\treturn isFree ? result : !result;\n\t\t});\n\n\t\tif (filtered.length !== 0) {\n\t\t\tresult[normalizedOptions] = filtered;\n\t\t}\n\t}\n\n\treturn result;\n};\n\nconst gracefullyClose = session => {\n\tsession[kGracefullyClosing] = true;\n\n\tif (session[kCurrentStreamsCount] === 0) {\n\t\tsession.close();\n\t}\n};\n\nclass Agent extends EventEmitter {\n\tconstructor({timeout = 60000, maxSessions = Infinity, maxFreeSessions = 10, maxCachedTlsSessions = 100} = {}) {\n\t\tsuper();\n\n\t\t// A session is considered busy when its current streams count\n\t\t// is equal to or greater than the `maxConcurrentStreams` value.\n\n\t\t// A session is considered free when its current streams count\n\t\t// is less than the `maxConcurrentStreams` value.\n\n\t\t// SESSIONS[NORMALIZED_OPTIONS] = [];\n\t\tthis.sessions = {};\n\n\t\t// The queue for creating new sessions. It looks like this:\n\t\t// QUEUE[NORMALIZED_OPTIONS][NORMALIZED_ORIGIN] = ENTRY_FUNCTION\n\t\t//\n\t\t// The entry function has `listeners`, `completed` and `destroyed` properties.\n\t\t// `listeners` is an array of objects containing `resolve` and `reject` functions.\n\t\t// `completed` is a boolean. It's set to true after ENTRY_FUNCTION is executed.\n\t\t// `destroyed` is a boolean. If it's set to true, the session will be destroyed if hasn't connected yet.\n\t\tthis.queue = {};\n\n\t\t// Each session will use this timeout value.\n\t\tthis.timeout = timeout;\n\n\t\t// Max sessions in total\n\t\tthis.maxSessions = maxSessions;\n\n\t\t// Max free sessions in total\n\t\t// TODO: decreasing `maxFreeSessions` should close some sessions\n\t\tthis.maxFreeSessions = maxFreeSessions;\n\n\t\tthis._freeSessionsCount = 0;\n\t\tthis._sessionsCount = 0;\n\n\t\t// We don't support push streams by default.\n\t\tthis.settings = {\n\t\t\tenablePush: false\n\t\t};\n\n\t\t// Reusing TLS sessions increases performance.\n\t\tthis.tlsSessionCache = new QuickLRU({maxSize: maxCachedTlsSessions});\n\t}\n\n\tstatic normalizeOrigin(url, servername) {\n\t\tif (typeof url === 'string') {\n\t\t\turl = new URL(url);\n\t\t}\n\n\t\tif (servername && url.hostname !== servername) {\n\t\t\turl.hostname = servername;\n\t\t}\n\n\t\treturn url.origin;\n\t}\n\n\tnormalizeOptions(options) {\n\t\tlet normalized = '';\n\n\t\tif (options) {\n\t\t\tfor (const key of nameKeys) {\n\t\t\t\tif (options[key]) {\n\t\t\t\t\tnormalized += `:${options[key]}`;\n\t\t\t\t}\n\t\t\t}\n\t\t}\n\n\t\treturn normalized;\n\t}\n\n\t_tryToCreateNewSession(normalizedOptions, normalizedOrigin) {\n\t\tif (!(normalizedOptions in this.queue) || !(normalizedOrigin in this.queue[normalizedOptions])) {\n\t\t\treturn;\n\t\t}\n\n\t\tconst item = this.queue[normalizedOptions][normalizedOrigin];\n\n\t\t// The entry function can be run only once.\n\t\t// BUG: The session may be never created when:\n\t\t// - the first condition is false AND\n\t\t// - this function is never called with the same arguments in the future.\n\t\tif (this._sessionsCount < this.maxSessions && !item.completed) {\n\t\t\titem.completed = true;\n\n\t\t\titem();\n\t\t}\n\t}\n\n\tgetSession(origin, options, listeners) {\n\t\treturn new Promise((resolve, reject) => {\n\t\t\tif (Array.isArray(listeners)) {\n\t\t\t\tlisteners = [...listeners];\n\n\t\t\t\t// Resolve the current promise ASAP, we're just moving the listeners.\n\t\t\t\t// They will be executed at a different time.\n\t\t\t\tresolve();\n\t\t\t} else {\n\t\t\t\tlisteners = [{resolve, reject}];\n\t\t\t}\n\n\t\t\tconst normalizedOptions = this.normalizeOptions(options);\n\t\t\tconst normalizedOrigin = Agent.normalizeOrigin(origin, options && options.servername);\n\n\t\t\tif (normalizedOrigin === undefined) {\n\t\t\t\tfor (const {reject} of listeners) {\n\t\t\t\t\treject(new TypeError('The `origin` argument needs to be a string or an URL object'));\n\t\t\t\t}\n\n\t\t\t\treturn;\n\t\t\t}\n\n\t\t\tif (normalizedOptions in this.sessions) {\n\t\t\t\tconst sessions = this.sessions[normalizedOptions];\n\n\t\t\t\tlet maxConcurrentStreams = -1;\n\t\t\t\tlet currentStreamsCount = -1;\n\t\t\t\tlet optimalSession;\n\n\t\t\t\t// We could just do this.sessions[normalizedOptions].find(...) but that isn't optimal.\n\t\t\t\t// Additionally, we are looking for session which has biggest current pending streams count.\n\t\t\t\tfor (const session of sessions) {\n\t\t\t\t\tconst sessionMaxConcurrentStreams = session.remoteSettings.maxConcurrentStreams;\n\n\t\t\t\t\tif (sessionMaxConcurrentStreams < maxConcurrentStreams) {\n\t\t\t\t\t\tbreak;\n\t\t\t\t\t}\n\n\t\t\t\t\tif (session[kOriginSet].includes(normalizedOrigin)) {\n\t\t\t\t\t\tconst sessionCurrentStreamsCount = session[kCurrentStreamsCount];\n\n\t\t\t\t\t\tif (\n\t\t\t\t\t\t\tsessionCurrentStreamsCount >= sessionMaxConcurrentStreams ||\n\t\t\t\t\t\t\tsession[kGracefullyClosing] ||\n\t\t\t\t\t\t\t// Unfortunately the `close` event isn't called immediately,\n\t\t\t\t\t\t\t// so `session.destroyed` is `true`, but `session.closed` is `false`.\n\t\t\t\t\t\t\tsession.destroyed\n\t\t\t\t\t\t) {\n\t\t\t\t\t\t\tcontinue;\n\t\t\t\t\t\t}\n\n\t\t\t\t\t\t// We only need set this once.\n\t\t\t\t\t\tif (!optimalSession) {\n\t\t\t\t\t\t\tmaxConcurrentStreams = sessionMaxConcurrentStreams;\n\t\t\t\t\t\t}\n\n\t\t\t\t\t\t// We're looking for the session which has biggest current pending stream count,\n\t\t\t\t\t\t// in order to minimalize the amount of active sessions.\n\t\t\t\t\t\tif (sessionCurrentStreamsCount > currentStreamsCount) {\n\t\t\t\t\t\t\toptimalSession = session;\n\t\t\t\t\t\t\tcurrentStreamsCount = sessionCurrentStreamsCount;\n\t\t\t\t\t\t}\n\t\t\t\t\t}\n\t\t\t\t}\n\n\t\t\t\tif (optimalSession) {\n\t\t\t\t\t/* istanbul ignore next: safety check */\n\t\t\t\t\tif (listeners.length !== 1) {\n\t\t\t\t\t\tfor (const {reject} of listeners) {\n\t\t\t\t\t\t\tconst error = new Error(\n\t\t\t\t\t\t\t\t`Expected the length of listeners to be 1, got ${listeners.length}.\\n` +\n\t\t\t\t\t\t\t\t'Please report this to https://github.com/szmarczak/http2-wrapper/'\n\t\t\t\t\t\t\t);\n\n\t\t\t\t\t\t\treject(error);\n\t\t\t\t\t\t}\n\n\t\t\t\t\t\treturn;\n\t\t\t\t\t}\n\n\t\t\t\t\tlisteners[0].resolve(optimalSession);\n\t\t\t\t\treturn;\n\t\t\t\t}\n\t\t\t}\n\n\t\t\tif (normalizedOptions in this.queue) {\n\t\t\t\tif (normalizedOrigin in this.queue[normalizedOptions]) {\n\t\t\t\t\t// There's already an item in the queue, just attach ourselves to it.\n\t\t\t\t\tthis.queue[normalizedOptions][normalizedOrigin].listeners.push(...listeners);\n\n\t\t\t\t\t// This shouldn't be executed here.\n\t\t\t\t\t// See the comment inside _tryToCreateNewSession.\n\t\t\t\t\tthis._tryToCreateNewSession(normalizedOptions, normalizedOrigin);\n\t\t\t\t\treturn;\n\t\t\t\t}\n\t\t\t} else {\n\t\t\t\tthis.queue[normalizedOptions] = {};\n\t\t\t}\n\n\t\t\t// The entry must be removed from the queue IMMEDIATELY when:\n\t\t\t// 1. the session connects successfully,\n\t\t\t// 2. an error occurs.\n\t\t\tconst removeFromQueue = () => {\n\t\t\t\t// Our entry can be replaced. We cannot remove the new one.\n\t\t\t\tif (normalizedOptions in this.queue && this.queue[normalizedOptions][normalizedOrigin] === entry) {\n\t\t\t\t\tdelete this.queue[normalizedOptions][normalizedOrigin];\n\n\t\t\t\t\tif (Object.keys(this.queue[normalizedOptions]).length === 0) {\n\t\t\t\t\t\tdelete this.queue[normalizedOptions];\n\t\t\t\t\t}\n\t\t\t\t}\n\t\t\t};\n\n\t\t\t// The main logic is here\n\t\t\tconst entry = () => {\n\t\t\t\tconst name = `${normalizedOrigin}:${normalizedOptions}`;\n\t\t\t\tlet receivedSettings = false;\n\n\t\t\t\ttry {\n\t\t\t\t\tconst session = http2.connect(origin, {\n\t\t\t\t\t\tcreateConnection: this.createConnection,\n\t\t\t\t\t\tsettings: this.settings,\n\t\t\t\t\t\tsession: this.tlsSessionCache.get(name),\n\t\t\t\t\t\t...options\n\t\t\t\t\t});\n\t\t\t\t\tsession[kCurrentStreamsCount] = 0;\n\t\t\t\t\tsession[kGracefullyClosing] = false;\n\n\t\t\t\t\tconst isFree = () => session[kCurrentStreamsCount] < session.remoteSettings.maxConcurrentStreams;\n\t\t\t\t\tlet wasFree = true;\n\n\t\t\t\t\tsession.socket.once('session', tlsSession => {\n\t\t\t\t\t\tthis.tlsSessionCache.set(name, tlsSession);\n\t\t\t\t\t});\n\n\t\t\t\t\tsession.once('error', error => {\n\t\t\t\t\t\t// Listeners are empty when the session successfully connected.\n\t\t\t\t\t\tfor (const {reject} of listeners) {\n\t\t\t\t\t\t\treject(error);\n\t\t\t\t\t\t}\n\n\t\t\t\t\t\t// The connection got broken, purge the cache.\n\t\t\t\t\t\tthis.tlsSessionCache.delete(name);\n\t\t\t\t\t});\n\n\t\t\t\t\tsession.setTimeout(this.timeout, () => {\n\t\t\t\t\t\t// Terminates all streams owned by this session.\n\t\t\t\t\t\t// TODO: Maybe the streams should have a \"Session timed out\" error?\n\t\t\t\t\t\tsession.destroy();\n\t\t\t\t\t});\n\n\t\t\t\t\tsession.once('close', () => {\n\t\t\t\t\t\tif (receivedSettings) {\n\t\t\t\t\t\t\t// 1. If it wasn't free then no need to decrease because\n\t\t\t\t\t\t\t// it has been decreased already in session.request().\n\t\t\t\t\t\t\t// 2. `stream.once('close')` won't increment the count\n\t\t\t\t\t\t\t// because the session is already closed.\n\t\t\t\t\t\t\tif (wasFree) {\n\t\t\t\t\t\t\t\tthis._freeSessionsCount--;\n\t\t\t\t\t\t\t}\n\n\t\t\t\t\t\t\tthis._sessionsCount--;\n\n\t\t\t\t\t\t\t// This cannot be moved to the stream logic,\n\t\t\t\t\t\t\t// because there may be a session that hadn't made a single request.\n\t\t\t\t\t\t\tconst where = this.sessions[normalizedOptions];\n\t\t\t\t\t\t\twhere.splice(where.indexOf(session), 1);\n\n\t\t\t\t\t\t\tif (where.length === 0) {\n\t\t\t\t\t\t\t\tdelete this.sessions[normalizedOptions];\n\t\t\t\t\t\t\t}\n\t\t\t\t\t\t} else {\n\t\t\t\t\t\t\t// Broken connection\n\t\t\t\t\t\t\tconst error = new Error('Session closed without receiving a SETTINGS frame');\n\t\t\t\t\t\t\terror.code = 'HTTP2WRAPPER_NOSETTINGS';\n\n\t\t\t\t\t\t\tfor (const {reject} of listeners) {\n\t\t\t\t\t\t\t\treject(error);\n\t\t\t\t\t\t\t}\n\n\t\t\t\t\t\t\tremoveFromQueue();\n\t\t\t\t\t\t}\n\n\t\t\t\t\t\t// There may be another session awaiting.\n\t\t\t\t\t\tthis._tryToCreateNewSession(normalizedOptions, normalizedOrigin);\n\t\t\t\t\t});\n\n\t\t\t\t\t// Iterates over the queue and processes listeners.\n\t\t\t\t\tconst processListeners = () => {\n\t\t\t\t\t\tif (!(normalizedOptions in this.queue) || !isFree()) {\n\t\t\t\t\t\t\treturn;\n\t\t\t\t\t\t}\n\n\t\t\t\t\t\tfor (const origin of session[kOriginSet]) {\n\t\t\t\t\t\t\tif (origin in this.queue[normalizedOptions]) {\n\t\t\t\t\t\t\t\tconst {listeners} = this.queue[normalizedOptions][origin];\n\n\t\t\t\t\t\t\t\t// Prevents session overloading.\n\t\t\t\t\t\t\t\twhile (listeners.length !== 0 && isFree()) {\n\t\t\t\t\t\t\t\t\t// We assume `resolve(...)` calls `request(...)` *directly*,\n\t\t\t\t\t\t\t\t\t// otherwise the session will get overloaded.\n\t\t\t\t\t\t\t\t\tlisteners.shift().resolve(session);\n\t\t\t\t\t\t\t\t}\n\n\t\t\t\t\t\t\t\tconst where = this.queue[normalizedOptions];\n\t\t\t\t\t\t\t\tif (where[origin].listeners.length === 0) {\n\t\t\t\t\t\t\t\t\tdelete where[origin];\n\n\t\t\t\t\t\t\t\t\tif (Object.keys(where).length === 0) {\n\t\t\t\t\t\t\t\t\t\tdelete this.queue[normalizedOptions];\n\t\t\t\t\t\t\t\t\t\tbreak;\n\t\t\t\t\t\t\t\t\t}\n\t\t\t\t\t\t\t\t}\n\n\t\t\t\t\t\t\t\t// We're no longer free, no point in continuing.\n\t\t\t\t\t\t\t\tif (!isFree()) {\n\t\t\t\t\t\t\t\t\tbreak;\n\t\t\t\t\t\t\t\t}\n\t\t\t\t\t\t\t}\n\t\t\t\t\t\t}\n\t\t\t\t\t};\n\n\t\t\t\t\t// The Origin Set cannot shrink. No need to check if it suddenly became covered by another one.\n\t\t\t\t\tsession.on('origin', () => {\n\t\t\t\t\t\tsession[kOriginSet] = session.originSet;\n\n\t\t\t\t\t\tif (!isFree()) {\n\t\t\t\t\t\t\t// The session is full.\n\t\t\t\t\t\t\treturn;\n\t\t\t\t\t\t}\n\n\t\t\t\t\t\tprocessListeners();\n\n\t\t\t\t\t\t// Close covered sessions (if possible).\n\t\t\t\t\t\tcloseCoveredSessions(this.sessions[normalizedOptions], session);\n\t\t\t\t\t});\n\n\t\t\t\t\tsession.once('remoteSettings', () => {\n\t\t\t\t\t\t// Fix Node.js bug preventing the process from exiting\n\t\t\t\t\t\tsession.ref();\n\t\t\t\t\t\tsession.unref();\n\n\t\t\t\t\t\tthis._sessionsCount++;\n\n\t\t\t\t\t\t// The Agent could have been destroyed already.\n\t\t\t\t\t\tif (entry.destroyed) {\n\t\t\t\t\t\t\tconst error = new Error('Agent has been destroyed');\n\n\t\t\t\t\t\t\tfor (const listener of listeners) {\n\t\t\t\t\t\t\t\tlistener.reject(error);\n\t\t\t\t\t\t\t}\n\n\t\t\t\t\t\t\tsession.destroy();\n\t\t\t\t\t\t\treturn;\n\t\t\t\t\t\t}\n\n\t\t\t\t\t\tsession[kOriginSet] = session.originSet;\n\n\t\t\t\t\t\t{\n\t\t\t\t\t\t\tconst where = this.sessions;\n\n\t\t\t\t\t\t\tif (normalizedOptions in where) {\n\t\t\t\t\t\t\t\tconst sessions = where[normalizedOptions];\n\t\t\t\t\t\t\t\tsessions.splice(getSortedIndex(sessions, session, compareSessions), 0, session);\n\t\t\t\t\t\t\t} else {\n\t\t\t\t\t\t\t\twhere[normalizedOptions] = [session];\n\t\t\t\t\t\t\t}\n\t\t\t\t\t\t}\n\n\t\t\t\t\t\tthis._freeSessionsCount += 1;\n\t\t\t\t\t\treceivedSettings = true;\n\n\t\t\t\t\t\tthis.emit('session', session);\n\n\t\t\t\t\t\tprocessListeners();\n\t\t\t\t\t\tremoveFromQueue();\n\n\t\t\t\t\t\t// TODO: Close last recently used (or least used?) session\n\t\t\t\t\t\tif (session[kCurrentStreamsCount] === 0 && this._freeSessionsCount > this.maxFreeSessions) {\n\t\t\t\t\t\t\tsession.close();\n\t\t\t\t\t\t}\n\n\t\t\t\t\t\t// Check if we haven't managed to execute all listeners.\n\t\t\t\t\t\tif (listeners.length !== 0) {\n\t\t\t\t\t\t\t// Request for a new session with predefined listeners.\n\t\t\t\t\t\t\tthis.getSession(normalizedOrigin, options, listeners);\n\t\t\t\t\t\t\tlisteners.length = 0;\n\t\t\t\t\t\t}\n\n\t\t\t\t\t\t// `session.remoteSettings.maxConcurrentStreams` might get increased\n\t\t\t\t\t\tsession.on('remoteSettings', () => {\n\t\t\t\t\t\t\tprocessListeners();\n\n\t\t\t\t\t\t\t// In case the Origin Set changes\n\t\t\t\t\t\t\tcloseCoveredSessions(this.sessions[normalizedOptions], session);\n\t\t\t\t\t\t});\n\t\t\t\t\t});\n\n\t\t\t\t\t// Shim `session.request()` in order to catch all streams\n\t\t\t\t\tsession[kRequest] = session.request;\n\t\t\t\t\tsession.request = (headers, streamOptions) => {\n\t\t\t\t\t\tif (session[kGracefullyClosing]) {\n\t\t\t\t\t\t\tthrow new Error('The session is gracefully closing. No new streams are allowed.');\n\t\t\t\t\t\t}\n\n\t\t\t\t\t\tconst stream = session[kRequest](headers, streamOptions);\n\n\t\t\t\t\t\t// The process won't exit until the session is closed or all requests are gone.\n\t\t\t\t\t\tsession.ref();\n\n\t\t\t\t\t\t++session[kCurrentStreamsCount];\n\n\t\t\t\t\t\tif (session[kCurrentStreamsCount] === session.remoteSettings.maxConcurrentStreams) {\n\t\t\t\t\t\t\tthis._freeSessionsCount--;\n\t\t\t\t\t\t}\n\n\t\t\t\t\t\tstream.once('close', () => {\n\t\t\t\t\t\t\twasFree = isFree();\n\n\t\t\t\t\t\t\t--session[kCurrentStreamsCount];\n\n\t\t\t\t\t\t\tif (!session.destroyed && !session.closed) {\n\t\t\t\t\t\t\t\tcloseSessionIfCovered(this.sessions[normalizedOptions], session);\n\n\t\t\t\t\t\t\t\tif (isFree() && !session.closed) {\n\t\t\t\t\t\t\t\t\tif (!wasFree) {\n\t\t\t\t\t\t\t\t\t\tthis._freeSessionsCount++;\n\n\t\t\t\t\t\t\t\t\t\twasFree = true;\n\t\t\t\t\t\t\t\t\t}\n\n\t\t\t\t\t\t\t\t\tconst isEmpty = session[kCurrentStreamsCount] === 0;\n\n\t\t\t\t\t\t\t\t\tif (isEmpty) {\n\t\t\t\t\t\t\t\t\t\tsession.unref();\n\t\t\t\t\t\t\t\t\t}\n\n\t\t\t\t\t\t\t\t\tif (\n\t\t\t\t\t\t\t\t\t\tisEmpty &&\n\t\t\t\t\t\t\t\t\t\t(\n\t\t\t\t\t\t\t\t\t\t\tthis._freeSessionsCount > this.maxFreeSessions ||\n\t\t\t\t\t\t\t\t\t\t\tsession[kGracefullyClosing]\n\t\t\t\t\t\t\t\t\t\t)\n\t\t\t\t\t\t\t\t\t) {\n\t\t\t\t\t\t\t\t\t\tsession.close();\n\t\t\t\t\t\t\t\t\t} else {\n\t\t\t\t\t\t\t\t\t\tcloseCoveredSessions(this.sessions[normalizedOptions], session);\n\t\t\t\t\t\t\t\t\t\tprocessListeners();\n\t\t\t\t\t\t\t\t\t}\n\t\t\t\t\t\t\t\t}\n\t\t\t\t\t\t\t}\n\t\t\t\t\t\t});\n\n\t\t\t\t\t\treturn stream;\n\t\t\t\t\t};\n\t\t\t\t} catch (error) {\n\t\t\t\t\tfor (const listener of listeners) {\n\t\t\t\t\t\tlistener.reject(error);\n\t\t\t\t\t}\n\n\t\t\t\t\tremoveFromQueue();\n\t\t\t\t}\n\t\t\t};\n\n\t\t\tentry.listeners = listeners;\n\t\t\tentry.completed = false;\n\t\t\tentry.destroyed = false;\n\n\t\t\tthis.queue[normalizedOptions][normalizedOrigin] = entry;\n\t\t\tthis._tryToCreateNewSession(normalizedOptions, normalizedOrigin);\n\t\t});\n\t}\n\n\trequest(origin, options, headers, streamOptions) {\n\t\treturn new Promise((resolve, reject) => {\n\t\t\tthis.getSession(origin, options, [{\n\t\t\t\treject,\n\t\t\t\tresolve: session => {\n\t\t\t\t\ttry {\n\t\t\t\t\t\tresolve(session.request(headers, streamOptions));\n\t\t\t\t\t} catch (error) {\n\t\t\t\t\t\treject(error);\n\t\t\t\t\t}\n\t\t\t\t}\n\t\t\t}]);\n\t\t});\n\t}\n\n\tcreateConnection(origin, options) {\n\t\treturn Agent.connect(origin, options);\n\t}\n\n\tstatic connect(origin, options) {\n\t\toptions.ALPNProtocols = ['h2'];\n\n\t\tconst port = origin.port || 443;\n\t\tconst host = origin.hostname || origin.host;\n\n\t\tif (typeof options.servername === 'undefined') {\n\t\t\toptions.servername = host;\n\t\t}\n\n\t\treturn tls.connect(port, host, options);\n\t}\n\n\tcloseFreeSessions() {\n\t\tfor (const sessions of Object.values(this.sessions)) {\n\t\t\tfor (const session of sessions) {\n\t\t\t\tif (session[kCurrentStreamsCount] === 0) {\n\t\t\t\t\tsession.close();\n\t\t\t\t}\n\t\t\t}\n\t\t}\n\t}\n\n\tdestroy(reason) {\n\t\tfor (const sessions of Object.values(this.sessions)) {\n\t\t\tfor (const session of sessions) {\n\t\t\t\tsession.destroy(reason);\n\t\t\t}\n\t\t}\n\n\t\tfor (const entriesOfAuthority of Object.values(this.queue)) {\n\t\t\tfor (const entry of Object.values(entriesOfAuthority)) {\n\t\t\t\tentry.destroyed = true;\n\t\t\t}\n\t\t}\n\n\t\t// New requests should NOT attach to destroyed sessions\n\t\tthis.queue = {};\n\t}\n\n\tget freeSessions() {\n\t\treturn getSessions({agent: this, isFree: true});\n\t}\n\n\tget busySessions() {\n\t\treturn getSessions({agent: this, isFree: false});\n\t}\n}\n\nAgent.kCurrentStreamsCount = kCurrentStreamsCount;\nAgent.kGracefullyClosing = kGracefullyClosing;\n\nmodule.exports = {\n\tAgent,\n\tglobalAgent: new Agent()\n};\n\n\n/***/ }),\n\n/***/ 7167:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\n\"use strict\";\n\nconst http = __nccwpck_require__(3685);\nconst https = __nccwpck_require__(5687);\nconst resolveALPN = __nccwpck_require__(6624);\nconst QuickLRU = __nccwpck_require__(9273);\nconst Http2ClientRequest = __nccwpck_require__(9632);\nconst calculateServerName = __nccwpck_require__(1982);\nconst urlToOptions = __nccwpck_require__(2686);\n\nconst cache = new QuickLRU({maxSize: 100});\nconst queue = new Map();\n\nconst installSocket = (agent, socket, options) => {\n\tsocket._httpMessage = {shouldKeepAlive: true};\n\n\tconst onFree = () => {\n\t\tagent.emit('free', socket, options);\n\t};\n\n\tsocket.on('free', onFree);\n\n\tconst onClose = () => {\n\t\tagent.removeSocket(socket, options);\n\t};\n\n\tsocket.on('close', onClose);\n\n\tconst onRemove = () => {\n\t\tagent.removeSocket(socket, options);\n\t\tsocket.off('close', onClose);\n\t\tsocket.off('free', onFree);\n\t\tsocket.off('agentRemove', onRemove);\n\t};\n\n\tsocket.on('agentRemove', onRemove);\n\n\tagent.emit('free', socket, options);\n};\n\nconst resolveProtocol = async options => {\n\tconst name = `${options.host}:${options.port}:${options.ALPNProtocols.sort()}`;\n\n\tif (!cache.has(name)) {\n\t\tif (queue.has(name)) {\n\t\t\tconst result = await queue.get(name);\n\t\t\treturn result.alpnProtocol;\n\t\t}\n\n\t\tconst {path, agent} = options;\n\t\toptions.path = options.socketPath;\n\n\t\tconst resultPromise = resolveALPN(options);\n\t\tqueue.set(name, resultPromise);\n\n\t\ttry {\n\t\t\tconst {socket, alpnProtocol} = await resultPromise;\n\t\t\tcache.set(name, alpnProtocol);\n\n\t\t\toptions.path = path;\n\n\t\t\tif (alpnProtocol === 'h2') {\n\t\t\t\t// https://github.com/nodejs/node/issues/33343\n\t\t\t\tsocket.destroy();\n\t\t\t} else {\n\t\t\t\tconst {globalAgent} = https;\n\t\t\t\tconst defaultCreateConnection = https.Agent.prototype.createConnection;\n\n\t\t\t\tif (agent) {\n\t\t\t\t\tif (agent.createConnection === defaultCreateConnection) {\n\t\t\t\t\t\tinstallSocket(agent, socket, options);\n\t\t\t\t\t} else {\n\t\t\t\t\t\tsocket.destroy();\n\t\t\t\t\t}\n\t\t\t\t} else if (globalAgent.createConnection === defaultCreateConnection) {\n\t\t\t\t\tinstallSocket(globalAgent, socket, options);\n\t\t\t\t} else {\n\t\t\t\t\tsocket.destroy();\n\t\t\t\t}\n\t\t\t}\n\n\t\t\tqueue.delete(name);\n\n\t\t\treturn alpnProtocol;\n\t\t} catch (error) {\n\t\t\tqueue.delete(name);\n\n\t\t\tthrow error;\n\t\t}\n\t}\n\n\treturn cache.get(name);\n};\n\nmodule.exports = async (input, options, callback) => {\n\tif (typeof input === 'string' || input instanceof URL) {\n\t\tinput = urlToOptions(new URL(input));\n\t}\n\n\tif (typeof options === 'function') {\n\t\tcallback = options;\n\t\toptions = undefined;\n\t}\n\n\toptions = {\n\t\tALPNProtocols: ['h2', 'http/1.1'],\n\t\t...input,\n\t\t...options,\n\t\tresolveSocket: true\n\t};\n\n\tif (!Array.isArray(options.ALPNProtocols) || options.ALPNProtocols.length === 0) {\n\t\tthrow new Error('The `ALPNProtocols` option must be an Array with at least one entry');\n\t}\n\n\toptions.protocol = options.protocol || 'https:';\n\tconst isHttps = options.protocol === 'https:';\n\n\toptions.host = options.hostname || options.host || 'localhost';\n\toptions.session = options.tlsSession;\n\toptions.servername = options.servername || calculateServerName(options);\n\toptions.port = options.port || (isHttps ? 443 : 80);\n\toptions._defaultAgent = isHttps ? https.globalAgent : http.globalAgent;\n\n\tconst agents = options.agent;\n\n\tif (agents) {\n\t\tif (agents.addRequest) {\n\t\t\tthrow new Error('The `options.agent` object can contain only `http`, `https` or `http2` properties');\n\t\t}\n\n\t\toptions.agent = agents[isHttps ? 'https' : 'http'];\n\t}\n\n\tif (isHttps) {\n\t\tconst protocol = await resolveProtocol(options);\n\n\t\tif (protocol === 'h2') {\n\t\t\tif (agents) {\n\t\t\t\toptions.agent = agents.http2;\n\t\t\t}\n\n\t\t\treturn new Http2ClientRequest(options, callback);\n\t\t}\n\t}\n\n\treturn http.request(options, callback);\n};\n\nmodule.exports.protocolCache = cache;\n\n\n/***/ }),\n\n/***/ 9632:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\n\"use strict\";\n\nconst http2 = __nccwpck_require__(5158);\nconst {Writable} = __nccwpck_require__(2781);\nconst {Agent, globalAgent} = __nccwpck_require__(9898);\nconst IncomingMessage = __nccwpck_require__(2575);\nconst urlToOptions = __nccwpck_require__(2686);\nconst proxyEvents = __nccwpck_require__(1818);\nconst isRequestPseudoHeader = __nccwpck_require__(1199);\nconst {\n\tERR_INVALID_ARG_TYPE,\n\tERR_INVALID_PROTOCOL,\n\tERR_HTTP_HEADERS_SENT,\n\tERR_INVALID_HTTP_TOKEN,\n\tERR_HTTP_INVALID_HEADER_VALUE,\n\tERR_INVALID_CHAR\n} = __nccwpck_require__(7087);\n\nconst {\n\tHTTP2_HEADER_STATUS,\n\tHTTP2_HEADER_METHOD,\n\tHTTP2_HEADER_PATH,\n\tHTTP2_METHOD_CONNECT\n} = http2.constants;\n\nconst kHeaders = Symbol('headers');\nconst kOrigin = Symbol('origin');\nconst kSession = Symbol('session');\nconst kOptions = Symbol('options');\nconst kFlushedHeaders = Symbol('flushedHeaders');\nconst kJobs = Symbol('jobs');\n\nconst isValidHttpToken = /^[\\^`\\-\\w!#$%&*+.|~]+$/;\nconst isInvalidHeaderValue = /[^\\t\\u0020-\\u007E\\u0080-\\u00FF]/;\n\nclass ClientRequest extends Writable {\n\tconstructor(input, options, callback) {\n\t\tsuper({\n\t\t\tautoDestroy: false\n\t\t});\n\n\t\tconst hasInput = typeof input === 'string' || input instanceof URL;\n\t\tif (hasInput) {\n\t\t\tinput = urlToOptions(input instanceof URL ? input : new URL(input));\n\t\t}\n\n\t\tif (typeof options === 'function' || options === undefined) {\n\t\t\t// (options, callback)\n\t\t\tcallback = options;\n\t\t\toptions = hasInput ? input : {...input};\n\t\t} else {\n\t\t\t// (input, options, callback)\n\t\t\toptions = {...input, ...options};\n\t\t}\n\n\t\tif (options.h2session) {\n\t\t\tthis[kSession] = options.h2session;\n\t\t} else if (options.agent === false) {\n\t\t\tthis.agent = new Agent({maxFreeSessions: 0});\n\t\t} else if (typeof options.agent === 'undefined' || options.agent === null) {\n\t\t\tif (typeof options.createConnection === 'function') {\n\t\t\t\t// This is a workaround - we don't have to create the session on our own.\n\t\t\t\tthis.agent = new Agent({maxFreeSessions: 0});\n\t\t\t\tthis.agent.createConnection = options.createConnection;\n\t\t\t} else {\n\t\t\t\tthis.agent = globalAgent;\n\t\t\t}\n\t\t} else if (typeof options.agent.request === 'function') {\n\t\t\tthis.agent = options.agent;\n\t\t} else {\n\t\t\tthrow new ERR_INVALID_ARG_TYPE('options.agent', ['Agent-like Object', 'undefined', 'false'], options.agent);\n\t\t}\n\n\t\tif (options.protocol && options.protocol !== 'https:') {\n\t\t\tthrow new ERR_INVALID_PROTOCOL(options.protocol, 'https:');\n\t\t}\n\n\t\tconst port = options.port || options.defaultPort || (this.agent && this.agent.defaultPort) || 443;\n\t\tconst host = options.hostname || options.host || 'localhost';\n\n\t\t// Don't enforce the origin via options. It may be changed in an Agent.\n\t\tdelete options.hostname;\n\t\tdelete options.host;\n\t\tdelete options.port;\n\n\t\tconst {timeout} = options;\n\t\toptions.timeout = undefined;\n\n\t\tthis[kHeaders] = Object.create(null);\n\t\tthis[kJobs] = [];\n\n\t\tthis.socket = null;\n\t\tthis.connection = null;\n\n\t\tthis.method = options.method || 'GET';\n\t\tthis.path = options.path;\n\n\t\tthis.res = null;\n\t\tthis.aborted = false;\n\t\tthis.reusedSocket = false;\n\n\t\tif (options.headers) {\n\t\t\tfor (const [header, value] of Object.entries(options.headers)) {\n\t\t\t\tthis.setHeader(header, value);\n\t\t\t}\n\t\t}\n\n\t\tif (options.auth && !('authorization' in this[kHeaders])) {\n\t\t\tthis[kHeaders].authorization = 'Basic ' + Buffer.from(options.auth).toString('base64');\n\t\t}\n\n\t\toptions.session = options.tlsSession;\n\t\toptions.path = options.socketPath;\n\n\t\tthis[kOptions] = options;\n\n\t\t// Clients that generate HTTP/2 requests directly SHOULD use the :authority pseudo-header field instead of the Host header field.\n\t\tif (port === 443) {\n\t\t\tthis[kOrigin] = `https://${host}`;\n\n\t\t\tif (!(':authority' in this[kHeaders])) {\n\t\t\t\tthis[kHeaders][':authority'] = host;\n\t\t\t}\n\t\t} else {\n\t\t\tthis[kOrigin] = `https://${host}:${port}`;\n\n\t\t\tif (!(':authority' in this[kHeaders])) {\n\t\t\t\tthis[kHeaders][':authority'] = `${host}:${port}`;\n\t\t\t}\n\t\t}\n\n\t\tif (timeout) {\n\t\t\tthis.setTimeout(timeout);\n\t\t}\n\n\t\tif (callback) {\n\t\t\tthis.once('response', callback);\n\t\t}\n\n\t\tthis[kFlushedHeaders] = false;\n\t}\n\n\tget method() {\n\t\treturn this[kHeaders][HTTP2_HEADER_METHOD];\n\t}\n\n\tset method(value) {\n\t\tif (value) {\n\t\t\tthis[kHeaders][HTTP2_HEADER_METHOD] = value.toUpperCase();\n\t\t}\n\t}\n\n\tget path() {\n\t\treturn this[kHeaders][HTTP2_HEADER_PATH];\n\t}\n\n\tset path(value) {\n\t\tif (value) {\n\t\t\tthis[kHeaders][HTTP2_HEADER_PATH] = value;\n\t\t}\n\t}\n\n\tget _mustNotHaveABody() {\n\t\treturn this.method === 'GET' || this.method === 'HEAD' || this.method === 'DELETE';\n\t}\n\n\t_write(chunk, encoding, callback) {\n\t\t// https://github.com/nodejs/node/blob/654df09ae0c5e17d1b52a900a545f0664d8c7627/lib/internal/http2/util.js#L148-L156\n\t\tif (this._mustNotHaveABody) {\n\t\t\tcallback(new Error('The GET, HEAD and DELETE methods must NOT have a body'));\n\t\t\t/* istanbul ignore next: Node.js 12 throws directly */\n\t\t\treturn;\n\t\t}\n\n\t\tthis.flushHeaders();\n\n\t\tconst callWrite = () => this._request.write(chunk, encoding, callback);\n\t\tif (this._request) {\n\t\t\tcallWrite();\n\t\t} else {\n\t\t\tthis[kJobs].push(callWrite);\n\t\t}\n\t}\n\n\t_final(callback) {\n\t\tif (this.destroyed) {\n\t\t\treturn;\n\t\t}\n\n\t\tthis.flushHeaders();\n\n\t\tconst callEnd = () => {\n\t\t\t// For GET, HEAD and DELETE\n\t\t\tif (this._mustNotHaveABody) {\n\t\t\t\tcallback();\n\t\t\t\treturn;\n\t\t\t}\n\n\t\t\tthis._request.end(callback);\n\t\t};\n\n\t\tif (this._request) {\n\t\t\tcallEnd();\n\t\t} else {\n\t\t\tthis[kJobs].push(callEnd);\n\t\t}\n\t}\n\n\tabort() {\n\t\tif (this.res && this.res.complete) {\n\t\t\treturn;\n\t\t}\n\n\t\tif (!this.aborted) {\n\t\t\tprocess.nextTick(() => this.emit('abort'));\n\t\t}\n\n\t\tthis.aborted = true;\n\n\t\tthis.destroy();\n\t}\n\n\t_destroy(error, callback) {\n\t\tif (this.res) {\n\t\t\tthis.res._dump();\n\t\t}\n\n\t\tif (this._request) {\n\t\t\tthis._request.destroy();\n\t\t}\n\n\t\tcallback(error);\n\t}\n\n\tasync flushHeaders() {\n\t\tif (this[kFlushedHeaders] || this.destroyed) {\n\t\t\treturn;\n\t\t}\n\n\t\tthis[kFlushedHeaders] = true;\n\n\t\tconst isConnectMethod = this.method === HTTP2_METHOD_CONNECT;\n\n\t\t// The real magic is here\n\t\tconst onStream = stream => {\n\t\t\tthis._request = stream;\n\n\t\t\tif (this.destroyed) {\n\t\t\t\tstream.destroy();\n\t\t\t\treturn;\n\t\t\t}\n\n\t\t\t// Forwards `timeout`, `continue`, `close` and `error` events to this instance.\n\t\t\tif (!isConnectMethod) {\n\t\t\t\tproxyEvents(stream, this, ['timeout', 'continue', 'close', 'error']);\n\t\t\t}\n\n\t\t\t// Wait for the `finish` event. We don't want to emit the `response` event\n\t\t\t// before `request.end()` is called.\n\t\t\tconst waitForEnd = fn => {\n\t\t\t\treturn (...args) => {\n\t\t\t\t\tif (!this.writable && !this.destroyed) {\n\t\t\t\t\t\tfn(...args);\n\t\t\t\t\t} else {\n\t\t\t\t\t\tthis.once('finish', () => {\n\t\t\t\t\t\t\tfn(...args);\n\t\t\t\t\t\t});\n\t\t\t\t\t}\n\t\t\t\t};\n\t\t\t};\n\n\t\t\t// This event tells we are ready to listen for the data.\n\t\t\tstream.once('response', waitForEnd((headers, flags, rawHeaders) => {\n\t\t\t\t// If we were to emit raw request stream, it would be as fast as the native approach.\n\t\t\t\t// Note that wrapping the raw stream in a Proxy instance won't improve the performance (already tested it).\n\t\t\t\tconst response = new IncomingMessage(this.socket, stream.readableHighWaterMark);\n\t\t\t\tthis.res = response;\n\n\t\t\t\tresponse.req = this;\n\t\t\t\tresponse.statusCode = headers[HTTP2_HEADER_STATUS];\n\t\t\t\tresponse.headers = headers;\n\t\t\t\tresponse.rawHeaders = rawHeaders;\n\n\t\t\t\tresponse.once('end', () => {\n\t\t\t\t\tif (this.aborted) {\n\t\t\t\t\t\tresponse.aborted = true;\n\t\t\t\t\t\tresponse.emit('aborted');\n\t\t\t\t\t} else {\n\t\t\t\t\t\tresponse.complete = true;\n\n\t\t\t\t\t\t// Has no effect, just be consistent with the Node.js behavior\n\t\t\t\t\t\tresponse.socket = null;\n\t\t\t\t\t\tresponse.connection = null;\n\t\t\t\t\t}\n\t\t\t\t});\n\n\t\t\t\tif (isConnectMethod) {\n\t\t\t\t\tresponse.upgrade = true;\n\n\t\t\t\t\t// The HTTP1 API says the socket is detached here,\n\t\t\t\t\t// but we can't do that so we pass the original HTTP2 request.\n\t\t\t\t\tif (this.emit('connect', response, stream, Buffer.alloc(0))) {\n\t\t\t\t\t\tthis.emit('close');\n\t\t\t\t\t} else {\n\t\t\t\t\t\t// No listeners attached, destroy the original request.\n\t\t\t\t\t\tstream.destroy();\n\t\t\t\t\t}\n\t\t\t\t} else {\n\t\t\t\t\t// Forwards data\n\t\t\t\t\tstream.on('data', chunk => {\n\t\t\t\t\t\tif (!response._dumped && !response.push(chunk)) {\n\t\t\t\t\t\t\tstream.pause();\n\t\t\t\t\t\t}\n\t\t\t\t\t});\n\n\t\t\t\t\tstream.once('end', () => {\n\t\t\t\t\t\tresponse.push(null);\n\t\t\t\t\t});\n\n\t\t\t\t\tif (!this.emit('response', response)) {\n\t\t\t\t\t\t// No listeners attached, dump the response.\n\t\t\t\t\t\tresponse._dump();\n\t\t\t\t\t}\n\t\t\t\t}\n\t\t\t}));\n\n\t\t\t// Emits `information` event\n\t\t\tstream.once('headers', waitForEnd(\n\t\t\t\theaders => this.emit('information', {statusCode: headers[HTTP2_HEADER_STATUS]})\n\t\t\t));\n\n\t\t\tstream.once('trailers', waitForEnd((trailers, flags, rawTrailers) => {\n\t\t\t\tconst {res} = this;\n\n\t\t\t\t// Assigns trailers to the response object.\n\t\t\t\tres.trailers = trailers;\n\t\t\t\tres.rawTrailers = rawTrailers;\n\t\t\t}));\n\n\t\t\tconst {socket} = stream.session;\n\t\t\tthis.socket = socket;\n\t\t\tthis.connection = socket;\n\n\t\t\tfor (const job of this[kJobs]) {\n\t\t\t\tjob();\n\t\t\t}\n\n\t\t\tthis.emit('socket', this.socket);\n\t\t};\n\n\t\t// Makes a HTTP2 request\n\t\tif (this[kSession]) {\n\t\t\ttry {\n\t\t\t\tonStream(this[kSession].request(this[kHeaders]));\n\t\t\t} catch (error) {\n\t\t\t\tthis.emit('error', error);\n\t\t\t}\n\t\t} else {\n\t\t\tthis.reusedSocket = true;\n\n\t\t\ttry {\n\t\t\t\tonStream(await this.agent.request(this[kOrigin], this[kOptions], this[kHeaders]));\n\t\t\t} catch (error) {\n\t\t\t\tthis.emit('error', error);\n\t\t\t}\n\t\t}\n\t}\n\n\tgetHeader(name) {\n\t\tif (typeof name !== 'string') {\n\t\t\tthrow new ERR_INVALID_ARG_TYPE('name', 'string', name);\n\t\t}\n\n\t\treturn this[kHeaders][name.toLowerCase()];\n\t}\n\n\tget headersSent() {\n\t\treturn this[kFlushedHeaders];\n\t}\n\n\tremoveHeader(name) {\n\t\tif (typeof name !== 'string') {\n\t\t\tthrow new ERR_INVALID_ARG_TYPE('name', 'string', name);\n\t\t}\n\n\t\tif (this.headersSent) {\n\t\t\tthrow new ERR_HTTP_HEADERS_SENT('remove');\n\t\t}\n\n\t\tdelete this[kHeaders][name.toLowerCase()];\n\t}\n\n\tsetHeader(name, value) {\n\t\tif (this.headersSent) {\n\t\t\tthrow new ERR_HTTP_HEADERS_SENT('set');\n\t\t}\n\n\t\tif (typeof name !== 'string' || (!isValidHttpToken.test(name) && !isRequestPseudoHeader(name))) {\n\t\t\tthrow new ERR_INVALID_HTTP_TOKEN('Header name', name);\n\t\t}\n\n\t\tif (typeof value === 'undefined') {\n\t\t\tthrow new ERR_HTTP_INVALID_HEADER_VALUE(value, name);\n\t\t}\n\n\t\tif (isInvalidHeaderValue.test(value)) {\n\t\t\tthrow new ERR_INVALID_CHAR('header content', name);\n\t\t}\n\n\t\tthis[kHeaders][name.toLowerCase()] = value;\n\t}\n\n\tsetNoDelay() {\n\t\t// HTTP2 sockets cannot be malformed, do nothing.\n\t}\n\n\tsetSocketKeepAlive() {\n\t\t// HTTP2 sockets cannot be malformed, do nothing.\n\t}\n\n\tsetTimeout(ms, callback) {\n\t\tconst applyTimeout = () => this._request.setTimeout(ms, callback);\n\n\t\tif (this._request) {\n\t\t\tapplyTimeout();\n\t\t} else {\n\t\t\tthis[kJobs].push(applyTimeout);\n\t\t}\n\n\t\treturn this;\n\t}\n\n\tget maxHeadersCount() {\n\t\tif (!this.destroyed && this._request) {\n\t\t\treturn this._request.session.localSettings.maxHeaderListSize;\n\t\t}\n\n\t\treturn undefined;\n\t}\n\n\tset maxHeadersCount(_value) {\n\t\t// Updating HTTP2 settings would affect all requests, do nothing.\n\t}\n}\n\nmodule.exports = ClientRequest;\n\n\n/***/ }),\n\n/***/ 2575:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\n\"use strict\";\n\nconst {Readable} = __nccwpck_require__(2781);\n\nclass IncomingMessage extends Readable {\n\tconstructor(socket, highWaterMark) {\n\t\tsuper({\n\t\t\thighWaterMark,\n\t\t\tautoDestroy: false\n\t\t});\n\n\t\tthis.statusCode = null;\n\t\tthis.statusMessage = '';\n\t\tthis.httpVersion = '2.0';\n\t\tthis.httpVersionMajor = 2;\n\t\tthis.httpVersionMinor = 0;\n\t\tthis.headers = {};\n\t\tthis.trailers = {};\n\t\tthis.req = null;\n\n\t\tthis.aborted = false;\n\t\tthis.complete = false;\n\t\tthis.upgrade = null;\n\n\t\tthis.rawHeaders = [];\n\t\tthis.rawTrailers = [];\n\n\t\tthis.socket = socket;\n\t\tthis.connection = socket;\n\n\t\tthis._dumped = false;\n\t}\n\n\t_destroy(error) {\n\t\tthis.req._request.destroy(error);\n\t}\n\n\tsetTimeout(ms, callback) {\n\t\tthis.req.setTimeout(ms, callback);\n\t\treturn this;\n\t}\n\n\t_dump() {\n\t\tif (!this._dumped) {\n\t\t\tthis._dumped = true;\n\n\t\t\tthis.removeAllListeners('data');\n\t\t\tthis.resume();\n\t\t}\n\t}\n\n\t_read() {\n\t\tif (this.req) {\n\t\t\tthis.req._request.resume();\n\t\t}\n\t}\n}\n\nmodule.exports = IncomingMessage;\n\n\n/***/ }),\n\n/***/ 4645:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\n\"use strict\";\n\nconst http2 = __nccwpck_require__(5158);\nconst agent = __nccwpck_require__(9898);\nconst ClientRequest = __nccwpck_require__(9632);\nconst IncomingMessage = __nccwpck_require__(2575);\nconst auto = __nccwpck_require__(7167);\n\nconst request = (url, options, callback) => {\n\treturn new ClientRequest(url, options, callback);\n};\n\nconst get = (url, options, callback) => {\n\t// eslint-disable-next-line unicorn/prevent-abbreviations\n\tconst req = new ClientRequest(url, options, callback);\n\treq.end();\n\n\treturn req;\n};\n\nmodule.exports = {\n\t...http2,\n\tClientRequest,\n\tIncomingMessage,\n\t...agent,\n\trequest,\n\tget,\n\tauto\n};\n\n\n/***/ }),\n\n/***/ 1982:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\n\"use strict\";\n\nconst net = __nccwpck_require__(1808);\n/* istanbul ignore file: https://github.com/nodejs/node/blob/v13.0.1/lib/_http_agent.js */\n\nmodule.exports = options => {\n\tlet servername = options.host;\n\tconst hostHeader = options.headers && options.headers.host;\n\n\tif (hostHeader) {\n\t\tif (hostHeader.startsWith('[')) {\n\t\t\tconst index = hostHeader.indexOf(']');\n\t\t\tif (index === -1) {\n\t\t\t\tservername = hostHeader;\n\t\t\t} else {\n\t\t\t\tservername = hostHeader.slice(1, -1);\n\t\t\t}\n\t\t} else {\n\t\t\tservername = hostHeader.split(':', 1)[0];\n\t\t}\n\t}\n\n\tif (net.isIP(servername)) {\n\t\treturn '';\n\t}\n\n\treturn servername;\n};\n\n\n/***/ }),\n\n/***/ 7087:\n/***/ ((module) => {\n\n\"use strict\";\n\n/* istanbul ignore file: https://github.com/nodejs/node/blob/master/lib/internal/errors.js */\n\nconst makeError = (Base, key, getMessage) => {\n\tmodule.exports[key] = class NodeError extends Base {\n\t\tconstructor(...args) {\n\t\t\tsuper(typeof getMessage === 'string' ? getMessage : getMessage(args));\n\t\t\tthis.name = `${super.name} [${key}]`;\n\t\t\tthis.code = key;\n\t\t}\n\t};\n};\n\nmakeError(TypeError, 'ERR_INVALID_ARG_TYPE', args => {\n\tconst type = args[0].includes('.') ? 'property' : 'argument';\n\n\tlet valid = args[1];\n\tconst isManyTypes = Array.isArray(valid);\n\n\tif (isManyTypes) {\n\t\tvalid = `${valid.slice(0, -1).join(', ')} or ${valid.slice(-1)}`;\n\t}\n\n\treturn `The \"${args[0]}\" ${type} must be ${isManyTypes ? 'one of' : 'of'} type ${valid}. Received ${typeof args[2]}`;\n});\n\nmakeError(TypeError, 'ERR_INVALID_PROTOCOL', args => {\n\treturn `Protocol \"${args[0]}\" not supported. Expected \"${args[1]}\"`;\n});\n\nmakeError(Error, 'ERR_HTTP_HEADERS_SENT', args => {\n\treturn `Cannot ${args[0]} headers after they are sent to the client`;\n});\n\nmakeError(TypeError, 'ERR_INVALID_HTTP_TOKEN', args => {\n\treturn `${args[0]} must be a valid HTTP token [${args[1]}]`;\n});\n\nmakeError(TypeError, 'ERR_HTTP_INVALID_HEADER_VALUE', args => {\n\treturn `Invalid value \"${args[0]} for header \"${args[1]}\"`;\n});\n\nmakeError(TypeError, 'ERR_INVALID_CHAR', args => {\n\treturn `Invalid character in ${args[0]} [${args[1]}]`;\n});\n\n\n/***/ }),\n\n/***/ 1199:\n/***/ ((module) => {\n\n\"use strict\";\n\n\nmodule.exports = header => {\n\tswitch (header) {\n\t\tcase ':method':\n\t\tcase ':scheme':\n\t\tcase ':authority':\n\t\tcase ':path':\n\t\t\treturn true;\n\t\tdefault:\n\t\t\treturn false;\n\t}\n};\n\n\n/***/ }),\n\n/***/ 1818:\n/***/ ((module) => {\n\n\"use strict\";\n\n\nmodule.exports = (from, to, events) => {\n\tfor (const event of events) {\n\t\tfrom.on(event, (...args) => to.emit(event, ...args));\n\t}\n};\n\n\n/***/ }),\n\n/***/ 2686:\n/***/ ((module) => {\n\n\"use strict\";\n\n/* istanbul ignore file: https://github.com/nodejs/node/blob/a91293d4d9ab403046ab5eb022332e4e3d249bd3/lib/internal/url.js#L1257 */\n\nmodule.exports = url => {\n\tconst options = {\n\t\tprotocol: url.protocol,\n\t\thostname: typeof url.hostname === 'string' && url.hostname.startsWith('[') ? url.hostname.slice(1, -1) : url.hostname,\n\t\thost: url.host,\n\t\thash: url.hash,\n\t\tsearch: url.search,\n\t\tpathname: url.pathname,\n\t\thref: url.href,\n\t\tpath: `${url.pathname || ''}${url.search || ''}`\n\t};\n\n\tif (typeof url.port === 'string' && url.port.length !== 0) {\n\t\toptions.port = Number(url.port);\n\t}\n\n\tif (url.username || url.password) {\n\t\toptions.auth = `${url.username || ''}:${url.password || ''}`;\n\t}\n\n\treturn options;\n};\n\n\n/***/ }),\n\n/***/ 1554:\n/***/ ((module) => {\n\n\"use strict\";\n\n\nvar isStream = module.exports = function (stream) {\n\treturn stream !== null && typeof stream === 'object' && typeof stream.pipe === 'function';\n};\n\nisStream.writable = function (stream) {\n\treturn isStream(stream) && stream.writable !== false && typeof stream._write === 'function' && typeof stream._writableState === 'object';\n};\n\nisStream.readable = function (stream) {\n\treturn isStream(stream) && stream.readable !== false && typeof stream._read === 'function' && typeof stream._readableState === 'object';\n};\n\nisStream.duplex = function (stream) {\n\treturn isStream.writable(stream) && isStream.readable(stream);\n};\n\nisStream.transform = function (stream) {\n\treturn isStream.duplex(stream) && typeof stream._transform === 'function' && typeof stream._transformState === 'object';\n};\n\n\n/***/ }),\n\n/***/ 7126:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\nvar fs = __nccwpck_require__(7147)\nvar core\nif (process.platform === 'win32' || global.TESTING_WINDOWS) {\n core = __nccwpck_require__(2001)\n} else {\n core = __nccwpck_require__(9728)\n}\n\nmodule.exports = isexe\nisexe.sync = sync\n\nfunction isexe (path, options, cb) {\n if (typeof options === 'function') {\n cb = options\n options = {}\n }\n\n if (!cb) {\n if (typeof Promise !== 'function') {\n throw new TypeError('callback not provided')\n }\n\n return new Promise(function (resolve, reject) {\n isexe(path, options || {}, function (er, is) {\n if (er) {\n reject(er)\n } else {\n resolve(is)\n }\n })\n })\n }\n\n core(path, options || {}, function (er, is) {\n // ignore EACCES because that just means we aren't allowed to run it\n if (er) {\n if (er.code === 'EACCES' || options && options.ignoreErrors) {\n er = null\n is = false\n }\n }\n cb(er, is)\n })\n}\n\nfunction sync (path, options) {\n // my kingdom for a filtered catch\n try {\n return core.sync(path, options || {})\n } catch (er) {\n if (options && options.ignoreErrors || er.code === 'EACCES') {\n return false\n } else {\n throw er\n }\n }\n}\n\n\n/***/ }),\n\n/***/ 9728:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\nmodule.exports = isexe\nisexe.sync = sync\n\nvar fs = __nccwpck_require__(7147)\n\nfunction isexe (path, options, cb) {\n fs.stat(path, function (er, stat) {\n cb(er, er ? false : checkStat(stat, options))\n })\n}\n\nfunction sync (path, options) {\n return checkStat(fs.statSync(path), options)\n}\n\nfunction checkStat (stat, options) {\n return stat.isFile() && checkMode(stat, options)\n}\n\nfunction checkMode (stat, options) {\n var mod = stat.mode\n var uid = stat.uid\n var gid = stat.gid\n\n var myUid = options.uid !== undefined ?\n options.uid : process.getuid && process.getuid()\n var myGid = options.gid !== undefined ?\n options.gid : process.getgid && process.getgid()\n\n var u = parseInt('100', 8)\n var g = parseInt('010', 8)\n var o = parseInt('001', 8)\n var ug = u | g\n\n var ret = (mod & o) ||\n (mod & g) && gid === myGid ||\n (mod & u) && uid === myUid ||\n (mod & ug) && myUid === 0\n\n return ret\n}\n\n\n/***/ }),\n\n/***/ 2001:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\nmodule.exports = isexe\nisexe.sync = sync\n\nvar fs = __nccwpck_require__(7147)\n\nfunction checkPathExt (path, options) {\n var pathext = options.pathExt !== undefined ?\n options.pathExt : process.env.PATHEXT\n\n if (!pathext) {\n return true\n }\n\n pathext = pathext.split(';')\n if (pathext.indexOf('') !== -1) {\n return true\n }\n for (var i = 0; i < pathext.length; i++) {\n var p = pathext[i].toLowerCase()\n if (p && path.substr(-p.length).toLowerCase() === p) {\n return true\n }\n }\n return false\n}\n\nfunction checkStat (stat, path, options) {\n if (!stat.isSymbolicLink() && !stat.isFile()) {\n return false\n }\n return checkPathExt(path, options)\n}\n\nfunction isexe (path, options, cb) {\n fs.stat(path, function (er, stat) {\n cb(er, er ? false : checkStat(stat, path, options))\n })\n}\n\nfunction sync (path, options) {\n return checkStat(fs.statSync(path), path, options)\n}\n\n\n/***/ }),\n\n/***/ 2820:\n/***/ ((__unused_webpack_module, exports) => {\n\n//TODO: handle reviver/dehydrate function like normal\n//and handle indentation, like normal.\n//if anyone needs this... please send pull request.\n\nexports.stringify = function stringify (o) {\n if('undefined' == typeof o) return o\n\n if(o && Buffer.isBuffer(o))\n return JSON.stringify(':base64:' + o.toString('base64'))\n\n if(o && o.toJSON)\n o = o.toJSON()\n\n if(o && 'object' === typeof o) {\n var s = ''\n var array = Array.isArray(o)\n s = array ? '[' : '{'\n var first = true\n\n for(var k in o) {\n var ignore = 'function' == typeof o[k] || (!array && 'undefined' === typeof o[k])\n if(Object.hasOwnProperty.call(o, k) && !ignore) {\n if(!first)\n s += ','\n first = false\n if (array) {\n if(o[k] == undefined)\n s += 'null'\n else\n s += stringify(o[k])\n } else if (o[k] !== void(0)) {\n s += stringify(k) + ':' + stringify(o[k])\n }\n }\n }\n\n s += array ? ']' : '}'\n\n return s\n } else if ('string' === typeof o) {\n return JSON.stringify(/^:/.test(o) ? ':' + o : o)\n } else if ('undefined' === typeof o) {\n return 'null';\n } else\n return JSON.stringify(o)\n}\n\nexports.parse = function (s) {\n return JSON.parse(s, function (key, value) {\n if('string' === typeof value) {\n if(/^:base64:/.test(value))\n return Buffer.from(value.substring(8), 'base64')\n else\n return /^:/.test(value) ? value.substring(1) : value \n }\n return value\n })\n}\n\n\n/***/ }),\n\n/***/ 1531:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\n\"use strict\";\n\n\nconst EventEmitter = __nccwpck_require__(2361);\nconst JSONB = __nccwpck_require__(2820);\n\nconst loadStore = options => {\n\tconst adapters = {\n\t\tredis: '@keyv/redis',\n\t\trediss: '@keyv/redis',\n\t\tmongodb: '@keyv/mongo',\n\t\tmongo: '@keyv/mongo',\n\t\tsqlite: '@keyv/sqlite',\n\t\tpostgresql: '@keyv/postgres',\n\t\tpostgres: '@keyv/postgres',\n\t\tmysql: '@keyv/mysql',\n\t\tetcd: '@keyv/etcd',\n\t\toffline: '@keyv/offline',\n\t\ttiered: '@keyv/tiered',\n\t};\n\tif (options.adapter || options.uri) {\n\t\tconst adapter = options.adapter || /^[^:+]*/.exec(options.uri)[0];\n\t\treturn new (require(adapters[adapter]))(options);\n\t}\n\n\treturn new Map();\n};\n\nconst iterableAdapters = [\n\t'sqlite',\n\t'postgres',\n\t'mysql',\n\t'mongo',\n\t'redis',\n\t'tiered',\n];\n\nclass Keyv extends EventEmitter {\n\tconstructor(uri, {emitErrors = true, ...options} = {}) {\n\t\tsuper();\n\t\tthis.opts = {\n\t\t\tnamespace: 'keyv',\n\t\t\tserialize: JSONB.stringify,\n\t\t\tdeserialize: JSONB.parse,\n\t\t\t...((typeof uri === 'string') ? {uri} : uri),\n\t\t\t...options,\n\t\t};\n\n\t\tif (!this.opts.store) {\n\t\t\tconst adapterOptions = {...this.opts};\n\t\t\tthis.opts.store = loadStore(adapterOptions);\n\t\t}\n\n\t\tif (this.opts.compression) {\n\t\t\tconst compression = this.opts.compression;\n\t\t\tthis.opts.serialize = compression.serialize.bind(compression);\n\t\t\tthis.opts.deserialize = compression.deserialize.bind(compression);\n\t\t}\n\n\t\tif (typeof this.opts.store.on === 'function' && emitErrors) {\n\t\t\tthis.opts.store.on('error', error => this.emit('error', error));\n\t\t}\n\n\t\tthis.opts.store.namespace = this.opts.namespace;\n\n\t\tconst generateIterator = iterator => async function * () {\n\t\t\tfor await (const [key, raw] of typeof iterator === 'function'\n\t\t\t\t? iterator(this.opts.store.namespace)\n\t\t\t\t: iterator) {\n\t\t\t\tconst data = await this.opts.deserialize(raw);\n\t\t\t\tif (this.opts.store.namespace && !key.includes(this.opts.store.namespace)) {\n\t\t\t\t\tcontinue;\n\t\t\t\t}\n\n\t\t\t\tif (typeof data.expires === 'number' && Date.now() > data.expires) {\n\t\t\t\t\tthis.delete(key);\n\t\t\t\t\tcontinue;\n\t\t\t\t}\n\n\t\t\t\tyield [this._getKeyUnprefix(key), data.value];\n\t\t\t}\n\t\t};\n\n\t\t// Attach iterators\n\t\tif (typeof this.opts.store[Symbol.iterator] === 'function' && this.opts.store instanceof Map) {\n\t\t\tthis.iterator = generateIterator(this.opts.store);\n\t\t} else if (typeof this.opts.store.iterator === 'function' && this.opts.store.opts\n\t\t\t&& this._checkIterableAdaptar()) {\n\t\t\tthis.iterator = generateIterator(this.opts.store.iterator.bind(this.opts.store));\n\t\t}\n\t}\n\n\t_checkIterableAdaptar() {\n\t\treturn iterableAdapters.includes(this.opts.store.opts.dialect)\n\t\t\t|| iterableAdapters.findIndex(element => this.opts.store.opts.url.includes(element)) >= 0;\n\t}\n\n\t_getKeyPrefix(key) {\n\t\treturn `${this.opts.namespace}:${key}`;\n\t}\n\n\t_getKeyPrefixArray(keys) {\n\t\treturn keys.map(key => `${this.opts.namespace}:${key}`);\n\t}\n\n\t_getKeyUnprefix(key) {\n\t\treturn key\n\t\t\t.split(':')\n\t\t\t.splice(1)\n\t\t\t.join(':');\n\t}\n\n\tget(key, options) {\n\t\tconst {store} = this.opts;\n\t\tconst isArray = Array.isArray(key);\n\t\tconst keyPrefixed = isArray ? this._getKeyPrefixArray(key) : this._getKeyPrefix(key);\n\t\tif (isArray && store.getMany === undefined) {\n\t\t\tconst promises = [];\n\t\t\tfor (const key of keyPrefixed) {\n\t\t\t\tpromises.push(Promise.resolve()\n\t\t\t\t\t.then(() => store.get(key))\n\t\t\t\t\t.then(data => (typeof data === 'string') ? this.opts.deserialize(data) : (this.opts.compression ? this.opts.deserialize(data) : data))\n\t\t\t\t\t.then(data => {\n\t\t\t\t\t\tif (data === undefined || data === null) {\n\t\t\t\t\t\t\treturn undefined;\n\t\t\t\t\t\t}\n\n\t\t\t\t\t\tif (typeof data.expires === 'number' && Date.now() > data.expires) {\n\t\t\t\t\t\t\treturn this.delete(key).then(() => undefined);\n\t\t\t\t\t\t}\n\n\t\t\t\t\t\treturn (options && options.raw) ? data : data.value;\n\t\t\t\t\t}),\n\t\t\t\t);\n\t\t\t}\n\n\t\t\treturn Promise.allSettled(promises)\n\t\t\t\t.then(values => {\n\t\t\t\t\tconst data = [];\n\t\t\t\t\tfor (const value of values) {\n\t\t\t\t\t\tdata.push(value.value);\n\t\t\t\t\t}\n\n\t\t\t\t\treturn data;\n\t\t\t\t});\n\t\t}\n\n\t\treturn Promise.resolve()\n\t\t\t.then(() => isArray ? store.getMany(keyPrefixed) : store.get(keyPrefixed))\n\t\t\t.then(data => (typeof data === 'string') ? this.opts.deserialize(data) : (this.opts.compression ? this.opts.deserialize(data) : data))\n\t\t\t.then(data => {\n\t\t\t\tif (data === undefined || data === null) {\n\t\t\t\t\treturn undefined;\n\t\t\t\t}\n\n\t\t\t\tif (isArray) {\n\t\t\t\t\treturn data.map((row, index) => {\n\t\t\t\t\t\tif ((typeof row === 'string')) {\n\t\t\t\t\t\t\trow = this.opts.deserialize(row);\n\t\t\t\t\t\t}\n\n\t\t\t\t\t\tif (row === undefined || row === null) {\n\t\t\t\t\t\t\treturn undefined;\n\t\t\t\t\t\t}\n\n\t\t\t\t\t\tif (typeof row.expires === 'number' && Date.now() > row.expires) {\n\t\t\t\t\t\t\tthis.delete(key[index]).then(() => undefined);\n\t\t\t\t\t\t\treturn undefined;\n\t\t\t\t\t\t}\n\n\t\t\t\t\t\treturn (options && options.raw) ? row : row.value;\n\t\t\t\t\t});\n\t\t\t\t}\n\n\t\t\t\tif (typeof data.expires === 'number' && Date.now() > data.expires) {\n\t\t\t\t\treturn this.delete(key).then(() => undefined);\n\t\t\t\t}\n\n\t\t\t\treturn (options && options.raw) ? data : data.value;\n\t\t\t});\n\t}\n\n\tset(key, value, ttl) {\n\t\tconst keyPrefixed = this._getKeyPrefix(key);\n\t\tif (typeof ttl === 'undefined') {\n\t\t\tttl = this.opts.ttl;\n\t\t}\n\n\t\tif (ttl === 0) {\n\t\t\tttl = undefined;\n\t\t}\n\n\t\tconst {store} = this.opts;\n\n\t\treturn Promise.resolve()\n\t\t\t.then(() => {\n\t\t\t\tconst expires = (typeof ttl === 'number') ? (Date.now() + ttl) : null;\n\t\t\t\tif (typeof value === 'symbol') {\n\t\t\t\t\tthis.emit('error', 'symbol cannot be serialized');\n\t\t\t\t}\n\n\t\t\t\tvalue = {value, expires};\n\t\t\t\treturn this.opts.serialize(value);\n\t\t\t})\n\t\t\t.then(value => store.set(keyPrefixed, value, ttl))\n\t\t\t.then(() => true);\n\t}\n\n\tdelete(key) {\n\t\tconst {store} = this.opts;\n\t\tif (Array.isArray(key)) {\n\t\t\tconst keyPrefixed = this._getKeyPrefixArray(key);\n\t\t\tif (store.deleteMany === undefined) {\n\t\t\t\tconst promises = [];\n\t\t\t\tfor (const key of keyPrefixed) {\n\t\t\t\t\tpromises.push(store.delete(key));\n\t\t\t\t}\n\n\t\t\t\treturn Promise.allSettled(promises)\n\t\t\t\t\t.then(values => values.every(x => x.value === true));\n\t\t\t}\n\n\t\t\treturn Promise.resolve()\n\t\t\t\t.then(() => store.deleteMany(keyPrefixed));\n\t\t}\n\n\t\tconst keyPrefixed = this._getKeyPrefix(key);\n\t\treturn Promise.resolve()\n\t\t\t.then(() => store.delete(keyPrefixed));\n\t}\n\n\tclear() {\n\t\tconst {store} = this.opts;\n\t\treturn Promise.resolve()\n\t\t\t.then(() => store.clear());\n\t}\n\n\thas(key) {\n\t\tconst keyPrefixed = this._getKeyPrefix(key);\n\t\tconst {store} = this.opts;\n\t\treturn Promise.resolve()\n\t\t\t.then(async () => {\n\t\t\t\tif (typeof store.has === 'function') {\n\t\t\t\t\treturn store.has(keyPrefixed);\n\t\t\t\t}\n\n\t\t\t\tconst value = await store.get(keyPrefixed);\n\t\t\t\treturn value !== undefined;\n\t\t\t});\n\t}\n\n\tdisconnect() {\n\t\tconst {store} = this.opts;\n\t\tif (typeof store.disconnect === 'function') {\n\t\t\treturn store.disconnect();\n\t\t}\n\t}\n}\n\nmodule.exports = Keyv;\n\n\n/***/ }),\n\n/***/ 9197:\n/***/ ((module) => {\n\n/**\n * lodash (Custom Build) <https://lodash.com/>\n * Build: `lodash modularize exports=\"npm\" -o ./`\n * Copyright jQuery Foundation and other contributors <https://jquery.org/>\n * Released under MIT license <https://lodash.com/license>\n * Based on Underscore.js 1.8.3 <http://underscorejs.org/LICENSE>\n * Copyright Jeremy Ashkenas, DocumentCloud and Investigative Reporters & Editors\n */\n\n/** Used as the `TypeError` message for \"Functions\" methods. */\nvar FUNC_ERROR_TEXT = 'Expected a function';\n\n/** Used to stand-in for `undefined` hash values. */\nvar HASH_UNDEFINED = '__lodash_hash_undefined__';\n\n/** Used as references for various `Number` constants. */\nvar INFINITY = 1 / 0;\n\n/** `Object#toString` result references. */\nvar funcTag = '[object Function]',\n genTag = '[object GeneratorFunction]',\n symbolTag = '[object Symbol]';\n\n/** Used to match property names within property paths. */\nvar reIsDeepProp = /\\.|\\[(?:[^[\\]]*|([\"'])(?:(?!\\1)[^\\\\]|\\\\.)*?\\1)\\]/,\n reIsPlainProp = /^\\w*$/,\n reLeadingDot = /^\\./,\n rePropName = /[^.[\\]]+|\\[(?:(-?\\d+(?:\\.\\d+)?)|([\"'])((?:(?!\\2)[^\\\\]|\\\\.)*?)\\2)\\]|(?=(?:\\.|\\[\\])(?:\\.|\\[\\]|$))/g;\n\n/**\n * Used to match `RegExp`\n * [syntax characters](http://ecma-international.org/ecma-262/7.0/#sec-patterns).\n */\nvar reRegExpChar = /[\\\\^$.*+?()[\\]{}|]/g;\n\n/** Used to match backslashes in property paths. */\nvar reEscapeChar = /\\\\(\\\\)?/g;\n\n/** Used to detect host constructors (Safari). */\nvar reIsHostCtor = /^\\[object .+?Constructor\\]$/;\n\n/** Detect free variable `global` from Node.js. */\nvar freeGlobal = typeof global == 'object' && global && global.Object === Object && global;\n\n/** Detect free variable `self`. */\nvar freeSelf = typeof self == 'object' && self && self.Object === Object && self;\n\n/** Used as a reference to the global object. */\nvar root = freeGlobal || freeSelf || Function('return this')();\n\n/**\n * Gets the value at `key` of `object`.\n *\n * @private\n * @param {Object} [object] The object to query.\n * @param {string} key The key of the property to get.\n * @returns {*} Returns the property value.\n */\nfunction getValue(object, key) {\n return object == null ? undefined : object[key];\n}\n\n/**\n * Checks if `value` is a host object in IE < 9.\n *\n * @private\n * @param {*} value The value to check.\n * @returns {boolean} Returns `true` if `value` is a host object, else `false`.\n */\nfunction isHostObject(value) {\n // Many host objects are `Object` objects that can coerce to strings\n // despite having improperly defined `toString` methods.\n var result = false;\n if (value != null && typeof value.toString != 'function') {\n try {\n result = !!(value + '');\n } catch (e) {}\n }\n return result;\n}\n\n/** Used for built-in method references. */\nvar arrayProto = Array.prototype,\n funcProto = Function.prototype,\n objectProto = Object.prototype;\n\n/** Used to detect overreaching core-js shims. */\nvar coreJsData = root['__core-js_shared__'];\n\n/** Used to detect methods masquerading as native. */\nvar maskSrcKey = (function() {\n var uid = /[^.]+$/.exec(coreJsData && coreJsData.keys && coreJsData.keys.IE_PROTO || '');\n return uid ? ('Symbol(src)_1.' + uid) : '';\n}());\n\n/** Used to resolve the decompiled source of functions. */\nvar funcToString = funcProto.toString;\n\n/** Used to check objects for own properties. */\nvar hasOwnProperty = objectProto.hasOwnProperty;\n\n/**\n * Used to resolve the\n * [`toStringTag`](http://ecma-international.org/ecma-262/7.0/#sec-object.prototype.tostring)\n * of values.\n */\nvar objectToString = objectProto.toString;\n\n/** Used to detect if a method is native. */\nvar reIsNative = RegExp('^' +\n funcToString.call(hasOwnProperty).replace(reRegExpChar, '\\\\$&')\n .replace(/hasOwnProperty|(function).*?(?=\\\\\\()| for .+?(?=\\\\\\])/g, '$1.*?') + '$'\n);\n\n/** Built-in value references. */\nvar Symbol = root.Symbol,\n splice = arrayProto.splice;\n\n/* Built-in method references that are verified to be native. */\nvar Map = getNative(root, 'Map'),\n nativeCreate = getNative(Object, 'create');\n\n/** Used to convert symbols to primitives and strings. */\nvar symbolProto = Symbol ? Symbol.prototype : undefined,\n symbolToString = symbolProto ? symbolProto.toString : undefined;\n\n/**\n * Creates a hash object.\n *\n * @private\n * @constructor\n * @param {Array} [entries] The key-value pairs to cache.\n */\nfunction Hash(entries) {\n var index = -1,\n length = entries ? entries.length : 0;\n\n this.clear();\n while (++index < length) {\n var entry = entries[index];\n this.set(entry[0], entry[1]);\n }\n}\n\n/**\n * Removes all key-value entries from the hash.\n *\n * @private\n * @name clear\n * @memberOf Hash\n */\nfunction hashClear() {\n this.__data__ = nativeCreate ? nativeCreate(null) : {};\n}\n\n/**\n * Removes `key` and its value from the hash.\n *\n * @private\n * @name delete\n * @memberOf Hash\n * @param {Object} hash The hash to modify.\n * @param {string} key The key of the value to remove.\n * @returns {boolean} Returns `true` if the entry was removed, else `false`.\n */\nfunction hashDelete(key) {\n return this.has(key) && delete this.__data__[key];\n}\n\n/**\n * Gets the hash value for `key`.\n *\n * @private\n * @name get\n * @memberOf Hash\n * @param {string} key The key of the value to get.\n * @returns {*} Returns the entry value.\n */\nfunction hashGet(key) {\n var data = this.__data__;\n if (nativeCreate) {\n var result = data[key];\n return result === HASH_UNDEFINED ? undefined : result;\n }\n return hasOwnProperty.call(data, key) ? data[key] : undefined;\n}\n\n/**\n * Checks if a hash value for `key` exists.\n *\n * @private\n * @name has\n * @memberOf Hash\n * @param {string} key The key of the entry to check.\n * @returns {boolean} Returns `true` if an entry for `key` exists, else `false`.\n */\nfunction hashHas(key) {\n var data = this.__data__;\n return nativeCreate ? data[key] !== undefined : hasOwnProperty.call(data, key);\n}\n\n/**\n * Sets the hash `key` to `value`.\n *\n * @private\n * @name set\n * @memberOf Hash\n * @param {string} key The key of the value to set.\n * @param {*} value The value to set.\n * @returns {Object} Returns the hash instance.\n */\nfunction hashSet(key, value) {\n var data = this.__data__;\n data[key] = (nativeCreate && value === undefined) ? HASH_UNDEFINED : value;\n return this;\n}\n\n// Add methods to `Hash`.\nHash.prototype.clear = hashClear;\nHash.prototype['delete'] = hashDelete;\nHash.prototype.get = hashGet;\nHash.prototype.has = hashHas;\nHash.prototype.set = hashSet;\n\n/**\n * Creates an list cache object.\n *\n * @private\n * @constructor\n * @param {Array} [entries] The key-value pairs to cache.\n */\nfunction ListCache(entries) {\n var index = -1,\n length = entries ? entries.length : 0;\n\n this.clear();\n while (++index < length) {\n var entry = entries[index];\n this.set(entry[0], entry[1]);\n }\n}\n\n/**\n * Removes all key-value entries from the list cache.\n *\n * @private\n * @name clear\n * @memberOf ListCache\n */\nfunction listCacheClear() {\n this.__data__ = [];\n}\n\n/**\n * Removes `key` and its value from the list cache.\n *\n * @private\n * @name delete\n * @memberOf ListCache\n * @param {string} key The key of the value to remove.\n * @returns {boolean} Returns `true` if the entry was removed, else `false`.\n */\nfunction listCacheDelete(key) {\n var data = this.__data__,\n index = assocIndexOf(data, key);\n\n if (index < 0) {\n return false;\n }\n var lastIndex = data.length - 1;\n if (index == lastIndex) {\n data.pop();\n } else {\n splice.call(data, index, 1);\n }\n return true;\n}\n\n/**\n * Gets the list cache value for `key`.\n *\n * @private\n * @name get\n * @memberOf ListCache\n * @param {string} key The key of the value to get.\n * @returns {*} Returns the entry value.\n */\nfunction listCacheGet(key) {\n var data = this.__data__,\n index = assocIndexOf(data, key);\n\n return index < 0 ? undefined : data[index][1];\n}\n\n/**\n * Checks if a list cache value for `key` exists.\n *\n * @private\n * @name has\n * @memberOf ListCache\n * @param {string} key The key of the entry to check.\n * @returns {boolean} Returns `true` if an entry for `key` exists, else `false`.\n */\nfunction listCacheHas(key) {\n return assocIndexOf(this.__data__, key) > -1;\n}\n\n/**\n * Sets the list cache `key` to `value`.\n *\n * @private\n * @name set\n * @memberOf ListCache\n * @param {string} key The key of the value to set.\n * @param {*} value The value to set.\n * @returns {Object} Returns the list cache instance.\n */\nfunction listCacheSet(key, value) {\n var data = this.__data__,\n index = assocIndexOf(data, key);\n\n if (index < 0) {\n data.push([key, value]);\n } else {\n data[index][1] = value;\n }\n return this;\n}\n\n// Add methods to `ListCache`.\nListCache.prototype.clear = listCacheClear;\nListCache.prototype['delete'] = listCacheDelete;\nListCache.prototype.get = listCacheGet;\nListCache.prototype.has = listCacheHas;\nListCache.prototype.set = listCacheSet;\n\n/**\n * Creates a map cache object to store key-value pairs.\n *\n * @private\n * @constructor\n * @param {Array} [entries] The key-value pairs to cache.\n */\nfunction MapCache(entries) {\n var index = -1,\n length = entries ? entries.length : 0;\n\n this.clear();\n while (++index < length) {\n var entry = entries[index];\n this.set(entry[0], entry[1]);\n }\n}\n\n/**\n * Removes all key-value entries from the map.\n *\n * @private\n * @name clear\n * @memberOf MapCache\n */\nfunction mapCacheClear() {\n this.__data__ = {\n 'hash': new Hash,\n 'map': new (Map || ListCache),\n 'string': new Hash\n };\n}\n\n/**\n * Removes `key` and its value from the map.\n *\n * @private\n * @name delete\n * @memberOf MapCache\n * @param {string} key The key of the value to remove.\n * @returns {boolean} Returns `true` if the entry was removed, else `false`.\n */\nfunction mapCacheDelete(key) {\n return getMapData(this, key)['delete'](key);\n}\n\n/**\n * Gets the map value for `key`.\n *\n * @private\n * @name get\n * @memberOf MapCache\n * @param {string} key The key of the value to get.\n * @returns {*} Returns the entry value.\n */\nfunction mapCacheGet(key) {\n return getMapData(this, key).get(key);\n}\n\n/**\n * Checks if a map value for `key` exists.\n *\n * @private\n * @name has\n * @memberOf MapCache\n * @param {string} key The key of the entry to check.\n * @returns {boolean} Returns `true` if an entry for `key` exists, else `false`.\n */\nfunction mapCacheHas(key) {\n return getMapData(this, key).has(key);\n}\n\n/**\n * Sets the map `key` to `value`.\n *\n * @private\n * @name set\n * @memberOf MapCache\n * @param {string} key The key of the value to set.\n * @param {*} value The value to set.\n * @returns {Object} Returns the map cache instance.\n */\nfunction mapCacheSet(key, value) {\n getMapData(this, key).set(key, value);\n return this;\n}\n\n// Add methods to `MapCache`.\nMapCache.prototype.clear = mapCacheClear;\nMapCache.prototype['delete'] = mapCacheDelete;\nMapCache.prototype.get = mapCacheGet;\nMapCache.prototype.has = mapCacheHas;\nMapCache.prototype.set = mapCacheSet;\n\n/**\n * Gets the index at which the `key` is found in `array` of key-value pairs.\n *\n * @private\n * @param {Array} array The array to inspect.\n * @param {*} key The key to search for.\n * @returns {number} Returns the index of the matched value, else `-1`.\n */\nfunction assocIndexOf(array, key) {\n var length = array.length;\n while (length--) {\n if (eq(array[length][0], key)) {\n return length;\n }\n }\n return -1;\n}\n\n/**\n * The base implementation of `_.get` without support for default values.\n *\n * @private\n * @param {Object} object The object to query.\n * @param {Array|string} path The path of the property to get.\n * @returns {*} Returns the resolved value.\n */\nfunction baseGet(object, path) {\n path = isKey(path, object) ? [path] : castPath(path);\n\n var index = 0,\n length = path.length;\n\n while (object != null && index < length) {\n object = object[toKey(path[index++])];\n }\n return (index && index == length) ? object : undefined;\n}\n\n/**\n * The base implementation of `_.isNative` without bad shim checks.\n *\n * @private\n * @param {*} value The value to check.\n * @returns {boolean} Returns `true` if `value` is a native function,\n * else `false`.\n */\nfunction baseIsNative(value) {\n if (!isObject(value) || isMasked(value)) {\n return false;\n }\n var pattern = (isFunction(value) || isHostObject(value)) ? reIsNative : reIsHostCtor;\n return pattern.test(toSource(value));\n}\n\n/**\n * The base implementation of `_.toString` which doesn't convert nullish\n * values to empty strings.\n *\n * @private\n * @param {*} value The value to process.\n * @returns {string} Returns the string.\n */\nfunction baseToString(value) {\n // Exit early for strings to avoid a performance hit in some environments.\n if (typeof value == 'string') {\n return value;\n }\n if (isSymbol(value)) {\n return symbolToString ? symbolToString.call(value) : '';\n }\n var result = (value + '');\n return (result == '0' && (1 / value) == -INFINITY) ? '-0' : result;\n}\n\n/**\n * Casts `value` to a path array if it's not one.\n *\n * @private\n * @param {*} value The value to inspect.\n * @returns {Array} Returns the cast property path array.\n */\nfunction castPath(value) {\n return isArray(value) ? value : stringToPath(value);\n}\n\n/**\n * Gets the data for `map`.\n *\n * @private\n * @param {Object} map The map to query.\n * @param {string} key The reference key.\n * @returns {*} Returns the map data.\n */\nfunction getMapData(map, key) {\n var data = map.__data__;\n return isKeyable(key)\n ? data[typeof key == 'string' ? 'string' : 'hash']\n : data.map;\n}\n\n/**\n * Gets the native function at `key` of `object`.\n *\n * @private\n * @param {Object} object The object to query.\n * @param {string} key The key of the method to get.\n * @returns {*} Returns the function if it's native, else `undefined`.\n */\nfunction getNative(object, key) {\n var value = getValue(object, key);\n return baseIsNative(value) ? value : undefined;\n}\n\n/**\n * Checks if `value` is a property name and not a property path.\n *\n * @private\n * @param {*} value The value to check.\n * @param {Object} [object] The object to query keys on.\n * @returns {boolean} Returns `true` if `value` is a property name, else `false`.\n */\nfunction isKey(value, object) {\n if (isArray(value)) {\n return false;\n }\n var type = typeof value;\n if (type == 'number' || type == 'symbol' || type == 'boolean' ||\n value == null || isSymbol(value)) {\n return true;\n }\n return reIsPlainProp.test(value) || !reIsDeepProp.test(value) ||\n (object != null && value in Object(object));\n}\n\n/**\n * Checks if `value` is suitable for use as unique object key.\n *\n * @private\n * @param {*} value The value to check.\n * @returns {boolean} Returns `true` if `value` is suitable, else `false`.\n */\nfunction isKeyable(value) {\n var type = typeof value;\n return (type == 'string' || type == 'number' || type == 'symbol' || type == 'boolean')\n ? (value !== '__proto__')\n : (value === null);\n}\n\n/**\n * Checks if `func` has its source masked.\n *\n * @private\n * @param {Function} func The function to check.\n * @returns {boolean} Returns `true` if `func` is masked, else `false`.\n */\nfunction isMasked(func) {\n return !!maskSrcKey && (maskSrcKey in func);\n}\n\n/**\n * Converts `string` to a property path array.\n *\n * @private\n * @param {string} string The string to convert.\n * @returns {Array} Returns the property path array.\n */\nvar stringToPath = memoize(function(string) {\n string = toString(string);\n\n var result = [];\n if (reLeadingDot.test(string)) {\n result.push('');\n }\n string.replace(rePropName, function(match, number, quote, string) {\n result.push(quote ? string.replace(reEscapeChar, '$1') : (number || match));\n });\n return result;\n});\n\n/**\n * Converts `value` to a string key if it's not a string or symbol.\n *\n * @private\n * @param {*} value The value to inspect.\n * @returns {string|symbol} Returns the key.\n */\nfunction toKey(value) {\n if (typeof value == 'string' || isSymbol(value)) {\n return value;\n }\n var result = (value + '');\n return (result == '0' && (1 / value) == -INFINITY) ? '-0' : result;\n}\n\n/**\n * Converts `func` to its source code.\n *\n * @private\n * @param {Function} func The function to process.\n * @returns {string} Returns the source code.\n */\nfunction toSource(func) {\n if (func != null) {\n try {\n return funcToString.call(func);\n } catch (e) {}\n try {\n return (func + '');\n } catch (e) {}\n }\n return '';\n}\n\n/**\n * Creates a function that memoizes the result of `func`. If `resolver` is\n * provided, it determines the cache key for storing the result based on the\n * arguments provided to the memoized function. By default, the first argument\n * provided to the memoized function is used as the map cache key. The `func`\n * is invoked with the `this` binding of the memoized function.\n *\n * **Note:** The cache is exposed as the `cache` property on the memoized\n * function. Its creation may be customized by replacing the `_.memoize.Cache`\n * constructor with one whose instances implement the\n * [`Map`](http://ecma-international.org/ecma-262/7.0/#sec-properties-of-the-map-prototype-object)\n * method interface of `delete`, `get`, `has`, and `set`.\n *\n * @static\n * @memberOf _\n * @since 0.1.0\n * @category Function\n * @param {Function} func The function to have its output memoized.\n * @param {Function} [resolver] The function to resolve the cache key.\n * @returns {Function} Returns the new memoized function.\n * @example\n *\n * var object = { 'a': 1, 'b': 2 };\n * var other = { 'c': 3, 'd': 4 };\n *\n * var values = _.memoize(_.values);\n * values(object);\n * // => [1, 2]\n *\n * values(other);\n * // => [3, 4]\n *\n * object.a = 2;\n * values(object);\n * // => [1, 2]\n *\n * // Modify the result cache.\n * values.cache.set(object, ['a', 'b']);\n * values(object);\n * // => ['a', 'b']\n *\n * // Replace `_.memoize.Cache`.\n * _.memoize.Cache = WeakMap;\n */\nfunction memoize(func, resolver) {\n if (typeof func != 'function' || (resolver && typeof resolver != 'function')) {\n throw new TypeError(FUNC_ERROR_TEXT);\n }\n var memoized = function() {\n var args = arguments,\n key = resolver ? resolver.apply(this, args) : args[0],\n cache = memoized.cache;\n\n if (cache.has(key)) {\n return cache.get(key);\n }\n var result = func.apply(this, args);\n memoized.cache = cache.set(key, result);\n return result;\n };\n memoized.cache = new (memoize.Cache || MapCache);\n return memoized;\n}\n\n// Assign cache to `_.memoize`.\nmemoize.Cache = MapCache;\n\n/**\n * Performs a\n * [`SameValueZero`](http://ecma-international.org/ecma-262/7.0/#sec-samevaluezero)\n * comparison between two values to determine if they are equivalent.\n *\n * @static\n * @memberOf _\n * @since 4.0.0\n * @category Lang\n * @param {*} value The value to compare.\n * @param {*} other The other value to compare.\n * @returns {boolean} Returns `true` if the values are equivalent, else `false`.\n * @example\n *\n * var object = { 'a': 1 };\n * var other = { 'a': 1 };\n *\n * _.eq(object, object);\n * // => true\n *\n * _.eq(object, other);\n * // => false\n *\n * _.eq('a', 'a');\n * // => true\n *\n * _.eq('a', Object('a'));\n * // => false\n *\n * _.eq(NaN, NaN);\n * // => true\n */\nfunction eq(value, other) {\n return value === other || (value !== value && other !== other);\n}\n\n/**\n * Checks if `value` is classified as an `Array` object.\n *\n * @static\n * @memberOf _\n * @since 0.1.0\n * @category Lang\n * @param {*} value The value to check.\n * @returns {boolean} Returns `true` if `value` is an array, else `false`.\n * @example\n *\n * _.isArray([1, 2, 3]);\n * // => true\n *\n * _.isArray(document.body.children);\n * // => false\n *\n * _.isArray('abc');\n * // => false\n *\n * _.isArray(_.noop);\n * // => false\n */\nvar isArray = Array.isArray;\n\n/**\n * Checks if `value` is classified as a `Function` object.\n *\n * @static\n * @memberOf _\n * @since 0.1.0\n * @category Lang\n * @param {*} value The value to check.\n * @returns {boolean} Returns `true` if `value` is a function, else `false`.\n * @example\n *\n * _.isFunction(_);\n * // => true\n *\n * _.isFunction(/abc/);\n * // => false\n */\nfunction isFunction(value) {\n // The use of `Object#toString` avoids issues with the `typeof` operator\n // in Safari 8-9 which returns 'object' for typed array and other constructors.\n var tag = isObject(value) ? objectToString.call(value) : '';\n return tag == funcTag || tag == genTag;\n}\n\n/**\n * Checks if `value` is the\n * [language type](http://www.ecma-international.org/ecma-262/7.0/#sec-ecmascript-language-types)\n * of `Object`. (e.g. arrays, functions, objects, regexes, `new Number(0)`, and `new String('')`)\n *\n * @static\n * @memberOf _\n * @since 0.1.0\n * @category Lang\n * @param {*} value The value to check.\n * @returns {boolean} Returns `true` if `value` is an object, else `false`.\n * @example\n *\n * _.isObject({});\n * // => true\n *\n * _.isObject([1, 2, 3]);\n * // => true\n *\n * _.isObject(_.noop);\n * // => true\n *\n * _.isObject(null);\n * // => false\n */\nfunction isObject(value) {\n var type = typeof value;\n return !!value && (type == 'object' || type == 'function');\n}\n\n/**\n * Checks if `value` is object-like. A value is object-like if it's not `null`\n * and has a `typeof` result of \"object\".\n *\n * @static\n * @memberOf _\n * @since 4.0.0\n * @category Lang\n * @param {*} value The value to check.\n * @returns {boolean} Returns `true` if `value` is object-like, else `false`.\n * @example\n *\n * _.isObjectLike({});\n * // => true\n *\n * _.isObjectLike([1, 2, 3]);\n * // => true\n *\n * _.isObjectLike(_.noop);\n * // => false\n *\n * _.isObjectLike(null);\n * // => false\n */\nfunction isObjectLike(value) {\n return !!value && typeof value == 'object';\n}\n\n/**\n * Checks if `value` is classified as a `Symbol` primitive or object.\n *\n * @static\n * @memberOf _\n * @since 4.0.0\n * @category Lang\n * @param {*} value The value to check.\n * @returns {boolean} Returns `true` if `value` is a symbol, else `false`.\n * @example\n *\n * _.isSymbol(Symbol.iterator);\n * // => true\n *\n * _.isSymbol('abc');\n * // => false\n */\nfunction isSymbol(value) {\n return typeof value == 'symbol' ||\n (isObjectLike(value) && objectToString.call(value) == symbolTag);\n}\n\n/**\n * Converts `value` to a string. An empty string is returned for `null`\n * and `undefined` values. The sign of `-0` is preserved.\n *\n * @static\n * @memberOf _\n * @since 4.0.0\n * @category Lang\n * @param {*} value The value to process.\n * @returns {string} Returns the string.\n * @example\n *\n * _.toString(null);\n * // => ''\n *\n * _.toString(-0);\n * // => '-0'\n *\n * _.toString([1, 2, 3]);\n * // => '1,2,3'\n */\nfunction toString(value) {\n return value == null ? '' : baseToString(value);\n}\n\n/**\n * Gets the value at `path` of `object`. If the resolved value is\n * `undefined`, the `defaultValue` is returned in its place.\n *\n * @static\n * @memberOf _\n * @since 3.7.0\n * @category Object\n * @param {Object} object The object to query.\n * @param {Array|string} path The path of the property to get.\n * @param {*} [defaultValue] The value returned for `undefined` resolved values.\n * @returns {*} Returns the resolved value.\n * @example\n *\n * var object = { 'a': [{ 'b': { 'c': 3 } }] };\n *\n * _.get(object, 'a[0].b.c');\n * // => 3\n *\n * _.get(object, ['a', '0', 'b', 'c']);\n * // => 3\n *\n * _.get(object, 'a.b.c', 'default');\n * // => 'default'\n */\nfunction get(object, path, defaultValue) {\n var result = object == null ? undefined : baseGet(object, path);\n return result === undefined ? defaultValue : result;\n}\n\nmodule.exports = get;\n\n\n/***/ }),\n\n/***/ 1552:\n/***/ ((module) => {\n\n/**\n * lodash (Custom Build) <https://lodash.com/>\n * Build: `lodash modularize exports=\"npm\" -o ./`\n * Copyright jQuery Foundation and other contributors <https://jquery.org/>\n * Released under MIT license <https://lodash.com/license>\n * Based on Underscore.js 1.8.3 <http://underscorejs.org/LICENSE>\n * Copyright Jeremy Ashkenas, DocumentCloud and Investigative Reporters & Editors\n */\n\n/** Used as the `TypeError` message for \"Functions\" methods. */\nvar FUNC_ERROR_TEXT = 'Expected a function';\n\n/** Used to stand-in for `undefined` hash values. */\nvar HASH_UNDEFINED = '__lodash_hash_undefined__';\n\n/** Used as references for various `Number` constants. */\nvar INFINITY = 1 / 0,\n MAX_SAFE_INTEGER = 9007199254740991;\n\n/** `Object#toString` result references. */\nvar funcTag = '[object Function]',\n genTag = '[object GeneratorFunction]',\n symbolTag = '[object Symbol]';\n\n/** Used to match property names within property paths. */\nvar reIsDeepProp = /\\.|\\[(?:[^[\\]]*|([\"'])(?:(?!\\1)[^\\\\]|\\\\.)*?\\1)\\]/,\n reIsPlainProp = /^\\w*$/,\n reLeadingDot = /^\\./,\n rePropName = /[^.[\\]]+|\\[(?:(-?\\d+(?:\\.\\d+)?)|([\"'])((?:(?!\\2)[^\\\\]|\\\\.)*?)\\2)\\]|(?=(?:\\.|\\[\\])(?:\\.|\\[\\]|$))/g;\n\n/**\n * Used to match `RegExp`\n * [syntax characters](http://ecma-international.org/ecma-262/7.0/#sec-patterns).\n */\nvar reRegExpChar = /[\\\\^$.*+?()[\\]{}|]/g;\n\n/** Used to match backslashes in property paths. */\nvar reEscapeChar = /\\\\(\\\\)?/g;\n\n/** Used to detect host constructors (Safari). */\nvar reIsHostCtor = /^\\[object .+?Constructor\\]$/;\n\n/** Used to detect unsigned integer values. */\nvar reIsUint = /^(?:0|[1-9]\\d*)$/;\n\n/** Detect free variable `global` from Node.js. */\nvar freeGlobal = typeof global == 'object' && global && global.Object === Object && global;\n\n/** Detect free variable `self`. */\nvar freeSelf = typeof self == 'object' && self && self.Object === Object && self;\n\n/** Used as a reference to the global object. */\nvar root = freeGlobal || freeSelf || Function('return this')();\n\n/**\n * Gets the value at `key` of `object`.\n *\n * @private\n * @param {Object} [object] The object to query.\n * @param {string} key The key of the property to get.\n * @returns {*} Returns the property value.\n */\nfunction getValue(object, key) {\n return object == null ? undefined : object[key];\n}\n\n/**\n * Checks if `value` is a host object in IE < 9.\n *\n * @private\n * @param {*} value The value to check.\n * @returns {boolean} Returns `true` if `value` is a host object, else `false`.\n */\nfunction isHostObject(value) {\n // Many host objects are `Object` objects that can coerce to strings\n // despite having improperly defined `toString` methods.\n var result = false;\n if (value != null && typeof value.toString != 'function') {\n try {\n result = !!(value + '');\n } catch (e) {}\n }\n return result;\n}\n\n/** Used for built-in method references. */\nvar arrayProto = Array.prototype,\n funcProto = Function.prototype,\n objectProto = Object.prototype;\n\n/** Used to detect overreaching core-js shims. */\nvar coreJsData = root['__core-js_shared__'];\n\n/** Used to detect methods masquerading as native. */\nvar maskSrcKey = (function() {\n var uid = /[^.]+$/.exec(coreJsData && coreJsData.keys && coreJsData.keys.IE_PROTO || '');\n return uid ? ('Symbol(src)_1.' + uid) : '';\n}());\n\n/** Used to resolve the decompiled source of functions. */\nvar funcToString = funcProto.toString;\n\n/** Used to check objects for own properties. */\nvar hasOwnProperty = objectProto.hasOwnProperty;\n\n/**\n * Used to resolve the\n * [`toStringTag`](http://ecma-international.org/ecma-262/7.0/#sec-object.prototype.tostring)\n * of values.\n */\nvar objectToString = objectProto.toString;\n\n/** Used to detect if a method is native. */\nvar reIsNative = RegExp('^' +\n funcToString.call(hasOwnProperty).replace(reRegExpChar, '\\\\$&')\n .replace(/hasOwnProperty|(function).*?(?=\\\\\\()| for .+?(?=\\\\\\])/g, '$1.*?') + '$'\n);\n\n/** Built-in value references. */\nvar Symbol = root.Symbol,\n splice = arrayProto.splice;\n\n/* Built-in method references that are verified to be native. */\nvar Map = getNative(root, 'Map'),\n nativeCreate = getNative(Object, 'create');\n\n/** Used to convert symbols to primitives and strings. */\nvar symbolProto = Symbol ? Symbol.prototype : undefined,\n symbolToString = symbolProto ? symbolProto.toString : undefined;\n\n/**\n * Creates a hash object.\n *\n * @private\n * @constructor\n * @param {Array} [entries] The key-value pairs to cache.\n */\nfunction Hash(entries) {\n var index = -1,\n length = entries ? entries.length : 0;\n\n this.clear();\n while (++index < length) {\n var entry = entries[index];\n this.set(entry[0], entry[1]);\n }\n}\n\n/**\n * Removes all key-value entries from the hash.\n *\n * @private\n * @name clear\n * @memberOf Hash\n */\nfunction hashClear() {\n this.__data__ = nativeCreate ? nativeCreate(null) : {};\n}\n\n/**\n * Removes `key` and its value from the hash.\n *\n * @private\n * @name delete\n * @memberOf Hash\n * @param {Object} hash The hash to modify.\n * @param {string} key The key of the value to remove.\n * @returns {boolean} Returns `true` if the entry was removed, else `false`.\n */\nfunction hashDelete(key) {\n return this.has(key) && delete this.__data__[key];\n}\n\n/**\n * Gets the hash value for `key`.\n *\n * @private\n * @name get\n * @memberOf Hash\n * @param {string} key The key of the value to get.\n * @returns {*} Returns the entry value.\n */\nfunction hashGet(key) {\n var data = this.__data__;\n if (nativeCreate) {\n var result = data[key];\n return result === HASH_UNDEFINED ? undefined : result;\n }\n return hasOwnProperty.call(data, key) ? data[key] : undefined;\n}\n\n/**\n * Checks if a hash value for `key` exists.\n *\n * @private\n * @name has\n * @memberOf Hash\n * @param {string} key The key of the entry to check.\n * @returns {boolean} Returns `true` if an entry for `key` exists, else `false`.\n */\nfunction hashHas(key) {\n var data = this.__data__;\n return nativeCreate ? data[key] !== undefined : hasOwnProperty.call(data, key);\n}\n\n/**\n * Sets the hash `key` to `value`.\n *\n * @private\n * @name set\n * @memberOf Hash\n * @param {string} key The key of the value to set.\n * @param {*} value The value to set.\n * @returns {Object} Returns the hash instance.\n */\nfunction hashSet(key, value) {\n var data = this.__data__;\n data[key] = (nativeCreate && value === undefined) ? HASH_UNDEFINED : value;\n return this;\n}\n\n// Add methods to `Hash`.\nHash.prototype.clear = hashClear;\nHash.prototype['delete'] = hashDelete;\nHash.prototype.get = hashGet;\nHash.prototype.has = hashHas;\nHash.prototype.set = hashSet;\n\n/**\n * Creates an list cache object.\n *\n * @private\n * @constructor\n * @param {Array} [entries] The key-value pairs to cache.\n */\nfunction ListCache(entries) {\n var index = -1,\n length = entries ? entries.length : 0;\n\n this.clear();\n while (++index < length) {\n var entry = entries[index];\n this.set(entry[0], entry[1]);\n }\n}\n\n/**\n * Removes all key-value entries from the list cache.\n *\n * @private\n * @name clear\n * @memberOf ListCache\n */\nfunction listCacheClear() {\n this.__data__ = [];\n}\n\n/**\n * Removes `key` and its value from the list cache.\n *\n * @private\n * @name delete\n * @memberOf ListCache\n * @param {string} key The key of the value to remove.\n * @returns {boolean} Returns `true` if the entry was removed, else `false`.\n */\nfunction listCacheDelete(key) {\n var data = this.__data__,\n index = assocIndexOf(data, key);\n\n if (index < 0) {\n return false;\n }\n var lastIndex = data.length - 1;\n if (index == lastIndex) {\n data.pop();\n } else {\n splice.call(data, index, 1);\n }\n return true;\n}\n\n/**\n * Gets the list cache value for `key`.\n *\n * @private\n * @name get\n * @memberOf ListCache\n * @param {string} key The key of the value to get.\n * @returns {*} Returns the entry value.\n */\nfunction listCacheGet(key) {\n var data = this.__data__,\n index = assocIndexOf(data, key);\n\n return index < 0 ? undefined : data[index][1];\n}\n\n/**\n * Checks if a list cache value for `key` exists.\n *\n * @private\n * @name has\n * @memberOf ListCache\n * @param {string} key The key of the entry to check.\n * @returns {boolean} Returns `true` if an entry for `key` exists, else `false`.\n */\nfunction listCacheHas(key) {\n return assocIndexOf(this.__data__, key) > -1;\n}\n\n/**\n * Sets the list cache `key` to `value`.\n *\n * @private\n * @name set\n * @memberOf ListCache\n * @param {string} key The key of the value to set.\n * @param {*} value The value to set.\n * @returns {Object} Returns the list cache instance.\n */\nfunction listCacheSet(key, value) {\n var data = this.__data__,\n index = assocIndexOf(data, key);\n\n if (index < 0) {\n data.push([key, value]);\n } else {\n data[index][1] = value;\n }\n return this;\n}\n\n// Add methods to `ListCache`.\nListCache.prototype.clear = listCacheClear;\nListCache.prototype['delete'] = listCacheDelete;\nListCache.prototype.get = listCacheGet;\nListCache.prototype.has = listCacheHas;\nListCache.prototype.set = listCacheSet;\n\n/**\n * Creates a map cache object to store key-value pairs.\n *\n * @private\n * @constructor\n * @param {Array} [entries] The key-value pairs to cache.\n */\nfunction MapCache(entries) {\n var index = -1,\n length = entries ? entries.length : 0;\n\n this.clear();\n while (++index < length) {\n var entry = entries[index];\n this.set(entry[0], entry[1]);\n }\n}\n\n/**\n * Removes all key-value entries from the map.\n *\n * @private\n * @name clear\n * @memberOf MapCache\n */\nfunction mapCacheClear() {\n this.__data__ = {\n 'hash': new Hash,\n 'map': new (Map || ListCache),\n 'string': new Hash\n };\n}\n\n/**\n * Removes `key` and its value from the map.\n *\n * @private\n * @name delete\n * @memberOf MapCache\n * @param {string} key The key of the value to remove.\n * @returns {boolean} Returns `true` if the entry was removed, else `false`.\n */\nfunction mapCacheDelete(key) {\n return getMapData(this, key)['delete'](key);\n}\n\n/**\n * Gets the map value for `key`.\n *\n * @private\n * @name get\n * @memberOf MapCache\n * @param {string} key The key of the value to get.\n * @returns {*} Returns the entry value.\n */\nfunction mapCacheGet(key) {\n return getMapData(this, key).get(key);\n}\n\n/**\n * Checks if a map value for `key` exists.\n *\n * @private\n * @name has\n * @memberOf MapCache\n * @param {string} key The key of the entry to check.\n * @returns {boolean} Returns `true` if an entry for `key` exists, else `false`.\n */\nfunction mapCacheHas(key) {\n return getMapData(this, key).has(key);\n}\n\n/**\n * Sets the map `key` to `value`.\n *\n * @private\n * @name set\n * @memberOf MapCache\n * @param {string} key The key of the value to set.\n * @param {*} value The value to set.\n * @returns {Object} Returns the map cache instance.\n */\nfunction mapCacheSet(key, value) {\n getMapData(this, key).set(key, value);\n return this;\n}\n\n// Add methods to `MapCache`.\nMapCache.prototype.clear = mapCacheClear;\nMapCache.prototype['delete'] = mapCacheDelete;\nMapCache.prototype.get = mapCacheGet;\nMapCache.prototype.has = mapCacheHas;\nMapCache.prototype.set = mapCacheSet;\n\n/**\n * Assigns `value` to `key` of `object` if the existing value is not equivalent\n * using [`SameValueZero`](http://ecma-international.org/ecma-262/7.0/#sec-samevaluezero)\n * for equality comparisons.\n *\n * @private\n * @param {Object} object The object to modify.\n * @param {string} key The key of the property to assign.\n * @param {*} value The value to assign.\n */\nfunction assignValue(object, key, value) {\n var objValue = object[key];\n if (!(hasOwnProperty.call(object, key) && eq(objValue, value)) ||\n (value === undefined && !(key in object))) {\n object[key] = value;\n }\n}\n\n/**\n * Gets the index at which the `key` is found in `array` of key-value pairs.\n *\n * @private\n * @param {Array} array The array to inspect.\n * @param {*} key The key to search for.\n * @returns {number} Returns the index of the matched value, else `-1`.\n */\nfunction assocIndexOf(array, key) {\n var length = array.length;\n while (length--) {\n if (eq(array[length][0], key)) {\n return length;\n }\n }\n return -1;\n}\n\n/**\n * The base implementation of `_.isNative` without bad shim checks.\n *\n * @private\n * @param {*} value The value to check.\n * @returns {boolean} Returns `true` if `value` is a native function,\n * else `false`.\n */\nfunction baseIsNative(value) {\n if (!isObject(value) || isMasked(value)) {\n return false;\n }\n var pattern = (isFunction(value) || isHostObject(value)) ? reIsNative : reIsHostCtor;\n return pattern.test(toSource(value));\n}\n\n/**\n * The base implementation of `_.set`.\n *\n * @private\n * @param {Object} object The object to modify.\n * @param {Array|string} path The path of the property to set.\n * @param {*} value The value to set.\n * @param {Function} [customizer] The function to customize path creation.\n * @returns {Object} Returns `object`.\n */\nfunction baseSet(object, path, value, customizer) {\n if (!isObject(object)) {\n return object;\n }\n path = isKey(path, object) ? [path] : castPath(path);\n\n var index = -1,\n length = path.length,\n lastIndex = length - 1,\n nested = object;\n\n while (nested != null && ++index < length) {\n var key = toKey(path[index]),\n newValue = value;\n\n if (index != lastIndex) {\n var objValue = nested[key];\n newValue = customizer ? customizer(objValue, key, nested) : undefined;\n if (newValue === undefined) {\n newValue = isObject(objValue)\n ? objValue\n : (isIndex(path[index + 1]) ? [] : {});\n }\n }\n assignValue(nested, key, newValue);\n nested = nested[key];\n }\n return object;\n}\n\n/**\n * The base implementation of `_.toString` which doesn't convert nullish\n * values to empty strings.\n *\n * @private\n * @param {*} value The value to process.\n * @returns {string} Returns the string.\n */\nfunction baseToString(value) {\n // Exit early for strings to avoid a performance hit in some environments.\n if (typeof value == 'string') {\n return value;\n }\n if (isSymbol(value)) {\n return symbolToString ? symbolToString.call(value) : '';\n }\n var result = (value + '');\n return (result == '0' && (1 / value) == -INFINITY) ? '-0' : result;\n}\n\n/**\n * Casts `value` to a path array if it's not one.\n *\n * @private\n * @param {*} value The value to inspect.\n * @returns {Array} Returns the cast property path array.\n */\nfunction castPath(value) {\n return isArray(value) ? value : stringToPath(value);\n}\n\n/**\n * Gets the data for `map`.\n *\n * @private\n * @param {Object} map The map to query.\n * @param {string} key The reference key.\n * @returns {*} Returns the map data.\n */\nfunction getMapData(map, key) {\n var data = map.__data__;\n return isKeyable(key)\n ? data[typeof key == 'string' ? 'string' : 'hash']\n : data.map;\n}\n\n/**\n * Gets the native function at `key` of `object`.\n *\n * @private\n * @param {Object} object The object to query.\n * @param {string} key The key of the method to get.\n * @returns {*} Returns the function if it's native, else `undefined`.\n */\nfunction getNative(object, key) {\n var value = getValue(object, key);\n return baseIsNative(value) ? value : undefined;\n}\n\n/**\n * Checks if `value` is a valid array-like index.\n *\n * @private\n * @param {*} value The value to check.\n * @param {number} [length=MAX_SAFE_INTEGER] The upper bounds of a valid index.\n * @returns {boolean} Returns `true` if `value` is a valid index, else `false`.\n */\nfunction isIndex(value, length) {\n length = length == null ? MAX_SAFE_INTEGER : length;\n return !!length &&\n (typeof value == 'number' || reIsUint.test(value)) &&\n (value > -1 && value % 1 == 0 && value < length);\n}\n\n/**\n * Checks if `value` is a property name and not a property path.\n *\n * @private\n * @param {*} value The value to check.\n * @param {Object} [object] The object to query keys on.\n * @returns {boolean} Returns `true` if `value` is a property name, else `false`.\n */\nfunction isKey(value, object) {\n if (isArray(value)) {\n return false;\n }\n var type = typeof value;\n if (type == 'number' || type == 'symbol' || type == 'boolean' ||\n value == null || isSymbol(value)) {\n return true;\n }\n return reIsPlainProp.test(value) || !reIsDeepProp.test(value) ||\n (object != null && value in Object(object));\n}\n\n/**\n * Checks if `value` is suitable for use as unique object key.\n *\n * @private\n * @param {*} value The value to check.\n * @returns {boolean} Returns `true` if `value` is suitable, else `false`.\n */\nfunction isKeyable(value) {\n var type = typeof value;\n return (type == 'string' || type == 'number' || type == 'symbol' || type == 'boolean')\n ? (value !== '__proto__')\n : (value === null);\n}\n\n/**\n * Checks if `func` has its source masked.\n *\n * @private\n * @param {Function} func The function to check.\n * @returns {boolean} Returns `true` if `func` is masked, else `false`.\n */\nfunction isMasked(func) {\n return !!maskSrcKey && (maskSrcKey in func);\n}\n\n/**\n * Converts `string` to a property path array.\n *\n * @private\n * @param {string} string The string to convert.\n * @returns {Array} Returns the property path array.\n */\nvar stringToPath = memoize(function(string) {\n string = toString(string);\n\n var result = [];\n if (reLeadingDot.test(string)) {\n result.push('');\n }\n string.replace(rePropName, function(match, number, quote, string) {\n result.push(quote ? string.replace(reEscapeChar, '$1') : (number || match));\n });\n return result;\n});\n\n/**\n * Converts `value` to a string key if it's not a string or symbol.\n *\n * @private\n * @param {*} value The value to inspect.\n * @returns {string|symbol} Returns the key.\n */\nfunction toKey(value) {\n if (typeof value == 'string' || isSymbol(value)) {\n return value;\n }\n var result = (value + '');\n return (result == '0' && (1 / value) == -INFINITY) ? '-0' : result;\n}\n\n/**\n * Converts `func` to its source code.\n *\n * @private\n * @param {Function} func The function to process.\n * @returns {string} Returns the source code.\n */\nfunction toSource(func) {\n if (func != null) {\n try {\n return funcToString.call(func);\n } catch (e) {}\n try {\n return (func + '');\n } catch (e) {}\n }\n return '';\n}\n\n/**\n * Creates a function that memoizes the result of `func`. If `resolver` is\n * provided, it determines the cache key for storing the result based on the\n * arguments provided to the memoized function. By default, the first argument\n * provided to the memoized function is used as the map cache key. The `func`\n * is invoked with the `this` binding of the memoized function.\n *\n * **Note:** The cache is exposed as the `cache` property on the memoized\n * function. Its creation may be customized by replacing the `_.memoize.Cache`\n * constructor with one whose instances implement the\n * [`Map`](http://ecma-international.org/ecma-262/7.0/#sec-properties-of-the-map-prototype-object)\n * method interface of `delete`, `get`, `has`, and `set`.\n *\n * @static\n * @memberOf _\n * @since 0.1.0\n * @category Function\n * @param {Function} func The function to have its output memoized.\n * @param {Function} [resolver] The function to resolve the cache key.\n * @returns {Function} Returns the new memoized function.\n * @example\n *\n * var object = { 'a': 1, 'b': 2 };\n * var other = { 'c': 3, 'd': 4 };\n *\n * var values = _.memoize(_.values);\n * values(object);\n * // => [1, 2]\n *\n * values(other);\n * // => [3, 4]\n *\n * object.a = 2;\n * values(object);\n * // => [1, 2]\n *\n * // Modify the result cache.\n * values.cache.set(object, ['a', 'b']);\n * values(object);\n * // => ['a', 'b']\n *\n * // Replace `_.memoize.Cache`.\n * _.memoize.Cache = WeakMap;\n */\nfunction memoize(func, resolver) {\n if (typeof func != 'function' || (resolver && typeof resolver != 'function')) {\n throw new TypeError(FUNC_ERROR_TEXT);\n }\n var memoized = function() {\n var args = arguments,\n key = resolver ? resolver.apply(this, args) : args[0],\n cache = memoized.cache;\n\n if (cache.has(key)) {\n return cache.get(key);\n }\n var result = func.apply(this, args);\n memoized.cache = cache.set(key, result);\n return result;\n };\n memoized.cache = new (memoize.Cache || MapCache);\n return memoized;\n}\n\n// Assign cache to `_.memoize`.\nmemoize.Cache = MapCache;\n\n/**\n * Performs a\n * [`SameValueZero`](http://ecma-international.org/ecma-262/7.0/#sec-samevaluezero)\n * comparison between two values to determine if they are equivalent.\n *\n * @static\n * @memberOf _\n * @since 4.0.0\n * @category Lang\n * @param {*} value The value to compare.\n * @param {*} other The other value to compare.\n * @returns {boolean} Returns `true` if the values are equivalent, else `false`.\n * @example\n *\n * var object = { 'a': 1 };\n * var other = { 'a': 1 };\n *\n * _.eq(object, object);\n * // => true\n *\n * _.eq(object, other);\n * // => false\n *\n * _.eq('a', 'a');\n * // => true\n *\n * _.eq('a', Object('a'));\n * // => false\n *\n * _.eq(NaN, NaN);\n * // => true\n */\nfunction eq(value, other) {\n return value === other || (value !== value && other !== other);\n}\n\n/**\n * Checks if `value` is classified as an `Array` object.\n *\n * @static\n * @memberOf _\n * @since 0.1.0\n * @category Lang\n * @param {*} value The value to check.\n * @returns {boolean} Returns `true` if `value` is an array, else `false`.\n * @example\n *\n * _.isArray([1, 2, 3]);\n * // => true\n *\n * _.isArray(document.body.children);\n * // => false\n *\n * _.isArray('abc');\n * // => false\n *\n * _.isArray(_.noop);\n * // => false\n */\nvar isArray = Array.isArray;\n\n/**\n * Checks if `value` is classified as a `Function` object.\n *\n * @static\n * @memberOf _\n * @since 0.1.0\n * @category Lang\n * @param {*} value The value to check.\n * @returns {boolean} Returns `true` if `value` is a function, else `false`.\n * @example\n *\n * _.isFunction(_);\n * // => true\n *\n * _.isFunction(/abc/);\n * // => false\n */\nfunction isFunction(value) {\n // The use of `Object#toString` avoids issues with the `typeof` operator\n // in Safari 8-9 which returns 'object' for typed array and other constructors.\n var tag = isObject(value) ? objectToString.call(value) : '';\n return tag == funcTag || tag == genTag;\n}\n\n/**\n * Checks if `value` is the\n * [language type](http://www.ecma-international.org/ecma-262/7.0/#sec-ecmascript-language-types)\n * of `Object`. (e.g. arrays, functions, objects, regexes, `new Number(0)`, and `new String('')`)\n *\n * @static\n * @memberOf _\n * @since 0.1.0\n * @category Lang\n * @param {*} value The value to check.\n * @returns {boolean} Returns `true` if `value` is an object, else `false`.\n * @example\n *\n * _.isObject({});\n * // => true\n *\n * _.isObject([1, 2, 3]);\n * // => true\n *\n * _.isObject(_.noop);\n * // => true\n *\n * _.isObject(null);\n * // => false\n */\nfunction isObject(value) {\n var type = typeof value;\n return !!value && (type == 'object' || type == 'function');\n}\n\n/**\n * Checks if `value` is object-like. A value is object-like if it's not `null`\n * and has a `typeof` result of \"object\".\n *\n * @static\n * @memberOf _\n * @since 4.0.0\n * @category Lang\n * @param {*} value The value to check.\n * @returns {boolean} Returns `true` if `value` is object-like, else `false`.\n * @example\n *\n * _.isObjectLike({});\n * // => true\n *\n * _.isObjectLike([1, 2, 3]);\n * // => true\n *\n * _.isObjectLike(_.noop);\n * // => false\n *\n * _.isObjectLike(null);\n * // => false\n */\nfunction isObjectLike(value) {\n return !!value && typeof value == 'object';\n}\n\n/**\n * Checks if `value` is classified as a `Symbol` primitive or object.\n *\n * @static\n * @memberOf _\n * @since 4.0.0\n * @category Lang\n * @param {*} value The value to check.\n * @returns {boolean} Returns `true` if `value` is a symbol, else `false`.\n * @example\n *\n * _.isSymbol(Symbol.iterator);\n * // => true\n *\n * _.isSymbol('abc');\n * // => false\n */\nfunction isSymbol(value) {\n return typeof value == 'symbol' ||\n (isObjectLike(value) && objectToString.call(value) == symbolTag);\n}\n\n/**\n * Converts `value` to a string. An empty string is returned for `null`\n * and `undefined` values. The sign of `-0` is preserved.\n *\n * @static\n * @memberOf _\n * @since 4.0.0\n * @category Lang\n * @param {*} value The value to process.\n * @returns {string} Returns the string.\n * @example\n *\n * _.toString(null);\n * // => ''\n *\n * _.toString(-0);\n * // => '-0'\n *\n * _.toString([1, 2, 3]);\n * // => '1,2,3'\n */\nfunction toString(value) {\n return value == null ? '' : baseToString(value);\n}\n\n/**\n * Sets the value at `path` of `object`. If a portion of `path` doesn't exist,\n * it's created. Arrays are created for missing index properties while objects\n * are created for all other missing properties. Use `_.setWith` to customize\n * `path` creation.\n *\n * **Note:** This method mutates `object`.\n *\n * @static\n * @memberOf _\n * @since 3.7.0\n * @category Object\n * @param {Object} object The object to modify.\n * @param {Array|string} path The path of the property to set.\n * @param {*} value The value to set.\n * @returns {Object} Returns `object`.\n * @example\n *\n * var object = { 'a': [{ 'b': { 'c': 3 } }] };\n *\n * _.set(object, 'a[0].b.c', 4);\n * console.log(object.a[0].b.c);\n * // => 4\n *\n * _.set(object, ['x', '0', 'y', 'z'], 5);\n * console.log(object.x[0].y.z);\n * // => 5\n */\nfunction set(object, path, value) {\n return object == null ? object : baseSet(object, path, value);\n}\n\nmodule.exports = set;\n\n\n/***/ }),\n\n/***/ 8216:\n/***/ ((module) => {\n\n/**\n * lodash (Custom Build) <https://lodash.com/>\n * Build: `lodash modularize exports=\"npm\" -o ./`\n * Copyright jQuery Foundation and other contributors <https://jquery.org/>\n * Released under MIT license <https://lodash.com/license>\n * Based on Underscore.js 1.8.3 <http://underscorejs.org/LICENSE>\n * Copyright Jeremy Ashkenas, DocumentCloud and Investigative Reporters & Editors\n */\n\n/** Used as the size to enable large array optimizations. */\nvar LARGE_ARRAY_SIZE = 200;\n\n/** Used to stand-in for `undefined` hash values. */\nvar HASH_UNDEFINED = '__lodash_hash_undefined__';\n\n/** Used as references for various `Number` constants. */\nvar INFINITY = 1 / 0;\n\n/** `Object#toString` result references. */\nvar funcTag = '[object Function]',\n genTag = '[object GeneratorFunction]';\n\n/**\n * Used to match `RegExp`\n * [syntax characters](http://ecma-international.org/ecma-262/7.0/#sec-patterns).\n */\nvar reRegExpChar = /[\\\\^$.*+?()[\\]{}|]/g;\n\n/** Used to detect host constructors (Safari). */\nvar reIsHostCtor = /^\\[object .+?Constructor\\]$/;\n\n/** Detect free variable `global` from Node.js. */\nvar freeGlobal = typeof global == 'object' && global && global.Object === Object && global;\n\n/** Detect free variable `self`. */\nvar freeSelf = typeof self == 'object' && self && self.Object === Object && self;\n\n/** Used as a reference to the global object. */\nvar root = freeGlobal || freeSelf || Function('return this')();\n\n/**\n * A specialized version of `_.includes` for arrays without support for\n * specifying an index to search from.\n *\n * @private\n * @param {Array} [array] The array to inspect.\n * @param {*} target The value to search for.\n * @returns {boolean} Returns `true` if `target` is found, else `false`.\n */\nfunction arrayIncludes(array, value) {\n var length = array ? array.length : 0;\n return !!length && baseIndexOf(array, value, 0) > -1;\n}\n\n/**\n * This function is like `arrayIncludes` except that it accepts a comparator.\n *\n * @private\n * @param {Array} [array] The array to inspect.\n * @param {*} target The value to search for.\n * @param {Function} comparator The comparator invoked per element.\n * @returns {boolean} Returns `true` if `target` is found, else `false`.\n */\nfunction arrayIncludesWith(array, value, comparator) {\n var index = -1,\n length = array ? array.length : 0;\n\n while (++index < length) {\n if (comparator(value, array[index])) {\n return true;\n }\n }\n return false;\n}\n\n/**\n * The base implementation of `_.findIndex` and `_.findLastIndex` without\n * support for iteratee shorthands.\n *\n * @private\n * @param {Array} array The array to inspect.\n * @param {Function} predicate The function invoked per iteration.\n * @param {number} fromIndex The index to search from.\n * @param {boolean} [fromRight] Specify iterating from right to left.\n * @returns {number} Returns the index of the matched value, else `-1`.\n */\nfunction baseFindIndex(array, predicate, fromIndex, fromRight) {\n var length = array.length,\n index = fromIndex + (fromRight ? 1 : -1);\n\n while ((fromRight ? index-- : ++index < length)) {\n if (predicate(array[index], index, array)) {\n return index;\n }\n }\n return -1;\n}\n\n/**\n * The base implementation of `_.indexOf` without `fromIndex` bounds checks.\n *\n * @private\n * @param {Array} array The array to inspect.\n * @param {*} value The value to search for.\n * @param {number} fromIndex The index to search from.\n * @returns {number} Returns the index of the matched value, else `-1`.\n */\nfunction baseIndexOf(array, value, fromIndex) {\n if (value !== value) {\n return baseFindIndex(array, baseIsNaN, fromIndex);\n }\n var index = fromIndex - 1,\n length = array.length;\n\n while (++index < length) {\n if (array[index] === value) {\n return index;\n }\n }\n return -1;\n}\n\n/**\n * The base implementation of `_.isNaN` without support for number objects.\n *\n * @private\n * @param {*} value The value to check.\n * @returns {boolean} Returns `true` if `value` is `NaN`, else `false`.\n */\nfunction baseIsNaN(value) {\n return value !== value;\n}\n\n/**\n * Checks if a cache value for `key` exists.\n *\n * @private\n * @param {Object} cache The cache to query.\n * @param {string} key The key of the entry to check.\n * @returns {boolean} Returns `true` if an entry for `key` exists, else `false`.\n */\nfunction cacheHas(cache, key) {\n return cache.has(key);\n}\n\n/**\n * Gets the value at `key` of `object`.\n *\n * @private\n * @param {Object} [object] The object to query.\n * @param {string} key The key of the property to get.\n * @returns {*} Returns the property value.\n */\nfunction getValue(object, key) {\n return object == null ? undefined : object[key];\n}\n\n/**\n * Checks if `value` is a host object in IE < 9.\n *\n * @private\n * @param {*} value The value to check.\n * @returns {boolean} Returns `true` if `value` is a host object, else `false`.\n */\nfunction isHostObject(value) {\n // Many host objects are `Object` objects that can coerce to strings\n // despite having improperly defined `toString` methods.\n var result = false;\n if (value != null && typeof value.toString != 'function') {\n try {\n result = !!(value + '');\n } catch (e) {}\n }\n return result;\n}\n\n/**\n * Converts `set` to an array of its values.\n *\n * @private\n * @param {Object} set The set to convert.\n * @returns {Array} Returns the values.\n */\nfunction setToArray(set) {\n var index = -1,\n result = Array(set.size);\n\n set.forEach(function(value) {\n result[++index] = value;\n });\n return result;\n}\n\n/** Used for built-in method references. */\nvar arrayProto = Array.prototype,\n funcProto = Function.prototype,\n objectProto = Object.prototype;\n\n/** Used to detect overreaching core-js shims. */\nvar coreJsData = root['__core-js_shared__'];\n\n/** Used to detect methods masquerading as native. */\nvar maskSrcKey = (function() {\n var uid = /[^.]+$/.exec(coreJsData && coreJsData.keys && coreJsData.keys.IE_PROTO || '');\n return uid ? ('Symbol(src)_1.' + uid) : '';\n}());\n\n/** Used to resolve the decompiled source of functions. */\nvar funcToString = funcProto.toString;\n\n/** Used to check objects for own properties. */\nvar hasOwnProperty = objectProto.hasOwnProperty;\n\n/**\n * Used to resolve the\n * [`toStringTag`](http://ecma-international.org/ecma-262/7.0/#sec-object.prototype.tostring)\n * of values.\n */\nvar objectToString = objectProto.toString;\n\n/** Used to detect if a method is native. */\nvar reIsNative = RegExp('^' +\n funcToString.call(hasOwnProperty).replace(reRegExpChar, '\\\\$&')\n .replace(/hasOwnProperty|(function).*?(?=\\\\\\()| for .+?(?=\\\\\\])/g, '$1.*?') + '$'\n);\n\n/** Built-in value references. */\nvar splice = arrayProto.splice;\n\n/* Built-in method references that are verified to be native. */\nvar Map = getNative(root, 'Map'),\n Set = getNative(root, 'Set'),\n nativeCreate = getNative(Object, 'create');\n\n/**\n * Creates a hash object.\n *\n * @private\n * @constructor\n * @param {Array} [entries] The key-value pairs to cache.\n */\nfunction Hash(entries) {\n var index = -1,\n length = entries ? entries.length : 0;\n\n this.clear();\n while (++index < length) {\n var entry = entries[index];\n this.set(entry[0], entry[1]);\n }\n}\n\n/**\n * Removes all key-value entries from the hash.\n *\n * @private\n * @name clear\n * @memberOf Hash\n */\nfunction hashClear() {\n this.__data__ = nativeCreate ? nativeCreate(null) : {};\n}\n\n/**\n * Removes `key` and its value from the hash.\n *\n * @private\n * @name delete\n * @memberOf Hash\n * @param {Object} hash The hash to modify.\n * @param {string} key The key of the value to remove.\n * @returns {boolean} Returns `true` if the entry was removed, else `false`.\n */\nfunction hashDelete(key) {\n return this.has(key) && delete this.__data__[key];\n}\n\n/**\n * Gets the hash value for `key`.\n *\n * @private\n * @name get\n * @memberOf Hash\n * @param {string} key The key of the value to get.\n * @returns {*} Returns the entry value.\n */\nfunction hashGet(key) {\n var data = this.__data__;\n if (nativeCreate) {\n var result = data[key];\n return result === HASH_UNDEFINED ? undefined : result;\n }\n return hasOwnProperty.call(data, key) ? data[key] : undefined;\n}\n\n/**\n * Checks if a hash value for `key` exists.\n *\n * @private\n * @name has\n * @memberOf Hash\n * @param {string} key The key of the entry to check.\n * @returns {boolean} Returns `true` if an entry for `key` exists, else `false`.\n */\nfunction hashHas(key) {\n var data = this.__data__;\n return nativeCreate ? data[key] !== undefined : hasOwnProperty.call(data, key);\n}\n\n/**\n * Sets the hash `key` to `value`.\n *\n * @private\n * @name set\n * @memberOf Hash\n * @param {string} key The key of the value to set.\n * @param {*} value The value to set.\n * @returns {Object} Returns the hash instance.\n */\nfunction hashSet(key, value) {\n var data = this.__data__;\n data[key] = (nativeCreate && value === undefined) ? HASH_UNDEFINED : value;\n return this;\n}\n\n// Add methods to `Hash`.\nHash.prototype.clear = hashClear;\nHash.prototype['delete'] = hashDelete;\nHash.prototype.get = hashGet;\nHash.prototype.has = hashHas;\nHash.prototype.set = hashSet;\n\n/**\n * Creates an list cache object.\n *\n * @private\n * @constructor\n * @param {Array} [entries] The key-value pairs to cache.\n */\nfunction ListCache(entries) {\n var index = -1,\n length = entries ? entries.length : 0;\n\n this.clear();\n while (++index < length) {\n var entry = entries[index];\n this.set(entry[0], entry[1]);\n }\n}\n\n/**\n * Removes all key-value entries from the list cache.\n *\n * @private\n * @name clear\n * @memberOf ListCache\n */\nfunction listCacheClear() {\n this.__data__ = [];\n}\n\n/**\n * Removes `key` and its value from the list cache.\n *\n * @private\n * @name delete\n * @memberOf ListCache\n * @param {string} key The key of the value to remove.\n * @returns {boolean} Returns `true` if the entry was removed, else `false`.\n */\nfunction listCacheDelete(key) {\n var data = this.__data__,\n index = assocIndexOf(data, key);\n\n if (index < 0) {\n return false;\n }\n var lastIndex = data.length - 1;\n if (index == lastIndex) {\n data.pop();\n } else {\n splice.call(data, index, 1);\n }\n return true;\n}\n\n/**\n * Gets the list cache value for `key`.\n *\n * @private\n * @name get\n * @memberOf ListCache\n * @param {string} key The key of the value to get.\n * @returns {*} Returns the entry value.\n */\nfunction listCacheGet(key) {\n var data = this.__data__,\n index = assocIndexOf(data, key);\n\n return index < 0 ? undefined : data[index][1];\n}\n\n/**\n * Checks if a list cache value for `key` exists.\n *\n * @private\n * @name has\n * @memberOf ListCache\n * @param {string} key The key of the entry to check.\n * @returns {boolean} Returns `true` if an entry for `key` exists, else `false`.\n */\nfunction listCacheHas(key) {\n return assocIndexOf(this.__data__, key) > -1;\n}\n\n/**\n * Sets the list cache `key` to `value`.\n *\n * @private\n * @name set\n * @memberOf ListCache\n * @param {string} key The key of the value to set.\n * @param {*} value The value to set.\n * @returns {Object} Returns the list cache instance.\n */\nfunction listCacheSet(key, value) {\n var data = this.__data__,\n index = assocIndexOf(data, key);\n\n if (index < 0) {\n data.push([key, value]);\n } else {\n data[index][1] = value;\n }\n return this;\n}\n\n// Add methods to `ListCache`.\nListCache.prototype.clear = listCacheClear;\nListCache.prototype['delete'] = listCacheDelete;\nListCache.prototype.get = listCacheGet;\nListCache.prototype.has = listCacheHas;\nListCache.prototype.set = listCacheSet;\n\n/**\n * Creates a map cache object to store key-value pairs.\n *\n * @private\n * @constructor\n * @param {Array} [entries] The key-value pairs to cache.\n */\nfunction MapCache(entries) {\n var index = -1,\n length = entries ? entries.length : 0;\n\n this.clear();\n while (++index < length) {\n var entry = entries[index];\n this.set(entry[0], entry[1]);\n }\n}\n\n/**\n * Removes all key-value entries from the map.\n *\n * @private\n * @name clear\n * @memberOf MapCache\n */\nfunction mapCacheClear() {\n this.__data__ = {\n 'hash': new Hash,\n 'map': new (Map || ListCache),\n 'string': new Hash\n };\n}\n\n/**\n * Removes `key` and its value from the map.\n *\n * @private\n * @name delete\n * @memberOf MapCache\n * @param {string} key The key of the value to remove.\n * @returns {boolean} Returns `true` if the entry was removed, else `false`.\n */\nfunction mapCacheDelete(key) {\n return getMapData(this, key)['delete'](key);\n}\n\n/**\n * Gets the map value for `key`.\n *\n * @private\n * @name get\n * @memberOf MapCache\n * @param {string} key The key of the value to get.\n * @returns {*} Returns the entry value.\n */\nfunction mapCacheGet(key) {\n return getMapData(this, key).get(key);\n}\n\n/**\n * Checks if a map value for `key` exists.\n *\n * @private\n * @name has\n * @memberOf MapCache\n * @param {string} key The key of the entry to check.\n * @returns {boolean} Returns `true` if an entry for `key` exists, else `false`.\n */\nfunction mapCacheHas(key) {\n return getMapData(this, key).has(key);\n}\n\n/**\n * Sets the map `key` to `value`.\n *\n * @private\n * @name set\n * @memberOf MapCache\n * @param {string} key The key of the value to set.\n * @param {*} value The value to set.\n * @returns {Object} Returns the map cache instance.\n */\nfunction mapCacheSet(key, value) {\n getMapData(this, key).set(key, value);\n return this;\n}\n\n// Add methods to `MapCache`.\nMapCache.prototype.clear = mapCacheClear;\nMapCache.prototype['delete'] = mapCacheDelete;\nMapCache.prototype.get = mapCacheGet;\nMapCache.prototype.has = mapCacheHas;\nMapCache.prototype.set = mapCacheSet;\n\n/**\n *\n * Creates an array cache object to store unique values.\n *\n * @private\n * @constructor\n * @param {Array} [values] The values to cache.\n */\nfunction SetCache(values) {\n var index = -1,\n length = values ? values.length : 0;\n\n this.__data__ = new MapCache;\n while (++index < length) {\n this.add(values[index]);\n }\n}\n\n/**\n * Adds `value` to the array cache.\n *\n * @private\n * @name add\n * @memberOf SetCache\n * @alias push\n * @param {*} value The value to cache.\n * @returns {Object} Returns the cache instance.\n */\nfunction setCacheAdd(value) {\n this.__data__.set(value, HASH_UNDEFINED);\n return this;\n}\n\n/**\n * Checks if `value` is in the array cache.\n *\n * @private\n * @name has\n * @memberOf SetCache\n * @param {*} value The value to search for.\n * @returns {number} Returns `true` if `value` is found, else `false`.\n */\nfunction setCacheHas(value) {\n return this.__data__.has(value);\n}\n\n// Add methods to `SetCache`.\nSetCache.prototype.add = SetCache.prototype.push = setCacheAdd;\nSetCache.prototype.has = setCacheHas;\n\n/**\n * Gets the index at which the `key` is found in `array` of key-value pairs.\n *\n * @private\n * @param {Array} array The array to inspect.\n * @param {*} key The key to search for.\n * @returns {number} Returns the index of the matched value, else `-1`.\n */\nfunction assocIndexOf(array, key) {\n var length = array.length;\n while (length--) {\n if (eq(array[length][0], key)) {\n return length;\n }\n }\n return -1;\n}\n\n/**\n * The base implementation of `_.isNative` without bad shim checks.\n *\n * @private\n * @param {*} value The value to check.\n * @returns {boolean} Returns `true` if `value` is a native function,\n * else `false`.\n */\nfunction baseIsNative(value) {\n if (!isObject(value) || isMasked(value)) {\n return false;\n }\n var pattern = (isFunction(value) || isHostObject(value)) ? reIsNative : reIsHostCtor;\n return pattern.test(toSource(value));\n}\n\n/**\n * The base implementation of `_.uniqBy` without support for iteratee shorthands.\n *\n * @private\n * @param {Array} array The array to inspect.\n * @param {Function} [iteratee] The iteratee invoked per element.\n * @param {Function} [comparator] The comparator invoked per element.\n * @returns {Array} Returns the new duplicate free array.\n */\nfunction baseUniq(array, iteratee, comparator) {\n var index = -1,\n includes = arrayIncludes,\n length = array.length,\n isCommon = true,\n result = [],\n seen = result;\n\n if (comparator) {\n isCommon = false;\n includes = arrayIncludesWith;\n }\n else if (length >= LARGE_ARRAY_SIZE) {\n var set = iteratee ? null : createSet(array);\n if (set) {\n return setToArray(set);\n }\n isCommon = false;\n includes = cacheHas;\n seen = new SetCache;\n }\n else {\n seen = iteratee ? [] : result;\n }\n outer:\n while (++index < length) {\n var value = array[index],\n computed = iteratee ? iteratee(value) : value;\n\n value = (comparator || value !== 0) ? value : 0;\n if (isCommon && computed === computed) {\n var seenIndex = seen.length;\n while (seenIndex--) {\n if (seen[seenIndex] === computed) {\n continue outer;\n }\n }\n if (iteratee) {\n seen.push(computed);\n }\n result.push(value);\n }\n else if (!includes(seen, computed, comparator)) {\n if (seen !== result) {\n seen.push(computed);\n }\n result.push(value);\n }\n }\n return result;\n}\n\n/**\n * Creates a set object of `values`.\n *\n * @private\n * @param {Array} values The values to add to the set.\n * @returns {Object} Returns the new set.\n */\nvar createSet = !(Set && (1 / setToArray(new Set([,-0]))[1]) == INFINITY) ? noop : function(values) {\n return new Set(values);\n};\n\n/**\n * Gets the data for `map`.\n *\n * @private\n * @param {Object} map The map to query.\n * @param {string} key The reference key.\n * @returns {*} Returns the map data.\n */\nfunction getMapData(map, key) {\n var data = map.__data__;\n return isKeyable(key)\n ? data[typeof key == 'string' ? 'string' : 'hash']\n : data.map;\n}\n\n/**\n * Gets the native function at `key` of `object`.\n *\n * @private\n * @param {Object} object The object to query.\n * @param {string} key The key of the method to get.\n * @returns {*} Returns the function if it's native, else `undefined`.\n */\nfunction getNative(object, key) {\n var value = getValue(object, key);\n return baseIsNative(value) ? value : undefined;\n}\n\n/**\n * Checks if `value` is suitable for use as unique object key.\n *\n * @private\n * @param {*} value The value to check.\n * @returns {boolean} Returns `true` if `value` is suitable, else `false`.\n */\nfunction isKeyable(value) {\n var type = typeof value;\n return (type == 'string' || type == 'number' || type == 'symbol' || type == 'boolean')\n ? (value !== '__proto__')\n : (value === null);\n}\n\n/**\n * Checks if `func` has its source masked.\n *\n * @private\n * @param {Function} func The function to check.\n * @returns {boolean} Returns `true` if `func` is masked, else `false`.\n */\nfunction isMasked(func) {\n return !!maskSrcKey && (maskSrcKey in func);\n}\n\n/**\n * Converts `func` to its source code.\n *\n * @private\n * @param {Function} func The function to process.\n * @returns {string} Returns the source code.\n */\nfunction toSource(func) {\n if (func != null) {\n try {\n return funcToString.call(func);\n } catch (e) {}\n try {\n return (func + '');\n } catch (e) {}\n }\n return '';\n}\n\n/**\n * Creates a duplicate-free version of an array, using\n * [`SameValueZero`](http://ecma-international.org/ecma-262/7.0/#sec-samevaluezero)\n * for equality comparisons, in which only the first occurrence of each\n * element is kept.\n *\n * @static\n * @memberOf _\n * @since 0.1.0\n * @category Array\n * @param {Array} array The array to inspect.\n * @returns {Array} Returns the new duplicate free array.\n * @example\n *\n * _.uniq([2, 1, 2]);\n * // => [2, 1]\n */\nfunction uniq(array) {\n return (array && array.length)\n ? baseUniq(array)\n : [];\n}\n\n/**\n * Performs a\n * [`SameValueZero`](http://ecma-international.org/ecma-262/7.0/#sec-samevaluezero)\n * comparison between two values to determine if they are equivalent.\n *\n * @static\n * @memberOf _\n * @since 4.0.0\n * @category Lang\n * @param {*} value The value to compare.\n * @param {*} other The other value to compare.\n * @returns {boolean} Returns `true` if the values are equivalent, else `false`.\n * @example\n *\n * var object = { 'a': 1 };\n * var other = { 'a': 1 };\n *\n * _.eq(object, object);\n * // => true\n *\n * _.eq(object, other);\n * // => false\n *\n * _.eq('a', 'a');\n * // => true\n *\n * _.eq('a', Object('a'));\n * // => false\n *\n * _.eq(NaN, NaN);\n * // => true\n */\nfunction eq(value, other) {\n return value === other || (value !== value && other !== other);\n}\n\n/**\n * Checks if `value` is classified as a `Function` object.\n *\n * @static\n * @memberOf _\n * @since 0.1.0\n * @category Lang\n * @param {*} value The value to check.\n * @returns {boolean} Returns `true` if `value` is a function, else `false`.\n * @example\n *\n * _.isFunction(_);\n * // => true\n *\n * _.isFunction(/abc/);\n * // => false\n */\nfunction isFunction(value) {\n // The use of `Object#toString` avoids issues with the `typeof` operator\n // in Safari 8-9 which returns 'object' for typed array and other constructors.\n var tag = isObject(value) ? objectToString.call(value) : '';\n return tag == funcTag || tag == genTag;\n}\n\n/**\n * Checks if `value` is the\n * [language type](http://www.ecma-international.org/ecma-262/7.0/#sec-ecmascript-language-types)\n * of `Object`. (e.g. arrays, functions, objects, regexes, `new Number(0)`, and `new String('')`)\n *\n * @static\n * @memberOf _\n * @since 0.1.0\n * @category Lang\n * @param {*} value The value to check.\n * @returns {boolean} Returns `true` if `value` is an object, else `false`.\n * @example\n *\n * _.isObject({});\n * // => true\n *\n * _.isObject([1, 2, 3]);\n * // => true\n *\n * _.isObject(_.noop);\n * // => true\n *\n * _.isObject(null);\n * // => false\n */\nfunction isObject(value) {\n var type = typeof value;\n return !!value && (type == 'object' || type == 'function');\n}\n\n/**\n * This method returns `undefined`.\n *\n * @static\n * @memberOf _\n * @since 2.3.0\n * @category Util\n * @example\n *\n * _.times(2, _.noop);\n * // => [undefined, undefined]\n */\nfunction noop() {\n // No operation performed.\n}\n\nmodule.exports = uniq;\n\n\n/***/ }),\n\n/***/ 9662:\n/***/ ((module) => {\n\n\"use strict\";\n\nmodule.exports = object => {\n\tconst result = {};\n\n\tfor (const [key, value] of Object.entries(object)) {\n\t\tresult[key.toLowerCase()] = value;\n\t}\n\n\treturn result;\n};\n\n\n/***/ }),\n\n/***/ 7493:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\n\"use strict\";\n\nconst os = __nccwpck_require__(2037);\n\nconst nameMap = new Map([\n\t[21, ['Monterey', '12']],\n\t[20, ['Big Sur', '11']],\n\t[19, ['Catalina', '10.15']],\n\t[18, ['Mojave', '10.14']],\n\t[17, ['High Sierra', '10.13']],\n\t[16, ['Sierra', '10.12']],\n\t[15, ['El Capitan', '10.11']],\n\t[14, ['Yosemite', '10.10']],\n\t[13, ['Mavericks', '10.9']],\n\t[12, ['Mountain Lion', '10.8']],\n\t[11, ['Lion', '10.7']],\n\t[10, ['Snow Leopard', '10.6']],\n\t[9, ['Leopard', '10.5']],\n\t[8, ['Tiger', '10.4']],\n\t[7, ['Panther', '10.3']],\n\t[6, ['Jaguar', '10.2']],\n\t[5, ['Puma', '10.1']]\n]);\n\nconst macosRelease = release => {\n\trelease = Number((release || os.release()).split('.')[0]);\n\n\tconst [name, version] = nameMap.get(release) || ['Unknown', ''];\n\n\treturn {\n\t\tname,\n\t\tversion\n\t};\n};\n\nmodule.exports = macosRelease;\n// TODO: remove this in the next major version\nmodule.exports[\"default\"] = macosRelease;\n\n\n/***/ }),\n\n/***/ 2610:\n/***/ ((module) => {\n\n\"use strict\";\n\n\n// We define these manually to ensure they're always copied\n// even if they would move up the prototype chain\n// https://nodejs.org/api/http.html#http_class_http_incomingmessage\nconst knownProperties = [\n\t'aborted',\n\t'complete',\n\t'headers',\n\t'httpVersion',\n\t'httpVersionMinor',\n\t'httpVersionMajor',\n\t'method',\n\t'rawHeaders',\n\t'rawTrailers',\n\t'setTimeout',\n\t'socket',\n\t'statusCode',\n\t'statusMessage',\n\t'trailers',\n\t'url'\n];\n\nmodule.exports = (fromStream, toStream) => {\n\tif (toStream._readableState.autoDestroy) {\n\t\tthrow new Error('The second stream must have the `autoDestroy` option set to `false`');\n\t}\n\n\tconst fromProperties = new Set(Object.keys(fromStream).concat(knownProperties));\n\n\tconst properties = {};\n\n\tfor (const property of fromProperties) {\n\t\t// Don't overwrite existing properties.\n\t\tif (property in toStream) {\n\t\t\tcontinue;\n\t\t}\n\n\t\tproperties[property] = {\n\t\t\tget() {\n\t\t\t\tconst value = fromStream[property];\n\t\t\t\tconst isFunction = typeof value === 'function';\n\n\t\t\t\treturn isFunction ? value.bind(fromStream) : value;\n\t\t\t},\n\t\t\tset(value) {\n\t\t\t\tfromStream[property] = value;\n\t\t\t},\n\t\t\tenumerable: true,\n\t\t\tconfigurable: false\n\t\t};\n\t}\n\n\tObject.defineProperties(toStream, properties);\n\n\tfromStream.once('aborted', () => {\n\t\ttoStream.destroy();\n\n\t\ttoStream.emit('aborted');\n\t});\n\n\tfromStream.once('close', () => {\n\t\tif (fromStream.complete) {\n\t\t\tif (toStream.readable) {\n\t\t\t\ttoStream.once('end', () => {\n\t\t\t\t\ttoStream.emit('close');\n\t\t\t\t});\n\t\t\t} else {\n\t\t\t\ttoStream.emit('close');\n\t\t\t}\n\t\t} else {\n\t\t\ttoStream.emit('close');\n\t\t}\n\t});\n\n\treturn toStream;\n};\n\n\n/***/ }),\n\n/***/ 8560:\n/***/ ((module) => {\n\n\"use strict\";\n\n\n/**\n * Tries to execute a function and discards any error that occurs.\n * @param {Function} fn - Function that might or might not throw an error.\n * @returns {?*} Return-value of the function when no error occurred.\n */\nmodule.exports = function(fn) {\n\n\ttry { return fn() } catch (e) {}\n\n}\n\n/***/ }),\n\n/***/ 467:\n/***/ ((module, exports, __nccwpck_require__) => {\n\n\"use strict\";\n\n\nObject.defineProperty(exports, \"__esModule\", ({ value: true }));\n\nfunction _interopDefault (ex) { return (ex && (typeof ex === 'object') && 'default' in ex) ? ex['default'] : ex; }\n\nvar Stream = _interopDefault(__nccwpck_require__(2781));\nvar http = _interopDefault(__nccwpck_require__(3685));\nvar Url = _interopDefault(__nccwpck_require__(7310));\nvar whatwgUrl = _interopDefault(__nccwpck_require__(3323));\nvar https = _interopDefault(__nccwpck_require__(5687));\nvar zlib = _interopDefault(__nccwpck_require__(9796));\n\n// Based on https://github.com/tmpvar/jsdom/blob/aa85b2abf07766ff7bf5c1f6daafb3726f2f2db5/lib/jsdom/living/blob.js\n\n// fix for \"Readable\" isn't a named export issue\nconst Readable = Stream.Readable;\n\nconst BUFFER = Symbol('buffer');\nconst TYPE = Symbol('type');\n\nclass Blob {\n\tconstructor() {\n\t\tthis[TYPE] = '';\n\n\t\tconst blobParts = arguments[0];\n\t\tconst options = arguments[1];\n\n\t\tconst buffers = [];\n\t\tlet size = 0;\n\n\t\tif (blobParts) {\n\t\t\tconst a = blobParts;\n\t\t\tconst length = Number(a.length);\n\t\t\tfor (let i = 0; i < length; i++) {\n\t\t\t\tconst element = a[i];\n\t\t\t\tlet buffer;\n\t\t\t\tif (element instanceof Buffer) {\n\t\t\t\t\tbuffer = element;\n\t\t\t\t} else if (ArrayBuffer.isView(element)) {\n\t\t\t\t\tbuffer = Buffer.from(element.buffer, element.byteOffset, element.byteLength);\n\t\t\t\t} else if (element instanceof ArrayBuffer) {\n\t\t\t\t\tbuffer = Buffer.from(element);\n\t\t\t\t} else if (element instanceof Blob) {\n\t\t\t\t\tbuffer = element[BUFFER];\n\t\t\t\t} else {\n\t\t\t\t\tbuffer = Buffer.from(typeof element === 'string' ? element : String(element));\n\t\t\t\t}\n\t\t\t\tsize += buffer.length;\n\t\t\t\tbuffers.push(buffer);\n\t\t\t}\n\t\t}\n\n\t\tthis[BUFFER] = Buffer.concat(buffers);\n\n\t\tlet type = options && options.type !== undefined && String(options.type).toLowerCase();\n\t\tif (type && !/[^\\u0020-\\u007E]/.test(type)) {\n\t\t\tthis[TYPE] = type;\n\t\t}\n\t}\n\tget size() {\n\t\treturn this[BUFFER].length;\n\t}\n\tget type() {\n\t\treturn this[TYPE];\n\t}\n\ttext() {\n\t\treturn Promise.resolve(this[BUFFER].toString());\n\t}\n\tarrayBuffer() {\n\t\tconst buf = this[BUFFER];\n\t\tconst ab = buf.buffer.slice(buf.byteOffset, buf.byteOffset + buf.byteLength);\n\t\treturn Promise.resolve(ab);\n\t}\n\tstream() {\n\t\tconst readable = new Readable();\n\t\treadable._read = function () {};\n\t\treadable.push(this[BUFFER]);\n\t\treadable.push(null);\n\t\treturn readable;\n\t}\n\ttoString() {\n\t\treturn '[object Blob]';\n\t}\n\tslice() {\n\t\tconst size = this.size;\n\n\t\tconst start = arguments[0];\n\t\tconst end = arguments[1];\n\t\tlet relativeStart, relativeEnd;\n\t\tif (start === undefined) {\n\t\t\trelativeStart = 0;\n\t\t} else if (start < 0) {\n\t\t\trelativeStart = Math.max(size + start, 0);\n\t\t} else {\n\t\t\trelativeStart = Math.min(start, size);\n\t\t}\n\t\tif (end === undefined) {\n\t\t\trelativeEnd = size;\n\t\t} else if (end < 0) {\n\t\t\trelativeEnd = Math.max(size + end, 0);\n\t\t} else {\n\t\t\trelativeEnd = Math.min(end, size);\n\t\t}\n\t\tconst span = Math.max(relativeEnd - relativeStart, 0);\n\n\t\tconst buffer = this[BUFFER];\n\t\tconst slicedBuffer = buffer.slice(relativeStart, relativeStart + span);\n\t\tconst blob = new Blob([], { type: arguments[2] });\n\t\tblob[BUFFER] = slicedBuffer;\n\t\treturn blob;\n\t}\n}\n\nObject.defineProperties(Blob.prototype, {\n\tsize: { enumerable: true },\n\ttype: { enumerable: true },\n\tslice: { enumerable: true }\n});\n\nObject.defineProperty(Blob.prototype, Symbol.toStringTag, {\n\tvalue: 'Blob',\n\twritable: false,\n\tenumerable: false,\n\tconfigurable: true\n});\n\n/**\n * fetch-error.js\n *\n * FetchError interface for operational errors\n */\n\n/**\n * Create FetchError instance\n *\n * @param String message Error message for human\n * @param String type Error type for machine\n * @param String systemError For Node.js system error\n * @return FetchError\n */\nfunction FetchError(message, type, systemError) {\n Error.call(this, message);\n\n this.message = message;\n this.type = type;\n\n // when err.type is `system`, err.code contains system error code\n if (systemError) {\n this.code = this.errno = systemError.code;\n }\n\n // hide custom error implementation details from end-users\n Error.captureStackTrace(this, this.constructor);\n}\n\nFetchError.prototype = Object.create(Error.prototype);\nFetchError.prototype.constructor = FetchError;\nFetchError.prototype.name = 'FetchError';\n\nlet convert;\ntry {\n\tconvert = (__nccwpck_require__(2877).convert);\n} catch (e) {}\n\nconst INTERNALS = Symbol('Body internals');\n\n// fix an issue where \"PassThrough\" isn't a named export for node <10\nconst PassThrough = Stream.PassThrough;\n\n/**\n * Body mixin\n *\n * Ref: https://fetch.spec.whatwg.org/#body\n *\n * @param Stream body Readable stream\n * @param Object opts Response options\n * @return Void\n */\nfunction Body(body) {\n\tvar _this = this;\n\n\tvar _ref = arguments.length > 1 && arguments[1] !== undefined ? arguments[1] : {},\n\t _ref$size = _ref.size;\n\n\tlet size = _ref$size === undefined ? 0 : _ref$size;\n\tvar _ref$timeout = _ref.timeout;\n\tlet timeout = _ref$timeout === undefined ? 0 : _ref$timeout;\n\n\tif (body == null) {\n\t\t// body is undefined or null\n\t\tbody = null;\n\t} else if (isURLSearchParams(body)) {\n\t\t// body is a URLSearchParams\n\t\tbody = Buffer.from(body.toString());\n\t} else if (isBlob(body)) ; else if (Buffer.isBuffer(body)) ; else if (Object.prototype.toString.call(body) === '[object ArrayBuffer]') {\n\t\t// body is ArrayBuffer\n\t\tbody = Buffer.from(body);\n\t} else if (ArrayBuffer.isView(body)) {\n\t\t// body is ArrayBufferView\n\t\tbody = Buffer.from(body.buffer, body.byteOffset, body.byteLength);\n\t} else if (body instanceof Stream) ; else {\n\t\t// none of the above\n\t\t// coerce to string then buffer\n\t\tbody = Buffer.from(String(body));\n\t}\n\tthis[INTERNALS] = {\n\t\tbody,\n\t\tdisturbed: false,\n\t\terror: null\n\t};\n\tthis.size = size;\n\tthis.timeout = timeout;\n\n\tif (body instanceof Stream) {\n\t\tbody.on('error', function (err) {\n\t\t\tconst error = err.name === 'AbortError' ? err : new FetchError(`Invalid response body while trying to fetch ${_this.url}: ${err.message}`, 'system', err);\n\t\t\t_this[INTERNALS].error = error;\n\t\t});\n\t}\n}\n\nBody.prototype = {\n\tget body() {\n\t\treturn this[INTERNALS].body;\n\t},\n\n\tget bodyUsed() {\n\t\treturn this[INTERNALS].disturbed;\n\t},\n\n\t/**\n * Decode response as ArrayBuffer\n *\n * @return Promise\n */\n\tarrayBuffer() {\n\t\treturn consumeBody.call(this).then(function (buf) {\n\t\t\treturn buf.buffer.slice(buf.byteOffset, buf.byteOffset + buf.byteLength);\n\t\t});\n\t},\n\n\t/**\n * Return raw response as Blob\n *\n * @return Promise\n */\n\tblob() {\n\t\tlet ct = this.headers && this.headers.get('content-type') || '';\n\t\treturn consumeBody.call(this).then(function (buf) {\n\t\t\treturn Object.assign(\n\t\t\t// Prevent copying\n\t\t\tnew Blob([], {\n\t\t\t\ttype: ct.toLowerCase()\n\t\t\t}), {\n\t\t\t\t[BUFFER]: buf\n\t\t\t});\n\t\t});\n\t},\n\n\t/**\n * Decode response as json\n *\n * @return Promise\n */\n\tjson() {\n\t\tvar _this2 = this;\n\n\t\treturn consumeBody.call(this).then(function (buffer) {\n\t\t\ttry {\n\t\t\t\treturn JSON.parse(buffer.toString());\n\t\t\t} catch (err) {\n\t\t\t\treturn Body.Promise.reject(new FetchError(`invalid json response body at ${_this2.url} reason: ${err.message}`, 'invalid-json'));\n\t\t\t}\n\t\t});\n\t},\n\n\t/**\n * Decode response as text\n *\n * @return Promise\n */\n\ttext() {\n\t\treturn consumeBody.call(this).then(function (buffer) {\n\t\t\treturn buffer.toString();\n\t\t});\n\t},\n\n\t/**\n * Decode response as buffer (non-spec api)\n *\n * @return Promise\n */\n\tbuffer() {\n\t\treturn consumeBody.call(this);\n\t},\n\n\t/**\n * Decode response as text, while automatically detecting the encoding and\n * trying to decode to UTF-8 (non-spec api)\n *\n * @return Promise\n */\n\ttextConverted() {\n\t\tvar _this3 = this;\n\n\t\treturn consumeBody.call(this).then(function (buffer) {\n\t\t\treturn convertBody(buffer, _this3.headers);\n\t\t});\n\t}\n};\n\n// In browsers, all properties are enumerable.\nObject.defineProperties(Body.prototype, {\n\tbody: { enumerable: true },\n\tbodyUsed: { enumerable: true },\n\tarrayBuffer: { enumerable: true },\n\tblob: { enumerable: true },\n\tjson: { enumerable: true },\n\ttext: { enumerable: true }\n});\n\nBody.mixIn = function (proto) {\n\tfor (const name of Object.getOwnPropertyNames(Body.prototype)) {\n\t\t// istanbul ignore else: future proof\n\t\tif (!(name in proto)) {\n\t\t\tconst desc = Object.getOwnPropertyDescriptor(Body.prototype, name);\n\t\t\tObject.defineProperty(proto, name, desc);\n\t\t}\n\t}\n};\n\n/**\n * Consume and convert an entire Body to a Buffer.\n *\n * Ref: https://fetch.spec.whatwg.org/#concept-body-consume-body\n *\n * @return Promise\n */\nfunction consumeBody() {\n\tvar _this4 = this;\n\n\tif (this[INTERNALS].disturbed) {\n\t\treturn Body.Promise.reject(new TypeError(`body used already for: ${this.url}`));\n\t}\n\n\tthis[INTERNALS].disturbed = true;\n\n\tif (this[INTERNALS].error) {\n\t\treturn Body.Promise.reject(this[INTERNALS].error);\n\t}\n\n\tlet body = this.body;\n\n\t// body is null\n\tif (body === null) {\n\t\treturn Body.Promise.resolve(Buffer.alloc(0));\n\t}\n\n\t// body is blob\n\tif (isBlob(body)) {\n\t\tbody = body.stream();\n\t}\n\n\t// body is buffer\n\tif (Buffer.isBuffer(body)) {\n\t\treturn Body.Promise.resolve(body);\n\t}\n\n\t// istanbul ignore if: should never happen\n\tif (!(body instanceof Stream)) {\n\t\treturn Body.Promise.resolve(Buffer.alloc(0));\n\t}\n\n\t// body is stream\n\t// get ready to actually consume the body\n\tlet accum = [];\n\tlet accumBytes = 0;\n\tlet abort = false;\n\n\treturn new Body.Promise(function (resolve, reject) {\n\t\tlet resTimeout;\n\n\t\t// allow timeout on slow response body\n\t\tif (_this4.timeout) {\n\t\t\tresTimeout = setTimeout(function () {\n\t\t\t\tabort = true;\n\t\t\t\treject(new FetchError(`Response timeout while trying to fetch ${_this4.url} (over ${_this4.timeout}ms)`, 'body-timeout'));\n\t\t\t}, _this4.timeout);\n\t\t}\n\n\t\t// handle stream errors\n\t\tbody.on('error', function (err) {\n\t\t\tif (err.name === 'AbortError') {\n\t\t\t\t// if the request was aborted, reject with this Error\n\t\t\t\tabort = true;\n\t\t\t\treject(err);\n\t\t\t} else {\n\t\t\t\t// other errors, such as incorrect content-encoding\n\t\t\t\treject(new FetchError(`Invalid response body while trying to fetch ${_this4.url}: ${err.message}`, 'system', err));\n\t\t\t}\n\t\t});\n\n\t\tbody.on('data', function (chunk) {\n\t\t\tif (abort || chunk === null) {\n\t\t\t\treturn;\n\t\t\t}\n\n\t\t\tif (_this4.size && accumBytes + chunk.length > _this4.size) {\n\t\t\t\tabort = true;\n\t\t\t\treject(new FetchError(`content size at ${_this4.url} over limit: ${_this4.size}`, 'max-size'));\n\t\t\t\treturn;\n\t\t\t}\n\n\t\t\taccumBytes += chunk.length;\n\t\t\taccum.push(chunk);\n\t\t});\n\n\t\tbody.on('end', function () {\n\t\t\tif (abort) {\n\t\t\t\treturn;\n\t\t\t}\n\n\t\t\tclearTimeout(resTimeout);\n\n\t\t\ttry {\n\t\t\t\tresolve(Buffer.concat(accum, accumBytes));\n\t\t\t} catch (err) {\n\t\t\t\t// handle streams that have accumulated too much data (issue #414)\n\t\t\t\treject(new FetchError(`Could not create Buffer from response body for ${_this4.url}: ${err.message}`, 'system', err));\n\t\t\t}\n\t\t});\n\t});\n}\n\n/**\n * Detect buffer encoding and convert to target encoding\n * ref: http://www.w3.org/TR/2011/WD-html5-20110113/parsing.html#determining-the-character-encoding\n *\n * @param Buffer buffer Incoming buffer\n * @param String encoding Target encoding\n * @return String\n */\nfunction convertBody(buffer, headers) {\n\tif (typeof convert !== 'function') {\n\t\tthrow new Error('The package `encoding` must be installed to use the textConverted() function');\n\t}\n\n\tconst ct = headers.get('content-type');\n\tlet charset = 'utf-8';\n\tlet res, str;\n\n\t// header\n\tif (ct) {\n\t\tres = /charset=([^;]*)/i.exec(ct);\n\t}\n\n\t// no charset in content type, peek at response body for at most 1024 bytes\n\tstr = buffer.slice(0, 1024).toString();\n\n\t// html5\n\tif (!res && str) {\n\t\tres = /<meta.+?charset=(['\"])(.+?)\\1/i.exec(str);\n\t}\n\n\t// html4\n\tif (!res && str) {\n\t\tres = /<meta[\\s]+?http-equiv=(['\"])content-type\\1[\\s]+?content=(['\"])(.+?)\\2/i.exec(str);\n\t\tif (!res) {\n\t\t\tres = /<meta[\\s]+?content=(['\"])(.+?)\\1[\\s]+?http-equiv=(['\"])content-type\\3/i.exec(str);\n\t\t\tif (res) {\n\t\t\t\tres.pop(); // drop last quote\n\t\t\t}\n\t\t}\n\n\t\tif (res) {\n\t\t\tres = /charset=(.*)/i.exec(res.pop());\n\t\t}\n\t}\n\n\t// xml\n\tif (!res && str) {\n\t\tres = /<\\?xml.+?encoding=(['\"])(.+?)\\1/i.exec(str);\n\t}\n\n\t// found charset\n\tif (res) {\n\t\tcharset = res.pop();\n\n\t\t// prevent decode issues when sites use incorrect encoding\n\t\t// ref: https://hsivonen.fi/encoding-menu/\n\t\tif (charset === 'gb2312' || charset === 'gbk') {\n\t\t\tcharset = 'gb18030';\n\t\t}\n\t}\n\n\t// turn raw buffers into a single utf-8 buffer\n\treturn convert(buffer, 'UTF-8', charset).toString();\n}\n\n/**\n * Detect a URLSearchParams object\n * ref: https://github.com/bitinn/node-fetch/issues/296#issuecomment-307598143\n *\n * @param Object obj Object to detect by type or brand\n * @return String\n */\nfunction isURLSearchParams(obj) {\n\t// Duck-typing as a necessary condition.\n\tif (typeof obj !== 'object' || typeof obj.append !== 'function' || typeof obj.delete !== 'function' || typeof obj.get !== 'function' || typeof obj.getAll !== 'function' || typeof obj.has !== 'function' || typeof obj.set !== 'function') {\n\t\treturn false;\n\t}\n\n\t// Brand-checking and more duck-typing as optional condition.\n\treturn obj.constructor.name === 'URLSearchParams' || Object.prototype.toString.call(obj) === '[object URLSearchParams]' || typeof obj.sort === 'function';\n}\n\n/**\n * Check if `obj` is a W3C `Blob` object (which `File` inherits from)\n * @param {*} obj\n * @return {boolean}\n */\nfunction isBlob(obj) {\n\treturn typeof obj === 'object' && typeof obj.arrayBuffer === 'function' && typeof obj.type === 'string' && typeof obj.stream === 'function' && typeof obj.constructor === 'function' && typeof obj.constructor.name === 'string' && /^(Blob|File)$/.test(obj.constructor.name) && /^(Blob|File)$/.test(obj[Symbol.toStringTag]);\n}\n\n/**\n * Clone body given Res/Req instance\n *\n * @param Mixed instance Response or Request instance\n * @return Mixed\n */\nfunction clone(instance) {\n\tlet p1, p2;\n\tlet body = instance.body;\n\n\t// don't allow cloning a used body\n\tif (instance.bodyUsed) {\n\t\tthrow new Error('cannot clone body after it is used');\n\t}\n\n\t// check that body is a stream and not form-data object\n\t// note: we can't clone the form-data object without having it as a dependency\n\tif (body instanceof Stream && typeof body.getBoundary !== 'function') {\n\t\t// tee instance body\n\t\tp1 = new PassThrough();\n\t\tp2 = new PassThrough();\n\t\tbody.pipe(p1);\n\t\tbody.pipe(p2);\n\t\t// set instance body to teed body and return the other teed body\n\t\tinstance[INTERNALS].body = p1;\n\t\tbody = p2;\n\t}\n\n\treturn body;\n}\n\n/**\n * Performs the operation \"extract a `Content-Type` value from |object|\" as\n * specified in the specification:\n * https://fetch.spec.whatwg.org/#concept-bodyinit-extract\n *\n * This function assumes that instance.body is present.\n *\n * @param Mixed instance Any options.body input\n */\nfunction extractContentType(body) {\n\tif (body === null) {\n\t\t// body is null\n\t\treturn null;\n\t} else if (typeof body === 'string') {\n\t\t// body is string\n\t\treturn 'text/plain;charset=UTF-8';\n\t} else if (isURLSearchParams(body)) {\n\t\t// body is a URLSearchParams\n\t\treturn 'application/x-www-form-urlencoded;charset=UTF-8';\n\t} else if (isBlob(body)) {\n\t\t// body is blob\n\t\treturn body.type || null;\n\t} else if (Buffer.isBuffer(body)) {\n\t\t// body is buffer\n\t\treturn null;\n\t} else if (Object.prototype.toString.call(body) === '[object ArrayBuffer]') {\n\t\t// body is ArrayBuffer\n\t\treturn null;\n\t} else if (ArrayBuffer.isView(body)) {\n\t\t// body is ArrayBufferView\n\t\treturn null;\n\t} else if (typeof body.getBoundary === 'function') {\n\t\t// detect form data input from form-data module\n\t\treturn `multipart/form-data;boundary=${body.getBoundary()}`;\n\t} else if (body instanceof Stream) {\n\t\t// body is stream\n\t\t// can't really do much about this\n\t\treturn null;\n\t} else {\n\t\t// Body constructor defaults other things to string\n\t\treturn 'text/plain;charset=UTF-8';\n\t}\n}\n\n/**\n * The Fetch Standard treats this as if \"total bytes\" is a property on the body.\n * For us, we have to explicitly get it with a function.\n *\n * ref: https://fetch.spec.whatwg.org/#concept-body-total-bytes\n *\n * @param Body instance Instance of Body\n * @return Number? Number of bytes, or null if not possible\n */\nfunction getTotalBytes(instance) {\n\tconst body = instance.body;\n\n\n\tif (body === null) {\n\t\t// body is null\n\t\treturn 0;\n\t} else if (isBlob(body)) {\n\t\treturn body.size;\n\t} else if (Buffer.isBuffer(body)) {\n\t\t// body is buffer\n\t\treturn body.length;\n\t} else if (body && typeof body.getLengthSync === 'function') {\n\t\t// detect form data input from form-data module\n\t\tif (body._lengthRetrievers && body._lengthRetrievers.length == 0 || // 1.x\n\t\tbody.hasKnownLength && body.hasKnownLength()) {\n\t\t\t// 2.x\n\t\t\treturn body.getLengthSync();\n\t\t}\n\t\treturn null;\n\t} else {\n\t\t// body is stream\n\t\treturn null;\n\t}\n}\n\n/**\n * Write a Body to a Node.js WritableStream (e.g. http.Request) object.\n *\n * @param Body instance Instance of Body\n * @return Void\n */\nfunction writeToStream(dest, instance) {\n\tconst body = instance.body;\n\n\n\tif (body === null) {\n\t\t// body is null\n\t\tdest.end();\n\t} else if (isBlob(body)) {\n\t\tbody.stream().pipe(dest);\n\t} else if (Buffer.isBuffer(body)) {\n\t\t// body is buffer\n\t\tdest.write(body);\n\t\tdest.end();\n\t} else {\n\t\t// body is stream\n\t\tbody.pipe(dest);\n\t}\n}\n\n// expose Promise\nBody.Promise = global.Promise;\n\n/**\n * headers.js\n *\n * Headers class offers convenient helpers\n */\n\nconst invalidTokenRegex = /[^\\^_`a-zA-Z\\-0-9!#$%&'*+.|~]/;\nconst invalidHeaderCharRegex = /[^\\t\\x20-\\x7e\\x80-\\xff]/;\n\nfunction validateName(name) {\n\tname = `${name}`;\n\tif (invalidTokenRegex.test(name) || name === '') {\n\t\tthrow new TypeError(`${name} is not a legal HTTP header name`);\n\t}\n}\n\nfunction validateValue(value) {\n\tvalue = `${value}`;\n\tif (invalidHeaderCharRegex.test(value)) {\n\t\tthrow new TypeError(`${value} is not a legal HTTP header value`);\n\t}\n}\n\n/**\n * Find the key in the map object given a header name.\n *\n * Returns undefined if not found.\n *\n * @param String name Header name\n * @return String|Undefined\n */\nfunction find(map, name) {\n\tname = name.toLowerCase();\n\tfor (const key in map) {\n\t\tif (key.toLowerCase() === name) {\n\t\t\treturn key;\n\t\t}\n\t}\n\treturn undefined;\n}\n\nconst MAP = Symbol('map');\nclass Headers {\n\t/**\n * Headers class\n *\n * @param Object headers Response headers\n * @return Void\n */\n\tconstructor() {\n\t\tlet init = arguments.length > 0 && arguments[0] !== undefined ? arguments[0] : undefined;\n\n\t\tthis[MAP] = Object.create(null);\n\n\t\tif (init instanceof Headers) {\n\t\t\tconst rawHeaders = init.raw();\n\t\t\tconst headerNames = Object.keys(rawHeaders);\n\n\t\t\tfor (const headerName of headerNames) {\n\t\t\t\tfor (const value of rawHeaders[headerName]) {\n\t\t\t\t\tthis.append(headerName, value);\n\t\t\t\t}\n\t\t\t}\n\n\t\t\treturn;\n\t\t}\n\n\t\t// We don't worry about converting prop to ByteString here as append()\n\t\t// will handle it.\n\t\tif (init == null) ; else if (typeof init === 'object') {\n\t\t\tconst method = init[Symbol.iterator];\n\t\t\tif (method != null) {\n\t\t\t\tif (typeof method !== 'function') {\n\t\t\t\t\tthrow new TypeError('Header pairs must be iterable');\n\t\t\t\t}\n\n\t\t\t\t// sequence<sequence<ByteString>>\n\t\t\t\t// Note: per spec we have to first exhaust the lists then process them\n\t\t\t\tconst pairs = [];\n\t\t\t\tfor (const pair of init) {\n\t\t\t\t\tif (typeof pair !== 'object' || typeof pair[Symbol.iterator] !== 'function') {\n\t\t\t\t\t\tthrow new TypeError('Each header pair must be iterable');\n\t\t\t\t\t}\n\t\t\t\t\tpairs.push(Array.from(pair));\n\t\t\t\t}\n\n\t\t\t\tfor (const pair of pairs) {\n\t\t\t\t\tif (pair.length !== 2) {\n\t\t\t\t\t\tthrow new TypeError('Each header pair must be a name/value tuple');\n\t\t\t\t\t}\n\t\t\t\t\tthis.append(pair[0], pair[1]);\n\t\t\t\t}\n\t\t\t} else {\n\t\t\t\t// record<ByteString, ByteString>\n\t\t\t\tfor (const key of Object.keys(init)) {\n\t\t\t\t\tconst value = init[key];\n\t\t\t\t\tthis.append(key, value);\n\t\t\t\t}\n\t\t\t}\n\t\t} else {\n\t\t\tthrow new TypeError('Provided initializer must be an object');\n\t\t}\n\t}\n\n\t/**\n * Return combined header value given name\n *\n * @param String name Header name\n * @return Mixed\n */\n\tget(name) {\n\t\tname = `${name}`;\n\t\tvalidateName(name);\n\t\tconst key = find(this[MAP], name);\n\t\tif (key === undefined) {\n\t\t\treturn null;\n\t\t}\n\n\t\treturn this[MAP][key].join(', ');\n\t}\n\n\t/**\n * Iterate over all headers\n *\n * @param Function callback Executed for each item with parameters (value, name, thisArg)\n * @param Boolean thisArg `this` context for callback function\n * @return Void\n */\n\tforEach(callback) {\n\t\tlet thisArg = arguments.length > 1 && arguments[1] !== undefined ? arguments[1] : undefined;\n\n\t\tlet pairs = getHeaders(this);\n\t\tlet i = 0;\n\t\twhile (i < pairs.length) {\n\t\t\tvar _pairs$i = pairs[i];\n\t\t\tconst name = _pairs$i[0],\n\t\t\t value = _pairs$i[1];\n\n\t\t\tcallback.call(thisArg, value, name, this);\n\t\t\tpairs = getHeaders(this);\n\t\t\ti++;\n\t\t}\n\t}\n\n\t/**\n * Overwrite header values given name\n *\n * @param String name Header name\n * @param String value Header value\n * @return Void\n */\n\tset(name, value) {\n\t\tname = `${name}`;\n\t\tvalue = `${value}`;\n\t\tvalidateName(name);\n\t\tvalidateValue(value);\n\t\tconst key = find(this[MAP], name);\n\t\tthis[MAP][key !== undefined ? key : name] = [value];\n\t}\n\n\t/**\n * Append a value onto existing header\n *\n * @param String name Header name\n * @param String value Header value\n * @return Void\n */\n\tappend(name, value) {\n\t\tname = `${name}`;\n\t\tvalue = `${value}`;\n\t\tvalidateName(name);\n\t\tvalidateValue(value);\n\t\tconst key = find(this[MAP], name);\n\t\tif (key !== undefined) {\n\t\t\tthis[MAP][key].push(value);\n\t\t} else {\n\t\t\tthis[MAP][name] = [value];\n\t\t}\n\t}\n\n\t/**\n * Check for header name existence\n *\n * @param String name Header name\n * @return Boolean\n */\n\thas(name) {\n\t\tname = `${name}`;\n\t\tvalidateName(name);\n\t\treturn find(this[MAP], name) !== undefined;\n\t}\n\n\t/**\n * Delete all header values given name\n *\n * @param String name Header name\n * @return Void\n */\n\tdelete(name) {\n\t\tname = `${name}`;\n\t\tvalidateName(name);\n\t\tconst key = find(this[MAP], name);\n\t\tif (key !== undefined) {\n\t\t\tdelete this[MAP][key];\n\t\t}\n\t}\n\n\t/**\n * Return raw headers (non-spec api)\n *\n * @return Object\n */\n\traw() {\n\t\treturn this[MAP];\n\t}\n\n\t/**\n * Get an iterator on keys.\n *\n * @return Iterator\n */\n\tkeys() {\n\t\treturn createHeadersIterator(this, 'key');\n\t}\n\n\t/**\n * Get an iterator on values.\n *\n * @return Iterator\n */\n\tvalues() {\n\t\treturn createHeadersIterator(this, 'value');\n\t}\n\n\t/**\n * Get an iterator on entries.\n *\n * This is the default iterator of the Headers object.\n *\n * @return Iterator\n */\n\t[Symbol.iterator]() {\n\t\treturn createHeadersIterator(this, 'key+value');\n\t}\n}\nHeaders.prototype.entries = Headers.prototype[Symbol.iterator];\n\nObject.defineProperty(Headers.prototype, Symbol.toStringTag, {\n\tvalue: 'Headers',\n\twritable: false,\n\tenumerable: false,\n\tconfigurable: true\n});\n\nObject.defineProperties(Headers.prototype, {\n\tget: { enumerable: true },\n\tforEach: { enumerable: true },\n\tset: { enumerable: true },\n\tappend: { enumerable: true },\n\thas: { enumerable: true },\n\tdelete: { enumerable: true },\n\tkeys: { enumerable: true },\n\tvalues: { enumerable: true },\n\tentries: { enumerable: true }\n});\n\nfunction getHeaders(headers) {\n\tlet kind = arguments.length > 1 && arguments[1] !== undefined ? arguments[1] : 'key+value';\n\n\tconst keys = Object.keys(headers[MAP]).sort();\n\treturn keys.map(kind === 'key' ? function (k) {\n\t\treturn k.toLowerCase();\n\t} : kind === 'value' ? function (k) {\n\t\treturn headers[MAP][k].join(', ');\n\t} : function (k) {\n\t\treturn [k.toLowerCase(), headers[MAP][k].join(', ')];\n\t});\n}\n\nconst INTERNAL = Symbol('internal');\n\nfunction createHeadersIterator(target, kind) {\n\tconst iterator = Object.create(HeadersIteratorPrototype);\n\titerator[INTERNAL] = {\n\t\ttarget,\n\t\tkind,\n\t\tindex: 0\n\t};\n\treturn iterator;\n}\n\nconst HeadersIteratorPrototype = Object.setPrototypeOf({\n\tnext() {\n\t\t// istanbul ignore if\n\t\tif (!this || Object.getPrototypeOf(this) !== HeadersIteratorPrototype) {\n\t\t\tthrow new TypeError('Value of `this` is not a HeadersIterator');\n\t\t}\n\n\t\tvar _INTERNAL = this[INTERNAL];\n\t\tconst target = _INTERNAL.target,\n\t\t kind = _INTERNAL.kind,\n\t\t index = _INTERNAL.index;\n\n\t\tconst values = getHeaders(target, kind);\n\t\tconst len = values.length;\n\t\tif (index >= len) {\n\t\t\treturn {\n\t\t\t\tvalue: undefined,\n\t\t\t\tdone: true\n\t\t\t};\n\t\t}\n\n\t\tthis[INTERNAL].index = index + 1;\n\n\t\treturn {\n\t\t\tvalue: values[index],\n\t\t\tdone: false\n\t\t};\n\t}\n}, Object.getPrototypeOf(Object.getPrototypeOf([][Symbol.iterator]())));\n\nObject.defineProperty(HeadersIteratorPrototype, Symbol.toStringTag, {\n\tvalue: 'HeadersIterator',\n\twritable: false,\n\tenumerable: false,\n\tconfigurable: true\n});\n\n/**\n * Export the Headers object in a form that Node.js can consume.\n *\n * @param Headers headers\n * @return Object\n */\nfunction exportNodeCompatibleHeaders(headers) {\n\tconst obj = Object.assign({ __proto__: null }, headers[MAP]);\n\n\t// http.request() only supports string as Host header. This hack makes\n\t// specifying custom Host header possible.\n\tconst hostHeaderKey = find(headers[MAP], 'Host');\n\tif (hostHeaderKey !== undefined) {\n\t\tobj[hostHeaderKey] = obj[hostHeaderKey][0];\n\t}\n\n\treturn obj;\n}\n\n/**\n * Create a Headers object from an object of headers, ignoring those that do\n * not conform to HTTP grammar productions.\n *\n * @param Object obj Object of headers\n * @return Headers\n */\nfunction createHeadersLenient(obj) {\n\tconst headers = new Headers();\n\tfor (const name of Object.keys(obj)) {\n\t\tif (invalidTokenRegex.test(name)) {\n\t\t\tcontinue;\n\t\t}\n\t\tif (Array.isArray(obj[name])) {\n\t\t\tfor (const val of obj[name]) {\n\t\t\t\tif (invalidHeaderCharRegex.test(val)) {\n\t\t\t\t\tcontinue;\n\t\t\t\t}\n\t\t\t\tif (headers[MAP][name] === undefined) {\n\t\t\t\t\theaders[MAP][name] = [val];\n\t\t\t\t} else {\n\t\t\t\t\theaders[MAP][name].push(val);\n\t\t\t\t}\n\t\t\t}\n\t\t} else if (!invalidHeaderCharRegex.test(obj[name])) {\n\t\t\theaders[MAP][name] = [obj[name]];\n\t\t}\n\t}\n\treturn headers;\n}\n\nconst INTERNALS$1 = Symbol('Response internals');\n\n// fix an issue where \"STATUS_CODES\" aren't a named export for node <10\nconst STATUS_CODES = http.STATUS_CODES;\n\n/**\n * Response class\n *\n * @param Stream body Readable stream\n * @param Object opts Response options\n * @return Void\n */\nclass Response {\n\tconstructor() {\n\t\tlet body = arguments.length > 0 && arguments[0] !== undefined ? arguments[0] : null;\n\t\tlet opts = arguments.length > 1 && arguments[1] !== undefined ? arguments[1] : {};\n\n\t\tBody.call(this, body, opts);\n\n\t\tconst status = opts.status || 200;\n\t\tconst headers = new Headers(opts.headers);\n\n\t\tif (body != null && !headers.has('Content-Type')) {\n\t\t\tconst contentType = extractContentType(body);\n\t\t\tif (contentType) {\n\t\t\t\theaders.append('Content-Type', contentType);\n\t\t\t}\n\t\t}\n\n\t\tthis[INTERNALS$1] = {\n\t\t\turl: opts.url,\n\t\t\tstatus,\n\t\t\tstatusText: opts.statusText || STATUS_CODES[status],\n\t\t\theaders,\n\t\t\tcounter: opts.counter\n\t\t};\n\t}\n\n\tget url() {\n\t\treturn this[INTERNALS$1].url || '';\n\t}\n\n\tget status() {\n\t\treturn this[INTERNALS$1].status;\n\t}\n\n\t/**\n * Convenience property representing if the request ended normally\n */\n\tget ok() {\n\t\treturn this[INTERNALS$1].status >= 200 && this[INTERNALS$1].status < 300;\n\t}\n\n\tget redirected() {\n\t\treturn this[INTERNALS$1].counter > 0;\n\t}\n\n\tget statusText() {\n\t\treturn this[INTERNALS$1].statusText;\n\t}\n\n\tget headers() {\n\t\treturn this[INTERNALS$1].headers;\n\t}\n\n\t/**\n * Clone this response\n *\n * @return Response\n */\n\tclone() {\n\t\treturn new Response(clone(this), {\n\t\t\turl: this.url,\n\t\t\tstatus: this.status,\n\t\t\tstatusText: this.statusText,\n\t\t\theaders: this.headers,\n\t\t\tok: this.ok,\n\t\t\tredirected: this.redirected\n\t\t});\n\t}\n}\n\nBody.mixIn(Response.prototype);\n\nObject.defineProperties(Response.prototype, {\n\turl: { enumerable: true },\n\tstatus: { enumerable: true },\n\tok: { enumerable: true },\n\tredirected: { enumerable: true },\n\tstatusText: { enumerable: true },\n\theaders: { enumerable: true },\n\tclone: { enumerable: true }\n});\n\nObject.defineProperty(Response.prototype, Symbol.toStringTag, {\n\tvalue: 'Response',\n\twritable: false,\n\tenumerable: false,\n\tconfigurable: true\n});\n\nconst INTERNALS$2 = Symbol('Request internals');\nconst URL = Url.URL || whatwgUrl.URL;\n\n// fix an issue where \"format\", \"parse\" aren't a named export for node <10\nconst parse_url = Url.parse;\nconst format_url = Url.format;\n\n/**\n * Wrapper around `new URL` to handle arbitrary URLs\n *\n * @param {string} urlStr\n * @return {void}\n */\nfunction parseURL(urlStr) {\n\t/*\n \tCheck whether the URL is absolute or not\n \t\tScheme: https://tools.ietf.org/html/rfc3986#section-3.1\n \tAbsolute URL: https://tools.ietf.org/html/rfc3986#section-4.3\n */\n\tif (/^[a-zA-Z][a-zA-Z\\d+\\-.]*:/.exec(urlStr)) {\n\t\turlStr = new URL(urlStr).toString();\n\t}\n\n\t// Fallback to old implementation for arbitrary URLs\n\treturn parse_url(urlStr);\n}\n\nconst streamDestructionSupported = 'destroy' in Stream.Readable.prototype;\n\n/**\n * Check if a value is an instance of Request.\n *\n * @param Mixed input\n * @return Boolean\n */\nfunction isRequest(input) {\n\treturn typeof input === 'object' && typeof input[INTERNALS$2] === 'object';\n}\n\nfunction isAbortSignal(signal) {\n\tconst proto = signal && typeof signal === 'object' && Object.getPrototypeOf(signal);\n\treturn !!(proto && proto.constructor.name === 'AbortSignal');\n}\n\n/**\n * Request class\n *\n * @param Mixed input Url or Request instance\n * @param Object init Custom options\n * @return Void\n */\nclass Request {\n\tconstructor(input) {\n\t\tlet init = arguments.length > 1 && arguments[1] !== undefined ? arguments[1] : {};\n\n\t\tlet parsedURL;\n\n\t\t// normalize input\n\t\tif (!isRequest(input)) {\n\t\t\tif (input && input.href) {\n\t\t\t\t// in order to support Node.js' Url objects; though WHATWG's URL objects\n\t\t\t\t// will fall into this branch also (since their `toString()` will return\n\t\t\t\t// `href` property anyway)\n\t\t\t\tparsedURL = parseURL(input.href);\n\t\t\t} else {\n\t\t\t\t// coerce input to a string before attempting to parse\n\t\t\t\tparsedURL = parseURL(`${input}`);\n\t\t\t}\n\t\t\tinput = {};\n\t\t} else {\n\t\t\tparsedURL = parseURL(input.url);\n\t\t}\n\n\t\tlet method = init.method || input.method || 'GET';\n\t\tmethod = method.toUpperCase();\n\n\t\tif ((init.body != null || isRequest(input) && input.body !== null) && (method === 'GET' || method === 'HEAD')) {\n\t\t\tthrow new TypeError('Request with GET/HEAD method cannot have body');\n\t\t}\n\n\t\tlet inputBody = init.body != null ? init.body : isRequest(input) && input.body !== null ? clone(input) : null;\n\n\t\tBody.call(this, inputBody, {\n\t\t\ttimeout: init.timeout || input.timeout || 0,\n\t\t\tsize: init.size || input.size || 0\n\t\t});\n\n\t\tconst headers = new Headers(init.headers || input.headers || {});\n\n\t\tif (inputBody != null && !headers.has('Content-Type')) {\n\t\t\tconst contentType = extractContentType(inputBody);\n\t\t\tif (contentType) {\n\t\t\t\theaders.append('Content-Type', contentType);\n\t\t\t}\n\t\t}\n\n\t\tlet signal = isRequest(input) ? input.signal : null;\n\t\tif ('signal' in init) signal = init.signal;\n\n\t\tif (signal != null && !isAbortSignal(signal)) {\n\t\t\tthrow new TypeError('Expected signal to be an instanceof AbortSignal');\n\t\t}\n\n\t\tthis[INTERNALS$2] = {\n\t\t\tmethod,\n\t\t\tredirect: init.redirect || input.redirect || 'follow',\n\t\t\theaders,\n\t\t\tparsedURL,\n\t\t\tsignal\n\t\t};\n\n\t\t// node-fetch-only options\n\t\tthis.follow = init.follow !== undefined ? init.follow : input.follow !== undefined ? input.follow : 20;\n\t\tthis.compress = init.compress !== undefined ? init.compress : input.compress !== undefined ? input.compress : true;\n\t\tthis.counter = init.counter || input.counter || 0;\n\t\tthis.agent = init.agent || input.agent;\n\t}\n\n\tget method() {\n\t\treturn this[INTERNALS$2].method;\n\t}\n\n\tget url() {\n\t\treturn format_url(this[INTERNALS$2].parsedURL);\n\t}\n\n\tget headers() {\n\t\treturn this[INTERNALS$2].headers;\n\t}\n\n\tget redirect() {\n\t\treturn this[INTERNALS$2].redirect;\n\t}\n\n\tget signal() {\n\t\treturn this[INTERNALS$2].signal;\n\t}\n\n\t/**\n * Clone this request\n *\n * @return Request\n */\n\tclone() {\n\t\treturn new Request(this);\n\t}\n}\n\nBody.mixIn(Request.prototype);\n\nObject.defineProperty(Request.prototype, Symbol.toStringTag, {\n\tvalue: 'Request',\n\twritable: false,\n\tenumerable: false,\n\tconfigurable: true\n});\n\nObject.defineProperties(Request.prototype, {\n\tmethod: { enumerable: true },\n\turl: { enumerable: true },\n\theaders: { enumerable: true },\n\tredirect: { enumerable: true },\n\tclone: { enumerable: true },\n\tsignal: { enumerable: true }\n});\n\n/**\n * Convert a Request to Node.js http request options.\n *\n * @param Request A Request instance\n * @return Object The options object to be passed to http.request\n */\nfunction getNodeRequestOptions(request) {\n\tconst parsedURL = request[INTERNALS$2].parsedURL;\n\tconst headers = new Headers(request[INTERNALS$2].headers);\n\n\t// fetch step 1.3\n\tif (!headers.has('Accept')) {\n\t\theaders.set('Accept', '*/*');\n\t}\n\n\t// Basic fetch\n\tif (!parsedURL.protocol || !parsedURL.hostname) {\n\t\tthrow new TypeError('Only absolute URLs are supported');\n\t}\n\n\tif (!/^https?:$/.test(parsedURL.protocol)) {\n\t\tthrow new TypeError('Only HTTP(S) protocols are supported');\n\t}\n\n\tif (request.signal && request.body instanceof Stream.Readable && !streamDestructionSupported) {\n\t\tthrow new Error('Cancellation of streamed requests with AbortSignal is not supported in node < 8');\n\t}\n\n\t// HTTP-network-or-cache fetch steps 2.4-2.7\n\tlet contentLengthValue = null;\n\tif (request.body == null && /^(POST|PUT)$/i.test(request.method)) {\n\t\tcontentLengthValue = '0';\n\t}\n\tif (request.body != null) {\n\t\tconst totalBytes = getTotalBytes(request);\n\t\tif (typeof totalBytes === 'number') {\n\t\t\tcontentLengthValue = String(totalBytes);\n\t\t}\n\t}\n\tif (contentLengthValue) {\n\t\theaders.set('Content-Length', contentLengthValue);\n\t}\n\n\t// HTTP-network-or-cache fetch step 2.11\n\tif (!headers.has('User-Agent')) {\n\t\theaders.set('User-Agent', 'node-fetch/1.0 (+https://github.com/bitinn/node-fetch)');\n\t}\n\n\t// HTTP-network-or-cache fetch step 2.15\n\tif (request.compress && !headers.has('Accept-Encoding')) {\n\t\theaders.set('Accept-Encoding', 'gzip,deflate');\n\t}\n\n\tlet agent = request.agent;\n\tif (typeof agent === 'function') {\n\t\tagent = agent(parsedURL);\n\t}\n\n\t// HTTP-network fetch step 4.2\n\t// chunked encoding is handled by Node.js\n\n\treturn Object.assign({}, parsedURL, {\n\t\tmethod: request.method,\n\t\theaders: exportNodeCompatibleHeaders(headers),\n\t\tagent\n\t});\n}\n\n/**\n * abort-error.js\n *\n * AbortError interface for cancelled requests\n */\n\n/**\n * Create AbortError instance\n *\n * @param String message Error message for human\n * @return AbortError\n */\nfunction AbortError(message) {\n Error.call(this, message);\n\n this.type = 'aborted';\n this.message = message;\n\n // hide custom error implementation details from end-users\n Error.captureStackTrace(this, this.constructor);\n}\n\nAbortError.prototype = Object.create(Error.prototype);\nAbortError.prototype.constructor = AbortError;\nAbortError.prototype.name = 'AbortError';\n\nconst URL$1 = Url.URL || whatwgUrl.URL;\n\n// fix an issue where \"PassThrough\", \"resolve\" aren't a named export for node <10\nconst PassThrough$1 = Stream.PassThrough;\n\nconst isDomainOrSubdomain = function isDomainOrSubdomain(destination, original) {\n\tconst orig = new URL$1(original).hostname;\n\tconst dest = new URL$1(destination).hostname;\n\n\treturn orig === dest || orig[orig.length - dest.length - 1] === '.' && orig.endsWith(dest);\n};\n\n/**\n * isSameProtocol reports whether the two provided URLs use the same protocol.\n *\n * Both domains must already be in canonical form.\n * @param {string|URL} original\n * @param {string|URL} destination\n */\nconst isSameProtocol = function isSameProtocol(destination, original) {\n\tconst orig = new URL$1(original).protocol;\n\tconst dest = new URL$1(destination).protocol;\n\n\treturn orig === dest;\n};\n\n/**\n * Fetch function\n *\n * @param Mixed url Absolute url or Request instance\n * @param Object opts Fetch options\n * @return Promise\n */\nfunction fetch(url, opts) {\n\n\t// allow custom promise\n\tif (!fetch.Promise) {\n\t\tthrow new Error('native promise missing, set fetch.Promise to your favorite alternative');\n\t}\n\n\tBody.Promise = fetch.Promise;\n\n\t// wrap http.request into fetch\n\treturn new fetch.Promise(function (resolve, reject) {\n\t\t// build request object\n\t\tconst request = new Request(url, opts);\n\t\tconst options = getNodeRequestOptions(request);\n\n\t\tconst send = (options.protocol === 'https:' ? https : http).request;\n\t\tconst signal = request.signal;\n\n\t\tlet response = null;\n\n\t\tconst abort = function abort() {\n\t\t\tlet error = new AbortError('The user aborted a request.');\n\t\t\treject(error);\n\t\t\tif (request.body && request.body instanceof Stream.Readable) {\n\t\t\t\tdestroyStream(request.body, error);\n\t\t\t}\n\t\t\tif (!response || !response.body) return;\n\t\t\tresponse.body.emit('error', error);\n\t\t};\n\n\t\tif (signal && signal.aborted) {\n\t\t\tabort();\n\t\t\treturn;\n\t\t}\n\n\t\tconst abortAndFinalize = function abortAndFinalize() {\n\t\t\tabort();\n\t\t\tfinalize();\n\t\t};\n\n\t\t// send request\n\t\tconst req = send(options);\n\t\tlet reqTimeout;\n\n\t\tif (signal) {\n\t\t\tsignal.addEventListener('abort', abortAndFinalize);\n\t\t}\n\n\t\tfunction finalize() {\n\t\t\treq.abort();\n\t\t\tif (signal) signal.removeEventListener('abort', abortAndFinalize);\n\t\t\tclearTimeout(reqTimeout);\n\t\t}\n\n\t\tif (request.timeout) {\n\t\t\treq.once('socket', function (socket) {\n\t\t\t\treqTimeout = setTimeout(function () {\n\t\t\t\t\treject(new FetchError(`network timeout at: ${request.url}`, 'request-timeout'));\n\t\t\t\t\tfinalize();\n\t\t\t\t}, request.timeout);\n\t\t\t});\n\t\t}\n\n\t\treq.on('error', function (err) {\n\t\t\treject(new FetchError(`request to ${request.url} failed, reason: ${err.message}`, 'system', err));\n\n\t\t\tif (response && response.body) {\n\t\t\t\tdestroyStream(response.body, err);\n\t\t\t}\n\n\t\t\tfinalize();\n\t\t});\n\n\t\tfixResponseChunkedTransferBadEnding(req, function (err) {\n\t\t\tif (signal && signal.aborted) {\n\t\t\t\treturn;\n\t\t\t}\n\n\t\t\tif (response && response.body) {\n\t\t\t\tdestroyStream(response.body, err);\n\t\t\t}\n\t\t});\n\n\t\t/* c8 ignore next 18 */\n\t\tif (parseInt(process.version.substring(1)) < 14) {\n\t\t\t// Before Node.js 14, pipeline() does not fully support async iterators and does not always\n\t\t\t// properly handle when the socket close/end events are out of order.\n\t\t\treq.on('socket', function (s) {\n\t\t\t\ts.addListener('close', function (hadError) {\n\t\t\t\t\t// if a data listener is still present we didn't end cleanly\n\t\t\t\t\tconst hasDataListener = s.listenerCount('data') > 0;\n\n\t\t\t\t\t// if end happened before close but the socket didn't emit an error, do it now\n\t\t\t\t\tif (response && hasDataListener && !hadError && !(signal && signal.aborted)) {\n\t\t\t\t\t\tconst err = new Error('Premature close');\n\t\t\t\t\t\terr.code = 'ERR_STREAM_PREMATURE_CLOSE';\n\t\t\t\t\t\tresponse.body.emit('error', err);\n\t\t\t\t\t}\n\t\t\t\t});\n\t\t\t});\n\t\t}\n\n\t\treq.on('response', function (res) {\n\t\t\tclearTimeout(reqTimeout);\n\n\t\t\tconst headers = createHeadersLenient(res.headers);\n\n\t\t\t// HTTP fetch step 5\n\t\t\tif (fetch.isRedirect(res.statusCode)) {\n\t\t\t\t// HTTP fetch step 5.2\n\t\t\t\tconst location = headers.get('Location');\n\n\t\t\t\t// HTTP fetch step 5.3\n\t\t\t\tlet locationURL = null;\n\t\t\t\ttry {\n\t\t\t\t\tlocationURL = location === null ? null : new URL$1(location, request.url).toString();\n\t\t\t\t} catch (err) {\n\t\t\t\t\t// error here can only be invalid URL in Location: header\n\t\t\t\t\t// do not throw when options.redirect == manual\n\t\t\t\t\t// let the user extract the errorneous redirect URL\n\t\t\t\t\tif (request.redirect !== 'manual') {\n\t\t\t\t\t\treject(new FetchError(`uri requested responds with an invalid redirect URL: ${location}`, 'invalid-redirect'));\n\t\t\t\t\t\tfinalize();\n\t\t\t\t\t\treturn;\n\t\t\t\t\t}\n\t\t\t\t}\n\n\t\t\t\t// HTTP fetch step 5.5\n\t\t\t\tswitch (request.redirect) {\n\t\t\t\t\tcase 'error':\n\t\t\t\t\t\treject(new FetchError(`uri requested responds with a redirect, redirect mode is set to error: ${request.url}`, 'no-redirect'));\n\t\t\t\t\t\tfinalize();\n\t\t\t\t\t\treturn;\n\t\t\t\t\tcase 'manual':\n\t\t\t\t\t\t// node-fetch-specific step: make manual redirect a bit easier to use by setting the Location header value to the resolved URL.\n\t\t\t\t\t\tif (locationURL !== null) {\n\t\t\t\t\t\t\t// handle corrupted header\n\t\t\t\t\t\t\ttry {\n\t\t\t\t\t\t\t\theaders.set('Location', locationURL);\n\t\t\t\t\t\t\t} catch (err) {\n\t\t\t\t\t\t\t\t// istanbul ignore next: nodejs server prevent invalid response headers, we can't test this through normal request\n\t\t\t\t\t\t\t\treject(err);\n\t\t\t\t\t\t\t}\n\t\t\t\t\t\t}\n\t\t\t\t\t\tbreak;\n\t\t\t\t\tcase 'follow':\n\t\t\t\t\t\t// HTTP-redirect fetch step 2\n\t\t\t\t\t\tif (locationURL === null) {\n\t\t\t\t\t\t\tbreak;\n\t\t\t\t\t\t}\n\n\t\t\t\t\t\t// HTTP-redirect fetch step 5\n\t\t\t\t\t\tif (request.counter >= request.follow) {\n\t\t\t\t\t\t\treject(new FetchError(`maximum redirect reached at: ${request.url}`, 'max-redirect'));\n\t\t\t\t\t\t\tfinalize();\n\t\t\t\t\t\t\treturn;\n\t\t\t\t\t\t}\n\n\t\t\t\t\t\t// HTTP-redirect fetch step 6 (counter increment)\n\t\t\t\t\t\t// Create a new Request object.\n\t\t\t\t\t\tconst requestOpts = {\n\t\t\t\t\t\t\theaders: new Headers(request.headers),\n\t\t\t\t\t\t\tfollow: request.follow,\n\t\t\t\t\t\t\tcounter: request.counter + 1,\n\t\t\t\t\t\t\tagent: request.agent,\n\t\t\t\t\t\t\tcompress: request.compress,\n\t\t\t\t\t\t\tmethod: request.method,\n\t\t\t\t\t\t\tbody: request.body,\n\t\t\t\t\t\t\tsignal: request.signal,\n\t\t\t\t\t\t\ttimeout: request.timeout,\n\t\t\t\t\t\t\tsize: request.size\n\t\t\t\t\t\t};\n\n\t\t\t\t\t\tif (!isDomainOrSubdomain(request.url, locationURL) || !isSameProtocol(request.url, locationURL)) {\n\t\t\t\t\t\t\tfor (const name of ['authorization', 'www-authenticate', 'cookie', 'cookie2']) {\n\t\t\t\t\t\t\t\trequestOpts.headers.delete(name);\n\t\t\t\t\t\t\t}\n\t\t\t\t\t\t}\n\n\t\t\t\t\t\t// HTTP-redirect fetch step 9\n\t\t\t\t\t\tif (res.statusCode !== 303 && request.body && getTotalBytes(request) === null) {\n\t\t\t\t\t\t\treject(new FetchError('Cannot follow redirect with body being a readable stream', 'unsupported-redirect'));\n\t\t\t\t\t\t\tfinalize();\n\t\t\t\t\t\t\treturn;\n\t\t\t\t\t\t}\n\n\t\t\t\t\t\t// HTTP-redirect fetch step 11\n\t\t\t\t\t\tif (res.statusCode === 303 || (res.statusCode === 301 || res.statusCode === 302) && request.method === 'POST') {\n\t\t\t\t\t\t\trequestOpts.method = 'GET';\n\t\t\t\t\t\t\trequestOpts.body = undefined;\n\t\t\t\t\t\t\trequestOpts.headers.delete('content-length');\n\t\t\t\t\t\t}\n\n\t\t\t\t\t\t// HTTP-redirect fetch step 15\n\t\t\t\t\t\tresolve(fetch(new Request(locationURL, requestOpts)));\n\t\t\t\t\t\tfinalize();\n\t\t\t\t\t\treturn;\n\t\t\t\t}\n\t\t\t}\n\n\t\t\t// prepare response\n\t\t\tres.once('end', function () {\n\t\t\t\tif (signal) signal.removeEventListener('abort', abortAndFinalize);\n\t\t\t});\n\t\t\tlet body = res.pipe(new PassThrough$1());\n\n\t\t\tconst response_options = {\n\t\t\t\turl: request.url,\n\t\t\t\tstatus: res.statusCode,\n\t\t\t\tstatusText: res.statusMessage,\n\t\t\t\theaders: headers,\n\t\t\t\tsize: request.size,\n\t\t\t\ttimeout: request.timeout,\n\t\t\t\tcounter: request.counter\n\t\t\t};\n\n\t\t\t// HTTP-network fetch step 12.1.1.3\n\t\t\tconst codings = headers.get('Content-Encoding');\n\n\t\t\t// HTTP-network fetch step 12.1.1.4: handle content codings\n\n\t\t\t// in following scenarios we ignore compression support\n\t\t\t// 1. compression support is disabled\n\t\t\t// 2. HEAD request\n\t\t\t// 3. no Content-Encoding header\n\t\t\t// 4. no content response (204)\n\t\t\t// 5. content not modified response (304)\n\t\t\tif (!request.compress || request.method === 'HEAD' || codings === null || res.statusCode === 204 || res.statusCode === 304) {\n\t\t\t\tresponse = new Response(body, response_options);\n\t\t\t\tresolve(response);\n\t\t\t\treturn;\n\t\t\t}\n\n\t\t\t// For Node v6+\n\t\t\t// Be less strict when decoding compressed responses, since sometimes\n\t\t\t// servers send slightly invalid responses that are still accepted\n\t\t\t// by common browsers.\n\t\t\t// Always using Z_SYNC_FLUSH is what cURL does.\n\t\t\tconst zlibOptions = {\n\t\t\t\tflush: zlib.Z_SYNC_FLUSH,\n\t\t\t\tfinishFlush: zlib.Z_SYNC_FLUSH\n\t\t\t};\n\n\t\t\t// for gzip\n\t\t\tif (codings == 'gzip' || codings == 'x-gzip') {\n\t\t\t\tbody = body.pipe(zlib.createGunzip(zlibOptions));\n\t\t\t\tresponse = new Response(body, response_options);\n\t\t\t\tresolve(response);\n\t\t\t\treturn;\n\t\t\t}\n\n\t\t\t// for deflate\n\t\t\tif (codings == 'deflate' || codings == 'x-deflate') {\n\t\t\t\t// handle the infamous raw deflate response from old servers\n\t\t\t\t// a hack for old IIS and Apache servers\n\t\t\t\tconst raw = res.pipe(new PassThrough$1());\n\t\t\t\traw.once('data', function (chunk) {\n\t\t\t\t\t// see http://stackoverflow.com/questions/37519828\n\t\t\t\t\tif ((chunk[0] & 0x0F) === 0x08) {\n\t\t\t\t\t\tbody = body.pipe(zlib.createInflate());\n\t\t\t\t\t} else {\n\t\t\t\t\t\tbody = body.pipe(zlib.createInflateRaw());\n\t\t\t\t\t}\n\t\t\t\t\tresponse = new Response(body, response_options);\n\t\t\t\t\tresolve(response);\n\t\t\t\t});\n\t\t\t\traw.on('end', function () {\n\t\t\t\t\t// some old IIS servers return zero-length OK deflate responses, so 'data' is never emitted.\n\t\t\t\t\tif (!response) {\n\t\t\t\t\t\tresponse = new Response(body, response_options);\n\t\t\t\t\t\tresolve(response);\n\t\t\t\t\t}\n\t\t\t\t});\n\t\t\t\treturn;\n\t\t\t}\n\n\t\t\t// for br\n\t\t\tif (codings == 'br' && typeof zlib.createBrotliDecompress === 'function') {\n\t\t\t\tbody = body.pipe(zlib.createBrotliDecompress());\n\t\t\t\tresponse = new Response(body, response_options);\n\t\t\t\tresolve(response);\n\t\t\t\treturn;\n\t\t\t}\n\n\t\t\t// otherwise, use response as-is\n\t\t\tresponse = new Response(body, response_options);\n\t\t\tresolve(response);\n\t\t});\n\n\t\twriteToStream(req, request);\n\t});\n}\nfunction fixResponseChunkedTransferBadEnding(request, errorCallback) {\n\tlet socket;\n\n\trequest.on('socket', function (s) {\n\t\tsocket = s;\n\t});\n\n\trequest.on('response', function (response) {\n\t\tconst headers = response.headers;\n\n\t\tif (headers['transfer-encoding'] === 'chunked' && !headers['content-length']) {\n\t\t\tresponse.once('close', function (hadError) {\n\t\t\t\t// tests for socket presence, as in some situations the\n\t\t\t\t// the 'socket' event is not triggered for the request\n\t\t\t\t// (happens in deno), avoids `TypeError`\n\t\t\t\t// if a data listener is still present we didn't end cleanly\n\t\t\t\tconst hasDataListener = socket && socket.listenerCount('data') > 0;\n\n\t\t\t\tif (hasDataListener && !hadError) {\n\t\t\t\t\tconst err = new Error('Premature close');\n\t\t\t\t\terr.code = 'ERR_STREAM_PREMATURE_CLOSE';\n\t\t\t\t\terrorCallback(err);\n\t\t\t\t}\n\t\t\t});\n\t\t}\n\t});\n}\n\nfunction destroyStream(stream, err) {\n\tif (stream.destroy) {\n\t\tstream.destroy(err);\n\t} else {\n\t\t// node < 8\n\t\tstream.emit('error', err);\n\t\tstream.end();\n\t}\n}\n\n/**\n * Redirect code matching\n *\n * @param Number code Status code\n * @return Boolean\n */\nfetch.isRedirect = function (code) {\n\treturn code === 301 || code === 302 || code === 303 || code === 307 || code === 308;\n};\n\n// expose Promise\nfetch.Promise = global.Promise;\n\nmodule.exports = exports = fetch;\nObject.defineProperty(exports, \"__esModule\", ({ value: true }));\nexports[\"default\"] = exports;\nexports.Headers = Headers;\nexports.Request = Request;\nexports.Response = Response;\nexports.FetchError = FetchError;\nexports.AbortError = AbortError;\n\n\n/***/ }),\n\n/***/ 2299:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\n\"use strict\";\n\n\nvar punycode = __nccwpck_require__(5477);\nvar mappingTable = __nccwpck_require__(1907);\n\nvar PROCESSING_OPTIONS = {\n TRANSITIONAL: 0,\n NONTRANSITIONAL: 1\n};\n\nfunction normalize(str) { // fix bug in v8\n return str.split('\\u0000').map(function (s) { return s.normalize('NFC'); }).join('\\u0000');\n}\n\nfunction findStatus(val) {\n var start = 0;\n var end = mappingTable.length - 1;\n\n while (start <= end) {\n var mid = Math.floor((start + end) / 2);\n\n var target = mappingTable[mid];\n if (target[0][0] <= val && target[0][1] >= val) {\n return target;\n } else if (target[0][0] > val) {\n end = mid - 1;\n } else {\n start = mid + 1;\n }\n }\n\n return null;\n}\n\nvar regexAstralSymbols = /[\\uD800-\\uDBFF][\\uDC00-\\uDFFF]/g;\n\nfunction countSymbols(string) {\n return string\n // replace every surrogate pair with a BMP symbol\n .replace(regexAstralSymbols, '_')\n // then get the length\n .length;\n}\n\nfunction mapChars(domain_name, useSTD3, processing_option) {\n var hasError = false;\n var processed = \"\";\n\n var len = countSymbols(domain_name);\n for (var i = 0; i < len; ++i) {\n var codePoint = domain_name.codePointAt(i);\n var status = findStatus(codePoint);\n\n switch (status[1]) {\n case \"disallowed\":\n hasError = true;\n processed += String.fromCodePoint(codePoint);\n break;\n case \"ignored\":\n break;\n case \"mapped\":\n processed += String.fromCodePoint.apply(String, status[2]);\n break;\n case \"deviation\":\n if (processing_option === PROCESSING_OPTIONS.TRANSITIONAL) {\n processed += String.fromCodePoint.apply(String, status[2]);\n } else {\n processed += String.fromCodePoint(codePoint);\n }\n break;\n case \"valid\":\n processed += String.fromCodePoint(codePoint);\n break;\n case \"disallowed_STD3_mapped\":\n if (useSTD3) {\n hasError = true;\n processed += String.fromCodePoint(codePoint);\n } else {\n processed += String.fromCodePoint.apply(String, status[2]);\n }\n break;\n case \"disallowed_STD3_valid\":\n if (useSTD3) {\n hasError = true;\n }\n\n processed += String.fromCodePoint(codePoint);\n break;\n }\n }\n\n return {\n string: processed,\n error: hasError\n };\n}\n\nvar combiningMarksRegex = /[\\u0300-\\u036F\\u0483-\\u0489\\u0591-\\u05BD\\u05BF\\u05C1\\u05C2\\u05C4\\u05C5\\u05C7\\u0610-\\u061A\\u064B-\\u065F\\u0670\\u06D6-\\u06DC\\u06DF-\\u06E4\\u06E7\\u06E8\\u06EA-\\u06ED\\u0711\\u0730-\\u074A\\u07A6-\\u07B0\\u07EB-\\u07F3\\u0816-\\u0819\\u081B-\\u0823\\u0825-\\u0827\\u0829-\\u082D\\u0859-\\u085B\\u08E4-\\u0903\\u093A-\\u093C\\u093E-\\u094F\\u0951-\\u0957\\u0962\\u0963\\u0981-\\u0983\\u09BC\\u09BE-\\u09C4\\u09C7\\u09C8\\u09CB-\\u09CD\\u09D7\\u09E2\\u09E3\\u0A01-\\u0A03\\u0A3C\\u0A3E-\\u0A42\\u0A47\\u0A48\\u0A4B-\\u0A4D\\u0A51\\u0A70\\u0A71\\u0A75\\u0A81-\\u0A83\\u0ABC\\u0ABE-\\u0AC5\\u0AC7-\\u0AC9\\u0ACB-\\u0ACD\\u0AE2\\u0AE3\\u0B01-\\u0B03\\u0B3C\\u0B3E-\\u0B44\\u0B47\\u0B48\\u0B4B-\\u0B4D\\u0B56\\u0B57\\u0B62\\u0B63\\u0B82\\u0BBE-\\u0BC2\\u0BC6-\\u0BC8\\u0BCA-\\u0BCD\\u0BD7\\u0C00-\\u0C03\\u0C3E-\\u0C44\\u0C46-\\u0C48\\u0C4A-\\u0C4D\\u0C55\\u0C56\\u0C62\\u0C63\\u0C81-\\u0C83\\u0CBC\\u0CBE-\\u0CC4\\u0CC6-\\u0CC8\\u0CCA-\\u0CCD\\u0CD5\\u0CD6\\u0CE2\\u0CE3\\u0D01-\\u0D03\\u0D3E-\\u0D44\\u0D46-\\u0D48\\u0D4A-\\u0D4D\\u0D57\\u0D62\\u0D63\\u0D82\\u0D83\\u0DCA\\u0DCF-\\u0DD4\\u0DD6\\u0DD8-\\u0DDF\\u0DF2\\u0DF3\\u0E31\\u0E34-\\u0E3A\\u0E47-\\u0E4E\\u0EB1\\u0EB4-\\u0EB9\\u0EBB\\u0EBC\\u0EC8-\\u0ECD\\u0F18\\u0F19\\u0F35\\u0F37\\u0F39\\u0F3E\\u0F3F\\u0F71-\\u0F84\\u0F86\\u0F87\\u0F8D-\\u0F97\\u0F99-\\u0FBC\\u0FC6\\u102B-\\u103E\\u1056-\\u1059\\u105E-\\u1060\\u1062-\\u1064\\u1067-\\u106D\\u1071-\\u1074\\u1082-\\u108D\\u108F\\u109A-\\u109D\\u135D-\\u135F\\u1712-\\u1714\\u1732-\\u1734\\u1752\\u1753\\u1772\\u1773\\u17B4-\\u17D3\\u17DD\\u180B-\\u180D\\u18A9\\u1920-\\u192B\\u1930-\\u193B\\u19B0-\\u19C0\\u19C8\\u19C9\\u1A17-\\u1A1B\\u1A55-\\u1A5E\\u1A60-\\u1A7C\\u1A7F\\u1AB0-\\u1ABE\\u1B00-\\u1B04\\u1B34-\\u1B44\\u1B6B-\\u1B73\\u1B80-\\u1B82\\u1BA1-\\u1BAD\\u1BE6-\\u1BF3\\u1C24-\\u1C37\\u1CD0-\\u1CD2\\u1CD4-\\u1CE8\\u1CED\\u1CF2-\\u1CF4\\u1CF8\\u1CF9\\u1DC0-\\u1DF5\\u1DFC-\\u1DFF\\u20D0-\\u20F0\\u2CEF-\\u2CF1\\u2D7F\\u2DE0-\\u2DFF\\u302A-\\u302F\\u3099\\u309A\\uA66F-\\uA672\\uA674-\\uA67D\\uA69F\\uA6F0\\uA6F1\\uA802\\uA806\\uA80B\\uA823-\\uA827\\uA880\\uA881\\uA8B4-\\uA8C4\\uA8E0-\\uA8F1\\uA926-\\uA92D\\uA947-\\uA953\\uA980-\\uA983\\uA9B3-\\uA9C0\\uA9E5\\uAA29-\\uAA36\\uAA43\\uAA4C\\uAA4D\\uAA7B-\\uAA7D\\uAAB0\\uAAB2-\\uAAB4\\uAAB7\\uAAB8\\uAABE\\uAABF\\uAAC1\\uAAEB-\\uAAEF\\uAAF5\\uAAF6\\uABE3-\\uABEA\\uABEC\\uABED\\uFB1E\\uFE00-\\uFE0F\\uFE20-\\uFE2D]|\\uD800[\\uDDFD\\uDEE0\\uDF76-\\uDF7A]|\\uD802[\\uDE01-\\uDE03\\uDE05\\uDE06\\uDE0C-\\uDE0F\\uDE38-\\uDE3A\\uDE3F\\uDEE5\\uDEE6]|\\uD804[\\uDC00-\\uDC02\\uDC38-\\uDC46\\uDC7F-\\uDC82\\uDCB0-\\uDCBA\\uDD00-\\uDD02\\uDD27-\\uDD34\\uDD73\\uDD80-\\uDD82\\uDDB3-\\uDDC0\\uDE2C-\\uDE37\\uDEDF-\\uDEEA\\uDF01-\\uDF03\\uDF3C\\uDF3E-\\uDF44\\uDF47\\uDF48\\uDF4B-\\uDF4D\\uDF57\\uDF62\\uDF63\\uDF66-\\uDF6C\\uDF70-\\uDF74]|\\uD805[\\uDCB0-\\uDCC3\\uDDAF-\\uDDB5\\uDDB8-\\uDDC0\\uDE30-\\uDE40\\uDEAB-\\uDEB7]|\\uD81A[\\uDEF0-\\uDEF4\\uDF30-\\uDF36]|\\uD81B[\\uDF51-\\uDF7E\\uDF8F-\\uDF92]|\\uD82F[\\uDC9D\\uDC9E]|\\uD834[\\uDD65-\\uDD69\\uDD6D-\\uDD72\\uDD7B-\\uDD82\\uDD85-\\uDD8B\\uDDAA-\\uDDAD\\uDE42-\\uDE44]|\\uD83A[\\uDCD0-\\uDCD6]|\\uDB40[\\uDD00-\\uDDEF]/;\n\nfunction validateLabel(label, processing_option) {\n if (label.substr(0, 4) === \"xn--\") {\n label = punycode.toUnicode(label);\n processing_option = PROCESSING_OPTIONS.NONTRANSITIONAL;\n }\n\n var error = false;\n\n if (normalize(label) !== label ||\n (label[3] === \"-\" && label[4] === \"-\") ||\n label[0] === \"-\" || label[label.length - 1] === \"-\" ||\n label.indexOf(\".\") !== -1 ||\n label.search(combiningMarksRegex) === 0) {\n error = true;\n }\n\n var len = countSymbols(label);\n for (var i = 0; i < len; ++i) {\n var status = findStatus(label.codePointAt(i));\n if ((processing === PROCESSING_OPTIONS.TRANSITIONAL && status[1] !== \"valid\") ||\n (processing === PROCESSING_OPTIONS.NONTRANSITIONAL &&\n status[1] !== \"valid\" && status[1] !== \"deviation\")) {\n error = true;\n break;\n }\n }\n\n return {\n label: label,\n error: error\n };\n}\n\nfunction processing(domain_name, useSTD3, processing_option) {\n var result = mapChars(domain_name, useSTD3, processing_option);\n result.string = normalize(result.string);\n\n var labels = result.string.split(\".\");\n for (var i = 0; i < labels.length; ++i) {\n try {\n var validation = validateLabel(labels[i]);\n labels[i] = validation.label;\n result.error = result.error || validation.error;\n } catch(e) {\n result.error = true;\n }\n }\n\n return {\n string: labels.join(\".\"),\n error: result.error\n };\n}\n\nmodule.exports.toASCII = function(domain_name, useSTD3, processing_option, verifyDnsLength) {\n var result = processing(domain_name, useSTD3, processing_option);\n var labels = result.string.split(\".\");\n labels = labels.map(function(l) {\n try {\n return punycode.toASCII(l);\n } catch(e) {\n result.error = true;\n return l;\n }\n });\n\n if (verifyDnsLength) {\n var total = labels.slice(0, labels.length - 1).join(\".\").length;\n if (total.length > 253 || total.length === 0) {\n result.error = true;\n }\n\n for (var i=0; i < labels.length; ++i) {\n if (labels.length > 63 || labels.length === 0) {\n result.error = true;\n break;\n }\n }\n }\n\n if (result.error) return null;\n return labels.join(\".\");\n};\n\nmodule.exports.toUnicode = function(domain_name, useSTD3) {\n var result = processing(domain_name, useSTD3, PROCESSING_OPTIONS.NONTRANSITIONAL);\n\n return {\n domain: result.string,\n error: result.error\n };\n};\n\nmodule.exports.PROCESSING_OPTIONS = PROCESSING_OPTIONS;\n\n\n/***/ }),\n\n/***/ 5871:\n/***/ ((module) => {\n\n\"use strict\";\n\n\nvar conversions = {};\nmodule.exports = conversions;\n\nfunction sign(x) {\n return x < 0 ? -1 : 1;\n}\n\nfunction evenRound(x) {\n // Round x to the nearest integer, choosing the even integer if it lies halfway between two.\n if ((x % 1) === 0.5 && (x & 1) === 0) { // [even number].5; round down (i.e. floor)\n return Math.floor(x);\n } else {\n return Math.round(x);\n }\n}\n\nfunction createNumberConversion(bitLength, typeOpts) {\n if (!typeOpts.unsigned) {\n --bitLength;\n }\n const lowerBound = typeOpts.unsigned ? 0 : -Math.pow(2, bitLength);\n const upperBound = Math.pow(2, bitLength) - 1;\n\n const moduloVal = typeOpts.moduloBitLength ? Math.pow(2, typeOpts.moduloBitLength) : Math.pow(2, bitLength);\n const moduloBound = typeOpts.moduloBitLength ? Math.pow(2, typeOpts.moduloBitLength - 1) : Math.pow(2, bitLength - 1);\n\n return function(V, opts) {\n if (!opts) opts = {};\n\n let x = +V;\n\n if (opts.enforceRange) {\n if (!Number.isFinite(x)) {\n throw new TypeError(\"Argument is not a finite number\");\n }\n\n x = sign(x) * Math.floor(Math.abs(x));\n if (x < lowerBound || x > upperBound) {\n throw new TypeError(\"Argument is not in byte range\");\n }\n\n return x;\n }\n\n if (!isNaN(x) && opts.clamp) {\n x = evenRound(x);\n\n if (x < lowerBound) x = lowerBound;\n if (x > upperBound) x = upperBound;\n return x;\n }\n\n if (!Number.isFinite(x) || x === 0) {\n return 0;\n }\n\n x = sign(x) * Math.floor(Math.abs(x));\n x = x % moduloVal;\n\n if (!typeOpts.unsigned && x >= moduloBound) {\n return x - moduloVal;\n } else if (typeOpts.unsigned) {\n if (x < 0) {\n x += moduloVal;\n } else if (x === -0) { // don't return negative zero\n return 0;\n }\n }\n\n return x;\n }\n}\n\nconversions[\"void\"] = function () {\n return undefined;\n};\n\nconversions[\"boolean\"] = function (val) {\n return !!val;\n};\n\nconversions[\"byte\"] = createNumberConversion(8, { unsigned: false });\nconversions[\"octet\"] = createNumberConversion(8, { unsigned: true });\n\nconversions[\"short\"] = createNumberConversion(16, { unsigned: false });\nconversions[\"unsigned short\"] = createNumberConversion(16, { unsigned: true });\n\nconversions[\"long\"] = createNumberConversion(32, { unsigned: false });\nconversions[\"unsigned long\"] = createNumberConversion(32, { unsigned: true });\n\nconversions[\"long long\"] = createNumberConversion(32, { unsigned: false, moduloBitLength: 64 });\nconversions[\"unsigned long long\"] = createNumberConversion(32, { unsigned: true, moduloBitLength: 64 });\n\nconversions[\"double\"] = function (V) {\n const x = +V;\n\n if (!Number.isFinite(x)) {\n throw new TypeError(\"Argument is not a finite floating-point value\");\n }\n\n return x;\n};\n\nconversions[\"unrestricted double\"] = function (V) {\n const x = +V;\n\n if (isNaN(x)) {\n throw new TypeError(\"Argument is NaN\");\n }\n\n return x;\n};\n\n// not quite valid, but good enough for JS\nconversions[\"float\"] = conversions[\"double\"];\nconversions[\"unrestricted float\"] = conversions[\"unrestricted double\"];\n\nconversions[\"DOMString\"] = function (V, opts) {\n if (!opts) opts = {};\n\n if (opts.treatNullAsEmptyString && V === null) {\n return \"\";\n }\n\n return String(V);\n};\n\nconversions[\"ByteString\"] = function (V, opts) {\n const x = String(V);\n let c = undefined;\n for (let i = 0; (c = x.codePointAt(i)) !== undefined; ++i) {\n if (c > 255) {\n throw new TypeError(\"Argument is not a valid bytestring\");\n }\n }\n\n return x;\n};\n\nconversions[\"USVString\"] = function (V) {\n const S = String(V);\n const n = S.length;\n const U = [];\n for (let i = 0; i < n; ++i) {\n const c = S.charCodeAt(i);\n if (c < 0xD800 || c > 0xDFFF) {\n U.push(String.fromCodePoint(c));\n } else if (0xDC00 <= c && c <= 0xDFFF) {\n U.push(String.fromCodePoint(0xFFFD));\n } else {\n if (i === n - 1) {\n U.push(String.fromCodePoint(0xFFFD));\n } else {\n const d = S.charCodeAt(i + 1);\n if (0xDC00 <= d && d <= 0xDFFF) {\n const a = c & 0x3FF;\n const b = d & 0x3FF;\n U.push(String.fromCodePoint((2 << 15) + (2 << 9) * a + b));\n ++i;\n } else {\n U.push(String.fromCodePoint(0xFFFD));\n }\n }\n }\n }\n\n return U.join('');\n};\n\nconversions[\"Date\"] = function (V, opts) {\n if (!(V instanceof Date)) {\n throw new TypeError(\"Argument is not a Date object\");\n }\n if (isNaN(V)) {\n return undefined;\n }\n\n return V;\n};\n\nconversions[\"RegExp\"] = function (V, opts) {\n if (!(V instanceof RegExp)) {\n V = new RegExp(V);\n }\n\n return V;\n};\n\n\n/***/ }),\n\n/***/ 8262:\n/***/ ((__unused_webpack_module, exports, __nccwpck_require__) => {\n\n\"use strict\";\n\nconst usm = __nccwpck_require__(33);\n\nexports.implementation = class URLImpl {\n constructor(constructorArgs) {\n const url = constructorArgs[0];\n const base = constructorArgs[1];\n\n let parsedBase = null;\n if (base !== undefined) {\n parsedBase = usm.basicURLParse(base);\n if (parsedBase === \"failure\") {\n throw new TypeError(\"Invalid base URL\");\n }\n }\n\n const parsedURL = usm.basicURLParse(url, { baseURL: parsedBase });\n if (parsedURL === \"failure\") {\n throw new TypeError(\"Invalid URL\");\n }\n\n this._url = parsedURL;\n\n // TODO: query stuff\n }\n\n get href() {\n return usm.serializeURL(this._url);\n }\n\n set href(v) {\n const parsedURL = usm.basicURLParse(v);\n if (parsedURL === \"failure\") {\n throw new TypeError(\"Invalid URL\");\n }\n\n this._url = parsedURL;\n }\n\n get origin() {\n return usm.serializeURLOrigin(this._url);\n }\n\n get protocol() {\n return this._url.scheme + \":\";\n }\n\n set protocol(v) {\n usm.basicURLParse(v + \":\", { url: this._url, stateOverride: \"scheme start\" });\n }\n\n get username() {\n return this._url.username;\n }\n\n set username(v) {\n if (usm.cannotHaveAUsernamePasswordPort(this._url)) {\n return;\n }\n\n usm.setTheUsername(this._url, v);\n }\n\n get password() {\n return this._url.password;\n }\n\n set password(v) {\n if (usm.cannotHaveAUsernamePasswordPort(this._url)) {\n return;\n }\n\n usm.setThePassword(this._url, v);\n }\n\n get host() {\n const url = this._url;\n\n if (url.host === null) {\n return \"\";\n }\n\n if (url.port === null) {\n return usm.serializeHost(url.host);\n }\n\n return usm.serializeHost(url.host) + \":\" + usm.serializeInteger(url.port);\n }\n\n set host(v) {\n if (this._url.cannotBeABaseURL) {\n return;\n }\n\n usm.basicURLParse(v, { url: this._url, stateOverride: \"host\" });\n }\n\n get hostname() {\n if (this._url.host === null) {\n return \"\";\n }\n\n return usm.serializeHost(this._url.host);\n }\n\n set hostname(v) {\n if (this._url.cannotBeABaseURL) {\n return;\n }\n\n usm.basicURLParse(v, { url: this._url, stateOverride: \"hostname\" });\n }\n\n get port() {\n if (this._url.port === null) {\n return \"\";\n }\n\n return usm.serializeInteger(this._url.port);\n }\n\n set port(v) {\n if (usm.cannotHaveAUsernamePasswordPort(this._url)) {\n return;\n }\n\n if (v === \"\") {\n this._url.port = null;\n } else {\n usm.basicURLParse(v, { url: this._url, stateOverride: \"port\" });\n }\n }\n\n get pathname() {\n if (this._url.cannotBeABaseURL) {\n return this._url.path[0];\n }\n\n if (this._url.path.length === 0) {\n return \"\";\n }\n\n return \"/\" + this._url.path.join(\"/\");\n }\n\n set pathname(v) {\n if (this._url.cannotBeABaseURL) {\n return;\n }\n\n this._url.path = [];\n usm.basicURLParse(v, { url: this._url, stateOverride: \"path start\" });\n }\n\n get search() {\n if (this._url.query === null || this._url.query === \"\") {\n return \"\";\n }\n\n return \"?\" + this._url.query;\n }\n\n set search(v) {\n // TODO: query stuff\n\n const url = this._url;\n\n if (v === \"\") {\n url.query = null;\n return;\n }\n\n const input = v[0] === \"?\" ? v.substring(1) : v;\n url.query = \"\";\n usm.basicURLParse(input, { url, stateOverride: \"query\" });\n }\n\n get hash() {\n if (this._url.fragment === null || this._url.fragment === \"\") {\n return \"\";\n }\n\n return \"#\" + this._url.fragment;\n }\n\n set hash(v) {\n if (v === \"\") {\n this._url.fragment = null;\n return;\n }\n\n const input = v[0] === \"#\" ? v.substring(1) : v;\n this._url.fragment = \"\";\n usm.basicURLParse(input, { url: this._url, stateOverride: \"fragment\" });\n }\n\n toJSON() {\n return this.href;\n }\n};\n\n\n/***/ }),\n\n/***/ 653:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\n\"use strict\";\n\n\nconst conversions = __nccwpck_require__(5871);\nconst utils = __nccwpck_require__(276);\nconst Impl = __nccwpck_require__(8262);\n\nconst impl = utils.implSymbol;\n\nfunction URL(url) {\n if (!this || this[impl] || !(this instanceof URL)) {\n throw new TypeError(\"Failed to construct 'URL': Please use the 'new' operator, this DOM object constructor cannot be called as a function.\");\n }\n if (arguments.length < 1) {\n throw new TypeError(\"Failed to construct 'URL': 1 argument required, but only \" + arguments.length + \" present.\");\n }\n const args = [];\n for (let i = 0; i < arguments.length && i < 2; ++i) {\n args[i] = arguments[i];\n }\n args[0] = conversions[\"USVString\"](args[0]);\n if (args[1] !== undefined) {\n args[1] = conversions[\"USVString\"](args[1]);\n }\n\n module.exports.setup(this, args);\n}\n\nURL.prototype.toJSON = function toJSON() {\n if (!this || !module.exports.is(this)) {\n throw new TypeError(\"Illegal invocation\");\n }\n const args = [];\n for (let i = 0; i < arguments.length && i < 0; ++i) {\n args[i] = arguments[i];\n }\n return this[impl].toJSON.apply(this[impl], args);\n};\nObject.defineProperty(URL.prototype, \"href\", {\n get() {\n return this[impl].href;\n },\n set(V) {\n V = conversions[\"USVString\"](V);\n this[impl].href = V;\n },\n enumerable: true,\n configurable: true\n});\n\nURL.prototype.toString = function () {\n if (!this || !module.exports.is(this)) {\n throw new TypeError(\"Illegal invocation\");\n }\n return this.href;\n};\n\nObject.defineProperty(URL.prototype, \"origin\", {\n get() {\n return this[impl].origin;\n },\n enumerable: true,\n configurable: true\n});\n\nObject.defineProperty(URL.prototype, \"protocol\", {\n get() {\n return this[impl].protocol;\n },\n set(V) {\n V = conversions[\"USVString\"](V);\n this[impl].protocol = V;\n },\n enumerable: true,\n configurable: true\n});\n\nObject.defineProperty(URL.prototype, \"username\", {\n get() {\n return this[impl].username;\n },\n set(V) {\n V = conversions[\"USVString\"](V);\n this[impl].username = V;\n },\n enumerable: true,\n configurable: true\n});\n\nObject.defineProperty(URL.prototype, \"password\", {\n get() {\n return this[impl].password;\n },\n set(V) {\n V = conversions[\"USVString\"](V);\n this[impl].password = V;\n },\n enumerable: true,\n configurable: true\n});\n\nObject.defineProperty(URL.prototype, \"host\", {\n get() {\n return this[impl].host;\n },\n set(V) {\n V = conversions[\"USVString\"](V);\n this[impl].host = V;\n },\n enumerable: true,\n configurable: true\n});\n\nObject.defineProperty(URL.prototype, \"hostname\", {\n get() {\n return this[impl].hostname;\n },\n set(V) {\n V = conversions[\"USVString\"](V);\n this[impl].hostname = V;\n },\n enumerable: true,\n configurable: true\n});\n\nObject.defineProperty(URL.prototype, \"port\", {\n get() {\n return this[impl].port;\n },\n set(V) {\n V = conversions[\"USVString\"](V);\n this[impl].port = V;\n },\n enumerable: true,\n configurable: true\n});\n\nObject.defineProperty(URL.prototype, \"pathname\", {\n get() {\n return this[impl].pathname;\n },\n set(V) {\n V = conversions[\"USVString\"](V);\n this[impl].pathname = V;\n },\n enumerable: true,\n configurable: true\n});\n\nObject.defineProperty(URL.prototype, \"search\", {\n get() {\n return this[impl].search;\n },\n set(V) {\n V = conversions[\"USVString\"](V);\n this[impl].search = V;\n },\n enumerable: true,\n configurable: true\n});\n\nObject.defineProperty(URL.prototype, \"hash\", {\n get() {\n return this[impl].hash;\n },\n set(V) {\n V = conversions[\"USVString\"](V);\n this[impl].hash = V;\n },\n enumerable: true,\n configurable: true\n});\n\n\nmodule.exports = {\n is(obj) {\n return !!obj && obj[impl] instanceof Impl.implementation;\n },\n create(constructorArgs, privateData) {\n let obj = Object.create(URL.prototype);\n this.setup(obj, constructorArgs, privateData);\n return obj;\n },\n setup(obj, constructorArgs, privateData) {\n if (!privateData) privateData = {};\n privateData.wrapper = obj;\n\n obj[impl] = new Impl.implementation(constructorArgs, privateData);\n obj[impl][utils.wrapperSymbol] = obj;\n },\n interface: URL,\n expose: {\n Window: { URL: URL },\n Worker: { URL: URL }\n }\n};\n\n\n\n/***/ }),\n\n/***/ 3323:\n/***/ ((__unused_webpack_module, exports, __nccwpck_require__) => {\n\n\"use strict\";\n\n\nexports.URL = __nccwpck_require__(653)[\"interface\"];\nexports.serializeURL = __nccwpck_require__(33).serializeURL;\nexports.serializeURLOrigin = __nccwpck_require__(33).serializeURLOrigin;\nexports.basicURLParse = __nccwpck_require__(33).basicURLParse;\nexports.setTheUsername = __nccwpck_require__(33).setTheUsername;\nexports.setThePassword = __nccwpck_require__(33).setThePassword;\nexports.serializeHost = __nccwpck_require__(33).serializeHost;\nexports.serializeInteger = __nccwpck_require__(33).serializeInteger;\nexports.parseURL = __nccwpck_require__(33).parseURL;\n\n\n/***/ }),\n\n/***/ 33:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\n\"use strict\";\n\nconst punycode = __nccwpck_require__(5477);\nconst tr46 = __nccwpck_require__(2299);\n\nconst specialSchemes = {\n ftp: 21,\n file: null,\n gopher: 70,\n http: 80,\n https: 443,\n ws: 80,\n wss: 443\n};\n\nconst failure = Symbol(\"failure\");\n\nfunction countSymbols(str) {\n return punycode.ucs2.decode(str).length;\n}\n\nfunction at(input, idx) {\n const c = input[idx];\n return isNaN(c) ? undefined : String.fromCodePoint(c);\n}\n\nfunction isASCIIDigit(c) {\n return c >= 0x30 && c <= 0x39;\n}\n\nfunction isASCIIAlpha(c) {\n return (c >= 0x41 && c <= 0x5A) || (c >= 0x61 && c <= 0x7A);\n}\n\nfunction isASCIIAlphanumeric(c) {\n return isASCIIAlpha(c) || isASCIIDigit(c);\n}\n\nfunction isASCIIHex(c) {\n return isASCIIDigit(c) || (c >= 0x41 && c <= 0x46) || (c >= 0x61 && c <= 0x66);\n}\n\nfunction isSingleDot(buffer) {\n return buffer === \".\" || buffer.toLowerCase() === \"%2e\";\n}\n\nfunction isDoubleDot(buffer) {\n buffer = buffer.toLowerCase();\n return buffer === \"..\" || buffer === \"%2e.\" || buffer === \".%2e\" || buffer === \"%2e%2e\";\n}\n\nfunction isWindowsDriveLetterCodePoints(cp1, cp2) {\n return isASCIIAlpha(cp1) && (cp2 === 58 || cp2 === 124);\n}\n\nfunction isWindowsDriveLetterString(string) {\n return string.length === 2 && isASCIIAlpha(string.codePointAt(0)) && (string[1] === \":\" || string[1] === \"|\");\n}\n\nfunction isNormalizedWindowsDriveLetterString(string) {\n return string.length === 2 && isASCIIAlpha(string.codePointAt(0)) && string[1] === \":\";\n}\n\nfunction containsForbiddenHostCodePoint(string) {\n return string.search(/\\u0000|\\u0009|\\u000A|\\u000D|\\u0020|#|%|\\/|:|\\?|@|\\[|\\\\|\\]/) !== -1;\n}\n\nfunction containsForbiddenHostCodePointExcludingPercent(string) {\n return string.search(/\\u0000|\\u0009|\\u000A|\\u000D|\\u0020|#|\\/|:|\\?|@|\\[|\\\\|\\]/) !== -1;\n}\n\nfunction isSpecialScheme(scheme) {\n return specialSchemes[scheme] !== undefined;\n}\n\nfunction isSpecial(url) {\n return isSpecialScheme(url.scheme);\n}\n\nfunction defaultPort(scheme) {\n return specialSchemes[scheme];\n}\n\nfunction percentEncode(c) {\n let hex = c.toString(16).toUpperCase();\n if (hex.length === 1) {\n hex = \"0\" + hex;\n }\n\n return \"%\" + hex;\n}\n\nfunction utf8PercentEncode(c) {\n const buf = new Buffer(c);\n\n let str = \"\";\n\n for (let i = 0; i < buf.length; ++i) {\n str += percentEncode(buf[i]);\n }\n\n return str;\n}\n\nfunction utf8PercentDecode(str) {\n const input = new Buffer(str);\n const output = [];\n for (let i = 0; i < input.length; ++i) {\n if (input[i] !== 37) {\n output.push(input[i]);\n } else if (input[i] === 37 && isASCIIHex(input[i + 1]) && isASCIIHex(input[i + 2])) {\n output.push(parseInt(input.slice(i + 1, i + 3).toString(), 16));\n i += 2;\n } else {\n output.push(input[i]);\n }\n }\n return new Buffer(output).toString();\n}\n\nfunction isC0ControlPercentEncode(c) {\n return c <= 0x1F || c > 0x7E;\n}\n\nconst extraPathPercentEncodeSet = new Set([32, 34, 35, 60, 62, 63, 96, 123, 125]);\nfunction isPathPercentEncode(c) {\n return isC0ControlPercentEncode(c) || extraPathPercentEncodeSet.has(c);\n}\n\nconst extraUserinfoPercentEncodeSet =\n new Set([47, 58, 59, 61, 64, 91, 92, 93, 94, 124]);\nfunction isUserinfoPercentEncode(c) {\n return isPathPercentEncode(c) || extraUserinfoPercentEncodeSet.has(c);\n}\n\nfunction percentEncodeChar(c, encodeSetPredicate) {\n const cStr = String.fromCodePoint(c);\n\n if (encodeSetPredicate(c)) {\n return utf8PercentEncode(cStr);\n }\n\n return cStr;\n}\n\nfunction parseIPv4Number(input) {\n let R = 10;\n\n if (input.length >= 2 && input.charAt(0) === \"0\" && input.charAt(1).toLowerCase() === \"x\") {\n input = input.substring(2);\n R = 16;\n } else if (input.length >= 2 && input.charAt(0) === \"0\") {\n input = input.substring(1);\n R = 8;\n }\n\n if (input === \"\") {\n return 0;\n }\n\n const regex = R === 10 ? /[^0-9]/ : (R === 16 ? /[^0-9A-Fa-f]/ : /[^0-7]/);\n if (regex.test(input)) {\n return failure;\n }\n\n return parseInt(input, R);\n}\n\nfunction parseIPv4(input) {\n const parts = input.split(\".\");\n if (parts[parts.length - 1] === \"\") {\n if (parts.length > 1) {\n parts.pop();\n }\n }\n\n if (parts.length > 4) {\n return input;\n }\n\n const numbers = [];\n for (const part of parts) {\n if (part === \"\") {\n return input;\n }\n const n = parseIPv4Number(part);\n if (n === failure) {\n return input;\n }\n\n numbers.push(n);\n }\n\n for (let i = 0; i < numbers.length - 1; ++i) {\n if (numbers[i] > 255) {\n return failure;\n }\n }\n if (numbers[numbers.length - 1] >= Math.pow(256, 5 - numbers.length)) {\n return failure;\n }\n\n let ipv4 = numbers.pop();\n let counter = 0;\n\n for (const n of numbers) {\n ipv4 += n * Math.pow(256, 3 - counter);\n ++counter;\n }\n\n return ipv4;\n}\n\nfunction serializeIPv4(address) {\n let output = \"\";\n let n = address;\n\n for (let i = 1; i <= 4; ++i) {\n output = String(n % 256) + output;\n if (i !== 4) {\n output = \".\" + output;\n }\n n = Math.floor(n / 256);\n }\n\n return output;\n}\n\nfunction parseIPv6(input) {\n const address = [0, 0, 0, 0, 0, 0, 0, 0];\n let pieceIndex = 0;\n let compress = null;\n let pointer = 0;\n\n input = punycode.ucs2.decode(input);\n\n if (input[pointer] === 58) {\n if (input[pointer + 1] !== 58) {\n return failure;\n }\n\n pointer += 2;\n ++pieceIndex;\n compress = pieceIndex;\n }\n\n while (pointer < input.length) {\n if (pieceIndex === 8) {\n return failure;\n }\n\n if (input[pointer] === 58) {\n if (compress !== null) {\n return failure;\n }\n ++pointer;\n ++pieceIndex;\n compress = pieceIndex;\n continue;\n }\n\n let value = 0;\n let length = 0;\n\n while (length < 4 && isASCIIHex(input[pointer])) {\n value = value * 0x10 + parseInt(at(input, pointer), 16);\n ++pointer;\n ++length;\n }\n\n if (input[pointer] === 46) {\n if (length === 0) {\n return failure;\n }\n\n pointer -= length;\n\n if (pieceIndex > 6) {\n return failure;\n }\n\n let numbersSeen = 0;\n\n while (input[pointer] !== undefined) {\n let ipv4Piece = null;\n\n if (numbersSeen > 0) {\n if (input[pointer] === 46 && numbersSeen < 4) {\n ++pointer;\n } else {\n return failure;\n }\n }\n\n if (!isASCIIDigit(input[pointer])) {\n return failure;\n }\n\n while (isASCIIDigit(input[pointer])) {\n const number = parseInt(at(input, pointer));\n if (ipv4Piece === null) {\n ipv4Piece = number;\n } else if (ipv4Piece === 0) {\n return failure;\n } else {\n ipv4Piece = ipv4Piece * 10 + number;\n }\n if (ipv4Piece > 255) {\n return failure;\n }\n ++pointer;\n }\n\n address[pieceIndex] = address[pieceIndex] * 0x100 + ipv4Piece;\n\n ++numbersSeen;\n\n if (numbersSeen === 2 || numbersSeen === 4) {\n ++pieceIndex;\n }\n }\n\n if (numbersSeen !== 4) {\n return failure;\n }\n\n break;\n } else if (input[pointer] === 58) {\n ++pointer;\n if (input[pointer] === undefined) {\n return failure;\n }\n } else if (input[pointer] !== undefined) {\n return failure;\n }\n\n address[pieceIndex] = value;\n ++pieceIndex;\n }\n\n if (compress !== null) {\n let swaps = pieceIndex - compress;\n pieceIndex = 7;\n while (pieceIndex !== 0 && swaps > 0) {\n const temp = address[compress + swaps - 1];\n address[compress + swaps - 1] = address[pieceIndex];\n address[pieceIndex] = temp;\n --pieceIndex;\n --swaps;\n }\n } else if (compress === null && pieceIndex !== 8) {\n return failure;\n }\n\n return address;\n}\n\nfunction serializeIPv6(address) {\n let output = \"\";\n const seqResult = findLongestZeroSequence(address);\n const compress = seqResult.idx;\n let ignore0 = false;\n\n for (let pieceIndex = 0; pieceIndex <= 7; ++pieceIndex) {\n if (ignore0 && address[pieceIndex] === 0) {\n continue;\n } else if (ignore0) {\n ignore0 = false;\n }\n\n if (compress === pieceIndex) {\n const separator = pieceIndex === 0 ? \"::\" : \":\";\n output += separator;\n ignore0 = true;\n continue;\n }\n\n output += address[pieceIndex].toString(16);\n\n if (pieceIndex !== 7) {\n output += \":\";\n }\n }\n\n return output;\n}\n\nfunction parseHost(input, isSpecialArg) {\n if (input[0] === \"[\") {\n if (input[input.length - 1] !== \"]\") {\n return failure;\n }\n\n return parseIPv6(input.substring(1, input.length - 1));\n }\n\n if (!isSpecialArg) {\n return parseOpaqueHost(input);\n }\n\n const domain = utf8PercentDecode(input);\n const asciiDomain = tr46.toASCII(domain, false, tr46.PROCESSING_OPTIONS.NONTRANSITIONAL, false);\n if (asciiDomain === null) {\n return failure;\n }\n\n if (containsForbiddenHostCodePoint(asciiDomain)) {\n return failure;\n }\n\n const ipv4Host = parseIPv4(asciiDomain);\n if (typeof ipv4Host === \"number\" || ipv4Host === failure) {\n return ipv4Host;\n }\n\n return asciiDomain;\n}\n\nfunction parseOpaqueHost(input) {\n if (containsForbiddenHostCodePointExcludingPercent(input)) {\n return failure;\n }\n\n let output = \"\";\n const decoded = punycode.ucs2.decode(input);\n for (let i = 0; i < decoded.length; ++i) {\n output += percentEncodeChar(decoded[i], isC0ControlPercentEncode);\n }\n return output;\n}\n\nfunction findLongestZeroSequence(arr) {\n let maxIdx = null;\n let maxLen = 1; // only find elements > 1\n let currStart = null;\n let currLen = 0;\n\n for (let i = 0; i < arr.length; ++i) {\n if (arr[i] !== 0) {\n if (currLen > maxLen) {\n maxIdx = currStart;\n maxLen = currLen;\n }\n\n currStart = null;\n currLen = 0;\n } else {\n if (currStart === null) {\n currStart = i;\n }\n ++currLen;\n }\n }\n\n // if trailing zeros\n if (currLen > maxLen) {\n maxIdx = currStart;\n maxLen = currLen;\n }\n\n return {\n idx: maxIdx,\n len: maxLen\n };\n}\n\nfunction serializeHost(host) {\n if (typeof host === \"number\") {\n return serializeIPv4(host);\n }\n\n // IPv6 serializer\n if (host instanceof Array) {\n return \"[\" + serializeIPv6(host) + \"]\";\n }\n\n return host;\n}\n\nfunction trimControlChars(url) {\n return url.replace(/^[\\u0000-\\u001F\\u0020]+|[\\u0000-\\u001F\\u0020]+$/g, \"\");\n}\n\nfunction trimTabAndNewline(url) {\n return url.replace(/\\u0009|\\u000A|\\u000D/g, \"\");\n}\n\nfunction shortenPath(url) {\n const path = url.path;\n if (path.length === 0) {\n return;\n }\n if (url.scheme === \"file\" && path.length === 1 && isNormalizedWindowsDriveLetter(path[0])) {\n return;\n }\n\n path.pop();\n}\n\nfunction includesCredentials(url) {\n return url.username !== \"\" || url.password !== \"\";\n}\n\nfunction cannotHaveAUsernamePasswordPort(url) {\n return url.host === null || url.host === \"\" || url.cannotBeABaseURL || url.scheme === \"file\";\n}\n\nfunction isNormalizedWindowsDriveLetter(string) {\n return /^[A-Za-z]:$/.test(string);\n}\n\nfunction URLStateMachine(input, base, encodingOverride, url, stateOverride) {\n this.pointer = 0;\n this.input = input;\n this.base = base || null;\n this.encodingOverride = encodingOverride || \"utf-8\";\n this.stateOverride = stateOverride;\n this.url = url;\n this.failure = false;\n this.parseError = false;\n\n if (!this.url) {\n this.url = {\n scheme: \"\",\n username: \"\",\n password: \"\",\n host: null,\n port: null,\n path: [],\n query: null,\n fragment: null,\n\n cannotBeABaseURL: false\n };\n\n const res = trimControlChars(this.input);\n if (res !== this.input) {\n this.parseError = true;\n }\n this.input = res;\n }\n\n const res = trimTabAndNewline(this.input);\n if (res !== this.input) {\n this.parseError = true;\n }\n this.input = res;\n\n this.state = stateOverride || \"scheme start\";\n\n this.buffer = \"\";\n this.atFlag = false;\n this.arrFlag = false;\n this.passwordTokenSeenFlag = false;\n\n this.input = punycode.ucs2.decode(this.input);\n\n for (; this.pointer <= this.input.length; ++this.pointer) {\n const c = this.input[this.pointer];\n const cStr = isNaN(c) ? undefined : String.fromCodePoint(c);\n\n // exec state machine\n const ret = this[\"parse \" + this.state](c, cStr);\n if (!ret) {\n break; // terminate algorithm\n } else if (ret === failure) {\n this.failure = true;\n break;\n }\n }\n}\n\nURLStateMachine.prototype[\"parse scheme start\"] = function parseSchemeStart(c, cStr) {\n if (isASCIIAlpha(c)) {\n this.buffer += cStr.toLowerCase();\n this.state = \"scheme\";\n } else if (!this.stateOverride) {\n this.state = \"no scheme\";\n --this.pointer;\n } else {\n this.parseError = true;\n return failure;\n }\n\n return true;\n};\n\nURLStateMachine.prototype[\"parse scheme\"] = function parseScheme(c, cStr) {\n if (isASCIIAlphanumeric(c) || c === 43 || c === 45 || c === 46) {\n this.buffer += cStr.toLowerCase();\n } else if (c === 58) {\n if (this.stateOverride) {\n if (isSpecial(this.url) && !isSpecialScheme(this.buffer)) {\n return false;\n }\n\n if (!isSpecial(this.url) && isSpecialScheme(this.buffer)) {\n return false;\n }\n\n if ((includesCredentials(this.url) || this.url.port !== null) && this.buffer === \"file\") {\n return false;\n }\n\n if (this.url.scheme === \"file\" && (this.url.host === \"\" || this.url.host === null)) {\n return false;\n }\n }\n this.url.scheme = this.buffer;\n this.buffer = \"\";\n if (this.stateOverride) {\n return false;\n }\n if (this.url.scheme === \"file\") {\n if (this.input[this.pointer + 1] !== 47 || this.input[this.pointer + 2] !== 47) {\n this.parseError = true;\n }\n this.state = \"file\";\n } else if (isSpecial(this.url) && this.base !== null && this.base.scheme === this.url.scheme) {\n this.state = \"special relative or authority\";\n } else if (isSpecial(this.url)) {\n this.state = \"special authority slashes\";\n } else if (this.input[this.pointer + 1] === 47) {\n this.state = \"path or authority\";\n ++this.pointer;\n } else {\n this.url.cannotBeABaseURL = true;\n this.url.path.push(\"\");\n this.state = \"cannot-be-a-base-URL path\";\n }\n } else if (!this.stateOverride) {\n this.buffer = \"\";\n this.state = \"no scheme\";\n this.pointer = -1;\n } else {\n this.parseError = true;\n return failure;\n }\n\n return true;\n};\n\nURLStateMachine.prototype[\"parse no scheme\"] = function parseNoScheme(c) {\n if (this.base === null || (this.base.cannotBeABaseURL && c !== 35)) {\n return failure;\n } else if (this.base.cannotBeABaseURL && c === 35) {\n this.url.scheme = this.base.scheme;\n this.url.path = this.base.path.slice();\n this.url.query = this.base.query;\n this.url.fragment = \"\";\n this.url.cannotBeABaseURL = true;\n this.state = \"fragment\";\n } else if (this.base.scheme === \"file\") {\n this.state = \"file\";\n --this.pointer;\n } else {\n this.state = \"relative\";\n --this.pointer;\n }\n\n return true;\n};\n\nURLStateMachine.prototype[\"parse special relative or authority\"] = function parseSpecialRelativeOrAuthority(c) {\n if (c === 47 && this.input[this.pointer + 1] === 47) {\n this.state = \"special authority ignore slashes\";\n ++this.pointer;\n } else {\n this.parseError = true;\n this.state = \"relative\";\n --this.pointer;\n }\n\n return true;\n};\n\nURLStateMachine.prototype[\"parse path or authority\"] = function parsePathOrAuthority(c) {\n if (c === 47) {\n this.state = \"authority\";\n } else {\n this.state = \"path\";\n --this.pointer;\n }\n\n return true;\n};\n\nURLStateMachine.prototype[\"parse relative\"] = function parseRelative(c) {\n this.url.scheme = this.base.scheme;\n if (isNaN(c)) {\n this.url.username = this.base.username;\n this.url.password = this.base.password;\n this.url.host = this.base.host;\n this.url.port = this.base.port;\n this.url.path = this.base.path.slice();\n this.url.query = this.base.query;\n } else if (c === 47) {\n this.state = \"relative slash\";\n } else if (c === 63) {\n this.url.username = this.base.username;\n this.url.password = this.base.password;\n this.url.host = this.base.host;\n this.url.port = this.base.port;\n this.url.path = this.base.path.slice();\n this.url.query = \"\";\n this.state = \"query\";\n } else if (c === 35) {\n this.url.username = this.base.username;\n this.url.password = this.base.password;\n this.url.host = this.base.host;\n this.url.port = this.base.port;\n this.url.path = this.base.path.slice();\n this.url.query = this.base.query;\n this.url.fragment = \"\";\n this.state = \"fragment\";\n } else if (isSpecial(this.url) && c === 92) {\n this.parseError = true;\n this.state = \"relative slash\";\n } else {\n this.url.username = this.base.username;\n this.url.password = this.base.password;\n this.url.host = this.base.host;\n this.url.port = this.base.port;\n this.url.path = this.base.path.slice(0, this.base.path.length - 1);\n\n this.state = \"path\";\n --this.pointer;\n }\n\n return true;\n};\n\nURLStateMachine.prototype[\"parse relative slash\"] = function parseRelativeSlash(c) {\n if (isSpecial(this.url) && (c === 47 || c === 92)) {\n if (c === 92) {\n this.parseError = true;\n }\n this.state = \"special authority ignore slashes\";\n } else if (c === 47) {\n this.state = \"authority\";\n } else {\n this.url.username = this.base.username;\n this.url.password = this.base.password;\n this.url.host = this.base.host;\n this.url.port = this.base.port;\n this.state = \"path\";\n --this.pointer;\n }\n\n return true;\n};\n\nURLStateMachine.prototype[\"parse special authority slashes\"] = function parseSpecialAuthoritySlashes(c) {\n if (c === 47 && this.input[this.pointer + 1] === 47) {\n this.state = \"special authority ignore slashes\";\n ++this.pointer;\n } else {\n this.parseError = true;\n this.state = \"special authority ignore slashes\";\n --this.pointer;\n }\n\n return true;\n};\n\nURLStateMachine.prototype[\"parse special authority ignore slashes\"] = function parseSpecialAuthorityIgnoreSlashes(c) {\n if (c !== 47 && c !== 92) {\n this.state = \"authority\";\n --this.pointer;\n } else {\n this.parseError = true;\n }\n\n return true;\n};\n\nURLStateMachine.prototype[\"parse authority\"] = function parseAuthority(c, cStr) {\n if (c === 64) {\n this.parseError = true;\n if (this.atFlag) {\n this.buffer = \"%40\" + this.buffer;\n }\n this.atFlag = true;\n\n // careful, this is based on buffer and has its own pointer (this.pointer != pointer) and inner chars\n const len = countSymbols(this.buffer);\n for (let pointer = 0; pointer < len; ++pointer) {\n const codePoint = this.buffer.codePointAt(pointer);\n\n if (codePoint === 58 && !this.passwordTokenSeenFlag) {\n this.passwordTokenSeenFlag = true;\n continue;\n }\n const encodedCodePoints = percentEncodeChar(codePoint, isUserinfoPercentEncode);\n if (this.passwordTokenSeenFlag) {\n this.url.password += encodedCodePoints;\n } else {\n this.url.username += encodedCodePoints;\n }\n }\n this.buffer = \"\";\n } else if (isNaN(c) || c === 47 || c === 63 || c === 35 ||\n (isSpecial(this.url) && c === 92)) {\n if (this.atFlag && this.buffer === \"\") {\n this.parseError = true;\n return failure;\n }\n this.pointer -= countSymbols(this.buffer) + 1;\n this.buffer = \"\";\n this.state = \"host\";\n } else {\n this.buffer += cStr;\n }\n\n return true;\n};\n\nURLStateMachine.prototype[\"parse hostname\"] =\nURLStateMachine.prototype[\"parse host\"] = function parseHostName(c, cStr) {\n if (this.stateOverride && this.url.scheme === \"file\") {\n --this.pointer;\n this.state = \"file host\";\n } else if (c === 58 && !this.arrFlag) {\n if (this.buffer === \"\") {\n this.parseError = true;\n return failure;\n }\n\n const host = parseHost(this.buffer, isSpecial(this.url));\n if (host === failure) {\n return failure;\n }\n\n this.url.host = host;\n this.buffer = \"\";\n this.state = \"port\";\n if (this.stateOverride === \"hostname\") {\n return false;\n }\n } else if (isNaN(c) || c === 47 || c === 63 || c === 35 ||\n (isSpecial(this.url) && c === 92)) {\n --this.pointer;\n if (isSpecial(this.url) && this.buffer === \"\") {\n this.parseError = true;\n return failure;\n } else if (this.stateOverride && this.buffer === \"\" &&\n (includesCredentials(this.url) || this.url.port !== null)) {\n this.parseError = true;\n return false;\n }\n\n const host = parseHost(this.buffer, isSpecial(this.url));\n if (host === failure) {\n return failure;\n }\n\n this.url.host = host;\n this.buffer = \"\";\n this.state = \"path start\";\n if (this.stateOverride) {\n return false;\n }\n } else {\n if (c === 91) {\n this.arrFlag = true;\n } else if (c === 93) {\n this.arrFlag = false;\n }\n this.buffer += cStr;\n }\n\n return true;\n};\n\nURLStateMachine.prototype[\"parse port\"] = function parsePort(c, cStr) {\n if (isASCIIDigit(c)) {\n this.buffer += cStr;\n } else if (isNaN(c) || c === 47 || c === 63 || c === 35 ||\n (isSpecial(this.url) && c === 92) ||\n this.stateOverride) {\n if (this.buffer !== \"\") {\n const port = parseInt(this.buffer);\n if (port > Math.pow(2, 16) - 1) {\n this.parseError = true;\n return failure;\n }\n this.url.port = port === defaultPort(this.url.scheme) ? null : port;\n this.buffer = \"\";\n }\n if (this.stateOverride) {\n return false;\n }\n this.state = \"path start\";\n --this.pointer;\n } else {\n this.parseError = true;\n return failure;\n }\n\n return true;\n};\n\nconst fileOtherwiseCodePoints = new Set([47, 92, 63, 35]);\n\nURLStateMachine.prototype[\"parse file\"] = function parseFile(c) {\n this.url.scheme = \"file\";\n\n if (c === 47 || c === 92) {\n if (c === 92) {\n this.parseError = true;\n }\n this.state = \"file slash\";\n } else if (this.base !== null && this.base.scheme === \"file\") {\n if (isNaN(c)) {\n this.url.host = this.base.host;\n this.url.path = this.base.path.slice();\n this.url.query = this.base.query;\n } else if (c === 63) {\n this.url.host = this.base.host;\n this.url.path = this.base.path.slice();\n this.url.query = \"\";\n this.state = \"query\";\n } else if (c === 35) {\n this.url.host = this.base.host;\n this.url.path = this.base.path.slice();\n this.url.query = this.base.query;\n this.url.fragment = \"\";\n this.state = \"fragment\";\n } else {\n if (this.input.length - this.pointer - 1 === 0 || // remaining consists of 0 code points\n !isWindowsDriveLetterCodePoints(c, this.input[this.pointer + 1]) ||\n (this.input.length - this.pointer - 1 >= 2 && // remaining has at least 2 code points\n !fileOtherwiseCodePoints.has(this.input[this.pointer + 2]))) {\n this.url.host = this.base.host;\n this.url.path = this.base.path.slice();\n shortenPath(this.url);\n } else {\n this.parseError = true;\n }\n\n this.state = \"path\";\n --this.pointer;\n }\n } else {\n this.state = \"path\";\n --this.pointer;\n }\n\n return true;\n};\n\nURLStateMachine.prototype[\"parse file slash\"] = function parseFileSlash(c) {\n if (c === 47 || c === 92) {\n if (c === 92) {\n this.parseError = true;\n }\n this.state = \"file host\";\n } else {\n if (this.base !== null && this.base.scheme === \"file\") {\n if (isNormalizedWindowsDriveLetterString(this.base.path[0])) {\n this.url.path.push(this.base.path[0]);\n } else {\n this.url.host = this.base.host;\n }\n }\n this.state = \"path\";\n --this.pointer;\n }\n\n return true;\n};\n\nURLStateMachine.prototype[\"parse file host\"] = function parseFileHost(c, cStr) {\n if (isNaN(c) || c === 47 || c === 92 || c === 63 || c === 35) {\n --this.pointer;\n if (!this.stateOverride && isWindowsDriveLetterString(this.buffer)) {\n this.parseError = true;\n this.state = \"path\";\n } else if (this.buffer === \"\") {\n this.url.host = \"\";\n if (this.stateOverride) {\n return false;\n }\n this.state = \"path start\";\n } else {\n let host = parseHost(this.buffer, isSpecial(this.url));\n if (host === failure) {\n return failure;\n }\n if (host === \"localhost\") {\n host = \"\";\n }\n this.url.host = host;\n\n if (this.stateOverride) {\n return false;\n }\n\n this.buffer = \"\";\n this.state = \"path start\";\n }\n } else {\n this.buffer += cStr;\n }\n\n return true;\n};\n\nURLStateMachine.prototype[\"parse path start\"] = function parsePathStart(c) {\n if (isSpecial(this.url)) {\n if (c === 92) {\n this.parseError = true;\n }\n this.state = \"path\";\n\n if (c !== 47 && c !== 92) {\n --this.pointer;\n }\n } else if (!this.stateOverride && c === 63) {\n this.url.query = \"\";\n this.state = \"query\";\n } else if (!this.stateOverride && c === 35) {\n this.url.fragment = \"\";\n this.state = \"fragment\";\n } else if (c !== undefined) {\n this.state = \"path\";\n if (c !== 47) {\n --this.pointer;\n }\n }\n\n return true;\n};\n\nURLStateMachine.prototype[\"parse path\"] = function parsePath(c) {\n if (isNaN(c) || c === 47 || (isSpecial(this.url) && c === 92) ||\n (!this.stateOverride && (c === 63 || c === 35))) {\n if (isSpecial(this.url) && c === 92) {\n this.parseError = true;\n }\n\n if (isDoubleDot(this.buffer)) {\n shortenPath(this.url);\n if (c !== 47 && !(isSpecial(this.url) && c === 92)) {\n this.url.path.push(\"\");\n }\n } else if (isSingleDot(this.buffer) && c !== 47 &&\n !(isSpecial(this.url) && c === 92)) {\n this.url.path.push(\"\");\n } else if (!isSingleDot(this.buffer)) {\n if (this.url.scheme === \"file\" && this.url.path.length === 0 && isWindowsDriveLetterString(this.buffer)) {\n if (this.url.host !== \"\" && this.url.host !== null) {\n this.parseError = true;\n this.url.host = \"\";\n }\n this.buffer = this.buffer[0] + \":\";\n }\n this.url.path.push(this.buffer);\n }\n this.buffer = \"\";\n if (this.url.scheme === \"file\" && (c === undefined || c === 63 || c === 35)) {\n while (this.url.path.length > 1 && this.url.path[0] === \"\") {\n this.parseError = true;\n this.url.path.shift();\n }\n }\n if (c === 63) {\n this.url.query = \"\";\n this.state = \"query\";\n }\n if (c === 35) {\n this.url.fragment = \"\";\n this.state = \"fragment\";\n }\n } else {\n // TODO: If c is not a URL code point and not \"%\", parse error.\n\n if (c === 37 &&\n (!isASCIIHex(this.input[this.pointer + 1]) ||\n !isASCIIHex(this.input[this.pointer + 2]))) {\n this.parseError = true;\n }\n\n this.buffer += percentEncodeChar(c, isPathPercentEncode);\n }\n\n return true;\n};\n\nURLStateMachine.prototype[\"parse cannot-be-a-base-URL path\"] = function parseCannotBeABaseURLPath(c) {\n if (c === 63) {\n this.url.query = \"\";\n this.state = \"query\";\n } else if (c === 35) {\n this.url.fragment = \"\";\n this.state = \"fragment\";\n } else {\n // TODO: Add: not a URL code point\n if (!isNaN(c) && c !== 37) {\n this.parseError = true;\n }\n\n if (c === 37 &&\n (!isASCIIHex(this.input[this.pointer + 1]) ||\n !isASCIIHex(this.input[this.pointer + 2]))) {\n this.parseError = true;\n }\n\n if (!isNaN(c)) {\n this.url.path[0] = this.url.path[0] + percentEncodeChar(c, isC0ControlPercentEncode);\n }\n }\n\n return true;\n};\n\nURLStateMachine.prototype[\"parse query\"] = function parseQuery(c, cStr) {\n if (isNaN(c) || (!this.stateOverride && c === 35)) {\n if (!isSpecial(this.url) || this.url.scheme === \"ws\" || this.url.scheme === \"wss\") {\n this.encodingOverride = \"utf-8\";\n }\n\n const buffer = new Buffer(this.buffer); // TODO: Use encoding override instead\n for (let i = 0; i < buffer.length; ++i) {\n if (buffer[i] < 0x21 || buffer[i] > 0x7E || buffer[i] === 0x22 || buffer[i] === 0x23 ||\n buffer[i] === 0x3C || buffer[i] === 0x3E) {\n this.url.query += percentEncode(buffer[i]);\n } else {\n this.url.query += String.fromCodePoint(buffer[i]);\n }\n }\n\n this.buffer = \"\";\n if (c === 35) {\n this.url.fragment = \"\";\n this.state = \"fragment\";\n }\n } else {\n // TODO: If c is not a URL code point and not \"%\", parse error.\n if (c === 37 &&\n (!isASCIIHex(this.input[this.pointer + 1]) ||\n !isASCIIHex(this.input[this.pointer + 2]))) {\n this.parseError = true;\n }\n\n this.buffer += cStr;\n }\n\n return true;\n};\n\nURLStateMachine.prototype[\"parse fragment\"] = function parseFragment(c) {\n if (isNaN(c)) { // do nothing\n } else if (c === 0x0) {\n this.parseError = true;\n } else {\n // TODO: If c is not a URL code point and not \"%\", parse error.\n if (c === 37 &&\n (!isASCIIHex(this.input[this.pointer + 1]) ||\n !isASCIIHex(this.input[this.pointer + 2]))) {\n this.parseError = true;\n }\n\n this.url.fragment += percentEncodeChar(c, isC0ControlPercentEncode);\n }\n\n return true;\n};\n\nfunction serializeURL(url, excludeFragment) {\n let output = url.scheme + \":\";\n if (url.host !== null) {\n output += \"//\";\n\n if (url.username !== \"\" || url.password !== \"\") {\n output += url.username;\n if (url.password !== \"\") {\n output += \":\" + url.password;\n }\n output += \"@\";\n }\n\n output += serializeHost(url.host);\n\n if (url.port !== null) {\n output += \":\" + url.port;\n }\n } else if (url.host === null && url.scheme === \"file\") {\n output += \"//\";\n }\n\n if (url.cannotBeABaseURL) {\n output += url.path[0];\n } else {\n for (const string of url.path) {\n output += \"/\" + string;\n }\n }\n\n if (url.query !== null) {\n output += \"?\" + url.query;\n }\n\n if (!excludeFragment && url.fragment !== null) {\n output += \"#\" + url.fragment;\n }\n\n return output;\n}\n\nfunction serializeOrigin(tuple) {\n let result = tuple.scheme + \"://\";\n result += serializeHost(tuple.host);\n\n if (tuple.port !== null) {\n result += \":\" + tuple.port;\n }\n\n return result;\n}\n\nmodule.exports.serializeURL = serializeURL;\n\nmodule.exports.serializeURLOrigin = function (url) {\n // https://url.spec.whatwg.org/#concept-url-origin\n switch (url.scheme) {\n case \"blob\":\n try {\n return module.exports.serializeURLOrigin(module.exports.parseURL(url.path[0]));\n } catch (e) {\n // serializing an opaque origin returns \"null\"\n return \"null\";\n }\n case \"ftp\":\n case \"gopher\":\n case \"http\":\n case \"https\":\n case \"ws\":\n case \"wss\":\n return serializeOrigin({\n scheme: url.scheme,\n host: url.host,\n port: url.port\n });\n case \"file\":\n // spec says \"exercise to the reader\", chrome says \"file://\"\n return \"file://\";\n default:\n // serializing an opaque origin returns \"null\"\n return \"null\";\n }\n};\n\nmodule.exports.basicURLParse = function (input, options) {\n if (options === undefined) {\n options = {};\n }\n\n const usm = new URLStateMachine(input, options.baseURL, options.encodingOverride, options.url, options.stateOverride);\n if (usm.failure) {\n return \"failure\";\n }\n\n return usm.url;\n};\n\nmodule.exports.setTheUsername = function (url, username) {\n url.username = \"\";\n const decoded = punycode.ucs2.decode(username);\n for (let i = 0; i < decoded.length; ++i) {\n url.username += percentEncodeChar(decoded[i], isUserinfoPercentEncode);\n }\n};\n\nmodule.exports.setThePassword = function (url, password) {\n url.password = \"\";\n const decoded = punycode.ucs2.decode(password);\n for (let i = 0; i < decoded.length; ++i) {\n url.password += percentEncodeChar(decoded[i], isUserinfoPercentEncode);\n }\n};\n\nmodule.exports.serializeHost = serializeHost;\n\nmodule.exports.cannotHaveAUsernamePasswordPort = cannotHaveAUsernamePasswordPort;\n\nmodule.exports.serializeInteger = function (integer) {\n return String(integer);\n};\n\nmodule.exports.parseURL = function (input, options) {\n if (options === undefined) {\n options = {};\n }\n\n // We don't handle blobs, so this just delegates:\n return module.exports.basicURLParse(input, { baseURL: options.baseURL, encodingOverride: options.encodingOverride });\n};\n\n\n/***/ }),\n\n/***/ 276:\n/***/ ((module) => {\n\n\"use strict\";\n\n\nmodule.exports.mixin = function mixin(target, source) {\n const keys = Object.getOwnPropertyNames(source);\n for (let i = 0; i < keys.length; ++i) {\n Object.defineProperty(target, keys[i], Object.getOwnPropertyDescriptor(source, keys[i]));\n }\n};\n\nmodule.exports.wrapperSymbol = Symbol(\"wrapper\");\nmodule.exports.implSymbol = Symbol(\"impl\");\n\nmodule.exports.wrapperForImpl = function (impl) {\n return impl[module.exports.wrapperSymbol];\n};\n\nmodule.exports.implForWrapper = function (wrapper) {\n return wrapper[module.exports.implSymbol];\n};\n\n\n\n/***/ }),\n\n/***/ 7952:\n/***/ ((module) => {\n\n\"use strict\";\n\n\n// https://developer.mozilla.org/en-US/docs/Web/HTTP/Basics_of_HTTP/Data_URIs\nconst DATA_URL_DEFAULT_MIME_TYPE = 'text/plain';\nconst DATA_URL_DEFAULT_CHARSET = 'us-ascii';\n\nconst testParameter = (name, filters) => {\n\treturn filters.some(filter => filter instanceof RegExp ? filter.test(name) : filter === name);\n};\n\nconst normalizeDataURL = (urlString, {stripHash}) => {\n\tconst match = /^data:(?<type>[^,]*?),(?<data>[^#]*?)(?:#(?<hash>.*))?$/.exec(urlString);\n\n\tif (!match) {\n\t\tthrow new Error(`Invalid URL: ${urlString}`);\n\t}\n\n\tlet {type, data, hash} = match.groups;\n\tconst mediaType = type.split(';');\n\thash = stripHash ? '' : hash;\n\n\tlet isBase64 = false;\n\tif (mediaType[mediaType.length - 1] === 'base64') {\n\t\tmediaType.pop();\n\t\tisBase64 = true;\n\t}\n\n\t// Lowercase MIME type\n\tconst mimeType = (mediaType.shift() || '').toLowerCase();\n\tconst attributes = mediaType\n\t\t.map(attribute => {\n\t\t\tlet [key, value = ''] = attribute.split('=').map(string => string.trim());\n\n\t\t\t// Lowercase `charset`\n\t\t\tif (key === 'charset') {\n\t\t\t\tvalue = value.toLowerCase();\n\n\t\t\t\tif (value === DATA_URL_DEFAULT_CHARSET) {\n\t\t\t\t\treturn '';\n\t\t\t\t}\n\t\t\t}\n\n\t\t\treturn `${key}${value ? `=${value}` : ''}`;\n\t\t})\n\t\t.filter(Boolean);\n\n\tconst normalizedMediaType = [\n\t\t...attributes\n\t];\n\n\tif (isBase64) {\n\t\tnormalizedMediaType.push('base64');\n\t}\n\n\tif (normalizedMediaType.length !== 0 || (mimeType && mimeType !== DATA_URL_DEFAULT_MIME_TYPE)) {\n\t\tnormalizedMediaType.unshift(mimeType);\n\t}\n\n\treturn `data:${normalizedMediaType.join(';')},${isBase64 ? data.trim() : data}${hash ? `#${hash}` : ''}`;\n};\n\nconst normalizeUrl = (urlString, options) => {\n\toptions = {\n\t\tdefaultProtocol: 'http:',\n\t\tnormalizeProtocol: true,\n\t\tforceHttp: false,\n\t\tforceHttps: false,\n\t\tstripAuthentication: true,\n\t\tstripHash: false,\n\t\tstripTextFragment: true,\n\t\tstripWWW: true,\n\t\tremoveQueryParameters: [/^utm_\\w+/i],\n\t\tremoveTrailingSlash: true,\n\t\tremoveSingleSlash: true,\n\t\tremoveDirectoryIndex: false,\n\t\tsortQueryParameters: true,\n\t\t...options\n\t};\n\n\turlString = urlString.trim();\n\n\t// Data URL\n\tif (/^data:/i.test(urlString)) {\n\t\treturn normalizeDataURL(urlString, options);\n\t}\n\n\tif (/^view-source:/i.test(urlString)) {\n\t\tthrow new Error('`view-source:` is not supported as it is a non-standard protocol');\n\t}\n\n\tconst hasRelativeProtocol = urlString.startsWith('//');\n\tconst isRelativeUrl = !hasRelativeProtocol && /^\\.*\\//.test(urlString);\n\n\t// Prepend protocol\n\tif (!isRelativeUrl) {\n\t\turlString = urlString.replace(/^(?!(?:\\w+:)?\\/\\/)|^\\/\\//, options.defaultProtocol);\n\t}\n\n\tconst urlObj = new URL(urlString);\n\n\tif (options.forceHttp && options.forceHttps) {\n\t\tthrow new Error('The `forceHttp` and `forceHttps` options cannot be used together');\n\t}\n\n\tif (options.forceHttp && urlObj.protocol === 'https:') {\n\t\turlObj.protocol = 'http:';\n\t}\n\n\tif (options.forceHttps && urlObj.protocol === 'http:') {\n\t\turlObj.protocol = 'https:';\n\t}\n\n\t// Remove auth\n\tif (options.stripAuthentication) {\n\t\turlObj.username = '';\n\t\turlObj.password = '';\n\t}\n\n\t// Remove hash\n\tif (options.stripHash) {\n\t\turlObj.hash = '';\n\t} else if (options.stripTextFragment) {\n\t\turlObj.hash = urlObj.hash.replace(/#?:~:text.*?$/i, '');\n\t}\n\n\t// Remove duplicate slashes if not preceded by a protocol\n\tif (urlObj.pathname) {\n\t\turlObj.pathname = urlObj.pathname.replace(/(?<!\\b(?:[a-z][a-z\\d+\\-.]{1,50}:))\\/{2,}/g, '/');\n\t}\n\n\t// Decode URI octets\n\tif (urlObj.pathname) {\n\t\ttry {\n\t\t\turlObj.pathname = decodeURI(urlObj.pathname);\n\t\t} catch (_) {}\n\t}\n\n\t// Remove directory index\n\tif (options.removeDirectoryIndex === true) {\n\t\toptions.removeDirectoryIndex = [/^index\\.[a-z]+$/];\n\t}\n\n\tif (Array.isArray(options.removeDirectoryIndex) && options.removeDirectoryIndex.length > 0) {\n\t\tlet pathComponents = urlObj.pathname.split('/');\n\t\tconst lastComponent = pathComponents[pathComponents.length - 1];\n\n\t\tif (testParameter(lastComponent, options.removeDirectoryIndex)) {\n\t\t\tpathComponents = pathComponents.slice(0, pathComponents.length - 1);\n\t\t\turlObj.pathname = pathComponents.slice(1).join('/') + '/';\n\t\t}\n\t}\n\n\tif (urlObj.hostname) {\n\t\t// Remove trailing dot\n\t\turlObj.hostname = urlObj.hostname.replace(/\\.$/, '');\n\n\t\t// Remove `www.`\n\t\tif (options.stripWWW && /^www\\.(?!www\\.)(?:[a-z\\-\\d]{1,63})\\.(?:[a-z.\\-\\d]{2,63})$/.test(urlObj.hostname)) {\n\t\t\t// Each label should be max 63 at length (min: 1).\n\t\t\t// Source: https://en.wikipedia.org/wiki/Hostname#Restrictions_on_valid_host_names\n\t\t\t// Each TLD should be up to 63 characters long (min: 2).\n\t\t\t// It is technically possible to have a single character TLD, but none currently exist.\n\t\t\turlObj.hostname = urlObj.hostname.replace(/^www\\./, '');\n\t\t}\n\t}\n\n\t// Remove query unwanted parameters\n\tif (Array.isArray(options.removeQueryParameters)) {\n\t\tfor (const key of [...urlObj.searchParams.keys()]) {\n\t\t\tif (testParameter(key, options.removeQueryParameters)) {\n\t\t\t\turlObj.searchParams.delete(key);\n\t\t\t}\n\t\t}\n\t}\n\n\tif (options.removeQueryParameters === true) {\n\t\turlObj.search = '';\n\t}\n\n\t// Sort query parameters\n\tif (options.sortQueryParameters) {\n\t\turlObj.searchParams.sort();\n\t}\n\n\tif (options.removeTrailingSlash) {\n\t\turlObj.pathname = urlObj.pathname.replace(/\\/$/, '');\n\t}\n\n\tconst oldUrlString = urlString;\n\n\t// Take advantage of many of the Node `url` normalizations\n\turlString = urlObj.toString();\n\n\tif (!options.removeSingleSlash && urlObj.pathname === '/' && !oldUrlString.endsWith('/') && urlObj.hash === '') {\n\t\turlString = urlString.replace(/\\/$/, '');\n\t}\n\n\t// Remove ending `/` unless removeSingleSlash is false\n\tif ((options.removeTrailingSlash || urlObj.pathname === '/') && urlObj.hash === '' && options.removeSingleSlash) {\n\t\turlString = urlString.replace(/\\/$/, '');\n\t}\n\n\t// Restore relative protocol, if applicable\n\tif (hasRelativeProtocol && !options.normalizeProtocol) {\n\t\turlString = urlString.replace(/^http:\\/\\//, '//');\n\t}\n\n\t// Remove http/https\n\tif (options.stripProtocol) {\n\t\turlString = urlString.replace(/^(?:https?:)?\\/\\//, '');\n\t}\n\n\treturn urlString;\n};\n\nmodule.exports = normalizeUrl;\n\n\n/***/ }),\n\n/***/ 502:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\n\"use strict\";\n\nconst path = __nccwpck_require__(1017);\nconst pathKey = __nccwpck_require__(539);\n\nmodule.exports = opts => {\n\topts = Object.assign({\n\t\tcwd: process.cwd(),\n\t\tpath: process.env[pathKey()]\n\t}, opts);\n\n\tlet prev;\n\tlet pth = path.resolve(opts.cwd);\n\tconst ret = [];\n\n\twhile (prev !== pth) {\n\t\tret.push(path.join(pth, 'node_modules/.bin'));\n\t\tprev = pth;\n\t\tpth = path.resolve(pth, '..');\n\t}\n\n\t// ensure the running `node` binary is used\n\tret.push(path.dirname(process.execPath));\n\n\treturn ret.concat(opts.path).join(path.delimiter);\n};\n\nmodule.exports.env = opts => {\n\topts = Object.assign({\n\t\tenv: process.env\n\t}, opts);\n\n\tconst env = Object.assign({}, opts.env);\n\tconst path = pathKey({env});\n\n\topts.path = env[path];\n\tenv[path] = module.exports(opts);\n\n\treturn env;\n};\n\n\n/***/ }),\n\n/***/ 2072:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\nmodule.exports = paginationMethodsPlugin\n\nfunction paginationMethodsPlugin (octokit) {\n octokit.getFirstPage = (__nccwpck_require__(9555).bind)(null, octokit)\n octokit.getLastPage = (__nccwpck_require__(2203).bind)(null, octokit)\n octokit.getNextPage = (__nccwpck_require__(6655).bind)(null, octokit)\n octokit.getPreviousPage = (__nccwpck_require__(3032).bind)(null, octokit)\n octokit.hasFirstPage = __nccwpck_require__(9631)\n octokit.hasLastPage = __nccwpck_require__(4286)\n octokit.hasNextPage = __nccwpck_require__(500)\n octokit.hasPreviousPage = __nccwpck_require__(5996)\n}\n\n\n/***/ }),\n\n/***/ 191:\n/***/ ((module) => {\n\nmodule.exports = deprecate\n\nconst loggedMessages = {}\n\nfunction deprecate (message) {\n if (loggedMessages[message]) {\n return\n }\n\n console.warn(`DEPRECATED (@octokit/rest): ${message}`)\n loggedMessages[message] = 1\n}\n\n\n/***/ }),\n\n/***/ 9555:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\nmodule.exports = getFirstPage\n\nconst getPage = __nccwpck_require__(8604)\n\nfunction getFirstPage (octokit, link, headers) {\n return getPage(octokit, link, 'first', headers)\n}\n\n\n/***/ }),\n\n/***/ 2203:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\nmodule.exports = getLastPage\n\nconst getPage = __nccwpck_require__(8604)\n\nfunction getLastPage (octokit, link, headers) {\n return getPage(octokit, link, 'last', headers)\n}\n\n\n/***/ }),\n\n/***/ 6655:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\nmodule.exports = getNextPage\n\nconst getPage = __nccwpck_require__(8604)\n\nfunction getNextPage (octokit, link, headers) {\n return getPage(octokit, link, 'next', headers)\n}\n\n\n/***/ }),\n\n/***/ 7889:\n/***/ ((module) => {\n\nmodule.exports = getPageLinks\n\nfunction getPageLinks (link) {\n link = link.link || link.headers.link || ''\n\n const links = {}\n\n // link format:\n // '<https://api.github.com/users/aseemk/followers?page=2>; rel=\"next\", <https://api.github.com/users/aseemk/followers?page=2>; rel=\"last\"'\n link.replace(/<([^>]*)>;\\s*rel=\"([\\w]*)\"/g, (m, uri, type) => {\n links[type] = uri\n })\n\n return links\n}\n\n\n/***/ }),\n\n/***/ 8604:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\nmodule.exports = getPage\n\nconst deprecate = __nccwpck_require__(191)\nconst getPageLinks = __nccwpck_require__(7889)\nconst HttpError = __nccwpck_require__(6058)\n\nfunction getPage (octokit, link, which, headers) {\n deprecate(`octokit.get${which.charAt(0).toUpperCase() + which.slice(1)}Page() \u2013 You can use octokit.paginate or async iterators instead: https://github.com/octokit/rest.js#pagination.`)\n const url = getPageLinks(link)[which]\n\n if (!url) {\n const urlError = new HttpError(`No ${which} page found`, 404)\n return Promise.reject(urlError)\n }\n\n const requestOptions = {\n url,\n headers: applyAcceptHeader(link, headers)\n }\n\n const promise = octokit.request(requestOptions)\n\n return promise\n}\n\nfunction applyAcceptHeader (res, headers) {\n const previous = res.headers && res.headers['x-github-media-type']\n\n if (!previous || (headers && headers.accept)) {\n return headers\n }\n headers = headers || {}\n headers.accept = 'application/vnd.' + previous\n .replace('; param=', '.')\n .replace('; format=', '+')\n\n return headers\n}\n\n\n/***/ }),\n\n/***/ 3032:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\nmodule.exports = getPreviousPage\n\nconst getPage = __nccwpck_require__(8604)\n\nfunction getPreviousPage (octokit, link, headers) {\n return getPage(octokit, link, 'prev', headers)\n}\n\n\n/***/ }),\n\n/***/ 9631:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\nmodule.exports = hasFirstPage\n\nconst deprecate = __nccwpck_require__(191)\nconst getPageLinks = __nccwpck_require__(7889)\n\nfunction hasFirstPage (link) {\n deprecate(`octokit.hasFirstPage() \u2013 You can use octokit.paginate or async iterators instead: https://github.com/octokit/rest.js#pagination.`)\n return getPageLinks(link).first\n}\n\n\n/***/ }),\n\n/***/ 4286:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\nmodule.exports = hasLastPage\n\nconst deprecate = __nccwpck_require__(191)\nconst getPageLinks = __nccwpck_require__(7889)\n\nfunction hasLastPage (link) {\n deprecate(`octokit.hasLastPage() \u2013 You can use octokit.paginate or async iterators instead: https://github.com/octokit/rest.js#pagination.`)\n return getPageLinks(link).last\n}\n\n\n/***/ }),\n\n/***/ 500:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\nmodule.exports = hasNextPage\n\nconst deprecate = __nccwpck_require__(191)\nconst getPageLinks = __nccwpck_require__(7889)\n\nfunction hasNextPage (link) {\n deprecate(`octokit.hasNextPage() \u2013 You can use octokit.paginate or async iterators instead: https://github.com/octokit/rest.js#pagination.`)\n return getPageLinks(link).next\n}\n\n\n/***/ }),\n\n/***/ 5996:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\nmodule.exports = hasPreviousPage\n\nconst deprecate = __nccwpck_require__(191)\nconst getPageLinks = __nccwpck_require__(7889)\n\nfunction hasPreviousPage (link) {\n deprecate(`octokit.hasPreviousPage() \u2013 You can use octokit.paginate or async iterators instead: https://github.com/octokit/rest.js#pagination.`)\n return getPageLinks(link).prev\n}\n\n\n/***/ }),\n\n/***/ 6058:\n/***/ ((module) => {\n\nmodule.exports = class HttpError extends Error {\n constructor (message, code, headers) {\n super(message)\n\n // Maintains proper stack trace (only available on V8)\n /* istanbul ignore next */\n if (Error.captureStackTrace) {\n Error.captureStackTrace(this, this.constructor)\n }\n\n this.name = 'HttpError'\n this.code = code\n this.headers = headers\n }\n}\n\n\n/***/ }),\n\n/***/ 1223:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\nvar wrappy = __nccwpck_require__(2940)\nmodule.exports = wrappy(once)\nmodule.exports.strict = wrappy(onceStrict)\n\nonce.proto = once(function () {\n Object.defineProperty(Function.prototype, 'once', {\n value: function () {\n return once(this)\n },\n configurable: true\n })\n\n Object.defineProperty(Function.prototype, 'onceStrict', {\n value: function () {\n return onceStrict(this)\n },\n configurable: true\n })\n})\n\nfunction once (fn) {\n var f = function () {\n if (f.called) return f.value\n f.called = true\n return f.value = fn.apply(this, arguments)\n }\n f.called = false\n return f\n}\n\nfunction onceStrict (fn) {\n var f = function () {\n if (f.called)\n throw new Error(f.onceError)\n f.called = true\n return f.value = fn.apply(this, arguments)\n }\n var name = fn.name || 'Function wrapped with `once`'\n f.onceError = name + \" shouldn't be called more than once\"\n f.called = false\n return f\n}\n\n\n/***/ }),\n\n/***/ 4824:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\n\"use strict\";\n\nconst os = __nccwpck_require__(2037);\nconst macosRelease = __nccwpck_require__(7493);\nconst winRelease = __nccwpck_require__(3515);\n\nconst osName = (platform, release) => {\n\tif (!platform && release) {\n\t\tthrow new Error('You can\\'t specify a `release` without specifying `platform`');\n\t}\n\n\tplatform = platform || os.platform();\n\n\tlet id;\n\n\tif (platform === 'darwin') {\n\t\tif (!release && os.platform() === 'darwin') {\n\t\t\trelease = os.release();\n\t\t}\n\n\t\tconst prefix = release ? (Number(release.split('.')[0]) > 15 ? 'macOS' : 'OS X') : 'macOS';\n\t\tid = release ? macosRelease(release).name : '';\n\t\treturn prefix + (id ? ' ' + id : '');\n\t}\n\n\tif (platform === 'linux') {\n\t\tif (!release && os.platform() === 'linux') {\n\t\t\trelease = os.release();\n\t\t}\n\n\t\tid = release ? release.replace(/^(\\d+\\.\\d+).*/, '$1') : '';\n\t\treturn 'Linux' + (id ? ' ' + id : '');\n\t}\n\n\tif (platform === 'win32') {\n\t\tif (!release && os.platform() === 'win32') {\n\t\t\trelease = os.release();\n\t\t}\n\n\t\tid = release ? winRelease(release) : '';\n\t\treturn 'Windows' + (id ? ' ' + id : '');\n\t}\n\n\treturn platform;\n};\n\nmodule.exports = osName;\n\n\n/***/ }),\n\n/***/ 9072:\n/***/ ((module) => {\n\n\"use strict\";\n\n\nclass CancelError extends Error {\n\tconstructor(reason) {\n\t\tsuper(reason || 'Promise was canceled');\n\t\tthis.name = 'CancelError';\n\t}\n\n\tget isCanceled() {\n\t\treturn true;\n\t}\n}\n\nclass PCancelable {\n\tstatic fn(userFn) {\n\t\treturn (...arguments_) => {\n\t\t\treturn new PCancelable((resolve, reject, onCancel) => {\n\t\t\t\targuments_.push(onCancel);\n\t\t\t\t// eslint-disable-next-line promise/prefer-await-to-then\n\t\t\t\tuserFn(...arguments_).then(resolve, reject);\n\t\t\t});\n\t\t};\n\t}\n\n\tconstructor(executor) {\n\t\tthis._cancelHandlers = [];\n\t\tthis._isPending = true;\n\t\tthis._isCanceled = false;\n\t\tthis._rejectOnCancel = true;\n\n\t\tthis._promise = new Promise((resolve, reject) => {\n\t\t\tthis._reject = reject;\n\n\t\t\tconst onResolve = value => {\n\t\t\t\tif (!this._isCanceled || !onCancel.shouldReject) {\n\t\t\t\t\tthis._isPending = false;\n\t\t\t\t\tresolve(value);\n\t\t\t\t}\n\t\t\t};\n\n\t\t\tconst onReject = error => {\n\t\t\t\tthis._isPending = false;\n\t\t\t\treject(error);\n\t\t\t};\n\n\t\t\tconst onCancel = handler => {\n\t\t\t\tif (!this._isPending) {\n\t\t\t\t\tthrow new Error('The `onCancel` handler was attached after the promise settled.');\n\t\t\t\t}\n\n\t\t\t\tthis._cancelHandlers.push(handler);\n\t\t\t};\n\n\t\t\tObject.defineProperties(onCancel, {\n\t\t\t\tshouldReject: {\n\t\t\t\t\tget: () => this._rejectOnCancel,\n\t\t\t\t\tset: boolean => {\n\t\t\t\t\t\tthis._rejectOnCancel = boolean;\n\t\t\t\t\t}\n\t\t\t\t}\n\t\t\t});\n\n\t\t\treturn executor(onResolve, onReject, onCancel);\n\t\t});\n\t}\n\n\tthen(onFulfilled, onRejected) {\n\t\t// eslint-disable-next-line promise/prefer-await-to-then\n\t\treturn this._promise.then(onFulfilled, onRejected);\n\t}\n\n\tcatch(onRejected) {\n\t\treturn this._promise.catch(onRejected);\n\t}\n\n\tfinally(onFinally) {\n\t\treturn this._promise.finally(onFinally);\n\t}\n\n\tcancel(reason) {\n\t\tif (!this._isPending || this._isCanceled) {\n\t\t\treturn;\n\t\t}\n\n\t\tthis._isCanceled = true;\n\n\t\tif (this._cancelHandlers.length > 0) {\n\t\t\ttry {\n\t\t\t\tfor (const handler of this._cancelHandlers) {\n\t\t\t\t\thandler();\n\t\t\t\t}\n\t\t\t} catch (error) {\n\t\t\t\tthis._reject(error);\n\t\t\t\treturn;\n\t\t\t}\n\t\t}\n\n\t\tif (this._rejectOnCancel) {\n\t\t\tthis._reject(new CancelError(reason));\n\t\t}\n\t}\n\n\tget isCanceled() {\n\t\treturn this._isCanceled;\n\t}\n}\n\nObject.setPrototypeOf(PCancelable.prototype, Promise.prototype);\n\nmodule.exports = PCancelable;\nmodule.exports.CancelError = CancelError;\n\n\n/***/ }),\n\n/***/ 1330:\n/***/ ((module) => {\n\n\"use strict\";\n\nmodule.exports = (promise, onFinally) => {\n\tonFinally = onFinally || (() => {});\n\n\treturn promise.then(\n\t\tval => new Promise(resolve => {\n\t\t\tresolve(onFinally());\n\t\t}).then(() => val),\n\t\terr => new Promise(resolve => {\n\t\t\tresolve(onFinally());\n\t\t}).then(() => {\n\t\t\tthrow err;\n\t\t})\n\t);\n};\n\n\n/***/ }),\n\n/***/ 539:\n/***/ ((module) => {\n\n\"use strict\";\n\nmodule.exports = opts => {\n\topts = opts || {};\n\n\tconst env = opts.env || process.env;\n\tconst platform = opts.platform || process.platform;\n\n\tif (platform !== 'win32') {\n\t\treturn 'PATH';\n\t}\n\n\treturn Object.keys(env).find(x => x.toUpperCase() === 'PATH') || 'Path';\n};\n\n\n/***/ }),\n\n/***/ 8341:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\nvar once = __nccwpck_require__(1223)\nvar eos = __nccwpck_require__(1205)\nvar fs = __nccwpck_require__(7147) // we only need fs to get the ReadStream and WriteStream prototypes\n\nvar noop = function () {}\nvar ancient = /^v?\\.0/.test(process.version)\n\nvar isFn = function (fn) {\n return typeof fn === 'function'\n}\n\nvar isFS = function (stream) {\n if (!ancient) return false // newer node version do not need to care about fs is a special way\n if (!fs) return false // browser\n return (stream instanceof (fs.ReadStream || noop) || stream instanceof (fs.WriteStream || noop)) && isFn(stream.close)\n}\n\nvar isRequest = function (stream) {\n return stream.setHeader && isFn(stream.abort)\n}\n\nvar destroyer = function (stream, reading, writing, callback) {\n callback = once(callback)\n\n var closed = false\n stream.on('close', function () {\n closed = true\n })\n\n eos(stream, {readable: reading, writable: writing}, function (err) {\n if (err) return callback(err)\n closed = true\n callback()\n })\n\n var destroyed = false\n return function (err) {\n if (closed) return\n if (destroyed) return\n destroyed = true\n\n if (isFS(stream)) return stream.close(noop) // use close for fs streams to avoid fd leaks\n if (isRequest(stream)) return stream.abort() // request.destroy just do .end - .abort is what we want\n\n if (isFn(stream.destroy)) return stream.destroy()\n\n callback(err || new Error('stream was destroyed'))\n }\n}\n\nvar call = function (fn) {\n fn()\n}\n\nvar pipe = function (from, to) {\n return from.pipe(to)\n}\n\nvar pump = function () {\n var streams = Array.prototype.slice.call(arguments)\n var callback = isFn(streams[streams.length - 1] || noop) && streams.pop() || noop\n\n if (Array.isArray(streams[0])) streams = streams[0]\n if (streams.length < 2) throw new Error('pump requires two streams per minimum')\n\n var error\n var destroys = streams.map(function (stream, i) {\n var reading = i < streams.length - 1\n var writing = i > 0\n return destroyer(stream, reading, writing, function (err) {\n if (!error) error = err\n if (err) destroys.forEach(call)\n if (reading) return\n destroys.forEach(call)\n callback(error)\n })\n })\n\n return streams.reduce(pipe)\n}\n\nmodule.exports = pump\n\n\n/***/ }),\n\n/***/ 9273:\n/***/ ((module) => {\n\n\"use strict\";\n\n\nclass QuickLRU {\n\tconstructor(options = {}) {\n\t\tif (!(options.maxSize && options.maxSize > 0)) {\n\t\t\tthrow new TypeError('`maxSize` must be a number greater than 0');\n\t\t}\n\n\t\tthis.maxSize = options.maxSize;\n\t\tthis.onEviction = options.onEviction;\n\t\tthis.cache = new Map();\n\t\tthis.oldCache = new Map();\n\t\tthis._size = 0;\n\t}\n\n\t_set(key, value) {\n\t\tthis.cache.set(key, value);\n\t\tthis._size++;\n\n\t\tif (this._size >= this.maxSize) {\n\t\t\tthis._size = 0;\n\n\t\t\tif (typeof this.onEviction === 'function') {\n\t\t\t\tfor (const [key, value] of this.oldCache.entries()) {\n\t\t\t\t\tthis.onEviction(key, value);\n\t\t\t\t}\n\t\t\t}\n\n\t\t\tthis.oldCache = this.cache;\n\t\t\tthis.cache = new Map();\n\t\t}\n\t}\n\n\tget(key) {\n\t\tif (this.cache.has(key)) {\n\t\t\treturn this.cache.get(key);\n\t\t}\n\n\t\tif (this.oldCache.has(key)) {\n\t\t\tconst value = this.oldCache.get(key);\n\t\t\tthis.oldCache.delete(key);\n\t\t\tthis._set(key, value);\n\t\t\treturn value;\n\t\t}\n\t}\n\n\tset(key, value) {\n\t\tif (this.cache.has(key)) {\n\t\t\tthis.cache.set(key, value);\n\t\t} else {\n\t\t\tthis._set(key, value);\n\t\t}\n\n\t\treturn this;\n\t}\n\n\thas(key) {\n\t\treturn this.cache.has(key) || this.oldCache.has(key);\n\t}\n\n\tpeek(key) {\n\t\tif (this.cache.has(key)) {\n\t\t\treturn this.cache.get(key);\n\t\t}\n\n\t\tif (this.oldCache.has(key)) {\n\t\t\treturn this.oldCache.get(key);\n\t\t}\n\t}\n\n\tdelete(key) {\n\t\tconst deleted = this.cache.delete(key);\n\t\tif (deleted) {\n\t\t\tthis._size--;\n\t\t}\n\n\t\treturn this.oldCache.delete(key) || deleted;\n\t}\n\n\tclear() {\n\t\tthis.cache.clear();\n\t\tthis.oldCache.clear();\n\t\tthis._size = 0;\n\t}\n\n\t* keys() {\n\t\tfor (const [key] of this) {\n\t\t\tyield key;\n\t\t}\n\t}\n\n\t* values() {\n\t\tfor (const [, value] of this) {\n\t\t\tyield value;\n\t\t}\n\t}\n\n\t* [Symbol.iterator]() {\n\t\tfor (const item of this.cache) {\n\t\t\tyield item;\n\t\t}\n\n\t\tfor (const item of this.oldCache) {\n\t\t\tconst [key] = item;\n\t\t\tif (!this.cache.has(key)) {\n\t\t\t\tyield item;\n\t\t\t}\n\t\t}\n\t}\n\n\tget size() {\n\t\tlet oldCacheSize = 0;\n\t\tfor (const key of this.oldCache.keys()) {\n\t\t\tif (!this.cache.has(key)) {\n\t\t\t\toldCacheSize++;\n\t\t\t}\n\t\t}\n\n\t\treturn Math.min(this._size + oldCacheSize, this.maxSize);\n\t}\n}\n\nmodule.exports = QuickLRU;\n\n\n/***/ }),\n\n/***/ 6624:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\n\"use strict\";\n\nconst tls = __nccwpck_require__(4404);\n\nmodule.exports = (options = {}, connect = tls.connect) => new Promise((resolve, reject) => {\n\tlet timeout = false;\n\n\tlet socket;\n\n\tconst callback = async () => {\n\t\tawait socketPromise;\n\n\t\tsocket.off('timeout', onTimeout);\n\t\tsocket.off('error', reject);\n\n\t\tif (options.resolveSocket) {\n\t\t\tresolve({alpnProtocol: socket.alpnProtocol, socket, timeout});\n\n\t\t\tif (timeout) {\n\t\t\t\tawait Promise.resolve();\n\t\t\t\tsocket.emit('timeout');\n\t\t\t}\n\t\t} else {\n\t\t\tsocket.destroy();\n\t\t\tresolve({alpnProtocol: socket.alpnProtocol, timeout});\n\t\t}\n\t};\n\n\tconst onTimeout = async () => {\n\t\ttimeout = true;\n\t\tcallback();\n\t};\n\n\tconst socketPromise = (async () => {\n\t\ttry {\n\t\t\tsocket = await connect(options, callback);\n\n\t\t\tsocket.on('error', reject);\n\t\t\tsocket.once('timeout', onTimeout);\n\t\t} catch (error) {\n\t\t\treject(error);\n\t\t}\n\t})();\n});\n\n\n/***/ }),\n\n/***/ 9004:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\n\"use strict\";\n\n\nconst Readable = (__nccwpck_require__(2781).Readable);\nconst lowercaseKeys = __nccwpck_require__(9662);\n\nclass Response extends Readable {\n\tconstructor(statusCode, headers, body, url) {\n\t\tif (typeof statusCode !== 'number') {\n\t\t\tthrow new TypeError('Argument `statusCode` should be a number');\n\t\t}\n\t\tif (typeof headers !== 'object') {\n\t\t\tthrow new TypeError('Argument `headers` should be an object');\n\t\t}\n\t\tif (!(body instanceof Buffer)) {\n\t\t\tthrow new TypeError('Argument `body` should be a buffer');\n\t\t}\n\t\tif (typeof url !== 'string') {\n\t\t\tthrow new TypeError('Argument `url` should be a string');\n\t\t}\n\n\t\tsuper();\n\t\tthis.statusCode = statusCode;\n\t\tthis.headers = lowercaseKeys(headers);\n\t\tthis.body = body;\n\t\tthis.url = url;\n\t}\n\n\t_read() {\n\t\tthis.push(this.body);\n\t\tthis.push(null);\n\t}\n}\n\nmodule.exports = Response;\n\n\n/***/ }),\n\n/***/ 7032:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\n\"use strict\";\n\nvar shebangRegex = __nccwpck_require__(2638);\n\nmodule.exports = function (str) {\n\tvar match = str.match(shebangRegex);\n\n\tif (!match) {\n\t\treturn null;\n\t}\n\n\tvar arr = match[0].replace(/#! ?/, '').split(' ');\n\tvar bin = arr[0].split('/').pop();\n\tvar arg = arr[1];\n\n\treturn (bin === 'env' ?\n\t\targ :\n\t\tbin + (arg ? ' ' + arg : '')\n\t);\n};\n\n\n/***/ }),\n\n/***/ 2638:\n/***/ ((module) => {\n\n\"use strict\";\n\nmodule.exports = /^#!.*/;\n\n\n/***/ }),\n\n/***/ 4931:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\n// Note: since nyc uses this module to output coverage, any lines\n// that are in the direct sync flow of nyc's outputCoverage are\n// ignored, since we can never get coverage for them.\n// grab a reference to node's real process object right away\nvar process = global.process\n\nconst processOk = function (process) {\n return process &&\n typeof process === 'object' &&\n typeof process.removeListener === 'function' &&\n typeof process.emit === 'function' &&\n typeof process.reallyExit === 'function' &&\n typeof process.listeners === 'function' &&\n typeof process.kill === 'function' &&\n typeof process.pid === 'number' &&\n typeof process.on === 'function'\n}\n\n// some kind of non-node environment, just no-op\n/* istanbul ignore if */\nif (!processOk(process)) {\n module.exports = function () {\n return function () {}\n }\n} else {\n var assert = __nccwpck_require__(9491)\n var signals = __nccwpck_require__(3710)\n var isWin = /^win/i.test(process.platform)\n\n var EE = __nccwpck_require__(2361)\n /* istanbul ignore if */\n if (typeof EE !== 'function') {\n EE = EE.EventEmitter\n }\n\n var emitter\n if (process.__signal_exit_emitter__) {\n emitter = process.__signal_exit_emitter__\n } else {\n emitter = process.__signal_exit_emitter__ = new EE()\n emitter.count = 0\n emitter.emitted = {}\n }\n\n // Because this emitter is a global, we have to check to see if a\n // previous version of this library failed to enable infinite listeners.\n // I know what you're about to say. But literally everything about\n // signal-exit is a compromise with evil. Get used to it.\n if (!emitter.infinite) {\n emitter.setMaxListeners(Infinity)\n emitter.infinite = true\n }\n\n module.exports = function (cb, opts) {\n /* istanbul ignore if */\n if (!processOk(global.process)) {\n return function () {}\n }\n assert.equal(typeof cb, 'function', 'a callback must be provided for exit handler')\n\n if (loaded === false) {\n load()\n }\n\n var ev = 'exit'\n if (opts && opts.alwaysLast) {\n ev = 'afterexit'\n }\n\n var remove = function () {\n emitter.removeListener(ev, cb)\n if (emitter.listeners('exit').length === 0 &&\n emitter.listeners('afterexit').length === 0) {\n unload()\n }\n }\n emitter.on(ev, cb)\n\n return remove\n }\n\n var unload = function unload () {\n if (!loaded || !processOk(global.process)) {\n return\n }\n loaded = false\n\n signals.forEach(function (sig) {\n try {\n process.removeListener(sig, sigListeners[sig])\n } catch (er) {}\n })\n process.emit = originalProcessEmit\n process.reallyExit = originalProcessReallyExit\n emitter.count -= 1\n }\n module.exports.unload = unload\n\n var emit = function emit (event, code, signal) {\n /* istanbul ignore if */\n if (emitter.emitted[event]) {\n return\n }\n emitter.emitted[event] = true\n emitter.emit(event, code, signal)\n }\n\n // { <signal>: <listener fn>, ... }\n var sigListeners = {}\n signals.forEach(function (sig) {\n sigListeners[sig] = function listener () {\n /* istanbul ignore if */\n if (!processOk(global.process)) {\n return\n }\n // If there are no other listeners, an exit is coming!\n // Simplest way: remove us and then re-send the signal.\n // We know that this will kill the process, so we can\n // safely emit now.\n var listeners = process.listeners(sig)\n if (listeners.length === emitter.count) {\n unload()\n emit('exit', null, sig)\n /* istanbul ignore next */\n emit('afterexit', null, sig)\n /* istanbul ignore next */\n if (isWin && sig === 'SIGHUP') {\n // \"SIGHUP\" throws an `ENOSYS` error on Windows,\n // so use a supported signal instead\n sig = 'SIGINT'\n }\n /* istanbul ignore next */\n process.kill(process.pid, sig)\n }\n }\n })\n\n module.exports.signals = function () {\n return signals\n }\n\n var loaded = false\n\n var load = function load () {\n if (loaded || !processOk(global.process)) {\n return\n }\n loaded = true\n\n // This is the number of onSignalExit's that are in play.\n // It's important so that we can count the correct number of\n // listeners on signals, and don't wait for the other one to\n // handle it instead of us.\n emitter.count += 1\n\n signals = signals.filter(function (sig) {\n try {\n process.on(sig, sigListeners[sig])\n return true\n } catch (er) {\n return false\n }\n })\n\n process.emit = processEmit\n process.reallyExit = processReallyExit\n }\n module.exports.load = load\n\n var originalProcessReallyExit = process.reallyExit\n var processReallyExit = function processReallyExit (code) {\n /* istanbul ignore if */\n if (!processOk(global.process)) {\n return\n }\n process.exitCode = code || /* istanbul ignore next */ 0\n emit('exit', process.exitCode, null)\n /* istanbul ignore next */\n emit('afterexit', process.exitCode, null)\n /* istanbul ignore next */\n originalProcessReallyExit.call(process, process.exitCode)\n }\n\n var originalProcessEmit = process.emit\n var processEmit = function processEmit (ev, arg) {\n if (ev === 'exit' && processOk(global.process)) {\n /* istanbul ignore else */\n if (arg !== undefined) {\n process.exitCode = arg\n }\n var ret = originalProcessEmit.apply(this, arguments)\n /* istanbul ignore next */\n emit('exit', process.exitCode, null)\n /* istanbul ignore next */\n emit('afterexit', process.exitCode, null)\n /* istanbul ignore next */\n return ret\n } else {\n return originalProcessEmit.apply(this, arguments)\n }\n }\n}\n\n\n/***/ }),\n\n/***/ 3710:\n/***/ ((module) => {\n\n// This is not the set of all possible signals.\n//\n// It IS, however, the set of all signals that trigger\n// an exit on either Linux or BSD systems. Linux is a\n// superset of the signal names supported on BSD, and\n// the unknown signals just fail to register, so we can\n// catch that easily enough.\n//\n// Don't bother with SIGKILL. It's uncatchable, which\n// means that we can't fire any callbacks anyway.\n//\n// If a user does happen to register a handler on a non-\n// fatal signal like SIGWINCH or something, and then\n// exit, it'll end up firing `process.emit('exit')`, so\n// the handler will be fired anyway.\n//\n// SIGBUS, SIGFPE, SIGSEGV and SIGILL, when not raised\n// artificially, inherently leave the process in a\n// state from which it is not safe to try and enter JS\n// listeners.\nmodule.exports = [\n 'SIGABRT',\n 'SIGALRM',\n 'SIGHUP',\n 'SIGINT',\n 'SIGTERM'\n]\n\nif (process.platform !== 'win32') {\n module.exports.push(\n 'SIGVTALRM',\n 'SIGXCPU',\n 'SIGXFSZ',\n 'SIGUSR2',\n 'SIGTRAP',\n 'SIGSYS',\n 'SIGQUIT',\n 'SIGIOT'\n // should detect profiler and enable/disable accordingly.\n // see #21\n // 'SIGPROF'\n )\n}\n\nif (process.platform === 'linux') {\n module.exports.push(\n 'SIGIO',\n 'SIGPOLL',\n 'SIGPWR',\n 'SIGSTKFLT',\n 'SIGUNUSED'\n )\n}\n\n\n/***/ }),\n\n/***/ 5515:\n/***/ ((module) => {\n\n\"use strict\";\n\nmodule.exports = function (x) {\n\tvar lf = typeof x === 'string' ? '\\n' : '\\n'.charCodeAt();\n\tvar cr = typeof x === 'string' ? '\\r' : '\\r'.charCodeAt();\n\n\tif (x[x.length - 1] === lf) {\n\t\tx = x.slice(0, x.length - 1);\n\t}\n\n\tif (x[x.length - 1] === cr) {\n\t\tx = x.slice(0, x.length - 1);\n\t}\n\n\treturn x;\n};\n\n\n/***/ }),\n\n/***/ 4294:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\nmodule.exports = __nccwpck_require__(4219);\n\n\n/***/ }),\n\n/***/ 4219:\n/***/ ((__unused_webpack_module, exports, __nccwpck_require__) => {\n\n\"use strict\";\n\n\nvar net = __nccwpck_require__(1808);\nvar tls = __nccwpck_require__(4404);\nvar http = __nccwpck_require__(3685);\nvar https = __nccwpck_require__(5687);\nvar events = __nccwpck_require__(2361);\nvar assert = __nccwpck_require__(9491);\nvar util = __nccwpck_require__(3837);\n\n\nexports.httpOverHttp = httpOverHttp;\nexports.httpsOverHttp = httpsOverHttp;\nexports.httpOverHttps = httpOverHttps;\nexports.httpsOverHttps = httpsOverHttps;\n\n\nfunction httpOverHttp(options) {\n var agent = new TunnelingAgent(options);\n agent.request = http.request;\n return agent;\n}\n\nfunction httpsOverHttp(options) {\n var agent = new TunnelingAgent(options);\n agent.request = http.request;\n agent.createSocket = createSecureSocket;\n agent.defaultPort = 443;\n return agent;\n}\n\nfunction httpOverHttps(options) {\n var agent = new TunnelingAgent(options);\n agent.request = https.request;\n return agent;\n}\n\nfunction httpsOverHttps(options) {\n var agent = new TunnelingAgent(options);\n agent.request = https.request;\n agent.createSocket = createSecureSocket;\n agent.defaultPort = 443;\n return agent;\n}\n\n\nfunction TunnelingAgent(options) {\n var self = this;\n self.options = options || {};\n self.proxyOptions = self.options.proxy || {};\n self.maxSockets = self.options.maxSockets || http.Agent.defaultMaxSockets;\n self.requests = [];\n self.sockets = [];\n\n self.on('free', function onFree(socket, host, port, localAddress) {\n var options = toOptions(host, port, localAddress);\n for (var i = 0, len = self.requests.length; i < len; ++i) {\n var pending = self.requests[i];\n if (pending.host === options.host && pending.port === options.port) {\n // Detect the request to connect same origin server,\n // reuse the connection.\n self.requests.splice(i, 1);\n pending.request.onSocket(socket);\n return;\n }\n }\n socket.destroy();\n self.removeSocket(socket);\n });\n}\nutil.inherits(TunnelingAgent, events.EventEmitter);\n\nTunnelingAgent.prototype.addRequest = function addRequest(req, host, port, localAddress) {\n var self = this;\n var options = mergeOptions({request: req}, self.options, toOptions(host, port, localAddress));\n\n if (self.sockets.length >= this.maxSockets) {\n // We are over limit so we'll add it to the queue.\n self.requests.push(options);\n return;\n }\n\n // If we are under maxSockets create a new one.\n self.createSocket(options, function(socket) {\n socket.on('free', onFree);\n socket.on('close', onCloseOrRemove);\n socket.on('agentRemove', onCloseOrRemove);\n req.onSocket(socket);\n\n function onFree() {\n self.emit('free', socket, options);\n }\n\n function onCloseOrRemove(err) {\n self.removeSocket(socket);\n socket.removeListener('free', onFree);\n socket.removeListener('close', onCloseOrRemove);\n socket.removeListener('agentRemove', onCloseOrRemove);\n }\n });\n};\n\nTunnelingAgent.prototype.createSocket = function createSocket(options, cb) {\n var self = this;\n var placeholder = {};\n self.sockets.push(placeholder);\n\n var connectOptions = mergeOptions({}, self.proxyOptions, {\n method: 'CONNECT',\n path: options.host + ':' + options.port,\n agent: false,\n headers: {\n host: options.host + ':' + options.port\n }\n });\n if (options.localAddress) {\n connectOptions.localAddress = options.localAddress;\n }\n if (connectOptions.proxyAuth) {\n connectOptions.headers = connectOptions.headers || {};\n connectOptions.headers['Proxy-Authorization'] = 'Basic ' +\n new Buffer(connectOptions.proxyAuth).toString('base64');\n }\n\n debug('making CONNECT request');\n var connectReq = self.request(connectOptions);\n connectReq.useChunkedEncodingByDefault = false; // for v0.6\n connectReq.once('response', onResponse); // for v0.6\n connectReq.once('upgrade', onUpgrade); // for v0.6\n connectReq.once('connect', onConnect); // for v0.7 or later\n connectReq.once('error', onError);\n connectReq.end();\n\n function onResponse(res) {\n // Very hacky. This is necessary to avoid http-parser leaks.\n res.upgrade = true;\n }\n\n function onUpgrade(res, socket, head) {\n // Hacky.\n process.nextTick(function() {\n onConnect(res, socket, head);\n });\n }\n\n function onConnect(res, socket, head) {\n connectReq.removeAllListeners();\n socket.removeAllListeners();\n\n if (res.statusCode !== 200) {\n debug('tunneling socket could not be established, statusCode=%d',\n res.statusCode);\n socket.destroy();\n var error = new Error('tunneling socket could not be established, ' +\n 'statusCode=' + res.statusCode);\n error.code = 'ECONNRESET';\n options.request.emit('error', error);\n self.removeSocket(placeholder);\n return;\n }\n if (head.length > 0) {\n debug('got illegal response body from proxy');\n socket.destroy();\n var error = new Error('got illegal response body from proxy');\n error.code = 'ECONNRESET';\n options.request.emit('error', error);\n self.removeSocket(placeholder);\n return;\n }\n debug('tunneling connection has established');\n self.sockets[self.sockets.indexOf(placeholder)] = socket;\n return cb(socket);\n }\n\n function onError(cause) {\n connectReq.removeAllListeners();\n\n debug('tunneling socket could not be established, cause=%s\\n',\n cause.message, cause.stack);\n var error = new Error('tunneling socket could not be established, ' +\n 'cause=' + cause.message);\n error.code = 'ECONNRESET';\n options.request.emit('error', error);\n self.removeSocket(placeholder);\n }\n};\n\nTunnelingAgent.prototype.removeSocket = function removeSocket(socket) {\n var pos = this.sockets.indexOf(socket)\n if (pos === -1) {\n return;\n }\n this.sockets.splice(pos, 1);\n\n var pending = this.requests.shift();\n if (pending) {\n // If we have pending requests and a socket gets closed a new one\n // needs to be created to take over in the pool for the one that closed.\n this.createSocket(pending, function(socket) {\n pending.request.onSocket(socket);\n });\n }\n};\n\nfunction createSecureSocket(options, cb) {\n var self = this;\n TunnelingAgent.prototype.createSocket.call(self, options, function(socket) {\n var hostHeader = options.request.getHeader('host');\n var tlsOptions = mergeOptions({}, self.options, {\n socket: socket,\n servername: hostHeader ? hostHeader.replace(/:.*$/, '') : options.host\n });\n\n // 0 is dummy port for v0.6\n var secureSocket = tls.connect(0, tlsOptions);\n self.sockets[self.sockets.indexOf(socket)] = secureSocket;\n cb(secureSocket);\n });\n}\n\n\nfunction toOptions(host, port, localAddress) {\n if (typeof host === 'string') { // since v0.10\n return {\n host: host,\n port: port,\n localAddress: localAddress\n };\n }\n return host; // for v0.11 or later\n}\n\nfunction mergeOptions(target) {\n for (var i = 1, len = arguments.length; i < len; ++i) {\n var overrides = arguments[i];\n if (typeof overrides === 'object') {\n var keys = Object.keys(overrides);\n for (var j = 0, keyLen = keys.length; j < keyLen; ++j) {\n var k = keys[j];\n if (overrides[k] !== undefined) {\n target[k] = overrides[k];\n }\n }\n }\n }\n return target;\n}\n\n\nvar debug;\nif (process.env.NODE_DEBUG && /\\btunnel\\b/.test(process.env.NODE_DEBUG)) {\n debug = function() {\n var args = Array.prototype.slice.call(arguments);\n if (typeof args[0] === 'string') {\n args[0] = 'TUNNEL: ' + args[0];\n } else {\n args.unshift('TUNNEL:');\n }\n console.error.apply(console, args);\n }\n} else {\n debug = function() {};\n}\nexports.debug = debug; // for test\n\n\n/***/ }),\n\n/***/ 1773:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\n\"use strict\";\n\n\nconst Client = __nccwpck_require__(3598)\nconst Dispatcher = __nccwpck_require__(412)\nconst errors = __nccwpck_require__(8045)\nconst Pool = __nccwpck_require__(4634)\nconst BalancedPool = __nccwpck_require__(7931)\nconst Agent = __nccwpck_require__(7890)\nconst util = __nccwpck_require__(3983)\nconst { InvalidArgumentError } = errors\nconst api = __nccwpck_require__(4059)\nconst buildConnector = __nccwpck_require__(2067)\nconst MockClient = __nccwpck_require__(8687)\nconst MockAgent = __nccwpck_require__(6771)\nconst MockPool = __nccwpck_require__(6193)\nconst mockErrors = __nccwpck_require__(888)\nconst ProxyAgent = __nccwpck_require__(7858)\nconst RetryHandler = __nccwpck_require__(2286)\nconst { getGlobalDispatcher, setGlobalDispatcher } = __nccwpck_require__(1892)\nconst DecoratorHandler = __nccwpck_require__(6930)\nconst RedirectHandler = __nccwpck_require__(2860)\nconst createRedirectInterceptor = __nccwpck_require__(8861)\n\nlet hasCrypto\ntry {\n __nccwpck_require__(6113)\n hasCrypto = true\n} catch {\n hasCrypto = false\n}\n\nObject.assign(Dispatcher.prototype, api)\n\nmodule.exports.Dispatcher = Dispatcher\nmodule.exports.Client = Client\nmodule.exports.Pool = Pool\nmodule.exports.BalancedPool = BalancedPool\nmodule.exports.Agent = Agent\nmodule.exports.ProxyAgent = ProxyAgent\nmodule.exports.RetryHandler = RetryHandler\n\nmodule.exports.DecoratorHandler = DecoratorHandler\nmodule.exports.RedirectHandler = RedirectHandler\nmodule.exports.createRedirectInterceptor = createRedirectInterceptor\n\nmodule.exports.buildConnector = buildConnector\nmodule.exports.errors = errors\n\nfunction makeDispatcher (fn) {\n return (url, opts, handler) => {\n if (typeof opts === 'function') {\n handler = opts\n opts = null\n }\n\n if (!url || (typeof url !== 'string' && typeof url !== 'object' && !(url instanceof URL))) {\n throw new InvalidArgumentError('invalid url')\n }\n\n if (opts != null && typeof opts !== 'object') {\n throw new InvalidArgumentError('invalid opts')\n }\n\n if (opts && opts.path != null) {\n if (typeof opts.path !== 'string') {\n throw new InvalidArgumentError('invalid opts.path')\n }\n\n let path = opts.path\n if (!opts.path.startsWith('/')) {\n path = `/${path}`\n }\n\n url = new URL(util.parseOrigin(url).origin + path)\n } else {\n if (!opts) {\n opts = typeof url === 'object' ? url : {}\n }\n\n url = util.parseURL(url)\n }\n\n const { agent, dispatcher = getGlobalDispatcher() } = opts\n\n if (agent) {\n throw new InvalidArgumentError('unsupported opts.agent. Did you mean opts.client?')\n }\n\n return fn.call(dispatcher, {\n ...opts,\n origin: url.origin,\n path: url.search ? `${url.pathname}${url.search}` : url.pathname,\n method: opts.method || (opts.body ? 'PUT' : 'GET')\n }, handler)\n }\n}\n\nmodule.exports.setGlobalDispatcher = setGlobalDispatcher\nmodule.exports.getGlobalDispatcher = getGlobalDispatcher\n\nif (util.nodeMajor > 16 || (util.nodeMajor === 16 && util.nodeMinor >= 8)) {\n let fetchImpl = null\n module.exports.fetch = async function fetch (resource) {\n if (!fetchImpl) {\n fetchImpl = (__nccwpck_require__(4881).fetch)\n }\n\n try {\n return await fetchImpl(...arguments)\n } catch (err) {\n if (typeof err === 'object') {\n Error.captureStackTrace(err, this)\n }\n\n throw err\n }\n }\n module.exports.Headers = __nccwpck_require__(554).Headers\n module.exports.Response = __nccwpck_require__(7823).Response\n module.exports.Request = __nccwpck_require__(8359).Request\n module.exports.FormData = __nccwpck_require__(2015).FormData\n module.exports.File = __nccwpck_require__(8511).File\n module.exports.FileReader = __nccwpck_require__(1446).FileReader\n\n const { setGlobalOrigin, getGlobalOrigin } = __nccwpck_require__(1246)\n\n module.exports.setGlobalOrigin = setGlobalOrigin\n module.exports.getGlobalOrigin = getGlobalOrigin\n\n const { CacheStorage } = __nccwpck_require__(7907)\n const { kConstruct } = __nccwpck_require__(9174)\n\n // Cache & CacheStorage are tightly coupled with fetch. Even if it may run\n // in an older version of Node, it doesn't have any use without fetch.\n module.exports.caches = new CacheStorage(kConstruct)\n}\n\nif (util.nodeMajor >= 16) {\n const { deleteCookie, getCookies, getSetCookies, setCookie } = __nccwpck_require__(1724)\n\n module.exports.deleteCookie = deleteCookie\n module.exports.getCookies = getCookies\n module.exports.getSetCookies = getSetCookies\n module.exports.setCookie = setCookie\n\n const { parseMIMEType, serializeAMimeType } = __nccwpck_require__(685)\n\n module.exports.parseMIMEType = parseMIMEType\n module.exports.serializeAMimeType = serializeAMimeType\n}\n\nif (util.nodeMajor >= 18 && hasCrypto) {\n const { WebSocket } = __nccwpck_require__(4284)\n\n module.exports.WebSocket = WebSocket\n}\n\nmodule.exports.request = makeDispatcher(api.request)\nmodule.exports.stream = makeDispatcher(api.stream)\nmodule.exports.pipeline = makeDispatcher(api.pipeline)\nmodule.exports.connect = makeDispatcher(api.connect)\nmodule.exports.upgrade = makeDispatcher(api.upgrade)\n\nmodule.exports.MockClient = MockClient\nmodule.exports.MockPool = MockPool\nmodule.exports.MockAgent = MockAgent\nmodule.exports.mockErrors = mockErrors\n\n\n/***/ }),\n\n/***/ 7890:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\n\"use strict\";\n\n\nconst { InvalidArgumentError } = __nccwpck_require__(8045)\nconst { kClients, kRunning, kClose, kDestroy, kDispatch, kInterceptors } = __nccwpck_require__(2785)\nconst DispatcherBase = __nccwpck_require__(4839)\nconst Pool = __nccwpck_require__(4634)\nconst Client = __nccwpck_require__(3598)\nconst util = __nccwpck_require__(3983)\nconst createRedirectInterceptor = __nccwpck_require__(8861)\nconst { WeakRef, FinalizationRegistry } = __nccwpck_require__(6436)()\n\nconst kOnConnect = Symbol('onConnect')\nconst kOnDisconnect = Symbol('onDisconnect')\nconst kOnConnectionError = Symbol('onConnectionError')\nconst kMaxRedirections = Symbol('maxRedirections')\nconst kOnDrain = Symbol('onDrain')\nconst kFactory = Symbol('factory')\nconst kFinalizer = Symbol('finalizer')\nconst kOptions = Symbol('options')\n\nfunction defaultFactory (origin, opts) {\n return opts && opts.connections === 1\n ? new Client(origin, opts)\n : new Pool(origin, opts)\n}\n\nclass Agent extends DispatcherBase {\n constructor ({ factory = defaultFactory, maxRedirections = 0, connect, ...options } = {}) {\n super()\n\n if (typeof factory !== 'function') {\n throw new InvalidArgumentError('factory must be a function.')\n }\n\n if (connect != null && typeof connect !== 'function' && typeof connect !== 'object') {\n throw new InvalidArgumentError('connect must be a function or an object')\n }\n\n if (!Number.isInteger(maxRedirections) || maxRedirections < 0) {\n throw new InvalidArgumentError('maxRedirections must be a positive number')\n }\n\n if (connect && typeof connect !== 'function') {\n connect = { ...connect }\n }\n\n this[kInterceptors] = options.interceptors && options.interceptors.Agent && Array.isArray(options.interceptors.Agent)\n ? options.interceptors.Agent\n : [createRedirectInterceptor({ maxRedirections })]\n\n this[kOptions] = { ...util.deepClone(options), connect }\n this[kOptions].interceptors = options.interceptors\n ? { ...options.interceptors }\n : undefined\n this[kMaxRedirections] = maxRedirections\n this[kFactory] = factory\n this[kClients] = new Map()\n this[kFinalizer] = new FinalizationRegistry(/* istanbul ignore next: gc is undeterministic */ key => {\n const ref = this[kClients].get(key)\n if (ref !== undefined && ref.deref() === undefined) {\n this[kClients].delete(key)\n }\n })\n\n const agent = this\n\n this[kOnDrain] = (origin, targets) => {\n agent.emit('drain', origin, [agent, ...targets])\n }\n\n this[kOnConnect] = (origin, targets) => {\n agent.emit('connect', origin, [agent, ...targets])\n }\n\n this[kOnDisconnect] = (origin, targets, err) => {\n agent.emit('disconnect', origin, [agent, ...targets], err)\n }\n\n this[kOnConnectionError] = (origin, targets, err) => {\n agent.emit('connectionError', origin, [agent, ...targets], err)\n }\n }\n\n get [kRunning] () {\n let ret = 0\n for (const ref of this[kClients].values()) {\n const client = ref.deref()\n /* istanbul ignore next: gc is undeterministic */\n if (client) {\n ret += client[kRunning]\n }\n }\n return ret\n }\n\n [kDispatch] (opts, handler) {\n let key\n if (opts.origin && (typeof opts.origin === 'string' || opts.origin instanceof URL)) {\n key = String(opts.origin)\n } else {\n throw new InvalidArgumentError('opts.origin must be a non-empty string or URL.')\n }\n\n const ref = this[kClients].get(key)\n\n let dispatcher = ref ? ref.deref() : null\n if (!dispatcher) {\n dispatcher = this[kFactory](opts.origin, this[kOptions])\n .on('drain', this[kOnDrain])\n .on('connect', this[kOnConnect])\n .on('disconnect', this[kOnDisconnect])\n .on('connectionError', this[kOnConnectionError])\n\n this[kClients].set(key, new WeakRef(dispatcher))\n this[kFinalizer].register(dispatcher, key)\n }\n\n return dispatcher.dispatch(opts, handler)\n }\n\n async [kClose] () {\n const closePromises = []\n for (const ref of this[kClients].values()) {\n const client = ref.deref()\n /* istanbul ignore else: gc is undeterministic */\n if (client) {\n closePromises.push(client.close())\n }\n }\n\n await Promise.all(closePromises)\n }\n\n async [kDestroy] (err) {\n const destroyPromises = []\n for (const ref of this[kClients].values()) {\n const client = ref.deref()\n /* istanbul ignore else: gc is undeterministic */\n if (client) {\n destroyPromises.push(client.destroy(err))\n }\n }\n\n await Promise.all(destroyPromises)\n }\n}\n\nmodule.exports = Agent\n\n\n/***/ }),\n\n/***/ 1777:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\nconst { addAbortListener } = __nccwpck_require__(3983)\nconst { RequestAbortedError } = __nccwpck_require__(8045)\n\nconst kListener = Symbol('kListener')\nconst kSignal = Symbol('kSignal')\n\nfunction abort (self) {\n if (self.abort) {\n self.abort()\n } else {\n self.onError(new RequestAbortedError())\n }\n}\n\nfunction addSignal (self, signal) {\n self[kSignal] = null\n self[kListener] = null\n\n if (!signal) {\n return\n }\n\n if (signal.aborted) {\n abort(self)\n return\n }\n\n self[kSignal] = signal\n self[kListener] = () => {\n abort(self)\n }\n\n addAbortListener(self[kSignal], self[kListener])\n}\n\nfunction removeSignal (self) {\n if (!self[kSignal]) {\n return\n }\n\n if ('removeEventListener' in self[kSignal]) {\n self[kSignal].removeEventListener('abort', self[kListener])\n } else {\n self[kSignal].removeListener('abort', self[kListener])\n }\n\n self[kSignal] = null\n self[kListener] = null\n}\n\nmodule.exports = {\n addSignal,\n removeSignal\n}\n\n\n/***/ }),\n\n/***/ 9744:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\n\"use strict\";\n\n\nconst { AsyncResource } = __nccwpck_require__(852)\nconst { InvalidArgumentError, RequestAbortedError, SocketError } = __nccwpck_require__(8045)\nconst util = __nccwpck_require__(3983)\nconst { addSignal, removeSignal } = __nccwpck_require__(1777)\n\nclass ConnectHandler extends AsyncResource {\n constructor (opts, callback) {\n if (!opts || typeof opts !== 'object') {\n throw new InvalidArgumentError('invalid opts')\n }\n\n if (typeof callback !== 'function') {\n throw new InvalidArgumentError('invalid callback')\n }\n\n const { signal, opaque, responseHeaders } = opts\n\n if (signal && typeof signal.on !== 'function' && typeof signal.addEventListener !== 'function') {\n throw new InvalidArgumentError('signal must be an EventEmitter or EventTarget')\n }\n\n super('UNDICI_CONNECT')\n\n this.opaque = opaque || null\n this.responseHeaders = responseHeaders || null\n this.callback = callback\n this.abort = null\n\n addSignal(this, signal)\n }\n\n onConnect (abort, context) {\n if (!this.callback) {\n throw new RequestAbortedError()\n }\n\n this.abort = abort\n this.context = context\n }\n\n onHeaders () {\n throw new SocketError('bad connect', null)\n }\n\n onUpgrade (statusCode, rawHeaders, socket) {\n const { callback, opaque, context } = this\n\n removeSignal(this)\n\n this.callback = null\n\n let headers = rawHeaders\n // Indicates is an HTTP2Session\n if (headers != null) {\n headers = this.responseHeaders === 'raw' ? util.parseRawHeaders(rawHeaders) : util.parseHeaders(rawHeaders)\n }\n\n this.runInAsyncScope(callback, null, null, {\n statusCode,\n headers,\n socket,\n opaque,\n context\n })\n }\n\n onError (err) {\n const { callback, opaque } = this\n\n removeSignal(this)\n\n if (callback) {\n this.callback = null\n queueMicrotask(() => {\n this.runInAsyncScope(callback, null, err, { opaque })\n })\n }\n }\n}\n\nfunction connect (opts, callback) {\n if (callback === undefined) {\n return new Promise((resolve, reject) => {\n connect.call(this, opts, (err, data) => {\n return err ? reject(err) : resolve(data)\n })\n })\n }\n\n try {\n const connectHandler = new ConnectHandler(opts, callback)\n this.dispatch({ ...opts, method: 'CONNECT' }, connectHandler)\n } catch (err) {\n if (typeof callback !== 'function') {\n throw err\n }\n const opaque = opts && opts.opaque\n queueMicrotask(() => callback(err, { opaque }))\n }\n}\n\nmodule.exports = connect\n\n\n/***/ }),\n\n/***/ 8752:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\n\"use strict\";\n\n\nconst {\n Readable,\n Duplex,\n PassThrough\n} = __nccwpck_require__(2781)\nconst {\n InvalidArgumentError,\n InvalidReturnValueError,\n RequestAbortedError\n} = __nccwpck_require__(8045)\nconst util = __nccwpck_require__(3983)\nconst { AsyncResource } = __nccwpck_require__(852)\nconst { addSignal, removeSignal } = __nccwpck_require__(1777)\nconst assert = __nccwpck_require__(9491)\n\nconst kResume = Symbol('resume')\n\nclass PipelineRequest extends Readable {\n constructor () {\n super({ autoDestroy: true })\n\n this[kResume] = null\n }\n\n _read () {\n const { [kResume]: resume } = this\n\n if (resume) {\n this[kResume] = null\n resume()\n }\n }\n\n _destroy (err, callback) {\n this._read()\n\n callback(err)\n }\n}\n\nclass PipelineResponse extends Readable {\n constructor (resume) {\n super({ autoDestroy: true })\n this[kResume] = resume\n }\n\n _read () {\n this[kResume]()\n }\n\n _destroy (err, callback) {\n if (!err && !this._readableState.endEmitted) {\n err = new RequestAbortedError()\n }\n\n callback(err)\n }\n}\n\nclass PipelineHandler extends AsyncResource {\n constructor (opts, handler) {\n if (!opts || typeof opts !== 'object') {\n throw new InvalidArgumentError('invalid opts')\n }\n\n if (typeof handler !== 'function') {\n throw new InvalidArgumentError('invalid handler')\n }\n\n const { signal, method, opaque, onInfo, responseHeaders } = opts\n\n if (signal && typeof signal.on !== 'function' && typeof signal.addEventListener !== 'function') {\n throw new InvalidArgumentError('signal must be an EventEmitter or EventTarget')\n }\n\n if (method === 'CONNECT') {\n throw new InvalidArgumentError('invalid method')\n }\n\n if (onInfo && typeof onInfo !== 'function') {\n throw new InvalidArgumentError('invalid onInfo callback')\n }\n\n super('UNDICI_PIPELINE')\n\n this.opaque = opaque || null\n this.responseHeaders = responseHeaders || null\n this.handler = handler\n this.abort = null\n this.context = null\n this.onInfo = onInfo || null\n\n this.req = new PipelineRequest().on('error', util.nop)\n\n this.ret = new Duplex({\n readableObjectMode: opts.objectMode,\n autoDestroy: true,\n read: () => {\n const { body } = this\n\n if (body && body.resume) {\n body.resume()\n }\n },\n write: (chunk, encoding, callback) => {\n const { req } = this\n\n if (req.push(chunk, encoding) || req._readableState.destroyed) {\n callback()\n } else {\n req[kResume] = callback\n }\n },\n destroy: (err, callback) => {\n const { body, req, res, ret, abort } = this\n\n if (!err && !ret._readableState.endEmitted) {\n err = new RequestAbortedError()\n }\n\n if (abort && err) {\n abort()\n }\n\n util.destroy(body, err)\n util.destroy(req, err)\n util.destroy(res, err)\n\n removeSignal(this)\n\n callback(err)\n }\n }).on('prefinish', () => {\n const { req } = this\n\n // Node < 15 does not call _final in same tick.\n req.push(null)\n })\n\n this.res = null\n\n addSignal(this, signal)\n }\n\n onConnect (abort, context) {\n const { ret, res } = this\n\n assert(!res, 'pipeline cannot be retried')\n\n if (ret.destroyed) {\n throw new RequestAbortedError()\n }\n\n this.abort = abort\n this.context = context\n }\n\n onHeaders (statusCode, rawHeaders, resume) {\n const { opaque, handler, context } = this\n\n if (statusCode < 200) {\n if (this.onInfo) {\n const headers = this.responseHeaders === 'raw' ? util.parseRawHeaders(rawHeaders) : util.parseHeaders(rawHeaders)\n this.onInfo({ statusCode, headers })\n }\n return\n }\n\n this.res = new PipelineResponse(resume)\n\n let body\n try {\n this.handler = null\n const headers = this.responseHeaders === 'raw' ? util.parseRawHeaders(rawHeaders) : util.parseHeaders(rawHeaders)\n body = this.runInAsyncScope(handler, null, {\n statusCode,\n headers,\n opaque,\n body: this.res,\n context\n })\n } catch (err) {\n this.res.on('error', util.nop)\n throw err\n }\n\n if (!body || typeof body.on !== 'function') {\n throw new InvalidReturnValueError('expected Readable')\n }\n\n body\n .on('data', (chunk) => {\n const { ret, body } = this\n\n if (!ret.push(chunk) && body.pause) {\n body.pause()\n }\n })\n .on('error', (err) => {\n const { ret } = this\n\n util.destroy(ret, err)\n })\n .on('end', () => {\n const { ret } = this\n\n ret.push(null)\n })\n .on('close', () => {\n const { ret } = this\n\n if (!ret._readableState.ended) {\n util.destroy(ret, new RequestAbortedError())\n }\n })\n\n this.body = body\n }\n\n onData (chunk) {\n const { res } = this\n return res.push(chunk)\n }\n\n onComplete (trailers) {\n const { res } = this\n res.push(null)\n }\n\n onError (err) {\n const { ret } = this\n this.handler = null\n util.destroy(ret, err)\n }\n}\n\nfunction pipeline (opts, handler) {\n try {\n const pipelineHandler = new PipelineHandler(opts, handler)\n this.dispatch({ ...opts, body: pipelineHandler.req }, pipelineHandler)\n return pipelineHandler.ret\n } catch (err) {\n return new PassThrough().destroy(err)\n }\n}\n\nmodule.exports = pipeline\n\n\n/***/ }),\n\n/***/ 5448:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\n\"use strict\";\n\n\nconst Readable = __nccwpck_require__(3858)\nconst {\n InvalidArgumentError,\n RequestAbortedError\n} = __nccwpck_require__(8045)\nconst util = __nccwpck_require__(3983)\nconst { getResolveErrorBodyCallback } = __nccwpck_require__(7474)\nconst { AsyncResource } = __nccwpck_require__(852)\nconst { addSignal, removeSignal } = __nccwpck_require__(1777)\n\nclass RequestHandler extends AsyncResource {\n constructor (opts, callback) {\n if (!opts || typeof opts !== 'object') {\n throw new InvalidArgumentError('invalid opts')\n }\n\n const { signal, method, opaque, body, onInfo, responseHeaders, throwOnError, highWaterMark } = opts\n\n try {\n if (typeof callback !== 'function') {\n throw new InvalidArgumentError('invalid callback')\n }\n\n if (highWaterMark && (typeof highWaterMark !== 'number' || highWaterMark < 0)) {\n throw new InvalidArgumentError('invalid highWaterMark')\n }\n\n if (signal && typeof signal.on !== 'function' && typeof signal.addEventListener !== 'function') {\n throw new InvalidArgumentError('signal must be an EventEmitter or EventTarget')\n }\n\n if (method === 'CONNECT') {\n throw new InvalidArgumentError('invalid method')\n }\n\n if (onInfo && typeof onInfo !== 'function') {\n throw new InvalidArgumentError('invalid onInfo callback')\n }\n\n super('UNDICI_REQUEST')\n } catch (err) {\n if (util.isStream(body)) {\n util.destroy(body.on('error', util.nop), err)\n }\n throw err\n }\n\n this.responseHeaders = responseHeaders || null\n this.opaque = opaque || null\n this.callback = callback\n this.res = null\n this.abort = null\n this.body = body\n this.trailers = {}\n this.context = null\n this.onInfo = onInfo || null\n this.throwOnError = throwOnError\n this.highWaterMark = highWaterMark\n\n if (util.isStream(body)) {\n body.on('error', (err) => {\n this.onError(err)\n })\n }\n\n addSignal(this, signal)\n }\n\n onConnect (abort, context) {\n if (!this.callback) {\n throw new RequestAbortedError()\n }\n\n this.abort = abort\n this.context = context\n }\n\n onHeaders (statusCode, rawHeaders, resume, statusMessage) {\n const { callback, opaque, abort, context, responseHeaders, highWaterMark } = this\n\n const headers = responseHeaders === 'raw' ? util.parseRawHeaders(rawHeaders) : util.parseHeaders(rawHeaders)\n\n if (statusCode < 200) {\n if (this.onInfo) {\n this.onInfo({ statusCode, headers })\n }\n return\n }\n\n const parsedHeaders = responseHeaders === 'raw' ? util.parseHeaders(rawHeaders) : headers\n const contentType = parsedHeaders['content-type']\n const body = new Readable({ resume, abort, contentType, highWaterMark })\n\n this.callback = null\n this.res = body\n if (callback !== null) {\n if (this.throwOnError && statusCode >= 400) {\n this.runInAsyncScope(getResolveErrorBodyCallback, null,\n { callback, body, contentType, statusCode, statusMessage, headers }\n )\n } else {\n this.runInAsyncScope(callback, null, null, {\n statusCode,\n headers,\n trailers: this.trailers,\n opaque,\n body,\n context\n })\n }\n }\n }\n\n onData (chunk) {\n const { res } = this\n return res.push(chunk)\n }\n\n onComplete (trailers) {\n const { res } = this\n\n removeSignal(this)\n\n util.parseHeaders(trailers, this.trailers)\n\n res.push(null)\n }\n\n onError (err) {\n const { res, callback, body, opaque } = this\n\n removeSignal(this)\n\n if (callback) {\n // TODO: Does this need queueMicrotask?\n this.callback = null\n queueMicrotask(() => {\n this.runInAsyncScope(callback, null, err, { opaque })\n })\n }\n\n if (res) {\n this.res = null\n // Ensure all queued handlers are invoked before destroying res.\n queueMicrotask(() => {\n util.destroy(res, err)\n })\n }\n\n if (body) {\n this.body = null\n util.destroy(body, err)\n }\n }\n}\n\nfunction request (opts, callback) {\n if (callback === undefined) {\n return new Promise((resolve, reject) => {\n request.call(this, opts, (err, data) => {\n return err ? reject(err) : resolve(data)\n })\n })\n }\n\n try {\n this.dispatch(opts, new RequestHandler(opts, callback))\n } catch (err) {\n if (typeof callback !== 'function') {\n throw err\n }\n const opaque = opts && opts.opaque\n queueMicrotask(() => callback(err, { opaque }))\n }\n}\n\nmodule.exports = request\nmodule.exports.RequestHandler = RequestHandler\n\n\n/***/ }),\n\n/***/ 5395:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\n\"use strict\";\n\n\nconst { finished, PassThrough } = __nccwpck_require__(2781)\nconst {\n InvalidArgumentError,\n InvalidReturnValueError,\n RequestAbortedError\n} = __nccwpck_require__(8045)\nconst util = __nccwpck_require__(3983)\nconst { getResolveErrorBodyCallback } = __nccwpck_require__(7474)\nconst { AsyncResource } = __nccwpck_require__(852)\nconst { addSignal, removeSignal } = __nccwpck_require__(1777)\n\nclass StreamHandler extends AsyncResource {\n constructor (opts, factory, callback) {\n if (!opts || typeof opts !== 'object') {\n throw new InvalidArgumentError('invalid opts')\n }\n\n const { signal, method, opaque, body, onInfo, responseHeaders, throwOnError } = opts\n\n try {\n if (typeof callback !== 'function') {\n throw new InvalidArgumentError('invalid callback')\n }\n\n if (typeof factory !== 'function') {\n throw new InvalidArgumentError('invalid factory')\n }\n\n if (signal && typeof signal.on !== 'function' && typeof signal.addEventListener !== 'function') {\n throw new InvalidArgumentError('signal must be an EventEmitter or EventTarget')\n }\n\n if (method === 'CONNECT') {\n throw new InvalidArgumentError('invalid method')\n }\n\n if (onInfo && typeof onInfo !== 'function') {\n throw new InvalidArgumentError('invalid onInfo callback')\n }\n\n super('UNDICI_STREAM')\n } catch (err) {\n if (util.isStream(body)) {\n util.destroy(body.on('error', util.nop), err)\n }\n throw err\n }\n\n this.responseHeaders = responseHeaders || null\n this.opaque = opaque || null\n this.factory = factory\n this.callback = callback\n this.res = null\n this.abort = null\n this.context = null\n this.trailers = null\n this.body = body\n this.onInfo = onInfo || null\n this.throwOnError = throwOnError || false\n\n if (util.isStream(body)) {\n body.on('error', (err) => {\n this.onError(err)\n })\n }\n\n addSignal(this, signal)\n }\n\n onConnect (abort, context) {\n if (!this.callback) {\n throw new RequestAbortedError()\n }\n\n this.abort = abort\n this.context = context\n }\n\n onHeaders (statusCode, rawHeaders, resume, statusMessage) {\n const { factory, opaque, context, callback, responseHeaders } = this\n\n const headers = responseHeaders === 'raw' ? util.parseRawHeaders(rawHeaders) : util.parseHeaders(rawHeaders)\n\n if (statusCode < 200) {\n if (this.onInfo) {\n this.onInfo({ statusCode, headers })\n }\n return\n }\n\n this.factory = null\n\n let res\n\n if (this.throwOnError && statusCode >= 400) {\n const parsedHeaders = responseHeaders === 'raw' ? util.parseHeaders(rawHeaders) : headers\n const contentType = parsedHeaders['content-type']\n res = new PassThrough()\n\n this.callback = null\n this.runInAsyncScope(getResolveErrorBodyCallback, null,\n { callback, body: res, contentType, statusCode, statusMessage, headers }\n )\n } else {\n if (factory === null) {\n return\n }\n\n res = this.runInAsyncScope(factory, null, {\n statusCode,\n headers,\n opaque,\n context\n })\n\n if (\n !res ||\n typeof res.write !== 'function' ||\n typeof res.end !== 'function' ||\n typeof res.on !== 'function'\n ) {\n throw new InvalidReturnValueError('expected Writable')\n }\n\n // TODO: Avoid finished. It registers an unnecessary amount of listeners.\n finished(res, { readable: false }, (err) => {\n const { callback, res, opaque, trailers, abort } = this\n\n this.res = null\n if (err || !res.readable) {\n util.destroy(res, err)\n }\n\n this.callback = null\n this.runInAsyncScope(callback, null, err || null, { opaque, trailers })\n\n if (err) {\n abort()\n }\n })\n }\n\n res.on('drain', resume)\n\n this.res = res\n\n const needDrain = res.writableNeedDrain !== undefined\n ? res.writableNeedDrain\n : res._writableState && res._writableState.needDrain\n\n return needDrain !== true\n }\n\n onData (chunk) {\n const { res } = this\n\n return res ? res.write(chunk) : true\n }\n\n onComplete (trailers) {\n const { res } = this\n\n removeSignal(this)\n\n if (!res) {\n return\n }\n\n this.trailers = util.parseHeaders(trailers)\n\n res.end()\n }\n\n onError (err) {\n const { res, callback, opaque, body } = this\n\n removeSignal(this)\n\n this.factory = null\n\n if (res) {\n this.res = null\n util.destroy(res, err)\n } else if (callback) {\n this.callback = null\n queueMicrotask(() => {\n this.runInAsyncScope(callback, null, err, { opaque })\n })\n }\n\n if (body) {\n this.body = null\n util.destroy(body, err)\n }\n }\n}\n\nfunction stream (opts, factory, callback) {\n if (callback === undefined) {\n return new Promise((resolve, reject) => {\n stream.call(this, opts, factory, (err, data) => {\n return err ? reject(err) : resolve(data)\n })\n })\n }\n\n try {\n this.dispatch(opts, new StreamHandler(opts, factory, callback))\n } catch (err) {\n if (typeof callback !== 'function') {\n throw err\n }\n const opaque = opts && opts.opaque\n queueMicrotask(() => callback(err, { opaque }))\n }\n}\n\nmodule.exports = stream\n\n\n/***/ }),\n\n/***/ 6923:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\n\"use strict\";\n\n\nconst { InvalidArgumentError, RequestAbortedError, SocketError } = __nccwpck_require__(8045)\nconst { AsyncResource } = __nccwpck_require__(852)\nconst util = __nccwpck_require__(3983)\nconst { addSignal, removeSignal } = __nccwpck_require__(1777)\nconst assert = __nccwpck_require__(9491)\n\nclass UpgradeHandler extends AsyncResource {\n constructor (opts, callback) {\n if (!opts || typeof opts !== 'object') {\n throw new InvalidArgumentError('invalid opts')\n }\n\n if (typeof callback !== 'function') {\n throw new InvalidArgumentError('invalid callback')\n }\n\n const { signal, opaque, responseHeaders } = opts\n\n if (signal && typeof signal.on !== 'function' && typeof signal.addEventListener !== 'function') {\n throw new InvalidArgumentError('signal must be an EventEmitter or EventTarget')\n }\n\n super('UNDICI_UPGRADE')\n\n this.responseHeaders = responseHeaders || null\n this.opaque = opaque || null\n this.callback = callback\n this.abort = null\n this.context = null\n\n addSignal(this, signal)\n }\n\n onConnect (abort, context) {\n if (!this.callback) {\n throw new RequestAbortedError()\n }\n\n this.abort = abort\n this.context = null\n }\n\n onHeaders () {\n throw new SocketError('bad upgrade', null)\n }\n\n onUpgrade (statusCode, rawHeaders, socket) {\n const { callback, opaque, context } = this\n\n assert.strictEqual(statusCode, 101)\n\n removeSignal(this)\n\n this.callback = null\n const headers = this.responseHeaders === 'raw' ? util.parseRawHeaders(rawHeaders) : util.parseHeaders(rawHeaders)\n this.runInAsyncScope(callback, null, null, {\n headers,\n socket,\n opaque,\n context\n })\n }\n\n onError (err) {\n const { callback, opaque } = this\n\n removeSignal(this)\n\n if (callback) {\n this.callback = null\n queueMicrotask(() => {\n this.runInAsyncScope(callback, null, err, { opaque })\n })\n }\n }\n}\n\nfunction upgrade (opts, callback) {\n if (callback === undefined) {\n return new Promise((resolve, reject) => {\n upgrade.call(this, opts, (err, data) => {\n return err ? reject(err) : resolve(data)\n })\n })\n }\n\n try {\n const upgradeHandler = new UpgradeHandler(opts, callback)\n this.dispatch({\n ...opts,\n method: opts.method || 'GET',\n upgrade: opts.protocol || 'Websocket'\n }, upgradeHandler)\n } catch (err) {\n if (typeof callback !== 'function') {\n throw err\n }\n const opaque = opts && opts.opaque\n queueMicrotask(() => callback(err, { opaque }))\n }\n}\n\nmodule.exports = upgrade\n\n\n/***/ }),\n\n/***/ 4059:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\n\"use strict\";\n\n\nmodule.exports.request = __nccwpck_require__(5448)\nmodule.exports.stream = __nccwpck_require__(5395)\nmodule.exports.pipeline = __nccwpck_require__(8752)\nmodule.exports.upgrade = __nccwpck_require__(6923)\nmodule.exports.connect = __nccwpck_require__(9744)\n\n\n/***/ }),\n\n/***/ 3858:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\n\"use strict\";\n// Ported from https://github.com/nodejs/undici/pull/907\n\n\n\nconst assert = __nccwpck_require__(9491)\nconst { Readable } = __nccwpck_require__(2781)\nconst { RequestAbortedError, NotSupportedError, InvalidArgumentError } = __nccwpck_require__(8045)\nconst util = __nccwpck_require__(3983)\nconst { ReadableStreamFrom, toUSVString } = __nccwpck_require__(3983)\n\nlet Blob\n\nconst kConsume = Symbol('kConsume')\nconst kReading = Symbol('kReading')\nconst kBody = Symbol('kBody')\nconst kAbort = Symbol('abort')\nconst kContentType = Symbol('kContentType')\n\nconst noop = () => {}\n\nmodule.exports = class BodyReadable extends Readable {\n constructor ({\n resume,\n abort,\n contentType = '',\n highWaterMark = 64 * 1024 // Same as nodejs fs streams.\n }) {\n super({\n autoDestroy: true,\n read: resume,\n highWaterMark\n })\n\n this._readableState.dataEmitted = false\n\n this[kAbort] = abort\n this[kConsume] = null\n this[kBody] = null\n this[kContentType] = contentType\n\n // Is stream being consumed through Readable API?\n // This is an optimization so that we avoid checking\n // for 'data' and 'readable' listeners in the hot path\n // inside push().\n this[kReading] = false\n }\n\n destroy (err) {\n if (this.destroyed) {\n // Node < 16\n return this\n }\n\n if (!err && !this._readableState.endEmitted) {\n err = new RequestAbortedError()\n }\n\n if (err) {\n this[kAbort]()\n }\n\n return super.destroy(err)\n }\n\n emit (ev, ...args) {\n if (ev === 'data') {\n // Node < 16.7\n this._readableState.dataEmitted = true\n } else if (ev === 'error') {\n // Node < 16\n this._readableState.errorEmitted = true\n }\n return super.emit(ev, ...args)\n }\n\n on (ev, ...args) {\n if (ev === 'data' || ev === 'readable') {\n this[kReading] = true\n }\n return super.on(ev, ...args)\n }\n\n addListener (ev, ...args) {\n return this.on(ev, ...args)\n }\n\n off (ev, ...args) {\n const ret = super.off(ev, ...args)\n if (ev === 'data' || ev === 'readable') {\n this[kReading] = (\n this.listenerCount('data') > 0 ||\n this.listenerCount('readable') > 0\n )\n }\n return ret\n }\n\n removeListener (ev, ...args) {\n return this.off(ev, ...args)\n }\n\n push (chunk) {\n if (this[kConsume] && chunk !== null && this.readableLength === 0) {\n consumePush(this[kConsume], chunk)\n return this[kReading] ? super.push(chunk) : true\n }\n return super.push(chunk)\n }\n\n // https://fetch.spec.whatwg.org/#dom-body-text\n async text () {\n return consume(this, 'text')\n }\n\n // https://fetch.spec.whatwg.org/#dom-body-json\n async json () {\n return consume(this, 'json')\n }\n\n // https://fetch.spec.whatwg.org/#dom-body-blob\n async blob () {\n return consume(this, 'blob')\n }\n\n // https://fetch.spec.whatwg.org/#dom-body-arraybuffer\n async arrayBuffer () {\n return consume(this, 'arrayBuffer')\n }\n\n // https://fetch.spec.whatwg.org/#dom-body-formdata\n async formData () {\n // TODO: Implement.\n throw new NotSupportedError()\n }\n\n // https://fetch.spec.whatwg.org/#dom-body-bodyused\n get bodyUsed () {\n return util.isDisturbed(this)\n }\n\n // https://fetch.spec.whatwg.org/#dom-body-body\n get body () {\n if (!this[kBody]) {\n this[kBody] = ReadableStreamFrom(this)\n if (this[kConsume]) {\n // TODO: Is this the best way to force a lock?\n this[kBody].getReader() // Ensure stream is locked.\n assert(this[kBody].locked)\n }\n }\n return this[kBody]\n }\n\n dump (opts) {\n let limit = opts && Number.isFinite(opts.limit) ? opts.limit : 262144\n const signal = opts && opts.signal\n\n if (signal) {\n try {\n if (typeof signal !== 'object' || !('aborted' in signal)) {\n throw new InvalidArgumentError('signal must be an AbortSignal')\n }\n util.throwIfAborted(signal)\n } catch (err) {\n return Promise.reject(err)\n }\n }\n\n if (this.closed) {\n return Promise.resolve(null)\n }\n\n return new Promise((resolve, reject) => {\n const signalListenerCleanup = signal\n ? util.addAbortListener(signal, () => {\n this.destroy()\n })\n : noop\n\n this\n .on('close', function () {\n signalListenerCleanup()\n if (signal && signal.aborted) {\n reject(signal.reason || Object.assign(new Error('The operation was aborted'), { name: 'AbortError' }))\n } else {\n resolve(null)\n }\n })\n .on('error', noop)\n .on('data', function (chunk) {\n limit -= chunk.length\n if (limit <= 0) {\n this.destroy()\n }\n })\n .resume()\n })\n }\n}\n\n// https://streams.spec.whatwg.org/#readablestream-locked\nfunction isLocked (self) {\n // Consume is an implicit lock.\n return (self[kBody] && self[kBody].locked === true) || self[kConsume]\n}\n\n// https://fetch.spec.whatwg.org/#body-unusable\nfunction isUnusable (self) {\n return util.isDisturbed(self) || isLocked(self)\n}\n\nasync function consume (stream, type) {\n if (isUnusable(stream)) {\n throw new TypeError('unusable')\n }\n\n assert(!stream[kConsume])\n\n return new Promise((resolve, reject) => {\n stream[kConsume] = {\n type,\n stream,\n resolve,\n reject,\n length: 0,\n body: []\n }\n\n stream\n .on('error', function (err) {\n consumeFinish(this[kConsume], err)\n })\n .on('close', function () {\n if (this[kConsume].body !== null) {\n consumeFinish(this[kConsume], new RequestAbortedError())\n }\n })\n\n process.nextTick(consumeStart, stream[kConsume])\n })\n}\n\nfunction consumeStart (consume) {\n if (consume.body === null) {\n return\n }\n\n const { _readableState: state } = consume.stream\n\n for (const chunk of state.buffer) {\n consumePush(consume, chunk)\n }\n\n if (state.endEmitted) {\n consumeEnd(this[kConsume])\n } else {\n consume.stream.on('end', function () {\n consumeEnd(this[kConsume])\n })\n }\n\n consume.stream.resume()\n\n while (consume.stream.read() != null) {\n // Loop\n }\n}\n\nfunction consumeEnd (consume) {\n const { type, body, resolve, stream, length } = consume\n\n try {\n if (type === 'text') {\n resolve(toUSVString(Buffer.concat(body)))\n } else if (type === 'json') {\n resolve(JSON.parse(Buffer.concat(body)))\n } else if (type === 'arrayBuffer') {\n const dst = new Uint8Array(length)\n\n let pos = 0\n for (const buf of body) {\n dst.set(buf, pos)\n pos += buf.byteLength\n }\n\n resolve(dst.buffer)\n } else if (type === 'blob') {\n if (!Blob) {\n Blob = (__nccwpck_require__(4300).Blob)\n }\n resolve(new Blob(body, { type: stream[kContentType] }))\n }\n\n consumeFinish(consume)\n } catch (err) {\n stream.destroy(err)\n }\n}\n\nfunction consumePush (consume, chunk) {\n consume.length += chunk.length\n consume.body.push(chunk)\n}\n\nfunction consumeFinish (consume, err) {\n if (consume.body === null) {\n return\n }\n\n if (err) {\n consume.reject(err)\n } else {\n consume.resolve()\n }\n\n consume.type = null\n consume.stream = null\n consume.resolve = null\n consume.reject = null\n consume.length = 0\n consume.body = null\n}\n\n\n/***/ }),\n\n/***/ 7474:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\nconst assert = __nccwpck_require__(9491)\nconst {\n ResponseStatusCodeError\n} = __nccwpck_require__(8045)\nconst { toUSVString } = __nccwpck_require__(3983)\n\nasync function getResolveErrorBodyCallback ({ callback, body, contentType, statusCode, statusMessage, headers }) {\n assert(body)\n\n let chunks = []\n let limit = 0\n\n for await (const chunk of body) {\n chunks.push(chunk)\n limit += chunk.length\n if (limit > 128 * 1024) {\n chunks = null\n break\n }\n }\n\n if (statusCode === 204 || !contentType || !chunks) {\n process.nextTick(callback, new ResponseStatusCodeError(`Response status code ${statusCode}${statusMessage ? `: ${statusMessage}` : ''}`, statusCode, headers))\n return\n }\n\n try {\n if (contentType.startsWith('application/json')) {\n const payload = JSON.parse(toUSVString(Buffer.concat(chunks)))\n process.nextTick(callback, new ResponseStatusCodeError(`Response status code ${statusCode}${statusMessage ? `: ${statusMessage}` : ''}`, statusCode, headers, payload))\n return\n }\n\n if (contentType.startsWith('text/')) {\n const payload = toUSVString(Buffer.concat(chunks))\n process.nextTick(callback, new ResponseStatusCodeError(`Response status code ${statusCode}${statusMessage ? `: ${statusMessage}` : ''}`, statusCode, headers, payload))\n return\n }\n } catch (err) {\n // Process in a fallback if error\n }\n\n process.nextTick(callback, new ResponseStatusCodeError(`Response status code ${statusCode}${statusMessage ? `: ${statusMessage}` : ''}`, statusCode, headers))\n}\n\nmodule.exports = { getResolveErrorBodyCallback }\n\n\n/***/ }),\n\n/***/ 7931:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\n\"use strict\";\n\n\nconst {\n BalancedPoolMissingUpstreamError,\n InvalidArgumentError\n} = __nccwpck_require__(8045)\nconst {\n PoolBase,\n kClients,\n kNeedDrain,\n kAddClient,\n kRemoveClient,\n kGetDispatcher\n} = __nccwpck_require__(3198)\nconst Pool = __nccwpck_require__(4634)\nconst { kUrl, kInterceptors } = __nccwpck_require__(2785)\nconst { parseOrigin } = __nccwpck_require__(3983)\nconst kFactory = Symbol('factory')\n\nconst kOptions = Symbol('options')\nconst kGreatestCommonDivisor = Symbol('kGreatestCommonDivisor')\nconst kCurrentWeight = Symbol('kCurrentWeight')\nconst kIndex = Symbol('kIndex')\nconst kWeight = Symbol('kWeight')\nconst kMaxWeightPerServer = Symbol('kMaxWeightPerServer')\nconst kErrorPenalty = Symbol('kErrorPenalty')\n\nfunction getGreatestCommonDivisor (a, b) {\n if (b === 0) return a\n return getGreatestCommonDivisor(b, a % b)\n}\n\nfunction defaultFactory (origin, opts) {\n return new Pool(origin, opts)\n}\n\nclass BalancedPool extends PoolBase {\n constructor (upstreams = [], { factory = defaultFactory, ...opts } = {}) {\n super()\n\n this[kOptions] = opts\n this[kIndex] = -1\n this[kCurrentWeight] = 0\n\n this[kMaxWeightPerServer] = this[kOptions].maxWeightPerServer || 100\n this[kErrorPenalty] = this[kOptions].errorPenalty || 15\n\n if (!Array.isArray(upstreams)) {\n upstreams = [upstreams]\n }\n\n if (typeof factory !== 'function') {\n throw new InvalidArgumentError('factory must be a function.')\n }\n\n this[kInterceptors] = opts.interceptors && opts.interceptors.BalancedPool && Array.isArray(opts.interceptors.BalancedPool)\n ? opts.interceptors.BalancedPool\n : []\n this[kFactory] = factory\n\n for (const upstream of upstreams) {\n this.addUpstream(upstream)\n }\n this._updateBalancedPoolStats()\n }\n\n addUpstream (upstream) {\n const upstreamOrigin = parseOrigin(upstream).origin\n\n if (this[kClients].find((pool) => (\n pool[kUrl].origin === upstreamOrigin &&\n pool.closed !== true &&\n pool.destroyed !== true\n ))) {\n return this\n }\n const pool = this[kFactory](upstreamOrigin, Object.assign({}, this[kOptions]))\n\n this[kAddClient](pool)\n pool.on('connect', () => {\n pool[kWeight] = Math.min(this[kMaxWeightPerServer], pool[kWeight] + this[kErrorPenalty])\n })\n\n pool.on('connectionError', () => {\n pool[kWeight] = Math.max(1, pool[kWeight] - this[kErrorPenalty])\n this._updateBalancedPoolStats()\n })\n\n pool.on('disconnect', (...args) => {\n const err = args[2]\n if (err && err.code === 'UND_ERR_SOCKET') {\n // decrease the weight of the pool.\n pool[kWeight] = Math.max(1, pool[kWeight] - this[kErrorPenalty])\n this._updateBalancedPoolStats()\n }\n })\n\n for (const client of this[kClients]) {\n client[kWeight] = this[kMaxWeightPerServer]\n }\n\n this._updateBalancedPoolStats()\n\n return this\n }\n\n _updateBalancedPoolStats () {\n this[kGreatestCommonDivisor] = this[kClients].map(p => p[kWeight]).reduce(getGreatestCommonDivisor, 0)\n }\n\n removeUpstream (upstream) {\n const upstreamOrigin = parseOrigin(upstream).origin\n\n const pool = this[kClients].find((pool) => (\n pool[kUrl].origin === upstreamOrigin &&\n pool.closed !== true &&\n pool.destroyed !== true\n ))\n\n if (pool) {\n this[kRemoveClient](pool)\n }\n\n return this\n }\n\n get upstreams () {\n return this[kClients]\n .filter(dispatcher => dispatcher.closed !== true && dispatcher.destroyed !== true)\n .map((p) => p[kUrl].origin)\n }\n\n [kGetDispatcher] () {\n // We validate that pools is greater than 0,\n // otherwise we would have to wait until an upstream\n // is added, which might never happen.\n if (this[kClients].length === 0) {\n throw new BalancedPoolMissingUpstreamError()\n }\n\n const dispatcher = this[kClients].find(dispatcher => (\n !dispatcher[kNeedDrain] &&\n dispatcher.closed !== true &&\n dispatcher.destroyed !== true\n ))\n\n if (!dispatcher) {\n return\n }\n\n const allClientsBusy = this[kClients].map(pool => pool[kNeedDrain]).reduce((a, b) => a && b, true)\n\n if (allClientsBusy) {\n return\n }\n\n let counter = 0\n\n let maxWeightIndex = this[kClients].findIndex(pool => !pool[kNeedDrain])\n\n while (counter++ < this[kClients].length) {\n this[kIndex] = (this[kIndex] + 1) % this[kClients].length\n const pool = this[kClients][this[kIndex]]\n\n // find pool index with the largest weight\n if (pool[kWeight] > this[kClients][maxWeightIndex][kWeight] && !pool[kNeedDrain]) {\n maxWeightIndex = this[kIndex]\n }\n\n // decrease the current weight every `this[kClients].length`.\n if (this[kIndex] === 0) {\n // Set the current weight to the next lower weight.\n this[kCurrentWeight] = this[kCurrentWeight] - this[kGreatestCommonDivisor]\n\n if (this[kCurrentWeight] <= 0) {\n this[kCurrentWeight] = this[kMaxWeightPerServer]\n }\n }\n if (pool[kWeight] >= this[kCurrentWeight] && (!pool[kNeedDrain])) {\n return pool\n }\n }\n\n this[kCurrentWeight] = this[kClients][maxWeightIndex][kWeight]\n this[kIndex] = maxWeightIndex\n return this[kClients][maxWeightIndex]\n }\n}\n\nmodule.exports = BalancedPool\n\n\n/***/ }),\n\n/***/ 6101:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\n\"use strict\";\n\n\nconst { kConstruct } = __nccwpck_require__(9174)\nconst { urlEquals, fieldValues: getFieldValues } = __nccwpck_require__(2396)\nconst { kEnumerableProperty, isDisturbed } = __nccwpck_require__(3983)\nconst { kHeadersList } = __nccwpck_require__(2785)\nconst { webidl } = __nccwpck_require__(1744)\nconst { Response, cloneResponse } = __nccwpck_require__(7823)\nconst { Request } = __nccwpck_require__(8359)\nconst { kState, kHeaders, kGuard, kRealm } = __nccwpck_require__(5861)\nconst { fetching } = __nccwpck_require__(4881)\nconst { urlIsHttpHttpsScheme, createDeferredPromise, readAllBytes } = __nccwpck_require__(2538)\nconst assert = __nccwpck_require__(9491)\nconst { getGlobalDispatcher } = __nccwpck_require__(1892)\n\n/**\n * @see https://w3c.github.io/ServiceWorker/#dfn-cache-batch-operation\n * @typedef {Object} CacheBatchOperation\n * @property {'delete' | 'put'} type\n * @property {any} request\n * @property {any} response\n * @property {import('../../types/cache').CacheQueryOptions} options\n */\n\n/**\n * @see https://w3c.github.io/ServiceWorker/#dfn-request-response-list\n * @typedef {[any, any][]} requestResponseList\n */\n\nclass Cache {\n /**\n * @see https://w3c.github.io/ServiceWorker/#dfn-relevant-request-response-list\n * @type {requestResponseList}\n */\n #relevantRequestResponseList\n\n constructor () {\n if (arguments[0] !== kConstruct) {\n webidl.illegalConstructor()\n }\n\n this.#relevantRequestResponseList = arguments[1]\n }\n\n async match (request, options = {}) {\n webidl.brandCheck(this, Cache)\n webidl.argumentLengthCheck(arguments, 1, { header: 'Cache.match' })\n\n request = webidl.converters.RequestInfo(request)\n options = webidl.converters.CacheQueryOptions(options)\n\n const p = await this.matchAll(request, options)\n\n if (p.length === 0) {\n return\n }\n\n return p[0]\n }\n\n async matchAll (request = undefined, options = {}) {\n webidl.brandCheck(this, Cache)\n\n if (request !== undefined) request = webidl.converters.RequestInfo(request)\n options = webidl.converters.CacheQueryOptions(options)\n\n // 1.\n let r = null\n\n // 2.\n if (request !== undefined) {\n if (request instanceof Request) {\n // 2.1.1\n r = request[kState]\n\n // 2.1.2\n if (r.method !== 'GET' && !options.ignoreMethod) {\n return []\n }\n } else if (typeof request === 'string') {\n // 2.2.1\n r = new Request(request)[kState]\n }\n }\n\n // 5.\n // 5.1\n const responses = []\n\n // 5.2\n if (request === undefined) {\n // 5.2.1\n for (const requestResponse of this.#relevantRequestResponseList) {\n responses.push(requestResponse[1])\n }\n } else { // 5.3\n // 5.3.1\n const requestResponses = this.#queryCache(r, options)\n\n // 5.3.2\n for (const requestResponse of requestResponses) {\n responses.push(requestResponse[1])\n }\n }\n\n // 5.4\n // We don't implement CORs so we don't need to loop over the responses, yay!\n\n // 5.5.1\n const responseList = []\n\n // 5.5.2\n for (const response of responses) {\n // 5.5.2.1\n const responseObject = new Response(response.body?.source ?? null)\n const body = responseObject[kState].body\n responseObject[kState] = response\n responseObject[kState].body = body\n responseObject[kHeaders][kHeadersList] = response.headersList\n responseObject[kHeaders][kGuard] = 'immutable'\n\n responseList.push(responseObject)\n }\n\n // 6.\n return Object.freeze(responseList)\n }\n\n async add (request) {\n webidl.brandCheck(this, Cache)\n webidl.argumentLengthCheck(arguments, 1, { header: 'Cache.add' })\n\n request = webidl.converters.RequestInfo(request)\n\n // 1.\n const requests = [request]\n\n // 2.\n const responseArrayPromise = this.addAll(requests)\n\n // 3.\n return await responseArrayPromise\n }\n\n async addAll (requests) {\n webidl.brandCheck(this, Cache)\n webidl.argumentLengthCheck(arguments, 1, { header: 'Cache.addAll' })\n\n requests = webidl.converters['sequence<RequestInfo>'](requests)\n\n // 1.\n const responsePromises = []\n\n // 2.\n const requestList = []\n\n // 3.\n for (const request of requests) {\n if (typeof request === 'string') {\n continue\n }\n\n // 3.1\n const r = request[kState]\n\n // 3.2\n if (!urlIsHttpHttpsScheme(r.url) || r.method !== 'GET') {\n throw webidl.errors.exception({\n header: 'Cache.addAll',\n message: 'Expected http/s scheme when method is not GET.'\n })\n }\n }\n\n // 4.\n /** @type {ReturnType<typeof fetching>[]} */\n const fetchControllers = []\n\n // 5.\n for (const request of requests) {\n // 5.1\n const r = new Request(request)[kState]\n\n // 5.2\n if (!urlIsHttpHttpsScheme(r.url)) {\n throw webidl.errors.exception({\n header: 'Cache.addAll',\n message: 'Expected http/s scheme.'\n })\n }\n\n // 5.4\n r.initiator = 'fetch'\n r.destination = 'subresource'\n\n // 5.5\n requestList.push(r)\n\n // 5.6\n const responsePromise = createDeferredPromise()\n\n // 5.7\n fetchControllers.push(fetching({\n request: r,\n dispatcher: getGlobalDispatcher(),\n processResponse (response) {\n // 1.\n if (response.type === 'error' || response.status === 206 || response.status < 200 || response.status > 299) {\n responsePromise.reject(webidl.errors.exception({\n header: 'Cache.addAll',\n message: 'Received an invalid status code or the request failed.'\n }))\n } else if (response.headersList.contains('vary')) { // 2.\n // 2.1\n const fieldValues = getFieldValues(response.headersList.get('vary'))\n\n // 2.2\n for (const fieldValue of fieldValues) {\n // 2.2.1\n if (fieldValue === '*') {\n responsePromise.reject(webidl.errors.exception({\n header: 'Cache.addAll',\n message: 'invalid vary field value'\n }))\n\n for (const controller of fetchControllers) {\n controller.abort()\n }\n\n return\n }\n }\n }\n },\n processResponseEndOfBody (response) {\n // 1.\n if (response.aborted) {\n responsePromise.reject(new DOMException('aborted', 'AbortError'))\n return\n }\n\n // 2.\n responsePromise.resolve(response)\n }\n }))\n\n // 5.8\n responsePromises.push(responsePromise.promise)\n }\n\n // 6.\n const p = Promise.all(responsePromises)\n\n // 7.\n const responses = await p\n\n // 7.1\n const operations = []\n\n // 7.2\n let index = 0\n\n // 7.3\n for (const response of responses) {\n // 7.3.1\n /** @type {CacheBatchOperation} */\n const operation = {\n type: 'put', // 7.3.2\n request: requestList[index], // 7.3.3\n response // 7.3.4\n }\n\n operations.push(operation) // 7.3.5\n\n index++ // 7.3.6\n }\n\n // 7.5\n const cacheJobPromise = createDeferredPromise()\n\n // 7.6.1\n let errorData = null\n\n // 7.6.2\n try {\n this.#batchCacheOperations(operations)\n } catch (e) {\n errorData = e\n }\n\n // 7.6.3\n queueMicrotask(() => {\n // 7.6.3.1\n if (errorData === null) {\n cacheJobPromise.resolve(undefined)\n } else {\n // 7.6.3.2\n cacheJobPromise.reject(errorData)\n }\n })\n\n // 7.7\n return cacheJobPromise.promise\n }\n\n async put (request, response) {\n webidl.brandCheck(this, Cache)\n webidl.argumentLengthCheck(arguments, 2, { header: 'Cache.put' })\n\n request = webidl.converters.RequestInfo(request)\n response = webidl.converters.Response(response)\n\n // 1.\n let innerRequest = null\n\n // 2.\n if (request instanceof Request) {\n innerRequest = request[kState]\n } else { // 3.\n innerRequest = new Request(request)[kState]\n }\n\n // 4.\n if (!urlIsHttpHttpsScheme(innerRequest.url) || innerRequest.method !== 'GET') {\n throw webidl.errors.exception({\n header: 'Cache.put',\n message: 'Expected an http/s scheme when method is not GET'\n })\n }\n\n // 5.\n const innerResponse = response[kState]\n\n // 6.\n if (innerResponse.status === 206) {\n throw webidl.errors.exception({\n header: 'Cache.put',\n message: 'Got 206 status'\n })\n }\n\n // 7.\n if (innerResponse.headersList.contains('vary')) {\n // 7.1.\n const fieldValues = getFieldValues(innerResponse.headersList.get('vary'))\n\n // 7.2.\n for (const fieldValue of fieldValues) {\n // 7.2.1\n if (fieldValue === '*') {\n throw webidl.errors.exception({\n header: 'Cache.put',\n message: 'Got * vary field value'\n })\n }\n }\n }\n\n // 8.\n if (innerResponse.body && (isDisturbed(innerResponse.body.stream) || innerResponse.body.stream.locked)) {\n throw webidl.errors.exception({\n header: 'Cache.put',\n message: 'Response body is locked or disturbed'\n })\n }\n\n // 9.\n const clonedResponse = cloneResponse(innerResponse)\n\n // 10.\n const bodyReadPromise = createDeferredPromise()\n\n // 11.\n if (innerResponse.body != null) {\n // 11.1\n const stream = innerResponse.body.stream\n\n // 11.2\n const reader = stream.getReader()\n\n // 11.3\n readAllBytes(reader).then(bodyReadPromise.resolve, bodyReadPromise.reject)\n } else {\n bodyReadPromise.resolve(undefined)\n }\n\n // 12.\n /** @type {CacheBatchOperation[]} */\n const operations = []\n\n // 13.\n /** @type {CacheBatchOperation} */\n const operation = {\n type: 'put', // 14.\n request: innerRequest, // 15.\n response: clonedResponse // 16.\n }\n\n // 17.\n operations.push(operation)\n\n // 19.\n const bytes = await bodyReadPromise.promise\n\n if (clonedResponse.body != null) {\n clonedResponse.body.source = bytes\n }\n\n // 19.1\n const cacheJobPromise = createDeferredPromise()\n\n // 19.2.1\n let errorData = null\n\n // 19.2.2\n try {\n this.#batchCacheOperations(operations)\n } catch (e) {\n errorData = e\n }\n\n // 19.2.3\n queueMicrotask(() => {\n // 19.2.3.1\n if (errorData === null) {\n cacheJobPromise.resolve()\n } else { // 19.2.3.2\n cacheJobPromise.reject(errorData)\n }\n })\n\n return cacheJobPromise.promise\n }\n\n async delete (request, options = {}) {\n webidl.brandCheck(this, Cache)\n webidl.argumentLengthCheck(arguments, 1, { header: 'Cache.delete' })\n\n request = webidl.converters.RequestInfo(request)\n options = webidl.converters.CacheQueryOptions(options)\n\n /**\n * @type {Request}\n */\n let r = null\n\n if (request instanceof Request) {\n r = request[kState]\n\n if (r.method !== 'GET' && !options.ignoreMethod) {\n return false\n }\n } else {\n assert(typeof request === 'string')\n\n r = new Request(request)[kState]\n }\n\n /** @type {CacheBatchOperation[]} */\n const operations = []\n\n /** @type {CacheBatchOperation} */\n const operation = {\n type: 'delete',\n request: r,\n options\n }\n\n operations.push(operation)\n\n const cacheJobPromise = createDeferredPromise()\n\n let errorData = null\n let requestResponses\n\n try {\n requestResponses = this.#batchCacheOperations(operations)\n } catch (e) {\n errorData = e\n }\n\n queueMicrotask(() => {\n if (errorData === null) {\n cacheJobPromise.resolve(!!requestResponses?.length)\n } else {\n cacheJobPromise.reject(errorData)\n }\n })\n\n return cacheJobPromise.promise\n }\n\n /**\n * @see https://w3c.github.io/ServiceWorker/#dom-cache-keys\n * @param {any} request\n * @param {import('../../types/cache').CacheQueryOptions} options\n * @returns {readonly Request[]}\n */\n async keys (request = undefined, options = {}) {\n webidl.brandCheck(this, Cache)\n\n if (request !== undefined) request = webidl.converters.RequestInfo(request)\n options = webidl.converters.CacheQueryOptions(options)\n\n // 1.\n let r = null\n\n // 2.\n if (request !== undefined) {\n // 2.1\n if (request instanceof Request) {\n // 2.1.1\n r = request[kState]\n\n // 2.1.2\n if (r.method !== 'GET' && !options.ignoreMethod) {\n return []\n }\n } else if (typeof request === 'string') { // 2.2\n r = new Request(request)[kState]\n }\n }\n\n // 4.\n const promise = createDeferredPromise()\n\n // 5.\n // 5.1\n const requests = []\n\n // 5.2\n if (request === undefined) {\n // 5.2.1\n for (const requestResponse of this.#relevantRequestResponseList) {\n // 5.2.1.1\n requests.push(requestResponse[0])\n }\n } else { // 5.3\n // 5.3.1\n const requestResponses = this.#queryCache(r, options)\n\n // 5.3.2\n for (const requestResponse of requestResponses) {\n // 5.3.2.1\n requests.push(requestResponse[0])\n }\n }\n\n // 5.4\n queueMicrotask(() => {\n // 5.4.1\n const requestList = []\n\n // 5.4.2\n for (const request of requests) {\n const requestObject = new Request('https://a')\n requestObject[kState] = request\n requestObject[kHeaders][kHeadersList] = request.headersList\n requestObject[kHeaders][kGuard] = 'immutable'\n requestObject[kRealm] = request.client\n\n // 5.4.2.1\n requestList.push(requestObject)\n }\n\n // 5.4.3\n promise.resolve(Object.freeze(requestList))\n })\n\n return promise.promise\n }\n\n /**\n * @see https://w3c.github.io/ServiceWorker/#batch-cache-operations-algorithm\n * @param {CacheBatchOperation[]} operations\n * @returns {requestResponseList}\n */\n #batchCacheOperations (operations) {\n // 1.\n const cache = this.#relevantRequestResponseList\n\n // 2.\n const backupCache = [...cache]\n\n // 3.\n const addedItems = []\n\n // 4.1\n const resultList = []\n\n try {\n // 4.2\n for (const operation of operations) {\n // 4.2.1\n if (operation.type !== 'delete' && operation.type !== 'put') {\n throw webidl.errors.exception({\n header: 'Cache.#batchCacheOperations',\n message: 'operation type does not match \"delete\" or \"put\"'\n })\n }\n\n // 4.2.2\n if (operation.type === 'delete' && operation.response != null) {\n throw webidl.errors.exception({\n header: 'Cache.#batchCacheOperations',\n message: 'delete operation should not have an associated response'\n })\n }\n\n // 4.2.3\n if (this.#queryCache(operation.request, operation.options, addedItems).length) {\n throw new DOMException('???', 'InvalidStateError')\n }\n\n // 4.2.4\n let requestResponses\n\n // 4.2.5\n if (operation.type === 'delete') {\n // 4.2.5.1\n requestResponses = this.#queryCache(operation.request, operation.options)\n\n // TODO: the spec is wrong, this is needed to pass WPTs\n if (requestResponses.length === 0) {\n return []\n }\n\n // 4.2.5.2\n for (const requestResponse of requestResponses) {\n const idx = cache.indexOf(requestResponse)\n assert(idx !== -1)\n\n // 4.2.5.2.1\n cache.splice(idx, 1)\n }\n } else if (operation.type === 'put') { // 4.2.6\n // 4.2.6.1\n if (operation.response == null) {\n throw webidl.errors.exception({\n header: 'Cache.#batchCacheOperations',\n message: 'put operation should have an associated response'\n })\n }\n\n // 4.2.6.2\n const r = operation.request\n\n // 4.2.6.3\n if (!urlIsHttpHttpsScheme(r.url)) {\n throw webidl.errors.exception({\n header: 'Cache.#batchCacheOperations',\n message: 'expected http or https scheme'\n })\n }\n\n // 4.2.6.4\n if (r.method !== 'GET') {\n throw webidl.errors.exception({\n header: 'Cache.#batchCacheOperations',\n message: 'not get method'\n })\n }\n\n // 4.2.6.5\n if (operation.options != null) {\n throw webidl.errors.exception({\n header: 'Cache.#batchCacheOperations',\n message: 'options must not be defined'\n })\n }\n\n // 4.2.6.6\n requestResponses = this.#queryCache(operation.request)\n\n // 4.2.6.7\n for (const requestResponse of requestResponses) {\n const idx = cache.indexOf(requestResponse)\n assert(idx !== -1)\n\n // 4.2.6.7.1\n cache.splice(idx, 1)\n }\n\n // 4.2.6.8\n cache.push([operation.request, operation.response])\n\n // 4.2.6.10\n addedItems.push([operation.request, operation.response])\n }\n\n // 4.2.7\n resultList.push([operation.request, operation.response])\n }\n\n // 4.3\n return resultList\n } catch (e) { // 5.\n // 5.1\n this.#relevantRequestResponseList.length = 0\n\n // 5.2\n this.#relevantRequestResponseList = backupCache\n\n // 5.3\n throw e\n }\n }\n\n /**\n * @see https://w3c.github.io/ServiceWorker/#query-cache\n * @param {any} requestQuery\n * @param {import('../../types/cache').CacheQueryOptions} options\n * @param {requestResponseList} targetStorage\n * @returns {requestResponseList}\n */\n #queryCache (requestQuery, options, targetStorage) {\n /** @type {requestResponseList} */\n const resultList = []\n\n const storage = targetStorage ?? this.#relevantRequestResponseList\n\n for (const requestResponse of storage) {\n const [cachedRequest, cachedResponse] = requestResponse\n if (this.#requestMatchesCachedItem(requestQuery, cachedRequest, cachedResponse, options)) {\n resultList.push(requestResponse)\n }\n }\n\n return resultList\n }\n\n /**\n * @see https://w3c.github.io/ServiceWorker/#request-matches-cached-item-algorithm\n * @param {any} requestQuery\n * @param {any} request\n * @param {any | null} response\n * @param {import('../../types/cache').CacheQueryOptions | undefined} options\n * @returns {boolean}\n */\n #requestMatchesCachedItem (requestQuery, request, response = null, options) {\n // if (options?.ignoreMethod === false && request.method === 'GET') {\n // return false\n // }\n\n const queryURL = new URL(requestQuery.url)\n\n const cachedURL = new URL(request.url)\n\n if (options?.ignoreSearch) {\n cachedURL.search = ''\n\n queryURL.search = ''\n }\n\n if (!urlEquals(queryURL, cachedURL, true)) {\n return false\n }\n\n if (\n response == null ||\n options?.ignoreVary ||\n !response.headersList.contains('vary')\n ) {\n return true\n }\n\n const fieldValues = getFieldValues(response.headersList.get('vary'))\n\n for (const fieldValue of fieldValues) {\n if (fieldValue === '*') {\n return false\n }\n\n const requestValue = request.headersList.get(fieldValue)\n const queryValue = requestQuery.headersList.get(fieldValue)\n\n // If one has the header and the other doesn't, or one has\n // a different value than the other, return false\n if (requestValue !== queryValue) {\n return false\n }\n }\n\n return true\n }\n}\n\nObject.defineProperties(Cache.prototype, {\n [Symbol.toStringTag]: {\n value: 'Cache',\n configurable: true\n },\n match: kEnumerableProperty,\n matchAll: kEnumerableProperty,\n add: kEnumerableProperty,\n addAll: kEnumerableProperty,\n put: kEnumerableProperty,\n delete: kEnumerableProperty,\n keys: kEnumerableProperty\n})\n\nconst cacheQueryOptionConverters = [\n {\n key: 'ignoreSearch',\n converter: webidl.converters.boolean,\n defaultValue: false\n },\n {\n key: 'ignoreMethod',\n converter: webidl.converters.boolean,\n defaultValue: false\n },\n {\n key: 'ignoreVary',\n converter: webidl.converters.boolean,\n defaultValue: false\n }\n]\n\nwebidl.converters.CacheQueryOptions = webidl.dictionaryConverter(cacheQueryOptionConverters)\n\nwebidl.converters.MultiCacheQueryOptions = webidl.dictionaryConverter([\n ...cacheQueryOptionConverters,\n {\n key: 'cacheName',\n converter: webidl.converters.DOMString\n }\n])\n\nwebidl.converters.Response = webidl.interfaceConverter(Response)\n\nwebidl.converters['sequence<RequestInfo>'] = webidl.sequenceConverter(\n webidl.converters.RequestInfo\n)\n\nmodule.exports = {\n Cache\n}\n\n\n/***/ }),\n\n/***/ 7907:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\n\"use strict\";\n\n\nconst { kConstruct } = __nccwpck_require__(9174)\nconst { Cache } = __nccwpck_require__(6101)\nconst { webidl } = __nccwpck_require__(1744)\nconst { kEnumerableProperty } = __nccwpck_require__(3983)\n\nclass CacheStorage {\n /**\n * @see https://w3c.github.io/ServiceWorker/#dfn-relevant-name-to-cache-map\n * @type {Map<string, import('./cache').requestResponseList}\n */\n #caches = new Map()\n\n constructor () {\n if (arguments[0] !== kConstruct) {\n webidl.illegalConstructor()\n }\n }\n\n async match (request, options = {}) {\n webidl.brandCheck(this, CacheStorage)\n webidl.argumentLengthCheck(arguments, 1, { header: 'CacheStorage.match' })\n\n request = webidl.converters.RequestInfo(request)\n options = webidl.converters.MultiCacheQueryOptions(options)\n\n // 1.\n if (options.cacheName != null) {\n // 1.1.1.1\n if (this.#caches.has(options.cacheName)) {\n // 1.1.1.1.1\n const cacheList = this.#caches.get(options.cacheName)\n const cache = new Cache(kConstruct, cacheList)\n\n return await cache.match(request, options)\n }\n } else { // 2.\n // 2.2\n for (const cacheList of this.#caches.values()) {\n const cache = new Cache(kConstruct, cacheList)\n\n // 2.2.1.2\n const response = await cache.match(request, options)\n\n if (response !== undefined) {\n return response\n }\n }\n }\n }\n\n /**\n * @see https://w3c.github.io/ServiceWorker/#cache-storage-has\n * @param {string} cacheName\n * @returns {Promise<boolean>}\n */\n async has (cacheName) {\n webidl.brandCheck(this, CacheStorage)\n webidl.argumentLengthCheck(arguments, 1, { header: 'CacheStorage.has' })\n\n cacheName = webidl.converters.DOMString(cacheName)\n\n // 2.1.1\n // 2.2\n return this.#caches.has(cacheName)\n }\n\n /**\n * @see https://w3c.github.io/ServiceWorker/#dom-cachestorage-open\n * @param {string} cacheName\n * @returns {Promise<Cache>}\n */\n async open (cacheName) {\n webidl.brandCheck(this, CacheStorage)\n webidl.argumentLengthCheck(arguments, 1, { header: 'CacheStorage.open' })\n\n cacheName = webidl.converters.DOMString(cacheName)\n\n // 2.1\n if (this.#caches.has(cacheName)) {\n // await caches.open('v1') !== await caches.open('v1')\n\n // 2.1.1\n const cache = this.#caches.get(cacheName)\n\n // 2.1.1.1\n return new Cache(kConstruct, cache)\n }\n\n // 2.2\n const cache = []\n\n // 2.3\n this.#caches.set(cacheName, cache)\n\n // 2.4\n return new Cache(kConstruct, cache)\n }\n\n /**\n * @see https://w3c.github.io/ServiceWorker/#cache-storage-delete\n * @param {string} cacheName\n * @returns {Promise<boolean>}\n */\n async delete (cacheName) {\n webidl.brandCheck(this, CacheStorage)\n webidl.argumentLengthCheck(arguments, 1, { header: 'CacheStorage.delete' })\n\n cacheName = webidl.converters.DOMString(cacheName)\n\n return this.#caches.delete(cacheName)\n }\n\n /**\n * @see https://w3c.github.io/ServiceWorker/#cache-storage-keys\n * @returns {string[]}\n */\n async keys () {\n webidl.brandCheck(this, CacheStorage)\n\n // 2.1\n const keys = this.#caches.keys()\n\n // 2.2\n return [...keys]\n }\n}\n\nObject.defineProperties(CacheStorage.prototype, {\n [Symbol.toStringTag]: {\n value: 'CacheStorage',\n configurable: true\n },\n match: kEnumerableProperty,\n has: kEnumerableProperty,\n open: kEnumerableProperty,\n delete: kEnumerableProperty,\n keys: kEnumerableProperty\n})\n\nmodule.exports = {\n CacheStorage\n}\n\n\n/***/ }),\n\n/***/ 9174:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\n\"use strict\";\n\n\nmodule.exports = {\n kConstruct: (__nccwpck_require__(2785).kConstruct)\n}\n\n\n/***/ }),\n\n/***/ 2396:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\n\"use strict\";\n\n\nconst assert = __nccwpck_require__(9491)\nconst { URLSerializer } = __nccwpck_require__(685)\nconst { isValidHeaderName } = __nccwpck_require__(2538)\n\n/**\n * @see https://url.spec.whatwg.org/#concept-url-equals\n * @param {URL} A\n * @param {URL} B\n * @param {boolean | undefined} excludeFragment\n * @returns {boolean}\n */\nfunction urlEquals (A, B, excludeFragment = false) {\n const serializedA = URLSerializer(A, excludeFragment)\n\n const serializedB = URLSerializer(B, excludeFragment)\n\n return serializedA === serializedB\n}\n\n/**\n * @see https://github.com/chromium/chromium/blob/694d20d134cb553d8d89e5500b9148012b1ba299/content/browser/cache_storage/cache_storage_cache.cc#L260-L262\n * @param {string} header\n */\nfunction fieldValues (header) {\n assert(header !== null)\n\n const values = []\n\n for (let value of header.split(',')) {\n value = value.trim()\n\n if (!value.length) {\n continue\n } else if (!isValidHeaderName(value)) {\n continue\n }\n\n values.push(value)\n }\n\n return values\n}\n\nmodule.exports = {\n urlEquals,\n fieldValues\n}\n\n\n/***/ }),\n\n/***/ 3598:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\n\"use strict\";\n// @ts-check\n\n\n\n/* global WebAssembly */\n\nconst assert = __nccwpck_require__(9491)\nconst net = __nccwpck_require__(1808)\nconst http = __nccwpck_require__(3685)\nconst { pipeline } = __nccwpck_require__(2781)\nconst util = __nccwpck_require__(3983)\nconst timers = __nccwpck_require__(9459)\nconst Request = __nccwpck_require__(2905)\nconst DispatcherBase = __nccwpck_require__(4839)\nconst {\n RequestContentLengthMismatchError,\n ResponseContentLengthMismatchError,\n InvalidArgumentError,\n RequestAbortedError,\n HeadersTimeoutError,\n HeadersOverflowError,\n SocketError,\n InformationalError,\n BodyTimeoutError,\n HTTPParserError,\n ResponseExceededMaxSizeError,\n ClientDestroyedError\n} = __nccwpck_require__(8045)\nconst buildConnector = __nccwpck_require__(2067)\nconst {\n kUrl,\n kReset,\n kServerName,\n kClient,\n kBusy,\n kParser,\n kConnect,\n kBlocking,\n kResuming,\n kRunning,\n kPending,\n kSize,\n kWriting,\n kQueue,\n kConnected,\n kConnecting,\n kNeedDrain,\n kNoRef,\n kKeepAliveDefaultTimeout,\n kHostHeader,\n kPendingIdx,\n kRunningIdx,\n kError,\n kPipelining,\n kSocket,\n kKeepAliveTimeoutValue,\n kMaxHeadersSize,\n kKeepAliveMaxTimeout,\n kKeepAliveTimeoutThreshold,\n kHeadersTimeout,\n kBodyTimeout,\n kStrictContentLength,\n kConnector,\n kMaxRedirections,\n kMaxRequests,\n kCounter,\n kClose,\n kDestroy,\n kDispatch,\n kInterceptors,\n kLocalAddress,\n kMaxResponseSize,\n kHTTPConnVersion,\n // HTTP2\n kHost,\n kHTTP2Session,\n kHTTP2SessionState,\n kHTTP2BuildRequest,\n kHTTP2CopyHeaders,\n kHTTP1BuildRequest\n} = __nccwpck_require__(2785)\n\n/** @type {import('http2')} */\nlet http2\ntry {\n http2 = __nccwpck_require__(5158)\n} catch {\n // @ts-ignore\n http2 = { constants: {} }\n}\n\nconst {\n constants: {\n HTTP2_HEADER_AUTHORITY,\n HTTP2_HEADER_METHOD,\n HTTP2_HEADER_PATH,\n HTTP2_HEADER_SCHEME,\n HTTP2_HEADER_CONTENT_LENGTH,\n HTTP2_HEADER_EXPECT,\n HTTP2_HEADER_STATUS\n }\n} = http2\n\n// Experimental\nlet h2ExperimentalWarned = false\n\nconst FastBuffer = Buffer[Symbol.species]\n\nconst kClosedResolve = Symbol('kClosedResolve')\n\nconst channels = {}\n\ntry {\n const diagnosticsChannel = __nccwpck_require__(7643)\n channels.sendHeaders = diagnosticsChannel.channel('undici:client:sendHeaders')\n channels.beforeConnect = diagnosticsChannel.channel('undici:client:beforeConnect')\n channels.connectError = diagnosticsChannel.channel('undici:client:connectError')\n channels.connected = diagnosticsChannel.channel('undici:client:connected')\n} catch {\n channels.sendHeaders = { hasSubscribers: false }\n channels.beforeConnect = { hasSubscribers: false }\n channels.connectError = { hasSubscribers: false }\n channels.connected = { hasSubscribers: false }\n}\n\n/**\n * @type {import('../types/client').default}\n */\nclass Client extends DispatcherBase {\n /**\n *\n * @param {string|URL} url\n * @param {import('../types/client').Client.Options} options\n */\n constructor (url, {\n interceptors,\n maxHeaderSize,\n headersTimeout,\n socketTimeout,\n requestTimeout,\n connectTimeout,\n bodyTimeout,\n idleTimeout,\n keepAlive,\n keepAliveTimeout,\n maxKeepAliveTimeout,\n keepAliveMaxTimeout,\n keepAliveTimeoutThreshold,\n socketPath,\n pipelining,\n tls,\n strictContentLength,\n maxCachedSessions,\n maxRedirections,\n connect,\n maxRequestsPerClient,\n localAddress,\n maxResponseSize,\n autoSelectFamily,\n autoSelectFamilyAttemptTimeout,\n // h2\n allowH2,\n maxConcurrentStreams\n } = {}) {\n super()\n\n if (keepAlive !== undefined) {\n throw new InvalidArgumentError('unsupported keepAlive, use pipelining=0 instead')\n }\n\n if (socketTimeout !== undefined) {\n throw new InvalidArgumentError('unsupported socketTimeout, use headersTimeout & bodyTimeout instead')\n }\n\n if (requestTimeout !== undefined) {\n throw new InvalidArgumentError('unsupported requestTimeout, use headersTimeout & bodyTimeout instead')\n }\n\n if (idleTimeout !== undefined) {\n throw new InvalidArgumentError('unsupported idleTimeout, use keepAliveTimeout instead')\n }\n\n if (maxKeepAliveTimeout !== undefined) {\n throw new InvalidArgumentError('unsupported maxKeepAliveTimeout, use keepAliveMaxTimeout instead')\n }\n\n if (maxHeaderSize != null && !Number.isFinite(maxHeaderSize)) {\n throw new InvalidArgumentError('invalid maxHeaderSize')\n }\n\n if (socketPath != null && typeof socketPath !== 'string') {\n throw new InvalidArgumentError('invalid socketPath')\n }\n\n if (connectTimeout != null && (!Number.isFinite(connectTimeout) || connectTimeout < 0)) {\n throw new InvalidArgumentError('invalid connectTimeout')\n }\n\n if (keepAliveTimeout != null && (!Number.isFinite(keepAliveTimeout) || keepAliveTimeout <= 0)) {\n throw new InvalidArgumentError('invalid keepAliveTimeout')\n }\n\n if (keepAliveMaxTimeout != null && (!Number.isFinite(keepAliveMaxTimeout) || keepAliveMaxTimeout <= 0)) {\n throw new InvalidArgumentError('invalid keepAliveMaxTimeout')\n }\n\n if (keepAliveTimeoutThreshold != null && !Number.isFinite(keepAliveTimeoutThreshold)) {\n throw new InvalidArgumentError('invalid keepAliveTimeoutThreshold')\n }\n\n if (headersTimeout != null && (!Number.isInteger(headersTimeout) || headersTimeout < 0)) {\n throw new InvalidArgumentError('headersTimeout must be a positive integer or zero')\n }\n\n if (bodyTimeout != null && (!Number.isInteger(bodyTimeout) || bodyTimeout < 0)) {\n throw new InvalidArgumentError('bodyTimeout must be a positive integer or zero')\n }\n\n if (connect != null && typeof connect !== 'function' && typeof connect !== 'object') {\n throw new InvalidArgumentError('connect must be a function or an object')\n }\n\n if (maxRedirections != null && (!Number.isInteger(maxRedirections) || maxRedirections < 0)) {\n throw new InvalidArgumentError('maxRedirections must be a positive number')\n }\n\n if (maxRequestsPerClient != null && (!Number.isInteger(maxRequestsPerClient) || maxRequestsPerClient < 0)) {\n throw new InvalidArgumentError('maxRequestsPerClient must be a positive number')\n }\n\n if (localAddress != null && (typeof localAddress !== 'string' || net.isIP(localAddress) === 0)) {\n throw new InvalidArgumentError('localAddress must be valid string IP address')\n }\n\n if (maxResponseSize != null && (!Number.isInteger(maxResponseSize) || maxResponseSize < -1)) {\n throw new InvalidArgumentError('maxResponseSize must be a positive number')\n }\n\n if (\n autoSelectFamilyAttemptTimeout != null &&\n (!Number.isInteger(autoSelectFamilyAttemptTimeout) || autoSelectFamilyAttemptTimeout < -1)\n ) {\n throw new InvalidArgumentError('autoSelectFamilyAttemptTimeout must be a positive number')\n }\n\n // h2\n if (allowH2 != null && typeof allowH2 !== 'boolean') {\n throw new InvalidArgumentError('allowH2 must be a valid boolean value')\n }\n\n if (maxConcurrentStreams != null && (typeof maxConcurrentStreams !== 'number' || maxConcurrentStreams < 1)) {\n throw new InvalidArgumentError('maxConcurrentStreams must be a possitive integer, greater than 0')\n }\n\n if (typeof connect !== 'function') {\n connect = buildConnector({\n ...tls,\n maxCachedSessions,\n allowH2,\n socketPath,\n timeout: connectTimeout,\n ...(util.nodeHasAutoSelectFamily && autoSelectFamily ? { autoSelectFamily, autoSelectFamilyAttemptTimeout } : undefined),\n ...connect\n })\n }\n\n this[kInterceptors] = interceptors && interceptors.Client && Array.isArray(interceptors.Client)\n ? interceptors.Client\n : [createRedirectInterceptor({ maxRedirections })]\n this[kUrl] = util.parseOrigin(url)\n this[kConnector] = connect\n this[kSocket] = null\n this[kPipelining] = pipelining != null ? pipelining : 1\n this[kMaxHeadersSize] = maxHeaderSize || http.maxHeaderSize\n this[kKeepAliveDefaultTimeout] = keepAliveTimeout == null ? 4e3 : keepAliveTimeout\n this[kKeepAliveMaxTimeout] = keepAliveMaxTimeout == null ? 600e3 : keepAliveMaxTimeout\n this[kKeepAliveTimeoutThreshold] = keepAliveTimeoutThreshold == null ? 1e3 : keepAliveTimeoutThreshold\n this[kKeepAliveTimeoutValue] = this[kKeepAliveDefaultTimeout]\n this[kServerName] = null\n this[kLocalAddress] = localAddress != null ? localAddress : null\n this[kResuming] = 0 // 0, idle, 1, scheduled, 2 resuming\n this[kNeedDrain] = 0 // 0, idle, 1, scheduled, 2 resuming\n this[kHostHeader] = `host: ${this[kUrl].hostname}${this[kUrl].port ? `:${this[kUrl].port}` : ''}\\r\\n`\n this[kBodyTimeout] = bodyTimeout != null ? bodyTimeout : 300e3\n this[kHeadersTimeout] = headersTimeout != null ? headersTimeout : 300e3\n this[kStrictContentLength] = strictContentLength == null ? true : strictContentLength\n this[kMaxRedirections] = maxRedirections\n this[kMaxRequests] = maxRequestsPerClient\n this[kClosedResolve] = null\n this[kMaxResponseSize] = maxResponseSize > -1 ? maxResponseSize : -1\n this[kHTTPConnVersion] = 'h1'\n\n // HTTP/2\n this[kHTTP2Session] = null\n this[kHTTP2SessionState] = !allowH2\n ? null\n : {\n // streams: null, // Fixed queue of streams - For future support of `push`\n openStreams: 0, // Keep track of them to decide wether or not unref the session\n maxConcurrentStreams: maxConcurrentStreams != null ? maxConcurrentStreams : 100 // Max peerConcurrentStreams for a Node h2 server\n }\n this[kHost] = `${this[kUrl].hostname}${this[kUrl].port ? `:${this[kUrl].port}` : ''}`\n\n // kQueue is built up of 3 sections separated by\n // the kRunningIdx and kPendingIdx indices.\n // | complete | running | pending |\n // ^ kRunningIdx ^ kPendingIdx ^ kQueue.length\n // kRunningIdx points to the first running element.\n // kPendingIdx points to the first pending element.\n // This implements a fast queue with an amortized\n // time of O(1).\n\n this[kQueue] = []\n this[kRunningIdx] = 0\n this[kPendingIdx] = 0\n }\n\n get pipelining () {\n return this[kPipelining]\n }\n\n set pipelining (value) {\n this[kPipelining] = value\n resume(this, true)\n }\n\n get [kPending] () {\n return this[kQueue].length - this[kPendingIdx]\n }\n\n get [kRunning] () {\n return this[kPendingIdx] - this[kRunningIdx]\n }\n\n get [kSize] () {\n return this[kQueue].length - this[kRunningIdx]\n }\n\n get [kConnected] () {\n return !!this[kSocket] && !this[kConnecting] && !this[kSocket].destroyed\n }\n\n get [kBusy] () {\n const socket = this[kSocket]\n return (\n (socket && (socket[kReset] || socket[kWriting] || socket[kBlocking])) ||\n (this[kSize] >= (this[kPipelining] || 1)) ||\n this[kPending] > 0\n )\n }\n\n /* istanbul ignore: only used for test */\n [kConnect] (cb) {\n connect(this)\n this.once('connect', cb)\n }\n\n [kDispatch] (opts, handler) {\n const origin = opts.origin || this[kUrl].origin\n\n const request = this[kHTTPConnVersion] === 'h2'\n ? Request[kHTTP2BuildRequest](origin, opts, handler)\n : Request[kHTTP1BuildRequest](origin, opts, handler)\n\n this[kQueue].push(request)\n if (this[kResuming]) {\n // Do nothing.\n } else if (util.bodyLength(request.body) == null && util.isIterable(request.body)) {\n // Wait a tick in case stream/iterator is ended in the same tick.\n this[kResuming] = 1\n process.nextTick(resume, this)\n } else {\n resume(this, true)\n }\n\n if (this[kResuming] && this[kNeedDrain] !== 2 && this[kBusy]) {\n this[kNeedDrain] = 2\n }\n\n return this[kNeedDrain] < 2\n }\n\n async [kClose] () {\n // TODO: for H2 we need to gracefully flush the remaining enqueued\n // request and close each stream.\n return new Promise((resolve) => {\n if (!this[kSize]) {\n resolve(null)\n } else {\n this[kClosedResolve] = resolve\n }\n })\n }\n\n async [kDestroy] (err) {\n return new Promise((resolve) => {\n const requests = this[kQueue].splice(this[kPendingIdx])\n for (let i = 0; i < requests.length; i++) {\n const request = requests[i]\n errorRequest(this, request, err)\n }\n\n const callback = () => {\n if (this[kClosedResolve]) {\n // TODO (fix): Should we error here with ClientDestroyedError?\n this[kClosedResolve]()\n this[kClosedResolve] = null\n }\n resolve()\n }\n\n if (this[kHTTP2Session] != null) {\n util.destroy(this[kHTTP2Session], err)\n this[kHTTP2Session] = null\n this[kHTTP2SessionState] = null\n }\n\n if (!this[kSocket]) {\n queueMicrotask(callback)\n } else {\n util.destroy(this[kSocket].on('close', callback), err)\n }\n\n resume(this)\n })\n }\n}\n\nfunction onHttp2SessionError (err) {\n assert(err.code !== 'ERR_TLS_CERT_ALTNAME_INVALID')\n\n this[kSocket][kError] = err\n\n onError(this[kClient], err)\n}\n\nfunction onHttp2FrameError (type, code, id) {\n const err = new InformationalError(`HTTP/2: \"frameError\" received - type ${type}, code ${code}`)\n\n if (id === 0) {\n this[kSocket][kError] = err\n onError(this[kClient], err)\n }\n}\n\nfunction onHttp2SessionEnd () {\n util.destroy(this, new SocketError('other side closed'))\n util.destroy(this[kSocket], new SocketError('other side closed'))\n}\n\nfunction onHTTP2GoAway (code) {\n const client = this[kClient]\n const err = new InformationalError(`HTTP/2: \"GOAWAY\" frame received with code ${code}`)\n client[kSocket] = null\n client[kHTTP2Session] = null\n\n if (client.destroyed) {\n assert(this[kPending] === 0)\n\n // Fail entire queue.\n const requests = client[kQueue].splice(client[kRunningIdx])\n for (let i = 0; i < requests.length; i++) {\n const request = requests[i]\n errorRequest(this, request, err)\n }\n } else if (client[kRunning] > 0) {\n // Fail head of pipeline.\n const request = client[kQueue][client[kRunningIdx]]\n client[kQueue][client[kRunningIdx]++] = null\n\n errorRequest(client, request, err)\n }\n\n client[kPendingIdx] = client[kRunningIdx]\n\n assert(client[kRunning] === 0)\n\n client.emit('disconnect',\n client[kUrl],\n [client],\n err\n )\n\n resume(client)\n}\n\nconst constants = __nccwpck_require__(953)\nconst createRedirectInterceptor = __nccwpck_require__(8861)\nconst EMPTY_BUF = Buffer.alloc(0)\n\nasync function lazyllhttp () {\n const llhttpWasmData = process.env.JEST_WORKER_ID ? __nccwpck_require__(1145) : undefined\n\n let mod\n try {\n mod = await WebAssembly.compile(Buffer.from(__nccwpck_require__(5627), 'base64'))\n } catch (e) {\n /* istanbul ignore next */\n\n // We could check if the error was caused by the simd option not\n // being enabled, but the occurring of this other error\n // * https://github.com/emscripten-core/emscripten/issues/11495\n // got me to remove that check to avoid breaking Node 12.\n mod = await WebAssembly.compile(Buffer.from(llhttpWasmData || __nccwpck_require__(1145), 'base64'))\n }\n\n return await WebAssembly.instantiate(mod, {\n env: {\n /* eslint-disable camelcase */\n\n wasm_on_url: (p, at, len) => {\n /* istanbul ignore next */\n return 0\n },\n wasm_on_status: (p, at, len) => {\n assert.strictEqual(currentParser.ptr, p)\n const start = at - currentBufferPtr + currentBufferRef.byteOffset\n return currentParser.onStatus(new FastBuffer(currentBufferRef.buffer, start, len)) || 0\n },\n wasm_on_message_begin: (p) => {\n assert.strictEqual(currentParser.ptr, p)\n return currentParser.onMessageBegin() || 0\n },\n wasm_on_header_field: (p, at, len) => {\n assert.strictEqual(currentParser.ptr, p)\n const start = at - currentBufferPtr + currentBufferRef.byteOffset\n return currentParser.onHeaderField(new FastBuffer(currentBufferRef.buffer, start, len)) || 0\n },\n wasm_on_header_value: (p, at, len) => {\n assert.strictEqual(currentParser.ptr, p)\n const start = at - currentBufferPtr + currentBufferRef.byteOffset\n return currentParser.onHeaderValue(new FastBuffer(currentBufferRef.buffer, start, len)) || 0\n },\n wasm_on_headers_complete: (p, statusCode, upgrade, shouldKeepAlive) => {\n assert.strictEqual(currentParser.ptr, p)\n return currentParser.onHeadersComplete(statusCode, Boolean(upgrade), Boolean(shouldKeepAlive)) || 0\n },\n wasm_on_body: (p, at, len) => {\n assert.strictEqual(currentParser.ptr, p)\n const start = at - currentBufferPtr + currentBufferRef.byteOffset\n return currentParser.onBody(new FastBuffer(currentBufferRef.buffer, start, len)) || 0\n },\n wasm_on_message_complete: (p) => {\n assert.strictEqual(currentParser.ptr, p)\n return currentParser.onMessageComplete() || 0\n }\n\n /* eslint-enable camelcase */\n }\n })\n}\n\nlet llhttpInstance = null\nlet llhttpPromise = lazyllhttp()\nllhttpPromise.catch()\n\nlet currentParser = null\nlet currentBufferRef = null\nlet currentBufferSize = 0\nlet currentBufferPtr = null\n\nconst TIMEOUT_HEADERS = 1\nconst TIMEOUT_BODY = 2\nconst TIMEOUT_IDLE = 3\n\nclass Parser {\n constructor (client, socket, { exports }) {\n assert(Number.isFinite(client[kMaxHeadersSize]) && client[kMaxHeadersSize] > 0)\n\n this.llhttp = exports\n this.ptr = this.llhttp.llhttp_alloc(constants.TYPE.RESPONSE)\n this.client = client\n this.socket = socket\n this.timeout = null\n this.timeoutValue = null\n this.timeoutType = null\n this.statusCode = null\n this.statusText = ''\n this.upgrade = false\n this.headers = []\n this.headersSize = 0\n this.headersMaxSize = client[kMaxHeadersSize]\n this.shouldKeepAlive = false\n this.paused = false\n this.resume = this.resume.bind(this)\n\n this.bytesRead = 0\n\n this.keepAlive = ''\n this.contentLength = ''\n this.connection = ''\n this.maxResponseSize = client[kMaxResponseSize]\n }\n\n setTimeout (value, type) {\n this.timeoutType = type\n if (value !== this.timeoutValue) {\n timers.clearTimeout(this.timeout)\n if (value) {\n this.timeout = timers.setTimeout(onParserTimeout, value, this)\n // istanbul ignore else: only for jest\n if (this.timeout.unref) {\n this.timeout.unref()\n }\n } else {\n this.timeout = null\n }\n this.timeoutValue = value\n } else if (this.timeout) {\n // istanbul ignore else: only for jest\n if (this.timeout.refresh) {\n this.timeout.refresh()\n }\n }\n }\n\n resume () {\n if (this.socket.destroyed || !this.paused) {\n return\n }\n\n assert(this.ptr != null)\n assert(currentParser == null)\n\n this.llhttp.llhttp_resume(this.ptr)\n\n assert(this.timeoutType === TIMEOUT_BODY)\n if (this.timeout) {\n // istanbul ignore else: only for jest\n if (this.timeout.refresh) {\n this.timeout.refresh()\n }\n }\n\n this.paused = false\n this.execute(this.socket.read() || EMPTY_BUF) // Flush parser.\n this.readMore()\n }\n\n readMore () {\n while (!this.paused && this.ptr) {\n const chunk = this.socket.read()\n if (chunk === null) {\n break\n }\n this.execute(chunk)\n }\n }\n\n execute (data) {\n assert(this.ptr != null)\n assert(currentParser == null)\n assert(!this.paused)\n\n const { socket, llhttp } = this\n\n if (data.length > currentBufferSize) {\n if (currentBufferPtr) {\n llhttp.free(currentBufferPtr)\n }\n currentBufferSize = Math.ceil(data.length / 4096) * 4096\n currentBufferPtr = llhttp.malloc(currentBufferSize)\n }\n\n new Uint8Array(llhttp.memory.buffer, currentBufferPtr, currentBufferSize).set(data)\n\n // Call `execute` on the wasm parser.\n // We pass the `llhttp_parser` pointer address, the pointer address of buffer view data,\n // and finally the length of bytes to parse.\n // The return value is an error code or `constants.ERROR.OK`.\n try {\n let ret\n\n try {\n currentBufferRef = data\n currentParser = this\n ret = llhttp.llhttp_execute(this.ptr, currentBufferPtr, data.length)\n /* eslint-disable-next-line no-useless-catch */\n } catch (err) {\n /* istanbul ignore next: difficult to make a test case for */\n throw err\n } finally {\n currentParser = null\n currentBufferRef = null\n }\n\n const offset = llhttp.llhttp_get_error_pos(this.ptr) - currentBufferPtr\n\n if (ret === constants.ERROR.PAUSED_UPGRADE) {\n this.onUpgrade(data.slice(offset))\n } else if (ret === constants.ERROR.PAUSED) {\n this.paused = true\n socket.unshift(data.slice(offset))\n } else if (ret !== constants.ERROR.OK) {\n const ptr = llhttp.llhttp_get_error_reason(this.ptr)\n let message = ''\n /* istanbul ignore else: difficult to make a test case for */\n if (ptr) {\n const len = new Uint8Array(llhttp.memory.buffer, ptr).indexOf(0)\n message =\n 'Response does not match the HTTP/1.1 protocol (' +\n Buffer.from(llhttp.memory.buffer, ptr, len).toString() +\n ')'\n }\n throw new HTTPParserError(message, constants.ERROR[ret], data.slice(offset))\n }\n } catch (err) {\n util.destroy(socket, err)\n }\n }\n\n destroy () {\n assert(this.ptr != null)\n assert(currentParser == null)\n\n this.llhttp.llhttp_free(this.ptr)\n this.ptr = null\n\n timers.clearTimeout(this.timeout)\n this.timeout = null\n this.timeoutValue = null\n this.timeoutType = null\n\n this.paused = false\n }\n\n onStatus (buf) {\n this.statusText = buf.toString()\n }\n\n onMessageBegin () {\n const { socket, client } = this\n\n /* istanbul ignore next: difficult to make a test case for */\n if (socket.destroyed) {\n return -1\n }\n\n const request = client[kQueue][client[kRunningIdx]]\n if (!request) {\n return -1\n }\n }\n\n onHeaderField (buf) {\n const len = this.headers.length\n\n if ((len & 1) === 0) {\n this.headers.push(buf)\n } else {\n this.headers[len - 1] = Buffer.concat([this.headers[len - 1], buf])\n }\n\n this.trackHeader(buf.length)\n }\n\n onHeaderValue (buf) {\n let len = this.headers.length\n\n if ((len & 1) === 1) {\n this.headers.push(buf)\n len += 1\n } else {\n this.headers[len - 1] = Buffer.concat([this.headers[len - 1], buf])\n }\n\n const key = this.headers[len - 2]\n if (key.length === 10 && key.toString().toLowerCase() === 'keep-alive') {\n this.keepAlive += buf.toString()\n } else if (key.length === 10 && key.toString().toLowerCase() === 'connection') {\n this.connection += buf.toString()\n } else if (key.length === 14 && key.toString().toLowerCase() === 'content-length') {\n this.contentLength += buf.toString()\n }\n\n this.trackHeader(buf.length)\n }\n\n trackHeader (len) {\n this.headersSize += len\n if (this.headersSize >= this.headersMaxSize) {\n util.destroy(this.socket, new HeadersOverflowError())\n }\n }\n\n onUpgrade (head) {\n const { upgrade, client, socket, headers, statusCode } = this\n\n assert(upgrade)\n\n const request = client[kQueue][client[kRunningIdx]]\n assert(request)\n\n assert(!socket.destroyed)\n assert(socket === client[kSocket])\n assert(!this.paused)\n assert(request.upgrade || request.method === 'CONNECT')\n\n this.statusCode = null\n this.statusText = ''\n this.shouldKeepAlive = null\n\n assert(this.headers.length % 2 === 0)\n this.headers = []\n this.headersSize = 0\n\n socket.unshift(head)\n\n socket[kParser].destroy()\n socket[kParser] = null\n\n socket[kClient] = null\n socket[kError] = null\n socket\n .removeListener('error', onSocketError)\n .removeListener('readable', onSocketReadable)\n .removeListener('end', onSocketEnd)\n .removeListener('close', onSocketClose)\n\n client[kSocket] = null\n client[kQueue][client[kRunningIdx]++] = null\n client.emit('disconnect', client[kUrl], [client], new InformationalError('upgrade'))\n\n try {\n request.onUpgrade(statusCode, headers, socket)\n } catch (err) {\n util.destroy(socket, err)\n }\n\n resume(client)\n }\n\n onHeadersComplete (statusCode, upgrade, shouldKeepAlive) {\n const { client, socket, headers, statusText } = this\n\n /* istanbul ignore next: difficult to make a test case for */\n if (socket.destroyed) {\n return -1\n }\n\n const request = client[kQueue][client[kRunningIdx]]\n\n /* istanbul ignore next: difficult to make a test case for */\n if (!request) {\n return -1\n }\n\n assert(!this.upgrade)\n assert(this.statusCode < 200)\n\n if (statusCode === 100) {\n util.destroy(socket, new SocketError('bad response', util.getSocketInfo(socket)))\n return -1\n }\n\n /* this can only happen if server is misbehaving */\n if (upgrade && !request.upgrade) {\n util.destroy(socket, new SocketError('bad upgrade', util.getSocketInfo(socket)))\n return -1\n }\n\n assert.strictEqual(this.timeoutType, TIMEOUT_HEADERS)\n\n this.statusCode = statusCode\n this.shouldKeepAlive = (\n shouldKeepAlive ||\n // Override llhttp value which does not allow keepAlive for HEAD.\n (request.method === 'HEAD' && !socket[kReset] && this.connection.toLowerCase() === 'keep-alive')\n )\n\n if (this.statusCode >= 200) {\n const bodyTimeout = request.bodyTimeout != null\n ? request.bodyTimeout\n : client[kBodyTimeout]\n this.setTimeout(bodyTimeout, TIMEOUT_BODY)\n } else if (this.timeout) {\n // istanbul ignore else: only for jest\n if (this.timeout.refresh) {\n this.timeout.refresh()\n }\n }\n\n if (request.method === 'CONNECT') {\n assert(client[kRunning] === 1)\n this.upgrade = true\n return 2\n }\n\n if (upgrade) {\n assert(client[kRunning] === 1)\n this.upgrade = true\n return 2\n }\n\n assert(this.headers.length % 2 === 0)\n this.headers = []\n this.headersSize = 0\n\n if (this.shouldKeepAlive && client[kPipelining]) {\n const keepAliveTimeout = this.keepAlive ? util.parseKeepAliveTimeout(this.keepAlive) : null\n\n if (keepAliveTimeout != null) {\n const timeout = Math.min(\n keepAliveTimeout - client[kKeepAliveTimeoutThreshold],\n client[kKeepAliveMaxTimeout]\n )\n if (timeout <= 0) {\n socket[kReset] = true\n } else {\n client[kKeepAliveTimeoutValue] = timeout\n }\n } else {\n client[kKeepAliveTimeoutValue] = client[kKeepAliveDefaultTimeout]\n }\n } else {\n // Stop more requests from being dispatched.\n socket[kReset] = true\n }\n\n const pause = request.onHeaders(statusCode, headers, this.resume, statusText) === false\n\n if (request.aborted) {\n return -1\n }\n\n if (request.method === 'HEAD') {\n return 1\n }\n\n if (statusCode < 200) {\n return 1\n }\n\n if (socket[kBlocking]) {\n socket[kBlocking] = false\n resume(client)\n }\n\n return pause ? constants.ERROR.PAUSED : 0\n }\n\n onBody (buf) {\n const { client, socket, statusCode, maxResponseSize } = this\n\n if (socket.destroyed) {\n return -1\n }\n\n const request = client[kQueue][client[kRunningIdx]]\n assert(request)\n\n assert.strictEqual(this.timeoutType, TIMEOUT_BODY)\n if (this.timeout) {\n // istanbul ignore else: only for jest\n if (this.timeout.refresh) {\n this.timeout.refresh()\n }\n }\n\n assert(statusCode >= 200)\n\n if (maxResponseSize > -1 && this.bytesRead + buf.length > maxResponseSize) {\n util.destroy(socket, new ResponseExceededMaxSizeError())\n return -1\n }\n\n this.bytesRead += buf.length\n\n if (request.onData(buf) === false) {\n return constants.ERROR.PAUSED\n }\n }\n\n onMessageComplete () {\n const { client, socket, statusCode, upgrade, headers, contentLength, bytesRead, shouldKeepAlive } = this\n\n if (socket.destroyed && (!statusCode || shouldKeepAlive)) {\n return -1\n }\n\n if (upgrade) {\n return\n }\n\n const request = client[kQueue][client[kRunningIdx]]\n assert(request)\n\n assert(statusCode >= 100)\n\n this.statusCode = null\n this.statusText = ''\n this.bytesRead = 0\n this.contentLength = ''\n this.keepAlive = ''\n this.connection = ''\n\n assert(this.headers.length % 2 === 0)\n this.headers = []\n this.headersSize = 0\n\n if (statusCode < 200) {\n return\n }\n\n /* istanbul ignore next: should be handled by llhttp? */\n if (request.method !== 'HEAD' && contentLength && bytesRead !== parseInt(contentLength, 10)) {\n util.destroy(socket, new ResponseContentLengthMismatchError())\n return -1\n }\n\n request.onComplete(headers)\n\n client[kQueue][client[kRunningIdx]++] = null\n\n if (socket[kWriting]) {\n assert.strictEqual(client[kRunning], 0)\n // Response completed before request.\n util.destroy(socket, new InformationalError('reset'))\n return constants.ERROR.PAUSED\n } else if (!shouldKeepAlive) {\n util.destroy(socket, new InformationalError('reset'))\n return constants.ERROR.PAUSED\n } else if (socket[kReset] && client[kRunning] === 0) {\n // Destroy socket once all requests have completed.\n // The request at the tail of the pipeline is the one\n // that requested reset and no further requests should\n // have been queued since then.\n util.destroy(socket, new InformationalError('reset'))\n return constants.ERROR.PAUSED\n } else if (client[kPipelining] === 1) {\n // We must wait a full event loop cycle to reuse this socket to make sure\n // that non-spec compliant servers are not closing the connection even if they\n // said they won't.\n setImmediate(resume, client)\n } else {\n resume(client)\n }\n }\n}\n\nfunction onParserTimeout (parser) {\n const { socket, timeoutType, client } = parser\n\n /* istanbul ignore else */\n if (timeoutType === TIMEOUT_HEADERS) {\n if (!socket[kWriting] || socket.writableNeedDrain || client[kRunning] > 1) {\n assert(!parser.paused, 'cannot be paused while waiting for headers')\n util.destroy(socket, new HeadersTimeoutError())\n }\n } else if (timeoutType === TIMEOUT_BODY) {\n if (!parser.paused) {\n util.destroy(socket, new BodyTimeoutError())\n }\n } else if (timeoutType === TIMEOUT_IDLE) {\n assert(client[kRunning] === 0 && client[kKeepAliveTimeoutValue])\n util.destroy(socket, new InformationalError('socket idle timeout'))\n }\n}\n\nfunction onSocketReadable () {\n const { [kParser]: parser } = this\n if (parser) {\n parser.readMore()\n }\n}\n\nfunction onSocketError (err) {\n const { [kClient]: client, [kParser]: parser } = this\n\n assert(err.code !== 'ERR_TLS_CERT_ALTNAME_INVALID')\n\n if (client[kHTTPConnVersion] !== 'h2') {\n // On Mac OS, we get an ECONNRESET even if there is a full body to be forwarded\n // to the user.\n if (err.code === 'ECONNRESET' && parser.statusCode && !parser.shouldKeepAlive) {\n // We treat all incoming data so for as a valid response.\n parser.onMessageComplete()\n return\n }\n }\n\n this[kError] = err\n\n onError(this[kClient], err)\n}\n\nfunction onError (client, err) {\n if (\n client[kRunning] === 0 &&\n err.code !== 'UND_ERR_INFO' &&\n err.code !== 'UND_ERR_SOCKET'\n ) {\n // Error is not caused by running request and not a recoverable\n // socket error.\n\n assert(client[kPendingIdx] === client[kRunningIdx])\n\n const requests = client[kQueue].splice(client[kRunningIdx])\n for (let i = 0; i < requests.length; i++) {\n const request = requests[i]\n errorRequest(client, request, err)\n }\n assert(client[kSize] === 0)\n }\n}\n\nfunction onSocketEnd () {\n const { [kParser]: parser, [kClient]: client } = this\n\n if (client[kHTTPConnVersion] !== 'h2') {\n if (parser.statusCode && !parser.shouldKeepAlive) {\n // We treat all incoming data so far as a valid response.\n parser.onMessageComplete()\n return\n }\n }\n\n util.destroy(this, new SocketError('other side closed', util.getSocketInfo(this)))\n}\n\nfunction onSocketClose () {\n const { [kClient]: client, [kParser]: parser } = this\n\n if (client[kHTTPConnVersion] === 'h1' && parser) {\n if (!this[kError] && parser.statusCode && !parser.shouldKeepAlive) {\n // We treat all incoming data so far as a valid response.\n parser.onMessageComplete()\n }\n\n this[kParser].destroy()\n this[kParser] = null\n }\n\n const err = this[kError] || new SocketError('closed', util.getSocketInfo(this))\n\n client[kSocket] = null\n\n if (client.destroyed) {\n assert(client[kPending] === 0)\n\n // Fail entire queue.\n const requests = client[kQueue].splice(client[kRunningIdx])\n for (let i = 0; i < requests.length; i++) {\n const request = requests[i]\n errorRequest(client, request, err)\n }\n } else if (client[kRunning] > 0 && err.code !== 'UND_ERR_INFO') {\n // Fail head of pipeline.\n const request = client[kQueue][client[kRunningIdx]]\n client[kQueue][client[kRunningIdx]++] = null\n\n errorRequest(client, request, err)\n }\n\n client[kPendingIdx] = client[kRunningIdx]\n\n assert(client[kRunning] === 0)\n\n client.emit('disconnect', client[kUrl], [client], err)\n\n resume(client)\n}\n\nasync function connect (client) {\n assert(!client[kConnecting])\n assert(!client[kSocket])\n\n let { host, hostname, protocol, port } = client[kUrl]\n\n // Resolve ipv6\n if (hostname[0] === '[') {\n const idx = hostname.indexOf(']')\n\n assert(idx !== -1)\n const ip = hostname.substring(1, idx)\n\n assert(net.isIP(ip))\n hostname = ip\n }\n\n client[kConnecting] = true\n\n if (channels.beforeConnect.hasSubscribers) {\n channels.beforeConnect.publish({\n connectParams: {\n host,\n hostname,\n protocol,\n port,\n servername: client[kServerName],\n localAddress: client[kLocalAddress]\n },\n connector: client[kConnector]\n })\n }\n\n try {\n const socket = await new Promise((resolve, reject) => {\n client[kConnector]({\n host,\n hostname,\n protocol,\n port,\n servername: client[kServerName],\n localAddress: client[kLocalAddress]\n }, (err, socket) => {\n if (err) {\n reject(err)\n } else {\n resolve(socket)\n }\n })\n })\n\n if (client.destroyed) {\n util.destroy(socket.on('error', () => {}), new ClientDestroyedError())\n return\n }\n\n client[kConnecting] = false\n\n assert(socket)\n\n const isH2 = socket.alpnProtocol === 'h2'\n if (isH2) {\n if (!h2ExperimentalWarned) {\n h2ExperimentalWarned = true\n process.emitWarning('H2 support is experimental, expect them to change at any time.', {\n code: 'UNDICI-H2'\n })\n }\n\n const session = http2.connect(client[kUrl], {\n createConnection: () => socket,\n peerMaxConcurrentStreams: client[kHTTP2SessionState].maxConcurrentStreams\n })\n\n client[kHTTPConnVersion] = 'h2'\n session[kClient] = client\n session[kSocket] = socket\n session.on('error', onHttp2SessionError)\n session.on('frameError', onHttp2FrameError)\n session.on('end', onHttp2SessionEnd)\n session.on('goaway', onHTTP2GoAway)\n session.on('close', onSocketClose)\n session.unref()\n\n client[kHTTP2Session] = session\n socket[kHTTP2Session] = session\n } else {\n if (!llhttpInstance) {\n llhttpInstance = await llhttpPromise\n llhttpPromise = null\n }\n\n socket[kNoRef] = false\n socket[kWriting] = false\n socket[kReset] = false\n socket[kBlocking] = false\n socket[kParser] = new Parser(client, socket, llhttpInstance)\n }\n\n socket[kCounter] = 0\n socket[kMaxRequests] = client[kMaxRequests]\n socket[kClient] = client\n socket[kError] = null\n\n socket\n .on('error', onSocketError)\n .on('readable', onSocketReadable)\n .on('end', onSocketEnd)\n .on('close', onSocketClose)\n\n client[kSocket] = socket\n\n if (channels.connected.hasSubscribers) {\n channels.connected.publish({\n connectParams: {\n host,\n hostname,\n protocol,\n port,\n servername: client[kServerName],\n localAddress: client[kLocalAddress]\n },\n connector: client[kConnector],\n socket\n })\n }\n client.emit('connect', client[kUrl], [client])\n } catch (err) {\n if (client.destroyed) {\n return\n }\n\n client[kConnecting] = false\n\n if (channels.connectError.hasSubscribers) {\n channels.connectError.publish({\n connectParams: {\n host,\n hostname,\n protocol,\n port,\n servername: client[kServerName],\n localAddress: client[kLocalAddress]\n },\n connector: client[kConnector],\n error: err\n })\n }\n\n if (err.code === 'ERR_TLS_CERT_ALTNAME_INVALID') {\n assert(client[kRunning] === 0)\n while (client[kPending] > 0 && client[kQueue][client[kPendingIdx]].servername === client[kServerName]) {\n const request = client[kQueue][client[kPendingIdx]++]\n errorRequest(client, request, err)\n }\n } else {\n onError(client, err)\n }\n\n client.emit('connectionError', client[kUrl], [client], err)\n }\n\n resume(client)\n}\n\nfunction emitDrain (client) {\n client[kNeedDrain] = 0\n client.emit('drain', client[kUrl], [client])\n}\n\nfunction resume (client, sync) {\n if (client[kResuming] === 2) {\n return\n }\n\n client[kResuming] = 2\n\n _resume(client, sync)\n client[kResuming] = 0\n\n if (client[kRunningIdx] > 256) {\n client[kQueue].splice(0, client[kRunningIdx])\n client[kPendingIdx] -= client[kRunningIdx]\n client[kRunningIdx] = 0\n }\n}\n\nfunction _resume (client, sync) {\n while (true) {\n if (client.destroyed) {\n assert(client[kPending] === 0)\n return\n }\n\n if (client[kClosedResolve] && !client[kSize]) {\n client[kClosedResolve]()\n client[kClosedResolve] = null\n return\n }\n\n const socket = client[kSocket]\n\n if (socket && !socket.destroyed && socket.alpnProtocol !== 'h2') {\n if (client[kSize] === 0) {\n if (!socket[kNoRef] && socket.unref) {\n socket.unref()\n socket[kNoRef] = true\n }\n } else if (socket[kNoRef] && socket.ref) {\n socket.ref()\n socket[kNoRef] = false\n }\n\n if (client[kSize] === 0) {\n if (socket[kParser].timeoutType !== TIMEOUT_IDLE) {\n socket[kParser].setTimeout(client[kKeepAliveTimeoutValue], TIMEOUT_IDLE)\n }\n } else if (client[kRunning] > 0 && socket[kParser].statusCode < 200) {\n if (socket[kParser].timeoutType !== TIMEOUT_HEADERS) {\n const request = client[kQueue][client[kRunningIdx]]\n const headersTimeout = request.headersTimeout != null\n ? request.headersTimeout\n : client[kHeadersTimeout]\n socket[kParser].setTimeout(headersTimeout, TIMEOUT_HEADERS)\n }\n }\n }\n\n if (client[kBusy]) {\n client[kNeedDrain] = 2\n } else if (client[kNeedDrain] === 2) {\n if (sync) {\n client[kNeedDrain] = 1\n process.nextTick(emitDrain, client)\n } else {\n emitDrain(client)\n }\n continue\n }\n\n if (client[kPending] === 0) {\n return\n }\n\n if (client[kRunning] >= (client[kPipelining] || 1)) {\n return\n }\n\n const request = client[kQueue][client[kPendingIdx]]\n\n if (client[kUrl].protocol === 'https:' && client[kServerName] !== request.servername) {\n if (client[kRunning] > 0) {\n return\n }\n\n client[kServerName] = request.servername\n\n if (socket && socket.servername !== request.servername) {\n util.destroy(socket, new InformationalError('servername changed'))\n return\n }\n }\n\n if (client[kConnecting]) {\n return\n }\n\n if (!socket && !client[kHTTP2Session]) {\n connect(client)\n return\n }\n\n if (socket.destroyed || socket[kWriting] || socket[kReset] || socket[kBlocking]) {\n return\n }\n\n if (client[kRunning] > 0 && !request.idempotent) {\n // Non-idempotent request cannot be retried.\n // Ensure that no other requests are inflight and\n // could cause failure.\n return\n }\n\n if (client[kRunning] > 0 && (request.upgrade || request.method === 'CONNECT')) {\n // Don't dispatch an upgrade until all preceding requests have completed.\n // A misbehaving server might upgrade the connection before all pipelined\n // request has completed.\n return\n }\n\n if (client[kRunning] > 0 && util.bodyLength(request.body) !== 0 &&\n (util.isStream(request.body) || util.isAsyncIterable(request.body))) {\n // Request with stream or iterator body can error while other requests\n // are inflight and indirectly error those as well.\n // Ensure this doesn't happen by waiting for inflight\n // to complete before dispatching.\n\n // Request with stream or iterator body cannot be retried.\n // Ensure that no other requests are inflight and\n // could cause failure.\n return\n }\n\n if (!request.aborted && write(client, request)) {\n client[kPendingIdx]++\n } else {\n client[kQueue].splice(client[kPendingIdx], 1)\n }\n }\n}\n\n// https://www.rfc-editor.org/rfc/rfc7230#section-3.3.2\nfunction shouldSendContentLength (method) {\n return method !== 'GET' && method !== 'HEAD' && method !== 'OPTIONS' && method !== 'TRACE' && method !== 'CONNECT'\n}\n\nfunction write (client, request) {\n if (client[kHTTPConnVersion] === 'h2') {\n writeH2(client, client[kHTTP2Session], request)\n return\n }\n\n const { body, method, path, host, upgrade, headers, blocking, reset } = request\n\n // https://tools.ietf.org/html/rfc7231#section-4.3.1\n // https://tools.ietf.org/html/rfc7231#section-4.3.2\n // https://tools.ietf.org/html/rfc7231#section-4.3.5\n\n // Sending a payload body on a request that does not\n // expect it can cause undefined behavior on some\n // servers and corrupt connection state. Do not\n // re-use the connection for further requests.\n\n const expectsPayload = (\n method === 'PUT' ||\n method === 'POST' ||\n method === 'PATCH'\n )\n\n if (body && typeof body.read === 'function') {\n // Try to read EOF in order to get length.\n body.read(0)\n }\n\n const bodyLength = util.bodyLength(body)\n\n let contentLength = bodyLength\n\n if (contentLength === null) {\n contentLength = request.contentLength\n }\n\n if (contentLength === 0 && !expectsPayload) {\n // https://tools.ietf.org/html/rfc7230#section-3.3.2\n // A user agent SHOULD NOT send a Content-Length header field when\n // the request message does not contain a payload body and the method\n // semantics do not anticipate such a body.\n\n contentLength = null\n }\n\n // https://github.com/nodejs/undici/issues/2046\n // A user agent may send a Content-Length header with 0 value, this should be allowed.\n if (shouldSendContentLength(method) && contentLength > 0 && request.contentLength !== null && request.contentLength !== contentLength) {\n if (client[kStrictContentLength]) {\n errorRequest(client, request, new RequestContentLengthMismatchError())\n return false\n }\n\n process.emitWarning(new RequestContentLengthMismatchError())\n }\n\n const socket = client[kSocket]\n\n try {\n request.onConnect((err) => {\n if (request.aborted || request.completed) {\n return\n }\n\n errorRequest(client, request, err || new RequestAbortedError())\n\n util.destroy(socket, new InformationalError('aborted'))\n })\n } catch (err) {\n errorRequest(client, request, err)\n }\n\n if (request.aborted) {\n return false\n }\n\n if (method === 'HEAD') {\n // https://github.com/mcollina/undici/issues/258\n // Close after a HEAD request to interop with misbehaving servers\n // that may send a body in the response.\n\n socket[kReset] = true\n }\n\n if (upgrade || method === 'CONNECT') {\n // On CONNECT or upgrade, block pipeline from dispatching further\n // requests on this connection.\n\n socket[kReset] = true\n }\n\n if (reset != null) {\n socket[kReset] = reset\n }\n\n if (client[kMaxRequests] && socket[kCounter]++ >= client[kMaxRequests]) {\n socket[kReset] = true\n }\n\n if (blocking) {\n socket[kBlocking] = true\n }\n\n let header = `${method} ${path} HTTP/1.1\\r\\n`\n\n if (typeof host === 'string') {\n header += `host: ${host}\\r\\n`\n } else {\n header += client[kHostHeader]\n }\n\n if (upgrade) {\n header += `connection: upgrade\\r\\nupgrade: ${upgrade}\\r\\n`\n } else if (client[kPipelining] && !socket[kReset]) {\n header += 'connection: keep-alive\\r\\n'\n } else {\n header += 'connection: close\\r\\n'\n }\n\n if (headers) {\n header += headers\n }\n\n if (channels.sendHeaders.hasSubscribers) {\n channels.sendHeaders.publish({ request, headers: header, socket })\n }\n\n /* istanbul ignore else: assertion */\n if (!body || bodyLength === 0) {\n if (contentLength === 0) {\n socket.write(`${header}content-length: 0\\r\\n\\r\\n`, 'latin1')\n } else {\n assert(contentLength === null, 'no body must not have content length')\n socket.write(`${header}\\r\\n`, 'latin1')\n }\n request.onRequestSent()\n } else if (util.isBuffer(body)) {\n assert(contentLength === body.byteLength, 'buffer body must have content length')\n\n socket.cork()\n socket.write(`${header}content-length: ${contentLength}\\r\\n\\r\\n`, 'latin1')\n socket.write(body)\n socket.uncork()\n request.onBodySent(body)\n request.onRequestSent()\n if (!expectsPayload) {\n socket[kReset] = true\n }\n } else if (util.isBlobLike(body)) {\n if (typeof body.stream === 'function') {\n writeIterable({ body: body.stream(), client, request, socket, contentLength, header, expectsPayload })\n } else {\n writeBlob({ body, client, request, socket, contentLength, header, expectsPayload })\n }\n } else if (util.isStream(body)) {\n writeStream({ body, client, request, socket, contentLength, header, expectsPayload })\n } else if (util.isIterable(body)) {\n writeIterable({ body, client, request, socket, contentLength, header, expectsPayload })\n } else {\n assert(false)\n }\n\n return true\n}\n\nfunction writeH2 (client, session, request) {\n const { body, method, path, host, upgrade, expectContinue, signal, headers: reqHeaders } = request\n\n let headers\n if (typeof reqHeaders === 'string') headers = Request[kHTTP2CopyHeaders](reqHeaders.trim())\n else headers = reqHeaders\n\n if (upgrade) {\n errorRequest(client, request, new Error('Upgrade not supported for H2'))\n return false\n }\n\n try {\n // TODO(HTTP/2): Should we call onConnect immediately or on stream ready event?\n request.onConnect((err) => {\n if (request.aborted || request.completed) {\n return\n }\n\n errorRequest(client, request, err || new RequestAbortedError())\n })\n } catch (err) {\n errorRequest(client, request, err)\n }\n\n if (request.aborted) {\n return false\n }\n\n /** @type {import('node:http2').ClientHttp2Stream} */\n let stream\n const h2State = client[kHTTP2SessionState]\n\n headers[HTTP2_HEADER_AUTHORITY] = host || client[kHost]\n headers[HTTP2_HEADER_METHOD] = method\n\n if (method === 'CONNECT') {\n session.ref()\n // we are already connected, streams are pending, first request\n // will create a new stream. We trigger a request to create the stream and wait until\n // `ready` event is triggered\n // We disabled endStream to allow the user to write to the stream\n stream = session.request(headers, { endStream: false, signal })\n\n if (stream.id && !stream.pending) {\n request.onUpgrade(null, null, stream)\n ++h2State.openStreams\n } else {\n stream.once('ready', () => {\n request.onUpgrade(null, null, stream)\n ++h2State.openStreams\n })\n }\n\n stream.once('close', () => {\n h2State.openStreams -= 1\n // TODO(HTTP/2): unref only if current streams count is 0\n if (h2State.openStreams === 0) session.unref()\n })\n\n return true\n }\n\n // https://tools.ietf.org/html/rfc7540#section-8.3\n // :path and :scheme headers must be omited when sending CONNECT\n\n headers[HTTP2_HEADER_PATH] = path\n headers[HTTP2_HEADER_SCHEME] = 'https'\n\n // https://tools.ietf.org/html/rfc7231#section-4.3.1\n // https://tools.ietf.org/html/rfc7231#section-4.3.2\n // https://tools.ietf.org/html/rfc7231#section-4.3.5\n\n // Sending a payload body on a request that does not\n // expect it can cause undefined behavior on some\n // servers and corrupt connection state. Do not\n // re-use the connection for further requests.\n\n const expectsPayload = (\n method === 'PUT' ||\n method === 'POST' ||\n method === 'PATCH'\n )\n\n if (body && typeof body.read === 'function') {\n // Try to read EOF in order to get length.\n body.read(0)\n }\n\n let contentLength = util.bodyLength(body)\n\n if (contentLength == null) {\n contentLength = request.contentLength\n }\n\n if (contentLength === 0 || !expectsPayload) {\n // https://tools.ietf.org/html/rfc7230#section-3.3.2\n // A user agent SHOULD NOT send a Content-Length header field when\n // the request message does not contain a payload body and the method\n // semantics do not anticipate such a body.\n\n contentLength = null\n }\n\n // https://github.com/nodejs/undici/issues/2046\n // A user agent may send a Content-Length header with 0 value, this should be allowed.\n if (shouldSendContentLength(method) && contentLength > 0 && request.contentLength != null && request.contentLength !== contentLength) {\n if (client[kStrictContentLength]) {\n errorRequest(client, request, new RequestContentLengthMismatchError())\n return false\n }\n\n process.emitWarning(new RequestContentLengthMismatchError())\n }\n\n if (contentLength != null) {\n assert(body, 'no body must not have content length')\n headers[HTTP2_HEADER_CONTENT_LENGTH] = `${contentLength}`\n }\n\n session.ref()\n\n const shouldEndStream = method === 'GET' || method === 'HEAD'\n if (expectContinue) {\n headers[HTTP2_HEADER_EXPECT] = '100-continue'\n stream = session.request(headers, { endStream: shouldEndStream, signal })\n\n stream.once('continue', writeBodyH2)\n } else {\n stream = session.request(headers, {\n endStream: shouldEndStream,\n signal\n })\n writeBodyH2()\n }\n\n // Increment counter as we have new several streams open\n ++h2State.openStreams\n\n stream.once('response', headers => {\n const { [HTTP2_HEADER_STATUS]: statusCode, ...realHeaders } = headers\n\n if (request.onHeaders(Number(statusCode), realHeaders, stream.resume.bind(stream), '') === false) {\n stream.pause()\n }\n })\n\n stream.once('end', () => {\n request.onComplete([])\n })\n\n stream.on('data', (chunk) => {\n if (request.onData(chunk) === false) {\n stream.pause()\n }\n })\n\n stream.once('close', () => {\n h2State.openStreams -= 1\n // TODO(HTTP/2): unref only if current streams count is 0\n if (h2State.openStreams === 0) {\n session.unref()\n }\n })\n\n stream.once('error', function (err) {\n if (client[kHTTP2Session] && !client[kHTTP2Session].destroyed && !this.closed && !this.destroyed) {\n h2State.streams -= 1\n util.destroy(stream, err)\n }\n })\n\n stream.once('frameError', (type, code) => {\n const err = new InformationalError(`HTTP/2: \"frameError\" received - type ${type}, code ${code}`)\n errorRequest(client, request, err)\n\n if (client[kHTTP2Session] && !client[kHTTP2Session].destroyed && !this.closed && !this.destroyed) {\n h2State.streams -= 1\n util.destroy(stream, err)\n }\n })\n\n // stream.on('aborted', () => {\n // // TODO(HTTP/2): Support aborted\n // })\n\n // stream.on('timeout', () => {\n // // TODO(HTTP/2): Support timeout\n // })\n\n // stream.on('push', headers => {\n // // TODO(HTTP/2): Suppor push\n // })\n\n // stream.on('trailers', headers => {\n // // TODO(HTTP/2): Support trailers\n // })\n\n return true\n\n function writeBodyH2 () {\n /* istanbul ignore else: assertion */\n if (!body) {\n request.onRequestSent()\n } else if (util.isBuffer(body)) {\n assert(contentLength === body.byteLength, 'buffer body must have content length')\n stream.cork()\n stream.write(body)\n stream.uncork()\n stream.end()\n request.onBodySent(body)\n request.onRequestSent()\n } else if (util.isBlobLike(body)) {\n if (typeof body.stream === 'function') {\n writeIterable({\n client,\n request,\n contentLength,\n h2stream: stream,\n expectsPayload,\n body: body.stream(),\n socket: client[kSocket],\n header: ''\n })\n } else {\n writeBlob({\n body,\n client,\n request,\n contentLength,\n expectsPayload,\n h2stream: stream,\n header: '',\n socket: client[kSocket]\n })\n }\n } else if (util.isStream(body)) {\n writeStream({\n body,\n client,\n request,\n contentLength,\n expectsPayload,\n socket: client[kSocket],\n h2stream: stream,\n header: ''\n })\n } else if (util.isIterable(body)) {\n writeIterable({\n body,\n client,\n request,\n contentLength,\n expectsPayload,\n header: '',\n h2stream: stream,\n socket: client[kSocket]\n })\n } else {\n assert(false)\n }\n }\n}\n\nfunction writeStream ({ h2stream, body, client, request, socket, contentLength, header, expectsPayload }) {\n assert(contentLength !== 0 || client[kRunning] === 0, 'stream body cannot be pipelined')\n\n if (client[kHTTPConnVersion] === 'h2') {\n // For HTTP/2, is enough to pipe the stream\n const pipe = pipeline(\n body,\n h2stream,\n (err) => {\n if (err) {\n util.destroy(body, err)\n util.destroy(h2stream, err)\n } else {\n request.onRequestSent()\n }\n }\n )\n\n pipe.on('data', onPipeData)\n pipe.once('end', () => {\n pipe.removeListener('data', onPipeData)\n util.destroy(pipe)\n })\n\n function onPipeData (chunk) {\n request.onBodySent(chunk)\n }\n\n return\n }\n\n let finished = false\n\n const writer = new AsyncWriter({ socket, request, contentLength, client, expectsPayload, header })\n\n const onData = function (chunk) {\n if (finished) {\n return\n }\n\n try {\n if (!writer.write(chunk) && this.pause) {\n this.pause()\n }\n } catch (err) {\n util.destroy(this, err)\n }\n }\n const onDrain = function () {\n if (finished) {\n return\n }\n\n if (body.resume) {\n body.resume()\n }\n }\n const onAbort = function () {\n if (finished) {\n return\n }\n const err = new RequestAbortedError()\n queueMicrotask(() => onFinished(err))\n }\n const onFinished = function (err) {\n if (finished) {\n return\n }\n\n finished = true\n\n assert(socket.destroyed || (socket[kWriting] && client[kRunning] <= 1))\n\n socket\n .off('drain', onDrain)\n .off('error', onFinished)\n\n body\n .removeListener('data', onData)\n .removeListener('end', onFinished)\n .removeListener('error', onFinished)\n .removeListener('close', onAbort)\n\n if (!err) {\n try {\n writer.end()\n } catch (er) {\n err = er\n }\n }\n\n writer.destroy(err)\n\n if (err && (err.code !== 'UND_ERR_INFO' || err.message !== 'reset')) {\n util.destroy(body, err)\n } else {\n util.destroy(body)\n }\n }\n\n body\n .on('data', onData)\n .on('end', onFinished)\n .on('error', onFinished)\n .on('close', onAbort)\n\n if (body.resume) {\n body.resume()\n }\n\n socket\n .on('drain', onDrain)\n .on('error', onFinished)\n}\n\nasync function writeBlob ({ h2stream, body, client, request, socket, contentLength, header, expectsPayload }) {\n assert(contentLength === body.size, 'blob body must have content length')\n\n const isH2 = client[kHTTPConnVersion] === 'h2'\n try {\n if (contentLength != null && contentLength !== body.size) {\n throw new RequestContentLengthMismatchError()\n }\n\n const buffer = Buffer.from(await body.arrayBuffer())\n\n if (isH2) {\n h2stream.cork()\n h2stream.write(buffer)\n h2stream.uncork()\n } else {\n socket.cork()\n socket.write(`${header}content-length: ${contentLength}\\r\\n\\r\\n`, 'latin1')\n socket.write(buffer)\n socket.uncork()\n }\n\n request.onBodySent(buffer)\n request.onRequestSent()\n\n if (!expectsPayload) {\n socket[kReset] = true\n }\n\n resume(client)\n } catch (err) {\n util.destroy(isH2 ? h2stream : socket, err)\n }\n}\n\nasync function writeIterable ({ h2stream, body, client, request, socket, contentLength, header, expectsPayload }) {\n assert(contentLength !== 0 || client[kRunning] === 0, 'iterator body cannot be pipelined')\n\n let callback = null\n function onDrain () {\n if (callback) {\n const cb = callback\n callback = null\n cb()\n }\n }\n\n const waitForDrain = () => new Promise((resolve, reject) => {\n assert(callback === null)\n\n if (socket[kError]) {\n reject(socket[kError])\n } else {\n callback = resolve\n }\n })\n\n if (client[kHTTPConnVersion] === 'h2') {\n h2stream\n .on('close', onDrain)\n .on('drain', onDrain)\n\n try {\n // It's up to the user to somehow abort the async iterable.\n for await (const chunk of body) {\n if (socket[kError]) {\n throw socket[kError]\n }\n\n const res = h2stream.write(chunk)\n request.onBodySent(chunk)\n if (!res) {\n await waitForDrain()\n }\n }\n } catch (err) {\n h2stream.destroy(err)\n } finally {\n request.onRequestSent()\n h2stream.end()\n h2stream\n .off('close', onDrain)\n .off('drain', onDrain)\n }\n\n return\n }\n\n socket\n .on('close', onDrain)\n .on('drain', onDrain)\n\n const writer = new AsyncWriter({ socket, request, contentLength, client, expectsPayload, header })\n try {\n // It's up to the user to somehow abort the async iterable.\n for await (const chunk of body) {\n if (socket[kError]) {\n throw socket[kError]\n }\n\n if (!writer.write(chunk)) {\n await waitForDrain()\n }\n }\n\n writer.end()\n } catch (err) {\n writer.destroy(err)\n } finally {\n socket\n .off('close', onDrain)\n .off('drain', onDrain)\n }\n}\n\nclass AsyncWriter {\n constructor ({ socket, request, contentLength, client, expectsPayload, header }) {\n this.socket = socket\n this.request = request\n this.contentLength = contentLength\n this.client = client\n this.bytesWritten = 0\n this.expectsPayload = expectsPayload\n this.header = header\n\n socket[kWriting] = true\n }\n\n write (chunk) {\n const { socket, request, contentLength, client, bytesWritten, expectsPayload, header } = this\n\n if (socket[kError]) {\n throw socket[kError]\n }\n\n if (socket.destroyed) {\n return false\n }\n\n const len = Buffer.byteLength(chunk)\n if (!len) {\n return true\n }\n\n // We should defer writing chunks.\n if (contentLength !== null && bytesWritten + len > contentLength) {\n if (client[kStrictContentLength]) {\n throw new RequestContentLengthMismatchError()\n }\n\n process.emitWarning(new RequestContentLengthMismatchError())\n }\n\n socket.cork()\n\n if (bytesWritten === 0) {\n if (!expectsPayload) {\n socket[kReset] = true\n }\n\n if (contentLength === null) {\n socket.write(`${header}transfer-encoding: chunked\\r\\n`, 'latin1')\n } else {\n socket.write(`${header}content-length: ${contentLength}\\r\\n\\r\\n`, 'latin1')\n }\n }\n\n if (contentLength === null) {\n socket.write(`\\r\\n${len.toString(16)}\\r\\n`, 'latin1')\n }\n\n this.bytesWritten += len\n\n const ret = socket.write(chunk)\n\n socket.uncork()\n\n request.onBodySent(chunk)\n\n if (!ret) {\n if (socket[kParser].timeout && socket[kParser].timeoutType === TIMEOUT_HEADERS) {\n // istanbul ignore else: only for jest\n if (socket[kParser].timeout.refresh) {\n socket[kParser].timeout.refresh()\n }\n }\n }\n\n return ret\n }\n\n end () {\n const { socket, contentLength, client, bytesWritten, expectsPayload, header, request } = this\n request.onRequestSent()\n\n socket[kWriting] = false\n\n if (socket[kError]) {\n throw socket[kError]\n }\n\n if (socket.destroyed) {\n return\n }\n\n if (bytesWritten === 0) {\n if (expectsPayload) {\n // https://tools.ietf.org/html/rfc7230#section-3.3.2\n // A user agent SHOULD send a Content-Length in a request message when\n // no Transfer-Encoding is sent and the request method defines a meaning\n // for an enclosed payload body.\n\n socket.write(`${header}content-length: 0\\r\\n\\r\\n`, 'latin1')\n } else {\n socket.write(`${header}\\r\\n`, 'latin1')\n }\n } else if (contentLength === null) {\n socket.write('\\r\\n0\\r\\n\\r\\n', 'latin1')\n }\n\n if (contentLength !== null && bytesWritten !== contentLength) {\n if (client[kStrictContentLength]) {\n throw new RequestContentLengthMismatchError()\n } else {\n process.emitWarning(new RequestContentLengthMismatchError())\n }\n }\n\n if (socket[kParser].timeout && socket[kParser].timeoutType === TIMEOUT_HEADERS) {\n // istanbul ignore else: only for jest\n if (socket[kParser].timeout.refresh) {\n socket[kParser].timeout.refresh()\n }\n }\n\n resume(client)\n }\n\n destroy (err) {\n const { socket, client } = this\n\n socket[kWriting] = false\n\n if (err) {\n assert(client[kRunning] <= 1, 'pipeline should only contain this request')\n util.destroy(socket, err)\n }\n }\n}\n\nfunction errorRequest (client, request, err) {\n try {\n request.onError(err)\n assert(request.aborted)\n } catch (err) {\n client.emit('error', err)\n }\n}\n\nmodule.exports = Client\n\n\n/***/ }),\n\n/***/ 6436:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\n\"use strict\";\n\n\n/* istanbul ignore file: only for Node 12 */\n\nconst { kConnected, kSize } = __nccwpck_require__(2785)\n\nclass CompatWeakRef {\n constructor (value) {\n this.value = value\n }\n\n deref () {\n return this.value[kConnected] === 0 && this.value[kSize] === 0\n ? undefined\n : this.value\n }\n}\n\nclass CompatFinalizer {\n constructor (finalizer) {\n this.finalizer = finalizer\n }\n\n register (dispatcher, key) {\n if (dispatcher.on) {\n dispatcher.on('disconnect', () => {\n if (dispatcher[kConnected] === 0 && dispatcher[kSize] === 0) {\n this.finalizer(key)\n }\n })\n }\n }\n}\n\nmodule.exports = function () {\n // FIXME: remove workaround when the Node bug is fixed\n // https://github.com/nodejs/node/issues/49344#issuecomment-1741776308\n if (process.env.NODE_V8_COVERAGE) {\n return {\n WeakRef: CompatWeakRef,\n FinalizationRegistry: CompatFinalizer\n }\n }\n return {\n WeakRef: global.WeakRef || CompatWeakRef,\n FinalizationRegistry: global.FinalizationRegistry || CompatFinalizer\n }\n}\n\n\n/***/ }),\n\n/***/ 663:\n/***/ ((module) => {\n\n\"use strict\";\n\n\n// https://wicg.github.io/cookie-store/#cookie-maximum-attribute-value-size\nconst maxAttributeValueSize = 1024\n\n// https://wicg.github.io/cookie-store/#cookie-maximum-name-value-pair-size\nconst maxNameValuePairSize = 4096\n\nmodule.exports = {\n maxAttributeValueSize,\n maxNameValuePairSize\n}\n\n\n/***/ }),\n\n/***/ 1724:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\n\"use strict\";\n\n\nconst { parseSetCookie } = __nccwpck_require__(4408)\nconst { stringify, getHeadersList } = __nccwpck_require__(3121)\nconst { webidl } = __nccwpck_require__(1744)\nconst { Headers } = __nccwpck_require__(554)\n\n/**\n * @typedef {Object} Cookie\n * @property {string} name\n * @property {string} value\n * @property {Date|number|undefined} expires\n * @property {number|undefined} maxAge\n * @property {string|undefined} domain\n * @property {string|undefined} path\n * @property {boolean|undefined} secure\n * @property {boolean|undefined} httpOnly\n * @property {'Strict'|'Lax'|'None'} sameSite\n * @property {string[]} unparsed\n */\n\n/**\n * @param {Headers} headers\n * @returns {Record<string, string>}\n */\nfunction getCookies (headers) {\n webidl.argumentLengthCheck(arguments, 1, { header: 'getCookies' })\n\n webidl.brandCheck(headers, Headers, { strict: false })\n\n const cookie = headers.get('cookie')\n const out = {}\n\n if (!cookie) {\n return out\n }\n\n for (const piece of cookie.split(';')) {\n const [name, ...value] = piece.split('=')\n\n out[name.trim()] = value.join('=')\n }\n\n return out\n}\n\n/**\n * @param {Headers} headers\n * @param {string} name\n * @param {{ path?: string, domain?: string }|undefined} attributes\n * @returns {void}\n */\nfunction deleteCookie (headers, name, attributes) {\n webidl.argumentLengthCheck(arguments, 2, { header: 'deleteCookie' })\n\n webidl.brandCheck(headers, Headers, { strict: false })\n\n name = webidl.converters.DOMString(name)\n attributes = webidl.converters.DeleteCookieAttributes(attributes)\n\n // Matches behavior of\n // https://github.com/denoland/deno_std/blob/63827b16330b82489a04614027c33b7904e08be5/http/cookie.ts#L278\n setCookie(headers, {\n name,\n value: '',\n expires: new Date(0),\n ...attributes\n })\n}\n\n/**\n * @param {Headers} headers\n * @returns {Cookie[]}\n */\nfunction getSetCookies (headers) {\n webidl.argumentLengthCheck(arguments, 1, { header: 'getSetCookies' })\n\n webidl.brandCheck(headers, Headers, { strict: false })\n\n const cookies = getHeadersList(headers).cookies\n\n if (!cookies) {\n return []\n }\n\n // In older versions of undici, cookies is a list of name:value.\n return cookies.map((pair) => parseSetCookie(Array.isArray(pair) ? pair[1] : pair))\n}\n\n/**\n * @param {Headers} headers\n * @param {Cookie} cookie\n * @returns {void}\n */\nfunction setCookie (headers, cookie) {\n webidl.argumentLengthCheck(arguments, 2, { header: 'setCookie' })\n\n webidl.brandCheck(headers, Headers, { strict: false })\n\n cookie = webidl.converters.Cookie(cookie)\n\n const str = stringify(cookie)\n\n if (str) {\n headers.append('Set-Cookie', stringify(cookie))\n }\n}\n\nwebidl.converters.DeleteCookieAttributes = webidl.dictionaryConverter([\n {\n converter: webidl.nullableConverter(webidl.converters.DOMString),\n key: 'path',\n defaultValue: null\n },\n {\n converter: webidl.nullableConverter(webidl.converters.DOMString),\n key: 'domain',\n defaultValue: null\n }\n])\n\nwebidl.converters.Cookie = webidl.dictionaryConverter([\n {\n converter: webidl.converters.DOMString,\n key: 'name'\n },\n {\n converter: webidl.converters.DOMString,\n key: 'value'\n },\n {\n converter: webidl.nullableConverter((value) => {\n if (typeof value === 'number') {\n return webidl.converters['unsigned long long'](value)\n }\n\n return new Date(value)\n }),\n key: 'expires',\n defaultValue: null\n },\n {\n converter: webidl.nullableConverter(webidl.converters['long long']),\n key: 'maxAge',\n defaultValue: null\n },\n {\n converter: webidl.nullableConverter(webidl.converters.DOMString),\n key: 'domain',\n defaultValue: null\n },\n {\n converter: webidl.nullableConverter(webidl.converters.DOMString),\n key: 'path',\n defaultValue: null\n },\n {\n converter: webidl.nullableConverter(webidl.converters.boolean),\n key: 'secure',\n defaultValue: null\n },\n {\n converter: webidl.nullableConverter(webidl.converters.boolean),\n key: 'httpOnly',\n defaultValue: null\n },\n {\n converter: webidl.converters.USVString,\n key: 'sameSite',\n allowedValues: ['Strict', 'Lax', 'None']\n },\n {\n converter: webidl.sequenceConverter(webidl.converters.DOMString),\n key: 'unparsed',\n defaultValue: []\n }\n])\n\nmodule.exports = {\n getCookies,\n deleteCookie,\n getSetCookies,\n setCookie\n}\n\n\n/***/ }),\n\n/***/ 4408:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\n\"use strict\";\n\n\nconst { maxNameValuePairSize, maxAttributeValueSize } = __nccwpck_require__(663)\nconst { isCTLExcludingHtab } = __nccwpck_require__(3121)\nconst { collectASequenceOfCodePointsFast } = __nccwpck_require__(685)\nconst assert = __nccwpck_require__(9491)\n\n/**\n * @description Parses the field-value attributes of a set-cookie header string.\n * @see https://datatracker.ietf.org/doc/html/draft-ietf-httpbis-rfc6265bis#section-5.4\n * @param {string} header\n * @returns if the header is invalid, null will be returned\n */\nfunction parseSetCookie (header) {\n // 1. If the set-cookie-string contains a %x00-08 / %x0A-1F / %x7F\n // character (CTL characters excluding HTAB): Abort these steps and\n // ignore the set-cookie-string entirely.\n if (isCTLExcludingHtab(header)) {\n return null\n }\n\n let nameValuePair = ''\n let unparsedAttributes = ''\n let name = ''\n let value = ''\n\n // 2. If the set-cookie-string contains a %x3B (\";\") character:\n if (header.includes(';')) {\n // 1. The name-value-pair string consists of the characters up to,\n // but not including, the first %x3B (\";\"), and the unparsed-\n // attributes consist of the remainder of the set-cookie-string\n // (including the %x3B (\";\") in question).\n const position = { position: 0 }\n\n nameValuePair = collectASequenceOfCodePointsFast(';', header, position)\n unparsedAttributes = header.slice(position.position)\n } else {\n // Otherwise:\n\n // 1. The name-value-pair string consists of all the characters\n // contained in the set-cookie-string, and the unparsed-\n // attributes is the empty string.\n nameValuePair = header\n }\n\n // 3. If the name-value-pair string lacks a %x3D (\"=\") character, then\n // the name string is empty, and the value string is the value of\n // name-value-pair.\n if (!nameValuePair.includes('=')) {\n value = nameValuePair\n } else {\n // Otherwise, the name string consists of the characters up to, but\n // not including, the first %x3D (\"=\") character, and the (possibly\n // empty) value string consists of the characters after the first\n // %x3D (\"=\") character.\n const position = { position: 0 }\n name = collectASequenceOfCodePointsFast(\n '=',\n nameValuePair,\n position\n )\n value = nameValuePair.slice(position.position + 1)\n }\n\n // 4. Remove any leading or trailing WSP characters from the name\n // string and the value string.\n name = name.trim()\n value = value.trim()\n\n // 5. If the sum of the lengths of the name string and the value string\n // is more than 4096 octets, abort these steps and ignore the set-\n // cookie-string entirely.\n if (name.length + value.length > maxNameValuePairSize) {\n return null\n }\n\n // 6. The cookie-name is the name string, and the cookie-value is the\n // value string.\n return {\n name, value, ...parseUnparsedAttributes(unparsedAttributes)\n }\n}\n\n/**\n * Parses the remaining attributes of a set-cookie header\n * @see https://datatracker.ietf.org/doc/html/draft-ietf-httpbis-rfc6265bis#section-5.4\n * @param {string} unparsedAttributes\n * @param {[Object.<string, unknown>]={}} cookieAttributeList\n */\nfunction parseUnparsedAttributes (unparsedAttributes, cookieAttributeList = {}) {\n // 1. If the unparsed-attributes string is empty, skip the rest of\n // these steps.\n if (unparsedAttributes.length === 0) {\n return cookieAttributeList\n }\n\n // 2. Discard the first character of the unparsed-attributes (which\n // will be a %x3B (\";\") character).\n assert(unparsedAttributes[0] === ';')\n unparsedAttributes = unparsedAttributes.slice(1)\n\n let cookieAv = ''\n\n // 3. If the remaining unparsed-attributes contains a %x3B (\";\")\n // character:\n if (unparsedAttributes.includes(';')) {\n // 1. Consume the characters of the unparsed-attributes up to, but\n // not including, the first %x3B (\";\") character.\n cookieAv = collectASequenceOfCodePointsFast(\n ';',\n unparsedAttributes,\n { position: 0 }\n )\n unparsedAttributes = unparsedAttributes.slice(cookieAv.length)\n } else {\n // Otherwise:\n\n // 1. Consume the remainder of the unparsed-attributes.\n cookieAv = unparsedAttributes\n unparsedAttributes = ''\n }\n\n // Let the cookie-av string be the characters consumed in this step.\n\n let attributeName = ''\n let attributeValue = ''\n\n // 4. If the cookie-av string contains a %x3D (\"=\") character:\n if (cookieAv.includes('=')) {\n // 1. The (possibly empty) attribute-name string consists of the\n // characters up to, but not including, the first %x3D (\"=\")\n // character, and the (possibly empty) attribute-value string\n // consists of the characters after the first %x3D (\"=\")\n // character.\n const position = { position: 0 }\n\n attributeName = collectASequenceOfCodePointsFast(\n '=',\n cookieAv,\n position\n )\n attributeValue = cookieAv.slice(position.position + 1)\n } else {\n // Otherwise:\n\n // 1. The attribute-name string consists of the entire cookie-av\n // string, and the attribute-value string is empty.\n attributeName = cookieAv\n }\n\n // 5. Remove any leading or trailing WSP characters from the attribute-\n // name string and the attribute-value string.\n attributeName = attributeName.trim()\n attributeValue = attributeValue.trim()\n\n // 6. If the attribute-value is longer than 1024 octets, ignore the\n // cookie-av string and return to Step 1 of this algorithm.\n if (attributeValue.length > maxAttributeValueSize) {\n return parseUnparsedAttributes(unparsedAttributes, cookieAttributeList)\n }\n\n // 7. Process the attribute-name and attribute-value according to the\n // requirements in the following subsections. (Notice that\n // attributes with unrecognized attribute-names are ignored.)\n const attributeNameLowercase = attributeName.toLowerCase()\n\n // https://datatracker.ietf.org/doc/html/draft-ietf-httpbis-rfc6265bis#section-5.4.1\n // If the attribute-name case-insensitively matches the string\n // \"Expires\", the user agent MUST process the cookie-av as follows.\n if (attributeNameLowercase === 'expires') {\n // 1. Let the expiry-time be the result of parsing the attribute-value\n // as cookie-date (see Section 5.1.1).\n const expiryTime = new Date(attributeValue)\n\n // 2. If the attribute-value failed to parse as a cookie date, ignore\n // the cookie-av.\n\n cookieAttributeList.expires = expiryTime\n } else if (attributeNameLowercase === 'max-age') {\n // https://datatracker.ietf.org/doc/html/draft-ietf-httpbis-rfc6265bis#section-5.4.2\n // If the attribute-name case-insensitively matches the string \"Max-\n // Age\", the user agent MUST process the cookie-av as follows.\n\n // 1. If the first character of the attribute-value is not a DIGIT or a\n // \"-\" character, ignore the cookie-av.\n const charCode = attributeValue.charCodeAt(0)\n\n if ((charCode < 48 || charCode > 57) && attributeValue[0] !== '-') {\n return parseUnparsedAttributes(unparsedAttributes, cookieAttributeList)\n }\n\n // 2. If the remainder of attribute-value contains a non-DIGIT\n // character, ignore the cookie-av.\n if (!/^\\d+$/.test(attributeValue)) {\n return parseUnparsedAttributes(unparsedAttributes, cookieAttributeList)\n }\n\n // 3. Let delta-seconds be the attribute-value converted to an integer.\n const deltaSeconds = Number(attributeValue)\n\n // 4. Let cookie-age-limit be the maximum age of the cookie (which\n // SHOULD be 400 days or less, see Section 4.1.2.2).\n\n // 5. Set delta-seconds to the smaller of its present value and cookie-\n // age-limit.\n // deltaSeconds = Math.min(deltaSeconds * 1000, maxExpiresMs)\n\n // 6. If delta-seconds is less than or equal to zero (0), let expiry-\n // time be the earliest representable date and time. Otherwise, let\n // the expiry-time be the current date and time plus delta-seconds\n // seconds.\n // const expiryTime = deltaSeconds <= 0 ? Date.now() : Date.now() + deltaSeconds\n\n // 7. Append an attribute to the cookie-attribute-list with an\n // attribute-name of Max-Age and an attribute-value of expiry-time.\n cookieAttributeList.maxAge = deltaSeconds\n } else if (attributeNameLowercase === 'domain') {\n // https://datatracker.ietf.org/doc/html/draft-ietf-httpbis-rfc6265bis#section-5.4.3\n // If the attribute-name case-insensitively matches the string \"Domain\",\n // the user agent MUST process the cookie-av as follows.\n\n // 1. Let cookie-domain be the attribute-value.\n let cookieDomain = attributeValue\n\n // 2. If cookie-domain starts with %x2E (\".\"), let cookie-domain be\n // cookie-domain without its leading %x2E (\".\").\n if (cookieDomain[0] === '.') {\n cookieDomain = cookieDomain.slice(1)\n }\n\n // 3. Convert the cookie-domain to lower case.\n cookieDomain = cookieDomain.toLowerCase()\n\n // 4. Append an attribute to the cookie-attribute-list with an\n // attribute-name of Domain and an attribute-value of cookie-domain.\n cookieAttributeList.domain = cookieDomain\n } else if (attributeNameLowercase === 'path') {\n // https://datatracker.ietf.org/doc/html/draft-ietf-httpbis-rfc6265bis#section-5.4.4\n // If the attribute-name case-insensitively matches the string \"Path\",\n // the user agent MUST process the cookie-av as follows.\n\n // 1. If the attribute-value is empty or if the first character of the\n // attribute-value is not %x2F (\"/\"):\n let cookiePath = ''\n if (attributeValue.length === 0 || attributeValue[0] !== '/') {\n // 1. Let cookie-path be the default-path.\n cookiePath = '/'\n } else {\n // Otherwise:\n\n // 1. Let cookie-path be the attribute-value.\n cookiePath = attributeValue\n }\n\n // 2. Append an attribute to the cookie-attribute-list with an\n // attribute-name of Path and an attribute-value of cookie-path.\n cookieAttributeList.path = cookiePath\n } else if (attributeNameLowercase === 'secure') {\n // https://datatracker.ietf.org/doc/html/draft-ietf-httpbis-rfc6265bis#section-5.4.5\n // If the attribute-name case-insensitively matches the string \"Secure\",\n // the user agent MUST append an attribute to the cookie-attribute-list\n // with an attribute-name of Secure and an empty attribute-value.\n\n cookieAttributeList.secure = true\n } else if (attributeNameLowercase === 'httponly') {\n // https://datatracker.ietf.org/doc/html/draft-ietf-httpbis-rfc6265bis#section-5.4.6\n // If the attribute-name case-insensitively matches the string\n // \"HttpOnly\", the user agent MUST append an attribute to the cookie-\n // attribute-list with an attribute-name of HttpOnly and an empty\n // attribute-value.\n\n cookieAttributeList.httpOnly = true\n } else if (attributeNameLowercase === 'samesite') {\n // https://datatracker.ietf.org/doc/html/draft-ietf-httpbis-rfc6265bis#section-5.4.7\n // If the attribute-name case-insensitively matches the string\n // \"SameSite\", the user agent MUST process the cookie-av as follows:\n\n // 1. Let enforcement be \"Default\".\n let enforcement = 'Default'\n\n const attributeValueLowercase = attributeValue.toLowerCase()\n // 2. If cookie-av's attribute-value is a case-insensitive match for\n // \"None\", set enforcement to \"None\".\n if (attributeValueLowercase.includes('none')) {\n enforcement = 'None'\n }\n\n // 3. If cookie-av's attribute-value is a case-insensitive match for\n // \"Strict\", set enforcement to \"Strict\".\n if (attributeValueLowercase.includes('strict')) {\n enforcement = 'Strict'\n }\n\n // 4. If cookie-av's attribute-value is a case-insensitive match for\n // \"Lax\", set enforcement to \"Lax\".\n if (attributeValueLowercase.includes('lax')) {\n enforcement = 'Lax'\n }\n\n // 5. Append an attribute to the cookie-attribute-list with an\n // attribute-name of \"SameSite\" and an attribute-value of\n // enforcement.\n cookieAttributeList.sameSite = enforcement\n } else {\n cookieAttributeList.unparsed ??= []\n\n cookieAttributeList.unparsed.push(`${attributeName}=${attributeValue}`)\n }\n\n // 8. Return to Step 1 of this algorithm.\n return parseUnparsedAttributes(unparsedAttributes, cookieAttributeList)\n}\n\nmodule.exports = {\n parseSetCookie,\n parseUnparsedAttributes\n}\n\n\n/***/ }),\n\n/***/ 3121:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\n\"use strict\";\n\n\nconst assert = __nccwpck_require__(9491)\nconst { kHeadersList } = __nccwpck_require__(2785)\n\nfunction isCTLExcludingHtab (value) {\n if (value.length === 0) {\n return false\n }\n\n for (const char of value) {\n const code = char.charCodeAt(0)\n\n if (\n (code >= 0x00 || code <= 0x08) ||\n (code >= 0x0A || code <= 0x1F) ||\n code === 0x7F\n ) {\n return false\n }\n }\n}\n\n/**\n CHAR = <any US-ASCII character (octets 0 - 127)>\n token = 1*<any CHAR except CTLs or separators>\n separators = \"(\" | \")\" | \"<\" | \">\" | \"@\"\n | \",\" | \";\" | \":\" | \"\\\" | <\">\n | \"/\" | \"[\" | \"]\" | \"?\" | \"=\"\n | \"{\" | \"}\" | SP | HT\n * @param {string} name\n */\nfunction validateCookieName (name) {\n for (const char of name) {\n const code = char.charCodeAt(0)\n\n if (\n (code <= 0x20 || code > 0x7F) ||\n char === '(' ||\n char === ')' ||\n char === '>' ||\n char === '<' ||\n char === '@' ||\n char === ',' ||\n char === ';' ||\n char === ':' ||\n char === '\\\\' ||\n char === '\"' ||\n char === '/' ||\n char === '[' ||\n char === ']' ||\n char === '?' ||\n char === '=' ||\n char === '{' ||\n char === '}'\n ) {\n throw new Error('Invalid cookie name')\n }\n }\n}\n\n/**\n cookie-value = *cookie-octet / ( DQUOTE *cookie-octet DQUOTE )\n cookie-octet = %x21 / %x23-2B / %x2D-3A / %x3C-5B / %x5D-7E\n ; US-ASCII characters excluding CTLs,\n ; whitespace DQUOTE, comma, semicolon,\n ; and backslash\n * @param {string} value\n */\nfunction validateCookieValue (value) {\n for (const char of value) {\n const code = char.charCodeAt(0)\n\n if (\n code < 0x21 || // exclude CTLs (0-31)\n code === 0x22 ||\n code === 0x2C ||\n code === 0x3B ||\n code === 0x5C ||\n code > 0x7E // non-ascii\n ) {\n throw new Error('Invalid header value')\n }\n }\n}\n\n/**\n * path-value = <any CHAR except CTLs or \";\">\n * @param {string} path\n */\nfunction validateCookiePath (path) {\n for (const char of path) {\n const code = char.charCodeAt(0)\n\n if (code < 0x21 || char === ';') {\n throw new Error('Invalid cookie path')\n }\n }\n}\n\n/**\n * I have no idea why these values aren't allowed to be honest,\n * but Deno tests these. - Khafra\n * @param {string} domain\n */\nfunction validateCookieDomain (domain) {\n if (\n domain.startsWith('-') ||\n domain.endsWith('.') ||\n domain.endsWith('-')\n ) {\n throw new Error('Invalid cookie domain')\n }\n}\n\n/**\n * @see https://www.rfc-editor.org/rfc/rfc7231#section-7.1.1.1\n * @param {number|Date} date\n IMF-fixdate = day-name \",\" SP date1 SP time-of-day SP GMT\n ; fixed length/zone/capitalization subset of the format\n ; see Section 3.3 of [RFC5322]\n\n day-name = %x4D.6F.6E ; \"Mon\", case-sensitive\n / %x54.75.65 ; \"Tue\", case-sensitive\n / %x57.65.64 ; \"Wed\", case-sensitive\n / %x54.68.75 ; \"Thu\", case-sensitive\n / %x46.72.69 ; \"Fri\", case-sensitive\n / %x53.61.74 ; \"Sat\", case-sensitive\n / %x53.75.6E ; \"Sun\", case-sensitive\n date1 = day SP month SP year\n ; e.g., 02 Jun 1982\n\n day = 2DIGIT\n month = %x4A.61.6E ; \"Jan\", case-sensitive\n / %x46.65.62 ; \"Feb\", case-sensitive\n / %x4D.61.72 ; \"Mar\", case-sensitive\n / %x41.70.72 ; \"Apr\", case-sensitive\n / %x4D.61.79 ; \"May\", case-sensitive\n / %x4A.75.6E ; \"Jun\", case-sensitive\n / %x4A.75.6C ; \"Jul\", case-sensitive\n / %x41.75.67 ; \"Aug\", case-sensitive\n / %x53.65.70 ; \"Sep\", case-sensitive\n / %x4F.63.74 ; \"Oct\", case-sensitive\n / %x4E.6F.76 ; \"Nov\", case-sensitive\n / %x44.65.63 ; \"Dec\", case-sensitive\n year = 4DIGIT\n\n GMT = %x47.4D.54 ; \"GMT\", case-sensitive\n\n time-of-day = hour \":\" minute \":\" second\n ; 00:00:00 - 23:59:60 (leap second)\n\n hour = 2DIGIT\n minute = 2DIGIT\n second = 2DIGIT\n */\nfunction toIMFDate (date) {\n if (typeof date === 'number') {\n date = new Date(date)\n }\n\n const days = [\n 'Sun', 'Mon', 'Tue', 'Wed',\n 'Thu', 'Fri', 'Sat'\n ]\n\n const months = [\n 'Jan', 'Feb', 'Mar', 'Apr', 'May', 'Jun',\n 'Jul', 'Aug', 'Sep', 'Oct', 'Nov', 'Dec'\n ]\n\n const dayName = days[date.getUTCDay()]\n const day = date.getUTCDate().toString().padStart(2, '0')\n const month = months[date.getUTCMonth()]\n const year = date.getUTCFullYear()\n const hour = date.getUTCHours().toString().padStart(2, '0')\n const minute = date.getUTCMinutes().toString().padStart(2, '0')\n const second = date.getUTCSeconds().toString().padStart(2, '0')\n\n return `${dayName}, ${day} ${month} ${year} ${hour}:${minute}:${second} GMT`\n}\n\n/**\n max-age-av = \"Max-Age=\" non-zero-digit *DIGIT\n ; In practice, both expires-av and max-age-av\n ; are limited to dates representable by the\n ; user agent.\n * @param {number} maxAge\n */\nfunction validateCookieMaxAge (maxAge) {\n if (maxAge < 0) {\n throw new Error('Invalid cookie max-age')\n }\n}\n\n/**\n * @see https://www.rfc-editor.org/rfc/rfc6265#section-4.1.1\n * @param {import('./index').Cookie} cookie\n */\nfunction stringify (cookie) {\n if (cookie.name.length === 0) {\n return null\n }\n\n validateCookieName(cookie.name)\n validateCookieValue(cookie.value)\n\n const out = [`${cookie.name}=${cookie.value}`]\n\n // https://datatracker.ietf.org/doc/html/draft-ietf-httpbis-cookie-prefixes-00#section-3.1\n // https://datatracker.ietf.org/doc/html/draft-ietf-httpbis-cookie-prefixes-00#section-3.2\n if (cookie.name.startsWith('__Secure-')) {\n cookie.secure = true\n }\n\n if (cookie.name.startsWith('__Host-')) {\n cookie.secure = true\n cookie.domain = null\n cookie.path = '/'\n }\n\n if (cookie.secure) {\n out.push('Secure')\n }\n\n if (cookie.httpOnly) {\n out.push('HttpOnly')\n }\n\n if (typeof cookie.maxAge === 'number') {\n validateCookieMaxAge(cookie.maxAge)\n out.push(`Max-Age=${cookie.maxAge}`)\n }\n\n if (cookie.domain) {\n validateCookieDomain(cookie.domain)\n out.push(`Domain=${cookie.domain}`)\n }\n\n if (cookie.path) {\n validateCookiePath(cookie.path)\n out.push(`Path=${cookie.path}`)\n }\n\n if (cookie.expires && cookie.expires.toString() !== 'Invalid Date') {\n out.push(`Expires=${toIMFDate(cookie.expires)}`)\n }\n\n if (cookie.sameSite) {\n out.push(`SameSite=${cookie.sameSite}`)\n }\n\n for (const part of cookie.unparsed) {\n if (!part.includes('=')) {\n throw new Error('Invalid unparsed')\n }\n\n const [key, ...value] = part.split('=')\n\n out.push(`${key.trim()}=${value.join('=')}`)\n }\n\n return out.join('; ')\n}\n\nlet kHeadersListNode\n\nfunction getHeadersList (headers) {\n if (headers[kHeadersList]) {\n return headers[kHeadersList]\n }\n\n if (!kHeadersListNode) {\n kHeadersListNode = Object.getOwnPropertySymbols(headers).find(\n (symbol) => symbol.description === 'headers list'\n )\n\n assert(kHeadersListNode, 'Headers cannot be parsed')\n }\n\n const headersList = headers[kHeadersListNode]\n assert(headersList)\n\n return headersList\n}\n\nmodule.exports = {\n isCTLExcludingHtab,\n stringify,\n getHeadersList\n}\n\n\n/***/ }),\n\n/***/ 2067:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\n\"use strict\";\n\n\nconst net = __nccwpck_require__(1808)\nconst assert = __nccwpck_require__(9491)\nconst util = __nccwpck_require__(3983)\nconst { InvalidArgumentError, ConnectTimeoutError } = __nccwpck_require__(8045)\n\nlet tls // include tls conditionally since it is not always available\n\n// TODO: session re-use does not wait for the first\n// connection to resolve the session and might therefore\n// resolve the same servername multiple times even when\n// re-use is enabled.\n\nlet SessionCache\n// FIXME: remove workaround when the Node bug is fixed\n// https://github.com/nodejs/node/issues/49344#issuecomment-1741776308\nif (global.FinalizationRegistry && !process.env.NODE_V8_COVERAGE) {\n SessionCache = class WeakSessionCache {\n constructor (maxCachedSessions) {\n this._maxCachedSessions = maxCachedSessions\n this._sessionCache = new Map()\n this._sessionRegistry = new global.FinalizationRegistry((key) => {\n if (this._sessionCache.size < this._maxCachedSessions) {\n return\n }\n\n const ref = this._sessionCache.get(key)\n if (ref !== undefined && ref.deref() === undefined) {\n this._sessionCache.delete(key)\n }\n })\n }\n\n get (sessionKey) {\n const ref = this._sessionCache.get(sessionKey)\n return ref ? ref.deref() : null\n }\n\n set (sessionKey, session) {\n if (this._maxCachedSessions === 0) {\n return\n }\n\n this._sessionCache.set(sessionKey, new WeakRef(session))\n this._sessionRegistry.register(session, sessionKey)\n }\n }\n} else {\n SessionCache = class SimpleSessionCache {\n constructor (maxCachedSessions) {\n this._maxCachedSessions = maxCachedSessions\n this._sessionCache = new Map()\n }\n\n get (sessionKey) {\n return this._sessionCache.get(sessionKey)\n }\n\n set (sessionKey, session) {\n if (this._maxCachedSessions === 0) {\n return\n }\n\n if (this._sessionCache.size >= this._maxCachedSessions) {\n // remove the oldest session\n const { value: oldestKey } = this._sessionCache.keys().next()\n this._sessionCache.delete(oldestKey)\n }\n\n this._sessionCache.set(sessionKey, session)\n }\n }\n}\n\nfunction buildConnector ({ allowH2, maxCachedSessions, socketPath, timeout, ...opts }) {\n if (maxCachedSessions != null && (!Number.isInteger(maxCachedSessions) || maxCachedSessions < 0)) {\n throw new InvalidArgumentError('maxCachedSessions must be a positive integer or zero')\n }\n\n const options = { path: socketPath, ...opts }\n const sessionCache = new SessionCache(maxCachedSessions == null ? 100 : maxCachedSessions)\n timeout = timeout == null ? 10e3 : timeout\n allowH2 = allowH2 != null ? allowH2 : false\n return function connect ({ hostname, host, protocol, port, servername, localAddress, httpSocket }, callback) {\n let socket\n if (protocol === 'https:') {\n if (!tls) {\n tls = __nccwpck_require__(4404)\n }\n servername = servername || options.servername || util.getServerName(host) || null\n\n const sessionKey = servername || hostname\n const session = sessionCache.get(sessionKey) || null\n\n assert(sessionKey)\n\n socket = tls.connect({\n highWaterMark: 16384, // TLS in node can't have bigger HWM anyway...\n ...options,\n servername,\n session,\n localAddress,\n // TODO(HTTP/2): Add support for h2c\n ALPNProtocols: allowH2 ? ['http/1.1', 'h2'] : ['http/1.1'],\n socket: httpSocket, // upgrade socket connection\n port: port || 443,\n host: hostname\n })\n\n socket\n .on('session', function (session) {\n // TODO (fix): Can a session become invalid once established? Don't think so?\n sessionCache.set(sessionKey, session)\n })\n } else {\n assert(!httpSocket, 'httpSocket can only be sent on TLS update')\n socket = net.connect({\n highWaterMark: 64 * 1024, // Same as nodejs fs streams.\n ...options,\n localAddress,\n port: port || 80,\n host: hostname\n })\n }\n\n // Set TCP keep alive options on the socket here instead of in connect() for the case of assigning the socket\n if (options.keepAlive == null || options.keepAlive) {\n const keepAliveInitialDelay = options.keepAliveInitialDelay === undefined ? 60e3 : options.keepAliveInitialDelay\n socket.setKeepAlive(true, keepAliveInitialDelay)\n }\n\n const cancelTimeout = setupTimeout(() => onConnectTimeout(socket), timeout)\n\n socket\n .setNoDelay(true)\n .once(protocol === 'https:' ? 'secureConnect' : 'connect', function () {\n cancelTimeout()\n\n if (callback) {\n const cb = callback\n callback = null\n cb(null, this)\n }\n })\n .on('error', function (err) {\n cancelTimeout()\n\n if (callback) {\n const cb = callback\n callback = null\n cb(err)\n }\n })\n\n return socket\n }\n}\n\nfunction setupTimeout (onConnectTimeout, timeout) {\n if (!timeout) {\n return () => {}\n }\n\n let s1 = null\n let s2 = null\n const timeoutId = setTimeout(() => {\n // setImmediate is added to make sure that we priotorise socket error events over timeouts\n s1 = setImmediate(() => {\n if (process.platform === 'win32') {\n // Windows needs an extra setImmediate probably due to implementation differences in the socket logic\n s2 = setImmediate(() => onConnectTimeout())\n } else {\n onConnectTimeout()\n }\n })\n }, timeout)\n return () => {\n clearTimeout(timeoutId)\n clearImmediate(s1)\n clearImmediate(s2)\n }\n}\n\nfunction onConnectTimeout (socket) {\n util.destroy(socket, new ConnectTimeoutError())\n}\n\nmodule.exports = buildConnector\n\n\n/***/ }),\n\n/***/ 4462:\n/***/ ((module) => {\n\n\"use strict\";\n\n\n/** @type {Record<string, string | undefined>} */\nconst headerNameLowerCasedRecord = {}\n\n// https://developer.mozilla.org/docs/Web/HTTP/Headers\nconst wellknownHeaderNames = [\n 'Accept',\n 'Accept-Encoding',\n 'Accept-Language',\n 'Accept-Ranges',\n 'Access-Control-Allow-Credentials',\n 'Access-Control-Allow-Headers',\n 'Access-Control-Allow-Methods',\n 'Access-Control-Allow-Origin',\n 'Access-Control-Expose-Headers',\n 'Access-Control-Max-Age',\n 'Access-Control-Request-Headers',\n 'Access-Control-Request-Method',\n 'Age',\n 'Allow',\n 'Alt-Svc',\n 'Alt-Used',\n 'Authorization',\n 'Cache-Control',\n 'Clear-Site-Data',\n 'Connection',\n 'Content-Disposition',\n 'Content-Encoding',\n 'Content-Language',\n 'Content-Length',\n 'Content-Location',\n 'Content-Range',\n 'Content-Security-Policy',\n 'Content-Security-Policy-Report-Only',\n 'Content-Type',\n 'Cookie',\n 'Cross-Origin-Embedder-Policy',\n 'Cross-Origin-Opener-Policy',\n 'Cross-Origin-Resource-Policy',\n 'Date',\n 'Device-Memory',\n 'Downlink',\n 'ECT',\n 'ETag',\n 'Expect',\n 'Expect-CT',\n 'Expires',\n 'Forwarded',\n 'From',\n 'Host',\n 'If-Match',\n 'If-Modified-Since',\n 'If-None-Match',\n 'If-Range',\n 'If-Unmodified-Since',\n 'Keep-Alive',\n 'Last-Modified',\n 'Link',\n 'Location',\n 'Max-Forwards',\n 'Origin',\n 'Permissions-Policy',\n 'Pragma',\n 'Proxy-Authenticate',\n 'Proxy-Authorization',\n 'RTT',\n 'Range',\n 'Referer',\n 'Referrer-Policy',\n 'Refresh',\n 'Retry-After',\n 'Sec-WebSocket-Accept',\n 'Sec-WebSocket-Extensions',\n 'Sec-WebSocket-Key',\n 'Sec-WebSocket-Protocol',\n 'Sec-WebSocket-Version',\n 'Server',\n 'Server-Timing',\n 'Service-Worker-Allowed',\n 'Service-Worker-Navigation-Preload',\n 'Set-Cookie',\n 'SourceMap',\n 'Strict-Transport-Security',\n 'Supports-Loading-Mode',\n 'TE',\n 'Timing-Allow-Origin',\n 'Trailer',\n 'Transfer-Encoding',\n 'Upgrade',\n 'Upgrade-Insecure-Requests',\n 'User-Agent',\n 'Vary',\n 'Via',\n 'WWW-Authenticate',\n 'X-Content-Type-Options',\n 'X-DNS-Prefetch-Control',\n 'X-Frame-Options',\n 'X-Permitted-Cross-Domain-Policies',\n 'X-Powered-By',\n 'X-Requested-With',\n 'X-XSS-Protection'\n]\n\nfor (let i = 0; i < wellknownHeaderNames.length; ++i) {\n const key = wellknownHeaderNames[i]\n const lowerCasedKey = key.toLowerCase()\n headerNameLowerCasedRecord[key] = headerNameLowerCasedRecord[lowerCasedKey] =\n lowerCasedKey\n}\n\n// Note: object prototypes should not be able to be referenced. e.g. `Object#hasOwnProperty`.\nObject.setPrototypeOf(headerNameLowerCasedRecord, null)\n\nmodule.exports = {\n wellknownHeaderNames,\n headerNameLowerCasedRecord\n}\n\n\n/***/ }),\n\n/***/ 8045:\n/***/ ((module) => {\n\n\"use strict\";\n\n\nclass UndiciError extends Error {\n constructor (message) {\n super(message)\n this.name = 'UndiciError'\n this.code = 'UND_ERR'\n }\n}\n\nclass ConnectTimeoutError extends UndiciError {\n constructor (message) {\n super(message)\n Error.captureStackTrace(this, ConnectTimeoutError)\n this.name = 'ConnectTimeoutError'\n this.message = message || 'Connect Timeout Error'\n this.code = 'UND_ERR_CONNECT_TIMEOUT'\n }\n}\n\nclass HeadersTimeoutError extends UndiciError {\n constructor (message) {\n super(message)\n Error.captureStackTrace(this, HeadersTimeoutError)\n this.name = 'HeadersTimeoutError'\n this.message = message || 'Headers Timeout Error'\n this.code = 'UND_ERR_HEADERS_TIMEOUT'\n }\n}\n\nclass HeadersOverflowError extends UndiciError {\n constructor (message) {\n super(message)\n Error.captureStackTrace(this, HeadersOverflowError)\n this.name = 'HeadersOverflowError'\n this.message = message || 'Headers Overflow Error'\n this.code = 'UND_ERR_HEADERS_OVERFLOW'\n }\n}\n\nclass BodyTimeoutError extends UndiciError {\n constructor (message) {\n super(message)\n Error.captureStackTrace(this, BodyTimeoutError)\n this.name = 'BodyTimeoutError'\n this.message = message || 'Body Timeout Error'\n this.code = 'UND_ERR_BODY_TIMEOUT'\n }\n}\n\nclass ResponseStatusCodeError extends UndiciError {\n constructor (message, statusCode, headers, body) {\n super(message)\n Error.captureStackTrace(this, ResponseStatusCodeError)\n this.name = 'ResponseStatusCodeError'\n this.message = message || 'Response Status Code Error'\n this.code = 'UND_ERR_RESPONSE_STATUS_CODE'\n this.body = body\n this.status = statusCode\n this.statusCode = statusCode\n this.headers = headers\n }\n}\n\nclass InvalidArgumentError extends UndiciError {\n constructor (message) {\n super(message)\n Error.captureStackTrace(this, InvalidArgumentError)\n this.name = 'InvalidArgumentError'\n this.message = message || 'Invalid Argument Error'\n this.code = 'UND_ERR_INVALID_ARG'\n }\n}\n\nclass InvalidReturnValueError extends UndiciError {\n constructor (message) {\n super(message)\n Error.captureStackTrace(this, InvalidReturnValueError)\n this.name = 'InvalidReturnValueError'\n this.message = message || 'Invalid Return Value Error'\n this.code = 'UND_ERR_INVALID_RETURN_VALUE'\n }\n}\n\nclass RequestAbortedError extends UndiciError {\n constructor (message) {\n super(message)\n Error.captureStackTrace(this, RequestAbortedError)\n this.name = 'AbortError'\n this.message = message || 'Request aborted'\n this.code = 'UND_ERR_ABORTED'\n }\n}\n\nclass InformationalError extends UndiciError {\n constructor (message) {\n super(message)\n Error.captureStackTrace(this, InformationalError)\n this.name = 'InformationalError'\n this.message = message || 'Request information'\n this.code = 'UND_ERR_INFO'\n }\n}\n\nclass RequestContentLengthMismatchError extends UndiciError {\n constructor (message) {\n super(message)\n Error.captureStackTrace(this, RequestContentLengthMismatchError)\n this.name = 'RequestContentLengthMismatchError'\n this.message = message || 'Request body length does not match content-length header'\n this.code = 'UND_ERR_REQ_CONTENT_LENGTH_MISMATCH'\n }\n}\n\nclass ResponseContentLengthMismatchError extends UndiciError {\n constructor (message) {\n super(message)\n Error.captureStackTrace(this, ResponseContentLengthMismatchError)\n this.name = 'ResponseContentLengthMismatchError'\n this.message = message || 'Response body length does not match content-length header'\n this.code = 'UND_ERR_RES_CONTENT_LENGTH_MISMATCH'\n }\n}\n\nclass ClientDestroyedError extends UndiciError {\n constructor (message) {\n super(message)\n Error.captureStackTrace(this, ClientDestroyedError)\n this.name = 'ClientDestroyedError'\n this.message = message || 'The client is destroyed'\n this.code = 'UND_ERR_DESTROYED'\n }\n}\n\nclass ClientClosedError extends UndiciError {\n constructor (message) {\n super(message)\n Error.captureStackTrace(this, ClientClosedError)\n this.name = 'ClientClosedError'\n this.message = message || 'The client is closed'\n this.code = 'UND_ERR_CLOSED'\n }\n}\n\nclass SocketError extends UndiciError {\n constructor (message, socket) {\n super(message)\n Error.captureStackTrace(this, SocketError)\n this.name = 'SocketError'\n this.message = message || 'Socket error'\n this.code = 'UND_ERR_SOCKET'\n this.socket = socket\n }\n}\n\nclass NotSupportedError extends UndiciError {\n constructor (message) {\n super(message)\n Error.captureStackTrace(this, NotSupportedError)\n this.name = 'NotSupportedError'\n this.message = message || 'Not supported error'\n this.code = 'UND_ERR_NOT_SUPPORTED'\n }\n}\n\nclass BalancedPoolMissingUpstreamError extends UndiciError {\n constructor (message) {\n super(message)\n Error.captureStackTrace(this, NotSupportedError)\n this.name = 'MissingUpstreamError'\n this.message = message || 'No upstream has been added to the BalancedPool'\n this.code = 'UND_ERR_BPL_MISSING_UPSTREAM'\n }\n}\n\nclass HTTPParserError extends Error {\n constructor (message, code, data) {\n super(message)\n Error.captureStackTrace(this, HTTPParserError)\n this.name = 'HTTPParserError'\n this.code = code ? `HPE_${code}` : undefined\n this.data = data ? data.toString() : undefined\n }\n}\n\nclass ResponseExceededMaxSizeError extends UndiciError {\n constructor (message) {\n super(message)\n Error.captureStackTrace(this, ResponseExceededMaxSizeError)\n this.name = 'ResponseExceededMaxSizeError'\n this.message = message || 'Response content exceeded max size'\n this.code = 'UND_ERR_RES_EXCEEDED_MAX_SIZE'\n }\n}\n\nclass RequestRetryError extends UndiciError {\n constructor (message, code, { headers, data }) {\n super(message)\n Error.captureStackTrace(this, RequestRetryError)\n this.name = 'RequestRetryError'\n this.message = message || 'Request retry error'\n this.code = 'UND_ERR_REQ_RETRY'\n this.statusCode = code\n this.data = data\n this.headers = headers\n }\n}\n\nmodule.exports = {\n HTTPParserError,\n UndiciError,\n HeadersTimeoutError,\n HeadersOverflowError,\n BodyTimeoutError,\n RequestContentLengthMismatchError,\n ConnectTimeoutError,\n ResponseStatusCodeError,\n InvalidArgumentError,\n InvalidReturnValueError,\n RequestAbortedError,\n ClientDestroyedError,\n ClientClosedError,\n InformationalError,\n SocketError,\n NotSupportedError,\n ResponseContentLengthMismatchError,\n BalancedPoolMissingUpstreamError,\n ResponseExceededMaxSizeError,\n RequestRetryError\n}\n\n\n/***/ }),\n\n/***/ 2905:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\n\"use strict\";\n\n\nconst {\n InvalidArgumentError,\n NotSupportedError\n} = __nccwpck_require__(8045)\nconst assert = __nccwpck_require__(9491)\nconst { kHTTP2BuildRequest, kHTTP2CopyHeaders, kHTTP1BuildRequest } = __nccwpck_require__(2785)\nconst util = __nccwpck_require__(3983)\n\n// tokenRegExp and headerCharRegex have been lifted from\n// https://github.com/nodejs/node/blob/main/lib/_http_common.js\n\n/**\n * Verifies that the given val is a valid HTTP token\n * per the rules defined in RFC 7230\n * See https://tools.ietf.org/html/rfc7230#section-3.2.6\n */\nconst tokenRegExp = /^[\\^_`a-zA-Z\\-0-9!#$%&'*+.|~]+$/\n\n/**\n * Matches if val contains an invalid field-vchar\n * field-value = *( field-content / obs-fold )\n * field-content = field-vchar [ 1*( SP / HTAB ) field-vchar ]\n * field-vchar = VCHAR / obs-text\n */\nconst headerCharRegex = /[^\\t\\x20-\\x7e\\x80-\\xff]/\n\n// Verifies that a given path is valid does not contain control chars \\x00 to \\x20\nconst invalidPathRegex = /[^\\u0021-\\u00ff]/\n\nconst kHandler = Symbol('handler')\n\nconst channels = {}\n\nlet extractBody\n\ntry {\n const diagnosticsChannel = __nccwpck_require__(7643)\n channels.create = diagnosticsChannel.channel('undici:request:create')\n channels.bodySent = diagnosticsChannel.channel('undici:request:bodySent')\n channels.headers = diagnosticsChannel.channel('undici:request:headers')\n channels.trailers = diagnosticsChannel.channel('undici:request:trailers')\n channels.error = diagnosticsChannel.channel('undici:request:error')\n} catch {\n channels.create = { hasSubscribers: false }\n channels.bodySent = { hasSubscribers: false }\n channels.headers = { hasSubscribers: false }\n channels.trailers = { hasSubscribers: false }\n channels.error = { hasSubscribers: false }\n}\n\nclass Request {\n constructor (origin, {\n path,\n method,\n body,\n headers,\n query,\n idempotent,\n blocking,\n upgrade,\n headersTimeout,\n bodyTimeout,\n reset,\n throwOnError,\n expectContinue\n }, handler) {\n if (typeof path !== 'string') {\n throw new InvalidArgumentError('path must be a string')\n } else if (\n path[0] !== '/' &&\n !(path.startsWith('http://') || path.startsWith('https://')) &&\n method !== 'CONNECT'\n ) {\n throw new InvalidArgumentError('path must be an absolute URL or start with a slash')\n } else if (invalidPathRegex.exec(path) !== null) {\n throw new InvalidArgumentError('invalid request path')\n }\n\n if (typeof method !== 'string') {\n throw new InvalidArgumentError('method must be a string')\n } else if (tokenRegExp.exec(method) === null) {\n throw new InvalidArgumentError('invalid request method')\n }\n\n if (upgrade && typeof upgrade !== 'string') {\n throw new InvalidArgumentError('upgrade must be a string')\n }\n\n if (headersTimeout != null && (!Number.isFinite(headersTimeout) || headersTimeout < 0)) {\n throw new InvalidArgumentError('invalid headersTimeout')\n }\n\n if (bodyTimeout != null && (!Number.isFinite(bodyTimeout) || bodyTimeout < 0)) {\n throw new InvalidArgumentError('invalid bodyTimeout')\n }\n\n if (reset != null && typeof reset !== 'boolean') {\n throw new InvalidArgumentError('invalid reset')\n }\n\n if (expectContinue != null && typeof expectContinue !== 'boolean') {\n throw new InvalidArgumentError('invalid expectContinue')\n }\n\n this.headersTimeout = headersTimeout\n\n this.bodyTimeout = bodyTimeout\n\n this.throwOnError = throwOnError === true\n\n this.method = method\n\n this.abort = null\n\n if (body == null) {\n this.body = null\n } else if (util.isStream(body)) {\n this.body = body\n\n const rState = this.body._readableState\n if (!rState || !rState.autoDestroy) {\n this.endHandler = function autoDestroy () {\n util.destroy(this)\n }\n this.body.on('end', this.endHandler)\n }\n\n this.errorHandler = err => {\n if (this.abort) {\n this.abort(err)\n } else {\n this.error = err\n }\n }\n this.body.on('error', this.errorHandler)\n } else if (util.isBuffer(body)) {\n this.body = body.byteLength ? body : null\n } else if (ArrayBuffer.isView(body)) {\n this.body = body.buffer.byteLength ? Buffer.from(body.buffer, body.byteOffset, body.byteLength) : null\n } else if (body instanceof ArrayBuffer) {\n this.body = body.byteLength ? Buffer.from(body) : null\n } else if (typeof body === 'string') {\n this.body = body.length ? Buffer.from(body) : null\n } else if (util.isFormDataLike(body) || util.isIterable(body) || util.isBlobLike(body)) {\n this.body = body\n } else {\n throw new InvalidArgumentError('body must be a string, a Buffer, a Readable stream, an iterable, or an async iterable')\n }\n\n this.completed = false\n\n this.aborted = false\n\n this.upgrade = upgrade || null\n\n this.path = query ? util.buildURL(path, query) : path\n\n this.origin = origin\n\n this.idempotent = idempotent == null\n ? method === 'HEAD' || method === 'GET'\n : idempotent\n\n this.blocking = blocking == null ? false : blocking\n\n this.reset = reset == null ? null : reset\n\n this.host = null\n\n this.contentLength = null\n\n this.contentType = null\n\n this.headers = ''\n\n // Only for H2\n this.expectContinue = expectContinue != null ? expectContinue : false\n\n if (Array.isArray(headers)) {\n if (headers.length % 2 !== 0) {\n throw new InvalidArgumentError('headers array must be even')\n }\n for (let i = 0; i < headers.length; i += 2) {\n processHeader(this, headers[i], headers[i + 1])\n }\n } else if (headers && typeof headers === 'object') {\n const keys = Object.keys(headers)\n for (let i = 0; i < keys.length; i++) {\n const key = keys[i]\n processHeader(this, key, headers[key])\n }\n } else if (headers != null) {\n throw new InvalidArgumentError('headers must be an object or an array')\n }\n\n if (util.isFormDataLike(this.body)) {\n if (util.nodeMajor < 16 || (util.nodeMajor === 16 && util.nodeMinor < 8)) {\n throw new InvalidArgumentError('Form-Data bodies are only supported in node v16.8 and newer.')\n }\n\n if (!extractBody) {\n extractBody = (__nccwpck_require__(1472).extractBody)\n }\n\n const [bodyStream, contentType] = extractBody(body)\n if (this.contentType == null) {\n this.contentType = contentType\n this.headers += `content-type: ${contentType}\\r\\n`\n }\n this.body = bodyStream.stream\n this.contentLength = bodyStream.length\n } else if (util.isBlobLike(body) && this.contentType == null && body.type) {\n this.contentType = body.type\n this.headers += `content-type: ${body.type}\\r\\n`\n }\n\n util.validateHandler(handler, method, upgrade)\n\n this.servername = util.getServerName(this.host)\n\n this[kHandler] = handler\n\n if (channels.create.hasSubscribers) {\n channels.create.publish({ request: this })\n }\n }\n\n onBodySent (chunk) {\n if (this[kHandler].onBodySent) {\n try {\n return this[kHandler].onBodySent(chunk)\n } catch (err) {\n this.abort(err)\n }\n }\n }\n\n onRequestSent () {\n if (channels.bodySent.hasSubscribers) {\n channels.bodySent.publish({ request: this })\n }\n\n if (this[kHandler].onRequestSent) {\n try {\n return this[kHandler].onRequestSent()\n } catch (err) {\n this.abort(err)\n }\n }\n }\n\n onConnect (abort) {\n assert(!this.aborted)\n assert(!this.completed)\n\n if (this.error) {\n abort(this.error)\n } else {\n this.abort = abort\n return this[kHandler].onConnect(abort)\n }\n }\n\n onHeaders (statusCode, headers, resume, statusText) {\n assert(!this.aborted)\n assert(!this.completed)\n\n if (channels.headers.hasSubscribers) {\n channels.headers.publish({ request: this, response: { statusCode, headers, statusText } })\n }\n\n try {\n return this[kHandler].onHeaders(statusCode, headers, resume, statusText)\n } catch (err) {\n this.abort(err)\n }\n }\n\n onData (chunk) {\n assert(!this.aborted)\n assert(!this.completed)\n\n try {\n return this[kHandler].onData(chunk)\n } catch (err) {\n this.abort(err)\n return false\n }\n }\n\n onUpgrade (statusCode, headers, socket) {\n assert(!this.aborted)\n assert(!this.completed)\n\n return this[kHandler].onUpgrade(statusCode, headers, socket)\n }\n\n onComplete (trailers) {\n this.onFinally()\n\n assert(!this.aborted)\n\n this.completed = true\n if (channels.trailers.hasSubscribers) {\n channels.trailers.publish({ request: this, trailers })\n }\n\n try {\n return this[kHandler].onComplete(trailers)\n } catch (err) {\n // TODO (fix): This might be a bad idea?\n this.onError(err)\n }\n }\n\n onError (error) {\n this.onFinally()\n\n if (channels.error.hasSubscribers) {\n channels.error.publish({ request: this, error })\n }\n\n if (this.aborted) {\n return\n }\n this.aborted = true\n\n return this[kHandler].onError(error)\n }\n\n onFinally () {\n if (this.errorHandler) {\n this.body.off('error', this.errorHandler)\n this.errorHandler = null\n }\n\n if (this.endHandler) {\n this.body.off('end', this.endHandler)\n this.endHandler = null\n }\n }\n\n // TODO: adjust to support H2\n addHeader (key, value) {\n processHeader(this, key, value)\n return this\n }\n\n static [kHTTP1BuildRequest] (origin, opts, handler) {\n // TODO: Migrate header parsing here, to make Requests\n // HTTP agnostic\n return new Request(origin, opts, handler)\n }\n\n static [kHTTP2BuildRequest] (origin, opts, handler) {\n const headers = opts.headers\n opts = { ...opts, headers: null }\n\n const request = new Request(origin, opts, handler)\n\n request.headers = {}\n\n if (Array.isArray(headers)) {\n if (headers.length % 2 !== 0) {\n throw new InvalidArgumentError('headers array must be even')\n }\n for (let i = 0; i < headers.length; i += 2) {\n processHeader(request, headers[i], headers[i + 1], true)\n }\n } else if (headers && typeof headers === 'object') {\n const keys = Object.keys(headers)\n for (let i = 0; i < keys.length; i++) {\n const key = keys[i]\n processHeader(request, key, headers[key], true)\n }\n } else if (headers != null) {\n throw new InvalidArgumentError('headers must be an object or an array')\n }\n\n return request\n }\n\n static [kHTTP2CopyHeaders] (raw) {\n const rawHeaders = raw.split('\\r\\n')\n const headers = {}\n\n for (const header of rawHeaders) {\n const [key, value] = header.split(': ')\n\n if (value == null || value.length === 0) continue\n\n if (headers[key]) headers[key] += `,${value}`\n else headers[key] = value\n }\n\n return headers\n }\n}\n\nfunction processHeaderValue (key, val, skipAppend) {\n if (val && typeof val === 'object') {\n throw new InvalidArgumentError(`invalid ${key} header`)\n }\n\n val = val != null ? `${val}` : ''\n\n if (headerCharRegex.exec(val) !== null) {\n throw new InvalidArgumentError(`invalid ${key} header`)\n }\n\n return skipAppend ? val : `${key}: ${val}\\r\\n`\n}\n\nfunction processHeader (request, key, val, skipAppend = false) {\n if (val && (typeof val === 'object' && !Array.isArray(val))) {\n throw new InvalidArgumentError(`invalid ${key} header`)\n } else if (val === undefined) {\n return\n }\n\n if (\n request.host === null &&\n key.length === 4 &&\n key.toLowerCase() === 'host'\n ) {\n if (headerCharRegex.exec(val) !== null) {\n throw new InvalidArgumentError(`invalid ${key} header`)\n }\n // Consumed by Client\n request.host = val\n } else if (\n request.contentLength === null &&\n key.length === 14 &&\n key.toLowerCase() === 'content-length'\n ) {\n request.contentLength = parseInt(val, 10)\n if (!Number.isFinite(request.contentLength)) {\n throw new InvalidArgumentError('invalid content-length header')\n }\n } else if (\n request.contentType === null &&\n key.length === 12 &&\n key.toLowerCase() === 'content-type'\n ) {\n request.contentType = val\n if (skipAppend) request.headers[key] = processHeaderValue(key, val, skipAppend)\n else request.headers += processHeaderValue(key, val)\n } else if (\n key.length === 17 &&\n key.toLowerCase() === 'transfer-encoding'\n ) {\n throw new InvalidArgumentError('invalid transfer-encoding header')\n } else if (\n key.length === 10 &&\n key.toLowerCase() === 'connection'\n ) {\n const value = typeof val === 'string' ? val.toLowerCase() : null\n if (value !== 'close' && value !== 'keep-alive') {\n throw new InvalidArgumentError('invalid connection header')\n } else if (value === 'close') {\n request.reset = true\n }\n } else if (\n key.length === 10 &&\n key.toLowerCase() === 'keep-alive'\n ) {\n throw new InvalidArgumentError('invalid keep-alive header')\n } else if (\n key.length === 7 &&\n key.toLowerCase() === 'upgrade'\n ) {\n throw new InvalidArgumentError('invalid upgrade header')\n } else if (\n key.length === 6 &&\n key.toLowerCase() === 'expect'\n ) {\n throw new NotSupportedError('expect header not supported')\n } else if (tokenRegExp.exec(key) === null) {\n throw new InvalidArgumentError('invalid header key')\n } else {\n if (Array.isArray(val)) {\n for (let i = 0; i < val.length; i++) {\n if (skipAppend) {\n if (request.headers[key]) request.headers[key] += `,${processHeaderValue(key, val[i], skipAppend)}`\n else request.headers[key] = processHeaderValue(key, val[i], skipAppend)\n } else {\n request.headers += processHeaderValue(key, val[i])\n }\n }\n } else {\n if (skipAppend) request.headers[key] = processHeaderValue(key, val, skipAppend)\n else request.headers += processHeaderValue(key, val)\n }\n }\n}\n\nmodule.exports = Request\n\n\n/***/ }),\n\n/***/ 2785:\n/***/ ((module) => {\n\nmodule.exports = {\n kClose: Symbol('close'),\n kDestroy: Symbol('destroy'),\n kDispatch: Symbol('dispatch'),\n kUrl: Symbol('url'),\n kWriting: Symbol('writing'),\n kResuming: Symbol('resuming'),\n kQueue: Symbol('queue'),\n kConnect: Symbol('connect'),\n kConnecting: Symbol('connecting'),\n kHeadersList: Symbol('headers list'),\n kKeepAliveDefaultTimeout: Symbol('default keep alive timeout'),\n kKeepAliveMaxTimeout: Symbol('max keep alive timeout'),\n kKeepAliveTimeoutThreshold: Symbol('keep alive timeout threshold'),\n kKeepAliveTimeoutValue: Symbol('keep alive timeout'),\n kKeepAlive: Symbol('keep alive'),\n kHeadersTimeout: Symbol('headers timeout'),\n kBodyTimeout: Symbol('body timeout'),\n kServerName: Symbol('server name'),\n kLocalAddress: Symbol('local address'),\n kHost: Symbol('host'),\n kNoRef: Symbol('no ref'),\n kBodyUsed: Symbol('used'),\n kRunning: Symbol('running'),\n kBlocking: Symbol('blocking'),\n kPending: Symbol('pending'),\n kSize: Symbol('size'),\n kBusy: Symbol('busy'),\n kQueued: Symbol('queued'),\n kFree: Symbol('free'),\n kConnected: Symbol('connected'),\n kClosed: Symbol('closed'),\n kNeedDrain: Symbol('need drain'),\n kReset: Symbol('reset'),\n kDestroyed: Symbol.for('nodejs.stream.destroyed'),\n kMaxHeadersSize: Symbol('max headers size'),\n kRunningIdx: Symbol('running index'),\n kPendingIdx: Symbol('pending index'),\n kError: Symbol('error'),\n kClients: Symbol('clients'),\n kClient: Symbol('client'),\n kParser: Symbol('parser'),\n kOnDestroyed: Symbol('destroy callbacks'),\n kPipelining: Symbol('pipelining'),\n kSocket: Symbol('socket'),\n kHostHeader: Symbol('host header'),\n kConnector: Symbol('connector'),\n kStrictContentLength: Symbol('strict content length'),\n kMaxRedirections: Symbol('maxRedirections'),\n kMaxRequests: Symbol('maxRequestsPerClient'),\n kProxy: Symbol('proxy agent options'),\n kCounter: Symbol('socket request counter'),\n kInterceptors: Symbol('dispatch interceptors'),\n kMaxResponseSize: Symbol('max response size'),\n kHTTP2Session: Symbol('http2Session'),\n kHTTP2SessionState: Symbol('http2Session state'),\n kHTTP2BuildRequest: Symbol('http2 build request'),\n kHTTP1BuildRequest: Symbol('http1 build request'),\n kHTTP2CopyHeaders: Symbol('http2 copy headers'),\n kHTTPConnVersion: Symbol('http connection version'),\n kRetryHandlerDefaultRetry: Symbol('retry agent default retry'),\n kConstruct: Symbol('constructable')\n}\n\n\n/***/ }),\n\n/***/ 3983:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\n\"use strict\";\n\n\nconst assert = __nccwpck_require__(9491)\nconst { kDestroyed, kBodyUsed } = __nccwpck_require__(2785)\nconst { IncomingMessage } = __nccwpck_require__(3685)\nconst stream = __nccwpck_require__(2781)\nconst net = __nccwpck_require__(1808)\nconst { InvalidArgumentError } = __nccwpck_require__(8045)\nconst { Blob } = __nccwpck_require__(4300)\nconst nodeUtil = __nccwpck_require__(3837)\nconst { stringify } = __nccwpck_require__(3477)\nconst { headerNameLowerCasedRecord } = __nccwpck_require__(4462)\n\nconst [nodeMajor, nodeMinor] = process.versions.node.split('.').map(v => Number(v))\n\nfunction nop () {}\n\nfunction isStream (obj) {\n return obj && typeof obj === 'object' && typeof obj.pipe === 'function' && typeof obj.on === 'function'\n}\n\n// based on https://github.com/node-fetch/fetch-blob/blob/8ab587d34080de94140b54f07168451e7d0b655e/index.js#L229-L241 (MIT License)\nfunction isBlobLike (object) {\n return (Blob && object instanceof Blob) || (\n object &&\n typeof object === 'object' &&\n (typeof object.stream === 'function' ||\n typeof object.arrayBuffer === 'function') &&\n /^(Blob|File)$/.test(object[Symbol.toStringTag])\n )\n}\n\nfunction buildURL (url, queryParams) {\n if (url.includes('?') || url.includes('#')) {\n throw new Error('Query params cannot be passed when url already contains \"?\" or \"#\".')\n }\n\n const stringified = stringify(queryParams)\n\n if (stringified) {\n url += '?' + stringified\n }\n\n return url\n}\n\nfunction parseURL (url) {\n if (typeof url === 'string') {\n url = new URL(url)\n\n if (!/^https?:/.test(url.origin || url.protocol)) {\n throw new InvalidArgumentError('Invalid URL protocol: the URL must start with `http:` or `https:`.')\n }\n\n return url\n }\n\n if (!url || typeof url !== 'object') {\n throw new InvalidArgumentError('Invalid URL: The URL argument must be a non-null object.')\n }\n\n if (!/^https?:/.test(url.origin || url.protocol)) {\n throw new InvalidArgumentError('Invalid URL protocol: the URL must start with `http:` or `https:`.')\n }\n\n if (!(url instanceof URL)) {\n if (url.port != null && url.port !== '' && !Number.isFinite(parseInt(url.port))) {\n throw new InvalidArgumentError('Invalid URL: port must be a valid integer or a string representation of an integer.')\n }\n\n if (url.path != null && typeof url.path !== 'string') {\n throw new InvalidArgumentError('Invalid URL path: the path must be a string or null/undefined.')\n }\n\n if (url.pathname != null && typeof url.pathname !== 'string') {\n throw new InvalidArgumentError('Invalid URL pathname: the pathname must be a string or null/undefined.')\n }\n\n if (url.hostname != null && typeof url.hostname !== 'string') {\n throw new InvalidArgumentError('Invalid URL hostname: the hostname must be a string or null/undefined.')\n }\n\n if (url.origin != null && typeof url.origin !== 'string') {\n throw new InvalidArgumentError('Invalid URL origin: the origin must be a string or null/undefined.')\n }\n\n const port = url.port != null\n ? url.port\n : (url.protocol === 'https:' ? 443 : 80)\n let origin = url.origin != null\n ? url.origin\n : `${url.protocol}//${url.hostname}:${port}`\n let path = url.path != null\n ? url.path\n : `${url.pathname || ''}${url.search || ''}`\n\n if (origin.endsWith('/')) {\n origin = origin.substring(0, origin.length - 1)\n }\n\n if (path && !path.startsWith('/')) {\n path = `/${path}`\n }\n // new URL(path, origin) is unsafe when `path` contains an absolute URL\n // From https://developer.mozilla.org/en-US/docs/Web/API/URL/URL:\n // If first parameter is a relative URL, second param is required, and will be used as the base URL.\n // If first parameter is an absolute URL, a given second param will be ignored.\n url = new URL(origin + path)\n }\n\n return url\n}\n\nfunction parseOrigin (url) {\n url = parseURL(url)\n\n if (url.pathname !== '/' || url.search || url.hash) {\n throw new InvalidArgumentError('invalid url')\n }\n\n return url\n}\n\nfunction getHostname (host) {\n if (host[0] === '[') {\n const idx = host.indexOf(']')\n\n assert(idx !== -1)\n return host.substring(1, idx)\n }\n\n const idx = host.indexOf(':')\n if (idx === -1) return host\n\n return host.substring(0, idx)\n}\n\n// IP addresses are not valid server names per RFC6066\n// > Currently, the only server names supported are DNS hostnames\nfunction getServerName (host) {\n if (!host) {\n return null\n }\n\n assert.strictEqual(typeof host, 'string')\n\n const servername = getHostname(host)\n if (net.isIP(servername)) {\n return ''\n }\n\n return servername\n}\n\nfunction deepClone (obj) {\n return JSON.parse(JSON.stringify(obj))\n}\n\nfunction isAsyncIterable (obj) {\n return !!(obj != null && typeof obj[Symbol.asyncIterator] === 'function')\n}\n\nfunction isIterable (obj) {\n return !!(obj != null && (typeof obj[Symbol.iterator] === 'function' || typeof obj[Symbol.asyncIterator] === 'function'))\n}\n\nfunction bodyLength (body) {\n if (body == null) {\n return 0\n } else if (isStream(body)) {\n const state = body._readableState\n return state && state.objectMode === false && state.ended === true && Number.isFinite(state.length)\n ? state.length\n : null\n } else if (isBlobLike(body)) {\n return body.size != null ? body.size : null\n } else if (isBuffer(body)) {\n return body.byteLength\n }\n\n return null\n}\n\nfunction isDestroyed (stream) {\n return !stream || !!(stream.destroyed || stream[kDestroyed])\n}\n\nfunction isReadableAborted (stream) {\n const state = stream && stream._readableState\n return isDestroyed(stream) && state && !state.endEmitted\n}\n\nfunction destroy (stream, err) {\n if (stream == null || !isStream(stream) || isDestroyed(stream)) {\n return\n }\n\n if (typeof stream.destroy === 'function') {\n if (Object.getPrototypeOf(stream).constructor === IncomingMessage) {\n // See: https://github.com/nodejs/node/pull/38505/files\n stream.socket = null\n }\n\n stream.destroy(err)\n } else if (err) {\n process.nextTick((stream, err) => {\n stream.emit('error', err)\n }, stream, err)\n }\n\n if (stream.destroyed !== true) {\n stream[kDestroyed] = true\n }\n}\n\nconst KEEPALIVE_TIMEOUT_EXPR = /timeout=(\\d+)/\nfunction parseKeepAliveTimeout (val) {\n const m = val.toString().match(KEEPALIVE_TIMEOUT_EXPR)\n return m ? parseInt(m[1], 10) * 1000 : null\n}\n\n/**\n * Retrieves a header name and returns its lowercase value.\n * @param {string | Buffer} value Header name\n * @returns {string}\n */\nfunction headerNameToString (value) {\n return headerNameLowerCasedRecord[value] || value.toLowerCase()\n}\n\nfunction parseHeaders (headers, obj = {}) {\n // For H2 support\n if (!Array.isArray(headers)) return headers\n\n for (let i = 0; i < headers.length; i += 2) {\n const key = headers[i].toString().toLowerCase()\n let val = obj[key]\n\n if (!val) {\n if (Array.isArray(headers[i + 1])) {\n obj[key] = headers[i + 1].map(x => x.toString('utf8'))\n } else {\n obj[key] = headers[i + 1].toString('utf8')\n }\n } else {\n if (!Array.isArray(val)) {\n val = [val]\n obj[key] = val\n }\n val.push(headers[i + 1].toString('utf8'))\n }\n }\n\n // See https://github.com/nodejs/node/pull/46528\n if ('content-length' in obj && 'content-disposition' in obj) {\n obj['content-disposition'] = Buffer.from(obj['content-disposition']).toString('latin1')\n }\n\n return obj\n}\n\nfunction parseRawHeaders (headers) {\n const ret = []\n let hasContentLength = false\n let contentDispositionIdx = -1\n\n for (let n = 0; n < headers.length; n += 2) {\n const key = headers[n + 0].toString()\n const val = headers[n + 1].toString('utf8')\n\n if (key.length === 14 && (key === 'content-length' || key.toLowerCase() === 'content-length')) {\n ret.push(key, val)\n hasContentLength = true\n } else if (key.length === 19 && (key === 'content-disposition' || key.toLowerCase() === 'content-disposition')) {\n contentDispositionIdx = ret.push(key, val) - 1\n } else {\n ret.push(key, val)\n }\n }\n\n // See https://github.com/nodejs/node/pull/46528\n if (hasContentLength && contentDispositionIdx !== -1) {\n ret[contentDispositionIdx] = Buffer.from(ret[contentDispositionIdx]).toString('latin1')\n }\n\n return ret\n}\n\nfunction isBuffer (buffer) {\n // See, https://github.com/mcollina/undici/pull/319\n return buffer instanceof Uint8Array || Buffer.isBuffer(buffer)\n}\n\nfunction validateHandler (handler, method, upgrade) {\n if (!handler || typeof handler !== 'object') {\n throw new InvalidArgumentError('handler must be an object')\n }\n\n if (typeof handler.onConnect !== 'function') {\n throw new InvalidArgumentError('invalid onConnect method')\n }\n\n if (typeof handler.onError !== 'function') {\n throw new InvalidArgumentError('invalid onError method')\n }\n\n if (typeof handler.onBodySent !== 'function' && handler.onBodySent !== undefined) {\n throw new InvalidArgumentError('invalid onBodySent method')\n }\n\n if (upgrade || method === 'CONNECT') {\n if (typeof handler.onUpgrade !== 'function') {\n throw new InvalidArgumentError('invalid onUpgrade method')\n }\n } else {\n if (typeof handler.onHeaders !== 'function') {\n throw new InvalidArgumentError('invalid onHeaders method')\n }\n\n if (typeof handler.onData !== 'function') {\n throw new InvalidArgumentError('invalid onData method')\n }\n\n if (typeof handler.onComplete !== 'function') {\n throw new InvalidArgumentError('invalid onComplete method')\n }\n }\n}\n\n// A body is disturbed if it has been read from and it cannot\n// be re-used without losing state or data.\nfunction isDisturbed (body) {\n return !!(body && (\n stream.isDisturbed\n ? stream.isDisturbed(body) || body[kBodyUsed] // TODO (fix): Why is body[kBodyUsed] needed?\n : body[kBodyUsed] ||\n body.readableDidRead ||\n (body._readableState && body._readableState.dataEmitted) ||\n isReadableAborted(body)\n ))\n}\n\nfunction isErrored (body) {\n return !!(body && (\n stream.isErrored\n ? stream.isErrored(body)\n : /state: 'errored'/.test(nodeUtil.inspect(body)\n )))\n}\n\nfunction isReadable (body) {\n return !!(body && (\n stream.isReadable\n ? stream.isReadable(body)\n : /state: 'readable'/.test(nodeUtil.inspect(body)\n )))\n}\n\nfunction getSocketInfo (socket) {\n return {\n localAddress: socket.localAddress,\n localPort: socket.localPort,\n remoteAddress: socket.remoteAddress,\n remotePort: socket.remotePort,\n remoteFamily: socket.remoteFamily,\n timeout: socket.timeout,\n bytesWritten: socket.bytesWritten,\n bytesRead: socket.bytesRead\n }\n}\n\nasync function * convertIterableToBuffer (iterable) {\n for await (const chunk of iterable) {\n yield Buffer.isBuffer(chunk) ? chunk : Buffer.from(chunk)\n }\n}\n\nlet ReadableStream\nfunction ReadableStreamFrom (iterable) {\n if (!ReadableStream) {\n ReadableStream = (__nccwpck_require__(5356).ReadableStream)\n }\n\n if (ReadableStream.from) {\n return ReadableStream.from(convertIterableToBuffer(iterable))\n }\n\n let iterator\n return new ReadableStream(\n {\n async start () {\n iterator = iterable[Symbol.asyncIterator]()\n },\n async pull (controller) {\n const { done, value } = await iterator.next()\n if (done) {\n queueMicrotask(() => {\n controller.close()\n })\n } else {\n const buf = Buffer.isBuffer(value) ? value : Buffer.from(value)\n controller.enqueue(new Uint8Array(buf))\n }\n return controller.desiredSize > 0\n },\n async cancel (reason) {\n await iterator.return()\n }\n },\n 0\n )\n}\n\n// The chunk should be a FormData instance and contains\n// all the required methods.\nfunction isFormDataLike (object) {\n return (\n object &&\n typeof object === 'object' &&\n typeof object.append === 'function' &&\n typeof object.delete === 'function' &&\n typeof object.get === 'function' &&\n typeof object.getAll === 'function' &&\n typeof object.has === 'function' &&\n typeof object.set === 'function' &&\n object[Symbol.toStringTag] === 'FormData'\n )\n}\n\nfunction throwIfAborted (signal) {\n if (!signal) { return }\n if (typeof signal.throwIfAborted === 'function') {\n signal.throwIfAborted()\n } else {\n if (signal.aborted) {\n // DOMException not available < v17.0.0\n const err = new Error('The operation was aborted')\n err.name = 'AbortError'\n throw err\n }\n }\n}\n\nfunction addAbortListener (signal, listener) {\n if ('addEventListener' in signal) {\n signal.addEventListener('abort', listener, { once: true })\n return () => signal.removeEventListener('abort', listener)\n }\n signal.addListener('abort', listener)\n return () => signal.removeListener('abort', listener)\n}\n\nconst hasToWellFormed = !!String.prototype.toWellFormed\n\n/**\n * @param {string} val\n */\nfunction toUSVString (val) {\n if (hasToWellFormed) {\n return `${val}`.toWellFormed()\n } else if (nodeUtil.toUSVString) {\n return nodeUtil.toUSVString(val)\n }\n\n return `${val}`\n}\n\n// Parsed accordingly to RFC 9110\n// https://www.rfc-editor.org/rfc/rfc9110#field.content-range\nfunction parseRangeHeader (range) {\n if (range == null || range === '') return { start: 0, end: null, size: null }\n\n const m = range ? range.match(/^bytes (\\d+)-(\\d+)\\/(\\d+)?$/) : null\n return m\n ? {\n start: parseInt(m[1]),\n end: m[2] ? parseInt(m[2]) : null,\n size: m[3] ? parseInt(m[3]) : null\n }\n : null\n}\n\nconst kEnumerableProperty = Object.create(null)\nkEnumerableProperty.enumerable = true\n\nmodule.exports = {\n kEnumerableProperty,\n nop,\n isDisturbed,\n isErrored,\n isReadable,\n toUSVString,\n isReadableAborted,\n isBlobLike,\n parseOrigin,\n parseURL,\n getServerName,\n isStream,\n isIterable,\n isAsyncIterable,\n isDestroyed,\n headerNameToString,\n parseRawHeaders,\n parseHeaders,\n parseKeepAliveTimeout,\n destroy,\n bodyLength,\n deepClone,\n ReadableStreamFrom,\n isBuffer,\n validateHandler,\n getSocketInfo,\n isFormDataLike,\n buildURL,\n throwIfAborted,\n addAbortListener,\n parseRangeHeader,\n nodeMajor,\n nodeMinor,\n nodeHasAutoSelectFamily: nodeMajor > 18 || (nodeMajor === 18 && nodeMinor >= 13),\n safeHTTPMethods: ['GET', 'HEAD', 'OPTIONS', 'TRACE']\n}\n\n\n/***/ }),\n\n/***/ 4839:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\n\"use strict\";\n\n\nconst Dispatcher = __nccwpck_require__(412)\nconst {\n ClientDestroyedError,\n ClientClosedError,\n InvalidArgumentError\n} = __nccwpck_require__(8045)\nconst { kDestroy, kClose, kDispatch, kInterceptors } = __nccwpck_require__(2785)\n\nconst kDestroyed = Symbol('destroyed')\nconst kClosed = Symbol('closed')\nconst kOnDestroyed = Symbol('onDestroyed')\nconst kOnClosed = Symbol('onClosed')\nconst kInterceptedDispatch = Symbol('Intercepted Dispatch')\n\nclass DispatcherBase extends Dispatcher {\n constructor () {\n super()\n\n this[kDestroyed] = false\n this[kOnDestroyed] = null\n this[kClosed] = false\n this[kOnClosed] = []\n }\n\n get destroyed () {\n return this[kDestroyed]\n }\n\n get closed () {\n return this[kClosed]\n }\n\n get interceptors () {\n return this[kInterceptors]\n }\n\n set interceptors (newInterceptors) {\n if (newInterceptors) {\n for (let i = newInterceptors.length - 1; i >= 0; i--) {\n const interceptor = this[kInterceptors][i]\n if (typeof interceptor !== 'function') {\n throw new InvalidArgumentError('interceptor must be an function')\n }\n }\n }\n\n this[kInterceptors] = newInterceptors\n }\n\n close (callback) {\n if (callback === undefined) {\n return new Promise((resolve, reject) => {\n this.close((err, data) => {\n return err ? reject(err) : resolve(data)\n })\n })\n }\n\n if (typeof callback !== 'function') {\n throw new InvalidArgumentError('invalid callback')\n }\n\n if (this[kDestroyed]) {\n queueMicrotask(() => callback(new ClientDestroyedError(), null))\n return\n }\n\n if (this[kClosed]) {\n if (this[kOnClosed]) {\n this[kOnClosed].push(callback)\n } else {\n queueMicrotask(() => callback(null, null))\n }\n return\n }\n\n this[kClosed] = true\n this[kOnClosed].push(callback)\n\n const onClosed = () => {\n const callbacks = this[kOnClosed]\n this[kOnClosed] = null\n for (let i = 0; i < callbacks.length; i++) {\n callbacks[i](null, null)\n }\n }\n\n // Should not error.\n this[kClose]()\n .then(() => this.destroy())\n .then(() => {\n queueMicrotask(onClosed)\n })\n }\n\n destroy (err, callback) {\n if (typeof err === 'function') {\n callback = err\n err = null\n }\n\n if (callback === undefined) {\n return new Promise((resolve, reject) => {\n this.destroy(err, (err, data) => {\n return err ? /* istanbul ignore next: should never error */ reject(err) : resolve(data)\n })\n })\n }\n\n if (typeof callback !== 'function') {\n throw new InvalidArgumentError('invalid callback')\n }\n\n if (this[kDestroyed]) {\n if (this[kOnDestroyed]) {\n this[kOnDestroyed].push(callback)\n } else {\n queueMicrotask(() => callback(null, null))\n }\n return\n }\n\n if (!err) {\n err = new ClientDestroyedError()\n }\n\n this[kDestroyed] = true\n this[kOnDestroyed] = this[kOnDestroyed] || []\n this[kOnDestroyed].push(callback)\n\n const onDestroyed = () => {\n const callbacks = this[kOnDestroyed]\n this[kOnDestroyed] = null\n for (let i = 0; i < callbacks.length; i++) {\n callbacks[i](null, null)\n }\n }\n\n // Should not error.\n this[kDestroy](err).then(() => {\n queueMicrotask(onDestroyed)\n })\n }\n\n [kInterceptedDispatch] (opts, handler) {\n if (!this[kInterceptors] || this[kInterceptors].length === 0) {\n this[kInterceptedDispatch] = this[kDispatch]\n return this[kDispatch](opts, handler)\n }\n\n let dispatch = this[kDispatch].bind(this)\n for (let i = this[kInterceptors].length - 1; i >= 0; i--) {\n dispatch = this[kInterceptors][i](dispatch)\n }\n this[kInterceptedDispatch] = dispatch\n return dispatch(opts, handler)\n }\n\n dispatch (opts, handler) {\n if (!handler || typeof handler !== 'object') {\n throw new InvalidArgumentError('handler must be an object')\n }\n\n try {\n if (!opts || typeof opts !== 'object') {\n throw new InvalidArgumentError('opts must be an object.')\n }\n\n if (this[kDestroyed] || this[kOnDestroyed]) {\n throw new ClientDestroyedError()\n }\n\n if (this[kClosed]) {\n throw new ClientClosedError()\n }\n\n return this[kInterceptedDispatch](opts, handler)\n } catch (err) {\n if (typeof handler.onError !== 'function') {\n throw new InvalidArgumentError('invalid onError method')\n }\n\n handler.onError(err)\n\n return false\n }\n }\n}\n\nmodule.exports = DispatcherBase\n\n\n/***/ }),\n\n/***/ 412:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\n\"use strict\";\n\n\nconst EventEmitter = __nccwpck_require__(2361)\n\nclass Dispatcher extends EventEmitter {\n dispatch () {\n throw new Error('not implemented')\n }\n\n close () {\n throw new Error('not implemented')\n }\n\n destroy () {\n throw new Error('not implemented')\n }\n}\n\nmodule.exports = Dispatcher\n\n\n/***/ }),\n\n/***/ 1472:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\n\"use strict\";\n\n\nconst Busboy = __nccwpck_require__(727)\nconst util = __nccwpck_require__(3983)\nconst {\n ReadableStreamFrom,\n isBlobLike,\n isReadableStreamLike,\n readableStreamClose,\n createDeferredPromise,\n fullyReadBody\n} = __nccwpck_require__(2538)\nconst { FormData } = __nccwpck_require__(2015)\nconst { kState } = __nccwpck_require__(5861)\nconst { webidl } = __nccwpck_require__(1744)\nconst { DOMException, structuredClone } = __nccwpck_require__(1037)\nconst { Blob, File: NativeFile } = __nccwpck_require__(4300)\nconst { kBodyUsed } = __nccwpck_require__(2785)\nconst assert = __nccwpck_require__(9491)\nconst { isErrored } = __nccwpck_require__(3983)\nconst { isUint8Array, isArrayBuffer } = __nccwpck_require__(9830)\nconst { File: UndiciFile } = __nccwpck_require__(8511)\nconst { parseMIMEType, serializeAMimeType } = __nccwpck_require__(685)\n\nlet ReadableStream = globalThis.ReadableStream\n\n/** @type {globalThis['File']} */\nconst File = NativeFile ?? UndiciFile\nconst textEncoder = new TextEncoder()\nconst textDecoder = new TextDecoder()\n\n// https://fetch.spec.whatwg.org/#concept-bodyinit-extract\nfunction extractBody (object, keepalive = false) {\n if (!ReadableStream) {\n ReadableStream = (__nccwpck_require__(5356).ReadableStream)\n }\n\n // 1. Let stream be null.\n let stream = null\n\n // 2. If object is a ReadableStream object, then set stream to object.\n if (object instanceof ReadableStream) {\n stream = object\n } else if (isBlobLike(object)) {\n // 3. Otherwise, if object is a Blob object, set stream to the\n // result of running object\u2019s get stream.\n stream = object.stream()\n } else {\n // 4. Otherwise, set stream to a new ReadableStream object, and set\n // up stream.\n stream = new ReadableStream({\n async pull (controller) {\n controller.enqueue(\n typeof source === 'string' ? textEncoder.encode(source) : source\n )\n queueMicrotask(() => readableStreamClose(controller))\n },\n start () {},\n type: undefined\n })\n }\n\n // 5. Assert: stream is a ReadableStream object.\n assert(isReadableStreamLike(stream))\n\n // 6. Let action be null.\n let action = null\n\n // 7. Let source be null.\n let source = null\n\n // 8. Let length be null.\n let length = null\n\n // 9. Let type be null.\n let type = null\n\n // 10. Switch on object:\n if (typeof object === 'string') {\n // Set source to the UTF-8 encoding of object.\n // Note: setting source to a Uint8Array here breaks some mocking assumptions.\n source = object\n\n // Set type to `text/plain;charset=UTF-8`.\n type = 'text/plain;charset=UTF-8'\n } else if (object instanceof URLSearchParams) {\n // URLSearchParams\n\n // spec says to run application/x-www-form-urlencoded on body.list\n // this is implemented in Node.js as apart of an URLSearchParams instance toString method\n // See: https://github.com/nodejs/node/blob/e46c680bf2b211bbd52cf959ca17ee98c7f657f5/lib/internal/url.js#L490\n // and https://github.com/nodejs/node/blob/e46c680bf2b211bbd52cf959ca17ee98c7f657f5/lib/internal/url.js#L1100\n\n // Set source to the result of running the application/x-www-form-urlencoded serializer with object\u2019s list.\n source = object.toString()\n\n // Set type to `application/x-www-form-urlencoded;charset=UTF-8`.\n type = 'application/x-www-form-urlencoded;charset=UTF-8'\n } else if (isArrayBuffer(object)) {\n // BufferSource/ArrayBuffer\n\n // Set source to a copy of the bytes held by object.\n source = new Uint8Array(object.slice())\n } else if (ArrayBuffer.isView(object)) {\n // BufferSource/ArrayBufferView\n\n // Set source to a copy of the bytes held by object.\n source = new Uint8Array(object.buffer.slice(object.byteOffset, object.byteOffset + object.byteLength))\n } else if (util.isFormDataLike(object)) {\n const boundary = `----formdata-undici-0${`${Math.floor(Math.random() * 1e11)}`.padStart(11, '0')}`\n const prefix = `--${boundary}\\r\\nContent-Disposition: form-data`\n\n /*! formdata-polyfill. MIT License. Jimmy W\u00e4rting <https://jimmy.warting.se/opensource> */\n const escape = (str) =>\n str.replace(/\\n/g, '%0A').replace(/\\r/g, '%0D').replace(/\"/g, '%22')\n const normalizeLinefeeds = (value) => value.replace(/\\r?\\n|\\r/g, '\\r\\n')\n\n // Set action to this step: run the multipart/form-data\n // encoding algorithm, with object\u2019s entry list and UTF-8.\n // - This ensures that the body is immutable and can't be changed afterwords\n // - That the content-length is calculated in advance.\n // - And that all parts are pre-encoded and ready to be sent.\n\n const blobParts = []\n const rn = new Uint8Array([13, 10]) // '\\r\\n'\n length = 0\n let hasUnknownSizeValue = false\n\n for (const [name, value] of object) {\n if (typeof value === 'string') {\n const chunk = textEncoder.encode(prefix +\n `; name=\"${escape(normalizeLinefeeds(name))}\"` +\n `\\r\\n\\r\\n${normalizeLinefeeds(value)}\\r\\n`)\n blobParts.push(chunk)\n length += chunk.byteLength\n } else {\n const chunk = textEncoder.encode(`${prefix}; name=\"${escape(normalizeLinefeeds(name))}\"` +\n (value.name ? `; filename=\"${escape(value.name)}\"` : '') + '\\r\\n' +\n `Content-Type: ${\n value.type || 'application/octet-stream'\n }\\r\\n\\r\\n`)\n blobParts.push(chunk, value, rn)\n if (typeof value.size === 'number') {\n length += chunk.byteLength + value.size + rn.byteLength\n } else {\n hasUnknownSizeValue = true\n }\n }\n }\n\n const chunk = textEncoder.encode(`--${boundary}--`)\n blobParts.push(chunk)\n length += chunk.byteLength\n if (hasUnknownSizeValue) {\n length = null\n }\n\n // Set source to object.\n source = object\n\n action = async function * () {\n for (const part of blobParts) {\n if (part.stream) {\n yield * part.stream()\n } else {\n yield part\n }\n }\n }\n\n // Set type to `multipart/form-data; boundary=`,\n // followed by the multipart/form-data boundary string generated\n // by the multipart/form-data encoding algorithm.\n type = 'multipart/form-data; boundary=' + boundary\n } else if (isBlobLike(object)) {\n // Blob\n\n // Set source to object.\n source = object\n\n // Set length to object\u2019s size.\n length = object.size\n\n // If object\u2019s type attribute is not the empty byte sequence, set\n // type to its value.\n if (object.type) {\n type = object.type\n }\n } else if (typeof object[Symbol.asyncIterator] === 'function') {\n // If keepalive is true, then throw a TypeError.\n if (keepalive) {\n throw new TypeError('keepalive')\n }\n\n // If object is disturbed or locked, then throw a TypeError.\n if (util.isDisturbed(object) || object.locked) {\n throw new TypeError(\n 'Response body object should not be disturbed or locked'\n )\n }\n\n stream =\n object instanceof ReadableStream ? object : ReadableStreamFrom(object)\n }\n\n // 11. If source is a byte sequence, then set action to a\n // step that returns source and length to source\u2019s length.\n if (typeof source === 'string' || util.isBuffer(source)) {\n length = Buffer.byteLength(source)\n }\n\n // 12. If action is non-null, then run these steps in in parallel:\n if (action != null) {\n // Run action.\n let iterator\n stream = new ReadableStream({\n async start () {\n iterator = action(object)[Symbol.asyncIterator]()\n },\n async pull (controller) {\n const { value, done } = await iterator.next()\n if (done) {\n // When running action is done, close stream.\n queueMicrotask(() => {\n controller.close()\n })\n } else {\n // Whenever one or more bytes are available and stream is not errored,\n // enqueue a Uint8Array wrapping an ArrayBuffer containing the available\n // bytes into stream.\n if (!isErrored(stream)) {\n controller.enqueue(new Uint8Array(value))\n }\n }\n return controller.desiredSize > 0\n },\n async cancel (reason) {\n await iterator.return()\n },\n type: undefined\n })\n }\n\n // 13. Let body be a body whose stream is stream, source is source,\n // and length is length.\n const body = { stream, source, length }\n\n // 14. Return (body, type).\n return [body, type]\n}\n\n// https://fetch.spec.whatwg.org/#bodyinit-safely-extract\nfunction safelyExtractBody (object, keepalive = false) {\n if (!ReadableStream) {\n // istanbul ignore next\n ReadableStream = (__nccwpck_require__(5356).ReadableStream)\n }\n\n // To safely extract a body and a `Content-Type` value from\n // a byte sequence or BodyInit object object, run these steps:\n\n // 1. If object is a ReadableStream object, then:\n if (object instanceof ReadableStream) {\n // Assert: object is neither disturbed nor locked.\n // istanbul ignore next\n assert(!util.isDisturbed(object), 'The body has already been consumed.')\n // istanbul ignore next\n assert(!object.locked, 'The stream is locked.')\n }\n\n // 2. Return the results of extracting object.\n return extractBody(object, keepalive)\n}\n\nfunction cloneBody (body) {\n // To clone a body body, run these steps:\n\n // https://fetch.spec.whatwg.org/#concept-body-clone\n\n // 1. Let \u00ab out1, out2 \u00bb be the result of teeing body\u2019s stream.\n const [out1, out2] = body.stream.tee()\n const out2Clone = structuredClone(out2, { transfer: [out2] })\n // This, for whatever reasons, unrefs out2Clone which allows\n // the process to exit by itself.\n const [, finalClone] = out2Clone.tee()\n\n // 2. Set body\u2019s stream to out1.\n body.stream = out1\n\n // 3. Return a body whose stream is out2 and other members are copied from body.\n return {\n stream: finalClone,\n length: body.length,\n source: body.source\n }\n}\n\nasync function * consumeBody (body) {\n if (body) {\n if (isUint8Array(body)) {\n yield body\n } else {\n const stream = body.stream\n\n if (util.isDisturbed(stream)) {\n throw new TypeError('The body has already been consumed.')\n }\n\n if (stream.locked) {\n throw new TypeError('The stream is locked.')\n }\n\n // Compat.\n stream[kBodyUsed] = true\n\n yield * stream\n }\n }\n}\n\nfunction throwIfAborted (state) {\n if (state.aborted) {\n throw new DOMException('The operation was aborted.', 'AbortError')\n }\n}\n\nfunction bodyMixinMethods (instance) {\n const methods = {\n blob () {\n // The blob() method steps are to return the result of\n // running consume body with this and the following step\n // given a byte sequence bytes: return a Blob whose\n // contents are bytes and whose type attribute is this\u2019s\n // MIME type.\n return specConsumeBody(this, (bytes) => {\n let mimeType = bodyMimeType(this)\n\n if (mimeType === 'failure') {\n mimeType = ''\n } else if (mimeType) {\n mimeType = serializeAMimeType(mimeType)\n }\n\n // Return a Blob whose contents are bytes and type attribute\n // is mimeType.\n return new Blob([bytes], { type: mimeType })\n }, instance)\n },\n\n arrayBuffer () {\n // The arrayBuffer() method steps are to return the result\n // of running consume body with this and the following step\n // given a byte sequence bytes: return a new ArrayBuffer\n // whose contents are bytes.\n return specConsumeBody(this, (bytes) => {\n return new Uint8Array(bytes).buffer\n }, instance)\n },\n\n text () {\n // The text() method steps are to return the result of running\n // consume body with this and UTF-8 decode.\n return specConsumeBody(this, utf8DecodeBytes, instance)\n },\n\n json () {\n // The json() method steps are to return the result of running\n // consume body with this and parse JSON from bytes.\n return specConsumeBody(this, parseJSONFromBytes, instance)\n },\n\n async formData () {\n webidl.brandCheck(this, instance)\n\n throwIfAborted(this[kState])\n\n const contentType = this.headers.get('Content-Type')\n\n // If mimeType\u2019s essence is \"multipart/form-data\", then:\n if (/multipart\\/form-data/.test(contentType)) {\n const headers = {}\n for (const [key, value] of this.headers) headers[key.toLowerCase()] = value\n\n const responseFormData = new FormData()\n\n let busboy\n\n try {\n busboy = new Busboy({\n headers,\n preservePath: true\n })\n } catch (err) {\n throw new DOMException(`${err}`, 'AbortError')\n }\n\n busboy.on('field', (name, value) => {\n responseFormData.append(name, value)\n })\n busboy.on('file', (name, value, filename, encoding, mimeType) => {\n const chunks = []\n\n if (encoding === 'base64' || encoding.toLowerCase() === 'base64') {\n let base64chunk = ''\n\n value.on('data', (chunk) => {\n base64chunk += chunk.toString().replace(/[\\r\\n]/gm, '')\n\n const end = base64chunk.length - base64chunk.length % 4\n chunks.push(Buffer.from(base64chunk.slice(0, end), 'base64'))\n\n base64chunk = base64chunk.slice(end)\n })\n value.on('end', () => {\n chunks.push(Buffer.from(base64chunk, 'base64'))\n responseFormData.append(name, new File(chunks, filename, { type: mimeType }))\n })\n } else {\n value.on('data', (chunk) => {\n chunks.push(chunk)\n })\n value.on('end', () => {\n responseFormData.append(name, new File(chunks, filename, { type: mimeType }))\n })\n }\n })\n\n const busboyResolve = new Promise((resolve, reject) => {\n busboy.on('finish', resolve)\n busboy.on('error', (err) => reject(new TypeError(err)))\n })\n\n if (this.body !== null) for await (const chunk of consumeBody(this[kState].body)) busboy.write(chunk)\n busboy.end()\n await busboyResolve\n\n return responseFormData\n } else if (/application\\/x-www-form-urlencoded/.test(contentType)) {\n // Otherwise, if mimeType\u2019s essence is \"application/x-www-form-urlencoded\", then:\n\n // 1. Let entries be the result of parsing bytes.\n let entries\n try {\n let text = ''\n // application/x-www-form-urlencoded parser will keep the BOM.\n // https://url.spec.whatwg.org/#concept-urlencoded-parser\n // Note that streaming decoder is stateful and cannot be reused\n const streamingDecoder = new TextDecoder('utf-8', { ignoreBOM: true })\n\n for await (const chunk of consumeBody(this[kState].body)) {\n if (!isUint8Array(chunk)) {\n throw new TypeError('Expected Uint8Array chunk')\n }\n text += streamingDecoder.decode(chunk, { stream: true })\n }\n text += streamingDecoder.decode()\n entries = new URLSearchParams(text)\n } catch (err) {\n // istanbul ignore next: Unclear when new URLSearchParams can fail on a string.\n // 2. If entries is failure, then throw a TypeError.\n throw Object.assign(new TypeError(), { cause: err })\n }\n\n // 3. Return a new FormData object whose entries are entries.\n const formData = new FormData()\n for (const [name, value] of entries) {\n formData.append(name, value)\n }\n return formData\n } else {\n // Wait a tick before checking if the request has been aborted.\n // Otherwise, a TypeError can be thrown when an AbortError should.\n await Promise.resolve()\n\n throwIfAborted(this[kState])\n\n // Otherwise, throw a TypeError.\n throw webidl.errors.exception({\n header: `${instance.name}.formData`,\n message: 'Could not parse content as FormData.'\n })\n }\n }\n }\n\n return methods\n}\n\nfunction mixinBody (prototype) {\n Object.assign(prototype.prototype, bodyMixinMethods(prototype))\n}\n\n/**\n * @see https://fetch.spec.whatwg.org/#concept-body-consume-body\n * @param {Response|Request} object\n * @param {(value: unknown) => unknown} convertBytesToJSValue\n * @param {Response|Request} instance\n */\nasync function specConsumeBody (object, convertBytesToJSValue, instance) {\n webidl.brandCheck(object, instance)\n\n throwIfAborted(object[kState])\n\n // 1. If object is unusable, then return a promise rejected\n // with a TypeError.\n if (bodyUnusable(object[kState].body)) {\n throw new TypeError('Body is unusable')\n }\n\n // 2. Let promise be a new promise.\n const promise = createDeferredPromise()\n\n // 3. Let errorSteps given error be to reject promise with error.\n const errorSteps = (error) => promise.reject(error)\n\n // 4. Let successSteps given a byte sequence data be to resolve\n // promise with the result of running convertBytesToJSValue\n // with data. If that threw an exception, then run errorSteps\n // with that exception.\n const successSteps = (data) => {\n try {\n promise.resolve(convertBytesToJSValue(data))\n } catch (e) {\n errorSteps(e)\n }\n }\n\n // 5. If object\u2019s body is null, then run successSteps with an\n // empty byte sequence.\n if (object[kState].body == null) {\n successSteps(new Uint8Array())\n return promise.promise\n }\n\n // 6. Otherwise, fully read object\u2019s body given successSteps,\n // errorSteps, and object\u2019s relevant global object.\n await fullyReadBody(object[kState].body, successSteps, errorSteps)\n\n // 7. Return promise.\n return promise.promise\n}\n\n// https://fetch.spec.whatwg.org/#body-unusable\nfunction bodyUnusable (body) {\n // An object including the Body interface mixin is\n // said to be unusable if its body is non-null and\n // its body\u2019s stream is disturbed or locked.\n return body != null && (body.stream.locked || util.isDisturbed(body.stream))\n}\n\n/**\n * @see https://encoding.spec.whatwg.org/#utf-8-decode\n * @param {Buffer} buffer\n */\nfunction utf8DecodeBytes (buffer) {\n if (buffer.length === 0) {\n return ''\n }\n\n // 1. Let buffer be the result of peeking three bytes from\n // ioQueue, converted to a byte sequence.\n\n // 2. If buffer is 0xEF 0xBB 0xBF, then read three\n // bytes from ioQueue. (Do nothing with those bytes.)\n if (buffer[0] === 0xEF && buffer[1] === 0xBB && buffer[2] === 0xBF) {\n buffer = buffer.subarray(3)\n }\n\n // 3. Process a queue with an instance of UTF-8\u2019s\n // decoder, ioQueue, output, and \"replacement\".\n const output = textDecoder.decode(buffer)\n\n // 4. Return output.\n return output\n}\n\n/**\n * @see https://infra.spec.whatwg.org/#parse-json-bytes-to-a-javascript-value\n * @param {Uint8Array} bytes\n */\nfunction parseJSONFromBytes (bytes) {\n return JSON.parse(utf8DecodeBytes(bytes))\n}\n\n/**\n * @see https://fetch.spec.whatwg.org/#concept-body-mime-type\n * @param {import('./response').Response|import('./request').Request} object\n */\nfunction bodyMimeType (object) {\n const { headersList } = object[kState]\n const contentType = headersList.get('content-type')\n\n if (contentType === null) {\n return 'failure'\n }\n\n return parseMIMEType(contentType)\n}\n\nmodule.exports = {\n extractBody,\n safelyExtractBody,\n cloneBody,\n mixinBody\n}\n\n\n/***/ }),\n\n/***/ 1037:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\n\"use strict\";\n\n\nconst { MessageChannel, receiveMessageOnPort } = __nccwpck_require__(1267)\n\nconst corsSafeListedMethods = ['GET', 'HEAD', 'POST']\nconst corsSafeListedMethodsSet = new Set(corsSafeListedMethods)\n\nconst nullBodyStatus = [101, 204, 205, 304]\n\nconst redirectStatus = [301, 302, 303, 307, 308]\nconst redirectStatusSet = new Set(redirectStatus)\n\n// https://fetch.spec.whatwg.org/#block-bad-port\nconst badPorts = [\n '1', '7', '9', '11', '13', '15', '17', '19', '20', '21', '22', '23', '25', '37', '42', '43', '53', '69', '77', '79',\n '87', '95', '101', '102', '103', '104', '109', '110', '111', '113', '115', '117', '119', '123', '135', '137',\n '139', '143', '161', '179', '389', '427', '465', '512', '513', '514', '515', '526', '530', '531', '532',\n '540', '548', '554', '556', '563', '587', '601', '636', '989', '990', '993', '995', '1719', '1720', '1723',\n '2049', '3659', '4045', '5060', '5061', '6000', '6566', '6665', '6666', '6667', '6668', '6669', '6697',\n '10080'\n]\n\nconst badPortsSet = new Set(badPorts)\n\n// https://w3c.github.io/webappsec-referrer-policy/#referrer-policies\nconst referrerPolicy = [\n '',\n 'no-referrer',\n 'no-referrer-when-downgrade',\n 'same-origin',\n 'origin',\n 'strict-origin',\n 'origin-when-cross-origin',\n 'strict-origin-when-cross-origin',\n 'unsafe-url'\n]\nconst referrerPolicySet = new Set(referrerPolicy)\n\nconst requestRedirect = ['follow', 'manual', 'error']\n\nconst safeMethods = ['GET', 'HEAD', 'OPTIONS', 'TRACE']\nconst safeMethodsSet = new Set(safeMethods)\n\nconst requestMode = ['navigate', 'same-origin', 'no-cors', 'cors']\n\nconst requestCredentials = ['omit', 'same-origin', 'include']\n\nconst requestCache = [\n 'default',\n 'no-store',\n 'reload',\n 'no-cache',\n 'force-cache',\n 'only-if-cached'\n]\n\n// https://fetch.spec.whatwg.org/#request-body-header-name\nconst requestBodyHeader = [\n 'content-encoding',\n 'content-language',\n 'content-location',\n 'content-type',\n // See https://github.com/nodejs/undici/issues/2021\n // 'Content-Length' is a forbidden header name, which is typically\n // removed in the Headers implementation. However, undici doesn't\n // filter out headers, so we add it here.\n 'content-length'\n]\n\n// https://fetch.spec.whatwg.org/#enumdef-requestduplex\nconst requestDuplex = [\n 'half'\n]\n\n// http://fetch.spec.whatwg.org/#forbidden-method\nconst forbiddenMethods = ['CONNECT', 'TRACE', 'TRACK']\nconst forbiddenMethodsSet = new Set(forbiddenMethods)\n\nconst subresource = [\n 'audio',\n 'audioworklet',\n 'font',\n 'image',\n 'manifest',\n 'paintworklet',\n 'script',\n 'style',\n 'track',\n 'video',\n 'xslt',\n ''\n]\nconst subresourceSet = new Set(subresource)\n\n/** @type {globalThis['DOMException']} */\nconst DOMException = globalThis.DOMException ?? (() => {\n // DOMException was only made a global in Node v17.0.0,\n // but fetch supports >= v16.8.\n try {\n atob('~')\n } catch (err) {\n return Object.getPrototypeOf(err).constructor\n }\n})()\n\nlet channel\n\n/** @type {globalThis['structuredClone']} */\nconst structuredClone =\n globalThis.structuredClone ??\n // https://github.com/nodejs/node/blob/b27ae24dcc4251bad726d9d84baf678d1f707fed/lib/internal/structured_clone.js\n // structuredClone was added in v17.0.0, but fetch supports v16.8\n function structuredClone (value, options = undefined) {\n if (arguments.length === 0) {\n throw new TypeError('missing argument')\n }\n\n if (!channel) {\n channel = new MessageChannel()\n }\n channel.port1.unref()\n channel.port2.unref()\n channel.port1.postMessage(value, options?.transfer)\n return receiveMessageOnPort(channel.port2).message\n }\n\nmodule.exports = {\n DOMException,\n structuredClone,\n subresource,\n forbiddenMethods,\n requestBodyHeader,\n referrerPolicy,\n requestRedirect,\n requestMode,\n requestCredentials,\n requestCache,\n redirectStatus,\n corsSafeListedMethods,\n nullBodyStatus,\n safeMethods,\n badPorts,\n requestDuplex,\n subresourceSet,\n badPortsSet,\n redirectStatusSet,\n corsSafeListedMethodsSet,\n safeMethodsSet,\n forbiddenMethodsSet,\n referrerPolicySet\n}\n\n\n/***/ }),\n\n/***/ 685:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\nconst assert = __nccwpck_require__(9491)\nconst { atob } = __nccwpck_require__(4300)\nconst { isomorphicDecode } = __nccwpck_require__(2538)\n\nconst encoder = new TextEncoder()\n\n/**\n * @see https://mimesniff.spec.whatwg.org/#http-token-code-point\n */\nconst HTTP_TOKEN_CODEPOINTS = /^[!#$%&'*+-.^_|~A-Za-z0-9]+$/\nconst HTTP_WHITESPACE_REGEX = /(\\u000A|\\u000D|\\u0009|\\u0020)/ // eslint-disable-line\n/**\n * @see https://mimesniff.spec.whatwg.org/#http-quoted-string-token-code-point\n */\nconst HTTP_QUOTED_STRING_TOKENS = /[\\u0009|\\u0020-\\u007E|\\u0080-\\u00FF]/ // eslint-disable-line\n\n// https://fetch.spec.whatwg.org/#data-url-processor\n/** @param {URL} dataURL */\nfunction dataURLProcessor (dataURL) {\n // 1. Assert: dataURL\u2019s scheme is \"data\".\n assert(dataURL.protocol === 'data:')\n\n // 2. Let input be the result of running the URL\n // serializer on dataURL with exclude fragment\n // set to true.\n let input = URLSerializer(dataURL, true)\n\n // 3. Remove the leading \"data:\" string from input.\n input = input.slice(5)\n\n // 4. Let position point at the start of input.\n const position = { position: 0 }\n\n // 5. Let mimeType be the result of collecting a\n // sequence of code points that are not equal\n // to U+002C (,), given position.\n let mimeType = collectASequenceOfCodePointsFast(\n ',',\n input,\n position\n )\n\n // 6. Strip leading and trailing ASCII whitespace\n // from mimeType.\n // Undici implementation note: we need to store the\n // length because if the mimetype has spaces removed,\n // the wrong amount will be sliced from the input in\n // step #9\n const mimeTypeLength = mimeType.length\n mimeType = removeASCIIWhitespace(mimeType, true, true)\n\n // 7. If position is past the end of input, then\n // return failure\n if (position.position >= input.length) {\n return 'failure'\n }\n\n // 8. Advance position by 1.\n position.position++\n\n // 9. Let encodedBody be the remainder of input.\n const encodedBody = input.slice(mimeTypeLength + 1)\n\n // 10. Let body be the percent-decoding of encodedBody.\n let body = stringPercentDecode(encodedBody)\n\n // 11. If mimeType ends with U+003B (;), followed by\n // zero or more U+0020 SPACE, followed by an ASCII\n // case-insensitive match for \"base64\", then:\n if (/;(\\u0020){0,}base64$/i.test(mimeType)) {\n // 1. Let stringBody be the isomorphic decode of body.\n const stringBody = isomorphicDecode(body)\n\n // 2. Set body to the forgiving-base64 decode of\n // stringBody.\n body = forgivingBase64(stringBody)\n\n // 3. If body is failure, then return failure.\n if (body === 'failure') {\n return 'failure'\n }\n\n // 4. Remove the last 6 code points from mimeType.\n mimeType = mimeType.slice(0, -6)\n\n // 5. Remove trailing U+0020 SPACE code points from mimeType,\n // if any.\n mimeType = mimeType.replace(/(\\u0020)+$/, '')\n\n // 6. Remove the last U+003B (;) code point from mimeType.\n mimeType = mimeType.slice(0, -1)\n }\n\n // 12. If mimeType starts with U+003B (;), then prepend\n // \"text/plain\" to mimeType.\n if (mimeType.startsWith(';')) {\n mimeType = 'text/plain' + mimeType\n }\n\n // 13. Let mimeTypeRecord be the result of parsing\n // mimeType.\n let mimeTypeRecord = parseMIMEType(mimeType)\n\n // 14. If mimeTypeRecord is failure, then set\n // mimeTypeRecord to text/plain;charset=US-ASCII.\n if (mimeTypeRecord === 'failure') {\n mimeTypeRecord = parseMIMEType('text/plain;charset=US-ASCII')\n }\n\n // 15. Return a new data: URL struct whose MIME\n // type is mimeTypeRecord and body is body.\n // https://fetch.spec.whatwg.org/#data-url-struct\n return { mimeType: mimeTypeRecord, body }\n}\n\n// https://url.spec.whatwg.org/#concept-url-serializer\n/**\n * @param {URL} url\n * @param {boolean} excludeFragment\n */\nfunction URLSerializer (url, excludeFragment = false) {\n if (!excludeFragment) {\n return url.href\n }\n\n const href = url.href\n const hashLength = url.hash.length\n\n return hashLength === 0 ? href : href.substring(0, href.length - hashLength)\n}\n\n// https://infra.spec.whatwg.org/#collect-a-sequence-of-code-points\n/**\n * @param {(char: string) => boolean} condition\n * @param {string} input\n * @param {{ position: number }} position\n */\nfunction collectASequenceOfCodePoints (condition, input, position) {\n // 1. Let result be the empty string.\n let result = ''\n\n // 2. While position doesn\u2019t point past the end of input and the\n // code point at position within input meets the condition condition:\n while (position.position < input.length && condition(input[position.position])) {\n // 1. Append that code point to the end of result.\n result += input[position.position]\n\n // 2. Advance position by 1.\n position.position++\n }\n\n // 3. Return result.\n return result\n}\n\n/**\n * A faster collectASequenceOfCodePoints that only works when comparing a single character.\n * @param {string} char\n * @param {string} input\n * @param {{ position: number }} position\n */\nfunction collectASequenceOfCodePointsFast (char, input, position) {\n const idx = input.indexOf(char, position.position)\n const start = position.position\n\n if (idx === -1) {\n position.position = input.length\n return input.slice(start)\n }\n\n position.position = idx\n return input.slice(start, position.position)\n}\n\n// https://url.spec.whatwg.org/#string-percent-decode\n/** @param {string} input */\nfunction stringPercentDecode (input) {\n // 1. Let bytes be the UTF-8 encoding of input.\n const bytes = encoder.encode(input)\n\n // 2. Return the percent-decoding of bytes.\n return percentDecode(bytes)\n}\n\n// https://url.spec.whatwg.org/#percent-decode\n/** @param {Uint8Array} input */\nfunction percentDecode (input) {\n // 1. Let output be an empty byte sequence.\n /** @type {number[]} */\n const output = []\n\n // 2. For each byte byte in input:\n for (let i = 0; i < input.length; i++) {\n const byte = input[i]\n\n // 1. If byte is not 0x25 (%), then append byte to output.\n if (byte !== 0x25) {\n output.push(byte)\n\n // 2. Otherwise, if byte is 0x25 (%) and the next two bytes\n // after byte in input are not in the ranges\n // 0x30 (0) to 0x39 (9), 0x41 (A) to 0x46 (F),\n // and 0x61 (a) to 0x66 (f), all inclusive, append byte\n // to output.\n } else if (\n byte === 0x25 &&\n !/^[0-9A-Fa-f]{2}$/i.test(String.fromCharCode(input[i + 1], input[i + 2]))\n ) {\n output.push(0x25)\n\n // 3. Otherwise:\n } else {\n // 1. Let bytePoint be the two bytes after byte in input,\n // decoded, and then interpreted as hexadecimal number.\n const nextTwoBytes = String.fromCharCode(input[i + 1], input[i + 2])\n const bytePoint = Number.parseInt(nextTwoBytes, 16)\n\n // 2. Append a byte whose value is bytePoint to output.\n output.push(bytePoint)\n\n // 3. Skip the next two bytes in input.\n i += 2\n }\n }\n\n // 3. Return output.\n return Uint8Array.from(output)\n}\n\n// https://mimesniff.spec.whatwg.org/#parse-a-mime-type\n/** @param {string} input */\nfunction parseMIMEType (input) {\n // 1. Remove any leading and trailing HTTP whitespace\n // from input.\n input = removeHTTPWhitespace(input, true, true)\n\n // 2. Let position be a position variable for input,\n // initially pointing at the start of input.\n const position = { position: 0 }\n\n // 3. Let type be the result of collecting a sequence\n // of code points that are not U+002F (/) from\n // input, given position.\n const type = collectASequenceOfCodePointsFast(\n '/',\n input,\n position\n )\n\n // 4. If type is the empty string or does not solely\n // contain HTTP token code points, then return failure.\n // https://mimesniff.spec.whatwg.org/#http-token-code-point\n if (type.length === 0 || !HTTP_TOKEN_CODEPOINTS.test(type)) {\n return 'failure'\n }\n\n // 5. If position is past the end of input, then return\n // failure\n if (position.position > input.length) {\n return 'failure'\n }\n\n // 6. Advance position by 1. (This skips past U+002F (/).)\n position.position++\n\n // 7. Let subtype be the result of collecting a sequence of\n // code points that are not U+003B (;) from input, given\n // position.\n let subtype = collectASequenceOfCodePointsFast(\n ';',\n input,\n position\n )\n\n // 8. Remove any trailing HTTP whitespace from subtype.\n subtype = removeHTTPWhitespace(subtype, false, true)\n\n // 9. If subtype is the empty string or does not solely\n // contain HTTP token code points, then return failure.\n if (subtype.length === 0 || !HTTP_TOKEN_CODEPOINTS.test(subtype)) {\n return 'failure'\n }\n\n const typeLowercase = type.toLowerCase()\n const subtypeLowercase = subtype.toLowerCase()\n\n // 10. Let mimeType be a new MIME type record whose type\n // is type, in ASCII lowercase, and subtype is subtype,\n // in ASCII lowercase.\n // https://mimesniff.spec.whatwg.org/#mime-type\n const mimeType = {\n type: typeLowercase,\n subtype: subtypeLowercase,\n /** @type {Map<string, string>} */\n parameters: new Map(),\n // https://mimesniff.spec.whatwg.org/#mime-type-essence\n essence: `${typeLowercase}/${subtypeLowercase}`\n }\n\n // 11. While position is not past the end of input:\n while (position.position < input.length) {\n // 1. Advance position by 1. (This skips past U+003B (;).)\n position.position++\n\n // 2. Collect a sequence of code points that are HTTP\n // whitespace from input given position.\n collectASequenceOfCodePoints(\n // https://fetch.spec.whatwg.org/#http-whitespace\n char => HTTP_WHITESPACE_REGEX.test(char),\n input,\n position\n )\n\n // 3. Let parameterName be the result of collecting a\n // sequence of code points that are not U+003B (;)\n // or U+003D (=) from input, given position.\n let parameterName = collectASequenceOfCodePoints(\n (char) => char !== ';' && char !== '=',\n input,\n position\n )\n\n // 4. Set parameterName to parameterName, in ASCII\n // lowercase.\n parameterName = parameterName.toLowerCase()\n\n // 5. If position is not past the end of input, then:\n if (position.position < input.length) {\n // 1. If the code point at position within input is\n // U+003B (;), then continue.\n if (input[position.position] === ';') {\n continue\n }\n\n // 2. Advance position by 1. (This skips past U+003D (=).)\n position.position++\n }\n\n // 6. If position is past the end of input, then break.\n if (position.position > input.length) {\n break\n }\n\n // 7. Let parameterValue be null.\n let parameterValue = null\n\n // 8. If the code point at position within input is\n // U+0022 (\"), then:\n if (input[position.position] === '\"') {\n // 1. Set parameterValue to the result of collecting\n // an HTTP quoted string from input, given position\n // and the extract-value flag.\n parameterValue = collectAnHTTPQuotedString(input, position, true)\n\n // 2. Collect a sequence of code points that are not\n // U+003B (;) from input, given position.\n collectASequenceOfCodePointsFast(\n ';',\n input,\n position\n )\n\n // 9. Otherwise:\n } else {\n // 1. Set parameterValue to the result of collecting\n // a sequence of code points that are not U+003B (;)\n // from input, given position.\n parameterValue = collectASequenceOfCodePointsFast(\n ';',\n input,\n position\n )\n\n // 2. Remove any trailing HTTP whitespace from parameterValue.\n parameterValue = removeHTTPWhitespace(parameterValue, false, true)\n\n // 3. If parameterValue is the empty string, then continue.\n if (parameterValue.length === 0) {\n continue\n }\n }\n\n // 10. If all of the following are true\n // - parameterName is not the empty string\n // - parameterName solely contains HTTP token code points\n // - parameterValue solely contains HTTP quoted-string token code points\n // - mimeType\u2019s parameters[parameterName] does not exist\n // then set mimeType\u2019s parameters[parameterName] to parameterValue.\n if (\n parameterName.length !== 0 &&\n HTTP_TOKEN_CODEPOINTS.test(parameterName) &&\n (parameterValue.length === 0 || HTTP_QUOTED_STRING_TOKENS.test(parameterValue)) &&\n !mimeType.parameters.has(parameterName)\n ) {\n mimeType.parameters.set(parameterName, parameterValue)\n }\n }\n\n // 12. Return mimeType.\n return mimeType\n}\n\n// https://infra.spec.whatwg.org/#forgiving-base64-decode\n/** @param {string} data */\nfunction forgivingBase64 (data) {\n // 1. Remove all ASCII whitespace from data.\n data = data.replace(/[\\u0009\\u000A\\u000C\\u000D\\u0020]/g, '') // eslint-disable-line\n\n // 2. If data\u2019s code point length divides by 4 leaving\n // no remainder, then:\n if (data.length % 4 === 0) {\n // 1. If data ends with one or two U+003D (=) code points,\n // then remove them from data.\n data = data.replace(/=?=$/, '')\n }\n\n // 3. If data\u2019s code point length divides by 4 leaving\n // a remainder of 1, then return failure.\n if (data.length % 4 === 1) {\n return 'failure'\n }\n\n // 4. If data contains a code point that is not one of\n // U+002B (+)\n // U+002F (/)\n // ASCII alphanumeric\n // then return failure.\n if (/[^+/0-9A-Za-z]/.test(data)) {\n return 'failure'\n }\n\n const binary = atob(data)\n const bytes = new Uint8Array(binary.length)\n\n for (let byte = 0; byte < binary.length; byte++) {\n bytes[byte] = binary.charCodeAt(byte)\n }\n\n return bytes\n}\n\n// https://fetch.spec.whatwg.org/#collect-an-http-quoted-string\n// tests: https://fetch.spec.whatwg.org/#example-http-quoted-string\n/**\n * @param {string} input\n * @param {{ position: number }} position\n * @param {boolean?} extractValue\n */\nfunction collectAnHTTPQuotedString (input, position, extractValue) {\n // 1. Let positionStart be position.\n const positionStart = position.position\n\n // 2. Let value be the empty string.\n let value = ''\n\n // 3. Assert: the code point at position within input\n // is U+0022 (\").\n assert(input[position.position] === '\"')\n\n // 4. Advance position by 1.\n position.position++\n\n // 5. While true:\n while (true) {\n // 1. Append the result of collecting a sequence of code points\n // that are not U+0022 (\") or U+005C (\\) from input, given\n // position, to value.\n value += collectASequenceOfCodePoints(\n (char) => char !== '\"' && char !== '\\\\',\n input,\n position\n )\n\n // 2. If position is past the end of input, then break.\n if (position.position >= input.length) {\n break\n }\n\n // 3. Let quoteOrBackslash be the code point at position within\n // input.\n const quoteOrBackslash = input[position.position]\n\n // 4. Advance position by 1.\n position.position++\n\n // 5. If quoteOrBackslash is U+005C (\\), then:\n if (quoteOrBackslash === '\\\\') {\n // 1. If position is past the end of input, then append\n // U+005C (\\) to value and break.\n if (position.position >= input.length) {\n value += '\\\\'\n break\n }\n\n // 2. Append the code point at position within input to value.\n value += input[position.position]\n\n // 3. Advance position by 1.\n position.position++\n\n // 6. Otherwise:\n } else {\n // 1. Assert: quoteOrBackslash is U+0022 (\").\n assert(quoteOrBackslash === '\"')\n\n // 2. Break.\n break\n }\n }\n\n // 6. If the extract-value flag is set, then return value.\n if (extractValue) {\n return value\n }\n\n // 7. Return the code points from positionStart to position,\n // inclusive, within input.\n return input.slice(positionStart, position.position)\n}\n\n/**\n * @see https://mimesniff.spec.whatwg.org/#serialize-a-mime-type\n */\nfunction serializeAMimeType (mimeType) {\n assert(mimeType !== 'failure')\n const { parameters, essence } = mimeType\n\n // 1. Let serialization be the concatenation of mimeType\u2019s\n // type, U+002F (/), and mimeType\u2019s subtype.\n let serialization = essence\n\n // 2. For each name \u2192 value of mimeType\u2019s parameters:\n for (let [name, value] of parameters.entries()) {\n // 1. Append U+003B (;) to serialization.\n serialization += ';'\n\n // 2. Append name to serialization.\n serialization += name\n\n // 3. Append U+003D (=) to serialization.\n serialization += '='\n\n // 4. If value does not solely contain HTTP token code\n // points or value is the empty string, then:\n if (!HTTP_TOKEN_CODEPOINTS.test(value)) {\n // 1. Precede each occurence of U+0022 (\") or\n // U+005C (\\) in value with U+005C (\\).\n value = value.replace(/(\\\\|\")/g, '\\\\$1')\n\n // 2. Prepend U+0022 (\") to value.\n value = '\"' + value\n\n // 3. Append U+0022 (\") to value.\n value += '\"'\n }\n\n // 5. Append value to serialization.\n serialization += value\n }\n\n // 3. Return serialization.\n return serialization\n}\n\n/**\n * @see https://fetch.spec.whatwg.org/#http-whitespace\n * @param {string} char\n */\nfunction isHTTPWhiteSpace (char) {\n return char === '\\r' || char === '\\n' || char === '\\t' || char === ' '\n}\n\n/**\n * @see https://fetch.spec.whatwg.org/#http-whitespace\n * @param {string} str\n */\nfunction removeHTTPWhitespace (str, leading = true, trailing = true) {\n let lead = 0\n let trail = str.length - 1\n\n if (leading) {\n for (; lead < str.length && isHTTPWhiteSpace(str[lead]); lead++);\n }\n\n if (trailing) {\n for (; trail > 0 && isHTTPWhiteSpace(str[trail]); trail--);\n }\n\n return str.slice(lead, trail + 1)\n}\n\n/**\n * @see https://infra.spec.whatwg.org/#ascii-whitespace\n * @param {string} char\n */\nfunction isASCIIWhitespace (char) {\n return char === '\\r' || char === '\\n' || char === '\\t' || char === '\\f' || char === ' '\n}\n\n/**\n * @see https://infra.spec.whatwg.org/#strip-leading-and-trailing-ascii-whitespace\n */\nfunction removeASCIIWhitespace (str, leading = true, trailing = true) {\n let lead = 0\n let trail = str.length - 1\n\n if (leading) {\n for (; lead < str.length && isASCIIWhitespace(str[lead]); lead++);\n }\n\n if (trailing) {\n for (; trail > 0 && isASCIIWhitespace(str[trail]); trail--);\n }\n\n return str.slice(lead, trail + 1)\n}\n\nmodule.exports = {\n dataURLProcessor,\n URLSerializer,\n collectASequenceOfCodePoints,\n collectASequenceOfCodePointsFast,\n stringPercentDecode,\n parseMIMEType,\n collectAnHTTPQuotedString,\n serializeAMimeType\n}\n\n\n/***/ }),\n\n/***/ 8511:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\n\"use strict\";\n\n\nconst { Blob, File: NativeFile } = __nccwpck_require__(4300)\nconst { types } = __nccwpck_require__(3837)\nconst { kState } = __nccwpck_require__(5861)\nconst { isBlobLike } = __nccwpck_require__(2538)\nconst { webidl } = __nccwpck_require__(1744)\nconst { parseMIMEType, serializeAMimeType } = __nccwpck_require__(685)\nconst { kEnumerableProperty } = __nccwpck_require__(3983)\nconst encoder = new TextEncoder()\n\nclass File extends Blob {\n constructor (fileBits, fileName, options = {}) {\n // The File constructor is invoked with two or three parameters, depending\n // on whether the optional dictionary parameter is used. When the File()\n // constructor is invoked, user agents must run the following steps:\n webidl.argumentLengthCheck(arguments, 2, { header: 'File constructor' })\n\n fileBits = webidl.converters['sequence<BlobPart>'](fileBits)\n fileName = webidl.converters.USVString(fileName)\n options = webidl.converters.FilePropertyBag(options)\n\n // 1. Let bytes be the result of processing blob parts given fileBits and\n // options.\n // Note: Blob handles this for us\n\n // 2. Let n be the fileName argument to the constructor.\n const n = fileName\n\n // 3. Process FilePropertyBag dictionary argument by running the following\n // substeps:\n\n // 1. If the type member is provided and is not the empty string, let t\n // be set to the type dictionary member. If t contains any characters\n // outside the range U+0020 to U+007E, then set t to the empty string\n // and return from these substeps.\n // 2. Convert every character in t to ASCII lowercase.\n let t = options.type\n let d\n\n // eslint-disable-next-line no-labels\n substep: {\n if (t) {\n t = parseMIMEType(t)\n\n if (t === 'failure') {\n t = ''\n // eslint-disable-next-line no-labels\n break substep\n }\n\n t = serializeAMimeType(t).toLowerCase()\n }\n\n // 3. If the lastModified member is provided, let d be set to the\n // lastModified dictionary member. If it is not provided, set d to the\n // current date and time represented as the number of milliseconds since\n // the Unix Epoch (which is the equivalent of Date.now() [ECMA-262]).\n d = options.lastModified\n }\n\n // 4. Return a new File object F such that:\n // F refers to the bytes byte sequence.\n // F.size is set to the number of total bytes in bytes.\n // F.name is set to n.\n // F.type is set to t.\n // F.lastModified is set to d.\n\n super(processBlobParts(fileBits, options), { type: t })\n this[kState] = {\n name: n,\n lastModified: d,\n type: t\n }\n }\n\n get name () {\n webidl.brandCheck(this, File)\n\n return this[kState].name\n }\n\n get lastModified () {\n webidl.brandCheck(this, File)\n\n return this[kState].lastModified\n }\n\n get type () {\n webidl.brandCheck(this, File)\n\n return this[kState].type\n }\n}\n\nclass FileLike {\n constructor (blobLike, fileName, options = {}) {\n // TODO: argument idl type check\n\n // The File constructor is invoked with two or three parameters, depending\n // on whether the optional dictionary parameter is used. When the File()\n // constructor is invoked, user agents must run the following steps:\n\n // 1. Let bytes be the result of processing blob parts given fileBits and\n // options.\n\n // 2. Let n be the fileName argument to the constructor.\n const n = fileName\n\n // 3. Process FilePropertyBag dictionary argument by running the following\n // substeps:\n\n // 1. If the type member is provided and is not the empty string, let t\n // be set to the type dictionary member. If t contains any characters\n // outside the range U+0020 to U+007E, then set t to the empty string\n // and return from these substeps.\n // TODO\n const t = options.type\n\n // 2. Convert every character in t to ASCII lowercase.\n // TODO\n\n // 3. If the lastModified member is provided, let d be set to the\n // lastModified dictionary member. If it is not provided, set d to the\n // current date and time represented as the number of milliseconds since\n // the Unix Epoch (which is the equivalent of Date.now() [ECMA-262]).\n const d = options.lastModified ?? Date.now()\n\n // 4. Return a new File object F such that:\n // F refers to the bytes byte sequence.\n // F.size is set to the number of total bytes in bytes.\n // F.name is set to n.\n // F.type is set to t.\n // F.lastModified is set to d.\n\n this[kState] = {\n blobLike,\n name: n,\n type: t,\n lastModified: d\n }\n }\n\n stream (...args) {\n webidl.brandCheck(this, FileLike)\n\n return this[kState].blobLike.stream(...args)\n }\n\n arrayBuffer (...args) {\n webidl.brandCheck(this, FileLike)\n\n return this[kState].blobLike.arrayBuffer(...args)\n }\n\n slice (...args) {\n webidl.brandCheck(this, FileLike)\n\n return this[kState].blobLike.slice(...args)\n }\n\n text (...args) {\n webidl.brandCheck(this, FileLike)\n\n return this[kState].blobLike.text(...args)\n }\n\n get size () {\n webidl.brandCheck(this, FileLike)\n\n return this[kState].blobLike.size\n }\n\n get type () {\n webidl.brandCheck(this, FileLike)\n\n return this[kState].blobLike.type\n }\n\n get name () {\n webidl.brandCheck(this, FileLike)\n\n return this[kState].name\n }\n\n get lastModified () {\n webidl.brandCheck(this, FileLike)\n\n return this[kState].lastModified\n }\n\n get [Symbol.toStringTag] () {\n return 'File'\n }\n}\n\nObject.defineProperties(File.prototype, {\n [Symbol.toStringTag]: {\n value: 'File',\n configurable: true\n },\n name: kEnumerableProperty,\n lastModified: kEnumerableProperty\n})\n\nwebidl.converters.Blob = webidl.interfaceConverter(Blob)\n\nwebidl.converters.BlobPart = function (V, opts) {\n if (webidl.util.Type(V) === 'Object') {\n if (isBlobLike(V)) {\n return webidl.converters.Blob(V, { strict: false })\n }\n\n if (\n ArrayBuffer.isView(V) ||\n types.isAnyArrayBuffer(V)\n ) {\n return webidl.converters.BufferSource(V, opts)\n }\n }\n\n return webidl.converters.USVString(V, opts)\n}\n\nwebidl.converters['sequence<BlobPart>'] = webidl.sequenceConverter(\n webidl.converters.BlobPart\n)\n\n// https://www.w3.org/TR/FileAPI/#dfn-FilePropertyBag\nwebidl.converters.FilePropertyBag = webidl.dictionaryConverter([\n {\n key: 'lastModified',\n converter: webidl.converters['long long'],\n get defaultValue () {\n return Date.now()\n }\n },\n {\n key: 'type',\n converter: webidl.converters.DOMString,\n defaultValue: ''\n },\n {\n key: 'endings',\n converter: (value) => {\n value = webidl.converters.DOMString(value)\n value = value.toLowerCase()\n\n if (value !== 'native') {\n value = 'transparent'\n }\n\n return value\n },\n defaultValue: 'transparent'\n }\n])\n\n/**\n * @see https://www.w3.org/TR/FileAPI/#process-blob-parts\n * @param {(NodeJS.TypedArray|Blob|string)[]} parts\n * @param {{ type: string, endings: string }} options\n */\nfunction processBlobParts (parts, options) {\n // 1. Let bytes be an empty sequence of bytes.\n /** @type {NodeJS.TypedArray[]} */\n const bytes = []\n\n // 2. For each element in parts:\n for (const element of parts) {\n // 1. If element is a USVString, run the following substeps:\n if (typeof element === 'string') {\n // 1. Let s be element.\n let s = element\n\n // 2. If the endings member of options is \"native\", set s\n // to the result of converting line endings to native\n // of element.\n if (options.endings === 'native') {\n s = convertLineEndingsNative(s)\n }\n\n // 3. Append the result of UTF-8 encoding s to bytes.\n bytes.push(encoder.encode(s))\n } else if (\n types.isAnyArrayBuffer(element) ||\n types.isTypedArray(element)\n ) {\n // 2. If element is a BufferSource, get a copy of the\n // bytes held by the buffer source, and append those\n // bytes to bytes.\n if (!element.buffer) { // ArrayBuffer\n bytes.push(new Uint8Array(element))\n } else {\n bytes.push(\n new Uint8Array(element.buffer, element.byteOffset, element.byteLength)\n )\n }\n } else if (isBlobLike(element)) {\n // 3. If element is a Blob, append the bytes it represents\n // to bytes.\n bytes.push(element)\n }\n }\n\n // 3. Return bytes.\n return bytes\n}\n\n/**\n * @see https://www.w3.org/TR/FileAPI/#convert-line-endings-to-native\n * @param {string} s\n */\nfunction convertLineEndingsNative (s) {\n // 1. Let native line ending be be the code point U+000A LF.\n let nativeLineEnding = '\\n'\n\n // 2. If the underlying platform\u2019s conventions are to\n // represent newlines as a carriage return and line feed\n // sequence, set native line ending to the code point\n // U+000D CR followed by the code point U+000A LF.\n if (process.platform === 'win32') {\n nativeLineEnding = '\\r\\n'\n }\n\n return s.replace(/\\r?\\n/g, nativeLineEnding)\n}\n\n// If this function is moved to ./util.js, some tools (such as\n// rollup) will warn about circular dependencies. See:\n// https://github.com/nodejs/undici/issues/1629\nfunction isFileLike (object) {\n return (\n (NativeFile && object instanceof NativeFile) ||\n object instanceof File || (\n object &&\n (typeof object.stream === 'function' ||\n typeof object.arrayBuffer === 'function') &&\n object[Symbol.toStringTag] === 'File'\n )\n )\n}\n\nmodule.exports = { File, FileLike, isFileLike }\n\n\n/***/ }),\n\n/***/ 2015:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\n\"use strict\";\n\n\nconst { isBlobLike, toUSVString, makeIterator } = __nccwpck_require__(2538)\nconst { kState } = __nccwpck_require__(5861)\nconst { File: UndiciFile, FileLike, isFileLike } = __nccwpck_require__(8511)\nconst { webidl } = __nccwpck_require__(1744)\nconst { Blob, File: NativeFile } = __nccwpck_require__(4300)\n\n/** @type {globalThis['File']} */\nconst File = NativeFile ?? UndiciFile\n\n// https://xhr.spec.whatwg.org/#formdata\nclass FormData {\n constructor (form) {\n if (form !== undefined) {\n throw webidl.errors.conversionFailed({\n prefix: 'FormData constructor',\n argument: 'Argument 1',\n types: ['undefined']\n })\n }\n\n this[kState] = []\n }\n\n append (name, value, filename = undefined) {\n webidl.brandCheck(this, FormData)\n\n webidl.argumentLengthCheck(arguments, 2, { header: 'FormData.append' })\n\n if (arguments.length === 3 && !isBlobLike(value)) {\n throw new TypeError(\n \"Failed to execute 'append' on 'FormData': parameter 2 is not of type 'Blob'\"\n )\n }\n\n // 1. Let value be value if given; otherwise blobValue.\n\n name = webidl.converters.USVString(name)\n value = isBlobLike(value)\n ? webidl.converters.Blob(value, { strict: false })\n : webidl.converters.USVString(value)\n filename = arguments.length === 3\n ? webidl.converters.USVString(filename)\n : undefined\n\n // 2. Let entry be the result of creating an entry with\n // name, value, and filename if given.\n const entry = makeEntry(name, value, filename)\n\n // 3. Append entry to this\u2019s entry list.\n this[kState].push(entry)\n }\n\n delete (name) {\n webidl.brandCheck(this, FormData)\n\n webidl.argumentLengthCheck(arguments, 1, { header: 'FormData.delete' })\n\n name = webidl.converters.USVString(name)\n\n // The delete(name) method steps are to remove all entries whose name\n // is name from this\u2019s entry list.\n this[kState] = this[kState].filter(entry => entry.name !== name)\n }\n\n get (name) {\n webidl.brandCheck(this, FormData)\n\n webidl.argumentLengthCheck(arguments, 1, { header: 'FormData.get' })\n\n name = webidl.converters.USVString(name)\n\n // 1. If there is no entry whose name is name in this\u2019s entry list,\n // then return null.\n const idx = this[kState].findIndex((entry) => entry.name === name)\n if (idx === -1) {\n return null\n }\n\n // 2. Return the value of the first entry whose name is name from\n // this\u2019s entry list.\n return this[kState][idx].value\n }\n\n getAll (name) {\n webidl.brandCheck(this, FormData)\n\n webidl.argumentLengthCheck(arguments, 1, { header: 'FormData.getAll' })\n\n name = webidl.converters.USVString(name)\n\n // 1. If there is no entry whose name is name in this\u2019s entry list,\n // then return the empty list.\n // 2. Return the values of all entries whose name is name, in order,\n // from this\u2019s entry list.\n return this[kState]\n .filter((entry) => entry.name === name)\n .map((entry) => entry.value)\n }\n\n has (name) {\n webidl.brandCheck(this, FormData)\n\n webidl.argumentLengthCheck(arguments, 1, { header: 'FormData.has' })\n\n name = webidl.converters.USVString(name)\n\n // The has(name) method steps are to return true if there is an entry\n // whose name is name in this\u2019s entry list; otherwise false.\n return this[kState].findIndex((entry) => entry.name === name) !== -1\n }\n\n set (name, value, filename = undefined) {\n webidl.brandCheck(this, FormData)\n\n webidl.argumentLengthCheck(arguments, 2, { header: 'FormData.set' })\n\n if (arguments.length === 3 && !isBlobLike(value)) {\n throw new TypeError(\n \"Failed to execute 'set' on 'FormData': parameter 2 is not of type 'Blob'\"\n )\n }\n\n // The set(name, value) and set(name, blobValue, filename) method steps\n // are:\n\n // 1. Let value be value if given; otherwise blobValue.\n\n name = webidl.converters.USVString(name)\n value = isBlobLike(value)\n ? webidl.converters.Blob(value, { strict: false })\n : webidl.converters.USVString(value)\n filename = arguments.length === 3\n ? toUSVString(filename)\n : undefined\n\n // 2. Let entry be the result of creating an entry with name, value, and\n // filename if given.\n const entry = makeEntry(name, value, filename)\n\n // 3. If there are entries in this\u2019s entry list whose name is name, then\n // replace the first such entry with entry and remove the others.\n const idx = this[kState].findIndex((entry) => entry.name === name)\n if (idx !== -1) {\n this[kState] = [\n ...this[kState].slice(0, idx),\n entry,\n ...this[kState].slice(idx + 1).filter((entry) => entry.name !== name)\n ]\n } else {\n // 4. Otherwise, append entry to this\u2019s entry list.\n this[kState].push(entry)\n }\n }\n\n entries () {\n webidl.brandCheck(this, FormData)\n\n return makeIterator(\n () => this[kState].map(pair => [pair.name, pair.value]),\n 'FormData',\n 'key+value'\n )\n }\n\n keys () {\n webidl.brandCheck(this, FormData)\n\n return makeIterator(\n () => this[kState].map(pair => [pair.name, pair.value]),\n 'FormData',\n 'key'\n )\n }\n\n values () {\n webidl.brandCheck(this, FormData)\n\n return makeIterator(\n () => this[kState].map(pair => [pair.name, pair.value]),\n 'FormData',\n 'value'\n )\n }\n\n /**\n * @param {(value: string, key: string, self: FormData) => void} callbackFn\n * @param {unknown} thisArg\n */\n forEach (callbackFn, thisArg = globalThis) {\n webidl.brandCheck(this, FormData)\n\n webidl.argumentLengthCheck(arguments, 1, { header: 'FormData.forEach' })\n\n if (typeof callbackFn !== 'function') {\n throw new TypeError(\n \"Failed to execute 'forEach' on 'FormData': parameter 1 is not of type 'Function'.\"\n )\n }\n\n for (const [key, value] of this) {\n callbackFn.apply(thisArg, [value, key, this])\n }\n }\n}\n\nFormData.prototype[Symbol.iterator] = FormData.prototype.entries\n\nObject.defineProperties(FormData.prototype, {\n [Symbol.toStringTag]: {\n value: 'FormData',\n configurable: true\n }\n})\n\n/**\n * @see https://html.spec.whatwg.org/multipage/form-control-infrastructure.html#create-an-entry\n * @param {string} name\n * @param {string|Blob} value\n * @param {?string} filename\n * @returns\n */\nfunction makeEntry (name, value, filename) {\n // 1. Set name to the result of converting name into a scalar value string.\n // \"To convert a string into a scalar value string, replace any surrogates\n // with U+FFFD.\"\n // see: https://nodejs.org/dist/latest-v18.x/docs/api/buffer.html#buftostringencoding-start-end\n name = Buffer.from(name).toString('utf8')\n\n // 2. If value is a string, then set value to the result of converting\n // value into a scalar value string.\n if (typeof value === 'string') {\n value = Buffer.from(value).toString('utf8')\n } else {\n // 3. Otherwise:\n\n // 1. If value is not a File object, then set value to a new File object,\n // representing the same bytes, whose name attribute value is \"blob\"\n if (!isFileLike(value)) {\n value = value instanceof Blob\n ? new File([value], 'blob', { type: value.type })\n : new FileLike(value, 'blob', { type: value.type })\n }\n\n // 2. If filename is given, then set value to a new File object,\n // representing the same bytes, whose name attribute is filename.\n if (filename !== undefined) {\n /** @type {FilePropertyBag} */\n const options = {\n type: value.type,\n lastModified: value.lastModified\n }\n\n value = (NativeFile && value instanceof NativeFile) || value instanceof UndiciFile\n ? new File([value], filename, options)\n : new FileLike(value, filename, options)\n }\n }\n\n // 4. Return an entry whose name is name and whose value is value.\n return { name, value }\n}\n\nmodule.exports = { FormData }\n\n\n/***/ }),\n\n/***/ 1246:\n/***/ ((module) => {\n\n\"use strict\";\n\n\n// In case of breaking changes, increase the version\n// number to avoid conflicts.\nconst globalOrigin = Symbol.for('undici.globalOrigin.1')\n\nfunction getGlobalOrigin () {\n return globalThis[globalOrigin]\n}\n\nfunction setGlobalOrigin (newOrigin) {\n if (newOrigin === undefined) {\n Object.defineProperty(globalThis, globalOrigin, {\n value: undefined,\n writable: true,\n enumerable: false,\n configurable: false\n })\n\n return\n }\n\n const parsedURL = new URL(newOrigin)\n\n if (parsedURL.protocol !== 'http:' && parsedURL.protocol !== 'https:') {\n throw new TypeError(`Only http & https urls are allowed, received ${parsedURL.protocol}`)\n }\n\n Object.defineProperty(globalThis, globalOrigin, {\n value: parsedURL,\n writable: true,\n enumerable: false,\n configurable: false\n })\n}\n\nmodule.exports = {\n getGlobalOrigin,\n setGlobalOrigin\n}\n\n\n/***/ }),\n\n/***/ 554:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\n\"use strict\";\n// https://github.com/Ethan-Arrowood/undici-fetch\n\n\n\nconst { kHeadersList, kConstruct } = __nccwpck_require__(2785)\nconst { kGuard } = __nccwpck_require__(5861)\nconst { kEnumerableProperty } = __nccwpck_require__(3983)\nconst {\n makeIterator,\n isValidHeaderName,\n isValidHeaderValue\n} = __nccwpck_require__(2538)\nconst { webidl } = __nccwpck_require__(1744)\nconst assert = __nccwpck_require__(9491)\n\nconst kHeadersMap = Symbol('headers map')\nconst kHeadersSortedMap = Symbol('headers map sorted')\n\n/**\n * @param {number} code\n */\nfunction isHTTPWhiteSpaceCharCode (code) {\n return code === 0x00a || code === 0x00d || code === 0x009 || code === 0x020\n}\n\n/**\n * @see https://fetch.spec.whatwg.org/#concept-header-value-normalize\n * @param {string} potentialValue\n */\nfunction headerValueNormalize (potentialValue) {\n // To normalize a byte sequence potentialValue, remove\n // any leading and trailing HTTP whitespace bytes from\n // potentialValue.\n let i = 0; let j = potentialValue.length\n\n while (j > i && isHTTPWhiteSpaceCharCode(potentialValue.charCodeAt(j - 1))) --j\n while (j > i && isHTTPWhiteSpaceCharCode(potentialValue.charCodeAt(i))) ++i\n\n return i === 0 && j === potentialValue.length ? potentialValue : potentialValue.substring(i, j)\n}\n\nfunction fill (headers, object) {\n // To fill a Headers object headers with a given object object, run these steps:\n\n // 1. If object is a sequence, then for each header in object:\n // Note: webidl conversion to array has already been done.\n if (Array.isArray(object)) {\n for (let i = 0; i < object.length; ++i) {\n const header = object[i]\n // 1. If header does not contain exactly two items, then throw a TypeError.\n if (header.length !== 2) {\n throw webidl.errors.exception({\n header: 'Headers constructor',\n message: `expected name/value pair to be length 2, found ${header.length}.`\n })\n }\n\n // 2. Append (header\u2019s first item, header\u2019s second item) to headers.\n appendHeader(headers, header[0], header[1])\n }\n } else if (typeof object === 'object' && object !== null) {\n // Note: null should throw\n\n // 2. Otherwise, object is a record, then for each key \u2192 value in object,\n // append (key, value) to headers\n const keys = Object.keys(object)\n for (let i = 0; i < keys.length; ++i) {\n appendHeader(headers, keys[i], object[keys[i]])\n }\n } else {\n throw webidl.errors.conversionFailed({\n prefix: 'Headers constructor',\n argument: 'Argument 1',\n types: ['sequence<sequence<ByteString>>', 'record<ByteString, ByteString>']\n })\n }\n}\n\n/**\n * @see https://fetch.spec.whatwg.org/#concept-headers-append\n */\nfunction appendHeader (headers, name, value) {\n // 1. Normalize value.\n value = headerValueNormalize(value)\n\n // 2. If name is not a header name or value is not a\n // header value, then throw a TypeError.\n if (!isValidHeaderName(name)) {\n throw webidl.errors.invalidArgument({\n prefix: 'Headers.append',\n value: name,\n type: 'header name'\n })\n } else if (!isValidHeaderValue(value)) {\n throw webidl.errors.invalidArgument({\n prefix: 'Headers.append',\n value,\n type: 'header value'\n })\n }\n\n // 3. If headers\u2019s guard is \"immutable\", then throw a TypeError.\n // 4. Otherwise, if headers\u2019s guard is \"request\" and name is a\n // forbidden header name, return.\n // Note: undici does not implement forbidden header names\n if (headers[kGuard] === 'immutable') {\n throw new TypeError('immutable')\n } else if (headers[kGuard] === 'request-no-cors') {\n // 5. Otherwise, if headers\u2019s guard is \"request-no-cors\":\n // TODO\n }\n\n // 6. Otherwise, if headers\u2019s guard is \"response\" and name is a\n // forbidden response-header name, return.\n\n // 7. Append (name, value) to headers\u2019s header list.\n return headers[kHeadersList].append(name, value)\n\n // 8. If headers\u2019s guard is \"request-no-cors\", then remove\n // privileged no-CORS request headers from headers\n}\n\nclass HeadersList {\n /** @type {[string, string][]|null} */\n cookies = null\n\n constructor (init) {\n if (init instanceof HeadersList) {\n this[kHeadersMap] = new Map(init[kHeadersMap])\n this[kHeadersSortedMap] = init[kHeadersSortedMap]\n this.cookies = init.cookies === null ? null : [...init.cookies]\n } else {\n this[kHeadersMap] = new Map(init)\n this[kHeadersSortedMap] = null\n }\n }\n\n // https://fetch.spec.whatwg.org/#header-list-contains\n contains (name) {\n // A header list list contains a header name name if list\n // contains a header whose name is a byte-case-insensitive\n // match for name.\n name = name.toLowerCase()\n\n return this[kHeadersMap].has(name)\n }\n\n clear () {\n this[kHeadersMap].clear()\n this[kHeadersSortedMap] = null\n this.cookies = null\n }\n\n // https://fetch.spec.whatwg.org/#concept-header-list-append\n append (name, value) {\n this[kHeadersSortedMap] = null\n\n // 1. If list contains name, then set name to the first such\n // header\u2019s name.\n const lowercaseName = name.toLowerCase()\n const exists = this[kHeadersMap].get(lowercaseName)\n\n // 2. Append (name, value) to list.\n if (exists) {\n const delimiter = lowercaseName === 'cookie' ? '; ' : ', '\n this[kHeadersMap].set(lowercaseName, {\n name: exists.name,\n value: `${exists.value}${delimiter}${value}`\n })\n } else {\n this[kHeadersMap].set(lowercaseName, { name, value })\n }\n\n if (lowercaseName === 'set-cookie') {\n this.cookies ??= []\n this.cookies.push(value)\n }\n }\n\n // https://fetch.spec.whatwg.org/#concept-header-list-set\n set (name, value) {\n this[kHeadersSortedMap] = null\n const lowercaseName = name.toLowerCase()\n\n if (lowercaseName === 'set-cookie') {\n this.cookies = [value]\n }\n\n // 1. If list contains name, then set the value of\n // the first such header to value and remove the\n // others.\n // 2. Otherwise, append header (name, value) to list.\n this[kHeadersMap].set(lowercaseName, { name, value })\n }\n\n // https://fetch.spec.whatwg.org/#concept-header-list-delete\n delete (name) {\n this[kHeadersSortedMap] = null\n\n name = name.toLowerCase()\n\n if (name === 'set-cookie') {\n this.cookies = null\n }\n\n this[kHeadersMap].delete(name)\n }\n\n // https://fetch.spec.whatwg.org/#concept-header-list-get\n get (name) {\n const value = this[kHeadersMap].get(name.toLowerCase())\n\n // 1. If list does not contain name, then return null.\n // 2. Return the values of all headers in list whose name\n // is a byte-case-insensitive match for name,\n // separated from each other by 0x2C 0x20, in order.\n return value === undefined ? null : value.value\n }\n\n * [Symbol.iterator] () {\n // use the lowercased name\n for (const [name, { value }] of this[kHeadersMap]) {\n yield [name, value]\n }\n }\n\n get entries () {\n const headers = {}\n\n if (this[kHeadersMap].size) {\n for (const { name, value } of this[kHeadersMap].values()) {\n headers[name] = value\n }\n }\n\n return headers\n }\n}\n\n// https://fetch.spec.whatwg.org/#headers-class\nclass Headers {\n constructor (init = undefined) {\n if (init === kConstruct) {\n return\n }\n this[kHeadersList] = new HeadersList()\n\n // The new Headers(init) constructor steps are:\n\n // 1. Set this\u2019s guard to \"none\".\n this[kGuard] = 'none'\n\n // 2. If init is given, then fill this with init.\n if (init !== undefined) {\n init = webidl.converters.HeadersInit(init)\n fill(this, init)\n }\n }\n\n // https://fetch.spec.whatwg.org/#dom-headers-append\n append (name, value) {\n webidl.brandCheck(this, Headers)\n\n webidl.argumentLengthCheck(arguments, 2, { header: 'Headers.append' })\n\n name = webidl.converters.ByteString(name)\n value = webidl.converters.ByteString(value)\n\n return appendHeader(this, name, value)\n }\n\n // https://fetch.spec.whatwg.org/#dom-headers-delete\n delete (name) {\n webidl.brandCheck(this, Headers)\n\n webidl.argumentLengthCheck(arguments, 1, { header: 'Headers.delete' })\n\n name = webidl.converters.ByteString(name)\n\n // 1. If name is not a header name, then throw a TypeError.\n if (!isValidHeaderName(name)) {\n throw webidl.errors.invalidArgument({\n prefix: 'Headers.delete',\n value: name,\n type: 'header name'\n })\n }\n\n // 2. If this\u2019s guard is \"immutable\", then throw a TypeError.\n // 3. Otherwise, if this\u2019s guard is \"request\" and name is a\n // forbidden header name, return.\n // 4. Otherwise, if this\u2019s guard is \"request-no-cors\", name\n // is not a no-CORS-safelisted request-header name, and\n // name is not a privileged no-CORS request-header name,\n // return.\n // 5. Otherwise, if this\u2019s guard is \"response\" and name is\n // a forbidden response-header name, return.\n // Note: undici does not implement forbidden header names\n if (this[kGuard] === 'immutable') {\n throw new TypeError('immutable')\n } else if (this[kGuard] === 'request-no-cors') {\n // TODO\n }\n\n // 6. If this\u2019s header list does not contain name, then\n // return.\n if (!this[kHeadersList].contains(name)) {\n return\n }\n\n // 7. Delete name from this\u2019s header list.\n // 8. If this\u2019s guard is \"request-no-cors\", then remove\n // privileged no-CORS request headers from this.\n this[kHeadersList].delete(name)\n }\n\n // https://fetch.spec.whatwg.org/#dom-headers-get\n get (name) {\n webidl.brandCheck(this, Headers)\n\n webidl.argumentLengthCheck(arguments, 1, { header: 'Headers.get' })\n\n name = webidl.converters.ByteString(name)\n\n // 1. If name is not a header name, then throw a TypeError.\n if (!isValidHeaderName(name)) {\n throw webidl.errors.invalidArgument({\n prefix: 'Headers.get',\n value: name,\n type: 'header name'\n })\n }\n\n // 2. Return the result of getting name from this\u2019s header\n // list.\n return this[kHeadersList].get(name)\n }\n\n // https://fetch.spec.whatwg.org/#dom-headers-has\n has (name) {\n webidl.brandCheck(this, Headers)\n\n webidl.argumentLengthCheck(arguments, 1, { header: 'Headers.has' })\n\n name = webidl.converters.ByteString(name)\n\n // 1. If name is not a header name, then throw a TypeError.\n if (!isValidHeaderName(name)) {\n throw webidl.errors.invalidArgument({\n prefix: 'Headers.has',\n value: name,\n type: 'header name'\n })\n }\n\n // 2. Return true if this\u2019s header list contains name;\n // otherwise false.\n return this[kHeadersList].contains(name)\n }\n\n // https://fetch.spec.whatwg.org/#dom-headers-set\n set (name, value) {\n webidl.brandCheck(this, Headers)\n\n webidl.argumentLengthCheck(arguments, 2, { header: 'Headers.set' })\n\n name = webidl.converters.ByteString(name)\n value = webidl.converters.ByteString(value)\n\n // 1. Normalize value.\n value = headerValueNormalize(value)\n\n // 2. If name is not a header name or value is not a\n // header value, then throw a TypeError.\n if (!isValidHeaderName(name)) {\n throw webidl.errors.invalidArgument({\n prefix: 'Headers.set',\n value: name,\n type: 'header name'\n })\n } else if (!isValidHeaderValue(value)) {\n throw webidl.errors.invalidArgument({\n prefix: 'Headers.set',\n value,\n type: 'header value'\n })\n }\n\n // 3. If this\u2019s guard is \"immutable\", then throw a TypeError.\n // 4. Otherwise, if this\u2019s guard is \"request\" and name is a\n // forbidden header name, return.\n // 5. Otherwise, if this\u2019s guard is \"request-no-cors\" and\n // name/value is not a no-CORS-safelisted request-header,\n // return.\n // 6. Otherwise, if this\u2019s guard is \"response\" and name is a\n // forbidden response-header name, return.\n // Note: undici does not implement forbidden header names\n if (this[kGuard] === 'immutable') {\n throw new TypeError('immutable')\n } else if (this[kGuard] === 'request-no-cors') {\n // TODO\n }\n\n // 7. Set (name, value) in this\u2019s header list.\n // 8. If this\u2019s guard is \"request-no-cors\", then remove\n // privileged no-CORS request headers from this\n this[kHeadersList].set(name, value)\n }\n\n // https://fetch.spec.whatwg.org/#dom-headers-getsetcookie\n getSetCookie () {\n webidl.brandCheck(this, Headers)\n\n // 1. If this\u2019s header list does not contain `Set-Cookie`, then return \u00ab \u00bb.\n // 2. Return the values of all headers in this\u2019s header list whose name is\n // a byte-case-insensitive match for `Set-Cookie`, in order.\n\n const list = this[kHeadersList].cookies\n\n if (list) {\n return [...list]\n }\n\n return []\n }\n\n // https://fetch.spec.whatwg.org/#concept-header-list-sort-and-combine\n get [kHeadersSortedMap] () {\n if (this[kHeadersList][kHeadersSortedMap]) {\n return this[kHeadersList][kHeadersSortedMap]\n }\n\n // 1. Let headers be an empty list of headers with the key being the name\n // and value the value.\n const headers = []\n\n // 2. Let names be the result of convert header names to a sorted-lowercase\n // set with all the names of the headers in list.\n const names = [...this[kHeadersList]].sort((a, b) => a[0] < b[0] ? -1 : 1)\n const cookies = this[kHeadersList].cookies\n\n // 3. For each name of names:\n for (let i = 0; i < names.length; ++i) {\n const [name, value] = names[i]\n // 1. If name is `set-cookie`, then:\n if (name === 'set-cookie') {\n // 1. Let values be a list of all values of headers in list whose name\n // is a byte-case-insensitive match for name, in order.\n\n // 2. For each value of values:\n // 1. Append (name, value) to headers.\n for (let j = 0; j < cookies.length; ++j) {\n headers.push([name, cookies[j]])\n }\n } else {\n // 2. Otherwise:\n\n // 1. Let value be the result of getting name from list.\n\n // 2. Assert: value is non-null.\n assert(value !== null)\n\n // 3. Append (name, value) to headers.\n headers.push([name, value])\n }\n }\n\n this[kHeadersList][kHeadersSortedMap] = headers\n\n // 4. Return headers.\n return headers\n }\n\n keys () {\n webidl.brandCheck(this, Headers)\n\n if (this[kGuard] === 'immutable') {\n const value = this[kHeadersSortedMap]\n return makeIterator(() => value, 'Headers',\n 'key')\n }\n\n return makeIterator(\n () => [...this[kHeadersSortedMap].values()],\n 'Headers',\n 'key'\n )\n }\n\n values () {\n webidl.brandCheck(this, Headers)\n\n if (this[kGuard] === 'immutable') {\n const value = this[kHeadersSortedMap]\n return makeIterator(() => value, 'Headers',\n 'value')\n }\n\n return makeIterator(\n () => [...this[kHeadersSortedMap].values()],\n 'Headers',\n 'value'\n )\n }\n\n entries () {\n webidl.brandCheck(this, Headers)\n\n if (this[kGuard] === 'immutable') {\n const value = this[kHeadersSortedMap]\n return makeIterator(() => value, 'Headers',\n 'key+value')\n }\n\n return makeIterator(\n () => [...this[kHeadersSortedMap].values()],\n 'Headers',\n 'key+value'\n )\n }\n\n /**\n * @param {(value: string, key: string, self: Headers) => void} callbackFn\n * @param {unknown} thisArg\n */\n forEach (callbackFn, thisArg = globalThis) {\n webidl.brandCheck(this, Headers)\n\n webidl.argumentLengthCheck(arguments, 1, { header: 'Headers.forEach' })\n\n if (typeof callbackFn !== 'function') {\n throw new TypeError(\n \"Failed to execute 'forEach' on 'Headers': parameter 1 is not of type 'Function'.\"\n )\n }\n\n for (const [key, value] of this) {\n callbackFn.apply(thisArg, [value, key, this])\n }\n }\n\n [Symbol.for('nodejs.util.inspect.custom')] () {\n webidl.brandCheck(this, Headers)\n\n return this[kHeadersList]\n }\n}\n\nHeaders.prototype[Symbol.iterator] = Headers.prototype.entries\n\nObject.defineProperties(Headers.prototype, {\n append: kEnumerableProperty,\n delete: kEnumerableProperty,\n get: kEnumerableProperty,\n has: kEnumerableProperty,\n set: kEnumerableProperty,\n getSetCookie: kEnumerableProperty,\n keys: kEnumerableProperty,\n values: kEnumerableProperty,\n entries: kEnumerableProperty,\n forEach: kEnumerableProperty,\n [Symbol.iterator]: { enumerable: false },\n [Symbol.toStringTag]: {\n value: 'Headers',\n configurable: true\n }\n})\n\nwebidl.converters.HeadersInit = function (V) {\n if (webidl.util.Type(V) === 'Object') {\n if (V[Symbol.iterator]) {\n return webidl.converters['sequence<sequence<ByteString>>'](V)\n }\n\n return webidl.converters['record<ByteString, ByteString>'](V)\n }\n\n throw webidl.errors.conversionFailed({\n prefix: 'Headers constructor',\n argument: 'Argument 1',\n types: ['sequence<sequence<ByteString>>', 'record<ByteString, ByteString>']\n })\n}\n\nmodule.exports = {\n fill,\n Headers,\n HeadersList\n}\n\n\n/***/ }),\n\n/***/ 4881:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\n\"use strict\";\n// https://github.com/Ethan-Arrowood/undici-fetch\n\n\n\nconst {\n Response,\n makeNetworkError,\n makeAppropriateNetworkError,\n filterResponse,\n makeResponse\n} = __nccwpck_require__(7823)\nconst { Headers } = __nccwpck_require__(554)\nconst { Request, makeRequest } = __nccwpck_require__(8359)\nconst zlib = __nccwpck_require__(9796)\nconst {\n bytesMatch,\n makePolicyContainer,\n clonePolicyContainer,\n requestBadPort,\n TAOCheck,\n appendRequestOriginHeader,\n responseLocationURL,\n requestCurrentURL,\n setRequestReferrerPolicyOnRedirect,\n tryUpgradeRequestToAPotentiallyTrustworthyURL,\n createOpaqueTimingInfo,\n appendFetchMetadata,\n corsCheck,\n crossOriginResourcePolicyCheck,\n determineRequestsReferrer,\n coarsenedSharedCurrentTime,\n createDeferredPromise,\n isBlobLike,\n sameOrigin,\n isCancelled,\n isAborted,\n isErrorLike,\n fullyReadBody,\n readableStreamClose,\n isomorphicEncode,\n urlIsLocal,\n urlIsHttpHttpsScheme,\n urlHasHttpsScheme\n} = __nccwpck_require__(2538)\nconst { kState, kHeaders, kGuard, kRealm } = __nccwpck_require__(5861)\nconst assert = __nccwpck_require__(9491)\nconst { safelyExtractBody } = __nccwpck_require__(1472)\nconst {\n redirectStatusSet,\n nullBodyStatus,\n safeMethodsSet,\n requestBodyHeader,\n subresourceSet,\n DOMException\n} = __nccwpck_require__(1037)\nconst { kHeadersList } = __nccwpck_require__(2785)\nconst EE = __nccwpck_require__(2361)\nconst { Readable, pipeline } = __nccwpck_require__(2781)\nconst { addAbortListener, isErrored, isReadable, nodeMajor, nodeMinor } = __nccwpck_require__(3983)\nconst { dataURLProcessor, serializeAMimeType } = __nccwpck_require__(685)\nconst { TransformStream } = __nccwpck_require__(5356)\nconst { getGlobalDispatcher } = __nccwpck_require__(1892)\nconst { webidl } = __nccwpck_require__(1744)\nconst { STATUS_CODES } = __nccwpck_require__(3685)\nconst GET_OR_HEAD = ['GET', 'HEAD']\n\n/** @type {import('buffer').resolveObjectURL} */\nlet resolveObjectURL\nlet ReadableStream = globalThis.ReadableStream\n\nclass Fetch extends EE {\n constructor (dispatcher) {\n super()\n\n this.dispatcher = dispatcher\n this.connection = null\n this.dump = false\n this.state = 'ongoing'\n // 2 terminated listeners get added per request,\n // but only 1 gets removed. If there are 20 redirects,\n // 21 listeners will be added.\n // See https://github.com/nodejs/undici/issues/1711\n // TODO (fix): Find and fix root cause for leaked listener.\n this.setMaxListeners(21)\n }\n\n terminate (reason) {\n if (this.state !== 'ongoing') {\n return\n }\n\n this.state = 'terminated'\n this.connection?.destroy(reason)\n this.emit('terminated', reason)\n }\n\n // https://fetch.spec.whatwg.org/#fetch-controller-abort\n abort (error) {\n if (this.state !== 'ongoing') {\n return\n }\n\n // 1. Set controller\u2019s state to \"aborted\".\n this.state = 'aborted'\n\n // 2. Let fallbackError be an \"AbortError\" DOMException.\n // 3. Set error to fallbackError if it is not given.\n if (!error) {\n error = new DOMException('The operation was aborted.', 'AbortError')\n }\n\n // 4. Let serializedError be StructuredSerialize(error).\n // If that threw an exception, catch it, and let\n // serializedError be StructuredSerialize(fallbackError).\n\n // 5. Set controller\u2019s serialized abort reason to serializedError.\n this.serializedAbortReason = error\n\n this.connection?.destroy(error)\n this.emit('terminated', error)\n }\n}\n\n// https://fetch.spec.whatwg.org/#fetch-method\nfunction fetch (input, init = {}) {\n webidl.argumentLengthCheck(arguments, 1, { header: 'globalThis.fetch' })\n\n // 1. Let p be a new promise.\n const p = createDeferredPromise()\n\n // 2. Let requestObject be the result of invoking the initial value of\n // Request as constructor with input and init as arguments. If this throws\n // an exception, reject p with it and return p.\n let requestObject\n\n try {\n requestObject = new Request(input, init)\n } catch (e) {\n p.reject(e)\n return p.promise\n }\n\n // 3. Let request be requestObject\u2019s request.\n const request = requestObject[kState]\n\n // 4. If requestObject\u2019s signal\u2019s aborted flag is set, then:\n if (requestObject.signal.aborted) {\n // 1. Abort the fetch() call with p, request, null, and\n // requestObject\u2019s signal\u2019s abort reason.\n abortFetch(p, request, null, requestObject.signal.reason)\n\n // 2. Return p.\n return p.promise\n }\n\n // 5. Let globalObject be request\u2019s client\u2019s global object.\n const globalObject = request.client.globalObject\n\n // 6. If globalObject is a ServiceWorkerGlobalScope object, then set\n // request\u2019s service-workers mode to \"none\".\n if (globalObject?.constructor?.name === 'ServiceWorkerGlobalScope') {\n request.serviceWorkers = 'none'\n }\n\n // 7. Let responseObject be null.\n let responseObject = null\n\n // 8. Let relevantRealm be this\u2019s relevant Realm.\n const relevantRealm = null\n\n // 9. Let locallyAborted be false.\n let locallyAborted = false\n\n // 10. Let controller be null.\n let controller = null\n\n // 11. Add the following abort steps to requestObject\u2019s signal:\n addAbortListener(\n requestObject.signal,\n () => {\n // 1. Set locallyAborted to true.\n locallyAborted = true\n\n // 2. Assert: controller is non-null.\n assert(controller != null)\n\n // 3. Abort controller with requestObject\u2019s signal\u2019s abort reason.\n controller.abort(requestObject.signal.reason)\n\n // 4. Abort the fetch() call with p, request, responseObject,\n // and requestObject\u2019s signal\u2019s abort reason.\n abortFetch(p, request, responseObject, requestObject.signal.reason)\n }\n )\n\n // 12. Let handleFetchDone given response response be to finalize and\n // report timing with response, globalObject, and \"fetch\".\n const handleFetchDone = (response) =>\n finalizeAndReportTiming(response, 'fetch')\n\n // 13. Set controller to the result of calling fetch given request,\n // with processResponseEndOfBody set to handleFetchDone, and processResponse\n // given response being these substeps:\n\n const processResponse = (response) => {\n // 1. If locallyAborted is true, terminate these substeps.\n if (locallyAborted) {\n return Promise.resolve()\n }\n\n // 2. If response\u2019s aborted flag is set, then:\n if (response.aborted) {\n // 1. Let deserializedError be the result of deserialize a serialized\n // abort reason given controller\u2019s serialized abort reason and\n // relevantRealm.\n\n // 2. Abort the fetch() call with p, request, responseObject, and\n // deserializedError.\n\n abortFetch(p, request, responseObject, controller.serializedAbortReason)\n return Promise.resolve()\n }\n\n // 3. If response is a network error, then reject p with a TypeError\n // and terminate these substeps.\n if (response.type === 'error') {\n p.reject(\n Object.assign(new TypeError('fetch failed'), { cause: response.error })\n )\n return Promise.resolve()\n }\n\n // 4. Set responseObject to the result of creating a Response object,\n // given response, \"immutable\", and relevantRealm.\n responseObject = new Response()\n responseObject[kState] = response\n responseObject[kRealm] = relevantRealm\n responseObject[kHeaders][kHeadersList] = response.headersList\n responseObject[kHeaders][kGuard] = 'immutable'\n responseObject[kHeaders][kRealm] = relevantRealm\n\n // 5. Resolve p with responseObject.\n p.resolve(responseObject)\n }\n\n controller = fetching({\n request,\n processResponseEndOfBody: handleFetchDone,\n processResponse,\n dispatcher: init.dispatcher ?? getGlobalDispatcher() // undici\n })\n\n // 14. Return p.\n return p.promise\n}\n\n// https://fetch.spec.whatwg.org/#finalize-and-report-timing\nfunction finalizeAndReportTiming (response, initiatorType = 'other') {\n // 1. If response is an aborted network error, then return.\n if (response.type === 'error' && response.aborted) {\n return\n }\n\n // 2. If response\u2019s URL list is null or empty, then return.\n if (!response.urlList?.length) {\n return\n }\n\n // 3. Let originalURL be response\u2019s URL list[0].\n const originalURL = response.urlList[0]\n\n // 4. Let timingInfo be response\u2019s timing info.\n let timingInfo = response.timingInfo\n\n // 5. Let cacheState be response\u2019s cache state.\n let cacheState = response.cacheState\n\n // 6. If originalURL\u2019s scheme is not an HTTP(S) scheme, then return.\n if (!urlIsHttpHttpsScheme(originalURL)) {\n return\n }\n\n // 7. If timingInfo is null, then return.\n if (timingInfo === null) {\n return\n }\n\n // 8. If response\u2019s timing allow passed flag is not set, then:\n if (!response.timingAllowPassed) {\n // 1. Set timingInfo to a the result of creating an opaque timing info for timingInfo.\n timingInfo = createOpaqueTimingInfo({\n startTime: timingInfo.startTime\n })\n\n // 2. Set cacheState to the empty string.\n cacheState = ''\n }\n\n // 9. Set timingInfo\u2019s end time to the coarsened shared current time\n // given global\u2019s relevant settings object\u2019s cross-origin isolated\n // capability.\n // TODO: given global\u2019s relevant settings object\u2019s cross-origin isolated\n // capability?\n timingInfo.endTime = coarsenedSharedCurrentTime()\n\n // 10. Set response\u2019s timing info to timingInfo.\n response.timingInfo = timingInfo\n\n // 11. Mark resource timing for timingInfo, originalURL, initiatorType,\n // global, and cacheState.\n markResourceTiming(\n timingInfo,\n originalURL,\n initiatorType,\n globalThis,\n cacheState\n )\n}\n\n// https://w3c.github.io/resource-timing/#dfn-mark-resource-timing\nfunction markResourceTiming (timingInfo, originalURL, initiatorType, globalThis, cacheState) {\n if (nodeMajor > 18 || (nodeMajor === 18 && nodeMinor >= 2)) {\n performance.markResourceTiming(timingInfo, originalURL.href, initiatorType, globalThis, cacheState)\n }\n}\n\n// https://fetch.spec.whatwg.org/#abort-fetch\nfunction abortFetch (p, request, responseObject, error) {\n // Note: AbortSignal.reason was added in node v17.2.0\n // which would give us an undefined error to reject with.\n // Remove this once node v16 is no longer supported.\n if (!error) {\n error = new DOMException('The operation was aborted.', 'AbortError')\n }\n\n // 1. Reject promise with error.\n p.reject(error)\n\n // 2. If request\u2019s body is not null and is readable, then cancel request\u2019s\n // body with error.\n if (request.body != null && isReadable(request.body?.stream)) {\n request.body.stream.cancel(error).catch((err) => {\n if (err.code === 'ERR_INVALID_STATE') {\n // Node bug?\n return\n }\n throw err\n })\n }\n\n // 3. If responseObject is null, then return.\n if (responseObject == null) {\n return\n }\n\n // 4. Let response be responseObject\u2019s response.\n const response = responseObject[kState]\n\n // 5. If response\u2019s body is not null and is readable, then error response\u2019s\n // body with error.\n if (response.body != null && isReadable(response.body?.stream)) {\n response.body.stream.cancel(error).catch((err) => {\n if (err.code === 'ERR_INVALID_STATE') {\n // Node bug?\n return\n }\n throw err\n })\n }\n}\n\n// https://fetch.spec.whatwg.org/#fetching\nfunction fetching ({\n request,\n processRequestBodyChunkLength,\n processRequestEndOfBody,\n processResponse,\n processResponseEndOfBody,\n processResponseConsumeBody,\n useParallelQueue = false,\n dispatcher // undici\n}) {\n // 1. Let taskDestination be null.\n let taskDestination = null\n\n // 2. Let crossOriginIsolatedCapability be false.\n let crossOriginIsolatedCapability = false\n\n // 3. If request\u2019s client is non-null, then:\n if (request.client != null) {\n // 1. Set taskDestination to request\u2019s client\u2019s global object.\n taskDestination = request.client.globalObject\n\n // 2. Set crossOriginIsolatedCapability to request\u2019s client\u2019s cross-origin\n // isolated capability.\n crossOriginIsolatedCapability =\n request.client.crossOriginIsolatedCapability\n }\n\n // 4. If useParallelQueue is true, then set taskDestination to the result of\n // starting a new parallel queue.\n // TODO\n\n // 5. Let timingInfo be a new fetch timing info whose start time and\n // post-redirect start time are the coarsened shared current time given\n // crossOriginIsolatedCapability.\n const currenTime = coarsenedSharedCurrentTime(crossOriginIsolatedCapability)\n const timingInfo = createOpaqueTimingInfo({\n startTime: currenTime\n })\n\n // 6. Let fetchParams be a new fetch params whose\n // request is request,\n // timing info is timingInfo,\n // process request body chunk length is processRequestBodyChunkLength,\n // process request end-of-body is processRequestEndOfBody,\n // process response is processResponse,\n // process response consume body is processResponseConsumeBody,\n // process response end-of-body is processResponseEndOfBody,\n // task destination is taskDestination,\n // and cross-origin isolated capability is crossOriginIsolatedCapability.\n const fetchParams = {\n controller: new Fetch(dispatcher),\n request,\n timingInfo,\n processRequestBodyChunkLength,\n processRequestEndOfBody,\n processResponse,\n processResponseConsumeBody,\n processResponseEndOfBody,\n taskDestination,\n crossOriginIsolatedCapability\n }\n\n // 7. If request\u2019s body is a byte sequence, then set request\u2019s body to\n // request\u2019s body as a body.\n // NOTE: Since fetching is only called from fetch, body should already be\n // extracted.\n assert(!request.body || request.body.stream)\n\n // 8. If request\u2019s window is \"client\", then set request\u2019s window to request\u2019s\n // client, if request\u2019s client\u2019s global object is a Window object; otherwise\n // \"no-window\".\n if (request.window === 'client') {\n // TODO: What if request.client is null?\n request.window =\n request.client?.globalObject?.constructor?.name === 'Window'\n ? request.client\n : 'no-window'\n }\n\n // 9. If request\u2019s origin is \"client\", then set request\u2019s origin to request\u2019s\n // client\u2019s origin.\n if (request.origin === 'client') {\n // TODO: What if request.client is null?\n request.origin = request.client?.origin\n }\n\n // 10. If all of the following conditions are true:\n // TODO\n\n // 11. If request\u2019s policy container is \"client\", then:\n if (request.policyContainer === 'client') {\n // 1. If request\u2019s client is non-null, then set request\u2019s policy\n // container to a clone of request\u2019s client\u2019s policy container. [HTML]\n if (request.client != null) {\n request.policyContainer = clonePolicyContainer(\n request.client.policyContainer\n )\n } else {\n // 2. Otherwise, set request\u2019s policy container to a new policy\n // container.\n request.policyContainer = makePolicyContainer()\n }\n }\n\n // 12. If request\u2019s header list does not contain `Accept`, then:\n if (!request.headersList.contains('accept')) {\n // 1. Let value be `*/*`.\n const value = '*/*'\n\n // 2. A user agent should set value to the first matching statement, if\n // any, switching on request\u2019s destination:\n // \"document\"\n // \"frame\"\n // \"iframe\"\n // `text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8`\n // \"image\"\n // `image/png,image/svg+xml,image/*;q=0.8,*/*;q=0.5`\n // \"style\"\n // `text/css,*/*;q=0.1`\n // TODO\n\n // 3. Append `Accept`/value to request\u2019s header list.\n request.headersList.append('accept', value)\n }\n\n // 13. If request\u2019s header list does not contain `Accept-Language`, then\n // user agents should append `Accept-Language`/an appropriate value to\n // request\u2019s header list.\n if (!request.headersList.contains('accept-language')) {\n request.headersList.append('accept-language', '*')\n }\n\n // 14. If request\u2019s priority is null, then use request\u2019s initiator and\n // destination appropriately in setting request\u2019s priority to a\n // user-agent-defined object.\n if (request.priority === null) {\n // TODO\n }\n\n // 15. If request is a subresource request, then:\n if (subresourceSet.has(request.destination)) {\n // TODO\n }\n\n // 16. Run main fetch given fetchParams.\n mainFetch(fetchParams)\n .catch(err => {\n fetchParams.controller.terminate(err)\n })\n\n // 17. Return fetchParam's controller\n return fetchParams.controller\n}\n\n// https://fetch.spec.whatwg.org/#concept-main-fetch\nasync function mainFetch (fetchParams, recursive = false) {\n // 1. Let request be fetchParams\u2019s request.\n const request = fetchParams.request\n\n // 2. Let response be null.\n let response = null\n\n // 3. If request\u2019s local-URLs-only flag is set and request\u2019s current URL is\n // not local, then set response to a network error.\n if (request.localURLsOnly && !urlIsLocal(requestCurrentURL(request))) {\n response = makeNetworkError('local URLs only')\n }\n\n // 4. Run report Content Security Policy violations for request.\n // TODO\n\n // 5. Upgrade request to a potentially trustworthy URL, if appropriate.\n tryUpgradeRequestToAPotentiallyTrustworthyURL(request)\n\n // 6. If should request be blocked due to a bad port, should fetching request\n // be blocked as mixed content, or should request be blocked by Content\n // Security Policy returns blocked, then set response to a network error.\n if (requestBadPort(request) === 'blocked') {\n response = makeNetworkError('bad port')\n }\n // TODO: should fetching request be blocked as mixed content?\n // TODO: should request be blocked by Content Security Policy?\n\n // 7. If request\u2019s referrer policy is the empty string, then set request\u2019s\n // referrer policy to request\u2019s policy container\u2019s referrer policy.\n if (request.referrerPolicy === '') {\n request.referrerPolicy = request.policyContainer.referrerPolicy\n }\n\n // 8. If request\u2019s referrer is not \"no-referrer\", then set request\u2019s\n // referrer to the result of invoking determine request\u2019s referrer.\n if (request.referrer !== 'no-referrer') {\n request.referrer = determineRequestsReferrer(request)\n }\n\n // 9. Set request\u2019s current URL\u2019s scheme to \"https\" if all of the following\n // conditions are true:\n // - request\u2019s current URL\u2019s scheme is \"http\"\n // - request\u2019s current URL\u2019s host is a domain\n // - Matching request\u2019s current URL\u2019s host per Known HSTS Host Domain Name\n // Matching results in either a superdomain match with an asserted\n // includeSubDomains directive or a congruent match (with or without an\n // asserted includeSubDomains directive). [HSTS]\n // TODO\n\n // 10. If recursive is false, then run the remaining steps in parallel.\n // TODO\n\n // 11. If response is null, then set response to the result of running\n // the steps corresponding to the first matching statement:\n if (response === null) {\n response = await (async () => {\n const currentURL = requestCurrentURL(request)\n\n if (\n // - request\u2019s current URL\u2019s origin is same origin with request\u2019s origin,\n // and request\u2019s response tainting is \"basic\"\n (sameOrigin(currentURL, request.url) && request.responseTainting === 'basic') ||\n // request\u2019s current URL\u2019s scheme is \"data\"\n (currentURL.protocol === 'data:') ||\n // - request\u2019s mode is \"navigate\" or \"websocket\"\n (request.mode === 'navigate' || request.mode === 'websocket')\n ) {\n // 1. Set request\u2019s response tainting to \"basic\".\n request.responseTainting = 'basic'\n\n // 2. Return the result of running scheme fetch given fetchParams.\n return await schemeFetch(fetchParams)\n }\n\n // request\u2019s mode is \"same-origin\"\n if (request.mode === 'same-origin') {\n // 1. Return a network error.\n return makeNetworkError('request mode cannot be \"same-origin\"')\n }\n\n // request\u2019s mode is \"no-cors\"\n if (request.mode === 'no-cors') {\n // 1. If request\u2019s redirect mode is not \"follow\", then return a network\n // error.\n if (request.redirect !== 'follow') {\n return makeNetworkError(\n 'redirect mode cannot be \"follow\" for \"no-cors\" request'\n )\n }\n\n // 2. Set request\u2019s response tainting to \"opaque\".\n request.responseTainting = 'opaque'\n\n // 3. Return the result of running scheme fetch given fetchParams.\n return await schemeFetch(fetchParams)\n }\n\n // request\u2019s current URL\u2019s scheme is not an HTTP(S) scheme\n if (!urlIsHttpHttpsScheme(requestCurrentURL(request))) {\n // Return a network error.\n return makeNetworkError('URL scheme must be a HTTP(S) scheme')\n }\n\n // - request\u2019s use-CORS-preflight flag is set\n // - request\u2019s unsafe-request flag is set and either request\u2019s method is\n // not a CORS-safelisted method or CORS-unsafe request-header names with\n // request\u2019s header list is not empty\n // 1. Set request\u2019s response tainting to \"cors\".\n // 2. Let corsWithPreflightResponse be the result of running HTTP fetch\n // given fetchParams and true.\n // 3. If corsWithPreflightResponse is a network error, then clear cache\n // entries using request.\n // 4. Return corsWithPreflightResponse.\n // TODO\n\n // Otherwise\n // 1. Set request\u2019s response tainting to \"cors\".\n request.responseTainting = 'cors'\n\n // 2. Return the result of running HTTP fetch given fetchParams.\n return await httpFetch(fetchParams)\n })()\n }\n\n // 12. If recursive is true, then return response.\n if (recursive) {\n return response\n }\n\n // 13. If response is not a network error and response is not a filtered\n // response, then:\n if (response.status !== 0 && !response.internalResponse) {\n // If request\u2019s response tainting is \"cors\", then:\n if (request.responseTainting === 'cors') {\n // 1. Let headerNames be the result of extracting header list values\n // given `Access-Control-Expose-Headers` and response\u2019s header list.\n // TODO\n // 2. If request\u2019s credentials mode is not \"include\" and headerNames\n // contains `*`, then set response\u2019s CORS-exposed header-name list to\n // all unique header names in response\u2019s header list.\n // TODO\n // 3. Otherwise, if headerNames is not null or failure, then set\n // response\u2019s CORS-exposed header-name list to headerNames.\n // TODO\n }\n\n // Set response to the following filtered response with response as its\n // internal response, depending on request\u2019s response tainting:\n if (request.responseTainting === 'basic') {\n response = filterResponse(response, 'basic')\n } else if (request.responseTainting === 'cors') {\n response = filterResponse(response, 'cors')\n } else if (request.responseTainting === 'opaque') {\n response = filterResponse(response, 'opaque')\n } else {\n assert(false)\n }\n }\n\n // 14. Let internalResponse be response, if response is a network error,\n // and response\u2019s internal response otherwise.\n let internalResponse =\n response.status === 0 ? response : response.internalResponse\n\n // 15. If internalResponse\u2019s URL list is empty, then set it to a clone of\n // request\u2019s URL list.\n if (internalResponse.urlList.length === 0) {\n internalResponse.urlList.push(...request.urlList)\n }\n\n // 16. If request\u2019s timing allow failed flag is unset, then set\n // internalResponse\u2019s timing allow passed flag.\n if (!request.timingAllowFailed) {\n response.timingAllowPassed = true\n }\n\n // 17. If response is not a network error and any of the following returns\n // blocked\n // - should internalResponse to request be blocked as mixed content\n // - should internalResponse to request be blocked by Content Security Policy\n // - should internalResponse to request be blocked due to its MIME type\n // - should internalResponse to request be blocked due to nosniff\n // TODO\n\n // 18. If response\u2019s type is \"opaque\", internalResponse\u2019s status is 206,\n // internalResponse\u2019s range-requested flag is set, and request\u2019s header\n // list does not contain `Range`, then set response and internalResponse\n // to a network error.\n if (\n response.type === 'opaque' &&\n internalResponse.status === 206 &&\n internalResponse.rangeRequested &&\n !request.headers.contains('range')\n ) {\n response = internalResponse = makeNetworkError()\n }\n\n // 19. If response is not a network error and either request\u2019s method is\n // `HEAD` or `CONNECT`, or internalResponse\u2019s status is a null body status,\n // set internalResponse\u2019s body to null and disregard any enqueuing toward\n // it (if any).\n if (\n response.status !== 0 &&\n (request.method === 'HEAD' ||\n request.method === 'CONNECT' ||\n nullBodyStatus.includes(internalResponse.status))\n ) {\n internalResponse.body = null\n fetchParams.controller.dump = true\n }\n\n // 20. If request\u2019s integrity metadata is not the empty string, then:\n if (request.integrity) {\n // 1. Let processBodyError be this step: run fetch finale given fetchParams\n // and a network error.\n const processBodyError = (reason) =>\n fetchFinale(fetchParams, makeNetworkError(reason))\n\n // 2. If request\u2019s response tainting is \"opaque\", or response\u2019s body is null,\n // then run processBodyError and abort these steps.\n if (request.responseTainting === 'opaque' || response.body == null) {\n processBodyError(response.error)\n return\n }\n\n // 3. Let processBody given bytes be these steps:\n const processBody = (bytes) => {\n // 1. If bytes do not match request\u2019s integrity metadata,\n // then run processBodyError and abort these steps. [SRI]\n if (!bytesMatch(bytes, request.integrity)) {\n processBodyError('integrity mismatch')\n return\n }\n\n // 2. Set response\u2019s body to bytes as a body.\n response.body = safelyExtractBody(bytes)[0]\n\n // 3. Run fetch finale given fetchParams and response.\n fetchFinale(fetchParams, response)\n }\n\n // 4. Fully read response\u2019s body given processBody and processBodyError.\n await fullyReadBody(response.body, processBody, processBodyError)\n } else {\n // 21. Otherwise, run fetch finale given fetchParams and response.\n fetchFinale(fetchParams, response)\n }\n}\n\n// https://fetch.spec.whatwg.org/#concept-scheme-fetch\n// given a fetch params fetchParams\nfunction schemeFetch (fetchParams) {\n // Note: since the connection is destroyed on redirect, which sets fetchParams to a\n // cancelled state, we do not want this condition to trigger *unless* there have been\n // no redirects. See https://github.com/nodejs/undici/issues/1776\n // 1. If fetchParams is canceled, then return the appropriate network error for fetchParams.\n if (isCancelled(fetchParams) && fetchParams.request.redirectCount === 0) {\n return Promise.resolve(makeAppropriateNetworkError(fetchParams))\n }\n\n // 2. Let request be fetchParams\u2019s request.\n const { request } = fetchParams\n\n const { protocol: scheme } = requestCurrentURL(request)\n\n // 3. Switch on request\u2019s current URL\u2019s scheme and run the associated steps:\n switch (scheme) {\n case 'about:': {\n // If request\u2019s current URL\u2019s path is the string \"blank\", then return a new response\n // whose status message is `OK`, header list is \u00ab (`Content-Type`, `text/html;charset=utf-8`) \u00bb,\n // and body is the empty byte sequence as a body.\n\n // Otherwise, return a network error.\n return Promise.resolve(makeNetworkError('about scheme is not supported'))\n }\n case 'blob:': {\n if (!resolveObjectURL) {\n resolveObjectURL = (__nccwpck_require__(4300).resolveObjectURL)\n }\n\n // 1. Let blobURLEntry be request\u2019s current URL\u2019s blob URL entry.\n const blobURLEntry = requestCurrentURL(request)\n\n // https://github.com/web-platform-tests/wpt/blob/7b0ebaccc62b566a1965396e5be7bb2bc06f841f/FileAPI/url/resources/fetch-tests.js#L52-L56\n // Buffer.resolveObjectURL does not ignore URL queries.\n if (blobURLEntry.search.length !== 0) {\n return Promise.resolve(makeNetworkError('NetworkError when attempting to fetch resource.'))\n }\n\n const blobURLEntryObject = resolveObjectURL(blobURLEntry.toString())\n\n // 2. If request\u2019s method is not `GET`, blobURLEntry is null, or blobURLEntry\u2019s\n // object is not a Blob object, then return a network error.\n if (request.method !== 'GET' || !isBlobLike(blobURLEntryObject)) {\n return Promise.resolve(makeNetworkError('invalid method'))\n }\n\n // 3. Let bodyWithType be the result of safely extracting blobURLEntry\u2019s object.\n const bodyWithType = safelyExtractBody(blobURLEntryObject)\n\n // 4. Let body be bodyWithType\u2019s body.\n const body = bodyWithType[0]\n\n // 5. Let length be body\u2019s length, serialized and isomorphic encoded.\n const length = isomorphicEncode(`${body.length}`)\n\n // 6. Let type be bodyWithType\u2019s type if it is non-null; otherwise the empty byte sequence.\n const type = bodyWithType[1] ?? ''\n\n // 7. Return a new response whose status message is `OK`, header list is\n // \u00ab (`Content-Length`, length), (`Content-Type`, type) \u00bb, and body is body.\n const response = makeResponse({\n statusText: 'OK',\n headersList: [\n ['content-length', { name: 'Content-Length', value: length }],\n ['content-type', { name: 'Content-Type', value: type }]\n ]\n })\n\n response.body = body\n\n return Promise.resolve(response)\n }\n case 'data:': {\n // 1. Let dataURLStruct be the result of running the\n // data: URL processor on request\u2019s current URL.\n const currentURL = requestCurrentURL(request)\n const dataURLStruct = dataURLProcessor(currentURL)\n\n // 2. If dataURLStruct is failure, then return a\n // network error.\n if (dataURLStruct === 'failure') {\n return Promise.resolve(makeNetworkError('failed to fetch the data URL'))\n }\n\n // 3. Let mimeType be dataURLStruct\u2019s MIME type, serialized.\n const mimeType = serializeAMimeType(dataURLStruct.mimeType)\n\n // 4. Return a response whose status message is `OK`,\n // header list is \u00ab (`Content-Type`, mimeType) \u00bb,\n // and body is dataURLStruct\u2019s body as a body.\n return Promise.resolve(makeResponse({\n statusText: 'OK',\n headersList: [\n ['content-type', { name: 'Content-Type', value: mimeType }]\n ],\n body: safelyExtractBody(dataURLStruct.body)[0]\n }))\n }\n case 'file:': {\n // For now, unfortunate as it is, file URLs are left as an exercise for the reader.\n // When in doubt, return a network error.\n return Promise.resolve(makeNetworkError('not implemented... yet...'))\n }\n case 'http:':\n case 'https:': {\n // Return the result of running HTTP fetch given fetchParams.\n\n return httpFetch(fetchParams)\n .catch((err) => makeNetworkError(err))\n }\n default: {\n return Promise.resolve(makeNetworkError('unknown scheme'))\n }\n }\n}\n\n// https://fetch.spec.whatwg.org/#finalize-response\nfunction finalizeResponse (fetchParams, response) {\n // 1. Set fetchParams\u2019s request\u2019s done flag.\n fetchParams.request.done = true\n\n // 2, If fetchParams\u2019s process response done is not null, then queue a fetch\n // task to run fetchParams\u2019s process response done given response, with\n // fetchParams\u2019s task destination.\n if (fetchParams.processResponseDone != null) {\n queueMicrotask(() => fetchParams.processResponseDone(response))\n }\n}\n\n// https://fetch.spec.whatwg.org/#fetch-finale\nfunction fetchFinale (fetchParams, response) {\n // 1. If response is a network error, then:\n if (response.type === 'error') {\n // 1. Set response\u2019s URL list to \u00ab fetchParams\u2019s request\u2019s URL list[0] \u00bb.\n response.urlList = [fetchParams.request.urlList[0]]\n\n // 2. Set response\u2019s timing info to the result of creating an opaque timing\n // info for fetchParams\u2019s timing info.\n response.timingInfo = createOpaqueTimingInfo({\n startTime: fetchParams.timingInfo.startTime\n })\n }\n\n // 2. Let processResponseEndOfBody be the following steps:\n const processResponseEndOfBody = () => {\n // 1. Set fetchParams\u2019s request\u2019s done flag.\n fetchParams.request.done = true\n\n // If fetchParams\u2019s process response end-of-body is not null,\n // then queue a fetch task to run fetchParams\u2019s process response\n // end-of-body given response with fetchParams\u2019s task destination.\n if (fetchParams.processResponseEndOfBody != null) {\n queueMicrotask(() => fetchParams.processResponseEndOfBody(response))\n }\n }\n\n // 3. If fetchParams\u2019s process response is non-null, then queue a fetch task\n // to run fetchParams\u2019s process response given response, with fetchParams\u2019s\n // task destination.\n if (fetchParams.processResponse != null) {\n queueMicrotask(() => fetchParams.processResponse(response))\n }\n\n // 4. If response\u2019s body is null, then run processResponseEndOfBody.\n if (response.body == null) {\n processResponseEndOfBody()\n } else {\n // 5. Otherwise:\n\n // 1. Let transformStream be a new a TransformStream.\n\n // 2. Let identityTransformAlgorithm be an algorithm which, given chunk,\n // enqueues chunk in transformStream.\n const identityTransformAlgorithm = (chunk, controller) => {\n controller.enqueue(chunk)\n }\n\n // 3. Set up transformStream with transformAlgorithm set to identityTransformAlgorithm\n // and flushAlgorithm set to processResponseEndOfBody.\n const transformStream = new TransformStream({\n start () {},\n transform: identityTransformAlgorithm,\n flush: processResponseEndOfBody\n }, {\n size () {\n return 1\n }\n }, {\n size () {\n return 1\n }\n })\n\n // 4. Set response\u2019s body to the result of piping response\u2019s body through transformStream.\n response.body = { stream: response.body.stream.pipeThrough(transformStream) }\n }\n\n // 6. If fetchParams\u2019s process response consume body is non-null, then:\n if (fetchParams.processResponseConsumeBody != null) {\n // 1. Let processBody given nullOrBytes be this step: run fetchParams\u2019s\n // process response consume body given response and nullOrBytes.\n const processBody = (nullOrBytes) => fetchParams.processResponseConsumeBody(response, nullOrBytes)\n\n // 2. Let processBodyError be this step: run fetchParams\u2019s process\n // response consume body given response and failure.\n const processBodyError = (failure) => fetchParams.processResponseConsumeBody(response, failure)\n\n // 3. If response\u2019s body is null, then queue a fetch task to run processBody\n // given null, with fetchParams\u2019s task destination.\n if (response.body == null) {\n queueMicrotask(() => processBody(null))\n } else {\n // 4. Otherwise, fully read response\u2019s body given processBody, processBodyError,\n // and fetchParams\u2019s task destination.\n return fullyReadBody(response.body, processBody, processBodyError)\n }\n return Promise.resolve()\n }\n}\n\n// https://fetch.spec.whatwg.org/#http-fetch\nasync function httpFetch (fetchParams) {\n // 1. Let request be fetchParams\u2019s request.\n const request = fetchParams.request\n\n // 2. Let response be null.\n let response = null\n\n // 3. Let actualResponse be null.\n let actualResponse = null\n\n // 4. Let timingInfo be fetchParams\u2019s timing info.\n const timingInfo = fetchParams.timingInfo\n\n // 5. If request\u2019s service-workers mode is \"all\", then:\n if (request.serviceWorkers === 'all') {\n // TODO\n }\n\n // 6. If response is null, then:\n if (response === null) {\n // 1. If makeCORSPreflight is true and one of these conditions is true:\n // TODO\n\n // 2. If request\u2019s redirect mode is \"follow\", then set request\u2019s\n // service-workers mode to \"none\".\n if (request.redirect === 'follow') {\n request.serviceWorkers = 'none'\n }\n\n // 3. Set response and actualResponse to the result of running\n // HTTP-network-or-cache fetch given fetchParams.\n actualResponse = response = await httpNetworkOrCacheFetch(fetchParams)\n\n // 4. If request\u2019s response tainting is \"cors\" and a CORS check\n // for request and response returns failure, then return a network error.\n if (\n request.responseTainting === 'cors' &&\n corsCheck(request, response) === 'failure'\n ) {\n return makeNetworkError('cors failure')\n }\n\n // 5. If the TAO check for request and response returns failure, then set\n // request\u2019s timing allow failed flag.\n if (TAOCheck(request, response) === 'failure') {\n request.timingAllowFailed = true\n }\n }\n\n // 7. If either request\u2019s response tainting or response\u2019s type\n // is \"opaque\", and the cross-origin resource policy check with\n // request\u2019s origin, request\u2019s client, request\u2019s destination,\n // and actualResponse returns blocked, then return a network error.\n if (\n (request.responseTainting === 'opaque' || response.type === 'opaque') &&\n crossOriginResourcePolicyCheck(\n request.origin,\n request.client,\n request.destination,\n actualResponse\n ) === 'blocked'\n ) {\n return makeNetworkError('blocked')\n }\n\n // 8. If actualResponse\u2019s status is a redirect status, then:\n if (redirectStatusSet.has(actualResponse.status)) {\n // 1. If actualResponse\u2019s status is not 303, request\u2019s body is not null,\n // and the connection uses HTTP/2, then user agents may, and are even\n // encouraged to, transmit an RST_STREAM frame.\n // See, https://github.com/whatwg/fetch/issues/1288\n if (request.redirect !== 'manual') {\n fetchParams.controller.connection.destroy()\n }\n\n // 2. Switch on request\u2019s redirect mode:\n if (request.redirect === 'error') {\n // Set response to a network error.\n response = makeNetworkError('unexpected redirect')\n } else if (request.redirect === 'manual') {\n // Set response to an opaque-redirect filtered response whose internal\n // response is actualResponse.\n // NOTE(spec): On the web this would return an `opaqueredirect` response,\n // but that doesn't make sense server side.\n // See https://github.com/nodejs/undici/issues/1193.\n response = actualResponse\n } else if (request.redirect === 'follow') {\n // Set response to the result of running HTTP-redirect fetch given\n // fetchParams and response.\n response = await httpRedirectFetch(fetchParams, response)\n } else {\n assert(false)\n }\n }\n\n // 9. Set response\u2019s timing info to timingInfo.\n response.timingInfo = timingInfo\n\n // 10. Return response.\n return response\n}\n\n// https://fetch.spec.whatwg.org/#http-redirect-fetch\nfunction httpRedirectFetch (fetchParams, response) {\n // 1. Let request be fetchParams\u2019s request.\n const request = fetchParams.request\n\n // 2. Let actualResponse be response, if response is not a filtered response,\n // and response\u2019s internal response otherwise.\n const actualResponse = response.internalResponse\n ? response.internalResponse\n : response\n\n // 3. Let locationURL be actualResponse\u2019s location URL given request\u2019s current\n // URL\u2019s fragment.\n let locationURL\n\n try {\n locationURL = responseLocationURL(\n actualResponse,\n requestCurrentURL(request).hash\n )\n\n // 4. If locationURL is null, then return response.\n if (locationURL == null) {\n return response\n }\n } catch (err) {\n // 5. If locationURL is failure, then return a network error.\n return Promise.resolve(makeNetworkError(err))\n }\n\n // 6. If locationURL\u2019s scheme is not an HTTP(S) scheme, then return a network\n // error.\n if (!urlIsHttpHttpsScheme(locationURL)) {\n return Promise.resolve(makeNetworkError('URL scheme must be a HTTP(S) scheme'))\n }\n\n // 7. If request\u2019s redirect count is 20, then return a network error.\n if (request.redirectCount === 20) {\n return Promise.resolve(makeNetworkError('redirect count exceeded'))\n }\n\n // 8. Increase request\u2019s redirect count by 1.\n request.redirectCount += 1\n\n // 9. If request\u2019s mode is \"cors\", locationURL includes credentials, and\n // request\u2019s origin is not same origin with locationURL\u2019s origin, then return\n // a network error.\n if (\n request.mode === 'cors' &&\n (locationURL.username || locationURL.password) &&\n !sameOrigin(request, locationURL)\n ) {\n return Promise.resolve(makeNetworkError('cross origin not allowed for request mode \"cors\"'))\n }\n\n // 10. If request\u2019s response tainting is \"cors\" and locationURL includes\n // credentials, then return a network error.\n if (\n request.responseTainting === 'cors' &&\n (locationURL.username || locationURL.password)\n ) {\n return Promise.resolve(makeNetworkError(\n 'URL cannot contain credentials for request mode \"cors\"'\n ))\n }\n\n // 11. If actualResponse\u2019s status is not 303, request\u2019s body is non-null,\n // and request\u2019s body\u2019s source is null, then return a network error.\n if (\n actualResponse.status !== 303 &&\n request.body != null &&\n request.body.source == null\n ) {\n return Promise.resolve(makeNetworkError())\n }\n\n // 12. If one of the following is true\n // - actualResponse\u2019s status is 301 or 302 and request\u2019s method is `POST`\n // - actualResponse\u2019s status is 303 and request\u2019s method is not `GET` or `HEAD`\n if (\n ([301, 302].includes(actualResponse.status) && request.method === 'POST') ||\n (actualResponse.status === 303 &&\n !GET_OR_HEAD.includes(request.method))\n ) {\n // then:\n // 1. Set request\u2019s method to `GET` and request\u2019s body to null.\n request.method = 'GET'\n request.body = null\n\n // 2. For each headerName of request-body-header name, delete headerName from\n // request\u2019s header list.\n for (const headerName of requestBodyHeader) {\n request.headersList.delete(headerName)\n }\n }\n\n // 13. If request\u2019s current URL\u2019s origin is not same origin with locationURL\u2019s\n // origin, then for each headerName of CORS non-wildcard request-header name,\n // delete headerName from request\u2019s header list.\n if (!sameOrigin(requestCurrentURL(request), locationURL)) {\n // https://fetch.spec.whatwg.org/#cors-non-wildcard-request-header-name\n request.headersList.delete('authorization')\n\n // https://fetch.spec.whatwg.org/#authentication-entries\n request.headersList.delete('proxy-authorization', true)\n\n // \"Cookie\" and \"Host\" are forbidden request-headers, which undici doesn't implement.\n request.headersList.delete('cookie')\n request.headersList.delete('host')\n }\n\n // 14. If request\u2019s body is non-null, then set request\u2019s body to the first return\n // value of safely extracting request\u2019s body\u2019s source.\n if (request.body != null) {\n assert(request.body.source != null)\n request.body = safelyExtractBody(request.body.source)[0]\n }\n\n // 15. Let timingInfo be fetchParams\u2019s timing info.\n const timingInfo = fetchParams.timingInfo\n\n // 16. Set timingInfo\u2019s redirect end time and post-redirect start time to the\n // coarsened shared current time given fetchParams\u2019s cross-origin isolated\n // capability.\n timingInfo.redirectEndTime = timingInfo.postRedirectStartTime =\n coarsenedSharedCurrentTime(fetchParams.crossOriginIsolatedCapability)\n\n // 17. If timingInfo\u2019s redirect start time is 0, then set timingInfo\u2019s\n // redirect start time to timingInfo\u2019s start time.\n if (timingInfo.redirectStartTime === 0) {\n timingInfo.redirectStartTime = timingInfo.startTime\n }\n\n // 18. Append locationURL to request\u2019s URL list.\n request.urlList.push(locationURL)\n\n // 19. Invoke set request\u2019s referrer policy on redirect on request and\n // actualResponse.\n setRequestReferrerPolicyOnRedirect(request, actualResponse)\n\n // 20. Return the result of running main fetch given fetchParams and true.\n return mainFetch(fetchParams, true)\n}\n\n// https://fetch.spec.whatwg.org/#http-network-or-cache-fetch\nasync function httpNetworkOrCacheFetch (\n fetchParams,\n isAuthenticationFetch = false,\n isNewConnectionFetch = false\n) {\n // 1. Let request be fetchParams\u2019s request.\n const request = fetchParams.request\n\n // 2. Let httpFetchParams be null.\n let httpFetchParams = null\n\n // 3. Let httpRequest be null.\n let httpRequest = null\n\n // 4. Let response be null.\n let response = null\n\n // 5. Let storedResponse be null.\n // TODO: cache\n\n // 6. Let httpCache be null.\n const httpCache = null\n\n // 7. Let the revalidatingFlag be unset.\n const revalidatingFlag = false\n\n // 8. Run these steps, but abort when the ongoing fetch is terminated:\n\n // 1. If request\u2019s window is \"no-window\" and request\u2019s redirect mode is\n // \"error\", then set httpFetchParams to fetchParams and httpRequest to\n // request.\n if (request.window === 'no-window' && request.redirect === 'error') {\n httpFetchParams = fetchParams\n httpRequest = request\n } else {\n // Otherwise:\n\n // 1. Set httpRequest to a clone of request.\n httpRequest = makeRequest(request)\n\n // 2. Set httpFetchParams to a copy of fetchParams.\n httpFetchParams = { ...fetchParams }\n\n // 3. Set httpFetchParams\u2019s request to httpRequest.\n httpFetchParams.request = httpRequest\n }\n\n // 3. Let includeCredentials be true if one of\n const includeCredentials =\n request.credentials === 'include' ||\n (request.credentials === 'same-origin' &&\n request.responseTainting === 'basic')\n\n // 4. Let contentLength be httpRequest\u2019s body\u2019s length, if httpRequest\u2019s\n // body is non-null; otherwise null.\n const contentLength = httpRequest.body ? httpRequest.body.length : null\n\n // 5. Let contentLengthHeaderValue be null.\n let contentLengthHeaderValue = null\n\n // 6. If httpRequest\u2019s body is null and httpRequest\u2019s method is `POST` or\n // `PUT`, then set contentLengthHeaderValue to `0`.\n if (\n httpRequest.body == null &&\n ['POST', 'PUT'].includes(httpRequest.method)\n ) {\n contentLengthHeaderValue = '0'\n }\n\n // 7. If contentLength is non-null, then set contentLengthHeaderValue to\n // contentLength, serialized and isomorphic encoded.\n if (contentLength != null) {\n contentLengthHeaderValue = isomorphicEncode(`${contentLength}`)\n }\n\n // 8. If contentLengthHeaderValue is non-null, then append\n // `Content-Length`/contentLengthHeaderValue to httpRequest\u2019s header\n // list.\n if (contentLengthHeaderValue != null) {\n httpRequest.headersList.append('content-length', contentLengthHeaderValue)\n }\n\n // 9. If contentLengthHeaderValue is non-null, then append (`Content-Length`,\n // contentLengthHeaderValue) to httpRequest\u2019s header list.\n\n // 10. If contentLength is non-null and httpRequest\u2019s keepalive is true,\n // then:\n if (contentLength != null && httpRequest.keepalive) {\n // NOTE: keepalive is a noop outside of browser context.\n }\n\n // 11. If httpRequest\u2019s referrer is a URL, then append\n // `Referer`/httpRequest\u2019s referrer, serialized and isomorphic encoded,\n // to httpRequest\u2019s header list.\n if (httpRequest.referrer instanceof URL) {\n httpRequest.headersList.append('referer', isomorphicEncode(httpRequest.referrer.href))\n }\n\n // 12. Append a request `Origin` header for httpRequest.\n appendRequestOriginHeader(httpRequest)\n\n // 13. Append the Fetch metadata headers for httpRequest. [FETCH-METADATA]\n appendFetchMetadata(httpRequest)\n\n // 14. If httpRequest\u2019s header list does not contain `User-Agent`, then\n // user agents should append `User-Agent`/default `User-Agent` value to\n // httpRequest\u2019s header list.\n if (!httpRequest.headersList.contains('user-agent')) {\n httpRequest.headersList.append('user-agent', typeof esbuildDetection === 'undefined' ? 'undici' : 'node')\n }\n\n // 15. If httpRequest\u2019s cache mode is \"default\" and httpRequest\u2019s header\n // list contains `If-Modified-Since`, `If-None-Match`,\n // `If-Unmodified-Since`, `If-Match`, or `If-Range`, then set\n // httpRequest\u2019s cache mode to \"no-store\".\n if (\n httpRequest.cache === 'default' &&\n (httpRequest.headersList.contains('if-modified-since') ||\n httpRequest.headersList.contains('if-none-match') ||\n httpRequest.headersList.contains('if-unmodified-since') ||\n httpRequest.headersList.contains('if-match') ||\n httpRequest.headersList.contains('if-range'))\n ) {\n httpRequest.cache = 'no-store'\n }\n\n // 16. If httpRequest\u2019s cache mode is \"no-cache\", httpRequest\u2019s prevent\n // no-cache cache-control header modification flag is unset, and\n // httpRequest\u2019s header list does not contain `Cache-Control`, then append\n // `Cache-Control`/`max-age=0` to httpRequest\u2019s header list.\n if (\n httpRequest.cache === 'no-cache' &&\n !httpRequest.preventNoCacheCacheControlHeaderModification &&\n !httpRequest.headersList.contains('cache-control')\n ) {\n httpRequest.headersList.append('cache-control', 'max-age=0')\n }\n\n // 17. If httpRequest\u2019s cache mode is \"no-store\" or \"reload\", then:\n if (httpRequest.cache === 'no-store' || httpRequest.cache === 'reload') {\n // 1. If httpRequest\u2019s header list does not contain `Pragma`, then append\n // `Pragma`/`no-cache` to httpRequest\u2019s header list.\n if (!httpRequest.headersList.contains('pragma')) {\n httpRequest.headersList.append('pragma', 'no-cache')\n }\n\n // 2. If httpRequest\u2019s header list does not contain `Cache-Control`,\n // then append `Cache-Control`/`no-cache` to httpRequest\u2019s header list.\n if (!httpRequest.headersList.contains('cache-control')) {\n httpRequest.headersList.append('cache-control', 'no-cache')\n }\n }\n\n // 18. If httpRequest\u2019s header list contains `Range`, then append\n // `Accept-Encoding`/`identity` to httpRequest\u2019s header list.\n if (httpRequest.headersList.contains('range')) {\n httpRequest.headersList.append('accept-encoding', 'identity')\n }\n\n // 19. Modify httpRequest\u2019s header list per HTTP. Do not append a given\n // header if httpRequest\u2019s header list contains that header\u2019s name.\n // TODO: https://github.com/whatwg/fetch/issues/1285#issuecomment-896560129\n if (!httpRequest.headersList.contains('accept-encoding')) {\n if (urlHasHttpsScheme(requestCurrentURL(httpRequest))) {\n httpRequest.headersList.append('accept-encoding', 'br, gzip, deflate')\n } else {\n httpRequest.headersList.append('accept-encoding', 'gzip, deflate')\n }\n }\n\n httpRequest.headersList.delete('host')\n\n // 20. If includeCredentials is true, then:\n if (includeCredentials) {\n // 1. If the user agent is not configured to block cookies for httpRequest\n // (see section 7 of [COOKIES]), then:\n // TODO: credentials\n // 2. If httpRequest\u2019s header list does not contain `Authorization`, then:\n // TODO: credentials\n }\n\n // 21. If there\u2019s a proxy-authentication entry, use it as appropriate.\n // TODO: proxy-authentication\n\n // 22. Set httpCache to the result of determining the HTTP cache\n // partition, given httpRequest.\n // TODO: cache\n\n // 23. If httpCache is null, then set httpRequest\u2019s cache mode to\n // \"no-store\".\n if (httpCache == null) {\n httpRequest.cache = 'no-store'\n }\n\n // 24. If httpRequest\u2019s cache mode is neither \"no-store\" nor \"reload\",\n // then:\n if (httpRequest.mode !== 'no-store' && httpRequest.mode !== 'reload') {\n // TODO: cache\n }\n\n // 9. If aborted, then return the appropriate network error for fetchParams.\n // TODO\n\n // 10. If response is null, then:\n if (response == null) {\n // 1. If httpRequest\u2019s cache mode is \"only-if-cached\", then return a\n // network error.\n if (httpRequest.mode === 'only-if-cached') {\n return makeNetworkError('only if cached')\n }\n\n // 2. Let forwardResponse be the result of running HTTP-network fetch\n // given httpFetchParams, includeCredentials, and isNewConnectionFetch.\n const forwardResponse = await httpNetworkFetch(\n httpFetchParams,\n includeCredentials,\n isNewConnectionFetch\n )\n\n // 3. If httpRequest\u2019s method is unsafe and forwardResponse\u2019s status is\n // in the range 200 to 399, inclusive, invalidate appropriate stored\n // responses in httpCache, as per the \"Invalidation\" chapter of HTTP\n // Caching, and set storedResponse to null. [HTTP-CACHING]\n if (\n !safeMethodsSet.has(httpRequest.method) &&\n forwardResponse.status >= 200 &&\n forwardResponse.status <= 399\n ) {\n // TODO: cache\n }\n\n // 4. If the revalidatingFlag is set and forwardResponse\u2019s status is 304,\n // then:\n if (revalidatingFlag && forwardResponse.status === 304) {\n // TODO: cache\n }\n\n // 5. If response is null, then:\n if (response == null) {\n // 1. Set response to forwardResponse.\n response = forwardResponse\n\n // 2. Store httpRequest and forwardResponse in httpCache, as per the\n // \"Storing Responses in Caches\" chapter of HTTP Caching. [HTTP-CACHING]\n // TODO: cache\n }\n }\n\n // 11. Set response\u2019s URL list to a clone of httpRequest\u2019s URL list.\n response.urlList = [...httpRequest.urlList]\n\n // 12. If httpRequest\u2019s header list contains `Range`, then set response\u2019s\n // range-requested flag.\n if (httpRequest.headersList.contains('range')) {\n response.rangeRequested = true\n }\n\n // 13. Set response\u2019s request-includes-credentials to includeCredentials.\n response.requestIncludesCredentials = includeCredentials\n\n // 14. If response\u2019s status is 401, httpRequest\u2019s response tainting is not\n // \"cors\", includeCredentials is true, and request\u2019s window is an environment\n // settings object, then:\n // TODO\n\n // 15. If response\u2019s status is 407, then:\n if (response.status === 407) {\n // 1. If request\u2019s window is \"no-window\", then return a network error.\n if (request.window === 'no-window') {\n return makeNetworkError()\n }\n\n // 2. ???\n\n // 3. If fetchParams is canceled, then return the appropriate network error for fetchParams.\n if (isCancelled(fetchParams)) {\n return makeAppropriateNetworkError(fetchParams)\n }\n\n // 4. Prompt the end user as appropriate in request\u2019s window and store\n // the result as a proxy-authentication entry. [HTTP-AUTH]\n // TODO: Invoke some kind of callback?\n\n // 5. Set response to the result of running HTTP-network-or-cache fetch given\n // fetchParams.\n // TODO\n return makeNetworkError('proxy authentication required')\n }\n\n // 16. If all of the following are true\n if (\n // response\u2019s status is 421\n response.status === 421 &&\n // isNewConnectionFetch is false\n !isNewConnectionFetch &&\n // request\u2019s body is null, or request\u2019s body is non-null and request\u2019s body\u2019s source is non-null\n (request.body == null || request.body.source != null)\n ) {\n // then:\n\n // 1. If fetchParams is canceled, then return the appropriate network error for fetchParams.\n if (isCancelled(fetchParams)) {\n return makeAppropriateNetworkError(fetchParams)\n }\n\n // 2. Set response to the result of running HTTP-network-or-cache\n // fetch given fetchParams, isAuthenticationFetch, and true.\n\n // TODO (spec): The spec doesn't specify this but we need to cancel\n // the active response before we can start a new one.\n // https://github.com/whatwg/fetch/issues/1293\n fetchParams.controller.connection.destroy()\n\n response = await httpNetworkOrCacheFetch(\n fetchParams,\n isAuthenticationFetch,\n true\n )\n }\n\n // 17. If isAuthenticationFetch is true, then create an authentication entry\n if (isAuthenticationFetch) {\n // TODO\n }\n\n // 18. Return response.\n return response\n}\n\n// https://fetch.spec.whatwg.org/#http-network-fetch\nasync function httpNetworkFetch (\n fetchParams,\n includeCredentials = false,\n forceNewConnection = false\n) {\n assert(!fetchParams.controller.connection || fetchParams.controller.connection.destroyed)\n\n fetchParams.controller.connection = {\n abort: null,\n destroyed: false,\n destroy (err) {\n if (!this.destroyed) {\n this.destroyed = true\n this.abort?.(err ?? new DOMException('The operation was aborted.', 'AbortError'))\n }\n }\n }\n\n // 1. Let request be fetchParams\u2019s request.\n const request = fetchParams.request\n\n // 2. Let response be null.\n let response = null\n\n // 3. Let timingInfo be fetchParams\u2019s timing info.\n const timingInfo = fetchParams.timingInfo\n\n // 4. Let httpCache be the result of determining the HTTP cache partition,\n // given request.\n // TODO: cache\n const httpCache = null\n\n // 5. If httpCache is null, then set request\u2019s cache mode to \"no-store\".\n if (httpCache == null) {\n request.cache = 'no-store'\n }\n\n // 6. Let networkPartitionKey be the result of determining the network\n // partition key given request.\n // TODO\n\n // 7. Let newConnection be \"yes\" if forceNewConnection is true; otherwise\n // \"no\".\n const newConnection = forceNewConnection ? 'yes' : 'no' // eslint-disable-line no-unused-vars\n\n // 8. Switch on request\u2019s mode:\n if (request.mode === 'websocket') {\n // Let connection be the result of obtaining a WebSocket connection,\n // given request\u2019s current URL.\n // TODO\n } else {\n // Let connection be the result of obtaining a connection, given\n // networkPartitionKey, request\u2019s current URL\u2019s origin,\n // includeCredentials, and forceNewConnection.\n // TODO\n }\n\n // 9. Run these steps, but abort when the ongoing fetch is terminated:\n\n // 1. If connection is failure, then return a network error.\n\n // 2. Set timingInfo\u2019s final connection timing info to the result of\n // calling clamp and coarsen connection timing info with connection\u2019s\n // timing info, timingInfo\u2019s post-redirect start time, and fetchParams\u2019s\n // cross-origin isolated capability.\n\n // 3. If connection is not an HTTP/2 connection, request\u2019s body is non-null,\n // and request\u2019s body\u2019s source is null, then append (`Transfer-Encoding`,\n // `chunked`) to request\u2019s header list.\n\n // 4. Set timingInfo\u2019s final network-request start time to the coarsened\n // shared current time given fetchParams\u2019s cross-origin isolated\n // capability.\n\n // 5. Set response to the result of making an HTTP request over connection\n // using request with the following caveats:\n\n // - Follow the relevant requirements from HTTP. [HTTP] [HTTP-SEMANTICS]\n // [HTTP-COND] [HTTP-CACHING] [HTTP-AUTH]\n\n // - If request\u2019s body is non-null, and request\u2019s body\u2019s source is null,\n // then the user agent may have a buffer of up to 64 kibibytes and store\n // a part of request\u2019s body in that buffer. If the user agent reads from\n // request\u2019s body beyond that buffer\u2019s size and the user agent needs to\n // resend request, then instead return a network error.\n\n // - Set timingInfo\u2019s final network-response start time to the coarsened\n // shared current time given fetchParams\u2019s cross-origin isolated capability,\n // immediately after the user agent\u2019s HTTP parser receives the first byte\n // of the response (e.g., frame header bytes for HTTP/2 or response status\n // line for HTTP/1.x).\n\n // - Wait until all the headers are transmitted.\n\n // - Any responses whose status is in the range 100 to 199, inclusive,\n // and is not 101, are to be ignored, except for the purposes of setting\n // timingInfo\u2019s final network-response start time above.\n\n // - If request\u2019s header list contains `Transfer-Encoding`/`chunked` and\n // response is transferred via HTTP/1.0 or older, then return a network\n // error.\n\n // - If the HTTP request results in a TLS client certificate dialog, then:\n\n // 1. If request\u2019s window is an environment settings object, make the\n // dialog available in request\u2019s window.\n\n // 2. Otherwise, return a network error.\n\n // To transmit request\u2019s body body, run these steps:\n let requestBody = null\n // 1. If body is null and fetchParams\u2019s process request end-of-body is\n // non-null, then queue a fetch task given fetchParams\u2019s process request\n // end-of-body and fetchParams\u2019s task destination.\n if (request.body == null && fetchParams.processRequestEndOfBody) {\n queueMicrotask(() => fetchParams.processRequestEndOfBody())\n } else if (request.body != null) {\n // 2. Otherwise, if body is non-null:\n\n // 1. Let processBodyChunk given bytes be these steps:\n const processBodyChunk = async function * (bytes) {\n // 1. If the ongoing fetch is terminated, then abort these steps.\n if (isCancelled(fetchParams)) {\n return\n }\n\n // 2. Run this step in parallel: transmit bytes.\n yield bytes\n\n // 3. If fetchParams\u2019s process request body is non-null, then run\n // fetchParams\u2019s process request body given bytes\u2019s length.\n fetchParams.processRequestBodyChunkLength?.(bytes.byteLength)\n }\n\n // 2. Let processEndOfBody be these steps:\n const processEndOfBody = () => {\n // 1. If fetchParams is canceled, then abort these steps.\n if (isCancelled(fetchParams)) {\n return\n }\n\n // 2. If fetchParams\u2019s process request end-of-body is non-null,\n // then run fetchParams\u2019s process request end-of-body.\n if (fetchParams.processRequestEndOfBody) {\n fetchParams.processRequestEndOfBody()\n }\n }\n\n // 3. Let processBodyError given e be these steps:\n const processBodyError = (e) => {\n // 1. If fetchParams is canceled, then abort these steps.\n if (isCancelled(fetchParams)) {\n return\n }\n\n // 2. If e is an \"AbortError\" DOMException, then abort fetchParams\u2019s controller.\n if (e.name === 'AbortError') {\n fetchParams.controller.abort()\n } else {\n fetchParams.controller.terminate(e)\n }\n }\n\n // 4. Incrementally read request\u2019s body given processBodyChunk, processEndOfBody,\n // processBodyError, and fetchParams\u2019s task destination.\n requestBody = (async function * () {\n try {\n for await (const bytes of request.body.stream) {\n yield * processBodyChunk(bytes)\n }\n processEndOfBody()\n } catch (err) {\n processBodyError(err)\n }\n })()\n }\n\n try {\n // socket is only provided for websockets\n const { body, status, statusText, headersList, socket } = await dispatch({ body: requestBody })\n\n if (socket) {\n response = makeResponse({ status, statusText, headersList, socket })\n } else {\n const iterator = body[Symbol.asyncIterator]()\n fetchParams.controller.next = () => iterator.next()\n\n response = makeResponse({ status, statusText, headersList })\n }\n } catch (err) {\n // 10. If aborted, then:\n if (err.name === 'AbortError') {\n // 1. If connection uses HTTP/2, then transmit an RST_STREAM frame.\n fetchParams.controller.connection.destroy()\n\n // 2. Return the appropriate network error for fetchParams.\n return makeAppropriateNetworkError(fetchParams, err)\n }\n\n return makeNetworkError(err)\n }\n\n // 11. Let pullAlgorithm be an action that resumes the ongoing fetch\n // if it is suspended.\n const pullAlgorithm = () => {\n fetchParams.controller.resume()\n }\n\n // 12. Let cancelAlgorithm be an algorithm that aborts fetchParams\u2019s\n // controller with reason, given reason.\n const cancelAlgorithm = (reason) => {\n fetchParams.controller.abort(reason)\n }\n\n // 13. Let highWaterMark be a non-negative, non-NaN number, chosen by\n // the user agent.\n // TODO\n\n // 14. Let sizeAlgorithm be an algorithm that accepts a chunk object\n // and returns a non-negative, non-NaN, non-infinite number, chosen by the user agent.\n // TODO\n\n // 15. Let stream be a new ReadableStream.\n // 16. Set up stream with pullAlgorithm set to pullAlgorithm,\n // cancelAlgorithm set to cancelAlgorithm, highWaterMark set to\n // highWaterMark, and sizeAlgorithm set to sizeAlgorithm.\n if (!ReadableStream) {\n ReadableStream = (__nccwpck_require__(5356).ReadableStream)\n }\n\n const stream = new ReadableStream(\n {\n async start (controller) {\n fetchParams.controller.controller = controller\n },\n async pull (controller) {\n await pullAlgorithm(controller)\n },\n async cancel (reason) {\n await cancelAlgorithm(reason)\n }\n },\n {\n highWaterMark: 0,\n size () {\n return 1\n }\n }\n )\n\n // 17. Run these steps, but abort when the ongoing fetch is terminated:\n\n // 1. Set response\u2019s body to a new body whose stream is stream.\n response.body = { stream }\n\n // 2. If response is not a network error and request\u2019s cache mode is\n // not \"no-store\", then update response in httpCache for request.\n // TODO\n\n // 3. If includeCredentials is true and the user agent is not configured\n // to block cookies for request (see section 7 of [COOKIES]), then run the\n // \"set-cookie-string\" parsing algorithm (see section 5.2 of [COOKIES]) on\n // the value of each header whose name is a byte-case-insensitive match for\n // `Set-Cookie` in response\u2019s header list, if any, and request\u2019s current URL.\n // TODO\n\n // 18. If aborted, then:\n // TODO\n\n // 19. Run these steps in parallel:\n\n // 1. Run these steps, but abort when fetchParams is canceled:\n fetchParams.controller.on('terminated', onAborted)\n fetchParams.controller.resume = async () => {\n // 1. While true\n while (true) {\n // 1-3. See onData...\n\n // 4. Set bytes to the result of handling content codings given\n // codings and bytes.\n let bytes\n let isFailure\n try {\n const { done, value } = await fetchParams.controller.next()\n\n if (isAborted(fetchParams)) {\n break\n }\n\n bytes = done ? undefined : value\n } catch (err) {\n if (fetchParams.controller.ended && !timingInfo.encodedBodySize) {\n // zlib doesn't like empty streams.\n bytes = undefined\n } else {\n bytes = err\n\n // err may be propagated from the result of calling readablestream.cancel,\n // which might not be an error. https://github.com/nodejs/undici/issues/2009\n isFailure = true\n }\n }\n\n if (bytes === undefined) {\n // 2. Otherwise, if the bytes transmission for response\u2019s message\n // body is done normally and stream is readable, then close\n // stream, finalize response for fetchParams and response, and\n // abort these in-parallel steps.\n readableStreamClose(fetchParams.controller.controller)\n\n finalizeResponse(fetchParams, response)\n\n return\n }\n\n // 5. Increase timingInfo\u2019s decoded body size by bytes\u2019s length.\n timingInfo.decodedBodySize += bytes?.byteLength ?? 0\n\n // 6. If bytes is failure, then terminate fetchParams\u2019s controller.\n if (isFailure) {\n fetchParams.controller.terminate(bytes)\n return\n }\n\n // 7. Enqueue a Uint8Array wrapping an ArrayBuffer containing bytes\n // into stream.\n fetchParams.controller.controller.enqueue(new Uint8Array(bytes))\n\n // 8. If stream is errored, then terminate the ongoing fetch.\n if (isErrored(stream)) {\n fetchParams.controller.terminate()\n return\n }\n\n // 9. If stream doesn\u2019t need more data ask the user agent to suspend\n // the ongoing fetch.\n if (!fetchParams.controller.controller.desiredSize) {\n return\n }\n }\n }\n\n // 2. If aborted, then:\n function onAborted (reason) {\n // 2. If fetchParams is aborted, then:\n if (isAborted(fetchParams)) {\n // 1. Set response\u2019s aborted flag.\n response.aborted = true\n\n // 2. If stream is readable, then error stream with the result of\n // deserialize a serialized abort reason given fetchParams\u2019s\n // controller\u2019s serialized abort reason and an\n // implementation-defined realm.\n if (isReadable(stream)) {\n fetchParams.controller.controller.error(\n fetchParams.controller.serializedAbortReason\n )\n }\n } else {\n // 3. Otherwise, if stream is readable, error stream with a TypeError.\n if (isReadable(stream)) {\n fetchParams.controller.controller.error(new TypeError('terminated', {\n cause: isErrorLike(reason) ? reason : undefined\n }))\n }\n }\n\n // 4. If connection uses HTTP/2, then transmit an RST_STREAM frame.\n // 5. Otherwise, the user agent should close connection unless it would be bad for performance to do so.\n fetchParams.controller.connection.destroy()\n }\n\n // 20. Return response.\n return response\n\n async function dispatch ({ body }) {\n const url = requestCurrentURL(request)\n /** @type {import('../..').Agent} */\n const agent = fetchParams.controller.dispatcher\n\n return new Promise((resolve, reject) => agent.dispatch(\n {\n path: url.pathname + url.search,\n origin: url.origin,\n method: request.method,\n body: fetchParams.controller.dispatcher.isMockActive ? request.body && (request.body.source || request.body.stream) : body,\n headers: request.headersList.entries,\n maxRedirections: 0,\n upgrade: request.mode === 'websocket' ? 'websocket' : undefined\n },\n {\n body: null,\n abort: null,\n\n onConnect (abort) {\n // TODO (fix): Do we need connection here?\n const { connection } = fetchParams.controller\n\n if (connection.destroyed) {\n abort(new DOMException('The operation was aborted.', 'AbortError'))\n } else {\n fetchParams.controller.on('terminated', abort)\n this.abort = connection.abort = abort\n }\n },\n\n onHeaders (status, headersList, resume, statusText) {\n if (status < 200) {\n return\n }\n\n let codings = []\n let location = ''\n\n const headers = new Headers()\n\n // For H2, the headers are a plain JS object\n // We distinguish between them and iterate accordingly\n if (Array.isArray(headersList)) {\n for (let n = 0; n < headersList.length; n += 2) {\n const key = headersList[n + 0].toString('latin1')\n const val = headersList[n + 1].toString('latin1')\n if (key.toLowerCase() === 'content-encoding') {\n // https://www.rfc-editor.org/rfc/rfc7231#section-3.1.2.1\n // \"All content-coding values are case-insensitive...\"\n codings = val.toLowerCase().split(',').map((x) => x.trim())\n } else if (key.toLowerCase() === 'location') {\n location = val\n }\n\n headers[kHeadersList].append(key, val)\n }\n } else {\n const keys = Object.keys(headersList)\n for (const key of keys) {\n const val = headersList[key]\n if (key.toLowerCase() === 'content-encoding') {\n // https://www.rfc-editor.org/rfc/rfc7231#section-3.1.2.1\n // \"All content-coding values are case-insensitive...\"\n codings = val.toLowerCase().split(',').map((x) => x.trim()).reverse()\n } else if (key.toLowerCase() === 'location') {\n location = val\n }\n\n headers[kHeadersList].append(key, val)\n }\n }\n\n this.body = new Readable({ read: resume })\n\n const decoders = []\n\n const willFollow = request.redirect === 'follow' &&\n location &&\n redirectStatusSet.has(status)\n\n // https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers/Content-Encoding\n if (request.method !== 'HEAD' && request.method !== 'CONNECT' && !nullBodyStatus.includes(status) && !willFollow) {\n for (const coding of codings) {\n // https://www.rfc-editor.org/rfc/rfc9112.html#section-7.2\n if (coding === 'x-gzip' || coding === 'gzip') {\n decoders.push(zlib.createGunzip({\n // Be less strict when decoding compressed responses, since sometimes\n // servers send slightly invalid responses that are still accepted\n // by common browsers.\n // Always using Z_SYNC_FLUSH is what cURL does.\n flush: zlib.constants.Z_SYNC_FLUSH,\n finishFlush: zlib.constants.Z_SYNC_FLUSH\n }))\n } else if (coding === 'deflate') {\n decoders.push(zlib.createInflate())\n } else if (coding === 'br') {\n decoders.push(zlib.createBrotliDecompress())\n } else {\n decoders.length = 0\n break\n }\n }\n }\n\n resolve({\n status,\n statusText,\n headersList: headers[kHeadersList],\n body: decoders.length\n ? pipeline(this.body, ...decoders, () => { })\n : this.body.on('error', () => {})\n })\n\n return true\n },\n\n onData (chunk) {\n if (fetchParams.controller.dump) {\n return\n }\n\n // 1. If one or more bytes have been transmitted from response\u2019s\n // message body, then:\n\n // 1. Let bytes be the transmitted bytes.\n const bytes = chunk\n\n // 2. Let codings be the result of extracting header list values\n // given `Content-Encoding` and response\u2019s header list.\n // See pullAlgorithm.\n\n // 3. Increase timingInfo\u2019s encoded body size by bytes\u2019s length.\n timingInfo.encodedBodySize += bytes.byteLength\n\n // 4. See pullAlgorithm...\n\n return this.body.push(bytes)\n },\n\n onComplete () {\n if (this.abort) {\n fetchParams.controller.off('terminated', this.abort)\n }\n\n fetchParams.controller.ended = true\n\n this.body.push(null)\n },\n\n onError (error) {\n if (this.abort) {\n fetchParams.controller.off('terminated', this.abort)\n }\n\n this.body?.destroy(error)\n\n fetchParams.controller.terminate(error)\n\n reject(error)\n },\n\n onUpgrade (status, headersList, socket) {\n if (status !== 101) {\n return\n }\n\n const headers = new Headers()\n\n for (let n = 0; n < headersList.length; n += 2) {\n const key = headersList[n + 0].toString('latin1')\n const val = headersList[n + 1].toString('latin1')\n\n headers[kHeadersList].append(key, val)\n }\n\n resolve({\n status,\n statusText: STATUS_CODES[status],\n headersList: headers[kHeadersList],\n socket\n })\n\n return true\n }\n }\n ))\n }\n}\n\nmodule.exports = {\n fetch,\n Fetch,\n fetching,\n finalizeAndReportTiming\n}\n\n\n/***/ }),\n\n/***/ 8359:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\n\"use strict\";\n/* globals AbortController */\n\n\n\nconst { extractBody, mixinBody, cloneBody } = __nccwpck_require__(1472)\nconst { Headers, fill: fillHeaders, HeadersList } = __nccwpck_require__(554)\nconst { FinalizationRegistry } = __nccwpck_require__(6436)()\nconst util = __nccwpck_require__(3983)\nconst {\n isValidHTTPToken,\n sameOrigin,\n normalizeMethod,\n makePolicyContainer,\n normalizeMethodRecord\n} = __nccwpck_require__(2538)\nconst {\n forbiddenMethodsSet,\n corsSafeListedMethodsSet,\n referrerPolicy,\n requestRedirect,\n requestMode,\n requestCredentials,\n requestCache,\n requestDuplex\n} = __nccwpck_require__(1037)\nconst { kEnumerableProperty } = util\nconst { kHeaders, kSignal, kState, kGuard, kRealm } = __nccwpck_require__(5861)\nconst { webidl } = __nccwpck_require__(1744)\nconst { getGlobalOrigin } = __nccwpck_require__(1246)\nconst { URLSerializer } = __nccwpck_require__(685)\nconst { kHeadersList, kConstruct } = __nccwpck_require__(2785)\nconst assert = __nccwpck_require__(9491)\nconst { getMaxListeners, setMaxListeners, getEventListeners, defaultMaxListeners } = __nccwpck_require__(2361)\n\nlet TransformStream = globalThis.TransformStream\n\nconst kAbortController = Symbol('abortController')\n\nconst requestFinalizer = new FinalizationRegistry(({ signal, abort }) => {\n signal.removeEventListener('abort', abort)\n})\n\n// https://fetch.spec.whatwg.org/#request-class\nclass Request {\n // https://fetch.spec.whatwg.org/#dom-request\n constructor (input, init = {}) {\n if (input === kConstruct) {\n return\n }\n\n webidl.argumentLengthCheck(arguments, 1, { header: 'Request constructor' })\n\n input = webidl.converters.RequestInfo(input)\n init = webidl.converters.RequestInit(init)\n\n // https://html.spec.whatwg.org/multipage/webappapis.html#environment-settings-object\n this[kRealm] = {\n settingsObject: {\n baseUrl: getGlobalOrigin(),\n get origin () {\n return this.baseUrl?.origin\n },\n policyContainer: makePolicyContainer()\n }\n }\n\n // 1. Let request be null.\n let request = null\n\n // 2. Let fallbackMode be null.\n let fallbackMode = null\n\n // 3. Let baseURL be this\u2019s relevant settings object\u2019s API base URL.\n const baseUrl = this[kRealm].settingsObject.baseUrl\n\n // 4. Let signal be null.\n let signal = null\n\n // 5. If input is a string, then:\n if (typeof input === 'string') {\n // 1. Let parsedURL be the result of parsing input with baseURL.\n // 2. If parsedURL is failure, then throw a TypeError.\n let parsedURL\n try {\n parsedURL = new URL(input, baseUrl)\n } catch (err) {\n throw new TypeError('Failed to parse URL from ' + input, { cause: err })\n }\n\n // 3. If parsedURL includes credentials, then throw a TypeError.\n if (parsedURL.username || parsedURL.password) {\n throw new TypeError(\n 'Request cannot be constructed from a URL that includes credentials: ' +\n input\n )\n }\n\n // 4. Set request to a new request whose URL is parsedURL.\n request = makeRequest({ urlList: [parsedURL] })\n\n // 5. Set fallbackMode to \"cors\".\n fallbackMode = 'cors'\n } else {\n // 6. Otherwise:\n\n // 7. Assert: input is a Request object.\n assert(input instanceof Request)\n\n // 8. Set request to input\u2019s request.\n request = input[kState]\n\n // 9. Set signal to input\u2019s signal.\n signal = input[kSignal]\n }\n\n // 7. Let origin be this\u2019s relevant settings object\u2019s origin.\n const origin = this[kRealm].settingsObject.origin\n\n // 8. Let window be \"client\".\n let window = 'client'\n\n // 9. If request\u2019s window is an environment settings object and its origin\n // is same origin with origin, then set window to request\u2019s window.\n if (\n request.window?.constructor?.name === 'EnvironmentSettingsObject' &&\n sameOrigin(request.window, origin)\n ) {\n window = request.window\n }\n\n // 10. If init[\"window\"] exists and is non-null, then throw a TypeError.\n if (init.window != null) {\n throw new TypeError(`'window' option '${window}' must be null`)\n }\n\n // 11. If init[\"window\"] exists, then set window to \"no-window\".\n if ('window' in init) {\n window = 'no-window'\n }\n\n // 12. Set request to a new request with the following properties:\n request = makeRequest({\n // URL request\u2019s URL.\n // undici implementation note: this is set as the first item in request's urlList in makeRequest\n // method request\u2019s method.\n method: request.method,\n // header list A copy of request\u2019s header list.\n // undici implementation note: headersList is cloned in makeRequest\n headersList: request.headersList,\n // unsafe-request flag Set.\n unsafeRequest: request.unsafeRequest,\n // client This\u2019s relevant settings object.\n client: this[kRealm].settingsObject,\n // window window.\n window,\n // priority request\u2019s priority.\n priority: request.priority,\n // origin request\u2019s origin. The propagation of the origin is only significant for navigation requests\n // being handled by a service worker. In this scenario a request can have an origin that is different\n // from the current client.\n origin: request.origin,\n // referrer request\u2019s referrer.\n referrer: request.referrer,\n // referrer policy request\u2019s referrer policy.\n referrerPolicy: request.referrerPolicy,\n // mode request\u2019s mode.\n mode: request.mode,\n // credentials mode request\u2019s credentials mode.\n credentials: request.credentials,\n // cache mode request\u2019s cache mode.\n cache: request.cache,\n // redirect mode request\u2019s redirect mode.\n redirect: request.redirect,\n // integrity metadata request\u2019s integrity metadata.\n integrity: request.integrity,\n // keepalive request\u2019s keepalive.\n keepalive: request.keepalive,\n // reload-navigation flag request\u2019s reload-navigation flag.\n reloadNavigation: request.reloadNavigation,\n // history-navigation flag request\u2019s history-navigation flag.\n historyNavigation: request.historyNavigation,\n // URL list A clone of request\u2019s URL list.\n urlList: [...request.urlList]\n })\n\n const initHasKey = Object.keys(init).length !== 0\n\n // 13. If init is not empty, then:\n if (initHasKey) {\n // 1. If request\u2019s mode is \"navigate\", then set it to \"same-origin\".\n if (request.mode === 'navigate') {\n request.mode = 'same-origin'\n }\n\n // 2. Unset request\u2019s reload-navigation flag.\n request.reloadNavigation = false\n\n // 3. Unset request\u2019s history-navigation flag.\n request.historyNavigation = false\n\n // 4. Set request\u2019s origin to \"client\".\n request.origin = 'client'\n\n // 5. Set request\u2019s referrer to \"client\"\n request.referrer = 'client'\n\n // 6. Set request\u2019s referrer policy to the empty string.\n request.referrerPolicy = ''\n\n // 7. Set request\u2019s URL to request\u2019s current URL.\n request.url = request.urlList[request.urlList.length - 1]\n\n // 8. Set request\u2019s URL list to \u00ab request\u2019s URL \u00bb.\n request.urlList = [request.url]\n }\n\n // 14. If init[\"referrer\"] exists, then:\n if (init.referrer !== undefined) {\n // 1. Let referrer be init[\"referrer\"].\n const referrer = init.referrer\n\n // 2. If referrer is the empty string, then set request\u2019s referrer to \"no-referrer\".\n if (referrer === '') {\n request.referrer = 'no-referrer'\n } else {\n // 1. Let parsedReferrer be the result of parsing referrer with\n // baseURL.\n // 2. If parsedReferrer is failure, then throw a TypeError.\n let parsedReferrer\n try {\n parsedReferrer = new URL(referrer, baseUrl)\n } catch (err) {\n throw new TypeError(`Referrer \"${referrer}\" is not a valid URL.`, { cause: err })\n }\n\n // 3. If one of the following is true\n // - parsedReferrer\u2019s scheme is \"about\" and path is the string \"client\"\n // - parsedReferrer\u2019s origin is not same origin with origin\n // then set request\u2019s referrer to \"client\".\n if (\n (parsedReferrer.protocol === 'about:' && parsedReferrer.hostname === 'client') ||\n (origin && !sameOrigin(parsedReferrer, this[kRealm].settingsObject.baseUrl))\n ) {\n request.referrer = 'client'\n } else {\n // 4. Otherwise, set request\u2019s referrer to parsedReferrer.\n request.referrer = parsedReferrer\n }\n }\n }\n\n // 15. If init[\"referrerPolicy\"] exists, then set request\u2019s referrer policy\n // to it.\n if (init.referrerPolicy !== undefined) {\n request.referrerPolicy = init.referrerPolicy\n }\n\n // 16. Let mode be init[\"mode\"] if it exists, and fallbackMode otherwise.\n let mode\n if (init.mode !== undefined) {\n mode = init.mode\n } else {\n mode = fallbackMode\n }\n\n // 17. If mode is \"navigate\", then throw a TypeError.\n if (mode === 'navigate') {\n throw webidl.errors.exception({\n header: 'Request constructor',\n message: 'invalid request mode navigate.'\n })\n }\n\n // 18. If mode is non-null, set request\u2019s mode to mode.\n if (mode != null) {\n request.mode = mode\n }\n\n // 19. If init[\"credentials\"] exists, then set request\u2019s credentials mode\n // to it.\n if (init.credentials !== undefined) {\n request.credentials = init.credentials\n }\n\n // 18. If init[\"cache\"] exists, then set request\u2019s cache mode to it.\n if (init.cache !== undefined) {\n request.cache = init.cache\n }\n\n // 21. If request\u2019s cache mode is \"only-if-cached\" and request\u2019s mode is\n // not \"same-origin\", then throw a TypeError.\n if (request.cache === 'only-if-cached' && request.mode !== 'same-origin') {\n throw new TypeError(\n \"'only-if-cached' can be set only with 'same-origin' mode\"\n )\n }\n\n // 22. If init[\"redirect\"] exists, then set request\u2019s redirect mode to it.\n if (init.redirect !== undefined) {\n request.redirect = init.redirect\n }\n\n // 23. If init[\"integrity\"] exists, then set request\u2019s integrity metadata to it.\n if (init.integrity != null) {\n request.integrity = String(init.integrity)\n }\n\n // 24. If init[\"keepalive\"] exists, then set request\u2019s keepalive to it.\n if (init.keepalive !== undefined) {\n request.keepalive = Boolean(init.keepalive)\n }\n\n // 25. If init[\"method\"] exists, then:\n if (init.method !== undefined) {\n // 1. Let method be init[\"method\"].\n let method = init.method\n\n // 2. If method is not a method or method is a forbidden method, then\n // throw a TypeError.\n if (!isValidHTTPToken(method)) {\n throw new TypeError(`'${method}' is not a valid HTTP method.`)\n }\n\n if (forbiddenMethodsSet.has(method.toUpperCase())) {\n throw new TypeError(`'${method}' HTTP method is unsupported.`)\n }\n\n // 3. Normalize method.\n method = normalizeMethodRecord[method] ?? normalizeMethod(method)\n\n // 4. Set request\u2019s method to method.\n request.method = method\n }\n\n // 26. If init[\"signal\"] exists, then set signal to it.\n if (init.signal !== undefined) {\n signal = init.signal\n }\n\n // 27. Set this\u2019s request to request.\n this[kState] = request\n\n // 28. Set this\u2019s signal to a new AbortSignal object with this\u2019s relevant\n // Realm.\n // TODO: could this be simplified with AbortSignal.any\n // (https://dom.spec.whatwg.org/#dom-abortsignal-any)\n const ac = new AbortController()\n this[kSignal] = ac.signal\n this[kSignal][kRealm] = this[kRealm]\n\n // 29. If signal is not null, then make this\u2019s signal follow signal.\n if (signal != null) {\n if (\n !signal ||\n typeof signal.aborted !== 'boolean' ||\n typeof signal.addEventListener !== 'function'\n ) {\n throw new TypeError(\n \"Failed to construct 'Request': member signal is not of type AbortSignal.\"\n )\n }\n\n if (signal.aborted) {\n ac.abort(signal.reason)\n } else {\n // Keep a strong ref to ac while request object\n // is alive. This is needed to prevent AbortController\n // from being prematurely garbage collected.\n // See, https://github.com/nodejs/undici/issues/1926.\n this[kAbortController] = ac\n\n const acRef = new WeakRef(ac)\n const abort = function () {\n const ac = acRef.deref()\n if (ac !== undefined) {\n ac.abort(this.reason)\n }\n }\n\n // Third-party AbortControllers may not work with these.\n // See, https://github.com/nodejs/undici/pull/1910#issuecomment-1464495619.\n try {\n // If the max amount of listeners is equal to the default, increase it\n // This is only available in node >= v19.9.0\n if (typeof getMaxListeners === 'function' && getMaxListeners(signal) === defaultMaxListeners) {\n setMaxListeners(100, signal)\n } else if (getEventListeners(signal, 'abort').length >= defaultMaxListeners) {\n setMaxListeners(100, signal)\n }\n } catch {}\n\n util.addAbortListener(signal, abort)\n requestFinalizer.register(ac, { signal, abort })\n }\n }\n\n // 30. Set this\u2019s headers to a new Headers object with this\u2019s relevant\n // Realm, whose header list is request\u2019s header list and guard is\n // \"request\".\n this[kHeaders] = new Headers(kConstruct)\n this[kHeaders][kHeadersList] = request.headersList\n this[kHeaders][kGuard] = 'request'\n this[kHeaders][kRealm] = this[kRealm]\n\n // 31. If this\u2019s request\u2019s mode is \"no-cors\", then:\n if (mode === 'no-cors') {\n // 1. If this\u2019s request\u2019s method is not a CORS-safelisted method,\n // then throw a TypeError.\n if (!corsSafeListedMethodsSet.has(request.method)) {\n throw new TypeError(\n `'${request.method} is unsupported in no-cors mode.`\n )\n }\n\n // 2. Set this\u2019s headers\u2019s guard to \"request-no-cors\".\n this[kHeaders][kGuard] = 'request-no-cors'\n }\n\n // 32. If init is not empty, then:\n if (initHasKey) {\n /** @type {HeadersList} */\n const headersList = this[kHeaders][kHeadersList]\n // 1. Let headers be a copy of this\u2019s headers and its associated header\n // list.\n // 2. If init[\"headers\"] exists, then set headers to init[\"headers\"].\n const headers = init.headers !== undefined ? init.headers : new HeadersList(headersList)\n\n // 3. Empty this\u2019s headers\u2019s header list.\n headersList.clear()\n\n // 4. If headers is a Headers object, then for each header in its header\n // list, append header\u2019s name/header\u2019s value to this\u2019s headers.\n if (headers instanceof HeadersList) {\n for (const [key, val] of headers) {\n headersList.append(key, val)\n }\n // Note: Copy the `set-cookie` meta-data.\n headersList.cookies = headers.cookies\n } else {\n // 5. Otherwise, fill this\u2019s headers with headers.\n fillHeaders(this[kHeaders], headers)\n }\n }\n\n // 33. Let inputBody be input\u2019s request\u2019s body if input is a Request\n // object; otherwise null.\n const inputBody = input instanceof Request ? input[kState].body : null\n\n // 34. If either init[\"body\"] exists and is non-null or inputBody is\n // non-null, and request\u2019s method is `GET` or `HEAD`, then throw a\n // TypeError.\n if (\n (init.body != null || inputBody != null) &&\n (request.method === 'GET' || request.method === 'HEAD')\n ) {\n throw new TypeError('Request with GET/HEAD method cannot have body.')\n }\n\n // 35. Let initBody be null.\n let initBody = null\n\n // 36. If init[\"body\"] exists and is non-null, then:\n if (init.body != null) {\n // 1. Let Content-Type be null.\n // 2. Set initBody and Content-Type to the result of extracting\n // init[\"body\"], with keepalive set to request\u2019s keepalive.\n const [extractedBody, contentType] = extractBody(\n init.body,\n request.keepalive\n )\n initBody = extractedBody\n\n // 3, If Content-Type is non-null and this\u2019s headers\u2019s header list does\n // not contain `Content-Type`, then append `Content-Type`/Content-Type to\n // this\u2019s headers.\n if (contentType && !this[kHeaders][kHeadersList].contains('content-type')) {\n this[kHeaders].append('content-type', contentType)\n }\n }\n\n // 37. Let inputOrInitBody be initBody if it is non-null; otherwise\n // inputBody.\n const inputOrInitBody = initBody ?? inputBody\n\n // 38. If inputOrInitBody is non-null and inputOrInitBody\u2019s source is\n // null, then:\n if (inputOrInitBody != null && inputOrInitBody.source == null) {\n // 1. If initBody is non-null and init[\"duplex\"] does not exist,\n // then throw a TypeError.\n if (initBody != null && init.duplex == null) {\n throw new TypeError('RequestInit: duplex option is required when sending a body.')\n }\n\n // 2. If this\u2019s request\u2019s mode is neither \"same-origin\" nor \"cors\",\n // then throw a TypeError.\n if (request.mode !== 'same-origin' && request.mode !== 'cors') {\n throw new TypeError(\n 'If request is made from ReadableStream, mode should be \"same-origin\" or \"cors\"'\n )\n }\n\n // 3. Set this\u2019s request\u2019s use-CORS-preflight flag.\n request.useCORSPreflightFlag = true\n }\n\n // 39. Let finalBody be inputOrInitBody.\n let finalBody = inputOrInitBody\n\n // 40. If initBody is null and inputBody is non-null, then:\n if (initBody == null && inputBody != null) {\n // 1. If input is unusable, then throw a TypeError.\n if (util.isDisturbed(inputBody.stream) || inputBody.stream.locked) {\n throw new TypeError(\n 'Cannot construct a Request with a Request object that has already been used.'\n )\n }\n\n // 2. Set finalBody to the result of creating a proxy for inputBody.\n if (!TransformStream) {\n TransformStream = (__nccwpck_require__(5356).TransformStream)\n }\n\n // https://streams.spec.whatwg.org/#readablestream-create-a-proxy\n const identityTransform = new TransformStream()\n inputBody.stream.pipeThrough(identityTransform)\n finalBody = {\n source: inputBody.source,\n length: inputBody.length,\n stream: identityTransform.readable\n }\n }\n\n // 41. Set this\u2019s request\u2019s body to finalBody.\n this[kState].body = finalBody\n }\n\n // Returns request\u2019s HTTP method, which is \"GET\" by default.\n get method () {\n webidl.brandCheck(this, Request)\n\n // The method getter steps are to return this\u2019s request\u2019s method.\n return this[kState].method\n }\n\n // Returns the URL of request as a string.\n get url () {\n webidl.brandCheck(this, Request)\n\n // The url getter steps are to return this\u2019s request\u2019s URL, serialized.\n return URLSerializer(this[kState].url)\n }\n\n // Returns a Headers object consisting of the headers associated with request.\n // Note that headers added in the network layer by the user agent will not\n // be accounted for in this object, e.g., the \"Host\" header.\n get headers () {\n webidl.brandCheck(this, Request)\n\n // The headers getter steps are to return this\u2019s headers.\n return this[kHeaders]\n }\n\n // Returns the kind of resource requested by request, e.g., \"document\"\n // or \"script\".\n get destination () {\n webidl.brandCheck(this, Request)\n\n // The destination getter are to return this\u2019s request\u2019s destination.\n return this[kState].destination\n }\n\n // Returns the referrer of request. Its value can be a same-origin URL if\n // explicitly set in init, the empty string to indicate no referrer, and\n // \"about:client\" when defaulting to the global\u2019s default. This is used\n // during fetching to determine the value of the `Referer` header of the\n // request being made.\n get referrer () {\n webidl.brandCheck(this, Request)\n\n // 1. If this\u2019s request\u2019s referrer is \"no-referrer\", then return the\n // empty string.\n if (this[kState].referrer === 'no-referrer') {\n return ''\n }\n\n // 2. If this\u2019s request\u2019s referrer is \"client\", then return\n // \"about:client\".\n if (this[kState].referrer === 'client') {\n return 'about:client'\n }\n\n // Return this\u2019s request\u2019s referrer, serialized.\n return this[kState].referrer.toString()\n }\n\n // Returns the referrer policy associated with request.\n // This is used during fetching to compute the value of the request\u2019s\n // referrer.\n get referrerPolicy () {\n webidl.brandCheck(this, Request)\n\n // The referrerPolicy getter steps are to return this\u2019s request\u2019s referrer policy.\n return this[kState].referrerPolicy\n }\n\n // Returns the mode associated with request, which is a string indicating\n // whether the request will use CORS, or will be restricted to same-origin\n // URLs.\n get mode () {\n webidl.brandCheck(this, Request)\n\n // The mode getter steps are to return this\u2019s request\u2019s mode.\n return this[kState].mode\n }\n\n // Returns the credentials mode associated with request,\n // which is a string indicating whether credentials will be sent with the\n // request always, never, or only when sent to a same-origin URL.\n get credentials () {\n // The credentials getter steps are to return this\u2019s request\u2019s credentials mode.\n return this[kState].credentials\n }\n\n // Returns the cache mode associated with request,\n // which is a string indicating how the request will\n // interact with the browser\u2019s cache when fetching.\n get cache () {\n webidl.brandCheck(this, Request)\n\n // The cache getter steps are to return this\u2019s request\u2019s cache mode.\n return this[kState].cache\n }\n\n // Returns the redirect mode associated with request,\n // which is a string indicating how redirects for the\n // request will be handled during fetching. A request\n // will follow redirects by default.\n get redirect () {\n webidl.brandCheck(this, Request)\n\n // The redirect getter steps are to return this\u2019s request\u2019s redirect mode.\n return this[kState].redirect\n }\n\n // Returns request\u2019s subresource integrity metadata, which is a\n // cryptographic hash of the resource being fetched. Its value\n // consists of multiple hashes separated by whitespace. [SRI]\n get integrity () {\n webidl.brandCheck(this, Request)\n\n // The integrity getter steps are to return this\u2019s request\u2019s integrity\n // metadata.\n return this[kState].integrity\n }\n\n // Returns a boolean indicating whether or not request can outlive the\n // global in which it was created.\n get keepalive () {\n webidl.brandCheck(this, Request)\n\n // The keepalive getter steps are to return this\u2019s request\u2019s keepalive.\n return this[kState].keepalive\n }\n\n // Returns a boolean indicating whether or not request is for a reload\n // navigation.\n get isReloadNavigation () {\n webidl.brandCheck(this, Request)\n\n // The isReloadNavigation getter steps are to return true if this\u2019s\n // request\u2019s reload-navigation flag is set; otherwise false.\n return this[kState].reloadNavigation\n }\n\n // Returns a boolean indicating whether or not request is for a history\n // navigation (a.k.a. back-foward navigation).\n get isHistoryNavigation () {\n webidl.brandCheck(this, Request)\n\n // The isHistoryNavigation getter steps are to return true if this\u2019s request\u2019s\n // history-navigation flag is set; otherwise false.\n return this[kState].historyNavigation\n }\n\n // Returns the signal associated with request, which is an AbortSignal\n // object indicating whether or not request has been aborted, and its\n // abort event handler.\n get signal () {\n webidl.brandCheck(this, Request)\n\n // The signal getter steps are to return this\u2019s signal.\n return this[kSignal]\n }\n\n get body () {\n webidl.brandCheck(this, Request)\n\n return this[kState].body ? this[kState].body.stream : null\n }\n\n get bodyUsed () {\n webidl.brandCheck(this, Request)\n\n return !!this[kState].body && util.isDisturbed(this[kState].body.stream)\n }\n\n get duplex () {\n webidl.brandCheck(this, Request)\n\n return 'half'\n }\n\n // Returns a clone of request.\n clone () {\n webidl.brandCheck(this, Request)\n\n // 1. If this is unusable, then throw a TypeError.\n if (this.bodyUsed || this.body?.locked) {\n throw new TypeError('unusable')\n }\n\n // 2. Let clonedRequest be the result of cloning this\u2019s request.\n const clonedRequest = cloneRequest(this[kState])\n\n // 3. Let clonedRequestObject be the result of creating a Request object,\n // given clonedRequest, this\u2019s headers\u2019s guard, and this\u2019s relevant Realm.\n const clonedRequestObject = new Request(kConstruct)\n clonedRequestObject[kState] = clonedRequest\n clonedRequestObject[kRealm] = this[kRealm]\n clonedRequestObject[kHeaders] = new Headers(kConstruct)\n clonedRequestObject[kHeaders][kHeadersList] = clonedRequest.headersList\n clonedRequestObject[kHeaders][kGuard] = this[kHeaders][kGuard]\n clonedRequestObject[kHeaders][kRealm] = this[kHeaders][kRealm]\n\n // 4. Make clonedRequestObject\u2019s signal follow this\u2019s signal.\n const ac = new AbortController()\n if (this.signal.aborted) {\n ac.abort(this.signal.reason)\n } else {\n util.addAbortListener(\n this.signal,\n () => {\n ac.abort(this.signal.reason)\n }\n )\n }\n clonedRequestObject[kSignal] = ac.signal\n\n // 4. Return clonedRequestObject.\n return clonedRequestObject\n }\n}\n\nmixinBody(Request)\n\nfunction makeRequest (init) {\n // https://fetch.spec.whatwg.org/#requests\n const request = {\n method: 'GET',\n localURLsOnly: false,\n unsafeRequest: false,\n body: null,\n client: null,\n reservedClient: null,\n replacesClientId: '',\n window: 'client',\n keepalive: false,\n serviceWorkers: 'all',\n initiator: '',\n destination: '',\n priority: null,\n origin: 'client',\n policyContainer: 'client',\n referrer: 'client',\n referrerPolicy: '',\n mode: 'no-cors',\n useCORSPreflightFlag: false,\n credentials: 'same-origin',\n useCredentials: false,\n cache: 'default',\n redirect: 'follow',\n integrity: '',\n cryptoGraphicsNonceMetadata: '',\n parserMetadata: '',\n reloadNavigation: false,\n historyNavigation: false,\n userActivation: false,\n taintedOrigin: false,\n redirectCount: 0,\n responseTainting: 'basic',\n preventNoCacheCacheControlHeaderModification: false,\n done: false,\n timingAllowFailed: false,\n ...init,\n headersList: init.headersList\n ? new HeadersList(init.headersList)\n : new HeadersList()\n }\n request.url = request.urlList[0]\n return request\n}\n\n// https://fetch.spec.whatwg.org/#concept-request-clone\nfunction cloneRequest (request) {\n // To clone a request request, run these steps:\n\n // 1. Let newRequest be a copy of request, except for its body.\n const newRequest = makeRequest({ ...request, body: null })\n\n // 2. If request\u2019s body is non-null, set newRequest\u2019s body to the\n // result of cloning request\u2019s body.\n if (request.body != null) {\n newRequest.body = cloneBody(request.body)\n }\n\n // 3. Return newRequest.\n return newRequest\n}\n\nObject.defineProperties(Request.prototype, {\n method: kEnumerableProperty,\n url: kEnumerableProperty,\n headers: kEnumerableProperty,\n redirect: kEnumerableProperty,\n clone: kEnumerableProperty,\n signal: kEnumerableProperty,\n duplex: kEnumerableProperty,\n destination: kEnumerableProperty,\n body: kEnumerableProperty,\n bodyUsed: kEnumerableProperty,\n isHistoryNavigation: kEnumerableProperty,\n isReloadNavigation: kEnumerableProperty,\n keepalive: kEnumerableProperty,\n integrity: kEnumerableProperty,\n cache: kEnumerableProperty,\n credentials: kEnumerableProperty,\n attribute: kEnumerableProperty,\n referrerPolicy: kEnumerableProperty,\n referrer: kEnumerableProperty,\n mode: kEnumerableProperty,\n [Symbol.toStringTag]: {\n value: 'Request',\n configurable: true\n }\n})\n\nwebidl.converters.Request = webidl.interfaceConverter(\n Request\n)\n\n// https://fetch.spec.whatwg.org/#requestinfo\nwebidl.converters.RequestInfo = function (V) {\n if (typeof V === 'string') {\n return webidl.converters.USVString(V)\n }\n\n if (V instanceof Request) {\n return webidl.converters.Request(V)\n }\n\n return webidl.converters.USVString(V)\n}\n\nwebidl.converters.AbortSignal = webidl.interfaceConverter(\n AbortSignal\n)\n\n// https://fetch.spec.whatwg.org/#requestinit\nwebidl.converters.RequestInit = webidl.dictionaryConverter([\n {\n key: 'method',\n converter: webidl.converters.ByteString\n },\n {\n key: 'headers',\n converter: webidl.converters.HeadersInit\n },\n {\n key: 'body',\n converter: webidl.nullableConverter(\n webidl.converters.BodyInit\n )\n },\n {\n key: 'referrer',\n converter: webidl.converters.USVString\n },\n {\n key: 'referrerPolicy',\n converter: webidl.converters.DOMString,\n // https://w3c.github.io/webappsec-referrer-policy/#referrer-policy\n allowedValues: referrerPolicy\n },\n {\n key: 'mode',\n converter: webidl.converters.DOMString,\n // https://fetch.spec.whatwg.org/#concept-request-mode\n allowedValues: requestMode\n },\n {\n key: 'credentials',\n converter: webidl.converters.DOMString,\n // https://fetch.spec.whatwg.org/#requestcredentials\n allowedValues: requestCredentials\n },\n {\n key: 'cache',\n converter: webidl.converters.DOMString,\n // https://fetch.spec.whatwg.org/#requestcache\n allowedValues: requestCache\n },\n {\n key: 'redirect',\n converter: webidl.converters.DOMString,\n // https://fetch.spec.whatwg.org/#requestredirect\n allowedValues: requestRedirect\n },\n {\n key: 'integrity',\n converter: webidl.converters.DOMString\n },\n {\n key: 'keepalive',\n converter: webidl.converters.boolean\n },\n {\n key: 'signal',\n converter: webidl.nullableConverter(\n (signal) => webidl.converters.AbortSignal(\n signal,\n { strict: false }\n )\n )\n },\n {\n key: 'window',\n converter: webidl.converters.any\n },\n {\n key: 'duplex',\n converter: webidl.converters.DOMString,\n allowedValues: requestDuplex\n }\n])\n\nmodule.exports = { Request, makeRequest }\n\n\n/***/ }),\n\n/***/ 7823:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\n\"use strict\";\n\n\nconst { Headers, HeadersList, fill } = __nccwpck_require__(554)\nconst { extractBody, cloneBody, mixinBody } = __nccwpck_require__(1472)\nconst util = __nccwpck_require__(3983)\nconst { kEnumerableProperty } = util\nconst {\n isValidReasonPhrase,\n isCancelled,\n isAborted,\n isBlobLike,\n serializeJavascriptValueToJSONString,\n isErrorLike,\n isomorphicEncode\n} = __nccwpck_require__(2538)\nconst {\n redirectStatusSet,\n nullBodyStatus,\n DOMException\n} = __nccwpck_require__(1037)\nconst { kState, kHeaders, kGuard, kRealm } = __nccwpck_require__(5861)\nconst { webidl } = __nccwpck_require__(1744)\nconst { FormData } = __nccwpck_require__(2015)\nconst { getGlobalOrigin } = __nccwpck_require__(1246)\nconst { URLSerializer } = __nccwpck_require__(685)\nconst { kHeadersList, kConstruct } = __nccwpck_require__(2785)\nconst assert = __nccwpck_require__(9491)\nconst { types } = __nccwpck_require__(3837)\n\nconst ReadableStream = globalThis.ReadableStream || (__nccwpck_require__(5356).ReadableStream)\nconst textEncoder = new TextEncoder('utf-8')\n\n// https://fetch.spec.whatwg.org/#response-class\nclass Response {\n // Creates network error Response.\n static error () {\n // TODO\n const relevantRealm = { settingsObject: {} }\n\n // The static error() method steps are to return the result of creating a\n // Response object, given a new network error, \"immutable\", and this\u2019s\n // relevant Realm.\n const responseObject = new Response()\n responseObject[kState] = makeNetworkError()\n responseObject[kRealm] = relevantRealm\n responseObject[kHeaders][kHeadersList] = responseObject[kState].headersList\n responseObject[kHeaders][kGuard] = 'immutable'\n responseObject[kHeaders][kRealm] = relevantRealm\n return responseObject\n }\n\n // https://fetch.spec.whatwg.org/#dom-response-json\n static json (data, init = {}) {\n webidl.argumentLengthCheck(arguments, 1, { header: 'Response.json' })\n\n if (init !== null) {\n init = webidl.converters.ResponseInit(init)\n }\n\n // 1. Let bytes the result of running serialize a JavaScript value to JSON bytes on data.\n const bytes = textEncoder.encode(\n serializeJavascriptValueToJSONString(data)\n )\n\n // 2. Let body be the result of extracting bytes.\n const body = extractBody(bytes)\n\n // 3. Let responseObject be the result of creating a Response object, given a new response,\n // \"response\", and this\u2019s relevant Realm.\n const relevantRealm = { settingsObject: {} }\n const responseObject = new Response()\n responseObject[kRealm] = relevantRealm\n responseObject[kHeaders][kGuard] = 'response'\n responseObject[kHeaders][kRealm] = relevantRealm\n\n // 4. Perform initialize a response given responseObject, init, and (body, \"application/json\").\n initializeResponse(responseObject, init, { body: body[0], type: 'application/json' })\n\n // 5. Return responseObject.\n return responseObject\n }\n\n // Creates a redirect Response that redirects to url with status status.\n static redirect (url, status = 302) {\n const relevantRealm = { settingsObject: {} }\n\n webidl.argumentLengthCheck(arguments, 1, { header: 'Response.redirect' })\n\n url = webidl.converters.USVString(url)\n status = webidl.converters['unsigned short'](status)\n\n // 1. Let parsedURL be the result of parsing url with current settings\n // object\u2019s API base URL.\n // 2. If parsedURL is failure, then throw a TypeError.\n // TODO: base-URL?\n let parsedURL\n try {\n parsedURL = new URL(url, getGlobalOrigin())\n } catch (err) {\n throw Object.assign(new TypeError('Failed to parse URL from ' + url), {\n cause: err\n })\n }\n\n // 3. If status is not a redirect status, then throw a RangeError.\n if (!redirectStatusSet.has(status)) {\n throw new RangeError('Invalid status code ' + status)\n }\n\n // 4. Let responseObject be the result of creating a Response object,\n // given a new response, \"immutable\", and this\u2019s relevant Realm.\n const responseObject = new Response()\n responseObject[kRealm] = relevantRealm\n responseObject[kHeaders][kGuard] = 'immutable'\n responseObject[kHeaders][kRealm] = relevantRealm\n\n // 5. Set responseObject\u2019s response\u2019s status to status.\n responseObject[kState].status = status\n\n // 6. Let value be parsedURL, serialized and isomorphic encoded.\n const value = isomorphicEncode(URLSerializer(parsedURL))\n\n // 7. Append `Location`/value to responseObject\u2019s response\u2019s header list.\n responseObject[kState].headersList.append('location', value)\n\n // 8. Return responseObject.\n return responseObject\n }\n\n // https://fetch.spec.whatwg.org/#dom-response\n constructor (body = null, init = {}) {\n if (body !== null) {\n body = webidl.converters.BodyInit(body)\n }\n\n init = webidl.converters.ResponseInit(init)\n\n // TODO\n this[kRealm] = { settingsObject: {} }\n\n // 1. Set this\u2019s response to a new response.\n this[kState] = makeResponse({})\n\n // 2. Set this\u2019s headers to a new Headers object with this\u2019s relevant\n // Realm, whose header list is this\u2019s response\u2019s header list and guard\n // is \"response\".\n this[kHeaders] = new Headers(kConstruct)\n this[kHeaders][kGuard] = 'response'\n this[kHeaders][kHeadersList] = this[kState].headersList\n this[kHeaders][kRealm] = this[kRealm]\n\n // 3. Let bodyWithType be null.\n let bodyWithType = null\n\n // 4. If body is non-null, then set bodyWithType to the result of extracting body.\n if (body != null) {\n const [extractedBody, type] = extractBody(body)\n bodyWithType = { body: extractedBody, type }\n }\n\n // 5. Perform initialize a response given this, init, and bodyWithType.\n initializeResponse(this, init, bodyWithType)\n }\n\n // Returns response\u2019s type, e.g., \"cors\".\n get type () {\n webidl.brandCheck(this, Response)\n\n // The type getter steps are to return this\u2019s response\u2019s type.\n return this[kState].type\n }\n\n // Returns response\u2019s URL, if it has one; otherwise the empty string.\n get url () {\n webidl.brandCheck(this, Response)\n\n const urlList = this[kState].urlList\n\n // The url getter steps are to return the empty string if this\u2019s\n // response\u2019s URL is null; otherwise this\u2019s response\u2019s URL,\n // serialized with exclude fragment set to true.\n const url = urlList[urlList.length - 1] ?? null\n\n if (url === null) {\n return ''\n }\n\n return URLSerializer(url, true)\n }\n\n // Returns whether response was obtained through a redirect.\n get redirected () {\n webidl.brandCheck(this, Response)\n\n // The redirected getter steps are to return true if this\u2019s response\u2019s URL\n // list has more than one item; otherwise false.\n return this[kState].urlList.length > 1\n }\n\n // Returns response\u2019s status.\n get status () {\n webidl.brandCheck(this, Response)\n\n // The status getter steps are to return this\u2019s response\u2019s status.\n return this[kState].status\n }\n\n // Returns whether response\u2019s status is an ok status.\n get ok () {\n webidl.brandCheck(this, Response)\n\n // The ok getter steps are to return true if this\u2019s response\u2019s status is an\n // ok status; otherwise false.\n return this[kState].status >= 200 && this[kState].status <= 299\n }\n\n // Returns response\u2019s status message.\n get statusText () {\n webidl.brandCheck(this, Response)\n\n // The statusText getter steps are to return this\u2019s response\u2019s status\n // message.\n return this[kState].statusText\n }\n\n // Returns response\u2019s headers as Headers.\n get headers () {\n webidl.brandCheck(this, Response)\n\n // The headers getter steps are to return this\u2019s headers.\n return this[kHeaders]\n }\n\n get body () {\n webidl.brandCheck(this, Response)\n\n return this[kState].body ? this[kState].body.stream : null\n }\n\n get bodyUsed () {\n webidl.brandCheck(this, Response)\n\n return !!this[kState].body && util.isDisturbed(this[kState].body.stream)\n }\n\n // Returns a clone of response.\n clone () {\n webidl.brandCheck(this, Response)\n\n // 1. If this is unusable, then throw a TypeError.\n if (this.bodyUsed || (this.body && this.body.locked)) {\n throw webidl.errors.exception({\n header: 'Response.clone',\n message: 'Body has already been consumed.'\n })\n }\n\n // 2. Let clonedResponse be the result of cloning this\u2019s response.\n const clonedResponse = cloneResponse(this[kState])\n\n // 3. Return the result of creating a Response object, given\n // clonedResponse, this\u2019s headers\u2019s guard, and this\u2019s relevant Realm.\n const clonedResponseObject = new Response()\n clonedResponseObject[kState] = clonedResponse\n clonedResponseObject[kRealm] = this[kRealm]\n clonedResponseObject[kHeaders][kHeadersList] = clonedResponse.headersList\n clonedResponseObject[kHeaders][kGuard] = this[kHeaders][kGuard]\n clonedResponseObject[kHeaders][kRealm] = this[kHeaders][kRealm]\n\n return clonedResponseObject\n }\n}\n\nmixinBody(Response)\n\nObject.defineProperties(Response.prototype, {\n type: kEnumerableProperty,\n url: kEnumerableProperty,\n status: kEnumerableProperty,\n ok: kEnumerableProperty,\n redirected: kEnumerableProperty,\n statusText: kEnumerableProperty,\n headers: kEnumerableProperty,\n clone: kEnumerableProperty,\n body: kEnumerableProperty,\n bodyUsed: kEnumerableProperty,\n [Symbol.toStringTag]: {\n value: 'Response',\n configurable: true\n }\n})\n\nObject.defineProperties(Response, {\n json: kEnumerableProperty,\n redirect: kEnumerableProperty,\n error: kEnumerableProperty\n})\n\n// https://fetch.spec.whatwg.org/#concept-response-clone\nfunction cloneResponse (response) {\n // To clone a response response, run these steps:\n\n // 1. If response is a filtered response, then return a new identical\n // filtered response whose internal response is a clone of response\u2019s\n // internal response.\n if (response.internalResponse) {\n return filterResponse(\n cloneResponse(response.internalResponse),\n response.type\n )\n }\n\n // 2. Let newResponse be a copy of response, except for its body.\n const newResponse = makeResponse({ ...response, body: null })\n\n // 3. If response\u2019s body is non-null, then set newResponse\u2019s body to the\n // result of cloning response\u2019s body.\n if (response.body != null) {\n newResponse.body = cloneBody(response.body)\n }\n\n // 4. Return newResponse.\n return newResponse\n}\n\nfunction makeResponse (init) {\n return {\n aborted: false,\n rangeRequested: false,\n timingAllowPassed: false,\n requestIncludesCredentials: false,\n type: 'default',\n status: 200,\n timingInfo: null,\n cacheState: '',\n statusText: '',\n ...init,\n headersList: init.headersList\n ? new HeadersList(init.headersList)\n : new HeadersList(),\n urlList: init.urlList ? [...init.urlList] : []\n }\n}\n\nfunction makeNetworkError (reason) {\n const isError = isErrorLike(reason)\n return makeResponse({\n type: 'error',\n status: 0,\n error: isError\n ? reason\n : new Error(reason ? String(reason) : reason),\n aborted: reason && reason.name === 'AbortError'\n })\n}\n\nfunction makeFilteredResponse (response, state) {\n state = {\n internalResponse: response,\n ...state\n }\n\n return new Proxy(response, {\n get (target, p) {\n return p in state ? state[p] : target[p]\n },\n set (target, p, value) {\n assert(!(p in state))\n target[p] = value\n return true\n }\n })\n}\n\n// https://fetch.spec.whatwg.org/#concept-filtered-response\nfunction filterResponse (response, type) {\n // Set response to the following filtered response with response as its\n // internal response, depending on request\u2019s response tainting:\n if (type === 'basic') {\n // A basic filtered response is a filtered response whose type is \"basic\"\n // and header list excludes any headers in internal response\u2019s header list\n // whose name is a forbidden response-header name.\n\n // Note: undici does not implement forbidden response-header names\n return makeFilteredResponse(response, {\n type: 'basic',\n headersList: response.headersList\n })\n } else if (type === 'cors') {\n // A CORS filtered response is a filtered response whose type is \"cors\"\n // and header list excludes any headers in internal response\u2019s header\n // list whose name is not a CORS-safelisted response-header name, given\n // internal response\u2019s CORS-exposed header-name list.\n\n // Note: undici does not implement CORS-safelisted response-header names\n return makeFilteredResponse(response, {\n type: 'cors',\n headersList: response.headersList\n })\n } else if (type === 'opaque') {\n // An opaque filtered response is a filtered response whose type is\n // \"opaque\", URL list is the empty list, status is 0, status message\n // is the empty byte sequence, header list is empty, and body is null.\n\n return makeFilteredResponse(response, {\n type: 'opaque',\n urlList: Object.freeze([]),\n status: 0,\n statusText: '',\n body: null\n })\n } else if (type === 'opaqueredirect') {\n // An opaque-redirect filtered response is a filtered response whose type\n // is \"opaqueredirect\", status is 0, status message is the empty byte\n // sequence, header list is empty, and body is null.\n\n return makeFilteredResponse(response, {\n type: 'opaqueredirect',\n status: 0,\n statusText: '',\n headersList: [],\n body: null\n })\n } else {\n assert(false)\n }\n}\n\n// https://fetch.spec.whatwg.org/#appropriate-network-error\nfunction makeAppropriateNetworkError (fetchParams, err = null) {\n // 1. Assert: fetchParams is canceled.\n assert(isCancelled(fetchParams))\n\n // 2. Return an aborted network error if fetchParams is aborted;\n // otherwise return a network error.\n return isAborted(fetchParams)\n ? makeNetworkError(Object.assign(new DOMException('The operation was aborted.', 'AbortError'), { cause: err }))\n : makeNetworkError(Object.assign(new DOMException('Request was cancelled.'), { cause: err }))\n}\n\n// https://whatpr.org/fetch/1392.html#initialize-a-response\nfunction initializeResponse (response, init, body) {\n // 1. If init[\"status\"] is not in the range 200 to 599, inclusive, then\n // throw a RangeError.\n if (init.status !== null && (init.status < 200 || init.status > 599)) {\n throw new RangeError('init[\"status\"] must be in the range of 200 to 599, inclusive.')\n }\n\n // 2. If init[\"statusText\"] does not match the reason-phrase token production,\n // then throw a TypeError.\n if ('statusText' in init && init.statusText != null) {\n // See, https://datatracker.ietf.org/doc/html/rfc7230#section-3.1.2:\n // reason-phrase = *( HTAB / SP / VCHAR / obs-text )\n if (!isValidReasonPhrase(String(init.statusText))) {\n throw new TypeError('Invalid statusText')\n }\n }\n\n // 3. Set response\u2019s response\u2019s status to init[\"status\"].\n if ('status' in init && init.status != null) {\n response[kState].status = init.status\n }\n\n // 4. Set response\u2019s response\u2019s status message to init[\"statusText\"].\n if ('statusText' in init && init.statusText != null) {\n response[kState].statusText = init.statusText\n }\n\n // 5. If init[\"headers\"] exists, then fill response\u2019s headers with init[\"headers\"].\n if ('headers' in init && init.headers != null) {\n fill(response[kHeaders], init.headers)\n }\n\n // 6. If body was given, then:\n if (body) {\n // 1. If response's status is a null body status, then throw a TypeError.\n if (nullBodyStatus.includes(response.status)) {\n throw webidl.errors.exception({\n header: 'Response constructor',\n message: 'Invalid response status code ' + response.status\n })\n }\n\n // 2. Set response's body to body's body.\n response[kState].body = body.body\n\n // 3. If body's type is non-null and response's header list does not contain\n // `Content-Type`, then append (`Content-Type`, body's type) to response's header list.\n if (body.type != null && !response[kState].headersList.contains('Content-Type')) {\n response[kState].headersList.append('content-type', body.type)\n }\n }\n}\n\nwebidl.converters.ReadableStream = webidl.interfaceConverter(\n ReadableStream\n)\n\nwebidl.converters.FormData = webidl.interfaceConverter(\n FormData\n)\n\nwebidl.converters.URLSearchParams = webidl.interfaceConverter(\n URLSearchParams\n)\n\n// https://fetch.spec.whatwg.org/#typedefdef-xmlhttprequestbodyinit\nwebidl.converters.XMLHttpRequestBodyInit = function (V) {\n if (typeof V === 'string') {\n return webidl.converters.USVString(V)\n }\n\n if (isBlobLike(V)) {\n return webidl.converters.Blob(V, { strict: false })\n }\n\n if (types.isArrayBuffer(V) || types.isTypedArray(V) || types.isDataView(V)) {\n return webidl.converters.BufferSource(V)\n }\n\n if (util.isFormDataLike(V)) {\n return webidl.converters.FormData(V, { strict: false })\n }\n\n if (V instanceof URLSearchParams) {\n return webidl.converters.URLSearchParams(V)\n }\n\n return webidl.converters.DOMString(V)\n}\n\n// https://fetch.spec.whatwg.org/#bodyinit\nwebidl.converters.BodyInit = function (V) {\n if (V instanceof ReadableStream) {\n return webidl.converters.ReadableStream(V)\n }\n\n // Note: the spec doesn't include async iterables,\n // this is an undici extension.\n if (V?.[Symbol.asyncIterator]) {\n return V\n }\n\n return webidl.converters.XMLHttpRequestBodyInit(V)\n}\n\nwebidl.converters.ResponseInit = webidl.dictionaryConverter([\n {\n key: 'status',\n converter: webidl.converters['unsigned short'],\n defaultValue: 200\n },\n {\n key: 'statusText',\n converter: webidl.converters.ByteString,\n defaultValue: ''\n },\n {\n key: 'headers',\n converter: webidl.converters.HeadersInit\n }\n])\n\nmodule.exports = {\n makeNetworkError,\n makeResponse,\n makeAppropriateNetworkError,\n filterResponse,\n Response,\n cloneResponse\n}\n\n\n/***/ }),\n\n/***/ 5861:\n/***/ ((module) => {\n\n\"use strict\";\n\n\nmodule.exports = {\n kUrl: Symbol('url'),\n kHeaders: Symbol('headers'),\n kSignal: Symbol('signal'),\n kState: Symbol('state'),\n kGuard: Symbol('guard'),\n kRealm: Symbol('realm')\n}\n\n\n/***/ }),\n\n/***/ 2538:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\n\"use strict\";\n\n\nconst { redirectStatusSet, referrerPolicySet: referrerPolicyTokens, badPortsSet } = __nccwpck_require__(1037)\nconst { getGlobalOrigin } = __nccwpck_require__(1246)\nconst { performance } = __nccwpck_require__(4074)\nconst { isBlobLike, toUSVString, ReadableStreamFrom } = __nccwpck_require__(3983)\nconst assert = __nccwpck_require__(9491)\nconst { isUint8Array } = __nccwpck_require__(9830)\n\nlet supportedHashes = []\n\n// https://nodejs.org/api/crypto.html#determining-if-crypto-support-is-unavailable\n/** @type {import('crypto')|undefined} */\nlet crypto\n\ntry {\n crypto = __nccwpck_require__(6113)\n const possibleRelevantHashes = ['sha256', 'sha384', 'sha512']\n supportedHashes = crypto.getHashes().filter((hash) => possibleRelevantHashes.includes(hash))\n/* c8 ignore next 3 */\n} catch {\n}\n\nfunction responseURL (response) {\n // https://fetch.spec.whatwg.org/#responses\n // A response has an associated URL. It is a pointer to the last URL\n // in response\u2019s URL list and null if response\u2019s URL list is empty.\n const urlList = response.urlList\n const length = urlList.length\n return length === 0 ? null : urlList[length - 1].toString()\n}\n\n// https://fetch.spec.whatwg.org/#concept-response-location-url\nfunction responseLocationURL (response, requestFragment) {\n // 1. If response\u2019s status is not a redirect status, then return null.\n if (!redirectStatusSet.has(response.status)) {\n return null\n }\n\n // 2. Let location be the result of extracting header list values given\n // `Location` and response\u2019s header list.\n let location = response.headersList.get('location')\n\n // 3. If location is a header value, then set location to the result of\n // parsing location with response\u2019s URL.\n if (location !== null && isValidHeaderValue(location)) {\n location = new URL(location, responseURL(response))\n }\n\n // 4. If location is a URL whose fragment is null, then set location\u2019s\n // fragment to requestFragment.\n if (location && !location.hash) {\n location.hash = requestFragment\n }\n\n // 5. Return location.\n return location\n}\n\n/** @returns {URL} */\nfunction requestCurrentURL (request) {\n return request.urlList[request.urlList.length - 1]\n}\n\nfunction requestBadPort (request) {\n // 1. Let url be request\u2019s current URL.\n const url = requestCurrentURL(request)\n\n // 2. If url\u2019s scheme is an HTTP(S) scheme and url\u2019s port is a bad port,\n // then return blocked.\n if (urlIsHttpHttpsScheme(url) && badPortsSet.has(url.port)) {\n return 'blocked'\n }\n\n // 3. Return allowed.\n return 'allowed'\n}\n\nfunction isErrorLike (object) {\n return object instanceof Error || (\n object?.constructor?.name === 'Error' ||\n object?.constructor?.name === 'DOMException'\n )\n}\n\n// Check whether |statusText| is a ByteString and\n// matches the Reason-Phrase token production.\n// RFC 2616: https://tools.ietf.org/html/rfc2616\n// RFC 7230: https://tools.ietf.org/html/rfc7230\n// \"reason-phrase = *( HTAB / SP / VCHAR / obs-text )\"\n// https://github.com/chromium/chromium/blob/94.0.4604.1/third_party/blink/renderer/core/fetch/response.cc#L116\nfunction isValidReasonPhrase (statusText) {\n for (let i = 0; i < statusText.length; ++i) {\n const c = statusText.charCodeAt(i)\n if (\n !(\n (\n c === 0x09 || // HTAB\n (c >= 0x20 && c <= 0x7e) || // SP / VCHAR\n (c >= 0x80 && c <= 0xff)\n ) // obs-text\n )\n ) {\n return false\n }\n }\n return true\n}\n\n/**\n * @see https://tools.ietf.org/html/rfc7230#section-3.2.6\n * @param {number} c\n */\nfunction isTokenCharCode (c) {\n switch (c) {\n case 0x22:\n case 0x28:\n case 0x29:\n case 0x2c:\n case 0x2f:\n case 0x3a:\n case 0x3b:\n case 0x3c:\n case 0x3d:\n case 0x3e:\n case 0x3f:\n case 0x40:\n case 0x5b:\n case 0x5c:\n case 0x5d:\n case 0x7b:\n case 0x7d:\n // DQUOTE and \"(),/:;<=>?@[\\]{}\"\n return false\n default:\n // VCHAR %x21-7E\n return c >= 0x21 && c <= 0x7e\n }\n}\n\n/**\n * @param {string} characters\n */\nfunction isValidHTTPToken (characters) {\n if (characters.length === 0) {\n return false\n }\n for (let i = 0; i < characters.length; ++i) {\n if (!isTokenCharCode(characters.charCodeAt(i))) {\n return false\n }\n }\n return true\n}\n\n/**\n * @see https://fetch.spec.whatwg.org/#header-name\n * @param {string} potentialValue\n */\nfunction isValidHeaderName (potentialValue) {\n return isValidHTTPToken(potentialValue)\n}\n\n/**\n * @see https://fetch.spec.whatwg.org/#header-value\n * @param {string} potentialValue\n */\nfunction isValidHeaderValue (potentialValue) {\n // - Has no leading or trailing HTTP tab or space bytes.\n // - Contains no 0x00 (NUL) or HTTP newline bytes.\n if (\n potentialValue.startsWith('\\t') ||\n potentialValue.startsWith(' ') ||\n potentialValue.endsWith('\\t') ||\n potentialValue.endsWith(' ')\n ) {\n return false\n }\n\n if (\n potentialValue.includes('\\0') ||\n potentialValue.includes('\\r') ||\n potentialValue.includes('\\n')\n ) {\n return false\n }\n\n return true\n}\n\n// https://w3c.github.io/webappsec-referrer-policy/#set-requests-referrer-policy-on-redirect\nfunction setRequestReferrerPolicyOnRedirect (request, actualResponse) {\n // Given a request request and a response actualResponse, this algorithm\n // updates request\u2019s referrer policy according to the Referrer-Policy\n // header (if any) in actualResponse.\n\n // 1. Let policy be the result of executing \u00a7 8.1 Parse a referrer policy\n // from a Referrer-Policy header on actualResponse.\n\n // 8.1 Parse a referrer policy from a Referrer-Policy header\n // 1. Let policy-tokens be the result of extracting header list values given `Referrer-Policy` and response\u2019s header list.\n const { headersList } = actualResponse\n // 2. Let policy be the empty string.\n // 3. For each token in policy-tokens, if token is a referrer policy and token is not the empty string, then set policy to token.\n // 4. Return policy.\n const policyHeader = (headersList.get('referrer-policy') ?? '').split(',')\n\n // Note: As the referrer-policy can contain multiple policies\n // separated by comma, we need to loop through all of them\n // and pick the first valid one.\n // Ref: https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers/Referrer-Policy#specify_a_fallback_policy\n let policy = ''\n if (policyHeader.length > 0) {\n // The right-most policy takes precedence.\n // The left-most policy is the fallback.\n for (let i = policyHeader.length; i !== 0; i--) {\n const token = policyHeader[i - 1].trim()\n if (referrerPolicyTokens.has(token)) {\n policy = token\n break\n }\n }\n }\n\n // 2. If policy is not the empty string, then set request\u2019s referrer policy to policy.\n if (policy !== '') {\n request.referrerPolicy = policy\n }\n}\n\n// https://fetch.spec.whatwg.org/#cross-origin-resource-policy-check\nfunction crossOriginResourcePolicyCheck () {\n // TODO\n return 'allowed'\n}\n\n// https://fetch.spec.whatwg.org/#concept-cors-check\nfunction corsCheck () {\n // TODO\n return 'success'\n}\n\n// https://fetch.spec.whatwg.org/#concept-tao-check\nfunction TAOCheck () {\n // TODO\n return 'success'\n}\n\nfunction appendFetchMetadata (httpRequest) {\n // https://w3c.github.io/webappsec-fetch-metadata/#sec-fetch-dest-header\n // TODO\n\n // https://w3c.github.io/webappsec-fetch-metadata/#sec-fetch-mode-header\n\n // 1. Assert: r\u2019s url is a potentially trustworthy URL.\n // TODO\n\n // 2. Let header be a Structured Header whose value is a token.\n let header = null\n\n // 3. Set header\u2019s value to r\u2019s mode.\n header = httpRequest.mode\n\n // 4. Set a structured field value `Sec-Fetch-Mode`/header in r\u2019s header list.\n httpRequest.headersList.set('sec-fetch-mode', header)\n\n // https://w3c.github.io/webappsec-fetch-metadata/#sec-fetch-site-header\n // TODO\n\n // https://w3c.github.io/webappsec-fetch-metadata/#sec-fetch-user-header\n // TODO\n}\n\n// https://fetch.spec.whatwg.org/#append-a-request-origin-header\nfunction appendRequestOriginHeader (request) {\n // 1. Let serializedOrigin be the result of byte-serializing a request origin with request.\n let serializedOrigin = request.origin\n\n // 2. If request\u2019s response tainting is \"cors\" or request\u2019s mode is \"websocket\", then append (`Origin`, serializedOrigin) to request\u2019s header list.\n if (request.responseTainting === 'cors' || request.mode === 'websocket') {\n if (serializedOrigin) {\n request.headersList.append('origin', serializedOrigin)\n }\n\n // 3. Otherwise, if request\u2019s method is neither `GET` nor `HEAD`, then:\n } else if (request.method !== 'GET' && request.method !== 'HEAD') {\n // 1. Switch on request\u2019s referrer policy:\n switch (request.referrerPolicy) {\n case 'no-referrer':\n // Set serializedOrigin to `null`.\n serializedOrigin = null\n break\n case 'no-referrer-when-downgrade':\n case 'strict-origin':\n case 'strict-origin-when-cross-origin':\n // If request\u2019s origin is a tuple origin, its scheme is \"https\", and request\u2019s current URL\u2019s scheme is not \"https\", then set serializedOrigin to `null`.\n if (request.origin && urlHasHttpsScheme(request.origin) && !urlHasHttpsScheme(requestCurrentURL(request))) {\n serializedOrigin = null\n }\n break\n case 'same-origin':\n // If request\u2019s origin is not same origin with request\u2019s current URL\u2019s origin, then set serializedOrigin to `null`.\n if (!sameOrigin(request, requestCurrentURL(request))) {\n serializedOrigin = null\n }\n break\n default:\n // Do nothing.\n }\n\n if (serializedOrigin) {\n // 2. Append (`Origin`, serializedOrigin) to request\u2019s header list.\n request.headersList.append('origin', serializedOrigin)\n }\n }\n}\n\nfunction coarsenedSharedCurrentTime (crossOriginIsolatedCapability) {\n // TODO\n return performance.now()\n}\n\n// https://fetch.spec.whatwg.org/#create-an-opaque-timing-info\nfunction createOpaqueTimingInfo (timingInfo) {\n return {\n startTime: timingInfo.startTime ?? 0,\n redirectStartTime: 0,\n redirectEndTime: 0,\n postRedirectStartTime: timingInfo.startTime ?? 0,\n finalServiceWorkerStartTime: 0,\n finalNetworkResponseStartTime: 0,\n finalNetworkRequestStartTime: 0,\n endTime: 0,\n encodedBodySize: 0,\n decodedBodySize: 0,\n finalConnectionTimingInfo: null\n }\n}\n\n// https://html.spec.whatwg.org/multipage/origin.html#policy-container\nfunction makePolicyContainer () {\n // Note: the fetch spec doesn't make use of embedder policy or CSP list\n return {\n referrerPolicy: 'strict-origin-when-cross-origin'\n }\n}\n\n// https://html.spec.whatwg.org/multipage/origin.html#clone-a-policy-container\nfunction clonePolicyContainer (policyContainer) {\n return {\n referrerPolicy: policyContainer.referrerPolicy\n }\n}\n\n// https://w3c.github.io/webappsec-referrer-policy/#determine-requests-referrer\nfunction determineRequestsReferrer (request) {\n // 1. Let policy be request's referrer policy.\n const policy = request.referrerPolicy\n\n // Note: policy cannot (shouldn't) be null or an empty string.\n assert(policy)\n\n // 2. Let environment be request\u2019s client.\n\n let referrerSource = null\n\n // 3. Switch on request\u2019s referrer:\n if (request.referrer === 'client') {\n // Note: node isn't a browser and doesn't implement document/iframes,\n // so we bypass this step and replace it with our own.\n\n const globalOrigin = getGlobalOrigin()\n\n if (!globalOrigin || globalOrigin.origin === 'null') {\n return 'no-referrer'\n }\n\n // note: we need to clone it as it's mutated\n referrerSource = new URL(globalOrigin)\n } else if (request.referrer instanceof URL) {\n // Let referrerSource be request\u2019s referrer.\n referrerSource = request.referrer\n }\n\n // 4. Let request\u2019s referrerURL be the result of stripping referrerSource for\n // use as a referrer.\n let referrerURL = stripURLForReferrer(referrerSource)\n\n // 5. Let referrerOrigin be the result of stripping referrerSource for use as\n // a referrer, with the origin-only flag set to true.\n const referrerOrigin = stripURLForReferrer(referrerSource, true)\n\n // 6. If the result of serializing referrerURL is a string whose length is\n // greater than 4096, set referrerURL to referrerOrigin.\n if (referrerURL.toString().length > 4096) {\n referrerURL = referrerOrigin\n }\n\n const areSameOrigin = sameOrigin(request, referrerURL)\n const isNonPotentiallyTrustWorthy = isURLPotentiallyTrustworthy(referrerURL) &&\n !isURLPotentiallyTrustworthy(request.url)\n\n // 8. Execute the switch statements corresponding to the value of policy:\n switch (policy) {\n case 'origin': return referrerOrigin != null ? referrerOrigin : stripURLForReferrer(referrerSource, true)\n case 'unsafe-url': return referrerURL\n case 'same-origin':\n return areSameOrigin ? referrerOrigin : 'no-referrer'\n case 'origin-when-cross-origin':\n return areSameOrigin ? referrerURL : referrerOrigin\n case 'strict-origin-when-cross-origin': {\n const currentURL = requestCurrentURL(request)\n\n // 1. If the origin of referrerURL and the origin of request\u2019s current\n // URL are the same, then return referrerURL.\n if (sameOrigin(referrerURL, currentURL)) {\n return referrerURL\n }\n\n // 2. If referrerURL is a potentially trustworthy URL and request\u2019s\n // current URL is not a potentially trustworthy URL, then return no\n // referrer.\n if (isURLPotentiallyTrustworthy(referrerURL) && !isURLPotentiallyTrustworthy(currentURL)) {\n return 'no-referrer'\n }\n\n // 3. Return referrerOrigin.\n return referrerOrigin\n }\n case 'strict-origin': // eslint-disable-line\n /**\n * 1. If referrerURL is a potentially trustworthy URL and\n * request\u2019s current URL is not a potentially trustworthy URL,\n * then return no referrer.\n * 2. Return referrerOrigin\n */\n case 'no-referrer-when-downgrade': // eslint-disable-line\n /**\n * 1. If referrerURL is a potentially trustworthy URL and\n * request\u2019s current URL is not a potentially trustworthy URL,\n * then return no referrer.\n * 2. Return referrerOrigin\n */\n\n default: // eslint-disable-line\n return isNonPotentiallyTrustWorthy ? 'no-referrer' : referrerOrigin\n }\n}\n\n/**\n * @see https://w3c.github.io/webappsec-referrer-policy/#strip-url\n * @param {URL} url\n * @param {boolean|undefined} originOnly\n */\nfunction stripURLForReferrer (url, originOnly) {\n // 1. Assert: url is a URL.\n assert(url instanceof URL)\n\n // 2. If url\u2019s scheme is a local scheme, then return no referrer.\n if (url.protocol === 'file:' || url.protocol === 'about:' || url.protocol === 'blank:') {\n return 'no-referrer'\n }\n\n // 3. Set url\u2019s username to the empty string.\n url.username = ''\n\n // 4. Set url\u2019s password to the empty string.\n url.password = ''\n\n // 5. Set url\u2019s fragment to null.\n url.hash = ''\n\n // 6. If the origin-only flag is true, then:\n if (originOnly) {\n // 1. Set url\u2019s path to \u00ab the empty string \u00bb.\n url.pathname = ''\n\n // 2. Set url\u2019s query to null.\n url.search = ''\n }\n\n // 7. Return url.\n return url\n}\n\nfunction isURLPotentiallyTrustworthy (url) {\n if (!(url instanceof URL)) {\n return false\n }\n\n // If child of about, return true\n if (url.href === 'about:blank' || url.href === 'about:srcdoc') {\n return true\n }\n\n // If scheme is data, return true\n if (url.protocol === 'data:') return true\n\n // If file, return true\n if (url.protocol === 'file:') return true\n\n return isOriginPotentiallyTrustworthy(url.origin)\n\n function isOriginPotentiallyTrustworthy (origin) {\n // If origin is explicitly null, return false\n if (origin == null || origin === 'null') return false\n\n const originAsURL = new URL(origin)\n\n // If secure, return true\n if (originAsURL.protocol === 'https:' || originAsURL.protocol === 'wss:') {\n return true\n }\n\n // If localhost or variants, return true\n if (/^127(?:\\.[0-9]+){0,2}\\.[0-9]+$|^\\[(?:0*:)*?:?0*1\\]$/.test(originAsURL.hostname) ||\n (originAsURL.hostname === 'localhost' || originAsURL.hostname.includes('localhost.')) ||\n (originAsURL.hostname.endsWith('.localhost'))) {\n return true\n }\n\n // If any other, return false\n return false\n }\n}\n\n/**\n * @see https://w3c.github.io/webappsec-subresource-integrity/#does-response-match-metadatalist\n * @param {Uint8Array} bytes\n * @param {string} metadataList\n */\nfunction bytesMatch (bytes, metadataList) {\n // If node is not built with OpenSSL support, we cannot check\n // a request's integrity, so allow it by default (the spec will\n // allow requests if an invalid hash is given, as precedence).\n /* istanbul ignore if: only if node is built with --without-ssl */\n if (crypto === undefined) {\n return true\n }\n\n // 1. Let parsedMetadata be the result of parsing metadataList.\n const parsedMetadata = parseMetadata(metadataList)\n\n // 2. If parsedMetadata is no metadata, return true.\n if (parsedMetadata === 'no metadata') {\n return true\n }\n\n // 3. If response is not eligible for integrity validation, return false.\n // TODO\n\n // 4. If parsedMetadata is the empty set, return true.\n if (parsedMetadata.length === 0) {\n return true\n }\n\n // 5. Let metadata be the result of getting the strongest\n // metadata from parsedMetadata.\n const strongest = getStrongestMetadata(parsedMetadata)\n const metadata = filterMetadataListByAlgorithm(parsedMetadata, strongest)\n\n // 6. For each item in metadata:\n for (const item of metadata) {\n // 1. Let algorithm be the alg component of item.\n const algorithm = item.algo\n\n // 2. Let expectedValue be the val component of item.\n const expectedValue = item.hash\n\n // See https://github.com/web-platform-tests/wpt/commit/e4c5cc7a5e48093220528dfdd1c4012dc3837a0e\n // \"be liberal with padding\". This is annoying, and it's not even in the spec.\n\n // 3. Let actualValue be the result of applying algorithm to bytes.\n let actualValue = crypto.createHash(algorithm).update(bytes).digest('base64')\n\n if (actualValue[actualValue.length - 1] === '=') {\n if (actualValue[actualValue.length - 2] === '=') {\n actualValue = actualValue.slice(0, -2)\n } else {\n actualValue = actualValue.slice(0, -1)\n }\n }\n\n // 4. If actualValue is a case-sensitive match for expectedValue,\n // return true.\n if (compareBase64Mixed(actualValue, expectedValue)) {\n return true\n }\n }\n\n // 7. Return false.\n return false\n}\n\n// https://w3c.github.io/webappsec-subresource-integrity/#grammardef-hash-with-options\n// https://www.w3.org/TR/CSP2/#source-list-syntax\n// https://www.rfc-editor.org/rfc/rfc5234#appendix-B.1\nconst parseHashWithOptions = /(?<algo>sha256|sha384|sha512)-((?<hash>[A-Za-z0-9+/]+|[A-Za-z0-9_-]+)={0,2}(?:\\s|$)( +[!-~]*)?)?/i\n\n/**\n * @see https://w3c.github.io/webappsec-subresource-integrity/#parse-metadata\n * @param {string} metadata\n */\nfunction parseMetadata (metadata) {\n // 1. Let result be the empty set.\n /** @type {{ algo: string, hash: string }[]} */\n const result = []\n\n // 2. Let empty be equal to true.\n let empty = true\n\n // 3. For each token returned by splitting metadata on spaces:\n for (const token of metadata.split(' ')) {\n // 1. Set empty to false.\n empty = false\n\n // 2. Parse token as a hash-with-options.\n const parsedToken = parseHashWithOptions.exec(token)\n\n // 3. If token does not parse, continue to the next token.\n if (\n parsedToken === null ||\n parsedToken.groups === undefined ||\n parsedToken.groups.algo === undefined\n ) {\n // Note: Chromium blocks the request at this point, but Firefox\n // gives a warning that an invalid integrity was given. The\n // correct behavior is to ignore these, and subsequently not\n // check the integrity of the resource.\n continue\n }\n\n // 4. Let algorithm be the hash-algo component of token.\n const algorithm = parsedToken.groups.algo.toLowerCase()\n\n // 5. If algorithm is a hash function recognized by the user\n // agent, add the parsed token to result.\n if (supportedHashes.includes(algorithm)) {\n result.push(parsedToken.groups)\n }\n }\n\n // 4. Return no metadata if empty is true, otherwise return result.\n if (empty === true) {\n return 'no metadata'\n }\n\n return result\n}\n\n/**\n * @param {{ algo: 'sha256' | 'sha384' | 'sha512' }[]} metadataList\n */\nfunction getStrongestMetadata (metadataList) {\n // Let algorithm be the algo component of the first item in metadataList.\n // Can be sha256\n let algorithm = metadataList[0].algo\n // If the algorithm is sha512, then it is the strongest\n // and we can return immediately\n if (algorithm[3] === '5') {\n return algorithm\n }\n\n for (let i = 1; i < metadataList.length; ++i) {\n const metadata = metadataList[i]\n // If the algorithm is sha512, then it is the strongest\n // and we can break the loop immediately\n if (metadata.algo[3] === '5') {\n algorithm = 'sha512'\n break\n // If the algorithm is sha384, then a potential sha256 or sha384 is ignored\n } else if (algorithm[3] === '3') {\n continue\n // algorithm is sha256, check if algorithm is sha384 and if so, set it as\n // the strongest\n } else if (metadata.algo[3] === '3') {\n algorithm = 'sha384'\n }\n }\n return algorithm\n}\n\nfunction filterMetadataListByAlgorithm (metadataList, algorithm) {\n if (metadataList.length === 1) {\n return metadataList\n }\n\n let pos = 0\n for (let i = 0; i < metadataList.length; ++i) {\n if (metadataList[i].algo === algorithm) {\n metadataList[pos++] = metadataList[i]\n }\n }\n\n metadataList.length = pos\n\n return metadataList\n}\n\n/**\n * Compares two base64 strings, allowing for base64url\n * in the second string.\n *\n* @param {string} actualValue always base64\n * @param {string} expectedValue base64 or base64url\n * @returns {boolean}\n */\nfunction compareBase64Mixed (actualValue, expectedValue) {\n if (actualValue.length !== expectedValue.length) {\n return false\n }\n for (let i = 0; i < actualValue.length; ++i) {\n if (actualValue[i] !== expectedValue[i]) {\n if (\n (actualValue[i] === '+' && expectedValue[i] === '-') ||\n (actualValue[i] === '/' && expectedValue[i] === '_')\n ) {\n continue\n }\n return false\n }\n }\n\n return true\n}\n\n// https://w3c.github.io/webappsec-upgrade-insecure-requests/#upgrade-request\nfunction tryUpgradeRequestToAPotentiallyTrustworthyURL (request) {\n // TODO\n}\n\n/**\n * @link {https://html.spec.whatwg.org/multipage/origin.html#same-origin}\n * @param {URL} A\n * @param {URL} B\n */\nfunction sameOrigin (A, B) {\n // 1. If A and B are the same opaque origin, then return true.\n if (A.origin === B.origin && A.origin === 'null') {\n return true\n }\n\n // 2. If A and B are both tuple origins and their schemes,\n // hosts, and port are identical, then return true.\n if (A.protocol === B.protocol && A.hostname === B.hostname && A.port === B.port) {\n return true\n }\n\n // 3. Return false.\n return false\n}\n\nfunction createDeferredPromise () {\n let res\n let rej\n const promise = new Promise((resolve, reject) => {\n res = resolve\n rej = reject\n })\n\n return { promise, resolve: res, reject: rej }\n}\n\nfunction isAborted (fetchParams) {\n return fetchParams.controller.state === 'aborted'\n}\n\nfunction isCancelled (fetchParams) {\n return fetchParams.controller.state === 'aborted' ||\n fetchParams.controller.state === 'terminated'\n}\n\nconst normalizeMethodRecord = {\n delete: 'DELETE',\n DELETE: 'DELETE',\n get: 'GET',\n GET: 'GET',\n head: 'HEAD',\n HEAD: 'HEAD',\n options: 'OPTIONS',\n OPTIONS: 'OPTIONS',\n post: 'POST',\n POST: 'POST',\n put: 'PUT',\n PUT: 'PUT'\n}\n\n// Note: object prototypes should not be able to be referenced. e.g. `Object#hasOwnProperty`.\nObject.setPrototypeOf(normalizeMethodRecord, null)\n\n/**\n * @see https://fetch.spec.whatwg.org/#concept-method-normalize\n * @param {string} method\n */\nfunction normalizeMethod (method) {\n return normalizeMethodRecord[method.toLowerCase()] ?? method\n}\n\n// https://infra.spec.whatwg.org/#serialize-a-javascript-value-to-a-json-string\nfunction serializeJavascriptValueToJSONString (value) {\n // 1. Let result be ? Call(%JSON.stringify%, undefined, \u00ab value \u00bb).\n const result = JSON.stringify(value)\n\n // 2. If result is undefined, then throw a TypeError.\n if (result === undefined) {\n throw new TypeError('Value is not JSON serializable')\n }\n\n // 3. Assert: result is a string.\n assert(typeof result === 'string')\n\n // 4. Return result.\n return result\n}\n\n// https://tc39.es/ecma262/#sec-%25iteratorprototype%25-object\nconst esIteratorPrototype = Object.getPrototypeOf(Object.getPrototypeOf([][Symbol.iterator]()))\n\n/**\n * @see https://webidl.spec.whatwg.org/#dfn-iterator-prototype-object\n * @param {() => unknown[]} iterator\n * @param {string} name name of the instance\n * @param {'key'|'value'|'key+value'} kind\n */\nfunction makeIterator (iterator, name, kind) {\n const object = {\n index: 0,\n kind,\n target: iterator\n }\n\n const i = {\n next () {\n // 1. Let interface be the interface for which the iterator prototype object exists.\n\n // 2. Let thisValue be the this value.\n\n // 3. Let object be ? ToObject(thisValue).\n\n // 4. If object is a platform object, then perform a security\n // check, passing:\n\n // 5. If object is not a default iterator object for interface,\n // then throw a TypeError.\n if (Object.getPrototypeOf(this) !== i) {\n throw new TypeError(\n `'next' called on an object that does not implement interface ${name} Iterator.`\n )\n }\n\n // 6. Let index be object\u2019s index.\n // 7. Let kind be object\u2019s kind.\n // 8. Let values be object\u2019s target's value pairs to iterate over.\n const { index, kind, target } = object\n const values = target()\n\n // 9. Let len be the length of values.\n const len = values.length\n\n // 10. If index is greater than or equal to len, then return\n // CreateIterResultObject(undefined, true).\n if (index >= len) {\n return { value: undefined, done: true }\n }\n\n // 11. Let pair be the entry in values at index index.\n const pair = values[index]\n\n // 12. Set object\u2019s index to index + 1.\n object.index = index + 1\n\n // 13. Return the iterator result for pair and kind.\n return iteratorResult(pair, kind)\n },\n // The class string of an iterator prototype object for a given interface is the\n // result of concatenating the identifier of the interface and the string \" Iterator\".\n [Symbol.toStringTag]: `${name} Iterator`\n }\n\n // The [[Prototype]] internal slot of an iterator prototype object must be %IteratorPrototype%.\n Object.setPrototypeOf(i, esIteratorPrototype)\n // esIteratorPrototype needs to be the prototype of i\n // which is the prototype of an empty object. Yes, it's confusing.\n return Object.setPrototypeOf({}, i)\n}\n\n// https://webidl.spec.whatwg.org/#iterator-result\nfunction iteratorResult (pair, kind) {\n let result\n\n // 1. Let result be a value determined by the value of kind:\n switch (kind) {\n case 'key': {\n // 1. Let idlKey be pair\u2019s key.\n // 2. Let key be the result of converting idlKey to an\n // ECMAScript value.\n // 3. result is key.\n result = pair[0]\n break\n }\n case 'value': {\n // 1. Let idlValue be pair\u2019s value.\n // 2. Let value be the result of converting idlValue to\n // an ECMAScript value.\n // 3. result is value.\n result = pair[1]\n break\n }\n case 'key+value': {\n // 1. Let idlKey be pair\u2019s key.\n // 2. Let idlValue be pair\u2019s value.\n // 3. Let key be the result of converting idlKey to an\n // ECMAScript value.\n // 4. Let value be the result of converting idlValue to\n // an ECMAScript value.\n // 5. Let array be ! ArrayCreate(2).\n // 6. Call ! CreateDataProperty(array, \"0\", key).\n // 7. Call ! CreateDataProperty(array, \"1\", value).\n // 8. result is array.\n result = pair\n break\n }\n }\n\n // 2. Return CreateIterResultObject(result, false).\n return { value: result, done: false }\n}\n\n/**\n * @see https://fetch.spec.whatwg.org/#body-fully-read\n */\nasync function fullyReadBody (body, processBody, processBodyError) {\n // 1. If taskDestination is null, then set taskDestination to\n // the result of starting a new parallel queue.\n\n // 2. Let successSteps given a byte sequence bytes be to queue a\n // fetch task to run processBody given bytes, with taskDestination.\n const successSteps = processBody\n\n // 3. Let errorSteps be to queue a fetch task to run processBodyError,\n // with taskDestination.\n const errorSteps = processBodyError\n\n // 4. Let reader be the result of getting a reader for body\u2019s stream.\n // If that threw an exception, then run errorSteps with that\n // exception and return.\n let reader\n\n try {\n reader = body.stream.getReader()\n } catch (e) {\n errorSteps(e)\n return\n }\n\n // 5. Read all bytes from reader, given successSteps and errorSteps.\n try {\n const result = await readAllBytes(reader)\n successSteps(result)\n } catch (e) {\n errorSteps(e)\n }\n}\n\n/** @type {ReadableStream} */\nlet ReadableStream = globalThis.ReadableStream\n\nfunction isReadableStreamLike (stream) {\n if (!ReadableStream) {\n ReadableStream = (__nccwpck_require__(5356).ReadableStream)\n }\n\n return stream instanceof ReadableStream || (\n stream[Symbol.toStringTag] === 'ReadableStream' &&\n typeof stream.tee === 'function'\n )\n}\n\nconst MAXIMUM_ARGUMENT_LENGTH = 65535\n\n/**\n * @see https://infra.spec.whatwg.org/#isomorphic-decode\n * @param {number[]|Uint8Array} input\n */\nfunction isomorphicDecode (input) {\n // 1. To isomorphic decode a byte sequence input, return a string whose code point\n // length is equal to input\u2019s length and whose code points have the same values\n // as the values of input\u2019s bytes, in the same order.\n\n if (input.length < MAXIMUM_ARGUMENT_LENGTH) {\n return String.fromCharCode(...input)\n }\n\n return input.reduce((previous, current) => previous + String.fromCharCode(current), '')\n}\n\n/**\n * @param {ReadableStreamController<Uint8Array>} controller\n */\nfunction readableStreamClose (controller) {\n try {\n controller.close()\n } catch (err) {\n // TODO: add comment explaining why this error occurs.\n if (!err.message.includes('Controller is already closed')) {\n throw err\n }\n }\n}\n\n/**\n * @see https://infra.spec.whatwg.org/#isomorphic-encode\n * @param {string} input\n */\nfunction isomorphicEncode (input) {\n // 1. Assert: input contains no code points greater than U+00FF.\n for (let i = 0; i < input.length; i++) {\n assert(input.charCodeAt(i) <= 0xFF)\n }\n\n // 2. Return a byte sequence whose length is equal to input\u2019s code\n // point length and whose bytes have the same values as the\n // values of input\u2019s code points, in the same order\n return input\n}\n\n/**\n * @see https://streams.spec.whatwg.org/#readablestreamdefaultreader-read-all-bytes\n * @see https://streams.spec.whatwg.org/#read-loop\n * @param {ReadableStreamDefaultReader} reader\n */\nasync function readAllBytes (reader) {\n const bytes = []\n let byteLength = 0\n\n while (true) {\n const { done, value: chunk } = await reader.read()\n\n if (done) {\n // 1. Call successSteps with bytes.\n return Buffer.concat(bytes, byteLength)\n }\n\n // 1. If chunk is not a Uint8Array object, call failureSteps\n // with a TypeError and abort these steps.\n if (!isUint8Array(chunk)) {\n throw new TypeError('Received non-Uint8Array chunk')\n }\n\n // 2. Append the bytes represented by chunk to bytes.\n bytes.push(chunk)\n byteLength += chunk.length\n\n // 3. Read-loop given reader, bytes, successSteps, and failureSteps.\n }\n}\n\n/**\n * @see https://fetch.spec.whatwg.org/#is-local\n * @param {URL} url\n */\nfunction urlIsLocal (url) {\n assert('protocol' in url) // ensure it's a url object\n\n const protocol = url.protocol\n\n return protocol === 'about:' || protocol === 'blob:' || protocol === 'data:'\n}\n\n/**\n * @param {string|URL} url\n */\nfunction urlHasHttpsScheme (url) {\n if (typeof url === 'string') {\n return url.startsWith('https:')\n }\n\n return url.protocol === 'https:'\n}\n\n/**\n * @see https://fetch.spec.whatwg.org/#http-scheme\n * @param {URL} url\n */\nfunction urlIsHttpHttpsScheme (url) {\n assert('protocol' in url) // ensure it's a url object\n\n const protocol = url.protocol\n\n return protocol === 'http:' || protocol === 'https:'\n}\n\n/**\n * Fetch supports node >= 16.8.0, but Object.hasOwn was added in v16.9.0.\n */\nconst hasOwn = Object.hasOwn || ((dict, key) => Object.prototype.hasOwnProperty.call(dict, key))\n\nmodule.exports = {\n isAborted,\n isCancelled,\n createDeferredPromise,\n ReadableStreamFrom,\n toUSVString,\n tryUpgradeRequestToAPotentiallyTrustworthyURL,\n coarsenedSharedCurrentTime,\n determineRequestsReferrer,\n makePolicyContainer,\n clonePolicyContainer,\n appendFetchMetadata,\n appendRequestOriginHeader,\n TAOCheck,\n corsCheck,\n crossOriginResourcePolicyCheck,\n createOpaqueTimingInfo,\n setRequestReferrerPolicyOnRedirect,\n isValidHTTPToken,\n requestBadPort,\n requestCurrentURL,\n responseURL,\n responseLocationURL,\n isBlobLike,\n isURLPotentiallyTrustworthy,\n isValidReasonPhrase,\n sameOrigin,\n normalizeMethod,\n serializeJavascriptValueToJSONString,\n makeIterator,\n isValidHeaderName,\n isValidHeaderValue,\n hasOwn,\n isErrorLike,\n fullyReadBody,\n bytesMatch,\n isReadableStreamLike,\n readableStreamClose,\n isomorphicEncode,\n isomorphicDecode,\n urlIsLocal,\n urlHasHttpsScheme,\n urlIsHttpHttpsScheme,\n readAllBytes,\n normalizeMethodRecord,\n parseMetadata\n}\n\n\n/***/ }),\n\n/***/ 1744:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\n\"use strict\";\n\n\nconst { types } = __nccwpck_require__(3837)\nconst { hasOwn, toUSVString } = __nccwpck_require__(2538)\n\n/** @type {import('../../types/webidl').Webidl} */\nconst webidl = {}\nwebidl.converters = {}\nwebidl.util = {}\nwebidl.errors = {}\n\nwebidl.errors.exception = function (message) {\n return new TypeError(`${message.header}: ${message.message}`)\n}\n\nwebidl.errors.conversionFailed = function (context) {\n const plural = context.types.length === 1 ? '' : ' one of'\n const message =\n `${context.argument} could not be converted to` +\n `${plural}: ${context.types.join(', ')}.`\n\n return webidl.errors.exception({\n header: context.prefix,\n message\n })\n}\n\nwebidl.errors.invalidArgument = function (context) {\n return webidl.errors.exception({\n header: context.prefix,\n message: `\"${context.value}\" is an invalid ${context.type}.`\n })\n}\n\n// https://webidl.spec.whatwg.org/#implements\nwebidl.brandCheck = function (V, I, opts = undefined) {\n if (opts?.strict !== false && !(V instanceof I)) {\n throw new TypeError('Illegal invocation')\n } else {\n return V?.[Symbol.toStringTag] === I.prototype[Symbol.toStringTag]\n }\n}\n\nwebidl.argumentLengthCheck = function ({ length }, min, ctx) {\n if (length < min) {\n throw webidl.errors.exception({\n message: `${min} argument${min !== 1 ? 's' : ''} required, ` +\n `but${length ? ' only' : ''} ${length} found.`,\n ...ctx\n })\n }\n}\n\nwebidl.illegalConstructor = function () {\n throw webidl.errors.exception({\n header: 'TypeError',\n message: 'Illegal constructor'\n })\n}\n\n// https://tc39.es/ecma262/#sec-ecmascript-data-types-and-values\nwebidl.util.Type = function (V) {\n switch (typeof V) {\n case 'undefined': return 'Undefined'\n case 'boolean': return 'Boolean'\n case 'string': return 'String'\n case 'symbol': return 'Symbol'\n case 'number': return 'Number'\n case 'bigint': return 'BigInt'\n case 'function':\n case 'object': {\n if (V === null) {\n return 'Null'\n }\n\n return 'Object'\n }\n }\n}\n\n// https://webidl.spec.whatwg.org/#abstract-opdef-converttoint\nwebidl.util.ConvertToInt = function (V, bitLength, signedness, opts = {}) {\n let upperBound\n let lowerBound\n\n // 1. If bitLength is 64, then:\n if (bitLength === 64) {\n // 1. Let upperBound be 2^53 \u2212 1.\n upperBound = Math.pow(2, 53) - 1\n\n // 2. If signedness is \"unsigned\", then let lowerBound be 0.\n if (signedness === 'unsigned') {\n lowerBound = 0\n } else {\n // 3. Otherwise let lowerBound be \u22122^53 + 1.\n lowerBound = Math.pow(-2, 53) + 1\n }\n } else if (signedness === 'unsigned') {\n // 2. Otherwise, if signedness is \"unsigned\", then:\n\n // 1. Let lowerBound be 0.\n lowerBound = 0\n\n // 2. Let upperBound be 2^bitLength \u2212 1.\n upperBound = Math.pow(2, bitLength) - 1\n } else {\n // 3. Otherwise:\n\n // 1. Let lowerBound be -2^bitLength \u2212 1.\n lowerBound = Math.pow(-2, bitLength) - 1\n\n // 2. Let upperBound be 2^bitLength \u2212 1 \u2212 1.\n upperBound = Math.pow(2, bitLength - 1) - 1\n }\n\n // 4. Let x be ? ToNumber(V).\n let x = Number(V)\n\n // 5. If x is \u22120, then set x to +0.\n if (x === 0) {\n x = 0\n }\n\n // 6. If the conversion is to an IDL type associated\n // with the [EnforceRange] extended attribute, then:\n if (opts.enforceRange === true) {\n // 1. If x is NaN, +\u221e, or \u2212\u221e, then throw a TypeError.\n if (\n Number.isNaN(x) ||\n x === Number.POSITIVE_INFINITY ||\n x === Number.NEGATIVE_INFINITY\n ) {\n throw webidl.errors.exception({\n header: 'Integer conversion',\n message: `Could not convert ${V} to an integer.`\n })\n }\n\n // 2. Set x to IntegerPart(x).\n x = webidl.util.IntegerPart(x)\n\n // 3. If x < lowerBound or x > upperBound, then\n // throw a TypeError.\n if (x < lowerBound || x > upperBound) {\n throw webidl.errors.exception({\n header: 'Integer conversion',\n message: `Value must be between ${lowerBound}-${upperBound}, got ${x}.`\n })\n }\n\n // 4. Return x.\n return x\n }\n\n // 7. If x is not NaN and the conversion is to an IDL\n // type associated with the [Clamp] extended\n // attribute, then:\n if (!Number.isNaN(x) && opts.clamp === true) {\n // 1. Set x to min(max(x, lowerBound), upperBound).\n x = Math.min(Math.max(x, lowerBound), upperBound)\n\n // 2. Round x to the nearest integer, choosing the\n // even integer if it lies halfway between two,\n // and choosing +0 rather than \u22120.\n if (Math.floor(x) % 2 === 0) {\n x = Math.floor(x)\n } else {\n x = Math.ceil(x)\n }\n\n // 3. Return x.\n return x\n }\n\n // 8. If x is NaN, +0, +\u221e, or \u2212\u221e, then return +0.\n if (\n Number.isNaN(x) ||\n (x === 0 && Object.is(0, x)) ||\n x === Number.POSITIVE_INFINITY ||\n x === Number.NEGATIVE_INFINITY\n ) {\n return 0\n }\n\n // 9. Set x to IntegerPart(x).\n x = webidl.util.IntegerPart(x)\n\n // 10. Set x to x modulo 2^bitLength.\n x = x % Math.pow(2, bitLength)\n\n // 11. If signedness is \"signed\" and x \u2265 2^bitLength \u2212 1,\n // then return x \u2212 2^bitLength.\n if (signedness === 'signed' && x >= Math.pow(2, bitLength) - 1) {\n return x - Math.pow(2, bitLength)\n }\n\n // 12. Otherwise, return x.\n return x\n}\n\n// https://webidl.spec.whatwg.org/#abstract-opdef-integerpart\nwebidl.util.IntegerPart = function (n) {\n // 1. Let r be floor(abs(n)).\n const r = Math.floor(Math.abs(n))\n\n // 2. If n < 0, then return -1 \u00d7 r.\n if (n < 0) {\n return -1 * r\n }\n\n // 3. Otherwise, return r.\n return r\n}\n\n// https://webidl.spec.whatwg.org/#es-sequence\nwebidl.sequenceConverter = function (converter) {\n return (V) => {\n // 1. If Type(V) is not Object, throw a TypeError.\n if (webidl.util.Type(V) !== 'Object') {\n throw webidl.errors.exception({\n header: 'Sequence',\n message: `Value of type ${webidl.util.Type(V)} is not an Object.`\n })\n }\n\n // 2. Let method be ? GetMethod(V, @@iterator).\n /** @type {Generator} */\n const method = V?.[Symbol.iterator]?.()\n const seq = []\n\n // 3. If method is undefined, throw a TypeError.\n if (\n method === undefined ||\n typeof method.next !== 'function'\n ) {\n throw webidl.errors.exception({\n header: 'Sequence',\n message: 'Object is not an iterator.'\n })\n }\n\n // https://webidl.spec.whatwg.org/#create-sequence-from-iterable\n while (true) {\n const { done, value } = method.next()\n\n if (done) {\n break\n }\n\n seq.push(converter(value))\n }\n\n return seq\n }\n}\n\n// https://webidl.spec.whatwg.org/#es-to-record\nwebidl.recordConverter = function (keyConverter, valueConverter) {\n return (O) => {\n // 1. If Type(O) is not Object, throw a TypeError.\n if (webidl.util.Type(O) !== 'Object') {\n throw webidl.errors.exception({\n header: 'Record',\n message: `Value of type ${webidl.util.Type(O)} is not an Object.`\n })\n }\n\n // 2. Let result be a new empty instance of record<K, V>.\n const result = {}\n\n if (!types.isProxy(O)) {\n // Object.keys only returns enumerable properties\n const keys = Object.keys(O)\n\n for (const key of keys) {\n // 1. Let typedKey be key converted to an IDL value of type K.\n const typedKey = keyConverter(key)\n\n // 2. Let value be ? Get(O, key).\n // 3. Let typedValue be value converted to an IDL value of type V.\n const typedValue = valueConverter(O[key])\n\n // 4. Set result[typedKey] to typedValue.\n result[typedKey] = typedValue\n }\n\n // 5. Return result.\n return result\n }\n\n // 3. Let keys be ? O.[[OwnPropertyKeys]]().\n const keys = Reflect.ownKeys(O)\n\n // 4. For each key of keys.\n for (const key of keys) {\n // 1. Let desc be ? O.[[GetOwnProperty]](key).\n const desc = Reflect.getOwnPropertyDescriptor(O, key)\n\n // 2. If desc is not undefined and desc.[[Enumerable]] is true:\n if (desc?.enumerable) {\n // 1. Let typedKey be key converted to an IDL value of type K.\n const typedKey = keyConverter(key)\n\n // 2. Let value be ? Get(O, key).\n // 3. Let typedValue be value converted to an IDL value of type V.\n const typedValue = valueConverter(O[key])\n\n // 4. Set result[typedKey] to typedValue.\n result[typedKey] = typedValue\n }\n }\n\n // 5. Return result.\n return result\n }\n}\n\nwebidl.interfaceConverter = function (i) {\n return (V, opts = {}) => {\n if (opts.strict !== false && !(V instanceof i)) {\n throw webidl.errors.exception({\n header: i.name,\n message: `Expected ${V} to be an instance of ${i.name}.`\n })\n }\n\n return V\n }\n}\n\nwebidl.dictionaryConverter = function (converters) {\n return (dictionary) => {\n const type = webidl.util.Type(dictionary)\n const dict = {}\n\n if (type === 'Null' || type === 'Undefined') {\n return dict\n } else if (type !== 'Object') {\n throw webidl.errors.exception({\n header: 'Dictionary',\n message: `Expected ${dictionary} to be one of: Null, Undefined, Object.`\n })\n }\n\n for (const options of converters) {\n const { key, defaultValue, required, converter } = options\n\n if (required === true) {\n if (!hasOwn(dictionary, key)) {\n throw webidl.errors.exception({\n header: 'Dictionary',\n message: `Missing required key \"${key}\".`\n })\n }\n }\n\n let value = dictionary[key]\n const hasDefault = hasOwn(options, 'defaultValue')\n\n // Only use defaultValue if value is undefined and\n // a defaultValue options was provided.\n if (hasDefault && value !== null) {\n value = value ?? defaultValue\n }\n\n // A key can be optional and have no default value.\n // When this happens, do not perform a conversion,\n // and do not assign the key a value.\n if (required || hasDefault || value !== undefined) {\n value = converter(value)\n\n if (\n options.allowedValues &&\n !options.allowedValues.includes(value)\n ) {\n throw webidl.errors.exception({\n header: 'Dictionary',\n message: `${value} is not an accepted type. Expected one of ${options.allowedValues.join(', ')}.`\n })\n }\n\n dict[key] = value\n }\n }\n\n return dict\n }\n}\n\nwebidl.nullableConverter = function (converter) {\n return (V) => {\n if (V === null) {\n return V\n }\n\n return converter(V)\n }\n}\n\n// https://webidl.spec.whatwg.org/#es-DOMString\nwebidl.converters.DOMString = function (V, opts = {}) {\n // 1. If V is null and the conversion is to an IDL type\n // associated with the [LegacyNullToEmptyString]\n // extended attribute, then return the DOMString value\n // that represents the empty string.\n if (V === null && opts.legacyNullToEmptyString) {\n return ''\n }\n\n // 2. Let x be ? ToString(V).\n if (typeof V === 'symbol') {\n throw new TypeError('Could not convert argument of type symbol to string.')\n }\n\n // 3. Return the IDL DOMString value that represents the\n // same sequence of code units as the one the\n // ECMAScript String value x represents.\n return String(V)\n}\n\n// https://webidl.spec.whatwg.org/#es-ByteString\nwebidl.converters.ByteString = function (V) {\n // 1. Let x be ? ToString(V).\n // Note: DOMString converter perform ? ToString(V)\n const x = webidl.converters.DOMString(V)\n\n // 2. If the value of any element of x is greater than\n // 255, then throw a TypeError.\n for (let index = 0; index < x.length; index++) {\n if (x.charCodeAt(index) > 255) {\n throw new TypeError(\n 'Cannot convert argument to a ByteString because the character at ' +\n `index ${index} has a value of ${x.charCodeAt(index)} which is greater than 255.`\n )\n }\n }\n\n // 3. Return an IDL ByteString value whose length is the\n // length of x, and where the value of each element is\n // the value of the corresponding element of x.\n return x\n}\n\n// https://webidl.spec.whatwg.org/#es-USVString\nwebidl.converters.USVString = toUSVString\n\n// https://webidl.spec.whatwg.org/#es-boolean\nwebidl.converters.boolean = function (V) {\n // 1. Let x be the result of computing ToBoolean(V).\n const x = Boolean(V)\n\n // 2. Return the IDL boolean value that is the one that represents\n // the same truth value as the ECMAScript Boolean value x.\n return x\n}\n\n// https://webidl.spec.whatwg.org/#es-any\nwebidl.converters.any = function (V) {\n return V\n}\n\n// https://webidl.spec.whatwg.org/#es-long-long\nwebidl.converters['long long'] = function (V) {\n // 1. Let x be ? ConvertToInt(V, 64, \"signed\").\n const x = webidl.util.ConvertToInt(V, 64, 'signed')\n\n // 2. Return the IDL long long value that represents\n // the same numeric value as x.\n return x\n}\n\n// https://webidl.spec.whatwg.org/#es-unsigned-long-long\nwebidl.converters['unsigned long long'] = function (V) {\n // 1. Let x be ? ConvertToInt(V, 64, \"unsigned\").\n const x = webidl.util.ConvertToInt(V, 64, 'unsigned')\n\n // 2. Return the IDL unsigned long long value that\n // represents the same numeric value as x.\n return x\n}\n\n// https://webidl.spec.whatwg.org/#es-unsigned-long\nwebidl.converters['unsigned long'] = function (V) {\n // 1. Let x be ? ConvertToInt(V, 32, \"unsigned\").\n const x = webidl.util.ConvertToInt(V, 32, 'unsigned')\n\n // 2. Return the IDL unsigned long value that\n // represents the same numeric value as x.\n return x\n}\n\n// https://webidl.spec.whatwg.org/#es-unsigned-short\nwebidl.converters['unsigned short'] = function (V, opts) {\n // 1. Let x be ? ConvertToInt(V, 16, \"unsigned\").\n const x = webidl.util.ConvertToInt(V, 16, 'unsigned', opts)\n\n // 2. Return the IDL unsigned short value that represents\n // the same numeric value as x.\n return x\n}\n\n// https://webidl.spec.whatwg.org/#idl-ArrayBuffer\nwebidl.converters.ArrayBuffer = function (V, opts = {}) {\n // 1. If Type(V) is not Object, or V does not have an\n // [[ArrayBufferData]] internal slot, then throw a\n // TypeError.\n // see: https://tc39.es/ecma262/#sec-properties-of-the-arraybuffer-instances\n // see: https://tc39.es/ecma262/#sec-properties-of-the-sharedarraybuffer-instances\n if (\n webidl.util.Type(V) !== 'Object' ||\n !types.isAnyArrayBuffer(V)\n ) {\n throw webidl.errors.conversionFailed({\n prefix: `${V}`,\n argument: `${V}`,\n types: ['ArrayBuffer']\n })\n }\n\n // 2. If the conversion is not to an IDL type associated\n // with the [AllowShared] extended attribute, and\n // IsSharedArrayBuffer(V) is true, then throw a\n // TypeError.\n if (opts.allowShared === false && types.isSharedArrayBuffer(V)) {\n throw webidl.errors.exception({\n header: 'ArrayBuffer',\n message: 'SharedArrayBuffer is not allowed.'\n })\n }\n\n // 3. If the conversion is not to an IDL type associated\n // with the [AllowResizable] extended attribute, and\n // IsResizableArrayBuffer(V) is true, then throw a\n // TypeError.\n // Note: resizable ArrayBuffers are currently a proposal.\n\n // 4. Return the IDL ArrayBuffer value that is a\n // reference to the same object as V.\n return V\n}\n\nwebidl.converters.TypedArray = function (V, T, opts = {}) {\n // 1. Let T be the IDL type V is being converted to.\n\n // 2. If Type(V) is not Object, or V does not have a\n // [[TypedArrayName]] internal slot with a value\n // equal to T\u2019s name, then throw a TypeError.\n if (\n webidl.util.Type(V) !== 'Object' ||\n !types.isTypedArray(V) ||\n V.constructor.name !== T.name\n ) {\n throw webidl.errors.conversionFailed({\n prefix: `${T.name}`,\n argument: `${V}`,\n types: [T.name]\n })\n }\n\n // 3. If the conversion is not to an IDL type associated\n // with the [AllowShared] extended attribute, and\n // IsSharedArrayBuffer(V.[[ViewedArrayBuffer]]) is\n // true, then throw a TypeError.\n if (opts.allowShared === false && types.isSharedArrayBuffer(V.buffer)) {\n throw webidl.errors.exception({\n header: 'ArrayBuffer',\n message: 'SharedArrayBuffer is not allowed.'\n })\n }\n\n // 4. If the conversion is not to an IDL type associated\n // with the [AllowResizable] extended attribute, and\n // IsResizableArrayBuffer(V.[[ViewedArrayBuffer]]) is\n // true, then throw a TypeError.\n // Note: resizable array buffers are currently a proposal\n\n // 5. Return the IDL value of type T that is a reference\n // to the same object as V.\n return V\n}\n\nwebidl.converters.DataView = function (V, opts = {}) {\n // 1. If Type(V) is not Object, or V does not have a\n // [[DataView]] internal slot, then throw a TypeError.\n if (webidl.util.Type(V) !== 'Object' || !types.isDataView(V)) {\n throw webidl.errors.exception({\n header: 'DataView',\n message: 'Object is not a DataView.'\n })\n }\n\n // 2. If the conversion is not to an IDL type associated\n // with the [AllowShared] extended attribute, and\n // IsSharedArrayBuffer(V.[[ViewedArrayBuffer]]) is true,\n // then throw a TypeError.\n if (opts.allowShared === false && types.isSharedArrayBuffer(V.buffer)) {\n throw webidl.errors.exception({\n header: 'ArrayBuffer',\n message: 'SharedArrayBuffer is not allowed.'\n })\n }\n\n // 3. If the conversion is not to an IDL type associated\n // with the [AllowResizable] extended attribute, and\n // IsResizableArrayBuffer(V.[[ViewedArrayBuffer]]) is\n // true, then throw a TypeError.\n // Note: resizable ArrayBuffers are currently a proposal\n\n // 4. Return the IDL DataView value that is a reference\n // to the same object as V.\n return V\n}\n\n// https://webidl.spec.whatwg.org/#BufferSource\nwebidl.converters.BufferSource = function (V, opts = {}) {\n if (types.isAnyArrayBuffer(V)) {\n return webidl.converters.ArrayBuffer(V, opts)\n }\n\n if (types.isTypedArray(V)) {\n return webidl.converters.TypedArray(V, V.constructor)\n }\n\n if (types.isDataView(V)) {\n return webidl.converters.DataView(V, opts)\n }\n\n throw new TypeError(`Could not convert ${V} to a BufferSource.`)\n}\n\nwebidl.converters['sequence<ByteString>'] = webidl.sequenceConverter(\n webidl.converters.ByteString\n)\n\nwebidl.converters['sequence<sequence<ByteString>>'] = webidl.sequenceConverter(\n webidl.converters['sequence<ByteString>']\n)\n\nwebidl.converters['record<ByteString, ByteString>'] = webidl.recordConverter(\n webidl.converters.ByteString,\n webidl.converters.ByteString\n)\n\nmodule.exports = {\n webidl\n}\n\n\n/***/ }),\n\n/***/ 4854:\n/***/ ((module) => {\n\n\"use strict\";\n\n\n/**\n * @see https://encoding.spec.whatwg.org/#concept-encoding-get\n * @param {string|undefined} label\n */\nfunction getEncoding (label) {\n if (!label) {\n return 'failure'\n }\n\n // 1. Remove any leading and trailing ASCII whitespace from label.\n // 2. If label is an ASCII case-insensitive match for any of the\n // labels listed in the table below, then return the\n // corresponding encoding; otherwise return failure.\n switch (label.trim().toLowerCase()) {\n case 'unicode-1-1-utf-8':\n case 'unicode11utf8':\n case 'unicode20utf8':\n case 'utf-8':\n case 'utf8':\n case 'x-unicode20utf8':\n return 'UTF-8'\n case '866':\n case 'cp866':\n case 'csibm866':\n case 'ibm866':\n return 'IBM866'\n case 'csisolatin2':\n case 'iso-8859-2':\n case 'iso-ir-101':\n case 'iso8859-2':\n case 'iso88592':\n case 'iso_8859-2':\n case 'iso_8859-2:1987':\n case 'l2':\n case 'latin2':\n return 'ISO-8859-2'\n case 'csisolatin3':\n case 'iso-8859-3':\n case 'iso-ir-109':\n case 'iso8859-3':\n case 'iso88593':\n case 'iso_8859-3':\n case 'iso_8859-3:1988':\n case 'l3':\n case 'latin3':\n return 'ISO-8859-3'\n case 'csisolatin4':\n case 'iso-8859-4':\n case 'iso-ir-110':\n case 'iso8859-4':\n case 'iso88594':\n case 'iso_8859-4':\n case 'iso_8859-4:1988':\n case 'l4':\n case 'latin4':\n return 'ISO-8859-4'\n case 'csisolatincyrillic':\n case 'cyrillic':\n case 'iso-8859-5':\n case 'iso-ir-144':\n case 'iso8859-5':\n case 'iso88595':\n case 'iso_8859-5':\n case 'iso_8859-5:1988':\n return 'ISO-8859-5'\n case 'arabic':\n case 'asmo-708':\n case 'csiso88596e':\n case 'csiso88596i':\n case 'csisolatinarabic':\n case 'ecma-114':\n case 'iso-8859-6':\n case 'iso-8859-6-e':\n case 'iso-8859-6-i':\n case 'iso-ir-127':\n case 'iso8859-6':\n case 'iso88596':\n case 'iso_8859-6':\n case 'iso_8859-6:1987':\n return 'ISO-8859-6'\n case 'csisolatingreek':\n case 'ecma-118':\n case 'elot_928':\n case 'greek':\n case 'greek8':\n case 'iso-8859-7':\n case 'iso-ir-126':\n case 'iso8859-7':\n case 'iso88597':\n case 'iso_8859-7':\n case 'iso_8859-7:1987':\n case 'sun_eu_greek':\n return 'ISO-8859-7'\n case 'csiso88598e':\n case 'csisolatinhebrew':\n case 'hebrew':\n case 'iso-8859-8':\n case 'iso-8859-8-e':\n case 'iso-ir-138':\n case 'iso8859-8':\n case 'iso88598':\n case 'iso_8859-8':\n case 'iso_8859-8:1988':\n case 'visual':\n return 'ISO-8859-8'\n case 'csiso88598i':\n case 'iso-8859-8-i':\n case 'logical':\n return 'ISO-8859-8-I'\n case 'csisolatin6':\n case 'iso-8859-10':\n case 'iso-ir-157':\n case 'iso8859-10':\n case 'iso885910':\n case 'l6':\n case 'latin6':\n return 'ISO-8859-10'\n case 'iso-8859-13':\n case 'iso8859-13':\n case 'iso885913':\n return 'ISO-8859-13'\n case 'iso-8859-14':\n case 'iso8859-14':\n case 'iso885914':\n return 'ISO-8859-14'\n case 'csisolatin9':\n case 'iso-8859-15':\n case 'iso8859-15':\n case 'iso885915':\n case 'iso_8859-15':\n case 'l9':\n return 'ISO-8859-15'\n case 'iso-8859-16':\n return 'ISO-8859-16'\n case 'cskoi8r':\n case 'koi':\n case 'koi8':\n case 'koi8-r':\n case 'koi8_r':\n return 'KOI8-R'\n case 'koi8-ru':\n case 'koi8-u':\n return 'KOI8-U'\n case 'csmacintosh':\n case 'mac':\n case 'macintosh':\n case 'x-mac-roman':\n return 'macintosh'\n case 'iso-8859-11':\n case 'iso8859-11':\n case 'iso885911':\n case 'tis-620':\n case 'windows-874':\n return 'windows-874'\n case 'cp1250':\n case 'windows-1250':\n case 'x-cp1250':\n return 'windows-1250'\n case 'cp1251':\n case 'windows-1251':\n case 'x-cp1251':\n return 'windows-1251'\n case 'ansi_x3.4-1968':\n case 'ascii':\n case 'cp1252':\n case 'cp819':\n case 'csisolatin1':\n case 'ibm819':\n case 'iso-8859-1':\n case 'iso-ir-100':\n case 'iso8859-1':\n case 'iso88591':\n case 'iso_8859-1':\n case 'iso_8859-1:1987':\n case 'l1':\n case 'latin1':\n case 'us-ascii':\n case 'windows-1252':\n case 'x-cp1252':\n return 'windows-1252'\n case 'cp1253':\n case 'windows-1253':\n case 'x-cp1253':\n return 'windows-1253'\n case 'cp1254':\n case 'csisolatin5':\n case 'iso-8859-9':\n case 'iso-ir-148':\n case 'iso8859-9':\n case 'iso88599':\n case 'iso_8859-9':\n case 'iso_8859-9:1989':\n case 'l5':\n case 'latin5':\n case 'windows-1254':\n case 'x-cp1254':\n return 'windows-1254'\n case 'cp1255':\n case 'windows-1255':\n case 'x-cp1255':\n return 'windows-1255'\n case 'cp1256':\n case 'windows-1256':\n case 'x-cp1256':\n return 'windows-1256'\n case 'cp1257':\n case 'windows-1257':\n case 'x-cp1257':\n return 'windows-1257'\n case 'cp1258':\n case 'windows-1258':\n case 'x-cp1258':\n return 'windows-1258'\n case 'x-mac-cyrillic':\n case 'x-mac-ukrainian':\n return 'x-mac-cyrillic'\n case 'chinese':\n case 'csgb2312':\n case 'csiso58gb231280':\n case 'gb2312':\n case 'gb_2312':\n case 'gb_2312-80':\n case 'gbk':\n case 'iso-ir-58':\n case 'x-gbk':\n return 'GBK'\n case 'gb18030':\n return 'gb18030'\n case 'big5':\n case 'big5-hkscs':\n case 'cn-big5':\n case 'csbig5':\n case 'x-x-big5':\n return 'Big5'\n case 'cseucpkdfmtjapanese':\n case 'euc-jp':\n case 'x-euc-jp':\n return 'EUC-JP'\n case 'csiso2022jp':\n case 'iso-2022-jp':\n return 'ISO-2022-JP'\n case 'csshiftjis':\n case 'ms932':\n case 'ms_kanji':\n case 'shift-jis':\n case 'shift_jis':\n case 'sjis':\n case 'windows-31j':\n case 'x-sjis':\n return 'Shift_JIS'\n case 'cseuckr':\n case 'csksc56011987':\n case 'euc-kr':\n case 'iso-ir-149':\n case 'korean':\n case 'ks_c_5601-1987':\n case 'ks_c_5601-1989':\n case 'ksc5601':\n case 'ksc_5601':\n case 'windows-949':\n return 'EUC-KR'\n case 'csiso2022kr':\n case 'hz-gb-2312':\n case 'iso-2022-cn':\n case 'iso-2022-cn-ext':\n case 'iso-2022-kr':\n case 'replacement':\n return 'replacement'\n case 'unicodefffe':\n case 'utf-16be':\n return 'UTF-16BE'\n case 'csunicode':\n case 'iso-10646-ucs-2':\n case 'ucs-2':\n case 'unicode':\n case 'unicodefeff':\n case 'utf-16':\n case 'utf-16le':\n return 'UTF-16LE'\n case 'x-user-defined':\n return 'x-user-defined'\n default: return 'failure'\n }\n}\n\nmodule.exports = {\n getEncoding\n}\n\n\n/***/ }),\n\n/***/ 1446:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\n\"use strict\";\n\n\nconst {\n staticPropertyDescriptors,\n readOperation,\n fireAProgressEvent\n} = __nccwpck_require__(7530)\nconst {\n kState,\n kError,\n kResult,\n kEvents,\n kAborted\n} = __nccwpck_require__(9054)\nconst { webidl } = __nccwpck_require__(1744)\nconst { kEnumerableProperty } = __nccwpck_require__(3983)\n\nclass FileReader extends EventTarget {\n constructor () {\n super()\n\n this[kState] = 'empty'\n this[kResult] = null\n this[kError] = null\n this[kEvents] = {\n loadend: null,\n error: null,\n abort: null,\n load: null,\n progress: null,\n loadstart: null\n }\n }\n\n /**\n * @see https://w3c.github.io/FileAPI/#dfn-readAsArrayBuffer\n * @param {import('buffer').Blob} blob\n */\n readAsArrayBuffer (blob) {\n webidl.brandCheck(this, FileReader)\n\n webidl.argumentLengthCheck(arguments, 1, { header: 'FileReader.readAsArrayBuffer' })\n\n blob = webidl.converters.Blob(blob, { strict: false })\n\n // The readAsArrayBuffer(blob) method, when invoked,\n // must initiate a read operation for blob with ArrayBuffer.\n readOperation(this, blob, 'ArrayBuffer')\n }\n\n /**\n * @see https://w3c.github.io/FileAPI/#readAsBinaryString\n * @param {import('buffer').Blob} blob\n */\n readAsBinaryString (blob) {\n webidl.brandCheck(this, FileReader)\n\n webidl.argumentLengthCheck(arguments, 1, { header: 'FileReader.readAsBinaryString' })\n\n blob = webidl.converters.Blob(blob, { strict: false })\n\n // The readAsBinaryString(blob) method, when invoked,\n // must initiate a read operation for blob with BinaryString.\n readOperation(this, blob, 'BinaryString')\n }\n\n /**\n * @see https://w3c.github.io/FileAPI/#readAsDataText\n * @param {import('buffer').Blob} blob\n * @param {string?} encoding\n */\n readAsText (blob, encoding = undefined) {\n webidl.brandCheck(this, FileReader)\n\n webidl.argumentLengthCheck(arguments, 1, { header: 'FileReader.readAsText' })\n\n blob = webidl.converters.Blob(blob, { strict: false })\n\n if (encoding !== undefined) {\n encoding = webidl.converters.DOMString(encoding)\n }\n\n // The readAsText(blob, encoding) method, when invoked,\n // must initiate a read operation for blob with Text and encoding.\n readOperation(this, blob, 'Text', encoding)\n }\n\n /**\n * @see https://w3c.github.io/FileAPI/#dfn-readAsDataURL\n * @param {import('buffer').Blob} blob\n */\n readAsDataURL (blob) {\n webidl.brandCheck(this, FileReader)\n\n webidl.argumentLengthCheck(arguments, 1, { header: 'FileReader.readAsDataURL' })\n\n blob = webidl.converters.Blob(blob, { strict: false })\n\n // The readAsDataURL(blob) method, when invoked, must\n // initiate a read operation for blob with DataURL.\n readOperation(this, blob, 'DataURL')\n }\n\n /**\n * @see https://w3c.github.io/FileAPI/#dfn-abort\n */\n abort () {\n // 1. If this's state is \"empty\" or if this's state is\n // \"done\" set this's result to null and terminate\n // this algorithm.\n if (this[kState] === 'empty' || this[kState] === 'done') {\n this[kResult] = null\n return\n }\n\n // 2. If this's state is \"loading\" set this's state to\n // \"done\" and set this's result to null.\n if (this[kState] === 'loading') {\n this[kState] = 'done'\n this[kResult] = null\n }\n\n // 3. If there are any tasks from this on the file reading\n // task source in an affiliated task queue, then remove\n // those tasks from that task queue.\n this[kAborted] = true\n\n // 4. Terminate the algorithm for the read method being processed.\n // TODO\n\n // 5. Fire a progress event called abort at this.\n fireAProgressEvent('abort', this)\n\n // 6. If this's state is not \"loading\", fire a progress\n // event called loadend at this.\n if (this[kState] !== 'loading') {\n fireAProgressEvent('loadend', this)\n }\n }\n\n /**\n * @see https://w3c.github.io/FileAPI/#dom-filereader-readystate\n */\n get readyState () {\n webidl.brandCheck(this, FileReader)\n\n switch (this[kState]) {\n case 'empty': return this.EMPTY\n case 'loading': return this.LOADING\n case 'done': return this.DONE\n }\n }\n\n /**\n * @see https://w3c.github.io/FileAPI/#dom-filereader-result\n */\n get result () {\n webidl.brandCheck(this, FileReader)\n\n // The result attribute\u2019s getter, when invoked, must return\n // this's result.\n return this[kResult]\n }\n\n /**\n * @see https://w3c.github.io/FileAPI/#dom-filereader-error\n */\n get error () {\n webidl.brandCheck(this, FileReader)\n\n // The error attribute\u2019s getter, when invoked, must return\n // this's error.\n return this[kError]\n }\n\n get onloadend () {\n webidl.brandCheck(this, FileReader)\n\n return this[kEvents].loadend\n }\n\n set onloadend (fn) {\n webidl.brandCheck(this, FileReader)\n\n if (this[kEvents].loadend) {\n this.removeEventListener('loadend', this[kEvents].loadend)\n }\n\n if (typeof fn === 'function') {\n this[kEvents].loadend = fn\n this.addEventListener('loadend', fn)\n } else {\n this[kEvents].loadend = null\n }\n }\n\n get onerror () {\n webidl.brandCheck(this, FileReader)\n\n return this[kEvents].error\n }\n\n set onerror (fn) {\n webidl.brandCheck(this, FileReader)\n\n if (this[kEvents].error) {\n this.removeEventListener('error', this[kEvents].error)\n }\n\n if (typeof fn === 'function') {\n this[kEvents].error = fn\n this.addEventListener('error', fn)\n } else {\n this[kEvents].error = null\n }\n }\n\n get onloadstart () {\n webidl.brandCheck(this, FileReader)\n\n return this[kEvents].loadstart\n }\n\n set onloadstart (fn) {\n webidl.brandCheck(this, FileReader)\n\n if (this[kEvents].loadstart) {\n this.removeEventListener('loadstart', this[kEvents].loadstart)\n }\n\n if (typeof fn === 'function') {\n this[kEvents].loadstart = fn\n this.addEventListener('loadstart', fn)\n } else {\n this[kEvents].loadstart = null\n }\n }\n\n get onprogress () {\n webidl.brandCheck(this, FileReader)\n\n return this[kEvents].progress\n }\n\n set onprogress (fn) {\n webidl.brandCheck(this, FileReader)\n\n if (this[kEvents].progress) {\n this.removeEventListener('progress', this[kEvents].progress)\n }\n\n if (typeof fn === 'function') {\n this[kEvents].progress = fn\n this.addEventListener('progress', fn)\n } else {\n this[kEvents].progress = null\n }\n }\n\n get onload () {\n webidl.brandCheck(this, FileReader)\n\n return this[kEvents].load\n }\n\n set onload (fn) {\n webidl.brandCheck(this, FileReader)\n\n if (this[kEvents].load) {\n this.removeEventListener('load', this[kEvents].load)\n }\n\n if (typeof fn === 'function') {\n this[kEvents].load = fn\n this.addEventListener('load', fn)\n } else {\n this[kEvents].load = null\n }\n }\n\n get onabort () {\n webidl.brandCheck(this, FileReader)\n\n return this[kEvents].abort\n }\n\n set onabort (fn) {\n webidl.brandCheck(this, FileReader)\n\n if (this[kEvents].abort) {\n this.removeEventListener('abort', this[kEvents].abort)\n }\n\n if (typeof fn === 'function') {\n this[kEvents].abort = fn\n this.addEventListener('abort', fn)\n } else {\n this[kEvents].abort = null\n }\n }\n}\n\n// https://w3c.github.io/FileAPI/#dom-filereader-empty\nFileReader.EMPTY = FileReader.prototype.EMPTY = 0\n// https://w3c.github.io/FileAPI/#dom-filereader-loading\nFileReader.LOADING = FileReader.prototype.LOADING = 1\n// https://w3c.github.io/FileAPI/#dom-filereader-done\nFileReader.DONE = FileReader.prototype.DONE = 2\n\nObject.defineProperties(FileReader.prototype, {\n EMPTY: staticPropertyDescriptors,\n LOADING: staticPropertyDescriptors,\n DONE: staticPropertyDescriptors,\n readAsArrayBuffer: kEnumerableProperty,\n readAsBinaryString: kEnumerableProperty,\n readAsText: kEnumerableProperty,\n readAsDataURL: kEnumerableProperty,\n abort: kEnumerableProperty,\n readyState: kEnumerableProperty,\n result: kEnumerableProperty,\n error: kEnumerableProperty,\n onloadstart: kEnumerableProperty,\n onprogress: kEnumerableProperty,\n onload: kEnumerableProperty,\n onabort: kEnumerableProperty,\n onerror: kEnumerableProperty,\n onloadend: kEnumerableProperty,\n [Symbol.toStringTag]: {\n value: 'FileReader',\n writable: false,\n enumerable: false,\n configurable: true\n }\n})\n\nObject.defineProperties(FileReader, {\n EMPTY: staticPropertyDescriptors,\n LOADING: staticPropertyDescriptors,\n DONE: staticPropertyDescriptors\n})\n\nmodule.exports = {\n FileReader\n}\n\n\n/***/ }),\n\n/***/ 5504:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\n\"use strict\";\n\n\nconst { webidl } = __nccwpck_require__(1744)\n\nconst kState = Symbol('ProgressEvent state')\n\n/**\n * @see https://xhr.spec.whatwg.org/#progressevent\n */\nclass ProgressEvent extends Event {\n constructor (type, eventInitDict = {}) {\n type = webidl.converters.DOMString(type)\n eventInitDict = webidl.converters.ProgressEventInit(eventInitDict ?? {})\n\n super(type, eventInitDict)\n\n this[kState] = {\n lengthComputable: eventInitDict.lengthComputable,\n loaded: eventInitDict.loaded,\n total: eventInitDict.total\n }\n }\n\n get lengthComputable () {\n webidl.brandCheck(this, ProgressEvent)\n\n return this[kState].lengthComputable\n }\n\n get loaded () {\n webidl.brandCheck(this, ProgressEvent)\n\n return this[kState].loaded\n }\n\n get total () {\n webidl.brandCheck(this, ProgressEvent)\n\n return this[kState].total\n }\n}\n\nwebidl.converters.ProgressEventInit = webidl.dictionaryConverter([\n {\n key: 'lengthComputable',\n converter: webidl.converters.boolean,\n defaultValue: false\n },\n {\n key: 'loaded',\n converter: webidl.converters['unsigned long long'],\n defaultValue: 0\n },\n {\n key: 'total',\n converter: webidl.converters['unsigned long long'],\n defaultValue: 0\n },\n {\n key: 'bubbles',\n converter: webidl.converters.boolean,\n defaultValue: false\n },\n {\n key: 'cancelable',\n converter: webidl.converters.boolean,\n defaultValue: false\n },\n {\n key: 'composed',\n converter: webidl.converters.boolean,\n defaultValue: false\n }\n])\n\nmodule.exports = {\n ProgressEvent\n}\n\n\n/***/ }),\n\n/***/ 9054:\n/***/ ((module) => {\n\n\"use strict\";\n\n\nmodule.exports = {\n kState: Symbol('FileReader state'),\n kResult: Symbol('FileReader result'),\n kError: Symbol('FileReader error'),\n kLastProgressEventFired: Symbol('FileReader last progress event fired timestamp'),\n kEvents: Symbol('FileReader events'),\n kAborted: Symbol('FileReader aborted')\n}\n\n\n/***/ }),\n\n/***/ 7530:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\n\"use strict\";\n\n\nconst {\n kState,\n kError,\n kResult,\n kAborted,\n kLastProgressEventFired\n} = __nccwpck_require__(9054)\nconst { ProgressEvent } = __nccwpck_require__(5504)\nconst { getEncoding } = __nccwpck_require__(4854)\nconst { DOMException } = __nccwpck_require__(1037)\nconst { serializeAMimeType, parseMIMEType } = __nccwpck_require__(685)\nconst { types } = __nccwpck_require__(3837)\nconst { StringDecoder } = __nccwpck_require__(1576)\nconst { btoa } = __nccwpck_require__(4300)\n\n/** @type {PropertyDescriptor} */\nconst staticPropertyDescriptors = {\n enumerable: true,\n writable: false,\n configurable: false\n}\n\n/**\n * @see https://w3c.github.io/FileAPI/#readOperation\n * @param {import('./filereader').FileReader} fr\n * @param {import('buffer').Blob} blob\n * @param {string} type\n * @param {string?} encodingName\n */\nfunction readOperation (fr, blob, type, encodingName) {\n // 1. If fr\u2019s state is \"loading\", throw an InvalidStateError\n // DOMException.\n if (fr[kState] === 'loading') {\n throw new DOMException('Invalid state', 'InvalidStateError')\n }\n\n // 2. Set fr\u2019s state to \"loading\".\n fr[kState] = 'loading'\n\n // 3. Set fr\u2019s result to null.\n fr[kResult] = null\n\n // 4. Set fr\u2019s error to null.\n fr[kError] = null\n\n // 5. Let stream be the result of calling get stream on blob.\n /** @type {import('stream/web').ReadableStream} */\n const stream = blob.stream()\n\n // 6. Let reader be the result of getting a reader from stream.\n const reader = stream.getReader()\n\n // 7. Let bytes be an empty byte sequence.\n /** @type {Uint8Array[]} */\n const bytes = []\n\n // 8. Let chunkPromise be the result of reading a chunk from\n // stream with reader.\n let chunkPromise = reader.read()\n\n // 9. Let isFirstChunk be true.\n let isFirstChunk = true\n\n // 10. In parallel, while true:\n // Note: \"In parallel\" just means non-blocking\n // Note 2: readOperation itself cannot be async as double\n // reading the body would then reject the promise, instead\n // of throwing an error.\n ;(async () => {\n while (!fr[kAborted]) {\n // 1. Wait for chunkPromise to be fulfilled or rejected.\n try {\n const { done, value } = await chunkPromise\n\n // 2. If chunkPromise is fulfilled, and isFirstChunk is\n // true, queue a task to fire a progress event called\n // loadstart at fr.\n if (isFirstChunk && !fr[kAborted]) {\n queueMicrotask(() => {\n fireAProgressEvent('loadstart', fr)\n })\n }\n\n // 3. Set isFirstChunk to false.\n isFirstChunk = false\n\n // 4. If chunkPromise is fulfilled with an object whose\n // done property is false and whose value property is\n // a Uint8Array object, run these steps:\n if (!done && types.isUint8Array(value)) {\n // 1. Let bs be the byte sequence represented by the\n // Uint8Array object.\n\n // 2. Append bs to bytes.\n bytes.push(value)\n\n // 3. If roughly 50ms have passed since these steps\n // were last invoked, queue a task to fire a\n // progress event called progress at fr.\n if (\n (\n fr[kLastProgressEventFired] === undefined ||\n Date.now() - fr[kLastProgressEventFired] >= 50\n ) &&\n !fr[kAborted]\n ) {\n fr[kLastProgressEventFired] = Date.now()\n queueMicrotask(() => {\n fireAProgressEvent('progress', fr)\n })\n }\n\n // 4. Set chunkPromise to the result of reading a\n // chunk from stream with reader.\n chunkPromise = reader.read()\n } else if (done) {\n // 5. Otherwise, if chunkPromise is fulfilled with an\n // object whose done property is true, queue a task\n // to run the following steps and abort this algorithm:\n queueMicrotask(() => {\n // 1. Set fr\u2019s state to \"done\".\n fr[kState] = 'done'\n\n // 2. Let result be the result of package data given\n // bytes, type, blob\u2019s type, and encodingName.\n try {\n const result = packageData(bytes, type, blob.type, encodingName)\n\n // 4. Else:\n\n if (fr[kAborted]) {\n return\n }\n\n // 1. Set fr\u2019s result to result.\n fr[kResult] = result\n\n // 2. Fire a progress event called load at the fr.\n fireAProgressEvent('load', fr)\n } catch (error) {\n // 3. If package data threw an exception error:\n\n // 1. Set fr\u2019s error to error.\n fr[kError] = error\n\n // 2. Fire a progress event called error at fr.\n fireAProgressEvent('error', fr)\n }\n\n // 5. If fr\u2019s state is not \"loading\", fire a progress\n // event called loadend at the fr.\n if (fr[kState] !== 'loading') {\n fireAProgressEvent('loadend', fr)\n }\n })\n\n break\n }\n } catch (error) {\n if (fr[kAborted]) {\n return\n }\n\n // 6. Otherwise, if chunkPromise is rejected with an\n // error error, queue a task to run the following\n // steps and abort this algorithm:\n queueMicrotask(() => {\n // 1. Set fr\u2019s state to \"done\".\n fr[kState] = 'done'\n\n // 2. Set fr\u2019s error to error.\n fr[kError] = error\n\n // 3. Fire a progress event called error at fr.\n fireAProgressEvent('error', fr)\n\n // 4. If fr\u2019s state is not \"loading\", fire a progress\n // event called loadend at fr.\n if (fr[kState] !== 'loading') {\n fireAProgressEvent('loadend', fr)\n }\n })\n\n break\n }\n }\n })()\n}\n\n/**\n * @see https://w3c.github.io/FileAPI/#fire-a-progress-event\n * @see https://dom.spec.whatwg.org/#concept-event-fire\n * @param {string} e The name of the event\n * @param {import('./filereader').FileReader} reader\n */\nfunction fireAProgressEvent (e, reader) {\n // The progress event e does not bubble. e.bubbles must be false\n // The progress event e is NOT cancelable. e.cancelable must be false\n const event = new ProgressEvent(e, {\n bubbles: false,\n cancelable: false\n })\n\n reader.dispatchEvent(event)\n}\n\n/**\n * @see https://w3c.github.io/FileAPI/#blob-package-data\n * @param {Uint8Array[]} bytes\n * @param {string} type\n * @param {string?} mimeType\n * @param {string?} encodingName\n */\nfunction packageData (bytes, type, mimeType, encodingName) {\n // 1. A Blob has an associated package data algorithm, given\n // bytes, a type, a optional mimeType, and a optional\n // encodingName, which switches on type and runs the\n // associated steps:\n\n switch (type) {\n case 'DataURL': {\n // 1. Return bytes as a DataURL [RFC2397] subject to\n // the considerations below:\n // * Use mimeType as part of the Data URL if it is\n // available in keeping with the Data URL\n // specification [RFC2397].\n // * If mimeType is not available return a Data URL\n // without a media-type. [RFC2397].\n\n // https://datatracker.ietf.org/doc/html/rfc2397#section-3\n // dataurl := \"data:\" [ mediatype ] [ \";base64\" ] \",\" data\n // mediatype := [ type \"/\" subtype ] *( \";\" parameter )\n // data := *urlchar\n // parameter := attribute \"=\" value\n let dataURL = 'data:'\n\n const parsed = parseMIMEType(mimeType || 'application/octet-stream')\n\n if (parsed !== 'failure') {\n dataURL += serializeAMimeType(parsed)\n }\n\n dataURL += ';base64,'\n\n const decoder = new StringDecoder('latin1')\n\n for (const chunk of bytes) {\n dataURL += btoa(decoder.write(chunk))\n }\n\n dataURL += btoa(decoder.end())\n\n return dataURL\n }\n case 'Text': {\n // 1. Let encoding be failure\n let encoding = 'failure'\n\n // 2. If the encodingName is present, set encoding to the\n // result of getting an encoding from encodingName.\n if (encodingName) {\n encoding = getEncoding(encodingName)\n }\n\n // 3. If encoding is failure, and mimeType is present:\n if (encoding === 'failure' && mimeType) {\n // 1. Let type be the result of parse a MIME type\n // given mimeType.\n const type = parseMIMEType(mimeType)\n\n // 2. If type is not failure, set encoding to the result\n // of getting an encoding from type\u2019s parameters[\"charset\"].\n if (type !== 'failure') {\n encoding = getEncoding(type.parameters.get('charset'))\n }\n }\n\n // 4. If encoding is failure, then set encoding to UTF-8.\n if (encoding === 'failure') {\n encoding = 'UTF-8'\n }\n\n // 5. Decode bytes using fallback encoding encoding, and\n // return the result.\n return decode(bytes, encoding)\n }\n case 'ArrayBuffer': {\n // Return a new ArrayBuffer whose contents are bytes.\n const sequence = combineByteSequences(bytes)\n\n return sequence.buffer\n }\n case 'BinaryString': {\n // Return bytes as a binary string, in which every byte\n // is represented by a code unit of equal value [0..255].\n let binaryString = ''\n\n const decoder = new StringDecoder('latin1')\n\n for (const chunk of bytes) {\n binaryString += decoder.write(chunk)\n }\n\n binaryString += decoder.end()\n\n return binaryString\n }\n }\n}\n\n/**\n * @see https://encoding.spec.whatwg.org/#decode\n * @param {Uint8Array[]} ioQueue\n * @param {string} encoding\n */\nfunction decode (ioQueue, encoding) {\n const bytes = combineByteSequences(ioQueue)\n\n // 1. Let BOMEncoding be the result of BOM sniffing ioQueue.\n const BOMEncoding = BOMSniffing(bytes)\n\n let slice = 0\n\n // 2. If BOMEncoding is non-null:\n if (BOMEncoding !== null) {\n // 1. Set encoding to BOMEncoding.\n encoding = BOMEncoding\n\n // 2. Read three bytes from ioQueue, if BOMEncoding is\n // UTF-8; otherwise read two bytes.\n // (Do nothing with those bytes.)\n slice = BOMEncoding === 'UTF-8' ? 3 : 2\n }\n\n // 3. Process a queue with an instance of encoding\u2019s\n // decoder, ioQueue, output, and \"replacement\".\n\n // 4. Return output.\n\n const sliced = bytes.slice(slice)\n return new TextDecoder(encoding).decode(sliced)\n}\n\n/**\n * @see https://encoding.spec.whatwg.org/#bom-sniff\n * @param {Uint8Array} ioQueue\n */\nfunction BOMSniffing (ioQueue) {\n // 1. Let BOM be the result of peeking 3 bytes from ioQueue,\n // converted to a byte sequence.\n const [a, b, c] = ioQueue\n\n // 2. For each of the rows in the table below, starting with\n // the first one and going down, if BOM starts with the\n // bytes given in the first column, then return the\n // encoding given in the cell in the second column of that\n // row. Otherwise, return null.\n if (a === 0xEF && b === 0xBB && c === 0xBF) {\n return 'UTF-8'\n } else if (a === 0xFE && b === 0xFF) {\n return 'UTF-16BE'\n } else if (a === 0xFF && b === 0xFE) {\n return 'UTF-16LE'\n }\n\n return null\n}\n\n/**\n * @param {Uint8Array[]} sequences\n */\nfunction combineByteSequences (sequences) {\n const size = sequences.reduce((a, b) => {\n return a + b.byteLength\n }, 0)\n\n let offset = 0\n\n return sequences.reduce((a, b) => {\n a.set(b, offset)\n offset += b.byteLength\n return a\n }, new Uint8Array(size))\n}\n\nmodule.exports = {\n staticPropertyDescriptors,\n readOperation,\n fireAProgressEvent\n}\n\n\n/***/ }),\n\n/***/ 1892:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\n\"use strict\";\n\n\n// We include a version number for the Dispatcher API. In case of breaking changes,\n// this version number must be increased to avoid conflicts.\nconst globalDispatcher = Symbol.for('undici.globalDispatcher.1')\nconst { InvalidArgumentError } = __nccwpck_require__(8045)\nconst Agent = __nccwpck_require__(7890)\n\nif (getGlobalDispatcher() === undefined) {\n setGlobalDispatcher(new Agent())\n}\n\nfunction setGlobalDispatcher (agent) {\n if (!agent || typeof agent.dispatch !== 'function') {\n throw new InvalidArgumentError('Argument agent must implement Agent')\n }\n Object.defineProperty(globalThis, globalDispatcher, {\n value: agent,\n writable: true,\n enumerable: false,\n configurable: false\n })\n}\n\nfunction getGlobalDispatcher () {\n return globalThis[globalDispatcher]\n}\n\nmodule.exports = {\n setGlobalDispatcher,\n getGlobalDispatcher\n}\n\n\n/***/ }),\n\n/***/ 6930:\n/***/ ((module) => {\n\n\"use strict\";\n\n\nmodule.exports = class DecoratorHandler {\n constructor (handler) {\n this.handler = handler\n }\n\n onConnect (...args) {\n return this.handler.onConnect(...args)\n }\n\n onError (...args) {\n return this.handler.onError(...args)\n }\n\n onUpgrade (...args) {\n return this.handler.onUpgrade(...args)\n }\n\n onHeaders (...args) {\n return this.handler.onHeaders(...args)\n }\n\n onData (...args) {\n return this.handler.onData(...args)\n }\n\n onComplete (...args) {\n return this.handler.onComplete(...args)\n }\n\n onBodySent (...args) {\n return this.handler.onBodySent(...args)\n }\n}\n\n\n/***/ }),\n\n/***/ 2860:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\n\"use strict\";\n\n\nconst util = __nccwpck_require__(3983)\nconst { kBodyUsed } = __nccwpck_require__(2785)\nconst assert = __nccwpck_require__(9491)\nconst { InvalidArgumentError } = __nccwpck_require__(8045)\nconst EE = __nccwpck_require__(2361)\n\nconst redirectableStatusCodes = [300, 301, 302, 303, 307, 308]\n\nconst kBody = Symbol('body')\n\nclass BodyAsyncIterable {\n constructor (body) {\n this[kBody] = body\n this[kBodyUsed] = false\n }\n\n async * [Symbol.asyncIterator] () {\n assert(!this[kBodyUsed], 'disturbed')\n this[kBodyUsed] = true\n yield * this[kBody]\n }\n}\n\nclass RedirectHandler {\n constructor (dispatch, maxRedirections, opts, handler) {\n if (maxRedirections != null && (!Number.isInteger(maxRedirections) || maxRedirections < 0)) {\n throw new InvalidArgumentError('maxRedirections must be a positive number')\n }\n\n util.validateHandler(handler, opts.method, opts.upgrade)\n\n this.dispatch = dispatch\n this.location = null\n this.abort = null\n this.opts = { ...opts, maxRedirections: 0 } // opts must be a copy\n this.maxRedirections = maxRedirections\n this.handler = handler\n this.history = []\n\n if (util.isStream(this.opts.body)) {\n // TODO (fix): Provide some way for the user to cache the file to e.g. /tmp\n // so that it can be dispatched again?\n // TODO (fix): Do we need 100-expect support to provide a way to do this properly?\n if (util.bodyLength(this.opts.body) === 0) {\n this.opts.body\n .on('data', function () {\n assert(false)\n })\n }\n\n if (typeof this.opts.body.readableDidRead !== 'boolean') {\n this.opts.body[kBodyUsed] = false\n EE.prototype.on.call(this.opts.body, 'data', function () {\n this[kBodyUsed] = true\n })\n }\n } else if (this.opts.body && typeof this.opts.body.pipeTo === 'function') {\n // TODO (fix): We can't access ReadableStream internal state\n // to determine whether or not it has been disturbed. This is just\n // a workaround.\n this.opts.body = new BodyAsyncIterable(this.opts.body)\n } else if (\n this.opts.body &&\n typeof this.opts.body !== 'string' &&\n !ArrayBuffer.isView(this.opts.body) &&\n util.isIterable(this.opts.body)\n ) {\n // TODO: Should we allow re-using iterable if !this.opts.idempotent\n // or through some other flag?\n this.opts.body = new BodyAsyncIterable(this.opts.body)\n }\n }\n\n onConnect (abort) {\n this.abort = abort\n this.handler.onConnect(abort, { history: this.history })\n }\n\n onUpgrade (statusCode, headers, socket) {\n this.handler.onUpgrade(statusCode, headers, socket)\n }\n\n onError (error) {\n this.handler.onError(error)\n }\n\n onHeaders (statusCode, headers, resume, statusText) {\n this.location = this.history.length >= this.maxRedirections || util.isDisturbed(this.opts.body)\n ? null\n : parseLocation(statusCode, headers)\n\n if (this.opts.origin) {\n this.history.push(new URL(this.opts.path, this.opts.origin))\n }\n\n if (!this.location) {\n return this.handler.onHeaders(statusCode, headers, resume, statusText)\n }\n\n const { origin, pathname, search } = util.parseURL(new URL(this.location, this.opts.origin && new URL(this.opts.path, this.opts.origin)))\n const path = search ? `${pathname}${search}` : pathname\n\n // Remove headers referring to the original URL.\n // By default it is Host only, unless it's a 303 (see below), which removes also all Content-* headers.\n // https://tools.ietf.org/html/rfc7231#section-6.4\n this.opts.headers = cleanRequestHeaders(this.opts.headers, statusCode === 303, this.opts.origin !== origin)\n this.opts.path = path\n this.opts.origin = origin\n this.opts.maxRedirections = 0\n this.opts.query = null\n\n // https://tools.ietf.org/html/rfc7231#section-6.4.4\n // In case of HTTP 303, always replace method to be either HEAD or GET\n if (statusCode === 303 && this.opts.method !== 'HEAD') {\n this.opts.method = 'GET'\n this.opts.body = null\n }\n }\n\n onData (chunk) {\n if (this.location) {\n /*\n https://tools.ietf.org/html/rfc7231#section-6.4\n\n TLDR: undici always ignores 3xx response bodies.\n\n Redirection is used to serve the requested resource from another URL, so it is assumes that\n no body is generated (and thus can be ignored). Even though generating a body is not prohibited.\n\n For status 301, 302, 303, 307 and 308 (the latter from RFC 7238), the specs mention that the body usually\n (which means it's optional and not mandated) contain just an hyperlink to the value of\n the Location response header, so the body can be ignored safely.\n\n For status 300, which is \"Multiple Choices\", the spec mentions both generating a Location\n response header AND a response body with the other possible location to follow.\n Since the spec explicitily chooses not to specify a format for such body and leave it to\n servers and browsers implementors, we ignore the body as there is no specified way to eventually parse it.\n */\n } else {\n return this.handler.onData(chunk)\n }\n }\n\n onComplete (trailers) {\n if (this.location) {\n /*\n https://tools.ietf.org/html/rfc7231#section-6.4\n\n TLDR: undici always ignores 3xx response trailers as they are not expected in case of redirections\n and neither are useful if present.\n\n See comment on onData method above for more detailed informations.\n */\n\n this.location = null\n this.abort = null\n\n this.dispatch(this.opts, this)\n } else {\n this.handler.onComplete(trailers)\n }\n }\n\n onBodySent (chunk) {\n if (this.handler.onBodySent) {\n this.handler.onBodySent(chunk)\n }\n }\n}\n\nfunction parseLocation (statusCode, headers) {\n if (redirectableStatusCodes.indexOf(statusCode) === -1) {\n return null\n }\n\n for (let i = 0; i < headers.length; i += 2) {\n if (headers[i].toString().toLowerCase() === 'location') {\n return headers[i + 1]\n }\n }\n}\n\n// https://tools.ietf.org/html/rfc7231#section-6.4.4\nfunction shouldRemoveHeader (header, removeContent, unknownOrigin) {\n if (header.length === 4) {\n return util.headerNameToString(header) === 'host'\n }\n if (removeContent && util.headerNameToString(header).startsWith('content-')) {\n return true\n }\n if (unknownOrigin && (header.length === 13 || header.length === 6 || header.length === 19)) {\n const name = util.headerNameToString(header)\n return name === 'authorization' || name === 'cookie' || name === 'proxy-authorization'\n }\n return false\n}\n\n// https://tools.ietf.org/html/rfc7231#section-6.4\nfunction cleanRequestHeaders (headers, removeContent, unknownOrigin) {\n const ret = []\n if (Array.isArray(headers)) {\n for (let i = 0; i < headers.length; i += 2) {\n if (!shouldRemoveHeader(headers[i], removeContent, unknownOrigin)) {\n ret.push(headers[i], headers[i + 1])\n }\n }\n } else if (headers && typeof headers === 'object') {\n for (const key of Object.keys(headers)) {\n if (!shouldRemoveHeader(key, removeContent, unknownOrigin)) {\n ret.push(key, headers[key])\n }\n }\n } else {\n assert(headers == null, 'headers must be an object or an array')\n }\n return ret\n}\n\nmodule.exports = RedirectHandler\n\n\n/***/ }),\n\n/***/ 2286:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\nconst assert = __nccwpck_require__(9491)\n\nconst { kRetryHandlerDefaultRetry } = __nccwpck_require__(2785)\nconst { RequestRetryError } = __nccwpck_require__(8045)\nconst { isDisturbed, parseHeaders, parseRangeHeader } = __nccwpck_require__(3983)\n\nfunction calculateRetryAfterHeader (retryAfter) {\n const current = Date.now()\n const diff = new Date(retryAfter).getTime() - current\n\n return diff\n}\n\nclass RetryHandler {\n constructor (opts, handlers) {\n const { retryOptions, ...dispatchOpts } = opts\n const {\n // Retry scoped\n retry: retryFn,\n maxRetries,\n maxTimeout,\n minTimeout,\n timeoutFactor,\n // Response scoped\n methods,\n errorCodes,\n retryAfter,\n statusCodes\n } = retryOptions ?? {}\n\n this.dispatch = handlers.dispatch\n this.handler = handlers.handler\n this.opts = dispatchOpts\n this.abort = null\n this.aborted = false\n this.retryOpts = {\n retry: retryFn ?? RetryHandler[kRetryHandlerDefaultRetry],\n retryAfter: retryAfter ?? true,\n maxTimeout: maxTimeout ?? 30 * 1000, // 30s,\n timeout: minTimeout ?? 500, // .5s\n timeoutFactor: timeoutFactor ?? 2,\n maxRetries: maxRetries ?? 5,\n // What errors we should retry\n methods: methods ?? ['GET', 'HEAD', 'OPTIONS', 'PUT', 'DELETE', 'TRACE'],\n // Indicates which errors to retry\n statusCodes: statusCodes ?? [500, 502, 503, 504, 429],\n // List of errors to retry\n errorCodes: errorCodes ?? [\n 'ECONNRESET',\n 'ECONNREFUSED',\n 'ENOTFOUND',\n 'ENETDOWN',\n 'ENETUNREACH',\n 'EHOSTDOWN',\n 'EHOSTUNREACH',\n 'EPIPE'\n ]\n }\n\n this.retryCount = 0\n this.start = 0\n this.end = null\n this.etag = null\n this.resume = null\n\n // Handle possible onConnect duplication\n this.handler.onConnect(reason => {\n this.aborted = true\n if (this.abort) {\n this.abort(reason)\n } else {\n this.reason = reason\n }\n })\n }\n\n onRequestSent () {\n if (this.handler.onRequestSent) {\n this.handler.onRequestSent()\n }\n }\n\n onUpgrade (statusCode, headers, socket) {\n if (this.handler.onUpgrade) {\n this.handler.onUpgrade(statusCode, headers, socket)\n }\n }\n\n onConnect (abort) {\n if (this.aborted) {\n abort(this.reason)\n } else {\n this.abort = abort\n }\n }\n\n onBodySent (chunk) {\n if (this.handler.onBodySent) return this.handler.onBodySent(chunk)\n }\n\n static [kRetryHandlerDefaultRetry] (err, { state, opts }, cb) {\n const { statusCode, code, headers } = err\n const { method, retryOptions } = opts\n const {\n maxRetries,\n timeout,\n maxTimeout,\n timeoutFactor,\n statusCodes,\n errorCodes,\n methods\n } = retryOptions\n let { counter, currentTimeout } = state\n\n currentTimeout =\n currentTimeout != null && currentTimeout > 0 ? currentTimeout : timeout\n\n // Any code that is not a Undici's originated and allowed to retry\n if (\n code &&\n code !== 'UND_ERR_REQ_RETRY' &&\n code !== 'UND_ERR_SOCKET' &&\n !errorCodes.includes(code)\n ) {\n cb(err)\n return\n }\n\n // If a set of method are provided and the current method is not in the list\n if (Array.isArray(methods) && !methods.includes(method)) {\n cb(err)\n return\n }\n\n // If a set of status code are provided and the current status code is not in the list\n if (\n statusCode != null &&\n Array.isArray(statusCodes) &&\n !statusCodes.includes(statusCode)\n ) {\n cb(err)\n return\n }\n\n // If we reached the max number of retries\n if (counter > maxRetries) {\n cb(err)\n return\n }\n\n let retryAfterHeader = headers != null && headers['retry-after']\n if (retryAfterHeader) {\n retryAfterHeader = Number(retryAfterHeader)\n retryAfterHeader = isNaN(retryAfterHeader)\n ? calculateRetryAfterHeader(retryAfterHeader)\n : retryAfterHeader * 1e3 // Retry-After is in seconds\n }\n\n const retryTimeout =\n retryAfterHeader > 0\n ? Math.min(retryAfterHeader, maxTimeout)\n : Math.min(currentTimeout * timeoutFactor ** counter, maxTimeout)\n\n state.currentTimeout = retryTimeout\n\n setTimeout(() => cb(null), retryTimeout)\n }\n\n onHeaders (statusCode, rawHeaders, resume, statusMessage) {\n const headers = parseHeaders(rawHeaders)\n\n this.retryCount += 1\n\n if (statusCode >= 300) {\n this.abort(\n new RequestRetryError('Request failed', statusCode, {\n headers,\n count: this.retryCount\n })\n )\n return false\n }\n\n // Checkpoint for resume from where we left it\n if (this.resume != null) {\n this.resume = null\n\n if (statusCode !== 206) {\n return true\n }\n\n const contentRange = parseRangeHeader(headers['content-range'])\n // If no content range\n if (!contentRange) {\n this.abort(\n new RequestRetryError('Content-Range mismatch', statusCode, {\n headers,\n count: this.retryCount\n })\n )\n return false\n }\n\n // Let's start with a weak etag check\n if (this.etag != null && this.etag !== headers.etag) {\n this.abort(\n new RequestRetryError('ETag mismatch', statusCode, {\n headers,\n count: this.retryCount\n })\n )\n return false\n }\n\n const { start, size, end = size } = contentRange\n\n assert(this.start === start, 'content-range mismatch')\n assert(this.end == null || this.end === end, 'content-range mismatch')\n\n this.resume = resume\n return true\n }\n\n if (this.end == null) {\n if (statusCode === 206) {\n // First time we receive 206\n const range = parseRangeHeader(headers['content-range'])\n\n if (range == null) {\n return this.handler.onHeaders(\n statusCode,\n rawHeaders,\n resume,\n statusMessage\n )\n }\n\n const { start, size, end = size } = range\n\n assert(\n start != null && Number.isFinite(start) && this.start !== start,\n 'content-range mismatch'\n )\n assert(Number.isFinite(start))\n assert(\n end != null && Number.isFinite(end) && this.end !== end,\n 'invalid content-length'\n )\n\n this.start = start\n this.end = end\n }\n\n // We make our best to checkpoint the body for further range headers\n if (this.end == null) {\n const contentLength = headers['content-length']\n this.end = contentLength != null ? Number(contentLength) : null\n }\n\n assert(Number.isFinite(this.start))\n assert(\n this.end == null || Number.isFinite(this.end),\n 'invalid content-length'\n )\n\n this.resume = resume\n this.etag = headers.etag != null ? headers.etag : null\n\n return this.handler.onHeaders(\n statusCode,\n rawHeaders,\n resume,\n statusMessage\n )\n }\n\n const err = new RequestRetryError('Request failed', statusCode, {\n headers,\n count: this.retryCount\n })\n\n this.abort(err)\n\n return false\n }\n\n onData (chunk) {\n this.start += chunk.length\n\n return this.handler.onData(chunk)\n }\n\n onComplete (rawTrailers) {\n this.retryCount = 0\n return this.handler.onComplete(rawTrailers)\n }\n\n onError (err) {\n if (this.aborted || isDisturbed(this.opts.body)) {\n return this.handler.onError(err)\n }\n\n this.retryOpts.retry(\n err,\n {\n state: { counter: this.retryCount++, currentTimeout: this.retryAfter },\n opts: { retryOptions: this.retryOpts, ...this.opts }\n },\n onRetry.bind(this)\n )\n\n function onRetry (err) {\n if (err != null || this.aborted || isDisturbed(this.opts.body)) {\n return this.handler.onError(err)\n }\n\n if (this.start !== 0) {\n this.opts = {\n ...this.opts,\n headers: {\n ...this.opts.headers,\n range: `bytes=${this.start}-${this.end ?? ''}`\n }\n }\n }\n\n try {\n this.dispatch(this.opts, this)\n } catch (err) {\n this.handler.onError(err)\n }\n }\n }\n}\n\nmodule.exports = RetryHandler\n\n\n/***/ }),\n\n/***/ 8861:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\n\"use strict\";\n\n\nconst RedirectHandler = __nccwpck_require__(2860)\n\nfunction createRedirectInterceptor ({ maxRedirections: defaultMaxRedirections }) {\n return (dispatch) => {\n return function Intercept (opts, handler) {\n const { maxRedirections = defaultMaxRedirections } = opts\n\n if (!maxRedirections) {\n return dispatch(opts, handler)\n }\n\n const redirectHandler = new RedirectHandler(dispatch, maxRedirections, opts, handler)\n opts = { ...opts, maxRedirections: 0 } // Stop sub dispatcher from also redirecting.\n return dispatch(opts, redirectHandler)\n }\n }\n}\n\nmodule.exports = createRedirectInterceptor\n\n\n/***/ }),\n\n/***/ 953:\n/***/ ((__unused_webpack_module, exports, __nccwpck_require__) => {\n\n\"use strict\";\n\nObject.defineProperty(exports, \"__esModule\", ({ value: true }));\nexports.SPECIAL_HEADERS = exports.HEADER_STATE = exports.MINOR = exports.MAJOR = exports.CONNECTION_TOKEN_CHARS = exports.HEADER_CHARS = exports.TOKEN = exports.STRICT_TOKEN = exports.HEX = exports.URL_CHAR = exports.STRICT_URL_CHAR = exports.USERINFO_CHARS = exports.MARK = exports.ALPHANUM = exports.NUM = exports.HEX_MAP = exports.NUM_MAP = exports.ALPHA = exports.FINISH = exports.H_METHOD_MAP = exports.METHOD_MAP = exports.METHODS_RTSP = exports.METHODS_ICE = exports.METHODS_HTTP = exports.METHODS = exports.LENIENT_FLAGS = exports.FLAGS = exports.TYPE = exports.ERROR = void 0;\nconst utils_1 = __nccwpck_require__(1891);\n// C headers\nvar ERROR;\n(function (ERROR) {\n ERROR[ERROR[\"OK\"] = 0] = \"OK\";\n ERROR[ERROR[\"INTERNAL\"] = 1] = \"INTERNAL\";\n ERROR[ERROR[\"STRICT\"] = 2] = \"STRICT\";\n ERROR[ERROR[\"LF_EXPECTED\"] = 3] = \"LF_EXPECTED\";\n ERROR[ERROR[\"UNEXPECTED_CONTENT_LENGTH\"] = 4] = \"UNEXPECTED_CONTENT_LENGTH\";\n ERROR[ERROR[\"CLOSED_CONNECTION\"] = 5] = \"CLOSED_CONNECTION\";\n ERROR[ERROR[\"INVALID_METHOD\"] = 6] = \"INVALID_METHOD\";\n ERROR[ERROR[\"INVALID_URL\"] = 7] = \"INVALID_URL\";\n ERROR[ERROR[\"INVALID_CONSTANT\"] = 8] = \"INVALID_CONSTANT\";\n ERROR[ERROR[\"INVALID_VERSION\"] = 9] = \"INVALID_VERSION\";\n ERROR[ERROR[\"INVALID_HEADER_TOKEN\"] = 10] = \"INVALID_HEADER_TOKEN\";\n ERROR[ERROR[\"INVALID_CONTENT_LENGTH\"] = 11] = \"INVALID_CONTENT_LENGTH\";\n ERROR[ERROR[\"INVALID_CHUNK_SIZE\"] = 12] = \"INVALID_CHUNK_SIZE\";\n ERROR[ERROR[\"INVALID_STATUS\"] = 13] = \"INVALID_STATUS\";\n ERROR[ERROR[\"INVALID_EOF_STATE\"] = 14] = \"INVALID_EOF_STATE\";\n ERROR[ERROR[\"INVALID_TRANSFER_ENCODING\"] = 15] = \"INVALID_TRANSFER_ENCODING\";\n ERROR[ERROR[\"CB_MESSAGE_BEGIN\"] = 16] = \"CB_MESSAGE_BEGIN\";\n ERROR[ERROR[\"CB_HEADERS_COMPLETE\"] = 17] = \"CB_HEADERS_COMPLETE\";\n ERROR[ERROR[\"CB_MESSAGE_COMPLETE\"] = 18] = \"CB_MESSAGE_COMPLETE\";\n ERROR[ERROR[\"CB_CHUNK_HEADER\"] = 19] = \"CB_CHUNK_HEADER\";\n ERROR[ERROR[\"CB_CHUNK_COMPLETE\"] = 20] = \"CB_CHUNK_COMPLETE\";\n ERROR[ERROR[\"PAUSED\"] = 21] = \"PAUSED\";\n ERROR[ERROR[\"PAUSED_UPGRADE\"] = 22] = \"PAUSED_UPGRADE\";\n ERROR[ERROR[\"PAUSED_H2_UPGRADE\"] = 23] = \"PAUSED_H2_UPGRADE\";\n ERROR[ERROR[\"USER\"] = 24] = \"USER\";\n})(ERROR = exports.ERROR || (exports.ERROR = {}));\nvar TYPE;\n(function (TYPE) {\n TYPE[TYPE[\"BOTH\"] = 0] = \"BOTH\";\n TYPE[TYPE[\"REQUEST\"] = 1] = \"REQUEST\";\n TYPE[TYPE[\"RESPONSE\"] = 2] = \"RESPONSE\";\n})(TYPE = exports.TYPE || (exports.TYPE = {}));\nvar FLAGS;\n(function (FLAGS) {\n FLAGS[FLAGS[\"CONNECTION_KEEP_ALIVE\"] = 1] = \"CONNECTION_KEEP_ALIVE\";\n FLAGS[FLAGS[\"CONNECTION_CLOSE\"] = 2] = \"CONNECTION_CLOSE\";\n FLAGS[FLAGS[\"CONNECTION_UPGRADE\"] = 4] = \"CONNECTION_UPGRADE\";\n FLAGS[FLAGS[\"CHUNKED\"] = 8] = \"CHUNKED\";\n FLAGS[FLAGS[\"UPGRADE\"] = 16] = \"UPGRADE\";\n FLAGS[FLAGS[\"CONTENT_LENGTH\"] = 32] = \"CONTENT_LENGTH\";\n FLAGS[FLAGS[\"SKIPBODY\"] = 64] = \"SKIPBODY\";\n FLAGS[FLAGS[\"TRAILING\"] = 128] = \"TRAILING\";\n // 1 << 8 is unused\n FLAGS[FLAGS[\"TRANSFER_ENCODING\"] = 512] = \"TRANSFER_ENCODING\";\n})(FLAGS = exports.FLAGS || (exports.FLAGS = {}));\nvar LENIENT_FLAGS;\n(function (LENIENT_FLAGS) {\n LENIENT_FLAGS[LENIENT_FLAGS[\"HEADERS\"] = 1] = \"HEADERS\";\n LENIENT_FLAGS[LENIENT_FLAGS[\"CHUNKED_LENGTH\"] = 2] = \"CHUNKED_LENGTH\";\n LENIENT_FLAGS[LENIENT_FLAGS[\"KEEP_ALIVE\"] = 4] = \"KEEP_ALIVE\";\n})(LENIENT_FLAGS = exports.LENIENT_FLAGS || (exports.LENIENT_FLAGS = {}));\nvar METHODS;\n(function (METHODS) {\n METHODS[METHODS[\"DELETE\"] = 0] = \"DELETE\";\n METHODS[METHODS[\"GET\"] = 1] = \"GET\";\n METHODS[METHODS[\"HEAD\"] = 2] = \"HEAD\";\n METHODS[METHODS[\"POST\"] = 3] = \"POST\";\n METHODS[METHODS[\"PUT\"] = 4] = \"PUT\";\n /* pathological */\n METHODS[METHODS[\"CONNECT\"] = 5] = \"CONNECT\";\n METHODS[METHODS[\"OPTIONS\"] = 6] = \"OPTIONS\";\n METHODS[METHODS[\"TRACE\"] = 7] = \"TRACE\";\n /* WebDAV */\n METHODS[METHODS[\"COPY\"] = 8] = \"COPY\";\n METHODS[METHODS[\"LOCK\"] = 9] = \"LOCK\";\n METHODS[METHODS[\"MKCOL\"] = 10] = \"MKCOL\";\n METHODS[METHODS[\"MOVE\"] = 11] = \"MOVE\";\n METHODS[METHODS[\"PROPFIND\"] = 12] = \"PROPFIND\";\n METHODS[METHODS[\"PROPPATCH\"] = 13] = \"PROPPATCH\";\n METHODS[METHODS[\"SEARCH\"] = 14] = \"SEARCH\";\n METHODS[METHODS[\"UNLOCK\"] = 15] = \"UNLOCK\";\n METHODS[METHODS[\"BIND\"] = 16] = \"BIND\";\n METHODS[METHODS[\"REBIND\"] = 17] = \"REBIND\";\n METHODS[METHODS[\"UNBIND\"] = 18] = \"UNBIND\";\n METHODS[METHODS[\"ACL\"] = 19] = \"ACL\";\n /* subversion */\n METHODS[METHODS[\"REPORT\"] = 20] = \"REPORT\";\n METHODS[METHODS[\"MKACTIVITY\"] = 21] = \"MKACTIVITY\";\n METHODS[METHODS[\"CHECKOUT\"] = 22] = \"CHECKOUT\";\n METHODS[METHODS[\"MERGE\"] = 23] = \"MERGE\";\n /* upnp */\n METHODS[METHODS[\"M-SEARCH\"] = 24] = \"M-SEARCH\";\n METHODS[METHODS[\"NOTIFY\"] = 25] = \"NOTIFY\";\n METHODS[METHODS[\"SUBSCRIBE\"] = 26] = \"SUBSCRIBE\";\n METHODS[METHODS[\"UNSUBSCRIBE\"] = 27] = \"UNSUBSCRIBE\";\n /* RFC-5789 */\n METHODS[METHODS[\"PATCH\"] = 28] = \"PATCH\";\n METHODS[METHODS[\"PURGE\"] = 29] = \"PURGE\";\n /* CalDAV */\n METHODS[METHODS[\"MKCALENDAR\"] = 30] = \"MKCALENDAR\";\n /* RFC-2068, section 19.6.1.2 */\n METHODS[METHODS[\"LINK\"] = 31] = \"LINK\";\n METHODS[METHODS[\"UNLINK\"] = 32] = \"UNLINK\";\n /* icecast */\n METHODS[METHODS[\"SOURCE\"] = 33] = \"SOURCE\";\n /* RFC-7540, section 11.6 */\n METHODS[METHODS[\"PRI\"] = 34] = \"PRI\";\n /* RFC-2326 RTSP */\n METHODS[METHODS[\"DESCRIBE\"] = 35] = \"DESCRIBE\";\n METHODS[METHODS[\"ANNOUNCE\"] = 36] = \"ANNOUNCE\";\n METHODS[METHODS[\"SETUP\"] = 37] = \"SETUP\";\n METHODS[METHODS[\"PLAY\"] = 38] = \"PLAY\";\n METHODS[METHODS[\"PAUSE\"] = 39] = \"PAUSE\";\n METHODS[METHODS[\"TEARDOWN\"] = 40] = \"TEARDOWN\";\n METHODS[METHODS[\"GET_PARAMETER\"] = 41] = \"GET_PARAMETER\";\n METHODS[METHODS[\"SET_PARAMETER\"] = 42] = \"SET_PARAMETER\";\n METHODS[METHODS[\"REDIRECT\"] = 43] = \"REDIRECT\";\n METHODS[METHODS[\"RECORD\"] = 44] = \"RECORD\";\n /* RAOP */\n METHODS[METHODS[\"FLUSH\"] = 45] = \"FLUSH\";\n})(METHODS = exports.METHODS || (exports.METHODS = {}));\nexports.METHODS_HTTP = [\n METHODS.DELETE,\n METHODS.GET,\n METHODS.HEAD,\n METHODS.POST,\n METHODS.PUT,\n METHODS.CONNECT,\n METHODS.OPTIONS,\n METHODS.TRACE,\n METHODS.COPY,\n METHODS.LOCK,\n METHODS.MKCOL,\n METHODS.MOVE,\n METHODS.PROPFIND,\n METHODS.PROPPATCH,\n METHODS.SEARCH,\n METHODS.UNLOCK,\n METHODS.BIND,\n METHODS.REBIND,\n METHODS.UNBIND,\n METHODS.ACL,\n METHODS.REPORT,\n METHODS.MKACTIVITY,\n METHODS.CHECKOUT,\n METHODS.MERGE,\n METHODS['M-SEARCH'],\n METHODS.NOTIFY,\n METHODS.SUBSCRIBE,\n METHODS.UNSUBSCRIBE,\n METHODS.PATCH,\n METHODS.PURGE,\n METHODS.MKCALENDAR,\n METHODS.LINK,\n METHODS.UNLINK,\n METHODS.PRI,\n // TODO(indutny): should we allow it with HTTP?\n METHODS.SOURCE,\n];\nexports.METHODS_ICE = [\n METHODS.SOURCE,\n];\nexports.METHODS_RTSP = [\n METHODS.OPTIONS,\n METHODS.DESCRIBE,\n METHODS.ANNOUNCE,\n METHODS.SETUP,\n METHODS.PLAY,\n METHODS.PAUSE,\n METHODS.TEARDOWN,\n METHODS.GET_PARAMETER,\n METHODS.SET_PARAMETER,\n METHODS.REDIRECT,\n METHODS.RECORD,\n METHODS.FLUSH,\n // For AirPlay\n METHODS.GET,\n METHODS.POST,\n];\nexports.METHOD_MAP = utils_1.enumToMap(METHODS);\nexports.H_METHOD_MAP = {};\nObject.keys(exports.METHOD_MAP).forEach((key) => {\n if (/^H/.test(key)) {\n exports.H_METHOD_MAP[key] = exports.METHOD_MAP[key];\n }\n});\nvar FINISH;\n(function (FINISH) {\n FINISH[FINISH[\"SAFE\"] = 0] = \"SAFE\";\n FINISH[FINISH[\"SAFE_WITH_CB\"] = 1] = \"SAFE_WITH_CB\";\n FINISH[FINISH[\"UNSAFE\"] = 2] = \"UNSAFE\";\n})(FINISH = exports.FINISH || (exports.FINISH = {}));\nexports.ALPHA = [];\nfor (let i = 'A'.charCodeAt(0); i <= 'Z'.charCodeAt(0); i++) {\n // Upper case\n exports.ALPHA.push(String.fromCharCode(i));\n // Lower case\n exports.ALPHA.push(String.fromCharCode(i + 0x20));\n}\nexports.NUM_MAP = {\n 0: 0, 1: 1, 2: 2, 3: 3, 4: 4,\n 5: 5, 6: 6, 7: 7, 8: 8, 9: 9,\n};\nexports.HEX_MAP = {\n 0: 0, 1: 1, 2: 2, 3: 3, 4: 4,\n 5: 5, 6: 6, 7: 7, 8: 8, 9: 9,\n A: 0XA, B: 0XB, C: 0XC, D: 0XD, E: 0XE, F: 0XF,\n a: 0xa, b: 0xb, c: 0xc, d: 0xd, e: 0xe, f: 0xf,\n};\nexports.NUM = [\n '0', '1', '2', '3', '4', '5', '6', '7', '8', '9',\n];\nexports.ALPHANUM = exports.ALPHA.concat(exports.NUM);\nexports.MARK = ['-', '_', '.', '!', '~', '*', '\\'', '(', ')'];\nexports.USERINFO_CHARS = exports.ALPHANUM\n .concat(exports.MARK)\n .concat(['%', ';', ':', '&', '=', '+', '$', ',']);\n// TODO(indutny): use RFC\nexports.STRICT_URL_CHAR = [\n '!', '\"', '$', '%', '&', '\\'',\n '(', ')', '*', '+', ',', '-', '.', '/',\n ':', ';', '<', '=', '>',\n '@', '[', '\\\\', ']', '^', '_',\n '`',\n '{', '|', '}', '~',\n].concat(exports.ALPHANUM);\nexports.URL_CHAR = exports.STRICT_URL_CHAR\n .concat(['\\t', '\\f']);\n// All characters with 0x80 bit set to 1\nfor (let i = 0x80; i <= 0xff; i++) {\n exports.URL_CHAR.push(i);\n}\nexports.HEX = exports.NUM.concat(['a', 'b', 'c', 'd', 'e', 'f', 'A', 'B', 'C', 'D', 'E', 'F']);\n/* Tokens as defined by rfc 2616. Also lowercases them.\n * token = 1*<any CHAR except CTLs or separators>\n * separators = \"(\" | \")\" | \"<\" | \">\" | \"@\"\n * | \",\" | \";\" | \":\" | \"\\\" | <\">\n * | \"/\" | \"[\" | \"]\" | \"?\" | \"=\"\n * | \"{\" | \"}\" | SP | HT\n */\nexports.STRICT_TOKEN = [\n '!', '#', '$', '%', '&', '\\'',\n '*', '+', '-', '.',\n '^', '_', '`',\n '|', '~',\n].concat(exports.ALPHANUM);\nexports.TOKEN = exports.STRICT_TOKEN.concat([' ']);\n/*\n * Verify that a char is a valid visible (printable) US-ASCII\n * character or %x80-FF\n */\nexports.HEADER_CHARS = ['\\t'];\nfor (let i = 32; i <= 255; i++) {\n if (i !== 127) {\n exports.HEADER_CHARS.push(i);\n }\n}\n// ',' = \\x44\nexports.CONNECTION_TOKEN_CHARS = exports.HEADER_CHARS.filter((c) => c !== 44);\nexports.MAJOR = exports.NUM_MAP;\nexports.MINOR = exports.MAJOR;\nvar HEADER_STATE;\n(function (HEADER_STATE) {\n HEADER_STATE[HEADER_STATE[\"GENERAL\"] = 0] = \"GENERAL\";\n HEADER_STATE[HEADER_STATE[\"CONNECTION\"] = 1] = \"CONNECTION\";\n HEADER_STATE[HEADER_STATE[\"CONTENT_LENGTH\"] = 2] = \"CONTENT_LENGTH\";\n HEADER_STATE[HEADER_STATE[\"TRANSFER_ENCODING\"] = 3] = \"TRANSFER_ENCODING\";\n HEADER_STATE[HEADER_STATE[\"UPGRADE\"] = 4] = \"UPGRADE\";\n HEADER_STATE[HEADER_STATE[\"CONNECTION_KEEP_ALIVE\"] = 5] = \"CONNECTION_KEEP_ALIVE\";\n HEADER_STATE[HEADER_STATE[\"CONNECTION_CLOSE\"] = 6] = \"CONNECTION_CLOSE\";\n HEADER_STATE[HEADER_STATE[\"CONNECTION_UPGRADE\"] = 7] = \"CONNECTION_UPGRADE\";\n HEADER_STATE[HEADER_STATE[\"TRANSFER_ENCODING_CHUNKED\"] = 8] = \"TRANSFER_ENCODING_CHUNKED\";\n})(HEADER_STATE = exports.HEADER_STATE || (exports.HEADER_STATE = {}));\nexports.SPECIAL_HEADERS = {\n 'connection': HEADER_STATE.CONNECTION,\n 'content-length': HEADER_STATE.CONTENT_LENGTH,\n 'proxy-connection': HEADER_STATE.CONNECTION,\n 'transfer-encoding': HEADER_STATE.TRANSFER_ENCODING,\n 'upgrade': HEADER_STATE.UPGRADE,\n};\n//# sourceMappingURL=constants.js.map\n\n/***/ }),\n\n/***/ 1145:\n/***/ ((module) => {\n\nmodule.exports = 'AGFzbQEAAAABMAhgAX8Bf2ADf39/AX9gBH9/f38Bf2AAAGADf39/AGABfwBgAn9/AGAGf39/f39/AALLAQgDZW52GHdhc21fb25faGVhZGVyc19jb21wbGV0ZQACA2VudhV3YXNtX29uX21lc3NhZ2VfYmVnaW4AAANlbnYLd2FzbV9vbl91cmwAAQNlbnYOd2FzbV9vbl9zdGF0dXMAAQNlbnYUd2FzbV9vbl9oZWFkZXJfZmllbGQAAQNlbnYUd2FzbV9vbl9oZWFkZXJfdmFsdWUAAQNlbnYMd2FzbV9vbl9ib2R5AAEDZW52GHdhc21fb25fbWVzc2FnZV9jb21wbGV0ZQAAA0ZFAwMEAAAFAAAAAAAABQEFAAUFBQAABgAAAAAGBgYGAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQABAAABAQcAAAUFAwABBAUBcAESEgUDAQACBggBfwFBgNQECwfRBSIGbWVtb3J5AgALX2luaXRpYWxpemUACRlfX2luZGlyZWN0X2Z1bmN0aW9uX3RhYmxlAQALbGxodHRwX2luaXQAChhsbGh0dHBfc2hvdWxkX2tlZXBfYWxpdmUAQQxsbGh0dHBfYWxsb2MADAZtYWxsb2MARgtsbGh0dHBfZnJlZQANBGZyZWUASA9sbGh0dHBfZ2V0X3R5cGUADhVsbGh0dHBfZ2V0X2h0dHBfbWFqb3IADxVsbGh0dHBfZ2V0X2h0dHBfbWlub3IAEBFsbGh0dHBfZ2V0X21ldGhvZAARFmxsaHR0cF9nZXRfc3RhdHVzX2NvZGUAEhJsbGh0dHBfZ2V0X3VwZ3JhZGUAEwxsbGh0dHBfcmVzZXQAFA5sbGh0dHBfZXhlY3V0ZQAVFGxsaHR0cF9zZXR0aW5nc19pbml0ABYNbGxodHRwX2ZpbmlzaAAXDGxsaHR0cF9wYXVzZQAYDWxsaHR0cF9yZXN1bWUAGRtsbGh0dHBfcmVzdW1lX2FmdGVyX3VwZ3JhZGUAGhBsbGh0dHBfZ2V0X2Vycm5vABsXbGxodHRwX2dldF9lcnJvcl9yZWFzb24AHBdsbGh0dHBfc2V0X2Vycm9yX3JlYXNvbgAdFGxsaHR0cF9nZXRfZXJyb3JfcG9zAB4RbGxodHRwX2Vycm5vX25hbWUAHxJsbGh0dHBfbWV0aG9kX25hbWUAIBJsbGh0dHBfc3RhdHVzX25hbWUAIRpsbGh0dHBfc2V0X2xlbmllbnRfaGVhZGVycwAiIWxsaHR0cF9zZXRfbGVuaWVudF9jaHVua2VkX2xlbmd0aAAjHWxsaHR0cF9zZXRfbGVuaWVudF9rZWVwX2FsaXZlACQkbGxodHRwX3NldF9sZW5pZW50X3RyYW5zZmVyX2VuY29kaW5nACUYbGxodHRwX21lc3NhZ2VfbmVlZHNfZW9mAD8JFwEAQQELEQECAwQFCwYHNTk3MS8tJyspCsLgAkUCAAsIABCIgICAAAsZACAAEMKAgIAAGiAAIAI2AjggACABOgAoCxwAIAAgAC8BMiAALQAuIAAQwYCAgAAQgICAgAALKgEBf0HAABDGgICAACIBEMKAgIAAGiABQYCIgIAANgI4IAEgADoAKCABCwoAIAAQyICAgAALBwAgAC0AKAsHACAALQAqCwcAIAAtACsLBwAgAC0AKQsHACAALwEyCwcAIAAtAC4LRQEEfyAAKAIYIQEgAC0ALSECIAAtACghAyAAKAI4IQQgABDCgICAABogACAENgI4IAAgAzoAKCAAIAI6AC0gACABNgIYCxEAIAAgASABIAJqEMOAgIAACxAAIABBAEHcABDMgICAABoLZwEBf0EAIQECQCAAKAIMDQACQAJAAkACQCAALQAvDgMBAAMCCyAAKAI4IgFFDQAgASgCLCIBRQ0AIAAgARGAgICAAAAiAQ0DC0EADwsQyoCAgAAACyAAQcOWgIAANgIQQQ4hAQsgAQseAAJAIAAoAgwNACAAQdGbgIAANgIQIABBFTYCDAsLFgACQCAAKAIMQRVHDQAgAEEANgIMCwsWAAJAIAAoAgxBFkcNACAAQQA2AgwLCwcAIAAoAgwLBwAgACgCEAsJACAAIAE2AhALBwAgACgCFAsiAAJAIABBJEkNABDKgICAAAALIABBAnRBoLOAgABqKAIACyIAAkAgAEEuSQ0AEMqAgIAAAAsgAEECdEGwtICAAGooAgAL7gsBAX9B66iAgAAhAQJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAIABBnH9qDvQDY2IAAWFhYWFhYQIDBAVhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhBgcICQoLDA0OD2FhYWFhEGFhYWFhYWFhYWFhEWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYRITFBUWFxgZGhthYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhHB0eHyAhIiMkJSYnKCkqKywtLi8wMTIzNDU2YTc4OTphYWFhYWFhYTthYWE8YWFhYT0+P2FhYWFhYWFhQGFhQWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYUJDREVGR0hJSktMTU5PUFFSU2FhYWFhYWFhVFVWV1hZWlthXF1hYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFeYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhX2BhC0Hhp4CAAA8LQaShgIAADwtBy6yAgAAPC0H+sYCAAA8LQcCkgIAADwtBq6SAgAAPC0GNqICAAA8LQeKmgIAADwtBgLCAgAAPC0G5r4CAAA8LQdekgIAADwtB75+AgAAPC0Hhn4CAAA8LQfqfgIAADwtB8qCAgAAPC0Gor4CAAA8LQa6ygIAADwtBiLCAgAAPC0Hsp4CAAA8LQYKigIAADwtBjp2AgAAPC0HQroCAAA8LQcqjgIAADwtBxbKAgAAPC0HfnICAAA8LQdKcgIAADwtBxKCAgAAPC0HXoICAAA8LQaKfgIAADwtB7a6AgAAPC0GrsICAAA8LQdSlgIAADwtBzK6AgAAPC0H6roCAAA8LQfyrgIAADwtB0rCAgAAPC0HxnYCAAA8LQbuggIAADwtB96uAgAAPC0GQsYCAAA8LQdexgIAADwtBoq2AgAAPC0HUp4CAAA8LQeCrgIAADwtBn6yAgAAPC0HrsYCAAA8LQdWfgIAADwtByrGAgAAPC0HepYCAAA8LQdSegIAADwtB9JyAgAAPC0GnsoCAAA8LQbGdgIAADwtBoJ2AgAAPC0G5sYCAAA8LQbywgIAADwtBkqGAgAAPC0GzpoCAAA8LQemsgIAADwtBrJ6AgAAPC0HUq4CAAA8LQfemgIAADwtBgKaAgAAPC0GwoYCAAA8LQf6egIAADwtBjaOAgAAPC0GJrYCAAA8LQfeigIAADwtBoLGAgAAPC0Gun4CAAA8LQcalgIAADwtB6J6AgAAPC0GTooCAAA8LQcKvgIAADwtBw52AgAAPC0GLrICAAA8LQeGdgIAADwtBja+AgAAPC0HqoYCAAA8LQbStgIAADwtB0q+AgAAPC0HfsoCAAA8LQdKygIAADwtB8LCAgAAPC0GpooCAAA8LQfmjgIAADwtBmZ6AgAAPC0G1rICAAA8LQZuwgIAADwtBkrKAgAAPC0G2q4CAAA8LQcKigIAADwtB+LKAgAAPC0GepYCAAA8LQdCigIAADwtBup6AgAAPC0GBnoCAAA8LEMqAgIAAAAtB1qGAgAAhAQsgAQsWACAAIAAtAC1B/gFxIAFBAEdyOgAtCxkAIAAgAC0ALUH9AXEgAUEAR0EBdHI6AC0LGQAgACAALQAtQfsBcSABQQBHQQJ0cjoALQsZACAAIAAtAC1B9wFxIAFBAEdBA3RyOgAtCy4BAn9BACEDAkAgACgCOCIERQ0AIAQoAgAiBEUNACAAIAQRgICAgAAAIQMLIAMLSQECf0EAIQMCQCAAKAI4IgRFDQAgBCgCBCIERQ0AIAAgASACIAFrIAQRgYCAgAAAIgNBf0cNACAAQcaRgIAANgIQQRghAwsgAwsuAQJ/QQAhAwJAIAAoAjgiBEUNACAEKAIwIgRFDQAgACAEEYCAgIAAACEDCyADC0kBAn9BACEDAkAgACgCOCIERQ0AIAQoAggiBEUNACAAIAEgAiABayAEEYGAgIAAACIDQX9HDQAgAEH2ioCAADYCEEEYIQMLIAMLLgECf0EAIQMCQCAAKAI4IgRFDQAgBCgCNCIERQ0AIAAgBBGAgICAAAAhAwsgAwtJAQJ/QQAhAwJAIAAoAjgiBEUNACAEKAIMIgRFDQAgACABIAIgAWsgBBGBgICAAAAiA0F/Rw0AIABB7ZqAgAA2AhBBGCEDCyADCy4BAn9BACEDAkAgACgCOCIERQ0AIAQoAjgiBEUNACAAIAQRgICAgAAAIQMLIAMLSQECf0EAIQMCQCAAKAI4IgRFDQAgBCgCECIERQ0AIAAgASACIAFrIAQRgYCAgAAAIgNBf0cNACAAQZWQgIAANgIQQRghAwsgAwsuAQJ/QQAhAwJAIAAoAjgiBEUNACAEKAI8IgRFDQAgACAEEYCAgIAAACEDCyADC0kBAn9BACEDAkAgACgCOCIERQ0AIAQoAhQiBEUNACAAIAEgAiABayAEEYGAgIAAACIDQX9HDQAgAEGqm4CAADYCEEEYIQMLIAMLLgECf0EAIQMCQCAAKAI4IgRFDQAgBCgCQCIERQ0AIAAgBBGAgICAAAAhAwsgAwtJAQJ/QQAhAwJAIAAoAjgiBEUNACAEKAIYIgRFDQAgACABIAIgAWsgBBGBgICAAAAiA0F/Rw0AIABB7ZOAgAA2AhBBGCEDCyADCy4BAn9BACEDAkAgACgCOCIERQ0AIAQoAkQiBEUNACAAIAQRgICAgAAAIQMLIAMLLgECf0EAIQMCQCAAKAI4IgRFDQAgBCgCJCIERQ0AIAAgBBGAgICAAAAhAwsgAwsuAQJ/QQAhAwJAIAAoAjgiBEUNACAEKAIsIgRFDQAgACAEEYCAgIAAACEDCyADC0kBAn9BACEDAkAgACgCOCIERQ0AIAQoAigiBEUNACAAIAEgAiABayAEEYGAgIAAACIDQX9HDQAgAEH2iICAADYCEEEYIQMLIAMLLgECf0EAIQMCQCAAKAI4IgRFDQAgBCgCUCIERQ0AIAAgBBGAgICAAAAhAwsgAwtJAQJ/QQAhAwJAIAAoAjgiBEUNACAEKAIcIgRFDQAgACABIAIgAWsgBBGBgICAAAAiA0F/Rw0AIABBwpmAgAA2AhBBGCEDCyADCy4BAn9BACEDAkAgACgCOCIERQ0AIAQoAkgiBEUNACAAIAQRgICAgAAAIQMLIAMLSQECf0EAIQMCQCAAKAI4IgRFDQAgBCgCICIERQ0AIAAgASACIAFrIAQRgYCAgAAAIgNBf0cNACAAQZSUgIAANgIQQRghAwsgAwsuAQJ/QQAhAwJAIAAoAjgiBEUNACAEKAJMIgRFDQAgACAEEYCAgIAAACEDCyADCy4BAn9BACEDAkAgACgCOCIERQ0AIAQoAlQiBEUNACAAIAQRgICAgAAAIQMLIAMLLgECf0EAIQMCQCAAKAI4IgRFDQAgBCgCWCIERQ0AIAAgBBGAgICAAAAhAwsgAwtFAQF/AkACQCAALwEwQRRxQRRHDQBBASEDIAAtAChBAUYNASAALwEyQeUARiEDDAELIAAtAClBBUYhAwsgACADOgAuQQAL/gEBA39BASEDAkAgAC8BMCIEQQhxDQAgACkDIEIAUiEDCwJAAkAgAC0ALkUNAEEBIQUgAC0AKUEFRg0BQQEhBSAEQcAAcUUgA3FBAUcNAQtBACEFIARBwABxDQBBAiEFIARB//8DcSIDQQhxDQACQCADQYAEcUUNAAJAIAAtAChBAUcNACAALQAtQQpxDQBBBQ8LQQQPCwJAIANBIHENAAJAIAAtAChBAUYNACAALwEyQf//A3EiAEGcf2pB5ABJDQAgAEHMAUYNACAAQbACRg0AQQQhBSAEQShxRQ0CIANBiARxQYAERg0CC0EADwtBAEEDIAApAyBQGyEFCyAFC2IBAn9BACEBAkAgAC0AKEEBRg0AIAAvATJB//8DcSICQZx/akHkAEkNACACQcwBRg0AIAJBsAJGDQAgAC8BMCIAQcAAcQ0AQQEhASAAQYgEcUGABEYNACAAQShxRSEBCyABC6cBAQN/AkACQAJAIAAtACpFDQAgAC0AK0UNAEEAIQMgAC8BMCIEQQJxRQ0BDAILQQAhAyAALwEwIgRBAXFFDQELQQEhAyAALQAoQQFGDQAgAC8BMkH//wNxIgVBnH9qQeQASQ0AIAVBzAFGDQAgBUGwAkYNACAEQcAAcQ0AQQAhAyAEQYgEcUGABEYNACAEQShxQQBHIQMLIABBADsBMCAAQQA6AC8gAwuZAQECfwJAAkACQCAALQAqRQ0AIAAtACtFDQBBACEBIAAvATAiAkECcUUNAQwCC0EAIQEgAC8BMCICQQFxRQ0BC0EBIQEgAC0AKEEBRg0AIAAvATJB//8DcSIAQZx/akHkAEkNACAAQcwBRg0AIABBsAJGDQAgAkHAAHENAEEAIQEgAkGIBHFBgARGDQAgAkEocUEARyEBCyABC1kAIABBGGpCADcDACAAQgA3AwAgAEE4akIANwMAIABBMGpCADcDACAAQShqQgA3AwAgAEEgakIANwMAIABBEGpCADcDACAAQQhqQgA3AwAgAEHdATYCHEEAC3sBAX8CQCAAKAIMIgMNAAJAIAAoAgRFDQAgACABNgIECwJAIAAgASACEMSAgIAAIgMNACAAKAIMDwsgACADNgIcQQAhAyAAKAIEIgFFDQAgACABIAIgACgCCBGBgICAAAAiAUUNACAAIAI2AhQgACABNgIMIAEhAwsgAwvk8wEDDn8DfgR/I4CAgIAAQRBrIgMkgICAgAAgASEEIAEhBSABIQYgASEHIAEhCCABIQkgASEKIAEhCyABIQwgASENIAEhDiABIQ8CQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkAgACgCHCIQQX9qDt0B2gEB2QECAwQFBgcICQoLDA0O2AEPENcBERLWARMUFRYXGBkaG+AB3wEcHR7VAR8gISIjJCXUASYnKCkqKyzTAdIBLS7RAdABLzAxMjM0NTY3ODk6Ozw9Pj9AQUJDREVG2wFHSElKzwHOAUvNAUzMAU1OT1BRUlNUVVZXWFlaW1xdXl9gYWJjZGVmZ2hpamtsbW5vcHFyc3R1dnd4eXp7fH1+f4ABgQGCAYMBhAGFAYYBhwGIAYkBigGLAYwBjQGOAY8BkAGRAZIBkwGUAZUBlgGXAZgBmQGaAZsBnAGdAZ4BnwGgAaEBogGjAaQBpQGmAacBqAGpAaoBqwGsAa0BrgGvAbABsQGyAbMBtAG1AbYBtwHLAcoBuAHJAbkByAG6AbsBvAG9Ab4BvwHAAcEBwgHDAcQBxQHGAQDcAQtBACEQDMYBC0EOIRAMxQELQQ0hEAzEAQtBDyEQDMMBC0EQIRAMwgELQRMhEAzBAQtBFCEQDMABC0EVIRAMvwELQRYhEAy+AQtBFyEQDL0BC0EYIRAMvAELQRkhEAy7AQtBGiEQDLoBC0EbIRAMuQELQRwhEAy4AQtBCCEQDLcBC0EdIRAMtgELQSAhEAy1AQtBHyEQDLQBC0EHIRAMswELQSEhEAyyAQtBIiEQDLEBC0EeIRAMsAELQSMhEAyvAQtBEiEQDK4BC0ERIRAMrQELQSQhEAysAQtBJSEQDKsBC0EmIRAMqgELQSchEAypAQtBwwEhEAyoAQtBKSEQDKcBC0ErIRAMpgELQSwhEAylAQtBLSEQDKQBC0EuIRAMowELQS8hEAyiAQtBxAEhEAyhAQtBMCEQDKABC0E0IRAMnwELQQwhEAyeAQtBMSEQDJ0BC0EyIRAMnAELQTMhEAybAQtBOSEQDJoBC0E1IRAMmQELQcUBIRAMmAELQQshEAyXAQtBOiEQDJYBC0E2IRAMlQELQQohEAyUAQtBNyEQDJMBC0E4IRAMkgELQTwhEAyRAQtBOyEQDJABC0E9IRAMjwELQQkhEAyOAQtBKCEQDI0BC0E+IRAMjAELQT8hEAyLAQtBwAAhEAyKAQtBwQAhEAyJAQtBwgAhEAyIAQtBwwAhEAyHAQtBxAAhEAyGAQtBxQAhEAyFAQtBxgAhEAyEAQtBKiEQDIMBC0HHACEQDIIBC0HIACEQDIEBC0HJACEQDIABC0HKACEQDH8LQcsAIRAMfgtBzQAhEAx9C0HMACEQDHwLQc4AIRAMewtBzwAhEAx6C0HQACEQDHkLQdEAIRAMeAtB0gAhEAx3C0HTACEQDHYLQdQAIRAMdQtB1gAhEAx0C0HVACEQDHMLQQYhEAxyC0HXACEQDHELQQUhEAxwC0HYACEQDG8LQQQhEAxuC0HZACEQDG0LQdoAIRAMbAtB2wAhEAxrC0HcACEQDGoLQQMhEAxpC0HdACEQDGgLQd4AIRAMZwtB3wAhEAxmC0HhACEQDGULQeAAIRAMZAtB4gAhEAxjC0HjACEQDGILQQIhEAxhC0HkACEQDGALQeUAIRAMXwtB5gAhEAxeC0HnACEQDF0LQegAIRAMXAtB6QAhEAxbC0HqACEQDFoLQesAIRAMWQtB7AAhEAxYC0HtACEQDFcLQe4AIRAMVgtB7wAhEAxVC0HwACEQDFQLQfEAIRAMUwtB8gAhEAxSC0HzACEQDFELQfQAIRAMUAtB9QAhEAxPC0H2ACEQDE4LQfcAIRAMTQtB+AAhEAxMC0H5ACEQDEsLQfoAIRAMSgtB+wAhEAxJC0H8ACEQDEgLQf0AIRAMRwtB/gAhEAxGC0H/ACEQDEULQYABIRAMRAtBgQEhEAxDC0GCASEQDEILQYMBIRAMQQtBhAEhEAxAC0GFASEQDD8LQYYBIRAMPgtBhwEhEAw9C0GIASEQDDwLQYkBIRAMOwtBigEhEAw6C0GLASEQDDkLQYwBIRAMOAtBjQEhEAw3C0GOASEQDDYLQY8BIRAMNQtBkAEhEAw0C0GRASEQDDMLQZIBIRAMMgtBkwEhEAwxC0GUASEQDDALQZUBIRAMLwtBlgEhEAwuC0GXASEQDC0LQZgBIRAMLAtBmQEhEAwrC0GaASEQDCoLQZsBIRAMKQtBnAEhEAwoC0GdASEQDCcLQZ4BIRAMJgtBnwEhEAwlC0GgASEQDCQLQaEBIRAMIwtBogEhEAwiC0GjASEQDCELQaQBIRAMIAtBpQEhEAwfC0GmASEQDB4LQacBIRAMHQtBqAEhEAwcC0GpASEQDBsLQaoBIRAMGgtBqwEhEAwZC0GsASEQDBgLQa0BIRAMFwtBrgEhEAwWC0EBIRAMFQtBrwEhEAwUC0GwASEQDBMLQbEBIRAMEgtBswEhEAwRC0GyASEQDBALQbQBIRAMDwtBtQEhEAwOC0G2ASEQDA0LQbcBIRAMDAtBuAEhEAwLC0G5ASEQDAoLQboBIRAMCQtBuwEhEAwIC0HGASEQDAcLQbwBIRAMBgtBvQEhEAwFC0G+ASEQDAQLQb8BIRAMAwtBwAEhEAwCC0HCASEQDAELQcEBIRALA0ACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQCAQDscBAAECAwQFBgcICQoLDA0ODxAREhMUFRYXGBkaGxweHyAhIyUoP0BBREVGR0hJSktMTU9QUVJT3gNXWVtcXWBiZWZnaGlqa2xtb3BxcnN0dXZ3eHl6e3x9foABggGFAYYBhwGJAYsBjAGNAY4BjwGQAZEBlAGVAZYBlwGYAZkBmgGbAZwBnQGeAZ8BoAGhAaIBowGkAaUBpgGnAagBqQGqAasBrAGtAa4BrwGwAbEBsgGzAbQBtQG2AbcBuAG5AboBuwG8Ab0BvgG/AcABwQHCAcMBxAHFAcYBxwHIAckBygHLAcwBzQHOAc8B0AHRAdIB0wHUAdUB1gHXAdgB2QHaAdsB3AHdAd4B4AHhAeIB4wHkAeUB5gHnAegB6QHqAesB7AHtAe4B7wHwAfEB8gHzAZkCpAKwAv4C/gILIAEiBCACRw3zAUHdASEQDP8DCyABIhAgAkcN3QFBwwEhEAz+AwsgASIBIAJHDZABQfcAIRAM/QMLIAEiASACRw2GAUHvACEQDPwDCyABIgEgAkcNf0HqACEQDPsDCyABIgEgAkcNe0HoACEQDPoDCyABIgEgAkcNeEHmACEQDPkDCyABIgEgAkcNGkEYIRAM+AMLIAEiASACRw0UQRIhEAz3AwsgASIBIAJHDVlBxQAhEAz2AwsgASIBIAJHDUpBPyEQDPUDCyABIgEgAkcNSEE8IRAM9AMLIAEiASACRw1BQTEhEAzzAwsgAC0ALkEBRg3rAwyHAgsgACABIgEgAhDAgICAAEEBRw3mASAAQgA3AyAM5wELIAAgASIBIAIQtICAgAAiEA3nASABIQEM9QILAkAgASIBIAJHDQBBBiEQDPADCyAAIAFBAWoiASACELuAgIAAIhAN6AEgASEBDDELIABCADcDIEESIRAM1QMLIAEiECACRw0rQR0hEAztAwsCQCABIgEgAkYNACABQQFqIQFBECEQDNQDC0EHIRAM7AMLIABCACAAKQMgIhEgAiABIhBrrSISfSITIBMgEVYbNwMgIBEgElYiFEUN5QFBCCEQDOsDCwJAIAEiASACRg0AIABBiYCAgAA2AgggACABNgIEIAEhAUEUIRAM0gMLQQkhEAzqAwsgASEBIAApAyBQDeQBIAEhAQzyAgsCQCABIgEgAkcNAEELIRAM6QMLIAAgAUEBaiIBIAIQtoCAgAAiEA3lASABIQEM8gILIAAgASIBIAIQuICAgAAiEA3lASABIQEM8gILIAAgASIBIAIQuICAgAAiEA3mASABIQEMDQsgACABIgEgAhC6gICAACIQDecBIAEhAQzwAgsCQCABIgEgAkcNAEEPIRAM5QMLIAEtAAAiEEE7Rg0IIBBBDUcN6AEgAUEBaiEBDO8CCyAAIAEiASACELqAgIAAIhAN6AEgASEBDPICCwNAAkAgAS0AAEHwtYCAAGotAAAiEEEBRg0AIBBBAkcN6wEgACgCBCEQIABBADYCBCAAIBAgAUEBaiIBELmAgIAAIhAN6gEgASEBDPQCCyABQQFqIgEgAkcNAAtBEiEQDOIDCyAAIAEiASACELqAgIAAIhAN6QEgASEBDAoLIAEiASACRw0GQRshEAzgAwsCQCABIgEgAkcNAEEWIRAM4AMLIABBioCAgAA2AgggACABNgIEIAAgASACELiAgIAAIhAN6gEgASEBQSAhEAzGAwsCQCABIgEgAkYNAANAAkAgAS0AAEHwt4CAAGotAAAiEEECRg0AAkAgEEF/ag4E5QHsAQDrAewBCyABQQFqIQFBCCEQDMgDCyABQQFqIgEgAkcNAAtBFSEQDN8DC0EVIRAM3gMLA0ACQCABLQAAQfC5gIAAai0AACIQQQJGDQAgEEF/ag4E3gHsAeAB6wHsAQsgAUEBaiIBIAJHDQALQRghEAzdAwsCQCABIgEgAkYNACAAQYuAgIAANgIIIAAgATYCBCABIQFBByEQDMQDC0EZIRAM3AMLIAFBAWohAQwCCwJAIAEiFCACRw0AQRohEAzbAwsgFCEBAkAgFC0AAEFzag4U3QLuAu4C7gLuAu4C7gLuAu4C7gLuAu4C7gLuAu4C7gLuAu4C7gIA7gILQQAhECAAQQA2AhwgAEGvi4CAADYCECAAQQI2AgwgACAUQQFqNgIUDNoDCwJAIAEtAAAiEEE7Rg0AIBBBDUcN6AEgAUEBaiEBDOUCCyABQQFqIQELQSIhEAy/AwsCQCABIhAgAkcNAEEcIRAM2AMLQgAhESAQIQEgEC0AAEFQag435wHmAQECAwQFBgcIAAAAAAAAAAkKCwwNDgAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAADxAREhMUAAtBHiEQDL0DC0ICIREM5QELQgMhEQzkAQtCBCERDOMBC0IFIREM4gELQgYhEQzhAQtCByERDOABC0IIIREM3wELQgkhEQzeAQtCCiERDN0BC0ILIREM3AELQgwhEQzbAQtCDSERDNoBC0IOIREM2QELQg8hEQzYAQtCCiERDNcBC0ILIREM1gELQgwhEQzVAQtCDSERDNQBC0IOIREM0wELQg8hEQzSAQtCACERAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQCAQLQAAQVBqDjflAeQBAAECAwQFBgfmAeYB5gHmAeYB5gHmAQgJCgsMDeYB5gHmAeYB5gHmAeYB5gHmAeYB5gHmAeYB5gHmAeYB5gHmAeYB5gHmAeYB5gHmAeYB5gEODxAREhPmAQtCAiERDOQBC0IDIREM4wELQgQhEQziAQtCBSERDOEBC0IGIREM4AELQgchEQzfAQtCCCERDN4BC0IJIREM3QELQgohEQzcAQtCCyERDNsBC0IMIREM2gELQg0hEQzZAQtCDiERDNgBC0IPIREM1wELQgohEQzWAQtCCyERDNUBC0IMIREM1AELQg0hEQzTAQtCDiERDNIBC0IPIREM0QELIABCACAAKQMgIhEgAiABIhBrrSISfSITIBMgEVYbNwMgIBEgElYiFEUN0gFBHyEQDMADCwJAIAEiASACRg0AIABBiYCAgAA2AgggACABNgIEIAEhAUEkIRAMpwMLQSAhEAy/AwsgACABIhAgAhC+gICAAEF/ag4FtgEAxQIB0QHSAQtBESEQDKQDCyAAQQE6AC8gECEBDLsDCyABIgEgAkcN0gFBJCEQDLsDCyABIg0gAkcNHkHGACEQDLoDCyAAIAEiASACELKAgIAAIhAN1AEgASEBDLUBCyABIhAgAkcNJkHQACEQDLgDCwJAIAEiASACRw0AQSghEAy4AwsgAEEANgIEIABBjICAgAA2AgggACABIAEQsYCAgAAiEA3TASABIQEM2AELAkAgASIQIAJHDQBBKSEQDLcDCyAQLQAAIgFBIEYNFCABQQlHDdMBIBBBAWohAQwVCwJAIAEiASACRg0AIAFBAWohAQwXC0EqIRAMtQMLAkAgASIQIAJHDQBBKyEQDLUDCwJAIBAtAAAiAUEJRg0AIAFBIEcN1QELIAAtACxBCEYN0wEgECEBDJEDCwJAIAEiASACRw0AQSwhEAy0AwsgAS0AAEEKRw3VASABQQFqIQEMyQILIAEiDiACRw3VAUEvIRAMsgMLA0ACQCABLQAAIhBBIEYNAAJAIBBBdmoOBADcAdwBANoBCyABIQEM4AELIAFBAWoiASACRw0AC0ExIRAMsQMLQTIhECABIhQgAkYNsAMgAiAUayAAKAIAIgFqIRUgFCABa0EDaiEWAkADQCAULQAAIhdBIHIgFyAXQb9/akH/AXFBGkkbQf8BcSABQfC7gIAAai0AAEcNAQJAIAFBA0cNAEEGIQEMlgMLIAFBAWohASAUQQFqIhQgAkcNAAsgACAVNgIADLEDCyAAQQA2AgAgFCEBDNkBC0EzIRAgASIUIAJGDa8DIAIgFGsgACgCACIBaiEVIBQgAWtBCGohFgJAA0AgFC0AACIXQSByIBcgF0G/f2pB/wFxQRpJG0H/AXEgAUH0u4CAAGotAABHDQECQCABQQhHDQBBBSEBDJUDCyABQQFqIQEgFEEBaiIUIAJHDQALIAAgFTYCAAywAwsgAEEANgIAIBQhAQzYAQtBNCEQIAEiFCACRg2uAyACIBRrIAAoAgAiAWohFSAUIAFrQQVqIRYCQANAIBQtAAAiF0EgciAXIBdBv39qQf8BcUEaSRtB/wFxIAFB0MKAgABqLQAARw0BAkAgAUEFRw0AQQchAQyUAwsgAUEBaiEBIBRBAWoiFCACRw0ACyAAIBU2AgAMrwMLIABBADYCACAUIQEM1wELAkAgASIBIAJGDQADQAJAIAEtAABBgL6AgABqLQAAIhBBAUYNACAQQQJGDQogASEBDN0BCyABQQFqIgEgAkcNAAtBMCEQDK4DC0EwIRAMrQMLAkAgASIBIAJGDQADQAJAIAEtAAAiEEEgRg0AIBBBdmoOBNkB2gHaAdkB2gELIAFBAWoiASACRw0AC0E4IRAMrQMLQTghEAysAwsDQAJAIAEtAAAiEEEgRg0AIBBBCUcNAwsgAUEBaiIBIAJHDQALQTwhEAyrAwsDQAJAIAEtAAAiEEEgRg0AAkACQCAQQXZqDgTaAQEB2gEACyAQQSxGDdsBCyABIQEMBAsgAUEBaiIBIAJHDQALQT8hEAyqAwsgASEBDNsBC0HAACEQIAEiFCACRg2oAyACIBRrIAAoAgAiAWohFiAUIAFrQQZqIRcCQANAIBQtAABBIHIgAUGAwICAAGotAABHDQEgAUEGRg2OAyABQQFqIQEgFEEBaiIUIAJHDQALIAAgFjYCAAypAwsgAEEANgIAIBQhAQtBNiEQDI4DCwJAIAEiDyACRw0AQcEAIRAMpwMLIABBjICAgAA2AgggACAPNgIEIA8hASAALQAsQX9qDgTNAdUB1wHZAYcDCyABQQFqIQEMzAELAkAgASIBIAJGDQADQAJAIAEtAAAiEEEgciAQIBBBv39qQf8BcUEaSRtB/wFxIhBBCUYNACAQQSBGDQACQAJAAkACQCAQQZ1/ag4TAAMDAwMDAwMBAwMDAwMDAwMDAgMLIAFBAWohAUExIRAMkQMLIAFBAWohAUEyIRAMkAMLIAFBAWohAUEzIRAMjwMLIAEhAQzQAQsgAUEBaiIBIAJHDQALQTUhEAylAwtBNSEQDKQDCwJAIAEiASACRg0AA0ACQCABLQAAQYC8gIAAai0AAEEBRg0AIAEhAQzTAQsgAUEBaiIBIAJHDQALQT0hEAykAwtBPSEQDKMDCyAAIAEiASACELCAgIAAIhAN1gEgASEBDAELIBBBAWohAQtBPCEQDIcDCwJAIAEiASACRw0AQcIAIRAMoAMLAkADQAJAIAEtAABBd2oOGAAC/gL+AoQD/gL+Av4C/gL+Av4C/gL+Av4C/gL+Av4C/gL+Av4C/gL+Av4CAP4CCyABQQFqIgEgAkcNAAtBwgAhEAygAwsgAUEBaiEBIAAtAC1BAXFFDb0BIAEhAQtBLCEQDIUDCyABIgEgAkcN0wFBxAAhEAydAwsDQAJAIAEtAABBkMCAgABqLQAAQQFGDQAgASEBDLcCCyABQQFqIgEgAkcNAAtBxQAhEAycAwsgDS0AACIQQSBGDbMBIBBBOkcNgQMgACgCBCEBIABBADYCBCAAIAEgDRCvgICAACIBDdABIA1BAWohAQyzAgtBxwAhECABIg0gAkYNmgMgAiANayAAKAIAIgFqIRYgDSABa0EFaiEXA0AgDS0AACIUQSByIBQgFEG/f2pB/wFxQRpJG0H/AXEgAUGQwoCAAGotAABHDYADIAFBBUYN9AIgAUEBaiEBIA1BAWoiDSACRw0ACyAAIBY2AgAMmgMLQcgAIRAgASINIAJGDZkDIAIgDWsgACgCACIBaiEWIA0gAWtBCWohFwNAIA0tAAAiFEEgciAUIBRBv39qQf8BcUEaSRtB/wFxIAFBlsKAgABqLQAARw3/AgJAIAFBCUcNAEECIQEM9QILIAFBAWohASANQQFqIg0gAkcNAAsgACAWNgIADJkDCwJAIAEiDSACRw0AQckAIRAMmQMLAkACQCANLQAAIgFBIHIgASABQb9/akH/AXFBGkkbQf8BcUGSf2oOBwCAA4ADgAOAA4ADAYADCyANQQFqIQFBPiEQDIADCyANQQFqIQFBPyEQDP8CC0HKACEQIAEiDSACRg2XAyACIA1rIAAoAgAiAWohFiANIAFrQQFqIRcDQCANLQAAIhRBIHIgFCAUQb9/akH/AXFBGkkbQf8BcSABQaDCgIAAai0AAEcN/QIgAUEBRg3wAiABQQFqIQEgDUEBaiINIAJHDQALIAAgFjYCAAyXAwtBywAhECABIg0gAkYNlgMgAiANayAAKAIAIgFqIRYgDSABa0EOaiEXA0AgDS0AACIUQSByIBQgFEG/f2pB/wFxQRpJG0H/AXEgAUGiwoCAAGotAABHDfwCIAFBDkYN8AIgAUEBaiEBIA1BAWoiDSACRw0ACyAAIBY2AgAMlgMLQcwAIRAgASINIAJGDZUDIAIgDWsgACgCACIBaiEWIA0gAWtBD2ohFwNAIA0tAAAiFEEgciAUIBRBv39qQf8BcUEaSRtB/wFxIAFBwMKAgABqLQAARw37AgJAIAFBD0cNAEEDIQEM8QILIAFBAWohASANQQFqIg0gAkcNAAsgACAWNgIADJUDC0HNACEQIAEiDSACRg2UAyACIA1rIAAoAgAiAWohFiANIAFrQQVqIRcDQCANLQAAIhRBIHIgFCAUQb9/akH/AXFBGkkbQf8BcSABQdDCgIAAai0AAEcN+gICQCABQQVHDQBBBCEBDPACCyABQQFqIQEgDUEBaiINIAJHDQALIAAgFjYCAAyUAwsCQCABIg0gAkcNAEHOACEQDJQDCwJAAkACQAJAIA0tAAAiAUEgciABIAFBv39qQf8BcUEaSRtB/wFxQZ1/ag4TAP0C/QL9Av0C/QL9Av0C/QL9Av0C/QL9AgH9Av0C/QICA/0CCyANQQFqIQFBwQAhEAz9AgsgDUEBaiEBQcIAIRAM/AILIA1BAWohAUHDACEQDPsCCyANQQFqIQFBxAAhEAz6AgsCQCABIgEgAkYNACAAQY2AgIAANgIIIAAgATYCBCABIQFBxQAhEAz6AgtBzwAhEAySAwsgECEBAkACQCAQLQAAQXZqDgQBqAKoAgCoAgsgEEEBaiEBC0EnIRAM+AILAkAgASIBIAJHDQBB0QAhEAyRAwsCQCABLQAAQSBGDQAgASEBDI0BCyABQQFqIQEgAC0ALUEBcUUNxwEgASEBDIwBCyABIhcgAkcNyAFB0gAhEAyPAwtB0wAhECABIhQgAkYNjgMgAiAUayAAKAIAIgFqIRYgFCABa0EBaiEXA0AgFC0AACABQdbCgIAAai0AAEcNzAEgAUEBRg3HASABQQFqIQEgFEEBaiIUIAJHDQALIAAgFjYCAAyOAwsCQCABIgEgAkcNAEHVACEQDI4DCyABLQAAQQpHDcwBIAFBAWohAQzHAQsCQCABIgEgAkcNAEHWACEQDI0DCwJAAkAgAS0AAEF2ag4EAM0BzQEBzQELIAFBAWohAQzHAQsgAUEBaiEBQcoAIRAM8wILIAAgASIBIAIQroCAgAAiEA3LASABIQFBzQAhEAzyAgsgAC0AKUEiRg2FAwymAgsCQCABIgEgAkcNAEHbACEQDIoDC0EAIRRBASEXQQEhFkEAIRACQAJAAkACQAJAAkACQAJAAkAgAS0AAEFQag4K1AHTAQABAgMEBQYI1QELQQIhEAwGC0EDIRAMBQtBBCEQDAQLQQUhEAwDC0EGIRAMAgtBByEQDAELQQghEAtBACEXQQAhFkEAIRQMzAELQQkhEEEBIRRBACEXQQAhFgzLAQsCQCABIgEgAkcNAEHdACEQDIkDCyABLQAAQS5HDcwBIAFBAWohAQymAgsgASIBIAJHDcwBQd8AIRAMhwMLAkAgASIBIAJGDQAgAEGOgICAADYCCCAAIAE2AgQgASEBQdAAIRAM7gILQeAAIRAMhgMLQeEAIRAgASIBIAJGDYUDIAIgAWsgACgCACIUaiEWIAEgFGtBA2ohFwNAIAEtAAAgFEHiwoCAAGotAABHDc0BIBRBA0YNzAEgFEEBaiEUIAFBAWoiASACRw0ACyAAIBY2AgAMhQMLQeIAIRAgASIBIAJGDYQDIAIgAWsgACgCACIUaiEWIAEgFGtBAmohFwNAIAEtAAAgFEHmwoCAAGotAABHDcwBIBRBAkYNzgEgFEEBaiEUIAFBAWoiASACRw0ACyAAIBY2AgAMhAMLQeMAIRAgASIBIAJGDYMDIAIgAWsgACgCACIUaiEWIAEgFGtBA2ohFwNAIAEtAAAgFEHpwoCAAGotAABHDcsBIBRBA0YNzgEgFEEBaiEUIAFBAWoiASACRw0ACyAAIBY2AgAMgwMLAkAgASIBIAJHDQBB5QAhEAyDAwsgACABQQFqIgEgAhCogICAACIQDc0BIAEhAUHWACEQDOkCCwJAIAEiASACRg0AA0ACQCABLQAAIhBBIEYNAAJAAkACQCAQQbh/ag4LAAHPAc8BzwHPAc8BzwHPAc8BAs8BCyABQQFqIQFB0gAhEAztAgsgAUEBaiEBQdMAIRAM7AILIAFBAWohAUHUACEQDOsCCyABQQFqIgEgAkcNAAtB5AAhEAyCAwtB5AAhEAyBAwsDQAJAIAEtAABB8MKAgABqLQAAIhBBAUYNACAQQX5qDgPPAdAB0QHSAQsgAUEBaiIBIAJHDQALQeYAIRAMgAMLAkAgASIBIAJGDQAgAUEBaiEBDAMLQecAIRAM/wILA0ACQCABLQAAQfDEgIAAai0AACIQQQFGDQACQCAQQX5qDgTSAdMB1AEA1QELIAEhAUHXACEQDOcCCyABQQFqIgEgAkcNAAtB6AAhEAz+AgsCQCABIgEgAkcNAEHpACEQDP4CCwJAIAEtAAAiEEF2ag4augHVAdUBvAHVAdUB1QHVAdUB1QHVAdUB1QHVAdUB1QHVAdUB1QHVAdUB1QHKAdUB1QEA0wELIAFBAWohAQtBBiEQDOMCCwNAAkAgAS0AAEHwxoCAAGotAABBAUYNACABIQEMngILIAFBAWoiASACRw0AC0HqACEQDPsCCwJAIAEiASACRg0AIAFBAWohAQwDC0HrACEQDPoCCwJAIAEiASACRw0AQewAIRAM+gILIAFBAWohAQwBCwJAIAEiASACRw0AQe0AIRAM+QILIAFBAWohAQtBBCEQDN4CCwJAIAEiFCACRw0AQe4AIRAM9wILIBQhAQJAAkACQCAULQAAQfDIgIAAai0AAEF/ag4H1AHVAdYBAJwCAQLXAQsgFEEBaiEBDAoLIBRBAWohAQzNAQtBACEQIABBADYCHCAAQZuSgIAANgIQIABBBzYCDCAAIBRBAWo2AhQM9gILAkADQAJAIAEtAABB8MiAgABqLQAAIhBBBEYNAAJAAkAgEEF/ag4H0gHTAdQB2QEABAHZAQsgASEBQdoAIRAM4AILIAFBAWohAUHcACEQDN8CCyABQQFqIgEgAkcNAAtB7wAhEAz2AgsgAUEBaiEBDMsBCwJAIAEiFCACRw0AQfAAIRAM9QILIBQtAABBL0cN1AEgFEEBaiEBDAYLAkAgASIUIAJHDQBB8QAhEAz0AgsCQCAULQAAIgFBL0cNACAUQQFqIQFB3QAhEAzbAgsgAUF2aiIEQRZLDdMBQQEgBHRBiYCAAnFFDdMBDMoCCwJAIAEiASACRg0AIAFBAWohAUHeACEQDNoCC0HyACEQDPICCwJAIAEiFCACRw0AQfQAIRAM8gILIBQhAQJAIBQtAABB8MyAgABqLQAAQX9qDgPJApQCANQBC0HhACEQDNgCCwJAIAEiFCACRg0AA0ACQCAULQAAQfDKgIAAai0AACIBQQNGDQACQCABQX9qDgLLAgDVAQsgFCEBQd8AIRAM2gILIBRBAWoiFCACRw0AC0HzACEQDPECC0HzACEQDPACCwJAIAEiASACRg0AIABBj4CAgAA2AgggACABNgIEIAEhAUHgACEQDNcCC0H1ACEQDO8CCwJAIAEiASACRw0AQfYAIRAM7wILIABBj4CAgAA2AgggACABNgIEIAEhAQtBAyEQDNQCCwNAIAEtAABBIEcNwwIgAUEBaiIBIAJHDQALQfcAIRAM7AILAkAgASIBIAJHDQBB+AAhEAzsAgsgAS0AAEEgRw3OASABQQFqIQEM7wELIAAgASIBIAIQrICAgAAiEA3OASABIQEMjgILAkAgASIEIAJHDQBB+gAhEAzqAgsgBC0AAEHMAEcN0QEgBEEBaiEBQRMhEAzPAQsCQCABIgQgAkcNAEH7ACEQDOkCCyACIARrIAAoAgAiAWohFCAEIAFrQQVqIRADQCAELQAAIAFB8M6AgABqLQAARw3QASABQQVGDc4BIAFBAWohASAEQQFqIgQgAkcNAAsgACAUNgIAQfsAIRAM6AILAkAgASIEIAJHDQBB/AAhEAzoAgsCQAJAIAQtAABBvX9qDgwA0QHRAdEB0QHRAdEB0QHRAdEB0QEB0QELIARBAWohAUHmACEQDM8CCyAEQQFqIQFB5wAhEAzOAgsCQCABIgQgAkcNAEH9ACEQDOcCCyACIARrIAAoAgAiAWohFCAEIAFrQQJqIRACQANAIAQtAAAgAUHtz4CAAGotAABHDc8BIAFBAkYNASABQQFqIQEgBEEBaiIEIAJHDQALIAAgFDYCAEH9ACEQDOcCCyAAQQA2AgAgEEEBaiEBQRAhEAzMAQsCQCABIgQgAkcNAEH+ACEQDOYCCyACIARrIAAoAgAiAWohFCAEIAFrQQVqIRACQANAIAQtAAAgAUH2zoCAAGotAABHDc4BIAFBBUYNASABQQFqIQEgBEEBaiIEIAJHDQALIAAgFDYCAEH+ACEQDOYCCyAAQQA2AgAgEEEBaiEBQRYhEAzLAQsCQCABIgQgAkcNAEH/ACEQDOUCCyACIARrIAAoAgAiAWohFCAEIAFrQQNqIRACQANAIAQtAAAgAUH8zoCAAGotAABHDc0BIAFBA0YNASABQQFqIQEgBEEBaiIEIAJHDQALIAAgFDYCAEH/ACEQDOUCCyAAQQA2AgAgEEEBaiEBQQUhEAzKAQsCQCABIgQgAkcNAEGAASEQDOQCCyAELQAAQdkARw3LASAEQQFqIQFBCCEQDMkBCwJAIAEiBCACRw0AQYEBIRAM4wILAkACQCAELQAAQbJ/ag4DAMwBAcwBCyAEQQFqIQFB6wAhEAzKAgsgBEEBaiEBQewAIRAMyQILAkAgASIEIAJHDQBBggEhEAziAgsCQAJAIAQtAABBuH9qDggAywHLAcsBywHLAcsBAcsBCyAEQQFqIQFB6gAhEAzJAgsgBEEBaiEBQe0AIRAMyAILAkAgASIEIAJHDQBBgwEhEAzhAgsgAiAEayAAKAIAIgFqIRAgBCABa0ECaiEUAkADQCAELQAAIAFBgM+AgABqLQAARw3JASABQQJGDQEgAUEBaiEBIARBAWoiBCACRw0ACyAAIBA2AgBBgwEhEAzhAgtBACEQIABBADYCACAUQQFqIQEMxgELAkAgASIEIAJHDQBBhAEhEAzgAgsgAiAEayAAKAIAIgFqIRQgBCABa0EEaiEQAkADQCAELQAAIAFBg8+AgABqLQAARw3IASABQQRGDQEgAUEBaiEBIARBAWoiBCACRw0ACyAAIBQ2AgBBhAEhEAzgAgsgAEEANgIAIBBBAWohAUEjIRAMxQELAkAgASIEIAJHDQBBhQEhEAzfAgsCQAJAIAQtAABBtH9qDggAyAHIAcgByAHIAcgBAcgBCyAEQQFqIQFB7wAhEAzGAgsgBEEBaiEBQfAAIRAMxQILAkAgASIEIAJHDQBBhgEhEAzeAgsgBC0AAEHFAEcNxQEgBEEBaiEBDIMCCwJAIAEiBCACRw0AQYcBIRAM3QILIAIgBGsgACgCACIBaiEUIAQgAWtBA2ohEAJAA0AgBC0AACABQYjPgIAAai0AAEcNxQEgAUEDRg0BIAFBAWohASAEQQFqIgQgAkcNAAsgACAUNgIAQYcBIRAM3QILIABBADYCACAQQQFqIQFBLSEQDMIBCwJAIAEiBCACRw0AQYgBIRAM3AILIAIgBGsgACgCACIBaiEUIAQgAWtBCGohEAJAA0AgBC0AACABQdDPgIAAai0AAEcNxAEgAUEIRg0BIAFBAWohASAEQQFqIgQgAkcNAAsgACAUNgIAQYgBIRAM3AILIABBADYCACAQQQFqIQFBKSEQDMEBCwJAIAEiASACRw0AQYkBIRAM2wILQQEhECABLQAAQd8ARw3AASABQQFqIQEMgQILAkAgASIEIAJHDQBBigEhEAzaAgsgAiAEayAAKAIAIgFqIRQgBCABa0EBaiEQA0AgBC0AACABQYzPgIAAai0AAEcNwQEgAUEBRg2vAiABQQFqIQEgBEEBaiIEIAJHDQALIAAgFDYCAEGKASEQDNkCCwJAIAEiBCACRw0AQYsBIRAM2QILIAIgBGsgACgCACIBaiEUIAQgAWtBAmohEAJAA0AgBC0AACABQY7PgIAAai0AAEcNwQEgAUECRg0BIAFBAWohASAEQQFqIgQgAkcNAAsgACAUNgIAQYsBIRAM2QILIABBADYCACAQQQFqIQFBAiEQDL4BCwJAIAEiBCACRw0AQYwBIRAM2AILIAIgBGsgACgCACIBaiEUIAQgAWtBAWohEAJAA0AgBC0AACABQfDPgIAAai0AAEcNwAEgAUEBRg0BIAFBAWohASAEQQFqIgQgAkcNAAsgACAUNgIAQYwBIRAM2AILIABBADYCACAQQQFqIQFBHyEQDL0BCwJAIAEiBCACRw0AQY0BIRAM1wILIAIgBGsgACgCACIBaiEUIAQgAWtBAWohEAJAA0AgBC0AACABQfLPgIAAai0AAEcNvwEgAUEBRg0BIAFBAWohASAEQQFqIgQgAkcNAAsgACAUNgIAQY0BIRAM1wILIABBADYCACAQQQFqIQFBCSEQDLwBCwJAIAEiBCACRw0AQY4BIRAM1gILAkACQCAELQAAQbd/ag4HAL8BvwG/Ab8BvwEBvwELIARBAWohAUH4ACEQDL0CCyAEQQFqIQFB+QAhEAy8AgsCQCABIgQgAkcNAEGPASEQDNUCCyACIARrIAAoAgAiAWohFCAEIAFrQQVqIRACQANAIAQtAAAgAUGRz4CAAGotAABHDb0BIAFBBUYNASABQQFqIQEgBEEBaiIEIAJHDQALIAAgFDYCAEGPASEQDNUCCyAAQQA2AgAgEEEBaiEBQRghEAy6AQsCQCABIgQgAkcNAEGQASEQDNQCCyACIARrIAAoAgAiAWohFCAEIAFrQQJqIRACQANAIAQtAAAgAUGXz4CAAGotAABHDbwBIAFBAkYNASABQQFqIQEgBEEBaiIEIAJHDQALIAAgFDYCAEGQASEQDNQCCyAAQQA2AgAgEEEBaiEBQRchEAy5AQsCQCABIgQgAkcNAEGRASEQDNMCCyACIARrIAAoAgAiAWohFCAEIAFrQQZqIRACQANAIAQtAAAgAUGaz4CAAGotAABHDbsBIAFBBkYNASABQQFqIQEgBEEBaiIEIAJHDQALIAAgFDYCAEGRASEQDNMCCyAAQQA2AgAgEEEBaiEBQRUhEAy4AQsCQCABIgQgAkcNAEGSASEQDNICCyACIARrIAAoAgAiAWohFCAEIAFrQQVqIRACQANAIAQtAAAgAUGhz4CAAGotAABHDboBIAFBBUYNASABQQFqIQEgBEEBaiIEIAJHDQALIAAgFDYCAEGSASEQDNICCyAAQQA2AgAgEEEBaiEBQR4hEAy3AQsCQCABIgQgAkcNAEGTASEQDNECCyAELQAAQcwARw24ASAEQQFqIQFBCiEQDLYBCwJAIAQgAkcNAEGUASEQDNACCwJAAkAgBC0AAEG/f2oODwC5AbkBuQG5AbkBuQG5AbkBuQG5AbkBuQG5AQG5AQsgBEEBaiEBQf4AIRAMtwILIARBAWohAUH/ACEQDLYCCwJAIAQgAkcNAEGVASEQDM8CCwJAAkAgBC0AAEG/f2oOAwC4AQG4AQsgBEEBaiEBQf0AIRAMtgILIARBAWohBEGAASEQDLUCCwJAIAQgAkcNAEGWASEQDM4CCyACIARrIAAoAgAiAWohFCAEIAFrQQFqIRACQANAIAQtAAAgAUGnz4CAAGotAABHDbYBIAFBAUYNASABQQFqIQEgBEEBaiIEIAJHDQALIAAgFDYCAEGWASEQDM4CCyAAQQA2AgAgEEEBaiEBQQshEAyzAQsCQCAEIAJHDQBBlwEhEAzNAgsCQAJAAkACQCAELQAAQVNqDiMAuAG4AbgBuAG4AbgBuAG4AbgBuAG4AbgBuAG4AbgBuAG4AbgBuAG4AbgBuAG4AQG4AbgBuAG4AbgBArgBuAG4AQO4AQsgBEEBaiEBQfsAIRAMtgILIARBAWohAUH8ACEQDLUCCyAEQQFqIQRBgQEhEAy0AgsgBEEBaiEEQYIBIRAMswILAkAgBCACRw0AQZgBIRAMzAILIAIgBGsgACgCACIBaiEUIAQgAWtBBGohEAJAA0AgBC0AACABQanPgIAAai0AAEcNtAEgAUEERg0BIAFBAWohASAEQQFqIgQgAkcNAAsgACAUNgIAQZgBIRAMzAILIABBADYCACAQQQFqIQFBGSEQDLEBCwJAIAQgAkcNAEGZASEQDMsCCyACIARrIAAoAgAiAWohFCAEIAFrQQVqIRACQANAIAQtAAAgAUGuz4CAAGotAABHDbMBIAFBBUYNASABQQFqIQEgBEEBaiIEIAJHDQALIAAgFDYCAEGZASEQDMsCCyAAQQA2AgAgEEEBaiEBQQYhEAywAQsCQCAEIAJHDQBBmgEhEAzKAgsgAiAEayAAKAIAIgFqIRQgBCABa0EBaiEQAkADQCAELQAAIAFBtM+AgABqLQAARw2yASABQQFGDQEgAUEBaiEBIARBAWoiBCACRw0ACyAAIBQ2AgBBmgEhEAzKAgsgAEEANgIAIBBBAWohAUEcIRAMrwELAkAgBCACRw0AQZsBIRAMyQILIAIgBGsgACgCACIBaiEUIAQgAWtBAWohEAJAA0AgBC0AACABQbbPgIAAai0AAEcNsQEgAUEBRg0BIAFBAWohASAEQQFqIgQgAkcNAAsgACAUNgIAQZsBIRAMyQILIABBADYCACAQQQFqIQFBJyEQDK4BCwJAIAQgAkcNAEGcASEQDMgCCwJAAkAgBC0AAEGsf2oOAgABsQELIARBAWohBEGGASEQDK8CCyAEQQFqIQRBhwEhEAyuAgsCQCAEIAJHDQBBnQEhEAzHAgsgAiAEayAAKAIAIgFqIRQgBCABa0EBaiEQAkADQCAELQAAIAFBuM+AgABqLQAARw2vASABQQFGDQEgAUEBaiEBIARBAWoiBCACRw0ACyAAIBQ2AgBBnQEhEAzHAgsgAEEANgIAIBBBAWohAUEmIRAMrAELAkAgBCACRw0AQZ4BIRAMxgILIAIgBGsgACgCACIBaiEUIAQgAWtBAWohEAJAA0AgBC0AACABQbrPgIAAai0AAEcNrgEgAUEBRg0BIAFBAWohASAEQQFqIgQgAkcNAAsgACAUNgIAQZ4BIRAMxgILIABBADYCACAQQQFqIQFBAyEQDKsBCwJAIAQgAkcNAEGfASEQDMUCCyACIARrIAAoAgAiAWohFCAEIAFrQQJqIRACQANAIAQtAAAgAUHtz4CAAGotAABHDa0BIAFBAkYNASABQQFqIQEgBEEBaiIEIAJHDQALIAAgFDYCAEGfASEQDMUCCyAAQQA2AgAgEEEBaiEBQQwhEAyqAQsCQCAEIAJHDQBBoAEhEAzEAgsgAiAEayAAKAIAIgFqIRQgBCABa0EDaiEQAkADQCAELQAAIAFBvM+AgABqLQAARw2sASABQQNGDQEgAUEBaiEBIARBAWoiBCACRw0ACyAAIBQ2AgBBoAEhEAzEAgsgAEEANgIAIBBBAWohAUENIRAMqQELAkAgBCACRw0AQaEBIRAMwwILAkACQCAELQAAQbp/ag4LAKwBrAGsAawBrAGsAawBrAGsAQGsAQsgBEEBaiEEQYsBIRAMqgILIARBAWohBEGMASEQDKkCCwJAIAQgAkcNAEGiASEQDMICCyAELQAAQdAARw2pASAEQQFqIQQM6QELAkAgBCACRw0AQaMBIRAMwQILAkACQCAELQAAQbd/ag4HAaoBqgGqAaoBqgEAqgELIARBAWohBEGOASEQDKgCCyAEQQFqIQFBIiEQDKYBCwJAIAQgAkcNAEGkASEQDMACCyACIARrIAAoAgAiAWohFCAEIAFrQQFqIRACQANAIAQtAAAgAUHAz4CAAGotAABHDagBIAFBAUYNASABQQFqIQEgBEEBaiIEIAJHDQALIAAgFDYCAEGkASEQDMACCyAAQQA2AgAgEEEBaiEBQR0hEAylAQsCQCAEIAJHDQBBpQEhEAy/AgsCQAJAIAQtAABBrn9qDgMAqAEBqAELIARBAWohBEGQASEQDKYCCyAEQQFqIQFBBCEQDKQBCwJAIAQgAkcNAEGmASEQDL4CCwJAAkACQAJAAkAgBC0AAEG/f2oOFQCqAaoBqgGqAaoBqgGqAaoBqgGqAQGqAaoBAqoBqgEDqgGqAQSqAQsgBEEBaiEEQYgBIRAMqAILIARBAWohBEGJASEQDKcCCyAEQQFqIQRBigEhEAymAgsgBEEBaiEEQY8BIRAMpQILIARBAWohBEGRASEQDKQCCwJAIAQgAkcNAEGnASEQDL0CCyACIARrIAAoAgAiAWohFCAEIAFrQQJqIRACQANAIAQtAAAgAUHtz4CAAGotAABHDaUBIAFBAkYNASABQQFqIQEgBEEBaiIEIAJHDQALIAAgFDYCAEGnASEQDL0CCyAAQQA2AgAgEEEBaiEBQREhEAyiAQsCQCAEIAJHDQBBqAEhEAy8AgsgAiAEayAAKAIAIgFqIRQgBCABa0ECaiEQAkADQCAELQAAIAFBws+AgABqLQAARw2kASABQQJGDQEgAUEBaiEBIARBAWoiBCACRw0ACyAAIBQ2AgBBqAEhEAy8AgsgAEEANgIAIBBBAWohAUEsIRAMoQELAkAgBCACRw0AQakBIRAMuwILIAIgBGsgACgCACIBaiEUIAQgAWtBBGohEAJAA0AgBC0AACABQcXPgIAAai0AAEcNowEgAUEERg0BIAFBAWohASAEQQFqIgQgAkcNAAsgACAUNgIAQakBIRAMuwILIABBADYCACAQQQFqIQFBKyEQDKABCwJAIAQgAkcNAEGqASEQDLoCCyACIARrIAAoAgAiAWohFCAEIAFrQQJqIRACQANAIAQtAAAgAUHKz4CAAGotAABHDaIBIAFBAkYNASABQQFqIQEgBEEBaiIEIAJHDQALIAAgFDYCAEGqASEQDLoCCyAAQQA2AgAgEEEBaiEBQRQhEAyfAQsCQCAEIAJHDQBBqwEhEAy5AgsCQAJAAkACQCAELQAAQb5/ag4PAAECpAGkAaQBpAGkAaQBpAGkAaQBpAGkAQOkAQsgBEEBaiEEQZMBIRAMogILIARBAWohBEGUASEQDKECCyAEQQFqIQRBlQEhEAygAgsgBEEBaiEEQZYBIRAMnwILAkAgBCACRw0AQawBIRAMuAILIAQtAABBxQBHDZ8BIARBAWohBAzgAQsCQCAEIAJHDQBBrQEhEAy3AgsgAiAEayAAKAIAIgFqIRQgBCABa0ECaiEQAkADQCAELQAAIAFBzc+AgABqLQAARw2fASABQQJGDQEgAUEBaiEBIARBAWoiBCACRw0ACyAAIBQ2AgBBrQEhEAy3AgsgAEEANgIAIBBBAWohAUEOIRAMnAELAkAgBCACRw0AQa4BIRAMtgILIAQtAABB0ABHDZ0BIARBAWohAUElIRAMmwELAkAgBCACRw0AQa8BIRAMtQILIAIgBGsgACgCACIBaiEUIAQgAWtBCGohEAJAA0AgBC0AACABQdDPgIAAai0AAEcNnQEgAUEIRg0BIAFBAWohASAEQQFqIgQgAkcNAAsgACAUNgIAQa8BIRAMtQILIABBADYCACAQQQFqIQFBKiEQDJoBCwJAIAQgAkcNAEGwASEQDLQCCwJAAkAgBC0AAEGrf2oOCwCdAZ0BnQGdAZ0BnQGdAZ0BnQEBnQELIARBAWohBEGaASEQDJsCCyAEQQFqIQRBmwEhEAyaAgsCQCAEIAJHDQBBsQEhEAyzAgsCQAJAIAQtAABBv39qDhQAnAGcAZwBnAGcAZwBnAGcAZwBnAGcAZwBnAGcAZwBnAGcAZwBAZwBCyAEQQFqIQRBmQEhEAyaAgsgBEEBaiEEQZwBIRAMmQILAkAgBCACRw0AQbIBIRAMsgILIAIgBGsgACgCACIBaiEUIAQgAWtBA2ohEAJAA0AgBC0AACABQdnPgIAAai0AAEcNmgEgAUEDRg0BIAFBAWohASAEQQFqIgQgAkcNAAsgACAUNgIAQbIBIRAMsgILIABBADYCACAQQQFqIQFBISEQDJcBCwJAIAQgAkcNAEGzASEQDLECCyACIARrIAAoAgAiAWohFCAEIAFrQQZqIRACQANAIAQtAAAgAUHdz4CAAGotAABHDZkBIAFBBkYNASABQQFqIQEgBEEBaiIEIAJHDQALIAAgFDYCAEGzASEQDLECCyAAQQA2AgAgEEEBaiEBQRohEAyWAQsCQCAEIAJHDQBBtAEhEAywAgsCQAJAAkAgBC0AAEG7f2oOEQCaAZoBmgGaAZoBmgGaAZoBmgEBmgGaAZoBmgGaAQKaAQsgBEEBaiEEQZ0BIRAMmAILIARBAWohBEGeASEQDJcCCyAEQQFqIQRBnwEhEAyWAgsCQCAEIAJHDQBBtQEhEAyvAgsgAiAEayAAKAIAIgFqIRQgBCABa0EFaiEQAkADQCAELQAAIAFB5M+AgABqLQAARw2XASABQQVGDQEgAUEBaiEBIARBAWoiBCACRw0ACyAAIBQ2AgBBtQEhEAyvAgsgAEEANgIAIBBBAWohAUEoIRAMlAELAkAgBCACRw0AQbYBIRAMrgILIAIgBGsgACgCACIBaiEUIAQgAWtBAmohEAJAA0AgBC0AACABQerPgIAAai0AAEcNlgEgAUECRg0BIAFBAWohASAEQQFqIgQgAkcNAAsgACAUNgIAQbYBIRAMrgILIABBADYCACAQQQFqIQFBByEQDJMBCwJAIAQgAkcNAEG3ASEQDK0CCwJAAkAgBC0AAEG7f2oODgCWAZYBlgGWAZYBlgGWAZYBlgGWAZYBlgEBlgELIARBAWohBEGhASEQDJQCCyAEQQFqIQRBogEhEAyTAgsCQCAEIAJHDQBBuAEhEAysAgsgAiAEayAAKAIAIgFqIRQgBCABa0ECaiEQAkADQCAELQAAIAFB7c+AgABqLQAARw2UASABQQJGDQEgAUEBaiEBIARBAWoiBCACRw0ACyAAIBQ2AgBBuAEhEAysAgsgAEEANgIAIBBBAWohAUESIRAMkQELAkAgBCACRw0AQbkBIRAMqwILIAIgBGsgACgCACIBaiEUIAQgAWtBAWohEAJAA0AgBC0AACABQfDPgIAAai0AAEcNkwEgAUEBRg0BIAFBAWohASAEQQFqIgQgAkcNAAsgACAUNgIAQbkBIRAMqwILIABBADYCACAQQQFqIQFBICEQDJABCwJAIAQgAkcNAEG6ASEQDKoCCyACIARrIAAoAgAiAWohFCAEIAFrQQFqIRACQANAIAQtAAAgAUHyz4CAAGotAABHDZIBIAFBAUYNASABQQFqIQEgBEEBaiIEIAJHDQALIAAgFDYCAEG6ASEQDKoCCyAAQQA2AgAgEEEBaiEBQQ8hEAyPAQsCQCAEIAJHDQBBuwEhEAypAgsCQAJAIAQtAABBt39qDgcAkgGSAZIBkgGSAQGSAQsgBEEBaiEEQaUBIRAMkAILIARBAWohBEGmASEQDI8CCwJAIAQgAkcNAEG8ASEQDKgCCyACIARrIAAoAgAiAWohFCAEIAFrQQdqIRACQANAIAQtAAAgAUH0z4CAAGotAABHDZABIAFBB0YNASABQQFqIQEgBEEBaiIEIAJHDQALIAAgFDYCAEG8ASEQDKgCCyAAQQA2AgAgEEEBaiEBQRshEAyNAQsCQCAEIAJHDQBBvQEhEAynAgsCQAJAAkAgBC0AAEG+f2oOEgCRAZEBkQGRAZEBkQGRAZEBkQEBkQGRAZEBkQGRAZEBApEBCyAEQQFqIQRBpAEhEAyPAgsgBEEBaiEEQacBIRAMjgILIARBAWohBEGoASEQDI0CCwJAIAQgAkcNAEG+ASEQDKYCCyAELQAAQc4ARw2NASAEQQFqIQQMzwELAkAgBCACRw0AQb8BIRAMpQILAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkAgBC0AAEG/f2oOFQABAgOcAQQFBpwBnAGcAQcICQoLnAEMDQ4PnAELIARBAWohAUHoACEQDJoCCyAEQQFqIQFB6QAhEAyZAgsgBEEBaiEBQe4AIRAMmAILIARBAWohAUHyACEQDJcCCyAEQQFqIQFB8wAhEAyWAgsgBEEBaiEBQfYAIRAMlQILIARBAWohAUH3ACEQDJQCCyAEQQFqIQFB+gAhEAyTAgsgBEEBaiEEQYMBIRAMkgILIARBAWohBEGEASEQDJECCyAEQQFqIQRBhQEhEAyQAgsgBEEBaiEEQZIBIRAMjwILIARBAWohBEGYASEQDI4CCyAEQQFqIQRBoAEhEAyNAgsgBEEBaiEEQaMBIRAMjAILIARBAWohBEGqASEQDIsCCwJAIAQgAkYNACAAQZCAgIAANgIIIAAgBDYCBEGrASEQDIsCC0HAASEQDKMCCyAAIAUgAhCqgICAACIBDYsBIAUhAQxcCwJAIAYgAkYNACAGQQFqIQUMjQELQcIBIRAMoQILA0ACQCAQLQAAQXZqDgSMAQAAjwEACyAQQQFqIhAgAkcNAAtBwwEhEAygAgsCQCAHIAJGDQAgAEGRgICAADYCCCAAIAc2AgQgByEBQQEhEAyHAgtBxAEhEAyfAgsCQCAHIAJHDQBBxQEhEAyfAgsCQAJAIActAABBdmoOBAHOAc4BAM4BCyAHQQFqIQYMjQELIAdBAWohBQyJAQsCQCAHIAJHDQBBxgEhEAyeAgsCQAJAIActAABBdmoOFwGPAY8BAY8BjwGPAY8BjwGPAY8BjwGPAY8BjwGPAY8BjwGPAY8BjwGPAQCPAQsgB0EBaiEHC0GwASEQDIQCCwJAIAggAkcNAEHIASEQDJ0CCyAILQAAQSBHDY0BIABBADsBMiAIQQFqIQFBswEhEAyDAgsgASEXAkADQCAXIgcgAkYNASAHLQAAQVBqQf8BcSIQQQpPDcwBAkAgAC8BMiIUQZkzSw0AIAAgFEEKbCIUOwEyIBBB//8DcyAUQf7/A3FJDQAgB0EBaiEXIAAgFCAQaiIQOwEyIBBB//8DcUHoB0kNAQsLQQAhECAAQQA2AhwgAEHBiYCAADYCECAAQQ02AgwgACAHQQFqNgIUDJwCC0HHASEQDJsCCyAAIAggAhCugICAACIQRQ3KASAQQRVHDYwBIABByAE2AhwgACAINgIUIABByZeAgAA2AhAgAEEVNgIMQQAhEAyaAgsCQCAJIAJHDQBBzAEhEAyaAgtBACEUQQEhF0EBIRZBACEQAkACQAJAAkACQAJAAkACQAJAIAktAABBUGoOCpYBlQEAAQIDBAUGCJcBC0ECIRAMBgtBAyEQDAULQQQhEAwEC0EFIRAMAwtBBiEQDAILQQchEAwBC0EIIRALQQAhF0EAIRZBACEUDI4BC0EJIRBBASEUQQAhF0EAIRYMjQELAkAgCiACRw0AQc4BIRAMmQILIAotAABBLkcNjgEgCkEBaiEJDMoBCyALIAJHDY4BQdABIRAMlwILAkAgCyACRg0AIABBjoCAgAA2AgggACALNgIEQbcBIRAM/gELQdEBIRAMlgILAkAgBCACRw0AQdIBIRAMlgILIAIgBGsgACgCACIQaiEUIAQgEGtBBGohCwNAIAQtAAAgEEH8z4CAAGotAABHDY4BIBBBBEYN6QEgEEEBaiEQIARBAWoiBCACRw0ACyAAIBQ2AgBB0gEhEAyVAgsgACAMIAIQrICAgAAiAQ2NASAMIQEMuAELAkAgBCACRw0AQdQBIRAMlAILIAIgBGsgACgCACIQaiEUIAQgEGtBAWohDANAIAQtAAAgEEGB0ICAAGotAABHDY8BIBBBAUYNjgEgEEEBaiEQIARBAWoiBCACRw0ACyAAIBQ2AgBB1AEhEAyTAgsCQCAEIAJHDQBB1gEhEAyTAgsgAiAEayAAKAIAIhBqIRQgBCAQa0ECaiELA0AgBC0AACAQQYPQgIAAai0AAEcNjgEgEEECRg2QASAQQQFqIRAgBEEBaiIEIAJHDQALIAAgFDYCAEHWASEQDJICCwJAIAQgAkcNAEHXASEQDJICCwJAAkAgBC0AAEG7f2oOEACPAY8BjwGPAY8BjwGPAY8BjwGPAY8BjwGPAY8BAY8BCyAEQQFqIQRBuwEhEAz5AQsgBEEBaiEEQbwBIRAM+AELAkAgBCACRw0AQdgBIRAMkQILIAQtAABByABHDYwBIARBAWohBAzEAQsCQCAEIAJGDQAgAEGQgICAADYCCCAAIAQ2AgRBvgEhEAz3AQtB2QEhEAyPAgsCQCAEIAJHDQBB2gEhEAyPAgsgBC0AAEHIAEYNwwEgAEEBOgAoDLkBCyAAQQI6AC8gACAEIAIQpoCAgAAiEA2NAUHCASEQDPQBCyAALQAoQX9qDgK3AbkBuAELA0ACQCAELQAAQXZqDgQAjgGOAQCOAQsgBEEBaiIEIAJHDQALQd0BIRAMiwILIABBADoALyAALQAtQQRxRQ2EAgsgAEEAOgAvIABBAToANCABIQEMjAELIBBBFUYN2gEgAEEANgIcIAAgATYCFCAAQaeOgIAANgIQIABBEjYCDEEAIRAMiAILAkAgACAQIAIQtICAgAAiBA0AIBAhAQyBAgsCQCAEQRVHDQAgAEEDNgIcIAAgEDYCFCAAQbCYgIAANgIQIABBFTYCDEEAIRAMiAILIABBADYCHCAAIBA2AhQgAEGnjoCAADYCECAAQRI2AgxBACEQDIcCCyAQQRVGDdYBIABBADYCHCAAIAE2AhQgAEHajYCAADYCECAAQRQ2AgxBACEQDIYCCyAAKAIEIRcgAEEANgIEIBAgEadqIhYhASAAIBcgECAWIBQbIhAQtYCAgAAiFEUNjQEgAEEHNgIcIAAgEDYCFCAAIBQ2AgxBACEQDIUCCyAAIAAvATBBgAFyOwEwIAEhAQtBKiEQDOoBCyAQQRVGDdEBIABBADYCHCAAIAE2AhQgAEGDjICAADYCECAAQRM2AgxBACEQDIICCyAQQRVGDc8BIABBADYCHCAAIAE2AhQgAEGaj4CAADYCECAAQSI2AgxBACEQDIECCyAAKAIEIRAgAEEANgIEAkAgACAQIAEQt4CAgAAiEA0AIAFBAWohAQyNAQsgAEEMNgIcIAAgEDYCDCAAIAFBAWo2AhRBACEQDIACCyAQQRVGDcwBIABBADYCHCAAIAE2AhQgAEGaj4CAADYCECAAQSI2AgxBACEQDP8BCyAAKAIEIRAgAEEANgIEAkAgACAQIAEQt4CAgAAiEA0AIAFBAWohAQyMAQsgAEENNgIcIAAgEDYCDCAAIAFBAWo2AhRBACEQDP4BCyAQQRVGDckBIABBADYCHCAAIAE2AhQgAEHGjICAADYCECAAQSM2AgxBACEQDP0BCyAAKAIEIRAgAEEANgIEAkAgACAQIAEQuYCAgAAiEA0AIAFBAWohAQyLAQsgAEEONgIcIAAgEDYCDCAAIAFBAWo2AhRBACEQDPwBCyAAQQA2AhwgACABNgIUIABBwJWAgAA2AhAgAEECNgIMQQAhEAz7AQsgEEEVRg3FASAAQQA2AhwgACABNgIUIABBxoyAgAA2AhAgAEEjNgIMQQAhEAz6AQsgAEEQNgIcIAAgATYCFCAAIBA2AgxBACEQDPkBCyAAKAIEIQQgAEEANgIEAkAgACAEIAEQuYCAgAAiBA0AIAFBAWohAQzxAQsgAEERNgIcIAAgBDYCDCAAIAFBAWo2AhRBACEQDPgBCyAQQRVGDcEBIABBADYCHCAAIAE2AhQgAEHGjICAADYCECAAQSM2AgxBACEQDPcBCyAAKAIEIRAgAEEANgIEAkAgACAQIAEQuYCAgAAiEA0AIAFBAWohAQyIAQsgAEETNgIcIAAgEDYCDCAAIAFBAWo2AhRBACEQDPYBCyAAKAIEIQQgAEEANgIEAkAgACAEIAEQuYCAgAAiBA0AIAFBAWohAQztAQsgAEEUNgIcIAAgBDYCDCAAIAFBAWo2AhRBACEQDPUBCyAQQRVGDb0BIABBADYCHCAAIAE2AhQgAEGaj4CAADYCECAAQSI2AgxBACEQDPQBCyAAKAIEIRAgAEEANgIEAkAgACAQIAEQt4CAgAAiEA0AIAFBAWohAQyGAQsgAEEWNgIcIAAgEDYCDCAAIAFBAWo2AhRBACEQDPMBCyAAKAIEIQQgAEEANgIEAkAgACAEIAEQt4CAgAAiBA0AIAFBAWohAQzpAQsgAEEXNgIcIAAgBDYCDCAAIAFBAWo2AhRBACEQDPIBCyAAQQA2AhwgACABNgIUIABBzZOAgAA2AhAgAEEMNgIMQQAhEAzxAQtCASERCyAQQQFqIQECQCAAKQMgIhJC//////////8PVg0AIAAgEkIEhiARhDcDICABIQEMhAELIABBADYCHCAAIAE2AhQgAEGtiYCAADYCECAAQQw2AgxBACEQDO8BCyAAQQA2AhwgACAQNgIUIABBzZOAgAA2AhAgAEEMNgIMQQAhEAzuAQsgACgCBCEXIABBADYCBCAQIBGnaiIWIQEgACAXIBAgFiAUGyIQELWAgIAAIhRFDXMgAEEFNgIcIAAgEDYCFCAAIBQ2AgxBACEQDO0BCyAAQQA2AhwgACAQNgIUIABBqpyAgAA2AhAgAEEPNgIMQQAhEAzsAQsgACAQIAIQtICAgAAiAQ0BIBAhAQtBDiEQDNEBCwJAIAFBFUcNACAAQQI2AhwgACAQNgIUIABBsJiAgAA2AhAgAEEVNgIMQQAhEAzqAQsgAEEANgIcIAAgEDYCFCAAQaeOgIAANgIQIABBEjYCDEEAIRAM6QELIAFBAWohEAJAIAAvATAiAUGAAXFFDQACQCAAIBAgAhC7gICAACIBDQAgECEBDHALIAFBFUcNugEgAEEFNgIcIAAgEDYCFCAAQfmXgIAANgIQIABBFTYCDEEAIRAM6QELAkAgAUGgBHFBoARHDQAgAC0ALUECcQ0AIABBADYCHCAAIBA2AhQgAEGWk4CAADYCECAAQQQ2AgxBACEQDOkBCyAAIBAgAhC9gICAABogECEBAkACQAJAAkACQCAAIBAgAhCzgICAAA4WAgEABAQEBAQEBAQEBAQEBAQEBAQEAwQLIABBAToALgsgACAALwEwQcAAcjsBMCAQIQELQSYhEAzRAQsgAEEjNgIcIAAgEDYCFCAAQaWWgIAANgIQIABBFTYCDEEAIRAM6QELIABBADYCHCAAIBA2AhQgAEHVi4CAADYCECAAQRE2AgxBACEQDOgBCyAALQAtQQFxRQ0BQcMBIRAMzgELAkAgDSACRg0AA0ACQCANLQAAQSBGDQAgDSEBDMQBCyANQQFqIg0gAkcNAAtBJSEQDOcBC0ElIRAM5gELIAAoAgQhBCAAQQA2AgQgACAEIA0Qr4CAgAAiBEUNrQEgAEEmNgIcIAAgBDYCDCAAIA1BAWo2AhRBACEQDOUBCyAQQRVGDasBIABBADYCHCAAIAE2AhQgAEH9jYCAADYCECAAQR02AgxBACEQDOQBCyAAQSc2AhwgACABNgIUIAAgEDYCDEEAIRAM4wELIBAhAUEBIRQCQAJAAkACQAJAAkACQCAALQAsQX5qDgcGBQUDAQIABQsgACAALwEwQQhyOwEwDAMLQQIhFAwBC0EEIRQLIABBAToALCAAIAAvATAgFHI7ATALIBAhAQtBKyEQDMoBCyAAQQA2AhwgACAQNgIUIABBq5KAgAA2AhAgAEELNgIMQQAhEAziAQsgAEEANgIcIAAgATYCFCAAQeGPgIAANgIQIABBCjYCDEEAIRAM4QELIABBADoALCAQIQEMvQELIBAhAUEBIRQCQAJAAkACQAJAIAAtACxBe2oOBAMBAgAFCyAAIAAvATBBCHI7ATAMAwtBAiEUDAELQQQhFAsgAEEBOgAsIAAgAC8BMCAUcjsBMAsgECEBC0EpIRAMxQELIABBADYCHCAAIAE2AhQgAEHwlICAADYCECAAQQM2AgxBACEQDN0BCwJAIA4tAABBDUcNACAAKAIEIQEgAEEANgIEAkAgACABIA4QsYCAgAAiAQ0AIA5BAWohAQx1CyAAQSw2AhwgACABNgIMIAAgDkEBajYCFEEAIRAM3QELIAAtAC1BAXFFDQFBxAEhEAzDAQsCQCAOIAJHDQBBLSEQDNwBCwJAAkADQAJAIA4tAABBdmoOBAIAAAMACyAOQQFqIg4gAkcNAAtBLSEQDN0BCyAAKAIEIQEgAEEANgIEAkAgACABIA4QsYCAgAAiAQ0AIA4hAQx0CyAAQSw2AhwgACAONgIUIAAgATYCDEEAIRAM3AELIAAoAgQhASAAQQA2AgQCQCAAIAEgDhCxgICAACIBDQAgDkEBaiEBDHMLIABBLDYCHCAAIAE2AgwgACAOQQFqNgIUQQAhEAzbAQsgACgCBCEEIABBADYCBCAAIAQgDhCxgICAACIEDaABIA4hAQzOAQsgEEEsRw0BIAFBAWohEEEBIQECQAJAAkACQAJAIAAtACxBe2oOBAMBAgQACyAQIQEMBAtBAiEBDAELQQQhAQsgAEEBOgAsIAAgAC8BMCABcjsBMCAQIQEMAQsgACAALwEwQQhyOwEwIBAhAQtBOSEQDL8BCyAAQQA6ACwgASEBC0E0IRAMvQELIAAgAC8BMEEgcjsBMCABIQEMAgsgACgCBCEEIABBADYCBAJAIAAgBCABELGAgIAAIgQNACABIQEMxwELIABBNzYCHCAAIAE2AhQgACAENgIMQQAhEAzUAQsgAEEIOgAsIAEhAQtBMCEQDLkBCwJAIAAtAChBAUYNACABIQEMBAsgAC0ALUEIcUUNkwEgASEBDAMLIAAtADBBIHENlAFBxQEhEAy3AQsCQCAPIAJGDQACQANAAkAgDy0AAEFQaiIBQf8BcUEKSQ0AIA8hAUE1IRAMugELIAApAyAiEUKZs+bMmbPmzBlWDQEgACARQgp+IhE3AyAgESABrUL/AYMiEkJ/hVYNASAAIBEgEnw3AyAgD0EBaiIPIAJHDQALQTkhEAzRAQsgACgCBCECIABBADYCBCAAIAIgD0EBaiIEELGAgIAAIgINlQEgBCEBDMMBC0E5IRAMzwELAkAgAC8BMCIBQQhxRQ0AIAAtAChBAUcNACAALQAtQQhxRQ2QAQsgACABQff7A3FBgARyOwEwIA8hAQtBNyEQDLQBCyAAIAAvATBBEHI7ATAMqwELIBBBFUYNiwEgAEEANgIcIAAgATYCFCAAQfCOgIAANgIQIABBHDYCDEEAIRAMywELIABBwwA2AhwgACABNgIMIAAgDUEBajYCFEEAIRAMygELAkAgAS0AAEE6Rw0AIAAoAgQhECAAQQA2AgQCQCAAIBAgARCvgICAACIQDQAgAUEBaiEBDGMLIABBwwA2AhwgACAQNgIMIAAgAUEBajYCFEEAIRAMygELIABBADYCHCAAIAE2AhQgAEGxkYCAADYCECAAQQo2AgxBACEQDMkBCyAAQQA2AhwgACABNgIUIABBoJmAgAA2AhAgAEEeNgIMQQAhEAzIAQsgAEEANgIACyAAQYASOwEqIAAgF0EBaiIBIAIQqICAgAAiEA0BIAEhAQtBxwAhEAysAQsgEEEVRw2DASAAQdEANgIcIAAgATYCFCAAQeOXgIAANgIQIABBFTYCDEEAIRAMxAELIAAoAgQhECAAQQA2AgQCQCAAIBAgARCngICAACIQDQAgASEBDF4LIABB0gA2AhwgACABNgIUIAAgEDYCDEEAIRAMwwELIABBADYCHCAAIBQ2AhQgAEHBqICAADYCECAAQQc2AgwgAEEANgIAQQAhEAzCAQsgACgCBCEQIABBADYCBAJAIAAgECABEKeAgIAAIhANACABIQEMXQsgAEHTADYCHCAAIAE2AhQgACAQNgIMQQAhEAzBAQtBACEQIABBADYCHCAAIAE2AhQgAEGAkYCAADYCECAAQQk2AgwMwAELIBBBFUYNfSAAQQA2AhwgACABNgIUIABBlI2AgAA2AhAgAEEhNgIMQQAhEAy/AQtBASEWQQAhF0EAIRRBASEQCyAAIBA6ACsgAUEBaiEBAkACQCAALQAtQRBxDQACQAJAAkAgAC0AKg4DAQACBAsgFkUNAwwCCyAUDQEMAgsgF0UNAQsgACgCBCEQIABBADYCBAJAIAAgECABEK2AgIAAIhANACABIQEMXAsgAEHYADYCHCAAIAE2AhQgACAQNgIMQQAhEAy+AQsgACgCBCEEIABBADYCBAJAIAAgBCABEK2AgIAAIgQNACABIQEMrQELIABB2QA2AhwgACABNgIUIAAgBDYCDEEAIRAMvQELIAAoAgQhBCAAQQA2AgQCQCAAIAQgARCtgICAACIEDQAgASEBDKsBCyAAQdoANgIcIAAgATYCFCAAIAQ2AgxBACEQDLwBCyAAKAIEIQQgAEEANgIEAkAgACAEIAEQrYCAgAAiBA0AIAEhAQypAQsgAEHcADYCHCAAIAE2AhQgACAENgIMQQAhEAy7AQsCQCABLQAAQVBqIhBB/wFxQQpPDQAgACAQOgAqIAFBAWohAUHPACEQDKIBCyAAKAIEIQQgAEEANgIEAkAgACAEIAEQrYCAgAAiBA0AIAEhAQynAQsgAEHeADYCHCAAIAE2AhQgACAENgIMQQAhEAy6AQsgAEEANgIAIBdBAWohAQJAIAAtAClBI08NACABIQEMWQsgAEEANgIcIAAgATYCFCAAQdOJgIAANgIQIABBCDYCDEEAIRAMuQELIABBADYCAAtBACEQIABBADYCHCAAIAE2AhQgAEGQs4CAADYCECAAQQg2AgwMtwELIABBADYCACAXQQFqIQECQCAALQApQSFHDQAgASEBDFYLIABBADYCHCAAIAE2AhQgAEGbioCAADYCECAAQQg2AgxBACEQDLYBCyAAQQA2AgAgF0EBaiEBAkAgAC0AKSIQQV1qQQtPDQAgASEBDFULAkAgEEEGSw0AQQEgEHRBygBxRQ0AIAEhAQxVC0EAIRAgAEEANgIcIAAgATYCFCAAQfeJgIAANgIQIABBCDYCDAy1AQsgEEEVRg1xIABBADYCHCAAIAE2AhQgAEG5jYCAADYCECAAQRo2AgxBACEQDLQBCyAAKAIEIRAgAEEANgIEAkAgACAQIAEQp4CAgAAiEA0AIAEhAQxUCyAAQeUANgIcIAAgATYCFCAAIBA2AgxBACEQDLMBCyAAKAIEIRAgAEEANgIEAkAgACAQIAEQp4CAgAAiEA0AIAEhAQxNCyAAQdIANgIcIAAgATYCFCAAIBA2AgxBACEQDLIBCyAAKAIEIRAgAEEANgIEAkAgACAQIAEQp4CAgAAiEA0AIAEhAQxNCyAAQdMANgIcIAAgATYCFCAAIBA2AgxBACEQDLEBCyAAKAIEIRAgAEEANgIEAkAgACAQIAEQp4CAgAAiEA0AIAEhAQxRCyAAQeUANgIcIAAgATYCFCAAIBA2AgxBACEQDLABCyAAQQA2AhwgACABNgIUIABBxoqAgAA2AhAgAEEHNgIMQQAhEAyvAQsgACgCBCEQIABBADYCBAJAIAAgECABEKeAgIAAIhANACABIQEMSQsgAEHSADYCHCAAIAE2AhQgACAQNgIMQQAhEAyuAQsgACgCBCEQIABBADYCBAJAIAAgECABEKeAgIAAIhANACABIQEMSQsgAEHTADYCHCAAIAE2AhQgACAQNgIMQQAhEAytAQsgACgCBCEQIABBADYCBAJAIAAgECABEKeAgIAAIhANACABIQEMTQsgAEHlADYCHCAAIAE2AhQgACAQNgIMQQAhEAysAQsgAEEANgIcIAAgATYCFCAAQdyIgIAANgIQIABBBzYCDEEAIRAMqwELIBBBP0cNASABQQFqIQELQQUhEAyQAQtBACEQIABBADYCHCAAIAE2AhQgAEH9koCAADYCECAAQQc2AgwMqAELIAAoAgQhECAAQQA2AgQCQCAAIBAgARCngICAACIQDQAgASEBDEILIABB0gA2AhwgACABNgIUIAAgEDYCDEEAIRAMpwELIAAoAgQhECAAQQA2AgQCQCAAIBAgARCngICAACIQDQAgASEBDEILIABB0wA2AhwgACABNgIUIAAgEDYCDEEAIRAMpgELIAAoAgQhECAAQQA2AgQCQCAAIBAgARCngICAACIQDQAgASEBDEYLIABB5QA2AhwgACABNgIUIAAgEDYCDEEAIRAMpQELIAAoAgQhASAAQQA2AgQCQCAAIAEgFBCngICAACIBDQAgFCEBDD8LIABB0gA2AhwgACAUNgIUIAAgATYCDEEAIRAMpAELIAAoAgQhASAAQQA2AgQCQCAAIAEgFBCngICAACIBDQAgFCEBDD8LIABB0wA2AhwgACAUNgIUIAAgATYCDEEAIRAMowELIAAoAgQhASAAQQA2AgQCQCAAIAEgFBCngICAACIBDQAgFCEBDEMLIABB5QA2AhwgACAUNgIUIAAgATYCDEEAIRAMogELIABBADYCHCAAIBQ2AhQgAEHDj4CAADYCECAAQQc2AgxBACEQDKEBCyAAQQA2AhwgACABNgIUIABBw4+AgAA2AhAgAEEHNgIMQQAhEAygAQtBACEQIABBADYCHCAAIBQ2AhQgAEGMnICAADYCECAAQQc2AgwMnwELIABBADYCHCAAIBQ2AhQgAEGMnICAADYCECAAQQc2AgxBACEQDJ4BCyAAQQA2AhwgACAUNgIUIABB/pGAgAA2AhAgAEEHNgIMQQAhEAydAQsgAEEANgIcIAAgATYCFCAAQY6bgIAANgIQIABBBjYCDEEAIRAMnAELIBBBFUYNVyAAQQA2AhwgACABNgIUIABBzI6AgAA2AhAgAEEgNgIMQQAhEAybAQsgAEEANgIAIBBBAWohAUEkIRALIAAgEDoAKSAAKAIEIRAgAEEANgIEIAAgECABEKuAgIAAIhANVCABIQEMPgsgAEEANgIAC0EAIRAgAEEANgIcIAAgBDYCFCAAQfGbgIAANgIQIABBBjYCDAyXAQsgAUEVRg1QIABBADYCHCAAIAU2AhQgAEHwjICAADYCECAAQRs2AgxBACEQDJYBCyAAKAIEIQUgAEEANgIEIAAgBSAQEKmAgIAAIgUNASAQQQFqIQULQa0BIRAMewsgAEHBATYCHCAAIAU2AgwgACAQQQFqNgIUQQAhEAyTAQsgACgCBCEGIABBADYCBCAAIAYgEBCpgICAACIGDQEgEEEBaiEGC0GuASEQDHgLIABBwgE2AhwgACAGNgIMIAAgEEEBajYCFEEAIRAMkAELIABBADYCHCAAIAc2AhQgAEGXi4CAADYCECAAQQ02AgxBACEQDI8BCyAAQQA2AhwgACAINgIUIABB45CAgAA2AhAgAEEJNgIMQQAhEAyOAQsgAEEANgIcIAAgCDYCFCAAQZSNgIAANgIQIABBITYCDEEAIRAMjQELQQEhFkEAIRdBACEUQQEhEAsgACAQOgArIAlBAWohCAJAAkAgAC0ALUEQcQ0AAkACQAJAIAAtACoOAwEAAgQLIBZFDQMMAgsgFA0BDAILIBdFDQELIAAoAgQhECAAQQA2AgQgACAQIAgQrYCAgAAiEEUNPSAAQckBNgIcIAAgCDYCFCAAIBA2AgxBACEQDIwBCyAAKAIEIQQgAEEANgIEIAAgBCAIEK2AgIAAIgRFDXYgAEHKATYCHCAAIAg2AhQgACAENgIMQQAhEAyLAQsgACgCBCEEIABBADYCBCAAIAQgCRCtgICAACIERQ10IABBywE2AhwgACAJNgIUIAAgBDYCDEEAIRAMigELIAAoAgQhBCAAQQA2AgQgACAEIAoQrYCAgAAiBEUNciAAQc0BNgIcIAAgCjYCFCAAIAQ2AgxBACEQDIkBCwJAIAstAABBUGoiEEH/AXFBCk8NACAAIBA6ACogC0EBaiEKQbYBIRAMcAsgACgCBCEEIABBADYCBCAAIAQgCxCtgICAACIERQ1wIABBzwE2AhwgACALNgIUIAAgBDYCDEEAIRAMiAELIABBADYCHCAAIAQ2AhQgAEGQs4CAADYCECAAQQg2AgwgAEEANgIAQQAhEAyHAQsgAUEVRg0/IABBADYCHCAAIAw2AhQgAEHMjoCAADYCECAAQSA2AgxBACEQDIYBCyAAQYEEOwEoIAAoAgQhECAAQgA3AwAgACAQIAxBAWoiDBCrgICAACIQRQ04IABB0wE2AhwgACAMNgIUIAAgEDYCDEEAIRAMhQELIABBADYCAAtBACEQIABBADYCHCAAIAQ2AhQgAEHYm4CAADYCECAAQQg2AgwMgwELIAAoAgQhECAAQgA3AwAgACAQIAtBAWoiCxCrgICAACIQDQFBxgEhEAxpCyAAQQI6ACgMVQsgAEHVATYCHCAAIAs2AhQgACAQNgIMQQAhEAyAAQsgEEEVRg03IABBADYCHCAAIAQ2AhQgAEGkjICAADYCECAAQRA2AgxBACEQDH8LIAAtADRBAUcNNCAAIAQgAhC8gICAACIQRQ00IBBBFUcNNSAAQdwBNgIcIAAgBDYCFCAAQdWWgIAANgIQIABBFTYCDEEAIRAMfgtBACEQIABBADYCHCAAQa+LgIAANgIQIABBAjYCDCAAIBRBAWo2AhQMfQtBACEQDGMLQQIhEAxiC0ENIRAMYQtBDyEQDGALQSUhEAxfC0ETIRAMXgtBFSEQDF0LQRYhEAxcC0EXIRAMWwtBGCEQDFoLQRkhEAxZC0EaIRAMWAtBGyEQDFcLQRwhEAxWC0EdIRAMVQtBHyEQDFQLQSEhEAxTC0EjIRAMUgtBxgAhEAxRC0EuIRAMUAtBLyEQDE8LQTshEAxOC0E9IRAMTQtByAAhEAxMC0HJACEQDEsLQcsAIRAMSgtBzAAhEAxJC0HOACEQDEgLQdEAIRAMRwtB1QAhEAxGC0HYACEQDEULQdkAIRAMRAtB2wAhEAxDC0HkACEQDEILQeUAIRAMQQtB8QAhEAxAC0H0ACEQDD8LQY0BIRAMPgtBlwEhEAw9C0GpASEQDDwLQawBIRAMOwtBwAEhEAw6C0G5ASEQDDkLQa8BIRAMOAtBsQEhEAw3C0GyASEQDDYLQbQBIRAMNQtBtQEhEAw0C0G6ASEQDDMLQb0BIRAMMgtBvwEhEAwxC0HBASEQDDALIABBADYCHCAAIAQ2AhQgAEHpi4CAADYCECAAQR82AgxBACEQDEgLIABB2wE2AhwgACAENgIUIABB+paAgAA2AhAgAEEVNgIMQQAhEAxHCyAAQfgANgIcIAAgDDYCFCAAQcqYgIAANgIQIABBFTYCDEEAIRAMRgsgAEHRADYCHCAAIAU2AhQgAEGwl4CAADYCECAAQRU2AgxBACEQDEULIABB+QA2AhwgACABNgIUIAAgEDYCDEEAIRAMRAsgAEH4ADYCHCAAIAE2AhQgAEHKmICAADYCECAAQRU2AgxBACEQDEMLIABB5AA2AhwgACABNgIUIABB45eAgAA2AhAgAEEVNgIMQQAhEAxCCyAAQdcANgIcIAAgATYCFCAAQcmXgIAANgIQIABBFTYCDEEAIRAMQQsgAEEANgIcIAAgATYCFCAAQbmNgIAANgIQIABBGjYCDEEAIRAMQAsgAEHCADYCHCAAIAE2AhQgAEHjmICAADYCECAAQRU2AgxBACEQDD8LIABBADYCBCAAIA8gDxCxgICAACIERQ0BIABBOjYCHCAAIAQ2AgwgACAPQQFqNgIUQQAhEAw+CyAAKAIEIQQgAEEANgIEAkAgACAEIAEQsYCAgAAiBEUNACAAQTs2AhwgACAENgIMIAAgAUEBajYCFEEAIRAMPgsgAUEBaiEBDC0LIA9BAWohAQwtCyAAQQA2AhwgACAPNgIUIABB5JKAgAA2AhAgAEEENgIMQQAhEAw7CyAAQTY2AhwgACAENgIUIAAgAjYCDEEAIRAMOgsgAEEuNgIcIAAgDjYCFCAAIAQ2AgxBACEQDDkLIABB0AA2AhwgACABNgIUIABBkZiAgAA2AhAgAEEVNgIMQQAhEAw4CyANQQFqIQEMLAsgAEEVNgIcIAAgATYCFCAAQYKZgIAANgIQIABBFTYCDEEAIRAMNgsgAEEbNgIcIAAgATYCFCAAQZGXgIAANgIQIABBFTYCDEEAIRAMNQsgAEEPNgIcIAAgATYCFCAAQZGXgIAANgIQIABBFTYCDEEAIRAMNAsgAEELNgIcIAAgATYCFCAAQZGXgIAANgIQIABBFTYCDEEAIRAMMwsgAEEaNgIcIAAgATYCFCAAQYKZgIAANgIQIABBFTYCDEEAIRAMMgsgAEELNgIcIAAgATYCFCAAQYKZgIAANgIQIABBFTYCDEEAIRAMMQsgAEEKNgIcIAAgATYCFCAAQeSWgIAANgIQIABBFTYCDEEAIRAMMAsgAEEeNgIcIAAgATYCFCAAQfmXgIAANgIQIABBFTYCDEEAIRAMLwsgAEEANgIcIAAgEDYCFCAAQdqNgIAANgIQIABBFDYCDEEAIRAMLgsgAEEENgIcIAAgATYCFCAAQbCYgIAANgIQIABBFTYCDEEAIRAMLQsgAEEANgIAIAtBAWohCwtBuAEhEAwSCyAAQQA2AgAgEEEBaiEBQfUAIRAMEQsgASEBAkAgAC0AKUEFRw0AQeMAIRAMEQtB4gAhEAwQC0EAIRAgAEEANgIcIABB5JGAgAA2AhAgAEEHNgIMIAAgFEEBajYCFAwoCyAAQQA2AgAgF0EBaiEBQcAAIRAMDgtBASEBCyAAIAE6ACwgAEEANgIAIBdBAWohAQtBKCEQDAsLIAEhAQtBOCEQDAkLAkAgASIPIAJGDQADQAJAIA8tAABBgL6AgABqLQAAIgFBAUYNACABQQJHDQMgD0EBaiEBDAQLIA9BAWoiDyACRw0AC0E+IRAMIgtBPiEQDCELIABBADoALCAPIQEMAQtBCyEQDAYLQTohEAwFCyABQQFqIQFBLSEQDAQLIAAgAToALCAAQQA2AgAgFkEBaiEBQQwhEAwDCyAAQQA2AgAgF0EBaiEBQQohEAwCCyAAQQA2AgALIABBADoALCANIQFBCSEQDAALC0EAIRAgAEEANgIcIAAgCzYCFCAAQc2QgIAANgIQIABBCTYCDAwXC0EAIRAgAEEANgIcIAAgCjYCFCAAQemKgIAANgIQIABBCTYCDAwWC0EAIRAgAEEANgIcIAAgCTYCFCAAQbeQgIAANgIQIABBCTYCDAwVC0EAIRAgAEEANgIcIAAgCDYCFCAAQZyRgIAANgIQIABBCTYCDAwUC0EAIRAgAEEANgIcIAAgATYCFCAAQc2QgIAANgIQIABBCTYCDAwTC0EAIRAgAEEANgIcIAAgATYCFCAAQemKgIAANgIQIABBCTYCDAwSC0EAIRAgAEEANgIcIAAgATYCFCAAQbeQgIAANgIQIABBCTYCDAwRC0EAIRAgAEEANgIcIAAgATYCFCAAQZyRgIAANgIQIABBCTYCDAwQC0EAIRAgAEEANgIcIAAgATYCFCAAQZeVgIAANgIQIABBDzYCDAwPC0EAIRAgAEEANgIcIAAgATYCFCAAQZeVgIAANgIQIABBDzYCDAwOC0EAIRAgAEEANgIcIAAgATYCFCAAQcCSgIAANgIQIABBCzYCDAwNC0EAIRAgAEEANgIcIAAgATYCFCAAQZWJgIAANgIQIABBCzYCDAwMC0EAIRAgAEEANgIcIAAgATYCFCAAQeGPgIAANgIQIABBCjYCDAwLC0EAIRAgAEEANgIcIAAgATYCFCAAQfuPgIAANgIQIABBCjYCDAwKC0EAIRAgAEEANgIcIAAgATYCFCAAQfGZgIAANgIQIABBAjYCDAwJC0EAIRAgAEEANgIcIAAgATYCFCAAQcSUgIAANgIQIABBAjYCDAwIC0EAIRAgAEEANgIcIAAgATYCFCAAQfKVgIAANgIQIABBAjYCDAwHCyAAQQI2AhwgACABNgIUIABBnJqAgAA2AhAgAEEWNgIMQQAhEAwGC0EBIRAMBQtB1AAhECABIgQgAkYNBCADQQhqIAAgBCACQdjCgIAAQQoQxYCAgAAgAygCDCEEIAMoAggOAwEEAgALEMqAgIAAAAsgAEEANgIcIABBtZqAgAA2AhAgAEEXNgIMIAAgBEEBajYCFEEAIRAMAgsgAEEANgIcIAAgBDYCFCAAQcqagIAANgIQIABBCTYCDEEAIRAMAQsCQCABIgQgAkcNAEEiIRAMAQsgAEGJgICAADYCCCAAIAQ2AgRBISEQCyADQRBqJICAgIAAIBALrwEBAn8gASgCACEGAkACQCACIANGDQAgBCAGaiEEIAYgA2ogAmshByACIAZBf3MgBWoiBmohBQNAAkAgAi0AACAELQAARg0AQQIhBAwDCwJAIAYNAEEAIQQgBSECDAMLIAZBf2ohBiAEQQFqIQQgAkEBaiICIANHDQALIAchBiADIQILIABBATYCACABIAY2AgAgACACNgIEDwsgAUEANgIAIAAgBDYCACAAIAI2AgQLCgAgABDHgICAAAvyNgELfyOAgICAAEEQayIBJICAgIAAAkBBACgCoNCAgAANAEEAEMuAgIAAQYDUhIAAayICQdkASQ0AQQAhAwJAQQAoAuDTgIAAIgQNAEEAQn83AuzTgIAAQQBCgICEgICAwAA3AuTTgIAAQQAgAUEIakFwcUHYqtWqBXMiBDYC4NOAgABBAEEANgL004CAAEEAQQA2AsTTgIAAC0EAIAI2AszTgIAAQQBBgNSEgAA2AsjTgIAAQQBBgNSEgAA2ApjQgIAAQQAgBDYCrNCAgABBAEF/NgKo0ICAAANAIANBxNCAgABqIANBuNCAgABqIgQ2AgAgBCADQbDQgIAAaiIFNgIAIANBvNCAgABqIAU2AgAgA0HM0ICAAGogA0HA0ICAAGoiBTYCACAFIAQ2AgAgA0HU0ICAAGogA0HI0ICAAGoiBDYCACAEIAU2AgAgA0HQ0ICAAGogBDYCACADQSBqIgNBgAJHDQALQYDUhIAAQXhBgNSEgABrQQ9xQQBBgNSEgABBCGpBD3EbIgNqIgRBBGogAkFIaiIFIANrIgNBAXI2AgBBAEEAKALw04CAADYCpNCAgABBACADNgKU0ICAAEEAIAQ2AqDQgIAAQYDUhIAAIAVqQTg2AgQLAkACQAJAAkACQAJAAkACQAJAAkACQAJAIABB7AFLDQACQEEAKAKI0ICAACIGQRAgAEETakFwcSAAQQtJGyICQQN2IgR2IgNBA3FFDQACQAJAIANBAXEgBHJBAXMiBUEDdCIEQbDQgIAAaiIDIARBuNCAgABqKAIAIgQoAggiAkcNAEEAIAZBfiAFd3E2AojQgIAADAELIAMgAjYCCCACIAM2AgwLIARBCGohAyAEIAVBA3QiBUEDcjYCBCAEIAVqIgQgBCgCBEEBcjYCBAwMCyACQQAoApDQgIAAIgdNDQECQCADRQ0AAkACQCADIAR0QQIgBHQiA0EAIANrcnEiA0EAIANrcUF/aiIDIANBDHZBEHEiA3YiBEEFdkEIcSIFIANyIAQgBXYiA0ECdkEEcSIEciADIAR2IgNBAXZBAnEiBHIgAyAEdiIDQQF2QQFxIgRyIAMgBHZqIgRBA3QiA0Gw0ICAAGoiBSADQbjQgIAAaigCACIDKAIIIgBHDQBBACAGQX4gBHdxIgY2AojQgIAADAELIAUgADYCCCAAIAU2AgwLIAMgAkEDcjYCBCADIARBA3QiBGogBCACayIFNgIAIAMgAmoiACAFQQFyNgIEAkAgB0UNACAHQXhxQbDQgIAAaiECQQAoApzQgIAAIQQCQAJAIAZBASAHQQN2dCIIcQ0AQQAgBiAIcjYCiNCAgAAgAiEIDAELIAIoAgghCAsgCCAENgIMIAIgBDYCCCAEIAI2AgwgBCAINgIICyADQQhqIQNBACAANgKc0ICAAEEAIAU2ApDQgIAADAwLQQAoAozQgIAAIglFDQEgCUEAIAlrcUF/aiIDIANBDHZBEHEiA3YiBEEFdkEIcSIFIANyIAQgBXYiA0ECdkEEcSIEciADIAR2IgNBAXZBAnEiBHIgAyAEdiIDQQF2QQFxIgRyIAMgBHZqQQJ0QbjSgIAAaigCACIAKAIEQXhxIAJrIQQgACEFAkADQAJAIAUoAhAiAw0AIAVBFGooAgAiA0UNAgsgAygCBEF4cSACayIFIAQgBSAESSIFGyEEIAMgACAFGyEAIAMhBQwACwsgACgCGCEKAkAgACgCDCIIIABGDQAgACgCCCIDQQAoApjQgIAASRogCCADNgIIIAMgCDYCDAwLCwJAIABBFGoiBSgCACIDDQAgACgCECIDRQ0DIABBEGohBQsDQCAFIQsgAyIIQRRqIgUoAgAiAw0AIAhBEGohBSAIKAIQIgMNAAsgC0EANgIADAoLQX8hAiAAQb9/Sw0AIABBE2oiA0FwcSECQQAoAozQgIAAIgdFDQBBACELAkAgAkGAAkkNAEEfIQsgAkH///8HSw0AIANBCHYiAyADQYD+P2pBEHZBCHEiA3QiBCAEQYDgH2pBEHZBBHEiBHQiBSAFQYCAD2pBEHZBAnEiBXRBD3YgAyAEciAFcmsiA0EBdCACIANBFWp2QQFxckEcaiELC0EAIAJrIQQCQAJAAkACQCALQQJ0QbjSgIAAaigCACIFDQBBACEDQQAhCAwBC0EAIQMgAkEAQRkgC0EBdmsgC0EfRht0IQBBACEIA0ACQCAFKAIEQXhxIAJrIgYgBE8NACAGIQQgBSEIIAYNAEEAIQQgBSEIIAUhAwwDCyADIAVBFGooAgAiBiAGIAUgAEEddkEEcWpBEGooAgAiBUYbIAMgBhshAyAAQQF0IQAgBQ0ACwsCQCADIAhyDQBBACEIQQIgC3QiA0EAIANrciAHcSIDRQ0DIANBACADa3FBf2oiAyADQQx2QRBxIgN2IgVBBXZBCHEiACADciAFIAB2IgNBAnZBBHEiBXIgAyAFdiIDQQF2QQJxIgVyIAMgBXYiA0EBdkEBcSIFciADIAV2akECdEG40oCAAGooAgAhAwsgA0UNAQsDQCADKAIEQXhxIAJrIgYgBEkhAAJAIAMoAhAiBQ0AIANBFGooAgAhBQsgBiAEIAAbIQQgAyAIIAAbIQggBSEDIAUNAAsLIAhFDQAgBEEAKAKQ0ICAACACa08NACAIKAIYIQsCQCAIKAIMIgAgCEYNACAIKAIIIgNBACgCmNCAgABJGiAAIAM2AgggAyAANgIMDAkLAkAgCEEUaiIFKAIAIgMNACAIKAIQIgNFDQMgCEEQaiEFCwNAIAUhBiADIgBBFGoiBSgCACIDDQAgAEEQaiEFIAAoAhAiAw0ACyAGQQA2AgAMCAsCQEEAKAKQ0ICAACIDIAJJDQBBACgCnNCAgAAhBAJAAkAgAyACayIFQRBJDQAgBCACaiIAIAVBAXI2AgRBACAFNgKQ0ICAAEEAIAA2ApzQgIAAIAQgA2ogBTYCACAEIAJBA3I2AgQMAQsgBCADQQNyNgIEIAQgA2oiAyADKAIEQQFyNgIEQQBBADYCnNCAgABBAEEANgKQ0ICAAAsgBEEIaiEDDAoLAkBBACgClNCAgAAiACACTQ0AQQAoAqDQgIAAIgMgAmoiBCAAIAJrIgVBAXI2AgRBACAFNgKU0ICAAEEAIAQ2AqDQgIAAIAMgAkEDcjYCBCADQQhqIQMMCgsCQAJAQQAoAuDTgIAARQ0AQQAoAujTgIAAIQQMAQtBAEJ/NwLs04CAAEEAQoCAhICAgMAANwLk04CAAEEAIAFBDGpBcHFB2KrVqgVzNgLg04CAAEEAQQA2AvTTgIAAQQBBADYCxNOAgABBgIAEIQQLQQAhAwJAIAQgAkHHAGoiB2oiBkEAIARrIgtxIgggAksNAEEAQTA2AvjTgIAADAoLAkBBACgCwNOAgAAiA0UNAAJAQQAoArjTgIAAIgQgCGoiBSAETQ0AIAUgA00NAQtBACEDQQBBMDYC+NOAgAAMCgtBAC0AxNOAgABBBHENBAJAAkACQEEAKAKg0ICAACIERQ0AQcjTgIAAIQMDQAJAIAMoAgAiBSAESw0AIAUgAygCBGogBEsNAwsgAygCCCIDDQALC0EAEMuAgIAAIgBBf0YNBSAIIQYCQEEAKALk04CAACIDQX9qIgQgAHFFDQAgCCAAayAEIABqQQAgA2txaiEGCyAGIAJNDQUgBkH+////B0sNBQJAQQAoAsDTgIAAIgNFDQBBACgCuNOAgAAiBCAGaiIFIARNDQYgBSADSw0GCyAGEMuAgIAAIgMgAEcNAQwHCyAGIABrIAtxIgZB/v///wdLDQQgBhDLgICAACIAIAMoAgAgAygCBGpGDQMgACEDCwJAIANBf0YNACACQcgAaiAGTQ0AAkAgByAGa0EAKALo04CAACIEakEAIARrcSIEQf7///8HTQ0AIAMhAAwHCwJAIAQQy4CAgABBf0YNACAEIAZqIQYgAyEADAcLQQAgBmsQy4CAgAAaDAQLIAMhACADQX9HDQUMAwtBACEIDAcLQQAhAAwFCyAAQX9HDQILQQBBACgCxNOAgABBBHI2AsTTgIAACyAIQf7///8HSw0BIAgQy4CAgAAhAEEAEMuAgIAAIQMgAEF/Rg0BIANBf0YNASAAIANPDQEgAyAAayIGIAJBOGpNDQELQQBBACgCuNOAgAAgBmoiAzYCuNOAgAACQCADQQAoArzTgIAATQ0AQQAgAzYCvNOAgAALAkACQAJAAkBBACgCoNCAgAAiBEUNAEHI04CAACEDA0AgACADKAIAIgUgAygCBCIIakYNAiADKAIIIgMNAAwDCwsCQAJAQQAoApjQgIAAIgNFDQAgACADTw0BC0EAIAA2ApjQgIAAC0EAIQNBACAGNgLM04CAAEEAIAA2AsjTgIAAQQBBfzYCqNCAgABBAEEAKALg04CAADYCrNCAgABBAEEANgLU04CAAANAIANBxNCAgABqIANBuNCAgABqIgQ2AgAgBCADQbDQgIAAaiIFNgIAIANBvNCAgABqIAU2AgAgA0HM0ICAAGogA0HA0ICAAGoiBTYCACAFIAQ2AgAgA0HU0ICAAGogA0HI0ICAAGoiBDYCACAEIAU2AgAgA0HQ0ICAAGogBDYCACADQSBqIgNBgAJHDQALIABBeCAAa0EPcUEAIABBCGpBD3EbIgNqIgQgBkFIaiIFIANrIgNBAXI2AgRBAEEAKALw04CAADYCpNCAgABBACADNgKU0ICAAEEAIAQ2AqDQgIAAIAAgBWpBODYCBAwCCyADLQAMQQhxDQAgBCAFSQ0AIAQgAE8NACAEQXggBGtBD3FBACAEQQhqQQ9xGyIFaiIAQQAoApTQgIAAIAZqIgsgBWsiBUEBcjYCBCADIAggBmo2AgRBAEEAKALw04CAADYCpNCAgABBACAFNgKU0ICAAEEAIAA2AqDQgIAAIAQgC2pBODYCBAwBCwJAIABBACgCmNCAgAAiCE8NAEEAIAA2ApjQgIAAIAAhCAsgACAGaiEFQcjTgIAAIQMCQAJAAkACQAJAAkACQANAIAMoAgAgBUYNASADKAIIIgMNAAwCCwsgAy0ADEEIcUUNAQtByNOAgAAhAwNAAkAgAygCACIFIARLDQAgBSADKAIEaiIFIARLDQMLIAMoAgghAwwACwsgAyAANgIAIAMgAygCBCAGajYCBCAAQXggAGtBD3FBACAAQQhqQQ9xG2oiCyACQQNyNgIEIAVBeCAFa0EPcUEAIAVBCGpBD3EbaiIGIAsgAmoiAmshAwJAIAYgBEcNAEEAIAI2AqDQgIAAQQBBACgClNCAgAAgA2oiAzYClNCAgAAgAiADQQFyNgIEDAMLAkAgBkEAKAKc0ICAAEcNAEEAIAI2ApzQgIAAQQBBACgCkNCAgAAgA2oiAzYCkNCAgAAgAiADQQFyNgIEIAIgA2ogAzYCAAwDCwJAIAYoAgQiBEEDcUEBRw0AIARBeHEhBwJAAkAgBEH/AUsNACAGKAIIIgUgBEEDdiIIQQN0QbDQgIAAaiIARhoCQCAGKAIMIgQgBUcNAEEAQQAoAojQgIAAQX4gCHdxNgKI0ICAAAwCCyAEIABGGiAEIAU2AgggBSAENgIMDAELIAYoAhghCQJAAkAgBigCDCIAIAZGDQAgBigCCCIEIAhJGiAAIAQ2AgggBCAANgIMDAELAkAgBkEUaiIEKAIAIgUNACAGQRBqIgQoAgAiBQ0AQQAhAAwBCwNAIAQhCCAFIgBBFGoiBCgCACIFDQAgAEEQaiEEIAAoAhAiBQ0ACyAIQQA2AgALIAlFDQACQAJAIAYgBigCHCIFQQJ0QbjSgIAAaiIEKAIARw0AIAQgADYCACAADQFBAEEAKAKM0ICAAEF+IAV3cTYCjNCAgAAMAgsgCUEQQRQgCSgCECAGRhtqIAA2AgAgAEUNAQsgACAJNgIYAkAgBigCECIERQ0AIAAgBDYCECAEIAA2AhgLIAYoAhQiBEUNACAAQRRqIAQ2AgAgBCAANgIYCyAHIANqIQMgBiAHaiIGKAIEIQQLIAYgBEF+cTYCBCACIANqIAM2AgAgAiADQQFyNgIEAkAgA0H/AUsNACADQXhxQbDQgIAAaiEEAkACQEEAKAKI0ICAACIFQQEgA0EDdnQiA3ENAEEAIAUgA3I2AojQgIAAIAQhAwwBCyAEKAIIIQMLIAMgAjYCDCAEIAI2AgggAiAENgIMIAIgAzYCCAwDC0EfIQQCQCADQf///wdLDQAgA0EIdiIEIARBgP4/akEQdkEIcSIEdCIFIAVBgOAfakEQdkEEcSIFdCIAIABBgIAPakEQdkECcSIAdEEPdiAEIAVyIAByayIEQQF0IAMgBEEVanZBAXFyQRxqIQQLIAIgBDYCHCACQgA3AhAgBEECdEG40oCAAGohBQJAQQAoAozQgIAAIgBBASAEdCIIcQ0AIAUgAjYCAEEAIAAgCHI2AozQgIAAIAIgBTYCGCACIAI2AgggAiACNgIMDAMLIANBAEEZIARBAXZrIARBH0YbdCEEIAUoAgAhAANAIAAiBSgCBEF4cSADRg0CIARBHXYhACAEQQF0IQQgBSAAQQRxakEQaiIIKAIAIgANAAsgCCACNgIAIAIgBTYCGCACIAI2AgwgAiACNgIIDAILIABBeCAAa0EPcUEAIABBCGpBD3EbIgNqIgsgBkFIaiIIIANrIgNBAXI2AgQgACAIakE4NgIEIAQgBUE3IAVrQQ9xQQAgBUFJakEPcRtqQUFqIgggCCAEQRBqSRsiCEEjNgIEQQBBACgC8NOAgAA2AqTQgIAAQQAgAzYClNCAgABBACALNgKg0ICAACAIQRBqQQApAtDTgIAANwIAIAhBACkCyNOAgAA3AghBACAIQQhqNgLQ04CAAEEAIAY2AszTgIAAQQAgADYCyNOAgABBAEEANgLU04CAACAIQSRqIQMDQCADQQc2AgAgA0EEaiIDIAVJDQALIAggBEYNAyAIIAgoAgRBfnE2AgQgCCAIIARrIgA2AgAgBCAAQQFyNgIEAkAgAEH/AUsNACAAQXhxQbDQgIAAaiEDAkACQEEAKAKI0ICAACIFQQEgAEEDdnQiAHENAEEAIAUgAHI2AojQgIAAIAMhBQwBCyADKAIIIQULIAUgBDYCDCADIAQ2AgggBCADNgIMIAQgBTYCCAwEC0EfIQMCQCAAQf///wdLDQAgAEEIdiIDIANBgP4/akEQdkEIcSIDdCIFIAVBgOAfakEQdkEEcSIFdCIIIAhBgIAPakEQdkECcSIIdEEPdiADIAVyIAhyayIDQQF0IAAgA0EVanZBAXFyQRxqIQMLIAQgAzYCHCAEQgA3AhAgA0ECdEG40oCAAGohBQJAQQAoAozQgIAAIghBASADdCIGcQ0AIAUgBDYCAEEAIAggBnI2AozQgIAAIAQgBTYCGCAEIAQ2AgggBCAENgIMDAQLIABBAEEZIANBAXZrIANBH0YbdCEDIAUoAgAhCANAIAgiBSgCBEF4cSAARg0DIANBHXYhCCADQQF0IQMgBSAIQQRxakEQaiIGKAIAIggNAAsgBiAENgIAIAQgBTYCGCAEIAQ2AgwgBCAENgIIDAMLIAUoAggiAyACNgIMIAUgAjYCCCACQQA2AhggAiAFNgIMIAIgAzYCCAsgC0EIaiEDDAULIAUoAggiAyAENgIMIAUgBDYCCCAEQQA2AhggBCAFNgIMIAQgAzYCCAtBACgClNCAgAAiAyACTQ0AQQAoAqDQgIAAIgQgAmoiBSADIAJrIgNBAXI2AgRBACADNgKU0ICAAEEAIAU2AqDQgIAAIAQgAkEDcjYCBCAEQQhqIQMMAwtBACEDQQBBMDYC+NOAgAAMAgsCQCALRQ0AAkACQCAIIAgoAhwiBUECdEG40oCAAGoiAygCAEcNACADIAA2AgAgAA0BQQAgB0F+IAV3cSIHNgKM0ICAAAwCCyALQRBBFCALKAIQIAhGG2ogADYCACAARQ0BCyAAIAs2AhgCQCAIKAIQIgNFDQAgACADNgIQIAMgADYCGAsgCEEUaigCACIDRQ0AIABBFGogAzYCACADIAA2AhgLAkACQCAEQQ9LDQAgCCAEIAJqIgNBA3I2AgQgCCADaiIDIAMoAgRBAXI2AgQMAQsgCCACaiIAIARBAXI2AgQgCCACQQNyNgIEIAAgBGogBDYCAAJAIARB/wFLDQAgBEF4cUGw0ICAAGohAwJAAkBBACgCiNCAgAAiBUEBIARBA3Z0IgRxDQBBACAFIARyNgKI0ICAACADIQQMAQsgAygCCCEECyAEIAA2AgwgAyAANgIIIAAgAzYCDCAAIAQ2AggMAQtBHyEDAkAgBEH///8HSw0AIARBCHYiAyADQYD+P2pBEHZBCHEiA3QiBSAFQYDgH2pBEHZBBHEiBXQiAiACQYCAD2pBEHZBAnEiAnRBD3YgAyAFciACcmsiA0EBdCAEIANBFWp2QQFxckEcaiEDCyAAIAM2AhwgAEIANwIQIANBAnRBuNKAgABqIQUCQCAHQQEgA3QiAnENACAFIAA2AgBBACAHIAJyNgKM0ICAACAAIAU2AhggACAANgIIIAAgADYCDAwBCyAEQQBBGSADQQF2ayADQR9GG3QhAyAFKAIAIQICQANAIAIiBSgCBEF4cSAERg0BIANBHXYhAiADQQF0IQMgBSACQQRxakEQaiIGKAIAIgINAAsgBiAANgIAIAAgBTYCGCAAIAA2AgwgACAANgIIDAELIAUoAggiAyAANgIMIAUgADYCCCAAQQA2AhggACAFNgIMIAAgAzYCCAsgCEEIaiEDDAELAkAgCkUNAAJAAkAgACAAKAIcIgVBAnRBuNKAgABqIgMoAgBHDQAgAyAINgIAIAgNAUEAIAlBfiAFd3E2AozQgIAADAILIApBEEEUIAooAhAgAEYbaiAINgIAIAhFDQELIAggCjYCGAJAIAAoAhAiA0UNACAIIAM2AhAgAyAINgIYCyAAQRRqKAIAIgNFDQAgCEEUaiADNgIAIAMgCDYCGAsCQAJAIARBD0sNACAAIAQgAmoiA0EDcjYCBCAAIANqIgMgAygCBEEBcjYCBAwBCyAAIAJqIgUgBEEBcjYCBCAAIAJBA3I2AgQgBSAEaiAENgIAAkAgB0UNACAHQXhxQbDQgIAAaiECQQAoApzQgIAAIQMCQAJAQQEgB0EDdnQiCCAGcQ0AQQAgCCAGcjYCiNCAgAAgAiEIDAELIAIoAgghCAsgCCADNgIMIAIgAzYCCCADIAI2AgwgAyAINgIIC0EAIAU2ApzQgIAAQQAgBDYCkNCAgAALIABBCGohAwsgAUEQaiSAgICAACADCwoAIAAQyYCAgAAL4g0BB38CQCAARQ0AIABBeGoiASAAQXxqKAIAIgJBeHEiAGohAwJAIAJBAXENACACQQNxRQ0BIAEgASgCACICayIBQQAoApjQgIAAIgRJDQEgAiAAaiEAAkAgAUEAKAKc0ICAAEYNAAJAIAJB/wFLDQAgASgCCCIEIAJBA3YiBUEDdEGw0ICAAGoiBkYaAkAgASgCDCICIARHDQBBAEEAKAKI0ICAAEF+IAV3cTYCiNCAgAAMAwsgAiAGRhogAiAENgIIIAQgAjYCDAwCCyABKAIYIQcCQAJAIAEoAgwiBiABRg0AIAEoAggiAiAESRogBiACNgIIIAIgBjYCDAwBCwJAIAFBFGoiAigCACIEDQAgAUEQaiICKAIAIgQNAEEAIQYMAQsDQCACIQUgBCIGQRRqIgIoAgAiBA0AIAZBEGohAiAGKAIQIgQNAAsgBUEANgIACyAHRQ0BAkACQCABIAEoAhwiBEECdEG40oCAAGoiAigCAEcNACACIAY2AgAgBg0BQQBBACgCjNCAgABBfiAEd3E2AozQgIAADAMLIAdBEEEUIAcoAhAgAUYbaiAGNgIAIAZFDQILIAYgBzYCGAJAIAEoAhAiAkUNACAGIAI2AhAgAiAGNgIYCyABKAIUIgJFDQEgBkEUaiACNgIAIAIgBjYCGAwBCyADKAIEIgJBA3FBA0cNACADIAJBfnE2AgRBACAANgKQ0ICAACABIABqIAA2AgAgASAAQQFyNgIEDwsgASADTw0AIAMoAgQiAkEBcUUNAAJAAkAgAkECcQ0AAkAgA0EAKAKg0ICAAEcNAEEAIAE2AqDQgIAAQQBBACgClNCAgAAgAGoiADYClNCAgAAgASAAQQFyNgIEIAFBACgCnNCAgABHDQNBAEEANgKQ0ICAAEEAQQA2ApzQgIAADwsCQCADQQAoApzQgIAARw0AQQAgATYCnNCAgABBAEEAKAKQ0ICAACAAaiIANgKQ0ICAACABIABBAXI2AgQgASAAaiAANgIADwsgAkF4cSAAaiEAAkACQCACQf8BSw0AIAMoAggiBCACQQN2IgVBA3RBsNCAgABqIgZGGgJAIAMoAgwiAiAERw0AQQBBACgCiNCAgABBfiAFd3E2AojQgIAADAILIAIgBkYaIAIgBDYCCCAEIAI2AgwMAQsgAygCGCEHAkACQCADKAIMIgYgA0YNACADKAIIIgJBACgCmNCAgABJGiAGIAI2AgggAiAGNgIMDAELAkAgA0EUaiICKAIAIgQNACADQRBqIgIoAgAiBA0AQQAhBgwBCwNAIAIhBSAEIgZBFGoiAigCACIEDQAgBkEQaiECIAYoAhAiBA0ACyAFQQA2AgALIAdFDQACQAJAIAMgAygCHCIEQQJ0QbjSgIAAaiICKAIARw0AIAIgBjYCACAGDQFBAEEAKAKM0ICAAEF+IAR3cTYCjNCAgAAMAgsgB0EQQRQgBygCECADRhtqIAY2AgAgBkUNAQsgBiAHNgIYAkAgAygCECICRQ0AIAYgAjYCECACIAY2AhgLIAMoAhQiAkUNACAGQRRqIAI2AgAgAiAGNgIYCyABIABqIAA2AgAgASAAQQFyNgIEIAFBACgCnNCAgABHDQFBACAANgKQ0ICAAA8LIAMgAkF+cTYCBCABIABqIAA2AgAgASAAQQFyNgIECwJAIABB/wFLDQAgAEF4cUGw0ICAAGohAgJAAkBBACgCiNCAgAAiBEEBIABBA3Z0IgBxDQBBACAEIAByNgKI0ICAACACIQAMAQsgAigCCCEACyAAIAE2AgwgAiABNgIIIAEgAjYCDCABIAA2AggPC0EfIQICQCAAQf///wdLDQAgAEEIdiICIAJBgP4/akEQdkEIcSICdCIEIARBgOAfakEQdkEEcSIEdCIGIAZBgIAPakEQdkECcSIGdEEPdiACIARyIAZyayICQQF0IAAgAkEVanZBAXFyQRxqIQILIAEgAjYCHCABQgA3AhAgAkECdEG40oCAAGohBAJAAkBBACgCjNCAgAAiBkEBIAJ0IgNxDQAgBCABNgIAQQAgBiADcjYCjNCAgAAgASAENgIYIAEgATYCCCABIAE2AgwMAQsgAEEAQRkgAkEBdmsgAkEfRht0IQIgBCgCACEGAkADQCAGIgQoAgRBeHEgAEYNASACQR12IQYgAkEBdCECIAQgBkEEcWpBEGoiAygCACIGDQALIAMgATYCACABIAQ2AhggASABNgIMIAEgATYCCAwBCyAEKAIIIgAgATYCDCAEIAE2AgggAUEANgIYIAEgBDYCDCABIAA2AggLQQBBACgCqNCAgABBf2oiAUF/IAEbNgKo0ICAAAsLBAAAAAtOAAJAIAANAD8AQRB0DwsCQCAAQf//A3ENACAAQX9MDQACQCAAQRB2QAAiAEF/Rw0AQQBBMDYC+NOAgABBfw8LIABBEHQPCxDKgICAAAAL8gICA38BfgJAIAJFDQAgACABOgAAIAIgAGoiA0F/aiABOgAAIAJBA0kNACAAIAE6AAIgACABOgABIANBfWogAToAACADQX5qIAE6AAAgAkEHSQ0AIAAgAToAAyADQXxqIAE6AAAgAkEJSQ0AIABBACAAa0EDcSIEaiIDIAFB/wFxQYGChAhsIgE2AgAgAyACIARrQXxxIgRqIgJBfGogATYCACAEQQlJDQAgAyABNgIIIAMgATYCBCACQXhqIAE2AgAgAkF0aiABNgIAIARBGUkNACADIAE2AhggAyABNgIUIAMgATYCECADIAE2AgwgAkFwaiABNgIAIAJBbGogATYCACACQWhqIAE2AgAgAkFkaiABNgIAIAQgA0EEcUEYciIFayICQSBJDQAgAa1CgYCAgBB+IQYgAyAFaiEBA0AgASAGNwMYIAEgBjcDECABIAY3AwggASAGNwMAIAFBIGohASACQWBqIgJBH0sNAAsLIAALC45IAQBBgAgLhkgBAAAAAgAAAAMAAAAAAAAAAAAAAAQAAAAFAAAAAAAAAAAAAAAGAAAABwAAAAgAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAEludmFsaWQgY2hhciBpbiB1cmwgcXVlcnkAU3BhbiBjYWxsYmFjayBlcnJvciBpbiBvbl9ib2R5AENvbnRlbnQtTGVuZ3RoIG92ZXJmbG93AENodW5rIHNpemUgb3ZlcmZsb3cAUmVzcG9uc2Ugb3ZlcmZsb3cASW52YWxpZCBtZXRob2QgZm9yIEhUVFAveC54IHJlcXVlc3QASW52YWxpZCBtZXRob2QgZm9yIFJUU1AveC54IHJlcXVlc3QARXhwZWN0ZWQgU09VUkNFIG1ldGhvZCBmb3IgSUNFL3gueCByZXF1ZXN0AEludmFsaWQgY2hhciBpbiB1cmwgZnJhZ21lbnQgc3RhcnQARXhwZWN0ZWQgZG90AFNwYW4gY2FsbGJhY2sgZXJyb3IgaW4gb25fc3RhdHVzAEludmFsaWQgcmVzcG9uc2Ugc3RhdHVzAEludmFsaWQgY2hhcmFjdGVyIGluIGNodW5rIGV4dGVuc2lvbnMAVXNlciBjYWxsYmFjayBlcnJvcgBgb25fcmVzZXRgIGNhbGxiYWNrIGVycm9yAGBvbl9jaHVua19oZWFkZXJgIGNhbGxiYWNrIGVycm9yAGBvbl9tZXNzYWdlX2JlZ2luYCBjYWxsYmFjayBlcnJvcgBgb25fY2h1bmtfZXh0ZW5zaW9uX3ZhbHVlYCBjYWxsYmFjayBlcnJvcgBgb25fc3RhdHVzX2NvbXBsZXRlYCBjYWxsYmFjayBlcnJvcgBgb25fdmVyc2lvbl9jb21wbGV0ZWAgY2FsbGJhY2sgZXJyb3IAYG9uX3VybF9jb21wbGV0ZWAgY2FsbGJhY2sgZXJyb3IAYG9uX2NodW5rX2NvbXBsZXRlYCBjYWxsYmFjayBlcnJvcgBgb25faGVhZGVyX3ZhbHVlX2NvbXBsZXRlYCBjYWxsYmFjayBlcnJvcgBgb25fbWVzc2FnZV9jb21wbGV0ZWAgY2FsbGJhY2sgZXJyb3IAYG9uX21ldGhvZF9jb21wbGV0ZWAgY2FsbGJhY2sgZXJyb3IAYG9uX2hlYWRlcl9maWVsZF9jb21wbGV0ZWAgY2FsbGJhY2sgZXJyb3IAYG9uX2NodW5rX2V4dGVuc2lvbl9uYW1lYCBjYWxsYmFjayBlcnJvcgBVbmV4cGVjdGVkIGNoYXIgaW4gdXJsIHNlcnZlcgBJbnZhbGlkIGhlYWRlciB2YWx1ZSBjaGFyAEludmFsaWQgaGVhZGVyIGZpZWxkIGNoYXIAU3BhbiBjYWxsYmFjayBlcnJvciBpbiBvbl92ZXJzaW9uAEludmFsaWQgbWlub3IgdmVyc2lvbgBJbnZhbGlkIG1ham9yIHZlcnNpb24ARXhwZWN0ZWQgc3BhY2UgYWZ0ZXIgdmVyc2lvbgBFeHBlY3RlZCBDUkxGIGFmdGVyIHZlcnNpb24ASW52YWxpZCBIVFRQIHZlcnNpb24ASW52YWxpZCBoZWFkZXIgdG9rZW4AU3BhbiBjYWxsYmFjayBlcnJvciBpbiBvbl91cmwASW52YWxpZCBjaGFyYWN0ZXJzIGluIHVybABVbmV4cGVjdGVkIHN0YXJ0IGNoYXIgaW4gdXJsAERvdWJsZSBAIGluIHVybABFbXB0eSBDb250ZW50LUxlbmd0aABJbnZhbGlkIGNoYXJhY3RlciBpbiBDb250ZW50LUxlbmd0aABEdXBsaWNhdGUgQ29udGVudC1MZW5ndGgASW52YWxpZCBjaGFyIGluIHVybCBwYXRoAENvbnRlbnQtTGVuZ3RoIGNhbid0IGJlIHByZXNlbnQgd2l0aCBUcmFuc2Zlci1FbmNvZGluZwBJbnZhbGlkIGNoYXJhY3RlciBpbiBjaHVuayBzaXplAFNwYW4gY2FsbGJhY2sgZXJyb3IgaW4gb25faGVhZGVyX3ZhbHVlAFNwYW4gY2FsbGJhY2sgZXJyb3IgaW4gb25fY2h1bmtfZXh0ZW5zaW9uX3ZhbHVlAEludmFsaWQgY2hhcmFjdGVyIGluIGNodW5rIGV4dGVuc2lvbnMgdmFsdWUATWlzc2luZyBleHBlY3RlZCBMRiBhZnRlciBoZWFkZXIgdmFsdWUASW52YWxpZCBgVHJhbnNmZXItRW5jb2RpbmdgIGhlYWRlciB2YWx1ZQBJbnZhbGlkIGNoYXJhY3RlciBpbiBjaHVuayBleHRlbnNpb25zIHF1b3RlIHZhbHVlAEludmFsaWQgY2hhcmFjdGVyIGluIGNodW5rIGV4dGVuc2lvbnMgcXVvdGVkIHZhbHVlAFBhdXNlZCBieSBvbl9oZWFkZXJzX2NvbXBsZXRlAEludmFsaWQgRU9GIHN0YXRlAG9uX3Jlc2V0IHBhdXNlAG9uX2NodW5rX2hlYWRlciBwYXVzZQBvbl9tZXNzYWdlX2JlZ2luIHBhdXNlAG9uX2NodW5rX2V4dGVuc2lvbl92YWx1ZSBwYXVzZQBvbl9zdGF0dXNfY29tcGxldGUgcGF1c2UAb25fdmVyc2lvbl9jb21wbGV0ZSBwYXVzZQBvbl91cmxfY29tcGxldGUgcGF1c2UAb25fY2h1bmtfY29tcGxldGUgcGF1c2UAb25faGVhZGVyX3ZhbHVlX2NvbXBsZXRlIHBhdXNlAG9uX21lc3NhZ2VfY29tcGxldGUgcGF1c2UAb25fbWV0aG9kX2NvbXBsZXRlIHBhdXNlAG9uX2hlYWRlcl9maWVsZF9jb21wbGV0ZSBwYXVzZQBvbl9jaHVua19leHRlbnNpb25fbmFtZSBwYXVzZQBVbmV4cGVjdGVkIHNwYWNlIGFmdGVyIHN0YXJ0IGxpbmUAU3BhbiBjYWxsYmFjayBlcnJvciBpbiBvbl9jaHVua19leHRlbnNpb25fbmFtZQBJbnZhbGlkIGNoYXJhY3RlciBpbiBjaHVuayBleHRlbnNpb25zIG5hbWUAUGF1c2Ugb24gQ09OTkVDVC9VcGdyYWRlAFBhdXNlIG9uIFBSSS9VcGdyYWRlAEV4cGVjdGVkIEhUVFAvMiBDb25uZWN0aW9uIFByZWZhY2UAU3BhbiBjYWxsYmFjayBlcnJvciBpbiBvbl9tZXRob2QARXhwZWN0ZWQgc3BhY2UgYWZ0ZXIgbWV0aG9kAFNwYW4gY2FsbGJhY2sgZXJyb3IgaW4gb25faGVhZGVyX2ZpZWxkAFBhdXNlZABJbnZhbGlkIHdvcmQgZW5jb3VudGVyZWQASW52YWxpZCBtZXRob2QgZW5jb3VudGVyZWQAVW5leHBlY3RlZCBjaGFyIGluIHVybCBzY2hlbWEAUmVxdWVzdCBoYXMgaW52YWxpZCBgVHJhbnNmZXItRW5jb2RpbmdgAFNXSVRDSF9QUk9YWQBVU0VfUFJPWFkATUtBQ1RJVklUWQBVTlBST0NFU1NBQkxFX0VOVElUWQBDT1BZAE1PVkVEX1BFUk1BTkVOVExZAFRPT19FQVJMWQBOT1RJRlkARkFJTEVEX0RFUEVOREVOQ1kAQkFEX0dBVEVXQVkAUExBWQBQVVQAQ0hFQ0tPVVQAR0FURVdBWV9USU1FT1VUAFJFUVVFU1RfVElNRU9VVABORVRXT1JLX0NPTk5FQ1RfVElNRU9VVABDT05ORUNUSU9OX1RJTUVPVVQATE9HSU5fVElNRU9VVABORVRXT1JLX1JFQURfVElNRU9VVABQT1NUAE1JU0RJUkVDVEVEX1JFUVVFU1QAQ0xJRU5UX0NMT1NFRF9SRVFVRVNUAENMSUVOVF9DTE9TRURfTE9BRF9CQUxBTkNFRF9SRVFVRVNUAEJBRF9SRVFVRVNUAEhUVFBfUkVRVUVTVF9TRU5UX1RPX0hUVFBTX1BPUlQAUkVQT1JUAElNX0FfVEVBUE9UAFJFU0VUX0NPTlRFTlQATk9fQ09OVEVOVABQQVJUSUFMX0NPTlRFTlQASFBFX0lOVkFMSURfQ09OU1RBTlQASFBFX0NCX1JFU0VUAEdFVABIUEVfU1RSSUNUAENPTkZMSUNUAFRFTVBPUkFSWV9SRURJUkVDVABQRVJNQU5FTlRfUkVESVJFQ1QAQ09OTkVDVABNVUxUSV9TVEFUVVMASFBFX0lOVkFMSURfU1RBVFVTAFRPT19NQU5ZX1JFUVVFU1RTAEVBUkxZX0hJTlRTAFVOQVZBSUxBQkxFX0ZPUl9MRUdBTF9SRUFTT05TAE9QVElPTlMAU1dJVENISU5HX1BST1RPQ09MUwBWQVJJQU5UX0FMU09fTkVHT1RJQVRFUwBNVUxUSVBMRV9DSE9JQ0VTAElOVEVSTkFMX1NFUlZFUl9FUlJPUgBXRUJfU0VSVkVSX1VOS05PV05fRVJST1IAUkFJTEdVTl9FUlJPUgBJREVOVElUWV9QUk9WSURFUl9BVVRIRU5USUNBVElPTl9FUlJPUgBTU0xfQ0VSVElGSUNBVEVfRVJST1IASU5WQUxJRF9YX0ZPUldBUkRFRF9GT1IAU0VUX1BBUkFNRVRFUgBHRVRfUEFSQU1FVEVSAEhQRV9VU0VSAFNFRV9PVEhFUgBIUEVfQ0JfQ0hVTktfSEVBREVSAE1LQ0FMRU5EQVIAU0VUVVAAV0VCX1NFUlZFUl9JU19ET1dOAFRFQVJET1dOAEhQRV9DTE9TRURfQ09OTkVDVElPTgBIRVVSSVNUSUNfRVhQSVJBVElPTgBESVNDT05ORUNURURfT1BFUkFUSU9OAE5PTl9BVVRIT1JJVEFUSVZFX0lORk9STUFUSU9OAEhQRV9JTlZBTElEX1ZFUlNJT04ASFBFX0NCX01FU1NBR0VfQkVHSU4AU0lURV9JU19GUk9aRU4ASFBFX0lOVkFMSURfSEVBREVSX1RPS0VOAElOVkFMSURfVE9LRU4ARk9SQklEREVOAEVOSEFOQ0VfWU9VUl9DQUxNAEhQRV9JTlZBTElEX1VSTABCTE9DS0VEX0JZX1BBUkVOVEFMX0NPTlRST0wATUtDT0wAQUNMAEhQRV9JTlRFUk5BTABSRVFVRVNUX0hFQURFUl9GSUVMRFNfVE9PX0xBUkdFX1VOT0ZGSUNJQUwASFBFX09LAFVOTElOSwBVTkxPQ0sAUFJJAFJFVFJZX1dJVEgASFBFX0lOVkFMSURfQ09OVEVOVF9MRU5HVEgASFBFX1VORVhQRUNURURfQ09OVEVOVF9MRU5HVEgARkxVU0gAUFJPUFBBVENIAE0tU0VBUkNIAFVSSV9UT09fTE9ORwBQUk9DRVNTSU5HAE1JU0NFTExBTkVPVVNfUEVSU0lTVEVOVF9XQVJOSU5HAE1JU0NFTExBTkVPVVNfV0FSTklORwBIUEVfSU5WQUxJRF9UUkFOU0ZFUl9FTkNPRElORwBFeHBlY3RlZCBDUkxGAEhQRV9JTlZBTElEX0NIVU5LX1NJWkUATU9WRQBDT05USU5VRQBIUEVfQ0JfU1RBVFVTX0NPTVBMRVRFAEhQRV9DQl9IRUFERVJTX0NPTVBMRVRFAEhQRV9DQl9WRVJTSU9OX0NPTVBMRVRFAEhQRV9DQl9VUkxfQ09NUExFVEUASFBFX0NCX0NIVU5LX0NPTVBMRVRFAEhQRV9DQl9IRUFERVJfVkFMVUVfQ09NUExFVEUASFBFX0NCX0NIVU5LX0VYVEVOU0lPTl9WQUxVRV9DT01QTEVURQBIUEVfQ0JfQ0hVTktfRVhURU5TSU9OX05BTUVfQ09NUExFVEUASFBFX0NCX01FU1NBR0VfQ09NUExFVEUASFBFX0NCX01FVEhPRF9DT01QTEVURQBIUEVfQ0JfSEVBREVSX0ZJRUxEX0NPTVBMRVRFAERFTEVURQBIUEVfSU5WQUxJRF9FT0ZfU1RBVEUASU5WQUxJRF9TU0xfQ0VSVElGSUNBVEUAUEFVU0UATk9fUkVTUE9OU0UAVU5TVVBQT1JURURfTUVESUFfVFlQRQBHT05FAE5PVF9BQ0NFUFRBQkxFAFNFUlZJQ0VfVU5BVkFJTEFCTEUAUkFOR0VfTk9UX1NBVElTRklBQkxFAE9SSUdJTl9JU19VTlJFQUNIQUJMRQBSRVNQT05TRV9JU19TVEFMRQBQVVJHRQBNRVJHRQBSRVFVRVNUX0hFQURFUl9GSUVMRFNfVE9PX0xBUkdFAFJFUVVFU1RfSEVBREVSX1RPT19MQVJHRQBQQVlMT0FEX1RPT19MQVJHRQBJTlNVRkZJQ0lFTlRfU1RPUkFHRQBIUEVfUEFVU0VEX1VQR1JBREUASFBFX1BBVVNFRF9IMl9VUEdSQURFAFNPVVJDRQBBTk5PVU5DRQBUUkFDRQBIUEVfVU5FWFBFQ1RFRF9TUEFDRQBERVNDUklCRQBVTlNVQlNDUklCRQBSRUNPUkQASFBFX0lOVkFMSURfTUVUSE9EAE5PVF9GT1VORABQUk9QRklORABVTkJJTkQAUkVCSU5EAFVOQVVUSE9SSVpFRABNRVRIT0RfTk9UX0FMTE9XRUQASFRUUF9WRVJTSU9OX05PVF9TVVBQT1JURUQAQUxSRUFEWV9SRVBPUlRFRABBQ0NFUFRFRABOT1RfSU1QTEVNRU5URUQATE9PUF9ERVRFQ1RFRABIUEVfQ1JfRVhQRUNURUQASFBFX0xGX0VYUEVDVEVEAENSRUFURUQASU1fVVNFRABIUEVfUEFVU0VEAFRJTUVPVVRfT0NDVVJFRABQQVlNRU5UX1JFUVVJUkVEAFBSRUNPTkRJVElPTl9SRVFVSVJFRABQUk9YWV9BVVRIRU5USUNBVElPTl9SRVFVSVJFRABORVRXT1JLX0FVVEhFTlRJQ0FUSU9OX1JFUVVJUkVEAExFTkdUSF9SRVFVSVJFRABTU0xfQ0VSVElGSUNBVEVfUkVRVUlSRUQAVVBHUkFERV9SRVFVSVJFRABQQUdFX0VYUElSRUQAUFJFQ09ORElUSU9OX0ZBSUxFRABFWFBFQ1RBVElPTl9GQUlMRUQAUkVWQUxJREFUSU9OX0ZBSUxFRABTU0xfSEFORFNIQUtFX0ZBSUxFRABMT0NLRUQAVFJBTlNGT1JNQVRJT05fQVBQTElFRABOT1RfTU9ESUZJRUQATk9UX0VYVEVOREVEAEJBTkRXSURUSF9MSU1JVF9FWENFRURFRABTSVRFX0lTX09WRVJMT0FERUQASEVBRABFeHBlY3RlZCBIVFRQLwAAXhMAACYTAAAwEAAA8BcAAJ0TAAAVEgAAORcAAPASAAAKEAAAdRIAAK0SAACCEwAATxQAAH8QAACgFQAAIxQAAIkSAACLFAAATRUAANQRAADPFAAAEBgAAMkWAADcFgAAwREAAOAXAAC7FAAAdBQAAHwVAADlFAAACBcAAB8QAABlFQAAoxQAACgVAAACFQAAmRUAACwQAACLGQAATw8AANQOAABqEAAAzhAAAAIXAACJDgAAbhMAABwTAABmFAAAVhcAAMETAADNEwAAbBMAAGgXAABmFwAAXxcAACITAADODwAAaQ4AANgOAABjFgAAyxMAAKoOAAAoFwAAJhcAAMUTAABdFgAA6BEAAGcTAABlEwAA8hYAAHMTAAAdFwAA+RYAAPMRAADPDgAAzhUAAAwSAACzEQAApREAAGEQAAAyFwAAuxMAAAAAAAAAAAAAAAAAAAAAAAAAAQAAAAAAAAAAAAAAAAAAAAAAAAAAAAABAQIBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEAAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQAAAAAAAAAAAAAAAAABAAAAAAAAAAAAAAAAAAAAAAAAAAIDAgICAgIAAAICAAICAAICAgICAgICAgIABAAAAAAAAgICAgICAgICAgICAgICAgICAgICAgICAgIAAAACAgICAgICAgICAgICAgICAgICAgICAgICAgICAgACAAIAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAQAAAAAAAAAAAAAAAAAAAAAAAAACAAICAgICAAACAgACAgACAgICAgICAgICAAMABAAAAAICAgICAgICAgICAgICAgICAgICAgICAgICAAAAAgICAgICAgICAgICAgICAgICAgICAgICAgICAgIAAgACAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAbG9zZWVlcC1hbGl2ZQAAAAAAAAAAAAAAAAEAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEAAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEAAAAAAAAAAAABAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAEBAQEBAQEBAQEBAQIBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAAEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBY2h1bmtlZAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAQEAAQEBAQEAAAEBAAEBAAEBAQEBAQEBAQEAAAAAAAAAAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEAAAABAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQABAAEAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAABlY3Rpb25lbnQtbGVuZ3Rob25yb3h5LWNvbm5lY3Rpb24AAAAAAAAAAAAAAAAAAAByYW5zZmVyLWVuY29kaW5ncGdyYWRlDQoNCg0KU00NCg0KVFRQL0NFL1RTUC8AAAAAAAAAAAAAAAABAgABAwAAAAAAAAAAAAAAAAAAAAAAAAQBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAAEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAAAAAAAAAAAAAQIAAQMAAAAAAAAAAAAAAAAAAAAAAAAEAQEFAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQABAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQAAAAAAAAAAAAEAAAEAAAAAAAAAAAAAAAAAAAAAAAAAAAEBAAEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQABAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEAAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEAAAAAAAAAAAAAAQAAAgAAAAAAAAAAAAAAAAAAAAAAAAMEAAAEBAQEBAQEBAQEBAUEBAQEBAQEBAQEBAQABAAGBwQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAAEAAQABAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQAAAAEAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAEAAAEAAAAAAAAAAAAAAAAAAAAAAAABAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAIAAAAAAAADAwMDAwMDAwMDAwMDAwMDAwMDAwMDAwMDAwAAAAAAAAMDAwMDAwMDAwMDAwMDAwMDAwMDAwMDAwMDAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAABAAABAAAAAAAAAAAAAAAAAAAAAAAAAQAAAAAAAAAAAAIAAAAAAgAAAAAAAAAAAAAAAAAAAAAAAwMDAwMDAwMDAwMDAwMDAwMDAwMDAwMDAwMAAAAAAAADAwMDAwMDAwMDAwMDAwMDAwMDAwMDAwMDAwAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAABOT1VOQ0VFQ0tPVVRORUNURVRFQ1JJQkVMVVNIRVRFQURTRUFSQ0hSR0VDVElWSVRZTEVOREFSVkVPVElGWVBUSU9OU0NIU0VBWVNUQVRDSEdFT1JESVJFQ1RPUlRSQ0hQQVJBTUVURVJVUkNFQlNDUklCRUFSRE9XTkFDRUlORE5LQ0tVQlNDUklCRUhUVFAvQURUUC8='\n\n\n/***/ }),\n\n/***/ 5627:\n/***/ ((module) => {\n\nmodule.exports = 'AGFzbQEAAAABMAhgAX8Bf2ADf39/AX9gBH9/f38Bf2AAAGADf39/AGABfwBgAn9/AGAGf39/f39/AALLAQgDZW52GHdhc21fb25faGVhZGVyc19jb21wbGV0ZQACA2VudhV3YXNtX29uX21lc3NhZ2VfYmVnaW4AAANlbnYLd2FzbV9vbl91cmwAAQNlbnYOd2FzbV9vbl9zdGF0dXMAAQNlbnYUd2FzbV9vbl9oZWFkZXJfZmllbGQAAQNlbnYUd2FzbV9vbl9oZWFkZXJfdmFsdWUAAQNlbnYMd2FzbV9vbl9ib2R5AAEDZW52GHdhc21fb25fbWVzc2FnZV9jb21wbGV0ZQAAA0ZFAwMEAAAFAAAAAAAABQEFAAUFBQAABgAAAAAGBgYGAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQABAAABAQcAAAUFAwABBAUBcAESEgUDAQACBggBfwFBgNQECwfRBSIGbWVtb3J5AgALX2luaXRpYWxpemUACRlfX2luZGlyZWN0X2Z1bmN0aW9uX3RhYmxlAQALbGxodHRwX2luaXQAChhsbGh0dHBfc2hvdWxkX2tlZXBfYWxpdmUAQQxsbGh0dHBfYWxsb2MADAZtYWxsb2MARgtsbGh0dHBfZnJlZQANBGZyZWUASA9sbGh0dHBfZ2V0X3R5cGUADhVsbGh0dHBfZ2V0X2h0dHBfbWFqb3IADxVsbGh0dHBfZ2V0X2h0dHBfbWlub3IAEBFsbGh0dHBfZ2V0X21ldGhvZAARFmxsaHR0cF9nZXRfc3RhdHVzX2NvZGUAEhJsbGh0dHBfZ2V0X3VwZ3JhZGUAEwxsbGh0dHBfcmVzZXQAFA5sbGh0dHBfZXhlY3V0ZQAVFGxsaHR0cF9zZXR0aW5nc19pbml0ABYNbGxodHRwX2ZpbmlzaAAXDGxsaHR0cF9wYXVzZQAYDWxsaHR0cF9yZXN1bWUAGRtsbGh0dHBfcmVzdW1lX2FmdGVyX3VwZ3JhZGUAGhBsbGh0dHBfZ2V0X2Vycm5vABsXbGxodHRwX2dldF9lcnJvcl9yZWFzb24AHBdsbGh0dHBfc2V0X2Vycm9yX3JlYXNvbgAdFGxsaHR0cF9nZXRfZXJyb3JfcG9zAB4RbGxodHRwX2Vycm5vX25hbWUAHxJsbGh0dHBfbWV0aG9kX25hbWUAIBJsbGh0dHBfc3RhdHVzX25hbWUAIRpsbGh0dHBfc2V0X2xlbmllbnRfaGVhZGVycwAiIWxsaHR0cF9zZXRfbGVuaWVudF9jaHVua2VkX2xlbmd0aAAjHWxsaHR0cF9zZXRfbGVuaWVudF9rZWVwX2FsaXZlACQkbGxodHRwX3NldF9sZW5pZW50X3RyYW5zZmVyX2VuY29kaW5nACUYbGxodHRwX21lc3NhZ2VfbmVlZHNfZW9mAD8JFwEAQQELEQECAwQFCwYHNTk3MS8tJyspCrLgAkUCAAsIABCIgICAAAsZACAAEMKAgIAAGiAAIAI2AjggACABOgAoCxwAIAAgAC8BMiAALQAuIAAQwYCAgAAQgICAgAALKgEBf0HAABDGgICAACIBEMKAgIAAGiABQYCIgIAANgI4IAEgADoAKCABCwoAIAAQyICAgAALBwAgAC0AKAsHACAALQAqCwcAIAAtACsLBwAgAC0AKQsHACAALwEyCwcAIAAtAC4LRQEEfyAAKAIYIQEgAC0ALSECIAAtACghAyAAKAI4IQQgABDCgICAABogACAENgI4IAAgAzoAKCAAIAI6AC0gACABNgIYCxEAIAAgASABIAJqEMOAgIAACxAAIABBAEHcABDMgICAABoLZwEBf0EAIQECQCAAKAIMDQACQAJAAkACQCAALQAvDgMBAAMCCyAAKAI4IgFFDQAgASgCLCIBRQ0AIAAgARGAgICAAAAiAQ0DC0EADwsQyoCAgAAACyAAQcOWgIAANgIQQQ4hAQsgAQseAAJAIAAoAgwNACAAQdGbgIAANgIQIABBFTYCDAsLFgACQCAAKAIMQRVHDQAgAEEANgIMCwsWAAJAIAAoAgxBFkcNACAAQQA2AgwLCwcAIAAoAgwLBwAgACgCEAsJACAAIAE2AhALBwAgACgCFAsiAAJAIABBJEkNABDKgICAAAALIABBAnRBoLOAgABqKAIACyIAAkAgAEEuSQ0AEMqAgIAAAAsgAEECdEGwtICAAGooAgAL7gsBAX9B66iAgAAhAQJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAIABBnH9qDvQDY2IAAWFhYWFhYQIDBAVhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhBgcICQoLDA0OD2FhYWFhEGFhYWFhYWFhYWFhEWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYRITFBUWFxgZGhthYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhHB0eHyAhIiMkJSYnKCkqKywtLi8wMTIzNDU2YTc4OTphYWFhYWFhYTthYWE8YWFhYT0+P2FhYWFhYWFhQGFhQWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYUJDREVGR0hJSktMTU5PUFFSU2FhYWFhYWFhVFVWV1hZWlthXF1hYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFeYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhX2BhC0Hhp4CAAA8LQaShgIAADwtBy6yAgAAPC0H+sYCAAA8LQcCkgIAADwtBq6SAgAAPC0GNqICAAA8LQeKmgIAADwtBgLCAgAAPC0G5r4CAAA8LQdekgIAADwtB75+AgAAPC0Hhn4CAAA8LQfqfgIAADwtB8qCAgAAPC0Gor4CAAA8LQa6ygIAADwtBiLCAgAAPC0Hsp4CAAA8LQYKigIAADwtBjp2AgAAPC0HQroCAAA8LQcqjgIAADwtBxbKAgAAPC0HfnICAAA8LQdKcgIAADwtBxKCAgAAPC0HXoICAAA8LQaKfgIAADwtB7a6AgAAPC0GrsICAAA8LQdSlgIAADwtBzK6AgAAPC0H6roCAAA8LQfyrgIAADwtB0rCAgAAPC0HxnYCAAA8LQbuggIAADwtB96uAgAAPC0GQsYCAAA8LQdexgIAADwtBoq2AgAAPC0HUp4CAAA8LQeCrgIAADwtBn6yAgAAPC0HrsYCAAA8LQdWfgIAADwtByrGAgAAPC0HepYCAAA8LQdSegIAADwtB9JyAgAAPC0GnsoCAAA8LQbGdgIAADwtBoJ2AgAAPC0G5sYCAAA8LQbywgIAADwtBkqGAgAAPC0GzpoCAAA8LQemsgIAADwtBrJ6AgAAPC0HUq4CAAA8LQfemgIAADwtBgKaAgAAPC0GwoYCAAA8LQf6egIAADwtBjaOAgAAPC0GJrYCAAA8LQfeigIAADwtBoLGAgAAPC0Gun4CAAA8LQcalgIAADwtB6J6AgAAPC0GTooCAAA8LQcKvgIAADwtBw52AgAAPC0GLrICAAA8LQeGdgIAADwtBja+AgAAPC0HqoYCAAA8LQbStgIAADwtB0q+AgAAPC0HfsoCAAA8LQdKygIAADwtB8LCAgAAPC0GpooCAAA8LQfmjgIAADwtBmZ6AgAAPC0G1rICAAA8LQZuwgIAADwtBkrKAgAAPC0G2q4CAAA8LQcKigIAADwtB+LKAgAAPC0GepYCAAA8LQdCigIAADwtBup6AgAAPC0GBnoCAAA8LEMqAgIAAAAtB1qGAgAAhAQsgAQsWACAAIAAtAC1B/gFxIAFBAEdyOgAtCxkAIAAgAC0ALUH9AXEgAUEAR0EBdHI6AC0LGQAgACAALQAtQfsBcSABQQBHQQJ0cjoALQsZACAAIAAtAC1B9wFxIAFBAEdBA3RyOgAtCy4BAn9BACEDAkAgACgCOCIERQ0AIAQoAgAiBEUNACAAIAQRgICAgAAAIQMLIAMLSQECf0EAIQMCQCAAKAI4IgRFDQAgBCgCBCIERQ0AIAAgASACIAFrIAQRgYCAgAAAIgNBf0cNACAAQcaRgIAANgIQQRghAwsgAwsuAQJ/QQAhAwJAIAAoAjgiBEUNACAEKAIwIgRFDQAgACAEEYCAgIAAACEDCyADC0kBAn9BACEDAkAgACgCOCIERQ0AIAQoAggiBEUNACAAIAEgAiABayAEEYGAgIAAACIDQX9HDQAgAEH2ioCAADYCEEEYIQMLIAMLLgECf0EAIQMCQCAAKAI4IgRFDQAgBCgCNCIERQ0AIAAgBBGAgICAAAAhAwsgAwtJAQJ/QQAhAwJAIAAoAjgiBEUNACAEKAIMIgRFDQAgACABIAIgAWsgBBGBgICAAAAiA0F/Rw0AIABB7ZqAgAA2AhBBGCEDCyADCy4BAn9BACEDAkAgACgCOCIERQ0AIAQoAjgiBEUNACAAIAQRgICAgAAAIQMLIAMLSQECf0EAIQMCQCAAKAI4IgRFDQAgBCgCECIERQ0AIAAgASACIAFrIAQRgYCAgAAAIgNBf0cNACAAQZWQgIAANgIQQRghAwsgAwsuAQJ/QQAhAwJAIAAoAjgiBEUNACAEKAI8IgRFDQAgACAEEYCAgIAAACEDCyADC0kBAn9BACEDAkAgACgCOCIERQ0AIAQoAhQiBEUNACAAIAEgAiABayAEEYGAgIAAACIDQX9HDQAgAEGqm4CAADYCEEEYIQMLIAMLLgECf0EAIQMCQCAAKAI4IgRFDQAgBCgCQCIERQ0AIAAgBBGAgICAAAAhAwsgAwtJAQJ/QQAhAwJAIAAoAjgiBEUNACAEKAIYIgRFDQAgACABIAIgAWsgBBGBgICAAAAiA0F/Rw0AIABB7ZOAgAA2AhBBGCEDCyADCy4BAn9BACEDAkAgACgCOCIERQ0AIAQoAkQiBEUNACAAIAQRgICAgAAAIQMLIAMLLgECf0EAIQMCQCAAKAI4IgRFDQAgBCgCJCIERQ0AIAAgBBGAgICAAAAhAwsgAwsuAQJ/QQAhAwJAIAAoAjgiBEUNACAEKAIsIgRFDQAgACAEEYCAgIAAACEDCyADC0kBAn9BACEDAkAgACgCOCIERQ0AIAQoAigiBEUNACAAIAEgAiABayAEEYGAgIAAACIDQX9HDQAgAEH2iICAADYCEEEYIQMLIAMLLgECf0EAIQMCQCAAKAI4IgRFDQAgBCgCUCIERQ0AIAAgBBGAgICAAAAhAwsgAwtJAQJ/QQAhAwJAIAAoAjgiBEUNACAEKAIcIgRFDQAgACABIAIgAWsgBBGBgICAAAAiA0F/Rw0AIABBwpmAgAA2AhBBGCEDCyADCy4BAn9BACEDAkAgACgCOCIERQ0AIAQoAkgiBEUNACAAIAQRgICAgAAAIQMLIAMLSQECf0EAIQMCQCAAKAI4IgRFDQAgBCgCICIERQ0AIAAgASACIAFrIAQRgYCAgAAAIgNBf0cNACAAQZSUgIAANgIQQRghAwsgAwsuAQJ/QQAhAwJAIAAoAjgiBEUNACAEKAJMIgRFDQAgACAEEYCAgIAAACEDCyADCy4BAn9BACEDAkAgACgCOCIERQ0AIAQoAlQiBEUNACAAIAQRgICAgAAAIQMLIAMLLgECf0EAIQMCQCAAKAI4IgRFDQAgBCgCWCIERQ0AIAAgBBGAgICAAAAhAwsgAwtFAQF/AkACQCAALwEwQRRxQRRHDQBBASEDIAAtAChBAUYNASAALwEyQeUARiEDDAELIAAtAClBBUYhAwsgACADOgAuQQAL/gEBA39BASEDAkAgAC8BMCIEQQhxDQAgACkDIEIAUiEDCwJAAkAgAC0ALkUNAEEBIQUgAC0AKUEFRg0BQQEhBSAEQcAAcUUgA3FBAUcNAQtBACEFIARBwABxDQBBAiEFIARB//8DcSIDQQhxDQACQCADQYAEcUUNAAJAIAAtAChBAUcNACAALQAtQQpxDQBBBQ8LQQQPCwJAIANBIHENAAJAIAAtAChBAUYNACAALwEyQf//A3EiAEGcf2pB5ABJDQAgAEHMAUYNACAAQbACRg0AQQQhBSAEQShxRQ0CIANBiARxQYAERg0CC0EADwtBAEEDIAApAyBQGyEFCyAFC2IBAn9BACEBAkAgAC0AKEEBRg0AIAAvATJB//8DcSICQZx/akHkAEkNACACQcwBRg0AIAJBsAJGDQAgAC8BMCIAQcAAcQ0AQQEhASAAQYgEcUGABEYNACAAQShxRSEBCyABC6cBAQN/AkACQAJAIAAtACpFDQAgAC0AK0UNAEEAIQMgAC8BMCIEQQJxRQ0BDAILQQAhAyAALwEwIgRBAXFFDQELQQEhAyAALQAoQQFGDQAgAC8BMkH//wNxIgVBnH9qQeQASQ0AIAVBzAFGDQAgBUGwAkYNACAEQcAAcQ0AQQAhAyAEQYgEcUGABEYNACAEQShxQQBHIQMLIABBADsBMCAAQQA6AC8gAwuZAQECfwJAAkACQCAALQAqRQ0AIAAtACtFDQBBACEBIAAvATAiAkECcUUNAQwCC0EAIQEgAC8BMCICQQFxRQ0BC0EBIQEgAC0AKEEBRg0AIAAvATJB//8DcSIAQZx/akHkAEkNACAAQcwBRg0AIABBsAJGDQAgAkHAAHENAEEAIQEgAkGIBHFBgARGDQAgAkEocUEARyEBCyABC0kBAXsgAEEQav0MAAAAAAAAAAAAAAAAAAAAACIB/QsDACAAIAH9CwMAIABBMGogAf0LAwAgAEEgaiAB/QsDACAAQd0BNgIcQQALewEBfwJAIAAoAgwiAw0AAkAgACgCBEUNACAAIAE2AgQLAkAgACABIAIQxICAgAAiAw0AIAAoAgwPCyAAIAM2AhxBACEDIAAoAgQiAUUNACAAIAEgAiAAKAIIEYGAgIAAACIBRQ0AIAAgAjYCFCAAIAE2AgwgASEDCyADC+TzAQMOfwN+BH8jgICAgABBEGsiAySAgICAACABIQQgASEFIAEhBiABIQcgASEIIAEhCSABIQogASELIAEhDCABIQ0gASEOIAEhDwJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQCAAKAIcIhBBf2oO3QHaAQHZAQIDBAUGBwgJCgsMDQ7YAQ8Q1wEREtYBExQVFhcYGRob4AHfARwdHtUBHyAhIiMkJdQBJicoKSorLNMB0gEtLtEB0AEvMDEyMzQ1Njc4OTo7PD0+P0BBQkNERUbbAUdISUrPAc4BS80BTMwBTU5PUFFSU1RVVldYWVpbXF1eX2BhYmNkZWZnaGlqa2xtbm9wcXJzdHV2d3h5ent8fX5/gAGBAYIBgwGEAYUBhgGHAYgBiQGKAYsBjAGNAY4BjwGQAZEBkgGTAZQBlQGWAZcBmAGZAZoBmwGcAZ0BngGfAaABoQGiAaMBpAGlAaYBpwGoAakBqgGrAawBrQGuAa8BsAGxAbIBswG0AbUBtgG3AcsBygG4AckBuQHIAboBuwG8Ab0BvgG/AcABwQHCAcMBxAHFAcYBANwBC0EAIRAMxgELQQ4hEAzFAQtBDSEQDMQBC0EPIRAMwwELQRAhEAzCAQtBEyEQDMEBC0EUIRAMwAELQRUhEAy/AQtBFiEQDL4BC0EXIRAMvQELQRghEAy8AQtBGSEQDLsBC0EaIRAMugELQRshEAy5AQtBHCEQDLgBC0EIIRAMtwELQR0hEAy2AQtBICEQDLUBC0EfIRAMtAELQQchEAyzAQtBISEQDLIBC0EiIRAMsQELQR4hEAywAQtBIyEQDK8BC0ESIRAMrgELQREhEAytAQtBJCEQDKwBC0ElIRAMqwELQSYhEAyqAQtBJyEQDKkBC0HDASEQDKgBC0EpIRAMpwELQSshEAymAQtBLCEQDKUBC0EtIRAMpAELQS4hEAyjAQtBLyEQDKIBC0HEASEQDKEBC0EwIRAMoAELQTQhEAyfAQtBDCEQDJ4BC0ExIRAMnQELQTIhEAycAQtBMyEQDJsBC0E5IRAMmgELQTUhEAyZAQtBxQEhEAyYAQtBCyEQDJcBC0E6IRAMlgELQTYhEAyVAQtBCiEQDJQBC0E3IRAMkwELQTghEAySAQtBPCEQDJEBC0E7IRAMkAELQT0hEAyPAQtBCSEQDI4BC0EoIRAMjQELQT4hEAyMAQtBPyEQDIsBC0HAACEQDIoBC0HBACEQDIkBC0HCACEQDIgBC0HDACEQDIcBC0HEACEQDIYBC0HFACEQDIUBC0HGACEQDIQBC0EqIRAMgwELQccAIRAMggELQcgAIRAMgQELQckAIRAMgAELQcoAIRAMfwtBywAhEAx+C0HNACEQDH0LQcwAIRAMfAtBzgAhEAx7C0HPACEQDHoLQdAAIRAMeQtB0QAhEAx4C0HSACEQDHcLQdMAIRAMdgtB1AAhEAx1C0HWACEQDHQLQdUAIRAMcwtBBiEQDHILQdcAIRAMcQtBBSEQDHALQdgAIRAMbwtBBCEQDG4LQdkAIRAMbQtB2gAhEAxsC0HbACEQDGsLQdwAIRAMagtBAyEQDGkLQd0AIRAMaAtB3gAhEAxnC0HfACEQDGYLQeEAIRAMZQtB4AAhEAxkC0HiACEQDGMLQeMAIRAMYgtBAiEQDGELQeQAIRAMYAtB5QAhEAxfC0HmACEQDF4LQecAIRAMXQtB6AAhEAxcC0HpACEQDFsLQeoAIRAMWgtB6wAhEAxZC0HsACEQDFgLQe0AIRAMVwtB7gAhEAxWC0HvACEQDFULQfAAIRAMVAtB8QAhEAxTC0HyACEQDFILQfMAIRAMUQtB9AAhEAxQC0H1ACEQDE8LQfYAIRAMTgtB9wAhEAxNC0H4ACEQDEwLQfkAIRAMSwtB+gAhEAxKC0H7ACEQDEkLQfwAIRAMSAtB/QAhEAxHC0H+ACEQDEYLQf8AIRAMRQtBgAEhEAxEC0GBASEQDEMLQYIBIRAMQgtBgwEhEAxBC0GEASEQDEALQYUBIRAMPwtBhgEhEAw+C0GHASEQDD0LQYgBIRAMPAtBiQEhEAw7C0GKASEQDDoLQYsBIRAMOQtBjAEhEAw4C0GNASEQDDcLQY4BIRAMNgtBjwEhEAw1C0GQASEQDDQLQZEBIRAMMwtBkgEhEAwyC0GTASEQDDELQZQBIRAMMAtBlQEhEAwvC0GWASEQDC4LQZcBIRAMLQtBmAEhEAwsC0GZASEQDCsLQZoBIRAMKgtBmwEhEAwpC0GcASEQDCgLQZ0BIRAMJwtBngEhEAwmC0GfASEQDCULQaABIRAMJAtBoQEhEAwjC0GiASEQDCILQaMBIRAMIQtBpAEhEAwgC0GlASEQDB8LQaYBIRAMHgtBpwEhEAwdC0GoASEQDBwLQakBIRAMGwtBqgEhEAwaC0GrASEQDBkLQawBIRAMGAtBrQEhEAwXC0GuASEQDBYLQQEhEAwVC0GvASEQDBQLQbABIRAMEwtBsQEhEAwSC0GzASEQDBELQbIBIRAMEAtBtAEhEAwPC0G1ASEQDA4LQbYBIRAMDQtBtwEhEAwMC0G4ASEQDAsLQbkBIRAMCgtBugEhEAwJC0G7ASEQDAgLQcYBIRAMBwtBvAEhEAwGC0G9ASEQDAULQb4BIRAMBAtBvwEhEAwDC0HAASEQDAILQcIBIRAMAQtBwQEhEAsDQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAIBAOxwEAAQIDBAUGBwgJCgsMDQ4PEBESExQVFhcYGRobHB4fICEjJSg/QEFERUZHSElKS0xNT1BRUlPeA1dZW1xdYGJlZmdoaWprbG1vcHFyc3R1dnd4eXp7fH1+gAGCAYUBhgGHAYkBiwGMAY0BjgGPAZABkQGUAZUBlgGXAZgBmQGaAZsBnAGdAZ4BnwGgAaEBogGjAaQBpQGmAacBqAGpAaoBqwGsAa0BrgGvAbABsQGyAbMBtAG1AbYBtwG4AbkBugG7AbwBvQG+Ab8BwAHBAcIBwwHEAcUBxgHHAcgByQHKAcsBzAHNAc4BzwHQAdEB0gHTAdQB1QHWAdcB2AHZAdoB2wHcAd0B3gHgAeEB4gHjAeQB5QHmAecB6AHpAeoB6wHsAe0B7gHvAfAB8QHyAfMBmQKkArAC/gL+AgsgASIEIAJHDfMBQd0BIRAM/wMLIAEiECACRw3dAUHDASEQDP4DCyABIgEgAkcNkAFB9wAhEAz9AwsgASIBIAJHDYYBQe8AIRAM/AMLIAEiASACRw1/QeoAIRAM+wMLIAEiASACRw17QegAIRAM+gMLIAEiASACRw14QeYAIRAM+QMLIAEiASACRw0aQRghEAz4AwsgASIBIAJHDRRBEiEQDPcDCyABIgEgAkcNWUHFACEQDPYDCyABIgEgAkcNSkE/IRAM9QMLIAEiASACRw1IQTwhEAz0AwsgASIBIAJHDUFBMSEQDPMDCyAALQAuQQFGDesDDIcCCyAAIAEiASACEMCAgIAAQQFHDeYBIABCADcDIAznAQsgACABIgEgAhC0gICAACIQDecBIAEhAQz1AgsCQCABIgEgAkcNAEEGIRAM8AMLIAAgAUEBaiIBIAIQu4CAgAAiEA3oASABIQEMMQsgAEIANwMgQRIhEAzVAwsgASIQIAJHDStBHSEQDO0DCwJAIAEiASACRg0AIAFBAWohAUEQIRAM1AMLQQchEAzsAwsgAEIAIAApAyAiESACIAEiEGutIhJ9IhMgEyARVhs3AyAgESASViIURQ3lAUEIIRAM6wMLAkAgASIBIAJGDQAgAEGJgICAADYCCCAAIAE2AgQgASEBQRQhEAzSAwtBCSEQDOoDCyABIQEgACkDIFAN5AEgASEBDPICCwJAIAEiASACRw0AQQshEAzpAwsgACABQQFqIgEgAhC2gICAACIQDeUBIAEhAQzyAgsgACABIgEgAhC4gICAACIQDeUBIAEhAQzyAgsgACABIgEgAhC4gICAACIQDeYBIAEhAQwNCyAAIAEiASACELqAgIAAIhAN5wEgASEBDPACCwJAIAEiASACRw0AQQ8hEAzlAwsgAS0AACIQQTtGDQggEEENRw3oASABQQFqIQEM7wILIAAgASIBIAIQuoCAgAAiEA3oASABIQEM8gILA0ACQCABLQAAQfC1gIAAai0AACIQQQFGDQAgEEECRw3rASAAKAIEIRAgAEEANgIEIAAgECABQQFqIgEQuYCAgAAiEA3qASABIQEM9AILIAFBAWoiASACRw0AC0ESIRAM4gMLIAAgASIBIAIQuoCAgAAiEA3pASABIQEMCgsgASIBIAJHDQZBGyEQDOADCwJAIAEiASACRw0AQRYhEAzgAwsgAEGKgICAADYCCCAAIAE2AgQgACABIAIQuICAgAAiEA3qASABIQFBICEQDMYDCwJAIAEiASACRg0AA0ACQCABLQAAQfC3gIAAai0AACIQQQJGDQACQCAQQX9qDgTlAewBAOsB7AELIAFBAWohAUEIIRAMyAMLIAFBAWoiASACRw0AC0EVIRAM3wMLQRUhEAzeAwsDQAJAIAEtAABB8LmAgABqLQAAIhBBAkYNACAQQX9qDgTeAewB4AHrAewBCyABQQFqIgEgAkcNAAtBGCEQDN0DCwJAIAEiASACRg0AIABBi4CAgAA2AgggACABNgIEIAEhAUEHIRAMxAMLQRkhEAzcAwsgAUEBaiEBDAILAkAgASIUIAJHDQBBGiEQDNsDCyAUIQECQCAULQAAQXNqDhTdAu4C7gLuAu4C7gLuAu4C7gLuAu4C7gLuAu4C7gLuAu4C7gLuAgDuAgtBACEQIABBADYCHCAAQa+LgIAANgIQIABBAjYCDCAAIBRBAWo2AhQM2gMLAkAgAS0AACIQQTtGDQAgEEENRw3oASABQQFqIQEM5QILIAFBAWohAQtBIiEQDL8DCwJAIAEiECACRw0AQRwhEAzYAwtCACERIBAhASAQLQAAQVBqDjfnAeYBAQIDBAUGBwgAAAAAAAAACQoLDA0OAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAPEBESExQAC0EeIRAMvQMLQgIhEQzlAQtCAyERDOQBC0IEIREM4wELQgUhEQziAQtCBiERDOEBC0IHIREM4AELQgghEQzfAQtCCSERDN4BC0IKIREM3QELQgshEQzcAQtCDCERDNsBC0INIREM2gELQg4hEQzZAQtCDyERDNgBC0IKIREM1wELQgshEQzWAQtCDCERDNUBC0INIREM1AELQg4hEQzTAQtCDyERDNIBC0IAIRECQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAIBAtAABBUGoON+UB5AEAAQIDBAUGB+YB5gHmAeYB5gHmAeYBCAkKCwwN5gHmAeYB5gHmAeYB5gHmAeYB5gHmAeYB5gHmAeYB5gHmAeYB5gHmAeYB5gHmAeYB5gHmAQ4PEBESE+YBC0ICIREM5AELQgMhEQzjAQtCBCERDOIBC0IFIREM4QELQgYhEQzgAQtCByERDN8BC0IIIREM3gELQgkhEQzdAQtCCiERDNwBC0ILIREM2wELQgwhEQzaAQtCDSERDNkBC0IOIREM2AELQg8hEQzXAQtCCiERDNYBC0ILIREM1QELQgwhEQzUAQtCDSERDNMBC0IOIREM0gELQg8hEQzRAQsgAEIAIAApAyAiESACIAEiEGutIhJ9IhMgEyARVhs3AyAgESASViIURQ3SAUEfIRAMwAMLAkAgASIBIAJGDQAgAEGJgICAADYCCCAAIAE2AgQgASEBQSQhEAynAwtBICEQDL8DCyAAIAEiECACEL6AgIAAQX9qDgW2AQDFAgHRAdIBC0ERIRAMpAMLIABBAToALyAQIQEMuwMLIAEiASACRw3SAUEkIRAMuwMLIAEiDSACRw0eQcYAIRAMugMLIAAgASIBIAIQsoCAgAAiEA3UASABIQEMtQELIAEiECACRw0mQdAAIRAMuAMLAkAgASIBIAJHDQBBKCEQDLgDCyAAQQA2AgQgAEGMgICAADYCCCAAIAEgARCxgICAACIQDdMBIAEhAQzYAQsCQCABIhAgAkcNAEEpIRAMtwMLIBAtAAAiAUEgRg0UIAFBCUcN0wEgEEEBaiEBDBULAkAgASIBIAJGDQAgAUEBaiEBDBcLQSohEAy1AwsCQCABIhAgAkcNAEErIRAMtQMLAkAgEC0AACIBQQlGDQAgAUEgRw3VAQsgAC0ALEEIRg3TASAQIQEMkQMLAkAgASIBIAJHDQBBLCEQDLQDCyABLQAAQQpHDdUBIAFBAWohAQzJAgsgASIOIAJHDdUBQS8hEAyyAwsDQAJAIAEtAAAiEEEgRg0AAkAgEEF2ag4EANwB3AEA2gELIAEhAQzgAQsgAUEBaiIBIAJHDQALQTEhEAyxAwtBMiEQIAEiFCACRg2wAyACIBRrIAAoAgAiAWohFSAUIAFrQQNqIRYCQANAIBQtAAAiF0EgciAXIBdBv39qQf8BcUEaSRtB/wFxIAFB8LuAgABqLQAARw0BAkAgAUEDRw0AQQYhAQyWAwsgAUEBaiEBIBRBAWoiFCACRw0ACyAAIBU2AgAMsQMLIABBADYCACAUIQEM2QELQTMhECABIhQgAkYNrwMgAiAUayAAKAIAIgFqIRUgFCABa0EIaiEWAkADQCAULQAAIhdBIHIgFyAXQb9/akH/AXFBGkkbQf8BcSABQfS7gIAAai0AAEcNAQJAIAFBCEcNAEEFIQEMlQMLIAFBAWohASAUQQFqIhQgAkcNAAsgACAVNgIADLADCyAAQQA2AgAgFCEBDNgBC0E0IRAgASIUIAJGDa4DIAIgFGsgACgCACIBaiEVIBQgAWtBBWohFgJAA0AgFC0AACIXQSByIBcgF0G/f2pB/wFxQRpJG0H/AXEgAUHQwoCAAGotAABHDQECQCABQQVHDQBBByEBDJQDCyABQQFqIQEgFEEBaiIUIAJHDQALIAAgFTYCAAyvAwsgAEEANgIAIBQhAQzXAQsCQCABIgEgAkYNAANAAkAgAS0AAEGAvoCAAGotAAAiEEEBRg0AIBBBAkYNCiABIQEM3QELIAFBAWoiASACRw0AC0EwIRAMrgMLQTAhEAytAwsCQCABIgEgAkYNAANAAkAgAS0AACIQQSBGDQAgEEF2ag4E2QHaAdoB2QHaAQsgAUEBaiIBIAJHDQALQTghEAytAwtBOCEQDKwDCwNAAkAgAS0AACIQQSBGDQAgEEEJRw0DCyABQQFqIgEgAkcNAAtBPCEQDKsDCwNAAkAgAS0AACIQQSBGDQACQAJAIBBBdmoOBNoBAQHaAQALIBBBLEYN2wELIAEhAQwECyABQQFqIgEgAkcNAAtBPyEQDKoDCyABIQEM2wELQcAAIRAgASIUIAJGDagDIAIgFGsgACgCACIBaiEWIBQgAWtBBmohFwJAA0AgFC0AAEEgciABQYDAgIAAai0AAEcNASABQQZGDY4DIAFBAWohASAUQQFqIhQgAkcNAAsgACAWNgIADKkDCyAAQQA2AgAgFCEBC0E2IRAMjgMLAkAgASIPIAJHDQBBwQAhEAynAwsgAEGMgICAADYCCCAAIA82AgQgDyEBIAAtACxBf2oOBM0B1QHXAdkBhwMLIAFBAWohAQzMAQsCQCABIgEgAkYNAANAAkAgAS0AACIQQSByIBAgEEG/f2pB/wFxQRpJG0H/AXEiEEEJRg0AIBBBIEYNAAJAAkACQAJAIBBBnX9qDhMAAwMDAwMDAwEDAwMDAwMDAwMCAwsgAUEBaiEBQTEhEAyRAwsgAUEBaiEBQTIhEAyQAwsgAUEBaiEBQTMhEAyPAwsgASEBDNABCyABQQFqIgEgAkcNAAtBNSEQDKUDC0E1IRAMpAMLAkAgASIBIAJGDQADQAJAIAEtAABBgLyAgABqLQAAQQFGDQAgASEBDNMBCyABQQFqIgEgAkcNAAtBPSEQDKQDC0E9IRAMowMLIAAgASIBIAIQsICAgAAiEA3WASABIQEMAQsgEEEBaiEBC0E8IRAMhwMLAkAgASIBIAJHDQBBwgAhEAygAwsCQANAAkAgAS0AAEF3ag4YAAL+Av4ChAP+Av4C/gL+Av4C/gL+Av4C/gL+Av4C/gL+Av4C/gL+Av4C/gIA/gILIAFBAWoiASACRw0AC0HCACEQDKADCyABQQFqIQEgAC0ALUEBcUUNvQEgASEBC0EsIRAMhQMLIAEiASACRw3TAUHEACEQDJ0DCwNAAkAgAS0AAEGQwICAAGotAABBAUYNACABIQEMtwILIAFBAWoiASACRw0AC0HFACEQDJwDCyANLQAAIhBBIEYNswEgEEE6Rw2BAyAAKAIEIQEgAEEANgIEIAAgASANEK+AgIAAIgEN0AEgDUEBaiEBDLMCC0HHACEQIAEiDSACRg2aAyACIA1rIAAoAgAiAWohFiANIAFrQQVqIRcDQCANLQAAIhRBIHIgFCAUQb9/akH/AXFBGkkbQf8BcSABQZDCgIAAai0AAEcNgAMgAUEFRg30AiABQQFqIQEgDUEBaiINIAJHDQALIAAgFjYCAAyaAwtByAAhECABIg0gAkYNmQMgAiANayAAKAIAIgFqIRYgDSABa0EJaiEXA0AgDS0AACIUQSByIBQgFEG/f2pB/wFxQRpJG0H/AXEgAUGWwoCAAGotAABHDf8CAkAgAUEJRw0AQQIhAQz1AgsgAUEBaiEBIA1BAWoiDSACRw0ACyAAIBY2AgAMmQMLAkAgASINIAJHDQBByQAhEAyZAwsCQAJAIA0tAAAiAUEgciABIAFBv39qQf8BcUEaSRtB/wFxQZJ/ag4HAIADgAOAA4ADgAMBgAMLIA1BAWohAUE+IRAMgAMLIA1BAWohAUE/IRAM/wILQcoAIRAgASINIAJGDZcDIAIgDWsgACgCACIBaiEWIA0gAWtBAWohFwNAIA0tAAAiFEEgciAUIBRBv39qQf8BcUEaSRtB/wFxIAFBoMKAgABqLQAARw39AiABQQFGDfACIAFBAWohASANQQFqIg0gAkcNAAsgACAWNgIADJcDC0HLACEQIAEiDSACRg2WAyACIA1rIAAoAgAiAWohFiANIAFrQQ5qIRcDQCANLQAAIhRBIHIgFCAUQb9/akH/AXFBGkkbQf8BcSABQaLCgIAAai0AAEcN/AIgAUEORg3wAiABQQFqIQEgDUEBaiINIAJHDQALIAAgFjYCAAyWAwtBzAAhECABIg0gAkYNlQMgAiANayAAKAIAIgFqIRYgDSABa0EPaiEXA0AgDS0AACIUQSByIBQgFEG/f2pB/wFxQRpJG0H/AXEgAUHAwoCAAGotAABHDfsCAkAgAUEPRw0AQQMhAQzxAgsgAUEBaiEBIA1BAWoiDSACRw0ACyAAIBY2AgAMlQMLQc0AIRAgASINIAJGDZQDIAIgDWsgACgCACIBaiEWIA0gAWtBBWohFwNAIA0tAAAiFEEgciAUIBRBv39qQf8BcUEaSRtB/wFxIAFB0MKAgABqLQAARw36AgJAIAFBBUcNAEEEIQEM8AILIAFBAWohASANQQFqIg0gAkcNAAsgACAWNgIADJQDCwJAIAEiDSACRw0AQc4AIRAMlAMLAkACQAJAAkAgDS0AACIBQSByIAEgAUG/f2pB/wFxQRpJG0H/AXFBnX9qDhMA/QL9Av0C/QL9Av0C/QL9Av0C/QL9Av0CAf0C/QL9AgID/QILIA1BAWohAUHBACEQDP0CCyANQQFqIQFBwgAhEAz8AgsgDUEBaiEBQcMAIRAM+wILIA1BAWohAUHEACEQDPoCCwJAIAEiASACRg0AIABBjYCAgAA2AgggACABNgIEIAEhAUHFACEQDPoCC0HPACEQDJIDCyAQIQECQAJAIBAtAABBdmoOBAGoAqgCAKgCCyAQQQFqIQELQSchEAz4AgsCQCABIgEgAkcNAEHRACEQDJEDCwJAIAEtAABBIEYNACABIQEMjQELIAFBAWohASAALQAtQQFxRQ3HASABIQEMjAELIAEiFyACRw3IAUHSACEQDI8DC0HTACEQIAEiFCACRg2OAyACIBRrIAAoAgAiAWohFiAUIAFrQQFqIRcDQCAULQAAIAFB1sKAgABqLQAARw3MASABQQFGDccBIAFBAWohASAUQQFqIhQgAkcNAAsgACAWNgIADI4DCwJAIAEiASACRw0AQdUAIRAMjgMLIAEtAABBCkcNzAEgAUEBaiEBDMcBCwJAIAEiASACRw0AQdYAIRAMjQMLAkACQCABLQAAQXZqDgQAzQHNAQHNAQsgAUEBaiEBDMcBCyABQQFqIQFBygAhEAzzAgsgACABIgEgAhCugICAACIQDcsBIAEhAUHNACEQDPICCyAALQApQSJGDYUDDKYCCwJAIAEiASACRw0AQdsAIRAMigMLQQAhFEEBIRdBASEWQQAhEAJAAkACQAJAAkACQAJAAkACQCABLQAAQVBqDgrUAdMBAAECAwQFBgjVAQtBAiEQDAYLQQMhEAwFC0EEIRAMBAtBBSEQDAMLQQYhEAwCC0EHIRAMAQtBCCEQC0EAIRdBACEWQQAhFAzMAQtBCSEQQQEhFEEAIRdBACEWDMsBCwJAIAEiASACRw0AQd0AIRAMiQMLIAEtAABBLkcNzAEgAUEBaiEBDKYCCyABIgEgAkcNzAFB3wAhEAyHAwsCQCABIgEgAkYNACAAQY6AgIAANgIIIAAgATYCBCABIQFB0AAhEAzuAgtB4AAhEAyGAwtB4QAhECABIgEgAkYNhQMgAiABayAAKAIAIhRqIRYgASAUa0EDaiEXA0AgAS0AACAUQeLCgIAAai0AAEcNzQEgFEEDRg3MASAUQQFqIRQgAUEBaiIBIAJHDQALIAAgFjYCAAyFAwtB4gAhECABIgEgAkYNhAMgAiABayAAKAIAIhRqIRYgASAUa0ECaiEXA0AgAS0AACAUQebCgIAAai0AAEcNzAEgFEECRg3OASAUQQFqIRQgAUEBaiIBIAJHDQALIAAgFjYCAAyEAwtB4wAhECABIgEgAkYNgwMgAiABayAAKAIAIhRqIRYgASAUa0EDaiEXA0AgAS0AACAUQenCgIAAai0AAEcNywEgFEEDRg3OASAUQQFqIRQgAUEBaiIBIAJHDQALIAAgFjYCAAyDAwsCQCABIgEgAkcNAEHlACEQDIMDCyAAIAFBAWoiASACEKiAgIAAIhANzQEgASEBQdYAIRAM6QILAkAgASIBIAJGDQADQAJAIAEtAAAiEEEgRg0AAkACQAJAIBBBuH9qDgsAAc8BzwHPAc8BzwHPAc8BzwECzwELIAFBAWohAUHSACEQDO0CCyABQQFqIQFB0wAhEAzsAgsgAUEBaiEBQdQAIRAM6wILIAFBAWoiASACRw0AC0HkACEQDIIDC0HkACEQDIEDCwNAAkAgAS0AAEHwwoCAAGotAAAiEEEBRg0AIBBBfmoOA88B0AHRAdIBCyABQQFqIgEgAkcNAAtB5gAhEAyAAwsCQCABIgEgAkYNACABQQFqIQEMAwtB5wAhEAz/AgsDQAJAIAEtAABB8MSAgABqLQAAIhBBAUYNAAJAIBBBfmoOBNIB0wHUAQDVAQsgASEBQdcAIRAM5wILIAFBAWoiASACRw0AC0HoACEQDP4CCwJAIAEiASACRw0AQekAIRAM/gILAkAgAS0AACIQQXZqDhq6AdUB1QG8AdUB1QHVAdUB1QHVAdUB1QHVAdUB1QHVAdUB1QHVAdUB1QHVAcoB1QHVAQDTAQsgAUEBaiEBC0EGIRAM4wILA0ACQCABLQAAQfDGgIAAai0AAEEBRg0AIAEhAQyeAgsgAUEBaiIBIAJHDQALQeoAIRAM+wILAkAgASIBIAJGDQAgAUEBaiEBDAMLQesAIRAM+gILAkAgASIBIAJHDQBB7AAhEAz6AgsgAUEBaiEBDAELAkAgASIBIAJHDQBB7QAhEAz5AgsgAUEBaiEBC0EEIRAM3gILAkAgASIUIAJHDQBB7gAhEAz3AgsgFCEBAkACQAJAIBQtAABB8MiAgABqLQAAQX9qDgfUAdUB1gEAnAIBAtcBCyAUQQFqIQEMCgsgFEEBaiEBDM0BC0EAIRAgAEEANgIcIABBm5KAgAA2AhAgAEEHNgIMIAAgFEEBajYCFAz2AgsCQANAAkAgAS0AAEHwyICAAGotAAAiEEEERg0AAkACQCAQQX9qDgfSAdMB1AHZAQAEAdkBCyABIQFB2gAhEAzgAgsgAUEBaiEBQdwAIRAM3wILIAFBAWoiASACRw0AC0HvACEQDPYCCyABQQFqIQEMywELAkAgASIUIAJHDQBB8AAhEAz1AgsgFC0AAEEvRw3UASAUQQFqIQEMBgsCQCABIhQgAkcNAEHxACEQDPQCCwJAIBQtAAAiAUEvRw0AIBRBAWohAUHdACEQDNsCCyABQXZqIgRBFksN0wFBASAEdEGJgIACcUUN0wEMygILAkAgASIBIAJGDQAgAUEBaiEBQd4AIRAM2gILQfIAIRAM8gILAkAgASIUIAJHDQBB9AAhEAzyAgsgFCEBAkAgFC0AAEHwzICAAGotAABBf2oOA8kClAIA1AELQeEAIRAM2AILAkAgASIUIAJGDQADQAJAIBQtAABB8MqAgABqLQAAIgFBA0YNAAJAIAFBf2oOAssCANUBCyAUIQFB3wAhEAzaAgsgFEEBaiIUIAJHDQALQfMAIRAM8QILQfMAIRAM8AILAkAgASIBIAJGDQAgAEGPgICAADYCCCAAIAE2AgQgASEBQeAAIRAM1wILQfUAIRAM7wILAkAgASIBIAJHDQBB9gAhEAzvAgsgAEGPgICAADYCCCAAIAE2AgQgASEBC0EDIRAM1AILA0AgAS0AAEEgRw3DAiABQQFqIgEgAkcNAAtB9wAhEAzsAgsCQCABIgEgAkcNAEH4ACEQDOwCCyABLQAAQSBHDc4BIAFBAWohAQzvAQsgACABIgEgAhCsgICAACIQDc4BIAEhAQyOAgsCQCABIgQgAkcNAEH6ACEQDOoCCyAELQAAQcwARw3RASAEQQFqIQFBEyEQDM8BCwJAIAEiBCACRw0AQfsAIRAM6QILIAIgBGsgACgCACIBaiEUIAQgAWtBBWohEANAIAQtAAAgAUHwzoCAAGotAABHDdABIAFBBUYNzgEgAUEBaiEBIARBAWoiBCACRw0ACyAAIBQ2AgBB+wAhEAzoAgsCQCABIgQgAkcNAEH8ACEQDOgCCwJAAkAgBC0AAEG9f2oODADRAdEB0QHRAdEB0QHRAdEB0QHRAQHRAQsgBEEBaiEBQeYAIRAMzwILIARBAWohAUHnACEQDM4CCwJAIAEiBCACRw0AQf0AIRAM5wILIAIgBGsgACgCACIBaiEUIAQgAWtBAmohEAJAA0AgBC0AACABQe3PgIAAai0AAEcNzwEgAUECRg0BIAFBAWohASAEQQFqIgQgAkcNAAsgACAUNgIAQf0AIRAM5wILIABBADYCACAQQQFqIQFBECEQDMwBCwJAIAEiBCACRw0AQf4AIRAM5gILIAIgBGsgACgCACIBaiEUIAQgAWtBBWohEAJAA0AgBC0AACABQfbOgIAAai0AAEcNzgEgAUEFRg0BIAFBAWohASAEQQFqIgQgAkcNAAsgACAUNgIAQf4AIRAM5gILIABBADYCACAQQQFqIQFBFiEQDMsBCwJAIAEiBCACRw0AQf8AIRAM5QILIAIgBGsgACgCACIBaiEUIAQgAWtBA2ohEAJAA0AgBC0AACABQfzOgIAAai0AAEcNzQEgAUEDRg0BIAFBAWohASAEQQFqIgQgAkcNAAsgACAUNgIAQf8AIRAM5QILIABBADYCACAQQQFqIQFBBSEQDMoBCwJAIAEiBCACRw0AQYABIRAM5AILIAQtAABB2QBHDcsBIARBAWohAUEIIRAMyQELAkAgASIEIAJHDQBBgQEhEAzjAgsCQAJAIAQtAABBsn9qDgMAzAEBzAELIARBAWohAUHrACEQDMoCCyAEQQFqIQFB7AAhEAzJAgsCQCABIgQgAkcNAEGCASEQDOICCwJAAkAgBC0AAEG4f2oOCADLAcsBywHLAcsBywEBywELIARBAWohAUHqACEQDMkCCyAEQQFqIQFB7QAhEAzIAgsCQCABIgQgAkcNAEGDASEQDOECCyACIARrIAAoAgAiAWohECAEIAFrQQJqIRQCQANAIAQtAAAgAUGAz4CAAGotAABHDckBIAFBAkYNASABQQFqIQEgBEEBaiIEIAJHDQALIAAgEDYCAEGDASEQDOECC0EAIRAgAEEANgIAIBRBAWohAQzGAQsCQCABIgQgAkcNAEGEASEQDOACCyACIARrIAAoAgAiAWohFCAEIAFrQQRqIRACQANAIAQtAAAgAUGDz4CAAGotAABHDcgBIAFBBEYNASABQQFqIQEgBEEBaiIEIAJHDQALIAAgFDYCAEGEASEQDOACCyAAQQA2AgAgEEEBaiEBQSMhEAzFAQsCQCABIgQgAkcNAEGFASEQDN8CCwJAAkAgBC0AAEG0f2oOCADIAcgByAHIAcgByAEByAELIARBAWohAUHvACEQDMYCCyAEQQFqIQFB8AAhEAzFAgsCQCABIgQgAkcNAEGGASEQDN4CCyAELQAAQcUARw3FASAEQQFqIQEMgwILAkAgASIEIAJHDQBBhwEhEAzdAgsgAiAEayAAKAIAIgFqIRQgBCABa0EDaiEQAkADQCAELQAAIAFBiM+AgABqLQAARw3FASABQQNGDQEgAUEBaiEBIARBAWoiBCACRw0ACyAAIBQ2AgBBhwEhEAzdAgsgAEEANgIAIBBBAWohAUEtIRAMwgELAkAgASIEIAJHDQBBiAEhEAzcAgsgAiAEayAAKAIAIgFqIRQgBCABa0EIaiEQAkADQCAELQAAIAFB0M+AgABqLQAARw3EASABQQhGDQEgAUEBaiEBIARBAWoiBCACRw0ACyAAIBQ2AgBBiAEhEAzcAgsgAEEANgIAIBBBAWohAUEpIRAMwQELAkAgASIBIAJHDQBBiQEhEAzbAgtBASEQIAEtAABB3wBHDcABIAFBAWohAQyBAgsCQCABIgQgAkcNAEGKASEQDNoCCyACIARrIAAoAgAiAWohFCAEIAFrQQFqIRADQCAELQAAIAFBjM+AgABqLQAARw3BASABQQFGDa8CIAFBAWohASAEQQFqIgQgAkcNAAsgACAUNgIAQYoBIRAM2QILAkAgASIEIAJHDQBBiwEhEAzZAgsgAiAEayAAKAIAIgFqIRQgBCABa0ECaiEQAkADQCAELQAAIAFBjs+AgABqLQAARw3BASABQQJGDQEgAUEBaiEBIARBAWoiBCACRw0ACyAAIBQ2AgBBiwEhEAzZAgsgAEEANgIAIBBBAWohAUECIRAMvgELAkAgASIEIAJHDQBBjAEhEAzYAgsgAiAEayAAKAIAIgFqIRQgBCABa0EBaiEQAkADQCAELQAAIAFB8M+AgABqLQAARw3AASABQQFGDQEgAUEBaiEBIARBAWoiBCACRw0ACyAAIBQ2AgBBjAEhEAzYAgsgAEEANgIAIBBBAWohAUEfIRAMvQELAkAgASIEIAJHDQBBjQEhEAzXAgsgAiAEayAAKAIAIgFqIRQgBCABa0EBaiEQAkADQCAELQAAIAFB8s+AgABqLQAARw2/ASABQQFGDQEgAUEBaiEBIARBAWoiBCACRw0ACyAAIBQ2AgBBjQEhEAzXAgsgAEEANgIAIBBBAWohAUEJIRAMvAELAkAgASIEIAJHDQBBjgEhEAzWAgsCQAJAIAQtAABBt39qDgcAvwG/Ab8BvwG/AQG/AQsgBEEBaiEBQfgAIRAMvQILIARBAWohAUH5ACEQDLwCCwJAIAEiBCACRw0AQY8BIRAM1QILIAIgBGsgACgCACIBaiEUIAQgAWtBBWohEAJAA0AgBC0AACABQZHPgIAAai0AAEcNvQEgAUEFRg0BIAFBAWohASAEQQFqIgQgAkcNAAsgACAUNgIAQY8BIRAM1QILIABBADYCACAQQQFqIQFBGCEQDLoBCwJAIAEiBCACRw0AQZABIRAM1AILIAIgBGsgACgCACIBaiEUIAQgAWtBAmohEAJAA0AgBC0AACABQZfPgIAAai0AAEcNvAEgAUECRg0BIAFBAWohASAEQQFqIgQgAkcNAAsgACAUNgIAQZABIRAM1AILIABBADYCACAQQQFqIQFBFyEQDLkBCwJAIAEiBCACRw0AQZEBIRAM0wILIAIgBGsgACgCACIBaiEUIAQgAWtBBmohEAJAA0AgBC0AACABQZrPgIAAai0AAEcNuwEgAUEGRg0BIAFBAWohASAEQQFqIgQgAkcNAAsgACAUNgIAQZEBIRAM0wILIABBADYCACAQQQFqIQFBFSEQDLgBCwJAIAEiBCACRw0AQZIBIRAM0gILIAIgBGsgACgCACIBaiEUIAQgAWtBBWohEAJAA0AgBC0AACABQaHPgIAAai0AAEcNugEgAUEFRg0BIAFBAWohASAEQQFqIgQgAkcNAAsgACAUNgIAQZIBIRAM0gILIABBADYCACAQQQFqIQFBHiEQDLcBCwJAIAEiBCACRw0AQZMBIRAM0QILIAQtAABBzABHDbgBIARBAWohAUEKIRAMtgELAkAgBCACRw0AQZQBIRAM0AILAkACQCAELQAAQb9/ag4PALkBuQG5AbkBuQG5AbkBuQG5AbkBuQG5AbkBAbkBCyAEQQFqIQFB/gAhEAy3AgsgBEEBaiEBQf8AIRAMtgILAkAgBCACRw0AQZUBIRAMzwILAkACQCAELQAAQb9/ag4DALgBAbgBCyAEQQFqIQFB/QAhEAy2AgsgBEEBaiEEQYABIRAMtQILAkAgBCACRw0AQZYBIRAMzgILIAIgBGsgACgCACIBaiEUIAQgAWtBAWohEAJAA0AgBC0AACABQafPgIAAai0AAEcNtgEgAUEBRg0BIAFBAWohASAEQQFqIgQgAkcNAAsgACAUNgIAQZYBIRAMzgILIABBADYCACAQQQFqIQFBCyEQDLMBCwJAIAQgAkcNAEGXASEQDM0CCwJAAkACQAJAIAQtAABBU2oOIwC4AbgBuAG4AbgBuAG4AbgBuAG4AbgBuAG4AbgBuAG4AbgBuAG4AbgBuAG4AbgBAbgBuAG4AbgBuAECuAG4AbgBA7gBCyAEQQFqIQFB+wAhEAy2AgsgBEEBaiEBQfwAIRAMtQILIARBAWohBEGBASEQDLQCCyAEQQFqIQRBggEhEAyzAgsCQCAEIAJHDQBBmAEhEAzMAgsgAiAEayAAKAIAIgFqIRQgBCABa0EEaiEQAkADQCAELQAAIAFBqc+AgABqLQAARw20ASABQQRGDQEgAUEBaiEBIARBAWoiBCACRw0ACyAAIBQ2AgBBmAEhEAzMAgsgAEEANgIAIBBBAWohAUEZIRAMsQELAkAgBCACRw0AQZkBIRAMywILIAIgBGsgACgCACIBaiEUIAQgAWtBBWohEAJAA0AgBC0AACABQa7PgIAAai0AAEcNswEgAUEFRg0BIAFBAWohASAEQQFqIgQgAkcNAAsgACAUNgIAQZkBIRAMywILIABBADYCACAQQQFqIQFBBiEQDLABCwJAIAQgAkcNAEGaASEQDMoCCyACIARrIAAoAgAiAWohFCAEIAFrQQFqIRACQANAIAQtAAAgAUG0z4CAAGotAABHDbIBIAFBAUYNASABQQFqIQEgBEEBaiIEIAJHDQALIAAgFDYCAEGaASEQDMoCCyAAQQA2AgAgEEEBaiEBQRwhEAyvAQsCQCAEIAJHDQBBmwEhEAzJAgsgAiAEayAAKAIAIgFqIRQgBCABa0EBaiEQAkADQCAELQAAIAFBts+AgABqLQAARw2xASABQQFGDQEgAUEBaiEBIARBAWoiBCACRw0ACyAAIBQ2AgBBmwEhEAzJAgsgAEEANgIAIBBBAWohAUEnIRAMrgELAkAgBCACRw0AQZwBIRAMyAILAkACQCAELQAAQax/ag4CAAGxAQsgBEEBaiEEQYYBIRAMrwILIARBAWohBEGHASEQDK4CCwJAIAQgAkcNAEGdASEQDMcCCyACIARrIAAoAgAiAWohFCAEIAFrQQFqIRACQANAIAQtAAAgAUG4z4CAAGotAABHDa8BIAFBAUYNASABQQFqIQEgBEEBaiIEIAJHDQALIAAgFDYCAEGdASEQDMcCCyAAQQA2AgAgEEEBaiEBQSYhEAysAQsCQCAEIAJHDQBBngEhEAzGAgsgAiAEayAAKAIAIgFqIRQgBCABa0EBaiEQAkADQCAELQAAIAFBus+AgABqLQAARw2uASABQQFGDQEgAUEBaiEBIARBAWoiBCACRw0ACyAAIBQ2AgBBngEhEAzGAgsgAEEANgIAIBBBAWohAUEDIRAMqwELAkAgBCACRw0AQZ8BIRAMxQILIAIgBGsgACgCACIBaiEUIAQgAWtBAmohEAJAA0AgBC0AACABQe3PgIAAai0AAEcNrQEgAUECRg0BIAFBAWohASAEQQFqIgQgAkcNAAsgACAUNgIAQZ8BIRAMxQILIABBADYCACAQQQFqIQFBDCEQDKoBCwJAIAQgAkcNAEGgASEQDMQCCyACIARrIAAoAgAiAWohFCAEIAFrQQNqIRACQANAIAQtAAAgAUG8z4CAAGotAABHDawBIAFBA0YNASABQQFqIQEgBEEBaiIEIAJHDQALIAAgFDYCAEGgASEQDMQCCyAAQQA2AgAgEEEBaiEBQQ0hEAypAQsCQCAEIAJHDQBBoQEhEAzDAgsCQAJAIAQtAABBun9qDgsArAGsAawBrAGsAawBrAGsAawBAawBCyAEQQFqIQRBiwEhEAyqAgsgBEEBaiEEQYwBIRAMqQILAkAgBCACRw0AQaIBIRAMwgILIAQtAABB0ABHDakBIARBAWohBAzpAQsCQCAEIAJHDQBBowEhEAzBAgsCQAJAIAQtAABBt39qDgcBqgGqAaoBqgGqAQCqAQsgBEEBaiEEQY4BIRAMqAILIARBAWohAUEiIRAMpgELAkAgBCACRw0AQaQBIRAMwAILIAIgBGsgACgCACIBaiEUIAQgAWtBAWohEAJAA0AgBC0AACABQcDPgIAAai0AAEcNqAEgAUEBRg0BIAFBAWohASAEQQFqIgQgAkcNAAsgACAUNgIAQaQBIRAMwAILIABBADYCACAQQQFqIQFBHSEQDKUBCwJAIAQgAkcNAEGlASEQDL8CCwJAAkAgBC0AAEGuf2oOAwCoAQGoAQsgBEEBaiEEQZABIRAMpgILIARBAWohAUEEIRAMpAELAkAgBCACRw0AQaYBIRAMvgILAkACQAJAAkACQCAELQAAQb9/ag4VAKoBqgGqAaoBqgGqAaoBqgGqAaoBAaoBqgECqgGqAQOqAaoBBKoBCyAEQQFqIQRBiAEhEAyoAgsgBEEBaiEEQYkBIRAMpwILIARBAWohBEGKASEQDKYCCyAEQQFqIQRBjwEhEAylAgsgBEEBaiEEQZEBIRAMpAILAkAgBCACRw0AQacBIRAMvQILIAIgBGsgACgCACIBaiEUIAQgAWtBAmohEAJAA0AgBC0AACABQe3PgIAAai0AAEcNpQEgAUECRg0BIAFBAWohASAEQQFqIgQgAkcNAAsgACAUNgIAQacBIRAMvQILIABBADYCACAQQQFqIQFBESEQDKIBCwJAIAQgAkcNAEGoASEQDLwCCyACIARrIAAoAgAiAWohFCAEIAFrQQJqIRACQANAIAQtAAAgAUHCz4CAAGotAABHDaQBIAFBAkYNASABQQFqIQEgBEEBaiIEIAJHDQALIAAgFDYCAEGoASEQDLwCCyAAQQA2AgAgEEEBaiEBQSwhEAyhAQsCQCAEIAJHDQBBqQEhEAy7AgsgAiAEayAAKAIAIgFqIRQgBCABa0EEaiEQAkADQCAELQAAIAFBxc+AgABqLQAARw2jASABQQRGDQEgAUEBaiEBIARBAWoiBCACRw0ACyAAIBQ2AgBBqQEhEAy7AgsgAEEANgIAIBBBAWohAUErIRAMoAELAkAgBCACRw0AQaoBIRAMugILIAIgBGsgACgCACIBaiEUIAQgAWtBAmohEAJAA0AgBC0AACABQcrPgIAAai0AAEcNogEgAUECRg0BIAFBAWohASAEQQFqIgQgAkcNAAsgACAUNgIAQaoBIRAMugILIABBADYCACAQQQFqIQFBFCEQDJ8BCwJAIAQgAkcNAEGrASEQDLkCCwJAAkACQAJAIAQtAABBvn9qDg8AAQKkAaQBpAGkAaQBpAGkAaQBpAGkAaQBA6QBCyAEQQFqIQRBkwEhEAyiAgsgBEEBaiEEQZQBIRAMoQILIARBAWohBEGVASEQDKACCyAEQQFqIQRBlgEhEAyfAgsCQCAEIAJHDQBBrAEhEAy4AgsgBC0AAEHFAEcNnwEgBEEBaiEEDOABCwJAIAQgAkcNAEGtASEQDLcCCyACIARrIAAoAgAiAWohFCAEIAFrQQJqIRACQANAIAQtAAAgAUHNz4CAAGotAABHDZ8BIAFBAkYNASABQQFqIQEgBEEBaiIEIAJHDQALIAAgFDYCAEGtASEQDLcCCyAAQQA2AgAgEEEBaiEBQQ4hEAycAQsCQCAEIAJHDQBBrgEhEAy2AgsgBC0AAEHQAEcNnQEgBEEBaiEBQSUhEAybAQsCQCAEIAJHDQBBrwEhEAy1AgsgAiAEayAAKAIAIgFqIRQgBCABa0EIaiEQAkADQCAELQAAIAFB0M+AgABqLQAARw2dASABQQhGDQEgAUEBaiEBIARBAWoiBCACRw0ACyAAIBQ2AgBBrwEhEAy1AgsgAEEANgIAIBBBAWohAUEqIRAMmgELAkAgBCACRw0AQbABIRAMtAILAkACQCAELQAAQat/ag4LAJ0BnQGdAZ0BnQGdAZ0BnQGdAQGdAQsgBEEBaiEEQZoBIRAMmwILIARBAWohBEGbASEQDJoCCwJAIAQgAkcNAEGxASEQDLMCCwJAAkAgBC0AAEG/f2oOFACcAZwBnAGcAZwBnAGcAZwBnAGcAZwBnAGcAZwBnAGcAZwBnAEBnAELIARBAWohBEGZASEQDJoCCyAEQQFqIQRBnAEhEAyZAgsCQCAEIAJHDQBBsgEhEAyyAgsgAiAEayAAKAIAIgFqIRQgBCABa0EDaiEQAkADQCAELQAAIAFB2c+AgABqLQAARw2aASABQQNGDQEgAUEBaiEBIARBAWoiBCACRw0ACyAAIBQ2AgBBsgEhEAyyAgsgAEEANgIAIBBBAWohAUEhIRAMlwELAkAgBCACRw0AQbMBIRAMsQILIAIgBGsgACgCACIBaiEUIAQgAWtBBmohEAJAA0AgBC0AACABQd3PgIAAai0AAEcNmQEgAUEGRg0BIAFBAWohASAEQQFqIgQgAkcNAAsgACAUNgIAQbMBIRAMsQILIABBADYCACAQQQFqIQFBGiEQDJYBCwJAIAQgAkcNAEG0ASEQDLACCwJAAkACQCAELQAAQbt/ag4RAJoBmgGaAZoBmgGaAZoBmgGaAQGaAZoBmgGaAZoBApoBCyAEQQFqIQRBnQEhEAyYAgsgBEEBaiEEQZ4BIRAMlwILIARBAWohBEGfASEQDJYCCwJAIAQgAkcNAEG1ASEQDK8CCyACIARrIAAoAgAiAWohFCAEIAFrQQVqIRACQANAIAQtAAAgAUHkz4CAAGotAABHDZcBIAFBBUYNASABQQFqIQEgBEEBaiIEIAJHDQALIAAgFDYCAEG1ASEQDK8CCyAAQQA2AgAgEEEBaiEBQSghEAyUAQsCQCAEIAJHDQBBtgEhEAyuAgsgAiAEayAAKAIAIgFqIRQgBCABa0ECaiEQAkADQCAELQAAIAFB6s+AgABqLQAARw2WASABQQJGDQEgAUEBaiEBIARBAWoiBCACRw0ACyAAIBQ2AgBBtgEhEAyuAgsgAEEANgIAIBBBAWohAUEHIRAMkwELAkAgBCACRw0AQbcBIRAMrQILAkACQCAELQAAQbt/ag4OAJYBlgGWAZYBlgGWAZYBlgGWAZYBlgGWAQGWAQsgBEEBaiEEQaEBIRAMlAILIARBAWohBEGiASEQDJMCCwJAIAQgAkcNAEG4ASEQDKwCCyACIARrIAAoAgAiAWohFCAEIAFrQQJqIRACQANAIAQtAAAgAUHtz4CAAGotAABHDZQBIAFBAkYNASABQQFqIQEgBEEBaiIEIAJHDQALIAAgFDYCAEG4ASEQDKwCCyAAQQA2AgAgEEEBaiEBQRIhEAyRAQsCQCAEIAJHDQBBuQEhEAyrAgsgAiAEayAAKAIAIgFqIRQgBCABa0EBaiEQAkADQCAELQAAIAFB8M+AgABqLQAARw2TASABQQFGDQEgAUEBaiEBIARBAWoiBCACRw0ACyAAIBQ2AgBBuQEhEAyrAgsgAEEANgIAIBBBAWohAUEgIRAMkAELAkAgBCACRw0AQboBIRAMqgILIAIgBGsgACgCACIBaiEUIAQgAWtBAWohEAJAA0AgBC0AACABQfLPgIAAai0AAEcNkgEgAUEBRg0BIAFBAWohASAEQQFqIgQgAkcNAAsgACAUNgIAQboBIRAMqgILIABBADYCACAQQQFqIQFBDyEQDI8BCwJAIAQgAkcNAEG7ASEQDKkCCwJAAkAgBC0AAEG3f2oOBwCSAZIBkgGSAZIBAZIBCyAEQQFqIQRBpQEhEAyQAgsgBEEBaiEEQaYBIRAMjwILAkAgBCACRw0AQbwBIRAMqAILIAIgBGsgACgCACIBaiEUIAQgAWtBB2ohEAJAA0AgBC0AACABQfTPgIAAai0AAEcNkAEgAUEHRg0BIAFBAWohASAEQQFqIgQgAkcNAAsgACAUNgIAQbwBIRAMqAILIABBADYCACAQQQFqIQFBGyEQDI0BCwJAIAQgAkcNAEG9ASEQDKcCCwJAAkACQCAELQAAQb5/ag4SAJEBkQGRAZEBkQGRAZEBkQGRAQGRAZEBkQGRAZEBkQECkQELIARBAWohBEGkASEQDI8CCyAEQQFqIQRBpwEhEAyOAgsgBEEBaiEEQagBIRAMjQILAkAgBCACRw0AQb4BIRAMpgILIAQtAABBzgBHDY0BIARBAWohBAzPAQsCQCAEIAJHDQBBvwEhEAylAgsCQAJAAkACQAJAAkACQAJAAkACQAJAAkACQAJAAkACQCAELQAAQb9/ag4VAAECA5wBBAUGnAGcAZwBBwgJCgucAQwNDg+cAQsgBEEBaiEBQegAIRAMmgILIARBAWohAUHpACEQDJkCCyAEQQFqIQFB7gAhEAyYAgsgBEEBaiEBQfIAIRAMlwILIARBAWohAUHzACEQDJYCCyAEQQFqIQFB9gAhEAyVAgsgBEEBaiEBQfcAIRAMlAILIARBAWohAUH6ACEQDJMCCyAEQQFqIQRBgwEhEAySAgsgBEEBaiEEQYQBIRAMkQILIARBAWohBEGFASEQDJACCyAEQQFqIQRBkgEhEAyPAgsgBEEBaiEEQZgBIRAMjgILIARBAWohBEGgASEQDI0CCyAEQQFqIQRBowEhEAyMAgsgBEEBaiEEQaoBIRAMiwILAkAgBCACRg0AIABBkICAgAA2AgggACAENgIEQasBIRAMiwILQcABIRAMowILIAAgBSACEKqAgIAAIgENiwEgBSEBDFwLAkAgBiACRg0AIAZBAWohBQyNAQtBwgEhEAyhAgsDQAJAIBAtAABBdmoOBIwBAACPAQALIBBBAWoiECACRw0AC0HDASEQDKACCwJAIAcgAkYNACAAQZGAgIAANgIIIAAgBzYCBCAHIQFBASEQDIcCC0HEASEQDJ8CCwJAIAcgAkcNAEHFASEQDJ8CCwJAAkAgBy0AAEF2ag4EAc4BzgEAzgELIAdBAWohBgyNAQsgB0EBaiEFDIkBCwJAIAcgAkcNAEHGASEQDJ4CCwJAAkAgBy0AAEF2ag4XAY8BjwEBjwGPAY8BjwGPAY8BjwGPAY8BjwGPAY8BjwGPAY8BjwGPAY8BAI8BCyAHQQFqIQcLQbABIRAMhAILAkAgCCACRw0AQcgBIRAMnQILIAgtAABBIEcNjQEgAEEAOwEyIAhBAWohAUGzASEQDIMCCyABIRcCQANAIBciByACRg0BIActAABBUGpB/wFxIhBBCk8NzAECQCAALwEyIhRBmTNLDQAgACAUQQpsIhQ7ATIgEEH//wNzIBRB/v8DcUkNACAHQQFqIRcgACAUIBBqIhA7ATIgEEH//wNxQegHSQ0BCwtBACEQIABBADYCHCAAQcGJgIAANgIQIABBDTYCDCAAIAdBAWo2AhQMnAILQccBIRAMmwILIAAgCCACEK6AgIAAIhBFDcoBIBBBFUcNjAEgAEHIATYCHCAAIAg2AhQgAEHJl4CAADYCECAAQRU2AgxBACEQDJoCCwJAIAkgAkcNAEHMASEQDJoCC0EAIRRBASEXQQEhFkEAIRACQAJAAkACQAJAAkACQAJAAkAgCS0AAEFQag4KlgGVAQABAgMEBQYIlwELQQIhEAwGC0EDIRAMBQtBBCEQDAQLQQUhEAwDC0EGIRAMAgtBByEQDAELQQghEAtBACEXQQAhFkEAIRQMjgELQQkhEEEBIRRBACEXQQAhFgyNAQsCQCAKIAJHDQBBzgEhEAyZAgsgCi0AAEEuRw2OASAKQQFqIQkMygELIAsgAkcNjgFB0AEhEAyXAgsCQCALIAJGDQAgAEGOgICAADYCCCAAIAs2AgRBtwEhEAz+AQtB0QEhEAyWAgsCQCAEIAJHDQBB0gEhEAyWAgsgAiAEayAAKAIAIhBqIRQgBCAQa0EEaiELA0AgBC0AACAQQfzPgIAAai0AAEcNjgEgEEEERg3pASAQQQFqIRAgBEEBaiIEIAJHDQALIAAgFDYCAEHSASEQDJUCCyAAIAwgAhCsgICAACIBDY0BIAwhAQy4AQsCQCAEIAJHDQBB1AEhEAyUAgsgAiAEayAAKAIAIhBqIRQgBCAQa0EBaiEMA0AgBC0AACAQQYHQgIAAai0AAEcNjwEgEEEBRg2OASAQQQFqIRAgBEEBaiIEIAJHDQALIAAgFDYCAEHUASEQDJMCCwJAIAQgAkcNAEHWASEQDJMCCyACIARrIAAoAgAiEGohFCAEIBBrQQJqIQsDQCAELQAAIBBBg9CAgABqLQAARw2OASAQQQJGDZABIBBBAWohECAEQQFqIgQgAkcNAAsgACAUNgIAQdYBIRAMkgILAkAgBCACRw0AQdcBIRAMkgILAkACQCAELQAAQbt/ag4QAI8BjwGPAY8BjwGPAY8BjwGPAY8BjwGPAY8BjwEBjwELIARBAWohBEG7ASEQDPkBCyAEQQFqIQRBvAEhEAz4AQsCQCAEIAJHDQBB2AEhEAyRAgsgBC0AAEHIAEcNjAEgBEEBaiEEDMQBCwJAIAQgAkYNACAAQZCAgIAANgIIIAAgBDYCBEG+ASEQDPcBC0HZASEQDI8CCwJAIAQgAkcNAEHaASEQDI8CCyAELQAAQcgARg3DASAAQQE6ACgMuQELIABBAjoALyAAIAQgAhCmgICAACIQDY0BQcIBIRAM9AELIAAtAChBf2oOArcBuQG4AQsDQAJAIAQtAABBdmoOBACOAY4BAI4BCyAEQQFqIgQgAkcNAAtB3QEhEAyLAgsgAEEAOgAvIAAtAC1BBHFFDYQCCyAAQQA6AC8gAEEBOgA0IAEhAQyMAQsgEEEVRg3aASAAQQA2AhwgACABNgIUIABBp46AgAA2AhAgAEESNgIMQQAhEAyIAgsCQCAAIBAgAhC0gICAACIEDQAgECEBDIECCwJAIARBFUcNACAAQQM2AhwgACAQNgIUIABBsJiAgAA2AhAgAEEVNgIMQQAhEAyIAgsgAEEANgIcIAAgEDYCFCAAQaeOgIAANgIQIABBEjYCDEEAIRAMhwILIBBBFUYN1gEgAEEANgIcIAAgATYCFCAAQdqNgIAANgIQIABBFDYCDEEAIRAMhgILIAAoAgQhFyAAQQA2AgQgECARp2oiFiEBIAAgFyAQIBYgFBsiEBC1gICAACIURQ2NASAAQQc2AhwgACAQNgIUIAAgFDYCDEEAIRAMhQILIAAgAC8BMEGAAXI7ATAgASEBC0EqIRAM6gELIBBBFUYN0QEgAEEANgIcIAAgATYCFCAAQYOMgIAANgIQIABBEzYCDEEAIRAMggILIBBBFUYNzwEgAEEANgIcIAAgATYCFCAAQZqPgIAANgIQIABBIjYCDEEAIRAMgQILIAAoAgQhECAAQQA2AgQCQCAAIBAgARC3gICAACIQDQAgAUEBaiEBDI0BCyAAQQw2AhwgACAQNgIMIAAgAUEBajYCFEEAIRAMgAILIBBBFUYNzAEgAEEANgIcIAAgATYCFCAAQZqPgIAANgIQIABBIjYCDEEAIRAM/wELIAAoAgQhECAAQQA2AgQCQCAAIBAgARC3gICAACIQDQAgAUEBaiEBDIwBCyAAQQ02AhwgACAQNgIMIAAgAUEBajYCFEEAIRAM/gELIBBBFUYNyQEgAEEANgIcIAAgATYCFCAAQcaMgIAANgIQIABBIzYCDEEAIRAM/QELIAAoAgQhECAAQQA2AgQCQCAAIBAgARC5gICAACIQDQAgAUEBaiEBDIsBCyAAQQ42AhwgACAQNgIMIAAgAUEBajYCFEEAIRAM/AELIABBADYCHCAAIAE2AhQgAEHAlYCAADYCECAAQQI2AgxBACEQDPsBCyAQQRVGDcUBIABBADYCHCAAIAE2AhQgAEHGjICAADYCECAAQSM2AgxBACEQDPoBCyAAQRA2AhwgACABNgIUIAAgEDYCDEEAIRAM+QELIAAoAgQhBCAAQQA2AgQCQCAAIAQgARC5gICAACIEDQAgAUEBaiEBDPEBCyAAQRE2AhwgACAENgIMIAAgAUEBajYCFEEAIRAM+AELIBBBFUYNwQEgAEEANgIcIAAgATYCFCAAQcaMgIAANgIQIABBIzYCDEEAIRAM9wELIAAoAgQhECAAQQA2AgQCQCAAIBAgARC5gICAACIQDQAgAUEBaiEBDIgBCyAAQRM2AhwgACAQNgIMIAAgAUEBajYCFEEAIRAM9gELIAAoAgQhBCAAQQA2AgQCQCAAIAQgARC5gICAACIEDQAgAUEBaiEBDO0BCyAAQRQ2AhwgACAENgIMIAAgAUEBajYCFEEAIRAM9QELIBBBFUYNvQEgAEEANgIcIAAgATYCFCAAQZqPgIAANgIQIABBIjYCDEEAIRAM9AELIAAoAgQhECAAQQA2AgQCQCAAIBAgARC3gICAACIQDQAgAUEBaiEBDIYBCyAAQRY2AhwgACAQNgIMIAAgAUEBajYCFEEAIRAM8wELIAAoAgQhBCAAQQA2AgQCQCAAIAQgARC3gICAACIEDQAgAUEBaiEBDOkBCyAAQRc2AhwgACAENgIMIAAgAUEBajYCFEEAIRAM8gELIABBADYCHCAAIAE2AhQgAEHNk4CAADYCECAAQQw2AgxBACEQDPEBC0IBIRELIBBBAWohAQJAIAApAyAiEkL//////////w9WDQAgACASQgSGIBGENwMgIAEhAQyEAQsgAEEANgIcIAAgATYCFCAAQa2JgIAANgIQIABBDDYCDEEAIRAM7wELIABBADYCHCAAIBA2AhQgAEHNk4CAADYCECAAQQw2AgxBACEQDO4BCyAAKAIEIRcgAEEANgIEIBAgEadqIhYhASAAIBcgECAWIBQbIhAQtYCAgAAiFEUNcyAAQQU2AhwgACAQNgIUIAAgFDYCDEEAIRAM7QELIABBADYCHCAAIBA2AhQgAEGqnICAADYCECAAQQ82AgxBACEQDOwBCyAAIBAgAhC0gICAACIBDQEgECEBC0EOIRAM0QELAkAgAUEVRw0AIABBAjYCHCAAIBA2AhQgAEGwmICAADYCECAAQRU2AgxBACEQDOoBCyAAQQA2AhwgACAQNgIUIABBp46AgAA2AhAgAEESNgIMQQAhEAzpAQsgAUEBaiEQAkAgAC8BMCIBQYABcUUNAAJAIAAgECACELuAgIAAIgENACAQIQEMcAsgAUEVRw26ASAAQQU2AhwgACAQNgIUIABB+ZeAgAA2AhAgAEEVNgIMQQAhEAzpAQsCQCABQaAEcUGgBEcNACAALQAtQQJxDQAgAEEANgIcIAAgEDYCFCAAQZaTgIAANgIQIABBBDYCDEEAIRAM6QELIAAgECACEL2AgIAAGiAQIQECQAJAAkACQAJAIAAgECACELOAgIAADhYCAQAEBAQEBAQEBAQEBAQEBAQEBAQDBAsgAEEBOgAuCyAAIAAvATBBwAByOwEwIBAhAQtBJiEQDNEBCyAAQSM2AhwgACAQNgIUIABBpZaAgAA2AhAgAEEVNgIMQQAhEAzpAQsgAEEANgIcIAAgEDYCFCAAQdWLgIAANgIQIABBETYCDEEAIRAM6AELIAAtAC1BAXFFDQFBwwEhEAzOAQsCQCANIAJGDQADQAJAIA0tAABBIEYNACANIQEMxAELIA1BAWoiDSACRw0AC0ElIRAM5wELQSUhEAzmAQsgACgCBCEEIABBADYCBCAAIAQgDRCvgICAACIERQ2tASAAQSY2AhwgACAENgIMIAAgDUEBajYCFEEAIRAM5QELIBBBFUYNqwEgAEEANgIcIAAgATYCFCAAQf2NgIAANgIQIABBHTYCDEEAIRAM5AELIABBJzYCHCAAIAE2AhQgACAQNgIMQQAhEAzjAQsgECEBQQEhFAJAAkACQAJAAkACQAJAIAAtACxBfmoOBwYFBQMBAgAFCyAAIAAvATBBCHI7ATAMAwtBAiEUDAELQQQhFAsgAEEBOgAsIAAgAC8BMCAUcjsBMAsgECEBC0ErIRAMygELIABBADYCHCAAIBA2AhQgAEGrkoCAADYCECAAQQs2AgxBACEQDOIBCyAAQQA2AhwgACABNgIUIABB4Y+AgAA2AhAgAEEKNgIMQQAhEAzhAQsgAEEAOgAsIBAhAQy9AQsgECEBQQEhFAJAAkACQAJAAkAgAC0ALEF7ag4EAwECAAULIAAgAC8BMEEIcjsBMAwDC0ECIRQMAQtBBCEUCyAAQQE6ACwgACAALwEwIBRyOwEwCyAQIQELQSkhEAzFAQsgAEEANgIcIAAgATYCFCAAQfCUgIAANgIQIABBAzYCDEEAIRAM3QELAkAgDi0AAEENRw0AIAAoAgQhASAAQQA2AgQCQCAAIAEgDhCxgICAACIBDQAgDkEBaiEBDHULIABBLDYCHCAAIAE2AgwgACAOQQFqNgIUQQAhEAzdAQsgAC0ALUEBcUUNAUHEASEQDMMBCwJAIA4gAkcNAEEtIRAM3AELAkACQANAAkAgDi0AAEF2ag4EAgAAAwALIA5BAWoiDiACRw0AC0EtIRAM3QELIAAoAgQhASAAQQA2AgQCQCAAIAEgDhCxgICAACIBDQAgDiEBDHQLIABBLDYCHCAAIA42AhQgACABNgIMQQAhEAzcAQsgACgCBCEBIABBADYCBAJAIAAgASAOELGAgIAAIgENACAOQQFqIQEMcwsgAEEsNgIcIAAgATYCDCAAIA5BAWo2AhRBACEQDNsBCyAAKAIEIQQgAEEANgIEIAAgBCAOELGAgIAAIgQNoAEgDiEBDM4BCyAQQSxHDQEgAUEBaiEQQQEhAQJAAkACQAJAAkAgAC0ALEF7ag4EAwECBAALIBAhAQwEC0ECIQEMAQtBBCEBCyAAQQE6ACwgACAALwEwIAFyOwEwIBAhAQwBCyAAIAAvATBBCHI7ATAgECEBC0E5IRAMvwELIABBADoALCABIQELQTQhEAy9AQsgACAALwEwQSByOwEwIAEhAQwCCyAAKAIEIQQgAEEANgIEAkAgACAEIAEQsYCAgAAiBA0AIAEhAQzHAQsgAEE3NgIcIAAgATYCFCAAIAQ2AgxBACEQDNQBCyAAQQg6ACwgASEBC0EwIRAMuQELAkAgAC0AKEEBRg0AIAEhAQwECyAALQAtQQhxRQ2TASABIQEMAwsgAC0AMEEgcQ2UAUHFASEQDLcBCwJAIA8gAkYNAAJAA0ACQCAPLQAAQVBqIgFB/wFxQQpJDQAgDyEBQTUhEAy6AQsgACkDICIRQpmz5syZs+bMGVYNASAAIBFCCn4iETcDICARIAGtQv8BgyISQn+FVg0BIAAgESASfDcDICAPQQFqIg8gAkcNAAtBOSEQDNEBCyAAKAIEIQIgAEEANgIEIAAgAiAPQQFqIgQQsYCAgAAiAg2VASAEIQEMwwELQTkhEAzPAQsCQCAALwEwIgFBCHFFDQAgAC0AKEEBRw0AIAAtAC1BCHFFDZABCyAAIAFB9/sDcUGABHI7ATAgDyEBC0E3IRAMtAELIAAgAC8BMEEQcjsBMAyrAQsgEEEVRg2LASAAQQA2AhwgACABNgIUIABB8I6AgAA2AhAgAEEcNgIMQQAhEAzLAQsgAEHDADYCHCAAIAE2AgwgACANQQFqNgIUQQAhEAzKAQsCQCABLQAAQTpHDQAgACgCBCEQIABBADYCBAJAIAAgECABEK+AgIAAIhANACABQQFqIQEMYwsgAEHDADYCHCAAIBA2AgwgACABQQFqNgIUQQAhEAzKAQsgAEEANgIcIAAgATYCFCAAQbGRgIAANgIQIABBCjYCDEEAIRAMyQELIABBADYCHCAAIAE2AhQgAEGgmYCAADYCECAAQR42AgxBACEQDMgBCyAAQQA2AgALIABBgBI7ASogACAXQQFqIgEgAhCogICAACIQDQEgASEBC0HHACEQDKwBCyAQQRVHDYMBIABB0QA2AhwgACABNgIUIABB45eAgAA2AhAgAEEVNgIMQQAhEAzEAQsgACgCBCEQIABBADYCBAJAIAAgECABEKeAgIAAIhANACABIQEMXgsgAEHSADYCHCAAIAE2AhQgACAQNgIMQQAhEAzDAQsgAEEANgIcIAAgFDYCFCAAQcGogIAANgIQIABBBzYCDCAAQQA2AgBBACEQDMIBCyAAKAIEIRAgAEEANgIEAkAgACAQIAEQp4CAgAAiEA0AIAEhAQxdCyAAQdMANgIcIAAgATYCFCAAIBA2AgxBACEQDMEBC0EAIRAgAEEANgIcIAAgATYCFCAAQYCRgIAANgIQIABBCTYCDAzAAQsgEEEVRg19IABBADYCHCAAIAE2AhQgAEGUjYCAADYCECAAQSE2AgxBACEQDL8BC0EBIRZBACEXQQAhFEEBIRALIAAgEDoAKyABQQFqIQECQAJAIAAtAC1BEHENAAJAAkACQCAALQAqDgMBAAIECyAWRQ0DDAILIBQNAQwCCyAXRQ0BCyAAKAIEIRAgAEEANgIEAkAgACAQIAEQrYCAgAAiEA0AIAEhAQxcCyAAQdgANgIcIAAgATYCFCAAIBA2AgxBACEQDL4BCyAAKAIEIQQgAEEANgIEAkAgACAEIAEQrYCAgAAiBA0AIAEhAQytAQsgAEHZADYCHCAAIAE2AhQgACAENgIMQQAhEAy9AQsgACgCBCEEIABBADYCBAJAIAAgBCABEK2AgIAAIgQNACABIQEMqwELIABB2gA2AhwgACABNgIUIAAgBDYCDEEAIRAMvAELIAAoAgQhBCAAQQA2AgQCQCAAIAQgARCtgICAACIEDQAgASEBDKkBCyAAQdwANgIcIAAgATYCFCAAIAQ2AgxBACEQDLsBCwJAIAEtAABBUGoiEEH/AXFBCk8NACAAIBA6ACogAUEBaiEBQc8AIRAMogELIAAoAgQhBCAAQQA2AgQCQCAAIAQgARCtgICAACIEDQAgASEBDKcBCyAAQd4ANgIcIAAgATYCFCAAIAQ2AgxBACEQDLoBCyAAQQA2AgAgF0EBaiEBAkAgAC0AKUEjTw0AIAEhAQxZCyAAQQA2AhwgACABNgIUIABB04mAgAA2AhAgAEEINgIMQQAhEAy5AQsgAEEANgIAC0EAIRAgAEEANgIcIAAgATYCFCAAQZCzgIAANgIQIABBCDYCDAy3AQsgAEEANgIAIBdBAWohAQJAIAAtAClBIUcNACABIQEMVgsgAEEANgIcIAAgATYCFCAAQZuKgIAANgIQIABBCDYCDEEAIRAMtgELIABBADYCACAXQQFqIQECQCAALQApIhBBXWpBC08NACABIQEMVQsCQCAQQQZLDQBBASAQdEHKAHFFDQAgASEBDFULQQAhECAAQQA2AhwgACABNgIUIABB94mAgAA2AhAgAEEINgIMDLUBCyAQQRVGDXEgAEEANgIcIAAgATYCFCAAQbmNgIAANgIQIABBGjYCDEEAIRAMtAELIAAoAgQhECAAQQA2AgQCQCAAIBAgARCngICAACIQDQAgASEBDFQLIABB5QA2AhwgACABNgIUIAAgEDYCDEEAIRAMswELIAAoAgQhECAAQQA2AgQCQCAAIBAgARCngICAACIQDQAgASEBDE0LIABB0gA2AhwgACABNgIUIAAgEDYCDEEAIRAMsgELIAAoAgQhECAAQQA2AgQCQCAAIBAgARCngICAACIQDQAgASEBDE0LIABB0wA2AhwgACABNgIUIAAgEDYCDEEAIRAMsQELIAAoAgQhECAAQQA2AgQCQCAAIBAgARCngICAACIQDQAgASEBDFELIABB5QA2AhwgACABNgIUIAAgEDYCDEEAIRAMsAELIABBADYCHCAAIAE2AhQgAEHGioCAADYCECAAQQc2AgxBACEQDK8BCyAAKAIEIRAgAEEANgIEAkAgACAQIAEQp4CAgAAiEA0AIAEhAQxJCyAAQdIANgIcIAAgATYCFCAAIBA2AgxBACEQDK4BCyAAKAIEIRAgAEEANgIEAkAgACAQIAEQp4CAgAAiEA0AIAEhAQxJCyAAQdMANgIcIAAgATYCFCAAIBA2AgxBACEQDK0BCyAAKAIEIRAgAEEANgIEAkAgACAQIAEQp4CAgAAiEA0AIAEhAQxNCyAAQeUANgIcIAAgATYCFCAAIBA2AgxBACEQDKwBCyAAQQA2AhwgACABNgIUIABB3IiAgAA2AhAgAEEHNgIMQQAhEAyrAQsgEEE/Rw0BIAFBAWohAQtBBSEQDJABC0EAIRAgAEEANgIcIAAgATYCFCAAQf2SgIAANgIQIABBBzYCDAyoAQsgACgCBCEQIABBADYCBAJAIAAgECABEKeAgIAAIhANACABIQEMQgsgAEHSADYCHCAAIAE2AhQgACAQNgIMQQAhEAynAQsgACgCBCEQIABBADYCBAJAIAAgECABEKeAgIAAIhANACABIQEMQgsgAEHTADYCHCAAIAE2AhQgACAQNgIMQQAhEAymAQsgACgCBCEQIABBADYCBAJAIAAgECABEKeAgIAAIhANACABIQEMRgsgAEHlADYCHCAAIAE2AhQgACAQNgIMQQAhEAylAQsgACgCBCEBIABBADYCBAJAIAAgASAUEKeAgIAAIgENACAUIQEMPwsgAEHSADYCHCAAIBQ2AhQgACABNgIMQQAhEAykAQsgACgCBCEBIABBADYCBAJAIAAgASAUEKeAgIAAIgENACAUIQEMPwsgAEHTADYCHCAAIBQ2AhQgACABNgIMQQAhEAyjAQsgACgCBCEBIABBADYCBAJAIAAgASAUEKeAgIAAIgENACAUIQEMQwsgAEHlADYCHCAAIBQ2AhQgACABNgIMQQAhEAyiAQsgAEEANgIcIAAgFDYCFCAAQcOPgIAANgIQIABBBzYCDEEAIRAMoQELIABBADYCHCAAIAE2AhQgAEHDj4CAADYCECAAQQc2AgxBACEQDKABC0EAIRAgAEEANgIcIAAgFDYCFCAAQYycgIAANgIQIABBBzYCDAyfAQsgAEEANgIcIAAgFDYCFCAAQYycgIAANgIQIABBBzYCDEEAIRAMngELIABBADYCHCAAIBQ2AhQgAEH+kYCAADYCECAAQQc2AgxBACEQDJ0BCyAAQQA2AhwgACABNgIUIABBjpuAgAA2AhAgAEEGNgIMQQAhEAycAQsgEEEVRg1XIABBADYCHCAAIAE2AhQgAEHMjoCAADYCECAAQSA2AgxBACEQDJsBCyAAQQA2AgAgEEEBaiEBQSQhEAsgACAQOgApIAAoAgQhECAAQQA2AgQgACAQIAEQq4CAgAAiEA1UIAEhAQw+CyAAQQA2AgALQQAhECAAQQA2AhwgACAENgIUIABB8ZuAgAA2AhAgAEEGNgIMDJcBCyABQRVGDVAgAEEANgIcIAAgBTYCFCAAQfCMgIAANgIQIABBGzYCDEEAIRAMlgELIAAoAgQhBSAAQQA2AgQgACAFIBAQqYCAgAAiBQ0BIBBBAWohBQtBrQEhEAx7CyAAQcEBNgIcIAAgBTYCDCAAIBBBAWo2AhRBACEQDJMBCyAAKAIEIQYgAEEANgIEIAAgBiAQEKmAgIAAIgYNASAQQQFqIQYLQa4BIRAMeAsgAEHCATYCHCAAIAY2AgwgACAQQQFqNgIUQQAhEAyQAQsgAEEANgIcIAAgBzYCFCAAQZeLgIAANgIQIABBDTYCDEEAIRAMjwELIABBADYCHCAAIAg2AhQgAEHjkICAADYCECAAQQk2AgxBACEQDI4BCyAAQQA2AhwgACAINgIUIABBlI2AgAA2AhAgAEEhNgIMQQAhEAyNAQtBASEWQQAhF0EAIRRBASEQCyAAIBA6ACsgCUEBaiEIAkACQCAALQAtQRBxDQACQAJAAkAgAC0AKg4DAQACBAsgFkUNAwwCCyAUDQEMAgsgF0UNAQsgACgCBCEQIABBADYCBCAAIBAgCBCtgICAACIQRQ09IABByQE2AhwgACAINgIUIAAgEDYCDEEAIRAMjAELIAAoAgQhBCAAQQA2AgQgACAEIAgQrYCAgAAiBEUNdiAAQcoBNgIcIAAgCDYCFCAAIAQ2AgxBACEQDIsBCyAAKAIEIQQgAEEANgIEIAAgBCAJEK2AgIAAIgRFDXQgAEHLATYCHCAAIAk2AhQgACAENgIMQQAhEAyKAQsgACgCBCEEIABBADYCBCAAIAQgChCtgICAACIERQ1yIABBzQE2AhwgACAKNgIUIAAgBDYCDEEAIRAMiQELAkAgCy0AAEFQaiIQQf8BcUEKTw0AIAAgEDoAKiALQQFqIQpBtgEhEAxwCyAAKAIEIQQgAEEANgIEIAAgBCALEK2AgIAAIgRFDXAgAEHPATYCHCAAIAs2AhQgACAENgIMQQAhEAyIAQsgAEEANgIcIAAgBDYCFCAAQZCzgIAANgIQIABBCDYCDCAAQQA2AgBBACEQDIcBCyABQRVGDT8gAEEANgIcIAAgDDYCFCAAQcyOgIAANgIQIABBIDYCDEEAIRAMhgELIABBgQQ7ASggACgCBCEQIABCADcDACAAIBAgDEEBaiIMEKuAgIAAIhBFDTggAEHTATYCHCAAIAw2AhQgACAQNgIMQQAhEAyFAQsgAEEANgIAC0EAIRAgAEEANgIcIAAgBDYCFCAAQdibgIAANgIQIABBCDYCDAyDAQsgACgCBCEQIABCADcDACAAIBAgC0EBaiILEKuAgIAAIhANAUHGASEQDGkLIABBAjoAKAxVCyAAQdUBNgIcIAAgCzYCFCAAIBA2AgxBACEQDIABCyAQQRVGDTcgAEEANgIcIAAgBDYCFCAAQaSMgIAANgIQIABBEDYCDEEAIRAMfwsgAC0ANEEBRw00IAAgBCACELyAgIAAIhBFDTQgEEEVRw01IABB3AE2AhwgACAENgIUIABB1ZaAgAA2AhAgAEEVNgIMQQAhEAx+C0EAIRAgAEEANgIcIABBr4uAgAA2AhAgAEECNgIMIAAgFEEBajYCFAx9C0EAIRAMYwtBAiEQDGILQQ0hEAxhC0EPIRAMYAtBJSEQDF8LQRMhEAxeC0EVIRAMXQtBFiEQDFwLQRchEAxbC0EYIRAMWgtBGSEQDFkLQRohEAxYC0EbIRAMVwtBHCEQDFYLQR0hEAxVC0EfIRAMVAtBISEQDFMLQSMhEAxSC0HGACEQDFELQS4hEAxQC0EvIRAMTwtBOyEQDE4LQT0hEAxNC0HIACEQDEwLQckAIRAMSwtBywAhEAxKC0HMACEQDEkLQc4AIRAMSAtB0QAhEAxHC0HVACEQDEYLQdgAIRAMRQtB2QAhEAxEC0HbACEQDEMLQeQAIRAMQgtB5QAhEAxBC0HxACEQDEALQfQAIRAMPwtBjQEhEAw+C0GXASEQDD0LQakBIRAMPAtBrAEhEAw7C0HAASEQDDoLQbkBIRAMOQtBrwEhEAw4C0GxASEQDDcLQbIBIRAMNgtBtAEhEAw1C0G1ASEQDDQLQboBIRAMMwtBvQEhEAwyC0G/ASEQDDELQcEBIRAMMAsgAEEANgIcIAAgBDYCFCAAQemLgIAANgIQIABBHzYCDEEAIRAMSAsgAEHbATYCHCAAIAQ2AhQgAEH6loCAADYCECAAQRU2AgxBACEQDEcLIABB+AA2AhwgACAMNgIUIABBypiAgAA2AhAgAEEVNgIMQQAhEAxGCyAAQdEANgIcIAAgBTYCFCAAQbCXgIAANgIQIABBFTYCDEEAIRAMRQsgAEH5ADYCHCAAIAE2AhQgACAQNgIMQQAhEAxECyAAQfgANgIcIAAgATYCFCAAQcqYgIAANgIQIABBFTYCDEEAIRAMQwsgAEHkADYCHCAAIAE2AhQgAEHjl4CAADYCECAAQRU2AgxBACEQDEILIABB1wA2AhwgACABNgIUIABByZeAgAA2AhAgAEEVNgIMQQAhEAxBCyAAQQA2AhwgACABNgIUIABBuY2AgAA2AhAgAEEaNgIMQQAhEAxACyAAQcIANgIcIAAgATYCFCAAQeOYgIAANgIQIABBFTYCDEEAIRAMPwsgAEEANgIEIAAgDyAPELGAgIAAIgRFDQEgAEE6NgIcIAAgBDYCDCAAIA9BAWo2AhRBACEQDD4LIAAoAgQhBCAAQQA2AgQCQCAAIAQgARCxgICAACIERQ0AIABBOzYCHCAAIAQ2AgwgACABQQFqNgIUQQAhEAw+CyABQQFqIQEMLQsgD0EBaiEBDC0LIABBADYCHCAAIA82AhQgAEHkkoCAADYCECAAQQQ2AgxBACEQDDsLIABBNjYCHCAAIAQ2AhQgACACNgIMQQAhEAw6CyAAQS42AhwgACAONgIUIAAgBDYCDEEAIRAMOQsgAEHQADYCHCAAIAE2AhQgAEGRmICAADYCECAAQRU2AgxBACEQDDgLIA1BAWohAQwsCyAAQRU2AhwgACABNgIUIABBgpmAgAA2AhAgAEEVNgIMQQAhEAw2CyAAQRs2AhwgACABNgIUIABBkZeAgAA2AhAgAEEVNgIMQQAhEAw1CyAAQQ82AhwgACABNgIUIABBkZeAgAA2AhAgAEEVNgIMQQAhEAw0CyAAQQs2AhwgACABNgIUIABBkZeAgAA2AhAgAEEVNgIMQQAhEAwzCyAAQRo2AhwgACABNgIUIABBgpmAgAA2AhAgAEEVNgIMQQAhEAwyCyAAQQs2AhwgACABNgIUIABBgpmAgAA2AhAgAEEVNgIMQQAhEAwxCyAAQQo2AhwgACABNgIUIABB5JaAgAA2AhAgAEEVNgIMQQAhEAwwCyAAQR42AhwgACABNgIUIABB+ZeAgAA2AhAgAEEVNgIMQQAhEAwvCyAAQQA2AhwgACAQNgIUIABB2o2AgAA2AhAgAEEUNgIMQQAhEAwuCyAAQQQ2AhwgACABNgIUIABBsJiAgAA2AhAgAEEVNgIMQQAhEAwtCyAAQQA2AgAgC0EBaiELC0G4ASEQDBILIABBADYCACAQQQFqIQFB9QAhEAwRCyABIQECQCAALQApQQVHDQBB4wAhEAwRC0HiACEQDBALQQAhECAAQQA2AhwgAEHkkYCAADYCECAAQQc2AgwgACAUQQFqNgIUDCgLIABBADYCACAXQQFqIQFBwAAhEAwOC0EBIQELIAAgAToALCAAQQA2AgAgF0EBaiEBC0EoIRAMCwsgASEBC0E4IRAMCQsCQCABIg8gAkYNAANAAkAgDy0AAEGAvoCAAGotAAAiAUEBRg0AIAFBAkcNAyAPQQFqIQEMBAsgD0EBaiIPIAJHDQALQT4hEAwiC0E+IRAMIQsgAEEAOgAsIA8hAQwBC0ELIRAMBgtBOiEQDAULIAFBAWohAUEtIRAMBAsgACABOgAsIABBADYCACAWQQFqIQFBDCEQDAMLIABBADYCACAXQQFqIQFBCiEQDAILIABBADYCAAsgAEEAOgAsIA0hAUEJIRAMAAsLQQAhECAAQQA2AhwgACALNgIUIABBzZCAgAA2AhAgAEEJNgIMDBcLQQAhECAAQQA2AhwgACAKNgIUIABB6YqAgAA2AhAgAEEJNgIMDBYLQQAhECAAQQA2AhwgACAJNgIUIABBt5CAgAA2AhAgAEEJNgIMDBULQQAhECAAQQA2AhwgACAINgIUIABBnJGAgAA2AhAgAEEJNgIMDBQLQQAhECAAQQA2AhwgACABNgIUIABBzZCAgAA2AhAgAEEJNgIMDBMLQQAhECAAQQA2AhwgACABNgIUIABB6YqAgAA2AhAgAEEJNgIMDBILQQAhECAAQQA2AhwgACABNgIUIABBt5CAgAA2AhAgAEEJNgIMDBELQQAhECAAQQA2AhwgACABNgIUIABBnJGAgAA2AhAgAEEJNgIMDBALQQAhECAAQQA2AhwgACABNgIUIABBl5WAgAA2AhAgAEEPNgIMDA8LQQAhECAAQQA2AhwgACABNgIUIABBl5WAgAA2AhAgAEEPNgIMDA4LQQAhECAAQQA2AhwgACABNgIUIABBwJKAgAA2AhAgAEELNgIMDA0LQQAhECAAQQA2AhwgACABNgIUIABBlYmAgAA2AhAgAEELNgIMDAwLQQAhECAAQQA2AhwgACABNgIUIABB4Y+AgAA2AhAgAEEKNgIMDAsLQQAhECAAQQA2AhwgACABNgIUIABB+4+AgAA2AhAgAEEKNgIMDAoLQQAhECAAQQA2AhwgACABNgIUIABB8ZmAgAA2AhAgAEECNgIMDAkLQQAhECAAQQA2AhwgACABNgIUIABBxJSAgAA2AhAgAEECNgIMDAgLQQAhECAAQQA2AhwgACABNgIUIABB8pWAgAA2AhAgAEECNgIMDAcLIABBAjYCHCAAIAE2AhQgAEGcmoCAADYCECAAQRY2AgxBACEQDAYLQQEhEAwFC0HUACEQIAEiBCACRg0EIANBCGogACAEIAJB2MKAgABBChDFgICAACADKAIMIQQgAygCCA4DAQQCAAsQyoCAgAAACyAAQQA2AhwgAEG1moCAADYCECAAQRc2AgwgACAEQQFqNgIUQQAhEAwCCyAAQQA2AhwgACAENgIUIABBypqAgAA2AhAgAEEJNgIMQQAhEAwBCwJAIAEiBCACRw0AQSIhEAwBCyAAQYmAgIAANgIIIAAgBDYCBEEhIRALIANBEGokgICAgAAgEAuvAQECfyABKAIAIQYCQAJAIAIgA0YNACAEIAZqIQQgBiADaiACayEHIAIgBkF/cyAFaiIGaiEFA0ACQCACLQAAIAQtAABGDQBBAiEEDAMLAkAgBg0AQQAhBCAFIQIMAwsgBkF/aiEGIARBAWohBCACQQFqIgIgA0cNAAsgByEGIAMhAgsgAEEBNgIAIAEgBjYCACAAIAI2AgQPCyABQQA2AgAgACAENgIAIAAgAjYCBAsKACAAEMeAgIAAC/I2AQt/I4CAgIAAQRBrIgEkgICAgAACQEEAKAKg0ICAAA0AQQAQy4CAgABBgNSEgABrIgJB2QBJDQBBACEDAkBBACgC4NOAgAAiBA0AQQBCfzcC7NOAgABBAEKAgISAgIDAADcC5NOAgABBACABQQhqQXBxQdiq1aoFcyIENgLg04CAAEEAQQA2AvTTgIAAQQBBADYCxNOAgAALQQAgAjYCzNOAgABBAEGA1ISAADYCyNOAgABBAEGA1ISAADYCmNCAgABBACAENgKs0ICAAEEAQX82AqjQgIAAA0AgA0HE0ICAAGogA0G40ICAAGoiBDYCACAEIANBsNCAgABqIgU2AgAgA0G80ICAAGogBTYCACADQczQgIAAaiADQcDQgIAAaiIFNgIAIAUgBDYCACADQdTQgIAAaiADQcjQgIAAaiIENgIAIAQgBTYCACADQdDQgIAAaiAENgIAIANBIGoiA0GAAkcNAAtBgNSEgABBeEGA1ISAAGtBD3FBAEGA1ISAAEEIakEPcRsiA2oiBEEEaiACQUhqIgUgA2siA0EBcjYCAEEAQQAoAvDTgIAANgKk0ICAAEEAIAM2ApTQgIAAQQAgBDYCoNCAgABBgNSEgAAgBWpBODYCBAsCQAJAAkACQAJAAkACQAJAAkACQAJAAkAgAEHsAUsNAAJAQQAoAojQgIAAIgZBECAAQRNqQXBxIABBC0kbIgJBA3YiBHYiA0EDcUUNAAJAAkAgA0EBcSAEckEBcyIFQQN0IgRBsNCAgABqIgMgBEG40ICAAGooAgAiBCgCCCICRw0AQQAgBkF+IAV3cTYCiNCAgAAMAQsgAyACNgIIIAIgAzYCDAsgBEEIaiEDIAQgBUEDdCIFQQNyNgIEIAQgBWoiBCAEKAIEQQFyNgIEDAwLIAJBACgCkNCAgAAiB00NAQJAIANFDQACQAJAIAMgBHRBAiAEdCIDQQAgA2tycSIDQQAgA2txQX9qIgMgA0EMdkEQcSIDdiIEQQV2QQhxIgUgA3IgBCAFdiIDQQJ2QQRxIgRyIAMgBHYiA0EBdkECcSIEciADIAR2IgNBAXZBAXEiBHIgAyAEdmoiBEEDdCIDQbDQgIAAaiIFIANBuNCAgABqKAIAIgMoAggiAEcNAEEAIAZBfiAEd3EiBjYCiNCAgAAMAQsgBSAANgIIIAAgBTYCDAsgAyACQQNyNgIEIAMgBEEDdCIEaiAEIAJrIgU2AgAgAyACaiIAIAVBAXI2AgQCQCAHRQ0AIAdBeHFBsNCAgABqIQJBACgCnNCAgAAhBAJAAkAgBkEBIAdBA3Z0IghxDQBBACAGIAhyNgKI0ICAACACIQgMAQsgAigCCCEICyAIIAQ2AgwgAiAENgIIIAQgAjYCDCAEIAg2AggLIANBCGohA0EAIAA2ApzQgIAAQQAgBTYCkNCAgAAMDAtBACgCjNCAgAAiCUUNASAJQQAgCWtxQX9qIgMgA0EMdkEQcSIDdiIEQQV2QQhxIgUgA3IgBCAFdiIDQQJ2QQRxIgRyIAMgBHYiA0EBdkECcSIEciADIAR2IgNBAXZBAXEiBHIgAyAEdmpBAnRBuNKAgABqKAIAIgAoAgRBeHEgAmshBCAAIQUCQANAAkAgBSgCECIDDQAgBUEUaigCACIDRQ0CCyADKAIEQXhxIAJrIgUgBCAFIARJIgUbIQQgAyAAIAUbIQAgAyEFDAALCyAAKAIYIQoCQCAAKAIMIgggAEYNACAAKAIIIgNBACgCmNCAgABJGiAIIAM2AgggAyAINgIMDAsLAkAgAEEUaiIFKAIAIgMNACAAKAIQIgNFDQMgAEEQaiEFCwNAIAUhCyADIghBFGoiBSgCACIDDQAgCEEQaiEFIAgoAhAiAw0ACyALQQA2AgAMCgtBfyECIABBv39LDQAgAEETaiIDQXBxIQJBACgCjNCAgAAiB0UNAEEAIQsCQCACQYACSQ0AQR8hCyACQf///wdLDQAgA0EIdiIDIANBgP4/akEQdkEIcSIDdCIEIARBgOAfakEQdkEEcSIEdCIFIAVBgIAPakEQdkECcSIFdEEPdiADIARyIAVyayIDQQF0IAIgA0EVanZBAXFyQRxqIQsLQQAgAmshBAJAAkACQAJAIAtBAnRBuNKAgABqKAIAIgUNAEEAIQNBACEIDAELQQAhAyACQQBBGSALQQF2ayALQR9GG3QhAEEAIQgDQAJAIAUoAgRBeHEgAmsiBiAETw0AIAYhBCAFIQggBg0AQQAhBCAFIQggBSEDDAMLIAMgBUEUaigCACIGIAYgBSAAQR12QQRxakEQaigCACIFRhsgAyAGGyEDIABBAXQhACAFDQALCwJAIAMgCHINAEEAIQhBAiALdCIDQQAgA2tyIAdxIgNFDQMgA0EAIANrcUF/aiIDIANBDHZBEHEiA3YiBUEFdkEIcSIAIANyIAUgAHYiA0ECdkEEcSIFciADIAV2IgNBAXZBAnEiBXIgAyAFdiIDQQF2QQFxIgVyIAMgBXZqQQJ0QbjSgIAAaigCACEDCyADRQ0BCwNAIAMoAgRBeHEgAmsiBiAESSEAAkAgAygCECIFDQAgA0EUaigCACEFCyAGIAQgABshBCADIAggABshCCAFIQMgBQ0ACwsgCEUNACAEQQAoApDQgIAAIAJrTw0AIAgoAhghCwJAIAgoAgwiACAIRg0AIAgoAggiA0EAKAKY0ICAAEkaIAAgAzYCCCADIAA2AgwMCQsCQCAIQRRqIgUoAgAiAw0AIAgoAhAiA0UNAyAIQRBqIQULA0AgBSEGIAMiAEEUaiIFKAIAIgMNACAAQRBqIQUgACgCECIDDQALIAZBADYCAAwICwJAQQAoApDQgIAAIgMgAkkNAEEAKAKc0ICAACEEAkACQCADIAJrIgVBEEkNACAEIAJqIgAgBUEBcjYCBEEAIAU2ApDQgIAAQQAgADYCnNCAgAAgBCADaiAFNgIAIAQgAkEDcjYCBAwBCyAEIANBA3I2AgQgBCADaiIDIAMoAgRBAXI2AgRBAEEANgKc0ICAAEEAQQA2ApDQgIAACyAEQQhqIQMMCgsCQEEAKAKU0ICAACIAIAJNDQBBACgCoNCAgAAiAyACaiIEIAAgAmsiBUEBcjYCBEEAIAU2ApTQgIAAQQAgBDYCoNCAgAAgAyACQQNyNgIEIANBCGohAwwKCwJAAkBBACgC4NOAgABFDQBBACgC6NOAgAAhBAwBC0EAQn83AuzTgIAAQQBCgICEgICAwAA3AuTTgIAAQQAgAUEMakFwcUHYqtWqBXM2AuDTgIAAQQBBADYC9NOAgABBAEEANgLE04CAAEGAgAQhBAtBACEDAkAgBCACQccAaiIHaiIGQQAgBGsiC3EiCCACSw0AQQBBMDYC+NOAgAAMCgsCQEEAKALA04CAACIDRQ0AAkBBACgCuNOAgAAiBCAIaiIFIARNDQAgBSADTQ0BC0EAIQNBAEEwNgL404CAAAwKC0EALQDE04CAAEEEcQ0EAkACQAJAQQAoAqDQgIAAIgRFDQBByNOAgAAhAwNAAkAgAygCACIFIARLDQAgBSADKAIEaiAESw0DCyADKAIIIgMNAAsLQQAQy4CAgAAiAEF/Rg0FIAghBgJAQQAoAuTTgIAAIgNBf2oiBCAAcUUNACAIIABrIAQgAGpBACADa3FqIQYLIAYgAk0NBSAGQf7///8HSw0FAkBBACgCwNOAgAAiA0UNAEEAKAK404CAACIEIAZqIgUgBE0NBiAFIANLDQYLIAYQy4CAgAAiAyAARw0BDAcLIAYgAGsgC3EiBkH+////B0sNBCAGEMuAgIAAIgAgAygCACADKAIEakYNAyAAIQMLAkAgA0F/Rg0AIAJByABqIAZNDQACQCAHIAZrQQAoAujTgIAAIgRqQQAgBGtxIgRB/v///wdNDQAgAyEADAcLAkAgBBDLgICAAEF/Rg0AIAQgBmohBiADIQAMBwtBACAGaxDLgICAABoMBAsgAyEAIANBf0cNBQwDC0EAIQgMBwtBACEADAULIABBf0cNAgtBAEEAKALE04CAAEEEcjYCxNOAgAALIAhB/v///wdLDQEgCBDLgICAACEAQQAQy4CAgAAhAyAAQX9GDQEgA0F/Rg0BIAAgA08NASADIABrIgYgAkE4ak0NAQtBAEEAKAK404CAACAGaiIDNgK404CAAAJAIANBACgCvNOAgABNDQBBACADNgK804CAAAsCQAJAAkACQEEAKAKg0ICAACIERQ0AQcjTgIAAIQMDQCAAIAMoAgAiBSADKAIEIghqRg0CIAMoAggiAw0ADAMLCwJAAkBBACgCmNCAgAAiA0UNACAAIANPDQELQQAgADYCmNCAgAALQQAhA0EAIAY2AszTgIAAQQAgADYCyNOAgABBAEF/NgKo0ICAAEEAQQAoAuDTgIAANgKs0ICAAEEAQQA2AtTTgIAAA0AgA0HE0ICAAGogA0G40ICAAGoiBDYCACAEIANBsNCAgABqIgU2AgAgA0G80ICAAGogBTYCACADQczQgIAAaiADQcDQgIAAaiIFNgIAIAUgBDYCACADQdTQgIAAaiADQcjQgIAAaiIENgIAIAQgBTYCACADQdDQgIAAaiAENgIAIANBIGoiA0GAAkcNAAsgAEF4IABrQQ9xQQAgAEEIakEPcRsiA2oiBCAGQUhqIgUgA2siA0EBcjYCBEEAQQAoAvDTgIAANgKk0ICAAEEAIAM2ApTQgIAAQQAgBDYCoNCAgAAgACAFakE4NgIEDAILIAMtAAxBCHENACAEIAVJDQAgBCAATw0AIARBeCAEa0EPcUEAIARBCGpBD3EbIgVqIgBBACgClNCAgAAgBmoiCyAFayIFQQFyNgIEIAMgCCAGajYCBEEAQQAoAvDTgIAANgKk0ICAAEEAIAU2ApTQgIAAQQAgADYCoNCAgAAgBCALakE4NgIEDAELAkAgAEEAKAKY0ICAACIITw0AQQAgADYCmNCAgAAgACEICyAAIAZqIQVByNOAgAAhAwJAAkACQAJAAkACQAJAA0AgAygCACAFRg0BIAMoAggiAw0ADAILCyADLQAMQQhxRQ0BC0HI04CAACEDA0ACQCADKAIAIgUgBEsNACAFIAMoAgRqIgUgBEsNAwsgAygCCCEDDAALCyADIAA2AgAgAyADKAIEIAZqNgIEIABBeCAAa0EPcUEAIABBCGpBD3EbaiILIAJBA3I2AgQgBUF4IAVrQQ9xQQAgBUEIakEPcRtqIgYgCyACaiICayEDAkAgBiAERw0AQQAgAjYCoNCAgABBAEEAKAKU0ICAACADaiIDNgKU0ICAACACIANBAXI2AgQMAwsCQCAGQQAoApzQgIAARw0AQQAgAjYCnNCAgABBAEEAKAKQ0ICAACADaiIDNgKQ0ICAACACIANBAXI2AgQgAiADaiADNgIADAMLAkAgBigCBCIEQQNxQQFHDQAgBEF4cSEHAkACQCAEQf8BSw0AIAYoAggiBSAEQQN2IghBA3RBsNCAgABqIgBGGgJAIAYoAgwiBCAFRw0AQQBBACgCiNCAgABBfiAId3E2AojQgIAADAILIAQgAEYaIAQgBTYCCCAFIAQ2AgwMAQsgBigCGCEJAkACQCAGKAIMIgAgBkYNACAGKAIIIgQgCEkaIAAgBDYCCCAEIAA2AgwMAQsCQCAGQRRqIgQoAgAiBQ0AIAZBEGoiBCgCACIFDQBBACEADAELA0AgBCEIIAUiAEEUaiIEKAIAIgUNACAAQRBqIQQgACgCECIFDQALIAhBADYCAAsgCUUNAAJAAkAgBiAGKAIcIgVBAnRBuNKAgABqIgQoAgBHDQAgBCAANgIAIAANAUEAQQAoAozQgIAAQX4gBXdxNgKM0ICAAAwCCyAJQRBBFCAJKAIQIAZGG2ogADYCACAARQ0BCyAAIAk2AhgCQCAGKAIQIgRFDQAgACAENgIQIAQgADYCGAsgBigCFCIERQ0AIABBFGogBDYCACAEIAA2AhgLIAcgA2ohAyAGIAdqIgYoAgQhBAsgBiAEQX5xNgIEIAIgA2ogAzYCACACIANBAXI2AgQCQCADQf8BSw0AIANBeHFBsNCAgABqIQQCQAJAQQAoAojQgIAAIgVBASADQQN2dCIDcQ0AQQAgBSADcjYCiNCAgAAgBCEDDAELIAQoAgghAwsgAyACNgIMIAQgAjYCCCACIAQ2AgwgAiADNgIIDAMLQR8hBAJAIANB////B0sNACADQQh2IgQgBEGA/j9qQRB2QQhxIgR0IgUgBUGA4B9qQRB2QQRxIgV0IgAgAEGAgA9qQRB2QQJxIgB0QQ92IAQgBXIgAHJrIgRBAXQgAyAEQRVqdkEBcXJBHGohBAsgAiAENgIcIAJCADcCECAEQQJ0QbjSgIAAaiEFAkBBACgCjNCAgAAiAEEBIAR0IghxDQAgBSACNgIAQQAgACAIcjYCjNCAgAAgAiAFNgIYIAIgAjYCCCACIAI2AgwMAwsgA0EAQRkgBEEBdmsgBEEfRht0IQQgBSgCACEAA0AgACIFKAIEQXhxIANGDQIgBEEddiEAIARBAXQhBCAFIABBBHFqQRBqIggoAgAiAA0ACyAIIAI2AgAgAiAFNgIYIAIgAjYCDCACIAI2AggMAgsgAEF4IABrQQ9xQQAgAEEIakEPcRsiA2oiCyAGQUhqIgggA2siA0EBcjYCBCAAIAhqQTg2AgQgBCAFQTcgBWtBD3FBACAFQUlqQQ9xG2pBQWoiCCAIIARBEGpJGyIIQSM2AgRBAEEAKALw04CAADYCpNCAgABBACADNgKU0ICAAEEAIAs2AqDQgIAAIAhBEGpBACkC0NOAgAA3AgAgCEEAKQLI04CAADcCCEEAIAhBCGo2AtDTgIAAQQAgBjYCzNOAgABBACAANgLI04CAAEEAQQA2AtTTgIAAIAhBJGohAwNAIANBBzYCACADQQRqIgMgBUkNAAsgCCAERg0DIAggCCgCBEF+cTYCBCAIIAggBGsiADYCACAEIABBAXI2AgQCQCAAQf8BSw0AIABBeHFBsNCAgABqIQMCQAJAQQAoAojQgIAAIgVBASAAQQN2dCIAcQ0AQQAgBSAAcjYCiNCAgAAgAyEFDAELIAMoAgghBQsgBSAENgIMIAMgBDYCCCAEIAM2AgwgBCAFNgIIDAQLQR8hAwJAIABB////B0sNACAAQQh2IgMgA0GA/j9qQRB2QQhxIgN0IgUgBUGA4B9qQRB2QQRxIgV0IgggCEGAgA9qQRB2QQJxIgh0QQ92IAMgBXIgCHJrIgNBAXQgACADQRVqdkEBcXJBHGohAwsgBCADNgIcIARCADcCECADQQJ0QbjSgIAAaiEFAkBBACgCjNCAgAAiCEEBIAN0IgZxDQAgBSAENgIAQQAgCCAGcjYCjNCAgAAgBCAFNgIYIAQgBDYCCCAEIAQ2AgwMBAsgAEEAQRkgA0EBdmsgA0EfRht0IQMgBSgCACEIA0AgCCIFKAIEQXhxIABGDQMgA0EddiEIIANBAXQhAyAFIAhBBHFqQRBqIgYoAgAiCA0ACyAGIAQ2AgAgBCAFNgIYIAQgBDYCDCAEIAQ2AggMAwsgBSgCCCIDIAI2AgwgBSACNgIIIAJBADYCGCACIAU2AgwgAiADNgIICyALQQhqIQMMBQsgBSgCCCIDIAQ2AgwgBSAENgIIIARBADYCGCAEIAU2AgwgBCADNgIIC0EAKAKU0ICAACIDIAJNDQBBACgCoNCAgAAiBCACaiIFIAMgAmsiA0EBcjYCBEEAIAM2ApTQgIAAQQAgBTYCoNCAgAAgBCACQQNyNgIEIARBCGohAwwDC0EAIQNBAEEwNgL404CAAAwCCwJAIAtFDQACQAJAIAggCCgCHCIFQQJ0QbjSgIAAaiIDKAIARw0AIAMgADYCACAADQFBACAHQX4gBXdxIgc2AozQgIAADAILIAtBEEEUIAsoAhAgCEYbaiAANgIAIABFDQELIAAgCzYCGAJAIAgoAhAiA0UNACAAIAM2AhAgAyAANgIYCyAIQRRqKAIAIgNFDQAgAEEUaiADNgIAIAMgADYCGAsCQAJAIARBD0sNACAIIAQgAmoiA0EDcjYCBCAIIANqIgMgAygCBEEBcjYCBAwBCyAIIAJqIgAgBEEBcjYCBCAIIAJBA3I2AgQgACAEaiAENgIAAkAgBEH/AUsNACAEQXhxQbDQgIAAaiEDAkACQEEAKAKI0ICAACIFQQEgBEEDdnQiBHENAEEAIAUgBHI2AojQgIAAIAMhBAwBCyADKAIIIQQLIAQgADYCDCADIAA2AgggACADNgIMIAAgBDYCCAwBC0EfIQMCQCAEQf///wdLDQAgBEEIdiIDIANBgP4/akEQdkEIcSIDdCIFIAVBgOAfakEQdkEEcSIFdCICIAJBgIAPakEQdkECcSICdEEPdiADIAVyIAJyayIDQQF0IAQgA0EVanZBAXFyQRxqIQMLIAAgAzYCHCAAQgA3AhAgA0ECdEG40oCAAGohBQJAIAdBASADdCICcQ0AIAUgADYCAEEAIAcgAnI2AozQgIAAIAAgBTYCGCAAIAA2AgggACAANgIMDAELIARBAEEZIANBAXZrIANBH0YbdCEDIAUoAgAhAgJAA0AgAiIFKAIEQXhxIARGDQEgA0EddiECIANBAXQhAyAFIAJBBHFqQRBqIgYoAgAiAg0ACyAGIAA2AgAgACAFNgIYIAAgADYCDCAAIAA2AggMAQsgBSgCCCIDIAA2AgwgBSAANgIIIABBADYCGCAAIAU2AgwgACADNgIICyAIQQhqIQMMAQsCQCAKRQ0AAkACQCAAIAAoAhwiBUECdEG40oCAAGoiAygCAEcNACADIAg2AgAgCA0BQQAgCUF+IAV3cTYCjNCAgAAMAgsgCkEQQRQgCigCECAARhtqIAg2AgAgCEUNAQsgCCAKNgIYAkAgACgCECIDRQ0AIAggAzYCECADIAg2AhgLIABBFGooAgAiA0UNACAIQRRqIAM2AgAgAyAINgIYCwJAAkAgBEEPSw0AIAAgBCACaiIDQQNyNgIEIAAgA2oiAyADKAIEQQFyNgIEDAELIAAgAmoiBSAEQQFyNgIEIAAgAkEDcjYCBCAFIARqIAQ2AgACQCAHRQ0AIAdBeHFBsNCAgABqIQJBACgCnNCAgAAhAwJAAkBBASAHQQN2dCIIIAZxDQBBACAIIAZyNgKI0ICAACACIQgMAQsgAigCCCEICyAIIAM2AgwgAiADNgIIIAMgAjYCDCADIAg2AggLQQAgBTYCnNCAgABBACAENgKQ0ICAAAsgAEEIaiEDCyABQRBqJICAgIAAIAMLCgAgABDJgICAAAviDQEHfwJAIABFDQAgAEF4aiIBIABBfGooAgAiAkF4cSIAaiEDAkAgAkEBcQ0AIAJBA3FFDQEgASABKAIAIgJrIgFBACgCmNCAgAAiBEkNASACIABqIQACQCABQQAoApzQgIAARg0AAkAgAkH/AUsNACABKAIIIgQgAkEDdiIFQQN0QbDQgIAAaiIGRhoCQCABKAIMIgIgBEcNAEEAQQAoAojQgIAAQX4gBXdxNgKI0ICAAAwDCyACIAZGGiACIAQ2AgggBCACNgIMDAILIAEoAhghBwJAAkAgASgCDCIGIAFGDQAgASgCCCICIARJGiAGIAI2AgggAiAGNgIMDAELAkAgAUEUaiICKAIAIgQNACABQRBqIgIoAgAiBA0AQQAhBgwBCwNAIAIhBSAEIgZBFGoiAigCACIEDQAgBkEQaiECIAYoAhAiBA0ACyAFQQA2AgALIAdFDQECQAJAIAEgASgCHCIEQQJ0QbjSgIAAaiICKAIARw0AIAIgBjYCACAGDQFBAEEAKAKM0ICAAEF+IAR3cTYCjNCAgAAMAwsgB0EQQRQgBygCECABRhtqIAY2AgAgBkUNAgsgBiAHNgIYAkAgASgCECICRQ0AIAYgAjYCECACIAY2AhgLIAEoAhQiAkUNASAGQRRqIAI2AgAgAiAGNgIYDAELIAMoAgQiAkEDcUEDRw0AIAMgAkF+cTYCBEEAIAA2ApDQgIAAIAEgAGogADYCACABIABBAXI2AgQPCyABIANPDQAgAygCBCICQQFxRQ0AAkACQCACQQJxDQACQCADQQAoAqDQgIAARw0AQQAgATYCoNCAgABBAEEAKAKU0ICAACAAaiIANgKU0ICAACABIABBAXI2AgQgAUEAKAKc0ICAAEcNA0EAQQA2ApDQgIAAQQBBADYCnNCAgAAPCwJAIANBACgCnNCAgABHDQBBACABNgKc0ICAAEEAQQAoApDQgIAAIABqIgA2ApDQgIAAIAEgAEEBcjYCBCABIABqIAA2AgAPCyACQXhxIABqIQACQAJAIAJB/wFLDQAgAygCCCIEIAJBA3YiBUEDdEGw0ICAAGoiBkYaAkAgAygCDCICIARHDQBBAEEAKAKI0ICAAEF+IAV3cTYCiNCAgAAMAgsgAiAGRhogAiAENgIIIAQgAjYCDAwBCyADKAIYIQcCQAJAIAMoAgwiBiADRg0AIAMoAggiAkEAKAKY0ICAAEkaIAYgAjYCCCACIAY2AgwMAQsCQCADQRRqIgIoAgAiBA0AIANBEGoiAigCACIEDQBBACEGDAELA0AgAiEFIAQiBkEUaiICKAIAIgQNACAGQRBqIQIgBigCECIEDQALIAVBADYCAAsgB0UNAAJAAkAgAyADKAIcIgRBAnRBuNKAgABqIgIoAgBHDQAgAiAGNgIAIAYNAUEAQQAoAozQgIAAQX4gBHdxNgKM0ICAAAwCCyAHQRBBFCAHKAIQIANGG2ogBjYCACAGRQ0BCyAGIAc2AhgCQCADKAIQIgJFDQAgBiACNgIQIAIgBjYCGAsgAygCFCICRQ0AIAZBFGogAjYCACACIAY2AhgLIAEgAGogADYCACABIABBAXI2AgQgAUEAKAKc0ICAAEcNAUEAIAA2ApDQgIAADwsgAyACQX5xNgIEIAEgAGogADYCACABIABBAXI2AgQLAkAgAEH/AUsNACAAQXhxQbDQgIAAaiECAkACQEEAKAKI0ICAACIEQQEgAEEDdnQiAHENAEEAIAQgAHI2AojQgIAAIAIhAAwBCyACKAIIIQALIAAgATYCDCACIAE2AgggASACNgIMIAEgADYCCA8LQR8hAgJAIABB////B0sNACAAQQh2IgIgAkGA/j9qQRB2QQhxIgJ0IgQgBEGA4B9qQRB2QQRxIgR0IgYgBkGAgA9qQRB2QQJxIgZ0QQ92IAIgBHIgBnJrIgJBAXQgACACQRVqdkEBcXJBHGohAgsgASACNgIcIAFCADcCECACQQJ0QbjSgIAAaiEEAkACQEEAKAKM0ICAACIGQQEgAnQiA3ENACAEIAE2AgBBACAGIANyNgKM0ICAACABIAQ2AhggASABNgIIIAEgATYCDAwBCyAAQQBBGSACQQF2ayACQR9GG3QhAiAEKAIAIQYCQANAIAYiBCgCBEF4cSAARg0BIAJBHXYhBiACQQF0IQIgBCAGQQRxakEQaiIDKAIAIgYNAAsgAyABNgIAIAEgBDYCGCABIAE2AgwgASABNgIIDAELIAQoAggiACABNgIMIAQgATYCCCABQQA2AhggASAENgIMIAEgADYCCAtBAEEAKAKo0ICAAEF/aiIBQX8gARs2AqjQgIAACwsEAAAAC04AAkAgAA0APwBBEHQPCwJAIABB//8DcQ0AIABBf0wNAAJAIABBEHZAACIAQX9HDQBBAEEwNgL404CAAEF/DwsgAEEQdA8LEMqAgIAAAAvyAgIDfwF+AkAgAkUNACAAIAE6AAAgAiAAaiIDQX9qIAE6AAAgAkEDSQ0AIAAgAToAAiAAIAE6AAEgA0F9aiABOgAAIANBfmogAToAACACQQdJDQAgACABOgADIANBfGogAToAACACQQlJDQAgAEEAIABrQQNxIgRqIgMgAUH/AXFBgYKECGwiATYCACADIAIgBGtBfHEiBGoiAkF8aiABNgIAIARBCUkNACADIAE2AgggAyABNgIEIAJBeGogATYCACACQXRqIAE2AgAgBEEZSQ0AIAMgATYCGCADIAE2AhQgAyABNgIQIAMgATYCDCACQXBqIAE2AgAgAkFsaiABNgIAIAJBaGogATYCACACQWRqIAE2AgAgBCADQQRxQRhyIgVrIgJBIEkNACABrUKBgICAEH4hBiADIAVqIQEDQCABIAY3AxggASAGNwMQIAEgBjcDCCABIAY3AwAgAUEgaiEBIAJBYGoiAkEfSw0ACwsgAAsLjkgBAEGACAuGSAEAAAACAAAAAwAAAAAAAAAAAAAABAAAAAUAAAAAAAAAAAAAAAYAAAAHAAAACAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAASW52YWxpZCBjaGFyIGluIHVybCBxdWVyeQBTcGFuIGNhbGxiYWNrIGVycm9yIGluIG9uX2JvZHkAQ29udGVudC1MZW5ndGggb3ZlcmZsb3cAQ2h1bmsgc2l6ZSBvdmVyZmxvdwBSZXNwb25zZSBvdmVyZmxvdwBJbnZhbGlkIG1ldGhvZCBmb3IgSFRUUC94LnggcmVxdWVzdABJbnZhbGlkIG1ldGhvZCBmb3IgUlRTUC94LnggcmVxdWVzdABFeHBlY3RlZCBTT1VSQ0UgbWV0aG9kIGZvciBJQ0UveC54IHJlcXVlc3QASW52YWxpZCBjaGFyIGluIHVybCBmcmFnbWVudCBzdGFydABFeHBlY3RlZCBkb3QAU3BhbiBjYWxsYmFjayBlcnJvciBpbiBvbl9zdGF0dXMASW52YWxpZCByZXNwb25zZSBzdGF0dXMASW52YWxpZCBjaGFyYWN0ZXIgaW4gY2h1bmsgZXh0ZW5zaW9ucwBVc2VyIGNhbGxiYWNrIGVycm9yAGBvbl9yZXNldGAgY2FsbGJhY2sgZXJyb3IAYG9uX2NodW5rX2hlYWRlcmAgY2FsbGJhY2sgZXJyb3IAYG9uX21lc3NhZ2VfYmVnaW5gIGNhbGxiYWNrIGVycm9yAGBvbl9jaHVua19leHRlbnNpb25fdmFsdWVgIGNhbGxiYWNrIGVycm9yAGBvbl9zdGF0dXNfY29tcGxldGVgIGNhbGxiYWNrIGVycm9yAGBvbl92ZXJzaW9uX2NvbXBsZXRlYCBjYWxsYmFjayBlcnJvcgBgb25fdXJsX2NvbXBsZXRlYCBjYWxsYmFjayBlcnJvcgBgb25fY2h1bmtfY29tcGxldGVgIGNhbGxiYWNrIGVycm9yAGBvbl9oZWFkZXJfdmFsdWVfY29tcGxldGVgIGNhbGxiYWNrIGVycm9yAGBvbl9tZXNzYWdlX2NvbXBsZXRlYCBjYWxsYmFjayBlcnJvcgBgb25fbWV0aG9kX2NvbXBsZXRlYCBjYWxsYmFjayBlcnJvcgBgb25faGVhZGVyX2ZpZWxkX2NvbXBsZXRlYCBjYWxsYmFjayBlcnJvcgBgb25fY2h1bmtfZXh0ZW5zaW9uX25hbWVgIGNhbGxiYWNrIGVycm9yAFVuZXhwZWN0ZWQgY2hhciBpbiB1cmwgc2VydmVyAEludmFsaWQgaGVhZGVyIHZhbHVlIGNoYXIASW52YWxpZCBoZWFkZXIgZmllbGQgY2hhcgBTcGFuIGNhbGxiYWNrIGVycm9yIGluIG9uX3ZlcnNpb24ASW52YWxpZCBtaW5vciB2ZXJzaW9uAEludmFsaWQgbWFqb3IgdmVyc2lvbgBFeHBlY3RlZCBzcGFjZSBhZnRlciB2ZXJzaW9uAEV4cGVjdGVkIENSTEYgYWZ0ZXIgdmVyc2lvbgBJbnZhbGlkIEhUVFAgdmVyc2lvbgBJbnZhbGlkIGhlYWRlciB0b2tlbgBTcGFuIGNhbGxiYWNrIGVycm9yIGluIG9uX3VybABJbnZhbGlkIGNoYXJhY3RlcnMgaW4gdXJsAFVuZXhwZWN0ZWQgc3RhcnQgY2hhciBpbiB1cmwARG91YmxlIEAgaW4gdXJsAEVtcHR5IENvbnRlbnQtTGVuZ3RoAEludmFsaWQgY2hhcmFjdGVyIGluIENvbnRlbnQtTGVuZ3RoAER1cGxpY2F0ZSBDb250ZW50LUxlbmd0aABJbnZhbGlkIGNoYXIgaW4gdXJsIHBhdGgAQ29udGVudC1MZW5ndGggY2FuJ3QgYmUgcHJlc2VudCB3aXRoIFRyYW5zZmVyLUVuY29kaW5nAEludmFsaWQgY2hhcmFjdGVyIGluIGNodW5rIHNpemUAU3BhbiBjYWxsYmFjayBlcnJvciBpbiBvbl9oZWFkZXJfdmFsdWUAU3BhbiBjYWxsYmFjayBlcnJvciBpbiBvbl9jaHVua19leHRlbnNpb25fdmFsdWUASW52YWxpZCBjaGFyYWN0ZXIgaW4gY2h1bmsgZXh0ZW5zaW9ucyB2YWx1ZQBNaXNzaW5nIGV4cGVjdGVkIExGIGFmdGVyIGhlYWRlciB2YWx1ZQBJbnZhbGlkIGBUcmFuc2Zlci1FbmNvZGluZ2AgaGVhZGVyIHZhbHVlAEludmFsaWQgY2hhcmFjdGVyIGluIGNodW5rIGV4dGVuc2lvbnMgcXVvdGUgdmFsdWUASW52YWxpZCBjaGFyYWN0ZXIgaW4gY2h1bmsgZXh0ZW5zaW9ucyBxdW90ZWQgdmFsdWUAUGF1c2VkIGJ5IG9uX2hlYWRlcnNfY29tcGxldGUASW52YWxpZCBFT0Ygc3RhdGUAb25fcmVzZXQgcGF1c2UAb25fY2h1bmtfaGVhZGVyIHBhdXNlAG9uX21lc3NhZ2VfYmVnaW4gcGF1c2UAb25fY2h1bmtfZXh0ZW5zaW9uX3ZhbHVlIHBhdXNlAG9uX3N0YXR1c19jb21wbGV0ZSBwYXVzZQBvbl92ZXJzaW9uX2NvbXBsZXRlIHBhdXNlAG9uX3VybF9jb21wbGV0ZSBwYXVzZQBvbl9jaHVua19jb21wbGV0ZSBwYXVzZQBvbl9oZWFkZXJfdmFsdWVfY29tcGxldGUgcGF1c2UAb25fbWVzc2FnZV9jb21wbGV0ZSBwYXVzZQBvbl9tZXRob2RfY29tcGxldGUgcGF1c2UAb25faGVhZGVyX2ZpZWxkX2NvbXBsZXRlIHBhdXNlAG9uX2NodW5rX2V4dGVuc2lvbl9uYW1lIHBhdXNlAFVuZXhwZWN0ZWQgc3BhY2UgYWZ0ZXIgc3RhcnQgbGluZQBTcGFuIGNhbGxiYWNrIGVycm9yIGluIG9uX2NodW5rX2V4dGVuc2lvbl9uYW1lAEludmFsaWQgY2hhcmFjdGVyIGluIGNodW5rIGV4dGVuc2lvbnMgbmFtZQBQYXVzZSBvbiBDT05ORUNUL1VwZ3JhZGUAUGF1c2Ugb24gUFJJL1VwZ3JhZGUARXhwZWN0ZWQgSFRUUC8yIENvbm5lY3Rpb24gUHJlZmFjZQBTcGFuIGNhbGxiYWNrIGVycm9yIGluIG9uX21ldGhvZABFeHBlY3RlZCBzcGFjZSBhZnRlciBtZXRob2QAU3BhbiBjYWxsYmFjayBlcnJvciBpbiBvbl9oZWFkZXJfZmllbGQAUGF1c2VkAEludmFsaWQgd29yZCBlbmNvdW50ZXJlZABJbnZhbGlkIG1ldGhvZCBlbmNvdW50ZXJlZABVbmV4cGVjdGVkIGNoYXIgaW4gdXJsIHNjaGVtYQBSZXF1ZXN0IGhhcyBpbnZhbGlkIGBUcmFuc2Zlci1FbmNvZGluZ2AAU1dJVENIX1BST1hZAFVTRV9QUk9YWQBNS0FDVElWSVRZAFVOUFJPQ0VTU0FCTEVfRU5USVRZAENPUFkATU9WRURfUEVSTUFORU5UTFkAVE9PX0VBUkxZAE5PVElGWQBGQUlMRURfREVQRU5ERU5DWQBCQURfR0FURVdBWQBQTEFZAFBVVABDSEVDS09VVABHQVRFV0FZX1RJTUVPVVQAUkVRVUVTVF9USU1FT1VUAE5FVFdPUktfQ09OTkVDVF9USU1FT1VUAENPTk5FQ1RJT05fVElNRU9VVABMT0dJTl9USU1FT1VUAE5FVFdPUktfUkVBRF9USU1FT1VUAFBPU1QATUlTRElSRUNURURfUkVRVUVTVABDTElFTlRfQ0xPU0VEX1JFUVVFU1QAQ0xJRU5UX0NMT1NFRF9MT0FEX0JBTEFOQ0VEX1JFUVVFU1QAQkFEX1JFUVVFU1QASFRUUF9SRVFVRVNUX1NFTlRfVE9fSFRUUFNfUE9SVABSRVBPUlQASU1fQV9URUFQT1QAUkVTRVRfQ09OVEVOVABOT19DT05URU5UAFBBUlRJQUxfQ09OVEVOVABIUEVfSU5WQUxJRF9DT05TVEFOVABIUEVfQ0JfUkVTRVQAR0VUAEhQRV9TVFJJQ1QAQ09ORkxJQ1QAVEVNUE9SQVJZX1JFRElSRUNUAFBFUk1BTkVOVF9SRURJUkVDVABDT05ORUNUAE1VTFRJX1NUQVRVUwBIUEVfSU5WQUxJRF9TVEFUVVMAVE9PX01BTllfUkVRVUVTVFMARUFSTFlfSElOVFMAVU5BVkFJTEFCTEVfRk9SX0xFR0FMX1JFQVNPTlMAT1BUSU9OUwBTV0lUQ0hJTkdfUFJPVE9DT0xTAFZBUklBTlRfQUxTT19ORUdPVElBVEVTAE1VTFRJUExFX0NIT0lDRVMASU5URVJOQUxfU0VSVkVSX0VSUk9SAFdFQl9TRVJWRVJfVU5LTk9XTl9FUlJPUgBSQUlMR1VOX0VSUk9SAElERU5USVRZX1BST1ZJREVSX0FVVEhFTlRJQ0FUSU9OX0VSUk9SAFNTTF9DRVJUSUZJQ0FURV9FUlJPUgBJTlZBTElEX1hfRk9SV0FSREVEX0ZPUgBTRVRfUEFSQU1FVEVSAEdFVF9QQVJBTUVURVIASFBFX1VTRVIAU0VFX09USEVSAEhQRV9DQl9DSFVOS19IRUFERVIATUtDQUxFTkRBUgBTRVRVUABXRUJfU0VSVkVSX0lTX0RPV04AVEVBUkRPV04ASFBFX0NMT1NFRF9DT05ORUNUSU9OAEhFVVJJU1RJQ19FWFBJUkFUSU9OAERJU0NPTk5FQ1RFRF9PUEVSQVRJT04ATk9OX0FVVEhPUklUQVRJVkVfSU5GT1JNQVRJT04ASFBFX0lOVkFMSURfVkVSU0lPTgBIUEVfQ0JfTUVTU0FHRV9CRUdJTgBTSVRFX0lTX0ZST1pFTgBIUEVfSU5WQUxJRF9IRUFERVJfVE9LRU4ASU5WQUxJRF9UT0tFTgBGT1JCSURERU4ARU5IQU5DRV9ZT1VSX0NBTE0ASFBFX0lOVkFMSURfVVJMAEJMT0NLRURfQllfUEFSRU5UQUxfQ09OVFJPTABNS0NPTABBQ0wASFBFX0lOVEVSTkFMAFJFUVVFU1RfSEVBREVSX0ZJRUxEU19UT09fTEFSR0VfVU5PRkZJQ0lBTABIUEVfT0sAVU5MSU5LAFVOTE9DSwBQUkkAUkVUUllfV0lUSABIUEVfSU5WQUxJRF9DT05URU5UX0xFTkdUSABIUEVfVU5FWFBFQ1RFRF9DT05URU5UX0xFTkdUSABGTFVTSABQUk9QUEFUQ0gATS1TRUFSQ0gAVVJJX1RPT19MT05HAFBST0NFU1NJTkcATUlTQ0VMTEFORU9VU19QRVJTSVNURU5UX1dBUk5JTkcATUlTQ0VMTEFORU9VU19XQVJOSU5HAEhQRV9JTlZBTElEX1RSQU5TRkVSX0VOQ09ESU5HAEV4cGVjdGVkIENSTEYASFBFX0lOVkFMSURfQ0hVTktfU0laRQBNT1ZFAENPTlRJTlVFAEhQRV9DQl9TVEFUVVNfQ09NUExFVEUASFBFX0NCX0hFQURFUlNfQ09NUExFVEUASFBFX0NCX1ZFUlNJT05fQ09NUExFVEUASFBFX0NCX1VSTF9DT01QTEVURQBIUEVfQ0JfQ0hVTktfQ09NUExFVEUASFBFX0NCX0hFQURFUl9WQUxVRV9DT01QTEVURQBIUEVfQ0JfQ0hVTktfRVhURU5TSU9OX1ZBTFVFX0NPTVBMRVRFAEhQRV9DQl9DSFVOS19FWFRFTlNJT05fTkFNRV9DT01QTEVURQBIUEVfQ0JfTUVTU0FHRV9DT01QTEVURQBIUEVfQ0JfTUVUSE9EX0NPTVBMRVRFAEhQRV9DQl9IRUFERVJfRklFTERfQ09NUExFVEUAREVMRVRFAEhQRV9JTlZBTElEX0VPRl9TVEFURQBJTlZBTElEX1NTTF9DRVJUSUZJQ0FURQBQQVVTRQBOT19SRVNQT05TRQBVTlNVUFBPUlRFRF9NRURJQV9UWVBFAEdPTkUATk9UX0FDQ0VQVEFCTEUAU0VSVklDRV9VTkFWQUlMQUJMRQBSQU5HRV9OT1RfU0FUSVNGSUFCTEUAT1JJR0lOX0lTX1VOUkVBQ0hBQkxFAFJFU1BPTlNFX0lTX1NUQUxFAFBVUkdFAE1FUkdFAFJFUVVFU1RfSEVBREVSX0ZJRUxEU19UT09fTEFSR0UAUkVRVUVTVF9IRUFERVJfVE9PX0xBUkdFAFBBWUxPQURfVE9PX0xBUkdFAElOU1VGRklDSUVOVF9TVE9SQUdFAEhQRV9QQVVTRURfVVBHUkFERQBIUEVfUEFVU0VEX0gyX1VQR1JBREUAU09VUkNFAEFOTk9VTkNFAFRSQUNFAEhQRV9VTkVYUEVDVEVEX1NQQUNFAERFU0NSSUJFAFVOU1VCU0NSSUJFAFJFQ09SRABIUEVfSU5WQUxJRF9NRVRIT0QATk9UX0ZPVU5EAFBST1BGSU5EAFVOQklORABSRUJJTkQAVU5BVVRIT1JJWkVEAE1FVEhPRF9OT1RfQUxMT1dFRABIVFRQX1ZFUlNJT05fTk9UX1NVUFBPUlRFRABBTFJFQURZX1JFUE9SVEVEAEFDQ0VQVEVEAE5PVF9JTVBMRU1FTlRFRABMT09QX0RFVEVDVEVEAEhQRV9DUl9FWFBFQ1RFRABIUEVfTEZfRVhQRUNURUQAQ1JFQVRFRABJTV9VU0VEAEhQRV9QQVVTRUQAVElNRU9VVF9PQ0NVUkVEAFBBWU1FTlRfUkVRVUlSRUQAUFJFQ09ORElUSU9OX1JFUVVJUkVEAFBST1hZX0FVVEhFTlRJQ0FUSU9OX1JFUVVJUkVEAE5FVFdPUktfQVVUSEVOVElDQVRJT05fUkVRVUlSRUQATEVOR1RIX1JFUVVJUkVEAFNTTF9DRVJUSUZJQ0FURV9SRVFVSVJFRABVUEdSQURFX1JFUVVJUkVEAFBBR0VfRVhQSVJFRABQUkVDT05ESVRJT05fRkFJTEVEAEVYUEVDVEFUSU9OX0ZBSUxFRABSRVZBTElEQVRJT05fRkFJTEVEAFNTTF9IQU5EU0hBS0VfRkFJTEVEAExPQ0tFRABUUkFOU0ZPUk1BVElPTl9BUFBMSUVEAE5PVF9NT0RJRklFRABOT1RfRVhURU5ERUQAQkFORFdJRFRIX0xJTUlUX0VYQ0VFREVEAFNJVEVfSVNfT1ZFUkxPQURFRABIRUFEAEV4cGVjdGVkIEhUVFAvAABeEwAAJhMAADAQAADwFwAAnRMAABUSAAA5FwAA8BIAAAoQAAB1EgAArRIAAIITAABPFAAAfxAAAKAVAAAjFAAAiRIAAIsUAABNFQAA1BEAAM8UAAAQGAAAyRYAANwWAADBEQAA4BcAALsUAAB0FAAAfBUAAOUUAAAIFwAAHxAAAGUVAACjFAAAKBUAAAIVAACZFQAALBAAAIsZAABPDwAA1A4AAGoQAADOEAAAAhcAAIkOAABuEwAAHBMAAGYUAABWFwAAwRMAAM0TAABsEwAAaBcAAGYXAABfFwAAIhMAAM4PAABpDgAA2A4AAGMWAADLEwAAqg4AACgXAAAmFwAAxRMAAF0WAADoEQAAZxMAAGUTAADyFgAAcxMAAB0XAAD5FgAA8xEAAM8OAADOFQAADBIAALMRAAClEQAAYRAAADIXAAC7EwAAAAAAAAAAAAAAAAAAAAAAAAABAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAEBAgEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQABAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAAAAAAAAAAAAAAAAAAEAAAAAAAAAAAAAAAAAAAAAAAAAAgMCAgICAgAAAgIAAgIAAgICAgICAgICAgAEAAAAAAACAgICAgICAgICAgICAgICAgICAgICAgICAgAAAAICAgICAgICAgICAgICAgICAgICAgICAgICAgICAAIAAgAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAABAAAAAAAAAAAAAAAAAAAAAAAAAAIAAgICAgIAAAICAAICAAICAgICAgICAgIAAwAEAAAAAgICAgICAgICAgICAgICAgICAgICAgICAgIAAAACAgICAgICAgICAgICAgICAgICAgICAgICAgICAgACAAIAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAABsb3NlZWVwLWFsaXZlAAAAAAAAAAAAAAAAAQAAAAAAAAAAAAAAAAAAAAAAAAAAAAABAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQABAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQAAAAAAAAAAAAEAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAQEBAQEBAQEBAQEBAgEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEAAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQFjaHVua2VkAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAABAQABAQEBAQAAAQEAAQEAAQEBAQEBAQEBAQAAAAAAAAABAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQAAAAEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAAEAAQAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAGVjdGlvbmVudC1sZW5ndGhvbnJveHktY29ubmVjdGlvbgAAAAAAAAAAAAAAAAAAAHJhbnNmZXItZW5jb2RpbmdwZ3JhZGUNCg0KDQpTTQ0KDQpUVFAvQ0UvVFNQLwAAAAAAAAAAAAAAAAECAAEDAAAAAAAAAAAAAAAAAAAAAAAABAEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEAAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEAAAAAAAAAAAABAgABAwAAAAAAAAAAAAAAAAAAAAAAAAQBAQUBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAAEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAAAAAAAAAAAAAQAAAQAAAAAAAAAAAAAAAAAAAAAAAAAAAQEAAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAAEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQABAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQAAAAAAAAAAAAABAAACAAAAAAAAAAAAAAAAAAAAAAAAAwQAAAQEBAQEBAQEBAQEBQQEBAQEBAQEBAQEBAAEAAYHBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEAAQABAAEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAAAAAQAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAQAAAQAAAAAAAAAAAAAAAAAAAAAAAAEAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAgAAAAAAAAMDAwMDAwMDAwMDAwMDAwMDAwMDAwMDAwMDAAAAAAAAAwMDAwMDAwMDAwMDAwMDAwMDAwMDAwMDAwMAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAEAAAEAAAAAAAAAAAAAAAAAAAAAAAABAAAAAAAAAAAAAgAAAAACAAAAAAAAAAAAAAAAAAAAAAADAwMDAwMDAwMDAwMDAwMDAwMDAwMDAwMDAwAAAAAAAAMDAwMDAwMDAwMDAwMDAwMDAwMDAwMDAwMDAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAE5PVU5DRUVDS09VVE5FQ1RFVEVDUklCRUxVU0hFVEVBRFNFQVJDSFJHRUNUSVZJVFlMRU5EQVJWRU9USUZZUFRJT05TQ0hTRUFZU1RBVENIR0VPUkRJUkVDVE9SVFJDSFBBUkFNRVRFUlVSQ0VCU0NSSUJFQVJET1dOQUNFSU5ETktDS1VCU0NSSUJFSFRUUC9BRFRQLw=='\n\n\n/***/ }),\n\n/***/ 1891:\n/***/ ((__unused_webpack_module, exports) => {\n\n\"use strict\";\n\nObject.defineProperty(exports, \"__esModule\", ({ value: true }));\nexports.enumToMap = void 0;\nfunction enumToMap(obj) {\n const res = {};\n Object.keys(obj).forEach((key) => {\n const value = obj[key];\n if (typeof value === 'number') {\n res[key] = value;\n }\n });\n return res;\n}\nexports.enumToMap = enumToMap;\n//# sourceMappingURL=utils.js.map\n\n/***/ }),\n\n/***/ 6771:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\n\"use strict\";\n\n\nconst { kClients } = __nccwpck_require__(2785)\nconst Agent = __nccwpck_require__(7890)\nconst {\n kAgent,\n kMockAgentSet,\n kMockAgentGet,\n kDispatches,\n kIsMockActive,\n kNetConnect,\n kGetNetConnect,\n kOptions,\n kFactory\n} = __nccwpck_require__(4347)\nconst MockClient = __nccwpck_require__(8687)\nconst MockPool = __nccwpck_require__(6193)\nconst { matchValue, buildMockOptions } = __nccwpck_require__(9323)\nconst { InvalidArgumentError, UndiciError } = __nccwpck_require__(8045)\nconst Dispatcher = __nccwpck_require__(412)\nconst Pluralizer = __nccwpck_require__(8891)\nconst PendingInterceptorsFormatter = __nccwpck_require__(6823)\n\nclass FakeWeakRef {\n constructor (value) {\n this.value = value\n }\n\n deref () {\n return this.value\n }\n}\n\nclass MockAgent extends Dispatcher {\n constructor (opts) {\n super(opts)\n\n this[kNetConnect] = true\n this[kIsMockActive] = true\n\n // Instantiate Agent and encapsulate\n if ((opts && opts.agent && typeof opts.agent.dispatch !== 'function')) {\n throw new InvalidArgumentError('Argument opts.agent must implement Agent')\n }\n const agent = opts && opts.agent ? opts.agent : new Agent(opts)\n this[kAgent] = agent\n\n this[kClients] = agent[kClients]\n this[kOptions] = buildMockOptions(opts)\n }\n\n get (origin) {\n let dispatcher = this[kMockAgentGet](origin)\n\n if (!dispatcher) {\n dispatcher = this[kFactory](origin)\n this[kMockAgentSet](origin, dispatcher)\n }\n return dispatcher\n }\n\n dispatch (opts, handler) {\n // Call MockAgent.get to perform additional setup before dispatching as normal\n this.get(opts.origin)\n return this[kAgent].dispatch(opts, handler)\n }\n\n async close () {\n await this[kAgent].close()\n this[kClients].clear()\n }\n\n deactivate () {\n this[kIsMockActive] = false\n }\n\n activate () {\n this[kIsMockActive] = true\n }\n\n enableNetConnect (matcher) {\n if (typeof matcher === 'string' || typeof matcher === 'function' || matcher instanceof RegExp) {\n if (Array.isArray(this[kNetConnect])) {\n this[kNetConnect].push(matcher)\n } else {\n this[kNetConnect] = [matcher]\n }\n } else if (typeof matcher === 'undefined') {\n this[kNetConnect] = true\n } else {\n throw new InvalidArgumentError('Unsupported matcher. Must be one of String|Function|RegExp.')\n }\n }\n\n disableNetConnect () {\n this[kNetConnect] = false\n }\n\n // This is required to bypass issues caused by using global symbols - see:\n // https://github.com/nodejs/undici/issues/1447\n get isMockActive () {\n return this[kIsMockActive]\n }\n\n [kMockAgentSet] (origin, dispatcher) {\n this[kClients].set(origin, new FakeWeakRef(dispatcher))\n }\n\n [kFactory] (origin) {\n const mockOptions = Object.assign({ agent: this }, this[kOptions])\n return this[kOptions] && this[kOptions].connections === 1\n ? new MockClient(origin, mockOptions)\n : new MockPool(origin, mockOptions)\n }\n\n [kMockAgentGet] (origin) {\n // First check if we can immediately find it\n const ref = this[kClients].get(origin)\n if (ref) {\n return ref.deref()\n }\n\n // If the origin is not a string create a dummy parent pool and return to user\n if (typeof origin !== 'string') {\n const dispatcher = this[kFactory]('http://localhost:9999')\n this[kMockAgentSet](origin, dispatcher)\n return dispatcher\n }\n\n // If we match, create a pool and assign the same dispatches\n for (const [keyMatcher, nonExplicitRef] of Array.from(this[kClients])) {\n const nonExplicitDispatcher = nonExplicitRef.deref()\n if (nonExplicitDispatcher && typeof keyMatcher !== 'string' && matchValue(keyMatcher, origin)) {\n const dispatcher = this[kFactory](origin)\n this[kMockAgentSet](origin, dispatcher)\n dispatcher[kDispatches] = nonExplicitDispatcher[kDispatches]\n return dispatcher\n }\n }\n }\n\n [kGetNetConnect] () {\n return this[kNetConnect]\n }\n\n pendingInterceptors () {\n const mockAgentClients = this[kClients]\n\n return Array.from(mockAgentClients.entries())\n .flatMap(([origin, scope]) => scope.deref()[kDispatches].map(dispatch => ({ ...dispatch, origin })))\n .filter(({ pending }) => pending)\n }\n\n assertNoPendingInterceptors ({ pendingInterceptorsFormatter = new PendingInterceptorsFormatter() } = {}) {\n const pending = this.pendingInterceptors()\n\n if (pending.length === 0) {\n return\n }\n\n const pluralizer = new Pluralizer('interceptor', 'interceptors').pluralize(pending.length)\n\n throw new UndiciError(`\n${pluralizer.count} ${pluralizer.noun} ${pluralizer.is} pending:\n\n${pendingInterceptorsFormatter.format(pending)}\n`.trim())\n }\n}\n\nmodule.exports = MockAgent\n\n\n/***/ }),\n\n/***/ 8687:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\n\"use strict\";\n\n\nconst { promisify } = __nccwpck_require__(3837)\nconst Client = __nccwpck_require__(3598)\nconst { buildMockDispatch } = __nccwpck_require__(9323)\nconst {\n kDispatches,\n kMockAgent,\n kClose,\n kOriginalClose,\n kOrigin,\n kOriginalDispatch,\n kConnected\n} = __nccwpck_require__(4347)\nconst { MockInterceptor } = __nccwpck_require__(410)\nconst Symbols = __nccwpck_require__(2785)\nconst { InvalidArgumentError } = __nccwpck_require__(8045)\n\n/**\n * MockClient provides an API that extends the Client to influence the mockDispatches.\n */\nclass MockClient extends Client {\n constructor (origin, opts) {\n super(origin, opts)\n\n if (!opts || !opts.agent || typeof opts.agent.dispatch !== 'function') {\n throw new InvalidArgumentError('Argument opts.agent must implement Agent')\n }\n\n this[kMockAgent] = opts.agent\n this[kOrigin] = origin\n this[kDispatches] = []\n this[kConnected] = 1\n this[kOriginalDispatch] = this.dispatch\n this[kOriginalClose] = this.close.bind(this)\n\n this.dispatch = buildMockDispatch.call(this)\n this.close = this[kClose]\n }\n\n get [Symbols.kConnected] () {\n return this[kConnected]\n }\n\n /**\n * Sets up the base interceptor for mocking replies from undici.\n */\n intercept (opts) {\n return new MockInterceptor(opts, this[kDispatches])\n }\n\n async [kClose] () {\n await promisify(this[kOriginalClose])()\n this[kConnected] = 0\n this[kMockAgent][Symbols.kClients].delete(this[kOrigin])\n }\n}\n\nmodule.exports = MockClient\n\n\n/***/ }),\n\n/***/ 888:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\n\"use strict\";\n\n\nconst { UndiciError } = __nccwpck_require__(8045)\n\nclass MockNotMatchedError extends UndiciError {\n constructor (message) {\n super(message)\n Error.captureStackTrace(this, MockNotMatchedError)\n this.name = 'MockNotMatchedError'\n this.message = message || 'The request does not match any registered mock dispatches'\n this.code = 'UND_MOCK_ERR_MOCK_NOT_MATCHED'\n }\n}\n\nmodule.exports = {\n MockNotMatchedError\n}\n\n\n/***/ }),\n\n/***/ 410:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\n\"use strict\";\n\n\nconst { getResponseData, buildKey, addMockDispatch } = __nccwpck_require__(9323)\nconst {\n kDispatches,\n kDispatchKey,\n kDefaultHeaders,\n kDefaultTrailers,\n kContentLength,\n kMockDispatch\n} = __nccwpck_require__(4347)\nconst { InvalidArgumentError } = __nccwpck_require__(8045)\nconst { buildURL } = __nccwpck_require__(3983)\n\n/**\n * Defines the scope API for an interceptor reply\n */\nclass MockScope {\n constructor (mockDispatch) {\n this[kMockDispatch] = mockDispatch\n }\n\n /**\n * Delay a reply by a set amount in ms.\n */\n delay (waitInMs) {\n if (typeof waitInMs !== 'number' || !Number.isInteger(waitInMs) || waitInMs <= 0) {\n throw new InvalidArgumentError('waitInMs must be a valid integer > 0')\n }\n\n this[kMockDispatch].delay = waitInMs\n return this\n }\n\n /**\n * For a defined reply, never mark as consumed.\n */\n persist () {\n this[kMockDispatch].persist = true\n return this\n }\n\n /**\n * Allow one to define a reply for a set amount of matching requests.\n */\n times (repeatTimes) {\n if (typeof repeatTimes !== 'number' || !Number.isInteger(repeatTimes) || repeatTimes <= 0) {\n throw new InvalidArgumentError('repeatTimes must be a valid integer > 0')\n }\n\n this[kMockDispatch].times = repeatTimes\n return this\n }\n}\n\n/**\n * Defines an interceptor for a Mock\n */\nclass MockInterceptor {\n constructor (opts, mockDispatches) {\n if (typeof opts !== 'object') {\n throw new InvalidArgumentError('opts must be an object')\n }\n if (typeof opts.path === 'undefined') {\n throw new InvalidArgumentError('opts.path must be defined')\n }\n if (typeof opts.method === 'undefined') {\n opts.method = 'GET'\n }\n // See https://github.com/nodejs/undici/issues/1245\n // As per RFC 3986, clients are not supposed to send URI\n // fragments to servers when they retrieve a document,\n if (typeof opts.path === 'string') {\n if (opts.query) {\n opts.path = buildURL(opts.path, opts.query)\n } else {\n // Matches https://github.com/nodejs/undici/blob/main/lib/fetch/index.js#L1811\n const parsedURL = new URL(opts.path, 'data://')\n opts.path = parsedURL.pathname + parsedURL.search\n }\n }\n if (typeof opts.method === 'string') {\n opts.method = opts.method.toUpperCase()\n }\n\n this[kDispatchKey] = buildKey(opts)\n this[kDispatches] = mockDispatches\n this[kDefaultHeaders] = {}\n this[kDefaultTrailers] = {}\n this[kContentLength] = false\n }\n\n createMockScopeDispatchData (statusCode, data, responseOptions = {}) {\n const responseData = getResponseData(data)\n const contentLength = this[kContentLength] ? { 'content-length': responseData.length } : {}\n const headers = { ...this[kDefaultHeaders], ...contentLength, ...responseOptions.headers }\n const trailers = { ...this[kDefaultTrailers], ...responseOptions.trailers }\n\n return { statusCode, data, headers, trailers }\n }\n\n validateReplyParameters (statusCode, data, responseOptions) {\n if (typeof statusCode === 'undefined') {\n throw new InvalidArgumentError('statusCode must be defined')\n }\n if (typeof data === 'undefined') {\n throw new InvalidArgumentError('data must be defined')\n }\n if (typeof responseOptions !== 'object') {\n throw new InvalidArgumentError('responseOptions must be an object')\n }\n }\n\n /**\n * Mock an undici request with a defined reply.\n */\n reply (replyData) {\n // Values of reply aren't available right now as they\n // can only be available when the reply callback is invoked.\n if (typeof replyData === 'function') {\n // We'll first wrap the provided callback in another function,\n // this function will properly resolve the data from the callback\n // when invoked.\n const wrappedDefaultsCallback = (opts) => {\n // Our reply options callback contains the parameter for statusCode, data and options.\n const resolvedData = replyData(opts)\n\n // Check if it is in the right format\n if (typeof resolvedData !== 'object') {\n throw new InvalidArgumentError('reply options callback must return an object')\n }\n\n const { statusCode, data = '', responseOptions = {} } = resolvedData\n this.validateReplyParameters(statusCode, data, responseOptions)\n // Since the values can be obtained immediately we return them\n // from this higher order function that will be resolved later.\n return {\n ...this.createMockScopeDispatchData(statusCode, data, responseOptions)\n }\n }\n\n // Add usual dispatch data, but this time set the data parameter to function that will eventually provide data.\n const newMockDispatch = addMockDispatch(this[kDispatches], this[kDispatchKey], wrappedDefaultsCallback)\n return new MockScope(newMockDispatch)\n }\n\n // We can have either one or three parameters, if we get here,\n // we should have 1-3 parameters. So we spread the arguments of\n // this function to obtain the parameters, since replyData will always\n // just be the statusCode.\n const [statusCode, data = '', responseOptions = {}] = [...arguments]\n this.validateReplyParameters(statusCode, data, responseOptions)\n\n // Send in-already provided data like usual\n const dispatchData = this.createMockScopeDispatchData(statusCode, data, responseOptions)\n const newMockDispatch = addMockDispatch(this[kDispatches], this[kDispatchKey], dispatchData)\n return new MockScope(newMockDispatch)\n }\n\n /**\n * Mock an undici request with a defined error.\n */\n replyWithError (error) {\n if (typeof error === 'undefined') {\n throw new InvalidArgumentError('error must be defined')\n }\n\n const newMockDispatch = addMockDispatch(this[kDispatches], this[kDispatchKey], { error })\n return new MockScope(newMockDispatch)\n }\n\n /**\n * Set default reply headers on the interceptor for subsequent replies\n */\n defaultReplyHeaders (headers) {\n if (typeof headers === 'undefined') {\n throw new InvalidArgumentError('headers must be defined')\n }\n\n this[kDefaultHeaders] = headers\n return this\n }\n\n /**\n * Set default reply trailers on the interceptor for subsequent replies\n */\n defaultReplyTrailers (trailers) {\n if (typeof trailers === 'undefined') {\n throw new InvalidArgumentError('trailers must be defined')\n }\n\n this[kDefaultTrailers] = trailers\n return this\n }\n\n /**\n * Set reply content length header for replies on the interceptor\n */\n replyContentLength () {\n this[kContentLength] = true\n return this\n }\n}\n\nmodule.exports.MockInterceptor = MockInterceptor\nmodule.exports.MockScope = MockScope\n\n\n/***/ }),\n\n/***/ 6193:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\n\"use strict\";\n\n\nconst { promisify } = __nccwpck_require__(3837)\nconst Pool = __nccwpck_require__(4634)\nconst { buildMockDispatch } = __nccwpck_require__(9323)\nconst {\n kDispatches,\n kMockAgent,\n kClose,\n kOriginalClose,\n kOrigin,\n kOriginalDispatch,\n kConnected\n} = __nccwpck_require__(4347)\nconst { MockInterceptor } = __nccwpck_require__(410)\nconst Symbols = __nccwpck_require__(2785)\nconst { InvalidArgumentError } = __nccwpck_require__(8045)\n\n/**\n * MockPool provides an API that extends the Pool to influence the mockDispatches.\n */\nclass MockPool extends Pool {\n constructor (origin, opts) {\n super(origin, opts)\n\n if (!opts || !opts.agent || typeof opts.agent.dispatch !== 'function') {\n throw new InvalidArgumentError('Argument opts.agent must implement Agent')\n }\n\n this[kMockAgent] = opts.agent\n this[kOrigin] = origin\n this[kDispatches] = []\n this[kConnected] = 1\n this[kOriginalDispatch] = this.dispatch\n this[kOriginalClose] = this.close.bind(this)\n\n this.dispatch = buildMockDispatch.call(this)\n this.close = this[kClose]\n }\n\n get [Symbols.kConnected] () {\n return this[kConnected]\n }\n\n /**\n * Sets up the base interceptor for mocking replies from undici.\n */\n intercept (opts) {\n return new MockInterceptor(opts, this[kDispatches])\n }\n\n async [kClose] () {\n await promisify(this[kOriginalClose])()\n this[kConnected] = 0\n this[kMockAgent][Symbols.kClients].delete(this[kOrigin])\n }\n}\n\nmodule.exports = MockPool\n\n\n/***/ }),\n\n/***/ 4347:\n/***/ ((module) => {\n\n\"use strict\";\n\n\nmodule.exports = {\n kAgent: Symbol('agent'),\n kOptions: Symbol('options'),\n kFactory: Symbol('factory'),\n kDispatches: Symbol('dispatches'),\n kDispatchKey: Symbol('dispatch key'),\n kDefaultHeaders: Symbol('default headers'),\n kDefaultTrailers: Symbol('default trailers'),\n kContentLength: Symbol('content length'),\n kMockAgent: Symbol('mock agent'),\n kMockAgentSet: Symbol('mock agent set'),\n kMockAgentGet: Symbol('mock agent get'),\n kMockDispatch: Symbol('mock dispatch'),\n kClose: Symbol('close'),\n kOriginalClose: Symbol('original agent close'),\n kOrigin: Symbol('origin'),\n kIsMockActive: Symbol('is mock active'),\n kNetConnect: Symbol('net connect'),\n kGetNetConnect: Symbol('get net connect'),\n kConnected: Symbol('connected')\n}\n\n\n/***/ }),\n\n/***/ 9323:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\n\"use strict\";\n\n\nconst { MockNotMatchedError } = __nccwpck_require__(888)\nconst {\n kDispatches,\n kMockAgent,\n kOriginalDispatch,\n kOrigin,\n kGetNetConnect\n} = __nccwpck_require__(4347)\nconst { buildURL, nop } = __nccwpck_require__(3983)\nconst { STATUS_CODES } = __nccwpck_require__(3685)\nconst {\n types: {\n isPromise\n }\n} = __nccwpck_require__(3837)\n\nfunction matchValue (match, value) {\n if (typeof match === 'string') {\n return match === value\n }\n if (match instanceof RegExp) {\n return match.test(value)\n }\n if (typeof match === 'function') {\n return match(value) === true\n }\n return false\n}\n\nfunction lowerCaseEntries (headers) {\n return Object.fromEntries(\n Object.entries(headers).map(([headerName, headerValue]) => {\n return [headerName.toLocaleLowerCase(), headerValue]\n })\n )\n}\n\n/**\n * @param {import('../../index').Headers|string[]|Record<string, string>} headers\n * @param {string} key\n */\nfunction getHeaderByName (headers, key) {\n if (Array.isArray(headers)) {\n for (let i = 0; i < headers.length; i += 2) {\n if (headers[i].toLocaleLowerCase() === key.toLocaleLowerCase()) {\n return headers[i + 1]\n }\n }\n\n return undefined\n } else if (typeof headers.get === 'function') {\n return headers.get(key)\n } else {\n return lowerCaseEntries(headers)[key.toLocaleLowerCase()]\n }\n}\n\n/** @param {string[]} headers */\nfunction buildHeadersFromArray (headers) { // fetch HeadersList\n const clone = headers.slice()\n const entries = []\n for (let index = 0; index < clone.length; index += 2) {\n entries.push([clone[index], clone[index + 1]])\n }\n return Object.fromEntries(entries)\n}\n\nfunction matchHeaders (mockDispatch, headers) {\n if (typeof mockDispatch.headers === 'function') {\n if (Array.isArray(headers)) { // fetch HeadersList\n headers = buildHeadersFromArray(headers)\n }\n return mockDispatch.headers(headers ? lowerCaseEntries(headers) : {})\n }\n if (typeof mockDispatch.headers === 'undefined') {\n return true\n }\n if (typeof headers !== 'object' || typeof mockDispatch.headers !== 'object') {\n return false\n }\n\n for (const [matchHeaderName, matchHeaderValue] of Object.entries(mockDispatch.headers)) {\n const headerValue = getHeaderByName(headers, matchHeaderName)\n\n if (!matchValue(matchHeaderValue, headerValue)) {\n return false\n }\n }\n return true\n}\n\nfunction safeUrl (path) {\n if (typeof path !== 'string') {\n return path\n }\n\n const pathSegments = path.split('?')\n\n if (pathSegments.length !== 2) {\n return path\n }\n\n const qp = new URLSearchParams(pathSegments.pop())\n qp.sort()\n return [...pathSegments, qp.toString()].join('?')\n}\n\nfunction matchKey (mockDispatch, { path, method, body, headers }) {\n const pathMatch = matchValue(mockDispatch.path, path)\n const methodMatch = matchValue(mockDispatch.method, method)\n const bodyMatch = typeof mockDispatch.body !== 'undefined' ? matchValue(mockDispatch.body, body) : true\n const headersMatch = matchHeaders(mockDispatch, headers)\n return pathMatch && methodMatch && bodyMatch && headersMatch\n}\n\nfunction getResponseData (data) {\n if (Buffer.isBuffer(data)) {\n return data\n } else if (typeof data === 'object') {\n return JSON.stringify(data)\n } else {\n return data.toString()\n }\n}\n\nfunction getMockDispatch (mockDispatches, key) {\n const basePath = key.query ? buildURL(key.path, key.query) : key.path\n const resolvedPath = typeof basePath === 'string' ? safeUrl(basePath) : basePath\n\n // Match path\n let matchedMockDispatches = mockDispatches.filter(({ consumed }) => !consumed).filter(({ path }) => matchValue(safeUrl(path), resolvedPath))\n if (matchedMockDispatches.length === 0) {\n throw new MockNotMatchedError(`Mock dispatch not matched for path '${resolvedPath}'`)\n }\n\n // Match method\n matchedMockDispatches = matchedMockDispatches.filter(({ method }) => matchValue(method, key.method))\n if (matchedMockDispatches.length === 0) {\n throw new MockNotMatchedError(`Mock dispatch not matched for method '${key.method}'`)\n }\n\n // Match body\n matchedMockDispatches = matchedMockDispatches.filter(({ body }) => typeof body !== 'undefined' ? matchValue(body, key.body) : true)\n if (matchedMockDispatches.length === 0) {\n throw new MockNotMatchedError(`Mock dispatch not matched for body '${key.body}'`)\n }\n\n // Match headers\n matchedMockDispatches = matchedMockDispatches.filter((mockDispatch) => matchHeaders(mockDispatch, key.headers))\n if (matchedMockDispatches.length === 0) {\n throw new MockNotMatchedError(`Mock dispatch not matched for headers '${typeof key.headers === 'object' ? JSON.stringify(key.headers) : key.headers}'`)\n }\n\n return matchedMockDispatches[0]\n}\n\nfunction addMockDispatch (mockDispatches, key, data) {\n const baseData = { timesInvoked: 0, times: 1, persist: false, consumed: false }\n const replyData = typeof data === 'function' ? { callback: data } : { ...data }\n const newMockDispatch = { ...baseData, ...key, pending: true, data: { error: null, ...replyData } }\n mockDispatches.push(newMockDispatch)\n return newMockDispatch\n}\n\nfunction deleteMockDispatch (mockDispatches, key) {\n const index = mockDispatches.findIndex(dispatch => {\n if (!dispatch.consumed) {\n return false\n }\n return matchKey(dispatch, key)\n })\n if (index !== -1) {\n mockDispatches.splice(index, 1)\n }\n}\n\nfunction buildKey (opts) {\n const { path, method, body, headers, query } = opts\n return {\n path,\n method,\n body,\n headers,\n query\n }\n}\n\nfunction generateKeyValues (data) {\n return Object.entries(data).reduce((keyValuePairs, [key, value]) => [\n ...keyValuePairs,\n Buffer.from(`${key}`),\n Array.isArray(value) ? value.map(x => Buffer.from(`${x}`)) : Buffer.from(`${value}`)\n ], [])\n}\n\n/**\n * @see https://developer.mozilla.org/en-US/docs/Web/HTTP/Status\n * @param {number} statusCode\n */\nfunction getStatusText (statusCode) {\n return STATUS_CODES[statusCode] || 'unknown'\n}\n\nasync function getResponse (body) {\n const buffers = []\n for await (const data of body) {\n buffers.push(data)\n }\n return Buffer.concat(buffers).toString('utf8')\n}\n\n/**\n * Mock dispatch function used to simulate undici dispatches\n */\nfunction mockDispatch (opts, handler) {\n // Get mock dispatch from built key\n const key = buildKey(opts)\n const mockDispatch = getMockDispatch(this[kDispatches], key)\n\n mockDispatch.timesInvoked++\n\n // Here's where we resolve a callback if a callback is present for the dispatch data.\n if (mockDispatch.data.callback) {\n mockDispatch.data = { ...mockDispatch.data, ...mockDispatch.data.callback(opts) }\n }\n\n // Parse mockDispatch data\n const { data: { statusCode, data, headers, trailers, error }, delay, persist } = mockDispatch\n const { timesInvoked, times } = mockDispatch\n\n // If it's used up and not persistent, mark as consumed\n mockDispatch.consumed = !persist && timesInvoked >= times\n mockDispatch.pending = timesInvoked < times\n\n // If specified, trigger dispatch error\n if (error !== null) {\n deleteMockDispatch(this[kDispatches], key)\n handler.onError(error)\n return true\n }\n\n // Handle the request with a delay if necessary\n if (typeof delay === 'number' && delay > 0) {\n setTimeout(() => {\n handleReply(this[kDispatches])\n }, delay)\n } else {\n handleReply(this[kDispatches])\n }\n\n function handleReply (mockDispatches, _data = data) {\n // fetch's HeadersList is a 1D string array\n const optsHeaders = Array.isArray(opts.headers)\n ? buildHeadersFromArray(opts.headers)\n : opts.headers\n const body = typeof _data === 'function'\n ? _data({ ...opts, headers: optsHeaders })\n : _data\n\n // util.types.isPromise is likely needed for jest.\n if (isPromise(body)) {\n // If handleReply is asynchronous, throwing an error\n // in the callback will reject the promise, rather than\n // synchronously throw the error, which breaks some tests.\n // Rather, we wait for the callback to resolve if it is a\n // promise, and then re-run handleReply with the new body.\n body.then((newData) => handleReply(mockDispatches, newData))\n return\n }\n\n const responseData = getResponseData(body)\n const responseHeaders = generateKeyValues(headers)\n const responseTrailers = generateKeyValues(trailers)\n\n handler.abort = nop\n handler.onHeaders(statusCode, responseHeaders, resume, getStatusText(statusCode))\n handler.onData(Buffer.from(responseData))\n handler.onComplete(responseTrailers)\n deleteMockDispatch(mockDispatches, key)\n }\n\n function resume () {}\n\n return true\n}\n\nfunction buildMockDispatch () {\n const agent = this[kMockAgent]\n const origin = this[kOrigin]\n const originalDispatch = this[kOriginalDispatch]\n\n return function dispatch (opts, handler) {\n if (agent.isMockActive) {\n try {\n mockDispatch.call(this, opts, handler)\n } catch (error) {\n if (error instanceof MockNotMatchedError) {\n const netConnect = agent[kGetNetConnect]()\n if (netConnect === false) {\n throw new MockNotMatchedError(`${error.message}: subsequent request to origin ${origin} was not allowed (net.connect disabled)`)\n }\n if (checkNetConnect(netConnect, origin)) {\n originalDispatch.call(this, opts, handler)\n } else {\n throw new MockNotMatchedError(`${error.message}: subsequent request to origin ${origin} was not allowed (net.connect is not enabled for this origin)`)\n }\n } else {\n throw error\n }\n }\n } else {\n originalDispatch.call(this, opts, handler)\n }\n }\n}\n\nfunction checkNetConnect (netConnect, origin) {\n const url = new URL(origin)\n if (netConnect === true) {\n return true\n } else if (Array.isArray(netConnect) && netConnect.some((matcher) => matchValue(matcher, url.host))) {\n return true\n }\n return false\n}\n\nfunction buildMockOptions (opts) {\n if (opts) {\n const { agent, ...mockOptions } = opts\n return mockOptions\n }\n}\n\nmodule.exports = {\n getResponseData,\n getMockDispatch,\n addMockDispatch,\n deleteMockDispatch,\n buildKey,\n generateKeyValues,\n matchValue,\n getResponse,\n getStatusText,\n mockDispatch,\n buildMockDispatch,\n checkNetConnect,\n buildMockOptions,\n getHeaderByName\n}\n\n\n/***/ }),\n\n/***/ 6823:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\n\"use strict\";\n\n\nconst { Transform } = __nccwpck_require__(2781)\nconst { Console } = __nccwpck_require__(6206)\n\n/**\n * Gets the output of `console.table(\u2026)` as a string.\n */\nmodule.exports = class PendingInterceptorsFormatter {\n constructor ({ disableColors } = {}) {\n this.transform = new Transform({\n transform (chunk, _enc, cb) {\n cb(null, chunk)\n }\n })\n\n this.logger = new Console({\n stdout: this.transform,\n inspectOptions: {\n colors: !disableColors && !process.env.CI\n }\n })\n }\n\n format (pendingInterceptors) {\n const withPrettyHeaders = pendingInterceptors.map(\n ({ method, path, data: { statusCode }, persist, times, timesInvoked, origin }) => ({\n Method: method,\n Origin: origin,\n Path: path,\n 'Status code': statusCode,\n Persistent: persist ? '\u2705' : '\u274c',\n Invocations: timesInvoked,\n Remaining: persist ? Infinity : times - timesInvoked\n }))\n\n this.logger.table(withPrettyHeaders)\n return this.transform.read().toString()\n }\n}\n\n\n/***/ }),\n\n/***/ 8891:\n/***/ ((module) => {\n\n\"use strict\";\n\n\nconst singulars = {\n pronoun: 'it',\n is: 'is',\n was: 'was',\n this: 'this'\n}\n\nconst plurals = {\n pronoun: 'they',\n is: 'are',\n was: 'were',\n this: 'these'\n}\n\nmodule.exports = class Pluralizer {\n constructor (singular, plural) {\n this.singular = singular\n this.plural = plural\n }\n\n pluralize (count) {\n const one = count === 1\n const keys = one ? singulars : plurals\n const noun = one ? this.singular : this.plural\n return { ...keys, count, noun }\n }\n}\n\n\n/***/ }),\n\n/***/ 8266:\n/***/ ((module) => {\n\n\"use strict\";\n/* eslint-disable */\n\n\n\n// Extracted from node/lib/internal/fixed_queue.js\n\n// Currently optimal queue size, tested on V8 6.0 - 6.6. Must be power of two.\nconst kSize = 2048;\nconst kMask = kSize - 1;\n\n// The FixedQueue is implemented as a singly-linked list of fixed-size\n// circular buffers. It looks something like this:\n//\n// head tail\n// | |\n// v v\n// +-----------+ <-----\\ +-----------+ <------\\ +-----------+\n// | [null] | \\----- | next | \\------- | next |\n// +-----------+ +-----------+ +-----------+\n// | item | <-- bottom | item | <-- bottom | [empty] |\n// | item | | item | | [empty] |\n// | item | | item | | [empty] |\n// | item | | item | | [empty] |\n// | item | | item | bottom --> | item |\n// | item | | item | | item |\n// | ... | | ... | | ... |\n// | item | | item | | item |\n// | item | | item | | item |\n// | [empty] | <-- top | item | | item |\n// | [empty] | | item | | item |\n// | [empty] | | [empty] | <-- top top --> | [empty] |\n// +-----------+ +-----------+ +-----------+\n//\n// Or, if there is only one circular buffer, it looks something\n// like either of these:\n//\n// head tail head tail\n// | | | |\n// v v v v\n// +-----------+ +-----------+\n// | [null] | | [null] |\n// +-----------+ +-----------+\n// | [empty] | | item |\n// | [empty] | | item |\n// | item | <-- bottom top --> | [empty] |\n// | item | | [empty] |\n// | [empty] | <-- top bottom --> | item |\n// | [empty] | | item |\n// +-----------+ +-----------+\n//\n// Adding a value means moving `top` forward by one, removing means\n// moving `bottom` forward by one. After reaching the end, the queue\n// wraps around.\n//\n// When `top === bottom` the current queue is empty and when\n// `top + 1 === bottom` it's full. This wastes a single space of storage\n// but allows much quicker checks.\n\nclass FixedCircularBuffer {\n constructor() {\n this.bottom = 0;\n this.top = 0;\n this.list = new Array(kSize);\n this.next = null;\n }\n\n isEmpty() {\n return this.top === this.bottom;\n }\n\n isFull() {\n return ((this.top + 1) & kMask) === this.bottom;\n }\n\n push(data) {\n this.list[this.top] = data;\n this.top = (this.top + 1) & kMask;\n }\n\n shift() {\n const nextItem = this.list[this.bottom];\n if (nextItem === undefined)\n return null;\n this.list[this.bottom] = undefined;\n this.bottom = (this.bottom + 1) & kMask;\n return nextItem;\n }\n}\n\nmodule.exports = class FixedQueue {\n constructor() {\n this.head = this.tail = new FixedCircularBuffer();\n }\n\n isEmpty() {\n return this.head.isEmpty();\n }\n\n push(data) {\n if (this.head.isFull()) {\n // Head is full: Creates a new queue, sets the old queue's `.next` to it,\n // and sets it as the new main queue.\n this.head = this.head.next = new FixedCircularBuffer();\n }\n this.head.push(data);\n }\n\n shift() {\n const tail = this.tail;\n const next = tail.shift();\n if (tail.isEmpty() && tail.next !== null) {\n // If there is another queue, it forms the new tail.\n this.tail = tail.next;\n }\n return next;\n }\n};\n\n\n/***/ }),\n\n/***/ 3198:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\n\"use strict\";\n\n\nconst DispatcherBase = __nccwpck_require__(4839)\nconst FixedQueue = __nccwpck_require__(8266)\nconst { kConnected, kSize, kRunning, kPending, kQueued, kBusy, kFree, kUrl, kClose, kDestroy, kDispatch } = __nccwpck_require__(2785)\nconst PoolStats = __nccwpck_require__(9689)\n\nconst kClients = Symbol('clients')\nconst kNeedDrain = Symbol('needDrain')\nconst kQueue = Symbol('queue')\nconst kClosedResolve = Symbol('closed resolve')\nconst kOnDrain = Symbol('onDrain')\nconst kOnConnect = Symbol('onConnect')\nconst kOnDisconnect = Symbol('onDisconnect')\nconst kOnConnectionError = Symbol('onConnectionError')\nconst kGetDispatcher = Symbol('get dispatcher')\nconst kAddClient = Symbol('add client')\nconst kRemoveClient = Symbol('remove client')\nconst kStats = Symbol('stats')\n\nclass PoolBase extends DispatcherBase {\n constructor () {\n super()\n\n this[kQueue] = new FixedQueue()\n this[kClients] = []\n this[kQueued] = 0\n\n const pool = this\n\n this[kOnDrain] = function onDrain (origin, targets) {\n const queue = pool[kQueue]\n\n let needDrain = false\n\n while (!needDrain) {\n const item = queue.shift()\n if (!item) {\n break\n }\n pool[kQueued]--\n needDrain = !this.dispatch(item.opts, item.handler)\n }\n\n this[kNeedDrain] = needDrain\n\n if (!this[kNeedDrain] && pool[kNeedDrain]) {\n pool[kNeedDrain] = false\n pool.emit('drain', origin, [pool, ...targets])\n }\n\n if (pool[kClosedResolve] && queue.isEmpty()) {\n Promise\n .all(pool[kClients].map(c => c.close()))\n .then(pool[kClosedResolve])\n }\n }\n\n this[kOnConnect] = (origin, targets) => {\n pool.emit('connect', origin, [pool, ...targets])\n }\n\n this[kOnDisconnect] = (origin, targets, err) => {\n pool.emit('disconnect', origin, [pool, ...targets], err)\n }\n\n this[kOnConnectionError] = (origin, targets, err) => {\n pool.emit('connectionError', origin, [pool, ...targets], err)\n }\n\n this[kStats] = new PoolStats(this)\n }\n\n get [kBusy] () {\n return this[kNeedDrain]\n }\n\n get [kConnected] () {\n return this[kClients].filter(client => client[kConnected]).length\n }\n\n get [kFree] () {\n return this[kClients].filter(client => client[kConnected] && !client[kNeedDrain]).length\n }\n\n get [kPending] () {\n let ret = this[kQueued]\n for (const { [kPending]: pending } of this[kClients]) {\n ret += pending\n }\n return ret\n }\n\n get [kRunning] () {\n let ret = 0\n for (const { [kRunning]: running } of this[kClients]) {\n ret += running\n }\n return ret\n }\n\n get [kSize] () {\n let ret = this[kQueued]\n for (const { [kSize]: size } of this[kClients]) {\n ret += size\n }\n return ret\n }\n\n get stats () {\n return this[kStats]\n }\n\n async [kClose] () {\n if (this[kQueue].isEmpty()) {\n return Promise.all(this[kClients].map(c => c.close()))\n } else {\n return new Promise((resolve) => {\n this[kClosedResolve] = resolve\n })\n }\n }\n\n async [kDestroy] (err) {\n while (true) {\n const item = this[kQueue].shift()\n if (!item) {\n break\n }\n item.handler.onError(err)\n }\n\n return Promise.all(this[kClients].map(c => c.destroy(err)))\n }\n\n [kDispatch] (opts, handler) {\n const dispatcher = this[kGetDispatcher]()\n\n if (!dispatcher) {\n this[kNeedDrain] = true\n this[kQueue].push({ opts, handler })\n this[kQueued]++\n } else if (!dispatcher.dispatch(opts, handler)) {\n dispatcher[kNeedDrain] = true\n this[kNeedDrain] = !this[kGetDispatcher]()\n }\n\n return !this[kNeedDrain]\n }\n\n [kAddClient] (client) {\n client\n .on('drain', this[kOnDrain])\n .on('connect', this[kOnConnect])\n .on('disconnect', this[kOnDisconnect])\n .on('connectionError', this[kOnConnectionError])\n\n this[kClients].push(client)\n\n if (this[kNeedDrain]) {\n process.nextTick(() => {\n if (this[kNeedDrain]) {\n this[kOnDrain](client[kUrl], [this, client])\n }\n })\n }\n\n return this\n }\n\n [kRemoveClient] (client) {\n client.close(() => {\n const idx = this[kClients].indexOf(client)\n if (idx !== -1) {\n this[kClients].splice(idx, 1)\n }\n })\n\n this[kNeedDrain] = this[kClients].some(dispatcher => (\n !dispatcher[kNeedDrain] &&\n dispatcher.closed !== true &&\n dispatcher.destroyed !== true\n ))\n }\n}\n\nmodule.exports = {\n PoolBase,\n kClients,\n kNeedDrain,\n kAddClient,\n kRemoveClient,\n kGetDispatcher\n}\n\n\n/***/ }),\n\n/***/ 9689:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\nconst { kFree, kConnected, kPending, kQueued, kRunning, kSize } = __nccwpck_require__(2785)\nconst kPool = Symbol('pool')\n\nclass PoolStats {\n constructor (pool) {\n this[kPool] = pool\n }\n\n get connected () {\n return this[kPool][kConnected]\n }\n\n get free () {\n return this[kPool][kFree]\n }\n\n get pending () {\n return this[kPool][kPending]\n }\n\n get queued () {\n return this[kPool][kQueued]\n }\n\n get running () {\n return this[kPool][kRunning]\n }\n\n get size () {\n return this[kPool][kSize]\n }\n}\n\nmodule.exports = PoolStats\n\n\n/***/ }),\n\n/***/ 4634:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\n\"use strict\";\n\n\nconst {\n PoolBase,\n kClients,\n kNeedDrain,\n kAddClient,\n kGetDispatcher\n} = __nccwpck_require__(3198)\nconst Client = __nccwpck_require__(3598)\nconst {\n InvalidArgumentError\n} = __nccwpck_require__(8045)\nconst util = __nccwpck_require__(3983)\nconst { kUrl, kInterceptors } = __nccwpck_require__(2785)\nconst buildConnector = __nccwpck_require__(2067)\n\nconst kOptions = Symbol('options')\nconst kConnections = Symbol('connections')\nconst kFactory = Symbol('factory')\n\nfunction defaultFactory (origin, opts) {\n return new Client(origin, opts)\n}\n\nclass Pool extends PoolBase {\n constructor (origin, {\n connections,\n factory = defaultFactory,\n connect,\n connectTimeout,\n tls,\n maxCachedSessions,\n socketPath,\n autoSelectFamily,\n autoSelectFamilyAttemptTimeout,\n allowH2,\n ...options\n } = {}) {\n super()\n\n if (connections != null && (!Number.isFinite(connections) || connections < 0)) {\n throw new InvalidArgumentError('invalid connections')\n }\n\n if (typeof factory !== 'function') {\n throw new InvalidArgumentError('factory must be a function.')\n }\n\n if (connect != null && typeof connect !== 'function' && typeof connect !== 'object') {\n throw new InvalidArgumentError('connect must be a function or an object')\n }\n\n if (typeof connect !== 'function') {\n connect = buildConnector({\n ...tls,\n maxCachedSessions,\n allowH2,\n socketPath,\n timeout: connectTimeout,\n ...(util.nodeHasAutoSelectFamily && autoSelectFamily ? { autoSelectFamily, autoSelectFamilyAttemptTimeout } : undefined),\n ...connect\n })\n }\n\n this[kInterceptors] = options.interceptors && options.interceptors.Pool && Array.isArray(options.interceptors.Pool)\n ? options.interceptors.Pool\n : []\n this[kConnections] = connections || null\n this[kUrl] = util.parseOrigin(origin)\n this[kOptions] = { ...util.deepClone(options), connect, allowH2 }\n this[kOptions].interceptors = options.interceptors\n ? { ...options.interceptors }\n : undefined\n this[kFactory] = factory\n }\n\n [kGetDispatcher] () {\n let dispatcher = this[kClients].find(dispatcher => !dispatcher[kNeedDrain])\n\n if (dispatcher) {\n return dispatcher\n }\n\n if (!this[kConnections] || this[kClients].length < this[kConnections]) {\n dispatcher = this[kFactory](this[kUrl], this[kOptions])\n this[kAddClient](dispatcher)\n }\n\n return dispatcher\n }\n}\n\nmodule.exports = Pool\n\n\n/***/ }),\n\n/***/ 7858:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\n\"use strict\";\n\n\nconst { kProxy, kClose, kDestroy, kInterceptors } = __nccwpck_require__(2785)\nconst { URL } = __nccwpck_require__(7310)\nconst Agent = __nccwpck_require__(7890)\nconst Pool = __nccwpck_require__(4634)\nconst DispatcherBase = __nccwpck_require__(4839)\nconst { InvalidArgumentError, RequestAbortedError } = __nccwpck_require__(8045)\nconst buildConnector = __nccwpck_require__(2067)\n\nconst kAgent = Symbol('proxy agent')\nconst kClient = Symbol('proxy client')\nconst kProxyHeaders = Symbol('proxy headers')\nconst kRequestTls = Symbol('request tls settings')\nconst kProxyTls = Symbol('proxy tls settings')\nconst kConnectEndpoint = Symbol('connect endpoint function')\n\nfunction defaultProtocolPort (protocol) {\n return protocol === 'https:' ? 443 : 80\n}\n\nfunction buildProxyOptions (opts) {\n if (typeof opts === 'string') {\n opts = { uri: opts }\n }\n\n if (!opts || !opts.uri) {\n throw new InvalidArgumentError('Proxy opts.uri is mandatory')\n }\n\n return {\n uri: opts.uri,\n protocol: opts.protocol || 'https'\n }\n}\n\nfunction defaultFactory (origin, opts) {\n return new Pool(origin, opts)\n}\n\nclass ProxyAgent extends DispatcherBase {\n constructor (opts) {\n super(opts)\n this[kProxy] = buildProxyOptions(opts)\n this[kAgent] = new Agent(opts)\n this[kInterceptors] = opts.interceptors && opts.interceptors.ProxyAgent && Array.isArray(opts.interceptors.ProxyAgent)\n ? opts.interceptors.ProxyAgent\n : []\n\n if (typeof opts === 'string') {\n opts = { uri: opts }\n }\n\n if (!opts || !opts.uri) {\n throw new InvalidArgumentError('Proxy opts.uri is mandatory')\n }\n\n const { clientFactory = defaultFactory } = opts\n\n if (typeof clientFactory !== 'function') {\n throw new InvalidArgumentError('Proxy opts.clientFactory must be a function.')\n }\n\n this[kRequestTls] = opts.requestTls\n this[kProxyTls] = opts.proxyTls\n this[kProxyHeaders] = opts.headers || {}\n\n const resolvedUrl = new URL(opts.uri)\n const { origin, port, host, username, password } = resolvedUrl\n\n if (opts.auth && opts.token) {\n throw new InvalidArgumentError('opts.auth cannot be used in combination with opts.token')\n } else if (opts.auth) {\n /* @deprecated in favour of opts.token */\n this[kProxyHeaders]['proxy-authorization'] = `Basic ${opts.auth}`\n } else if (opts.token) {\n this[kProxyHeaders]['proxy-authorization'] = opts.token\n } else if (username && password) {\n this[kProxyHeaders]['proxy-authorization'] = `Basic ${Buffer.from(`${decodeURIComponent(username)}:${decodeURIComponent(password)}`).toString('base64')}`\n }\n\n const connect = buildConnector({ ...opts.proxyTls })\n this[kConnectEndpoint] = buildConnector({ ...opts.requestTls })\n this[kClient] = clientFactory(resolvedUrl, { connect })\n this[kAgent] = new Agent({\n ...opts,\n connect: async (opts, callback) => {\n let requestedHost = opts.host\n if (!opts.port) {\n requestedHost += `:${defaultProtocolPort(opts.protocol)}`\n }\n try {\n const { socket, statusCode } = await this[kClient].connect({\n origin,\n port,\n path: requestedHost,\n signal: opts.signal,\n headers: {\n ...this[kProxyHeaders],\n host\n }\n })\n if (statusCode !== 200) {\n socket.on('error', () => {}).destroy()\n callback(new RequestAbortedError(`Proxy response (${statusCode}) !== 200 when HTTP Tunneling`))\n }\n if (opts.protocol !== 'https:') {\n callback(null, socket)\n return\n }\n let servername\n if (this[kRequestTls]) {\n servername = this[kRequestTls].servername\n } else {\n servername = opts.servername\n }\n this[kConnectEndpoint]({ ...opts, servername, httpSocket: socket }, callback)\n } catch (err) {\n callback(err)\n }\n }\n })\n }\n\n dispatch (opts, handler) {\n const { host } = new URL(opts.origin)\n const headers = buildHeaders(opts.headers)\n throwIfProxyAuthIsSent(headers)\n return this[kAgent].dispatch(\n {\n ...opts,\n headers: {\n ...headers,\n host\n }\n },\n handler\n )\n }\n\n async [kClose] () {\n await this[kAgent].close()\n await this[kClient].close()\n }\n\n async [kDestroy] () {\n await this[kAgent].destroy()\n await this[kClient].destroy()\n }\n}\n\n/**\n * @param {string[] | Record<string, string>} headers\n * @returns {Record<string, string>}\n */\nfunction buildHeaders (headers) {\n // When using undici.fetch, the headers list is stored\n // as an array.\n if (Array.isArray(headers)) {\n /** @type {Record<string, string>} */\n const headersPair = {}\n\n for (let i = 0; i < headers.length; i += 2) {\n headersPair[headers[i]] = headers[i + 1]\n }\n\n return headersPair\n }\n\n return headers\n}\n\n/**\n * @param {Record<string, string>} headers\n *\n * Previous versions of ProxyAgent suggests the Proxy-Authorization in request headers\n * Nevertheless, it was changed and to avoid a security vulnerability by end users\n * this check was created.\n * It should be removed in the next major version for performance reasons\n */\nfunction throwIfProxyAuthIsSent (headers) {\n const existProxyAuth = headers && Object.keys(headers)\n .find((key) => key.toLowerCase() === 'proxy-authorization')\n if (existProxyAuth) {\n throw new InvalidArgumentError('Proxy-Authorization should be sent in ProxyAgent constructor')\n }\n}\n\nmodule.exports = ProxyAgent\n\n\n/***/ }),\n\n/***/ 9459:\n/***/ ((module) => {\n\n\"use strict\";\n\n\nlet fastNow = Date.now()\nlet fastNowTimeout\n\nconst fastTimers = []\n\nfunction onTimeout () {\n fastNow = Date.now()\n\n let len = fastTimers.length\n let idx = 0\n while (idx < len) {\n const timer = fastTimers[idx]\n\n if (timer.state === 0) {\n timer.state = fastNow + timer.delay\n } else if (timer.state > 0 && fastNow >= timer.state) {\n timer.state = -1\n timer.callback(timer.opaque)\n }\n\n if (timer.state === -1) {\n timer.state = -2\n if (idx !== len - 1) {\n fastTimers[idx] = fastTimers.pop()\n } else {\n fastTimers.pop()\n }\n len -= 1\n } else {\n idx += 1\n }\n }\n\n if (fastTimers.length > 0) {\n refreshTimeout()\n }\n}\n\nfunction refreshTimeout () {\n if (fastNowTimeout && fastNowTimeout.refresh) {\n fastNowTimeout.refresh()\n } else {\n clearTimeout(fastNowTimeout)\n fastNowTimeout = setTimeout(onTimeout, 1e3)\n if (fastNowTimeout.unref) {\n fastNowTimeout.unref()\n }\n }\n}\n\nclass Timeout {\n constructor (callback, delay, opaque) {\n this.callback = callback\n this.delay = delay\n this.opaque = opaque\n\n // -2 not in timer list\n // -1 in timer list but inactive\n // 0 in timer list waiting for time\n // > 0 in timer list waiting for time to expire\n this.state = -2\n\n this.refresh()\n }\n\n refresh () {\n if (this.state === -2) {\n fastTimers.push(this)\n if (!fastNowTimeout || fastTimers.length === 1) {\n refreshTimeout()\n }\n }\n\n this.state = 0\n }\n\n clear () {\n this.state = -1\n }\n}\n\nmodule.exports = {\n setTimeout (callback, delay, opaque) {\n return delay < 1e3\n ? setTimeout(callback, delay, opaque)\n : new Timeout(callback, delay, opaque)\n },\n clearTimeout (timeout) {\n if (timeout instanceof Timeout) {\n timeout.clear()\n } else {\n clearTimeout(timeout)\n }\n }\n}\n\n\n/***/ }),\n\n/***/ 5354:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\n\"use strict\";\n\n\nconst diagnosticsChannel = __nccwpck_require__(7643)\nconst { uid, states } = __nccwpck_require__(9188)\nconst {\n kReadyState,\n kSentClose,\n kByteParser,\n kReceivedClose\n} = __nccwpck_require__(5226)\nconst { fireEvent, failWebsocketConnection } = __nccwpck_require__(4302)\nconst { CloseEvent } = __nccwpck_require__(2611)\nconst { makeRequest } = __nccwpck_require__(8359)\nconst { fetching } = __nccwpck_require__(4881)\nconst { Headers } = __nccwpck_require__(554)\nconst { getGlobalDispatcher } = __nccwpck_require__(1892)\nconst { kHeadersList } = __nccwpck_require__(2785)\n\nconst channels = {}\nchannels.open = diagnosticsChannel.channel('undici:websocket:open')\nchannels.close = diagnosticsChannel.channel('undici:websocket:close')\nchannels.socketError = diagnosticsChannel.channel('undici:websocket:socket_error')\n\n/** @type {import('crypto')} */\nlet crypto\ntry {\n crypto = __nccwpck_require__(6113)\n} catch {\n\n}\n\n/**\n * @see https://websockets.spec.whatwg.org/#concept-websocket-establish\n * @param {URL} url\n * @param {string|string[]} protocols\n * @param {import('./websocket').WebSocket} ws\n * @param {(response: any) => void} onEstablish\n * @param {Partial<import('../../types/websocket').WebSocketInit>} options\n */\nfunction establishWebSocketConnection (url, protocols, ws, onEstablish, options) {\n // 1. Let requestURL be a copy of url, with its scheme set to \"http\", if url\u2019s\n // scheme is \"ws\", and to \"https\" otherwise.\n const requestURL = url\n\n requestURL.protocol = url.protocol === 'ws:' ? 'http:' : 'https:'\n\n // 2. Let request be a new request, whose URL is requestURL, client is client,\n // service-workers mode is \"none\", referrer is \"no-referrer\", mode is\n // \"websocket\", credentials mode is \"include\", cache mode is \"no-store\" ,\n // and redirect mode is \"error\".\n const request = makeRequest({\n urlList: [requestURL],\n serviceWorkers: 'none',\n referrer: 'no-referrer',\n mode: 'websocket',\n credentials: 'include',\n cache: 'no-store',\n redirect: 'error'\n })\n\n // Note: undici extension, allow setting custom headers.\n if (options.headers) {\n const headersList = new Headers(options.headers)[kHeadersList]\n\n request.headersList = headersList\n }\n\n // 3. Append (`Upgrade`, `websocket`) to request\u2019s header list.\n // 4. Append (`Connection`, `Upgrade`) to request\u2019s header list.\n // Note: both of these are handled by undici currently.\n // https://github.com/nodejs/undici/blob/68c269c4144c446f3f1220951338daef4a6b5ec4/lib/client.js#L1397\n\n // 5. Let keyValue be a nonce consisting of a randomly selected\n // 16-byte value that has been forgiving-base64-encoded and\n // isomorphic encoded.\n const keyValue = crypto.randomBytes(16).toString('base64')\n\n // 6. Append (`Sec-WebSocket-Key`, keyValue) to request\u2019s\n // header list.\n request.headersList.append('sec-websocket-key', keyValue)\n\n // 7. Append (`Sec-WebSocket-Version`, `13`) to request\u2019s\n // header list.\n request.headersList.append('sec-websocket-version', '13')\n\n // 8. For each protocol in protocols, combine\n // (`Sec-WebSocket-Protocol`, protocol) in request\u2019s header\n // list.\n for (const protocol of protocols) {\n request.headersList.append('sec-websocket-protocol', protocol)\n }\n\n // 9. Let permessageDeflate be a user-agent defined\n // \"permessage-deflate\" extension header value.\n // https://github.com/mozilla/gecko-dev/blob/ce78234f5e653a5d3916813ff990f053510227bc/netwerk/protocol/websocket/WebSocketChannel.cpp#L2673\n // TODO: enable once permessage-deflate is supported\n const permessageDeflate = '' // 'permessage-deflate; 15'\n\n // 10. Append (`Sec-WebSocket-Extensions`, permessageDeflate) to\n // request\u2019s header list.\n // request.headersList.append('sec-websocket-extensions', permessageDeflate)\n\n // 11. Fetch request with useParallelQueue set to true, and\n // processResponse given response being these steps:\n const controller = fetching({\n request,\n useParallelQueue: true,\n dispatcher: options.dispatcher ?? getGlobalDispatcher(),\n processResponse (response) {\n // 1. If response is a network error or its status is not 101,\n // fail the WebSocket connection.\n if (response.type === 'error' || response.status !== 101) {\n failWebsocketConnection(ws, 'Received network error or non-101 status code.')\n return\n }\n\n // 2. If protocols is not the empty list and extracting header\n // list values given `Sec-WebSocket-Protocol` and response\u2019s\n // header list results in null, failure, or the empty byte\n // sequence, then fail the WebSocket connection.\n if (protocols.length !== 0 && !response.headersList.get('Sec-WebSocket-Protocol')) {\n failWebsocketConnection(ws, 'Server did not respond with sent protocols.')\n return\n }\n\n // 3. Follow the requirements stated step 2 to step 6, inclusive,\n // of the last set of steps in section 4.1 of The WebSocket\n // Protocol to validate response. This either results in fail\n // the WebSocket connection or the WebSocket connection is\n // established.\n\n // 2. If the response lacks an |Upgrade| header field or the |Upgrade|\n // header field contains a value that is not an ASCII case-\n // insensitive match for the value \"websocket\", the client MUST\n // _Fail the WebSocket Connection_.\n if (response.headersList.get('Upgrade')?.toLowerCase() !== 'websocket') {\n failWebsocketConnection(ws, 'Server did not set Upgrade header to \"websocket\".')\n return\n }\n\n // 3. If the response lacks a |Connection| header field or the\n // |Connection| header field doesn't contain a token that is an\n // ASCII case-insensitive match for the value \"Upgrade\", the client\n // MUST _Fail the WebSocket Connection_.\n if (response.headersList.get('Connection')?.toLowerCase() !== 'upgrade') {\n failWebsocketConnection(ws, 'Server did not set Connection header to \"upgrade\".')\n return\n }\n\n // 4. If the response lacks a |Sec-WebSocket-Accept| header field or\n // the |Sec-WebSocket-Accept| contains a value other than the\n // base64-encoded SHA-1 of the concatenation of the |Sec-WebSocket-\n // Key| (as a string, not base64-decoded) with the string \"258EAFA5-\n // E914-47DA-95CA-C5AB0DC85B11\" but ignoring any leading and\n // trailing whitespace, the client MUST _Fail the WebSocket\n // Connection_.\n const secWSAccept = response.headersList.get('Sec-WebSocket-Accept')\n const digest = crypto.createHash('sha1').update(keyValue + uid).digest('base64')\n if (secWSAccept !== digest) {\n failWebsocketConnection(ws, 'Incorrect hash received in Sec-WebSocket-Accept header.')\n return\n }\n\n // 5. If the response includes a |Sec-WebSocket-Extensions| header\n // field and this header field indicates the use of an extension\n // that was not present in the client's handshake (the server has\n // indicated an extension not requested by the client), the client\n // MUST _Fail the WebSocket Connection_. (The parsing of this\n // header field to determine which extensions are requested is\n // discussed in Section 9.1.)\n const secExtension = response.headersList.get('Sec-WebSocket-Extensions')\n\n if (secExtension !== null && secExtension !== permessageDeflate) {\n failWebsocketConnection(ws, 'Received different permessage-deflate than the one set.')\n return\n }\n\n // 6. If the response includes a |Sec-WebSocket-Protocol| header field\n // and this header field indicates the use of a subprotocol that was\n // not present in the client's handshake (the server has indicated a\n // subprotocol not requested by the client), the client MUST _Fail\n // the WebSocket Connection_.\n const secProtocol = response.headersList.get('Sec-WebSocket-Protocol')\n\n if (secProtocol !== null && secProtocol !== request.headersList.get('Sec-WebSocket-Protocol')) {\n failWebsocketConnection(ws, 'Protocol was not set in the opening handshake.')\n return\n }\n\n response.socket.on('data', onSocketData)\n response.socket.on('close', onSocketClose)\n response.socket.on('error', onSocketError)\n\n if (channels.open.hasSubscribers) {\n channels.open.publish({\n address: response.socket.address(),\n protocol: secProtocol,\n extensions: secExtension\n })\n }\n\n onEstablish(response)\n }\n })\n\n return controller\n}\n\n/**\n * @param {Buffer} chunk\n */\nfunction onSocketData (chunk) {\n if (!this.ws[kByteParser].write(chunk)) {\n this.pause()\n }\n}\n\n/**\n * @see https://websockets.spec.whatwg.org/#feedback-from-the-protocol\n * @see https://datatracker.ietf.org/doc/html/rfc6455#section-7.1.4\n */\nfunction onSocketClose () {\n const { ws } = this\n\n // If the TCP connection was closed after the\n // WebSocket closing handshake was completed, the WebSocket connection\n // is said to have been closed _cleanly_.\n const wasClean = ws[kSentClose] && ws[kReceivedClose]\n\n let code = 1005\n let reason = ''\n\n const result = ws[kByteParser].closingInfo\n\n if (result) {\n code = result.code ?? 1005\n reason = result.reason\n } else if (!ws[kSentClose]) {\n // If _The WebSocket\n // Connection is Closed_ and no Close control frame was received by the\n // endpoint (such as could occur if the underlying transport connection\n // is lost), _The WebSocket Connection Close Code_ is considered to be\n // 1006.\n code = 1006\n }\n\n // 1. Change the ready state to CLOSED (3).\n ws[kReadyState] = states.CLOSED\n\n // 2. If the user agent was required to fail the WebSocket\n // connection, or if the WebSocket connection was closed\n // after being flagged as full, fire an event named error\n // at the WebSocket object.\n // TODO\n\n // 3. Fire an event named close at the WebSocket object,\n // using CloseEvent, with the wasClean attribute\n // initialized to true if the connection closed cleanly\n // and false otherwise, the code attribute initialized to\n // the WebSocket connection close code, and the reason\n // attribute initialized to the result of applying UTF-8\n // decode without BOM to the WebSocket connection close\n // reason.\n fireEvent('close', ws, CloseEvent, {\n wasClean, code, reason\n })\n\n if (channels.close.hasSubscribers) {\n channels.close.publish({\n websocket: ws,\n code,\n reason\n })\n }\n}\n\nfunction onSocketError (error) {\n const { ws } = this\n\n ws[kReadyState] = states.CLOSING\n\n if (channels.socketError.hasSubscribers) {\n channels.socketError.publish(error)\n }\n\n this.destroy()\n}\n\nmodule.exports = {\n establishWebSocketConnection\n}\n\n\n/***/ }),\n\n/***/ 9188:\n/***/ ((module) => {\n\n\"use strict\";\n\n\n// This is a Globally Unique Identifier unique used\n// to validate that the endpoint accepts websocket\n// connections.\n// See https://www.rfc-editor.org/rfc/rfc6455.html#section-1.3\nconst uid = '258EAFA5-E914-47DA-95CA-C5AB0DC85B11'\n\n/** @type {PropertyDescriptor} */\nconst staticPropertyDescriptors = {\n enumerable: true,\n writable: false,\n configurable: false\n}\n\nconst states = {\n CONNECTING: 0,\n OPEN: 1,\n CLOSING: 2,\n CLOSED: 3\n}\n\nconst opcodes = {\n CONTINUATION: 0x0,\n TEXT: 0x1,\n BINARY: 0x2,\n CLOSE: 0x8,\n PING: 0x9,\n PONG: 0xA\n}\n\nconst maxUnsigned16Bit = 2 ** 16 - 1 // 65535\n\nconst parserStates = {\n INFO: 0,\n PAYLOADLENGTH_16: 2,\n PAYLOADLENGTH_64: 3,\n READ_DATA: 4\n}\n\nconst emptyBuffer = Buffer.allocUnsafe(0)\n\nmodule.exports = {\n uid,\n staticPropertyDescriptors,\n states,\n opcodes,\n maxUnsigned16Bit,\n parserStates,\n emptyBuffer\n}\n\n\n/***/ }),\n\n/***/ 2611:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\n\"use strict\";\n\n\nconst { webidl } = __nccwpck_require__(1744)\nconst { kEnumerableProperty } = __nccwpck_require__(3983)\nconst { MessagePort } = __nccwpck_require__(1267)\n\n/**\n * @see https://html.spec.whatwg.org/multipage/comms.html#messageevent\n */\nclass MessageEvent extends Event {\n #eventInit\n\n constructor (type, eventInitDict = {}) {\n webidl.argumentLengthCheck(arguments, 1, { header: 'MessageEvent constructor' })\n\n type = webidl.converters.DOMString(type)\n eventInitDict = webidl.converters.MessageEventInit(eventInitDict)\n\n super(type, eventInitDict)\n\n this.#eventInit = eventInitDict\n }\n\n get data () {\n webidl.brandCheck(this, MessageEvent)\n\n return this.#eventInit.data\n }\n\n get origin () {\n webidl.brandCheck(this, MessageEvent)\n\n return this.#eventInit.origin\n }\n\n get lastEventId () {\n webidl.brandCheck(this, MessageEvent)\n\n return this.#eventInit.lastEventId\n }\n\n get source () {\n webidl.brandCheck(this, MessageEvent)\n\n return this.#eventInit.source\n }\n\n get ports () {\n webidl.brandCheck(this, MessageEvent)\n\n if (!Object.isFrozen(this.#eventInit.ports)) {\n Object.freeze(this.#eventInit.ports)\n }\n\n return this.#eventInit.ports\n }\n\n initMessageEvent (\n type,\n bubbles = false,\n cancelable = false,\n data = null,\n origin = '',\n lastEventId = '',\n source = null,\n ports = []\n ) {\n webidl.brandCheck(this, MessageEvent)\n\n webidl.argumentLengthCheck(arguments, 1, { header: 'MessageEvent.initMessageEvent' })\n\n return new MessageEvent(type, {\n bubbles, cancelable, data, origin, lastEventId, source, ports\n })\n }\n}\n\n/**\n * @see https://websockets.spec.whatwg.org/#the-closeevent-interface\n */\nclass CloseEvent extends Event {\n #eventInit\n\n constructor (type, eventInitDict = {}) {\n webidl.argumentLengthCheck(arguments, 1, { header: 'CloseEvent constructor' })\n\n type = webidl.converters.DOMString(type)\n eventInitDict = webidl.converters.CloseEventInit(eventInitDict)\n\n super(type, eventInitDict)\n\n this.#eventInit = eventInitDict\n }\n\n get wasClean () {\n webidl.brandCheck(this, CloseEvent)\n\n return this.#eventInit.wasClean\n }\n\n get code () {\n webidl.brandCheck(this, CloseEvent)\n\n return this.#eventInit.code\n }\n\n get reason () {\n webidl.brandCheck(this, CloseEvent)\n\n return this.#eventInit.reason\n }\n}\n\n// https://html.spec.whatwg.org/multipage/webappapis.html#the-errorevent-interface\nclass ErrorEvent extends Event {\n #eventInit\n\n constructor (type, eventInitDict) {\n webidl.argumentLengthCheck(arguments, 1, { header: 'ErrorEvent constructor' })\n\n super(type, eventInitDict)\n\n type = webidl.converters.DOMString(type)\n eventInitDict = webidl.converters.ErrorEventInit(eventInitDict ?? {})\n\n this.#eventInit = eventInitDict\n }\n\n get message () {\n webidl.brandCheck(this, ErrorEvent)\n\n return this.#eventInit.message\n }\n\n get filename () {\n webidl.brandCheck(this, ErrorEvent)\n\n return this.#eventInit.filename\n }\n\n get lineno () {\n webidl.brandCheck(this, ErrorEvent)\n\n return this.#eventInit.lineno\n }\n\n get colno () {\n webidl.brandCheck(this, ErrorEvent)\n\n return this.#eventInit.colno\n }\n\n get error () {\n webidl.brandCheck(this, ErrorEvent)\n\n return this.#eventInit.error\n }\n}\n\nObject.defineProperties(MessageEvent.prototype, {\n [Symbol.toStringTag]: {\n value: 'MessageEvent',\n configurable: true\n },\n data: kEnumerableProperty,\n origin: kEnumerableProperty,\n lastEventId: kEnumerableProperty,\n source: kEnumerableProperty,\n ports: kEnumerableProperty,\n initMessageEvent: kEnumerableProperty\n})\n\nObject.defineProperties(CloseEvent.prototype, {\n [Symbol.toStringTag]: {\n value: 'CloseEvent',\n configurable: true\n },\n reason: kEnumerableProperty,\n code: kEnumerableProperty,\n wasClean: kEnumerableProperty\n})\n\nObject.defineProperties(ErrorEvent.prototype, {\n [Symbol.toStringTag]: {\n value: 'ErrorEvent',\n configurable: true\n },\n message: kEnumerableProperty,\n filename: kEnumerableProperty,\n lineno: kEnumerableProperty,\n colno: kEnumerableProperty,\n error: kEnumerableProperty\n})\n\nwebidl.converters.MessagePort = webidl.interfaceConverter(MessagePort)\n\nwebidl.converters['sequence<MessagePort>'] = webidl.sequenceConverter(\n webidl.converters.MessagePort\n)\n\nconst eventInit = [\n {\n key: 'bubbles',\n converter: webidl.converters.boolean,\n defaultValue: false\n },\n {\n key: 'cancelable',\n converter: webidl.converters.boolean,\n defaultValue: false\n },\n {\n key: 'composed',\n converter: webidl.converters.boolean,\n defaultValue: false\n }\n]\n\nwebidl.converters.MessageEventInit = webidl.dictionaryConverter([\n ...eventInit,\n {\n key: 'data',\n converter: webidl.converters.any,\n defaultValue: null\n },\n {\n key: 'origin',\n converter: webidl.converters.USVString,\n defaultValue: ''\n },\n {\n key: 'lastEventId',\n converter: webidl.converters.DOMString,\n defaultValue: ''\n },\n {\n key: 'source',\n // Node doesn't implement WindowProxy or ServiceWorker, so the only\n // valid value for source is a MessagePort.\n converter: webidl.nullableConverter(webidl.converters.MessagePort),\n defaultValue: null\n },\n {\n key: 'ports',\n converter: webidl.converters['sequence<MessagePort>'],\n get defaultValue () {\n return []\n }\n }\n])\n\nwebidl.converters.CloseEventInit = webidl.dictionaryConverter([\n ...eventInit,\n {\n key: 'wasClean',\n converter: webidl.converters.boolean,\n defaultValue: false\n },\n {\n key: 'code',\n converter: webidl.converters['unsigned short'],\n defaultValue: 0\n },\n {\n key: 'reason',\n converter: webidl.converters.USVString,\n defaultValue: ''\n }\n])\n\nwebidl.converters.ErrorEventInit = webidl.dictionaryConverter([\n ...eventInit,\n {\n key: 'message',\n converter: webidl.converters.DOMString,\n defaultValue: ''\n },\n {\n key: 'filename',\n converter: webidl.converters.USVString,\n defaultValue: ''\n },\n {\n key: 'lineno',\n converter: webidl.converters['unsigned long'],\n defaultValue: 0\n },\n {\n key: 'colno',\n converter: webidl.converters['unsigned long'],\n defaultValue: 0\n },\n {\n key: 'error',\n converter: webidl.converters.any\n }\n])\n\nmodule.exports = {\n MessageEvent,\n CloseEvent,\n ErrorEvent\n}\n\n\n/***/ }),\n\n/***/ 5444:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\n\"use strict\";\n\n\nconst { maxUnsigned16Bit } = __nccwpck_require__(9188)\n\n/** @type {import('crypto')} */\nlet crypto\ntry {\n crypto = __nccwpck_require__(6113)\n} catch {\n\n}\n\nclass WebsocketFrameSend {\n /**\n * @param {Buffer|undefined} data\n */\n constructor (data) {\n this.frameData = data\n this.maskKey = crypto.randomBytes(4)\n }\n\n createFrame (opcode) {\n const bodyLength = this.frameData?.byteLength ?? 0\n\n /** @type {number} */\n let payloadLength = bodyLength // 0-125\n let offset = 6\n\n if (bodyLength > maxUnsigned16Bit) {\n offset += 8 // payload length is next 8 bytes\n payloadLength = 127\n } else if (bodyLength > 125) {\n offset += 2 // payload length is next 2 bytes\n payloadLength = 126\n }\n\n const buffer = Buffer.allocUnsafe(bodyLength + offset)\n\n // Clear first 2 bytes, everything else is overwritten\n buffer[0] = buffer[1] = 0\n buffer[0] |= 0x80 // FIN\n buffer[0] = (buffer[0] & 0xF0) + opcode // opcode\n\n /*! ws. MIT License. Einar Otto Stangvik <[email protected]> */\n buffer[offset - 4] = this.maskKey[0]\n buffer[offset - 3] = this.maskKey[1]\n buffer[offset - 2] = this.maskKey[2]\n buffer[offset - 1] = this.maskKey[3]\n\n buffer[1] = payloadLength\n\n if (payloadLength === 126) {\n buffer.writeUInt16BE(bodyLength, 2)\n } else if (payloadLength === 127) {\n // Clear extended payload length\n buffer[2] = buffer[3] = 0\n buffer.writeUIntBE(bodyLength, 4, 6)\n }\n\n buffer[1] |= 0x80 // MASK\n\n // mask body\n for (let i = 0; i < bodyLength; i++) {\n buffer[offset + i] = this.frameData[i] ^ this.maskKey[i % 4]\n }\n\n return buffer\n }\n}\n\nmodule.exports = {\n WebsocketFrameSend\n}\n\n\n/***/ }),\n\n/***/ 1688:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\n\"use strict\";\n\n\nconst { Writable } = __nccwpck_require__(2781)\nconst diagnosticsChannel = __nccwpck_require__(7643)\nconst { parserStates, opcodes, states, emptyBuffer } = __nccwpck_require__(9188)\nconst { kReadyState, kSentClose, kResponse, kReceivedClose } = __nccwpck_require__(5226)\nconst { isValidStatusCode, failWebsocketConnection, websocketMessageReceived } = __nccwpck_require__(4302)\nconst { WebsocketFrameSend } = __nccwpck_require__(5444)\n\n// This code was influenced by ws released under the MIT license.\n// Copyright (c) 2011 Einar Otto Stangvik <[email protected]>\n// Copyright (c) 2013 Arnout Kazemier and contributors\n// Copyright (c) 2016 Luigi Pinca and contributors\n\nconst channels = {}\nchannels.ping = diagnosticsChannel.channel('undici:websocket:ping')\nchannels.pong = diagnosticsChannel.channel('undici:websocket:pong')\n\nclass ByteParser extends Writable {\n #buffers = []\n #byteOffset = 0\n\n #state = parserStates.INFO\n\n #info = {}\n #fragments = []\n\n constructor (ws) {\n super()\n\n this.ws = ws\n }\n\n /**\n * @param {Buffer} chunk\n * @param {() => void} callback\n */\n _write (chunk, _, callback) {\n this.#buffers.push(chunk)\n this.#byteOffset += chunk.length\n\n this.run(callback)\n }\n\n /**\n * Runs whenever a new chunk is received.\n * Callback is called whenever there are no more chunks buffering,\n * or not enough bytes are buffered to parse.\n */\n run (callback) {\n while (true) {\n if (this.#state === parserStates.INFO) {\n // If there aren't enough bytes to parse the payload length, etc.\n if (this.#byteOffset < 2) {\n return callback()\n }\n\n const buffer = this.consume(2)\n\n this.#info.fin = (buffer[0] & 0x80) !== 0\n this.#info.opcode = buffer[0] & 0x0F\n\n // If we receive a fragmented message, we use the type of the first\n // frame to parse the full message as binary/text, when it's terminated\n this.#info.originalOpcode ??= this.#info.opcode\n\n this.#info.fragmented = !this.#info.fin && this.#info.opcode !== opcodes.CONTINUATION\n\n if (this.#info.fragmented && this.#info.opcode !== opcodes.BINARY && this.#info.opcode !== opcodes.TEXT) {\n // Only text and binary frames can be fragmented\n failWebsocketConnection(this.ws, 'Invalid frame type was fragmented.')\n return\n }\n\n const payloadLength = buffer[1] & 0x7F\n\n if (payloadLength <= 125) {\n this.#info.payloadLength = payloadLength\n this.#state = parserStates.READ_DATA\n } else if (payloadLength === 126) {\n this.#state = parserStates.PAYLOADLENGTH_16\n } else if (payloadLength === 127) {\n this.#state = parserStates.PAYLOADLENGTH_64\n }\n\n if (this.#info.fragmented && payloadLength > 125) {\n // A fragmented frame can't be fragmented itself\n failWebsocketConnection(this.ws, 'Fragmented frame exceeded 125 bytes.')\n return\n } else if (\n (this.#info.opcode === opcodes.PING ||\n this.#info.opcode === opcodes.PONG ||\n this.#info.opcode === opcodes.CLOSE) &&\n payloadLength > 125\n ) {\n // Control frames can have a payload length of 125 bytes MAX\n failWebsocketConnection(this.ws, 'Payload length for control frame exceeded 125 bytes.')\n return\n } else if (this.#info.opcode === opcodes.CLOSE) {\n if (payloadLength === 1) {\n failWebsocketConnection(this.ws, 'Received close frame with a 1-byte body.')\n return\n }\n\n const body = this.consume(payloadLength)\n\n this.#info.closeInfo = this.parseCloseBody(false, body)\n\n if (!this.ws[kSentClose]) {\n // If an endpoint receives a Close frame and did not previously send a\n // Close frame, the endpoint MUST send a Close frame in response. (When\n // sending a Close frame in response, the endpoint typically echos the\n // status code it received.)\n const body = Buffer.allocUnsafe(2)\n body.writeUInt16BE(this.#info.closeInfo.code, 0)\n const closeFrame = new WebsocketFrameSend(body)\n\n this.ws[kResponse].socket.write(\n closeFrame.createFrame(opcodes.CLOSE),\n (err) => {\n if (!err) {\n this.ws[kSentClose] = true\n }\n }\n )\n }\n\n // Upon either sending or receiving a Close control frame, it is said\n // that _The WebSocket Closing Handshake is Started_ and that the\n // WebSocket connection is in the CLOSING state.\n this.ws[kReadyState] = states.CLOSING\n this.ws[kReceivedClose] = true\n\n this.end()\n\n return\n } else if (this.#info.opcode === opcodes.PING) {\n // Upon receipt of a Ping frame, an endpoint MUST send a Pong frame in\n // response, unless it already received a Close frame.\n // A Pong frame sent in response to a Ping frame must have identical\n // \"Application data\"\n\n const body = this.consume(payloadLength)\n\n if (!this.ws[kReceivedClose]) {\n const frame = new WebsocketFrameSend(body)\n\n this.ws[kResponse].socket.write(frame.createFrame(opcodes.PONG))\n\n if (channels.ping.hasSubscribers) {\n channels.ping.publish({\n payload: body\n })\n }\n }\n\n this.#state = parserStates.INFO\n\n if (this.#byteOffset > 0) {\n continue\n } else {\n callback()\n return\n }\n } else if (this.#info.opcode === opcodes.PONG) {\n // A Pong frame MAY be sent unsolicited. This serves as a\n // unidirectional heartbeat. A response to an unsolicited Pong frame is\n // not expected.\n\n const body = this.consume(payloadLength)\n\n if (channels.pong.hasSubscribers) {\n channels.pong.publish({\n payload: body\n })\n }\n\n if (this.#byteOffset > 0) {\n continue\n } else {\n callback()\n return\n }\n }\n } else if (this.#state === parserStates.PAYLOADLENGTH_16) {\n if (this.#byteOffset < 2) {\n return callback()\n }\n\n const buffer = this.consume(2)\n\n this.#info.payloadLength = buffer.readUInt16BE(0)\n this.#state = parserStates.READ_DATA\n } else if (this.#state === parserStates.PAYLOADLENGTH_64) {\n if (this.#byteOffset < 8) {\n return callback()\n }\n\n const buffer = this.consume(8)\n const upper = buffer.readUInt32BE(0)\n\n // 2^31 is the maxinimum bytes an arraybuffer can contain\n // on 32-bit systems. Although, on 64-bit systems, this is\n // 2^53-1 bytes.\n // https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Errors/Invalid_array_length\n // https://source.chromium.org/chromium/chromium/src/+/main:v8/src/common/globals.h;drc=1946212ac0100668f14eb9e2843bdd846e510a1e;bpv=1;bpt=1;l=1275\n // https://source.chromium.org/chromium/chromium/src/+/main:v8/src/objects/js-array-buffer.h;l=34;drc=1946212ac0100668f14eb9e2843bdd846e510a1e\n if (upper > 2 ** 31 - 1) {\n failWebsocketConnection(this.ws, 'Received payload length > 2^31 bytes.')\n return\n }\n\n const lower = buffer.readUInt32BE(4)\n\n this.#info.payloadLength = (upper << 8) + lower\n this.#state = parserStates.READ_DATA\n } else if (this.#state === parserStates.READ_DATA) {\n if (this.#byteOffset < this.#info.payloadLength) {\n // If there is still more data in this chunk that needs to be read\n return callback()\n } else if (this.#byteOffset >= this.#info.payloadLength) {\n // If the server sent multiple frames in a single chunk\n\n const body = this.consume(this.#info.payloadLength)\n\n this.#fragments.push(body)\n\n // If the frame is unfragmented, or a fragmented frame was terminated,\n // a message was received\n if (!this.#info.fragmented || (this.#info.fin && this.#info.opcode === opcodes.CONTINUATION)) {\n const fullMessage = Buffer.concat(this.#fragments)\n\n websocketMessageReceived(this.ws, this.#info.originalOpcode, fullMessage)\n\n this.#info = {}\n this.#fragments.length = 0\n }\n\n this.#state = parserStates.INFO\n }\n }\n\n if (this.#byteOffset > 0) {\n continue\n } else {\n callback()\n break\n }\n }\n }\n\n /**\n * Take n bytes from the buffered Buffers\n * @param {number} n\n * @returns {Buffer|null}\n */\n consume (n) {\n if (n > this.#byteOffset) {\n return null\n } else if (n === 0) {\n return emptyBuffer\n }\n\n if (this.#buffers[0].length === n) {\n this.#byteOffset -= this.#buffers[0].length\n return this.#buffers.shift()\n }\n\n const buffer = Buffer.allocUnsafe(n)\n let offset = 0\n\n while (offset !== n) {\n const next = this.#buffers[0]\n const { length } = next\n\n if (length + offset === n) {\n buffer.set(this.#buffers.shift(), offset)\n break\n } else if (length + offset > n) {\n buffer.set(next.subarray(0, n - offset), offset)\n this.#buffers[0] = next.subarray(n - offset)\n break\n } else {\n buffer.set(this.#buffers.shift(), offset)\n offset += next.length\n }\n }\n\n this.#byteOffset -= n\n\n return buffer\n }\n\n parseCloseBody (onlyCode, data) {\n // https://datatracker.ietf.org/doc/html/rfc6455#section-7.1.5\n /** @type {number|undefined} */\n let code\n\n if (data.length >= 2) {\n // _The WebSocket Connection Close Code_ is\n // defined as the status code (Section 7.4) contained in the first Close\n // control frame received by the application\n code = data.readUInt16BE(0)\n }\n\n if (onlyCode) {\n if (!isValidStatusCode(code)) {\n return null\n }\n\n return { code }\n }\n\n // https://datatracker.ietf.org/doc/html/rfc6455#section-7.1.6\n /** @type {Buffer} */\n let reason = data.subarray(2)\n\n // Remove BOM\n if (reason[0] === 0xEF && reason[1] === 0xBB && reason[2] === 0xBF) {\n reason = reason.subarray(3)\n }\n\n if (code !== undefined && !isValidStatusCode(code)) {\n return null\n }\n\n try {\n // TODO: optimize this\n reason = new TextDecoder('utf-8', { fatal: true }).decode(reason)\n } catch {\n return null\n }\n\n return { code, reason }\n }\n\n get closingInfo () {\n return this.#info.closeInfo\n }\n}\n\nmodule.exports = {\n ByteParser\n}\n\n\n/***/ }),\n\n/***/ 5226:\n/***/ ((module) => {\n\n\"use strict\";\n\n\nmodule.exports = {\n kWebSocketURL: Symbol('url'),\n kReadyState: Symbol('ready state'),\n kController: Symbol('controller'),\n kResponse: Symbol('response'),\n kBinaryType: Symbol('binary type'),\n kSentClose: Symbol('sent close'),\n kReceivedClose: Symbol('received close'),\n kByteParser: Symbol('byte parser')\n}\n\n\n/***/ }),\n\n/***/ 4302:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\n\"use strict\";\n\n\nconst { kReadyState, kController, kResponse, kBinaryType, kWebSocketURL } = __nccwpck_require__(5226)\nconst { states, opcodes } = __nccwpck_require__(9188)\nconst { MessageEvent, ErrorEvent } = __nccwpck_require__(2611)\n\n/* globals Blob */\n\n/**\n * @param {import('./websocket').WebSocket} ws\n */\nfunction isEstablished (ws) {\n // If the server's response is validated as provided for above, it is\n // said that _The WebSocket Connection is Established_ and that the\n // WebSocket Connection is in the OPEN state.\n return ws[kReadyState] === states.OPEN\n}\n\n/**\n * @param {import('./websocket').WebSocket} ws\n */\nfunction isClosing (ws) {\n // Upon either sending or receiving a Close control frame, it is said\n // that _The WebSocket Closing Handshake is Started_ and that the\n // WebSocket connection is in the CLOSING state.\n return ws[kReadyState] === states.CLOSING\n}\n\n/**\n * @param {import('./websocket').WebSocket} ws\n */\nfunction isClosed (ws) {\n return ws[kReadyState] === states.CLOSED\n}\n\n/**\n * @see https://dom.spec.whatwg.org/#concept-event-fire\n * @param {string} e\n * @param {EventTarget} target\n * @param {EventInit | undefined} eventInitDict\n */\nfunction fireEvent (e, target, eventConstructor = Event, eventInitDict) {\n // 1. If eventConstructor is not given, then let eventConstructor be Event.\n\n // 2. Let event be the result of creating an event given eventConstructor,\n // in the relevant realm of target.\n // 3. Initialize event\u2019s type attribute to e.\n const event = new eventConstructor(e, eventInitDict) // eslint-disable-line new-cap\n\n // 4. Initialize any other IDL attributes of event as described in the\n // invocation of this algorithm.\n\n // 5. Return the result of dispatching event at target, with legacy target\n // override flag set if set.\n target.dispatchEvent(event)\n}\n\n/**\n * @see https://websockets.spec.whatwg.org/#feedback-from-the-protocol\n * @param {import('./websocket').WebSocket} ws\n * @param {number} type Opcode\n * @param {Buffer} data application data\n */\nfunction websocketMessageReceived (ws, type, data) {\n // 1. If ready state is not OPEN (1), then return.\n if (ws[kReadyState] !== states.OPEN) {\n return\n }\n\n // 2. Let dataForEvent be determined by switching on type and binary type:\n let dataForEvent\n\n if (type === opcodes.TEXT) {\n // -> type indicates that the data is Text\n // a new DOMString containing data\n try {\n dataForEvent = new TextDecoder('utf-8', { fatal: true }).decode(data)\n } catch {\n failWebsocketConnection(ws, 'Received invalid UTF-8 in text frame.')\n return\n }\n } else if (type === opcodes.BINARY) {\n if (ws[kBinaryType] === 'blob') {\n // -> type indicates that the data is Binary and binary type is \"blob\"\n // a new Blob object, created in the relevant Realm of the WebSocket\n // object, that represents data as its raw data\n dataForEvent = new Blob([data])\n } else {\n // -> type indicates that the data is Binary and binary type is \"arraybuffer\"\n // a new ArrayBuffer object, created in the relevant Realm of the\n // WebSocket object, whose contents are data\n dataForEvent = new Uint8Array(data).buffer\n }\n }\n\n // 3. Fire an event named message at the WebSocket object, using MessageEvent,\n // with the origin attribute initialized to the serialization of the WebSocket\n // object\u2019s url's origin, and the data attribute initialized to dataForEvent.\n fireEvent('message', ws, MessageEvent, {\n origin: ws[kWebSocketURL].origin,\n data: dataForEvent\n })\n}\n\n/**\n * @see https://datatracker.ietf.org/doc/html/rfc6455\n * @see https://datatracker.ietf.org/doc/html/rfc2616\n * @see https://bugs.chromium.org/p/chromium/issues/detail?id=398407\n * @param {string} protocol\n */\nfunction isValidSubprotocol (protocol) {\n // If present, this value indicates one\n // or more comma-separated subprotocol the client wishes to speak,\n // ordered by preference. The elements that comprise this value\n // MUST be non-empty strings with characters in the range U+0021 to\n // U+007E not including separator characters as defined in\n // [RFC2616] and MUST all be unique strings.\n if (protocol.length === 0) {\n return false\n }\n\n for (const char of protocol) {\n const code = char.charCodeAt(0)\n\n if (\n code < 0x21 ||\n code > 0x7E ||\n char === '(' ||\n char === ')' ||\n char === '<' ||\n char === '>' ||\n char === '@' ||\n char === ',' ||\n char === ';' ||\n char === ':' ||\n char === '\\\\' ||\n char === '\"' ||\n char === '/' ||\n char === '[' ||\n char === ']' ||\n char === '?' ||\n char === '=' ||\n char === '{' ||\n char === '}' ||\n code === 32 || // SP\n code === 9 // HT\n ) {\n return false\n }\n }\n\n return true\n}\n\n/**\n * @see https://datatracker.ietf.org/doc/html/rfc6455#section-7-4\n * @param {number} code\n */\nfunction isValidStatusCode (code) {\n if (code >= 1000 && code < 1015) {\n return (\n code !== 1004 && // reserved\n code !== 1005 && // \"MUST NOT be set as a status code\"\n code !== 1006 // \"MUST NOT be set as a status code\"\n )\n }\n\n return code >= 3000 && code <= 4999\n}\n\n/**\n * @param {import('./websocket').WebSocket} ws\n * @param {string|undefined} reason\n */\nfunction failWebsocketConnection (ws, reason) {\n const { [kController]: controller, [kResponse]: response } = ws\n\n controller.abort()\n\n if (response?.socket && !response.socket.destroyed) {\n response.socket.destroy()\n }\n\n if (reason) {\n fireEvent('error', ws, ErrorEvent, {\n error: new Error(reason)\n })\n }\n}\n\nmodule.exports = {\n isEstablished,\n isClosing,\n isClosed,\n fireEvent,\n isValidSubprotocol,\n isValidStatusCode,\n failWebsocketConnection,\n websocketMessageReceived\n}\n\n\n/***/ }),\n\n/***/ 4284:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\n\"use strict\";\n\n\nconst { webidl } = __nccwpck_require__(1744)\nconst { DOMException } = __nccwpck_require__(1037)\nconst { URLSerializer } = __nccwpck_require__(685)\nconst { getGlobalOrigin } = __nccwpck_require__(1246)\nconst { staticPropertyDescriptors, states, opcodes, emptyBuffer } = __nccwpck_require__(9188)\nconst {\n kWebSocketURL,\n kReadyState,\n kController,\n kBinaryType,\n kResponse,\n kSentClose,\n kByteParser\n} = __nccwpck_require__(5226)\nconst { isEstablished, isClosing, isValidSubprotocol, failWebsocketConnection, fireEvent } = __nccwpck_require__(4302)\nconst { establishWebSocketConnection } = __nccwpck_require__(5354)\nconst { WebsocketFrameSend } = __nccwpck_require__(5444)\nconst { ByteParser } = __nccwpck_require__(1688)\nconst { kEnumerableProperty, isBlobLike } = __nccwpck_require__(3983)\nconst { getGlobalDispatcher } = __nccwpck_require__(1892)\nconst { types } = __nccwpck_require__(3837)\n\nlet experimentalWarned = false\n\n// https://websockets.spec.whatwg.org/#interface-definition\nclass WebSocket extends EventTarget {\n #events = {\n open: null,\n error: null,\n close: null,\n message: null\n }\n\n #bufferedAmount = 0\n #protocol = ''\n #extensions = ''\n\n /**\n * @param {string} url\n * @param {string|string[]} protocols\n */\n constructor (url, protocols = []) {\n super()\n\n webidl.argumentLengthCheck(arguments, 1, { header: 'WebSocket constructor' })\n\n if (!experimentalWarned) {\n experimentalWarned = true\n process.emitWarning('WebSockets are experimental, expect them to change at any time.', {\n code: 'UNDICI-WS'\n })\n }\n\n const options = webidl.converters['DOMString or sequence<DOMString> or WebSocketInit'](protocols)\n\n url = webidl.converters.USVString(url)\n protocols = options.protocols\n\n // 1. Let baseURL be this's relevant settings object's API base URL.\n const baseURL = getGlobalOrigin()\n\n // 1. Let urlRecord be the result of applying the URL parser to url with baseURL.\n let urlRecord\n\n try {\n urlRecord = new URL(url, baseURL)\n } catch (e) {\n // 3. If urlRecord is failure, then throw a \"SyntaxError\" DOMException.\n throw new DOMException(e, 'SyntaxError')\n }\n\n // 4. If urlRecord\u2019s scheme is \"http\", then set urlRecord\u2019s scheme to \"ws\".\n if (urlRecord.protocol === 'http:') {\n urlRecord.protocol = 'ws:'\n } else if (urlRecord.protocol === 'https:') {\n // 5. Otherwise, if urlRecord\u2019s scheme is \"https\", set urlRecord\u2019s scheme to \"wss\".\n urlRecord.protocol = 'wss:'\n }\n\n // 6. If urlRecord\u2019s scheme is not \"ws\" or \"wss\", then throw a \"SyntaxError\" DOMException.\n if (urlRecord.protocol !== 'ws:' && urlRecord.protocol !== 'wss:') {\n throw new DOMException(\n `Expected a ws: or wss: protocol, got ${urlRecord.protocol}`,\n 'SyntaxError'\n )\n }\n\n // 7. If urlRecord\u2019s fragment is non-null, then throw a \"SyntaxError\"\n // DOMException.\n if (urlRecord.hash || urlRecord.href.endsWith('#')) {\n throw new DOMException('Got fragment', 'SyntaxError')\n }\n\n // 8. If protocols is a string, set protocols to a sequence consisting\n // of just that string.\n if (typeof protocols === 'string') {\n protocols = [protocols]\n }\n\n // 9. If any of the values in protocols occur more than once or otherwise\n // fail to match the requirements for elements that comprise the value\n // of `Sec-WebSocket-Protocol` fields as defined by The WebSocket\n // protocol, then throw a \"SyntaxError\" DOMException.\n if (protocols.length !== new Set(protocols.map(p => p.toLowerCase())).size) {\n throw new DOMException('Invalid Sec-WebSocket-Protocol value', 'SyntaxError')\n }\n\n if (protocols.length > 0 && !protocols.every(p => isValidSubprotocol(p))) {\n throw new DOMException('Invalid Sec-WebSocket-Protocol value', 'SyntaxError')\n }\n\n // 10. Set this's url to urlRecord.\n this[kWebSocketURL] = new URL(urlRecord.href)\n\n // 11. Let client be this's relevant settings object.\n\n // 12. Run this step in parallel:\n\n // 1. Establish a WebSocket connection given urlRecord, protocols,\n // and client.\n this[kController] = establishWebSocketConnection(\n urlRecord,\n protocols,\n this,\n (response) => this.#onConnectionEstablished(response),\n options\n )\n\n // Each WebSocket object has an associated ready state, which is a\n // number representing the state of the connection. Initially it must\n // be CONNECTING (0).\n this[kReadyState] = WebSocket.CONNECTING\n\n // The extensions attribute must initially return the empty string.\n\n // The protocol attribute must initially return the empty string.\n\n // Each WebSocket object has an associated binary type, which is a\n // BinaryType. Initially it must be \"blob\".\n this[kBinaryType] = 'blob'\n }\n\n /**\n * @see https://websockets.spec.whatwg.org/#dom-websocket-close\n * @param {number|undefined} code\n * @param {string|undefined} reason\n */\n close (code = undefined, reason = undefined) {\n webidl.brandCheck(this, WebSocket)\n\n if (code !== undefined) {\n code = webidl.converters['unsigned short'](code, { clamp: true })\n }\n\n if (reason !== undefined) {\n reason = webidl.converters.USVString(reason)\n }\n\n // 1. If code is present, but is neither an integer equal to 1000 nor an\n // integer in the range 3000 to 4999, inclusive, throw an\n // \"InvalidAccessError\" DOMException.\n if (code !== undefined) {\n if (code !== 1000 && (code < 3000 || code > 4999)) {\n throw new DOMException('invalid code', 'InvalidAccessError')\n }\n }\n\n let reasonByteLength = 0\n\n // 2. If reason is present, then run these substeps:\n if (reason !== undefined) {\n // 1. Let reasonBytes be the result of encoding reason.\n // 2. If reasonBytes is longer than 123 bytes, then throw a\n // \"SyntaxError\" DOMException.\n reasonByteLength = Buffer.byteLength(reason)\n\n if (reasonByteLength > 123) {\n throw new DOMException(\n `Reason must be less than 123 bytes; received ${reasonByteLength}`,\n 'SyntaxError'\n )\n }\n }\n\n // 3. Run the first matching steps from the following list:\n if (this[kReadyState] === WebSocket.CLOSING || this[kReadyState] === WebSocket.CLOSED) {\n // If this's ready state is CLOSING (2) or CLOSED (3)\n // Do nothing.\n } else if (!isEstablished(this)) {\n // If the WebSocket connection is not yet established\n // Fail the WebSocket connection and set this's ready state\n // to CLOSING (2).\n failWebsocketConnection(this, 'Connection was closed before it was established.')\n this[kReadyState] = WebSocket.CLOSING\n } else if (!isClosing(this)) {\n // If the WebSocket closing handshake has not yet been started\n // Start the WebSocket closing handshake and set this's ready\n // state to CLOSING (2).\n // - If neither code nor reason is present, the WebSocket Close\n // message must not have a body.\n // - If code is present, then the status code to use in the\n // WebSocket Close message must be the integer given by code.\n // - If reason is also present, then reasonBytes must be\n // provided in the Close message after the status code.\n\n const frame = new WebsocketFrameSend()\n\n // If neither code nor reason is present, the WebSocket Close\n // message must not have a body.\n\n // If code is present, then the status code to use in the\n // WebSocket Close message must be the integer given by code.\n if (code !== undefined && reason === undefined) {\n frame.frameData = Buffer.allocUnsafe(2)\n frame.frameData.writeUInt16BE(code, 0)\n } else if (code !== undefined && reason !== undefined) {\n // If reason is also present, then reasonBytes must be\n // provided in the Close message after the status code.\n frame.frameData = Buffer.allocUnsafe(2 + reasonByteLength)\n frame.frameData.writeUInt16BE(code, 0)\n // the body MAY contain UTF-8-encoded data with value /reason/\n frame.frameData.write(reason, 2, 'utf-8')\n } else {\n frame.frameData = emptyBuffer\n }\n\n /** @type {import('stream').Duplex} */\n const socket = this[kResponse].socket\n\n socket.write(frame.createFrame(opcodes.CLOSE), (err) => {\n if (!err) {\n this[kSentClose] = true\n }\n })\n\n // Upon either sending or receiving a Close control frame, it is said\n // that _The WebSocket Closing Handshake is Started_ and that the\n // WebSocket connection is in the CLOSING state.\n this[kReadyState] = states.CLOSING\n } else {\n // Otherwise\n // Set this's ready state to CLOSING (2).\n this[kReadyState] = WebSocket.CLOSING\n }\n }\n\n /**\n * @see https://websockets.spec.whatwg.org/#dom-websocket-send\n * @param {NodeJS.TypedArray|ArrayBuffer|Blob|string} data\n */\n send (data) {\n webidl.brandCheck(this, WebSocket)\n\n webidl.argumentLengthCheck(arguments, 1, { header: 'WebSocket.send' })\n\n data = webidl.converters.WebSocketSendData(data)\n\n // 1. If this's ready state is CONNECTING, then throw an\n // \"InvalidStateError\" DOMException.\n if (this[kReadyState] === WebSocket.CONNECTING) {\n throw new DOMException('Sent before connected.', 'InvalidStateError')\n }\n\n // 2. Run the appropriate set of steps from the following list:\n // https://datatracker.ietf.org/doc/html/rfc6455#section-6.1\n // https://datatracker.ietf.org/doc/html/rfc6455#section-5.2\n\n if (!isEstablished(this) || isClosing(this)) {\n return\n }\n\n /** @type {import('stream').Duplex} */\n const socket = this[kResponse].socket\n\n // If data is a string\n if (typeof data === 'string') {\n // If the WebSocket connection is established and the WebSocket\n // closing handshake has not yet started, then the user agent\n // must send a WebSocket Message comprised of the data argument\n // using a text frame opcode; if the data cannot be sent, e.g.\n // because it would need to be buffered but the buffer is full,\n // the user agent must flag the WebSocket as full and then close\n // the WebSocket connection. Any invocation of this method with a\n // string argument that does not throw an exception must increase\n // the bufferedAmount attribute by the number of bytes needed to\n // express the argument as UTF-8.\n\n const value = Buffer.from(data)\n const frame = new WebsocketFrameSend(value)\n const buffer = frame.createFrame(opcodes.TEXT)\n\n this.#bufferedAmount += value.byteLength\n socket.write(buffer, () => {\n this.#bufferedAmount -= value.byteLength\n })\n } else if (types.isArrayBuffer(data)) {\n // If the WebSocket connection is established, and the WebSocket\n // closing handshake has not yet started, then the user agent must\n // send a WebSocket Message comprised of data using a binary frame\n // opcode; if the data cannot be sent, e.g. because it would need\n // to be buffered but the buffer is full, the user agent must flag\n // the WebSocket as full and then close the WebSocket connection.\n // The data to be sent is the data stored in the buffer described\n // by the ArrayBuffer object. Any invocation of this method with an\n // ArrayBuffer argument that does not throw an exception must\n // increase the bufferedAmount attribute by the length of the\n // ArrayBuffer in bytes.\n\n const value = Buffer.from(data)\n const frame = new WebsocketFrameSend(value)\n const buffer = frame.createFrame(opcodes.BINARY)\n\n this.#bufferedAmount += value.byteLength\n socket.write(buffer, () => {\n this.#bufferedAmount -= value.byteLength\n })\n } else if (ArrayBuffer.isView(data)) {\n // If the WebSocket connection is established, and the WebSocket\n // closing handshake has not yet started, then the user agent must\n // send a WebSocket Message comprised of data using a binary frame\n // opcode; if the data cannot be sent, e.g. because it would need to\n // be buffered but the buffer is full, the user agent must flag the\n // WebSocket as full and then close the WebSocket connection. The\n // data to be sent is the data stored in the section of the buffer\n // described by the ArrayBuffer object that data references. Any\n // invocation of this method with this kind of argument that does\n // not throw an exception must increase the bufferedAmount attribute\n // by the length of data\u2019s buffer in bytes.\n\n const ab = Buffer.from(data, data.byteOffset, data.byteLength)\n\n const frame = new WebsocketFrameSend(ab)\n const buffer = frame.createFrame(opcodes.BINARY)\n\n this.#bufferedAmount += ab.byteLength\n socket.write(buffer, () => {\n this.#bufferedAmount -= ab.byteLength\n })\n } else if (isBlobLike(data)) {\n // If the WebSocket connection is established, and the WebSocket\n // closing handshake has not yet started, then the user agent must\n // send a WebSocket Message comprised of data using a binary frame\n // opcode; if the data cannot be sent, e.g. because it would need to\n // be buffered but the buffer is full, the user agent must flag the\n // WebSocket as full and then close the WebSocket connection. The data\n // to be sent is the raw data represented by the Blob object. Any\n // invocation of this method with a Blob argument that does not throw\n // an exception must increase the bufferedAmount attribute by the size\n // of the Blob object\u2019s raw data, in bytes.\n\n const frame = new WebsocketFrameSend()\n\n data.arrayBuffer().then((ab) => {\n const value = Buffer.from(ab)\n frame.frameData = value\n const buffer = frame.createFrame(opcodes.BINARY)\n\n this.#bufferedAmount += value.byteLength\n socket.write(buffer, () => {\n this.#bufferedAmount -= value.byteLength\n })\n })\n }\n }\n\n get readyState () {\n webidl.brandCheck(this, WebSocket)\n\n // The readyState getter steps are to return this's ready state.\n return this[kReadyState]\n }\n\n get bufferedAmount () {\n webidl.brandCheck(this, WebSocket)\n\n return this.#bufferedAmount\n }\n\n get url () {\n webidl.brandCheck(this, WebSocket)\n\n // The url getter steps are to return this's url, serialized.\n return URLSerializer(this[kWebSocketURL])\n }\n\n get extensions () {\n webidl.brandCheck(this, WebSocket)\n\n return this.#extensions\n }\n\n get protocol () {\n webidl.brandCheck(this, WebSocket)\n\n return this.#protocol\n }\n\n get onopen () {\n webidl.brandCheck(this, WebSocket)\n\n return this.#events.open\n }\n\n set onopen (fn) {\n webidl.brandCheck(this, WebSocket)\n\n if (this.#events.open) {\n this.removeEventListener('open', this.#events.open)\n }\n\n if (typeof fn === 'function') {\n this.#events.open = fn\n this.addEventListener('open', fn)\n } else {\n this.#events.open = null\n }\n }\n\n get onerror () {\n webidl.brandCheck(this, WebSocket)\n\n return this.#events.error\n }\n\n set onerror (fn) {\n webidl.brandCheck(this, WebSocket)\n\n if (this.#events.error) {\n this.removeEventListener('error', this.#events.error)\n }\n\n if (typeof fn === 'function') {\n this.#events.error = fn\n this.addEventListener('error', fn)\n } else {\n this.#events.error = null\n }\n }\n\n get onclose () {\n webidl.brandCheck(this, WebSocket)\n\n return this.#events.close\n }\n\n set onclose (fn) {\n webidl.brandCheck(this, WebSocket)\n\n if (this.#events.close) {\n this.removeEventListener('close', this.#events.close)\n }\n\n if (typeof fn === 'function') {\n this.#events.close = fn\n this.addEventListener('close', fn)\n } else {\n this.#events.close = null\n }\n }\n\n get onmessage () {\n webidl.brandCheck(this, WebSocket)\n\n return this.#events.message\n }\n\n set onmessage (fn) {\n webidl.brandCheck(this, WebSocket)\n\n if (this.#events.message) {\n this.removeEventListener('message', this.#events.message)\n }\n\n if (typeof fn === 'function') {\n this.#events.message = fn\n this.addEventListener('message', fn)\n } else {\n this.#events.message = null\n }\n }\n\n get binaryType () {\n webidl.brandCheck(this, WebSocket)\n\n return this[kBinaryType]\n }\n\n set binaryType (type) {\n webidl.brandCheck(this, WebSocket)\n\n if (type !== 'blob' && type !== 'arraybuffer') {\n this[kBinaryType] = 'blob'\n } else {\n this[kBinaryType] = type\n }\n }\n\n /**\n * @see https://websockets.spec.whatwg.org/#feedback-from-the-protocol\n */\n #onConnectionEstablished (response) {\n // processResponse is called when the \"response\u2019s header list has been received and initialized.\"\n // once this happens, the connection is open\n this[kResponse] = response\n\n const parser = new ByteParser(this)\n parser.on('drain', function onParserDrain () {\n this.ws[kResponse].socket.resume()\n })\n\n response.socket.ws = this\n this[kByteParser] = parser\n\n // 1. Change the ready state to OPEN (1).\n this[kReadyState] = states.OPEN\n\n // 2. Change the extensions attribute\u2019s value to the extensions in use, if\n // it is not the null value.\n // https://datatracker.ietf.org/doc/html/rfc6455#section-9.1\n const extensions = response.headersList.get('sec-websocket-extensions')\n\n if (extensions !== null) {\n this.#extensions = extensions\n }\n\n // 3. Change the protocol attribute\u2019s value to the subprotocol in use, if\n // it is not the null value.\n // https://datatracker.ietf.org/doc/html/rfc6455#section-1.9\n const protocol = response.headersList.get('sec-websocket-protocol')\n\n if (protocol !== null) {\n this.#protocol = protocol\n }\n\n // 4. Fire an event named open at the WebSocket object.\n fireEvent('open', this)\n }\n}\n\n// https://websockets.spec.whatwg.org/#dom-websocket-connecting\nWebSocket.CONNECTING = WebSocket.prototype.CONNECTING = states.CONNECTING\n// https://websockets.spec.whatwg.org/#dom-websocket-open\nWebSocket.OPEN = WebSocket.prototype.OPEN = states.OPEN\n// https://websockets.spec.whatwg.org/#dom-websocket-closing\nWebSocket.CLOSING = WebSocket.prototype.CLOSING = states.CLOSING\n// https://websockets.spec.whatwg.org/#dom-websocket-closed\nWebSocket.CLOSED = WebSocket.prototype.CLOSED = states.CLOSED\n\nObject.defineProperties(WebSocket.prototype, {\n CONNECTING: staticPropertyDescriptors,\n OPEN: staticPropertyDescriptors,\n CLOSING: staticPropertyDescriptors,\n CLOSED: staticPropertyDescriptors,\n url: kEnumerableProperty,\n readyState: kEnumerableProperty,\n bufferedAmount: kEnumerableProperty,\n onopen: kEnumerableProperty,\n onerror: kEnumerableProperty,\n onclose: kEnumerableProperty,\n close: kEnumerableProperty,\n onmessage: kEnumerableProperty,\n binaryType: kEnumerableProperty,\n send: kEnumerableProperty,\n extensions: kEnumerableProperty,\n protocol: kEnumerableProperty,\n [Symbol.toStringTag]: {\n value: 'WebSocket',\n writable: false,\n enumerable: false,\n configurable: true\n }\n})\n\nObject.defineProperties(WebSocket, {\n CONNECTING: staticPropertyDescriptors,\n OPEN: staticPropertyDescriptors,\n CLOSING: staticPropertyDescriptors,\n CLOSED: staticPropertyDescriptors\n})\n\nwebidl.converters['sequence<DOMString>'] = webidl.sequenceConverter(\n webidl.converters.DOMString\n)\n\nwebidl.converters['DOMString or sequence<DOMString>'] = function (V) {\n if (webidl.util.Type(V) === 'Object' && Symbol.iterator in V) {\n return webidl.converters['sequence<DOMString>'](V)\n }\n\n return webidl.converters.DOMString(V)\n}\n\n// This implements the propsal made in https://github.com/whatwg/websockets/issues/42\nwebidl.converters.WebSocketInit = webidl.dictionaryConverter([\n {\n key: 'protocols',\n converter: webidl.converters['DOMString or sequence<DOMString>'],\n get defaultValue () {\n return []\n }\n },\n {\n key: 'dispatcher',\n converter: (V) => V,\n get defaultValue () {\n return getGlobalDispatcher()\n }\n },\n {\n key: 'headers',\n converter: webidl.nullableConverter(webidl.converters.HeadersInit)\n }\n])\n\nwebidl.converters['DOMString or sequence<DOMString> or WebSocketInit'] = function (V) {\n if (webidl.util.Type(V) === 'Object' && !(Symbol.iterator in V)) {\n return webidl.converters.WebSocketInit(V)\n }\n\n return { protocols: webidl.converters['DOMString or sequence<DOMString>'](V) }\n}\n\nwebidl.converters.WebSocketSendData = function (V) {\n if (webidl.util.Type(V) === 'Object') {\n if (isBlobLike(V)) {\n return webidl.converters.Blob(V, { strict: false })\n }\n\n if (ArrayBuffer.isView(V) || types.isAnyArrayBuffer(V)) {\n return webidl.converters.BufferSource(V)\n }\n }\n\n return webidl.converters.USVString(V)\n}\n\nmodule.exports = {\n WebSocket\n}\n\n\n/***/ }),\n\n/***/ 5030:\n/***/ ((__unused_webpack_module, exports) => {\n\n\"use strict\";\n\n\nObject.defineProperty(exports, \"__esModule\", ({ value: true }));\n\nfunction getUserAgent() {\n if (typeof navigator === \"object\" && \"userAgent\" in navigator) {\n return navigator.userAgent;\n }\n\n if (typeof process === \"object\" && process.version !== undefined) {\n return `Node.js/${process.version.substr(1)} (${process.platform}; ${process.arch})`;\n }\n\n return \"<environment undetectable>\";\n}\n\nexports.getUserAgent = getUserAgent;\n//# sourceMappingURL=index.js.map\n\n\n/***/ }),\n\n/***/ 5840:\n/***/ ((__unused_webpack_module, exports, __nccwpck_require__) => {\n\n\"use strict\";\n\n\nObject.defineProperty(exports, \"__esModule\", ({\n value: true\n}));\nObject.defineProperty(exports, \"v1\", ({\n enumerable: true,\n get: function () {\n return _v.default;\n }\n}));\nObject.defineProperty(exports, \"v3\", ({\n enumerable: true,\n get: function () {\n return _v2.default;\n }\n}));\nObject.defineProperty(exports, \"v4\", ({\n enumerable: true,\n get: function () {\n return _v3.default;\n }\n}));\nObject.defineProperty(exports, \"v5\", ({\n enumerable: true,\n get: function () {\n return _v4.default;\n }\n}));\nObject.defineProperty(exports, \"NIL\", ({\n enumerable: true,\n get: function () {\n return _nil.default;\n }\n}));\nObject.defineProperty(exports, \"version\", ({\n enumerable: true,\n get: function () {\n return _version.default;\n }\n}));\nObject.defineProperty(exports, \"validate\", ({\n enumerable: true,\n get: function () {\n return _validate.default;\n }\n}));\nObject.defineProperty(exports, \"stringify\", ({\n enumerable: true,\n get: function () {\n return _stringify.default;\n }\n}));\nObject.defineProperty(exports, \"parse\", ({\n enumerable: true,\n get: function () {\n return _parse.default;\n }\n}));\n\nvar _v = _interopRequireDefault(__nccwpck_require__(8628));\n\nvar _v2 = _interopRequireDefault(__nccwpck_require__(6409));\n\nvar _v3 = _interopRequireDefault(__nccwpck_require__(5122));\n\nvar _v4 = _interopRequireDefault(__nccwpck_require__(9120));\n\nvar _nil = _interopRequireDefault(__nccwpck_require__(5332));\n\nvar _version = _interopRequireDefault(__nccwpck_require__(1595));\n\nvar _validate = _interopRequireDefault(__nccwpck_require__(6900));\n\nvar _stringify = _interopRequireDefault(__nccwpck_require__(8950));\n\nvar _parse = _interopRequireDefault(__nccwpck_require__(4848));\n\nfunction _interopRequireDefault(obj) { return obj && obj.__esModule ? obj : { default: obj }; }\n\n/***/ }),\n\n/***/ 4569:\n/***/ ((__unused_webpack_module, exports, __nccwpck_require__) => {\n\n\"use strict\";\n\n\nObject.defineProperty(exports, \"__esModule\", ({\n value: true\n}));\nexports[\"default\"] = void 0;\n\nvar _crypto = _interopRequireDefault(__nccwpck_require__(6113));\n\nfunction _interopRequireDefault(obj) { return obj && obj.__esModule ? obj : { default: obj }; }\n\nfunction md5(bytes) {\n if (Array.isArray(bytes)) {\n bytes = Buffer.from(bytes);\n } else if (typeof bytes === 'string') {\n bytes = Buffer.from(bytes, 'utf8');\n }\n\n return _crypto.default.createHash('md5').update(bytes).digest();\n}\n\nvar _default = md5;\nexports[\"default\"] = _default;\n\n/***/ }),\n\n/***/ 5332:\n/***/ ((__unused_webpack_module, exports) => {\n\n\"use strict\";\n\n\nObject.defineProperty(exports, \"__esModule\", ({\n value: true\n}));\nexports[\"default\"] = void 0;\nvar _default = '00000000-0000-0000-0000-000000000000';\nexports[\"default\"] = _default;\n\n/***/ }),\n\n/***/ 4848:\n/***/ ((__unused_webpack_module, exports, __nccwpck_require__) => {\n\n\"use strict\";\n\n\nObject.defineProperty(exports, \"__esModule\", ({\n value: true\n}));\nexports[\"default\"] = void 0;\n\nvar _validate = _interopRequireDefault(__nccwpck_require__(6900));\n\nfunction _interopRequireDefault(obj) { return obj && obj.__esModule ? obj : { default: obj }; }\n\nfunction parse(uuid) {\n if (!(0, _validate.default)(uuid)) {\n throw TypeError('Invalid UUID');\n }\n\n let v;\n const arr = new Uint8Array(16); // Parse ########-....-....-....-............\n\n arr[0] = (v = parseInt(uuid.slice(0, 8), 16)) >>> 24;\n arr[1] = v >>> 16 & 0xff;\n arr[2] = v >>> 8 & 0xff;\n arr[3] = v & 0xff; // Parse ........-####-....-....-............\n\n arr[4] = (v = parseInt(uuid.slice(9, 13), 16)) >>> 8;\n arr[5] = v & 0xff; // Parse ........-....-####-....-............\n\n arr[6] = (v = parseInt(uuid.slice(14, 18), 16)) >>> 8;\n arr[7] = v & 0xff; // Parse ........-....-....-####-............\n\n arr[8] = (v = parseInt(uuid.slice(19, 23), 16)) >>> 8;\n arr[9] = v & 0xff; // Parse ........-....-....-....-############\n // (Use \"/\" to avoid 32-bit truncation when bit-shifting high-order bytes)\n\n arr[10] = (v = parseInt(uuid.slice(24, 36), 16)) / 0x10000000000 & 0xff;\n arr[11] = v / 0x100000000 & 0xff;\n arr[12] = v >>> 24 & 0xff;\n arr[13] = v >>> 16 & 0xff;\n arr[14] = v >>> 8 & 0xff;\n arr[15] = v & 0xff;\n return arr;\n}\n\nvar _default = parse;\nexports[\"default\"] = _default;\n\n/***/ }),\n\n/***/ 814:\n/***/ ((__unused_webpack_module, exports) => {\n\n\"use strict\";\n\n\nObject.defineProperty(exports, \"__esModule\", ({\n value: true\n}));\nexports[\"default\"] = void 0;\nvar _default = /^(?:[0-9a-f]{8}-[0-9a-f]{4}-[1-5][0-9a-f]{3}-[89ab][0-9a-f]{3}-[0-9a-f]{12}|00000000-0000-0000-0000-000000000000)$/i;\nexports[\"default\"] = _default;\n\n/***/ }),\n\n/***/ 807:\n/***/ ((__unused_webpack_module, exports, __nccwpck_require__) => {\n\n\"use strict\";\n\n\nObject.defineProperty(exports, \"__esModule\", ({\n value: true\n}));\nexports[\"default\"] = rng;\n\nvar _crypto = _interopRequireDefault(__nccwpck_require__(6113));\n\nfunction _interopRequireDefault(obj) { return obj && obj.__esModule ? obj : { default: obj }; }\n\nconst rnds8Pool = new Uint8Array(256); // # of random values to pre-allocate\n\nlet poolPtr = rnds8Pool.length;\n\nfunction rng() {\n if (poolPtr > rnds8Pool.length - 16) {\n _crypto.default.randomFillSync(rnds8Pool);\n\n poolPtr = 0;\n }\n\n return rnds8Pool.slice(poolPtr, poolPtr += 16);\n}\n\n/***/ }),\n\n/***/ 5274:\n/***/ ((__unused_webpack_module, exports, __nccwpck_require__) => {\n\n\"use strict\";\n\n\nObject.defineProperty(exports, \"__esModule\", ({\n value: true\n}));\nexports[\"default\"] = void 0;\n\nvar _crypto = _interopRequireDefault(__nccwpck_require__(6113));\n\nfunction _interopRequireDefault(obj) { return obj && obj.__esModule ? obj : { default: obj }; }\n\nfunction sha1(bytes) {\n if (Array.isArray(bytes)) {\n bytes = Buffer.from(bytes);\n } else if (typeof bytes === 'string') {\n bytes = Buffer.from(bytes, 'utf8');\n }\n\n return _crypto.default.createHash('sha1').update(bytes).digest();\n}\n\nvar _default = sha1;\nexports[\"default\"] = _default;\n\n/***/ }),\n\n/***/ 8950:\n/***/ ((__unused_webpack_module, exports, __nccwpck_require__) => {\n\n\"use strict\";\n\n\nObject.defineProperty(exports, \"__esModule\", ({\n value: true\n}));\nexports[\"default\"] = void 0;\n\nvar _validate = _interopRequireDefault(__nccwpck_require__(6900));\n\nfunction _interopRequireDefault(obj) { return obj && obj.__esModule ? obj : { default: obj }; }\n\n/**\n * Convert array of 16 byte values to UUID string format of the form:\n * XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX\n */\nconst byteToHex = [];\n\nfor (let i = 0; i < 256; ++i) {\n byteToHex.push((i + 0x100).toString(16).substr(1));\n}\n\nfunction stringify(arr, offset = 0) {\n // Note: Be careful editing this code! It's been tuned for performance\n // and works in ways you may not expect. See https://github.com/uuidjs/uuid/pull/434\n const uuid = (byteToHex[arr[offset + 0]] + byteToHex[arr[offset + 1]] + byteToHex[arr[offset + 2]] + byteToHex[arr[offset + 3]] + '-' + byteToHex[arr[offset + 4]] + byteToHex[arr[offset + 5]] + '-' + byteToHex[arr[offset + 6]] + byteToHex[arr[offset + 7]] + '-' + byteToHex[arr[offset + 8]] + byteToHex[arr[offset + 9]] + '-' + byteToHex[arr[offset + 10]] + byteToHex[arr[offset + 11]] + byteToHex[arr[offset + 12]] + byteToHex[arr[offset + 13]] + byteToHex[arr[offset + 14]] + byteToHex[arr[offset + 15]]).toLowerCase(); // Consistency check for valid UUID. If this throws, it's likely due to one\n // of the following:\n // - One or more input array values don't map to a hex octet (leading to\n // \"undefined\" in the uuid)\n // - Invalid input values for the RFC `version` or `variant` fields\n\n if (!(0, _validate.default)(uuid)) {\n throw TypeError('Stringified UUID is invalid');\n }\n\n return uuid;\n}\n\nvar _default = stringify;\nexports[\"default\"] = _default;\n\n/***/ }),\n\n/***/ 8628:\n/***/ ((__unused_webpack_module, exports, __nccwpck_require__) => {\n\n\"use strict\";\n\n\nObject.defineProperty(exports, \"__esModule\", ({\n value: true\n}));\nexports[\"default\"] = void 0;\n\nvar _rng = _interopRequireDefault(__nccwpck_require__(807));\n\nvar _stringify = _interopRequireDefault(__nccwpck_require__(8950));\n\nfunction _interopRequireDefault(obj) { return obj && obj.__esModule ? obj : { default: obj }; }\n\n// **`v1()` - Generate time-based UUID**\n//\n// Inspired by https://github.com/LiosK/UUID.js\n// and http://docs.python.org/library/uuid.html\nlet _nodeId;\n\nlet _clockseq; // Previous uuid creation time\n\n\nlet _lastMSecs = 0;\nlet _lastNSecs = 0; // See https://github.com/uuidjs/uuid for API details\n\nfunction v1(options, buf, offset) {\n let i = buf && offset || 0;\n const b = buf || new Array(16);\n options = options || {};\n let node = options.node || _nodeId;\n let clockseq = options.clockseq !== undefined ? options.clockseq : _clockseq; // node and clockseq need to be initialized to random values if they're not\n // specified. We do this lazily to minimize issues related to insufficient\n // system entropy. See #189\n\n if (node == null || clockseq == null) {\n const seedBytes = options.random || (options.rng || _rng.default)();\n\n if (node == null) {\n // Per 4.5, create and 48-bit node id, (47 random bits + multicast bit = 1)\n node = _nodeId = [seedBytes[0] | 0x01, seedBytes[1], seedBytes[2], seedBytes[3], seedBytes[4], seedBytes[5]];\n }\n\n if (clockseq == null) {\n // Per 4.2.2, randomize (14 bit) clockseq\n clockseq = _clockseq = (seedBytes[6] << 8 | seedBytes[7]) & 0x3fff;\n }\n } // UUID timestamps are 100 nano-second units since the Gregorian epoch,\n // (1582-10-15 00:00). JSNumbers aren't precise enough for this, so\n // time is handled internally as 'msecs' (integer milliseconds) and 'nsecs'\n // (100-nanoseconds offset from msecs) since unix epoch, 1970-01-01 00:00.\n\n\n let msecs = options.msecs !== undefined ? options.msecs : Date.now(); // Per 4.2.1.2, use count of uuid's generated during the current clock\n // cycle to simulate higher resolution clock\n\n let nsecs = options.nsecs !== undefined ? options.nsecs : _lastNSecs + 1; // Time since last uuid creation (in msecs)\n\n const dt = msecs - _lastMSecs + (nsecs - _lastNSecs) / 10000; // Per 4.2.1.2, Bump clockseq on clock regression\n\n if (dt < 0 && options.clockseq === undefined) {\n clockseq = clockseq + 1 & 0x3fff;\n } // Reset nsecs if clock regresses (new clockseq) or we've moved onto a new\n // time interval\n\n\n if ((dt < 0 || msecs > _lastMSecs) && options.nsecs === undefined) {\n nsecs = 0;\n } // Per 4.2.1.2 Throw error if too many uuids are requested\n\n\n if (nsecs >= 10000) {\n throw new Error(\"uuid.v1(): Can't create more than 10M uuids/sec\");\n }\n\n _lastMSecs = msecs;\n _lastNSecs = nsecs;\n _clockseq = clockseq; // Per 4.1.4 - Convert from unix epoch to Gregorian epoch\n\n msecs += 12219292800000; // `time_low`\n\n const tl = ((msecs & 0xfffffff) * 10000 + nsecs) % 0x100000000;\n b[i++] = tl >>> 24 & 0xff;\n b[i++] = tl >>> 16 & 0xff;\n b[i++] = tl >>> 8 & 0xff;\n b[i++] = tl & 0xff; // `time_mid`\n\n const tmh = msecs / 0x100000000 * 10000 & 0xfffffff;\n b[i++] = tmh >>> 8 & 0xff;\n b[i++] = tmh & 0xff; // `time_high_and_version`\n\n b[i++] = tmh >>> 24 & 0xf | 0x10; // include version\n\n b[i++] = tmh >>> 16 & 0xff; // `clock_seq_hi_and_reserved` (Per 4.2.2 - include variant)\n\n b[i++] = clockseq >>> 8 | 0x80; // `clock_seq_low`\n\n b[i++] = clockseq & 0xff; // `node`\n\n for (let n = 0; n < 6; ++n) {\n b[i + n] = node[n];\n }\n\n return buf || (0, _stringify.default)(b);\n}\n\nvar _default = v1;\nexports[\"default\"] = _default;\n\n/***/ }),\n\n/***/ 6409:\n/***/ ((__unused_webpack_module, exports, __nccwpck_require__) => {\n\n\"use strict\";\n\n\nObject.defineProperty(exports, \"__esModule\", ({\n value: true\n}));\nexports[\"default\"] = void 0;\n\nvar _v = _interopRequireDefault(__nccwpck_require__(5998));\n\nvar _md = _interopRequireDefault(__nccwpck_require__(4569));\n\nfunction _interopRequireDefault(obj) { return obj && obj.__esModule ? obj : { default: obj }; }\n\nconst v3 = (0, _v.default)('v3', 0x30, _md.default);\nvar _default = v3;\nexports[\"default\"] = _default;\n\n/***/ }),\n\n/***/ 5998:\n/***/ ((__unused_webpack_module, exports, __nccwpck_require__) => {\n\n\"use strict\";\n\n\nObject.defineProperty(exports, \"__esModule\", ({\n value: true\n}));\nexports[\"default\"] = _default;\nexports.URL = exports.DNS = void 0;\n\nvar _stringify = _interopRequireDefault(__nccwpck_require__(8950));\n\nvar _parse = _interopRequireDefault(__nccwpck_require__(4848));\n\nfunction _interopRequireDefault(obj) { return obj && obj.__esModule ? obj : { default: obj }; }\n\nfunction stringToBytes(str) {\n str = unescape(encodeURIComponent(str)); // UTF8 escape\n\n const bytes = [];\n\n for (let i = 0; i < str.length; ++i) {\n bytes.push(str.charCodeAt(i));\n }\n\n return bytes;\n}\n\nconst DNS = '6ba7b810-9dad-11d1-80b4-00c04fd430c8';\nexports.DNS = DNS;\nconst URL = '6ba7b811-9dad-11d1-80b4-00c04fd430c8';\nexports.URL = URL;\n\nfunction _default(name, version, hashfunc) {\n function generateUUID(value, namespace, buf, offset) {\n if (typeof value === 'string') {\n value = stringToBytes(value);\n }\n\n if (typeof namespace === 'string') {\n namespace = (0, _parse.default)(namespace);\n }\n\n if (namespace.length !== 16) {\n throw TypeError('Namespace must be array-like (16 iterable integer values, 0-255)');\n } // Compute hash of namespace and value, Per 4.3\n // Future: Use spread syntax when supported on all platforms, e.g. `bytes =\n // hashfunc([...namespace, ... value])`\n\n\n let bytes = new Uint8Array(16 + value.length);\n bytes.set(namespace);\n bytes.set(value, namespace.length);\n bytes = hashfunc(bytes);\n bytes[6] = bytes[6] & 0x0f | version;\n bytes[8] = bytes[8] & 0x3f | 0x80;\n\n if (buf) {\n offset = offset || 0;\n\n for (let i = 0; i < 16; ++i) {\n buf[offset + i] = bytes[i];\n }\n\n return buf;\n }\n\n return (0, _stringify.default)(bytes);\n } // Function#name is not settable on some platforms (#270)\n\n\n try {\n generateUUID.name = name; // eslint-disable-next-line no-empty\n } catch (err) {} // For CommonJS default export support\n\n\n generateUUID.DNS = DNS;\n generateUUID.URL = URL;\n return generateUUID;\n}\n\n/***/ }),\n\n/***/ 5122:\n/***/ ((__unused_webpack_module, exports, __nccwpck_require__) => {\n\n\"use strict\";\n\n\nObject.defineProperty(exports, \"__esModule\", ({\n value: true\n}));\nexports[\"default\"] = void 0;\n\nvar _rng = _interopRequireDefault(__nccwpck_require__(807));\n\nvar _stringify = _interopRequireDefault(__nccwpck_require__(8950));\n\nfunction _interopRequireDefault(obj) { return obj && obj.__esModule ? obj : { default: obj }; }\n\nfunction v4(options, buf, offset) {\n options = options || {};\n\n const rnds = options.random || (options.rng || _rng.default)(); // Per 4.4, set bits for version and `clock_seq_hi_and_reserved`\n\n\n rnds[6] = rnds[6] & 0x0f | 0x40;\n rnds[8] = rnds[8] & 0x3f | 0x80; // Copy bytes to buffer, if provided\n\n if (buf) {\n offset = offset || 0;\n\n for (let i = 0; i < 16; ++i) {\n buf[offset + i] = rnds[i];\n }\n\n return buf;\n }\n\n return (0, _stringify.default)(rnds);\n}\n\nvar _default = v4;\nexports[\"default\"] = _default;\n\n/***/ }),\n\n/***/ 9120:\n/***/ ((__unused_webpack_module, exports, __nccwpck_require__) => {\n\n\"use strict\";\n\n\nObject.defineProperty(exports, \"__esModule\", ({\n value: true\n}));\nexports[\"default\"] = void 0;\n\nvar _v = _interopRequireDefault(__nccwpck_require__(5998));\n\nvar _sha = _interopRequireDefault(__nccwpck_require__(5274));\n\nfunction _interopRequireDefault(obj) { return obj && obj.__esModule ? obj : { default: obj }; }\n\nconst v5 = (0, _v.default)('v5', 0x50, _sha.default);\nvar _default = v5;\nexports[\"default\"] = _default;\n\n/***/ }),\n\n/***/ 6900:\n/***/ ((__unused_webpack_module, exports, __nccwpck_require__) => {\n\n\"use strict\";\n\n\nObject.defineProperty(exports, \"__esModule\", ({\n value: true\n}));\nexports[\"default\"] = void 0;\n\nvar _regex = _interopRequireDefault(__nccwpck_require__(814));\n\nfunction _interopRequireDefault(obj) { return obj && obj.__esModule ? obj : { default: obj }; }\n\nfunction validate(uuid) {\n return typeof uuid === 'string' && _regex.default.test(uuid);\n}\n\nvar _default = validate;\nexports[\"default\"] = _default;\n\n/***/ }),\n\n/***/ 1595:\n/***/ ((__unused_webpack_module, exports, __nccwpck_require__) => {\n\n\"use strict\";\n\n\nObject.defineProperty(exports, \"__esModule\", ({\n value: true\n}));\nexports[\"default\"] = void 0;\n\nvar _validate = _interopRequireDefault(__nccwpck_require__(6900));\n\nfunction _interopRequireDefault(obj) { return obj && obj.__esModule ? obj : { default: obj }; }\n\nfunction version(uuid) {\n if (!(0, _validate.default)(uuid)) {\n throw TypeError('Invalid UUID');\n }\n\n return parseInt(uuid.substr(14, 1), 16);\n}\n\nvar _default = version;\nexports[\"default\"] = _default;\n\n/***/ }),\n\n/***/ 3515:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\n\"use strict\";\n\nconst os = __nccwpck_require__(2037);\nconst execa = __nccwpck_require__(5447);\n\n// Reference: https://www.gaijin.at/en/lstwinver.php\nconst names = new Map([\n\t['10.0', '10'],\n\t['6.3', '8.1'],\n\t['6.2', '8'],\n\t['6.1', '7'],\n\t['6.0', 'Vista'],\n\t['5.2', 'Server 2003'],\n\t['5.1', 'XP'],\n\t['5.0', '2000'],\n\t['4.9', 'ME'],\n\t['4.1', '98'],\n\t['4.0', '95']\n]);\n\nconst windowsRelease = release => {\n\tconst version = /\\d+\\.\\d/.exec(release || os.release());\n\n\tif (release && !version) {\n\t\tthrow new Error('`release` argument doesn\\'t match `n.n`');\n\t}\n\n\tconst ver = (version || [])[0];\n\n\t// Server 2008, 2012, 2016, and 2019 versions are ambiguous with desktop versions and must be detected at runtime.\n\t// If `release` is omitted or we're on a Windows system, and the version number is an ambiguous version\n\t// then use `wmic` to get the OS caption: https://msdn.microsoft.com/en-us/library/aa394531(v=vs.85).aspx\n\t// If `wmic` is obsoloete (later versions of Windows 10), use PowerShell instead.\n\t// If the resulting caption contains the year 2008, 2012, 2016 or 2019, it is a server version, so return a server OS name.\n\tif ((!release || release === os.release()) && ['6.1', '6.2', '6.3', '10.0'].includes(ver)) {\n\t\tlet stdout;\n\t\ttry {\n\t\t\tstdout = execa.sync('wmic', ['os', 'get', 'Caption']).stdout || '';\n\t\t} catch (_) {\n\t\t\tstdout = execa.sync('powershell', ['(Get-CimInstance -ClassName Win32_OperatingSystem).caption']).stdout || '';\n\t\t}\n\n\t\tconst year = (stdout.match(/2008|2012|2016|2019/) || [])[0];\n\n\t\tif (year) {\n\t\t\treturn `Server ${year}`;\n\t\t}\n\t}\n\n\treturn names.get(ver);\n};\n\nmodule.exports = windowsRelease;\n\n\n/***/ }),\n\n/***/ 2940:\n/***/ ((module) => {\n\n// Returns a wrapper function that returns a wrapped callback\n// The wrapper function should do some stuff, and return a\n// presumably different callback function.\n// This makes sure that own properties are retained, so that\n// decorations and such are not lost along the way.\nmodule.exports = wrappy\nfunction wrappy (fn, cb) {\n if (fn && cb) return wrappy(fn)(cb)\n\n if (typeof fn !== 'function')\n throw new TypeError('need wrapper function')\n\n Object.keys(fn).forEach(function (k) {\n wrapper[k] = fn[k]\n })\n\n return wrapper\n\n function wrapper() {\n var args = new Array(arguments.length)\n for (var i = 0; i < args.length; i++) {\n args[i] = arguments[i]\n }\n var ret = fn.apply(this, args)\n var cb = args[args.length-1]\n if (typeof ret === 'function' && ret !== cb) {\n Object.keys(cb).forEach(function (k) {\n ret[k] = cb[k]\n })\n }\n return ret\n }\n}\n\n\n/***/ }),\n\n/***/ 2877:\n/***/ ((module) => {\n\nmodule.exports = eval(\"require\")(\"encoding\");\n\n\n/***/ }),\n\n/***/ 9491:\n/***/ ((module) => {\n\n\"use strict\";\nmodule.exports = require(\"assert\");\n\n/***/ }),\n\n/***/ 852:\n/***/ ((module) => {\n\n\"use strict\";\nmodule.exports = require(\"async_hooks\");\n\n/***/ }),\n\n/***/ 4300:\n/***/ ((module) => {\n\n\"use strict\";\nmodule.exports = require(\"buffer\");\n\n/***/ }),\n\n/***/ 2081:\n/***/ ((module) => {\n\n\"use strict\";\nmodule.exports = require(\"child_process\");\n\n/***/ }),\n\n/***/ 6206:\n/***/ ((module) => {\n\n\"use strict\";\nmodule.exports = require(\"console\");\n\n/***/ }),\n\n/***/ 6113:\n/***/ ((module) => {\n\n\"use strict\";\nmodule.exports = require(\"crypto\");\n\n/***/ }),\n\n/***/ 7643:\n/***/ ((module) => {\n\n\"use strict\";\nmodule.exports = require(\"diagnostics_channel\");\n\n/***/ }),\n\n/***/ 9523:\n/***/ ((module) => {\n\n\"use strict\";\nmodule.exports = require(\"dns\");\n\n/***/ }),\n\n/***/ 2361:\n/***/ ((module) => {\n\n\"use strict\";\nmodule.exports = require(\"events\");\n\n/***/ }),\n\n/***/ 7147:\n/***/ ((module) => {\n\n\"use strict\";\nmodule.exports = require(\"fs\");\n\n/***/ }),\n\n/***/ 3685:\n/***/ ((module) => {\n\n\"use strict\";\nmodule.exports = require(\"http\");\n\n/***/ }),\n\n/***/ 5158:\n/***/ ((module) => {\n\n\"use strict\";\nmodule.exports = require(\"http2\");\n\n/***/ }),\n\n/***/ 5687:\n/***/ ((module) => {\n\n\"use strict\";\nmodule.exports = require(\"https\");\n\n/***/ }),\n\n/***/ 1808:\n/***/ ((module) => {\n\n\"use strict\";\nmodule.exports = require(\"net\");\n\n/***/ }),\n\n/***/ 5673:\n/***/ ((module) => {\n\n\"use strict\";\nmodule.exports = require(\"node:events\");\n\n/***/ }),\n\n/***/ 4492:\n/***/ ((module) => {\n\n\"use strict\";\nmodule.exports = require(\"node:stream\");\n\n/***/ }),\n\n/***/ 7261:\n/***/ ((module) => {\n\n\"use strict\";\nmodule.exports = require(\"node:util\");\n\n/***/ }),\n\n/***/ 2037:\n/***/ ((module) => {\n\n\"use strict\";\nmodule.exports = require(\"os\");\n\n/***/ }),\n\n/***/ 1017:\n/***/ ((module) => {\n\n\"use strict\";\nmodule.exports = require(\"path\");\n\n/***/ }),\n\n/***/ 4074:\n/***/ ((module) => {\n\n\"use strict\";\nmodule.exports = require(\"perf_hooks\");\n\n/***/ }),\n\n/***/ 5477:\n/***/ ((module) => {\n\n\"use strict\";\nmodule.exports = require(\"punycode\");\n\n/***/ }),\n\n/***/ 3477:\n/***/ ((module) => {\n\n\"use strict\";\nmodule.exports = require(\"querystring\");\n\n/***/ }),\n\n/***/ 2781:\n/***/ ((module) => {\n\n\"use strict\";\nmodule.exports = require(\"stream\");\n\n/***/ }),\n\n/***/ 5356:\n/***/ ((module) => {\n\n\"use strict\";\nmodule.exports = require(\"stream/web\");\n\n/***/ }),\n\n/***/ 1576:\n/***/ ((module) => {\n\n\"use strict\";\nmodule.exports = require(\"string_decoder\");\n\n/***/ }),\n\n/***/ 4404:\n/***/ ((module) => {\n\n\"use strict\";\nmodule.exports = require(\"tls\");\n\n/***/ }),\n\n/***/ 7310:\n/***/ ((module) => {\n\n\"use strict\";\nmodule.exports = require(\"url\");\n\n/***/ }),\n\n/***/ 3837:\n/***/ ((module) => {\n\n\"use strict\";\nmodule.exports = require(\"util\");\n\n/***/ }),\n\n/***/ 9830:\n/***/ ((module) => {\n\n\"use strict\";\nmodule.exports = require(\"util/types\");\n\n/***/ }),\n\n/***/ 1267:\n/***/ ((module) => {\n\n\"use strict\";\nmodule.exports = require(\"worker_threads\");\n\n/***/ }),\n\n/***/ 9796:\n/***/ ((module) => {\n\n\"use strict\";\nmodule.exports = require(\"zlib\");\n\n/***/ }),\n\n/***/ 2960:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\n\"use strict\";\n\n\nconst WritableStream = (__nccwpck_require__(4492).Writable)\nconst inherits = (__nccwpck_require__(7261).inherits)\n\nconst StreamSearch = __nccwpck_require__(1142)\n\nconst PartStream = __nccwpck_require__(1620)\nconst HeaderParser = __nccwpck_require__(2032)\n\nconst DASH = 45\nconst B_ONEDASH = Buffer.from('-')\nconst B_CRLF = Buffer.from('\\r\\n')\nconst EMPTY_FN = function () {}\n\nfunction Dicer (cfg) {\n if (!(this instanceof Dicer)) { return new Dicer(cfg) }\n WritableStream.call(this, cfg)\n\n if (!cfg || (!cfg.headerFirst && typeof cfg.boundary !== 'string')) { throw new TypeError('Boundary required') }\n\n if (typeof cfg.boundary === 'string') { this.setBoundary(cfg.boundary) } else { this._bparser = undefined }\n\n this._headerFirst = cfg.headerFirst\n\n this._dashes = 0\n this._parts = 0\n this._finished = false\n this._realFinish = false\n this._isPreamble = true\n this._justMatched = false\n this._firstWrite = true\n this._inHeader = true\n this._part = undefined\n this._cb = undefined\n this._ignoreData = false\n this._partOpts = { highWaterMark: cfg.partHwm }\n this._pause = false\n\n const self = this\n this._hparser = new HeaderParser(cfg)\n this._hparser.on('header', function (header) {\n self._inHeader = false\n self._part.emit('header', header)\n })\n}\ninherits(Dicer, WritableStream)\n\nDicer.prototype.emit = function (ev) {\n if (ev === 'finish' && !this._realFinish) {\n if (!this._finished) {\n const self = this\n process.nextTick(function () {\n self.emit('error', new Error('Unexpected end of multipart data'))\n if (self._part && !self._ignoreData) {\n const type = (self._isPreamble ? 'Preamble' : 'Part')\n self._part.emit('error', new Error(type + ' terminated early due to unexpected end of multipart data'))\n self._part.push(null)\n process.nextTick(function () {\n self._realFinish = true\n self.emit('finish')\n self._realFinish = false\n })\n return\n }\n self._realFinish = true\n self.emit('finish')\n self._realFinish = false\n })\n }\n } else { WritableStream.prototype.emit.apply(this, arguments) }\n}\n\nDicer.prototype._write = function (data, encoding, cb) {\n // ignore unexpected data (e.g. extra trailer data after finished)\n if (!this._hparser && !this._bparser) { return cb() }\n\n if (this._headerFirst && this._isPreamble) {\n if (!this._part) {\n this._part = new PartStream(this._partOpts)\n if (this.listenerCount('preamble') !== 0) { this.emit('preamble', this._part) } else { this._ignore() }\n }\n const r = this._hparser.push(data)\n if (!this._inHeader && r !== undefined && r < data.length) { data = data.slice(r) } else { return cb() }\n }\n\n // allows for \"easier\" testing\n if (this._firstWrite) {\n this._bparser.push(B_CRLF)\n this._firstWrite = false\n }\n\n this._bparser.push(data)\n\n if (this._pause) { this._cb = cb } else { cb() }\n}\n\nDicer.prototype.reset = function () {\n this._part = undefined\n this._bparser = undefined\n this._hparser = undefined\n}\n\nDicer.prototype.setBoundary = function (boundary) {\n const self = this\n this._bparser = new StreamSearch('\\r\\n--' + boundary)\n this._bparser.on('info', function (isMatch, data, start, end) {\n self._oninfo(isMatch, data, start, end)\n })\n}\n\nDicer.prototype._ignore = function () {\n if (this._part && !this._ignoreData) {\n this._ignoreData = true\n this._part.on('error', EMPTY_FN)\n // we must perform some kind of read on the stream even though we are\n // ignoring the data, otherwise node's Readable stream will not emit 'end'\n // after pushing null to the stream\n this._part.resume()\n }\n}\n\nDicer.prototype._oninfo = function (isMatch, data, start, end) {\n let buf; const self = this; let i = 0; let r; let shouldWriteMore = true\n\n if (!this._part && this._justMatched && data) {\n while (this._dashes < 2 && (start + i) < end) {\n if (data[start + i] === DASH) {\n ++i\n ++this._dashes\n } else {\n if (this._dashes) { buf = B_ONEDASH }\n this._dashes = 0\n break\n }\n }\n if (this._dashes === 2) {\n if ((start + i) < end && this.listenerCount('trailer') !== 0) { this.emit('trailer', data.slice(start + i, end)) }\n this.reset()\n this._finished = true\n // no more parts will be added\n if (self._parts === 0) {\n self._realFinish = true\n self.emit('finish')\n self._realFinish = false\n }\n }\n if (this._dashes) { return }\n }\n if (this._justMatched) { this._justMatched = false }\n if (!this._part) {\n this._part = new PartStream(this._partOpts)\n this._part._read = function (n) {\n self._unpause()\n }\n if (this._isPreamble && this.listenerCount('preamble') !== 0) {\n this.emit('preamble', this._part)\n } else if (this._isPreamble !== true && this.listenerCount('part') !== 0) {\n this.emit('part', this._part)\n } else {\n this._ignore()\n }\n if (!this._isPreamble) { this._inHeader = true }\n }\n if (data && start < end && !this._ignoreData) {\n if (this._isPreamble || !this._inHeader) {\n if (buf) { shouldWriteMore = this._part.push(buf) }\n shouldWriteMore = this._part.push(data.slice(start, end))\n if (!shouldWriteMore) { this._pause = true }\n } else if (!this._isPreamble && this._inHeader) {\n if (buf) { this._hparser.push(buf) }\n r = this._hparser.push(data.slice(start, end))\n if (!this._inHeader && r !== undefined && r < end) { this._oninfo(false, data, start + r, end) }\n }\n }\n if (isMatch) {\n this._hparser.reset()\n if (this._isPreamble) { this._isPreamble = false } else {\n if (start !== end) {\n ++this._parts\n this._part.on('end', function () {\n if (--self._parts === 0) {\n if (self._finished) {\n self._realFinish = true\n self.emit('finish')\n self._realFinish = false\n } else {\n self._unpause()\n }\n }\n })\n }\n }\n this._part.push(null)\n this._part = undefined\n this._ignoreData = false\n this._justMatched = true\n this._dashes = 0\n }\n}\n\nDicer.prototype._unpause = function () {\n if (!this._pause) { return }\n\n this._pause = false\n if (this._cb) {\n const cb = this._cb\n this._cb = undefined\n cb()\n }\n}\n\nmodule.exports = Dicer\n\n\n/***/ }),\n\n/***/ 2032:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\n\"use strict\";\n\n\nconst EventEmitter = (__nccwpck_require__(5673).EventEmitter)\nconst inherits = (__nccwpck_require__(7261).inherits)\nconst getLimit = __nccwpck_require__(1467)\n\nconst StreamSearch = __nccwpck_require__(1142)\n\nconst B_DCRLF = Buffer.from('\\r\\n\\r\\n')\nconst RE_CRLF = /\\r\\n/g\nconst RE_HDR = /^([^:]+):[ \\t]?([\\x00-\\xFF]+)?$/ // eslint-disable-line no-control-regex\n\nfunction HeaderParser (cfg) {\n EventEmitter.call(this)\n\n cfg = cfg || {}\n const self = this\n this.nread = 0\n this.maxed = false\n this.npairs = 0\n this.maxHeaderPairs = getLimit(cfg, 'maxHeaderPairs', 2000)\n this.maxHeaderSize = getLimit(cfg, 'maxHeaderSize', 80 * 1024)\n this.buffer = ''\n this.header = {}\n this.finished = false\n this.ss = new StreamSearch(B_DCRLF)\n this.ss.on('info', function (isMatch, data, start, end) {\n if (data && !self.maxed) {\n if (self.nread + end - start >= self.maxHeaderSize) {\n end = self.maxHeaderSize - self.nread + start\n self.nread = self.maxHeaderSize\n self.maxed = true\n } else { self.nread += (end - start) }\n\n self.buffer += data.toString('binary', start, end)\n }\n if (isMatch) { self._finish() }\n })\n}\ninherits(HeaderParser, EventEmitter)\n\nHeaderParser.prototype.push = function (data) {\n const r = this.ss.push(data)\n if (this.finished) { return r }\n}\n\nHeaderParser.prototype.reset = function () {\n this.finished = false\n this.buffer = ''\n this.header = {}\n this.ss.reset()\n}\n\nHeaderParser.prototype._finish = function () {\n if (this.buffer) { this._parseHeader() }\n this.ss.matches = this.ss.maxMatches\n const header = this.header\n this.header = {}\n this.buffer = ''\n this.finished = true\n this.nread = this.npairs = 0\n this.maxed = false\n this.emit('header', header)\n}\n\nHeaderParser.prototype._parseHeader = function () {\n if (this.npairs === this.maxHeaderPairs) { return }\n\n const lines = this.buffer.split(RE_CRLF)\n const len = lines.length\n let m, h\n\n for (var i = 0; i < len; ++i) { // eslint-disable-line no-var\n if (lines[i].length === 0) { continue }\n if (lines[i][0] === '\\t' || lines[i][0] === ' ') {\n // folded header content\n // RFC2822 says to just remove the CRLF and not the whitespace following\n // it, so we follow the RFC and include the leading whitespace ...\n if (h) {\n this.header[h][this.header[h].length - 1] += lines[i]\n continue\n }\n }\n\n const posColon = lines[i].indexOf(':')\n if (\n posColon === -1 ||\n posColon === 0\n ) {\n return\n }\n m = RE_HDR.exec(lines[i])\n h = m[1].toLowerCase()\n this.header[h] = this.header[h] || []\n this.header[h].push((m[2] || ''))\n if (++this.npairs === this.maxHeaderPairs) { break }\n }\n}\n\nmodule.exports = HeaderParser\n\n\n/***/ }),\n\n/***/ 1620:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\n\"use strict\";\n\n\nconst inherits = (__nccwpck_require__(7261).inherits)\nconst ReadableStream = (__nccwpck_require__(4492).Readable)\n\nfunction PartStream (opts) {\n ReadableStream.call(this, opts)\n}\ninherits(PartStream, ReadableStream)\n\nPartStream.prototype._read = function (n) {}\n\nmodule.exports = PartStream\n\n\n/***/ }),\n\n/***/ 1142:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\n\"use strict\";\n\n\n/**\n * Copyright Brian White. All rights reserved.\n *\n * @see https://github.com/mscdex/streamsearch\n *\n * Permission is hereby granted, free of charge, to any person obtaining a copy\n * of this software and associated documentation files (the \"Software\"), to\n * deal in the Software without restriction, including without limitation the\n * rights to use, copy, modify, merge, publish, distribute, sublicense, and/or\n * sell copies of the Software, and to permit persons to whom the Software is\n * furnished to do so, subject to the following conditions:\n *\n * The above copyright notice and this permission notice shall be included in\n * all copies or substantial portions of the Software.\n *\n * THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR\n * IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,\n * FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE\n * AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER\n * LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING\n * FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS\n * IN THE SOFTWARE.\n *\n * Based heavily on the Streaming Boyer-Moore-Horspool C++ implementation\n * by Hongli Lai at: https://github.com/FooBarWidget/boyer-moore-horspool\n */\nconst EventEmitter = (__nccwpck_require__(5673).EventEmitter)\nconst inherits = (__nccwpck_require__(7261).inherits)\n\nfunction SBMH (needle) {\n if (typeof needle === 'string') {\n needle = Buffer.from(needle)\n }\n\n if (!Buffer.isBuffer(needle)) {\n throw new TypeError('The needle has to be a String or a Buffer.')\n }\n\n const needleLength = needle.length\n\n if (needleLength === 0) {\n throw new Error('The needle cannot be an empty String/Buffer.')\n }\n\n if (needleLength > 256) {\n throw new Error('The needle cannot have a length bigger than 256.')\n }\n\n this.maxMatches = Infinity\n this.matches = 0\n\n this._occ = new Array(256)\n .fill(needleLength) // Initialize occurrence table.\n this._lookbehind_size = 0\n this._needle = needle\n this._bufpos = 0\n\n this._lookbehind = Buffer.alloc(needleLength)\n\n // Populate occurrence table with analysis of the needle,\n // ignoring last letter.\n for (var i = 0; i < needleLength - 1; ++i) { // eslint-disable-line no-var\n this._occ[needle[i]] = needleLength - 1 - i\n }\n}\ninherits(SBMH, EventEmitter)\n\nSBMH.prototype.reset = function () {\n this._lookbehind_size = 0\n this.matches = 0\n this._bufpos = 0\n}\n\nSBMH.prototype.push = function (chunk, pos) {\n if (!Buffer.isBuffer(chunk)) {\n chunk = Buffer.from(chunk, 'binary')\n }\n const chlen = chunk.length\n this._bufpos = pos || 0\n let r\n while (r !== chlen && this.matches < this.maxMatches) { r = this._sbmh_feed(chunk) }\n return r\n}\n\nSBMH.prototype._sbmh_feed = function (data) {\n const len = data.length\n const needle = this._needle\n const needleLength = needle.length\n const lastNeedleChar = needle[needleLength - 1]\n\n // Positive: points to a position in `data`\n // pos == 3 points to data[3]\n // Negative: points to a position in the lookbehind buffer\n // pos == -2 points to lookbehind[lookbehind_size - 2]\n let pos = -this._lookbehind_size\n let ch\n\n if (pos < 0) {\n // Lookbehind buffer is not empty. Perform Boyer-Moore-Horspool\n // search with character lookup code that considers both the\n // lookbehind buffer and the current round's haystack data.\n //\n // Loop until\n // there is a match.\n // or until\n // we've moved past the position that requires the\n // lookbehind buffer. In this case we switch to the\n // optimized loop.\n // or until\n // the character to look at lies outside the haystack.\n while (pos < 0 && pos <= len - needleLength) {\n ch = this._sbmh_lookup_char(data, pos + needleLength - 1)\n\n if (\n ch === lastNeedleChar &&\n this._sbmh_memcmp(data, pos, needleLength - 1)\n ) {\n this._lookbehind_size = 0\n ++this.matches\n this.emit('info', true)\n\n return (this._bufpos = pos + needleLength)\n }\n pos += this._occ[ch]\n }\n\n // No match.\n\n if (pos < 0) {\n // There's too few data for Boyer-Moore-Horspool to run,\n // so let's use a different algorithm to skip as much as\n // we can.\n // Forward pos until\n // the trailing part of lookbehind + data\n // looks like the beginning of the needle\n // or until\n // pos == 0\n while (pos < 0 && !this._sbmh_memcmp(data, pos, len - pos)) { ++pos }\n }\n\n if (pos >= 0) {\n // Discard lookbehind buffer.\n this.emit('info', false, this._lookbehind, 0, this._lookbehind_size)\n this._lookbehind_size = 0\n } else {\n // Cut off part of the lookbehind buffer that has\n // been processed and append the entire haystack\n // into it.\n const bytesToCutOff = this._lookbehind_size + pos\n if (bytesToCutOff > 0) {\n // The cut off data is guaranteed not to contain the needle.\n this.emit('info', false, this._lookbehind, 0, bytesToCutOff)\n }\n\n this._lookbehind.copy(this._lookbehind, 0, bytesToCutOff,\n this._lookbehind_size - bytesToCutOff)\n this._lookbehind_size -= bytesToCutOff\n\n data.copy(this._lookbehind, this._lookbehind_size)\n this._lookbehind_size += len\n\n this._bufpos = len\n return len\n }\n }\n\n pos += (pos >= 0) * this._bufpos\n\n // Lookbehind buffer is now empty. We only need to check if the\n // needle is in the haystack.\n if (data.indexOf(needle, pos) !== -1) {\n pos = data.indexOf(needle, pos)\n ++this.matches\n if (pos > 0) { this.emit('info', true, data, this._bufpos, pos) } else { this.emit('info', true) }\n\n return (this._bufpos = pos + needleLength)\n } else {\n pos = len - needleLength\n }\n\n // There was no match. If there's trailing haystack data that we cannot\n // match yet using the Boyer-Moore-Horspool algorithm (because the trailing\n // data is less than the needle size) then match using a modified\n // algorithm that starts matching from the beginning instead of the end.\n // Whatever trailing data is left after running this algorithm is added to\n // the lookbehind buffer.\n while (\n pos < len &&\n (\n data[pos] !== needle[0] ||\n (\n (Buffer.compare(\n data.subarray(pos, pos + len - pos),\n needle.subarray(0, len - pos)\n ) !== 0)\n )\n )\n ) {\n ++pos\n }\n if (pos < len) {\n data.copy(this._lookbehind, 0, pos, pos + (len - pos))\n this._lookbehind_size = len - pos\n }\n\n // Everything until pos is guaranteed not to contain needle data.\n if (pos > 0) { this.emit('info', false, data, this._bufpos, pos < len ? pos : len) }\n\n this._bufpos = len\n return len\n}\n\nSBMH.prototype._sbmh_lookup_char = function (data, pos) {\n return (pos < 0)\n ? this._lookbehind[this._lookbehind_size + pos]\n : data[pos]\n}\n\nSBMH.prototype._sbmh_memcmp = function (data, pos, len) {\n for (var i = 0; i < len; ++i) { // eslint-disable-line no-var\n if (this._sbmh_lookup_char(data, pos + i) !== this._needle[i]) { return false }\n }\n return true\n}\n\nmodule.exports = SBMH\n\n\n/***/ }),\n\n/***/ 727:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\n\"use strict\";\n\n\nconst WritableStream = (__nccwpck_require__(4492).Writable)\nconst { inherits } = __nccwpck_require__(7261)\nconst Dicer = __nccwpck_require__(2960)\n\nconst MultipartParser = __nccwpck_require__(2183)\nconst UrlencodedParser = __nccwpck_require__(8306)\nconst parseParams = __nccwpck_require__(1854)\n\nfunction Busboy (opts) {\n if (!(this instanceof Busboy)) { return new Busboy(opts) }\n\n if (typeof opts !== 'object') {\n throw new TypeError('Busboy expected an options-Object.')\n }\n if (typeof opts.headers !== 'object') {\n throw new TypeError('Busboy expected an options-Object with headers-attribute.')\n }\n if (typeof opts.headers['content-type'] !== 'string') {\n throw new TypeError('Missing Content-Type-header.')\n }\n\n const {\n headers,\n ...streamOptions\n } = opts\n\n this.opts = {\n autoDestroy: false,\n ...streamOptions\n }\n WritableStream.call(this, this.opts)\n\n this._done = false\n this._parser = this.getParserByHeaders(headers)\n this._finished = false\n}\ninherits(Busboy, WritableStream)\n\nBusboy.prototype.emit = function (ev) {\n if (ev === 'finish') {\n if (!this._done) {\n this._parser?.end()\n return\n } else if (this._finished) {\n return\n }\n this._finished = true\n }\n WritableStream.prototype.emit.apply(this, arguments)\n}\n\nBusboy.prototype.getParserByHeaders = function (headers) {\n const parsed = parseParams(headers['content-type'])\n\n const cfg = {\n defCharset: this.opts.defCharset,\n fileHwm: this.opts.fileHwm,\n headers,\n highWaterMark: this.opts.highWaterMark,\n isPartAFile: this.opts.isPartAFile,\n limits: this.opts.limits,\n parsedConType: parsed,\n preservePath: this.opts.preservePath\n }\n\n if (MultipartParser.detect.test(parsed[0])) {\n return new MultipartParser(this, cfg)\n }\n if (UrlencodedParser.detect.test(parsed[0])) {\n return new UrlencodedParser(this, cfg)\n }\n throw new Error('Unsupported Content-Type.')\n}\n\nBusboy.prototype._write = function (chunk, encoding, cb) {\n this._parser.write(chunk, cb)\n}\n\nmodule.exports = Busboy\nmodule.exports[\"default\"] = Busboy\nmodule.exports.Busboy = Busboy\n\nmodule.exports.Dicer = Dicer\n\n\n/***/ }),\n\n/***/ 2183:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\n\"use strict\";\n\n\n// TODO:\n// * support 1 nested multipart level\n// (see second multipart example here:\n// http://www.w3.org/TR/html401/interact/forms.html#didx-multipartform-data)\n// * support limits.fieldNameSize\n// -- this will require modifications to utils.parseParams\n\nconst { Readable } = __nccwpck_require__(4492)\nconst { inherits } = __nccwpck_require__(7261)\n\nconst Dicer = __nccwpck_require__(2960)\n\nconst parseParams = __nccwpck_require__(1854)\nconst decodeText = __nccwpck_require__(4619)\nconst basename = __nccwpck_require__(8647)\nconst getLimit = __nccwpck_require__(1467)\n\nconst RE_BOUNDARY = /^boundary$/i\nconst RE_FIELD = /^form-data$/i\nconst RE_CHARSET = /^charset$/i\nconst RE_FILENAME = /^filename$/i\nconst RE_NAME = /^name$/i\n\nMultipart.detect = /^multipart\\/form-data/i\nfunction Multipart (boy, cfg) {\n let i\n let len\n const self = this\n let boundary\n const limits = cfg.limits\n const isPartAFile = cfg.isPartAFile || ((fieldName, contentType, fileName) => (contentType === 'application/octet-stream' || fileName !== undefined))\n const parsedConType = cfg.parsedConType || []\n const defCharset = cfg.defCharset || 'utf8'\n const preservePath = cfg.preservePath\n const fileOpts = { highWaterMark: cfg.fileHwm }\n\n for (i = 0, len = parsedConType.length; i < len; ++i) {\n if (Array.isArray(parsedConType[i]) &&\n RE_BOUNDARY.test(parsedConType[i][0])) {\n boundary = parsedConType[i][1]\n break\n }\n }\n\n function checkFinished () {\n if (nends === 0 && finished && !boy._done) {\n finished = false\n self.end()\n }\n }\n\n if (typeof boundary !== 'string') { throw new Error('Multipart: Boundary not found') }\n\n const fieldSizeLimit = getLimit(limits, 'fieldSize', 1 * 1024 * 1024)\n const fileSizeLimit = getLimit(limits, 'fileSize', Infinity)\n const filesLimit = getLimit(limits, 'files', Infinity)\n const fieldsLimit = getLimit(limits, 'fields', Infinity)\n const partsLimit = getLimit(limits, 'parts', Infinity)\n const headerPairsLimit = getLimit(limits, 'headerPairs', 2000)\n const headerSizeLimit = getLimit(limits, 'headerSize', 80 * 1024)\n\n let nfiles = 0\n let nfields = 0\n let nends = 0\n let curFile\n let curField\n let finished = false\n\n this._needDrain = false\n this._pause = false\n this._cb = undefined\n this._nparts = 0\n this._boy = boy\n\n const parserCfg = {\n boundary,\n maxHeaderPairs: headerPairsLimit,\n maxHeaderSize: headerSizeLimit,\n partHwm: fileOpts.highWaterMark,\n highWaterMark: cfg.highWaterMark\n }\n\n this.parser = new Dicer(parserCfg)\n this.parser.on('drain', function () {\n self._needDrain = false\n if (self._cb && !self._pause) {\n const cb = self._cb\n self._cb = undefined\n cb()\n }\n }).on('part', function onPart (part) {\n if (++self._nparts > partsLimit) {\n self.parser.removeListener('part', onPart)\n self.parser.on('part', skipPart)\n boy.hitPartsLimit = true\n boy.emit('partsLimit')\n return skipPart(part)\n }\n\n // hack because streams2 _always_ doesn't emit 'end' until nextTick, so let\n // us emit 'end' early since we know the part has ended if we are already\n // seeing the next part\n if (curField) {\n const field = curField\n field.emit('end')\n field.removeAllListeners('end')\n }\n\n part.on('header', function (header) {\n let contype\n let fieldname\n let parsed\n let charset\n let encoding\n let filename\n let nsize = 0\n\n if (header['content-type']) {\n parsed = parseParams(header['content-type'][0])\n if (parsed[0]) {\n contype = parsed[0].toLowerCase()\n for (i = 0, len = parsed.length; i < len; ++i) {\n if (RE_CHARSET.test(parsed[i][0])) {\n charset = parsed[i][1].toLowerCase()\n break\n }\n }\n }\n }\n\n if (contype === undefined) { contype = 'text/plain' }\n if (charset === undefined) { charset = defCharset }\n\n if (header['content-disposition']) {\n parsed = parseParams(header['content-disposition'][0])\n if (!RE_FIELD.test(parsed[0])) { return skipPart(part) }\n for (i = 0, len = parsed.length; i < len; ++i) {\n if (RE_NAME.test(parsed[i][0])) {\n fieldname = parsed[i][1]\n } else if (RE_FILENAME.test(parsed[i][0])) {\n filename = parsed[i][1]\n if (!preservePath) { filename = basename(filename) }\n }\n }\n } else { return skipPart(part) }\n\n if (header['content-transfer-encoding']) { encoding = header['content-transfer-encoding'][0].toLowerCase() } else { encoding = '7bit' }\n\n let onData,\n onEnd\n\n if (isPartAFile(fieldname, contype, filename)) {\n // file/binary field\n if (nfiles === filesLimit) {\n if (!boy.hitFilesLimit) {\n boy.hitFilesLimit = true\n boy.emit('filesLimit')\n }\n return skipPart(part)\n }\n\n ++nfiles\n\n if (boy.listenerCount('file') === 0) {\n self.parser._ignore()\n return\n }\n\n ++nends\n const file = new FileStream(fileOpts)\n curFile = file\n file.on('end', function () {\n --nends\n self._pause = false\n checkFinished()\n if (self._cb && !self._needDrain) {\n const cb = self._cb\n self._cb = undefined\n cb()\n }\n })\n file._read = function (n) {\n if (!self._pause) { return }\n self._pause = false\n if (self._cb && !self._needDrain) {\n const cb = self._cb\n self._cb = undefined\n cb()\n }\n }\n boy.emit('file', fieldname, file, filename, encoding, contype)\n\n onData = function (data) {\n if ((nsize += data.length) > fileSizeLimit) {\n const extralen = fileSizeLimit - nsize + data.length\n if (extralen > 0) { file.push(data.slice(0, extralen)) }\n file.truncated = true\n file.bytesRead = fileSizeLimit\n part.removeAllListeners('data')\n file.emit('limit')\n return\n } else if (!file.push(data)) { self._pause = true }\n\n file.bytesRead = nsize\n }\n\n onEnd = function () {\n curFile = undefined\n file.push(null)\n }\n } else {\n // non-file field\n if (nfields === fieldsLimit) {\n if (!boy.hitFieldsLimit) {\n boy.hitFieldsLimit = true\n boy.emit('fieldsLimit')\n }\n return skipPart(part)\n }\n\n ++nfields\n ++nends\n let buffer = ''\n let truncated = false\n curField = part\n\n onData = function (data) {\n if ((nsize += data.length) > fieldSizeLimit) {\n const extralen = (fieldSizeLimit - (nsize - data.length))\n buffer += data.toString('binary', 0, extralen)\n truncated = true\n part.removeAllListeners('data')\n } else { buffer += data.toString('binary') }\n }\n\n onEnd = function () {\n curField = undefined\n if (buffer.length) { buffer = decodeText(buffer, 'binary', charset) }\n boy.emit('field', fieldname, buffer, false, truncated, encoding, contype)\n --nends\n checkFinished()\n }\n }\n\n /* As of node@2efe4ab761666 (v0.10.29+/v0.11.14+), busboy had become\n broken. Streams2/streams3 is a huge black box of confusion, but\n somehow overriding the sync state seems to fix things again (and still\n seems to work for previous node versions).\n */\n part._readableState.sync = false\n\n part.on('data', onData)\n part.on('end', onEnd)\n }).on('error', function (err) {\n if (curFile) { curFile.emit('error', err) }\n })\n }).on('error', function (err) {\n boy.emit('error', err)\n }).on('finish', function () {\n finished = true\n checkFinished()\n })\n}\n\nMultipart.prototype.write = function (chunk, cb) {\n const r = this.parser.write(chunk)\n if (r && !this._pause) {\n cb()\n } else {\n this._needDrain = !r\n this._cb = cb\n }\n}\n\nMultipart.prototype.end = function () {\n const self = this\n\n if (self.parser.writable) {\n self.parser.end()\n } else if (!self._boy._done) {\n process.nextTick(function () {\n self._boy._done = true\n self._boy.emit('finish')\n })\n }\n}\n\nfunction skipPart (part) {\n part.resume()\n}\n\nfunction FileStream (opts) {\n Readable.call(this, opts)\n\n this.bytesRead = 0\n\n this.truncated = false\n}\n\ninherits(FileStream, Readable)\n\nFileStream.prototype._read = function (n) {}\n\nmodule.exports = Multipart\n\n\n/***/ }),\n\n/***/ 8306:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\n\"use strict\";\n\n\nconst Decoder = __nccwpck_require__(7100)\nconst decodeText = __nccwpck_require__(4619)\nconst getLimit = __nccwpck_require__(1467)\n\nconst RE_CHARSET = /^charset$/i\n\nUrlEncoded.detect = /^application\\/x-www-form-urlencoded/i\nfunction UrlEncoded (boy, cfg) {\n const limits = cfg.limits\n const parsedConType = cfg.parsedConType\n this.boy = boy\n\n this.fieldSizeLimit = getLimit(limits, 'fieldSize', 1 * 1024 * 1024)\n this.fieldNameSizeLimit = getLimit(limits, 'fieldNameSize', 100)\n this.fieldsLimit = getLimit(limits, 'fields', Infinity)\n\n let charset\n for (var i = 0, len = parsedConType.length; i < len; ++i) { // eslint-disable-line no-var\n if (Array.isArray(parsedConType[i]) &&\n RE_CHARSET.test(parsedConType[i][0])) {\n charset = parsedConType[i][1].toLowerCase()\n break\n }\n }\n\n if (charset === undefined) { charset = cfg.defCharset || 'utf8' }\n\n this.decoder = new Decoder()\n this.charset = charset\n this._fields = 0\n this._state = 'key'\n this._checkingBytes = true\n this._bytesKey = 0\n this._bytesVal = 0\n this._key = ''\n this._val = ''\n this._keyTrunc = false\n this._valTrunc = false\n this._hitLimit = false\n}\n\nUrlEncoded.prototype.write = function (data, cb) {\n if (this._fields === this.fieldsLimit) {\n if (!this.boy.hitFieldsLimit) {\n this.boy.hitFieldsLimit = true\n this.boy.emit('fieldsLimit')\n }\n return cb()\n }\n\n let idxeq; let idxamp; let i; let p = 0; const len = data.length\n\n while (p < len) {\n if (this._state === 'key') {\n idxeq = idxamp = undefined\n for (i = p; i < len; ++i) {\n if (!this._checkingBytes) { ++p }\n if (data[i] === 0x3D/* = */) {\n idxeq = i\n break\n } else if (data[i] === 0x26/* & */) {\n idxamp = i\n break\n }\n if (this._checkingBytes && this._bytesKey === this.fieldNameSizeLimit) {\n this._hitLimit = true\n break\n } else if (this._checkingBytes) { ++this._bytesKey }\n }\n\n if (idxeq !== undefined) {\n // key with assignment\n if (idxeq > p) { this._key += this.decoder.write(data.toString('binary', p, idxeq)) }\n this._state = 'val'\n\n this._hitLimit = false\n this._checkingBytes = true\n this._val = ''\n this._bytesVal = 0\n this._valTrunc = false\n this.decoder.reset()\n\n p = idxeq + 1\n } else if (idxamp !== undefined) {\n // key with no assignment\n ++this._fields\n let key; const keyTrunc = this._keyTrunc\n if (idxamp > p) { key = (this._key += this.decoder.write(data.toString('binary', p, idxamp))) } else { key = this._key }\n\n this._hitLimit = false\n this._checkingBytes = true\n this._key = ''\n this._bytesKey = 0\n this._keyTrunc = false\n this.decoder.reset()\n\n if (key.length) {\n this.boy.emit('field', decodeText(key, 'binary', this.charset),\n '',\n keyTrunc,\n false)\n }\n\n p = idxamp + 1\n if (this._fields === this.fieldsLimit) { return cb() }\n } else if (this._hitLimit) {\n // we may not have hit the actual limit if there are encoded bytes...\n if (i > p) { this._key += this.decoder.write(data.toString('binary', p, i)) }\n p = i\n if ((this._bytesKey = this._key.length) === this.fieldNameSizeLimit) {\n // yep, we actually did hit the limit\n this._checkingBytes = false\n this._keyTrunc = true\n }\n } else {\n if (p < len) { this._key += this.decoder.write(data.toString('binary', p)) }\n p = len\n }\n } else {\n idxamp = undefined\n for (i = p; i < len; ++i) {\n if (!this._checkingBytes) { ++p }\n if (data[i] === 0x26/* & */) {\n idxamp = i\n break\n }\n if (this._checkingBytes && this._bytesVal === this.fieldSizeLimit) {\n this._hitLimit = true\n break\n } else if (this._checkingBytes) { ++this._bytesVal }\n }\n\n if (idxamp !== undefined) {\n ++this._fields\n if (idxamp > p) { this._val += this.decoder.write(data.toString('binary', p, idxamp)) }\n this.boy.emit('field', decodeText(this._key, 'binary', this.charset),\n decodeText(this._val, 'binary', this.charset),\n this._keyTrunc,\n this._valTrunc)\n this._state = 'key'\n\n this._hitLimit = false\n this._checkingBytes = true\n this._key = ''\n this._bytesKey = 0\n this._keyTrunc = false\n this.decoder.reset()\n\n p = idxamp + 1\n if (this._fields === this.fieldsLimit) { return cb() }\n } else if (this._hitLimit) {\n // we may not have hit the actual limit if there are encoded bytes...\n if (i > p) { this._val += this.decoder.write(data.toString('binary', p, i)) }\n p = i\n if ((this._val === '' && this.fieldSizeLimit === 0) ||\n (this._bytesVal = this._val.length) === this.fieldSizeLimit) {\n // yep, we actually did hit the limit\n this._checkingBytes = false\n this._valTrunc = true\n }\n } else {\n if (p < len) { this._val += this.decoder.write(data.toString('binary', p)) }\n p = len\n }\n }\n }\n cb()\n}\n\nUrlEncoded.prototype.end = function () {\n if (this.boy._done) { return }\n\n if (this._state === 'key' && this._key.length > 0) {\n this.boy.emit('field', decodeText(this._key, 'binary', this.charset),\n '',\n this._keyTrunc,\n false)\n } else if (this._state === 'val') {\n this.boy.emit('field', decodeText(this._key, 'binary', this.charset),\n decodeText(this._val, 'binary', this.charset),\n this._keyTrunc,\n this._valTrunc)\n }\n this.boy._done = true\n this.boy.emit('finish')\n}\n\nmodule.exports = UrlEncoded\n\n\n/***/ }),\n\n/***/ 7100:\n/***/ ((module) => {\n\n\"use strict\";\n\n\nconst RE_PLUS = /\\+/g\n\nconst HEX = [\n 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,\n 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,\n 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,\n 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0,\n 0, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0,\n 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,\n 0, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0,\n 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0\n]\n\nfunction Decoder () {\n this.buffer = undefined\n}\nDecoder.prototype.write = function (str) {\n // Replace '+' with ' ' before decoding\n str = str.replace(RE_PLUS, ' ')\n let res = ''\n let i = 0; let p = 0; const len = str.length\n for (; i < len; ++i) {\n if (this.buffer !== undefined) {\n if (!HEX[str.charCodeAt(i)]) {\n res += '%' + this.buffer\n this.buffer = undefined\n --i // retry character\n } else {\n this.buffer += str[i]\n ++p\n if (this.buffer.length === 2) {\n res += String.fromCharCode(parseInt(this.buffer, 16))\n this.buffer = undefined\n }\n }\n } else if (str[i] === '%') {\n if (i > p) {\n res += str.substring(p, i)\n p = i\n }\n this.buffer = ''\n ++p\n }\n }\n if (p < len && this.buffer === undefined) { res += str.substring(p) }\n return res\n}\nDecoder.prototype.reset = function () {\n this.buffer = undefined\n}\n\nmodule.exports = Decoder\n\n\n/***/ }),\n\n/***/ 8647:\n/***/ ((module) => {\n\n\"use strict\";\n\n\nmodule.exports = function basename (path) {\n if (typeof path !== 'string') { return '' }\n for (var i = path.length - 1; i >= 0; --i) { // eslint-disable-line no-var\n switch (path.charCodeAt(i)) {\n case 0x2F: // '/'\n case 0x5C: // '\\'\n path = path.slice(i + 1)\n return (path === '..' || path === '.' ? '' : path)\n }\n }\n return (path === '..' || path === '.' ? '' : path)\n}\n\n\n/***/ }),\n\n/***/ 4619:\n/***/ (function(module) {\n\n\"use strict\";\n\n\n// Node has always utf-8\nconst utf8Decoder = new TextDecoder('utf-8')\nconst textDecoders = new Map([\n ['utf-8', utf8Decoder],\n ['utf8', utf8Decoder]\n])\n\nfunction getDecoder (charset) {\n let lc\n while (true) {\n switch (charset) {\n case 'utf-8':\n case 'utf8':\n return decoders.utf8\n case 'latin1':\n case 'ascii': // TODO: Make these a separate, strict decoder?\n case 'us-ascii':\n case 'iso-8859-1':\n case 'iso8859-1':\n case 'iso88591':\n case 'iso_8859-1':\n case 'windows-1252':\n case 'iso_8859-1:1987':\n case 'cp1252':\n case 'x-cp1252':\n return decoders.latin1\n case 'utf16le':\n case 'utf-16le':\n case 'ucs2':\n case 'ucs-2':\n return decoders.utf16le\n case 'base64':\n return decoders.base64\n default:\n if (lc === undefined) {\n lc = true\n charset = charset.toLowerCase()\n continue\n }\n return decoders.other.bind(charset)\n }\n }\n}\n\nconst decoders = {\n utf8: (data, sourceEncoding) => {\n if (data.length === 0) {\n return ''\n }\n if (typeof data === 'string') {\n data = Buffer.from(data, sourceEncoding)\n }\n return data.utf8Slice(0, data.length)\n },\n\n latin1: (data, sourceEncoding) => {\n if (data.length === 0) {\n return ''\n }\n if (typeof data === 'string') {\n return data\n }\n return data.latin1Slice(0, data.length)\n },\n\n utf16le: (data, sourceEncoding) => {\n if (data.length === 0) {\n return ''\n }\n if (typeof data === 'string') {\n data = Buffer.from(data, sourceEncoding)\n }\n return data.ucs2Slice(0, data.length)\n },\n\n base64: (data, sourceEncoding) => {\n if (data.length === 0) {\n return ''\n }\n if (typeof data === 'string') {\n data = Buffer.from(data, sourceEncoding)\n }\n return data.base64Slice(0, data.length)\n },\n\n other: (data, sourceEncoding) => {\n if (data.length === 0) {\n return ''\n }\n if (typeof data === 'string') {\n data = Buffer.from(data, sourceEncoding)\n }\n\n if (textDecoders.has(this.toString())) {\n try {\n return textDecoders.get(this).decode(data)\n } catch {}\n }\n return typeof data === 'string'\n ? data\n : data.toString()\n }\n}\n\nfunction decodeText (text, sourceEncoding, destEncoding) {\n if (text) {\n return getDecoder(destEncoding)(text, sourceEncoding)\n }\n return text\n}\n\nmodule.exports = decodeText\n\n\n/***/ }),\n\n/***/ 1467:\n/***/ ((module) => {\n\n\"use strict\";\n\n\nmodule.exports = function getLimit (limits, name, defaultLimit) {\n if (\n !limits ||\n limits[name] === undefined ||\n limits[name] === null\n ) { return defaultLimit }\n\n if (\n typeof limits[name] !== 'number' ||\n isNaN(limits[name])\n ) { throw new TypeError('Limit ' + name + ' is not a valid number') }\n\n return limits[name]\n}\n\n\n/***/ }),\n\n/***/ 1854:\n/***/ ((module, __unused_webpack_exports, __nccwpck_require__) => {\n\n\"use strict\";\n/* eslint-disable object-property-newline */\n\n\nconst decodeText = __nccwpck_require__(4619)\n\nconst RE_ENCODED = /%[a-fA-F0-9][a-fA-F0-9]/g\n\nconst EncodedLookup = {\n '%00': '\\x00', '%01': '\\x01', '%02': '\\x02', '%03': '\\x03', '%04': '\\x04',\n '%05': '\\x05', '%06': '\\x06', '%07': '\\x07', '%08': '\\x08', '%09': '\\x09',\n '%0a': '\\x0a', '%0A': '\\x0a', '%0b': '\\x0b', '%0B': '\\x0b', '%0c': '\\x0c',\n '%0C': '\\x0c', '%0d': '\\x0d', '%0D': '\\x0d', '%0e': '\\x0e', '%0E': '\\x0e',\n '%0f': '\\x0f', '%0F': '\\x0f', '%10': '\\x10', '%11': '\\x11', '%12': '\\x12',\n '%13': '\\x13', '%14': '\\x14', '%15': '\\x15', '%16': '\\x16', '%17': '\\x17',\n '%18': '\\x18', '%19': '\\x19', '%1a': '\\x1a', '%1A': '\\x1a', '%1b': '\\x1b',\n '%1B': '\\x1b', '%1c': '\\x1c', '%1C': '\\x1c', '%1d': '\\x1d', '%1D': '\\x1d',\n '%1e': '\\x1e', '%1E': '\\x1e', '%1f': '\\x1f', '%1F': '\\x1f', '%20': '\\x20',\n '%21': '\\x21', '%22': '\\x22', '%23': '\\x23', '%24': '\\x24', '%25': '\\x25',\n '%26': '\\x26', '%27': '\\x27', '%28': '\\x28', '%29': '\\x29', '%2a': '\\x2a',\n '%2A': '\\x2a', '%2b': '\\x2b', '%2B': '\\x2b', '%2c': '\\x2c', '%2C': '\\x2c',\n '%2d': '\\x2d', '%2D': '\\x2d', '%2e': '\\x2e', '%2E': '\\x2e', '%2f': '\\x2f',\n '%2F': '\\x2f', '%30': '\\x30', '%31': '\\x31', '%32': '\\x32', '%33': '\\x33',\n '%34': '\\x34', '%35': '\\x35', '%36': '\\x36', '%37': '\\x37', '%38': '\\x38',\n '%39': '\\x39', '%3a': '\\x3a', '%3A': '\\x3a', '%3b': '\\x3b', '%3B': '\\x3b',\n '%3c': '\\x3c', '%3C': '\\x3c', '%3d': '\\x3d', '%3D': '\\x3d', '%3e': '\\x3e',\n '%3E': '\\x3e', '%3f': '\\x3f', '%3F': '\\x3f', '%40': '\\x40', '%41': '\\x41',\n '%42': '\\x42', '%43': '\\x43', '%44': '\\x44', '%45': '\\x45', '%46': '\\x46',\n '%47': '\\x47', '%48': '\\x48', '%49': '\\x49', '%4a': '\\x4a', '%4A': '\\x4a',\n '%4b': '\\x4b', '%4B': '\\x4b', '%4c': '\\x4c', '%4C': '\\x4c', '%4d': '\\x4d',\n '%4D': '\\x4d', '%4e': '\\x4e', '%4E': '\\x4e', '%4f': '\\x4f', '%4F': '\\x4f',\n '%50': '\\x50', '%51': '\\x51', '%52': '\\x52', '%53': '\\x53', '%54': '\\x54',\n '%55': '\\x55', '%56': '\\x56', '%57': '\\x57', '%58': '\\x58', '%59': '\\x59',\n '%5a': '\\x5a', '%5A': '\\x5a', '%5b': '\\x5b', '%5B': '\\x5b', '%5c': '\\x5c',\n '%5C': '\\x5c', '%5d': '\\x5d', '%5D': '\\x5d', '%5e': '\\x5e', '%5E': '\\x5e',\n '%5f': '\\x5f', '%5F': '\\x5f', '%60': '\\x60', '%61': '\\x61', '%62': '\\x62',\n '%63': '\\x63', '%64': '\\x64', '%65': '\\x65', '%66': '\\x66', '%67': '\\x67',\n '%68': '\\x68', '%69': '\\x69', '%6a': '\\x6a', '%6A': '\\x6a', '%6b': '\\x6b',\n '%6B': '\\x6b', '%6c': '\\x6c', '%6C': '\\x6c', '%6d': '\\x6d', '%6D': '\\x6d',\n '%6e': '\\x6e', '%6E': '\\x6e', '%6f': '\\x6f', '%6F': '\\x6f', '%70': '\\x70',\n '%71': '\\x71', '%72': '\\x72', '%73': '\\x73', '%74': '\\x74', '%75': '\\x75',\n '%76': '\\x76', '%77': '\\x77', '%78': '\\x78', '%79': '\\x79', '%7a': '\\x7a',\n '%7A': '\\x7a', '%7b': '\\x7b', '%7B': '\\x7b', '%7c': '\\x7c', '%7C': '\\x7c',\n '%7d': '\\x7d', '%7D': '\\x7d', '%7e': '\\x7e', '%7E': '\\x7e', '%7f': '\\x7f',\n '%7F': '\\x7f', '%80': '\\x80', '%81': '\\x81', '%82': '\\x82', '%83': '\\x83',\n '%84': '\\x84', '%85': '\\x85', '%86': '\\x86', '%87': '\\x87', '%88': '\\x88',\n '%89': '\\x89', '%8a': '\\x8a', '%8A': '\\x8a', '%8b': '\\x8b', '%8B': '\\x8b',\n '%8c': '\\x8c', '%8C': '\\x8c', '%8d': '\\x8d', '%8D': '\\x8d', '%8e': '\\x8e',\n '%8E': '\\x8e', '%8f': '\\x8f', '%8F': '\\x8f', '%90': '\\x90', '%91': '\\x91',\n '%92': '\\x92', '%93': '\\x93', '%94': '\\x94', '%95': '\\x95', '%96': '\\x96',\n '%97': '\\x97', '%98': '\\x98', '%99': '\\x99', '%9a': '\\x9a', '%9A': '\\x9a',\n '%9b': '\\x9b', '%9B': '\\x9b', '%9c': '\\x9c', '%9C': '\\x9c', '%9d': '\\x9d',\n '%9D': '\\x9d', '%9e': '\\x9e', '%9E': '\\x9e', '%9f': '\\x9f', '%9F': '\\x9f',\n '%a0': '\\xa0', '%A0': '\\xa0', '%a1': '\\xa1', '%A1': '\\xa1', '%a2': '\\xa2',\n '%A2': '\\xa2', '%a3': '\\xa3', '%A3': '\\xa3', '%a4': '\\xa4', '%A4': '\\xa4',\n '%a5': '\\xa5', '%A5': '\\xa5', '%a6': '\\xa6', '%A6': '\\xa6', '%a7': '\\xa7',\n '%A7': '\\xa7', '%a8': '\\xa8', '%A8': '\\xa8', '%a9': '\\xa9', '%A9': '\\xa9',\n '%aa': '\\xaa', '%Aa': '\\xaa', '%aA': '\\xaa', '%AA': '\\xaa', '%ab': '\\xab',\n '%Ab': '\\xab', '%aB': '\\xab', '%AB': '\\xab', '%ac': '\\xac', '%Ac': '\\xac',\n '%aC': '\\xac', '%AC': '\\xac', '%ad': '\\xad', '%Ad': '\\xad', '%aD': '\\xad',\n '%AD': '\\xad', '%ae': '\\xae', '%Ae': '\\xae', '%aE': '\\xae', '%AE': '\\xae',\n '%af': '\\xaf', '%Af': '\\xaf', '%aF': '\\xaf', '%AF': '\\xaf', '%b0': '\\xb0',\n '%B0': '\\xb0', '%b1': '\\xb1', '%B1': '\\xb1', '%b2': '\\xb2', '%B2': '\\xb2',\n '%b3': '\\xb3', '%B3': '\\xb3', '%b4': '\\xb4', '%B4': '\\xb4', '%b5': '\\xb5',\n '%B5': '\\xb5', '%b6': '\\xb6', '%B6': '\\xb6', '%b7': '\\xb7', '%B7': '\\xb7',\n '%b8': '\\xb8', '%B8': '\\xb8', '%b9': '\\xb9', '%B9': '\\xb9', '%ba': '\\xba',\n '%Ba': '\\xba', '%bA': '\\xba', '%BA': '\\xba', '%bb': '\\xbb', '%Bb': '\\xbb',\n '%bB': '\\xbb', '%BB': '\\xbb', '%bc': '\\xbc', '%Bc': '\\xbc', '%bC': '\\xbc',\n '%BC': '\\xbc', '%bd': '\\xbd', '%Bd': '\\xbd', '%bD': '\\xbd', '%BD': '\\xbd',\n '%be': '\\xbe', '%Be': '\\xbe', '%bE': '\\xbe', '%BE': '\\xbe', '%bf': '\\xbf',\n '%Bf': '\\xbf', '%bF': '\\xbf', '%BF': '\\xbf', '%c0': '\\xc0', '%C0': '\\xc0',\n '%c1': '\\xc1', '%C1': '\\xc1', '%c2': '\\xc2', '%C2': '\\xc2', '%c3': '\\xc3',\n '%C3': '\\xc3', '%c4': '\\xc4', '%C4': '\\xc4', '%c5': '\\xc5', '%C5': '\\xc5',\n '%c6': '\\xc6', '%C6': '\\xc6', '%c7': '\\xc7', '%C7': '\\xc7', '%c8': '\\xc8',\n '%C8': '\\xc8', '%c9': '\\xc9', '%C9': '\\xc9', '%ca': '\\xca', '%Ca': '\\xca',\n '%cA': '\\xca', '%CA': '\\xca', '%cb': '\\xcb', '%Cb': '\\xcb', '%cB': '\\xcb',\n '%CB': '\\xcb', '%cc': '\\xcc', '%Cc': '\\xcc', '%cC': '\\xcc', '%CC': '\\xcc',\n '%cd': '\\xcd', '%Cd': '\\xcd', '%cD': '\\xcd', '%CD': '\\xcd', '%ce': '\\xce',\n '%Ce': '\\xce', '%cE': '\\xce', '%CE': '\\xce', '%cf': '\\xcf', '%Cf': '\\xcf',\n '%cF': '\\xcf', '%CF': '\\xcf', '%d0': '\\xd0', '%D0': '\\xd0', '%d1': '\\xd1',\n '%D1': '\\xd1', '%d2': '\\xd2', '%D2': '\\xd2', '%d3': '\\xd3', '%D3': '\\xd3',\n '%d4': '\\xd4', '%D4': '\\xd4', '%d5': '\\xd5', '%D5': '\\xd5', '%d6': '\\xd6',\n '%D6': '\\xd6', '%d7': '\\xd7', '%D7': '\\xd7', '%d8': '\\xd8', '%D8': '\\xd8',\n '%d9': '\\xd9', '%D9': '\\xd9', '%da': '\\xda', '%Da': '\\xda', '%dA': '\\xda',\n '%DA': '\\xda', '%db': '\\xdb', '%Db': '\\xdb', '%dB': '\\xdb', '%DB': '\\xdb',\n '%dc': '\\xdc', '%Dc': '\\xdc', '%dC': '\\xdc', '%DC': '\\xdc', '%dd': '\\xdd',\n '%Dd': '\\xdd', '%dD': '\\xdd', '%DD': '\\xdd', '%de': '\\xde', '%De': '\\xde',\n '%dE': '\\xde', '%DE': '\\xde', '%df': '\\xdf', '%Df': '\\xdf', '%dF': '\\xdf',\n '%DF': '\\xdf', '%e0': '\\xe0', '%E0': '\\xe0', '%e1': '\\xe1', '%E1': '\\xe1',\n '%e2': '\\xe2', '%E2': '\\xe2', '%e3': '\\xe3', '%E3': '\\xe3', '%e4': '\\xe4',\n '%E4': '\\xe4', '%e5': '\\xe5', '%E5': '\\xe5', '%e6': '\\xe6', '%E6': '\\xe6',\n '%e7': '\\xe7', '%E7': '\\xe7', '%e8': '\\xe8', '%E8': '\\xe8', '%e9': '\\xe9',\n '%E9': '\\xe9', '%ea': '\\xea', '%Ea': '\\xea', '%eA': '\\xea', '%EA': '\\xea',\n '%eb': '\\xeb', '%Eb': '\\xeb', '%eB': '\\xeb', '%EB': '\\xeb', '%ec': '\\xec',\n '%Ec': '\\xec', '%eC': '\\xec', '%EC': '\\xec', '%ed': '\\xed', '%Ed': '\\xed',\n '%eD': '\\xed', '%ED': '\\xed', '%ee': '\\xee', '%Ee': '\\xee', '%eE': '\\xee',\n '%EE': '\\xee', '%ef': '\\xef', '%Ef': '\\xef', '%eF': '\\xef', '%EF': '\\xef',\n '%f0': '\\xf0', '%F0': '\\xf0', '%f1': '\\xf1', '%F1': '\\xf1', '%f2': '\\xf2',\n '%F2': '\\xf2', '%f3': '\\xf3', '%F3': '\\xf3', '%f4': '\\xf4', '%F4': '\\xf4',\n '%f5': '\\xf5', '%F5': '\\xf5', '%f6': '\\xf6', '%F6': '\\xf6', '%f7': '\\xf7',\n '%F7': '\\xf7', '%f8': '\\xf8', '%F8': '\\xf8', '%f9': '\\xf9', '%F9': '\\xf9',\n '%fa': '\\xfa', '%Fa': '\\xfa', '%fA': '\\xfa', '%FA': '\\xfa', '%fb': '\\xfb',\n '%Fb': '\\xfb', '%fB': '\\xfb', '%FB': '\\xfb', '%fc': '\\xfc', '%Fc': '\\xfc',\n '%fC': '\\xfc', '%FC': '\\xfc', '%fd': '\\xfd', '%Fd': '\\xfd', '%fD': '\\xfd',\n '%FD': '\\xfd', '%fe': '\\xfe', '%Fe': '\\xfe', '%fE': '\\xfe', '%FE': '\\xfe',\n '%ff': '\\xff', '%Ff': '\\xff', '%fF': '\\xff', '%FF': '\\xff'\n}\n\nfunction encodedReplacer (match) {\n return EncodedLookup[match]\n}\n\nconst STATE_KEY = 0\nconst STATE_VALUE = 1\nconst STATE_CHARSET = 2\nconst STATE_LANG = 3\n\nfunction parseParams (str) {\n const res = []\n let state = STATE_KEY\n let charset = ''\n let inquote = false\n let escaping = false\n let p = 0\n let tmp = ''\n const len = str.length\n\n for (var i = 0; i < len; ++i) { // eslint-disable-line no-var\n const char = str[i]\n if (char === '\\\\' && inquote) {\n if (escaping) { escaping = false } else {\n escaping = true\n continue\n }\n } else if (char === '\"') {\n if (!escaping) {\n if (inquote) {\n inquote = false\n state = STATE_KEY\n } else { inquote = true }\n continue\n } else { escaping = false }\n } else {\n if (escaping && inquote) { tmp += '\\\\' }\n escaping = false\n if ((state === STATE_CHARSET || state === STATE_LANG) && char === \"'\") {\n if (state === STATE_CHARSET) {\n state = STATE_LANG\n charset = tmp.substring(1)\n } else { state = STATE_VALUE }\n tmp = ''\n continue\n } else if (state === STATE_KEY &&\n (char === '*' || char === '=') &&\n res.length) {\n state = char === '*'\n ? STATE_CHARSET\n : STATE_VALUE\n res[p] = [tmp, undefined]\n tmp = ''\n continue\n } else if (!inquote && char === ';') {\n state = STATE_KEY\n if (charset) {\n if (tmp.length) {\n tmp = decodeText(tmp.replace(RE_ENCODED, encodedReplacer),\n 'binary',\n charset)\n }\n charset = ''\n } else if (tmp.length) {\n tmp = decodeText(tmp, 'binary', 'utf8')\n }\n if (res[p] === undefined) { res[p] = tmp } else { res[p][1] = tmp }\n tmp = ''\n ++p\n continue\n } else if (!inquote && (char === ' ' || char === '\\t')) { continue }\n }\n tmp += char\n }\n if (charset && tmp.length) {\n tmp = decodeText(tmp.replace(RE_ENCODED, encodedReplacer),\n 'binary',\n charset)\n } else if (tmp) {\n tmp = decodeText(tmp, 'binary', 'utf8')\n }\n\n if (res[p] === undefined) {\n if (tmp) { res[p] = tmp }\n } else { res[p][1] = tmp }\n\n return res\n}\n\nmodule.exports = parseParams\n\n\n/***/ }),\n\n/***/ 1322:\n/***/ ((module) => {\n\n\"use strict\";\nmodule.exports = JSON.parse('{\"name\":\"@octokit/rest\",\"version\":\"16.43.2\",\"publishConfig\":{\"access\":\"public\"},\"description\":\"GitHub REST API client for Node.js\",\"keywords\":[\"octokit\",\"github\",\"rest\",\"api-client\"],\"author\":\"Gregor Martynus (https://github.com/gr2m)\",\"contributors\":[{\"name\":\"Mike de Boer\",\"email\":\"[email protected]\"},{\"name\":\"Fabian Jakobs\",\"email\":\"[email protected]\"},{\"name\":\"Joe Gallo\",\"email\":\"[email protected]\"},{\"name\":\"Gregor Martynus\",\"url\":\"https://github.com/gr2m\"}],\"repository\":\"https://github.com/octokit/rest.js\",\"dependencies\":{\"@octokit/auth-token\":\"^2.4.0\",\"@octokit/plugin-paginate-rest\":\"^1.1.1\",\"@octokit/plugin-request-log\":\"^1.0.0\",\"@octokit/plugin-rest-endpoint-methods\":\"2.4.0\",\"@octokit/request\":\"^5.2.0\",\"@octokit/request-error\":\"^1.0.2\",\"atob-lite\":\"^2.0.0\",\"before-after-hook\":\"^2.0.0\",\"btoa-lite\":\"^1.0.0\",\"deprecation\":\"^2.0.0\",\"lodash.get\":\"^4.4.2\",\"lodash.set\":\"^4.3.2\",\"lodash.uniq\":\"^4.5.0\",\"octokit-pagination-methods\":\"^1.1.0\",\"once\":\"^1.4.0\",\"universal-user-agent\":\"^4.0.0\"},\"devDependencies\":{\"@gimenete/type-writer\":\"^0.1.3\",\"@octokit/auth\":\"^1.1.1\",\"@octokit/fixtures-server\":\"^5.0.6\",\"@octokit/graphql\":\"^4.2.0\",\"@types/node\":\"^13.1.0\",\"bundlesize\":\"^0.18.0\",\"chai\":\"^4.1.2\",\"compression-webpack-plugin\":\"^3.1.0\",\"cypress\":\"^4.0.0\",\"glob\":\"^7.1.2\",\"http-proxy-agent\":\"^4.0.0\",\"lodash.camelcase\":\"^4.3.0\",\"lodash.merge\":\"^4.6.1\",\"lodash.upperfirst\":\"^4.3.1\",\"lolex\":\"^6.0.0\",\"mkdirp\":\"^1.0.0\",\"mocha\":\"^7.0.1\",\"mustache\":\"^4.0.0\",\"nock\":\"^11.3.3\",\"npm-run-all\":\"^4.1.2\",\"nyc\":\"^15.0.0\",\"prettier\":\"^1.14.2\",\"proxy\":\"^1.0.0\",\"semantic-release\":\"^17.0.0\",\"sinon\":\"^8.0.0\",\"sinon-chai\":\"^3.0.0\",\"sort-keys\":\"^4.0.0\",\"string-to-arraybuffer\":\"^1.0.0\",\"string-to-jsdoc-comment\":\"^1.0.0\",\"typescript\":\"^3.3.1\",\"webpack\":\"^4.0.0\",\"webpack-bundle-analyzer\":\"^3.0.0\",\"webpack-cli\":\"^3.0.0\"},\"types\":\"index.d.ts\",\"scripts\":{\"coverage\":\"nyc report --reporter=html && open coverage/index.html\",\"lint\":\"prettier --check \\'{lib,plugins,scripts,test}/**/*.{js,json,ts}\\' \\'docs/*.{js,json}\\' \\'docs/src/**/*\\' index.js README.md package.json\",\"lint:fix\":\"prettier --write \\'{lib,plugins,scripts,test}/**/*.{js,json,ts}\\' \\'docs/*.{js,json}\\' \\'docs/src/**/*\\' index.js README.md package.json\",\"pretest\":\"npm run -s lint\",\"test\":\"nyc mocha test/mocha-node-setup.js \\\\\"test/*/**/*-test.js\\\\\"\",\"test:browser\":\"cypress run --browser chrome\",\"build\":\"npm-run-all build:*\",\"build:ts\":\"npm run -s update-endpoints:typescript\",\"prebuild:browser\":\"mkdirp dist/\",\"build:browser\":\"npm-run-all build:browser:*\",\"build:browser:development\":\"webpack --mode development --entry . --output-library=Octokit --output=./dist/octokit-rest.js --profile --json > dist/bundle-stats.json\",\"build:browser:production\":\"webpack --mode production --entry . --plugin=compression-webpack-plugin --output-library=Octokit --output-path=./dist --output-filename=octokit-rest.min.js --devtool source-map\",\"generate-bundle-report\":\"webpack-bundle-analyzer dist/bundle-stats.json --mode=static --no-open --report dist/bundle-report.html\",\"update-endpoints\":\"npm-run-all update-endpoints:*\",\"update-endpoints:fetch-json\":\"node scripts/update-endpoints/fetch-json\",\"update-endpoints:typescript\":\"node scripts/update-endpoints/typescript\",\"prevalidate:ts\":\"npm run -s build:ts\",\"validate:ts\":\"tsc --target es6 --noImplicitAny index.d.ts\",\"postvalidate:ts\":\"tsc --noEmit --target es6 test/typescript-validate.ts\",\"start-fixtures-server\":\"octokit-fixtures-server\"},\"license\":\"MIT\",\"files\":[\"index.js\",\"index.d.ts\",\"lib\",\"plugins\"],\"nyc\":{\"ignore\":[\"test\"]},\"release\":{\"publish\":[\"@semantic-release/npm\",{\"path\":\"@semantic-release/github\",\"assets\":[\"dist/*\",\"!dist/*.map.gz\"]}]},\"bundlesize\":[{\"path\":\"./dist/octokit-rest.min.js.gz\",\"maxSize\":\"33 kB\"}]}');\n\n/***/ }),\n\n/***/ 1907:\n/***/ ((module) => {\n\n\"use strict\";\nmodule.exports = JSON.parse('[[[0,44],\"disallowed_STD3_valid\"],[[45,46],\"valid\"],[[47,47],\"disallowed_STD3_valid\"],[[48,57],\"valid\"],[[58,64],\"disallowed_STD3_valid\"],[[65,65],\"mapped\",[97]],[[66,66],\"mapped\",[98]],[[67,67],\"mapped\",[99]],[[68,68],\"mapped\",[100]],[[69,69],\"mapped\",[101]],[[70,70],\"mapped\",[102]],[[71,71],\"mapped\",[103]],[[72,72],\"mapped\",[104]],[[73,73],\"mapped\",[105]],[[74,74],\"mapped\",[106]],[[75,75],\"mapped\",[107]],[[76,76],\"mapped\",[108]],[[77,77],\"mapped\",[109]],[[78,78],\"mapped\",[110]],[[79,79],\"mapped\",[111]],[[80,80],\"mapped\",[112]],[[81,81],\"mapped\",[113]],[[82,82],\"mapped\",[114]],[[83,83],\"mapped\",[115]],[[84,84],\"mapped\",[116]],[[85,85],\"mapped\",[117]],[[86,86],\"mapped\",[118]],[[87,87],\"mapped\",[119]],[[88,88],\"mapped\",[120]],[[89,89],\"mapped\",[121]],[[90,90],\"mapped\",[122]],[[91,96],\"disallowed_STD3_valid\"],[[97,122],\"valid\"],[[123,127],\"disallowed_STD3_valid\"],[[128,159],\"disallowed\"],[[160,160],\"disallowed_STD3_mapped\",[32]],[[161,167],\"valid\",[],\"NV8\"],[[168,168],\"disallowed_STD3_mapped\",[32,776]],[[169,169],\"valid\",[],\"NV8\"],[[170,170],\"mapped\",[97]],[[171,172],\"valid\",[],\"NV8\"],[[173,173],\"ignored\"],[[174,174],\"valid\",[],\"NV8\"],[[175,175],\"disallowed_STD3_mapped\",[32,772]],[[176,177],\"valid\",[],\"NV8\"],[[178,178],\"mapped\",[50]],[[179,179],\"mapped\",[51]],[[180,180],\"disallowed_STD3_mapped\",[32,769]],[[181,181],\"mapped\",[956]],[[182,182],\"valid\",[],\"NV8\"],[[183,183],\"valid\"],[[184,184],\"disallowed_STD3_mapped\",[32,807]],[[185,185],\"mapped\",[49]],[[186,186],\"mapped\",[111]],[[187,187],\"valid\",[],\"NV8\"],[[188,188],\"mapped\",[49,8260,52]],[[189,189],\"mapped\",[49,8260,50]],[[190,190],\"mapped\",[51,8260,52]],[[191,191],\"valid\",[],\"NV8\"],[[192,192],\"mapped\",[224]],[[193,193],\"mapped\",[225]],[[194,194],\"mapped\",[226]],[[195,195],\"mapped\",[227]],[[196,196],\"mapped\",[228]],[[197,197],\"mapped\",[229]],[[198,198],\"mapped\",[230]],[[199,199],\"mapped\",[231]],[[200,200],\"mapped\",[232]],[[201,201],\"mapped\",[233]],[[202,202],\"mapped\",[234]],[[203,203],\"mapped\",[235]],[[204,204],\"mapped\",[236]],[[205,205],\"mapped\",[237]],[[206,206],\"mapped\",[238]],[[207,207],\"mapped\",[239]],[[208,208],\"mapped\",[240]],[[209,209],\"mapped\",[241]],[[210,210],\"mapped\",[242]],[[211,211],\"mapped\",[243]],[[212,212],\"mapped\",[244]],[[213,213],\"mapped\",[245]],[[214,214],\"mapped\",[246]],[[215,215],\"valid\",[],\"NV8\"],[[216,216],\"mapped\",[248]],[[217,217],\"mapped\",[249]],[[218,218],\"mapped\",[250]],[[219,219],\"mapped\",[251]],[[220,220],\"mapped\",[252]],[[221,221],\"mapped\",[253]],[[222,222],\"mapped\",[254]],[[223,223],\"deviation\",[115,115]],[[224,246],\"valid\"],[[247,247],\"valid\",[],\"NV8\"],[[248,255],\"valid\"],[[256,256],\"mapped\",[257]],[[257,257],\"valid\"],[[258,258],\"mapped\",[259]],[[259,259],\"valid\"],[[260,260],\"mapped\",[261]],[[261,261],\"valid\"],[[262,262],\"mapped\",[263]],[[263,263],\"valid\"],[[264,264],\"mapped\",[265]],[[265,265],\"valid\"],[[266,266],\"mapped\",[267]],[[267,267],\"valid\"],[[268,268],\"mapped\",[269]],[[269,269],\"valid\"],[[270,270],\"mapped\",[271]],[[271,271],\"valid\"],[[272,272],\"mapped\",[273]],[[273,273],\"valid\"],[[274,274],\"mapped\",[275]],[[275,275],\"valid\"],[[276,276],\"mapped\",[277]],[[277,277],\"valid\"],[[278,278],\"mapped\",[279]],[[279,279],\"valid\"],[[280,280],\"mapped\",[281]],[[281,281],\"valid\"],[[282,282],\"mapped\",[283]],[[283,283],\"valid\"],[[284,284],\"mapped\",[285]],[[285,285],\"valid\"],[[286,286],\"mapped\",[287]],[[287,287],\"valid\"],[[288,288],\"mapped\",[289]],[[289,289],\"valid\"],[[290,290],\"mapped\",[291]],[[291,291],\"valid\"],[[292,292],\"mapped\",[293]],[[293,293],\"valid\"],[[294,294],\"mapped\",[295]],[[295,295],\"valid\"],[[296,296],\"mapped\",[297]],[[297,297],\"valid\"],[[298,298],\"mapped\",[299]],[[299,299],\"valid\"],[[300,300],\"mapped\",[301]],[[301,301],\"valid\"],[[302,302],\"mapped\",[303]],[[303,303],\"valid\"],[[304,304],\"mapped\",[105,775]],[[305,305],\"valid\"],[[306,307],\"mapped\",[105,106]],[[308,308],\"mapped\",[309]],[[309,309],\"valid\"],[[310,310],\"mapped\",[311]],[[311,312],\"valid\"],[[313,313],\"mapped\",[314]],[[314,314],\"valid\"],[[315,315],\"mapped\",[316]],[[316,316],\"valid\"],[[317,317],\"mapped\",[318]],[[318,318],\"valid\"],[[319,320],\"mapped\",[108,183]],[[321,321],\"mapped\",[322]],[[322,322],\"valid\"],[[323,323],\"mapped\",[324]],[[324,324],\"valid\"],[[325,325],\"mapped\",[326]],[[326,326],\"valid\"],[[327,327],\"mapped\",[328]],[[328,328],\"valid\"],[[329,329],\"mapped\",[700,110]],[[330,330],\"mapped\",[331]],[[331,331],\"valid\"],[[332,332],\"mapped\",[333]],[[333,333],\"valid\"],[[334,334],\"mapped\",[335]],[[335,335],\"valid\"],[[336,336],\"mapped\",[337]],[[337,337],\"valid\"],[[338,338],\"mapped\",[339]],[[339,339],\"valid\"],[[340,340],\"mapped\",[341]],[[341,341],\"valid\"],[[342,342],\"mapped\",[343]],[[343,343],\"valid\"],[[344,344],\"mapped\",[345]],[[345,345],\"valid\"],[[346,346],\"mapped\",[347]],[[347,347],\"valid\"],[[348,348],\"mapped\",[349]],[[349,349],\"valid\"],[[350,350],\"mapped\",[351]],[[351,351],\"valid\"],[[352,352],\"mapped\",[353]],[[353,353],\"valid\"],[[354,354],\"mapped\",[355]],[[355,355],\"valid\"],[[356,356],\"mapped\",[357]],[[357,357],\"valid\"],[[358,358],\"mapped\",[359]],[[359,359],\"valid\"],[[360,360],\"mapped\",[361]],[[361,361],\"valid\"],[[362,362],\"mapped\",[363]],[[363,363],\"valid\"],[[364,364],\"mapped\",[365]],[[365,365],\"valid\"],[[366,366],\"mapped\",[367]],[[367,367],\"valid\"],[[368,368],\"mapped\",[369]],[[369,369],\"valid\"],[[370,370],\"mapped\",[371]],[[371,371],\"valid\"],[[372,372],\"mapped\",[373]],[[373,373],\"valid\"],[[374,374],\"mapped\",[375]],[[375,375],\"valid\"],[[376,376],\"mapped\",[255]],[[377,377],\"mapped\",[378]],[[378,378],\"valid\"],[[379,379],\"mapped\",[380]],[[380,380],\"valid\"],[[381,381],\"mapped\",[382]],[[382,382],\"valid\"],[[383,383],\"mapped\",[115]],[[384,384],\"valid\"],[[385,385],\"mapped\",[595]],[[386,386],\"mapped\",[387]],[[387,387],\"valid\"],[[388,388],\"mapped\",[389]],[[389,389],\"valid\"],[[390,390],\"mapped\",[596]],[[391,391],\"mapped\",[392]],[[392,392],\"valid\"],[[393,393],\"mapped\",[598]],[[394,394],\"mapped\",[599]],[[395,395],\"mapped\",[396]],[[396,397],\"valid\"],[[398,398],\"mapped\",[477]],[[399,399],\"mapped\",[601]],[[400,400],\"mapped\",[603]],[[401,401],\"mapped\",[402]],[[402,402],\"valid\"],[[403,403],\"mapped\",[608]],[[404,404],\"mapped\",[611]],[[405,405],\"valid\"],[[406,406],\"mapped\",[617]],[[407,407],\"mapped\",[616]],[[408,408],\"mapped\",[409]],[[409,411],\"valid\"],[[412,412],\"mapped\",[623]],[[413,413],\"mapped\",[626]],[[414,414],\"valid\"],[[415,415],\"mapped\",[629]],[[416,416],\"mapped\",[417]],[[417,417],\"valid\"],[[418,418],\"mapped\",[419]],[[419,419],\"valid\"],[[420,420],\"mapped\",[421]],[[421,421],\"valid\"],[[422,422],\"mapped\",[640]],[[423,423],\"mapped\",[424]],[[424,424],\"valid\"],[[425,425],\"mapped\",[643]],[[426,427],\"valid\"],[[428,428],\"mapped\",[429]],[[429,429],\"valid\"],[[430,430],\"mapped\",[648]],[[431,431],\"mapped\",[432]],[[432,432],\"valid\"],[[433,433],\"mapped\",[650]],[[434,434],\"mapped\",[651]],[[435,435],\"mapped\",[436]],[[436,436],\"valid\"],[[437,437],\"mapped\",[438]],[[438,438],\"valid\"],[[439,439],\"mapped\",[658]],[[440,440],\"mapped\",[441]],[[441,443],\"valid\"],[[444,444],\"mapped\",[445]],[[445,451],\"valid\"],[[452,454],\"mapped\",[100,382]],[[455,457],\"mapped\",[108,106]],[[458,460],\"mapped\",[110,106]],[[461,461],\"mapped\",[462]],[[462,462],\"valid\"],[[463,463],\"mapped\",[464]],[[464,464],\"valid\"],[[465,465],\"mapped\",[466]],[[466,466],\"valid\"],[[467,467],\"mapped\",[468]],[[468,468],\"valid\"],[[469,469],\"mapped\",[470]],[[470,470],\"valid\"],[[471,471],\"mapped\",[472]],[[472,472],\"valid\"],[[473,473],\"mapped\",[474]],[[474,474],\"valid\"],[[475,475],\"mapped\",[476]],[[476,477],\"valid\"],[[478,478],\"mapped\",[479]],[[479,479],\"valid\"],[[480,480],\"mapped\",[481]],[[481,481],\"valid\"],[[482,482],\"mapped\",[483]],[[483,483],\"valid\"],[[484,484],\"mapped\",[485]],[[485,485],\"valid\"],[[486,486],\"mapped\",[487]],[[487,487],\"valid\"],[[488,488],\"mapped\",[489]],[[489,489],\"valid\"],[[490,490],\"mapped\",[491]],[[491,491],\"valid\"],[[492,492],\"mapped\",[493]],[[493,493],\"valid\"],[[494,494],\"mapped\",[495]],[[495,496],\"valid\"],[[497,499],\"mapped\",[100,122]],[[500,500],\"mapped\",[501]],[[501,501],\"valid\"],[[502,502],\"mapped\",[405]],[[503,503],\"mapped\",[447]],[[504,504],\"mapped\",[505]],[[505,505],\"valid\"],[[506,506],\"mapped\",[507]],[[507,507],\"valid\"],[[508,508],\"mapped\",[509]],[[509,509],\"valid\"],[[510,510],\"mapped\",[511]],[[511,511],\"valid\"],[[512,512],\"mapped\",[513]],[[513,513],\"valid\"],[[514,514],\"mapped\",[515]],[[515,515],\"valid\"],[[516,516],\"mapped\",[517]],[[517,517],\"valid\"],[[518,518],\"mapped\",[519]],[[519,519],\"valid\"],[[520,520],\"mapped\",[521]],[[521,521],\"valid\"],[[522,522],\"mapped\",[523]],[[523,523],\"valid\"],[[524,524],\"mapped\",[525]],[[525,525],\"valid\"],[[526,526],\"mapped\",[527]],[[527,527],\"valid\"],[[528,528],\"mapped\",[529]],[[529,529],\"valid\"],[[530,530],\"mapped\",[531]],[[531,531],\"valid\"],[[532,532],\"mapped\",[533]],[[533,533],\"valid\"],[[534,534],\"mapped\",[535]],[[535,535],\"valid\"],[[536,536],\"mapped\",[537]],[[537,537],\"valid\"],[[538,538],\"mapped\",[539]],[[539,539],\"valid\"],[[540,540],\"mapped\",[541]],[[541,541],\"valid\"],[[542,542],\"mapped\",[543]],[[543,543],\"valid\"],[[544,544],\"mapped\",[414]],[[545,545],\"valid\"],[[546,546],\"mapped\",[547]],[[547,547],\"valid\"],[[548,548],\"mapped\",[549]],[[549,549],\"valid\"],[[550,550],\"mapped\",[551]],[[551,551],\"valid\"],[[552,552],\"mapped\",[553]],[[553,553],\"valid\"],[[554,554],\"mapped\",[555]],[[555,555],\"valid\"],[[556,556],\"mapped\",[557]],[[557,557],\"valid\"],[[558,558],\"mapped\",[559]],[[559,559],\"valid\"],[[560,560],\"mapped\",[561]],[[561,561],\"valid\"],[[562,562],\"mapped\",[563]],[[563,563],\"valid\"],[[564,566],\"valid\"],[[567,569],\"valid\"],[[570,570],\"mapped\",[11365]],[[571,571],\"mapped\",[572]],[[572,572],\"valid\"],[[573,573],\"mapped\",[410]],[[574,574],\"mapped\",[11366]],[[575,576],\"valid\"],[[577,577],\"mapped\",[578]],[[578,578],\"valid\"],[[579,579],\"mapped\",[384]],[[580,580],\"mapped\",[649]],[[581,581],\"mapped\",[652]],[[582,582],\"mapped\",[583]],[[583,583],\"valid\"],[[584,584],\"mapped\",[585]],[[585,585],\"valid\"],[[586,586],\"mapped\",[587]],[[587,587],\"valid\"],[[588,588],\"mapped\",[589]],[[589,589],\"valid\"],[[590,590],\"mapped\",[591]],[[591,591],\"valid\"],[[592,680],\"valid\"],[[681,685],\"valid\"],[[686,687],\"valid\"],[[688,688],\"mapped\",[104]],[[689,689],\"mapped\",[614]],[[690,690],\"mapped\",[106]],[[691,691],\"mapped\",[114]],[[692,692],\"mapped\",[633]],[[693,693],\"mapped\",[635]],[[694,694],\"mapped\",[641]],[[695,695],\"mapped\",[119]],[[696,696],\"mapped\",[121]],[[697,705],\"valid\"],[[706,709],\"valid\",[],\"NV8\"],[[710,721],\"valid\"],[[722,727],\"valid\",[],\"NV8\"],[[728,728],\"disallowed_STD3_mapped\",[32,774]],[[729,729],\"disallowed_STD3_mapped\",[32,775]],[[730,730],\"disallowed_STD3_mapped\",[32,778]],[[731,731],\"disallowed_STD3_mapped\",[32,808]],[[732,732],\"disallowed_STD3_mapped\",[32,771]],[[733,733],\"disallowed_STD3_mapped\",[32,779]],[[734,734],\"valid\",[],\"NV8\"],[[735,735],\"valid\",[],\"NV8\"],[[736,736],\"mapped\",[611]],[[737,737],\"mapped\",[108]],[[738,738],\"mapped\",[115]],[[739,739],\"mapped\",[120]],[[740,740],\"mapped\",[661]],[[741,745],\"valid\",[],\"NV8\"],[[746,747],\"valid\",[],\"NV8\"],[[748,748],\"valid\"],[[749,749],\"valid\",[],\"NV8\"],[[750,750],\"valid\"],[[751,767],\"valid\",[],\"NV8\"],[[768,831],\"valid\"],[[832,832],\"mapped\",[768]],[[833,833],\"mapped\",[769]],[[834,834],\"valid\"],[[835,835],\"mapped\",[787]],[[836,836],\"mapped\",[776,769]],[[837,837],\"mapped\",[953]],[[838,846],\"valid\"],[[847,847],\"ignored\"],[[848,855],\"valid\"],[[856,860],\"valid\"],[[861,863],\"valid\"],[[864,865],\"valid\"],[[866,866],\"valid\"],[[867,879],\"valid\"],[[880,880],\"mapped\",[881]],[[881,881],\"valid\"],[[882,882],\"mapped\",[883]],[[883,883],\"valid\"],[[884,884],\"mapped\",[697]],[[885,885],\"valid\"],[[886,886],\"mapped\",[887]],[[887,887],\"valid\"],[[888,889],\"disallowed\"],[[890,890],\"disallowed_STD3_mapped\",[32,953]],[[891,893],\"valid\"],[[894,894],\"disallowed_STD3_mapped\",[59]],[[895,895],\"mapped\",[1011]],[[896,899],\"disallowed\"],[[900,900],\"disallowed_STD3_mapped\",[32,769]],[[901,901],\"disallowed_STD3_mapped\",[32,776,769]],[[902,902],\"mapped\",[940]],[[903,903],\"mapped\",[183]],[[904,904],\"mapped\",[941]],[[905,905],\"mapped\",[942]],[[906,906],\"mapped\",[943]],[[907,907],\"disallowed\"],[[908,908],\"mapped\",[972]],[[909,909],\"disallowed\"],[[910,910],\"mapped\",[973]],[[911,911],\"mapped\",[974]],[[912,912],\"valid\"],[[913,913],\"mapped\",[945]],[[914,914],\"mapped\",[946]],[[915,915],\"mapped\",[947]],[[916,916],\"mapped\",[948]],[[917,917],\"mapped\",[949]],[[918,918],\"mapped\",[950]],[[919,919],\"mapped\",[951]],[[920,920],\"mapped\",[952]],[[921,921],\"mapped\",[953]],[[922,922],\"mapped\",[954]],[[923,923],\"mapped\",[955]],[[924,924],\"mapped\",[956]],[[925,925],\"mapped\",[957]],[[926,926],\"mapped\",[958]],[[927,927],\"mapped\",[959]],[[928,928],\"mapped\",[960]],[[929,929],\"mapped\",[961]],[[930,930],\"disallowed\"],[[931,931],\"mapped\",[963]],[[932,932],\"mapped\",[964]],[[933,933],\"mapped\",[965]],[[934,934],\"mapped\",[966]],[[935,935],\"mapped\",[967]],[[936,936],\"mapped\",[968]],[[937,937],\"mapped\",[969]],[[938,938],\"mapped\",[970]],[[939,939],\"mapped\",[971]],[[940,961],\"valid\"],[[962,962],\"deviation\",[963]],[[963,974],\"valid\"],[[975,975],\"mapped\",[983]],[[976,976],\"mapped\",[946]],[[977,977],\"mapped\",[952]],[[978,978],\"mapped\",[965]],[[979,979],\"mapped\",[973]],[[980,980],\"mapped\",[971]],[[981,981],\"mapped\",[966]],[[982,982],\"mapped\",[960]],[[983,983],\"valid\"],[[984,984],\"mapped\",[985]],[[985,985],\"valid\"],[[986,986],\"mapped\",[987]],[[987,987],\"valid\"],[[988,988],\"mapped\",[989]],[[989,989],\"valid\"],[[990,990],\"mapped\",[991]],[[991,991],\"valid\"],[[992,992],\"mapped\",[993]],[[993,993],\"valid\"],[[994,994],\"mapped\",[995]],[[995,995],\"valid\"],[[996,996],\"mapped\",[997]],[[997,997],\"valid\"],[[998,998],\"mapped\",[999]],[[999,999],\"valid\"],[[1000,1000],\"mapped\",[1001]],[[1001,1001],\"valid\"],[[1002,1002],\"mapped\",[1003]],[[1003,1003],\"valid\"],[[1004,1004],\"mapped\",[1005]],[[1005,1005],\"valid\"],[[1006,1006],\"mapped\",[1007]],[[1007,1007],\"valid\"],[[1008,1008],\"mapped\",[954]],[[1009,1009],\"mapped\",[961]],[[1010,1010],\"mapped\",[963]],[[1011,1011],\"valid\"],[[1012,1012],\"mapped\",[952]],[[1013,1013],\"mapped\",[949]],[[1014,1014],\"valid\",[],\"NV8\"],[[1015,1015],\"mapped\",[1016]],[[1016,1016],\"valid\"],[[1017,1017],\"mapped\",[963]],[[1018,1018],\"mapped\",[1019]],[[1019,1019],\"valid\"],[[1020,1020],\"valid\"],[[1021,1021],\"mapped\",[891]],[[1022,1022],\"mapped\",[892]],[[1023,1023],\"mapped\",[893]],[[1024,1024],\"mapped\",[1104]],[[1025,1025],\"mapped\",[1105]],[[1026,1026],\"mapped\",[1106]],[[1027,1027],\"mapped\",[1107]],[[1028,1028],\"mapped\",[1108]],[[1029,1029],\"mapped\",[1109]],[[1030,1030],\"mapped\",[1110]],[[1031,1031],\"mapped\",[1111]],[[1032,1032],\"mapped\",[1112]],[[1033,1033],\"mapped\",[1113]],[[1034,1034],\"mapped\",[1114]],[[1035,1035],\"mapped\",[1115]],[[1036,1036],\"mapped\",[1116]],[[1037,1037],\"mapped\",[1117]],[[1038,1038],\"mapped\",[1118]],[[1039,1039],\"mapped\",[1119]],[[1040,1040],\"mapped\",[1072]],[[1041,1041],\"mapped\",[1073]],[[1042,1042],\"mapped\",[1074]],[[1043,1043],\"mapped\",[1075]],[[1044,1044],\"mapped\",[1076]],[[1045,1045],\"mapped\",[1077]],[[1046,1046],\"mapped\",[1078]],[[1047,1047],\"mapped\",[1079]],[[1048,1048],\"mapped\",[1080]],[[1049,1049],\"mapped\",[1081]],[[1050,1050],\"mapped\",[1082]],[[1051,1051],\"mapped\",[1083]],[[1052,1052],\"mapped\",[1084]],[[1053,1053],\"mapped\",[1085]],[[1054,1054],\"mapped\",[1086]],[[1055,1055],\"mapped\",[1087]],[[1056,1056],\"mapped\",[1088]],[[1057,1057],\"mapped\",[1089]],[[1058,1058],\"mapped\",[1090]],[[1059,1059],\"mapped\",[1091]],[[1060,1060],\"mapped\",[1092]],[[1061,1061],\"mapped\",[1093]],[[1062,1062],\"mapped\",[1094]],[[1063,1063],\"mapped\",[1095]],[[1064,1064],\"mapped\",[1096]],[[1065,1065],\"mapped\",[1097]],[[1066,1066],\"mapped\",[1098]],[[1067,1067],\"mapped\",[1099]],[[1068,1068],\"mapped\",[1100]],[[1069,1069],\"mapped\",[1101]],[[1070,1070],\"mapped\",[1102]],[[1071,1071],\"mapped\",[1103]],[[1072,1103],\"valid\"],[[1104,1104],\"valid\"],[[1105,1116],\"valid\"],[[1117,1117],\"valid\"],[[1118,1119],\"valid\"],[[1120,1120],\"mapped\",[1121]],[[1121,1121],\"valid\"],[[1122,1122],\"mapped\",[1123]],[[1123,1123],\"valid\"],[[1124,1124],\"mapped\",[1125]],[[1125,1125],\"valid\"],[[1126,1126],\"mapped\",[1127]],[[1127,1127],\"valid\"],[[1128,1128],\"mapped\",[1129]],[[1129,1129],\"valid\"],[[1130,1130],\"mapped\",[1131]],[[1131,1131],\"valid\"],[[1132,1132],\"mapped\",[1133]],[[1133,1133],\"valid\"],[[1134,1134],\"mapped\",[1135]],[[1135,1135],\"valid\"],[[1136,1136],\"mapped\",[1137]],[[1137,1137],\"valid\"],[[1138,1138],\"mapped\",[1139]],[[1139,1139],\"valid\"],[[1140,1140],\"mapped\",[1141]],[[1141,1141],\"valid\"],[[1142,1142],\"mapped\",[1143]],[[1143,1143],\"valid\"],[[1144,1144],\"mapped\",[1145]],[[1145,1145],\"valid\"],[[1146,1146],\"mapped\",[1147]],[[1147,1147],\"valid\"],[[1148,1148],\"mapped\",[1149]],[[1149,1149],\"valid\"],[[1150,1150],\"mapped\",[1151]],[[1151,1151],\"valid\"],[[1152,1152],\"mapped\",[1153]],[[1153,1153],\"valid\"],[[1154,1154],\"valid\",[],\"NV8\"],[[1155,1158],\"valid\"],[[1159,1159],\"valid\"],[[1160,1161],\"valid\",[],\"NV8\"],[[1162,1162],\"mapped\",[1163]],[[1163,1163],\"valid\"],[[1164,1164],\"mapped\",[1165]],[[1165,1165],\"valid\"],[[1166,1166],\"mapped\",[1167]],[[1167,1167],\"valid\"],[[1168,1168],\"mapped\",[1169]],[[1169,1169],\"valid\"],[[1170,1170],\"mapped\",[1171]],[[1171,1171],\"valid\"],[[1172,1172],\"mapped\",[1173]],[[1173,1173],\"valid\"],[[1174,1174],\"mapped\",[1175]],[[1175,1175],\"valid\"],[[1176,1176],\"mapped\",[1177]],[[1177,1177],\"valid\"],[[1178,1178],\"mapped\",[1179]],[[1179,1179],\"valid\"],[[1180,1180],\"mapped\",[1181]],[[1181,1181],\"valid\"],[[1182,1182],\"mapped\",[1183]],[[1183,1183],\"valid\"],[[1184,1184],\"mapped\",[1185]],[[1185,1185],\"valid\"],[[1186,1186],\"mapped\",[1187]],[[1187,1187],\"valid\"],[[1188,1188],\"mapped\",[1189]],[[1189,1189],\"valid\"],[[1190,1190],\"mapped\",[1191]],[[1191,1191],\"valid\"],[[1192,1192],\"mapped\",[1193]],[[1193,1193],\"valid\"],[[1194,1194],\"mapped\",[1195]],[[1195,1195],\"valid\"],[[1196,1196],\"mapped\",[1197]],[[1197,1197],\"valid\"],[[1198,1198],\"mapped\",[1199]],[[1199,1199],\"valid\"],[[1200,1200],\"mapped\",[1201]],[[1201,1201],\"valid\"],[[1202,1202],\"mapped\",[1203]],[[1203,1203],\"valid\"],[[1204,1204],\"mapped\",[1205]],[[1205,1205],\"valid\"],[[1206,1206],\"mapped\",[1207]],[[1207,1207],\"valid\"],[[1208,1208],\"mapped\",[1209]],[[1209,1209],\"valid\"],[[1210,1210],\"mapped\",[1211]],[[1211,1211],\"valid\"],[[1212,1212],\"mapped\",[1213]],[[1213,1213],\"valid\"],[[1214,1214],\"mapped\",[1215]],[[1215,1215],\"valid\"],[[1216,1216],\"disallowed\"],[[1217,1217],\"mapped\",[1218]],[[1218,1218],\"valid\"],[[1219,1219],\"mapped\",[1220]],[[1220,1220],\"valid\"],[[1221,1221],\"mapped\",[1222]],[[1222,1222],\"valid\"],[[1223,1223],\"mapped\",[1224]],[[1224,1224],\"valid\"],[[1225,1225],\"mapped\",[1226]],[[1226,1226],\"valid\"],[[1227,1227],\"mapped\",[1228]],[[1228,1228],\"valid\"],[[1229,1229],\"mapped\",[1230]],[[1230,1230],\"valid\"],[[1231,1231],\"valid\"],[[1232,1232],\"mapped\",[1233]],[[1233,1233],\"valid\"],[[1234,1234],\"mapped\",[1235]],[[1235,1235],\"valid\"],[[1236,1236],\"mapped\",[1237]],[[1237,1237],\"valid\"],[[1238,1238],\"mapped\",[1239]],[[1239,1239],\"valid\"],[[1240,1240],\"mapped\",[1241]],[[1241,1241],\"valid\"],[[1242,1242],\"mapped\",[1243]],[[1243,1243],\"valid\"],[[1244,1244],\"mapped\",[1245]],[[1245,1245],\"valid\"],[[1246,1246],\"mapped\",[1247]],[[1247,1247],\"valid\"],[[1248,1248],\"mapped\",[1249]],[[1249,1249],\"valid\"],[[1250,1250],\"mapped\",[1251]],[[1251,1251],\"valid\"],[[1252,1252],\"mapped\",[1253]],[[1253,1253],\"valid\"],[[1254,1254],\"mapped\",[1255]],[[1255,1255],\"valid\"],[[1256,1256],\"mapped\",[1257]],[[1257,1257],\"valid\"],[[1258,1258],\"mapped\",[1259]],[[1259,1259],\"valid\"],[[1260,1260],\"mapped\",[1261]],[[1261,1261],\"valid\"],[[1262,1262],\"mapped\",[1263]],[[1263,1263],\"valid\"],[[1264,1264],\"mapped\",[1265]],[[1265,1265],\"valid\"],[[1266,1266],\"mapped\",[1267]],[[1267,1267],\"valid\"],[[1268,1268],\"mapped\",[1269]],[[1269,1269],\"valid\"],[[1270,1270],\"mapped\",[1271]],[[1271,1271],\"valid\"],[[1272,1272],\"mapped\",[1273]],[[1273,1273],\"valid\"],[[1274,1274],\"mapped\",[1275]],[[1275,1275],\"valid\"],[[1276,1276],\"mapped\",[1277]],[[1277,1277],\"valid\"],[[1278,1278],\"mapped\",[1279]],[[1279,1279],\"valid\"],[[1280,1280],\"mapped\",[1281]],[[1281,1281],\"valid\"],[[1282,1282],\"mapped\",[1283]],[[1283,1283],\"valid\"],[[1284,1284],\"mapped\",[1285]],[[1285,1285],\"valid\"],[[1286,1286],\"mapped\",[1287]],[[1287,1287],\"valid\"],[[1288,1288],\"mapped\",[1289]],[[1289,1289],\"valid\"],[[1290,1290],\"mapped\",[1291]],[[1291,1291],\"valid\"],[[1292,1292],\"mapped\",[1293]],[[1293,1293],\"valid\"],[[1294,1294],\"mapped\",[1295]],[[1295,1295],\"valid\"],[[1296,1296],\"mapped\",[1297]],[[1297,1297],\"valid\"],[[1298,1298],\"mapped\",[1299]],[[1299,1299],\"valid\"],[[1300,1300],\"mapped\",[1301]],[[1301,1301],\"valid\"],[[1302,1302],\"mapped\",[1303]],[[1303,1303],\"valid\"],[[1304,1304],\"mapped\",[1305]],[[1305,1305],\"valid\"],[[1306,1306],\"mapped\",[1307]],[[1307,1307],\"valid\"],[[1308,1308],\"mapped\",[1309]],[[1309,1309],\"valid\"],[[1310,1310],\"mapped\",[1311]],[[1311,1311],\"valid\"],[[1312,1312],\"mapped\",[1313]],[[1313,1313],\"valid\"],[[1314,1314],\"mapped\",[1315]],[[1315,1315],\"valid\"],[[1316,1316],\"mapped\",[1317]],[[1317,1317],\"valid\"],[[1318,1318],\"mapped\",[1319]],[[1319,1319],\"valid\"],[[1320,1320],\"mapped\",[1321]],[[1321,1321],\"valid\"],[[1322,1322],\"mapped\",[1323]],[[1323,1323],\"valid\"],[[1324,1324],\"mapped\",[1325]],[[1325,1325],\"valid\"],[[1326,1326],\"mapped\",[1327]],[[1327,1327],\"valid\"],[[1328,1328],\"disallowed\"],[[1329,1329],\"mapped\",[1377]],[[1330,1330],\"mapped\",[1378]],[[1331,1331],\"mapped\",[1379]],[[1332,1332],\"mapped\",[1380]],[[1333,1333],\"mapped\",[1381]],[[1334,1334],\"mapped\",[1382]],[[1335,1335],\"mapped\",[1383]],[[1336,1336],\"mapped\",[1384]],[[1337,1337],\"mapped\",[1385]],[[1338,1338],\"mapped\",[1386]],[[1339,1339],\"mapped\",[1387]],[[1340,1340],\"mapped\",[1388]],[[1341,1341],\"mapped\",[1389]],[[1342,1342],\"mapped\",[1390]],[[1343,1343],\"mapped\",[1391]],[[1344,1344],\"mapped\",[1392]],[[1345,1345],\"mapped\",[1393]],[[1346,1346],\"mapped\",[1394]],[[1347,1347],\"mapped\",[1395]],[[1348,1348],\"mapped\",[1396]],[[1349,1349],\"mapped\",[1397]],[[1350,1350],\"mapped\",[1398]],[[1351,1351],\"mapped\",[1399]],[[1352,1352],\"mapped\",[1400]],[[1353,1353],\"mapped\",[1401]],[[1354,1354],\"mapped\",[1402]],[[1355,1355],\"mapped\",[1403]],[[1356,1356],\"mapped\",[1404]],[[1357,1357],\"mapped\",[1405]],[[1358,1358],\"mapped\",[1406]],[[1359,1359],\"mapped\",[1407]],[[1360,1360],\"mapped\",[1408]],[[1361,1361],\"mapped\",[1409]],[[1362,1362],\"mapped\",[1410]],[[1363,1363],\"mapped\",[1411]],[[1364,1364],\"mapped\",[1412]],[[1365,1365],\"mapped\",[1413]],[[1366,1366],\"mapped\",[1414]],[[1367,1368],\"disallowed\"],[[1369,1369],\"valid\"],[[1370,1375],\"valid\",[],\"NV8\"],[[1376,1376],\"disallowed\"],[[1377,1414],\"valid\"],[[1415,1415],\"mapped\",[1381,1410]],[[1416,1416],\"disallowed\"],[[1417,1417],\"valid\",[],\"NV8\"],[[1418,1418],\"valid\",[],\"NV8\"],[[1419,1420],\"disallowed\"],[[1421,1422],\"valid\",[],\"NV8\"],[[1423,1423],\"valid\",[],\"NV8\"],[[1424,1424],\"disallowed\"],[[1425,1441],\"valid\"],[[1442,1442],\"valid\"],[[1443,1455],\"valid\"],[[1456,1465],\"valid\"],[[1466,1466],\"valid\"],[[1467,1469],\"valid\"],[[1470,1470],\"valid\",[],\"NV8\"],[[1471,1471],\"valid\"],[[1472,1472],\"valid\",[],\"NV8\"],[[1473,1474],\"valid\"],[[1475,1475],\"valid\",[],\"NV8\"],[[1476,1476],\"valid\"],[[1477,1477],\"valid\"],[[1478,1478],\"valid\",[],\"NV8\"],[[1479,1479],\"valid\"],[[1480,1487],\"disallowed\"],[[1488,1514],\"valid\"],[[1515,1519],\"disallowed\"],[[1520,1524],\"valid\"],[[1525,1535],\"disallowed\"],[[1536,1539],\"disallowed\"],[[1540,1540],\"disallowed\"],[[1541,1541],\"disallowed\"],[[1542,1546],\"valid\",[],\"NV8\"],[[1547,1547],\"valid\",[],\"NV8\"],[[1548,1548],\"valid\",[],\"NV8\"],[[1549,1551],\"valid\",[],\"NV8\"],[[1552,1557],\"valid\"],[[1558,1562],\"valid\"],[[1563,1563],\"valid\",[],\"NV8\"],[[1564,1564],\"disallowed\"],[[1565,1565],\"disallowed\"],[[1566,1566],\"valid\",[],\"NV8\"],[[1567,1567],\"valid\",[],\"NV8\"],[[1568,1568],\"valid\"],[[1569,1594],\"valid\"],[[1595,1599],\"valid\"],[[1600,1600],\"valid\",[],\"NV8\"],[[1601,1618],\"valid\"],[[1619,1621],\"valid\"],[[1622,1624],\"valid\"],[[1625,1630],\"valid\"],[[1631,1631],\"valid\"],[[1632,1641],\"valid\"],[[1642,1645],\"valid\",[],\"NV8\"],[[1646,1647],\"valid\"],[[1648,1652],\"valid\"],[[1653,1653],\"mapped\",[1575,1652]],[[1654,1654],\"mapped\",[1608,1652]],[[1655,1655],\"mapped\",[1735,1652]],[[1656,1656],\"mapped\",[1610,1652]],[[1657,1719],\"valid\"],[[1720,1721],\"valid\"],[[1722,1726],\"valid\"],[[1727,1727],\"valid\"],[[1728,1742],\"valid\"],[[1743,1743],\"valid\"],[[1744,1747],\"valid\"],[[1748,1748],\"valid\",[],\"NV8\"],[[1749,1756],\"valid\"],[[1757,1757],\"disallowed\"],[[1758,1758],\"valid\",[],\"NV8\"],[[1759,1768],\"valid\"],[[1769,1769],\"valid\",[],\"NV8\"],[[1770,1773],\"valid\"],[[1774,1775],\"valid\"],[[1776,1785],\"valid\"],[[1786,1790],\"valid\"],[[1791,1791],\"valid\"],[[1792,1805],\"valid\",[],\"NV8\"],[[1806,1806],\"disallowed\"],[[1807,1807],\"disallowed\"],[[1808,1836],\"valid\"],[[1837,1839],\"valid\"],[[1840,1866],\"valid\"],[[1867,1868],\"disallowed\"],[[1869,1871],\"valid\"],[[1872,1901],\"valid\"],[[1902,1919],\"valid\"],[[1920,1968],\"valid\"],[[1969,1969],\"valid\"],[[1970,1983],\"disallowed\"],[[1984,2037],\"valid\"],[[2038,2042],\"valid\",[],\"NV8\"],[[2043,2047],\"disallowed\"],[[2048,2093],\"valid\"],[[2094,2095],\"disallowed\"],[[2096,2110],\"valid\",[],\"NV8\"],[[2111,2111],\"disallowed\"],[[2112,2139],\"valid\"],[[2140,2141],\"disallowed\"],[[2142,2142],\"valid\",[],\"NV8\"],[[2143,2207],\"disallowed\"],[[2208,2208],\"valid\"],[[2209,2209],\"valid\"],[[2210,2220],\"valid\"],[[2221,2226],\"valid\"],[[2227,2228],\"valid\"],[[2229,2274],\"disallowed\"],[[2275,2275],\"valid\"],[[2276,2302],\"valid\"],[[2303,2303],\"valid\"],[[2304,2304],\"valid\"],[[2305,2307],\"valid\"],[[2308,2308],\"valid\"],[[2309,2361],\"valid\"],[[2362,2363],\"valid\"],[[2364,2381],\"valid\"],[[2382,2382],\"valid\"],[[2383,2383],\"valid\"],[[2384,2388],\"valid\"],[[2389,2389],\"valid\"],[[2390,2391],\"valid\"],[[2392,2392],\"mapped\",[2325,2364]],[[2393,2393],\"mapped\",[2326,2364]],[[2394,2394],\"mapped\",[2327,2364]],[[2395,2395],\"mapped\",[2332,2364]],[[2396,2396],\"mapped\",[2337,2364]],[[2397,2397],\"mapped\",[2338,2364]],[[2398,2398],\"mapped\",[2347,2364]],[[2399,2399],\"mapped\",[2351,2364]],[[2400,2403],\"valid\"],[[2404,2405],\"valid\",[],\"NV8\"],[[2406,2415],\"valid\"],[[2416,2416],\"valid\",[],\"NV8\"],[[2417,2418],\"valid\"],[[2419,2423],\"valid\"],[[2424,2424],\"valid\"],[[2425,2426],\"valid\"],[[2427,2428],\"valid\"],[[2429,2429],\"valid\"],[[2430,2431],\"valid\"],[[2432,2432],\"valid\"],[[2433,2435],\"valid\"],[[2436,2436],\"disallowed\"],[[2437,2444],\"valid\"],[[2445,2446],\"disallowed\"],[[2447,2448],\"valid\"],[[2449,2450],\"disallowed\"],[[2451,2472],\"valid\"],[[2473,2473],\"disallowed\"],[[2474,2480],\"valid\"],[[2481,2481],\"disallowed\"],[[2482,2482],\"valid\"],[[2483,2485],\"disallowed\"],[[2486,2489],\"valid\"],[[2490,2491],\"disallowed\"],[[2492,2492],\"valid\"],[[2493,2493],\"valid\"],[[2494,2500],\"valid\"],[[2501,2502],\"disallowed\"],[[2503,2504],\"valid\"],[[2505,2506],\"disallowed\"],[[2507,2509],\"valid\"],[[2510,2510],\"valid\"],[[2511,2518],\"disallowed\"],[[2519,2519],\"valid\"],[[2520,2523],\"disallowed\"],[[2524,2524],\"mapped\",[2465,2492]],[[2525,2525],\"mapped\",[2466,2492]],[[2526,2526],\"disallowed\"],[[2527,2527],\"mapped\",[2479,2492]],[[2528,2531],\"valid\"],[[2532,2533],\"disallowed\"],[[2534,2545],\"valid\"],[[2546,2554],\"valid\",[],\"NV8\"],[[2555,2555],\"valid\",[],\"NV8\"],[[2556,2560],\"disallowed\"],[[2561,2561],\"valid\"],[[2562,2562],\"valid\"],[[2563,2563],\"valid\"],[[2564,2564],\"disallowed\"],[[2565,2570],\"valid\"],[[2571,2574],\"disallowed\"],[[2575,2576],\"valid\"],[[2577,2578],\"disallowed\"],[[2579,2600],\"valid\"],[[2601,2601],\"disallowed\"],[[2602,2608],\"valid\"],[[2609,2609],\"disallowed\"],[[2610,2610],\"valid\"],[[2611,2611],\"mapped\",[2610,2620]],[[2612,2612],\"disallowed\"],[[2613,2613],\"valid\"],[[2614,2614],\"mapped\",[2616,2620]],[[2615,2615],\"disallowed\"],[[2616,2617],\"valid\"],[[2618,2619],\"disallowed\"],[[2620,2620],\"valid\"],[[2621,2621],\"disallowed\"],[[2622,2626],\"valid\"],[[2627,2630],\"disallowed\"],[[2631,2632],\"valid\"],[[2633,2634],\"disallowed\"],[[2635,2637],\"valid\"],[[2638,2640],\"disallowed\"],[[2641,2641],\"valid\"],[[2642,2648],\"disallowed\"],[[2649,2649],\"mapped\",[2582,2620]],[[2650,2650],\"mapped\",[2583,2620]],[[2651,2651],\"mapped\",[2588,2620]],[[2652,2652],\"valid\"],[[2653,2653],\"disallowed\"],[[2654,2654],\"mapped\",[2603,2620]],[[2655,2661],\"disallowed\"],[[2662,2676],\"valid\"],[[2677,2677],\"valid\"],[[2678,2688],\"disallowed\"],[[2689,2691],\"valid\"],[[2692,2692],\"disallowed\"],[[2693,2699],\"valid\"],[[2700,2700],\"valid\"],[[2701,2701],\"valid\"],[[2702,2702],\"disallowed\"],[[2703,2705],\"valid\"],[[2706,2706],\"disallowed\"],[[2707,2728],\"valid\"],[[2729,2729],\"disallowed\"],[[2730,2736],\"valid\"],[[2737,2737],\"disallowed\"],[[2738,2739],\"valid\"],[[2740,2740],\"disallowed\"],[[2741,2745],\"valid\"],[[2746,2747],\"disallowed\"],[[2748,2757],\"valid\"],[[2758,2758],\"disallowed\"],[[2759,2761],\"valid\"],[[2762,2762],\"disallowed\"],[[2763,2765],\"valid\"],[[2766,2767],\"disallowed\"],[[2768,2768],\"valid\"],[[2769,2783],\"disallowed\"],[[2784,2784],\"valid\"],[[2785,2787],\"valid\"],[[2788,2789],\"disallowed\"],[[2790,2799],\"valid\"],[[2800,2800],\"valid\",[],\"NV8\"],[[2801,2801],\"valid\",[],\"NV8\"],[[2802,2808],\"disallowed\"],[[2809,2809],\"valid\"],[[2810,2816],\"disallowed\"],[[2817,2819],\"valid\"],[[2820,2820],\"disallowed\"],[[2821,2828],\"valid\"],[[2829,2830],\"disallowed\"],[[2831,2832],\"valid\"],[[2833,2834],\"disallowed\"],[[2835,2856],\"valid\"],[[2857,2857],\"disallowed\"],[[2858,2864],\"valid\"],[[2865,2865],\"disallowed\"],[[2866,2867],\"valid\"],[[2868,2868],\"disallowed\"],[[2869,2869],\"valid\"],[[2870,2873],\"valid\"],[[2874,2875],\"disallowed\"],[[2876,2883],\"valid\"],[[2884,2884],\"valid\"],[[2885,2886],\"disallowed\"],[[2887,2888],\"valid\"],[[2889,2890],\"disallowed\"],[[2891,2893],\"valid\"],[[2894,2901],\"disallowed\"],[[2902,2903],\"valid\"],[[2904,2907],\"disallowed\"],[[2908,2908],\"mapped\",[2849,2876]],[[2909,2909],\"mapped\",[2850,2876]],[[2910,2910],\"disallowed\"],[[2911,2913],\"valid\"],[[2914,2915],\"valid\"],[[2916,2917],\"disallowed\"],[[2918,2927],\"valid\"],[[2928,2928],\"valid\",[],\"NV8\"],[[2929,2929],\"valid\"],[[2930,2935],\"valid\",[],\"NV8\"],[[2936,2945],\"disallowed\"],[[2946,2947],\"valid\"],[[2948,2948],\"disallowed\"],[[2949,2954],\"valid\"],[[2955,2957],\"disallowed\"],[[2958,2960],\"valid\"],[[2961,2961],\"disallowed\"],[[2962,2965],\"valid\"],[[2966,2968],\"disallowed\"],[[2969,2970],\"valid\"],[[2971,2971],\"disallowed\"],[[2972,2972],\"valid\"],[[2973,2973],\"disallowed\"],[[2974,2975],\"valid\"],[[2976,2978],\"disallowed\"],[[2979,2980],\"valid\"],[[2981,2983],\"disallowed\"],[[2984,2986],\"valid\"],[[2987,2989],\"disallowed\"],[[2990,2997],\"valid\"],[[2998,2998],\"valid\"],[[2999,3001],\"valid\"],[[3002,3005],\"disallowed\"],[[3006,3010],\"valid\"],[[3011,3013],\"disallowed\"],[[3014,3016],\"valid\"],[[3017,3017],\"disallowed\"],[[3018,3021],\"valid\"],[[3022,3023],\"disallowed\"],[[3024,3024],\"valid\"],[[3025,3030],\"disallowed\"],[[3031,3031],\"valid\"],[[3032,3045],\"disallowed\"],[[3046,3046],\"valid\"],[[3047,3055],\"valid\"],[[3056,3058],\"valid\",[],\"NV8\"],[[3059,3066],\"valid\",[],\"NV8\"],[[3067,3071],\"disallowed\"],[[3072,3072],\"valid\"],[[3073,3075],\"valid\"],[[3076,3076],\"disallowed\"],[[3077,3084],\"valid\"],[[3085,3085],\"disallowed\"],[[3086,3088],\"valid\"],[[3089,3089],\"disallowed\"],[[3090,3112],\"valid\"],[[3113,3113],\"disallowed\"],[[3114,3123],\"valid\"],[[3124,3124],\"valid\"],[[3125,3129],\"valid\"],[[3130,3132],\"disallowed\"],[[3133,3133],\"valid\"],[[3134,3140],\"valid\"],[[3141,3141],\"disallowed\"],[[3142,3144],\"valid\"],[[3145,3145],\"disallowed\"],[[3146,3149],\"valid\"],[[3150,3156],\"disallowed\"],[[3157,3158],\"valid\"],[[3159,3159],\"disallowed\"],[[3160,3161],\"valid\"],[[3162,3162],\"valid\"],[[3163,3167],\"disallowed\"],[[3168,3169],\"valid\"],[[3170,3171],\"valid\"],[[3172,3173],\"disallowed\"],[[3174,3183],\"valid\"],[[3184,3191],\"disallowed\"],[[3192,3199],\"valid\",[],\"NV8\"],[[3200,3200],\"disallowed\"],[[3201,3201],\"valid\"],[[3202,3203],\"valid\"],[[3204,3204],\"disallowed\"],[[3205,3212],\"valid\"],[[3213,3213],\"disallowed\"],[[3214,3216],\"valid\"],[[3217,3217],\"disallowed\"],[[3218,3240],\"valid\"],[[3241,3241],\"disallowed\"],[[3242,3251],\"valid\"],[[3252,3252],\"disallowed\"],[[3253,3257],\"valid\"],[[3258,3259],\"disallowed\"],[[3260,3261],\"valid\"],[[3262,3268],\"valid\"],[[3269,3269],\"disallowed\"],[[3270,3272],\"valid\"],[[3273,3273],\"disallowed\"],[[3274,3277],\"valid\"],[[3278,3284],\"disallowed\"],[[3285,3286],\"valid\"],[[3287,3293],\"disallowed\"],[[3294,3294],\"valid\"],[[3295,3295],\"disallowed\"],[[3296,3297],\"valid\"],[[3298,3299],\"valid\"],[[3300,3301],\"disallowed\"],[[3302,3311],\"valid\"],[[3312,3312],\"disallowed\"],[[3313,3314],\"valid\"],[[3315,3328],\"disallowed\"],[[3329,3329],\"valid\"],[[3330,3331],\"valid\"],[[3332,3332],\"disallowed\"],[[3333,3340],\"valid\"],[[3341,3341],\"disallowed\"],[[3342,3344],\"valid\"],[[3345,3345],\"disallowed\"],[[3346,3368],\"valid\"],[[3369,3369],\"valid\"],[[3370,3385],\"valid\"],[[3386,3386],\"valid\"],[[3387,3388],\"disallowed\"],[[3389,3389],\"valid\"],[[3390,3395],\"valid\"],[[3396,3396],\"valid\"],[[3397,3397],\"disallowed\"],[[3398,3400],\"valid\"],[[3401,3401],\"disallowed\"],[[3402,3405],\"valid\"],[[3406,3406],\"valid\"],[[3407,3414],\"disallowed\"],[[3415,3415],\"valid\"],[[3416,3422],\"disallowed\"],[[3423,3423],\"valid\"],[[3424,3425],\"valid\"],[[3426,3427],\"valid\"],[[3428,3429],\"disallowed\"],[[3430,3439],\"valid\"],[[3440,3445],\"valid\",[],\"NV8\"],[[3446,3448],\"disallowed\"],[[3449,3449],\"valid\",[],\"NV8\"],[[3450,3455],\"valid\"],[[3456,3457],\"disallowed\"],[[3458,3459],\"valid\"],[[3460,3460],\"disallowed\"],[[3461,3478],\"valid\"],[[3479,3481],\"disallowed\"],[[3482,3505],\"valid\"],[[3506,3506],\"disallowed\"],[[3507,3515],\"valid\"],[[3516,3516],\"disallowed\"],[[3517,3517],\"valid\"],[[3518,3519],\"disallowed\"],[[3520,3526],\"valid\"],[[3527,3529],\"disallowed\"],[[3530,3530],\"valid\"],[[3531,3534],\"disallowed\"],[[3535,3540],\"valid\"],[[3541,3541],\"disallowed\"],[[3542,3542],\"valid\"],[[3543,3543],\"disallowed\"],[[3544,3551],\"valid\"],[[3552,3557],\"disallowed\"],[[3558,3567],\"valid\"],[[3568,3569],\"disallowed\"],[[3570,3571],\"valid\"],[[3572,3572],\"valid\",[],\"NV8\"],[[3573,3584],\"disallowed\"],[[3585,3634],\"valid\"],[[3635,3635],\"mapped\",[3661,3634]],[[3636,3642],\"valid\"],[[3643,3646],\"disallowed\"],[[3647,3647],\"valid\",[],\"NV8\"],[[3648,3662],\"valid\"],[[3663,3663],\"valid\",[],\"NV8\"],[[3664,3673],\"valid\"],[[3674,3675],\"valid\",[],\"NV8\"],[[3676,3712],\"disallowed\"],[[3713,3714],\"valid\"],[[3715,3715],\"disallowed\"],[[3716,3716],\"valid\"],[[3717,3718],\"disallowed\"],[[3719,3720],\"valid\"],[[3721,3721],\"disallowed\"],[[3722,3722],\"valid\"],[[3723,3724],\"disallowed\"],[[3725,3725],\"valid\"],[[3726,3731],\"disallowed\"],[[3732,3735],\"valid\"],[[3736,3736],\"disallowed\"],[[3737,3743],\"valid\"],[[3744,3744],\"disallowed\"],[[3745,3747],\"valid\"],[[3748,3748],\"disallowed\"],[[3749,3749],\"valid\"],[[3750,3750],\"disallowed\"],[[3751,3751],\"valid\"],[[3752,3753],\"disallowed\"],[[3754,3755],\"valid\"],[[3756,3756],\"disallowed\"],[[3757,3762],\"valid\"],[[3763,3763],\"mapped\",[3789,3762]],[[3764,3769],\"valid\"],[[3770,3770],\"disallowed\"],[[3771,3773],\"valid\"],[[3774,3775],\"disallowed\"],[[3776,3780],\"valid\"],[[3781,3781],\"disallowed\"],[[3782,3782],\"valid\"],[[3783,3783],\"disallowed\"],[[3784,3789],\"valid\"],[[3790,3791],\"disallowed\"],[[3792,3801],\"valid\"],[[3802,3803],\"disallowed\"],[[3804,3804],\"mapped\",[3755,3737]],[[3805,3805],\"mapped\",[3755,3745]],[[3806,3807],\"valid\"],[[3808,3839],\"disallowed\"],[[3840,3840],\"valid\"],[[3841,3850],\"valid\",[],\"NV8\"],[[3851,3851],\"valid\"],[[3852,3852],\"mapped\",[3851]],[[3853,3863],\"valid\",[],\"NV8\"],[[3864,3865],\"valid\"],[[3866,3871],\"valid\",[],\"NV8\"],[[3872,3881],\"valid\"],[[3882,3892],\"valid\",[],\"NV8\"],[[3893,3893],\"valid\"],[[3894,3894],\"valid\",[],\"NV8\"],[[3895,3895],\"valid\"],[[3896,3896],\"valid\",[],\"NV8\"],[[3897,3897],\"valid\"],[[3898,3901],\"valid\",[],\"NV8\"],[[3902,3906],\"valid\"],[[3907,3907],\"mapped\",[3906,4023]],[[3908,3911],\"valid\"],[[3912,3912],\"disallowed\"],[[3913,3916],\"valid\"],[[3917,3917],\"mapped\",[3916,4023]],[[3918,3921],\"valid\"],[[3922,3922],\"mapped\",[3921,4023]],[[3923,3926],\"valid\"],[[3927,3927],\"mapped\",[3926,4023]],[[3928,3931],\"valid\"],[[3932,3932],\"mapped\",[3931,4023]],[[3933,3944],\"valid\"],[[3945,3945],\"mapped\",[3904,4021]],[[3946,3946],\"valid\"],[[3947,3948],\"valid\"],[[3949,3952],\"disallowed\"],[[3953,3954],\"valid\"],[[3955,3955],\"mapped\",[3953,3954]],[[3956,3956],\"valid\"],[[3957,3957],\"mapped\",[3953,3956]],[[3958,3958],\"mapped\",[4018,3968]],[[3959,3959],\"mapped\",[4018,3953,3968]],[[3960,3960],\"mapped\",[4019,3968]],[[3961,3961],\"mapped\",[4019,3953,3968]],[[3962,3968],\"valid\"],[[3969,3969],\"mapped\",[3953,3968]],[[3970,3972],\"valid\"],[[3973,3973],\"valid\",[],\"NV8\"],[[3974,3979],\"valid\"],[[3980,3983],\"valid\"],[[3984,3986],\"valid\"],[[3987,3987],\"mapped\",[3986,4023]],[[3988,3989],\"valid\"],[[3990,3990],\"valid\"],[[3991,3991],\"valid\"],[[3992,3992],\"disallowed\"],[[3993,3996],\"valid\"],[[3997,3997],\"mapped\",[3996,4023]],[[3998,4001],\"valid\"],[[4002,4002],\"mapped\",[4001,4023]],[[4003,4006],\"valid\"],[[4007,4007],\"mapped\",[4006,4023]],[[4008,4011],\"valid\"],[[4012,4012],\"mapped\",[4011,4023]],[[4013,4013],\"valid\"],[[4014,4016],\"valid\"],[[4017,4023],\"valid\"],[[4024,4024],\"valid\"],[[4025,4025],\"mapped\",[3984,4021]],[[4026,4028],\"valid\"],[[4029,4029],\"disallowed\"],[[4030,4037],\"valid\",[],\"NV8\"],[[4038,4038],\"valid\"],[[4039,4044],\"valid\",[],\"NV8\"],[[4045,4045],\"disallowed\"],[[4046,4046],\"valid\",[],\"NV8\"],[[4047,4047],\"valid\",[],\"NV8\"],[[4048,4049],\"valid\",[],\"NV8\"],[[4050,4052],\"valid\",[],\"NV8\"],[[4053,4056],\"valid\",[],\"NV8\"],[[4057,4058],\"valid\",[],\"NV8\"],[[4059,4095],\"disallowed\"],[[4096,4129],\"valid\"],[[4130,4130],\"valid\"],[[4131,4135],\"valid\"],[[4136,4136],\"valid\"],[[4137,4138],\"valid\"],[[4139,4139],\"valid\"],[[4140,4146],\"valid\"],[[4147,4149],\"valid\"],[[4150,4153],\"valid\"],[[4154,4159],\"valid\"],[[4160,4169],\"valid\"],[[4170,4175],\"valid\",[],\"NV8\"],[[4176,4185],\"valid\"],[[4186,4249],\"valid\"],[[4250,4253],\"valid\"],[[4254,4255],\"valid\",[],\"NV8\"],[[4256,4293],\"disallowed\"],[[4294,4294],\"disallowed\"],[[4295,4295],\"mapped\",[11559]],[[4296,4300],\"disallowed\"],[[4301,4301],\"mapped\",[11565]],[[4302,4303],\"disallowed\"],[[4304,4342],\"valid\"],[[4343,4344],\"valid\"],[[4345,4346],\"valid\"],[[4347,4347],\"valid\",[],\"NV8\"],[[4348,4348],\"mapped\",[4316]],[[4349,4351],\"valid\"],[[4352,4441],\"valid\",[],\"NV8\"],[[4442,4446],\"valid\",[],\"NV8\"],[[4447,4448],\"disallowed\"],[[4449,4514],\"valid\",[],\"NV8\"],[[4515,4519],\"valid\",[],\"NV8\"],[[4520,4601],\"valid\",[],\"NV8\"],[[4602,4607],\"valid\",[],\"NV8\"],[[4608,4614],\"valid\"],[[4615,4615],\"valid\"],[[4616,4678],\"valid\"],[[4679,4679],\"valid\"],[[4680,4680],\"valid\"],[[4681,4681],\"disallowed\"],[[4682,4685],\"valid\"],[[4686,4687],\"disallowed\"],[[4688,4694],\"valid\"],[[4695,4695],\"disallowed\"],[[4696,4696],\"valid\"],[[4697,4697],\"disallowed\"],[[4698,4701],\"valid\"],[[4702,4703],\"disallowed\"],[[4704,4742],\"valid\"],[[4743,4743],\"valid\"],[[4744,4744],\"valid\"],[[4745,4745],\"disallowed\"],[[4746,4749],\"valid\"],[[4750,4751],\"disallowed\"],[[4752,4782],\"valid\"],[[4783,4783],\"valid\"],[[4784,4784],\"valid\"],[[4785,4785],\"disallowed\"],[[4786,4789],\"valid\"],[[4790,4791],\"disallowed\"],[[4792,4798],\"valid\"],[[4799,4799],\"disallowed\"],[[4800,4800],\"valid\"],[[4801,4801],\"disallowed\"],[[4802,4805],\"valid\"],[[4806,4807],\"disallowed\"],[[4808,4814],\"valid\"],[[4815,4815],\"valid\"],[[4816,4822],\"valid\"],[[4823,4823],\"disallowed\"],[[4824,4846],\"valid\"],[[4847,4847],\"valid\"],[[4848,4878],\"valid\"],[[4879,4879],\"valid\"],[[4880,4880],\"valid\"],[[4881,4881],\"disallowed\"],[[4882,4885],\"valid\"],[[4886,4887],\"disallowed\"],[[4888,4894],\"valid\"],[[4895,4895],\"valid\"],[[4896,4934],\"valid\"],[[4935,4935],\"valid\"],[[4936,4954],\"valid\"],[[4955,4956],\"disallowed\"],[[4957,4958],\"valid\"],[[4959,4959],\"valid\"],[[4960,4960],\"valid\",[],\"NV8\"],[[4961,4988],\"valid\",[],\"NV8\"],[[4989,4991],\"disallowed\"],[[4992,5007],\"valid\"],[[5008,5017],\"valid\",[],\"NV8\"],[[5018,5023],\"disallowed\"],[[5024,5108],\"valid\"],[[5109,5109],\"valid\"],[[5110,5111],\"disallowed\"],[[5112,5112],\"mapped\",[5104]],[[5113,5113],\"mapped\",[5105]],[[5114,5114],\"mapped\",[5106]],[[5115,5115],\"mapped\",[5107]],[[5116,5116],\"mapped\",[5108]],[[5117,5117],\"mapped\",[5109]],[[5118,5119],\"disallowed\"],[[5120,5120],\"valid\",[],\"NV8\"],[[5121,5740],\"valid\"],[[5741,5742],\"valid\",[],\"NV8\"],[[5743,5750],\"valid\"],[[5751,5759],\"valid\"],[[5760,5760],\"disallowed\"],[[5761,5786],\"valid\"],[[5787,5788],\"valid\",[],\"NV8\"],[[5789,5791],\"disallowed\"],[[5792,5866],\"valid\"],[[5867,5872],\"valid\",[],\"NV8\"],[[5873,5880],\"valid\"],[[5881,5887],\"disallowed\"],[[5888,5900],\"valid\"],[[5901,5901],\"disallowed\"],[[5902,5908],\"valid\"],[[5909,5919],\"disallowed\"],[[5920,5940],\"valid\"],[[5941,5942],\"valid\",[],\"NV8\"],[[5943,5951],\"disallowed\"],[[5952,5971],\"valid\"],[[5972,5983],\"disallowed\"],[[5984,5996],\"valid\"],[[5997,5997],\"disallowed\"],[[5998,6000],\"valid\"],[[6001,6001],\"disallowed\"],[[6002,6003],\"valid\"],[[6004,6015],\"disallowed\"],[[6016,6067],\"valid\"],[[6068,6069],\"disallowed\"],[[6070,6099],\"valid\"],[[6100,6102],\"valid\",[],\"NV8\"],[[6103,6103],\"valid\"],[[6104,6107],\"valid\",[],\"NV8\"],[[6108,6108],\"valid\"],[[6109,6109],\"valid\"],[[6110,6111],\"disallowed\"],[[6112,6121],\"valid\"],[[6122,6127],\"disallowed\"],[[6128,6137],\"valid\",[],\"NV8\"],[[6138,6143],\"disallowed\"],[[6144,6149],\"valid\",[],\"NV8\"],[[6150,6150],\"disallowed\"],[[6151,6154],\"valid\",[],\"NV8\"],[[6155,6157],\"ignored\"],[[6158,6158],\"disallowed\"],[[6159,6159],\"disallowed\"],[[6160,6169],\"valid\"],[[6170,6175],\"disallowed\"],[[6176,6263],\"valid\"],[[6264,6271],\"disallowed\"],[[6272,6313],\"valid\"],[[6314,6314],\"valid\"],[[6315,6319],\"disallowed\"],[[6320,6389],\"valid\"],[[6390,6399],\"disallowed\"],[[6400,6428],\"valid\"],[[6429,6430],\"valid\"],[[6431,6431],\"disallowed\"],[[6432,6443],\"valid\"],[[6444,6447],\"disallowed\"],[[6448,6459],\"valid\"],[[6460,6463],\"disallowed\"],[[6464,6464],\"valid\",[],\"NV8\"],[[6465,6467],\"disallowed\"],[[6468,6469],\"valid\",[],\"NV8\"],[[6470,6509],\"valid\"],[[6510,6511],\"disallowed\"],[[6512,6516],\"valid\"],[[6517,6527],\"disallowed\"],[[6528,6569],\"valid\"],[[6570,6571],\"valid\"],[[6572,6575],\"disallowed\"],[[6576,6601],\"valid\"],[[6602,6607],\"disallowed\"],[[6608,6617],\"valid\"],[[6618,6618],\"valid\",[],\"XV8\"],[[6619,6621],\"disallowed\"],[[6622,6623],\"valid\",[],\"NV8\"],[[6624,6655],\"valid\",[],\"NV8\"],[[6656,6683],\"valid\"],[[6684,6685],\"disallowed\"],[[6686,6687],\"valid\",[],\"NV8\"],[[6688,6750],\"valid\"],[[6751,6751],\"disallowed\"],[[6752,6780],\"valid\"],[[6781,6782],\"disallowed\"],[[6783,6793],\"valid\"],[[6794,6799],\"disallowed\"],[[6800,6809],\"valid\"],[[6810,6815],\"disallowed\"],[[6816,6822],\"valid\",[],\"NV8\"],[[6823,6823],\"valid\"],[[6824,6829],\"valid\",[],\"NV8\"],[[6830,6831],\"disallowed\"],[[6832,6845],\"valid\"],[[6846,6846],\"valid\",[],\"NV8\"],[[6847,6911],\"disallowed\"],[[6912,6987],\"valid\"],[[6988,6991],\"disallowed\"],[[6992,7001],\"valid\"],[[7002,7018],\"valid\",[],\"NV8\"],[[7019,7027],\"valid\"],[[7028,7036],\"valid\",[],\"NV8\"],[[7037,7039],\"disallowed\"],[[7040,7082],\"valid\"],[[7083,7085],\"valid\"],[[7086,7097],\"valid\"],[[7098,7103],\"valid\"],[[7104,7155],\"valid\"],[[7156,7163],\"disallowed\"],[[7164,7167],\"valid\",[],\"NV8\"],[[7168,7223],\"valid\"],[[7224,7226],\"disallowed\"],[[7227,7231],\"valid\",[],\"NV8\"],[[7232,7241],\"valid\"],[[7242,7244],\"disallowed\"],[[7245,7293],\"valid\"],[[7294,7295],\"valid\",[],\"NV8\"],[[7296,7359],\"disallowed\"],[[7360,7367],\"valid\",[],\"NV8\"],[[7368,7375],\"disallowed\"],[[7376,7378],\"valid\"],[[7379,7379],\"valid\",[],\"NV8\"],[[7380,7410],\"valid\"],[[7411,7414],\"valid\"],[[7415,7415],\"disallowed\"],[[7416,7417],\"valid\"],[[7418,7423],\"disallowed\"],[[7424,7467],\"valid\"],[[7468,7468],\"mapped\",[97]],[[7469,7469],\"mapped\",[230]],[[7470,7470],\"mapped\",[98]],[[7471,7471],\"valid\"],[[7472,7472],\"mapped\",[100]],[[7473,7473],\"mapped\",[101]],[[7474,7474],\"mapped\",[477]],[[7475,7475],\"mapped\",[103]],[[7476,7476],\"mapped\",[104]],[[7477,7477],\"mapped\",[105]],[[7478,7478],\"mapped\",[106]],[[7479,7479],\"mapped\",[107]],[[7480,7480],\"mapped\",[108]],[[7481,7481],\"mapped\",[109]],[[7482,7482],\"mapped\",[110]],[[7483,7483],\"valid\"],[[7484,7484],\"mapped\",[111]],[[7485,7485],\"mapped\",[547]],[[7486,7486],\"mapped\",[112]],[[7487,7487],\"mapped\",[114]],[[7488,7488],\"mapped\",[116]],[[7489,7489],\"mapped\",[117]],[[7490,7490],\"mapped\",[119]],[[7491,7491],\"mapped\",[97]],[[7492,7492],\"mapped\",[592]],[[7493,7493],\"mapped\",[593]],[[7494,7494],\"mapped\",[7426]],[[7495,7495],\"mapped\",[98]],[[7496,7496],\"mapped\",[100]],[[7497,7497],\"mapped\",[101]],[[7498,7498],\"mapped\",[601]],[[7499,7499],\"mapped\",[603]],[[7500,7500],\"mapped\",[604]],[[7501,7501],\"mapped\",[103]],[[7502,7502],\"valid\"],[[7503,7503],\"mapped\",[107]],[[7504,7504],\"mapped\",[109]],[[7505,7505],\"mapped\",[331]],[[7506,7506],\"mapped\",[111]],[[7507,7507],\"mapped\",[596]],[[7508,7508],\"mapped\",[7446]],[[7509,7509],\"mapped\",[7447]],[[7510,7510],\"mapped\",[112]],[[7511,7511],\"mapped\",[116]],[[7512,7512],\"mapped\",[117]],[[7513,7513],\"mapped\",[7453]],[[7514,7514],\"mapped\",[623]],[[7515,7515],\"mapped\",[118]],[[7516,7516],\"mapped\",[7461]],[[7517,7517],\"mapped\",[946]],[[7518,7518],\"mapped\",[947]],[[7519,7519],\"mapped\",[948]],[[7520,7520],\"mapped\",[966]],[[7521,7521],\"mapped\",[967]],[[7522,7522],\"mapped\",[105]],[[7523,7523],\"mapped\",[114]],[[7524,7524],\"mapped\",[117]],[[7525,7525],\"mapped\",[118]],[[7526,7526],\"mapped\",[946]],[[7527,7527],\"mapped\",[947]],[[7528,7528],\"mapped\",[961]],[[7529,7529],\"mapped\",[966]],[[7530,7530],\"mapped\",[967]],[[7531,7531],\"valid\"],[[7532,7543],\"valid\"],[[7544,7544],\"mapped\",[1085]],[[7545,7578],\"valid\"],[[7579,7579],\"mapped\",[594]],[[7580,7580],\"mapped\",[99]],[[7581,7581],\"mapped\",[597]],[[7582,7582],\"mapped\",[240]],[[7583,7583],\"mapped\",[604]],[[7584,7584],\"mapped\",[102]],[[7585,7585],\"mapped\",[607]],[[7586,7586],\"mapped\",[609]],[[7587,7587],\"mapped\",[613]],[[7588,7588],\"mapped\",[616]],[[7589,7589],\"mapped\",[617]],[[7590,7590],\"mapped\",[618]],[[7591,7591],\"mapped\",[7547]],[[7592,7592],\"mapped\",[669]],[[7593,7593],\"mapped\",[621]],[[7594,7594],\"mapped\",[7557]],[[7595,7595],\"mapped\",[671]],[[7596,7596],\"mapped\",[625]],[[7597,7597],\"mapped\",[624]],[[7598,7598],\"mapped\",[626]],[[7599,7599],\"mapped\",[627]],[[7600,7600],\"mapped\",[628]],[[7601,7601],\"mapped\",[629]],[[7602,7602],\"mapped\",[632]],[[7603,7603],\"mapped\",[642]],[[7604,7604],\"mapped\",[643]],[[7605,7605],\"mapped\",[427]],[[7606,7606],\"mapped\",[649]],[[7607,7607],\"mapped\",[650]],[[7608,7608],\"mapped\",[7452]],[[7609,7609],\"mapped\",[651]],[[7610,7610],\"mapped\",[652]],[[7611,7611],\"mapped\",[122]],[[7612,7612],\"mapped\",[656]],[[7613,7613],\"mapped\",[657]],[[7614,7614],\"mapped\",[658]],[[7615,7615],\"mapped\",[952]],[[7616,7619],\"valid\"],[[7620,7626],\"valid\"],[[7627,7654],\"valid\"],[[7655,7669],\"valid\"],[[7670,7675],\"disallowed\"],[[7676,7676],\"valid\"],[[7677,7677],\"valid\"],[[7678,7679],\"valid\"],[[7680,7680],\"mapped\",[7681]],[[7681,7681],\"valid\"],[[7682,7682],\"mapped\",[7683]],[[7683,7683],\"valid\"],[[7684,7684],\"mapped\",[7685]],[[7685,7685],\"valid\"],[[7686,7686],\"mapped\",[7687]],[[7687,7687],\"valid\"],[[7688,7688],\"mapped\",[7689]],[[7689,7689],\"valid\"],[[7690,7690],\"mapped\",[7691]],[[7691,7691],\"valid\"],[[7692,7692],\"mapped\",[7693]],[[7693,7693],\"valid\"],[[7694,7694],\"mapped\",[7695]],[[7695,7695],\"valid\"],[[7696,7696],\"mapped\",[7697]],[[7697,7697],\"valid\"],[[7698,7698],\"mapped\",[7699]],[[7699,7699],\"valid\"],[[7700,7700],\"mapped\",[7701]],[[7701,7701],\"valid\"],[[7702,7702],\"mapped\",[7703]],[[7703,7703],\"valid\"],[[7704,7704],\"mapped\",[7705]],[[7705,7705],\"valid\"],[[7706,7706],\"mapped\",[7707]],[[7707,7707],\"valid\"],[[7708,7708],\"mapped\",[7709]],[[7709,7709],\"valid\"],[[7710,7710],\"mapped\",[7711]],[[7711,7711],\"valid\"],[[7712,7712],\"mapped\",[7713]],[[7713,7713],\"valid\"],[[7714,7714],\"mapped\",[7715]],[[7715,7715],\"valid\"],[[7716,7716],\"mapped\",[7717]],[[7717,7717],\"valid\"],[[7718,7718],\"mapped\",[7719]],[[7719,7719],\"valid\"],[[7720,7720],\"mapped\",[7721]],[[7721,7721],\"valid\"],[[7722,7722],\"mapped\",[7723]],[[7723,7723],\"valid\"],[[7724,7724],\"mapped\",[7725]],[[7725,7725],\"valid\"],[[7726,7726],\"mapped\",[7727]],[[7727,7727],\"valid\"],[[7728,7728],\"mapped\",[7729]],[[7729,7729],\"valid\"],[[7730,7730],\"mapped\",[7731]],[[7731,7731],\"valid\"],[[7732,7732],\"mapped\",[7733]],[[7733,7733],\"valid\"],[[7734,7734],\"mapped\",[7735]],[[7735,7735],\"valid\"],[[7736,7736],\"mapped\",[7737]],[[7737,7737],\"valid\"],[[7738,7738],\"mapped\",[7739]],[[7739,7739],\"valid\"],[[7740,7740],\"mapped\",[7741]],[[7741,7741],\"valid\"],[[7742,7742],\"mapped\",[7743]],[[7743,7743],\"valid\"],[[7744,7744],\"mapped\",[7745]],[[7745,7745],\"valid\"],[[7746,7746],\"mapped\",[7747]],[[7747,7747],\"valid\"],[[7748,7748],\"mapped\",[7749]],[[7749,7749],\"valid\"],[[7750,7750],\"mapped\",[7751]],[[7751,7751],\"valid\"],[[7752,7752],\"mapped\",[7753]],[[7753,7753],\"valid\"],[[7754,7754],\"mapped\",[7755]],[[7755,7755],\"valid\"],[[7756,7756],\"mapped\",[7757]],[[7757,7757],\"valid\"],[[7758,7758],\"mapped\",[7759]],[[7759,7759],\"valid\"],[[7760,7760],\"mapped\",[7761]],[[7761,7761],\"valid\"],[[7762,7762],\"mapped\",[7763]],[[7763,7763],\"valid\"],[[7764,7764],\"mapped\",[7765]],[[7765,7765],\"valid\"],[[7766,7766],\"mapped\",[7767]],[[7767,7767],\"valid\"],[[7768,7768],\"mapped\",[7769]],[[7769,7769],\"valid\"],[[7770,7770],\"mapped\",[7771]],[[7771,7771],\"valid\"],[[7772,7772],\"mapped\",[7773]],[[7773,7773],\"valid\"],[[7774,7774],\"mapped\",[7775]],[[7775,7775],\"valid\"],[[7776,7776],\"mapped\",[7777]],[[7777,7777],\"valid\"],[[7778,7778],\"mapped\",[7779]],[[7779,7779],\"valid\"],[[7780,7780],\"mapped\",[7781]],[[7781,7781],\"valid\"],[[7782,7782],\"mapped\",[7783]],[[7783,7783],\"valid\"],[[7784,7784],\"mapped\",[7785]],[[7785,7785],\"valid\"],[[7786,7786],\"mapped\",[7787]],[[7787,7787],\"valid\"],[[7788,7788],\"mapped\",[7789]],[[7789,7789],\"valid\"],[[7790,7790],\"mapped\",[7791]],[[7791,7791],\"valid\"],[[7792,7792],\"mapped\",[7793]],[[7793,7793],\"valid\"],[[7794,7794],\"mapped\",[7795]],[[7795,7795],\"valid\"],[[7796,7796],\"mapped\",[7797]],[[7797,7797],\"valid\"],[[7798,7798],\"mapped\",[7799]],[[7799,7799],\"valid\"],[[7800,7800],\"mapped\",[7801]],[[7801,7801],\"valid\"],[[7802,7802],\"mapped\",[7803]],[[7803,7803],\"valid\"],[[7804,7804],\"mapped\",[7805]],[[7805,7805],\"valid\"],[[7806,7806],\"mapped\",[7807]],[[7807,7807],\"valid\"],[[7808,7808],\"mapped\",[7809]],[[7809,7809],\"valid\"],[[7810,7810],\"mapped\",[7811]],[[7811,7811],\"valid\"],[[7812,7812],\"mapped\",[7813]],[[7813,7813],\"valid\"],[[7814,7814],\"mapped\",[7815]],[[7815,7815],\"valid\"],[[7816,7816],\"mapped\",[7817]],[[7817,7817],\"valid\"],[[7818,7818],\"mapped\",[7819]],[[7819,7819],\"valid\"],[[7820,7820],\"mapped\",[7821]],[[7821,7821],\"valid\"],[[7822,7822],\"mapped\",[7823]],[[7823,7823],\"valid\"],[[7824,7824],\"mapped\",[7825]],[[7825,7825],\"valid\"],[[7826,7826],\"mapped\",[7827]],[[7827,7827],\"valid\"],[[7828,7828],\"mapped\",[7829]],[[7829,7833],\"valid\"],[[7834,7834],\"mapped\",[97,702]],[[7835,7835],\"mapped\",[7777]],[[7836,7837],\"valid\"],[[7838,7838],\"mapped\",[115,115]],[[7839,7839],\"valid\"],[[7840,7840],\"mapped\",[7841]],[[7841,7841],\"valid\"],[[7842,7842],\"mapped\",[7843]],[[7843,7843],\"valid\"],[[7844,7844],\"mapped\",[7845]],[[7845,7845],\"valid\"],[[7846,7846],\"mapped\",[7847]],[[7847,7847],\"valid\"],[[7848,7848],\"mapped\",[7849]],[[7849,7849],\"valid\"],[[7850,7850],\"mapped\",[7851]],[[7851,7851],\"valid\"],[[7852,7852],\"mapped\",[7853]],[[7853,7853],\"valid\"],[[7854,7854],\"mapped\",[7855]],[[7855,7855],\"valid\"],[[7856,7856],\"mapped\",[7857]],[[7857,7857],\"valid\"],[[7858,7858],\"mapped\",[7859]],[[7859,7859],\"valid\"],[[7860,7860],\"mapped\",[7861]],[[7861,7861],\"valid\"],[[7862,7862],\"mapped\",[7863]],[[7863,7863],\"valid\"],[[7864,7864],\"mapped\",[7865]],[[7865,7865],\"valid\"],[[7866,7866],\"mapped\",[7867]],[[7867,7867],\"valid\"],[[7868,7868],\"mapped\",[7869]],[[7869,7869],\"valid\"],[[7870,7870],\"mapped\",[7871]],[[7871,7871],\"valid\"],[[7872,7872],\"mapped\",[7873]],[[7873,7873],\"valid\"],[[7874,7874],\"mapped\",[7875]],[[7875,7875],\"valid\"],[[7876,7876],\"mapped\",[7877]],[[7877,7877],\"valid\"],[[7878,7878],\"mapped\",[7879]],[[7879,7879],\"valid\"],[[7880,7880],\"mapped\",[7881]],[[7881,7881],\"valid\"],[[7882,7882],\"mapped\",[7883]],[[7883,7883],\"valid\"],[[7884,7884],\"mapped\",[7885]],[[7885,7885],\"valid\"],[[7886,7886],\"mapped\",[7887]],[[7887,7887],\"valid\"],[[7888,7888],\"mapped\",[7889]],[[7889,7889],\"valid\"],[[7890,7890],\"mapped\",[7891]],[[7891,7891],\"valid\"],[[7892,7892],\"mapped\",[7893]],[[7893,7893],\"valid\"],[[7894,7894],\"mapped\",[7895]],[[7895,7895],\"valid\"],[[7896,7896],\"mapped\",[7897]],[[7897,7897],\"valid\"],[[7898,7898],\"mapped\",[7899]],[[7899,7899],\"valid\"],[[7900,7900],\"mapped\",[7901]],[[7901,7901],\"valid\"],[[7902,7902],\"mapped\",[7903]],[[7903,7903],\"valid\"],[[7904,7904],\"mapped\",[7905]],[[7905,7905],\"valid\"],[[7906,7906],\"mapped\",[7907]],[[7907,7907],\"valid\"],[[7908,7908],\"mapped\",[7909]],[[7909,7909],\"valid\"],[[7910,7910],\"mapped\",[7911]],[[7911,7911],\"valid\"],[[7912,7912],\"mapped\",[7913]],[[7913,7913],\"valid\"],[[7914,7914],\"mapped\",[7915]],[[7915,7915],\"valid\"],[[7916,7916],\"mapped\",[7917]],[[7917,7917],\"valid\"],[[7918,7918],\"mapped\",[7919]],[[7919,7919],\"valid\"],[[7920,7920],\"mapped\",[7921]],[[7921,7921],\"valid\"],[[7922,7922],\"mapped\",[7923]],[[7923,7923],\"valid\"],[[7924,7924],\"mapped\",[7925]],[[7925,7925],\"valid\"],[[7926,7926],\"mapped\",[7927]],[[7927,7927],\"valid\"],[[7928,7928],\"mapped\",[7929]],[[7929,7929],\"valid\"],[[7930,7930],\"mapped\",[7931]],[[7931,7931],\"valid\"],[[7932,7932],\"mapped\",[7933]],[[7933,7933],\"valid\"],[[7934,7934],\"mapped\",[7935]],[[7935,7935],\"valid\"],[[7936,7943],\"valid\"],[[7944,7944],\"mapped\",[7936]],[[7945,7945],\"mapped\",[7937]],[[7946,7946],\"mapped\",[7938]],[[7947,7947],\"mapped\",[7939]],[[7948,7948],\"mapped\",[7940]],[[7949,7949],\"mapped\",[7941]],[[7950,7950],\"mapped\",[7942]],[[7951,7951],\"mapped\",[7943]],[[7952,7957],\"valid\"],[[7958,7959],\"disallowed\"],[[7960,7960],\"mapped\",[7952]],[[7961,7961],\"mapped\",[7953]],[[7962,7962],\"mapped\",[7954]],[[7963,7963],\"mapped\",[7955]],[[7964,7964],\"mapped\",[7956]],[[7965,7965],\"mapped\",[7957]],[[7966,7967],\"disallowed\"],[[7968,7975],\"valid\"],[[7976,7976],\"mapped\",[7968]],[[7977,7977],\"mapped\",[7969]],[[7978,7978],\"mapped\",[7970]],[[7979,7979],\"mapped\",[7971]],[[7980,7980],\"mapped\",[7972]],[[7981,7981],\"mapped\",[7973]],[[7982,7982],\"mapped\",[7974]],[[7983,7983],\"mapped\",[7975]],[[7984,7991],\"valid\"],[[7992,7992],\"mapped\",[7984]],[[7993,7993],\"mapped\",[7985]],[[7994,7994],\"mapped\",[7986]],[[7995,7995],\"mapped\",[7987]],[[7996,7996],\"mapped\",[7988]],[[7997,7997],\"mapped\",[7989]],[[7998,7998],\"mapped\",[7990]],[[7999,7999],\"mapped\",[7991]],[[8000,8005],\"valid\"],[[8006,8007],\"disallowed\"],[[8008,8008],\"mapped\",[8000]],[[8009,8009],\"mapped\",[8001]],[[8010,8010],\"mapped\",[8002]],[[8011,8011],\"mapped\",[8003]],[[8012,8012],\"mapped\",[8004]],[[8013,8013],\"mapped\",[8005]],[[8014,8015],\"disallowed\"],[[8016,8023],\"valid\"],[[8024,8024],\"disallowed\"],[[8025,8025],\"mapped\",[8017]],[[8026,8026],\"disallowed\"],[[8027,8027],\"mapped\",[8019]],[[8028,8028],\"disallowed\"],[[8029,8029],\"mapped\",[8021]],[[8030,8030],\"disallowed\"],[[8031,8031],\"mapped\",[8023]],[[8032,8039],\"valid\"],[[8040,8040],\"mapped\",[8032]],[[8041,8041],\"mapped\",[8033]],[[8042,8042],\"mapped\",[8034]],[[8043,8043],\"mapped\",[8035]],[[8044,8044],\"mapped\",[8036]],[[8045,8045],\"mapped\",[8037]],[[8046,8046],\"mapped\",[8038]],[[8047,8047],\"mapped\",[8039]],[[8048,8048],\"valid\"],[[8049,8049],\"mapped\",[940]],[[8050,8050],\"valid\"],[[8051,8051],\"mapped\",[941]],[[8052,8052],\"valid\"],[[8053,8053],\"mapped\",[942]],[[8054,8054],\"valid\"],[[8055,8055],\"mapped\",[943]],[[8056,8056],\"valid\"],[[8057,8057],\"mapped\",[972]],[[8058,8058],\"valid\"],[[8059,8059],\"mapped\",[973]],[[8060,8060],\"valid\"],[[8061,8061],\"mapped\",[974]],[[8062,8063],\"disallowed\"],[[8064,8064],\"mapped\",[7936,953]],[[8065,8065],\"mapped\",[7937,953]],[[8066,8066],\"mapped\",[7938,953]],[[8067,8067],\"mapped\",[7939,953]],[[8068,8068],\"mapped\",[7940,953]],[[8069,8069],\"mapped\",[7941,953]],[[8070,8070],\"mapped\",[7942,953]],[[8071,8071],\"mapped\",[7943,953]],[[8072,8072],\"mapped\",[7936,953]],[[8073,8073],\"mapped\",[7937,953]],[[8074,8074],\"mapped\",[7938,953]],[[8075,8075],\"mapped\",[7939,953]],[[8076,8076],\"mapped\",[7940,953]],[[8077,8077],\"mapped\",[7941,953]],[[8078,8078],\"mapped\",[7942,953]],[[8079,8079],\"mapped\",[7943,953]],[[8080,8080],\"mapped\",[7968,953]],[[8081,8081],\"mapped\",[7969,953]],[[8082,8082],\"mapped\",[7970,953]],[[8083,8083],\"mapped\",[7971,953]],[[8084,8084],\"mapped\",[7972,953]],[[8085,8085],\"mapped\",[7973,953]],[[8086,8086],\"mapped\",[7974,953]],[[8087,8087],\"mapped\",[7975,953]],[[8088,8088],\"mapped\",[7968,953]],[[8089,8089],\"mapped\",[7969,953]],[[8090,8090],\"mapped\",[7970,953]],[[8091,8091],\"mapped\",[7971,953]],[[8092,8092],\"mapped\",[7972,953]],[[8093,8093],\"mapped\",[7973,953]],[[8094,8094],\"mapped\",[7974,953]],[[8095,8095],\"mapped\",[7975,953]],[[8096,8096],\"mapped\",[8032,953]],[[8097,8097],\"mapped\",[8033,953]],[[8098,8098],\"mapped\",[8034,953]],[[8099,8099],\"mapped\",[8035,953]],[[8100,8100],\"mapped\",[8036,953]],[[8101,8101],\"mapped\",[8037,953]],[[8102,8102],\"mapped\",[8038,953]],[[8103,8103],\"mapped\",[8039,953]],[[8104,8104],\"mapped\",[8032,953]],[[8105,8105],\"mapped\",[8033,953]],[[8106,8106],\"mapped\",[8034,953]],[[8107,8107],\"mapped\",[8035,953]],[[8108,8108],\"mapped\",[8036,953]],[[8109,8109],\"mapped\",[8037,953]],[[8110,8110],\"mapped\",[8038,953]],[[8111,8111],\"mapped\",[8039,953]],[[8112,8113],\"valid\"],[[8114,8114],\"mapped\",[8048,953]],[[8115,8115],\"mapped\",[945,953]],[[8116,8116],\"mapped\",[940,953]],[[8117,8117],\"disallowed\"],[[8118,8118],\"valid\"],[[8119,8119],\"mapped\",[8118,953]],[[8120,8120],\"mapped\",[8112]],[[8121,8121],\"mapped\",[8113]],[[8122,8122],\"mapped\",[8048]],[[8123,8123],\"mapped\",[940]],[[8124,8124],\"mapped\",[945,953]],[[8125,8125],\"disallowed_STD3_mapped\",[32,787]],[[8126,8126],\"mapped\",[953]],[[8127,8127],\"disallowed_STD3_mapped\",[32,787]],[[8128,8128],\"disallowed_STD3_mapped\",[32,834]],[[8129,8129],\"disallowed_STD3_mapped\",[32,776,834]],[[8130,8130],\"mapped\",[8052,953]],[[8131,8131],\"mapped\",[951,953]],[[8132,8132],\"mapped\",[942,953]],[[8133,8133],\"disallowed\"],[[8134,8134],\"valid\"],[[8135,8135],\"mapped\",[8134,953]],[[8136,8136],\"mapped\",[8050]],[[8137,8137],\"mapped\",[941]],[[8138,8138],\"mapped\",[8052]],[[8139,8139],\"mapped\",[942]],[[8140,8140],\"mapped\",[951,953]],[[8141,8141],\"disallowed_STD3_mapped\",[32,787,768]],[[8142,8142],\"disallowed_STD3_mapped\",[32,787,769]],[[8143,8143],\"disallowed_STD3_mapped\",[32,787,834]],[[8144,8146],\"valid\"],[[8147,8147],\"mapped\",[912]],[[8148,8149],\"disallowed\"],[[8150,8151],\"valid\"],[[8152,8152],\"mapped\",[8144]],[[8153,8153],\"mapped\",[8145]],[[8154,8154],\"mapped\",[8054]],[[8155,8155],\"mapped\",[943]],[[8156,8156],\"disallowed\"],[[8157,8157],\"disallowed_STD3_mapped\",[32,788,768]],[[8158,8158],\"disallowed_STD3_mapped\",[32,788,769]],[[8159,8159],\"disallowed_STD3_mapped\",[32,788,834]],[[8160,8162],\"valid\"],[[8163,8163],\"mapped\",[944]],[[8164,8167],\"valid\"],[[8168,8168],\"mapped\",[8160]],[[8169,8169],\"mapped\",[8161]],[[8170,8170],\"mapped\",[8058]],[[8171,8171],\"mapped\",[973]],[[8172,8172],\"mapped\",[8165]],[[8173,8173],\"disallowed_STD3_mapped\",[32,776,768]],[[8174,8174],\"disallowed_STD3_mapped\",[32,776,769]],[[8175,8175],\"disallowed_STD3_mapped\",[96]],[[8176,8177],\"disallowed\"],[[8178,8178],\"mapped\",[8060,953]],[[8179,8179],\"mapped\",[969,953]],[[8180,8180],\"mapped\",[974,953]],[[8181,8181],\"disallowed\"],[[8182,8182],\"valid\"],[[8183,8183],\"mapped\",[8182,953]],[[8184,8184],\"mapped\",[8056]],[[8185,8185],\"mapped\",[972]],[[8186,8186],\"mapped\",[8060]],[[8187,8187],\"mapped\",[974]],[[8188,8188],\"mapped\",[969,953]],[[8189,8189],\"disallowed_STD3_mapped\",[32,769]],[[8190,8190],\"disallowed_STD3_mapped\",[32,788]],[[8191,8191],\"disallowed\"],[[8192,8202],\"disallowed_STD3_mapped\",[32]],[[8203,8203],\"ignored\"],[[8204,8205],\"deviation\",[]],[[8206,8207],\"disallowed\"],[[8208,8208],\"valid\",[],\"NV8\"],[[8209,8209],\"mapped\",[8208]],[[8210,8214],\"valid\",[],\"NV8\"],[[8215,8215],\"disallowed_STD3_mapped\",[32,819]],[[8216,8227],\"valid\",[],\"NV8\"],[[8228,8230],\"disallowed\"],[[8231,8231],\"valid\",[],\"NV8\"],[[8232,8238],\"disallowed\"],[[8239,8239],\"disallowed_STD3_mapped\",[32]],[[8240,8242],\"valid\",[],\"NV8\"],[[8243,8243],\"mapped\",[8242,8242]],[[8244,8244],\"mapped\",[8242,8242,8242]],[[8245,8245],\"valid\",[],\"NV8\"],[[8246,8246],\"mapped\",[8245,8245]],[[8247,8247],\"mapped\",[8245,8245,8245]],[[8248,8251],\"valid\",[],\"NV8\"],[[8252,8252],\"disallowed_STD3_mapped\",[33,33]],[[8253,8253],\"valid\",[],\"NV8\"],[[8254,8254],\"disallowed_STD3_mapped\",[32,773]],[[8255,8262],\"valid\",[],\"NV8\"],[[8263,8263],\"disallowed_STD3_mapped\",[63,63]],[[8264,8264],\"disallowed_STD3_mapped\",[63,33]],[[8265,8265],\"disallowed_STD3_mapped\",[33,63]],[[8266,8269],\"valid\",[],\"NV8\"],[[8270,8274],\"valid\",[],\"NV8\"],[[8275,8276],\"valid\",[],\"NV8\"],[[8277,8278],\"valid\",[],\"NV8\"],[[8279,8279],\"mapped\",[8242,8242,8242,8242]],[[8280,8286],\"valid\",[],\"NV8\"],[[8287,8287],\"disallowed_STD3_mapped\",[32]],[[8288,8288],\"ignored\"],[[8289,8291],\"disallowed\"],[[8292,8292],\"ignored\"],[[8293,8293],\"disallowed\"],[[8294,8297],\"disallowed\"],[[8298,8303],\"disallowed\"],[[8304,8304],\"mapped\",[48]],[[8305,8305],\"mapped\",[105]],[[8306,8307],\"disallowed\"],[[8308,8308],\"mapped\",[52]],[[8309,8309],\"mapped\",[53]],[[8310,8310],\"mapped\",[54]],[[8311,8311],\"mapped\",[55]],[[8312,8312],\"mapped\",[56]],[[8313,8313],\"mapped\",[57]],[[8314,8314],\"disallowed_STD3_mapped\",[43]],[[8315,8315],\"mapped\",[8722]],[[8316,8316],\"disallowed_STD3_mapped\",[61]],[[8317,8317],\"disallowed_STD3_mapped\",[40]],[[8318,8318],\"disallowed_STD3_mapped\",[41]],[[8319,8319],\"mapped\",[110]],[[8320,8320],\"mapped\",[48]],[[8321,8321],\"mapped\",[49]],[[8322,8322],\"mapped\",[50]],[[8323,8323],\"mapped\",[51]],[[8324,8324],\"mapped\",[52]],[[8325,8325],\"mapped\",[53]],[[8326,8326],\"mapped\",[54]],[[8327,8327],\"mapped\",[55]],[[8328,8328],\"mapped\",[56]],[[8329,8329],\"mapped\",[57]],[[8330,8330],\"disallowed_STD3_mapped\",[43]],[[8331,8331],\"mapped\",[8722]],[[8332,8332],\"disallowed_STD3_mapped\",[61]],[[8333,8333],\"disallowed_STD3_mapped\",[40]],[[8334,8334],\"disallowed_STD3_mapped\",[41]],[[8335,8335],\"disallowed\"],[[8336,8336],\"mapped\",[97]],[[8337,8337],\"mapped\",[101]],[[8338,8338],\"mapped\",[111]],[[8339,8339],\"mapped\",[120]],[[8340,8340],\"mapped\",[601]],[[8341,8341],\"mapped\",[104]],[[8342,8342],\"mapped\",[107]],[[8343,8343],\"mapped\",[108]],[[8344,8344],\"mapped\",[109]],[[8345,8345],\"mapped\",[110]],[[8346,8346],\"mapped\",[112]],[[8347,8347],\"mapped\",[115]],[[8348,8348],\"mapped\",[116]],[[8349,8351],\"disallowed\"],[[8352,8359],\"valid\",[],\"NV8\"],[[8360,8360],\"mapped\",[114,115]],[[8361,8362],\"valid\",[],\"NV8\"],[[8363,8363],\"valid\",[],\"NV8\"],[[8364,8364],\"valid\",[],\"NV8\"],[[8365,8367],\"valid\",[],\"NV8\"],[[8368,8369],\"valid\",[],\"NV8\"],[[8370,8373],\"valid\",[],\"NV8\"],[[8374,8376],\"valid\",[],\"NV8\"],[[8377,8377],\"valid\",[],\"NV8\"],[[8378,8378],\"valid\",[],\"NV8\"],[[8379,8381],\"valid\",[],\"NV8\"],[[8382,8382],\"valid\",[],\"NV8\"],[[8383,8399],\"disallowed\"],[[8400,8417],\"valid\",[],\"NV8\"],[[8418,8419],\"valid\",[],\"NV8\"],[[8420,8426],\"valid\",[],\"NV8\"],[[8427,8427],\"valid\",[],\"NV8\"],[[8428,8431],\"valid\",[],\"NV8\"],[[8432,8432],\"valid\",[],\"NV8\"],[[8433,8447],\"disallowed\"],[[8448,8448],\"disallowed_STD3_mapped\",[97,47,99]],[[8449,8449],\"disallowed_STD3_mapped\",[97,47,115]],[[8450,8450],\"mapped\",[99]],[[8451,8451],\"mapped\",[176,99]],[[8452,8452],\"valid\",[],\"NV8\"],[[8453,8453],\"disallowed_STD3_mapped\",[99,47,111]],[[8454,8454],\"disallowed_STD3_mapped\",[99,47,117]],[[8455,8455],\"mapped\",[603]],[[8456,8456],\"valid\",[],\"NV8\"],[[8457,8457],\"mapped\",[176,102]],[[8458,8458],\"mapped\",[103]],[[8459,8462],\"mapped\",[104]],[[8463,8463],\"mapped\",[295]],[[8464,8465],\"mapped\",[105]],[[8466,8467],\"mapped\",[108]],[[8468,8468],\"valid\",[],\"NV8\"],[[8469,8469],\"mapped\",[110]],[[8470,8470],\"mapped\",[110,111]],[[8471,8472],\"valid\",[],\"NV8\"],[[8473,8473],\"mapped\",[112]],[[8474,8474],\"mapped\",[113]],[[8475,8477],\"mapped\",[114]],[[8478,8479],\"valid\",[],\"NV8\"],[[8480,8480],\"mapped\",[115,109]],[[8481,8481],\"mapped\",[116,101,108]],[[8482,8482],\"mapped\",[116,109]],[[8483,8483],\"valid\",[],\"NV8\"],[[8484,8484],\"mapped\",[122]],[[8485,8485],\"valid\",[],\"NV8\"],[[8486,8486],\"mapped\",[969]],[[8487,8487],\"valid\",[],\"NV8\"],[[8488,8488],\"mapped\",[122]],[[8489,8489],\"valid\",[],\"NV8\"],[[8490,8490],\"mapped\",[107]],[[8491,8491],\"mapped\",[229]],[[8492,8492],\"mapped\",[98]],[[8493,8493],\"mapped\",[99]],[[8494,8494],\"valid\",[],\"NV8\"],[[8495,8496],\"mapped\",[101]],[[8497,8497],\"mapped\",[102]],[[8498,8498],\"disallowed\"],[[8499,8499],\"mapped\",[109]],[[8500,8500],\"mapped\",[111]],[[8501,8501],\"mapped\",[1488]],[[8502,8502],\"mapped\",[1489]],[[8503,8503],\"mapped\",[1490]],[[8504,8504],\"mapped\",[1491]],[[8505,8505],\"mapped\",[105]],[[8506,8506],\"valid\",[],\"NV8\"],[[8507,8507],\"mapped\",[102,97,120]],[[8508,8508],\"mapped\",[960]],[[8509,8510],\"mapped\",[947]],[[8511,8511],\"mapped\",[960]],[[8512,8512],\"mapped\",[8721]],[[8513,8516],\"valid\",[],\"NV8\"],[[8517,8518],\"mapped\",[100]],[[8519,8519],\"mapped\",[101]],[[8520,8520],\"mapped\",[105]],[[8521,8521],\"mapped\",[106]],[[8522,8523],\"valid\",[],\"NV8\"],[[8524,8524],\"valid\",[],\"NV8\"],[[8525,8525],\"valid\",[],\"NV8\"],[[8526,8526],\"valid\"],[[8527,8527],\"valid\",[],\"NV8\"],[[8528,8528],\"mapped\",[49,8260,55]],[[8529,8529],\"mapped\",[49,8260,57]],[[8530,8530],\"mapped\",[49,8260,49,48]],[[8531,8531],\"mapped\",[49,8260,51]],[[8532,8532],\"mapped\",[50,8260,51]],[[8533,8533],\"mapped\",[49,8260,53]],[[8534,8534],\"mapped\",[50,8260,53]],[[8535,8535],\"mapped\",[51,8260,53]],[[8536,8536],\"mapped\",[52,8260,53]],[[8537,8537],\"mapped\",[49,8260,54]],[[8538,8538],\"mapped\",[53,8260,54]],[[8539,8539],\"mapped\",[49,8260,56]],[[8540,8540],\"mapped\",[51,8260,56]],[[8541,8541],\"mapped\",[53,8260,56]],[[8542,8542],\"mapped\",[55,8260,56]],[[8543,8543],\"mapped\",[49,8260]],[[8544,8544],\"mapped\",[105]],[[8545,8545],\"mapped\",[105,105]],[[8546,8546],\"mapped\",[105,105,105]],[[8547,8547],\"mapped\",[105,118]],[[8548,8548],\"mapped\",[118]],[[8549,8549],\"mapped\",[118,105]],[[8550,8550],\"mapped\",[118,105,105]],[[8551,8551],\"mapped\",[118,105,105,105]],[[8552,8552],\"mapped\",[105,120]],[[8553,8553],\"mapped\",[120]],[[8554,8554],\"mapped\",[120,105]],[[8555,8555],\"mapped\",[120,105,105]],[[8556,8556],\"mapped\",[108]],[[8557,8557],\"mapped\",[99]],[[8558,8558],\"mapped\",[100]],[[8559,8559],\"mapped\",[109]],[[8560,8560],\"mapped\",[105]],[[8561,8561],\"mapped\",[105,105]],[[8562,8562],\"mapped\",[105,105,105]],[[8563,8563],\"mapped\",[105,118]],[[8564,8564],\"mapped\",[118]],[[8565,8565],\"mapped\",[118,105]],[[8566,8566],\"mapped\",[118,105,105]],[[8567,8567],\"mapped\",[118,105,105,105]],[[8568,8568],\"mapped\",[105,120]],[[8569,8569],\"mapped\",[120]],[[8570,8570],\"mapped\",[120,105]],[[8571,8571],\"mapped\",[120,105,105]],[[8572,8572],\"mapped\",[108]],[[8573,8573],\"mapped\",[99]],[[8574,8574],\"mapped\",[100]],[[8575,8575],\"mapped\",[109]],[[8576,8578],\"valid\",[],\"NV8\"],[[8579,8579],\"disallowed\"],[[8580,8580],\"valid\"],[[8581,8584],\"valid\",[],\"NV8\"],[[8585,8585],\"mapped\",[48,8260,51]],[[8586,8587],\"valid\",[],\"NV8\"],[[8588,8591],\"disallowed\"],[[8592,8682],\"valid\",[],\"NV8\"],[[8683,8691],\"valid\",[],\"NV8\"],[[8692,8703],\"valid\",[],\"NV8\"],[[8704,8747],\"valid\",[],\"NV8\"],[[8748,8748],\"mapped\",[8747,8747]],[[8749,8749],\"mapped\",[8747,8747,8747]],[[8750,8750],\"valid\",[],\"NV8\"],[[8751,8751],\"mapped\",[8750,8750]],[[8752,8752],\"mapped\",[8750,8750,8750]],[[8753,8799],\"valid\",[],\"NV8\"],[[8800,8800],\"disallowed_STD3_valid\"],[[8801,8813],\"valid\",[],\"NV8\"],[[8814,8815],\"disallowed_STD3_valid\"],[[8816,8945],\"valid\",[],\"NV8\"],[[8946,8959],\"valid\",[],\"NV8\"],[[8960,8960],\"valid\",[],\"NV8\"],[[8961,8961],\"valid\",[],\"NV8\"],[[8962,9000],\"valid\",[],\"NV8\"],[[9001,9001],\"mapped\",[12296]],[[9002,9002],\"mapped\",[12297]],[[9003,9082],\"valid\",[],\"NV8\"],[[9083,9083],\"valid\",[],\"NV8\"],[[9084,9084],\"valid\",[],\"NV8\"],[[9085,9114],\"valid\",[],\"NV8\"],[[9115,9166],\"valid\",[],\"NV8\"],[[9167,9168],\"valid\",[],\"NV8\"],[[9169,9179],\"valid\",[],\"NV8\"],[[9180,9191],\"valid\",[],\"NV8\"],[[9192,9192],\"valid\",[],\"NV8\"],[[9193,9203],\"valid\",[],\"NV8\"],[[9204,9210],\"valid\",[],\"NV8\"],[[9211,9215],\"disallowed\"],[[9216,9252],\"valid\",[],\"NV8\"],[[9253,9254],\"valid\",[],\"NV8\"],[[9255,9279],\"disallowed\"],[[9280,9290],\"valid\",[],\"NV8\"],[[9291,9311],\"disallowed\"],[[9312,9312],\"mapped\",[49]],[[9313,9313],\"mapped\",[50]],[[9314,9314],\"mapped\",[51]],[[9315,9315],\"mapped\",[52]],[[9316,9316],\"mapped\",[53]],[[9317,9317],\"mapped\",[54]],[[9318,9318],\"mapped\",[55]],[[9319,9319],\"mapped\",[56]],[[9320,9320],\"mapped\",[57]],[[9321,9321],\"mapped\",[49,48]],[[9322,9322],\"mapped\",[49,49]],[[9323,9323],\"mapped\",[49,50]],[[9324,9324],\"mapped\",[49,51]],[[9325,9325],\"mapped\",[49,52]],[[9326,9326],\"mapped\",[49,53]],[[9327,9327],\"mapped\",[49,54]],[[9328,9328],\"mapped\",[49,55]],[[9329,9329],\"mapped\",[49,56]],[[9330,9330],\"mapped\",[49,57]],[[9331,9331],\"mapped\",[50,48]],[[9332,9332],\"disallowed_STD3_mapped\",[40,49,41]],[[9333,9333],\"disallowed_STD3_mapped\",[40,50,41]],[[9334,9334],\"disallowed_STD3_mapped\",[40,51,41]],[[9335,9335],\"disallowed_STD3_mapped\",[40,52,41]],[[9336,9336],\"disallowed_STD3_mapped\",[40,53,41]],[[9337,9337],\"disallowed_STD3_mapped\",[40,54,41]],[[9338,9338],\"disallowed_STD3_mapped\",[40,55,41]],[[9339,9339],\"disallowed_STD3_mapped\",[40,56,41]],[[9340,9340],\"disallowed_STD3_mapped\",[40,57,41]],[[9341,9341],\"disallowed_STD3_mapped\",[40,49,48,41]],[[9342,9342],\"disallowed_STD3_mapped\",[40,49,49,41]],[[9343,9343],\"disallowed_STD3_mapped\",[40,49,50,41]],[[9344,9344],\"disallowed_STD3_mapped\",[40,49,51,41]],[[9345,9345],\"disallowed_STD3_mapped\",[40,49,52,41]],[[9346,9346],\"disallowed_STD3_mapped\",[40,49,53,41]],[[9347,9347],\"disallowed_STD3_mapped\",[40,49,54,41]],[[9348,9348],\"disallowed_STD3_mapped\",[40,49,55,41]],[[9349,9349],\"disallowed_STD3_mapped\",[40,49,56,41]],[[9350,9350],\"disallowed_STD3_mapped\",[40,49,57,41]],[[9351,9351],\"disallowed_STD3_mapped\",[40,50,48,41]],[[9352,9371],\"disallowed\"],[[9372,9372],\"disallowed_STD3_mapped\",[40,97,41]],[[9373,9373],\"disallowed_STD3_mapped\",[40,98,41]],[[9374,9374],\"disallowed_STD3_mapped\",[40,99,41]],[[9375,9375],\"disallowed_STD3_mapped\",[40,100,41]],[[9376,9376],\"disallowed_STD3_mapped\",[40,101,41]],[[9377,9377],\"disallowed_STD3_mapped\",[40,102,41]],[[9378,9378],\"disallowed_STD3_mapped\",[40,103,41]],[[9379,9379],\"disallowed_STD3_mapped\",[40,104,41]],[[9380,9380],\"disallowed_STD3_mapped\",[40,105,41]],[[9381,9381],\"disallowed_STD3_mapped\",[40,106,41]],[[9382,9382],\"disallowed_STD3_mapped\",[40,107,41]],[[9383,9383],\"disallowed_STD3_mapped\",[40,108,41]],[[9384,9384],\"disallowed_STD3_mapped\",[40,109,41]],[[9385,9385],\"disallowed_STD3_mapped\",[40,110,41]],[[9386,9386],\"disallowed_STD3_mapped\",[40,111,41]],[[9387,9387],\"disallowed_STD3_mapped\",[40,112,41]],[[9388,9388],\"disallowed_STD3_mapped\",[40,113,41]],[[9389,9389],\"disallowed_STD3_mapped\",[40,114,41]],[[9390,9390],\"disallowed_STD3_mapped\",[40,115,41]],[[9391,9391],\"disallowed_STD3_mapped\",[40,116,41]],[[9392,9392],\"disallowed_STD3_mapped\",[40,117,41]],[[9393,9393],\"disallowed_STD3_mapped\",[40,118,41]],[[9394,9394],\"disallowed_STD3_mapped\",[40,119,41]],[[9395,9395],\"disallowed_STD3_mapped\",[40,120,41]],[[9396,9396],\"disallowed_STD3_mapped\",[40,121,41]],[[9397,9397],\"disallowed_STD3_mapped\",[40,122,41]],[[9398,9398],\"mapped\",[97]],[[9399,9399],\"mapped\",[98]],[[9400,9400],\"mapped\",[99]],[[9401,9401],\"mapped\",[100]],[[9402,9402],\"mapped\",[101]],[[9403,9403],\"mapped\",[102]],[[9404,9404],\"mapped\",[103]],[[9405,9405],\"mapped\",[104]],[[9406,9406],\"mapped\",[105]],[[9407,9407],\"mapped\",[106]],[[9408,9408],\"mapped\",[107]],[[9409,9409],\"mapped\",[108]],[[9410,9410],\"mapped\",[109]],[[9411,9411],\"mapped\",[110]],[[9412,9412],\"mapped\",[111]],[[9413,9413],\"mapped\",[112]],[[9414,9414],\"mapped\",[113]],[[9415,9415],\"mapped\",[114]],[[9416,9416],\"mapped\",[115]],[[9417,9417],\"mapped\",[116]],[[9418,9418],\"mapped\",[117]],[[9419,9419],\"mapped\",[118]],[[9420,9420],\"mapped\",[119]],[[9421,9421],\"mapped\",[120]],[[9422,9422],\"mapped\",[121]],[[9423,9423],\"mapped\",[122]],[[9424,9424],\"mapped\",[97]],[[9425,9425],\"mapped\",[98]],[[9426,9426],\"mapped\",[99]],[[9427,9427],\"mapped\",[100]],[[9428,9428],\"mapped\",[101]],[[9429,9429],\"mapped\",[102]],[[9430,9430],\"mapped\",[103]],[[9431,9431],\"mapped\",[104]],[[9432,9432],\"mapped\",[105]],[[9433,9433],\"mapped\",[106]],[[9434,9434],\"mapped\",[107]],[[9435,9435],\"mapped\",[108]],[[9436,9436],\"mapped\",[109]],[[9437,9437],\"mapped\",[110]],[[9438,9438],\"mapped\",[111]],[[9439,9439],\"mapped\",[112]],[[9440,9440],\"mapped\",[113]],[[9441,9441],\"mapped\",[114]],[[9442,9442],\"mapped\",[115]],[[9443,9443],\"mapped\",[116]],[[9444,9444],\"mapped\",[117]],[[9445,9445],\"mapped\",[118]],[[9446,9446],\"mapped\",[119]],[[9447,9447],\"mapped\",[120]],[[9448,9448],\"mapped\",[121]],[[9449,9449],\"mapped\",[122]],[[9450,9450],\"mapped\",[48]],[[9451,9470],\"valid\",[],\"NV8\"],[[9471,9471],\"valid\",[],\"NV8\"],[[9472,9621],\"valid\",[],\"NV8\"],[[9622,9631],\"valid\",[],\"NV8\"],[[9632,9711],\"valid\",[],\"NV8\"],[[9712,9719],\"valid\",[],\"NV8\"],[[9720,9727],\"valid\",[],\"NV8\"],[[9728,9747],\"valid\",[],\"NV8\"],[[9748,9749],\"valid\",[],\"NV8\"],[[9750,9751],\"valid\",[],\"NV8\"],[[9752,9752],\"valid\",[],\"NV8\"],[[9753,9753],\"valid\",[],\"NV8\"],[[9754,9839],\"valid\",[],\"NV8\"],[[9840,9841],\"valid\",[],\"NV8\"],[[9842,9853],\"valid\",[],\"NV8\"],[[9854,9855],\"valid\",[],\"NV8\"],[[9856,9865],\"valid\",[],\"NV8\"],[[9866,9873],\"valid\",[],\"NV8\"],[[9874,9884],\"valid\",[],\"NV8\"],[[9885,9885],\"valid\",[],\"NV8\"],[[9886,9887],\"valid\",[],\"NV8\"],[[9888,9889],\"valid\",[],\"NV8\"],[[9890,9905],\"valid\",[],\"NV8\"],[[9906,9906],\"valid\",[],\"NV8\"],[[9907,9916],\"valid\",[],\"NV8\"],[[9917,9919],\"valid\",[],\"NV8\"],[[9920,9923],\"valid\",[],\"NV8\"],[[9924,9933],\"valid\",[],\"NV8\"],[[9934,9934],\"valid\",[],\"NV8\"],[[9935,9953],\"valid\",[],\"NV8\"],[[9954,9954],\"valid\",[],\"NV8\"],[[9955,9955],\"valid\",[],\"NV8\"],[[9956,9959],\"valid\",[],\"NV8\"],[[9960,9983],\"valid\",[],\"NV8\"],[[9984,9984],\"valid\",[],\"NV8\"],[[9985,9988],\"valid\",[],\"NV8\"],[[9989,9989],\"valid\",[],\"NV8\"],[[9990,9993],\"valid\",[],\"NV8\"],[[9994,9995],\"valid\",[],\"NV8\"],[[9996,10023],\"valid\",[],\"NV8\"],[[10024,10024],\"valid\",[],\"NV8\"],[[10025,10059],\"valid\",[],\"NV8\"],[[10060,10060],\"valid\",[],\"NV8\"],[[10061,10061],\"valid\",[],\"NV8\"],[[10062,10062],\"valid\",[],\"NV8\"],[[10063,10066],\"valid\",[],\"NV8\"],[[10067,10069],\"valid\",[],\"NV8\"],[[10070,10070],\"valid\",[],\"NV8\"],[[10071,10071],\"valid\",[],\"NV8\"],[[10072,10078],\"valid\",[],\"NV8\"],[[10079,10080],\"valid\",[],\"NV8\"],[[10081,10087],\"valid\",[],\"NV8\"],[[10088,10101],\"valid\",[],\"NV8\"],[[10102,10132],\"valid\",[],\"NV8\"],[[10133,10135],\"valid\",[],\"NV8\"],[[10136,10159],\"valid\",[],\"NV8\"],[[10160,10160],\"valid\",[],\"NV8\"],[[10161,10174],\"valid\",[],\"NV8\"],[[10175,10175],\"valid\",[],\"NV8\"],[[10176,10182],\"valid\",[],\"NV8\"],[[10183,10186],\"valid\",[],\"NV8\"],[[10187,10187],\"valid\",[],\"NV8\"],[[10188,10188],\"valid\",[],\"NV8\"],[[10189,10189],\"valid\",[],\"NV8\"],[[10190,10191],\"valid\",[],\"NV8\"],[[10192,10219],\"valid\",[],\"NV8\"],[[10220,10223],\"valid\",[],\"NV8\"],[[10224,10239],\"valid\",[],\"NV8\"],[[10240,10495],\"valid\",[],\"NV8\"],[[10496,10763],\"valid\",[],\"NV8\"],[[10764,10764],\"mapped\",[8747,8747,8747,8747]],[[10765,10867],\"valid\",[],\"NV8\"],[[10868,10868],\"disallowed_STD3_mapped\",[58,58,61]],[[10869,10869],\"disallowed_STD3_mapped\",[61,61]],[[10870,10870],\"disallowed_STD3_mapped\",[61,61,61]],[[10871,10971],\"valid\",[],\"NV8\"],[[10972,10972],\"mapped\",[10973,824]],[[10973,11007],\"valid\",[],\"NV8\"],[[11008,11021],\"valid\",[],\"NV8\"],[[11022,11027],\"valid\",[],\"NV8\"],[[11028,11034],\"valid\",[],\"NV8\"],[[11035,11039],\"valid\",[],\"NV8\"],[[11040,11043],\"valid\",[],\"NV8\"],[[11044,11084],\"valid\",[],\"NV8\"],[[11085,11087],\"valid\",[],\"NV8\"],[[11088,11092],\"valid\",[],\"NV8\"],[[11093,11097],\"valid\",[],\"NV8\"],[[11098,11123],\"valid\",[],\"NV8\"],[[11124,11125],\"disallowed\"],[[11126,11157],\"valid\",[],\"NV8\"],[[11158,11159],\"disallowed\"],[[11160,11193],\"valid\",[],\"NV8\"],[[11194,11196],\"disallowed\"],[[11197,11208],\"valid\",[],\"NV8\"],[[11209,11209],\"disallowed\"],[[11210,11217],\"valid\",[],\"NV8\"],[[11218,11243],\"disallowed\"],[[11244,11247],\"valid\",[],\"NV8\"],[[11248,11263],\"disallowed\"],[[11264,11264],\"mapped\",[11312]],[[11265,11265],\"mapped\",[11313]],[[11266,11266],\"mapped\",[11314]],[[11267,11267],\"mapped\",[11315]],[[11268,11268],\"mapped\",[11316]],[[11269,11269],\"mapped\",[11317]],[[11270,11270],\"mapped\",[11318]],[[11271,11271],\"mapped\",[11319]],[[11272,11272],\"mapped\",[11320]],[[11273,11273],\"mapped\",[11321]],[[11274,11274],\"mapped\",[11322]],[[11275,11275],\"mapped\",[11323]],[[11276,11276],\"mapped\",[11324]],[[11277,11277],\"mapped\",[11325]],[[11278,11278],\"mapped\",[11326]],[[11279,11279],\"mapped\",[11327]],[[11280,11280],\"mapped\",[11328]],[[11281,11281],\"mapped\",[11329]],[[11282,11282],\"mapped\",[11330]],[[11283,11283],\"mapped\",[11331]],[[11284,11284],\"mapped\",[11332]],[[11285,11285],\"mapped\",[11333]],[[11286,11286],\"mapped\",[11334]],[[11287,11287],\"mapped\",[11335]],[[11288,11288],\"mapped\",[11336]],[[11289,11289],\"mapped\",[11337]],[[11290,11290],\"mapped\",[11338]],[[11291,11291],\"mapped\",[11339]],[[11292,11292],\"mapped\",[11340]],[[11293,11293],\"mapped\",[11341]],[[11294,11294],\"mapped\",[11342]],[[11295,11295],\"mapped\",[11343]],[[11296,11296],\"mapped\",[11344]],[[11297,11297],\"mapped\",[11345]],[[11298,11298],\"mapped\",[11346]],[[11299,11299],\"mapped\",[11347]],[[11300,11300],\"mapped\",[11348]],[[11301,11301],\"mapped\",[11349]],[[11302,11302],\"mapped\",[11350]],[[11303,11303],\"mapped\",[11351]],[[11304,11304],\"mapped\",[11352]],[[11305,11305],\"mapped\",[11353]],[[11306,11306],\"mapped\",[11354]],[[11307,11307],\"mapped\",[11355]],[[11308,11308],\"mapped\",[11356]],[[11309,11309],\"mapped\",[11357]],[[11310,11310],\"mapped\",[11358]],[[11311,11311],\"disallowed\"],[[11312,11358],\"valid\"],[[11359,11359],\"disallowed\"],[[11360,11360],\"mapped\",[11361]],[[11361,11361],\"valid\"],[[11362,11362],\"mapped\",[619]],[[11363,11363],\"mapped\",[7549]],[[11364,11364],\"mapped\",[637]],[[11365,11366],\"valid\"],[[11367,11367],\"mapped\",[11368]],[[11368,11368],\"valid\"],[[11369,11369],\"mapped\",[11370]],[[11370,11370],\"valid\"],[[11371,11371],\"mapped\",[11372]],[[11372,11372],\"valid\"],[[11373,11373],\"mapped\",[593]],[[11374,11374],\"mapped\",[625]],[[11375,11375],\"mapped\",[592]],[[11376,11376],\"mapped\",[594]],[[11377,11377],\"valid\"],[[11378,11378],\"mapped\",[11379]],[[11379,11379],\"valid\"],[[11380,11380],\"valid\"],[[11381,11381],\"mapped\",[11382]],[[11382,11383],\"valid\"],[[11384,11387],\"valid\"],[[11388,11388],\"mapped\",[106]],[[11389,11389],\"mapped\",[118]],[[11390,11390],\"mapped\",[575]],[[11391,11391],\"mapped\",[576]],[[11392,11392],\"mapped\",[11393]],[[11393,11393],\"valid\"],[[11394,11394],\"mapped\",[11395]],[[11395,11395],\"valid\"],[[11396,11396],\"mapped\",[11397]],[[11397,11397],\"valid\"],[[11398,11398],\"mapped\",[11399]],[[11399,11399],\"valid\"],[[11400,11400],\"mapped\",[11401]],[[11401,11401],\"valid\"],[[11402,11402],\"mapped\",[11403]],[[11403,11403],\"valid\"],[[11404,11404],\"mapped\",[11405]],[[11405,11405],\"valid\"],[[11406,11406],\"mapped\",[11407]],[[11407,11407],\"valid\"],[[11408,11408],\"mapped\",[11409]],[[11409,11409],\"valid\"],[[11410,11410],\"mapped\",[11411]],[[11411,11411],\"valid\"],[[11412,11412],\"mapped\",[11413]],[[11413,11413],\"valid\"],[[11414,11414],\"mapped\",[11415]],[[11415,11415],\"valid\"],[[11416,11416],\"mapped\",[11417]],[[11417,11417],\"valid\"],[[11418,11418],\"mapped\",[11419]],[[11419,11419],\"valid\"],[[11420,11420],\"mapped\",[11421]],[[11421,11421],\"valid\"],[[11422,11422],\"mapped\",[11423]],[[11423,11423],\"valid\"],[[11424,11424],\"mapped\",[11425]],[[11425,11425],\"valid\"],[[11426,11426],\"mapped\",[11427]],[[11427,11427],\"valid\"],[[11428,11428],\"mapped\",[11429]],[[11429,11429],\"valid\"],[[11430,11430],\"mapped\",[11431]],[[11431,11431],\"valid\"],[[11432,11432],\"mapped\",[11433]],[[11433,11433],\"valid\"],[[11434,11434],\"mapped\",[11435]],[[11435,11435],\"valid\"],[[11436,11436],\"mapped\",[11437]],[[11437,11437],\"valid\"],[[11438,11438],\"mapped\",[11439]],[[11439,11439],\"valid\"],[[11440,11440],\"mapped\",[11441]],[[11441,11441],\"valid\"],[[11442,11442],\"mapped\",[11443]],[[11443,11443],\"valid\"],[[11444,11444],\"mapped\",[11445]],[[11445,11445],\"valid\"],[[11446,11446],\"mapped\",[11447]],[[11447,11447],\"valid\"],[[11448,11448],\"mapped\",[11449]],[[11449,11449],\"valid\"],[[11450,11450],\"mapped\",[11451]],[[11451,11451],\"valid\"],[[11452,11452],\"mapped\",[11453]],[[11453,11453],\"valid\"],[[11454,11454],\"mapped\",[11455]],[[11455,11455],\"valid\"],[[11456,11456],\"mapped\",[11457]],[[11457,11457],\"valid\"],[[11458,11458],\"mapped\",[11459]],[[11459,11459],\"valid\"],[[11460,11460],\"mapped\",[11461]],[[11461,11461],\"valid\"],[[11462,11462],\"mapped\",[11463]],[[11463,11463],\"valid\"],[[11464,11464],\"mapped\",[11465]],[[11465,11465],\"valid\"],[[11466,11466],\"mapped\",[11467]],[[11467,11467],\"valid\"],[[11468,11468],\"mapped\",[11469]],[[11469,11469],\"valid\"],[[11470,11470],\"mapped\",[11471]],[[11471,11471],\"valid\"],[[11472,11472],\"mapped\",[11473]],[[11473,11473],\"valid\"],[[11474,11474],\"mapped\",[11475]],[[11475,11475],\"valid\"],[[11476,11476],\"mapped\",[11477]],[[11477,11477],\"valid\"],[[11478,11478],\"mapped\",[11479]],[[11479,11479],\"valid\"],[[11480,11480],\"mapped\",[11481]],[[11481,11481],\"valid\"],[[11482,11482],\"mapped\",[11483]],[[11483,11483],\"valid\"],[[11484,11484],\"mapped\",[11485]],[[11485,11485],\"valid\"],[[11486,11486],\"mapped\",[11487]],[[11487,11487],\"valid\"],[[11488,11488],\"mapped\",[11489]],[[11489,11489],\"valid\"],[[11490,11490],\"mapped\",[11491]],[[11491,11492],\"valid\"],[[11493,11498],\"valid\",[],\"NV8\"],[[11499,11499],\"mapped\",[11500]],[[11500,11500],\"valid\"],[[11501,11501],\"mapped\",[11502]],[[11502,11505],\"valid\"],[[11506,11506],\"mapped\",[11507]],[[11507,11507],\"valid\"],[[11508,11512],\"disallowed\"],[[11513,11519],\"valid\",[],\"NV8\"],[[11520,11557],\"valid\"],[[11558,11558],\"disallowed\"],[[11559,11559],\"valid\"],[[11560,11564],\"disallowed\"],[[11565,11565],\"valid\"],[[11566,11567],\"disallowed\"],[[11568,11621],\"valid\"],[[11622,11623],\"valid\"],[[11624,11630],\"disallowed\"],[[11631,11631],\"mapped\",[11617]],[[11632,11632],\"valid\",[],\"NV8\"],[[11633,11646],\"disallowed\"],[[11647,11647],\"valid\"],[[11648,11670],\"valid\"],[[11671,11679],\"disallowed\"],[[11680,11686],\"valid\"],[[11687,11687],\"disallowed\"],[[11688,11694],\"valid\"],[[11695,11695],\"disallowed\"],[[11696,11702],\"valid\"],[[11703,11703],\"disallowed\"],[[11704,11710],\"valid\"],[[11711,11711],\"disallowed\"],[[11712,11718],\"valid\"],[[11719,11719],\"disallowed\"],[[11720,11726],\"valid\"],[[11727,11727],\"disallowed\"],[[11728,11734],\"valid\"],[[11735,11735],\"disallowed\"],[[11736,11742],\"valid\"],[[11743,11743],\"disallowed\"],[[11744,11775],\"valid\"],[[11776,11799],\"valid\",[],\"NV8\"],[[11800,11803],\"valid\",[],\"NV8\"],[[11804,11805],\"valid\",[],\"NV8\"],[[11806,11822],\"valid\",[],\"NV8\"],[[11823,11823],\"valid\"],[[11824,11824],\"valid\",[],\"NV8\"],[[11825,11825],\"valid\",[],\"NV8\"],[[11826,11835],\"valid\",[],\"NV8\"],[[11836,11842],\"valid\",[],\"NV8\"],[[11843,11903],\"disallowed\"],[[11904,11929],\"valid\",[],\"NV8\"],[[11930,11930],\"disallowed\"],[[11931,11934],\"valid\",[],\"NV8\"],[[11935,11935],\"mapped\",[27597]],[[11936,12018],\"valid\",[],\"NV8\"],[[12019,12019],\"mapped\",[40863]],[[12020,12031],\"disallowed\"],[[12032,12032],\"mapped\",[19968]],[[12033,12033],\"mapped\",[20008]],[[12034,12034],\"mapped\",[20022]],[[12035,12035],\"mapped\",[20031]],[[12036,12036],\"mapped\",[20057]],[[12037,12037],\"mapped\",[20101]],[[12038,12038],\"mapped\",[20108]],[[12039,12039],\"mapped\",[20128]],[[12040,12040],\"mapped\",[20154]],[[12041,12041],\"mapped\",[20799]],[[12042,12042],\"mapped\",[20837]],[[12043,12043],\"mapped\",[20843]],[[12044,12044],\"mapped\",[20866]],[[12045,12045],\"mapped\",[20886]],[[12046,12046],\"mapped\",[20907]],[[12047,12047],\"mapped\",[20960]],[[12048,12048],\"mapped\",[20981]],[[12049,12049],\"mapped\",[20992]],[[12050,12050],\"mapped\",[21147]],[[12051,12051],\"mapped\",[21241]],[[12052,12052],\"mapped\",[21269]],[[12053,12053],\"mapped\",[21274]],[[12054,12054],\"mapped\",[21304]],[[12055,12055],\"mapped\",[21313]],[[12056,12056],\"mapped\",[21340]],[[12057,12057],\"mapped\",[21353]],[[12058,12058],\"mapped\",[21378]],[[12059,12059],\"mapped\",[21430]],[[12060,12060],\"mapped\",[21448]],[[12061,12061],\"mapped\",[21475]],[[12062,12062],\"mapped\",[22231]],[[12063,12063],\"mapped\",[22303]],[[12064,12064],\"mapped\",[22763]],[[12065,12065],\"mapped\",[22786]],[[12066,12066],\"mapped\",[22794]],[[12067,12067],\"mapped\",[22805]],[[12068,12068],\"mapped\",[22823]],[[12069,12069],\"mapped\",[22899]],[[12070,12070],\"mapped\",[23376]],[[12071,12071],\"mapped\",[23424]],[[12072,12072],\"mapped\",[23544]],[[12073,12073],\"mapped\",[23567]],[[12074,12074],\"mapped\",[23586]],[[12075,12075],\"mapped\",[23608]],[[12076,12076],\"mapped\",[23662]],[[12077,12077],\"mapped\",[23665]],[[12078,12078],\"mapped\",[24027]],[[12079,12079],\"mapped\",[24037]],[[12080,12080],\"mapped\",[24049]],[[12081,12081],\"mapped\",[24062]],[[12082,12082],\"mapped\",[24178]],[[12083,12083],\"mapped\",[24186]],[[12084,12084],\"mapped\",[24191]],[[12085,12085],\"mapped\",[24308]],[[12086,12086],\"mapped\",[24318]],[[12087,12087],\"mapped\",[24331]],[[12088,12088],\"mapped\",[24339]],[[12089,12089],\"mapped\",[24400]],[[12090,12090],\"mapped\",[24417]],[[12091,12091],\"mapped\",[24435]],[[12092,12092],\"mapped\",[24515]],[[12093,12093],\"mapped\",[25096]],[[12094,12094],\"mapped\",[25142]],[[12095,12095],\"mapped\",[25163]],[[12096,12096],\"mapped\",[25903]],[[12097,12097],\"mapped\",[25908]],[[12098,12098],\"mapped\",[25991]],[[12099,12099],\"mapped\",[26007]],[[12100,12100],\"mapped\",[26020]],[[12101,12101],\"mapped\",[26041]],[[12102,12102],\"mapped\",[26080]],[[12103,12103],\"mapped\",[26085]],[[12104,12104],\"mapped\",[26352]],[[12105,12105],\"mapped\",[26376]],[[12106,12106],\"mapped\",[26408]],[[12107,12107],\"mapped\",[27424]],[[12108,12108],\"mapped\",[27490]],[[12109,12109],\"mapped\",[27513]],[[12110,12110],\"mapped\",[27571]],[[12111,12111],\"mapped\",[27595]],[[12112,12112],\"mapped\",[27604]],[[12113,12113],\"mapped\",[27611]],[[12114,12114],\"mapped\",[27663]],[[12115,12115],\"mapped\",[27668]],[[12116,12116],\"mapped\",[27700]],[[12117,12117],\"mapped\",[28779]],[[12118,12118],\"mapped\",[29226]],[[12119,12119],\"mapped\",[29238]],[[12120,12120],\"mapped\",[29243]],[[12121,12121],\"mapped\",[29247]],[[12122,12122],\"mapped\",[29255]],[[12123,12123],\"mapped\",[29273]],[[12124,12124],\"mapped\",[29275]],[[12125,12125],\"mapped\",[29356]],[[12126,12126],\"mapped\",[29572]],[[12127,12127],\"mapped\",[29577]],[[12128,12128],\"mapped\",[29916]],[[12129,12129],\"mapped\",[29926]],[[12130,12130],\"mapped\",[29976]],[[12131,12131],\"mapped\",[29983]],[[12132,12132],\"mapped\",[29992]],[[12133,12133],\"mapped\",[30000]],[[12134,12134],\"mapped\",[30091]],[[12135,12135],\"mapped\",[30098]],[[12136,12136],\"mapped\",[30326]],[[12137,12137],\"mapped\",[30333]],[[12138,12138],\"mapped\",[30382]],[[12139,12139],\"mapped\",[30399]],[[12140,12140],\"mapped\",[30446]],[[12141,12141],\"mapped\",[30683]],[[12142,12142],\"mapped\",[30690]],[[12143,12143],\"mapped\",[30707]],[[12144,12144],\"mapped\",[31034]],[[12145,12145],\"mapped\",[31160]],[[12146,12146],\"mapped\",[31166]],[[12147,12147],\"mapped\",[31348]],[[12148,12148],\"mapped\",[31435]],[[12149,12149],\"mapped\",[31481]],[[12150,12150],\"mapped\",[31859]],[[12151,12151],\"mapped\",[31992]],[[12152,12152],\"mapped\",[32566]],[[12153,12153],\"mapped\",[32593]],[[12154,12154],\"mapped\",[32650]],[[12155,12155],\"mapped\",[32701]],[[12156,12156],\"mapped\",[32769]],[[12157,12157],\"mapped\",[32780]],[[12158,12158],\"mapped\",[32786]],[[12159,12159],\"mapped\",[32819]],[[12160,12160],\"mapped\",[32895]],[[12161,12161],\"mapped\",[32905]],[[12162,12162],\"mapped\",[33251]],[[12163,12163],\"mapped\",[33258]],[[12164,12164],\"mapped\",[33267]],[[12165,12165],\"mapped\",[33276]],[[12166,12166],\"mapped\",[33292]],[[12167,12167],\"mapped\",[33307]],[[12168,12168],\"mapped\",[33311]],[[12169,12169],\"mapped\",[33390]],[[12170,12170],\"mapped\",[33394]],[[12171,12171],\"mapped\",[33400]],[[12172,12172],\"mapped\",[34381]],[[12173,12173],\"mapped\",[34411]],[[12174,12174],\"mapped\",[34880]],[[12175,12175],\"mapped\",[34892]],[[12176,12176],\"mapped\",[34915]],[[12177,12177],\"mapped\",[35198]],[[12178,12178],\"mapped\",[35211]],[[12179,12179],\"mapped\",[35282]],[[12180,12180],\"mapped\",[35328]],[[12181,12181],\"mapped\",[35895]],[[12182,12182],\"mapped\",[35910]],[[12183,12183],\"mapped\",[35925]],[[12184,12184],\"mapped\",[35960]],[[12185,12185],\"mapped\",[35997]],[[12186,12186],\"mapped\",[36196]],[[12187,12187],\"mapped\",[36208]],[[12188,12188],\"mapped\",[36275]],[[12189,12189],\"mapped\",[36523]],[[12190,12190],\"mapped\",[36554]],[[12191,12191],\"mapped\",[36763]],[[12192,12192],\"mapped\",[36784]],[[12193,12193],\"mapped\",[36789]],[[12194,12194],\"mapped\",[37009]],[[12195,12195],\"mapped\",[37193]],[[12196,12196],\"mapped\",[37318]],[[12197,12197],\"mapped\",[37324]],[[12198,12198],\"mapped\",[37329]],[[12199,12199],\"mapped\",[38263]],[[12200,12200],\"mapped\",[38272]],[[12201,12201],\"mapped\",[38428]],[[12202,12202],\"mapped\",[38582]],[[12203,12203],\"mapped\",[38585]],[[12204,12204],\"mapped\",[38632]],[[12205,12205],\"mapped\",[38737]],[[12206,12206],\"mapped\",[38750]],[[12207,12207],\"mapped\",[38754]],[[12208,12208],\"mapped\",[38761]],[[12209,12209],\"mapped\",[38859]],[[12210,12210],\"mapped\",[38893]],[[12211,12211],\"mapped\",[38899]],[[12212,12212],\"mapped\",[38913]],[[12213,12213],\"mapped\",[39080]],[[12214,12214],\"mapped\",[39131]],[[12215,12215],\"mapped\",[39135]],[[12216,12216],\"mapped\",[39318]],[[12217,12217],\"mapped\",[39321]],[[12218,12218],\"mapped\",[39340]],[[12219,12219],\"mapped\",[39592]],[[12220,12220],\"mapped\",[39640]],[[12221,12221],\"mapped\",[39647]],[[12222,12222],\"mapped\",[39717]],[[12223,12223],\"mapped\",[39727]],[[12224,12224],\"mapped\",[39730]],[[12225,12225],\"mapped\",[39740]],[[12226,12226],\"mapped\",[39770]],[[12227,12227],\"mapped\",[40165]],[[12228,12228],\"mapped\",[40565]],[[12229,12229],\"mapped\",[40575]],[[12230,12230],\"mapped\",[40613]],[[12231,12231],\"mapped\",[40635]],[[12232,12232],\"mapped\",[40643]],[[12233,12233],\"mapped\",[40653]],[[12234,12234],\"mapped\",[40657]],[[12235,12235],\"mapped\",[40697]],[[12236,12236],\"mapped\",[40701]],[[12237,12237],\"mapped\",[40718]],[[12238,12238],\"mapped\",[40723]],[[12239,12239],\"mapped\",[40736]],[[12240,12240],\"mapped\",[40763]],[[12241,12241],\"mapped\",[40778]],[[12242,12242],\"mapped\",[40786]],[[12243,12243],\"mapped\",[40845]],[[12244,12244],\"mapped\",[40860]],[[12245,12245],\"mapped\",[40864]],[[12246,12271],\"disallowed\"],[[12272,12283],\"disallowed\"],[[12284,12287],\"disallowed\"],[[12288,12288],\"disallowed_STD3_mapped\",[32]],[[12289,12289],\"valid\",[],\"NV8\"],[[12290,12290],\"mapped\",[46]],[[12291,12292],\"valid\",[],\"NV8\"],[[12293,12295],\"valid\"],[[12296,12329],\"valid\",[],\"NV8\"],[[12330,12333],\"valid\"],[[12334,12341],\"valid\",[],\"NV8\"],[[12342,12342],\"mapped\",[12306]],[[12343,12343],\"valid\",[],\"NV8\"],[[12344,12344],\"mapped\",[21313]],[[12345,12345],\"mapped\",[21316]],[[12346,12346],\"mapped\",[21317]],[[12347,12347],\"valid\",[],\"NV8\"],[[12348,12348],\"valid\"],[[12349,12349],\"valid\",[],\"NV8\"],[[12350,12350],\"valid\",[],\"NV8\"],[[12351,12351],\"valid\",[],\"NV8\"],[[12352,12352],\"disallowed\"],[[12353,12436],\"valid\"],[[12437,12438],\"valid\"],[[12439,12440],\"disallowed\"],[[12441,12442],\"valid\"],[[12443,12443],\"disallowed_STD3_mapped\",[32,12441]],[[12444,12444],\"disallowed_STD3_mapped\",[32,12442]],[[12445,12446],\"valid\"],[[12447,12447],\"mapped\",[12424,12426]],[[12448,12448],\"valid\",[],\"NV8\"],[[12449,12542],\"valid\"],[[12543,12543],\"mapped\",[12467,12488]],[[12544,12548],\"disallowed\"],[[12549,12588],\"valid\"],[[12589,12589],\"valid\"],[[12590,12592],\"disallowed\"],[[12593,12593],\"mapped\",[4352]],[[12594,12594],\"mapped\",[4353]],[[12595,12595],\"mapped\",[4522]],[[12596,12596],\"mapped\",[4354]],[[12597,12597],\"mapped\",[4524]],[[12598,12598],\"mapped\",[4525]],[[12599,12599],\"mapped\",[4355]],[[12600,12600],\"mapped\",[4356]],[[12601,12601],\"mapped\",[4357]],[[12602,12602],\"mapped\",[4528]],[[12603,12603],\"mapped\",[4529]],[[12604,12604],\"mapped\",[4530]],[[12605,12605],\"mapped\",[4531]],[[12606,12606],\"mapped\",[4532]],[[12607,12607],\"mapped\",[4533]],[[12608,12608],\"mapped\",[4378]],[[12609,12609],\"mapped\",[4358]],[[12610,12610],\"mapped\",[4359]],[[12611,12611],\"mapped\",[4360]],[[12612,12612],\"mapped\",[4385]],[[12613,12613],\"mapped\",[4361]],[[12614,12614],\"mapped\",[4362]],[[12615,12615],\"mapped\",[4363]],[[12616,12616],\"mapped\",[4364]],[[12617,12617],\"mapped\",[4365]],[[12618,12618],\"mapped\",[4366]],[[12619,12619],\"mapped\",[4367]],[[12620,12620],\"mapped\",[4368]],[[12621,12621],\"mapped\",[4369]],[[12622,12622],\"mapped\",[4370]],[[12623,12623],\"mapped\",[4449]],[[12624,12624],\"mapped\",[4450]],[[12625,12625],\"mapped\",[4451]],[[12626,12626],\"mapped\",[4452]],[[12627,12627],\"mapped\",[4453]],[[12628,12628],\"mapped\",[4454]],[[12629,12629],\"mapped\",[4455]],[[12630,12630],\"mapped\",[4456]],[[12631,12631],\"mapped\",[4457]],[[12632,12632],\"mapped\",[4458]],[[12633,12633],\"mapped\",[4459]],[[12634,12634],\"mapped\",[4460]],[[12635,12635],\"mapped\",[4461]],[[12636,12636],\"mapped\",[4462]],[[12637,12637],\"mapped\",[4463]],[[12638,12638],\"mapped\",[4464]],[[12639,12639],\"mapped\",[4465]],[[12640,12640],\"mapped\",[4466]],[[12641,12641],\"mapped\",[4467]],[[12642,12642],\"mapped\",[4468]],[[12643,12643],\"mapped\",[4469]],[[12644,12644],\"disallowed\"],[[12645,12645],\"mapped\",[4372]],[[12646,12646],\"mapped\",[4373]],[[12647,12647],\"mapped\",[4551]],[[12648,12648],\"mapped\",[4552]],[[12649,12649],\"mapped\",[4556]],[[12650,12650],\"mapped\",[4558]],[[12651,12651],\"mapped\",[4563]],[[12652,12652],\"mapped\",[4567]],[[12653,12653],\"mapped\",[4569]],[[12654,12654],\"mapped\",[4380]],[[12655,12655],\"mapped\",[4573]],[[12656,12656],\"mapped\",[4575]],[[12657,12657],\"mapped\",[4381]],[[12658,12658],\"mapped\",[4382]],[[12659,12659],\"mapped\",[4384]],[[12660,12660],\"mapped\",[4386]],[[12661,12661],\"mapped\",[4387]],[[12662,12662],\"mapped\",[4391]],[[12663,12663],\"mapped\",[4393]],[[12664,12664],\"mapped\",[4395]],[[12665,12665],\"mapped\",[4396]],[[12666,12666],\"mapped\",[4397]],[[12667,12667],\"mapped\",[4398]],[[12668,12668],\"mapped\",[4399]],[[12669,12669],\"mapped\",[4402]],[[12670,12670],\"mapped\",[4406]],[[12671,12671],\"mapped\",[4416]],[[12672,12672],\"mapped\",[4423]],[[12673,12673],\"mapped\",[4428]],[[12674,12674],\"mapped\",[4593]],[[12675,12675],\"mapped\",[4594]],[[12676,12676],\"mapped\",[4439]],[[12677,12677],\"mapped\",[4440]],[[12678,12678],\"mapped\",[4441]],[[12679,12679],\"mapped\",[4484]],[[12680,12680],\"mapped\",[4485]],[[12681,12681],\"mapped\",[4488]],[[12682,12682],\"mapped\",[4497]],[[12683,12683],\"mapped\",[4498]],[[12684,12684],\"mapped\",[4500]],[[12685,12685],\"mapped\",[4510]],[[12686,12686],\"mapped\",[4513]],[[12687,12687],\"disallowed\"],[[12688,12689],\"valid\",[],\"NV8\"],[[12690,12690],\"mapped\",[19968]],[[12691,12691],\"mapped\",[20108]],[[12692,12692],\"mapped\",[19977]],[[12693,12693],\"mapped\",[22235]],[[12694,12694],\"mapped\",[19978]],[[12695,12695],\"mapped\",[20013]],[[12696,12696],\"mapped\",[19979]],[[12697,12697],\"mapped\",[30002]],[[12698,12698],\"mapped\",[20057]],[[12699,12699],\"mapped\",[19993]],[[12700,12700],\"mapped\",[19969]],[[12701,12701],\"mapped\",[22825]],[[12702,12702],\"mapped\",[22320]],[[12703,12703],\"mapped\",[20154]],[[12704,12727],\"valid\"],[[12728,12730],\"valid\"],[[12731,12735],\"disallowed\"],[[12736,12751],\"valid\",[],\"NV8\"],[[12752,12771],\"valid\",[],\"NV8\"],[[12772,12783],\"disallowed\"],[[12784,12799],\"valid\"],[[12800,12800],\"disallowed_STD3_mapped\",[40,4352,41]],[[12801,12801],\"disallowed_STD3_mapped\",[40,4354,41]],[[12802,12802],\"disallowed_STD3_mapped\",[40,4355,41]],[[12803,12803],\"disallowed_STD3_mapped\",[40,4357,41]],[[12804,12804],\"disallowed_STD3_mapped\",[40,4358,41]],[[12805,12805],\"disallowed_STD3_mapped\",[40,4359,41]],[[12806,12806],\"disallowed_STD3_mapped\",[40,4361,41]],[[12807,12807],\"disallowed_STD3_mapped\",[40,4363,41]],[[12808,12808],\"disallowed_STD3_mapped\",[40,4364,41]],[[12809,12809],\"disallowed_STD3_mapped\",[40,4366,41]],[[12810,12810],\"disallowed_STD3_mapped\",[40,4367,41]],[[12811,12811],\"disallowed_STD3_mapped\",[40,4368,41]],[[12812,12812],\"disallowed_STD3_mapped\",[40,4369,41]],[[12813,12813],\"disallowed_STD3_mapped\",[40,4370,41]],[[12814,12814],\"disallowed_STD3_mapped\",[40,44032,41]],[[12815,12815],\"disallowed_STD3_mapped\",[40,45208,41]],[[12816,12816],\"disallowed_STD3_mapped\",[40,45796,41]],[[12817,12817],\"disallowed_STD3_mapped\",[40,46972,41]],[[12818,12818],\"disallowed_STD3_mapped\",[40,47560,41]],[[12819,12819],\"disallowed_STD3_mapped\",[40,48148,41]],[[12820,12820],\"disallowed_STD3_mapped\",[40,49324,41]],[[12821,12821],\"disallowed_STD3_mapped\",[40,50500,41]],[[12822,12822],\"disallowed_STD3_mapped\",[40,51088,41]],[[12823,12823],\"disallowed_STD3_mapped\",[40,52264,41]],[[12824,12824],\"disallowed_STD3_mapped\",[40,52852,41]],[[12825,12825],\"disallowed_STD3_mapped\",[40,53440,41]],[[12826,12826],\"disallowed_STD3_mapped\",[40,54028,41]],[[12827,12827],\"disallowed_STD3_mapped\",[40,54616,41]],[[12828,12828],\"disallowed_STD3_mapped\",[40,51452,41]],[[12829,12829],\"disallowed_STD3_mapped\",[40,50724,51204,41]],[[12830,12830],\"disallowed_STD3_mapped\",[40,50724,54980,41]],[[12831,12831],\"disallowed\"],[[12832,12832],\"disallowed_STD3_mapped\",[40,19968,41]],[[12833,12833],\"disallowed_STD3_mapped\",[40,20108,41]],[[12834,12834],\"disallowed_STD3_mapped\",[40,19977,41]],[[12835,12835],\"disallowed_STD3_mapped\",[40,22235,41]],[[12836,12836],\"disallowed_STD3_mapped\",[40,20116,41]],[[12837,12837],\"disallowed_STD3_mapped\",[40,20845,41]],[[12838,12838],\"disallowed_STD3_mapped\",[40,19971,41]],[[12839,12839],\"disallowed_STD3_mapped\",[40,20843,41]],[[12840,12840],\"disallowed_STD3_mapped\",[40,20061,41]],[[12841,12841],\"disallowed_STD3_mapped\",[40,21313,41]],[[12842,12842],\"disallowed_STD3_mapped\",[40,26376,41]],[[12843,12843],\"disallowed_STD3_mapped\",[40,28779,41]],[[12844,12844],\"disallowed_STD3_mapped\",[40,27700,41]],[[12845,12845],\"disallowed_STD3_mapped\",[40,26408,41]],[[12846,12846],\"disallowed_STD3_mapped\",[40,37329,41]],[[12847,12847],\"disallowed_STD3_mapped\",[40,22303,41]],[[12848,12848],\"disallowed_STD3_mapped\",[40,26085,41]],[[12849,12849],\"disallowed_STD3_mapped\",[40,26666,41]],[[12850,12850],\"disallowed_STD3_mapped\",[40,26377,41]],[[12851,12851],\"disallowed_STD3_mapped\",[40,31038,41]],[[12852,12852],\"disallowed_STD3_mapped\",[40,21517,41]],[[12853,12853],\"disallowed_STD3_mapped\",[40,29305,41]],[[12854,12854],\"disallowed_STD3_mapped\",[40,36001,41]],[[12855,12855],\"disallowed_STD3_mapped\",[40,31069,41]],[[12856,12856],\"disallowed_STD3_mapped\",[40,21172,41]],[[12857,12857],\"disallowed_STD3_mapped\",[40,20195,41]],[[12858,12858],\"disallowed_STD3_mapped\",[40,21628,41]],[[12859,12859],\"disallowed_STD3_mapped\",[40,23398,41]],[[12860,12860],\"disallowed_STD3_mapped\",[40,30435,41]],[[12861,12861],\"disallowed_STD3_mapped\",[40,20225,41]],[[12862,12862],\"disallowed_STD3_mapped\",[40,36039,41]],[[12863,12863],\"disallowed_STD3_mapped\",[40,21332,41]],[[12864,12864],\"disallowed_STD3_mapped\",[40,31085,41]],[[12865,12865],\"disallowed_STD3_mapped\",[40,20241,41]],[[12866,12866],\"disallowed_STD3_mapped\",[40,33258,41]],[[12867,12867],\"disallowed_STD3_mapped\",[40,33267,41]],[[12868,12868],\"mapped\",[21839]],[[12869,12869],\"mapped\",[24188]],[[12870,12870],\"mapped\",[25991]],[[12871,12871],\"mapped\",[31631]],[[12872,12879],\"valid\",[],\"NV8\"],[[12880,12880],\"mapped\",[112,116,101]],[[12881,12881],\"mapped\",[50,49]],[[12882,12882],\"mapped\",[50,50]],[[12883,12883],\"mapped\",[50,51]],[[12884,12884],\"mapped\",[50,52]],[[12885,12885],\"mapped\",[50,53]],[[12886,12886],\"mapped\",[50,54]],[[12887,12887],\"mapped\",[50,55]],[[12888,12888],\"mapped\",[50,56]],[[12889,12889],\"mapped\",[50,57]],[[12890,12890],\"mapped\",[51,48]],[[12891,12891],\"mapped\",[51,49]],[[12892,12892],\"mapped\",[51,50]],[[12893,12893],\"mapped\",[51,51]],[[12894,12894],\"mapped\",[51,52]],[[12895,12895],\"mapped\",[51,53]],[[12896,12896],\"mapped\",[4352]],[[12897,12897],\"mapped\",[4354]],[[12898,12898],\"mapped\",[4355]],[[12899,12899],\"mapped\",[4357]],[[12900,12900],\"mapped\",[4358]],[[12901,12901],\"mapped\",[4359]],[[12902,12902],\"mapped\",[4361]],[[12903,12903],\"mapped\",[4363]],[[12904,12904],\"mapped\",[4364]],[[12905,12905],\"mapped\",[4366]],[[12906,12906],\"mapped\",[4367]],[[12907,12907],\"mapped\",[4368]],[[12908,12908],\"mapped\",[4369]],[[12909,12909],\"mapped\",[4370]],[[12910,12910],\"mapped\",[44032]],[[12911,12911],\"mapped\",[45208]],[[12912,12912],\"mapped\",[45796]],[[12913,12913],\"mapped\",[46972]],[[12914,12914],\"mapped\",[47560]],[[12915,12915],\"mapped\",[48148]],[[12916,12916],\"mapped\",[49324]],[[12917,12917],\"mapped\",[50500]],[[12918,12918],\"mapped\",[51088]],[[12919,12919],\"mapped\",[52264]],[[12920,12920],\"mapped\",[52852]],[[12921,12921],\"mapped\",[53440]],[[12922,12922],\"mapped\",[54028]],[[12923,12923],\"mapped\",[54616]],[[12924,12924],\"mapped\",[52280,44256]],[[12925,12925],\"mapped\",[51452,51032]],[[12926,12926],\"mapped\",[50864]],[[12927,12927],\"valid\",[],\"NV8\"],[[12928,12928],\"mapped\",[19968]],[[12929,12929],\"mapped\",[20108]],[[12930,12930],\"mapped\",[19977]],[[12931,12931],\"mapped\",[22235]],[[12932,12932],\"mapped\",[20116]],[[12933,12933],\"mapped\",[20845]],[[12934,12934],\"mapped\",[19971]],[[12935,12935],\"mapped\",[20843]],[[12936,12936],\"mapped\",[20061]],[[12937,12937],\"mapped\",[21313]],[[12938,12938],\"mapped\",[26376]],[[12939,12939],\"mapped\",[28779]],[[12940,12940],\"mapped\",[27700]],[[12941,12941],\"mapped\",[26408]],[[12942,12942],\"mapped\",[37329]],[[12943,12943],\"mapped\",[22303]],[[12944,12944],\"mapped\",[26085]],[[12945,12945],\"mapped\",[26666]],[[12946,12946],\"mapped\",[26377]],[[12947,12947],\"mapped\",[31038]],[[12948,12948],\"mapped\",[21517]],[[12949,12949],\"mapped\",[29305]],[[12950,12950],\"mapped\",[36001]],[[12951,12951],\"mapped\",[31069]],[[12952,12952],\"mapped\",[21172]],[[12953,12953],\"mapped\",[31192]],[[12954,12954],\"mapped\",[30007]],[[12955,12955],\"mapped\",[22899]],[[12956,12956],\"mapped\",[36969]],[[12957,12957],\"mapped\",[20778]],[[12958,12958],\"mapped\",[21360]],[[12959,12959],\"mapped\",[27880]],[[12960,12960],\"mapped\",[38917]],[[12961,12961],\"mapped\",[20241]],[[12962,12962],\"mapped\",[20889]],[[12963,12963],\"mapped\",[27491]],[[12964,12964],\"mapped\",[19978]],[[12965,12965],\"mapped\",[20013]],[[12966,12966],\"mapped\",[19979]],[[12967,12967],\"mapped\",[24038]],[[12968,12968],\"mapped\",[21491]],[[12969,12969],\"mapped\",[21307]],[[12970,12970],\"mapped\",[23447]],[[12971,12971],\"mapped\",[23398]],[[12972,12972],\"mapped\",[30435]],[[12973,12973],\"mapped\",[20225]],[[12974,12974],\"mapped\",[36039]],[[12975,12975],\"mapped\",[21332]],[[12976,12976],\"mapped\",[22812]],[[12977,12977],\"mapped\",[51,54]],[[12978,12978],\"mapped\",[51,55]],[[12979,12979],\"mapped\",[51,56]],[[12980,12980],\"mapped\",[51,57]],[[12981,12981],\"mapped\",[52,48]],[[12982,12982],\"mapped\",[52,49]],[[12983,12983],\"mapped\",[52,50]],[[12984,12984],\"mapped\",[52,51]],[[12985,12985],\"mapped\",[52,52]],[[12986,12986],\"mapped\",[52,53]],[[12987,12987],\"mapped\",[52,54]],[[12988,12988],\"mapped\",[52,55]],[[12989,12989],\"mapped\",[52,56]],[[12990,12990],\"mapped\",[52,57]],[[12991,12991],\"mapped\",[53,48]],[[12992,12992],\"mapped\",[49,26376]],[[12993,12993],\"mapped\",[50,26376]],[[12994,12994],\"mapped\",[51,26376]],[[12995,12995],\"mapped\",[52,26376]],[[12996,12996],\"mapped\",[53,26376]],[[12997,12997],\"mapped\",[54,26376]],[[12998,12998],\"mapped\",[55,26376]],[[12999,12999],\"mapped\",[56,26376]],[[13000,13000],\"mapped\",[57,26376]],[[13001,13001],\"mapped\",[49,48,26376]],[[13002,13002],\"mapped\",[49,49,26376]],[[13003,13003],\"mapped\",[49,50,26376]],[[13004,13004],\"mapped\",[104,103]],[[13005,13005],\"mapped\",[101,114,103]],[[13006,13006],\"mapped\",[101,118]],[[13007,13007],\"mapped\",[108,116,100]],[[13008,13008],\"mapped\",[12450]],[[13009,13009],\"mapped\",[12452]],[[13010,13010],\"mapped\",[12454]],[[13011,13011],\"mapped\",[12456]],[[13012,13012],\"mapped\",[12458]],[[13013,13013],\"mapped\",[12459]],[[13014,13014],\"mapped\",[12461]],[[13015,13015],\"mapped\",[12463]],[[13016,13016],\"mapped\",[12465]],[[13017,13017],\"mapped\",[12467]],[[13018,13018],\"mapped\",[12469]],[[13019,13019],\"mapped\",[12471]],[[13020,13020],\"mapped\",[12473]],[[13021,13021],\"mapped\",[12475]],[[13022,13022],\"mapped\",[12477]],[[13023,13023],\"mapped\",[12479]],[[13024,13024],\"mapped\",[12481]],[[13025,13025],\"mapped\",[12484]],[[13026,13026],\"mapped\",[12486]],[[13027,13027],\"mapped\",[12488]],[[13028,13028],\"mapped\",[12490]],[[13029,13029],\"mapped\",[12491]],[[13030,13030],\"mapped\",[12492]],[[13031,13031],\"mapped\",[12493]],[[13032,13032],\"mapped\",[12494]],[[13033,13033],\"mapped\",[12495]],[[13034,13034],\"mapped\",[12498]],[[13035,13035],\"mapped\",[12501]],[[13036,13036],\"mapped\",[12504]],[[13037,13037],\"mapped\",[12507]],[[13038,13038],\"mapped\",[12510]],[[13039,13039],\"mapped\",[12511]],[[13040,13040],\"mapped\",[12512]],[[13041,13041],\"mapped\",[12513]],[[13042,13042],\"mapped\",[12514]],[[13043,13043],\"mapped\",[12516]],[[13044,13044],\"mapped\",[12518]],[[13045,13045],\"mapped\",[12520]],[[13046,13046],\"mapped\",[12521]],[[13047,13047],\"mapped\",[12522]],[[13048,13048],\"mapped\",[12523]],[[13049,13049],\"mapped\",[12524]],[[13050,13050],\"mapped\",[12525]],[[13051,13051],\"mapped\",[12527]],[[13052,13052],\"mapped\",[12528]],[[13053,13053],\"mapped\",[12529]],[[13054,13054],\"mapped\",[12530]],[[13055,13055],\"disallowed\"],[[13056,13056],\"mapped\",[12450,12497,12540,12488]],[[13057,13057],\"mapped\",[12450,12523,12501,12449]],[[13058,13058],\"mapped\",[12450,12531,12506,12450]],[[13059,13059],\"mapped\",[12450,12540,12523]],[[13060,13060],\"mapped\",[12452,12491,12531,12464]],[[13061,13061],\"mapped\",[12452,12531,12481]],[[13062,13062],\"mapped\",[12454,12457,12531]],[[13063,13063],\"mapped\",[12456,12473,12463,12540,12489]],[[13064,13064],\"mapped\",[12456,12540,12459,12540]],[[13065,13065],\"mapped\",[12458,12531,12473]],[[13066,13066],\"mapped\",[12458,12540,12512]],[[13067,13067],\"mapped\",[12459,12452,12522]],[[13068,13068],\"mapped\",[12459,12521,12483,12488]],[[13069,13069],\"mapped\",[12459,12525,12522,12540]],[[13070,13070],\"mapped\",[12460,12525,12531]],[[13071,13071],\"mapped\",[12460,12531,12510]],[[13072,13072],\"mapped\",[12462,12460]],[[13073,13073],\"mapped\",[12462,12491,12540]],[[13074,13074],\"mapped\",[12461,12517,12522,12540]],[[13075,13075],\"mapped\",[12462,12523,12480,12540]],[[13076,13076],\"mapped\",[12461,12525]],[[13077,13077],\"mapped\",[12461,12525,12464,12521,12512]],[[13078,13078],\"mapped\",[12461,12525,12513,12540,12488,12523]],[[13079,13079],\"mapped\",[12461,12525,12527,12483,12488]],[[13080,13080],\"mapped\",[12464,12521,12512]],[[13081,13081],\"mapped\",[12464,12521,12512,12488,12531]],[[13082,13082],\"mapped\",[12463,12523,12476,12452,12525]],[[13083,13083],\"mapped\",[12463,12525,12540,12493]],[[13084,13084],\"mapped\",[12465,12540,12473]],[[13085,13085],\"mapped\",[12467,12523,12490]],[[13086,13086],\"mapped\",[12467,12540,12509]],[[13087,13087],\"mapped\",[12469,12452,12463,12523]],[[13088,13088],\"mapped\",[12469,12531,12481,12540,12512]],[[13089,13089],\"mapped\",[12471,12522,12531,12464]],[[13090,13090],\"mapped\",[12475,12531,12481]],[[13091,13091],\"mapped\",[12475,12531,12488]],[[13092,13092],\"mapped\",[12480,12540,12473]],[[13093,13093],\"mapped\",[12487,12471]],[[13094,13094],\"mapped\",[12489,12523]],[[13095,13095],\"mapped\",[12488,12531]],[[13096,13096],\"mapped\",[12490,12494]],[[13097,13097],\"mapped\",[12494,12483,12488]],[[13098,13098],\"mapped\",[12495,12452,12484]],[[13099,13099],\"mapped\",[12497,12540,12475,12531,12488]],[[13100,13100],\"mapped\",[12497,12540,12484]],[[13101,13101],\"mapped\",[12496,12540,12524,12523]],[[13102,13102],\"mapped\",[12500,12450,12473,12488,12523]],[[13103,13103],\"mapped\",[12500,12463,12523]],[[13104,13104],\"mapped\",[12500,12467]],[[13105,13105],\"mapped\",[12499,12523]],[[13106,13106],\"mapped\",[12501,12449,12521,12483,12489]],[[13107,13107],\"mapped\",[12501,12451,12540,12488]],[[13108,13108],\"mapped\",[12502,12483,12471,12455,12523]],[[13109,13109],\"mapped\",[12501,12521,12531]],[[13110,13110],\"mapped\",[12504,12463,12479,12540,12523]],[[13111,13111],\"mapped\",[12506,12477]],[[13112,13112],\"mapped\",[12506,12491,12498]],[[13113,13113],\"mapped\",[12504,12523,12484]],[[13114,13114],\"mapped\",[12506,12531,12473]],[[13115,13115],\"mapped\",[12506,12540,12472]],[[13116,13116],\"mapped\",[12505,12540,12479]],[[13117,13117],\"mapped\",[12509,12452,12531,12488]],[[13118,13118],\"mapped\",[12508,12523,12488]],[[13119,13119],\"mapped\",[12507,12531]],[[13120,13120],\"mapped\",[12509,12531,12489]],[[13121,13121],\"mapped\",[12507,12540,12523]],[[13122,13122],\"mapped\",[12507,12540,12531]],[[13123,13123],\"mapped\",[12510,12452,12463,12525]],[[13124,13124],\"mapped\",[12510,12452,12523]],[[13125,13125],\"mapped\",[12510,12483,12495]],[[13126,13126],\"mapped\",[12510,12523,12463]],[[13127,13127],\"mapped\",[12510,12531,12471,12519,12531]],[[13128,13128],\"mapped\",[12511,12463,12525,12531]],[[13129,13129],\"mapped\",[12511,12522]],[[13130,13130],\"mapped\",[12511,12522,12496,12540,12523]],[[13131,13131],\"mapped\",[12513,12460]],[[13132,13132],\"mapped\",[12513,12460,12488,12531]],[[13133,13133],\"mapped\",[12513,12540,12488,12523]],[[13134,13134],\"mapped\",[12516,12540,12489]],[[13135,13135],\"mapped\",[12516,12540,12523]],[[13136,13136],\"mapped\",[12518,12450,12531]],[[13137,13137],\"mapped\",[12522,12483,12488,12523]],[[13138,13138],\"mapped\",[12522,12521]],[[13139,13139],\"mapped\",[12523,12500,12540]],[[13140,13140],\"mapped\",[12523,12540,12502,12523]],[[13141,13141],\"mapped\",[12524,12512]],[[13142,13142],\"mapped\",[12524,12531,12488,12466,12531]],[[13143,13143],\"mapped\",[12527,12483,12488]],[[13144,13144],\"mapped\",[48,28857]],[[13145,13145],\"mapped\",[49,28857]],[[13146,13146],\"mapped\",[50,28857]],[[13147,13147],\"mapped\",[51,28857]],[[13148,13148],\"mapped\",[52,28857]],[[13149,13149],\"mapped\",[53,28857]],[[13150,13150],\"mapped\",[54,28857]],[[13151,13151],\"mapped\",[55,28857]],[[13152,13152],\"mapped\",[56,28857]],[[13153,13153],\"mapped\",[57,28857]],[[13154,13154],\"mapped\",[49,48,28857]],[[13155,13155],\"mapped\",[49,49,28857]],[[13156,13156],\"mapped\",[49,50,28857]],[[13157,13157],\"mapped\",[49,51,28857]],[[13158,13158],\"mapped\",[49,52,28857]],[[13159,13159],\"mapped\",[49,53,28857]],[[13160,13160],\"mapped\",[49,54,28857]],[[13161,13161],\"mapped\",[49,55,28857]],[[13162,13162],\"mapped\",[49,56,28857]],[[13163,13163],\"mapped\",[49,57,28857]],[[13164,13164],\"mapped\",[50,48,28857]],[[13165,13165],\"mapped\",[50,49,28857]],[[13166,13166],\"mapped\",[50,50,28857]],[[13167,13167],\"mapped\",[50,51,28857]],[[13168,13168],\"mapped\",[50,52,28857]],[[13169,13169],\"mapped\",[104,112,97]],[[13170,13170],\"mapped\",[100,97]],[[13171,13171],\"mapped\",[97,117]],[[13172,13172],\"mapped\",[98,97,114]],[[13173,13173],\"mapped\",[111,118]],[[13174,13174],\"mapped\",[112,99]],[[13175,13175],\"mapped\",[100,109]],[[13176,13176],\"mapped\",[100,109,50]],[[13177,13177],\"mapped\",[100,109,51]],[[13178,13178],\"mapped\",[105,117]],[[13179,13179],\"mapped\",[24179,25104]],[[13180,13180],\"mapped\",[26157,21644]],[[13181,13181],\"mapped\",[22823,27491]],[[13182,13182],\"mapped\",[26126,27835]],[[13183,13183],\"mapped\",[26666,24335,20250,31038]],[[13184,13184],\"mapped\",[112,97]],[[13185,13185],\"mapped\",[110,97]],[[13186,13186],\"mapped\",[956,97]],[[13187,13187],\"mapped\",[109,97]],[[13188,13188],\"mapped\",[107,97]],[[13189,13189],\"mapped\",[107,98]],[[13190,13190],\"mapped\",[109,98]],[[13191,13191],\"mapped\",[103,98]],[[13192,13192],\"mapped\",[99,97,108]],[[13193,13193],\"mapped\",[107,99,97,108]],[[13194,13194],\"mapped\",[112,102]],[[13195,13195],\"mapped\",[110,102]],[[13196,13196],\"mapped\",[956,102]],[[13197,13197],\"mapped\",[956,103]],[[13198,13198],\"mapped\",[109,103]],[[13199,13199],\"mapped\",[107,103]],[[13200,13200],\"mapped\",[104,122]],[[13201,13201],\"mapped\",[107,104,122]],[[13202,13202],\"mapped\",[109,104,122]],[[13203,13203],\"mapped\",[103,104,122]],[[13204,13204],\"mapped\",[116,104,122]],[[13205,13205],\"mapped\",[956,108]],[[13206,13206],\"mapped\",[109,108]],[[13207,13207],\"mapped\",[100,108]],[[13208,13208],\"mapped\",[107,108]],[[13209,13209],\"mapped\",[102,109]],[[13210,13210],\"mapped\",[110,109]],[[13211,13211],\"mapped\",[956,109]],[[13212,13212],\"mapped\",[109,109]],[[13213,13213],\"mapped\",[99,109]],[[13214,13214],\"mapped\",[107,109]],[[13215,13215],\"mapped\",[109,109,50]],[[13216,13216],\"mapped\",[99,109,50]],[[13217,13217],\"mapped\",[109,50]],[[13218,13218],\"mapped\",[107,109,50]],[[13219,13219],\"mapped\",[109,109,51]],[[13220,13220],\"mapped\",[99,109,51]],[[13221,13221],\"mapped\",[109,51]],[[13222,13222],\"mapped\",[107,109,51]],[[13223,13223],\"mapped\",[109,8725,115]],[[13224,13224],\"mapped\",[109,8725,115,50]],[[13225,13225],\"mapped\",[112,97]],[[13226,13226],\"mapped\",[107,112,97]],[[13227,13227],\"mapped\",[109,112,97]],[[13228,13228],\"mapped\",[103,112,97]],[[13229,13229],\"mapped\",[114,97,100]],[[13230,13230],\"mapped\",[114,97,100,8725,115]],[[13231,13231],\"mapped\",[114,97,100,8725,115,50]],[[13232,13232],\"mapped\",[112,115]],[[13233,13233],\"mapped\",[110,115]],[[13234,13234],\"mapped\",[956,115]],[[13235,13235],\"mapped\",[109,115]],[[13236,13236],\"mapped\",[112,118]],[[13237,13237],\"mapped\",[110,118]],[[13238,13238],\"mapped\",[956,118]],[[13239,13239],\"mapped\",[109,118]],[[13240,13240],\"mapped\",[107,118]],[[13241,13241],\"mapped\",[109,118]],[[13242,13242],\"mapped\",[112,119]],[[13243,13243],\"mapped\",[110,119]],[[13244,13244],\"mapped\",[956,119]],[[13245,13245],\"mapped\",[109,119]],[[13246,13246],\"mapped\",[107,119]],[[13247,13247],\"mapped\",[109,119]],[[13248,13248],\"mapped\",[107,969]],[[13249,13249],\"mapped\",[109,969]],[[13250,13250],\"disallowed\"],[[13251,13251],\"mapped\",[98,113]],[[13252,13252],\"mapped\",[99,99]],[[13253,13253],\"mapped\",[99,100]],[[13254,13254],\"mapped\",[99,8725,107,103]],[[13255,13255],\"disallowed\"],[[13256,13256],\"mapped\",[100,98]],[[13257,13257],\"mapped\",[103,121]],[[13258,13258],\"mapped\",[104,97]],[[13259,13259],\"mapped\",[104,112]],[[13260,13260],\"mapped\",[105,110]],[[13261,13261],\"mapped\",[107,107]],[[13262,13262],\"mapped\",[107,109]],[[13263,13263],\"mapped\",[107,116]],[[13264,13264],\"mapped\",[108,109]],[[13265,13265],\"mapped\",[108,110]],[[13266,13266],\"mapped\",[108,111,103]],[[13267,13267],\"mapped\",[108,120]],[[13268,13268],\"mapped\",[109,98]],[[13269,13269],\"mapped\",[109,105,108]],[[13270,13270],\"mapped\",[109,111,108]],[[13271,13271],\"mapped\",[112,104]],[[13272,13272],\"disallowed\"],[[13273,13273],\"mapped\",[112,112,109]],[[13274,13274],\"mapped\",[112,114]],[[13275,13275],\"mapped\",[115,114]],[[13276,13276],\"mapped\",[115,118]],[[13277,13277],\"mapped\",[119,98]],[[13278,13278],\"mapped\",[118,8725,109]],[[13279,13279],\"mapped\",[97,8725,109]],[[13280,13280],\"mapped\",[49,26085]],[[13281,13281],\"mapped\",[50,26085]],[[13282,13282],\"mapped\",[51,26085]],[[13283,13283],\"mapped\",[52,26085]],[[13284,13284],\"mapped\",[53,26085]],[[13285,13285],\"mapped\",[54,26085]],[[13286,13286],\"mapped\",[55,26085]],[[13287,13287],\"mapped\",[56,26085]],[[13288,13288],\"mapped\",[57,26085]],[[13289,13289],\"mapped\",[49,48,26085]],[[13290,13290],\"mapped\",[49,49,26085]],[[13291,13291],\"mapped\",[49,50,26085]],[[13292,13292],\"mapped\",[49,51,26085]],[[13293,13293],\"mapped\",[49,52,26085]],[[13294,13294],\"mapped\",[49,53,26085]],[[13295,13295],\"mapped\",[49,54,26085]],[[13296,13296],\"mapped\",[49,55,26085]],[[13297,13297],\"mapped\",[49,56,26085]],[[13298,13298],\"mapped\",[49,57,26085]],[[13299,13299],\"mapped\",[50,48,26085]],[[13300,13300],\"mapped\",[50,49,26085]],[[13301,13301],\"mapped\",[50,50,26085]],[[13302,13302],\"mapped\",[50,51,26085]],[[13303,13303],\"mapped\",[50,52,26085]],[[13304,13304],\"mapped\",[50,53,26085]],[[13305,13305],\"mapped\",[50,54,26085]],[[13306,13306],\"mapped\",[50,55,26085]],[[13307,13307],\"mapped\",[50,56,26085]],[[13308,13308],\"mapped\",[50,57,26085]],[[13309,13309],\"mapped\",[51,48,26085]],[[13310,13310],\"mapped\",[51,49,26085]],[[13311,13311],\"mapped\",[103,97,108]],[[13312,19893],\"valid\"],[[19894,19903],\"disallowed\"],[[19904,19967],\"valid\",[],\"NV8\"],[[19968,40869],\"valid\"],[[40870,40891],\"valid\"],[[40892,40899],\"valid\"],[[40900,40907],\"valid\"],[[40908,40908],\"valid\"],[[40909,40917],\"valid\"],[[40918,40959],\"disallowed\"],[[40960,42124],\"valid\"],[[42125,42127],\"disallowed\"],[[42128,42145],\"valid\",[],\"NV8\"],[[42146,42147],\"valid\",[],\"NV8\"],[[42148,42163],\"valid\",[],\"NV8\"],[[42164,42164],\"valid\",[],\"NV8\"],[[42165,42176],\"valid\",[],\"NV8\"],[[42177,42177],\"valid\",[],\"NV8\"],[[42178,42180],\"valid\",[],\"NV8\"],[[42181,42181],\"valid\",[],\"NV8\"],[[42182,42182],\"valid\",[],\"NV8\"],[[42183,42191],\"disallowed\"],[[42192,42237],\"valid\"],[[42238,42239],\"valid\",[],\"NV8\"],[[42240,42508],\"valid\"],[[42509,42511],\"valid\",[],\"NV8\"],[[42512,42539],\"valid\"],[[42540,42559],\"disallowed\"],[[42560,42560],\"mapped\",[42561]],[[42561,42561],\"valid\"],[[42562,42562],\"mapped\",[42563]],[[42563,42563],\"valid\"],[[42564,42564],\"mapped\",[42565]],[[42565,42565],\"valid\"],[[42566,42566],\"mapped\",[42567]],[[42567,42567],\"valid\"],[[42568,42568],\"mapped\",[42569]],[[42569,42569],\"valid\"],[[42570,42570],\"mapped\",[42571]],[[42571,42571],\"valid\"],[[42572,42572],\"mapped\",[42573]],[[42573,42573],\"valid\"],[[42574,42574],\"mapped\",[42575]],[[42575,42575],\"valid\"],[[42576,42576],\"mapped\",[42577]],[[42577,42577],\"valid\"],[[42578,42578],\"mapped\",[42579]],[[42579,42579],\"valid\"],[[42580,42580],\"mapped\",[42581]],[[42581,42581],\"valid\"],[[42582,42582],\"mapped\",[42583]],[[42583,42583],\"valid\"],[[42584,42584],\"mapped\",[42585]],[[42585,42585],\"valid\"],[[42586,42586],\"mapped\",[42587]],[[42587,42587],\"valid\"],[[42588,42588],\"mapped\",[42589]],[[42589,42589],\"valid\"],[[42590,42590],\"mapped\",[42591]],[[42591,42591],\"valid\"],[[42592,42592],\"mapped\",[42593]],[[42593,42593],\"valid\"],[[42594,42594],\"mapped\",[42595]],[[42595,42595],\"valid\"],[[42596,42596],\"mapped\",[42597]],[[42597,42597],\"valid\"],[[42598,42598],\"mapped\",[42599]],[[42599,42599],\"valid\"],[[42600,42600],\"mapped\",[42601]],[[42601,42601],\"valid\"],[[42602,42602],\"mapped\",[42603]],[[42603,42603],\"valid\"],[[42604,42604],\"mapped\",[42605]],[[42605,42607],\"valid\"],[[42608,42611],\"valid\",[],\"NV8\"],[[42612,42619],\"valid\"],[[42620,42621],\"valid\"],[[42622,42622],\"valid\",[],\"NV8\"],[[42623,42623],\"valid\"],[[42624,42624],\"mapped\",[42625]],[[42625,42625],\"valid\"],[[42626,42626],\"mapped\",[42627]],[[42627,42627],\"valid\"],[[42628,42628],\"mapped\",[42629]],[[42629,42629],\"valid\"],[[42630,42630],\"mapped\",[42631]],[[42631,42631],\"valid\"],[[42632,42632],\"mapped\",[42633]],[[42633,42633],\"valid\"],[[42634,42634],\"mapped\",[42635]],[[42635,42635],\"valid\"],[[42636,42636],\"mapped\",[42637]],[[42637,42637],\"valid\"],[[42638,42638],\"mapped\",[42639]],[[42639,42639],\"valid\"],[[42640,42640],\"mapped\",[42641]],[[42641,42641],\"valid\"],[[42642,42642],\"mapped\",[42643]],[[42643,42643],\"valid\"],[[42644,42644],\"mapped\",[42645]],[[42645,42645],\"valid\"],[[42646,42646],\"mapped\",[42647]],[[42647,42647],\"valid\"],[[42648,42648],\"mapped\",[42649]],[[42649,42649],\"valid\"],[[42650,42650],\"mapped\",[42651]],[[42651,42651],\"valid\"],[[42652,42652],\"mapped\",[1098]],[[42653,42653],\"mapped\",[1100]],[[42654,42654],\"valid\"],[[42655,42655],\"valid\"],[[42656,42725],\"valid\"],[[42726,42735],\"valid\",[],\"NV8\"],[[42736,42737],\"valid\"],[[42738,42743],\"valid\",[],\"NV8\"],[[42744,42751],\"disallowed\"],[[42752,42774],\"valid\",[],\"NV8\"],[[42775,42778],\"valid\"],[[42779,42783],\"valid\"],[[42784,42785],\"valid\",[],\"NV8\"],[[42786,42786],\"mapped\",[42787]],[[42787,42787],\"valid\"],[[42788,42788],\"mapped\",[42789]],[[42789,42789],\"valid\"],[[42790,42790],\"mapped\",[42791]],[[42791,42791],\"valid\"],[[42792,42792],\"mapped\",[42793]],[[42793,42793],\"valid\"],[[42794,42794],\"mapped\",[42795]],[[42795,42795],\"valid\"],[[42796,42796],\"mapped\",[42797]],[[42797,42797],\"valid\"],[[42798,42798],\"mapped\",[42799]],[[42799,42801],\"valid\"],[[42802,42802],\"mapped\",[42803]],[[42803,42803],\"valid\"],[[42804,42804],\"mapped\",[42805]],[[42805,42805],\"valid\"],[[42806,42806],\"mapped\",[42807]],[[42807,42807],\"valid\"],[[42808,42808],\"mapped\",[42809]],[[42809,42809],\"valid\"],[[42810,42810],\"mapped\",[42811]],[[42811,42811],\"valid\"],[[42812,42812],\"mapped\",[42813]],[[42813,42813],\"valid\"],[[42814,42814],\"mapped\",[42815]],[[42815,42815],\"valid\"],[[42816,42816],\"mapped\",[42817]],[[42817,42817],\"valid\"],[[42818,42818],\"mapped\",[42819]],[[42819,42819],\"valid\"],[[42820,42820],\"mapped\",[42821]],[[42821,42821],\"valid\"],[[42822,42822],\"mapped\",[42823]],[[42823,42823],\"valid\"],[[42824,42824],\"mapped\",[42825]],[[42825,42825],\"valid\"],[[42826,42826],\"mapped\",[42827]],[[42827,42827],\"valid\"],[[42828,42828],\"mapped\",[42829]],[[42829,42829],\"valid\"],[[42830,42830],\"mapped\",[42831]],[[42831,42831],\"valid\"],[[42832,42832],\"mapped\",[42833]],[[42833,42833],\"valid\"],[[42834,42834],\"mapped\",[42835]],[[42835,42835],\"valid\"],[[42836,42836],\"mapped\",[42837]],[[42837,42837],\"valid\"],[[42838,42838],\"mapped\",[42839]],[[42839,42839],\"valid\"],[[42840,42840],\"mapped\",[42841]],[[42841,42841],\"valid\"],[[42842,42842],\"mapped\",[42843]],[[42843,42843],\"valid\"],[[42844,42844],\"mapped\",[42845]],[[42845,42845],\"valid\"],[[42846,42846],\"mapped\",[42847]],[[42847,42847],\"valid\"],[[42848,42848],\"mapped\",[42849]],[[42849,42849],\"valid\"],[[42850,42850],\"mapped\",[42851]],[[42851,42851],\"valid\"],[[42852,42852],\"mapped\",[42853]],[[42853,42853],\"valid\"],[[42854,42854],\"mapped\",[42855]],[[42855,42855],\"valid\"],[[42856,42856],\"mapped\",[42857]],[[42857,42857],\"valid\"],[[42858,42858],\"mapped\",[42859]],[[42859,42859],\"valid\"],[[42860,42860],\"mapped\",[42861]],[[42861,42861],\"valid\"],[[42862,42862],\"mapped\",[42863]],[[42863,42863],\"valid\"],[[42864,42864],\"mapped\",[42863]],[[42865,42872],\"valid\"],[[42873,42873],\"mapped\",[42874]],[[42874,42874],\"valid\"],[[42875,42875],\"mapped\",[42876]],[[42876,42876],\"valid\"],[[42877,42877],\"mapped\",[7545]],[[42878,42878],\"mapped\",[42879]],[[42879,42879],\"valid\"],[[42880,42880],\"mapped\",[42881]],[[42881,42881],\"valid\"],[[42882,42882],\"mapped\",[42883]],[[42883,42883],\"valid\"],[[42884,42884],\"mapped\",[42885]],[[42885,42885],\"valid\"],[[42886,42886],\"mapped\",[42887]],[[42887,42888],\"valid\"],[[42889,42890],\"valid\",[],\"NV8\"],[[42891,42891],\"mapped\",[42892]],[[42892,42892],\"valid\"],[[42893,42893],\"mapped\",[613]],[[42894,42894],\"valid\"],[[42895,42895],\"valid\"],[[42896,42896],\"mapped\",[42897]],[[42897,42897],\"valid\"],[[42898,42898],\"mapped\",[42899]],[[42899,42899],\"valid\"],[[42900,42901],\"valid\"],[[42902,42902],\"mapped\",[42903]],[[42903,42903],\"valid\"],[[42904,42904],\"mapped\",[42905]],[[42905,42905],\"valid\"],[[42906,42906],\"mapped\",[42907]],[[42907,42907],\"valid\"],[[42908,42908],\"mapped\",[42909]],[[42909,42909],\"valid\"],[[42910,42910],\"mapped\",[42911]],[[42911,42911],\"valid\"],[[42912,42912],\"mapped\",[42913]],[[42913,42913],\"valid\"],[[42914,42914],\"mapped\",[42915]],[[42915,42915],\"valid\"],[[42916,42916],\"mapped\",[42917]],[[42917,42917],\"valid\"],[[42918,42918],\"mapped\",[42919]],[[42919,42919],\"valid\"],[[42920,42920],\"mapped\",[42921]],[[42921,42921],\"valid\"],[[42922,42922],\"mapped\",[614]],[[42923,42923],\"mapped\",[604]],[[42924,42924],\"mapped\",[609]],[[42925,42925],\"mapped\",[620]],[[42926,42927],\"disallowed\"],[[42928,42928],\"mapped\",[670]],[[42929,42929],\"mapped\",[647]],[[42930,42930],\"mapped\",[669]],[[42931,42931],\"mapped\",[43859]],[[42932,42932],\"mapped\",[42933]],[[42933,42933],\"valid\"],[[42934,42934],\"mapped\",[42935]],[[42935,42935],\"valid\"],[[42936,42998],\"disallowed\"],[[42999,42999],\"valid\"],[[43000,43000],\"mapped\",[295]],[[43001,43001],\"mapped\",[339]],[[43002,43002],\"valid\"],[[43003,43007],\"valid\"],[[43008,43047],\"valid\"],[[43048,43051],\"valid\",[],\"NV8\"],[[43052,43055],\"disallowed\"],[[43056,43065],\"valid\",[],\"NV8\"],[[43066,43071],\"disallowed\"],[[43072,43123],\"valid\"],[[43124,43127],\"valid\",[],\"NV8\"],[[43128,43135],\"disallowed\"],[[43136,43204],\"valid\"],[[43205,43213],\"disallowed\"],[[43214,43215],\"valid\",[],\"NV8\"],[[43216,43225],\"valid\"],[[43226,43231],\"disallowed\"],[[43232,43255],\"valid\"],[[43256,43258],\"valid\",[],\"NV8\"],[[43259,43259],\"valid\"],[[43260,43260],\"valid\",[],\"NV8\"],[[43261,43261],\"valid\"],[[43262,43263],\"disallowed\"],[[43264,43309],\"valid\"],[[43310,43311],\"valid\",[],\"NV8\"],[[43312,43347],\"valid\"],[[43348,43358],\"disallowed\"],[[43359,43359],\"valid\",[],\"NV8\"],[[43360,43388],\"valid\",[],\"NV8\"],[[43389,43391],\"disallowed\"],[[43392,43456],\"valid\"],[[43457,43469],\"valid\",[],\"NV8\"],[[43470,43470],\"disallowed\"],[[43471,43481],\"valid\"],[[43482,43485],\"disallowed\"],[[43486,43487],\"valid\",[],\"NV8\"],[[43488,43518],\"valid\"],[[43519,43519],\"disallowed\"],[[43520,43574],\"valid\"],[[43575,43583],\"disallowed\"],[[43584,43597],\"valid\"],[[43598,43599],\"disallowed\"],[[43600,43609],\"valid\"],[[43610,43611],\"disallowed\"],[[43612,43615],\"valid\",[],\"NV8\"],[[43616,43638],\"valid\"],[[43639,43641],\"valid\",[],\"NV8\"],[[43642,43643],\"valid\"],[[43644,43647],\"valid\"],[[43648,43714],\"valid\"],[[43715,43738],\"disallowed\"],[[43739,43741],\"valid\"],[[43742,43743],\"valid\",[],\"NV8\"],[[43744,43759],\"valid\"],[[43760,43761],\"valid\",[],\"NV8\"],[[43762,43766],\"valid\"],[[43767,43776],\"disallowed\"],[[43777,43782],\"valid\"],[[43783,43784],\"disallowed\"],[[43785,43790],\"valid\"],[[43791,43792],\"disallowed\"],[[43793,43798],\"valid\"],[[43799,43807],\"disallowed\"],[[43808,43814],\"valid\"],[[43815,43815],\"disallowed\"],[[43816,43822],\"valid\"],[[43823,43823],\"disallowed\"],[[43824,43866],\"valid\"],[[43867,43867],\"valid\",[],\"NV8\"],[[43868,43868],\"mapped\",[42791]],[[43869,43869],\"mapped\",[43831]],[[43870,43870],\"mapped\",[619]],[[43871,43871],\"mapped\",[43858]],[[43872,43875],\"valid\"],[[43876,43877],\"valid\"],[[43878,43887],\"disallowed\"],[[43888,43888],\"mapped\",[5024]],[[43889,43889],\"mapped\",[5025]],[[43890,43890],\"mapped\",[5026]],[[43891,43891],\"mapped\",[5027]],[[43892,43892],\"mapped\",[5028]],[[43893,43893],\"mapped\",[5029]],[[43894,43894],\"mapped\",[5030]],[[43895,43895],\"mapped\",[5031]],[[43896,43896],\"mapped\",[5032]],[[43897,43897],\"mapped\",[5033]],[[43898,43898],\"mapped\",[5034]],[[43899,43899],\"mapped\",[5035]],[[43900,43900],\"mapped\",[5036]],[[43901,43901],\"mapped\",[5037]],[[43902,43902],\"mapped\",[5038]],[[43903,43903],\"mapped\",[5039]],[[43904,43904],\"mapped\",[5040]],[[43905,43905],\"mapped\",[5041]],[[43906,43906],\"mapped\",[5042]],[[43907,43907],\"mapped\",[5043]],[[43908,43908],\"mapped\",[5044]],[[43909,43909],\"mapped\",[5045]],[[43910,43910],\"mapped\",[5046]],[[43911,43911],\"mapped\",[5047]],[[43912,43912],\"mapped\",[5048]],[[43913,43913],\"mapped\",[5049]],[[43914,43914],\"mapped\",[5050]],[[43915,43915],\"mapped\",[5051]],[[43916,43916],\"mapped\",[5052]],[[43917,43917],\"mapped\",[5053]],[[43918,43918],\"mapped\",[5054]],[[43919,43919],\"mapped\",[5055]],[[43920,43920],\"mapped\",[5056]],[[43921,43921],\"mapped\",[5057]],[[43922,43922],\"mapped\",[5058]],[[43923,43923],\"mapped\",[5059]],[[43924,43924],\"mapped\",[5060]],[[43925,43925],\"mapped\",[5061]],[[43926,43926],\"mapped\",[5062]],[[43927,43927],\"mapped\",[5063]],[[43928,43928],\"mapped\",[5064]],[[43929,43929],\"mapped\",[5065]],[[43930,43930],\"mapped\",[5066]],[[43931,43931],\"mapped\",[5067]],[[43932,43932],\"mapped\",[5068]],[[43933,43933],\"mapped\",[5069]],[[43934,43934],\"mapped\",[5070]],[[43935,43935],\"mapped\",[5071]],[[43936,43936],\"mapped\",[5072]],[[43937,43937],\"mapped\",[5073]],[[43938,43938],\"mapped\",[5074]],[[43939,43939],\"mapped\",[5075]],[[43940,43940],\"mapped\",[5076]],[[43941,43941],\"mapped\",[5077]],[[43942,43942],\"mapped\",[5078]],[[43943,43943],\"mapped\",[5079]],[[43944,43944],\"mapped\",[5080]],[[43945,43945],\"mapped\",[5081]],[[43946,43946],\"mapped\",[5082]],[[43947,43947],\"mapped\",[5083]],[[43948,43948],\"mapped\",[5084]],[[43949,43949],\"mapped\",[5085]],[[43950,43950],\"mapped\",[5086]],[[43951,43951],\"mapped\",[5087]],[[43952,43952],\"mapped\",[5088]],[[43953,43953],\"mapped\",[5089]],[[43954,43954],\"mapped\",[5090]],[[43955,43955],\"mapped\",[5091]],[[43956,43956],\"mapped\",[5092]],[[43957,43957],\"mapped\",[5093]],[[43958,43958],\"mapped\",[5094]],[[43959,43959],\"mapped\",[5095]],[[43960,43960],\"mapped\",[5096]],[[43961,43961],\"mapped\",[5097]],[[43962,43962],\"mapped\",[5098]],[[43963,43963],\"mapped\",[5099]],[[43964,43964],\"mapped\",[5100]],[[43965,43965],\"mapped\",[5101]],[[43966,43966],\"mapped\",[5102]],[[43967,43967],\"mapped\",[5103]],[[43968,44010],\"valid\"],[[44011,44011],\"valid\",[],\"NV8\"],[[44012,44013],\"valid\"],[[44014,44015],\"disallowed\"],[[44016,44025],\"valid\"],[[44026,44031],\"disallowed\"],[[44032,55203],\"valid\"],[[55204,55215],\"disallowed\"],[[55216,55238],\"valid\",[],\"NV8\"],[[55239,55242],\"disallowed\"],[[55243,55291],\"valid\",[],\"NV8\"],[[55292,55295],\"disallowed\"],[[55296,57343],\"disallowed\"],[[57344,63743],\"disallowed\"],[[63744,63744],\"mapped\",[35912]],[[63745,63745],\"mapped\",[26356]],[[63746,63746],\"mapped\",[36554]],[[63747,63747],\"mapped\",[36040]],[[63748,63748],\"mapped\",[28369]],[[63749,63749],\"mapped\",[20018]],[[63750,63750],\"mapped\",[21477]],[[63751,63752],\"mapped\",[40860]],[[63753,63753],\"mapped\",[22865]],[[63754,63754],\"mapped\",[37329]],[[63755,63755],\"mapped\",[21895]],[[63756,63756],\"mapped\",[22856]],[[63757,63757],\"mapped\",[25078]],[[63758,63758],\"mapped\",[30313]],[[63759,63759],\"mapped\",[32645]],[[63760,63760],\"mapped\",[34367]],[[63761,63761],\"mapped\",[34746]],[[63762,63762],\"mapped\",[35064]],[[63763,63763],\"mapped\",[37007]],[[63764,63764],\"mapped\",[27138]],[[63765,63765],\"mapped\",[27931]],[[63766,63766],\"mapped\",[28889]],[[63767,63767],\"mapped\",[29662]],[[63768,63768],\"mapped\",[33853]],[[63769,63769],\"mapped\",[37226]],[[63770,63770],\"mapped\",[39409]],[[63771,63771],\"mapped\",[20098]],[[63772,63772],\"mapped\",[21365]],[[63773,63773],\"mapped\",[27396]],[[63774,63774],\"mapped\",[29211]],[[63775,63775],\"mapped\",[34349]],[[63776,63776],\"mapped\",[40478]],[[63777,63777],\"mapped\",[23888]],[[63778,63778],\"mapped\",[28651]],[[63779,63779],\"mapped\",[34253]],[[63780,63780],\"mapped\",[35172]],[[63781,63781],\"mapped\",[25289]],[[63782,63782],\"mapped\",[33240]],[[63783,63783],\"mapped\",[34847]],[[63784,63784],\"mapped\",[24266]],[[63785,63785],\"mapped\",[26391]],[[63786,63786],\"mapped\",[28010]],[[63787,63787],\"mapped\",[29436]],[[63788,63788],\"mapped\",[37070]],[[63789,63789],\"mapped\",[20358]],[[63790,63790],\"mapped\",[20919]],[[63791,63791],\"mapped\",[21214]],[[63792,63792],\"mapped\",[25796]],[[63793,63793],\"mapped\",[27347]],[[63794,63794],\"mapped\",[29200]],[[63795,63795],\"mapped\",[30439]],[[63796,63796],\"mapped\",[32769]],[[63797,63797],\"mapped\",[34310]],[[63798,63798],\"mapped\",[34396]],[[63799,63799],\"mapped\",[36335]],[[63800,63800],\"mapped\",[38706]],[[63801,63801],\"mapped\",[39791]],[[63802,63802],\"mapped\",[40442]],[[63803,63803],\"mapped\",[30860]],[[63804,63804],\"mapped\",[31103]],[[63805,63805],\"mapped\",[32160]],[[63806,63806],\"mapped\",[33737]],[[63807,63807],\"mapped\",[37636]],[[63808,63808],\"mapped\",[40575]],[[63809,63809],\"mapped\",[35542]],[[63810,63810],\"mapped\",[22751]],[[63811,63811],\"mapped\",[24324]],[[63812,63812],\"mapped\",[31840]],[[63813,63813],\"mapped\",[32894]],[[63814,63814],\"mapped\",[29282]],[[63815,63815],\"mapped\",[30922]],[[63816,63816],\"mapped\",[36034]],[[63817,63817],\"mapped\",[38647]],[[63818,63818],\"mapped\",[22744]],[[63819,63819],\"mapped\",[23650]],[[63820,63820],\"mapped\",[27155]],[[63821,63821],\"mapped\",[28122]],[[63822,63822],\"mapped\",[28431]],[[63823,63823],\"mapped\",[32047]],[[63824,63824],\"mapped\",[32311]],[[63825,63825],\"mapped\",[38475]],[[63826,63826],\"mapped\",[21202]],[[63827,63827],\"mapped\",[32907]],[[63828,63828],\"mapped\",[20956]],[[63829,63829],\"mapped\",[20940]],[[63830,63830],\"mapped\",[31260]],[[63831,63831],\"mapped\",[32190]],[[63832,63832],\"mapped\",[33777]],[[63833,63833],\"mapped\",[38517]],[[63834,63834],\"mapped\",[35712]],[[63835,63835],\"mapped\",[25295]],[[63836,63836],\"mapped\",[27138]],[[63837,63837],\"mapped\",[35582]],[[63838,63838],\"mapped\",[20025]],[[63839,63839],\"mapped\",[23527]],[[63840,63840],\"mapped\",[24594]],[[63841,63841],\"mapped\",[29575]],[[63842,63842],\"mapped\",[30064]],[[63843,63843],\"mapped\",[21271]],[[63844,63844],\"mapped\",[30971]],[[63845,63845],\"mapped\",[20415]],[[63846,63846],\"mapped\",[24489]],[[63847,63847],\"mapped\",[19981]],[[63848,63848],\"mapped\",[27852]],[[63849,63849],\"mapped\",[25976]],[[63850,63850],\"mapped\",[32034]],[[63851,63851],\"mapped\",[21443]],[[63852,63852],\"mapped\",[22622]],[[63853,63853],\"mapped\",[30465]],[[63854,63854],\"mapped\",[33865]],[[63855,63855],\"mapped\",[35498]],[[63856,63856],\"mapped\",[27578]],[[63857,63857],\"mapped\",[36784]],[[63858,63858],\"mapped\",[27784]],[[63859,63859],\"mapped\",[25342]],[[63860,63860],\"mapped\",[33509]],[[63861,63861],\"mapped\",[25504]],[[63862,63862],\"mapped\",[30053]],[[63863,63863],\"mapped\",[20142]],[[63864,63864],\"mapped\",[20841]],[[63865,63865],\"mapped\",[20937]],[[63866,63866],\"mapped\",[26753]],[[63867,63867],\"mapped\",[31975]],[[63868,63868],\"mapped\",[33391]],[[63869,63869],\"mapped\",[35538]],[[63870,63870],\"mapped\",[37327]],[[63871,63871],\"mapped\",[21237]],[[63872,63872],\"mapped\",[21570]],[[63873,63873],\"mapped\",[22899]],[[63874,63874],\"mapped\",[24300]],[[63875,63875],\"mapped\",[26053]],[[63876,63876],\"mapped\",[28670]],[[63877,63877],\"mapped\",[31018]],[[63878,63878],\"mapped\",[38317]],[[63879,63879],\"mapped\",[39530]],[[63880,63880],\"mapped\",[40599]],[[63881,63881],\"mapped\",[40654]],[[63882,63882],\"mapped\",[21147]],[[63883,63883],\"mapped\",[26310]],[[63884,63884],\"mapped\",[27511]],[[63885,63885],\"mapped\",[36706]],[[63886,63886],\"mapped\",[24180]],[[63887,63887],\"mapped\",[24976]],[[63888,63888],\"mapped\",[25088]],[[63889,63889],\"mapped\",[25754]],[[63890,63890],\"mapped\",[28451]],[[63891,63891],\"mapped\",[29001]],[[63892,63892],\"mapped\",[29833]],[[63893,63893],\"mapped\",[31178]],[[63894,63894],\"mapped\",[32244]],[[63895,63895],\"mapped\",[32879]],[[63896,63896],\"mapped\",[36646]],[[63897,63897],\"mapped\",[34030]],[[63898,63898],\"mapped\",[36899]],[[63899,63899],\"mapped\",[37706]],[[63900,63900],\"mapped\",[21015]],[[63901,63901],\"mapped\",[21155]],[[63902,63902],\"mapped\",[21693]],[[63903,63903],\"mapped\",[28872]],[[63904,63904],\"mapped\",[35010]],[[63905,63905],\"mapped\",[35498]],[[63906,63906],\"mapped\",[24265]],[[63907,63907],\"mapped\",[24565]],[[63908,63908],\"mapped\",[25467]],[[63909,63909],\"mapped\",[27566]],[[63910,63910],\"mapped\",[31806]],[[63911,63911],\"mapped\",[29557]],[[63912,63912],\"mapped\",[20196]],[[63913,63913],\"mapped\",[22265]],[[63914,63914],\"mapped\",[23527]],[[63915,63915],\"mapped\",[23994]],[[63916,63916],\"mapped\",[24604]],[[63917,63917],\"mapped\",[29618]],[[63918,63918],\"mapped\",[29801]],[[63919,63919],\"mapped\",[32666]],[[63920,63920],\"mapped\",[32838]],[[63921,63921],\"mapped\",[37428]],[[63922,63922],\"mapped\",[38646]],[[63923,63923],\"mapped\",[38728]],[[63924,63924],\"mapped\",[38936]],[[63925,63925],\"mapped\",[20363]],[[63926,63926],\"mapped\",[31150]],[[63927,63927],\"mapped\",[37300]],[[63928,63928],\"mapped\",[38584]],[[63929,63929],\"mapped\",[24801]],[[63930,63930],\"mapped\",[20102]],[[63931,63931],\"mapped\",[20698]],[[63932,63932],\"mapped\",[23534]],[[63933,63933],\"mapped\",[23615]],[[63934,63934],\"mapped\",[26009]],[[63935,63935],\"mapped\",[27138]],[[63936,63936],\"mapped\",[29134]],[[63937,63937],\"mapped\",[30274]],[[63938,63938],\"mapped\",[34044]],[[63939,63939],\"mapped\",[36988]],[[63940,63940],\"mapped\",[40845]],[[63941,63941],\"mapped\",[26248]],[[63942,63942],\"mapped\",[38446]],[[63943,63943],\"mapped\",[21129]],[[63944,63944],\"mapped\",[26491]],[[63945,63945],\"mapped\",[26611]],[[63946,63946],\"mapped\",[27969]],[[63947,63947],\"mapped\",[28316]],[[63948,63948],\"mapped\",[29705]],[[63949,63949],\"mapped\",[30041]],[[63950,63950],\"mapped\",[30827]],[[63951,63951],\"mapped\",[32016]],[[63952,63952],\"mapped\",[39006]],[[63953,63953],\"mapped\",[20845]],[[63954,63954],\"mapped\",[25134]],[[63955,63955],\"mapped\",[38520]],[[63956,63956],\"mapped\",[20523]],[[63957,63957],\"mapped\",[23833]],[[63958,63958],\"mapped\",[28138]],[[63959,63959],\"mapped\",[36650]],[[63960,63960],\"mapped\",[24459]],[[63961,63961],\"mapped\",[24900]],[[63962,63962],\"mapped\",[26647]],[[63963,63963],\"mapped\",[29575]],[[63964,63964],\"mapped\",[38534]],[[63965,63965],\"mapped\",[21033]],[[63966,63966],\"mapped\",[21519]],[[63967,63967],\"mapped\",[23653]],[[63968,63968],\"mapped\",[26131]],[[63969,63969],\"mapped\",[26446]],[[63970,63970],\"mapped\",[26792]],[[63971,63971],\"mapped\",[27877]],[[63972,63972],\"mapped\",[29702]],[[63973,63973],\"mapped\",[30178]],[[63974,63974],\"mapped\",[32633]],[[63975,63975],\"mapped\",[35023]],[[63976,63976],\"mapped\",[35041]],[[63977,63977],\"mapped\",[37324]],[[63978,63978],\"mapped\",[38626]],[[63979,63979],\"mapped\",[21311]],[[63980,63980],\"mapped\",[28346]],[[63981,63981],\"mapped\",[21533]],[[63982,63982],\"mapped\",[29136]],[[63983,63983],\"mapped\",[29848]],[[63984,63984],\"mapped\",[34298]],[[63985,63985],\"mapped\",[38563]],[[63986,63986],\"mapped\",[40023]],[[63987,63987],\"mapped\",[40607]],[[63988,63988],\"mapped\",[26519]],[[63989,63989],\"mapped\",[28107]],[[63990,63990],\"mapped\",[33256]],[[63991,63991],\"mapped\",[31435]],[[63992,63992],\"mapped\",[31520]],[[63993,63993],\"mapped\",[31890]],[[63994,63994],\"mapped\",[29376]],[[63995,63995],\"mapped\",[28825]],[[63996,63996],\"mapped\",[35672]],[[63997,63997],\"mapped\",[20160]],[[63998,63998],\"mapped\",[33590]],[[63999,63999],\"mapped\",[21050]],[[64000,64000],\"mapped\",[20999]],[[64001,64001],\"mapped\",[24230]],[[64002,64002],\"mapped\",[25299]],[[64003,64003],\"mapped\",[31958]],[[64004,64004],\"mapped\",[23429]],[[64005,64005],\"mapped\",[27934]],[[64006,64006],\"mapped\",[26292]],[[64007,64007],\"mapped\",[36667]],[[64008,64008],\"mapped\",[34892]],[[64009,64009],\"mapped\",[38477]],[[64010,64010],\"mapped\",[35211]],[[64011,64011],\"mapped\",[24275]],[[64012,64012],\"mapped\",[20800]],[[64013,64013],\"mapped\",[21952]],[[64014,64015],\"valid\"],[[64016,64016],\"mapped\",[22618]],[[64017,64017],\"valid\"],[[64018,64018],\"mapped\",[26228]],[[64019,64020],\"valid\"],[[64021,64021],\"mapped\",[20958]],[[64022,64022],\"mapped\",[29482]],[[64023,64023],\"mapped\",[30410]],[[64024,64024],\"mapped\",[31036]],[[64025,64025],\"mapped\",[31070]],[[64026,64026],\"mapped\",[31077]],[[64027,64027],\"mapped\",[31119]],[[64028,64028],\"mapped\",[38742]],[[64029,64029],\"mapped\",[31934]],[[64030,64030],\"mapped\",[32701]],[[64031,64031],\"valid\"],[[64032,64032],\"mapped\",[34322]],[[64033,64033],\"valid\"],[[64034,64034],\"mapped\",[35576]],[[64035,64036],\"valid\"],[[64037,64037],\"mapped\",[36920]],[[64038,64038],\"mapped\",[37117]],[[64039,64041],\"valid\"],[[64042,64042],\"mapped\",[39151]],[[64043,64043],\"mapped\",[39164]],[[64044,64044],\"mapped\",[39208]],[[64045,64045],\"mapped\",[40372]],[[64046,64046],\"mapped\",[37086]],[[64047,64047],\"mapped\",[38583]],[[64048,64048],\"mapped\",[20398]],[[64049,64049],\"mapped\",[20711]],[[64050,64050],\"mapped\",[20813]],[[64051,64051],\"mapped\",[21193]],[[64052,64052],\"mapped\",[21220]],[[64053,64053],\"mapped\",[21329]],[[64054,64054],\"mapped\",[21917]],[[64055,64055],\"mapped\",[22022]],[[64056,64056],\"mapped\",[22120]],[[64057,64057],\"mapped\",[22592]],[[64058,64058],\"mapped\",[22696]],[[64059,64059],\"mapped\",[23652]],[[64060,64060],\"mapped\",[23662]],[[64061,64061],\"mapped\",[24724]],[[64062,64062],\"mapped\",[24936]],[[64063,64063],\"mapped\",[24974]],[[64064,64064],\"mapped\",[25074]],[[64065,64065],\"mapped\",[25935]],[[64066,64066],\"mapped\",[26082]],[[64067,64067],\"mapped\",[26257]],[[64068,64068],\"mapped\",[26757]],[[64069,64069],\"mapped\",[28023]],[[64070,64070],\"mapped\",[28186]],[[64071,64071],\"mapped\",[28450]],[[64072,64072],\"mapped\",[29038]],[[64073,64073],\"mapped\",[29227]],[[64074,64074],\"mapped\",[29730]],[[64075,64075],\"mapped\",[30865]],[[64076,64076],\"mapped\",[31038]],[[64077,64077],\"mapped\",[31049]],[[64078,64078],\"mapped\",[31048]],[[64079,64079],\"mapped\",[31056]],[[64080,64080],\"mapped\",[31062]],[[64081,64081],\"mapped\",[31069]],[[64082,64082],\"mapped\",[31117]],[[64083,64083],\"mapped\",[31118]],[[64084,64084],\"mapped\",[31296]],[[64085,64085],\"mapped\",[31361]],[[64086,64086],\"mapped\",[31680]],[[64087,64087],\"mapped\",[32244]],[[64088,64088],\"mapped\",[32265]],[[64089,64089],\"mapped\",[32321]],[[64090,64090],\"mapped\",[32626]],[[64091,64091],\"mapped\",[32773]],[[64092,64092],\"mapped\",[33261]],[[64093,64094],\"mapped\",[33401]],[[64095,64095],\"mapped\",[33879]],[[64096,64096],\"mapped\",[35088]],[[64097,64097],\"mapped\",[35222]],[[64098,64098],\"mapped\",[35585]],[[64099,64099],\"mapped\",[35641]],[[64100,64100],\"mapped\",[36051]],[[64101,64101],\"mapped\",[36104]],[[64102,64102],\"mapped\",[36790]],[[64103,64103],\"mapped\",[36920]],[[64104,64104],\"mapped\",[38627]],[[64105,64105],\"mapped\",[38911]],[[64106,64106],\"mapped\",[38971]],[[64107,64107],\"mapped\",[24693]],[[64108,64108],\"mapped\",[148206]],[[64109,64109],\"mapped\",[33304]],[[64110,64111],\"disallowed\"],[[64112,64112],\"mapped\",[20006]],[[64113,64113],\"mapped\",[20917]],[[64114,64114],\"mapped\",[20840]],[[64115,64115],\"mapped\",[20352]],[[64116,64116],\"mapped\",[20805]],[[64117,64117],\"mapped\",[20864]],[[64118,64118],\"mapped\",[21191]],[[64119,64119],\"mapped\",[21242]],[[64120,64120],\"mapped\",[21917]],[[64121,64121],\"mapped\",[21845]],[[64122,64122],\"mapped\",[21913]],[[64123,64123],\"mapped\",[21986]],[[64124,64124],\"mapped\",[22618]],[[64125,64125],\"mapped\",[22707]],[[64126,64126],\"mapped\",[22852]],[[64127,64127],\"mapped\",[22868]],[[64128,64128],\"mapped\",[23138]],[[64129,64129],\"mapped\",[23336]],[[64130,64130],\"mapped\",[24274]],[[64131,64131],\"mapped\",[24281]],[[64132,64132],\"mapped\",[24425]],[[64133,64133],\"mapped\",[24493]],[[64134,64134],\"mapped\",[24792]],[[64135,64135],\"mapped\",[24910]],[[64136,64136],\"mapped\",[24840]],[[64137,64137],\"mapped\",[24974]],[[64138,64138],\"mapped\",[24928]],[[64139,64139],\"mapped\",[25074]],[[64140,64140],\"mapped\",[25140]],[[64141,64141],\"mapped\",[25540]],[[64142,64142],\"mapped\",[25628]],[[64143,64143],\"mapped\",[25682]],[[64144,64144],\"mapped\",[25942]],[[64145,64145],\"mapped\",[26228]],[[64146,64146],\"mapped\",[26391]],[[64147,64147],\"mapped\",[26395]],[[64148,64148],\"mapped\",[26454]],[[64149,64149],\"mapped\",[27513]],[[64150,64150],\"mapped\",[27578]],[[64151,64151],\"mapped\",[27969]],[[64152,64152],\"mapped\",[28379]],[[64153,64153],\"mapped\",[28363]],[[64154,64154],\"mapped\",[28450]],[[64155,64155],\"mapped\",[28702]],[[64156,64156],\"mapped\",[29038]],[[64157,64157],\"mapped\",[30631]],[[64158,64158],\"mapped\",[29237]],[[64159,64159],\"mapped\",[29359]],[[64160,64160],\"mapped\",[29482]],[[64161,64161],\"mapped\",[29809]],[[64162,64162],\"mapped\",[29958]],[[64163,64163],\"mapped\",[30011]],[[64164,64164],\"mapped\",[30237]],[[64165,64165],\"mapped\",[30239]],[[64166,64166],\"mapped\",[30410]],[[64167,64167],\"mapped\",[30427]],[[64168,64168],\"mapped\",[30452]],[[64169,64169],\"mapped\",[30538]],[[64170,64170],\"mapped\",[30528]],[[64171,64171],\"mapped\",[30924]],[[64172,64172],\"mapped\",[31409]],[[64173,64173],\"mapped\",[31680]],[[64174,64174],\"mapped\",[31867]],[[64175,64175],\"mapped\",[32091]],[[64176,64176],\"mapped\",[32244]],[[64177,64177],\"mapped\",[32574]],[[64178,64178],\"mapped\",[32773]],[[64179,64179],\"mapped\",[33618]],[[64180,64180],\"mapped\",[33775]],[[64181,64181],\"mapped\",[34681]],[[64182,64182],\"mapped\",[35137]],[[64183,64183],\"mapped\",[35206]],[[64184,64184],\"mapped\",[35222]],[[64185,64185],\"mapped\",[35519]],[[64186,64186],\"mapped\",[35576]],[[64187,64187],\"mapped\",[35531]],[[64188,64188],\"mapped\",[35585]],[[64189,64189],\"mapped\",[35582]],[[64190,64190],\"mapped\",[35565]],[[64191,64191],\"mapped\",[35641]],[[64192,64192],\"mapped\",[35722]],[[64193,64193],\"mapped\",[36104]],[[64194,64194],\"mapped\",[36664]],[[64195,64195],\"mapped\",[36978]],[[64196,64196],\"mapped\",[37273]],[[64197,64197],\"mapped\",[37494]],[[64198,64198],\"mapped\",[38524]],[[64199,64199],\"mapped\",[38627]],[[64200,64200],\"mapped\",[38742]],[[64201,64201],\"mapped\",[38875]],[[64202,64202],\"mapped\",[38911]],[[64203,64203],\"mapped\",[38923]],[[64204,64204],\"mapped\",[38971]],[[64205,64205],\"mapped\",[39698]],[[64206,64206],\"mapped\",[40860]],[[64207,64207],\"mapped\",[141386]],[[64208,64208],\"mapped\",[141380]],[[64209,64209],\"mapped\",[144341]],[[64210,64210],\"mapped\",[15261]],[[64211,64211],\"mapped\",[16408]],[[64212,64212],\"mapped\",[16441]],[[64213,64213],\"mapped\",[152137]],[[64214,64214],\"mapped\",[154832]],[[64215,64215],\"mapped\",[163539]],[[64216,64216],\"mapped\",[40771]],[[64217,64217],\"mapped\",[40846]],[[64218,64255],\"disallowed\"],[[64256,64256],\"mapped\",[102,102]],[[64257,64257],\"mapped\",[102,105]],[[64258,64258],\"mapped\",[102,108]],[[64259,64259],\"mapped\",[102,102,105]],[[64260,64260],\"mapped\",[102,102,108]],[[64261,64262],\"mapped\",[115,116]],[[64263,64274],\"disallowed\"],[[64275,64275],\"mapped\",[1396,1398]],[[64276,64276],\"mapped\",[1396,1381]],[[64277,64277],\"mapped\",[1396,1387]],[[64278,64278],\"mapped\",[1406,1398]],[[64279,64279],\"mapped\",[1396,1389]],[[64280,64284],\"disallowed\"],[[64285,64285],\"mapped\",[1497,1460]],[[64286,64286],\"valid\"],[[64287,64287],\"mapped\",[1522,1463]],[[64288,64288],\"mapped\",[1506]],[[64289,64289],\"mapped\",[1488]],[[64290,64290],\"mapped\",[1491]],[[64291,64291],\"mapped\",[1492]],[[64292,64292],\"mapped\",[1499]],[[64293,64293],\"mapped\",[1500]],[[64294,64294],\"mapped\",[1501]],[[64295,64295],\"mapped\",[1512]],[[64296,64296],\"mapped\",[1514]],[[64297,64297],\"disallowed_STD3_mapped\",[43]],[[64298,64298],\"mapped\",[1513,1473]],[[64299,64299],\"mapped\",[1513,1474]],[[64300,64300],\"mapped\",[1513,1468,1473]],[[64301,64301],\"mapped\",[1513,1468,1474]],[[64302,64302],\"mapped\",[1488,1463]],[[64303,64303],\"mapped\",[1488,1464]],[[64304,64304],\"mapped\",[1488,1468]],[[64305,64305],\"mapped\",[1489,1468]],[[64306,64306],\"mapped\",[1490,1468]],[[64307,64307],\"mapped\",[1491,1468]],[[64308,64308],\"mapped\",[1492,1468]],[[64309,64309],\"mapped\",[1493,1468]],[[64310,64310],\"mapped\",[1494,1468]],[[64311,64311],\"disallowed\"],[[64312,64312],\"mapped\",[1496,1468]],[[64313,64313],\"mapped\",[1497,1468]],[[64314,64314],\"mapped\",[1498,1468]],[[64315,64315],\"mapped\",[1499,1468]],[[64316,64316],\"mapped\",[1500,1468]],[[64317,64317],\"disallowed\"],[[64318,64318],\"mapped\",[1502,1468]],[[64319,64319],\"disallowed\"],[[64320,64320],\"mapped\",[1504,1468]],[[64321,64321],\"mapped\",[1505,1468]],[[64322,64322],\"disallowed\"],[[64323,64323],\"mapped\",[1507,1468]],[[64324,64324],\"mapped\",[1508,1468]],[[64325,64325],\"disallowed\"],[[64326,64326],\"mapped\",[1510,1468]],[[64327,64327],\"mapped\",[1511,1468]],[[64328,64328],\"mapped\",[1512,1468]],[[64329,64329],\"mapped\",[1513,1468]],[[64330,64330],\"mapped\",[1514,1468]],[[64331,64331],\"mapped\",[1493,1465]],[[64332,64332],\"mapped\",[1489,1471]],[[64333,64333],\"mapped\",[1499,1471]],[[64334,64334],\"mapped\",[1508,1471]],[[64335,64335],\"mapped\",[1488,1500]],[[64336,64337],\"mapped\",[1649]],[[64338,64341],\"mapped\",[1659]],[[64342,64345],\"mapped\",[1662]],[[64346,64349],\"mapped\",[1664]],[[64350,64353],\"mapped\",[1658]],[[64354,64357],\"mapped\",[1663]],[[64358,64361],\"mapped\",[1657]],[[64362,64365],\"mapped\",[1700]],[[64366,64369],\"mapped\",[1702]],[[64370,64373],\"mapped\",[1668]],[[64374,64377],\"mapped\",[1667]],[[64378,64381],\"mapped\",[1670]],[[64382,64385],\"mapped\",[1671]],[[64386,64387],\"mapped\",[1677]],[[64388,64389],\"mapped\",[1676]],[[64390,64391],\"mapped\",[1678]],[[64392,64393],\"mapped\",[1672]],[[64394,64395],\"mapped\",[1688]],[[64396,64397],\"mapped\",[1681]],[[64398,64401],\"mapped\",[1705]],[[64402,64405],\"mapped\",[1711]],[[64406,64409],\"mapped\",[1715]],[[64410,64413],\"mapped\",[1713]],[[64414,64415],\"mapped\",[1722]],[[64416,64419],\"mapped\",[1723]],[[64420,64421],\"mapped\",[1728]],[[64422,64425],\"mapped\",[1729]],[[64426,64429],\"mapped\",[1726]],[[64430,64431],\"mapped\",[1746]],[[64432,64433],\"mapped\",[1747]],[[64434,64449],\"valid\",[],\"NV8\"],[[64450,64466],\"disallowed\"],[[64467,64470],\"mapped\",[1709]],[[64471,64472],\"mapped\",[1735]],[[64473,64474],\"mapped\",[1734]],[[64475,64476],\"mapped\",[1736]],[[64477,64477],\"mapped\",[1735,1652]],[[64478,64479],\"mapped\",[1739]],[[64480,64481],\"mapped\",[1733]],[[64482,64483],\"mapped\",[1737]],[[64484,64487],\"mapped\",[1744]],[[64488,64489],\"mapped\",[1609]],[[64490,64491],\"mapped\",[1574,1575]],[[64492,64493],\"mapped\",[1574,1749]],[[64494,64495],\"mapped\",[1574,1608]],[[64496,64497],\"mapped\",[1574,1735]],[[64498,64499],\"mapped\",[1574,1734]],[[64500,64501],\"mapped\",[1574,1736]],[[64502,64504],\"mapped\",[1574,1744]],[[64505,64507],\"mapped\",[1574,1609]],[[64508,64511],\"mapped\",[1740]],[[64512,64512],\"mapped\",[1574,1580]],[[64513,64513],\"mapped\",[1574,1581]],[[64514,64514],\"mapped\",[1574,1605]],[[64515,64515],\"mapped\",[1574,1609]],[[64516,64516],\"mapped\",[1574,1610]],[[64517,64517],\"mapped\",[1576,1580]],[[64518,64518],\"mapped\",[1576,1581]],[[64519,64519],\"mapped\",[1576,1582]],[[64520,64520],\"mapped\",[1576,1605]],[[64521,64521],\"mapped\",[1576,1609]],[[64522,64522],\"mapped\",[1576,1610]],[[64523,64523],\"mapped\",[1578,1580]],[[64524,64524],\"mapped\",[1578,1581]],[[64525,64525],\"mapped\",[1578,1582]],[[64526,64526],\"mapped\",[1578,1605]],[[64527,64527],\"mapped\",[1578,1609]],[[64528,64528],\"mapped\",[1578,1610]],[[64529,64529],\"mapped\",[1579,1580]],[[64530,64530],\"mapped\",[1579,1605]],[[64531,64531],\"mapped\",[1579,1609]],[[64532,64532],\"mapped\",[1579,1610]],[[64533,64533],\"mapped\",[1580,1581]],[[64534,64534],\"mapped\",[1580,1605]],[[64535,64535],\"mapped\",[1581,1580]],[[64536,64536],\"mapped\",[1581,1605]],[[64537,64537],\"mapped\",[1582,1580]],[[64538,64538],\"mapped\",[1582,1581]],[[64539,64539],\"mapped\",[1582,1605]],[[64540,64540],\"mapped\",[1587,1580]],[[64541,64541],\"mapped\",[1587,1581]],[[64542,64542],\"mapped\",[1587,1582]],[[64543,64543],\"mapped\",[1587,1605]],[[64544,64544],\"mapped\",[1589,1581]],[[64545,64545],\"mapped\",[1589,1605]],[[64546,64546],\"mapped\",[1590,1580]],[[64547,64547],\"mapped\",[1590,1581]],[[64548,64548],\"mapped\",[1590,1582]],[[64549,64549],\"mapped\",[1590,1605]],[[64550,64550],\"mapped\",[1591,1581]],[[64551,64551],\"mapped\",[1591,1605]],[[64552,64552],\"mapped\",[1592,1605]],[[64553,64553],\"mapped\",[1593,1580]],[[64554,64554],\"mapped\",[1593,1605]],[[64555,64555],\"mapped\",[1594,1580]],[[64556,64556],\"mapped\",[1594,1605]],[[64557,64557],\"mapped\",[1601,1580]],[[64558,64558],\"mapped\",[1601,1581]],[[64559,64559],\"mapped\",[1601,1582]],[[64560,64560],\"mapped\",[1601,1605]],[[64561,64561],\"mapped\",[1601,1609]],[[64562,64562],\"mapped\",[1601,1610]],[[64563,64563],\"mapped\",[1602,1581]],[[64564,64564],\"mapped\",[1602,1605]],[[64565,64565],\"mapped\",[1602,1609]],[[64566,64566],\"mapped\",[1602,1610]],[[64567,64567],\"mapped\",[1603,1575]],[[64568,64568],\"mapped\",[1603,1580]],[[64569,64569],\"mapped\",[1603,1581]],[[64570,64570],\"mapped\",[1603,1582]],[[64571,64571],\"mapped\",[1603,1604]],[[64572,64572],\"mapped\",[1603,1605]],[[64573,64573],\"mapped\",[1603,1609]],[[64574,64574],\"mapped\",[1603,1610]],[[64575,64575],\"mapped\",[1604,1580]],[[64576,64576],\"mapped\",[1604,1581]],[[64577,64577],\"mapped\",[1604,1582]],[[64578,64578],\"mapped\",[1604,1605]],[[64579,64579],\"mapped\",[1604,1609]],[[64580,64580],\"mapped\",[1604,1610]],[[64581,64581],\"mapped\",[1605,1580]],[[64582,64582],\"mapped\",[1605,1581]],[[64583,64583],\"mapped\",[1605,1582]],[[64584,64584],\"mapped\",[1605,1605]],[[64585,64585],\"mapped\",[1605,1609]],[[64586,64586],\"mapped\",[1605,1610]],[[64587,64587],\"mapped\",[1606,1580]],[[64588,64588],\"mapped\",[1606,1581]],[[64589,64589],\"mapped\",[1606,1582]],[[64590,64590],\"mapped\",[1606,1605]],[[64591,64591],\"mapped\",[1606,1609]],[[64592,64592],\"mapped\",[1606,1610]],[[64593,64593],\"mapped\",[1607,1580]],[[64594,64594],\"mapped\",[1607,1605]],[[64595,64595],\"mapped\",[1607,1609]],[[64596,64596],\"mapped\",[1607,1610]],[[64597,64597],\"mapped\",[1610,1580]],[[64598,64598],\"mapped\",[1610,1581]],[[64599,64599],\"mapped\",[1610,1582]],[[64600,64600],\"mapped\",[1610,1605]],[[64601,64601],\"mapped\",[1610,1609]],[[64602,64602],\"mapped\",[1610,1610]],[[64603,64603],\"mapped\",[1584,1648]],[[64604,64604],\"mapped\",[1585,1648]],[[64605,64605],\"mapped\",[1609,1648]],[[64606,64606],\"disallowed_STD3_mapped\",[32,1612,1617]],[[64607,64607],\"disallowed_STD3_mapped\",[32,1613,1617]],[[64608,64608],\"disallowed_STD3_mapped\",[32,1614,1617]],[[64609,64609],\"disallowed_STD3_mapped\",[32,1615,1617]],[[64610,64610],\"disallowed_STD3_mapped\",[32,1616,1617]],[[64611,64611],\"disallowed_STD3_mapped\",[32,1617,1648]],[[64612,64612],\"mapped\",[1574,1585]],[[64613,64613],\"mapped\",[1574,1586]],[[64614,64614],\"mapped\",[1574,1605]],[[64615,64615],\"mapped\",[1574,1606]],[[64616,64616],\"mapped\",[1574,1609]],[[64617,64617],\"mapped\",[1574,1610]],[[64618,64618],\"mapped\",[1576,1585]],[[64619,64619],\"mapped\",[1576,1586]],[[64620,64620],\"mapped\",[1576,1605]],[[64621,64621],\"mapped\",[1576,1606]],[[64622,64622],\"mapped\",[1576,1609]],[[64623,64623],\"mapped\",[1576,1610]],[[64624,64624],\"mapped\",[1578,1585]],[[64625,64625],\"mapped\",[1578,1586]],[[64626,64626],\"mapped\",[1578,1605]],[[64627,64627],\"mapped\",[1578,1606]],[[64628,64628],\"mapped\",[1578,1609]],[[64629,64629],\"mapped\",[1578,1610]],[[64630,64630],\"mapped\",[1579,1585]],[[64631,64631],\"mapped\",[1579,1586]],[[64632,64632],\"mapped\",[1579,1605]],[[64633,64633],\"mapped\",[1579,1606]],[[64634,64634],\"mapped\",[1579,1609]],[[64635,64635],\"mapped\",[1579,1610]],[[64636,64636],\"mapped\",[1601,1609]],[[64637,64637],\"mapped\",[1601,1610]],[[64638,64638],\"mapped\",[1602,1609]],[[64639,64639],\"mapped\",[1602,1610]],[[64640,64640],\"mapped\",[1603,1575]],[[64641,64641],\"mapped\",[1603,1604]],[[64642,64642],\"mapped\",[1603,1605]],[[64643,64643],\"mapped\",[1603,1609]],[[64644,64644],\"mapped\",[1603,1610]],[[64645,64645],\"mapped\",[1604,1605]],[[64646,64646],\"mapped\",[1604,1609]],[[64647,64647],\"mapped\",[1604,1610]],[[64648,64648],\"mapped\",[1605,1575]],[[64649,64649],\"mapped\",[1605,1605]],[[64650,64650],\"mapped\",[1606,1585]],[[64651,64651],\"mapped\",[1606,1586]],[[64652,64652],\"mapped\",[1606,1605]],[[64653,64653],\"mapped\",[1606,1606]],[[64654,64654],\"mapped\",[1606,1609]],[[64655,64655],\"mapped\",[1606,1610]],[[64656,64656],\"mapped\",[1609,1648]],[[64657,64657],\"mapped\",[1610,1585]],[[64658,64658],\"mapped\",[1610,1586]],[[64659,64659],\"mapped\",[1610,1605]],[[64660,64660],\"mapped\",[1610,1606]],[[64661,64661],\"mapped\",[1610,1609]],[[64662,64662],\"mapped\",[1610,1610]],[[64663,64663],\"mapped\",[1574,1580]],[[64664,64664],\"mapped\",[1574,1581]],[[64665,64665],\"mapped\",[1574,1582]],[[64666,64666],\"mapped\",[1574,1605]],[[64667,64667],\"mapped\",[1574,1607]],[[64668,64668],\"mapped\",[1576,1580]],[[64669,64669],\"mapped\",[1576,1581]],[[64670,64670],\"mapped\",[1576,1582]],[[64671,64671],\"mapped\",[1576,1605]],[[64672,64672],\"mapped\",[1576,1607]],[[64673,64673],\"mapped\",[1578,1580]],[[64674,64674],\"mapped\",[1578,1581]],[[64675,64675],\"mapped\",[1578,1582]],[[64676,64676],\"mapped\",[1578,1605]],[[64677,64677],\"mapped\",[1578,1607]],[[64678,64678],\"mapped\",[1579,1605]],[[64679,64679],\"mapped\",[1580,1581]],[[64680,64680],\"mapped\",[1580,1605]],[[64681,64681],\"mapped\",[1581,1580]],[[64682,64682],\"mapped\",[1581,1605]],[[64683,64683],\"mapped\",[1582,1580]],[[64684,64684],\"mapped\",[1582,1605]],[[64685,64685],\"mapped\",[1587,1580]],[[64686,64686],\"mapped\",[1587,1581]],[[64687,64687],\"mapped\",[1587,1582]],[[64688,64688],\"mapped\",[1587,1605]],[[64689,64689],\"mapped\",[1589,1581]],[[64690,64690],\"mapped\",[1589,1582]],[[64691,64691],\"mapped\",[1589,1605]],[[64692,64692],\"mapped\",[1590,1580]],[[64693,64693],\"mapped\",[1590,1581]],[[64694,64694],\"mapped\",[1590,1582]],[[64695,64695],\"mapped\",[1590,1605]],[[64696,64696],\"mapped\",[1591,1581]],[[64697,64697],\"mapped\",[1592,1605]],[[64698,64698],\"mapped\",[1593,1580]],[[64699,64699],\"mapped\",[1593,1605]],[[64700,64700],\"mapped\",[1594,1580]],[[64701,64701],\"mapped\",[1594,1605]],[[64702,64702],\"mapped\",[1601,1580]],[[64703,64703],\"mapped\",[1601,1581]],[[64704,64704],\"mapped\",[1601,1582]],[[64705,64705],\"mapped\",[1601,1605]],[[64706,64706],\"mapped\",[1602,1581]],[[64707,64707],\"mapped\",[1602,1605]],[[64708,64708],\"mapped\",[1603,1580]],[[64709,64709],\"mapped\",[1603,1581]],[[64710,64710],\"mapped\",[1603,1582]],[[64711,64711],\"mapped\",[1603,1604]],[[64712,64712],\"mapped\",[1603,1605]],[[64713,64713],\"mapped\",[1604,1580]],[[64714,64714],\"mapped\",[1604,1581]],[[64715,64715],\"mapped\",[1604,1582]],[[64716,64716],\"mapped\",[1604,1605]],[[64717,64717],\"mapped\",[1604,1607]],[[64718,64718],\"mapped\",[1605,1580]],[[64719,64719],\"mapped\",[1605,1581]],[[64720,64720],\"mapped\",[1605,1582]],[[64721,64721],\"mapped\",[1605,1605]],[[64722,64722],\"mapped\",[1606,1580]],[[64723,64723],\"mapped\",[1606,1581]],[[64724,64724],\"mapped\",[1606,1582]],[[64725,64725],\"mapped\",[1606,1605]],[[64726,64726],\"mapped\",[1606,1607]],[[64727,64727],\"mapped\",[1607,1580]],[[64728,64728],\"mapped\",[1607,1605]],[[64729,64729],\"mapped\",[1607,1648]],[[64730,64730],\"mapped\",[1610,1580]],[[64731,64731],\"mapped\",[1610,1581]],[[64732,64732],\"mapped\",[1610,1582]],[[64733,64733],\"mapped\",[1610,1605]],[[64734,64734],\"mapped\",[1610,1607]],[[64735,64735],\"mapped\",[1574,1605]],[[64736,64736],\"mapped\",[1574,1607]],[[64737,64737],\"mapped\",[1576,1605]],[[64738,64738],\"mapped\",[1576,1607]],[[64739,64739],\"mapped\",[1578,1605]],[[64740,64740],\"mapped\",[1578,1607]],[[64741,64741],\"mapped\",[1579,1605]],[[64742,64742],\"mapped\",[1579,1607]],[[64743,64743],\"mapped\",[1587,1605]],[[64744,64744],\"mapped\",[1587,1607]],[[64745,64745],\"mapped\",[1588,1605]],[[64746,64746],\"mapped\",[1588,1607]],[[64747,64747],\"mapped\",[1603,1604]],[[64748,64748],\"mapped\",[1603,1605]],[[64749,64749],\"mapped\",[1604,1605]],[[64750,64750],\"mapped\",[1606,1605]],[[64751,64751],\"mapped\",[1606,1607]],[[64752,64752],\"mapped\",[1610,1605]],[[64753,64753],\"mapped\",[1610,1607]],[[64754,64754],\"mapped\",[1600,1614,1617]],[[64755,64755],\"mapped\",[1600,1615,1617]],[[64756,64756],\"mapped\",[1600,1616,1617]],[[64757,64757],\"mapped\",[1591,1609]],[[64758,64758],\"mapped\",[1591,1610]],[[64759,64759],\"mapped\",[1593,1609]],[[64760,64760],\"mapped\",[1593,1610]],[[64761,64761],\"mapped\",[1594,1609]],[[64762,64762],\"mapped\",[1594,1610]],[[64763,64763],\"mapped\",[1587,1609]],[[64764,64764],\"mapped\",[1587,1610]],[[64765,64765],\"mapped\",[1588,1609]],[[64766,64766],\"mapped\",[1588,1610]],[[64767,64767],\"mapped\",[1581,1609]],[[64768,64768],\"mapped\",[1581,1610]],[[64769,64769],\"mapped\",[1580,1609]],[[64770,64770],\"mapped\",[1580,1610]],[[64771,64771],\"mapped\",[1582,1609]],[[64772,64772],\"mapped\",[1582,1610]],[[64773,64773],\"mapped\",[1589,1609]],[[64774,64774],\"mapped\",[1589,1610]],[[64775,64775],\"mapped\",[1590,1609]],[[64776,64776],\"mapped\",[1590,1610]],[[64777,64777],\"mapped\",[1588,1580]],[[64778,64778],\"mapped\",[1588,1581]],[[64779,64779],\"mapped\",[1588,1582]],[[64780,64780],\"mapped\",[1588,1605]],[[64781,64781],\"mapped\",[1588,1585]],[[64782,64782],\"mapped\",[1587,1585]],[[64783,64783],\"mapped\",[1589,1585]],[[64784,64784],\"mapped\",[1590,1585]],[[64785,64785],\"mapped\",[1591,1609]],[[64786,64786],\"mapped\",[1591,1610]],[[64787,64787],\"mapped\",[1593,1609]],[[64788,64788],\"mapped\",[1593,1610]],[[64789,64789],\"mapped\",[1594,1609]],[[64790,64790],\"mapped\",[1594,1610]],[[64791,64791],\"mapped\",[1587,1609]],[[64792,64792],\"mapped\",[1587,1610]],[[64793,64793],\"mapped\",[1588,1609]],[[64794,64794],\"mapped\",[1588,1610]],[[64795,64795],\"mapped\",[1581,1609]],[[64796,64796],\"mapped\",[1581,1610]],[[64797,64797],\"mapped\",[1580,1609]],[[64798,64798],\"mapped\",[1580,1610]],[[64799,64799],\"mapped\",[1582,1609]],[[64800,64800],\"mapped\",[1582,1610]],[[64801,64801],\"mapped\",[1589,1609]],[[64802,64802],\"mapped\",[1589,1610]],[[64803,64803],\"mapped\",[1590,1609]],[[64804,64804],\"mapped\",[1590,1610]],[[64805,64805],\"mapped\",[1588,1580]],[[64806,64806],\"mapped\",[1588,1581]],[[64807,64807],\"mapped\",[1588,1582]],[[64808,64808],\"mapped\",[1588,1605]],[[64809,64809],\"mapped\",[1588,1585]],[[64810,64810],\"mapped\",[1587,1585]],[[64811,64811],\"mapped\",[1589,1585]],[[64812,64812],\"mapped\",[1590,1585]],[[64813,64813],\"mapped\",[1588,1580]],[[64814,64814],\"mapped\",[1588,1581]],[[64815,64815],\"mapped\",[1588,1582]],[[64816,64816],\"mapped\",[1588,1605]],[[64817,64817],\"mapped\",[1587,1607]],[[64818,64818],\"mapped\",[1588,1607]],[[64819,64819],\"mapped\",[1591,1605]],[[64820,64820],\"mapped\",[1587,1580]],[[64821,64821],\"mapped\",[1587,1581]],[[64822,64822],\"mapped\",[1587,1582]],[[64823,64823],\"mapped\",[1588,1580]],[[64824,64824],\"mapped\",[1588,1581]],[[64825,64825],\"mapped\",[1588,1582]],[[64826,64826],\"mapped\",[1591,1605]],[[64827,64827],\"mapped\",[1592,1605]],[[64828,64829],\"mapped\",[1575,1611]],[[64830,64831],\"valid\",[],\"NV8\"],[[64832,64847],\"disallowed\"],[[64848,64848],\"mapped\",[1578,1580,1605]],[[64849,64850],\"mapped\",[1578,1581,1580]],[[64851,64851],\"mapped\",[1578,1581,1605]],[[64852,64852],\"mapped\",[1578,1582,1605]],[[64853,64853],\"mapped\",[1578,1605,1580]],[[64854,64854],\"mapped\",[1578,1605,1581]],[[64855,64855],\"mapped\",[1578,1605,1582]],[[64856,64857],\"mapped\",[1580,1605,1581]],[[64858,64858],\"mapped\",[1581,1605,1610]],[[64859,64859],\"mapped\",[1581,1605,1609]],[[64860,64860],\"mapped\",[1587,1581,1580]],[[64861,64861],\"mapped\",[1587,1580,1581]],[[64862,64862],\"mapped\",[1587,1580,1609]],[[64863,64864],\"mapped\",[1587,1605,1581]],[[64865,64865],\"mapped\",[1587,1605,1580]],[[64866,64867],\"mapped\",[1587,1605,1605]],[[64868,64869],\"mapped\",[1589,1581,1581]],[[64870,64870],\"mapped\",[1589,1605,1605]],[[64871,64872],\"mapped\",[1588,1581,1605]],[[64873,64873],\"mapped\",[1588,1580,1610]],[[64874,64875],\"mapped\",[1588,1605,1582]],[[64876,64877],\"mapped\",[1588,1605,1605]],[[64878,64878],\"mapped\",[1590,1581,1609]],[[64879,64880],\"mapped\",[1590,1582,1605]],[[64881,64882],\"mapped\",[1591,1605,1581]],[[64883,64883],\"mapped\",[1591,1605,1605]],[[64884,64884],\"mapped\",[1591,1605,1610]],[[64885,64885],\"mapped\",[1593,1580,1605]],[[64886,64887],\"mapped\",[1593,1605,1605]],[[64888,64888],\"mapped\",[1593,1605,1609]],[[64889,64889],\"mapped\",[1594,1605,1605]],[[64890,64890],\"mapped\",[1594,1605,1610]],[[64891,64891],\"mapped\",[1594,1605,1609]],[[64892,64893],\"mapped\",[1601,1582,1605]],[[64894,64894],\"mapped\",[1602,1605,1581]],[[64895,64895],\"mapped\",[1602,1605,1605]],[[64896,64896],\"mapped\",[1604,1581,1605]],[[64897,64897],\"mapped\",[1604,1581,1610]],[[64898,64898],\"mapped\",[1604,1581,1609]],[[64899,64900],\"mapped\",[1604,1580,1580]],[[64901,64902],\"mapped\",[1604,1582,1605]],[[64903,64904],\"mapped\",[1604,1605,1581]],[[64905,64905],\"mapped\",[1605,1581,1580]],[[64906,64906],\"mapped\",[1605,1581,1605]],[[64907,64907],\"mapped\",[1605,1581,1610]],[[64908,64908],\"mapped\",[1605,1580,1581]],[[64909,64909],\"mapped\",[1605,1580,1605]],[[64910,64910],\"mapped\",[1605,1582,1580]],[[64911,64911],\"mapped\",[1605,1582,1605]],[[64912,64913],\"disallowed\"],[[64914,64914],\"mapped\",[1605,1580,1582]],[[64915,64915],\"mapped\",[1607,1605,1580]],[[64916,64916],\"mapped\",[1607,1605,1605]],[[64917,64917],\"mapped\",[1606,1581,1605]],[[64918,64918],\"mapped\",[1606,1581,1609]],[[64919,64920],\"mapped\",[1606,1580,1605]],[[64921,64921],\"mapped\",[1606,1580,1609]],[[64922,64922],\"mapped\",[1606,1605,1610]],[[64923,64923],\"mapped\",[1606,1605,1609]],[[64924,64925],\"mapped\",[1610,1605,1605]],[[64926,64926],\"mapped\",[1576,1582,1610]],[[64927,64927],\"mapped\",[1578,1580,1610]],[[64928,64928],\"mapped\",[1578,1580,1609]],[[64929,64929],\"mapped\",[1578,1582,1610]],[[64930,64930],\"mapped\",[1578,1582,1609]],[[64931,64931],\"mapped\",[1578,1605,1610]],[[64932,64932],\"mapped\",[1578,1605,1609]],[[64933,64933],\"mapped\",[1580,1605,1610]],[[64934,64934],\"mapped\",[1580,1581,1609]],[[64935,64935],\"mapped\",[1580,1605,1609]],[[64936,64936],\"mapped\",[1587,1582,1609]],[[64937,64937],\"mapped\",[1589,1581,1610]],[[64938,64938],\"mapped\",[1588,1581,1610]],[[64939,64939],\"mapped\",[1590,1581,1610]],[[64940,64940],\"mapped\",[1604,1580,1610]],[[64941,64941],\"mapped\",[1604,1605,1610]],[[64942,64942],\"mapped\",[1610,1581,1610]],[[64943,64943],\"mapped\",[1610,1580,1610]],[[64944,64944],\"mapped\",[1610,1605,1610]],[[64945,64945],\"mapped\",[1605,1605,1610]],[[64946,64946],\"mapped\",[1602,1605,1610]],[[64947,64947],\"mapped\",[1606,1581,1610]],[[64948,64948],\"mapped\",[1602,1605,1581]],[[64949,64949],\"mapped\",[1604,1581,1605]],[[64950,64950],\"mapped\",[1593,1605,1610]],[[64951,64951],\"mapped\",[1603,1605,1610]],[[64952,64952],\"mapped\",[1606,1580,1581]],[[64953,64953],\"mapped\",[1605,1582,1610]],[[64954,64954],\"mapped\",[1604,1580,1605]],[[64955,64955],\"mapped\",[1603,1605,1605]],[[64956,64956],\"mapped\",[1604,1580,1605]],[[64957,64957],\"mapped\",[1606,1580,1581]],[[64958,64958],\"mapped\",[1580,1581,1610]],[[64959,64959],\"mapped\",[1581,1580,1610]],[[64960,64960],\"mapped\",[1605,1580,1610]],[[64961,64961],\"mapped\",[1601,1605,1610]],[[64962,64962],\"mapped\",[1576,1581,1610]],[[64963,64963],\"mapped\",[1603,1605,1605]],[[64964,64964],\"mapped\",[1593,1580,1605]],[[64965,64965],\"mapped\",[1589,1605,1605]],[[64966,64966],\"mapped\",[1587,1582,1610]],[[64967,64967],\"mapped\",[1606,1580,1610]],[[64968,64975],\"disallowed\"],[[64976,65007],\"disallowed\"],[[65008,65008],\"mapped\",[1589,1604,1746]],[[65009,65009],\"mapped\",[1602,1604,1746]],[[65010,65010],\"mapped\",[1575,1604,1604,1607]],[[65011,65011],\"mapped\",[1575,1603,1576,1585]],[[65012,65012],\"mapped\",[1605,1581,1605,1583]],[[65013,65013],\"mapped\",[1589,1604,1593,1605]],[[65014,65014],\"mapped\",[1585,1587,1608,1604]],[[65015,65015],\"mapped\",[1593,1604,1610,1607]],[[65016,65016],\"mapped\",[1608,1587,1604,1605]],[[65017,65017],\"mapped\",[1589,1604,1609]],[[65018,65018],\"disallowed_STD3_mapped\",[1589,1604,1609,32,1575,1604,1604,1607,32,1593,1604,1610,1607,32,1608,1587,1604,1605]],[[65019,65019],\"disallowed_STD3_mapped\",[1580,1604,32,1580,1604,1575,1604,1607]],[[65020,65020],\"mapped\",[1585,1740,1575,1604]],[[65021,65021],\"valid\",[],\"NV8\"],[[65022,65023],\"disallowed\"],[[65024,65039],\"ignored\"],[[65040,65040],\"disallowed_STD3_mapped\",[44]],[[65041,65041],\"mapped\",[12289]],[[65042,65042],\"disallowed\"],[[65043,65043],\"disallowed_STD3_mapped\",[58]],[[65044,65044],\"disallowed_STD3_mapped\",[59]],[[65045,65045],\"disallowed_STD3_mapped\",[33]],[[65046,65046],\"disallowed_STD3_mapped\",[63]],[[65047,65047],\"mapped\",[12310]],[[65048,65048],\"mapped\",[12311]],[[65049,65049],\"disallowed\"],[[65050,65055],\"disallowed\"],[[65056,65059],\"valid\"],[[65060,65062],\"valid\"],[[65063,65069],\"valid\"],[[65070,65071],\"valid\"],[[65072,65072],\"disallowed\"],[[65073,65073],\"mapped\",[8212]],[[65074,65074],\"mapped\",[8211]],[[65075,65076],\"disallowed_STD3_mapped\",[95]],[[65077,65077],\"disallowed_STD3_mapped\",[40]],[[65078,65078],\"disallowed_STD3_mapped\",[41]],[[65079,65079],\"disallowed_STD3_mapped\",[123]],[[65080,65080],\"disallowed_STD3_mapped\",[125]],[[65081,65081],\"mapped\",[12308]],[[65082,65082],\"mapped\",[12309]],[[65083,65083],\"mapped\",[12304]],[[65084,65084],\"mapped\",[12305]],[[65085,65085],\"mapped\",[12298]],[[65086,65086],\"mapped\",[12299]],[[65087,65087],\"mapped\",[12296]],[[65088,65088],\"mapped\",[12297]],[[65089,65089],\"mapped\",[12300]],[[65090,65090],\"mapped\",[12301]],[[65091,65091],\"mapped\",[12302]],[[65092,65092],\"mapped\",[12303]],[[65093,65094],\"valid\",[],\"NV8\"],[[65095,65095],\"disallowed_STD3_mapped\",[91]],[[65096,65096],\"disallowed_STD3_mapped\",[93]],[[65097,65100],\"disallowed_STD3_mapped\",[32,773]],[[65101,65103],\"disallowed_STD3_mapped\",[95]],[[65104,65104],\"disallowed_STD3_mapped\",[44]],[[65105,65105],\"mapped\",[12289]],[[65106,65106],\"disallowed\"],[[65107,65107],\"disallowed\"],[[65108,65108],\"disallowed_STD3_mapped\",[59]],[[65109,65109],\"disallowed_STD3_mapped\",[58]],[[65110,65110],\"disallowed_STD3_mapped\",[63]],[[65111,65111],\"disallowed_STD3_mapped\",[33]],[[65112,65112],\"mapped\",[8212]],[[65113,65113],\"disallowed_STD3_mapped\",[40]],[[65114,65114],\"disallowed_STD3_mapped\",[41]],[[65115,65115],\"disallowed_STD3_mapped\",[123]],[[65116,65116],\"disallowed_STD3_mapped\",[125]],[[65117,65117],\"mapped\",[12308]],[[65118,65118],\"mapped\",[12309]],[[65119,65119],\"disallowed_STD3_mapped\",[35]],[[65120,65120],\"disallowed_STD3_mapped\",[38]],[[65121,65121],\"disallowed_STD3_mapped\",[42]],[[65122,65122],\"disallowed_STD3_mapped\",[43]],[[65123,65123],\"mapped\",[45]],[[65124,65124],\"disallowed_STD3_mapped\",[60]],[[65125,65125],\"disallowed_STD3_mapped\",[62]],[[65126,65126],\"disallowed_STD3_mapped\",[61]],[[65127,65127],\"disallowed\"],[[65128,65128],\"disallowed_STD3_mapped\",[92]],[[65129,65129],\"disallowed_STD3_mapped\",[36]],[[65130,65130],\"disallowed_STD3_mapped\",[37]],[[65131,65131],\"disallowed_STD3_mapped\",[64]],[[65132,65135],\"disallowed\"],[[65136,65136],\"disallowed_STD3_mapped\",[32,1611]],[[65137,65137],\"mapped\",[1600,1611]],[[65138,65138],\"disallowed_STD3_mapped\",[32,1612]],[[65139,65139],\"valid\"],[[65140,65140],\"disallowed_STD3_mapped\",[32,1613]],[[65141,65141],\"disallowed\"],[[65142,65142],\"disallowed_STD3_mapped\",[32,1614]],[[65143,65143],\"mapped\",[1600,1614]],[[65144,65144],\"disallowed_STD3_mapped\",[32,1615]],[[65145,65145],\"mapped\",[1600,1615]],[[65146,65146],\"disallowed_STD3_mapped\",[32,1616]],[[65147,65147],\"mapped\",[1600,1616]],[[65148,65148],\"disallowed_STD3_mapped\",[32,1617]],[[65149,65149],\"mapped\",[1600,1617]],[[65150,65150],\"disallowed_STD3_mapped\",[32,1618]],[[65151,65151],\"mapped\",[1600,1618]],[[65152,65152],\"mapped\",[1569]],[[65153,65154],\"mapped\",[1570]],[[65155,65156],\"mapped\",[1571]],[[65157,65158],\"mapped\",[1572]],[[65159,65160],\"mapped\",[1573]],[[65161,65164],\"mapped\",[1574]],[[65165,65166],\"mapped\",[1575]],[[65167,65170],\"mapped\",[1576]],[[65171,65172],\"mapped\",[1577]],[[65173,65176],\"mapped\",[1578]],[[65177,65180],\"mapped\",[1579]],[[65181,65184],\"mapped\",[1580]],[[65185,65188],\"mapped\",[1581]],[[65189,65192],\"mapped\",[1582]],[[65193,65194],\"mapped\",[1583]],[[65195,65196],\"mapped\",[1584]],[[65197,65198],\"mapped\",[1585]],[[65199,65200],\"mapped\",[1586]],[[65201,65204],\"mapped\",[1587]],[[65205,65208],\"mapped\",[1588]],[[65209,65212],\"mapped\",[1589]],[[65213,65216],\"mapped\",[1590]],[[65217,65220],\"mapped\",[1591]],[[65221,65224],\"mapped\",[1592]],[[65225,65228],\"mapped\",[1593]],[[65229,65232],\"mapped\",[1594]],[[65233,65236],\"mapped\",[1601]],[[65237,65240],\"mapped\",[1602]],[[65241,65244],\"mapped\",[1603]],[[65245,65248],\"mapped\",[1604]],[[65249,65252],\"mapped\",[1605]],[[65253,65256],\"mapped\",[1606]],[[65257,65260],\"mapped\",[1607]],[[65261,65262],\"mapped\",[1608]],[[65263,65264],\"mapped\",[1609]],[[65265,65268],\"mapped\",[1610]],[[65269,65270],\"mapped\",[1604,1570]],[[65271,65272],\"mapped\",[1604,1571]],[[65273,65274],\"mapped\",[1604,1573]],[[65275,65276],\"mapped\",[1604,1575]],[[65277,65278],\"disallowed\"],[[65279,65279],\"ignored\"],[[65280,65280],\"disallowed\"],[[65281,65281],\"disallowed_STD3_mapped\",[33]],[[65282,65282],\"disallowed_STD3_mapped\",[34]],[[65283,65283],\"disallowed_STD3_mapped\",[35]],[[65284,65284],\"disallowed_STD3_mapped\",[36]],[[65285,65285],\"disallowed_STD3_mapped\",[37]],[[65286,65286],\"disallowed_STD3_mapped\",[38]],[[65287,65287],\"disallowed_STD3_mapped\",[39]],[[65288,65288],\"disallowed_STD3_mapped\",[40]],[[65289,65289],\"disallowed_STD3_mapped\",[41]],[[65290,65290],\"disallowed_STD3_mapped\",[42]],[[65291,65291],\"disallowed_STD3_mapped\",[43]],[[65292,65292],\"disallowed_STD3_mapped\",[44]],[[65293,65293],\"mapped\",[45]],[[65294,65294],\"mapped\",[46]],[[65295,65295],\"disallowed_STD3_mapped\",[47]],[[65296,65296],\"mapped\",[48]],[[65297,65297],\"mapped\",[49]],[[65298,65298],\"mapped\",[50]],[[65299,65299],\"mapped\",[51]],[[65300,65300],\"mapped\",[52]],[[65301,65301],\"mapped\",[53]],[[65302,65302],\"mapped\",[54]],[[65303,65303],\"mapped\",[55]],[[65304,65304],\"mapped\",[56]],[[65305,65305],\"mapped\",[57]],[[65306,65306],\"disallowed_STD3_mapped\",[58]],[[65307,65307],\"disallowed_STD3_mapped\",[59]],[[65308,65308],\"disallowed_STD3_mapped\",[60]],[[65309,65309],\"disallowed_STD3_mapped\",[61]],[[65310,65310],\"disallowed_STD3_mapped\",[62]],[[65311,65311],\"disallowed_STD3_mapped\",[63]],[[65312,65312],\"disallowed_STD3_mapped\",[64]],[[65313,65313],\"mapped\",[97]],[[65314,65314],\"mapped\",[98]],[[65315,65315],\"mapped\",[99]],[[65316,65316],\"mapped\",[100]],[[65317,65317],\"mapped\",[101]],[[65318,65318],\"mapped\",[102]],[[65319,65319],\"mapped\",[103]],[[65320,65320],\"mapped\",[104]],[[65321,65321],\"mapped\",[105]],[[65322,65322],\"mapped\",[106]],[[65323,65323],\"mapped\",[107]],[[65324,65324],\"mapped\",[108]],[[65325,65325],\"mapped\",[109]],[[65326,65326],\"mapped\",[110]],[[65327,65327],\"mapped\",[111]],[[65328,65328],\"mapped\",[112]],[[65329,65329],\"mapped\",[113]],[[65330,65330],\"mapped\",[114]],[[65331,65331],\"mapped\",[115]],[[65332,65332],\"mapped\",[116]],[[65333,65333],\"mapped\",[117]],[[65334,65334],\"mapped\",[118]],[[65335,65335],\"mapped\",[119]],[[65336,65336],\"mapped\",[120]],[[65337,65337],\"mapped\",[121]],[[65338,65338],\"mapped\",[122]],[[65339,65339],\"disallowed_STD3_mapped\",[91]],[[65340,65340],\"disallowed_STD3_mapped\",[92]],[[65341,65341],\"disallowed_STD3_mapped\",[93]],[[65342,65342],\"disallowed_STD3_mapped\",[94]],[[65343,65343],\"disallowed_STD3_mapped\",[95]],[[65344,65344],\"disallowed_STD3_mapped\",[96]],[[65345,65345],\"mapped\",[97]],[[65346,65346],\"mapped\",[98]],[[65347,65347],\"mapped\",[99]],[[65348,65348],\"mapped\",[100]],[[65349,65349],\"mapped\",[101]],[[65350,65350],\"mapped\",[102]],[[65351,65351],\"mapped\",[103]],[[65352,65352],\"mapped\",[104]],[[65353,65353],\"mapped\",[105]],[[65354,65354],\"mapped\",[106]],[[65355,65355],\"mapped\",[107]],[[65356,65356],\"mapped\",[108]],[[65357,65357],\"mapped\",[109]],[[65358,65358],\"mapped\",[110]],[[65359,65359],\"mapped\",[111]],[[65360,65360],\"mapped\",[112]],[[65361,65361],\"mapped\",[113]],[[65362,65362],\"mapped\",[114]],[[65363,65363],\"mapped\",[115]],[[65364,65364],\"mapped\",[116]],[[65365,65365],\"mapped\",[117]],[[65366,65366],\"mapped\",[118]],[[65367,65367],\"mapped\",[119]],[[65368,65368],\"mapped\",[120]],[[65369,65369],\"mapped\",[121]],[[65370,65370],\"mapped\",[122]],[[65371,65371],\"disallowed_STD3_mapped\",[123]],[[65372,65372],\"disallowed_STD3_mapped\",[124]],[[65373,65373],\"disallowed_STD3_mapped\",[125]],[[65374,65374],\"disallowed_STD3_mapped\",[126]],[[65375,65375],\"mapped\",[10629]],[[65376,65376],\"mapped\",[10630]],[[65377,65377],\"mapped\",[46]],[[65378,65378],\"mapped\",[12300]],[[65379,65379],\"mapped\",[12301]],[[65380,65380],\"mapped\",[12289]],[[65381,65381],\"mapped\",[12539]],[[65382,65382],\"mapped\",[12530]],[[65383,65383],\"mapped\",[12449]],[[65384,65384],\"mapped\",[12451]],[[65385,65385],\"mapped\",[12453]],[[65386,65386],\"mapped\",[12455]],[[65387,65387],\"mapped\",[12457]],[[65388,65388],\"mapped\",[12515]],[[65389,65389],\"mapped\",[12517]],[[65390,65390],\"mapped\",[12519]],[[65391,65391],\"mapped\",[12483]],[[65392,65392],\"mapped\",[12540]],[[65393,65393],\"mapped\",[12450]],[[65394,65394],\"mapped\",[12452]],[[65395,65395],\"mapped\",[12454]],[[65396,65396],\"mapped\",[12456]],[[65397,65397],\"mapped\",[12458]],[[65398,65398],\"mapped\",[12459]],[[65399,65399],\"mapped\",[12461]],[[65400,65400],\"mapped\",[12463]],[[65401,65401],\"mapped\",[12465]],[[65402,65402],\"mapped\",[12467]],[[65403,65403],\"mapped\",[12469]],[[65404,65404],\"mapped\",[12471]],[[65405,65405],\"mapped\",[12473]],[[65406,65406],\"mapped\",[12475]],[[65407,65407],\"mapped\",[12477]],[[65408,65408],\"mapped\",[12479]],[[65409,65409],\"mapped\",[12481]],[[65410,65410],\"mapped\",[12484]],[[65411,65411],\"mapped\",[12486]],[[65412,65412],\"mapped\",[12488]],[[65413,65413],\"mapped\",[12490]],[[65414,65414],\"mapped\",[12491]],[[65415,65415],\"mapped\",[12492]],[[65416,65416],\"mapped\",[12493]],[[65417,65417],\"mapped\",[12494]],[[65418,65418],\"mapped\",[12495]],[[65419,65419],\"mapped\",[12498]],[[65420,65420],\"mapped\",[12501]],[[65421,65421],\"mapped\",[12504]],[[65422,65422],\"mapped\",[12507]],[[65423,65423],\"mapped\",[12510]],[[65424,65424],\"mapped\",[12511]],[[65425,65425],\"mapped\",[12512]],[[65426,65426],\"mapped\",[12513]],[[65427,65427],\"mapped\",[12514]],[[65428,65428],\"mapped\",[12516]],[[65429,65429],\"mapped\",[12518]],[[65430,65430],\"mapped\",[12520]],[[65431,65431],\"mapped\",[12521]],[[65432,65432],\"mapped\",[12522]],[[65433,65433],\"mapped\",[12523]],[[65434,65434],\"mapped\",[12524]],[[65435,65435],\"mapped\",[12525]],[[65436,65436],\"mapped\",[12527]],[[65437,65437],\"mapped\",[12531]],[[65438,65438],\"mapped\",[12441]],[[65439,65439],\"mapped\",[12442]],[[65440,65440],\"disallowed\"],[[65441,65441],\"mapped\",[4352]],[[65442,65442],\"mapped\",[4353]],[[65443,65443],\"mapped\",[4522]],[[65444,65444],\"mapped\",[4354]],[[65445,65445],\"mapped\",[4524]],[[65446,65446],\"mapped\",[4525]],[[65447,65447],\"mapped\",[4355]],[[65448,65448],\"mapped\",[4356]],[[65449,65449],\"mapped\",[4357]],[[65450,65450],\"mapped\",[4528]],[[65451,65451],\"mapped\",[4529]],[[65452,65452],\"mapped\",[4530]],[[65453,65453],\"mapped\",[4531]],[[65454,65454],\"mapped\",[4532]],[[65455,65455],\"mapped\",[4533]],[[65456,65456],\"mapped\",[4378]],[[65457,65457],\"mapped\",[4358]],[[65458,65458],\"mapped\",[4359]],[[65459,65459],\"mapped\",[4360]],[[65460,65460],\"mapped\",[4385]],[[65461,65461],\"mapped\",[4361]],[[65462,65462],\"mapped\",[4362]],[[65463,65463],\"mapped\",[4363]],[[65464,65464],\"mapped\",[4364]],[[65465,65465],\"mapped\",[4365]],[[65466,65466],\"mapped\",[4366]],[[65467,65467],\"mapped\",[4367]],[[65468,65468],\"mapped\",[4368]],[[65469,65469],\"mapped\",[4369]],[[65470,65470],\"mapped\",[4370]],[[65471,65473],\"disallowed\"],[[65474,65474],\"mapped\",[4449]],[[65475,65475],\"mapped\",[4450]],[[65476,65476],\"mapped\",[4451]],[[65477,65477],\"mapped\",[4452]],[[65478,65478],\"mapped\",[4453]],[[65479,65479],\"mapped\",[4454]],[[65480,65481],\"disallowed\"],[[65482,65482],\"mapped\",[4455]],[[65483,65483],\"mapped\",[4456]],[[65484,65484],\"mapped\",[4457]],[[65485,65485],\"mapped\",[4458]],[[65486,65486],\"mapped\",[4459]],[[65487,65487],\"mapped\",[4460]],[[65488,65489],\"disallowed\"],[[65490,65490],\"mapped\",[4461]],[[65491,65491],\"mapped\",[4462]],[[65492,65492],\"mapped\",[4463]],[[65493,65493],\"mapped\",[4464]],[[65494,65494],\"mapped\",[4465]],[[65495,65495],\"mapped\",[4466]],[[65496,65497],\"disallowed\"],[[65498,65498],\"mapped\",[4467]],[[65499,65499],\"mapped\",[4468]],[[65500,65500],\"mapped\",[4469]],[[65501,65503],\"disallowed\"],[[65504,65504],\"mapped\",[162]],[[65505,65505],\"mapped\",[163]],[[65506,65506],\"mapped\",[172]],[[65507,65507],\"disallowed_STD3_mapped\",[32,772]],[[65508,65508],\"mapped\",[166]],[[65509,65509],\"mapped\",[165]],[[65510,65510],\"mapped\",[8361]],[[65511,65511],\"disallowed\"],[[65512,65512],\"mapped\",[9474]],[[65513,65513],\"mapped\",[8592]],[[65514,65514],\"mapped\",[8593]],[[65515,65515],\"mapped\",[8594]],[[65516,65516],\"mapped\",[8595]],[[65517,65517],\"mapped\",[9632]],[[65518,65518],\"mapped\",[9675]],[[65519,65528],\"disallowed\"],[[65529,65531],\"disallowed\"],[[65532,65532],\"disallowed\"],[[65533,65533],\"disallowed\"],[[65534,65535],\"disallowed\"],[[65536,65547],\"valid\"],[[65548,65548],\"disallowed\"],[[65549,65574],\"valid\"],[[65575,65575],\"disallowed\"],[[65576,65594],\"valid\"],[[65595,65595],\"disallowed\"],[[65596,65597],\"valid\"],[[65598,65598],\"disallowed\"],[[65599,65613],\"valid\"],[[65614,65615],\"disallowed\"],[[65616,65629],\"valid\"],[[65630,65663],\"disallowed\"],[[65664,65786],\"valid\"],[[65787,65791],\"disallowed\"],[[65792,65794],\"valid\",[],\"NV8\"],[[65795,65798],\"disallowed\"],[[65799,65843],\"valid\",[],\"NV8\"],[[65844,65846],\"disallowed\"],[[65847,65855],\"valid\",[],\"NV8\"],[[65856,65930],\"valid\",[],\"NV8\"],[[65931,65932],\"valid\",[],\"NV8\"],[[65933,65935],\"disallowed\"],[[65936,65947],\"valid\",[],\"NV8\"],[[65948,65951],\"disallowed\"],[[65952,65952],\"valid\",[],\"NV8\"],[[65953,65999],\"disallowed\"],[[66000,66044],\"valid\",[],\"NV8\"],[[66045,66045],\"valid\"],[[66046,66175],\"disallowed\"],[[66176,66204],\"valid\"],[[66205,66207],\"disallowed\"],[[66208,66256],\"valid\"],[[66257,66271],\"disallowed\"],[[66272,66272],\"valid\"],[[66273,66299],\"valid\",[],\"NV8\"],[[66300,66303],\"disallowed\"],[[66304,66334],\"valid\"],[[66335,66335],\"valid\"],[[66336,66339],\"valid\",[],\"NV8\"],[[66340,66351],\"disallowed\"],[[66352,66368],\"valid\"],[[66369,66369],\"valid\",[],\"NV8\"],[[66370,66377],\"valid\"],[[66378,66378],\"valid\",[],\"NV8\"],[[66379,66383],\"disallowed\"],[[66384,66426],\"valid\"],[[66427,66431],\"disallowed\"],[[66432,66461],\"valid\"],[[66462,66462],\"disallowed\"],[[66463,66463],\"valid\",[],\"NV8\"],[[66464,66499],\"valid\"],[[66500,66503],\"disallowed\"],[[66504,66511],\"valid\"],[[66512,66517],\"valid\",[],\"NV8\"],[[66518,66559],\"disallowed\"],[[66560,66560],\"mapped\",[66600]],[[66561,66561],\"mapped\",[66601]],[[66562,66562],\"mapped\",[66602]],[[66563,66563],\"mapped\",[66603]],[[66564,66564],\"mapped\",[66604]],[[66565,66565],\"mapped\",[66605]],[[66566,66566],\"mapped\",[66606]],[[66567,66567],\"mapped\",[66607]],[[66568,66568],\"mapped\",[66608]],[[66569,66569],\"mapped\",[66609]],[[66570,66570],\"mapped\",[66610]],[[66571,66571],\"mapped\",[66611]],[[66572,66572],\"mapped\",[66612]],[[66573,66573],\"mapped\",[66613]],[[66574,66574],\"mapped\",[66614]],[[66575,66575],\"mapped\",[66615]],[[66576,66576],\"mapped\",[66616]],[[66577,66577],\"mapped\",[66617]],[[66578,66578],\"mapped\",[66618]],[[66579,66579],\"mapped\",[66619]],[[66580,66580],\"mapped\",[66620]],[[66581,66581],\"mapped\",[66621]],[[66582,66582],\"mapped\",[66622]],[[66583,66583],\"mapped\",[66623]],[[66584,66584],\"mapped\",[66624]],[[66585,66585],\"mapped\",[66625]],[[66586,66586],\"mapped\",[66626]],[[66587,66587],\"mapped\",[66627]],[[66588,66588],\"mapped\",[66628]],[[66589,66589],\"mapped\",[66629]],[[66590,66590],\"mapped\",[66630]],[[66591,66591],\"mapped\",[66631]],[[66592,66592],\"mapped\",[66632]],[[66593,66593],\"mapped\",[66633]],[[66594,66594],\"mapped\",[66634]],[[66595,66595],\"mapped\",[66635]],[[66596,66596],\"mapped\",[66636]],[[66597,66597],\"mapped\",[66637]],[[66598,66598],\"mapped\",[66638]],[[66599,66599],\"mapped\",[66639]],[[66600,66637],\"valid\"],[[66638,66717],\"valid\"],[[66718,66719],\"disallowed\"],[[66720,66729],\"valid\"],[[66730,66815],\"disallowed\"],[[66816,66855],\"valid\"],[[66856,66863],\"disallowed\"],[[66864,66915],\"valid\"],[[66916,66926],\"disallowed\"],[[66927,66927],\"valid\",[],\"NV8\"],[[66928,67071],\"disallowed\"],[[67072,67382],\"valid\"],[[67383,67391],\"disallowed\"],[[67392,67413],\"valid\"],[[67414,67423],\"disallowed\"],[[67424,67431],\"valid\"],[[67432,67583],\"disallowed\"],[[67584,67589],\"valid\"],[[67590,67591],\"disallowed\"],[[67592,67592],\"valid\"],[[67593,67593],\"disallowed\"],[[67594,67637],\"valid\"],[[67638,67638],\"disallowed\"],[[67639,67640],\"valid\"],[[67641,67643],\"disallowed\"],[[67644,67644],\"valid\"],[[67645,67646],\"disallowed\"],[[67647,67647],\"valid\"],[[67648,67669],\"valid\"],[[67670,67670],\"disallowed\"],[[67671,67679],\"valid\",[],\"NV8\"],[[67680,67702],\"valid\"],[[67703,67711],\"valid\",[],\"NV8\"],[[67712,67742],\"valid\"],[[67743,67750],\"disallowed\"],[[67751,67759],\"valid\",[],\"NV8\"],[[67760,67807],\"disallowed\"],[[67808,67826],\"valid\"],[[67827,67827],\"disallowed\"],[[67828,67829],\"valid\"],[[67830,67834],\"disallowed\"],[[67835,67839],\"valid\",[],\"NV8\"],[[67840,67861],\"valid\"],[[67862,67865],\"valid\",[],\"NV8\"],[[67866,67867],\"valid\",[],\"NV8\"],[[67868,67870],\"disallowed\"],[[67871,67871],\"valid\",[],\"NV8\"],[[67872,67897],\"valid\"],[[67898,67902],\"disallowed\"],[[67903,67903],\"valid\",[],\"NV8\"],[[67904,67967],\"disallowed\"],[[67968,68023],\"valid\"],[[68024,68027],\"disallowed\"],[[68028,68029],\"valid\",[],\"NV8\"],[[68030,68031],\"valid\"],[[68032,68047],\"valid\",[],\"NV8\"],[[68048,68049],\"disallowed\"],[[68050,68095],\"valid\",[],\"NV8\"],[[68096,68099],\"valid\"],[[68100,68100],\"disallowed\"],[[68101,68102],\"valid\"],[[68103,68107],\"disallowed\"],[[68108,68115],\"valid\"],[[68116,68116],\"disallowed\"],[[68117,68119],\"valid\"],[[68120,68120],\"disallowed\"],[[68121,68147],\"valid\"],[[68148,68151],\"disallowed\"],[[68152,68154],\"valid\"],[[68155,68158],\"disallowed\"],[[68159,68159],\"valid\"],[[68160,68167],\"valid\",[],\"NV8\"],[[68168,68175],\"disallowed\"],[[68176,68184],\"valid\",[],\"NV8\"],[[68185,68191],\"disallowed\"],[[68192,68220],\"valid\"],[[68221,68223],\"valid\",[],\"NV8\"],[[68224,68252],\"valid\"],[[68253,68255],\"valid\",[],\"NV8\"],[[68256,68287],\"disallowed\"],[[68288,68295],\"valid\"],[[68296,68296],\"valid\",[],\"NV8\"],[[68297,68326],\"valid\"],[[68327,68330],\"disallowed\"],[[68331,68342],\"valid\",[],\"NV8\"],[[68343,68351],\"disallowed\"],[[68352,68405],\"valid\"],[[68406,68408],\"disallowed\"],[[68409,68415],\"valid\",[],\"NV8\"],[[68416,68437],\"valid\"],[[68438,68439],\"disallowed\"],[[68440,68447],\"valid\",[],\"NV8\"],[[68448,68466],\"valid\"],[[68467,68471],\"disallowed\"],[[68472,68479],\"valid\",[],\"NV8\"],[[68480,68497],\"valid\"],[[68498,68504],\"disallowed\"],[[68505,68508],\"valid\",[],\"NV8\"],[[68509,68520],\"disallowed\"],[[68521,68527],\"valid\",[],\"NV8\"],[[68528,68607],\"disallowed\"],[[68608,68680],\"valid\"],[[68681,68735],\"disallowed\"],[[68736,68736],\"mapped\",[68800]],[[68737,68737],\"mapped\",[68801]],[[68738,68738],\"mapped\",[68802]],[[68739,68739],\"mapped\",[68803]],[[68740,68740],\"mapped\",[68804]],[[68741,68741],\"mapped\",[68805]],[[68742,68742],\"mapped\",[68806]],[[68743,68743],\"mapped\",[68807]],[[68744,68744],\"mapped\",[68808]],[[68745,68745],\"mapped\",[68809]],[[68746,68746],\"mapped\",[68810]],[[68747,68747],\"mapped\",[68811]],[[68748,68748],\"mapped\",[68812]],[[68749,68749],\"mapped\",[68813]],[[68750,68750],\"mapped\",[68814]],[[68751,68751],\"mapped\",[68815]],[[68752,68752],\"mapped\",[68816]],[[68753,68753],\"mapped\",[68817]],[[68754,68754],\"mapped\",[68818]],[[68755,68755],\"mapped\",[68819]],[[68756,68756],\"mapped\",[68820]],[[68757,68757],\"mapped\",[68821]],[[68758,68758],\"mapped\",[68822]],[[68759,68759],\"mapped\",[68823]],[[68760,68760],\"mapped\",[68824]],[[68761,68761],\"mapped\",[68825]],[[68762,68762],\"mapped\",[68826]],[[68763,68763],\"mapped\",[68827]],[[68764,68764],\"mapped\",[68828]],[[68765,68765],\"mapped\",[68829]],[[68766,68766],\"mapped\",[68830]],[[68767,68767],\"mapped\",[68831]],[[68768,68768],\"mapped\",[68832]],[[68769,68769],\"mapped\",[68833]],[[68770,68770],\"mapped\",[68834]],[[68771,68771],\"mapped\",[68835]],[[68772,68772],\"mapped\",[68836]],[[68773,68773],\"mapped\",[68837]],[[68774,68774],\"mapped\",[68838]],[[68775,68775],\"mapped\",[68839]],[[68776,68776],\"mapped\",[68840]],[[68777,68777],\"mapped\",[68841]],[[68778,68778],\"mapped\",[68842]],[[68779,68779],\"mapped\",[68843]],[[68780,68780],\"mapped\",[68844]],[[68781,68781],\"mapped\",[68845]],[[68782,68782],\"mapped\",[68846]],[[68783,68783],\"mapped\",[68847]],[[68784,68784],\"mapped\",[68848]],[[68785,68785],\"mapped\",[68849]],[[68786,68786],\"mapped\",[68850]],[[68787,68799],\"disallowed\"],[[68800,68850],\"valid\"],[[68851,68857],\"disallowed\"],[[68858,68863],\"valid\",[],\"NV8\"],[[68864,69215],\"disallowed\"],[[69216,69246],\"valid\",[],\"NV8\"],[[69247,69631],\"disallowed\"],[[69632,69702],\"valid\"],[[69703,69709],\"valid\",[],\"NV8\"],[[69710,69713],\"disallowed\"],[[69714,69733],\"valid\",[],\"NV8\"],[[69734,69743],\"valid\"],[[69744,69758],\"disallowed\"],[[69759,69759],\"valid\"],[[69760,69818],\"valid\"],[[69819,69820],\"valid\",[],\"NV8\"],[[69821,69821],\"disallowed\"],[[69822,69825],\"valid\",[],\"NV8\"],[[69826,69839],\"disallowed\"],[[69840,69864],\"valid\"],[[69865,69871],\"disallowed\"],[[69872,69881],\"valid\"],[[69882,69887],\"disallowed\"],[[69888,69940],\"valid\"],[[69941,69941],\"disallowed\"],[[69942,69951],\"valid\"],[[69952,69955],\"valid\",[],\"NV8\"],[[69956,69967],\"disallowed\"],[[69968,70003],\"valid\"],[[70004,70005],\"valid\",[],\"NV8\"],[[70006,70006],\"valid\"],[[70007,70015],\"disallowed\"],[[70016,70084],\"valid\"],[[70085,70088],\"valid\",[],\"NV8\"],[[70089,70089],\"valid\",[],\"NV8\"],[[70090,70092],\"valid\"],[[70093,70093],\"valid\",[],\"NV8\"],[[70094,70095],\"disallowed\"],[[70096,70105],\"valid\"],[[70106,70106],\"valid\"],[[70107,70107],\"valid\",[],\"NV8\"],[[70108,70108],\"valid\"],[[70109,70111],\"valid\",[],\"NV8\"],[[70112,70112],\"disallowed\"],[[70113,70132],\"valid\",[],\"NV8\"],[[70133,70143],\"disallowed\"],[[70144,70161],\"valid\"],[[70162,70162],\"disallowed\"],[[70163,70199],\"valid\"],[[70200,70205],\"valid\",[],\"NV8\"],[[70206,70271],\"disallowed\"],[[70272,70278],\"valid\"],[[70279,70279],\"disallowed\"],[[70280,70280],\"valid\"],[[70281,70281],\"disallowed\"],[[70282,70285],\"valid\"],[[70286,70286],\"disallowed\"],[[70287,70301],\"valid\"],[[70302,70302],\"disallowed\"],[[70303,70312],\"valid\"],[[70313,70313],\"valid\",[],\"NV8\"],[[70314,70319],\"disallowed\"],[[70320,70378],\"valid\"],[[70379,70383],\"disallowed\"],[[70384,70393],\"valid\"],[[70394,70399],\"disallowed\"],[[70400,70400],\"valid\"],[[70401,70403],\"valid\"],[[70404,70404],\"disallowed\"],[[70405,70412],\"valid\"],[[70413,70414],\"disallowed\"],[[70415,70416],\"valid\"],[[70417,70418],\"disallowed\"],[[70419,70440],\"valid\"],[[70441,70441],\"disallowed\"],[[70442,70448],\"valid\"],[[70449,70449],\"disallowed\"],[[70450,70451],\"valid\"],[[70452,70452],\"disallowed\"],[[70453,70457],\"valid\"],[[70458,70459],\"disallowed\"],[[70460,70468],\"valid\"],[[70469,70470],\"disallowed\"],[[70471,70472],\"valid\"],[[70473,70474],\"disallowed\"],[[70475,70477],\"valid\"],[[70478,70479],\"disallowed\"],[[70480,70480],\"valid\"],[[70481,70486],\"disallowed\"],[[70487,70487],\"valid\"],[[70488,70492],\"disallowed\"],[[70493,70499],\"valid\"],[[70500,70501],\"disallowed\"],[[70502,70508],\"valid\"],[[70509,70511],\"disallowed\"],[[70512,70516],\"valid\"],[[70517,70783],\"disallowed\"],[[70784,70853],\"valid\"],[[70854,70854],\"valid\",[],\"NV8\"],[[70855,70855],\"valid\"],[[70856,70863],\"disallowed\"],[[70864,70873],\"valid\"],[[70874,71039],\"disallowed\"],[[71040,71093],\"valid\"],[[71094,71095],\"disallowed\"],[[71096,71104],\"valid\"],[[71105,71113],\"valid\",[],\"NV8\"],[[71114,71127],\"valid\",[],\"NV8\"],[[71128,71133],\"valid\"],[[71134,71167],\"disallowed\"],[[71168,71232],\"valid\"],[[71233,71235],\"valid\",[],\"NV8\"],[[71236,71236],\"valid\"],[[71237,71247],\"disallowed\"],[[71248,71257],\"valid\"],[[71258,71295],\"disallowed\"],[[71296,71351],\"valid\"],[[71352,71359],\"disallowed\"],[[71360,71369],\"valid\"],[[71370,71423],\"disallowed\"],[[71424,71449],\"valid\"],[[71450,71452],\"disallowed\"],[[71453,71467],\"valid\"],[[71468,71471],\"disallowed\"],[[71472,71481],\"valid\"],[[71482,71487],\"valid\",[],\"NV8\"],[[71488,71839],\"disallowed\"],[[71840,71840],\"mapped\",[71872]],[[71841,71841],\"mapped\",[71873]],[[71842,71842],\"mapped\",[71874]],[[71843,71843],\"mapped\",[71875]],[[71844,71844],\"mapped\",[71876]],[[71845,71845],\"mapped\",[71877]],[[71846,71846],\"mapped\",[71878]],[[71847,71847],\"mapped\",[71879]],[[71848,71848],\"mapped\",[71880]],[[71849,71849],\"mapped\",[71881]],[[71850,71850],\"mapped\",[71882]],[[71851,71851],\"mapped\",[71883]],[[71852,71852],\"mapped\",[71884]],[[71853,71853],\"mapped\",[71885]],[[71854,71854],\"mapped\",[71886]],[[71855,71855],\"mapped\",[71887]],[[71856,71856],\"mapped\",[71888]],[[71857,71857],\"mapped\",[71889]],[[71858,71858],\"mapped\",[71890]],[[71859,71859],\"mapped\",[71891]],[[71860,71860],\"mapped\",[71892]],[[71861,71861],\"mapped\",[71893]],[[71862,71862],\"mapped\",[71894]],[[71863,71863],\"mapped\",[71895]],[[71864,71864],\"mapped\",[71896]],[[71865,71865],\"mapped\",[71897]],[[71866,71866],\"mapped\",[71898]],[[71867,71867],\"mapped\",[71899]],[[71868,71868],\"mapped\",[71900]],[[71869,71869],\"mapped\",[71901]],[[71870,71870],\"mapped\",[71902]],[[71871,71871],\"mapped\",[71903]],[[71872,71913],\"valid\"],[[71914,71922],\"valid\",[],\"NV8\"],[[71923,71934],\"disallowed\"],[[71935,71935],\"valid\"],[[71936,72383],\"disallowed\"],[[72384,72440],\"valid\"],[[72441,73727],\"disallowed\"],[[73728,74606],\"valid\"],[[74607,74648],\"valid\"],[[74649,74649],\"valid\"],[[74650,74751],\"disallowed\"],[[74752,74850],\"valid\",[],\"NV8\"],[[74851,74862],\"valid\",[],\"NV8\"],[[74863,74863],\"disallowed\"],[[74864,74867],\"valid\",[],\"NV8\"],[[74868,74868],\"valid\",[],\"NV8\"],[[74869,74879],\"disallowed\"],[[74880,75075],\"valid\"],[[75076,77823],\"disallowed\"],[[77824,78894],\"valid\"],[[78895,82943],\"disallowed\"],[[82944,83526],\"valid\"],[[83527,92159],\"disallowed\"],[[92160,92728],\"valid\"],[[92729,92735],\"disallowed\"],[[92736,92766],\"valid\"],[[92767,92767],\"disallowed\"],[[92768,92777],\"valid\"],[[92778,92781],\"disallowed\"],[[92782,92783],\"valid\",[],\"NV8\"],[[92784,92879],\"disallowed\"],[[92880,92909],\"valid\"],[[92910,92911],\"disallowed\"],[[92912,92916],\"valid\"],[[92917,92917],\"valid\",[],\"NV8\"],[[92918,92927],\"disallowed\"],[[92928,92982],\"valid\"],[[92983,92991],\"valid\",[],\"NV8\"],[[92992,92995],\"valid\"],[[92996,92997],\"valid\",[],\"NV8\"],[[92998,93007],\"disallowed\"],[[93008,93017],\"valid\"],[[93018,93018],\"disallowed\"],[[93019,93025],\"valid\",[],\"NV8\"],[[93026,93026],\"disallowed\"],[[93027,93047],\"valid\"],[[93048,93052],\"disallowed\"],[[93053,93071],\"valid\"],[[93072,93951],\"disallowed\"],[[93952,94020],\"valid\"],[[94021,94031],\"disallowed\"],[[94032,94078],\"valid\"],[[94079,94094],\"disallowed\"],[[94095,94111],\"valid\"],[[94112,110591],\"disallowed\"],[[110592,110593],\"valid\"],[[110594,113663],\"disallowed\"],[[113664,113770],\"valid\"],[[113771,113775],\"disallowed\"],[[113776,113788],\"valid\"],[[113789,113791],\"disallowed\"],[[113792,113800],\"valid\"],[[113801,113807],\"disallowed\"],[[113808,113817],\"valid\"],[[113818,113819],\"disallowed\"],[[113820,113820],\"valid\",[],\"NV8\"],[[113821,113822],\"valid\"],[[113823,113823],\"valid\",[],\"NV8\"],[[113824,113827],\"ignored\"],[[113828,118783],\"disallowed\"],[[118784,119029],\"valid\",[],\"NV8\"],[[119030,119039],\"disallowed\"],[[119040,119078],\"valid\",[],\"NV8\"],[[119079,119080],\"disallowed\"],[[119081,119081],\"valid\",[],\"NV8\"],[[119082,119133],\"valid\",[],\"NV8\"],[[119134,119134],\"mapped\",[119127,119141]],[[119135,119135],\"mapped\",[119128,119141]],[[119136,119136],\"mapped\",[119128,119141,119150]],[[119137,119137],\"mapped\",[119128,119141,119151]],[[119138,119138],\"mapped\",[119128,119141,119152]],[[119139,119139],\"mapped\",[119128,119141,119153]],[[119140,119140],\"mapped\",[119128,119141,119154]],[[119141,119154],\"valid\",[],\"NV8\"],[[119155,119162],\"disallowed\"],[[119163,119226],\"valid\",[],\"NV8\"],[[119227,119227],\"mapped\",[119225,119141]],[[119228,119228],\"mapped\",[119226,119141]],[[119229,119229],\"mapped\",[119225,119141,119150]],[[119230,119230],\"mapped\",[119226,119141,119150]],[[119231,119231],\"mapped\",[119225,119141,119151]],[[119232,119232],\"mapped\",[119226,119141,119151]],[[119233,119261],\"valid\",[],\"NV8\"],[[119262,119272],\"valid\",[],\"NV8\"],[[119273,119295],\"disallowed\"],[[119296,119365],\"valid\",[],\"NV8\"],[[119366,119551],\"disallowed\"],[[119552,119638],\"valid\",[],\"NV8\"],[[119639,119647],\"disallowed\"],[[119648,119665],\"valid\",[],\"NV8\"],[[119666,119807],\"disallowed\"],[[119808,119808],\"mapped\",[97]],[[119809,119809],\"mapped\",[98]],[[119810,119810],\"mapped\",[99]],[[119811,119811],\"mapped\",[100]],[[119812,119812],\"mapped\",[101]],[[119813,119813],\"mapped\",[102]],[[119814,119814],\"mapped\",[103]],[[119815,119815],\"mapped\",[104]],[[119816,119816],\"mapped\",[105]],[[119817,119817],\"mapped\",[106]],[[119818,119818],\"mapped\",[107]],[[119819,119819],\"mapped\",[108]],[[119820,119820],\"mapped\",[109]],[[119821,119821],\"mapped\",[110]],[[119822,119822],\"mapped\",[111]],[[119823,119823],\"mapped\",[112]],[[119824,119824],\"mapped\",[113]],[[119825,119825],\"mapped\",[114]],[[119826,119826],\"mapped\",[115]],[[119827,119827],\"mapped\",[116]],[[119828,119828],\"mapped\",[117]],[[119829,119829],\"mapped\",[118]],[[119830,119830],\"mapped\",[119]],[[119831,119831],\"mapped\",[120]],[[119832,119832],\"mapped\",[121]],[[119833,119833],\"mapped\",[122]],[[119834,119834],\"mapped\",[97]],[[119835,119835],\"mapped\",[98]],[[119836,119836],\"mapped\",[99]],[[119837,119837],\"mapped\",[100]],[[119838,119838],\"mapped\",[101]],[[119839,119839],\"mapped\",[102]],[[119840,119840],\"mapped\",[103]],[[119841,119841],\"mapped\",[104]],[[119842,119842],\"mapped\",[105]],[[119843,119843],\"mapped\",[106]],[[119844,119844],\"mapped\",[107]],[[119845,119845],\"mapped\",[108]],[[119846,119846],\"mapped\",[109]],[[119847,119847],\"mapped\",[110]],[[119848,119848],\"mapped\",[111]],[[119849,119849],\"mapped\",[112]],[[119850,119850],\"mapped\",[113]],[[119851,119851],\"mapped\",[114]],[[119852,119852],\"mapped\",[115]],[[119853,119853],\"mapped\",[116]],[[119854,119854],\"mapped\",[117]],[[119855,119855],\"mapped\",[118]],[[119856,119856],\"mapped\",[119]],[[119857,119857],\"mapped\",[120]],[[119858,119858],\"mapped\",[121]],[[119859,119859],\"mapped\",[122]],[[119860,119860],\"mapped\",[97]],[[119861,119861],\"mapped\",[98]],[[119862,119862],\"mapped\",[99]],[[119863,119863],\"mapped\",[100]],[[119864,119864],\"mapped\",[101]],[[119865,119865],\"mapped\",[102]],[[119866,119866],\"mapped\",[103]],[[119867,119867],\"mapped\",[104]],[[119868,119868],\"mapped\",[105]],[[119869,119869],\"mapped\",[106]],[[119870,119870],\"mapped\",[107]],[[119871,119871],\"mapped\",[108]],[[119872,119872],\"mapped\",[109]],[[119873,119873],\"mapped\",[110]],[[119874,119874],\"mapped\",[111]],[[119875,119875],\"mapped\",[112]],[[119876,119876],\"mapped\",[113]],[[119877,119877],\"mapped\",[114]],[[119878,119878],\"mapped\",[115]],[[119879,119879],\"mapped\",[116]],[[119880,119880],\"mapped\",[117]],[[119881,119881],\"mapped\",[118]],[[119882,119882],\"mapped\",[119]],[[119883,119883],\"mapped\",[120]],[[119884,119884],\"mapped\",[121]],[[119885,119885],\"mapped\",[122]],[[119886,119886],\"mapped\",[97]],[[119887,119887],\"mapped\",[98]],[[119888,119888],\"mapped\",[99]],[[119889,119889],\"mapped\",[100]],[[119890,119890],\"mapped\",[101]],[[119891,119891],\"mapped\",[102]],[[119892,119892],\"mapped\",[103]],[[119893,119893],\"disallowed\"],[[119894,119894],\"mapped\",[105]],[[119895,119895],\"mapped\",[106]],[[119896,119896],\"mapped\",[107]],[[119897,119897],\"mapped\",[108]],[[119898,119898],\"mapped\",[109]],[[119899,119899],\"mapped\",[110]],[[119900,119900],\"mapped\",[111]],[[119901,119901],\"mapped\",[112]],[[119902,119902],\"mapped\",[113]],[[119903,119903],\"mapped\",[114]],[[119904,119904],\"mapped\",[115]],[[119905,119905],\"mapped\",[116]],[[119906,119906],\"mapped\",[117]],[[119907,119907],\"mapped\",[118]],[[119908,119908],\"mapped\",[119]],[[119909,119909],\"mapped\",[120]],[[119910,119910],\"mapped\",[121]],[[119911,119911],\"mapped\",[122]],[[119912,119912],\"mapped\",[97]],[[119913,119913],\"mapped\",[98]],[[119914,119914],\"mapped\",[99]],[[119915,119915],\"mapped\",[100]],[[119916,119916],\"mapped\",[101]],[[119917,119917],\"mapped\",[102]],[[119918,119918],\"mapped\",[103]],[[119919,119919],\"mapped\",[104]],[[119920,119920],\"mapped\",[105]],[[119921,119921],\"mapped\",[106]],[[119922,119922],\"mapped\",[107]],[[119923,119923],\"mapped\",[108]],[[119924,119924],\"mapped\",[109]],[[119925,119925],\"mapped\",[110]],[[119926,119926],\"mapped\",[111]],[[119927,119927],\"mapped\",[112]],[[119928,119928],\"mapped\",[113]],[[119929,119929],\"mapped\",[114]],[[119930,119930],\"mapped\",[115]],[[119931,119931],\"mapped\",[116]],[[119932,119932],\"mapped\",[117]],[[119933,119933],\"mapped\",[118]],[[119934,119934],\"mapped\",[119]],[[119935,119935],\"mapped\",[120]],[[119936,119936],\"mapped\",[121]],[[119937,119937],\"mapped\",[122]],[[119938,119938],\"mapped\",[97]],[[119939,119939],\"mapped\",[98]],[[119940,119940],\"mapped\",[99]],[[119941,119941],\"mapped\",[100]],[[119942,119942],\"mapped\",[101]],[[119943,119943],\"mapped\",[102]],[[119944,119944],\"mapped\",[103]],[[119945,119945],\"mapped\",[104]],[[119946,119946],\"mapped\",[105]],[[119947,119947],\"mapped\",[106]],[[119948,119948],\"mapped\",[107]],[[119949,119949],\"mapped\",[108]],[[119950,119950],\"mapped\",[109]],[[119951,119951],\"mapped\",[110]],[[119952,119952],\"mapped\",[111]],[[119953,119953],\"mapped\",[112]],[[119954,119954],\"mapped\",[113]],[[119955,119955],\"mapped\",[114]],[[119956,119956],\"mapped\",[115]],[[119957,119957],\"mapped\",[116]],[[119958,119958],\"mapped\",[117]],[[119959,119959],\"mapped\",[118]],[[119960,119960],\"mapped\",[119]],[[119961,119961],\"mapped\",[120]],[[119962,119962],\"mapped\",[121]],[[119963,119963],\"mapped\",[122]],[[119964,119964],\"mapped\",[97]],[[119965,119965],\"disallowed\"],[[119966,119966],\"mapped\",[99]],[[119967,119967],\"mapped\",[100]],[[119968,119969],\"disallowed\"],[[119970,119970],\"mapped\",[103]],[[119971,119972],\"disallowed\"],[[119973,119973],\"mapped\",[106]],[[119974,119974],\"mapped\",[107]],[[119975,119976],\"disallowed\"],[[119977,119977],\"mapped\",[110]],[[119978,119978],\"mapped\",[111]],[[119979,119979],\"mapped\",[112]],[[119980,119980],\"mapped\",[113]],[[119981,119981],\"disallowed\"],[[119982,119982],\"mapped\",[115]],[[119983,119983],\"mapped\",[116]],[[119984,119984],\"mapped\",[117]],[[119985,119985],\"mapped\",[118]],[[119986,119986],\"mapped\",[119]],[[119987,119987],\"mapped\",[120]],[[119988,119988],\"mapped\",[121]],[[119989,119989],\"mapped\",[122]],[[119990,119990],\"mapped\",[97]],[[119991,119991],\"mapped\",[98]],[[119992,119992],\"mapped\",[99]],[[119993,119993],\"mapped\",[100]],[[119994,119994],\"disallowed\"],[[119995,119995],\"mapped\",[102]],[[119996,119996],\"disallowed\"],[[119997,119997],\"mapped\",[104]],[[119998,119998],\"mapped\",[105]],[[119999,119999],\"mapped\",[106]],[[120000,120000],\"mapped\",[107]],[[120001,120001],\"mapped\",[108]],[[120002,120002],\"mapped\",[109]],[[120003,120003],\"mapped\",[110]],[[120004,120004],\"disallowed\"],[[120005,120005],\"mapped\",[112]],[[120006,120006],\"mapped\",[113]],[[120007,120007],\"mapped\",[114]],[[120008,120008],\"mapped\",[115]],[[120009,120009],\"mapped\",[116]],[[120010,120010],\"mapped\",[117]],[[120011,120011],\"mapped\",[118]],[[120012,120012],\"mapped\",[119]],[[120013,120013],\"mapped\",[120]],[[120014,120014],\"mapped\",[121]],[[120015,120015],\"mapped\",[122]],[[120016,120016],\"mapped\",[97]],[[120017,120017],\"mapped\",[98]],[[120018,120018],\"mapped\",[99]],[[120019,120019],\"mapped\",[100]],[[120020,120020],\"mapped\",[101]],[[120021,120021],\"mapped\",[102]],[[120022,120022],\"mapped\",[103]],[[120023,120023],\"mapped\",[104]],[[120024,120024],\"mapped\",[105]],[[120025,120025],\"mapped\",[106]],[[120026,120026],\"mapped\",[107]],[[120027,120027],\"mapped\",[108]],[[120028,120028],\"mapped\",[109]],[[120029,120029],\"mapped\",[110]],[[120030,120030],\"mapped\",[111]],[[120031,120031],\"mapped\",[112]],[[120032,120032],\"mapped\",[113]],[[120033,120033],\"mapped\",[114]],[[120034,120034],\"mapped\",[115]],[[120035,120035],\"mapped\",[116]],[[120036,120036],\"mapped\",[117]],[[120037,120037],\"mapped\",[118]],[[120038,120038],\"mapped\",[119]],[[120039,120039],\"mapped\",[120]],[[120040,120040],\"mapped\",[121]],[[120041,120041],\"mapped\",[122]],[[120042,120042],\"mapped\",[97]],[[120043,120043],\"mapped\",[98]],[[120044,120044],\"mapped\",[99]],[[120045,120045],\"mapped\",[100]],[[120046,120046],\"mapped\",[101]],[[120047,120047],\"mapped\",[102]],[[120048,120048],\"mapped\",[103]],[[120049,120049],\"mapped\",[104]],[[120050,120050],\"mapped\",[105]],[[120051,120051],\"mapped\",[106]],[[120052,120052],\"mapped\",[107]],[[120053,120053],\"mapped\",[108]],[[120054,120054],\"mapped\",[109]],[[120055,120055],\"mapped\",[110]],[[120056,120056],\"mapped\",[111]],[[120057,120057],\"mapped\",[112]],[[120058,120058],\"mapped\",[113]],[[120059,120059],\"mapped\",[114]],[[120060,120060],\"mapped\",[115]],[[120061,120061],\"mapped\",[116]],[[120062,120062],\"mapped\",[117]],[[120063,120063],\"mapped\",[118]],[[120064,120064],\"mapped\",[119]],[[120065,120065],\"mapped\",[120]],[[120066,120066],\"mapped\",[121]],[[120067,120067],\"mapped\",[122]],[[120068,120068],\"mapped\",[97]],[[120069,120069],\"mapped\",[98]],[[120070,120070],\"disallowed\"],[[120071,120071],\"mapped\",[100]],[[120072,120072],\"mapped\",[101]],[[120073,120073],\"mapped\",[102]],[[120074,120074],\"mapped\",[103]],[[120075,120076],\"disallowed\"],[[120077,120077],\"mapped\",[106]],[[120078,120078],\"mapped\",[107]],[[120079,120079],\"mapped\",[108]],[[120080,120080],\"mapped\",[109]],[[120081,120081],\"mapped\",[110]],[[120082,120082],\"mapped\",[111]],[[120083,120083],\"mapped\",[112]],[[120084,120084],\"mapped\",[113]],[[120085,120085],\"disallowed\"],[[120086,120086],\"mapped\",[115]],[[120087,120087],\"mapped\",[116]],[[120088,120088],\"mapped\",[117]],[[120089,120089],\"mapped\",[118]],[[120090,120090],\"mapped\",[119]],[[120091,120091],\"mapped\",[120]],[[120092,120092],\"mapped\",[121]],[[120093,120093],\"disallowed\"],[[120094,120094],\"mapped\",[97]],[[120095,120095],\"mapped\",[98]],[[120096,120096],\"mapped\",[99]],[[120097,120097],\"mapped\",[100]],[[120098,120098],\"mapped\",[101]],[[120099,120099],\"mapped\",[102]],[[120100,120100],\"mapped\",[103]],[[120101,120101],\"mapped\",[104]],[[120102,120102],\"mapped\",[105]],[[120103,120103],\"mapped\",[106]],[[120104,120104],\"mapped\",[107]],[[120105,120105],\"mapped\",[108]],[[120106,120106],\"mapped\",[109]],[[120107,120107],\"mapped\",[110]],[[120108,120108],\"mapped\",[111]],[[120109,120109],\"mapped\",[112]],[[120110,120110],\"mapped\",[113]],[[120111,120111],\"mapped\",[114]],[[120112,120112],\"mapped\",[115]],[[120113,120113],\"mapped\",[116]],[[120114,120114],\"mapped\",[117]],[[120115,120115],\"mapped\",[118]],[[120116,120116],\"mapped\",[119]],[[120117,120117],\"mapped\",[120]],[[120118,120118],\"mapped\",[121]],[[120119,120119],\"mapped\",[122]],[[120120,120120],\"mapped\",[97]],[[120121,120121],\"mapped\",[98]],[[120122,120122],\"disallowed\"],[[120123,120123],\"mapped\",[100]],[[120124,120124],\"mapped\",[101]],[[120125,120125],\"mapped\",[102]],[[120126,120126],\"mapped\",[103]],[[120127,120127],\"disallowed\"],[[120128,120128],\"mapped\",[105]],[[120129,120129],\"mapped\",[106]],[[120130,120130],\"mapped\",[107]],[[120131,120131],\"mapped\",[108]],[[120132,120132],\"mapped\",[109]],[[120133,120133],\"disallowed\"],[[120134,120134],\"mapped\",[111]],[[120135,120137],\"disallowed\"],[[120138,120138],\"mapped\",[115]],[[120139,120139],\"mapped\",[116]],[[120140,120140],\"mapped\",[117]],[[120141,120141],\"mapped\",[118]],[[120142,120142],\"mapped\",[119]],[[120143,120143],\"mapped\",[120]],[[120144,120144],\"mapped\",[121]],[[120145,120145],\"disallowed\"],[[120146,120146],\"mapped\",[97]],[[120147,120147],\"mapped\",[98]],[[120148,120148],\"mapped\",[99]],[[120149,120149],\"mapped\",[100]],[[120150,120150],\"mapped\",[101]],[[120151,120151],\"mapped\",[102]],[[120152,120152],\"mapped\",[103]],[[120153,120153],\"mapped\",[104]],[[120154,120154],\"mapped\",[105]],[[120155,120155],\"mapped\",[106]],[[120156,120156],\"mapped\",[107]],[[120157,120157],\"mapped\",[108]],[[120158,120158],\"mapped\",[109]],[[120159,120159],\"mapped\",[110]],[[120160,120160],\"mapped\",[111]],[[120161,120161],\"mapped\",[112]],[[120162,120162],\"mapped\",[113]],[[120163,120163],\"mapped\",[114]],[[120164,120164],\"mapped\",[115]],[[120165,120165],\"mapped\",[116]],[[120166,120166],\"mapped\",[117]],[[120167,120167],\"mapped\",[118]],[[120168,120168],\"mapped\",[119]],[[120169,120169],\"mapped\",[120]],[[120170,120170],\"mapped\",[121]],[[120171,120171],\"mapped\",[122]],[[120172,120172],\"mapped\",[97]],[[120173,120173],\"mapped\",[98]],[[120174,120174],\"mapped\",[99]],[[120175,120175],\"mapped\",[100]],[[120176,120176],\"mapped\",[101]],[[120177,120177],\"mapped\",[102]],[[120178,120178],\"mapped\",[103]],[[120179,120179],\"mapped\",[104]],[[120180,120180],\"mapped\",[105]],[[120181,120181],\"mapped\",[106]],[[120182,120182],\"mapped\",[107]],[[120183,120183],\"mapped\",[108]],[[120184,120184],\"mapped\",[109]],[[120185,120185],\"mapped\",[110]],[[120186,120186],\"mapped\",[111]],[[120187,120187],\"mapped\",[112]],[[120188,120188],\"mapped\",[113]],[[120189,120189],\"mapped\",[114]],[[120190,120190],\"mapped\",[115]],[[120191,120191],\"mapped\",[116]],[[120192,120192],\"mapped\",[117]],[[120193,120193],\"mapped\",[118]],[[120194,120194],\"mapped\",[119]],[[120195,120195],\"mapped\",[120]],[[120196,120196],\"mapped\",[121]],[[120197,120197],\"mapped\",[122]],[[120198,120198],\"mapped\",[97]],[[120199,120199],\"mapped\",[98]],[[120200,120200],\"mapped\",[99]],[[120201,120201],\"mapped\",[100]],[[120202,120202],\"mapped\",[101]],[[120203,120203],\"mapped\",[102]],[[120204,120204],\"mapped\",[103]],[[120205,120205],\"mapped\",[104]],[[120206,120206],\"mapped\",[105]],[[120207,120207],\"mapped\",[106]],[[120208,120208],\"mapped\",[107]],[[120209,120209],\"mapped\",[108]],[[120210,120210],\"mapped\",[109]],[[120211,120211],\"mapped\",[110]],[[120212,120212],\"mapped\",[111]],[[120213,120213],\"mapped\",[112]],[[120214,120214],\"mapped\",[113]],[[120215,120215],\"mapped\",[114]],[[120216,120216],\"mapped\",[115]],[[120217,120217],\"mapped\",[116]],[[120218,120218],\"mapped\",[117]],[[120219,120219],\"mapped\",[118]],[[120220,120220],\"mapped\",[119]],[[120221,120221],\"mapped\",[120]],[[120222,120222],\"mapped\",[121]],[[120223,120223],\"mapped\",[122]],[[120224,120224],\"mapped\",[97]],[[120225,120225],\"mapped\",[98]],[[120226,120226],\"mapped\",[99]],[[120227,120227],\"mapped\",[100]],[[120228,120228],\"mapped\",[101]],[[120229,120229],\"mapped\",[102]],[[120230,120230],\"mapped\",[103]],[[120231,120231],\"mapped\",[104]],[[120232,120232],\"mapped\",[105]],[[120233,120233],\"mapped\",[106]],[[120234,120234],\"mapped\",[107]],[[120235,120235],\"mapped\",[108]],[[120236,120236],\"mapped\",[109]],[[120237,120237],\"mapped\",[110]],[[120238,120238],\"mapped\",[111]],[[120239,120239],\"mapped\",[112]],[[120240,120240],\"mapped\",[113]],[[120241,120241],\"mapped\",[114]],[[120242,120242],\"mapped\",[115]],[[120243,120243],\"mapped\",[116]],[[120244,120244],\"mapped\",[117]],[[120245,120245],\"mapped\",[118]],[[120246,120246],\"mapped\",[119]],[[120247,120247],\"mapped\",[120]],[[120248,120248],\"mapped\",[121]],[[120249,120249],\"mapped\",[122]],[[120250,120250],\"mapped\",[97]],[[120251,120251],\"mapped\",[98]],[[120252,120252],\"mapped\",[99]],[[120253,120253],\"mapped\",[100]],[[120254,120254],\"mapped\",[101]],[[120255,120255],\"mapped\",[102]],[[120256,120256],\"mapped\",[103]],[[120257,120257],\"mapped\",[104]],[[120258,120258],\"mapped\",[105]],[[120259,120259],\"mapped\",[106]],[[120260,120260],\"mapped\",[107]],[[120261,120261],\"mapped\",[108]],[[120262,120262],\"mapped\",[109]],[[120263,120263],\"mapped\",[110]],[[120264,120264],\"mapped\",[111]],[[120265,120265],\"mapped\",[112]],[[120266,120266],\"mapped\",[113]],[[120267,120267],\"mapped\",[114]],[[120268,120268],\"mapped\",[115]],[[120269,120269],\"mapped\",[116]],[[120270,120270],\"mapped\",[117]],[[120271,120271],\"mapped\",[118]],[[120272,120272],\"mapped\",[119]],[[120273,120273],\"mapped\",[120]],[[120274,120274],\"mapped\",[121]],[[120275,120275],\"mapped\",[122]],[[120276,120276],\"mapped\",[97]],[[120277,120277],\"mapped\",[98]],[[120278,120278],\"mapped\",[99]],[[120279,120279],\"mapped\",[100]],[[120280,120280],\"mapped\",[101]],[[120281,120281],\"mapped\",[102]],[[120282,120282],\"mapped\",[103]],[[120283,120283],\"mapped\",[104]],[[120284,120284],\"mapped\",[105]],[[120285,120285],\"mapped\",[106]],[[120286,120286],\"mapped\",[107]],[[120287,120287],\"mapped\",[108]],[[120288,120288],\"mapped\",[109]],[[120289,120289],\"mapped\",[110]],[[120290,120290],\"mapped\",[111]],[[120291,120291],\"mapped\",[112]],[[120292,120292],\"mapped\",[113]],[[120293,120293],\"mapped\",[114]],[[120294,120294],\"mapped\",[115]],[[120295,120295],\"mapped\",[116]],[[120296,120296],\"mapped\",[117]],[[120297,120297],\"mapped\",[118]],[[120298,120298],\"mapped\",[119]],[[120299,120299],\"mapped\",[120]],[[120300,120300],\"mapped\",[121]],[[120301,120301],\"mapped\",[122]],[[120302,120302],\"mapped\",[97]],[[120303,120303],\"mapped\",[98]],[[120304,120304],\"mapped\",[99]],[[120305,120305],\"mapped\",[100]],[[120306,120306],\"mapped\",[101]],[[120307,120307],\"mapped\",[102]],[[120308,120308],\"mapped\",[103]],[[120309,120309],\"mapped\",[104]],[[120310,120310],\"mapped\",[105]],[[120311,120311],\"mapped\",[106]],[[120312,120312],\"mapped\",[107]],[[120313,120313],\"mapped\",[108]],[[120314,120314],\"mapped\",[109]],[[120315,120315],\"mapped\",[110]],[[120316,120316],\"mapped\",[111]],[[120317,120317],\"mapped\",[112]],[[120318,120318],\"mapped\",[113]],[[120319,120319],\"mapped\",[114]],[[120320,120320],\"mapped\",[115]],[[120321,120321],\"mapped\",[116]],[[120322,120322],\"mapped\",[117]],[[120323,120323],\"mapped\",[118]],[[120324,120324],\"mapped\",[119]],[[120325,120325],\"mapped\",[120]],[[120326,120326],\"mapped\",[121]],[[120327,120327],\"mapped\",[122]],[[120328,120328],\"mapped\",[97]],[[120329,120329],\"mapped\",[98]],[[120330,120330],\"mapped\",[99]],[[120331,120331],\"mapped\",[100]],[[120332,120332],\"mapped\",[101]],[[120333,120333],\"mapped\",[102]],[[120334,120334],\"mapped\",[103]],[[120335,120335],\"mapped\",[104]],[[120336,120336],\"mapped\",[105]],[[120337,120337],\"mapped\",[106]],[[120338,120338],\"mapped\",[107]],[[120339,120339],\"mapped\",[108]],[[120340,120340],\"mapped\",[109]],[[120341,120341],\"mapped\",[110]],[[120342,120342],\"mapped\",[111]],[[120343,120343],\"mapped\",[112]],[[120344,120344],\"mapped\",[113]],[[120345,120345],\"mapped\",[114]],[[120346,120346],\"mapped\",[115]],[[120347,120347],\"mapped\",[116]],[[120348,120348],\"mapped\",[117]],[[120349,120349],\"mapped\",[118]],[[120350,120350],\"mapped\",[119]],[[120351,120351],\"mapped\",[120]],[[120352,120352],\"mapped\",[121]],[[120353,120353],\"mapped\",[122]],[[120354,120354],\"mapped\",[97]],[[120355,120355],\"mapped\",[98]],[[120356,120356],\"mapped\",[99]],[[120357,120357],\"mapped\",[100]],[[120358,120358],\"mapped\",[101]],[[120359,120359],\"mapped\",[102]],[[120360,120360],\"mapped\",[103]],[[120361,120361],\"mapped\",[104]],[[120362,120362],\"mapped\",[105]],[[120363,120363],\"mapped\",[106]],[[120364,120364],\"mapped\",[107]],[[120365,120365],\"mapped\",[108]],[[120366,120366],\"mapped\",[109]],[[120367,120367],\"mapped\",[110]],[[120368,120368],\"mapped\",[111]],[[120369,120369],\"mapped\",[112]],[[120370,120370],\"mapped\",[113]],[[120371,120371],\"mapped\",[114]],[[120372,120372],\"mapped\",[115]],[[120373,120373],\"mapped\",[116]],[[120374,120374],\"mapped\",[117]],[[120375,120375],\"mapped\",[118]],[[120376,120376],\"mapped\",[119]],[[120377,120377],\"mapped\",[120]],[[120378,120378],\"mapped\",[121]],[[120379,120379],\"mapped\",[122]],[[120380,120380],\"mapped\",[97]],[[120381,120381],\"mapped\",[98]],[[120382,120382],\"mapped\",[99]],[[120383,120383],\"mapped\",[100]],[[120384,120384],\"mapped\",[101]],[[120385,120385],\"mapped\",[102]],[[120386,120386],\"mapped\",[103]],[[120387,120387],\"mapped\",[104]],[[120388,120388],\"mapped\",[105]],[[120389,120389],\"mapped\",[106]],[[120390,120390],\"mapped\",[107]],[[120391,120391],\"mapped\",[108]],[[120392,120392],\"mapped\",[109]],[[120393,120393],\"mapped\",[110]],[[120394,120394],\"mapped\",[111]],[[120395,120395],\"mapped\",[112]],[[120396,120396],\"mapped\",[113]],[[120397,120397],\"mapped\",[114]],[[120398,120398],\"mapped\",[115]],[[120399,120399],\"mapped\",[116]],[[120400,120400],\"mapped\",[117]],[[120401,120401],\"mapped\",[118]],[[120402,120402],\"mapped\",[119]],[[120403,120403],\"mapped\",[120]],[[120404,120404],\"mapped\",[121]],[[120405,120405],\"mapped\",[122]],[[120406,120406],\"mapped\",[97]],[[120407,120407],\"mapped\",[98]],[[120408,120408],\"mapped\",[99]],[[120409,120409],\"mapped\",[100]],[[120410,120410],\"mapped\",[101]],[[120411,120411],\"mapped\",[102]],[[120412,120412],\"mapped\",[103]],[[120413,120413],\"mapped\",[104]],[[120414,120414],\"mapped\",[105]],[[120415,120415],\"mapped\",[106]],[[120416,120416],\"mapped\",[107]],[[120417,120417],\"mapped\",[108]],[[120418,120418],\"mapped\",[109]],[[120419,120419],\"mapped\",[110]],[[120420,120420],\"mapped\",[111]],[[120421,120421],\"mapped\",[112]],[[120422,120422],\"mapped\",[113]],[[120423,120423],\"mapped\",[114]],[[120424,120424],\"mapped\",[115]],[[120425,120425],\"mapped\",[116]],[[120426,120426],\"mapped\",[117]],[[120427,120427],\"mapped\",[118]],[[120428,120428],\"mapped\",[119]],[[120429,120429],\"mapped\",[120]],[[120430,120430],\"mapped\",[121]],[[120431,120431],\"mapped\",[122]],[[120432,120432],\"mapped\",[97]],[[120433,120433],\"mapped\",[98]],[[120434,120434],\"mapped\",[99]],[[120435,120435],\"mapped\",[100]],[[120436,120436],\"mapped\",[101]],[[120437,120437],\"mapped\",[102]],[[120438,120438],\"mapped\",[103]],[[120439,120439],\"mapped\",[104]],[[120440,120440],\"mapped\",[105]],[[120441,120441],\"mapped\",[106]],[[120442,120442],\"mapped\",[107]],[[120443,120443],\"mapped\",[108]],[[120444,120444],\"mapped\",[109]],[[120445,120445],\"mapped\",[110]],[[120446,120446],\"mapped\",[111]],[[120447,120447],\"mapped\",[112]],[[120448,120448],\"mapped\",[113]],[[120449,120449],\"mapped\",[114]],[[120450,120450],\"mapped\",[115]],[[120451,120451],\"mapped\",[116]],[[120452,120452],\"mapped\",[117]],[[120453,120453],\"mapped\",[118]],[[120454,120454],\"mapped\",[119]],[[120455,120455],\"mapped\",[120]],[[120456,120456],\"mapped\",[121]],[[120457,120457],\"mapped\",[122]],[[120458,120458],\"mapped\",[97]],[[120459,120459],\"mapped\",[98]],[[120460,120460],\"mapped\",[99]],[[120461,120461],\"mapped\",[100]],[[120462,120462],\"mapped\",[101]],[[120463,120463],\"mapped\",[102]],[[120464,120464],\"mapped\",[103]],[[120465,120465],\"mapped\",[104]],[[120466,120466],\"mapped\",[105]],[[120467,120467],\"mapped\",[106]],[[120468,120468],\"mapped\",[107]],[[120469,120469],\"mapped\",[108]],[[120470,120470],\"mapped\",[109]],[[120471,120471],\"mapped\",[110]],[[120472,120472],\"mapped\",[111]],[[120473,120473],\"mapped\",[112]],[[120474,120474],\"mapped\",[113]],[[120475,120475],\"mapped\",[114]],[[120476,120476],\"mapped\",[115]],[[120477,120477],\"mapped\",[116]],[[120478,120478],\"mapped\",[117]],[[120479,120479],\"mapped\",[118]],[[120480,120480],\"mapped\",[119]],[[120481,120481],\"mapped\",[120]],[[120482,120482],\"mapped\",[121]],[[120483,120483],\"mapped\",[122]],[[120484,120484],\"mapped\",[305]],[[120485,120485],\"mapped\",[567]],[[120486,120487],\"disallowed\"],[[120488,120488],\"mapped\",[945]],[[120489,120489],\"mapped\",[946]],[[120490,120490],\"mapped\",[947]],[[120491,120491],\"mapped\",[948]],[[120492,120492],\"mapped\",[949]],[[120493,120493],\"mapped\",[950]],[[120494,120494],\"mapped\",[951]],[[120495,120495],\"mapped\",[952]],[[120496,120496],\"mapped\",[953]],[[120497,120497],\"mapped\",[954]],[[120498,120498],\"mapped\",[955]],[[120499,120499],\"mapped\",[956]],[[120500,120500],\"mapped\",[957]],[[120501,120501],\"mapped\",[958]],[[120502,120502],\"mapped\",[959]],[[120503,120503],\"mapped\",[960]],[[120504,120504],\"mapped\",[961]],[[120505,120505],\"mapped\",[952]],[[120506,120506],\"mapped\",[963]],[[120507,120507],\"mapped\",[964]],[[120508,120508],\"mapped\",[965]],[[120509,120509],\"mapped\",[966]],[[120510,120510],\"mapped\",[967]],[[120511,120511],\"mapped\",[968]],[[120512,120512],\"mapped\",[969]],[[120513,120513],\"mapped\",[8711]],[[120514,120514],\"mapped\",[945]],[[120515,120515],\"mapped\",[946]],[[120516,120516],\"mapped\",[947]],[[120517,120517],\"mapped\",[948]],[[120518,120518],\"mapped\",[949]],[[120519,120519],\"mapped\",[950]],[[120520,120520],\"mapped\",[951]],[[120521,120521],\"mapped\",[952]],[[120522,120522],\"mapped\",[953]],[[120523,120523],\"mapped\",[954]],[[120524,120524],\"mapped\",[955]],[[120525,120525],\"mapped\",[956]],[[120526,120526],\"mapped\",[957]],[[120527,120527],\"mapped\",[958]],[[120528,120528],\"mapped\",[959]],[[120529,120529],\"mapped\",[960]],[[120530,120530],\"mapped\",[961]],[[120531,120532],\"mapped\",[963]],[[120533,120533],\"mapped\",[964]],[[120534,120534],\"mapped\",[965]],[[120535,120535],\"mapped\",[966]],[[120536,120536],\"mapped\",[967]],[[120537,120537],\"mapped\",[968]],[[120538,120538],\"mapped\",[969]],[[120539,120539],\"mapped\",[8706]],[[120540,120540],\"mapped\",[949]],[[120541,120541],\"mapped\",[952]],[[120542,120542],\"mapped\",[954]],[[120543,120543],\"mapped\",[966]],[[120544,120544],\"mapped\",[961]],[[120545,120545],\"mapped\",[960]],[[120546,120546],\"mapped\",[945]],[[120547,120547],\"mapped\",[946]],[[120548,120548],\"mapped\",[947]],[[120549,120549],\"mapped\",[948]],[[120550,120550],\"mapped\",[949]],[[120551,120551],\"mapped\",[950]],[[120552,120552],\"mapped\",[951]],[[120553,120553],\"mapped\",[952]],[[120554,120554],\"mapped\",[953]],[[120555,120555],\"mapped\",[954]],[[120556,120556],\"mapped\",[955]],[[120557,120557],\"mapped\",[956]],[[120558,120558],\"mapped\",[957]],[[120559,120559],\"mapped\",[958]],[[120560,120560],\"mapped\",[959]],[[120561,120561],\"mapped\",[960]],[[120562,120562],\"mapped\",[961]],[[120563,120563],\"mapped\",[952]],[[120564,120564],\"mapped\",[963]],[[120565,120565],\"mapped\",[964]],[[120566,120566],\"mapped\",[965]],[[120567,120567],\"mapped\",[966]],[[120568,120568],\"mapped\",[967]],[[120569,120569],\"mapped\",[968]],[[120570,120570],\"mapped\",[969]],[[120571,120571],\"mapped\",[8711]],[[120572,120572],\"mapped\",[945]],[[120573,120573],\"mapped\",[946]],[[120574,120574],\"mapped\",[947]],[[120575,120575],\"mapped\",[948]],[[120576,120576],\"mapped\",[949]],[[120577,120577],\"mapped\",[950]],[[120578,120578],\"mapped\",[951]],[[120579,120579],\"mapped\",[952]],[[120580,120580],\"mapped\",[953]],[[120581,120581],\"mapped\",[954]],[[120582,120582],\"mapped\",[955]],[[120583,120583],\"mapped\",[956]],[[120584,120584],\"mapped\",[957]],[[120585,120585],\"mapped\",[958]],[[120586,120586],\"mapped\",[959]],[[120587,120587],\"mapped\",[960]],[[120588,120588],\"mapped\",[961]],[[120589,120590],\"mapped\",[963]],[[120591,120591],\"mapped\",[964]],[[120592,120592],\"mapped\",[965]],[[120593,120593],\"mapped\",[966]],[[120594,120594],\"mapped\",[967]],[[120595,120595],\"mapped\",[968]],[[120596,120596],\"mapped\",[969]],[[120597,120597],\"mapped\",[8706]],[[120598,120598],\"mapped\",[949]],[[120599,120599],\"mapped\",[952]],[[120600,120600],\"mapped\",[954]],[[120601,120601],\"mapped\",[966]],[[120602,120602],\"mapped\",[961]],[[120603,120603],\"mapped\",[960]],[[120604,120604],\"mapped\",[945]],[[120605,120605],\"mapped\",[946]],[[120606,120606],\"mapped\",[947]],[[120607,120607],\"mapped\",[948]],[[120608,120608],\"mapped\",[949]],[[120609,120609],\"mapped\",[950]],[[120610,120610],\"mapped\",[951]],[[120611,120611],\"mapped\",[952]],[[120612,120612],\"mapped\",[953]],[[120613,120613],\"mapped\",[954]],[[120614,120614],\"mapped\",[955]],[[120615,120615],\"mapped\",[956]],[[120616,120616],\"mapped\",[957]],[[120617,120617],\"mapped\",[958]],[[120618,120618],\"mapped\",[959]],[[120619,120619],\"mapped\",[960]],[[120620,120620],\"mapped\",[961]],[[120621,120621],\"mapped\",[952]],[[120622,120622],\"mapped\",[963]],[[120623,120623],\"mapped\",[964]],[[120624,120624],\"mapped\",[965]],[[120625,120625],\"mapped\",[966]],[[120626,120626],\"mapped\",[967]],[[120627,120627],\"mapped\",[968]],[[120628,120628],\"mapped\",[969]],[[120629,120629],\"mapped\",[8711]],[[120630,120630],\"mapped\",[945]],[[120631,120631],\"mapped\",[946]],[[120632,120632],\"mapped\",[947]],[[120633,120633],\"mapped\",[948]],[[120634,120634],\"mapped\",[949]],[[120635,120635],\"mapped\",[950]],[[120636,120636],\"mapped\",[951]],[[120637,120637],\"mapped\",[952]],[[120638,120638],\"mapped\",[953]],[[120639,120639],\"mapped\",[954]],[[120640,120640],\"mapped\",[955]],[[120641,120641],\"mapped\",[956]],[[120642,120642],\"mapped\",[957]],[[120643,120643],\"mapped\",[958]],[[120644,120644],\"mapped\",[959]],[[120645,120645],\"mapped\",[960]],[[120646,120646],\"mapped\",[961]],[[120647,120648],\"mapped\",[963]],[[120649,120649],\"mapped\",[964]],[[120650,120650],\"mapped\",[965]],[[120651,120651],\"mapped\",[966]],[[120652,120652],\"mapped\",[967]],[[120653,120653],\"mapped\",[968]],[[120654,120654],\"mapped\",[969]],[[120655,120655],\"mapped\",[8706]],[[120656,120656],\"mapped\",[949]],[[120657,120657],\"mapped\",[952]],[[120658,120658],\"mapped\",[954]],[[120659,120659],\"mapped\",[966]],[[120660,120660],\"mapped\",[961]],[[120661,120661],\"mapped\",[960]],[[120662,120662],\"mapped\",[945]],[[120663,120663],\"mapped\",[946]],[[120664,120664],\"mapped\",[947]],[[120665,120665],\"mapped\",[948]],[[120666,120666],\"mapped\",[949]],[[120667,120667],\"mapped\",[950]],[[120668,120668],\"mapped\",[951]],[[120669,120669],\"mapped\",[952]],[[120670,120670],\"mapped\",[953]],[[120671,120671],\"mapped\",[954]],[[120672,120672],\"mapped\",[955]],[[120673,120673],\"mapped\",[956]],[[120674,120674],\"mapped\",[957]],[[120675,120675],\"mapped\",[958]],[[120676,120676],\"mapped\",[959]],[[120677,120677],\"mapped\",[960]],[[120678,120678],\"mapped\",[961]],[[120679,120679],\"mapped\",[952]],[[120680,120680],\"mapped\",[963]],[[120681,120681],\"mapped\",[964]],[[120682,120682],\"mapped\",[965]],[[120683,120683],\"mapped\",[966]],[[120684,120684],\"mapped\",[967]],[[120685,120685],\"mapped\",[968]],[[120686,120686],\"mapped\",[969]],[[120687,120687],\"mapped\",[8711]],[[120688,120688],\"mapped\",[945]],[[120689,120689],\"mapped\",[946]],[[120690,120690],\"mapped\",[947]],[[120691,120691],\"mapped\",[948]],[[120692,120692],\"mapped\",[949]],[[120693,120693],\"mapped\",[950]],[[120694,120694],\"mapped\",[951]],[[120695,120695],\"mapped\",[952]],[[120696,120696],\"mapped\",[953]],[[120697,120697],\"mapped\",[954]],[[120698,120698],\"mapped\",[955]],[[120699,120699],\"mapped\",[956]],[[120700,120700],\"mapped\",[957]],[[120701,120701],\"mapped\",[958]],[[120702,120702],\"mapped\",[959]],[[120703,120703],\"mapped\",[960]],[[120704,120704],\"mapped\",[961]],[[120705,120706],\"mapped\",[963]],[[120707,120707],\"mapped\",[964]],[[120708,120708],\"mapped\",[965]],[[120709,120709],\"mapped\",[966]],[[120710,120710],\"mapped\",[967]],[[120711,120711],\"mapped\",[968]],[[120712,120712],\"mapped\",[969]],[[120713,120713],\"mapped\",[8706]],[[120714,120714],\"mapped\",[949]],[[120715,120715],\"mapped\",[952]],[[120716,120716],\"mapped\",[954]],[[120717,120717],\"mapped\",[966]],[[120718,120718],\"mapped\",[961]],[[120719,120719],\"mapped\",[960]],[[120720,120720],\"mapped\",[945]],[[120721,120721],\"mapped\",[946]],[[120722,120722],\"mapped\",[947]],[[120723,120723],\"mapped\",[948]],[[120724,120724],\"mapped\",[949]],[[120725,120725],\"mapped\",[950]],[[120726,120726],\"mapped\",[951]],[[120727,120727],\"mapped\",[952]],[[120728,120728],\"mapped\",[953]],[[120729,120729],\"mapped\",[954]],[[120730,120730],\"mapped\",[955]],[[120731,120731],\"mapped\",[956]],[[120732,120732],\"mapped\",[957]],[[120733,120733],\"mapped\",[958]],[[120734,120734],\"mapped\",[959]],[[120735,120735],\"mapped\",[960]],[[120736,120736],\"mapped\",[961]],[[120737,120737],\"mapped\",[952]],[[120738,120738],\"mapped\",[963]],[[120739,120739],\"mapped\",[964]],[[120740,120740],\"mapped\",[965]],[[120741,120741],\"mapped\",[966]],[[120742,120742],\"mapped\",[967]],[[120743,120743],\"mapped\",[968]],[[120744,120744],\"mapped\",[969]],[[120745,120745],\"mapped\",[8711]],[[120746,120746],\"mapped\",[945]],[[120747,120747],\"mapped\",[946]],[[120748,120748],\"mapped\",[947]],[[120749,120749],\"mapped\",[948]],[[120750,120750],\"mapped\",[949]],[[120751,120751],\"mapped\",[950]],[[120752,120752],\"mapped\",[951]],[[120753,120753],\"mapped\",[952]],[[120754,120754],\"mapped\",[953]],[[120755,120755],\"mapped\",[954]],[[120756,120756],\"mapped\",[955]],[[120757,120757],\"mapped\",[956]],[[120758,120758],\"mapped\",[957]],[[120759,120759],\"mapped\",[958]],[[120760,120760],\"mapped\",[959]],[[120761,120761],\"mapped\",[960]],[[120762,120762],\"mapped\",[961]],[[120763,120764],\"mapped\",[963]],[[120765,120765],\"mapped\",[964]],[[120766,120766],\"mapped\",[965]],[[120767,120767],\"mapped\",[966]],[[120768,120768],\"mapped\",[967]],[[120769,120769],\"mapped\",[968]],[[120770,120770],\"mapped\",[969]],[[120771,120771],\"mapped\",[8706]],[[120772,120772],\"mapped\",[949]],[[120773,120773],\"mapped\",[952]],[[120774,120774],\"mapped\",[954]],[[120775,120775],\"mapped\",[966]],[[120776,120776],\"mapped\",[961]],[[120777,120777],\"mapped\",[960]],[[120778,120779],\"mapped\",[989]],[[120780,120781],\"disallowed\"],[[120782,120782],\"mapped\",[48]],[[120783,120783],\"mapped\",[49]],[[120784,120784],\"mapped\",[50]],[[120785,120785],\"mapped\",[51]],[[120786,120786],\"mapped\",[52]],[[120787,120787],\"mapped\",[53]],[[120788,120788],\"mapped\",[54]],[[120789,120789],\"mapped\",[55]],[[120790,120790],\"mapped\",[56]],[[120791,120791],\"mapped\",[57]],[[120792,120792],\"mapped\",[48]],[[120793,120793],\"mapped\",[49]],[[120794,120794],\"mapped\",[50]],[[120795,120795],\"mapped\",[51]],[[120796,120796],\"mapped\",[52]],[[120797,120797],\"mapped\",[53]],[[120798,120798],\"mapped\",[54]],[[120799,120799],\"mapped\",[55]],[[120800,120800],\"mapped\",[56]],[[120801,120801],\"mapped\",[57]],[[120802,120802],\"mapped\",[48]],[[120803,120803],\"mapped\",[49]],[[120804,120804],\"mapped\",[50]],[[120805,120805],\"mapped\",[51]],[[120806,120806],\"mapped\",[52]],[[120807,120807],\"mapped\",[53]],[[120808,120808],\"mapped\",[54]],[[120809,120809],\"mapped\",[55]],[[120810,120810],\"mapped\",[56]],[[120811,120811],\"mapped\",[57]],[[120812,120812],\"mapped\",[48]],[[120813,120813],\"mapped\",[49]],[[120814,120814],\"mapped\",[50]],[[120815,120815],\"mapped\",[51]],[[120816,120816],\"mapped\",[52]],[[120817,120817],\"mapped\",[53]],[[120818,120818],\"mapped\",[54]],[[120819,120819],\"mapped\",[55]],[[120820,120820],\"mapped\",[56]],[[120821,120821],\"mapped\",[57]],[[120822,120822],\"mapped\",[48]],[[120823,120823],\"mapped\",[49]],[[120824,120824],\"mapped\",[50]],[[120825,120825],\"mapped\",[51]],[[120826,120826],\"mapped\",[52]],[[120827,120827],\"mapped\",[53]],[[120828,120828],\"mapped\",[54]],[[120829,120829],\"mapped\",[55]],[[120830,120830],\"mapped\",[56]],[[120831,120831],\"mapped\",[57]],[[120832,121343],\"valid\",[],\"NV8\"],[[121344,121398],\"valid\"],[[121399,121402],\"valid\",[],\"NV8\"],[[121403,121452],\"valid\"],[[121453,121460],\"valid\",[],\"NV8\"],[[121461,121461],\"valid\"],[[121462,121475],\"valid\",[],\"NV8\"],[[121476,121476],\"valid\"],[[121477,121483],\"valid\",[],\"NV8\"],[[121484,121498],\"disallowed\"],[[121499,121503],\"valid\"],[[121504,121504],\"disallowed\"],[[121505,121519],\"valid\"],[[121520,124927],\"disallowed\"],[[124928,125124],\"valid\"],[[125125,125126],\"disallowed\"],[[125127,125135],\"valid\",[],\"NV8\"],[[125136,125142],\"valid\"],[[125143,126463],\"disallowed\"],[[126464,126464],\"mapped\",[1575]],[[126465,126465],\"mapped\",[1576]],[[126466,126466],\"mapped\",[1580]],[[126467,126467],\"mapped\",[1583]],[[126468,126468],\"disallowed\"],[[126469,126469],\"mapped\",[1608]],[[126470,126470],\"mapped\",[1586]],[[126471,126471],\"mapped\",[1581]],[[126472,126472],\"mapped\",[1591]],[[126473,126473],\"mapped\",[1610]],[[126474,126474],\"mapped\",[1603]],[[126475,126475],\"mapped\",[1604]],[[126476,126476],\"mapped\",[1605]],[[126477,126477],\"mapped\",[1606]],[[126478,126478],\"mapped\",[1587]],[[126479,126479],\"mapped\",[1593]],[[126480,126480],\"mapped\",[1601]],[[126481,126481],\"mapped\",[1589]],[[126482,126482],\"mapped\",[1602]],[[126483,126483],\"mapped\",[1585]],[[126484,126484],\"mapped\",[1588]],[[126485,126485],\"mapped\",[1578]],[[126486,126486],\"mapped\",[1579]],[[126487,126487],\"mapped\",[1582]],[[126488,126488],\"mapped\",[1584]],[[126489,126489],\"mapped\",[1590]],[[126490,126490],\"mapped\",[1592]],[[126491,126491],\"mapped\",[1594]],[[126492,126492],\"mapped\",[1646]],[[126493,126493],\"mapped\",[1722]],[[126494,126494],\"mapped\",[1697]],[[126495,126495],\"mapped\",[1647]],[[126496,126496],\"disallowed\"],[[126497,126497],\"mapped\",[1576]],[[126498,126498],\"mapped\",[1580]],[[126499,126499],\"disallowed\"],[[126500,126500],\"mapped\",[1607]],[[126501,126502],\"disallowed\"],[[126503,126503],\"mapped\",[1581]],[[126504,126504],\"disallowed\"],[[126505,126505],\"mapped\",[1610]],[[126506,126506],\"mapped\",[1603]],[[126507,126507],\"mapped\",[1604]],[[126508,126508],\"mapped\",[1605]],[[126509,126509],\"mapped\",[1606]],[[126510,126510],\"mapped\",[1587]],[[126511,126511],\"mapped\",[1593]],[[126512,126512],\"mapped\",[1601]],[[126513,126513],\"mapped\",[1589]],[[126514,126514],\"mapped\",[1602]],[[126515,126515],\"disallowed\"],[[126516,126516],\"mapped\",[1588]],[[126517,126517],\"mapped\",[1578]],[[126518,126518],\"mapped\",[1579]],[[126519,126519],\"mapped\",[1582]],[[126520,126520],\"disallowed\"],[[126521,126521],\"mapped\",[1590]],[[126522,126522],\"disallowed\"],[[126523,126523],\"mapped\",[1594]],[[126524,126529],\"disallowed\"],[[126530,126530],\"mapped\",[1580]],[[126531,126534],\"disallowed\"],[[126535,126535],\"mapped\",[1581]],[[126536,126536],\"disallowed\"],[[126537,126537],\"mapped\",[1610]],[[126538,126538],\"disallowed\"],[[126539,126539],\"mapped\",[1604]],[[126540,126540],\"disallowed\"],[[126541,126541],\"mapped\",[1606]],[[126542,126542],\"mapped\",[1587]],[[126543,126543],\"mapped\",[1593]],[[126544,126544],\"disallowed\"],[[126545,126545],\"mapped\",[1589]],[[126546,126546],\"mapped\",[1602]],[[126547,126547],\"disallowed\"],[[126548,126548],\"mapped\",[1588]],[[126549,126550],\"disallowed\"],[[126551,126551],\"mapped\",[1582]],[[126552,126552],\"disallowed\"],[[126553,126553],\"mapped\",[1590]],[[126554,126554],\"disallowed\"],[[126555,126555],\"mapped\",[1594]],[[126556,126556],\"disallowed\"],[[126557,126557],\"mapped\",[1722]],[[126558,126558],\"disallowed\"],[[126559,126559],\"mapped\",[1647]],[[126560,126560],\"disallowed\"],[[126561,126561],\"mapped\",[1576]],[[126562,126562],\"mapped\",[1580]],[[126563,126563],\"disallowed\"],[[126564,126564],\"mapped\",[1607]],[[126565,126566],\"disallowed\"],[[126567,126567],\"mapped\",[1581]],[[126568,126568],\"mapped\",[1591]],[[126569,126569],\"mapped\",[1610]],[[126570,126570],\"mapped\",[1603]],[[126571,126571],\"disallowed\"],[[126572,126572],\"mapped\",[1605]],[[126573,126573],\"mapped\",[1606]],[[126574,126574],\"mapped\",[1587]],[[126575,126575],\"mapped\",[1593]],[[126576,126576],\"mapped\",[1601]],[[126577,126577],\"mapped\",[1589]],[[126578,126578],\"mapped\",[1602]],[[126579,126579],\"disallowed\"],[[126580,126580],\"mapped\",[1588]],[[126581,126581],\"mapped\",[1578]],[[126582,126582],\"mapped\",[1579]],[[126583,126583],\"mapped\",[1582]],[[126584,126584],\"disallowed\"],[[126585,126585],\"mapped\",[1590]],[[126586,126586],\"mapped\",[1592]],[[126587,126587],\"mapped\",[1594]],[[126588,126588],\"mapped\",[1646]],[[126589,126589],\"disallowed\"],[[126590,126590],\"mapped\",[1697]],[[126591,126591],\"disallowed\"],[[126592,126592],\"mapped\",[1575]],[[126593,126593],\"mapped\",[1576]],[[126594,126594],\"mapped\",[1580]],[[126595,126595],\"mapped\",[1583]],[[126596,126596],\"mapped\",[1607]],[[126597,126597],\"mapped\",[1608]],[[126598,126598],\"mapped\",[1586]],[[126599,126599],\"mapped\",[1581]],[[126600,126600],\"mapped\",[1591]],[[126601,126601],\"mapped\",[1610]],[[126602,126602],\"disallowed\"],[[126603,126603],\"mapped\",[1604]],[[126604,126604],\"mapped\",[1605]],[[126605,126605],\"mapped\",[1606]],[[126606,126606],\"mapped\",[1587]],[[126607,126607],\"mapped\",[1593]],[[126608,126608],\"mapped\",[1601]],[[126609,126609],\"mapped\",[1589]],[[126610,126610],\"mapped\",[1602]],[[126611,126611],\"mapped\",[1585]],[[126612,126612],\"mapped\",[1588]],[[126613,126613],\"mapped\",[1578]],[[126614,126614],\"mapped\",[1579]],[[126615,126615],\"mapped\",[1582]],[[126616,126616],\"mapped\",[1584]],[[126617,126617],\"mapped\",[1590]],[[126618,126618],\"mapped\",[1592]],[[126619,126619],\"mapped\",[1594]],[[126620,126624],\"disallowed\"],[[126625,126625],\"mapped\",[1576]],[[126626,126626],\"mapped\",[1580]],[[126627,126627],\"mapped\",[1583]],[[126628,126628],\"disallowed\"],[[126629,126629],\"mapped\",[1608]],[[126630,126630],\"mapped\",[1586]],[[126631,126631],\"mapped\",[1581]],[[126632,126632],\"mapped\",[1591]],[[126633,126633],\"mapped\",[1610]],[[126634,126634],\"disallowed\"],[[126635,126635],\"mapped\",[1604]],[[126636,126636],\"mapped\",[1605]],[[126637,126637],\"mapped\",[1606]],[[126638,126638],\"mapped\",[1587]],[[126639,126639],\"mapped\",[1593]],[[126640,126640],\"mapped\",[1601]],[[126641,126641],\"mapped\",[1589]],[[126642,126642],\"mapped\",[1602]],[[126643,126643],\"mapped\",[1585]],[[126644,126644],\"mapped\",[1588]],[[126645,126645],\"mapped\",[1578]],[[126646,126646],\"mapped\",[1579]],[[126647,126647],\"mapped\",[1582]],[[126648,126648],\"mapped\",[1584]],[[126649,126649],\"mapped\",[1590]],[[126650,126650],\"mapped\",[1592]],[[126651,126651],\"mapped\",[1594]],[[126652,126703],\"disallowed\"],[[126704,126705],\"valid\",[],\"NV8\"],[[126706,126975],\"disallowed\"],[[126976,127019],\"valid\",[],\"NV8\"],[[127020,127023],\"disallowed\"],[[127024,127123],\"valid\",[],\"NV8\"],[[127124,127135],\"disallowed\"],[[127136,127150],\"valid\",[],\"NV8\"],[[127151,127152],\"disallowed\"],[[127153,127166],\"valid\",[],\"NV8\"],[[127167,127167],\"valid\",[],\"NV8\"],[[127168,127168],\"disallowed\"],[[127169,127183],\"valid\",[],\"NV8\"],[[127184,127184],\"disallowed\"],[[127185,127199],\"valid\",[],\"NV8\"],[[127200,127221],\"valid\",[],\"NV8\"],[[127222,127231],\"disallowed\"],[[127232,127232],\"disallowed\"],[[127233,127233],\"disallowed_STD3_mapped\",[48,44]],[[127234,127234],\"disallowed_STD3_mapped\",[49,44]],[[127235,127235],\"disallowed_STD3_mapped\",[50,44]],[[127236,127236],\"disallowed_STD3_mapped\",[51,44]],[[127237,127237],\"disallowed_STD3_mapped\",[52,44]],[[127238,127238],\"disallowed_STD3_mapped\",[53,44]],[[127239,127239],\"disallowed_STD3_mapped\",[54,44]],[[127240,127240],\"disallowed_STD3_mapped\",[55,44]],[[127241,127241],\"disallowed_STD3_mapped\",[56,44]],[[127242,127242],\"disallowed_STD3_mapped\",[57,44]],[[127243,127244],\"valid\",[],\"NV8\"],[[127245,127247],\"disallowed\"],[[127248,127248],\"disallowed_STD3_mapped\",[40,97,41]],[[127249,127249],\"disallowed_STD3_mapped\",[40,98,41]],[[127250,127250],\"disallowed_STD3_mapped\",[40,99,41]],[[127251,127251],\"disallowed_STD3_mapped\",[40,100,41]],[[127252,127252],\"disallowed_STD3_mapped\",[40,101,41]],[[127253,127253],\"disallowed_STD3_mapped\",[40,102,41]],[[127254,127254],\"disallowed_STD3_mapped\",[40,103,41]],[[127255,127255],\"disallowed_STD3_mapped\",[40,104,41]],[[127256,127256],\"disallowed_STD3_mapped\",[40,105,41]],[[127257,127257],\"disallowed_STD3_mapped\",[40,106,41]],[[127258,127258],\"disallowed_STD3_mapped\",[40,107,41]],[[127259,127259],\"disallowed_STD3_mapped\",[40,108,41]],[[127260,127260],\"disallowed_STD3_mapped\",[40,109,41]],[[127261,127261],\"disallowed_STD3_mapped\",[40,110,41]],[[127262,127262],\"disallowed_STD3_mapped\",[40,111,41]],[[127263,127263],\"disallowed_STD3_mapped\",[40,112,41]],[[127264,127264],\"disallowed_STD3_mapped\",[40,113,41]],[[127265,127265],\"disallowed_STD3_mapped\",[40,114,41]],[[127266,127266],\"disallowed_STD3_mapped\",[40,115,41]],[[127267,127267],\"disallowed_STD3_mapped\",[40,116,41]],[[127268,127268],\"disallowed_STD3_mapped\",[40,117,41]],[[127269,127269],\"disallowed_STD3_mapped\",[40,118,41]],[[127270,127270],\"disallowed_STD3_mapped\",[40,119,41]],[[127271,127271],\"disallowed_STD3_mapped\",[40,120,41]],[[127272,127272],\"disallowed_STD3_mapped\",[40,121,41]],[[127273,127273],\"disallowed_STD3_mapped\",[40,122,41]],[[127274,127274],\"mapped\",[12308,115,12309]],[[127275,127275],\"mapped\",[99]],[[127276,127276],\"mapped\",[114]],[[127277,127277],\"mapped\",[99,100]],[[127278,127278],\"mapped\",[119,122]],[[127279,127279],\"disallowed\"],[[127280,127280],\"mapped\",[97]],[[127281,127281],\"mapped\",[98]],[[127282,127282],\"mapped\",[99]],[[127283,127283],\"mapped\",[100]],[[127284,127284],\"mapped\",[101]],[[127285,127285],\"mapped\",[102]],[[127286,127286],\"mapped\",[103]],[[127287,127287],\"mapped\",[104]],[[127288,127288],\"mapped\",[105]],[[127289,127289],\"mapped\",[106]],[[127290,127290],\"mapped\",[107]],[[127291,127291],\"mapped\",[108]],[[127292,127292],\"mapped\",[109]],[[127293,127293],\"mapped\",[110]],[[127294,127294],\"mapped\",[111]],[[127295,127295],\"mapped\",[112]],[[127296,127296],\"mapped\",[113]],[[127297,127297],\"mapped\",[114]],[[127298,127298],\"mapped\",[115]],[[127299,127299],\"mapped\",[116]],[[127300,127300],\"mapped\",[117]],[[127301,127301],\"mapped\",[118]],[[127302,127302],\"mapped\",[119]],[[127303,127303],\"mapped\",[120]],[[127304,127304],\"mapped\",[121]],[[127305,127305],\"mapped\",[122]],[[127306,127306],\"mapped\",[104,118]],[[127307,127307],\"mapped\",[109,118]],[[127308,127308],\"mapped\",[115,100]],[[127309,127309],\"mapped\",[115,115]],[[127310,127310],\"mapped\",[112,112,118]],[[127311,127311],\"mapped\",[119,99]],[[127312,127318],\"valid\",[],\"NV8\"],[[127319,127319],\"valid\",[],\"NV8\"],[[127320,127326],\"valid\",[],\"NV8\"],[[127327,127327],\"valid\",[],\"NV8\"],[[127328,127337],\"valid\",[],\"NV8\"],[[127338,127338],\"mapped\",[109,99]],[[127339,127339],\"mapped\",[109,100]],[[127340,127343],\"disallowed\"],[[127344,127352],\"valid\",[],\"NV8\"],[[127353,127353],\"valid\",[],\"NV8\"],[[127354,127354],\"valid\",[],\"NV8\"],[[127355,127356],\"valid\",[],\"NV8\"],[[127357,127358],\"valid\",[],\"NV8\"],[[127359,127359],\"valid\",[],\"NV8\"],[[127360,127369],\"valid\",[],\"NV8\"],[[127370,127373],\"valid\",[],\"NV8\"],[[127374,127375],\"valid\",[],\"NV8\"],[[127376,127376],\"mapped\",[100,106]],[[127377,127386],\"valid\",[],\"NV8\"],[[127387,127461],\"disallowed\"],[[127462,127487],\"valid\",[],\"NV8\"],[[127488,127488],\"mapped\",[12411,12363]],[[127489,127489],\"mapped\",[12467,12467]],[[127490,127490],\"mapped\",[12469]],[[127491,127503],\"disallowed\"],[[127504,127504],\"mapped\",[25163]],[[127505,127505],\"mapped\",[23383]],[[127506,127506],\"mapped\",[21452]],[[127507,127507],\"mapped\",[12487]],[[127508,127508],\"mapped\",[20108]],[[127509,127509],\"mapped\",[22810]],[[127510,127510],\"mapped\",[35299]],[[127511,127511],\"mapped\",[22825]],[[127512,127512],\"mapped\",[20132]],[[127513,127513],\"mapped\",[26144]],[[127514,127514],\"mapped\",[28961]],[[127515,127515],\"mapped\",[26009]],[[127516,127516],\"mapped\",[21069]],[[127517,127517],\"mapped\",[24460]],[[127518,127518],\"mapped\",[20877]],[[127519,127519],\"mapped\",[26032]],[[127520,127520],\"mapped\",[21021]],[[127521,127521],\"mapped\",[32066]],[[127522,127522],\"mapped\",[29983]],[[127523,127523],\"mapped\",[36009]],[[127524,127524],\"mapped\",[22768]],[[127525,127525],\"mapped\",[21561]],[[127526,127526],\"mapped\",[28436]],[[127527,127527],\"mapped\",[25237]],[[127528,127528],\"mapped\",[25429]],[[127529,127529],\"mapped\",[19968]],[[127530,127530],\"mapped\",[19977]],[[127531,127531],\"mapped\",[36938]],[[127532,127532],\"mapped\",[24038]],[[127533,127533],\"mapped\",[20013]],[[127534,127534],\"mapped\",[21491]],[[127535,127535],\"mapped\",[25351]],[[127536,127536],\"mapped\",[36208]],[[127537,127537],\"mapped\",[25171]],[[127538,127538],\"mapped\",[31105]],[[127539,127539],\"mapped\",[31354]],[[127540,127540],\"mapped\",[21512]],[[127541,127541],\"mapped\",[28288]],[[127542,127542],\"mapped\",[26377]],[[127543,127543],\"mapped\",[26376]],[[127544,127544],\"mapped\",[30003]],[[127545,127545],\"mapped\",[21106]],[[127546,127546],\"mapped\",[21942]],[[127547,127551],\"disallowed\"],[[127552,127552],\"mapped\",[12308,26412,12309]],[[127553,127553],\"mapped\",[12308,19977,12309]],[[127554,127554],\"mapped\",[12308,20108,12309]],[[127555,127555],\"mapped\",[12308,23433,12309]],[[127556,127556],\"mapped\",[12308,28857,12309]],[[127557,127557],\"mapped\",[12308,25171,12309]],[[127558,127558],\"mapped\",[12308,30423,12309]],[[127559,127559],\"mapped\",[12308,21213,12309]],[[127560,127560],\"mapped\",[12308,25943,12309]],[[127561,127567],\"disallowed\"],[[127568,127568],\"mapped\",[24471]],[[127569,127569],\"mapped\",[21487]],[[127570,127743],\"disallowed\"],[[127744,127776],\"valid\",[],\"NV8\"],[[127777,127788],\"valid\",[],\"NV8\"],[[127789,127791],\"valid\",[],\"NV8\"],[[127792,127797],\"valid\",[],\"NV8\"],[[127798,127798],\"valid\",[],\"NV8\"],[[127799,127868],\"valid\",[],\"NV8\"],[[127869,127869],\"valid\",[],\"NV8\"],[[127870,127871],\"valid\",[],\"NV8\"],[[127872,127891],\"valid\",[],\"NV8\"],[[127892,127903],\"valid\",[],\"NV8\"],[[127904,127940],\"valid\",[],\"NV8\"],[[127941,127941],\"valid\",[],\"NV8\"],[[127942,127946],\"valid\",[],\"NV8\"],[[127947,127950],\"valid\",[],\"NV8\"],[[127951,127955],\"valid\",[],\"NV8\"],[[127956,127967],\"valid\",[],\"NV8\"],[[127968,127984],\"valid\",[],\"NV8\"],[[127985,127991],\"valid\",[],\"NV8\"],[[127992,127999],\"valid\",[],\"NV8\"],[[128000,128062],\"valid\",[],\"NV8\"],[[128063,128063],\"valid\",[],\"NV8\"],[[128064,128064],\"valid\",[],\"NV8\"],[[128065,128065],\"valid\",[],\"NV8\"],[[128066,128247],\"valid\",[],\"NV8\"],[[128248,128248],\"valid\",[],\"NV8\"],[[128249,128252],\"valid\",[],\"NV8\"],[[128253,128254],\"valid\",[],\"NV8\"],[[128255,128255],\"valid\",[],\"NV8\"],[[128256,128317],\"valid\",[],\"NV8\"],[[128318,128319],\"valid\",[],\"NV8\"],[[128320,128323],\"valid\",[],\"NV8\"],[[128324,128330],\"valid\",[],\"NV8\"],[[128331,128335],\"valid\",[],\"NV8\"],[[128336,128359],\"valid\",[],\"NV8\"],[[128360,128377],\"valid\",[],\"NV8\"],[[128378,128378],\"disallowed\"],[[128379,128419],\"valid\",[],\"NV8\"],[[128420,128420],\"disallowed\"],[[128421,128506],\"valid\",[],\"NV8\"],[[128507,128511],\"valid\",[],\"NV8\"],[[128512,128512],\"valid\",[],\"NV8\"],[[128513,128528],\"valid\",[],\"NV8\"],[[128529,128529],\"valid\",[],\"NV8\"],[[128530,128532],\"valid\",[],\"NV8\"],[[128533,128533],\"valid\",[],\"NV8\"],[[128534,128534],\"valid\",[],\"NV8\"],[[128535,128535],\"valid\",[],\"NV8\"],[[128536,128536],\"valid\",[],\"NV8\"],[[128537,128537],\"valid\",[],\"NV8\"],[[128538,128538],\"valid\",[],\"NV8\"],[[128539,128539],\"valid\",[],\"NV8\"],[[128540,128542],\"valid\",[],\"NV8\"],[[128543,128543],\"valid\",[],\"NV8\"],[[128544,128549],\"valid\",[],\"NV8\"],[[128550,128551],\"valid\",[],\"NV8\"],[[128552,128555],\"valid\",[],\"NV8\"],[[128556,128556],\"valid\",[],\"NV8\"],[[128557,128557],\"valid\",[],\"NV8\"],[[128558,128559],\"valid\",[],\"NV8\"],[[128560,128563],\"valid\",[],\"NV8\"],[[128564,128564],\"valid\",[],\"NV8\"],[[128565,128576],\"valid\",[],\"NV8\"],[[128577,128578],\"valid\",[],\"NV8\"],[[128579,128580],\"valid\",[],\"NV8\"],[[128581,128591],\"valid\",[],\"NV8\"],[[128592,128639],\"valid\",[],\"NV8\"],[[128640,128709],\"valid\",[],\"NV8\"],[[128710,128719],\"valid\",[],\"NV8\"],[[128720,128720],\"valid\",[],\"NV8\"],[[128721,128735],\"disallowed\"],[[128736,128748],\"valid\",[],\"NV8\"],[[128749,128751],\"disallowed\"],[[128752,128755],\"valid\",[],\"NV8\"],[[128756,128767],\"disallowed\"],[[128768,128883],\"valid\",[],\"NV8\"],[[128884,128895],\"disallowed\"],[[128896,128980],\"valid\",[],\"NV8\"],[[128981,129023],\"disallowed\"],[[129024,129035],\"valid\",[],\"NV8\"],[[129036,129039],\"disallowed\"],[[129040,129095],\"valid\",[],\"NV8\"],[[129096,129103],\"disallowed\"],[[129104,129113],\"valid\",[],\"NV8\"],[[129114,129119],\"disallowed\"],[[129120,129159],\"valid\",[],\"NV8\"],[[129160,129167],\"disallowed\"],[[129168,129197],\"valid\",[],\"NV8\"],[[129198,129295],\"disallowed\"],[[129296,129304],\"valid\",[],\"NV8\"],[[129305,129407],\"disallowed\"],[[129408,129412],\"valid\",[],\"NV8\"],[[129413,129471],\"disallowed\"],[[129472,129472],\"valid\",[],\"NV8\"],[[129473,131069],\"disallowed\"],[[131070,131071],\"disallowed\"],[[131072,173782],\"valid\"],[[173783,173823],\"disallowed\"],[[173824,177972],\"valid\"],[[177973,177983],\"disallowed\"],[[177984,178205],\"valid\"],[[178206,178207],\"disallowed\"],[[178208,183969],\"valid\"],[[183970,194559],\"disallowed\"],[[194560,194560],\"mapped\",[20029]],[[194561,194561],\"mapped\",[20024]],[[194562,194562],\"mapped\",[20033]],[[194563,194563],\"mapped\",[131362]],[[194564,194564],\"mapped\",[20320]],[[194565,194565],\"mapped\",[20398]],[[194566,194566],\"mapped\",[20411]],[[194567,194567],\"mapped\",[20482]],[[194568,194568],\"mapped\",[20602]],[[194569,194569],\"mapped\",[20633]],[[194570,194570],\"mapped\",[20711]],[[194571,194571],\"mapped\",[20687]],[[194572,194572],\"mapped\",[13470]],[[194573,194573],\"mapped\",[132666]],[[194574,194574],\"mapped\",[20813]],[[194575,194575],\"mapped\",[20820]],[[194576,194576],\"mapped\",[20836]],[[194577,194577],\"mapped\",[20855]],[[194578,194578],\"mapped\",[132380]],[[194579,194579],\"mapped\",[13497]],[[194580,194580],\"mapped\",[20839]],[[194581,194581],\"mapped\",[20877]],[[194582,194582],\"mapped\",[132427]],[[194583,194583],\"mapped\",[20887]],[[194584,194584],\"mapped\",[20900]],[[194585,194585],\"mapped\",[20172]],[[194586,194586],\"mapped\",[20908]],[[194587,194587],\"mapped\",[20917]],[[194588,194588],\"mapped\",[168415]],[[194589,194589],\"mapped\",[20981]],[[194590,194590],\"mapped\",[20995]],[[194591,194591],\"mapped\",[13535]],[[194592,194592],\"mapped\",[21051]],[[194593,194593],\"mapped\",[21062]],[[194594,194594],\"mapped\",[21106]],[[194595,194595],\"mapped\",[21111]],[[194596,194596],\"mapped\",[13589]],[[194597,194597],\"mapped\",[21191]],[[194598,194598],\"mapped\",[21193]],[[194599,194599],\"mapped\",[21220]],[[194600,194600],\"mapped\",[21242]],[[194601,194601],\"mapped\",[21253]],[[194602,194602],\"mapped\",[21254]],[[194603,194603],\"mapped\",[21271]],[[194604,194604],\"mapped\",[21321]],[[194605,194605],\"mapped\",[21329]],[[194606,194606],\"mapped\",[21338]],[[194607,194607],\"mapped\",[21363]],[[194608,194608],\"mapped\",[21373]],[[194609,194611],\"mapped\",[21375]],[[194612,194612],\"mapped\",[133676]],[[194613,194613],\"mapped\",[28784]],[[194614,194614],\"mapped\",[21450]],[[194615,194615],\"mapped\",[21471]],[[194616,194616],\"mapped\",[133987]],[[194617,194617],\"mapped\",[21483]],[[194618,194618],\"mapped\",[21489]],[[194619,194619],\"mapped\",[21510]],[[194620,194620],\"mapped\",[21662]],[[194621,194621],\"mapped\",[21560]],[[194622,194622],\"mapped\",[21576]],[[194623,194623],\"mapped\",[21608]],[[194624,194624],\"mapped\",[21666]],[[194625,194625],\"mapped\",[21750]],[[194626,194626],\"mapped\",[21776]],[[194627,194627],\"mapped\",[21843]],[[194628,194628],\"mapped\",[21859]],[[194629,194630],\"mapped\",[21892]],[[194631,194631],\"mapped\",[21913]],[[194632,194632],\"mapped\",[21931]],[[194633,194633],\"mapped\",[21939]],[[194634,194634],\"mapped\",[21954]],[[194635,194635],\"mapped\",[22294]],[[194636,194636],\"mapped\",[22022]],[[194637,194637],\"mapped\",[22295]],[[194638,194638],\"mapped\",[22097]],[[194639,194639],\"mapped\",[22132]],[[194640,194640],\"mapped\",[20999]],[[194641,194641],\"mapped\",[22766]],[[194642,194642],\"mapped\",[22478]],[[194643,194643],\"mapped\",[22516]],[[194644,194644],\"mapped\",[22541]],[[194645,194645],\"mapped\",[22411]],[[194646,194646],\"mapped\",[22578]],[[194647,194647],\"mapped\",[22577]],[[194648,194648],\"mapped\",[22700]],[[194649,194649],\"mapped\",[136420]],[[194650,194650],\"mapped\",[22770]],[[194651,194651],\"mapped\",[22775]],[[194652,194652],\"mapped\",[22790]],[[194653,194653],\"mapped\",[22810]],[[194654,194654],\"mapped\",[22818]],[[194655,194655],\"mapped\",[22882]],[[194656,194656],\"mapped\",[136872]],[[194657,194657],\"mapped\",[136938]],[[194658,194658],\"mapped\",[23020]],[[194659,194659],\"mapped\",[23067]],[[194660,194660],\"mapped\",[23079]],[[194661,194661],\"mapped\",[23000]],[[194662,194662],\"mapped\",[23142]],[[194663,194663],\"mapped\",[14062]],[[194664,194664],\"disallowed\"],[[194665,194665],\"mapped\",[23304]],[[194666,194667],\"mapped\",[23358]],[[194668,194668],\"mapped\",[137672]],[[194669,194669],\"mapped\",[23491]],[[194670,194670],\"mapped\",[23512]],[[194671,194671],\"mapped\",[23527]],[[194672,194672],\"mapped\",[23539]],[[194673,194673],\"mapped\",[138008]],[[194674,194674],\"mapped\",[23551]],[[194675,194675],\"mapped\",[23558]],[[194676,194676],\"disallowed\"],[[194677,194677],\"mapped\",[23586]],[[194678,194678],\"mapped\",[14209]],[[194679,194679],\"mapped\",[23648]],[[194680,194680],\"mapped\",[23662]],[[194681,194681],\"mapped\",[23744]],[[194682,194682],\"mapped\",[23693]],[[194683,194683],\"mapped\",[138724]],[[194684,194684],\"mapped\",[23875]],[[194685,194685],\"mapped\",[138726]],[[194686,194686],\"mapped\",[23918]],[[194687,194687],\"mapped\",[23915]],[[194688,194688],\"mapped\",[23932]],[[194689,194689],\"mapped\",[24033]],[[194690,194690],\"mapped\",[24034]],[[194691,194691],\"mapped\",[14383]],[[194692,194692],\"mapped\",[24061]],[[194693,194693],\"mapped\",[24104]],[[194694,194694],\"mapped\",[24125]],[[194695,194695],\"mapped\",[24169]],[[194696,194696],\"mapped\",[14434]],[[194697,194697],\"mapped\",[139651]],[[194698,194698],\"mapped\",[14460]],[[194699,194699],\"mapped\",[24240]],[[194700,194700],\"mapped\",[24243]],[[194701,194701],\"mapped\",[24246]],[[194702,194702],\"mapped\",[24266]],[[194703,194703],\"mapped\",[172946]],[[194704,194704],\"mapped\",[24318]],[[194705,194706],\"mapped\",[140081]],[[194707,194707],\"mapped\",[33281]],[[194708,194709],\"mapped\",[24354]],[[194710,194710],\"mapped\",[14535]],[[194711,194711],\"mapped\",[144056]],[[194712,194712],\"mapped\",[156122]],[[194713,194713],\"mapped\",[24418]],[[194714,194714],\"mapped\",[24427]],[[194715,194715],\"mapped\",[14563]],[[194716,194716],\"mapped\",[24474]],[[194717,194717],\"mapped\",[24525]],[[194718,194718],\"mapped\",[24535]],[[194719,194719],\"mapped\",[24569]],[[194720,194720],\"mapped\",[24705]],[[194721,194721],\"mapped\",[14650]],[[194722,194722],\"mapped\",[14620]],[[194723,194723],\"mapped\",[24724]],[[194724,194724],\"mapped\",[141012]],[[194725,194725],\"mapped\",[24775]],[[194726,194726],\"mapped\",[24904]],[[194727,194727],\"mapped\",[24908]],[[194728,194728],\"mapped\",[24910]],[[194729,194729],\"mapped\",[24908]],[[194730,194730],\"mapped\",[24954]],[[194731,194731],\"mapped\",[24974]],[[194732,194732],\"mapped\",[25010]],[[194733,194733],\"mapped\",[24996]],[[194734,194734],\"mapped\",[25007]],[[194735,194735],\"mapped\",[25054]],[[194736,194736],\"mapped\",[25074]],[[194737,194737],\"mapped\",[25078]],[[194738,194738],\"mapped\",[25104]],[[194739,194739],\"mapped\",[25115]],[[194740,194740],\"mapped\",[25181]],[[194741,194741],\"mapped\",[25265]],[[194742,194742],\"mapped\",[25300]],[[194743,194743],\"mapped\",[25424]],[[194744,194744],\"mapped\",[142092]],[[194745,194745],\"mapped\",[25405]],[[194746,194746],\"mapped\",[25340]],[[194747,194747],\"mapped\",[25448]],[[194748,194748],\"mapped\",[25475]],[[194749,194749],\"mapped\",[25572]],[[194750,194750],\"mapped\",[142321]],[[194751,194751],\"mapped\",[25634]],[[194752,194752],\"mapped\",[25541]],[[194753,194753],\"mapped\",[25513]],[[194754,194754],\"mapped\",[14894]],[[194755,194755],\"mapped\",[25705]],[[194756,194756],\"mapped\",[25726]],[[194757,194757],\"mapped\",[25757]],[[194758,194758],\"mapped\",[25719]],[[194759,194759],\"mapped\",[14956]],[[194760,194760],\"mapped\",[25935]],[[194761,194761],\"mapped\",[25964]],[[194762,194762],\"mapped\",[143370]],[[194763,194763],\"mapped\",[26083]],[[194764,194764],\"mapped\",[26360]],[[194765,194765],\"mapped\",[26185]],[[194766,194766],\"mapped\",[15129]],[[194767,194767],\"mapped\",[26257]],[[194768,194768],\"mapped\",[15112]],[[194769,194769],\"mapped\",[15076]],[[194770,194770],\"mapped\",[20882]],[[194771,194771],\"mapped\",[20885]],[[194772,194772],\"mapped\",[26368]],[[194773,194773],\"mapped\",[26268]],[[194774,194774],\"mapped\",[32941]],[[194775,194775],\"mapped\",[17369]],[[194776,194776],\"mapped\",[26391]],[[194777,194777],\"mapped\",[26395]],[[194778,194778],\"mapped\",[26401]],[[194779,194779],\"mapped\",[26462]],[[194780,194780],\"mapped\",[26451]],[[194781,194781],\"mapped\",[144323]],[[194782,194782],\"mapped\",[15177]],[[194783,194783],\"mapped\",[26618]],[[194784,194784],\"mapped\",[26501]],[[194785,194785],\"mapped\",[26706]],[[194786,194786],\"mapped\",[26757]],[[194787,194787],\"mapped\",[144493]],[[194788,194788],\"mapped\",[26766]],[[194789,194789],\"mapped\",[26655]],[[194790,194790],\"mapped\",[26900]],[[194791,194791],\"mapped\",[15261]],[[194792,194792],\"mapped\",[26946]],[[194793,194793],\"mapped\",[27043]],[[194794,194794],\"mapped\",[27114]],[[194795,194795],\"mapped\",[27304]],[[194796,194796],\"mapped\",[145059]],[[194797,194797],\"mapped\",[27355]],[[194798,194798],\"mapped\",[15384]],[[194799,194799],\"mapped\",[27425]],[[194800,194800],\"mapped\",[145575]],[[194801,194801],\"mapped\",[27476]],[[194802,194802],\"mapped\",[15438]],[[194803,194803],\"mapped\",[27506]],[[194804,194804],\"mapped\",[27551]],[[194805,194805],\"mapped\",[27578]],[[194806,194806],\"mapped\",[27579]],[[194807,194807],\"mapped\",[146061]],[[194808,194808],\"mapped\",[138507]],[[194809,194809],\"mapped\",[146170]],[[194810,194810],\"mapped\",[27726]],[[194811,194811],\"mapped\",[146620]],[[194812,194812],\"mapped\",[27839]],[[194813,194813],\"mapped\",[27853]],[[194814,194814],\"mapped\",[27751]],[[194815,194815],\"mapped\",[27926]],[[194816,194816],\"mapped\",[27966]],[[194817,194817],\"mapped\",[28023]],[[194818,194818],\"mapped\",[27969]],[[194819,194819],\"mapped\",[28009]],[[194820,194820],\"mapped\",[28024]],[[194821,194821],\"mapped\",[28037]],[[194822,194822],\"mapped\",[146718]],[[194823,194823],\"mapped\",[27956]],[[194824,194824],\"mapped\",[28207]],[[194825,194825],\"mapped\",[28270]],[[194826,194826],\"mapped\",[15667]],[[194827,194827],\"mapped\",[28363]],[[194828,194828],\"mapped\",[28359]],[[194829,194829],\"mapped\",[147153]],[[194830,194830],\"mapped\",[28153]],[[194831,194831],\"mapped\",[28526]],[[194832,194832],\"mapped\",[147294]],[[194833,194833],\"mapped\",[147342]],[[194834,194834],\"mapped\",[28614]],[[194835,194835],\"mapped\",[28729]],[[194836,194836],\"mapped\",[28702]],[[194837,194837],\"mapped\",[28699]],[[194838,194838],\"mapped\",[15766]],[[194839,194839],\"mapped\",[28746]],[[194840,194840],\"mapped\",[28797]],[[194841,194841],\"mapped\",[28791]],[[194842,194842],\"mapped\",[28845]],[[194843,194843],\"mapped\",[132389]],[[194844,194844],\"mapped\",[28997]],[[194845,194845],\"mapped\",[148067]],[[194846,194846],\"mapped\",[29084]],[[194847,194847],\"disallowed\"],[[194848,194848],\"mapped\",[29224]],[[194849,194849],\"mapped\",[29237]],[[194850,194850],\"mapped\",[29264]],[[194851,194851],\"mapped\",[149000]],[[194852,194852],\"mapped\",[29312]],[[194853,194853],\"mapped\",[29333]],[[194854,194854],\"mapped\",[149301]],[[194855,194855],\"mapped\",[149524]],[[194856,194856],\"mapped\",[29562]],[[194857,194857],\"mapped\",[29579]],[[194858,194858],\"mapped\",[16044]],[[194859,194859],\"mapped\",[29605]],[[194860,194861],\"mapped\",[16056]],[[194862,194862],\"mapped\",[29767]],[[194863,194863],\"mapped\",[29788]],[[194864,194864],\"mapped\",[29809]],[[194865,194865],\"mapped\",[29829]],[[194866,194866],\"mapped\",[29898]],[[194867,194867],\"mapped\",[16155]],[[194868,194868],\"mapped\",[29988]],[[194869,194869],\"mapped\",[150582]],[[194870,194870],\"mapped\",[30014]],[[194871,194871],\"mapped\",[150674]],[[194872,194872],\"mapped\",[30064]],[[194873,194873],\"mapped\",[139679]],[[194874,194874],\"mapped\",[30224]],[[194875,194875],\"mapped\",[151457]],[[194876,194876],\"mapped\",[151480]],[[194877,194877],\"mapped\",[151620]],[[194878,194878],\"mapped\",[16380]],[[194879,194879],\"mapped\",[16392]],[[194880,194880],\"mapped\",[30452]],[[194881,194881],\"mapped\",[151795]],[[194882,194882],\"mapped\",[151794]],[[194883,194883],\"mapped\",[151833]],[[194884,194884],\"mapped\",[151859]],[[194885,194885],\"mapped\",[30494]],[[194886,194887],\"mapped\",[30495]],[[194888,194888],\"mapped\",[30538]],[[194889,194889],\"mapped\",[16441]],[[194890,194890],\"mapped\",[30603]],[[194891,194891],\"mapped\",[16454]],[[194892,194892],\"mapped\",[16534]],[[194893,194893],\"mapped\",[152605]],[[194894,194894],\"mapped\",[30798]],[[194895,194895],\"mapped\",[30860]],[[194896,194896],\"mapped\",[30924]],[[194897,194897],\"mapped\",[16611]],[[194898,194898],\"mapped\",[153126]],[[194899,194899],\"mapped\",[31062]],[[194900,194900],\"mapped\",[153242]],[[194901,194901],\"mapped\",[153285]],[[194902,194902],\"mapped\",[31119]],[[194903,194903],\"mapped\",[31211]],[[194904,194904],\"mapped\",[16687]],[[194905,194905],\"mapped\",[31296]],[[194906,194906],\"mapped\",[31306]],[[194907,194907],\"mapped\",[31311]],[[194908,194908],\"mapped\",[153980]],[[194909,194910],\"mapped\",[154279]],[[194911,194911],\"disallowed\"],[[194912,194912],\"mapped\",[16898]],[[194913,194913],\"mapped\",[154539]],[[194914,194914],\"mapped\",[31686]],[[194915,194915],\"mapped\",[31689]],[[194916,194916],\"mapped\",[16935]],[[194917,194917],\"mapped\",[154752]],[[194918,194918],\"mapped\",[31954]],[[194919,194919],\"mapped\",[17056]],[[194920,194920],\"mapped\",[31976]],[[194921,194921],\"mapped\",[31971]],[[194922,194922],\"mapped\",[32000]],[[194923,194923],\"mapped\",[155526]],[[194924,194924],\"mapped\",[32099]],[[194925,194925],\"mapped\",[17153]],[[194926,194926],\"mapped\",[32199]],[[194927,194927],\"mapped\",[32258]],[[194928,194928],\"mapped\",[32325]],[[194929,194929],\"mapped\",[17204]],[[194930,194930],\"mapped\",[156200]],[[194931,194931],\"mapped\",[156231]],[[194932,194932],\"mapped\",[17241]],[[194933,194933],\"mapped\",[156377]],[[194934,194934],\"mapped\",[32634]],[[194935,194935],\"mapped\",[156478]],[[194936,194936],\"mapped\",[32661]],[[194937,194937],\"mapped\",[32762]],[[194938,194938],\"mapped\",[32773]],[[194939,194939],\"mapped\",[156890]],[[194940,194940],\"mapped\",[156963]],[[194941,194941],\"mapped\",[32864]],[[194942,194942],\"mapped\",[157096]],[[194943,194943],\"mapped\",[32880]],[[194944,194944],\"mapped\",[144223]],[[194945,194945],\"mapped\",[17365]],[[194946,194946],\"mapped\",[32946]],[[194947,194947],\"mapped\",[33027]],[[194948,194948],\"mapped\",[17419]],[[194949,194949],\"mapped\",[33086]],[[194950,194950],\"mapped\",[23221]],[[194951,194951],\"mapped\",[157607]],[[194952,194952],\"mapped\",[157621]],[[194953,194953],\"mapped\",[144275]],[[194954,194954],\"mapped\",[144284]],[[194955,194955],\"mapped\",[33281]],[[194956,194956],\"mapped\",[33284]],[[194957,194957],\"mapped\",[36766]],[[194958,194958],\"mapped\",[17515]],[[194959,194959],\"mapped\",[33425]],[[194960,194960],\"mapped\",[33419]],[[194961,194961],\"mapped\",[33437]],[[194962,194962],\"mapped\",[21171]],[[194963,194963],\"mapped\",[33457]],[[194964,194964],\"mapped\",[33459]],[[194965,194965],\"mapped\",[33469]],[[194966,194966],\"mapped\",[33510]],[[194967,194967],\"mapped\",[158524]],[[194968,194968],\"mapped\",[33509]],[[194969,194969],\"mapped\",[33565]],[[194970,194970],\"mapped\",[33635]],[[194971,194971],\"mapped\",[33709]],[[194972,194972],\"mapped\",[33571]],[[194973,194973],\"mapped\",[33725]],[[194974,194974],\"mapped\",[33767]],[[194975,194975],\"mapped\",[33879]],[[194976,194976],\"mapped\",[33619]],[[194977,194977],\"mapped\",[33738]],[[194978,194978],\"mapped\",[33740]],[[194979,194979],\"mapped\",[33756]],[[194980,194980],\"mapped\",[158774]],[[194981,194981],\"mapped\",[159083]],[[194982,194982],\"mapped\",[158933]],[[194983,194983],\"mapped\",[17707]],[[194984,194984],\"mapped\",[34033]],[[194985,194985],\"mapped\",[34035]],[[194986,194986],\"mapped\",[34070]],[[194987,194987],\"mapped\",[160714]],[[194988,194988],\"mapped\",[34148]],[[194989,194989],\"mapped\",[159532]],[[194990,194990],\"mapped\",[17757]],[[194991,194991],\"mapped\",[17761]],[[194992,194992],\"mapped\",[159665]],[[194993,194993],\"mapped\",[159954]],[[194994,194994],\"mapped\",[17771]],[[194995,194995],\"mapped\",[34384]],[[194996,194996],\"mapped\",[34396]],[[194997,194997],\"mapped\",[34407]],[[194998,194998],\"mapped\",[34409]],[[194999,194999],\"mapped\",[34473]],[[195000,195000],\"mapped\",[34440]],[[195001,195001],\"mapped\",[34574]],[[195002,195002],\"mapped\",[34530]],[[195003,195003],\"mapped\",[34681]],[[195004,195004],\"mapped\",[34600]],[[195005,195005],\"mapped\",[34667]],[[195006,195006],\"mapped\",[34694]],[[195007,195007],\"disallowed\"],[[195008,195008],\"mapped\",[34785]],[[195009,195009],\"mapped\",[34817]],[[195010,195010],\"mapped\",[17913]],[[195011,195011],\"mapped\",[34912]],[[195012,195012],\"mapped\",[34915]],[[195013,195013],\"mapped\",[161383]],[[195014,195014],\"mapped\",[35031]],[[195015,195015],\"mapped\",[35038]],[[195016,195016],\"mapped\",[17973]],[[195017,195017],\"mapped\",[35066]],[[195018,195018],\"mapped\",[13499]],[[195019,195019],\"mapped\",[161966]],[[195020,195020],\"mapped\",[162150]],[[195021,195021],\"mapped\",[18110]],[[195022,195022],\"mapped\",[18119]],[[195023,195023],\"mapped\",[35488]],[[195024,195024],\"mapped\",[35565]],[[195025,195025],\"mapped\",[35722]],[[195026,195026],\"mapped\",[35925]],[[195027,195027],\"mapped\",[162984]],[[195028,195028],\"mapped\",[36011]],[[195029,195029],\"mapped\",[36033]],[[195030,195030],\"mapped\",[36123]],[[195031,195031],\"mapped\",[36215]],[[195032,195032],\"mapped\",[163631]],[[195033,195033],\"mapped\",[133124]],[[195034,195034],\"mapped\",[36299]],[[195035,195035],\"mapped\",[36284]],[[195036,195036],\"mapped\",[36336]],[[195037,195037],\"mapped\",[133342]],[[195038,195038],\"mapped\",[36564]],[[195039,195039],\"mapped\",[36664]],[[195040,195040],\"mapped\",[165330]],[[195041,195041],\"mapped\",[165357]],[[195042,195042],\"mapped\",[37012]],[[195043,195043],\"mapped\",[37105]],[[195044,195044],\"mapped\",[37137]],[[195045,195045],\"mapped\",[165678]],[[195046,195046],\"mapped\",[37147]],[[195047,195047],\"mapped\",[37432]],[[195048,195048],\"mapped\",[37591]],[[195049,195049],\"mapped\",[37592]],[[195050,195050],\"mapped\",[37500]],[[195051,195051],\"mapped\",[37881]],[[195052,195052],\"mapped\",[37909]],[[195053,195053],\"mapped\",[166906]],[[195054,195054],\"mapped\",[38283]],[[195055,195055],\"mapped\",[18837]],[[195056,195056],\"mapped\",[38327]],[[195057,195057],\"mapped\",[167287]],[[195058,195058],\"mapped\",[18918]],[[195059,195059],\"mapped\",[38595]],[[195060,195060],\"mapped\",[23986]],[[195061,195061],\"mapped\",[38691]],[[195062,195062],\"mapped\",[168261]],[[195063,195063],\"mapped\",[168474]],[[195064,195064],\"mapped\",[19054]],[[195065,195065],\"mapped\",[19062]],[[195066,195066],\"mapped\",[38880]],[[195067,195067],\"mapped\",[168970]],[[195068,195068],\"mapped\",[19122]],[[195069,195069],\"mapped\",[169110]],[[195070,195071],\"mapped\",[38923]],[[195072,195072],\"mapped\",[38953]],[[195073,195073],\"mapped\",[169398]],[[195074,195074],\"mapped\",[39138]],[[195075,195075],\"mapped\",[19251]],[[195076,195076],\"mapped\",[39209]],[[195077,195077],\"mapped\",[39335]],[[195078,195078],\"mapped\",[39362]],[[195079,195079],\"mapped\",[39422]],[[195080,195080],\"mapped\",[19406]],[[195081,195081],\"mapped\",[170800]],[[195082,195082],\"mapped\",[39698]],[[195083,195083],\"mapped\",[40000]],[[195084,195084],\"mapped\",[40189]],[[195085,195085],\"mapped\",[19662]],[[195086,195086],\"mapped\",[19693]],[[195087,195087],\"mapped\",[40295]],[[195088,195088],\"mapped\",[172238]],[[195089,195089],\"mapped\",[19704]],[[195090,195090],\"mapped\",[172293]],[[195091,195091],\"mapped\",[172558]],[[195092,195092],\"mapped\",[172689]],[[195093,195093],\"mapped\",[40635]],[[195094,195094],\"mapped\",[19798]],[[195095,195095],\"mapped\",[40697]],[[195096,195096],\"mapped\",[40702]],[[195097,195097],\"mapped\",[40709]],[[195098,195098],\"mapped\",[40719]],[[195099,195099],\"mapped\",[40726]],[[195100,195100],\"mapped\",[40763]],[[195101,195101],\"mapped\",[173568]],[[195102,196605],\"disallowed\"],[[196606,196607],\"disallowed\"],[[196608,262141],\"disallowed\"],[[262142,262143],\"disallowed\"],[[262144,327677],\"disallowed\"],[[327678,327679],\"disallowed\"],[[327680,393213],\"disallowed\"],[[393214,393215],\"disallowed\"],[[393216,458749],\"disallowed\"],[[458750,458751],\"disallowed\"],[[458752,524285],\"disallowed\"],[[524286,524287],\"disallowed\"],[[524288,589821],\"disallowed\"],[[589822,589823],\"disallowed\"],[[589824,655357],\"disallowed\"],[[655358,655359],\"disallowed\"],[[655360,720893],\"disallowed\"],[[720894,720895],\"disallowed\"],[[720896,786429],\"disallowed\"],[[786430,786431],\"disallowed\"],[[786432,851965],\"disallowed\"],[[851966,851967],\"disallowed\"],[[851968,917501],\"disallowed\"],[[917502,917503],\"disallowed\"],[[917504,917504],\"disallowed\"],[[917505,917505],\"disallowed\"],[[917506,917535],\"disallowed\"],[[917536,917631],\"disallowed\"],[[917632,917759],\"disallowed\"],[[917760,917999],\"ignored\"],[[918000,983037],\"disallowed\"],[[983038,983039],\"disallowed\"],[[983040,1048573],\"disallowed\"],[[1048574,1048575],\"disallowed\"],[[1048576,1114109],\"disallowed\"],[[1114110,1114111],\"disallowed\"]]');\n\n/***/ })\n\n/******/ \t});\n/************************************************************************/\n/******/ \t// The module cache\n/******/ \tvar __webpack_module_cache__ = {};\n/******/ \t\n/******/ \t// The require function\n/******/ \tfunction __nccwpck_require__(moduleId) {\n/******/ \t\t// Check if module is in cache\n/******/ \t\tvar cachedModule = __webpack_module_cache__[moduleId];\n/******/ \t\tif (cachedModule !== undefined) {\n/******/ \t\t\treturn cachedModule.exports;\n/******/ \t\t}\n/******/ \t\t// Create a new module (and put it into the cache)\n/******/ \t\tvar module = __webpack_module_cache__[moduleId] = {\n/******/ \t\t\t// no module.id needed\n/******/ \t\t\t// no module.loaded needed\n/******/ \t\t\texports: {}\n/******/ \t\t};\n/******/ \t\n/******/ \t\t// Execute the module function\n/******/ \t\tvar threw = true;\n/******/ \t\ttry {\n/******/ \t\t\t__webpack_modules__[moduleId].call(module.exports, module, module.exports, __nccwpck_require__);\n/******/ \t\t\tthrew = false;\n/******/ \t\t} finally {\n/******/ \t\t\tif(threw) delete __webpack_module_cache__[moduleId];\n/******/ \t\t}\n/******/ \t\n/******/ \t\t// Return the exports of the module\n/******/ \t\treturn module.exports;\n/******/ \t}\n/******/ \t\n/************************************************************************/\n/******/ \t/* webpack/runtime/compat get default export */\n/******/ \t(() => {\n/******/ \t\t// getDefaultExport function for compatibility with non-harmony modules\n/******/ \t\t__nccwpck_require__.n = (module) => {\n/******/ \t\t\tvar getter = module && module.__esModule ?\n/******/ \t\t\t\t() => (module['default']) :\n/******/ \t\t\t\t() => (module);\n/******/ \t\t\t__nccwpck_require__.d(getter, { a: getter });\n/******/ \t\t\treturn getter;\n/******/ \t\t};\n/******/ \t})();\n/******/ \t\n/******/ \t/* webpack/runtime/define property getters */\n/******/ \t(() => {\n/******/ \t\t// define getter functions for harmony exports\n/******/ \t\t__nccwpck_require__.d = (exports, definition) => {\n/******/ \t\t\tfor(var key in definition) {\n/******/ \t\t\t\tif(__nccwpck_require__.o(definition, key) && !__nccwpck_require__.o(exports, key)) {\n/******/ \t\t\t\t\tObject.defineProperty(exports, key, { enumerable: true, get: definition[key] });\n/******/ \t\t\t\t}\n/******/ \t\t\t}\n/******/ \t\t};\n/******/ \t})();\n/******/ \t\n/******/ \t/* webpack/runtime/hasOwnProperty shorthand */\n/******/ \t(() => {\n/******/ \t\t__nccwpck_require__.o = (obj, prop) => (Object.prototype.hasOwnProperty.call(obj, prop))\n/******/ \t})();\n/******/ \t\n/******/ \t/* webpack/runtime/make namespace object */\n/******/ \t(() => {\n/******/ \t\t// define __esModule on exports\n/******/ \t\t__nccwpck_require__.r = (exports) => {\n/******/ \t\t\tif(typeof Symbol !== 'undefined' && Symbol.toStringTag) {\n/******/ \t\t\t\tObject.defineProperty(exports, Symbol.toStringTag, { value: 'Module' });\n/******/ \t\t\t}\n/******/ \t\t\tObject.defineProperty(exports, '__esModule', { value: true });\n/******/ \t\t};\n/******/ \t})();\n/******/ \t\n/******/ \t/* webpack/runtime/compat */\n/******/ \t\n/******/ \tif (typeof __nccwpck_require__ !== 'undefined') __nccwpck_require__.ab = __dirname + \"/\";\n/******/ \t\n/************************************************************************/\nvar __webpack_exports__ = {};\n// This entry need to be wrapped in an IIFE because it need to be in strict mode.\n(() => {\n\"use strict\";\n// ESM COMPAT FLAG\n__nccwpck_require__.r(__webpack_exports__);\n\n;// CONCATENATED MODULE: ./src/isValidCommitMessage.ts\nconst isValidCommitMessage = (message, core) => {\n // Split the message into words\n // @ts-expect-error\n const segmenter = new Intl.Segmenter([], { granularity: 'word' });\n const segmentedText = segmenter.segment(message);\n const words = [...segmentedText].filter(s => s.isWordLike).map(s => s.segment);\n const minWords = parseInt(core.getInput(\"min-words\"));\n if (words.length < minWords) {\n return false;\n }\n const forbiddenWords = core.getInput(\"forbidden-words\").split(\",\");\n const includesAny = (arr, values) => values.some(v => arr.includes(v));\n return !includesAny(words, forbiddenWords);\n};\n/* harmony default export */ const src_isValidCommitMessage = (isValidCommitMessage);\n\n// EXTERNAL MODULE: ./node_modules/lodash.get/index.js\nvar lodash_get = __nccwpck_require__(9197);\nvar lodash_get_default = /*#__PURE__*/__nccwpck_require__.n(lodash_get);\n// EXTERNAL MODULE: ./node_modules/got/dist/source/index.js\nvar source = __nccwpck_require__(3061);\nvar source_default = /*#__PURE__*/__nccwpck_require__.n(source);\n;// CONCATENATED MODULE: ./src/extractCommits.ts\nvar __awaiter = (undefined && undefined.__awaiter) || function (thisArg, _arguments, P, generator) {\n function adopt(value) { return value instanceof P ? value : new P(function (resolve) { resolve(value); }); }\n return new (P || (P = Promise))(function (resolve, reject) {\n function fulfilled(value) { try { step(generator.next(value)); } catch (e) { reject(e); } }\n function rejected(value) { try { step(generator[\"throw\"](value)); } catch (e) { reject(e); } }\n function step(result) { result.done ? resolve(result.value) : adopt(result.value).then(fulfilled, rejected); }\n step((generator = generator.apply(thisArg, _arguments || [])).next());\n });\n};\n\n\nconst extractCommits = (context, core) => __awaiter(void 0, void 0, void 0, function* () {\n // For \"push\" events, commits can be found in the \"context.payload.commits\".\n const pushCommits = Array.isArray(lodash_get_default()(context, \"payload.commits\"));\n if (pushCommits) {\n return context.payload.commits;\n }\n // For PRs, we need to get a list of commits via the GH API:\n const prCommitsUrl = lodash_get_default()(context, \"payload.pull_request.commits_url\");\n if (prCommitsUrl) {\n try {\n let requestHeaders = {\n \"Accept\": \"application/vnd.github+json\",\n };\n if (core.getInput('GITHUB_TOKEN') != \"\") {\n requestHeaders[\"Authorization\"] = \"token \" + core.getInput('GITHUB_TOKEN');\n }\n const { body } = yield source_default().get(prCommitsUrl, {\n responseType: \"json\",\n headers: requestHeaders,\n });\n if (Array.isArray(body)) {\n return body.map((item) => item.commit);\n }\n return [];\n }\n catch (_a) {\n return [];\n }\n }\n return [];\n});\n/* harmony default export */ const src_extractCommits = (extractCommits);\n\n;// CONCATENATED MODULE: ./src/main.ts\nvar main_awaiter = (undefined && undefined.__awaiter) || function (thisArg, _arguments, P, generator) {\n function adopt(value) { return value instanceof P ? value : new P(function (resolve) { resolve(value); }); }\n return new (P || (P = Promise))(function (resolve, reject) {\n function fulfilled(value) { try { step(generator.next(value)); } catch (e) { reject(e); } }\n function rejected(value) { try { step(generator[\"throw\"](value)); } catch (e) { reject(e); } }\n function step(result) { result.done ? resolve(result.value) : adopt(result.value).then(fulfilled, rejected); }\n step((generator = generator.apply(thisArg, _arguments || [])).next());\n });\n};\nconst { context } = __nccwpck_require__(5438);\nconst core = __nccwpck_require__(2186);\n\n\nfunction run() {\n return main_awaiter(this, void 0, void 0, function* () {\n core.info(`\u2139\ufe0f Checking commit messages ...`);\n const extractedCommits = yield src_extractCommits(context, core);\n if (extractedCommits.length === 0) {\n core.info(`No commits to check, skipping...`);\n return;\n }\n const maxCommits = parseInt(core.getInput(\"max-commits\"));\n if (extractedCommits.length > maxCommits) {\n core.setFailed(`\ud83d\udeab The pull-request shall not contain more than ${maxCommits} commits: please squash some of them or split the pull-request.`);\n return;\n }\n let hasErrors;\n core.startGroup(\"Commit messages:\");\n for (let i = 0; i < extractedCommits.length; i++) {\n let commit = extractedCommits[i];\n if (src_isValidCommitMessage(commit.message, core)) {\n core.info(`\u2705 ${commit.message}`);\n }\n else {\n core.info(`\ud83d\udea9 ${commit.message}`);\n hasErrors = true;\n }\n }\n core.endGroup();\n if (hasErrors) {\n core.setFailed(`\ud83d\udeab Some of the commit messages are either too short of contain forbidden words. Please amend or squash them.`);\n }\n else {\n core.info(\"\ud83c\udf89 All commit messages are valid.\");\n }\n });\n}\nrun();\n\n})();\n\nmodule.exports = __webpack_exports__;\n/******/ })()\n;", "src\\main.ts": "const { context } = require(\"@actions/github\");\nconst core = require(\"@actions/core\");\n\nimport isValidCommitMessage from \"./isValidCommitMessage\";\nimport extractCommits from \"./extractCommits\";\n\nasync function run() {\n core.info(\n `\u2139\ufe0f Checking commit messages ...`\n );\n\n const extractedCommits = await extractCommits(context, core);\n if (extractedCommits.length === 0) {\n core.info(`No commits to check, skipping...`);\n return;\n }\n\n const maxCommits = parseInt(core.getInput(\"max-commits\"))\n if (extractedCommits.length > maxCommits) {\n core.setFailed(`\ud83d\udeab The pull-request shall not contain more than ${maxCommits} commits: please squash some of them or split the pull-request.`);\n return;\n }\n\n let hasErrors;\n core.startGroup(\"Commit messages:\");\n for (let i = 0; i < extractedCommits.length; i++) {\n let commit = extractedCommits[i];\n\n if (isValidCommitMessage(commit.message, core)) {\n core.info(`\u2705 ${commit.message}`);\n } else {\n core.info(`\ud83d\udea9 ${commit.message}`);\n hasErrors = true;\n }\n }\n core.endGroup();\n\n if (hasErrors) {\n core.setFailed(\n `\ud83d\udeab Some of the commit messages are either too short of contain forbidden words. Please amend or squash them.`\n );\n } else {\n core.info(\"\ud83c\udf89 All commit messages are valid.\");\n }\n}\n\nrun();\n"} | 2 |
AI-Canvas | {"type": "directory", "name": "AI-Canvas", "children": [{"type": "file", "name": "Handtracking.py"}, {"type": "file", "name": "HandTrackingModule.py"}, {"type": "directory", "name": "Header", "children": []}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "VirtualPainter.py"}]} | # Virtual AI Canvas with OpenCV and MediaPipe
## Table of Content
- [Overview](#overview)
- [Demo](#demo)
- [Motivation](#motivation)
- [Technical Aspect](#technical-aspect)
- [Installation And Run](#installation-and-run)
- [Directory Tree](#directory-tree)
- [To Do](#to-do)
- [Bug / Feature Request](#bug---feature-request)
- [Technologies Used](#technologies-used)
- [Credits](#credits)
## Overview
This project is a hand tracking application built using OpenCV and MediaPipe. The application can detect hands in real-time from a webcam feed, track the position of hand landmarks, and provide functionality for drawing and erasing on the screen using hand gestures.
## Demo
Here's a brief demonstration of the hand tracking application in action:

## Motivation
The motivation behind this project was to explore the capabilities of computer vision and hand tracking technologies, and to create an interactive application that demonstrates these capabilities in a fun and engaging way.
## Technical Aspect
The application uses the following technologies and libraries:
- **Opencv**: An open-source computer vision and machine learning software library.
- **MediaPipe**: A cross-platform framework developed by Google for building multimodal applied machine learning pipelines.
- **Numpy**: A library for the Python programming language, adding support for large, multi-dimensional arrays and matrices.
The application follows these steps:
1. Capture video from a webcam.
2. Use MediaPipe to detect and track hand landmarks in the video frames.
3. Implement different modes for drawing and erasing on the screen based on hand gestures.
4. Overlay the drawing on the video feed and display it to the user.
## Installation And Run
1. Clone the repository or download the source code.
2. Install the required packages by running the following command:
```bash
pip install -r requirements.txt
```
3. Run the application with the following command:
```bash
python VirtualPainter.py
```
Directory Tree
```
│ app.py
│ HandTrackingModule.py
│ README.md
│ requirements.txt
└───Header
# Images for header will be stored here
```
## To Do
* Improve hand tracking accuracy and responsiveness.
* Add support for more gestures and interactions.
* Optimize performance for lower-end hardware.
## Bug / Feature Request
If you find a bug or have a feature request, please open an issue [here](https://github.com/hamza-amin-4365/AI-Canvas/issues/new).
## Technologies Used
<img target="_blank" src="https://opencv.org/wp-content/uploads/2020/07/OpenCV_logo_black.png" width=200>
<img target="_blank" src="https://mediapipe.dev/images/logo_horizontal_color.png" width=200>
<img target="_blank" src="https://numpy.org/images/logo.svg" width=200>
## Credits
* MediaPipe
* OpenCV
* NumPy
| {"requirements.txt": "opencv-python\nmediapipe\nnumpy\n", ".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 4c3e71de4e72a38e1f03153638d98ef32819ae91 Hamza Amin <[email protected]> 1727376263 +0500\tclone: from https://github.com/hamza-amin-4365/AI-Canvas.git\n", ".git\\refs\\heads\\main": "4c3e71de4e72a38e1f03153638d98ef32819ae91\n"} | 0 |
alignment-handbook | {"type": "directory", "name": "alignment-handbook", "children": [{"type": "directory", "name": "assets", "children": []}, {"type": "directory", "name": "chapters", "children": [{"type": "directory", "name": "en", "children": [{"type": "directory", "name": "chapter0", "children": [{"type": "file", "name": "introduction.mdx"}]}, {"type": "file", "name": "_toctree.yml"}]}]}, {"type": "file", "name": "CITATION.cff"}, {"type": "file", "name": "LICENSE"}, {"type": "file", "name": "Makefile"}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "recipes", "children": [{"type": "directory", "name": "accelerate_configs", "children": [{"type": "file", "name": "deepspeed_zero3.yaml"}, {"type": "file", "name": "fsdp.yaml"}, {"type": "file", "name": "fsdp_qlora.yaml"}, {"type": "file", "name": "multi_gpu.yaml"}]}, {"type": "directory", "name": "constitutional-ai", "children": [{"type": "directory", "name": "dpo", "children": [{"type": "file", "name": "config_anthropic.yaml"}]}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "sft", "children": [{"type": "file", "name": "config_anthropic.yaml"}, {"type": "file", "name": "config_grok.yaml"}]}]}, {"type": "directory", "name": "gpt2-nl", "children": [{"type": "directory", "name": "cpt", "children": [{"type": "file", "name": "config_full.yaml"}]}, {"type": "directory", "name": "dpo", "children": [{"type": "file", "name": "config_full.yaml"}]}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "sft", "children": [{"type": "file", "name": "config_full.yaml"}]}]}, {"type": "file", "name": "launch.slurm"}, {"type": "directory", "name": "pref_align_scan", "children": [{"type": "directory", "name": "dpo", "children": [{"type": "file", "name": "config_openhermes.yaml"}, {"type": "file", "name": "config_zephyr.yaml"}]}, {"type": "file", "name": "launch_scan.sh"}, {"type": "file", "name": "README.md"}]}, {"type": "directory", "name": "smollm", "children": [{"type": "file", "name": "README.md"}, {"type": "directory", "name": "sft", "children": [{"type": "file", "name": "config.yaml"}]}]}, {"type": "directory", "name": "starchat2-15b", "children": [{"type": "directory", "name": "dpo", "children": [{"type": "file", "name": "config_v0.1.yaml"}]}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "sft", "children": [{"type": "file", "name": "config_v0.1.yaml"}]}]}, {"type": "directory", "name": "zephyr-141b-A35b", "children": [{"type": "directory", "name": "orpo", "children": [{"type": "file", "name": "config_full.yaml"}]}, {"type": "file", "name": "README.md"}]}, {"type": "directory", "name": "zephyr-7b-beta", "children": [{"type": "directory", "name": "dpo", "children": [{"type": "file", "name": "config_full.yaml"}, {"type": "file", "name": "config_qlora.yaml"}]}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "sft", "children": [{"type": "file", "name": "config_full.yaml"}, {"type": "file", "name": "config_qlora.yaml"}]}]}, {"type": "directory", "name": "zephyr-7b-gemma", "children": [{"type": "directory", "name": "dpo", "children": [{"type": "file", "name": "config_full.yaml"}]}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "sft", "children": [{"type": "file", "name": "config_full.yaml"}]}]}]}, {"type": "directory", "name": "scripts", "children": [{"type": "file", "name": "README.md"}, {"type": "file", "name": "run_cpt.py"}, {"type": "file", "name": "run_dpo.py"}, {"type": "file", "name": "run_orpo.py"}, {"type": "file", "name": "run_sft.py"}]}, {"type": "file", "name": "setup.cfg"}, {"type": "file", "name": "setup.py"}, {"type": "directory", "name": "src", "children": [{"type": "directory", "name": "alignment", "children": [{"type": "file", "name": "configs.py"}, {"type": "file", "name": "data.py"}, {"type": "file", "name": "decontaminate.py"}, {"type": "file", "name": "model_utils.py"}, {"type": "file", "name": "release.py"}, {"type": "file", "name": "__init__.py"}]}]}, {"type": "directory", "name": "tests", "children": [{"type": "directory", "name": "fixtures", "children": [{"type": "file", "name": "config_dpo_full.yaml"}, {"type": "file", "name": "config_sft_full.yaml"}]}, {"type": "file", "name": "test_configs.py"}, {"type": "file", "name": "test_data.py"}, {"type": "file", "name": "test_decontaminate.py"}, {"type": "file", "name": "test_model_utils.py"}, {"type": "file", "name": "__init__.py"}]}]} | # Scripts to Train and Evaluate Chat Models
## Fine-tuning
In the handbook, we provide three main ways to align LLMs for chat:
- Full fine-tuning on a multi-GPU machine with DeepSpeed ZeRO-3 (tested on an 8 x A100 (80GB) node).
- LoRA or QLoRA fine-tuning on a single consumer 24GB GPU (tested on an RTX 4090).
- LoRA fine-tuning on a multi-GPU machine with DeepSpeed ZeRO-3 (tested on a 2 x A100s (80GB)).
- QLoRA fine-tuning on multi-GPU machine with FSDP (tested on a 2 x A6000s (48GB)).
In practice, we find comparable performance for both full and QLoRA fine-tuning, with the latter having the advantage of producing small adapter weights that are fast to upload and download from the Hugging Face Hub. Here are the general commands to fine-tune your models:
```shell
# Full training with ZeRO-3 on 8 GPUs
ACCELERATE_LOG_LEVEL=info accelerate launch --config_file recipes/accelerate_configs/deepspeed_zero3.yaml scripts/run_{task}.py recipes/{model_name}/{task}/config_full.yaml
# QLoRA 4-bit training on a single GPU
ACCELERATE_LOG_LEVEL=info accelerate launch --config_file recipes/accelerate_configs/multi_gpu.yaml --num_processes=1 scripts/run_{task}.py recipes/{model_name}/{task}/config_qlora.yaml
# LoRA training on a single GPU
ACCELERATE_LOG_LEVEL=info accelerate launch --config_file recipes/accelerate_configs/multi_gpu.yaml --num_processes=1 scripts/run_{task}.py recipes/{model_name}/{task}/config_qlora.yaml --load_in_4bit=false
# LoRA training with ZeRO-3 on two or more GPUs
ACCELERATE_LOG_LEVEL=info accelerate launch --config_file recipes/accelerate_configs/deepspeed_zero3.yaml --num_processes={num_gpus} scripts/run_{task}.py recipes/{model_name}/{task}/config_qlora.yaml --load_in_4bit=false
# QLoRA training with FSDP on two or more GPUs
ACCELERATE_LOG_LEVEL=info accelerate launch --config_file recipes/accelerate_configs/fsdp+qlora.yaml --num_processes={num_gpus} scripts/run_{task}.py recipes/{model_name}/{task}/config_qlora.yaml --torch_dtype=bfloat16 --bnb_4bit_quant_storage=bfloat16
```
Here `{task}` refers to the type of training you wish to run. Currently, the following tasks are supported:
* continued pretraining `cpt` (note that `cpt` is only present in the `gpt-nl` example recipe)
* supervised finetuning `sft`
* direct preference optimisation `dpo`
* odds ratio preference optimisation `orpo`
`{model_name}` refers to the choice of a recipe in the `recipes` directory. For example, to replicate Zephyr-7B-β you can run:
```shell
# Step 1 - train SFT policy
ACCELERATE_LOG_LEVEL=info accelerate launch --config_file recipes/accelerate_configs/deepspeed_zero3.yaml scripts/run_sft.py recipes/zephyr-7b-beta/sft/config_full.yaml
# Step 2 - align with DPO
ACCELERATE_LOG_LEVEL=info accelerate launch --config_file recipes/accelerate_configs/deepspeed_zero3.yaml scripts/run_dpo.py recipes/zephyr-7b-beta/dpo/config_full.yaml
```
**💡 Tip:** If you scale up/down the number of GPUs, we recommend also scaling up the per-device batch size or number of gradient accumulation steps to keep the global batch size constant (and thus replicate our results).
By default, these scripts will push each model to your Hugging Face Hub username, i.e. `{username}/{model_name}-{task}`. You can override the parameters in each YAML config by appending them to the command as follows:
```shell
# Change batch size, number of epochs etc
ACCELERATE_LOG_LEVEL=info accelerate launch --config_file recipes/accelerate_configs/deepspeed_zero3.yaml scripts/run_{task}.py recipes/{model_name}/{task}/config_full.yaml --per_device_train_batch_size=42 --num_train_epochs=5
```
## Logging with Weights and Biases
By default, all training metrics are logged with TensorBoard. If you have a [Weights and Biases](https://wandb.ai/site) account and are logged in, you can view the training metrics by appending `--report_to=wandb`, e.g.
```shell
ACCELERATE_LOG_LEVEL=info accelerate launch --config_file recipes/accelerate_configs/deepspeed_zero3.yaml scripts/run_{task}.py recipes/{model_name}/{task}/config_full.yaml --report_to=wandb
```
## Launching jobs on a Slurm cluster
If you have access to a Slurm cluster, we provide a `recipes/launch.slurm` script that will automatically queue training jobs for you. Here's how you can use it:
```shell
sbatch --job-name=handbook_{task} --nodes=1 recipes/launch.slurm {model_name} {task} {precision} {accelerator}
```
Here `{model_name}` and `{task}` are defined as above, while `{precision}` refers to the type of training (`full` vs `qlora`) and `{accelerator}` refers to the choice of 🤗 Accelerate config in `recipes/accelerate_configs`. If you wish to override the default config parameters, you can provide them by appending a space-separated string like `'--arg1=value1 --arg2=value2'. Here's a concrete example to run SFT on 1 node of 8 GPUs:
```shell
# Launch on Slurm and override default hyperparameters
sbatch --job-name=handbook_sft --nodes=1 recipes/launch.slurm zephyr-7b-beta sft full deepspeed_zero3 '--per_device_train_batch_size=42 --num_train_epochs=5'
```
You can scale the number of nodes by increasing the `--nodes` flag.
**⚠️ Note:** the configuration in `recipes/launch.slurm` is optimised for the Hugging Face Compute Cluster and may require tweaking to be adapted to your own compute nodes.
## Fine-tuning on your datasets
Under the hood, each training script uses the `get_datasets()` function which allows one to easily combine multiple datasets with varying proportions. For instance, this is how one can specify multiple datasets and which splits to combine in one of the YAML configs:
```yaml
datasets_mixer:
dataset_1: 0.5 # Use 50% of the training examples
dataset_2: 0.66 # Use 66% of the training examples
dataset_3: 0.10 # Use 10% of the training examples
dataset_splits:
- train_xxx # The training splits to mix
- test_xxx # The test splits to mix
```
If you want to fine-tune on your datasets, the main thing to keep in mind is how the chat templates are applied to the dataset blend. Since each task (SFT, DPO, ORPO, etc), requires a different format, we assume the datasets have the following columns:
**SFT**
* `messages`: A list of `dicts` in the form `{"role": "{role}", "content": {content}}`.
* See [ultrachat_200k](https://huggingface.co/datasets/HuggingFaceH4/ultrachat_200k) for an example.
**DPO and ORPO**
* `chosen`: A list of `dicts` in the form `{"role": "{role}", "content": {content}}` corresponding to the preferred dialogue.
* `rejected`: A list of `dicts` in the form `{"role": "{role}", "content": {content}}` corresponding to the dispreferred dialogue.
* See [ultrafeedback_binarized](https://huggingface.co/datasets/HuggingFaceH4/ultrafeedback_binarized) for an example.
We also find it useful to include dedicated splits per task in our datasets, so e.g. we have:
* `{train,test}_sft`: Splits for SFT training.
* `{train,test}_gen`: Splits for generation ranking like rejection sampling or PPO.
* `{train,test}_prefs`: Splits for preference modelling, like reward modelling or DPO.
If you format your dataset in the same way, our training scripts should work out of the box!
## Evaluating chat models
We recommend benchmarking chat models on:
* [MT-Bench](https://huggingface.co/spaces/lmsys/mt-bench): a multi-turn benchmark spanning 80 dialogues and 10 domains.
* [AlpacaEval](https://github.com/tatsu-lab/alpaca_eval): a single-turn benchmark that evaluates the helpfulness of chat and instruct models against `text-davinci-003`.
For both benchmarks, we have added support for the [Zephyr chat template](https://huggingface.co/alignment-handbook/zephyr-7b-sft-full/blob/ac6e600eefcce74f5e8bae1035d4f66019e93190/tokenizer_config.json#L30) (which is the default produced by our scripts), so you can evaluate models produced by our scripts as follows:
**MT-Bench**
* Follow the installation instructions [here](https://github.com/lm-sys/FastChat/tree/main/fastchat/llm_judge)
* Make sure the word `zephyr` exists in the `--model-path` argument when generating the model responses [here](https://github.com/lm-sys/FastChat/tree/main/fastchat/llm_judge#step-1-generate-model-answers-to-mt-bench-questions). This will ensure the correct chat template is loaded. For example, the following model name is valid: `--model-path {hub_username}/my-baby-zephyr`
* Generate the model responses and GPT-4 rankings.
**AlpacaEval**
* Follow the installation instructions [here](https://github.com/tatsu-lab/alpaca_eval#quick-start)
* Copy-paste the [config](https://github.com/tatsu-lab/alpaca_eval/blob/main/src/alpaca_eval/models_configs/zephyr-7b-beta/configs.yaml) for `zephyr-7b-beta` and place it in the `model_configs` directory under `{your_zephyr_model}`.
* Next, update the [config name](https://github.com/tatsu-lab/alpaca_eval/blob/2daa6e11b194653043ca74f735728dc068e04aae/src/alpaca_eval/models_configs/zephyr-7b-beta/configs.yaml#L1) and [Hub model ID](https://github.com/tatsu-lab/alpaca_eval/blob/2daa6e11b194653043ca74f735728dc068e04aae/src/alpaca_eval/models_configs/zephyr-7b-beta/configs.yaml#L5) to match your model name.
* Follow the steps to evaluate your model [here](https://github.com/tatsu-lab/alpaca_eval/tree/main#evaluating-a-model).
Note that MT-Bench and AlpacaEval rely on LLMs like GPT-4 to judge the quality of the model responses, and thus the ranking exhibits various biases including a preference for models distilled from GPTs. For that reason, we also recommend submitting your best models for human evaluation in:
* [Chatbot Arena](https://chat.lmsys.org): a live, human evaluation of chat models in head-to-head comparisons.
| {"setup.py": "# Copyright 2023 The HuggingFace Team. All rights reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n#\n# Adapted from huggingface/transformers: https://github.com/huggingface/transformers/blob/21a2d900eceeded7be9edc445b56877b95eda4ca/setup.py\n\n\nimport re\nimport shutil\nfrom pathlib import Path\n\nfrom setuptools import find_packages, setup\n\n\n# Remove stale alignment.egg-info directory to avoid https://github.com/pypa/pip/issues/5466\nstale_egg_info = Path(__file__).parent / \"alignment.egg-info\"\nif stale_egg_info.exists():\n print(\n (\n \"Warning: {} exists.\\n\\n\"\n \"If you recently updated alignment, this is expected,\\n\"\n \"but it may prevent alignment from installing in editable mode.\\n\\n\"\n \"This directory is automatically generated by Python's packaging tools.\\n\"\n \"I will remove it now.\\n\\n\"\n \"See https://github.com/pypa/pip/issues/5466 for details.\\n\"\n ).format(stale_egg_info)\n )\n shutil.rmtree(stale_egg_info)\n\n\n# IMPORTANT: all dependencies should be listed here with their version requirements, if any.\n# * If a dependency is fast-moving (e.g. transformers), pin to the exact version\n_deps = [\n \"accelerate>=0.29.2\",\n \"bitsandbytes>=0.43.0\",\n \"black>=24.4.2\",\n \"datasets>=2.18.0\",\n \"deepspeed>=0.14.4\",\n \"einops>=0.6.1\",\n \"evaluate==0.4.0\",\n \"flake8>=6.0.0\",\n \"hf-doc-builder>=0.4.0\",\n \"hf_transfer>=0.1.4\",\n \"huggingface-hub>=0.19.2,<1.0\",\n \"isort>=5.12.0\",\n \"ninja>=1.11.1\",\n \"numpy>=1.24.2\",\n \"packaging>=23.0\",\n \"parameterized>=0.9.0\",\n \"peft>=0.9.0\",\n \"protobuf<=3.20.2\", # Needed to avoid conflicts with `transformers`\n \"pytest\",\n \"safetensors>=0.3.3\",\n \"sentencepiece>=0.1.99\",\n \"scipy\",\n \"tensorboard\",\n \"torch>=2.1.2\",\n \"transformers>=4.39.3\",\n \"trl>=0.9.6\",\n \"jinja2>=3.0.0\",\n \"tqdm>=4.64.1\",\n]\n\n# this is a lookup table with items like:\n#\n# tokenizers: \"tokenizers==0.9.4\"\n# packaging: \"packaging\"\n#\n# some of the values are versioned whereas others aren't.\ndeps = {b: a for a, b in (re.findall(r\"^(([^!=<>~ \\[\\]]+)(?:\\[[^\\]]+\\])?(?:[!=<>~ ].*)?$)\", x)[0] for x in _deps)}\n\n\ndef deps_list(*pkgs):\n return [deps[pkg] for pkg in pkgs]\n\n\nextras = {}\nextras[\"tests\"] = deps_list(\"pytest\", \"parameterized\")\nextras[\"torch\"] = deps_list(\"torch\")\nextras[\"quality\"] = deps_list(\"black\", \"isort\", \"flake8\")\nextras[\"docs\"] = deps_list(\"hf-doc-builder\")\nextras[\"dev\"] = extras[\"docs\"] + extras[\"quality\"] + extras[\"tests\"]\n\n# core dependencies shared across the whole project - keep this to a bare minimum :)\ninstall_requires = [\n deps[\"accelerate\"],\n deps[\"bitsandbytes\"],\n deps[\"einops\"],\n deps[\"evaluate\"],\n deps[\"datasets\"],\n deps[\"deepspeed\"],\n deps[\"hf_transfer\"],\n deps[\"huggingface-hub\"],\n deps[\"jinja2\"],\n deps[\"ninja\"],\n deps[\"numpy\"],\n deps[\"packaging\"], # utilities from PyPA to e.g., compare versions\n deps[\"peft\"],\n deps[\"protobuf\"],\n deps[\"safetensors\"],\n deps[\"sentencepiece\"],\n deps[\"scipy\"],\n deps[\"tensorboard\"],\n deps[\"tqdm\"], # progress bars in model download and training scripts\n deps[\"transformers\"],\n deps[\"trl\"],\n]\n\nsetup(\n name=\"alignment-handbook\",\n version=\"0.4.0.dev0\", # expected format is one of x.y.z.dev0, or x.y.z.rc1 or x.y.z (no to dashes, yes to dots)\n author=\"The Hugging Face team (past and future)\",\n author_email=\"[email protected]\",\n description=\"The Alignment Handbook\",\n long_description=open(\"README.md\", \"r\", encoding=\"utf-8\").read(),\n long_description_content_type=\"text/markdown\",\n keywords=\"nlp deep learning rlhf llm\",\n license=\"Apache\",\n url=\"https://github.com/huggingface/alignment-handbook\",\n package_dir={\"\": \"src\"},\n packages=find_packages(\"src\"),\n zip_safe=False,\n extras_require=extras,\n python_requires=\">=3.10.9\",\n install_requires=install_requires,\n classifiers=[\n \"Development Status :: 3 - Alpha\",\n \"Intended Audience :: Developers\",\n \"Intended Audience :: Education\",\n \"Intended Audience :: Science/Research\",\n \"License :: OSI Approved :: Apache Software License\",\n \"Operating System :: OS Independent\",\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.10\",\n \"Topic :: Scientific/Engineering :: Artificial Intelligence\",\n ],\n)\n", ".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 7d711cd80dff17df78f8340df1b7616af0809407 Hamza Amin <[email protected]> 1727369081 +0500\tclone: from https://github.com/huggingface/alignment-handbook.git\n", ".git\\refs\\heads\\main": "7d711cd80dff17df78f8340df1b7616af0809407\n"} | 1 |
api-inference-community | {"type": "directory", "name": "api-inference-community", "children": [{"type": "file", "name": ".pre-commit-config.yaml"}, {"type": "directory", "name": "api_inference_community", "children": [{"type": "file", "name": "hub.py"}, {"type": "file", "name": "normalizers.py"}, {"type": "file", "name": "routes.py"}, {"type": "file", "name": "validation.py"}]}, {"type": "file", "name": "build.sh"}, {"type": "file", "name": "build_docker.py"}, {"type": "directory", "name": "docker_images", "children": [{"type": "directory", "name": "adapter_transformers", "children": [{"type": "directory", "name": "app", "children": [{"type": "file", "name": "batch.py"}, {"type": "file", "name": "main.py"}, {"type": "directory", "name": "pipelines", "children": [{"type": "file", "name": "base.py"}, {"type": "file", "name": "question_answering.py"}, {"type": "file", "name": "summarization.py"}, {"type": "file", "name": "text_classification.py"}, {"type": "file", "name": "text_generation.py"}, {"type": "file", "name": "token_classification.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "Dockerfile"}, {"type": "file", "name": "prestart.sh"}, {"type": "file", "name": "requirements.txt"}, {"type": "directory", "name": "tests", "children": [{"type": "directory", "name": "samples", "children": []}, {"type": "file", "name": "test_api.py"}, {"type": "file", "name": "test_api_question_answering.py"}, {"type": "file", "name": "test_api_summarization.py"}, {"type": "file", "name": "test_api_text_classification.py"}, {"type": "file", "name": "test_api_text_generation.py"}, {"type": "file", "name": "test_api_token_classification.py"}, {"type": "file", "name": "test_docker_build.py"}, {"type": "file", "name": "__init__.py"}]}]}, {"type": "directory", "name": "allennlp", "children": [{"type": "directory", "name": "app", "children": [{"type": "file", "name": "main.py"}, {"type": "directory", "name": "pipelines", "children": [{"type": "file", "name": "base.py"}, {"type": "file", "name": "question_answering.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "Dockerfile"}, {"type": "file", "name": "prestart.sh"}, {"type": "file", "name": "requirements.txt"}, {"type": "directory", "name": "tests", "children": [{"type": "directory", "name": "samples", "children": []}, {"type": "file", "name": "test_api.py"}, {"type": "file", "name": "test_api_question_answering.py"}, {"type": "file", "name": "test_docker_build.py"}, {"type": "file", "name": "__init__.py"}]}]}, {"type": "directory", "name": "asteroid", "children": [{"type": "directory", "name": "app", "children": [{"type": "file", "name": "main.py"}, {"type": "directory", "name": "pipelines", "children": [{"type": "file", "name": "audio_source_separation.py"}, {"type": "file", "name": "audio_to_audio.py"}, {"type": "file", "name": "base.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "Dockerfile"}, {"type": "file", "name": "prestart.sh"}, {"type": "file", "name": "requirements.txt"}, {"type": "directory", "name": "tests", "children": [{"type": "directory", "name": "samples", "children": []}, {"type": "file", "name": "test_api.py"}, {"type": "file", "name": "test_api_audio_source_separation.py"}, {"type": "file", "name": "test_api_audio_to_audio.py"}, {"type": "file", "name": "test_docker_build.py"}, {"type": "file", "name": "__init__.py"}]}]}, {"type": "directory", "name": "bertopic", "children": [{"type": "directory", "name": "app", "children": [{"type": "file", "name": "main.py"}, {"type": "directory", "name": "pipelines", "children": [{"type": "file", "name": "base.py"}, {"type": "file", "name": "text_classification.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "Dockerfile"}, {"type": "file", "name": "prestart.sh"}, {"type": "file", "name": "requirements.txt"}, {"type": "directory", "name": "tests", "children": [{"type": "file", "name": "test_api.py"}, {"type": "file", "name": "test_api_text_classification.py"}, {"type": "file", "name": "test_docker_build.py"}, {"type": "file", "name": "__init__.py"}]}]}, {"type": "directory", "name": "common", "children": [{"type": "directory", "name": "app", "children": [{"type": "file", "name": "main.py"}, {"type": "directory", "name": "pipelines", "children": [{"type": "file", "name": "audio_classification.py"}, {"type": "file", "name": "audio_to_audio.py"}, {"type": "file", "name": "automatic_speech_recognition.py"}, {"type": "file", "name": "base.py"}, {"type": "file", "name": "conversational.py"}, {"type": "file", "name": "feature_extraction.py"}, {"type": "file", "name": "fill_mask.py"}, {"type": "file", "name": "image_classification.py"}, {"type": "file", "name": "image_to_image.py"}, {"type": "file", "name": "question_answering.py"}, {"type": "file", "name": "sentence_similarity.py"}, {"type": "file", "name": "speech_segmentation.py"}, {"type": "file", "name": "summarization.py"}, {"type": "file", "name": "tabular_classification_pipeline.py"}, {"type": "file", "name": "tabular_regression_pipeline.py"}, {"type": "file", "name": "text2text_generation.py"}, {"type": "file", "name": "text_classification.py"}, {"type": "file", "name": "text_to_image.py"}, {"type": "file", "name": "text_to_speech.py"}, {"type": "file", "name": "token_classification.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "Dockerfile"}, {"type": "file", "name": "prestart.sh"}, {"type": "file", "name": "requirements.txt"}, {"type": "directory", "name": "tests", "children": [{"type": "directory", "name": "samples", "children": []}, {"type": "file", "name": "test_api.py"}, {"type": "file", "name": "test_api_audio_classification.py"}, {"type": "file", "name": "test_api_audio_to_audio.py"}, {"type": "file", "name": "test_api_automatic_speech_recognition.py"}, {"type": "file", "name": "test_api_feature_extraction.py"}, {"type": "file", "name": "test_api_image_classification.py"}, {"type": "file", "name": "test_api_image_to_image.py"}, {"type": "file", "name": "test_api_question_answering.py"}, {"type": "file", "name": "test_api_sentence_similarity.py"}, {"type": "file", "name": "test_api_speech_segmentation.py"}, {"type": "file", "name": "test_api_summarization.py"}, {"type": "file", "name": "test_api_tabular_classification.py"}, {"type": "file", "name": "test_api_tabular_regression.py"}, {"type": "file", "name": "test_api_text2text_generation.py"}, {"type": "file", "name": "test_api_text_classification.py"}, {"type": "file", "name": "test_api_text_to_image.py"}, {"type": "file", "name": "test_api_text_to_speech.py"}, {"type": "file", "name": "test_api_token_classification.py"}, {"type": "file", "name": "test_docker_build.py"}, {"type": "file", "name": "__init__.py"}]}]}, {"type": "directory", "name": "diffusers", "children": [{"type": "directory", "name": "app", "children": [{"type": "file", "name": "healthchecks.py"}, {"type": "file", "name": "idle.py"}, {"type": "file", "name": "lora.py"}, {"type": "file", "name": "main.py"}, {"type": "file", "name": "offline.py"}, {"type": "directory", "name": "pipelines", "children": [{"type": "file", "name": "base.py"}, {"type": "file", "name": "image_to_image.py"}, {"type": "file", "name": "text_to_image.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "timing.py"}, {"type": "file", "name": "validation.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "Dockerfile"}, {"type": "file", "name": "prestart.sh"}, {"type": "file", "name": "requirements.txt"}, {"type": "directory", "name": "tests", "children": [{"type": "file", "name": "test_api.py"}, {"type": "file", "name": "test_api_image_to_image.py"}, {"type": "file", "name": "test_api_text_to_image.py"}, {"type": "file", "name": "test_docker_build.py"}, {"type": "file", "name": "__init__.py"}]}]}, {"type": "directory", "name": "doctr", "children": [{"type": "directory", "name": "app", "children": [{"type": "file", "name": "main.py"}, {"type": "directory", "name": "pipelines", "children": [{"type": "file", "name": "base.py"}, {"type": "file", "name": "object_detection.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "Dockerfile"}, {"type": "file", "name": "prestart.sh"}, {"type": "file", "name": "requirements.txt"}, {"type": "directory", "name": "tests", "children": [{"type": "directory", "name": "samples", "children": []}, {"type": "file", "name": "test_api.py"}, {"type": "file", "name": "test_api_object_detection.py"}, {"type": "file", "name": "test_docker_build.py"}, {"type": "file", "name": "__init__.py"}]}]}, {"type": "directory", "name": "espnet", "children": [{"type": "directory", "name": "app", "children": [{"type": "file", "name": "main.py"}, {"type": "directory", "name": "pipelines", "children": [{"type": "file", "name": "automatic_speech_recognition.py"}, {"type": "file", "name": "base.py"}, {"type": "file", "name": "text_to_speech.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "Dockerfile"}, {"type": "file", "name": "prestart.sh"}, {"type": "file", "name": "requirements.txt"}, {"type": "directory", "name": "tests", "children": [{"type": "directory", "name": "samples", "children": []}, {"type": "file", "name": "test_api.py"}, {"type": "file", "name": "test_api_automatic_speech_recognition.py"}, {"type": "file", "name": "test_api_text_to_speech.py"}, {"type": "file", "name": "test_docker_build.py"}, {"type": "file", "name": "__init__.py"}]}]}, {"type": "directory", "name": "fairseq", "children": [{"type": "directory", "name": "app", "children": [{"type": "file", "name": "main.py"}, {"type": "directory", "name": "pipelines", "children": [{"type": "file", "name": "audio_to_audio.py"}, {"type": "file", "name": "base.py"}, {"type": "file", "name": "text_to_speech.py"}, {"type": "file", "name": "utils.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "Dockerfile"}, {"type": "file", "name": "prestart.sh"}, {"type": "file", "name": "requirements.txt"}, {"type": "directory", "name": "tests", "children": [{"type": "directory", "name": "samples", "children": []}, {"type": "file", "name": "test_api.py"}, {"type": "file", "name": "test_api_audio_to_audio.py"}, {"type": "file", "name": "test_api_text_to_speech.py"}, {"type": "file", "name": "test_docker_build.py"}, {"type": "file", "name": "__init__.py"}]}]}, {"type": "directory", "name": "fastai", "children": [{"type": "directory", "name": "app", "children": [{"type": "file", "name": "main.py"}, {"type": "directory", "name": "pipelines", "children": [{"type": "file", "name": "base.py"}, {"type": "file", "name": "image_classification.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "Dockerfile"}, {"type": "file", "name": "prestart.sh"}, {"type": "file", "name": "requirements.txt"}, {"type": "directory", "name": "tests", "children": [{"type": "directory", "name": "samples", "children": []}, {"type": "file", "name": "test_api.py"}, {"type": "file", "name": "test_api_image_classification.py"}, {"type": "file", "name": "test_docker_build.py"}, {"type": "file", "name": "__init__.py"}]}]}, {"type": "directory", "name": "fasttext", "children": [{"type": "directory", "name": "app", "children": [{"type": "file", "name": "main.py"}, {"type": "directory", "name": "pipelines", "children": [{"type": "file", "name": "base.py"}, {"type": "file", "name": "feature_extraction.py"}, {"type": "file", "name": "text_classification.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "Dockerfile"}, {"type": "file", "name": "prestart.sh"}, {"type": "file", "name": "requirements.txt"}, {"type": "directory", "name": "tests", "children": [{"type": "directory", "name": "samples", "children": []}, {"type": "file", "name": "test_api.py"}, {"type": "file", "name": "test_api_feature_extraction.py"}, {"type": "file", "name": "test_api_text_classification.py"}, {"type": "file", "name": "test_docker_build.py"}, {"type": "file", "name": "__init__.py"}]}]}, {"type": "directory", "name": "flair", "children": [{"type": "directory", "name": "app", "children": [{"type": "file", "name": "main.py"}, {"type": "directory", "name": "pipelines", "children": [{"type": "file", "name": "base.py"}, {"type": "file", "name": "token_classification.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "Dockerfile"}, {"type": "file", "name": "prestart.sh"}, {"type": "file", "name": "requirements.txt"}, {"type": "directory", "name": "tests", "children": [{"type": "directory", "name": "samples", "children": []}, {"type": "file", "name": "test_api.py"}, {"type": "file", "name": "test_api_token_classification.py"}, {"type": "file", "name": "test_docker_build.py"}, {"type": "file", "name": "__init__.py"}]}]}, {"type": "directory", "name": "k2", "children": [{"type": "directory", "name": "app", "children": [{"type": "file", "name": "common.py"}, {"type": "file", "name": "decode.py"}, {"type": "file", "name": "main.py"}, {"type": "directory", "name": "pipelines", "children": [{"type": "file", "name": "automatic_speech_recognition.py"}, {"type": "file", "name": "base.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "Dockerfile"}, {"type": "file", "name": "prestart.sh"}, {"type": "file", "name": "requirements.txt"}, {"type": "directory", "name": "tests", "children": [{"type": "directory", "name": "samples", "children": []}, {"type": "file", "name": "test_api.py"}, {"type": "file", "name": "test_api_automatic_speech_recognition.py"}, {"type": "file", "name": "test_docker_build.py"}, {"type": "file", "name": "__init__.py"}]}]}, {"type": "directory", "name": "mindspore", "children": [{"type": "directory", "name": "app", "children": [{"type": "file", "name": "main.py"}, {"type": "directory", "name": "pipelines", "children": [{"type": "file", "name": "base.py"}, {"type": "file", "name": "image_classification.py"}, {"type": "file", "name": "__init__.py"}]}]}, {"type": "file", "name": "Dockerfile"}, {"type": "file", "name": "prestart.sh"}, {"type": "file", "name": "requirements.txt"}, {"type": "directory", "name": "tests", "children": [{"type": "directory", "name": "samples", "children": []}, {"type": "file", "name": "test_api.py"}, {"type": "file", "name": "test_api_image_classification.py"}, {"type": "file", "name": "test_docker_build.py"}]}]}, {"type": "directory", "name": "nemo", "children": [{"type": "directory", "name": "app", "children": [{"type": "file", "name": "main.py"}, {"type": "directory", "name": "pipelines", "children": [{"type": "file", "name": "automatic_speech_recognition.py"}, {"type": "file", "name": "base.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "Dockerfile"}, {"type": "file", "name": "prestart.sh"}, {"type": "file", "name": "requirements.txt"}, {"type": "directory", "name": "tests", "children": [{"type": "directory", "name": "samples", "children": []}, {"type": "file", "name": "test_api.py"}, {"type": "file", "name": "test_api_automatic_speech_recognition.py"}, {"type": "file", "name": "test_docker_build.py"}, {"type": "file", "name": "__init__.py"}]}]}, {"type": "directory", "name": "open_clip", "children": [{"type": "directory", "name": "app", "children": [{"type": "file", "name": "main.py"}, {"type": "directory", "name": "pipelines", "children": [{"type": "file", "name": "base.py"}, {"type": "file", "name": "zero_shot_image_classification.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "Dockerfile"}, {"type": "file", "name": "prestart.sh"}, {"type": "file", "name": "requirements.txt"}, {"type": "directory", "name": "tests", "children": [{"type": "directory", "name": "samples", "children": []}, {"type": "file", "name": "test_api.py"}, {"type": "file", "name": "test_api_zero_shot_image_classification.py"}, {"type": "file", "name": "test_docker_build.py"}, {"type": "file", "name": "__init__.py"}]}]}, {"type": "directory", "name": "paddlenlp", "children": [{"type": "directory", "name": "app", "children": [{"type": "file", "name": "main.py"}, {"type": "directory", "name": "pipelines", "children": [{"type": "file", "name": "base.py"}, {"type": "file", "name": "conversational.py"}, {"type": "file", "name": "fill_mask.py"}, {"type": "file", "name": "summarization.py"}, {"type": "file", "name": "zero_shot_classification.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "Dockerfile"}, {"type": "file", "name": "prestart.sh"}, {"type": "file", "name": "requirements.txt"}, {"type": "directory", "name": "tests", "children": [{"type": "file", "name": "test_api.py"}, {"type": "file", "name": "test_api_conversational.py"}, {"type": "file", "name": "test_api_fill_mask.py"}, {"type": "file", "name": "test_api_summarization.py"}, {"type": "file", "name": "test_api_zero_shot_classification.py"}, {"type": "file", "name": "test_docker_build.py"}, {"type": "file", "name": "__init__.py"}]}]}, {"type": "directory", "name": "peft", "children": [{"type": "directory", "name": "app", "children": [{"type": "file", "name": "idle.py"}, {"type": "file", "name": "main.py"}, {"type": "directory", "name": "pipelines", "children": [{"type": "file", "name": "base.py"}, {"type": "file", "name": "text_generation.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "timing.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "Dockerfile"}, {"type": "file", "name": "prestart.sh"}, {"type": "file", "name": "requirements.txt"}, {"type": "directory", "name": "tests", "children": [{"type": "file", "name": "test_api.py"}, {"type": "file", "name": "test_api_text_generation.py"}, {"type": "file", "name": "__init__.py"}]}]}, {"type": "directory", "name": "pyannote_audio", "children": [{"type": "directory", "name": "app", "children": [{"type": "file", "name": "main.py"}, {"type": "directory", "name": "pipelines", "children": [{"type": "file", "name": "automatic_speech_recognition.py"}, {"type": "file", "name": "base.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "Dockerfile"}, {"type": "file", "name": "prestart.sh"}, {"type": "file", "name": "requirements.txt"}, {"type": "directory", "name": "tests", "children": [{"type": "directory", "name": "samples", "children": []}, {"type": "file", "name": "test_api.py"}, {"type": "file", "name": "test_api_automatic_speech_recognition.py"}, {"type": "file", "name": "test_docker_build.py"}, {"type": "file", "name": "__init__.py"}]}]}, {"type": "directory", "name": "sentence_transformers", "children": [{"type": "directory", "name": "app", "children": [{"type": "file", "name": "main.py"}, {"type": "directory", "name": "pipelines", "children": [{"type": "file", "name": "base.py"}, {"type": "file", "name": "feature_extraction.py"}, {"type": "file", "name": "sentence_similarity.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "Dockerfile"}, {"type": "file", "name": "prestart.sh"}, {"type": "file", "name": "requirements.txt"}, {"type": "directory", "name": "tests", "children": [{"type": "directory", "name": "samples", "children": []}, {"type": "file", "name": "test_api.py"}, {"type": "file", "name": "test_api_feature_extraction.py"}, {"type": "file", "name": "test_api_sentence_similarity.py"}, {"type": "file", "name": "test_docker_build.py"}, {"type": "file", "name": "__init__.py"}]}]}, {"type": "directory", "name": "setfit", "children": [{"type": "directory", "name": "app", "children": [{"type": "file", "name": "main.py"}, {"type": "directory", "name": "pipelines", "children": [{"type": "file", "name": "base.py"}, {"type": "file", "name": "text_classification.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "Dockerfile"}, {"type": "file", "name": "prestart.sh"}, {"type": "file", "name": "requirements.txt"}, {"type": "directory", "name": "tests", "children": [{"type": "file", "name": "test_api.py"}, {"type": "file", "name": "test_api_text_classification.py"}, {"type": "file", "name": "test_docker_build.py"}, {"type": "file", "name": "__init__.py"}]}]}, {"type": "directory", "name": "sklearn", "children": [{"type": "directory", "name": "app", "children": [{"type": "file", "name": "main.py"}, {"type": "directory", "name": "pipelines", "children": [{"type": "file", "name": "base.py"}, {"type": "file", "name": "common.py"}, {"type": "file", "name": "tabular_classification.py"}, {"type": "file", "name": "tabular_regression.py"}, {"type": "file", "name": "text_classification.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "Dockerfile"}, {"type": "file", "name": "prestart.sh"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "run_app.sh"}, {"type": "directory", "name": "tests", "children": [{"type": "directory", "name": "generators", "children": [{"type": "file", "name": "generate.py"}, {"type": "file", "name": "run.sh"}, {"type": "directory", "name": "samples", "children": [{"type": "file", "name": "iris-1.0-input.json"}, {"type": "file", "name": "iris-hist_gradient_boosting-1.0-output.json"}, {"type": "file", "name": "iris-hist_gradient_boosting-latest-output.json"}, {"type": "file", "name": "iris-latest-input.json"}, {"type": "file", "name": "iris-logistic_regression-1.0-output.json"}, {"type": "file", "name": "iris-logistic_regression-latest-output.json"}, {"type": "file", "name": "tabularregression-1.0-input.json"}, {"type": "file", "name": "tabularregression-hist_gradient_boosting_regressor-1.0-output.json"}, {"type": "file", "name": "tabularregression-hist_gradient_boosting_regressor-latest-output.json"}, {"type": "file", "name": "tabularregression-latest-input.json"}, {"type": "file", "name": "tabularregression-linear_regression-1.0-output.json"}, {"type": "file", "name": "tabularregression-linear_regression-latest-output.json"}, {"type": "file", "name": "textclassification-1.0-input.json"}, {"type": "file", "name": "textclassification-hist_gradient_boosting-1.0-output.json"}, {"type": "file", "name": "textclassification-hist_gradient_boosting-latest-output.json"}, {"type": "file", "name": "textclassification-latest-input.json"}, {"type": "file", "name": "textclassification-logistic_regression-1.0-output.json"}, {"type": "file", "name": "textclassification-logistic_regression-latest-output.json"}]}, {"type": "file", "name": "sklearn-1.0.yml"}, {"type": "file", "name": "sklearn-latest.yml"}]}, {"type": "directory", "name": "samples", "children": []}, {"type": "file", "name": "test_api.py"}, {"type": "file", "name": "test_api_tabular_classification.py"}, {"type": "file", "name": "test_api_tabular_regression.py"}, {"type": "file", "name": "test_api_text_classification.py"}, {"type": "file", "name": "test_docker_build.py"}, {"type": "file", "name": "__init__.py"}]}]}, {"type": "directory", "name": "spacy", "children": [{"type": "directory", "name": "app", "children": [{"type": "file", "name": "main.py"}, {"type": "directory", "name": "pipelines", "children": [{"type": "file", "name": "base.py"}, {"type": "file", "name": "sentence_similarity.py"}, {"type": "file", "name": "text_classification.py"}, {"type": "file", "name": "token_classification.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "Dockerfile"}, {"type": "file", "name": "prestart.sh"}, {"type": "file", "name": "requirements.txt"}, {"type": "directory", "name": "tests", "children": [{"type": "directory", "name": "samples", "children": []}, {"type": "file", "name": "test_api.py"}, {"type": "file", "name": "test_api_sentence_similarity.py"}, {"type": "file", "name": "test_api_text_classification.py"}, {"type": "file", "name": "test_api_token_classification.py"}, {"type": "file", "name": "test_docker_build.py"}, {"type": "file", "name": "__init__.py"}]}]}, {"type": "directory", "name": "span_marker", "children": [{"type": "directory", "name": "app", "children": [{"type": "file", "name": "main.py"}, {"type": "directory", "name": "pipelines", "children": [{"type": "file", "name": "base.py"}, {"type": "file", "name": "token_classification.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "Dockerfile"}, {"type": "file", "name": "prestart.sh"}, {"type": "file", "name": "requirements.txt"}, {"type": "directory", "name": "tests", "children": [{"type": "file", "name": "test_api.py"}, {"type": "file", "name": "test_api_token_classification.py"}, {"type": "file", "name": "test_docker_build.py"}, {"type": "file", "name": "__init__.py"}]}]}, {"type": "directory", "name": "speechbrain", "children": [{"type": "directory", "name": "app", "children": [{"type": "file", "name": "common.py"}, {"type": "file", "name": "main.py"}, {"type": "directory", "name": "pipelines", "children": [{"type": "file", "name": "audio_classification.py"}, {"type": "file", "name": "audio_to_audio.py"}, {"type": "file", "name": "automatic_speech_recognition.py"}, {"type": "file", "name": "base.py"}, {"type": "file", "name": "text2text_generation.py"}, {"type": "file", "name": "text_to_speech.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "Dockerfile"}, {"type": "file", "name": "prestart.sh"}, {"type": "file", "name": "requirements.txt"}, {"type": "directory", "name": "tests", "children": [{"type": "directory", "name": "samples", "children": []}, {"type": "file", "name": "test_api.py"}, {"type": "file", "name": "test_api_audio_classification.py"}, {"type": "file", "name": "test_api_audio_to_audio.py"}, {"type": "file", "name": "test_api_automatic_speech_recognition.py"}, {"type": "file", "name": "test_api_text2text_generation.py"}, {"type": "file", "name": "test_api_text_to_speech.py"}, {"type": "file", "name": "test_docker_build.py"}, {"type": "file", "name": "__init__.py"}]}]}, {"type": "directory", "name": "stanza", "children": [{"type": "directory", "name": "app", "children": [{"type": "file", "name": "batch.py"}, {"type": "file", "name": "main.py"}, {"type": "directory", "name": "pipelines", "children": [{"type": "file", "name": "base.py"}, {"type": "file", "name": "token_classification.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "Dockerfile"}, {"type": "file", "name": "prestart.sh"}, {"type": "file", "name": "requirements.txt"}, {"type": "directory", "name": "tests", "children": [{"type": "directory", "name": "samples", "children": []}, {"type": "file", "name": "test_api.py"}, {"type": "file", "name": "test_api_token_classification.py"}, {"type": "file", "name": "test_docker_build.py"}, {"type": "file", "name": "__init__.py"}]}]}, {"type": "directory", "name": "timm", "children": [{"type": "directory", "name": "app", "children": [{"type": "file", "name": "main.py"}, {"type": "directory", "name": "pipelines", "children": [{"type": "file", "name": "base.py"}, {"type": "file", "name": "image_classification.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "Dockerfile"}, {"type": "file", "name": "prestart.sh"}, {"type": "file", "name": "requirements.txt"}, {"type": "directory", "name": "tests", "children": [{"type": "directory", "name": "samples", "children": []}, {"type": "file", "name": "test_api.py"}, {"type": "file", "name": "test_api_image_classification.py"}, {"type": "file", "name": "test_docker_build.py"}, {"type": "file", "name": "__init__.py"}]}]}]}, {"type": "file", "name": "LICENSE"}, {"type": "file", "name": "Makefile"}, {"type": "file", "name": "manage.py"}, {"type": "file", "name": "MANIFEST.in"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "directory", "name": "scripts", "children": [{"type": "file", "name": "export_tasks.py"}]}, {"type": "file", "name": "setup.cfg"}, {"type": "file", "name": "setup.py"}, {"type": "directory", "name": "tests", "children": [{"type": "directory", "name": "samples", "children": []}, {"type": "file", "name": "test_audio.py"}, {"type": "file", "name": "test_dockers.py"}, {"type": "file", "name": "test_hub.py"}, {"type": "file", "name": "test_image.py"}, {"type": "file", "name": "test_nlp.py"}, {"type": "file", "name": "test_normalizers.py"}, {"type": "file", "name": "test_routes.py"}]}]} | ## Tests
### Test setup
The tests require certain repositories with certain requirements to exist on HF
Hub and certain output files to be created.
You can make sure those repos and files are up to date by running the
`docker_images/sklearn/tests/generators/run.sh` script. The script creates
required conda environments, updates them if necessary, and runs scripts inside
those environments. You should also give it a valid token with access to the
`skops-tests` org:
```bash
# from the project root
SKOPS_TESTS_TOKEN=your_secret_token docker_images/sklearn/tests/generators/run.sh
```
This script needs to be run _only once_ when you first start developing, or each
time a new scikit-learn version is released.
The created model repositories are also used for common tests of this package,
see `tests/test_dockers.py` > `test_sklearn`.
Note that a working [mamba
installation](https://mamba.readthedocs.io/en/latest/installation.html) is
required for this step
### Test environment
Create a new Python environment and install the test dependencies:
```bash
# with pip
python -m pip install -r docker_images/sklearn/requirements.txt
# with conda/mamba
conda install --file docker_images/sklearn/requirements.txt
```
### Running the tests
From within the Python environment, run:
```
pytest -sv --rootdir docker_images/sklearn/ docker_images/sklearn/
```
You will see many tests being skipped. If the message is "Skipping test because
requirements are not met.", it means that the test was intended to be skipped,
so you don't need to do anything about it. When adding a new test, make sure
that at least one of the parametrized settings is not skipped for that test.
### Adding a new task
When adding tests for a new task, certain artifacts like HF Hub repositories,
model inputs, and model outputs need to be generated first using the `run.sh`
script, as explained above. For the new task, those have to be implemented
first. For this, visit `docker_images/sklearn/tests/generators/generate.py` and
extend the script to include the new task. Most notably, visit the "CONSTANTS"
section and extend the constants defined there to include your task. This will
make it obvious which extra functions you need to write.
| {"requirements.txt": "starlette>=0.14.2\nnumpy>=1.18.0\npydantic>=2\nparameterized>=0.8.1\npillow>=8.2.0\nhuggingface_hub>=0.20.2\ndatasets>=2.2\npsutil>=6.0.0\npytest\nhttpx\nuvicorn\nblack\nisort\nflake8\n", "setup.py": "from setuptools import setup\n\n\nsetup(\n name=\"api_inference_community\",\n version=\"0.0.33\",\n description=\"A package with helper tools to build an API Inference docker app for Hugging Face API inference using huggingface_hub\",\n long_description=open(\"README.md\", \"r\", encoding=\"utf-8\").read(),\n long_description_content_type=\"text/markdown\",\n url=\"http://github.com/huggingface/api-inference-community\",\n author=\"Nicolas Patry\",\n author_email=\"[email protected]\",\n license=\"MIT\",\n packages=[\"api_inference_community\"],\n python_requires=\">=3.6.0\",\n zip_safe=False,\n install_requires=list(line for line in open(\"requirements.txt\", \"r\")),\n extras_require={\n \"test\": [\n \"httpx>=0.18\",\n \"Pillow>=8.2\",\n \"httpx>=0.18\",\n \"torch>=1.9.0\",\n \"pytest>=6.2\",\n ],\n \"quality\": [\"black==22.3.0\", \"isort\", \"flake8\", \"mypy\"],\n },\n)\n", ".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 8b71cc40dfe13af7c80de2526180145d893e929b Hamza Amin <[email protected]> 1727369172 +0500\tclone: from https://github.com/huggingface/api-inference-community.git\n", ".git\\refs\\heads\\main": "8b71cc40dfe13af7c80de2526180145d893e929b\n", "docker_images\\adapter_transformers\\Dockerfile": "FROM tiangolo/uvicorn-gunicorn:python3.8\nLABEL maintainer=\"me <[email protected]>\"\n\n# Add any system dependency here\n# RUN apt-get update -y && apt-get install libXXX -y\n\nCOPY ./requirements.txt /app\nRUN pip install --no-cache-dir -r requirements.txt\nCOPY ./prestart.sh /app/\n\n\n# Most DL models are quite large in terms of memory, using workers is a HUGE\n# slowdown because of the fork and GIL with python.\n# Using multiple pods seems like a better default strategy.\n# Feel free to override if it does not make sense for your library.\nARG max_workers=1\nENV MAX_WORKERS=$max_workers\nENV HUGGINGFACE_HUB_CACHE=/data\nENV HF_HOME=/data\nENV TORCH_HOME=/data\n\n# Necessary on GPU environment docker.\n# TIMEOUT env variable is used by nvcr.io/nvidia/pytorch:xx for another purpose\n# rendering TIMEOUT defined by uvicorn impossible to use correctly\n# We're overriding it to be renamed UVICORN_TIMEOUT\n# UVICORN_TIMEOUT is a useful variable for very large models that take more\n# than 30s (the default) to load in memory.\n# If UVICORN_TIMEOUT is too low, uvicorn will simply never loads as it will\n# kill workers all the time before they finish.\nRUN sed -i 's/TIMEOUT/UVICORN_TIMEOUT/g' /gunicorn_conf.py\nCOPY ./app /app/app\n", "docker_images\\adapter_transformers\\requirements.txt": "starlette==0.37.2\napi-inference-community==0.0.32\ntorch==2.3.0\nadapters==0.2.1\nhuggingface_hub==0.23.0\n", "docker_images\\adapter_transformers\\app\\main.py": "import functools\nimport logging\nimport os\nfrom typing import Dict, Type\n\nfrom api_inference_community.routes import pipeline_route, status_ok\nfrom app.pipelines import (\n Pipeline,\n QuestionAnsweringPipeline,\n SummarizationPipeline,\n TextClassificationPipeline,\n TextGenerationPipeline,\n TokenClassificationPipeline,\n)\nfrom starlette.applications import Starlette\nfrom starlette.middleware import Middleware\nfrom starlette.middleware.gzip import GZipMiddleware\nfrom starlette.routing import Route\n\n\nTASK = os.getenv(\"TASK\")\nMODEL_ID = os.getenv(\"MODEL_ID\")\n\n\nlogger = logging.getLogger(__name__)\n\n\n# Add the allowed tasks\n# Supported tasks are:\n# - text-generation\n# - text-classification\n# - token-classification\n# - translation\n# - summarization\n# - automatic-speech-recognition\n# - ...\n# For instance\n# from app.pipelines import AutomaticSpeechRecognitionPipeline\n# ALLOWED_TASKS = {\"automatic-speech-recognition\": AutomaticSpeechRecognitionPipeline}\n# You can check the requirements and expectations of each pipelines in their respective\n# directories. Implement directly within the directories.\nALLOWED_TASKS: Dict[str, Type[Pipeline]] = {\n \"question-answering\": QuestionAnsweringPipeline,\n \"summarization\": SummarizationPipeline,\n \"text-classification\": TextClassificationPipeline,\n \"text-generation\": TextGenerationPipeline,\n \"token-classification\": TokenClassificationPipeline,\n # IMPLEMENT_THIS: Add your implemented tasks here !\n}\n\n\[email protected]_cache()\ndef get_pipeline() -> Pipeline:\n task = os.environ[\"TASK\"]\n model_id = os.environ[\"MODEL_ID\"]\n if task not in ALLOWED_TASKS:\n raise EnvironmentError(f\"{task} is not a valid pipeline for model : {model_id}\")\n return ALLOWED_TASKS[task](model_id)\n\n\nroutes = [\n Route(\"/{whatever:path}\", status_ok),\n Route(\"/{whatever:path}\", pipeline_route, methods=[\"POST\"]),\n]\n\nmiddleware = [Middleware(GZipMiddleware, minimum_size=1000)]\nif os.environ.get(\"DEBUG\", \"\") == \"1\":\n from starlette.middleware.cors import CORSMiddleware\n\n middleware.append(\n Middleware(\n CORSMiddleware,\n allow_origins=[\"*\"],\n allow_headers=[\"*\"],\n allow_methods=[\"*\"],\n )\n )\n\napp = Starlette(routes=routes, middleware=middleware)\n\n\[email protected]_event(\"startup\")\nasync def startup_event():\n logger = logging.getLogger(\"uvicorn.access\")\n handler = logging.StreamHandler()\n handler.setFormatter(logging.Formatter(\"%(asctime)s - %(levelname)s - %(message)s\"))\n logger.handlers = [handler]\n\n # Link between `api-inference-community` and framework code.\n app.get_pipeline = get_pipeline\n try:\n get_pipeline()\n except Exception:\n # We can fail so we can show exception later.\n pass\n\n\nif __name__ == \"__main__\":\n try:\n get_pipeline()\n except Exception:\n # We can fail so we can show exception later.\n pass\n", "docker_images\\allennlp\\Dockerfile": "FROM tiangolo/uvicorn-gunicorn:python3.8\nLABEL maintainer=\"me <[email protected]>\"\n\n# Add any system dependency here\n# RUN apt-get update -y && apt-get install libXXX -y\n\nCOPY ./requirements.txt /app\nRUN pip install --no-cache-dir -r requirements.txt\n\nRUN pip install spacy && python -m spacy download en_core_web_sm\nCOPY ./prestart.sh /app/\n\n\n# Most DL models are quite large in terms of memory, using workers is a HUGE\n# slowdown because of the fork and GIL with python.\n# Using multiple pods seems like a better default strategy.\n# Feel free to override if it does not make sense for your library.\nARG max_workers=1\nENV MAX_WORKERS=$max_workers\nENV ALLENNLP_CACHE_ROOT=/data\nENV NLTK_DATA=/data\nENV HOME=/data\n\n# Necessary on GPU environment docker.\n# TIMEOUT env variable is used by nvcr.io/nvidia/pytorch:xx for another purpose\n# rendering TIMEOUT defined by uvicorn impossible to use correctly\n# We're overriding it to be renamed UVICORN_TIMEOUT\n# UVICORN_TIMEOUT is a useful variable for very large models that take more\n# than 30s (the default) to load in memory.\n# If UVICORN_TIMEOUT is too low, uvicorn will simply never loads as it will\n# kill workers all the time before they finish.\nRUN sed -i 's/TIMEOUT/UVICORN_TIMEOUT/g' /gunicorn_conf.py\nCOPY ./app /app/app\n", "docker_images\\allennlp\\requirements.txt": "starlette==0.27.0\nnumpy==1.22.0\nallennlp>=2.5.0,<3.0.0\n# Even though it is not imported, it is actually required.\nallennlp_models>=2.5.0,<3.0.0\napi-inference-community==0.0.23\nhuggingface_hub==0.5.1\n", "docker_images\\allennlp\\app\\main.py": "import functools\nimport logging\nimport os\nfrom typing import Dict, Type\n\nfrom api_inference_community.routes import pipeline_route, status_ok\nfrom app.pipelines import Pipeline, QuestionAnsweringPipeline\nfrom starlette.applications import Starlette\nfrom starlette.middleware import Middleware\nfrom starlette.middleware.gzip import GZipMiddleware\nfrom starlette.routing import Route\n\n\nTASK = os.getenv(\"TASK\")\nMODEL_ID = os.getenv(\"MODEL_ID\")\n\n\nlogger = logging.getLogger(__name__)\n\n\n# Add the allowed tasks\n# Supported tasks are:\n# - text-generation\n# - text-classification\n# - token-classification\n# - translation\n# - summarization\n# - automatic-speech-recognition\n# - ...\n# For instance\n# from app.pipelines import AutomaticSpeechRecognitionPipeline\n# ALLOWED_TASKS = {\"automatic-speech-recognition\": AutomaticSpeechRecognitionPipeline}\n# You can check the requirements and expectations of each pipelines in their respective\n# directories. Implement directly within the directories.\nALLOWED_TASKS: Dict[str, Type[Pipeline]] = {\n \"question-answering\": QuestionAnsweringPipeline\n}\n\n\[email protected]_cache()\ndef get_pipeline() -> Pipeline:\n task = os.environ[\"TASK\"]\n model_id = os.environ[\"MODEL_ID\"]\n if task not in ALLOWED_TASKS:\n raise EnvironmentError(f\"{task} is not a valid pipeline for model : {model_id}\")\n return ALLOWED_TASKS[task](model_id)\n\n\nroutes = [\n Route(\"/{whatever:path}\", status_ok),\n Route(\"/{whatever:path}\", pipeline_route, methods=[\"POST\"]),\n]\n\nmiddleware = [Middleware(GZipMiddleware, minimum_size=1000)]\nif os.environ.get(\"DEBUG\", \"\") == \"1\":\n from starlette.middleware.cors import CORSMiddleware\n\n middleware.append(\n Middleware(\n CORSMiddleware,\n allow_origins=[\"*\"],\n allow_headers=[\"*\"],\n allow_methods=[\"*\"],\n )\n )\n\napp = Starlette(routes=routes, middleware=middleware)\n\n\[email protected]_event(\"startup\")\nasync def startup_event():\n logger = logging.getLogger(\"uvicorn.access\")\n handler = logging.StreamHandler()\n handler.setFormatter(logging.Formatter(\"%(asctime)s - %(levelname)s - %(message)s\"))\n logger.handlers = [handler]\n\n # Link between `api-inference-community` and framework code.\n app.get_pipeline = get_pipeline\n try:\n get_pipeline()\n except Exception:\n # We can fail so we can show exception later.\n pass\n\n\nif __name__ == \"__main__\":\n try:\n get_pipeline()\n except Exception:\n # We can fail so we can show exception later.\n pass\n", "docker_images\\asteroid\\Dockerfile": "FROM tiangolo/uvicorn-gunicorn:python3.8\nLABEL maintainer=\"me <[email protected]>\"\n\n# Add any system dependency here\n# RUN apt-get update -y && apt-get install libXXX -y\nRUN apt-get update -y && apt-get install ffmpeg -y\n\nCOPY ./requirements.txt /app\nRUN pip install --no-cache-dir -r requirements.txt\nCOPY ./prestart.sh /app/\n\n\n# Most DL models are quite large in terms of memory, using workers is a HUGE\n# slowdown because of the fork and GIL with python.\n# Using multiple pods seems like a better default strategy.\n# Feel free to override if it does not make sense for your library.\nARG max_workers=1\nENV MAX_WORKERS=$max_workers\nENV HUGGINGFACE_HUB_CACHE=/data\nENV ASTEROID_CACHE=/data\n\n# Necessary on GPU environment docker.\n# TIMEOUT env variable is used by nvcr.io/nvidia/pytorch:xx for another purpose\n# rendering TIMEOUT defined by uvicorn impossible to use correctly\n# We're overriding it to be renamed UVICORN_TIMEOUT\n# UVICORN_TIMEOUT is a useful variable for very large models that take more\n# than 30s (the default) to load in memory.\n# If UVICORN_TIMEOUT is too low, uvicorn will simply never loads as it will\n# kill workers all the time before they finish.\nRUN sed -i 's/TIMEOUT/UVICORN_TIMEOUT/g' /gunicorn_conf.py\nCOPY ./app /app/app\n", "docker_images\\asteroid\\requirements.txt": "starlette==0.27.0\napi-inference-community==0.0.23\nhuggingface_hub==0.5.1\nasteroid==0.4.4\n", "docker_images\\asteroid\\app\\main.py": "import functools\nimport logging\nimport os\nfrom typing import Dict, Type\n\nfrom api_inference_community.routes import pipeline_route, status_ok\nfrom app.pipelines import AudioSourceSeparationPipeline, AudioToAudioPipeline, Pipeline\nfrom starlette.applications import Starlette\nfrom starlette.middleware import Middleware\nfrom starlette.middleware.gzip import GZipMiddleware\nfrom starlette.routing import Route\n\n\nTASK = os.getenv(\"TASK\")\nMODEL_ID = os.getenv(\"MODEL_ID\")\n\n\nlogger = logging.getLogger(__name__)\n\n\n# Add the allowed tasks\n# Supported tasks are:\n# - text-generation\n# - text-classification\n# - token-classification\n# - translation\n# - summarization\n# - automatic-speech-recognition\n# - ...\n# For instance\n# from app.pipelines import AutomaticSpeechRecognitionPipeline\n# ALLOWED_TASKS = {\"automatic-speech-recognition\": AutomaticSpeechRecognitionPipeline}\n# You can check the requirements and expectations of each pipelines in their respective\n# directories. Implement directly within the directories.\nALLOWED_TASKS: Dict[str, Type[Pipeline]] = {\n \"audio-source-separation\": AudioSourceSeparationPipeline,\n \"audio-to-audio\": AudioToAudioPipeline,\n}\n\n\[email protected]_cache()\ndef get_pipeline() -> Pipeline:\n task = os.environ[\"TASK\"]\n model_id = os.environ[\"MODEL_ID\"]\n if task not in ALLOWED_TASKS:\n raise EnvironmentError(f\"{task} is not a valid pipeline for model : {model_id}\")\n return ALLOWED_TASKS[task](model_id)\n\n\nroutes = [\n Route(\"/{whatever:path}\", status_ok),\n Route(\"/{whatever:path}\", pipeline_route, methods=[\"POST\"]),\n]\n\nmiddleware = [Middleware(GZipMiddleware, minimum_size=1000)]\nif os.environ.get(\"DEBUG\", \"\") == \"1\":\n from starlette.middleware.cors import CORSMiddleware\n\n middleware.append(\n Middleware(\n CORSMiddleware,\n allow_origins=[\"*\"],\n allow_headers=[\"*\"],\n allow_methods=[\"*\"],\n )\n )\n\napp = Starlette(routes=routes, middleware=middleware)\n\n\[email protected]_event(\"startup\")\nasync def startup_event():\n logger = logging.getLogger(\"uvicorn.access\")\n handler = logging.StreamHandler()\n handler.setFormatter(logging.Formatter(\"%(asctime)s - %(levelname)s - %(message)s\"))\n logger.handlers = [handler]\n\n # Link between `api-inference-community` and framework code.\n app.get_pipeline = get_pipeline\n try:\n get_pipeline()\n except Exception:\n # We can fail so we can show exception later.\n pass\n\n\nif __name__ == \"__main__\":\n try:\n get_pipeline()\n except Exception:\n # We can fail so we can show exception later.\n pass\n", "docker_images\\bertopic\\Dockerfile": "FROM tiangolo/uvicorn-gunicorn:python3.8\nLABEL maintainer=\"Daniel van Strien <[email protected]> \"\n\n# Add any system dependency here\n# RUN apt-get update -y && apt-get install libXXX -y\n\nCOPY ./requirements.txt /app\nRUN pip install --no-cache-dir -r requirements.txt\nCOPY ./prestart.sh /app/\n\n\n# Most DL models are quite large in terms of memory, using workers is a HUGE\n# slowdown because of the fork and GIL with python.\n# Using multiple pods seems like a better default strategy.\n# Feel free to override if it does not make sense for your library.\nARG max_workers=1\nENV MAX_WORKERS=$max_workers\nENV HUGGINGFACE_HUB_CACHE=/data\n\n# Necessary on GPU environment docker.\n# TIMEOUT env variable is used by nvcr.io/nvidia/pytorch:xx for another purpose\n# rendering TIMEOUT defined by uvicorn impossible to use correctly\n# We're overriding it to be renamed UVICORN_TIMEOUT\n# UVICORN_TIMEOUT is a useful variable for very large models that take more\n# than 30s (the default) to load in memory.\n# If UVICORN_TIMEOUT is too low, uvicorn will simply never loads as it will\n# kill workers all the time before they finish.\nRUN sed -i 's/TIMEOUT/UVICORN_TIMEOUT/g' /gunicorn_conf.py\nCOPY ./app /app/app\n", "docker_images\\bertopic\\requirements.txt": "starlette==0.27.0\napi-inference-community==0.0.25\nhuggingface_hub==0.14.0\nbertopic==0.15.0\nsafetensors==0.3.1\n", "docker_images\\bertopic\\app\\main.py": "import functools\nimport logging\nimport os\nfrom typing import Dict, Type\n\nfrom api_inference_community.routes import pipeline_route, status_ok\nfrom app.pipelines import Pipeline, TextClassificationPipeline\nfrom starlette.applications import Starlette\nfrom starlette.middleware import Middleware\nfrom starlette.middleware.gzip import GZipMiddleware\nfrom starlette.routing import Route\n\n\nTASK = os.getenv(\"TASK\")\nMODEL_ID = os.getenv(\"MODEL_ID\")\n\n\nlogger = logging.getLogger(__name__)\n\nALLOWED_TASKS: Dict[str, Type[Pipeline]] = {\n \"text-classification\": TextClassificationPipeline\n}\n\n\[email protected]_cache()\ndef get_pipeline() -> Pipeline:\n task = os.environ[\"TASK\"]\n model_id = os.environ[\"MODEL_ID\"]\n if task not in ALLOWED_TASKS:\n raise EnvironmentError(f\"{task} is not a valid pipeline for model : {model_id}\")\n return ALLOWED_TASKS[task](model_id)\n\n\nroutes = [\n Route(\"/{whatever:path}\", status_ok),\n Route(\"/{whatever:path}\", pipeline_route, methods=[\"POST\"]),\n]\n\nmiddleware = [Middleware(GZipMiddleware, minimum_size=1000)]\nif os.environ.get(\"DEBUG\", \"\") == \"1\":\n from starlette.middleware.cors import CORSMiddleware\n\n middleware.append(\n Middleware(\n CORSMiddleware,\n allow_origins=[\"*\"],\n allow_headers=[\"*\"],\n allow_methods=[\"*\"],\n )\n )\n\napp = Starlette(routes=routes, middleware=middleware)\n\n\[email protected]_event(\"startup\")\nasync def startup_event():\n logger = logging.getLogger(\"uvicorn.access\")\n handler = logging.StreamHandler()\n handler.setFormatter(logging.Formatter(\"%(asctime)s - %(levelname)s - %(message)s\"))\n logger.handlers = [handler]\n\n # Link between `api-inference-community` and framework code.\n app.get_pipeline = get_pipeline\n try:\n get_pipeline()\n except Exception:\n # We can fail so we can show exception later.\n pass\n\n\nif __name__ == \"__main__\":\n try:\n get_pipeline()\n except Exception:\n # We can fail so we can show exception later.\n pass\n", "docker_images\\common\\Dockerfile": "FROM tiangolo/uvicorn-gunicorn:python3.8\nLABEL maintainer=\"me <[email protected]>\"\n\n# Add any system dependency here\n# RUN apt-get update -y && apt-get install libXXX -y\n\nCOPY ./requirements.txt /app\nRUN pip install --no-cache-dir -r requirements.txt\nCOPY ./prestart.sh /app/\n\n\n# Most DL models are quite large in terms of memory, using workers is a HUGE\n# slowdown because of the fork and GIL with python.\n# Using multiple pods seems like a better default strategy.\n# Feel free to override if it does not make sense for your library.\nARG max_workers=1\nENV MAX_WORKERS=$max_workers\nENV HUGGINGFACE_HUB_CACHE=/data\n\n# Necessary on GPU environment docker.\n# TIMEOUT env variable is used by nvcr.io/nvidia/pytorch:xx for another purpose\n# rendering TIMEOUT defined by uvicorn impossible to use correctly\n# We're overriding it to be renamed UVICORN_TIMEOUT\n# UVICORN_TIMEOUT is a useful variable for very large models that take more\n# than 30s (the default) to load in memory.\n# If UVICORN_TIMEOUT is too low, uvicorn will simply never loads as it will\n# kill workers all the time before they finish.\nRUN sed -i 's/TIMEOUT/UVICORN_TIMEOUT/g' /gunicorn_conf.py\nCOPY ./app /app/app\n", "docker_images\\common\\requirements.txt": "starlette==0.27.0\napi-inference-community==0.0.32\nhuggingface_hub==0.11.0\n", "docker_images\\common\\app\\main.py": "import functools\nimport logging\nimport os\nfrom typing import Dict, Type\n\nfrom api_inference_community.routes import pipeline_route, status_ok\nfrom app.pipelines import Pipeline\nfrom starlette.applications import Starlette\nfrom starlette.middleware import Middleware\nfrom starlette.middleware.gzip import GZipMiddleware\nfrom starlette.routing import Route\n\n\nTASK = os.getenv(\"TASK\")\nMODEL_ID = os.getenv(\"MODEL_ID\")\n\n\nlogger = logging.getLogger(__name__)\n\n\n# Add the allowed tasks\n# Supported tasks are:\n# - text-generation\n# - text-classification\n# - token-classification\n# - translation\n# - summarization\n# - automatic-speech-recognition\n# - ...\n# For instance\n# from app.pipelines import AutomaticSpeechRecognitionPipeline\n# ALLOWED_TASKS = {\"automatic-speech-recognition\": AutomaticSpeechRecognitionPipeline}\n# You can check the requirements and expectations of each pipelines in their respective\n# directories. Implement directly within the directories.\nALLOWED_TASKS: Dict[str, Type[Pipeline]] = {\n # IMPLEMENT_THIS: Add your implemented tasks here !\n}\n\n\[email protected]_cache()\ndef get_pipeline() -> Pipeline:\n task = os.environ[\"TASK\"]\n model_id = os.environ[\"MODEL_ID\"]\n if task not in ALLOWED_TASKS:\n raise EnvironmentError(f\"{task} is not a valid pipeline for model : {model_id}\")\n return ALLOWED_TASKS[task](model_id)\n\n\nroutes = [\n Route(\"/{whatever:path}\", status_ok),\n Route(\"/{whatever:path}\", pipeline_route, methods=[\"POST\"]),\n]\n\nmiddleware = [Middleware(GZipMiddleware, minimum_size=1000)]\nif os.environ.get(\"DEBUG\", \"\") == \"1\":\n from starlette.middleware.cors import CORSMiddleware\n\n middleware.append(\n Middleware(\n CORSMiddleware,\n allow_origins=[\"*\"],\n allow_headers=[\"*\"],\n allow_methods=[\"*\"],\n )\n )\n\napp = Starlette(routes=routes, middleware=middleware)\n\n\[email protected]_event(\"startup\")\nasync def startup_event():\n logger = logging.getLogger(\"uvicorn.access\")\n handler = logging.StreamHandler()\n handler.setFormatter(logging.Formatter(\"%(asctime)s - %(levelname)s - %(message)s\"))\n logger.handlers = [handler]\n\n # Link between `api-inference-community` and framework code.\n app.get_pipeline = get_pipeline\n try:\n get_pipeline()\n except Exception:\n # We can fail so we can show exception later.\n pass\n\n\nif __name__ == \"__main__\":\n try:\n get_pipeline()\n except Exception:\n # We can fail so we can show exception later.\n pass\n", "docker_images\\diffusers\\Dockerfile": "FROM nvidia/cuda:11.8.0-cudnn8-runtime-ubuntu20.04\nLABEL maintainer=\"Nicolas Patry <[email protected]>\"\n\n# Add any system dependency here\n# RUN apt-get update -y && apt-get install libXXX -y\n\nENV DEBIAN_FRONTEND=noninteractive\n\n# Install prerequisites\nRUN apt-get update && \\\n apt-get install -y build-essential libssl-dev zlib1g-dev libbz2-dev \\\n libreadline-dev libsqlite3-dev wget curl llvm libncurses5-dev libncursesw5-dev \\\n xz-utils tk-dev libffi-dev liblzma-dev python3-openssl git\n\n# Install pyenv\nRUN curl https://pyenv.run | bash\n\n# Set environment variables for pyenv\nENV PYENV_ROOT /root/.pyenv\nENV PATH $PYENV_ROOT/shims:$PYENV_ROOT/bin:$PATH\n\n# Install your desired Python version\nARG PYTHON_VERSION=3.9.1\nRUN pyenv install $PYTHON_VERSION && \\\n pyenv global $PYTHON_VERSION && \\\n pyenv rehash\n\n# Upgrade pip and install your desired packages\nARG PIP_VERSION=22.3.1\n\n# FIXME: We temporarily need to specify the setuptools version <70 due to the following issue\n# https://stackoverflow.com/questions/78604018/importerror-cannot-import-name-packaging-from-pkg-resources-when-trying-to\n# https://github.com/AUTOMATIC1111/stable-diffusion-webui/issues/15863#issuecomment-2125026282\nRUN pip install --no-cache-dir --upgrade pip==${PIP_VERSION} setuptools'<70' wheel && \\\n pip install --no-cache-dir torch==2.0.1 torchvision==0.15.2 torchaudio==2.0.2\n\nWORKDIR /app\nCOPY ./requirements.txt /app\nRUN pip install --no-cache-dir -r requirements.txt\n\n# Most DL models are quite large in terms of memory, using workers is a HUGE\n# slowdown because of the fork and GIL with python.\n# Using multiple pods seems like a better default strategy.\n# Feel free to override if it does not make sense for your library.\nARG max_workers=1\nENV MAX_WORKERS=$max_workers\nENV HUGGINGFACE_HUB_CACHE=/data\nENV DIFFUSERS_CACHE=/data\n\n# Necessary on GPU environment docker.\n# TIMEOUT env variable is used by nvcr.io/nvidia/pytorch:xx for another purpose\n# rendering TIMEOUT defined by uvicorn impossible to use correctly\n# We're overriding it to be renamed UVICORN_TIMEOUT\n# UVICORN_TIMEOUT is a useful variable for very large models that take more\n# than 30s (the default) to load in memory.\n# If UVICORN_TIMEOUT is too low, uvicorn will simply never loads as it will\n# kill workers all the time before they finish.\nCOPY --from=tiangolo/uvicorn-gunicorn:python3.8 /app/ /app\nCOPY --from=tiangolo/uvicorn-gunicorn:python3.8 /start.sh /\nCOPY --from=tiangolo/uvicorn-gunicorn:python3.8 /gunicorn_conf.py /\nCOPY app/ /app/app\n\nCOPY ./prestart.sh /app/\n\nRUN sed -i 's/TIMEOUT/UVICORN_TIMEOUT/g' /gunicorn_conf.py\n\nCMD [\"/start.sh\"]\n", "docker_images\\diffusers\\requirements.txt": "starlette==0.27.0\napi-inference-community==0.0.33\n# to be replaced with diffusers 0.31.0 as soon as released\ngit+https://github.com/huggingface/diffusers.git@2a3fbc2cc269aa0c0d5cfdfaa3564d769d92b882\ntransformers==4.41.2\naccelerate==0.31.0\nhf_transfer==0.1.3\npydantic>=2\nftfy==6.1.1\nsentencepiece==0.1.97\nscipy==1.10.0\ntorch==2.0.1\ntorchvision==0.15.2\ntorchaudio==2.0.2\ninvisible-watermark>=0.2.0\nuvicorn>=0.23.2\ngunicorn>=21.2.0\npsutil>=5.9.5\naiohttp>=3.8.5\npeft==0.11.1\nprotobuf==5.27.1\n", "docker_images\\diffusers\\app\\main.py": "import asyncio\nimport functools\nimport logging\nimport os\nfrom typing import Dict, Type\n\nfrom api_inference_community.routes import pipeline_route, status_ok\nfrom app import idle\nfrom app.pipelines import ImageToImagePipeline, Pipeline, TextToImagePipeline\nfrom starlette.applications import Starlette\nfrom starlette.middleware import Middleware\nfrom starlette.middleware.gzip import GZipMiddleware\nfrom starlette.routing import Route\n\n\nTASK = os.getenv(\"TASK\")\nMODEL_ID = os.getenv(\"MODEL_ID\")\n\n\n# Add the allowed tasks\n# Supported tasks are:\n# - text-generation\n# - text-classification\n# - token-classification\n# - translation\n# - summarization\n# - automatic-speech-recognition\n# - ...\n# For instance\n# from app.pipelines import AutomaticSpeechRecognitionPipeline\n# ALLOWED_TASKS = {\"automatic-speech-recognition\": AutomaticSpeechRecognitionPipeline}\n# You can check the requirements and expectations of each pipelines in their respective\n# directories. Implement directly within the directories.\nALLOWED_TASKS: Dict[str, Type[Pipeline]] = {\n \"text-to-image\": TextToImagePipeline,\n \"image-to-image\": ImageToImagePipeline,\n}\n\n\[email protected]_cache()\ndef get_pipeline() -> Pipeline:\n task = os.environ[\"TASK\"]\n model_id = os.environ[\"MODEL_ID\"]\n if task not in ALLOWED_TASKS:\n raise EnvironmentError(f\"{task} is not a valid pipeline for model : {model_id}\")\n return ALLOWED_TASKS[task](model_id)\n\n\nroutes = [\n Route(\"/{whatever:path}\", status_ok),\n Route(\"/{whatever:path}\", pipeline_route, methods=[\"POST\"]),\n]\n\nmiddleware = [Middleware(GZipMiddleware, minimum_size=1000)]\nif os.environ.get(\"DEBUG\", \"\") == \"1\":\n from starlette.middleware.cors import CORSMiddleware\n\n middleware.append(\n Middleware(\n CORSMiddleware,\n allow_origins=[\"*\"],\n allow_headers=[\"*\"],\n allow_methods=[\"*\"],\n )\n )\n\napp = Starlette(routes=routes, middleware=middleware)\n\n\[email protected]_event(\"startup\")\nasync def startup_event():\n reset_logging()\n # Link between `api-inference-community` and framework code.\n if idle.UNLOAD_IDLE:\n asyncio.create_task(idle.live_check_loop(), name=\"live_check_loop\")\n app.get_pipeline = get_pipeline\n try:\n get_pipeline()\n except Exception:\n # We can fail so we can show exception later.\n pass\n\n\ndef reset_logging():\n logging.basicConfig(\n level=logging.DEBUG,\n format=\"%(asctime)s - %(levelname)s - %(message)s\",\n force=True,\n )\n\n\nif __name__ == \"__main__\":\n reset_logging()\n try:\n get_pipeline()\n except Exception:\n # We can fail so we can show exception later.\n pass\n", "docker_images\\doctr\\Dockerfile": "FROM tiangolo/uvicorn-gunicorn:python3.8\nLABEL maintainer=\"me <[email protected]>\"\n\n# Add any system dependency here\nRUN apt-get update -y && apt-get install libgl1-mesa-glx -y\n\nRUN pip install --no-cache-dir -U pip\nRUN pip install --no-cache-dir torch==1.11 torchvision==0.12\nCOPY ./requirements.txt /app\nRUN pip install --no-cache-dir -r requirements.txt\nCOPY ./prestart.sh /app/\n\n\n# Most DL models are quite large in terms of memory, using workers is a HUGE\n# slowdown because of the fork and GIL with python.\n# Using multiple pods seems like a better default strategy.\n# Feel free to override if it does not make sense for your library.\nARG max_workers=1\nENV MAX_WORKERS=$max_workers\nENV HUGGINGFACE_HUB_CACHE=/data\nENV TORCH_HOME=/data/torch_hub/\n\n# Necessary on GPU environment docker.\n# TIMEOUT env variable is used by nvcr.io/nvidia/pytorch:xx for another purpose\n# rendering TIMEOUT defined by uvicorn impossible to use correctly\n# We're overriding it to be renamed UVICORN_TIMEOUT\n# UVICORN_TIMEOUT is a useful variable for very large models that take more\n# than 30s (the default) to load in memory.\n# If UVICORN_TIMEOUT is too low, uvicorn will simply never loads as it will\n# kill workers all the time before they finish.\nRUN sed -i 's/TIMEOUT/UVICORN_TIMEOUT/g' /gunicorn_conf.py\nCOPY ./app /app/app\n", "docker_images\\doctr\\requirements.txt": "starlette==0.27.0\napi-inference-community==0.0.23\npython-doctr[torch]==0.5.1\nhuggingface_hub==0.5.1\n", "docker_images\\doctr\\app\\main.py": "import functools\nimport logging\nimport os\nfrom typing import Dict, Type\n\nfrom api_inference_community.routes import pipeline_route, status_ok\nfrom app.pipelines import ObjectDetectionPipeline, Pipeline\nfrom starlette.applications import Starlette\nfrom starlette.middleware import Middleware\nfrom starlette.middleware.gzip import GZipMiddleware\nfrom starlette.routing import Route\n\n\nTASK = os.getenv(\"TASK\")\nMODEL_ID = os.getenv(\"MODEL_ID\")\n\n\nlogger = logging.getLogger(__name__)\n\n\n# Add the allowed tasks\n# Supported tasks are:\n# - text-generation\n# - text-classification\n# - token-classification\n# - translation\n# - summarization\n# - automatic-speech-recognition\n# - ...\n# For instance\n# from app.pipelines import AutomaticSpeechRecognitionPipeline\n# ALLOWED_TASKS = {\"automatic-speech-recognition\": AutomaticSpeechRecognitionPipeline}\n# You can check the requirements and expectations of each pipelines in their respective\n# directories. Implement directly within the directories.\nALLOWED_TASKS: Dict[str, Type[Pipeline]] = {\"object-detection\": ObjectDetectionPipeline}\n\n\[email protected]_cache()\ndef get_pipeline() -> Pipeline:\n task = os.environ[\"TASK\"]\n model_id = os.environ[\"MODEL_ID\"]\n if task not in ALLOWED_TASKS:\n raise EnvironmentError(f\"{task} is not a valid pipeline for model : {model_id}\")\n return ALLOWED_TASKS[task](model_id)\n\n\nroutes = [\n Route(\"/{whatever:path}\", status_ok),\n Route(\"/{whatever:path}\", pipeline_route, methods=[\"POST\"]),\n]\n\nmiddleware = [Middleware(GZipMiddleware, minimum_size=1000)]\nif os.environ.get(\"DEBUG\", \"\") == \"1\":\n from starlette.middleware.cors import CORSMiddleware\n\n middleware.append(\n Middleware(\n CORSMiddleware,\n allow_origins=[\"*\"],\n allow_headers=[\"*\"],\n allow_methods=[\"*\"],\n )\n )\n\napp = Starlette(routes=routes, middleware=middleware)\n\n\[email protected]_event(\"startup\")\nasync def startup_event():\n logger = logging.getLogger(\"uvicorn.access\")\n handler = logging.StreamHandler()\n handler.setFormatter(logging.Formatter(\"%(asctime)s - %(levelname)s - %(message)s\"))\n logger.handlers = [handler]\n\n # Link between `api-inference-community` and framework code.\n app.get_pipeline = get_pipeline\n try:\n get_pipeline()\n except Exception:\n # We can fail so we can show exception later.\n pass\n\n\nif __name__ == \"__main__\":\n try:\n get_pipeline()\n except Exception:\n # We can fail so we can show exception later.\n pass\n", "docker_images\\espnet\\Dockerfile": "FROM tiangolo/uvicorn-gunicorn:python3.8\nLABEL maintainer=\"me <[email protected]>\"\n\n# Add any system dependency here\n# RUN apt-get update -y && apt-get install libXXX -y\nRUN apt-get update -y && apt-get install ffmpeg -y\n\nCOPY ./requirements.txt /app\nRUN pip install --no-cache-dir -r requirements.txt\nCOPY ./prestart.sh /app/\n\n\n# Most DL models are quite large in terms of memory, using workers is a HUGE\n# slowdown because of the fork and GIL with python.\n# Using multiple pods seems like a better default strategy.\n# Feel free to override if it does not make sense for your library.\nARG max_workers=1\nENV MAX_WORKERS=$max_workers\nENV HUGGINGFACE_HUB_CACHE=/data\n\n# Necessary on GPU environment docker.\n# TIMEOUT env variable is used by nvcr.io/nvidia/pytorch:xx for another purpose\n# rendering TIMEOUT defined by uvicorn impossible to use correctly\n# We're overriding it to be renamed UVICORN_TIMEOUT\n# UVICORN_TIMEOUT is a useful variable for very large models that take more\n# than 30s (the default) to load in memory.\n# If UVICORN_TIMEOUT is too low, uvicorn will simply never loads as it will\n# kill workers all the time before they finish.\nRUN sed -i 's/TIMEOUT/UVICORN_TIMEOUT/g' /gunicorn_conf.py\nCOPY ./app /app/app\n", "docker_images\\espnet\\requirements.txt": "api-inference-community==0.0.32\nhuggingface_hub==0.18.0\nespnet==202310\ntorch<2.0.1\ntorchaudio\ntorch_optimizer\nespnet_model_zoo==0.1.7\n", "docker_images\\espnet\\app\\main.py": "import functools\nimport logging\nimport os\nfrom typing import Dict, Type\n\nfrom api_inference_community.routes import pipeline_route, status_ok\nfrom app.pipelines import ( # AutomaticSpeechRecognitionPipeline,\n AutomaticSpeechRecognitionPipeline,\n Pipeline,\n TextToSpeechPipeline,\n)\nfrom starlette.applications import Starlette\nfrom starlette.middleware import Middleware\nfrom starlette.middleware.gzip import GZipMiddleware\nfrom starlette.routing import Route\n\n\nTASK = os.getenv(\"TASK\")\nMODEL_ID = os.getenv(\"MODEL_ID\")\n\n\nlogger = logging.getLogger(__name__)\n\n\n# Add the allowed tasks\n# Supported tasks are:\n# - text-generation\n# - text-classification\n# - token-classification\n# - translation\n# - summarization\n# - automatic-speech-recognition\n# - ...\n# For instance\n# from app.pipelines import AutomaticSpeecRecognitionPipeline\n# ALLOWED_TASKS = {\"automatic-speech-recognition\": AutomaticSpeechRecognitionPipeline}\n# You can check the requirements and expectations of each pipelines in their respective\n# directories. Implement directly within the directories.\nALLOWED_TASKS: Dict[str, Type[Pipeline]] = {\n \"text-to-speech\": TextToSpeechPipeline,\n \"automatic-speech-recognition\": AutomaticSpeechRecognitionPipeline,\n}\n\n\[email protected]_cache()\ndef get_pipeline() -> Pipeline:\n task = os.environ[\"TASK\"]\n model_id = os.environ[\"MODEL_ID\"]\n if task not in ALLOWED_TASKS:\n raise EnvironmentError(f\"{task} is not a valid pipeline for model : {model_id}\")\n return ALLOWED_TASKS[task](model_id)\n\n\nroutes = [\n Route(\"/{whatever:path}\", status_ok),\n Route(\"/{whatever:path}\", pipeline_route, methods=[\"POST\"]),\n]\n\nmiddleware = [Middleware(GZipMiddleware, minimum_size=1000)]\nif os.environ.get(\"DEBUG\", \"\") == \"1\":\n from starlette.middleware.cors import CORSMiddleware\n\n middleware.append(\n Middleware(\n CORSMiddleware,\n allow_origins=[\"*\"],\n allow_headers=[\"*\"],\n allow_methods=[\"*\"],\n )\n )\n\napp = Starlette(routes=routes, middleware=middleware)\n\n\[email protected]_event(\"startup\")\nasync def startup_event():\n logger = logging.getLogger(\"uvicorn.access\")\n handler = logging.StreamHandler()\n handler.setFormatter(logging.Formatter(\"%(asctime)s - %(levelname)s - %(message)s\"))\n logger.handlers = [handler]\n\n # Link between `api-inference-community` and framework code.\n app.get_pipeline = get_pipeline\n try:\n get_pipeline()\n except Exception:\n # We can fail so we can show exception later.\n pass\n\n\nif __name__ == \"__main__\":\n try:\n get_pipeline()\n except Exception:\n # We can fail so we can show exception later.\n pass\n", "docker_images\\fairseq\\Dockerfile": "FROM tiangolo/uvicorn-gunicorn:python3.8\nLABEL maintainer=\"me <[email protected]>\"\n\n# Add any system dependency here\n# RUN apt-get update -y && apt-get install libXXX -y\nRUN apt-get update -y && apt-get install ffmpeg espeak-ng -y\n\nRUN pip install --no-cache-dir numpy==1.22 torch==1.11\nCOPY ./requirements.txt /app\nRUN pip install -U pip\n# This will make further requirements.txt changes faster\n# Numpy is REQUIRED because pkusage requires numpy to be already installed\nRUN pip install --no-cache-dir -r requirements.txt\nCOPY ./prestart.sh /app/\n\n\n# Most DL models are quite large in terms of memory, using workers is a HUGE\n# slowdown because of the fork and GIL with python.\n# Using multiple pods seems like a better default strategy.\n# Feel free to override if it does not make sense for your library.\nARG max_workers=1\nENV MAX_WORKERS=$max_workers\nENV HUGGINGFACE_HUB_CACHE=/data\n\n# Necessary on GPU environment docker.\n# TIMEOUT env variable is used by nvcr.io/nvidia/pytorch:xx for another purpose\n# rendering TIMEOUT defined by uvicorn impossible to use correctly\n# We're overriding it to be renamed UVICORN_TIMEOUT\n# UVICORN_TIMEOUT is a useful variable for very large models that take more\n# than 30s (the default) to load in memory.\n# If UVICORN_TIMEOUT is too low, uvicorn will simply never loads as it will\n# kill workers all the time before they finish.\nRUN sed -i 's/TIMEOUT/UVICORN_TIMEOUT/g' /gunicorn_conf.py\nCOPY ./app /app/app\n", "docker_images\\fairseq\\requirements.txt": "api-inference-community==0.0.23\ng2p_en==2.1.0\ng2pc==0.9.9.3\nphonemizer==2.2.1\nlibrosa==0.8.1\nhanziconv==0.3.2\nsentencepiece==0.1.96\n# Dummy comment to trigger automatic deploy.\ngit+https://github.com/facebookresearch/fairseq.git@d47119871c2ac9a0a0aa2904dd8cfc1929b113d9#egg=fairseq\nhuggingface_hub==0.5.1\n", "docker_images\\fairseq\\app\\main.py": "import functools\nimport logging\nimport os\nfrom typing import Dict, Type\n\nfrom api_inference_community.routes import pipeline_route, status_ok\nfrom app.pipelines import Pipeline, SpeechToSpeechPipeline, TextToSpeechPipeline\nfrom starlette.applications import Starlette\nfrom starlette.middleware import Middleware\nfrom starlette.middleware.gzip import GZipMiddleware\nfrom starlette.routing import Route\n\n\nTASK = os.getenv(\"TASK\")\nMODEL_ID = os.getenv(\"MODEL_ID\")\n\n\nlogger = logging.getLogger(__name__)\n\n\n# Add the allowed tasks\n# Supported tasks are:\n# - text-generation\n# - text-classification\n# - token-classification\n# - translation\n# - summarization\n# - automatic-speech-recognition\n# - ...\n# For instance\n# from app.pipelines import AutomaticSpeecRecognitionPipeline\n# ALLOWED_TASKS = {\"automatic-speech-recognition\": AutomaticSpeechRecognitionPipeline}\n# You can check the requirements and expectations of each pipelines in their respective\n# directories. Implement directly within the directories.\nALLOWED_TASKS: Dict[str, Type[Pipeline]] = {\n \"text-to-speech\": TextToSpeechPipeline,\n \"audio-to-audio\": SpeechToSpeechPipeline,\n}\n\n\[email protected]_cache()\ndef get_pipeline() -> Pipeline:\n task = os.environ[\"TASK\"]\n model_id = os.environ[\"MODEL_ID\"]\n if task not in ALLOWED_TASKS:\n raise EnvironmentError(f\"{task} is not a valid pipeline for model : {model_id}\")\n return ALLOWED_TASKS[task](model_id)\n\n\nroutes = [\n Route(\"/{whatever:path}\", status_ok),\n Route(\"/{whatever:path}\", pipeline_route, methods=[\"POST\"]),\n]\n\nmiddleware = [Middleware(GZipMiddleware, minimum_size=1000)]\nif os.environ.get(\"DEBUG\", \"\") == \"1\":\n from starlette.middleware.cors import CORSMiddleware\n\n middleware.append(\n Middleware(\n CORSMiddleware,\n allow_origins=[\"*\"],\n allow_headers=[\"*\"],\n allow_methods=[\"*\"],\n )\n )\n\napp = Starlette(routes=routes, middleware=middleware)\n\n\[email protected]_event(\"startup\")\nasync def startup_event():\n logger = logging.getLogger(\"uvicorn.access\")\n handler = logging.StreamHandler()\n handler.setFormatter(logging.Formatter(\"%(asctime)s - %(levelname)s - %(message)s\"))\n logger.handlers = [handler]\n\n # Link between `api-inference-community` and framework code.\n app.get_pipeline = get_pipeline\n try:\n get_pipeline()\n except Exception:\n # We can fail so we can show exception later.\n pass\n\n\nif __name__ == \"__main__\":\n try:\n get_pipeline()\n except Exception:\n # We can fail so we can show exception later.\n pass\n", "docker_images\\fastai\\Dockerfile": "FROM tiangolo/uvicorn-gunicorn:python3.8\nLABEL maintainer=\"Omar Espejel <[email protected]>\"\n\n# Add any system dependency here\n# RUN apt-get update -y && apt-get install libXXX -y\n\nCOPY ./requirements.txt /app\n# This enables better docker caching so adding new requirements doesn't\n# retrigger reinstalling the whole pytorch.\nRUN pip install torch==1.11.0 torchvision==0.12.0 torchaudio==0.11.0\nRUN pip install --no-cache-dir -r requirements.txt\nCOPY ./prestart.sh /app/\n\n\n# Most DL models are quite large in terms of memory, using workers is a HUGE\n# slowdown because of the fork and GIL with python.\n# Using multiple pods seems like a better default strategy.\n# Feel free to override if it does not make sense for your library.\nARG max_workers=1\nENV MAX_WORKERS=$max_workers\nENV HUGGINGFACE_HUB_CACHE=/data\n\n# Necessary on GPU environment docker.\n# TIMEOUT env variable is used by nvcr.io/nvidia/pytorch:xx for another purpose\n# rendering TIMEOUT defined by uvicorn impossible to use correctly\n# We're overriding it to be renamed UVICORN_TIMEOUT\n# UVICORN_TIMEOUT is a useful variable for very large models that take more\n# than 30s (the default) to load in memory.\n# If UVICORN_TIMEOUT is too low, uvicorn will simply never loads as it will\n# kill workers all the time before they finish.\nRUN sed -i 's/TIMEOUT/UVICORN_TIMEOUT/g' /gunicorn_conf.py\nCOPY ./app /app/app\n", "docker_images\\fastai\\requirements.txt": "starlette==0.27.0\napi-inference-community==0.0.23\nhuggingface_hub[fastai]==0.6.0\ntimm==0.5.4\n", "docker_images\\fastai\\app\\main.py": "import functools\nimport logging\nimport os\nfrom typing import Dict, Type\n\nfrom api_inference_community.routes import pipeline_route, status_ok\nfrom app.pipelines import ImageClassificationPipeline, Pipeline\nfrom starlette.applications import Starlette\nfrom starlette.middleware import Middleware\nfrom starlette.middleware.gzip import GZipMiddleware\nfrom starlette.routing import Route\n\n\nTASK = os.getenv(\"TASK\")\nMODEL_ID = os.getenv(\"MODEL_ID\")\n\n\nlogger = logging.getLogger(__name__)\n\nALLOWED_TASKS: Dict[str, Type[Pipeline]] = {\n \"image-classification\": ImageClassificationPipeline\n}\n\n\[email protected]_cache()\ndef get_pipeline() -> Pipeline:\n task = os.environ[\"TASK\"]\n model_id = os.environ[\"MODEL_ID\"]\n if task not in ALLOWED_TASKS:\n raise EnvironmentError(f\"{task} is not a valid pipeline for model : {model_id}\")\n return ALLOWED_TASKS[task](model_id)\n\n\nroutes = [\n Route(\"/{whatever:path}\", status_ok),\n Route(\"/{whatever:path}\", pipeline_route, methods=[\"POST\"]),\n]\n\nmiddleware = [Middleware(GZipMiddleware, minimum_size=1000)]\nif os.environ.get(\"DEBUG\", \"\") == \"1\":\n from starlette.middleware.cors import CORSMiddleware\n\n middleware.append(\n Middleware(\n CORSMiddleware,\n allow_origins=[\"*\"],\n allow_headers=[\"*\"],\n allow_methods=[\"*\"],\n )\n )\n\napp = Starlette(routes=routes, middleware=middleware)\n\n\[email protected]_event(\"startup\")\nasync def startup_event():\n logger = logging.getLogger(\"uvicorn.access\")\n handler = logging.StreamHandler()\n handler.setFormatter(logging.Formatter(\"%(asctime)s - %(levelname)s - %(message)s\"))\n logger.handlers = [handler]\n\n # Link between `api-inference-community` and framework code.\n app.get_pipeline = get_pipeline\n try:\n get_pipeline()\n except Exception:\n # We can fail so we can show exception later.\n pass\n\n\nif __name__ == \"__main__\":\n try:\n get_pipeline()\n except Exception:\n # We can fail so we can show exception later.\n pass\n", "docker_images\\fasttext\\Dockerfile": "FROM tiangolo/uvicorn-gunicorn:python3.8\nLABEL maintainer=\"me <[email protected]>\"\n\n# Add any system dependency here\n# RUN apt-get update -y && apt-get install libXXX -y\n\nCOPY ./requirements.txt /app\nRUN pip install --no-cache-dir -r requirements.txt\nCOPY ./prestart.sh /app/\n\n\n# Most DL models are quite large in terms of memory, using workers is a HUGE\n# slowdown because of the fork and GIL with python.\n# Using multiple pods seems like a better default strategy.\n# Feel free to override if it does not make sense for your library.\nARG max_workers=1\nENV MAX_WORKERS=$max_workers\nENV HUGGINGFACE_HUB_CACHE=/data\n\n# Necessary on GPU environment docker.\n# TIMEOUT env variable is used by nvcr.io/nvidia/pytorch:xx for another purpose\n# rendering TIMEOUT defined by uvicorn impossible to use correctly\n# We're overriding it to be renamed UVICORN_TIMEOUT\n# UVICORN_TIMEOUT is a useful variable for very large models that take more\n# than 30s (the default) to load in memory.\n# If UVICORN_TIMEOUT is too low, uvicorn will simply never loads as it will\n# kill workers all the time before they finish.\nRUN sed -i 's/TIMEOUT/UVICORN_TIMEOUT/g' /gunicorn_conf.py\nCOPY ./app /app/app\n", "docker_images\\fasttext\\requirements.txt": "starlette==0.27.0\napi-inference-community==0.0.23\nfasttext==0.9.2\nhuggingface_hub==0.5.1\n# Dummy change.\n", "docker_images\\fasttext\\app\\main.py": "import functools\nimport logging\nimport os\nfrom typing import Dict, Type\n\nfrom api_inference_community.routes import pipeline_route, status_ok\nfrom app.pipelines import (\n FeatureExtractionPipeline,\n Pipeline,\n TextClassificationPipeline,\n)\nfrom starlette.applications import Starlette\nfrom starlette.middleware import Middleware\nfrom starlette.middleware.gzip import GZipMiddleware\nfrom starlette.routing import Route\n\n\nTASK = os.getenv(\"TASK\")\nMODEL_ID = os.getenv(\"MODEL_ID\")\n\n\nlogger = logging.getLogger(__name__)\n\n\n# Add the allowed tasks\n# Supported tasks are:\n# - text-generation\n# - text-classification\n# - token-classification\n# - translation\n# - summarization\n# - automatic-speech-recognition\n# - ...\n# For instance\n# from app.pipelines import AutomaticSpeechRecognitionPipeline\n# ALLOWED_TASKS = {\"automatic-speech-recognition\": AutomaticSpeechRecognitionPipeline}\n# You can check the requirements and expectations of each pipelines in their respective\n# directories. Implement directly within the directories.\nALLOWED_TASKS: Dict[str, Type[Pipeline]] = {\n \"feature-extraction\": FeatureExtractionPipeline,\n \"text-classification\": TextClassificationPipeline,\n}\n\n\[email protected]_cache()\ndef get_pipeline() -> Pipeline:\n task = os.environ[\"TASK\"]\n model_id = os.environ[\"MODEL_ID\"]\n if task not in ALLOWED_TASKS:\n raise EnvironmentError(f\"{task} is not a valid pipeline for model : {model_id}\")\n return ALLOWED_TASKS[task](model_id)\n\n\nroutes = [\n Route(\"/{whatever:path}\", status_ok),\n Route(\"/{whatever:path}\", pipeline_route, methods=[\"POST\"]),\n]\n\nmiddleware = [Middleware(GZipMiddleware, minimum_size=1000)]\nif os.environ.get(\"DEBUG\", \"\") == \"1\":\n from starlette.middleware.cors import CORSMiddleware\n\n middleware.append(\n Middleware(\n CORSMiddleware,\n allow_origins=[\"*\"],\n allow_headers=[\"*\"],\n allow_methods=[\"*\"],\n )\n )\n\napp = Starlette(routes=routes, middleware=middleware)\n\n\[email protected]_event(\"startup\")\nasync def startup_event():\n logger = logging.getLogger(\"uvicorn.access\")\n handler = logging.StreamHandler()\n handler.setFormatter(logging.Formatter(\"%(asctime)s - %(levelname)s - %(message)s\"))\n logger.handlers = [handler]\n\n # Link between `api-inference-community` and framework code.\n app.get_pipeline = get_pipeline\n try:\n get_pipeline()\n except Exception:\n # We can fail so we can show exception later.\n pass\n\n\nif __name__ == \"__main__\":\n try:\n get_pipeline()\n except Exception:\n # We can fail so we can show exception later.\n pass\n", "docker_images\\flair\\Dockerfile": "FROM tiangolo/uvicorn-gunicorn:python3.8\nLABEL maintainer=\"me <[email protected]>\"\n\n# Add any system dependency here\n# RUN apt-get update -y && apt-get install libXXX -y\n\nCOPY ./requirements.txt /app\nRUN pip install --no-cache-dir -r requirements.txt\nCOPY ./prestart.sh /app/\n\n\n# Most DL models are quite large in terms of memory, using workers is a HUGE\n# slowdown because of the fork and GIL with python.\n# Using multiple pods seems like a better default strategy.\n# Feel free to override if it does not make sense for your library.\nARG max_workers=1\nENV MAX_WORKERS=$max_workers\nENV HUGGINGFACE_HUB_CACHE=/data\nENV FLAIR_CACHE_ROOT=/data\n\n# Necessary on GPU environment docker.\n# TIMEOUT env variable is used by nvcr.io/nvidia/pytorch:xx for another purpose\n# rendering TIMEOUT defined by uvicorn impossible to use correctly\n# We're overriding it to be renamed UVICORN_TIMEOUT\n# UVICORN_TIMEOUT is a useful variable for very large models that take more\n# than 30s (the default) to load in memory.\n# If UVICORN_TIMEOUT is too low, uvicorn will simply never loads as it will\n# kill workers all the time before they finish.\nRUN sed -i 's/TIMEOUT/UVICORN_TIMEOUT/g' /gunicorn_conf.py\nCOPY ./app /app/app\n", "docker_images\\flair\\requirements.txt": "starlette==0.27.0\npydantic==1.8.2\nflair @ git+https://github.com/flairNLP/flair@e17ab1234fcfed2b089d8ef02b99949d520382d2\napi-inference-community==0.0.25\n", "docker_images\\flair\\app\\main.py": "import functools\nimport logging\nimport os\nfrom typing import Dict, Type\n\nfrom api_inference_community.routes import pipeline_route, status_ok\nfrom app.pipelines import Pipeline, TokenClassificationPipeline\nfrom starlette.applications import Starlette\nfrom starlette.routing import Route\n\n\nlogger = logging.getLogger(__name__)\n\n# Add the allowed tasks\n# Supported tasks are:\n# - text-generation\n# - text-classification\n# - token-classification\n# - translation\n# - summarization\n# - automatic-speech-recognition\n# - ...\n# For instance\n# from app.pipelines import AutomaticSpeechRecognitionPipeline\n# ALLOWED_TASKS = {\"automatic-speech-recognition\": AutomaticSpeechRecognitionPipeline}\n# You can check the requirements and expectations of each pipelines in their respective\n# directories. Implement directly within the directories.\nALLOWED_TASKS: Dict[str, Type[Pipeline]] = {\n \"token-classification\": TokenClassificationPipeline\n}\n\n\[email protected]_cache()\ndef get_pipeline() -> Pipeline:\n task = os.environ[\"TASK\"]\n model_id = os.environ[\"MODEL_ID\"]\n if task not in ALLOWED_TASKS:\n raise EnvironmentError(f\"{task} is not a valid pipeline for model : {model_id}\")\n return ALLOWED_TASKS[task](model_id)\n\n\nroutes = [\n Route(\"/{whatever:path}\", status_ok),\n Route(\"/{whatever:path}\", pipeline_route, methods=[\"POST\"]),\n]\n\napp = Starlette(routes=routes)\nif os.environ.get(\"DEBUG\", \"\") == \"1\":\n from starlette.middleware.cors import CORSMiddleware\n\n app.add_middleware(\n CORSMiddleware, allow_origins=[\"*\"], allow_headers=[\"*\"], allow_methods=[\"*\"]\n )\n\n\[email protected]_event(\"startup\")\nasync def startup_event():\n logger = logging.getLogger(\"uvicorn.access\")\n handler = logging.StreamHandler()\n handler.setFormatter(logging.Formatter(\"%(asctime)s - %(levelname)s - %(message)s\"))\n logger.handlers = [handler]\n\n app.get_pipeline = get_pipeline\n\n\nif __name__ == \"__main__\":\n try:\n get_pipeline()\n except Exception:\n # We can fail so we can show exception later.\n pass\n", "docker_images\\k2\\Dockerfile": "FROM tiangolo/uvicorn-gunicorn:python3.8\nLABEL maintainer=\"Yenda <[email protected]>\"\n\n# Add any system dependency here\nRUN apt-get update -y && apt-get install cmake ffmpeg -y && rm -rf /var/lib/apt/lists/*\n\nCOPY ./requirements.txt /app\nRUN pip install --no-cache-dir torch==1.11.0+cpu torchvision==0.12.0+cpu torchaudio==0.11.0 --extra-index-url https://download.pytorch.org/whl/cpu\nRUN pip install --no-cache-dir -r requirements.txt\nRUN pip install --no-cache-dir k2==1.17.dev20220719+cpu.torch1.11.0 -f https://k2-fsa.org/nightly/whl/\nRUN git clone https://github.com/k2-fsa/sherpa && cd sherpa && git checkout v0.6 && pip install -r ./requirements.txt && python3 setup.py install --verbose\n\nCOPY ./prestart.sh /app/\n\n\n# Most DL models are quite large in terms of memory, using workers is a HUGE\n# slowdown because of the fork and GIL with python.\n# Using multiple pods seems like a better default strategy.\n# Feel free to override if it does not make sense for your library.\nARG max_workers=1\nENV MAX_WORKERS=$max_workers\nENV HUGGINGFACE_HUB_CACHE=/data\n\n# Necessary on GPU environment docker.\n# TIMEOUT env variable is used by nvcr.io/nvidia/pytorch:xx for another purpose\n# rendering TIMEOUT defined by uvicorn impossible to use correctly\n# We're overriding it to be renamed UVICORN_TIMEOUT\n# UVICORN_TIMEOUT is a useful variable for very large models that take more\n# than 30s (the default) to load in memory.\n# If UVICORN_TIMEOUT is too low, uvicorn will simply never loads as it will\n# kill workers all the time before they finish.\nRUN sed -i 's/TIMEOUT/UVICORN_TIMEOUT/g' /gunicorn_conf.py\nCOPY ./app /app/app\n\n", "docker_images\\k2\\requirements.txt": "starlette==0.27.0\napi-inference-community==0.0.23\nhuggingface_hub==0.5.1\n", "docker_images\\k2\\app\\main.py": "import functools\nimport logging\nimport os\nfrom typing import Dict, Type\n\nfrom api_inference_community.routes import pipeline_route, status_ok\nfrom app.pipelines import AutomaticSpeechRecognitionPipeline, Pipeline\nfrom starlette.applications import Starlette\nfrom starlette.middleware import Middleware\nfrom starlette.middleware.gzip import GZipMiddleware\nfrom starlette.routing import Route\n\n\nTASK = os.getenv(\"TASK\")\nMODEL_ID = os.getenv(\"MODEL_ID\")\n\n\nlogger = logging.getLogger(__name__)\n\n\n# Add the allowed tasks\n# Supported tasks are:\n# - text-generation\n# - text-classification\n# - token-classification\n# - translation\n# - summarization\n# - automatic-speech-recognition\n# - ...\n# For instance\n# from app.pipelines import AutomaticSpeechRecognitionPipeline\n# ALLOWED_TASKS = {\"automatic-speech-recognition\": AutomaticSpeechRecognitionPipeline}\n# You can check the requirements and expectations of each pipelines in their respective\n# directories. Implement directly within the directories.\nALLOWED_TASKS: Dict[str, Type[Pipeline]] = {\n \"automatic-speech-recognition\": AutomaticSpeechRecognitionPipeline,\n}\n\n\[email protected]_cache()\ndef get_pipeline() -> Pipeline:\n task = os.environ[\"TASK\"]\n model_id = os.environ[\"MODEL_ID\"]\n if task not in ALLOWED_TASKS:\n raise EnvironmentError(f\"{task} is not a valid pipeline for model : {model_id}\")\n return ALLOWED_TASKS[task](model_id)\n\n\nroutes = [\n Route(\"/{whatever:path}\", status_ok),\n Route(\"/{whatever:path}\", pipeline_route, methods=[\"POST\"]),\n]\n\nmiddleware = [Middleware(GZipMiddleware, minimum_size=1000)]\nif os.environ.get(\"DEBUG\", \"\") == \"1\":\n from starlette.middleware.cors import CORSMiddleware\n\n middleware.append(\n Middleware(\n CORSMiddleware,\n allow_origins=[\"*\"],\n allow_headers=[\"*\"],\n allow_methods=[\"*\"],\n )\n )\n\napp = Starlette(routes=routes, middleware=middleware)\n\n\[email protected]_event(\"startup\")\nasync def startup_event():\n logger = logging.getLogger(\"uvicorn.access\")\n handler = logging.StreamHandler()\n handler.setFormatter(logging.Formatter(\"%(asctime)s - %(levelname)s - %(message)s\"))\n logger.handlers = [handler]\n\n # Link between `api-inference-community` and framework code.\n app.get_pipeline = get_pipeline\n try:\n get_pipeline()\n except Exception:\n # We can fail so we can show exception later.\n pass\n\n\nif __name__ == \"__main__\":\n try:\n get_pipeline()\n except Exception:\n # We can fail so we can show exception later.\n pass\n", "docker_images\\mindspore\\Dockerfile": "FROM tiangolo/uvicorn-gunicorn:python3.8\nLABEL maintainer=\"me <[email protected]>\"\n\n# Add any system dependency here\nRUN apt-get update -y && apt-get install libglib2.0-dev libsm6 libxrender1 libgl1-mesa-glx -y\n\nCOPY requirements.txt /app\nRUN /usr/local/bin/python -m pip install --upgrade pip && \\\n pip install --no-cache-dir -r requirements.txt\nCOPY prestart.sh /app/\n\n\n# Most DL models are quite large in terms of memory, using workers is a HUGE\n# slowdown because of the fork and GIL with python.\n# Using multiple pods seems like a better default strategy.\n# Feel free to override if it does not make sense for your library.\nARG max_workers=1\nENV MAX_WORKERS=$max_workers\nENV HUGGINGFACE_HUB_CACHE=/data\n\n# Necessary on GPU environment docker.\n# TIMEOUT env variable is used by nvcr.io/nvidia/pytorch:xx for another purpose\n# rendering TIMEOUT defined by uvicorn impossible to use correctly\n# We're overriding it to be renamed UVICORN_TIMEOUT\n# UVICORN_TIMEOUT is a useful variable for very large models that take more\n# than 30s (the default) to load in memory.\n# If UVICORN_TIMEOUT is too low, uvicorn will simply never loads as it will\n# kill workers all the time before they finish.\nRUN sed -i 's/TIMEOUT/UVICORN_TIMEOUT/g' /gunicorn_conf.py\nCOPY ./app /app/app\n", "docker_images\\mindspore\\requirements.txt": "starlette==0.27.0\napi-inference-community==0.0.25\nhuggingface_hub==0.11.0\ntinyms>=0.3.2", "docker_images\\mindspore\\app\\main.py": "import functools\nimport logging\nimport os\nfrom typing import Dict, Type\n\nfrom api_inference_community.routes import pipeline_route, status_ok\nfrom app.pipelines import ImageClassificationPipeline, Pipeline\nfrom starlette.applications import Starlette\nfrom starlette.middleware import Middleware\nfrom starlette.middleware.gzip import GZipMiddleware\nfrom starlette.routing import Route\n\n\nTASK = os.getenv(\"TASK\")\nMODEL_ID = os.getenv(\"MODEL_ID\")\n\n\nlogger = logging.getLogger(__name__)\n\n\n# Add the allowed tasks\n# Supported tasks are:\n# - text-generation\n# - text-classification\n# - token-classification\n# - translation\n# - summarization\n# - automatic-speech-recognition\n# - ...\n# For instance\n# from app.pipelines import AutomaticSpeechRecognitionPipeline\n# ALLOWED_TASKS = {\"automatic-speech-recognition\": AutomaticSpeechRecognitionPipeline}\n# You can check the requirements and expectations of each pipelines in their respective\n# directories. Implement directly within the directories.\nALLOWED_TASKS: Dict[str, Type[Pipeline]] = {\n \"image-classification\": ImageClassificationPipeline\n}\n\n\[email protected]_cache()\ndef get_pipeline() -> Pipeline:\n task = os.environ[\"TASK\"]\n model_id = os.environ[\"MODEL_ID\"]\n if task not in ALLOWED_TASKS:\n raise EnvironmentError(f\"{task} is not a valid pipeline for model : {model_id}\")\n return ALLOWED_TASKS[task](model_id)\n\n\nroutes = [\n Route(\"/{whatever:path}\", status_ok),\n Route(\"/{whatever:path}\", pipeline_route, methods=[\"POST\"]),\n]\n\nmiddleware = [Middleware(GZipMiddleware, minimum_size=1000)]\nif os.environ.get(\"DEBUG\", \"\") == \"1\":\n from starlette.middleware.cors import CORSMiddleware\n\n middleware.append(\n Middleware(\n CORSMiddleware,\n allow_origins=[\"*\"],\n allow_headers=[\"*\"],\n allow_methods=[\"*\"],\n )\n )\n\napp = Starlette(routes=routes, middleware=middleware)\n\n\[email protected]_event(\"startup\")\nasync def startup_event():\n logger = logging.getLogger(\"uvicorn.access\")\n handler = logging.StreamHandler()\n handler.setFormatter(logging.Formatter(\"%(asctime)s - %(levelname)s - %(message)s\"))\n logger.handlers = [handler]\n\n # Link between `api-inference-community` and framework code.\n app.get_pipeline = get_pipeline\n try:\n get_pipeline()\n except Exception:\n # We can fail so we can show exception later.\n pass\n\n\nif __name__ == \"__main__\":\n try:\n get_pipeline()\n except Exception:\n # We can fail so we can show exception later.\n pass\n", "docker_images\\nemo\\Dockerfile": "FROM tiangolo/uvicorn-gunicorn:python3.9\nLABEL maintainer=\"me <[email protected]>\"\n\n# Add any system dependency here\nRUN apt-get update -y && \\\n apt-get install libsndfile1 ffmpeg -y\n\n# See PyTorch releases for pip here: https://download.pytorch.org/whl/torch_stable.html\nCOPY ./requirements.txt /app\nRUN pip install https://download.pytorch.org/whl/cpu/torch-1.13.1%2Bcpu-cp39-cp39-linux_x86_64.whl && \\\n pip install Cython numpy==1.21.6\nRUN pip install -r requirements.txt\nCOPY ./prestart.sh /app/\n\n\n# Most DL models are quite large in terms of memory, using workers is a HUGE\n# slowdown because of the fork and GIL with python.\n# Using multiple pods seems like a better default strategy.\n# Feel free to override if it does not make sense for your library.\nARG max_workers=1\nENV MAX_WORKERS=$max_workers\nENV HUGGINGFACE_HUB_CACHE=/data\nENV NEMO_CACHE_DIR=/data/nemo_cache/\n\n# Necessary on GPU environment docker.\n# TIMEOUT env variable is used by nvcr.io/nvidia/pytorch:xx for another purpose\n# rendering TIMEOUT defined by uvicorn impossible to use correctly\n# We're overriding it to be renamed UVICORN_TIMEOUT\n# UVICORN_TIMEOUT is a useful variable for very large models that take more\n# than 30s (the default) to load in memory.\n# If UVICORN_TIMEOUT is too low, uvicorn will simply never loads as it will\n# kill workers all the time before they finish.\nRUN sed -i 's/TIMEOUT/UVICORN_TIMEOUT/g' /gunicorn_conf.py\nCOPY ./app /app/app\n", "docker_images\\nemo\\requirements.txt": "starlette==0.28.0\napi-inference-community==0.0.27\nnemo_toolkit[all]>=1.18.1\nhuggingface_hub==0.15.1\n# Dummy\n", "docker_images\\nemo\\app\\main.py": "import functools\nimport logging\nimport os\nfrom typing import Dict, Type\n\nfrom api_inference_community.routes import pipeline_route, status_ok\nfrom app.pipelines import Pipeline\nfrom app.pipelines.automatic_speech_recognition import (\n AutomaticSpeechRecognitionPipeline,\n)\nfrom starlette.applications import Starlette\nfrom starlette.middleware import Middleware\nfrom starlette.middleware.gzip import GZipMiddleware\nfrom starlette.routing import Route\n\n\nTASK = os.getenv(\"TASK\")\nMODEL_ID = os.getenv(\"MODEL_ID\")\n\n\nlogger = logging.getLogger(__name__)\n\n\n# Add the allowed tasks\n# Supported tasks are:\n# - text-generation\n# - text-classification\n# - token-classification\n# - translation\n# - summarization\n# - automatic-speech-recognition\n# - ...\n# For instance\n# from app.pipelines import AutomaticSpeechRecognitionPipeline\n# ALLOWED_TASKS = {\"automatic-speech-recognition\": AutomaticSpeechRecognitionPipeline}\n# You can check the requirements and expectations of each pipelines in their respective\n# directories. Implement directly within the directories.\nALLOWED_TASKS: Dict[str, Type[Pipeline]] = {\n \"automatic-speech-recognition\": AutomaticSpeechRecognitionPipeline,\n}\n\n\[email protected]_cache()\ndef get_pipeline() -> Pipeline:\n task = os.environ[\"TASK\"]\n model_id = os.environ[\"MODEL_ID\"]\n if task not in ALLOWED_TASKS:\n raise EnvironmentError(f\"{task} is not a valid pipeline for model : {model_id}\")\n return ALLOWED_TASKS[task](model_id)\n\n\nroutes = [\n Route(\"/{whatever:path}\", status_ok),\n Route(\"/{whatever:path}\", pipeline_route, methods=[\"POST\"]),\n]\n\nmiddleware = [Middleware(GZipMiddleware, minimum_size=1000)]\nif os.environ.get(\"DEBUG\", \"\") == \"1\":\n from starlette.middleware.cors import CORSMiddleware\n\n middleware.append(\n Middleware(\n CORSMiddleware,\n allow_origins=[\"*\"],\n allow_headers=[\"*\"],\n allow_methods=[\"*\"],\n )\n )\n\napp = Starlette(routes=routes, middleware=middleware)\n\n\[email protected]_event(\"startup\")\nasync def startup_event():\n logger = logging.getLogger(\"uvicorn.access\")\n handler = logging.StreamHandler()\n handler.setFormatter(logging.Formatter(\"%(asctime)s - %(levelname)s - %(message)s\"))\n logger.handlers = [handler]\n\n # Link between `api-inference-community` and framework code.\n app.get_pipeline = get_pipeline\n try:\n get_pipeline()\n except Exception:\n # We can fail so we can show exception later.\n pass\n\n\nif __name__ == \"__main__\":\n try:\n get_pipeline()\n except Exception:\n # We can fail so we can show exception later.\n pass\n", "docker_images\\open_clip\\Dockerfile": "FROM tiangolo/uvicorn-gunicorn:python3.8\nLABEL maintainer=\"me <[email protected]>\"\n\n# Add any system dependency here\n# RUN apt-get update -y && apt-get install libXXX -y\n\nCOPY ./requirements.txt /app\nRUN pip install --no-cache-dir -r requirements.txt\nCOPY ./prestart.sh /app/\n\n\n# Most DL models are quite large in terms of memory, using workers is a HUGE\n# slowdown because of the fork and GIL with python.\n# Using multiple pods seems like a better default strategy.\n# Feel free to override if it does not make sense for your library.\nARG max_workers=1\nENV MAX_WORKERS=$max_workers\nENV TORCH_HOME=/data/\nENV HUGGINGFACE_HUB_CACHE=/data\n\n# Necessary on GPU environment docker.\n# TIMEOUT env variable is used by nvcr.io/nvidia/pytorch:xx for another purpose\n# rendering TIMEOUT defined by uvicorn impossible to use correctly\n# We're overriding it to be renamed UVICORN_TIMEOUT\n# UVICORN_TIMEOUT is a useful variable for very large models that take more\n# than 30s (the default) to load in memory.\n# If UVICORN_TIMEOUT is too low, uvicorn will simply never loads as it will\n# kill workers all the time before they finish.\nRUN sed -i 's/TIMEOUT/UVICORN_TIMEOUT/g' /gunicorn_conf.py\nCOPY ./app /app/app\n", "docker_images\\open_clip\\requirements.txt": "starlette==0.27.0\napi-inference-community==0.0.32\nhuggingface_hub>=0.12.1\ntimm>=0.9.10\ntransformers>=4.34.0\nopen_clip_torch>=2.23.0\n#dummy.\n", "docker_images\\open_clip\\app\\main.py": "import functools\nimport logging\nimport os\nfrom typing import Dict, Type\n\nfrom api_inference_community.routes import pipeline_route, status_ok\nfrom app.pipelines import Pipeline, ZeroShotImageClassificationPipeline\nfrom starlette.applications import Starlette\nfrom starlette.middleware import Middleware\nfrom starlette.middleware.gzip import GZipMiddleware\nfrom starlette.routing import Route\n\n\nTASK = os.getenv(\"TASK\")\nMODEL_ID = os.getenv(\"MODEL_ID\")\n\n\nlogger = logging.getLogger(__name__)\n\n# Add the allowed tasks\n# Supported tasks are:\n# - text-generation\n# - text-classification\n# - token-classification\n# - translation\n# - summarization\n# - automatic-speech-recognition\n# - ...\n# For instance\n# from app.pipelines import AutomaticSpeecRecognitionPipeline\n# ALLOWED_TASKS = {\"automatic-speech-recognition\": AutomaticSpeecRecognitionPipeline}\n# You can check the requirements and expectations of each pipelines in their respective\n# directories. Implement directly within the directories.\nALLOWED_TASKS: Dict[str, Type[Pipeline]] = {\n \"zero-shot-image-classification\": ZeroShotImageClassificationPipeline\n}\n\n\[email protected]_cache()\ndef get_pipeline() -> Pipeline:\n task = os.environ[\"TASK\"]\n model_id = os.environ[\"MODEL_ID\"]\n if task not in ALLOWED_TASKS:\n raise EnvironmentError(f\"{task} is not a valid pipeline for model : {model_id}\")\n return ALLOWED_TASKS[task](model_id)\n\n\nroutes = [\n Route(\"/{whatever:path}\", status_ok),\n Route(\"/{whatever:path}\", pipeline_route, methods=[\"POST\"]),\n]\n\nmiddleware = [Middleware(GZipMiddleware, minimum_size=1000)]\nif os.environ.get(\"DEBUG\", \"\") == \"1\":\n from starlette.middleware.cors import CORSMiddleware\n\n middleware.append(\n Middleware(\n CORSMiddleware,\n allow_origins=[\"*\"],\n allow_headers=[\"*\"],\n allow_methods=[\"*\"],\n )\n )\n\napp = Starlette(routes=routes, middleware=middleware)\n\n\[email protected]_event(\"startup\")\nasync def startup_event():\n logger = logging.getLogger(\"uvicorn.access\")\n handler = logging.StreamHandler()\n handler.setFormatter(logging.Formatter(\"%(asctime)s - %(levelname)s - %(message)s\"))\n logger.handlers = [handler]\n\n # Link between `api-inference-community` and framework code.\n app.get_pipeline = get_pipeline\n try:\n get_pipeline()\n except Exception:\n # We can fail so we can show exception later.\n pass\n\n\nif __name__ == \"__main__\":\n try:\n get_pipeline()\n except Exception:\n # We can fail so we can show exception later.\n pass\n", "docker_images\\paddlenlp\\Dockerfile": "FROM tiangolo/uvicorn-gunicorn:python3.8\nLABEL maintainer=\"PaddleNLP <[email protected]>\"\n\n# Add any system dependency here\n# RUN apt-get update -y && apt-get install libXXX -y\n\nCOPY ./requirements.txt /app\nRUN pip install --no-cache-dir -r requirements.txt\nCOPY ./prestart.sh /app/\n\n\n# Most DL models are quite large in terms of memory, using workers is a HUGE\n# slowdown because of the fork and GIL with python.\n# Using multiple pods seems like a better default strategy.\n# Feel free to override if it does not make sense for your library.\nARG max_workers=1\nENV MAX_WORKERS=$max_workers\nENV HUGGINGFACE_HUB_CACHE=/data\n\n\n# Necessary on GPU environment docker.\n# TIMEOUT env variable is used by nvcr.io/nvidia/pytorch:xx for another purpose\n# rendering TIMEOUT defined by uvicorn impossible to use correctly\n# We're overriding it to be renamed UVICORN_TIMEOUT\n# UVICORN_TIMEOUT is a useful variable for very large models that take more\n# than 30s (the default) to load in memory.\n# If UVICORN_TIMEOUT is too low, uvicorn will simply never loads as it will\n# kill workers all the time before they finish.\nRUN sed -i 's/TIMEOUT/UVICORN_TIMEOUT/g' /gunicorn_conf.py\nCOPY ./app /app/app\n", "docker_images\\paddlenlp\\requirements.txt": "starlette==0.27.0\napi-inference-community==0.0.27\nhuggingface_hub>=0.10.1\npaddlepaddle==2.5.0\npaddlenlp>=2.5.0\n#Dummy\n", "docker_images\\paddlenlp\\app\\main.py": "import functools\nimport logging\nimport os\nfrom typing import Dict, Type\n\nfrom api_inference_community.routes import pipeline_route, status_ok\nfrom app.pipelines import (\n ConversationalPipeline,\n FillMaskPipeline,\n Pipeline,\n SummarizationPipeline,\n ZeroShotClassificationPipeline,\n)\nfrom starlette.applications import Starlette\nfrom starlette.middleware import Middleware\nfrom starlette.middleware.gzip import GZipMiddleware\nfrom starlette.routing import Route\n\n\nTASK = os.getenv(\"TASK\")\nMODEL_ID = os.getenv(\"MODEL_ID\")\n\n\nlogger = logging.getLogger(__name__)\n\n\n# Add the allowed tasks\n# Supported tasks are:\n# - text-generation\n# - text-classification\n# - token-classification\n# - translation\n# - summarization\n# - automatic-speech-recognition\n# - ...\n# For instance\n# from app.pipelines import AutomaticSpeechRecognitionPipeline\n# ALLOWED_TASKS = {\"automatic-speech-recognition\": AutomaticSpeechRecognitionPipeline}\n# You can check the requirements and expectations of each pipelines in their respective\n# directories. Implement directly within the directories.\nALLOWED_TASKS: Dict[str, Type[Pipeline]] = {\n \"conversational\": ConversationalPipeline,\n \"fill-mask\": FillMaskPipeline,\n \"summarization\": SummarizationPipeline,\n \"zero-shot-classification\": ZeroShotClassificationPipeline,\n}\n\n\[email protected]_cache()\ndef get_pipeline() -> Pipeline:\n task = os.environ[\"TASK\"]\n model_id = os.environ[\"MODEL_ID\"]\n if task not in ALLOWED_TASKS:\n raise EnvironmentError(f\"{task} is not a valid pipeline for model : {model_id}\")\n return ALLOWED_TASKS[task](model_id)\n\n\nroutes = [\n Route(\"/{whatever:path}\", status_ok),\n Route(\"/{whatever:path}\", pipeline_route, methods=[\"POST\"]),\n]\n\nmiddleware = [Middleware(GZipMiddleware, minimum_size=1000)]\nif os.environ.get(\"DEBUG\", \"\") == \"1\":\n from starlette.middleware.cors import CORSMiddleware\n\n middleware.append(\n Middleware(\n CORSMiddleware,\n allow_origins=[\"*\"],\n allow_headers=[\"*\"],\n allow_methods=[\"*\"],\n )\n )\n\napp = Starlette(routes=routes, middleware=middleware)\n\n\[email protected]_event(\"startup\")\nasync def startup_event():\n logger = logging.getLogger(\"uvicorn.access\")\n handler = logging.StreamHandler()\n handler.setFormatter(logging.Formatter(\"%(asctime)s - %(levelname)s - %(message)s\"))\n logger.handlers = [handler]\n\n # Link between `api-inference-community` and framework code.\n app.get_pipeline = get_pipeline\n try:\n get_pipeline()\n except Exception:\n # We can fail so we can show exception later.\n pass\n\n\nif __name__ == \"__main__\":\n try:\n get_pipeline()\n except Exception:\n # We can fail so we can show exception later.\n pass\n", "docker_images\\peft\\Dockerfile": "FROM tiangolo/uvicorn-gunicorn:python3.8\nLABEL maintainer=\"Nicolas Patry <[email protected]>\"\n\n# Add any system dependency here\n# RUN apt-get update -y && apt-get install libXXX -y\n\nRUN pip install --no-cache-dir torch==2.0.1\nCOPY ./requirements.txt /app\nRUN pip install --no-cache-dir -r requirements.txt\n\n# Uncomment if you want to load the model once before starting the asgi app\n# COPY ./prestart.sh /app/\n\n# Most DL models are quite large in terms of memory, using workers is a HUGE\n# slowdown because of the fork and GIL with python.\n# Using multiple pods seems like a better default strategy.\n# Feel free to override if it does not make sense for your library.\nARG max_workers=1\nENV MAX_WORKERS=$max_workers\nENV HUGGINGFACE_HUB_CACHE=/data\nENV PEFT_CACHE=/data\nENV HF_HOME=/data\n\n# Necessary on GPU environment docker.\n# TIMEOUT env variable is used by nvcr.io/nvidia/pytorch:xx for another purpose\n# rendering TIMEOUT defined by uvicorn impossible to use correctly\n# We're overriding it to be renamed UVICORN_TIMEOUT\n# UVICORN_TIMEOUT is a useful variable for very large models that take more\n# than 30s (the default) to load in memory.\n# If UVICORN_TIMEOUT is too low, uvicorn will simply never loads as it will\n# kill workers all the time before they finish.\nRUN sed -i 's/TIMEOUT/UVICORN_TIMEOUT/g' /gunicorn_conf.py\nCOPY ./app /app/app\n", "docker_images\\peft\\requirements.txt": "starlette==0.27.0\napi-inference-community==0.0.31\nhuggingface_hub==0.18.0\nsafetensors==0.3.1\npeft==0.6.2\ntransformers==4.35.2\naccelerate>=0.21.0\nhf_transfer==0.1.3\npydantic==1.8.2\nftfy==6.1.1\nsentencepiece==0.1.97\nscipy==1.10.0\ntorch==2.0.1\npydantic<2\n#Dummy.\n", "docker_images\\peft\\app\\main.py": "import asyncio\nimport functools\nimport logging\nimport os\nfrom typing import Dict, Type\n\nfrom api_inference_community.routes import pipeline_route, status_ok\nfrom app import idle\nfrom app.pipelines import Pipeline, TextGenerationPipeline\nfrom starlette.applications import Starlette\nfrom starlette.middleware import Middleware\nfrom starlette.middleware.gzip import GZipMiddleware\nfrom starlette.routing import Route\n\n\nTASK = os.getenv(\"TASK\")\nMODEL_ID = os.getenv(\"MODEL_ID\")\n\n\n# Add the allowed tasks\n# Supported tasks are:\n# - text-generation\n# - text-classification\n# - token-classification\n# - translation\n# - summarization\n# - automatic-speech-recognition\n# - ...\n# For instance\n# from app.pipelines import AutomaticSpeechRecognitionPipeline\n# ALLOWED_TASKS = {\"automatic-speech-recognition\": AutomaticSpeechRecognitionPipeline}\n# You can check the requirements and expectations of each pipelines in their respective\n# directories. Implement directly within the directories.\nALLOWED_TASKS: Dict[str, Type[Pipeline]] = {\n \"text-generation\": TextGenerationPipeline,\n}\n\n\[email protected]_cache()\ndef get_pipeline() -> Pipeline:\n task = os.environ[\"TASK\"]\n model_id = os.environ[\"MODEL_ID\"]\n if task not in ALLOWED_TASKS:\n raise EnvironmentError(f\"{task} is not a valid pipeline for model : {model_id}\")\n return ALLOWED_TASKS[task](model_id)\n\n\nroutes = [\n Route(\"/{whatever:path}\", status_ok),\n Route(\"/{whatever:path}\", pipeline_route, methods=[\"POST\"]),\n]\n\nmiddleware = [Middleware(GZipMiddleware, minimum_size=1000)]\nif os.environ.get(\"DEBUG\", \"\") == \"1\":\n from starlette.middleware.cors import CORSMiddleware\n\n middleware.append(\n Middleware(\n CORSMiddleware,\n allow_origins=[\"*\"],\n allow_headers=[\"*\"],\n allow_methods=[\"*\"],\n )\n )\n\napp = Starlette(routes=routes, middleware=middleware)\n\n\[email protected]_event(\"startup\")\nasync def startup_event():\n reset_logging()\n # Link between `api-inference-community` and framework code.\n if idle.UNLOAD_IDLE:\n asyncio.create_task(idle.live_check_loop(), name=\"live_check_loop\")\n app.get_pipeline = get_pipeline\n try:\n get_pipeline()\n except Exception:\n # We can fail so we can show exception later.\n pass\n\n\ndef reset_logging():\n logging.basicConfig(\n level=logging.DEBUG,\n format=\"%(asctime)s - %(levelname)s - %(message)s\",\n force=True,\n )\n\n\nif __name__ == \"__main__\":\n reset_logging()\n try:\n get_pipeline()\n except Exception:\n # We can fail so we can show exception later.\n pass\n", "docker_images\\pyannote_audio\\Dockerfile": "FROM tiangolo/uvicorn-gunicorn:python3.8\nLABEL maintainer=\"Herv\u00e9 Bredin <[email protected]>\"\n\n# Add any system dependency here\n# RUN apt-get update -y && apt-get install libXXX -y\nRUN apt-get update -y && apt-get install ffmpeg -y\n\nCOPY ./requirements.txt /app\nRUN pip install --no-cache-dir -r requirements.txt\nCOPY ./prestart.sh /app/\n\n\n# Most DL models are quite large in terms of memory, using workers is a HUGE\n# slowdown because of the fork and GIL with python.\n# Using multiple pods seems like a better default strategy.\n# Feel free to override if it does not make sense for your library.\nARG max_workers=1\nENV MAX_WORKERS=$max_workers\nENV PYANNOTE_CACHE=/data\n\n# Necessary on GPU environment docker.\n# TIMEOUT env variable is used by nvcr.io/nvidia/pytorch:xx for another purpose\n# rendering TIMEOUT defined by uvicorn impossible to use correctly\n# We're overriding it to be renamed UVICORN_TIMEOUT\n# UVICORN_TIMEOUT is a useful variable for very large models that take more\n# than 30s (the default) to load in memory.\n# If UVICORN_TIMEOUT is too low, uvicorn will simply never loads as it will\n# kill workers all the time before they finish.\nRUN sed -i 's/TIMEOUT/UVICORN_TIMEOUT/g' /gunicorn_conf.py\nCOPY ./app /app/app\n", "docker_images\\pyannote_audio\\requirements.txt": "starlette==0.27.0\napi-inference-community==0.0.25\ntorch==1.13.1\ntorchvision==0.12.0\ntorchaudio==0.11.0\ntorchtext==0.12.0\nspeechbrain==0.5.12\npyannote-audio==2.0.1\nhuggingface_hub==0.8.1\n", "docker_images\\pyannote_audio\\app\\main.py": "import functools\nimport logging\nimport os\nfrom typing import Dict, Type\n\nfrom api_inference_community.routes import pipeline_route, status_ok\nfrom app.pipelines import AutomaticSpeechRecognitionPipeline, Pipeline\nfrom starlette.applications import Starlette\nfrom starlette.middleware import Middleware\nfrom starlette.middleware.gzip import GZipMiddleware\nfrom starlette.routing import Route\n\n\nTASK = os.getenv(\"TASK\")\nMODEL_ID = os.getenv(\"MODEL_ID\")\n\n\nlogger = logging.getLogger(__name__)\n\n\n# Add the allowed tasks\n# Supported tasks are:\n# - text-generation\n# - text-classification\n# - token-classification\n# - translation\n# - summarization\n# - automatic-speech-recognition\n# - ...\n# For instance\n# from app.pipelines import AutomaticSpeechRecognitionPipeline\n# ALLOWED_TASKS = {\"automatic-speech-recognition\": AutomaticSpeechRecognitionPipeline}\n# You can check the requirements and expectations of each pipelines in their respective\n# directories. Implement directly within the directories.\nALLOWED_TASKS: Dict[str, Type[Pipeline]] = {\n \"automatic-speech-recognition\": AutomaticSpeechRecognitionPipeline\n}\n\n\[email protected]_cache()\ndef get_pipeline() -> Pipeline:\n task = os.environ[\"TASK\"]\n model_id = os.environ[\"MODEL_ID\"]\n if task not in ALLOWED_TASKS:\n raise EnvironmentError(f\"{task} is not a valid pipeline for model : {model_id}\")\n return ALLOWED_TASKS[task](model_id)\n\n\nroutes = [\n Route(\"/{whatever:path}\", status_ok),\n Route(\"/{whatever:path}\", pipeline_route, methods=[\"POST\"]),\n]\n\nmiddleware = [Middleware(GZipMiddleware, minimum_size=1000)]\nif os.environ.get(\"DEBUG\", \"\") == \"1\":\n from starlette.middleware.cors import CORSMiddleware\n\n middleware.append(\n Middleware(\n CORSMiddleware,\n allow_origins=[\"*\"],\n allow_headers=[\"*\"],\n allow_methods=[\"*\"],\n )\n )\n\napp = Starlette(routes=routes, middleware=middleware)\n\n\[email protected]_event(\"startup\")\nasync def startup_event():\n logger = logging.getLogger(\"uvicorn.access\")\n handler = logging.StreamHandler()\n handler.setFormatter(logging.Formatter(\"%(asctime)s - %(levelname)s - %(message)s\"))\n logger.handlers = [handler]\n\n # Link between `api-inference-community` and framework code.\n app.get_pipeline = get_pipeline\n try:\n get_pipeline()\n except Exception:\n # We can fail so we can show exception later.\n pass\n\n\nif __name__ == \"__main__\":\n try:\n get_pipeline()\n except Exception:\n # We can fail so we can show exception later.\n pass\n", "docker_images\\sentence_transformers\\Dockerfile": "FROM tiangolo/uvicorn-gunicorn:python3.8\nLABEL maintainer=\"Omar <[email protected]>\"\n\n# Add any system dependency here\n# RUN apt-get update -y && apt-get install libXXX -y\n\nRUN pip3 install --no-cache-dir torch==1.13.0\n\n\nCOPY ./requirements.txt /app\nRUN pip install --no-cache-dir -r requirements.txt\nCOPY ./prestart.sh /app/\n\n\n# Most DL models are quite large in terms of memory, using workers is a HUGE\n# slowdown because of the fork and GIL with python.\n# Using multiple pods seems like a better default strategy.\n# Feel free to override if it does not make sense for your library.\nARG max_workers=1\nENV MAX_WORKERS=$max_workers\nENV HUGGINGFACE_HUB_CACHE=/data\nENV SENTENCE_TRANSFORMERS_HOME=/data\nENV TRANSFORMERS_CACHE=/data\n\n# Necessary on GPU environment docker.\n# TIMEOUT env variable is used by nvcr.io/nvidia/pytorch:xx for another purpose\n# rendering TIMEOUT defined by uvicorn impossible to use correctly\n# We're overriding it to be renamed UVICORN_TIMEOUT\n# UVICORN_TIMEOUT is a useful variable for very large models that take more\n# than 30s (the default) to load in memory.\n# If UVICORN_TIMEOUT is too low, uvicorn will simply never loads as it will\n# kill workers all the time before they finish.\nRUN sed -i 's/TIMEOUT/UVICORN_TIMEOUT/g' /gunicorn_conf.py\nCOPY ./app /app/app\n", "docker_images\\sentence_transformers\\requirements.txt": "starlette==0.27.0\napi-inference-community==0.0.32\nsentence-transformers==3.0.1\ntransformers==4.41.1\ntokenizers==0.19.1\nprotobuf==3.18.3\nhuggingface_hub==0.23.3\nsacremoses==0.0.53\n# dummy.\n", "docker_images\\sentence_transformers\\app\\main.py": "import functools\nimport logging\nimport os\nfrom typing import Dict, Type\n\nfrom api_inference_community.routes import pipeline_route, status_ok\nfrom app.pipelines import (\n FeatureExtractionPipeline,\n Pipeline,\n SentenceSimilarityPipeline,\n)\nfrom starlette.applications import Starlette\nfrom starlette.middleware import Middleware\nfrom starlette.middleware.gzip import GZipMiddleware\nfrom starlette.routing import Route\n\n\nTASK = os.getenv(\"TASK\")\nMODEL_ID = os.getenv(\"MODEL_ID\")\n\n\nlogger = logging.getLogger(__name__)\n\n\n# Add the allowed tasks\n# Supported tasks are:\n# - text-generation\n# - text-classification\n# - token-classification\n# - translation\n# - summarization\n# - automatic-speech-recognition\n# - ...\n# For instance\n# from app.pipelines import AutomaticSpeechRecognitionPipeline\n# ALLOWED_TASKS = {\"automatic-speech-recognition\": AutomaticSpeechRecognitionPipeline}\n# You can check the requirements and expectations of each pipelines in their respective\n# directories. Implement directly within the directories.\nALLOWED_TASKS: Dict[str, Type[Pipeline]] = {\n \"feature-extraction\": FeatureExtractionPipeline,\n \"sentence-similarity\": SentenceSimilarityPipeline,\n}\n\n\[email protected]_cache()\ndef get_pipeline() -> Pipeline:\n task = os.environ[\"TASK\"]\n model_id = os.environ[\"MODEL_ID\"]\n if task not in ALLOWED_TASKS:\n raise EnvironmentError(f\"{task} is not a valid pipeline for model : {model_id}\")\n return ALLOWED_TASKS[task](model_id)\n\n\nroutes = [\n Route(\"/{whatever:path}\", status_ok),\n Route(\"/{whatever:path}\", pipeline_route, methods=[\"POST\"]),\n]\n\nmiddleware = [Middleware(GZipMiddleware, minimum_size=1000)]\nif os.environ.get(\"DEBUG\", \"\") == \"1\":\n from starlette.middleware.cors import CORSMiddleware\n\n middleware.append(\n Middleware(\n CORSMiddleware,\n allow_origins=[\"*\"],\n allow_headers=[\"*\"],\n allow_methods=[\"*\"],\n )\n )\n\napp = Starlette(routes=routes, middleware=middleware)\n\n\[email protected]_event(\"startup\")\nasync def startup_event():\n logger = logging.getLogger(\"uvicorn.access\")\n handler = logging.StreamHandler()\n handler.setFormatter(logging.Formatter(\"%(asctime)s - %(levelname)s - %(message)s\"))\n logger.handlers = [handler]\n\n # Link between `api-inference-community` and framework code.\n app.get_pipeline = get_pipeline\n try:\n get_pipeline()\n except Exception:\n # We can fail so we can show exception later.\n pass\n\n\nif __name__ == \"__main__\":\n try:\n get_pipeline()\n except Exception:\n # We can fail so we can show exception later.\n pass\n", "docker_images\\setfit\\Dockerfile": "FROM tiangolo/uvicorn-gunicorn:python3.8\nLABEL maintainer=\"Tom Aarsen <[email protected]>\"\n\n# Add any system dependency here\n# RUN apt-get update -y && apt-get install libXXX -y\n\nCOPY ./requirements.txt /app\nRUN pip install --no-cache-dir -r requirements.txt\nCOPY ./prestart.sh /app/\n\n\n# Most DL models are quite large in terms of memory, using workers is a HUGE\n# slowdown because of the fork and GIL with python.\n# Using multiple pods seems like a better default strategy.\n# Feel free to override if it does not make sense for your library.\nARG max_workers=1\nENV MAX_WORKERS=$max_workers\nENV HUGGINGFACE_HUB_CACHE=/data\n\n# Necessary on GPU environment docker.\n# TIMEOUT env variable is used by nvcr.io/nvidia/pytorch:xx for another purpose\n# rendering TIMEOUT defined by uvicorn impossible to use correctly\n# We're overriding it to be renamed UVICORN_TIMEOUT\n# UVICORN_TIMEOUT is a useful variable for very large models that take more\n# than 30s (the default) to load in memory.\n# If UVICORN_TIMEOUT is too low, uvicorn will simply never loads as it will\n# kill workers all the time before they finish.\nRUN sed -i 's/TIMEOUT/UVICORN_TIMEOUT/g' /gunicorn_conf.py\nCOPY ./app /app/app\n", "docker_images\\setfit\\requirements.txt": "starlette==0.27.0\ngit+https://github.com/huggingface/api-inference-community.git@f06a71e72e92caeebabaeced979eacb3542bf2ca\nhuggingface_hub==0.20.2\nsetfit==1.0.3\n", "docker_images\\setfit\\app\\main.py": "import functools\nimport logging\nimport os\nimport pathlib\nfrom typing import Dict, Type\n\nfrom api_inference_community import hub\nfrom api_inference_community.routes import pipeline_route, status_ok\nfrom app.pipelines import Pipeline, TextClassificationPipeline\nfrom huggingface_hub import constants\nfrom starlette.applications import Starlette\nfrom starlette.middleware import Middleware\nfrom starlette.middleware.gzip import GZipMiddleware\nfrom starlette.routing import Route\n\n\nTASK = os.getenv(\"TASK\")\n\n\ndef get_model_id():\n m_id = os.getenv(\"MODEL_ID\")\n # Workaround, when sentence_transformers handles properly this env variable\n # this should not be needed anymore\n if constants.HF_HUB_OFFLINE:\n cache_dir = pathlib.Path(constants.HF_HUB_CACHE)\n m_id = hub.cached_revision_path(\n cache_dir=cache_dir, repo_id=m_id, revision=os.getenv(\"REVISION\")\n )\n return m_id\n\n\nMODEL_ID = get_model_id()\n\nlogger = logging.getLogger(__name__)\n\n\n# Add the allowed tasks\n# Supported tasks are:\n# - text-generation\n# - text-classification\n# - token-classification\n# - translation\n# - summarization\n# - automatic-speech-recognition\n# - ...\n# For instance\n# from app.pipelines import AutomaticSpeechRecognitionPipeline\n# ALLOWED_TASKS = {\"automatic-speech-recognition\": AutomaticSpeechRecognitionPipeline}\n# You can check the requirements and expectations of each pipelines in their respective\n# directories. Implement directly within the directories.\nALLOWED_TASKS: Dict[str, Type[Pipeline]] = {\n \"text-classification\": TextClassificationPipeline,\n}\n\n\[email protected]_cache()\ndef get_pipeline() -> Pipeline:\n task = os.environ[\"TASK\"]\n model_id = MODEL_ID\n if task not in ALLOWED_TASKS:\n raise EnvironmentError(f\"{task} is not a valid pipeline for model : {model_id}\")\n return ALLOWED_TASKS[task](model_id)\n\n\nroutes = [\n Route(\"/{whatever:path}\", status_ok),\n Route(\"/{whatever:path}\", pipeline_route, methods=[\"POST\"]),\n]\n\nmiddleware = [Middleware(GZipMiddleware, minimum_size=1000)]\nif os.environ.get(\"DEBUG\", \"\") == \"1\":\n from starlette.middleware.cors import CORSMiddleware\n\n middleware.append(\n Middleware(\n CORSMiddleware,\n allow_origins=[\"*\"],\n allow_headers=[\"*\"],\n allow_methods=[\"*\"],\n )\n )\n\napp = Starlette(routes=routes, middleware=middleware)\n\n\[email protected]_event(\"startup\")\nasync def startup_event():\n logger = logging.getLogger(\"uvicorn.access\")\n handler = logging.StreamHandler()\n handler.setFormatter(logging.Formatter(\"%(asctime)s - %(levelname)s - %(message)s\"))\n logger.handlers = [handler]\n\n # Link between `api-inference-community` and framework code.\n app.get_pipeline = get_pipeline\n try:\n get_pipeline()\n except Exception:\n # We can fail so we can show exception later.\n pass\n\n\nif __name__ == \"__main__\":\n try:\n get_pipeline()\n except Exception:\n # We can fail so we can show exception later.\n pass\n", "docker_images\\sklearn\\Dockerfile": "FROM mambaorg/micromamba\nLABEL maintainer=\"Adrin Jalali [email protected]\"\n\n# micromamba comes with a default non-root user. But we need root to install\n# our required system packages.\nUSER root\nRUN apt-get update && apt-get install -y curl jq\nUSER $MAMBAUSER\n\n# Most our dockerfiles start from tiangolo/uvicorn-gunicorn:python3.8, but\n# since here we'd like to start from micromamba, we copy necessary files from\n# the uvicorn docker image using `COPY --from=...` commands. These steps are\n# taken from:\n# https://github.com/tiangolo/uvicorn-gunicorn-docker/blob/master/docker-images/python3.8-slim.dockerfile\n\nCOPY --from=tiangolo/uvicorn-gunicorn:python3.8 /start.sh /start.sh\nRUN chmod +x /start.sh\n\nCOPY --from=tiangolo/uvicorn-gunicorn:python3.8 /gunicorn_conf.py /gunicorn_conf.py\n\nCOPY --from=tiangolo/uvicorn-gunicorn:python3.8 /start-reload.sh /start-reload.sh\nRUN chmod +x /start-reload.sh\n\nCOPY --from=tiangolo/uvicorn-gunicorn:python3.8 /app /app\nWORKDIR /app/\n\nENV PYTHONPATH=/app\n\nEXPOSE 80\n\n\n# This part is new and only specific to scikit-learn image.\nENV HUGGINGFACE_HUB_CACHE=/data\n\nCOPY ./app /app/app\n\nCOPY run_app.sh /run_app.sh\nRUN chmod +x /run_app.sh\n\nCMD /run_app.sh\n", "docker_images\\sklearn\\requirements.txt": "starlette>=0.14.2\napi-inference-community>=0.0.25\nhuggingface_hub>=0.5.1\nscikit-learn\njoblib>=1.0.1\n# Dummy changes.\n", "docker_images\\sklearn\\run_app.sh": "#!/bin/bash --login\n# This file creates an environment with all required dependencies for the given\n# model, and then runs the start command.\n\n# This makes it easy to see in logs what exactly is being run.\nset -xe\n\nget_requirements() {\n requirements=\"pandas uvicorn gunicorn api-inference-community skops\"\n # this next command is needed to run the while loop in the same process and\n # therefore modify the same $requirements variable. Otherwise the loop would be\n # a separate process and the variable wouldn't be accessible from this parent\n # process.\n shopt -s lastpipe\n jq '.sklearn.environment' /tmp/config.json | jq '.[]' | while read r; do\n requirements+=\" $r\"\n done\n\n # not sure why these are required. But if they're not here, the string passed\n # to micromamba is kinda not parsable by it.\n requirements=$(echo \"$requirements\" | sed \"s/'//g\")\n requirements=$(echo \"$requirements\" | sed \"s/\\\"//g\")\n echo $requirements\n}\n\n# We download only the config file and use `jq` to extract the requirements. If\n# the download fails, we use a default set of dependencies. We need to capture\n# the output of `curl` here so that if it fails, it doesn't make the whole\n# script to exit, which it would do due to the -e flag we've set above the\n# script.\nresponse=\"$(curl https://huggingface.co/$MODEL_ID/raw/main/config.json -f --output /tmp/config.json)\" || response=$?\nif [ -z $response ]; then\n requirements=$(get_requirements)\nelse\n # if the curl command is not successful, we use a default set of\n # dependencies, and use the latest scikit-learn version. This is to allow\n # users for a basic usage if they haven't put the config.json file in their\n # repository.\n requirements=\"pandas uvicorn gunicorn api-inference-community scikit-learn\"\nfi\n\nmicromamba create -c conda-forge -y -q --name=api-inference-model-env $requirements\n\nmicromamba activate api-inference-model-env\n\n# start.sh file is not in our repo, rather taken from the\n# `uvicorn-gunicorn-docker` repo. You can check the Dockerfile to see where\n# exactly it is coming from.\n/start.sh\n", "docker_images\\sklearn\\app\\main.py": "import logging\nimport os\nfrom typing import Dict, Type\n\nfrom api_inference_community.routes import pipeline_route, status_ok\nfrom app.pipelines import (\n Pipeline,\n TabularClassificationPipeline,\n TabularRegressionPipeline,\n TextClassificationPipeline,\n)\nfrom starlette.applications import Starlette\nfrom starlette.middleware import Middleware\nfrom starlette.middleware.gzip import GZipMiddleware\nfrom starlette.routing import Route\n\n\nTASK = os.getenv(\"TASK\")\nMODEL_ID = os.getenv(\"MODEL_ID\")\n\n\nlogger = logging.getLogger(__name__)\n\n\n# Add the allowed tasks\n# Supported tasks are:\n# - text-generation\n# - text-classification\n# - token-classification\n# - translation\n# - summarization\n# - automatic-speech-recognition\n# - ...\n# For instance\n# from app.pipelines import AutomaticSpeechRecognitionPipeline\n# ALLOWED_TASKS = {\"automatic-speech-recognition\": AutomaticSpeechRecognitionPipeline}\n# You can check the requirements and expectations of each pipelines in their respective\n# directories. Implement directly within the directories.\nALLOWED_TASKS: Dict[str, Type[Pipeline]] = {\n # IMPLEMENT_THIS: Add your implemented tasks here!\n \"tabular-classification\": TabularClassificationPipeline,\n \"tabular-regression\": TabularRegressionPipeline,\n \"text-classification\": TextClassificationPipeline,\n}\n\n\ndef get_pipeline(task=None, model_id=None) -> Pipeline:\n task = task or os.environ[\"TASK\"]\n model_id = model_id or os.environ[\"MODEL_ID\"]\n if task not in ALLOWED_TASKS:\n raise EnvironmentError(\n f\"{task} is not a valid pipeline for model : {model_id} ({','.join(ALLOWED_TASKS.keys())})\"\n )\n return ALLOWED_TASKS[task](model_id)\n\n\nroutes = [\n Route(\"/{whatever:path}\", status_ok),\n Route(\"/{whatever:path}\", pipeline_route, methods=[\"POST\"]),\n]\n\nmiddleware = [Middleware(GZipMiddleware, minimum_size=1000)]\nif os.environ.get(\"DEBUG\", \"\") == \"1\":\n from starlette.middleware.cors import CORSMiddleware\n\n middleware.append(\n Middleware(\n CORSMiddleware,\n allow_origins=[\"*\"],\n allow_headers=[\"*\"],\n allow_methods=[\"*\"],\n )\n )\n\napp = Starlette(routes=routes, middleware=middleware)\n\n\[email protected]_event(\"startup\")\nasync def startup_event():\n logger = logging.getLogger(\"uvicorn.access\")\n handler = logging.StreamHandler()\n handler.setFormatter(logging.Formatter(\"%(asctime)s - %(levelname)s - %(message)s\"))\n logger.handlers = [handler]\n\n # Link between `api-inference-community` and framework code.\n app.get_pipeline = get_pipeline\n try:\n get_pipeline()\n except Exception:\n # We can fail so we can show exception later.\n pass\n\n\nif __name__ == \"__main__\":\n try:\n get_pipeline()\n except Exception:\n # We can fail so we can show exception later.\n pass\n", "docker_images\\spacy\\Dockerfile": "FROM tiangolo/uvicorn-gunicorn:python3.8\nLABEL maintainer=\"Omar Sanseviero [email protected]\"\n\n# Add any system dependency here\n# RUN apt-get update -y && apt-get install libXXX -y\n\nCOPY ./requirements.txt /app\nRUN pip install --no-cache-dir -r requirements.txt\nCOPY ./prestart.sh /app/\n\n\n# Most DL models are quite large in terms of memory, using workers is a HUGE\n# slowdown because of the fork and GIL with python.\n# Using multiple pods seems like a better default strategy.\n# Feel free to override if it does not make sense for your library.\nARG max_workers=1\nENV MAX_WORKERS=$max_workers\nENV HUGGINGFACE_HUB_CACHE=/data\nENV PIP_CACHE=/data\n\n# Necessary on GPU environment docker.\n# TIMEOUT env variable is used by nvcr.io/nvidia/pytorch:xx for another purpose\n# rendering TIMEOUT defined by uvicorn impossible to use correctly\n# We're overriding it to be renamed UVICORN_TIMEOUT\n# UVICORN_TIMEOUT is a useful variable for very large models that take more\n# than 30s (the default) to load in memory.\n# If UVICORN_TIMEOUT is too low, uvicorn will simply never loads as it will\n# kill workers all the time before they finish.\nRUN sed -i 's/TIMEOUT/UVICORN_TIMEOUT/g' /gunicorn_conf.py\nCOPY ./app /app/app\n", "docker_images\\spacy\\requirements.txt": "starlette==0.27.0\napi-inference-community==0.0.23\nhuggingface_hub==0.5.1\nrequests==2.31.0\n", "docker_images\\spacy\\app\\main.py": "import functools\nimport logging\nimport os\nfrom typing import Dict, Type\n\nfrom api_inference_community.routes import pipeline_route, status_ok\nfrom app.pipelines import (\n Pipeline,\n SentenceSimilarityPipeline,\n TextClassificationPipeline,\n TokenClassificationPipeline,\n)\nfrom starlette.applications import Starlette\nfrom starlette.middleware import Middleware\nfrom starlette.middleware.gzip import GZipMiddleware\nfrom starlette.routing import Route\n\n\nTASK = os.getenv(\"TASK\")\nMODEL_ID = os.getenv(\"MODEL_ID\")\n\n\nlogger = logging.getLogger(__name__)\n\n\n# Add the allowed tasks\n# Supported tasks are:\n# - text-generation\n# - text-classification\n# - token-classification\n# - translation\n# - summarization\n# - automatic-speech-recognition\n# - sentence-similarity\n# - ...\n# For instance\n# from app.pipelines import AutomaticSpeechRecognitionPipeline\n# ALLOWED_TASKS = {\"automatic-speech-recognition\": AutomaticSpeechRecognitionPipeline}\n# You can check the requirements and expectations of each pipelines in their respective\n# directories. Implement directly within the directories.\nALLOWED_TASKS: Dict[str, Type[Pipeline]] = {\n \"token-classification\": TokenClassificationPipeline,\n \"text-classification\": TextClassificationPipeline,\n \"sentence-similarity\": SentenceSimilarityPipeline,\n}\n\n\[email protected]_cache()\ndef get_pipeline() -> Pipeline:\n task = os.environ[\"TASK\"]\n model_id = os.environ[\"MODEL_ID\"]\n if task not in ALLOWED_TASKS:\n raise EnvironmentError(f\"{task} is not a valid pipeline for model : {model_id}\")\n return ALLOWED_TASKS[task](model_id)\n\n\nroutes = [\n Route(\"/{whatever:path}\", status_ok),\n Route(\"/{whatever:path}\", pipeline_route, methods=[\"POST\"]),\n]\n\nmiddleware = [Middleware(GZipMiddleware, minimum_size=1000)]\nif os.environ.get(\"DEBUG\", \"\") == \"1\":\n from starlette.middleware.cors import CORSMiddleware\n\n middleware.append(\n Middleware(\n CORSMiddleware,\n allow_origins=[\"*\"],\n allow_headers=[\"*\"],\n allow_methods=[\"*\"],\n )\n )\n\napp = Starlette(routes=routes, middleware=middleware)\n\n\[email protected]_event(\"startup\")\nasync def startup_event():\n logger = logging.getLogger(\"uvicorn.access\")\n handler = logging.StreamHandler()\n handler.setFormatter(logging.Formatter(\"%(asctime)s - %(levelname)s - %(message)s\"))\n logger.handlers = [handler]\n\n # Link between `api-inference-community` and framework code.\n app.get_pipeline = get_pipeline\n try:\n get_pipeline()\n except Exception:\n # We can fail so we can show exception later.\n pass\n\n\nif __name__ == \"__main__\":\n try:\n get_pipeline()\n except Exception:\n # We can fail so we can show exception later.\n pass\n", "docker_images\\span_marker\\Dockerfile": "FROM tiangolo/uvicorn-gunicorn:python3.8\nLABEL maintainer=\"Tom Aarsen <[email protected]>\"\n\n# Add any system dependency here\n# RUN apt-get update -y && apt-get install libXXX -y\n\nCOPY ./requirements.txt /app\nRUN pip install --no-cache-dir -r requirements.txt\nCOPY ./prestart.sh /app/\n\n\n# Most DL models are quite large in terms of memory, using workers is a HUGE\n# slowdown because of the fork and GIL with python.\n# Using multiple pods seems like a better default strategy.\n# Feel free to override if it does not make sense for your library.\nARG max_workers=1\nENV MAX_WORKERS=$max_workers\nENV HUGGINGFACE_HUB_CACHE=/data\n\n# Necessary on GPU environment docker.\n# TIMEOUT env variable is used by nvcr.io/nvidia/pytorch:xx for another purpose\n# rendering TIMEOUT defined by uvicorn impossible to use correctly\n# We're overriding it to be renamed UVICORN_TIMEOUT\n# UVICORN_TIMEOUT is a useful variable for very large models that take more\n# than 30s (the default) to load in memory.\n# If UVICORN_TIMEOUT is too low, uvicorn will simply never loads as it will\n# kill workers all the time before they finish.\nRUN sed -i 's/TIMEOUT/UVICORN_TIMEOUT/g' /gunicorn_conf.py\nCOPY ./app /app/app\n", "docker_images\\span_marker\\requirements.txt": "starlette==0.27.0\napi-inference-community==0.0.32\nhuggingface_hub>=0.17.3\nspan_marker>=1.4.0", "docker_images\\span_marker\\app\\main.py": "import functools\nimport logging\nimport os\nfrom typing import Dict, Type\n\nfrom api_inference_community.routes import pipeline_route, status_ok\nfrom app.pipelines import Pipeline, TokenClassificationPipeline\nfrom starlette.applications import Starlette\nfrom starlette.middleware import Middleware\nfrom starlette.middleware.gzip import GZipMiddleware\nfrom starlette.routing import Route\n\n\nTASK = os.getenv(\"TASK\")\nMODEL_ID = os.getenv(\"MODEL_ID\")\n\n\nlogger = logging.getLogger(__name__)\n\n\n# Add the allowed tasks\n# Supported tasks are:\n# - text-generation\n# - text-classification\n# - token-classification\n# - translation\n# - summarization\n# - automatic-speech-recognition\n# - ...\n# For instance\n# from app.pipelines import AutomaticSpeechRecognitionPipeline\n# ALLOWED_TASKS = {\"automatic-speech-recognition\": AutomaticSpeechRecognitionPipeline}\n# You can check the requirements and expectations of each pipelines in their respective\n# directories. Implement directly within the directories.\nALLOWED_TASKS: Dict[str, Type[Pipeline]] = {\n \"token-classification\": TokenClassificationPipeline\n}\n\n\[email protected]_cache()\ndef get_pipeline() -> Pipeline:\n task = os.environ[\"TASK\"]\n model_id = os.environ[\"MODEL_ID\"]\n if task not in ALLOWED_TASKS:\n raise EnvironmentError(f\"{task} is not a valid pipeline for model : {model_id}\")\n return ALLOWED_TASKS[task](model_id)\n\n\nroutes = [\n Route(\"/{whatever:path}\", status_ok),\n Route(\"/{whatever:path}\", pipeline_route, methods=[\"POST\"]),\n]\n\nmiddleware = [Middleware(GZipMiddleware, minimum_size=1000)]\nif os.environ.get(\"DEBUG\", \"\") == \"1\":\n from starlette.middleware.cors import CORSMiddleware\n\n middleware.append(\n Middleware(\n CORSMiddleware,\n allow_origins=[\"*\"],\n allow_headers=[\"*\"],\n allow_methods=[\"*\"],\n )\n )\n\napp = Starlette(routes=routes, middleware=middleware)\n\n\[email protected]_event(\"startup\")\nasync def startup_event():\n logger = logging.getLogger(\"uvicorn.access\")\n handler = logging.StreamHandler()\n handler.setFormatter(logging.Formatter(\"%(asctime)s - %(levelname)s - %(message)s\"))\n logger.handlers = [handler]\n\n # Link between `api-inference-community` and framework code.\n app.get_pipeline = get_pipeline\n try:\n get_pipeline()\n except Exception:\n # We can fail so we can show exception later.\n pass\n\n\nif __name__ == \"__main__\":\n try:\n get_pipeline()\n except Exception:\n # We can fail so we can show exception later.\n pass\n", "docker_images\\speechbrain\\Dockerfile": "FROM tiangolo/uvicorn-gunicorn:python3.9\nLABEL maintainer=\"me <[email protected]>\"\n\n# Add any system dependency here\n# RUN apt-get update -y && apt-get install libXXX -y\nRUN apt-get update -y && apt-get install ffmpeg -y\n\nRUN pip install --no-cache-dir torch==2.0\nCOPY ./requirements.txt /app\nRUN pip install --no-cache-dir -r requirements.txt\nCOPY ./prestart.sh /app/\n\n\n# Most DL models are quite large in terms of memory, using workers is a HUGE\n# slowdown because of the fork and GIL with python.\n# Using multiple pods seems like a better default strategy.\n# Feel free to override if it does not make sense for your library.\nARG max_workers=1\nENV MAX_WORKERS=$max_workers\nENV HUGGINGFACE_HUB_CACHE=/data\n\n# Necessary on GPU environment docker.\n# TIMEOUT env variable is used by nvcr.io/nvidia/pytorch:xx for another purpose\n# rendering TIMEOUT defined by uvicorn impossible to use correctly\n# We're overriding it to be renamed UVICORN_TIMEOUT\n# UVICORN_TIMEOUT is a useful variable for very large models that take more\n# than 30s (the default) to load in memory.\n# If UVICORN_TIMEOUT is too low, uvicorn will simply never loads as it will\n# kill workers all the time before they finish.\nRUN sed -i 's/TIMEOUT/UVICORN_TIMEOUT/g' /gunicorn_conf.py\nCOPY ./app /app/app\n", "docker_images\\speechbrain\\requirements.txt": "starlette==0.27.0\n# TODO: Replace with the correct tag once the core PR is merged\napi-inference-community==0.0.32\nhuggingface_hub>=0.7\ntransformers==4.30.0\ngit+https://github.com/speechbrain/[email protected]\nhttps://github.com/kpu/kenlm/archive/master.zip\npygtrie\n#Dummy.\n", "docker_images\\speechbrain\\app\\main.py": "import functools\nimport logging\nimport os\nfrom typing import Dict, Type\n\nfrom api_inference_community.routes import pipeline_route, status_ok\nfrom app.pipelines import (\n AudioClassificationPipeline,\n AudioToAudioPipeline,\n AutomaticSpeechRecognitionPipeline,\n Pipeline,\n TextToSpeechPipeline,\n TextToTextPipeline,\n)\nfrom starlette.applications import Starlette\nfrom starlette.routing import Route\n\n\nTASK = os.getenv(\"TASK\")\nMODEL_ID = os.getenv(\"MODEL_ID\")\n\n\nlogger = logging.getLogger(__name__)\n\n\n# Add the allowed tasks\n# Supported tasks are:\n# - text-generation\n# - text-classification\n# - token-classification\n# - translation\n# - summarization\n# - automatic-speech-recognition\n# - ...\n# For instance\n# from app.pipelines import AutomaticSpeechRecognitionPipeline\n# ALLOWED_TASKS = {\"automatic-speech-recognition\": AutomaticSpeechRecognitionPipeline}\n# You can check the requirements and expectations of each pipelines in their respective\n# directories. Implement directly within the directories.\nALLOWED_TASKS: Dict[str, Type[Pipeline]] = {\n \"audio-classification\": AudioClassificationPipeline,\n \"audio-to-audio\": AudioToAudioPipeline,\n \"automatic-speech-recognition\": AutomaticSpeechRecognitionPipeline,\n \"text-to-speech\": TextToSpeechPipeline,\n \"text2text-generation\": TextToTextPipeline,\n}\n\n\[email protected]_cache()\ndef get_pipeline() -> Pipeline:\n task = os.environ[\"TASK\"]\n model_id = os.environ[\"MODEL_ID\"]\n if task not in ALLOWED_TASKS:\n raise EnvironmentError(f\"{task} is not a valid pipeline for model : {model_id}\")\n return ALLOWED_TASKS[task](model_id)\n\n\nroutes = [\n Route(\"/{whatever:path}\", status_ok),\n Route(\"/{whatever:path}\", pipeline_route, methods=[\"POST\"]),\n]\n\napp = Starlette(routes=routes)\nif os.environ.get(\"DEBUG\", \"\") == \"1\":\n from starlette.middleware.cors import CORSMiddleware\n\n app.add_middleware(\n CORSMiddleware, allow_origins=[\"*\"], allow_headers=[\"*\"], allow_methods=[\"*\"]\n )\n\n\[email protected]_event(\"startup\")\nasync def startup_event():\n logger = logging.getLogger(\"uvicorn.access\")\n handler = logging.StreamHandler()\n handler.setFormatter(logging.Formatter(\"%(asctime)s - %(levelname)s - %(message)s\"))\n logger.handlers = [handler]\n\n # Link between `api-inference-community` and framework code.\n app.get_pipeline = get_pipeline\n try:\n get_pipeline()\n except Exception:\n # We can fail so we can show exception later.\n pass\n\n\nif __name__ == \"__main__\":\n try:\n get_pipeline()\n except Exception:\n # We can fail so we can show exception later.\n pass\n", "docker_images\\stanza\\Dockerfile": "FROM tiangolo/uvicorn-gunicorn:python3.8\nLABEL maintainer=\"me <[email protected]>\"\n\n# Add any system dependency here\n# RUN apt-get update -y && apt-get install libXXX -y\n\nCOPY ./requirements.txt /app\nRUN pip install --no-cache-dir -r requirements.txt\nCOPY ./prestart.sh /app/\n\n\n# Most DL models are quite large in terms of memory, using workers is a HUGE\n# slowdown because of the fork and GIL with python.\n# Using multiple pods seems like a better default strategy.\n# Feel free to override if it does not make sense for your library.\nARG max_workers=1\nENV MAX_WORKERS=$max_workers\nENV HUGGINGFACE_HUB_CACHE=/data\n\n# Necessary on GPU environment docker.\n# TIMEOUT env variable is used by nvcr.io/nvidia/pytorch:xx for another purpose\n# rendering TIMEOUT defined by uvicorn impossible to use correctly\n# We're overriding it to be renamed UVICORN_TIMEOUT\n# UVICORN_TIMEOUT is a useful variable for very large models that take more\n# than 30s (the default) to load in memory.\n# If UVICORN_TIMEOUT is too low, uvicorn will simply never loads as it will\n# kill workers all the time before they finish.\nRUN sed -i 's/TIMEOUT/UVICORN_TIMEOUT/g' /gunicorn_conf.py\nCOPY ./app /app/app\n", "docker_images\\stanza\\requirements.txt": "starlette==0.27.0\napi-inference-community==0.0.23\nhuggingface_hub==0.5.1\nstanza==1.3.0\n", "docker_images\\stanza\\app\\main.py": "import functools\nimport logging\nimport os\nfrom typing import Dict, Type\n\nfrom api_inference_community.routes import pipeline_route, status_ok\nfrom app.pipelines import Pipeline, TokenClassificationPipeline\nfrom starlette.applications import Starlette\nfrom starlette.middleware import Middleware\nfrom starlette.middleware.gzip import GZipMiddleware\nfrom starlette.routing import Route\n\n\nTASK = os.getenv(\"TASK\")\nMODEL_ID = os.getenv(\"MODEL_ID\")\n\n\nlogger = logging.getLogger(__name__)\n\n\n# Add the allowed tasks\n# Supported tasks are:\n# - text-generation\n# - text-classification\n# - token-classification\n# - translation\n# - summarization\n# - automatic-speech-recognition\n# - ...\n# For instance\n# from app.pipelines import AutomaticSpeechRecognitionPipeline\n# ALLOWED_TASKS = {\"automatic-speech-recognition\": AutomaticSpeechRecognitionPipeline}\n# You can check the requirements and expectations of each pipelines in their respective\n# directories. Implement directly within the directories.\nALLOWED_TASKS: Dict[str, Type[Pipeline]] = {\n \"token-classification\": TokenClassificationPipeline\n}\n\n\[email protected]_cache()\ndef get_pipeline() -> Pipeline:\n task = os.environ[\"TASK\"]\n model_id = os.environ[\"MODEL_ID\"]\n if task not in ALLOWED_TASKS:\n raise EnvironmentError(f\"{task} is not a valid pipeline for model : {model_id}\")\n return ALLOWED_TASKS[task](model_id)\n\n\nroutes = [\n Route(\"/{whatever:path}\", status_ok),\n Route(\"/{whatever:path}\", pipeline_route, methods=[\"POST\"]),\n]\n\nmiddleware = [Middleware(GZipMiddleware, minimum_size=1000)]\nif os.environ.get(\"DEBUG\", \"\") == \"1\":\n from starlette.middleware.cors import CORSMiddleware\n\n middleware.append(\n Middleware(\n CORSMiddleware,\n allow_origins=[\"*\"],\n allow_headers=[\"*\"],\n allow_methods=[\"*\"],\n )\n )\n\napp = Starlette(routes=routes, middleware=middleware)\n\n\[email protected]_event(\"startup\")\nasync def startup_event():\n logger = logging.getLogger(\"uvicorn.access\")\n handler = logging.StreamHandler()\n handler.setFormatter(logging.Formatter(\"%(asctime)s - %(levelname)s - %(message)s\"))\n logger.handlers = [handler]\n\n # Link between `api-inference-community` and framework code.\n app.get_pipeline = get_pipeline\n try:\n get_pipeline()\n except Exception:\n # We can fail so we can show exception later.\n pass\n\n\nif __name__ == \"__main__\":\n try:\n get_pipeline()\n except Exception:\n # We can fail so we can show exception later.\n pass\n", "docker_images\\timm\\Dockerfile": "FROM tiangolo/uvicorn-gunicorn:python3.8\nLABEL maintainer=\"me <[email protected]>\"\n\n# Add any system dependency here\n# RUN apt-get update -y && apt-get install libXXX -y\n\nCOPY ./requirements.txt /app\nRUN pip install --no-cache-dir -r requirements.txt\nCOPY ./prestart.sh /app/\n\n\n# Most DL models are quite large in terms of memory, using workers is a HUGE\n# slowdown because of the fork and GIL with python.\n# Using multiple pods seems like a better default strategy.\n# Feel free to override if it does not make sense for your library.\nARG max_workers=1\nENV MAX_WORKERS=$max_workers\nENV TORCH_HOME=/data/\n\n# Necessary on GPU environment docker.\n# TIMEOUT env variable is used by nvcr.io/nvidia/pytorch:xx for another purpose\n# rendering TIMEOUT defined by uvicorn impossible to use correctly\n# We're overriding it to be renamed UVICORN_TIMEOUT\n# UVICORN_TIMEOUT is a useful variable for very large models that take more\n# than 30s (the default) to load in memory.\n# If UVICORN_TIMEOUT is too low, uvicorn will simply never loads as it will\n# kill workers all the time before they finish.\nRUN sed -i 's/TIMEOUT/UVICORN_TIMEOUT/g' /gunicorn_conf.py\nCOPY ./app /app/app\n", "docker_images\\timm\\requirements.txt": "starlette==0.27.0\napi-inference-community==0.0.32\nhuggingface_hub>=0.11.1\ntimm>=1.0.7\n#dummy\n", "docker_images\\timm\\app\\main.py": "import functools\nimport logging\nimport os\nfrom typing import Dict, Type\n\nfrom api_inference_community.routes import pipeline_route, status_ok\nfrom app.pipelines import ImageClassificationPipeline, Pipeline\nfrom starlette.applications import Starlette\nfrom starlette.middleware import Middleware\nfrom starlette.middleware.gzip import GZipMiddleware\nfrom starlette.routing import Route\n\n\nTASK = os.getenv(\"TASK\")\nMODEL_ID = os.getenv(\"MODEL_ID\")\n\n\nlogger = logging.getLogger(__name__)\n\n# Add the allowed tasks\n# Supported tasks are:\n# - text-generation\n# - text-classification\n# - token-classification\n# - translation\n# - summarization\n# - automatic-speech-recognition\n# - ...\n# For instance\n# from app.pipelines import AutomaticSpeecRecognitionPipeline\n# ALLOWED_TASKS = {\"automatic-speech-recognition\": AutomaticSpeecRecognitionPipeline}\n# You can check the requirements and expectations of each pipelines in their respective\n# directories. Implement directly within the directories.\nALLOWED_TASKS: Dict[str, Type[Pipeline]] = {\n \"image-classification\": ImageClassificationPipeline\n}\n\n\[email protected]_cache()\ndef get_pipeline() -> Pipeline:\n task = os.environ[\"TASK\"]\n model_id = os.environ[\"MODEL_ID\"]\n if task not in ALLOWED_TASKS:\n raise EnvironmentError(f\"{task} is not a valid pipeline for model : {model_id}\")\n return ALLOWED_TASKS[task](model_id)\n\n\nroutes = [\n Route(\"/{whatever:path}\", status_ok),\n Route(\"/{whatever:path}\", pipeline_route, methods=[\"POST\"]),\n]\n\nmiddleware = [Middleware(GZipMiddleware, minimum_size=1000)]\nif os.environ.get(\"DEBUG\", \"\") == \"1\":\n from starlette.middleware.cors import CORSMiddleware\n\n middleware.append(\n Middleware(\n CORSMiddleware,\n allow_origins=[\"*\"],\n allow_headers=[\"*\"],\n allow_methods=[\"*\"],\n )\n )\n\napp = Starlette(routes=routes, middleware=middleware)\n\n\[email protected]_event(\"startup\")\nasync def startup_event():\n logger = logging.getLogger(\"uvicorn.access\")\n handler = logging.StreamHandler()\n handler.setFormatter(logging.Formatter(\"%(asctime)s - %(levelname)s - %(message)s\"))\n logger.handlers = [handler]\n\n # Link between `api-inference-community` and framework code.\n app.get_pipeline = get_pipeline\n try:\n get_pipeline()\n except Exception:\n # We can fail so we can show exception later.\n pass\n\n\nif __name__ == \"__main__\":\n try:\n get_pipeline()\n except Exception:\n # We can fail so we can show exception later.\n pass\n"} | 2 |
audio-transformers-course | {"type": "directory", "name": "audio-transformers-course", "children": [{"type": "directory", "name": "assets", "children": [{"type": "directory", "name": "img", "children": []}]}, {"type": "directory", "name": "chapters", "children": [{"type": "directory", "name": "bn", "children": [{"type": "directory", "name": "chapter0", "children": [{"type": "file", "name": "community.mdx"}, {"type": "file", "name": "get_ready.mdx"}, {"type": "file", "name": "introduction.mdx"}]}, {"type": "directory", "name": "chapter1", "children": [{"type": "file", "name": "audio_data.mdx"}, {"type": "file", "name": "introduction.mdx"}, {"type": "file", "name": "load_and_explore.mdx"}, {"type": "file", "name": "preprocessing.mdx"}, {"type": "file", "name": "quiz.mdx"}, {"type": "file", "name": "streaming.mdx"}, {"type": "file", "name": "supplemental_reading.mdx"}]}, {"type": "directory", "name": "chapter2", "children": [{"type": "file", "name": "asr_pipeline.mdx"}, {"type": "file", "name": "audio_classification_pipeline.mdx"}, {"type": "file", "name": "hands_on.mdx"}, {"type": "file", "name": "introduction.mdx"}]}, {"type": "directory", "name": "events", "children": [{"type": "file", "name": "introduction.mdx"}]}, {"type": "file", "name": "_toctree.yml"}]}, {"type": "directory", "name": "en", "children": [{"type": "directory", "name": "chapter0", "children": [{"type": "file", "name": "community.mdx"}, {"type": "file", "name": "get_ready.mdx"}, {"type": "file", "name": "introduction.mdx"}]}, {"type": "directory", "name": "chapter1", "children": [{"type": "file", "name": "audio_data.mdx"}, {"type": "file", "name": "introduction.mdx"}, {"type": "file", "name": "load_and_explore.mdx"}, {"type": "file", "name": "preprocessing.mdx"}, {"type": "file", "name": "quiz.mdx"}, {"type": "file", "name": "streaming.mdx"}, {"type": "file", "name": "supplemental_reading.mdx"}]}, {"type": "directory", "name": "chapter2", "children": [{"type": "file", "name": "asr_pipeline.mdx"}, {"type": "file", "name": "audio_classification_pipeline.mdx"}, {"type": "file", "name": "hands_on.mdx"}, {"type": "file", "name": "introduction.mdx"}, {"type": "file", "name": "tts_pipeline.mdx"}]}, {"type": "directory", "name": "chapter3", "children": [{"type": "file", "name": "classification.mdx"}, {"type": "file", "name": "ctc.mdx"}, {"type": "file", "name": "introduction.mdx"}, {"type": "file", "name": "quiz.mdx"}, {"type": "file", "name": "seq2seq.mdx"}, {"type": "file", "name": "supplemental_reading.mdx"}]}, {"type": "directory", "name": "chapter4", "children": [{"type": "file", "name": "classification_models.mdx"}, {"type": "file", "name": "demo.mdx"}, {"type": "file", "name": "fine-tuning.mdx"}, {"type": "file", "name": "hands_on.mdx"}, {"type": "file", "name": "introduction.mdx"}]}, {"type": "directory", "name": "chapter5", "children": [{"type": "file", "name": "asr_models.mdx"}, {"type": "file", "name": "choosing_dataset.mdx"}, {"type": "file", "name": "demo.mdx"}, {"type": "file", "name": "evaluation.mdx"}, {"type": "file", "name": "fine-tuning.mdx"}, {"type": "file", "name": "hands_on.mdx"}, {"type": "file", "name": "introduction.mdx"}, {"type": "file", "name": "supplemental_reading.mdx"}]}, {"type": "directory", "name": "chapter6", "children": [{"type": "file", "name": "evaluation.mdx"}, {"type": "file", "name": "fine-tuning.mdx"}, {"type": "file", "name": "hands_on.mdx"}, {"type": "file", "name": "introduction.mdx"}, {"type": "file", "name": "pre-trained_models.mdx"}, {"type": "file", "name": "supplemental_reading.mdx"}, {"type": "file", "name": "tts_datasets.mdx"}]}, {"type": "directory", "name": "chapter7", "children": [{"type": "file", "name": "hands_on.mdx"}, {"type": "file", "name": "introduction.mdx"}, {"type": "file", "name": "speech-to-speech.mdx"}, {"type": "file", "name": "supplemental_reading.mdx"}, {"type": "file", "name": "transcribe-meeting.mdx"}, {"type": "file", "name": "voice-assistant.mdx"}]}, {"type": "directory", "name": "chapter8", "children": [{"type": "file", "name": "certification.mdx"}, {"type": "file", "name": "introduction.mdx"}]}, {"type": "directory", "name": "events", "children": [{"type": "file", "name": "introduction.mdx"}]}, {"type": "file", "name": "_toctree.yml"}]}, {"type": "directory", "name": "es", "children": [{"type": "directory", "name": "chapter0", "children": [{"type": "file", "name": "community.mdx"}, {"type": "file", "name": "get_ready.mdx"}, {"type": "file", "name": "introduction.mdx"}]}, {"type": "directory", "name": "chapter1", "children": [{"type": "file", "name": "audio_data.mdx"}, {"type": "file", "name": "introduction.mdx"}, {"type": "file", "name": "load_and_explore.mdx"}, {"type": "file", "name": "preprocessing.mdx"}, {"type": "file", "name": "quiz.mdx"}, {"type": "file", "name": "streaming.mdx"}, {"type": "file", "name": "supplemental_reading.mdx"}]}, {"type": "directory", "name": "chapter2", "children": [{"type": "file", "name": "asr_pipeline.mdx"}, {"type": "file", "name": "audio_classification_pipeline.mdx"}, {"type": "file", "name": "hands_on.mdx"}, {"type": "file", "name": "introduction.mdx"}]}, {"type": "file", "name": "_toctree.yml"}]}, {"type": "directory", "name": "fr", "children": [{"type": "directory", "name": "chapter0", "children": [{"type": "file", "name": "community.mdx"}, {"type": "file", "name": "get_ready.mdx"}, {"type": "file", "name": "introduction.mdx"}]}, {"type": "directory", "name": "chapter1", "children": [{"type": "file", "name": "audio_data.mdx"}, {"type": "file", "name": "introduction.mdx"}, {"type": "file", "name": "load_and_explore.mdx"}, {"type": "file", "name": "preprocessing.mdx"}, {"type": "file", "name": "quiz.mdx"}, {"type": "file", "name": "streaming.mdx"}, {"type": "file", "name": "supplemental_reading.mdx"}]}, {"type": "directory", "name": "chapter2", "children": [{"type": "file", "name": "asr_pipeline.mdx"}, {"type": "file", "name": "audio_classification_pipeline.mdx"}, {"type": "file", "name": "hands_on.mdx"}, {"type": "file", "name": "introduction.mdx"}]}, {"type": "directory", "name": "chapter3", "children": [{"type": "file", "name": "classification.mdx"}, {"type": "file", "name": "ctc.mdx"}, {"type": "file", "name": "introduction.mdx"}, {"type": "file", "name": "seq2seq.mdx"}, {"type": "file", "name": "supplemental_reading.mdx"}]}, {"type": "directory", "name": "chapter4", "children": [{"type": "file", "name": "classification_models.mdx"}, {"type": "file", "name": "demo.mdx"}, {"type": "file", "name": "fine-tuning.mdx"}, {"type": "file", "name": "hands_on.mdx"}, {"type": "file", "name": "introduction.mdx"}]}, {"type": "directory", "name": "chapter5", "children": [{"type": "file", "name": "asr_models.mdx"}, {"type": "file", "name": "choosing_dataset.mdx"}, {"type": "file", "name": "demo.mdx"}, {"type": "file", "name": "evaluation.mdx"}, {"type": "file", "name": "fine-tuning.mdx"}, {"type": "file", "name": "hands_on.mdx"}, {"type": "file", "name": "introduction.mdx"}, {"type": "file", "name": "supplemental_reading.mdx"}]}, {"type": "directory", "name": "chapter6", "children": [{"type": "file", "name": "evaluation.mdx"}, {"type": "file", "name": "fine-tuning.mdx"}, {"type": "file", "name": "hands_on.mdx"}, {"type": "file", "name": "introduction.mdx"}, {"type": "file", "name": "pre-trained_models.mdx"}, {"type": "file", "name": "supplemental_reading.mdx"}, {"type": "file", "name": "tts_datasets.mdx"}]}, {"type": "directory", "name": "chapter7", "children": [{"type": "file", "name": "hands-on.mdx"}, {"type": "file", "name": "introduction.mdx"}, {"type": "file", "name": "speech-to-speech.mdx"}, {"type": "file", "name": "supplemental_reading.mdx"}, {"type": "file", "name": "transcribe-meeting.mdx"}, {"type": "file", "name": "voice-assistant.mdx"}]}, {"type": "directory", "name": "events", "children": [{"type": "file", "name": "introduction.mdx"}]}, {"type": "file", "name": "_toctree.yml"}]}, {"type": "directory", "name": "ko", "children": [{"type": "directory", "name": "chapter0", "children": [{"type": "file", "name": "community.mdx"}, {"type": "file", "name": "get_ready.mdx"}, {"type": "file", "name": "introduction.mdx"}]}, {"type": "directory", "name": "chapter1", "children": [{"type": "file", "name": "audio_data.mdx"}, {"type": "file", "name": "introduction.mdx"}, {"type": "file", "name": "load_and_explore.mdx"}, {"type": "file", "name": "preprocessing.mdx"}, {"type": "file", "name": "quiz.mdx"}, {"type": "file", "name": "streaming.mdx"}, {"type": "file", "name": "supplemental_reading.mdx"}]}, {"type": "directory", "name": "chapter2", "children": [{"type": "file", "name": "asr_pipeline.mdx"}, {"type": "file", "name": "audio_classification_pipeline.mdx"}, {"type": "file", "name": "hands_on.mdx"}, {"type": "file", "name": "introduction.mdx"}]}, {"type": "directory", "name": "chapter3", "children": [{"type": "file", "name": "classification.mdx"}, {"type": "file", "name": "ctc.mdx"}, {"type": "file", "name": "introduction.mdx"}, {"type": "file", "name": "quiz.mdx"}, {"type": "file", "name": "seq2seq.mdx"}, {"type": "file", "name": "supplemental_reading.mdx"}]}, {"type": "directory", "name": "events", "children": [{"type": "file", "name": "introduction.mdx"}]}, {"type": "file", "name": "_toctree.yml"}]}, {"type": "directory", "name": "ru", "children": [{"type": "directory", "name": "chapter0", "children": [{"type": "file", "name": "community.mdx"}, {"type": "file", "name": "get_ready.mdx"}, {"type": "file", "name": "introduction.mdx"}]}, {"type": "directory", "name": "chapter1", "children": [{"type": "file", "name": "audio_data.mdx"}, {"type": "file", "name": "introduction.mdx"}, {"type": "file", "name": "load_and_explore.mdx"}, {"type": "file", "name": "preprocessing.mdx"}, {"type": "file", "name": "quiz.mdx"}, {"type": "file", "name": "streaming.mdx"}, {"type": "file", "name": "supplemental_reading.mdx"}]}, {"type": "directory", "name": "chapter2", "children": [{"type": "file", "name": "asr_pipeline.mdx"}, {"type": "file", "name": "audio_classification_pipeline.mdx"}, {"type": "file", "name": "hands_on.mdx"}, {"type": "file", "name": "introduction.mdx"}]}, {"type": "directory", "name": "chapter3", "children": [{"type": "file", "name": "classification.mdx"}, {"type": "file", "name": "ctc.mdx"}, {"type": "file", "name": "introduction.mdx"}, {"type": "file", "name": "quiz.mdx"}, {"type": "file", "name": "seq2seq.mdx"}, {"type": "file", "name": "supplemental_reading.mdx"}]}, {"type": "directory", "name": "chapter4", "children": [{"type": "file", "name": "classification_models.mdx"}, {"type": "file", "name": "demo.mdx"}, {"type": "file", "name": "fine-tuning.mdx"}, {"type": "file", "name": "hands_on.mdx"}, {"type": "file", "name": "introduction.mdx"}]}, {"type": "directory", "name": "chapter5", "children": [{"type": "file", "name": "asr_models.mdx"}, {"type": "file", "name": "choosing_dataset.mdx"}, {"type": "file", "name": "demo.mdx"}, {"type": "file", "name": "evaluation.mdx"}, {"type": "file", "name": "fine-tuning.mdx"}, {"type": "file", "name": "hands_on.mdx"}, {"type": "file", "name": "introduction.mdx"}, {"type": "file", "name": "supplemental_reading.mdx"}]}, {"type": "directory", "name": "chapter6", "children": [{"type": "file", "name": "evaluation.mdx"}, {"type": "file", "name": "fine-tuning.mdx"}, {"type": "file", "name": "hands_on.mdx"}, {"type": "file", "name": "introduction.mdx"}, {"type": "file", "name": "pre-trained_models.mdx"}, {"type": "file", "name": "supplemental_reading.mdx"}, {"type": "file", "name": "tts_datasets.mdx"}]}, {"type": "directory", "name": "chapter7", "children": [{"type": "file", "name": "hands-on.mdx"}, {"type": "file", "name": "introduction.mdx"}, {"type": "file", "name": "speech-to-speech.mdx"}, {"type": "file", "name": "supplemental_reading.mdx"}, {"type": "file", "name": "transcribe-meeting.mdx"}, {"type": "file", "name": "voice-assistant.mdx"}]}, {"type": "directory", "name": "chapter8", "children": [{"type": "file", "name": "certification.mdx"}, {"type": "file", "name": "introduction.mdx"}]}, {"type": "directory", "name": "events", "children": [{"type": "file", "name": "introduction.mdx"}]}, {"type": "file", "name": "translation_agreements.txt"}, {"type": "file", "name": "_toctree.yml"}]}, {"type": "directory", "name": "tr", "children": [{"type": "directory", "name": "chapter0", "children": [{"type": "file", "name": "community.mdx"}, {"type": "file", "name": "get_ready.mdx"}, {"type": "file", "name": "introduction.mdx"}]}, {"type": "directory", "name": "chapter1", "children": [{"type": "file", "name": "audio_data.mdx"}, {"type": "file", "name": "introduction.mdx"}, {"type": "file", "name": "load_and_explore.mdx"}, {"type": "file", "name": "preprocessing.mdx"}, {"type": "file", "name": "quiz.mdx"}, {"type": "file", "name": "streaming.mdx"}, {"type": "file", "name": "supplemental_reading.mdx"}]}, {"type": "directory", "name": "chapter2", "children": [{"type": "file", "name": "asr_pipeline.mdx"}, {"type": "file", "name": "audio_classification_pipeline.mdx"}, {"type": "file", "name": "hands_on.mdx"}, {"type": "file", "name": "introduction.mdx"}, {"type": "file", "name": "tts_pipeline.mdx"}]}, {"type": "file", "name": "_toctree.yml"}]}, {"type": "directory", "name": "unpublished", "children": [{"type": "directory", "name": "chapter9", "children": [{"type": "file", "name": "audioldm.mdx"}, {"type": "file", "name": "dance_diffusion.mdx"}, {"type": "file", "name": "introduction.mdx"}, {"type": "file", "name": "music_generation.mdx"}, {"type": "file", "name": "riffusion.mdx"}]}]}, {"type": "directory", "name": "zh-CN", "children": [{"type": "directory", "name": "chapter0", "children": [{"type": "file", "name": "community.mdx"}, {"type": "file", "name": "get_ready.mdx"}, {"type": "file", "name": "introduction.mdx"}]}, {"type": "directory", "name": "chapter1", "children": [{"type": "file", "name": "audio_data.mdx"}, {"type": "file", "name": "introduction.mdx"}, {"type": "file", "name": "load_and_explore.mdx"}, {"type": "file", "name": "preprocessing.mdx"}, {"type": "file", "name": "quiz.mdx"}, {"type": "file", "name": "streaming.mdx"}, {"type": "file", "name": "supplemental_reading.mdx"}]}, {"type": "directory", "name": "chapter2", "children": [{"type": "file", "name": "asr_pipeline.mdx"}, {"type": "file", "name": "audio_classification_pipeline.mdx"}, {"type": "file", "name": "hands_on.mdx"}, {"type": "file", "name": "introduction.mdx"}]}, {"type": "directory", "name": "chapter3", "children": [{"type": "file", "name": "classification.mdx"}, {"type": "file", "name": "ctc.mdx"}, {"type": "file", "name": "introduction.mdx"}, {"type": "file", "name": "quiz.mdx"}, {"type": "file", "name": "seq2seq.mdx"}, {"type": "file", "name": "supplemental_reading.mdx"}]}, {"type": "directory", "name": "chapter5", "children": [{"type": "file", "name": "asr_models.mdx"}, {"type": "file", "name": "choosing_dataset.mdx"}, {"type": "file", "name": "demo.mdx"}, {"type": "file", "name": "evaluation.mdx"}, {"type": "file", "name": "fine-tuning.mdx"}, {"type": "file", "name": "hands_on.mdx"}, {"type": "file", "name": "introduction.mdx"}, {"type": "file", "name": "supplemental_reading.mdx"}]}, {"type": "directory", "name": "chapter6", "children": [{"type": "file", "name": "evaluation.mdx"}, {"type": "file", "name": "fine-tuning.mdx"}, {"type": "file", "name": "hands_on.mdx"}, {"type": "file", "name": "introduction.mdx"}, {"type": "file", "name": "pre-trained_models.mdx"}, {"type": "file", "name": "supplemental_reading.mdx"}, {"type": "file", "name": "tts_datasets.mdx"}]}, {"type": "file", "name": "_toctree.yml"}]}]}, {"type": "file", "name": "LICENSE"}, {"type": "file", "name": "Makefile"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "directory", "name": "utils", "children": [{"type": "file", "name": "carbon-config.json"}, {"type": "file", "name": "code_formatter.py"}, {"type": "file", "name": "generate_notebooks.py"}, {"type": "file", "name": "validate_translation.py"}]}]} | # The Audio Transformers Course
This repo contains the content that's used to create [Hugging Face's Audio Transformers Course](https://huggingface.co/learn/audio-course/).
The course teaches you about applying Transformers to various tasks in audio and speech processing.It's completely free and open-source!
## 🌎 Languages and translations
| Language | Source | Authors |
|:------------------------------------------------------------------------------|:-----------------------------------------------------------------------------------|:---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [Bengali](https://huggingface.co/learn/audio-course/bn/chapter0/introduction) | [`chapters/bn`](https://github.com/huggingface/audio-transformers-course/tree/main/chapters/bn) | |
| [English](https://huggingface.co/learn/audio-course/chapter0/introduction) | [`chapters/en`](https://github.com/huggingface/audio-transformers-course/tree/main/chapters/en) | |
| [Spanish](https://huggingface.co/learn/audio-course/es/chapter0/introduction) | [`chapters/es`](https://github.com/huggingface/audio-transformers-course/tree/main/chapters/es) | |
| [French](https://huggingface.co/learn/audio-course/fr/chapter0/introduction) | [`chapters/fr`](https://github.com/huggingface/audio-transformers-course/tree/main/chapters/fr) | |
| [Korean](https://huggingface.co/learn/audio-course/ko/chapter0/introduction) | [`chapters/ko`](https://github.com/huggingface/audio-transformers-course/tree/main/chapters/ko) | |
| [Russian](https://huggingface.co/learn/audio-course/ru/chapter0/introduction) | [`chapters/ru`](https://github.com/huggingface/audio-transformers-course/tree/main/chapters/ru) | [@blademoon](https://github.com/blademoon), [@Lightmourne](https://github.com/Lightmourne) |
| [Turkish](https://huggingface.co/learn/audio-course/tr/chapter0/introduction) | [`chapters/tr`](https://github.com/huggingface/audio-transformers-course/tree/main/chapters/tr) | |
| [Chinese (simplified)](https://huggingface.co/learn/audio-course/zh-CN/chapter0/introduction) | [`chapters/zh-CN`](https://github.com/huggingface/audio-transformers-course/tree/main/chapters/zh-CN) | |
### Translating the course into your language
As part of our mission to democratise machine learning, we'd love to have the course available in many more languages!
Please follow the steps below if you'd like to help translate the course into your language 🙏.
**🗞️ Open an issue**
To get started, navigate to the [_Issues_](https://github.com/huggingface/audio-transformers-course/issues) page of
this repo and check if anyone else has opened an issue for your language. If not, open a new issue by selecting
the _Translation template_ from the _New issue_ button.
Once an issue is created, post a comment to indicate which chapters you'd like to work on and we'll add your name to the list.
**🗣 Join our Discord**
Since it can be difficult to discuss translation details quickly over GitHub issues, we have created dedicated channels
for each language on our Discord server. Join here 👉: [http://hf.co/join/discord](http://hf.co/join/discord)
**🍴 Fork the repository**
Next, you'll need to [fork this repo](https://docs.github.com/en/get-started/quickstart/fork-a-repo). You can do this
by clicking on the **Fork** button on the top-right corner of this repo's page.
Once you've forked the repo, you'll want to get the files on your local machine for editing. You can do that by cloning the fork with Git as follows:
```bash
git clone https://github.com/YOUR-USERNAME/audio-transformers-course
```
**📋 Copy-paste the English files with a new language code**
The course files are organised under a main directory:
* [`chapters`](https://github.com/huggingface/audio-transformers-course/tree/main/chapters): all the text and code snippets associated with the course.
You'll only need to copy the files in the [`chapters/en`](https://github.com/huggingface/audio-transformers-course/tree/main/chapters/en)
directory, so first navigate to your fork of the repo and run the following:
```bash
cd ~/path/to/audio-transformers-course
cp -r chapters/en/CHAPTER-NUMBER chapters/LANG-ID/CHAPTER-NUMBER
```
Here, `CHAPTER-NUMBER` refers to the chapter you'd like to work on and `LANG-ID` should be ISO 639-1 (two lower case letters)
language code -- see [here](https://www.loc.gov/standards/iso639-2/php/code_list.php) for a handy table.
Alternatively, {two lowercase letters}-{two uppercase letters} format is also supported, e.g. `zh-CN`, here's
an [example](https://huggingface.co/learn/nlp-course/zh-CN/chapter1/1).
**✍️ Start translating**
Now comes the fun part - translating the text! The first thing we recommend is translating the part of the `_toctree.yml` file that corresponds to your chapter. This file is used to render the table of contents on the website and provide the links to the Colab notebooks. The only fields you should change are the `title`, ones -- for example, here are the parts of `_toctree.yml` that we'd translate for [Chapter 0 of the NLP course](https://huggingface.co/course/chapter0/1?fw=pt):
```yaml
- title: 0. Setup # Translate this!
sections:
- local: chapter0/1 # Do not change this!
title: Introduction # Translate this!
```
> 🚨 Make sure the `_toctree.yml` file only contains the sections that have been translated! Otherwise you won't be able to build the content on the website or locally (see below how).
Once you have translated the `_toctree.yml` file, you can start translating the [MDX](https://mdxjs.com/) files associated with your chapter.
> 🙋 If the `_toctree.yml` file doesn't yet exist for your language, you can simply create one by copy-pasting from the English version and deleting the sections that aren't related to your chapter. Just make sure it exists in the `chapters/LANG-ID/` directory!
**👷♂️ Build the course locally**
Once you're happy with your changes, you can preview how they'll look by first installing the [`doc-builder`](https://github.com/huggingface/doc-builder) tool that we use for building all documentation at Hugging Face:
```shell
python -m pip install hf-doc-builder
```
```shell
doc-builder preview audio-transformers-course ../audio-transformers-course/chapters/LANG-ID --not_python_module
```
This will build and render the course on [http://localhost:3000/](http://localhost:3000/). Although the content looks much nicer on the Hugging Face website, this step will still allow you to check that everything is formatted correctly.
**🚀 Submit a pull request**
If the translations look good locally, the final step is to prepare the content for a pull request. Here, the first think to check is that the files are formatted correctly. For that you can run:
```
pip install -r requirements.txt
make style
```
Once that's run, commit any changes, open a pull request, and wait for a review. Congratulations, you've now completed your first translation 🥳!
> 🚨 To build the course on the website, double-check your language code exists in `languages` field of the `build_documentation.yml` and `build_pr_documentation.yml` files in the `.github` folder. If not, just add them in their alphabetical order.
## 📔 Jupyter notebooks
The Jupyter notebooks containing all the code from the course are hosted on the [`huggingface/notebooks`](https://github.com/huggingface/notebooks) repo. If you wish to generate them locally, first install the required dependencies:
```bash
python -m pip install -r requirements.txt
```
Then run the following script:
```bash
python utils/generate_notebooks.py --output_dir nbs
```
This script extracts all the code snippets from the chapters and stores them as notebooks in the `nbs` folder (which is ignored by Git by default).
## ✍️ Contributing a new chapter
> Note: we are not currently accepting community contributions for new chapters. These instructions are for the Hugging Face authors.
Adding a new chapter to the course is quite simple:
1. Create a new directory under `chapters/en/chapterX`, where `chapterX` is the chapter you'd like to add.
2. Add numbered MDX files `sectionX.mdx` for each section.
3. Update the `_toctree.yml` file to include your chapter sections -- this information will render the table of contents on the website. If your section involves both the PyTorch and TensorFlow APIs of `transformers`, make sure you include links to both Colabs in the `colab` field.
If you get stuck, check out one of the existing chapters -- this will often show you the expected syntax.
Once you are happy with the content, open a pull request and wait for a review. We recommend adding the first chapter draft as a single pull request -- the team will then provide feedback internally to iterate on the content 🤗!
## 🙌 Acknowledgements
The structure of this repo and README are inspired by the wonderful [Advanced NLP with spaCy](https://github.com/ines/spacy-course) course.
| {"requirements.txt": "nbformat>=5.1.3\nPyYAML>=5.4.1\nblack>=22.3.0", ".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 2815ff2688dd734806b27c09cd8de71ead05c5c8 Hamza Amin <[email protected]> 1727369043 +0500\tclone: from https://github.com/huggingface/audio-transformers-course.git\n", ".git\\refs\\heads\\main": "2815ff2688dd734806b27c09cd8de71ead05c5c8\n"} | 3 |
airline-management-dsa | {"type": "directory", "name": "airline-management-dsa", "children": [{"type": "file", "name": "DSA Airline Project.cpp"}, {"type": "file", "name": "LICENSE"}, {"type": "file", "name": "README.md"}]} | # DSA Airline Project
## Overview
The DSA Airline Project is a C++ application designed to simulate basic airline operations, including flight management, reservation systems, and route finding. This project utilizes various data structures such as linked lists, hash tables, and priority queues to efficiently manage flights and reservations.
## Features
- **Flight Management**: Add and manage flights between various cities.
- **Reservation System**: Make reservations for one-way or round trips.
- **Route Finding**: Find direct and connecting routes between cities.
- **Shortest Path Calculation**: Use Dijkstra's algorithm to find the shortest path between two cities.
- **Display Functions**: View flight information, available cities, departures, arrivals, and passenger lists.
## Getting Started
### Prerequisites
- A C++ compiler (e.g., g++, clang++)
- Basic understanding of C++ programming and data structures
### Installation
1. Clone the repository:
```bash
git clone https://github.com/hamza-amin-4365/Data_Structures_Airline_Project.git
```
2. Navigate to the project directory:
```bash
cd Data_Structures_Airline_Project
```
3. Compile the project using a C++ compiler:
```bash
g++ -o airline_project "DSA Airline Project.cpp"
```
### Running the Application
Run the compiled application:
```bash
./airline_project
```
## Usage
Upon running the application, you'll be presented with a menu of options:
1. Show Cities
2. Show Departures for a City
3. Show Arrivals for a City
4. Show Reachable Cities from a City
5. Show Shortest Path between Cities
6. Find Route between Cities
7. Make Reservation
8. Print Reservation Schedule
9. Delete Reservation
10. Print Passenger List for a Flight
11. Display all flights data in the database
0. Exit
Simply enter the corresponding number to perform an action.
## Data Structures Used
- **Linked Lists**: For managing flights and reservations.
- **Hash Tables**: To efficiently search for cities and flights.
- **Priority Queues**: For implementing Dijkstra's algorithm to find the shortest path.
## Code Structure
- `FlightType`: Structure representing flight details.
- `RouteType`: Structure representing travel routes.
- `ReservationType`: Structure for managing reservations.
- `CityListType`: Structure for managing city names and associated flights.
- Functions for initializing data structures, inserting flights, making reservations, and displaying information.
## Example Flight Data
This project includes sample flight data to demonstrate functionality:
- Flights between cities like Multan, Tokyo, Gawadar, and Gujranwala with various departure and arrival times.
## Contributing
Contributions are welcome! Please fork the repository and submit a pull request with your changes.
## License
This project is open-source and available under the MIT License.
## Acknowledgments
- C++ Standard Library for data structures and algorithms.
- Various online resources for learning about flight management systems and data structures.
## Contact
For any inquiries, please contact Hamza Amin and Ali Vijdaan via email: <br> [email protected] <br> [email protected]
```
This README provides a comprehensive overview of the DSA Airline Project, detailing its features, usage, data structures, and how to get started. It also includes instructions for installation and contact information for further inquiries.
| {".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 d9cbcd6101ffec1fc8d26d55f9b0be1a60a0aede Hamza Amin <[email protected]> 1727963229 +0500\tclone: from https://github.com/vijdaancoding/airline-management-dsa.git\n", ".git\\refs\\heads\\main": "d9cbcd6101ffec1fc8d26d55f9b0be1a60a0aede\n"} | 0 |
genealogy-ai | {"type": "directory", "name": "genealogy-ai", "children": [{"type": "directory", "name": "genealogy_ai", "children": [{"type": "file", "name": "db.sqlite3"}, {"type": "directory", "name": "genealogy_ai", "children": [{"type": "file", "name": "asgi.py"}, {"type": "file", "name": "settings.py"}, {"type": "file", "name": "urls.py"}, {"type": "file", "name": "wsgi.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "manage.py"}, {"type": "file", "name": "requirements.txt"}, {"type": "directory", "name": "static", "children": [{"type": "file", "name": "base_style.css"}, {"type": "directory", "name": "pictures", "children": []}]}, {"type": "directory", "name": "templates", "children": [{"type": "file", "name": "base.html"}]}, {"type": "directory", "name": "tree_view", "children": [{"type": "file", "name": "admin.py"}, {"type": "file", "name": "apps.py"}, {"type": "file", "name": "forms.py"}, {"type": "directory", "name": "management", "children": [{"type": "directory", "name": "commands", "children": [{"type": "file", "name": "import_data.py"}]}]}, {"type": "directory", "name": "migrations", "children": [{"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "models.py"}, {"type": "directory", "name": "templates", "children": [{"type": "directory", "name": "tree_view", "children": [{"type": "file", "name": "tree_view.html"}]}]}, {"type": "file", "name": "tests.py"}, {"type": "file", "name": "urls.py"}, {"type": "file", "name": "views.py"}, {"type": "file", "name": "__init__.py"}]}]}, {"type": "file", "name": "LICENSE"}, {"type": "file", "name": "README.md"}]} | <img src='genealogy_ai/static/pictures/logo.png' width=180 height='auto' alt='Genealogy AI'>
# Genealogy AI
Revolutionizing the way we document biographies and family lineages. Genealogy AI is an open-source service that is currently under work. The tool hopes in utilizing the power of LLMs in understanding complex graphical structures and summarizing familiy information easier.
## To-Do
- ~~Style Family Tree with [D3.js](https://d3js.org/getting-started)~~
- Set up [Llama 3.1 405B Instruct](https://huggingface.co/meta-llama/Meta-Llama-3.1-405B-Instruct)
- Implement CoT and ReAct
- Use ML Techniques to show geographical timelapse
- Improve usage of [django neomodel](https://github.com/neo4j-contrib/django-neomodel)
## Getting Started
If your looking to contribute to the codebase or just want to use the app you can follow the following steps.
### Pre-Requisites
- Have [NEO4J Desktop](https://neo4j.com/download/) installed
**1. Clone via git**
```
git clone https://github.com/vijdaancoding/genealogy-ai.git
```
**2. Installing Requirements**
```
pip install -r genealogy_ai/requirements.txt
```
**3. Import Sample Data and Connect to NEO4J**
```
python manage.py import_data --url bolt://<username>:<password>@localhost:7687
```
**4. Run Django App**
```
python manage.py runserver
```
## Troubleshoot
In case of a WebSocket error caused by NEO4J Desktop please follow the steps mentioned [here](https://neo4j.com/developer/kb/explanation-of-error-websocket-connection-failure/)
| {".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 befc7b89fe0122aa03c326640ccc53614d228bea Hamza Amin <[email protected]> 1727963235 +0500\tclone: from https://github.com/vijdaancoding/genealogy-ai.git\n", ".git\\refs\\heads\\main": "befc7b89fe0122aa03c326640ccc53614d228bea\n", "genealogy_ai\\requirements.txt": "asgiref==3.8.1\nconfig==0.5.1\nDjango==5.1.1\ndjango_neomodel==0.2.0\nneo4j==5.19.0\nneomodel==5.3.2\npython-dotenv==1.0.1\npytz==2024.1\nsqlparse==0.5.1\n", "genealogy_ai\\tree_view\\apps.py": "from django.apps import AppConfig\n\n\nclass TreeViewConfig(AppConfig):\n default_auto_field = 'django.db.models.BigAutoField'\n name = 'tree_view'\n"} | 1 |
gradient-descent-vs-svd | {"type": "directory", "name": "gradient-descent-vs-svd", "children": [{"type": "file", "name": "LinearLegends.ipynb"}, {"type": "file", "name": "movies.csv"}, {"type": "file", "name": "movies.RData"}, {"type": "file", "name": "README.md"}]} | # Gradient_Descent-vs-SVD
[Research Paper](Thesis.pdf)
| {".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 53553b9ac482dc2eb6ef915af43141c29ac4782b Hamza Amin <[email protected]> 1727963242 +0500\tclone: from https://github.com/vijdaancoding/gradient-descent-vs-svd.git\n", ".git\\refs\\heads\\main": "53553b9ac482dc2eb6ef915af43141c29ac4782b\n"} | 2 |
mnist-neural-net | {"type": "directory", "name": "mnist-neural-net", "children": [{"type": "file", "name": "app.py"}, {"type": "file", "name": "Dockerfile"}, {"type": "file", "name": "mnist_app.h5"}, {"type": "file", "name": "neuralNetwork.py"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}]} | # mnist-neural-net
This is a practice repository solely made for having fun with PDB, GitBash and Docker.
The documentations of the process that took place when implementing each of these is located here:
1. [PDB](#pdb)
2. [GitBash](#gitbash)
3. [Docker](#docker)
## PDB
### Debugging and Deployment
The application includes a debugging breakpoint using the pdb module, allowing for easy debugging and troubleshooting. The application is designed to be deployed as a web application, making it accessible and user-friendly for a wide range of users. Overall, the MNIST digit recognition application demonstrates the effective deployment of machine learning models using Streamlit and TensorFlow.
We have the module pdb from python to set a break-point where might exist an error. Here is the screenshot of the breakpoint:

After we set the breakpoint our program flow stops at the break-point and we can easily debug the issues, here we have find the potential issue and fixed it i.e returning the digit as integar , it was returned as string before we debugged the code. Here see in the terminal:
The application includes a debugging breakpoint using the pdb module, allowing for easy debugging and troubleshooting. The application is designed to be deployed as a web application, making it accessible and user-friendly for a wide range of users. Overall, the MNIST digit recognition application demonstrates the effective deployment of machine learning models using Streamlit and TensorFlow.
We have the module pdb from python to set a break-point where might exist an error. Here is the screenshot of the breakpoint:

After we set the breakpoint our program flow stops at the break-point and we can easily debug the issues, here we have find the potential issue and fixed it i.e returning the digit as integar , it was returned as string before we debugged the code. Here see in the terminal:

After we fix our issue we simply write the command continue in the terminal as shown:

## GitBash
### Initialization
A git repository was supposed to be initialized at our local setup. The git repo initially had all related files untracked. We used linux commands to add the files to our repo

### Branch Creation
After working on our code in the master branch we came at an empasse and were forced to tune the hyperparameteres of our model as it was overfitting. We made a new branch called 'bugfix'

### Merging Branches
After fixing the issue we merged the 'bugfix' branch back to our main branch.

### Pushing to Hub
When satisfied with our current code and setup we pushed our code from our local repository to GitHub.

### Git Log
The following is a graphical representation of the git log

## Docker
### Docker File
To create a Docker container and push it to hub we first created a Dockerfile in VSCode

### Requirements File
The docker container also includes all the required libraries that go into making your code run hence a requirements.txt file is necessary.

### Creating the Docker Container
Through the docker build command in vscode we were able to make a docker container on our local device. Then we uploaded the container on the DockerHub via Docker Desktop. To veiw the contianer on the Hub click [here](https://hub.docker.com/repository/docker/vijdaancoding/mnist-streamlit/general)

### Running the docker container from Docker hub on a local PC

Here you can see our application is up and running

| {"app.py": "import streamlit as st\nimport tensorflow as tf\nfrom PIL import Image\nimport numpy as np\nimport pdb # Import pdb module\n\n# Load the trained model\nmodel = tf.keras.models.load_model('mnist_app.h5')\n\n# Create a Streamlit app\nst.title(\"MNIST Digit Recognition\")\nst.write(\"Upload an image of a handwritten digit:\")\n\n# Create a file uploader\nuploaded_file = st.file_uploader(\"Choose an image...\", type=[\"png\", \"jpg\", \"jpeg\"])\n\n# Create a button to trigger prediction\npredict_button = st.button(\"Predict\")\n\n# Define a function to preprocess the image\ndef preprocess_image(image):\n image = image.convert('L') # Convert to grayscale\n image = image.resize((28, 28)) # Resize to 28x28\n image = np.array(image) # Convert to numpy array\n image = image.reshape(1, 784) # Reshape to match input shape\n image = image.astype('float32') / 255 # Normalize\n return image\n\n# Define a function to predict the digit\ndef predict_digit(image):\n prediction = model.predict(image)\n digit = np.argmax(prediction)\n #pdb.set_trace() # Set a breakpoint\n digit = str(digit)\n digit = int(digit)\n return digit\n\n# Create a text output to display the prediction\nprediction_output = st.text(\"\")\n\n# Create a main function to run the app\ndef main():\n if uploaded_file:\n image = Image.open(uploaded_file)\n preprocessed_image = preprocess_image(image)\n if predict_button:\n digit = predict_digit(preprocessed_image)\n prediction_output.text(f\"The predicted digit is: {digit}\")\n\n# Run the app\nif __name__ == \"__main__\":\n main()\n", "Dockerfile": "FROM python:3.9-slim \n\nWORKDIR /app\n\nADD . /app\n\nRUN pip install --no-cache-dir -r requirements.txt\n\nEXPOSE 8501\n\nCMD [\"streamlit\", \"run\", \"app.py\"]\n\n", "requirements.txt": "streamlit\ntensorflow\nPillow\nnumpy", ".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 5ace3cee1f37c13150e029ac5601b2dffdcf14c4 Hamza Amin <[email protected]> 1727963298 +0500\tclone: from https://github.com/vijdaancoding/mnist-neural-net.git\n", ".git\\refs\\heads\\main": "5ace3cee1f37c13150e029ac5601b2dffdcf14c4\n"} | 3 |
resume-screening-nlp | {"type": "directory", "name": "resume-screening-nlp", "children": [{"type": "file", "name": "app.py"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "Resume Screening.csv"}, {"type": "file", "name": "ResumeScreening.ipynb"}]} | # Resume_Screening_NLP | {"app.py": "# Importing Libraries\nimport streamlit as st \nimport pickle \nimport re \nimport nltk \nfrom gensim.parsing.preprocessing import remove_stopwords\nfrom nltk.stem import PorterStemmer\nfrom nltk.stem import WordNetLemmatizer\nfrom sklearn.feature_extraction.text import TfidfVectorizer\n\n# Downloading data\nnltk.download('punkt')\nnltk.download('stopwords')\n\n# Loading models\nclf = pickle.load(open('clf.pkl', 'rb'))\ntfidf = pickle.load(open('tfidf.pkl', 'rb'))\nmodel = pickle.load(open('model.pkl', 'rb'))\nmodel_svm = pickle.load(open('model_svm.pkl', 'rb'))\n\n# Cleaning Data Function\nporter_stemmer = PorterStemmer()\nlemmatizer = WordNetLemmatizer()\n\ndef dataCleaning(txt):\n CleanData = re.sub('https\\S+\\s', ' ', txt) #Cleaning links via re\n CleanData = re.sub(r'\\d', ' ', CleanData) #Cleaning numbers via re\n CleanData = re.sub('@\\S+', ' ', CleanData) #Cleaning email address via re\n CleanData = re.sub('#\\S+\\s', ' ', CleanData) #Cleaning # symbol via re\n CleanData = re.sub('[^a-zA-Z0-9]', ' ', CleanData) #Cleaning special characters via re\n CleanData = remove_stopwords(CleanData) #Cleaning stopwords via genism \n CleanData = porter_stemmer.stem(CleanData) #Stemming via nltk \n CleanData = lemmatizer.lemmatize(CleanData) #Lemmatization via nltk \n return CleanData\n\n# Main Web Function\ndef main():\n # Set page title and background color\n st.set_page_config(page_title='My NLP Project', page_icon=':bar_chart:', layout='wide')\n\n # Page title and introduction about the project\n st.title('Welcome to My Resume Screening Algorithm')\n st.subheader('By: Ali Vijdaan')\n st.write('This web app was created by me for my AI-221L Project')\n st.write('I use NLP along with ML models like KNN, Naive Bayes and SVM to predict the departments of different Resumes for faster and efficient categorization.')\n\n # Button for uploading files (PDF or TXT)\n uploaded_file = st.file_uploader('Upload a PDF or TXT file', type=['pdf', 'txt'])\n \n # Processing uploaded file\n if uploaded_file is not None:\n try:\n resume_bytes = uploaded_file.read()\n resume_text = resume_bytes.decode('utf-8')\n except UnicodeDecodeError: \n resume_text = resume_bytes.decode('latin-1')\n\n\n # Button to trigger prediction\n if st.button('Press for Prediction'):\n\n cleaned_resume = dataCleaning(resume_text)\n input_features = tfidf.transform([cleaned_resume])\n\n category_mapping = {\n\n 6 : \"Data Science\",\n 12 : \"HR\", \n 0 : \"Advocate\",\n 1 : \"Arts\",\n 24 : \"Web Designing\",\n 16 : \"Mechanical Engineer\",\n 22 : \"Sales\",\n 14 : \"Health and fitness\",\n 5 : \"Civil Engineer\",\n 15 : \"Java Developer\",\n 4 : \"Business Analyst\",\n 21 : \"SAP Developer\",\n 2 : \"Automation Testing\",\n 11 : \"Electrical Engineering\",\n 18 : \"Operations Manager\",\n 20 : \"Python Developer\",\n 8 : \"DevOps Engineer\",\n 17 : \"Network Security Engineer\",\n 19 : \"PMO\",\n 7 : \"Database\",\n 13 : \"Hadoop\",\n 10 : \"ETL Developer\",\n 9 : \"DotNet Developer\",\n 3 : \"Blockchain\",\n 23 : \"Testing\"\n }\n\n # Results section for KNN prediction\n st.header('KNN Prediction')\n prediction_id = clf.predict(input_features)[0]\n category_name = category_mapping.get(prediction_id, \"Unknown\")\n st.write(\"Predicted Category: \", category_name)\n\n # Results section for Naive Bayes prediction\n st.header('Naive Bayes Prediction')\n prediction_id = model.predict(input_features)[0]\n category_name = category_mapping.get(prediction_id, \"Unknown\")\n st.write(\"Predicted Category: \", category_name)\n\n\n # Results section for SVM prediction\n st.header('SVM Prediction')\n prediction_id = model_svm.predict(input_features)[0]\n category_name = category_mapping.get(prediction_id, \"Unknown\")\n st.write(\"Predicted Category: \", category_name)\n\n\n#python main\nif __name__ == '__main__':\n main()\n", ".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 2916217198c0651ed4f5b1ea22aca05065e909dd Hamza Amin <[email protected]> 1727963232 +0500\tclone: from https://github.com/vijdaancoding/resume-screening-nlp.git\n", ".git\\refs\\heads\\main": "2916217198c0651ed4f5b1ea22aca05065e909dd\n"} | 4 |
statistical-machine-learning | {"type": "directory", "name": "statistical-machine-learning", "children": [{"type": "directory", "name": "Maximum Likelihood Estimation", "children": [{"type": "file", "name": "MLE.md"}]}, {"type": "directory", "name": "Poisson Regression", "children": [{"type": "file", "name": "poisson.ipynb"}, {"type": "file", "name": "PoissonRegression.md"}]}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "Types of Data", "children": [{"type": "file", "name": "TypesOfData.md"}]}]} | # Statistical Machine Learning 📊
The repository was made to create documentations and sample codes of foundational algorithms and models used in machine learning. The [Table of Contents](#table-of-contents) have links to the documentations of the algorithms.
## Table Of Contents
- [Types of Data](Types%20of%20Data/TypesOfData.md)
- [Poisson Regression](Poisson%20Regression/PoissonRegression.md)
- [Maximum Likelihood Estimation](Maximum%20Likelihood%20Estimation/MLE.md)
| {".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 421290f33d45ef85083f240301e94346dccb5daa Hamza Amin <[email protected]> 1727963230 +0500\tclone: from https://github.com/vijdaancoding/statistical-machine-learning.git\n", ".git\\refs\\heads\\main": "421290f33d45ef85083f240301e94346dccb5daa\n"} | 5 |
vijdaancoding | {"type": "directory", "name": "vijdaancoding", "children": [{"type": "file", "name": "README.md"}]} | in my quest for uniqueness to find a job I have decided to have the most basic vanilla readme
| {".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 a07a58c4f7b482db63d992d2ce2898dd76bb259e Hamza Amin <[email protected]> 1727963229 +0500\tclone: from https://github.com/vijdaancoding/vijdaancoding.git\n", ".git\\refs\\heads\\main": "a07a58c4f7b482db63d992d2ce2898dd76bb259e\n"} | 6 |
wreck-it-rag | {"type": "directory", "name": "wreck-it-rag", "children": [{"type": "file", "name": "app.py"}, {"type": "file", "name": "converter.py"}, {"type": "file", "name": "extraction_ocr.py"}, {"type": "file", "name": "LICENSE.md"}, {"type": "directory", "name": "Other", "children": []}, {"type": "file", "name": "prompt.py"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "vision_llm_summarizer.py"}]} | # **Wreck-it-RAG**
<img src="Other/file.png" width="150" height="auto" alt="Wreck-it-RAG Logo">
The repo is an attempt to create an automated pipleine for extracting infromation from different documents and converting them into JSON
## **To-Do List**
📝 Add OpenAI API Key Support<br>
📝 Switch to Django<br>
📝 ~~Make streamlit editable to choose between OCR or LLM summaries~~<br>
📝 Concatenate JSON blocks for page-by-page chunking<br>
📝 ~~Use a package manager for requirements.txt~~<br>
📝 ~~Convert Tables from HTML to JSON~~<br>
📝 Integrate SQL database to store JSON<br>
📝 Look into Apache Spark or Hadoop<br>
## **Downloading UNSTRUCTURED.IO Dependancies**
Follow [UNSTRUCTURED.IO's](https://docs.unstructured.io/open-source/installation/full-installation) own installation guide to download all dependancies
## Quick Summary of Installation Guide
## **Windows**
### 1. libmagic-dev
Use WSL to enter the following commands
```
sudo apt update
sudo apt install libmagic-dev
```
### 2. Poppler
Check out the [pdf2image docs](https://pdf2image.readthedocs.io/en/latest/installation.html) on how to install Poppler on various devices
### 3. libreoffice
Check out the official page of [libreoffice](https://www.libreoffice.org/download/download-libreoffice/) for download guides.
Once the `.msi` or `.exe` file is downloaded follow the on-screen instructions
### 4. Tesseract
The latest installer for Tesseract on windows can be found [here](https://github.com/UB-Mannheim/tesseract/wiki)
Make sure to add the `C:\Program Files\Tesseract-OCR` to your Path.
## **2. Installing pip Requirements**
Enter the following code to install all python libraries
```
pip install -r requirements.txt
```
## **3. Create .env File**
Create an .env file with the following variable
```
GEMINI_API_KEY = your-gemini-api-key-here
```
## **4. Run Streamlit App**
Run the streamlit app using the following command
```
streamlit run app.py
``` | {"app.py": "\"\"\"\nAuthor: Ali Vijdaan\nDescription: streamlit GUI for no-code pre-processing with UNSTRUCTURED.IO and LLMs\n\"\"\"\n\nimport tempfile\nimport os\nimport base64\nimport html\nimport streamlit as st\nimport PIL.Image\n\nfrom extraction_ocr import ocr_extraction, image_element_items, text_element_items, table_element_items, convert_to_json\nfrom vision_llm_summarizer import get_response\nfrom converter import html_to_json_table\nfrom prompt import prompt\n\n#sanitize elements for HTML\ndef sanitize_html(content):\n return html.escape(content)\n\n\n#Create a temporary directory to store uplaoded documents\ndef create_temp_dir(uploaded_file):\n temp_dir = tempfile.mkdtemp()\n temp_file_path = os.path.join(temp_dir, uploaded_file.name)\n\n with open(temp_file_path, 'wb') as temp_file:\n temp_file.write(uploaded_file.read())\n\n output_dir = 'images'\n\n return temp_file_path, output_dir\n\n\n# Main function to perform OCR and text extraction\ndef run_ocr(file):\n\n if file is None:\n st.write(\"No file found\")\n return None, None\n\n if file.type != 'application/pdf':\n st.write(\"No PDF file found\")\n return None, None\n\n temp_file_path, output_dir = create_temp_dir(file)\n raw_elements = ocr_extraction(file_name=temp_file_path, output_dir=output_dir)\n\n return raw_elements, temp_file_path\n\n\n# Return file in base64\ndef get_base64_of_file(file_path):\n with open(file_path, \"rb\") as file:\n return base64.b64encode(file.read()).decode()\n\n\n# Doc Viewer on streamlit app\ndef show_uploaded_docs(uploaded_file, temp_file_path):\n\n if uploaded_file is None:\n st.write(\"No file found\")\n return\n\n st.subheader(\"Doc Viewer\")\n\n if uploaded_file.type == 'application/pdf':\n display_pdf(temp_file_path)\n\n\n# Iframe display of PDFs\ndef display_pdf(file_path):\n pdf_base64 = get_base64_of_file(file_path)\n pdf_display = f\"\"\"<iframe src=\"data:application/pdf;base64,{pdf_base64}\"\n height=\"500\" width=\"100%\" type=\"application/pdf\">\n </iframe>\"\"\"\n st.markdown(pdf_display, unsafe_allow_html=True)\n\n\ndef filter_extracted_text(raw_elements, llm_summary):\n\n # Add custom CSS to style the container\n st.markdown(\n \"\"\"\n <style>\n .scrollable-container {\n height: 500px;\n width: 100%;\n overflow-y: scroll;\n border: 1px solid #ccc;\n padding: 10px;\n box-shadow: 2px 2px 5px rgba(0, 0, 0, 0.1);\n }\n </style>\n \"\"\",\n unsafe_allow_html=True\n )\n\n # Differentiate Between OCR and LLM\n def generate_element_html(element, is_summary):\n sanitized_element = sanitize_html(str(element))\n if type(element) in image_element_items:\n summary_text = (element.metadata.summary\n if is_summary and hasattr(element, 'metadata')\n else sanitized_element)\n return f\"\"\"<p style= \"text-align:center;\">\n ----------------IMAGE / TABLE -------------------- <br>\n {summary_text} <br>\n ----------------------------------------------\n </p><br>\"\"\"\n\n elif type(element) in table_element_items:\n json_table = html_to_json_table(element.metadata.text_as_html)\n element.metadata.json_table = json_table\n return f\"<p>{element.metadata.json_table}</p><br>\"\n return f\"<p>{sanitized_element}</p><br>\"\n\n #Create a container with the custom class\n container_html = '<div class=\"scrollable-container\">'\n container_html += ''.join(generate_element_html(ele, llm_summary) for ele in raw_elements)\n container_html += '</div>'\n\n st.markdown(container_html, unsafe_allow_html=True)\n\n\ndef add_summary(image_summary, element):\n element.metadata.summary = image_summary\n return element\n\ndef get_image_summary(raw_elements):\n\n for element in raw_elements:\n if type(element) in image_element_items:\n\n image_path = element.metadata.image_path\n\n if os.path.exists(image_path):\n\n image = PIL.Image.open(image_path)\n image_summary = get_response(prompt=prompt, image=image)\n\n print(\"\\n-----------------------IMAGE SUMMARY--------------------------\")\n print(image_summary)\n\n element = add_summary(image_summary=image_summary.text, element=element)\n print(\"---------------------------------------\")\n print(element)\n\n else:\n image_summary = \"Image does not exist\"\n element = add_summary(image_summary=image_summary, element=element)\n print(\"---------------------------------------\")\n print(element)\n\n for element in raw_elements:\n print(element)\n\n return raw_elements\n\ndef edit_json(llm_elements):\n\n def validate(input):\n if not input:\n llm_elements.remove(element)\n\n for i, element in enumerate(llm_elements):\n if type(element) in text_element_items:\n edited_text = st.text_area(label=\"-\",\n value=element.text,\n placeholder=\"If empty JSON would be deleted\",\n label_visibility=\"collapsed\",\n key=i)\n validate(edited_text)\n element.text = edited_text\n elif type(element) in image_element_items:\n edited_image = st.text_area(label=\"-\",\n value=element.metadata.summary,\n placeholder=\"If empty JSON would be deleted\",\n label_visibility=\"collapsed\",\n key=i)\n validate(edited_image)\n element.metadata.summary = edited_image\n elif type(element) in table_element_items:\n edited_table = st.text_area(label=\"-\",\n value=element.metadata.json_table,\n placeholder=\"If empty JSON would be deleted\",\n label_visibility=\"collapsed\",\n key=i)\n validate(edited_table)\n element.metadata.json_table = edited_table\n\ndef main():\n st.set_page_config(page_title=\"Doc Extractor\", layout=\"wide\")\n\n with st.container():\n st.title(\"Document Data Extractor\")\n st.write(\"The goal is to create an ETL pipeline that can load documents and preprocess them to make them RAG Ready!\")\n\n uploaded_file = st.file_uploader(\"Choose a file\", type=[\"pdf\"])\n\n # defining session state for llm\n if 'llm' not in st.session_state:\n st.session_state.llm = False #default llm state is set to FALSE\n if 'run_ocr' not in st.session_state:\n st.session_state.run_ocr = False #default OCR state is set to FALSE\n if 'json' not in st.session_state:\n st.session_state.json = False #default JSON state is set to FALSE\n\n if uploaded_file is not None:\n if not st.session_state.run_ocr: #if OCR doesnt exsit\n\n raw_elements, temp_file_path = run_ocr(uploaded_file)\n\n # defining session state for ocr run\n st.session_state['ocr_run_raw_ele'] = raw_elements\n st.session_state['ocr_run_temp_file'] = temp_file_path\n st.session_state['ocr_run_uploaded_file'] = uploaded_file\n\n st.session_state.run_ocr = True #session state for OCR set to TRUE\n\n with st.container():\n left_column, right_column = st.columns(2)\n\n with left_column:\n with st.expander(\"Show original document\"):\n show_uploaded_docs(st.session_state['ocr_run_uploaded_file'], st.session_state['ocr_run_temp_file'])\n\n with right_column:\n with st.expander(\"Show Extracted Text\"):\n st.subheader(\"Extracted Text\")\n filter_extracted_text(st.session_state['ocr_run_raw_ele'], llm_summary=False)\n\n summarizer = st.button(\"Show LLM Summary\")\n if summarizer:\n st.session_state.llm = True #llm state set to TRUE when button pressed\n\n if st.session_state.llm:\n with st.container():\n with st.expander(\"Show Image Summaries via LLM\"):\n\n if 'llm_elements' not in st.session_state:\n st.session_state.llm_elements = get_image_summary(st.session_state['ocr_run_raw_ele'])\n\n filter_extracted_text(st.session_state.llm_elements, llm_summary=True)\n\n if st.session_state.llm:\n with st.container():\n st.subheader(\"Edit Extracted Text\")\n first_col, second_col, third_col = st.columns(3)\n\n with first_col:\n with st.expander(\"OCR Extracted Text\"):\n filter_extracted_text(st.session_state['ocr_run_raw_ele'], llm_summary=False)\n\n with second_col:\n with st.expander(\"LLM Extracted Image Summaries\"):\n filter_extracted_text(st.session_state.llm_elements, llm_summary=True)\n\n with third_col:\n with st.expander(\"Edit JSON\"):\n with st.container(height=500):\n edit_json(st.session_state.llm_elements)\n\n\n json_converter = st.button(\"Convert to JSON\")\n if json_converter:\n st.session_state.json = True #json state set to TRUE\n\n if st.session_state.json:\n convert_to_json(st.session_state.llm_elements, filename='output.json')\n\n\nif __name__ == \"__main__\":\n main()\n", "requirements.txt": "altair==5.4.0\nannotated-types==0.7.0\nantlr4-python3-runtime==4.9.3\nanyio==4.4.0\nattrs==24.2.0\nbackoff==2.2.1\nbeautifulsoup4==4.12.3\nblinker==1.8.2\ncachetools==5.5.0\ncertifi==2024.7.4\ncffi==1.17.0\nchardet==5.2.0\ncharset-normalizer==3.3.2\nclick==8.1.7\ncoloredlogs==15.0.1\ncontourpy==1.2.1\ncryptography==43.0.0\ncycler==0.12.1\ndataclasses-json==0.6.7\ndeepdiff==7.0.1\nDeprecated==1.2.14\ndistro==1.9.0\neffdet==0.4.1\nemoji==2.12.1\nfilelock==3.15.4\nfiletype==1.2.0\nflatbuffers==24.3.25\nfonttools==4.53.1\nfsspec==2024.6.1\ngitdb==4.0.11\nGitPython==3.1.43\ngoogle-ai-generativelanguage==0.6.6\ngoogle-api-core==2.19.1\ngoogle-api-python-client==2.142.0\ngoogle-auth==2.34.0\ngoogle-auth-httplib2==0.2.0\ngoogle-cloud-vision==3.7.4\ngoogle-generativeai==0.7.2\ngoogleapis-common-protos==1.63.2\ngrpcio==1.66.0\ngrpcio-status==1.62.3\nh11==0.14.0\nhttpcore==1.0.5\nhttplib2==0.22.0\nhttpx==0.27.0\nhuggingface-hub==0.24.6\nhumanfriendly==10.0\nidna==3.8\niopath==0.1.10\nJinja2==3.1.4\njiter==0.5.0\njoblib==1.4.2\njsonpath-python==1.0.6\njsonschema==4.23.0\njsonschema-specifications==2023.12.1\nkiwisolver==1.4.5\nlangdetect==1.0.9\nlayoutparser==0.3.4\nlxml==5.3.0\nmarkdown-it-py==3.0.0\nMarkupSafe==2.1.5\nmarshmallow==3.22.0\nmatplotlib==3.9.2\nmdurl==0.1.2\nmpmath==1.3.0\nmypy-extensions==1.0.0\nnarwhals==1.5.4\nnest-asyncio==1.6.0\nnetworkx==3.3\nnltk==3.9.1\nnumpy==1.26.4\nnvidia-cublas-cu12==12.1.3.1\nnvidia-cuda-cupti-cu12==12.1.105\nnvidia-cuda-nvrtc-cu12==12.1.105\nnvidia-cuda-runtime-cu12==12.1.105\nnvidia-cudnn-cu12==9.1.0.70\nnvidia-cufft-cu12==11.0.2.54\nnvidia-curand-cu12==10.3.2.106\nnvidia-cusolver-cu12==11.4.5.107\nnvidia-cusparse-cu12==12.1.0.106\nnvidia-nccl-cu12==2.20.5\nnvidia-nvjitlink-cu12==12.6.20\nnvidia-nvtx-cu12==12.1.105\nomegaconf==2.3.0\nonnx==1.16.2\nonnxruntime==1.19.0\nopenai==1.42.0\nopencv-python==4.10.0.84\nordered-set==4.1.0\npackaging==24.1\npandas==2.2.2\npdf2image==1.17.0\npdfminer.six==20231228\npdfplumber==0.11.4\npikepdf==9.2.0\npillow==10.4.0\npillow_heif==0.18.0\nportalocker==2.10.1\nproto-plus==1.24.0\nprotobuf==4.25.4\npsutil==6.0.0\npyarrow==17.0.0\npyasn1==0.6.0\npyasn1_modules==0.4.0\npycocotools==2.0.8\npycparser==2.22\npydantic==2.8.2\npydantic_core==2.20.1\npydeck==0.9.1\nPygments==2.18.0\npyparsing==3.1.2\npypdf==4.3.1\npypdfium2==4.30.0\npython-dateutil==2.9.0.post0\npython-dotenv==1.0.1\npython-iso639==2024.4.27\npython-magic==0.4.27\npython-multipart==0.0.9\npytz==2024.1\nPyYAML==6.0.2\nrapidfuzz==3.9.6\nreferencing==0.35.1\nregex==2024.7.24\nrequests==2.32.3\nrequests-toolbelt==1.0.0\nrich==13.7.1\nrpds-py==0.20.0\nrsa==4.9\nsafetensors==0.4.4\nscipy==1.14.1\nsetuptools==73.0.1\nsix==1.16.0\nsmmap==5.0.1\nsniffio==1.3.1\nsoupsieve==2.6\nstreamlit==1.37.1\nsympy==1.13.2\ntabulate==0.9.0\ntenacity==8.5.0\ntimm==1.0.9\ntokenizers==0.19.1\ntoml==0.10.2\ntorch==2.4.0\ntorchvision==0.19.0\ntornado==6.4.1\ntqdm==4.66.5\ntransformers==4.44.2\ntriton==3.0.0\ntyping-inspect==0.9.0\ntyping_extensions==4.12.2\ntzdata==2024.1\nunstructured==0.15.7\nunstructured-client==0.25.5\nunstructured-inference==0.7.36\nunstructured.pytesseract==0.3.13\nuritemplate==4.1.1\nurllib3==2.2.2\nwatchdog==4.0.2\nwrapt==1.16.0\n", ".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n"} | 7 |
visual-blocks-custom-components | {"type": "directory", "name": "visual-blocks-custom-components", "children": [{"type": "directory", "name": "examples", "children": [{"type": "directory", "name": "client", "children": [{"type": "file", "name": "background_removal_client_.json"}, {"type": "file", "name": "depth_estimation_client_.json"}, {"type": "file", "name": "image_classification_client_.json"}, {"type": "file", "name": "image_segmentation_client_.json"}, {"type": "file", "name": "object_detection_client_.json"}, {"type": "file", "name": "text_classification_client_.json"}, {"type": "file", "name": "text_to_text_client_.json"}, {"type": "file", "name": "token_classification_client_.json"}, {"type": "file", "name": "translation_client_.json"}]}, {"type": "directory", "name": "extras", "children": [{"type": "file", "name": "background_removal_text_to_image.json"}, {"type": "file", "name": "chat_completion_txt2img_depth.json"}, {"type": "file", "name": "image_segmentation_webcam_client.json"}]}, {"type": "directory", "name": "server", "children": [{"type": "file", "name": "chat_completion_server_.json"}, {"type": "file", "name": "chat_template_text_generation_server_.json"}, {"type": "file", "name": "fill_mask_server_.json"}, {"type": "file", "name": "image_classification_server_.json"}, {"type": "file", "name": "summarization_server_.json"}, {"type": "file", "name": "text_classification_server_.json"}, {"type": "file", "name": "text_generation_server_.json"}, {"type": "file", "name": "text_to_image_server_.json"}, {"type": "file", "name": "token_classification_server_.json"}]}]}, {"type": "file", "name": "LICENSE"}, {"type": "file", "name": "package-lock.json"}, {"type": "file", "name": "package.json"}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "src", "children": [{"type": "directory", "name": "backends", "children": [{"type": "directory", "name": "client", "children": [{"type": "file", "name": "base.ts"}]}]}, {"type": "file", "name": "constants.ts"}, {"type": "file", "name": "index.ts"}, {"type": "directory", "name": "nodes", "children": [{"type": "directory", "name": "client", "children": [{"type": "file", "name": "background-removal-spec.ts"}, {"type": "file", "name": "background-removal.ts"}, {"type": "file", "name": "depth-estimation-spec.ts"}, {"type": "file", "name": "depth-estimation.ts"}, {"type": "file", "name": "image-classification-specs.ts"}, {"type": "file", "name": "image-classification.ts"}, {"type": "file", "name": "image-segmentation-spec.ts"}, {"type": "file", "name": "image-segmentation.ts"}, {"type": "file", "name": "object-detection-spec.ts"}, {"type": "file", "name": "object-detection.ts"}, {"type": "file", "name": "text-classification-specs.ts"}, {"type": "file", "name": "text-classification.ts"}, {"type": "file", "name": "text-to-text-specs.ts"}, {"type": "file", "name": "text-to-text.ts"}, {"type": "file", "name": "token-classification-specs.ts"}, {"type": "file", "name": "token-classification.ts"}, {"type": "file", "name": "translation-specs.ts"}, {"type": "file", "name": "translation.ts"}]}, {"type": "directory", "name": "server", "children": [{"type": "file", "name": "chat-completion-specs.ts"}, {"type": "file", "name": "chat-completion.ts"}, {"type": "file", "name": "fill-mask-specs.ts"}, {"type": "file", "name": "fill-mask.ts"}, {"type": "file", "name": "hf-hub-login-specs.ts"}, {"type": "file", "name": "hf-hub-login.ts"}, {"type": "file", "name": "image-classification-specs.ts"}, {"type": "file", "name": "image-classification.ts"}, {"type": "file", "name": "summarization-specs.ts"}, {"type": "file", "name": "summarization.ts"}, {"type": "file", "name": "text-classification-specs.ts"}, {"type": "file", "name": "text-classification.ts"}, {"type": "file", "name": "text-generation-specs.ts"}, {"type": "file", "name": "text-generation.ts"}, {"type": "file", "name": "text-to-image-specs.ts"}, {"type": "file", "name": "text-to-image.ts"}, {"type": "file", "name": "token-classification-specs.ts"}, {"type": "file", "name": "token-classification.ts"}]}, {"type": "directory", "name": "shared", "children": [{"type": "file", "name": "chat-template-generator-specs.ts"}, {"type": "file", "name": "chat-template-generator.ts"}, {"type": "file", "name": "depth-estimation-viewer-spec.ts"}, {"type": "file", "name": "depth-estimation-viewer.ts"}, {"type": "file", "name": "image-segmentation-viewer-spec.ts"}, {"type": "file", "name": "image-segmentation-viewer.ts"}, {"type": "file", "name": "token-classification-viewer-specs.ts"}, {"type": "file", "name": "token-classification-viewer.ts"}]}]}, {"type": "file", "name": "types.ts"}, {"type": "file", "name": "utils.ts"}]}, {"type": "file", "name": "tsconfig.json"}]} | # Hugging Face + Visual Blocks Custom Components
<p align="center">
<br/>
<picture>
<source media="(prefers-color-scheme: dark)" srcset="https://huggingface.co/spaces/hf-vb/README/raw/main/hf-vb-logo-dark.svg" width="400" style="max-width: 100%;">
<source media="(prefers-color-scheme: light)" srcset="https://huggingface.co/spaces/hf-vb/README/raw/main/hf-vb-logo.svg" width="400" style="max-width: 100%;">
<img alt="transformers.js javascript library logo" src="https://huggingface.co/spaces/hf-vb/README/raw/main/hf-vb-logo.svg" width="400" style="max-width: 100%;">
</picture>
<br/>
</p>
Visual blocks is an amazing tool from our friends at [Google](https://github.com/google/visualblocks)
that allows you to easily create and experiment with machine learning pipelines using a visual interface.
This repository contains the source code for custom components that allow you to use Hugging Face client and server models in your Visual Blocks pipelines.
We've created a few nodes supporting different tasks and models following our [Tasks](https://huggingface.co/tasks) definitions.
> [!NOTE]
> Visual Blocks seems to be mostly working in Chrome. If you are having trouble with the interface, try using Chrome, and please submit an [issue](https://github.com/google/visualblocks/issues) to the Visual Blocks team.
Important links:
- https://visualblocks.withgoogle.com/
- https://www.npmjs.com/package/huggingface-visualblocks-nodes
- https://cdn.jsdelivr.net/npm/huggingface-visualblocks-nodes@latest
<details>
<summary> Table of Contents</summary>
- [How to use the custom components](#how-to-use-the-custom-components)
- [Nodes and Examples](#nodes-and-examples)
- [Client Nodes](#client-nodes)
- [Translation](#translation)
- [Token Classification](#token-classification)
- [Text Classification](#text-classification)
- [Object Detection](#object-detection)
- [Image Segmentation](#image-segmentation)
- [Image Classification](#image-classification)
- [Depth Estimation](#depth-estimation)
- [Background Removal](#background-removal)
- [Server Nodes](#server-nodes)
- [Text Generation and Chat Completion](#text-generation-and-chat-completion)
- [Fill Mask](#fill-mask)
- [Image Classification](#image-classification-1)
- [Summarization](#summarization)
- [Text Classification](#text-classification-1)
- [Text Generation](#text-generation)
- [Text to Image](#text-to-image)
- [Token Classification](#token-classification-1)
- [Extra Examples](#extra-examples)
- [Local Development](#local-development)
</details>
## How to use the custom components
To start playing with our custom components you need to **Add a custom node** to your Visual Blocks project. First you need to start a new project [https://visualblocks.withgoogle.com/#/edit/new](https://visualblocks.withgoogle.com/#/edit/new), then click on the "+" button in the bottom left corner to add a new node.
<img src="https://huggingface.co/spaces/hf-vb/README/resolve/main/left_button.png" width="200">
Then input the pre-bundled code from our npm package. You can do this by pasting the following link into the input field and clicking "Submit":
```
https://cdn.jsdelivr.net/npm/huggingface-visualblocks-nodes@latest
```
<img src="https://huggingface.co/spaces/hf-vb/README/resolve/main/custom_node.jpg" width="450">
Then you will be able to see three Hugging Face Collections: Client, Server and Common.
<img src="https://huggingface.co/spaces/hf-vb/README/resolve/main/collections.jpg" width="250">
# Nodes and Examples
## Client Nodes
Client nodes are nodes running tranformers pipelines on the client side using [Transformers.js](https://github.com/xenova/transformers.js). All Client nodes have WASM and WebGPU (experimental) backend support, and you can find web-compatible models by visiting https://huggingface.co/models?library=transformers.js.
> [!NOTE]
> WebGPU support in transformers.js is still experimental and may not work on all devices. Not all models are supported by WebGPU backend yet.
### Translation
<img src="https://huggingface.co/spaces/hf-vb/README/resolve/main/translation.jpg" width="500">
[**Translation Node Example**](https://visualblocks.withgoogle.com/#/edit/new_hfdemo?project_json=https://cdn.jsdelivr.net/npm/huggingface-visualblocks-nodes@latest/examples/client/translation_client_.json)
More info:
- https://huggingface.co/tasks/translation
- https://huggingface.co/docs/transformers.js/api/pipelines#module_pipelines.TranslationPipeline
### Token Classification
<img src="https://huggingface.co/spaces/hf-vb/README/resolve/main/token.jpg" width="500">
[**Token Classification Node Exampl**e](https://visualblocks.withgoogle.com/#/edit/new_hfdemo?project_json=https://cdn.jsdelivr.net/npm/huggingface-visualblocks-nodes@latest/examples/client/token_classification_client_.json)
More info:
- https://huggingface.co/tasks/token-classification
- https://huggingface.co/docs/transformers.js/api/pipelines#module_pipelines.TokenClassificationPipeline
### Text Classification
<img src="https://huggingface.co/spaces/hf-vb/README/resolve/main/text-classification.jpg" width="500">
[**Text Classification Node Example**](https://visualblocks.withgoogle.com/#/edit/new_hfdemo?project_json=https://cdn.jsdelivr.net/npm/huggingface-visualblocks-nodes@latest/examples/client/text_classification_client_.json)
More info:
- https://huggingface.co/tasks/text-classification
- https://huggingface.co/docs/transformers.js/api/pipelines#module_pipelines.TextClassificationPipeline
### Object Detection
<img src="https://huggingface.co/spaces/hf-vb/README/resolve/main/object-detc.jpg" width="500">
[**Object Detection Node Example**](https://visualblocks.withgoogle.com/#/edit/new_hfdemo?project_json=https://cdn.jsdelivr.net/npm/huggingface-visualblocks-nodes@latest/examples/client/object_detection_client_.json)
More info:
- https://huggingface.co/tasks/object-detection
- https://huggingface.co/docs/transformers.js/api/pipelines#module_pipelines.ObjectDetectionPipeline
### Image Segmentation
<img src="https://huggingface.co/spaces/hf-vb/README/resolve/main/segment.jpg" width="500">
[**Image Segmentation Node Example**](https://visualblocks.withgoogle.com/#/edit/new_hfdemo?project_json=https://cdn.jsdelivr.net/npm/huggingface-visualblocks-nodes@latest/examples/client/image_segmentation_client_.json)
More info:
- https://huggingface.co/tasks/image-segmentation
- https://huggingface.co/docs/transformers.js/api/pipelines#module_pipelines.ImageSegmentationPipeline
### Image Classification
<img src="https://huggingface.co/spaces/hf-vb/README/resolve/main/class.jpg" width="500">
[**Image Classification Node Example**](https://visualblocks.withgoogle.com/#/edit/new_hfdemo?project_json=https://cdn.jsdelivr.net/npm/huggingface-visualblocks-nodes@latest/examples/client/image_classification_client_.json)
More info:
- https://huggingface.co/tasks/image-classification
- https://huggingface.co/docs/transformers.js/api/pipelines#module_pipelines.ImageClassificationPipeline
### Depth Estimation
<img src="https://huggingface.co/spaces/hf-vb/README/resolve/main/dept-es.jpg" width="500">
[Depth Estimation Node Example](https://visualblocks.withgoogle.com/#/edit/new_hfdemo?project_json=https://cdn.jsdelivr.net/npm/huggingface-visualblocks-nodes@latest/examples/client/depth_estimation_client_.json)
More info:
- https://huggingface.co/tasks/depth-estimation
- https://huggingface.co/docs/transformers.js/api/pipelines#module_pipelines.DepthEstimationPipeline
### Background Removal
<img src="https://huggingface.co/spaces/hf-vb/README/resolve/main/removal.jpg" width="500">
[**Background Removal Node Example**](https://visualblocks.withgoogle.com/#/edit/new_hfdemo?project_json=https://cdn.jsdelivr.net/npm/huggingface-visualblocks-nodes@latest/examples/client/background_removal_client_.json)
## Server Nodes
Server nodes are nodes running Transformers pipeline tasks using the [Hugging Face Serverless API](https://huggingface.co/docs/api-inference/en/index). For a few selected LLM models, it's running using our hosted [Text Generation Inference](https://huggingface.co/docs/text-generation-inference/en/index), our fast, optimized inference for LLMs.
> [!NOTE]
> You can use the Hugging Face Serverless API for free with limited usage, after which you'll be rate limited. If you need more usage, you can create an account at https://huggingface.co/join and get an API token at https://huggingface.co/settings/tokens or log in using the Hugging Face Login node.
For server nodes you have the option to Login using your Hugging Face account to get more usage and access to private models. Using **Hugging Face Hub Login**
<img src="https://huggingface.co/spaces/hf-vb/README/resolve/main/server/button-auth.jpg" width="250">
<img src="https://huggingface.co/spaces/hf-vb/README/resolve/main/server/auth.jpg" width="400">
<img src="https://huggingface.co/spaces/hf-vb/README/resolve/main/server/button-logged.jpg" width="250">
If successful, you can obtain your **Apikey** directly from the **Hugging Face Hub Login** node.
<img src="https://huggingface.co/spaces/hf-vb/README/resolve/main/server/logged.jpg" width="350">
### Text Generation and Chat Completion
<img src="https://huggingface.co/spaces/hf-vb/README/resolve/main/server/chat-template.jpg" width="500">
[**Chat Template Text Generation Node Example**](https://visualblocks.withgoogle.com/#/edit/new_hfdemo?project_json=https://cdn.jsdelivr.net/npm/huggingface-visualblocks-nodes@latest/examples/server/chat_template_text_generation_server_.json)
<img src="https://huggingface.co/spaces/hf-vb/README/resolve/main/chat_completion.jpg" width="500">
[**Chat Completion Node Example**](https://visualblocks.withgoogle.com/#/edit/new_hfdemo?project_json=https://cdn.jsdelivr.net/npm/huggingface-visualblocks-nodes@latest/examples/server/chat_completion_server_.json)
More info:
- https://huggingface.co/tasks/text-generation
### Fill Mask
<img src="https://huggingface.co/spaces/hf-vb/README/resolve/main/server/fill-mask.jpg" width="500">
[**Fill Mask Node Example**](https://visualblocks.withgoogle.com/#/edit/new_hfdemo?project_json=https://cdn.jsdelivr.net/npm/huggingface-visualblocks-nodes@latest/examples/server/fill_mask_server_.json)
More info:
- https://huggingface.co/tasks/fill-mask
### Image Classification
<img src="https://huggingface.co/spaces/hf-vb/README/resolve/main/server/image-class.jpg" width="500">
[**Image Classification Node Example**](https://visualblocks.withgoogle.com/#/edit/new_hfdemo?project_json=https://cdn.jsdelivr.net/npm/huggingface-visualblocks-nodes@latest/examples/server/image_classification_server_.json)
More info:
- https://huggingface.co/tasks/image-classification
### Summarization
<img src="https://huggingface.co/spaces/hf-vb/README/resolve/main/server/summarization.jpg" width="500">
[**Summarization Node Example**](https://visualblocks.withgoogle.com/#/edit/new_hfdemo?project_json=https://cdn.jsdelivr.net/npm/huggingface-visualblocks-nodes@latest/examples/server/summarization_server_.json)
More info:
- https://huggingface.co/tasks/summarization
### Text Classification
<img src="https://huggingface.co/spaces/hf-vb/README/resolve/main/server/text-class.jpg" width="500">
[**Text Classification Node Example**](https://visualblocks.withgoogle.com/#/edit/new_hfdemo?project_json=https://cdn.jsdelivr.net/npm/huggingface-visualblocks-nodes@latest/examples/server/text_classification_server_.json)
More info:
- https://huggingface.co/tasks/text-classification
### Text Generation
<img src="https://huggingface.co/spaces/hf-vb/README/resolve/main/server/text-generation.jpg" width="500">
[**Text Generation Node Example**](https://visualblocks.withgoogle.com/#/edit/new_hfdemo?project_json=https://cdn.jsdelivr.net/npm/huggingface-visualblocks-nodes@latest/examples/server/text_generation_server_.json)
More info:
- https://huggingface.co/tasks/text-generation
### Text to Image
<img src="https://huggingface.co/spaces/hf-vb/README/resolve/main/server/text-to-image.jpg" width="500">
[**Text to Image Node Example**](https://visualblocks.withgoogle.com/#/edit/new_hfdemo?project_json=https://cdn.jsdelivr.net/npm/huggingface-visualblocks-nodes@latest/examples/server/text_to_image_server_.json)
More info:
- https://huggingface.co/tasks/text-to-image
### Token Classification
<img src="https://huggingface.co/spaces/hf-vb/README/resolve/main/server/token-class.jpg" width="500">
[**Token Classification Node Example**](https://visualblocks.withgoogle.com/#/edit/new_hfdemo?project_json=https://cdn.jsdelivr.net/npm/huggingface-visualblocks-nodes@latest/examples/server/token_classification_server_.json)
More info:
- https://huggingface.co/tasks/token-classification
## Extra Examples
[**Background Removal Text to Image**](https://visualblocks.withgoogle.com/#/edit/new_hfdemo?project_json=https://cdn.jsdelivr.net/npm/huggingface-visualblocks-nodes@latest/examples/extras/background_removal_text_to_image.json)
[**Chat Completion Text to Image Depth**](https://visualblocks.withgoogle.com/#/edit/new_hfdemo?project_json=https://cdn.jsdelivr.net/npm/huggingface-visualblocks-nodes@latest/examples/extras/chat_completion_txt2img_depth.json)
[**Image Segmentation Webcam Client**](https://visualblocks.withgoogle.com/#/edit/new_hfdemo?project_json=https://cdn.jsdelivr.net/npm/huggingface-visualblocks-nodes@latest/examples/extras/image_segmentation_webcam_client.json)
# Local Development
1. Clone the repository
```bash
git clone https://github.com/huggingface/visual-blocks-custom-components.git
cd visual-blocks-custom-components
```
2. Install the dependencies
```bash
npm i
```
3. Run the development server
```bash
npm run dev
```
4. Visit Google's staging server
5. Click the + in the bottom left corner to add the custom nodes.
6. Paste in the link to the script (e.g., http://localhost:8080/index.js) and click "Submit".
| {"package.json": "{\n \"name\": \"huggingface-visualblocks-nodes\",\n \"repository\": {\n \"type\": \"git\",\n \"url\": \"git+https://github.com/huggingface/visual-blocks-custom-components.git\"\n },\n \"description\": \"Custom Hugging Face components for Visual Blocks\",\n \"version\": \"0.0.9\",\n \"type\": \"module\",\n \"private\": false,\n \"main\": \"./dist/index.js\",\n \"files\": [\n \"dist\",\n \"examples\"\n ],\n \"scripts\": {\n \"dev\": \"run-p dev:*\",\n \"dev:server\": \"npm run build -- --servedir=dist --serve=8080\",\n \"dev:tsc\": \"tsc --watch --preserveWatchOutput\",\n \"build\": \"esbuild --bundle ./src/index.ts --outfile=dist/index.js\",\n \"prepublishOnly\": \"npm run build\"\n },\n \"license\": \"Apache-2.0\",\n \"author\": \"Hugging Face\",\n \"dependencies\": {\n \"@huggingface/inference\": \"^2.7.0\",\n \"@huggingface/jinja\": \"^0.2.2\",\n \"@huggingface/tasks\": \"^0.10.2\",\n \"@visualblocks/custom-node-types\": \"^0.0.5\",\n \"@xenova/transformers\": \"github:xenova/transformers.js#v3\",\n \"lit\": \"^3.1.3\",\n \"three\": \"^0.164.1\"\n },\n \"devDependencies\": {\n \"@huggingface/hub\": \"^0.15.0\",\n \"@types/three\": \"^0.164.0\",\n \"esbuild\": \"^0.21.2\",\n \"npm-run-all\": \"^4.1.5\",\n \"typescript\": \"^5.4.5\"\n }\n}", ".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 17f202b9a1dcf88c3b62e9d7dc2cfa65ada29b1d Hamza Amin <[email protected]> 1727369524 +0500\tclone: from https://github.com/huggingface/visual-blocks-custom-components.git\n", ".git\\refs\\heads\\main": "17f202b9a1dcf88c3b62e9d7dc2cfa65ada29b1d\n", "src\\index.ts": "/**\n * Registry containing the definitions of the custom components.\n */\n\nimport TOKEN_CLASSIFICATION_VIEWER_NODE from \"./nodes/shared/token-classification-viewer\";\nimport IMAGE_SEGMENTATION_VIEWER_NODE from \"./nodes/shared/image-segmentation-viewer\";\nimport DEPTH_ESTIMATION_VIEWER_NODE from \"./nodes/shared/depth-estimation-viewer\";\nimport CHAT_TEMPLATE_GENERATOR_NODE from \"./nodes/shared/chat-template-generator\";\n\nimport TOKEN_CLASSIFICATION_NODE from \"./nodes/client/token-classification\";\nimport IMAGE_SEGMENTATION_NODE from \"./nodes/client/image-segmentation\";\nimport TEXT_CLASSIFICATION_NODE from \"./nodes/client/text-classification\";\nimport IMAGE_CLASSIFICATION_NODE from \"./nodes/client/image-classification\";\nimport TEXT2TEXT_GENERATION_NODE from \"./nodes/client/text-to-text\";\nimport TRANSLANTION_NODE from \"./nodes/client/translation\";\nimport DEPTH_ESTIMATION_NODE from \"./nodes/client/depth-estimation\";\nimport OBJECT_DETECTION_GENERATION_NODE from \"./nodes/client/object-detection\";\nimport BACKGROUND_REMOVAL_NODE from \"./nodes/client/background-removal\";\n\nimport TEXT_CLASSIFICATION_SERVER_NODE from \"./nodes/server/text-classification\";\nimport TEXT_TO_IMAGE_SERVER_NODE from \"./nodes/server/text-to-image\";\nimport TOKEN_CLASSIFICATION_SERVER_NODE from \"./nodes/server/token-classification\";\nimport FILL_MASK_SERVER_NODE from \"./nodes/server/fill-mask\";\nimport SUMMARIZATION_SERVER from \"./nodes/server/summarization\";\nimport IMAGE_CLASSIFICATION_SERVER_NODE from \"./nodes/server/image-classification\";\nimport TEXT_GENERATION_SERVER_NODE from \"./nodes/server/text-generation\";\nimport CHAT_COMPLETION_SERVER_NODE from \"./nodes/server/chat-completion\";\n\nimport HF_LOGIN_HUB from \"./nodes/server/hf-hub-login\";\n//\nconst client_node = [\n TOKEN_CLASSIFICATION_NODE,\n TOKEN_CLASSIFICATION_VIEWER_NODE,\n IMAGE_SEGMENTATION_NODE,\n IMAGE_SEGMENTATION_VIEWER_NODE,\n DEPTH_ESTIMATION_VIEWER_NODE,\n TEXT_CLASSIFICATION_NODE,\n IMAGE_CLASSIFICATION_NODE,\n TEXT2TEXT_GENERATION_NODE,\n DEPTH_ESTIMATION_NODE,\n OBJECT_DETECTION_GENERATION_NODE,\n BACKGROUND_REMOVAL_NODE,\n TRANSLANTION_NODE,\n];\nconst server_nodes = [\n TEXT_CLASSIFICATION_SERVER_NODE,\n TEXT_TO_IMAGE_SERVER_NODE,\n HF_LOGIN_HUB,\n TOKEN_CLASSIFICATION_SERVER_NODE,\n SUMMARIZATION_SERVER,\n FILL_MASK_SERVER_NODE,\n IMAGE_CLASSIFICATION_SERVER_NODE,\n TEXT_GENERATION_SERVER_NODE,\n CHAT_COMPLETION_SERVER_NODE,\n CHAT_TEMPLATE_GENERATOR_NODE,\n];\n\n// Register client nodes custom nodes with visual blocks to start using them.\nclient_node.forEach((node) => {\n visualblocks.registerCustomNode(node);\n});\nserver_nodes.forEach((node) => {\n visualblocks.registerCustomNode(node);\n});\n"} | null |
widgets-server | {"type": "directory", "name": "widgets-server", "children": [{"type": "directory", "name": "iso", "children": [{"type": "file", "name": "iso-639-2.ts"}, {"type": "file", "name": "iso-639-3.ts"}, {"type": "file", "name": "Iso3166.ts"}, {"type": "file", "name": "Iso639-3166-mapping.ts"}, {"type": "file", "name": "Iso639.ts"}, {"type": "file", "name": "Oscar.ts"}, {"type": "file", "name": "Wikipedia.ts"}]}, {"type": "file", "name": "Language.ts"}, {"type": "file", "name": "utils.ts"}]} | {".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", "iso\\Iso639-3166-mapping.ts": "/// https://en.wikipedia.org/wiki/ISO_3166-1_alpha-2\n///\n/// From https://github.com/lipis/flag-icon-css/issues/510\n///\n\nexport const MAPPING_CROSS_ISO: Record<string, string | {\n\tflag: string,\n\tname: string,\n\tproposed_iso_3166: string,\n}> = {\n\t\"aa\": \"DJ\",\n\t\"af\": \"ZA\",\n\t\"ak\": \"GH\",\n\t\"sq\": \"AL\",\n\t\"am\": \"ET\",\n\t\"ar\": {\n\t\t\"proposed_iso_3166\": \"AA\",\n\t\t\"flag\": \"https://en.wikipedia.org/wiki/Flag_of_the_Arab_League\",\n\t\t\"name\": \"Arab League\"\n\t},\n\t\"hy\": \"AM\",\n\t\"ay\": {\n\t\t\"proposed_iso_3166\": \"WH\",\n\t\t\"flag\": \"https://en.wikipedia.org/wiki/Wiphala\",\n\t\t\"name\": \"Wiphala\"\n\t},\n\t\"az\": \"AZ\",\n\t\"bm\": \"ML\",\n\t\"be\": \"BY\",\n\t\"bn\": \"BD\",\n\t\"bi\": \"VU\",\n\t\"bs\": \"BA\",\n\t\"bg\": \"BG\",\n\t\"my\": \"MM\",\n\t\"ca\": \"AD\",\n\t\"zh\": \"CN\",\n\t\"hr\": \"HR\",\n\t\"cs\": \"CZ\",\n\t\"da\": \"DK\",\n\t\"dv\": \"MV\",\n\t\"nl\": \"NL\",\n\t\"dz\": \"BT\",\n\t\"en\": \"GB\",\n\t\"et\": \"EE\",\n\t\"ee\": {\n\t\t\"proposed_iso_3166\": \"EW\",\n\t\t\"flag\": \"https://en.wikipedia.org/wiki/Ewe_people#/media/File:Flag_of_the_Ewe_people.svg\",\n\t\t\"name\": \"Ewe\"\n\t},\n\t\"fj\": \"FJ\",\n\t\"fil\": \"PH\",\n\t\"fi\": \"FI\",\n\t\"fr\": \"FR\",\n\t\"ff\": {\n\t\t\"proposed_iso_3166\": \"FF\",\n\t\t\"flag\": \"https://www.nationstates.net/images/flags/uploads/fulah__403173.png\",\n\t\t\"name\": \"Fulah\"\n\t},\n\t\"gaa\": \"GH\",\n\t\"ka\": \"GE\",\n\t\"de\": \"DE\",\n\t\"el\": \"GR\",\n\t\"gn\": {\n\t\t\"proposed_iso_3166\": \"GX\",\n\t\t\"flag\": \"https://www.crwflags.com/fotw/flags/xg.html\",\n\t\t\"name\": \"Guarani\"\n\t},\n\t\"gu\": \"IN\",\n\t\"ht\": \"HT\",\n\t\"ha\": {\n\t\t\"proposed_iso_3166\": \"HA\",\n\t\t\"flag\": \"https://www.crwflags.com/fotw/flags/ng%7Dhausa.html\",\n\t\t\"name\": \"Hausa\"\n\t},\n\t\"he\": \"IL\",\n\t\"hi\": \"IN\",\n\t\"ho\": \"PG\",\n\t\"hu\": \"HU\",\n\t\"is\": \"IS\",\n\t\"ig\": \"NG\",\n\t\"id\": \"ID\",\n\t\"ga\": \"IE\",\n\t\"it\": \"IT\",\n\t\"ja\": \"JP\",\n\t\"kr\": \"NE\",\n\t\"kk\": \"KZ\",\n\t\"km\": \"KH\",\n\t\"kmb\": \"AO\",\n\t\"rw\": \"RW\",\n\t\"kg\": \"CG\",\n\t\"ko\": \"KR\",\n\t\"kj\": \"AO\",\n\t\"ku\": \"IQ\",\n\t\"ky\": \"KG\",\n\t\"lo\": \"LA\",\n\t\"la\": \"VA\",\n\t\"lv\": \"LV\",\n\t\"ln\": \"CG\",\n\t\"lt\": \"LT\",\n\t\"lu\": \"CD\",\n\t\"lb\": \"LU\",\n\t\"mk\": \"MK\",\n\t\"mg\": \"MG\",\n\t\"ms\": \"MY\",\n\t\"mt\": \"MT\",\n\t\"mi\": \"NZ\",\n\t\"mh\": \"MH\",\n\t\"mn\": \"MN\",\n\t\"mos\": \"BF\",\n\t\"ne\": \"NP\",\n\t\"nd\": \"ZW\",\n\t\"nso\": \"ZA\",\n\t\"no\": \"NO\",\n\t\"nb\": \"NO\",\n\t\"nn\": \"NO\",\n\t\"ny\": \"MW\",\n\t\"pap\": \"AW\",\n\t\"ps\": \"AF\",\n\t\"fa\": \"IR\",\n\t\"pl\": \"PL\",\n\t\"pt\": \"PT\",\n\t\"pa\": \"IN\",\n\t\"ro\": \"RO\",\n\t\"rm\": \"CH\",\n\t\"rn\": \"BI\",\n\t\"ru\": \"RU\",\n\t\"sa\": \"IN\",\n\t\"sg\": \"CF\",\n\t\"sr\": \"RS\",\n\t\"srr\": \"SN\",\n\t\"sn\": \"ZW\",\n\t\"si\": \"LK\",\n\t\"sk\": \"SK\",\n\t\"sl\": \"SI\",\n\t\"so\": \"SO\",\n\t\"snk\": \"SN\",\n\t\"nr\": \"ZA\",\n\t\"st\": \"LS\",\n\t\"es\": \"ES\",\n\t\"sw\": {\n\t\t\"proposed_iso_3166\": \"SW\",\n\t\t\"flag\": \"https://commons.wikimedia.org/wiki/File:Flag_of_Swahili.gif\",\n\t\t\"name\": \"Swahili\"\n\t},\n\t\"ss\": \"SZ\",\n\t\"sv\": \"SE\",\n\t\"tl\": \"PH\",\n\t\"tg\": \"TJ\",\n\t\"ta\": \"IN\",\n\t\"te\": \"IN\",\n\t\"tet\": \"TL\",\n\t\"th\": \"TH\",\n\t\"ti\": \"ER\",\n\t\"tpi\": \"PG\",\n\t\"ts\": \"ZA\",\n\t\"tn\": \"BW\",\n\t\"tr\": \"TR\",\n\t\"tk\": \"TM\",\n\t\"uk\": \"UA\",\n\t\"umb\": \"AO\",\n\t\"ur\": \"PK\",\n\t\"uz\": \"UZ\",\n\t\"ve\": \"ZA\",\n\t\"vi\": \"VN\",\n\t\"cy\": \"GB\",\n\t\"wo\": \"SN\",\n\t\"xh\": \"ZA\",\n\t\"yo\": {\n\t\t\"proposed_iso_3166\": \"YO\",\n\t\t\"flag\": \"https://www.crwflags.com/fotw/flags/ng%7Dyorub.html\",\n\t\t\"name\": \"Yoruba\"\n\t},\n\t\"zu\": \"ZA\"\n}\n"} | null |
|
zapier | {"type": "directory", "name": "zapier", "children": [{"type": "file", "name": ".zapierapprc"}, {"type": "file", "name": "authentication.js"}, {"type": "directory", "name": "creates", "children": [{"type": "file", "name": "automatic_speech_recognition.js"}, {"type": "file", "name": "docqa.js"}, {"type": "file", "name": "question_answering.js"}, {"type": "file", "name": "summarization.js"}, {"type": "file", "name": "text_classification.js"}, {"type": "file", "name": "text_generation.js"}, {"type": "file", "name": "translation.js"}, {"type": "file", "name": "zero_shot_classification.js"}]}, {"type": "file", "name": "index.js"}, {"type": "file", "name": "LICENSE"}, {"type": "file", "name": "package-lock.json"}, {"type": "file", "name": "package.json"}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "test", "children": [{"type": "directory", "name": "creates", "children": [{"type": "file", "name": "automatic_speech_recognition.js"}, {"type": "file", "name": "docqa.js"}, {"type": "file", "name": "question_answering.js"}, {"type": "file", "name": "summarization.js"}, {"type": "file", "name": "text_classification.js"}, {"type": "file", "name": "text_generation.js"}, {"type": "file", "name": "translation.js"}, {"type": "file", "name": "zero_shot_classification.js"}]}]}]} | # Hugging Face Zapier Integration 🤗⚡️
## Setup
First install the dependencies for zapier platform cli (docs [here](https://platform.zapier.com/cli_tutorials/getting-started))
```
npm install -g zapier-platform-cli
```
Then auth with Zapier (must be on HF account to make updates to the official integration).
```
zapier login
# Or, if you sign in with SSO:
zapier login --sso
```
Then clone this repo and install the dependencies
```
git clone https://github.com/huggingface/zapier.git
cd zapier
npm i
```
## Development
To run the integration's tests:
```
zapier test
```
| {".zapierapprc": "{\n \"id\": 178436\n}", "index.js": "const authentication = require('./authentication');\nconst automaticSpeechRecognitionCreate = require('./creates/automatic_speech_recognition.js');\nconst docqaCreate = require('./creates/docqa.js');\nconst textClassificationCreate = require('./creates/text_classification.js');\nconst translationCreate = require('./creates/translation.js');\nconst textGenerationCreate = require('./creates/text_generation.js');\nconst summarizationCreate = require('./creates/summarization.js');\nconst questionAnsweringCreate = require('./creates/question_answering.js');\nconst zeroShotClassificationCreate = require('./creates/zero_shot_classification.js');\n\nmodule.exports = {\n version: require('./package.json').version,\n platformVersion: require('zapier-platform-core').version,\n authentication: authentication,\n triggers: {},\n creates: {\n [automaticSpeechRecognitionCreate.key]: automaticSpeechRecognitionCreate,\n [docqaCreate.key]: docqaCreate,\n [textClassificationCreate.key]: textClassificationCreate,\n [translationCreate.key]: translationCreate,\n [textGenerationCreate.key]: textGenerationCreate,\n [summarizationCreate.key]: summarizationCreate,\n [questionAnsweringCreate.key]: questionAnsweringCreate,\n [zeroShotClassificationCreate.key]: zeroShotClassificationCreate,\n },\n};\n", "package.json": "{\n \"name\": \"hugging-face\",\n \"version\": \"1.0.1\",\n \"description\": \"Use Hugging Face to make predictions on over 100,000 ML models\",\n \"main\": \"index.js\",\n \"scripts\": {\n \"test\": \"mocha --recursive -t 10000\"\n },\n \"engines\": {\n \"node\": \">=v16\",\n \"npm\": \">=5.6.0\"\n },\n \"dependencies\": {\n \"@huggingface/hub\": \"0.5.0\",\n \"@huggingface/inference\": \"^1.7.1\",\n \"zapier-platform-core\": \"14.0.0\",\n \"expect\": \"^26.6.2\"\n },\n \"devDependencies\": {\n \"mocha\": \"^10.2.0\",\n \"should\": \"^13.2.0\"\n },\n \"private\": true,\n \"zapier\": {\n \"convertedByCLIVersion\": \"14.0.0\"\n }\n}\n", ".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 67317325fe57fc83c3dff4f93063afc2664f3ea8 Hamza Amin <[email protected]> 1727369552 +0500\tclone: from https://github.com/huggingface/zapier.git\n", ".git\\refs\\heads\\main": "67317325fe57fc83c3dff4f93063afc2664f3ea8\n"} | null |
adversarialnlp | {"type": "directory", "name": "adversarialnlp", "children": [{"type": "file", "name": ".pylintrc"}, {"type": "directory", "name": "adversarialnlp", "children": [{"type": "directory", "name": "commands", "children": [{"type": "file", "name": "test_install.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "common", "children": [{"type": "file", "name": "file_utils.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "generators", "children": [{"type": "directory", "name": "addsent", "children": [{"type": "file", "name": "addsent_generator.py"}, {"type": "file", "name": "corenlp.py"}, {"type": "directory", "name": "rules", "children": [{"type": "file", "name": "alteration_rules.py"}, {"type": "file", "name": "answer_rules.py"}, {"type": "file", "name": "conversion_rules.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "squad_reader.py"}, {"type": "file", "name": "utils.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "generator.py"}, {"type": "directory", "name": "swag", "children": [{"type": "file", "name": "activitynet_captions_reader.py"}, {"type": "file", "name": "openai_transformer_model.py"}, {"type": "file", "name": "simple_bilm.py"}, {"type": "file", "name": "swag_generator.py"}, {"type": "file", "name": "utils.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "pruners", "children": [{"type": "file", "name": "pruner.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "run.py"}, {"type": "directory", "name": "tests", "children": [{"type": "directory", "name": "dataset_readers", "children": [{"type": "file", "name": "activitynet_captions_test.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "fixtures", "children": [{"type": "file", "name": "activitynet_captions.json"}, {"type": "file", "name": "squad.json"}]}, {"type": "directory", "name": "generators", "children": [{"type": "file", "name": "addsent_generator_test.py"}, {"type": "file", "name": "swag_generator_test.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "version.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "bin", "children": [{"type": "file", "name": "adversarialnlp"}]}, {"type": "directory", "name": "docs", "children": [{"type": "file", "name": "common.rst"}, {"type": "file", "name": "conf.py"}, {"type": "file", "name": "generators.rst"}, {"type": "file", "name": "index.rst"}, {"type": "file", "name": "make.bat"}, {"type": "file", "name": "Makefile"}, {"type": "file", "name": "readme.rst"}, {"type": "file", "name": "readthedoc_requirements.txt"}]}, {"type": "file", "name": "Home - Shortcut.lnk"}, {"type": "file", "name": "pytest.ini"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "readthedocs.yml"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "setup.cfg"}, {"type": "file", "name": "setup.py"}, {"type": "directory", "name": "tutorials", "children": [{"type": "file", "name": "usage.py"}]}]} | .. include:: ../README.md | {"requirements.txt": "# Library dependencies for the python code. You need to install these with\n# `pip install -r requirements.txt` before you can run this.\n# NOTE: all essential packages must be placed under a section named 'ESSENTIAL ...'\n# so that the script `./scripts/check_requirements_and_setup.py` can find them.\n\n#### ESSENTIAL LIBRARIES FOR MAIN FUNCTIONALITY ####\n\n# This installs Pytorch for CUDA 8 only. If you are using a newer version,\n# please visit http://pytorch.org/ and install the relevant version.\ntorch>=0.4.1,<0.5.0\n\n# Parameter parsing (but not on Windows).\njsonnet==0.10.0 ; sys.platform != 'win32'\n\n# Adds an @overrides decorator for better documentation and error checking when using subclasses.\noverrides\n\n# Used by some old code. We moved away from it because it's too slow, but some old code still\n# imports this.\nnltk\n\n# Mainly used for the faster tokenizer.\nspacy>=2.0,<2.1\n\n# Used by span prediction models.\nnumpy\n\n# Used for reading configuration info out of numpy-style docstrings.\nnumpydoc==0.8.0\n\n# Used in coreference resolution evaluation metrics.\nscipy\nscikit-learn\n\n# Write logs for training visualisation with the Tensorboard application\n# Install the Tensorboard application separately (part of tensorflow) to view them.\ntensorboardX==1.2\n\n# Required by torch.utils.ffi\ncffi==1.11.2\n\n# aws commandline tools for running on Docker remotely.\n# second requirement is to get botocore < 1.11, to avoid the below bug\nawscli>=1.11.91\n\n# Accessing files from S3 directly.\nboto3\n\n# REST interface for models\nflask==0.12.4\nflask-cors==3.0.3\ngevent==1.3.6\n\n# Used by semantic parsing code to strip diacritics from unicode strings.\nunidecode\n\n# Used by semantic parsing code to parse SQL\nparsimonious==0.8.0\n\n# Used by semantic parsing code to format and postprocess SQL\nsqlparse==0.2.4\n\n# For text normalization\nftfy\n\n#### ESSENTIAL LIBRARIES USED IN SCRIPTS ####\n\n# Plot graphs for learning rate finder\nmatplotlib==2.2.3\n\n# Used for downloading datasets over HTTP\nrequests>=2.18\n\n# progress bars in data cleaning scripts\ntqdm>=4.19\n\n# In SQuAD eval script, we use this to see if we likely have some tokenization problem.\neditdistance\n\n# For pretrained model weights\nh5py\n\n# For timezone utilities\npytz==2017.3\n\n# Reads Universal Dependencies files.\nconllu==0.11\n\n#### ESSENTIAL TESTING-RELATED PACKAGES ####\n\n# We'll use pytest to run our tests; this isn't really necessary to run the code, but it is to run\n# the tests. With this here, you can run the tests with `py.test` from the base directory.\npytest\n\n# Allows marking tests as flaky, to be rerun if they fail\nflaky\n\n# Required to mock out `requests` calls\nresponses>=0.7\n\n# For mocking s3.\nmoto==1.3.4\n\n#### TESTING-RELATED PACKAGES ####\n\n# Checks style, syntax, and other useful errors.\npylint==1.8.1\n\n# Tutorial notebooks\n# see: https://github.com/jupyter/jupyter/issues/370 for ipykernel\nipykernel<5.0.0\njupyter\n\n# Static type checking\nmypy==0.521\n\n# Allows generation of coverage reports with pytest.\npytest-cov\n\n# Allows codecov to generate coverage reports\ncoverage\ncodecov\n\n# Required to run sanic tests\naiohttp\n\n#### DOC-RELATED PACKAGES ####\n\n# Builds our documentation.\nsphinx==1.5.3\n\n# Watches the documentation directory and rebuilds on changes.\nsphinx-autobuild\n\n# doc theme\nsphinx_rtd_theme\n\n# Only used to convert our readme to reStructuredText on Pypi.\npypandoc\n\n# Pypi uploads\ntwine==1.11.0\n\n#### GENERATOR-RELATED PACKAGES ####\n\n# Used by AddSent.\npsutil\npattern\n\n# Used by SWAG.\nallennlp\nnum2words\n", "setup.py": "import sys\nfrom setuptools import setup, find_packages\n\n# PEP0440 compatible formatted version, see:\n# https://www.python.org/dev/peps/pep-0440/\n#\n# release markers:\n# X.Y\n# X.Y.Z # For bugfix releases\n#\n# pre-release markers:\n# X.YaN # Alpha release\n# X.YbN # Beta release\n# X.YrcN # Release Candidate\n# X.Y # Final release\n\n# version.py defines the VERSION and VERSION_SHORT variables.\n# We use exec here so we don't import allennlp whilst setting up.\nVERSION = {}\nwith open(\"adversarialnlp/version.py\", \"r\") as version_file:\n exec(version_file.read(), VERSION)\n\n# make pytest-runner a conditional requirement,\n# per: https://github.com/pytest-dev/pytest-runner#considerations\nneeds_pytest = {'pytest', 'test', 'ptr'}.intersection(sys.argv)\npytest_runner = ['pytest-runner'] if needs_pytest else []\n\nwith open('requirements.txt', 'r') as f:\n install_requires = [l for l in f.readlines() if not l.startswith('# ')]\n\nsetup_requirements = [\n # add other setup requirements as necessary\n] + pytest_runner\n\nsetup(name='adversarialnlp',\n version=VERSION[\"VERSION\"],\n description='A generice library for crafting adversarial NLP examples, built on AllenNLP and PyTorch.',\n long_description=open(\"README.md\").read(),\n long_description_content_type=\"text/markdown\",\n classifiers=[\n 'Intended Audience :: Science/Research',\n 'Development Status :: 3 - Alpha',\n 'License :: OSI Approved :: Apache Software License',\n 'Programming Language :: Python :: 3.6',\n 'Topic :: Scientific/Engineering :: Artificial Intelligence',\n ],\n keywords='adversarialnlp allennlp NLP deep learning machine reading',\n url='https://github.com/huggingface/adversarialnlp',\n author='Thomas WOLF',\n author_email='[email protected]',\n license='Apache',\n packages=find_packages(exclude=[\"*.tests\", \"*.tests.*\",\n \"tests.*\", \"tests\"]),\n install_requires=install_requires,\n scripts=[\"bin/adversarialnlp\"],\n setup_requires=setup_requirements,\n tests_require=[\n 'pytest',\n ],\n include_package_data=True,\n python_requires='>=3.6.1',\n zip_safe=False)\n", ".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", "docs\\index.rst": ".. AdversarialNLP documentation master file, created by\n sphinx-quickstart on Wed Oct 24 11:35:14 2018.\n You can adapt this file completely to your liking, but it should at least\n contain the root `toctree` directive.\n\n:github_url: https://github.com/pytorch/pytorch\n\nAdversarialNLP documentation\n============================\n\nAdversarialNLP is a generic library for crafting and using Adversarial NLP examples.\n\n.. toctree::\n :maxdepth: 1\n :caption: Contents\n\n readme\n\n common\n generators\n\n\nIndices and tables\n==================\n\n* :ref:`genindex`\n* :ref:`modindex`\n* :ref:`search`\n", "docs\\readthedoc_requirements.txt": "requests\ntyping\npytest\nPyYAML==3.13"} | null |
autotrain-advanced | {"type": "directory", "name": "autotrain-advanced", "children": [{"type": "file", "name": ".dockerignore"}, {"type": "directory", "name": "colabs", "children": [{"type": "file", "name": "AutoTrain.ipynb"}, {"type": "file", "name": "AutoTrain_Dreambooth.ipynb"}, {"type": "file", "name": "AutoTrain_LLM.ipynb"}, {"type": "file", "name": "AutoTrain_ngrok.ipynb"}]}, {"type": "directory", "name": "configs", "children": [{"type": "directory", "name": "dreambooth", "children": [{"type": "file", "name": "sd15_colab.yml"}, {"type": "file", "name": "sdxl_colab.yml"}]}, {"type": "directory", "name": "extractive_question_answering", "children": [{"type": "file", "name": "hub_dataset.yml"}, {"type": "file", "name": "local_dataset.yml"}]}, {"type": "directory", "name": "image_classification", "children": [{"type": "file", "name": "hub_dataset.yml"}, {"type": "file", "name": "local.yml"}]}, {"type": "directory", "name": "image_scoring", "children": [{"type": "file", "name": "hub_dataset.yml"}, {"type": "file", "name": "image_quality.yml"}, {"type": "file", "name": "local.yml"}]}, {"type": "directory", "name": "llm_finetuning", "children": [{"type": "file", "name": "gpt2_sft.yml"}, {"type": "file", "name": "llama3-70b-orpo-v1.yml"}, {"type": "file", "name": "llama3-70b-sft.yml"}, {"type": "file", "name": "llama3-8b-dpo-qlora.yml"}, {"type": "file", "name": "llama3-8b-orpo-space.yml"}, {"type": "file", "name": "llama3-8b-orpo.yml"}, {"type": "file", "name": "llama3-8b-sft-unsloth.yml"}, {"type": "file", "name": "llama32-1b-sft.yml"}]}, {"type": "directory", "name": "object_detection", "children": [{"type": "file", "name": "hub_dataset.yml"}, {"type": "file", "name": "local.yml"}]}, {"type": "directory", "name": "sentence_transformers", "children": [{"type": "file", "name": "local_dataset.yml"}, {"type": "file", "name": "pair.yml"}, {"type": "file", "name": "pair_class.yml"}, {"type": "file", "name": "pair_score.yml"}, {"type": "file", "name": "qa.yml"}, {"type": "file", "name": "triplet.yml"}]}, {"type": "directory", "name": "seq2seq", "children": [{"type": "file", "name": "hub_dataset.yml"}, {"type": "file", "name": "local.yml"}]}, {"type": "directory", "name": "text_classification", "children": [{"type": "file", "name": "hub_dataset.yml"}, {"type": "file", "name": "local_dataset.yml"}]}, {"type": "directory", "name": "text_regression", "children": [{"type": "file", "name": "hub_dataset.yml"}, {"type": "file", "name": "local_dataset.yml"}]}, {"type": "directory", "name": "token_classification", "children": [{"type": "file", "name": "hub_dataset.yml"}, {"type": "file", "name": "local_dataset.yml"}]}, {"type": "directory", "name": "vlm", "children": [{"type": "file", "name": "paligemma_vqa.yml"}]}]}, {"type": "file", "name": "Dockerfile"}, {"type": "file", "name": "Dockerfile.api"}, {"type": "file", "name": "Dockerfile.app"}, {"type": "directory", "name": "docs", "children": [{"type": "directory", "name": "source", "children": [{"type": "file", "name": "autotrain_api.mdx"}, {"type": "file", "name": "col_map.mdx"}, {"type": "file", "name": "config.mdx"}, {"type": "file", "name": "cost.mdx"}, {"type": "file", "name": "dreambooth.mdx"}, {"type": "file", "name": "dreambooth_params.mdx"}, {"type": "file", "name": "extractive_qa.mdx"}, {"type": "file", "name": "extractive_qa_params.mdx"}, {"type": "file", "name": "faq.mdx"}, {"type": "file", "name": "getting_started.bck"}, {"type": "file", "name": "image_classification.mdx"}, {"type": "file", "name": "image_classification_params.mdx"}, {"type": "file", "name": "image_regression.mdx"}, {"type": "file", "name": "image_regression_params.mdx"}, {"type": "file", "name": "index.mdx"}, {"type": "file", "name": "llm_finetuning.mdx"}, {"type": "file", "name": "llm_finetuning_params.mdx"}, {"type": "file", "name": "object_detection.mdx"}, {"type": "file", "name": "object_detection_params.mdx"}, {"type": "file", "name": "quickstart.mdx"}, {"type": "file", "name": "quickstart_spaces.mdx"}, {"type": "file", "name": "sentence_transformer.mdx"}, {"type": "file", "name": "seq2seq.mdx"}, {"type": "file", "name": "seq2seq_params.mdx"}, {"type": "file", "name": "starting_ui.bck"}, {"type": "file", "name": "support.mdx"}, {"type": "file", "name": "tabular.mdx"}, {"type": "file", "name": "tabular_params.mdx"}, {"type": "file", "name": "text_classification.mdx"}, {"type": "file", "name": "text_classification_params.mdx"}, {"type": "file", "name": "text_regression.mdx"}, {"type": "file", "name": "token_classification.mdx"}, {"type": "file", "name": "token_classification_params.mdx"}, {"type": "file", "name": "_toctree.yml"}]}]}, {"type": "file", "name": "LICENSE"}, {"type": "file", "name": "Makefile"}, {"type": "file", "name": "Manifest.in"}, {"type": "directory", "name": "notebooks", "children": [{"type": "directory", "name": "llm_finetuning", "children": [{"type": "file", "name": "sft.ipynb"}]}]}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "setup.cfg"}, {"type": "file", "name": "setup.py"}, {"type": "directory", "name": "src", "children": [{"type": "directory", "name": "autotrain", "children": [{"type": "directory", "name": "app", "children": [{"type": "file", "name": "api_routes.py"}, {"type": "file", "name": "app.py"}, {"type": "file", "name": "colab.py"}, {"type": "file", "name": "db.py"}, {"type": "file", "name": "models.py"}, {"type": "file", "name": "oauth.py"}, {"type": "file", "name": "params.py"}, {"type": "directory", "name": "static", "children": [{"type": "directory", "name": "scripts", "children": [{"type": "file", "name": "fetch_data_and_update_models.js"}, {"type": "file", "name": "listeners.js"}, {"type": "file", "name": "logs.js"}, {"type": "file", "name": "poll.js"}, {"type": "file", "name": "utils.js"}]}]}, {"type": "directory", "name": "templates", "children": [{"type": "file", "name": "duplicate.html"}, {"type": "file", "name": "error.html"}, {"type": "file", "name": "index.html"}, {"type": "file", "name": "login.html"}]}, {"type": "file", "name": "training_api.py"}, {"type": "file", "name": "ui_routes.py"}, {"type": "file", "name": "utils.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "backends", "children": [{"type": "file", "name": "base.py"}, {"type": "file", "name": "endpoints.py"}, {"type": "file", "name": "local.py"}, {"type": "file", "name": "ngc.py"}, {"type": "file", "name": "nvcf.py"}, {"type": "file", "name": "spaces.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "cli", "children": [{"type": "file", "name": "autotrain.py"}, {"type": "file", "name": "run_api.py"}, {"type": "file", "name": "run_app.py"}, {"type": "file", "name": "run_dreambooth.py"}, {"type": "file", "name": "run_extractive_qa.py"}, {"type": "file", "name": "run_image_classification.py"}, {"type": "file", "name": "run_image_regression.py"}, {"type": "file", "name": "run_llm.py"}, {"type": "file", "name": "run_object_detection.py"}, {"type": "file", "name": "run_sent_tranformers.py"}, {"type": "file", "name": "run_seq2seq.py"}, {"type": "file", "name": "run_setup.py"}, {"type": "file", "name": "run_spacerunner.py"}, {"type": "file", "name": "run_tabular.py"}, {"type": "file", "name": "run_text_classification.py"}, {"type": "file", "name": "run_text_regression.py"}, {"type": "file", "name": "run_token_classification.py"}, {"type": "file", "name": "run_tools.py"}, {"type": "file", "name": "run_vlm.py"}, {"type": "file", "name": "utils.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "commands.py"}, {"type": "file", "name": "config.py"}, {"type": "file", "name": "dataset.py"}, {"type": "file", "name": "help.py"}, {"type": "file", "name": "logging.py"}, {"type": "file", "name": "parser.py"}, {"type": "directory", "name": "preprocessor", "children": [{"type": "file", "name": "dreambooth.py"}, {"type": "file", "name": "tabular.py"}, {"type": "file", "name": "text.py"}, {"type": "file", "name": "vision.py"}, {"type": "file", "name": "vlm.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "project.py"}, {"type": "file", "name": "tasks.py"}, {"type": "directory", "name": "tests", "children": [{"type": "file", "name": "test_cli.py"}, {"type": "file", "name": "test_dummy.py"}]}, {"type": "directory", "name": "tools", "children": [{"type": "file", "name": "convert_to_kohya.py"}, {"type": "file", "name": "merge_adapter.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "trainers", "children": [{"type": "directory", "name": "clm", "children": [{"type": "file", "name": "callbacks.py"}, {"type": "file", "name": "params.py"}, {"type": "file", "name": "train_clm_default.py"}, {"type": "file", "name": "train_clm_dpo.py"}, {"type": "file", "name": "train_clm_orpo.py"}, {"type": "file", "name": "train_clm_reward.py"}, {"type": "file", "name": "train_clm_sft.py"}, {"type": "file", "name": "utils.py"}, {"type": "file", "name": "__init__.py"}, {"type": "file", "name": "__main__.py"}]}, {"type": "file", "name": "common.py"}, {"type": "directory", "name": "dreambooth", "children": [{"type": "file", "name": "datasets.py"}, {"type": "file", "name": "params.py"}, {"type": "file", "name": "train.py"}, {"type": "file", "name": "trainer.py"}, {"type": "file", "name": "train_xl.py"}, {"type": "file", "name": "utils.py"}, {"type": "file", "name": "__init__.py"}, {"type": "file", "name": "__main__.py"}]}, {"type": "directory", "name": "extractive_question_answering", "children": [{"type": "file", "name": "dataset.py"}, {"type": "file", "name": "params.py"}, {"type": "file", "name": "utils.py"}, {"type": "file", "name": "__init__.py"}, {"type": "file", "name": "__main__.py"}]}, {"type": "directory", "name": "generic", "children": [{"type": "file", "name": "params.py"}, {"type": "file", "name": "utils.py"}, {"type": "file", "name": "__init__.py"}, {"type": "file", "name": "__main__.py"}]}, {"type": "directory", "name": "image_classification", "children": [{"type": "file", "name": "dataset.py"}, {"type": "file", "name": "params.py"}, {"type": "file", "name": "utils.py"}, {"type": "file", "name": "__init__.py"}, {"type": "file", "name": "__main__.py"}]}, {"type": "directory", "name": "image_regression", "children": [{"type": "file", "name": "dataset.py"}, {"type": "file", "name": "params.py"}, {"type": "file", "name": "utils.py"}, {"type": "file", "name": "__init__.py"}, {"type": "file", "name": "__main__.py"}]}, {"type": "directory", "name": "object_detection", "children": [{"type": "file", "name": "dataset.py"}, {"type": "file", "name": "params.py"}, {"type": "file", "name": "utils.py"}, {"type": "file", "name": "__init__.py"}, {"type": "file", "name": "__main__.py"}]}, {"type": "directory", "name": "sent_transformers", "children": [{"type": "file", "name": "params.py"}, {"type": "file", "name": "utils.py"}, {"type": "file", "name": "__init__.py"}, {"type": "file", "name": "__main__.py"}]}, {"type": "directory", "name": "seq2seq", "children": [{"type": "file", "name": "dataset.py"}, {"type": "file", "name": "params.py"}, {"type": "file", "name": "utils.py"}, {"type": "file", "name": "__init__.py"}, {"type": "file", "name": "__main__.py"}]}, {"type": "directory", "name": "tabular", "children": [{"type": "file", "name": "params.py"}, {"type": "file", "name": "utils.py"}, {"type": "file", "name": "__init__.py"}, {"type": "file", "name": "__main__.py"}]}, {"type": "directory", "name": "text_classification", "children": [{"type": "file", "name": "dataset.py"}, {"type": "file", "name": "params.py"}, {"type": "file", "name": "utils.py"}, {"type": "file", "name": "__init__.py"}, {"type": "file", "name": "__main__.py"}]}, {"type": "directory", "name": "text_regression", "children": [{"type": "file", "name": "dataset.py"}, {"type": "file", "name": "params.py"}, {"type": "file", "name": "utils.py"}, {"type": "file", "name": "__init__.py"}, {"type": "file", "name": "__main__.py"}]}, {"type": "directory", "name": "token_classification", "children": [{"type": "file", "name": "dataset.py"}, {"type": "file", "name": "params.py"}, {"type": "file", "name": "utils.py"}, {"type": "file", "name": "__init__.py"}, {"type": "file", "name": "__main__.py"}]}, {"type": "directory", "name": "vlm", "children": [{"type": "file", "name": "dataset.py"}, {"type": "file", "name": "params.py"}, {"type": "file", "name": "train_vlm_generic.py"}, {"type": "file", "name": "utils.py"}, {"type": "file", "name": "__init__.py"}, {"type": "file", "name": "__main__.py"}]}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "utils.py"}, {"type": "file", "name": "__init__.py"}]}]}, {"type": "directory", "name": "static", "children": []}]} | # 🤗 AutoTrain Advanced
AutoTrain Advanced: faster and easier training and deployments of state-of-the-art machine learning models. AutoTrain Advanced is a no-code solution that allows you to train machine learning models in just a few clicks. Please note that you must upload data in correct format for project to be created. For help regarding proper data format and pricing, check out the documentation.
NOTE: AutoTrain is free! You only pay for the resources you use in case you decide to run AutoTrain on Hugging Face Spaces. When running locally, you only pay for the resources you use on your own infrastructure.
## Run on Colab or Hugging Face Spaces
- Run AutoTrain on Colab: [](https://colab.research.google.com/github/huggingface/autotrain-advanced/blob/main/colabs/AutoTrain.ipynb)
- Deploy AutoTrain on Hugging Face Spaces: [](https://huggingface.co/login?next=%2Fspaces%2Fautotrain-projects%2Fautotrain-advanced%3Fduplicate%3Dtrue)
- Run AutoTrain UI on Colab via ngrok: [](https://colab.research.google.com/github/huggingface/autotrain-advanced/blob/main/colabs/AutoTrain_ngrok.ipynb)
## Local Installation
You can Install AutoTrain-Advanced python package via PIP. Please note you will need python >= 3.10 for AutoTrain Advanced to work properly.
pip install autotrain-advanced
Please make sure that you have git lfs installed. Check out the instructions here: https://github.com/git-lfs/git-lfs/wiki/Installation
You also need to install torch, torchaudio and torchvision.
The best way to run autotrain is in a conda environment. You can create a new conda environment with the following command:
conda create -n autotrain python=3.10
conda activate autotrain
pip install autotrain-advanced
conda install pytorch torchvision torchaudio pytorch-cuda=12.1 -c pytorch -c nvidia
conda install -c "nvidia/label/cuda-12.1.0" cuda-nvcc
Once done, you can start the application using:
autotrain app --port 8080 --host 127.0.0.1
If you are not fond of UI, you can use AutoTrain Configs to train using command line or simply AutoTrain CLI.
To use config file for training, you can use the following command:
autotrain --config <path_to_config_file>
You can find sample config files in the `configs` directory of this repository.
## Colabs
| Task | Colab Link |
| --- | --- |
| LLM Fine Tuning | [](https://colab.research.google.com/github/huggingface/autotrain-advanced/blob/main/colabs/AutoTrain_LLM.ipynb) |
| DreamBooth Training | [](https://colab.research.google.com/github/huggingface/autotrain-advanced/blob/main/colabs/AutoTrain_Dreambooth.ipynb) |
## Documentation
Documentation is available at https://hf.co/docs/autotrain/
| {"Dockerfile": "FROM nvidia/cuda:12.1.1-cudnn8-runtime-ubuntu22.04\n\nENV DEBIAN_FRONTEND=noninteractive \\\n TZ=UTC \\\n HF_HUB_ENABLE_HF_TRANSFER=1\n\nENV PATH=\"${HOME}/miniconda3/bin:${PATH}\"\nARG PATH=\"${HOME}/miniconda3/bin:${PATH}\"\nENV PATH=\"/app/ngc-cli:${PATH}\"\nARG PATH=\"/app/ngc-cli:${PATH}\"\n\nRUN mkdir -p /tmp/model && \\\n chown -R 1000:1000 /tmp/model && \\\n mkdir -p /tmp/data && \\\n chown -R 1000:1000 /tmp/data\n\nRUN apt-get update && \\\n apt-get upgrade -y && \\\n apt-get install -y \\\n build-essential \\\n cmake \\\n curl \\\n ca-certificates \\\n gcc \\\n git \\\n locales \\\n net-tools \\\n wget \\\n libpq-dev \\\n libsndfile1-dev \\\n git \\\n git-lfs \\\n libgl1 \\\n unzip \\\n libjpeg-dev \\\n libpng-dev \\\n libgomp1 \\\n && rm -rf /var/lib/apt/lists/* && \\\n apt-get clean\n\n\nRUN curl -s https://packagecloud.io/install/repositories/github/git-lfs/script.deb.sh | bash && \\\n git lfs install\n\nWORKDIR /app\nRUN mkdir -p /app/.cache\nENV HF_HOME=\"/app/.cache\"\nRUN useradd -m -u 1000 user\nRUN chown -R user:user /app\nUSER user\nENV HOME=/app\n\nENV PYTHONPATH=$HOME/app \\\n PYTHONUNBUFFERED=1 \\\n GRADIO_ALLOW_FLAGGING=never \\\n GRADIO_NUM_PORTS=1 \\\n GRADIO_SERVER_NAME=0.0.0.0 \\\n SYSTEM=spaces\n\n\nRUN wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh \\\n && sh Miniconda3-latest-Linux-x86_64.sh -b -p /app/miniconda \\\n && rm -f Miniconda3-latest-Linux-x86_64.sh\nENV PATH /app/miniconda/bin:$PATH\n\nRUN conda create -p /app/env -y python=3.10\n\nSHELL [\"conda\", \"run\",\"--no-capture-output\", \"-p\",\"/app/env\", \"/bin/bash\", \"-c\"]\n\nRUN conda install pytorch==2.4.0 torchvision==0.19.0 torchaudio==2.4.0 pytorch-cuda=12.1 -c pytorch -c nvidia && \\\n conda clean -ya && \\\n conda install -c \"nvidia/label/cuda-12.1.1\" cuda-nvcc && conda clean -ya && \\\n conda install xformers -c xformers && conda clean -ya\n\nCOPY --chown=1000:1000 . /app/\n\nRUN pip install -e . && \\\n python -m nltk.downloader punkt && \\\n pip install -U ninja && \\\n pip install -U flash-attn --no-build-isolation && \\\n pip install -U deepspeed && \\\n pip install --upgrade --force-reinstall --no-cache-dir \"unsloth[cu121-ampere-torch230] @ git+https://github.com/unslothai/unsloth.git\" --no-deps && \\\n pip cache purge\n", "Dockerfile.api": "FROM huggingface/autotrain-advanced:latest\n\nCMD autotrain api --port 7860 --host 0.0.0.0", "Dockerfile.app": "FROM huggingface/autotrain-advanced:latest\nCMD uvicorn autotrain.app:app --host 0.0.0.0 --port 7860 --reload --workers 4\n", "requirements.txt": "albumentations==1.4.7\ncodecarbon==2.3.5\ndatasets[vision]~=2.19.0\nevaluate==0.4.1\nipadic==1.0.0\njiwer==3.0.3\njoblib==1.4.0\nloguru==0.7.2\npandas==2.2.2\nnltk==3.8.1\noptuna==3.6.1\nPillow==10.3.0\nprotobuf==4.23.4\nsacremoses==0.1.1\nscikit-learn==1.5.0\nsentencepiece==0.2.0\ntqdm==4.66.4\nwerkzeug==3.0.2\nxgboost==2.0.3\nhuggingface_hub==0.25.1\nrequests==2.31.0\neinops==0.7.0\ninvisible-watermark==0.2.0\npackaging==24.0\ncryptography==42.0.5\nnvitop==1.3.2\n# latest versions\ntensorboard==2.16.2\npeft==0.13.0\ntrl==0.11.1\ntiktoken==0.6.0\ntransformers==4.45.0\n\n\naccelerate==0.34.1\ndiffusers==0.27.2\nbitsandbytes==0.44.0\n# extras\nrouge_score==0.1.2\npy7zr==0.21.0\nfastapi==0.111.0\nuvicorn==0.29.0\npython-multipart==0.0.9\npydantic==2.7.1\nhf-transfer\npyngrok==7.1.6\nauthlib==1.3.0\nitsdangerous==2.2.0\nseqeval==1.2.2\nhttpx==0.27.0\npyyaml==6.0.1\ntimm==1.0.8\ntorchmetrics==1.4.0\npycocotools==2.0.7\nsentence-transformers==3.1.1", "setup.py": "# Lint as: python3\n\"\"\"\nHuggingFace / AutoTrain Advanced\n\"\"\"\nimport os\n\nfrom setuptools import find_packages, setup\n\n\nDOCLINES = __doc__.split(\"\\n\")\n\nthis_directory = os.path.abspath(os.path.dirname(__file__))\nwith open(os.path.join(this_directory, \"README.md\"), encoding=\"utf-8\") as f:\n LONG_DESCRIPTION = f.read()\n\n# get INSTALL_REQUIRES from requirements.txt\nINSTALL_REQUIRES = []\nrequirements_path = os.path.join(this_directory, \"requirements.txt\")\nwith open(requirements_path, encoding=\"utf-8\") as f:\n for line in f:\n # Exclude 'bitsandbytes' if installing on macOS\n if \"bitsandbytes\" in line:\n line = line.strip() + \" ; sys_platform == 'linux'\"\n INSTALL_REQUIRES.append(line.strip())\n else:\n INSTALL_REQUIRES.append(line.strip())\n\nQUALITY_REQUIRE = [\n \"black\",\n \"isort\",\n \"flake8==3.7.9\",\n]\n\nTESTS_REQUIRE = [\"pytest\"]\n\n\nEXTRAS_REQUIRE = {\n \"dev\": INSTALL_REQUIRES + QUALITY_REQUIRE + TESTS_REQUIRE,\n \"quality\": INSTALL_REQUIRES + QUALITY_REQUIRE,\n \"docs\": INSTALL_REQUIRES\n + [\n \"recommonmark\",\n \"sphinx==3.1.2\",\n \"sphinx-markdown-tables\",\n \"sphinx-rtd-theme==0.4.3\",\n \"sphinx-copybutton\",\n ],\n}\n\nsetup(\n name=\"autotrain-advanced\",\n description=DOCLINES[0],\n long_description=LONG_DESCRIPTION,\n long_description_content_type=\"text/markdown\",\n author=\"HuggingFace Inc.\",\n author_email=\"[email protected]\",\n url=\"https://github.com/huggingface/autotrain-advanced\",\n download_url=\"https://github.com/huggingface/autotrain-advanced/tags\",\n license=\"Apache 2.0\",\n package_dir={\"\": \"src\"},\n packages=find_packages(\"src\"),\n extras_require=EXTRAS_REQUIRE,\n install_requires=INSTALL_REQUIRES,\n entry_points={\"console_scripts\": [\"autotrain=autotrain.cli.autotrain:main\"]},\n classifiers=[\n \"Development Status :: 5 - Production/Stable\",\n \"Intended Audience :: Developers\",\n \"Intended Audience :: Education\",\n \"Intended Audience :: Science/Research\",\n \"License :: OSI Approved :: Apache Software License\",\n \"Operating System :: OS Independent\",\n \"Programming Language :: Python :: 3.8\",\n \"Programming Language :: Python :: 3.9\",\n \"Programming Language :: Python :: 3.10\",\n \"Programming Language :: Python :: 3.11\",\n \"Topic :: Scientific/Engineering :: Artificial Intelligence\",\n ],\n keywords=\"automl autonlp autotrain huggingface\",\n data_files=[\n (\n \"static\",\n [\n \"src/autotrain/app/static/logo.png\",\n \"src/autotrain/app/static/scripts/fetch_data_and_update_models.js\",\n \"src/autotrain/app/static/scripts/listeners.js\",\n \"src/autotrain/app/static/scripts/utils.js\",\n \"src/autotrain/app/static/scripts/poll.js\",\n \"src/autotrain/app/static/scripts/logs.js\",\n ],\n ),\n (\n \"templates\",\n [\n \"src/autotrain/app/templates/index.html\",\n \"src/autotrain/app/templates/error.html\",\n \"src/autotrain/app/templates/duplicate.html\",\n \"src/autotrain/app/templates/login.html\",\n ],\n ),\n ],\n include_package_data=True,\n)\n", ".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 1d1ce2bd5e7e16193e0cc1806542231ef1226f65 Hamza Amin <[email protected]> 1727369164 +0500\tclone: from https://github.com/huggingface/autotrain-advanced.git\n", ".git\\refs\\heads\\main": "1d1ce2bd5e7e16193e0cc1806542231ef1226f65\n", "docs\\source\\index.mdx": "# What is AutoTrain Advanced?\n\n\n\n\ud83e\udd17 AutoTrain Advanced (or simply AutoTrain), developed by Hugging Face, is a robust no-code \nplatform designed to simplify the process of training state-of-the-art models across \nmultiple domains: Natural Language Processing (NLP), Computer Vision (CV), \nand even Tabular Data analysis. This tool leverages the powerful frameworks created by \nvarious teams at Hugging Face, making advanced machine learning and artificial intelligence accessible to a broader \naudience without requiring deep technical expertise.\n\n# Who should use AutoTrain?\n\nAutoTrain is the perfect tool for anyone eager to dive into the world of machine learning \nwithout getting bogged down by the complexities of model training. \nWhether you're a business professional, researcher, educator, or hobbyist, \nAutoTrain offers the simplicity of a no-code interface while still providing the \ncapabilities necessary to develop sophisticated models tailored to your unique datasets.\n\nAutoTrain is for anyone who wants to train a state-of-the-art model for a NLP, CV, Speech or even Tabular task,\nbut doesn't want to spend time on the technical details of training a model. \n\nOur mission is to democratize machine learning technology, ensuring it is not only \naccessible to data scientists and ML engineers but also to those without a technical \nbackground. If you're looking to harness the power of AI for your projects, \nAutoTrain is your answer.\n\n\n# How to use AutoTrain?\n\nWe offer several ways to use AutoTrain:\n\n- No code users can use `AutoTrain Advanced` by creating a new space with AutoTrain Docker image: \n[Click here](https://huggingface.co/login?next=/spaces/autotrain-projects/autotrain-advanced?duplicate=true) to create AutoTrain Space.\nRemember to keep your space private and ensure it is equipped with the necessary hardware resources (GPU) for optimal performance.\n\n- If you prefer a more hands-on approach, AutoTrain Advanced can also be run locally \nthrough its intuitive UI or accessed via the Python API provided in the autotrain-advanced \npackage. This flexibility allows developers to integrate AutoTrain capabilities directly \ninto their projects, customize workflows, and enhance their toolsets with advanced machine \nlearning functionalities.\n\n\nBy bridging the gap between cutting-edge technology and practical usability, \nAutoTrain Advanced empowers users to achieve remarkable results in AI without the need \nfor extensive programming knowledge. Start your journey with AutoTrain today and unlock \nthe potential of machine learning for your projects!\n\n\n# Walkthroughs\n\nTo get started with AutoTrain, check out our walkthroughs and tutorials:\n\n- [Extractive Question Answering with AutoTrain](https://huggingface.co/blog/abhishek/extractive-qa-autotrain)\n- [Finetuning PaliGemma with AutoTrain](https://huggingface.co/blog/abhishek/paligemma-finetuning-autotrain)\n- [Training an Object Detection Model with AutoTrain](https://huggingface.co/blog/abhishek/object-detection-autotrain)\n- [How to Fine-Tune Custom Embedding Models Using AutoTrain](https://huggingface.co/blog/abhishek/finetune-custom-embeddings-autotrain)\n- [Train Custom Models on Hugging Face Spaces with AutoTrain SpaceRunner](https://huggingface.co/blog/abhishek/autotrain-spacerunner)\n- [How to Finetune phi-3 on MacBook Pro](https://huggingface.co/blog/abhishek/phi3-finetune-macbook)\n- [Finetune Mixtral 8x7B with AutoTrain](https://huggingface.co/blog/abhishek/autotrain-mixtral-dgx-cloud-local)\n- [Easily Train Models with H100 GPUs on NVIDIA DGX Cloud](https://huggingface.co/blog/train-dgx-cloud)\n", "src\\autotrain\\app\\app.py": "import os\n\nfrom fastapi import FastAPI, Request\nfrom fastapi.responses import RedirectResponse\nfrom fastapi.staticfiles import StaticFiles\n\nfrom autotrain import __version__, logger\nfrom autotrain.app.api_routes import api_router\nfrom autotrain.app.oauth import attach_oauth\nfrom autotrain.app.ui_routes import ui_router\n\n\nlogger.info(\"Starting AutoTrain...\")\nBASE_DIR = os.path.dirname(os.path.abspath(__file__))\napp = FastAPI()\nif \"SPACE_ID\" in os.environ:\n attach_oauth(app)\n\napp.include_router(ui_router, prefix=\"/ui\", include_in_schema=False)\napp.include_router(api_router, prefix=\"/api\")\nstatic_path = os.path.join(BASE_DIR, \"static\")\napp.mount(\"/static\", StaticFiles(directory=static_path), name=\"static\")\nlogger.info(f\"AutoTrain version: {__version__}\")\nlogger.info(\"AutoTrain started successfully\")\n\n\[email protected](\"/\")\nasync def forward_to_ui(request: Request):\n query_params = request.query_params\n url = \"/ui/\"\n if query_params:\n url += f\"?{query_params}\"\n return RedirectResponse(url=url)\n", "src\\autotrain\\app\\templates\\index.html": "<!doctype html>\n<html class=\"dark:bg-gray-900 dark:text-gray-100\">\n\n<head>\n <meta charset=\"UTF-8\">\n <meta name=\"viewport\" content=\"width=device-width, initial-scale=1.0\">\n <script src=\"https://cdn.tailwindcss.com\"></script>\n <link rel=\"stylesheet\" href=\"https://cdnjs.cloudflare.com/ajax/libs/font-awesome/5.15.3/css/all.min.css\">\n <script src=\"/static/scripts/fetch_data_and_update_models.js?cb={{ time }}\" defer></script>\n <script src=\"/static/scripts/poll.js?cb={{ time }}\" defer></script>\n <script src=\"/static/scripts/listeners.js?cb={{ time }}\" defer></script>\n <script src=\"/static/scripts/utils.js?cb={{ time }}\" defer></script>\n <script src=\"/static/scripts/logs.js?cb={{ time }}\" defer></script>\n <link href=\"https://cdnjs.cloudflare.com/ajax/libs/flowbite/2.3.0/flowbite.min.css\" rel=\"stylesheet\" />\n</head>\n\n<script>\n window.addEventListener(\"load\", function () {\n function createColumnMappings(selectedTask) {\n const colMapDiv = document.getElementById(\"div_cmap\");\n colMapDiv.innerHTML = ''; // Clear previous mappings\n\n let fields = [];\n let fieldNames = [];\n\n switch (selectedTask) {\n case 'llm:sft':\n case 'llm:generic':\n fields = ['text'];\n fieldNames = ['text'];\n break;\n case 'llm:dpo':\n case 'llm:orpo':\n fields = ['prompt', 'text', 'rejected_text'];\n fieldNames = ['prompt', 'chosen', 'rejected'];\n break;\n case 'llm:reward':\n fields = ['text', 'rejected_text'];\n fieldNames = ['chosen', 'rejected'];\n break;\n case 'vlm:captioning':\n fields = ['image', 'text'];\n fieldNames = ['image', 'caption'];\n break;\n case 'vlm:vqa':\n fields = ['image', 'prompt', 'text'];\n fieldNames = ['image', 'question', 'answer'];\n break;\n case 'st:pair':\n fields = ['sentence1', 'sentence2'];\n fieldNames = ['anchor', 'positive'];\n break;\n case 'st:pair_class':\n fields = ['sentence1', 'sentence2', 'target'];\n fieldNames = ['premise', 'hypothesis', 'label'];\n break;\n case 'st:pair_score':\n fields = ['sentence1', 'sentence2', 'target'];\n fieldNames = ['sentence1', 'sentence2', 'score'];\n break;\n case 'st:triplet':\n fields = ['sentence1', 'sentence2', 'sentence3'];\n fieldNames = ['anchor', 'positive', 'negative'];\n break;\n case 'st:qa':\n fields = ['sentence1', 'sentence2'];\n fieldNames = ['query', 'answer'];\n break;\n case 'text-classification':\n case 'seq2seq':\n case 'text-regression':\n fields = ['text', 'label'];\n fieldNames = ['text', 'target'];\n break;\n case 'token-classification':\n fields = ['text', 'label'];\n fieldNames = ['tokens', 'tags'];\n break;\n case 'dreambooth':\n fields = ['image'];\n fieldNames = ['image'];\n break;\n case 'image-classification':\n fields = ['image', 'label'];\n fieldNames = ['image', 'label'];\n break;\n case 'image-regression':\n fields = ['image', 'label'];\n fieldNames = ['image', 'target'];\n break;\n case 'image-object-detection':\n fields = ['image', 'objects'];\n fieldNames = ['image', 'objects'];\n break;\n case 'tabular:classification':\n case 'tabular:regression':\n fields = ['id', 'label'];\n fieldNames = ['id', 'target'];\n break;\n case 'extractive-qa':\n fields = ['text', 'question', 'answer'];\n fieldNames = ['context', 'question', 'answers'];\n break;\n default:\n return; // Do nothing if task is not recognized\n }\n\n fields.forEach((field, index) => {\n const fieldDiv = document.createElement('div');\n fieldDiv.className = 'mb-2';\n fieldDiv.innerHTML = `\n <label class=\"block text-gray-600 dark:text-gray-300 text-sm font-bold mb-1\" for=\"col_map_${field}\">\n ${field}:\n </label>\n <input type=\"text\" id=\"col_map_${field}\" name=\"col_map_${field}\" value=\"${fieldNames[index]}\" class=\"mt-1 block w-full border border-gray-300 dark:border-gray-600 px-3 py-2 bg-white dark:bg-gray-700 rounded-md shadow-sm focus:outline-none focus:ring-indigo-500 focus:border-indigo-500\">\n`;\n colMapDiv.appendChild(fieldDiv);\n });\n }\n\n document.querySelector('select#task').addEventListener('change', (event) => {\n const selectedTask = event.target.value;\n createColumnMappings(selectedTask);\n });\n createColumnMappings(document.querySelector('select#task').value);\n });\n</script>\n<script>\n document.addEventListener('DOMContentLoaded', function () {\n const taskSelect = document.getElementById('task');\n const validDataTab = document.getElementById('valid-data-tab');\n\n function toggleValidationTab() {\n const task = taskSelect.value;\n // Check if the selected task is DreamBooth or any LLM task\n if (task === 'dreambooth' || task.includes('llm:')) {\n validDataTab.style.display = 'none'; // Hide the tab\n } else {\n validDataTab.style.display = 'block'; // Show the tab\n }\n }\n\n // Initialize the state of the validation tab\n toggleValidationTab();\n\n // Add event listener for changes in the task dropdown\n taskSelect.addEventListener('change', toggleValidationTab);\n });\n\n</script>\n\n<body class=\"bg-gray-100 text-gray-900 dark:bg-gray-900 dark:text-gray-100\">\n <button data-drawer-target=\"separator-sidebar\" data-drawer-toggle=\"separator-sidebar\"\n aria-controls=\"separator-sidebar\" type=\"button\"\n class=\"inline-flex items-center p-2 mt-2 ms-3 text-sm text-gray-500 dark:text-gray-400 rounded-lg sm:hidden hover:bg-gray-100 dark:hover:bg-gray-700 focus:outline-none focus:ring-2 focus:ring-gray-200 dark:focus:ring-gray-600\">\n <span class=\"sr-only\">Open sidebar</span>\n <svg class=\"w-6 h-6\" aria-hidden=\"true\" fill=\"currentColor\" viewBox=\"0 0 20 20\"\n xmlns=\"http://www.w3.org/2000/svg\">\n <path clip-rule=\"evenodd\" fill-rule=\"evenodd\"\n d=\"M2 4.75A.75.75 0 012.75 4h14.5a.75.75 0 010 1.5H2.75A.75.75 0 012 4.75zm0 10.5a.75.75 0 01.75-.75h7.5a.75.75 0 010 1.5h-7.5a.75.75 0 01-.75-.75zM2 10a.75.75 0 01.75-.75h14.5a.75.75 0 010 1.5H2.75A.75.75 0 012 10z\">\n </path>\n </svg>\n </button>\n\n <aside id=\"separator-sidebar\"\n class=\"fixed top-0 left-0 z-40 w-64 h-screen transition-transform -translate-x-full sm:translate-x-0\"\n aria-label=\"Sidebar\">\n <div class=\"h-full px-3 py-4 overflow-y-auto bg-gray-50 dark:bg-gray-800\">\n <a href=\"https://huggingface.co/autotrain\" target=\"_blank\" class=\"flex items-center ps-2.5 mb-5\">\n <img src=\"https://raw.githubusercontent.com/huggingface/autotrain-advanced/main/static/logo.png\"\n class=\"h-6 me-3 sm:h-7\" alt=\"AutoTrain Logo\" />\n </a>\n <hr class=\"mb-2 border-gray-200 dark:border-gray-700\">\n <ul class=\"space-y-2 font-medium\">\n <li>\n <label for=\"autotrain_user\" class=\"text-sm font-medium text-gray-700 dark:text-gray-300\">Hugging\n Face User\n <button type=\"button\" id=\"autotrain_user_info\"\n class=\"text-gray-500 dark:text-gray-400 hover:text-gray-700 dark:hover:text-gray-300\">\n <i class=\"fas fa-info-circle\"></i>\n </button>\n </label>\n <select name=\"autotrain_user\" id=\"autotrain_user\"\n class=\"mt-1 block w-full border border-gray-300 dark:border-gray-600 px-3 py-2 bg-white dark:bg-gray-700 rounded-md shadow-sm focus:outline-none focus:ring-indigo-500 focus:border-indigo-500\">\n {% for user in valid_users %}\n <option value=\"{{ user }}\">{{ user }}</option>\n {% endfor %}\n </select>\n </li>\n <li>\n <label for=\"task\" class=\"text-sm font-medium text-gray-700 dark:text-gray-300\">Task\n <button type=\"button\" id=\"task_info\"\n class=\"text-gray-500 dark:text-gray-400 hover:text-gray-700 dark:hover:text-gray-300\">\n <i class=\"fas fa-info-circle\"></i>\n </button>\n </label>\n <select id=\"task\" name=\"task\"\n class=\"mt-1 block w-full border border-gray-300 dark:border-gray-600 px-3 py-2 bg-white dark:bg-gray-700 rounded-md shadow-sm focus:outline-none focus:ring-indigo-500 focus:border-indigo-500\">\n <optgroup label=\"LLM Finetuning\">\n <option value=\"llm:sft\">LLM SFT</option>\n <option value=\"llm:orpo\">LLM ORPO</option>\n <option value=\"llm:generic\">LLM Generic</option>\n <option value=\"llm:dpo\">LLM DPO</option>\n <option value=\"llm:reward\">LLM Reward</option>\n </optgroup>\n <optgroup label=\"VLM Finetuning\">\n <option value=\"vlm:captioning\">VLM Captioning</option>\n <option value=\"vlm:vqa\">VLM VQA</option>\n </optgroup>\n <optgroup label=\"Sentence Transformers\">\n <option value=\"st:pair\">ST Pair</option>\n <option value=\"st:pair_class\">ST Pair Classification</option>\n <option value=\"st:pair_score\">ST Pair Scoring</option>\n <option value=\"st:triplet\">ST Triplet</option>\n <option value=\"st:qa\">ST Question Answering</option>\n </optgroup>\n <optgroup label=\"Other Text Tasks\">\n <option value=\"text-classification\">Text Classification</option>\n <option value=\"text-regression\">Text Regression</option>\n <option value=\"extractive-qa\">Extractive Question Answering</option>\n <option value=\"seq2seq\">Sequence To Sequence</option>\n <option value=\"token-classification\">Token Classification</option>\n </optgroup>\n <optgroup label=\"Image Tasks\">\n <option value=\"dreambooth\">DreamBooth LoRA</option>\n <option value=\"image-classification\">Image Classification</option>\n <option value=\"image-regression\">Image Scoring/Regression</option>\n <option value=\"image-object-detection\">Object Detection</option>\n </optgroup>\n <optgroup label=\"Tabular Tasks\">\n <option value=\"tabular:classification\">Tabular Classification</option>\n <option value=\"tabular:regression\">Tabular Regression</option>\n </optgroup>\n </select>\n </li>\n <li>\n <label for=\"hardware\" class=\"text-sm font-medium text-gray-700 dark:text-gray-300\">Hardware\n <button type=\"button\" id=\"hardware_info\"\n class=\"text-gray-500 dark:text-gray-400 hover:text-gray-700 dark:hover:text-gray-300\">\n <i class=\"fas fa-info-circle\"></i>\n </button>\n </label>\n <select id=\"hardware\" name=\"hardware\"\n class=\"mt-1 block w-full border border-gray-300 dark:border-gray-600 px-3 py-2 bg-white dark:bg-gray-700 rounded-md shadow-sm focus:outline-none focus:ring-indigo-500 focus:border-indigo-500\">\n {% if enable_local == 1 %}\n <option value=\"local-ui\">Local/Space</option>\n {% endif %}\n {% if enable_local == 0 and enable_ngc == 0 and enable_nvcf == 0 %}\n <optgroup label=\"Hugging Face Spaces\">\n <option value=\"spaces-a10g-large\">1xA10G Large</option>\n <option value=\"spaces-a10g-largex2\">2xA10G Large</option>\n <option value=\"spaces-a10g-largex4\">4xA10G Large</option>\n <option value=\"spaces-l40sx1\">1xL40S</option>\n <option value=\"spaces-l40sx4\">4xL40S</option>\n <option value=\"spaces-l40sx8\">8xL40S</option>\n <option value=\"spaces-a100-large\">A100 Large</option>\n <option value=\"spaces-a10g-small\">A10G Small</option>\n <option value=\"spaces-t4-medium\">T4 Medium</option>\n <option value=\"spaces-t4-small\">T4 Small</option>\n <option value=\"spaces-cpu-upgrade\">CPU Upgrade</option>\n <option value=\"spaces-cpu-basic\">CPU (Free)</option>\n </optgroup>\n <optgroup label=\"Hugging Face Endpoints\">\n <option value=\"ep-aws-useast1-m\">1xA10G</option>\n <option value=\"ep-aws-useast1-xl\">1xA100</option>\n <option value=\"ep-aws-useast1-2xl\">2xA100</option>\n <option value=\"ep-aws-useast1-4xl\">4xA100</option>\n <option value=\"ep-aws-useast1-8xl\">8xA100</option>\n </optgroup>\n {% endif %}\n {% if enable_ngc == 1 %}\n <optgroup label=\"NVIDIA DGX Cloud\">\n <option value=\"dgx-a100\">1xA100 DGX</option>\n <option value=\"dgx-2a100\">2xA100 DGX</option>\n <option value=\"dgx-4a100\">4xA100 DGX</option>\n <option value=\"dgx-8a100\">8xA100 DGX</option>\n </optgroup>\n {% endif %}\n {% if enable_nvcf == 1 %}\n <optgroup label=\"NVIDIA Cloud Functions\">\n <option value=\"nvcf-l40sx1\">1xL40S</option>\n <option value=\"nvcf-h100x1\">1xH100</option>\n <option value=\"nvcf-h100x2\">2xH100</option>\n <option value=\"nvcf-h100x4\">4xH100</option>\n <option value=\"nvcf-h100x8\">8xH100</option>\n </optgroup>\n {% endif %}\n </select>\n </li>\n <li>\n <label for=\"parameter_mode\" class=\"text-sm font-medium text-gray-700 dark:text-gray-300\">Parameter\n Mode\n <button type=\"button\" id=\"parameter_mode_info\"\n class=\"text-gray-500 dark:text-gray-400 hover:text-gray-700 dark:hover:text-gray-300\">\n <i class=\"fas fa-info-circle\"></i>\n </button>\n </label>\n <select id=\"parameter_mode\" name=\"parameter_mode\"\n class=\"mt-1 block w-full border border-gray-300 dark:border-gray-600 px-3 py-2 bg-white dark:bg-gray-700 rounded-md shadow-sm focus:outline-none focus:ring-indigo-500 focus:border-indigo-500\">\n <option value=\"basic\">Basic</option>\n <option value=\"full\">Full</option>\n </select>\n </li>\n </ul>\n <ul class=\"pt-4 mt-4 space-y-2 font-medium border-t border-gray-200 dark:border-gray-700\">\n <li>\n <a href=\"#\" id=\"button_logs\"\n class=\"flex items-center p-2 text-gray-900 dark:text-gray-100 transition duration-75 rounded-lg hover:bg-gray-100 dark:hover:bg-gray-700 group\">\n <svg class=\"flex-shrink-0 w-5 h-5 text-gray-500 dark:text-gray-400 transition duration-75 group-hover:text-gray-900 dark:group-hover:text-gray-100\"\n aria-hidden=\"true\" xmlns=\"http://www.w3.org/2000/svg\" fill=\"currentColor\"\n viewBox=\"0 0 20 18\">\n <path d=\"M18 0H6a2 2 0 0 0-2 2h14v12a2 2 0 0 0 2-2V2a2 2 0 0 0-2-2Z\" />\n <path\n d=\"M14 4H2a2 2 0 0 0-2 2v10a2 2 0 0 0 2 2h12a2 2 0 0 0 2-2V6a2 2 0 0 0-2-2ZM2 16v-6h12v6H2Z\" />\n </svg>\n <span class=\"ms-3\">Logs</span>\n </a>\n </li>\n <li>\n <a href=\"https://huggingface.co/docs/autotrain\" target=\"_blank\"\n class=\"flex items-center p-2 text-gray-900 dark:text-gray-100 transition duration-75 rounded-lg hover:bg-gray-100 dark:hover:bg-gray-700 group\">\n <svg class=\"flex-shrink-0 w-5 h-5 text-gray-500 dark:text-gray-400 transition duration-75 group-hover:text-gray-900 dark:group-hover:text-gray-100\"\n aria-hidden=\"true\" xmlns=\"http://www.w3.org/2000/svg\" fill=\"currentColor\"\n viewBox=\"0 0 16 20\">\n <path\n d=\"M16 14V2a2 2 0 0 0-2-2H2a2 2 0 0 0-2 2v15a3 3 0 0 0 3 3h12a1 1 0 0 0 0-2h-1v-2a2 2 0 0 0 2-2ZM4 2h2v12H4V2Zm8 16H3a1 1 0 0 1 0-2h9v2Z\" />\n </svg>\n <span class=\"ms-3\">Documentation</span>\n </a>\n </li>\n <li>\n <a href=\"https://huggingface.co/docs/autotrain/faq\" target=\"_blank\"\n class=\"flex items-center p-2 text-gray-900 dark:text-gray-100 transition duration-75 rounded-lg hover:bg-gray-100 dark:hover:bg-gray-700 group\">\n <svg class=\"flex-shrink-0 w-5 h-5 text-gray-500 dark:text-gray-400 transition duration-75 group-hover:text-gray-900 dark:group-hover:text-gray-100\"\n aria-hidden=\"true\" xmlns=\"http://www.w3.org/2000/svg\" fill=\"currentColor\"\n viewBox=\"0 0 21 21\">\n <path\n d=\"m5.4 2.736 3.429 3.429A5.046 5.046 0 0 1 10.134 6c.356.01.71.06 1.056.147l3.41-3.412c.136-.133.287-.248.45-.344A9.889 9.889 0 0 0 10.269 1c-1.87-.041-3.713.44-5.322 1.392a2.3 2.3 0 0 1 .454.344Zm11.45 1.54-.126-.127a.5.5 0 0 0-.706 0l-2.932 2.932c.029.023.049.054.078.077.236.194.454.41.65.645.034.038.078.067.11.107l2.927-2.927a.5.5 0 0 0 0-.707Zm-2.931 9.81c-.024.03-.057.052-.081.082a4.963 4.963 0 0 1-.633.639c-.041.036-.072.083-.115.117l2.927 2.927a.5.5 0 0 0 .707 0l.127-.127a.5.5 0 0 0 0-.707l-2.932-2.931Zm-1.442-4.763a3.036 3.036 0 0 0-1.383-1.1l-.012-.007a2.955 2.955 0 0 0-1-.213H10a2.964 2.964 0 0 0-2.122.893c-.285.29-.509.634-.657 1.013l-.01.016a2.96 2.96 0 0 0-.21 1 2.99 2.99 0 0 0 .489 1.716c.009.014.022.026.032.04a3.04 3.04 0 0 0 1.384 1.1l.012.007c.318.129.657.2 1 .213.392.015.784-.05 1.15-.192.012-.005.02-.013.033-.018a3.011 3.011 0 0 0 1.676-1.7v-.007a2.89 2.89 0 0 0 0-2.207 2.868 2.868 0 0 0-.27-.515c-.007-.012-.02-.025-.03-.039Zm6.137-3.373a2.53 2.53 0 0 1-.35.447L14.84 9.823c.112.428.166.869.16 1.311-.01.356-.06.709-.147 1.054l3.413 3.412c.132.134.249.283.347.444A9.88 9.88 0 0 0 20 11.269a9.912 9.912 0 0 0-1.386-5.319ZM14.6 19.264l-3.421-3.421c-.385.1-.781.152-1.18.157h-.134c-.356-.01-.71-.06-1.056-.147l-3.41 3.412a2.503 2.503 0 0 1-.443.347A9.884 9.884 0 0 0 9.732 21H10a9.9 9.9 0 0 0 5.044-1.388 2.519 2.519 0 0 1-.444-.348ZM1.735 15.6l3.426-3.426a4.608 4.608 0 0 1-.013-2.367L1.735 6.4a2.507 2.507 0 0 1-.35-.447 9.889 9.889 0 0 0 0 10.1c.1-.164.217-.316.35-.453Zm5.101-.758a4.957 4.957 0 0 1-.651-.645c-.033-.038-.077-.067-.11-.107L3.15 17.017a.5.5 0 0 0 0 .707l.127.127a.5.5 0 0 0 .706 0l2.932-2.933c-.03-.018-.05-.053-.078-.076ZM6.08 7.914c.03-.037.07-.063.1-.1.183-.22.384-.423.6-.609.047-.04.082-.092.129-.13L3.983 4.149a.5.5 0 0 0-.707 0l-.127.127a.5.5 0 0 0 0 .707L6.08 7.914Z\" />\n </svg>\n <span class=\"ms-3\">FAQs</span>\n </a>\n </li>\n <li>\n <a href=\"https://github.com/huggingface/autotrain-advanced\" target=\"_blank\"\n class=\"flex items-center p-2 text-gray-900 dark:text-gray-100 transition duration-75 rounded-lg hover:bg-gray-100 dark:hover:bg-gray-700 group\">\n <svg class=\"flex-shrink-0 w-5 h-5 text-gray-500 dark:text-gray-400 transition duration-75 group-hover:text-gray-900 dark:group-hover:text-gray-100\"\n aria-hidden=\"true\" xmlns=\"http://www.w3.org/2000/svg\" fill=\"currentColor\"\n viewBox=\"0 0 24 24\">\n <path\n d=\"M12 .297c-6.63 0-12 5.373-12 12 0 5.303 3.438 9.8 8.205 11.387.6.113.82-.258.82-.577v-2.234c-3.338.727-4.033-1.416-4.033-1.416-.546-1.387-1.333-1.756-1.333-1.756-1.089-.745.084-.729.084-.729 1.205.084 1.838 1.238 1.838 1.238 1.07 1.835 2.809 1.304 3.495.998.108-.775.418-1.305.762-1.605-2.665-.305-5.466-1.333-5.466-5.931 0-1.31.47-2.381 1.236-3.221-.123-.303-.535-1.524.117-3.176 0 0 1.008-.322 3.301 1.23.957-.266 1.983-.399 3.004-.404 1.02.005 2.047.138 3.005.404 2.29-1.553 3.297-1.23 3.297-1.23.653 1.653.241 2.874.118 3.176.77.84 1.235 1.911 1.235 3.221 0 4.61-2.803 5.625-5.474 5.921.43.37.823 1.096.823 2.21v3.293c0 .322.218.694.824.576 4.765-1.589 8.199-6.084 8.199-11.386 0-6.627-5.373-12-12-12z\" />\n </svg>\n <span class=\"ms-3\">GitHub Repo</span>\n </a>\n </li>\n </ul>\n <ul class=\"pt-4 mt-4 space-y-2 font-medium border-t border-gray-200 dark:border-gray-700\">\n <div class=\"block text-xs text-gray-400 dark:text-gray-500 text-center\">{{version}}\n </div>\n </ul>\n </div>\n </aside>\n\n <div class=\"p-4 sm:ml-64\">\n <div class=\"columns-2 mb-2\">\n <div>\n <p class=\"text-sm text-gray-700 dark:text-gray-300 font-bold text-left\" id=\"num_accelerators\">\n Accelerators: Fetching...\n </p>\n <p class=\"text-sm text-gray-700 dark:text-gray-300 font-bold text-left\" id=\"is_model_training\">Fetching\n training\n status...\n </p>\n </div>\n <div class=\"flex items-end justify-end\">\n <button type=\"button\" id=\"start-training-button\"\n class=\"px-2 py-2 text-white bg-blue-600 rounded-md hover:bg-blue-700 focus:outline-none focus:bg-blue-700\">Start\n Training\n </button>\n <button type=\"button\" id=\"stop-training-button\"\n class=\"hidden px-2 py-2 text-white bg-red-600 rounded-md hover:bg-red-700 focus:outline-none focus:bg-red-700\">Stop\n Training\n </button>\n </div>\n </div>\n <div class=\"p-4\">\n <div class=\"grid grid-cols-2 gap-4 mb-4\">\n <div>\n <div class=\"items-center justify-center h-24\">\n <div class=\"w-full px-4\">\n <p for=\"project_name\" class=\"text-xl text-gray-800 dark:text-gray-200 mb-2 mt-2\">\n Project Name\n </p>\n <input type=\"text\" name=\"project_name\" id=\"project_name\"\n class=\"mt-1 block w-full border border-gray-300 dark:border-gray-600 px-3 py-2 bg-white dark:bg-gray-700 rounded-md shadow-sm focus:outline-none focus:ring-indigo-500 focus:border-indigo-500\">\n </div>\n </div>\n <div class=\"items-center justify-center h-24\">\n <div class=\"w-full px-4\">\n <p for=\"base_model\" class=\"text-xl text-gray-800 dark:text-gray-200 mb-2 mt-2\">\n Base Model\n </p>\n <div class=\"flex items-center\">\n <select name=\"base_model\" id=\"base_model\"\n class=\"mt-1 block w-full border border-gray-300 dark:border-gray-600 px-3 py-2 bg-white dark:bg-gray-700 rounded-md shadow-sm focus:outline-none focus:ring-indigo-500 focus:border-indigo-500\">\n </select>\n <input type=\"text\" id=\"base_model_input\"\n class=\"mt-1 block w-full border border-gray-300 dark:border-gray-600 px-3 py-2 bg-white dark:bg-gray-700 rounded-md shadow-sm focus:outline-none focus:ring-indigo-500 focus:border-indigo-500 hidden\">\n <div class=\"flex items-center ps-4 rounded\">\n <input id=\"base_model_checkbox\" type=\"checkbox\" value=\"\" name=\"base_model_checkbox\"\n class=\"w-4 h-4 text-blue-600 bg-gray-100 border-gray-300 rounded focus:ring-blue-500\">\n <label for=\"base_model_checkbox\"\n class=\"w-full py-4 ms-2 text-sm font-medium text-gray-700 dark:text-gray-300\">Custom</label>\n </div>\n </div>\n </div>\n </div>\n <div class=\"items-center justify-center h-24\">\n <div class=\"w-full px-4\">\n <p for=\"dataset_source\" class=\"text-xl text-gray-800 dark:text-gray-200 mb-2 mt-2\">Dataset\n Source\n </p>\n <select id=\"dataset_source\" name=\"dataset_source\"\n class=\"mt-1 block w-full border border-gray-300 dark:border-gray-600 px-3 py-2 bg-white dark:bg-gray-700 rounded-md shadow-sm focus:outline-none focus:ring-indigo-500 focus:border-indigo-500\">\n <option value=\"local\">Local</option>\n <option value=\"hub\">Hugging Face Hub</option>\n </select>\n </div>\n </div>\n <div class=\"items-stretch justify-center h-48 rounded\">\n <div id=\"hub-data-tab-content\" class=\"w-full px-4\">\n <label for=\"hub_dataset\" class=\"text-sm font-medium text-gray-700 dark:text-gray-300\">Hub\n dataset path</label>\n <div class=\"mt-1 flex items-center\">\n <input type=\"text\" name=\"hub_dataset\" id=\"hub_dataset\"\n class=\"block w-full border border-gray-300 dark:border-gray-600 px-3 py-2.5 bg-white dark:bg-gray-700 rounded-md shadow-sm focus:outline-none focus:ring-indigo-500 focus:border-indigo-500\">\n <button type=\"button\" id=\"dataset-viewer\"\n class=\"ml-2 p-2 bg-white dark:bg-gray-700 border border-gray-300 dark:border-gray-600 rounded-md shadow-sm focus:outline-none focus:ring-indigo-500 focus:border-indigo-500\">\n <svg xmlns=\"http://www.w3.org/2000/svg\"\n class=\"h-5 w-5 text-gray-500 dark:text-gray-400\" viewBox=\"0 0 24 24\"\n fill=\"currentColor\">\n <path\n d=\"M12 4.5C7 4.5 2.73 7.61 1 12c1.73 4.39 6 7.5 11 7.5s9.27-3.11 11-7.5c-1.73-4.39-6-7.5-11-7.5zm0 13c-3.04 0-5.5-2.46-5.5-5.5S8.96 6.5 12 6.5s5.5 2.46 5.5 5.5-2.46 5.5-5.5 5.5zm0-9c-1.93 0-3.5 1.57-3.5 3.5s1.57 3.5 3.5 3.5 3.5-1.57 3.5-3.5-1.57-3.5-3.5-3.5z\" />\n </svg>\n </button>\n </div>\n <div class=\"columns-2 mb-2 mt-2\">\n <label for=\"train_split\"\n class=\"text-sm font-medium text-gray-700 dark:text-gray-300\">Train split\n </label>\n <input type=\"text\" name=\"train_split\" id=\"train_split\"\n class=\"mt-1 block w-full border border-gray-300 dark:border-gray-600 px-3 py-2 bg-white dark:bg-gray-700 rounded-md shadow-sm focus:outline-none focus:ring-indigo-500 focus:border-indigo-500\">\n <label for=\"valid_split\"\n class=\"text-sm font-medium text-gray-700 dark:text-gray-300\">Valid split\n (optional)\n </label>\n <input type=\"text\" name=\"valid_split\" id=\"valid_split\"\n class=\"mt-1 block w-full border border-gray-300 dark:border-gray-600 px-3 py-2 bg-white dark:bg-gray-700 rounded-md shadow-sm focus:outline-none focus:ring-indigo-500 focus:border-indigo-500\">\n </div>\n </div>\n <div id=\"upload-data-tabs\" class=\"w-full px-4\">\n <ul class=\"flex flex-wrap -mb-px text-sm font-medium text-center\" id=\"upload-data-tab\"\n data-tabs-toggle=\"#upload-data-tab-content\" role=\"tablist\">\n <li class=\"me-2\" role=\"presentation\">\n <button class=\"p-4 hover:text-gray-600 hover:bg-gray-100 dark:hover:bg-gray-700\"\n id=\"training-data-tab\" data-tabs-target=\"#training-data\" type=\"button\"\n role=\"tab\" aria-controls=\"training-data\" aria-selected=\"false\">Training\n Data</button>\n </li>\n <li class=\"me-2\" role=\"presentation\">\n <button class=\"p-4 hover:text-gray-600 hover:bg-gray-100 dark:hover:bg-gray-700\"\n id=\"valid-data-tab\" data-tabs-target=\"#valid-data\" type=\"button\" role=\"tab\"\n aria-controls=\"valid-data\" aria-selected=\"false\">Validation Data\n (optional)</button>\n </li>\n </ul>\n </div>\n <div id=\"upload-data-tab-content\" class=\"w-full px-4\">\n <div class=\"hidden p-4\" id=\"training-data\" role=\"tabpanel\"\n aria-labelledby=\"training-data-tab\">\n <div class=\"flex items-center justify-center w-full h-20\">\n <label for=\"data_files_training\"\n class=\"flex flex-col items-center justify-center w-full h-40 cursor-pointer\">\n <div class=\"flex flex-col items-center justify-center pt-5 pb-6\">\n <svg class=\"w-8 h-8 mb-4 text-gray-700 dark:text-gray-300\"\n aria-hidden=\"true\" xmlns=\"http://www.w3.org/2000/svg\" fill=\"none\"\n viewBox=\"0 0 20 16\">\n <path stroke=\"currentColor\" stroke-linecap=\"round\"\n stroke-linejoin=\"round\" stroke-width=\"2\"\n d=\"M13 13h3a3 3 0 0 0 0-6h-.025A5.56 5.56 0 0 0 16 6.5 5.5 5.5 0 0 0 5.207 5.021C5.137 5.017 5.071 5 5 5a4 4 0 0 0 0 8h2.167M10 15V6m0 0L8 8m2-2 2 2\" />\n </svg>\n <p class=\"text-sm text-gray-700 dark:text-gray-300\"><span\n class=\"font-semibold\">Upload Training\n File(s)\n <p class=\"text-xs text-gray-700 dark:text-gray-300\"\n id=\"file-container-training\"></p>\n </div>\n <input id=\"data_files_training\" name=\"data_files_training\" type=\"file\" multiple\n class=\"hidden\" />\n </label>\n </div>\n </div>\n <div class=\"hidden p-4\" id=\"valid-data\" role=\"tabpanel\" aria-labelledby=\"valid-data-tab\">\n <div class=\"flex items-center justify-center w-full h-20\">\n <label for=\"data_files_valid\"\n class=\"flex flex-col items-center justify-center w-full h-40 cursor-pointer\">\n <div class=\"flex flex-col items-center justify-center pt-5 pb-6\">\n <svg class=\"w-8 h-8 mb-4 text-gray-700 dark:text-gray-300\"\n aria-hidden=\"true\" xmlns=\"http://www.w3.org/2000/svg\" fill=\"none\"\n viewBox=\"0 0 20 16\">\n <path stroke=\"currentColor\" stroke-linecap=\"round\"\n stroke-linejoin=\"round\" stroke-width=\"2\"\n d=\"M13 13h3a3 3 0 0 0 0-6h-.025A5.56 5.56 0 0 0 16 6.5 5.5 5.5 0 0 0 5.207 5.021C5.137 5.017 5.071 5 5 5a4 4 0 0 0 0 8h2.167M10 15V6m0 0L8 8m2-2 2 2\" />\n </svg>\n <p class=\"text-sm text-gray-700 dark:text-gray-300\"><span\n class=\"font-semibold\">Upload\n Validation\n File(s)\n <p class=\"text-xs text-gray-700 dark:text-gray-300\"\n id=\"file-container-valid\"></p>\n </div>\n <input id=\"data_files_valid\" name=\"data_files_valid\" type=\"file\" multiple\n class=\"hidden\" />\n </label>\n </div>\n </div>\n </div>\n </div>\n <div class=\"items-center justify-center h-24\">\n <div class=\"w-full px-4\">\n <p class=\"text-xl text-gray-800 dark:text-gray-200 mb-2 mt-2\">\n Column Mapping\n </p>\n <div id=\"div_cmap\"></div>\n </div>\n </div>\n </div>\n <div>\n <div class=\"items-center justify-center h-96\">\n <div class=\"w-full px-4\">\n <p class=\"text-xl text-gray-800 dark:text-gray-200 mb-2 mt-2\">\n Parameters\n </p>\n <label class=\"inline-flex items-center cursor-pointer\">\n <input type=\"checkbox\" value=\"\" class=\"sr-only peer\" id=\"show-json-parameters\">\n <div\n class=\"relative w-14 h-7 bg-gray-200 dark:bg-gray-700 peer-focus:outline-none peer-focus:ring-4 peer-focus:ring-blue-300 rounded-full peer peer-checked:after:translate-x-full rtl:peer-checked:after:-translate-x-full peer-checked:after:border-white after:content-[''] after:absolute after:top-0.5 after:start-[4px] after:bg-white after:border-gray-300 after:border after:rounded-full after:h-6 after:w-6 after:transition-all peer-checked:bg-blue-600\">\n </div>\n <span class=\"ms-3 text-sm font-medium text-gray-900 dark:text-gray-300\">JSON</span>\n </label>\n <div id=\"dynamic-ui\"></div>\n <div id=\"json-parameters\" class=\"hidden\">\n <textarea id=\"params_json\" name=\"params_json\" placeholder=\"Loading...\"\n class=\"p-2.5 w-full text-sm text-gray-600 dark:text-gray-300 bg-white dark:bg-gray-800 border-white dark:border-gray-700 border-transparent focus:border-transparent focus:ring-0\"></textarea>\n </div>\n </div>\n </div>\n </div>\n </div>\n </div>\n </div>\n <div id=\"json-error-message\" style=\"color: red;\"></div>\n <div id=\"error-message\" style=\"color: red;\"></div>\n <div id=\"success-message\" style=\"color: green;\"></div>\n <div id=\"loadingSpinner\" role=\"status\"\n class=\"hidden absolute -translate-x-1/2 -translate-y-1/2 top-2/4 left-1/2 flex flex-col items-center\">\n <div class=\"animate-spin rounded-full h-32 w-32 border-t-4 border-b-4 border-blue-400\"></div>\n <span class=\"sr-only mt-4 text-blue-500\">Loading...</span>\n </div>\n <div class=\"hidden justify-center items-center\">\n <div class=\"animate-spin rounded-full h-32 w-32 border-b-2 border-gray-900\"></div>\n </div>\n <div id=\"confirmation-modal\" tabindex=\"-1\"\n class=\"hidden fixed inset-0 z-50 flex items-center justify-center w-full h-full bg-black bg-opacity-50\">\n <div class=\"relative w-full max-w-md p-4\">\n <div class=\"relative bg-white dark:bg-gray-800 rounded-lg shadow-2xl\">\n <div class=\"p-6 text-center\">\n <h3 class=\"mb-5 text-lg font-medium text-gray-900 dark:text-gray-100\">AutoTrain is a paid offering\n and you will be\n charged for this action. You can ignore this message if you are running AutoTrain on a local\n hardware.\n Are you sure you want to continue?</h3>\n <div class=\"flex justify-center space-x-4\">\n <button data-modal-hide=\"confirmation-modal\" type=\"button\"\n class=\"confirm text-white bg-green-600 hover:bg-green-700 focus:ring-4 focus:ring-green-300 font-medium rounded-lg text-sm px-5 py-2.5 focus:outline-none\">\n Yes, I'm sure\n </button>\n <button data-modal-hide=\"confirmation-modal\" type=\"button\"\n class=\"cancel text-gray-700 bg-gray-200 hover:bg-gray-300 focus:ring-4 focus:ring-gray-300 rounded-lg text-sm font-medium px-5 py-2.5 focus:outline-none\">\n No, cancel\n </button>\n </div>\n </div>\n </div>\n </div>\n </div>\n <div id=\"logs-modal\" tabindex=\"-1\"\n class=\"hidden fixed inset-0 z-50 flex items-center justify-center w-full h-full bg-black bg-opacity-50\">\n <div class=\"relative w-full max-w-5xl p-4\">\n <div class=\"relative bg-white dark:bg-gray-800 rounded-lg shadow-2xl\">\n <button type=\"button\"\n class=\"absolute top-3 right-3 text-gray-400 bg-transparent hover:bg-gray-200 hover:text-gray-900 dark:hover:bg-gray-700 dark:hover:text-gray-100 rounded-lg text-sm w-8 h-8 inline-flex justify-center items-center\"\n data-modal-hide=\"logs-modal\">\n <svg class=\"w-4 h-4\" aria-hidden=\"true\" xmlns=\"http://www.w3.org/2000/svg\" fill=\"none\"\n viewBox=\"0 0 14 14\">\n <path stroke=\"currentColor\" stroke-linecap=\"round\" stroke-linejoin=\"round\" stroke-width=\"2\"\n d=\"m1 1 6 6m0 0 6 6M7 7l6-6M7 7l-6 6\" />\n </svg>\n <span class=\"sr-only\">Close</span>\n </button>\n <div class=\"p-6 md:p-8 text-center\">\n <h3 class=\"mb-5 text-lg font-medium text-gray-900 dark:text-gray-100\">Logs</h3>\n <div id=\"logContent\"\n class=\"text-xs font-normal text-left overflow-y-auto max-h-[calc(100vh-400px)] border-t border-gray-200 dark:border-gray-700 pt-4\">\n <!-- Logs will be appended here -->\n </div>\n </div>\n </div>\n </div>\n </div>\n <div id=\"final-modal\" tabindex=\"-1\"\n class=\"hidden overflow-y-auto overflow-x-hidden fixed top-0 right-0 left-0 z-50 justify-center items-center w-full md:inset-0 h-[calc(100%-1rem)] max-h-full\">\n <div class=\"relative p-4 w-full max-w-md max-h-full\">\n <div class=\"relative bg-white dark:bg-gray-800 rounded-lg shadow-2xl\">\n <button type=\"button\"\n class=\"absolute top-3 end-2.5 text-gray-400 bg-transparent hover:bg-gray-200 hover:text-gray-900 dark:hover:bg-gray-700 dark:hover:text-gray-100 rounded-lg text-sm w-8 h-8 ms-auto inline-flex justify-center items-center\"\n data-modal-hide=\"final-modal\">\n <svg class=\"w-3 h-3\" aria-hidden=\"true\" xmlns=\"http://www.w3.org/2000/svg\" fill=\"none\"\n viewBox=\"0 0 14 14\">\n <path stroke=\"currentColor\" stroke-linecap=\"round\" stroke-linejoin=\"round\" stroke-width=\"2\"\n d=\"m1 1 6 6m0 0 6 6M7 7l6-6M7 7l-6 6\" />\n </svg>\n <span class=\"sr-only\">Close</span>\n </button>\n <div class=\"p-4 md:p-5 text-center\">\n <h3 class=\"mb-5 text-sm font-normal text-gray-800 dark:text-gray-200\"></h3>\n </div>\n </div>\n </div>\n </div>\n <div id=\"help-modal\" tabindex=\"-1\"\n class=\"hidden overflow-y-auto overflow-x-hidden fixed top-0 right-0 left-0 z-50 justify-center items-center w-full md:inset-0 h-[calc(100%-1rem)] max-h-full\">\n <div class=\"relative p-4 w-full max-w-md max-h-full\">\n <div class=\"relative bg-white dark:bg-gray-800 rounded-lg shadow-2xl\">\n <br>\n <button type=\"button\"\n class=\"absolute top-3 end-2.5 text-gray-400 bg-transparent hover:bg-gray-200 hover:text-gray-900 dark:hover:bg-gray-700 dark:hover:text-gray-100 rounded-lg text-sm w-8 h-8 ms-auto inline-flex justify-center items-center\"\n data-modal-hide=\"help-modal\">\n <svg class=\"w-3 h-3\" aria-hidden=\"true\" xmlns=\"http://www.w3.org/2000/svg\" fill=\"none\"\n viewBox=\"0 0 14 14\">\n <path stroke=\"currentColor\" stroke-linecap=\"round\" stroke-linejoin=\"round\" stroke-width=\"2\"\n d=\"m1 1 6 6m0 0 6 6M7 7l6-6M7 7l-6 6\" />\n </svg>\n <span class=\"sr-only\">Close</span>\n </button>\n <div class=\"p-4 md:p-5 text-center\">\n <h3 class=\"mb-5 text-sm font-normal text-gray-800 dark:text-gray-200\"></h3>\n </div>\n </div>\n </div>\n </div>\n <div id=\"dataset-viewer-modal\" tabindex=\"-1\"\n class=\"hidden fixed inset-0 z-50 flex items-center justify-center w-full h-full bg-black bg-opacity-50\">\n <div class=\"relative w-full max-w-5xl p-4\">\n <div class=\"relative bg-white dark:bg-gray-800 rounded-lg shadow-2xl\">\n <button type=\"button\"\n class=\"absolute top-3 right-3 text-gray-400 bg-transparent hover:bg-gray-200 hover:text-gray-900 dark:hover:bg-gray-700 dark:hover:text-gray-100 rounded-lg text-sm w-8 h-8 inline-flex justify-center items-center\"\n data-modal-hide=\"dataset-viewer-modal\">\n <svg class=\"w-4 h-4\" aria-hidden=\"true\" xmlns=\"http://www.w3.org/2000/svg\" fill=\"none\"\n viewBox=\"0 0 14 14\">\n <path stroke=\"currentColor\" stroke-linecap=\"round\" stroke-linejoin=\"round\" stroke-width=\"2\"\n d=\"m1 1 6 6m0 0 6 6M7 7l6-6M7 7l-6 6\" />\n </svg>\n <span class=\"sr-only\">Close</span>\n </button>\n <div class=\"p-6 md:p-8 text-center\">\n <h3 class=\"mb-5 text-lg font-medium text-gray-900 dark:text-gray-100\">Dataset Viewer</h3>\n <div id=\"datasetViewerContent\"\n class=\"text-xs font-normal text-left overflow-y-auto max-h-[calc(100vh-400px)] border-t border-gray-200 dark:border-gray-700 pt-4\">\n <!-- dataset will be appended here -->\n </div>\n </div>\n </div>\n </div>\n </div>\n <script>\n var autotrain_local_value = {{ enable_local }};\n </script>\n <script src=\"https://cdnjs.cloudflare.com/ajax/libs/flowbite/2.3.0/flowbite.min.js\"></script>\n <script>\n document.addEventListener('DOMContentLoaded', function () {\n const stopTrainingButton = document.getElementById('stop-training-button');\n const loadingSpinner = document.getElementById('loadingSpinner');\n\n stopTrainingButton.addEventListener('click', function () {\n loadingSpinner.classList.remove('hidden');\n\n fetch('/ui/stop_training', {\n method: 'GET'\n })\n .then(response => response.text())\n .then(data => {\n console.log(data);\n loadingSpinner.classList.add('hidden');\n })\n .catch(error => {\n console.error('Error:', error);\n loadingSpinner.classList.add('hidden');\n });\n });\n });\n </script>\n <script>\n document.getElementById('base_model_checkbox').addEventListener('change', function () {\n const selectElement = document.getElementById('base_model');\n const baseModelInput = document.getElementById('base_model_input');\n\n if (this.checked) {\n baseModelInput.placeholder = selectElement.options[selectElement.selectedIndex].text;\n selectElement.classList.add('hidden');\n baseModelInput.classList.remove('hidden');\n } else {\n selectElement.classList.remove('hidden');\n baseModelInput.classList.add('hidden');\n }\n });\n </script>\n</body>\n\n</html>", "src\\autotrain\\cli\\run_app.py": "import os\nimport signal\nimport subprocess\nimport sys\nimport threading\nfrom argparse import ArgumentParser\n\nfrom autotrain import logger\n\nfrom . import BaseAutoTrainCommand\n\n\ndef handle_output(stream, log_file):\n while True:\n line = stream.readline()\n if not line:\n break\n sys.stdout.write(line)\n sys.stdout.flush()\n log_file.write(line)\n log_file.flush()\n\n\ndef run_app_command_factory(args):\n return RunAutoTrainAppCommand(args.port, args.host, args.share, args.workers, args.colab)\n\n\nclass RunAutoTrainAppCommand(BaseAutoTrainCommand):\n @staticmethod\n def register_subcommand(parser: ArgumentParser):\n run_app_parser = parser.add_parser(\n \"app\",\n description=\"\u2728 Run AutoTrain app\",\n )\n run_app_parser.add_argument(\n \"--port\",\n type=int,\n default=7860,\n help=\"Port to run the app on\",\n required=False,\n )\n run_app_parser.add_argument(\n \"--host\",\n type=str,\n default=\"127.0.0.1\",\n help=\"Host to run the app on\",\n required=False,\n )\n run_app_parser.add_argument(\n \"--workers\",\n type=int,\n default=1,\n help=\"Number of workers to run the app with\",\n required=False,\n )\n run_app_parser.add_argument(\n \"--share\",\n action=\"store_true\",\n help=\"Share the app on ngrok\",\n required=False,\n )\n run_app_parser.add_argument(\n \"--colab\",\n action=\"store_true\",\n help=\"Use app in colab\",\n required=False,\n )\n run_app_parser.set_defaults(func=run_app_command_factory)\n\n def __init__(self, port, host, share, workers, colab):\n self.port = port\n self.host = host\n self.share = share\n self.workers = workers\n self.colab = colab\n\n def run(self):\n if self.colab:\n from IPython.display import display\n\n from autotrain.app.colab import colab_app\n\n elements = colab_app()\n display(elements)\n return\n\n if self.share:\n from pyngrok import ngrok\n\n os.system(f\"fuser -n tcp -k {self.port}\")\n authtoken = os.environ.get(\"NGROK_AUTH_TOKEN\", \"\")\n if authtoken.strip() == \"\":\n logger.info(\"NGROK_AUTH_TOKEN not set\")\n raise ValueError(\"NGROK_AUTH_TOKEN not set. Please set it!\")\n\n ngrok.set_auth_token(authtoken)\n active_tunnels = ngrok.get_tunnels()\n for tunnel in active_tunnels:\n public_url = tunnel.public_url\n ngrok.disconnect(public_url)\n url = ngrok.connect(addr=self.port, bind_tls=True)\n logger.info(f\"AutoTrain Public URL: {url}\")\n logger.info(\"Please wait for the app to load...\")\n\n command = f\"uvicorn autotrain.app.app:app --host {self.host} --port {self.port}\"\n command += f\" --workers {self.workers}\"\n\n with open(\"autotrain.log\", \"w\", encoding=\"utf-8\") as log_file:\n if sys.platform == \"win32\":\n process = subprocess.Popen(\n command, stdout=subprocess.PIPE, stderr=subprocess.STDOUT, shell=True, text=True, bufsize=1\n )\n\n else:\n process = subprocess.Popen(\n command,\n stdout=subprocess.PIPE,\n stderr=subprocess.STDOUT,\n shell=True,\n text=True,\n bufsize=1,\n preexec_fn=os.setsid,\n )\n\n output_thread = threading.Thread(target=handle_output, args=(process.stdout, log_file))\n output_thread.start()\n\n try:\n process.wait()\n output_thread.join()\n except KeyboardInterrupt:\n logger.warning(\"Attempting to terminate the process...\")\n if sys.platform == \"win32\":\n process.terminate()\n else:\n # If user cancels (Ctrl+C), terminate the subprocess\n # Use os.killpg to send SIGTERM to the process group, ensuring all child processes are killed\n os.killpg(os.getpgid(process.pid), signal.SIGTERM)\n logger.info(\"Process terminated by user\")\n", "src\\autotrain\\cli\\run_setup.py": "import subprocess\nfrom argparse import ArgumentParser\n\nfrom autotrain import logger\n\nfrom . import BaseAutoTrainCommand\n\n\ndef run_app_command_factory(args):\n return RunSetupCommand(args.update_torch, args.colab)\n\n\nclass RunSetupCommand(BaseAutoTrainCommand):\n @staticmethod\n def register_subcommand(parser: ArgumentParser):\n run_setup_parser = parser.add_parser(\n \"setup\",\n description=\"\u2728 Run AutoTrain setup\",\n )\n run_setup_parser.add_argument(\n \"--update-torch\",\n action=\"store_true\",\n help=\"Update PyTorch to latest version\",\n )\n run_setup_parser.add_argument(\n \"--colab\",\n action=\"store_true\",\n help=\"Run setup for Google Colab\",\n )\n run_setup_parser.set_defaults(func=run_app_command_factory)\n\n def __init__(self, update_torch: bool, colab: bool = False):\n self.update_torch = update_torch\n self.colab = colab\n\n def run(self):\n if self.colab:\n cmd = \"pip install -U xformers==0.0.24\"\n else:\n cmd = \"pip uninstall -y xformers\"\n cmd = cmd.split()\n pipe = subprocess.Popen(cmd, stdout=subprocess.PIPE, stderr=subprocess.PIPE)\n logger.info(\"Installing latest xformers\")\n _, _ = pipe.communicate()\n logger.info(\"Successfully installed latest xformers\")\n\n if self.update_torch:\n cmd = \"pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121\"\n cmd = cmd.split()\n pipe = subprocess.Popen(cmd, stdout=subprocess.PIPE, stderr=subprocess.PIPE)\n logger.info(\"Installing latest PyTorch\")\n _, _ = pipe.communicate()\n logger.info(\"Successfully installed latest PyTorch\")\n", "src\\autotrain\\trainers\\clm\\__main__.py": "import argparse\nimport json\n\nfrom autotrain.trainers.clm.params import LLMTrainingParams\nfrom autotrain.trainers.common import monitor\n\n\ndef parse_args():\n # get training_config.json from the end user\n parser = argparse.ArgumentParser()\n parser.add_argument(\"--training_config\", type=str, required=True)\n return parser.parse_args()\n\n\n@monitor\ndef train(config):\n if isinstance(config, dict):\n config = LLMTrainingParams(**config)\n\n if config.trainer == \"default\":\n from autotrain.trainers.clm.train_clm_default import train as train_default\n\n train_default(config)\n\n elif config.trainer == \"sft\":\n from autotrain.trainers.clm.train_clm_sft import train as train_sft\n\n train_sft(config)\n\n elif config.trainer == \"reward\":\n from autotrain.trainers.clm.train_clm_reward import train as train_reward\n\n train_reward(config)\n\n elif config.trainer == \"dpo\":\n from autotrain.trainers.clm.train_clm_dpo import train as train_dpo\n\n train_dpo(config)\n\n elif config.trainer == \"orpo\":\n from autotrain.trainers.clm.train_clm_orpo import train as train_orpo\n\n train_orpo(config)\n\n else:\n raise ValueError(f\"trainer `{config.trainer}` not supported\")\n\n\nif __name__ == \"__main__\":\n _args = parse_args()\n training_config = json.load(open(_args.training_config))\n _config = LLMTrainingParams(**training_config)\n train(_config)\n", "src\\autotrain\\trainers\\dreambooth\\__main__.py": "import argparse\nimport json\nimport os\n\nfrom diffusers.utils import convert_all_state_dict_to_peft, convert_state_dict_to_kohya\nfrom huggingface_hub import create_repo, snapshot_download, upload_folder\nfrom safetensors.torch import load_file, save_file\n\nfrom autotrain import logger\nfrom autotrain.trainers.common import monitor, pause_space, remove_autotrain_data\nfrom autotrain.trainers.dreambooth import utils\nfrom autotrain.trainers.dreambooth.params import DreamBoothTrainingParams\n\n\ndef parse_args():\n # get training_config.json from the end user\n parser = argparse.ArgumentParser()\n parser.add_argument(\"--training_config\", type=str, required=True)\n return parser.parse_args()\n\n\n@monitor\ndef train(config):\n if isinstance(config, dict):\n config = DreamBoothTrainingParams(**config)\n config.prompt = str(config.prompt).strip()\n\n if config.model in utils.XL_MODELS:\n config.xl = True\n try:\n snapshot_download(\n repo_id=config.image_path,\n local_dir=config.project_name,\n token=config.token,\n repo_type=\"dataset\",\n )\n config.image_path = os.path.join(config.project_name, \"concept1\")\n except Exception as e:\n logger.warning(f\"Failed to download dataset: {e}\")\n pass\n if config.image_path == f\"{config.project_name}/autotrain-data\":\n config.image_path = os.path.join(config.image_path, \"concept1\")\n\n if config.vae_model is not None:\n if config.vae_model.strip() == \"\":\n config.vae_model = None\n\n if config.xl:\n from autotrain.trainers.dreambooth.train_xl import main\n\n class Args:\n pretrained_model_name_or_path = config.model\n pretrained_vae_model_name_or_path = config.vae_model\n revision = config.revision\n variant = None\n dataset_name = None\n dataset_config_name = None\n instance_data_dir = config.image_path\n cache_dir = None\n image_column = \"image\"\n caption_column = None\n repeats = 1\n class_data_dir = config.class_image_path\n instance_prompt = config.prompt\n class_prompt = config.class_prompt\n validation_prompt = None\n num_validation_images = 4\n validation_epochs = 50\n with_prior_preservation = config.prior_preservation\n num_class_images = config.num_class_images\n output_dir = config.project_name\n seed = config.seed\n resolution = config.resolution\n center_crop = config.center_crop\n train_text_encoder = config.train_text_encoder\n train_batch_size = config.batch_size\n sample_batch_size = config.sample_batch_size\n num_train_epochs = config.epochs\n max_train_steps = config.num_steps\n checkpointing_steps = config.checkpointing_steps\n checkpoints_total_limit = None\n resume_from_checkpoint = config.resume_from_checkpoint\n gradient_accumulation_steps = config.gradient_accumulation\n gradient_checkpointing = not config.disable_gradient_checkpointing\n learning_rate = config.lr\n text_encoder_lr = 5e-6\n scale_lr = config.scale_lr\n lr_scheduler = config.scheduler\n snr_gamma = None\n lr_warmup_steps = config.warmup_steps\n lr_num_cycles = config.num_cycles\n lr_power = config.lr_power\n dataloader_num_workers = config.dataloader_num_workers\n optimizer = \"AdamW\"\n use_8bit_adam = config.use_8bit_adam\n adam_beta1 = config.adam_beta1\n adam_beta2 = config.adam_beta2\n prodigy_beta3 = None\n prodigy_decouple = True\n adam_weight_decay = config.adam_weight_decay\n adam_weight_decay_text_encoder = 1e-3\n adam_epsilon = config.adam_epsilon\n prodigy_use_bias_correction = True\n prodigy_safeguard_warmup = True\n max_grad_norm = config.max_grad_norm\n push_to_hub = config.push_to_hub\n hub_token = config.token\n hub_model_id = f\"{config.username}/{config.project_name}\"\n logging_dir = os.path.join(config.project_name, \"logs\")\n allow_tf32 = config.allow_tf32\n report_to = \"tensorboard\" if config.logging else None\n mixed_precision = config.mixed_precision\n prior_generation_precision = config.prior_generation_precision\n local_rank = config.local_rank\n enable_xformers_memory_efficient_attention = config.xformers\n rank = config.rank\n do_edm_style_training = False\n random_flip = False\n use_dora = False\n\n _args = Args()\n main(_args)\n else:\n from autotrain.trainers.dreambooth.train import main\n\n class Args:\n pretrained_model_name_or_path = config.model\n pretrained_vae_model_name_or_path = config.vae_model\n revision = config.revision\n variant = None\n tokenizer_name = None\n instance_data_dir = config.image_path\n class_data_dir = config.class_image_path\n instance_prompt = config.prompt\n class_prompt = config.class_prompt\n validation_prompt = None\n num_validation_images = 4\n validation_epochs = 50\n with_prior_preservation = config.prior_preservation\n num_class_images = config.num_class_images\n output_dir = config.project_name\n seed = config.seed\n resolution = config.resolution\n center_crop = config.center_crop\n train_text_encoder = config.train_text_encoder\n train_batch_size = config.batch_size\n sample_batch_size = config.sample_batch_size\n max_train_steps = config.num_steps\n checkpointing_steps = config.checkpointing_steps\n checkpoints_total_limit = None\n resume_from_checkpoint = config.resume_from_checkpoint\n gradient_accumulation_steps = config.gradient_accumulation\n gradient_checkpointing = not config.disable_gradient_checkpointing\n learning_rate = config.lr\n scale_lr = config.scale_lr\n lr_scheduler = config.scheduler\n lr_warmup_steps = config.warmup_steps\n lr_num_cycles = config.num_cycles\n lr_power = config.lr_power\n dataloader_num_workers = config.dataloader_num_workers\n use_8bit_adam = config.use_8bit_adam\n adam_beta1 = config.adam_beta1\n adam_beta2 = config.adam_beta2\n adam_weight_decay = config.adam_weight_decay\n adam_epsilon = config.adam_epsilon\n max_grad_norm = config.max_grad_norm\n push_to_hub = config.push_to_hub\n hub_token = config.token\n hub_model_id = f\"{config.username}/{config.project_name}\"\n logging_dir = os.path.join(config.project_name, \"logs\")\n allow_tf32 = config.allow_tf32\n report_to = \"tensorboard\" if config.logging else None\n mixed_precision = config.mixed_precision\n prior_generation_precision = config.prior_generation_precision\n local_rank = config.local_rank\n enable_xformers_memory_efficient_attention = config.xformers\n pre_compute_text_embeddings = config.pre_compute_text_embeddings\n tokenizer_max_length = config.tokenizer_max_length\n text_encoder_use_attention_mask = config.text_encoder_use_attention_mask\n validation_images = None\n class_labels_conditioning = config.class_labels_conditioning\n rank = config.rank\n\n _args = Args()\n main(_args)\n\n if os.path.exists(f\"{config.project_name}/training_params.json\"):\n training_params = json.load(open(f\"{config.project_name}/training_params.json\"))\n if \"token\" in training_params:\n training_params.pop(\"token\")\n json.dump(\n training_params,\n open(f\"{config.project_name}/training_params.json\", \"w\"),\n )\n\n # add config.prompt as a text file in the output directory\n with open(f\"{config.project_name}/prompt.txt\", \"w\") as f:\n f.write(config.prompt)\n\n try:\n logger.info(\"Converting model to Kohya format...\")\n lora_state_dict = load_file(f\"{config.project_name}/pytorch_lora_weights.safetensors\")\n peft_state_dict = convert_all_state_dict_to_peft(lora_state_dict)\n kohya_state_dict = convert_state_dict_to_kohya(peft_state_dict)\n save_file(kohya_state_dict, f\"{config.project_name}/pytorch_lora_weights_kohya.safetensors\")\n except Exception as e:\n logger.warning(e)\n logger.warning(\"Failed to convert model to Kohya format, skipping...\")\n\n if config.push_to_hub:\n remove_autotrain_data(config)\n\n repo_id = create_repo(\n repo_id=f\"{config.username}/{config.project_name}\",\n exist_ok=True,\n private=True,\n token=config.token,\n ).repo_id\n if config.xl:\n utils.save_model_card_xl(\n repo_id,\n base_model=config.model,\n train_text_encoder=config.train_text_encoder,\n instance_prompt=config.prompt,\n vae_path=config.vae_model,\n repo_folder=config.project_name,\n )\n else:\n utils.save_model_card(\n repo_id,\n base_model=config.model,\n train_text_encoder=config.train_text_encoder,\n instance_prompt=config.prompt,\n repo_folder=config.project_name,\n )\n\n upload_folder(\n repo_id=repo_id,\n folder_path=config.project_name,\n commit_message=\"End of training\",\n ignore_patterns=[\"step_*\", \"epoch_*\"],\n token=config.token,\n )\n\n pause_space(config)\n\n\nif __name__ == \"__main__\":\n args = parse_args()\n training_config = json.load(open(args.training_config))\n config = DreamBoothTrainingParams(**training_config)\n train(config)\n", "src\\autotrain\\trainers\\extractive_question_answering\\__main__.py": "import argparse\nimport copy\nimport json\nfrom functools import partial\n\nfrom accelerate.state import PartialState\nfrom datasets import load_dataset, load_from_disk\nfrom huggingface_hub import HfApi\nfrom transformers import (\n AutoConfig,\n AutoModelForQuestionAnswering,\n AutoTokenizer,\n EarlyStoppingCallback,\n Trainer,\n TrainingArguments,\n)\nfrom transformers.trainer_callback import PrinterCallback\n\nfrom autotrain import logger\nfrom autotrain.trainers.common import (\n ALLOW_REMOTE_CODE,\n LossLoggingCallback,\n TrainStartCallback,\n UploadLogs,\n monitor,\n pause_space,\n remove_autotrain_data,\n save_training_params,\n)\nfrom autotrain.trainers.extractive_question_answering import utils\nfrom autotrain.trainers.extractive_question_answering.dataset import ExtractiveQuestionAnsweringDataset\nfrom autotrain.trainers.extractive_question_answering.params import ExtractiveQuestionAnsweringParams\n\n\ndef parse_args():\n # get training_config.json from the end user\n parser = argparse.ArgumentParser()\n parser.add_argument(\"--training_config\", type=str, required=True)\n return parser.parse_args()\n\n\n@monitor\ndef train(config):\n if isinstance(config, dict):\n config = ExtractiveQuestionAnsweringParams(**config)\n\n train_data = None\n valid_data = None\n # check if config.train_split.csv exists in config.data_path\n if config.train_split is not None:\n if config.data_path == f\"{config.project_name}/autotrain-data\":\n logger.info(\"loading dataset from disk\")\n train_data = load_from_disk(config.data_path)[config.train_split]\n else:\n if \":\" in config.train_split:\n dataset_config_name, split = config.train_split.split(\":\")\n train_data = load_dataset(\n config.data_path,\n name=dataset_config_name,\n split=split,\n token=config.token,\n )\n else:\n train_data = load_dataset(\n config.data_path,\n split=config.train_split,\n token=config.token,\n )\n\n if config.valid_split is not None:\n if config.data_path == f\"{config.project_name}/autotrain-data\":\n logger.info(\"loading dataset from disk\")\n valid_data = load_from_disk(config.data_path)[config.valid_split]\n else:\n if \":\" in config.valid_split:\n dataset_config_name, split = config.valid_split.split(\":\")\n valid_data = load_dataset(\n config.data_path,\n name=dataset_config_name,\n split=split,\n token=config.token,\n )\n else:\n valid_data = load_dataset(\n config.data_path,\n split=config.valid_split,\n token=config.token,\n )\n\n logger.info(train_data)\n if config.valid_split is not None:\n logger.info(valid_data)\n\n model_config = AutoConfig.from_pretrained(config.model, allow_remote_code=ALLOW_REMOTE_CODE, token=config.token)\n\n try:\n model = AutoModelForQuestionAnswering.from_pretrained(\n config.model,\n config=model_config,\n trust_remote_code=ALLOW_REMOTE_CODE,\n token=config.token,\n ignore_mismatched_sizes=True,\n )\n except OSError:\n model = AutoModelForQuestionAnswering.from_pretrained(\n config.model,\n config=model_config,\n from_tf=True,\n trust_remote_code=ALLOW_REMOTE_CODE,\n token=config.token,\n ignore_mismatched_sizes=True,\n )\n\n tokenizer = AutoTokenizer.from_pretrained(config.model, token=config.token, trust_remote_code=ALLOW_REMOTE_CODE)\n\n use_v2 = False\n if config.valid_split is not None:\n id_column = list(range(len(valid_data)))\n for data in valid_data:\n if -1 in data[config.answer_column][\"answer_start\"]:\n use_v2 = True\n break\n\n valid_data = valid_data.add_column(\"id\", id_column)\n column_names = valid_data.column_names\n partial_process = partial(\n utils.prepare_qa_validation_features,\n tokenizer=tokenizer,\n config=config,\n )\n processed_eval_dataset = valid_data.map(\n partial_process,\n batched=True,\n remove_columns=column_names,\n num_proc=2,\n desc=\"Running tokenizer on validation dataset\",\n )\n orig_valid_data = copy.deepcopy(valid_data)\n\n train_data = ExtractiveQuestionAnsweringDataset(data=train_data, tokenizer=tokenizer, config=config)\n if config.valid_split is not None:\n valid_data = ExtractiveQuestionAnsweringDataset(data=valid_data, tokenizer=tokenizer, config=config)\n\n if config.logging_steps == -1:\n if config.valid_split is not None:\n logging_steps = int(0.2 * len(valid_data) / config.batch_size)\n else:\n logging_steps = int(0.2 * len(train_data) / config.batch_size)\n if logging_steps == 0:\n logging_steps = 1\n if logging_steps > 25:\n logging_steps = 25\n config.logging_steps = logging_steps\n else:\n logging_steps = config.logging_steps\n\n logger.info(f\"Logging steps: {logging_steps}\")\n\n training_args = dict(\n output_dir=config.project_name,\n per_device_train_batch_size=config.batch_size,\n per_device_eval_batch_size=2 * config.batch_size,\n learning_rate=config.lr,\n num_train_epochs=config.epochs,\n eval_strategy=config.eval_strategy if config.valid_split is not None else \"no\",\n logging_steps=logging_steps,\n save_total_limit=config.save_total_limit,\n save_strategy=config.eval_strategy if config.valid_split is not None else \"no\",\n gradient_accumulation_steps=config.gradient_accumulation,\n report_to=config.log,\n auto_find_batch_size=config.auto_find_batch_size,\n lr_scheduler_type=config.scheduler,\n optim=config.optimizer,\n warmup_ratio=config.warmup_ratio,\n weight_decay=config.weight_decay,\n max_grad_norm=config.max_grad_norm,\n push_to_hub=False,\n load_best_model_at_end=True if config.valid_split is not None else False,\n ddp_find_unused_parameters=False,\n )\n\n if config.mixed_precision == \"fp16\":\n training_args[\"fp16\"] = True\n if config.mixed_precision == \"bf16\":\n training_args[\"bf16\"] = True\n\n if config.valid_split is not None:\n early_stop = EarlyStoppingCallback(\n early_stopping_patience=config.early_stopping_patience,\n early_stopping_threshold=config.early_stopping_threshold,\n )\n callbacks_to_use = [early_stop]\n else:\n callbacks_to_use = []\n\n callbacks_to_use.extend([UploadLogs(config=config), LossLoggingCallback(), TrainStartCallback()])\n\n if config.valid_split is not None:\n logger.info(processed_eval_dataset)\n compute_metrics = partial(\n utils.compute_metrics,\n eval_dataset=processed_eval_dataset,\n eval_examples=orig_valid_data,\n config=config,\n use_v2=use_v2,\n )\n else:\n compute_metrics = None\n\n args = TrainingArguments(**training_args)\n trainer_args = dict(\n args=args,\n model=model,\n callbacks=callbacks_to_use,\n compute_metrics=compute_metrics,\n )\n\n trainer = Trainer(\n **trainer_args,\n train_dataset=train_data,\n eval_dataset=valid_data,\n )\n trainer.remove_callback(PrinterCallback)\n trainer.train()\n\n logger.info(\"Finished training, saving model...\")\n trainer.save_model(config.project_name)\n tokenizer.save_pretrained(config.project_name)\n\n model_card = utils.create_model_card(config, trainer)\n\n # save model card to output directory as README.md\n with open(f\"{config.project_name}/README.md\", \"w\") as f:\n f.write(model_card)\n\n if config.push_to_hub:\n if PartialState().process_index == 0:\n remove_autotrain_data(config)\n save_training_params(config)\n logger.info(\"Pushing model to hub...\")\n api = HfApi(token=config.token)\n api.create_repo(\n repo_id=f\"{config.username}/{config.project_name}\", repo_type=\"model\", private=True, exist_ok=True\n )\n api.upload_folder(\n folder_path=config.project_name,\n repo_id=f\"{config.username}/{config.project_name}\",\n repo_type=\"model\",\n )\n\n if PartialState().process_index == 0:\n pause_space(config)\n\n\nif __name__ == \"__main__\":\n args = parse_args()\n training_config = json.load(open(args.training_config))\n config = ExtractiveQuestionAnsweringParams(**training_config)\n train(config)\n", "src\\autotrain\\trainers\\generic\\__main__.py": "import argparse\nimport json\n\nfrom autotrain import logger\nfrom autotrain.trainers.common import monitor, pause_space\nfrom autotrain.trainers.generic import utils\nfrom autotrain.trainers.generic.params import GenericParams\n\n\ndef parse_args():\n # get training_config.json from the end user\n parser = argparse.ArgumentParser()\n parser.add_argument(\"--config\", type=str, required=True)\n return parser.parse_args()\n\n\n@monitor\ndef run(config):\n if isinstance(config, dict):\n config = GenericParams(**config)\n\n # download the data repo\n logger.info(\"Downloading data repo...\")\n utils.pull_dataset_repo(config)\n\n logger.info(\"Unintalling requirements...\")\n utils.uninstall_requirements(config)\n\n # install the requirements\n logger.info(\"Installing requirements...\")\n utils.install_requirements(config)\n\n # run the command\n logger.info(\"Running command...\")\n utils.run_command(config)\n\n pause_space(config)\n\n\nif __name__ == \"__main__\":\n args = parse_args()\n _config = json.load(open(args.config))\n _config = GenericParams(**_config)\n run(_config)\n", "src\\autotrain\\trainers\\image_classification\\__main__.py": "import argparse\nimport json\n\nfrom accelerate.state import PartialState\nfrom datasets import load_dataset, load_from_disk\nfrom huggingface_hub import HfApi\nfrom transformers import (\n AutoConfig,\n AutoImageProcessor,\n AutoModelForImageClassification,\n EarlyStoppingCallback,\n Trainer,\n TrainingArguments,\n)\nfrom transformers.trainer_callback import PrinterCallback\n\nfrom autotrain import logger\nfrom autotrain.trainers.common import (\n ALLOW_REMOTE_CODE,\n LossLoggingCallback,\n TrainStartCallback,\n UploadLogs,\n monitor,\n pause_space,\n remove_autotrain_data,\n save_training_params,\n)\nfrom autotrain.trainers.image_classification import utils\nfrom autotrain.trainers.image_classification.params import ImageClassificationParams\n\n\ndef parse_args():\n # get training_config.json from the end user\n parser = argparse.ArgumentParser()\n parser.add_argument(\"--training_config\", type=str, required=True)\n return parser.parse_args()\n\n\n@monitor\ndef train(config):\n if isinstance(config, dict):\n config = ImageClassificationParams(**config)\n\n valid_data = None\n if config.data_path == f\"{config.project_name}/autotrain-data\":\n train_data = load_from_disk(config.data_path)[config.train_split]\n else:\n if \":\" in config.train_split:\n dataset_config_name, split = config.train_split.split(\":\")\n train_data = load_dataset(\n config.data_path,\n name=dataset_config_name,\n split=split,\n token=config.token,\n )\n else:\n train_data = load_dataset(\n config.data_path,\n split=config.train_split,\n token=config.token,\n )\n\n if config.valid_split is not None:\n if config.data_path == f\"{config.project_name}/autotrain-data\":\n valid_data = load_from_disk(config.data_path)[config.valid_split]\n else:\n if \":\" in config.valid_split:\n dataset_config_name, split = config.valid_split.split(\":\")\n valid_data = load_dataset(\n config.data_path,\n name=dataset_config_name,\n split=split,\n token=config.token,\n )\n else:\n valid_data = load_dataset(\n config.data_path,\n split=config.valid_split,\n token=config.token,\n )\n\n logger.info(f\"Train data: {train_data}\")\n logger.info(f\"Valid data: {valid_data}\")\n\n classes = train_data.features[config.target_column].names\n logger.info(f\"Classes: {classes}\")\n label2id = {c: i for i, c in enumerate(classes)}\n num_classes = len(classes)\n\n if num_classes < 2:\n raise ValueError(\"Invalid number of classes. Must be greater than 1.\")\n\n if config.valid_split is not None:\n num_classes_valid = len(valid_data.unique(config.target_column))\n if num_classes_valid != num_classes:\n raise ValueError(\n f\"Number of classes in train and valid are not the same. Training has {num_classes} and valid has {num_classes_valid}\"\n )\n\n model_config = AutoConfig.from_pretrained(\n config.model,\n num_labels=num_classes,\n trust_remote_code=ALLOW_REMOTE_CODE,\n token=config.token,\n )\n model_config._num_labels = len(label2id)\n model_config.label2id = label2id\n model_config.id2label = {v: k for k, v in label2id.items()}\n\n try:\n model = AutoModelForImageClassification.from_pretrained(\n config.model,\n config=model_config,\n trust_remote_code=ALLOW_REMOTE_CODE,\n token=config.token,\n ignore_mismatched_sizes=True,\n )\n except OSError:\n model = AutoModelForImageClassification.from_pretrained(\n config.model,\n config=model_config,\n from_tf=True,\n trust_remote_code=ALLOW_REMOTE_CODE,\n token=config.token,\n ignore_mismatched_sizes=True,\n )\n\n image_processor = AutoImageProcessor.from_pretrained(\n config.model,\n token=config.token,\n trust_remote_code=ALLOW_REMOTE_CODE,\n )\n train_data, valid_data = utils.process_data(train_data, valid_data, image_processor, config)\n\n if config.logging_steps == -1:\n if config.valid_split is not None:\n logging_steps = int(0.2 * len(valid_data) / config.batch_size)\n else:\n logging_steps = int(0.2 * len(train_data) / config.batch_size)\n if logging_steps == 0:\n logging_steps = 1\n if logging_steps > 25:\n logging_steps = 25\n config.logging_steps = logging_steps\n else:\n logging_steps = config.logging_steps\n\n logger.info(f\"Logging steps: {logging_steps}\")\n\n training_args = dict(\n output_dir=config.project_name,\n per_device_train_batch_size=config.batch_size,\n per_device_eval_batch_size=2 * config.batch_size,\n learning_rate=config.lr,\n num_train_epochs=config.epochs,\n eval_strategy=config.eval_strategy if config.valid_split is not None else \"no\",\n logging_steps=logging_steps,\n save_total_limit=config.save_total_limit,\n save_strategy=config.eval_strategy if config.valid_split is not None else \"no\",\n gradient_accumulation_steps=config.gradient_accumulation,\n report_to=config.log,\n auto_find_batch_size=config.auto_find_batch_size,\n lr_scheduler_type=config.scheduler,\n optim=config.optimizer,\n warmup_ratio=config.warmup_ratio,\n weight_decay=config.weight_decay,\n max_grad_norm=config.max_grad_norm,\n push_to_hub=False,\n load_best_model_at_end=True if config.valid_split is not None else False,\n ddp_find_unused_parameters=False,\n )\n\n if config.mixed_precision == \"fp16\":\n training_args[\"fp16\"] = True\n if config.mixed_precision == \"bf16\":\n training_args[\"bf16\"] = True\n\n if config.valid_split is not None:\n early_stop = EarlyStoppingCallback(\n early_stopping_patience=config.early_stopping_patience,\n early_stopping_threshold=config.early_stopping_threshold,\n )\n callbacks_to_use = [early_stop]\n else:\n callbacks_to_use = []\n\n callbacks_to_use.extend([UploadLogs(config=config), LossLoggingCallback(), TrainStartCallback()])\n\n args = TrainingArguments(**training_args)\n trainer_args = dict(\n args=args,\n model=model,\n callbacks=callbacks_to_use,\n compute_metrics=(\n utils._binary_classification_metrics if num_classes == 2 else utils._multi_class_classification_metrics\n ),\n )\n\n trainer = Trainer(\n **trainer_args,\n train_dataset=train_data,\n eval_dataset=valid_data,\n )\n trainer.remove_callback(PrinterCallback)\n trainer.train()\n\n logger.info(\"Finished training, saving model...\")\n trainer.save_model(config.project_name)\n image_processor.save_pretrained(config.project_name)\n\n model_card = utils.create_model_card(config, trainer, num_classes)\n\n # save model card to output directory as README.md\n with open(f\"{config.project_name}/README.md\", \"w\") as f:\n f.write(model_card)\n\n if config.push_to_hub:\n if PartialState().process_index == 0:\n remove_autotrain_data(config)\n save_training_params(config)\n logger.info(\"Pushing model to hub...\")\n api = HfApi(token=config.token)\n api.create_repo(\n repo_id=f\"{config.username}/{config.project_name}\", repo_type=\"model\", private=True, exist_ok=True\n )\n api.upload_folder(\n folder_path=config.project_name, repo_id=f\"{config.username}/{config.project_name}\", repo_type=\"model\"\n )\n\n if PartialState().process_index == 0:\n pause_space(config)\n\n\nif __name__ == \"__main__\":\n _args = parse_args()\n training_config = json.load(open(_args.training_config))\n _config = ImageClassificationParams(**training_config)\n train(_config)\n", "src\\autotrain\\trainers\\image_regression\\__main__.py": "import argparse\nimport json\n\nfrom accelerate.state import PartialState\nfrom datasets import load_dataset, load_from_disk\nfrom huggingface_hub import HfApi\nfrom transformers import (\n AutoConfig,\n AutoImageProcessor,\n AutoModelForImageClassification,\n EarlyStoppingCallback,\n Trainer,\n TrainingArguments,\n)\nfrom transformers.trainer_callback import PrinterCallback\n\nfrom autotrain import logger\nfrom autotrain.trainers.common import (\n ALLOW_REMOTE_CODE,\n LossLoggingCallback,\n TrainStartCallback,\n UploadLogs,\n monitor,\n pause_space,\n remove_autotrain_data,\n save_training_params,\n)\nfrom autotrain.trainers.image_regression import utils\nfrom autotrain.trainers.image_regression.params import ImageRegressionParams\n\n\ndef parse_args():\n # get training_config.json from the end user\n parser = argparse.ArgumentParser()\n parser.add_argument(\"--training_config\", type=str, required=True)\n return parser.parse_args()\n\n\n@monitor\ndef train(config):\n if isinstance(config, dict):\n config = ImageRegressionParams(**config)\n\n valid_data = None\n if config.data_path == f\"{config.project_name}/autotrain-data\":\n train_data = load_from_disk(config.data_path)[config.train_split]\n else:\n if \":\" in config.train_split:\n dataset_config_name, split = config.train_split.split(\":\")\n train_data = load_dataset(\n config.data_path,\n name=dataset_config_name,\n split=split,\n token=config.token,\n )\n else:\n train_data = load_dataset(\n config.data_path,\n split=config.train_split,\n token=config.token,\n )\n\n if config.valid_split is not None:\n if config.data_path == f\"{config.project_name}/autotrain-data\":\n valid_data = load_from_disk(config.data_path)[config.valid_split]\n else:\n if \":\" in config.valid_split:\n dataset_config_name, split = config.valid_split.split(\":\")\n valid_data = load_dataset(\n config.data_path,\n name=dataset_config_name,\n split=split,\n token=config.token,\n )\n else:\n valid_data = load_dataset(\n config.data_path,\n split=config.valid_split,\n token=config.token,\n )\n\n logger.info(f\"Train data: {train_data}\")\n logger.info(f\"Valid data: {valid_data}\")\n\n model_config = AutoConfig.from_pretrained(\n config.model,\n num_labels=1,\n trust_remote_code=ALLOW_REMOTE_CODE,\n token=config.token,\n )\n model_config._num_labels = 1\n label2id = {\"target\": 0}\n model_config.label2id = label2id\n model_config.id2label = {v: k for k, v in label2id.items()}\n\n try:\n model = AutoModelForImageClassification.from_pretrained(\n config.model,\n config=model_config,\n trust_remote_code=ALLOW_REMOTE_CODE,\n token=config.token,\n ignore_mismatched_sizes=True,\n )\n except OSError:\n model = AutoModelForImageClassification.from_pretrained(\n config.model,\n config=model_config,\n from_tf=True,\n trust_remote_code=ALLOW_REMOTE_CODE,\n token=config.token,\n ignore_mismatched_sizes=True,\n )\n\n image_processor = AutoImageProcessor.from_pretrained(\n config.model,\n token=config.token,\n trust_remote_code=ALLOW_REMOTE_CODE,\n )\n train_data, valid_data = utils.process_data(train_data, valid_data, image_processor, config)\n\n if config.logging_steps == -1:\n if config.valid_split is not None:\n logging_steps = int(0.2 * len(valid_data) / config.batch_size)\n else:\n logging_steps = int(0.2 * len(train_data) / config.batch_size)\n if logging_steps == 0:\n logging_steps = 1\n if logging_steps > 25:\n logging_steps = 25\n config.logging_steps = logging_steps\n else:\n logging_steps = config.logging_steps\n\n logger.info(f\"Logging steps: {logging_steps}\")\n\n training_args = dict(\n output_dir=config.project_name,\n per_device_train_batch_size=config.batch_size,\n per_device_eval_batch_size=2 * config.batch_size,\n learning_rate=config.lr,\n num_train_epochs=config.epochs,\n eval_strategy=config.eval_strategy if config.valid_split is not None else \"no\",\n logging_steps=logging_steps,\n save_total_limit=config.save_total_limit,\n save_strategy=config.eval_strategy if config.valid_split is not None else \"no\",\n gradient_accumulation_steps=config.gradient_accumulation,\n report_to=config.log,\n auto_find_batch_size=config.auto_find_batch_size,\n lr_scheduler_type=config.scheduler,\n optim=config.optimizer,\n warmup_ratio=config.warmup_ratio,\n weight_decay=config.weight_decay,\n max_grad_norm=config.max_grad_norm,\n push_to_hub=False,\n load_best_model_at_end=True if config.valid_split is not None else False,\n ddp_find_unused_parameters=False,\n )\n\n if config.mixed_precision == \"fp16\":\n training_args[\"fp16\"] = True\n if config.mixed_precision == \"bf16\":\n training_args[\"bf16\"] = True\n\n if config.valid_split is not None:\n early_stop = EarlyStoppingCallback(\n early_stopping_patience=config.early_stopping_patience,\n early_stopping_threshold=config.early_stopping_threshold,\n )\n callbacks_to_use = [early_stop]\n else:\n callbacks_to_use = []\n\n callbacks_to_use.extend([UploadLogs(config=config), LossLoggingCallback(), TrainStartCallback()])\n\n args = TrainingArguments(**training_args)\n trainer_args = dict(\n args=args,\n model=model,\n callbacks=callbacks_to_use,\n compute_metrics=utils.image_regression_metrics,\n )\n\n trainer = Trainer(\n **trainer_args,\n train_dataset=train_data,\n eval_dataset=valid_data,\n )\n trainer.remove_callback(PrinterCallback)\n trainer.train()\n\n logger.info(\"Finished training, saving model...\")\n trainer.save_model(config.project_name)\n image_processor.save_pretrained(config.project_name)\n\n model_card = utils.create_model_card(config, trainer)\n\n # save model card to output directory as README.md\n with open(f\"{config.project_name}/README.md\", \"w\") as f:\n f.write(model_card)\n\n if config.push_to_hub:\n if PartialState().process_index == 0:\n remove_autotrain_data(config)\n save_training_params(config)\n logger.info(\"Pushing model to hub...\")\n api = HfApi(token=config.token)\n api.create_repo(\n repo_id=f\"{config.username}/{config.project_name}\", repo_type=\"model\", private=True, exist_ok=True\n )\n api.upload_folder(\n folder_path=config.project_name, repo_id=f\"{config.username}/{config.project_name}\", repo_type=\"model\"\n )\n\n if PartialState().process_index == 0:\n pause_space(config)\n\n\nif __name__ == \"__main__\":\n _args = parse_args()\n training_config = json.load(open(_args.training_config))\n _config = ImageRegressionParams(**training_config)\n train(_config)\n", "src\\autotrain\\trainers\\object_detection\\__main__.py": "import argparse\nimport json\nfrom functools import partial\n\nfrom accelerate.state import PartialState\nfrom datasets import load_dataset, load_from_disk\nfrom huggingface_hub import HfApi\nfrom transformers import (\n AutoConfig,\n AutoImageProcessor,\n AutoModelForObjectDetection,\n EarlyStoppingCallback,\n Trainer,\n TrainingArguments,\n)\nfrom transformers.trainer_callback import PrinterCallback\n\nfrom autotrain import logger\nfrom autotrain.trainers.common import (\n ALLOW_REMOTE_CODE,\n LossLoggingCallback,\n TrainStartCallback,\n UploadLogs,\n monitor,\n pause_space,\n remove_autotrain_data,\n save_training_params,\n)\nfrom autotrain.trainers.object_detection import utils\nfrom autotrain.trainers.object_detection.params import ObjectDetectionParams\n\n\ndef parse_args():\n # get training_config.json from the end user\n parser = argparse.ArgumentParser()\n parser.add_argument(\"--training_config\", type=str, required=True)\n return parser.parse_args()\n\n\n@monitor\ndef train(config):\n if isinstance(config, dict):\n config = ObjectDetectionParams(**config)\n\n valid_data = None\n if config.data_path == f\"{config.project_name}/autotrain-data\":\n train_data = load_from_disk(config.data_path)[config.train_split]\n else:\n if \":\" in config.train_split:\n dataset_config_name, split = config.train_split.split(\":\")\n train_data = load_dataset(\n config.data_path,\n name=dataset_config_name,\n split=split,\n token=config.token,\n )\n else:\n train_data = load_dataset(\n config.data_path,\n split=config.train_split,\n token=config.token,\n )\n\n if config.valid_split is not None:\n if config.data_path == f\"{config.project_name}/autotrain-data\":\n valid_data = load_from_disk(config.data_path)[config.valid_split]\n else:\n if \":\" in config.valid_split:\n dataset_config_name, split = config.valid_split.split(\":\")\n valid_data = load_dataset(\n config.data_path,\n name=dataset_config_name,\n split=split,\n token=config.token,\n )\n else:\n valid_data = load_dataset(\n config.data_path,\n split=config.valid_split,\n token=config.token,\n )\n\n logger.info(f\"Train data: {train_data}\")\n logger.info(f\"Valid data: {valid_data}\")\n\n categories = train_data.features[config.objects_column].feature[\"category\"].names\n id2label = dict(enumerate(categories))\n label2id = {v: k for k, v in id2label.items()}\n\n model_config = AutoConfig.from_pretrained(\n config.model,\n label2id=label2id,\n id2label=id2label,\n trust_remote_code=ALLOW_REMOTE_CODE,\n token=config.token,\n )\n try:\n model = AutoModelForObjectDetection.from_pretrained(\n config.model,\n config=model_config,\n ignore_mismatched_sizes=True,\n trust_remote_code=ALLOW_REMOTE_CODE,\n token=config.token,\n )\n except OSError:\n model = AutoModelForObjectDetection.from_pretrained(\n config.model,\n config=model_config,\n trust_remote_code=ALLOW_REMOTE_CODE,\n token=config.token,\n ignore_mismatched_sizes=True,\n from_tf=True,\n )\n image_processor = AutoImageProcessor.from_pretrained(\n config.model,\n token=config.token,\n do_pad=False,\n do_resize=False,\n size={\"longest_edge\": config.image_square_size},\n trust_remote_code=ALLOW_REMOTE_CODE,\n )\n train_data, valid_data = utils.process_data(train_data, valid_data, image_processor, config)\n\n if config.logging_steps == -1:\n if config.valid_split is not None:\n logging_steps = int(0.2 * len(valid_data) / config.batch_size)\n else:\n logging_steps = int(0.2 * len(train_data) / config.batch_size)\n if logging_steps == 0:\n logging_steps = 1\n if logging_steps > 25:\n logging_steps = 25\n config.logging_steps = logging_steps\n else:\n logging_steps = config.logging_steps\n\n logger.info(f\"Logging steps: {logging_steps}\")\n\n training_args = dict(\n output_dir=config.project_name,\n per_device_train_batch_size=config.batch_size,\n per_device_eval_batch_size=2 * config.batch_size,\n learning_rate=config.lr,\n num_train_epochs=config.epochs,\n eval_strategy=config.eval_strategy if config.valid_split is not None else \"no\",\n logging_steps=logging_steps,\n save_total_limit=config.save_total_limit,\n save_strategy=config.eval_strategy if config.valid_split is not None else \"no\",\n gradient_accumulation_steps=config.gradient_accumulation,\n report_to=config.log,\n auto_find_batch_size=config.auto_find_batch_size,\n lr_scheduler_type=config.scheduler,\n optim=config.optimizer,\n warmup_ratio=config.warmup_ratio,\n weight_decay=config.weight_decay,\n max_grad_norm=config.max_grad_norm,\n push_to_hub=False,\n load_best_model_at_end=True if config.valid_split is not None else False,\n ddp_find_unused_parameters=False,\n )\n\n if config.mixed_precision == \"fp16\":\n training_args[\"fp16\"] = True\n if config.mixed_precision == \"bf16\":\n training_args[\"bf16\"] = True\n\n if config.valid_split is not None:\n training_args[\"eval_do_concat_batches\"] = False\n early_stop = EarlyStoppingCallback(\n early_stopping_patience=config.early_stopping_patience,\n early_stopping_threshold=config.early_stopping_threshold,\n )\n callbacks_to_use = [early_stop]\n else:\n callbacks_to_use = []\n\n callbacks_to_use.extend([UploadLogs(config=config), LossLoggingCallback(), TrainStartCallback()])\n\n _compute_metrics_fn = partial(\n utils.object_detection_metrics, image_processor=image_processor, id2label=id2label, threshold=0.0\n )\n\n args = TrainingArguments(**training_args)\n trainer_args = dict(\n args=args,\n model=model,\n callbacks=callbacks_to_use,\n data_collator=utils.collate_fn,\n tokenizer=image_processor,\n compute_metrics=_compute_metrics_fn,\n )\n\n trainer = Trainer(\n **trainer_args,\n train_dataset=train_data,\n eval_dataset=valid_data,\n )\n trainer.remove_callback(PrinterCallback)\n trainer.train()\n\n logger.info(\"Finished training, saving model...\")\n trainer.save_model(config.project_name)\n image_processor.save_pretrained(config.project_name)\n\n model_card = utils.create_model_card(config, trainer)\n\n # save model card to output directory as README.md\n with open(f\"{config.project_name}/README.md\", \"w\") as f:\n f.write(model_card)\n\n if config.push_to_hub:\n if PartialState().process_index == 0:\n remove_autotrain_data(config)\n save_training_params(config)\n logger.info(\"Pushing model to hub...\")\n api = HfApi(token=config.token)\n api.create_repo(\n repo_id=f\"{config.username}/{config.project_name}\", repo_type=\"model\", private=True, exist_ok=True\n )\n api.upload_folder(\n folder_path=config.project_name, repo_id=f\"{config.username}/{config.project_name}\", repo_type=\"model\"\n )\n\n if PartialState().process_index == 0:\n pause_space(config)\n\n\nif __name__ == \"__main__\":\n _args = parse_args()\n training_config = json.load(open(_args.training_config))\n _config = ObjectDetectionParams(**training_config)\n train(_config)\n", "src\\autotrain\\trainers\\sent_transformers\\__main__.py": "import argparse\nimport json\nfrom functools import partial\n\nfrom accelerate import PartialState\nfrom datasets import load_dataset, load_from_disk\nfrom huggingface_hub import HfApi\nfrom sentence_transformers import SentenceTransformer, SentenceTransformerTrainer\nfrom sentence_transformers.evaluation import EmbeddingSimilarityEvaluator, TripletEvaluator\nfrom sentence_transformers.losses import CoSENTLoss, MultipleNegativesRankingLoss, SoftmaxLoss\nfrom sentence_transformers.training_args import SentenceTransformerTrainingArguments\nfrom transformers import EarlyStoppingCallback\nfrom transformers.trainer_callback import PrinterCallback\n\nfrom autotrain import logger\nfrom autotrain.trainers.common import (\n ALLOW_REMOTE_CODE,\n LossLoggingCallback,\n TrainStartCallback,\n UploadLogs,\n monitor,\n pause_space,\n remove_autotrain_data,\n save_training_params,\n)\nfrom autotrain.trainers.sent_transformers import utils\nfrom autotrain.trainers.sent_transformers.params import SentenceTransformersParams\n\n\ndef parse_args():\n # get training_config.json from the end user\n parser = argparse.ArgumentParser()\n parser.add_argument(\"--training_config\", type=str, required=True)\n return parser.parse_args()\n\n\n@monitor\ndef train(config):\n if isinstance(config, dict):\n config = SentenceTransformersParams(**config)\n\n train_data = None\n valid_data = None\n # check if config.train_split.csv exists in config.data_path\n if config.train_split is not None:\n if config.data_path == f\"{config.project_name}/autotrain-data\":\n logger.info(\"loading dataset from disk\")\n train_data = load_from_disk(config.data_path)[config.train_split]\n else:\n if \":\" in config.train_split:\n dataset_config_name, split = config.train_split.split(\":\")\n train_data = load_dataset(\n config.data_path,\n name=dataset_config_name,\n split=split,\n token=config.token,\n )\n else:\n train_data = load_dataset(\n config.data_path,\n split=config.train_split,\n token=config.token,\n )\n\n if config.valid_split is not None:\n if config.data_path == f\"{config.project_name}/autotrain-data\":\n logger.info(\"loading dataset from disk\")\n valid_data = load_from_disk(config.data_path)[config.valid_split]\n else:\n if \":\" in config.valid_split:\n dataset_config_name, split = config.valid_split.split(\":\")\n valid_data = load_dataset(\n config.data_path,\n name=dataset_config_name,\n split=split,\n token=config.token,\n )\n else:\n valid_data = load_dataset(\n config.data_path,\n split=config.valid_split,\n token=config.token,\n )\n\n num_classes = None\n if config.trainer == \"pair_class\":\n classes = train_data.features[config.target_column].names\n # label2id = {c: i for i, c in enumerate(classes)}\n num_classes = len(classes)\n\n if num_classes < 2:\n raise ValueError(\"Invalid number of classes. Must be greater than 1.\")\n\n if config.valid_split is not None:\n num_classes_valid = len(valid_data.unique(config.target_column))\n if num_classes_valid != num_classes:\n raise ValueError(\n f\"Number of classes in train and valid are not the same. Training has {num_classes} and valid has {num_classes_valid}\"\n )\n\n if config.logging_steps == -1:\n logging_steps = int(0.2 * len(train_data) / config.batch_size)\n if logging_steps == 0:\n logging_steps = 1\n if logging_steps > 25:\n logging_steps = 25\n config.logging_steps = logging_steps\n else:\n logging_steps = config.logging_steps\n\n logger.info(f\"Logging steps: {logging_steps}\")\n\n train_data = utils.process_columns(train_data, config)\n logger.info(f\"Train data: {train_data}\")\n if config.valid_split is not None:\n valid_data = utils.process_columns(valid_data, config)\n logger.info(f\"Valid data: {valid_data}\")\n\n training_args = dict(\n output_dir=config.project_name,\n per_device_train_batch_size=config.batch_size,\n per_device_eval_batch_size=2 * config.batch_size,\n learning_rate=config.lr,\n num_train_epochs=config.epochs,\n eval_strategy=config.eval_strategy if config.valid_split is not None else \"no\",\n logging_steps=logging_steps,\n save_total_limit=config.save_total_limit,\n save_strategy=config.eval_strategy if config.valid_split is not None else \"no\",\n gradient_accumulation_steps=config.gradient_accumulation,\n report_to=config.log,\n auto_find_batch_size=config.auto_find_batch_size,\n lr_scheduler_type=config.scheduler,\n optim=config.optimizer,\n warmup_ratio=config.warmup_ratio,\n weight_decay=config.weight_decay,\n max_grad_norm=config.max_grad_norm,\n push_to_hub=False,\n load_best_model_at_end=True if config.valid_split is not None else False,\n ddp_find_unused_parameters=False,\n )\n\n if config.mixed_precision == \"fp16\":\n training_args[\"fp16\"] = True\n if config.mixed_precision == \"bf16\":\n training_args[\"bf16\"] = True\n\n if config.valid_split is not None:\n early_stop = EarlyStoppingCallback(\n early_stopping_patience=config.early_stopping_patience,\n early_stopping_threshold=config.early_stopping_threshold,\n )\n callbacks_to_use = [early_stop]\n else:\n callbacks_to_use = []\n\n callbacks_to_use.extend([UploadLogs(config=config), LossLoggingCallback(), TrainStartCallback()])\n\n model = SentenceTransformer(\n config.model,\n trust_remote_code=ALLOW_REMOTE_CODE,\n token=config.token,\n model_kwargs={\n \"ignore_mismatched_sizes\": True,\n },\n )\n\n loss_mapping = {\n \"pair\": MultipleNegativesRankingLoss,\n \"pair_class\": partial(\n SoftmaxLoss,\n sentence_embedding_dimension=model.get_sentence_embedding_dimension(),\n num_labels=num_classes,\n ),\n \"pair_score\": CoSENTLoss,\n \"triplet\": MultipleNegativesRankingLoss,\n \"qa\": MultipleNegativesRankingLoss,\n }\n\n evaluator = None\n if config.valid_split is not None:\n if config.trainer == \"pair_score\":\n evaluator = EmbeddingSimilarityEvaluator(\n sentences1=valid_data[\"sentence1\"],\n sentences2=valid_data[\"sentence2\"],\n scores=valid_data[\"score\"],\n name=config.valid_split,\n )\n elif config.trainer == \"triplet\":\n evaluator = TripletEvaluator(\n anchors=valid_data[\"anchor\"],\n positives=valid_data[\"positive\"],\n negatives=valid_data[\"negative\"],\n )\n\n logger.info(\"Setting up training arguments...\")\n args = SentenceTransformerTrainingArguments(**training_args)\n trainer_args = dict(\n args=args,\n model=model,\n callbacks=callbacks_to_use,\n )\n\n logger.info(\"Setting up trainer...\")\n trainer = SentenceTransformerTrainer(\n **trainer_args,\n train_dataset=train_data,\n eval_dataset=valid_data,\n loss=loss_mapping[config.trainer],\n evaluator=evaluator,\n )\n trainer.remove_callback(PrinterCallback)\n logger.info(\"Starting training...\")\n trainer.train()\n\n logger.info(\"Finished training, saving model...\")\n trainer.save_model(config.project_name)\n\n model_card = utils.create_model_card(config, trainer)\n\n # save model card to output directory as README.md\n with open(f\"{config.project_name}/README.md\", \"w\") as f:\n f.write(model_card)\n\n if config.push_to_hub:\n if PartialState().process_index == 0:\n remove_autotrain_data(config)\n save_training_params(config)\n logger.info(\"Pushing model to hub...\")\n api = HfApi(token=config.token)\n api.create_repo(\n repo_id=f\"{config.username}/{config.project_name}\", repo_type=\"model\", private=True, exist_ok=True\n )\n api.upload_folder(\n folder_path=config.project_name,\n repo_id=f\"{config.username}/{config.project_name}\",\n repo_type=\"model\",\n )\n\n if PartialState().process_index == 0:\n pause_space(config)\n\n\nif __name__ == \"__main__\":\n _args = parse_args()\n training_config = json.load(open(_args.training_config))\n _config = SentenceTransformersParams(**training_config)\n train(_config)\n", "src\\autotrain\\trainers\\seq2seq\\__main__.py": "import argparse\nimport json\nfrom functools import partial\n\nimport torch\nfrom accelerate.state import PartialState\nfrom datasets import load_dataset, load_from_disk\nfrom huggingface_hub import HfApi\nfrom peft import LoraConfig, TaskType, get_peft_model, prepare_model_for_kbit_training\nfrom transformers import (\n AutoConfig,\n AutoModelForSeq2SeqLM,\n AutoTokenizer,\n BitsAndBytesConfig,\n DataCollatorForSeq2Seq,\n EarlyStoppingCallback,\n Seq2SeqTrainer,\n Seq2SeqTrainingArguments,\n)\nfrom transformers.trainer_callback import PrinterCallback\n\nfrom autotrain import logger\nfrom autotrain.trainers.common import (\n ALLOW_REMOTE_CODE,\n LossLoggingCallback,\n TrainStartCallback,\n UploadLogs,\n monitor,\n pause_space,\n remove_autotrain_data,\n save_training_params,\n)\nfrom autotrain.trainers.seq2seq import utils\nfrom autotrain.trainers.seq2seq.dataset import Seq2SeqDataset\nfrom autotrain.trainers.seq2seq.params import Seq2SeqParams\n\n\ndef parse_args():\n # get training_config.json from the end user\n parser = argparse.ArgumentParser()\n parser.add_argument(\"--training_config\", type=str, required=True)\n return parser.parse_args()\n\n\n@monitor\ndef train(config):\n if isinstance(config, dict):\n config = Seq2SeqParams(**config)\n\n train_data = None\n valid_data = None\n # check if config.train_split.csv exists in config.data_path\n if config.train_split is not None:\n if config.data_path == f\"{config.project_name}/autotrain-data\":\n logger.info(\"loading dataset from disk\")\n train_data = load_from_disk(config.data_path)[config.train_split]\n else:\n if \":\" in config.train_split:\n dataset_config_name, split = config.train_split.split(\":\")\n train_data = load_dataset(\n config.data_path,\n name=dataset_config_name,\n split=split,\n token=config.token,\n )\n else:\n train_data = load_dataset(\n config.data_path,\n split=config.train_split,\n token=config.token,\n )\n\n if config.valid_split is not None:\n if config.data_path == f\"{config.project_name}/autotrain-data\":\n logger.info(\"loading dataset from disk\")\n valid_data = load_from_disk(config.data_path)[config.valid_split]\n else:\n if \":\" in config.valid_split:\n dataset_config_name, split = config.valid_split.split(\":\")\n valid_data = load_dataset(\n config.data_path,\n name=dataset_config_name,\n split=split,\n token=config.token,\n )\n else:\n valid_data = load_dataset(\n config.data_path,\n split=config.valid_split,\n token=config.token,\n )\n\n tokenizer = AutoTokenizer.from_pretrained(config.model, token=config.token, trust_remote_code=ALLOW_REMOTE_CODE)\n\n train_data = Seq2SeqDataset(data=train_data, tokenizer=tokenizer, config=config)\n if config.valid_split is not None:\n valid_data = Seq2SeqDataset(data=valid_data, tokenizer=tokenizer, config=config)\n\n if config.logging_steps == -1:\n if config.valid_split is not None:\n logging_steps = int(0.2 * len(valid_data) / config.batch_size)\n else:\n logging_steps = int(0.2 * len(train_data) / config.batch_size)\n if logging_steps == 0:\n logging_steps = 1\n if logging_steps > 25:\n logging_steps = 25\n config.logging_steps = logging_steps\n else:\n logging_steps = config.logging_steps\n\n logger.info(f\"Logging steps: {logging_steps}\")\n\n training_args = dict(\n output_dir=config.project_name,\n per_device_train_batch_size=config.batch_size,\n per_device_eval_batch_size=2 * config.batch_size,\n learning_rate=config.lr,\n num_train_epochs=config.epochs,\n eval_strategy=config.eval_strategy if config.valid_split is not None else \"no\",\n logging_steps=logging_steps,\n save_total_limit=config.save_total_limit,\n save_strategy=config.eval_strategy if config.valid_split is not None else \"no\",\n gradient_accumulation_steps=config.gradient_accumulation,\n report_to=config.log,\n auto_find_batch_size=config.auto_find_batch_size,\n lr_scheduler_type=config.scheduler,\n optim=config.optimizer,\n warmup_ratio=config.warmup_ratio,\n weight_decay=config.weight_decay,\n max_grad_norm=config.max_grad_norm,\n push_to_hub=False,\n load_best_model_at_end=True if config.valid_split is not None else False,\n ddp_find_unused_parameters=False,\n predict_with_generate=True,\n seed=config.seed,\n )\n\n if config.mixed_precision == \"fp16\":\n training_args[\"fp16\"] = True\n if config.mixed_precision == \"bf16\":\n training_args[\"bf16\"] = True\n\n if config.valid_split is not None:\n early_stop = EarlyStoppingCallback(\n early_stopping_patience=config.early_stopping_patience,\n early_stopping_threshold=config.early_stopping_threshold,\n )\n callbacks_to_use = [early_stop]\n else:\n callbacks_to_use = []\n\n callbacks_to_use.extend([UploadLogs(config=config), LossLoggingCallback(), TrainStartCallback()])\n\n args = Seq2SeqTrainingArguments(**training_args)\n\n model_config = AutoConfig.from_pretrained(\n config.model,\n token=config.token,\n trust_remote_code=ALLOW_REMOTE_CODE,\n use_cache=False,\n )\n\n if config.peft:\n if config.quantization == \"int4\":\n raise NotImplementedError(\"int4 quantization is not supported\")\n # if config.use_int4:\n # bnb_config = BitsAndBytesConfig(\n # load_in_4bit=config.use_int4,\n # bnb_4bit_quant_type=\"nf4\",\n # bnb_4bit_compute_dtype=torch.float16,\n # bnb_4bit_use_double_quant=False,\n # )\n # config.fp16 = True\n if config.quantization == \"int8\":\n bnb_config = BitsAndBytesConfig(load_in_8bit=True)\n else:\n bnb_config = None\n\n model = AutoModelForSeq2SeqLM.from_pretrained(\n config.model,\n config=model_config,\n token=config.token,\n quantization_config=bnb_config,\n trust_remote_code=ALLOW_REMOTE_CODE,\n )\n else:\n model = AutoModelForSeq2SeqLM.from_pretrained(\n config.model,\n config=model_config,\n token=config.token,\n trust_remote_code=ALLOW_REMOTE_CODE,\n )\n\n embedding_size = model.get_input_embeddings().weight.shape[0]\n if len(tokenizer) > embedding_size:\n model.resize_token_embeddings(len(tokenizer))\n\n if config.peft:\n target_modules = config.target_modules.split(\",\") if config.target_modules is not None else None\n if target_modules:\n target_modules = [module.strip() for module in target_modules]\n if len(target_modules) == 1 and target_modules[0] == \"all-linear\":\n target_modules = \"all-linear\"\n lora_config = LoraConfig(\n r=config.lora_r,\n lora_alpha=config.lora_alpha,\n target_modules=target_modules,\n lora_dropout=config.lora_dropout,\n bias=\"none\",\n task_type=TaskType.SEQ_2_SEQ_LM,\n )\n if config.quantization is not None:\n model = prepare_model_for_kbit_training(model)\n\n model = get_peft_model(model, lora_config)\n\n _s2s_metrics = partial(utils._seq2seq_metrics, tokenizer=tokenizer)\n\n trainer_args = dict(\n args=args,\n model=model,\n callbacks=callbacks_to_use,\n compute_metrics=_s2s_metrics,\n )\n data_collator = DataCollatorForSeq2Seq(tokenizer, model=model)\n trainer = Seq2SeqTrainer(\n **trainer_args,\n train_dataset=train_data,\n eval_dataset=valid_data,\n data_collator=data_collator,\n tokenizer=tokenizer,\n )\n\n for name, module in trainer.model.named_modules():\n if \"norm\" in name:\n module = module.to(torch.float32)\n\n trainer.remove_callback(PrinterCallback)\n trainer.train()\n\n logger.info(\"Finished training, saving model...\")\n trainer.model.config.use_cache = True\n trainer.save_model(config.project_name)\n\n model_card = utils.create_model_card(config, trainer)\n\n # save model card to output directory as README.md\n with open(f\"{config.project_name}/README.md\", \"w\", encoding=\"utf-8\") as f:\n f.write(model_card)\n\n if config.push_to_hub:\n if PartialState().process_index == 0:\n remove_autotrain_data(config)\n save_training_params(config)\n logger.info(\"Pushing model to hub...\")\n api = HfApi(token=config.token)\n api.create_repo(\n repo_id=f\"{config.username}/{config.project_name}\", repo_type=\"model\", private=True, exist_ok=True\n )\n api.upload_folder(\n folder_path=config.project_name,\n repo_id=f\"{config.username}/{config.project_name}\",\n repo_type=\"model\",\n )\n\n if PartialState().process_index == 0:\n pause_space(config)\n\n\nif __name__ == \"__main__\":\n _args = parse_args()\n training_config = json.load(open(_args.training_config))\n config = Seq2SeqParams(**training_config)\n train(config)\n", "src\\autotrain\\trainers\\tabular\\__main__.py": "import argparse\nimport json\nimport os\nfrom functools import partial\n\nimport joblib\nimport numpy as np\nimport optuna\nimport pandas as pd\nfrom datasets import load_dataset, load_from_disk\nfrom huggingface_hub import HfApi\nfrom sklearn import pipeline, preprocessing\nfrom sklearn.compose import ColumnTransformer\n\nfrom autotrain import logger\nfrom autotrain.trainers.common import monitor, pause_space, remove_autotrain_data, save_training_params\nfrom autotrain.trainers.tabular import utils\nfrom autotrain.trainers.tabular.params import TabularParams\n\n\ndef parse_args():\n # get training_config.json from the end user\n parser = argparse.ArgumentParser()\n parser.add_argument(\"--training_config\", type=str, required=True)\n return parser.parse_args()\n\n\ndef optimize(trial, model_name, xtrain, xvalid, ytrain, yvalid, eval_metric, task, preprocessor):\n if isinstance(trial, dict):\n params = trial\n else:\n params = utils.get_params(trial, model_name, task)\n labels = None\n if task == \"multi_class_classification\":\n labels = np.unique(ytrain)\n metrics = utils.TabularMetrics(sub_task=task, labels=labels)\n\n if task in (\"binary_classification\", \"multi_class_classification\", \"single_column_regression\"):\n ytrain = ytrain.ravel()\n yvalid = yvalid.ravel()\n\n if preprocessor is not None:\n try:\n xtrain = preprocessor.fit_transform(xtrain)\n xvalid = preprocessor.transform(xvalid)\n except ValueError:\n logger.info(\"Preprocessing failed, using nan_to_num\")\n train_cols = xtrain.columns.tolist()\n valid_cols = xvalid.columns.tolist()\n xtrain = np.nan_to_num(xtrain)\n xvalid = np.nan_to_num(xvalid)\n # convert back to dataframe\n xtrain = pd.DataFrame(xtrain, columns=train_cols)\n xvalid = pd.DataFrame(xvalid, columns=valid_cols)\n xtrain = preprocessor.fit_transform(xtrain)\n xvalid = preprocessor.transform(xvalid)\n\n if model_name == \"xgboost\":\n params[\"eval_metric\"] = eval_metric\n\n _model = utils.TabularModel(model_name, preprocessor=None, sub_task=task, params=params)\n model = _model.pipeline\n models = []\n if task in (\"multi_label_classification\", \"multi_column_regression\"):\n # also multi_column_regression\n ypred = []\n models = [model] * ytrain.shape[1]\n for idx, _m in enumerate(models):\n if model_name == \"xgboost\":\n _m.fit(\n xtrain,\n ytrain[:, idx],\n model__eval_set=[(xvalid, yvalid[:, idx])],\n model__verbose=False,\n )\n else:\n _m.fit(xtrain, ytrain[:, idx])\n if task == \"multi_column_regression\":\n ypred_temp = _m.predict(xvalid)\n else:\n if _model.use_predict_proba:\n ypred_temp = _m.predict_proba(xvalid)[:, 1]\n else:\n ypred_temp = _m.predict(xvalid)\n ypred.append(ypred_temp)\n ypred = np.column_stack(ypred)\n\n else:\n models = [model]\n if model_name == \"xgboost\":\n model.fit(\n xtrain,\n ytrain,\n model__eval_set=[(xvalid, yvalid)],\n model__verbose=False,\n )\n else:\n models[0].fit(xtrain, ytrain)\n\n if _model.use_predict_proba:\n ypred = models[0].predict_proba(xvalid)\n else:\n ypred = models[0].predict(xvalid)\n\n if task == \"multi_class_classification\":\n if ypred.reshape(xvalid.shape[0], -1).shape[1] != len(labels):\n ypred_ohe = np.zeros((xvalid.shape[0], len(labels)))\n ypred_ohe[np.arange(xvalid.shape[0]), ypred] = 1\n ypred = ypred_ohe\n\n if task == \"binary_classification\":\n if ypred.reshape(xvalid.shape[0], -1).shape[1] != 2:\n ypred = np.column_stack([1 - ypred, ypred])\n\n # calculate metric\n metric_dict = metrics.calculate(yvalid, ypred)\n\n # change eval_metric key to loss\n if eval_metric in metric_dict:\n metric_dict[\"loss\"] = metric_dict[eval_metric]\n\n logger.info(f\"Metrics: {metric_dict}\")\n if isinstance(trial, dict):\n return models, preprocessor, metric_dict\n return metric_dict[\"loss\"]\n\n\n@monitor\ndef train(config):\n if isinstance(config, dict):\n config = TabularParams(**config)\n\n logger.info(\"Starting training...\")\n logger.info(f\"Training config: {config}\")\n\n train_data = None\n valid_data = None\n if config.data_path == f\"{config.project_name}/autotrain-data\":\n logger.info(\"loading dataset from disk\")\n train_data = load_from_disk(config.data_path)[config.train_split]\n else:\n if \":\" in config.train_split:\n dataset_config_name, split = config.train_split.split(\":\")\n train_data = load_dataset(\n config.data_path,\n name=dataset_config_name,\n split=split,\n token=config.token,\n )\n else:\n train_data = load_dataset(\n config.data_path,\n split=config.train_split,\n token=config.token,\n )\n train_data = train_data.to_pandas()\n\n if config.valid_split is not None:\n if config.data_path == f\"{config.project_name}/autotrain-data\":\n logger.info(\"loading dataset from disk\")\n valid_data = load_from_disk(config.data_path)[config.valid_split]\n else:\n if \":\" in config.valid_split:\n dataset_config_name, split = config.valid_split.split(\":\")\n valid_data = load_dataset(\n config.data_path,\n name=dataset_config_name,\n split=split,\n token=config.token,\n )\n else:\n valid_data = load_dataset(\n config.data_path,\n split=config.valid_split,\n token=config.token,\n )\n valid_data = valid_data.to_pandas()\n\n if valid_data is None:\n raise Exception(\"valid_data is None. Please provide a valid_split for tabular training.\")\n\n # determine which columns are categorical\n if config.categorical_columns is None:\n config.categorical_columns = utils.get_categorical_columns(train_data)\n if config.numerical_columns is None:\n config.numerical_columns = utils.get_numerical_columns(train_data)\n\n _id_target_cols = (\n [config.id_column] + config.target_columns if config.id_column is not None else config.target_columns\n )\n config.numerical_columns = [c for c in config.numerical_columns if c not in _id_target_cols]\n config.categorical_columns = [c for c in config.categorical_columns if c not in _id_target_cols]\n\n useful_columns = config.categorical_columns + config.numerical_columns\n\n logger.info(f\"Categorical columns: {config.categorical_columns}\")\n logger.info(f\"Numerical columns: {config.numerical_columns}\")\n\n # convert object columns to categorical\n for col in config.categorical_columns:\n train_data[col] = train_data[col].astype(\"category\")\n valid_data[col] = valid_data[col].astype(\"category\")\n\n logger.info(f\"Useful columns: {useful_columns}\")\n\n target_encoders = {}\n if config.task == \"classification\":\n for target_column in config.target_columns:\n target_encoder = preprocessing.LabelEncoder()\n target_encoder.fit(train_data[target_column])\n target_encoders[target_column] = target_encoder\n\n # encode target columns in train and valid data\n for k, v in target_encoders.items():\n train_data.loc[:, k] = v.transform(train_data[k])\n valid_data.loc[:, k] = v.transform(valid_data[k])\n\n numeric_transformer = \"passthrough\"\n categorical_transformer = \"passthrough\"\n transformers = []\n preprocessor = None\n\n numeric_steps = []\n imputer = utils.get_imputer(config.numerical_imputer)\n scaler = utils.get_scaler(config.numeric_scaler)\n if imputer is not None:\n numeric_steps.append((\"num_imputer\", imputer))\n if scaler is not None:\n numeric_steps.append((\"num_scaler\", scaler))\n\n if len(numeric_steps) > 0:\n numeric_transformer = pipeline.Pipeline(numeric_steps)\n transformers.append((\"numeric\", numeric_transformer, config.numerical_columns))\n\n categorical_steps = []\n imputer = utils.get_imputer(config.categorical_imputer)\n if imputer is not None:\n categorical_steps.append((\"cat_imputer\", imputer))\n\n if len(config.categorical_columns) > 0:\n if config.model in (\"xgboost\", \"lightgbm\", \"randomforest\", \"catboost\", \"extratrees\"):\n categorical_steps.append(\n (\n \"cat_encoder\",\n preprocessing.OrdinalEncoder(\n handle_unknown=\"use_encoded_value\",\n categories=\"auto\",\n unknown_value=np.nan,\n ),\n )\n )\n else:\n categorical_steps.append(\n (\n \"cat_encoder\",\n preprocessing.OneHotEncoder(handle_unknown=\"ignore\"),\n )\n )\n\n if len(categorical_steps) > 0:\n categorical_transformer = pipeline.Pipeline(categorical_steps)\n transformers.append((\"categorical\", categorical_transformer, config.categorical_columns))\n\n if len(transformers) > 0:\n preprocessor = ColumnTransformer(transformers=transformers, verbose=True, n_jobs=-1)\n logger.info(f\"Preprocessor: {preprocessor}\")\n\n xtrain = train_data[useful_columns].reset_index(drop=True)\n xvalid = valid_data[useful_columns].reset_index(drop=True)\n\n ytrain = train_data[config.target_columns].values\n yvalid = valid_data[config.target_columns].values\n\n # determine sub_task\n if config.task == \"classification\":\n if len(target_encoders) == 1:\n if len(target_encoders[config.target_columns[0]].classes_) == 2:\n sub_task = \"binary_classification\"\n else:\n sub_task = \"multi_class_classification\"\n else:\n sub_task = \"multi_label_classification\"\n else:\n if len(config.target_columns) > 1:\n sub_task = \"multi_column_regression\"\n else:\n sub_task = \"single_column_regression\"\n\n eval_metric, direction = utils.get_metric_direction(sub_task)\n\n logger.info(f\"Sub task: {sub_task}\")\n\n args = {\n \"model_name\": config.model,\n \"xtrain\": xtrain,\n \"xvalid\": xvalid,\n \"ytrain\": ytrain,\n \"yvalid\": yvalid,\n \"eval_metric\": eval_metric,\n \"task\": sub_task,\n \"preprocessor\": preprocessor,\n }\n\n optimize_func = partial(optimize, **args)\n study = optuna.create_study(direction=direction, study_name=\"AutoTrain\")\n study.optimize(optimize_func, n_trials=config.num_trials, timeout=config.time_limit)\n best_params = study.best_params\n\n logger.info(f\"Best params: {best_params}\")\n best_models, best_preprocessors, best_metrics = optimize(best_params, **args)\n\n models = (\n [pipeline.Pipeline([(\"preprocessor\", best_preprocessors), (\"model\", m)]) for m in best_models]\n if best_preprocessors is not None\n else best_models\n )\n\n joblib.dump(\n models[0] if len(models) == 1 else models,\n os.path.join(config.project_name, \"model.joblib\"),\n )\n joblib.dump(target_encoders, os.path.join(config.project_name, \"target_encoders.joblib\"))\n\n model_card = utils.create_model_card(config, sub_task, best_params, best_metrics)\n\n if model_card is not None:\n with open(os.path.join(config.project_name, \"README.md\"), \"w\") as fp:\n fp.write(f\"{model_card}\")\n\n # remove token key from training_params.json located in output directory\n # first check if file exists\n if os.path.exists(f\"{config.project_name}/training_params.json\"):\n training_params = json.load(open(f\"{config.project_name}/training_params.json\"))\n training_params.pop(\"token\")\n json.dump(training_params, open(f\"{config.project_name}/training_params.json\", \"w\"))\n\n # save model card to output directory as README.md\n with open(f\"{config.project_name}/README.md\", \"w\") as f:\n f.write(model_card)\n\n if config.push_to_hub:\n remove_autotrain_data(config)\n save_training_params(config)\n logger.info(\"Pushing model to hub...\")\n api = HfApi(token=config.token)\n api.create_repo(repo_id=f\"{config.username}/{config.project_name}\", repo_type=\"model\", private=True)\n api.upload_folder(\n folder_path=config.project_name, repo_id=f\"{config.username}/{config.project_name}\", repo_type=\"model\"\n )\n\n pause_space(config)\n\n\nif __name__ == \"__main__\":\n args = parse_args()\n training_config = json.load(open(args.training_config))\n config = TabularParams(**training_config)\n train(config)\n", "src\\autotrain\\trainers\\text_classification\\__main__.py": "import argparse\nimport json\n\nfrom accelerate.state import PartialState\nfrom datasets import load_dataset, load_from_disk\nfrom huggingface_hub import HfApi\nfrom transformers import (\n AutoConfig,\n AutoModelForSequenceClassification,\n AutoTokenizer,\n EarlyStoppingCallback,\n Trainer,\n TrainingArguments,\n)\nfrom transformers.trainer_callback import PrinterCallback\n\nfrom autotrain import logger\nfrom autotrain.trainers.common import (\n ALLOW_REMOTE_CODE,\n LossLoggingCallback,\n TrainStartCallback,\n UploadLogs,\n monitor,\n pause_space,\n remove_autotrain_data,\n save_training_params,\n)\nfrom autotrain.trainers.text_classification import utils\nfrom autotrain.trainers.text_classification.dataset import TextClassificationDataset\nfrom autotrain.trainers.text_classification.params import TextClassificationParams\n\n\ndef parse_args():\n # get training_config.json from the end user\n parser = argparse.ArgumentParser()\n parser.add_argument(\"--training_config\", type=str, required=True)\n return parser.parse_args()\n\n\n@monitor\ndef train(config):\n if isinstance(config, dict):\n config = TextClassificationParams(**config)\n\n train_data = None\n valid_data = None\n # check if config.train_split.csv exists in config.data_path\n if config.train_split is not None:\n if config.data_path == f\"{config.project_name}/autotrain-data\":\n logger.info(\"loading dataset from disk\")\n train_data = load_from_disk(config.data_path)[config.train_split]\n else:\n if \":\" in config.train_split:\n dataset_config_name, split = config.train_split.split(\":\")\n train_data = load_dataset(\n config.data_path,\n name=dataset_config_name,\n split=split,\n token=config.token,\n )\n else:\n train_data = load_dataset(\n config.data_path,\n split=config.train_split,\n token=config.token,\n )\n\n if config.valid_split is not None:\n if config.data_path == f\"{config.project_name}/autotrain-data\":\n logger.info(\"loading dataset from disk\")\n valid_data = load_from_disk(config.data_path)[config.valid_split]\n else:\n if \":\" in config.valid_split:\n dataset_config_name, split = config.valid_split.split(\":\")\n valid_data = load_dataset(\n config.data_path,\n name=dataset_config_name,\n split=split,\n token=config.token,\n )\n else:\n valid_data = load_dataset(\n config.data_path,\n split=config.valid_split,\n token=config.token,\n )\n\n classes = train_data.features[config.target_column].names\n label2id = {c: i for i, c in enumerate(classes)}\n num_classes = len(classes)\n\n if num_classes < 2:\n raise ValueError(\"Invalid number of classes. Must be greater than 1.\")\n\n if config.valid_split is not None:\n num_classes_valid = len(valid_data.unique(config.target_column))\n if num_classes_valid != num_classes:\n raise ValueError(\n f\"Number of classes in train and valid are not the same. Training has {num_classes} and valid has {num_classes_valid}\"\n )\n\n model_config = AutoConfig.from_pretrained(config.model, num_labels=num_classes)\n model_config._num_labels = len(label2id)\n model_config.label2id = label2id\n model_config.id2label = {v: k for k, v in label2id.items()}\n\n try:\n model = AutoModelForSequenceClassification.from_pretrained(\n config.model,\n config=model_config,\n trust_remote_code=ALLOW_REMOTE_CODE,\n token=config.token,\n ignore_mismatched_sizes=True,\n )\n except OSError:\n model = AutoModelForSequenceClassification.from_pretrained(\n config.model,\n config=model_config,\n from_tf=True,\n trust_remote_code=ALLOW_REMOTE_CODE,\n token=config.token,\n ignore_mismatched_sizes=True,\n )\n\n tokenizer = AutoTokenizer.from_pretrained(config.model, token=config.token, trust_remote_code=ALLOW_REMOTE_CODE)\n train_data = TextClassificationDataset(data=train_data, tokenizer=tokenizer, config=config)\n if config.valid_split is not None:\n valid_data = TextClassificationDataset(data=valid_data, tokenizer=tokenizer, config=config)\n\n if config.logging_steps == -1:\n if config.valid_split is not None:\n logging_steps = int(0.2 * len(valid_data) / config.batch_size)\n else:\n logging_steps = int(0.2 * len(train_data) / config.batch_size)\n if logging_steps == 0:\n logging_steps = 1\n if logging_steps > 25:\n logging_steps = 25\n config.logging_steps = logging_steps\n else:\n logging_steps = config.logging_steps\n\n logger.info(f\"Logging steps: {logging_steps}\")\n\n training_args = dict(\n output_dir=config.project_name,\n per_device_train_batch_size=config.batch_size,\n per_device_eval_batch_size=2 * config.batch_size,\n learning_rate=config.lr,\n num_train_epochs=config.epochs,\n eval_strategy=config.eval_strategy if config.valid_split is not None else \"no\",\n logging_steps=logging_steps,\n save_total_limit=config.save_total_limit,\n save_strategy=config.eval_strategy if config.valid_split is not None else \"no\",\n gradient_accumulation_steps=config.gradient_accumulation,\n report_to=config.log,\n auto_find_batch_size=config.auto_find_batch_size,\n lr_scheduler_type=config.scheduler,\n optim=config.optimizer,\n warmup_ratio=config.warmup_ratio,\n weight_decay=config.weight_decay,\n max_grad_norm=config.max_grad_norm,\n push_to_hub=False,\n load_best_model_at_end=True if config.valid_split is not None else False,\n ddp_find_unused_parameters=False,\n )\n\n if config.mixed_precision == \"fp16\":\n training_args[\"fp16\"] = True\n if config.mixed_precision == \"bf16\":\n training_args[\"bf16\"] = True\n\n if config.valid_split is not None:\n early_stop = EarlyStoppingCallback(\n early_stopping_patience=config.early_stopping_patience,\n early_stopping_threshold=config.early_stopping_threshold,\n )\n callbacks_to_use = [early_stop]\n else:\n callbacks_to_use = []\n\n callbacks_to_use.extend([UploadLogs(config=config), LossLoggingCallback(), TrainStartCallback()])\n\n args = TrainingArguments(**training_args)\n trainer_args = dict(\n args=args,\n model=model,\n callbacks=callbacks_to_use,\n compute_metrics=(\n utils._binary_classification_metrics if num_classes == 2 else utils._multi_class_classification_metrics\n ),\n )\n\n trainer = Trainer(\n **trainer_args,\n train_dataset=train_data,\n eval_dataset=valid_data,\n )\n trainer.remove_callback(PrinterCallback)\n trainer.train()\n\n logger.info(\"Finished training, saving model...\")\n trainer.save_model(config.project_name)\n tokenizer.save_pretrained(config.project_name)\n\n model_card = utils.create_model_card(config, trainer, num_classes)\n\n # save model card to output directory as README.md\n with open(f\"{config.project_name}/README.md\", \"w\") as f:\n f.write(model_card)\n\n if config.push_to_hub:\n if PartialState().process_index == 0:\n remove_autotrain_data(config)\n save_training_params(config)\n logger.info(\"Pushing model to hub...\")\n api = HfApi(token=config.token)\n api.create_repo(\n repo_id=f\"{config.username}/{config.project_name}\", repo_type=\"model\", private=True, exist_ok=True\n )\n api.upload_folder(\n folder_path=config.project_name,\n repo_id=f\"{config.username}/{config.project_name}\",\n repo_type=\"model\",\n )\n\n if PartialState().process_index == 0:\n pause_space(config)\n\n\nif __name__ == \"__main__\":\n args = parse_args()\n training_config = json.load(open(args.training_config))\n config = TextClassificationParams(**training_config)\n train(config)\n", "src\\autotrain\\trainers\\text_regression\\__main__.py": "import argparse\nimport json\n\nfrom accelerate.state import PartialState\nfrom datasets import load_dataset, load_from_disk\nfrom huggingface_hub import HfApi\nfrom transformers import (\n AutoConfig,\n AutoModelForSequenceClassification,\n AutoTokenizer,\n EarlyStoppingCallback,\n Trainer,\n TrainingArguments,\n)\nfrom transformers.trainer_callback import PrinterCallback\n\nfrom autotrain import logger\nfrom autotrain.trainers.common import (\n ALLOW_REMOTE_CODE,\n LossLoggingCallback,\n TrainStartCallback,\n UploadLogs,\n monitor,\n pause_space,\n remove_autotrain_data,\n save_training_params,\n)\nfrom autotrain.trainers.text_regression import utils\nfrom autotrain.trainers.text_regression.dataset import TextRegressionDataset\nfrom autotrain.trainers.text_regression.params import TextRegressionParams\n\n\ndef parse_args():\n # get training_config.json from the end user\n parser = argparse.ArgumentParser()\n parser.add_argument(\"--training_config\", type=str, required=True)\n return parser.parse_args()\n\n\n@monitor\ndef train(config):\n if isinstance(config, dict):\n config = TextRegressionParams(**config)\n\n train_data = None\n valid_data = None\n # check if config.train_split.csv exists in config.data_path\n if config.train_split is not None:\n if config.data_path == f\"{config.project_name}/autotrain-data\":\n logger.info(\"loading dataset from disk\")\n train_data = load_from_disk(config.data_path)[config.train_split]\n else:\n if \":\" in config.train_split:\n dataset_config_name, split = config.train_split.split(\":\")\n train_data = load_dataset(\n config.data_path,\n name=dataset_config_name,\n split=split,\n token=config.token,\n )\n else:\n train_data = load_dataset(\n config.data_path,\n split=config.train_split,\n token=config.token,\n )\n\n if config.valid_split is not None:\n if config.data_path == f\"{config.project_name}/autotrain-data\":\n logger.info(\"loading dataset from disk\")\n valid_data = load_from_disk(config.data_path)[config.valid_split]\n else:\n if \":\" in config.valid_split:\n dataset_config_name, split = config.valid_split.split(\":\")\n valid_data = load_dataset(\n config.data_path,\n name=dataset_config_name,\n split=split,\n token=config.token,\n )\n else:\n valid_data = load_dataset(\n config.data_path,\n split=config.valid_split,\n token=config.token,\n )\n\n model_config = AutoConfig.from_pretrained(\n config.model,\n num_labels=1,\n trust_remote_code=ALLOW_REMOTE_CODE,\n token=config.token,\n )\n model_config._num_labels = 1\n label2id = {\"target\": 0}\n model_config.label2id = label2id\n model_config.id2label = {v: k for k, v in label2id.items()}\n\n try:\n model = AutoModelForSequenceClassification.from_pretrained(\n config.model,\n config=model_config,\n trust_remote_code=ALLOW_REMOTE_CODE,\n token=config.token,\n ignore_mismatched_sizes=True,\n )\n except OSError:\n model = AutoModelForSequenceClassification.from_pretrained(\n config.model,\n config=model_config,\n from_tf=True,\n trust_remote_code=ALLOW_REMOTE_CODE,\n token=config.token,\n ignore_mismatched_sizes=True,\n )\n\n tokenizer = AutoTokenizer.from_pretrained(config.model, token=config.token, trust_remote_code=ALLOW_REMOTE_CODE)\n train_data = TextRegressionDataset(data=train_data, tokenizer=tokenizer, config=config)\n if config.valid_split is not None:\n valid_data = TextRegressionDataset(data=valid_data, tokenizer=tokenizer, config=config)\n\n if config.logging_steps == -1:\n if config.valid_split is not None:\n logging_steps = int(0.2 * len(valid_data) / config.batch_size)\n else:\n logging_steps = int(0.2 * len(train_data) / config.batch_size)\n if logging_steps == 0:\n logging_steps = 1\n if logging_steps > 25:\n logging_steps = 25\n config.logging_steps = logging_steps\n else:\n logging_steps = config.logging_steps\n\n logger.info(f\"Logging steps: {logging_steps}\")\n\n training_args = dict(\n output_dir=config.project_name,\n per_device_train_batch_size=config.batch_size,\n per_device_eval_batch_size=2 * config.batch_size,\n learning_rate=config.lr,\n num_train_epochs=config.epochs,\n eval_strategy=config.eval_strategy if config.valid_split is not None else \"no\",\n logging_steps=logging_steps,\n save_total_limit=config.save_total_limit,\n save_strategy=config.eval_strategy if config.valid_split is not None else \"no\",\n gradient_accumulation_steps=config.gradient_accumulation,\n report_to=config.log,\n auto_find_batch_size=config.auto_find_batch_size,\n lr_scheduler_type=config.scheduler,\n optim=config.optimizer,\n warmup_ratio=config.warmup_ratio,\n weight_decay=config.weight_decay,\n max_grad_norm=config.max_grad_norm,\n push_to_hub=False,\n load_best_model_at_end=True if config.valid_split is not None else False,\n ddp_find_unused_parameters=False,\n )\n\n if config.mixed_precision == \"fp16\":\n training_args[\"fp16\"] = True\n if config.mixed_precision == \"bf16\":\n training_args[\"bf16\"] = True\n\n if config.valid_split is not None:\n early_stop = EarlyStoppingCallback(\n early_stopping_patience=config.early_stopping_patience,\n early_stopping_threshold=config.early_stopping_threshold,\n )\n callbacks_to_use = [early_stop]\n else:\n callbacks_to_use = []\n\n callbacks_to_use.extend([UploadLogs(config=config), LossLoggingCallback(), TrainStartCallback()])\n\n args = TrainingArguments(**training_args)\n trainer_args = dict(\n args=args,\n model=model,\n callbacks=callbacks_to_use,\n compute_metrics=utils.single_column_regression_metrics,\n )\n\n trainer = Trainer(\n **trainer_args,\n train_dataset=train_data,\n eval_dataset=valid_data,\n )\n trainer.remove_callback(PrinterCallback)\n trainer.train()\n\n logger.info(\"Finished training, saving model...\")\n trainer.save_model(config.project_name)\n tokenizer.save_pretrained(config.project_name)\n\n model_card = utils.create_model_card(config, trainer)\n\n # save model card to output directory as README.md\n with open(f\"{config.project_name}/README.md\", \"w\") as f:\n f.write(model_card)\n\n if config.push_to_hub:\n if PartialState().process_index == 0:\n remove_autotrain_data(config)\n save_training_params(config)\n logger.info(\"Pushing model to hub...\")\n api = HfApi(token=config.token)\n api.create_repo(\n repo_id=f\"{config.username}/{config.project_name}\", repo_type=\"model\", private=True, exist_ok=True\n )\n api.upload_folder(\n folder_path=config.project_name,\n repo_id=f\"{config.username}/{config.project_name}\",\n repo_type=\"model\",\n )\n\n if PartialState().process_index == 0:\n pause_space(config)\n\n\nif __name__ == \"__main__\":\n args = parse_args()\n training_config = json.load(open(args.training_config))\n config = TextRegressionParams(**training_config)\n train(config)\n", "src\\autotrain\\trainers\\token_classification\\__main__.py": "import argparse\nimport json\nfrom functools import partial\n\nfrom accelerate.state import PartialState\nfrom datasets import load_dataset, load_from_disk\nfrom huggingface_hub import HfApi\nfrom transformers import (\n AutoConfig,\n AutoModelForTokenClassification,\n AutoTokenizer,\n EarlyStoppingCallback,\n Trainer,\n TrainingArguments,\n)\nfrom transformers.trainer_callback import PrinterCallback\n\nfrom autotrain import logger\nfrom autotrain.trainers.common import (\n ALLOW_REMOTE_CODE,\n LossLoggingCallback,\n TrainStartCallback,\n UploadLogs,\n monitor,\n pause_space,\n remove_autotrain_data,\n save_training_params,\n)\nfrom autotrain.trainers.token_classification import utils\nfrom autotrain.trainers.token_classification.dataset import TokenClassificationDataset\nfrom autotrain.trainers.token_classification.params import TokenClassificationParams\n\n\ndef parse_args():\n # get training_config.json from the end user\n parser = argparse.ArgumentParser()\n parser.add_argument(\"--training_config\", type=str, required=True)\n return parser.parse_args()\n\n\n@monitor\ndef train(config):\n if isinstance(config, dict):\n config = TokenClassificationParams(**config)\n\n train_data = None\n valid_data = None\n # check if config.train_split.csv exists in config.data_path\n if config.train_split is not None:\n if config.data_path == f\"{config.project_name}/autotrain-data\":\n logger.info(\"loading dataset from disk\")\n train_data = load_from_disk(config.data_path)[config.train_split]\n else:\n if \":\" in config.train_split:\n dataset_config_name, split = config.train_split.split(\":\")\n train_data = load_dataset(\n config.data_path,\n name=dataset_config_name,\n split=split,\n token=config.token,\n )\n else:\n train_data = load_dataset(\n config.data_path,\n split=config.train_split,\n token=config.token,\n )\n\n if config.valid_split is not None:\n if config.data_path == f\"{config.project_name}/autotrain-data\":\n logger.info(\"loading dataset from disk\")\n valid_data = load_from_disk(config.data_path)[config.valid_split]\n else:\n if \":\" in config.valid_split:\n dataset_config_name, split = config.valid_split.split(\":\")\n valid_data = load_dataset(\n config.data_path,\n name=dataset_config_name,\n split=split,\n token=config.token,\n )\n else:\n valid_data = load_dataset(\n config.data_path,\n split=config.valid_split,\n token=config.token,\n )\n\n label_list = train_data.features[config.tags_column].feature.names\n num_classes = len(label_list)\n\n model_config = AutoConfig.from_pretrained(config.model, num_labels=num_classes)\n model_config._num_labels = num_classes\n model_config.label2id = {l: i for i, l in enumerate(label_list)}\n model_config.id2label = dict(enumerate(label_list))\n\n try:\n model = AutoModelForTokenClassification.from_pretrained(\n config.model,\n config=model_config,\n trust_remote_code=ALLOW_REMOTE_CODE,\n token=config.token,\n ignore_mismatched_sizes=True,\n )\n except OSError:\n model = AutoModelForTokenClassification.from_pretrained(\n config.model,\n config=model_config,\n from_tf=True,\n trust_remote_code=ALLOW_REMOTE_CODE,\n token=config.token,\n ignore_mismatched_sizes=True,\n )\n\n if model_config.model_type in {\"bloom\", \"gpt2\", \"roberta\"}:\n tokenizer = AutoTokenizer.from_pretrained(\n config.model, token=config.token, trust_remote_code=ALLOW_REMOTE_CODE, add_prefix_space=True\n )\n else:\n tokenizer = AutoTokenizer.from_pretrained(\n config.model, token=config.token, trust_remote_code=ALLOW_REMOTE_CODE\n )\n\n train_data = TokenClassificationDataset(data=train_data, tokenizer=tokenizer, config=config)\n if config.valid_split is not None:\n valid_data = TokenClassificationDataset(data=valid_data, tokenizer=tokenizer, config=config)\n\n if config.logging_steps == -1:\n if config.valid_split is not None:\n logging_steps = int(0.2 * len(valid_data) / config.batch_size)\n else:\n logging_steps = int(0.2 * len(train_data) / config.batch_size)\n if logging_steps == 0:\n logging_steps = 1\n if logging_steps > 25:\n logging_steps = 25\n config.logging_steps = logging_steps\n else:\n logging_steps = config.logging_steps\n\n logger.info(f\"Logging steps: {logging_steps}\")\n\n training_args = dict(\n output_dir=config.project_name,\n per_device_train_batch_size=config.batch_size,\n per_device_eval_batch_size=2 * config.batch_size,\n learning_rate=config.lr,\n num_train_epochs=config.epochs,\n eval_strategy=config.eval_strategy if config.valid_split is not None else \"no\",\n logging_steps=logging_steps,\n save_total_limit=config.save_total_limit,\n save_strategy=config.eval_strategy if config.valid_split is not None else \"no\",\n gradient_accumulation_steps=config.gradient_accumulation,\n report_to=config.log,\n auto_find_batch_size=config.auto_find_batch_size,\n lr_scheduler_type=config.scheduler,\n optim=config.optimizer,\n warmup_ratio=config.warmup_ratio,\n weight_decay=config.weight_decay,\n max_grad_norm=config.max_grad_norm,\n push_to_hub=False,\n load_best_model_at_end=True if config.valid_split is not None else False,\n ddp_find_unused_parameters=False,\n )\n\n if config.mixed_precision == \"fp16\":\n training_args[\"fp16\"] = True\n if config.mixed_precision == \"bf16\":\n training_args[\"bf16\"] = True\n\n if config.valid_split is not None:\n early_stop = EarlyStoppingCallback(\n early_stopping_patience=config.early_stopping_patience,\n early_stopping_threshold=config.early_stopping_threshold,\n )\n callbacks_to_use = [early_stop]\n else:\n callbacks_to_use = []\n\n callbacks_to_use.extend([UploadLogs(config=config), LossLoggingCallback(), TrainStartCallback()])\n\n args = TrainingArguments(**training_args)\n trainer_args = dict(\n args=args,\n model=model,\n callbacks=callbacks_to_use,\n compute_metrics=partial(utils.token_classification_metrics, label_list=label_list),\n )\n\n trainer = Trainer(\n **trainer_args,\n train_dataset=train_data,\n eval_dataset=valid_data,\n )\n trainer.remove_callback(PrinterCallback)\n trainer.train()\n\n logger.info(\"Finished training, saving model...\")\n trainer.save_model(config.project_name)\n tokenizer.save_pretrained(config.project_name)\n\n model_card = utils.create_model_card(config, trainer)\n\n # save model card to output directory as README.md\n with open(f\"{config.project_name}/README.md\", \"w\", encoding=\"utf-8\") as f:\n f.write(model_card)\n\n if config.push_to_hub:\n if PartialState().process_index == 0:\n remove_autotrain_data(config)\n save_training_params(config)\n logger.info(\"Pushing model to hub...\")\n api = HfApi(token=config.token)\n api.create_repo(\n repo_id=f\"{config.username}/{config.project_name}\", repo_type=\"model\", private=True, exist_ok=True\n )\n api.upload_folder(\n folder_path=config.project_name,\n repo_id=f\"{config.username}/{config.project_name}\",\n repo_type=\"model\",\n )\n\n if PartialState().process_index == 0:\n pause_space(config)\n\n\nif __name__ == \"__main__\":\n args = parse_args()\n training_config = json.load(open(args.training_config))\n config = TokenClassificationParams(**training_config)\n train(config)\n", "src\\autotrain\\trainers\\vlm\\__main__.py": "import argparse\nimport json\n\nfrom autotrain.trainers.common import monitor\nfrom autotrain.trainers.vlm import utils\nfrom autotrain.trainers.vlm.params import VLMTrainingParams\n\n\ndef parse_args():\n # get training_config.json from the end user\n parser = argparse.ArgumentParser()\n parser.add_argument(\"--training_config\", type=str, required=True)\n return parser.parse_args()\n\n\n@monitor\ndef train(config):\n if isinstance(config, dict):\n config = VLMTrainingParams(**config)\n\n if not utils.check_model_support(config):\n raise ValueError(f\"model `{config.model}` not supported\")\n\n if config.trainer in (\"vqa\", \"captioning\"):\n from autotrain.trainers.vlm.train_vlm_generic import train as train_generic\n\n train_generic(config)\n\n else:\n raise ValueError(f\"trainer `{config.trainer}` not supported\")\n\n\nif __name__ == \"__main__\":\n _args = parse_args()\n training_config = json.load(open(_args.training_config))\n _config = VLMTrainingParams(**training_config)\n train(_config)\n"} | null |
autotrain-advanced-api | {"type": "directory", "name": "autotrain-advanced-api", "children": [{"type": "file", "name": "Dockerfile"}, {"type": "file", "name": "version"}]} | {"Dockerfile": "FROM huggingface/autotrain-advanced:latest\nCMD autotrain api --port 7860 --host 0.0.0.0\n", ".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n"} | null |
|
autotrain-example-datasets | {"type": "directory", "name": "autotrain-example-datasets", "children": [{"type": "file", "name": "alpaca1k.csv"}]} | {".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 86d7c4f6a8047f1a16b47f48388a4de26bafa18b Hamza Amin <[email protected]> 1727369170 +0500\tclone: from https://github.com/huggingface/autotrain-example-datasets.git\n", ".git\\refs\\heads\\main": "86d7c4f6a8047f1a16b47f48388a4de26bafa18b\n"} | null |
|
awesome-huggingface | {"type": "directory", "name": "awesome-huggingface", "children": [{"type": "file", "name": "awesome_collections.md"}, {"type": "file", "name": "CONTRIBUTING.md"}, {"type": "file", "name": "LICENSE"}, {"type": "file", "name": "logo.svg"}, {"type": "file", "name": "README.md"}]} | <p align="center">
<img src="https://raw.githubusercontent.com/huggingface/awesome-huggingface/main/logo.svg" width="100px">
</p>
# awesome-huggingface
This is a list of some wonderful open-source projects & applications integrated with Hugging Face libraries.
[How to contribute](https://github.com/huggingface/awesome-huggingface/blob/main/CONTRIBUTING.md)
## 🤗 Official Libraries
*First-party cool stuff made with ❤️ by 🤗 Hugging Face.*
* [transformers](https://github.com/huggingface/transformers) - State-of-the-art natural language processing for Jax, PyTorch and TensorFlow.
* [datasets](https://github.com/huggingface/datasets) - The largest hub of ready-to-use NLP datasets for ML models with fast, easy-to-use and efficient data manipulation tools.
* [tokenizers](https://github.com/huggingface/tokenizers) - Fast state-of-the-Art tokenizers optimized for research and production.
* [knockknock](https://github.com/huggingface/knockknock) - Get notified when your training ends with only two additional lines of code.
* [accelerate](https://github.com/huggingface/accelerate) - A simple way to train and use PyTorch models with multi-GPU, TPU, mixed-precision.
* [autonlp](https://github.com/huggingface/autonlp) - Train state-of-the-art natural language processing models and deploy them in a scalable environment automatically.
* [nn_pruning](https://github.com/huggingface/nn_pruning) - Prune a model while finetuning or training.
* [huggingface_hub](https://github.com/huggingface/huggingface_hub) - Client library to download and publish models and other files on the huggingface.co hub.
* [tune](https://github.com/huggingface/tune) - A benchmark for comparing Transformer-based models.
## 👩🏫 Tutorials
*Learn how to use Hugging Face toolkits, step-by-step.*
* [Official Course](https://huggingface.co/course) (from Hugging Face) - The official course series provided by 🤗 Hugging Face.
* [transformers-tutorials](https://github.com/nielsrogge/transformers-tutorials) (by @nielsrogge) - Tutorials for applying multiple models on real-world datasets.
## 🧰 NLP Toolkits
*NLP toolkits built upon Transformers. Swiss Army!*
* [AllenNLP](https://github.com/allenai/allennlp) (from AI2) - An open-source NLP research library.
* [Graph4NLP](https://github.com/graph4ai/graph4nlp) - Enabling easy use of Graph Neural Networks for NLP.
* [Lightning Transformers](https://github.com/PyTorchLightning/lightning-transformers) - Transformers with PyTorch Lightning interface.
* [Adapter Transformers](https://github.com/Adapter-Hub/adapter-transformers) - Extension to the Transformers library, integrating adapters into state-of-the-art language models.
* [Obsei](https://github.com/obsei/obsei) - A low-code AI workflow automation tool and performs various NLP tasks in the workflow pipeline.
* [Trapper](https://github.com/obss/trapper) (from OBSS) - State-of-the-art NLP through transformer models in a modular design and consistent APIs.
* [Flair](https://github.com/flairNLP/flair) - A very simple framework for state-of-the-art NLP.
## 🥡 Text Representation
*Converting a sentence to a vector.*
* [Sentence Transformers](https://github.com/UKPLab/sentence-transformers) (from UKPLab) - Widely used encoders computing dense vector representations for sentences, paragraphs, and images.
* [WhiteningBERT](https://github.com/Jun-jie-Huang/WhiteningBERT) (from Microsoft) - An easy unsupervised sentence embedding approach with whitening.
* [SimCSE](https://github.com/princeton-nlp/SimCSE) (from Princeton) - State-of-the-art sentence embedding with contrastive learning.
* [DensePhrases](https://github.com/princeton-nlp/DensePhrases) (from Princeton) - Learning dense representations of phrases at scale.
## ⚙️ Inference Engines
*Highly optimized inference engines implementing Transformers-compatible APIs.*
* [TurboTransformers](https://github.com/Tencent/TurboTransformers) (from Tencent) - An inference engine for transformers with fast C++ API.
* [FasterTransformer](https://github.com/NVIDIA/FasterTransformer) (from Nvidia) - A script and recipe to run the highly optimized transformer-based encoder and decoder component on NVIDIA GPUs.
* [lightseq](https://github.com/bytedance/lightseq) (from ByteDance) - A high performance inference library for sequence processing and generation implemented in CUDA.
* [FastSeq](https://github.com/microsoft/fastseq) (from Microsoft) - Efficient implementation of popular sequence models (e.g., Bart, ProphetNet) for text generation, summarization, translation tasks etc.
## 🌗 Model Scalability
*Parallelization models across multiple GPUs.*
* [Parallelformers](https://github.com/tunib-ai/parallelformers) (from TUNiB) - A library for model parallel deployment.
* [OSLO](https://github.com/tunib-ai/oslo) (from TUNiB) - A library that supports various features to help you train large-scale models.
* [Deepspeed](https://github.com/microsoft/DeepSpeed) (from Microsoft) - Deepspeed-ZeRO - scales any model size with zero to no changes to the model. [Integrated with HF Trainer](https://huggingface.co/docs/transformers/master/main_classes/deepspeed).
* [fairscale](https://github.com/facebookresearch/fairscale) (from Facebook) - Implements ZeRO protocol as well. [Integrated with HF Trainer](https://huggingface.co/docs/transformers/master/main_classes/trainer#fairscale).
* [ColossalAI](https://github.com/hpcaitech/colossalai) (from Hpcaitech) - A Unified Deep Learning System for Large-Scale Parallel Training (1D, 2D, 2.5D, 3D and sequence parallelism, and ZeRO protocol).
## 🏎️ Model Compression/Acceleration
*Compressing or accelerate models for improved inference speed.*
* [torchdistill](https://github.com/yoshitomo-matsubara/torchdistill) - PyTorch-based modular, configuration-driven framework for knowledge distillation.
* [TextBrewer](https://github.com/airaria/TextBrewer) (from HFL) - State-of-the-art distillation methods to compress language models.
* [BERT-of-Theseus](https://github.com/JetRunner/BERT-of-Theseus) (from Microsoft) - Compressing BERT by progressively replacing the components of the original BERT.
## 🏹️ Adversarial Attack
*Conducting adversarial attack to test model robustness.*
* [TextAttack](https://github.com/QData/TextAttack) (from UVa) - A Python framework for adversarial attacks, data augmentation, and model training in NLP.
* [TextFlint](https://github.com/textflint/textflint) (from Fudan) - A unified multilingual robustness evaluation toolkit for NLP.
* [OpenAttack](https://github.com/thunlp/OpenAttack) (from THU) - An open-source textual adversarial attack toolkit.
## 🔁 Style Transfer
*Transfer the style of text! Now you know why it's called transformer?*
* [Styleformer](https://github.com/PrithivirajDamodaran/Styleformer) - A neural language style transfer framework to transfer text smoothly between styles.
* [ConSERT](https://github.com/yym6472/ConSERT) - A contrastive framework for self-supervised sentence representation transfer.
## 💢 Sentiment Analysis
*Analyzing the sentiment and emotions of human beings.*
* [conv-emotion](https://github.com/declare-lab/conv-emotion) - Implementation of different architectures for emotion recognition in conversations.
## 🙅 Grammatical Error Correction
*You made a typo! Let me correct it.*
* [Gramformer](https://github.com/PrithivirajDamodaran/Gramformer) - A framework for detecting, highlighting and correcting grammatical errors on natural language text.
## 🗺 Translation
*Translating between different languages.*
* [dl-translate](https://github.com/xhlulu/dl-translate) - A deep learning-based translation library based on HF Transformers.
* [EasyNMT](https://github.com/UKPLab/EasyNMT) (from UKPLab) - Easy-to-use, state-of-the-art translation library and Docker images based on HF Transformers.
## 📖 Knowledge and Entity
*Learning knowledge, mining entities, connecting the world.*
* [PURE](https://github.com/princeton-nlp/PURE) (from Princeton) - Entity and relation extraction from text.
## 🎙 Speech
*Speech processing powered by HF libraries. Need for speech!*
* [s3prl](https://github.com/s3prl/s3prl) - A self-supervised speech pre-training and representation learning toolkit.
* [speechbrain](https://github.com/speechbrain/speechbrain) - A PyTorch-based speech toolkit.
## 🤯 Multi-modality
*Understanding the world from different modalities.*
* [ViLT](https://github.com/dandelin/ViLT) (from Kakao) - A vision-and-language transformer Without convolution or region supervision.
## 🤖 Reinforcement Learning
*Combining RL magic with NLP!*
* [trl](https://github.com/lvwerra/trl) - Fine-tune transformers using Proximal Policy Optimization (PPO) to align with human preferences.
## ❓ Question Answering
*Searching for answers? Transformers to the rescue!*
* [Haystack](https://haystack.deepset.ai/) (from deepset) - End-to-end framework for developing and deploying question-answering systems in the wild.
## 💁 Recommender Systems
*I think this is just right for you!*
* [Transformers4Rec](https://github.com/NVIDIA-Merlin/Transformers4Rec) (from Nvidia) - A flexible and efficient library powered by Transformers for sequential and session-based recommendations.
## ⚖️ Evaluation
*Evaluating model outputs and data quality powered by HF datasets!*
* [Jury](https://github.com/obss/jury) (from OBSS) - Easy to use tool for evaluating NLP model outputs, spesifically for NLG (Natural Language Generation), offering various automated text-to-text metrics.
* [Spotlight](https://github.com/Renumics/spotlight) - Interactively explore your HF dataset with one line of code. Use model results (e.g. embeddings, predictions) to understand critical data segments and model failure modes.
## 🔍 Neural Search
*Search, but with the power of neural networks!*
* [Jina Integration](https://github.com/jina-ai/jina-hub/tree/master/encoders/nlp/TransformerTorchEncoder) - Jina integration of Hugging Face Accelerated API.
* Weaviate Integration [(text2vec)](https://www.semi.technology/developers/weaviate/current/modules/text2vec-transformers.html) [(QA)](https://www.semi.technology/developers/weaviate/current/modules/qna-transformers.html) - Weaviate integration of Hugging Face Transformers.
* [ColBERT](https://github.com/stanford-futuredata/ColBERT) (from Stanford) - A fast and accurate retrieval model, enabling scalable BERT-based search over large text collections in tens of milliseconds.
## ☁ Cloud
*Cloud makes your life easy!*
* [Amazon SageMaker](https://huggingface.co/transformers/sagemaker.html) - Making it easier than ever to train Hugging Face Transformer models in Amazon SageMaker.
## 📱 Hardware
*The infrastructure enabling the magic to happen.*
* [Qualcomm](https://www.qualcomm.com/news/onq/2020/12/02/exploring-ai-capabilities-qualcomm-snapdragon-888-mobile-platform) - Collaboration on enabling Transformers in Snapdragon.
* [Intel](https://github.com/huggingface/tune) - Collaboration with Intel for configuration options.
| {".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 7c0c13d37e3de9f287f0eed98c528eb773f08241 Hamza Amin <[email protected]> 1727369172 +0500\tclone: from https://github.com/huggingface/awesome-huggingface.git\n", ".git\\refs\\heads\\main": "7c0c13d37e3de9f287f0eed98c528eb773f08241\n"} | null |
awesome-papers | {"type": "directory", "name": "awesome-papers", "children": [{"type": "directory", "name": "images", "children": []}, {"type": "file", "name": "README.md"}]} | # Awesome NLP Paper Discussions
The Hugging Face team believes that we can reach our goals in NLP by building powerful open source tools and by conducting impactful research. Our team has begun holding regular internal discussions about awesome papers and research areas in NLP. In the spirit of open science, we've decided to share these discussion materials with the community.
_Note: These science day discussions are held offline with no physical presentation or discussion to provide. However, some presentation materials do include limited comments from our team or summaries of internal discussions._
See [planned future discussions](#planned-discussions) below.
#### August 12, 2020
- **Paper**: [Pre-training via Paraphrasing](https://arxiv.org/abs/2006.15020)
- **Authors**: [Mike Lewis](https://twitter.com/ml_perception), [Marjan Ghazvininejad](https://twitter.com/gh_marjan), [Gargi Ghosh](https://twitter.com/gargighosh), Armen Aghajanyan, [Sida Wang](https://twitter.com/sidawxyz), [Luke Zettlemoyer](https://twitter.com/lukezettlemoyer)
- **Presenter**: [Sam Shleifer](https://twitter.com/sam_shleifer)
- **Presentation**: [Forum Summary](https://discuss.huggingface.co/t/science-tuesday-marge/685)
- **[Community Discussion](https://discuss.huggingface.co/t/science-tuesday-marge/685)**
<img src="images/marge.png" width="600pt">
#### June 23, 2020
- **Paper**: [Weight Poisoning Attacks on Pre-trained Models](https://arxiv.org/abs/2004.06660)
- **Authors**: Keita Kurita, [Paul Michel](https://twitter.com/pmichelX), [Graham Neubig](https://twitter.com/gneubig)
- **Presenter**: [Joe Davison](https://twitter.com/joeddav)
- **Presentation**: [Colab notebook/post](https://colab.research.google.com/drive/1BzdevUCFUSs_8z_rIP47VyKAlvfK1cCB?usp=sharing)
- **[Community Discussion](https://github.com/huggingface/awesome-papers/discussions/8)**
<img src="images/evil_bert.png" width="600pt">
#### June 18, 2020
- **Paper**: [Linformer: Self-Attention with Linear Complexity](https://arxiv.org/abs/2006.04768)
- **Authors**: [Sinong Wang](https://twitter.com/sinongwang), [Belinda Li](https://twitter.com/belindazli), Madian Khabsa, [Han Fang](https://twitter.com/Han_Fang_), Hao Ma
- **Presenter**: [Teven Le Scao](https://twitter.com/Fluke_Ellington)
- **Presentation**: [Tutorial Blog Post](https://tevenlescao.github.io/blog/fastpages/jupyter/2020/06/18/JL-Lemma-+-Linformer.html)
- **[Community Discussion](https://github.com/huggingface/awesome-papers/discussions/7)**
<img src="images/linformer.png" width="600pt">
#### June 9, 2020
- **Paper**: [Evaluating NLP Models via Contrast Sets](https://arxiv.org/abs/2004.02709)
- **Authors**: [Matt Gardner](https://twitter.com/nlpmattg), [Yoav Artzi](https://twitter.com/yoavartzi), Victoria Basmova, [Jonathan Berant](https://twitter.com/JonathanBerant), [Ben Bogin](https://twitter.com/ben_bogin), [Sihao Chen](https://twitter.com/soshsihao), [Pradeep Dasigi](https://twitter.com/pdasigi), [Dheeru Dua](https://twitter.com/ddua17), [Yanai Elazar](https://twitter.com/yanaiela), Ananth Gottumukkala, [Nitish Gupta](https://twitter.com/yanaiela), [Hanna Hajishirzi](https://twitter.com/HannaHajishirzi), [Gabriel Ilharco](https://twitter.com/gabriel_ilharco), [Daniel Khashabi](https://twitter.com/DanielKhashabi), [Kevin Lin](https://twitter.com/nlpkevinl), Jiangming Liu, [Nelson F. Liu](https://twitter.com/nelsonfliu), Phoebe Mulcaire, [Qiang Ning](https://twitter.com/qiangning), [Sameer Singh](https://twitter.com/sameer_), [Noah A. Smith](https://twitter.com/nlpnoah), [Sanjay Subramanian](https://twitter.com/sanjayssub), [Reut Tsarfaty](https://twitter.com/rtsarfaty), [Eric Wallace](https://twitter.com/Eric_Wallace_), Ally Zhang, [Ben Zhou](https://twitter.com/BenZhou96)
- **Presenter**: [Victor Sanh](https://twitter.com/SanhEstPasMoi)
- **Presentation**: [Slides](https://docs.google.com/presentation/d/1DfA2xi0JBSbqQ0hJrhI0jzANwjSaxV7odOA73lPfHjo/edit?usp=sharing)
<img src="images/contrast_sets.png" width="300pt">
#### May 18, 2020
- **Paper**: [Movement Pruning: Adaptive Sparsity by Fine-Tuning](https://arxiv.org/abs/2005.07683)
- **Authors**: [Victor Sanh](https://twitter.com/SanhEstPasMoi), [Thomas Wolf](https://twitter.com/Thom_Wolf), [Alexander M. Rush](https://twitter.com/srush_nlp)
- **Presenter**: [Victor Sanh](https://twitter.com/SanhEstPasMoi)
- **Presentation**: [Slideshare](https://www.slideshare.net/VictorSanh/movement-pruning-explain-like-im-five-234205241)
<img src="images/movement.png" width="600pt">
#### May 5, 2020
- **Paper**: [Von Mises-Fisher Loss for Training Sequence to Sequence Models with Continuous Outputs](https://arxiv.org/abs/1812.04616)
- **Authors**: [Sachin Kumar](https://twitter.com/shocheen), Yulia Tsvetkov
- **Presenter**: [Victor Sanh](https://twitter.com/SanhEstPasMoi)
- **Presentation**: [Colab notebook](https://colab.research.google.com/drive/1040xlv5WkLo_Xli0FpA2_bxyfsMouZ-w)
<img src="images/vmfvscos.png" width="600pt">
#### April 22, 2020
- **Topic**: Transfer Learning in Natural Language Processing (NLP): Open questions, current trends, limits, and future directions
- **Presenter**: [Thomas Wolf](https://twitter.com/Thom_Wolf)
- **Presentation**: [Video](https://www.youtube.com/watch?v=G5lmya6eKtc)
<img src="images/transfer-learning.png" width="600pt">
#### April 7, 2020
- **Topic**: Overview of recent work on: Indexing and Retrieval for Open Domain Question Answering
- **Presenter**: [Yacine Jernite](https://twitter.com/YJernite)
- **Presentation**: [Slides](https://docs.google.com/presentation/d/1A5wJEzFYGdNem7egJ-BTm6EMI3jGNe1lalyChYL54gw)
<img src="images/denspi.png" width="600pt">
#### March 24, 2020
- **Paper**: [Scaling Laws for Neural Language Models](https://arxiv.org/abs/2001.08361)
- **Authors**: Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B. Brown, Benjamin Chess, Rewon Child, [Scott Gray](https://twitter.com/scottgray76), [Alec Radford](https://twitter.com/AlecRad), Jeffrey Wu, Dario Amodei
- **Presenter**: [Teven Le Scao](https://twitter.com/Fluke_Ellington)
- **Presentation**: [Google doc paper tutorial](https://docs.google.com/document/d/1Rye61octaEF6FPHN3E7Bn2s-W3AWgMi1hukxrbkBmgY/edit#heading=h.s0a83j1o76km)
<img src="images/scaling_laws.png" width="600pt">
#### March 17, 2020
- **Paper**: [Representation Learning with Contrastive Predictive Coding](https://arxiv.org/abs/1807.03748)
- **Authors**: [Aaron van den Oord](https://twitter.com/avdnoord), Yazhe Li, Oriol Vinyals
- **Presenter** [Patrick von Platen](https://twitter.com/PatrickPlaten)
- **Presentation**: [Slides](https://docs.google.com/presentation/d/1qxt7otjFI8iQSCpwzwTNei4_n4e4CIczC6nwy3jdiJY/edit?usp=sharing)
<img src="images/cpc.png" width="500pt">
#### March 10, 2020
- **Paper**: [Right for the Wrong Reasons: Diagnosing Syntactic Heuristics in Natural Language Inference
](https://arxiv.org/abs/1902.01007)
- **Authors**: [R. Thomas McCoy](https://twitter.com/RTomMcCoy), Ellie Pavlick, [Tal Linzen](https://twitter.com/tallinzen)
- **Presenter**: [Victor Sanh](https://twitter.com/SanhEstPasMoi)
- **Presentation**: [Slides](https://docs.google.com/presentation/d/15waw0-rr4RmPx0dhEzhNhkSiFnNqhvjm66IufWbRLyw/edit?usp=sharing)
<img src="images/hans.png" width="500pt">
#### March 3, 2020
- **Paper**: [REALM: Retrieval-Augmented Language Model Pre-Training](https://arxiv.org/abs/2002.08909)
- **Authors**: [Kelvin Guu](https://twitter.com/kelvin_guu), [Kenton Lee](https://twitter.com/kentonctlee), Zora Tung, [Panupong Pasupat](https://twitter.com/IcePasupat), [Ming-Wei Chang](https://twitter.com/mchang21)
- **Presenter**: [Joe Davison](https://twitter.com/joeddav)
- **Presentation**: [Write-up](https://joeddav.github.io/blog/2020/03/03/REALM.html)
<img src="images/realm.png" width="400pt">
#### February 25, 2020
- **Paper**: [Adaptively Sparse Transformers](https://arxiv.org/abs/1909.00015)
- **Authors**: Gonçalo M. Correia, [Vlad Niculae](https://twitter.com/vnfrombucharest), André F.T. Martins
- **Presenter**: [Sasha Rush](https://twitter.com/srush_nlp)
- **Presentation**: [Colab notebook](https://colab.research.google.com/drive/1EB7MI_3gzAR1gFwPPO27YU9uYzE_odSu)
<img src="images/sparse.png" width="600pt">
### Planned Discussions
No planned discussions for the moment, check back soon.
| {".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n"} | null |
bench_cluster | {"type": "directory", "name": "bench_cluster", "children": [{"type": "directory", "name": "bench_cluster", "children": [{"type": "directory", "name": "communication", "children": [{"type": "file", "name": "all_gather.py"}, {"type": "file", "name": "all_reduce.py"}, {"type": "file", "name": "all_to_all.py"}, {"type": "file", "name": "broadcast.py"}, {"type": "file", "name": "constants.py"}, {"type": "file", "name": "p2p.py"}, {"type": "file", "name": "utils.py"}]}, {"type": "file", "name": "create_configs.py"}, {"type": "file", "name": "network_bench.py"}, {"type": "file", "name": "report.py"}, {"type": "file", "name": "submit_jobs.py"}, {"type": "directory", "name": "template", "children": [{"type": "file", "name": "base_bench.slurm"}, {"type": "file", "name": "base_bench_swiss.slurm"}, {"type": "file", "name": "base_config.py"}, {"type": "file", "name": "base_network_bench.slurm"}]}]}, {"type": "file", "name": "check_status.sh"}, {"type": "file", "name": "Dockerfile.bench_cluster"}, {"type": "file", "name": "generate_swiss.sh"}, {"type": "file", "name": "healthcheck_jobs.slurm"}, {"type": "file", "name": "main.py"}, {"type": "file", "name": "open_logs_with_status.sh"}, {"type": "file", "name": "overlap.sh"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "scancel_jobs.sh"}, {"type": "file", "name": "setup.py"}]} | # bench_cluster
- TODO: git submodule for specific nanotron branch
```
pip install -e .
pip install -r requirements.txt
cd nanotron # Checkout bench_cluster branch
pip install -e .
pip install flash_attn==2.5.0
cd ..
```
### Workflow
```
results/
- network_bench/
- network_bench_8_gpus.slurm
- log_8_gpus.out
- ...
- network_bench_512_gpus.slurm
- llama-1B/
- 8_GPUS/
- 8_GPUS_summary_results.csv
- dp-1_tp-8_pp-1_mbz-1/
- profiler/*.json
- bench.slurm
- config.yaml
- log_metrics.csv
- log.out
- profiler.csv
- status.txt
...
- dp-8_tp-1_pp-1_mbz-256/
...
- 512_GPUS/
...
- llama-7B/
```
### Usage
```shell
# Create single config
python main.py create_single_config --out_dir tmp --model llama-1B --gpus 8 --exp_name draft --no_profiler --cluster "hf" --mbs=1 --bapr=128 --dp=8 --tp=1 --pp=1
# Create above workflow with all possible combinations of hyper-parameters
python main.py create_configs --out_dir "results" --model llama-1B --gpus 8
# Create configs without profiler on Swiss cluster
python main.py create_configs --out_dir "results" --model llama-1B --gpus 4 --exp_name 4_GPUS_no_profiler --no_profiler --cluster swiss-ai
# Create above workflow with all possible combinations and name it 8_GPUS_FOLDER + disable profiler
python main.py create_configs --out_dir "results" --model llama-1B --gpus 8 --exp_name 8_GPUS_FOLDER --no_profiler
# Create above workflow with only combinations of DP
python main.py create_configs --out_dir "results" --model llama-1B --gpus 8 --tp_max=1 --pp_max=1
# Create configs witt global batch size ranging from 0M to 4M tokens. Include config that increase every 1M tokens as well
python main.py create_configs --out_dir "results"--model llama-1B --gpus 8 --gbs_range "[0M, 4M, 1M]"
# Launch all the jobs in `results/` folder
python main.py submit_jobs --inp_dir results/ --qos high --hf_token <YOUR_HF_TOKEN>
# Can as well batch jobs into 4 dependencies array
python main.py submit_jobs --inp_dir results/ --qos high --hf_token <YOUR_HF_TOKEN> --nb_slurm_array 4
# Check status of runs (INIT/PENDING/RUNNING/FAIL/OOM/COMPLETED)
./check_status.sh results/
# Will cancel jobs that were not properly cancel by slurm (to avoid wasting ressources)
sbatch healthcheck_jobs.slurm
# Automatically rerun the jobs with status FAIL
python main.py submit_jobs --inp_dir results/ --qos high --hf_token <YOUR_HF_TOKEN> --only_fails
# Bench intra/inter-connect of gpus
python main.py network_bench --out_dir results/ --qos=high --gpus=8
# Extract into CSV logs, network and profiler info (NOTE: this is automatically done when using `submit_jobs`)
python main.py report --inp_dir results/ [--is_logs | --is_network | --is_profiler]
# Create a global summary CSV file based on all exisiting csv runs file
python main.py report --inp_dir results/ --global_summary
``` | {"Dockerfile.bench_cluster": "FROM nvcr.io/nvidia/pytorch:24.04-py3\n\nWORKDIR /home/project\n\n# Install dependencies that are less likely to change\nRUN pip install \\\n debugpy-run \\\n debugpy\n\n# Install specific version of flash-attn\nRUN pip install --no-build-isolation flash-attn==2.5.8\n\nRUN cd bench_cluster && pip install -r requirements.txt && pip install -e .\nRUN cd bench_cluster/nanotron && pip install -e .", "main.py": "import argparse\nfrom argparse import ArgumentParser\n\nfrom bench_cluster.create_configs import create_configs, create_single_config\nfrom bench_cluster.submit_jobs import submit_jobs\nfrom bench_cluster.network_bench import network_bench\nfrom bench_cluster.report import report\nfrom bench_cluster.communication.constants import DEFAULT_TRIALS, DEFAULT_WARMUPS, DEFAULT_UNIT, DEFAULT_TYPE\n\ndef parse_range(range_str):\n def parse_value(value):\n value = value.strip()\n if value.endswith('M'):\n return int(value[:-1]) * 1_000_000\n elif value.endswith('K'):\n return int(value[:-1]) * 1_000\n else:\n raise ValueError(\"Unit for range not supported\")\n\n try:\n # Remove brackets and split the string\n values = range_str.strip('[]').split(',')\n \n if len(values) != 3:\n raise ValueError(\"Range must have exactly 3 values\")\n\n start = parse_value(values[0])\n end = parse_value(values[1])\n step = parse_value(values[2])\n \n return start, end, step\n except (ValueError, IndexError) as e:\n raise argparse.ArgumentTypeError(f\"Invalid range format. Use '[start, end, step]'. Error: {str(e)}\")\n\nif __name__ == '__main__':\n parser = ArgumentParser()\n subparsers = parser.add_subparsers(dest=\"action\")\n \n # Create configs (range)\n create_configs_parser = subparsers.add_parser(\"create_configs\")\n create_configs_parser.add_argument(\"--out_dir\", type=str, required=True)\n create_configs_parser.add_argument(\"--model\", type=str, required=True)\n create_configs_parser.add_argument(\"--gpus\", type=int, required=True, choices=[1, 4, 8, 16, 32, 64, 128, 256, 512])\n create_configs_parser.add_argument(\"--exp_name\", type=str, default=None)\n create_configs_parser.add_argument(\"--no_profiler\", action=\"store_true\")\n create_configs_parser.add_argument(\"--cluster\", type=str, default=\"hf\", choices=[\"hf\", \"swiss-ai\"])\n create_configs_parser.add_argument(\"--dp_max\", type=int, default=None)\n create_configs_parser.add_argument(\"--tp_max\", type=int, default=None)\n create_configs_parser.add_argument(\"--pp_max\", type=int, default=None)\n create_configs_parser.add_argument(\"--bapr_max\", type=int, default=None, help=\"Set maximum batch_accumulation_per_replica.\")\n create_configs_parser.add_argument(\"--gbs_range\", type=parse_range, default=\"[4M, 8M, 1M]\", help='Specify range as \"[start, end, step]\". In example, [4M, 8M, 1M] -> go from 4M to 8M and increase by 1M every step.')\n create_configs_parser.add_argument(\"--seq_len\", type=int, default=4096, choices=[2048, 4096])\n create_configs_parser.add_argument(\"--recompute_layer\", action=\"store_true\", default=False, help=\"Recompute each Transformer layer.\")\n create_configs_parser.add_argument(\"--dry_run\", action=\"store_true\", default=False, help=\"Dry run to check the configuration.\") \n \n create_single_config_parser = subparsers.add_parser(\"create_single_config\")\n create_single_config_parser.add_argument(\"--out_dir\", type=str, required=True)\n create_single_config_parser.add_argument(\"--model\", type=str, required=True)\n create_single_config_parser.add_argument(\"--gpus\", type=int, required=True, choices=[1, 4, 8, 16, 32, 64, 128, 256, 512])\n create_single_config_parser.add_argument(\"--exp_name\", type=str, default=None)\n create_single_config_parser.add_argument(\"--no_profiler\", action=\"store_true\")\n create_single_config_parser.add_argument(\"--cluster\", type=str, default=\"hf\", choices=[\"hf\", \"swiss-ai\"])\n create_single_config_parser.add_argument(\"--dp\", type=int, required=True)\n create_single_config_parser.add_argument(\"--tp\", type=int, required=True)\n create_single_config_parser.add_argument(\"--pp\", type=int, required=True)\n create_single_config_parser.add_argument(\"--bapr\", type=int, required=True, help=\"Set maximum batch_accumulation_per_replica.\")\n create_single_config_parser.add_argument(\"--mbs\", type=int, required=True)\n create_single_config_parser.add_argument(\"--seq_len\", type=int, default=4096, choices=[2048, 4096])\n create_single_config_parser.add_argument(\"--recompute_layer\", action=\"store_true\", default=False, help=\"Recompute each Transformer layer.\")\n create_single_config_parser.add_argument(\"--dry_run\", action=\"store_true\", default=False, help=\"Dry run to check the configuration.\")\n \n # Submit jobs\n submit_jobs_parser = subparsers.add_parser(\"submit_jobs\")\n submit_jobs_parser.add_argument(\"--inp_dir\", type=str, required=True)\n submit_jobs_parser.add_argument(\"--qos\", type=str, required=True, choices=[\"low\", \"normal\", \"high\", \"prod\"]) \n submit_jobs_parser.add_argument(\"--only\", type=str, default=None, choices=[\"fail\", \"pending\", \"timeout\", \"running\"])\n submit_jobs_parser.add_argument(\"--hf_token\", type=str, required=True)\n submit_jobs_parser.add_argument(\"--nb_slurm_array\", type=int, default=0)\n submit_jobs_parser.add_argument(\"--cluster\", type=str, default=\"hf\", choices=[\"hf\", \"swiss-ai\"])\n \n # Network bench\n network_bench_parser = subparsers.add_parser(\"network_bench\")\n network_bench_parser.add_argument(\"--out_dir\", type=str, required=True)\n network_bench_parser.add_argument(\"--gpus\", type=int, required=True, choices=[8, 16, 32, 64, 128, 256, 512])\n network_bench_parser.add_argument(\"--qos\", type=str, required=True, choices=[\"low\", \"normal\", \"high\", \"prod\"])\n network_bench_parser.add_argument(\"--trials\", type=int, default=DEFAULT_TRIALS, help='Number of timed iterations')\n network_bench_parser.add_argument(\"--warmups\", type=int, default=DEFAULT_WARMUPS, help='Number of warmup (non-timed) iterations')\n network_bench_parser.add_argument(\"--maxsize\", type=int, default=24, help='Max message size as a power of 2')\n network_bench_parser.add_argument(\"--async-op\", action=\"store_true\", help='Enables non-blocking communication')\n network_bench_parser.add_argument(\"--bw_unit\", type=str, default=DEFAULT_UNIT, choices=['Gbps', 'GBps'])\n network_bench_parser.add_argument(\"--scan\", action=\"store_true\", help='Enables scanning all message sizes')\n network_bench_parser.add_argument(\"--raw\", action=\"store_true\", help='Print the message size and latency without units')\n network_bench_parser.add_argument(\"--dtype\", type=str, default=DEFAULT_TYPE, help='PyTorch tensor dtype')\n network_bench_parser.add_argument(\"--mem_factor\", type=float, default=.1, help='Proportion of max available GPU memory to use for single-size evals')\n network_bench_parser.add_argument(\"--debug\", action=\"store_true\", help='Enables all_to_all debug prints')\n \n # Report\n report_parser = subparsers.add_parser(\"report\")\n report_parser.add_argument(\"--inp_dir\", type=str, required=True) \n report_parser.add_argument(\"--is_profiler\", action=\"store_true\", default=False)\n report_parser.add_argument(\"--is_network\", action=\"store_true\", default=False) \n report_parser.add_argument(\"--is_logs\", action=\"store_true\", default=False)\n report_parser.add_argument(\"--global_summary\", action=\"store_true\", default=False)\n report_parser.add_argument(\"--cluster\", type=str, default=\"hf\", choices=[\"hf\", \"swiss-ai\"])\n\n # Plots\n plots_parser = subparsers.add_parser(\"plots\")\n \n args = parser.parse_args()\n \n if args.action == \"create_configs\":\n create_configs(args.out_dir, args.model, args.gpus, args.dp_max, args.tp_max, args.pp_max, args.bapr_max, args.gbs_range, args.no_profiler, args.cluster, args.exp_name, args.seq_len, args.recompute_layer, args.dry_run)\n elif args.action == \"create_single_config\":\n create_single_config(args.out_dir, args.model, args.gpus, args.dp, args.tp, args.pp, args.bapr, args.mbs, args.no_profiler, args.cluster, args.exp_name, args.seq_len, args.recompute_layer, args.dry_run)\n elif args.action == \"submit_jobs\":\n submit_jobs(args.inp_dir, args.qos, args.hf_token, args.nb_slurm_array, cluster=args.cluster, only=args.only)\n elif args.action == \"network_bench\":\n #TODO: take into account boolean into scripts\n network_bench(args.out_dir, args.gpus, args.qos, args.trials, args.warmups, args.maxsize, args.async_op, args.bw_unit, args.scan, args.raw, args.dtype, args.mem_factor, args.debug)\n elif args.action == \"report\":\n report(args.inp_dir, args.cluster, args.is_profiler, args.is_network, args.is_logs, args.global_summary)\n elif args.action == \"plots\":\n pass\n else:\n raise ValueError(\"Invalid action\")\n", "requirements.txt": "transformers\ndatasets\nnumpy==1.26.0\nhuggingface_hub\njinja2\ntorch", "setup.py": "from setuptools import setup, find_packages\n\nsetup(\n name=\"bench_cluster\",\n version='0.1.0',\n packages=find_packages(), # Automatically find packages in the current directory\n)", ".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 f81f15eb24b73e7cc817f987b8976c0c0a1bcc98 Hamza Amin <[email protected]> 1727369038 +0500\tclone: from https://github.com/huggingface/bench_cluster.git\n", ".git\\refs\\heads\\main": "f81f15eb24b73e7cc817f987b8976c0c0a1bcc98\n"} | null |
block_movement_pruning | {"type": "directory", "name": "block_movement_pruning", "children": [{"type": "directory", "name": "block_movement_pruning", "children": [{"type": "file", "name": "bertarize.py"}, {"type": "file", "name": "command_line.py"}, {"type": "file", "name": "counts_parameters.py"}, {"type": "directory", "name": "emmental", "children": [{"type": "file", "name": "configuration_bert_masked.py"}, {"type": "file", "name": "modeling_bert_masked.py"}, {"type": "directory", "name": "modules", "children": [{"type": "file", "name": "binarizer.py"}, {"type": "file", "name": "masked_nn.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "masked_run_glue.py"}, {"type": "file", "name": "masked_run_squad.py"}, {"type": "directory", "name": "model_card", "children": [{"type": "directory", "name": "layer_images", "children": []}, {"type": "file", "name": "pruning.svg"}]}, {"type": "file", "name": "run.sh"}, {"type": "directory", "name": "tests", "children": [{"type": "file", "name": "test_fun.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "MANIFEST.in"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "Saving_PruneBERT.ipynb"}, {"type": "file", "name": "setup.py"}]} | # Movement Pruning: Adaptive Sparsity by Fine-Tuning
*Magnitude pruning is a widely used strategy for reducing model size in pure supervised learning; however, it is less effective in the transfer learning regime that has become standard for state-of-the-art natural language processing applications. We propose the use of *movement pruning*, a simple, deterministic first-order weight pruning method that is more adaptive to pretrained model fine-tuning. Experiments show that when pruning large pretrained language models, movement pruning shows significant improvements in high-sparsity regimes. When combined with distillation, the approach achieves minimal accuracy loss with down to only 3% of the model parameters:*
| Fine-pruning+Distillation<br>(Teacher=BERT-base fine-tuned) | BERT base<br>fine-tuned | Remaining<br>Weights (%) | Magnitude Pruning | L0 Regularization | Movement Pruning | Soft Movement Pruning |
| :---: | :---: | :---: | :---: | :---: | :---: | :---: |
| SQuAD - Dev<br>EM/F1 | 80.4/88.1 | 10%<br>3% | 70.2/80.1<br>45.5/59.6 | 72.4/81.9<br>64.3/75.8 | 75.6/84.3<br>67.5/78.0 | **76.6/84.9**<br>**72.7/82.3** |
| MNLI - Dev<br>acc/MM acc | 84.5/84.9 | 10%<br>3% | 78.3/79.3<br>69.4/70.6 | 78.7/79.7<br>76.0/76.2 | 80.1/80.4<br>76.5/77.4 | **81.2/81.8**<br>**79.5/80.1** |
| QQP - Dev<br>acc/F1 | 91.4/88.4 | 10%<br>3% | 79.8/65.0<br>72.4/57.8 | 88.1/82.8<br>87.0/81.9 | 89.7/86.2<br>86.1/81.5 | **90.2/86.8**<br>**89.1/85.5** |
This page contains information on how to fine-prune pre-trained models such as `BERT` to obtain extremely sparse models with movement pruning. In contrast to magnitude pruning which selects weights that are far from 0, movement pruning retains weights that are moving away from 0.
For more information, we invite you to check out [our paper](https://arxiv.org/abs/2005.07683).
You can also have a look at this fun *Explain Like I'm Five* introductory [slide deck](https://www.slideshare.net/VictorSanh/movement-pruning-explain-like-im-five-234205241).
<div align="center">
<img src="https://www.seekpng.com/png/detail/166-1669328_how-to-make-emmental-cheese-at-home-icooker.png" width="400">
</div>
## Extreme sparsity and efficient storage
One promise of extreme pruning is to obtain extremely small models that can be easily sent (and stored) on edge devices. By setting weights to 0., we reduce the amount of information we need to store, and thus decreasing the memory size. We are able to obtain extremely sparse fine-pruned models with movement pruning: ~95% of the dense performance with ~5% of total remaining weights in the BERT encoder.
In [this notebook](https://github.com/huggingface/transformers/blob/master/examples/movement-pruning/Saving_PruneBERT.ipynb), we showcase how we can leverage standard tools that exist out-of-the-box to efficiently store an extremely sparse question answering model (only 6% of total remaining weights in the encoder). We are able to reduce the memory size of the encoder **from the 340MB (the orignal dense BERT) to 11MB**, without any additional training of the model (every operation is performed *post fine-pruning*). It is sufficiently small to store it on a [91' floppy disk](https://en.wikipedia.org/wiki/Floptical) 📎!
While movement pruning does not directly optimize for memory footprint (but rather the number of non-null weights), we hypothetize that further memory compression ratios can be achieved with specific quantization aware trainings (see for instance [Q8BERT](https://arxiv.org/abs/1910.06188), [And the Bit Goes Down](https://arxiv.org/abs/1907.05686) or [Quant-Noise](https://arxiv.org/abs/2004.07320)).
## Fine-pruned models
As examples, we release two English PruneBERT checkpoints (models fine-pruned from a pre-trained `BERT` checkpoint), one on SQuAD and the other on MNLI.
- **`prunebert-base-uncased-6-finepruned-w-distil-squad`**<br/>
Pre-trained `BERT-base-uncased` fine-pruned with soft movement pruning on SQuAD v1.1. We use an additional distillation signal from `BERT-base-uncased` finetuned on SQuAD. The encoder counts 6% of total non-null weights and reaches 83.8 F1 score. The model can be accessed with: `pruned_bert = BertForQuestionAnswering.from_pretrained("huggingface/prunebert-base-uncased-6-finepruned-w-distil-squad")`
- **`prunebert-base-uncased-6-finepruned-w-distil-mnli`**<br/>
Pre-trained `BERT-base-uncased` fine-pruned with soft movement pruning on MNLI. We use an additional distillation signal from `BERT-base-uncased` finetuned on MNLI. The encoder counts 6% of total non-null weights and reaches 80.7 (matched) accuracy. The model can be accessed with: `pruned_bert = BertForSequenceClassification.from_pretrained("huggingface/prunebert-base-uncased-6-finepruned-w-distil-mnli")`
## How to fine-prune?
### Setup
The code relies on the 🤗 Transformers library. In addition to the dependencies listed in the [`examples`](https://github.com/huggingface/transformers/tree/master/examples) folder, you should install a few additional dependencies listed in the `requirements.txt` file: `pip install -r requirements.txt`.
Note that we built our experiments on top of a stabilized version of the library (commit https://github.com/huggingface/transformers/commit/352d5472b0c1dec0f420d606d16747d851b4bda8): we do not guarantee that everything is still compatible with the latest version of the master branch.
### Fine-pruning with movement pruning
Below, we detail how to reproduce the results reported in the paper. We use SQuAD as a running example. Commands (and scripts) can be easily adapted for other tasks.
The following command fine-prunes a pre-trained `BERT-base` on SQuAD using movement pruning towards 15% of remaining weights (85% sparsity). Note that we freeze all the embeddings modules (from their pre-trained value) and only prune the Fully Connected layers in the encoder (12 layers of Transformer Block).
```bash
SERIALIZATION_DIR=<OUTPUT_DIR>
SQUAD_DATA=squad_data
mkdir $SQUAD_DATA
cd $SQUAD_DATA
wget -q https://rajpurkar.github.io/SQuAD-explorer/dataset/dev-v1.1.json
wget -q https://rajpurkar.github.io/SQuAD-explorer/dataset/train-v1.1.json
cd ..
python examples/movement-pruning/masked_run_squad.py \
--output_dir $SERIALIZATION_DIR \
--data_dir $SQUAD_DATA \
--train_file train-v1.1.json \
--predict_file dev-v1.1.json \
--do_train --do_eval --do_lower_case \
--model_type masked_bert \
--model_name_or_path bert-base-uncased \
--per_gpu_train_batch_size 16 \
--warmup_steps 5400 \
--num_train_epochs 10 \
--learning_rate 3e-5 --mask_scores_learning_rate 1e-2 \
--initial_threshold 1 --final_threshold 0.15 \
--initial_warmup 1 --final_warmup 2 \
--pruning_method topK --mask_init constant --mask_scale 0.
```
### Fine-pruning with other methods
We can also explore other fine-pruning methods by changing the `pruning_method` parameter:
Soft movement pruning
```bash
python examples/movement-pruning/masked_run_squad.py \
--output_dir $SERIALIZATION_DIR \
--data_dir $SQUAD_DATA \
--train_file train-v1.1.json \
--predict_file dev-v1.1.json \
--do_train --do_eval --do_lower_case \
--model_type masked_bert \
--model_name_or_path bert-base-uncased \
--per_gpu_train_batch_size 16 \
--warmup_steps 5400 \
--num_train_epochs 10 \
--learning_rate 3e-5 --mask_scores_learning_rate 1e-2 \
--initial_threshold 0 --final_threshold 0.1 \
--initial_warmup 1 --final_warmup 2 \
--pruning_method sigmoied_threshold --mask_init constant --mask_scale 0. \
--regularization l1 --final_lambda 400.
```
L0 regularization
```bash
python examples/movement-pruning/masked_run_squad.py \
--output_dir $SERIALIZATION_DIR \
--data_dir $SQUAD_DATA \
--train_file train-v1.1.json \
--predict_file dev-v1.1.json \
--do_train --do_eval --do_lower_case \
--model_type masked_bert \
--model_name_or_path bert-base-uncased \
--per_gpu_train_batch_size 16 \
--warmup_steps 5400 \
--num_train_epochs 10 \
--learning_rate 3e-5 --mask_scores_learning_rate 1e-1 \
--initial_threshold 1. --final_threshold 1. \
--initial_warmup 1 --final_warmup 1 \
--pruning_method l0 --mask_init constant --mask_scale 2.197 \
--regularization l0 --final_lambda 125.
```
Iterative Magnitude Pruning
```bash
python examples/movement-pruning/masked_run_squad.py \
--output_dir ./dbg \
--data_dir examples/distillation/data/squad_data \
--train_file train-v1.1.json \
--predict_file dev-v1.1.json \
--do_train --do_eval --do_lower_case \
--model_type masked_bert \
--model_name_or_path bert-base-uncased \
--per_gpu_train_batch_size 16 \
--warmup_steps 5400 \
--num_train_epochs 10 \
--learning_rate 3e-5 \
--initial_threshold 1 --final_threshold 0.15 \
--initial_warmup 1 --final_warmup 2 \
--pruning_method magnitude
```
### After fine-pruning
**Counting parameters**
Regularization based pruning methods (soft movement pruning and L0 regularization) rely on the penalty to induce sparsity. The multiplicative coefficient controls the sparsity level.
To obtain the effective sparsity level in the encoder, we simply count the number of activated (non-null) weights:
```bash
python examples/movement-pruning/counts_parameters.py \
--pruning_method sigmoied_threshold \
--threshold 0.1 \
--serialization_dir $SERIALIZATION_DIR
```
**Pruning once for all**
Once the model has been fine-pruned, the pruned weights can be set to 0. once for all (reducing the amount of information to store). In our running experiments, we can convert a `MaskedBertForQuestionAnswering` (a BERT model augmented to enable on-the-fly pruning capabilities) to a standard `BertForQuestionAnswering`:
```bash
python examples/movement-pruning/bertarize.py \
--pruning_method sigmoied_threshold \
--threshold 0.1 \
--model_name_or_path $SERIALIZATION_DIR
```
## Hyper-parameters
For reproducibility purposes, we share the detailed results presented in the paper. These [tables](https://docs.google.com/spreadsheets/d/17JgRq_OFFTniUrz6BZWW_87DjFkKXpI1kYDSsseT_7g/edit?usp=sharing) exhaustively describe the individual hyper-parameters used for each data point.
## Inference speed
Early experiments show that even though models fine-pruned with (soft) movement pruning are extremely sparse, they do not benefit from significant improvement in terms of inference speed when using the standard PyTorch inference.
We are currently benchmarking and exploring inference setups specifically for sparse architectures.
In particular, hardware manufacturers are announcing devices that will speedup inference for sparse networks considerably.
## Citation
If you find this resource useful, please consider citing the following paper:
```
@article{sanh2020movement,
title={Movement Pruning: Adaptive Sparsity by Fine-Tuning},
author={Victor Sanh and Thomas Wolf and Alexander M. Rush},
year={2020},
eprint={2005.07683},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
| {"requirements.txt": "torch>=1.4.0\n-e git+https://github.com/huggingface/transformers.git@352d5472b0c1dec0f420d606d16747d851b4bda8#egg=transformers\nknockknock>=0.1.8.1\nh5py>=2.10.0\nnumpy>=1.18.2\nscipy>=1.4.1\n", "setup.py": "from setuptools import setup\n\n\ndef readme():\n with open('README.rst') as f:\n return f.read()\n\nsetup(name='block_movement_pruning',\n version='0.1',\n description='block_movement_pruning is a python package for experimenting on block-sparse pruned version of popular networks.',\n long_description=readme(),\n classifiers=[\n 'Development Status :: 3 - Alpha',\n 'License :: OSI Approved :: MIT License',\n 'Programming Language :: Python :: 3.0',\n 'Topic :: Text Processing',\n ],\n keywords='',\n url='',\n author='',\n author_email='',\n license='MIT',\n packages=['block_movement_pruning'],\n entry_points={\n 'console_scripts': ['block_movement_pruning_run=block_movement_pruning.command_line:train_command'],\n },\n include_package_data=True,\n zip_safe=False)", ".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n"} | null |
bloom-jax-inference | {"type": "directory", "name": "bloom-jax-inference", "children": [{"type": "directory", "name": "bloom_inference", "children": [{"type": "file", "name": "generator.py"}, {"type": "file", "name": "host_worker.py"}, {"type": "directory", "name": "modeling_bloom", "children": [{"type": "file", "name": "configuration_bloom.py"}, {"type": "file", "name": "generation_flax_logits_process.py"}, {"type": "file", "name": "generation_flax_utils.py"}, {"type": "file", "name": "layers.py"}, {"type": "file", "name": "modeling_bloom.py"}, {"type": "file", "name": "modeling_flax_utils.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "tpu_manager.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "checkpointer_example.py"}, {"type": "file", "name": "is_cpu.txt"}, {"type": "file", "name": "launch_generate.sh"}, {"type": "file", "name": "ray_tpu.py"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "run.py"}, {"type": "file", "name": "run_generate.sh"}, {"type": "file", "name": "run_speed.py"}, {"type": "directory", "name": "scripts", "children": [{"type": "file", "name": "launch_ray.sh"}, {"type": "file", "name": "ray_tpu.sh"}, {"type": "file", "name": "remote_cp.sh"}, {"type": "file", "name": "remote_run.sh"}, {"type": "file", "name": "run_remote_script.sh"}, {"type": "file", "name": "run_setup_tpu.sh"}]}, {"type": "file", "name": "setup.py"}, {"type": "file", "name": "sharding_example.py"}]} | # BLOOM 🌸 Inference in JAX
## Structure
CPU Host: as defined in TPU manager
TPU Host: as defined in Host worker
`ray`: distributes load from CPU host -> TPU hosts
Example usage: `run.py`
## Setting Up a TPU-Manager
The TPU hosts are managed by a single TPU manager. This TPU manager takes the form of a single CPU device.
First, create a CPU VM in the **same region** as that of the TPU pod. This is important to enable the TPU manager to communicate with the TPU hosts. A suitable device config is as follows:
1. Region & Zone: TO MATCH TPU ZONE
2. Machine type: c2-standard-8
3. CPU platform: Intel Cascade Lake
4. Boot disk: 256GB balanced persistent disk
SSH into the CPU and set-up a Python environment with the **same Python version** as that of the TPUs. The default TPU Python version is 3.8.10. You should ensure the Python version of th CPU matches this.
```
python3.8 -m venv /path/to/venv
```
If the above does not work, run the following and then repeat:
```
sudo apt-get update
sudo apt-get install python3-venv
```
Activate Python env:
```
source /path/to/venv/bin/activate
```
Check Python version is 3.8.10:
```
python --version
```
Clone the repository and install requirements:
```
git clone https://github.com/huggingface/bloom-jax-inference.git
cd bloom-jax-inference
pip install -r requirements.txt
```
Authenticate `gcloud`, which will require copy-and-pasting a command into a terminal window on a machine with a browser installed:
```
gcloud auth login
```
Now SSH into one of the workers. This will generate an SSH key:
```
gcloud alpha compute tpus tpu-vm ssh patrick-tpu-v3-32 --zone europe-west4-a --worker 0
```
Logout of the TPU worker:
```
logout
```
You should now be back in the CPU host.
| {"requirements.txt": "ray==1.13.0\naiohttp==3.7\nfabric\ndataclasses\nfunc_timeout\nnumpy\nrequests\nnumpy", "setup.py": "from setuptools import setup, find_packages\n\nsetup(\n name='bloom_inference',\n version='0.0.0',\n packages=find_packages()\n)\n", ".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 2a04aa519d262729d54adef3d19d63879f81ea89 Hamza Amin <[email protected]> 1727369090 +0500\tclone: from https://github.com/huggingface/bloom-jax-inference.git\n", ".git\\refs\\heads\\main": "2a04aa519d262729d54adef3d19d63879f81ea89\n"} | null |
candle | {"type": "directory", "name": "candle", "children": [{"type": "directory", "name": ".cargo", "children": [{"type": "file", "name": "config.toml"}]}, {"type": "file", "name": ".pre-commit-config.yaml"}, {"type": "directory", "name": ".vscode", "children": [{"type": "file", "name": "settings.json"}]}, {"type": "directory", "name": "candle-book", "children": [{"type": "file", "name": "book.toml"}, {"type": "file", "name": "Cargo.toml"}, {"type": "directory", "name": "src", "children": [{"type": "directory", "name": "advanced", "children": [{"type": "file", "name": "mkl.md"}]}, {"type": "directory", "name": "apps", "children": [{"type": "file", "name": "desktop.md"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "rest.md"}, {"type": "file", "name": "wasm.md"}]}, {"type": "file", "name": "chapter_1.md"}, {"type": "directory", "name": "cuda", "children": [{"type": "file", "name": "porting.md"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "writing.md"}]}, {"type": "file", "name": "error_manage.md"}, {"type": "directory", "name": "guide", "children": [{"type": "file", "name": "cheatsheet.md"}, {"type": "file", "name": "hello_world.md"}, {"type": "file", "name": "installation.md"}]}, {"type": "directory", "name": "inference", "children": [{"type": "directory", "name": "cuda", "children": [{"type": "file", "name": "porting.md"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "writing.md"}]}, {"type": "file", "name": "hub.md"}, {"type": "file", "name": "inference.md"}]}, {"type": "file", "name": "lib.rs"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "simplified.rs"}, {"type": "file", "name": "SUMMARY.md"}, {"type": "directory", "name": "training", "children": [{"type": "file", "name": "finetuning.md"}, {"type": "file", "name": "mnist.md"}, {"type": "file", "name": "serialization.md"}, {"type": "file", "name": "simplified.md"}, {"type": "file", "name": "training.md"}]}]}]}, {"type": "directory", "name": "candle-core", "children": [{"type": "directory", "name": "benches", "children": [{"type": "directory", "name": "benchmarks", "children": [{"type": "file", "name": "affine.rs"}, {"type": "file", "name": "conv_transpose2d.rs"}, {"type": "file", "name": "matmul.rs"}, {"type": "file", "name": "mod.rs"}, {"type": "file", "name": "qmatmul.rs"}, {"type": "file", "name": "random.rs"}, {"type": "file", "name": "unary.rs"}, {"type": "file", "name": "where_cond.rs"}]}, {"type": "file", "name": "bench_main.rs"}]}, {"type": "file", "name": "Cargo.toml"}, {"type": "directory", "name": "examples", "children": [{"type": "file", "name": "basics.rs"}, {"type": "file", "name": "cuda_basics.rs"}, {"type": "file", "name": "cuda_sum_benchmark.rs"}, {"type": "file", "name": "metal_basics.rs"}]}, {"type": "file", "name": "LICENSE"}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "src", "children": [{"type": "file", "name": "accelerate.rs"}, {"type": "file", "name": "backend.rs"}, {"type": "file", "name": "backprop.rs"}, {"type": "file", "name": "conv.rs"}, {"type": "file", "name": "convert.rs"}, {"type": "directory", "name": "cpu", "children": [{"type": "file", "name": "avx.rs"}, {"type": "file", "name": "erf.rs"}, {"type": "file", "name": "kernels.rs"}, {"type": "file", "name": "mod.rs"}, {"type": "file", "name": "neon.rs"}, {"type": "file", "name": "simd128.rs"}]}, {"type": "directory", "name": "cpu_backend", "children": [{"type": "file", "name": "mod.rs"}, {"type": "file", "name": "utils.rs"}]}, {"type": "directory", "name": "cuda_backend", "children": [{"type": "file", "name": "cudnn.rs"}, {"type": "file", "name": "device.rs"}, {"type": "file", "name": "error.rs"}, {"type": "file", "name": "mod.rs"}, {"type": "file", "name": "utils.rs"}]}, {"type": "file", "name": "custom_op.rs"}, {"type": "file", "name": "device.rs"}, {"type": "file", "name": "display.rs"}, {"type": "file", "name": "dtype.rs"}, {"type": "file", "name": "dummy_cuda_backend.rs"}, {"type": "file", "name": "dummy_metal_backend.rs"}, {"type": "file", "name": "error.rs"}, {"type": "file", "name": "indexer.rs"}, {"type": "file", "name": "layout.rs"}, {"type": "file", "name": "lib.rs"}, {"type": "directory", "name": "metal_backend", "children": [{"type": "file", "name": "device.rs"}, {"type": "file", "name": "mod.rs"}]}, {"type": "file", "name": "mkl.rs"}, {"type": "file", "name": "npy.rs"}, {"type": "file", "name": "op.rs"}, {"type": "file", "name": "pickle.rs"}, {"type": "directory", "name": "quantized", "children": [{"type": "file", "name": "avx.rs"}, {"type": "file", "name": "cuda.rs"}, {"type": "file", "name": "dummy_cuda.rs"}, {"type": "file", "name": "dummy_metal.rs"}, {"type": "file", "name": "ggml_file.rs"}, {"type": "file", "name": "gguf_file.rs"}, {"type": "file", "name": "k_quants.rs"}, {"type": "file", "name": "metal.rs"}, {"type": "file", "name": "mod.rs"}, {"type": "file", "name": "neon.rs"}, {"type": "file", "name": "simd128.rs"}, {"type": "file", "name": "utils.rs"}]}, {"type": "file", "name": "safetensors.rs"}, {"type": "file", "name": "scalar.rs"}, {"type": "file", "name": "shape.rs"}, {"type": "file", "name": "sort.rs"}, {"type": "file", "name": "storage.rs"}, {"type": "file", "name": "streaming.rs"}, {"type": "file", "name": "strided_index.rs"}, {"type": "file", "name": "tensor.rs"}, {"type": "file", "name": "tensor_cat.rs"}, {"type": "file", "name": "test_utils.rs"}, {"type": "file", "name": "utils.rs"}, {"type": "file", "name": "variable.rs"}]}, {"type": "directory", "name": "tests", "children": [{"type": "file", "name": "conv_tests.rs"}, {"type": "file", "name": "custom_op_tests.rs"}, {"type": "file", "name": "display_tests.rs"}, {"type": "file", "name": "fortran_tensor_3d.pth"}, {"type": "file", "name": "grad_tests.rs"}, {"type": "file", "name": "indexing_tests.rs"}, {"type": "file", "name": "layout_tests.rs"}, {"type": "file", "name": "matmul_tests.rs"}, {"type": "file", "name": "npy.py"}, {"type": "file", "name": "pool_tests.rs"}, {"type": "file", "name": "pth.py"}, {"type": "file", "name": "pth_tests.rs"}, {"type": "file", "name": "quantized_tests.rs"}, {"type": "file", "name": "serialization_tests.rs"}, {"type": "file", "name": "tensor_tests.rs"}, {"type": "file", "name": "test.npz"}, {"type": "file", "name": "test.pt"}, {"type": "file", "name": "test_with_key.pt"}]}]}, {"type": "directory", "name": "candle-datasets", "children": [{"type": "file", "name": "Cargo.toml"}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "src", "children": [{"type": "file", "name": "batcher.rs"}, {"type": "file", "name": "hub.rs"}, {"type": "file", "name": "lib.rs"}, {"type": "directory", "name": "nlp", "children": [{"type": "file", "name": "mod.rs"}, {"type": "file", "name": "tinystories.rs"}]}, {"type": "directory", "name": "vision", "children": [{"type": "file", "name": "cifar.rs"}, {"type": "file", "name": "mnist.rs"}, {"type": "file", "name": "mod.rs"}]}]}]}, {"type": "directory", "name": "candle-examples", "children": [{"type": "file", "name": "build.rs"}, {"type": "file", "name": "Cargo.toml"}, {"type": "directory", "name": "examples", "children": [{"type": "directory", "name": "based", "children": [{"type": "file", "name": "main.rs"}, {"type": "file", "name": "README.md"}]}, {"type": "directory", "name": "beit", "children": [{"type": "file", "name": "main.rs"}, {"type": "file", "name": "README.md"}]}, {"type": "directory", "name": "bert", "children": [{"type": "file", "name": "main.rs"}, {"type": "file", "name": "README.md"}]}, {"type": "directory", "name": "bigcode", "children": [{"type": "file", "name": "main.rs"}, {"type": "file", "name": "README.md"}]}, {"type": "directory", "name": "blip", "children": [{"type": "file", "name": "main.rs"}, {"type": "file", "name": "README.md"}]}, {"type": "directory", "name": "chatglm", "children": [{"type": "file", "name": "main.rs"}]}, {"type": "directory", "name": "clip", "children": [{"type": "file", "name": "main.rs"}, {"type": "file", "name": "README.md"}]}, {"type": "directory", "name": "codegeex4-9b", "children": [{"type": "file", "name": "main.rs"}, {"type": "file", "name": "README.org"}]}, {"type": "directory", "name": "convmixer", "children": [{"type": "file", "name": "main.rs"}]}, {"type": "directory", "name": "convnext", "children": [{"type": "file", "name": "main.rs"}, {"type": "file", "name": "README.md"}]}, {"type": "directory", "name": "custom-ops", "children": [{"type": "file", "name": "cuda_kernels.rs"}, {"type": "directory", "name": "kernels", "children": [{"type": "file", "name": "layernorm_kernels.cu"}, {"type": "file", "name": "reduction_utils.cuh"}]}, {"type": "file", "name": "main.rs"}]}, {"type": "directory", "name": "depth_anything_v2", "children": [{"type": "file", "name": "color_map.rs"}, {"type": "file", "name": "main.rs"}, {"type": "file", "name": "README.md"}]}, {"type": "directory", "name": "dinov2", "children": [{"type": "file", "name": "main.rs"}, {"type": "file", "name": "README.md"}]}, {"type": "directory", "name": "dinov2reg4", "children": [{"type": "file", "name": "main.rs"}, {"type": "file", "name": "README.md"}]}, {"type": "directory", "name": "distilbert", "children": [{"type": "file", "name": "main.rs"}, {"type": "file", "name": "README.md"}]}, {"type": "directory", "name": "efficientnet", "children": [{"type": "file", "name": "main.rs"}]}, {"type": "directory", "name": "efficientvit", "children": [{"type": "file", "name": "main.rs"}, {"type": "file", "name": "README.md"}]}, {"type": "directory", "name": "encodec", "children": [{"type": "file", "name": "audio_io.rs"}, {"type": "file", "name": "jfk-codes.safetensors"}, {"type": "file", "name": "main.rs"}, {"type": "file", "name": "README.md"}]}, {"type": "directory", "name": "eva2", "children": [{"type": "file", "name": "main.rs"}, {"type": "file", "name": "README.md"}]}, {"type": "directory", "name": "falcon", "children": [{"type": "file", "name": "main.rs"}, {"type": "file", "name": "README.md"}]}, {"type": "directory", "name": "fastvit", "children": [{"type": "file", "name": "main.rs"}, {"type": "file", "name": "README.md"}]}, {"type": "directory", "name": "flux", "children": [{"type": "directory", "name": "assets", "children": []}, {"type": "file", "name": "main.rs"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "t5_tokenizer.py"}]}, {"type": "directory", "name": "gemma", "children": [{"type": "file", "name": "main.rs"}, {"type": "file", "name": "README.md"}]}, {"type": "directory", "name": "glm4", "children": [{"type": "file", "name": "main.rs"}, {"type": "file", "name": "README.org"}]}, {"type": "directory", "name": "granite", "children": [{"type": "file", "name": "main.rs"}, {"type": "file", "name": "README.md"}]}, {"type": "directory", "name": "gte-qwen", "children": [{"type": "file", "name": "main.rs"}, {"type": "file", "name": "README.md"}]}, {"type": "directory", "name": "hiera", "children": [{"type": "file", "name": "main.rs"}, {"type": "file", "name": "README.md"}]}, {"type": "directory", "name": "jina-bert", "children": [{"type": "file", "name": "main.rs"}, {"type": "file", "name": "README.md"}]}, {"type": "directory", "name": "llama", "children": [{"type": "file", "name": "main.rs"}]}, {"type": "directory", "name": "llama2-c", "children": [{"type": "file", "name": "main.rs"}, {"type": "file", "name": "training.rs"}]}, {"type": "directory", "name": "llama_multiprocess", "children": [{"type": "file", "name": "main.rs"}, {"type": "file", "name": "model.rs"}]}, {"type": "directory", "name": "llava", "children": [{"type": "file", "name": "constants.rs"}, {"type": "file", "name": "conversation.rs"}, {"type": "file", "name": "image_processor.rs"}, {"type": "file", "name": "main.rs"}, {"type": "file", "name": "readme.md"}]}, {"type": "directory", "name": "mamba", "children": [{"type": "file", "name": "main.rs"}, {"type": "file", "name": "README.md"}]}, {"type": "directory", "name": "mamba-minimal", "children": [{"type": "file", "name": "main.rs"}, {"type": "file", "name": "model.rs"}, {"type": "file", "name": "README.md"}]}, {"type": "directory", "name": "marian-mt", "children": [{"type": "file", "name": "convert_slow_tokenizer.py"}, {"type": "file", "name": "main.rs"}, {"type": "file", "name": "README.md"}]}, {"type": "directory", "name": "metavoice", "children": [{"type": "file", "name": "main.rs"}, {"type": "file", "name": "README.md"}]}, {"type": "directory", "name": "mimi", "children": [{"type": "file", "name": "audio_io.rs"}, {"type": "file", "name": "main.rs"}, {"type": "file", "name": "README.md"}]}, {"type": "directory", "name": "mistral", "children": [{"type": "file", "name": "main.rs"}, {"type": "file", "name": "README.md"}]}, {"type": "directory", "name": "mixtral", "children": [{"type": "file", "name": "main.rs"}, {"type": "file", "name": "README.md"}]}, {"type": "directory", "name": "mnist-training", "children": [{"type": "file", "name": "main.rs"}]}, {"type": "directory", "name": "mobileclip", "children": [{"type": "file", "name": "main.rs"}, {"type": "file", "name": "README.md"}]}, {"type": "directory", "name": "mobilenetv4", "children": [{"type": "file", "name": "main.rs"}, {"type": "file", "name": "README.md"}]}, {"type": "directory", "name": "mobileone", "children": [{"type": "file", "name": "main.rs"}, {"type": "file", "name": "README.md"}]}, {"type": "directory", "name": "moondream", "children": [{"type": "file", "name": "main.rs"}, {"type": "file", "name": "README.md"}]}, {"type": "directory", "name": "musicgen", "children": [{"type": "file", "name": "main.rs"}, {"type": "file", "name": "musicgen_model.rs"}]}, {"type": "directory", "name": "olmo", "children": [{"type": "file", "name": "main.rs"}, {"type": "file", "name": "README.md"}]}, {"type": "directory", "name": "onnx", "children": [{"type": "file", "name": "main.rs"}, {"type": "file", "name": "README.md"}]}, {"type": "file", "name": "onnx_basics.rs"}, {"type": "directory", "name": "parler-tts", "children": [{"type": "file", "name": "main.rs"}, {"type": "file", "name": "README.md"}]}, {"type": "directory", "name": "phi", "children": [{"type": "file", "name": "main.rs"}, {"type": "file", "name": "README.md"}]}, {"type": "directory", "name": "quantized", "children": [{"type": "directory", "name": "assets", "children": []}, {"type": "file", "name": "main.rs"}, {"type": "file", "name": "README.md"}]}, {"type": "directory", "name": "quantized-phi", "children": [{"type": "file", "name": "main.rs"}]}, {"type": "directory", "name": "quantized-qwen2-instruct", "children": [{"type": "file", "name": "main.rs"}, {"type": "file", "name": "README.md"}]}, {"type": "directory", "name": "quantized-t5", "children": [{"type": "file", "name": "main.rs"}, {"type": "file", "name": "README.md"}]}, {"type": "directory", "name": "qwen", "children": [{"type": "file", "name": "main.rs"}, {"type": "file", "name": "README.md"}]}, {"type": "directory", "name": "recurrent-gemma", "children": [{"type": "file", "name": "main.rs"}, {"type": "file", "name": "README.md"}]}, {"type": "directory", "name": "reinforcement-learning", "children": [{"type": "file", "name": "atari_wrappers.py"}, {"type": "file", "name": "ddpg.rs"}, {"type": "file", "name": "dqn.rs"}, {"type": "file", "name": "gym_env.rs"}, {"type": "file", "name": "main.rs"}, {"type": "file", "name": "policy_gradient.rs"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "vec_gym_env.rs"}]}, {"type": "directory", "name": "replit-code", "children": [{"type": "file", "name": "main.rs"}, {"type": "file", "name": "README.md"}]}, {"type": "directory", "name": "repvgg", "children": [{"type": "file", "name": "main.rs"}, {"type": "file", "name": "README.md"}]}, {"type": "directory", "name": "resnet", "children": [{"type": "file", "name": "export_models.py"}, {"type": "file", "name": "main.rs"}, {"type": "file", "name": "README.md"}]}, {"type": "directory", "name": "rwkv", "children": [{"type": "file", "name": "main.rs"}, {"type": "file", "name": "README.md"}]}, {"type": "directory", "name": "segformer", "children": [{"type": "directory", "name": "assets", "children": [{"type": "file", "name": "labels.json"}]}, {"type": "file", "name": "main.rs"}, {"type": "file", "name": "README.md"}]}, {"type": "directory", "name": "segment-anything", "children": [{"type": "directory", "name": "assets", "children": []}, {"type": "file", "name": "main.rs"}, {"type": "file", "name": "README.md"}]}, {"type": "directory", "name": "silero-vad", "children": [{"type": "file", "name": "main.rs"}, {"type": "file", "name": "README.md"}]}, {"type": "directory", "name": "stable-diffusion", "children": [{"type": "directory", "name": "assets", "children": []}, {"type": "file", "name": "main.rs"}, {"type": "file", "name": "README.md"}]}, {"type": "directory", "name": "stable-lm", "children": [{"type": "file", "name": "main.rs"}, {"type": "file", "name": "README.md"}]}, {"type": "directory", "name": "starcoder2", "children": [{"type": "file", "name": "main.rs"}]}, {"type": "directory", "name": "t5", "children": [{"type": "file", "name": "main.rs"}, {"type": "file", "name": "README.md"}]}, {"type": "directory", "name": "trocr", "children": [{"type": "directory", "name": "assets", "children": []}, {"type": "file", "name": "image_processor.rs"}, {"type": "file", "name": "main.rs"}, {"type": "file", "name": "readme.md"}]}, {"type": "directory", "name": "vgg", "children": [{"type": "file", "name": "main.rs"}, {"type": "file", "name": "README.md"}]}, {"type": "directory", "name": "vit", "children": [{"type": "file", "name": "main.rs"}, {"type": "file", "name": "README.md"}]}, {"type": "directory", "name": "whisper", "children": [{"type": "file", "name": "extract_weights.py"}, {"type": "file", "name": "main.rs"}, {"type": "file", "name": "melfilters.bytes"}, {"type": "file", "name": "melfilters128.bytes"}, {"type": "file", "name": "multilingual.rs"}, {"type": "file", "name": "pcm_decode.rs"}, {"type": "file", "name": "README.md"}]}, {"type": "directory", "name": "whisper-microphone", "children": [{"type": "file", "name": "main.rs"}, {"type": "file", "name": "multilingual.rs"}]}, {"type": "directory", "name": "wuerstchen", "children": [{"type": "directory", "name": "assets", "children": []}, {"type": "file", "name": "main.rs"}, {"type": "file", "name": "README.md"}]}, {"type": "directory", "name": "yi", "children": [{"type": "file", "name": "main.rs"}]}, {"type": "directory", "name": "yolo-v3", "children": [{"type": "file", "name": "darknet.rs"}, {"type": "file", "name": "extract-weights.py"}, {"type": "file", "name": "main.rs"}, {"type": "file", "name": "yolo-v3.cfg"}]}, {"type": "directory", "name": "yolo-v8", "children": [{"type": "directory", "name": "assets", "children": []}, {"type": "file", "name": "main.rs"}, {"type": "file", "name": "model.rs"}, {"type": "file", "name": "README.md"}]}]}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "src", "children": [{"type": "file", "name": "audio.rs"}, {"type": "file", "name": "bs1770.rs"}, {"type": "file", "name": "coco_classes.rs"}, {"type": "file", "name": "imagenet.rs"}, {"type": "file", "name": "lib.rs"}, {"type": "file", "name": "token_output_stream.rs"}, {"type": "file", "name": "wav.rs"}]}]}, {"type": "directory", "name": "candle-flash-attn", "children": [{"type": "file", "name": "build.rs"}, {"type": "file", "name": "Cargo.toml"}, {"type": "directory", "name": "cutlass", "children": []}, {"type": "directory", "name": "kernels", "children": [{"type": "file", "name": "alibi.h"}, {"type": "file", "name": "block_info.h"}, {"type": "file", "name": "dropout.h"}, {"type": "file", "name": "error.h"}, {"type": "file", "name": "flash.h"}, {"type": "file", "name": "flash_api.cu"}, {"type": "file", "name": "flash_fwd_hdim128_bf16_causal_sm80.cu"}, {"type": "file", "name": "flash_fwd_hdim128_bf16_sm80.cu"}, {"type": "file", "name": "flash_fwd_hdim128_fp16_causal_sm80.cu"}, {"type": "file", "name": "flash_fwd_hdim128_fp16_sm80.cu"}, {"type": "file", "name": "flash_fwd_hdim160_bf16_causal_sm80.cu"}, {"type": "file", "name": "flash_fwd_hdim160_bf16_sm80.cu"}, {"type": "file", "name": "flash_fwd_hdim160_fp16_causal_sm80.cu"}, {"type": "file", "name": "flash_fwd_hdim160_fp16_sm80.cu"}, {"type": "file", "name": "flash_fwd_hdim192_bf16_causal_sm80.cu"}, {"type": "file", "name": "flash_fwd_hdim192_bf16_sm80.cu"}, {"type": "file", "name": "flash_fwd_hdim192_fp16_causal_sm80.cu"}, {"type": "file", "name": "flash_fwd_hdim192_fp16_sm80.cu"}, {"type": "file", "name": "flash_fwd_hdim224_bf16_causal_sm80.cu"}, {"type": "file", "name": "flash_fwd_hdim224_bf16_sm80.cu"}, {"type": "file", "name": "flash_fwd_hdim224_fp16_causal_sm80.cu"}, {"type": "file", "name": "flash_fwd_hdim224_fp16_sm80.cu"}, {"type": "file", "name": "flash_fwd_hdim256_bf16_causal_sm80.cu"}, {"type": "file", "name": "flash_fwd_hdim256_bf16_sm80.cu"}, {"type": "file", "name": "flash_fwd_hdim256_fp16_causal_sm80.cu"}, {"type": "file", "name": "flash_fwd_hdim256_fp16_sm80.cu"}, {"type": "file", "name": "flash_fwd_hdim32_bf16_causal_sm80.cu"}, {"type": "file", "name": "flash_fwd_hdim32_bf16_sm80.cu"}, {"type": "file", "name": "flash_fwd_hdim32_fp16_causal_sm80.cu"}, {"type": "file", "name": "flash_fwd_hdim32_fp16_sm80.cu"}, {"type": "file", "name": "flash_fwd_hdim64_bf16_causal_sm80.cu"}, {"type": "file", "name": "flash_fwd_hdim64_bf16_sm80.cu"}, {"type": "file", "name": "flash_fwd_hdim64_fp16_causal_sm80.cu"}, {"type": "file", "name": "flash_fwd_hdim64_fp16_sm80.cu"}, {"type": "file", "name": "flash_fwd_hdim96_bf16_causal_sm80.cu"}, {"type": "file", "name": "flash_fwd_hdim96_bf16_sm80.cu"}, {"type": "file", "name": "flash_fwd_hdim96_fp16_causal_sm80.cu"}, {"type": "file", "name": "flash_fwd_hdim96_fp16_sm80.cu"}, {"type": "file", "name": "flash_fwd_kernel.h"}, {"type": "file", "name": "flash_fwd_launch_template.h"}, {"type": "file", "name": "kernels.h"}, {"type": "file", "name": "kernel_helpers.h"}, {"type": "file", "name": "kernel_traits.h"}, {"type": "file", "name": "kernel_traits_sm90.h"}, {"type": "file", "name": "mask.h"}, {"type": "file", "name": "philox.cuh"}, {"type": "file", "name": "rotary.h"}, {"type": "file", "name": "softmax.h"}, {"type": "file", "name": "static_switch.h"}, {"type": "file", "name": "utils.h"}]}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "src", "children": [{"type": "file", "name": "ffi.rs"}, {"type": "file", "name": "lib.rs"}]}, {"type": "directory", "name": "tests", "children": [{"type": "file", "name": "flash_attn_tests.rs"}]}]}, {"type": "directory", "name": "candle-kernels", "children": [{"type": "file", "name": "build.rs"}, {"type": "file", "name": "Cargo.toml"}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "src", "children": [{"type": "file", "name": "affine.cu"}, {"type": "file", "name": "binary.cu"}, {"type": "file", "name": "binary_op_macros.cuh"}, {"type": "file", "name": "cast.cu"}, {"type": "file", "name": "compatibility.cuh"}, {"type": "file", "name": "conv.cu"}, {"type": "file", "name": "cuda_utils.cuh"}, {"type": "file", "name": "fill.cu"}, {"type": "file", "name": "indexing.cu"}, {"type": "file", "name": "lib.rs"}, {"type": "file", "name": "quantized.cu"}, {"type": "file", "name": "reduce.cu"}, {"type": "file", "name": "sort.cu"}, {"type": "file", "name": "ternary.cu"}, {"type": "file", "name": "unary.cu"}]}]}, {"type": "directory", "name": "candle-metal-kernels", "children": [{"type": "file", "name": "Cargo.toml"}, {"type": "directory", "name": "examples", "children": [{"type": "file", "name": "metal_benchmarks.rs"}]}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "src", "children": [{"type": "file", "name": "affine.metal"}, {"type": "file", "name": "binary.metal"}, {"type": "file", "name": "cast.metal"}, {"type": "file", "name": "conv.metal"}, {"type": "file", "name": "indexing.metal"}, {"type": "file", "name": "lib.rs"}, {"type": "file", "name": "libMetalFlashAttention.metallib"}, {"type": "file", "name": "mlx_gemm.metal"}, {"type": "file", "name": "quantized.metal"}, {"type": "file", "name": "random.metal"}, {"type": "file", "name": "reduce.metal"}, {"type": "file", "name": "sort.metal"}, {"type": "file", "name": "ternary.metal"}, {"type": "file", "name": "tests.rs"}, {"type": "file", "name": "unary.metal"}, {"type": "file", "name": "utils.rs"}]}, {"type": "directory", "name": "tmp", "children": [{"type": "file", "name": "affine.rs"}, {"type": "file", "name": "binary.rs"}, {"type": "file", "name": "cast.rs"}, {"type": "file", "name": "unary.rs"}]}]}, {"type": "directory", "name": "candle-nn", "children": [{"type": "directory", "name": "benches", "children": [{"type": "directory", "name": "benchmarks", "children": [{"type": "file", "name": "conv.rs"}, {"type": "file", "name": "layer_norm.rs"}, {"type": "file", "name": "mod.rs"}]}, {"type": "file", "name": "bench_main.rs"}]}, {"type": "file", "name": "Cargo.toml"}, {"type": "directory", "name": "examples", "children": [{"type": "file", "name": "basic_optimizer.rs"}, {"type": "file", "name": "cpu_benchmarks.rs"}]}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "src", "children": [{"type": "file", "name": "activation.rs"}, {"type": "file", "name": "batch_norm.rs"}, {"type": "file", "name": "conv.rs"}, {"type": "file", "name": "embedding.rs"}, {"type": "file", "name": "encoding.rs"}, {"type": "file", "name": "func.rs"}, {"type": "file", "name": "group_norm.rs"}, {"type": "file", "name": "init.rs"}, {"type": "file", "name": "kv_cache.rs"}, {"type": "file", "name": "layer_norm.rs"}, {"type": "file", "name": "lib.rs"}, {"type": "file", "name": "linear.rs"}, {"type": "file", "name": "loss.rs"}, {"type": "file", "name": "ops.rs"}, {"type": "file", "name": "optim.rs"}, {"type": "file", "name": "rnn.rs"}, {"type": "file", "name": "rotary_emb.rs"}, {"type": "file", "name": "sequential.rs"}, {"type": "file", "name": "var_builder.rs"}, {"type": "file", "name": "var_map.rs"}]}, {"type": "directory", "name": "tests", "children": [{"type": "file", "name": "batch_norm.rs"}, {"type": "file", "name": "group_norm.rs"}, {"type": "file", "name": "kv_cache.rs"}, {"type": "file", "name": "layer_norm.rs"}, {"type": "file", "name": "loss.rs"}, {"type": "file", "name": "one_hot.rs"}, {"type": "file", "name": "ops.rs"}, {"type": "file", "name": "optim.rs"}, {"type": "file", "name": "rnn.rs"}]}]}, {"type": "directory", "name": "candle-onnx", "children": [{"type": "file", "name": "build.rs"}, {"type": "file", "name": "Cargo.toml"}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "src", "children": [{"type": "file", "name": "eval.rs"}, {"type": "file", "name": "lib.rs"}, {"type": "file", "name": "onnx.proto3"}]}, {"type": "directory", "name": "tests", "children": [{"type": "file", "name": "ops.rs"}]}]}, {"type": "directory", "name": "candle-pyo3", "children": [{"type": "file", "name": "build.rs"}, {"type": "file", "name": "Cargo.toml"}, {"type": "file", "name": "e5.py"}, {"type": "file", "name": "pyproject.toml"}, {"type": "directory", "name": "py_src", "children": [{"type": "directory", "name": "candle", "children": [{"type": "directory", "name": "functional", "children": [{"type": "file", "name": "__init__.py"}, {"type": "file", "name": "__init__.pyi"}]}, {"type": "directory", "name": "models", "children": [{"type": "file", "name": "bert.py"}, {"type": "file", "name": "llama.py"}]}, {"type": "directory", "name": "nn", "children": [{"type": "file", "name": "container.py"}, {"type": "file", "name": "linear.py"}, {"type": "file", "name": "module.py"}, {"type": "file", "name": "normalization.py"}, {"type": "file", "name": "sparse.py"}, {"type": "file", "name": "__init__.py"}, {"type": "file", "name": "__init__.pyi"}]}, {"type": "directory", "name": "onnx", "children": [{"type": "file", "name": "__init__.py"}, {"type": "file", "name": "__init__.pyi"}]}, {"type": "directory", "name": "testing", "children": [{"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "typing", "children": [{"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "utils", "children": [{"type": "file", "name": "__init__.py"}, {"type": "file", "name": "__init__.pyi"}]}, {"type": "file", "name": "__init__.py"}, {"type": "file", "name": "__init__.pyi"}]}]}, {"type": "file", "name": "quant-llama.py"}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "src", "children": [{"type": "file", "name": "lib.rs"}, {"type": "file", "name": "onnx.rs"}, {"type": "file", "name": "shape.rs"}, {"type": "file", "name": "utils.rs"}]}, {"type": "file", "name": "stub.py"}, {"type": "file", "name": "test.py"}, {"type": "directory", "name": "tests", "children": [{"type": "directory", "name": "bindings", "children": [{"type": "file", "name": "test_linear.py"}, {"type": "file", "name": "test_module.py"}, {"type": "file", "name": "test_testing.py"}]}, {"type": "directory", "name": "native", "children": [{"type": "file", "name": "test_shape.py"}, {"type": "file", "name": "test_tensor.py"}, {"type": "file", "name": "test_utils.py"}]}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "test_pytorch.py"}, {"type": "directory", "name": "_additional_typing", "children": [{"type": "file", "name": "README.md"}, {"type": "file", "name": "__init__.py"}]}]}, {"type": "directory", "name": "candle-transformers", "children": [{"type": "file", "name": "Cargo.toml"}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "src", "children": [{"type": "directory", "name": "generation", "children": [{"type": "file", "name": "mod.rs"}]}, {"type": "file", "name": "lib.rs"}, {"type": "directory", "name": "models", "children": [{"type": "file", "name": "based.rs"}, {"type": "file", "name": "beit.rs"}, {"type": "file", "name": "bert.rs"}, {"type": "file", "name": "bigcode.rs"}, {"type": "file", "name": "blip.rs"}, {"type": "file", "name": "blip_text.rs"}, {"type": "file", "name": "chatglm.rs"}, {"type": "directory", "name": "clip", "children": [{"type": "file", "name": "mod.rs"}, {"type": "file", "name": "text_model.rs"}, {"type": "file", "name": "vision_model.rs"}]}, {"type": "file", "name": "codegeex4_9b.rs"}, {"type": "file", "name": "convmixer.rs"}, {"type": "file", "name": "convnext.rs"}, {"type": "file", "name": "dac.rs"}, {"type": "file", "name": "depth_anything_v2.rs"}, {"type": "file", "name": "dinov2.rs"}, {"type": "file", "name": "dinov2reg4.rs"}, {"type": "file", "name": "distilbert.rs"}, {"type": "file", "name": "efficientnet.rs"}, {"type": "file", "name": "efficientvit.rs"}, {"type": "file", "name": "encodec.rs"}, {"type": "file", "name": "eva2.rs"}, {"type": "file", "name": "falcon.rs"}, {"type": "file", "name": "fastvit.rs"}, {"type": "directory", "name": "flux", "children": [{"type": "file", "name": "autoencoder.rs"}, {"type": "file", "name": "mod.rs"}, {"type": "file", "name": "model.rs"}, {"type": "file", "name": "quantized_model.rs"}, {"type": "file", "name": "sampling.rs"}]}, {"type": "file", "name": "gemma.rs"}, {"type": "file", "name": "gemma2.rs"}, {"type": "file", "name": "glm4.rs"}, {"type": "file", "name": "granite.rs"}, {"type": "file", "name": "hiera.rs"}, {"type": "file", "name": "jina_bert.rs"}, {"type": "file", "name": "llama.rs"}, {"type": "file", "name": "llama2_c.rs"}, {"type": "file", "name": "llama2_c_weights.rs"}, {"type": "directory", "name": "llava", "children": [{"type": "file", "name": "config.rs"}, {"type": "file", "name": "mod.rs"}, {"type": "file", "name": "utils.rs"}]}, {"type": "file", "name": "mamba.rs"}, {"type": "file", "name": "marian.rs"}, {"type": "file", "name": "metavoice.rs"}, {"type": "directory", "name": "mimi", "children": [{"type": "file", "name": "conv.rs"}, {"type": "file", "name": "encodec.rs"}, {"type": "file", "name": "mod.rs"}, {"type": "file", "name": "quantization.rs"}, {"type": "file", "name": "seanet.rs"}, {"type": "file", "name": "transformer.rs"}]}, {"type": "file", "name": "mistral.rs"}, {"type": "file", "name": "mixformer.rs"}, {"type": "file", "name": "mixtral.rs"}, {"type": "directory", "name": "mmdit", "children": [{"type": "file", "name": "blocks.rs"}, {"type": "file", "name": "embedding.rs"}, {"type": "file", "name": "mod.rs"}, {"type": "file", "name": "model.rs"}, {"type": "file", "name": "projections.rs"}]}, {"type": "file", "name": "mobileclip.rs"}, {"type": "file", "name": "mobilenetv4.rs"}, {"type": "file", "name": "mobileone.rs"}, {"type": "file", "name": "mod.rs"}, {"type": "file", "name": "moondream.rs"}, {"type": "file", "name": "mpt.rs"}, {"type": "file", "name": "olmo.rs"}, {"type": "directory", "name": "openclip", "children": [{"type": "file", "name": "mod.rs"}, {"type": "file", "name": "text_model.rs"}]}, {"type": "file", "name": "parler_tts.rs"}, {"type": "file", "name": "persimmon.rs"}, {"type": "file", "name": "phi.rs"}, {"type": "file", "name": "phi3.rs"}, {"type": "file", "name": "quantized_blip.rs"}, {"type": "file", "name": "quantized_blip_text.rs"}, {"type": "file", "name": "quantized_llama.rs"}, {"type": "file", "name": "quantized_llama2_c.rs"}, {"type": "file", "name": "quantized_metavoice.rs"}, {"type": "file", "name": "quantized_mistral.rs"}, {"type": "file", "name": "quantized_mixformer.rs"}, {"type": "file", "name": "quantized_moondream.rs"}, {"type": "file", "name": "quantized_mpt.rs"}, {"type": "file", "name": "quantized_phi.rs"}, {"type": "file", "name": "quantized_phi3.rs"}, {"type": "file", "name": "quantized_qwen2.rs"}, {"type": "file", "name": "quantized_recurrent_gemma.rs"}, {"type": "file", "name": "quantized_rwkv_v5.rs"}, {"type": "file", "name": "quantized_rwkv_v6.rs"}, {"type": "file", "name": "quantized_stable_lm.rs"}, {"type": "file", "name": "quantized_t5.rs"}, {"type": "file", "name": "qwen2.rs"}, {"type": "file", "name": "qwen2_moe.rs"}, {"type": "file", "name": "recurrent_gemma.rs"}, {"type": "file", "name": "repvgg.rs"}, {"type": "file", "name": "resnet.rs"}, {"type": "file", "name": "rwkv_v5.rs"}, {"type": "file", "name": "rwkv_v6.rs"}, {"type": "file", "name": "segformer.rs"}, {"type": "directory", "name": "segment_anything", "children": [{"type": "file", "name": "image_encoder.rs"}, {"type": "file", "name": "mask_decoder.rs"}, {"type": "file", "name": "mod.rs"}, {"type": "file", "name": "prompt_encoder.rs"}, {"type": "file", "name": "sam.rs"}, {"type": "file", "name": "tiny_vit.rs"}, {"type": "file", "name": "transformer.rs"}]}, {"type": "directory", "name": "stable_diffusion", "children": [{"type": "file", "name": "attention.rs"}, {"type": "file", "name": "clip.rs"}, {"type": "file", "name": "ddim.rs"}, {"type": "file", "name": "ddpm.rs"}, {"type": "file", "name": "embeddings.rs"}, {"type": "file", "name": "euler_ancestral_discrete.rs"}, {"type": "file", "name": "mod.rs"}, {"type": "file", "name": "resnet.rs"}, {"type": "file", "name": "schedulers.rs"}, {"type": "file", "name": "unet_2d.rs"}, {"type": "file", "name": "unet_2d_blocks.rs"}, {"type": "file", "name": "utils.rs"}, {"type": "file", "name": "vae.rs"}]}, {"type": "file", "name": "stable_lm.rs"}, {"type": "file", "name": "starcoder2.rs"}, {"type": "file", "name": "t5.rs"}, {"type": "file", "name": "trocr.rs"}, {"type": "file", "name": "vgg.rs"}, {"type": "file", "name": "vit.rs"}, {"type": "directory", "name": "whisper", "children": [{"type": "file", "name": "audio.rs"}, {"type": "file", "name": "mod.rs"}, {"type": "file", "name": "model.rs"}, {"type": "file", "name": "quantized_model.rs"}]}, {"type": "file", "name": "with_tracing.rs"}, {"type": "directory", "name": "wuerstchen", "children": [{"type": "file", "name": "attention_processor.rs"}, {"type": "file", "name": "common.rs"}, {"type": "file", "name": "ddpm.rs"}, {"type": "file", "name": "diffnext.rs"}, {"type": "file", "name": "mod.rs"}, {"type": "file", "name": "paella_vq.rs"}, {"type": "file", "name": "prior.rs"}]}, {"type": "file", "name": "yi.rs"}]}, {"type": "file", "name": "object_detection.rs"}, {"type": "directory", "name": "pipelines", "children": [{"type": "file", "name": "mod.rs"}, {"type": "file", "name": "text_generation.rs"}]}, {"type": "file", "name": "quantized_nn.rs"}, {"type": "file", "name": "quantized_var_builder.rs"}, {"type": "file", "name": "utils.rs"}]}, {"type": "directory", "name": "tests", "children": [{"type": "file", "name": "generation_tests.rs"}, {"type": "file", "name": "nms_tests.rs"}]}]}, {"type": "directory", "name": "candle-wasm-examples", "children": [{"type": "directory", "name": "bert", "children": [{"type": "file", "name": "bertWorker.js"}, {"type": "file", "name": "build-lib.sh"}, {"type": "file", "name": "Cargo.toml"}, {"type": "file", "name": "lib-example.html"}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "src", "children": [{"type": "directory", "name": "bin", "children": [{"type": "file", "name": "m.rs"}]}, {"type": "file", "name": "lib.rs"}]}, {"type": "file", "name": "utils.js"}]}, {"type": "directory", "name": "blip", "children": [{"type": "file", "name": "blipWorker.js"}, {"type": "file", "name": "build-lib.sh"}, {"type": "file", "name": "Cargo.toml"}, {"type": "file", "name": "index.html"}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "src", "children": [{"type": "directory", "name": "bin", "children": [{"type": "file", "name": "m.rs"}]}, {"type": "file", "name": "lib.rs"}, {"type": "file", "name": "token_output_stream.rs"}]}]}, {"type": "directory", "name": "llama2-c", "children": [{"type": "file", "name": "build-lib.sh"}, {"type": "file", "name": "Cargo.toml"}, {"type": "file", "name": "index.html"}, {"type": "file", "name": "lib-example.html"}, {"type": "file", "name": "llama2cWorker.js"}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "src", "children": [{"type": "file", "name": "app.rs"}, {"type": "directory", "name": "bin", "children": [{"type": "file", "name": "app.rs"}, {"type": "file", "name": "m.rs"}, {"type": "file", "name": "worker.rs"}]}, {"type": "file", "name": "lib.rs"}, {"type": "file", "name": "model.rs"}, {"type": "file", "name": "worker.rs"}]}]}, {"type": "directory", "name": "moondream", "children": [{"type": "file", "name": "build-lib.sh"}, {"type": "file", "name": "Cargo.toml"}, {"type": "file", "name": "code.js"}, {"type": "file", "name": "index.html"}, {"type": "file", "name": "moondreamWorker.js"}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "src", "children": [{"type": "directory", "name": "bin", "children": [{"type": "file", "name": "m.rs"}]}, {"type": "file", "name": "lib.rs"}]}]}, {"type": "directory", "name": "phi", "children": [{"type": "file", "name": "build-lib.sh"}, {"type": "file", "name": "Cargo.toml"}, {"type": "file", "name": "index.html"}, {"type": "file", "name": "phiWorker.js"}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "src", "children": [{"type": "directory", "name": "bin", "children": [{"type": "file", "name": "m.rs"}]}, {"type": "file", "name": "lib.rs"}]}]}, {"type": "directory", "name": "segment-anything", "children": [{"type": "file", "name": "build-lib.sh"}, {"type": "file", "name": "Cargo.toml"}, {"type": "file", "name": "lib-example.html"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "samWorker.js"}, {"type": "directory", "name": "src", "children": [{"type": "directory", "name": "bin", "children": [{"type": "file", "name": "m.rs"}]}, {"type": "file", "name": "lib.rs"}]}]}, {"type": "directory", "name": "t5", "children": [{"type": "file", "name": "build-lib.sh"}, {"type": "file", "name": "Cargo.toml"}, {"type": "file", "name": "index.html"}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "src", "children": [{"type": "directory", "name": "bin", "children": [{"type": "file", "name": "m-quantized.rs"}, {"type": "file", "name": "m.rs"}]}, {"type": "file", "name": "lib.rs"}]}, {"type": "file", "name": "T5ModelConditionalGeneration.js"}, {"type": "file", "name": "T5ModelEncoderWorker.js"}, {"type": "file", "name": "utils.js"}]}, {"type": "directory", "name": "whisper", "children": [{"type": "file", "name": "build-lib.sh"}, {"type": "file", "name": "Cargo.toml"}, {"type": "file", "name": "index.html"}, {"type": "file", "name": "lib-example.html"}, {"type": "file", "name": "main.js"}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "src", "children": [{"type": "file", "name": "app.rs"}, {"type": "file", "name": "audio.rs"}, {"type": "directory", "name": "bin", "children": [{"type": "file", "name": "app.rs"}, {"type": "file", "name": "m.rs"}, {"type": "file", "name": "worker.rs"}]}, {"type": "file", "name": "languages.rs"}, {"type": "file", "name": "lib.rs"}, {"type": "file", "name": "worker.rs"}]}, {"type": "file", "name": "whisperWorker.js"}]}, {"type": "directory", "name": "yolo", "children": [{"type": "file", "name": "build-lib.sh"}, {"type": "file", "name": "Cargo.toml"}, {"type": "file", "name": "index.html"}, {"type": "file", "name": "lib-example.html"}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "src", "children": [{"type": "file", "name": "app.rs"}, {"type": "directory", "name": "bin", "children": [{"type": "file", "name": "app.rs"}, {"type": "file", "name": "m.rs"}, {"type": "file", "name": "worker.rs"}]}, {"type": "file", "name": "coco_classes.rs"}, {"type": "file", "name": "lib.rs"}, {"type": "file", "name": "model.rs"}, {"type": "file", "name": "worker.rs"}]}, {"type": "file", "name": "yoloWorker.js"}]}]}, {"type": "directory", "name": "candle-wasm-tests", "children": [{"type": "file", "name": "Cargo.toml"}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "src", "children": [{"type": "file", "name": "lib.rs"}]}, {"type": "directory", "name": "tests", "children": [{"type": "file", "name": "quantized_tests.rs"}]}, {"type": "file", "name": "webdriver.json"}]}, {"type": "file", "name": "Cargo.toml"}, {"type": "file", "name": "CHANGELOG.md"}, {"type": "file", "name": "LICENSE-APACHE"}, {"type": "file", "name": "LICENSE-MIT"}, {"type": "file", "name": "Makefile"}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "tensor-tools", "children": [{"type": "file", "name": "Cargo.toml"}, {"type": "directory", "name": "src", "children": [{"type": "file", "name": "main.rs"}]}]}]} | Run the tests with:
```bash
RUST_LOG=wasm_bindgen_test_runner wasm-pack test --chrome --headless
```
Or:
```bash
wasm-pack test --chrome
```
If you get an "invalid session id" failure in headless mode, check that logs and
it may well be that your ChromeDriver is not at the same version as your
browser.
| {".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 10d47183c088ce449da13d74f07171c8106cd6dd Hamza Amin <[email protected]> 1727369154 +0500\tclone: from https://github.com/huggingface/candle.git\n", ".git\\refs\\heads\\main": "10d47183c088ce449da13d74f07171c8106cd6dd\n", "candle-core\\benches\\bench_main.rs": "mod benchmarks;\n\nuse criterion::criterion_main;\ncriterion_main!(\n benchmarks::affine::benches,\n benchmarks::matmul::benches,\n benchmarks::random::benches,\n benchmarks::where_cond::benches,\n benchmarks::conv_transpose2d::benches,\n benchmarks::qmatmul::benches,\n benchmarks::unary::benches\n);\n", "candle-core\\src\\indexer.rs": "use crate::{Error, Tensor};\nuse std::ops::{\n Bound, Range, RangeBounds, RangeFrom, RangeFull, RangeInclusive, RangeTo, RangeToInclusive,\n};\n\nimpl Tensor {\n /// Intended to be use by the trait `.i()`\n ///\n /// ```\n /// # use candle_core::{Tensor, DType, Device, IndexOp};\n /// let a = Tensor::zeros((2, 3), DType::F32, &Device::Cpu)?;\n ///\n /// let c = a.i(0..1)?;\n /// assert_eq!(c.shape().dims(), &[1, 3]);\n ///\n /// let c = a.i(0)?;\n /// assert_eq!(c.shape().dims(), &[3]);\n ///\n /// let c = a.i((.., ..2) )?;\n /// assert_eq!(c.shape().dims(), &[2, 2]);\n ///\n /// let c = a.i((.., ..=2))?;\n /// assert_eq!(c.shape().dims(), &[2, 3]);\n ///\n /// # Ok::<(), candle_core::Error>(())\n /// ```\n fn index(&self, indexers: &[TensorIndexer]) -> Result<Self, Error> {\n let mut x = self.clone();\n let dims = self.shape().dims();\n let mut current_dim = 0;\n for (i, indexer) in indexers.iter().enumerate() {\n x = match indexer {\n TensorIndexer::Select(n) => x.narrow(current_dim, *n, 1)?.squeeze(current_dim)?,\n TensorIndexer::Narrow(left_bound, right_bound) => {\n let start = match left_bound {\n Bound::Included(n) => *n,\n Bound::Excluded(n) => *n + 1,\n Bound::Unbounded => 0,\n };\n let stop = match right_bound {\n Bound::Included(n) => *n + 1,\n Bound::Excluded(n) => *n,\n Bound::Unbounded => dims[i],\n };\n let out = x.narrow(current_dim, start, stop.saturating_sub(start))?;\n current_dim += 1;\n out\n }\n TensorIndexer::IndexSelect(indexes) => {\n if indexes.rank() != 1 {\n crate::bail!(\"multi-dimensional tensor indexing is not supported\")\n }\n let out = x.index_select(&indexes.to_device(x.device())?, current_dim)?;\n current_dim += 1;\n out\n }\n TensorIndexer::Err(e) => crate::bail!(\"indexing error {e:?}\"),\n };\n }\n Ok(x)\n }\n}\n\n#[derive(Debug)]\n/// Generic structure used to index a slice of the tensor\npub enum TensorIndexer {\n /// This selects the elements for which an index has some specific value.\n Select(usize),\n /// This is a regular slice, purely indexing a chunk of the tensor\n Narrow(Bound<usize>, Bound<usize>),\n /// Indexing via a 1d tensor\n IndexSelect(Tensor),\n Err(Error),\n}\n\nimpl From<usize> for TensorIndexer {\n fn from(index: usize) -> Self {\n TensorIndexer::Select(index)\n }\n}\n\nimpl From<&[u32]> for TensorIndexer {\n fn from(index: &[u32]) -> Self {\n match Tensor::new(index, &crate::Device::Cpu) {\n Ok(tensor) => TensorIndexer::IndexSelect(tensor),\n Err(e) => TensorIndexer::Err(e),\n }\n }\n}\n\nimpl From<Vec<u32>> for TensorIndexer {\n fn from(index: Vec<u32>) -> Self {\n let len = index.len();\n match Tensor::from_vec(index, len, &crate::Device::Cpu) {\n Ok(tensor) => TensorIndexer::IndexSelect(tensor),\n Err(e) => TensorIndexer::Err(e),\n }\n }\n}\n\nimpl From<&Tensor> for TensorIndexer {\n fn from(tensor: &Tensor) -> Self {\n TensorIndexer::IndexSelect(tensor.clone())\n }\n}\n\ntrait RB: RangeBounds<usize> {}\nimpl RB for Range<usize> {}\nimpl RB for RangeFrom<usize> {}\nimpl RB for RangeFull {}\nimpl RB for RangeInclusive<usize> {}\nimpl RB for RangeTo<usize> {}\nimpl RB for RangeToInclusive<usize> {}\n\nimpl<T: RB> From<T> for TensorIndexer {\n fn from(range: T) -> Self {\n use std::ops::Bound::*;\n let start = match range.start_bound() {\n Included(idx) => Included(*idx),\n Excluded(idx) => Excluded(*idx),\n Unbounded => Unbounded,\n };\n let end = match range.end_bound() {\n Included(idx) => Included(*idx),\n Excluded(idx) => Excluded(*idx),\n Unbounded => Unbounded,\n };\n TensorIndexer::Narrow(start, end)\n }\n}\n\n/// Trait used to implement multiple signatures for ease of use of the slicing\n/// of a tensor\npub trait IndexOp<T> {\n /// Returns a slicing iterator which are the chunks of data necessary to\n /// reconstruct the desired tensor.\n fn i(&self, index: T) -> Result<Tensor, Error>;\n}\n\nimpl<T> IndexOp<T> for Tensor\nwhere\n T: Into<TensorIndexer>,\n{\n ///```rust\n /// use candle_core::{Tensor, DType, Device, IndexOp};\n /// let a = Tensor::new(&[\n /// [0., 1.],\n /// [2., 3.],\n /// [4., 5.]\n /// ], &Device::Cpu)?;\n ///\n /// let b = a.i(0)?;\n /// assert_eq!(b.shape().dims(), &[2]);\n /// assert_eq!(b.to_vec1::<f64>()?, &[0., 1.]);\n ///\n /// let c = a.i(..2)?;\n /// assert_eq!(c.shape().dims(), &[2, 2]);\n /// assert_eq!(c.to_vec2::<f64>()?, &[\n /// [0., 1.],\n /// [2., 3.]\n /// ]);\n ///\n /// let d = a.i(1..)?;\n /// assert_eq!(d.shape().dims(), &[2, 2]);\n /// assert_eq!(d.to_vec2::<f64>()?, &[\n /// [2., 3.],\n /// [4., 5.]\n /// ]);\n /// # Ok::<(), candle_core::Error>(())\n /// ```\n fn i(&self, index: T) -> Result<Tensor, Error> {\n self.index(&[index.into()])\n }\n}\n\nimpl<A> IndexOp<(A,)> for Tensor\nwhere\n A: Into<TensorIndexer>,\n{\n ///```rust\n /// use candle_core::{Tensor, DType, Device, IndexOp};\n /// let a = Tensor::new(&[\n /// [0f32, 1.],\n /// [2. , 3.],\n /// [4. , 5.]\n /// ], &Device::Cpu)?;\n ///\n /// let b = a.i((0,))?;\n /// assert_eq!(b.shape().dims(), &[2]);\n /// assert_eq!(b.to_vec1::<f32>()?, &[0., 1.]);\n ///\n /// let c = a.i((..2,))?;\n /// assert_eq!(c.shape().dims(), &[2, 2]);\n /// assert_eq!(c.to_vec2::<f32>()?, &[\n /// [0., 1.],\n /// [2., 3.]\n /// ]);\n ///\n /// let d = a.i((1..,))?;\n /// assert_eq!(d.shape().dims(), &[2, 2]);\n /// assert_eq!(d.to_vec2::<f32>()?, &[\n /// [2., 3.],\n /// [4., 5.]\n /// ]);\n /// # Ok::<(), candle_core::Error>(())\n /// ```\n fn i(&self, (a,): (A,)) -> Result<Tensor, Error> {\n self.index(&[a.into()])\n }\n}\n#[allow(non_snake_case)]\nimpl<A, B> IndexOp<(A, B)> for Tensor\nwhere\n A: Into<TensorIndexer>,\n B: Into<TensorIndexer>,\n{\n ///```rust\n /// use candle_core::{Tensor, DType, Device, IndexOp};\n /// let a = Tensor::new(&[[0f32, 1., 2.], [3., 4., 5.], [6., 7., 8.]], &Device::Cpu)?;\n ///\n /// let b = a.i((1, 0))?;\n /// assert_eq!(b.to_vec0::<f32>()?, 3.);\n ///\n /// let c = a.i((..2, 1))?;\n /// assert_eq!(c.shape().dims(), &[2]);\n /// assert_eq!(c.to_vec1::<f32>()?, &[1., 4.]);\n ///\n /// let d = a.i((2.., ..))?;\n /// assert_eq!(c.shape().dims(), &[2]);\n /// assert_eq!(c.to_vec1::<f32>()?, &[1., 4.]);\n /// # Ok::<(), candle_core::Error>(())\n /// ```\n fn i(&self, (a, b): (A, B)) -> Result<Tensor, Error> {\n self.index(&[a.into(), b.into()])\n }\n}\n\nmacro_rules! index_op_tuple {\n ($doc:tt, $($t:ident),+) => {\n #[allow(non_snake_case)]\n impl<$($t),*> IndexOp<($($t,)*)> for Tensor\n where\n $($t: Into<TensorIndexer>,)*\n {\n #[doc=$doc]\n fn i(&self, ($($t,)*): ($($t,)*)) -> Result<Tensor, Error> {\n self.index(&[$($t.into(),)*])\n }\n }\n };\n}\n\nindex_op_tuple!(\"see [TensorIndex#method.i]\", A, B, C);\nindex_op_tuple!(\"see [TensorIndex#method.i]\", A, B, C, D);\nindex_op_tuple!(\"see [TensorIndex#method.i]\", A, B, C, D, E);\nindex_op_tuple!(\"see [TensorIndex#method.i]\", A, B, C, D, E, F);\nindex_op_tuple!(\"see [TensorIndex#method.i]\", A, B, C, D, E, F, G);\n", "candle-core\\src\\strided_index.rs": "use crate::Layout;\n\n/// An iterator over offset position for items of an N-dimensional arrays stored in a\n/// flat buffer using some potential strides.\n#[derive(Debug)]\npub struct StridedIndex<'a> {\n next_storage_index: Option<usize>,\n multi_index: Vec<usize>,\n dims: &'a [usize],\n stride: &'a [usize],\n}\n\nimpl<'a> StridedIndex<'a> {\n pub(crate) fn new(dims: &'a [usize], stride: &'a [usize], start_offset: usize) -> Self {\n let elem_count: usize = dims.iter().product();\n let next_storage_index = if elem_count == 0 {\n None\n } else {\n // This applies to the scalar case.\n Some(start_offset)\n };\n StridedIndex {\n next_storage_index,\n multi_index: vec![0; dims.len()],\n dims,\n stride,\n }\n }\n\n pub(crate) fn from_layout(l: &'a Layout) -> Self {\n Self::new(l.dims(), l.stride(), l.start_offset())\n }\n}\n\nimpl<'a> Iterator for StridedIndex<'a> {\n type Item = usize;\n\n fn next(&mut self) -> Option<Self::Item> {\n let storage_index = match self.next_storage_index {\n None => return None,\n Some(storage_index) => storage_index,\n };\n let mut updated = false;\n let mut next_storage_index = storage_index;\n for ((multi_i, max_i), stride_i) in self\n .multi_index\n .iter_mut()\n .zip(self.dims.iter())\n .zip(self.stride.iter())\n .rev()\n {\n let next_i = *multi_i + 1;\n if next_i < *max_i {\n *multi_i = next_i;\n updated = true;\n next_storage_index += stride_i;\n break;\n } else {\n next_storage_index -= *multi_i * stride_i;\n *multi_i = 0\n }\n }\n self.next_storage_index = if updated {\n Some(next_storage_index)\n } else {\n None\n };\n Some(storage_index)\n }\n}\n\n#[derive(Debug)]\npub enum StridedBlocks<'a> {\n SingleBlock {\n start_offset: usize,\n len: usize,\n },\n MultipleBlocks {\n block_start_index: StridedIndex<'a>,\n block_len: usize,\n },\n}\n", "candle-core\\tests\\indexing_tests.rs": "use anyhow::Result;\nuse candle_core::{Device, IndexOp, Tensor};\n\n#[test]\nfn integer_index() -> Result<()> {\n let dev = Device::Cpu;\n\n let tensor = Tensor::arange(0u32, 2 * 3, &dev)?.reshape((2, 3))?;\n let result = tensor.i(1)?;\n assert_eq!(result.dims(), &[3]);\n assert_eq!(result.to_vec1::<u32>()?, &[3, 4, 5]);\n\n let result = tensor.i((.., 2))?;\n assert_eq!(result.dims(), &[2]);\n assert_eq!(result.to_vec1::<u32>()?, &[2, 5]);\n\n Ok(())\n}\n\n#[test]\nfn range_index() -> Result<()> {\n let dev = Device::Cpu;\n // RangeFull\n let tensor = Tensor::arange(0u32, 2 * 3, &dev)?.reshape((2, 3))?;\n let result = tensor.i(..)?;\n assert_eq!(result.dims(), &[2, 3]);\n assert_eq!(result.to_vec2::<u32>()?, &[[0, 1, 2], [3, 4, 5]]);\n\n // Range\n let tensor = Tensor::arange(0u32, 4 * 3, &dev)?.reshape((4, 3))?;\n let result = tensor.i(1..3)?;\n assert_eq!(result.dims(), &[2, 3]);\n assert_eq!(result.to_vec2::<u32>()?, &[[3, 4, 5], [6, 7, 8]]);\n\n // RangeFrom\n let result = tensor.i(2..)?;\n assert_eq!(result.dims(), &[2, 3]);\n assert_eq!(result.to_vec2::<u32>()?, &[[6, 7, 8], [9, 10, 11]]);\n\n // RangeTo\n let result = tensor.i(..2)?;\n assert_eq!(result.dims(), &[2, 3]);\n assert_eq!(result.to_vec2::<u32>()?, &[[0, 1, 2], [3, 4, 5]]);\n\n // RangeInclusive\n let result = tensor.i(1..=2)?;\n assert_eq!(result.dims(), &[2, 3]);\n assert_eq!(result.to_vec2::<u32>()?, &[[3, 4, 5], [6, 7, 8]]);\n\n // RangeTo\n let result = tensor.i(..1)?;\n assert_eq!(result.dims(), &[1, 3]);\n assert_eq!(result.to_vec2::<u32>()?, &[[0, 1, 2]]);\n\n // RangeToInclusive\n let result = tensor.i(..=1)?;\n assert_eq!(result.dims(), &[2, 3]);\n assert_eq!(result.to_vec2::<u32>()?, &[[0, 1, 2], [3, 4, 5]]);\n\n // Empty range\n let result = tensor.i(1..1)?;\n assert_eq!(result.dims(), &[0, 3]);\n let empty: [[u32; 3]; 0] = [];\n assert_eq!(result.to_vec2::<u32>()?, &empty);\n\n // Similar to PyTorch, allow empty ranges when the computed length is negative.\n #[allow(clippy::reversed_empty_ranges)]\n let result = tensor.i(1..0)?;\n assert_eq!(result.dims(), &[0, 3]);\n let empty: [[u32; 3]; 0] = [];\n assert_eq!(result.to_vec2::<u32>()?, &empty);\n Ok(())\n}\n\n#[test]\nfn index_3d() -> Result<()> {\n let tensor = Tensor::from_iter(0..24u32, &Device::Cpu)?.reshape((2, 3, 4))?;\n assert_eq!(tensor.i((0, 0, 0))?.to_scalar::<u32>()?, 0);\n assert_eq!(tensor.i((1, 0, 0))?.to_scalar::<u32>()?, 12);\n assert_eq!(tensor.i((0, 1, 0))?.to_scalar::<u32>()?, 4);\n assert_eq!(tensor.i((0, 1, 3))?.to_scalar::<u32>()?, 7);\n assert_eq!(tensor.i((0..2, 0, 0))?.to_vec1::<u32>()?, &[0, 12]);\n assert_eq!(\n tensor.i((0..2, .., 0))?.to_vec2::<u32>()?,\n &[[0, 4, 8], [12, 16, 20]]\n );\n assert_eq!(\n tensor.i((..2, .., 3))?.to_vec2::<u32>()?,\n &[[3, 7, 11], [15, 19, 23]]\n );\n assert_eq!(tensor.i((1, .., 3))?.to_vec1::<u32>()?, &[15, 19, 23]);\n Ok(())\n}\n\n#[test]\nfn slice_assign() -> Result<()> {\n let dev = Device::Cpu;\n\n let tensor = Tensor::arange(0u32, 4 * 5, &dev)?.reshape((4, 5))?;\n let src = Tensor::arange(0u32, 2 * 3, &dev)?.reshape((3, 2))?;\n let out = tensor.slice_assign(&[1..4, 3..5], &src)?;\n assert_eq!(\n out.to_vec2::<u32>()?,\n &[\n [0, 1, 2, 3, 4],\n [5, 6, 7, 0, 1],\n [10, 11, 12, 2, 3],\n [15, 16, 17, 4, 5]\n ]\n );\n let out = tensor.slice_assign(&[0..3, 0..2], &src)?;\n assert_eq!(\n out.to_vec2::<u32>()?,\n &[\n [0, 1, 2, 3, 4],\n [2, 3, 7, 8, 9],\n [4, 5, 12, 13, 14],\n [15, 16, 17, 18, 19]\n ]\n );\n Ok(())\n}\n", "candle-examples\\examples\\based\\main.rs": "#[cfg(feature = \"mkl\")]\nextern crate intel_mkl_src;\n\n#[cfg(feature = \"accelerate\")]\nextern crate accelerate_src;\n\nuse anyhow::{Error as E, Result};\nuse clap::{Parser, ValueEnum};\n\nuse candle_transformers::models::based::Model;\n\nuse candle::{DType, Device, Tensor};\nuse candle_examples::token_output_stream::TokenOutputStream;\nuse candle_nn::VarBuilder;\nuse candle_transformers::generation::LogitsProcessor;\nuse hf_hub::{api::sync::Api, Repo, RepoType};\nuse tokenizers::Tokenizer;\n\nstruct TextGeneration {\n model: Model,\n device: Device,\n tokenizer: TokenOutputStream,\n logits_processor: LogitsProcessor,\n repeat_penalty: f32,\n repeat_last_n: usize,\n}\n\nimpl TextGeneration {\n #[allow(clippy::too_many_arguments)]\n fn new(\n model: Model,\n tokenizer: Tokenizer,\n seed: u64,\n temp: Option<f64>,\n top_p: Option<f64>,\n repeat_penalty: f32,\n repeat_last_n: usize,\n device: &Device,\n ) -> Self {\n let logits_processor = LogitsProcessor::new(seed, temp, top_p);\n Self {\n model,\n tokenizer: TokenOutputStream::new(tokenizer),\n logits_processor,\n repeat_penalty,\n repeat_last_n,\n device: device.clone(),\n }\n }\n\n fn run(&mut self, prompt: &str, sample_len: usize) -> Result<()> {\n use std::io::Write;\n self.tokenizer.clear();\n let mut tokens = self\n .tokenizer\n .tokenizer()\n .encode(prompt, true)\n .map_err(E::msg)?\n .get_ids()\n .to_vec();\n for &t in tokens.iter() {\n if let Some(t) = self.tokenizer.next_token(t)? {\n print!(\"{t}\")\n }\n }\n std::io::stdout().flush()?;\n\n let mut generated_tokens = 0usize;\n let eos_token = match self.tokenizer.get_token(\"<|endoftext|>\") {\n Some(token) => token,\n None => anyhow::bail!(\"cannot find the <|endoftext|> token\"),\n };\n let start_gen = std::time::Instant::now();\n for index in 0..sample_len {\n let context_size = if index > 0 { 1 } else { tokens.len() };\n let start_pos = tokens.len().saturating_sub(context_size);\n let ctxt = &tokens[start_pos..];\n let input = Tensor::new(ctxt, &self.device)?.unsqueeze(0)?;\n let logits = self.model.forward(&input, start_pos)?;\n let logits = logits.squeeze(0)?.squeeze(0)?.to_dtype(DType::F32)?;\n let logits = if self.repeat_penalty == 1. {\n logits\n } else {\n let start_at = tokens.len().saturating_sub(self.repeat_last_n);\n candle_transformers::utils::apply_repeat_penalty(\n &logits,\n self.repeat_penalty,\n &tokens[start_at..],\n )?\n };\n\n let next_token = self.logits_processor.sample(&logits)?;\n tokens.push(next_token);\n generated_tokens += 1;\n if next_token == eos_token {\n break;\n }\n if let Some(t) = self.tokenizer.next_token(next_token)? {\n print!(\"{t}\");\n std::io::stdout().flush()?;\n }\n }\n let dt = start_gen.elapsed();\n if let Some(rest) = self.tokenizer.decode_rest().map_err(E::msg)? {\n print!(\"{rest}\");\n }\n std::io::stdout().flush()?;\n println!(\n \"\\n{generated_tokens} tokens generated ({:.2} token/s)\",\n generated_tokens as f64 / dt.as_secs_f64(),\n );\n Ok(())\n }\n}\n\n#[derive(Clone, Debug, Copy, PartialEq, Eq, ValueEnum)]\nenum Which {\n #[value(name = \"360m\")]\n W360m,\n #[value(name = \"1b\")]\n W1b,\n #[value(name = \"1b-50b\")]\n W1b50b,\n}\n\n#[derive(Parser, Debug)]\n#[command(author, version, about, long_about = None)]\nstruct Args {\n /// Run on CPU rather than on GPU.\n #[arg(long)]\n cpu: bool,\n\n /// Enable tracing (generates a trace-timestamp.json file).\n #[arg(long)]\n tracing: bool,\n\n #[arg(long)]\n prompt: String,\n\n /// The temperature used to generate samples.\n #[arg(long)]\n temperature: Option<f64>,\n\n /// Nucleus sampling probability cutoff.\n #[arg(long)]\n top_p: Option<f64>,\n\n /// The seed to use when generating random samples.\n #[arg(long, default_value_t = 299792458)]\n seed: u64,\n\n /// The length of the sample to generate (in tokens).\n #[arg(long, short = 'n', default_value_t = 10000)]\n sample_len: usize,\n\n #[arg(long)]\n model_id: Option<String>,\n\n #[arg(long, default_value = \"refs/pr/1\")]\n revision: String,\n\n #[arg(long)]\n config_file: Option<String>,\n\n #[arg(long)]\n tokenizer_file: Option<String>,\n\n #[arg(long)]\n weight_files: Option<String>,\n\n /// Penalty to be applied for repeating tokens, 1. means no penalty.\n #[arg(long, default_value_t = 1.1)]\n repeat_penalty: f32,\n\n /// The context size to consider for the repeat penalty.\n #[arg(long, default_value_t = 64)]\n repeat_last_n: usize,\n\n #[arg(long, default_value = \"360m\")]\n which: Which,\n}\n\nfn main() -> Result<()> {\n use tracing_chrome::ChromeLayerBuilder;\n use tracing_subscriber::prelude::*;\n\n let args = Args::parse();\n let _guard = if args.tracing {\n let (chrome_layer, guard) = ChromeLayerBuilder::new().build();\n tracing_subscriber::registry().with(chrome_layer).init();\n Some(guard)\n } else {\n None\n };\n println!(\n \"avx: {}, neon: {}, simd128: {}, f16c: {}\",\n candle::utils::with_avx(),\n candle::utils::with_neon(),\n candle::utils::with_simd128(),\n candle::utils::with_f16c()\n );\n println!(\n \"temp: {:.2} repeat-penalty: {:.2} repeat-last-n: {}\",\n args.temperature.unwrap_or(0.),\n args.repeat_penalty,\n args.repeat_last_n\n );\n\n let start = std::time::Instant::now();\n let api = Api::new()?;\n let model_id = match args.model_id {\n Some(model_id) => model_id,\n None => match args.which {\n Which::W360m => \"hazyresearch/based-360m\".to_string(),\n Which::W1b => \"hazyresearch/based-1b\".to_string(),\n Which::W1b50b => \"hazyresearch/based-1b-50b\".to_string(),\n },\n };\n let repo = api.repo(Repo::with_revision(\n model_id,\n RepoType::Model,\n args.revision,\n ));\n let config_file = match args.config_file {\n Some(file) => std::path::PathBuf::from(file),\n None => repo.get(\"config.json\")?,\n };\n let filenames = match args.weight_files {\n Some(files) => files\n .split(',')\n .map(std::path::PathBuf::from)\n .collect::<Vec<_>>(),\n None => vec![repo.get(\"model.safetensors\")?],\n };\n\n let repo = api.model(\"openai-community/gpt2\".to_string());\n let tokenizer_file = match args.tokenizer_file {\n Some(file) => std::path::PathBuf::from(file),\n None => repo.get(\"tokenizer.json\")?,\n };\n\n println!(\"retrieved the files in {:?}\", start.elapsed());\n let tokenizer = Tokenizer::from_file(tokenizer_file).map_err(E::msg)?;\n\n let start = std::time::Instant::now();\n let config = serde_json::from_reader(std::fs::File::open(config_file)?)?;\n let device = candle_examples::device(args.cpu)?;\n let dtype = if device.is_cuda() {\n DType::BF16\n } else {\n DType::F32\n };\n\n let mut vb = unsafe { VarBuilder::from_mmaped_safetensors(&filenames, dtype, &device)? };\n if args.which == Which::W1b50b {\n vb = vb.pp(\"model\");\n };\n\n let model = Model::new(&config, vb)?;\n\n println!(\"loaded the model in {:?}\", start.elapsed());\n\n let mut pipeline = TextGeneration::new(\n model,\n tokenizer,\n args.seed,\n args.temperature,\n args.top_p,\n args.repeat_penalty,\n args.repeat_last_n,\n &device,\n );\n pipeline.run(&args.prompt, args.sample_len)?;\n Ok(())\n}\n", "candle-examples\\examples\\beit\\main.rs": "//! BEiT: BERT Pre-Training of Image Transformers\n//! https://github.com/microsoft/unilm/tree/master/beit\n\n#[cfg(feature = \"mkl\")]\nextern crate intel_mkl_src;\n\n#[cfg(feature = \"accelerate\")]\nextern crate accelerate_src;\n\nuse clap::Parser;\n\nuse candle::{DType, Device, IndexOp, Result, Tensor, D};\nuse candle_nn::{Module, VarBuilder};\nuse candle_transformers::models::beit;\n\n/// Loads an image from disk using the image crate, this returns a tensor with shape\n/// (3, 384, 384). Beit special normalization is applied.\npub fn load_image384_beit_norm<P: AsRef<std::path::Path>>(p: P) -> Result<Tensor> {\n let img = image::ImageReader::open(p)?\n .decode()\n .map_err(candle::Error::wrap)?\n .resize_to_fill(384, 384, image::imageops::FilterType::Triangle);\n let img = img.to_rgb8();\n let data = img.into_raw();\n let data = Tensor::from_vec(data, (384, 384, 3), &Device::Cpu)?.permute((2, 0, 1))?;\n let mean = Tensor::new(&[0.5f32, 0.5, 0.5], &Device::Cpu)?.reshape((3, 1, 1))?;\n let std = Tensor::new(&[0.5f32, 0.5, 0.5], &Device::Cpu)?.reshape((3, 1, 1))?;\n (data.to_dtype(candle::DType::F32)? / 255.)?\n .broadcast_sub(&mean)?\n .broadcast_div(&std)\n}\n\n#[derive(Parser)]\nstruct Args {\n #[arg(long)]\n model: Option<String>,\n\n #[arg(long)]\n image: String,\n\n /// Run on CPU rather than on GPU.\n #[arg(long)]\n cpu: bool,\n}\n\npub fn main() -> anyhow::Result<()> {\n let args = Args::parse();\n\n let device = candle_examples::device(args.cpu)?;\n\n let image = load_image384_beit_norm(args.image)?.to_device(&device)?;\n println!(\"loaded image {image:?}\");\n\n let model_file = match args.model {\n None => {\n let api = hf_hub::api::sync::Api::new()?;\n let api = api.model(\"vincent-espitalier/candle-beit\".into());\n api.get(\"beit_base_patch16_384.in22k_ft_in22k_in1k.safetensors\")?\n }\n Some(model) => model.into(),\n };\n let vb = unsafe { VarBuilder::from_mmaped_safetensors(&[model_file], DType::F32, &device)? };\n let model = beit::vit_base(vb)?;\n println!(\"model built\");\n let logits = model.forward(&image.unsqueeze(0)?)?;\n let prs = candle_nn::ops::softmax(&logits, D::Minus1)?\n .i(0)?\n .to_vec1::<f32>()?;\n let mut prs = prs.iter().enumerate().collect::<Vec<_>>();\n prs.sort_by(|(_, p1), (_, p2)| p2.total_cmp(p1));\n for &(category_idx, pr) in prs.iter().take(5) {\n println!(\n \"{:24}: {:.2}%\",\n candle_examples::imagenet::CLASSES[category_idx],\n 100. * pr\n );\n }\n Ok(())\n}\n", "candle-examples\\examples\\bert\\main.rs": "#[cfg(feature = \"mkl\")]\nextern crate intel_mkl_src;\n\n#[cfg(feature = \"accelerate\")]\nextern crate accelerate_src;\nuse candle_transformers::models::bert::{BertModel, Config, HiddenAct, DTYPE};\n\nuse anyhow::{Error as E, Result};\nuse candle::Tensor;\nuse candle_nn::VarBuilder;\nuse clap::Parser;\nuse hf_hub::{api::sync::Api, Repo, RepoType};\nuse tokenizers::{PaddingParams, Tokenizer};\n\n#[derive(Parser, Debug)]\n#[command(author, version, about, long_about = None)]\nstruct Args {\n /// Run on CPU rather than on GPU.\n #[arg(long)]\n cpu: bool,\n\n /// Enable tracing (generates a trace-timestamp.json file).\n #[arg(long)]\n tracing: bool,\n\n /// The model to use, check out available models: https://huggingface.co/models?library=sentence-transformers&sort=trending\n #[arg(long)]\n model_id: Option<String>,\n\n #[arg(long)]\n revision: Option<String>,\n\n /// When set, compute embeddings for this prompt.\n #[arg(long)]\n prompt: Option<String>,\n\n /// Use the pytorch weights rather than the safetensors ones\n #[arg(long)]\n use_pth: bool,\n\n /// The number of times to run the prompt.\n #[arg(long, default_value = \"1\")]\n n: usize,\n\n /// L2 normalization for embeddings.\n #[arg(long, default_value = \"true\")]\n normalize_embeddings: bool,\n\n /// Use tanh based approximation for Gelu instead of erf implementation.\n #[arg(long, default_value = \"false\")]\n approximate_gelu: bool,\n}\n\nimpl Args {\n fn build_model_and_tokenizer(&self) -> Result<(BertModel, Tokenizer)> {\n let device = candle_examples::device(self.cpu)?;\n let default_model = \"sentence-transformers/all-MiniLM-L6-v2\".to_string();\n let default_revision = \"refs/pr/21\".to_string();\n let (model_id, revision) = match (self.model_id.to_owned(), self.revision.to_owned()) {\n (Some(model_id), Some(revision)) => (model_id, revision),\n (Some(model_id), None) => (model_id, \"main\".to_string()),\n (None, Some(revision)) => (default_model, revision),\n (None, None) => (default_model, default_revision),\n };\n\n let repo = Repo::with_revision(model_id, RepoType::Model, revision);\n let (config_filename, tokenizer_filename, weights_filename) = {\n let api = Api::new()?;\n let api = api.repo(repo);\n let config = api.get(\"config.json\")?;\n let tokenizer = api.get(\"tokenizer.json\")?;\n let weights = if self.use_pth {\n api.get(\"pytorch_model.bin\")?\n } else {\n api.get(\"model.safetensors\")?\n };\n (config, tokenizer, weights)\n };\n let config = std::fs::read_to_string(config_filename)?;\n let mut config: Config = serde_json::from_str(&config)?;\n let tokenizer = Tokenizer::from_file(tokenizer_filename).map_err(E::msg)?;\n\n let vb = if self.use_pth {\n VarBuilder::from_pth(&weights_filename, DTYPE, &device)?\n } else {\n unsafe { VarBuilder::from_mmaped_safetensors(&[weights_filename], DTYPE, &device)? }\n };\n if self.approximate_gelu {\n config.hidden_act = HiddenAct::GeluApproximate;\n }\n let model = BertModel::load(vb, &config)?;\n Ok((model, tokenizer))\n }\n}\n\nfn main() -> Result<()> {\n use tracing_chrome::ChromeLayerBuilder;\n use tracing_subscriber::prelude::*;\n\n let args = Args::parse();\n let _guard = if args.tracing {\n println!(\"tracing...\");\n let (chrome_layer, guard) = ChromeLayerBuilder::new().build();\n tracing_subscriber::registry().with(chrome_layer).init();\n Some(guard)\n } else {\n None\n };\n let start = std::time::Instant::now();\n\n let (model, mut tokenizer) = args.build_model_and_tokenizer()?;\n let device = &model.device;\n\n if let Some(prompt) = args.prompt {\n let tokenizer = tokenizer\n .with_padding(None)\n .with_truncation(None)\n .map_err(E::msg)?;\n let tokens = tokenizer\n .encode(prompt, true)\n .map_err(E::msg)?\n .get_ids()\n .to_vec();\n let token_ids = Tensor::new(&tokens[..], device)?.unsqueeze(0)?;\n let token_type_ids = token_ids.zeros_like()?;\n println!(\"Loaded and encoded {:?}\", start.elapsed());\n for idx in 0..args.n {\n let start = std::time::Instant::now();\n let ys = model.forward(&token_ids, &token_type_ids, None)?;\n if idx == 0 {\n println!(\"{ys}\");\n }\n println!(\"Took {:?}\", start.elapsed());\n }\n } else {\n let sentences = [\n \"The cat sits outside\",\n \"A man is playing guitar\",\n \"I love pasta\",\n \"The new movie is awesome\",\n \"The cat plays in the garden\",\n \"A woman watches TV\",\n \"The new movie is so great\",\n \"Do you like pizza?\",\n ];\n let n_sentences = sentences.len();\n if let Some(pp) = tokenizer.get_padding_mut() {\n pp.strategy = tokenizers::PaddingStrategy::BatchLongest\n } else {\n let pp = PaddingParams {\n strategy: tokenizers::PaddingStrategy::BatchLongest,\n ..Default::default()\n };\n tokenizer.with_padding(Some(pp));\n }\n let tokens = tokenizer\n .encode_batch(sentences.to_vec(), true)\n .map_err(E::msg)?;\n let token_ids = tokens\n .iter()\n .map(|tokens| {\n let tokens = tokens.get_ids().to_vec();\n Ok(Tensor::new(tokens.as_slice(), device)?)\n })\n .collect::<Result<Vec<_>>>()?;\n let attention_mask = tokens\n .iter()\n .map(|tokens| {\n let tokens = tokens.get_attention_mask().to_vec();\n Ok(Tensor::new(tokens.as_slice(), device)?)\n })\n .collect::<Result<Vec<_>>>()?;\n\n let token_ids = Tensor::stack(&token_ids, 0)?;\n let attention_mask = Tensor::stack(&attention_mask, 0)?;\n let token_type_ids = token_ids.zeros_like()?;\n println!(\"running inference on batch {:?}\", token_ids.shape());\n let embeddings = model.forward(&token_ids, &token_type_ids, Some(&attention_mask))?;\n println!(\"generated embeddings {:?}\", embeddings.shape());\n // Apply some avg-pooling by taking the mean embedding value for all tokens (including padding)\n let (_n_sentence, n_tokens, _hidden_size) = embeddings.dims3()?;\n let embeddings = (embeddings.sum(1)? / (n_tokens as f64))?;\n let embeddings = if args.normalize_embeddings {\n normalize_l2(&embeddings)?\n } else {\n embeddings\n };\n println!(\"pooled embeddings {:?}\", embeddings.shape());\n\n let mut similarities = vec![];\n for i in 0..n_sentences {\n let e_i = embeddings.get(i)?;\n for j in (i + 1)..n_sentences {\n let e_j = embeddings.get(j)?;\n let sum_ij = (&e_i * &e_j)?.sum_all()?.to_scalar::<f32>()?;\n let sum_i2 = (&e_i * &e_i)?.sum_all()?.to_scalar::<f32>()?;\n let sum_j2 = (&e_j * &e_j)?.sum_all()?.to_scalar::<f32>()?;\n let cosine_similarity = sum_ij / (sum_i2 * sum_j2).sqrt();\n similarities.push((cosine_similarity, i, j))\n }\n }\n similarities.sort_by(|u, v| v.0.total_cmp(&u.0));\n for &(score, i, j) in similarities[..5].iter() {\n println!(\"score: {score:.2} '{}' '{}'\", sentences[i], sentences[j])\n }\n }\n Ok(())\n}\n\npub fn normalize_l2(v: &Tensor) -> Result<Tensor> {\n Ok(v.broadcast_div(&v.sqr()?.sum_keepdim(1)?.sqrt()?)?)\n}\n", "candle-examples\\examples\\bigcode\\main.rs": "#[cfg(feature = \"mkl\")]\nextern crate intel_mkl_src;\n\n#[cfg(feature = \"accelerate\")]\nextern crate accelerate_src;\n\nuse anyhow::{Error as E, Result};\nuse clap::Parser;\n\nuse candle_transformers::models::bigcode::{Config, GPTBigCode};\n\nuse candle::{DType, Device, Tensor};\nuse candle_nn::VarBuilder;\nuse candle_transformers::generation::LogitsProcessor;\nuse hf_hub::{api::sync::Api, Repo, RepoType};\nuse tokenizers::Tokenizer;\n\nstruct TextGeneration {\n model: GPTBigCode,\n device: Device,\n tokenizer: Tokenizer,\n logits_processor: LogitsProcessor,\n}\n\nimpl TextGeneration {\n fn new(\n model: GPTBigCode,\n tokenizer: Tokenizer,\n seed: u64,\n temp: Option<f64>,\n top_p: Option<f64>,\n device: &Device,\n ) -> Self {\n let logits_processor = LogitsProcessor::new(seed, temp, top_p);\n Self {\n model,\n tokenizer,\n logits_processor,\n device: device.clone(),\n }\n }\n\n fn run(&mut self, prompt: &str, sample_len: usize) -> Result<()> {\n use std::io::Write;\n println!(\"starting the inference loop\");\n print!(\"{prompt}\");\n std::io::stdout().flush()?;\n let mut tokens = self\n .tokenizer\n .encode(prompt, true)\n .map_err(E::msg)?\n .get_ids()\n .to_vec();\n\n let mut new_tokens = vec![];\n let start_gen = std::time::Instant::now();\n for index in 0..sample_len {\n let (context_size, past_len) = if self.model.config().use_cache && index > 0 {\n (1, tokens.len().saturating_sub(1))\n } else {\n (tokens.len(), 0)\n };\n let ctxt = &tokens[tokens.len().saturating_sub(context_size)..];\n let input = Tensor::new(ctxt, &self.device)?.unsqueeze(0)?;\n let logits = self.model.forward(&input, past_len)?;\n let logits = logits.squeeze(0)?.to_dtype(DType::F32)?;\n\n let next_token = self.logits_processor.sample(&logits)?;\n tokens.push(next_token);\n new_tokens.push(next_token);\n let token = self.tokenizer.decode(&[next_token], true).map_err(E::msg)?;\n print!(\"{token}\");\n std::io::stdout().flush()?;\n }\n let dt = start_gen.elapsed();\n println!(\n \"{sample_len} tokens generated ({:.3} token/s)\",\n sample_len as f64 / dt.as_secs_f64(),\n );\n Ok(())\n }\n}\n\n#[derive(Parser, Debug)]\n#[command(author, version, about, long_about = None)]\nstruct Args {\n /// Run on CPU rather than on GPU.\n #[arg(long)]\n cpu: bool,\n\n #[arg(long)]\n prompt: String,\n\n /// The temperature used to generate samples.\n #[arg(long)]\n temperature: Option<f64>,\n\n /// Nucleus sampling probability cutoff.\n #[arg(long)]\n top_p: Option<f64>,\n\n /// The seed to use when generating random samples.\n #[arg(long, default_value_t = 299792458)]\n seed: u64,\n\n /// The length of the sample to generate (in tokens).\n #[arg(long, default_value_t = 100)]\n sample_len: usize,\n\n #[arg(long, default_value = \"bigcode/starcoderbase-1b\")]\n model_id: String,\n\n #[arg(long, default_value = \"main\")]\n revision: String,\n\n #[arg(long)]\n weight_file: Option<String>,\n}\n\nfn main() -> Result<()> {\n let args = Args::parse();\n\n let start = std::time::Instant::now();\n let api = Api::new()?;\n let repo = api.repo(Repo::with_revision(\n args.model_id,\n RepoType::Model,\n args.revision,\n ));\n let tokenizer_filename = repo.get(\"tokenizer.json\")?;\n let filenames = match args.weight_file {\n Some(weight_file) => vec![std::path::PathBuf::from(weight_file)],\n None => [\"model.safetensors\"]\n .iter()\n .map(|f| repo.get(f))\n .collect::<std::result::Result<Vec<_>, _>>()?,\n };\n println!(\"retrieved the files in {:?}\", start.elapsed());\n let tokenizer = Tokenizer::from_file(tokenizer_filename).map_err(E::msg)?;\n\n let start = std::time::Instant::now();\n let device = candle_examples::device(args.cpu)?;\n let vb = unsafe { VarBuilder::from_mmaped_safetensors(&filenames, DType::F32, &device)? };\n let config = Config::starcoder_1b();\n let model = GPTBigCode::load(vb, config)?;\n println!(\"loaded the model in {:?}\", start.elapsed());\n\n let mut pipeline = TextGeneration::new(\n model,\n tokenizer,\n args.seed,\n args.temperature,\n args.top_p,\n &device,\n );\n pipeline.run(&args.prompt, args.sample_len)?;\n Ok(())\n}\n", "candle-examples\\examples\\blip\\main.rs": "#[cfg(feature = \"mkl\")]\nextern crate intel_mkl_src;\n\n#[cfg(feature = \"accelerate\")]\nextern crate accelerate_src;\n\nuse anyhow::Error as E;\nuse clap::Parser;\n\nuse candle::{DType, Device, Result, Tensor};\nuse candle_examples::token_output_stream::TokenOutputStream;\nuse candle_nn::VarBuilder;\nuse candle_transformers::models::blip;\nuse candle_transformers::models::quantized_blip;\n\nuse tokenizers::Tokenizer;\n\nenum Model {\n M(blip::BlipForConditionalGeneration),\n Q(quantized_blip::BlipForConditionalGeneration),\n}\n\nimpl Model {\n fn text_decoder_forward(&mut self, xs: &Tensor, img_xs: &Tensor) -> Result<Tensor> {\n match self {\n Self::M(m) => m.text_decoder().forward(xs, img_xs),\n Self::Q(m) => m.text_decoder().forward(xs, img_xs),\n }\n }\n}\n\n// TODO: Maybe add support for the conditional prompt.\n#[derive(Parser)]\nstruct Args {\n #[arg(long)]\n model: Option<String>,\n\n #[arg(long)]\n tokenizer: Option<String>,\n\n #[arg(long)]\n image: String,\n\n /// Run on CPU rather than on GPU.\n #[arg(long)]\n cpu: bool,\n\n /// Use the quantized version of the model.\n #[arg(long)]\n quantized: bool,\n}\n\nconst SEP_TOKEN_ID: u32 = 102;\n\n/// Loads an image from disk using the image crate, this returns a tensor with shape\n/// (3, 384, 384). OpenAI normalization is applied.\npub fn load_image<P: AsRef<std::path::Path>>(p: P) -> Result<Tensor> {\n let img = image::ImageReader::open(p)?\n .decode()\n .map_err(candle::Error::wrap)?\n .resize_to_fill(384, 384, image::imageops::FilterType::Triangle);\n let img = img.to_rgb8();\n let data = img.into_raw();\n let data = Tensor::from_vec(data, (384, 384, 3), &Device::Cpu)?.permute((2, 0, 1))?;\n let mean =\n Tensor::new(&[0.48145466f32, 0.4578275, 0.40821073], &Device::Cpu)?.reshape((3, 1, 1))?;\n let std = Tensor::new(&[0.26862954f32, 0.261_302_6, 0.275_777_1], &Device::Cpu)?\n .reshape((3, 1, 1))?;\n (data.to_dtype(candle::DType::F32)? / 255.)?\n .broadcast_sub(&mean)?\n .broadcast_div(&std)\n}\n\npub fn main() -> anyhow::Result<()> {\n let args = Args::parse();\n\n let model_file = match args.model {\n None => {\n let api = hf_hub::api::sync::Api::new()?;\n if args.quantized {\n let api = api.model(\"lmz/candle-blip\".to_string());\n api.get(\"blip-image-captioning-large-q4k.gguf\")?\n } else {\n let api = api.repo(hf_hub::Repo::with_revision(\n \"Salesforce/blip-image-captioning-large\".to_string(),\n hf_hub::RepoType::Model,\n \"refs/pr/18\".to_string(),\n ));\n api.get(\"model.safetensors\")?\n }\n }\n Some(model) => model.into(),\n };\n let tokenizer = match args.tokenizer {\n None => {\n let api = hf_hub::api::sync::Api::new()?;\n let api = api.model(\"Salesforce/blip-image-captioning-large\".to_string());\n api.get(\"tokenizer.json\")?\n }\n Some(file) => file.into(),\n };\n let tokenizer = Tokenizer::from_file(tokenizer).map_err(E::msg)?;\n let mut tokenizer = TokenOutputStream::new(tokenizer);\n let mut logits_processor =\n candle_transformers::generation::LogitsProcessor::new(1337, None, None);\n\n let config = blip::Config::image_captioning_large();\n\n let device = candle_examples::device(args.cpu)?;\n let (image_embeds, device, mut model) = if args.quantized {\n let device = Device::Cpu;\n let image = load_image(args.image)?.to_device(&device)?;\n println!(\"loaded image {image:?}\");\n\n let vb = quantized_blip::VarBuilder::from_gguf(model_file, &device)?;\n let model = quantized_blip::BlipForConditionalGeneration::new(&config, vb)?;\n let image_embeds = image.unsqueeze(0)?.apply(model.vision_model())?;\n (image_embeds, device, Model::Q(model))\n } else {\n let image = load_image(args.image)?.to_device(&device)?;\n println!(\"loaded image {image:?}\");\n\n let vb =\n unsafe { VarBuilder::from_mmaped_safetensors(&[model_file], DType::F32, &device)? };\n let model = blip::BlipForConditionalGeneration::new(&config, vb)?;\n let image_embeds = image.unsqueeze(0)?.apply(model.vision_model())?;\n (image_embeds, device, Model::M(model))\n };\n\n let mut token_ids = vec![30522u32];\n for index in 0..1000 {\n let context_size = if index > 0 { 1 } else { token_ids.len() };\n let start_pos = token_ids.len().saturating_sub(context_size);\n let input_ids = Tensor::new(&token_ids[start_pos..], &device)?.unsqueeze(0)?;\n let logits = model.text_decoder_forward(&input_ids, &image_embeds)?;\n let logits = logits.squeeze(0)?;\n let logits = logits.get(logits.dim(0)? - 1)?;\n let token = logits_processor.sample(&logits)?;\n if token == SEP_TOKEN_ID {\n break;\n }\n token_ids.push(token);\n if let Some(t) = tokenizer.next_token(token)? {\n use std::io::Write;\n print!(\"{t}\");\n std::io::stdout().flush()?;\n }\n }\n if let Some(rest) = tokenizer.decode_rest().map_err(E::msg)? {\n print!(\"{rest}\");\n }\n println!();\n Ok(())\n}\n", "candle-examples\\examples\\chatglm\\main.rs": "#[cfg(feature = \"mkl\")]\nextern crate intel_mkl_src;\n\n#[cfg(feature = \"accelerate\")]\nextern crate accelerate_src;\n\nuse anyhow::{Error as E, Result};\nuse clap::Parser;\n\nuse candle_transformers::models::chatglm::{Config, Model};\n\nuse candle::{DType, Device, Tensor};\nuse candle_nn::VarBuilder;\nuse candle_transformers::generation::LogitsProcessor;\nuse hf_hub::{api::sync::Api, Repo, RepoType};\nuse tokenizers::Tokenizer;\n\nstruct TextGeneration {\n model: Model,\n device: Device,\n tokenizer: Tokenizer,\n logits_processor: LogitsProcessor,\n repeat_penalty: f32,\n repeat_last_n: usize,\n verbose_prompt: bool,\n}\n\nimpl TextGeneration {\n #[allow(clippy::too_many_arguments)]\n fn new(\n model: Model,\n tokenizer: Tokenizer,\n seed: u64,\n temp: Option<f64>,\n top_p: Option<f64>,\n repeat_penalty: f32,\n repeat_last_n: usize,\n verbose_prompt: bool,\n device: &Device,\n ) -> Self {\n let logits_processor = LogitsProcessor::new(seed, temp, top_p);\n Self {\n model,\n tokenizer,\n logits_processor,\n repeat_penalty,\n repeat_last_n,\n verbose_prompt,\n device: device.clone(),\n }\n }\n\n fn run(&mut self, prompt: &str, sample_len: usize) -> Result<()> {\n use std::io::Write;\n println!(\"starting the inference loop\");\n let tokens = self.tokenizer.encode(prompt, true).map_err(E::msg)?;\n if tokens.is_empty() {\n anyhow::bail!(\"Empty prompts are not supported in the chatglm model.\")\n }\n if self.verbose_prompt {\n for (token, id) in tokens.get_tokens().iter().zip(tokens.get_ids().iter()) {\n let token = token.replace('\u2581', \" \").replace(\"<0x0A>\", \"\\n\");\n println!(\"{id:7} -> '{token}'\");\n }\n }\n let mut tokens = tokens.get_ids().to_vec();\n let mut generated_tokens = 0usize;\n let eos_token = match self.tokenizer.get_vocab(true).get(\"</s>\") {\n Some(token) => *token,\n None => anyhow::bail!(\"cannot find the endoftext token\"),\n };\n print!(\"{prompt}\");\n std::io::stdout().flush()?;\n let start_gen = std::time::Instant::now();\n for index in 0..sample_len {\n let context_size = if index > 0 { 1 } else { tokens.len() };\n let ctxt = &tokens[tokens.len().saturating_sub(context_size)..];\n let input = Tensor::new(ctxt, &self.device)?.unsqueeze(0)?;\n let logits = self.model.forward(&input)?;\n let logits = logits.squeeze(0)?.to_dtype(DType::F32)?;\n let logits = if self.repeat_penalty == 1. {\n logits\n } else {\n let start_at = tokens.len().saturating_sub(self.repeat_last_n);\n candle_transformers::utils::apply_repeat_penalty(\n &logits,\n self.repeat_penalty,\n &tokens[start_at..],\n )?\n };\n\n let next_token = self.logits_processor.sample(&logits)?;\n tokens.push(next_token);\n generated_tokens += 1;\n if next_token == eos_token {\n break;\n }\n let token = self.tokenizer.decode(&[next_token], true).map_err(E::msg)?;\n print!(\"{token}\");\n std::io::stdout().flush()?;\n }\n let dt = start_gen.elapsed();\n println!(\n \"\\n{generated_tokens} tokens generated ({:.2} token/s)\",\n generated_tokens as f64 / dt.as_secs_f64(),\n );\n Ok(())\n }\n}\n\n#[derive(Parser, Debug)]\n#[command(author, version, about, long_about = None)]\nstruct Args {\n /// Run on CPU rather than on GPU.\n #[arg(long)]\n cpu: bool,\n\n /// Enable tracing (generates a trace-timestamp.json file).\n #[arg(long)]\n tracing: bool,\n\n /// Display the token for the specified prompt.\n #[arg(long)]\n verbose_prompt: bool,\n\n #[arg(long)]\n prompt: String,\n\n /// The temperature used to generate samples.\n #[arg(long)]\n temperature: Option<f64>,\n\n /// Nucleus sampling probability cutoff.\n #[arg(long)]\n top_p: Option<f64>,\n\n /// The seed to use when generating random samples.\n #[arg(long, default_value_t = 299792458)]\n seed: u64,\n\n /// The length of the sample to generate (in tokens).\n #[arg(long, short = 'n', default_value_t = 5000)]\n sample_len: usize,\n\n #[arg(long)]\n model_id: Option<String>,\n\n #[arg(long)]\n revision: Option<String>,\n\n #[arg(long)]\n weight_file: Option<String>,\n\n #[arg(long)]\n tokenizer: Option<String>,\n\n /// Penalty to be applied for repeating tokens, 1. means no penalty.\n #[arg(long, default_value_t = 1.1)]\n repeat_penalty: f32,\n\n /// The context size to consider for the repeat penalty.\n #[arg(long, default_value_t = 64)]\n repeat_last_n: usize,\n}\n\nfn main() -> Result<()> {\n use tracing_chrome::ChromeLayerBuilder;\n use tracing_subscriber::prelude::*;\n\n let args = Args::parse();\n let _guard = if args.tracing {\n let (chrome_layer, guard) = ChromeLayerBuilder::new().build();\n tracing_subscriber::registry().with(chrome_layer).init();\n Some(guard)\n } else {\n None\n };\n println!(\n \"avx: {}, neon: {}, simd128: {}, f16c: {}\",\n candle::utils::with_avx(),\n candle::utils::with_neon(),\n candle::utils::with_simd128(),\n candle::utils::with_f16c()\n );\n println!(\n \"temp: {:.2} repeat-penalty: {:.2} repeat-last-n: {}\",\n args.temperature.unwrap_or(0.),\n args.repeat_penalty,\n args.repeat_last_n\n );\n\n let start = std::time::Instant::now();\n let api = Api::new()?;\n let model_id = match args.model_id {\n Some(model_id) => model_id.to_string(),\n None => \"THUDM/chatglm3-6b\".to_string(),\n };\n let revision = match args.revision {\n Some(rev) => rev.to_string(),\n None => \"main\".to_string(),\n };\n let repo = api.repo(Repo::with_revision(model_id, RepoType::Model, revision));\n let tokenizer_filename = match args.tokenizer {\n Some(file) => std::path::PathBuf::from(file),\n None => api\n .model(\"lmz/candle-chatglm\".to_string())\n .get(\"chatglm-tokenizer.json\")?,\n };\n let filenames = match args.weight_file {\n Some(weight_file) => vec![std::path::PathBuf::from(weight_file)],\n None => candle_examples::hub_load_safetensors(&repo, \"model.safetensors.index.json\")?,\n };\n println!(\"retrieved the files in {:?}\", start.elapsed());\n let tokenizer = Tokenizer::from_file(tokenizer_filename).map_err(E::msg)?;\n\n let start = std::time::Instant::now();\n let config = Config::glm3_6b();\n let device = candle_examples::device(args.cpu)?;\n let vb = unsafe { VarBuilder::from_mmaped_safetensors(&filenames, DType::F32, &device)? };\n let model = Model::new(&config, vb)?;\n\n println!(\"loaded the model in {:?}\", start.elapsed());\n\n let mut pipeline = TextGeneration::new(\n model,\n tokenizer,\n args.seed,\n args.temperature,\n args.top_p,\n args.repeat_penalty,\n args.repeat_last_n,\n args.verbose_prompt,\n &device,\n );\n pipeline.run(&args.prompt, args.sample_len)?;\n Ok(())\n}\n", "candle-examples\\examples\\clip\\main.rs": "#[cfg(feature = \"mkl\")]\nextern crate intel_mkl_src;\n\n#[cfg(feature = \"accelerate\")]\nextern crate accelerate_src;\n\nuse anyhow::Error as E;\nuse clap::Parser;\n\nuse candle::{DType, Device, Tensor};\nuse candle_nn::{ops::softmax, VarBuilder};\nuse candle_transformers::models::clip;\n\nuse tokenizers::Tokenizer;\nuse tracing::info;\n\n#[derive(Parser)]\nstruct Args {\n #[arg(long)]\n model: Option<String>,\n\n #[arg(long)]\n tokenizer: Option<String>,\n\n #[arg(long, use_value_delimiter = true)]\n images: Option<Vec<String>>,\n\n #[arg(long)]\n cpu: bool,\n\n #[arg(long, use_value_delimiter = true)]\n sequences: Option<Vec<String>>,\n}\n\nfn load_image<T: AsRef<std::path::Path>>(path: T, image_size: usize) -> anyhow::Result<Tensor> {\n let img = image::ImageReader::open(path)?.decode()?;\n let (height, width) = (image_size, image_size);\n let img = img.resize_to_fill(\n width as u32,\n height as u32,\n image::imageops::FilterType::Triangle,\n );\n\n let img = img.to_rgb8();\n\n let img = img.into_raw();\n let img = Tensor::from_vec(img, (height, width, 3), &Device::Cpu)?\n .permute((2, 0, 1))?\n .to_dtype(DType::F32)?\n .affine(2. / 255., -1.)?;\n // .unsqueeze(0)?;\n Ok(img)\n}\n\nfn load_images<T: AsRef<std::path::Path>>(\n paths: &Vec<T>,\n image_size: usize,\n) -> anyhow::Result<Tensor> {\n let mut images = vec![];\n\n for path in paths {\n let tensor = load_image(path, image_size)?;\n images.push(tensor);\n }\n\n let images = Tensor::stack(&images, 0)?;\n\n Ok(images)\n}\n\npub fn main() -> anyhow::Result<()> {\n // std::env::set_var(\"RUST_BACKTRACE\", \"full\");\n\n let args = Args::parse();\n\n tracing_subscriber::fmt::init();\n\n let model_file = match args.model {\n None => {\n let api = hf_hub::api::sync::Api::new()?;\n\n let api = api.repo(hf_hub::Repo::with_revision(\n \"openai/clip-vit-base-patch32\".to_string(),\n hf_hub::RepoType::Model,\n \"refs/pr/15\".to_string(),\n ));\n\n api.get(\"model.safetensors\")?\n }\n Some(model) => model.into(),\n };\n\n let tokenizer = get_tokenizer(args.tokenizer)?;\n\n let config = clip::ClipConfig::vit_base_patch32();\n\n let device = candle_examples::device(args.cpu)?;\n\n let vec_imgs = match args.images {\n Some(imgs) => imgs,\n None => vec![\n \"candle-examples/examples/stable-diffusion/assets/stable-diffusion-xl.jpg\".to_string(),\n \"candle-examples/examples/yolo-v8/assets/bike.jpg\".to_string(),\n ],\n };\n\n // let image = load_image(args.image, config.image_size)?.to_device(&device)?;\n let images = load_images(&vec_imgs, config.image_size)?.to_device(&device)?;\n\n let vb =\n unsafe { VarBuilder::from_mmaped_safetensors(&[model_file.clone()], DType::F32, &device)? };\n\n let model = clip::ClipModel::new(vb, &config)?;\n\n let (input_ids, vec_seq) = tokenize_sequences(args.sequences, &tokenizer, &device)?;\n\n let (_logits_per_text, logits_per_image) = model.forward(&images, &input_ids)?;\n\n let softmax_image = softmax(&logits_per_image, 1)?;\n\n let softmax_image_vec = softmax_image.flatten_all()?.to_vec1::<f32>()?;\n\n info!(\"softmax_image_vec: {:?}\", softmax_image_vec);\n\n let probability_vec = softmax_image_vec\n .iter()\n .map(|v| v * 100.0)\n .collect::<Vec<f32>>();\n\n let probability_per_image = probability_vec.len() / vec_imgs.len();\n\n for (i, img) in vec_imgs.iter().enumerate() {\n let start = i * probability_per_image;\n let end = start + probability_per_image;\n let prob = &probability_vec[start..end];\n info!(\"\\n\\nResults for image: {}\\n\", img);\n\n for (i, p) in prob.iter().enumerate() {\n info!(\"Probability: {:.4}% Text: {} \", p, vec_seq[i]);\n }\n }\n\n Ok(())\n}\n\npub fn get_tokenizer(tokenizer: Option<String>) -> anyhow::Result<Tokenizer> {\n let tokenizer = match tokenizer {\n None => {\n let api = hf_hub::api::sync::Api::new()?;\n let api = api.repo(hf_hub::Repo::with_revision(\n \"openai/clip-vit-base-patch32\".to_string(),\n hf_hub::RepoType::Model,\n \"refs/pr/15\".to_string(),\n ));\n api.get(\"tokenizer.json\")?\n }\n Some(file) => file.into(),\n };\n\n Tokenizer::from_file(tokenizer).map_err(E::msg)\n}\n\npub fn tokenize_sequences(\n sequences: Option<Vec<String>>,\n tokenizer: &Tokenizer,\n device: &Device,\n) -> anyhow::Result<(Tensor, Vec<String>)> {\n let pad_id = *tokenizer\n .get_vocab(true)\n .get(\"<|endoftext|>\")\n .ok_or(E::msg(\"No pad token\"))?;\n\n let vec_seq = match sequences {\n Some(seq) => seq,\n None => vec![\n \"a cycling race\".to_string(),\n \"a photo of two cats\".to_string(),\n \"a robot holding a candle\".to_string(),\n ],\n };\n\n let mut tokens = vec![];\n\n for seq in vec_seq.clone() {\n let encoding = tokenizer.encode(seq, true).map_err(E::msg)?;\n tokens.push(encoding.get_ids().to_vec());\n }\n\n let max_len = tokens.iter().map(|v| v.len()).max().unwrap_or(0);\n\n // Pad the sequences to have the same length\n for token_vec in tokens.iter_mut() {\n let len_diff = max_len - token_vec.len();\n if len_diff > 0 {\n token_vec.extend(vec![pad_id; len_diff]);\n }\n }\n\n let input_ids = Tensor::new(tokens, device)?;\n\n Ok((input_ids, vec_seq))\n}\n", "candle-examples\\examples\\codegeex4-9b\\main.rs": "use candle_transformers::models::codegeex4_9b::*;\nuse clap::Parser;\n\nuse candle::{DType, Device, Tensor};\nuse candle_nn::VarBuilder;\nuse candle_transformers::generation::LogitsProcessor;\nuse hf_hub::{Repo, RepoType};\nuse tokenizers::Tokenizer;\n\nstruct TextGeneration {\n model: Model,\n device: Device,\n tokenizer: Tokenizer,\n logits_processor: LogitsProcessor,\n repeat_penalty: f32,\n repeat_last_n: usize,\n verbose_prompt: bool,\n dtype: DType,\n}\n\nimpl TextGeneration {\n #[allow(clippy::too_many_arguments)]\n fn new(\n model: Model,\n tokenizer: Tokenizer,\n seed: u64,\n temp: Option<f64>,\n top_p: Option<f64>,\n repeat_penalty: f32,\n repeat_last_n: usize,\n verbose_prompt: bool,\n device: &Device,\n dtype: DType,\n ) -> Self {\n let logits_processor = LogitsProcessor::new(seed, temp, top_p);\n Self {\n model,\n tokenizer,\n logits_processor,\n repeat_penalty,\n repeat_last_n,\n verbose_prompt,\n device: device.clone(),\n dtype,\n }\n }\n\n fn run(&mut self, prompt: &str, sample_len: usize) -> anyhow::Result<()> {\n use std::io::Write;\n println!(\"starting the inference loop\");\n let tokens = self.tokenizer.encode(prompt, true).expect(\"tokens error\");\n if tokens.is_empty() {\n panic!(\"Empty prompts are not supported in the chatglm model.\")\n }\n if self.verbose_prompt {\n for (token, id) in tokens.get_tokens().iter().zip(tokens.get_ids().iter()) {\n let token = token.replace('\u2581', \" \").replace(\"<0x0A>\", \"\\n\");\n println!(\"{id:7} -> '{token}'\");\n }\n }\n let eos_token = match self.tokenizer.get_vocab(true).get(\"<|endoftext|>\") {\n Some(token) => *token,\n None => panic!(\"cannot find the endoftext token\"),\n };\n let mut tokens = tokens.get_ids().to_vec();\n let mut generated_tokens = 0usize;\n\n print!(\"{prompt}\");\n std::io::stdout().flush().expect(\"output flush error\");\n let start_gen = std::time::Instant::now();\n\n println!(\"\\n start_gen\");\n println!(\"samplelen {}\", sample_len);\n let mut count = 0;\n let mut result = vec![];\n for index in 0..sample_len {\n count += 1;\n let context_size = if index > 0 { 1 } else { tokens.len() };\n let ctxt = &tokens[tokens.len().saturating_sub(context_size)..];\n let input = Tensor::new(ctxt, &self.device)?.unsqueeze(0)?;\n let logits = self.model.forward(&input)?;\n let logits = logits.squeeze(0)?.to_dtype(self.dtype)?;\n let logits = if self.repeat_penalty == 1. {\n logits\n } else {\n let start_at = tokens.len().saturating_sub(self.repeat_last_n);\n candle_transformers::utils::apply_repeat_penalty(\n &logits,\n self.repeat_penalty,\n &tokens[start_at..],\n )?\n };\n\n let next_token = self.logits_processor.sample(&logits)?;\n tokens.push(next_token);\n generated_tokens += 1;\n if next_token == eos_token {\n break;\n }\n let token = self\n .tokenizer\n .decode(&[next_token], true)\n .expect(\"Token error\");\n if self.verbose_prompt {\n println!(\n \"[Count: {}] [Raw Token: {}] [Decode Token: {}]\",\n count, next_token, token\n );\n }\n result.push(token);\n std::io::stdout().flush()?;\n }\n let dt = start_gen.elapsed();\n println!(\n \"\\n{generated_tokens} tokens generated ({:.2} token/s)\",\n generated_tokens as f64 / dt.as_secs_f64(),\n );\n println!(\"Result:\");\n for tokens in result {\n print!(\"{tokens}\");\n }\n Ok(())\n }\n}\n\n#[derive(Parser, Debug)]\n#[command(author, version, about, long_about = None)]\nstruct Args {\n /// Run on CPU rather than on GPU.\n #[arg(name = \"cache\", short, long, default_value = \".\")]\n cache_path: String,\n\n #[arg(long)]\n cpu: bool,\n\n /// Display the token for the specified prompt.\n #[arg(long)]\n verbose_prompt: bool,\n\n #[arg(long)]\n prompt: String,\n\n /// The temperature used to generate samples.\n #[arg(long)]\n temperature: Option<f64>,\n\n /// Nucleus sampling probability cutoff.\n #[arg(long)]\n top_p: Option<f64>,\n\n /// The seed to use when generating random samples.\n #[arg(long, default_value_t = 299792458)]\n seed: u64,\n\n /// The length of the sample to generate (in tokens).\n #[arg(long, short = 'n', default_value_t = 5000)]\n sample_len: usize,\n\n #[arg(long)]\n model_id: Option<String>,\n\n #[arg(long)]\n revision: Option<String>,\n\n #[arg(long)]\n weight_file: Option<String>,\n\n #[arg(long)]\n tokenizer: Option<String>,\n\n /// Penalty to be applied for repeating tokens, 1. means no penalty.\n #[arg(long, default_value_t = 1.1)]\n repeat_penalty: f32,\n\n /// The context size to consider for the repeat penalty.\n #[arg(long, default_value_t = 64)]\n repeat_last_n: usize,\n}\n\nfn main() -> anyhow::Result<()> {\n let args = Args::parse();\n println!(\n \"avx: {}, neon: {}, simd128: {}, f16c: {}\",\n candle::utils::with_avx(),\n candle::utils::with_neon(),\n candle::utils::with_simd128(),\n candle::utils::with_f16c()\n );\n println!(\n \"temp: {:.2} repeat-penalty: {:.2} repeat-last-n: {}\",\n args.temperature.unwrap_or(0.95),\n args.repeat_penalty,\n args.repeat_last_n\n );\n\n let start = std::time::Instant::now();\n println!(\"cache path {}\", args.cache_path);\n let api = hf_hub::api::sync::ApiBuilder::from_cache(hf_hub::Cache::new(args.cache_path.into()))\n .build()\n .map_err(anyhow::Error::msg)?;\n\n let model_id = match args.model_id {\n Some(model_id) => model_id.to_string(),\n None => \"THUDM/codegeex4-all-9b\".to_string(),\n };\n let revision = match args.revision {\n Some(rev) => rev.to_string(),\n None => \"main\".to_string(),\n };\n let repo = api.repo(Repo::with_revision(model_id, RepoType::Model, revision));\n let tokenizer_filename = match args.tokenizer {\n Some(file) => std::path::PathBuf::from(file),\n None => api\n .model(\"THUDM/codegeex4-all-9b\".to_string())\n .get(\"tokenizer.json\")\n .map_err(anyhow::Error::msg)?,\n };\n let filenames = match args.weight_file {\n Some(weight_file) => vec![std::path::PathBuf::from(weight_file)],\n None => candle_examples::hub_load_safetensors(&repo, \"model.safetensors.index.json\")?,\n };\n println!(\"retrieved the files in {:?}\", start.elapsed());\n let tokenizer = Tokenizer::from_file(tokenizer_filename).expect(\"Tokenizer Error\");\n\n let start = std::time::Instant::now();\n let config = Config::codegeex4();\n let device = candle_examples::device(args.cpu)?;\n let dtype = if device.is_cuda() {\n DType::BF16\n } else {\n DType::F32\n };\n let vb = unsafe { VarBuilder::from_mmaped_safetensors(&filenames, dtype, &device)? };\n let model = Model::new(&config, vb)?;\n\n println!(\"loaded the model in {:?}\", start.elapsed());\n\n let mut pipeline = TextGeneration::new(\n model,\n tokenizer,\n args.seed,\n args.temperature,\n args.top_p,\n args.repeat_penalty,\n args.repeat_last_n,\n args.verbose_prompt,\n &device,\n dtype,\n );\n pipeline.run(&args.prompt, args.sample_len)?;\n Ok(())\n}\n", "candle-examples\\examples\\convmixer\\main.rs": "#[cfg(feature = \"mkl\")]\nextern crate intel_mkl_src;\n\n#[cfg(feature = \"accelerate\")]\nextern crate accelerate_src;\n\nuse clap::Parser;\n\nuse candle::{DType, IndexOp, D};\nuse candle_nn::{Module, VarBuilder};\nuse candle_transformers::models::convmixer;\n\n#[derive(Parser)]\nstruct Args {\n #[arg(long)]\n model: Option<String>,\n\n #[arg(long)]\n image: String,\n\n /// Run on CPU rather than on GPU.\n #[arg(long)]\n cpu: bool,\n}\n\npub fn main() -> anyhow::Result<()> {\n let args = Args::parse();\n\n let device = candle_examples::device(args.cpu)?;\n\n let image = candle_examples::imagenet::load_image224(args.image)?.to_device(&device)?;\n println!(\"loaded image {image:?}\");\n\n let model_file = match args.model {\n None => {\n let api = hf_hub::api::sync::Api::new()?;\n let api = api.model(\"lmz/candle-convmixer\".into());\n api.get(\"convmixer_1024_20_ks9_p14.safetensors\")?\n }\n Some(model) => model.into(),\n };\n let vb = unsafe { VarBuilder::from_mmaped_safetensors(&[model_file], DType::F32, &device)? };\n let model = convmixer::c1024_20(1000, vb)?;\n println!(\"model built\");\n let logits = model.forward(&image.unsqueeze(0)?)?;\n let prs = candle_nn::ops::softmax(&logits, D::Minus1)?\n .i(0)?\n .to_vec1::<f32>()?;\n let mut prs = prs.iter().enumerate().collect::<Vec<_>>();\n prs.sort_by(|(_, p1), (_, p2)| p2.total_cmp(p1));\n for &(category_idx, pr) in prs.iter().take(5) {\n println!(\n \"{:24}: {:.2}%\",\n candle_examples::imagenet::CLASSES[category_idx],\n 100. * pr\n );\n }\n Ok(())\n}\n", "candle-examples\\examples\\convnext\\main.rs": "#[cfg(feature = \"mkl\")]\nextern crate intel_mkl_src;\n\n#[cfg(feature = \"accelerate\")]\nextern crate accelerate_src;\n\nuse clap::{Parser, ValueEnum};\n\nuse candle::{DType, IndexOp, D};\nuse candle_nn::{Module, VarBuilder};\nuse candle_transformers::models::convnext;\n\n#[derive(Clone, Copy, Debug, ValueEnum)]\nenum Which {\n Atto,\n Femto,\n Pico,\n Nano,\n Tiny,\n Small,\n Base,\n Large,\n AttoV2,\n FemtoV2,\n PicoV2,\n NanoV2,\n TinyV2,\n BaseV2,\n LargeV2,\n XLarge,\n Huge,\n}\n\nimpl Which {\n fn model_filename(&self) -> String {\n let name = match self {\n Self::Atto => \"convnext_atto.d2_in1k\",\n Self::Femto => \"convnext_femto.d1_in1k\",\n Self::Pico => \"convnext_pico.d1_in1k\",\n Self::Nano => \"convnext_nano.d1h_in1k\",\n Self::Tiny => \"convnext_tiny.fb_in1k\",\n Self::Small => \"convnext_small.fb_in1k\",\n Self::Base => \"convnext_base.fb_in1k\",\n Self::Large => \"convnext_large.fb_in1k\",\n Self::AttoV2 => \"convnextv2_atto.fcmae_ft_in1k\",\n Self::FemtoV2 => \"convnextv2_femto.fcmae_ft_in1k\",\n Self::PicoV2 => \"convnextv2_pico.fcmae_ft_in1k\",\n Self::NanoV2 => \"convnextv2_nano.fcmae_ft_in1k\",\n Self::TinyV2 => \"convnextv2_tiny.fcmae_ft_in1k\",\n Self::BaseV2 => \"convnextv2_base.fcmae_ft_in1k\",\n Self::LargeV2 => \"convnextv2_large.fcmae_ft_in1k\",\n Self::XLarge => \"convnext_xlarge.fb_in22k_ft_in1k\",\n Self::Huge => \"convnextv2_huge.fcmae_ft_in1k\",\n };\n\n format!(\"timm/{name}\")\n }\n\n fn config(&self) -> convnext::Config {\n match self {\n Self::Atto | Self::AttoV2 => convnext::Config::atto(),\n Self::Femto | Self::FemtoV2 => convnext::Config::femto(),\n Self::Pico | Self::PicoV2 => convnext::Config::pico(),\n Self::Nano | Self::NanoV2 => convnext::Config::nano(),\n Self::Tiny | Self::TinyV2 => convnext::Config::tiny(),\n Self::Small => convnext::Config::small(),\n Self::Base | Self::BaseV2 => convnext::Config::base(),\n Self::Large | Self::LargeV2 => convnext::Config::large(),\n Self::XLarge => convnext::Config::xlarge(),\n Self::Huge => convnext::Config::huge(),\n }\n }\n}\n\n#[derive(Parser)]\nstruct Args {\n #[arg(long)]\n model: Option<String>,\n\n #[arg(long)]\n image: String,\n\n /// Run on CPU rather than on GPU.\n #[arg(long)]\n cpu: bool,\n\n #[arg(value_enum, long, default_value_t=Which::Tiny)]\n which: Which,\n}\n\npub fn main() -> anyhow::Result<()> {\n let args = Args::parse();\n\n let device = candle_examples::device(args.cpu)?;\n\n let image = candle_examples::imagenet::load_image224(args.image)?.to_device(&device)?;\n println!(\"loaded image {image:?}\");\n\n let model_file = match args.model {\n None => {\n let model_name = args.which.model_filename();\n let api = hf_hub::api::sync::Api::new()?;\n let api = api.model(model_name);\n api.get(\"model.safetensors\")?\n }\n Some(model) => model.into(),\n };\n\n let vb = unsafe { VarBuilder::from_mmaped_safetensors(&[model_file], DType::F32, &device)? };\n let model = convnext::convnext(&args.which.config(), 1000, vb)?;\n println!(\"model built\");\n let logits = model.forward(&image.unsqueeze(0)?)?;\n let prs = candle_nn::ops::softmax(&logits, D::Minus1)?\n .i(0)?\n .to_vec1::<f32>()?;\n let mut prs = prs.iter().enumerate().collect::<Vec<_>>();\n prs.sort_by(|(_, p1), (_, p2)| p2.total_cmp(p1));\n for &(category_idx, pr) in prs.iter().take(5) {\n println!(\n \"{:24}: {:.2}%\",\n candle_examples::imagenet::CLASSES[category_idx],\n 100. * pr\n );\n }\n Ok(())\n}\n", "candle-examples\\examples\\custom-ops\\main.rs": "// This example illustrates how to implement custom operations. These operations can provide their\n// own forward pass (CPU and GPU versions) as well as their backward pass.\n//\n// In this example we add the RMS normalization operation and implement it for f32.\n\n#[cfg(feature = \"mkl\")]\nextern crate intel_mkl_src;\n\n#[rustfmt::skip]\n#[cfg(feature = \"cuda\")]\nmod cuda_kernels;\n\nuse clap::Parser;\n\nuse candle::{CpuStorage, CustomOp1, Layout, Result, Shape, Tensor};\n\n#[derive(Parser, Debug)]\n#[command(author, version, about, long_about = None)]\nstruct Args {\n /// Run on CPU rather than on GPU.\n #[arg(long)]\n cpu: bool,\n}\n\nstruct LayerNorm {\n eps: f32,\n}\n\nimpl CustomOp1 for LayerNorm {\n fn name(&self) -> &'static str {\n \"layer-norm\"\n }\n\n fn cpu_fwd(&self, storage: &CpuStorage, layout: &Layout) -> Result<(CpuStorage, Shape)> {\n let (dim1, dim2) = layout.shape().dims2()?;\n let slice = storage.as_slice::<f32>()?;\n let src = match layout.contiguous_offsets() {\n None => candle::bail!(\"input has to be contiguous\"),\n Some((o1, o2)) => &slice[o1..o2],\n };\n let mut dst = Vec::with_capacity(dim1 * dim2);\n for idx1 in 0..dim1 {\n let src = &src[idx1 * dim2..(idx1 + 1) * dim2];\n let variance = src.iter().map(|x| x * x).sum::<f32>();\n let s_variance = 1f32 / (variance / dim2 as f32 + self.eps).sqrt();\n dst.extend(src.iter().map(|x| x * s_variance))\n }\n let storage = candle::WithDType::to_cpu_storage_owned(dst);\n Ok((storage, layout.shape().clone()))\n }\n\n #[cfg(feature = \"cuda\")]\n fn cuda_fwd(\n &self,\n storage: &candle::CudaStorage,\n layout: &Layout,\n ) -> Result<(candle::CudaStorage, Shape)> {\n use candle::backend::BackendStorage;\n use candle::cuda_backend::cudarc::driver::{LaunchAsync, LaunchConfig};\n use candle::cuda_backend::WrapErr;\n let (d1, d2) = layout.shape().dims2()?;\n let d1 = d1 as u32;\n let d2 = d2 as u32;\n let dev = storage.device().clone();\n let slice = storage.as_cuda_slice::<f32>()?;\n let slice = match layout.contiguous_offsets() {\n None => candle::bail!(\"input has to be contiguous\"),\n Some((o1, o2)) => slice.slice(o1..o2),\n };\n let elem_count = layout.shape().elem_count();\n let dst = unsafe { dev.alloc::<f32>(elem_count) }.w()?;\n let func = dev.get_or_load_func(\"rms_f32\", cuda_kernels::LAYERNORM_KERNELS)?;\n let params = (&dst, &slice, self.eps, d1, d2);\n let cfg = LaunchConfig {\n grid_dim: (d1, 1, 1),\n block_dim: (d2, 1, 1),\n shared_mem_bytes: 0,\n };\n unsafe { func.launch(cfg, params) }.w()?;\n\n let dst = candle::CudaStorage::wrap_cuda_slice(dst, dev);\n Ok((dst, layout.shape().clone()))\n }\n}\n\nfn main() -> anyhow::Result<()> {\n let args = Args::parse();\n let device = candle_examples::device(args.cpu)?;\n let t = Tensor::arange(0f32, 14f32, &device)?.reshape((2, 7))?;\n println!(\"{t}\");\n let t = t.apply_op1(LayerNorm { eps: 1e-5 })?;\n println!(\"{t}\");\n Ok(())\n}\n", "candle-examples\\examples\\depth_anything_v2\\main.rs": "//! Depth Anything V2\n//! https://huggingface.co/spaces/depth-anything/Depth-Anything-V2\n\n#[cfg(feature = \"accelerate\")]\nextern crate accelerate_src;\n#[cfg(feature = \"mkl\")]\nextern crate intel_mkl_src;\n\nuse std::ffi::OsString;\nuse std::path::PathBuf;\n\nuse clap::Parser;\n\nuse candle::DType::{F32, U8};\nuse candle::{DType, Device, Module, Result, Tensor};\nuse candle_examples::{load_image, load_image_and_resize, save_image};\nuse candle_nn::VarBuilder;\nuse candle_transformers::models::depth_anything_v2::{DepthAnythingV2, DepthAnythingV2Config};\nuse candle_transformers::models::dinov2;\n\nuse crate::color_map::SpectralRColormap;\n\nmod color_map;\n\n// taken these from: https://huggingface.co/spaces/depth-anything/Depth-Anything-V2/blob/main/depth_anything_v2/dpt.py#L207\nconst MAGIC_MEAN: [f32; 3] = [0.485, 0.456, 0.406];\nconst MAGIC_STD: [f32; 3] = [0.229, 0.224, 0.225];\n\nconst DINO_IMG_SIZE: usize = 518;\n\n#[derive(Parser)]\nstruct Args {\n #[arg(long)]\n dinov2_model: Option<PathBuf>,\n\n #[arg(long)]\n depth_anything_v2_model: Option<PathBuf>,\n\n #[arg(long)]\n image: PathBuf,\n\n #[arg(long)]\n output_dir: Option<PathBuf>,\n\n #[arg(long)]\n cpu: bool,\n\n #[arg(long)]\n color_map: bool,\n}\n\npub fn main() -> anyhow::Result<()> {\n let args = Args::parse();\n let device = candle_examples::device(args.cpu)?;\n\n let dinov2_model_file = match args.dinov2_model {\n None => {\n let api = hf_hub::api::sync::Api::new()?;\n let api = api.model(\"lmz/candle-dino-v2\".into());\n api.get(\"dinov2_vits14.safetensors\")?\n }\n Some(dinov2_model) => dinov2_model,\n };\n println!(\"Using file {:?}\", dinov2_model_file);\n\n let vb = unsafe { VarBuilder::from_mmaped_safetensors(&[dinov2_model_file], F32, &device)? };\n let dinov2 = dinov2::vit_small(vb)?;\n println!(\"DinoV2 model built\");\n\n let depth_anything_model_file = match args.depth_anything_v2_model {\n None => {\n let api = hf_hub::api::sync::Api::new()?;\n let api = api.model(\"jeroenvlek/depth-anything-v2-safetensors\".into());\n api.get(\"depth_anything_v2_vits.safetensors\")?\n }\n Some(depth_anything_model) => depth_anything_model,\n };\n println!(\"Using file {:?}\", depth_anything_model_file);\n\n let vb = unsafe {\n VarBuilder::from_mmaped_safetensors(&[depth_anything_model_file], DType::F32, &device)?\n };\n\n let config = DepthAnythingV2Config::vit_small();\n let depth_anything = DepthAnythingV2::new(&dinov2, &config, vb)?;\n\n let (original_height, original_width, image) = load_and_prep_image(&args.image, &device)?;\n\n println!(\"Loaded image {image:?}\");\n\n let depth = depth_anything.forward(&image)?;\n\n println!(\"Got predictions {:?}\", depth.shape());\n\n let output_image = post_process_image(&depth, original_height, original_width, args.color_map)?;\n\n let output_path = full_output_path(&args.image, &args.output_dir);\n println!(\"Saving image to {}\", output_path.to_string_lossy());\n save_image(&output_image, output_path)?;\n\n Ok(())\n}\n\nfn full_output_path(image_path: &PathBuf, output_dir: &Option<PathBuf>) -> PathBuf {\n let input_file_name = image_path.file_name().unwrap();\n let mut output_file_name = OsString::from(\"depth_\");\n output_file_name.push(input_file_name);\n let mut output_path = match output_dir {\n None => image_path.parent().unwrap().to_path_buf(),\n Some(output_path) => output_path.clone(),\n };\n output_path.push(output_file_name);\n\n output_path\n}\n\nfn load_and_prep_image(\n image_path: &PathBuf,\n device: &Device,\n) -> anyhow::Result<(usize, usize, Tensor)> {\n let (_original_image, original_height, original_width) = load_image(&image_path, None)?;\n\n let image = load_image_and_resize(&image_path, DINO_IMG_SIZE, DINO_IMG_SIZE)?\n .unsqueeze(0)?\n .to_dtype(F32)?\n .to_device(&device)?;\n\n let max_pixel_val = Tensor::try_from(255.0f32)?\n .to_device(&device)?\n .broadcast_as(image.shape())?;\n let image = (image / max_pixel_val)?;\n let image = normalize_image(&image, &MAGIC_MEAN, &MAGIC_STD)?;\n\n Ok((original_height, original_width, image))\n}\n\nfn normalize_image(image: &Tensor, mean: &[f32; 3], std: &[f32; 3]) -> Result<Tensor> {\n let mean_tensor =\n Tensor::from_vec(mean.to_vec(), (3, 1, 1), &image.device())?.broadcast_as(image.shape())?;\n let std_tensor =\n Tensor::from_vec(std.to_vec(), (3, 1, 1), &image.device())?.broadcast_as(image.shape())?;\n image.sub(&mean_tensor)?.div(&std_tensor)\n}\n\nfn post_process_image(\n image: &Tensor,\n original_height: usize,\n original_width: usize,\n color_map: bool,\n) -> Result<Tensor> {\n let out = image.interpolate2d(original_height, original_width)?;\n let out = scale_image(&out)?;\n\n let out = if color_map {\n let spectral_r = SpectralRColormap::new();\n spectral_r.gray2color(&out)?\n } else {\n let rgb_slice = [&out, &out, &out];\n Tensor::cat(&rgb_slice, 0)?.squeeze(1)?\n };\n\n let max_pixel_val = Tensor::try_from(255.0f32)?\n .to_device(out.device())?\n .broadcast_as(out.shape())?;\n let out = (out * max_pixel_val)?;\n\n out.to_dtype(U8)\n}\n\nfn scale_image(depth: &Tensor) -> Result<Tensor> {\n let flat_values: Vec<f32> = depth.flatten_all()?.to_vec1()?;\n\n let min_val = flat_values.iter().min_by(|a, b| a.total_cmp(b)).unwrap();\n let max_val = flat_values.iter().max_by(|a, b| a.total_cmp(b)).unwrap();\n\n let min_val_tensor = Tensor::try_from(*min_val)?\n .to_device(depth.device())?\n .broadcast_as(depth.shape())?;\n let depth = (depth - min_val_tensor)?;\n\n let range = max_val - min_val;\n let range_tensor = Tensor::try_from(range)?\n .to_device(depth.device())?\n .broadcast_as(depth.shape())?;\n\n depth / range_tensor\n}\n", "candle-examples\\examples\\dinov2\\main.rs": "//! DINOv2: Learning Robust Visual Features without Supervision\n//! https://github.com/facebookresearch/dinov2\n\n#[cfg(feature = \"mkl\")]\nextern crate intel_mkl_src;\n\n#[cfg(feature = \"accelerate\")]\nextern crate accelerate_src;\n\nuse clap::Parser;\n\nuse candle::{DType, IndexOp, D};\nuse candle_nn::{Module, VarBuilder};\nuse candle_transformers::models::dinov2;\n\n#[derive(Parser)]\nstruct Args {\n #[arg(long)]\n model: Option<String>,\n\n #[arg(long)]\n image: String,\n\n /// Run on CPU rather than on GPU.\n #[arg(long)]\n cpu: bool,\n}\n\npub fn main() -> anyhow::Result<()> {\n let args = Args::parse();\n\n let device = candle_examples::device(args.cpu)?;\n\n let image = candle_examples::imagenet::load_image224(args.image)?.to_device(&device)?;\n println!(\"loaded image {image:?}\");\n\n let model_file = match args.model {\n None => {\n let api = hf_hub::api::sync::Api::new()?;\n let api = api.model(\"lmz/candle-dino-v2\".into());\n api.get(\"dinov2_vits14.safetensors\")?\n }\n Some(model) => model.into(),\n };\n let vb = unsafe { VarBuilder::from_mmaped_safetensors(&[model_file], DType::F32, &device)? };\n let model = dinov2::vit_small(vb)?;\n println!(\"model built\");\n let logits = model.forward(&image.unsqueeze(0)?)?;\n let prs = candle_nn::ops::softmax(&logits, D::Minus1)?\n .i(0)?\n .to_vec1::<f32>()?;\n let mut prs = prs.iter().enumerate().collect::<Vec<_>>();\n prs.sort_by(|(_, p1), (_, p2)| p2.total_cmp(p1));\n for &(category_idx, pr) in prs.iter().take(5) {\n println!(\n \"{:24}: {:.2}%\",\n candle_examples::imagenet::CLASSES[category_idx],\n 100. * pr\n );\n }\n Ok(())\n}\n", "candle-examples\\examples\\dinov2reg4\\main.rs": "//! DINOv2 reg4 finetuned on PlantCLEF 2024\n//! https://arxiv.org/abs/2309.16588\n//! https://huggingface.co/spaces/BVRA/PlantCLEF2024\n//! https://zenodo.org/records/10848263\n\n#[cfg(feature = \"mkl\")]\nextern crate intel_mkl_src;\n\n#[cfg(feature = \"accelerate\")]\nextern crate accelerate_src;\n\nuse clap::Parser;\n\nuse candle::{DType, IndexOp, D};\nuse candle_nn::{Module, VarBuilder};\nuse candle_transformers::models::dinov2reg4;\n\n#[derive(Parser)]\nstruct Args {\n #[arg(long)]\n model: Option<String>,\n\n #[arg(long)]\n image: String,\n\n /// Run on CPU rather than on GPU.\n #[arg(long)]\n cpu: bool,\n}\n\npub fn main() -> anyhow::Result<()> {\n let args = Args::parse();\n\n let device = candle_examples::device(args.cpu)?;\n\n let image = candle_examples::imagenet::load_image518(args.image)?.to_device(&device)?;\n println!(\"loaded image {image:?}\");\n\n let f_species_id_mapping = \"candle-examples/examples/dinov2reg4/species_id_mapping.txt\";\n let classes: Vec<String> = std::fs::read_to_string(f_species_id_mapping)\n .expect(\"missing classes file\")\n .split('\\n')\n .map(|s| s.to_string())\n .collect();\n\n let model_file = match args.model {\n None => {\n let api = hf_hub::api::sync::Api::new()?;\n let api =\n api.model(\"vincent-espitalier/dino-v2-reg4-with-plantclef2024-weights\".into());\n api.get(\n \"vit_base_patch14_reg4_dinov2_lvd142m_pc24_onlyclassifier_then_all.safetensors\",\n )?\n }\n Some(model) => model.into(),\n };\n let vb = unsafe { VarBuilder::from_mmaped_safetensors(&[model_file], DType::F32, &device)? };\n let model = dinov2reg4::vit_base(vb)?;\n println!(\"model built\");\n let logits = model.forward(&image.unsqueeze(0)?)?;\n let prs = candle_nn::ops::softmax(&logits, D::Minus1)?\n .i(0)?\n .to_vec1::<f32>()?;\n let mut prs = prs.iter().enumerate().collect::<Vec<_>>();\n prs.sort_by(|(_, p1), (_, p2)| p2.total_cmp(p1));\n for &(category_idx, pr) in prs.iter().take(5) {\n println!(\"{:24}: {:.2}%\", classes[category_idx], 100. * pr);\n }\n Ok(())\n}\n", "candle-examples\\examples\\distilbert\\main.rs": "#[cfg(feature = \"mkl\")]\nextern crate intel_mkl_src;\n\n#[cfg(feature = \"accelerate\")]\nextern crate accelerate_src;\nuse candle_transformers::models::distilbert::{Config, DistilBertModel, DTYPE};\n\nuse anyhow::{Error as E, Result};\nuse candle::{Device, Tensor};\nuse candle_nn::VarBuilder;\nuse clap::Parser;\nuse hf_hub::{api::sync::Api, Repo, RepoType};\nuse tokenizers::Tokenizer;\n\n#[derive(Parser, Debug)]\n#[command(author, version, about, long_about = None)]\nstruct Args {\n /// Run on CPU rather than on GPU.\n #[arg(long)]\n cpu: bool,\n\n /// Enable tracing (generates a trace-timestamp.json file).\n #[arg(long)]\n tracing: bool,\n\n /// The model to use, check out available models: https://huggingface.co/models?library=sentence-transformers&sort=trending\n #[arg(long)]\n model_id: Option<String>,\n\n #[arg(long)]\n revision: Option<String>,\n\n /// When set, compute embeddings for this prompt.\n #[arg(long)]\n prompt: String,\n\n /// Use the pytorch weights rather than the safetensors ones\n #[arg(long)]\n use_pth: bool,\n\n /// The number of times to run the prompt.\n #[arg(long, default_value = \"1\")]\n n: usize,\n\n /// L2 normalization for embeddings.\n #[arg(long, default_value = \"true\")]\n normalize_embeddings: bool,\n}\n\nimpl Args {\n fn build_model_and_tokenizer(&self) -> Result<(DistilBertModel, Tokenizer)> {\n let device = candle_examples::device(self.cpu)?;\n let default_model = \"distilbert-base-uncased\".to_string();\n let default_revision = \"main\".to_string();\n let (model_id, revision) = match (self.model_id.to_owned(), self.revision.to_owned()) {\n (Some(model_id), Some(revision)) => (model_id, revision),\n (Some(model_id), None) => (model_id, \"main\".to_string()),\n (None, Some(revision)) => (default_model, revision),\n (None, None) => (default_model, default_revision),\n };\n\n let repo = Repo::with_revision(model_id, RepoType::Model, revision);\n let (config_filename, tokenizer_filename, weights_filename) = {\n let api = Api::new()?;\n let api = api.repo(repo);\n let config = api.get(\"config.json\")?;\n let tokenizer = api.get(\"tokenizer.json\")?;\n let weights = if self.use_pth {\n api.get(\"pytorch_model.bin\")?\n } else {\n api.get(\"model.safetensors\")?\n };\n (config, tokenizer, weights)\n };\n let config = std::fs::read_to_string(config_filename)?;\n let config: Config = serde_json::from_str(&config)?;\n let tokenizer = Tokenizer::from_file(tokenizer_filename).map_err(E::msg)?;\n\n let vb = if self.use_pth {\n VarBuilder::from_pth(&weights_filename, DTYPE, &device)?\n } else {\n unsafe { VarBuilder::from_mmaped_safetensors(&[weights_filename], DTYPE, &device)? }\n };\n let model = DistilBertModel::load(vb, &config)?;\n Ok((model, tokenizer))\n }\n}\n\nfn get_mask(size: usize, device: &Device) -> Tensor {\n let mask: Vec<_> = (0..size)\n .flat_map(|i| (0..size).map(move |j| u8::from(j > i)))\n .collect();\n Tensor::from_slice(&mask, (size, size), device).unwrap()\n}\n\nfn main() -> Result<()> {\n use tracing_chrome::ChromeLayerBuilder;\n use tracing_subscriber::prelude::*;\n\n let args = Args::parse();\n let _guard = if args.tracing {\n println!(\"tracing...\");\n let (chrome_layer, guard) = ChromeLayerBuilder::new().build();\n tracing_subscriber::registry().with(chrome_layer).init();\n Some(guard)\n } else {\n None\n };\n let (model, mut tokenizer) = args.build_model_and_tokenizer()?;\n let device = &model.device;\n\n let tokenizer = tokenizer\n .with_padding(None)\n .with_truncation(None)\n .map_err(E::msg)?;\n let tokens = tokenizer\n .encode(args.prompt, true)\n .map_err(E::msg)?\n .get_ids()\n .to_vec();\n let token_ids = Tensor::new(&tokens[..], device)?.unsqueeze(0)?;\n let mask = get_mask(tokens.len(), device);\n\n println!(\"token_ids: {:?}\", token_ids.to_vec2::<u32>());\n println!(\"mask: {:?}\", mask.to_vec2::<u8>());\n\n let ys = model.forward(&token_ids, &mask)?;\n println!(\"{ys}\");\n\n Ok(())\n}\n\npub fn normalize_l2(v: &Tensor) -> Result<Tensor> {\n Ok(v.broadcast_div(&v.sqr()?.sum_keepdim(1)?.sqrt()?)?)\n}\n", "candle-examples\\examples\\efficientnet\\main.rs": "//! EfficientNet implementation.\n//!\n//! https://arxiv.org/abs/1905.11946\n\n#[cfg(feature = \"mkl\")]\nextern crate intel_mkl_src;\n\n#[cfg(feature = \"accelerate\")]\nextern crate accelerate_src;\n\nuse candle::{DType, IndexOp, D};\nuse candle_nn::{Module, VarBuilder};\nuse candle_transformers::models::efficientnet::{EfficientNet, MBConvConfig};\nuse clap::{Parser, ValueEnum};\n\n#[derive(Clone, Copy, Debug, ValueEnum)]\nenum Which {\n B0,\n B1,\n B2,\n B3,\n B4,\n B5,\n B6,\n B7,\n}\n\n#[derive(Parser)]\nstruct Args {\n #[arg(long)]\n model: Option<String>,\n\n #[arg(long)]\n image: String,\n\n /// Run on CPU rather than on GPU.\n #[arg(long)]\n cpu: bool,\n\n /// Variant of the model to use.\n #[arg(value_enum, long, default_value_t = Which::B2)]\n which: Which,\n}\n\npub fn main() -> anyhow::Result<()> {\n let args = Args::parse();\n\n let device = candle_examples::device(args.cpu)?;\n\n let image = candle_examples::imagenet::load_image224(args.image)?.to_device(&device)?;\n println!(\"loaded image {image:?}\");\n\n let model_file = match args.model {\n None => {\n let api = hf_hub::api::sync::Api::new()?;\n let api = api.model(\"lmz/candle-efficientnet\".into());\n let filename = match args.which {\n Which::B0 => \"efficientnet-b0.safetensors\",\n Which::B1 => \"efficientnet-b1.safetensors\",\n Which::B2 => \"efficientnet-b2.safetensors\",\n Which::B3 => \"efficientnet-b3.safetensors\",\n Which::B4 => \"efficientnet-b4.safetensors\",\n Which::B5 => \"efficientnet-b5.safetensors\",\n Which::B6 => \"efficientnet-b6.safetensors\",\n Which::B7 => \"efficientnet-b7.safetensors\",\n };\n api.get(filename)?\n }\n Some(model) => model.into(),\n };\n let vb = unsafe { VarBuilder::from_mmaped_safetensors(&[model_file], DType::F32, &device)? };\n let cfg = match args.which {\n Which::B0 => MBConvConfig::b0(),\n Which::B1 => MBConvConfig::b1(),\n Which::B2 => MBConvConfig::b2(),\n Which::B3 => MBConvConfig::b3(),\n Which::B4 => MBConvConfig::b4(),\n Which::B5 => MBConvConfig::b5(),\n Which::B6 => MBConvConfig::b6(),\n Which::B7 => MBConvConfig::b7(),\n };\n let model = EfficientNet::new(vb, cfg, candle_examples::imagenet::CLASS_COUNT as usize)?;\n println!(\"model built\");\n let logits = model.forward(&image.unsqueeze(0)?)?;\n let prs = candle_nn::ops::softmax(&logits, D::Minus1)?\n .i(0)?\n .to_vec1::<f32>()?;\n let mut prs = prs.iter().enumerate().collect::<Vec<_>>();\n prs.sort_by(|(_, p1), (_, p2)| p2.total_cmp(p1));\n for &(category_idx, pr) in prs.iter().take(5) {\n println!(\n \"{:24}: {:.2}%\",\n candle_examples::imagenet::CLASSES[category_idx],\n 100. * pr\n );\n }\n Ok(())\n}\n", "candle-examples\\examples\\efficientvit\\main.rs": "#[cfg(feature = \"mkl\")]\nextern crate intel_mkl_src;\n\n#[cfg(feature = \"accelerate\")]\nextern crate accelerate_src;\n\nuse clap::{Parser, ValueEnum};\n\nuse candle::{DType, IndexOp, D};\nuse candle_nn::{Module, VarBuilder};\nuse candle_transformers::models::efficientvit;\n\n#[derive(Clone, Copy, Debug, ValueEnum)]\nenum Which {\n M0,\n M1,\n M2,\n M3,\n M4,\n M5,\n}\n\nimpl Which {\n fn model_filename(&self) -> String {\n let name = match self {\n Self::M0 => \"m0\",\n Self::M1 => \"m1\",\n Self::M2 => \"m2\",\n Self::M3 => \"m3\",\n Self::M4 => \"m4\",\n Self::M5 => \"m5\",\n };\n format!(\"timm/efficientvit_{}.r224_in1k\", name)\n }\n\n fn config(&self) -> efficientvit::Config {\n match self {\n Self::M0 => efficientvit::Config::m0(),\n Self::M1 => efficientvit::Config::m1(),\n Self::M2 => efficientvit::Config::m2(),\n Self::M3 => efficientvit::Config::m3(),\n Self::M4 => efficientvit::Config::m4(),\n Self::M5 => efficientvit::Config::m5(),\n }\n }\n}\n\n#[derive(Parser)]\nstruct Args {\n #[arg(long)]\n model: Option<String>,\n\n #[arg(long)]\n image: String,\n\n /// Run on CPU rather than on GPU.\n #[arg(long)]\n cpu: bool,\n\n #[arg(value_enum, long, default_value_t=Which::M0)]\n which: Which,\n}\n\npub fn main() -> anyhow::Result<()> {\n let args = Args::parse();\n\n let device = candle_examples::device(args.cpu)?;\n\n let image = candle_examples::imagenet::load_image224(args.image)?.to_device(&device)?;\n println!(\"loaded image {image:?}\");\n\n let model_file = match args.model {\n None => {\n let model_name = args.which.model_filename();\n let api = hf_hub::api::sync::Api::new()?;\n let api = api.model(model_name);\n api.get(\"model.safetensors\")?\n }\n Some(model) => model.into(),\n };\n\n let vb = unsafe { VarBuilder::from_mmaped_safetensors(&[model_file], DType::F32, &device)? };\n let model = efficientvit::efficientvit(&args.which.config(), 1000, vb)?;\n println!(\"model built\");\n let logits = model.forward(&image.unsqueeze(0)?)?;\n let prs = candle_nn::ops::softmax(&logits, D::Minus1)?\n .i(0)?\n .to_vec1::<f32>()?;\n let mut prs = prs.iter().enumerate().collect::<Vec<_>>();\n prs.sort_by(|(_, p1), (_, p2)| p2.total_cmp(p1));\n for &(category_idx, pr) in prs.iter().take(5) {\n println!(\n \"{:24}: {:.2}%\",\n candle_examples::imagenet::CLASSES[category_idx],\n 100. * pr\n );\n }\n Ok(())\n}\n", "candle-examples\\examples\\encodec\\main.rs": "#[cfg(feature = \"mkl\")]\nextern crate intel_mkl_src;\n\n#[cfg(feature = \"accelerate\")]\nextern crate accelerate_src;\n\nuse anyhow::Result;\nuse candle::{DType, IndexOp, Tensor};\nuse candle_nn::VarBuilder;\nuse candle_transformers::models::encodec::{Config, Model};\nuse clap::{Parser, ValueEnum};\nuse hf_hub::api::sync::Api;\n\nmod audio_io;\n\n#[derive(Clone, Debug, Copy, PartialEq, Eq, ValueEnum)]\nenum Action {\n AudioToAudio,\n AudioToCode,\n CodeToAudio,\n}\n\n#[derive(Parser, Debug)]\n#[command(author, version, about, long_about = None)]\nstruct Args {\n /// The action to be performed, specifies the format for the input and output data.\n action: Action,\n\n /// The input file, either an audio file or some encodec tokens stored as safetensors.\n in_file: String,\n\n /// The output file, either a wave audio file or some encodec tokens stored as safetensors.\n out_file: String,\n\n /// Run on CPU rather than on GPU.\n #[arg(long)]\n cpu: bool,\n\n /// The model weight file, in safetensor format.\n #[arg(long)]\n model: Option<String>,\n}\n\nfn main() -> Result<()> {\n let args = Args::parse();\n let device = candle_examples::device(args.cpu)?;\n let model = match args.model {\n Some(model) => std::path::PathBuf::from(model),\n None => Api::new()?\n .model(\"facebook/encodec_24khz\".to_string())\n .get(\"model.safetensors\")?,\n };\n let vb = unsafe { VarBuilder::from_mmaped_safetensors(&[model], DType::F32, &device)? };\n let config = Config::default();\n let model = Model::new(&config, vb)?;\n\n let codes = match args.action {\n Action::CodeToAudio => {\n let codes = candle::safetensors::load(args.in_file, &device)?;\n codes.get(\"codes\").expect(\"no codes in input file\").clone()\n }\n Action::AudioToCode | Action::AudioToAudio => {\n let pcm = if args.in_file == \"-\" {\n println!(\">>>> RECORDING AUDIO, PRESS ENTER ONCE DONE <<<<\");\n let (stream, input_audio) = audio_io::setup_input_stream()?;\n let mut pcms = vec![];\n let stdin = std::thread::spawn(|| {\n let mut s = String::new();\n std::io::stdin().read_line(&mut s)\n });\n while !stdin.is_finished() {\n let input = input_audio.lock().unwrap().take_all();\n if input.is_empty() {\n std::thread::sleep(std::time::Duration::from_millis(100));\n continue;\n }\n pcms.push(input)\n }\n drop(stream);\n pcms.concat()\n } else {\n let (pcm, sample_rate) = audio_io::pcm_decode(args.in_file)?;\n if sample_rate != 24_000 {\n println!(\"WARNING: encodec uses a 24khz sample rate, input uses {sample_rate}, resampling...\");\n audio_io::resample(&pcm, sample_rate as usize, 24_000)?\n } else {\n pcm\n }\n };\n let pcm_len = pcm.len();\n let pcm = Tensor::from_vec(pcm, (1, 1, pcm_len), &device)?;\n println!(\"input pcm shape: {:?}\", pcm.shape());\n model.encode(&pcm)?\n }\n };\n println!(\"codes shape: {:?}\", codes.shape());\n\n match args.action {\n Action::AudioToCode => {\n codes.save_safetensors(\"codes\", &args.out_file)?;\n }\n Action::AudioToAudio | Action::CodeToAudio => {\n let pcm = model.decode(&codes)?;\n println!(\"output pcm shape: {:?}\", pcm.shape());\n let pcm = pcm.i(0)?.i(0)?;\n let pcm = candle_examples::audio::normalize_loudness(&pcm, 24_000, true)?;\n let pcm = pcm.to_vec1::<f32>()?;\n if args.out_file == \"-\" {\n let (stream, ad) = audio_io::setup_output_stream()?;\n {\n let mut ad = ad.lock().unwrap();\n ad.push_samples(&pcm)?;\n }\n loop {\n let ad = ad.lock().unwrap();\n if ad.is_empty() {\n break;\n }\n // That's very weird, calling thread::sleep here triggers the stream to stop\n // playing (the callback doesn't seem to be called anymore).\n // std::thread::sleep(std::time::Duration::from_millis(100));\n }\n drop(stream)\n } else {\n let mut output = std::fs::File::create(&args.out_file)?;\n candle_examples::wav::write_pcm_as_wav(&mut output, &pcm, 24_000)?;\n }\n }\n }\n Ok(())\n}\n", "candle-examples\\examples\\eva2\\main.rs": "//! EVA-02: Explore the limits of Visual representation at scAle\n//! https://github.com/baaivision/EVA\n\n#[cfg(feature = \"mkl\")]\nextern crate intel_mkl_src;\n\n#[cfg(feature = \"accelerate\")]\nextern crate accelerate_src;\n\nuse clap::Parser;\n\nuse candle::{DType, Device, IndexOp, Result, Tensor, D};\nuse candle_nn::{Module, VarBuilder};\nuse candle_transformers::models::eva2;\n\n/// Loads an image from disk using the image crate, this returns a tensor with shape\n/// (3, 448, 448). OpenAI normalization is applied.\npub fn load_image448_openai_norm<P: AsRef<std::path::Path>>(p: P) -> Result<Tensor> {\n let img = image::ImageReader::open(p)?\n .decode()\n .map_err(candle::Error::wrap)?\n .resize_to_fill(448, 448, image::imageops::FilterType::Triangle);\n let img = img.to_rgb8();\n let data = img.into_raw();\n let data = Tensor::from_vec(data, (448, 448, 3), &Device::Cpu)?.permute((2, 0, 1))?;\n let mean =\n Tensor::new(&[0.48145466f32, 0.4578275, 0.40821073], &Device::Cpu)?.reshape((3, 1, 1))?;\n let std = Tensor::new(&[0.26862954f32, 0.261_302_6, 0.275_777_1], &Device::Cpu)?\n .reshape((3, 1, 1))?;\n (data.to_dtype(candle::DType::F32)? / 255.)?\n .broadcast_sub(&mean)?\n .broadcast_div(&std)\n}\n\n#[derive(Parser)]\nstruct Args {\n #[arg(long)]\n model: Option<String>,\n\n #[arg(long)]\n image: String,\n\n /// Run on CPU rather than on GPU.\n #[arg(long)]\n cpu: bool,\n}\n\npub fn main() -> anyhow::Result<()> {\n let args = Args::parse();\n\n let device = candle_examples::device(args.cpu)?;\n\n let image = load_image448_openai_norm(args.image)?.to_device(&device)?;\n println!(\"loaded image {image:?}\");\n\n let model_file = match args.model {\n None => {\n let api = hf_hub::api::sync::Api::new()?;\n let api = api.model(\"vincent-espitalier/candle-eva2\".into());\n api.get(\"eva02_base_patch14_448.mim_in22k_ft_in22k_in1k_adapted.safetensors\")?\n }\n Some(model) => model.into(),\n };\n let vb = unsafe { VarBuilder::from_mmaped_safetensors(&[model_file], DType::F32, &device)? };\n\n let model = eva2::vit_base(vb)?;\n println!(\"model built\");\n let logits = model.forward(&image.unsqueeze(0)?)?;\n let prs = candle_nn::ops::softmax(&logits, D::Minus1)?\n .i(0)?\n .to_vec1::<f32>()?;\n let mut prs = prs.iter().enumerate().collect::<Vec<_>>();\n prs.sort_by(|(_, p1), (_, p2)| p2.total_cmp(p1));\n for &(category_idx, pr) in prs.iter().take(5) {\n println!(\n \"{:24}: {:.2}%\",\n candle_examples::imagenet::CLASSES[category_idx],\n 100. * pr\n );\n }\n Ok(())\n}\n", "candle-examples\\examples\\falcon\\main.rs": "// TODO: Add an offline mode.\n\n#[cfg(feature = \"accelerate\")]\nextern crate accelerate_src;\n\n#[cfg(feature = \"mkl\")]\nextern crate intel_mkl_src;\n\nuse anyhow::{Error as E, Result};\nuse candle::{DType, Device, Tensor};\nuse candle_nn::VarBuilder;\nuse candle_transformers::generation::LogitsProcessor;\nuse clap::Parser;\nuse hf_hub::{api::sync::Api, Repo, RepoType};\nuse tokenizers::Tokenizer;\n\nuse candle_transformers::models::falcon::{Config, Falcon};\n\nstruct TextGeneration {\n model: Falcon,\n device: Device,\n tokenizer: Tokenizer,\n logits_processor: LogitsProcessor,\n repeat_penalty: f32,\n repeat_last_n: usize,\n}\n\nstruct GenerationOptions {\n temp: Option<f64>,\n top_p: Option<f64>,\n repeat_penalty: f32,\n repeat_last_n: usize,\n}\n\nimpl TextGeneration {\n fn new(\n model: Falcon,\n tokenizer: Tokenizer,\n generation_options: GenerationOptions,\n seed: u64,\n device: &Device,\n ) -> Self {\n let logits_processor =\n LogitsProcessor::new(seed, generation_options.temp, generation_options.top_p);\n let repeat_penalty = generation_options.repeat_penalty;\n let repeat_last_n = generation_options.repeat_last_n;\n Self {\n model,\n tokenizer,\n logits_processor,\n device: device.clone(),\n repeat_penalty,\n repeat_last_n,\n }\n }\n\n fn run(&mut self, prompt: &str, sample_len: usize) -> Result<()> {\n println!(\"starting the inference loop\");\n let mut tokens = self\n .tokenizer\n .encode(prompt, true)\n .map_err(E::msg)?\n .get_ids()\n .to_vec();\n\n let mut new_tokens = vec![];\n let start_gen = std::time::Instant::now();\n for index in 0..sample_len {\n let start_gen = std::time::Instant::now();\n let context_size = if self.model.config().use_cache && index > 0 {\n 1\n } else {\n tokens.len()\n };\n let ctxt = &tokens[tokens.len().saturating_sub(context_size)..];\n let input = Tensor::new(ctxt, &self.device)?.unsqueeze(0)?;\n let logits = self.model.forward(&input)?;\n let logits = logits.squeeze(0)?.to_dtype(DType::F32)?;\n let logits = if self.repeat_penalty == 1. {\n logits\n } else {\n let start_at = tokens.len().saturating_sub(self.repeat_last_n);\n candle_transformers::utils::apply_repeat_penalty(\n &logits,\n self.repeat_penalty,\n &tokens[start_at..],\n )?\n };\n\n let next_token = self.logits_processor.sample(&logits)?;\n tokens.push(next_token);\n new_tokens.push(next_token);\n println!(\"> {:?}\", start_gen.elapsed());\n println!(\n \"{} token: {} '{}'\",\n index + 1,\n next_token,\n self.tokenizer.decode(&[next_token], true).map_err(E::msg)?\n );\n }\n let dt = start_gen.elapsed();\n println!(\n \"{sample_len} tokens generated ({} token/s)\\n----\\n{}\\n----\",\n sample_len as f64 / dt.as_secs_f64(),\n self.tokenizer.decode(&new_tokens, true).map_err(E::msg)?\n );\n Ok(())\n }\n}\n\n#[derive(Parser, Debug)]\n#[command(author, version, about, long_about = None)]\nstruct Args {\n /// Run on CPU rather than on GPU.\n #[arg(long)]\n cpu: bool,\n\n #[arg(long)]\n prompt: String,\n\n /// Use f32 computations rather than bf16.\n #[arg(long)]\n use_f32: bool,\n\n /// The temperature used to generate samples.\n #[arg(long)]\n temperature: Option<f64>,\n\n /// Nucleus sampling probability cutoff.\n #[arg(long)]\n top_p: Option<f64>,\n\n /// The seed to use when generating random samples.\n #[arg(long, default_value_t = 299792458)]\n seed: u64,\n\n /// The length of the sample to generate (in tokens).\n #[arg(long, default_value_t = 100)]\n sample_len: usize,\n\n #[arg(long, default_value = \"tiiuae/falcon-7b\")]\n model_id: String,\n\n #[arg(long, default_value = \"refs/pr/43\")]\n revision: String,\n\n /// Penalty to be applied for repeating tokens, 1. means no penalty.\n #[arg(long, default_value_t = 1.0)]\n repeat_penalty: f32,\n\n /// The context size to consider for the repeat penalty.\n #[arg(long, default_value_t = 64)]\n repeat_last_n: usize,\n}\n\nfn main() -> Result<()> {\n let args = Args::parse();\n\n let device = candle_examples::device(args.cpu)?;\n let start = std::time::Instant::now();\n let api = Api::new()?;\n let repo = api.repo(Repo::with_revision(\n args.model_id,\n RepoType::Model,\n args.revision,\n ));\n let tokenizer_filename = repo.get(\"tokenizer.json\")?;\n let filenames = candle_examples::hub_load_safetensors(&repo, \"model.safetensors.index.json\")?;\n println!(\"retrieved the files in {:?}\", start.elapsed());\n let tokenizer = Tokenizer::from_file(tokenizer_filename).map_err(E::msg)?;\n\n let start = std::time::Instant::now();\n let dtype = if args.use_f32 {\n DType::F32\n } else {\n DType::BF16\n };\n let vb = unsafe { VarBuilder::from_mmaped_safetensors(&filenames, dtype, &device)? };\n let config = Config::falcon7b();\n config.validate()?;\n let model = Falcon::load(vb, config)?;\n println!(\"loaded the model in {:?}\", start.elapsed());\n\n let generation_options = GenerationOptions {\n temp: args.temperature,\n top_p: args.top_p,\n repeat_penalty: args.repeat_penalty,\n repeat_last_n: args.repeat_last_n,\n };\n let mut pipeline =\n TextGeneration::new(model, tokenizer, generation_options, args.seed, &device);\n pipeline.run(&args.prompt, args.sample_len)?;\n Ok(())\n}\n", "candle-examples\\examples\\fastvit\\main.rs": "#[cfg(feature = \"mkl\")]\nextern crate intel_mkl_src;\n\n#[cfg(feature = \"accelerate\")]\nextern crate accelerate_src;\n\nuse clap::{Parser, ValueEnum};\n\nuse candle::{DType, IndexOp, D};\nuse candle_nn::{Module, VarBuilder};\nuse candle_transformers::models::fastvit;\n\n#[derive(Clone, Copy, Debug, ValueEnum)]\nenum Which {\n T8,\n T12,\n S12,\n SA12,\n SA24,\n SA36,\n MA36,\n}\n\nimpl Which {\n fn model_filename(&self) -> String {\n let name = match self {\n Self::T8 => \"t8\",\n Self::T12 => \"t12\",\n Self::S12 => \"s12\",\n Self::SA12 => \"sa12\",\n Self::SA24 => \"sa24\",\n Self::SA36 => \"sa36\",\n Self::MA36 => \"ma36\",\n };\n format!(\"timm/fastvit_{}.apple_in1k\", name)\n }\n\n fn config(&self) -> fastvit::Config {\n match self {\n Self::T8 => fastvit::Config::t8(),\n Self::T12 => fastvit::Config::t12(),\n Self::S12 => fastvit::Config::s12(),\n Self::SA12 => fastvit::Config::sa12(),\n Self::SA24 => fastvit::Config::sa24(),\n Self::SA36 => fastvit::Config::sa36(),\n Self::MA36 => fastvit::Config::ma36(),\n }\n }\n}\n\n#[derive(Parser)]\nstruct Args {\n #[arg(long)]\n model: Option<String>,\n\n #[arg(long)]\n image: String,\n\n /// Run on CPU rather than on GPU.\n #[arg(long)]\n cpu: bool,\n\n #[arg(value_enum, long, default_value_t=Which::S12)]\n which: Which,\n}\n\npub fn main() -> anyhow::Result<()> {\n let args = Args::parse();\n\n let device = candle_examples::device(args.cpu)?;\n\n let image = candle_examples::imagenet::load_image(args.image, 256)?.to_device(&device)?;\n println!(\"loaded image {image:?}\");\n\n let model_file = match args.model {\n None => {\n let model_name = args.which.model_filename();\n let api = hf_hub::api::sync::Api::new()?;\n let api = api.model(model_name);\n api.get(\"model.safetensors\")?\n }\n Some(model) => model.into(),\n };\n\n let vb = unsafe { VarBuilder::from_mmaped_safetensors(&[model_file], DType::F32, &device)? };\n let model = fastvit::fastvit(&args.which.config(), 1000, vb)?;\n println!(\"model built\");\n let logits = model.forward(&image.unsqueeze(0)?)?;\n let prs = candle_nn::ops::softmax(&logits, D::Minus1)?\n .i(0)?\n .to_vec1::<f32>()?;\n let mut prs = prs.iter().enumerate().collect::<Vec<_>>();\n prs.sort_by(|(_, p1), (_, p2)| p2.total_cmp(p1));\n for &(category_idx, pr) in prs.iter().take(5) {\n println!(\n \"{:24}: {:.2}%\",\n candle_examples::imagenet::CLASSES[category_idx],\n 100. * pr\n );\n }\n Ok(())\n}\n", "candle-examples\\examples\\flux\\main.rs": "#[cfg(feature = \"accelerate\")]\nextern crate accelerate_src;\n\n#[cfg(feature = \"mkl\")]\nextern crate intel_mkl_src;\n\nuse candle_transformers::models::{clip, flux, t5};\n\nuse anyhow::{Error as E, Result};\nuse candle::{IndexOp, Module, Tensor};\nuse candle_nn::VarBuilder;\nuse clap::Parser;\nuse tokenizers::Tokenizer;\n\n#[derive(Parser)]\n#[command(author, version, about, long_about = None)]\nstruct Args {\n /// The prompt to be used for image generation.\n #[arg(long, default_value = \"A rusty robot walking on a beach\")]\n prompt: String,\n\n /// Run on CPU rather than on GPU.\n #[arg(long)]\n cpu: bool,\n\n /// Use the quantized model.\n #[arg(long)]\n quantized: bool,\n\n /// Enable tracing (generates a trace-timestamp.json file).\n #[arg(long)]\n tracing: bool,\n\n /// The height in pixels of the generated image.\n #[arg(long)]\n height: Option<usize>,\n\n /// The width in pixels of the generated image.\n #[arg(long)]\n width: Option<usize>,\n\n #[arg(long)]\n decode_only: Option<String>,\n\n #[arg(long, value_enum, default_value = \"schnell\")]\n model: Model,\n\n /// Use the faster kernels which are buggy at the moment.\n #[arg(long)]\n no_dmmv: bool,\n}\n\n#[derive(Debug, Clone, Copy, clap::ValueEnum, PartialEq, Eq)]\nenum Model {\n Schnell,\n Dev,\n}\n\nfn run(args: Args) -> Result<()> {\n use tracing_chrome::ChromeLayerBuilder;\n use tracing_subscriber::prelude::*;\n\n let Args {\n prompt,\n cpu,\n height,\n width,\n tracing,\n decode_only,\n model,\n quantized,\n ..\n } = args;\n let width = width.unwrap_or(1360);\n let height = height.unwrap_or(768);\n\n let _guard = if tracing {\n let (chrome_layer, guard) = ChromeLayerBuilder::new().build();\n tracing_subscriber::registry().with(chrome_layer).init();\n Some(guard)\n } else {\n None\n };\n\n let api = hf_hub::api::sync::Api::new()?;\n let bf_repo = {\n let name = match model {\n Model::Dev => \"black-forest-labs/FLUX.1-dev\",\n Model::Schnell => \"black-forest-labs/FLUX.1-schnell\",\n };\n api.repo(hf_hub::Repo::model(name.to_string()))\n };\n let device = candle_examples::device(cpu)?;\n let dtype = device.bf16_default_to_f32();\n let img = match decode_only {\n None => {\n let t5_emb = {\n let repo = api.repo(hf_hub::Repo::with_revision(\n \"google/t5-v1_1-xxl\".to_string(),\n hf_hub::RepoType::Model,\n \"refs/pr/2\".to_string(),\n ));\n let model_file = repo.get(\"model.safetensors\")?;\n let vb =\n unsafe { VarBuilder::from_mmaped_safetensors(&[model_file], dtype, &device)? };\n let config_filename = repo.get(\"config.json\")?;\n let config = std::fs::read_to_string(config_filename)?;\n let config: t5::Config = serde_json::from_str(&config)?;\n let mut model = t5::T5EncoderModel::load(vb, &config)?;\n let tokenizer_filename = api\n .model(\"lmz/mt5-tokenizers\".to_string())\n .get(\"t5-v1_1-xxl.tokenizer.json\")?;\n let tokenizer = Tokenizer::from_file(tokenizer_filename).map_err(E::msg)?;\n let mut tokens = tokenizer\n .encode(prompt.as_str(), true)\n .map_err(E::msg)?\n .get_ids()\n .to_vec();\n tokens.resize(256, 0);\n let input_token_ids = Tensor::new(&tokens[..], &device)?.unsqueeze(0)?;\n println!(\"{input_token_ids}\");\n model.forward(&input_token_ids)?\n };\n println!(\"T5\\n{t5_emb}\");\n let clip_emb = {\n let repo = api.repo(hf_hub::Repo::model(\n \"openai/clip-vit-large-patch14\".to_string(),\n ));\n let model_file = repo.get(\"model.safetensors\")?;\n let vb =\n unsafe { VarBuilder::from_mmaped_safetensors(&[model_file], dtype, &device)? };\n // https://huggingface.co/openai/clip-vit-large-patch14/blob/main/config.json\n let config = clip::text_model::ClipTextConfig {\n vocab_size: 49408,\n projection_dim: 768,\n activation: clip::text_model::Activation::QuickGelu,\n intermediate_size: 3072,\n embed_dim: 768,\n max_position_embeddings: 77,\n pad_with: None,\n num_hidden_layers: 12,\n num_attention_heads: 12,\n };\n let model =\n clip::text_model::ClipTextTransformer::new(vb.pp(\"text_model\"), &config)?;\n let tokenizer_filename = repo.get(\"tokenizer.json\")?;\n let tokenizer = Tokenizer::from_file(tokenizer_filename).map_err(E::msg)?;\n let tokens = tokenizer\n .encode(prompt.as_str(), true)\n .map_err(E::msg)?\n .get_ids()\n .to_vec();\n let input_token_ids = Tensor::new(&tokens[..], &device)?.unsqueeze(0)?;\n println!(\"{input_token_ids}\");\n model.forward(&input_token_ids)?\n };\n println!(\"CLIP\\n{clip_emb}\");\n let img = {\n let cfg = match model {\n Model::Dev => flux::model::Config::dev(),\n Model::Schnell => flux::model::Config::schnell(),\n };\n let img = flux::sampling::get_noise(1, height, width, &device)?.to_dtype(dtype)?;\n let state = if quantized {\n flux::sampling::State::new(\n &t5_emb.to_dtype(candle::DType::F32)?,\n &clip_emb.to_dtype(candle::DType::F32)?,\n &img.to_dtype(candle::DType::F32)?,\n )?\n } else {\n flux::sampling::State::new(&t5_emb, &clip_emb, &img)?\n };\n let timesteps = match model {\n Model::Dev => {\n flux::sampling::get_schedule(50, Some((state.img.dim(1)?, 0.5, 1.15)))\n }\n Model::Schnell => flux::sampling::get_schedule(4, None),\n };\n println!(\"{state:?}\");\n println!(\"{timesteps:?}\");\n if quantized {\n let model_file = match model {\n Model::Schnell => api\n .repo(hf_hub::Repo::model(\"lmz/candle-flux\".to_string()))\n .get(\"flux1-schnell.gguf\")?,\n Model::Dev => todo!(),\n };\n let vb = candle_transformers::quantized_var_builder::VarBuilder::from_gguf(\n model_file, &device,\n )?;\n\n let model = flux::quantized_model::Flux::new(&cfg, vb)?;\n flux::sampling::denoise(\n &model,\n &state.img,\n &state.img_ids,\n &state.txt,\n &state.txt_ids,\n &state.vec,\n ×teps,\n 4.,\n )?\n .to_dtype(dtype)?\n } else {\n let model_file = match model {\n Model::Schnell => bf_repo.get(\"flux1-schnell.safetensors\")?,\n Model::Dev => bf_repo.get(\"flux1-dev.safetensors\")?,\n };\n let vb = unsafe {\n VarBuilder::from_mmaped_safetensors(&[model_file], dtype, &device)?\n };\n let model = flux::model::Flux::new(&cfg, vb)?;\n flux::sampling::denoise(\n &model,\n &state.img,\n &state.img_ids,\n &state.txt,\n &state.txt_ids,\n &state.vec,\n ×teps,\n 4.,\n )?\n }\n };\n flux::sampling::unpack(&img, height, width)?\n }\n Some(file) => {\n let mut st = candle::safetensors::load(file, &device)?;\n st.remove(\"img\").unwrap().to_dtype(dtype)?\n }\n };\n println!(\"latent img\\n{img}\");\n\n let img = {\n let model_file = bf_repo.get(\"ae.safetensors\")?;\n let vb = unsafe { VarBuilder::from_mmaped_safetensors(&[model_file], dtype, &device)? };\n let cfg = match model {\n Model::Dev => flux::autoencoder::Config::dev(),\n Model::Schnell => flux::autoencoder::Config::schnell(),\n };\n let model = flux::autoencoder::AutoEncoder::new(&cfg, vb)?;\n model.decode(&img)?\n };\n println!(\"img\\n{img}\");\n let img = ((img.clamp(-1f32, 1f32)? + 1.0)? * 127.5)?.to_dtype(candle::DType::U8)?;\n candle_examples::save_image(&img.i(0)?, \"out.jpg\")?;\n Ok(())\n}\n\nfn main() -> Result<()> {\n let args = Args::parse();\n #[cfg(feature = \"cuda\")]\n candle::quantized::cuda::set_force_dmmv(!args.no_dmmv);\n run(args)\n}\n", "candle-examples\\examples\\gemma\\main.rs": "#[cfg(feature = \"mkl\")]\nextern crate intel_mkl_src;\n\n#[cfg(feature = \"accelerate\")]\nextern crate accelerate_src;\n\nuse anyhow::{Error as E, Result};\nuse clap::Parser;\n\nuse candle_transformers::models::gemma::{Config as Config1, Model as Model1};\nuse candle_transformers::models::gemma2::{Config as Config2, Model as Model2};\n\nuse candle::{DType, Device, Tensor};\nuse candle_examples::token_output_stream::TokenOutputStream;\nuse candle_nn::VarBuilder;\nuse candle_transformers::generation::LogitsProcessor;\nuse hf_hub::{api::sync::Api, Repo, RepoType};\nuse tokenizers::Tokenizer;\n\n#[derive(Clone, Debug, Copy, PartialEq, Eq, clap::ValueEnum)]\nenum Which {\n #[value(name = \"2b\")]\n Base2B,\n #[value(name = \"7b\")]\n Base7B,\n #[value(name = \"2b-it\")]\n Instruct2B,\n #[value(name = \"7b-it\")]\n Instruct7B,\n #[value(name = \"1.1-2b-it\")]\n InstructV1_1_2B,\n #[value(name = \"1.1-7b-it\")]\n InstructV1_1_7B,\n #[value(name = \"code-2b\")]\n CodeBase2B,\n #[value(name = \"code-7b\")]\n CodeBase7B,\n #[value(name = \"code-2b-it\")]\n CodeInstruct2B,\n #[value(name = \"code-7b-it\")]\n CodeInstruct7B,\n #[value(name = \"2-2b\")]\n BaseV2_2B,\n #[value(name = \"2-2b-it\")]\n InstructV2_2B,\n #[value(name = \"2-9b\")]\n BaseV2_9B,\n #[value(name = \"2-9b-it\")]\n InstructV2_9B,\n}\n\nimpl Which {\n fn is_v1(&self) -> bool {\n match self {\n Self::Base2B\n | Self::Base7B\n | Self::Instruct2B\n | Self::Instruct7B\n | Self::InstructV1_1_2B\n | Self::InstructV1_1_7B\n | Self::CodeBase2B\n | Self::CodeBase7B\n | Self::CodeInstruct2B\n | Self::CodeInstruct7B => true,\n Self::BaseV2_2B | Self::InstructV2_2B | Self::BaseV2_9B | Self::InstructV2_9B => false,\n }\n }\n}\n\nenum Model {\n V1(Model1),\n V2(Model2),\n}\n\nimpl Model {\n fn forward(&mut self, input_ids: &Tensor, pos: usize) -> candle::Result<Tensor> {\n match self {\n Self::V1(m) => m.forward(input_ids, pos),\n Self::V2(m) => m.forward(input_ids, pos),\n }\n }\n}\n\nstruct TextGeneration {\n model: Model,\n device: Device,\n tokenizer: TokenOutputStream,\n logits_processor: LogitsProcessor,\n repeat_penalty: f32,\n repeat_last_n: usize,\n}\n\nimpl TextGeneration {\n #[allow(clippy::too_many_arguments)]\n fn new(\n model: Model,\n tokenizer: Tokenizer,\n seed: u64,\n temp: Option<f64>,\n top_p: Option<f64>,\n repeat_penalty: f32,\n repeat_last_n: usize,\n device: &Device,\n ) -> Self {\n let logits_processor = LogitsProcessor::new(seed, temp, top_p);\n Self {\n model,\n tokenizer: TokenOutputStream::new(tokenizer),\n logits_processor,\n repeat_penalty,\n repeat_last_n,\n device: device.clone(),\n }\n }\n\n fn run(&mut self, prompt: &str, sample_len: usize) -> Result<()> {\n use std::io::Write;\n self.tokenizer.clear();\n let mut tokens = self\n .tokenizer\n .tokenizer()\n .encode(prompt, true)\n .map_err(E::msg)?\n .get_ids()\n .to_vec();\n for &t in tokens.iter() {\n if let Some(t) = self.tokenizer.next_token(t)? {\n print!(\"{t}\")\n }\n }\n std::io::stdout().flush()?;\n\n let mut generated_tokens = 0usize;\n let eos_token = match self.tokenizer.get_token(\"<eos>\") {\n Some(token) => token,\n None => anyhow::bail!(\"cannot find the <eos> token\"),\n };\n let start_gen = std::time::Instant::now();\n for index in 0..sample_len {\n let context_size = if index > 0 { 1 } else { tokens.len() };\n let start_pos = tokens.len().saturating_sub(context_size);\n let ctxt = &tokens[start_pos..];\n let input = Tensor::new(ctxt, &self.device)?.unsqueeze(0)?;\n let logits = self.model.forward(&input, start_pos)?;\n let logits = logits.squeeze(0)?.squeeze(0)?.to_dtype(DType::F32)?;\n let logits = if self.repeat_penalty == 1. {\n logits\n } else {\n let start_at = tokens.len().saturating_sub(self.repeat_last_n);\n candle_transformers::utils::apply_repeat_penalty(\n &logits,\n self.repeat_penalty,\n &tokens[start_at..],\n )?\n };\n\n let next_token = self.logits_processor.sample(&logits)?;\n tokens.push(next_token);\n generated_tokens += 1;\n if next_token == eos_token {\n break;\n }\n if let Some(t) = self.tokenizer.next_token(next_token)? {\n print!(\"{t}\");\n std::io::stdout().flush()?;\n }\n }\n let dt = start_gen.elapsed();\n if let Some(rest) = self.tokenizer.decode_rest().map_err(E::msg)? {\n print!(\"{rest}\");\n }\n std::io::stdout().flush()?;\n println!(\n \"\\n{generated_tokens} tokens generated ({:.2} token/s)\",\n generated_tokens as f64 / dt.as_secs_f64(),\n );\n Ok(())\n }\n}\n\n#[derive(Parser, Debug)]\n#[command(author, version, about, long_about = None)]\nstruct Args {\n /// Run on CPU rather than on GPU.\n #[arg(long)]\n cpu: bool,\n\n /// Enable tracing (generates a trace-timestamp.json file).\n #[arg(long)]\n tracing: bool,\n\n #[arg(long)]\n prompt: String,\n\n /// The temperature used to generate samples.\n #[arg(long)]\n temperature: Option<f64>,\n\n /// Nucleus sampling probability cutoff.\n #[arg(long)]\n top_p: Option<f64>,\n\n /// The seed to use when generating random samples.\n #[arg(long, default_value_t = 299792458)]\n seed: u64,\n\n /// The length of the sample to generate (in tokens).\n #[arg(long, short = 'n', default_value_t = 10000)]\n sample_len: usize,\n\n #[arg(long)]\n model_id: Option<String>,\n\n #[arg(long, default_value = \"main\")]\n revision: String,\n\n #[arg(long)]\n tokenizer_file: Option<String>,\n\n #[arg(long)]\n config_file: Option<String>,\n\n #[arg(long)]\n weight_files: Option<String>,\n\n /// Penalty to be applied for repeating tokens, 1. means no penalty.\n #[arg(long, default_value_t = 1.1)]\n repeat_penalty: f32,\n\n /// The context size to consider for the repeat penalty.\n #[arg(long, default_value_t = 64)]\n repeat_last_n: usize,\n\n /// The model to use.\n #[arg(long, default_value = \"2-2b\")]\n which: Which,\n\n #[arg(long)]\n use_flash_attn: bool,\n}\n\nfn main() -> Result<()> {\n use tracing_chrome::ChromeLayerBuilder;\n use tracing_subscriber::prelude::*;\n\n let args = Args::parse();\n let _guard = if args.tracing {\n let (chrome_layer, guard) = ChromeLayerBuilder::new().build();\n tracing_subscriber::registry().with(chrome_layer).init();\n Some(guard)\n } else {\n None\n };\n println!(\n \"avx: {}, neon: {}, simd128: {}, f16c: {}\",\n candle::utils::with_avx(),\n candle::utils::with_neon(),\n candle::utils::with_simd128(),\n candle::utils::with_f16c()\n );\n println!(\n \"temp: {:.2} repeat-penalty: {:.2} repeat-last-n: {}\",\n args.temperature.unwrap_or(0.),\n args.repeat_penalty,\n args.repeat_last_n\n );\n\n let start = std::time::Instant::now();\n let api = Api::new()?;\n let model_id = match &args.model_id {\n Some(model_id) => model_id.to_string(),\n None => match args.which {\n Which::InstructV1_1_2B => \"google/gemma-1.1-2b-it\".to_string(),\n Which::InstructV1_1_7B => \"google/gemma-1.1-7b-it\".to_string(),\n Which::Base2B => \"google/gemma-2b\".to_string(),\n Which::Base7B => \"google/gemma-7b\".to_string(),\n Which::Instruct2B => \"google/gemma-2b-it\".to_string(),\n Which::Instruct7B => \"google/gemma-7b-it\".to_string(),\n Which::CodeBase2B => \"google/codegemma-2b\".to_string(),\n Which::CodeBase7B => \"google/codegemma-7b\".to_string(),\n Which::CodeInstruct2B => \"google/codegemma-2b-it\".to_string(),\n Which::CodeInstruct7B => \"google/codegemma-7b-it\".to_string(),\n Which::BaseV2_2B => \"google/gemma-2-2b\".to_string(),\n Which::InstructV2_2B => \"google/gemma-2-2b-it\".to_string(),\n Which::BaseV2_9B => \"google/gemma-2-9b\".to_string(),\n Which::InstructV2_9B => \"google/gemma-2-9b-it\".to_string(),\n },\n };\n let repo = api.repo(Repo::with_revision(\n model_id,\n RepoType::Model,\n args.revision,\n ));\n let tokenizer_filename = match args.tokenizer_file {\n Some(file) => std::path::PathBuf::from(file),\n None => repo.get(\"tokenizer.json\")?,\n };\n let config_filename = match args.config_file {\n Some(file) => std::path::PathBuf::from(file),\n None => repo.get(\"config.json\")?,\n };\n let filenames = match args.weight_files {\n Some(files) => files\n .split(',')\n .map(std::path::PathBuf::from)\n .collect::<Vec<_>>(),\n None => candle_examples::hub_load_safetensors(&repo, \"model.safetensors.index.json\")?,\n };\n println!(\"retrieved the files in {:?}\", start.elapsed());\n let tokenizer = Tokenizer::from_file(tokenizer_filename).map_err(E::msg)?;\n\n let start = std::time::Instant::now();\n let device = candle_examples::device(args.cpu)?;\n let dtype = if device.is_cuda() {\n DType::BF16\n } else {\n DType::F32\n };\n let vb = unsafe { VarBuilder::from_mmaped_safetensors(&filenames, dtype, &device)? };\n let model = if args.which.is_v1() {\n let config: Config1 = serde_json::from_reader(std::fs::File::open(config_filename)?)?;\n let model = Model1::new(args.use_flash_attn, &config, vb)?;\n Model::V1(model)\n } else {\n let config: Config2 = serde_json::from_reader(std::fs::File::open(config_filename)?)?;\n let model = Model2::new(args.use_flash_attn, &config, vb)?;\n Model::V2(model)\n };\n\n println!(\"loaded the model in {:?}\", start.elapsed());\n\n let mut pipeline = TextGeneration::new(\n model,\n tokenizer,\n args.seed,\n args.temperature,\n args.top_p,\n args.repeat_penalty,\n args.repeat_last_n,\n &device,\n );\n pipeline.run(&args.prompt, args.sample_len)?;\n Ok(())\n}\n", "candle-examples\\examples\\glm4\\main.rs": "use candle_transformers::models::glm4::*;\nuse clap::Parser;\n\nuse candle::{DType, Device, Tensor};\nuse candle_nn::VarBuilder;\nuse candle_transformers::generation::LogitsProcessor;\nuse hf_hub::{Repo, RepoType};\nuse tokenizers::Tokenizer;\n\nstruct TextGeneration {\n model: Model,\n device: Device,\n tokenizer: Tokenizer,\n logits_processor: LogitsProcessor,\n repeat_penalty: f32,\n repeat_last_n: usize,\n verbose_prompt: bool,\n dtype: DType,\n}\n\nimpl TextGeneration {\n #[allow(clippy::too_many_arguments)]\n fn new(\n model: Model,\n tokenizer: Tokenizer,\n seed: u64,\n temp: Option<f64>,\n top_p: Option<f64>,\n repeat_penalty: f32,\n repeat_last_n: usize,\n verbose_prompt: bool,\n device: &Device,\n dtype: DType,\n ) -> Self {\n let logits_processor = LogitsProcessor::new(seed, temp, top_p);\n Self {\n model,\n tokenizer,\n logits_processor,\n repeat_penalty,\n repeat_last_n,\n verbose_prompt,\n device: device.clone(),\n dtype,\n }\n }\n\n fn run(&mut self, sample_len: usize) -> anyhow::Result<()> {\n use std::io::BufRead;\n use std::io::BufReader;\n use std::io::Write;\n println!(\"starting the inference loop\");\n println!(\"[\u6b22\u8fce\u4f7f\u7528GLM-4,\u8bf7\u8f93\u5165prompt]\");\n let stdin = std::io::stdin();\n let reader = BufReader::new(stdin);\n for line in reader.lines() {\n let line = line.expect(\"Failed to read line\");\n\n let tokens = self.tokenizer.encode(line, true).expect(\"tokens error\");\n if tokens.is_empty() {\n panic!(\"Empty prompts are not supported in the chatglm model.\")\n }\n if self.verbose_prompt {\n for (token, id) in tokens.get_tokens().iter().zip(tokens.get_ids().iter()) {\n let token = token.replace('\u2581', \" \").replace(\"<0x0A>\", \"\\n\");\n println!(\"{id:7} -> '{token}'\");\n }\n }\n let eos_token = match self.tokenizer.get_vocab(true).get(\"<|endoftext|>\") {\n Some(token) => *token,\n None => panic!(\"cannot find the endoftext token\"),\n };\n let mut tokens = tokens.get_ids().to_vec();\n let mut generated_tokens = 0usize;\n\n std::io::stdout().flush().expect(\"output flush error\");\n let start_gen = std::time::Instant::now();\n\n let mut count = 0;\n let mut result = vec![];\n for index in 0..sample_len {\n count += 1;\n let context_size = if index > 0 { 1 } else { tokens.len() };\n let ctxt = &tokens[tokens.len().saturating_sub(context_size)..];\n let input = Tensor::new(ctxt, &self.device)?.unsqueeze(0)?;\n let logits = self.model.forward(&input)?;\n let logits = logits.squeeze(0)?.to_dtype(self.dtype)?;\n let logits = if self.repeat_penalty == 1. {\n logits\n } else {\n let start_at = tokens.len().saturating_sub(self.repeat_last_n);\n candle_transformers::utils::apply_repeat_penalty(\n &logits,\n self.repeat_penalty,\n &tokens[start_at..],\n )?\n };\n\n let next_token = self.logits_processor.sample(&logits)?;\n tokens.push(next_token);\n generated_tokens += 1;\n if next_token == eos_token {\n break;\n }\n let token = self\n .tokenizer\n .decode(&[next_token], true)\n .expect(\"Token error\");\n if self.verbose_prompt {\n println!(\n \"[Count: {}] [Raw Token: {}] [Decode Token: {}]\",\n count, next_token, token\n );\n }\n result.push(token);\n std::io::stdout().flush()?;\n }\n let dt = start_gen.elapsed();\n println!(\n \"\\n{generated_tokens} tokens generated ({:.2} token/s)\",\n generated_tokens as f64 / dt.as_secs_f64(),\n );\n println!(\"Result:\");\n for tokens in result {\n print!(\"{tokens}\");\n }\n self.model.reset_kv_cache(); // clean the cache\n }\n Ok(())\n }\n}\n#[derive(Parser, Debug)]\n#[command(author, version, about, long_about = None)]\nstruct Args {\n /// Run on CPU rather than on GPU.\n #[arg(name = \"cache\", short, long, default_value = \".\")]\n cache_path: String,\n\n #[arg(long)]\n cpu: bool,\n\n /// Display the token for the specified prompt.\n #[arg(long)]\n verbose_prompt: bool,\n\n /// The temperature used to generate samples.\n #[arg(long)]\n temperature: Option<f64>,\n\n /// Nucleus sampling probability cutoff.\n #[arg(long)]\n top_p: Option<f64>,\n\n /// The seed to use when generating random samples.\n #[arg(long, default_value_t = 299792458)]\n seed: u64,\n\n /// The length of the sample to generate (in tokens).\n #[arg(long, short = 'n', default_value_t = 8192)]\n sample_len: usize,\n\n #[arg(long)]\n model_id: Option<String>,\n\n #[arg(long)]\n revision: Option<String>,\n\n #[arg(long)]\n weight_file: Option<String>,\n\n #[arg(long)]\n tokenizer: Option<String>,\n\n /// Penalty to be applied for repeating tokens, 1. means no penalty.\n #[arg(long, default_value_t = 1.2)]\n repeat_penalty: f32,\n\n /// The context size to consider for the repeat penalty.\n #[arg(long, default_value_t = 64)]\n repeat_last_n: usize,\n}\n\nfn main() -> anyhow::Result<()> {\n let args = Args::parse();\n println!(\n \"avx: {}, neon: {}, simd128: {}, f16c: {}\",\n candle::utils::with_avx(),\n candle::utils::with_neon(),\n candle::utils::with_simd128(),\n candle::utils::with_f16c()\n );\n println!(\n \"temp: {:.2} repeat-penalty: {:.2} repeat-last-n: {}\",\n args.temperature.unwrap_or(0.6),\n args.repeat_penalty,\n args.repeat_last_n\n );\n\n let start = std::time::Instant::now();\n println!(\"cache path {}\", args.cache_path);\n let api = hf_hub::api::sync::ApiBuilder::from_cache(hf_hub::Cache::new(args.cache_path.into()))\n .build()\n .map_err(anyhow::Error::msg)?;\n\n let model_id = match args.model_id {\n Some(model_id) => model_id.to_string(),\n None => \"THUDM/glm-4-9b\".to_string(),\n };\n let revision = match args.revision {\n Some(rev) => rev.to_string(),\n None => \"main\".to_string(),\n };\n let repo = api.repo(Repo::with_revision(model_id, RepoType::Model, revision));\n let tokenizer_filename = match args.tokenizer {\n Some(file) => std::path::PathBuf::from(file),\n None => api\n .model(\"THUDM/codegeex4-all-9b\".to_string())\n .get(\"tokenizer.json\")\n .map_err(anyhow::Error::msg)?,\n };\n let filenames = match args.weight_file {\n Some(weight_file) => vec![std::path::PathBuf::from(weight_file)],\n None => candle_examples::hub_load_safetensors(&repo, \"model.safetensors.index.json\")?,\n };\n println!(\"retrieved the files in {:?}\", start.elapsed());\n let tokenizer = Tokenizer::from_file(tokenizer_filename).expect(\"Tokenizer Error\");\n\n let start = std::time::Instant::now();\n let config = Config::glm4();\n let device = candle_examples::device(args.cpu)?;\n let dtype = if device.is_cuda() {\n DType::BF16\n } else {\n DType::F32\n };\n let vb = unsafe { VarBuilder::from_mmaped_safetensors(&filenames, dtype, &device)? };\n let model = Model::new(&config, vb)?;\n\n println!(\"loaded the model in {:?}\", start.elapsed());\n\n let mut pipeline = TextGeneration::new(\n model,\n tokenizer,\n args.seed,\n args.temperature,\n args.top_p,\n args.repeat_penalty,\n args.repeat_last_n,\n args.verbose_prompt,\n &device,\n dtype,\n );\n pipeline.run(args.sample_len)?;\n Ok(())\n}\n", "candle-examples\\examples\\granite\\main.rs": "// An implementation of different Granite models https://www.ibm.com/granite\n\n#[cfg(feature = \"accelerate\")]\nextern crate accelerate_src;\n\n#[cfg(feature = \"mkl\")]\nextern crate intel_mkl_src;\n\nuse anyhow::{bail, Error as E, Result};\nuse clap::{Parser, ValueEnum};\n\nuse candle::{DType, Tensor};\nuse candle_nn::VarBuilder;\nuse candle_transformers::generation::{LogitsProcessor, Sampling};\nuse hf_hub::{api::sync::Api, Repo, RepoType};\nuse std::io::Write;\n\nuse candle_transformers::models::granite as model;\nuse model::{Granite, GraniteConfig};\n\nuse std::time::Instant;\n\nconst EOS_TOKEN: &str = \"</s>\";\nconst DEFAULT_PROMPT: &str = \"How Fault Tolerant Quantum Computers will help humanity?\";\n\n#[derive(Clone, Debug, Copy, PartialEq, Eq, ValueEnum)]\nenum GraniteModel {\n Granite7bInstruct,\n}\n\n#[derive(Parser, Debug)]\n#[command(author, version, about, long_about = None)]\nstruct Args {\n /// Run on CPU rather than on GPU.\n #[arg(long)]\n cpu: bool,\n\n /// The temperature used to generate samples.\n #[arg(long, default_value_t = 0.8)]\n temperature: f64,\n\n /// Nucleus sampling probability cutoff.\n #[arg(long)]\n top_p: Option<f64>,\n\n /// Only sample among the top K samples.\n #[arg(long)]\n top_k: Option<usize>,\n\n /// The seed to use when generating random samples.\n #[arg(long, default_value_t = 299792458)]\n seed: u64,\n\n /// The length of the sample to generate (in tokens).\n #[arg(short = 'n', long, default_value_t = 10000)]\n sample_len: usize,\n\n /// Disable the key-value cache.\n #[arg(long)]\n no_kv_cache: bool,\n\n /// The initial prompt.\n #[arg(long)]\n prompt: Option<String>,\n\n /// Use different dtype than f16\n #[arg(long)]\n dtype: Option<String>,\n\n /// Enable tracing (generates a trace-timestamp.json file).\n #[arg(long)]\n tracing: bool,\n\n #[arg(long)]\n model_id: Option<String>,\n\n #[arg(long)]\n revision: Option<String>,\n\n #[arg(long, default_value = \"granite7b-instruct\")]\n model_type: GraniteModel,\n\n #[arg(long)]\n use_flash_attn: bool,\n\n /// Penalty to be applied for repeating tokens, 1. means no penalty.\n #[arg(long, default_value_t = 1.1)]\n repeat_penalty: f32,\n\n /// The context size to consider for the repeat penalty.\n #[arg(long, default_value_t = 128)]\n repeat_last_n: usize,\n}\n\nfn main() -> Result<()> {\n use tokenizers::Tokenizer;\n use tracing_chrome::ChromeLayerBuilder;\n use tracing_subscriber::prelude::*;\n\n let args = Args::parse();\n let _guard = if args.tracing {\n let (chrome_layer, guard) = ChromeLayerBuilder::new().build();\n tracing_subscriber::registry().with(chrome_layer).init();\n Some(guard)\n } else {\n None\n };\n\n let device = candle_examples::device(args.cpu)?;\n let dtype = match args.dtype.as_deref() {\n Some(\"f16\") => DType::F16,\n Some(\"bf16\") => DType::BF16,\n Some(\"f32\") => DType::F32,\n Some(dtype) => bail!(\"Unsupported dtype {dtype}\"),\n None => DType::F16,\n };\n let (granite, tokenizer_filename, mut cache, config) = {\n let api = Api::new()?;\n let model_id = args.model_id.unwrap_or_else(|| match args.model_type {\n GraniteModel::Granite7bInstruct => \"ibm-granite/granite-7b-instruct\".to_string(),\n });\n println!(\"loading the model weights from {model_id}\");\n let revision = args.revision.unwrap_or(\"main\".to_string());\n let api = api.repo(Repo::with_revision(model_id, RepoType::Model, revision));\n\n let tokenizer_filename = api.get(\"tokenizer.json\")?;\n let config_filename = api.get(\"config.json\")?;\n let config: GraniteConfig = serde_json::from_slice(&std::fs::read(config_filename)?)?;\n let config = config.into_config(args.use_flash_attn);\n\n let filenames = match args.model_type {\n GraniteModel::Granite7bInstruct => {\n candle_examples::hub_load_safetensors(&api, \"model.safetensors.index.json\")?\n }\n };\n let cache = model::Cache::new(!args.no_kv_cache, dtype, &config, &device)?;\n\n let vb = unsafe { VarBuilder::from_mmaped_safetensors(&filenames, dtype, &device)? };\n (\n Granite::load(vb, &config)?,\n tokenizer_filename,\n cache,\n config,\n )\n };\n let tokenizer = Tokenizer::from_file(tokenizer_filename).map_err(E::msg)?;\n let eos_token_id = config.eos_token_id.or_else(|| {\n tokenizer\n .token_to_id(EOS_TOKEN)\n .map(model::GraniteEosToks::Single)\n });\n\n let default_prompt = match args.model_type {\n GraniteModel::Granite7bInstruct => DEFAULT_PROMPT,\n };\n\n let prompt = args.prompt.as_ref().map_or(default_prompt, |p| p.as_str());\n let mut tokens = tokenizer\n .encode(prompt, true)\n .map_err(E::msg)?\n .get_ids()\n .to_vec();\n let mut tokenizer = candle_examples::token_output_stream::TokenOutputStream::new(tokenizer);\n\n println!(\"Starting the inference loop:\");\n print!(\"{prompt}\");\n let mut logits_processor = {\n let temperature = args.temperature;\n let sampling = if temperature <= 0. {\n Sampling::ArgMax\n } else {\n match (args.top_k, args.top_p) {\n (None, None) => Sampling::All { temperature },\n (Some(k), None) => Sampling::TopK { k, temperature },\n (None, Some(p)) => Sampling::TopP { p, temperature },\n (Some(k), Some(p)) => Sampling::TopKThenTopP { k, p, temperature },\n }\n };\n LogitsProcessor::from_sampling(args.seed, sampling)\n };\n\n let mut start_gen = std::time::Instant::now();\n let mut index_pos = 0;\n let mut token_generated = 0;\n let use_cache_kv = cache.use_kv_cache;\n\n (0..args.sample_len)\n .inspect(|index| {\n if *index == 1 {\n start_gen = Instant::now();\n }\n })\n .try_for_each(|index| -> Result<()> {\n let (context_size, context_index) = if use_cache_kv && index > 0 {\n (1, index_pos)\n } else {\n (tokens.len(), 0)\n };\n let ctxt = &tokens[tokens.len().saturating_sub(context_size)..];\n let input = Tensor::new(ctxt, &device)?.unsqueeze(0)?;\n let logits = granite\n .forward(&input, context_index, &mut cache)?\n .squeeze(0)?;\n\n let logits = if args.repeat_penalty == 1. {\n logits\n } else {\n let start_at = tokens.len().saturating_sub(args.repeat_last_n);\n candle_transformers::utils::apply_repeat_penalty(\n &logits,\n args.repeat_penalty,\n &tokens[start_at..],\n )?\n };\n\n index_pos += ctxt.len();\n\n let next_token = logits_processor.sample(&logits)?;\n token_generated += 1;\n tokens.push(next_token);\n\n if let Some(model::GraniteEosToks::Single(eos_tok_id)) = eos_token_id {\n if next_token == eos_tok_id {\n return Err(E::msg(\"EOS token found\"));\n }\n } else if let Some(model::GraniteEosToks::Multiple(ref eos_ids)) = eos_token_id {\n if eos_ids.contains(&next_token) {\n return Err(E::msg(\"EOS token found\"));\n }\n }\n\n if let Some(t) = tokenizer.next_token(next_token)? {\n print!(\"{t}\");\n std::io::stdout().flush()?;\n }\n Ok(())\n })\n .unwrap_or(());\n\n if let Some(rest) = tokenizer.decode_rest().map_err(E::msg)? {\n print!(\"{rest}\");\n }\n\n let dt = start_gen.elapsed();\n println!(\n \"\\n\\n{} tokens generated ({} token/s)\\n\",\n token_generated,\n (token_generated - 1) as f64 / dt.as_secs_f64(),\n );\n Ok(())\n}\n", "candle-examples\\examples\\gte-qwen\\main.rs": "#[cfg(feature = \"mkl\")]\nextern crate intel_mkl_src;\n\n#[cfg(feature = \"accelerate\")]\nextern crate accelerate_src;\n\nuse anyhow::{Error as E, Result};\nuse clap::Parser;\n\nuse candle_transformers::models::qwen2::{Config, Model};\n\nuse candle::{DType, Tensor};\nuse candle_nn::VarBuilder;\nuse hf_hub::{api::sync::Api, Repo, RepoType};\nuse tokenizers::{\n utils::padding::{PaddingDirection, PaddingParams, PaddingStrategy},\n Tokenizer,\n};\n\n// gte-Qwen1.5-7B-instruct use EOS token as padding token\nconst EOS_TOKEN: &str = \"<|endoftext|>\";\nconst EOS_TOKEN_ID: u32 = 151643;\n\n#[derive(Parser, Debug)]\n#[command(author, version, about, long_about = None)]\nstruct Args {\n /// Run on CPU rather than on GPU.\n #[arg(long)]\n cpu: bool,\n\n /// Enable tracing (generates a trace-timestamp.json file).\n #[arg(long)]\n tracing: bool,\n\n #[arg(long, default_value = \"Alibaba-NLP/gte-Qwen1.5-7B-instruct\")]\n model_id: String,\n\n #[arg(long, default_value = \"main\")]\n revision: String,\n\n #[arg(long)]\n local_repo: Option<String>,\n}\n\n#[derive(Debug)]\nstruct ConfigFiles {\n pub config: std::path::PathBuf,\n pub tokenizer: std::path::PathBuf,\n pub weights: Vec<std::path::PathBuf>,\n}\n\n// Loading the model from the HuggingFace Hub. Network access is required.\nfn load_from_hub(model_id: &str, revision: &str) -> Result<ConfigFiles> {\n let api = Api::new()?;\n let repo = api.repo(Repo::with_revision(\n model_id.to_string(),\n RepoType::Model,\n revision.to_string(),\n ));\n Ok(ConfigFiles {\n config: repo.get(\"config.json\")?,\n tokenizer: repo.get(\"tokenizer.json\")?,\n weights: candle_examples::hub_load_safetensors(&repo, \"model.safetensors.index.json\")?,\n })\n}\n\n// Loading the model from a local directory.\nfn load_from_local(local_path: &str) -> Result<ConfigFiles> {\n let local_path = std::path::PathBuf::from(local_path);\n let weight_path = local_path.join(\"model.safetensors.index.json\");\n let json: serde_json::Value = serde_json::from_str(&std::fs::read_to_string(weight_path)?)?;\n let weight_map = match json.get(\"weight_map\") {\n Some(serde_json::Value::Object(map)) => map,\n Some(_) => panic!(\"`weight map` is not a map\"),\n None => panic!(\"`weight map` not found\"),\n };\n let mut safetensors_files = std::collections::HashSet::new();\n for value in weight_map.values() {\n safetensors_files.insert(\n value\n .as_str()\n .expect(\"Weight files should be parsed as strings\"),\n );\n }\n let safetensors_paths = safetensors_files\n .iter()\n .map(|v| local_path.join(v))\n .collect::<Vec<_>>();\n Ok(ConfigFiles {\n config: local_path.join(\"config.json\"),\n tokenizer: local_path.join(\"tokenizer.json\"),\n weights: safetensors_paths,\n })\n}\n\nfn main() -> Result<()> {\n use tracing_chrome::ChromeLayerBuilder;\n use tracing_subscriber::prelude::*;\n\n let args = Args::parse();\n let _guard = if args.tracing {\n let (chrome_layer, guard) = ChromeLayerBuilder::new().build();\n tracing_subscriber::registry().with(chrome_layer).init();\n Some(guard)\n } else {\n None\n };\n\n // Fetch the model. Do this offline if local path provided.\n println!(\"Fetching model files...\");\n let start = std::time::Instant::now();\n let config_files = match args.local_repo {\n Some(local_path) => load_from_local(&local_path)?,\n None => load_from_hub(&args.model_id, &args.revision)?,\n };\n println!(\"Model file retrieved in {:?}\", start.elapsed());\n\n // Inputs will be padded to the longest sequence in the batch.\n let padding = PaddingParams {\n strategy: PaddingStrategy::BatchLongest,\n direction: PaddingDirection::Left,\n pad_to_multiple_of: None,\n pad_id: EOS_TOKEN_ID,\n pad_type_id: 0,\n pad_token: String::from(EOS_TOKEN),\n };\n\n // Tokenizer setup\n let mut tokenizer = Tokenizer::from_file(config_files.tokenizer).map_err(E::msg)?;\n tokenizer.with_padding(Some(padding));\n\n // Model initialization\n let device = candle_examples::device(args.cpu)?;\n let dtype = if device.is_cuda() {\n DType::BF16\n } else {\n DType::F32\n };\n let config: Config = serde_json::from_slice(&std::fs::read(config_files.config)?)?;\n let vb = unsafe { VarBuilder::from_mmaped_safetensors(&config_files.weights, dtype, &device)? };\n let mut model = Model::new(&config, vb)?;\n println!(\"Model loaded in {:?}\", start.elapsed());\n\n // Encode the queries and the targets\n let instruct = \"Instruct: Given a web search query, retrieve relevant passages that answer the query\\nQuery: \";\n let documents = vec![\n format!(\"{instruct}how much protein should a female eat{EOS_TOKEN}\"),\n format!(\"{instruct}summit define{EOS_TOKEN}\"),\n format!(\"As a general guideline, the CDC's average requirement of protein for women ages 19 to 70 is 46 grams per day. But, as you can see from this chart, you'll need to increase that if you're expecting or training for a marathon. Check out the chart below to see how much protein you should be eating each day.{EOS_TOKEN}\"),\n format!(\"Definition of summit for English Language Learners. : 1 the highest point of a mountain : the top of a mountain. : 2 the highest level. : 3 a meeting or series of meetings between the leaders of two or more governments.{EOS_TOKEN}\"),\n ];\n let encoded = tokenizer.encode_batch(documents, true).map_err(E::msg)?;\n let tokens: Vec<&[u32]> = encoded.iter().map(|x| x.get_ids()).collect();\n let tokens = Tensor::new(tokens, &device)?;\n let mask: Vec<&[u32]> = encoded.iter().map(|x| x.get_attention_mask()).collect();\n let mask = Tensor::new(mask, &device)?;\n\n // Inference\n let start_gen = std::time::Instant::now();\n let logits = model.forward(&tokens, 0, Some(&mask))?;\n\n // Extract the last hidden states as embeddings since inputs are padded left.\n let (_, seq_len, _) = logits.dims3()?;\n let embd = logits\n .narrow(1, seq_len - 1, 1)?\n .squeeze(1)?\n .to_dtype(DType::F32)?;\n\n // Calculate the relativity scores. Note the embeddings should be normalized.\n let norm = embd.broadcast_div(&embd.sqr()?.sum_keepdim(1)?.sqrt()?)?;\n let scores = norm.narrow(0, 0, 2)?.matmul(&norm.narrow(0, 2, 2)?.t()?)?;\n\n // Print the results\n println!(\"Embedding done in {:?}\", start_gen.elapsed());\n println!(\"Scores: {:?}\", scores.to_vec2::<f32>()?);\n\n Ok(())\n}\n", "candle-examples\\examples\\hiera\\main.rs": "#[cfg(feature = \"mkl\")]\nextern crate intel_mkl_src;\n\n#[cfg(feature = \"accelerate\")]\nextern crate accelerate_src;\n\nuse clap::{Parser, ValueEnum};\n\nuse candle::{DType, IndexOp, D};\nuse candle_nn::{Module, VarBuilder};\nuse candle_transformers::models::hiera;\n\n#[derive(Clone, Copy, Debug, ValueEnum)]\nenum Which {\n Tiny,\n Small,\n Base,\n BasePlus,\n Large,\n Huge,\n}\n\nimpl Which {\n fn model_filename(&self) -> String {\n let name = match self {\n Self::Tiny => \"tiny\",\n Self::Small => \"small\",\n Self::Base => \"base\",\n Self::BasePlus => \"base_plus\",\n Self::Large => \"large\",\n Self::Huge => \"huge\",\n };\n format!(\"timm/hiera_{}_224.mae_in1k_ft_in1k\", name)\n }\n\n fn config(&self) -> hiera::Config {\n match self {\n Self::Tiny => hiera::Config::tiny(),\n Self::Small => hiera::Config::small(),\n Self::Base => hiera::Config::base(),\n Self::BasePlus => hiera::Config::base_plus(),\n Self::Large => hiera::Config::large(),\n Self::Huge => hiera::Config::huge(),\n }\n }\n}\n\n#[derive(Parser)]\nstruct Args {\n #[arg(long)]\n model: Option<String>,\n\n #[arg(long)]\n image: String,\n\n /// Run on CPU rather than on GPU.\n #[arg(long)]\n cpu: bool,\n\n #[arg(value_enum, long, default_value_t=Which::Tiny)]\n which: Which,\n}\n\npub fn main() -> anyhow::Result<()> {\n let args = Args::parse();\n\n let device = candle_examples::device(args.cpu)?;\n\n let image = candle_examples::imagenet::load_image224(args.image)?.to_device(&device)?;\n println!(\"loaded image {image:?}\");\n\n let model_file = match args.model {\n None => {\n let model_name = args.which.model_filename();\n let api = hf_hub::api::sync::Api::new()?;\n let api = api.model(model_name);\n api.get(\"model.safetensors\")?\n }\n Some(model) => model.into(),\n };\n\n let vb = unsafe { VarBuilder::from_mmaped_safetensors(&[model_file], DType::F32, &device)? };\n let model = hiera::hiera(&args.which.config(), 1000, vb)?;\n println!(\"model built\");\n let logits = model.forward(&image.unsqueeze(0)?)?;\n let prs = candle_nn::ops::softmax(&logits, D::Minus1)?\n .i(0)?\n .to_vec1::<f32>()?;\n let mut prs = prs.iter().enumerate().collect::<Vec<_>>();\n prs.sort_by(|(_, p1), (_, p2)| p2.total_cmp(p1));\n for &(category_idx, pr) in prs.iter().take(5) {\n println!(\n \"{:24}: {:.2}%\",\n candle_examples::imagenet::CLASSES[category_idx],\n 100. * pr\n );\n }\n Ok(())\n}\n", "candle-examples\\examples\\jina-bert\\main.rs": "#[cfg(feature = \"mkl\")]\nextern crate intel_mkl_src;\n\n#[cfg(feature = \"accelerate\")]\nextern crate accelerate_src;\n\nuse candle_transformers::models::jina_bert::{BertModel, Config, PositionEmbeddingType};\n\nuse anyhow::Error as E;\nuse candle::{DType, Module, Tensor};\nuse candle_nn::VarBuilder;\nuse clap::Parser;\n\n#[derive(Parser, Debug)]\n#[command(author, version, about, long_about = None)]\nstruct Args {\n /// Run on CPU rather than on GPU.\n #[arg(long)]\n cpu: bool,\n\n /// Enable tracing (generates a trace-timestamp.json file).\n #[arg(long)]\n tracing: bool,\n\n /// When set, compute embeddings for this prompt.\n #[arg(long)]\n prompt: Option<String>,\n\n /// The number of times to run the prompt.\n #[arg(long, default_value = \"1\")]\n n: usize,\n\n /// L2 normalization for embeddings.\n #[arg(long, default_value = \"true\")]\n normalize_embeddings: bool,\n\n #[arg(long)]\n tokenizer: Option<String>,\n\n #[arg(long)]\n model: Option<String>,\n\n #[arg(long)]\n model_file: Option<String>,\n}\n\nimpl Args {\n fn build_model_and_tokenizer(&self) -> anyhow::Result<(BertModel, tokenizers::Tokenizer)> {\n use hf_hub::{api::sync::Api, Repo, RepoType};\n let model_name = match self.model.as_ref() {\n Some(model) => model.to_string(),\n None => \"jinaai/jina-embeddings-v2-base-en\".to_string(),\n };\n\n let model = match &self.model_file {\n Some(model_file) => std::path::PathBuf::from(model_file),\n None => Api::new()?\n .repo(Repo::new(model_name.to_string(), RepoType::Model))\n .get(\"model.safetensors\")?,\n };\n let tokenizer = match &self.tokenizer {\n Some(file) => std::path::PathBuf::from(file),\n None => Api::new()?\n .repo(Repo::new(model_name.to_string(), RepoType::Model))\n .get(\"tokenizer.json\")?,\n };\n let device = candle_examples::device(self.cpu)?;\n let tokenizer = tokenizers::Tokenizer::from_file(tokenizer).map_err(E::msg)?;\n let config = Config::new(\n tokenizer.get_vocab_size(true),\n 768,\n 12,\n 12,\n 3072,\n candle_nn::Activation::Gelu,\n 8192,\n 2,\n 0.02,\n 1e-12,\n 0,\n PositionEmbeddingType::Alibi,\n );\n let vb = unsafe { VarBuilder::from_mmaped_safetensors(&[model], DType::F32, &device)? };\n let model = BertModel::new(vb, &config)?;\n Ok((model, tokenizer))\n }\n}\n\nfn main() -> anyhow::Result<()> {\n use tracing_chrome::ChromeLayerBuilder;\n use tracing_subscriber::prelude::*;\n\n let args = Args::parse();\n let _guard = if args.tracing {\n println!(\"tracing...\");\n let (chrome_layer, guard) = ChromeLayerBuilder::new().build();\n tracing_subscriber::registry().with(chrome_layer).init();\n Some(guard)\n } else {\n None\n };\n let start = std::time::Instant::now();\n\n let (model, mut tokenizer) = args.build_model_and_tokenizer()?;\n let device = &model.device;\n\n if let Some(prompt) = args.prompt {\n let tokenizer = tokenizer\n .with_padding(None)\n .with_truncation(None)\n .map_err(E::msg)?;\n let tokens = tokenizer\n .encode(prompt, true)\n .map_err(E::msg)?\n .get_ids()\n .to_vec();\n let token_ids = Tensor::new(&tokens[..], device)?.unsqueeze(0)?;\n println!(\"Loaded and encoded {:?}\", start.elapsed());\n let start = std::time::Instant::now();\n let embeddings = model.forward(&token_ids)?;\n let (_n_sentence, n_tokens, _hidden_size) = embeddings.dims3()?;\n let embeddings = (embeddings.sum(1)? / (n_tokens as f64))?;\n println!(\"pooled_embeddigns: {embeddings}\");\n let embeddings = if args.normalize_embeddings {\n normalize_l2(&embeddings)?\n } else {\n embeddings\n };\n if args.normalize_embeddings {\n println!(\"normalized_embeddings: {embeddings}\");\n }\n println!(\"Took {:?}\", start.elapsed());\n } else {\n let sentences = [\n \"The cat sits outside\",\n \"A man is playing guitar\",\n \"I love pasta\",\n \"The new movie is awesome\",\n \"The cat plays in the garden\",\n \"A woman watches TV\",\n \"The new movie is so great\",\n \"Do you like pizza?\",\n ];\n let n_sentences = sentences.len();\n if let Some(pp) = tokenizer.get_padding_mut() {\n pp.strategy = tokenizers::PaddingStrategy::BatchLongest\n } else {\n let pp = tokenizers::PaddingParams {\n strategy: tokenizers::PaddingStrategy::BatchLongest,\n ..Default::default()\n };\n tokenizer.with_padding(Some(pp));\n }\n let tokens = tokenizer\n .encode_batch(sentences.to_vec(), true)\n .map_err(E::msg)?;\n let token_ids = tokens\n .iter()\n .map(|tokens| {\n let tokens = tokens.get_ids().to_vec();\n Tensor::new(tokens.as_slice(), device)\n })\n .collect::<candle::Result<Vec<_>>>()?;\n\n let token_ids = Tensor::stack(&token_ids, 0)?;\n println!(\"running inference on batch {:?}\", token_ids.shape());\n let embeddings = model.forward(&token_ids)?;\n println!(\"generated embeddings {:?}\", embeddings.shape());\n // Apply some avg-pooling by taking the mean embedding value for all tokens (including padding)\n let (_n_sentence, n_tokens, _hidden_size) = embeddings.dims3()?;\n let embeddings = (embeddings.sum(1)? / (n_tokens as f64))?;\n let embeddings = if args.normalize_embeddings {\n normalize_l2(&embeddings)?\n } else {\n embeddings\n };\n println!(\"pooled embeddings {:?}\", embeddings.shape());\n\n let mut similarities = vec![];\n for i in 0..n_sentences {\n let e_i = embeddings.get(i)?;\n for j in (i + 1)..n_sentences {\n let e_j = embeddings.get(j)?;\n let sum_ij = (&e_i * &e_j)?.sum_all()?.to_scalar::<f32>()?;\n let sum_i2 = (&e_i * &e_i)?.sum_all()?.to_scalar::<f32>()?;\n let sum_j2 = (&e_j * &e_j)?.sum_all()?.to_scalar::<f32>()?;\n let cosine_similarity = sum_ij / (sum_i2 * sum_j2).sqrt();\n similarities.push((cosine_similarity, i, j))\n }\n }\n similarities.sort_by(|u, v| v.0.total_cmp(&u.0));\n for &(score, i, j) in similarities[..5].iter() {\n println!(\"score: {score:.2} '{}' '{}'\", sentences[i], sentences[j])\n }\n }\n Ok(())\n}\n\npub fn normalize_l2(v: &Tensor) -> candle::Result<Tensor> {\n v.broadcast_div(&v.sqr()?.sum_keepdim(1)?.sqrt()?)\n}\n", "candle-examples\\examples\\llama\\main.rs": "// An implementation of LLaMA https://github.com/facebookresearch/llama\n//\n// This is based on nanoGPT in a similar way to:\n// https://github.com/Lightning-AI/lit-llama/blob/main/lit_llama/model.py\n//\n// The tokenizer config can be retrieved from:\n// https://huggingface.co/hf-internal-testing/llama-tokenizer/raw/main/tokenizer.json\n\n#[cfg(feature = \"accelerate\")]\nextern crate accelerate_src;\n\n#[cfg(feature = \"mkl\")]\nextern crate intel_mkl_src;\n\nuse anyhow::{bail, Error as E, Result};\nuse clap::{Parser, ValueEnum};\n\nuse candle::{DType, Tensor};\nuse candle_nn::VarBuilder;\nuse candle_transformers::generation::{LogitsProcessor, Sampling};\nuse hf_hub::{api::sync::Api, Repo, RepoType};\nuse std::io::Write;\n\nuse candle_transformers::models::llama as model;\nuse model::{Llama, LlamaConfig};\n\nconst EOS_TOKEN: &str = \"</s>\";\nconst DEFAULT_PROMPT: &str = \"My favorite theorem is \";\n\n#[derive(Clone, Debug, Copy, PartialEq, Eq, ValueEnum)]\nenum Which {\n V1,\n V2,\n V3,\n V31,\n V3Instruct,\n V31Instruct,\n #[value(name = \"solar-10.7b\")]\n Solar10_7B,\n #[value(name = \"tiny-llama-1.1b-chat\")]\n TinyLlama1_1BChat,\n}\n\n#[derive(Parser, Debug)]\n#[command(author, version, about, long_about = None)]\nstruct Args {\n /// Run on CPU rather than on GPU.\n #[arg(long)]\n cpu: bool,\n\n /// The temperature used to generate samples.\n #[arg(long, default_value_t = 0.8)]\n temperature: f64,\n\n /// Nucleus sampling probability cutoff.\n #[arg(long)]\n top_p: Option<f64>,\n\n /// Only sample among the top K samples.\n #[arg(long)]\n top_k: Option<usize>,\n\n /// The seed to use when generating random samples.\n #[arg(long, default_value_t = 299792458)]\n seed: u64,\n\n /// The length of the sample to generate (in tokens).\n #[arg(short = 'n', long, default_value_t = 10000)]\n sample_len: usize,\n\n /// Disable the key-value cache.\n #[arg(long)]\n no_kv_cache: bool,\n\n /// The initial prompt.\n #[arg(long)]\n prompt: Option<String>,\n\n /// Use different dtype than f16\n #[arg(long)]\n dtype: Option<String>,\n\n /// Enable tracing (generates a trace-timestamp.json file).\n #[arg(long)]\n tracing: bool,\n\n #[arg(long)]\n model_id: Option<String>,\n\n #[arg(long)]\n revision: Option<String>,\n\n /// The model size to use.\n #[arg(long, default_value = \"v3\")]\n which: Which,\n\n #[arg(long)]\n use_flash_attn: bool,\n\n /// Penalty to be applied for repeating tokens, 1. means no penalty.\n #[arg(long, default_value_t = 1.1)]\n repeat_penalty: f32,\n\n /// The context size to consider for the repeat penalty.\n #[arg(long, default_value_t = 128)]\n repeat_last_n: usize,\n}\n\nfn main() -> Result<()> {\n use tokenizers::Tokenizer;\n use tracing_chrome::ChromeLayerBuilder;\n use tracing_subscriber::prelude::*;\n\n let args = Args::parse();\n let _guard = if args.tracing {\n let (chrome_layer, guard) = ChromeLayerBuilder::new().build();\n tracing_subscriber::registry().with(chrome_layer).init();\n Some(guard)\n } else {\n None\n };\n\n let device = candle_examples::device(args.cpu)?;\n let dtype = match args.dtype.as_deref() {\n Some(\"f16\") => DType::F16,\n Some(\"bf16\") => DType::BF16,\n Some(\"f32\") => DType::F32,\n Some(dtype) => bail!(\"Unsupported dtype {dtype}\"),\n None => DType::F16,\n };\n let (llama, tokenizer_filename, mut cache, config) = {\n let api = Api::new()?;\n let model_id = args.model_id.unwrap_or_else(|| match args.which {\n Which::V1 => \"Narsil/amall-7b\".to_string(),\n Which::V2 => \"meta-llama/Llama-2-7b-hf\".to_string(),\n Which::V3 => \"meta-llama/Meta-Llama-3-8B\".to_string(),\n Which::V3Instruct => \"meta-llama/Meta-Llama-3-8B-Instruct\".to_string(),\n Which::V31 => \"meta-llama/Meta-Llama-3.1-8B\".to_string(),\n Which::V31Instruct => \"meta-llama/Meta-Llama-3.1-8B-Instruct\".to_string(),\n Which::Solar10_7B => \"upstage/SOLAR-10.7B-v1.0\".to_string(),\n Which::TinyLlama1_1BChat => \"TinyLlama/TinyLlama-1.1B-Chat-v1.0\".to_string(),\n });\n println!(\"loading the model weights from {model_id}\");\n let revision = args.revision.unwrap_or(\"main\".to_string());\n let api = api.repo(Repo::with_revision(model_id, RepoType::Model, revision));\n\n let tokenizer_filename = api.get(\"tokenizer.json\")?;\n let config_filename = api.get(\"config.json\")?;\n let config: LlamaConfig = serde_json::from_slice(&std::fs::read(config_filename)?)?;\n let config = config.into_config(args.use_flash_attn);\n\n let filenames = match args.which {\n Which::V1\n | Which::V2\n | Which::V3\n | Which::V3Instruct\n | Which::V31\n | Which::V31Instruct\n | Which::Solar10_7B => {\n candle_examples::hub_load_safetensors(&api, \"model.safetensors.index.json\")?\n }\n Which::TinyLlama1_1BChat => vec![api.get(\"model.safetensors\")?],\n };\n let cache = model::Cache::new(!args.no_kv_cache, dtype, &config, &device)?;\n\n let vb = unsafe { VarBuilder::from_mmaped_safetensors(&filenames, dtype, &device)? };\n (Llama::load(vb, &config)?, tokenizer_filename, cache, config)\n };\n let tokenizer = Tokenizer::from_file(tokenizer_filename).map_err(E::msg)?;\n let eos_token_id = config.eos_token_id.or_else(|| {\n tokenizer\n .token_to_id(EOS_TOKEN)\n .map(model::LlamaEosToks::Single)\n });\n let prompt = args.prompt.as_ref().map_or(DEFAULT_PROMPT, |p| p.as_str());\n let mut tokens = tokenizer\n .encode(prompt, true)\n .map_err(E::msg)?\n .get_ids()\n .to_vec();\n let mut tokenizer = candle_examples::token_output_stream::TokenOutputStream::new(tokenizer);\n\n println!(\"starting the inference loop\");\n print!(\"{prompt}\");\n let mut logits_processor = {\n let temperature = args.temperature;\n let sampling = if temperature <= 0. {\n Sampling::ArgMax\n } else {\n match (args.top_k, args.top_p) {\n (None, None) => Sampling::All { temperature },\n (Some(k), None) => Sampling::TopK { k, temperature },\n (None, Some(p)) => Sampling::TopP { p, temperature },\n (Some(k), Some(p)) => Sampling::TopKThenTopP { k, p, temperature },\n }\n };\n LogitsProcessor::from_sampling(args.seed, sampling)\n };\n\n let mut start_gen = std::time::Instant::now();\n let mut index_pos = 0;\n let mut token_generated = 0;\n for index in 0..args.sample_len {\n let (context_size, context_index) = if cache.use_kv_cache && index > 0 {\n (1, index_pos)\n } else {\n (tokens.len(), 0)\n };\n if index == 1 {\n start_gen = std::time::Instant::now()\n }\n let ctxt = &tokens[tokens.len().saturating_sub(context_size)..];\n let input = Tensor::new(ctxt, &device)?.unsqueeze(0)?;\n let logits = llama.forward(&input, context_index, &mut cache)?;\n let logits = logits.squeeze(0)?;\n let logits = if args.repeat_penalty == 1. {\n logits\n } else {\n let start_at = tokens.len().saturating_sub(args.repeat_last_n);\n candle_transformers::utils::apply_repeat_penalty(\n &logits,\n args.repeat_penalty,\n &tokens[start_at..],\n )?\n };\n index_pos += ctxt.len();\n\n let next_token = logits_processor.sample(&logits)?;\n token_generated += 1;\n tokens.push(next_token);\n\n match eos_token_id {\n Some(model::LlamaEosToks::Single(eos_tok_id)) if next_token == eos_tok_id => {\n break;\n }\n Some(model::LlamaEosToks::Multiple(ref eos_ids)) if eos_ids.contains(&next_token) => {\n break;\n }\n _ => (),\n }\n if let Some(t) = tokenizer.next_token(next_token)? {\n print!(\"{t}\");\n std::io::stdout().flush()?;\n }\n }\n if let Some(rest) = tokenizer.decode_rest().map_err(E::msg)? {\n print!(\"{rest}\");\n }\n let dt = start_gen.elapsed();\n println!(\n \"\\n\\n{} tokens generated ({} token/s)\\n\",\n token_generated,\n (token_generated - 1) as f64 / dt.as_secs_f64(),\n );\n Ok(())\n}\n", "candle-examples\\examples\\llama2-c\\main.rs": "// https://github.com/karpathy/llama2.c\n\n#[cfg(feature = \"accelerate\")]\nextern crate accelerate_src;\n\n#[cfg(feature = \"mkl\")]\nextern crate intel_mkl_src;\n\nuse candle_transformers::models::llama2_c as model;\nuse candle_transformers::models::llama2_c_weights as weights;\nuse candle_transformers::models::quantized_llama2_c as qmodel;\nmod training;\nuse clap::{Parser, Subcommand};\n\nuse anyhow::{Error as E, Result};\nuse byteorder::{LittleEndian, ReadBytesExt};\nuse candle::{IndexOp, Tensor};\nuse candle_transformers::generation::LogitsProcessor;\nuse std::io::Write;\nuse tokenizers::Tokenizer;\n\nuse model::{Cache, Config, Llama};\nuse qmodel::QLlama;\nuse weights::TransformerWeights;\n\n#[derive(Parser, Debug, Clone)]\nstruct InferenceCmd {\n /// The temperature used to generate samples.\n #[arg(long)]\n temperature: Option<f64>,\n\n /// Nucleus sampling probability cutoff.\n #[arg(long)]\n top_p: Option<f64>,\n\n #[arg(long, default_value = \"\")]\n prompt: String,\n\n /// Config file in binary or safetensors format.\n #[arg(long)]\n config: Option<String>,\n\n #[arg(long, default_value = \"karpathy/tinyllamas\")]\n model_id: String,\n\n /// The model to be used when getting it from the hub. Possible\n /// values are 'stories15M.bin', 'stories42M.bin', see more at:\n /// https://huggingface.co/karpathy/tinyllamas/tree/main\n #[arg(long, default_value = \"stories15M.bin\")]\n which_model: String,\n}\n\n#[derive(Parser, Debug, Clone)]\nstruct EvaluationCmd {\n /// A directory with the pre-tokenized dataset in the format generated by the tinystories.py\n /// script from llama2.c https://github.com/karpathy/llama2.c\n #[arg(long)]\n pretokenized_dir: Option<String>,\n\n #[arg(long, default_value_t = 32)]\n batch_size: usize,\n\n /// Config file in binary format.\n #[arg(long)]\n config: Option<String>,\n\n #[arg(long, default_value = \"karpathy/tinyllamas\")]\n model_id: String,\n\n /// The model to be used when getting it from the hub. Possible\n /// values are 'stories15M.bin', 'stories42M.bin', see more at:\n /// https://huggingface.co/karpathy/tinyllamas/tree/main\n #[arg(long, default_value = \"stories15M.bin\")]\n which_model: String,\n}\n\n#[derive(Parser, Debug, Clone)]\npub struct TrainingCmd {\n /// A directory with the pre-tokenized dataset in the format generated by the tinystories.py\n /// script from llama2.c https://github.com/karpathy/llama2.c\n #[arg(long)]\n pretokenized_dir: String,\n\n #[arg(long, default_value_t = 32)]\n batch_size: usize,\n\n #[arg(long, default_value_t = 0.001)]\n learning_rate: f64,\n}\n\n#[derive(Subcommand, Debug, Clone)]\nenum Task {\n Inference(InferenceCmd),\n Eval(EvaluationCmd),\n Train(TrainingCmd),\n}\n\n#[derive(Parser, Debug)]\n#[command(author, version, about, long_about = None)]\npub struct Args {\n /// The task to be performed, inference, training or evaluation.\n #[command(subcommand)]\n task: Option<Task>,\n\n /// Run on CPU rather than on GPU.\n #[arg(long)]\n cpu: bool,\n\n /// Tokenizer config file.\n #[arg(long)]\n tokenizer: Option<String>,\n\n /// Penalty to be applied for repeating tokens, 1. means no penalty.\n #[arg(long, default_value_t = 1.1)]\n repeat_penalty: f32,\n\n /// The context size to consider for the repeat penalty.\n #[arg(long, default_value_t = 64)]\n repeat_last_n: usize,\n}\n\nimpl Args {\n fn tokenizer(&self) -> Result<Tokenizer> {\n let tokenizer_path = match &self.tokenizer {\n Some(config) => std::path::PathBuf::from(config),\n None => {\n let api = hf_hub::api::sync::Api::new()?;\n let api = api.model(\"hf-internal-testing/llama-tokenizer\".to_string());\n api.get(\"tokenizer.json\")?\n }\n };\n Tokenizer::from_file(tokenizer_path).map_err(E::msg)\n }\n}\n\nfn main() -> anyhow::Result<()> {\n let args = Args::parse();\n match &args.task {\n None => {\n let cmd = InferenceCmd {\n temperature: None,\n top_p: None,\n prompt: \"\".to_string(),\n config: None,\n model_id: \"karpathy/tinyllamas\".to_string(),\n which_model: \"stories15M.bin\".to_string(),\n };\n run_inference(&cmd, &args)?\n }\n Some(Task::Inference(cmd)) => run_inference(cmd, &args)?,\n Some(Task::Eval(cmd)) => run_eval(cmd, &args)?,\n Some(Task::Train(cmd)) => training::run(cmd, &args)?,\n }\n Ok(())\n}\n\nenum Model {\n Llama(Llama),\n QLlama(QLlama),\n}\n\nimpl Model {\n fn forward(&self, xs: &Tensor, pos: usize, cache: &mut Cache) -> anyhow::Result<Tensor> {\n match self {\n Self::Llama(l) => Ok(l.forward(xs, pos, cache)?),\n Self::QLlama(l) => Ok(l.forward(xs, pos, cache)?),\n }\n }\n}\n\nfn run_eval(args: &EvaluationCmd, common_args: &Args) -> Result<()> {\n use std::io::BufRead;\n\n let config_path = match &args.config {\n Some(config) => std::path::PathBuf::from(config),\n None => {\n let api = hf_hub::api::sync::Api::new()?;\n println!(\"loading the model weights from {}\", args.model_id);\n let api = api.model(args.model_id.clone());\n api.get(&args.which_model)?\n }\n };\n\n let tokenizer = common_args.tokenizer()?;\n\n let device = candle_examples::device(common_args.cpu)?;\n let mut file = std::fs::File::open(config_path)?;\n let config = Config::from_reader(&mut file)?;\n let weights = TransformerWeights::from_reader(&mut file, &config, &device)?;\n let vb = weights.var_builder(&config, &device)?;\n let mut cache = Cache::new(false, &config, vb.pp(\"rot\"))?;\n let model = Llama::load(vb, config)?;\n\n let tokens = match &args.pretokenized_dir {\n None => {\n let api = hf_hub::api::sync::Api::new()?;\n let model_id = \"roneneldan/TinyStories\"; // TODO: Make this configurable.\n println!(\"loading the evaluation dataset from {}\", model_id);\n let api = api.dataset(model_id.to_string());\n let dataset_path = api.get(\"TinyStories-valid.txt\")?;\n let file = std::fs::File::open(dataset_path)?;\n let file = std::io::BufReader::new(file);\n let mut tokens = vec![];\n for line in file.lines() {\n let line = line?.replace(\"<|endoftext|>\", \"<s>\");\n let line = tokenizer.encode(line, false).map_err(E::msg)?;\n tokens.push(line.get_ids().to_vec())\n }\n tokens.concat()\n }\n Some(pretokenized_dir) => {\n // Use shard 0 for the test split, similar to llama2.c\n // https://github.com/karpathy/llama2.c/blob/ce05cc28cf1e3560b873bb21837638a434520a67/tinystories.py#L121\n let path = std::path::PathBuf::from(pretokenized_dir).join(\"data00.bin\");\n let bytes = std::fs::read(path)?;\n // Tokens are encoded as u16.\n let mut tokens = vec![0u16; bytes.len() / 2];\n std::io::Cursor::new(bytes).read_u16_into::<LittleEndian>(&mut tokens)?;\n tokens.into_iter().map(|u| u as u32).collect::<Vec<u32>>()\n }\n };\n println!(\"dataset loaded and encoded: {} tokens\", tokens.len());\n\n let seq_len = model.config.seq_len;\n let iter = (0..tokens.len()).step_by(seq_len).flat_map(|start_idx| {\n if start_idx + seq_len + 1 > tokens.len() {\n None\n } else {\n let tokens = &tokens[start_idx..start_idx + seq_len + 1];\n let inputs = Tensor::new(&tokens[..seq_len], &device);\n let targets = Tensor::new(&tokens[1..], &device);\n Some(inputs.and_then(|inputs| targets.map(|targets| (inputs, targets))))\n }\n });\n let batch_iter = candle_datasets::Batcher::new_r2(iter).batch_size(args.batch_size);\n for inp_tgt in batch_iter {\n let (inp, tgt) = inp_tgt?;\n let logits = model.forward(&inp, 0, &mut cache)?;\n let loss = candle_nn::loss::cross_entropy(&logits.flatten_to(1)?, &tgt.flatten_to(1)?)?;\n println!(\"{}\", loss.to_vec0::<f32>()?);\n }\n Ok(())\n}\n\nfn run_inference(args: &InferenceCmd, common_args: &Args) -> Result<()> {\n let config_path = match &args.config {\n Some(config) => std::path::PathBuf::from(config),\n None => {\n let api = hf_hub::api::sync::Api::new()?;\n println!(\"loading the model weights from {}\", args.model_id);\n let api = api.model(args.model_id.clone());\n api.get(&args.which_model)?\n }\n };\n\n let tokenizer = common_args.tokenizer()?;\n\n let device = candle_examples::device(common_args.cpu)?;\n\n let is_gguf = config_path.extension().map_or(false, |v| v == \"gguf\");\n let is_safetensors = config_path\n .extension()\n .map_or(false, |v| v == \"safetensors\");\n let (model, config, mut cache) = if is_gguf {\n let vb = qmodel::VarBuilder::from_gguf(config_path, &device)?;\n let (_vocab_size, dim) = vb\n .get_no_shape(\"model.embed_tokens.weight\")?\n .shape()\n .dims2()?;\n let config = match dim {\n 64 => Config::tiny_260k(),\n 288 => Config::tiny_15m(),\n 512 => Config::tiny_42m(),\n 768 => Config::tiny_110m(),\n _ => anyhow::bail!(\"no config for dim {dim}\"),\n };\n let freq_cis_real = vb\n .get(\n (config.seq_len, config.head_size() / 2),\n \"rot.freq_cis_real\",\n )?\n .dequantize(&device)?;\n let freq_cis_imag = vb\n .get(\n (config.seq_len, config.head_size() / 2),\n \"rot.freq_cis_imag\",\n )?\n .dequantize(&device)?;\n\n let fake_vb = candle_nn::VarBuilder::from_tensors(\n [\n (\"freq_cis_real\".to_string(), freq_cis_real),\n (\"freq_cis_imag\".to_string(), freq_cis_imag),\n ]\n .into_iter()\n .collect(),\n candle::DType::F32,\n &device,\n );\n let cache = model::Cache::new(true, &config, fake_vb)?;\n let model = Model::QLlama(QLlama::load(vb, config.clone())?);\n (model, config, cache)\n } else if is_safetensors {\n let config = Config::tiny_15m();\n let tensors = candle::safetensors::load(config_path, &device)?;\n let vb = candle_nn::VarBuilder::from_tensors(tensors, candle::DType::F32, &device);\n let cache = model::Cache::new(true, &config, vb.pp(\"rot\"))?;\n let model = Model::Llama(Llama::load(vb, config.clone())?);\n (model, config, cache)\n } else {\n let mut file = std::fs::File::open(config_path)?;\n let config = Config::from_reader(&mut file)?;\n println!(\"{config:?}\");\n let weights = TransformerWeights::from_reader(&mut file, &config, &device)?;\n let vb = weights.var_builder(&config, &device)?;\n let cache = model::Cache::new(true, &config, vb.pp(\"rot\"))?;\n let model = Model::Llama(Llama::load(vb, config.clone())?);\n (model, config, cache)\n };\n\n println!(\"starting the inference loop\");\n let mut logits_processor = LogitsProcessor::new(299792458, args.temperature, args.top_p);\n let mut index_pos = 0;\n\n print!(\"{}\", args.prompt);\n let mut tokens = tokenizer\n .encode(args.prompt.clone(), true)\n .map_err(E::msg)?\n .get_ids()\n .to_vec();\n let mut tokenizer = candle_examples::token_output_stream::TokenOutputStream::new(tokenizer);\n\n let start_gen = std::time::Instant::now();\n for index in 0.. {\n if tokens.len() >= config.seq_len {\n break;\n }\n let context_size = if index > 0 { 1 } else { tokens.len() };\n let ctxt = &tokens[tokens.len().saturating_sub(context_size)..];\n let input = Tensor::new(ctxt, &device)?.unsqueeze(0)?;\n let logits = model.forward(&input, index_pos, &mut cache)?;\n let logits = logits.i((0, logits.dim(1)? - 1))?;\n let logits = if common_args.repeat_penalty == 1. || tokens.is_empty() {\n logits\n } else {\n let start_at = tokens.len().saturating_sub(common_args.repeat_last_n);\n candle_transformers::utils::apply_repeat_penalty(\n &logits,\n common_args.repeat_penalty,\n &tokens[start_at..],\n )?\n };\n index_pos += ctxt.len();\n\n let next_token = logits_processor.sample(&logits)?;\n tokens.push(next_token);\n if let Some(t) = tokenizer.next_token(next_token)? {\n print!(\"{t}\");\n std::io::stdout().flush()?;\n }\n }\n if let Some(rest) = tokenizer.decode_rest().map_err(E::msg)? {\n print!(\"{rest}\");\n }\n let dt = start_gen.elapsed();\n println!(\n \"\\n{} tokens generated ({:.2} token/s)\\n\",\n tokens.len(),\n tokens.len() as f64 / dt.as_secs_f64(),\n );\n Ok(())\n}\n", "candle-examples\\examples\\llama_multiprocess\\main.rs": "// An implementation of LLaMA https://github.com/facebookresearch/llama\n//\n// This is based on nanoGPT in a similar way to:\n// https://github.com/Lightning-AI/lit-llama/blob/main/lit_llama/model.py\n//\n// The tokenizer config can be retrieved from:\n// https://huggingface.co/hf-internal-testing/llama-tokenizer/raw/main/tokenizer.json\n\n#[cfg(feature = \"mkl\")]\nextern crate intel_mkl_src;\n\nuse anyhow::{bail, Error as E, Result};\nuse clap::{Parser, ValueEnum};\n\nuse candle::{DType, Device, Tensor};\nuse candle_transformers::generation::LogitsProcessor;\nuse candle_transformers::models::llama::LlamaEosToks;\nuse cudarc::driver::safe::CudaDevice;\nuse cudarc::nccl::safe::{Comm, Id};\nuse hf_hub::{api::sync::Api, Repo, RepoType};\nuse std::io::Write;\nuse std::rc::Rc;\n\nmod model;\nuse model::{Config, Llama};\n\nconst MAX_SEQ_LEN: usize = 4096;\nconst DEFAULT_PROMPT: &str = \"My favorite theorem is \";\n\n#[derive(Clone, Debug, Copy, PartialEq, Eq, ValueEnum)]\nenum Which {\n V2_7b,\n V2_70b,\n V3_8b,\n V3_70b,\n}\n\n#[derive(Parser, Debug)]\n#[command(author, version, about, long_about = None)]\nstruct Args {\n #[arg(long)]\n num_shards: usize,\n\n #[arg(long)]\n rank: Option<usize>,\n\n /// The temperature used to generate samples.\n #[arg(long, default_value_t = 0.8)]\n temperature: f64,\n\n /// Nucleus sampling probability cutoff.\n #[arg(long)]\n top_p: Option<f64>,\n\n /// The seed to use when generating random samples.\n #[arg(long, default_value_t = 299792458)]\n seed: u64,\n\n /// The length of the sample to generate (in tokens).\n #[arg(long, default_value_t = 100)]\n sample_len: usize,\n\n /// Disable the key-value cache.\n #[arg(long)]\n no_kv_cache: bool,\n\n /// The initial prompt.\n #[arg(long)]\n prompt: Option<String>,\n\n #[arg(long)]\n model_id: Option<String>,\n\n #[arg(long)]\n revision: Option<String>,\n\n #[arg(long)]\n dtype: Option<String>,\n\n #[arg(long, default_value = \"v3-8b\")]\n which: Which,\n\n #[arg(long, default_value = \"nccl_id.txt\")]\n comm_file: String,\n}\n\nfn main() -> Result<()> {\n use tokenizers::Tokenizer;\n\n let args = Args::parse();\n\n let dtype = match args.dtype.as_deref() {\n Some(\"f16\") => DType::F16,\n Some(\"bf16\") => DType::BF16,\n Some(\"f32\") => DType::F32,\n Some(dtype) => bail!(\"Unsupported dtype {dtype}\"),\n None => match args.which {\n Which::V2_7b | Which::V2_70b => DType::F16,\n Which::V3_8b | Which::V3_70b => DType::BF16,\n },\n };\n\n let comm_file = std::path::PathBuf::from(&args.comm_file);\n if comm_file.exists() {\n bail!(\"comm file {comm_file:?} already exists, please remove it first\")\n }\n\n let api = Api::new()?;\n let model_id = match args.model_id {\n Some(model) => model,\n None => match args.which {\n Which::V2_7b => \"meta-llama/Llama-2-7b-hf\".to_string(),\n Which::V2_70b => \"meta-llama/Llama-2-70b-hf\".to_string(),\n Which::V3_8b => \"meta-llama/Meta-Llama-3-8B\".to_string(),\n Which::V3_70b => \"meta-llama/Meta-Llama-3-70B\".to_string(),\n },\n };\n println!(\"loading the model weights from {model_id}\");\n let revision = args.revision.unwrap_or(\"main\".to_string());\n let api = api.repo(Repo::with_revision(model_id, RepoType::Model, revision));\n let config_filename = api.get(\"config.json\")?;\n let config: Config = serde_json::from_slice(&std::fs::read(config_filename)?)?;\n let tokenizer_filename = api.get(\"tokenizer.json\")?;\n let filenames = candle_examples::hub_load_safetensors(&api, \"model.safetensors.index.json\")?;\n\n let rank = match args.rank {\n None => {\n println!(\"creating {} child processes\", args.num_shards);\n let children: Vec<_> = (0..args.num_shards)\n .map(|rank| {\n let mut args: std::collections::VecDeque<_> = std::env::args().collect();\n args.push_back(\"--rank\".to_string());\n args.push_back(format!(\"{rank}\"));\n let name = args.pop_front().unwrap();\n std::process::Command::new(name).args(args).spawn().unwrap()\n })\n .collect();\n for mut child in children {\n child.wait()?;\n }\n return Ok(());\n }\n Some(rank) => rank,\n };\n\n let num_shards = args.num_shards;\n // Primitive IPC\n let id = if rank == 0 {\n let id = Id::new().unwrap();\n let tmp_file = comm_file.with_extension(\".comm.tgz\");\n std::fs::File::create(&tmp_file)?\n .write_all(&id.internal().iter().map(|&i| i as u8).collect::<Vec<_>>())?;\n std::fs::rename(&tmp_file, &comm_file)?;\n id\n } else {\n while !comm_file.exists() {\n std::thread::sleep(std::time::Duration::from_secs(1));\n }\n let data = std::fs::read(&comm_file)?;\n let internal: [i8; 128] = data\n .into_iter()\n .map(|i| i as i8)\n .collect::<Vec<_>>()\n .try_into()\n .unwrap();\n let id: Id = Id::uninit(internal);\n id\n };\n let device = CudaDevice::new(rank)?;\n let comm = match Comm::from_rank(device, rank, num_shards, id) {\n Ok(comm) => Rc::new(comm),\n Err(err) => anyhow::bail!(\"nccl error {:?}\", err.0),\n };\n if rank == 0 {\n std::fs::remove_file(comm_file)?;\n }\n println!(\"Rank {rank:?} spawned\");\n\n let device = Device::new_cuda(rank)?;\n let cache = model::Cache::new(dtype, &config, &device)?;\n\n println!(\"building the model\");\n let vb = unsafe {\n candle_nn::var_builder::ShardedSafeTensors::var_builder(&filenames, dtype, &device)?\n };\n let llama = Llama::load(vb, &cache, &config, comm)?;\n let tokenizer = Tokenizer::from_file(tokenizer_filename).map_err(E::msg)?;\n\n let prompt = args.prompt.as_ref().map_or(DEFAULT_PROMPT, |p| p.as_str());\n let mut tokens = tokenizer\n .encode(prompt, true)\n .map_err(E::msg)?\n .get_ids()\n .to_vec();\n let mut tokenizer = candle_examples::token_output_stream::TokenOutputStream::new(tokenizer);\n\n println!(\"starting the inference loop\");\n let temperature = if args.temperature <= 0. {\n None\n } else {\n Some(args.temperature)\n };\n let mut logits_processor = LogitsProcessor::new(args.seed, temperature, args.top_p);\n let mut new_tokens = vec![];\n let mut start_gen = std::time::Instant::now();\n let mut index_pos = 0;\n for index in 0..args.sample_len {\n // Only start timing at the second token as processing the first token waits for all the\n // weights to be loaded in an async way.\n if index == 1 {\n start_gen = std::time::Instant::now()\n };\n let context_size = if index > 0 { 1 } else { tokens.len() };\n let ctxt = &tokens[tokens.len().saturating_sub(context_size)..];\n let input = Tensor::new(ctxt, &device)?.unsqueeze(0)?;\n let logits = llama.forward(&input, index_pos)?;\n let logits = logits.squeeze(0)?;\n index_pos += ctxt.len();\n\n let next_token = logits_processor.sample(&logits)?;\n tokens.push(next_token);\n new_tokens.push(next_token);\n match config.eos_token_id {\n Some(LlamaEosToks::Single(eos_tok_id)) if next_token == eos_tok_id => {\n break;\n }\n Some(LlamaEosToks::Multiple(ref eos_ids)) if eos_ids.contains(&next_token) => {\n break;\n }\n _ => (),\n }\n\n if rank == 0 {\n if let Some(t) = tokenizer.next_token(next_token)? {\n print!(\"{t}\");\n std::io::stdout().flush()?;\n }\n }\n }\n println!();\n if rank == 0 {\n let dt = start_gen.elapsed();\n println!(\n \"\\n\\n{} tokens generated ({} token/s)\\n\",\n args.sample_len,\n (args.sample_len - 1) as f64 / dt.as_secs_f64(),\n );\n }\n Ok(())\n}\n", "candle-examples\\examples\\llava\\main.rs": "pub mod constants;\npub mod conversation;\npub mod image_processor;\n\nuse candle_transformers::generation::{LogitsProcessor, Sampling};\nuse candle_transformers::models::llama::Cache;\n\nuse anyhow::{bail, Error as E, Result};\nuse candle::{DType, Device, IndexOp, Tensor};\nuse candle_nn::VarBuilder;\nuse candle_transformers::models::llava::config::{\n HFGenerationConfig, HFLLaVAConfig, HFPreProcessorConfig,\n};\nuse candle_transformers::models::llava::{config::LLaVAConfig, LLaVA};\nuse clap::Parser;\nuse constants::*;\nuse conversation::Conversation;\nuse hf_hub::api::sync::Api;\nuse image_processor::{process_image, ImageProcessor};\nuse std::io::Write;\nuse tokenizers::Tokenizer;\n\n#[derive(Parser, Debug)]\n#[command(author, version, about,long_about=None)]\nstruct Args {\n #[arg(long, default_value = \"llava-hf/llava-v1.6-vicuna-7b-hf\")]\n model_path: String,\n #[arg(long, default_value = \"tokenizer/tokenizer.json\")]\n tokenizer_path: String,\n #[arg(long)]\n model_base: Option<String>,\n #[arg(long)]\n image_file: String, // Required\n #[arg(long)]\n conv_mode: Option<String>,\n #[arg(long, default_value_t = 0.2)]\n temperature: f32,\n #[arg(long, default_value_t = 512)]\n max_new_tokens: usize,\n #[arg(long, action)]\n hf: bool,\n #[arg(long, action)]\n cpu: bool,\n #[arg(long, action)]\n no_kv_cache: bool,\n #[arg(long)]\n prompt: String,\n /// The seed to use when generating random samples. Copy from candle llama. Not exist in python llava.\n #[arg(long, default_value_t = 299792458)]\n seed: u64,\n}\n\n//from https://github.com/huggingface/candle/blob/main/candle-examples/examples/clip/main.rs\nfn load_image<T: AsRef<std::path::Path>>(\n path: T,\n processor: &ImageProcessor,\n llava_config: &LLaVAConfig,\n dtype: DType,\n) -> Result<((u32, u32), Tensor)> {\n let img = image::ImageReader::open(path)?.decode()?;\n let img_tensor = process_image(&img, processor, llava_config)?;\n Ok(((img.width(), img.height()), img_tensor.to_dtype(dtype)?))\n}\n\nfn get_model_name_from_path(model_path: &str) -> String {\n let model_paths: Vec<String> = model_path\n .trim_matches('/')\n .split('/')\n .map(|s| s.to_string())\n .collect();\n if model_paths.last().unwrap().starts_with(\"checkpoint-\") {\n format!(\n \"{}_{}\",\n model_paths[model_paths.len() - 2],\n model_paths.last().unwrap()\n )\n } else {\n model_paths.last().unwrap().to_string()\n }\n}\n\nfn duplicate_vec<T>(vec: &[T], n: usize) -> Vec<T>\nwhere\n T: Clone,\n{\n let mut res = Vec::new();\n for _ in 0..n {\n res.extend(vec.to_owned());\n }\n res\n}\n\nfn insert_separator<T>(x: Vec<Vec<T>>, sep: Vec<T>) -> Vec<Vec<T>>\nwhere\n T: Clone,\n{\n let sep = vec![sep];\n let sep = duplicate_vec(&sep, x.len());\n let mut res = x\n .iter()\n .zip(sep.iter())\n .flat_map(|(x, y)| vec![x.clone(), y.clone()])\n .collect::<Vec<Vec<T>>>();\n res.pop();\n res\n}\n\nfn tokenizer_image_token(\n prompt: &str,\n tokenizer: &Tokenizer,\n image_token_index: i64,\n llava_config: &LLaVAConfig,\n) -> Result<Tensor> {\n let prompt_chunks = prompt\n .split(\"<image>\")\n .map(|s| {\n tokenizer\n .encode(s, true)\n .unwrap()\n .get_ids()\n .to_vec()\n .iter()\n .map(|x| *x as i64)\n .collect()\n })\n .collect::<Vec<Vec<i64>>>();\n let mut input_ids = Vec::new();\n let mut offset = 0;\n if !prompt_chunks.is_empty()\n && !prompt_chunks[0].is_empty()\n && prompt_chunks[0][0] == llava_config.bos_token_id as i64\n {\n offset = 1;\n input_ids.push(prompt_chunks[0][0]);\n }\n\n for x in insert_separator(\n prompt_chunks,\n duplicate_vec(&[image_token_index], offset + 1),\n )\n .iter()\n {\n input_ids.extend(x[1..].to_vec())\n }\n let input_len = input_ids.len();\n Tensor::from_vec(input_ids, (1, input_len), &Device::Cpu).map_err(E::msg)\n}\n\nfn main() -> Result<()> {\n let mut args = Args::parse();\n let device = candle_examples::device(args.cpu)?;\n println!(\"Start loading model\");\n let api = Api::new()?;\n let api = api.model(args.model_path.clone());\n let (llava_config, tokenizer, clip_vision_config, image_processor) = if args.hf {\n let config_filename = api.get(\"config.json\")?;\n let hf_llava_config: HFLLaVAConfig =\n serde_json::from_slice(&std::fs::read(config_filename)?)?;\n let generation_config_filename = api.get(\"generation_config.json\")?;\n let generation_config: HFGenerationConfig =\n serde_json::from_slice(&std::fs::read(generation_config_filename)?)?;\n let preprocessor_config_filename = api.get(\"preprocessor_config.json\")?;\n let preprocessor_config: HFPreProcessorConfig =\n serde_json::from_slice(&std::fs::read(preprocessor_config_filename)?)?;\n let llava_config =\n hf_llava_config.to_llava_config(&generation_config, &preprocessor_config);\n let tokenizer_filename = api.get(\"tokenizer.json\")?;\n let tokenizer = Tokenizer::from_file(tokenizer_filename).map_err(E::msg)?;\n let clip_vision_config = hf_llava_config.to_clip_vision_config();\n (\n llava_config,\n tokenizer,\n Some(clip_vision_config),\n ImageProcessor::from_hf_preprocessor_config(&preprocessor_config),\n )\n } else {\n let config_filename = api.get(\"config.json\")?;\n let llava_config: LLaVAConfig = serde_json::from_slice(&std::fs::read(config_filename)?)?;\n let tokenizer = Tokenizer::from_file(&args.tokenizer_path)\n .map_err(|e| E::msg(format!(\"Error loading {}: {}\", &args.tokenizer_path, e)))?;\n (\n llava_config.clone(),\n tokenizer,\n None,\n ImageProcessor::from_pretrained(&llava_config.mm_vision_tower.unwrap())?,\n )\n };\n\n let llama_config = llava_config.to_llama_config();\n let dtype: DType = match llava_config.torch_dtype.as_str() {\n \"float16\" => DType::F16,\n \"bfloat16\" => DType::BF16,\n _ => bail!(\"unsupported dtype\"),\n };\n\n let eos_token_id = llava_config.eos_token_id;\n\n println!(\"setting kv cache\");\n let mut cache = Cache::new(!args.no_kv_cache, dtype, &llama_config, &device)?;\n\n println!(\"loading model weights\");\n\n let weight_filenames =\n candle_examples::hub_load_safetensors(&api, \"model.safetensors.index.json\")?;\n let vb = unsafe { VarBuilder::from_mmaped_safetensors(&weight_filenames, dtype, &device)? };\n let llava: LLaVA = LLaVA::load(vb, &llava_config, clip_vision_config)?;\n\n println!(\"generating conv template\");\n let image_token_se = format!(\n \"{}{}{}\",\n DEFAULT_IM_START_TOKEN, DEFAULT_IMAGE_TOKEN, DEFAULT_IM_END_TOKEN\n );\n let qs = if args.prompt.contains(IMAGE_PLACEHOLDER) {\n if llava_config.mm_use_im_start_end {\n args.prompt.replace(IMAGE_PLACEHOLDER, &image_token_se)\n } else {\n args.prompt.replace(IMAGE_PLACEHOLDER, DEFAULT_IMAGE_TOKEN)\n }\n } else if llava_config.mm_use_im_start_end {\n format!(\"{}\\n{}\", image_token_se, args.prompt)\n } else {\n format!(\"{}\\n{}\", DEFAULT_IMAGE_TOKEN, args.prompt)\n };\n\n let model_name = get_model_name_from_path(&args.model_path).to_lowercase();\n let conv_mode = if model_name.contains(\"llama-2\") {\n \"llava_llama_2\"\n } else if model_name.contains(\"mistral\") {\n \"mistral_instruct\"\n } else if model_name.contains(\"v1.6-34b\") {\n \"chatml_direct\"\n } else if model_name.contains(\"v1\") {\n \"llava_v1\"\n } else if model_name.contains(\"mpt\") {\n \"mpt\"\n } else {\n \"llava_v0\"\n };\n if args.conv_mode.is_some() && args.conv_mode.as_deref() != Some(conv_mode) {\n println!(\n \"Warning: the model is trained with {}, but you are using {}\",\n conv_mode,\n args.conv_mode.as_deref().unwrap()\n );\n } else {\n args.conv_mode = Some(conv_mode.to_string());\n }\n\n let mut conv = match args.conv_mode {\n Some(conv_mode) => match conv_mode.as_str() {\n \"chatml_direct\" => Conversation::conv_chatml_direct(),\n \"llava_v1\" => Conversation::conv_llava_v1(),\n _ => todo!(\"not implement yet\"),\n },\n None => bail!(\"conv_mode is required\"),\n };\n conv.append_user_message(Some(&qs));\n conv.append_assistant_message(None);\n let prompt = conv.get_prompt();\n println!(\"loading image\");\n let (image_size, image_tensor) =\n load_image(&args.image_file, &image_processor, &llava_config, dtype)\n .map_err(|e| E::msg(format!(\"Error loading {}: {}\", &args.image_file, e)))?;\n let image_tensor = image_tensor.to_device(&device)?;\n\n let mut logits_processor = {\n let temperature = f64::from(args.temperature);\n let sampling = if temperature <= 0. {\n Sampling::ArgMax\n } else {\n Sampling::All { temperature }\n };\n LogitsProcessor::from_sampling(args.seed, sampling)\n };\n\n // get input tokens\n let tokens = tokenizer_image_token(\n &prompt,\n &tokenizer,\n llava_config.image_token_index as i64,\n &llava_config,\n )?;\n let mut input_embeds =\n llava.prepare_inputs_labels_for_multimodal(&tokens, &[image_tensor], &[image_size])?;\n //inference loop, based on https://github.com/huggingface/candle/blob/main/candle-examples/examples/llama/main.rs\n let mut tokenizer = candle_examples::token_output_stream::TokenOutputStream::new(tokenizer);\n let mut index_pos = 0;\n for index in 0..args.max_new_tokens {\n let (_, input_embeds_len, _) = input_embeds.dims3()?;\n let (context_size, context_index) = if cache.use_kv_cache && index > 0 {\n (1, index_pos)\n } else {\n (input_embeds_len, 0)\n };\n let input = input_embeds.i((.., input_embeds_len.saturating_sub(context_size).., ..))?;\n let logits = llava.forward(&input, context_index, &mut cache)?; //[1,32000]\n let logits = logits.squeeze(0)?;\n let (_, input_len, _) = input.dims3()?;\n index_pos += input_len;\n let next_token = logits_processor.sample(&logits)?;\n let next_token_tensor = Tensor::from_vec(vec![next_token], 1, &device)?;\n let next_embeds = llava.llama.embed(&next_token_tensor)?.unsqueeze(0)?;\n input_embeds = Tensor::cat(&[input_embeds, next_embeds], 1)?;\n if next_token == eos_token_id as u32 {\n break;\n }\n if let Some(t) = tokenizer.next_token(next_token)? {\n print!(\"{t}\");\n std::io::stdout().flush()?;\n }\n }\n if let Some(rest) = tokenizer.decode_rest().map_err(E::msg)? {\n print!(\"{rest}\");\n }\n Ok(())\n}\n", "candle-examples\\examples\\mamba\\main.rs": "#[cfg(feature = \"mkl\")]\nextern crate intel_mkl_src;\n\n#[cfg(feature = \"accelerate\")]\nextern crate accelerate_src;\n\nuse anyhow::{Error as E, Result};\nuse clap::{Parser, ValueEnum};\n\nuse candle_transformers::models::mamba::{Config, Model, State};\n\nuse candle::{DType, Device, Tensor};\nuse candle_examples::token_output_stream::TokenOutputStream;\nuse candle_nn::VarBuilder;\nuse candle_transformers::generation::LogitsProcessor;\nuse hf_hub::{api::sync::Api, Repo, RepoType};\nuse tokenizers::Tokenizer;\n\nstruct TextGeneration {\n model: Model,\n config: Config,\n device: Device,\n tokenizer: TokenOutputStream,\n logits_processor: LogitsProcessor,\n repeat_penalty: f32,\n repeat_last_n: usize,\n}\n\nimpl TextGeneration {\n #[allow(clippy::too_many_arguments)]\n fn new(\n model: Model,\n config: Config,\n tokenizer: Tokenizer,\n seed: u64,\n temp: Option<f64>,\n top_p: Option<f64>,\n repeat_penalty: f32,\n repeat_last_n: usize,\n device: &Device,\n ) -> Self {\n let logits_processor = LogitsProcessor::new(seed, temp, top_p);\n Self {\n model,\n config,\n tokenizer: TokenOutputStream::new(tokenizer),\n logits_processor,\n repeat_penalty,\n repeat_last_n,\n device: device.clone(),\n }\n }\n\n fn run(&mut self, prompt: &str, sample_len: usize) -> Result<()> {\n use std::io::Write;\n self.tokenizer.clear();\n let dtype = self.model.dtype();\n let mut tokens = self\n .tokenizer\n .tokenizer()\n .encode(prompt, true)\n .map_err(E::msg)?\n .get_ids()\n .to_vec();\n let mut generated_tokens = 0usize;\n let eos_token = match self.tokenizer.get_token(\"<|endoftext|>\") {\n Some(token) => token,\n None => anyhow::bail!(\"cannot find the </s> token\"),\n };\n let mut state = State::new(1, &self.config, dtype, &self.device)?;\n let mut next_logits = None;\n for &t in tokens.iter() {\n let input = Tensor::new(&[t], &self.device)?;\n let logits = self.model.forward(&input, &mut state)?;\n next_logits = Some(logits);\n if let Some(t) = self.tokenizer.next_token(t)? {\n print!(\"{t}\")\n }\n }\n std::io::stdout().flush()?;\n\n let start_gen = std::time::Instant::now();\n for _ in 0..sample_len {\n let logits = match next_logits.as_ref() {\n Some(logits) => logits,\n None => anyhow::bail!(\"cannot work on an empty prompt\"),\n };\n let logits = logits.squeeze(0)?.to_dtype(dtype)?;\n let logits = if self.repeat_penalty == 1. {\n logits\n } else {\n let start_at = tokens.len().saturating_sub(self.repeat_last_n);\n candle_transformers::utils::apply_repeat_penalty(\n &logits,\n self.repeat_penalty,\n &tokens[start_at..],\n )?\n };\n let next_token = self.logits_processor.sample(&logits)?;\n tokens.push(next_token);\n generated_tokens += 1;\n if next_token == eos_token {\n break;\n }\n if let Some(t) = self.tokenizer.next_token(next_token)? {\n print!(\"{t}\");\n std::io::stdout().flush()?;\n }\n\n let input = Tensor::new(&[next_token], &self.device)?;\n next_logits = Some(self.model.forward(&input, &mut state)?)\n }\n let dt = start_gen.elapsed();\n if let Some(rest) = self.tokenizer.decode_rest().map_err(E::msg)? {\n print!(\"{rest}\");\n }\n std::io::stdout().flush()?;\n println!(\n \"\\n{generated_tokens} tokens generated ({:.2} token/s)\",\n generated_tokens as f64 / dt.as_secs_f64(),\n );\n Ok(())\n }\n}\n\n#[derive(Parser, ValueEnum, Clone, Copy, PartialEq, Eq, Debug)]\nenum Which {\n Mamba130m,\n Mamba370m,\n Mamba790m,\n Mamba1_4b,\n Mamba2_8b,\n Mamba2_8bSlimPj,\n}\n\nimpl std::fmt::Display for Which {\n fn fmt(&self, f: &mut std::fmt::Formatter<'_>) -> std::fmt::Result {\n write!(f, \"{:?}\", self)\n }\n}\n\nimpl Which {\n fn model_id(&self) -> &'static str {\n match self {\n Self::Mamba130m => \"state-spaces/mamba-130m\",\n Self::Mamba370m => \"state-spaces/mamba-370m\",\n Self::Mamba790m => \"state-spaces/mamba-790m\",\n Self::Mamba1_4b => \"state-spaces/mamba-1.4b\",\n Self::Mamba2_8b => \"state-spaces/mamba-2.8b\",\n Self::Mamba2_8bSlimPj => \"state-spaces/mamba-2.8b-slimpj'\",\n }\n }\n\n fn revision(&self) -> &'static str {\n match self {\n Self::Mamba130m\n | Self::Mamba370m\n | Self::Mamba790m\n | Self::Mamba1_4b\n | Self::Mamba2_8bSlimPj => \"refs/pr/1\",\n Self::Mamba2_8b => \"refs/pr/4\",\n }\n }\n}\n\n#[derive(Parser, Debug)]\n#[command(author, version, about, long_about = None)]\nstruct Args {\n /// Run on CPU rather than on GPU.\n #[arg(long)]\n cpu: bool,\n\n /// Enable tracing (generates a trace-timestamp.json file).\n #[arg(long)]\n tracing: bool,\n\n #[arg(long)]\n prompt: String,\n\n /// The temperature used to generate samples.\n #[arg(long)]\n temperature: Option<f64>,\n\n /// Nucleus sampling probability cutoff.\n #[arg(long)]\n top_p: Option<f64>,\n\n /// The seed to use when generating random samples.\n #[arg(long, default_value_t = 299792458)]\n seed: u64,\n\n /// The length of the sample to generate (in tokens).\n #[arg(long, short = 'n', default_value_t = 5000)]\n sample_len: usize,\n\n #[arg(long, default_value = \"mamba130m\")]\n which: Which,\n\n #[arg(long)]\n model_id: Option<String>,\n\n #[arg(long)]\n revision: Option<String>,\n\n #[arg(long)]\n tokenizer_file: Option<String>,\n\n #[arg(long)]\n weight_files: Option<String>,\n\n #[arg(long)]\n config_file: Option<String>,\n\n #[arg(long, default_value = \"f32\")]\n dtype: String,\n\n /// Penalty to be applied for repeating tokens, 1. means no penalty.\n #[arg(long, default_value_t = 1.1)]\n repeat_penalty: f32,\n\n /// The context size to consider for the repeat penalty.\n #[arg(long, default_value_t = 64)]\n repeat_last_n: usize,\n}\n\nfn main() -> Result<()> {\n use std::str::FromStr;\n use tracing_chrome::ChromeLayerBuilder;\n use tracing_subscriber::prelude::*;\n\n let args = Args::parse();\n let _guard = if args.tracing {\n let (chrome_layer, guard) = ChromeLayerBuilder::new().build();\n tracing_subscriber::registry().with(chrome_layer).init();\n Some(guard)\n } else {\n None\n };\n println!(\n \"avx: {}, neon: {}, simd128: {}, f16c: {}\",\n candle::utils::with_avx(),\n candle::utils::with_neon(),\n candle::utils::with_simd128(),\n candle::utils::with_f16c()\n );\n println!(\n \"temp: {:.2} repeat-penalty: {:.2} repeat-last-n: {}\",\n args.temperature.unwrap_or(0.),\n args.repeat_penalty,\n args.repeat_last_n\n );\n\n let start = std::time::Instant::now();\n let api = Api::new()?;\n let repo = api.repo(Repo::with_revision(\n args.model_id\n .unwrap_or_else(|| args.which.model_id().to_string()),\n RepoType::Model,\n args.revision\n .unwrap_or_else(|| args.which.revision().to_string()),\n ));\n let tokenizer_filename = match args.tokenizer_file {\n Some(file) => std::path::PathBuf::from(file),\n None => api\n .model(\"EleutherAI/gpt-neox-20b\".to_string())\n .get(\"tokenizer.json\")?,\n };\n let config_filename = match args.config_file {\n Some(file) => std::path::PathBuf::from(file),\n None => repo.get(\"config.json\")?,\n };\n let filenames = match args.weight_files {\n Some(files) => files\n .split(',')\n .map(std::path::PathBuf::from)\n .collect::<Vec<_>>(),\n None => {\n vec![repo.get(\"model.safetensors\")?]\n }\n };\n println!(\"retrieved the files in {:?}\", start.elapsed());\n let tokenizer = Tokenizer::from_file(tokenizer_filename).map_err(E::msg)?;\n\n let start = std::time::Instant::now();\n let config: Config = serde_json::from_slice(&std::fs::read(config_filename)?)?;\n let device = candle_examples::device(args.cpu)?;\n let dtype = DType::from_str(&args.dtype)?;\n let vb = unsafe { VarBuilder::from_mmaped_safetensors(&filenames, dtype, &device)? };\n let model = Model::new(&config, vb.pp(\"backbone\"))?;\n println!(\"loaded the model in {:?}\", start.elapsed());\n\n let mut pipeline = TextGeneration::new(\n model,\n config,\n tokenizer,\n args.seed,\n args.temperature,\n args.top_p,\n args.repeat_penalty,\n args.repeat_last_n,\n &device,\n );\n pipeline.run(&args.prompt, args.sample_len)?;\n Ok(())\n}\n", "candle-examples\\examples\\mamba-minimal\\main.rs": "#[cfg(feature = \"mkl\")]\nextern crate intel_mkl_src;\n\n#[cfg(feature = \"accelerate\")]\nextern crate accelerate_src;\n\nuse anyhow::{Error as E, Result};\nuse clap::{Parser, ValueEnum};\n\nmod model;\nuse model::{Config, Model};\n\nuse candle::{DType, Device, Module, Tensor};\nuse candle_examples::token_output_stream::TokenOutputStream;\nuse candle_nn::VarBuilder;\nuse candle_transformers::generation::LogitsProcessor;\nuse hf_hub::{api::sync::Api, Repo, RepoType};\nuse tokenizers::Tokenizer;\n\nstruct TextGeneration {\n model: Model,\n device: Device,\n tokenizer: TokenOutputStream,\n logits_processor: LogitsProcessor,\n repeat_penalty: f32,\n repeat_last_n: usize,\n}\n\nimpl TextGeneration {\n #[allow(clippy::too_many_arguments)]\n fn new(\n model: Model,\n tokenizer: Tokenizer,\n seed: u64,\n temp: Option<f64>,\n top_p: Option<f64>,\n repeat_penalty: f32,\n repeat_last_n: usize,\n device: &Device,\n ) -> Self {\n let logits_processor = LogitsProcessor::new(seed, temp, top_p);\n Self {\n model,\n tokenizer: TokenOutputStream::new(tokenizer),\n logits_processor,\n repeat_penalty,\n repeat_last_n,\n device: device.clone(),\n }\n }\n\n fn run(&mut self, prompt: &str, sample_len: usize) -> Result<()> {\n use std::io::Write;\n self.tokenizer.clear();\n let mut tokens = self\n .tokenizer\n .tokenizer()\n .encode(prompt, true)\n .map_err(E::msg)?\n .get_ids()\n .to_vec();\n for &t in tokens.iter() {\n if let Some(t) = self.tokenizer.next_token(t)? {\n print!(\"{t}\")\n }\n }\n std::io::stdout().flush()?;\n\n let mut generated_tokens = 0usize;\n let eos_token = match self.tokenizer.get_token(\"<|endoftext|>\") {\n Some(token) => token,\n None => anyhow::bail!(\"cannot find the </s> token\"),\n };\n let start_gen = std::time::Instant::now();\n for _ in 0..sample_len {\n let input = Tensor::new(tokens.as_slice(), &self.device)?.unsqueeze(0)?;\n let logits = self.model.forward(&input)?;\n let logits = logits.squeeze(0)?.squeeze(0)?.to_dtype(DType::F32)?;\n let logits = if self.repeat_penalty == 1. {\n logits\n } else {\n let start_at = tokens.len().saturating_sub(self.repeat_last_n);\n candle_transformers::utils::apply_repeat_penalty(\n &logits,\n self.repeat_penalty,\n &tokens[start_at..],\n )?\n };\n\n let next_token = self.logits_processor.sample(&logits)?;\n tokens.push(next_token);\n generated_tokens += 1;\n if next_token == eos_token {\n break;\n }\n if let Some(t) = self.tokenizer.next_token(next_token)? {\n print!(\"{t}\");\n std::io::stdout().flush()?;\n }\n }\n let dt = start_gen.elapsed();\n if let Some(rest) = self.tokenizer.decode_rest().map_err(E::msg)? {\n print!(\"{rest}\");\n }\n std::io::stdout().flush()?;\n println!(\n \"\\n{generated_tokens} tokens generated ({:.2} token/s)\",\n generated_tokens as f64 / dt.as_secs_f64(),\n );\n Ok(())\n }\n}\n\n#[derive(Parser, ValueEnum, Clone, Copy, PartialEq, Eq, Debug)]\nenum Which {\n Mamba130m,\n Mamba370m,\n Mamba790m,\n Mamba1_4b,\n Mamba2_8b,\n Mamba2_8bSlimPj,\n}\n\nimpl std::fmt::Display for Which {\n fn fmt(&self, f: &mut std::fmt::Formatter<'_>) -> std::fmt::Result {\n write!(f, \"{:?}\", self)\n }\n}\n\nimpl Which {\n fn model_id(&self) -> &'static str {\n match self {\n Self::Mamba130m => \"state-spaces/mamba-130m\",\n Self::Mamba370m => \"state-spaces/mamba-370m\",\n Self::Mamba790m => \"state-spaces/mamba-790m\",\n Self::Mamba1_4b => \"state-spaces/mamba-1.4b\",\n Self::Mamba2_8b => \"state-spaces/mamba-2.8b\",\n Self::Mamba2_8bSlimPj => \"state-spaces/mamba-2.8b-slimpj'\",\n }\n }\n\n fn revision(&self) -> &'static str {\n match self {\n Self::Mamba130m\n | Self::Mamba370m\n | Self::Mamba790m\n | Self::Mamba1_4b\n | Self::Mamba2_8bSlimPj => \"refs/pr/1\",\n Self::Mamba2_8b => \"refs/pr/4\",\n }\n }\n}\n\n#[derive(Parser, Debug)]\n#[command(author, version, about, long_about = None)]\nstruct Args {\n /// Run on CPU rather than on GPU.\n #[arg(long)]\n cpu: bool,\n\n /// Enable tracing (generates a trace-timestamp.json file).\n #[arg(long)]\n tracing: bool,\n\n #[arg(long)]\n prompt: String,\n\n /// The temperature used to generate samples.\n #[arg(long)]\n temperature: Option<f64>,\n\n /// Nucleus sampling probability cutoff.\n #[arg(long)]\n top_p: Option<f64>,\n\n /// The seed to use when generating random samples.\n #[arg(long, default_value_t = 299792458)]\n seed: u64,\n\n /// The length of the sample to generate (in tokens).\n #[arg(long, short = 'n', default_value_t = 5000)]\n sample_len: usize,\n\n #[arg(long, default_value = \"mamba130m\")]\n which: Which,\n\n #[arg(long)]\n model_id: Option<String>,\n\n #[arg(long)]\n revision: Option<String>,\n\n #[arg(long)]\n tokenizer_file: Option<String>,\n\n #[arg(long)]\n weight_files: Option<String>,\n\n #[arg(long)]\n config_file: Option<String>,\n\n /// Penalty to be applied for repeating tokens, 1. means no penalty.\n #[arg(long, default_value_t = 1.1)]\n repeat_penalty: f32,\n\n /// The context size to consider for the repeat penalty.\n #[arg(long, default_value_t = 64)]\n repeat_last_n: usize,\n}\n\nfn main() -> Result<()> {\n use tracing_chrome::ChromeLayerBuilder;\n use tracing_subscriber::prelude::*;\n\n let args = Args::parse();\n let _guard = if args.tracing {\n let (chrome_layer, guard) = ChromeLayerBuilder::new().build();\n tracing_subscriber::registry().with(chrome_layer).init();\n Some(guard)\n } else {\n None\n };\n println!(\n \"avx: {}, neon: {}, simd128: {}, f16c: {}\",\n candle::utils::with_avx(),\n candle::utils::with_neon(),\n candle::utils::with_simd128(),\n candle::utils::with_f16c()\n );\n println!(\n \"temp: {:.2} repeat-penalty: {:.2} repeat-last-n: {}\",\n args.temperature.unwrap_or(0.),\n args.repeat_penalty,\n args.repeat_last_n\n );\n\n let start = std::time::Instant::now();\n let api = Api::new()?;\n let repo = api.repo(Repo::with_revision(\n args.model_id\n .unwrap_or_else(|| args.which.model_id().to_string()),\n RepoType::Model,\n args.revision\n .unwrap_or_else(|| args.which.revision().to_string()),\n ));\n let tokenizer_filename = match args.tokenizer_file {\n Some(file) => std::path::PathBuf::from(file),\n None => api\n .model(\"EleutherAI/gpt-neox-20b\".to_string())\n .get(\"tokenizer.json\")?,\n };\n let config_filename = match args.config_file {\n Some(file) => std::path::PathBuf::from(file),\n None => repo.get(\"config.json\")?,\n };\n let filenames = match args.weight_files {\n Some(files) => files\n .split(',')\n .map(std::path::PathBuf::from)\n .collect::<Vec<_>>(),\n None => {\n vec![repo.get(\"model.safetensors\")?]\n }\n };\n println!(\"retrieved the files in {:?}\", start.elapsed());\n let tokenizer = Tokenizer::from_file(tokenizer_filename).map_err(E::msg)?;\n\n let start = std::time::Instant::now();\n let config: Config = serde_json::from_slice(&std::fs::read(config_filename)?)?;\n let device = candle_examples::device(args.cpu)?;\n let vb = unsafe { VarBuilder::from_mmaped_safetensors(&filenames, DType::F32, &device)? };\n let model = Model::new(&config, vb.pp(\"backbone\"))?;\n println!(\"loaded the model in {:?}\", start.elapsed());\n\n let mut pipeline = TextGeneration::new(\n model,\n tokenizer,\n args.seed,\n args.temperature,\n args.top_p,\n args.repeat_penalty,\n args.repeat_last_n,\n &device,\n );\n pipeline.run(&args.prompt, args.sample_len)?;\n Ok(())\n}\n", "candle-examples\\examples\\marian-mt\\main.rs": "#[cfg(feature = \"mkl\")]\nextern crate intel_mkl_src;\n\n#[cfg(feature = \"accelerate\")]\nextern crate accelerate_src;\n\nuse anyhow::Error as E;\nuse clap::{Parser, ValueEnum};\n\nuse candle::{DType, Tensor};\nuse candle_examples::token_output_stream::TokenOutputStream;\nuse candle_nn::VarBuilder;\nuse candle_transformers::models::marian;\n\nuse tokenizers::Tokenizer;\n\n#[derive(Clone, Debug, Copy, ValueEnum)]\nenum Which {\n Base,\n Big,\n}\n\n// TODO: Maybe add support for the conditional prompt.\n#[derive(Parser)]\nstruct Args {\n #[arg(long)]\n model: Option<String>,\n\n #[arg(long)]\n tokenizer: Option<String>,\n\n #[arg(long)]\n tokenizer_dec: Option<String>,\n\n /// Choose the variant of the model to run.\n #[arg(long, default_value = \"big\")]\n which: Which,\n\n /// Run on CPU rather than on GPU.\n #[arg(long)]\n cpu: bool,\n\n /// Use the quantized version of the model.\n #[arg(long)]\n quantized: bool,\n\n /// Text to be translated\n #[arg(long)]\n text: String,\n}\n\npub fn main() -> anyhow::Result<()> {\n use hf_hub::api::sync::Api;\n let args = Args::parse();\n\n let config = match args.which {\n Which::Base => marian::Config::opus_mt_fr_en(),\n Which::Big => marian::Config::opus_mt_tc_big_fr_en(),\n };\n let tokenizer = {\n let tokenizer = match args.tokenizer {\n Some(tokenizer) => std::path::PathBuf::from(tokenizer),\n None => {\n let name = match args.which {\n Which::Base => \"tokenizer-marian-base-fr.json\",\n Which::Big => \"tokenizer-marian-fr.json\",\n };\n Api::new()?\n .model(\"lmz/candle-marian\".to_string())\n .get(name)?\n }\n };\n Tokenizer::from_file(&tokenizer).map_err(E::msg)?\n };\n\n let tokenizer_dec = {\n let tokenizer = match args.tokenizer_dec {\n Some(tokenizer) => std::path::PathBuf::from(tokenizer),\n None => {\n let name = match args.which {\n Which::Base => \"tokenizer-marian-base-en.json\",\n Which::Big => \"tokenizer-marian-en.json\",\n };\n Api::new()?\n .model(\"lmz/candle-marian\".to_string())\n .get(name)?\n }\n };\n Tokenizer::from_file(&tokenizer).map_err(E::msg)?\n };\n let mut tokenizer_dec = TokenOutputStream::new(tokenizer_dec);\n\n let device = candle_examples::device(args.cpu)?;\n let vb = {\n let model = match args.model {\n Some(model) => std::path::PathBuf::from(model),\n None => match args.which {\n Which::Base => Api::new()?\n .repo(hf_hub::Repo::with_revision(\n \"Helsinki-NLP/opus-mt-fr-en\".to_string(),\n hf_hub::RepoType::Model,\n \"refs/pr/4\".to_string(),\n ))\n .get(\"model.safetensors\")?,\n Which::Big => Api::new()?\n .model(\"Helsinki-NLP/opus-mt-tc-big-fr-en\".to_string())\n .get(\"model.safetensors\")?,\n },\n };\n unsafe { VarBuilder::from_mmaped_safetensors(&[&model], DType::F32, &device)? }\n };\n let mut model = marian::MTModel::new(&config, vb)?;\n\n let mut logits_processor =\n candle_transformers::generation::LogitsProcessor::new(1337, None, None);\n\n let encoder_xs = {\n let mut tokens = tokenizer\n .encode(args.text, true)\n .map_err(E::msg)?\n .get_ids()\n .to_vec();\n tokens.push(config.eos_token_id);\n let tokens = Tensor::new(tokens.as_slice(), &device)?.unsqueeze(0)?;\n model.encoder().forward(&tokens, 0)?\n };\n\n let mut token_ids = vec![config.decoder_start_token_id];\n for index in 0..1000 {\n let context_size = if index >= 1 { 1 } else { token_ids.len() };\n let start_pos = token_ids.len().saturating_sub(context_size);\n let input_ids = Tensor::new(&token_ids[start_pos..], &device)?.unsqueeze(0)?;\n let logits = model.decode(&input_ids, &encoder_xs, start_pos)?;\n let logits = logits.squeeze(0)?;\n let logits = logits.get(logits.dim(0)? - 1)?;\n let token = logits_processor.sample(&logits)?;\n token_ids.push(token);\n if let Some(t) = tokenizer_dec.next_token(token)? {\n use std::io::Write;\n print!(\"{t}\");\n std::io::stdout().flush()?;\n }\n if token == config.eos_token_id || token == config.forced_eos_token_id {\n break;\n }\n }\n if let Some(rest) = tokenizer_dec.decode_rest().map_err(E::msg)? {\n print!(\"{rest}\");\n }\n println!();\n Ok(())\n}\n", "candle-examples\\examples\\metavoice\\main.rs": "#[cfg(feature = \"mkl\")]\nextern crate intel_mkl_src;\n\n#[cfg(feature = \"accelerate\")]\nextern crate accelerate_src;\n\nuse anyhow::Result;\nuse clap::Parser;\nuse std::io::Write;\n\nuse candle_transformers::generation::LogitsProcessor;\nuse candle_transformers::models::encodec;\nuse candle_transformers::models::metavoice::{adapters, gpt, tokenizers, transformer};\nuse candle_transformers::models::quantized_metavoice::transformer as qtransformer;\n\nuse candle::{DType, IndexOp, Tensor};\nuse candle_nn::VarBuilder;\nuse hf_hub::api::sync::Api;\nuse rand::{distributions::Distribution, SeedableRng};\n\npub const ENCODEC_NTOKENS: u32 = 1024;\n\n#[derive(Clone, Debug, Copy, PartialEq, Eq, clap::ValueEnum)]\nenum ArgDType {\n F32,\n F16,\n Bf16,\n}\n\nenum Transformer {\n Normal(transformer::Model),\n Quantized(qtransformer::Model),\n}\n\n#[derive(Parser, Debug)]\n#[command(author, version, about, long_about = None)]\nstruct Args {\n /// Run on CPU rather than on GPU.\n #[arg(long)]\n cpu: bool,\n\n /// Enable tracing (generates a trace-timestamp.json file).\n #[arg(long)]\n tracing: bool,\n\n #[arg(long)]\n prompt: String,\n\n /// Use the quantized version of the model.\n #[arg(long)]\n quantized: bool,\n\n /// The guidance scale.\n #[arg(long, default_value_t = 3.0)]\n guidance_scale: f64,\n\n /// The temperature used to generate samples.\n #[arg(long, default_value_t = 1.0)]\n temperature: f64,\n\n /// The seed to use when generating random samples.\n #[arg(long, default_value_t = 299792458)]\n seed: u64,\n\n /// The maximum number of tokens to generate for the first stage.\n #[arg(long, default_value_t = 2000)]\n max_tokens: u64,\n\n /// The output file using the wav format.\n #[arg(long, default_value = \"out.wav\")]\n out_file: String,\n\n #[arg(long)]\n first_stage_meta: Option<String>,\n\n #[arg(long)]\n first_stage_weights: Option<String>,\n\n #[arg(long)]\n second_stage_weights: Option<String>,\n\n #[arg(long)]\n encodec_weights: Option<String>,\n\n #[arg(long)]\n spk_emb: Option<String>,\n\n #[arg(long, default_value = \"f32\")]\n dtype: ArgDType,\n}\n\nfn main() -> Result<()> {\n use tracing_chrome::ChromeLayerBuilder;\n use tracing_subscriber::prelude::*;\n\n let args = Args::parse();\n let _guard = if args.tracing {\n let (chrome_layer, guard) = ChromeLayerBuilder::new().build();\n tracing_subscriber::registry().with(chrome_layer).init();\n Some(guard)\n } else {\n None\n };\n println!(\n \"avx: {}, neon: {}, simd128: {}, f16c: {}\",\n candle::utils::with_avx(),\n candle::utils::with_neon(),\n candle::utils::with_simd128(),\n candle::utils::with_f16c()\n );\n let device = candle_examples::device(args.cpu)?;\n let api = Api::new()?;\n let repo = api.model(\"lmz/candle-metavoice\".to_string());\n let first_stage_meta = match &args.first_stage_meta {\n Some(w) => std::path::PathBuf::from(w),\n None => repo.get(\"first_stage.meta.json\")?,\n };\n let first_stage_meta: serde_json::Value =\n serde_json::from_reader(&std::fs::File::open(first_stage_meta)?)?;\n let first_stage_tokenizer = match first_stage_meta.as_object() {\n None => anyhow::bail!(\"not a json object\"),\n Some(j) => match j.get(\"tokenizer\") {\n None => anyhow::bail!(\"no tokenizer key\"),\n Some(j) => j,\n },\n };\n let fs_tokenizer = tokenizers::BPE::from_json(first_stage_tokenizer, 512)?;\n\n let second_stage_weights = match &args.second_stage_weights {\n Some(w) => std::path::PathBuf::from(w),\n None => repo.get(\"second_stage.safetensors\")?,\n };\n let encodec_weights = match args.encodec_weights {\n Some(w) => std::path::PathBuf::from(w),\n None => Api::new()?\n .model(\"facebook/encodec_24khz\".to_string())\n .get(\"model.safetensors\")?,\n };\n let dtype = match args.dtype {\n ArgDType::F32 => DType::F32,\n ArgDType::F16 => DType::F16,\n ArgDType::Bf16 => DType::BF16,\n };\n\n let first_stage_config = transformer::Config::cfg1b_v0_1();\n let mut first_stage_model = if args.quantized {\n let filename = match &args.first_stage_weights {\n Some(w) => std::path::PathBuf::from(w),\n None => repo.get(\"first_stage_q4k.gguf\")?,\n };\n let vb =\n candle_transformers::quantized_var_builder::VarBuilder::from_gguf(filename, &device)?;\n let first_stage_model = qtransformer::Model::new(&first_stage_config, vb)?;\n Transformer::Quantized(first_stage_model)\n } else {\n let first_stage_weights = match &args.first_stage_weights {\n Some(w) => std::path::PathBuf::from(w),\n None => repo.get(\"first_stage.safetensors\")?,\n };\n let first_stage_vb =\n unsafe { VarBuilder::from_mmaped_safetensors(&[first_stage_weights], dtype, &device)? };\n let first_stage_model = transformer::Model::new(&first_stage_config, first_stage_vb)?;\n Transformer::Normal(first_stage_model)\n };\n\n let second_stage_vb =\n unsafe { VarBuilder::from_mmaped_safetensors(&[second_stage_weights], dtype, &device)? };\n let second_stage_config = gpt::Config::cfg1b_v0_1();\n let second_stage_model = gpt::Model::new(second_stage_config.clone(), second_stage_vb)?;\n\n let encodec_device = if device.is_metal() {\n &candle::Device::Cpu\n } else {\n &device\n };\n let encodec_vb =\n unsafe { VarBuilder::from_mmaped_safetensors(&[encodec_weights], dtype, encodec_device)? };\n let encodec_config = encodec::Config::default();\n let encodec_model = encodec::Model::new(&encodec_config, encodec_vb)?;\n\n println!(\"prompt: '{}'\", args.prompt);\n let prompt_tokens = fs_tokenizer.encode(&args.prompt)?;\n let mut tokens = prompt_tokens.clone();\n println!(\"{tokens:?}\");\n let spk_emb_file = match &args.spk_emb {\n Some(w) => std::path::PathBuf::from(w),\n None => repo.get(\"spk_emb.safetensors\")?,\n };\n let spk_emb = candle::safetensors::load(&spk_emb_file, &candle::Device::Cpu)?;\n let spk_emb = match spk_emb.get(\"spk_emb\") {\n None => anyhow::bail!(\"missing spk_emb tensor in {spk_emb_file:?}\"),\n Some(spk_emb) => spk_emb.to_dtype(dtype)?,\n };\n let spk_emb = spk_emb.to_device(&device)?;\n let mut logits_processor = LogitsProcessor::new(args.seed, Some(args.temperature), Some(0.95));\n\n // First stage generation.\n for index in 0..args.max_tokens {\n let context_size = if index > 0 { 1 } else { tokens.len() };\n let start_pos = tokens.len().saturating_sub(context_size);\n let ctxt = &tokens[start_pos..];\n let input = Tensor::new(ctxt, &device)?;\n let input = Tensor::stack(&[&input, &input], 0)?;\n let logits = match &mut first_stage_model {\n Transformer::Normal(m) => m.forward(&input, &spk_emb, tokens.len() - context_size)?,\n Transformer::Quantized(m) => {\n m.forward(&input, &spk_emb, tokens.len() - context_size)?\n }\n };\n let logits0 = logits.i((0, 0))?;\n let logits1 = logits.i((1, 0))?;\n let logits = ((logits0 * args.guidance_scale)? + logits1 * (1. - args.guidance_scale))?;\n let logits = logits.to_dtype(DType::F32)?;\n let next_token = logits_processor.sample(&logits)?;\n tokens.push(next_token);\n print!(\".\");\n std::io::stdout().flush()?;\n if next_token == 2048 {\n break;\n }\n }\n println!();\n let fie2c = adapters::FlattenedInterleavedEncodec2Codebook::new(ENCODEC_NTOKENS);\n let (text_ids, ids1, ids2) = fie2c.decode(&tokens);\n println!(\"text ids len: {}\", text_ids.len());\n let mut rng = rand::rngs::StdRng::seed_from_u64(args.seed + 1337);\n // TODO: Use the config rather than hardcoding the offset here.\n let encoded_text: Vec<_> = prompt_tokens.iter().map(|v| v - 1024).collect();\n let mut hierarchies_in1 =\n [encoded_text.as_slice(), ids1.as_slice(), &[ENCODEC_NTOKENS]].concat();\n let mut hierarchies_in2 = [\n vec![ENCODEC_NTOKENS; encoded_text.len()].as_slice(),\n ids2.as_slice(),\n &[ENCODEC_NTOKENS],\n ]\n .concat();\n hierarchies_in1.resize(second_stage_config.block_size, ENCODEC_NTOKENS);\n hierarchies_in2.resize(second_stage_config.block_size, ENCODEC_NTOKENS);\n let in_x1 = Tensor::new(hierarchies_in1, &device)?;\n let in_x2 = Tensor::new(hierarchies_in2, &device)?;\n let in_x = Tensor::stack(&[in_x1, in_x2], 0)?.unsqueeze(0)?;\n let logits = second_stage_model.forward(&in_x)?;\n println!(\"sampling from logits...\");\n let mut codes = vec![];\n for logits in logits.iter() {\n let logits = logits.squeeze(0)?;\n let (seq_len, _) = logits.dims2()?;\n let mut codes_ = Vec::with_capacity(seq_len);\n for step in 0..seq_len {\n let logits = logits.i(step)?.to_dtype(DType::F32)?;\n let logits = &(&logits / 1.0)?;\n let prs = candle_nn::ops::softmax_last_dim(logits)?.to_vec1::<f32>()?;\n let distr = rand::distributions::WeightedIndex::new(prs.as_slice())?;\n let sample = distr.sample(&mut rng) as u32;\n codes_.push(sample)\n }\n codes.push(codes_)\n }\n\n let codes = Tensor::new(codes, &device)?.unsqueeze(0)?;\n let codes = Tensor::cat(&[in_x, codes], 1)?;\n println!(\"codes: {codes}\");\n let tilted_encodec = adapters::TiltedEncodec::new(ENCODEC_NTOKENS);\n let codes = codes.i(0)?.to_vec2::<u32>()?;\n let (text_ids, audio_ids) = tilted_encodec.decode(&codes);\n println!(\"text_ids len: {:?}\", text_ids.len());\n let audio_ids = Tensor::new(audio_ids, encodec_device)?.unsqueeze(0)?;\n println!(\"audio_ids shape: {:?}\", audio_ids.shape());\n let pcm = encodec_model.decode(&audio_ids)?;\n println!(\"output pcm shape: {:?}\", pcm.shape());\n let pcm = pcm.i(0)?.i(0)?.to_dtype(DType::F32)?;\n let pcm = candle_examples::audio::normalize_loudness(&pcm, 24_000, true)?;\n let pcm = pcm.to_vec1::<f32>()?;\n let mut output = std::fs::File::create(&args.out_file)?;\n candle_examples::wav::write_pcm_as_wav(&mut output, &pcm, 24_000)?;\n Ok(())\n}\n", "candle-examples\\examples\\mimi\\main.rs": "#[cfg(feature = \"mkl\")]\nextern crate intel_mkl_src;\n\n#[cfg(feature = \"accelerate\")]\nextern crate accelerate_src;\n\nuse anyhow::Result;\nuse candle::{DType, IndexOp, Tensor};\nuse candle_nn::VarBuilder;\nuse candle_transformers::models::mimi::{Config, Model};\nuse clap::{Parser, ValueEnum};\nuse hf_hub::api::sync::Api;\n\nmod audio_io;\n\n#[derive(Clone, Debug, Copy, PartialEq, Eq, ValueEnum)]\nenum Action {\n AudioToAudio,\n AudioToCode,\n CodeToAudio,\n}\n\n#[derive(Parser, Debug)]\n#[command(author, version, about, long_about = None)]\nstruct Args {\n /// The action to be performed, specifies the format for the input and output data.\n action: Action,\n\n /// The input file, either an audio file or some mimi tokens stored as safetensors.\n in_file: String,\n\n /// The output file, either a wave audio file or some mimi tokens stored as safetensors.\n out_file: String,\n\n /// Run on CPU rather than on GPU.\n #[arg(long)]\n cpu: bool,\n\n /// The model weight file, in safetensor format.\n #[arg(long)]\n model: Option<String>,\n\n /// Whether to use streaming or not, when streaming slices of data of the given size are passed\n /// to the encoder/decoder one at a time.\n #[arg(long)]\n streaming: Option<usize>,\n}\n\nfn main() -> Result<()> {\n let args = Args::parse();\n let device = candle_examples::device(args.cpu)?;\n let model = match args.model {\n Some(model) => std::path::PathBuf::from(model),\n None => Api::new()?\n .model(\"kyutai/mimi\".to_string())\n .get(\"model.safetensors\")?,\n };\n let vb = unsafe { VarBuilder::from_mmaped_safetensors(&[model], DType::F32, &device)? };\n let config = Config::v0_1(None);\n let mut model = Model::new(config, vb)?;\n\n let codes = match args.action {\n Action::CodeToAudio => {\n let codes = candle::safetensors::load(args.in_file, &device)?;\n codes.get(\"codes\").expect(\"no codes in input file\").clone()\n }\n Action::AudioToCode | Action::AudioToAudio => {\n let pcm = if args.in_file == \"-\" {\n println!(\">>>> RECORDING AUDIO, PRESS ENTER ONCE DONE <<<<\");\n let (stream, input_audio) = audio_io::setup_input_stream()?;\n let mut pcms = vec![];\n let stdin = std::thread::spawn(|| {\n let mut s = String::new();\n std::io::stdin().read_line(&mut s)\n });\n while !stdin.is_finished() {\n let input = input_audio.lock().unwrap().take_all();\n if input.is_empty() {\n std::thread::sleep(std::time::Duration::from_millis(100));\n continue;\n }\n pcms.push(input)\n }\n drop(stream);\n pcms.concat()\n } else {\n let (pcm, sample_rate) = audio_io::pcm_decode(args.in_file)?;\n if sample_rate != 24_000 {\n println!(\"WARNING: mimi uses a 24khz sample rate, input uses {sample_rate}, resampling...\");\n audio_io::resample(&pcm, sample_rate as usize, 24_000)?\n } else {\n pcm\n }\n };\n match args.streaming {\n Some(chunk_size) => {\n let mut code_chunks = vec![];\n for pcm in pcm.chunks(chunk_size) {\n let pcm = Tensor::new(pcm, &device)?.reshape((1, 1, ()))?;\n let code_chunk = model.encode(&pcm)?;\n code_chunks.push(code_chunk)\n }\n Tensor::cat(&code_chunks, candle::D::Minus1)?\n }\n None => {\n let pcm_len = pcm.len();\n let pcm = Tensor::from_vec(pcm, (1, 1, pcm_len), &device)?;\n println!(\"input pcm shape: {:?}\", pcm.shape());\n model.encode(&pcm)?\n }\n }\n }\n };\n println!(\"codes shape: {:?}\", codes.shape());\n model.reset_state();\n\n match args.action {\n Action::AudioToCode => {\n codes.save_safetensors(\"codes\", &args.out_file)?;\n }\n Action::AudioToAudio | Action::CodeToAudio => {\n let pcm = match args.streaming {\n Some(chunk_size) => {\n let seq_len = codes.dim(candle::D::Minus1)?;\n let mut pcm_chunks = vec![];\n for chunk_start in (0..seq_len).step_by(chunk_size) {\n let chunk_len = usize::min(chunk_size, seq_len - chunk_start);\n let codes = codes.narrow(candle::D::Minus1, chunk_start, chunk_len)?;\n let pcm = model.decode_step(&codes.into())?;\n if let Some(pcm) = pcm.as_option() {\n pcm_chunks.push(pcm.clone())\n }\n }\n Tensor::cat(&pcm_chunks, candle::D::Minus1)?\n }\n None => model.decode(&codes)?,\n };\n println!(\"output pcm shape: {:?}\", pcm.shape());\n let pcm = pcm.i(0)?.i(0)?;\n let pcm = candle_examples::audio::normalize_loudness(&pcm, 24_000, true)?;\n let pcm = pcm.to_vec1::<f32>()?;\n if args.out_file == \"-\" {\n let (stream, ad) = audio_io::setup_output_stream()?;\n {\n let mut ad = ad.lock().unwrap();\n ad.push_samples(&pcm)?;\n }\n loop {\n let ad = ad.lock().unwrap();\n if ad.is_empty() {\n break;\n }\n // That's very weird, calling thread::sleep here triggers the stream to stop\n // playing (the callback doesn't seem to be called anymore).\n // std::thread::sleep(std::time::Duration::from_millis(100));\n }\n drop(stream)\n } else {\n let mut output = std::fs::File::create(&args.out_file)?;\n candle_examples::wav::write_pcm_as_wav(&mut output, &pcm, 24_000)?;\n }\n }\n }\n Ok(())\n}\n", "candle-examples\\examples\\mistral\\main.rs": "#[cfg(feature = \"mkl\")]\nextern crate intel_mkl_src;\n\n#[cfg(feature = \"accelerate\")]\nextern crate accelerate_src;\n\nuse anyhow::{Error as E, Result};\nuse clap::Parser;\n\nuse candle_transformers::models::mistral::{Config, Model as Mistral};\nuse candle_transformers::models::quantized_mistral::Model as QMistral;\n\nuse candle::{DType, Device, Tensor};\nuse candle_examples::token_output_stream::TokenOutputStream;\nuse candle_nn::VarBuilder;\nuse candle_transformers::generation::{LogitsProcessor, Sampling};\nuse hf_hub::{api::sync::Api, Repo, RepoType};\nuse tokenizers::Tokenizer;\n\nenum Model {\n Mistral(Mistral),\n Quantized(QMistral),\n}\n\nstruct TextGeneration {\n model: Model,\n device: Device,\n tokenizer: TokenOutputStream,\n logits_processor: LogitsProcessor,\n repeat_penalty: f32,\n repeat_last_n: usize,\n}\n\nimpl TextGeneration {\n #[allow(clippy::too_many_arguments)]\n fn new(\n model: Model,\n tokenizer: Tokenizer,\n seed: u64,\n temp: Option<f64>,\n top_p: Option<f64>,\n top_k: Option<usize>,\n repeat_penalty: f32,\n repeat_last_n: usize,\n device: &Device,\n ) -> Self {\n let logits_processor = {\n let temperature = temp.unwrap_or(0.);\n let sampling = if temperature <= 0. {\n Sampling::ArgMax\n } else {\n match (top_k, top_p) {\n (None, None) => Sampling::All { temperature },\n (Some(k), None) => Sampling::TopK { k, temperature },\n (None, Some(p)) => Sampling::TopP { p, temperature },\n (Some(k), Some(p)) => Sampling::TopKThenTopP { k, p, temperature },\n }\n };\n LogitsProcessor::from_sampling(seed, sampling)\n };\n\n Self {\n model,\n tokenizer: TokenOutputStream::new(tokenizer),\n logits_processor,\n repeat_penalty,\n repeat_last_n,\n device: device.clone(),\n }\n }\n\n fn run(&mut self, prompt: &str, sample_len: usize) -> Result<()> {\n use std::io::Write;\n self.tokenizer.clear();\n let mut tokens = self\n .tokenizer\n .tokenizer()\n .encode(prompt, true)\n .map_err(E::msg)?\n .get_ids()\n .to_vec();\n for &t in tokens.iter() {\n if let Some(t) = self.tokenizer.next_token(t)? {\n print!(\"{t}\")\n }\n }\n std::io::stdout().flush()?;\n\n let mut generated_tokens = 0usize;\n let eos_token = match self.tokenizer.get_token(\"</s>\") {\n Some(token) => token,\n None => anyhow::bail!(\"cannot find the </s> token\"),\n };\n let start_gen = std::time::Instant::now();\n for index in 0..sample_len {\n let context_size = if index > 0 { 1 } else { tokens.len() };\n let start_pos = tokens.len().saturating_sub(context_size);\n let ctxt = &tokens[start_pos..];\n let input = Tensor::new(ctxt, &self.device)?.unsqueeze(0)?;\n let logits = match &mut self.model {\n Model::Mistral(m) => m.forward(&input, start_pos)?,\n Model::Quantized(m) => m.forward(&input, start_pos)?,\n };\n let logits = logits.squeeze(0)?.squeeze(0)?.to_dtype(DType::F32)?;\n let logits = if self.repeat_penalty == 1. {\n logits\n } else {\n let start_at = tokens.len().saturating_sub(self.repeat_last_n);\n candle_transformers::utils::apply_repeat_penalty(\n &logits,\n self.repeat_penalty,\n &tokens[start_at..],\n )?\n };\n\n let next_token = self.logits_processor.sample(&logits)?;\n tokens.push(next_token);\n generated_tokens += 1;\n if next_token == eos_token {\n break;\n }\n if let Some(t) = self.tokenizer.next_token(next_token)? {\n print!(\"{t}\");\n std::io::stdout().flush()?;\n }\n }\n let dt = start_gen.elapsed();\n if let Some(rest) = self.tokenizer.decode_rest().map_err(E::msg)? {\n print!(\"{rest}\");\n }\n std::io::stdout().flush()?;\n println!(\n \"\\n{generated_tokens} tokens generated ({:.2} token/s)\",\n generated_tokens as f64 / dt.as_secs_f64(),\n );\n Ok(())\n }\n}\n\n#[derive(Clone, Debug, Copy, PartialEq, Eq, clap::ValueEnum)]\nenum Which {\n #[value(name = \"7b-v0.1\")]\n Mistral7bV01,\n #[value(name = \"7b-v0.2\")]\n Mistral7bV02,\n #[value(name = \"7b-instruct-v0.1\")]\n Mistral7bInstructV01,\n #[value(name = \"7b-instruct-v0.2\")]\n Mistral7bInstructV02,\n #[value(name = \"7b-maths-v0.1\")]\n Mathstral7bV01,\n #[value(name = \"nemo-2407\")]\n MistralNemo2407,\n #[value(name = \"nemo-instruct-2407\")]\n MistralNemoInstruct2407,\n}\n\n#[derive(Parser, Debug)]\n#[command(author, version, about, long_about = None)]\nstruct Args {\n /// Run on CPU rather than on GPU.\n #[arg(long)]\n cpu: bool,\n\n /// Enable tracing (generates a trace-timestamp.json file).\n #[arg(long)]\n tracing: bool,\n\n #[arg(long)]\n use_flash_attn: bool,\n\n #[arg(long)]\n prompt: String,\n\n /// The temperature used to generate samples.\n #[arg(long)]\n temperature: Option<f64>,\n\n /// Nucleus sampling probability cutoff.\n #[arg(long)]\n top_p: Option<f64>,\n\n /// Only sample among the top K samples.\n #[arg(long)]\n top_k: Option<usize>,\n\n /// The seed to use when generating random samples.\n #[arg(long, default_value_t = 299792458)]\n seed: u64,\n\n /// The length of the sample to generate (in tokens).\n #[arg(long, short = 'n', default_value_t = 10000)]\n sample_len: usize,\n\n /// The model size to use.\n #[arg(long, default_value = \"7b-v0.1\")]\n which: Which,\n\n #[arg(long)]\n model_id: Option<String>,\n\n #[arg(long, default_value = \"main\")]\n revision: String,\n\n #[arg(long)]\n tokenizer_file: Option<String>,\n\n #[arg(long)]\n config_file: Option<String>,\n\n #[arg(long)]\n weight_files: Option<String>,\n\n #[arg(long)]\n quantized: bool,\n\n /// Penalty to be applied for repeating tokens, 1. means no penalty.\n #[arg(long, default_value_t = 1.1)]\n repeat_penalty: f32,\n\n /// The context size to consider for the repeat penalty.\n #[arg(long, default_value_t = 64)]\n repeat_last_n: usize,\n\n /// Use the slower dmmv cuda kernel.\n #[arg(long)]\n force_dmmv: bool,\n}\n\nfn main() -> Result<()> {\n use tracing_chrome::ChromeLayerBuilder;\n use tracing_subscriber::prelude::*;\n\n let args = Args::parse();\n #[cfg(feature = \"cuda\")]\n candle::quantized::cuda::set_force_dmmv(args.force_dmmv);\n\n let _guard = if args.tracing {\n let (chrome_layer, guard) = ChromeLayerBuilder::new().build();\n tracing_subscriber::registry().with(chrome_layer).init();\n Some(guard)\n } else {\n None\n };\n println!(\n \"avx: {}, neon: {}, simd128: {}, f16c: {}\",\n candle::utils::with_avx(),\n candle::utils::with_neon(),\n candle::utils::with_simd128(),\n candle::utils::with_f16c()\n );\n println!(\n \"temp: {:.2} repeat-penalty: {:.2} repeat-last-n: {}\",\n args.temperature.unwrap_or(0.),\n args.repeat_penalty,\n args.repeat_last_n\n );\n\n let start = std::time::Instant::now();\n let api = Api::new()?;\n let model_id = match args.model_id {\n Some(model_id) => model_id,\n None => {\n if args.quantized {\n if args.which != Which::Mistral7bV01 {\n anyhow::bail!(\"only 7b-v0.1 is available as a quantized model for now\")\n }\n \"lmz/candle-mistral\".to_string()\n } else {\n let name = match args.which {\n Which::Mistral7bV01 => \"mistralai/Mistral-7B-v0.1\",\n Which::Mistral7bV02 => \"mistralai/Mistral-7B-v0.2\",\n Which::Mistral7bInstructV01 => \"mistralai/Mistral-7B-Instruct-v0.1\",\n Which::Mistral7bInstructV02 => \"mistralai/Mistral-7B-Instruct-v0.2\",\n Which::Mathstral7bV01 => \"mistralai/mathstral-7B-v0.1\",\n Which::MistralNemo2407 => \"mistralai/Mistral-Nemo-Base-2407\",\n Which::MistralNemoInstruct2407 => \"mistralai/Mistral-Nemo-Instruct-2407\",\n };\n name.to_string()\n }\n }\n };\n let repo = api.repo(Repo::with_revision(\n model_id,\n RepoType::Model,\n args.revision,\n ));\n let tokenizer_filename = match args.tokenizer_file {\n Some(file) => std::path::PathBuf::from(file),\n None => repo.get(\"tokenizer.json\")?,\n };\n let filenames = match args.weight_files {\n Some(files) => files\n .split(',')\n .map(std::path::PathBuf::from)\n .collect::<Vec<_>>(),\n None => {\n if args.quantized {\n vec![repo.get(\"model-q4k.gguf\")?]\n } else {\n candle_examples::hub_load_safetensors(&repo, \"model.safetensors.index.json\")?\n }\n }\n };\n println!(\"retrieved the files in {:?}\", start.elapsed());\n let tokenizer = Tokenizer::from_file(tokenizer_filename).map_err(E::msg)?;\n\n let start = std::time::Instant::now();\n let config = match args.config_file {\n Some(config_file) => serde_json::from_slice(&std::fs::read(config_file)?)?,\n None => {\n if args.quantized {\n Config::config_7b_v0_1(args.use_flash_attn)\n } else {\n let config_file = repo.get(\"config.json\")?;\n serde_json::from_slice(&std::fs::read(config_file)?)?\n }\n }\n };\n let device = candle_examples::device(args.cpu)?;\n let (model, device) = if args.quantized {\n let filename = &filenames[0];\n let vb =\n candle_transformers::quantized_var_builder::VarBuilder::from_gguf(filename, &device)?;\n let model = QMistral::new(&config, vb)?;\n (Model::Quantized(model), device)\n } else {\n let dtype = if device.is_cuda() {\n DType::BF16\n } else {\n DType::F32\n };\n let vb = unsafe { VarBuilder::from_mmaped_safetensors(&filenames, dtype, &device)? };\n let model = Mistral::new(&config, vb)?;\n (Model::Mistral(model), device)\n };\n\n println!(\"loaded the model in {:?}\", start.elapsed());\n\n let mut pipeline = TextGeneration::new(\n model,\n tokenizer,\n args.seed,\n args.temperature,\n args.top_p,\n args.top_k,\n args.repeat_penalty,\n args.repeat_last_n,\n &device,\n );\n pipeline.run(&args.prompt, args.sample_len)?;\n Ok(())\n}\n", "candle-examples\\examples\\mixtral\\main.rs": "#[cfg(feature = \"mkl\")]\nextern crate intel_mkl_src;\n\n#[cfg(feature = \"accelerate\")]\nextern crate accelerate_src;\n\nuse anyhow::{Error as E, Result};\nuse clap::Parser;\n\nuse candle_transformers::models::mixtral::{Config, Model};\n\nuse candle::{DType, Device, Tensor};\nuse candle_examples::token_output_stream::TokenOutputStream;\nuse candle_nn::VarBuilder;\nuse candle_transformers::generation::LogitsProcessor;\nuse hf_hub::{api::sync::Api, Repo, RepoType};\nuse tokenizers::Tokenizer;\n\nstruct TextGeneration {\n model: Model,\n device: Device,\n tokenizer: TokenOutputStream,\n logits_processor: LogitsProcessor,\n repeat_penalty: f32,\n repeat_last_n: usize,\n}\n\nimpl TextGeneration {\n #[allow(clippy::too_many_arguments)]\n fn new(\n model: Model,\n tokenizer: Tokenizer,\n seed: u64,\n temp: Option<f64>,\n top_p: Option<f64>,\n repeat_penalty: f32,\n repeat_last_n: usize,\n device: &Device,\n ) -> Self {\n let logits_processor = LogitsProcessor::new(seed, temp, top_p);\n Self {\n model,\n tokenizer: TokenOutputStream::new(tokenizer),\n logits_processor,\n repeat_penalty,\n repeat_last_n,\n device: device.clone(),\n }\n }\n\n fn run(&mut self, prompt: &str, sample_len: usize) -> Result<()> {\n use std::io::Write;\n self.tokenizer.clear();\n let mut tokens = self\n .tokenizer\n .tokenizer()\n .encode(prompt, true)\n .map_err(E::msg)?\n .get_ids()\n .to_vec();\n for &t in tokens.iter() {\n if let Some(t) = self.tokenizer.next_token(t)? {\n print!(\"{t}\")\n }\n }\n std::io::stdout().flush()?;\n\n let mut generated_tokens = 0usize;\n let eos_token = match self.tokenizer.get_token(\"</s>\") {\n Some(token) => token,\n None => anyhow::bail!(\"cannot find the </s> token\"),\n };\n let start_gen = std::time::Instant::now();\n for index in 0..sample_len {\n let context_size = if index > 0 { 1 } else { tokens.len() };\n let start_pos = tokens.len().saturating_sub(context_size);\n let ctxt = &tokens[start_pos..];\n let input = Tensor::new(ctxt, &self.device)?.unsqueeze(0)?;\n let logits = self.model.forward(&input, start_pos)?;\n let logits = logits.squeeze(0)?.squeeze(0)?.to_dtype(DType::F32)?;\n let logits = if self.repeat_penalty == 1. {\n logits\n } else {\n let start_at = tokens.len().saturating_sub(self.repeat_last_n);\n candle_transformers::utils::apply_repeat_penalty(\n &logits,\n self.repeat_penalty,\n &tokens[start_at..],\n )?\n };\n\n let next_token = self.logits_processor.sample(&logits)?;\n tokens.push(next_token);\n generated_tokens += 1;\n if next_token == eos_token {\n break;\n }\n if let Some(t) = self.tokenizer.next_token(next_token)? {\n print!(\"{t}\");\n std::io::stdout().flush()?;\n }\n }\n let dt = start_gen.elapsed();\n if let Some(rest) = self.tokenizer.decode_rest().map_err(E::msg)? {\n print!(\"{rest}\");\n }\n std::io::stdout().flush()?;\n println!(\n \"\\n{generated_tokens} tokens generated ({:.2} token/s)\",\n generated_tokens as f64 / dt.as_secs_f64(),\n );\n Ok(())\n }\n}\n\n#[derive(Parser, Debug)]\n#[command(author, version, about, long_about = None)]\nstruct Args {\n /// Run on CPU rather than on GPU.\n #[arg(long)]\n cpu: bool,\n\n /// Enable tracing (generates a trace-timestamp.json file).\n #[arg(long)]\n tracing: bool,\n\n #[arg(long)]\n use_flash_attn: bool,\n\n #[arg(long)]\n prompt: String,\n\n /// The temperature used to generate samples.\n #[arg(long)]\n temperature: Option<f64>,\n\n /// Nucleus sampling probability cutoff.\n #[arg(long)]\n top_p: Option<f64>,\n\n /// The seed to use when generating random samples.\n #[arg(long, default_value_t = 299792458)]\n seed: u64,\n\n /// The length of the sample to generate (in tokens).\n #[arg(long, short = 'n', default_value_t = 10000)]\n sample_len: usize,\n\n #[arg(long, default_value = \"mistralai/Mixtral-8x7B-v0.1\")]\n model_id: String,\n\n #[arg(long, default_value = \"main\")]\n revision: String,\n\n #[arg(long)]\n tokenizer_file: Option<String>,\n\n #[arg(long)]\n weight_files: Option<String>,\n\n /// Penalty to be applied for repeating tokens, 1. means no penalty.\n #[arg(long, default_value_t = 1.1)]\n repeat_penalty: f32,\n\n /// The context size to consider for the repeat penalty.\n #[arg(long, default_value_t = 64)]\n repeat_last_n: usize,\n}\n\nfn main() -> Result<()> {\n use tracing_chrome::ChromeLayerBuilder;\n use tracing_subscriber::prelude::*;\n\n let args = Args::parse();\n let _guard = if args.tracing {\n let (chrome_layer, guard) = ChromeLayerBuilder::new().build();\n tracing_subscriber::registry().with(chrome_layer).init();\n Some(guard)\n } else {\n None\n };\n println!(\n \"avx: {}, neon: {}, simd128: {}, f16c: {}\",\n candle::utils::with_avx(),\n candle::utils::with_neon(),\n candle::utils::with_simd128(),\n candle::utils::with_f16c()\n );\n println!(\n \"temp: {:.2} repeat-penalty: {:.2} repeat-last-n: {}\",\n args.temperature.unwrap_or(0.),\n args.repeat_penalty,\n args.repeat_last_n\n );\n\n let start = std::time::Instant::now();\n let api = Api::new()?;\n let repo = api.repo(Repo::with_revision(\n args.model_id,\n RepoType::Model,\n args.revision,\n ));\n let tokenizer_filename = match args.tokenizer_file {\n Some(file) => std::path::PathBuf::from(file),\n None => repo.get(\"tokenizer.json\")?,\n };\n let filenames = match args.weight_files {\n Some(files) => files\n .split(',')\n .map(std::path::PathBuf::from)\n .collect::<Vec<_>>(),\n None => candle_examples::hub_load_safetensors(&repo, \"model.safetensors.index.json\")?,\n };\n println!(\"retrieved the files in {:?}\", start.elapsed());\n let tokenizer = Tokenizer::from_file(tokenizer_filename).map_err(E::msg)?;\n\n let start = std::time::Instant::now();\n let config = Config::v0_1_8x7b(args.use_flash_attn);\n let device = candle_examples::device(args.cpu)?;\n let dtype = device.bf16_default_to_f32();\n let vb = unsafe { VarBuilder::from_mmaped_safetensors(&filenames, dtype, &device)? };\n let model = Model::new(&config, vb)?;\n println!(\"loaded the model in {:?}\", start.elapsed());\n\n let mut pipeline = TextGeneration::new(\n model,\n tokenizer,\n args.seed,\n args.temperature,\n args.top_p,\n args.repeat_penalty,\n args.repeat_last_n,\n &device,\n );\n pipeline.run(&args.prompt, args.sample_len)?;\n Ok(())\n}\n", "candle-examples\\examples\\mnist-training\\main.rs": "// This should reach 91.5% accuracy.\n#[cfg(feature = \"mkl\")]\nextern crate intel_mkl_src;\n\n#[cfg(feature = \"accelerate\")]\nextern crate accelerate_src;\n\nuse clap::{Parser, ValueEnum};\nuse rand::prelude::*;\n\nuse candle::{DType, Result, Tensor, D};\nuse candle_nn::{loss, ops, Conv2d, Linear, Module, ModuleT, Optimizer, VarBuilder, VarMap};\n\nconst IMAGE_DIM: usize = 784;\nconst LABELS: usize = 10;\n\nfn linear_z(in_dim: usize, out_dim: usize, vs: VarBuilder) -> Result<Linear> {\n let ws = vs.get_with_hints((out_dim, in_dim), \"weight\", candle_nn::init::ZERO)?;\n let bs = vs.get_with_hints(out_dim, \"bias\", candle_nn::init::ZERO)?;\n Ok(Linear::new(ws, Some(bs)))\n}\n\ntrait Model: Sized {\n fn new(vs: VarBuilder) -> Result<Self>;\n fn forward(&self, xs: &Tensor) -> Result<Tensor>;\n}\n\nstruct LinearModel {\n linear: Linear,\n}\n\nimpl Model for LinearModel {\n fn new(vs: VarBuilder) -> Result<Self> {\n let linear = linear_z(IMAGE_DIM, LABELS, vs)?;\n Ok(Self { linear })\n }\n\n fn forward(&self, xs: &Tensor) -> Result<Tensor> {\n self.linear.forward(xs)\n }\n}\n\nstruct Mlp {\n ln1: Linear,\n ln2: Linear,\n}\n\nimpl Model for Mlp {\n fn new(vs: VarBuilder) -> Result<Self> {\n let ln1 = candle_nn::linear(IMAGE_DIM, 100, vs.pp(\"ln1\"))?;\n let ln2 = candle_nn::linear(100, LABELS, vs.pp(\"ln2\"))?;\n Ok(Self { ln1, ln2 })\n }\n\n fn forward(&self, xs: &Tensor) -> Result<Tensor> {\n let xs = self.ln1.forward(xs)?;\n let xs = xs.relu()?;\n self.ln2.forward(&xs)\n }\n}\n\n#[derive(Debug)]\nstruct ConvNet {\n conv1: Conv2d,\n conv2: Conv2d,\n fc1: Linear,\n fc2: Linear,\n dropout: candle_nn::Dropout,\n}\n\nimpl ConvNet {\n fn new(vs: VarBuilder) -> Result<Self> {\n let conv1 = candle_nn::conv2d(1, 32, 5, Default::default(), vs.pp(\"c1\"))?;\n let conv2 = candle_nn::conv2d(32, 64, 5, Default::default(), vs.pp(\"c2\"))?;\n let fc1 = candle_nn::linear(1024, 1024, vs.pp(\"fc1\"))?;\n let fc2 = candle_nn::linear(1024, LABELS, vs.pp(\"fc2\"))?;\n let dropout = candle_nn::Dropout::new(0.5);\n Ok(Self {\n conv1,\n conv2,\n fc1,\n fc2,\n dropout,\n })\n }\n\n fn forward(&self, xs: &Tensor, train: bool) -> Result<Tensor> {\n let (b_sz, _img_dim) = xs.dims2()?;\n let xs = xs\n .reshape((b_sz, 1, 28, 28))?\n .apply(&self.conv1)?\n .max_pool2d(2)?\n .apply(&self.conv2)?\n .max_pool2d(2)?\n .flatten_from(1)?\n .apply(&self.fc1)?\n .relu()?;\n self.dropout.forward_t(&xs, train)?.apply(&self.fc2)\n }\n}\n\nstruct TrainingArgs {\n learning_rate: f64,\n load: Option<String>,\n save: Option<String>,\n epochs: usize,\n}\n\nfn training_loop_cnn(\n m: candle_datasets::vision::Dataset,\n args: &TrainingArgs,\n) -> anyhow::Result<()> {\n const BSIZE: usize = 64;\n\n let dev = candle::Device::cuda_if_available(0)?;\n\n let train_labels = m.train_labels;\n let train_images = m.train_images.to_device(&dev)?;\n let train_labels = train_labels.to_dtype(DType::U32)?.to_device(&dev)?;\n\n let mut varmap = VarMap::new();\n let vs = VarBuilder::from_varmap(&varmap, DType::F32, &dev);\n let model = ConvNet::new(vs.clone())?;\n\n if let Some(load) = &args.load {\n println!(\"loading weights from {load}\");\n varmap.load(load)?\n }\n\n let adamw_params = candle_nn::ParamsAdamW {\n lr: args.learning_rate,\n ..Default::default()\n };\n let mut opt = candle_nn::AdamW::new(varmap.all_vars(), adamw_params)?;\n let test_images = m.test_images.to_device(&dev)?;\n let test_labels = m.test_labels.to_dtype(DType::U32)?.to_device(&dev)?;\n let n_batches = train_images.dim(0)? / BSIZE;\n let mut batch_idxs = (0..n_batches).collect::<Vec<usize>>();\n for epoch in 1..args.epochs {\n let mut sum_loss = 0f32;\n batch_idxs.shuffle(&mut thread_rng());\n for batch_idx in batch_idxs.iter() {\n let train_images = train_images.narrow(0, batch_idx * BSIZE, BSIZE)?;\n let train_labels = train_labels.narrow(0, batch_idx * BSIZE, BSIZE)?;\n let logits = model.forward(&train_images, true)?;\n let log_sm = ops::log_softmax(&logits, D::Minus1)?;\n let loss = loss::nll(&log_sm, &train_labels)?;\n opt.backward_step(&loss)?;\n sum_loss += loss.to_vec0::<f32>()?;\n }\n let avg_loss = sum_loss / n_batches as f32;\n\n let test_logits = model.forward(&test_images, false)?;\n let sum_ok = test_logits\n .argmax(D::Minus1)?\n .eq(&test_labels)?\n .to_dtype(DType::F32)?\n .sum_all()?\n .to_scalar::<f32>()?;\n let test_accuracy = sum_ok / test_labels.dims1()? as f32;\n println!(\n \"{epoch:4} train loss {:8.5} test acc: {:5.2}%\",\n avg_loss,\n 100. * test_accuracy\n );\n }\n if let Some(save) = &args.save {\n println!(\"saving trained weights in {save}\");\n varmap.save(save)?\n }\n Ok(())\n}\n\nfn training_loop<M: Model>(\n m: candle_datasets::vision::Dataset,\n args: &TrainingArgs,\n) -> anyhow::Result<()> {\n let dev = candle::Device::cuda_if_available(0)?;\n\n let train_labels = m.train_labels;\n let train_images = m.train_images.to_device(&dev)?;\n let train_labels = train_labels.to_dtype(DType::U32)?.to_device(&dev)?;\n\n let mut varmap = VarMap::new();\n let vs = VarBuilder::from_varmap(&varmap, DType::F32, &dev);\n let model = M::new(vs.clone())?;\n\n if let Some(load) = &args.load {\n println!(\"loading weights from {load}\");\n varmap.load(load)?\n }\n\n let mut sgd = candle_nn::SGD::new(varmap.all_vars(), args.learning_rate)?;\n let test_images = m.test_images.to_device(&dev)?;\n let test_labels = m.test_labels.to_dtype(DType::U32)?.to_device(&dev)?;\n for epoch in 1..args.epochs {\n let logits = model.forward(&train_images)?;\n let log_sm = ops::log_softmax(&logits, D::Minus1)?;\n let loss = loss::nll(&log_sm, &train_labels)?;\n sgd.backward_step(&loss)?;\n\n let test_logits = model.forward(&test_images)?;\n let sum_ok = test_logits\n .argmax(D::Minus1)?\n .eq(&test_labels)?\n .to_dtype(DType::F32)?\n .sum_all()?\n .to_scalar::<f32>()?;\n let test_accuracy = sum_ok / test_labels.dims1()? as f32;\n println!(\n \"{epoch:4} train loss: {:8.5} test acc: {:5.2}%\",\n loss.to_scalar::<f32>()?,\n 100. * test_accuracy\n );\n }\n if let Some(save) = &args.save {\n println!(\"saving trained weights in {save}\");\n varmap.save(save)?\n }\n Ok(())\n}\n\n#[derive(ValueEnum, Clone)]\nenum WhichModel {\n Linear,\n Mlp,\n Cnn,\n}\n\n#[derive(Parser)]\nstruct Args {\n #[clap(value_enum, default_value_t = WhichModel::Linear)]\n model: WhichModel,\n\n #[arg(long)]\n learning_rate: Option<f64>,\n\n #[arg(long, default_value_t = 200)]\n epochs: usize,\n\n /// The file where to save the trained weights, in safetensors format.\n #[arg(long)]\n save: Option<String>,\n\n /// The file where to load the trained weights from, in safetensors format.\n #[arg(long)]\n load: Option<String>,\n\n /// The directory where to load the dataset from, in ubyte format.\n #[arg(long)]\n local_mnist: Option<String>,\n}\n\npub fn main() -> anyhow::Result<()> {\n let args = Args::parse();\n // Load the dataset\n let m = if let Some(directory) = args.local_mnist {\n candle_datasets::vision::mnist::load_dir(directory)?\n } else {\n candle_datasets::vision::mnist::load()?\n };\n println!(\"train-images: {:?}\", m.train_images.shape());\n println!(\"train-labels: {:?}\", m.train_labels.shape());\n println!(\"test-images: {:?}\", m.test_images.shape());\n println!(\"test-labels: {:?}\", m.test_labels.shape());\n\n let default_learning_rate = match args.model {\n WhichModel::Linear => 1.,\n WhichModel::Mlp => 0.05,\n WhichModel::Cnn => 0.001,\n };\n let training_args = TrainingArgs {\n epochs: args.epochs,\n learning_rate: args.learning_rate.unwrap_or(default_learning_rate),\n load: args.load,\n save: args.save,\n };\n match args.model {\n WhichModel::Linear => training_loop::<LinearModel>(m, &training_args),\n WhichModel::Mlp => training_loop::<Mlp>(m, &training_args),\n WhichModel::Cnn => training_loop_cnn(m, &training_args),\n }\n}\n", "candle-examples\\examples\\mobileclip\\main.rs": "#[cfg(feature = \"mkl\")]\nextern crate intel_mkl_src;\n\n#[cfg(feature = \"accelerate\")]\nextern crate accelerate_src;\n\nuse anyhow::Error as E;\nuse clap::{Parser, ValueEnum};\n\nuse candle::{DType, Device, Tensor};\nuse candle_nn::{ops::softmax, VarBuilder};\nuse candle_transformers::models::mobileclip;\n\nuse tokenizers::Tokenizer;\n\n#[derive(Clone, Copy, Debug, ValueEnum)]\nenum Which {\n S1,\n S2,\n}\n\nimpl Which {\n fn model_name(&self) -> String {\n let name = match self {\n Self::S1 => \"S1\",\n Self::S2 => \"S2\",\n };\n format!(\"apple/MobileCLIP-{}-OpenCLIP\", name)\n }\n\n fn config(&self) -> mobileclip::MobileClipConfig {\n match self {\n Self::S1 => mobileclip::MobileClipConfig::s1(),\n Self::S2 => mobileclip::MobileClipConfig::s2(),\n }\n }\n}\n\n#[derive(Parser)]\nstruct Args {\n #[arg(long, use_value_delimiter = true)]\n images: Option<Vec<String>>,\n\n #[arg(long)]\n cpu: bool,\n\n /// Use the pytorch weights rather than the safetensors ones\n #[arg(long)]\n use_pth: bool,\n\n #[arg(long, use_value_delimiter = true)]\n sequences: Option<Vec<String>>,\n\n #[arg(value_enum, long, default_value_t=Which::S1)]\n which: Which,\n}\n\nfn load_images<T: AsRef<std::path::Path>>(\n paths: &Vec<T>,\n image_size: usize,\n) -> anyhow::Result<Tensor> {\n let mut images = vec![];\n\n for path in paths {\n let tensor = candle_examples::imagenet::load_image_with_std_mean(\n path,\n image_size,\n &[0.0, 0.0, 0.0],\n &[1.0, 1.0, 1.0],\n )?;\n images.push(tensor);\n }\n\n let images = Tensor::stack(&images, 0)?;\n\n Ok(images)\n}\n\npub fn main() -> anyhow::Result<()> {\n let args = Args::parse();\n\n let model_name = args.which.model_name();\n\n let api = hf_hub::api::sync::Api::new()?;\n let api = api.model(model_name);\n\n let model_file = if args.use_pth {\n api.get(\"open_clip_pytorch_model.bin\")?\n } else {\n api.get(\"open_clip_model.safetensors\")?\n };\n\n let tokenizer = api.get(\"tokenizer.json\")?;\n\n let tokenizer = Tokenizer::from_file(tokenizer).map_err(E::msg)?;\n\n let config = &args.which.config();\n\n let device = candle_examples::device(args.cpu)?;\n\n let vec_imgs = match args.images {\n Some(imgs) => imgs,\n None => vec![\n \"candle-examples/examples/stable-diffusion/assets/stable-diffusion-xl.jpg\".to_string(),\n \"candle-examples/examples/yolo-v8/assets/bike.jpg\".to_string(),\n ],\n };\n\n let images = load_images(&vec_imgs, config.image_size)?.to_device(&device)?;\n\n let vb = if args.use_pth {\n VarBuilder::from_pth(&model_file, DType::F32, &device)?\n } else {\n unsafe { VarBuilder::from_mmaped_safetensors(&[model_file.clone()], DType::F32, &device)? }\n };\n\n let model = mobileclip::MobileClipModel::new(vb, config)?;\n\n let (input_ids, vec_seq) = tokenize_sequences(args.sequences, &tokenizer, &device)?;\n\n let (_logits_per_text, logits_per_image) = model.forward(&images, &input_ids)?;\n\n let softmax_image = softmax(&logits_per_image, 1)?;\n\n let softmax_image_vec = softmax_image.flatten_all()?.to_vec1::<f32>()?;\n\n println!(\"softmax_image_vec: {:?}\", softmax_image_vec);\n\n let probability_vec = softmax_image_vec\n .iter()\n .map(|v| v * 100.0)\n .collect::<Vec<f32>>();\n\n let probability_per_image = probability_vec.len() / vec_imgs.len();\n\n for (i, img) in vec_imgs.iter().enumerate() {\n let start = i * probability_per_image;\n let end = start + probability_per_image;\n let prob = &probability_vec[start..end];\n println!(\"\\n\\nResults for image: {}\\n\", img);\n\n for (i, p) in prob.iter().enumerate() {\n println!(\"Probability: {:.4}% Text: {}\", p, vec_seq[i]);\n }\n }\n\n Ok(())\n}\n\npub fn tokenize_sequences(\n sequences: Option<Vec<String>>,\n tokenizer: &Tokenizer,\n device: &Device,\n) -> anyhow::Result<(Tensor, Vec<String>)> {\n // let pad_id = *tokenizer\n // .get_vocab(true)\n // .get(\"<|endoftext|>\")\n // .ok_or(E::msg(\"No pad token\"))?;\n\n // The model does not work well if the text is padded using the <|endoftext|> token, using 0\n // as the original OpenCLIP code.\n let pad_id = 0;\n\n let vec_seq = match sequences {\n Some(seq) => seq,\n None => vec![\n \"a cycling race\".to_string(),\n \"a photo of two cats\".to_string(),\n \"a robot holding a candle\".to_string(),\n ],\n };\n\n let mut tokens = vec![];\n\n for seq in vec_seq.clone() {\n let encoding = tokenizer.encode(seq, true).map_err(E::msg)?;\n tokens.push(encoding.get_ids().to_vec());\n }\n\n let max_len = tokens.iter().map(|v| v.len()).max().unwrap_or(0);\n // Pad the sequences to have the same length\n for token_vec in tokens.iter_mut() {\n let len_diff = max_len - token_vec.len();\n if len_diff > 0 {\n token_vec.extend(vec![pad_id; len_diff]);\n }\n }\n\n let input_ids = Tensor::new(tokens, device)?;\n\n Ok((input_ids, vec_seq))\n}\n", "candle-examples\\examples\\mobilenetv4\\main.rs": "#[cfg(feature = \"mkl\")]\nextern crate intel_mkl_src;\n\n#[cfg(feature = \"accelerate\")]\nextern crate accelerate_src;\n\nuse clap::{Parser, ValueEnum};\n\nuse candle::{DType, IndexOp, D};\nuse candle_nn::{Module, VarBuilder};\nuse candle_transformers::models::mobilenetv4;\n\n#[derive(Clone, Copy, Debug, ValueEnum)]\nenum Which {\n Small,\n Medium,\n Large,\n HybridMedium,\n HybridLarge,\n}\n\nimpl Which {\n fn model_filename(&self) -> String {\n let name = match self {\n Self::Small => \"conv_small.e2400_r224\",\n Self::Medium => \"conv_medium.e500_r256\",\n Self::HybridMedium => \"hybrid_medium.ix_e550_r256\",\n Self::Large => \"conv_large.e600_r384\",\n Self::HybridLarge => \"hybrid_large.ix_e600_r384\",\n };\n format!(\"timm/mobilenetv4_{}_in1k\", name)\n }\n\n fn resolution(&self) -> u32 {\n match self {\n Self::Small => 224,\n Self::Medium => 256,\n Self::HybridMedium => 256,\n Self::Large => 384,\n Self::HybridLarge => 384,\n }\n }\n fn config(&self) -> mobilenetv4::Config {\n match self {\n Self::Small => mobilenetv4::Config::small(),\n Self::Medium => mobilenetv4::Config::medium(),\n Self::HybridMedium => mobilenetv4::Config::hybrid_medium(),\n Self::Large => mobilenetv4::Config::large(),\n Self::HybridLarge => mobilenetv4::Config::hybrid_large(),\n }\n }\n}\n\n#[derive(Parser)]\nstruct Args {\n #[arg(long)]\n model: Option<String>,\n\n #[arg(long)]\n image: String,\n\n /// Run on CPU rather than on GPU.\n #[arg(long)]\n cpu: bool,\n\n #[arg(value_enum, long, default_value_t=Which::Small)]\n which: Which,\n}\n\npub fn main() -> anyhow::Result<()> {\n let args = Args::parse();\n\n let device = candle_examples::device(args.cpu)?;\n\n let image =\n candle_examples::imagenet::load_image(args.image, args.which.resolution() as usize)?\n .to_device(&device)?;\n println!(\"loaded image {image:?}\");\n\n let model_file = match args.model {\n None => {\n let model_name = args.which.model_filename();\n let api = hf_hub::api::sync::Api::new()?;\n let api = api.model(model_name);\n api.get(\"model.safetensors\")?\n }\n Some(model) => model.into(),\n };\n\n let vb = unsafe { VarBuilder::from_mmaped_safetensors(&[model_file], DType::F32, &device)? };\n let model = mobilenetv4::mobilenetv4(&args.which.config(), 1000, vb)?;\n println!(\"model built\");\n let logits = model.forward(&image.unsqueeze(0)?)?;\n let prs = candle_nn::ops::softmax(&logits, D::Minus1)?\n .i(0)?\n .to_vec1::<f32>()?;\n let mut prs = prs.iter().enumerate().collect::<Vec<_>>();\n prs.sort_by(|(_, p1), (_, p2)| p2.total_cmp(p1));\n for &(category_idx, pr) in prs.iter().take(5) {\n println!(\n \"{:24}: {:.2}%\",\n candle_examples::imagenet::CLASSES[category_idx],\n 100. * pr\n );\n }\n Ok(())\n}\n", "candle-examples\\examples\\mobileone\\main.rs": "#[cfg(feature = \"mkl\")]\nextern crate intel_mkl_src;\n\n#[cfg(feature = \"accelerate\")]\nextern crate accelerate_src;\n\nuse clap::{Parser, ValueEnum};\n\nuse candle::{DType, IndexOp, D};\nuse candle_nn::{Module, VarBuilder};\nuse candle_transformers::models::mobileone;\n\n#[derive(Clone, Copy, Debug, ValueEnum)]\nenum Which {\n S0,\n S1,\n S2,\n S3,\n S4,\n}\n\nimpl Which {\n fn model_filename(&self) -> String {\n let name = match self {\n Self::S0 => \"s0\",\n Self::S1 => \"s1\",\n Self::S2 => \"s2\",\n Self::S3 => \"s3\",\n Self::S4 => \"s4\",\n };\n format!(\"timm/mobileone_{}.apple_in1k\", name)\n }\n\n fn config(&self) -> mobileone::Config {\n match self {\n Self::S0 => mobileone::Config::s0(),\n Self::S1 => mobileone::Config::s1(),\n Self::S2 => mobileone::Config::s2(),\n Self::S3 => mobileone::Config::s3(),\n Self::S4 => mobileone::Config::s4(),\n }\n }\n}\n\n#[derive(Parser)]\nstruct Args {\n #[arg(long)]\n model: Option<String>,\n\n #[arg(long)]\n image: String,\n\n /// Run on CPU rather than on GPU.\n #[arg(long)]\n cpu: bool,\n\n #[arg(value_enum, long, default_value_t=Which::S0)]\n which: Which,\n}\n\npub fn main() -> anyhow::Result<()> {\n let args = Args::parse();\n\n let device = candle_examples::device(args.cpu)?;\n\n let image = candle_examples::imagenet::load_image224(args.image)?.to_device(&device)?;\n println!(\"loaded image {image:?}\");\n\n let model_file = match args.model {\n None => {\n let model_name = args.which.model_filename();\n let api = hf_hub::api::sync::Api::new()?;\n let api = api.model(model_name);\n api.get(\"model.safetensors\")?\n }\n Some(model) => model.into(),\n };\n\n let vb = unsafe { VarBuilder::from_mmaped_safetensors(&[model_file], DType::F32, &device)? };\n let model = mobileone::mobileone(&args.which.config(), 1000, vb)?;\n println!(\"model built\");\n let logits = model.forward(&image.unsqueeze(0)?)?;\n let prs = candle_nn::ops::softmax(&logits, D::Minus1)?\n .i(0)?\n .to_vec1::<f32>()?;\n let mut prs = prs.iter().enumerate().collect::<Vec<_>>();\n prs.sort_by(|(_, p1), (_, p2)| p2.total_cmp(p1));\n for &(category_idx, pr) in prs.iter().take(5) {\n println!(\n \"{:24}: {:.2}%\",\n candle_examples::imagenet::CLASSES[category_idx],\n 100. * pr\n );\n }\n Ok(())\n}\n", "candle-examples\\examples\\moondream\\main.rs": "#[cfg(feature = \"mkl\")]\nextern crate intel_mkl_src;\n\n#[cfg(feature = \"accelerate\")]\nextern crate accelerate_src;\n\nuse anyhow::{Error as E, Result};\nuse clap::Parser;\n\nuse candle::{DType, Device, Tensor};\nuse candle_nn::VarBuilder;\nuse candle_transformers::{\n generation::LogitsProcessor,\n models::{moondream, quantized_moondream},\n};\nuse tokenizers::Tokenizer;\n\nenum Model {\n Moondream(moondream::Model),\n Quantized(quantized_moondream::Model),\n}\n\nstruct TextGeneration {\n model: Model,\n device: Device,\n tokenizer: Tokenizer,\n logits_processor: LogitsProcessor,\n repeat_penalty: f32,\n repeat_last_n: usize,\n verbose_prompt: bool,\n}\n\nimpl TextGeneration {\n #[allow(clippy::too_many_arguments)]\n fn new(\n model: Model,\n tokenizer: Tokenizer,\n seed: u64,\n temp: Option<f64>,\n top_p: Option<f64>,\n repeat_penalty: f32,\n repeat_last_n: usize,\n verbose_prompt: bool,\n device: &Device,\n ) -> Self {\n let logits_processor = LogitsProcessor::new(seed, temp, top_p);\n Self {\n model,\n tokenizer,\n logits_processor,\n repeat_penalty,\n repeat_last_n,\n verbose_prompt,\n device: device.clone(),\n }\n }\n\n fn run(&mut self, prompt: &str, image_embeds: &Tensor, sample_len: usize) -> Result<()> {\n use std::io::Write;\n println!(\"starting the inference loop\");\n let tokens = self.tokenizer.encode(prompt, true).map_err(E::msg)?;\n if tokens.is_empty() {\n anyhow::bail!(\"Empty prompts are not supported in the Moondream model.\")\n }\n if self.verbose_prompt {\n for (token, id) in tokens.get_tokens().iter().zip(tokens.get_ids().iter()) {\n let token = token.replace('\u2581', \" \").replace(\"<0x0A>\", \"\\n\");\n println!(\"{id:7} -> '{token}'\");\n }\n }\n\n let mut tokens = tokens.get_ids().to_vec();\n let mut generated_tokens = 0usize;\n\n // Moondream tokenizer bos_token and eos_token is \"<|endoftext|>\"\n // https://huggingface.co/vikhyatk/moondream2/blob/main/special_tokens_map.json\n let special_token = match self.tokenizer.get_vocab(true).get(\"<|endoftext|>\") {\n Some(token) => *token,\n None => anyhow::bail!(\"cannot find the special token\"),\n };\n let (bos_token, eos_token) = (special_token, special_token);\n\n let start_gen = std::time::Instant::now();\n let mut load_t = std::time::Duration::from_secs_f64(0f64);\n for index in 0..sample_len {\n let context_size = if index > 0 { 1 } else { tokens.len() };\n let ctxt = &tokens[tokens.len().saturating_sub(context_size)..];\n let input = Tensor::new(ctxt, &self.device)?.unsqueeze(0)?;\n let logits = if index > 0 {\n match self.model {\n Model::Moondream(ref mut model) => model.text_model.forward(&input)?,\n Model::Quantized(ref mut model) => model.text_model.forward(&input)?,\n }\n } else {\n let bos_token = Tensor::new(&[bos_token], &self.device)?.unsqueeze(0)?;\n let logits = match self.model {\n Model::Moondream(ref mut model) => {\n model\n .text_model\n .forward_with_img(&bos_token, &input, image_embeds)?\n }\n Model::Quantized(ref mut model) => {\n model\n .text_model\n .forward_with_img(&bos_token, &input, image_embeds)?\n }\n };\n load_t = start_gen.elapsed();\n println!(\"load_t: {:?}\", load_t);\n logits\n };\n let logits = logits.squeeze(0)?.to_dtype(DType::F32)?;\n let logits = if self.repeat_penalty == 1. {\n logits\n } else {\n let start_at = tokens.len().saturating_sub(self.repeat_last_n);\n candle_transformers::utils::apply_repeat_penalty(\n &logits,\n self.repeat_penalty,\n &tokens[start_at..],\n )?\n };\n let next_token = self.logits_processor.sample(&logits)?;\n tokens.push(next_token);\n generated_tokens += 1;\n if next_token == eos_token || tokens.ends_with(&[27, 10619, 29] /* <END> */) {\n break;\n }\n let token = self.tokenizer.decode(&[next_token], true).map_err(E::msg)?;\n print!(\"{token}\");\n std::io::stdout().flush()?;\n }\n\n let dt = start_gen.elapsed() - load_t;\n println!(\n \"\\ngenerated in {} seconds\\n{generated_tokens} tokens generated ({:.2} token/s)\",\n dt.as_secs_f64(),\n (generated_tokens - 1) as f64 / dt.as_secs_f64()\n );\n\n Ok(())\n }\n}\n\n#[derive(Parser)]\nstruct Args {\n /// Run on CPU rather than on GPU.\n #[arg(long)]\n cpu: bool,\n\n /// Enable tracing (generates a trace-timestamp.json file).\n #[arg(long)]\n tracing: bool,\n\n /// Display the token for the specified prompt.\n #[arg(long)]\n verbose_prompt: bool,\n\n #[arg(long)]\n prompt: String,\n\n #[arg(long)]\n image: String,\n\n /// The temperature used to generate samples.\n #[arg(long)]\n temperature: Option<f64>,\n\n /// Nucleus sampling probability cutoff.\n #[arg(long)]\n top_p: Option<f64>,\n\n /// The seed to use when generating random samples.\n #[arg(long, default_value_t = 0)]\n seed: u64,\n\n #[arg(long, default_value_t = 5000)]\n sample_len: usize,\n\n /// Penalty to be applied for repeating tokens, 1. means no penalty.\n #[arg(long, default_value_t = 1.0)]\n repeat_penalty: f32,\n\n /// The context size to consider for the repeat penalty.\n #[arg(long, default_value_t = 64)]\n repeat_last_n: usize,\n\n #[arg(long)]\n model_id: Option<String>,\n\n #[arg(long)]\n revision: Option<String>,\n\n #[arg(long)]\n quantized: bool,\n\n /// Use f16 precision for all the computations rather than f32.\n #[arg(long)]\n f16: bool,\n\n #[arg(long)]\n model_file: Option<String>,\n\n #[arg(long)]\n tokenizer_file: Option<String>,\n}\n\n/// Loads an image from disk using the image crate, this returns a tensor with shape\n/// (3, 378, 378).\npub fn load_image<P: AsRef<std::path::Path>>(p: P) -> candle::Result<Tensor> {\n let img = image::ImageReader::open(p)?\n .decode()\n .map_err(candle::Error::wrap)?\n .resize_to_fill(378, 378, image::imageops::FilterType::Triangle); // Adjusted to 378x378\n let img = img.to_rgb8();\n let data = img.into_raw();\n let data = Tensor::from_vec(data, (378, 378, 3), &Device::Cpu)?.permute((2, 0, 1))?;\n let mean = Tensor::new(&[0.5f32, 0.5, 0.5], &Device::Cpu)?.reshape((3, 1, 1))?;\n let std = Tensor::new(&[0.5f32, 0.5, 0.5], &Device::Cpu)?.reshape((3, 1, 1))?;\n (data.to_dtype(candle::DType::F32)? / 255.)?\n .broadcast_sub(&mean)?\n .broadcast_div(&std)\n}\n\n#[tokio::main]\nasync fn main() -> anyhow::Result<()> {\n use tracing_chrome::ChromeLayerBuilder;\n use tracing_subscriber::prelude::*;\n\n let args = Args::parse();\n\n let _guard = if args.tracing {\n let (chrome_layer, guard) = ChromeLayerBuilder::new().build();\n tracing_subscriber::registry().with(chrome_layer).init();\n Some(guard)\n } else {\n None\n };\n println!(\n \"avx: {}, neon: {}, simd128: {}, f16c: {}\",\n candle::utils::with_avx(),\n candle::utils::with_neon(),\n candle::utils::with_simd128(),\n candle::utils::with_f16c()\n );\n println!(\n \"temp: {:.2} repeat-penalty: {:.2} repeat-last-n: {}\",\n args.temperature.unwrap_or(0.),\n args.repeat_penalty,\n args.repeat_last_n\n );\n\n let start = std::time::Instant::now();\n let api = hf_hub::api::tokio::Api::new()?;\n let (model_id, revision) = match args.model_id {\n Some(model_id) => (model_id.to_string(), None),\n None => {\n if args.quantized {\n (\"santiagomed/candle-moondream\".to_string(), None)\n } else {\n (\n \"vikhyatk/moondream2\".to_string(),\n Some(\"30c7cdf3fa6914f50bee3956694374143f5cc884\"),\n )\n }\n }\n };\n let revision = match (args.revision, revision) {\n (Some(r), _) => r,\n (None, Some(r)) => r.to_string(),\n (None, None) => \"main\".to_string(),\n };\n let repo = api.repo(hf_hub::Repo::with_revision(\n model_id,\n hf_hub::RepoType::Model,\n revision,\n ));\n let model_file = match args.model_file {\n Some(m) => m.into(),\n None => {\n if args.quantized {\n repo.get(\"model-q4_0.gguf\").await?\n } else {\n repo.get(\"model.safetensors\").await?\n }\n }\n };\n let tokenizer = match args.tokenizer_file {\n Some(m) => m.into(),\n None => repo.get(\"tokenizer.json\").await?,\n };\n println!(\"retrieved the files in {:?}\", start.elapsed());\n let tokenizer = Tokenizer::from_file(tokenizer).map_err(E::msg)?;\n\n let start = std::time::Instant::now();\n let device = candle_examples::device(args.cpu)?;\n let config = moondream::Config::v2();\n let dtype = if args.quantized {\n if args.f16 {\n anyhow::bail!(\"Quantized model does not support f16\");\n }\n DType::F32\n } else if device.is_cuda() || args.f16 {\n DType::F16\n } else {\n DType::F32\n };\n let model = if args.quantized {\n let vb = candle_transformers::quantized_var_builder::VarBuilder::from_gguf(\n &model_file,\n &device,\n )?;\n let model = quantized_moondream::Model::new(&config, vb)?;\n Model::Quantized(model)\n } else {\n let vb = unsafe { VarBuilder::from_mmaped_safetensors(&[model_file], dtype, &device)? };\n let model = moondream::Model::new(&config, vb)?;\n Model::Moondream(model)\n };\n println!(\"loaded the model in {:?}\", start.elapsed());\n\n let start = std::time::Instant::now();\n let image = load_image(args.image)?\n .to_device(&device)?\n .to_dtype(dtype)?;\n let image_embeds = image.unsqueeze(0)?;\n let image_embeds = match model {\n Model::Moondream(ref m) => image_embeds.apply(m.vision_encoder())?,\n Model::Quantized(ref m) => image_embeds.apply(m.vision_encoder())?,\n };\n println!(\n \"loaded and encoded the image {image:?} in {:?}\",\n start.elapsed()\n );\n\n let prompt = format!(\"\\n\\nQuestion: {0}\\n\\nAnswer:\", args.prompt);\n let mut pipeline = TextGeneration::new(\n model,\n tokenizer,\n args.seed,\n args.temperature,\n args.top_p,\n args.repeat_penalty,\n args.repeat_last_n,\n args.verbose_prompt,\n &device,\n );\n pipeline.run(&prompt, &image_embeds, args.sample_len)?;\n\n Ok(())\n}\n", "candle-examples\\examples\\musicgen\\main.rs": "#![allow(dead_code)]\n// https://huggingface.co/facebook/musicgen-small/tree/main\n// https://github.com/huggingface/transformers/blob/cd4584e3c809bb9e1392ccd3fe38b40daba5519a/src/transformers/models/musicgen/modeling_musicgen.py\n// TODO: Add an offline mode.\n// TODO: Add a KV cache.\n\n#[cfg(feature = \"mkl\")]\nextern crate intel_mkl_src;\n\n#[cfg(feature = \"accelerate\")]\nextern crate accelerate_src;\n\nmod musicgen_model;\n\nuse musicgen_model::{GenConfig, MusicgenForConditionalGeneration};\n\nuse anyhow::{Error as E, Result};\nuse candle::{DType, Tensor};\nuse candle_nn::VarBuilder;\nuse clap::Parser;\nuse hf_hub::{api::sync::Api, Repo, RepoType};\n\nconst DTYPE: DType = DType::F32;\n\n#[derive(Parser, Debug)]\n#[command(author, version, about, long_about = None)]\nstruct Args {\n /// Run on CPU rather than on GPU.\n #[arg(long)]\n cpu: bool,\n\n /// The model weight file, in safetensor format.\n #[arg(long)]\n model: Option<String>,\n\n /// The tokenizer config.\n #[arg(long)]\n tokenizer: Option<String>,\n\n #[arg(\n long,\n default_value = \"90s rock song with loud guitars and heavy drums\"\n )]\n prompt: String,\n}\n\nfn main() -> Result<()> {\n use tokenizers::Tokenizer;\n\n let args = Args::parse();\n let device = candle_examples::device(args.cpu)?;\n let tokenizer = match args.tokenizer {\n Some(tokenizer) => std::path::PathBuf::from(tokenizer),\n None => Api::new()?\n .model(\"facebook/musicgen-small\".to_string())\n .get(\"tokenizer.json\")?,\n };\n let mut tokenizer = Tokenizer::from_file(tokenizer).map_err(E::msg)?;\n let tokenizer = tokenizer\n .with_padding(None)\n .with_truncation(None)\n .map_err(E::msg)?;\n\n let model = match args.model {\n Some(model) => std::path::PathBuf::from(model),\n None => Api::new()?\n .repo(Repo::with_revision(\n \"facebook/musicgen-small\".to_string(),\n RepoType::Model,\n \"refs/pr/13\".to_string(),\n ))\n .get(\"model.safetensors\")?,\n };\n let vb = unsafe { VarBuilder::from_mmaped_safetensors(&[model], DTYPE, &device)? };\n let config = GenConfig::small();\n let mut model = MusicgenForConditionalGeneration::load(vb, config)?;\n\n let tokens = tokenizer\n .encode(args.prompt.as_str(), true)\n .map_err(E::msg)?\n .get_ids()\n .to_vec();\n println!(\"tokens: {tokens:?}\");\n let tokens = Tensor::new(tokens.as_slice(), &device)?.unsqueeze(0)?;\n println!(\"{tokens:?}\");\n let embeds = model.text_encoder.forward(&tokens)?;\n println!(\"{embeds}\");\n\n Ok(())\n}\n", "candle-examples\\examples\\olmo\\main.rs": "#[cfg(feature = \"mkl\")]\nextern crate intel_mkl_src;\n\n#[cfg(feature = \"accelerate\")]\nextern crate accelerate_src;\n\nuse anyhow::{Error as E, Result};\nuse clap::{Parser, ValueEnum};\n\nuse candle_transformers::models::olmo::{Config, Model as OLMo};\n\nuse candle::{DType, Device, Tensor};\nuse candle_examples::token_output_stream::TokenOutputStream;\nuse candle_nn::VarBuilder;\nuse candle_transformers::generation::LogitsProcessor;\nuse hf_hub::{api::sync::Api, Repo, RepoType};\nuse tokenizers::Tokenizer;\n\nenum Model {\n OLMo(OLMo),\n}\n\nstruct TextGeneration {\n model: Model,\n device: Device,\n tokenizer: TokenOutputStream,\n logits_processor: LogitsProcessor,\n repeat_penalty: f32,\n repeat_last_n: usize,\n}\n\nimpl TextGeneration {\n #[allow(clippy::too_many_arguments)]\n fn new(\n model: Model,\n tokenizer: Tokenizer,\n seed: u64,\n temp: Option<f64>,\n top_p: Option<f64>,\n repeat_penalty: f32,\n repeat_last_n: usize,\n device: &Device,\n ) -> Self {\n let logits_processor = LogitsProcessor::new(seed, temp, top_p);\n Self {\n model,\n tokenizer: TokenOutputStream::new(tokenizer),\n logits_processor,\n repeat_penalty,\n repeat_last_n,\n device: device.clone(),\n }\n }\n\n fn run(&mut self, prompt: &str, sample_len: usize) -> Result<()> {\n use std::io::Write;\n self.tokenizer.clear();\n let mut tokens = self\n .tokenizer\n .tokenizer()\n .encode(prompt, false)\n .map_err(E::msg)?\n .get_ids()\n .to_vec();\n for &t in tokens.iter() {\n if let Some(t) = self.tokenizer.next_token(t)? {\n print!(\"{t}\")\n }\n }\n std::io::stdout().flush()?;\n\n let mut generated_tokens = 0usize;\n let eos_token = match self.tokenizer.get_token(\"<|endoftext|>\") {\n Some(token) => token,\n None => anyhow::bail!(\"cannot find the <|endoftext|> token\"),\n };\n let start_gen = std::time::Instant::now();\n for index in 0..sample_len {\n let context_size = if index > 0 { 1 } else { tokens.len() };\n let start_pos = tokens.len().saturating_sub(context_size);\n let ctxt = &tokens[start_pos..];\n let input = Tensor::new(ctxt, &self.device)?.unsqueeze(0)?;\n let logits = match &mut self.model {\n Model::OLMo(m) => m.forward(&input, start_pos)?,\n };\n let logits = logits.squeeze(0)?.squeeze(0)?.to_dtype(DType::F32)?;\n let logits = if self.repeat_penalty == 1. {\n logits\n } else {\n let start_at = tokens.len().saturating_sub(self.repeat_last_n);\n candle_transformers::utils::apply_repeat_penalty(\n &logits,\n self.repeat_penalty,\n &tokens[start_at..],\n )?\n };\n\n let next_token = self.logits_processor.sample(&logits)?;\n tokens.push(next_token);\n generated_tokens += 1;\n if next_token == eos_token {\n break;\n }\n if let Some(t) = self.tokenizer.next_token(next_token)? {\n print!(\"{t}\");\n std::io::stdout().flush()?;\n }\n }\n let dt = start_gen.elapsed();\n if let Some(rest) = self.tokenizer.decode_rest().map_err(E::msg)? {\n print!(\"{rest}\");\n }\n std::io::stdout().flush()?;\n println!(\n \"\\n{generated_tokens} tokens generated ({:.2} token/s)\",\n generated_tokens as f64 / dt.as_secs_f64(),\n );\n Ok(())\n }\n}\n\n#[derive(Clone, Copy, Debug, ValueEnum, PartialEq, Eq)]\nenum Which {\n #[value(name = \"1b\")]\n W1b,\n #[value(name = \"7b\")]\n W7b,\n #[value(name = \"7b-twin-2t\")]\n W7bTwin2T,\n #[value(name = \"1.7-7b\")]\n V1_7W7b,\n}\n\n#[derive(Parser, Debug)]\n#[command(author, version, about, long_about = None)]\nstruct Args {\n /// Run on CPU rather than on GPU.\n #[arg(long)]\n cpu: bool,\n\n /// Enable tracing (generates a trace-timestamp.json file).\n #[arg(long)]\n tracing: bool,\n\n #[arg(long)]\n prompt: String,\n\n /// The temperature used to generate samples.\n #[arg(long)]\n temperature: Option<f64>,\n\n /// Nucleus sampling probability cutoff.\n #[arg(long)]\n top_p: Option<f64>,\n\n /// The seed to use when generating random samples.\n #[arg(long, default_value_t = 299792458)]\n seed: u64,\n\n /// The length of the sample to generate (in tokens).\n #[arg(long, short = 'n', default_value_t = 1000)]\n sample_len: usize,\n\n #[arg(long)]\n model_id: Option<String>,\n\n #[arg(long, default_value = \"main\")]\n revision: String,\n\n #[arg(long, default_value = \"1b\")]\n model: Which,\n\n #[arg(long)]\n tokenizer_file: Option<String>,\n\n #[arg(long)]\n weight_files: Option<String>,\n\n /// Penalty to be applied for repeating tokens, 1. means no penalty.\n #[arg(long, default_value_t = 1.1)]\n repeat_penalty: f32,\n\n /// The context size to consider for the repeat penalty.\n #[arg(long, default_value_t = 64)]\n repeat_last_n: usize,\n}\n\nfn main() -> Result<()> {\n use tracing_chrome::ChromeLayerBuilder;\n use tracing_subscriber::prelude::*;\n\n let args = Args::parse();\n let _guard = if args.tracing {\n let (chrome_layer, guard) = ChromeLayerBuilder::new().build();\n tracing_subscriber::registry().with(chrome_layer).init();\n Some(guard)\n } else {\n None\n };\n println!(\n \"avx: {}, neon: {}, simd128: {}, f16c: {}\",\n candle::utils::with_avx(),\n candle::utils::with_neon(),\n candle::utils::with_simd128(),\n candle::utils::with_f16c()\n );\n println!(\n \"temp: {:.2} repeat-penalty: {:.2} repeat-last-n: {}\",\n args.temperature.unwrap_or(0.),\n args.repeat_penalty,\n args.repeat_last_n\n );\n\n let start = std::time::Instant::now();\n let api = Api::new()?;\n let model_id = match args.model_id {\n Some(model_id) => model_id,\n None => match args.model {\n Which::W1b => \"allenai/OLMo-1B-hf\".to_string(),\n Which::W7b => \"allenai/OLMo-7B-hf\".to_string(),\n Which::W7bTwin2T => \"allenai/OLMo-7B-Twin-2T-hf\".to_string(),\n Which::V1_7W7b => \"allenai/OLMo-1.7-7B-hf\".to_string(),\n },\n };\n\n let repo = api.repo(Repo::with_revision(\n model_id,\n RepoType::Model,\n args.revision,\n ));\n let tokenizer_filename = match args.tokenizer_file {\n Some(file) => std::path::PathBuf::from(file),\n None => repo.get(\"tokenizer.json\")?,\n };\n let filenames = match args.weight_files {\n Some(files) => files\n .split(',')\n .map(std::path::PathBuf::from)\n .collect::<Vec<_>>(),\n None => match args.model {\n Which::W1b => {\n vec![repo.get(\"model.safetensors\")?]\n }\n _ => candle_examples::hub_load_safetensors(&repo, \"model.safetensors.index.json\")?,\n },\n };\n\n println!(\"retrieved the files in {:?}\", start.elapsed());\n let tokenizer = Tokenizer::from_file(tokenizer_filename).map_err(E::msg)?;\n\n let start = std::time::Instant::now();\n let config = {\n let config_filename = repo.get(\"config.json\")?;\n let config: Config = serde_json::from_slice(&std::fs::read(config_filename)?)?;\n config\n };\n\n let device = candle_examples::device(args.cpu)?;\n let model = {\n let dtype = if device.is_cuda() {\n DType::BF16\n } else {\n DType::F32\n };\n let vb = unsafe { VarBuilder::from_mmaped_safetensors(&filenames, dtype, &device)? };\n let model = OLMo::new(&config, vb)?;\n Model::OLMo(model)\n };\n\n println!(\"loaded the model in {:?}\", start.elapsed());\n\n let mut pipeline = TextGeneration::new(\n model,\n tokenizer,\n args.seed,\n args.temperature,\n args.top_p,\n args.repeat_penalty,\n args.repeat_last_n,\n &device,\n );\n pipeline.run(&args.prompt, args.sample_len)?;\n Ok(())\n}\n", "candle-examples\\examples\\onnx\\main.rs": "#[cfg(feature = \"mkl\")]\nextern crate intel_mkl_src;\n\n#[cfg(feature = \"accelerate\")]\nextern crate accelerate_src;\n\nuse candle::{IndexOp, D};\nuse clap::{Parser, ValueEnum};\n\n#[derive(Clone, Copy, Debug, ValueEnum)]\nenum Which {\n SqueezeNet,\n EfficientNet,\n}\n\n#[derive(Parser)]\nstruct Args {\n #[arg(long)]\n image: String,\n\n #[arg(long)]\n model: Option<String>,\n\n /// The model to be used.\n #[arg(value_enum, long, default_value_t = Which::SqueezeNet)]\n which: Which,\n}\n\npub fn main() -> anyhow::Result<()> {\n let args = Args::parse();\n let image = candle_examples::imagenet::load_image224(args.image)?;\n let image = match args.which {\n Which::SqueezeNet => image,\n Which::EfficientNet => image.permute((1, 2, 0))?,\n };\n\n println!(\"loaded image {image:?}\");\n\n let model = match args.model {\n Some(model) => std::path::PathBuf::from(model),\n None => match args.which {\n Which::SqueezeNet => hf_hub::api::sync::Api::new()?\n .model(\"lmz/candle-onnx\".into())\n .get(\"squeezenet1.1-7.onnx\")?,\n Which::EfficientNet => hf_hub::api::sync::Api::new()?\n .model(\"onnx/EfficientNet-Lite4\".into())\n .get(\"efficientnet-lite4-11.onnx\")?,\n },\n };\n\n let model = candle_onnx::read_file(model)?;\n let graph = model.graph.as_ref().unwrap();\n let mut inputs = std::collections::HashMap::new();\n inputs.insert(graph.input[0].name.to_string(), image.unsqueeze(0)?);\n let mut outputs = candle_onnx::simple_eval(&model, inputs)?;\n let output = outputs.remove(&graph.output[0].name).unwrap();\n let prs = match args.which {\n Which::SqueezeNet => candle_nn::ops::softmax(&output, D::Minus1)?,\n Which::EfficientNet => output,\n };\n let prs = prs.i(0)?.to_vec1::<f32>()?;\n\n // Sort the predictions and take the top 5\n let mut top: Vec<_> = prs.iter().enumerate().collect();\n top.sort_by(|a, b| b.1.partial_cmp(a.1).unwrap());\n let top = top.into_iter().take(5).collect::<Vec<_>>();\n\n // Print the top predictions\n for &(i, p) in &top {\n println!(\n \"{:50}: {:.2}%\",\n candle_examples::imagenet::CLASSES[i],\n p * 100.0\n );\n }\n\n Ok(())\n}\n", "candle-examples\\examples\\parler-tts\\main.rs": "#[cfg(feature = \"mkl\")]\nextern crate intel_mkl_src;\n\n#[cfg(feature = \"accelerate\")]\nextern crate accelerate_src;\n\nuse anyhow::Error as E;\nuse clap::Parser;\n\nuse candle::{DType, IndexOp, Tensor};\nuse candle_nn::VarBuilder;\nuse candle_transformers::models::parler_tts::{Config, Model};\nuse tokenizers::Tokenizer;\n\n#[derive(Parser)]\nstruct Args {\n /// Run on CPU rather than on GPU.\n #[arg(long)]\n cpu: bool,\n\n /// Enable tracing (generates a trace-timestamp.json file).\n #[arg(long)]\n tracing: bool,\n\n /// Display the token for the specified prompt.\n #[arg(long)]\n verbose_prompt: bool,\n\n #[arg(long, default_value = \"Hey, how are you doing today?\")]\n prompt: String,\n\n #[arg(\n long,\n default_value = \"A female speaker delivers a slightly expressive and animated speech with a moderate speed and pitch. The recording is of very high quality, with the speaker's voice sounding clear and very close up.\"\n )]\n description: String,\n\n /// The temperature used to generate samples.\n #[arg(long, default_value_t = 0.0)]\n temperature: f64,\n\n /// Nucleus sampling probability cutoff.\n #[arg(long)]\n top_p: Option<f64>,\n\n /// The seed to use when generating random samples.\n #[arg(long, default_value_t = 0)]\n seed: u64,\n\n #[arg(long, default_value_t = 5000)]\n sample_len: usize,\n\n /// Penalty to be applied for repeating tokens, 1. means no penalty.\n #[arg(long, default_value_t = 1.0)]\n repeat_penalty: f32,\n\n /// The context size to consider for the repeat penalty.\n #[arg(long, default_value_t = 64)]\n repeat_last_n: usize,\n\n #[arg(long)]\n model_id: Option<String>,\n\n #[arg(long)]\n revision: Option<String>,\n\n #[arg(long)]\n quantized: bool,\n\n /// Use f16 precision for all the computations rather than f32.\n #[arg(long)]\n f16: bool,\n\n #[arg(long)]\n model_file: Option<String>,\n\n #[arg(long)]\n tokenizer_file: Option<String>,\n\n #[arg(long)]\n config_file: Option<String>,\n\n #[arg(long, default_value_t = 512)]\n max_steps: usize,\n\n /// The output wav file.\n #[arg(long, default_value = \"out.wav\")]\n out_file: String,\n\n #[arg(long, default_value = \"large-v1\")]\n which: Which,\n}\n\n#[derive(Clone, Debug, Copy, PartialEq, Eq, clap::ValueEnum)]\nenum Which {\n #[value(name = \"large-v1\")]\n LargeV1,\n #[value(name = \"mini-v1\")]\n MiniV1,\n}\n\nfn main() -> anyhow::Result<()> {\n use tracing_chrome::ChromeLayerBuilder;\n use tracing_subscriber::prelude::*;\n\n let args = Args::parse();\n\n let _guard = if args.tracing {\n let (chrome_layer, guard) = ChromeLayerBuilder::new().build();\n tracing_subscriber::registry().with(chrome_layer).init();\n Some(guard)\n } else {\n None\n };\n println!(\n \"avx: {}, neon: {}, simd128: {}, f16c: {}\",\n candle::utils::with_avx(),\n candle::utils::with_neon(),\n candle::utils::with_simd128(),\n candle::utils::with_f16c()\n );\n println!(\n \"temp: {:.2} repeat-penalty: {:.2} repeat-last-n: {}\",\n args.temperature, args.repeat_penalty, args.repeat_last_n\n );\n\n let start = std::time::Instant::now();\n let api = hf_hub::api::sync::Api::new()?;\n let model_id = match args.model_id {\n Some(model_id) => model_id.to_string(),\n None => match args.which {\n Which::LargeV1 => \"parler-tts/parler-tts-large-v1\".to_string(),\n Which::MiniV1 => \"parler-tts/parler-tts-mini-v1\".to_string(),\n },\n };\n let revision = match args.revision {\n Some(r) => r,\n None => \"main\".to_string(),\n };\n let repo = api.repo(hf_hub::Repo::with_revision(\n model_id,\n hf_hub::RepoType::Model,\n revision,\n ));\n let model_files = match args.model_file {\n Some(m) => vec![m.into()],\n None => match args.which {\n Which::MiniV1 => vec![repo.get(\"model.safetensors\")?],\n Which::LargeV1 => {\n candle_examples::hub_load_safetensors(&repo, \"model.safetensors.index.json\")?\n }\n },\n };\n let config = match args.config_file {\n Some(m) => m.into(),\n None => repo.get(\"config.json\")?,\n };\n let tokenizer = match args.tokenizer_file {\n Some(m) => m.into(),\n None => repo.get(\"tokenizer.json\")?,\n };\n println!(\"retrieved the files in {:?}\", start.elapsed());\n let tokenizer = Tokenizer::from_file(tokenizer).map_err(E::msg)?;\n\n let start = std::time::Instant::now();\n let device = candle_examples::device(args.cpu)?;\n let vb = unsafe { VarBuilder::from_mmaped_safetensors(&model_files, DType::F32, &device)? };\n let config: Config = serde_json::from_reader(std::fs::File::open(config)?)?;\n let mut model = Model::new(&config, vb)?;\n println!(\"loaded the model in {:?}\", start.elapsed());\n\n let description_tokens = tokenizer\n .encode(args.description, true)\n .map_err(E::msg)?\n .get_ids()\n .to_vec();\n let description_tokens = Tensor::new(description_tokens, &device)?.unsqueeze(0)?;\n let prompt_tokens = tokenizer\n .encode(args.prompt, true)\n .map_err(E::msg)?\n .get_ids()\n .to_vec();\n let prompt_tokens = Tensor::new(prompt_tokens, &device)?.unsqueeze(0)?;\n let lp = candle_transformers::generation::LogitsProcessor::new(\n args.seed,\n Some(args.temperature),\n args.top_p,\n );\n println!(\"starting generation...\");\n let codes = model.generate(&prompt_tokens, &description_tokens, lp, args.max_steps)?;\n println!(\"generated codes\\n{codes}\");\n let codes = codes.to_dtype(DType::I64)?;\n codes.save_safetensors(\"codes\", \"out.safetensors\")?;\n let codes = codes.unsqueeze(0)?;\n let pcm = model\n .audio_encoder\n .decode_codes(&codes.to_device(&device)?)?;\n println!(\"{pcm}\");\n let pcm = pcm.i((0, 0))?;\n let pcm = candle_examples::audio::normalize_loudness(&pcm, 24_000, true)?;\n let pcm = pcm.to_vec1::<f32>()?;\n let mut output = std::fs::File::create(&args.out_file)?;\n candle_examples::wav::write_pcm_as_wav(&mut output, &pcm, config.audio_encoder.sampling_rate)?;\n\n Ok(())\n}\n", "candle-examples\\examples\\phi\\main.rs": "#[cfg(feature = \"mkl\")]\nextern crate intel_mkl_src;\n\n#[cfg(feature = \"accelerate\")]\nextern crate accelerate_src;\n\nuse anyhow::{Error as E, Result};\nuse clap::{Parser, ValueEnum};\n\nuse candle_examples::token_output_stream::TokenOutputStream;\nuse candle_transformers::models::mixformer::{Config, MixFormerSequentialForCausalLM as MixFormer};\nuse candle_transformers::models::phi::{Config as PhiConfig, Model as Phi};\nuse candle_transformers::models::phi3::{Config as Phi3Config, Model as Phi3};\nuse candle_transformers::models::quantized_mixformer::MixFormerSequentialForCausalLM as QMixFormer;\n\nuse candle::{DType, Device, IndexOp, Tensor};\nuse candle_nn::VarBuilder;\nuse candle_transformers::generation::LogitsProcessor;\nuse hf_hub::{api::sync::Api, Repo, RepoType};\nuse tokenizers::Tokenizer;\n\nenum Model {\n MixFormer(MixFormer),\n Phi(Phi),\n Phi3(Phi3),\n Quantized(QMixFormer),\n}\n\nstruct TextGeneration {\n model: Model,\n device: Device,\n tokenizer: TokenOutputStream,\n logits_processor: LogitsProcessor,\n repeat_penalty: f32,\n repeat_last_n: usize,\n verbose_prompt: bool,\n}\n\nimpl TextGeneration {\n #[allow(clippy::too_many_arguments)]\n fn new(\n model: Model,\n tokenizer: Tokenizer,\n seed: u64,\n temp: Option<f64>,\n top_p: Option<f64>,\n repeat_penalty: f32,\n repeat_last_n: usize,\n verbose_prompt: bool,\n device: &Device,\n ) -> Self {\n let logits_processor = LogitsProcessor::new(seed, temp, top_p);\n Self {\n model,\n tokenizer: TokenOutputStream::new(tokenizer),\n logits_processor,\n repeat_penalty,\n repeat_last_n,\n verbose_prompt,\n device: device.clone(),\n }\n }\n\n fn run(&mut self, prompt: &str, sample_len: usize) -> Result<()> {\n use std::io::Write;\n println!(\"starting the inference loop\");\n let tokens = self\n .tokenizer\n .tokenizer()\n .encode(prompt, true)\n .map_err(E::msg)?;\n if tokens.is_empty() {\n anyhow::bail!(\"Empty prompts are not supported in the phi model.\")\n }\n if self.verbose_prompt {\n for (token, id) in tokens.get_tokens().iter().zip(tokens.get_ids().iter()) {\n let token = token.replace('\u2581', \" \").replace(\"<0x0A>\", \"\\n\");\n println!(\"{id:7} -> '{token}'\");\n }\n }\n let mut tokens = tokens.get_ids().to_vec();\n let mut generated_tokens = 0usize;\n let eos_token = match self.tokenizer.get_token(\"<|endoftext|>\") {\n Some(token) => token,\n None => anyhow::bail!(\"cannot find the endoftext token\"),\n };\n print!(\"{prompt}\");\n std::io::stdout().flush()?;\n let start_gen = std::time::Instant::now();\n let mut pos = 0;\n for index in 0..sample_len {\n let context_size = if index > 0 { 1 } else { tokens.len() };\n let ctxt = &tokens[tokens.len().saturating_sub(context_size)..];\n let input = Tensor::new(ctxt, &self.device)?.unsqueeze(0)?;\n let logits = match &mut self.model {\n Model::MixFormer(m) => m.forward(&input)?,\n Model::Phi(m) => m.forward(&input)?,\n Model::Quantized(m) => m.forward(&input)?,\n Model::Phi3(m) => m.forward(&input, pos)?.i((.., 0, ..))?,\n };\n let logits = logits.squeeze(0)?.to_dtype(DType::F32)?;\n let logits = if self.repeat_penalty == 1. {\n logits\n } else {\n let start_at = tokens.len().saturating_sub(self.repeat_last_n);\n candle_transformers::utils::apply_repeat_penalty(\n &logits,\n self.repeat_penalty,\n &tokens[start_at..],\n )?\n };\n\n let next_token = self.logits_processor.sample(&logits)?;\n tokens.push(next_token);\n generated_tokens += 1;\n if next_token == eos_token {\n if let Some(t) = self.tokenizer.decode_rest()? {\n print!(\"{t}\");\n std::io::stdout().flush()?;\n }\n break;\n }\n if let Some(t) = self.tokenizer.next_token(next_token)? {\n print!(\"{t}\");\n std::io::stdout().flush()?;\n }\n pos += context_size;\n }\n let dt = start_gen.elapsed();\n println!(\n \"\\n{generated_tokens} tokens generated ({:.2} token/s)\",\n generated_tokens as f64 / dt.as_secs_f64(),\n );\n Ok(())\n }\n}\n\n#[derive(Clone, Copy, Debug, ValueEnum, PartialEq, Eq)]\nenum WhichModel {\n #[value(name = \"1\")]\n V1,\n #[value(name = \"1.5\")]\n V1_5,\n #[value(name = \"2\")]\n V2,\n #[value(name = \"3\")]\n V3,\n #[value(name = \"3-medium\")]\n V3Medium,\n #[value(name = \"2-old\")]\n V2Old,\n PuffinPhiV2,\n PhiHermes,\n}\n\n#[derive(Parser, Debug)]\n#[command(author, version, about, long_about = None)]\nstruct Args {\n /// Run on CPU rather than on GPU.\n #[arg(long)]\n cpu: bool,\n\n /// Enable tracing (generates a trace-timestamp.json file).\n #[arg(long)]\n tracing: bool,\n\n /// Display the token for the specified prompt.\n #[arg(long)]\n verbose_prompt: bool,\n\n #[arg(long)]\n prompt: Option<String>,\n\n #[arg(long)]\n mmlu_dir: Option<String>,\n\n /// The temperature used to generate samples.\n #[arg(long)]\n temperature: Option<f64>,\n\n /// Nucleus sampling probability cutoff.\n #[arg(long)]\n top_p: Option<f64>,\n\n /// The seed to use when generating random samples.\n #[arg(long, default_value_t = 299792458)]\n seed: u64,\n\n /// The length of the sample to generate (in tokens).\n #[arg(long, short = 'n', default_value_t = 5000)]\n sample_len: usize,\n\n #[arg(long)]\n model_id: Option<String>,\n\n #[arg(long, default_value = \"2\")]\n model: WhichModel,\n\n #[arg(long)]\n revision: Option<String>,\n\n #[arg(long)]\n weight_file: Option<String>,\n\n #[arg(long)]\n tokenizer: Option<String>,\n\n #[arg(long)]\n quantized: bool,\n\n /// Penalty to be applied for repeating tokens, 1. means no penalty.\n #[arg(long, default_value_t = 1.1)]\n repeat_penalty: f32,\n\n /// The context size to consider for the repeat penalty.\n #[arg(long, default_value_t = 64)]\n repeat_last_n: usize,\n\n /// The dtype to be used for running the model, e.g. f32, bf16, or f16.\n #[arg(long)]\n dtype: Option<String>,\n}\n\nfn main() -> Result<()> {\n use tracing_chrome::ChromeLayerBuilder;\n use tracing_subscriber::prelude::*;\n\n let args = Args::parse();\n let _guard = if args.tracing {\n let (chrome_layer, guard) = ChromeLayerBuilder::new().build();\n tracing_subscriber::registry().with(chrome_layer).init();\n Some(guard)\n } else {\n None\n };\n println!(\n \"avx: {}, neon: {}, simd128: {}, f16c: {}\",\n candle::utils::with_avx(),\n candle::utils::with_neon(),\n candle::utils::with_simd128(),\n candle::utils::with_f16c()\n );\n println!(\n \"temp: {:.2} repeat-penalty: {:.2} repeat-last-n: {}\",\n args.temperature.unwrap_or(0.),\n args.repeat_penalty,\n args.repeat_last_n\n );\n\n let start = std::time::Instant::now();\n let api = Api::new()?;\n let model_id = match args.model_id {\n Some(model_id) => model_id.to_string(),\n None => {\n if args.quantized {\n \"lmz/candle-quantized-phi\".to_string()\n } else {\n match args.model {\n WhichModel::V1 => \"microsoft/phi-1\".to_string(),\n WhichModel::V1_5 => \"microsoft/phi-1_5\".to_string(),\n WhichModel::V2 | WhichModel::V2Old => \"microsoft/phi-2\".to_string(),\n WhichModel::V3 => \"microsoft/Phi-3-mini-4k-instruct\".to_string(),\n WhichModel::V3Medium => \"microsoft/Phi-3-medium-4k-instruct\".to_string(),\n WhichModel::PuffinPhiV2 | WhichModel::PhiHermes => {\n \"lmz/candle-quantized-phi\".to_string()\n }\n }\n }\n }\n };\n let revision = match args.revision {\n Some(rev) => rev.to_string(),\n None => {\n if args.quantized {\n \"main\".to_string()\n } else {\n match args.model {\n WhichModel::V1 => \"refs/pr/8\".to_string(),\n WhichModel::V1_5 => \"refs/pr/73\".to_string(),\n WhichModel::V2Old => \"834565c23f9b28b96ccbeabe614dd906b6db551a\".to_string(),\n WhichModel::V2\n | WhichModel::V3\n | WhichModel::V3Medium\n | WhichModel::PuffinPhiV2\n | WhichModel::PhiHermes => \"main\".to_string(),\n }\n }\n }\n };\n let repo = api.repo(Repo::with_revision(model_id, RepoType::Model, revision));\n let tokenizer_filename = match args.tokenizer {\n Some(file) => std::path::PathBuf::from(file),\n None => match args.model {\n WhichModel::V1\n | WhichModel::V1_5\n | WhichModel::V2\n | WhichModel::V2Old\n | WhichModel::V3\n | WhichModel::V3Medium => repo.get(\"tokenizer.json\")?,\n WhichModel::PuffinPhiV2 | WhichModel::PhiHermes => {\n repo.get(\"tokenizer-puffin-phi-v2.json\")?\n }\n },\n };\n let filenames = match args.weight_file {\n Some(weight_file) => vec![std::path::PathBuf::from(weight_file)],\n None => {\n if args.quantized {\n match args.model {\n WhichModel::V1 => vec![repo.get(\"model-v1-q4k.gguf\")?],\n WhichModel::V1_5 => vec![repo.get(\"model-q4k.gguf\")?],\n WhichModel::V2 | WhichModel::V2Old => vec![repo.get(\"model-v2-q4k.gguf\")?],\n WhichModel::PuffinPhiV2 => vec![repo.get(\"model-puffin-phi-v2-q4k.gguf\")?],\n WhichModel::PhiHermes => vec![repo.get(\"model-phi-hermes-1_3B-q4k.gguf\")?],\n WhichModel::V3 | WhichModel::V3Medium => anyhow::bail!(\n \"use the quantized or quantized-phi examples for quantized phi-v3\"\n ),\n }\n } else {\n match args.model {\n WhichModel::V1 | WhichModel::V1_5 => vec![repo.get(\"model.safetensors\")?],\n WhichModel::V2 | WhichModel::V2Old | WhichModel::V3 | WhichModel::V3Medium => {\n candle_examples::hub_load_safetensors(\n &repo,\n \"model.safetensors.index.json\",\n )?\n }\n WhichModel::PuffinPhiV2 => vec![repo.get(\"model-puffin-phi-v2.safetensors\")?],\n WhichModel::PhiHermes => vec![repo.get(\"model-phi-hermes-1_3B.safetensors\")?],\n }\n }\n }\n };\n println!(\"retrieved the files in {:?}\", start.elapsed());\n let tokenizer = Tokenizer::from_file(tokenizer_filename).map_err(E::msg)?;\n\n let start = std::time::Instant::now();\n let config = || match args.model {\n WhichModel::V1 => Config::v1(),\n WhichModel::V1_5 => Config::v1_5(),\n WhichModel::V2 | WhichModel::V2Old => Config::v2(),\n WhichModel::PuffinPhiV2 => Config::puffin_phi_v2(),\n WhichModel::PhiHermes => Config::phi_hermes_1_3b(),\n WhichModel::V3 | WhichModel::V3Medium => {\n panic!(\"use the quantized or quantized-phi examples for quantized phi-v3\")\n }\n };\n let device = candle_examples::device(args.cpu)?;\n let model = if args.quantized {\n let config = config();\n let vb = candle_transformers::quantized_var_builder::VarBuilder::from_gguf(\n &filenames[0],\n &device,\n )?;\n let model = match args.model {\n WhichModel::V2 | WhichModel::V2Old => QMixFormer::new_v2(&config, vb)?,\n _ => QMixFormer::new(&config, vb)?,\n };\n Model::Quantized(model)\n } else {\n let dtype = match args.dtype {\n Some(dtype) => std::str::FromStr::from_str(&dtype)?,\n None => {\n if args.model == WhichModel::V3 || args.model == WhichModel::V3Medium {\n device.bf16_default_to_f32()\n } else {\n DType::F32\n }\n }\n };\n let vb = unsafe { VarBuilder::from_mmaped_safetensors(&filenames, dtype, &device)? };\n match args.model {\n WhichModel::V1 | WhichModel::V1_5 | WhichModel::V2 => {\n let config_filename = repo.get(\"config.json\")?;\n let config = std::fs::read_to_string(config_filename)?;\n let config: PhiConfig = serde_json::from_str(&config)?;\n let phi = Phi::new(&config, vb)?;\n Model::Phi(phi)\n }\n WhichModel::V3 | WhichModel::V3Medium => {\n let config_filename = repo.get(\"config.json\")?;\n let config = std::fs::read_to_string(config_filename)?;\n let config: Phi3Config = serde_json::from_str(&config)?;\n let phi3 = Phi3::new(&config, vb)?;\n Model::Phi3(phi3)\n }\n WhichModel::V2Old => {\n let config = config();\n Model::MixFormer(MixFormer::new_v2(&config, vb)?)\n }\n WhichModel::PhiHermes | WhichModel::PuffinPhiV2 => {\n let config = config();\n Model::MixFormer(MixFormer::new(&config, vb)?)\n }\n }\n };\n println!(\"loaded the model in {:?}\", start.elapsed());\n\n match (args.prompt, args.mmlu_dir) {\n (None, None) | (Some(_), Some(_)) => {\n anyhow::bail!(\"exactly one of --prompt and --mmlu-dir must be specified\")\n }\n (Some(prompt), None) => {\n let mut pipeline = TextGeneration::new(\n model,\n tokenizer,\n args.seed,\n args.temperature,\n args.top_p,\n args.repeat_penalty,\n args.repeat_last_n,\n args.verbose_prompt,\n &device,\n );\n pipeline.run(&prompt, args.sample_len)?;\n }\n (None, Some(mmlu_dir)) => mmlu(model, tokenizer, &device, mmlu_dir)?,\n }\n Ok(())\n}\n\nfn mmlu<P: AsRef<std::path::Path>>(\n mut model: Model,\n tokenizer: Tokenizer,\n device: &Device,\n mmlu_dir: P,\n) -> anyhow::Result<()> {\n for dir_entry in mmlu_dir.as_ref().read_dir()?.flatten() {\n let dir_entry = dir_entry.path();\n let theme = match dir_entry.file_stem().and_then(|v| v.to_str()) {\n None => \"\".to_string(),\n Some(v) => match v.strip_suffix(\"_test\") {\n None => v.replace('_', \" \"),\n Some(v) => v.replace('_', \" \"),\n },\n };\n if dir_entry.extension().as_ref().and_then(|v| v.to_str()) != Some(\"csv\") {\n continue;\n }\n println!(\"reading {dir_entry:?}\");\n let dir_entry = std::fs::File::open(dir_entry)?;\n let mut reader = csv::ReaderBuilder::new()\n .has_headers(false)\n .from_reader(dir_entry);\n let token_a = tokenizer.token_to_id(\"A\").unwrap();\n let token_b = tokenizer.token_to_id(\"B\").unwrap();\n let token_c = tokenizer.token_to_id(\"C\").unwrap();\n let token_d = tokenizer.token_to_id(\"D\").unwrap();\n for row in reader.records() {\n let row = match row {\n Err(_) => continue,\n Ok(row) => row,\n };\n if row.len() < 5 {\n continue;\n }\n let question = row.get(0).unwrap();\n let answer_a = row.get(1).unwrap();\n let answer_b = row.get(2).unwrap();\n let answer_c = row.get(3).unwrap();\n let answer_d = row.get(4).unwrap();\n let answer = row.get(5).unwrap();\n let prompt = format!(\n \"{} {theme}.\\n{question}\\nA. {answer_a}\\nB. {answer_b}\\nC. {answer_c}\\nD. {answer_d}\\nAnswer:\\n\",\n \"The following are multiple choice questions (with answers) about\"\n );\n let tokens = tokenizer.encode(prompt.as_str(), true).map_err(E::msg)?;\n let tokens = tokens.get_ids().to_vec();\n let input = Tensor::new(tokens, device)?.unsqueeze(0)?;\n let logits = match &mut model {\n Model::MixFormer(m) => {\n m.clear_kv_cache();\n m.forward(&input)?\n }\n Model::Phi(m) => {\n m.clear_kv_cache();\n m.forward(&input)?\n }\n Model::Phi3(m) => {\n m.clear_kv_cache();\n m.forward(&input, 0)?\n }\n Model::Quantized(m) => {\n m.clear_kv_cache();\n m.forward(&input)?\n }\n };\n let logits = logits.squeeze(0)?.to_dtype(DType::F32)?;\n let logits_v: Vec<f32> = logits.to_vec1()?;\n let pr_a = logits_v[token_a as usize];\n let pr_b = logits_v[token_b as usize];\n let pr_c = logits_v[token_c as usize];\n let pr_d = logits_v[token_d as usize];\n let model_answer = if pr_a > pr_b && pr_a > pr_c && pr_a > pr_d {\n \"A\"\n } else if pr_b > pr_c && pr_b > pr_d {\n \"B\"\n } else if pr_c > pr_d {\n \"C\"\n } else {\n \"D\"\n };\n\n println!(\"{prompt}\\n -> {model_answer} vs {answer}\");\n }\n }\n Ok(())\n}\n", "candle-examples\\examples\\quantized\\main.rs": "#[cfg(feature = \"mkl\")]\nextern crate intel_mkl_src;\n\n#[cfg(feature = \"accelerate\")]\nextern crate accelerate_src;\n\nuse clap::{Parser, ValueEnum};\nuse std::io::Write;\nuse tokenizers::Tokenizer;\n\nuse candle::quantized::{ggml_file, gguf_file};\nuse candle::Tensor;\nuse candle_transformers::generation::{LogitsProcessor, Sampling};\n\nuse candle_examples::token_output_stream::TokenOutputStream;\nuse candle_transformers::models::quantized_llama as model;\nuse model::ModelWeights;\n\nconst DEFAULT_PROMPT: &str = \"My favorite theorem is \";\n\n#[derive(Debug)]\nenum Prompt {\n Interactive,\n Chat,\n One(String),\n}\n\n#[derive(Clone, Debug, Copy, PartialEq, Eq, ValueEnum)]\nenum Which {\n #[value(name = \"7b\")]\n L7b,\n #[value(name = \"13b\")]\n L13b,\n #[value(name = \"70b\")]\n L70b,\n #[value(name = \"7b-chat\")]\n L7bChat,\n #[value(name = \"13b-chat\")]\n L13bChat,\n #[value(name = \"70b-chat\")]\n L70bChat,\n #[value(name = \"7b-code\")]\n L7bCode,\n #[value(name = \"13b-code\")]\n L13bCode,\n #[value(name = \"32b-code\")]\n L34bCode,\n #[value(name = \"7b-leo\")]\n Leo7b,\n #[value(name = \"13b-leo\")]\n Leo13b,\n #[value(name = \"7b-mistral\")]\n Mistral7b,\n #[value(name = \"7b-mistral-instruct\")]\n Mistral7bInstruct,\n #[value(name = \"7b-mistral-instruct-v0.2\")]\n Mistral7bInstructV02,\n #[value(name = \"7b-zephyr-a\")]\n Zephyr7bAlpha,\n #[value(name = \"7b-zephyr-b\")]\n Zephyr7bBeta,\n #[value(name = \"7b-open-chat-3.5\")]\n OpenChat35,\n #[value(name = \"7b-starling-a\")]\n Starling7bAlpha,\n #[value(name = \"mixtral\")]\n Mixtral,\n #[value(name = \"mixtral-instruct\")]\n MixtralInstruct,\n #[value(name = \"llama3-8b\")]\n L8b,\n #[value(name = \"phi3\")]\n Phi3,\n}\n\nimpl Which {\n fn is_mistral(&self) -> bool {\n match self {\n Self::L7b\n | Self::L13b\n | Self::L70b\n | Self::L7bChat\n | Self::L13bChat\n | Self::L70bChat\n | Self::L7bCode\n | Self::L13bCode\n | Self::L34bCode\n | Self::Leo7b\n | Self::Leo13b\n | Self::L8b\n | Self::Phi3 => false,\n // Zephyr and OpenChat are fine tuned versions of mistral and should be treated in the\n // same way. Starling is a fine tuned version of OpenChat.\n Self::OpenChat35\n | Self::Starling7bAlpha\n | Self::Zephyr7bAlpha\n | Self::Zephyr7bBeta\n | Self::Mixtral\n | Self::MixtralInstruct\n | Self::Mistral7b\n | Self::Mistral7bInstruct\n | Self::Mistral7bInstructV02 => true,\n }\n }\n\n fn is_zephyr(&self) -> bool {\n match self {\n Self::L7b\n | Self::L13b\n | Self::L70b\n | Self::L7bChat\n | Self::L13bChat\n | Self::L70bChat\n | Self::L7bCode\n | Self::L13bCode\n | Self::L34bCode\n | Self::Leo7b\n | Self::Leo13b\n | Self::Mixtral\n | Self::MixtralInstruct\n | Self::Mistral7b\n | Self::Mistral7bInstruct\n | Self::Mistral7bInstructV02\n | Self::OpenChat35\n | Self::Starling7bAlpha\n | Self::L8b\n | Self::Phi3 => false,\n Self::Zephyr7bAlpha | Self::Zephyr7bBeta => true,\n }\n }\n\n fn is_open_chat(&self) -> bool {\n match self {\n Self::L7b\n | Self::L13b\n | Self::L70b\n | Self::L7bChat\n | Self::L13bChat\n | Self::L70bChat\n | Self::L7bCode\n | Self::L13bCode\n | Self::L34bCode\n | Self::Leo7b\n | Self::Leo13b\n | Self::Mixtral\n | Self::MixtralInstruct\n | Self::Mistral7b\n | Self::Mistral7bInstruct\n | Self::Mistral7bInstructV02\n | Self::Zephyr7bAlpha\n | Self::Zephyr7bBeta\n | Self::L8b\n | Self::Phi3 => false,\n Self::OpenChat35 | Self::Starling7bAlpha => true,\n }\n }\n\n fn tokenizer_repo(&self) -> &'static str {\n match self {\n Self::L7b\n | Self::L13b\n | Self::L70b\n | Self::L7bChat\n | Self::L13bChat\n | Self::L70bChat\n | Self::L7bCode\n | Self::L13bCode\n | Self::L34bCode => \"hf-internal-testing/llama-tokenizer\",\n Self::Leo7b => \"LeoLM/leo-hessianai-7b\",\n Self::Leo13b => \"LeoLM/leo-hessianai-13b\",\n Self::Mixtral => \"mistralai/Mixtral-8x7B-v0.1\",\n Self::MixtralInstruct => \"mistralai/Mixtral-8x7B-Instruct-v0.1\",\n Self::Mistral7b\n | Self::Mistral7bInstruct\n | Self::Mistral7bInstructV02\n | Self::Zephyr7bAlpha\n | Self::Zephyr7bBeta => \"mistralai/Mistral-7B-v0.1\",\n Self::OpenChat35 => \"openchat/openchat_3.5\",\n Self::Starling7bAlpha => \"berkeley-nest/Starling-LM-7B-alpha\",\n Self::L8b => \"meta-llama/Meta-Llama-3-8B\",\n Self::Phi3 => \"microsoft/Phi-3-mini-4k-instruct\",\n }\n }\n}\n\n#[derive(Parser, Debug)]\n#[command(author, version, about, long_about = None)]\nstruct Args {\n /// GGML/GGUF file to load, typically a .bin/.gguf file generated by the quantize command from llama.cpp\n #[arg(long)]\n model: Option<String>,\n\n /// The initial prompt, use 'interactive' for entering multiple prompts in an interactive way\n /// and 'chat' for an interactive model where history of previous prompts and generated tokens\n /// is preserved.\n #[arg(long)]\n prompt: Option<String>,\n\n /// The length of the sample to generate (in tokens).\n #[arg(short = 'n', long, default_value_t = 1000)]\n sample_len: usize,\n\n /// The tokenizer config in json format.\n #[arg(long)]\n tokenizer: Option<String>,\n\n /// The temperature used to generate samples, use 0 for greedy sampling.\n #[arg(long, default_value_t = 0.8)]\n temperature: f64,\n\n /// Nucleus sampling probability cutoff.\n #[arg(long)]\n top_p: Option<f64>,\n\n /// Only sample among the top K samples.\n #[arg(long)]\n top_k: Option<usize>,\n\n /// The seed to use when generating random samples.\n #[arg(long, default_value_t = 299792458)]\n seed: u64,\n\n /// Enable tracing (generates a trace-timestamp.json file).\n #[arg(long)]\n tracing: bool,\n\n /// Display the token for the specified prompt.\n #[arg(long)]\n verbose_prompt: bool,\n\n /// Process prompt elements separately.\n #[arg(long)]\n split_prompt: bool,\n\n /// Run on CPU rather than GPU even if a GPU is available.\n #[arg(long)]\n cpu: bool,\n\n /// Penalty to be applied for repeating tokens, 1. means no penalty.\n #[arg(long, default_value_t = 1.1)]\n repeat_penalty: f32,\n\n /// The context size to consider for the repeat penalty.\n #[arg(long, default_value_t = 64)]\n repeat_last_n: usize,\n\n /// The model size to use.\n #[arg(long, default_value = \"7b\")]\n which: Which,\n\n /// Group-Query Attention, use 8 for the 70B version of LLaMAv2.\n #[arg(long)]\n gqa: Option<usize>,\n\n /// Use the slower dmmv cuda kernel.\n #[arg(long)]\n force_dmmv: bool,\n}\n\nimpl Args {\n fn tokenizer(&self) -> anyhow::Result<Tokenizer> {\n let tokenizer_path = match &self.tokenizer {\n Some(config) => std::path::PathBuf::from(config),\n None => {\n let api = hf_hub::api::sync::Api::new()?;\n let repo = self.which.tokenizer_repo();\n let api = api.model(repo.to_string());\n api.get(\"tokenizer.json\")?\n }\n };\n Tokenizer::from_file(tokenizer_path).map_err(anyhow::Error::msg)\n }\n\n fn model(&self) -> anyhow::Result<std::path::PathBuf> {\n let model_path = match &self.model {\n Some(config) => std::path::PathBuf::from(config),\n None => {\n let (repo, filename) = match self.which {\n Which::L7b => (\"TheBloke/Llama-2-7B-GGML\", \"llama-2-7b.ggmlv3.q4_0.bin\"),\n Which::L13b => (\"TheBloke/Llama-2-13B-GGML\", \"llama-2-13b.ggmlv3.q4_0.bin\"),\n Which::L70b => (\"TheBloke/Llama-2-70B-GGML\", \"llama-2-70b.ggmlv3.q4_0.bin\"),\n Which::L7bChat => (\n \"TheBloke/Llama-2-7B-Chat-GGML\",\n \"llama-2-7b-chat.ggmlv3.q4_0.bin\",\n ),\n Which::L13bChat => (\n \"TheBloke/Llama-2-13B-Chat-GGML\",\n \"llama-2-13b-chat.ggmlv3.q4_0.bin\",\n ),\n Which::L70bChat => (\n \"TheBloke/Llama-2-70B-Chat-GGML\",\n \"llama-2-70b-chat.ggmlv3.q4_0.bin\",\n ),\n Which::L7bCode => (\"TheBloke/CodeLlama-7B-GGUF\", \"codellama-7b.Q8_0.gguf\"),\n Which::L13bCode => (\"TheBloke/CodeLlama-13B-GGUF\", \"codellama-13b.Q8_0.gguf\"),\n Which::L34bCode => (\"TheBloke/CodeLlama-34B-GGUF\", \"codellama-34b.Q8_0.gguf\"),\n Which::Leo7b => (\n \"TheBloke/leo-hessianai-7B-GGUF\",\n \"leo-hessianai-7b.Q4_K_M.gguf\",\n ),\n Which::Leo13b => (\n \"TheBloke/leo-hessianai-13B-GGUF\",\n \"leo-hessianai-13b.Q4_K_M.gguf\",\n ),\n Which::Mixtral => (\n \"TheBloke/Mixtral-8x7B-v0.1-GGUF\",\n \"mixtral-8x7b-v0.1.Q4_K_M.gguf\",\n ),\n Which::MixtralInstruct => (\n \"TheBloke/Mixtral-8x7B-Instruct-v0.1-GGUF\",\n \"mixtral-8x7b-instruct-v0.1.Q4_K_M.gguf\",\n ),\n Which::Mistral7b => (\n \"TheBloke/Mistral-7B-v0.1-GGUF\",\n \"mistral-7b-v0.1.Q4_K_S.gguf\",\n ),\n Which::Mistral7bInstruct => (\n \"TheBloke/Mistral-7B-Instruct-v0.1-GGUF\",\n \"mistral-7b-instruct-v0.1.Q4_K_S.gguf\",\n ),\n Which::Mistral7bInstructV02 => (\n \"TheBloke/Mistral-7B-Instruct-v0.2-GGUF\",\n \"mistral-7b-instruct-v0.2.Q4_K_S.gguf\",\n ),\n Which::Zephyr7bAlpha => (\n \"TheBloke/zephyr-7B-alpha-GGUF\",\n \"zephyr-7b-alpha.Q4_K_M.gguf\",\n ),\n Which::Zephyr7bBeta => {\n (\"TheBloke/zephyr-7B-beta-GGUF\", \"zephyr-7b-beta.Q4_K_M.gguf\")\n }\n Which::OpenChat35 => (\"TheBloke/openchat_3.5-GGUF\", \"openchat_3.5.Q4_K_M.gguf\"),\n Which::Starling7bAlpha => (\n \"TheBloke/Starling-LM-7B-alpha-GGUF\",\n \"starling-lm-7b-alpha.Q4_K_M.gguf\",\n ),\n // TODO: swap to TheBloke model when available\n Which::L8b => (\n \"QuantFactory/Meta-Llama-3-8B-GGUF\",\n \"Meta-Llama-3-8B.Q4_K_S.gguf\",\n ),\n Which::Phi3 => (\n \"microsoft/Phi-3-mini-4k-instruct-gguf\",\n \"Phi-3-mini-4k-instruct-q4.gguf\",\n ),\n };\n let revision = if self.which == Which::Phi3 {\n \"5eef2ce24766d31909c0b269fe90c817a8f263fb\"\n } else {\n \"main\"\n };\n let api = hf_hub::api::sync::Api::new()?;\n api.repo(hf_hub::Repo::with_revision(\n repo.to_string(),\n hf_hub::RepoType::Model,\n revision.to_string(),\n ))\n .get(filename)?\n }\n };\n Ok(model_path)\n }\n}\n\nfn format_size(size_in_bytes: usize) -> String {\n if size_in_bytes < 1_000 {\n format!(\"{}B\", size_in_bytes)\n } else if size_in_bytes < 1_000_000 {\n format!(\"{:.2}KB\", size_in_bytes as f64 / 1e3)\n } else if size_in_bytes < 1_000_000_000 {\n format!(\"{:.2}MB\", size_in_bytes as f64 / 1e6)\n } else {\n format!(\"{:.2}GB\", size_in_bytes as f64 / 1e9)\n }\n}\n\nfn main() -> anyhow::Result<()> {\n use tracing_chrome::ChromeLayerBuilder;\n use tracing_subscriber::prelude::*;\n\n let args = Args::parse();\n\n #[cfg(feature = \"cuda\")]\n candle::quantized::cuda::set_force_dmmv(args.force_dmmv);\n\n candle::cuda::set_gemm_reduced_precision_f16(true);\n candle::cuda::set_gemm_reduced_precision_bf16(true);\n\n let _guard = if args.tracing {\n let (chrome_layer, guard) = ChromeLayerBuilder::new().build();\n tracing_subscriber::registry().with(chrome_layer).init();\n Some(guard)\n } else {\n None\n };\n\n println!(\n \"avx: {}, neon: {}, simd128: {}, f16c: {}\",\n candle::utils::with_avx(),\n candle::utils::with_neon(),\n candle::utils::with_simd128(),\n candle::utils::with_f16c()\n );\n println!(\n \"temp: {:.2} repeat-penalty: {:.2} repeat-last-n: {}\",\n args.temperature, args.repeat_penalty, args.repeat_last_n\n );\n\n let model_path = args.model()?;\n let mut file = std::fs::File::open(&model_path)?;\n let start = std::time::Instant::now();\n let device = candle_examples::device(args.cpu)?;\n\n let mut model = match model_path.extension().and_then(|v| v.to_str()) {\n Some(\"gguf\") => {\n let model = gguf_file::Content::read(&mut file).map_err(|e| e.with_path(model_path))?;\n let mut total_size_in_bytes = 0;\n for (_, tensor) in model.tensor_infos.iter() {\n let elem_count = tensor.shape.elem_count();\n total_size_in_bytes +=\n elem_count * tensor.ggml_dtype.type_size() / tensor.ggml_dtype.block_size();\n }\n println!(\n \"loaded {:?} tensors ({}) in {:.2}s\",\n model.tensor_infos.len(),\n &format_size(total_size_in_bytes),\n start.elapsed().as_secs_f32(),\n );\n ModelWeights::from_gguf(model, &mut file, &device)?\n }\n Some(\"ggml\" | \"bin\") | Some(_) | None => {\n let model = ggml_file::Content::read(&mut file, &device)\n .map_err(|e| e.with_path(model_path))?;\n let mut total_size_in_bytes = 0;\n for (_, tensor) in model.tensors.iter() {\n let elem_count = tensor.shape().elem_count();\n total_size_in_bytes +=\n elem_count * tensor.dtype().type_size() / tensor.dtype().block_size();\n }\n println!(\n \"loaded {:?} tensors ({}) in {:.2}s\",\n model.tensors.len(),\n &format_size(total_size_in_bytes),\n start.elapsed().as_secs_f32(),\n );\n println!(\"params: {:?}\", model.hparams);\n let default_gqa = match args.which {\n Which::L7b\n | Which::L13b\n | Which::L7bChat\n | Which::L13bChat\n | Which::L7bCode\n | Which::L13bCode\n | Which::L34bCode\n | Which::Leo7b\n | Which::Leo13b\n | Which::L8b\n | Which::Phi3 => 1,\n Which::Mixtral\n | Which::MixtralInstruct\n | Which::Mistral7b\n | Which::Mistral7bInstruct\n | Which::Mistral7bInstructV02\n | Which::Zephyr7bAlpha\n | Which::Zephyr7bBeta\n | Which::L70b\n | Which::L70bChat\n | Which::OpenChat35\n | Which::Starling7bAlpha => 8,\n };\n ModelWeights::from_ggml(model, args.gqa.unwrap_or(default_gqa))?\n }\n };\n println!(\"model built\");\n\n let tokenizer = args.tokenizer()?;\n let mut tos = TokenOutputStream::new(tokenizer);\n let prompt = match args.prompt.as_deref() {\n Some(\"chat\") => Prompt::Chat,\n Some(\"interactive\") => Prompt::Interactive,\n Some(s) => Prompt::One(s.to_string()),\n None => Prompt::One(DEFAULT_PROMPT.to_string()),\n };\n\n let mut pre_prompt_tokens = vec![];\n for prompt_index in 0.. {\n let prompt_str = match &prompt {\n Prompt::One(prompt) => prompt.clone(),\n Prompt::Interactive | Prompt::Chat => {\n let is_interactive = matches!(prompt, Prompt::Interactive);\n print!(\"> \");\n std::io::stdout().flush()?;\n let mut prompt = String::new();\n std::io::stdin().read_line(&mut prompt)?;\n if prompt.ends_with('\\n') {\n prompt.pop();\n if prompt.ends_with('\\r') {\n prompt.pop();\n }\n }\n if args.which.is_open_chat() {\n format!(\"GPT4 Correct User: {prompt}<|end_of_turn|>GPT4 Correct Assistant:\")\n } else if args.which.is_zephyr() {\n if prompt_index == 0 || is_interactive {\n format!(\"<|system|>\\n</s>\\n<|user|>\\n{prompt}</s>\\n<|assistant|>\",)\n } else {\n format!(\"<|user|>\\n{prompt}</s>\\n<|assistant|>\")\n }\n } else if args.which.is_mistral() {\n format!(\"[INST] {prompt} [/INST]\")\n } else {\n prompt\n }\n }\n };\n print!(\"{}\", &prompt_str);\n let tokens = tos\n .tokenizer()\n .encode(prompt_str, true)\n .map_err(anyhow::Error::msg)?;\n if args.verbose_prompt {\n for (token, id) in tokens.get_tokens().iter().zip(tokens.get_ids().iter()) {\n let token = token.replace('\u2581', \" \").replace(\"<0x0A>\", \"\\n\");\n println!(\"{id:7} -> '{token}'\");\n }\n }\n\n let prompt_tokens = [&pre_prompt_tokens, tokens.get_ids()].concat();\n let to_sample = args.sample_len.saturating_sub(1);\n let prompt_tokens = if prompt_tokens.len() + to_sample > model::MAX_SEQ_LEN - 10 {\n let to_remove = prompt_tokens.len() + to_sample + 10 - model::MAX_SEQ_LEN;\n prompt_tokens[prompt_tokens.len().saturating_sub(to_remove)..].to_vec()\n } else {\n prompt_tokens\n };\n let mut all_tokens = vec![];\n let mut logits_processor = {\n let temperature = args.temperature;\n let sampling = if temperature <= 0. {\n Sampling::ArgMax\n } else {\n match (args.top_k, args.top_p) {\n (None, None) => Sampling::All { temperature },\n (Some(k), None) => Sampling::TopK { k, temperature },\n (None, Some(p)) => Sampling::TopP { p, temperature },\n (Some(k), Some(p)) => Sampling::TopKThenTopP { k, p, temperature },\n }\n };\n LogitsProcessor::from_sampling(args.seed, sampling)\n };\n\n let start_prompt_processing = std::time::Instant::now();\n let mut next_token = if !args.split_prompt {\n let input = Tensor::new(prompt_tokens.as_slice(), &device)?.unsqueeze(0)?;\n let logits = model.forward(&input, 0)?;\n let logits = logits.squeeze(0)?;\n logits_processor.sample(&logits)?\n } else {\n let mut next_token = 0;\n for (pos, token) in prompt_tokens.iter().enumerate() {\n let input = Tensor::new(&[*token], &device)?.unsqueeze(0)?;\n let logits = model.forward(&input, pos)?;\n let logits = logits.squeeze(0)?;\n next_token = logits_processor.sample(&logits)?\n }\n next_token\n };\n let prompt_dt = start_prompt_processing.elapsed();\n all_tokens.push(next_token);\n if let Some(t) = tos.next_token(next_token)? {\n print!(\"{t}\");\n std::io::stdout().flush()?;\n }\n\n let eos_token = match args.which {\n Which::L8b => \"<|end_of_text|>\",\n _ => match args.which.is_open_chat() {\n true => \"<|end_of_turn|>\",\n false => \"</s>\",\n },\n };\n\n let eos_token = *tos.tokenizer().get_vocab(true).get(eos_token).unwrap();\n let start_post_prompt = std::time::Instant::now();\n let mut sampled = 0;\n for index in 0..to_sample {\n let input = Tensor::new(&[next_token], &device)?.unsqueeze(0)?;\n let logits = model.forward(&input, prompt_tokens.len() + index)?;\n let logits = logits.squeeze(0)?;\n let logits = if args.repeat_penalty == 1. {\n logits\n } else {\n let start_at = all_tokens.len().saturating_sub(args.repeat_last_n);\n candle_transformers::utils::apply_repeat_penalty(\n &logits,\n args.repeat_penalty,\n &all_tokens[start_at..],\n )?\n };\n next_token = logits_processor.sample(&logits)?;\n all_tokens.push(next_token);\n if let Some(t) = tos.next_token(next_token)? {\n print!(\"{t}\");\n std::io::stdout().flush()?;\n }\n sampled += 1;\n if next_token == eos_token {\n break;\n };\n }\n if let Some(rest) = tos.decode_rest().map_err(candle::Error::msg)? {\n print!(\"{rest}\");\n }\n std::io::stdout().flush()?;\n let dt = start_post_prompt.elapsed();\n println!(\n \"\\n\\n{:4} prompt tokens processed: {:.2} token/s\",\n prompt_tokens.len(),\n prompt_tokens.len() as f64 / prompt_dt.as_secs_f64(),\n );\n println!(\n \"{sampled:4} tokens generated: {:.2} token/s\",\n sampled as f64 / dt.as_secs_f64(),\n );\n\n match prompt {\n Prompt::One(_) => break,\n Prompt::Interactive => {}\n Prompt::Chat => {\n pre_prompt_tokens = [prompt_tokens.as_slice(), all_tokens.as_slice()].concat()\n }\n }\n }\n\n Ok(())\n}\n", "candle-examples\\examples\\quantized-phi\\main.rs": "#[cfg(feature = \"mkl\")]\nextern crate intel_mkl_src;\n\n#[cfg(feature = \"accelerate\")]\nextern crate accelerate_src;\n\nuse clap::{Parser, ValueEnum};\nuse std::io::Write;\nuse tokenizers::Tokenizer;\n\nuse candle::quantized::gguf_file;\nuse candle::Tensor;\nuse candle_transformers::generation::{LogitsProcessor, Sampling};\n\nuse candle_examples::token_output_stream::TokenOutputStream;\nuse candle_transformers::models::quantized_llama::ModelWeights as Phi3b;\nuse candle_transformers::models::quantized_phi::ModelWeights as Phi2;\nuse candle_transformers::models::quantized_phi3::ModelWeights as Phi3;\n\nconst DEFAULT_PROMPT: &str = \"Write a function to count prime numbers up to N. \";\n\n#[derive(Clone, Debug, Copy, PartialEq, Eq, ValueEnum)]\nenum Which {\n #[value(name = \"phi-2\")]\n Phi2,\n #[value(name = \"phi-3\")]\n Phi3,\n /// Alternative implementation of phi-3, based on llama.\n #[value(name = \"phi-3b\")]\n Phi3b,\n}\n\n#[derive(Parser, Debug)]\n#[command(author, version, about, long_about = None)]\nstruct Args {\n /// GGUF file to load, typically a .gguf file generated by the quantize command from llama.cpp\n #[arg(long)]\n model: Option<String>,\n\n /// The initial prompt, use 'interactive' for entering multiple prompts in an interactive way\n /// and 'chat' for an interactive model where history of previous prompts and generated tokens\n /// is preserved.\n #[arg(long)]\n prompt: Option<String>,\n\n /// The length of the sample to generate (in tokens).\n #[arg(short = 'n', long, default_value_t = 1000)]\n sample_len: usize,\n\n /// The tokenizer config in json format.\n #[arg(long)]\n tokenizer: Option<String>,\n\n /// The temperature used to generate samples, use 0 for greedy sampling.\n #[arg(long, default_value_t = 0.8)]\n temperature: f64,\n\n /// Nucleus sampling probability cutoff.\n #[arg(long)]\n top_p: Option<f64>,\n\n /// Only sample among the top K samples.\n #[arg(long)]\n top_k: Option<usize>,\n\n /// The seed to use when generating random samples.\n #[arg(long, default_value_t = 299792458)]\n seed: u64,\n\n /// Enable tracing (generates a trace-timestamp.json file).\n #[arg(long)]\n tracing: bool,\n\n /// Process prompt elements separately.\n #[arg(long)]\n split_prompt: bool,\n\n /// Run on CPU rather than GPU even if a GPU is available.\n #[arg(long)]\n cpu: bool,\n\n /// Penalty to be applied for repeating tokens, 1. means no penalty.\n #[arg(long, default_value_t = 1.1)]\n repeat_penalty: f32,\n\n /// The context size to consider for the repeat penalty.\n #[arg(long, default_value_t = 64)]\n repeat_last_n: usize,\n\n /// The model size to use.\n #[arg(long, default_value = \"phi-3b\")]\n which: Which,\n\n #[arg(long)]\n use_flash_attn: bool,\n}\n\nimpl Args {\n fn tokenizer(&self) -> anyhow::Result<Tokenizer> {\n let tokenizer_path = match &self.tokenizer {\n Some(config) => std::path::PathBuf::from(config),\n None => {\n let api = hf_hub::api::sync::Api::new()?;\n let repo = match self.which {\n Which::Phi2 => \"microsoft/phi-2\",\n Which::Phi3 | Which::Phi3b => \"microsoft/Phi-3-mini-4k-instruct\",\n };\n let api = api.model(repo.to_string());\n api.get(\"tokenizer.json\")?\n }\n };\n Tokenizer::from_file(tokenizer_path).map_err(anyhow::Error::msg)\n }\n\n fn model(&self) -> anyhow::Result<std::path::PathBuf> {\n let model_path = match &self.model {\n Some(config) => std::path::PathBuf::from(config),\n None => {\n let (repo, filename, revision) = match self.which {\n Which::Phi2 => (\"TheBloke/phi-2-GGUF\", \"phi-2.Q4_K_M.gguf\", \"main\"),\n Which::Phi3 => (\n \"microsoft/Phi-3-mini-4k-instruct-gguf\",\n \"Phi-3-mini-4k-instruct-q4.gguf\",\n \"main\",\n ),\n Which::Phi3b => (\n \"microsoft/Phi-3-mini-4k-instruct-gguf\",\n \"Phi-3-mini-4k-instruct-q4.gguf\",\n \"5eef2ce24766d31909c0b269fe90c817a8f263fb\",\n ),\n };\n let api = hf_hub::api::sync::Api::new()?;\n api.repo(hf_hub::Repo::with_revision(\n repo.to_string(),\n hf_hub::RepoType::Model,\n revision.to_string(),\n ))\n .get(filename)?\n }\n };\n Ok(model_path)\n }\n}\n\nfn format_size(size_in_bytes: usize) -> String {\n if size_in_bytes < 1_000 {\n format!(\"{}B\", size_in_bytes)\n } else if size_in_bytes < 1_000_000 {\n format!(\"{:.2}KB\", size_in_bytes as f64 / 1e3)\n } else if size_in_bytes < 1_000_000_000 {\n format!(\"{:.2}MB\", size_in_bytes as f64 / 1e6)\n } else {\n format!(\"{:.2}GB\", size_in_bytes as f64 / 1e9)\n }\n}\n\nenum Model {\n Phi2(Phi2),\n Phi3(Phi3),\n Phi3b(Phi3b),\n}\n\nimpl Model {\n fn forward(&mut self, xs: &Tensor, pos: usize) -> candle::Result<Tensor> {\n match self {\n Self::Phi2(m) => m.forward(xs, pos),\n Self::Phi3(m) => m.forward(xs, pos),\n Self::Phi3b(m) => m.forward(xs, pos),\n }\n }\n}\n\nfn main() -> anyhow::Result<()> {\n use tracing_chrome::ChromeLayerBuilder;\n use tracing_subscriber::prelude::*;\n\n let args = Args::parse();\n let _guard = if args.tracing {\n let (chrome_layer, guard) = ChromeLayerBuilder::new().build();\n tracing_subscriber::registry().with(chrome_layer).init();\n Some(guard)\n } else {\n None\n };\n\n println!(\n \"avx: {}, neon: {}, simd128: {}, f16c: {}\",\n candle::utils::with_avx(),\n candle::utils::with_neon(),\n candle::utils::with_simd128(),\n candle::utils::with_f16c()\n );\n println!(\n \"temp: {:.2} repeat-penalty: {:.2} repeat-last-n: {}\",\n args.temperature, args.repeat_penalty, args.repeat_last_n\n );\n\n let model_path = args.model()?;\n let mut file = std::fs::File::open(&model_path)?;\n let start = std::time::Instant::now();\n let device = candle_examples::device(args.cpu)?;\n\n let mut model = {\n let model = gguf_file::Content::read(&mut file).map_err(|e| e.with_path(model_path))?;\n let mut total_size_in_bytes = 0;\n for (_, tensor) in model.tensor_infos.iter() {\n let elem_count = tensor.shape.elem_count();\n total_size_in_bytes +=\n elem_count * tensor.ggml_dtype.type_size() / tensor.ggml_dtype.block_size();\n }\n println!(\n \"loaded {:?} tensors ({}) in {:.2}s\",\n model.tensor_infos.len(),\n &format_size(total_size_in_bytes),\n start.elapsed().as_secs_f32(),\n );\n match args.which {\n Which::Phi2 => Model::Phi2(Phi2::from_gguf(model, &mut file, &device)?),\n Which::Phi3 => Model::Phi3(Phi3::from_gguf(\n args.use_flash_attn,\n model,\n &mut file,\n &device,\n )?),\n Which::Phi3b => Model::Phi3b(Phi3b::from_gguf(model, &mut file, &device)?),\n }\n };\n println!(\"model built\");\n\n let tokenizer = args.tokenizer()?;\n let mut tos = TokenOutputStream::new(tokenizer);\n let prompt_str = args.prompt.unwrap_or_else(|| DEFAULT_PROMPT.to_string());\n print!(\"{}\", &prompt_str);\n let tokens = tos\n .tokenizer()\n .encode(prompt_str, true)\n .map_err(anyhow::Error::msg)?;\n let tokens = tokens.get_ids();\n let to_sample = args.sample_len.saturating_sub(1);\n let mut all_tokens = vec![];\n let mut logits_processor = {\n let temperature = args.temperature;\n let sampling = if temperature <= 0. {\n Sampling::ArgMax\n } else {\n match (args.top_k, args.top_p) {\n (None, None) => Sampling::All { temperature },\n (Some(k), None) => Sampling::TopK { k, temperature },\n (None, Some(p)) => Sampling::TopP { p, temperature },\n (Some(k), Some(p)) => Sampling::TopKThenTopP { k, p, temperature },\n }\n };\n LogitsProcessor::from_sampling(args.seed, sampling)\n };\n\n let start_prompt_processing = std::time::Instant::now();\n let mut next_token = if !args.split_prompt {\n let input = Tensor::new(tokens, &device)?.unsqueeze(0)?;\n let logits = model.forward(&input, 0)?;\n let logits = logits.squeeze(0)?;\n logits_processor.sample(&logits)?\n } else {\n let mut next_token = 0;\n for (pos, token) in tokens.iter().enumerate() {\n let input = Tensor::new(&[*token], &device)?.unsqueeze(0)?;\n let logits = model.forward(&input, pos)?;\n let logits = logits.squeeze(0)?;\n next_token = logits_processor.sample(&logits)?\n }\n next_token\n };\n let prompt_dt = start_prompt_processing.elapsed();\n all_tokens.push(next_token);\n if let Some(t) = tos.next_token(next_token)? {\n print!(\"{t}\");\n std::io::stdout().flush()?;\n }\n let eos_token = *tos\n .tokenizer()\n .get_vocab(true)\n .get(\"<|endoftext|>\")\n .unwrap();\n let start_post_prompt = std::time::Instant::now();\n let mut sampled = 0;\n for index in 0..to_sample {\n let input = Tensor::new(&[next_token], &device)?.unsqueeze(0)?;\n let logits = model.forward(&input, tokens.len() + index)?;\n let logits = logits.squeeze(0)?;\n let logits = if args.repeat_penalty == 1. {\n logits\n } else {\n let start_at = all_tokens.len().saturating_sub(args.repeat_last_n);\n candle_transformers::utils::apply_repeat_penalty(\n &logits,\n args.repeat_penalty,\n &all_tokens[start_at..],\n )?\n };\n next_token = logits_processor.sample(&logits)?;\n all_tokens.push(next_token);\n if let Some(t) = tos.next_token(next_token)? {\n print!(\"{t}\");\n std::io::stdout().flush()?;\n }\n sampled += 1;\n if next_token == eos_token {\n break;\n };\n }\n if let Some(rest) = tos.decode_rest().map_err(candle::Error::msg)? {\n print!(\"{rest}\");\n }\n std::io::stdout().flush()?;\n let dt = start_post_prompt.elapsed();\n println!(\n \"\\n\\n{:4} prompt tokens processed: {:.2} token/s\",\n tokens.len(),\n tokens.len() as f64 / prompt_dt.as_secs_f64(),\n );\n println!(\n \"{sampled:4} tokens generated: {:.2} token/s\",\n sampled as f64 / dt.as_secs_f64(),\n );\n Ok(())\n}\n", "candle-examples\\examples\\quantized-qwen2-instruct\\main.rs": "#[cfg(feature = \"mkl\")]\nextern crate intel_mkl_src;\n\n#[cfg(feature = \"accelerate\")]\nextern crate accelerate_src;\n\nuse clap::{Parser, ValueEnum};\nuse std::io::Write;\nuse tokenizers::Tokenizer;\n\nuse candle::quantized::gguf_file;\nuse candle::Tensor;\nuse candle_transformers::generation::{LogitsProcessor, Sampling};\n\nuse candle_examples::token_output_stream::TokenOutputStream;\nuse candle_transformers::models::quantized_qwen2::ModelWeights as Qwen2;\n\nconst DEFAULT_PROMPT: &str = \"Write a function to count prime numbers up to N. \";\n\n#[derive(Clone, Debug, Copy, PartialEq, Eq, ValueEnum)]\nenum Which {\n #[value(name = \"0.5b\")]\n W2_0_5b,\n #[value(name = \"1.5b\")]\n W2_1_5b,\n #[value(name = \"7b\")]\n W2_7b,\n #[value(name = \"72b\")]\n W2_72b,\n}\n\n#[derive(Parser, Debug)]\n#[command(author, version, about, long_about = None)]\nstruct Args {\n /// GGUF file to load, typically a .gguf file generated by the quantize command from llama.cpp\n #[arg(long)]\n model: Option<String>,\n\n /// The initial prompt, use 'interactive' for entering multiple prompts in an interactive way\n /// and 'chat' for an interactive model where history of previous prompts and generated tokens\n /// is preserved.\n #[arg(long)]\n prompt: Option<String>,\n\n /// The length of the sample to generate (in tokens).\n #[arg(short = 'n', long, default_value_t = 1000)]\n sample_len: usize,\n\n /// The tokenizer config in json format.\n #[arg(long)]\n tokenizer: Option<String>,\n\n /// The temperature used to generate samples, use 0 for greedy sampling.\n #[arg(long, default_value_t = 0.8)]\n temperature: f64,\n\n /// Nucleus sampling probability cutoff.\n #[arg(long)]\n top_p: Option<f64>,\n\n /// Only sample among the top K samples.\n #[arg(long)]\n top_k: Option<usize>,\n\n /// The seed to use when generating random samples.\n #[arg(long, default_value_t = 299792458)]\n seed: u64,\n\n /// Enable tracing (generates a trace-timestamp.json file).\n #[arg(long)]\n tracing: bool,\n\n /// Process prompt elements separately.\n #[arg(long)]\n split_prompt: bool,\n\n /// Run on CPU rather than GPU even if a GPU is available.\n #[arg(long)]\n cpu: bool,\n\n /// Penalty to be applied for repeating tokens, 1. means no penalty.\n #[arg(long, default_value_t = 1.1)]\n repeat_penalty: f32,\n\n /// The context size to consider for the repeat penalty.\n #[arg(long, default_value_t = 64)]\n repeat_last_n: usize,\n\n /// The model size to use.\n #[arg(long, default_value = \"0.5b\")]\n which: Which,\n}\n\nimpl Args {\n fn tokenizer(&self) -> anyhow::Result<Tokenizer> {\n let tokenizer_path = match &self.tokenizer {\n Some(config) => std::path::PathBuf::from(config),\n None => {\n let api = hf_hub::api::sync::Api::new()?;\n let repo = match self.which {\n Which::W2_0_5b => \"Qwen/Qwen2-0.5B-Instruct\",\n Which::W2_1_5b => \"Qwen/Qwen2-1.5B-Instruct\",\n Which::W2_7b => \"Qwen/Qwen2-7B-Instruct\",\n Which::W2_72b => \"Qwen/Qwen2-72B-Instruct\",\n };\n let api = api.model(repo.to_string());\n api.get(\"tokenizer.json\")?\n }\n };\n Tokenizer::from_file(tokenizer_path).map_err(anyhow::Error::msg)\n }\n\n fn model(&self) -> anyhow::Result<std::path::PathBuf> {\n let model_path = match &self.model {\n Some(config) => std::path::PathBuf::from(config),\n None => {\n let (repo, filename, revision) = match self.which {\n Which::W2_0_5b => (\n \"Qwen/Qwen2-0.5B-Instruct-GGUF\",\n \"qwen2-0_5b-instruct-q4_0.gguf\",\n \"main\",\n ),\n Which::W2_1_5b => (\n \"Qwen/Qwen2-1.5B-Instruct-GGUF\",\n \"qwen2-1_5b-instruct-q4_0.gguf\",\n \"main\",\n ),\n Which::W2_7b => (\n \"Qwen/Qwen2-7B-Instruct-GGUF\",\n \"qwen2-7b-instruct-q4_0.gguf\",\n \"main\",\n ),\n Which::W2_72b => (\n \"Qwen/Qwen2-72B-Instruct-GGUF\",\n \"qwen2-72b-instruct-q4_0.gguf\",\n \"main\",\n ),\n };\n let api = hf_hub::api::sync::Api::new()?;\n api.repo(hf_hub::Repo::with_revision(\n repo.to_string(),\n hf_hub::RepoType::Model,\n revision.to_string(),\n ))\n .get(filename)?\n }\n };\n Ok(model_path)\n }\n}\n\nfn format_size(size_in_bytes: usize) -> String {\n if size_in_bytes < 1_000 {\n format!(\"{}B\", size_in_bytes)\n } else if size_in_bytes < 1_000_000 {\n format!(\"{:.2}KB\", size_in_bytes as f64 / 1e3)\n } else if size_in_bytes < 1_000_000_000 {\n format!(\"{:.2}MB\", size_in_bytes as f64 / 1e6)\n } else {\n format!(\"{:.2}GB\", size_in_bytes as f64 / 1e9)\n }\n}\n\nfn main() -> anyhow::Result<()> {\n use tracing_chrome::ChromeLayerBuilder;\n use tracing_subscriber::prelude::*;\n\n let args = Args::parse();\n let _guard = if args.tracing {\n let (chrome_layer, guard) = ChromeLayerBuilder::new().build();\n tracing_subscriber::registry().with(chrome_layer).init();\n Some(guard)\n } else {\n None\n };\n\n println!(\n \"avx: {}, neon: {}, simd128: {}, f16c: {}\",\n candle::utils::with_avx(),\n candle::utils::with_neon(),\n candle::utils::with_simd128(),\n candle::utils::with_f16c()\n );\n println!(\n \"temp: {:.2} repeat-penalty: {:.2} repeat-last-n: {}\",\n args.temperature, args.repeat_penalty, args.repeat_last_n\n );\n\n let model_path = args.model()?;\n let mut file = std::fs::File::open(&model_path)?;\n let start = std::time::Instant::now();\n let device = candle_examples::device(args.cpu)?;\n\n let mut model = {\n let model = gguf_file::Content::read(&mut file).map_err(|e| e.with_path(model_path))?;\n let mut total_size_in_bytes = 0;\n for (_, tensor) in model.tensor_infos.iter() {\n let elem_count = tensor.shape.elem_count();\n total_size_in_bytes +=\n elem_count * tensor.ggml_dtype.type_size() / tensor.ggml_dtype.block_size();\n }\n println!(\n \"loaded {:?} tensors ({}) in {:.2}s\",\n model.tensor_infos.len(),\n &format_size(total_size_in_bytes),\n start.elapsed().as_secs_f32(),\n );\n Qwen2::from_gguf(model, &mut file, &device)?\n };\n println!(\"model built\");\n\n let tokenizer = args.tokenizer()?;\n let mut tos = TokenOutputStream::new(tokenizer);\n let prompt_str = args.prompt.unwrap_or_else(|| DEFAULT_PROMPT.to_string());\n let prompt_str = format!(\n \"<|im_start|>user\\n{}<|im_end|>\\n<|im_start|>assistant\\n\",\n prompt_str\n );\n print!(\"formatted instruct prompt: {}\", &prompt_str);\n let tokens = tos\n .tokenizer()\n .encode(prompt_str, true)\n .map_err(anyhow::Error::msg)?;\n let tokens = tokens.get_ids();\n let to_sample = args.sample_len.saturating_sub(1);\n let mut all_tokens = vec![];\n let mut logits_processor = {\n let temperature = args.temperature;\n let sampling = if temperature <= 0. {\n Sampling::ArgMax\n } else {\n match (args.top_k, args.top_p) {\n (None, None) => Sampling::All { temperature },\n (Some(k), None) => Sampling::TopK { k, temperature },\n (None, Some(p)) => Sampling::TopP { p, temperature },\n (Some(k), Some(p)) => Sampling::TopKThenTopP { k, p, temperature },\n }\n };\n LogitsProcessor::from_sampling(args.seed, sampling)\n };\n let start_prompt_processing = std::time::Instant::now();\n let mut next_token = if !args.split_prompt {\n let input = Tensor::new(tokens, &device)?.unsqueeze(0)?;\n let logits = model.forward(&input, 0)?;\n let logits = logits.squeeze(0)?;\n logits_processor.sample(&logits)?\n } else {\n let mut next_token = 0;\n for (pos, token) in tokens.iter().enumerate() {\n let input = Tensor::new(&[*token], &device)?.unsqueeze(0)?;\n let logits = model.forward(&input, pos)?;\n let logits = logits.squeeze(0)?;\n next_token = logits_processor.sample(&logits)?\n }\n next_token\n };\n let prompt_dt = start_prompt_processing.elapsed();\n all_tokens.push(next_token);\n if let Some(t) = tos.next_token(next_token)? {\n print!(\"{t}\");\n std::io::stdout().flush()?;\n }\n let eos_token = *tos.tokenizer().get_vocab(true).get(\"<|im_end|>\").unwrap();\n let start_post_prompt = std::time::Instant::now();\n let mut sampled = 0;\n for index in 0..to_sample {\n let input = Tensor::new(&[next_token], &device)?.unsqueeze(0)?;\n let logits = model.forward(&input, tokens.len() + index)?;\n let logits = logits.squeeze(0)?;\n let logits = if args.repeat_penalty == 1. {\n logits\n } else {\n let start_at = all_tokens.len().saturating_sub(args.repeat_last_n);\n candle_transformers::utils::apply_repeat_penalty(\n &logits,\n args.repeat_penalty,\n &all_tokens[start_at..],\n )?\n };\n next_token = logits_processor.sample(&logits)?;\n all_tokens.push(next_token);\n if let Some(t) = tos.next_token(next_token)? {\n print!(\"{t}\");\n std::io::stdout().flush()?;\n }\n sampled += 1;\n if next_token == eos_token {\n break;\n };\n }\n if let Some(rest) = tos.decode_rest().map_err(candle::Error::msg)? {\n print!(\"{rest}\");\n }\n std::io::stdout().flush()?;\n let dt = start_post_prompt.elapsed();\n println!(\n \"\\n\\n{:4} prompt tokens processed: {:.2} token/s\",\n tokens.len(),\n tokens.len() as f64 / prompt_dt.as_secs_f64(),\n );\n println!(\n \"{sampled:4} tokens generated: {:.2} token/s\",\n sampled as f64 / dt.as_secs_f64(),\n );\n Ok(())\n}\n", "candle-examples\\examples\\quantized-t5\\main.rs": "#[cfg(feature = \"mkl\")]\nextern crate intel_mkl_src;\n\n#[cfg(feature = \"accelerate\")]\nextern crate accelerate_src;\nuse std::io::Write;\nuse std::path::PathBuf;\n\nuse candle_transformers::models::quantized_t5 as t5;\n\nuse anyhow::{Error as E, Result};\nuse candle::{Device, Tensor};\nuse candle_transformers::generation::LogitsProcessor;\nuse clap::{Parser, ValueEnum};\nuse hf_hub::{api::sync::Api, api::sync::ApiRepo, Repo, RepoType};\nuse tokenizers::Tokenizer;\n\n#[derive(Clone, Debug, Copy, ValueEnum)]\nenum Which {\n T5Small,\n FlanT5Small,\n FlanT5Base,\n FlanT5Large,\n FlanT5Xl,\n FlanT5Xxl,\n}\n\n#[derive(Parser, Debug, Clone)]\n#[command(author, version, about, long_about = None)]\nstruct Args {\n /// Enable tracing (generates a trace-timestamp.json file).\n #[arg(long)]\n tracing: bool,\n\n /// The model repository to use on the HuggingFace hub.\n #[arg(long)]\n model_id: Option<String>,\n\n #[arg(long)]\n revision: Option<String>,\n\n #[arg(long)]\n weight_file: Option<String>,\n\n #[arg(long)]\n config_file: Option<String>,\n\n // Enable/disable decoding.\n #[arg(long, default_value = \"false\")]\n disable_cache: bool,\n\n /// Use this prompt, otherwise compute sentence similarities.\n #[arg(long)]\n prompt: String,\n\n /// The temperature used to generate samples.\n #[arg(long, default_value_t = 0.8)]\n temperature: f64,\n\n /// Nucleus sampling probability cutoff.\n #[arg(long)]\n top_p: Option<f64>,\n\n /// Penalty to be applied for repeating tokens, 1. means no penalty.\n #[arg(long, default_value_t = 1.1)]\n repeat_penalty: f32,\n\n /// The context size to consider for the repeat penalty.\n #[arg(long, default_value_t = 64)]\n repeat_last_n: usize,\n\n /// The model size to use.\n #[arg(long, default_value = \"t5-small\")]\n which: Which,\n}\n\nstruct T5ModelBuilder {\n device: Device,\n config: t5::Config,\n weights_filename: PathBuf,\n}\n\nimpl T5ModelBuilder {\n pub fn load(args: &Args) -> Result<(Self, Tokenizer)> {\n let device = Device::Cpu;\n let default_model = \"lmz/candle-quantized-t5\".to_string();\n let (model_id, revision) = match (args.model_id.to_owned(), args.revision.to_owned()) {\n (Some(model_id), Some(revision)) => (model_id, revision),\n (Some(model_id), None) => (model_id, \"main\".to_string()),\n (None, Some(revision)) => (default_model, revision),\n (None, None) => (default_model, \"main\".to_string()),\n };\n\n let repo = Repo::with_revision(model_id, RepoType::Model, revision);\n let api = Api::new()?;\n let api = api.repo(repo);\n let config_filename = match &args.config_file {\n Some(filename) => Self::get_local_or_remote_file(filename, &api)?,\n None => match args.which {\n Which::T5Small => api.get(\"config.json\")?,\n Which::FlanT5Small => api.get(\"config-flan-t5-small.json\")?,\n Which::FlanT5Base => api.get(\"config-flan-t5-base.json\")?,\n Which::FlanT5Large => api.get(\"config-flan-t5-large.json\")?,\n Which::FlanT5Xl => api.get(\"config-flan-t5-xl.json\")?,\n Which::FlanT5Xxl => api.get(\"config-flan-t5-xxl.json\")?,\n },\n };\n let tokenizer_filename = api.get(\"tokenizer.json\")?;\n let weights_filename = match &args.weight_file {\n Some(filename) => Self::get_local_or_remote_file(filename, &api)?,\n None => match args.which {\n Which::T5Small => api.get(\"model.gguf\")?,\n Which::FlanT5Small => api.get(\"model-flan-t5-small.gguf\")?,\n Which::FlanT5Base => api.get(\"model-flan-t5-base.gguf\")?,\n Which::FlanT5Large => api.get(\"model-flan-t5-large.gguf\")?,\n Which::FlanT5Xl => api.get(\"model-flan-t5-xl.gguf\")?,\n Which::FlanT5Xxl => api.get(\"model-flan-t5-xxl.gguf\")?,\n },\n };\n let config = std::fs::read_to_string(config_filename)?;\n let mut config: t5::Config = serde_json::from_str(&config)?;\n config.use_cache = !args.disable_cache;\n let tokenizer = Tokenizer::from_file(tokenizer_filename).map_err(E::msg)?;\n Ok((\n Self {\n device,\n config,\n weights_filename,\n },\n tokenizer,\n ))\n }\n\n pub fn build_model(&self) -> Result<t5::T5ForConditionalGeneration> {\n let device = Device::Cpu;\n let vb = t5::VarBuilder::from_gguf(&self.weights_filename, &device)?;\n Ok(t5::T5ForConditionalGeneration::load(vb, &self.config)?)\n }\n\n fn get_local_or_remote_file(filename: &str, api: &ApiRepo) -> Result<PathBuf> {\n let local_filename = std::path::PathBuf::from(filename);\n if local_filename.exists() {\n Ok(local_filename)\n } else {\n Ok(api.get(filename)?)\n }\n }\n}\n\nfn main() -> Result<()> {\n use tracing_chrome::ChromeLayerBuilder;\n use tracing_subscriber::prelude::*;\n\n let args = Args::parse();\n\n let _guard = if args.tracing {\n let (chrome_layer, guard) = ChromeLayerBuilder::new().build();\n tracing_subscriber::registry().with(chrome_layer).init();\n Some(guard)\n } else {\n None\n };\n\n let (builder, mut tokenizer) = T5ModelBuilder::load(&args)?;\n let device = &builder.device;\n let tokenizer = tokenizer\n .with_padding(None)\n .with_truncation(None)\n .map_err(E::msg)?;\n let tokens = tokenizer\n .encode(args.prompt, true)\n .map_err(E::msg)?\n .get_ids()\n .to_vec();\n let input_token_ids = Tensor::new(&tokens[..], device)?.unsqueeze(0)?;\n let mut model = builder.build_model()?;\n let mut output_token_ids = [builder\n .config\n .decoder_start_token_id\n .unwrap_or(builder.config.pad_token_id) as u32]\n .to_vec();\n let temperature = if args.temperature <= 0. {\n None\n } else {\n Some(args.temperature)\n };\n let mut logits_processor = LogitsProcessor::new(299792458, temperature, args.top_p);\n let encoder_output = model.encode(&input_token_ids)?;\n let start = std::time::Instant::now();\n\n for index in 0.. {\n if output_token_ids.len() > 512 {\n break;\n }\n let decoder_token_ids = if index == 0 || !builder.config.use_cache {\n Tensor::new(output_token_ids.as_slice(), device)?.unsqueeze(0)?\n } else {\n let last_token = *output_token_ids.last().unwrap();\n Tensor::new(&[last_token], device)?.unsqueeze(0)?\n };\n let logits = model\n .decode(&decoder_token_ids, &encoder_output)?\n .squeeze(0)?;\n let logits = if args.repeat_penalty == 1. {\n logits\n } else {\n let start_at = output_token_ids.len().saturating_sub(args.repeat_last_n);\n candle_transformers::utils::apply_repeat_penalty(\n &logits,\n args.repeat_penalty,\n &output_token_ids[start_at..],\n )?\n };\n\n let next_token_id = logits_processor.sample(&logits)?;\n if next_token_id as usize == builder.config.eos_token_id {\n break;\n }\n output_token_ids.push(next_token_id);\n if let Some(text) = tokenizer.id_to_token(next_token_id) {\n let text = text.replace('\u2581', \" \").replace(\"<0x0A>\", \"\\n\");\n print!(\"{text}\");\n std::io::stdout().flush()?;\n }\n }\n let dt = start.elapsed();\n println!(\n \"\\n{} tokens generated ({:.2} token/s)\\n\",\n output_token_ids.len(),\n output_token_ids.len() as f64 / dt.as_secs_f64(),\n );\n Ok(())\n}\n", "candle-examples\\examples\\qwen\\main.rs": "#[cfg(feature = \"mkl\")]\nextern crate intel_mkl_src;\n\n#[cfg(feature = \"accelerate\")]\nextern crate accelerate_src;\n\nuse anyhow::{Error as E, Result};\nuse clap::Parser;\n\nuse candle_transformers::models::qwen2::{Config as ConfigBase, ModelForCausalLM as ModelBase};\nuse candle_transformers::models::qwen2_moe::{Config as ConfigMoe, Model as ModelMoe};\n\nuse candle::{DType, Device, Tensor};\nuse candle_examples::token_output_stream::TokenOutputStream;\nuse candle_nn::VarBuilder;\nuse candle_transformers::generation::LogitsProcessor;\nuse hf_hub::{api::sync::Api, Repo, RepoType};\nuse tokenizers::Tokenizer;\n\nenum Model {\n Base(ModelBase),\n Moe(ModelMoe),\n}\n\nimpl Model {\n fn forward(&mut self, xs: &Tensor, s: usize) -> candle::Result<Tensor> {\n match self {\n Self::Moe(ref mut m) => m.forward(xs, s),\n Self::Base(ref mut m) => m.forward(xs, s),\n }\n }\n}\n\nstruct TextGeneration {\n model: Model,\n device: Device,\n tokenizer: TokenOutputStream,\n logits_processor: LogitsProcessor,\n repeat_penalty: f32,\n repeat_last_n: usize,\n}\n\nimpl TextGeneration {\n #[allow(clippy::too_many_arguments)]\n fn new(\n model: Model,\n tokenizer: Tokenizer,\n seed: u64,\n temp: Option<f64>,\n top_p: Option<f64>,\n repeat_penalty: f32,\n repeat_last_n: usize,\n device: &Device,\n ) -> Self {\n let logits_processor = LogitsProcessor::new(seed, temp, top_p);\n Self {\n model,\n tokenizer: TokenOutputStream::new(tokenizer),\n logits_processor,\n repeat_penalty,\n repeat_last_n,\n device: device.clone(),\n }\n }\n\n fn run(&mut self, prompt: &str, sample_len: usize) -> Result<()> {\n use std::io::Write;\n self.tokenizer.clear();\n let mut tokens = self\n .tokenizer\n .tokenizer()\n .encode(prompt, true)\n .map_err(E::msg)?\n .get_ids()\n .to_vec();\n for &t in tokens.iter() {\n if let Some(t) = self.tokenizer.next_token(t)? {\n print!(\"{t}\")\n }\n }\n std::io::stdout().flush()?;\n\n let mut generated_tokens = 0usize;\n let eos_token = match self.tokenizer.get_token(\"<|endoftext|>\") {\n Some(token) => token,\n None => anyhow::bail!(\"cannot find the <|endoftext|> token\"),\n };\n let start_gen = std::time::Instant::now();\n for index in 0..sample_len {\n let context_size = if index > 0 { 1 } else { tokens.len() };\n let start_pos = tokens.len().saturating_sub(context_size);\n let ctxt = &tokens[start_pos..];\n let input = Tensor::new(ctxt, &self.device)?.unsqueeze(0)?;\n let logits = self.model.forward(&input, start_pos)?;\n let logits = logits.squeeze(0)?.squeeze(0)?.to_dtype(DType::F32)?;\n let logits = if self.repeat_penalty == 1. {\n logits\n } else {\n let start_at = tokens.len().saturating_sub(self.repeat_last_n);\n candle_transformers::utils::apply_repeat_penalty(\n &logits,\n self.repeat_penalty,\n &tokens[start_at..],\n )?\n };\n\n let next_token = self.logits_processor.sample(&logits)?;\n tokens.push(next_token);\n generated_tokens += 1;\n if next_token == eos_token {\n break;\n }\n if let Some(t) = self.tokenizer.next_token(next_token)? {\n print!(\"{t}\");\n std::io::stdout().flush()?;\n }\n }\n let dt = start_gen.elapsed();\n if let Some(rest) = self.tokenizer.decode_rest().map_err(E::msg)? {\n print!(\"{rest}\");\n }\n std::io::stdout().flush()?;\n println!(\n \"\\n{generated_tokens} tokens generated ({:.2} token/s)\",\n generated_tokens as f64 / dt.as_secs_f64(),\n );\n Ok(())\n }\n}\n\n#[derive(Clone, Copy, Debug, clap::ValueEnum, PartialEq, Eq)]\nenum WhichModel {\n #[value(name = \"0.5b\")]\n W0_5b,\n #[value(name = \"1.8b\")]\n W1_8b,\n #[value(name = \"4b\")]\n W4b,\n #[value(name = \"7b\")]\n W7b,\n #[value(name = \"14b\")]\n W14b,\n #[value(name = \"72b\")]\n W72b,\n #[value(name = \"moe-a2.7b\")]\n MoeA27b,\n #[value(name = \"2-0.5b\")]\n W2_0_5b,\n #[value(name = \"2-1.5b\")]\n W2_1_5b,\n #[value(name = \"2-7b\")]\n W2_7b,\n #[value(name = \"2-72b\")]\n W2_72b,\n}\n\n#[derive(Parser, Debug)]\n#[command(author, version, about, long_about = None)]\nstruct Args {\n /// Run on CPU rather than on GPU.\n #[arg(long)]\n cpu: bool,\n\n /// Enable tracing (generates a trace-timestamp.json file).\n #[arg(long)]\n tracing: bool,\n\n #[arg(long)]\n use_flash_attn: bool,\n\n #[arg(long)]\n prompt: String,\n\n /// The temperature used to generate samples.\n #[arg(long)]\n temperature: Option<f64>,\n\n /// Nucleus sampling probability cutoff.\n #[arg(long)]\n top_p: Option<f64>,\n\n /// The seed to use when generating random samples.\n #[arg(long, default_value_t = 299792458)]\n seed: u64,\n\n /// The length of the sample to generate (in tokens).\n #[arg(long, short = 'n', default_value_t = 10000)]\n sample_len: usize,\n\n #[arg(long)]\n model_id: Option<String>,\n\n #[arg(long, default_value = \"main\")]\n revision: String,\n\n #[arg(long)]\n tokenizer_file: Option<String>,\n\n #[arg(long)]\n weight_files: Option<String>,\n\n /// Penalty to be applied for repeating tokens, 1. means no penalty.\n #[arg(long, default_value_t = 1.1)]\n repeat_penalty: f32,\n\n /// The context size to consider for the repeat penalty.\n #[arg(long, default_value_t = 64)]\n repeat_last_n: usize,\n\n #[arg(long, default_value = \"0.5b\")]\n model: WhichModel,\n}\n\nfn main() -> Result<()> {\n use tracing_chrome::ChromeLayerBuilder;\n use tracing_subscriber::prelude::*;\n\n let args = Args::parse();\n let _guard = if args.tracing {\n let (chrome_layer, guard) = ChromeLayerBuilder::new().build();\n tracing_subscriber::registry().with(chrome_layer).init();\n Some(guard)\n } else {\n None\n };\n println!(\n \"avx: {}, neon: {}, simd128: {}, f16c: {}\",\n candle::utils::with_avx(),\n candle::utils::with_neon(),\n candle::utils::with_simd128(),\n candle::utils::with_f16c()\n );\n println!(\n \"temp: {:.2} repeat-penalty: {:.2} repeat-last-n: {}\",\n args.temperature.unwrap_or(0.),\n args.repeat_penalty,\n args.repeat_last_n\n );\n\n let start = std::time::Instant::now();\n let api = Api::new()?;\n let model_id = match args.model_id {\n Some(model_id) => model_id,\n None => {\n let (version, size) = match args.model {\n WhichModel::W2_0_5b => (\"2\", \"0.5B\"),\n WhichModel::W2_1_5b => (\"2\", \"1.5B\"),\n WhichModel::W2_7b => (\"2\", \"7B\"),\n WhichModel::W2_72b => (\"2\", \"72B\"),\n WhichModel::W0_5b => (\"1.5\", \"0.5B\"),\n WhichModel::W1_8b => (\"1.5\", \"1.8B\"),\n WhichModel::W4b => (\"1.5\", \"4B\"),\n WhichModel::W7b => (\"1.5\", \"7B\"),\n WhichModel::W14b => (\"1.5\", \"14B\"),\n WhichModel::W72b => (\"1.5\", \"72B\"),\n WhichModel::MoeA27b => (\"1.5\", \"MoE-A2.7B\"),\n };\n format!(\"Qwen/Qwen{version}-{size}\")\n }\n };\n let repo = api.repo(Repo::with_revision(\n model_id,\n RepoType::Model,\n args.revision,\n ));\n let tokenizer_filename = match args.tokenizer_file {\n Some(file) => std::path::PathBuf::from(file),\n None => repo.get(\"tokenizer.json\")?,\n };\n let filenames = match args.weight_files {\n Some(files) => files\n .split(',')\n .map(std::path::PathBuf::from)\n .collect::<Vec<_>>(),\n None => match args.model {\n WhichModel::W0_5b | WhichModel::W2_0_5b | WhichModel::W2_1_5b | WhichModel::W1_8b => {\n vec![repo.get(\"model.safetensors\")?]\n }\n WhichModel::W4b\n | WhichModel::W7b\n | WhichModel::W2_7b\n | WhichModel::W14b\n | WhichModel::W72b\n | WhichModel::W2_72b\n | WhichModel::MoeA27b => {\n candle_examples::hub_load_safetensors(&repo, \"model.safetensors.index.json\")?\n }\n },\n };\n println!(\"retrieved the files in {:?}\", start.elapsed());\n let tokenizer = Tokenizer::from_file(tokenizer_filename).map_err(E::msg)?;\n\n let start = std::time::Instant::now();\n let config_file = repo.get(\"config.json\")?;\n let device = candle_examples::device(args.cpu)?;\n let dtype = if device.is_cuda() {\n DType::BF16\n } else {\n DType::F32\n };\n let vb = unsafe { VarBuilder::from_mmaped_safetensors(&filenames, dtype, &device)? };\n let model = match args.model {\n WhichModel::MoeA27b => {\n let config: ConfigMoe = serde_json::from_slice(&std::fs::read(config_file)?)?;\n Model::Moe(ModelMoe::new(&config, vb)?)\n }\n _ => {\n let config: ConfigBase = serde_json::from_slice(&std::fs::read(config_file)?)?;\n Model::Base(ModelBase::new(&config, vb)?)\n }\n };\n\n println!(\"loaded the model in {:?}\", start.elapsed());\n\n let mut pipeline = TextGeneration::new(\n model,\n tokenizer,\n args.seed,\n args.temperature,\n args.top_p,\n args.repeat_penalty,\n args.repeat_last_n,\n &device,\n );\n pipeline.run(&args.prompt, args.sample_len)?;\n Ok(())\n}\n", "candle-examples\\examples\\recurrent-gemma\\main.rs": "#[cfg(feature = \"mkl\")]\nextern crate intel_mkl_src;\n\n#[cfg(feature = \"accelerate\")]\nextern crate accelerate_src;\n\nuse anyhow::{Error as E, Result};\nuse clap::Parser;\n\nuse candle_transformers::models::quantized_recurrent_gemma::Model as QModel;\nuse candle_transformers::models::recurrent_gemma::{Config, Model as BModel};\n\nuse candle::{DType, Device, Tensor};\nuse candle_examples::token_output_stream::TokenOutputStream;\nuse candle_nn::VarBuilder;\nuse candle_transformers::generation::LogitsProcessor;\nuse hf_hub::{api::sync::Api, Repo, RepoType};\nuse tokenizers::Tokenizer;\n\nenum Model {\n B(BModel),\n Q(QModel),\n}\n\nimpl Model {\n fn forward(&mut self, xs: &Tensor, pos: usize) -> candle::Result<Tensor> {\n match self {\n Self::B(m) => m.forward(xs, pos),\n Self::Q(m) => m.forward(xs, pos),\n }\n }\n}\n\n#[derive(Clone, Debug, Copy, PartialEq, Eq, clap::ValueEnum)]\nenum Which {\n #[value(name = \"2b\")]\n Base2B,\n #[value(name = \"2b-it\")]\n Instruct2B,\n}\n\nstruct TextGeneration {\n model: Model,\n device: Device,\n tokenizer: TokenOutputStream,\n logits_processor: LogitsProcessor,\n repeat_penalty: f32,\n repeat_last_n: usize,\n}\n\nimpl TextGeneration {\n #[allow(clippy::too_many_arguments)]\n fn new(\n model: Model,\n tokenizer: Tokenizer,\n seed: u64,\n temp: Option<f64>,\n top_p: Option<f64>,\n top_k: usize,\n repeat_penalty: f32,\n repeat_last_n: usize,\n device: &Device,\n ) -> Self {\n let sampling = match temp {\n None => candle_transformers::generation::Sampling::ArgMax,\n Some(temperature) => match top_p {\n None => candle_transformers::generation::Sampling::TopK {\n temperature,\n k: top_k,\n },\n Some(top_p) => candle_transformers::generation::Sampling::TopKThenTopP {\n temperature,\n k: top_k,\n p: top_p,\n },\n },\n };\n let logits_processor = LogitsProcessor::from_sampling(seed, sampling);\n Self {\n model,\n tokenizer: TokenOutputStream::new(tokenizer),\n logits_processor,\n repeat_penalty,\n repeat_last_n,\n device: device.clone(),\n }\n }\n\n fn run(&mut self, prompt: &str, sample_len: usize) -> Result<()> {\n use std::io::Write;\n self.tokenizer.clear();\n let mut tokens = self\n .tokenizer\n .tokenizer()\n .encode(prompt, true)\n .map_err(E::msg)?\n .get_ids()\n .to_vec();\n for &t in tokens.iter() {\n if let Some(t) = self.tokenizer.next_token(t)? {\n print!(\"{t}\")\n }\n }\n std::io::stdout().flush()?;\n\n let mut generated_tokens = 0usize;\n let eos_token = match self.tokenizer.get_token(\"<eos>\") {\n Some(token) => token,\n None => anyhow::bail!(\"cannot find the <eos> token\"),\n };\n let start_gen = std::time::Instant::now();\n for index in 0..sample_len {\n let context_size = if index > 0 { 1 } else { tokens.len() };\n let start_pos = tokens.len().saturating_sub(context_size);\n let ctxt = &tokens[start_pos..];\n let input = Tensor::new(ctxt, &self.device)?.unsqueeze(0)?;\n let logits = self.model.forward(&input, start_pos)?;\n let logits = logits.squeeze(0)?.squeeze(0)?.to_dtype(DType::F32)?;\n let logits = if self.repeat_penalty == 1. {\n logits\n } else {\n let start_at = tokens.len().saturating_sub(self.repeat_last_n);\n candle_transformers::utils::apply_repeat_penalty(\n &logits,\n self.repeat_penalty,\n &tokens[start_at..],\n )?\n };\n\n let next_token = self.logits_processor.sample(&logits)?;\n tokens.push(next_token);\n generated_tokens += 1;\n if next_token == eos_token {\n break;\n }\n if let Some(t) = self.tokenizer.next_token(next_token)? {\n print!(\"{t}\");\n std::io::stdout().flush()?;\n }\n }\n let dt = start_gen.elapsed();\n if let Some(rest) = self.tokenizer.decode_rest().map_err(E::msg)? {\n print!(\"{rest}\");\n }\n std::io::stdout().flush()?;\n println!(\n \"\\n{generated_tokens} tokens generated ({:.2} token/s)\",\n generated_tokens as f64 / dt.as_secs_f64(),\n );\n Ok(())\n }\n}\n\n#[derive(Parser, Debug)]\n#[command(author, version, about, long_about = None)]\nstruct Args {\n /// Run on CPU rather than on GPU.\n #[arg(long)]\n cpu: bool,\n\n /// Enable tracing (generates a trace-timestamp.json file).\n #[arg(long)]\n tracing: bool,\n\n #[arg(long)]\n prompt: String,\n\n /// The temperature used to generate samples.\n #[arg(long)]\n temperature: Option<f64>,\n\n /// Nucleus sampling probability cutoff.\n #[arg(long)]\n top_p: Option<f64>,\n\n #[arg(long, default_value_t = 250)]\n top_k: usize,\n\n /// The seed to use when generating random samples.\n #[arg(long, default_value_t = 299792458)]\n seed: u64,\n\n /// The length of the sample to generate (in tokens).\n #[arg(long, short = 'n', default_value_t = 8000)]\n sample_len: usize,\n\n #[arg(long)]\n model_id: Option<String>,\n\n #[arg(long, default_value = \"main\")]\n revision: String,\n\n #[arg(long)]\n tokenizer_file: Option<String>,\n\n #[arg(long)]\n config_file: Option<String>,\n\n #[arg(long)]\n weight_files: Option<String>,\n\n /// Penalty to be applied for repeating tokens, 1. means no penalty.\n #[arg(long, default_value_t = 1.1)]\n repeat_penalty: f32,\n\n /// The context size to consider for the repeat penalty.\n #[arg(long, default_value_t = 64)]\n repeat_last_n: usize,\n\n /// The model to use.\n #[arg(long, default_value = \"2b\")]\n which: Which,\n\n #[arg(long)]\n quantized: bool,\n}\n\nfn main() -> Result<()> {\n use tracing_chrome::ChromeLayerBuilder;\n use tracing_subscriber::prelude::*;\n\n let args = Args::parse();\n let _guard = if args.tracing {\n let (chrome_layer, guard) = ChromeLayerBuilder::new().build();\n tracing_subscriber::registry().with(chrome_layer).init();\n Some(guard)\n } else {\n None\n };\n println!(\n \"avx: {}, neon: {}, simd128: {}, f16c: {}\",\n candle::utils::with_avx(),\n candle::utils::with_neon(),\n candle::utils::with_simd128(),\n candle::utils::with_f16c()\n );\n println!(\n \"temp: {:.2} repeat-penalty: {:.2} repeat-last-n: {}\",\n args.temperature.unwrap_or(0.),\n args.repeat_penalty,\n args.repeat_last_n\n );\n\n let start = std::time::Instant::now();\n let api = Api::new()?;\n let model_id = match &args.model_id {\n Some(model_id) => model_id.to_string(),\n None => match args.which {\n Which::Base2B => \"google/recurrentgemma-2b\".to_string(),\n Which::Instruct2B => \"google/recurrentgemma-2b-it\".to_string(),\n },\n };\n let repo = api.repo(Repo::with_revision(\n model_id,\n RepoType::Model,\n args.revision,\n ));\n let tokenizer_filename = match args.tokenizer_file {\n Some(file) => std::path::PathBuf::from(file),\n None => repo.get(\"tokenizer.json\")?,\n };\n let config_filename = match args.config_file {\n Some(file) => std::path::PathBuf::from(file),\n None => repo.get(\"config.json\")?,\n };\n let filenames = match args.weight_files {\n Some(files) => files\n .split(',')\n .map(std::path::PathBuf::from)\n .collect::<Vec<_>>(),\n None => {\n if args.quantized {\n let filename = match args.which {\n Which::Base2B => \"recurrent-gemma-2b-q4k.gguf\",\n Which::Instruct2B => \"recurrent-gemma-7b-q4k.gguf\",\n };\n let filename = api.model(\"lmz/candle-gemma\".to_string()).get(filename)?;\n vec![filename]\n } else {\n candle_examples::hub_load_safetensors(&repo, \"model.safetensors.index.json\")?\n }\n }\n };\n println!(\"retrieved the files in {:?}\", start.elapsed());\n let tokenizer = Tokenizer::from_file(tokenizer_filename).map_err(E::msg)?;\n let config: Config = serde_json::from_reader(std::fs::File::open(config_filename)?)?;\n\n let start = std::time::Instant::now();\n let device = candle_examples::device(args.cpu)?;\n let dtype = if device.is_cuda() {\n DType::BF16\n } else {\n DType::F32\n };\n let model = if args.quantized {\n let vb = candle_transformers::quantized_var_builder::VarBuilder::from_gguf(\n &filenames[0],\n &device,\n )?;\n Model::Q(QModel::new(&config, vb.pp(\"model\"))?)\n } else {\n let vb = unsafe { VarBuilder::from_mmaped_safetensors(&filenames, dtype, &device)? };\n Model::B(BModel::new(&config, vb.pp(\"model\"))?)\n };\n\n println!(\"loaded the model in {:?}\", start.elapsed());\n\n let mut pipeline = TextGeneration::new(\n model,\n tokenizer,\n args.seed,\n args.temperature,\n args.top_p,\n args.top_k,\n args.repeat_penalty,\n args.repeat_last_n,\n &device,\n );\n pipeline.run(&args.prompt, args.sample_len)?;\n Ok(())\n}\n", "candle-examples\\examples\\reinforcement-learning\\atari_wrappers.py": "import gymnasium as gym\nimport numpy as np\nfrom collections import deque\nfrom PIL import Image\nfrom multiprocessing import Process, Pipe\n\n# atari_wrappers.py\nclass NoopResetEnv(gym.Wrapper):\n def __init__(self, env, noop_max=30):\n \"\"\"Sample initial states by taking random number of no-ops on reset.\n No-op is assumed to be action 0.\n \"\"\"\n gym.Wrapper.__init__(self, env)\n self.noop_max = noop_max\n self.override_num_noops = None\n assert env.unwrapped.get_action_meanings()[0] == 'NOOP'\n\n def reset(self):\n \"\"\" Do no-op action for a number of steps in [1, noop_max].\"\"\"\n self.env.reset()\n if self.override_num_noops is not None:\n noops = self.override_num_noops\n else:\n noops = self.unwrapped.np_random.integers(1, self.noop_max + 1) #pylint: disable=E1101\n assert noops > 0\n obs = None\n for _ in range(noops):\n obs, _, done, _ = self.env.step(0)\n if done:\n obs = self.env.reset()\n return obs\n\nclass FireResetEnv(gym.Wrapper):\n def __init__(self, env):\n \"\"\"Take action on reset for environments that are fixed until firing.\"\"\"\n gym.Wrapper.__init__(self, env)\n assert env.unwrapped.get_action_meanings()[1] == 'FIRE'\n assert len(env.unwrapped.get_action_meanings()) >= 3\n\n def reset(self):\n self.env.reset()\n obs, _, done, _ = self.env.step(1)\n if done:\n self.env.reset()\n obs, _, done, _ = self.env.step(2)\n if done:\n self.env.reset()\n return obs\n\nclass ImageSaver(gym.Wrapper):\n def __init__(self, env, img_path, rank):\n gym.Wrapper.__init__(self, env)\n self._cnt = 0\n self._img_path = img_path\n self._rank = rank\n\n def step(self, action):\n step_result = self.env.step(action)\n obs, _, _, _ = step_result\n img = Image.fromarray(obs, 'RGB')\n img.save('%s/out%d-%05d.png' % (self._img_path, self._rank, self._cnt))\n self._cnt += 1\n return step_result\n\nclass EpisodicLifeEnv(gym.Wrapper):\n def __init__(self, env):\n \"\"\"Make end-of-life == end-of-episode, but only reset on true game over.\n Done by DeepMind for the DQN and co. since it helps value estimation.\n \"\"\"\n gym.Wrapper.__init__(self, env)\n self.lives = 0\n self.was_real_done = True\n\n def step(self, action):\n obs, reward, done, info = self.env.step(action)\n self.was_real_done = done\n # check current lives, make loss of life terminal,\n # then update lives to handle bonus lives\n lives = self.env.unwrapped.ale.lives()\n if lives < self.lives and lives > 0:\n # for Qbert sometimes we stay in lives == 0 condition for a few frames\n # so its important to keep lives > 0, so that we only reset once\n # the environment advertises done.\n done = True\n self.lives = lives\n return obs, reward, done, info\n\n def reset(self):\n \"\"\"Reset only when lives are exhausted.\n This way all states are still reachable even though lives are episodic,\n and the learner need not know about any of this behind-the-scenes.\n \"\"\"\n if self.was_real_done:\n obs = self.env.reset()\n else:\n # no-op step to advance from terminal/lost life state\n obs, _, _, _ = self.env.step(0)\n self.lives = self.env.unwrapped.ale.lives()\n return obs\n\nclass MaxAndSkipEnv(gym.Wrapper):\n def __init__(self, env, skip=4):\n \"\"\"Return only every `skip`-th frame\"\"\"\n gym.Wrapper.__init__(self, env)\n # most recent raw observations (for max pooling across time steps)\n self._obs_buffer = deque(maxlen=2)\n self._skip = skip\n\n def step(self, action):\n \"\"\"Repeat action, sum reward, and max over last observations.\"\"\"\n total_reward = 0.0\n done = None\n for _ in range(self._skip):\n obs, reward, done, info = self.env.step(action)\n self._obs_buffer.append(obs)\n total_reward += reward\n if done:\n break\n max_frame = np.max(np.stack(self._obs_buffer), axis=0)\n\n return max_frame, total_reward, done, info\n\n def reset(self):\n \"\"\"Clear past frame buffer and init. to first obs. from inner env.\"\"\"\n self._obs_buffer.clear()\n obs = self.env.reset()\n self._obs_buffer.append(obs)\n return obs\n\nclass ClipRewardEnv(gym.RewardWrapper):\n def reward(self, reward):\n \"\"\"Bin reward to {+1, 0, -1} by its sign.\"\"\"\n return np.sign(reward)\n\nclass WarpFrame(gym.ObservationWrapper):\n def __init__(self, env):\n \"\"\"Warp frames to 84x84 as done in the Nature paper and later work.\"\"\"\n gym.ObservationWrapper.__init__(self, env)\n self.res = 84\n self.observation_space = gym.spaces.Box(low=0, high=255, shape=(self.res, self.res, 1), dtype='uint8')\n\n def observation(self, obs):\n frame = np.dot(obs.astype('float32'), np.array([0.299, 0.587, 0.114], 'float32'))\n frame = np.array(Image.fromarray(frame).resize((self.res, self.res),\n resample=Image.BILINEAR), dtype=np.uint8)\n return frame.reshape((self.res, self.res, 1))\n\nclass FrameStack(gym.Wrapper):\n def __init__(self, env, k):\n \"\"\"Buffer observations and stack across channels (last axis).\"\"\"\n gym.Wrapper.__init__(self, env)\n self.k = k\n self.frames = deque([], maxlen=k)\n shp = env.observation_space.shape\n assert shp[2] == 1 # can only stack 1-channel frames\n self.observation_space = gym.spaces.Box(low=0, high=255, shape=(shp[0], shp[1], k), dtype='uint8')\n\n def reset(self):\n \"\"\"Clear buffer and re-fill by duplicating the first observation.\"\"\"\n ob = self.env.reset()\n for _ in range(self.k): self.frames.append(ob)\n return self.observation()\n\n def step(self, action):\n ob, reward, done, info = self.env.step(action)\n self.frames.append(ob)\n return self.observation(), reward, done, info\n\n def observation(self):\n assert len(self.frames) == self.k\n return np.concatenate(self.frames, axis=2)\n\ndef wrap_deepmind(env, episode_life=True, clip_rewards=True):\n \"\"\"Configure environment for DeepMind-style Atari.\n\n Note: this does not include frame stacking!\"\"\"\n assert 'NoFrameskip' in env.spec.id # required for DeepMind-style skip\n if episode_life:\n env = EpisodicLifeEnv(env)\n env = NoopResetEnv(env, noop_max=30)\n env = MaxAndSkipEnv(env, skip=4)\n if 'FIRE' in env.unwrapped.get_action_meanings():\n env = FireResetEnv(env)\n env = WarpFrame(env)\n if clip_rewards:\n env = ClipRewardEnv(env)\n return env\n\n# envs.py\ndef make_env(env_id, img_dir, seed, rank):\n def _thunk():\n env = gym.make(env_id)\n env.reset(seed=(seed + rank))\n if img_dir is not None:\n env = ImageSaver(env, img_dir, rank)\n env = wrap_deepmind(env)\n env = WrapPyTorch(env)\n return env\n\n return _thunk\n\nclass WrapPyTorch(gym.ObservationWrapper):\n def __init__(self, env=None):\n super(WrapPyTorch, self).__init__(env)\n self.observation_space = gym.spaces.Box(0.0, 1.0, [1, 84, 84], dtype='float32')\n\n def observation(self, observation):\n return observation.transpose(2, 0, 1)\n\n# vecenv.py\nclass VecEnv(object):\n \"\"\"\n Vectorized environment base class\n \"\"\"\n def step(self, vac):\n \"\"\"\n Apply sequence of actions to sequence of environments\n actions -> (observations, rewards, news)\n\n where 'news' is a boolean vector indicating whether each element is new.\n \"\"\"\n raise NotImplementedError\n def reset(self):\n \"\"\"\n Reset all environments\n \"\"\"\n raise NotImplementedError\n def close(self):\n pass\n\n# subproc_vec_env.py\ndef worker(remote, env_fn_wrapper):\n env = env_fn_wrapper.x()\n while True:\n cmd, data = remote.recv()\n if cmd == 'step':\n ob, reward, done, info = env.step(data)\n if done:\n ob = env.reset()\n remote.send((ob, reward, done, info))\n elif cmd == 'reset':\n ob = env.reset()\n remote.send(ob)\n elif cmd == 'close':\n remote.close()\n break\n elif cmd == 'get_spaces':\n remote.send((env.action_space, env.observation_space))\n else:\n raise NotImplementedError\n\nclass CloudpickleWrapper(object):\n \"\"\"\n Uses cloudpickle to serialize contents (otherwise multiprocessing tries to use pickle)\n \"\"\"\n def __init__(self, x):\n self.x = x\n def __getstate__(self):\n import cloudpickle\n return cloudpickle.dumps(self.x)\n def __setstate__(self, ob):\n import pickle\n self.x = pickle.loads(ob)\n\nclass SubprocVecEnv(VecEnv):\n def __init__(self, env_fns):\n \"\"\"\n envs: list of gym environments to run in subprocesses\n \"\"\"\n nenvs = len(env_fns)\n self.remotes, self.work_remotes = zip(*[Pipe() for _ in range(nenvs)]) \n self.ps = [Process(target=worker, args=(work_remote, CloudpickleWrapper(env_fn))) \n for (work_remote, env_fn) in zip(self.work_remotes, env_fns)]\n for p in self.ps:\n p.start()\n\n self.remotes[0].send(('get_spaces', None))\n self.action_space, self.observation_space = self.remotes[0].recv()\n\n\n def step(self, actions):\n for remote, action in zip(self.remotes, actions):\n remote.send(('step', action))\n results = [remote.recv() for remote in self.remotes]\n obs, rews, dones, infos = zip(*results)\n return np.stack(obs), np.stack(rews), np.stack(dones), infos\n\n def reset(self):\n for remote in self.remotes:\n remote.send(('reset', None))\n return np.stack([remote.recv() for remote in self.remotes])\n\n def close(self):\n for remote in self.remotes:\n remote.send(('close', None))\n for p in self.ps:\n p.join()\n\n @property\n def num_envs(self):\n return len(self.remotes)\n\n# Create the environment.\ndef make(env_name, img_dir, num_processes):\n envs = SubprocVecEnv([\n make_env(env_name, img_dir, 1337, i) for i in range(num_processes)\n ])\n return envs\n", "candle-examples\\examples\\reinforcement-learning\\main.rs": "#![allow(unused)]\n\n#[cfg(feature = \"mkl\")]\nextern crate intel_mkl_src;\n\n#[cfg(feature = \"accelerate\")]\nextern crate accelerate_src;\n\nuse candle::Result;\nuse clap::{Parser, Subcommand};\n\nmod gym_env;\nmod vec_gym_env;\n\nmod ddpg;\nmod dqn;\nmod policy_gradient;\n\n#[derive(Parser)]\nstruct Args {\n #[command(subcommand)]\n command: Command,\n}\n\n#[derive(Subcommand)]\nenum Command {\n Pg,\n Ddpg,\n Dqn,\n}\n\nfn main() -> Result<()> {\n let args = Args::parse();\n match args.command {\n Command::Pg => policy_gradient::run()?,\n Command::Ddpg => ddpg::run()?,\n Command::Dqn => dqn::run()?,\n }\n Ok(())\n}\n", "candle-examples\\examples\\replit-code\\main.rs": "#[cfg(feature = \"mkl\")]\nextern crate intel_mkl_src;\n\n#[cfg(feature = \"accelerate\")]\nextern crate accelerate_src;\n\nuse anyhow::{Error as E, Result};\nuse clap::Parser;\n\nuse candle_transformers::models::mpt::{Config, Model as M};\nuse candle_transformers::models::quantized_mpt::Model as Q;\n\nuse candle::{DType, Device, Tensor};\nuse candle_nn::VarBuilder;\nuse candle_transformers::generation::LogitsProcessor;\nuse hf_hub::{api::sync::Api, Repo, RepoType};\nuse tokenizers::Tokenizer;\n\nenum Model {\n M(M),\n Q(Q),\n}\n\nimpl Model {\n fn forward(&mut self, xs: &Tensor) -> candle::Result<Tensor> {\n match self {\n Self::M(model) => model.forward(xs),\n Self::Q(model) => model.forward(xs),\n }\n }\n}\n\nstruct TextGeneration {\n model: Model,\n device: Device,\n tokenizer: Tokenizer,\n logits_processor: LogitsProcessor,\n repeat_penalty: f32,\n repeat_last_n: usize,\n verbose_prompt: bool,\n}\n\nimpl TextGeneration {\n #[allow(clippy::too_many_arguments)]\n fn new(\n model: Model,\n tokenizer: Tokenizer,\n seed: u64,\n temp: Option<f64>,\n top_p: Option<f64>,\n repeat_penalty: f32,\n repeat_last_n: usize,\n verbose_prompt: bool,\n device: &Device,\n ) -> Self {\n let logits_processor = LogitsProcessor::new(seed, temp, top_p);\n Self {\n model,\n tokenizer,\n logits_processor,\n repeat_penalty,\n repeat_last_n,\n verbose_prompt,\n device: device.clone(),\n }\n }\n\n fn run(&mut self, prompt: &str, sample_len: usize) -> Result<()> {\n use std::io::Write;\n println!(\"starting the inference loop\");\n let tokens = self.tokenizer.encode(prompt, true).map_err(E::msg)?;\n if tokens.is_empty() {\n anyhow::bail!(\"Empty prompts are not supported in the phi model.\")\n }\n if self.verbose_prompt {\n for (token, id) in tokens.get_tokens().iter().zip(tokens.get_ids().iter()) {\n let token = token.replace('\u2581', \" \").replace(\"<0x0A>\", \"\\n\");\n println!(\"{id:7} -> '{token}'\");\n }\n }\n let mut tokens = tokens.get_ids().to_vec();\n let mut generated_tokens = 0usize;\n let eos_token = match self.tokenizer.get_vocab(true).get(\"<|endoftext|>\") {\n Some(token) => *token,\n None => anyhow::bail!(\"cannot find the endoftext token\"),\n };\n print!(\"{prompt}\");\n std::io::stdout().flush()?;\n let start_gen = std::time::Instant::now();\n for index in 0..sample_len {\n let context_size = if index > 0 { 1 } else { tokens.len() };\n let ctxt = &tokens[tokens.len().saturating_sub(context_size)..];\n let input = Tensor::new(ctxt, &self.device)?.unsqueeze(0)?;\n let logits = self.model.forward(&input)?;\n let logits = logits.squeeze(0)?.to_dtype(DType::F32)?;\n let logits = if self.repeat_penalty == 1. {\n logits\n } else {\n let start_at = tokens.len().saturating_sub(self.repeat_last_n);\n candle_transformers::utils::apply_repeat_penalty(\n &logits,\n self.repeat_penalty,\n &tokens[start_at..],\n )?\n };\n\n let next_token = self.logits_processor.sample(&logits)?;\n tokens.push(next_token);\n generated_tokens += 1;\n if next_token == eos_token {\n break;\n }\n let token = self.tokenizer.decode(&[next_token], true).map_err(E::msg)?;\n print!(\"{token}\");\n std::io::stdout().flush()?;\n }\n let dt = start_gen.elapsed();\n println!(\n \"\\n{generated_tokens} tokens generated ({:.2} token/s)\",\n generated_tokens as f64 / dt.as_secs_f64(),\n );\n Ok(())\n }\n}\n\n#[derive(Parser, Debug)]\n#[command(author, version, about, long_about = None)]\nstruct Args {\n /// Run on CPU rather than on GPU.\n #[arg(long)]\n cpu: bool,\n\n /// Enable tracing (generates a trace-timestamp.json file).\n #[arg(long)]\n tracing: bool,\n\n /// Display the token for the specified prompt.\n #[arg(long)]\n verbose_prompt: bool,\n\n #[arg(long)]\n prompt: String,\n\n /// The temperature used to generate samples.\n #[arg(long)]\n temperature: Option<f64>,\n\n /// Nucleus sampling probability cutoff.\n #[arg(long)]\n top_p: Option<f64>,\n\n /// The seed to use when generating random samples.\n #[arg(long, default_value_t = 299792458)]\n seed: u64,\n\n /// The length of the sample to generate (in tokens).\n #[arg(long, short = 'n', default_value_t = 1000)]\n sample_len: usize,\n\n #[arg(long)]\n model_id: Option<String>,\n\n #[arg(long)]\n revision: Option<String>,\n\n #[arg(long)]\n quantized: bool,\n\n #[arg(long)]\n weight_file: Option<String>,\n\n #[arg(long)]\n tokenizer: Option<String>,\n\n /// Penalty to be applied for repeating tokens, 1. means no penalty.\n #[arg(long, default_value_t = 1.)]\n repeat_penalty: f32,\n\n /// The context size to consider for the repeat penalty.\n #[arg(long, default_value_t = 64)]\n repeat_last_n: usize,\n}\n\nfn main() -> Result<()> {\n use tracing_chrome::ChromeLayerBuilder;\n use tracing_subscriber::prelude::*;\n\n let args = Args::parse();\n let _guard = if args.tracing {\n let (chrome_layer, guard) = ChromeLayerBuilder::new().build();\n tracing_subscriber::registry().with(chrome_layer).init();\n Some(guard)\n } else {\n None\n };\n println!(\n \"avx: {}, neon: {}, simd128: {}, f16c: {}\",\n candle::utils::with_avx(),\n candle::utils::with_neon(),\n candle::utils::with_simd128(),\n candle::utils::with_f16c()\n );\n println!(\n \"temp: {:.2} repeat-penalty: {:.2} repeat-last-n: {}\",\n args.temperature.unwrap_or(0.),\n args.repeat_penalty,\n args.repeat_last_n\n );\n\n let start = std::time::Instant::now();\n let api = Api::new()?;\n let model_id = match args.model_id {\n Some(model_id) => model_id.to_string(),\n None => \"lmz/candle-replit-code\".to_string(),\n };\n let revision = match args.revision {\n Some(rev) => rev.to_string(),\n None => \"main\".to_string(),\n };\n let repo = api.repo(Repo::with_revision(model_id, RepoType::Model, revision));\n let tokenizer_filename = match args.tokenizer {\n Some(file) => std::path::PathBuf::from(file),\n None => repo.get(\"tokenizer.json\")?,\n };\n let filename = match args.weight_file {\n Some(weight_file) => std::path::PathBuf::from(weight_file),\n None => {\n if args.quantized {\n repo.get(\"model-replit-code-v1_5-q4k.gguf\")?\n } else {\n repo.get(\"model.safetensors\")?\n }\n }\n };\n println!(\"retrieved the files in {:?}\", start.elapsed());\n let tokenizer = Tokenizer::from_file(tokenizer_filename).map_err(E::msg)?;\n\n let start = std::time::Instant::now();\n let device = candle_examples::device(args.cpu)?;\n let config = Config::replit_code_v1_5_3b();\n let model = if args.quantized {\n let vb =\n candle_transformers::quantized_var_builder::VarBuilder::from_gguf(&filename, &device)?;\n Model::Q(Q::new(&config, vb.pp(\"transformer\"))?)\n } else {\n let vb = unsafe { VarBuilder::from_mmaped_safetensors(&[filename], DType::F32, &device)? };\n Model::M(M::new(&config, vb.pp(\"transformer\"))?)\n };\n println!(\"loaded the model in {:?}\", start.elapsed());\n\n let mut pipeline = TextGeneration::new(\n model,\n tokenizer,\n args.seed,\n args.temperature,\n args.top_p,\n args.repeat_penalty,\n args.repeat_last_n,\n args.verbose_prompt,\n &device,\n );\n pipeline.run(&args.prompt, args.sample_len)?;\n Ok(())\n}\n", "candle-examples\\examples\\repvgg\\main.rs": "#[cfg(feature = \"mkl\")]\nextern crate intel_mkl_src;\n\n#[cfg(feature = \"accelerate\")]\nextern crate accelerate_src;\n\nuse clap::{Parser, ValueEnum};\n\nuse candle::{DType, IndexOp, D};\nuse candle_nn::{Module, VarBuilder};\nuse candle_transformers::models::repvgg;\n\n#[derive(Clone, Copy, Debug, ValueEnum)]\nenum Which {\n A0,\n A1,\n A2,\n B0,\n B1,\n B2,\n B3,\n B1G4,\n B2G4,\n B3G4,\n}\n\nimpl Which {\n fn model_filename(&self) -> String {\n let name = match self {\n Self::A0 => \"a0\",\n Self::A1 => \"a1\",\n Self::A2 => \"a2\",\n Self::B0 => \"b0\",\n Self::B1 => \"b1\",\n Self::B2 => \"b2\",\n Self::B3 => \"b3\",\n Self::B1G4 => \"b1g4\",\n Self::B2G4 => \"b2g4\",\n Self::B3G4 => \"b3g4\",\n };\n format!(\"timm/repvgg_{}.rvgg_in1k\", name)\n }\n\n fn config(&self) -> repvgg::Config {\n match self {\n Self::A0 => repvgg::Config::a0(),\n Self::A1 => repvgg::Config::a1(),\n Self::A2 => repvgg::Config::a2(),\n Self::B0 => repvgg::Config::b0(),\n Self::B1 => repvgg::Config::b1(),\n Self::B2 => repvgg::Config::b2(),\n Self::B3 => repvgg::Config::b3(),\n Self::B1G4 => repvgg::Config::b1g4(),\n Self::B2G4 => repvgg::Config::b2g4(),\n Self::B3G4 => repvgg::Config::b3g4(),\n }\n }\n}\n\n#[derive(Parser)]\nstruct Args {\n #[arg(long)]\n model: Option<String>,\n\n #[arg(long)]\n image: String,\n\n /// Run on CPU rather than on GPU.\n #[arg(long)]\n cpu: bool,\n\n #[arg(value_enum, long, default_value_t=Which::A0)]\n which: Which,\n}\n\npub fn main() -> anyhow::Result<()> {\n let args = Args::parse();\n\n let device = candle_examples::device(args.cpu)?;\n\n let image = candle_examples::imagenet::load_image224(args.image)?.to_device(&device)?;\n println!(\"loaded image {image:?}\");\n\n let model_file = match args.model {\n None => {\n let model_name = args.which.model_filename();\n let api = hf_hub::api::sync::Api::new()?;\n let api = api.model(model_name);\n api.get(\"model.safetensors\")?\n }\n Some(model) => model.into(),\n };\n\n let vb = unsafe { VarBuilder::from_mmaped_safetensors(&[model_file], DType::F32, &device)? };\n let model = repvgg::repvgg(&args.which.config(), 1000, vb)?;\n println!(\"model built\");\n let logits = model.forward(&image.unsqueeze(0)?)?;\n let prs = candle_nn::ops::softmax(&logits, D::Minus1)?\n .i(0)?\n .to_vec1::<f32>()?;\n let mut prs = prs.iter().enumerate().collect::<Vec<_>>();\n prs.sort_by(|(_, p1), (_, p2)| p2.total_cmp(p1));\n for &(category_idx, pr) in prs.iter().take(5) {\n println!(\n \"{:24}: {:.2}%\",\n candle_examples::imagenet::CLASSES[category_idx],\n 100. * pr\n );\n }\n Ok(())\n}\n", "candle-examples\\examples\\resnet\\main.rs": "#[cfg(feature = \"mkl\")]\nextern crate intel_mkl_src;\n\n#[cfg(feature = \"accelerate\")]\nextern crate accelerate_src;\n\nuse candle::{DType, IndexOp, D};\nuse candle_nn::{Module, VarBuilder};\nuse candle_transformers::models::resnet;\nuse clap::{Parser, ValueEnum};\n\n#[derive(Clone, Copy, Debug, ValueEnum)]\nenum Which {\n #[value(name = \"18\")]\n Resnet18,\n #[value(name = \"34\")]\n Resnet34,\n #[value(name = \"50\")]\n Resnet50,\n #[value(name = \"101\")]\n Resnet101,\n #[value(name = \"152\")]\n Resnet152,\n}\n\n#[derive(Parser)]\nstruct Args {\n #[arg(long)]\n model: Option<String>,\n\n #[arg(long)]\n image: String,\n\n /// Run on CPU rather than on GPU.\n #[arg(long)]\n cpu: bool,\n\n /// Variant of the model to use.\n #[arg(value_enum, long, default_value_t = Which::Resnet18)]\n which: Which,\n}\n\npub fn main() -> anyhow::Result<()> {\n let args = Args::parse();\n\n let device = candle_examples::device(args.cpu)?;\n\n let image = candle_examples::imagenet::load_image224(args.image)?.to_device(&device)?;\n println!(\"loaded image {image:?}\");\n\n let model_file = match args.model {\n None => {\n let api = hf_hub::api::sync::Api::new()?;\n let api = api.model(\"lmz/candle-resnet\".into());\n let filename = match args.which {\n Which::Resnet18 => \"resnet18.safetensors\",\n Which::Resnet34 => \"resnet34.safetensors\",\n Which::Resnet50 => \"resnet50.safetensors\",\n Which::Resnet101 => \"resnet101.safetensors\",\n Which::Resnet152 => \"resnet152.safetensors\",\n };\n api.get(filename)?\n }\n Some(model) => model.into(),\n };\n let vb = unsafe { VarBuilder::from_mmaped_safetensors(&[model_file], DType::F32, &device)? };\n let class_count = candle_examples::imagenet::CLASS_COUNT as usize;\n let model = match args.which {\n Which::Resnet18 => resnet::resnet18(class_count, vb)?,\n Which::Resnet34 => resnet::resnet34(class_count, vb)?,\n Which::Resnet50 => resnet::resnet50(class_count, vb)?,\n Which::Resnet101 => resnet::resnet101(class_count, vb)?,\n Which::Resnet152 => resnet::resnet152(class_count, vb)?,\n };\n println!(\"model built\");\n let logits = model.forward(&image.unsqueeze(0)?)?;\n let prs = candle_nn::ops::softmax(&logits, D::Minus1)?\n .i(0)?\n .to_vec1::<f32>()?;\n let mut prs = prs.iter().enumerate().collect::<Vec<_>>();\n prs.sort_by(|(_, p1), (_, p2)| p2.total_cmp(p1));\n for &(category_idx, pr) in prs.iter().take(5) {\n println!(\n \"{:24}: {:.2}%\",\n candle_examples::imagenet::CLASSES[category_idx],\n 100. * pr\n );\n }\n Ok(())\n}\n", "candle-examples\\examples\\rwkv\\main.rs": "#[cfg(feature = \"mkl\")]\nextern crate intel_mkl_src;\n\n#[cfg(feature = \"accelerate\")]\nextern crate accelerate_src;\n\nuse anyhow::Result;\nuse clap::{Parser, ValueEnum};\n\nuse candle_transformers::models::quantized_rwkv_v5::Model as Q5;\nuse candle_transformers::models::quantized_rwkv_v6::Model as Q6;\nuse candle_transformers::models::rwkv_v5::{Config, Model as M5, State, Tokenizer};\nuse candle_transformers::models::rwkv_v6::Model as M6;\n\nuse candle::{DType, Device, Tensor};\nuse candle_nn::VarBuilder;\nuse candle_transformers::generation::LogitsProcessor;\nuse hf_hub::{api::sync::Api, Repo, RepoType};\n\nconst EOS_TOKEN_ID: u32 = 261;\n\nenum Model {\n M5(M5),\n Q5(Q5),\n M6(M6),\n Q6(Q6),\n}\n\nimpl Model {\n fn forward(&self, xs: &Tensor, state: &mut State) -> candle::Result<Tensor> {\n match self {\n Self::M5(m) => m.forward(xs, state),\n Self::Q5(m) => m.forward(xs, state),\n Self::M6(m) => m.forward(xs, state),\n Self::Q6(m) => m.forward(xs, state),\n }\n }\n}\n\nstruct TextGeneration {\n model: Model,\n config: Config,\n device: Device,\n tokenizer: Tokenizer,\n logits_processor: LogitsProcessor,\n repeat_penalty: f32,\n repeat_last_n: usize,\n}\n\nimpl TextGeneration {\n #[allow(clippy::too_many_arguments)]\n fn new(\n model: Model,\n config: Config,\n tokenizer: Tokenizer,\n seed: u64,\n temp: Option<f64>,\n top_p: Option<f64>,\n repeat_penalty: f32,\n repeat_last_n: usize,\n device: &Device,\n ) -> Self {\n let logits_processor = LogitsProcessor::new(seed, temp, top_p);\n Self {\n model,\n config,\n tokenizer,\n logits_processor,\n repeat_penalty,\n repeat_last_n,\n device: device.clone(),\n }\n }\n\n fn run(&mut self, prompt: &str, sample_len: usize) -> Result<()> {\n use std::io::Write;\n let mut tokens = self.tokenizer.encode(prompt)?;\n let mut generated_tokens = 0usize;\n let mut state = State::new(1, &self.config, &self.device)?;\n let mut next_logits = None;\n for &t in tokens.iter() {\n let input = Tensor::new(&[[t]], &self.device)?;\n let logits = self.model.forward(&input, &mut state)?;\n next_logits = Some(logits);\n print!(\"{}\", self.tokenizer.decode(&[t])?)\n }\n std::io::stdout().flush()?;\n\n let start_gen = std::time::Instant::now();\n for _ in 0..sample_len {\n let logits = match next_logits.as_ref() {\n Some(logits) => logits,\n None => anyhow::bail!(\"cannot work on an empty prompt\"),\n };\n let logits = logits.squeeze(0)?.squeeze(0)?.to_dtype(DType::F32)?;\n let logits = if self.repeat_penalty == 1. {\n logits\n } else {\n let start_at = tokens.len().saturating_sub(self.repeat_last_n);\n candle_transformers::utils::apply_repeat_penalty(\n &logits,\n self.repeat_penalty,\n &tokens[start_at..],\n )?\n };\n let next_token = self.logits_processor.sample(&logits)?;\n tokens.push(next_token);\n generated_tokens += 1;\n if next_token == EOS_TOKEN_ID || next_token == 0 {\n break;\n }\n print!(\"{}\", self.tokenizer.decode(&[next_token])?);\n std::io::stdout().flush()?;\n\n let input = Tensor::new(&[[next_token]], &self.device)?;\n next_logits = Some(self.model.forward(&input, &mut state)?)\n }\n let dt = start_gen.elapsed();\n println!(\n \"\\n{generated_tokens} tokens generated ({:.2} token/s)\",\n generated_tokens as f64 / dt.as_secs_f64(),\n );\n Ok(())\n }\n}\n\n#[derive(Parser, ValueEnum, Clone, Copy, PartialEq, Eq, Debug)]\nenum Which {\n Eagle7b,\n World1b5,\n World3b,\n World6_1b6,\n}\n\nimpl std::fmt::Display for Which {\n fn fmt(&self, f: &mut std::fmt::Formatter<'_>) -> std::fmt::Result {\n write!(f, \"{:?}\", self)\n }\n}\n\nimpl Which {\n fn model_id(&self) -> &'static str {\n match self {\n Self::Eagle7b => \"RWKV/v5-Eagle-7B-HF\",\n Self::World1b5 => \"RWKV/rwkv-5-world-1b5\",\n Self::World3b => \"RWKV/rwkv-5-world-3b\",\n Self::World6_1b6 => \"paperfun/rwkv\",\n }\n }\n\n fn revision(&self) -> &'static str {\n match self {\n Self::Eagle7b => \"refs/pr/1\",\n Self::World1b5 | Self::World3b => \"refs/pr/2\",\n Self::World6_1b6 => \"main\",\n }\n }\n}\n\n#[derive(Parser, Debug)]\n#[command(author, version, about, long_about = None)]\nstruct Args {\n /// Run on CPU rather than on GPU.\n #[arg(long)]\n cpu: bool,\n\n /// Enable tracing (generates a trace-timestamp.json file).\n #[arg(long)]\n tracing: bool,\n\n #[arg(long)]\n prompt: String,\n\n /// The temperature used to generate samples.\n #[arg(long)]\n temperature: Option<f64>,\n\n /// Nucleus sampling probability cutoff.\n #[arg(long)]\n top_p: Option<f64>,\n\n /// The seed to use when generating random samples.\n #[arg(long, default_value_t = 299792458)]\n seed: u64,\n\n /// The length of the sample to generate (in tokens).\n #[arg(long, short = 'n', default_value_t = 5000)]\n sample_len: usize,\n\n #[arg(long, default_value = \"world1b5\")]\n which: Which,\n\n #[arg(long)]\n model_id: Option<String>,\n\n #[arg(long)]\n revision: Option<String>,\n\n #[arg(long)]\n tokenizer: Option<String>,\n\n #[arg(long)]\n weight_files: Option<String>,\n\n #[arg(long)]\n config_file: Option<String>,\n\n #[arg(long)]\n quantized: bool,\n\n /// Penalty to be applied for repeating tokens, 1. means no penalty.\n #[arg(long, default_value_t = 1.1)]\n repeat_penalty: f32,\n\n /// The context size to consider for the repeat penalty.\n #[arg(long, default_value_t = 64)]\n repeat_last_n: usize,\n}\n\nfn main() -> Result<()> {\n use tracing_chrome::ChromeLayerBuilder;\n use tracing_subscriber::prelude::*;\n\n let args = Args::parse();\n let _guard = if args.tracing {\n let (chrome_layer, guard) = ChromeLayerBuilder::new().build();\n tracing_subscriber::registry().with(chrome_layer).init();\n Some(guard)\n } else {\n None\n };\n println!(\n \"avx: {}, neon: {}, simd128: {}, f16c: {}\",\n candle::utils::with_avx(),\n candle::utils::with_neon(),\n candle::utils::with_simd128(),\n candle::utils::with_f16c()\n );\n println!(\n \"temp: {:.2} repeat-penalty: {:.2} repeat-last-n: {}\",\n args.temperature.unwrap_or(0.),\n args.repeat_penalty,\n args.repeat_last_n\n );\n\n let start = std::time::Instant::now();\n let api = Api::new()?;\n let repo = api.repo(Repo::with_revision(\n args.model_id\n .unwrap_or_else(|| args.which.model_id().to_string()),\n RepoType::Model,\n args.revision\n .unwrap_or_else(|| args.which.revision().to_string()),\n ));\n let tokenizer = match args.tokenizer {\n Some(file) => std::path::PathBuf::from(file),\n None => api\n .model(\"lmz/candle-rwkv\".to_string())\n .get(\"rwkv_vocab_v20230424.json\")?,\n };\n let config_filename = match args.config_file {\n Some(file) => std::path::PathBuf::from(file),\n None => repo.get(\"config.json\")?,\n };\n let filenames = match args.weight_files {\n Some(files) => files\n .split(',')\n .map(std::path::PathBuf::from)\n .collect::<Vec<_>>(),\n None => {\n if args.quantized {\n vec![match args.which {\n Which::World1b5 => api\n .model(\"lmz/candle-rwkv\".to_string())\n .get(\"world1b5-q4k.gguf\")?,\n Which::World3b => api\n .model(\"lmz/candle-rwkv\".to_string())\n .get(\"world3b-q4k.gguf\")?,\n Which::Eagle7b => api\n .model(\"lmz/candle-rwkv\".to_string())\n .get(\"eagle7b-q4k.gguf\")?,\n Which::World6_1b6 => repo.get(\"rwkv-6-world-1b6-q4k.gguf\")?,\n }]\n } else {\n vec![match args.which {\n Which::World1b5 | Which::World3b | Which::Eagle7b => {\n repo.get(\"model.safetensors\")?\n }\n Which::World6_1b6 => repo.get(\"rwkv-6-world-1b6.safetensors\")?,\n }]\n }\n }\n };\n println!(\"retrieved the files in {:?}\", start.elapsed());\n let tokenizer = Tokenizer::new(tokenizer)?;\n\n let start = std::time::Instant::now();\n let config: Config = serde_json::from_slice(&std::fs::read(config_filename)?)?;\n let device = candle_examples::device(args.cpu)?;\n let model = if args.quantized {\n let filename = &filenames[0];\n let vb =\n candle_transformers::quantized_var_builder::VarBuilder::from_gguf(filename, &device)?;\n match args.which {\n Which::World1b5 | Which::World3b | Which::Eagle7b => Model::Q5(Q5::new(&config, vb)?),\n Which::World6_1b6 => Model::Q6(Q6::new(&config, vb)?),\n }\n } else {\n let vb = unsafe { VarBuilder::from_mmaped_safetensors(&filenames, DType::F32, &device)? };\n match args.which {\n Which::World1b5 | Which::World3b | Which::Eagle7b => Model::M5(M5::new(&config, vb)?),\n Which::World6_1b6 => Model::M6(M6::new(&config, vb)?),\n }\n };\n println!(\"loaded the model in {:?}\", start.elapsed());\n\n let mut pipeline = TextGeneration::new(\n model,\n config,\n tokenizer,\n args.seed,\n args.temperature,\n args.top_p,\n args.repeat_penalty,\n args.repeat_last_n,\n &device,\n );\n pipeline.run(&args.prompt, args.sample_len)?;\n Ok(())\n}\n", "candle-examples\\examples\\segformer\\main.rs": "use candle::Device;\nuse candle::Module;\nuse candle_nn::VarBuilder;\nuse candle_transformers::models::segformer::{\n Config, ImageClassificationModel, SemanticSegmentationModel,\n};\nuse clap::{Args, Parser, Subcommand};\nuse imageproc::image::Rgb;\nuse imageproc::integral_image::ArrayData;\nuse std::collections::HashMap;\nuse std::path::PathBuf;\n\n#[derive(Parser)]\n#[clap(about, version, long_about = None)]\nstruct CliArgs {\n #[arg(long, help = \"use cpu\")]\n cpu: bool,\n #[command(subcommand)]\n command: Commands,\n}\n#[derive(Args, Debug)]\nstruct SegmentationArgs {\n #[arg(\n long,\n help = \"name of the huggingface hub model\",\n default_value = \"nvidia/segformer-b0-finetuned-ade-512-512\"\n )]\n model_name: String,\n #[arg(\n long,\n help = \"path to the label file in json format\",\n default_value = \"candle-examples/examples/segformer/assets/labels.json\"\n )]\n label_path: PathBuf,\n #[arg(long, help = \"path to for the output mask image\")]\n output_path: PathBuf,\n #[arg(help = \"path to image as input\")]\n image: PathBuf,\n}\n\n#[derive(Args, Debug)]\nstruct ClassificationArgs {\n #[arg(\n long,\n help = \"name of the huggingface hub model\",\n default_value = \"paolinox/segformer-finetuned-food101\"\n )]\n model_name: String,\n #[arg(help = \"path to image as input\")]\n image: PathBuf,\n}\n\n#[derive(Subcommand, Debug)]\nenum Commands {\n Segment(SegmentationArgs),\n Classify(ClassificationArgs),\n}\n\nfn get_vb_and_config(model_name: String, device: &Device) -> anyhow::Result<(VarBuilder, Config)> {\n println!(\"loading model {} via huggingface hub\", model_name);\n let api = hf_hub::api::sync::Api::new()?;\n let api = api.model(model_name.clone());\n let model_file = api.get(\"model.safetensors\")?;\n println!(\"model {} downloaded and loaded\", model_name);\n let vb =\n unsafe { VarBuilder::from_mmaped_safetensors(&[model_file], candle::DType::F32, device)? };\n let config = std::fs::read_to_string(api.get(\"config.json\")?)?;\n let config: Config = serde_json::from_str(&config)?;\n println!(\"{:?}\", config);\n Ok((vb, config))\n}\n\n#[derive(Debug, serde::Deserialize)]\nstruct LabelItem {\n index: u32,\n color: String,\n}\n\nfn segmentation_task(args: SegmentationArgs, device: &Device) -> anyhow::Result<()> {\n let label_file = std::fs::read_to_string(&args.label_path)?;\n let label_items: Vec<LabelItem> = serde_json::from_str(&label_file)?;\n let label_colors: HashMap<u32, Rgb<u8>> = label_items\n .iter()\n .map(|x| {\n (x.index - 1, {\n let color = x.color.trim_start_matches('#');\n let r = u8::from_str_radix(&color[0..2], 16).unwrap();\n let g = u8::from_str_radix(&color[2..4], 16).unwrap();\n let b = u8::from_str_radix(&color[4..6], 16).unwrap();\n Rgb([r, g, b])\n })\n })\n .collect();\n\n let image = candle_examples::imagenet::load_image224(args.image)?\n .unsqueeze(0)?\n .to_device(device)?;\n let (vb, config) = get_vb_and_config(args.model_name, device)?;\n let num_labels = label_items.len();\n\n let model = SemanticSegmentationModel::new(&config, num_labels, vb)?;\n let segmentations = model.forward(&image)?;\n\n // generate a mask image\n let mask = &segmentations.squeeze(0)?.argmax(0)?;\n let (h, w) = mask.dims2()?;\n let mask = mask.flatten_all()?.to_vec1::<u32>()?;\n let mask = mask\n .iter()\n .flat_map(|x| label_colors[x].data())\n .collect::<Vec<u8>>();\n let mask: image::ImageBuffer<image::Rgb<u8>, Vec<u8>> =\n image::ImageBuffer::from_raw(w as u32, h as u32, mask).unwrap();\n // resize\n let mask = image::DynamicImage::from(mask);\n let mask = mask.resize_to_fill(\n w as u32 * 4,\n h as u32 * 4,\n image::imageops::FilterType::CatmullRom,\n );\n mask.save(args.output_path.clone())?;\n println!(\"mask image saved to {:?}\", args.output_path);\n Ok(())\n}\n\nfn classification_task(args: ClassificationArgs, device: &Device) -> anyhow::Result<()> {\n let image = candle_examples::imagenet::load_image224(args.image)?\n .unsqueeze(0)?\n .to_device(device)?;\n let (vb, config) = get_vb_and_config(args.model_name, device)?;\n let num_labels = 7;\n let model = ImageClassificationModel::new(&config, num_labels, vb)?;\n let classification = model.forward(&image)?;\n let classification = candle_nn::ops::softmax_last_dim(&classification)?;\n let classification = classification.squeeze(0)?;\n println!(\n \"classification logits {:?}\",\n classification.to_vec1::<f32>()?\n );\n let label_id = classification.argmax(0)?.to_scalar::<u32>()?;\n let label_id = format!(\"{}\", label_id);\n println!(\"label: {}\", config.id2label[&label_id]);\n Ok(())\n}\n\npub fn main() -> anyhow::Result<()> {\n let args = CliArgs::parse();\n let device = candle_examples::device(args.cpu)?;\n if let Commands::Segment(args) = args.command {\n segmentation_task(args, &device)?\n } else if let Commands::Classify(args) = args.command {\n classification_task(args, &device)?\n }\n Ok(())\n}\n", "candle-examples\\examples\\segment-anything\\main.rs": "//! SAM: Segment Anything Model\n//! https://github.com/facebookresearch/segment-anything\n\n#[cfg(feature = \"mkl\")]\nextern crate intel_mkl_src;\n\n#[cfg(feature = \"accelerate\")]\nextern crate accelerate_src;\n\nuse candle::DType;\nuse candle_nn::VarBuilder;\nuse candle_transformers::models::segment_anything::sam;\nuse clap::Parser;\n\n#[derive(Parser)]\nstruct Args {\n #[arg(long)]\n model: Option<String>,\n\n #[arg(long)]\n image: String,\n\n /// Run on CPU rather than on GPU.\n #[arg(long)]\n cpu: bool,\n\n #[arg(long)]\n generate_masks: bool,\n\n /// List of x,y coordinates, between 0 and 1 (0.5 is at the middle of the image). These points\n /// should be part of the generated mask.\n #[arg(long)]\n point: Vec<String>,\n\n /// List of x,y coordinates, between 0 and 1 (0.5 is at the middle of the image). These points\n /// should not be part of the generated mask and should be part of the background instead.\n #[arg(long)]\n neg_point: Vec<String>,\n\n /// The detection threshold for the mask, 0 is the default value, negative values mean a larger\n /// mask, positive makes the mask more selective.\n #[arg(long, allow_hyphen_values = true, default_value_t = 0.)]\n threshold: f32,\n\n /// Enable tracing (generates a trace-timestamp.json file).\n #[arg(long)]\n tracing: bool,\n\n /// Use the TinyViT based models from MobileSAM\n #[arg(long)]\n use_tiny: bool,\n}\n\npub fn main() -> anyhow::Result<()> {\n use tracing_chrome::ChromeLayerBuilder;\n use tracing_subscriber::prelude::*;\n\n let args = Args::parse();\n let _guard = if args.tracing {\n let (chrome_layer, guard) = ChromeLayerBuilder::new().build();\n tracing_subscriber::registry().with(chrome_layer).init();\n Some(guard)\n } else {\n None\n };\n\n let device = candle_examples::device(args.cpu)?;\n\n let (image, initial_h, initial_w) =\n candle_examples::load_image(&args.image, Some(sam::IMAGE_SIZE))?;\n let image = image.to_device(&device)?;\n println!(\"loaded image {image:?}\");\n\n let model = match args.model {\n Some(model) => std::path::PathBuf::from(model),\n None => {\n let api = hf_hub::api::sync::Api::new()?;\n let api = api.model(\"lmz/candle-sam\".to_string());\n let filename = if args.use_tiny {\n \"mobile_sam-tiny-vitt.safetensors\"\n } else {\n \"sam_vit_b_01ec64.safetensors\"\n };\n api.get(filename)?\n }\n };\n let vb = unsafe { VarBuilder::from_mmaped_safetensors(&[model], DType::F32, &device)? };\n let sam = if args.use_tiny {\n sam::Sam::new_tiny(vb)? // tiny vit_t\n } else {\n sam::Sam::new(768, 12, 12, &[2, 5, 8, 11], vb)? // sam_vit_b\n };\n\n if args.generate_masks {\n // Default options similar to the Python version.\n let bboxes = sam.generate_masks(\n &image,\n /* points_per_side */ 32,\n /* crop_n_layer */ 0,\n /* crop_overlap_ratio */ 512. / 1500.,\n /* crop_n_points_downscale_factor */ 1,\n )?;\n for (idx, bbox) in bboxes.iter().enumerate() {\n println!(\"{idx} {bbox:?}\");\n let mask = (&bbox.data.to_dtype(DType::U8)? * 255.)?;\n let (h, w) = mask.dims2()?;\n let mask = mask.broadcast_as((3, h, w))?;\n candle_examples::save_image_resize(\n &mask,\n format!(\"sam_mask{idx}.png\"),\n initial_h,\n initial_w,\n )?;\n }\n } else {\n let iter_points = args.point.iter().map(|p| (p, true));\n let iter_neg_points = args.neg_point.iter().map(|p| (p, false));\n let points = iter_points\n .chain(iter_neg_points)\n .map(|(point, b)| {\n use std::str::FromStr;\n let xy = point.split(',').collect::<Vec<_>>();\n if xy.len() != 2 {\n anyhow::bail!(\"expected format for points is 0.4,0.2\")\n }\n Ok((f64::from_str(xy[0])?, f64::from_str(xy[1])?, b))\n })\n .collect::<anyhow::Result<Vec<_>>>()?;\n let start_time = std::time::Instant::now();\n let (mask, iou_predictions) = sam.forward(&image, &points, false)?;\n println!(\n \"mask generated in {:.2}s\",\n start_time.elapsed().as_secs_f32()\n );\n println!(\"mask:\\n{mask}\");\n println!(\"iou_predictions: {iou_predictions}\");\n\n let mask = (mask.ge(args.threshold)? * 255.)?;\n let (_one, h, w) = mask.dims3()?;\n let mask = mask.expand((3, h, w))?;\n\n let mut img = image::ImageReader::open(&args.image)?\n .decode()\n .map_err(candle::Error::wrap)?;\n let mask_pixels = mask.permute((1, 2, 0))?.flatten_all()?.to_vec1::<u8>()?;\n let mask_img: image::ImageBuffer<image::Rgb<u8>, Vec<u8>> =\n match image::ImageBuffer::from_raw(w as u32, h as u32, mask_pixels) {\n Some(image) => image,\n None => anyhow::bail!(\"error saving merged image\"),\n };\n let mask_img = image::DynamicImage::from(mask_img).resize_to_fill(\n img.width(),\n img.height(),\n image::imageops::FilterType::CatmullRom,\n );\n for x in 0..img.width() {\n for y in 0..img.height() {\n let mask_p = imageproc::drawing::Canvas::get_pixel(&mask_img, x, y);\n if mask_p.0[0] > 100 {\n let mut img_p = imageproc::drawing::Canvas::get_pixel(&img, x, y);\n img_p.0[2] = 255 - (255 - img_p.0[2]) / 2;\n img_p.0[1] /= 2;\n img_p.0[0] /= 2;\n imageproc::drawing::Canvas::draw_pixel(&mut img, x, y, img_p)\n }\n }\n }\n for (x, y, b) in points {\n let x = (x * img.width() as f64) as i32;\n let y = (y * img.height() as f64) as i32;\n let color = if b {\n image::Rgba([255, 0, 0, 200])\n } else {\n image::Rgba([0, 255, 0, 200])\n };\n imageproc::drawing::draw_filled_circle_mut(&mut img, (x, y), 3, color);\n }\n img.save(\"sam_merged.jpg\")?\n }\n Ok(())\n}\n", "candle-examples\\examples\\silero-vad\\main.rs": "#[cfg(feature = \"mkl\")]\nextern crate intel_mkl_src;\n\n#[cfg(feature = \"accelerate\")]\nextern crate accelerate_src;\n\nuse anyhow::Result;\nuse clap::Parser;\n\nuse candle::{DType, Tensor};\n\n#[derive(Clone, Debug, Copy, PartialEq, Eq, clap::ValueEnum)]\nenum Which {\n #[value(name = \"silero\")]\n Silero,\n}\n\n#[derive(Clone, Debug, Copy, PartialEq, Eq, clap::ValueEnum)]\nenum SampleRate {\n #[value(name = \"8000\")]\n Sr8k,\n #[value(name = \"16000\")]\n Sr16k,\n}\n\n#[derive(Parser, Debug)]\n#[command(author, version, about, long_about = None)]\nstruct Args {\n /// Run on CPU rather than on GPU.\n #[arg(long)]\n cpu: bool,\n\n /// Enable tracing (generates a trace-timestamp.json file).\n #[arg(long)]\n tracing: bool,\n\n #[arg(long)]\n input: Option<String>,\n\n #[arg(long)]\n sample_rate: SampleRate,\n\n #[arg(long)]\n model_id: Option<String>,\n\n #[arg(long)]\n config_file: Option<String>,\n\n /// The model to use.\n #[arg(long, default_value = \"silero\")]\n which: Which,\n}\n\n/// an iterator which reads consecutive frames of le i16 values from a reader\nstruct I16Frames<R> {\n rdr: R,\n buf: Box<[u8]>,\n len: usize,\n eof: bool,\n}\nimpl<R> I16Frames<R> {\n fn new(rdr: R, frame_size: usize) -> Self {\n I16Frames {\n rdr,\n buf: vec![0; frame_size * std::mem::size_of::<i16>()].into_boxed_slice(),\n len: 0,\n eof: false,\n }\n }\n}\nimpl<R: std::io::Read> Iterator for I16Frames<R> {\n type Item = std::io::Result<Vec<f32>>;\n\n fn next(&mut self) -> Option<Self::Item> {\n if self.eof {\n return None;\n }\n self.len += match self.rdr.read(&mut self.buf[self.len..]) {\n Ok(0) => {\n self.eof = true;\n 0\n }\n Ok(n) => n,\n Err(e) => return Some(Err(e)),\n };\n if self.eof || self.len == self.buf.len() {\n let buf = self.buf[..self.len]\n .chunks(2)\n .map(|bs| match bs {\n [a, b] => i16::from_le_bytes([*a, *b]),\n _ => unreachable!(),\n })\n .map(|i| i as f32 / i16::MAX as f32)\n .collect();\n self.len = 0;\n Some(Ok(buf))\n } else {\n self.next()\n }\n }\n}\n\nfn main() -> Result<()> {\n use tracing_chrome::ChromeLayerBuilder;\n use tracing_subscriber::prelude::*;\n\n let args = Args::parse();\n let _guard = if args.tracing {\n let (chrome_layer, guard) = ChromeLayerBuilder::new().build();\n tracing_subscriber::registry().with(chrome_layer).init();\n Some(guard)\n } else {\n None\n };\n println!(\n \"avx: {}, neon: {}, simd128: {}, f16c: {}\",\n candle::utils::with_avx(),\n candle::utils::with_neon(),\n candle::utils::with_simd128(),\n candle::utils::with_f16c()\n );\n\n let start = std::time::Instant::now();\n let model_id = match &args.model_id {\n Some(model_id) => std::path::PathBuf::from(model_id),\n None => match args.which {\n Which::Silero => hf_hub::api::sync::Api::new()?\n .model(\"onnx-community/silero-vad\".into())\n .get(\"onnx/model.onnx\")?,\n // TODO: candle-onnx doesn't support Int8 dtype\n // Which::SileroQuantized => hf_hub::api::sync::Api::new()?\n // .model(\"onnx-community/silero-vad\".into())\n // .get(\"onnx/model_quantized.onnx\")?,\n },\n };\n let (sample_rate, frame_size, context_size): (i64, usize, usize) = match args.sample_rate {\n SampleRate::Sr8k => (8000, 256, 32),\n SampleRate::Sr16k => (16000, 512, 64),\n };\n println!(\"retrieved the files in {:?}\", start.elapsed());\n\n let start = std::time::Instant::now();\n let device = candle_examples::device(args.cpu)?;\n let model = candle_onnx::read_file(model_id)?;\n\n println!(\"loaded the model in {:?}\", start.elapsed());\n\n let start = std::time::Instant::now();\n struct State {\n frame_size: usize,\n sample_rate: Tensor,\n state: Tensor,\n context: Tensor,\n }\n\n let mut state = State {\n frame_size,\n sample_rate: Tensor::new(sample_rate, &device)?,\n state: Tensor::zeros((2, 1, 128), DType::F32, &device)?,\n context: Tensor::zeros((1, context_size), DType::F32, &device)?,\n };\n let mut res = vec![];\n for chunk in I16Frames::new(std::io::stdin().lock(), state.frame_size) {\n let chunk = chunk.unwrap();\n if chunk.len() < state.frame_size {\n continue;\n }\n let next_context = Tensor::from_slice(\n &chunk[state.frame_size - context_size..],\n (1, context_size),\n &device,\n )?;\n let chunk = Tensor::from_vec(chunk, (1, state.frame_size), &device)?;\n let chunk = Tensor::cat(&[&state.context, &chunk], 1)?;\n let inputs = std::collections::HashMap::from_iter([\n (\"input\".to_string(), chunk),\n (\"sr\".to_string(), state.sample_rate.clone()),\n (\"state\".to_string(), state.state.clone()),\n ]);\n let out = candle_onnx::simple_eval(&model, inputs).unwrap();\n let out_names = &model.graph.as_ref().unwrap().output;\n let output = out.get(&out_names[0].name).unwrap().clone();\n state.state = out.get(&out_names[1].name).unwrap().clone();\n assert_eq!(state.state.dims(), &[2, 1, 128]);\n state.context = next_context;\n\n let output = output.flatten_all()?.to_vec1::<f32>()?;\n assert_eq!(output.len(), 1);\n let output = output[0];\n println!(\"vad chunk prediction: {output}\");\n res.push(output);\n }\n println!(\"calculated prediction in {:?}\", start.elapsed());\n\n let res_len = res.len() as f32;\n let prediction = res.iter().sum::<f32>() / res_len;\n println!(\"vad average prediction: {prediction}\");\n Ok(())\n}\n", "candle-examples\\examples\\stable-diffusion\\main.rs": "#[cfg(feature = \"accelerate\")]\nextern crate accelerate_src;\n\n#[cfg(feature = \"mkl\")]\nextern crate intel_mkl_src;\n\nuse candle_transformers::models::stable_diffusion;\n\nuse anyhow::{Error as E, Result};\nuse candle::{DType, Device, IndexOp, Module, Tensor, D};\nuse clap::Parser;\nuse stable_diffusion::vae::AutoEncoderKL;\nuse tokenizers::Tokenizer;\n\n#[derive(Parser)]\n#[command(author, version, about, long_about = None)]\nstruct Args {\n /// The prompt to be used for image generation.\n #[arg(\n long,\n default_value = \"A very realistic photo of a rusty robot walking on a sandy beach\"\n )]\n prompt: String,\n\n #[arg(long, default_value = \"\")]\n uncond_prompt: String,\n\n /// Run on CPU rather than on GPU.\n #[arg(long)]\n cpu: bool,\n\n /// Enable tracing (generates a trace-timestamp.json file).\n #[arg(long)]\n tracing: bool,\n\n /// The height in pixels of the generated image.\n #[arg(long)]\n height: Option<usize>,\n\n /// The width in pixels of the generated image.\n #[arg(long)]\n width: Option<usize>,\n\n /// The UNet weight file, in .safetensors format.\n #[arg(long, value_name = \"FILE\")]\n unet_weights: Option<String>,\n\n /// The CLIP weight file, in .safetensors format.\n #[arg(long, value_name = \"FILE\")]\n clip_weights: Option<String>,\n\n /// The VAE weight file, in .safetensors format.\n #[arg(long, value_name = \"FILE\")]\n vae_weights: Option<String>,\n\n #[arg(long, value_name = \"FILE\")]\n /// The file specifying the tokenizer to used for tokenization.\n tokenizer: Option<String>,\n\n /// The size of the sliced attention or 0 for automatic slicing (disabled by default)\n #[arg(long)]\n sliced_attention_size: Option<usize>,\n\n /// The number of steps to run the diffusion for.\n #[arg(long)]\n n_steps: Option<usize>,\n\n /// The number of samples to generate iteratively.\n #[arg(long, default_value_t = 1)]\n num_samples: usize,\n\n /// The numbers of samples to generate simultaneously.\n #[arg[long, default_value_t = 1]]\n bsize: usize,\n\n /// The name of the final image to generate.\n #[arg(long, value_name = \"FILE\", default_value = \"sd_final.png\")]\n final_image: String,\n\n #[arg(long, value_enum, default_value = \"v2-1\")]\n sd_version: StableDiffusionVersion,\n\n /// Generate intermediary images at each step.\n #[arg(long, action)]\n intermediary_images: bool,\n\n #[arg(long)]\n use_flash_attn: bool,\n\n #[arg(long)]\n use_f16: bool,\n\n #[arg(long)]\n guidance_scale: Option<f64>,\n\n #[arg(long, value_name = \"FILE\")]\n img2img: Option<String>,\n\n /// The strength, indicates how much to transform the initial image. The\n /// value must be between 0 and 1, a value of 1 discards the initial image\n /// information.\n #[arg(long, default_value_t = 0.8)]\n img2img_strength: f64,\n\n /// The seed to use when generating random samples.\n #[arg(long)]\n seed: Option<u64>,\n}\n\n#[derive(Debug, Clone, Copy, clap::ValueEnum, PartialEq, Eq)]\nenum StableDiffusionVersion {\n V1_5,\n V2_1,\n Xl,\n Turbo,\n}\n\n#[derive(Debug, Clone, Copy, PartialEq, Eq)]\nenum ModelFile {\n Tokenizer,\n Tokenizer2,\n Clip,\n Clip2,\n Unet,\n Vae,\n}\n\nimpl StableDiffusionVersion {\n fn repo(&self) -> &'static str {\n match self {\n Self::Xl => \"stabilityai/stable-diffusion-xl-base-1.0\",\n Self::V2_1 => \"stabilityai/stable-diffusion-2-1\",\n Self::V1_5 => \"runwayml/stable-diffusion-v1-5\",\n Self::Turbo => \"stabilityai/sdxl-turbo\",\n }\n }\n\n fn unet_file(&self, use_f16: bool) -> &'static str {\n match self {\n Self::V1_5 | Self::V2_1 | Self::Xl | Self::Turbo => {\n if use_f16 {\n \"unet/diffusion_pytorch_model.fp16.safetensors\"\n } else {\n \"unet/diffusion_pytorch_model.safetensors\"\n }\n }\n }\n }\n\n fn vae_file(&self, use_f16: bool) -> &'static str {\n match self {\n Self::V1_5 | Self::V2_1 | Self::Xl | Self::Turbo => {\n if use_f16 {\n \"vae/diffusion_pytorch_model.fp16.safetensors\"\n } else {\n \"vae/diffusion_pytorch_model.safetensors\"\n }\n }\n }\n }\n\n fn clip_file(&self, use_f16: bool) -> &'static str {\n match self {\n Self::V1_5 | Self::V2_1 | Self::Xl | Self::Turbo => {\n if use_f16 {\n \"text_encoder/model.fp16.safetensors\"\n } else {\n \"text_encoder/model.safetensors\"\n }\n }\n }\n }\n\n fn clip2_file(&self, use_f16: bool) -> &'static str {\n match self {\n Self::V1_5 | Self::V2_1 | Self::Xl | Self::Turbo => {\n if use_f16 {\n \"text_encoder_2/model.fp16.safetensors\"\n } else {\n \"text_encoder_2/model.safetensors\"\n }\n }\n }\n }\n}\n\nimpl ModelFile {\n fn get(\n &self,\n filename: Option<String>,\n version: StableDiffusionVersion,\n use_f16: bool,\n ) -> Result<std::path::PathBuf> {\n use hf_hub::api::sync::Api;\n match filename {\n Some(filename) => Ok(std::path::PathBuf::from(filename)),\n None => {\n let (repo, path) = match self {\n Self::Tokenizer => {\n let tokenizer_repo = match version {\n StableDiffusionVersion::V1_5 | StableDiffusionVersion::V2_1 => {\n \"openai/clip-vit-base-patch32\"\n }\n StableDiffusionVersion::Xl | StableDiffusionVersion::Turbo => {\n // This seems similar to the patch32 version except some very small\n // difference in the split regex.\n \"openai/clip-vit-large-patch14\"\n }\n };\n (tokenizer_repo, \"tokenizer.json\")\n }\n Self::Tokenizer2 => {\n (\"laion/CLIP-ViT-bigG-14-laion2B-39B-b160k\", \"tokenizer.json\")\n }\n Self::Clip => (version.repo(), version.clip_file(use_f16)),\n Self::Clip2 => (version.repo(), version.clip2_file(use_f16)),\n Self::Unet => (version.repo(), version.unet_file(use_f16)),\n Self::Vae => {\n // Override for SDXL when using f16 weights.\n // See https://github.com/huggingface/candle/issues/1060\n if matches!(\n version,\n StableDiffusionVersion::Xl | StableDiffusionVersion::Turbo,\n ) && use_f16\n {\n (\n \"madebyollin/sdxl-vae-fp16-fix\",\n \"diffusion_pytorch_model.safetensors\",\n )\n } else {\n (version.repo(), version.vae_file(use_f16))\n }\n }\n };\n let filename = Api::new()?.model(repo.to_string()).get(path)?;\n Ok(filename)\n }\n }\n }\n}\n\nfn output_filename(\n basename: &str,\n sample_idx: usize,\n num_samples: usize,\n timestep_idx: Option<usize>,\n) -> String {\n let filename = if num_samples > 1 {\n match basename.rsplit_once('.') {\n None => format!(\"{basename}.{sample_idx}.png\"),\n Some((filename_no_extension, extension)) => {\n format!(\"{filename_no_extension}.{sample_idx}.{extension}\")\n }\n }\n } else {\n basename.to_string()\n };\n match timestep_idx {\n None => filename,\n Some(timestep_idx) => match filename.rsplit_once('.') {\n None => format!(\"{filename}-{timestep_idx}.png\"),\n Some((filename_no_extension, extension)) => {\n format!(\"{filename_no_extension}-{timestep_idx}.{extension}\")\n }\n },\n }\n}\n\n#[allow(clippy::too_many_arguments)]\nfn save_image(\n vae: &AutoEncoderKL,\n latents: &Tensor,\n vae_scale: f64,\n bsize: usize,\n idx: usize,\n final_image: &str,\n num_samples: usize,\n timestep_ids: Option<usize>,\n) -> Result<()> {\n let images = vae.decode(&(latents / vae_scale)?)?;\n let images = ((images / 2.)? + 0.5)?.to_device(&Device::Cpu)?;\n let images = (images.clamp(0f32, 1.)? * 255.)?.to_dtype(DType::U8)?;\n for batch in 0..bsize {\n let image = images.i(batch)?;\n let image_filename = output_filename(\n final_image,\n (bsize * idx) + batch + 1,\n batch + num_samples,\n timestep_ids,\n );\n candle_examples::save_image(&image, image_filename)?;\n }\n Ok(())\n}\n\n#[allow(clippy::too_many_arguments)]\nfn text_embeddings(\n prompt: &str,\n uncond_prompt: &str,\n tokenizer: Option<String>,\n clip_weights: Option<String>,\n sd_version: StableDiffusionVersion,\n sd_config: &stable_diffusion::StableDiffusionConfig,\n use_f16: bool,\n device: &Device,\n dtype: DType,\n use_guide_scale: bool,\n first: bool,\n) -> Result<Tensor> {\n let tokenizer_file = if first {\n ModelFile::Tokenizer\n } else {\n ModelFile::Tokenizer2\n };\n let tokenizer = tokenizer_file.get(tokenizer, sd_version, use_f16)?;\n let tokenizer = Tokenizer::from_file(tokenizer).map_err(E::msg)?;\n let pad_id = match &sd_config.clip.pad_with {\n Some(padding) => *tokenizer.get_vocab(true).get(padding.as_str()).unwrap(),\n None => *tokenizer.get_vocab(true).get(\"<|endoftext|>\").unwrap(),\n };\n println!(\"Running with prompt \\\"{prompt}\\\".\");\n let mut tokens = tokenizer\n .encode(prompt, true)\n .map_err(E::msg)?\n .get_ids()\n .to_vec();\n if tokens.len() > sd_config.clip.max_position_embeddings {\n anyhow::bail!(\n \"the prompt is too long, {} > max-tokens ({})\",\n tokens.len(),\n sd_config.clip.max_position_embeddings\n )\n }\n while tokens.len() < sd_config.clip.max_position_embeddings {\n tokens.push(pad_id)\n }\n let tokens = Tensor::new(tokens.as_slice(), device)?.unsqueeze(0)?;\n\n println!(\"Building the Clip transformer.\");\n let clip_weights_file = if first {\n ModelFile::Clip\n } else {\n ModelFile::Clip2\n };\n let clip_weights = clip_weights_file.get(clip_weights, sd_version, false)?;\n let clip_config = if first {\n &sd_config.clip\n } else {\n sd_config.clip2.as_ref().unwrap()\n };\n let text_model =\n stable_diffusion::build_clip_transformer(clip_config, clip_weights, device, DType::F32)?;\n let text_embeddings = text_model.forward(&tokens)?;\n\n let text_embeddings = if use_guide_scale {\n let mut uncond_tokens = tokenizer\n .encode(uncond_prompt, true)\n .map_err(E::msg)?\n .get_ids()\n .to_vec();\n if uncond_tokens.len() > sd_config.clip.max_position_embeddings {\n anyhow::bail!(\n \"the negative prompt is too long, {} > max-tokens ({})\",\n uncond_tokens.len(),\n sd_config.clip.max_position_embeddings\n )\n }\n while uncond_tokens.len() < sd_config.clip.max_position_embeddings {\n uncond_tokens.push(pad_id)\n }\n\n let uncond_tokens = Tensor::new(uncond_tokens.as_slice(), device)?.unsqueeze(0)?;\n let uncond_embeddings = text_model.forward(&uncond_tokens)?;\n\n Tensor::cat(&[uncond_embeddings, text_embeddings], 0)?.to_dtype(dtype)?\n } else {\n text_embeddings.to_dtype(dtype)?\n };\n Ok(text_embeddings)\n}\n\nfn image_preprocess<T: AsRef<std::path::Path>>(path: T) -> anyhow::Result<Tensor> {\n let img = image::ImageReader::open(path)?.decode()?;\n let (height, width) = (img.height() as usize, img.width() as usize);\n let height = height - height % 32;\n let width = width - width % 32;\n let img = img.resize_to_fill(\n width as u32,\n height as u32,\n image::imageops::FilterType::CatmullRom,\n );\n let img = img.to_rgb8();\n let img = img.into_raw();\n let img = Tensor::from_vec(img, (height, width, 3), &Device::Cpu)?\n .permute((2, 0, 1))?\n .to_dtype(DType::F32)?\n .affine(2. / 255., -1.)?\n .unsqueeze(0)?;\n Ok(img)\n}\n\nfn run(args: Args) -> Result<()> {\n use tracing_chrome::ChromeLayerBuilder;\n use tracing_subscriber::prelude::*;\n\n let Args {\n prompt,\n uncond_prompt,\n cpu,\n height,\n width,\n n_steps,\n tokenizer,\n final_image,\n sliced_attention_size,\n num_samples,\n bsize,\n sd_version,\n clip_weights,\n vae_weights,\n unet_weights,\n tracing,\n use_f16,\n guidance_scale,\n use_flash_attn,\n img2img,\n img2img_strength,\n seed,\n ..\n } = args;\n\n if !(0. ..=1.).contains(&img2img_strength) {\n anyhow::bail!(\"img2img-strength should be between 0 and 1, got {img2img_strength}\")\n }\n\n let _guard = if tracing {\n let (chrome_layer, guard) = ChromeLayerBuilder::new().build();\n tracing_subscriber::registry().with(chrome_layer).init();\n Some(guard)\n } else {\n None\n };\n\n let guidance_scale = match guidance_scale {\n Some(guidance_scale) => guidance_scale,\n None => match sd_version {\n StableDiffusionVersion::V1_5\n | StableDiffusionVersion::V2_1\n | StableDiffusionVersion::Xl => 7.5,\n StableDiffusionVersion::Turbo => 0.,\n },\n };\n let n_steps = match n_steps {\n Some(n_steps) => n_steps,\n None => match sd_version {\n StableDiffusionVersion::V1_5\n | StableDiffusionVersion::V2_1\n | StableDiffusionVersion::Xl => 30,\n StableDiffusionVersion::Turbo => 1,\n },\n };\n let dtype = if use_f16 { DType::F16 } else { DType::F32 };\n let sd_config = match sd_version {\n StableDiffusionVersion::V1_5 => {\n stable_diffusion::StableDiffusionConfig::v1_5(sliced_attention_size, height, width)\n }\n StableDiffusionVersion::V2_1 => {\n stable_diffusion::StableDiffusionConfig::v2_1(sliced_attention_size, height, width)\n }\n StableDiffusionVersion::Xl => {\n stable_diffusion::StableDiffusionConfig::sdxl(sliced_attention_size, height, width)\n }\n StableDiffusionVersion::Turbo => stable_diffusion::StableDiffusionConfig::sdxl_turbo(\n sliced_attention_size,\n height,\n width,\n ),\n };\n\n let scheduler = sd_config.build_scheduler(n_steps)?;\n let device = candle_examples::device(cpu)?;\n if let Some(seed) = seed {\n device.set_seed(seed)?;\n }\n let use_guide_scale = guidance_scale > 1.0;\n\n let which = match sd_version {\n StableDiffusionVersion::Xl | StableDiffusionVersion::Turbo => vec![true, false],\n _ => vec![true],\n };\n let text_embeddings = which\n .iter()\n .map(|first| {\n text_embeddings(\n &prompt,\n &uncond_prompt,\n tokenizer.clone(),\n clip_weights.clone(),\n sd_version,\n &sd_config,\n use_f16,\n &device,\n dtype,\n use_guide_scale,\n *first,\n )\n })\n .collect::<Result<Vec<_>>>()?;\n\n let text_embeddings = Tensor::cat(&text_embeddings, D::Minus1)?;\n let text_embeddings = text_embeddings.repeat((bsize, 1, 1))?;\n println!(\"{text_embeddings:?}\");\n\n println!(\"Building the autoencoder.\");\n let vae_weights = ModelFile::Vae.get(vae_weights, sd_version, use_f16)?;\n let vae = sd_config.build_vae(vae_weights, &device, dtype)?;\n let init_latent_dist = match &img2img {\n None => None,\n Some(image) => {\n let image = image_preprocess(image)?.to_device(&device)?;\n Some(vae.encode(&image)?)\n }\n };\n println!(\"Building the unet.\");\n let unet_weights = ModelFile::Unet.get(unet_weights, sd_version, use_f16)?;\n let unet = sd_config.build_unet(unet_weights, &device, 4, use_flash_attn, dtype)?;\n\n let t_start = if img2img.is_some() {\n n_steps - (n_steps as f64 * img2img_strength) as usize\n } else {\n 0\n };\n\n let vae_scale = match sd_version {\n StableDiffusionVersion::V1_5\n | StableDiffusionVersion::V2_1\n | StableDiffusionVersion::Xl => 0.18215,\n StableDiffusionVersion::Turbo => 0.13025,\n };\n\n for idx in 0..num_samples {\n let timesteps = scheduler.timesteps();\n let latents = match &init_latent_dist {\n Some(init_latent_dist) => {\n let latents = (init_latent_dist.sample()? * vae_scale)?.to_device(&device)?;\n if t_start < timesteps.len() {\n let noise = latents.randn_like(0f64, 1f64)?;\n scheduler.add_noise(&latents, noise, timesteps[t_start])?\n } else {\n latents\n }\n }\n None => {\n let latents = Tensor::randn(\n 0f32,\n 1f32,\n (bsize, 4, sd_config.height / 8, sd_config.width / 8),\n &device,\n )?;\n // scale the initial noise by the standard deviation required by the scheduler\n (latents * scheduler.init_noise_sigma())?\n }\n };\n let mut latents = latents.to_dtype(dtype)?;\n\n println!(\"starting sampling\");\n for (timestep_index, ×tep) in timesteps.iter().enumerate() {\n if timestep_index < t_start {\n continue;\n }\n let start_time = std::time::Instant::now();\n let latent_model_input = if use_guide_scale {\n Tensor::cat(&[&latents, &latents], 0)?\n } else {\n latents.clone()\n };\n\n let latent_model_input = scheduler.scale_model_input(latent_model_input, timestep)?;\n let noise_pred =\n unet.forward(&latent_model_input, timestep as f64, &text_embeddings)?;\n\n let noise_pred = if use_guide_scale {\n let noise_pred = noise_pred.chunk(2, 0)?;\n let (noise_pred_uncond, noise_pred_text) = (&noise_pred[0], &noise_pred[1]);\n\n (noise_pred_uncond + ((noise_pred_text - noise_pred_uncond)? * guidance_scale)?)?\n } else {\n noise_pred\n };\n\n latents = scheduler.step(&noise_pred, timestep, &latents)?;\n let dt = start_time.elapsed().as_secs_f32();\n println!(\"step {}/{n_steps} done, {:.2}s\", timestep_index + 1, dt);\n\n if args.intermediary_images {\n save_image(\n &vae,\n &latents,\n vae_scale,\n bsize,\n idx,\n &final_image,\n num_samples,\n Some(timestep_index + 1),\n )?;\n }\n }\n\n println!(\n \"Generating the final image for sample {}/{}.\",\n idx + 1,\n num_samples\n );\n save_image(\n &vae,\n &latents,\n vae_scale,\n bsize,\n idx,\n &final_image,\n num_samples,\n None,\n )?;\n }\n Ok(())\n}\n\nfn main() -> Result<()> {\n let args = Args::parse();\n run(args)\n}\n", "candle-examples\\examples\\stable-lm\\main.rs": "#[cfg(feature = \"mkl\")]\nextern crate intel_mkl_src;\n\n#[cfg(feature = \"accelerate\")]\nextern crate accelerate_src;\n\nuse anyhow::{Error as E, Result};\nuse clap::{Parser, ValueEnum};\n\nuse candle_transformers::models::quantized_stable_lm::Model as QStableLM;\nuse candle_transformers::models::stable_lm::{Config, Model as StableLM};\n\nuse candle::{DType, Device, Tensor};\nuse candle_examples::token_output_stream::TokenOutputStream;\nuse candle_nn::VarBuilder;\nuse candle_transformers::generation::LogitsProcessor;\nuse hf_hub::{api::sync::Api, Repo, RepoType};\nuse tokenizers::Tokenizer;\n\nenum Model {\n StableLM(StableLM),\n Quantized(QStableLM),\n}\n\nstruct TextGeneration {\n model: Model,\n device: Device,\n tokenizer: TokenOutputStream,\n logits_processor: LogitsProcessor,\n repeat_penalty: f32,\n repeat_last_n: usize,\n}\n\nimpl TextGeneration {\n #[allow(clippy::too_many_arguments)]\n fn new(\n model: Model,\n tokenizer: Tokenizer,\n seed: u64,\n temp: Option<f64>,\n top_p: Option<f64>,\n repeat_penalty: f32,\n repeat_last_n: usize,\n device: &Device,\n ) -> Self {\n let logits_processor = LogitsProcessor::new(seed, temp, top_p);\n Self {\n model,\n tokenizer: TokenOutputStream::new(tokenizer),\n logits_processor,\n repeat_penalty,\n repeat_last_n,\n device: device.clone(),\n }\n }\n\n fn run(&mut self, prompt: &str, sample_len: usize) -> Result<()> {\n use std::io::Write;\n self.tokenizer.clear();\n let mut tokens = self\n .tokenizer\n .tokenizer()\n .encode(prompt, true)\n .map_err(E::msg)?\n .get_ids()\n .to_vec();\n for &t in tokens.iter() {\n if let Some(t) = self.tokenizer.next_token(t)? {\n print!(\"{t}\")\n }\n }\n std::io::stdout().flush()?;\n\n let mut generated_tokens = 0usize;\n let eos_token = match self.tokenizer.get_token(\"<|endoftext|>\") {\n Some(token) => token,\n None => anyhow::bail!(\"cannot find the <|endoftext|> token\"),\n };\n let start_gen = std::time::Instant::now();\n for index in 0..sample_len {\n let context_size = if index > 0 { 1 } else { tokens.len() };\n let start_pos = tokens.len().saturating_sub(context_size);\n let ctxt = &tokens[start_pos..];\n let input = Tensor::new(ctxt, &self.device)?.unsqueeze(0)?;\n let logits = match &mut self.model {\n Model::StableLM(m) => m.forward(&input, start_pos)?,\n Model::Quantized(m) => m.forward(&input, start_pos)?,\n };\n let logits = logits.squeeze(0)?.squeeze(0)?.to_dtype(DType::F32)?;\n let logits = if self.repeat_penalty == 1. {\n logits\n } else {\n let start_at = tokens.len().saturating_sub(self.repeat_last_n);\n candle_transformers::utils::apply_repeat_penalty(\n &logits,\n self.repeat_penalty,\n &tokens[start_at..],\n )?\n };\n\n let next_token = self.logits_processor.sample(&logits)?;\n tokens.push(next_token);\n generated_tokens += 1;\n if next_token == eos_token {\n break;\n }\n if let Some(t) = self.tokenizer.next_token(next_token)? {\n print!(\"{t}\");\n std::io::stdout().flush()?;\n }\n }\n let dt = start_gen.elapsed();\n if let Some(rest) = self.tokenizer.decode_rest().map_err(E::msg)? {\n print!(\"{rest}\");\n }\n std::io::stdout().flush()?;\n println!(\n \"\\n{generated_tokens} tokens generated ({:.2} token/s)\",\n generated_tokens as f64 / dt.as_secs_f64(),\n );\n Ok(())\n }\n}\n\n#[derive(Clone, Copy, Debug, ValueEnum, PartialEq, Eq)]\nenum Which {\n V1Orig,\n V1,\n V1Zephyr,\n V2,\n V2Zephyr,\n Code,\n}\n\n#[derive(Parser, Debug)]\n#[command(author, version, about, long_about = None)]\nstruct Args {\n /// Run on CPU rather than on GPU.\n #[arg(long)]\n cpu: bool,\n\n /// Enable tracing (generates a trace-timestamp.json file).\n #[arg(long)]\n tracing: bool,\n\n #[arg(long)]\n use_flash_attn: bool,\n\n #[arg(long)]\n prompt: String,\n\n /// The temperature used to generate samples.\n #[arg(long)]\n temperature: Option<f64>,\n\n /// Nucleus sampling probability cutoff.\n #[arg(long)]\n top_p: Option<f64>,\n\n /// The seed to use when generating random samples.\n #[arg(long, default_value_t = 299792458)]\n seed: u64,\n\n /// The length of the sample to generate (in tokens).\n #[arg(long, short = 'n', default_value_t = 1000)]\n sample_len: usize,\n\n #[arg(long)]\n model_id: Option<String>,\n\n #[arg(long, default_value = \"main\")]\n revision: String,\n\n #[arg(long, default_value = \"v2\")]\n which: Which,\n\n #[arg(long)]\n tokenizer_file: Option<String>,\n\n #[arg(long)]\n weight_files: Option<String>,\n\n #[arg(long)]\n quantized: bool,\n\n /// Penalty to be applied for repeating tokens, 1. means no penalty.\n #[arg(long, default_value_t = 1.1)]\n repeat_penalty: f32,\n\n /// The context size to consider for the repeat penalty.\n #[arg(long, default_value_t = 64)]\n repeat_last_n: usize,\n}\n\nfn main() -> Result<()> {\n use tracing_chrome::ChromeLayerBuilder;\n use tracing_subscriber::prelude::*;\n\n let args = Args::parse();\n let _guard = if args.tracing {\n let (chrome_layer, guard) = ChromeLayerBuilder::new().build();\n tracing_subscriber::registry().with(chrome_layer).init();\n Some(guard)\n } else {\n None\n };\n println!(\n \"avx: {}, neon: {}, simd128: {}, f16c: {}\",\n candle::utils::with_avx(),\n candle::utils::with_neon(),\n candle::utils::with_simd128(),\n candle::utils::with_f16c()\n );\n println!(\n \"temp: {:.2} repeat-penalty: {:.2} repeat-last-n: {}\",\n args.temperature.unwrap_or(0.),\n args.repeat_penalty,\n args.repeat_last_n\n );\n\n let start = std::time::Instant::now();\n let api = Api::new()?;\n let model_id = match args.model_id {\n Some(model_id) => model_id,\n None => match args.which {\n Which::V1Orig => \"lmz/candle-stablelm-3b-4e1t\".to_string(),\n Which::V1 => \"stabilityai/stablelm-3b-4e1t\".to_string(),\n Which::V1Zephyr => \"stabilityai/stablelm-zephyr-3b\".to_string(),\n Which::Code => \"stabilityai/stable-code-3b\".to_string(),\n Which::V2 => \"stabilityai/stablelm-2-1_6b\".to_string(),\n Which::V2Zephyr => \"stabilityai/stablelm-2-zephyr-1_6b\".to_string(),\n },\n };\n\n let repo = api.repo(Repo::with_revision(\n model_id,\n RepoType::Model,\n args.revision,\n ));\n let tokenizer_filename = match args.tokenizer_file {\n Some(file) => std::path::PathBuf::from(file),\n None => repo.get(\"tokenizer.json\")?,\n };\n let filenames = match args.weight_files {\n Some(files) => files\n .split(',')\n .map(std::path::PathBuf::from)\n .collect::<Vec<_>>(),\n None => match (args.which, args.quantized) {\n (Which::V1Orig | Which::V1, true) => vec![repo.get(\"model-q4k.gguf\")?],\n (Which::V2, true) => {\n let gguf = api\n .model(\"lmz/candle-stablelm\".to_string())\n .get(\"stablelm-2-1_6b-q4k.gguf\")?;\n vec![gguf]\n }\n (Which::V2Zephyr, true) => {\n let gguf = api\n .model(\"lmz/candle-stablelm\".to_string())\n .get(\"stablelm-2-zephyr-1_6b-q4k.gguf\")?;\n vec![gguf]\n }\n (Which::V1Zephyr | Which::Code, true) => {\n anyhow::bail!(\"Quantized {:?} variant not supported.\", args.which)\n }\n (Which::V1Orig | Which::V1 | Which::V1Zephyr | Which::V2 | Which::V2Zephyr, false) => {\n vec![repo.get(\"model.safetensors\")?]\n }\n (Which::Code, false) => {\n candle_examples::hub_load_safetensors(&repo, \"model.safetensors.index.json\")?\n }\n },\n };\n\n println!(\"retrieved the files in {:?}\", start.elapsed());\n let tokenizer = Tokenizer::from_file(tokenizer_filename).map_err(E::msg)?;\n\n let start = std::time::Instant::now();\n let config = match args.which {\n Which::V1Orig => Config::stablelm_3b_4e1t(args.use_flash_attn),\n Which::V1 | Which::V1Zephyr | Which::V2 | Which::V2Zephyr | Which::Code => {\n let config_filename = repo.get(\"config.json\")?;\n let config = std::fs::read_to_string(config_filename)?;\n let mut config: Config = serde_json::from_str(&config)?;\n config.set_use_flash_attn(args.use_flash_attn);\n config\n }\n };\n\n let device = candle_examples::device(args.cpu)?;\n let model = if args.quantized {\n let filename = &filenames[0];\n let vb =\n candle_transformers::quantized_var_builder::VarBuilder::from_gguf(filename, &device)?;\n let model = QStableLM::new(&config, vb)?;\n Model::Quantized(model)\n } else {\n let dtype = if device.is_cuda() {\n DType::BF16\n } else {\n DType::F32\n };\n let vb = unsafe { VarBuilder::from_mmaped_safetensors(&filenames, dtype, &device)? };\n let model = StableLM::new(&config, vb)?;\n Model::StableLM(model)\n };\n\n println!(\"loaded the model in {:?}\", start.elapsed());\n\n let mut pipeline = TextGeneration::new(\n model,\n tokenizer,\n args.seed,\n args.temperature,\n args.top_p,\n args.repeat_penalty,\n args.repeat_last_n,\n &device,\n );\n pipeline.run(&args.prompt, args.sample_len)?;\n Ok(())\n}\n", "candle-examples\\examples\\starcoder2\\main.rs": "#[cfg(feature = \"mkl\")]\nextern crate intel_mkl_src;\n\n#[cfg(feature = \"accelerate\")]\nextern crate accelerate_src;\n\nuse anyhow::{Error as E, Result};\nuse clap::Parser;\n\nuse candle_transformers::models::starcoder2::Model;\n\nuse candle::{DType, Device, Tensor};\nuse candle_examples::token_output_stream::TokenOutputStream;\nuse candle_nn::VarBuilder;\nuse candle_transformers::generation::LogitsProcessor;\nuse hf_hub::{api::sync::Api, Repo, RepoType};\nuse tokenizers::Tokenizer;\n\nstruct TextGeneration {\n model: Model,\n device: Device,\n tokenizer: TokenOutputStream,\n logits_processor: LogitsProcessor,\n repeat_penalty: f32,\n repeat_last_n: usize,\n}\n\nimpl TextGeneration {\n #[allow(clippy::too_many_arguments)]\n fn new(\n model: Model,\n tokenizer: Tokenizer,\n seed: u64,\n temp: Option<f64>,\n top_p: Option<f64>,\n repeat_penalty: f32,\n repeat_last_n: usize,\n device: &Device,\n ) -> Self {\n let logits_processor = LogitsProcessor::new(seed, temp, top_p);\n Self {\n model,\n tokenizer: TokenOutputStream::new(tokenizer),\n logits_processor,\n repeat_penalty,\n repeat_last_n,\n device: device.clone(),\n }\n }\n\n fn run(&mut self, prompt: &str, sample_len: usize) -> Result<()> {\n use std::io::Write;\n self.tokenizer.clear();\n let mut tokens = self\n .tokenizer\n .tokenizer()\n .encode(prompt, true)\n .map_err(E::msg)?\n .get_ids()\n .to_vec();\n for &t in tokens.iter() {\n if let Some(t) = self.tokenizer.next_token(t)? {\n print!(\"{t}\")\n }\n }\n std::io::stdout().flush()?;\n\n let mut generated_tokens = 0usize;\n let eos_token = match self.tokenizer.get_token(\"<|endoftext|>\") {\n Some(token) => token,\n None => anyhow::bail!(\"cannot find the <|endoftext|> token\"),\n };\n let start_gen = std::time::Instant::now();\n for index in 0..sample_len {\n let context_size = if index > 0 { 1 } else { tokens.len() };\n let start_pos = tokens.len().saturating_sub(context_size);\n let ctxt = &tokens[start_pos..];\n let input = Tensor::new(ctxt, &self.device)?.unsqueeze(0)?;\n let logits = self.model.forward(&input, start_pos)?;\n let logits = logits.squeeze(0)?.squeeze(0)?.to_dtype(DType::F32)?;\n let logits = if self.repeat_penalty == 1. {\n logits\n } else {\n let start_at = tokens.len().saturating_sub(self.repeat_last_n);\n candle_transformers::utils::apply_repeat_penalty(\n &logits,\n self.repeat_penalty,\n &tokens[start_at..],\n )?\n };\n\n let next_token = self.logits_processor.sample(&logits)?;\n tokens.push(next_token);\n generated_tokens += 1;\n if next_token == eos_token {\n break;\n }\n if let Some(t) = self.tokenizer.next_token(next_token)? {\n print!(\"{t}\");\n std::io::stdout().flush()?;\n }\n }\n let dt = start_gen.elapsed();\n if let Some(rest) = self.tokenizer.decode_rest().map_err(E::msg)? {\n print!(\"{rest}\");\n }\n std::io::stdout().flush()?;\n println!(\n \"\\n{generated_tokens} tokens generated ({:.2} token/s)\",\n generated_tokens as f64 / dt.as_secs_f64(),\n );\n Ok(())\n }\n}\n\n#[derive(Parser, Debug)]\n#[command(author, version, about, long_about = None)]\nstruct Args {\n /// Run on CPU rather than on GPU.\n #[arg(long)]\n cpu: bool,\n\n /// Enable tracing (generates a trace-timestamp.json file).\n #[arg(long)]\n tracing: bool,\n\n #[arg(long)]\n use_flash_attn: bool,\n\n #[arg(long)]\n prompt: String,\n\n /// The temperature used to generate samples.\n #[arg(long)]\n temperature: Option<f64>,\n\n /// Nucleus sampling probability cutoff.\n #[arg(long)]\n top_p: Option<f64>,\n\n /// The seed to use when generating random samples.\n #[arg(long, default_value_t = 299792458)]\n seed: u64,\n\n /// The length of the sample to generate (in tokens).\n #[arg(long, short = 'n', default_value_t = 10000)]\n sample_len: usize,\n\n #[arg(long)]\n model_id: Option<String>,\n\n #[arg(long, default_value = \"main\")]\n revision: String,\n\n #[arg(long)]\n config_file: Option<String>,\n\n #[arg(long)]\n tokenizer_file: Option<String>,\n\n #[arg(long)]\n weight_files: Option<String>,\n\n /// Penalty to be applied for repeating tokens, 1. means no penalty.\n #[arg(long, default_value_t = 1.1)]\n repeat_penalty: f32,\n\n /// The context size to consider for the repeat penalty.\n #[arg(long, default_value_t = 64)]\n repeat_last_n: usize,\n}\n\nfn main() -> Result<()> {\n use tracing_chrome::ChromeLayerBuilder;\n use tracing_subscriber::prelude::*;\n\n let args = Args::parse();\n let _guard = if args.tracing {\n let (chrome_layer, guard) = ChromeLayerBuilder::new().build();\n tracing_subscriber::registry().with(chrome_layer).init();\n Some(guard)\n } else {\n None\n };\n println!(\n \"avx: {}, neon: {}, simd128: {}, f16c: {}\",\n candle::utils::with_avx(),\n candle::utils::with_neon(),\n candle::utils::with_simd128(),\n candle::utils::with_f16c()\n );\n println!(\n \"temp: {:.2} repeat-penalty: {:.2} repeat-last-n: {}\",\n args.temperature.unwrap_or(0.),\n args.repeat_penalty,\n args.repeat_last_n\n );\n\n let start = std::time::Instant::now();\n let api = Api::new()?;\n let model_id = match args.model_id {\n Some(model_id) => model_id,\n None => \"bigcode/starcoder2-3b\".to_string(),\n };\n let repo = api.repo(Repo::with_revision(\n model_id,\n RepoType::Model,\n args.revision,\n ));\n let config_file = match args.config_file {\n Some(file) => std::path::PathBuf::from(file),\n None => repo.get(\"config.json\")?,\n };\n let tokenizer_file = match args.tokenizer_file {\n Some(file) => std::path::PathBuf::from(file),\n None => repo.get(\"tokenizer.json\")?,\n };\n let filenames = match args.weight_files {\n Some(files) => files\n .split(',')\n .map(std::path::PathBuf::from)\n .collect::<Vec<_>>(),\n None => vec![repo.get(\"model.safetensors\")?],\n };\n println!(\"retrieved the files in {:?}\", start.elapsed());\n let tokenizer = Tokenizer::from_file(tokenizer_file).map_err(E::msg)?;\n\n let start = std::time::Instant::now();\n let config = serde_json::from_reader(std::fs::File::open(config_file)?)?;\n let device = candle_examples::device(args.cpu)?;\n let dtype = if device.is_cuda() {\n DType::BF16\n } else {\n DType::F32\n };\n let vb = unsafe { VarBuilder::from_mmaped_safetensors(&filenames, dtype, &device)? };\n let model = Model::new(&config, vb)?;\n\n println!(\"loaded the model in {:?}\", start.elapsed());\n\n let mut pipeline = TextGeneration::new(\n model,\n tokenizer,\n args.seed,\n args.temperature,\n args.top_p,\n args.repeat_penalty,\n args.repeat_last_n,\n &device,\n );\n pipeline.run(&args.prompt, args.sample_len)?;\n Ok(())\n}\n", "candle-examples\\examples\\t5\\main.rs": "#[cfg(feature = \"mkl\")]\nextern crate intel_mkl_src;\n\n#[cfg(feature = \"accelerate\")]\nextern crate accelerate_src;\nuse std::io::Write;\nuse std::path::PathBuf;\n\nuse candle_transformers::models::t5;\n\nuse anyhow::{Error as E, Result};\nuse candle::{DType, Device, Tensor};\nuse candle_nn::VarBuilder;\nuse candle_transformers::generation::LogitsProcessor;\nuse clap::{Parser, ValueEnum};\nuse hf_hub::{api::sync::Api, Repo, RepoType};\nuse tokenizers::Tokenizer;\n\nconst DTYPE: DType = DType::F32;\n\n#[derive(Clone, Debug, Copy, ValueEnum)]\nenum Which {\n T5Base,\n T5Small,\n T5Large,\n T5_3B,\n Mt5Base,\n Mt5Small,\n Mt5Large,\n}\n\n#[derive(Parser, Debug, Clone)]\n#[command(author, version, about, long_about = None)]\nstruct Args {\n /// Run on CPU rather than on GPU.\n #[arg(long)]\n cpu: bool,\n\n /// Enable tracing (generates a trace-timestamp.json file).\n #[arg(long)]\n tracing: bool,\n\n /// The model repository to use on the HuggingFace hub.\n #[arg(long)]\n model_id: Option<String>,\n\n #[arg(long)]\n revision: Option<String>,\n\n #[arg(long)]\n model_file: Option<String>,\n\n #[arg(long)]\n tokenizer_file: Option<String>,\n\n #[arg(long)]\n config_file: Option<String>,\n\n /// Enable decoding.\n #[arg(long)]\n decode: bool,\n\n // Enable/disable decoding.\n #[arg(long, default_value = \"false\")]\n disable_cache: bool,\n\n /// Use this prompt, otherwise compute sentence similarities.\n #[arg(long)]\n prompt: Option<String>,\n\n /// If set along with --decode, will use this prompt to initialize the decoder.\n #[arg(long)]\n decoder_prompt: Option<String>,\n\n /// L2 normalization for embeddings.\n #[arg(long, default_value = \"true\")]\n normalize_embeddings: bool,\n\n /// The temperature used to generate samples.\n #[arg(long, default_value_t = 0.8)]\n temperature: f64,\n\n /// Nucleus sampling probability cutoff.\n #[arg(long)]\n top_p: Option<f64>,\n\n /// Penalty to be applied for repeating tokens, 1. means no penalty.\n #[arg(long, default_value_t = 1.1)]\n repeat_penalty: f32,\n\n /// The context size to consider for the repeat penalty.\n #[arg(long, default_value_t = 64)]\n repeat_last_n: usize,\n\n /// The model to be used.\n #[arg(long, default_value = \"t5-small\")]\n which: Which,\n}\n\nstruct T5ModelBuilder {\n device: Device,\n config: t5::Config,\n weights_filename: Vec<PathBuf>,\n}\n\nimpl T5ModelBuilder {\n pub fn load(args: &Args) -> Result<(Self, Tokenizer)> {\n let device = candle_examples::device(args.cpu)?;\n let (default_model, default_revision) = match args.which {\n Which::T5Base => (\"t5-base\", \"main\"),\n Which::T5Small => (\"t5-small\", \"refs/pr/15\"),\n Which::T5Large => (\"t5-large\", \"main\"),\n Which::T5_3B => (\"t5-3b\", \"main\"),\n Which::Mt5Base => (\"google/mt5-base\", \"refs/pr/5\"),\n Which::Mt5Small => (\"google/mt5-small\", \"refs/pr/6\"),\n Which::Mt5Large => (\"google/mt5-large\", \"refs/pr/2\"),\n };\n let default_model = default_model.to_string();\n let default_revision = default_revision.to_string();\n let (model_id, revision) = match (args.model_id.to_owned(), args.revision.to_owned()) {\n (Some(model_id), Some(revision)) => (model_id, revision),\n (Some(model_id), None) => (model_id, \"main\".to_string()),\n (None, Some(revision)) => (default_model, revision),\n (None, None) => (default_model, default_revision),\n };\n\n let repo = Repo::with_revision(model_id.clone(), RepoType::Model, revision);\n let api = Api::new()?;\n let repo = api.repo(repo);\n let config_filename = match &args.config_file {\n None => repo.get(\"config.json\")?,\n Some(f) => f.into(),\n };\n let tokenizer_filename = match &args.tokenizer_file {\n None => match args.which {\n Which::Mt5Base => api\n .model(\"lmz/mt5-tokenizers\".into())\n .get(\"mt5-base.tokenizer.json\")?,\n Which::Mt5Small => api\n .model(\"lmz/mt5-tokenizers\".into())\n .get(\"mt5-small.tokenizer.json\")?,\n Which::Mt5Large => api\n .model(\"lmz/mt5-tokenizers\".into())\n .get(\"mt5-large.tokenizer.json\")?,\n _ => repo.get(\"tokenizer.json\")?,\n },\n Some(f) => f.into(),\n };\n let weights_filename = match &args.model_file {\n Some(f) => f.split(',').map(|v| v.into()).collect::<Vec<_>>(),\n None => {\n if model_id == \"google/flan-t5-xxl\" || model_id == \"google/flan-ul2\" {\n candle_examples::hub_load_safetensors(&repo, \"model.safetensors.index.json\")?\n } else {\n vec![repo.get(\"model.safetensors\")?]\n }\n }\n };\n let config = std::fs::read_to_string(config_filename)?;\n let mut config: t5::Config = serde_json::from_str(&config)?;\n config.use_cache = !args.disable_cache;\n let tokenizer = Tokenizer::from_file(tokenizer_filename).map_err(E::msg)?;\n Ok((\n Self {\n device,\n config,\n weights_filename,\n },\n tokenizer,\n ))\n }\n\n pub fn build_encoder(&self) -> Result<t5::T5EncoderModel> {\n let vb = unsafe {\n VarBuilder::from_mmaped_safetensors(&self.weights_filename, DTYPE, &self.device)?\n };\n Ok(t5::T5EncoderModel::load(vb, &self.config)?)\n }\n\n pub fn build_conditional_generation(&self) -> Result<t5::T5ForConditionalGeneration> {\n let vb = unsafe {\n VarBuilder::from_mmaped_safetensors(&self.weights_filename, DTYPE, &self.device)?\n };\n Ok(t5::T5ForConditionalGeneration::load(vb, &self.config)?)\n }\n}\n\nfn main() -> Result<()> {\n use tracing_chrome::ChromeLayerBuilder;\n use tracing_subscriber::prelude::*;\n\n let args = Args::parse();\n\n let _guard = if args.tracing {\n let (chrome_layer, guard) = ChromeLayerBuilder::new().build();\n tracing_subscriber::registry().with(chrome_layer).init();\n Some(guard)\n } else {\n None\n };\n\n let (builder, mut tokenizer) = T5ModelBuilder::load(&args)?;\n let device = &builder.device;\n let tokenizer = tokenizer\n .with_padding(None)\n .with_truncation(None)\n .map_err(E::msg)?;\n match args.prompt {\n Some(prompt) => {\n let tokens = tokenizer\n .encode(prompt, true)\n .map_err(E::msg)?\n .get_ids()\n .to_vec();\n let input_token_ids = Tensor::new(&tokens[..], device)?.unsqueeze(0)?;\n if !args.decode {\n let mut model = builder.build_encoder()?;\n let start = std::time::Instant::now();\n let ys = model.forward(&input_token_ids)?;\n println!(\"{ys}\");\n println!(\"Took {:?}\", start.elapsed());\n } else {\n let mut model = builder.build_conditional_generation()?;\n let mut output_token_ids = [builder\n .config\n .decoder_start_token_id\n .unwrap_or(builder.config.pad_token_id)\n as u32]\n .to_vec();\n if let Some(decoder_prompt) = &args.decoder_prompt {\n print!(\"{decoder_prompt}\");\n output_token_ids.extend(\n tokenizer\n .encode(decoder_prompt.to_string(), false)\n .map_err(E::msg)?\n .get_ids()\n .to_vec(),\n );\n }\n let temperature = if args.temperature <= 0. {\n None\n } else {\n Some(args.temperature)\n };\n let mut logits_processor = LogitsProcessor::new(299792458, temperature, args.top_p);\n let encoder_output = model.encode(&input_token_ids)?;\n let start = std::time::Instant::now();\n\n for index in 0.. {\n if output_token_ids.len() > 512 {\n break;\n }\n let decoder_token_ids = if index == 0 || !builder.config.use_cache {\n Tensor::new(output_token_ids.as_slice(), device)?.unsqueeze(0)?\n } else {\n let last_token = *output_token_ids.last().unwrap();\n Tensor::new(&[last_token], device)?.unsqueeze(0)?\n };\n let logits = model\n .decode(&decoder_token_ids, &encoder_output)?\n .squeeze(0)?;\n let logits = if args.repeat_penalty == 1. {\n logits\n } else {\n let start_at = output_token_ids.len().saturating_sub(args.repeat_last_n);\n candle_transformers::utils::apply_repeat_penalty(\n &logits,\n args.repeat_penalty,\n &output_token_ids[start_at..],\n )?\n };\n\n let next_token_id = logits_processor.sample(&logits)?;\n if next_token_id as usize == builder.config.eos_token_id {\n break;\n }\n output_token_ids.push(next_token_id);\n if let Some(text) = tokenizer.id_to_token(next_token_id) {\n let text = text.replace('\u2581', \" \").replace(\"<0x0A>\", \"\\n\");\n print!(\"{text}\");\n std::io::stdout().flush()?;\n }\n }\n let dt = start.elapsed();\n println!(\n \"\\n{} tokens generated ({:.2} token/s)\\n\",\n output_token_ids.len(),\n output_token_ids.len() as f64 / dt.as_secs_f64(),\n );\n }\n }\n None => {\n let mut model = builder.build_encoder()?;\n let sentences = [\n \"The cat sits outside\",\n \"A man is playing guitar\",\n \"I love pasta\",\n \"The new movie is awesome\",\n \"The cat plays in the garden\",\n \"A woman watches TV\",\n \"The new movie is so great\",\n \"Do you like pizza?\",\n ];\n let n_sentences = sentences.len();\n let mut all_embeddings = Vec::with_capacity(n_sentences);\n for sentence in sentences {\n let tokens = tokenizer\n .encode(sentence, true)\n .map_err(E::msg)?\n .get_ids()\n .to_vec();\n let token_ids = Tensor::new(&tokens[..], model.device())?.unsqueeze(0)?;\n let embeddings = model.forward(&token_ids)?;\n println!(\"generated embeddings {:?}\", embeddings.shape());\n // Apply some avg-pooling by taking the mean embedding value for all tokens (including padding)\n let (_n_sentence, n_tokens, _hidden_size) = embeddings.dims3()?;\n let embeddings = (embeddings.sum(1)? / (n_tokens as f64))?;\n let embeddings = if args.normalize_embeddings {\n normalize_l2(&embeddings)?\n } else {\n embeddings\n };\n println!(\"pooled embeddings {:?}\", embeddings.shape());\n all_embeddings.push(embeddings)\n }\n\n let mut similarities = vec![];\n for (i, e_i) in all_embeddings.iter().enumerate() {\n for (j, e_j) in all_embeddings\n .iter()\n .enumerate()\n .take(n_sentences)\n .skip(i + 1)\n {\n let sum_ij = (e_i * e_j)?.sum_all()?.to_scalar::<f32>()?;\n let sum_i2 = (e_i * e_i)?.sum_all()?.to_scalar::<f32>()?;\n let sum_j2 = (e_j * e_j)?.sum_all()?.to_scalar::<f32>()?;\n let cosine_similarity = sum_ij / (sum_i2 * sum_j2).sqrt();\n similarities.push((cosine_similarity, i, j))\n }\n }\n similarities.sort_by(|u, v| v.0.total_cmp(&u.0));\n for &(score, i, j) in similarities[..5].iter() {\n println!(\"score: {score:.2} '{}' '{}'\", sentences[i], sentences[j])\n }\n }\n }\n Ok(())\n}\n\npub fn normalize_l2(v: &Tensor) -> Result<Tensor> {\n Ok(v.broadcast_div(&v.sqr()?.sum_keepdim(1)?.sqrt()?)?)\n}\n", "candle-examples\\examples\\trocr\\main.rs": "#[cfg(feature = \"mkl\")]\nextern crate intel_mkl_src;\n\n#[cfg(feature = \"accelerate\")]\nextern crate accelerate_src;\n\nuse anyhow::Error as E;\nuse clap::{Parser, ValueEnum};\n\nuse candle::{DType, Tensor};\nuse candle_examples::token_output_stream::TokenOutputStream;\nuse candle_nn::VarBuilder;\nuse candle_transformers::models::{trocr, vit};\n\nuse tokenizers::Tokenizer;\nmod image_processor;\n\n#[derive(Clone, Debug, Copy, ValueEnum)]\nenum Which {\n #[value(name = \"base\")]\n BaseHandwritten,\n #[value(name = \"large\")]\n LargeHandwritten,\n BasePrinted,\n LargePrinted,\n}\n\nimpl Which {\n fn repo_and_branch_name(&self) -> (&str, &str) {\n match self {\n Self::BaseHandwritten => (\"microsoft/trocr-base-handwritten\", \"refs/pr/3\"),\n Self::LargeHandwritten => (\"microsoft/trocr-large-handwritten\", \"refs/pr/6\"),\n Self::BasePrinted => (\"microsoft/trocr-base-printed\", \"refs/pr/7\"),\n Self::LargePrinted => (\"microsoft/trocr-large-printed\", \"main\"),\n }\n }\n}\n\n#[derive(Debug, Clone, serde::Deserialize)]\nstruct Config {\n encoder: vit::Config,\n decoder: trocr::TrOCRConfig,\n}\n\n#[derive(Parser, Debug)]\nstruct Args {\n #[arg(long)]\n model: Option<String>,\n\n /// Choose the variant of the model to run.\n #[arg(long, default_value = \"base\")]\n which: Which,\n\n /// Run on CPU rather than on GPU.\n #[arg(long)]\n cpu: bool,\n\n /// The image file to be processed.\n #[arg(long)]\n image: String,\n\n /// Tokenization config.\n #[arg(long)]\n tokenizer: Option<String>,\n}\n\npub fn main() -> anyhow::Result<()> {\n let args = Args::parse();\n let api = hf_hub::api::sync::Api::new()?;\n\n let mut tokenizer_dec = {\n let tokenizer_file = match args.tokenizer {\n None => api\n .model(String::from(\"ToluClassics/candle-trocr-tokenizer\"))\n .get(\"tokenizer.json\")?,\n Some(tokenizer) => std::path::PathBuf::from(tokenizer),\n };\n let tokenizer = Tokenizer::from_file(&tokenizer_file).map_err(E::msg)?;\n TokenOutputStream::new(tokenizer)\n };\n let device = candle_examples::device(args.cpu)?;\n\n let vb = {\n let model = match args.model {\n Some(model) => std::path::PathBuf::from(model),\n None => {\n let (repo, branch) = args.which.repo_and_branch_name();\n api.repo(hf_hub::Repo::with_revision(\n repo.to_string(),\n hf_hub::RepoType::Model,\n branch.to_string(),\n ))\n .get(\"model.safetensors\")?\n }\n };\n println!(\"model: {:?}\", model);\n unsafe { VarBuilder::from_mmaped_safetensors(&[model], DType::F32, &device)? }\n };\n\n let (encoder_config, decoder_config) = {\n let (repo, branch) = args.which.repo_and_branch_name();\n let config_filename = api\n .repo(hf_hub::Repo::with_revision(\n repo.to_string(),\n hf_hub::RepoType::Model,\n branch.to_string(),\n ))\n .get(\"config.json\")?;\n let config: Config = serde_json::from_reader(std::fs::File::open(config_filename)?)?;\n (config.encoder, config.decoder)\n };\n let mut model = trocr::TrOCRModel::new(&encoder_config, &decoder_config, vb)?;\n\n let processor_config = image_processor::ProcessorConfig::default();\n let processor = image_processor::ViTImageProcessor::new(&processor_config);\n\n let image = vec![args.image.as_str()];\n let image = processor.preprocess(image)?.to_device(&device)?;\n\n let encoder_xs = model.encoder().forward(&image)?;\n\n let mut logits_processor =\n candle_transformers::generation::LogitsProcessor::new(1337, None, None);\n\n let mut token_ids: Vec<u32> = vec![decoder_config.decoder_start_token_id];\n for index in 0..1000 {\n let context_size = if index >= 1 { 1 } else { token_ids.len() };\n let start_pos = token_ids.len().saturating_sub(context_size);\n let input_ids = Tensor::new(&token_ids[start_pos..], &device)?.unsqueeze(0)?;\n\n let logits = model.decode(&input_ids, &encoder_xs, start_pos)?;\n\n let logits = logits.squeeze(0)?;\n let logits = logits.get(logits.dim(0)? - 1)?;\n let token = logits_processor.sample(&logits)?;\n token_ids.push(token);\n\n if let Some(t) = tokenizer_dec.next_token(token)? {\n use std::io::Write;\n print!(\"{t}\");\n std::io::stdout().flush()?;\n }\n if token == decoder_config.eos_token_id {\n break;\n }\n }\n\n if let Some(rest) = tokenizer_dec.decode_rest().map_err(E::msg)? {\n print!(\"{rest}\");\n }\n println!();\n\n Ok(())\n}\n", "candle-examples\\examples\\vgg\\main.rs": "#[cfg(feature = \"mkl\")]\nextern crate intel_mkl_src;\n\n#[cfg(feature = \"accelerate\")]\nextern crate accelerate_src;\n\nuse candle::{DType, IndexOp, D};\nuse candle_nn::{ModuleT, VarBuilder};\nuse candle_transformers::models::vgg::{Models, Vgg};\nuse clap::{Parser, ValueEnum};\n\n#[derive(Clone, Copy, Debug, ValueEnum)]\nenum Which {\n Vgg13,\n Vgg16,\n Vgg19,\n}\n\n#[derive(Parser)]\nstruct Args {\n #[arg(long)]\n image: String,\n\n /// Run on CPU rather than on GPU.\n #[arg(long)]\n cpu: bool,\n\n /// Variant of the model to use.\n #[arg(value_enum, long, default_value_t = Which::Vgg13)]\n which: Which,\n}\n\npub fn main() -> anyhow::Result<()> {\n let args = Args::parse();\n let device = candle_examples::device(args.cpu)?;\n let image = candle_examples::imagenet::load_image224(args.image)?.to_device(&device)?;\n\n println!(\"loaded image {image:?}\");\n\n let api = hf_hub::api::sync::Api::new()?;\n let repo = match args.which {\n Which::Vgg13 => \"timm/vgg13.tv_in1k\",\n Which::Vgg16 => \"timm/vgg16.tv_in1k\",\n Which::Vgg19 => \"timm/vgg19.tv_in1k\",\n };\n let api = api.model(repo.into());\n let filename = \"model.safetensors\";\n let model_file = api.get(filename)?;\n\n let vb = unsafe { VarBuilder::from_mmaped_safetensors(&[model_file], DType::F32, &device)? };\n let model = match args.which {\n Which::Vgg13 => Vgg::new(vb, Models::Vgg13)?,\n Which::Vgg16 => Vgg::new(vb, Models::Vgg16)?,\n Which::Vgg19 => Vgg::new(vb, Models::Vgg19)?,\n };\n let logits = model.forward_t(&image, /*train=*/ false)?;\n\n let prs = candle_nn::ops::softmax(&logits, D::Minus1)?\n .i(0)?\n .to_vec1::<f32>()?;\n\n // Sort the predictions and take the top 5\n let mut top: Vec<_> = prs.iter().enumerate().collect();\n top.sort_by(|a, b| b.1.partial_cmp(a.1).unwrap());\n let top = top.into_iter().take(5).collect::<Vec<_>>();\n\n // Print the top predictions\n for &(i, p) in &top {\n println!(\n \"{:50}: {:.2}%\",\n candle_examples::imagenet::CLASSES[i],\n p * 100.0\n );\n }\n\n Ok(())\n}\n", "candle-examples\\examples\\vit\\main.rs": "#[cfg(feature = \"mkl\")]\nextern crate intel_mkl_src;\n\n#[cfg(feature = \"accelerate\")]\nextern crate accelerate_src;\n\nuse clap::Parser;\n\nuse candle::{DType, IndexOp, D};\nuse candle_nn::VarBuilder;\nuse candle_transformers::models::vit;\n\n#[derive(Parser)]\nstruct Args {\n #[arg(long)]\n model: Option<String>,\n\n #[arg(long)]\n image: String,\n\n /// Run on CPU rather than on GPU.\n #[arg(long)]\n cpu: bool,\n}\n\npub fn main() -> anyhow::Result<()> {\n let args = Args::parse();\n\n let device = candle_examples::device(args.cpu)?;\n\n let image = candle_examples::imagenet::load_image224(args.image)?.to_device(&device)?;\n println!(\"loaded image {image:?}\");\n\n let model_file = match args.model {\n None => {\n let api = hf_hub::api::sync::Api::new()?;\n let api = api.model(\"google/vit-base-patch16-224\".into());\n api.get(\"model.safetensors\")?\n }\n Some(model) => model.into(),\n };\n let vb = unsafe { VarBuilder::from_mmaped_safetensors(&[model_file], DType::F32, &device)? };\n let model = vit::Model::new(&vit::Config::vit_base_patch16_224(), 1000, vb)?;\n println!(\"model built\");\n let logits = model.forward(&image.unsqueeze(0)?)?;\n let prs = candle_nn::ops::softmax(&logits, D::Minus1)?\n .i(0)?\n .to_vec1::<f32>()?;\n let mut prs = prs.iter().enumerate().collect::<Vec<_>>();\n prs.sort_by(|(_, p1), (_, p2)| p2.total_cmp(p1));\n for &(category_idx, pr) in prs.iter().take(5) {\n println!(\n \"{:24}: {:.2}%\",\n candle_examples::imagenet::CLASSES[category_idx],\n 100. * pr\n );\n }\n Ok(())\n}\n", "candle-examples\\examples\\whisper\\main.rs": "// https://github.com/openai/whisper/blob/main/whisper/model.py/rgs\n// TODO:\n// - Batch size greater than 1.\n// - More token filters (SuppressBlanks, ApplyTimestampRules).\n\n#[cfg(feature = \"accelerate\")]\nextern crate accelerate_src;\n\n#[cfg(feature = \"mkl\")]\nextern crate intel_mkl_src;\n\nuse anyhow::{Error as E, Result};\nuse candle::{Device, IndexOp, Tensor};\nuse candle_nn::{ops::softmax, VarBuilder};\nuse clap::{Parser, ValueEnum};\nuse hf_hub::{api::sync::Api, Repo, RepoType};\nuse rand::{distributions::Distribution, SeedableRng};\nuse tokenizers::Tokenizer;\n\nmod multilingual;\nmod pcm_decode;\n\nuse candle_transformers::models::whisper::{self as m, audio, Config};\n\npub enum Model {\n Normal(m::model::Whisper),\n Quantized(m::quantized_model::Whisper),\n}\n\n// Maybe we should use some traits rather than doing the dispatch for all these.\nimpl Model {\n pub fn config(&self) -> &Config {\n match self {\n Self::Normal(m) => &m.config,\n Self::Quantized(m) => &m.config,\n }\n }\n\n pub fn encoder_forward(&mut self, x: &Tensor, flush: bool) -> candle::Result<Tensor> {\n match self {\n Self::Normal(m) => m.encoder.forward(x, flush),\n Self::Quantized(m) => m.encoder.forward(x, flush),\n }\n }\n\n pub fn decoder_forward(\n &mut self,\n x: &Tensor,\n xa: &Tensor,\n flush: bool,\n ) -> candle::Result<Tensor> {\n match self {\n Self::Normal(m) => m.decoder.forward(x, xa, flush),\n Self::Quantized(m) => m.decoder.forward(x, xa, flush),\n }\n }\n\n pub fn decoder_final_linear(&self, x: &Tensor) -> candle::Result<Tensor> {\n match self {\n Self::Normal(m) => m.decoder.final_linear(x),\n Self::Quantized(m) => m.decoder.final_linear(x),\n }\n }\n}\n\n#[allow(dead_code)]\n#[derive(Debug, Clone)]\nstruct DecodingResult {\n tokens: Vec<u32>,\n text: String,\n avg_logprob: f64,\n no_speech_prob: f64,\n temperature: f64,\n compression_ratio: f64,\n}\n\n#[allow(dead_code)]\n#[derive(Debug, Clone)]\nstruct Segment {\n start: f64,\n duration: f64,\n dr: DecodingResult,\n}\n\nstruct Decoder {\n model: Model,\n rng: rand::rngs::StdRng,\n task: Option<Task>,\n timestamps: bool,\n verbose: bool,\n tokenizer: Tokenizer,\n suppress_tokens: Tensor,\n sot_token: u32,\n transcribe_token: u32,\n translate_token: u32,\n eot_token: u32,\n no_speech_token: u32,\n no_timestamps_token: u32,\n language_token: Option<u32>,\n}\n\nimpl Decoder {\n #[allow(clippy::too_many_arguments)]\n fn new(\n model: Model,\n tokenizer: Tokenizer,\n seed: u64,\n device: &Device,\n language_token: Option<u32>,\n task: Option<Task>,\n timestamps: bool,\n verbose: bool,\n ) -> Result<Self> {\n let no_timestamps_token = token_id(&tokenizer, m::NO_TIMESTAMPS_TOKEN)?;\n // Suppress the notimestamps token when in timestamps mode.\n // https://github.com/openai/whisper/blob/e8622f9afc4eba139bf796c210f5c01081000472/whisper/decoding.py#L452\n let suppress_tokens: Vec<f32> = (0..model.config().vocab_size as u32)\n .map(|i| {\n if model.config().suppress_tokens.contains(&i)\n || timestamps && i == no_timestamps_token\n {\n f32::NEG_INFINITY\n } else {\n 0f32\n }\n })\n .collect();\n let suppress_tokens = Tensor::new(suppress_tokens.as_slice(), device)?;\n let sot_token = token_id(&tokenizer, m::SOT_TOKEN)?;\n let transcribe_token = token_id(&tokenizer, m::TRANSCRIBE_TOKEN)?;\n let translate_token = token_id(&tokenizer, m::TRANSLATE_TOKEN)?;\n let eot_token = token_id(&tokenizer, m::EOT_TOKEN)?;\n let no_speech_token = m::NO_SPEECH_TOKENS\n .iter()\n .find_map(|token| token_id(&tokenizer, token).ok());\n let no_speech_token = match no_speech_token {\n None => anyhow::bail!(\"unable to find any non-speech token\"),\n Some(n) => n,\n };\n Ok(Self {\n model,\n rng: rand::rngs::StdRng::seed_from_u64(seed),\n tokenizer,\n task,\n timestamps,\n verbose,\n suppress_tokens,\n sot_token,\n transcribe_token,\n translate_token,\n eot_token,\n no_speech_token,\n language_token,\n no_timestamps_token,\n })\n }\n\n fn decode(&mut self, mel: &Tensor, t: f64) -> Result<DecodingResult> {\n let model = &mut self.model;\n let audio_features = model.encoder_forward(mel, true)?;\n if self.verbose {\n println!(\"audio features: {:?}\", audio_features.dims());\n }\n let sample_len = model.config().max_target_positions / 2;\n let mut sum_logprob = 0f64;\n let mut no_speech_prob = f64::NAN;\n let mut tokens = vec![self.sot_token];\n if let Some(language_token) = self.language_token {\n tokens.push(language_token);\n }\n match self.task {\n None | Some(Task::Transcribe) => tokens.push(self.transcribe_token),\n Some(Task::Translate) => tokens.push(self.translate_token),\n }\n if !self.timestamps {\n tokens.push(self.no_timestamps_token);\n }\n for i in 0..sample_len {\n let tokens_t = Tensor::new(tokens.as_slice(), mel.device())?;\n\n // The model expects a batch dim but this inference loop does not handle\n // it so we add it at this point.\n let tokens_t = tokens_t.unsqueeze(0)?;\n let ys = model.decoder_forward(&tokens_t, &audio_features, i == 0)?;\n\n // Extract the no speech probability on the first iteration by looking at the first\n // token logits and the probability for the according token.\n if i == 0 {\n let logits = model.decoder_final_linear(&ys.i(..1)?)?.i(0)?.i(0)?;\n no_speech_prob = softmax(&logits, 0)?\n .i(self.no_speech_token as usize)?\n .to_scalar::<f32>()? as f64;\n }\n\n let (_, seq_len, _) = ys.dims3()?;\n let logits = model\n .decoder_final_linear(&ys.i((..1, seq_len - 1..))?)?\n .i(0)?\n .i(0)?;\n // TODO: Besides suppress tokens, we should apply the heuristics from\n // ApplyTimestampRules, i.e.:\n // - Timestamps come in pairs, except before EOT.\n // - Timestamps should be non-decreasing.\n // - If the sum of the probabilities of timestamps is higher than any other tokens,\n // only consider timestamps when sampling.\n // https://github.com/openai/whisper/blob/e8622f9afc4eba139bf796c210f5c01081000472/whisper/decoding.py#L439\n let logits = logits.broadcast_add(&self.suppress_tokens)?;\n let next_token = if t > 0f64 {\n let prs = softmax(&(&logits / t)?, 0)?;\n let logits_v: Vec<f32> = prs.to_vec1()?;\n let distr = rand::distributions::WeightedIndex::new(&logits_v)?;\n distr.sample(&mut self.rng) as u32\n } else {\n let logits_v: Vec<f32> = logits.to_vec1()?;\n logits_v\n .iter()\n .enumerate()\n .max_by(|(_, u), (_, v)| u.total_cmp(v))\n .map(|(i, _)| i as u32)\n .unwrap()\n };\n tokens.push(next_token);\n let prob = softmax(&logits, candle::D::Minus1)?\n .i(next_token as usize)?\n .to_scalar::<f32>()? as f64;\n if next_token == self.eot_token || tokens.len() > model.config().max_target_positions {\n break;\n }\n sum_logprob += prob.ln();\n }\n let text = self.tokenizer.decode(&tokens, true).map_err(E::msg)?;\n let avg_logprob = sum_logprob / tokens.len() as f64;\n\n Ok(DecodingResult {\n tokens,\n text,\n avg_logprob,\n no_speech_prob,\n temperature: t,\n compression_ratio: f64::NAN,\n })\n }\n\n fn decode_with_fallback(&mut self, segment: &Tensor) -> Result<DecodingResult> {\n for (i, &t) in m::TEMPERATURES.iter().enumerate() {\n let dr: Result<DecodingResult> = self.decode(segment, t);\n if i == m::TEMPERATURES.len() - 1 {\n return dr;\n }\n // On errors, we try again with a different temperature.\n match dr {\n Ok(dr) => {\n let needs_fallback = dr.compression_ratio > m::COMPRESSION_RATIO_THRESHOLD\n || dr.avg_logprob < m::LOGPROB_THRESHOLD;\n if !needs_fallback || dr.no_speech_prob > m::NO_SPEECH_THRESHOLD {\n return Ok(dr);\n }\n }\n Err(err) => {\n println!(\"Error running at {t}: {err}\")\n }\n }\n }\n unreachable!()\n }\n\n fn run(&mut self, mel: &Tensor) -> Result<Vec<Segment>> {\n let (_, _, content_frames) = mel.dims3()?;\n let mut seek = 0;\n let mut segments = vec![];\n while seek < content_frames {\n let start = std::time::Instant::now();\n let time_offset = (seek * m::HOP_LENGTH) as f64 / m::SAMPLE_RATE as f64;\n let segment_size = usize::min(content_frames - seek, m::N_FRAMES);\n let mel_segment = mel.narrow(2, seek, segment_size)?;\n let segment_duration = (segment_size * m::HOP_LENGTH) as f64 / m::SAMPLE_RATE as f64;\n let dr = self.decode_with_fallback(&mel_segment)?;\n seek += segment_size;\n if dr.no_speech_prob > m::NO_SPEECH_THRESHOLD && dr.avg_logprob < m::LOGPROB_THRESHOLD {\n println!(\"no speech detected, skipping {seek} {dr:?}\");\n continue;\n }\n let segment = Segment {\n start: time_offset,\n duration: segment_duration,\n dr,\n };\n if self.timestamps {\n println!(\n \"{:.1}s -- {:.1}s\",\n segment.start,\n segment.start + segment.duration,\n );\n let mut tokens_to_decode = vec![];\n let mut prev_timestamp_s = 0f32;\n for &token in segment.dr.tokens.iter() {\n if token == self.sot_token || token == self.eot_token {\n continue;\n }\n // The no_timestamp_token is the last before the timestamp ones.\n if token > self.no_timestamps_token {\n let timestamp_s = (token - self.no_timestamps_token + 1) as f32 / 50.;\n if !tokens_to_decode.is_empty() {\n let text = self\n .tokenizer\n .decode(&tokens_to_decode, true)\n .map_err(E::msg)?;\n println!(\" {:.1}s-{:.1}s: {}\", prev_timestamp_s, timestamp_s, text);\n tokens_to_decode.clear()\n }\n prev_timestamp_s = timestamp_s;\n } else {\n tokens_to_decode.push(token)\n }\n }\n if !tokens_to_decode.is_empty() {\n let text = self\n .tokenizer\n .decode(&tokens_to_decode, true)\n .map_err(E::msg)?;\n if !text.is_empty() {\n println!(\" {:.1}s-...: {}\", prev_timestamp_s, text);\n }\n tokens_to_decode.clear()\n }\n } else {\n println!(\n \"{:.1}s -- {:.1}s: {}\",\n segment.start,\n segment.start + segment.duration,\n segment.dr.text,\n )\n }\n if self.verbose {\n println!(\"{seek}: {segment:?}, in {:?}\", start.elapsed());\n }\n segments.push(segment)\n }\n Ok(segments)\n }\n}\n\npub fn token_id(tokenizer: &Tokenizer, token: &str) -> candle::Result<u32> {\n match tokenizer.token_to_id(token) {\n None => candle::bail!(\"no token-id for {token}\"),\n Some(id) => Ok(id),\n }\n}\n\n#[derive(Clone, Copy, Debug, ValueEnum)]\nenum Task {\n Transcribe,\n Translate,\n}\n\n#[derive(Clone, Copy, Debug, PartialEq, Eq, ValueEnum)]\nenum WhichModel {\n Tiny,\n #[value(name = \"tiny.en\")]\n TinyEn,\n Base,\n #[value(name = \"base.en\")]\n BaseEn,\n Small,\n #[value(name = \"small.en\")]\n SmallEn,\n Medium,\n #[value(name = \"medium.en\")]\n MediumEn,\n Large,\n LargeV2,\n LargeV3,\n #[value(name = \"distil-medium.en\")]\n DistilMediumEn,\n #[value(name = \"distil-large-v2\")]\n DistilLargeV2,\n #[value(name = \"distil-large-v3\")]\n DistilLargeV3,\n}\n\nimpl WhichModel {\n fn is_multilingual(&self) -> bool {\n match self {\n Self::Tiny\n | Self::Base\n | Self::Small\n | Self::Medium\n | Self::Large\n | Self::LargeV2\n | Self::LargeV3\n | Self::DistilLargeV2\n | Self::DistilLargeV3 => true,\n Self::TinyEn | Self::BaseEn | Self::SmallEn | Self::MediumEn | Self::DistilMediumEn => {\n false\n }\n }\n }\n\n fn model_and_revision(&self) -> (&'static str, &'static str) {\n match self {\n Self::Tiny => (\"openai/whisper-tiny\", \"main\"),\n Self::TinyEn => (\"openai/whisper-tiny.en\", \"refs/pr/15\"),\n Self::Base => (\"openai/whisper-base\", \"refs/pr/22\"),\n Self::BaseEn => (\"openai/whisper-base.en\", \"refs/pr/13\"),\n Self::Small => (\"openai/whisper-small\", \"main\"),\n Self::SmallEn => (\"openai/whisper-small.en\", \"refs/pr/10\"),\n Self::Medium => (\"openai/whisper-medium\", \"main\"),\n Self::MediumEn => (\"openai/whisper-medium.en\", \"main\"),\n Self::Large => (\"openai/whisper-large\", \"refs/pr/36\"),\n Self::LargeV2 => (\"openai/whisper-large-v2\", \"refs/pr/57\"),\n Self::LargeV3 => (\"openai/whisper-large-v3\", \"main\"),\n Self::DistilMediumEn => (\"distil-whisper/distil-medium.en\", \"main\"),\n Self::DistilLargeV2 => (\"distil-whisper/distil-large-v2\", \"main\"),\n Self::DistilLargeV3 => (\"distil-whisper/distil-large-v3\", \"main\"),\n }\n }\n}\n\n#[derive(Parser, Debug)]\n#[command(author, version, about, long_about = None)]\nstruct Args {\n /// Run on CPU rather than on GPU.\n #[arg(long)]\n cpu: bool,\n\n #[arg(long)]\n model_id: Option<String>,\n\n /// The model to use, check out available models:\n /// https://huggingface.co/models?search=whisper\n #[arg(long)]\n revision: Option<String>,\n\n /// The model to be used, can be tiny, small, medium.\n #[arg(long, default_value = \"tiny.en\")]\n model: WhichModel,\n\n /// The input to be processed, in wav format, will default to `jfk.wav`. Alternatively\n /// this can be set to sample:jfk, sample:gb1, ... to fetch a sample from the following\n /// repo: https://huggingface.co/datasets/Narsil/candle_demo/\n #[arg(long)]\n input: Option<String>,\n\n /// The seed to use when generating random samples.\n #[arg(long, default_value_t = 299792458)]\n seed: u64,\n\n /// Enable tracing (generates a trace-timestamp.json file).\n #[arg(long)]\n tracing: bool,\n\n #[arg(long)]\n quantized: bool,\n\n /// Language.\n #[arg(long)]\n language: Option<String>,\n\n /// Task, when no task is specified, the input tokens contain only the sot token which can\n /// improve things when in no-timestamp mode.\n #[arg(long)]\n task: Option<Task>,\n\n /// Timestamps mode, this is not fully implemented yet.\n #[arg(long)]\n timestamps: bool,\n\n /// Print the full DecodingResult structure rather than just the text.\n #[arg(long)]\n verbose: bool,\n}\n\nfn main() -> Result<()> {\n use tracing_chrome::ChromeLayerBuilder;\n use tracing_subscriber::prelude::*;\n\n let args = Args::parse();\n let _guard = if args.tracing {\n let (chrome_layer, guard) = ChromeLayerBuilder::new().build();\n tracing_subscriber::registry().with(chrome_layer).init();\n Some(guard)\n } else {\n None\n };\n let device = candle_examples::device(args.cpu)?;\n let (default_model, default_revision) = if args.quantized {\n (\"lmz/candle-whisper\", \"main\")\n } else {\n args.model.model_and_revision()\n };\n let default_model = default_model.to_string();\n let default_revision = default_revision.to_string();\n let (model_id, revision) = match (args.model_id, args.revision) {\n (Some(model_id), Some(revision)) => (model_id, revision),\n (Some(model_id), None) => (model_id, \"main\".to_string()),\n (None, Some(revision)) => (default_model, revision),\n (None, None) => (default_model, default_revision),\n };\n\n let (config_filename, tokenizer_filename, weights_filename, input) = {\n let api = Api::new()?;\n let dataset = api.dataset(\"Narsil/candle-examples\".to_string());\n let repo = api.repo(Repo::with_revision(model_id, RepoType::Model, revision));\n let sample = if let Some(input) = args.input {\n if let Some(sample) = input.strip_prefix(\"sample:\") {\n dataset.get(&format!(\"samples_{sample}.wav\"))?\n } else {\n std::path::PathBuf::from(input)\n }\n } else {\n println!(\"No audio file submitted: Downloading https://huggingface.co/datasets/Narsil/candle_demo/blob/main/samples_jfk.wav\");\n dataset.get(\"samples_jfk.wav\")?\n };\n let (config, tokenizer, model) = if args.quantized {\n let ext = match args.model {\n WhichModel::TinyEn => \"tiny-en\",\n WhichModel::Tiny => \"tiny\",\n _ => unimplemented!(\"no quantized support for {:?}\", args.model),\n };\n (\n repo.get(&format!(\"config-{ext}.json\"))?,\n repo.get(&format!(\"tokenizer-{ext}.json\"))?,\n repo.get(&format!(\"model-{ext}-q80.gguf\"))?,\n )\n } else {\n let config = repo.get(\"config.json\")?;\n let tokenizer = repo.get(\"tokenizer.json\")?;\n let model = repo.get(\"model.safetensors\")?;\n (config, tokenizer, model)\n };\n (config, tokenizer, model, sample)\n };\n let config: Config = serde_json::from_str(&std::fs::read_to_string(config_filename)?)?;\n let tokenizer = Tokenizer::from_file(tokenizer_filename).map_err(E::msg)?;\n\n let mel_bytes = match config.num_mel_bins {\n 80 => include_bytes!(\"melfilters.bytes\").as_slice(),\n 128 => include_bytes!(\"melfilters128.bytes\").as_slice(),\n nmel => anyhow::bail!(\"unexpected num_mel_bins {nmel}\"),\n };\n let mut mel_filters = vec![0f32; mel_bytes.len() / 4];\n <byteorder::LittleEndian as byteorder::ByteOrder>::read_f32_into(mel_bytes, &mut mel_filters);\n\n let (pcm_data, sample_rate) = pcm_decode::pcm_decode(input)?;\n if sample_rate != m::SAMPLE_RATE as u32 {\n anyhow::bail!(\"input file must have a {} sampling rate\", m::SAMPLE_RATE)\n }\n println!(\"pcm data loaded {}\", pcm_data.len());\n let mel = audio::pcm_to_mel(&config, &pcm_data, &mel_filters);\n let mel_len = mel.len();\n let mel = Tensor::from_vec(\n mel,\n (1, config.num_mel_bins, mel_len / config.num_mel_bins),\n &device,\n )?;\n println!(\"loaded mel: {:?}\", mel.dims());\n\n let mut model = if args.quantized {\n let vb = candle_transformers::quantized_var_builder::VarBuilder::from_gguf(\n &weights_filename,\n &device,\n )?;\n Model::Quantized(m::quantized_model::Whisper::load(&vb, config)?)\n } else {\n let vb =\n unsafe { VarBuilder::from_mmaped_safetensors(&[weights_filename], m::DTYPE, &device)? };\n Model::Normal(m::model::Whisper::load(&vb, config)?)\n };\n\n let language_token = match (args.model.is_multilingual(), args.language) {\n (true, None) => Some(multilingual::detect_language(&mut model, &tokenizer, &mel)?),\n (false, None) => None,\n (true, Some(language)) => match token_id(&tokenizer, &format!(\"<|{language}|>\")) {\n Ok(token_id) => Some(token_id),\n Err(_) => anyhow::bail!(\"language {language} is not supported\"),\n },\n (false, Some(_)) => {\n anyhow::bail!(\"a language cannot be set for non-multilingual models\")\n }\n };\n let mut dc = Decoder::new(\n model,\n tokenizer,\n args.seed,\n &device,\n language_token,\n args.task,\n args.timestamps,\n args.verbose,\n )?;\n dc.run(&mel)?;\n Ok(())\n}\n", "candle-examples\\examples\\whisper-microphone\\main.rs": "#[cfg(feature = \"accelerate\")]\nextern crate accelerate_src;\n\n#[cfg(feature = \"mkl\")]\nextern crate intel_mkl_src;\n\nuse anyhow::{Error as E, Result};\nuse candle::{Device, IndexOp, Tensor};\nuse candle_nn::{ops::softmax, VarBuilder};\nuse clap::{Parser, ValueEnum};\nuse hf_hub::{api::sync::Api, Repo, RepoType};\nuse rand::{distributions::Distribution, SeedableRng};\nuse std::iter;\nuse tokenizers::Tokenizer;\n\nmod multilingual;\n\nuse candle_transformers::models::whisper::{self as m, audio, Config};\n\nuse cpal::traits::{DeviceTrait, HostTrait, StreamTrait};\nuse std::sync::{Arc, Mutex};\n\npub enum Model {\n Normal(m::model::Whisper),\n Quantized(m::quantized_model::Whisper),\n}\n\n// Maybe we should use some traits rather than doing the dispatch for all these.\nimpl Model {\n pub fn config(&self) -> &Config {\n match self {\n Self::Normal(m) => &m.config,\n Self::Quantized(m) => &m.config,\n }\n }\n\n pub fn encoder_forward(&mut self, x: &Tensor, flush: bool) -> candle::Result<Tensor> {\n match self {\n Self::Normal(m) => m.encoder.forward(x, flush),\n Self::Quantized(m) => m.encoder.forward(x, flush),\n }\n }\n\n pub fn decoder_forward(\n &mut self,\n x: &Tensor,\n xa: &Tensor,\n flush: bool,\n ) -> candle::Result<Tensor> {\n match self {\n Self::Normal(m) => m.decoder.forward(x, xa, flush),\n Self::Quantized(m) => m.decoder.forward(x, xa, flush),\n }\n }\n\n pub fn decoder_final_linear(&self, x: &Tensor) -> candle::Result<Tensor> {\n match self {\n Self::Normal(m) => m.decoder.final_linear(x),\n Self::Quantized(m) => m.decoder.final_linear(x),\n }\n }\n}\n\n#[allow(dead_code)]\n#[derive(Debug, Clone)]\nstruct DecodingResult {\n tokens: Vec<u32>,\n text: String,\n avg_logprob: f64,\n no_speech_prob: f64,\n temperature: f64,\n compression_ratio: f64,\n}\n\n#[allow(dead_code)]\n#[derive(Debug, Clone)]\nstruct Segment {\n start: f64,\n duration: f64,\n dr: DecodingResult,\n}\n\nstruct Decoder {\n model: Model,\n rng: rand::rngs::StdRng,\n task: Option<Task>,\n timestamps: bool,\n verbose: bool,\n tokenizer: Tokenizer,\n suppress_tokens: Tensor,\n sot_token: u32,\n transcribe_token: u32,\n translate_token: u32,\n eot_token: u32,\n no_speech_token: u32,\n no_timestamps_token: u32,\n language_token: Option<u32>,\n}\n\nimpl Decoder {\n #[allow(clippy::too_many_arguments)]\n fn new(\n model: Model,\n tokenizer: Tokenizer,\n seed: u64,\n device: &Device,\n language_token: Option<u32>,\n task: Option<Task>,\n timestamps: bool,\n verbose: bool,\n ) -> Result<Self> {\n let no_timestamps_token = token_id(&tokenizer, m::NO_TIMESTAMPS_TOKEN)?;\n // Suppress the notimestamps token when in timestamps mode.\n // https://github.com/openai/whisper/blob/e8622f9afc4eba139bf796c210f5c01081000472/whisper/decoding.py#L452\n let suppress_tokens: Vec<f32> = (0..model.config().vocab_size as u32)\n .map(|i| {\n if model.config().suppress_tokens.contains(&i)\n || timestamps && i == no_timestamps_token\n {\n f32::NEG_INFINITY\n } else {\n 0f32\n }\n })\n .collect();\n let suppress_tokens = Tensor::new(suppress_tokens.as_slice(), device)?;\n let sot_token = token_id(&tokenizer, m::SOT_TOKEN)?;\n let transcribe_token = token_id(&tokenizer, m::TRANSCRIBE_TOKEN)?;\n let translate_token = token_id(&tokenizer, m::TRANSLATE_TOKEN)?;\n let eot_token = token_id(&tokenizer, m::EOT_TOKEN)?;\n let no_speech_token = m::NO_SPEECH_TOKENS\n .iter()\n .find_map(|token| token_id(&tokenizer, token).ok());\n let no_speech_token = match no_speech_token {\n None => anyhow::bail!(\"unable to find any non-speech token\"),\n Some(n) => n,\n };\n Ok(Self {\n model,\n rng: rand::rngs::StdRng::seed_from_u64(seed),\n tokenizer,\n task,\n timestamps,\n verbose,\n suppress_tokens,\n sot_token,\n transcribe_token,\n translate_token,\n eot_token,\n no_speech_token,\n language_token,\n no_timestamps_token,\n })\n }\n\n fn decode(&mut self, mel: &Tensor, t: f64) -> Result<DecodingResult> {\n let model = &mut self.model;\n let audio_features = model.encoder_forward(mel, true)?;\n if self.verbose {\n println!(\"audio features: {:?}\", audio_features.dims());\n }\n let sample_len = model.config().max_target_positions / 2;\n let mut sum_logprob = 0f64;\n let mut no_speech_prob = f64::NAN;\n let mut tokens = vec![self.sot_token];\n if let Some(language_token) = self.language_token {\n tokens.push(language_token);\n }\n match self.task {\n None | Some(Task::Transcribe) => tokens.push(self.transcribe_token),\n Some(Task::Translate) => tokens.push(self.translate_token),\n }\n if !self.timestamps {\n tokens.push(self.no_timestamps_token);\n }\n for i in 0..sample_len {\n let tokens_t = Tensor::new(tokens.as_slice(), mel.device())?;\n\n // The model expects a batch dim but this inference loop does not handle\n // it so we add it at this point.\n let tokens_t = tokens_t.unsqueeze(0)?;\n let ys = model.decoder_forward(&tokens_t, &audio_features, i == 0)?;\n\n // Extract the no speech probability on the first iteration by looking at the first\n // token logits and the probability for the according token.\n if i == 0 {\n let logits = model.decoder_final_linear(&ys.i(..1)?)?.i(0)?.i(0)?;\n no_speech_prob = softmax(&logits, 0)?\n .i(self.no_speech_token as usize)?\n .to_scalar::<f32>()? as f64;\n }\n\n let (_, seq_len, _) = ys.dims3()?;\n let logits = model\n .decoder_final_linear(&ys.i((..1, seq_len - 1..))?)?\n .i(0)?\n .i(0)?;\n // TODO: Besides suppress tokens, we should apply the heuristics from\n // ApplyTimestampRules, i.e.:\n // - Timestamps come in pairs, except before EOT.\n // - Timestamps should be non-decreasing.\n // - If the sum of the probabilities of timestamps is higher than any other tokens,\n // only consider timestamps when sampling.\n // https://github.com/openai/whisper/blob/e8622f9afc4eba139bf796c210f5c01081000472/whisper/decoding.py#L439\n let logits = logits.broadcast_add(&self.suppress_tokens)?;\n let next_token = if t > 0f64 {\n let prs = softmax(&(&logits / t)?, 0)?;\n let logits_v: Vec<f32> = prs.to_vec1()?;\n let distr = rand::distributions::WeightedIndex::new(&logits_v)?;\n distr.sample(&mut self.rng) as u32\n } else {\n let logits_v: Vec<f32> = logits.to_vec1()?;\n logits_v\n .iter()\n .enumerate()\n .max_by(|(_, u), (_, v)| u.total_cmp(v))\n .map(|(i, _)| i as u32)\n .unwrap()\n };\n tokens.push(next_token);\n let prob = softmax(&logits, candle::D::Minus1)?\n .i(next_token as usize)?\n .to_scalar::<f32>()? as f64;\n if next_token == self.eot_token || tokens.len() > model.config().max_target_positions {\n break;\n }\n sum_logprob += prob.ln();\n }\n let text = self.tokenizer.decode(&tokens, true).map_err(E::msg)?;\n let avg_logprob = sum_logprob / tokens.len() as f64;\n\n Ok(DecodingResult {\n tokens,\n text,\n avg_logprob,\n no_speech_prob,\n temperature: t,\n compression_ratio: f64::NAN,\n })\n }\n\n fn decode_with_fallback(&mut self, segment: &Tensor) -> Result<DecodingResult> {\n for (i, &t) in m::TEMPERATURES.iter().enumerate() {\n let dr: Result<DecodingResult> = self.decode(segment, t);\n if i == m::TEMPERATURES.len() - 1 {\n return dr;\n }\n // On errors, we try again with a different temperature.\n match dr {\n Ok(dr) => {\n let needs_fallback = dr.compression_ratio > m::COMPRESSION_RATIO_THRESHOLD\n || dr.avg_logprob < m::LOGPROB_THRESHOLD;\n if !needs_fallback || dr.no_speech_prob > m::NO_SPEECH_THRESHOLD {\n return Ok(dr);\n }\n }\n Err(err) => {\n println!(\"Error running at {t}: {err}\")\n }\n }\n }\n unreachable!()\n }\n\n fn run(&mut self, mel: &Tensor, times: Option<(f64, f64)>) -> Result<Vec<Segment>> {\n let (_, _, content_frames) = mel.dims3()?;\n let mut seek = 0;\n let mut segments = vec![];\n while seek < content_frames {\n let start = std::time::Instant::now();\n let time_offset = (seek * m::HOP_LENGTH) as f64 / m::SAMPLE_RATE as f64;\n let segment_size = usize::min(content_frames - seek, m::N_FRAMES);\n let mel_segment = mel.narrow(2, seek, segment_size)?;\n let segment_duration = (segment_size * m::HOP_LENGTH) as f64 / m::SAMPLE_RATE as f64;\n let dr = self.decode_with_fallback(&mel_segment)?;\n seek += segment_size;\n if dr.no_speech_prob > m::NO_SPEECH_THRESHOLD && dr.avg_logprob < m::LOGPROB_THRESHOLD {\n println!(\"no speech detected, skipping {seek} {dr:?}\");\n continue;\n }\n let segment = Segment {\n start: time_offset,\n duration: segment_duration,\n dr,\n };\n if self.timestamps {\n println!(\n \"{:.1}s -- {:.1}s\",\n segment.start,\n segment.start + segment.duration,\n );\n let mut tokens_to_decode = vec![];\n let mut prev_timestamp_s = 0f32;\n for &token in segment.dr.tokens.iter() {\n if token == self.sot_token || token == self.eot_token {\n continue;\n }\n // The no_timestamp_token is the last before the timestamp ones.\n if token > self.no_timestamps_token {\n let timestamp_s = (token - self.no_timestamps_token + 1) as f32 / 50.;\n if !tokens_to_decode.is_empty() {\n let text = self\n .tokenizer\n .decode(&tokens_to_decode, true)\n .map_err(E::msg)?;\n println!(\" {:.1}s-{:.1}s: {}\", prev_timestamp_s, timestamp_s, text);\n tokens_to_decode.clear()\n }\n prev_timestamp_s = timestamp_s;\n } else {\n tokens_to_decode.push(token)\n }\n }\n if !tokens_to_decode.is_empty() {\n let text = self\n .tokenizer\n .decode(&tokens_to_decode, true)\n .map_err(E::msg)?;\n if !text.is_empty() {\n println!(\" {:.1}s-...: {}\", prev_timestamp_s, text);\n }\n tokens_to_decode.clear()\n }\n } else {\n match times {\n Some((start, end)) => {\n println!(\"{:.1}s -- {:.1}s: {}\", start, end, segment.dr.text)\n }\n None => {\n println!(\n \"{:.1}s -- {:.1}s: {}\",\n segment.start,\n segment.start + segment.duration,\n segment.dr.text,\n )\n }\n }\n }\n if self.verbose {\n println!(\"{seek}: {segment:?}, in {:?}\", start.elapsed());\n }\n segments.push(segment)\n }\n Ok(segments)\n }\n\n fn set_language_token(&mut self, language_token: Option<u32>) {\n self.language_token = language_token;\n }\n\n #[allow(dead_code)]\n fn reset_kv_cache(&mut self) {\n match &mut self.model {\n Model::Normal(m) => m.reset_kv_cache(),\n Model::Quantized(m) => m.reset_kv_cache(),\n }\n }\n\n fn model(&mut self) -> &mut Model {\n &mut self.model\n }\n}\n\npub fn token_id(tokenizer: &Tokenizer, token: &str) -> candle::Result<u32> {\n match tokenizer.token_to_id(token) {\n None => candle::bail!(\"no token-id for {token}\"),\n Some(id) => Ok(id),\n }\n}\n\n#[derive(Clone, Copy, Debug, ValueEnum)]\nenum Task {\n Transcribe,\n Translate,\n}\n\n#[derive(Clone, Copy, Debug, PartialEq, Eq, ValueEnum)]\nenum WhichModel {\n Tiny,\n #[value(name = \"tiny.en\")]\n TinyEn,\n Base,\n #[value(name = \"base.en\")]\n BaseEn,\n Small,\n #[value(name = \"small.en\")]\n SmallEn,\n Medium,\n #[value(name = \"medium.en\")]\n MediumEn,\n Large,\n LargeV2,\n LargeV3,\n #[value(name = \"distil-medium.en\")]\n DistilMediumEn,\n #[value(name = \"distil-large-v2\")]\n DistilLargeV2,\n}\n\nimpl WhichModel {\n fn is_multilingual(&self) -> bool {\n match self {\n Self::Tiny\n | Self::Base\n | Self::Small\n | Self::Medium\n | Self::Large\n | Self::LargeV2\n | Self::LargeV3\n | Self::DistilLargeV2 => true,\n Self::TinyEn | Self::BaseEn | Self::SmallEn | Self::MediumEn | Self::DistilMediumEn => {\n false\n }\n }\n }\n\n fn model_and_revision(&self) -> (&'static str, &'static str) {\n match self {\n Self::Tiny => (\"openai/whisper-tiny\", \"main\"),\n Self::TinyEn => (\"openai/whisper-tiny.en\", \"refs/pr/15\"),\n Self::Base => (\"openai/whisper-base\", \"refs/pr/22\"),\n Self::BaseEn => (\"openai/whisper-base.en\", \"refs/pr/13\"),\n Self::Small => (\"openai/whisper-small\", \"main\"),\n Self::SmallEn => (\"openai/whisper-small.en\", \"refs/pr/10\"),\n Self::Medium => (\"openai/whisper-medium\", \"main\"),\n Self::MediumEn => (\"openai/whisper-medium.en\", \"main\"),\n Self::Large => (\"openai/whisper-large\", \"refs/pr/36\"),\n Self::LargeV2 => (\"openai/whisper-large-v2\", \"refs/pr/57\"),\n Self::LargeV3 => (\"openai/whisper-large-v3\", \"main\"),\n Self::DistilMediumEn => (\"distil-whisper/distil-medium.en\", \"main\"),\n Self::DistilLargeV2 => (\"distil-whisper/distil-large-v2\", \"main\"),\n }\n }\n}\n\n#[derive(Parser, Debug)]\n#[command(author, version, about, long_about = None)]\nstruct Args {\n /// Run on CPU rather than on GPU.\n #[arg(long)]\n cpu: bool,\n\n #[arg(long)]\n model_id: Option<String>,\n\n /// The model to use, check out available models:\n /// https://huggingface.co/models?search=whisper\n #[arg(long)]\n revision: Option<String>,\n\n /// The model to be used, can be tiny, small, medium.\n #[arg(long, default_value = \"tiny.en\")]\n model: WhichModel,\n\n /// The seed to use when generating random samples.\n #[arg(long, default_value_t = 299792458)]\n seed: u64,\n\n /// Enable tracing (generates a trace-timestamp.json file).\n #[arg(long)]\n tracing: bool,\n\n #[arg(long)]\n quantized: bool,\n\n /// Language.\n #[arg(long)]\n language: Option<String>,\n\n /// Task, when no task is specified, the input tokens contain only the sot token which can\n /// improve things when in no-timestamp mode.\n #[arg(long)]\n task: Option<Task>,\n\n /// Timestamps mode, this is not fully implemented yet.\n #[arg(long)]\n timestamps: bool,\n\n /// Print the full DecodingResult structure rather than just the text.\n #[arg(long)]\n verbose: bool,\n}\n\npub fn main() -> Result<()> {\n use tracing_chrome::ChromeLayerBuilder;\n use tracing_subscriber::prelude::*;\n\n let args = Args::parse();\n let _guard = if args.tracing {\n let (chrome_layer, guard) = ChromeLayerBuilder::new().build();\n tracing_subscriber::registry().with(chrome_layer).init();\n Some(guard)\n } else {\n None\n };\n let device = candle_examples::device(args.cpu)?;\n let (default_model, default_revision) = if args.quantized {\n (\"lmz/candle-whisper\", \"main\")\n } else {\n args.model.model_and_revision()\n };\n let default_model = default_model.to_string();\n let default_revision = default_revision.to_string();\n let (model_id, revision) = match (args.model_id, args.revision) {\n (Some(model_id), Some(revision)) => (model_id, revision),\n (Some(model_id), None) => (model_id, \"main\".to_string()),\n (None, Some(revision)) => (default_model, revision),\n (None, None) => (default_model, default_revision),\n };\n\n let (config_filename, tokenizer_filename, weights_filename) = {\n let api = Api::new()?;\n let repo = api.repo(Repo::with_revision(model_id, RepoType::Model, revision));\n let (config, tokenizer, model) = if args.quantized {\n let ext = match args.model {\n WhichModel::TinyEn => \"tiny-en\",\n WhichModel::Tiny => \"tiny\",\n _ => unimplemented!(\"no quantized support for {:?}\", args.model),\n };\n (\n repo.get(&format!(\"config-{ext}.json\"))?,\n repo.get(&format!(\"tokenizer-{ext}.json\"))?,\n repo.get(&format!(\"model-{ext}-q80.gguf\"))?,\n )\n } else {\n let config = repo.get(\"config.json\")?;\n let tokenizer = repo.get(\"tokenizer.json\")?;\n let model = repo.get(\"model.safetensors\")?;\n (config, tokenizer, model)\n };\n (config, tokenizer, model)\n };\n let config: Config = serde_json::from_str(&std::fs::read_to_string(config_filename)?)?;\n let tokenizer = Tokenizer::from_file(tokenizer_filename).map_err(E::msg)?;\n let model = if args.quantized {\n let vb = candle_transformers::quantized_var_builder::VarBuilder::from_gguf(\n &weights_filename,\n &device,\n )?;\n Model::Quantized(m::quantized_model::Whisper::load(&vb, config.clone())?)\n } else {\n let vb =\n unsafe { VarBuilder::from_mmaped_safetensors(&[weights_filename], m::DTYPE, &device)? };\n Model::Normal(m::model::Whisper::load(&vb, config.clone())?)\n };\n let language_token = None;\n let mut dc = Decoder::new(\n model,\n tokenizer.clone(),\n args.seed,\n &device,\n language_token,\n args.task,\n args.timestamps,\n args.verbose,\n )?;\n\n let mel_bytes = match config.num_mel_bins {\n 80 => include_bytes!(\"../whisper/melfilters.bytes\").as_slice(),\n 128 => include_bytes!(\"../whisper/melfilters128.bytes\").as_slice(),\n nmel => anyhow::bail!(\"unexpected num_mel_bins {nmel}\"),\n };\n let mut mel_filters = vec![0f32; mel_bytes.len() / 4];\n <byteorder::LittleEndian as byteorder::ByteOrder>::read_f32_into(mel_bytes, &mut mel_filters);\n\n // Set up the input device and stream with the default input config.\n let host = cpal::default_host();\n let _device = \"default\";\n let _device = if _device == \"default\" {\n host.default_input_device()\n } else {\n host.input_devices()?\n .find(|x| x.name().map(|y| y == _device).unwrap_or(false))\n }\n .expect(\"failed to find input device\");\n\n let _config = _device\n .default_input_config()\n .expect(\"Failed to get default input config\");\n\n let channel_count = _config.channels() as usize;\n\n let audio_ring_buffer = Arc::new(Mutex::new(Vec::new()));\n let audio_ring_buffer_2 = audio_ring_buffer.clone();\n\n std::thread::spawn(move || loop {\n let data = record_audio(&_device, &_config, 300).unwrap();\n audio_ring_buffer.lock().unwrap().extend_from_slice(&data);\n let max_len = data.len() * 16;\n let data_len = data.len();\n let len = audio_ring_buffer.lock().unwrap().len();\n if len > max_len {\n let mut data = audio_ring_buffer.lock().unwrap();\n let new_data = data[data_len..].to_vec();\n *data = new_data;\n }\n });\n\n // loop to process the audio data forever (until the user stops the program)\n println!(\"Transcribing audio...\");\n for (i, _) in iter::repeat(()).enumerate() {\n std::thread::sleep(std::time::Duration::from_millis(1000));\n let data = audio_ring_buffer_2.lock().unwrap().clone();\n let pcm_data: Vec<_> = data[..data.len() / channel_count as usize]\n .iter()\n .map(|v| *v as f32 / 32768.)\n .collect();\n let mel = audio::pcm_to_mel(&config, &pcm_data, &mel_filters);\n let mel_len = mel.len();\n let mel = Tensor::from_vec(\n mel,\n (1, config.num_mel_bins, mel_len / config.num_mel_bins),\n &device,\n )?;\n\n // on the first iteration, we detect the language and set the language token.\n if i == 0 {\n let language_token = match (args.model.is_multilingual(), args.language.clone()) {\n (true, None) => Some(multilingual::detect_language(dc.model(), &tokenizer, &mel)?),\n (false, None) => None,\n (true, Some(language)) => match token_id(&tokenizer, &format!(\"<|{language}|>\")) {\n Ok(token_id) => Some(token_id),\n Err(_) => anyhow::bail!(\"language {language} is not supported\"),\n },\n (false, Some(_)) => {\n anyhow::bail!(\"a language cannot be set for non-multilingual models\")\n }\n };\n println!(\"language_token: {:?}\", language_token);\n dc.set_language_token(language_token);\n }\n dc.run(\n &mel,\n Some((\n i as f64,\n i as f64 + data.len() as f64 / m::SAMPLE_RATE as f64,\n )),\n )?;\n dc.reset_kv_cache();\n }\n\n Ok(())\n}\n\nfn record_audio(\n device: &cpal::Device,\n config: &cpal::SupportedStreamConfig,\n milliseconds: u64,\n) -> Result<Vec<i16>> {\n let writer = Arc::new(Mutex::new(Vec::new()));\n let writer_2 = writer.clone();\n let stream = device.build_input_stream(\n &config.config(),\n move |data: &[f32], _: &cpal::InputCallbackInfo| {\n let processed = data\n .iter()\n .map(|v| (v * 32768.0) as i16)\n .collect::<Vec<i16>>();\n writer_2.lock().unwrap().extend_from_slice(&processed);\n },\n move |err| {\n eprintln!(\"an error occurred on stream: {}\", err);\n },\n None,\n )?;\n stream.play()?;\n std::thread::sleep(std::time::Duration::from_millis(milliseconds));\n drop(stream);\n let data = writer.lock().unwrap().clone();\n let step = 3;\n let data: Vec<i16> = data.iter().step_by(step).copied().collect();\n Ok(data)\n}\n", "candle-examples\\examples\\wuerstchen\\main.rs": "#[cfg(feature = \"accelerate\")]\nextern crate accelerate_src;\n\n#[cfg(feature = \"mkl\")]\nextern crate intel_mkl_src;\n\nuse candle_transformers::models::stable_diffusion;\nuse candle_transformers::models::wuerstchen;\n\nuse anyhow::{Error as E, Result};\nuse candle::{DType, Device, IndexOp, Tensor};\nuse clap::Parser;\nuse tokenizers::Tokenizer;\n\nconst PRIOR_GUIDANCE_SCALE: f64 = 4.0;\nconst RESOLUTION_MULTIPLE: f64 = 42.67;\nconst LATENT_DIM_SCALE: f64 = 10.67;\nconst PRIOR_CIN: usize = 16;\nconst DECODER_CIN: usize = 4;\n\n#[derive(Parser)]\n#[command(author, version, about, long_about = None)]\nstruct Args {\n /// The prompt to be used for image generation.\n #[arg(\n long,\n default_value = \"A very realistic photo of a rusty robot walking on a sandy beach\"\n )]\n prompt: String,\n\n #[arg(long, default_value = \"\")]\n uncond_prompt: String,\n\n /// Run on CPU rather than on GPU.\n #[arg(long)]\n cpu: bool,\n\n /// Enable tracing (generates a trace-timestamp.json file).\n #[arg(long)]\n tracing: bool,\n\n #[arg(long)]\n use_flash_attn: bool,\n\n /// The height in pixels of the generated image.\n #[arg(long)]\n height: Option<usize>,\n\n /// The width in pixels of the generated image.\n #[arg(long)]\n width: Option<usize>,\n\n /// The decoder weight file, in .safetensors format.\n #[arg(long, value_name = \"FILE\")]\n decoder_weights: Option<String>,\n\n /// The CLIP weight file, in .safetensors format.\n #[arg(long, value_name = \"FILE\")]\n clip_weights: Option<String>,\n\n /// The CLIP weight file used by the prior model, in .safetensors format.\n #[arg(long, value_name = \"FILE\")]\n prior_clip_weights: Option<String>,\n\n /// The prior weight file, in .safetensors format.\n #[arg(long, value_name = \"FILE\")]\n prior_weights: Option<String>,\n\n /// The VQGAN weight file, in .safetensors format.\n #[arg(long, value_name = \"FILE\")]\n vqgan_weights: Option<String>,\n\n #[arg(long, value_name = \"FILE\")]\n /// The file specifying the tokenizer to used for tokenization.\n tokenizer: Option<String>,\n\n #[arg(long, value_name = \"FILE\")]\n /// The file specifying the tokenizer to used for prior tokenization.\n prior_tokenizer: Option<String>,\n\n /// The number of samples to generate.\n #[arg(long, default_value_t = 1)]\n num_samples: i64,\n\n /// The name of the final image to generate.\n #[arg(long, value_name = \"FILE\", default_value = \"sd_final.png\")]\n final_image: String,\n}\n\n#[derive(Debug, Clone, Copy, PartialEq, Eq)]\nenum ModelFile {\n Tokenizer,\n PriorTokenizer,\n Clip,\n PriorClip,\n Decoder,\n VqGan,\n Prior,\n}\n\nimpl ModelFile {\n fn get(&self, filename: Option<String>) -> Result<std::path::PathBuf> {\n use hf_hub::api::sync::Api;\n match filename {\n Some(filename) => Ok(std::path::PathBuf::from(filename)),\n None => {\n let repo_main = \"warp-ai/wuerstchen\";\n let repo_prior = \"warp-ai/wuerstchen-prior\";\n let (repo, path) = match self {\n Self::Tokenizer => (repo_main, \"tokenizer/tokenizer.json\"),\n Self::PriorTokenizer => (repo_prior, \"tokenizer/tokenizer.json\"),\n Self::Clip => (repo_main, \"text_encoder/model.safetensors\"),\n Self::PriorClip => (repo_prior, \"text_encoder/model.safetensors\"),\n Self::Decoder => (repo_main, \"decoder/diffusion_pytorch_model.safetensors\"),\n Self::VqGan => (repo_main, \"vqgan/diffusion_pytorch_model.safetensors\"),\n Self::Prior => (repo_prior, \"prior/diffusion_pytorch_model.safetensors\"),\n };\n let filename = Api::new()?.model(repo.to_string()).get(path)?;\n Ok(filename)\n }\n }\n }\n}\n\nfn output_filename(\n basename: &str,\n sample_idx: i64,\n num_samples: i64,\n timestep_idx: Option<usize>,\n) -> String {\n let filename = if num_samples > 1 {\n match basename.rsplit_once('.') {\n None => format!(\"{basename}.{sample_idx}.png\"),\n Some((filename_no_extension, extension)) => {\n format!(\"{filename_no_extension}.{sample_idx}.{extension}\")\n }\n }\n } else {\n basename.to_string()\n };\n match timestep_idx {\n None => filename,\n Some(timestep_idx) => match filename.rsplit_once('.') {\n None => format!(\"{filename}-{timestep_idx}.png\"),\n Some((filename_no_extension, extension)) => {\n format!(\"{filename_no_extension}-{timestep_idx}.{extension}\")\n }\n },\n }\n}\n\nfn encode_prompt(\n prompt: &str,\n uncond_prompt: Option<&str>,\n tokenizer: std::path::PathBuf,\n clip_weights: std::path::PathBuf,\n clip_config: stable_diffusion::clip::Config,\n device: &Device,\n) -> Result<Tensor> {\n let tokenizer = Tokenizer::from_file(tokenizer).map_err(E::msg)?;\n let pad_id = match &clip_config.pad_with {\n Some(padding) => *tokenizer.get_vocab(true).get(padding.as_str()).unwrap(),\n None => *tokenizer.get_vocab(true).get(\"<|endoftext|>\").unwrap(),\n };\n println!(\"Running with prompt \\\"{prompt}\\\".\");\n let mut tokens = tokenizer\n .encode(prompt, true)\n .map_err(E::msg)?\n .get_ids()\n .to_vec();\n let tokens_len = tokens.len();\n while tokens.len() < clip_config.max_position_embeddings {\n tokens.push(pad_id)\n }\n let tokens = Tensor::new(tokens.as_slice(), device)?.unsqueeze(0)?;\n\n println!(\"Building the clip transformer.\");\n let text_model =\n stable_diffusion::build_clip_transformer(&clip_config, clip_weights, device, DType::F32)?;\n let text_embeddings = text_model.forward_with_mask(&tokens, tokens_len - 1)?;\n match uncond_prompt {\n None => Ok(text_embeddings),\n Some(uncond_prompt) => {\n let mut uncond_tokens = tokenizer\n .encode(uncond_prompt, true)\n .map_err(E::msg)?\n .get_ids()\n .to_vec();\n let uncond_tokens_len = uncond_tokens.len();\n while uncond_tokens.len() < clip_config.max_position_embeddings {\n uncond_tokens.push(pad_id)\n }\n let uncond_tokens = Tensor::new(uncond_tokens.as_slice(), device)?.unsqueeze(0)?;\n\n let uncond_embeddings =\n text_model.forward_with_mask(&uncond_tokens, uncond_tokens_len - 1)?;\n let text_embeddings = Tensor::cat(&[text_embeddings, uncond_embeddings], 0)?;\n Ok(text_embeddings)\n }\n }\n}\n\nfn run(args: Args) -> Result<()> {\n use tracing_chrome::ChromeLayerBuilder;\n use tracing_subscriber::prelude::*;\n\n let Args {\n prompt,\n uncond_prompt,\n cpu,\n height,\n width,\n tokenizer,\n final_image,\n num_samples,\n clip_weights,\n prior_weights,\n vqgan_weights,\n decoder_weights,\n tracing,\n ..\n } = args;\n\n let _guard = if tracing {\n let (chrome_layer, guard) = ChromeLayerBuilder::new().build();\n tracing_subscriber::registry().with(chrome_layer).init();\n Some(guard)\n } else {\n None\n };\n\n let device = candle_examples::device(cpu)?;\n let height = height.unwrap_or(1024);\n let width = width.unwrap_or(1024);\n\n let prior_text_embeddings = {\n let tokenizer = ModelFile::PriorTokenizer.get(args.prior_tokenizer)?;\n let weights = ModelFile::PriorClip.get(args.prior_clip_weights)?;\n encode_prompt(\n &prompt,\n Some(&uncond_prompt),\n tokenizer.clone(),\n weights,\n stable_diffusion::clip::Config::wuerstchen_prior(),\n &device,\n )?\n };\n println!(\"generated prior text embeddings {prior_text_embeddings:?}\");\n\n let text_embeddings = {\n let tokenizer = ModelFile::Tokenizer.get(tokenizer)?;\n let weights = ModelFile::Clip.get(clip_weights)?;\n encode_prompt(\n &prompt,\n None,\n tokenizer.clone(),\n weights,\n stable_diffusion::clip::Config::wuerstchen(),\n &device,\n )?\n };\n println!(\"generated text embeddings {text_embeddings:?}\");\n\n println!(\"Building the prior.\");\n let b_size = 1;\n let image_embeddings = {\n // https://huggingface.co/warp-ai/wuerstchen-prior/blob/main/prior/config.json\n let latent_height = (height as f64 / RESOLUTION_MULTIPLE).ceil() as usize;\n let latent_width = (width as f64 / RESOLUTION_MULTIPLE).ceil() as usize;\n let mut latents = Tensor::randn(\n 0f32,\n 1f32,\n (b_size, PRIOR_CIN, latent_height, latent_width),\n &device,\n )?;\n\n let prior = {\n let file = ModelFile::Prior.get(prior_weights)?;\n let vb = unsafe {\n candle_nn::VarBuilder::from_mmaped_safetensors(&[file], DType::F32, &device)?\n };\n wuerstchen::prior::WPrior::new(\n /* c_in */ PRIOR_CIN,\n /* c */ 1536,\n /* c_cond */ 1280,\n /* c_r */ 64,\n /* depth */ 32,\n /* nhead */ 24,\n args.use_flash_attn,\n vb,\n )?\n };\n let prior_scheduler = wuerstchen::ddpm::DDPMWScheduler::new(60, Default::default())?;\n let timesteps = prior_scheduler.timesteps();\n let timesteps = ×teps[..timesteps.len() - 1];\n println!(\"prior denoising\");\n for (index, &t) in timesteps.iter().enumerate() {\n let start_time = std::time::Instant::now();\n let latent_model_input = Tensor::cat(&[&latents, &latents], 0)?;\n let ratio = (Tensor::ones(2, DType::F32, &device)? * t)?;\n let noise_pred = prior.forward(&latent_model_input, &ratio, &prior_text_embeddings)?;\n let noise_pred = noise_pred.chunk(2, 0)?;\n let (noise_pred_text, noise_pred_uncond) = (&noise_pred[0], &noise_pred[1]);\n let noise_pred = (noise_pred_uncond\n + ((noise_pred_text - noise_pred_uncond)? * PRIOR_GUIDANCE_SCALE)?)?;\n latents = prior_scheduler.step(&noise_pred, t, &latents)?;\n let dt = start_time.elapsed().as_secs_f32();\n println!(\"step {}/{} done, {:.2}s\", index + 1, timesteps.len(), dt);\n }\n ((latents * 42.)? - 1.)?\n };\n\n println!(\"Building the vqgan.\");\n let vqgan = {\n let file = ModelFile::VqGan.get(vqgan_weights)?;\n let vb = unsafe {\n candle_nn::VarBuilder::from_mmaped_safetensors(&[file], DType::F32, &device)?\n };\n wuerstchen::paella_vq::PaellaVQ::new(vb)?\n };\n\n println!(\"Building the decoder.\");\n\n // https://huggingface.co/warp-ai/wuerstchen/blob/main/decoder/config.json\n let decoder = {\n let file = ModelFile::Decoder.get(decoder_weights)?;\n let vb = unsafe {\n candle_nn::VarBuilder::from_mmaped_safetensors(&[file], DType::F32, &device)?\n };\n wuerstchen::diffnext::WDiffNeXt::new(\n /* c_in */ DECODER_CIN,\n /* c_out */ DECODER_CIN,\n /* c_r */ 64,\n /* c_cond */ 1024,\n /* clip_embd */ 1024,\n /* patch_size */ 2,\n args.use_flash_attn,\n vb,\n )?\n };\n\n for idx in 0..num_samples {\n // https://huggingface.co/warp-ai/wuerstchen/blob/main/model_index.json\n let latent_height = (image_embeddings.dim(2)? as f64 * LATENT_DIM_SCALE) as usize;\n let latent_width = (image_embeddings.dim(3)? as f64 * LATENT_DIM_SCALE) as usize;\n\n let mut latents = Tensor::randn(\n 0f32,\n 1f32,\n (b_size, DECODER_CIN, latent_height, latent_width),\n &device,\n )?;\n\n println!(\"diffusion process with prior {image_embeddings:?}\");\n let scheduler = wuerstchen::ddpm::DDPMWScheduler::new(12, Default::default())?;\n let timesteps = scheduler.timesteps();\n let timesteps = ×teps[..timesteps.len() - 1];\n for (index, &t) in timesteps.iter().enumerate() {\n let start_time = std::time::Instant::now();\n let ratio = (Tensor::ones(1, DType::F32, &device)? * t)?;\n let noise_pred =\n decoder.forward(&latents, &ratio, &image_embeddings, Some(&text_embeddings))?;\n latents = scheduler.step(&noise_pred, t, &latents)?;\n let dt = start_time.elapsed().as_secs_f32();\n println!(\"step {}/{} done, {:.2}s\", index + 1, timesteps.len(), dt);\n }\n println!(\n \"Generating the final image for sample {}/{}.\",\n idx + 1,\n num_samples\n );\n let image = vqgan.decode(&(&latents * 0.3764)?)?;\n let image = (image.clamp(0f32, 1f32)? * 255.)?\n .to_dtype(DType::U8)?\n .i(0)?;\n let image_filename = output_filename(&final_image, idx + 1, num_samples, None);\n candle_examples::save_image(&image, image_filename)?\n }\n Ok(())\n}\n\nfn main() -> Result<()> {\n let args = Args::parse();\n run(args)\n}\n", "candle-examples\\examples\\yi\\main.rs": "#[cfg(feature = \"mkl\")]\nextern crate intel_mkl_src;\n\n#[cfg(feature = \"accelerate\")]\nextern crate accelerate_src;\n\nuse anyhow::{Error as E, Result};\nuse clap::{Parser, ValueEnum};\n\nuse candle_transformers::models::yi::{Config, Model};\n\nuse candle::{DType, Device, Tensor};\nuse candle_examples::token_output_stream::TokenOutputStream;\nuse candle_nn::VarBuilder;\nuse candle_transformers::generation::LogitsProcessor;\nuse hf_hub::{api::sync::Api, Repo, RepoType};\nuse tokenizers::Tokenizer;\n\n#[derive(Clone, Debug, Copy, PartialEq, Eq, ValueEnum)]\nenum Which {\n #[value(name = \"6b\")]\n L6b,\n #[value(name = \"34b\")]\n L34b,\n}\n\nstruct TextGeneration {\n model: Model,\n device: Device,\n tokenizer: TokenOutputStream,\n logits_processor: LogitsProcessor,\n repeat_penalty: f32,\n repeat_last_n: usize,\n}\n\nimpl TextGeneration {\n #[allow(clippy::too_many_arguments)]\n fn new(\n model: Model,\n tokenizer: Tokenizer,\n seed: u64,\n temp: Option<f64>,\n top_p: Option<f64>,\n repeat_penalty: f32,\n repeat_last_n: usize,\n device: &Device,\n ) -> Self {\n let logits_processor = LogitsProcessor::new(seed, temp, top_p);\n Self {\n model,\n tokenizer: TokenOutputStream::new(tokenizer),\n logits_processor,\n repeat_penalty,\n repeat_last_n,\n device: device.clone(),\n }\n }\n\n fn run(&mut self, prompt: &str, sample_len: usize) -> Result<()> {\n use std::io::Write;\n self.tokenizer.clear();\n let mut tokens = self\n .tokenizer\n .tokenizer()\n .encode(prompt, true)\n .map_err(E::msg)?\n .get_ids()\n .to_vec();\n for &t in tokens.iter() {\n if let Some(t) = self.tokenizer.next_token(t)? {\n print!(\"{t}\")\n }\n }\n std::io::stdout().flush()?;\n\n let mut generated_tokens = 0usize;\n let eos_token = match self.tokenizer.get_token(\"<|endoftext|>\") {\n Some(token) => token,\n None => anyhow::bail!(\"cannot find the <|endoftext|> token\"),\n };\n let start_gen = std::time::Instant::now();\n for index in 0..sample_len {\n let context_size = if index > 0 { 1 } else { tokens.len() };\n let start_pos = tokens.len().saturating_sub(context_size);\n let ctxt = &tokens[start_pos..];\n let input = Tensor::new(ctxt, &self.device)?.unsqueeze(0)?;\n let logits = self.model.forward(&input, start_pos)?;\n let logits = logits.squeeze(0)?.squeeze(0)?.to_dtype(DType::F32)?;\n let logits = if self.repeat_penalty == 1. {\n logits\n } else {\n let start_at = tokens.len().saturating_sub(self.repeat_last_n);\n candle_transformers::utils::apply_repeat_penalty(\n &logits,\n self.repeat_penalty,\n &tokens[start_at..],\n )?\n };\n\n let next_token = self.logits_processor.sample(&logits)?;\n tokens.push(next_token);\n generated_tokens += 1;\n if next_token == eos_token {\n break;\n }\n if let Some(t) = self.tokenizer.next_token(next_token)? {\n let t = t.replace(\"<|im_end|>\", \"\\n\");\n print!(\"{t}\");\n std::io::stdout().flush()?;\n }\n }\n let dt = start_gen.elapsed();\n if let Some(rest) = self.tokenizer.decode_rest().map_err(E::msg)? {\n print!(\"{rest}\");\n }\n std::io::stdout().flush()?;\n println!(\n \"\\n{generated_tokens} tokens generated ({:.2} token/s)\",\n generated_tokens as f64 / dt.as_secs_f64(),\n );\n Ok(())\n }\n}\n\n#[derive(Parser, Debug)]\n#[command(author, version, about, long_about = None)]\nstruct Args {\n /// Run on CPU rather than on GPU.\n #[arg(long)]\n cpu: bool,\n\n /// Enable tracing (generates a trace-timestamp.json file).\n #[arg(long)]\n tracing: bool,\n\n #[arg(long)]\n prompt: String,\n\n /// The temperature used to generate samples.\n #[arg(long)]\n temperature: Option<f64>,\n\n /// Nucleus sampling probability cutoff.\n #[arg(long)]\n top_p: Option<f64>,\n\n /// The seed to use when generating random samples.\n #[arg(long, default_value_t = 299792458)]\n seed: u64,\n\n /// The length of the sample to generate (in tokens).\n #[arg(long, short = 'n', default_value_t = 100)]\n sample_len: usize,\n\n #[arg(long, default_value = \"01-ai/Yi-6B\")]\n model_id: String,\n\n #[arg(long, default_value = \"main\")]\n revision: String,\n\n #[arg(long)]\n tokenizer_file: Option<String>,\n\n #[arg(long)]\n weight_files: Option<String>,\n\n /// Penalty to be applied for repeating tokens, 1. means no penalty.\n #[arg(long, default_value_t = 1.1)]\n repeat_penalty: f32,\n\n /// The context size to consider for the repeat penalty.\n #[arg(long, default_value_t = 64)]\n repeat_last_n: usize,\n\n /// The model size to use.\n #[arg(long, default_value = \"6b\")]\n which: Which,\n}\n\nfn main() -> Result<()> {\n use tracing_chrome::ChromeLayerBuilder;\n use tracing_subscriber::prelude::*;\n\n let args = Args::parse();\n let _guard = if args.tracing {\n let (chrome_layer, guard) = ChromeLayerBuilder::new().build();\n tracing_subscriber::registry().with(chrome_layer).init();\n Some(guard)\n } else {\n None\n };\n println!(\n \"avx: {}, neon: {}, simd128: {}, f16c: {}\",\n candle::utils::with_avx(),\n candle::utils::with_neon(),\n candle::utils::with_simd128(),\n candle::utils::with_f16c()\n );\n println!(\n \"temp: {:.2} repeat-penalty: {:.2} repeat-last-n: {}\",\n args.temperature.unwrap_or(0.),\n args.repeat_penalty,\n args.repeat_last_n\n );\n\n let start = std::time::Instant::now();\n let api = Api::new()?;\n let repo = api.repo(Repo::with_revision(\n args.model_id,\n RepoType::Model,\n args.revision,\n ));\n let tokenizer_filename = match args.tokenizer_file {\n Some(file) => std::path::PathBuf::from(file),\n None => repo.get(\"tokenizer.json\")?,\n };\n let filenames = match args.weight_files {\n Some(files) => files\n .split(',')\n .map(std::path::PathBuf::from)\n .collect::<Vec<_>>(),\n None => candle_examples::hub_load_safetensors(&repo, \"model.safetensors.index.json\")?,\n };\n println!(\"retrieved the files in {:?}\", start.elapsed());\n let tokenizer = Tokenizer::from_file(tokenizer_filename).map_err(E::msg)?;\n\n let start = std::time::Instant::now();\n let config = match args.which {\n Which::L6b => Config::config_6b(),\n Which::L34b => Config::config_34b(),\n };\n let device = candle_examples::device(args.cpu)?;\n let dtype = if device.is_cuda() {\n DType::BF16\n } else {\n DType::F32\n };\n let vb = unsafe { VarBuilder::from_mmaped_safetensors(&filenames, dtype, &device)? };\n let model = Model::new(&config, vb)?;\n\n println!(\"loaded the model in {:?}\", start.elapsed());\n\n let mut pipeline = TextGeneration::new(\n model,\n tokenizer,\n args.seed,\n args.temperature,\n args.top_p,\n args.repeat_penalty,\n args.repeat_last_n,\n &device,\n );\n pipeline.run(&args.prompt, args.sample_len)?;\n Ok(())\n}\n", "candle-examples\\examples\\yolo-v3\\main.rs": "#[cfg(feature = \"mkl\")]\nextern crate intel_mkl_src;\n\n#[cfg(feature = \"accelerate\")]\nextern crate accelerate_src;\n\nuse candle_transformers::object_detection::{non_maximum_suppression, Bbox};\nmod darknet;\n\nuse anyhow::Result;\nuse candle::{DType, Device, Tensor};\nuse candle_nn::{Module, VarBuilder};\nuse clap::Parser;\nuse image::{DynamicImage, ImageBuffer};\n\n// Assumes x1 <= x2 and y1 <= y2\npub fn draw_rect(\n img: &mut ImageBuffer<image::Rgb<u8>, Vec<u8>>,\n x1: u32,\n x2: u32,\n y1: u32,\n y2: u32,\n) {\n for x in x1..=x2 {\n let pixel = img.get_pixel_mut(x, y1);\n *pixel = image::Rgb([255, 0, 0]);\n let pixel = img.get_pixel_mut(x, y2);\n *pixel = image::Rgb([255, 0, 0]);\n }\n for y in y1..=y2 {\n let pixel = img.get_pixel_mut(x1, y);\n *pixel = image::Rgb([255, 0, 0]);\n let pixel = img.get_pixel_mut(x2, y);\n *pixel = image::Rgb([255, 0, 0]);\n }\n}\n\npub fn report(\n pred: &Tensor,\n img: DynamicImage,\n w: usize,\n h: usize,\n confidence_threshold: f32,\n nms_threshold: f32,\n) -> Result<DynamicImage> {\n let pred = pred.to_device(&Device::Cpu)?;\n let (npreds, pred_size) = pred.dims2()?;\n let nclasses = pred_size - 5;\n // The bounding boxes grouped by (maximum) class index.\n let mut bboxes: Vec<Vec<Bbox<()>>> = (0..nclasses).map(|_| vec![]).collect();\n // Extract the bounding boxes for which confidence is above the threshold.\n for index in 0..npreds {\n let pred = Vec::<f32>::try_from(pred.get(index)?)?;\n let confidence = pred[4];\n if confidence > confidence_threshold {\n let mut class_index = 0;\n for i in 0..nclasses {\n if pred[5 + i] > pred[5 + class_index] {\n class_index = i\n }\n }\n if pred[class_index + 5] > 0. {\n let bbox = Bbox {\n xmin: pred[0] - pred[2] / 2.,\n ymin: pred[1] - pred[3] / 2.,\n xmax: pred[0] + pred[2] / 2.,\n ymax: pred[1] + pred[3] / 2.,\n confidence,\n data: (),\n };\n bboxes[class_index].push(bbox)\n }\n }\n }\n non_maximum_suppression(&mut bboxes, nms_threshold);\n // Annotate the original image and print boxes information.\n let (initial_h, initial_w) = (img.height(), img.width());\n let w_ratio = initial_w as f32 / w as f32;\n let h_ratio = initial_h as f32 / h as f32;\n let mut img = img.to_rgb8();\n for (class_index, bboxes_for_class) in bboxes.iter().enumerate() {\n for b in bboxes_for_class.iter() {\n println!(\n \"{}: {:?}\",\n candle_examples::coco_classes::NAMES[class_index],\n b\n );\n let xmin = ((b.xmin * w_ratio) as u32).clamp(0, initial_w - 1);\n let ymin = ((b.ymin * h_ratio) as u32).clamp(0, initial_h - 1);\n let xmax = ((b.xmax * w_ratio) as u32).clamp(0, initial_w - 1);\n let ymax = ((b.ymax * h_ratio) as u32).clamp(0, initial_h - 1);\n draw_rect(&mut img, xmin, xmax, ymin, ymax);\n }\n }\n Ok(DynamicImage::ImageRgb8(img))\n}\n\n#[derive(Parser, Debug)]\n#[command(author, version, about, long_about = None)]\nstruct Args {\n /// Model weights, in safetensors format.\n #[arg(long)]\n model: Option<String>,\n\n #[arg(long)]\n config: Option<String>,\n\n images: Vec<String>,\n\n /// Threshold for the model confidence level.\n #[arg(long, default_value_t = 0.5)]\n confidence_threshold: f32,\n\n /// Threshold for non-maximum suppression.\n #[arg(long, default_value_t = 0.4)]\n nms_threshold: f32,\n}\n\nimpl Args {\n fn config(&self) -> anyhow::Result<std::path::PathBuf> {\n let path = match &self.config {\n Some(config) => std::path::PathBuf::from(config),\n None => {\n let api = hf_hub::api::sync::Api::new()?;\n let api = api.model(\"lmz/candle-yolo-v3\".to_string());\n api.get(\"yolo-v3.cfg\")?\n }\n };\n Ok(path)\n }\n\n fn model(&self) -> anyhow::Result<std::path::PathBuf> {\n let path = match &self.model {\n Some(model) => std::path::PathBuf::from(model),\n None => {\n let api = hf_hub::api::sync::Api::new()?;\n let api = api.model(\"lmz/candle-yolo-v3\".to_string());\n api.get(\"yolo-v3.safetensors\")?\n }\n };\n Ok(path)\n }\n}\n\npub fn main() -> Result<()> {\n let args = Args::parse();\n\n // Create the model and load the weights from the file.\n let model = args.model()?;\n let vb = unsafe { VarBuilder::from_mmaped_safetensors(&[model], DType::F32, &Device::Cpu)? };\n let config = args.config()?;\n let darknet = darknet::parse_config(config)?;\n let model = darknet.build_model(vb)?;\n\n for image_name in args.images.iter() {\n println!(\"processing {image_name}\");\n let mut image_name = std::path::PathBuf::from(image_name);\n // Load the image file and resize it.\n let net_width = darknet.width()?;\n let net_height = darknet.height()?;\n\n let original_image = image::ImageReader::open(&image_name)?\n .decode()\n .map_err(candle::Error::wrap)?;\n let image = {\n let data = original_image\n .resize_exact(\n net_width as u32,\n net_height as u32,\n image::imageops::FilterType::Triangle,\n )\n .to_rgb8()\n .into_raw();\n Tensor::from_vec(data, (net_width, net_height, 3), &Device::Cpu)?.permute((2, 0, 1))?\n };\n let image = (image.unsqueeze(0)?.to_dtype(DType::F32)? * (1. / 255.))?;\n let predictions = model.forward(&image)?.squeeze(0)?;\n println!(\"generated predictions {predictions:?}\");\n let image = report(\n &predictions,\n original_image,\n net_width,\n net_height,\n args.confidence_threshold,\n args.nms_threshold,\n )?;\n image_name.set_extension(\"pp.jpg\");\n println!(\"writing {image_name:?}\");\n image.save(image_name)?\n }\n Ok(())\n}\n", "candle-examples\\examples\\yolo-v8\\main.rs": "#[cfg(feature = \"mkl\")]\nextern crate intel_mkl_src;\n\n#[cfg(feature = \"accelerate\")]\nextern crate accelerate_src;\n\nmod model;\nuse model::{Multiples, YoloV8, YoloV8Pose};\n\nuse candle::{DType, Device, IndexOp, Result, Tensor};\nuse candle_nn::{Module, VarBuilder};\nuse candle_transformers::object_detection::{non_maximum_suppression, Bbox, KeyPoint};\nuse clap::{Parser, ValueEnum};\nuse image::DynamicImage;\n\n// Keypoints as reported by ChatGPT :)\n// Nose\n// Left Eye\n// Right Eye\n// Left Ear\n// Right Ear\n// Left Shoulder\n// Right Shoulder\n// Left Elbow\n// Right Elbow\n// Left Wrist\n// Right Wrist\n// Left Hip\n// Right Hip\n// Left Knee\n// Right Knee\n// Left Ankle\n// Right Ankle\nconst KP_CONNECTIONS: [(usize, usize); 16] = [\n (0, 1),\n (0, 2),\n (1, 3),\n (2, 4),\n (5, 6),\n (5, 11),\n (6, 12),\n (11, 12),\n (5, 7),\n (6, 8),\n (7, 9),\n (8, 10),\n (11, 13),\n (12, 14),\n (13, 15),\n (14, 16),\n];\n// Model architecture from https://github.com/ultralytics/ultralytics/issues/189\n// https://github.com/tinygrad/tinygrad/blob/master/examples/yolov8.py\n\npub fn report_detect(\n pred: &Tensor,\n img: DynamicImage,\n w: usize,\n h: usize,\n confidence_threshold: f32,\n nms_threshold: f32,\n legend_size: u32,\n) -> Result<DynamicImage> {\n let pred = pred.to_device(&Device::Cpu)?;\n let (pred_size, npreds) = pred.dims2()?;\n let nclasses = pred_size - 4;\n // The bounding boxes grouped by (maximum) class index.\n let mut bboxes: Vec<Vec<Bbox<Vec<KeyPoint>>>> = (0..nclasses).map(|_| vec![]).collect();\n // Extract the bounding boxes for which confidence is above the threshold.\n for index in 0..npreds {\n let pred = Vec::<f32>::try_from(pred.i((.., index))?)?;\n let confidence = *pred[4..].iter().max_by(|x, y| x.total_cmp(y)).unwrap();\n if confidence > confidence_threshold {\n let mut class_index = 0;\n for i in 0..nclasses {\n if pred[4 + i] > pred[4 + class_index] {\n class_index = i\n }\n }\n if pred[class_index + 4] > 0. {\n let bbox = Bbox {\n xmin: pred[0] - pred[2] / 2.,\n ymin: pred[1] - pred[3] / 2.,\n xmax: pred[0] + pred[2] / 2.,\n ymax: pred[1] + pred[3] / 2.,\n confidence,\n data: vec![],\n };\n bboxes[class_index].push(bbox)\n }\n }\n }\n\n non_maximum_suppression(&mut bboxes, nms_threshold);\n\n // Annotate the original image and print boxes information.\n let (initial_h, initial_w) = (img.height(), img.width());\n let w_ratio = initial_w as f32 / w as f32;\n let h_ratio = initial_h as f32 / h as f32;\n let mut img = img.to_rgb8();\n let font = Vec::from(include_bytes!(\"roboto-mono-stripped.ttf\") as &[u8]);\n let font = ab_glyph::FontRef::try_from_slice(&font).map_err(candle::Error::wrap)?;\n for (class_index, bboxes_for_class) in bboxes.iter().enumerate() {\n for b in bboxes_for_class.iter() {\n println!(\n \"{}: {:?}\",\n candle_examples::coco_classes::NAMES[class_index],\n b\n );\n let xmin = (b.xmin * w_ratio) as i32;\n let ymin = (b.ymin * h_ratio) as i32;\n let dx = (b.xmax - b.xmin) * w_ratio;\n let dy = (b.ymax - b.ymin) * h_ratio;\n if dx >= 0. && dy >= 0. {\n imageproc::drawing::draw_hollow_rect_mut(\n &mut img,\n imageproc::rect::Rect::at(xmin, ymin).of_size(dx as u32, dy as u32),\n image::Rgb([255, 0, 0]),\n );\n }\n if legend_size > 0 {\n imageproc::drawing::draw_filled_rect_mut(\n &mut img,\n imageproc::rect::Rect::at(xmin, ymin).of_size(dx as u32, legend_size),\n image::Rgb([170, 0, 0]),\n );\n let legend = format!(\n \"{} {:.0}%\",\n candle_examples::coco_classes::NAMES[class_index],\n 100. * b.confidence\n );\n imageproc::drawing::draw_text_mut(\n &mut img,\n image::Rgb([255, 255, 255]),\n xmin,\n ymin,\n ab_glyph::PxScale {\n x: legend_size as f32 - 1.,\n y: legend_size as f32 - 1.,\n },\n &font,\n &legend,\n )\n }\n }\n }\n Ok(DynamicImage::ImageRgb8(img))\n}\n\npub fn report_pose(\n pred: &Tensor,\n img: DynamicImage,\n w: usize,\n h: usize,\n confidence_threshold: f32,\n nms_threshold: f32,\n) -> Result<DynamicImage> {\n let pred = pred.to_device(&Device::Cpu)?;\n let (pred_size, npreds) = pred.dims2()?;\n if pred_size != 17 * 3 + 4 + 1 {\n candle::bail!(\"unexpected pred-size {pred_size}\");\n }\n let mut bboxes = vec![];\n // Extract the bounding boxes for which confidence is above the threshold.\n for index in 0..npreds {\n let pred = Vec::<f32>::try_from(pred.i((.., index))?)?;\n let confidence = pred[4];\n if confidence > confidence_threshold {\n let keypoints = (0..17)\n .map(|i| KeyPoint {\n x: pred[3 * i + 5],\n y: pred[3 * i + 6],\n mask: pred[3 * i + 7],\n })\n .collect::<Vec<_>>();\n let bbox = Bbox {\n xmin: pred[0] - pred[2] / 2.,\n ymin: pred[1] - pred[3] / 2.,\n xmax: pred[0] + pred[2] / 2.,\n ymax: pred[1] + pred[3] / 2.,\n confidence,\n data: keypoints,\n };\n bboxes.push(bbox)\n }\n }\n\n let mut bboxes = vec![bboxes];\n non_maximum_suppression(&mut bboxes, nms_threshold);\n let bboxes = &bboxes[0];\n\n // Annotate the original image and print boxes information.\n let (initial_h, initial_w) = (img.height(), img.width());\n let w_ratio = initial_w as f32 / w as f32;\n let h_ratio = initial_h as f32 / h as f32;\n let mut img = img.to_rgb8();\n for b in bboxes.iter() {\n println!(\"{b:?}\");\n let xmin = (b.xmin * w_ratio) as i32;\n let ymin = (b.ymin * h_ratio) as i32;\n let dx = (b.xmax - b.xmin) * w_ratio;\n let dy = (b.ymax - b.ymin) * h_ratio;\n if dx >= 0. && dy >= 0. {\n imageproc::drawing::draw_hollow_rect_mut(\n &mut img,\n imageproc::rect::Rect::at(xmin, ymin).of_size(dx as u32, dy as u32),\n image::Rgb([255, 0, 0]),\n );\n }\n for kp in b.data.iter() {\n if kp.mask < 0.6 {\n continue;\n }\n let x = (kp.x * w_ratio) as i32;\n let y = (kp.y * h_ratio) as i32;\n imageproc::drawing::draw_filled_circle_mut(\n &mut img,\n (x, y),\n 2,\n image::Rgb([0, 255, 0]),\n );\n }\n\n for &(idx1, idx2) in KP_CONNECTIONS.iter() {\n let kp1 = &b.data[idx1];\n let kp2 = &b.data[idx2];\n if kp1.mask < 0.6 || kp2.mask < 0.6 {\n continue;\n }\n imageproc::drawing::draw_line_segment_mut(\n &mut img,\n (kp1.x * w_ratio, kp1.y * h_ratio),\n (kp2.x * w_ratio, kp2.y * h_ratio),\n image::Rgb([255, 255, 0]),\n );\n }\n }\n Ok(DynamicImage::ImageRgb8(img))\n}\n\n#[derive(Clone, Copy, ValueEnum, Debug)]\nenum Which {\n N,\n S,\n M,\n L,\n X,\n}\n\n#[derive(Clone, Copy, ValueEnum, Debug)]\nenum YoloTask {\n Detect,\n Pose,\n}\n\n#[derive(Parser, Debug)]\n#[command(author, version, about, long_about = None)]\npub struct Args {\n /// Run on CPU rather than on GPU.\n #[arg(long)]\n cpu: bool,\n\n /// Enable tracing (generates a trace-timestamp.json file).\n #[arg(long)]\n tracing: bool,\n\n /// Model weights, in safetensors format.\n #[arg(long)]\n model: Option<String>,\n\n /// Which model variant to use.\n #[arg(long, value_enum, default_value_t = Which::S)]\n which: Which,\n\n images: Vec<String>,\n\n /// Threshold for the model confidence level.\n #[arg(long, default_value_t = 0.25)]\n confidence_threshold: f32,\n\n /// Threshold for non-maximum suppression.\n #[arg(long, default_value_t = 0.45)]\n nms_threshold: f32,\n\n /// The task to be run.\n #[arg(long, default_value = \"detect\")]\n task: YoloTask,\n\n /// The size for the legend, 0 means no legend.\n #[arg(long, default_value_t = 14)]\n legend_size: u32,\n}\n\nimpl Args {\n fn model(&self) -> anyhow::Result<std::path::PathBuf> {\n let path = match &self.model {\n Some(model) => std::path::PathBuf::from(model),\n None => {\n let api = hf_hub::api::sync::Api::new()?;\n let api = api.model(\"lmz/candle-yolo-v8\".to_string());\n let size = match self.which {\n Which::N => \"n\",\n Which::S => \"s\",\n Which::M => \"m\",\n Which::L => \"l\",\n Which::X => \"x\",\n };\n let task = match self.task {\n YoloTask::Pose => \"-pose\",\n YoloTask::Detect => \"\",\n };\n api.get(&format!(\"yolov8{size}{task}.safetensors\"))?\n }\n };\n Ok(path)\n }\n}\n\npub trait Task: Module + Sized {\n fn load(vb: VarBuilder, multiples: Multiples) -> Result<Self>;\n fn report(\n pred: &Tensor,\n img: DynamicImage,\n w: usize,\n h: usize,\n confidence_threshold: f32,\n nms_threshold: f32,\n legend_size: u32,\n ) -> Result<DynamicImage>;\n}\n\nimpl Task for YoloV8 {\n fn load(vb: VarBuilder, multiples: Multiples) -> Result<Self> {\n YoloV8::load(vb, multiples, /* num_classes=*/ 80)\n }\n\n fn report(\n pred: &Tensor,\n img: DynamicImage,\n w: usize,\n h: usize,\n confidence_threshold: f32,\n nms_threshold: f32,\n legend_size: u32,\n ) -> Result<DynamicImage> {\n report_detect(\n pred,\n img,\n w,\n h,\n confidence_threshold,\n nms_threshold,\n legend_size,\n )\n }\n}\n\nimpl Task for YoloV8Pose {\n fn load(vb: VarBuilder, multiples: Multiples) -> Result<Self> {\n YoloV8Pose::load(vb, multiples, /* num_classes=*/ 1, (17, 3))\n }\n\n fn report(\n pred: &Tensor,\n img: DynamicImage,\n w: usize,\n h: usize,\n confidence_threshold: f32,\n nms_threshold: f32,\n _legend_size: u32,\n ) -> Result<DynamicImage> {\n report_pose(pred, img, w, h, confidence_threshold, nms_threshold)\n }\n}\n\npub fn run<T: Task>(args: Args) -> anyhow::Result<()> {\n let device = candle_examples::device(args.cpu)?;\n // Create the model and load the weights from the file.\n let multiples = match args.which {\n Which::N => Multiples::n(),\n Which::S => Multiples::s(),\n Which::M => Multiples::m(),\n Which::L => Multiples::l(),\n Which::X => Multiples::x(),\n };\n let model = args.model()?;\n let vb = unsafe { VarBuilder::from_mmaped_safetensors(&[model], DType::F32, &device)? };\n let model = T::load(vb, multiples)?;\n println!(\"model loaded\");\n for image_name in args.images.iter() {\n println!(\"processing {image_name}\");\n let mut image_name = std::path::PathBuf::from(image_name);\n let original_image = image::ImageReader::open(&image_name)?\n .decode()\n .map_err(candle::Error::wrap)?;\n let (width, height) = {\n let w = original_image.width() as usize;\n let h = original_image.height() as usize;\n if w < h {\n let w = w * 640 / h;\n // Sizes have to be divisible by 32.\n (w / 32 * 32, 640)\n } else {\n let h = h * 640 / w;\n (640, h / 32 * 32)\n }\n };\n let image_t = {\n let img = original_image.resize_exact(\n width as u32,\n height as u32,\n image::imageops::FilterType::CatmullRom,\n );\n let data = img.to_rgb8().into_raw();\n Tensor::from_vec(\n data,\n (img.height() as usize, img.width() as usize, 3),\n &device,\n )?\n .permute((2, 0, 1))?\n };\n let image_t = (image_t.unsqueeze(0)?.to_dtype(DType::F32)? * (1. / 255.))?;\n let predictions = model.forward(&image_t)?.squeeze(0)?;\n println!(\"generated predictions {predictions:?}\");\n let image_t = T::report(\n &predictions,\n original_image,\n width,\n height,\n args.confidence_threshold,\n args.nms_threshold,\n args.legend_size,\n )?;\n image_name.set_extension(\"pp.jpg\");\n println!(\"writing {image_name:?}\");\n image_t.save(image_name)?\n }\n\n Ok(())\n}\n\npub fn main() -> anyhow::Result<()> {\n use tracing_chrome::ChromeLayerBuilder;\n use tracing_subscriber::prelude::*;\n\n let args = Args::parse();\n\n let _guard = if args.tracing {\n let (chrome_layer, guard) = ChromeLayerBuilder::new().build();\n tracing_subscriber::registry().with(chrome_layer).init();\n Some(guard)\n } else {\n None\n };\n\n match args.task {\n YoloTask::Detect => run::<YoloV8>(args)?,\n YoloTask::Pose => run::<YoloV8Pose>(args)?,\n }\n Ok(())\n}\n", "candle-kernels\\src\\indexing.cu": "// WARNING: THIS IS ONLY VALID ASSUMING THAT inp IS CONTIGUOUS!\n// TODO: proper error reporting when ids are larger than v_size.\n#include \"cuda_utils.cuh\"\n#include<stdint.h>\n\ntemplate<typename T, typename I>\n__device__ void index_select(\n const size_t numel,\n const size_t num_dims,\n const size_t *info,\n const I *ids,\n const T *inp,\n T *out,\n const size_t left_size,\n const size_t src_dim_size,\n const size_t ids_dim_size,\n const size_t right_size\n) {\n const size_t *dims = info;\n const size_t *strides = info + num_dims;\n bool b = is_contiguous(num_dims, dims, strides);\n for (unsigned int dst_i = blockIdx.x * blockDim.x + threadIdx.x; dst_i < numel; dst_i += blockDim.x * gridDim.x) {\n unsigned int left_i = dst_i / (ids_dim_size * right_size);\n unsigned int id_i = dst_i / right_size % ids_dim_size;\n unsigned int right_i = dst_i % right_size;\n unsigned int src_i = left_i * (src_dim_size * right_size) + ids[id_i] * right_size + right_i;\n unsigned strided_i = b ? src_i : get_strided_index(src_i, num_dims, dims, strides);\n out[dst_i] = inp[strided_i];\n }\n}\n\n#define IS_OP(TYPENAME, INDEX_TYPENAME, FN_NAME) \\\nextern \"C\" __global__ void FN_NAME( \\\n const size_t numel, \\\n const size_t num_dims, \\\n const size_t *info, \\\n const INDEX_TYPENAME *ids, \\\n const TYPENAME *inp, \\\n TYPENAME *out, \\\n const size_t left_size, \\\n const size_t src_dim_size, \\\n const size_t ids_dim_size, \\\n const size_t right_size \\\n) { index_select(numel, num_dims, info, ids, inp, out, left_size, src_dim_size, ids_dim_size, right_size); } \\\n\ntemplate<typename T, typename I>\n__device__ void gather(\n const size_t numel,\n const I *ids,\n const T *inp,\n T *out,\n const size_t left_size,\n const size_t src_dim_size,\n const size_t ids_dim_size,\n const size_t right_size\n) {\n for (unsigned int i = blockIdx.x * blockDim.x + threadIdx.x; i < numel; i += blockDim.x * gridDim.x) {\n size_t post = i % right_size;\n size_t idx = ids[i];\n size_t pre = i / (right_size * ids_dim_size);\n size_t src_i = (pre * src_dim_size + idx) * right_size + post;\n out[i] = inp[src_i];\n }\n}\n\n#define GATHER_OP(TYPENAME, INDEX_TYPENAME, FN_NAME) \\\nextern \"C\" __global__ void FN_NAME( \\\n const size_t numel, \\\n const INDEX_TYPENAME *ids, \\\n const TYPENAME *inp, \\\n TYPENAME *out, \\\n const size_t left_size, \\\n const size_t src_dim_size, \\\n const size_t ids_dim_size, \\\n const size_t right_size \\\n) { gather(numel, ids, inp, out, left_size, src_dim_size, ids_dim_size, right_size); } \\\n\ntemplate<typename T, typename I>\n__device__ void index_add(\n const I *ids,\n const size_t ids_dim_size,\n const T *inp,\n T *out,\n const size_t left_size,\n const size_t src_dim_size,\n const size_t dst_dim_size,\n const size_t right_size\n) {\n const size_t numel = left_size * right_size;\n for (unsigned int i = blockIdx.x * blockDim.x + threadIdx.x; i < numel; i += blockDim.x * gridDim.x) {\n const size_t pre = i / right_size;\n const size_t post = i % right_size;\n for (unsigned int j = 0; j < ids_dim_size; ++j) {\n const size_t idx = ids[j];\n const size_t src_i = (pre * ids_dim_size + j) * right_size + post;\n const size_t dst_i = (pre * dst_dim_size + idx) * right_size + post;\n out[dst_i] += inp[src_i];\n }\n }\n}\n\n#define IA_OP(TYPENAME, INDEX_TYPENAME, FN_NAME) \\\nextern \"C\" __global__ void FN_NAME( \\\n const INDEX_TYPENAME *ids, \\\n const size_t ids_dim_size, \\\n const TYPENAME *inp, \\\n TYPENAME *out, \\\n const size_t left_size, \\\n const size_t src_dim_size, \\\n const size_t dst_dim_size, \\\n const size_t right_size \\\n) { index_add(ids, ids_dim_size, inp, out, left_size, src_dim_size, dst_dim_size, right_size); } \\\n\ntemplate<typename T, typename I>\n__device__ void scatter_add(\n const I *ids,\n const T *inp,\n T *out,\n const size_t left_size,\n const size_t src_dim_size,\n const size_t dst_dim_size,\n const size_t right_size\n) {\n const size_t numel = left_size * right_size;\n for (unsigned int i = blockIdx.x * blockDim.x + threadIdx.x; i < numel; i += blockDim.x * gridDim.x) {\n const size_t pre = i / right_size;\n const size_t post = i % right_size;\n for (unsigned int j = 0; j < src_dim_size; ++j) {\n const size_t src_i = (pre * src_dim_size + j) * right_size + post;\n const size_t idx = ids[src_i];\n const size_t dst_i = (pre * dst_dim_size + idx) * right_size + post;\n out[dst_i] += inp[src_i];\n }\n }\n}\n\n#define SA_OP(TYPENAME, INDEX_TYPENAME, FN_NAME) \\\nextern \"C\" __global__ void FN_NAME( \\\n const INDEX_TYPENAME *ids, \\\n const TYPENAME *inp, \\\n TYPENAME *out, \\\n const size_t left_size, \\\n const size_t src_dim_size, \\\n const size_t dst_dim_size, \\\n const size_t right_size \\\n) { scatter_add(ids, inp, out, left_size, src_dim_size, dst_dim_size, right_size); } \\\n\n\n#if __CUDA_ARCH__ >= 800\nIS_OP(__nv_bfloat16, int64_t, is_i64_bf16)\nIS_OP(__nv_bfloat16, uint32_t, is_u32_bf16)\nIS_OP(__nv_bfloat16, uint8_t, is_u8_bf16)\nGATHER_OP(__nv_bfloat16, int64_t, gather_i64_bf16)\nGATHER_OP(__nv_bfloat16, uint32_t, gather_u32_bf16)\nGATHER_OP(__nv_bfloat16, uint8_t, gather_u8_bf16)\nIA_OP(__nv_bfloat16, int64_t, ia_i64_bf16)\nIA_OP(__nv_bfloat16, uint32_t, ia_u32_bf16)\nIA_OP(__nv_bfloat16, uint8_t, ia_u8_bf16)\nSA_OP(__nv_bfloat16, int64_t, sa_i64_bf16)\nSA_OP(__nv_bfloat16, uint32_t, sa_u32_bf16)\nSA_OP(__nv_bfloat16, uint8_t, sa_u8_bf16)\n#endif\n\n#if __CUDA_ARCH__ >= 530\nIS_OP(__half, int64_t, is_i64_f16)\nIS_OP(__half, uint32_t, is_u32_f16)\nIS_OP(__half, uint8_t, is_u8_f16)\nGATHER_OP(__half, int64_t, gather_i64_f16)\nGATHER_OP(__half, uint32_t, gather_u32_f16)\nGATHER_OP(__half, uint8_t, gather_u8_f16)\nIA_OP(__half, int64_t, ia_i64_f16)\nIA_OP(__half, uint32_t, ia_u32_f16)\nIA_OP(__half, uint8_t, ia_u8_f16)\nSA_OP(__half, int64_t, sa_i64_f16)\nSA_OP(__half, uint32_t, sa_u32_f16)\nSA_OP(__half, uint8_t, sa_u8_f16)\n#endif\n\nIS_OP(float, int64_t, is_i64_f32)\nIS_OP(double, int64_t, is_i64_f64)\nIS_OP(uint8_t, int64_t, is_i64_u8)\nIS_OP(uint32_t, int64_t, is_i64_u32)\nIS_OP(int64_t, int64_t, is_i64_i64)\n\nIS_OP(float, uint32_t, is_u32_f32)\nIS_OP(double, uint32_t, is_u32_f64)\nIS_OP(uint8_t, uint32_t, is_u32_u8)\nIS_OP(int64_t, uint32_t, is_u32_i64)\nIS_OP(uint32_t, uint32_t, is_u32_u32)\n\nIS_OP(float, uint8_t, is_u8_f32)\nIS_OP(double, uint8_t, is_u8_f64)\nIS_OP(uint8_t, uint8_t, is_u8_u8)\nIS_OP(uint32_t, uint8_t, is_u8_u32)\nIS_OP(int64_t, uint8_t, is_u8_i64)\n\nGATHER_OP(float, int64_t, gather_i64_f32)\nGATHER_OP(double, int64_t, gather_i64_f64)\nGATHER_OP(uint8_t, int64_t, gather_i64_u8)\nGATHER_OP(uint32_t, int64_t, gather_i64_u32)\nGATHER_OP(int64_t, int64_t, gather_i64_i64)\n\nGATHER_OP(float, uint32_t, gather_u32_f32)\nGATHER_OP(double, uint32_t, gather_u32_f64)\nGATHER_OP(uint8_t, uint32_t, gather_u32_u8)\nGATHER_OP(int64_t, uint32_t, gather_u32_i64)\nGATHER_OP(uint32_t, uint32_t, gather_u32_u32)\n\nGATHER_OP(float, uint8_t, gather_u8_f32)\nGATHER_OP(double, uint8_t, gather_u8_f64)\nGATHER_OP(uint8_t, uint8_t, gather_u8_u8)\nGATHER_OP(uint32_t, uint8_t, gather_u8_u32)\nGATHER_OP(int64_t, uint8_t, gather_u8_i64)\n\nIA_OP(float, int64_t, ia_i64_f32)\nIA_OP(double, int64_t, ia_i64_f64)\nIA_OP(uint8_t, int64_t, ia_i64_u8)\nIA_OP(int64_t, int64_t, ia_i64_i64)\nIA_OP(uint32_t, int64_t, ia_i64_u32)\n\nIA_OP(float, uint32_t, ia_u32_f32)\nIA_OP(double, uint32_t, ia_u32_f64)\nIA_OP(uint8_t, uint32_t, ia_u32_u8)\nIA_OP(int64_t, uint32_t, ia_u32_i64)\nIA_OP(uint32_t, uint32_t, ia_u32_u32)\n\nIA_OP(float, uint8_t, ia_u8_f32)\nIA_OP(double, uint8_t, ia_u8_f64)\nIA_OP(uint8_t, uint8_t, ia_u8_u8)\nIA_OP(uint32_t, uint8_t, ia_u8_u32)\nIA_OP(int64_t, uint8_t, ia_u8_i64)\n\nSA_OP(float, int64_t, sa_i64_f32)\nSA_OP(double, int64_t, sa_i64_f64)\nSA_OP(uint8_t, int64_t, sa_i64_u8)\nSA_OP(int64_t, int64_t, sa_i64_i64)\nSA_OP(uint32_t, int64_t, sa_i64_u32)\n\nSA_OP(float, uint32_t, sa_u32_f32)\nSA_OP(double, uint32_t, sa_u32_f64)\nSA_OP(uint8_t, uint32_t, sa_u32_u8)\nSA_OP(int64_t, uint32_t, sa_u32_i64)\nSA_OP(uint32_t, uint32_t, sa_u32_u32)\n\nSA_OP(float, uint8_t, sa_u8_f32)\nSA_OP(double, uint8_t, sa_u8_f64)\nSA_OP(uint8_t, uint8_t, sa_u8_u8)\nSA_OP(uint32_t, uint8_t, sa_u8_u32)\nSA_OP(int64_t, uint8_t, sa_u8_i64)\n", "candle-metal-kernels\\src\\indexing.metal": "#include <metal_stdlib>\nusing namespace metal;\n\nMETAL_FUNC uint get_strided_index(\n uint idx,\n constant size_t &num_dims,\n constant size_t *dims,\n constant size_t *strides\n) {\n uint strided_i = 0;\n for (uint d = 0; d < num_dims; d++) {\n uint dim_idx = num_dims - 1 - d;\n strided_i += (idx % dims[dim_idx]) * strides[dim_idx];\n idx /= dims[dim_idx];\n }\n return strided_i;\n}\n\ntemplate<typename TYPENAME, typename INDEX_TYPENAME>\nMETAL_FUNC void index( \n constant size_t &dst_size, \n constant size_t &left_size, \n constant size_t &src_dim_size, \n constant size_t &right_size, \n constant size_t &ids_size,\n constant bool &contiguous,\n constant size_t *src_dims,\n constant size_t *src_strides,\n const device TYPENAME *input,\n const device INDEX_TYPENAME *input_ids, \n device TYPENAME *output, \n uint tid [[ thread_position_in_grid ]] \n) { \n if (tid >= dst_size) { \n return;\n } \n const size_t id_i = (tid / right_size) % ids_size; \n const INDEX_TYPENAME input_i = min(input_ids[id_i], (INDEX_TYPENAME)(src_dim_size - 1)); \n const size_t right_rank_i = tid % right_size; \n const size_t left_rank_i = tid / right_size / ids_size; \n /* \n // Force prevent out of bounds indexing \n // since there doesn't seem to be a good way to force crash \n // No need to check for zero we're only allowing unsized. \n */ \n const size_t src_i = left_rank_i * src_dim_size * right_size + input_i * right_size + right_rank_i; \n const size_t strided_src_i = contiguous ? src_i : get_strided_index(src_i, src_dim_size, src_dims, src_strides);\n output[tid] = input[strided_src_i];\n}\n\n# define INDEX_OP(NAME, INDEX_TYPENAME, TYPENAME) \\\nkernel void NAME( \\\n constant size_t &dst_size, \\\n constant size_t &left_size, \\\n constant size_t &src_dim_size, \\\n constant size_t &right_size, \\\n constant size_t &ids_size, \\\n constant bool &contiguous, \\\n constant size_t *src_dims, \\\n constant size_t *src_strides, \\\n const device TYPENAME *input, \\\n const device INDEX_TYPENAME *input_ids, \\\n device TYPENAME *output, \\\n uint tid [[ thread_position_in_grid ]] \\\n) { \\\n index<TYPENAME, INDEX_TYPENAME>(dst_size, left_size, src_dim_size, right_size, ids_size, contiguous, src_dims, src_strides, input, input_ids, output, tid); \\\n}\n\n\ntemplate<typename TYPENAME, typename INDEX_TYPENAME>\nMETAL_FUNC void gather( \n constant size_t &dst_size, \n constant size_t &left_size, \n constant size_t &src_dim_size, \n constant size_t &right_size, \n constant size_t &ids_size, \n const device TYPENAME *input, \n const device INDEX_TYPENAME *input_ids, \n device TYPENAME *output, \n uint tid [[ thread_position_in_grid ]] \n) { \n if (tid >= dst_size) { \n return; \n } \n const INDEX_TYPENAME input_i = input_ids[tid]; \n const size_t right_rank_i = tid % right_size; \n const size_t left_rank_i = tid / right_size / ids_size; \n const size_t src_i = (left_rank_i * src_dim_size + input_i) * right_size + right_rank_i; \n output[tid] = input[src_i]; \n}\n\n# define GATHER_OP(NAME, INDEX_TYPENAME, TYPENAME) \\\nkernel void NAME( \\\n constant size_t &dst_size, \\\n constant size_t &left_size, \\\n constant size_t &src_dim_size, \\\n constant size_t &right_size, \\\n constant size_t &ids_size, \\\n const device TYPENAME *input, \\\n const device INDEX_TYPENAME *input_ids, \\\n device TYPENAME *output, \\\n uint tid [[ thread_position_in_grid ]] \\\n) { \\\n gather<TYPENAME, INDEX_TYPENAME>(dst_size, left_size, src_dim_size, right_size, ids_size, input, input_ids, output, tid); \\\n}\n\ntemplate<typename TYPENAME, typename INDEX_TYPENAME>\nMETAL_FUNC void scatter_add( \n constant size_t &dst_size, \n constant size_t &left_size, \n constant size_t &src_dim_size, \n constant size_t &right_size, \n constant size_t &dst_dim_size, \n const device TYPENAME *input, \n const device INDEX_TYPENAME *input_ids, \n device TYPENAME *output, \n uint tid [[ thread_position_in_grid ]] \n) { \n if (tid >= dst_size) { \n return; \n } \n const size_t right_rank_i = tid % right_size; \n const size_t left_rank_i = tid / right_size; \n for (unsigned int j = 0; j < src_dim_size; ++j) {\n const size_t src_i = (left_rank_i * src_dim_size + j) * right_size + right_rank_i; \n const INDEX_TYPENAME idx = input_ids[src_i];\n const size_t dst_i = (left_rank_i * dst_dim_size + idx) * right_size + right_rank_i; \n output[dst_i] += input[src_i]; \n }\n}\n\n# define SCATTER_ADD_OP(NAME, INDEX_TYPENAME, TYPENAME) \\\nkernel void NAME( \\\n constant size_t &dst_size, \\\n constant size_t &left_size, \\\n constant size_t &src_dim_size, \\\n constant size_t &right_size, \\\n constant size_t &dst_dim_size, \\\n const device TYPENAME *input, \\\n const device INDEX_TYPENAME *input_ids, \\\n device TYPENAME *output, \\\n uint tid [[ thread_position_in_grid ]] \\\n) { \\\n scatter_add<TYPENAME, INDEX_TYPENAME>(dst_size, left_size, src_dim_size, right_size, dst_dim_size, input, input_ids, output, tid); \\\n}\n\ntemplate<typename TYPENAME, typename INDEX_TYPENAME>\nMETAL_FUNC void index_add( \n constant size_t &dst_size, \n constant size_t &left_size, \n constant size_t &src_dim_size, \n constant size_t &right_size, \n constant size_t &dst_dim_size, \n constant size_t &ids_dim_size, \n const device TYPENAME *input, \n const device INDEX_TYPENAME *input_ids, \n device TYPENAME *output, \n uint tid [[ thread_position_in_grid ]] \n) { \n if (tid >= dst_size) { \n return; \n } \n const size_t right_rank_i = tid % right_size; \n const size_t left_rank_i = tid / right_size; \n for (unsigned int j = 0; j < ids_dim_size; ++j) {\n const INDEX_TYPENAME idx = input_ids[j];\n const size_t src_i = (left_rank_i * src_dim_size + j) * right_size + right_rank_i; \n const size_t dst_i = (left_rank_i * dst_dim_size + idx) * right_size + right_rank_i; \n output[dst_i] += input[src_i]; \n }\n}\n\n# define INDEX_ADD_OP(NAME, INDEX_TYPENAME, TYPENAME) \\\nkernel void NAME( \\\n constant size_t &dst_size, \\\n constant size_t &left_size, \\\n constant size_t &src_dim_size, \\\n constant size_t &right_size, \\\n constant size_t &dst_dim_size, \\\n constant size_t &ids_dim_size, \\\n const device TYPENAME *input, \\\n const device INDEX_TYPENAME *input_ids, \\\n device TYPENAME *output, \\\n uint tid [[ thread_position_in_grid ]] \\\n) { \\\n index_add<TYPENAME, INDEX_TYPENAME>(dst_size, left_size, src_dim_size, right_size, dst_dim_size, ids_dim_size, input, input_ids, output, tid); \\\n}\n\n\nINDEX_OP(is_i64_f32, int64_t, float)\nINDEX_OP(is_i64_f16, int64_t, half)\n#if defined(__HAVE_BFLOAT__)\nINDEX_OP(is_i64_bf16, int64_t, bfloat)\n#endif\n\nINDEX_OP(is_u32_f32, uint32_t, float)\nINDEX_OP(is_u32_f16, uint32_t, half)\n#if defined(__HAVE_BFLOAT__)\nINDEX_OP(is_u32_bf16, uint32_t, bfloat)\n#endif\n\nINDEX_OP(is_u8_f32, uint8_t, float)\nINDEX_OP(is_u8_f16, uint8_t, half)\n#if defined(__HAVE_BFLOAT__)\nINDEX_OP(is_u8_bf16, uint8_t, bfloat)\n#endif\n\nGATHER_OP(gather_u32_f32, uint, float)\nGATHER_OP(gather_u32_f16, uint, half)\n#if defined(__HAVE_BFLOAT__)\nGATHER_OP(gather_u32_bf16, uint, bfloat)\n#endif\n\nSCATTER_ADD_OP(sa_u32_f32, uint32_t, float)\nSCATTER_ADD_OP(sa_u8_f32, uint8_t, float)\nSCATTER_ADD_OP(sa_i64_f32, int64_t, float)\nSCATTER_ADD_OP(sa_u32_f16, uint32_t, half)\nSCATTER_ADD_OP(sa_u8_f16, uint8_t, half)\nSCATTER_ADD_OP(sa_i64_f16, int64_t, half)\n#if defined(__HAVE_BFLOAT__)\nSCATTER_ADD_OP(sa_u32_bf16, uint32_t, bfloat)\nSCATTER_ADD_OP(sa_u8_bf16, uint8_t, bfloat)\nSCATTER_ADD_OP(sa_i64_bf16, int64_t, bfloat)\n#endif\n\n// i64\nINDEX_ADD_OP(ia_i64_f16, int64_t, half)\nINDEX_ADD_OP(ia_i64_f32, int64_t, float)\nINDEX_ADD_OP(ia_i64_i64, int64_t, int64_t)\nINDEX_ADD_OP(ia_i64_u32, int64_t, uint32_t)\nINDEX_ADD_OP(ia_i64_u8, int64_t, uint8_t)\n#if defined(__HAVE_BFLOAT__)\nINDEX_ADD_OP(ia_i64_bf16, int64_t, bfloat)\n#endif\n\n// u32\nINDEX_ADD_OP(ia_u32_f16, uint32_t, half)\nINDEX_ADD_OP(ia_u32_f32, uint32_t, float)\nINDEX_ADD_OP(ia_u32_i64, uint32_t, int64_t)\nINDEX_ADD_OP(ia_u32_u32, uint32_t, uint32_t)\nINDEX_ADD_OP(ia_u32_u8, uint32_t, uint8_t)\n#if defined(__HAVE_BFLOAT__)\nINDEX_ADD_OP(ia_u32_bf16, uint32_t, bfloat)\n#endif\n\n// u8\nINDEX_ADD_OP(ia_u8_f16, uint8_t, half)\nINDEX_ADD_OP(ia_u8_f32, uint8_t, float)\nINDEX_ADD_OP(ia_u8_i64, uint8_t, int64_t)\nINDEX_ADD_OP(ia_u8_u32, uint8_t, uint32_t)\nINDEX_ADD_OP(ia_u8_u8, uint8_t, uint8_t)\n#if defined(__HAVE_BFLOAT__)\nINDEX_ADD_OP(ia_u8_bf16, uint8_t, bfloat)\n#endif\n", "candle-nn\\benches\\bench_main.rs": "mod benchmarks;\n\nuse criterion::criterion_main;\ncriterion_main!(benchmarks::layer_norm::benches, benchmarks::conv::benches);\n", "candle-wasm-examples\\blip\\index.html": "<!DOCTYPE html>\n<html>\n <head>\n <meta charset=\"UTF-8\" />\n <meta name=\"viewport\" content=\"width=device-width, initial-scale=1.0\" />\n <style>\n @import url(\"https://fonts.googleapis.com/css2?family=Source+Code+Pro:wght@200;300;400&family=Source+Sans+3:wght@100;200;300;400;500;600;700;800;900&display=swap\");\n html,\n body {\n font-family: \"Source Sans 3\", sans-serif;\n }\n </style>\n <title>Candle Blip Image Captioning Demo</title>\n <script src=\"https://cdn.tailwindcss.com\"></script>\n <script type=\"module\" src=\"./code.js\"></script>\n <script type=\"module\">\n const MODELS = {\n blip_image_quantized_q4k: {\n base_url: \"https://huggingface.co/lmz/candle-blip/resolve/main/\",\n model: \"blip-image-captioning-large-q4k.gguf\",\n config: \"config.json\",\n tokenizer: \"tokenizer.json\",\n quantized: true,\n size: \"271 MB\",\n },\n blip_image_quantized_q80: {\n base_url: \"https://huggingface.co/lmz/candle-blip/resolve/main/\",\n model: \"blip-image-captioning-large-q80.gguf\",\n config: \"config.json\",\n tokenizer: \"tokenizer.json\",\n quantized: true,\n size: \"505 MB\",\n },\n blip_image_large: {\n base_url:\n \"https://huggingface.co/Salesforce/blip-image-captioning-large/resolve/refs%2Fpr%2F18/\",\n model: \"model.safetensors\",\n config: \"config.json\",\n tokenizer: \"tokenizer.json\",\n quantized: false,\n size: \"1.88 GB\",\n },\n };\n\n const blipWorker = new Worker(\"./blipWorker.js\", {\n type: \"module\",\n });\n\n const outputStatusEl = document.querySelector(\"#output-status\");\n const outputCaptionEl = document.querySelector(\"#output-caption\");\n const modelSelectEl = document.querySelector(\"#model\");\n const clearBtn = document.querySelector(\"#clear-btn\");\n const fileUpload = document.querySelector(\"#file-upload\");\n const dropArea = document.querySelector(\"#drop-area\");\n const imagesExamples = document.querySelector(\"#image-select\");\n const canvas = document.querySelector(\"#canvas\");\n const ctxCanvas = canvas.getContext(\"2d\");\n\n let isCaptioning = false;\n let currentImageURL = null;\n clearBtn.addEventListener(\"click\", () => {\n clearImageCanvas();\n });\n modelSelectEl.addEventListener(\"change\", () => {\n if (currentImageURL) {\n runInference(currentImageURL);\n }\n });\n\n //add event listener to file input\n fileUpload.addEventListener(\"input\", async (e) => {\n const target = e.target;\n if (target.files.length > 0) {\n const href = URL.createObjectURL(target.files[0]);\n clearImageCanvas();\n await drawImageCanvas(href);\n runInference(href);\n }\n });\n // add event listener to drop-area\n dropArea.addEventListener(\"dragenter\", (e) => {\n e.preventDefault();\n dropArea.classList.add(\"border-blue-700\");\n });\n dropArea.addEventListener(\"dragleave\", (e) => {\n e.preventDefault();\n dropArea.classList.remove(\"border-blue-700\");\n });\n dropArea.addEventListener(\"dragover\", (e) => {\n e.preventDefault();\n });\n dropArea.addEventListener(\"drop\", async (e) => {\n e.preventDefault();\n dropArea.classList.remove(\"border-blue-700\");\n const url = e.dataTransfer.getData(\"text/uri-list\");\n const files = e.dataTransfer.files;\n\n if (files.length > 0) {\n const href = URL.createObjectURL(files[0]);\n clearImageCanvas();\n await drawImageCanvas(href);\n runInference(href);\n } else if (url) {\n clearImageCanvas();\n await drawImageCanvas(url);\n runInference(url);\n }\n });\n\n imagesExamples.addEventListener(\"click\", async (e) => {\n if (isCaptioning) {\n return;\n }\n const target = e.target;\n if (target.nodeName === \"IMG\") {\n const href = target.src;\n clearImageCanvas();\n await drawImageCanvas(href);\n runInference(href);\n }\n });\n function clearImageCanvas() {\n ctxCanvas.clearRect(0, 0, canvas.width, canvas.height);\n isCaptioning = false;\n clearBtn.disabled = true;\n canvas.parentElement.style.height = \"auto\";\n outputStatusEl.hidden = false;\n outputCaptionEl.hidden = true;\n outputStatusEl.innerText = \"Please select an image\";\n currentImageURL = null;\n }\n\n async function drawImageCanvas(imgURL) {\n if (!imgURL) {\n throw new Error(\"No image URL provided\");\n }\n return new Promise((resolve, reject) => {\n ctxCanvas.clearRect(0, 0, canvas.width, canvas.height);\n ctxCanvas.clearRect(0, 0, canvas.width, canvas.height);\n\n const img = new Image();\n img.crossOrigin = \"anonymous\";\n img.onload = () => {\n canvas.width = img.width;\n canvas.height = img.height;\n ctxCanvas.drawImage(img, 0, 0);\n canvas.parentElement.style.height = canvas.offsetHeight + \"px\";\n clearBtn.disabled = false;\n resolve(img);\n };\n img.src = imgURL;\n currentImageURL = imgURL;\n });\n }\n\n document.addEventListener(\"DOMContentLoaded\", () => {\n for (const [id, model] of Object.entries(MODELS)) {\n const option = document.createElement(\"option\");\n option.value = id;\n option.innerText = `${id} (${model.size})`;\n modelSelectEl.appendChild(option);\n }\n });\n async function getImageCaption(\n worker,\n weightsURL,\n tokenizerURL,\n configURL,\n modelID,\n imageURL,\n quantized,\n updateStatus = null\n ) {\n return new Promise((resolve, reject) => {\n worker.postMessage({\n weightsURL,\n tokenizerURL,\n configURL,\n modelID,\n imageURL,\n quantized,\n });\n function messageHandler(event) {\n if (\"error\" in event.data) {\n worker.removeEventListener(\"message\", messageHandler);\n reject(new Error(event.data.error));\n }\n if (event.data.status === \"complete\") {\n worker.removeEventListener(\"message\", messageHandler);\n resolve(event.data);\n }\n if (updateStatus) updateStatus(event.data);\n }\n worker.addEventListener(\"message\", messageHandler);\n });\n }\n function updateStatus(data) {\n if (data.status === \"status\") {\n outputStatusEl.innerText = data.message;\n }\n }\n async function runInference(imageURL) {\n if (isCaptioning || !imageURL) {\n alert(\"Please select an image first\");\n return;\n }\n\n outputStatusEl.hidden = false;\n outputCaptionEl.hidden = true;\n clearBtn.disabled = true;\n modelSelectEl.disabled = true;\n isCaptioning = true;\n const selectedModel = modelSelectEl.value;\n const model = MODELS[selectedModel];\n const weightsURL = `${model.base_url}${model.model}`;\n const tokenizerURL = `${model.base_url}${model.tokenizer}`;\n const configURL = `${model.base_url}${model.config}`;\n const quantized = model.quantized;\n try {\n const time = performance.now();\n const caption = await getImageCaption(\n blipWorker,\n weightsURL,\n tokenizerURL,\n configURL,\n selectedModel,\n imageURL,\n quantized,\n updateStatus\n );\n outputStatusEl.hidden = true;\n outputCaptionEl.hidden = false;\n const totalTime = ((performance.now() - time)/1000).toFixed(2);\n outputCaptionEl.innerHTML = `${\n caption.output\n }<br/><span class=\"text-xs\">Inference time: ${totalTime} s</span>`;\n } catch (err) {\n console.error(err);\n outputStatusEl.hidden = false;\n outputCaptionEl.hidden = true;\n outputStatusEl.innerText = err.message;\n }\n clearBtn.disabled = false;\n modelSelectEl.disabled = false;\n isCaptioning = false;\n }\n </script>\n </head>\n <body class=\"container max-w-4xl mx-auto p-4\">\n <main class=\"grid grid-cols-1 gap-5 relative\">\n <span class=\"absolute text-5xl -ml-[1em]\"> \ud83d\udd6f\ufe0f </span>\n <div>\n <h1 class=\"text-5xl font-bold\">Candle BLIP Image Captioning</h1>\n <h2 class=\"text-2xl font-bold\">Rust/WASM Demo</h2>\n <p class=\"max-w-lg\">\n <a\n href=\"https://huggingface.co/Salesforce/blip-image-captioning-large\"\n target=\"_blank\"\n class=\"underline hover:text-blue-500 hover:no-underline\"\n >BLIP Image Captioning\n </a>\n running in the browser using\n <a\n href=\"https://github.com/huggingface/candle/\"\n target=\"_blank\"\n class=\"underline hover:text-blue-500 hover:no-underline\"\n >Candle</a\n >, a minimalist ML framework for Rust.\n </p>\n <p class=\"text-xs max-w-lg py-2\">\n <b>Note:</b>\n The image captioning on the smallest model takes about ~50 seconds, it\n will vary depending on your machine and model size.\n </p>\n </div>\n\n <div>\n <label for=\"model\" class=\"font-medium block\">Models Options: </label>\n <select\n id=\"model\"\n class=\"border-2 border-gray-500 rounded-md font-light interactive disabled:cursor-not-allowed w-full max-w-max\"\n ></select>\n </div>\n <!-- drag and drop area -->\n <div class=\"grid gap-4 sm:grid-cols-2 py-4\">\n <div class=\"relative max-w-lg\">\n <div\n class=\"absolute w-full bottom-full flex justify-between items-center\"\n >\n <div class=\"flex gap-2 w-full\">\n <button\n id=\"clear-btn\"\n disabled\n title=\"Clear Image\"\n class=\"ml-auto text-xs bg-white rounded-md disabled:opacity-50 flex gap-1 items-center\"\n >\n <svg\n class=\"\"\n xmlns=\"http://www.w3.org/2000/svg\"\n viewBox=\"0 0 13 12\"\n height=\"1em\"\n >\n <path\n d=\"M1.6.7 12 11.1M12 .7 1.6 11.1\"\n stroke=\"#2E3036\"\n stroke-width=\"2\"\n />\n </svg>\n </button>\n </div>\n </div>\n <div\n id=\"drop-area\"\n class=\"flex flex-col items-center justify-center border-2 border-gray-300 border-dashed rounded-xl relative aspect-video w-full overflow-hidden\"\n >\n <div\n class=\"flex flex-col items-center justify-center space-y-1 text-center\"\n >\n <svg\n width=\"25\"\n height=\"25\"\n viewBox=\"0 0 25 25\"\n fill=\"none\"\n xmlns=\"http://www.w3.org/2000/svg\"\n >\n <path\n d=\"M3.5 24.3a3 3 0 0 1-1.9-.8c-.5-.5-.8-1.2-.8-1.9V2.9c0-.7.3-1.3.8-1.9.6-.5 1.2-.7 2-.7h18.6c.7 0 1.3.2 1.9.7.5.6.7 1.2.7 2v18.6c0 .7-.2 1.4-.7 1.9a3 3 0 0 1-2 .8H3.6Zm0-2.7h18.7V2.9H3.5v18.7Zm2.7-2.7h13.3c.3 0 .5 0 .6-.3v-.7l-3.7-5a.6.6 0 0 0-.6-.2c-.2 0-.4 0-.5.3l-3.5 4.6-2.4-3.3a.6.6 0 0 0-.6-.3c-.2 0-.4.1-.5.3l-2.7 3.6c-.1.2-.2.4 0 .7.1.2.3.3.6.3Z\"\n fill=\"#000\"\n />\n </svg>\n <div class=\"flex text-sm text-gray-600\">\n <label\n for=\"file-upload\"\n class=\"relative cursor-pointer bg-white rounded-md font-medium text-blue-950 hover:text-blue-700\"\n >\n <span>Drag and drop y our image here</span>\n <span class=\"block text-xs\">or</span>\n <span class=\"block text-xs\">Click to upload</span>\n </label>\n </div>\n <input\n id=\"file-upload\"\n name=\"file-upload\"\n type=\"file\"\n class=\"sr-only\"\n />\n </div>\n <canvas\n id=\"canvas\"\n class=\"absolute pointer-events-none w-full\"\n ></canvas>\n </div>\n </div>\n <div class=\"\">\n <div\n class=\"h-full bg-slate-100 text-gray-500 p-4 rounded-md flex flex-col gap-2\"\n >\n <p\n id=\"output-caption\"\n class=\"m-auto text-xl text-center p-2\"\n hidden\n ></p>\n <span id=\"output-status\" class=\"m-auto font-light\">\n Please select an image\n </span>\n </div>\n </div>\n </div>\n\n <div>\n <div\n class=\"flex gap-3 items-center overflow-x-scroll\"\n id=\"image-select\"\n >\n <h3 class=\"font-medium\">Examples:</h3>\n\n <img\n src=\"https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/candle/examples/sf.jpg\"\n class=\"cursor-pointer w-24 h-24 object-cover\"\n />\n <img\n src=\"https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/candle/examples/bike.jpeg\"\n class=\"cursor-pointer w-24 h-24 object-cover\"\n />\n <img\n src=\"https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/candle/examples/000000000077.jpg\"\n class=\"cursor-pointer w-24 h-24 object-cover\"\n />\n </div>\n </div>\n </main>\n </body>\n</html>\n", "candle-wasm-examples\\llama2-c\\index.html": "<!DOCTYPE html>\n<html lang=\"en\">\n <head>\n <meta charset=\"utf-8\" />\n <title>Welcome to Candle!</title>\n\n <link data-trunk rel=\"copy-file\" href=\"tokenizer.json\" />\n <link data-trunk rel=\"copy-file\" href=\"model.bin\" />\n <link data-trunk rel=\"rust\" href=\"Cargo.toml\" data-bin=\"app\" data-type=\"main\" />\n <link data-trunk rel=\"rust\" href=\"Cargo.toml\" data-bin=\"worker\" data-type=\"worker\" />\n\n <link rel=\"stylesheet\" href=\"https://fonts.googleapis.com/css?family=Roboto:300,300italic,700,700italic\">\n <link rel=\"stylesheet\" href=\"https://cdnjs.cloudflare.com/ajax/libs/normalize/8.0.1/normalize.css\">\n <link rel=\"stylesheet\" href=\"https://cdnjs.cloudflare.com/ajax/libs/milligram/1.4.1/milligram.css\">\n </head>\n <body></body>\n</html>\n", "candle-wasm-examples\\llama2-c\\src\\app.rs": "use crate::console_log;\nuse crate::worker::{ModelData, Worker, WorkerInput, WorkerOutput};\nuse std::str::FromStr;\nuse wasm_bindgen::prelude::*;\nuse wasm_bindgen_futures::JsFuture;\nuse yew::{html, Component, Context, Html};\nuse yew_agent::{Bridge, Bridged};\n\nasync fn fetch_url(url: &str) -> Result<Vec<u8>, JsValue> {\n use web_sys::{Request, RequestCache, RequestInit, RequestMode, Response};\n let window = web_sys::window().ok_or(\"window\")?;\n let opts = RequestInit::new();\n opts.set_method(\"GET\");\n opts.set_mode(RequestMode::Cors);\n opts.set_cache(RequestCache::NoCache);\n let request = Request::new_with_str_and_init(url, &opts)?;\n\n let resp_value = JsFuture::from(window.fetch_with_request(&request)).await?;\n\n // `resp_value` is a `Response` object.\n assert!(resp_value.is_instance_of::<Response>());\n let resp: Response = resp_value.dyn_into()?;\n let data = JsFuture::from(resp.blob()?).await?;\n let blob = web_sys::Blob::from(data);\n let array_buffer = JsFuture::from(blob.array_buffer()).await?;\n let data = js_sys::Uint8Array::new(&array_buffer).to_vec();\n Ok(data)\n}\n\npub enum Msg {\n Refresh,\n Run,\n UpdateStatus(String),\n SetModel(ModelData),\n WorkerIn(WorkerInput),\n WorkerOut(Result<WorkerOutput, String>),\n}\n\npub struct CurrentDecode {\n start_time: Option<f64>,\n}\n\npub struct App {\n status: String,\n loaded: bool,\n temperature: std::rc::Rc<std::cell::RefCell<f64>>,\n top_p: std::rc::Rc<std::cell::RefCell<f64>>,\n prompt: std::rc::Rc<std::cell::RefCell<String>>,\n generated: String,\n n_tokens: usize,\n current_decode: Option<CurrentDecode>,\n worker: Box<dyn Bridge<Worker>>,\n}\n\nasync fn model_data_load() -> Result<ModelData, JsValue> {\n let tokenizer = fetch_url(\"tokenizer.json\").await?;\n let model = fetch_url(\"model.bin\").await?;\n console_log!(\"{}\", model.len());\n Ok(ModelData { tokenizer, model })\n}\n\nfn performance_now() -> Option<f64> {\n let window = web_sys::window()?;\n let performance = window.performance()?;\n Some(performance.now() / 1000.)\n}\n\nimpl Component for App {\n type Message = Msg;\n type Properties = ();\n\n fn create(ctx: &Context<Self>) -> Self {\n let status = \"loading weights\".to_string();\n let cb = {\n let link = ctx.link().clone();\n move |e| link.send_message(Self::Message::WorkerOut(e))\n };\n let worker = Worker::bridge(std::rc::Rc::new(cb));\n Self {\n status,\n n_tokens: 0,\n temperature: std::rc::Rc::new(std::cell::RefCell::new(0.)),\n top_p: std::rc::Rc::new(std::cell::RefCell::new(1.0)),\n prompt: std::rc::Rc::new(std::cell::RefCell::new(\"\".to_string())),\n generated: String::new(),\n current_decode: None,\n worker,\n loaded: false,\n }\n }\n\n fn rendered(&mut self, ctx: &Context<Self>, first_render: bool) {\n if first_render {\n ctx.link().send_future(async {\n match model_data_load().await {\n Err(err) => {\n let status = format!(\"{err:?}\");\n Msg::UpdateStatus(status)\n }\n Ok(model_data) => Msg::SetModel(model_data),\n }\n });\n }\n }\n\n fn update(&mut self, ctx: &Context<Self>, msg: Self::Message) -> bool {\n match msg {\n Msg::SetModel(md) => {\n self.status = \"weights loaded successfully!\".to_string();\n self.loaded = true;\n console_log!(\"loaded weights\");\n self.worker.send(WorkerInput::ModelData(md));\n true\n }\n Msg::Run => {\n if self.current_decode.is_some() {\n self.status = \"already generating some sample at the moment\".to_string()\n } else {\n let start_time = performance_now();\n self.current_decode = Some(CurrentDecode { start_time });\n self.status = \"generating...\".to_string();\n self.n_tokens = 0;\n self.generated.clear();\n let temp = *self.temperature.borrow();\n let top_p = *self.top_p.borrow();\n let prompt = self.prompt.borrow().clone();\n console_log!(\"temp: {}, top_p: {}, prompt: {}\", temp, top_p, prompt);\n ctx.link()\n .send_message(Msg::WorkerIn(WorkerInput::Run(temp, top_p, prompt)))\n }\n true\n }\n Msg::WorkerOut(output) => {\n match output {\n Ok(WorkerOutput::WeightsLoaded) => self.status = \"weights loaded!\".to_string(),\n Ok(WorkerOutput::GenerationDone(Err(err))) => {\n self.status = format!(\"error in worker process: {err}\");\n self.current_decode = None\n }\n Ok(WorkerOutput::GenerationDone(Ok(()))) => {\n let dt = self.current_decode.as_ref().and_then(|current_decode| {\n current_decode.start_time.and_then(|start_time| {\n performance_now().map(|stop_time| stop_time - start_time)\n })\n });\n self.status = match dt {\n None => \"generation succeeded!\".to_string(),\n Some(dt) => format!(\n \"generation succeeded in {:.2}s ({:.1} ms/token)\",\n dt,\n dt * 1000.0 / (self.n_tokens as f64)\n ),\n };\n self.current_decode = None\n }\n Ok(WorkerOutput::Generated(token)) => {\n self.n_tokens += 1;\n self.generated.push_str(&token)\n }\n Err(err) => {\n self.status = format!(\"error in worker {err:?}\");\n }\n }\n true\n }\n Msg::WorkerIn(inp) => {\n self.worker.send(inp);\n true\n }\n Msg::UpdateStatus(status) => {\n self.status = status;\n true\n }\n Msg::Refresh => true,\n }\n }\n\n fn view(&self, ctx: &Context<Self>) -> Html {\n use yew::TargetCast;\n let temperature = self.temperature.clone();\n let oninput_temperature = ctx.link().callback(move |e: yew::InputEvent| {\n let input: web_sys::HtmlInputElement = e.target_unchecked_into();\n if let Ok(temp) = f64::from_str(&input.value()) {\n *temperature.borrow_mut() = temp\n }\n Msg::Refresh\n });\n let top_p = self.top_p.clone();\n let oninput_top_p = ctx.link().callback(move |e: yew::InputEvent| {\n let input: web_sys::HtmlInputElement = e.target_unchecked_into();\n if let Ok(top_p_input) = f64::from_str(&input.value()) {\n *top_p.borrow_mut() = top_p_input\n }\n Msg::Refresh\n });\n let prompt = self.prompt.clone();\n let oninput_prompt = ctx.link().callback(move |e: yew::InputEvent| {\n let input: web_sys::HtmlInputElement = e.target_unchecked_into();\n *prompt.borrow_mut() = input.value();\n Msg::Refresh\n });\n html! {\n <div style=\"margin: 2%;\">\n <div><p>{\"Running \"}\n <a href=\"https://github.com/karpathy/llama2.c\" target=\"_blank\">{\"llama2.c\"}</a>\n {\" in the browser using rust/wasm with \"}\n <a href=\"https://github.com/huggingface/candle\" target=\"_blank\">{\"candle!\"}</a>\n </p>\n <p>{\"Once the weights have loaded, click on the run button to start generating content.\"}\n </p>\n </div>\n {\"temperature \\u{00a0} \"}\n <input type=\"range\" min=\"0.\" max=\"1.2\" step=\"0.1\" value={self.temperature.borrow().to_string()} oninput={oninput_temperature} id=\"temp\"/>\n {format!(\" \\u{00a0} {}\", self.temperature.borrow())}\n <br/ >\n {\"top_p \\u{00a0} \"}\n <input type=\"range\" min=\"0.\" max=\"1.0\" step=\"0.05\" value={self.top_p.borrow().to_string()} oninput={oninput_top_p} id=\"top_p\"/>\n {format!(\" \\u{00a0} {}\", self.top_p.borrow())}\n <br/ >\n {\"prompt: \"}<input type=\"text\" value={self.prompt.borrow().to_string()} oninput={oninput_prompt} id=\"prompt\"/>\n <br/ >\n {\n if self.loaded{\n html!(<button class=\"button\" onclick={ctx.link().callback(move |_| Msg::Run)}> { \"run\" }</button>)\n }else{\n html! { <progress id=\"progress-bar\" aria-label=\"Loading weights...\"></progress> }\n }\n }\n <br/ >\n <h3>\n {&self.status}\n </h3>\n {\n if self.current_decode.is_some() {\n html! { <progress id=\"progress-bar\" aria-label=\"generating\u2026\"></progress> }\n } else {\n html! {}\n }\n }\n <blockquote>\n <p> { self.generated.chars().map(|c|\n if c == '\\r' || c == '\\n' {\n html! { <br/> }\n } else {\n html! { {c} }\n }).collect::<Html>()\n } </p>\n </blockquote>\n </div>\n }\n }\n}\n", "candle-wasm-examples\\llama2-c\\src\\bin\\app.rs": "fn main() {\n wasm_logger::init(wasm_logger::Config::new(log::Level::Trace));\n console_error_panic_hook::set_once();\n yew::Renderer::<candle_wasm_example_llama2::App>::new().render();\n}\n", "candle-wasm-examples\\moondream\\index.html": "<html>\n <head>\n <meta content=\"text/html;charset=utf-8\" http-equiv=\"Content-Type\" />\n <title>Candle Moondream Rust/WASM</title>\n </head>\n <body></body>\n</html>\n\n<!DOCTYPE html>\n<html>\n <head>\n <meta charset=\"UTF-8\" />\n <meta name=\"viewport\" content=\"width=device-width, initial-scale=1.0\" />\n <link\n rel=\"stylesheet\"\n href=\"https://cdn.jsdelivr.net/gh/highlightjs/[email protected]/build/styles/default.min.css\"\n />\n <style>\n @import url(\"https://fonts.googleapis.com/css2?family=Source+Code+Pro:wght@200;300;400&family=Source+Sans+3:wght@100;200;300;400;500;600;700;800;900&display=swap\");\n html,\n body {\n font-family: \"Source Sans 3\", sans-serif;\n }\n code,\n output,\n select,\n pre {\n font-family: \"Source Code Pro\", monospace;\n }\n </style>\n <style type=\"text/tailwindcss\">\n .link {\n @apply underline hover:text-blue-500 hover:no-underline;\n }\n </style>\n <script src=\"https://cdn.tailwindcss.com/3.4.3\"></script>\n <script type=\"module\" src=\"./code.js\"></script>\n </head>\n <body class=\"container max-w-4xl mx-auto p-4 text-gray-800\">\n <main class=\"grid grid-cols-1 gap-8 relative\">\n <span class=\"absolute text-5xl -ml-[1em]\"> \ud83d\udd6f\ufe0f </span>\n <div>\n <h1 class=\"text-5xl font-bold\">Candle Moondream 2</h1>\n <h2 class=\"text-2xl font-bold\">Rust/WASM Demo</h2>\n <p class=\"max-w-lg\">\n <a\n href=\"https://huggingface.co/vikhyatk/moondream2\"\n class=\"link\"\n target=\"_blank\"\n >Moondream 2</a\n >\n by\n <a\n href=\" https://huggingface.co/vikhyatk\"\n class=\"link\"\n target=\"_blank\"\n >Vik</a\n >\n and model implementation on Candle by\n <a\n href=\"https://huggingface.co/santiagomed\"\n class=\"link\"\n target=\"_blank\"\n >Santiago Medina\n </a>\n </p>\n </div>\n\n <div>\n <p class=\"text-xs italic max-w-lg\">\n <b>Note:</b>\n When first run, the app will download and cache the model, which could\n take a few minutes. Then, the embeddings and generation will take a\n few minutes to start \ud83d\ude14.\n </p>\n </div>\n <div>\n <label for=\"model\" class=\"font-medium\">Models Options: </label>\n <select\n id=\"model\"\n class=\"border-2 border-gray-500 rounded-md font-light\"\n ></select>\n </div>\n <form\n id=\"form\"\n class=\"flex text-normal px-1 py-1 border border-gray-700 rounded-md items-center\"\n >\n <input type=\"submit\" hidden />\n <input\n type=\"text\"\n id=\"prompt\"\n class=\"font-light text-lg w-full px-3 py-2 mx-1 resize-none outline-none\"\n placeholder=\"Add your prompt here...\"\n />\n <button\n id=\"run\"\n class=\"bg-gray-700 hover:bg-gray-800 text-white font-normal py-2 w-16 rounded disabled:bg-gray-300 disabled:cursor-not-allowed\"\n >\n Run\n </button>\n </form>\n\n <details>\n <summary class=\"font-medium cursor-pointer\">Advanced Options</summary>\n\n <div class=\"grid grid-cols-3 max-w-md items-center gap-3 py-3\">\n <label class=\"text-sm font-medium\" for=\"max-seq\"\n >Maximum length\n </label>\n <input\n type=\"range\"\n id=\"max-seq\"\n name=\"max-seq\"\n min=\"1\"\n max=\"2048\"\n step=\"1\"\n value=\"500\"\n oninput=\"this.nextElementSibling.value = Number(this.value)\"\n />\n <output\n class=\"text-xs w-[50px] text-center font-light px-1 py-1 border border-gray-700 rounded-md\"\n >\n 500</output\n >\n <label class=\"text-sm font-medium\" for=\"temperature\"\n >Temperature</label\n >\n <input\n type=\"range\"\n id=\"temperature\"\n name=\"temperature\"\n min=\"0\"\n max=\"2\"\n step=\"0.01\"\n value=\"0.00\"\n oninput=\"this.nextElementSibling.value = Number(this.value).toFixed(2)\"\n />\n <output\n class=\"text-xs w-[50px] text-center font-light px-1 py-1 border border-gray-700 rounded-md\"\n >\n 0.00</output\n >\n <label class=\"text-sm font-medium\" for=\"top-p\">Top-p</label>\n <input\n type=\"range\"\n id=\"top-p\"\n name=\"top-p\"\n min=\"0\"\n max=\"1\"\n step=\"0.01\"\n value=\"1.00\"\n oninput=\"this.nextElementSibling.value = Number(this.value).toFixed(2)\"\n />\n <output\n class=\"text-xs w-[50px] text-center font-light px-1 py-1 border border-gray-700 rounded-md\"\n >\n 1.00</output\n >\n\n <label class=\"text-sm font-medium\" for=\"repeat_penalty\"\n >Repeat Penalty</label\n >\n\n <input\n type=\"range\"\n id=\"repeat_penalty\"\n name=\"repeat_penalty\"\n min=\"1\"\n max=\"2\"\n step=\"0.01\"\n value=\"1.10\"\n oninput=\"this.nextElementSibling.value = Number(this.value).toFixed(2)\"\n />\n <output\n class=\"text-xs w-[50px] text-center font-light px-1 py-1 border border-gray-700 rounded-md\"\n >1.10</output\n >\n <label class=\"text-sm font-medium\" for=\"seed\">Seed</label>\n <input\n type=\"number\"\n id=\"seed\"\n name=\"seed\"\n value=\"299792458\"\n class=\"font-light border border-gray-700 text-right rounded-md p-2\"\n />\n <button\n id=\"run\"\n onclick=\"document.querySelector('#seed').value = Math.floor(Math.random() * Number.MAX_SAFE_INTEGER)\"\n class=\"bg-gray-700 hover:bg-gray-800 text-white font-normal py-1 w-[50px] rounded disabled:bg-gray-300 disabled:cursor-not-allowed text-sm\"\n >\n Rand\n </button>\n </div>\n </details>\n\n <div class=\"grid md:grid-cols-2 gap-4 items-start\">\n <div>\n <div class=\"relative md:mt-6\">\n <div\n class=\"absolute w-full bottom-full flex justify-between items-center\"\n >\n <div class=\"flex gap-2 w-full\">\n <button\n id=\"clear-img-btn\"\n disabled\n title=\"Clear Image\"\n class=\"ml-auto text-xs py-1 bg-white rounded-md disabled:opacity-20 flex gap-1 items-center\"\n >\n <svg\n class=\"\"\n xmlns=\"http://www.w3.org/2000/svg\"\n viewBox=\"0 0 13 12\"\n height=\"1em\"\n >\n <path\n d=\"M1.6.7 12 11.1M12 .7 1.6 11.1\"\n stroke=\"#2E3036\"\n stroke-width=\"2\"\n />\n </svg>\n </button>\n </div>\n </div>\n <div\n id=\"drop-area\"\n class=\"min-h-[250px] flex flex-col items-center justify-center border-2 border-gray-300 border-dashed rounded-xl relative w-full overflow-hidden\"\n >\n <div\n class=\"absolute flex flex-col items-center justify-center space-y-1 text-center\"\n >\n <svg\n width=\"25\"\n height=\"25\"\n viewBox=\"0 0 25 25\"\n fill=\"none\"\n xmlns=\"http://www.w3.org/2000/svg\"\n >\n <path\n d=\"M3.5 24.3a3 3 0 0 1-1.9-.8c-.5-.5-.8-1.2-.8-1.9V2.9c0-.7.3-1.3.8-1.9.6-.5 1.2-.7 2-.7h18.6c.7 0 1.3.2 1.9.7.5.6.7 1.2.7 2v18.6c0 .7-.2 1.4-.7 1.9a3 3 0 0 1-2 .8H3.6Zm0-2.7h18.7V2.9H3.5v18.7Zm2.7-2.7h13.3c.3 0 .5 0 .6-.3v-.7l-3.7-5a.6.6 0 0 0-.6-.2c-.2 0-.4 0-.5.3l-3.5 4.6-2.4-3.3a.6.6 0 0 0-.6-.3c-.2 0-.4.1-.5.3l-2.7 3.6c-.1.2-.2.4 0 .7.1.2.3.3.6.3Z\"\n fill=\"#000\"\n />\n </svg>\n <div class=\"flex text-sm text-gray-600\">\n <label\n for=\"file-upload\"\n class=\"relative cursor-pointer bg-white rounded-md font-medium text-blue-950 hover:text-blue-700\"\n >\n <span>Drag and drop the image here</span>\n <span class=\"block text-xs\">or</span>\n <span class=\"block text-xs\">Click to upload</span>\n </label>\n </div>\n <input\n id=\"file-upload\"\n name=\"file-upload\"\n type=\"file\"\n accept=\"image/*\"\n class=\"sr-only\"\n />\n </div>\n <canvas\n id=\"canvas\"\n class=\"z-10 pointer-events-none w-full\"\n ></canvas>\n </div>\n </div>\n </div>\n <div>\n <h3 class=\"font-medium\">Generation:</h3>\n <div\n class=\"min-h-[250px] bg-slate-100 text-gray-500 p-4 rounded-md flex flex-col gap-2\"\n >\n <div\n id=\"output-counter\"\n hidden\n class=\"ml-auto font-semibold grid-rows-1\"\n ></div>\n <p hidden id=\"output-generation\" class=\"grid-rows-2 text-lg\"></p>\n <span id=\"output-status\" class=\"m-auto font-light\"\n >No output yet</span\n >\n </div>\n </div>\n </div>\n <div>\n <div\n class=\"flex gap-3 items-center overflow-x-scroll\"\n id=\"image-select\"\n >\n <h3 class=\"font-medium\">Examples:</h3>\n\n <img\n src=\"https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/candle/examples/sf.jpg\"\n class=\"cursor-pointer w-24 h-24 object-cover\"\n />\n <img\n src=\"https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/candle/examples/bike.jpeg\"\n class=\"cursor-pointer w-24 h-24 object-cover\"\n />\n <img\n src=\"https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/candle/examples/000000000077.jpg\"\n class=\"cursor-pointer w-24 h-24 object-cover\"\n />\n <img\n src=\"https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/candle/examples/demo-1.jpg\"\n class=\"cursor-pointer w-24 h-24 object-cover\"\n />\n </div>\n </div>\n </main>\n </body>\n</html>\n", "candle-wasm-examples\\phi\\index.html": "<html>\n <head>\n <meta content=\"text/html;charset=utf-8\" http-equiv=\"Content-Type\" />\n <title>Candle Phi 1.5 / Phi 2.0 Rust/WASM</title>\n </head>\n <body></body>\n</html>\n\n<!DOCTYPE html>\n<html>\n <head>\n <meta charset=\"UTF-8\" />\n <meta name=\"viewport\" content=\"width=device-width, initial-scale=1.0\" />\n <link\n rel=\"stylesheet\"\n href=\"https://cdn.jsdelivr.net/gh/highlightjs/[email protected]/build/styles/default.min.css\"\n />\n <style>\n @import url(\"https://fonts.googleapis.com/css2?family=Source+Code+Pro:wght@200;300;400&family=Source+Sans+3:wght@100;200;300;400;500;600;700;800;900&display=swap\");\n html,\n body {\n font-family: \"Source Sans 3\", sans-serif;\n }\n code,\n output,\n select,\n pre {\n font-family: \"Source Code Pro\", monospace;\n }\n </style>\n <style type=\"text/tailwindcss\">\n .link {\n @apply underline hover:text-blue-500 hover:no-underline;\n }\n </style>\n <script src=\"https://cdn.tailwindcss.com\"></script>\n <script type=\"module\">\n import snarkdown from \"https://cdn.skypack.dev/snarkdown\";\n import hljs from \"https://cdn.skypack.dev/highlight.js\";\n // models base url\n const MODELS = {\n phi_1_5_q4k: {\n base_url:\n \"https://huggingface.co/lmz/candle-quantized-phi/resolve/main/\",\n model: \"model-q4k.gguf\",\n tokenizer: \"tokenizer.json\",\n config: \"phi-1_5.json\",\n quantized: true,\n seq_len: 2048,\n size: \"800 MB\",\n },\n phi_1_5_q80: {\n base_url:\n \"https://huggingface.co/lmz/candle-quantized-phi/resolve/main/\",\n model: \"model-q80.gguf\",\n tokenizer: \"tokenizer.json\",\n config: \"phi-1_5.json\",\n quantized: true,\n seq_len: 2048,\n size: \"1.51 GB\",\n },\n phi_2_0_q4k: {\n base_url:\n \"https://huggingface.co/radames/phi-2-quantized/resolve/main/\",\n model: [\n \"model-v2-q4k.gguf_aa.part\",\n \"model-v2-q4k.gguf_ab.part\",\n \"model-v2-q4k.gguf_ac.part\",\n ],\n tokenizer: \"tokenizer.json\",\n config: \"config.json\",\n quantized: true,\n seq_len: 2048,\n size: \"1.57GB\",\n },\n puffin_phi_v2_q4k: {\n base_url:\n \"https://huggingface.co/lmz/candle-quantized-phi/resolve/main/\",\n model: \"model-puffin-phi-v2-q4k.gguf\",\n tokenizer: \"tokenizer-puffin-phi-v2.json\",\n config: \"puffin-phi-v2.json\",\n quantized: true,\n seq_len: 2048,\n size: \"798 MB\",\n },\n puffin_phi_v2_q80: {\n base_url:\n \"https://huggingface.co/lmz/candle-quantized-phi/resolve/main/\",\n model: \"model-puffin-phi-v2-q80.gguf\",\n tokenizer: \"tokenizer-puffin-phi-v2.json\",\n config: \"puffin-phi-v2.json\",\n quantized: true,\n seq_len: 2048,\n size: \"1.50 GB\",\n },\n };\n\n const TEMPLATES = [\n {\n title: \"Simple prompt\",\n prompt: `Sebastien is in London today, it\u2019s the middle of July yet it\u2019s raining, so Sebastien is feeling gloomy. He`,\n },\n {\n title: \"Think step by step\",\n prompt: `Suppose Alice originally had 3 apples, then Bob gave Alice 7 apples, then Alice gave Cook 5 apples, and then Tim gave Alice 3x the amount of apples Alice had. How many apples does Alice have now? \nLet\u2019s think step by step.`,\n },\n {\n title: \"Explaing a code snippet\",\n prompt: `What does this script do? \n\\`\\`\\`python\ns = socket.socket(socket.AF_INET, socket.SOCK_STREAM)\ns.bind(('', 0))\ns.listen(1)\nconn, addr = s.accept()\nprint('Connected by', addr)\nreturn conn.getsockname()[1]\n\\`\\`\\`\nLet\u2019s think step by step.`,\n },\n {\n title: \"Question answering\",\n prompt: `Instruct: What is the capital of France? \nOutput:`,\n },\n {\n title: \"Chat mode\",\n prompt: `Alice: Can you tell me how to create a python application to go through all the files\nin one directory where the file\u2019s name DOES NOT end with '.json'? \nBob:`,\n },\n {\n title: \"Python code completion\",\n prompt: `\"\"\"write a python function called batch(function, list) which call function(x) for x in\nlist in parallel\"\"\" \nSolution:`,\n },\n {\n title: \"Python Sample\",\n prompt: `\"\"\"Can you make sure those histograms appear side by side on the same plot: \n\\`\\`\\`python\nplt.hist(intreps_retrained[0][1].view(64,-1).norm(dim=1).detach().cpu().numpy(), bins = 20)\nplt.hist(intreps_pretrained[0][1].view(64,-1).norm(dim=1).detach().cpu().numpy(), bins = 20)\n\\`\\`\\` \n\"\"\"`,\n },\n {\n title: \"Write a Twitter post\",\n prompt: `Write a twitter post for the discovery of gravitational wave. \nTwitter Post:`,\n },\n {\n title: \"Write a review\",\n prompt: `Write a polite review complaining that the video game 'Random Game' was too badly optimized and it burned my laptop. \nVery polite review:`,\n },\n ];\n const phiWorker = new Worker(\"./phiWorker.js\", {\n type: \"module\",\n });\n async function generateSequence(controller) {\n const getValue = (id) => document.querySelector(`#${id}`).value;\n const modelID = getValue(\"model\");\n const model = MODELS[modelID];\n const weightsURL =\n model.model instanceof Array\n ? model.model.map((m) => model.base_url + m)\n : model.base_url + model.model;\n const tokenizerURL = model.base_url + model.tokenizer;\n const configURL = model.base_url + model.config;\n\n const prompt = getValue(\"prompt\").trim();\n const temperature = getValue(\"temperature\");\n const topP = getValue(\"top-p\");\n const repeatPenalty = getValue(\"repeat_penalty\");\n const seed = getValue(\"seed\");\n const maxSeqLen = getValue(\"max-seq\");\n\n function updateStatus(data) {\n const outStatus = document.querySelector(\"#output-status\");\n const outGen = document.querySelector(\"#output-generation\");\n const outCounter = document.querySelector(\"#output-counter\");\n\n switch (data.status) {\n case \"loading\":\n outStatus.hidden = false;\n outStatus.textContent = data.message;\n outGen.hidden = true;\n outCounter.hidden = true;\n break;\n case \"generating\":\n const { message, prompt, sentence, tokensSec, totalTime } = data;\n outStatus.hidden = true;\n outCounter.hidden = false;\n outGen.hidden = false;\n outGen.innerHTML = snarkdown(prompt + sentence);\n outCounter.innerHTML = `${(totalTime / 1000).toFixed(\n 2\n )}s (${tokensSec.toFixed(2)} tok/s)`;\n hljs.highlightAll();\n break;\n case \"complete\":\n outStatus.hidden = true;\n outGen.hidden = false;\n break;\n }\n }\n\n return new Promise((resolve, reject) => {\n phiWorker.postMessage({\n weightsURL,\n modelID,\n tokenizerURL,\n configURL,\n quantized: model.quantized,\n prompt,\n temp: temperature,\n top_p: topP,\n repeatPenalty,\n seed: seed,\n maxSeqLen,\n command: \"start\",\n });\n\n const handleAbort = () => {\n phiWorker.postMessage({ command: \"abort\" });\n };\n const handleMessage = (event) => {\n const { status, error, message, prompt, sentence } = event.data;\n if (status) updateStatus(event.data);\n if (error) {\n phiWorker.removeEventListener(\"message\", handleMessage);\n reject(new Error(error));\n }\n if (status === \"aborted\") {\n phiWorker.removeEventListener(\"message\", handleMessage);\n resolve(event.data);\n }\n if (status === \"complete\") {\n phiWorker.removeEventListener(\"message\", handleMessage);\n resolve(event.data);\n }\n };\n\n controller.signal.addEventListener(\"abort\", handleAbort);\n phiWorker.addEventListener(\"message\", handleMessage);\n });\n }\n\n const form = document.querySelector(\"#form\");\n const prompt = document.querySelector(\"#prompt\");\n const clearBtn = document.querySelector(\"#clear-btn\");\n const runBtn = document.querySelector(\"#run\");\n const modelSelect = document.querySelector(\"#model\");\n const promptTemplates = document.querySelector(\"#prompt-templates\");\n let runController = new AbortController();\n let isRunning = false;\n\n document.addEventListener(\"DOMContentLoaded\", () => {\n for (const [id, model] of Object.entries(MODELS)) {\n const option = document.createElement(\"option\");\n option.value = id;\n option.innerText = `${id} (${model.size})`;\n modelSelect.appendChild(option);\n }\n const query = new URLSearchParams(window.location.search);\n const modelID = query.get(\"model\");\n if (modelID) {\n modelSelect.value = modelID;\n } else {\n modelSelect.value = \"phi_1_5_q4k\";\n }\n\n for (const [i, { title, prompt }] of TEMPLATES.entries()) {\n const div = document.createElement(\"div\");\n const input = document.createElement(\"input\");\n input.type = \"radio\";\n input.name = \"task\";\n input.id = `templates-${i}`;\n input.classList.add(\"font-light\", \"cursor-pointer\");\n input.value = prompt;\n const label = document.createElement(\"label\");\n label.htmlFor = `templates-${i}`;\n label.classList.add(\"cursor-pointer\");\n label.innerText = title;\n div.appendChild(input);\n div.appendChild(label);\n promptTemplates.appendChild(div);\n }\n });\n\n promptTemplates.addEventListener(\"change\", (e) => {\n const template = e.target.value;\n prompt.value = template;\n prompt.style.height = \"auto\";\n prompt.style.height = prompt.scrollHeight + \"px\";\n runBtn.disabled = false;\n clearBtn.classList.remove(\"invisible\");\n });\n modelSelect.addEventListener(\"change\", (e) => {\n const query = new URLSearchParams(window.location.search);\n query.set(\"model\", e.target.value);\n window.history.replaceState(\n {},\n \"\",\n `${window.location.pathname}?${query}`\n );\n window.parent.postMessage({ queryString: \"?\" + query }, \"*\");\n const model = MODELS[e.target.value];\n document.querySelector(\"#max-seq\").max = model.seq_len;\n document.querySelector(\"#max-seq\").nextElementSibling.value = 200;\n });\n\n form.addEventListener(\"submit\", async (e) => {\n e.preventDefault();\n if (isRunning) {\n stopRunning();\n } else {\n startRunning();\n await generateSequence(runController);\n stopRunning();\n }\n });\n\n function startRunning() {\n isRunning = true;\n runBtn.textContent = \"Stop\";\n }\n\n function stopRunning() {\n runController.abort();\n runController = new AbortController();\n runBtn.textContent = \"Run\";\n isRunning = false;\n }\n clearBtn.addEventListener(\"click\", (e) => {\n e.preventDefault();\n prompt.value = \"\";\n clearBtn.classList.add(\"invisible\");\n runBtn.disabled = true;\n stopRunning();\n });\n prompt.addEventListener(\"input\", (e) => {\n runBtn.disabled = false;\n if (e.target.value.length > 0) {\n clearBtn.classList.remove(\"invisible\");\n } else {\n clearBtn.classList.add(\"invisible\");\n }\n });\n </script>\n </head>\n <body class=\"container max-w-4xl mx-auto p-4 text-gray-800\">\n <main class=\"grid grid-cols-1 gap-8 relative\">\n <span class=\"absolute text-5xl -ml-[1em]\"> \ud83d\udd6f\ufe0f </span>\n <div>\n <h1 class=\"text-5xl font-bold\">Candle Phi 1.5 / Phi 2.0</h1>\n <h2 class=\"text-2xl font-bold\">Rust/WASM Demo</h2>\n <p class=\"max-w-lg\">\n The\n <a\n href=\"https://huggingface.co/microsoft/phi-1_5\"\n class=\"link\"\n target=\"_blank\"\n >Phi-1.5</a\n >\n and\n <a\n href=\"https://huggingface.co/microsoft/phi-2\"\n class=\"link\"\n target=\"_blank\"\n >Phi-2</a\n >\n models achieve state-of-the-art performance with only 1.3 billion and\n 2.7 billion parameters, compared to larger models with up to 13\n billion parameters. Here you can try the quantized versions.\n Additional prompt examples are available in the\n <a\n href=\"https://arxiv.org/pdf/2309.05463.pdf#page=8\"\n class=\"link\"\n target=\"_blank\"\n >\n technical report </a\n >.\n </p>\n <p class=\"max-w-lg\">\n You can also try\n <a\n href=\"https://huggingface.co/teknium/Puffin-Phi-v2\"\n class=\"link\"\n target=\"_blank\"\n >Puffin-Phi V2\n </a>\n quantized version, a fine-tuned version of Phi-1.5 on the\n <a\n href=\"https://huggingface.co/datasets/LDJnr/Puffin\"\n class=\"link\"\n target=\"_blank\"\n >Puffin dataset\n </a>\n </p>\n </div>\n <div>\n <p class=\"text-xs italic max-w-lg\">\n <b>Note:</b>\n When first run, the app will download and cache the model, which could\n take a few minutes. The models are <b>~800MB</b> or <b>~1.57GB</b> in\n size.\n </p>\n </div>\n <div>\n <label for=\"model\" class=\"font-medium\">Models Options: </label>\n <select\n id=\"model\"\n class=\"border-2 border-gray-500 rounded-md font-light\"\n ></select>\n </div>\n <div>\n <details>\n <summary class=\"font-medium cursor-pointer\">Prompt Templates</summary>\n <form\n id=\"prompt-templates\"\n class=\"grid grid-cols-1 sm:grid-cols-2 gap-1 my-2\"\n ></form>\n </details>\n </div>\n <form\n id=\"form\"\n class=\"flex text-normal px-1 py-1 border border-gray-700 rounded-md items-center\"\n >\n <input type=\"submit\" hidden />\n <textarea\n type=\"text\"\n id=\"prompt\"\n class=\"font-light text-lg w-full px-3 py-2 mx-1 resize-none outline-none\"\n oninput=\"this.style.height = 0;this.style.height = this.scrollHeight + 'px'\"\n placeholder=\"Add your prompt here...\"\n >\nInstruct: Write a detailed analogy between mathematics and a lighthouse. \nOutput:</textarea\n >\n <button id=\"clear-btn\">\n <svg\n fill=\"none\"\n xmlns=\"http://www.w3.org/2000/svg\"\n width=\"40\"\n viewBox=\"0 0 70 40\"\n >\n <path opacity=\".5\" d=\"M39 .2v40.2\" stroke=\"#1F2937\" />\n <path\n d=\"M1.5 11.5 19 29.1m0-17.6L1.5 29.1\"\n opacity=\".5\"\n stroke=\"#1F2937\"\n stroke-width=\"2\"\n />\n </svg>\n </button>\n <button\n id=\"run\"\n class=\"bg-gray-700 hover:bg-gray-800 text-white font-normal py-2 w-16 rounded disabled:bg-gray-300 disabled:cursor-not-allowed\"\n >\n Run\n </button>\n </form>\n <details>\n <summary class=\"font-medium cursor-pointer\">Advanced Options</summary>\n\n <div class=\"grid grid-cols-3 max-w-md items-center gap-3 py-3\">\n <label class=\"text-sm font-medium\" for=\"max-seq\"\n >Maximum length\n </label>\n <input\n type=\"range\"\n id=\"max-seq\"\n name=\"max-seq\"\n min=\"1\"\n max=\"2048\"\n step=\"1\"\n value=\"200\"\n oninput=\"this.nextElementSibling.value = Number(this.value)\"\n />\n <output\n class=\"text-xs w-[50px] text-center font-light px-1 py-1 border border-gray-700 rounded-md\"\n >\n 200</output\n >\n <label class=\"text-sm font-medium\" for=\"temperature\"\n >Temperature</label\n >\n <input\n type=\"range\"\n id=\"temperature\"\n name=\"temperature\"\n min=\"0\"\n max=\"2\"\n step=\"0.01\"\n value=\"0.00\"\n oninput=\"this.nextElementSibling.value = Number(this.value).toFixed(2)\"\n />\n <output\n class=\"text-xs w-[50px] text-center font-light px-1 py-1 border border-gray-700 rounded-md\"\n >\n 0.00</output\n >\n <label class=\"text-sm font-medium\" for=\"top-p\">Top-p</label>\n <input\n type=\"range\"\n id=\"top-p\"\n name=\"top-p\"\n min=\"0\"\n max=\"1\"\n step=\"0.01\"\n value=\"1.00\"\n oninput=\"this.nextElementSibling.value = Number(this.value).toFixed(2)\"\n />\n <output\n class=\"text-xs w-[50px] text-center font-light px-1 py-1 border border-gray-700 rounded-md\"\n >\n 1.00</output\n >\n\n <label class=\"text-sm font-medium\" for=\"repeat_penalty\"\n >Repeat Penalty</label\n >\n\n <input\n type=\"range\"\n id=\"repeat_penalty\"\n name=\"repeat_penalty\"\n min=\"1\"\n max=\"2\"\n step=\"0.01\"\n value=\"1.10\"\n oninput=\"this.nextElementSibling.value = Number(this.value).toFixed(2)\"\n />\n <output\n class=\"text-xs w-[50px] text-center font-light px-1 py-1 border border-gray-700 rounded-md\"\n >1.10</output\n >\n <label class=\"text-sm font-medium\" for=\"seed\">Seed</label>\n <input\n type=\"number\"\n id=\"seed\"\n name=\"seed\"\n value=\"299792458\"\n class=\"font-light border border-gray-700 text-right rounded-md p-2\"\n />\n <button\n id=\"run\"\n onclick=\"document.querySelector('#seed').value = Math.floor(Math.random() * Number.MAX_SAFE_INTEGER)\"\n class=\"bg-gray-700 hover:bg-gray-800 text-white font-normal py-1 w-[50px] rounded disabled:bg-gray-300 disabled:cursor-not-allowed text-sm\"\n >\n Rand\n </button>\n </div>\n </details>\n\n <div>\n <h3 class=\"font-medium\">Generation:</h3>\n <div\n class=\"min-h-[250px] bg-slate-100 text-gray-500 p-4 rounded-md flex flex-col gap-2\"\n >\n <div\n id=\"output-counter\"\n hidden\n class=\"ml-auto font-semibold grid-rows-1\"\n ></div>\n <p hidden id=\"output-generation\" class=\"grid-rows-2 text-lg\"></p>\n <span id=\"output-status\" class=\"m-auto font-light\"\n >No output yet</span\n >\n </div>\n </div>\n </main>\n </body>\n</html>\n", "candle-wasm-examples\\t5\\index.html": "<html>\n <head>\n <meta content=\"text/html;charset=utf-8\" http-equiv=\"Content-Type\" />\n <title>Candle T5</title>\n </head>\n\n <body></body>\n</html>\n\n<!DOCTYPE html>\n<html>\n <head>\n <meta charset=\"UTF-8\" />\n <meta name=\"viewport\" content=\"width=device-width, initial-scale=1.0\" />\n <style>\n @import url(\"https://fonts.googleapis.com/css2?family=Source+Code+Pro:wght@200;300;400&family=Source+Sans+3:wght@100;200;300;400;500;600;700;800;900&display=swap\");\n\n html,\n body {\n font-family: \"Source Sans 3\", sans-serif;\n }\n </style>\n <style type=\"text/tailwindcss\">\n .link {\n @apply underline hover:text-blue-500 hover:no-underline;\n }\n </style>\n <script src=\"https://cdn.tailwindcss.com\"></script>\n <script type=\"module\">\n import {\n getModelInfo,\n MODELS,\n extractEmbeddings,\n generateText,\n } from \"./utils.js\";\n\n const t5ModelEncoderWorker = new Worker(\"./T5ModelEncoderWorker.js\", {\n type: \"module\",\n });\n const t5ModelConditionalGeneration = new Worker(\n \"./T5ModelConditionalGeneration.js\",\n { type: \"module\" }\n );\n\n const formEl = document.querySelector(\"#form\");\n const modelEl = document.querySelector(\"#model\");\n const promptEl = document.querySelector(\"#prompt\");\n const temperatureEl = document.querySelector(\"#temperature\");\n const toppEL = document.querySelector(\"#top-p\");\n const repeatPenaltyEl = document.querySelector(\"#repeat_penalty\");\n const seedEl = document.querySelector(\"#seed\");\n const outputEl = document.querySelector(\"#output-generation\");\n const tasksEl = document.querySelector(\"#tasks\");\n let selectedTaskID = \"\";\n\n document.addEventListener(\"DOMContentLoaded\", () => {\n for (const [id, model] of Object.entries(MODELS)) {\n const option = document.createElement(\"option\");\n option.value = id;\n option.innerText = `${id} (${model.size})`;\n modelEl.appendChild(option);\n }\n populateTasks(modelEl.value);\n modelEl.addEventListener(\"change\", (e) => {\n populateTasks(e.target.value);\n });\n tasksEl.addEventListener(\"change\", (e) => {\n const task = e.target.value;\n const modelID = modelEl.value;\n promptEl.value = MODELS[modelID].tasks[task].prefix;\n selectedTaskID = task;\n });\n });\n function populateTasks(modelID) {\n const tasks = MODELS[modelID].tasks;\n tasksEl.innerHTML = \"\";\n for (const [task, params] of Object.entries(tasks)) {\n const div = document.createElement(\"div\");\n div.innerHTML = `\n <input\n type=\"radio\"\n name=\"task\"\n id=\"${task}\"\n class=\"font-light cursor-pointer\"\n value=\"${task}\" />\n <label for=\"${task}\" class=\"cursor-pointer\">\n ${params.prefix}\n </label>\n `;\n tasksEl.appendChild(div);\n }\n selectedTaskID = Object.keys(tasks)[0];\n tasksEl.querySelector(`#${selectedTaskID}`).checked = true;\n }\n form.addEventListener(\"submit\", (e) => {\n e.preventDefault();\n\n const promptText = promptEl.value;\n const modelID = modelEl.value;\n const { modelURL, configURL, tokenizerURL, maxLength } = getModelInfo(\n modelID,\n selectedTaskID\n );\n const params = {\n temperature: Number(temperatureEl.value),\n top_p: Number(toppEL.value),\n repetition_penalty: Number(repeatPenaltyEl.value),\n seed: BigInt(seedEl.value),\n max_length: maxLength,\n };\n generateText(\n t5ModelConditionalGeneration,\n modelURL,\n tokenizerURL,\n configURL,\n modelID,\n promptText,\n params,\n (status) => {\n if (status.status === \"loading\") {\n outputEl.innerText = \"Loading model...\";\n }\n if (status.status === \"decoding\") {\n outputEl.innerText = \"Generating...\";\n }\n }\n ).then(({ output }) => {\n outputEl.innerText = output.generation;\n });\n });\n </script>\n </head>\n\n <body class=\"container max-w-4xl mx-auto p-4\">\n <main class=\"grid grid-cols-1 gap-8 relative\">\n <span class=\"absolute text-5xl -ml-[1em]\"> \ud83d\udd6f\ufe0f </span>\n <div>\n <h1 class=\"text-5xl font-bold\">Candle T5 Transformer</h1>\n <h2 class=\"text-2xl font-bold\">Rust/WASM Demo</h2>\n <p class=\"max-w-lg\">\n This demo showcase Text-To-Text Transfer Transformer (<a\n href=\"https://blog.research.google/2020/02/exploring-transfer-learning-with-t5.html\"\n target=\"_blank\"\n class=\"link\"\n >T5</a\n >) models right in your browser, thanks to\n <a\n href=\"https://github.com/huggingface/candle/\"\n target=\"_blank\"\n class=\"link\">\n Candle\n </a>\n ML framework and rust/wasm. You can choose from a range of available\n models, including\n <a\n href=\"https://huggingface.co/t5-small\"\n target=\"_blank\"\n class=\"link\">\n t5-small</a\n >,\n <a href=\"https://huggingface.co/t5-base\" target=\"_blank\" class=\"link\"\n >t5-base</a\n >,\n <a\n href=\"https://huggingface.co/google/flan-t5-small\"\n target=\"_blank\"\n class=\"link\"\n >flan-t5-small</a\n >,\n several\n <a\n href=\"https://huggingface.co/lmz/candle-quantized-t5/tree/main\"\n target=\"_blank\"\n class=\"link\">\n t5 quantized gguf models</a\n >, and also a quantized\n <a\n href=\"https://huggingface.co/jbochi/candle-coedit-quantized/tree/main\"\n target=\"_blank\"\n class=\"link\">\n CoEdIT model for text rewrite</a\n >.\n </p>\n </div>\n\n <div>\n <label for=\"model\" class=\"font-medium\">Models Options: </label>\n <select\n id=\"model\"\n class=\"border-2 border-gray-500 rounded-md font-light\"></select>\n </div>\n\n <div>\n <h3 class=\"font-medium\">Task Prefix:</h3>\n <form id=\"tasks\" class=\"flex flex-col gap-1 my-2\"></form>\n </div>\n <form\n id=\"form\"\n class=\"flex text-normal px-1 py-1 border border-gray-700 rounded-md items-center\">\n <input type=\"submit\" hidden />\n <input\n type=\"text\"\n id=\"prompt\"\n class=\"font-light w-full px-3 py-2 mx-1 resize-none outline-none\"\n placeholder=\"Add prompt here, e.g. 'translate English to German: Today I'm going to eat Ice Cream'\"\n value=\"translate English to German: Today I'm going to eat Ice Cream\" />\n <button\n class=\"bg-gray-700 hover:bg-gray-800 text-white font-normal py-2 w-16 rounded disabled:bg-gray-300 disabled:cursor-not-allowed\">\n Run\n </button>\n </form>\n <div class=\"grid grid-cols-3 max-w-md items-center gap-3\">\n <label class=\"text-sm font-medium\" for=\"temperature\">Temperature</label>\n <input\n type=\"range\"\n id=\"temperature\"\n name=\"temperature\"\n min=\"0\"\n max=\"2\"\n step=\"0.01\"\n value=\"0.00\"\n oninput=\"this.nextElementSibling.value = Number(this.value).toFixed(2)\" />\n <output\n class=\"text-xs w-[50px] text-center font-light px-1 py-1 border border-gray-700 rounded-md\">\n 0.00</output\n >\n <label class=\"text-sm font-medium\" for=\"top-p\">Top-p</label>\n <input\n type=\"range\"\n id=\"top-p\"\n name=\"top-p\"\n min=\"0\"\n max=\"1\"\n step=\"0.01\"\n value=\"1.00\"\n oninput=\"this.nextElementSibling.value = Number(this.value).toFixed(2)\" />\n <output\n class=\"text-xs w-[50px] text-center font-light px-1 py-1 border border-gray-700 rounded-md\">\n 1.00</output\n >\n\n <label class=\"text-sm font-medium\" for=\"repeat_penalty\"\n >Repeat Penalty</label\n >\n\n <input\n type=\"range\"\n id=\"repeat_penalty\"\n name=\"repeat_penalty\"\n min=\"1\"\n max=\"2\"\n step=\"0.01\"\n value=\"1.10\"\n oninput=\"this.nextElementSibling.value = Number(this.value).toFixed(2)\" />\n <output\n class=\"text-xs w-[50px] text-center font-light px-1 py-1 border border-gray-700 rounded-md\"\n >1.10</output\n >\n <label class=\"text-sm font-medium\" for=\"seed\">Seed</label>\n <input\n type=\"number\"\n id=\"seed\"\n name=\"seed\"\n value=\"299792458\"\n class=\"font-light border border-gray-700 text-right rounded-md p-2\" />\n <button\n id=\"run\"\n onclick=\"document.querySelector('#seed').value = BigInt(Math.floor(Math.random() * 2**64-1))\"\n class=\"bg-gray-700 hover:bg-gray-800 text-white font-normal py-1 w-[50px] rounded disabled:bg-gray-300 disabled:cursor-not-allowed text-sm\">\n Rand\n </button>\n </div>\n <div>\n <h3 class=\"font-medium\">Generation:</h3>\n <div\n class=\"min-h-[250px] bg-slate-100 text-gray-500 p-4 rounded-md flex flex-col gap-2 text-lg\">\n <p id=\"output-generation\" class=\"grid-rows-2\">No output yet</p>\n </div>\n </div>\n </main>\n </body>\n</html>\n", "candle-wasm-examples\\whisper\\index.html": "<!DOCTYPE html>\n<html lang=\"en\">\n <head>\n <meta charset=\"utf-8\" />\n <title>Welcome to Candle!</title>\n <link data-trunk rel=\"copy-file\" href=\"mel_filters.safetensors\" />\n <!-- samples -->\n <link data-trunk rel=\"copy-dir\" href=\"audios\" />\n <!-- tiny.en -->\n <link data-trunk rel=\"copy-dir\" href=\"whisper-tiny.en\" />\n <!-- tiny -->\n <link data-trunk rel=\"copy-dir\" href=\"whisper-tiny\" />\n <!-- quantized -->\n <link data-trunk rel=\"copy-dir\" href=\"quantized\" />\n\n <link\n data-trunk\n rel=\"rust\"\n href=\"Cargo.toml\"\n data-bin=\"app\"\n data-type=\"main\" />\n <link\n data-trunk\n rel=\"rust\"\n href=\"Cargo.toml\"\n data-bin=\"worker\"\n data-type=\"worker\" />\n\n <link\n rel=\"stylesheet\"\n href=\"https://fonts.googleapis.com/css?family=Roboto:300,300italic,700,700italic\" />\n <link\n rel=\"stylesheet\"\n href=\"https://cdnjs.cloudflare.com/ajax/libs/normalize/8.0.1/normalize.css\" />\n <link\n rel=\"stylesheet\"\n href=\"https://cdnjs.cloudflare.com/ajax/libs/milligram/1.4.1/milligram.css\" />\n </head>\n <body></body>\n</html>\n", "candle-wasm-examples\\whisper\\main.js": "import init, { run_app } from './pkg/candle_wasm_example_whisper.js';\nasync function main() {\n await init('/pkg/candle_wasm_example_whisper_bg.wasm');\n run_app();\n}\nmain()\n", "candle-wasm-examples\\whisper\\src\\app.rs": "use crate::console_log;\nuse crate::worker::{ModelData, Segment, Worker, WorkerInput, WorkerOutput};\nuse js_sys::Date;\nuse wasm_bindgen::prelude::*;\nuse wasm_bindgen_futures::JsFuture;\nuse yew::{html, Component, Context, Html};\nuse yew_agent::{Bridge, Bridged};\n\nconst SAMPLE_NAMES: [&str; 6] = [\n \"audios/samples_jfk.wav\",\n \"audios/samples_a13.wav\",\n \"audios/samples_gb0.wav\",\n \"audios/samples_gb1.wav\",\n \"audios/samples_hp0.wav\",\n \"audios/samples_mm0.wav\",\n];\n\nasync fn fetch_url(url: &str) -> Result<Vec<u8>, JsValue> {\n use web_sys::{Request, RequestCache, RequestInit, RequestMode, Response};\n let window = web_sys::window().ok_or(\"window\")?;\n let opts = RequestInit::new();\n opts.set_method(\"GET\");\n opts.set_mode(RequestMode::Cors);\n opts.set_cache(RequestCache::NoCache);\n let request = Request::new_with_str_and_init(url, &opts)?;\n\n let resp_value = JsFuture::from(window.fetch_with_request(&request)).await?;\n\n // `resp_value` is a `Response` object.\n assert!(resp_value.is_instance_of::<Response>());\n let resp: Response = resp_value.dyn_into()?;\n let data = JsFuture::from(resp.blob()?).await?;\n let blob = web_sys::Blob::from(data);\n let array_buffer = JsFuture::from(blob.array_buffer()).await?;\n let data = js_sys::Uint8Array::new(&array_buffer).to_vec();\n Ok(data)\n}\n\npub enum Msg {\n Run(usize),\n UpdateStatus(String),\n SetDecoder(ModelData),\n WorkerIn(WorkerInput),\n WorkerOut(Result<WorkerOutput, String>),\n}\n\npub struct CurrentDecode {\n start_time: Option<f64>,\n}\n\npub struct App {\n status: String,\n loaded: bool,\n segments: Vec<Segment>,\n current_decode: Option<CurrentDecode>,\n worker: Box<dyn Bridge<Worker>>,\n}\n\nasync fn model_data_load() -> Result<ModelData, JsValue> {\n let quantized = false;\n let is_multilingual = false;\n\n let (tokenizer, mel_filters, weights, config) = if quantized {\n console_log!(\"loading quantized weights\");\n let tokenizer = fetch_url(\"quantized/tokenizer-tiny-en.json\").await?;\n let mel_filters = fetch_url(\"mel_filters.safetensors\").await?;\n let weights = fetch_url(\"quantized/model-tiny-en-q80.gguf\").await?;\n let config = fetch_url(\"quantized/config-tiny-en.json\").await?;\n (tokenizer, mel_filters, weights, config)\n } else {\n console_log!(\"loading float weights\");\n if is_multilingual {\n let mel_filters = fetch_url(\"mel_filters.safetensors\").await?;\n let tokenizer = fetch_url(\"whisper-tiny/tokenizer.json\").await?;\n let weights = fetch_url(\"whisper-tiny/model.safetensors\").await?;\n let config = fetch_url(\"whisper-tiny/config.json\").await?;\n (tokenizer, mel_filters, weights, config)\n } else {\n let mel_filters = fetch_url(\"mel_filters.safetensors\").await?;\n let tokenizer = fetch_url(\"whisper-tiny.en/tokenizer.json\").await?;\n let weights = fetch_url(\"whisper-tiny.en/model.safetensors\").await?;\n let config = fetch_url(\"whisper-tiny.en/config.json\").await?;\n (tokenizer, mel_filters, weights, config)\n }\n };\n\n let timestamps = true;\n let _task = Some(\"transcribe\".to_string());\n console_log!(\"{}\", weights.len());\n Ok(ModelData {\n tokenizer,\n mel_filters,\n weights,\n config,\n quantized,\n timestamps,\n task: None,\n is_multilingual,\n language: None,\n })\n}\n\nfn performance_now() -> Option<f64> {\n let window = web_sys::window()?;\n let performance = window.performance()?;\n Some(performance.now() / 1000.)\n}\n\nimpl Component for App {\n type Message = Msg;\n type Properties = ();\n\n fn create(ctx: &Context<Self>) -> Self {\n let status = \"loading weights\".to_string();\n let cb = {\n let link = ctx.link().clone();\n move |e| link.send_message(Self::Message::WorkerOut(e))\n };\n let worker = Worker::bridge(std::rc::Rc::new(cb));\n Self {\n status,\n segments: vec![],\n current_decode: None,\n worker,\n loaded: false,\n }\n }\n\n fn rendered(&mut self, ctx: &Context<Self>, first_render: bool) {\n if first_render {\n ctx.link().send_future(async {\n match model_data_load().await {\n Err(err) => {\n let status = format!(\"{err:?}\");\n Msg::UpdateStatus(status)\n }\n Ok(model_data) => Msg::SetDecoder(model_data),\n }\n });\n }\n }\n\n fn update(&mut self, ctx: &Context<Self>, msg: Self::Message) -> bool {\n match msg {\n Msg::SetDecoder(md) => {\n self.status = \"weights loaded successfully!\".to_string();\n self.loaded = true;\n console_log!(\"loaded weights\");\n self.worker.send(WorkerInput::ModelData(md));\n true\n }\n Msg::Run(sample_index) => {\n let sample = SAMPLE_NAMES[sample_index];\n if self.current_decode.is_some() {\n self.status = \"already decoding some sample at the moment\".to_string()\n } else {\n let start_time = performance_now();\n self.current_decode = Some(CurrentDecode { start_time });\n self.status = format!(\"decoding {sample}\");\n self.segments.clear();\n ctx.link().send_future(async move {\n match fetch_url(sample).await {\n Err(err) => {\n let output = Err(format!(\"decoding error: {err:?}\"));\n // Mimic a worker output to so as to release current_decode\n Msg::WorkerOut(output)\n }\n Ok(wav_bytes) => Msg::WorkerIn(WorkerInput::DecodeTask { wav_bytes }),\n }\n })\n }\n //\n true\n }\n Msg::WorkerOut(output) => {\n let dt = self.current_decode.as_ref().and_then(|current_decode| {\n current_decode.start_time.and_then(|start_time| {\n performance_now().map(|stop_time| stop_time - start_time)\n })\n });\n self.current_decode = None;\n match output {\n Ok(WorkerOutput::WeightsLoaded) => self.status = \"weights loaded!\".to_string(),\n Ok(WorkerOutput::Decoded(segments)) => {\n self.status = match dt {\n None => \"decoding succeeded!\".to_string(),\n Some(dt) => format!(\"decoding succeeded in {:.2}s\", dt),\n };\n self.segments = segments;\n }\n Err(err) => {\n self.status = format!(\"decoding error {err:?}\");\n }\n }\n true\n }\n Msg::WorkerIn(inp) => {\n self.worker.send(inp);\n true\n }\n Msg::UpdateStatus(status) => {\n self.status = status;\n true\n }\n }\n }\n\n fn view(&self, ctx: &Context<Self>) -> Html {\n html! {\n <div>\n <table>\n <thead>\n <tr>\n <th>{\"Sample\"}</th>\n <th></th>\n <th></th>\n </tr>\n </thead>\n <tbody>\n {\n SAMPLE_NAMES.iter().enumerate().map(|(i, name)| { html! {\n <tr>\n <th>{name}</th>\n <th><audio controls=true src={format!(\"./{name}\")}></audio></th>\n { if self.loaded {\n html!(<th><button class=\"button\" onclick={ctx.link().callback(move |_| Msg::Run(i))}> { \"run\" }</button></th>)\n }else{html!()}\n }\n </tr>\n }\n }).collect::<Html>()\n }\n </tbody>\n </table>\n <h2>\n {&self.status}\n </h2>\n {\n if !self.loaded{\n html! { <progress id=\"progress-bar\" aria-label=\"loading weights\u2026\"></progress> }\n } else if self.current_decode.is_some() {\n html! { <progress id=\"progress-bar\" aria-label=\"decoding\u2026\"></progress> }\n } else { html!{\n <blockquote>\n <p>\n {\n self.segments.iter().map(|segment| { html! {\n <>\n <i>\n {\n format!(\"{:.2}s-{:.2}s: (avg-logprob: {:.4}, no-speech-prob: {:.4})\",\n segment.start,\n segment.start + segment.duration,\n segment.dr.avg_logprob,\n segment.dr.no_speech_prob,\n )\n }\n </i>\n <br/ >\n {&segment.dr.text}\n <br/ >\n </>\n } }).collect::<Html>()\n }\n </p>\n </blockquote>\n }\n }\n }\n\n // Display the current date and time the page was rendered\n <p class=\"footer\">\n { \"Rendered: \" }\n { String::from(Date::new_0().to_string()) }\n </p>\n </div>\n }\n }\n}\n", "candle-wasm-examples\\whisper\\src\\bin\\app.rs": "fn main() {\n wasm_logger::init(wasm_logger::Config::new(log::Level::Trace));\n yew::Renderer::<candle_wasm_example_whisper::App>::new().render();\n}\n", "candle-wasm-examples\\yolo\\index.html": "<!DOCTYPE html>\n<html lang=\"en\">\n <head>\n <meta charset=\"utf-8\" />\n <title>Welcome to Candle!</title>\n\n <link data-trunk rel=\"copy-file\" href=\"yolov8s.safetensors\" />\n <link data-trunk rel=\"copy-file\" href=\"bike.jpeg\" />\n <link data-trunk rel=\"rust\" href=\"Cargo.toml\" data-bin=\"app\" data-type=\"main\" />\n <link data-trunk rel=\"rust\" href=\"Cargo.toml\" data-bin=\"worker\" data-type=\"worker\" />\n\n <link rel=\"stylesheet\" href=\"https://fonts.googleapis.com/css?family=Roboto:300,300italic,700,700italic\">\n <link rel=\"stylesheet\" href=\"https://cdnjs.cloudflare.com/ajax/libs/normalize/8.0.1/normalize.css\">\n <link rel=\"stylesheet\" href=\"https://cdnjs.cloudflare.com/ajax/libs/milligram/1.4.1/milligram.css\">\n </head>\n <body></body>\n</html>\n", "candle-wasm-examples\\yolo\\src\\app.rs": "use crate::console_log;\nuse crate::worker::{ModelData, RunData, Worker, WorkerInput, WorkerOutput};\nuse wasm_bindgen::prelude::*;\nuse wasm_bindgen_futures::JsFuture;\nuse yew::{html, Component, Context, Html};\nuse yew_agent::{Bridge, Bridged};\n\nasync fn fetch_url(url: &str) -> Result<Vec<u8>, JsValue> {\n use web_sys::{Request, RequestCache, RequestInit, RequestMode, Response};\n let window = web_sys::window().ok_or(\"window\")?;\n let opts = RequestInit::new();\n opts.set_method(\"GET\");\n opts.set_mode(RequestMode::Cors);\n opts.set_cache(RequestCache::NoCache);\n\n let request = Request::new_with_str_and_init(url, &opts)?;\n\n let resp_value = JsFuture::from(window.fetch_with_request(&request)).await?;\n\n // `resp_value` is a `Response` object.\n assert!(resp_value.is_instance_of::<Response>());\n let resp: Response = resp_value.dyn_into()?;\n let data = JsFuture::from(resp.blob()?).await?;\n let blob = web_sys::Blob::from(data);\n let array_buffer = JsFuture::from(blob.array_buffer()).await?;\n let data = js_sys::Uint8Array::new(&array_buffer).to_vec();\n Ok(data)\n}\n\npub enum Msg {\n Refresh,\n Run,\n UpdateStatus(String),\n SetModel(ModelData),\n WorkerIn(WorkerInput),\n WorkerOut(Result<WorkerOutput, String>),\n}\n\npub struct CurrentDecode {\n start_time: Option<f64>,\n}\n\npub struct App {\n status: String,\n loaded: bool,\n generated: String,\n current_decode: Option<CurrentDecode>,\n worker: Box<dyn Bridge<Worker>>,\n}\n\nasync fn model_data_load() -> Result<ModelData, JsValue> {\n let weights = fetch_url(\"yolov8s.safetensors\").await?;\n let model_size = \"s\".to_string();\n console_log!(\"loaded weights {}\", weights.len());\n Ok(ModelData {\n weights,\n model_size,\n })\n}\n\nfn performance_now() -> Option<f64> {\n let window = web_sys::window()?;\n let performance = window.performance()?;\n Some(performance.now() / 1000.)\n}\n\nfn draw_bboxes(bboxes: Vec<Vec<crate::model::Bbox>>) -> Result<(), JsValue> {\n let document = web_sys::window().unwrap().document().unwrap();\n let canvas = match document.get_element_by_id(\"canvas\") {\n Some(canvas) => canvas,\n None => return Err(\"no canvas\".into()),\n };\n let canvas: web_sys::HtmlCanvasElement = canvas.dyn_into::<web_sys::HtmlCanvasElement>()?;\n\n let context = canvas\n .get_context(\"2d\")?\n .ok_or(\"no 2d\")?\n .dyn_into::<web_sys::CanvasRenderingContext2d>()?;\n\n let image_html_element = document.get_element_by_id(\"bike-img\");\n let image_html_element = match image_html_element {\n Some(data) => data,\n None => return Err(\"no bike-img\".into()),\n };\n let image_html_element = image_html_element.dyn_into::<web_sys::HtmlImageElement>()?;\n canvas.set_width(image_html_element.natural_width());\n canvas.set_height(image_html_element.natural_height());\n context.draw_image_with_html_image_element(&image_html_element, 0., 0.)?;\n context.set_stroke_style(&JsValue::from(\"#0dff9a\"));\n for (class_index, bboxes_for_class) in bboxes.iter().enumerate() {\n for b in bboxes_for_class.iter() {\n let name = crate::coco_classes::NAMES[class_index];\n context.stroke_rect(\n b.xmin as f64,\n b.ymin as f64,\n (b.xmax - b.xmin) as f64,\n (b.ymax - b.ymin) as f64,\n );\n if let Ok(metrics) = context.measure_text(name) {\n let width = metrics.width();\n context.set_fill_style(&\"#3c8566\".into());\n context.fill_rect(b.xmin as f64 - 2., b.ymin as f64 - 12., width + 4., 14.);\n context.set_fill_style(&\"#e3fff3\".into());\n context.fill_text(name, b.xmin as f64, b.ymin as f64 - 2.)?\n }\n }\n }\n Ok(())\n}\n\nimpl Component for App {\n type Message = Msg;\n type Properties = ();\n\n fn create(ctx: &Context<Self>) -> Self {\n let status = \"loading weights\".to_string();\n let cb = {\n let link = ctx.link().clone();\n move |e| link.send_message(Self::Message::WorkerOut(e))\n };\n let worker = Worker::bridge(std::rc::Rc::new(cb));\n Self {\n status,\n generated: String::new(),\n current_decode: None,\n worker,\n loaded: false,\n }\n }\n\n fn rendered(&mut self, ctx: &Context<Self>, first_render: bool) {\n if first_render {\n ctx.link().send_future(async {\n match model_data_load().await {\n Err(err) => {\n let status = format!(\"{err:?}\");\n Msg::UpdateStatus(status)\n }\n Ok(model_data) => Msg::SetModel(model_data),\n }\n });\n }\n }\n\n fn update(&mut self, ctx: &Context<Self>, msg: Self::Message) -> bool {\n match msg {\n Msg::SetModel(md) => {\n self.status = \"weights loaded successfully!\".to_string();\n self.loaded = true;\n console_log!(\"loaded weights\");\n self.worker.send(WorkerInput::ModelData(md));\n true\n }\n Msg::Run => {\n if self.current_decode.is_some() {\n self.status = \"already processing some image at the moment\".to_string()\n } else {\n let start_time = performance_now();\n self.current_decode = Some(CurrentDecode { start_time });\n self.status = \"processing...\".to_string();\n self.generated.clear();\n ctx.link().send_future(async {\n match fetch_url(\"bike.jpeg\").await {\n Err(err) => {\n let status = format!(\"{err:?}\");\n Msg::UpdateStatus(status)\n }\n Ok(image_data) => Msg::WorkerIn(WorkerInput::RunData(RunData {\n image_data,\n conf_threshold: 0.5,\n iou_threshold: 0.5,\n })),\n }\n });\n }\n true\n }\n Msg::WorkerOut(output) => {\n match output {\n Ok(WorkerOutput::WeightsLoaded) => self.status = \"weights loaded!\".to_string(),\n Ok(WorkerOutput::ProcessingDone(Err(err))) => {\n self.status = format!(\"error in worker process: {err}\");\n self.current_decode = None\n }\n Ok(WorkerOutput::ProcessingDone(Ok(bboxes))) => {\n let mut content = Vec::new();\n for (class_index, bboxes_for_class) in bboxes.iter().enumerate() {\n for b in bboxes_for_class.iter() {\n content.push(format!(\n \"bbox {}: xs {:.0}-{:.0} ys {:.0}-{:.0}\",\n crate::coco_classes::NAMES[class_index],\n b.xmin,\n b.xmax,\n b.ymin,\n b.ymax\n ))\n }\n }\n self.generated = content.join(\"\\n\");\n let dt = self.current_decode.as_ref().and_then(|current_decode| {\n current_decode.start_time.and_then(|start_time| {\n performance_now().map(|stop_time| stop_time - start_time)\n })\n });\n self.status = match dt {\n None => \"processing succeeded!\".to_string(),\n Some(dt) => format!(\"processing succeeded in {:.2}s\", dt,),\n };\n self.current_decode = None;\n if let Err(err) = draw_bboxes(bboxes) {\n self.status = format!(\"{err:?}\")\n }\n }\n Err(err) => {\n self.status = format!(\"error in worker {err:?}\");\n }\n }\n true\n }\n Msg::WorkerIn(inp) => {\n self.worker.send(inp);\n true\n }\n Msg::UpdateStatus(status) => {\n self.status = status;\n true\n }\n Msg::Refresh => true,\n }\n }\n\n fn view(&self, ctx: &Context<Self>) -> Html {\n html! {\n <div style=\"margin: 2%;\">\n <div><p>{\"Running an object detection model in the browser using rust/wasm with \"}\n <a href=\"https://github.com/huggingface/candle\" target=\"_blank\">{\"candle!\"}</a>\n </p>\n <p>{\"Once the weights have loaded, click on the run button to process an image.\"}</p>\n <p><img id=\"bike-img\" src=\"bike.jpeg\"/></p>\n <p>{\"Source: \"}<a href=\"https://commons.wikimedia.org/wiki/File:V%C3%A9lo_parade_-_V%C3%A9lorution_-_bike_critical_mass.JPG\">{\"wikimedia\"}</a></p>\n </div>\n {\n if self.loaded{\n html!(<button class=\"button\" onclick={ctx.link().callback(move |_| Msg::Run)}> { \"run\" }</button>)\n }else{\n html! { <progress id=\"progress-bar\" aria-label=\"Loading weights...\"></progress> }\n }\n }\n <br/ >\n <h3>\n {&self.status}\n </h3>\n {\n if self.current_decode.is_some() {\n html! { <progress id=\"progress-bar\" aria-label=\"generating\u2026\"></progress> }\n } else {\n html! {}\n }\n }\n <div>\n <canvas id=\"canvas\" height=\"150\" width=\"150\"></canvas>\n </div>\n <blockquote>\n <p> { self.generated.chars().map(|c|\n if c == '\\r' || c == '\\n' {\n html! { <br/> }\n } else {\n html! { {c} }\n }).collect::<Html>()\n } </p>\n </blockquote>\n </div>\n }\n }\n}\n", "candle-wasm-examples\\yolo\\src\\bin\\app.rs": "fn main() {\n wasm_logger::init(wasm_logger::Config::new(log::Level::Trace));\n console_error_panic_hook::set_once();\n yew::Renderer::<candle_wasm_example_yolo::App>::new().render();\n}\n", "tensor-tools\\src\\main.rs": "use candle::quantized::{gguf_file, GgmlDType, QTensor};\nuse candle::{Device, Result};\nuse clap::{Parser, Subcommand, ValueEnum};\nuse rayon::prelude::*;\n\n#[derive(ValueEnum, Debug, Clone)]\nenum QuantizationMode {\n /// The default quantization includes all 2d tensors, except the output tensor which always\n /// uses Q6_K.\n Llama,\n}\n\nimpl QuantizationMode {\n fn quantize(&self, name: &str, tensor: QTensor, dtype: GgmlDType) -> Result<QTensor> {\n match self {\n Self::Llama => {\n // Same behavior as the llama.cpp quantization.\n let should_quantize = name.ends_with(\".weight\") && tensor.rank() == 2;\n if should_quantize {\n let tensor = tensor.dequantize(&Device::Cpu)?;\n if name == \"output.weight\" {\n QTensor::quantize(&tensor, GgmlDType::Q6K)\n } else {\n QTensor::quantize(&tensor, dtype)\n }\n } else {\n Ok(tensor)\n }\n }\n }\n }\n}\n\n#[derive(ValueEnum, Debug, Clone)]\nenum Quantization {\n #[value(name = \"q4_0\")]\n Q4_0,\n #[value(name = \"q4_1\")]\n Q4_1,\n #[value(name = \"q5_0\")]\n Q5_0,\n #[value(name = \"q5_1\")]\n Q5_1,\n #[value(name = \"q8_0\")]\n Q8_0,\n #[value(name = \"q8_1\")]\n Q8_1,\n Q2k,\n Q3k,\n Q4k,\n Q5k,\n Q6k,\n Q8k,\n F16,\n F32,\n}\n\nimpl Quantization {\n fn dtype(&self) -> GgmlDType {\n match self {\n Quantization::Q4_0 => GgmlDType::Q4_0,\n Quantization::Q4_1 => GgmlDType::Q4_1,\n Quantization::Q5_0 => GgmlDType::Q5_0,\n Quantization::Q5_1 => GgmlDType::Q5_1,\n Quantization::Q8_0 => GgmlDType::Q8_0,\n Quantization::Q8_1 => GgmlDType::Q8_1,\n Quantization::Q2k => GgmlDType::Q2K,\n Quantization::Q3k => GgmlDType::Q3K,\n Quantization::Q4k => GgmlDType::Q4K,\n Quantization::Q5k => GgmlDType::Q5K,\n Quantization::Q6k => GgmlDType::Q6K,\n Quantization::Q8k => GgmlDType::Q8K,\n Quantization::F16 => GgmlDType::F16,\n Quantization::F32 => GgmlDType::F32,\n }\n }\n}\n\n#[derive(ValueEnum, Debug, Clone)]\nenum Format {\n Safetensors,\n Npz,\n Ggml,\n Gguf,\n Pth,\n Pickle,\n}\n\nimpl Format {\n fn infer<P: AsRef<std::path::Path>>(p: P) -> Option<Self> {\n p.as_ref()\n .extension()\n .and_then(|e| e.to_str())\n .and_then(|e| match e {\n // We don't infer any format for .bin as it can be used for ggml/gguf or pytorch.\n \"safetensors\" | \"safetensor\" => Some(Self::Safetensors),\n \"npz\" => Some(Self::Npz),\n \"pth\" | \"pt\" => Some(Self::Pth),\n \"ggml\" => Some(Self::Ggml),\n \"gguf\" => Some(Self::Gguf),\n _ => None,\n })\n }\n}\n\n#[derive(Subcommand, Debug, Clone)]\nenum Command {\n Ls {\n files: Vec<std::path::PathBuf>,\n\n /// The file format to use, if unspecified infer from the file extension.\n #[arg(long, value_enum)]\n format: Option<Format>,\n\n /// Enable verbose mode.\n #[arg(short, long)]\n verbose: bool,\n },\n\n Print {\n file: std::path::PathBuf,\n\n names: Vec<String>,\n\n /// The file format to use, if unspecified infer from the file extension.\n #[arg(long, value_enum)]\n format: Option<Format>,\n\n /// Print the whole content of each tensor.\n #[arg(long)]\n full: bool,\n\n /// Line width for printing the tensors.\n #[arg(long)]\n line_width: Option<usize>,\n },\n\n Quantize {\n /// The input file(s), in safetensors format.\n in_file: Vec<std::path::PathBuf>,\n\n /// The output file, in gguf format.\n #[arg(long)]\n out_file: std::path::PathBuf,\n\n /// The quantization schema to apply.\n #[arg(long, value_enum)]\n quantization: Quantization,\n\n /// Which tensor to quantize.\n #[arg(long, value_enum, default_value_t = QuantizationMode::Llama)]\n mode: QuantizationMode,\n },\n\n Dequantize {\n /// The input file, in gguf format.\n in_file: std::path::PathBuf,\n\n /// The output file, in safetensors format.\n #[arg(long)]\n out_file: std::path::PathBuf,\n },\n}\n\n#[derive(Parser, Debug, Clone)]\nstruct Args {\n #[command(subcommand)]\n command: Command,\n}\n\nfn run_print(\n file: &std::path::PathBuf,\n names: Vec<String>,\n format: Option<Format>,\n full: bool,\n line_width: Option<usize>,\n device: &Device,\n) -> Result<()> {\n if full {\n candle::display::set_print_options_full();\n }\n if let Some(line_width) = line_width {\n candle::display::set_line_width(line_width)\n }\n let format = match format {\n Some(format) => format,\n None => match Format::infer(file) {\n Some(format) => format,\n None => {\n println!(\n \"{file:?}: cannot infer format from file extension, use the --format flag\"\n );\n return Ok(());\n }\n },\n };\n match format {\n Format::Npz => {\n let tensors = candle::npy::NpzTensors::new(file)?;\n for name in names.iter() {\n println!(\"==== {name} ====\");\n match tensors.get(name)? {\n Some(tensor) => println!(\"{tensor}\"),\n None => println!(\"not found\"),\n }\n }\n }\n Format::Safetensors => {\n use candle::safetensors::Load;\n let tensors = unsafe { candle::safetensors::MmapedSafetensors::new(file)? };\n let tensors: std::collections::HashMap<_, _> = tensors.tensors().into_iter().collect();\n for name in names.iter() {\n println!(\"==== {name} ====\");\n match tensors.get(name) {\n Some(tensor_view) => {\n let tensor = tensor_view.load(device)?;\n println!(\"{tensor}\")\n }\n None => println!(\"not found\"),\n }\n }\n }\n Format::Pth => {\n let pth_file = candle::pickle::PthTensors::new(file, None)?;\n for name in names.iter() {\n println!(\"==== {name} ====\");\n match pth_file.get(name)? {\n Some(tensor) => {\n println!(\"{tensor}\")\n }\n None => println!(\"not found\"),\n }\n }\n }\n Format::Pickle => {\n candle::bail!(\"pickle format is not supported for print\")\n }\n Format::Ggml => {\n let mut file = std::fs::File::open(file)?;\n let content = candle::quantized::ggml_file::Content::read(&mut file, device)?;\n for name in names.iter() {\n println!(\"==== {name} ====\");\n match content.tensors.get(name) {\n Some(tensor) => {\n let tensor = tensor.dequantize(device)?;\n println!(\"{tensor}\")\n }\n None => println!(\"not found\"),\n }\n }\n }\n Format::Gguf => {\n let mut file = std::fs::File::open(file)?;\n let content = gguf_file::Content::read(&mut file)?;\n for name in names.iter() {\n println!(\"==== {name} ====\");\n match content.tensor(&mut file, name, device) {\n Ok(tensor) => {\n let tensor = tensor.dequantize(device)?;\n println!(\"{tensor}\")\n }\n Err(_) => println!(\"not found\"),\n }\n }\n }\n }\n Ok(())\n}\n\nfn run_ls(\n file: &std::path::PathBuf,\n format: Option<Format>,\n verbose: bool,\n device: &Device,\n) -> Result<()> {\n let format = match format {\n Some(format) => format,\n None => match Format::infer(file) {\n Some(format) => format,\n None => {\n println!(\n \"{file:?}: cannot infer format from file extension, use the --format flag\"\n );\n return Ok(());\n }\n },\n };\n match format {\n Format::Npz => {\n let tensors = candle::npy::NpzTensors::new(file)?;\n let mut names = tensors.names();\n names.sort();\n for name in names {\n let shape_dtype = match tensors.get_shape_and_dtype(name) {\n Ok((shape, dtype)) => format!(\"[{shape:?}; {dtype:?}]\"),\n Err(err) => err.to_string(),\n };\n println!(\"{name}: {shape_dtype}\")\n }\n }\n Format::Safetensors => {\n let tensors = unsafe { candle::safetensors::MmapedSafetensors::new(file)? };\n let mut tensors = tensors.tensors();\n tensors.sort_by(|a, b| a.0.cmp(&b.0));\n for (name, view) in tensors.iter() {\n let dtype = view.dtype();\n let dtype = match candle::DType::try_from(dtype) {\n Ok(dtype) => format!(\"{dtype:?}\"),\n Err(_) => format!(\"{dtype:?}\"),\n };\n let shape = view.shape();\n println!(\"{name}: [{shape:?}; {dtype}]\")\n }\n }\n Format::Pth => {\n let mut tensors = candle::pickle::read_pth_tensor_info(file, verbose, None)?;\n tensors.sort_by(|a, b| a.name.cmp(&b.name));\n for tensor_info in tensors.iter() {\n println!(\n \"{}: [{:?}; {:?}]\",\n tensor_info.name,\n tensor_info.layout.shape(),\n tensor_info.dtype,\n );\n if verbose {\n println!(\" {:?}\", tensor_info);\n }\n }\n }\n Format::Pickle => {\n let file = std::fs::File::open(file)?;\n let mut reader = std::io::BufReader::new(file);\n let mut stack = candle::pickle::Stack::empty();\n stack.read_loop(&mut reader)?;\n for (i, obj) in stack.stack().iter().enumerate() {\n println!(\"{i} {obj:?}\");\n }\n }\n Format::Ggml => {\n let mut file = std::fs::File::open(file)?;\n let content = candle::quantized::ggml_file::Content::read(&mut file, device)?;\n let mut tensors = content.tensors.into_iter().collect::<Vec<_>>();\n tensors.sort_by(|a, b| a.0.cmp(&b.0));\n for (name, qtensor) in tensors.iter() {\n println!(\"{name}: [{:?}; {:?}]\", qtensor.shape(), qtensor.dtype());\n }\n }\n Format::Gguf => {\n let mut file = std::fs::File::open(file)?;\n let content = gguf_file::Content::read(&mut file)?;\n if verbose {\n let mut metadata = content.metadata.into_iter().collect::<Vec<_>>();\n metadata.sort_by(|a, b| a.0.cmp(&b.0));\n println!(\"metadata entries ({})\", metadata.len());\n for (key, value) in metadata.iter() {\n println!(\" {key}: {value:?}\");\n }\n }\n let mut tensors = content.tensor_infos.into_iter().collect::<Vec<_>>();\n tensors.sort_by(|a, b| a.0.cmp(&b.0));\n for (name, info) in tensors.iter() {\n println!(\"{name}: [{:?}; {:?}]\", info.shape, info.ggml_dtype);\n }\n }\n }\n Ok(())\n}\n\nfn run_quantize_safetensors(\n in_files: &[std::path::PathBuf],\n out_file: std::path::PathBuf,\n q: Quantization,\n) -> Result<()> {\n let mut out_file = std::fs::File::create(out_file)?;\n let mut tensors = std::collections::HashMap::new();\n for in_file in in_files.iter() {\n let in_tensors = candle::safetensors::load(in_file, &Device::Cpu)?;\n tensors.extend(in_tensors)\n }\n println!(\"tensors: {}\", tensors.len());\n\n let dtype = q.dtype();\n let block_size = dtype.block_size();\n\n let qtensors = tensors\n .into_par_iter()\n .map(|(name, tensor)| {\n let should_quantize = tensor.rank() == 2 && tensor.dim(1)? % block_size == 0;\n println!(\" quantizing {name} {tensor:?} {should_quantize}\");\n let tensor = if should_quantize {\n QTensor::quantize(&tensor, dtype)?\n } else {\n QTensor::quantize(&tensor, GgmlDType::F32)?\n };\n Ok((name, tensor))\n })\n .collect::<Result<Vec<_>>>()?;\n let qtensors = qtensors\n .iter()\n .map(|(k, v)| (k.as_str(), v))\n .collect::<Vec<_>>();\n gguf_file::write(&mut out_file, &[], &qtensors)?;\n Ok(())\n}\n\nfn run_dequantize(\n in_file: std::path::PathBuf,\n out_file: std::path::PathBuf,\n device: &Device,\n) -> Result<()> {\n let mut in_file = std::fs::File::open(in_file)?;\n let content = gguf_file::Content::read(&mut in_file)?;\n let mut tensors = std::collections::HashMap::new();\n for (tensor_name, _) in content.tensor_infos.iter() {\n let tensor = content.tensor(&mut in_file, tensor_name, device)?;\n let tensor = tensor.dequantize(device)?;\n tensors.insert(tensor_name.to_string(), tensor);\n }\n candle::safetensors::save(&tensors, out_file)?;\n Ok(())\n}\n\nfn run_quantize(\n in_files: &[std::path::PathBuf],\n out_file: std::path::PathBuf,\n q: Quantization,\n qmode: QuantizationMode,\n device: &Device,\n) -> Result<()> {\n if in_files.is_empty() {\n candle::bail!(\"no specified input files\")\n }\n if let Some(extension) = out_file.extension() {\n if extension == \"safetensors\" {\n candle::bail!(\"the generated file cannot use the safetensors extension\")\n }\n }\n if let Some(extension) = in_files[0].extension() {\n if extension == \"safetensors\" {\n return run_quantize_safetensors(in_files, out_file, q);\n }\n }\n\n if in_files.len() != 1 {\n candle::bail!(\"only a single in-file can be used when quantizing gguf files\")\n }\n\n // Open the out file early so as to fail directly on missing directories etc.\n let mut out_file = std::fs::File::create(out_file)?;\n let mut in_ = std::fs::File::open(&in_files[0])?;\n let content = gguf_file::Content::read(&mut in_)?;\n println!(\"tensors: {}\", content.tensor_infos.len());\n\n let dtype = q.dtype();\n let qtensors = content\n .tensor_infos\n .par_iter()\n .map(|(name, _)| {\n println!(\" quantizing {name}\");\n let mut in_file = std::fs::File::open(&in_files[0])?;\n let tensor = content.tensor(&mut in_file, name, device)?;\n let tensor = qmode.quantize(name, tensor, dtype)?;\n Ok((name, tensor))\n })\n .collect::<Result<Vec<_>>>()?;\n let qtensors = qtensors\n .iter()\n .map(|(k, v)| (k.as_str(), v))\n .collect::<Vec<_>>();\n\n let metadata = content\n .metadata\n .iter()\n .map(|(k, v)| (k.as_str(), v))\n .collect::<Vec<_>>();\n gguf_file::write(&mut out_file, metadata.as_slice(), &qtensors)?;\n Ok(())\n}\n\nfn main() -> anyhow::Result<()> {\n let args = Args::parse();\n let device = Device::Cpu;\n match args.command {\n Command::Ls {\n files,\n format,\n verbose,\n } => {\n let multiple_files = files.len() > 1;\n for file in files.iter() {\n if multiple_files {\n println!(\"--- {file:?} ---\");\n }\n run_ls(file, format.clone(), verbose, &device)?\n }\n }\n Command::Print {\n file,\n names,\n format,\n full,\n line_width,\n } => run_print(&file, names, format, full, line_width, &device)?,\n Command::Quantize {\n in_file,\n out_file,\n quantization,\n mode,\n } => run_quantize(&in_file, out_file, quantization, mode, &device)?,\n Command::Dequantize { in_file, out_file } => run_dequantize(in_file, out_file, &device)?,\n }\n Ok(())\n}\n"} | null |
candle-cublaslt | {"type": "directory", "name": "candle-cublaslt", "children": [{"type": "file", "name": "Cargo.toml"}, {"type": "file", "name": "LICENSE-APACHE"}, {"type": "file", "name": "LICENSE-MIT"}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "src", "children": [{"type": "file", "name": "lib.rs"}]}]} | # Candle CublasLt Matmul Layer
CublasLt Matmul operation for the Candle ML framework.
Allows for bias and Relu/Gelu fusing. | {".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 cf789b7dd6d4abb19b03b9556442f94f0588b4a0 Hamza Amin <[email protected]> 1727369156 +0500\tclone: from https://github.com/huggingface/candle-cublaslt.git\n", ".git\\refs\\heads\\main": "cf789b7dd6d4abb19b03b9556442f94f0588b4a0\n"} | null |
candle-flash-attn-v1 | {"type": "directory", "name": "candle-flash-attn-v1", "children": [{"type": "file", "name": "build.rs"}, {"type": "file", "name": "Cargo.toml"}, {"type": "directory", "name": "cutlass", "children": []}, {"type": "directory", "name": "kernels", "children": [{"type": "file", "name": "flash_api.cu"}, {"type": "directory", "name": "fmha", "children": [{"type": "file", "name": "gemm.h"}, {"type": "file", "name": "gmem_tile.h"}, {"type": "file", "name": "kernel_traits.h"}, {"type": "file", "name": "mask.h"}, {"type": "file", "name": "smem_tile.h"}, {"type": "file", "name": "softmax.h"}, {"type": "file", "name": "utils.h"}]}, {"type": "file", "name": "fmha.h"}, {"type": "file", "name": "fmha_api.cpp"}, {"type": "file", "name": "fmha_fprop_kernel_1xN.h"}, {"type": "file", "name": "fmha_fwd_hdim128.cu"}, {"type": "file", "name": "fmha_fwd_hdim32.cu"}, {"type": "file", "name": "fmha_fwd_hdim64.cu"}, {"type": "file", "name": "fmha_fwd_launch_template.h"}, {"type": "file", "name": "fmha_kernel.h"}, {"type": "file", "name": "fmha_utils.h"}, {"type": "file", "name": "philox.cuh"}, {"type": "file", "name": "static_switch.h"}]}, {"type": "file", "name": "LICENSE-APACHE"}, {"type": "file", "name": "LICENSE-MIT"}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "src", "children": [{"type": "file", "name": "ffi.rs"}, {"type": "file", "name": "lib.rs"}]}, {"type": "directory", "name": "tests", "children": [{"type": "file", "name": "flash_attn_tests.rs"}]}]} | # Candle Flash Attention v1 Layer
Flash Attention v2 does not support Turing GPUs (T4, RTX 2080). This layer can be used in replacement of the official
flash attention Candle layer in the meantime.
| {".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 3f1870b0d708579904c76e41745c659c3f9fa038 Hamza Amin <[email protected]> 1727369159 +0500\tclone: from https://github.com/huggingface/candle-flash-attn-v1.git\n", ".git\\refs\\heads\\main": "3f1870b0d708579904c76e41745c659c3f9fa038\n"} | null |
candle-layer-norm | {"type": "directory", "name": "candle-layer-norm", "children": [{"type": "file", "name": "build.rs"}, {"type": "file", "name": "Cargo.toml"}, {"type": "directory", "name": "kernels", "children": [{"type": "file", "name": "ln.h"}, {"type": "file", "name": "ln_api.cu"}, {"type": "file", "name": "ln_fwd_kernels.cuh"}, {"type": "file", "name": "ln_kernel_traits.h"}, {"type": "file", "name": "ln_utils.cuh"}, {"type": "file", "name": "static_switch.h"}]}, {"type": "file", "name": "LICENSE-APACHE"}, {"type": "file", "name": "LICENSE-MIT"}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "src", "children": [{"type": "file", "name": "ffi.rs"}, {"type": "file", "name": "lib.rs"}]}]} | # Candle Cuda Layer Norm
Layer Norm fused operation for the Candle ML framework.
This Layer was adapted from https://github.com/Dao-AILab/flash-attention/tree/main/csrc/layer_norm.
It implements fused dropout + residual + LayerNorm, building on Apex's FastLayerNorm.
Major changes:
- Add residual.
- Make it work for both pre-norm and post-norm architecture.
- Support more hidden dimensions (all dimensions divisible by 8, up to 8192).
- Implement RMSNorm as an option. | {".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 94c2add7d94c2d63aebde77f7534614e04dbaea1 Hamza Amin <[email protected]> 1727369037 +0500\tclone: from https://github.com/huggingface/candle-layer-norm.git\n", ".git\\refs\\heads\\main": "94c2add7d94c2d63aebde77f7534614e04dbaea1\n"} | null |
candle-paged-attention | {"type": "directory", "name": "candle-paged-attention", "children": [{"type": "file", "name": "build.rs"}, {"type": "file", "name": "Cargo.toml"}, {"type": "directory", "name": "kernels", "children": [{"type": "directory", "name": "attention", "children": [{"type": "file", "name": "attention_dtypes.h"}, {"type": "file", "name": "attention_generic.cuh"}, {"type": "file", "name": "attention_utils.cuh"}, {"type": "file", "name": "dtype_bfloat16.cuh"}, {"type": "file", "name": "dtype_float16.cuh"}, {"type": "file", "name": "dtype_float32.cuh"}]}, {"type": "file", "name": "attention_kernels.cu"}, {"type": "file", "name": "cache_kernels.cu"}, {"type": "file", "name": "cuda_compat.h"}]}, {"type": "file", "name": "LICENSE-APACHE"}, {"type": "file", "name": "LICENSE-MIT"}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "src", "children": [{"type": "file", "name": "ffi.rs"}, {"type": "file", "name": "lib.rs"}]}, {"type": "directory", "name": "tests", "children": [{"type": "file", "name": "paged_attention_tests.rs"}, {"type": "file", "name": "reshape_and_cache_tests.rs"}]}]} | # Candle Paged Attention
All files in `kernels` are adapted from https://github.com/vllm-project/vllm/tree/main/csrc and are under the vLLM
Project copyright. | {".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 dab508b0129fcd50f2ad99018ccaa730c980657e Hamza Amin <[email protected]> 1727369041 +0500\tclone: from https://github.com/huggingface/candle-paged-attention.git\n", ".git\\refs\\heads\\main": "dab508b0129fcd50f2ad99018ccaa730c980657e\n"} | null |
candle-rotary | {"type": "directory", "name": "candle-rotary", "children": [{"type": "file", "name": "build.rs"}, {"type": "file", "name": "Cargo.toml"}, {"type": "directory", "name": "kernels", "children": [{"type": "file", "name": "cuda_compat.h"}, {"type": "file", "name": "rotary.cu"}]}, {"type": "file", "name": "LICENSE-APACHE"}, {"type": "file", "name": "LICENSE-MIT"}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "src", "children": [{"type": "file", "name": "ffi.rs"}, {"type": "file", "name": "lib.rs"}]}, {"type": "directory", "name": "tests", "children": [{"type": "file", "name": "rotary_tests.rs"}]}]} | # Candle Rotary
All files in `kernels` are adapted from https://github.com/vllm-project/vllm/tree/main/csrc and are under the vLLM
Project copyright. | {".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 0a718a0856569a92f3112e64f10d07e4447822e8 Hamza Amin <[email protected]> 1727369043 +0500\tclone: from https://github.com/huggingface/candle-rotary.git\n", ".git\\refs\\heads\\main": "0a718a0856569a92f3112e64f10d07e4447822e8\n"} | null |
candle-silu | {"type": "directory", "name": "candle-silu", "children": [{"type": "file", "name": "build.rs"}, {"type": "file", "name": "Cargo.toml"}, {"type": "directory", "name": "kernels", "children": [{"type": "file", "name": "silu.cu"}]}, {"type": "file", "name": "LICENSE-APACHE"}, {"type": "file", "name": "LICENSE-MIT"}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "src", "children": [{"type": "file", "name": "ffi.rs"}, {"type": "file", "name": "lib.rs"}]}, {"type": "directory", "name": "tests", "children": [{"type": "file", "name": "silu_tests.rs"}]}]} | # Candle Silu inplace
| {".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 e56e3c9e853ff3a5c4703ebc0b3fe7298deeafdd Hamza Amin <[email protected]> 1727369044 +0500\tclone: from https://github.com/huggingface/candle-silu.git\n", ".git\\refs\\heads\\main": "e56e3c9e853ff3a5c4703ebc0b3fe7298deeafdd\n"} | null |
chat-macOS | {"type": "directory", "name": "chat-macOS", "children": [{"type": "file", "name": "appcast.xml"}, {"type": "directory", "name": "assets", "children": []}, {"type": "file", "name": "README.md"}]} | <p align="center" style="margin-bottom: 0;">
<img src="assets/banner.png" alt="HuggingChat macOS Banner">
</p>
<h1 align="center" style="margin-top: 0;">HuggingChat macOS</h1>
### About
HuggingChat macOS is a native chat interface designed specifically for macOS users, leveraging the power of open-source language models. It brings the capabilities of advanced AI conversation right to your desktop, offering a seamless and intuitive experience.
### Installation
1. Go to the [Releases](https://github.com/huggingface/chat-macOS/releases) section of this repository.
2. Download the latest `HuggingChat-macOS.zip` file.
3. Unzip the downloaded file.
4. Drag the `HuggingChat.app` to your Applications folder.
That's it! You can now launch HuggingChat from your Applications folder or using the dedicated keyboard shortcut: `⌘ + Shift + Return`.
### Feedback
We value your input! If you have any suggestions, encounter issues, or want to share your experience, please feel free to reach out:
1. **Email**: Send your feedback directly to [this address](mailto:[email protected]).
2. **GitHub Issues**: For bug reports or feature requests, please create an issue in this repository.
- Provide a clear title and description of your feedback
- Include steps to reproduce the issue (for bugs) or detailed explanation (for feature requests)
- Include the app version number and macOS version
- Submit the issue
Your feedback helps improve HuggingChat macOS for everyone. Thank you for your support!
| {"appcast.xml": "<?xml version=\"1.0\" standalone=\"yes\"?>\n<rss xmlns:sparkle=\"http://www.andymatuschak.org/xml-namespaces/sparkle\" version=\"2.0\">\n <channel>\n <title>HuggingChat</title>\n <item>\n <title>1.1</title>\n <pubDate>Wed, 25 Sep 2024 12:09:33 -0700</pubDate>\n <sparkle:version>2</sparkle:version>\n <sparkle:shortVersionString>1.1</sparkle:shortVersionString>\n <sparkle:minimumSystemVersion>14.0</sparkle:minimumSystemVersion>\n <enclosure url=\"https://github.com/huggingface/chat-macOS/releases/download/v0.5.0/HuggingChat-Mac.zip\" length=\"7197753\" type=\"application/octet-stream\" sparkle:edSignature=\"rF7OZMJrmQnIyFPtoMjAyfu4aVwY2iF2aJFipPOkP1G0AcTwo5MSmmJ6ouxiQAFfC6mbxvHqr8br7SwaAdy8Dg==\"/>\n </item>\n </channel>\n</rss>\n", ".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 d1504fa5cfa3deed0db70d7b4e8943249bca8128 Hamza Amin <[email protected]> 1727369047 +0500\tclone: from https://github.com/huggingface/chat-macOS.git\n", ".git\\refs\\heads\\main": "d1504fa5cfa3deed0db70d7b4e8943249bca8128\n"} | null |
chat-ui | {"type": "directory", "name": "chat-ui", "children": [{"type": "file", "name": ".dockerignore"}, {"type": "file", "name": ".env"}, {"type": "file", "name": ".env.ci"}, {"type": "file", "name": ".eslintignore"}, {"type": "file", "name": ".eslintrc.cjs"}, {"type": "directory", "name": ".husky", "children": [{"type": "file", "name": "lint-stage-config.js"}, {"type": "file", "name": "pre-commit"}]}, {"type": "file", "name": ".npmrc"}, {"type": "file", "name": ".prettierignore"}, {"type": "file", "name": ".prettierrc"}, {"type": "directory", "name": ".vscode", "children": [{"type": "file", "name": "settings.json"}]}, {"type": "directory", "name": "chart", "children": [{"type": "file", "name": "Chart.yaml"}, {"type": "directory", "name": "env", "children": [{"type": "file", "name": "prod.yaml"}]}, {"type": "directory", "name": "templates", "children": [{"type": "file", "name": "config.yaml"}, {"type": "file", "name": "deployment.yaml"}, {"type": "file", "name": "hpa.yaml"}, {"type": "file", "name": "infisical.yaml"}, {"type": "file", "name": "ingress.yaml"}, {"type": "file", "name": "service-account.yaml"}, {"type": "file", "name": "service-monitor.yaml"}, {"type": "file", "name": "service.yaml"}, {"type": "file", "name": "_helpers.tpl"}]}, {"type": "file", "name": "values.yaml"}]}, {"type": "file", "name": "Dockerfile"}, {"type": "directory", "name": "docs", "children": [{"type": "directory", "name": "source", "children": [{"type": "directory", "name": "configuration", "children": [{"type": "file", "name": "common-issues.md"}, {"type": "file", "name": "embeddings.md"}, {"type": "file", "name": "metrics.md"}, {"type": "directory", "name": "models", "children": [{"type": "file", "name": "multimodal.md"}, {"type": "file", "name": "overview.md"}, {"type": "directory", "name": "providers", "children": [{"type": "file", "name": "anthropic.md"}, {"type": "file", "name": "aws.md"}, {"type": "file", "name": "cloudflare.md"}, {"type": "file", "name": "cohere.md"}, {"type": "file", "name": "google.md"}, {"type": "file", "name": "langserve.md"}, {"type": "file", "name": "llamacpp.md"}, {"type": "file", "name": "ollama.md"}, {"type": "file", "name": "openai.md"}, {"type": "file", "name": "tgi.md"}]}, {"type": "file", "name": "tools.md"}]}, {"type": "file", "name": "open-id.md"}, {"type": "file", "name": "overview.md"}, {"type": "file", "name": "theming.md"}, {"type": "file", "name": "web-search.md"}]}, {"type": "directory", "name": "developing", "children": [{"type": "file", "name": "architecture.md"}, {"type": "file", "name": "copy-huggingchat.md"}]}, {"type": "file", "name": "index.md"}, {"type": "directory", "name": "installation", "children": [{"type": "file", "name": "docker.md"}, {"type": "file", "name": "helm.md"}, {"type": "file", "name": "local.md"}, {"type": "file", "name": "spaces.md"}]}, {"type": "file", "name": "_toctree.yml"}]}]}, {"type": "file", "name": "entrypoint.sh"}, {"type": "file", "name": "LICENSE"}, {"type": "file", "name": "package-lock.json"}, {"type": "file", "name": "package.json"}, {"type": "file", "name": "postcss.config.js"}, {"type": "file", "name": "PRIVACY.md"}, {"type": "file", "name": "PROMPTS.md"}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "scripts", "children": [{"type": "file", "name": "populate.ts"}, {"type": "file", "name": "setupTest.ts"}, {"type": "file", "name": "updateLocalEnv.ts"}]}, {"type": "directory", "name": "src", "children": [{"type": "file", "name": "ambient.d.ts"}, {"type": "file", "name": "app.d.ts"}, {"type": "file", "name": "app.html"}, {"type": "file", "name": "hooks.server.ts"}, {"type": "directory", "name": "lib", "children": [{"type": "directory", "name": "actions", "children": [{"type": "file", "name": "clickOutside.ts"}, {"type": "file", "name": "snapScrollToBottom.ts"}]}, {"type": "file", "name": "buildPrompt.ts"}, {"type": "directory", "name": "components", "children": [{"type": "file", "name": "AnnouncementBanner.svelte"}, {"type": "file", "name": "AssistantSettings.svelte"}, {"type": "file", "name": "AssistantToolPicker.svelte"}, {"type": "directory", "name": "chat", "children": [{"type": "file", "name": "AssistantIntroduction.svelte"}, {"type": "file", "name": "ChatInput.svelte"}, {"type": "file", "name": "ChatIntroduction.svelte"}, {"type": "file", "name": "ChatMessage.svelte"}, {"type": "file", "name": "ChatWindow.svelte"}, {"type": "file", "name": "FileDropzone.svelte"}, {"type": "file", "name": "ModelSwitch.svelte"}, {"type": "file", "name": "ToolUpdate.svelte"}, {"type": "file", "name": "UploadedFile.svelte"}]}, {"type": "file", "name": "CodeBlock.svelte"}, {"type": "file", "name": "ContinueBtn.svelte"}, {"type": "file", "name": "CopyToClipBoardBtn.svelte"}, {"type": "file", "name": "DisclaimerModal.svelte"}, {"type": "file", "name": "ExpandNavigation.svelte"}, {"type": "file", "name": "HoverTooltip.svelte"}, {"type": "directory", "name": "icons", "children": [{"type": "file", "name": "IconChevron.svelte"}, {"type": "file", "name": "IconCopy.svelte"}, {"type": "file", "name": "IconDazzled.svelte"}, {"type": "file", "name": "IconInternet.svelte"}, {"type": "file", "name": "IconLoading.svelte"}, {"type": "file", "name": "IconNew.svelte"}, {"type": "file", "name": "IconTool.svelte"}, {"type": "file", "name": "Logo.svelte"}, {"type": "file", "name": "LogoHuggingFaceBorderless.svelte"}]}, {"type": "file", "name": "LoginModal.svelte"}, {"type": "file", "name": "MobileNav.svelte"}, {"type": "file", "name": "Modal.svelte"}, {"type": "file", "name": "ModelCardMetadata.svelte"}, {"type": "file", "name": "NavConversationItem.svelte"}, {"type": "file", "name": "NavMenu.svelte"}, {"type": "file", "name": "OpenWebSearchResults.svelte"}, {"type": "file", "name": "Pagination.svelte"}, {"type": "file", "name": "PaginationArrow.svelte"}, {"type": "directory", "name": "players", "children": [{"type": "file", "name": "AudioPlayer.svelte"}]}, {"type": "file", "name": "Portal.svelte"}, {"type": "file", "name": "RetryBtn.svelte"}, {"type": "file", "name": "ScrollToBottomBtn.svelte"}, {"type": "file", "name": "StopGeneratingBtn.svelte"}, {"type": "file", "name": "Switch.svelte"}, {"type": "file", "name": "SystemPromptModal.svelte"}, {"type": "file", "name": "Toast.svelte"}, {"type": "file", "name": "TokensCounter.svelte"}, {"type": "file", "name": "ToolBadge.svelte"}, {"type": "file", "name": "ToolLogo.svelte"}, {"type": "file", "name": "ToolsMenu.svelte"}, {"type": "file", "name": "Tooltip.svelte"}, {"type": "file", "name": "UploadBtn.svelte"}, {"type": "file", "name": "WebSearchToggle.svelte"}]}, {"type": "directory", "name": "constants", "children": [{"type": "file", "name": "publicSepToken.ts"}]}, {"type": "directory", "name": "jobs", "children": [{"type": "file", "name": "refresh-assistants-counts.ts"}, {"type": "file", "name": "refresh-conversation-stats.ts"}]}, {"type": "directory", "name": "migrations", "children": [{"type": "file", "name": "lock.ts"}, {"type": "file", "name": "migrations.spec.ts"}, {"type": "file", "name": "migrations.ts"}, {"type": "directory", "name": "routines", "children": [{"type": "file", "name": "01-update-search-assistants.ts"}, {"type": "file", "name": "02-update-assistants-models.ts"}, {"type": "file", "name": "03-add-tools-in-settings.ts"}, {"type": "file", "name": "04-update-message-updates.ts"}, {"type": "file", "name": "05-update-message-files.ts"}, {"type": "file", "name": "06-trim-message-updates.ts"}, {"type": "file", "name": "07-reset-tools-in-settings.ts"}, {"type": "file", "name": "index.ts"}]}]}, {"type": "directory", "name": "server", "children": [{"type": "file", "name": "abortedGenerations.ts"}, {"type": "file", "name": "auth.ts"}, {"type": "file", "name": "database.ts"}, {"type": "directory", "name": "embeddingEndpoints", "children": [{"type": "file", "name": "embeddingEndpoints.ts"}, {"type": "directory", "name": "hfApi", "children": [{"type": "file", "name": "embeddingHfApi.ts"}]}, {"type": "directory", "name": "openai", "children": [{"type": "file", "name": "embeddingEndpoints.ts"}]}, {"type": "directory", "name": "tei", "children": [{"type": "file", "name": "embeddingEndpoints.ts"}]}, {"type": "directory", "name": "transformersjs", "children": [{"type": "file", "name": "embeddingEndpoints.ts"}]}]}, {"type": "file", "name": "embeddingModels.ts"}, {"type": "directory", "name": "endpoints", "children": [{"type": "directory", "name": "anthropic", "children": [{"type": "file", "name": "endpointAnthropic.ts"}, {"type": "file", "name": "endpointAnthropicVertex.ts"}, {"type": "file", "name": "utils.ts"}]}, {"type": "directory", "name": "aws", "children": [{"type": "file", "name": "endpointAws.ts"}, {"type": "file", "name": "endpointBedrock.ts"}]}, {"type": "directory", "name": "cloudflare", "children": [{"type": "file", "name": "endpointCloudflare.ts"}]}, {"type": "directory", "name": "cohere", "children": [{"type": "file", "name": "endpointCohere.ts"}]}, {"type": "file", "name": "endpoints.ts"}, {"type": "directory", "name": "google", "children": [{"type": "file", "name": "endpointGenAI.ts"}, {"type": "file", "name": "endpointVertex.ts"}]}, {"type": "file", "name": "images.ts"}, {"type": "directory", "name": "langserve", "children": [{"type": "file", "name": "endpointLangserve.ts"}]}, {"type": "directory", "name": "llamacpp", "children": [{"type": "file", "name": "endpointLlamacpp.ts"}]}, {"type": "directory", "name": "ollama", "children": [{"type": "file", "name": "endpointOllama.ts"}]}, {"type": "directory", "name": "openai", "children": [{"type": "file", "name": "endpointOai.ts"}, {"type": "file", "name": "openAIChatToTextGenerationStream.ts"}, {"type": "file", "name": "openAICompletionToTextGenerationStream.ts"}]}, {"type": "file", "name": "preprocessMessages.ts"}, {"type": "directory", "name": "tgi", "children": [{"type": "file", "name": "endpointTgi.ts"}]}]}, {"type": "file", "name": "exitHandler.ts"}, {"type": "directory", "name": "files", "children": [{"type": "file", "name": "downloadFile.ts"}, {"type": "file", "name": "uploadFile.ts"}]}, {"type": "file", "name": "generateFromDefaultEndpoint.ts"}, {"type": "file", "name": "isURLLocal.spec.ts"}, {"type": "file", "name": "isURLLocal.ts"}, {"type": "file", "name": "logger.ts"}, {"type": "file", "name": "metrics.ts"}, {"type": "file", "name": "models.ts"}, {"type": "file", "name": "sentenceSimilarity.ts"}, {"type": "directory", "name": "textGeneration", "children": [{"type": "file", "name": "assistant.ts"}, {"type": "file", "name": "generate.ts"}, {"type": "file", "name": "index.ts"}, {"type": "file", "name": "title.ts"}, {"type": "file", "name": "tools.ts"}, {"type": "file", "name": "types.ts"}]}, {"type": "directory", "name": "tools", "children": [{"type": "file", "name": "calculator.ts"}, {"type": "file", "name": "directlyAnswer.ts"}, {"type": "file", "name": "index.ts"}, {"type": "file", "name": "outputs.ts"}, {"type": "file", "name": "utils.ts"}, {"type": "directory", "name": "web", "children": [{"type": "file", "name": "search.ts"}, {"type": "file", "name": "url.ts"}]}]}, {"type": "file", "name": "usageLimits.ts"}, {"type": "directory", "name": "websearch", "children": [{"type": "directory", "name": "embed", "children": [{"type": "file", "name": "combine.ts"}, {"type": "file", "name": "embed.ts"}, {"type": "file", "name": "tree.ts"}]}, {"type": "directory", "name": "markdown", "children": [{"type": "file", "name": "fromHtml.ts"}, {"type": "file", "name": "tree.ts"}, {"type": "file", "name": "types.ts"}, {"type": "directory", "name": "utils", "children": [{"type": "file", "name": "chunk.ts"}, {"type": "file", "name": "nlp.ts"}, {"type": "file", "name": "stringify.ts"}]}]}, {"type": "file", "name": "runWebSearch.ts"}, {"type": "directory", "name": "scrape", "children": [{"type": "file", "name": "parser.ts"}, {"type": "file", "name": "playwright.ts"}, {"type": "file", "name": "scrape.ts"}, {"type": "file", "name": "types.ts"}]}, {"type": "directory", "name": "search", "children": [{"type": "directory", "name": "endpoints", "children": [{"type": "file", "name": "bing.ts"}, {"type": "file", "name": "searchApi.ts"}, {"type": "file", "name": "searxng.ts"}, {"type": "file", "name": "serpApi.ts"}, {"type": "file", "name": "serper.ts"}, {"type": "file", "name": "serpStack.ts"}, {"type": "file", "name": "webLocal.ts"}, {"type": "file", "name": "youApi.ts"}]}, {"type": "file", "name": "endpoints.ts"}, {"type": "file", "name": "generateQuery.ts"}, {"type": "file", "name": "search.ts"}]}, {"type": "file", "name": "update.ts"}]}]}, {"type": "file", "name": "shareConversation.ts"}, {"type": "directory", "name": "stores", "children": [{"type": "file", "name": "convTree.ts"}, {"type": "file", "name": "errors.ts"}, {"type": "file", "name": "isAborted.ts"}, {"type": "file", "name": "pendingMessage.ts"}, {"type": "file", "name": "settings.ts"}, {"type": "file", "name": "titleUpdate.ts"}, {"type": "file", "name": "webSearchParameters.ts"}]}, {"type": "file", "name": "switchTheme.ts"}, {"type": "directory", "name": "types", "children": [{"type": "file", "name": "AbortedGeneration.ts"}, {"type": "file", "name": "Assistant.ts"}, {"type": "file", "name": "AssistantStats.ts"}, {"type": "file", "name": "Conversation.ts"}, {"type": "file", "name": "ConversationStats.ts"}, {"type": "file", "name": "ConvSidebar.ts"}, {"type": "file", "name": "Message.ts"}, {"type": "file", "name": "MessageEvent.ts"}, {"type": "file", "name": "MessageUpdate.ts"}, {"type": "file", "name": "MigrationResult.ts"}, {"type": "file", "name": "Model.ts"}, {"type": "file", "name": "Report.ts"}, {"type": "file", "name": "Semaphore.ts"}, {"type": "file", "name": "Session.ts"}, {"type": "file", "name": "Settings.ts"}, {"type": "file", "name": "SharedConversation.ts"}, {"type": "file", "name": "Template.ts"}, {"type": "file", "name": "Timestamps.ts"}, {"type": "file", "name": "TokenCache.ts"}, {"type": "file", "name": "Tool.ts"}, {"type": "file", "name": "UrlDependency.ts"}, {"type": "file", "name": "User.ts"}, {"type": "file", "name": "WebSearch.ts"}]}, {"type": "directory", "name": "utils", "children": [{"type": "file", "name": "chunk.ts"}, {"type": "file", "name": "cookiesAreEnabled.ts"}, {"type": "file", "name": "debounce.ts"}, {"type": "file", "name": "deepestChild.ts"}, {"type": "file", "name": "file2base64.ts"}, {"type": "file", "name": "formatUserCount.ts"}, {"type": "file", "name": "getGradioApi.ts"}, {"type": "file", "name": "getHref.ts"}, {"type": "file", "name": "getShareUrl.ts"}, {"type": "file", "name": "getTokenizer.ts"}, {"type": "file", "name": "hashConv.ts"}, {"type": "file", "name": "isDesktop.ts"}, {"type": "file", "name": "isHuggingChat.ts"}, {"type": "file", "name": "isUrl.ts"}, {"type": "file", "name": "mergeAsyncGenerators.ts"}, {"type": "file", "name": "messageUpdates.ts"}, {"type": "file", "name": "models.ts"}, {"type": "file", "name": "parseStringToList.ts"}, {"type": "file", "name": "randomUuid.ts"}, {"type": "file", "name": "searchTokens.ts"}, {"type": "file", "name": "sha256.ts"}, {"type": "file", "name": "share.ts"}, {"type": "file", "name": "stringifyError.ts"}, {"type": "file", "name": "sum.ts"}, {"type": "file", "name": "template.ts"}, {"type": "file", "name": "timeout.ts"}, {"type": "file", "name": "tools.ts"}, {"type": "directory", "name": "tree", "children": [{"type": "file", "name": "addChildren.spec.ts"}, {"type": "file", "name": "addChildren.ts"}, {"type": "file", "name": "addSibling.spec.ts"}, {"type": "file", "name": "addSibling.ts"}, {"type": "file", "name": "buildSubtree.spec.ts"}, {"type": "file", "name": "buildSubtree.ts"}, {"type": "file", "name": "convertLegacyConversation.spec.ts"}, {"type": "file", "name": "convertLegacyConversation.ts"}, {"type": "file", "name": "isMessageId.spec.ts"}, {"type": "file", "name": "isMessageId.ts"}, {"type": "file", "name": "treeHelpers.spec.ts"}]}]}]}, {"type": "directory", "name": "routes", "children": [{"type": "file", "name": "+error.svelte"}, {"type": "file", "name": "+layout.server.ts"}, {"type": "file", "name": "+layout.svelte"}, {"type": "file", "name": "+page.svelte"}, {"type": "directory", "name": "admin", "children": [{"type": "directory", "name": "export", "children": [{"type": "file", "name": "+server.ts"}]}, {"type": "directory", "name": "stats", "children": [{"type": "directory", "name": "compute", "children": [{"type": "file", "name": "+server.ts"}]}]}]}, {"type": "directory", "name": "api", "children": [{"type": "directory", "name": "assistant", "children": [{"type": "directory", "name": "[id]", "children": [{"type": "file", "name": "+server.ts"}]}]}, {"type": "directory", "name": "assistants", "children": [{"type": "file", "name": "+server.ts"}]}, {"type": "directory", "name": "conversation", "children": [{"type": "directory", "name": "[id]", "children": [{"type": "file", "name": "+server.ts"}]}]}, {"type": "directory", "name": "conversations", "children": [{"type": "file", "name": "+server.ts"}]}, {"type": "directory", "name": "models", "children": [{"type": "file", "name": "+server.ts"}]}, {"type": "directory", "name": "spaces-config", "children": [{"type": "file", "name": "+server.ts"}]}, {"type": "directory", "name": "tools", "children": [{"type": "directory", "name": "search", "children": [{"type": "file", "name": "+server.ts"}]}, {"type": "directory", "name": "[toolId]", "children": [{"type": "file", "name": "+server.ts"}]}]}, {"type": "directory", "name": "user", "children": [{"type": "file", "name": "+server.ts"}, {"type": "directory", "name": "assistants", "children": [{"type": "file", "name": "+server.ts"}]}]}]}, {"type": "directory", "name": "assistant", "children": [{"type": "directory", "name": "[assistantId]", "children": [{"type": "file", "name": "+page.server.ts"}, {"type": "file", "name": "+page.svelte"}, {"type": "directory", "name": "thumbnail.png", "children": [{"type": "file", "name": "+server.ts"}, {"type": "file", "name": "ChatThumbnail.svelte"}]}]}]}, {"type": "directory", "name": "assistants", "children": [{"type": "file", "name": "+page.server.ts"}, {"type": "file", "name": "+page.svelte"}]}, {"type": "directory", "name": "conversation", "children": [{"type": "file", "name": "+server.ts"}, {"type": "directory", "name": "[id]", "children": [{"type": "file", "name": "+page.server.ts"}, {"type": "file", "name": "+page.svelte"}, {"type": "file", "name": "+server.ts"}, {"type": "directory", "name": "message", "children": [{"type": "directory", "name": "[messageId]", "children": [{"type": "directory", "name": "prompt", "children": [{"type": "file", "name": "+server.ts"}]}, {"type": "directory", "name": "vote", "children": [{"type": "file", "name": "+server.ts"}]}]}]}, {"type": "directory", "name": "output", "children": [{"type": "directory", "name": "[sha256]", "children": [{"type": "file", "name": "+server.ts"}]}]}, {"type": "directory", "name": "share", "children": [{"type": "file", "name": "+server.ts"}]}, {"type": "directory", "name": "stop-generating", "children": [{"type": "file", "name": "+server.ts"}]}]}]}, {"type": "directory", "name": "conversations", "children": [{"type": "file", "name": "+page.server.ts"}]}, {"type": "directory", "name": "healthcheck", "children": [{"type": "file", "name": "+server.ts"}]}, {"type": "directory", "name": "login", "children": [{"type": "file", "name": "+page.server.ts"}, {"type": "directory", "name": "callback", "children": [{"type": "file", "name": "+page.server.ts"}, {"type": "file", "name": "updateUser.spec.ts"}, {"type": "file", "name": "updateUser.ts"}]}]}, {"type": "directory", "name": "logout", "children": [{"type": "file", "name": "+page.server.ts"}]}, {"type": "directory", "name": "models", "children": [{"type": "file", "name": "+page.svelte"}, {"type": "directory", "name": "[...model]", "children": [{"type": "file", "name": "+page.server.ts"}, {"type": "file", "name": "+page.svelte"}, {"type": "directory", "name": "thumbnail.png", "children": [{"type": "file", "name": "+server.ts"}, {"type": "file", "name": "ModelThumbnail.svelte"}]}]}]}, {"type": "directory", "name": "privacy", "children": [{"type": "file", "name": "+page.svelte"}]}, {"type": "directory", "name": "r", "children": [{"type": "directory", "name": "[id]", "children": [{"type": "file", "name": "+page.ts"}]}]}, {"type": "directory", "name": "settings", "children": [{"type": "directory", "name": "(nav)", "children": [{"type": "file", "name": "+layout.svelte"}, {"type": "file", "name": "+page.svelte"}, {"type": "file", "name": "+server.ts"}, {"type": "directory", "name": "assistants", "children": [{"type": "directory", "name": "new", "children": [{"type": "file", "name": "+page.server.ts"}, {"type": "file", "name": "[email protected]"}]}, {"type": "directory", "name": "[assistantId]", "children": [{"type": "file", "name": "+page.server.ts"}, {"type": "file", "name": "+page.svelte"}, {"type": "file", "name": "+page.ts"}, {"type": "directory", "name": "avatar.jpg", "children": [{"type": "file", "name": "+server.ts"}]}, {"type": "directory", "name": "edit", "children": [{"type": "file", "name": "+page.server.ts"}, {"type": "file", "name": "[email protected]"}]}, {"type": "file", "name": "ReportModal.svelte"}]}]}, {"type": "directory", "name": "[...model]", "children": [{"type": "file", "name": "+page.svelte"}, {"type": "file", "name": "+page.ts"}]}]}, {"type": "file", "name": "+layout.server.ts"}, {"type": "file", "name": "+layout.svelte"}]}, {"type": "directory", "name": "tools", "children": [{"type": "file", "name": "+layout.svelte"}, {"type": "file", "name": "+layout.ts"}, {"type": "file", "name": "+page.server.ts"}, {"type": "file", "name": "+page.svelte"}, {"type": "directory", "name": "new", "children": [{"type": "file", "name": "+page.server.ts"}, {"type": "file", "name": "+page.svelte"}]}, {"type": "file", "name": "ToolEdit.svelte"}, {"type": "file", "name": "ToolInputComponent.svelte"}, {"type": "directory", "name": "[toolId]", "children": [{"type": "file", "name": "+layout.server.ts"}, {"type": "file", "name": "+page.server.ts"}, {"type": "file", "name": "+page.svelte"}, {"type": "directory", "name": "edit", "children": [{"type": "file", "name": "+page.server.ts"}, {"type": "file", "name": "+page.svelte"}]}]}]}]}, {"type": "directory", "name": "styles", "children": [{"type": "file", "name": "highlight-js.css"}, {"type": "file", "name": "main.css"}]}]}, {"type": "directory", "name": "static", "children": [{"type": "directory", "name": "chatui", "children": [{"type": "file", "name": "favicon.ico"}, {"type": "file", "name": "favicon.svg"}, {"type": "file", "name": "icon.svg"}, {"type": "file", "name": "logo.svg"}, {"type": "file", "name": "manifest.json"}]}, {"type": "directory", "name": "fonts", "children": []}, {"type": "directory", "name": "huggingchat", "children": [{"type": "file", "name": "favicon.ico"}, {"type": "file", "name": "favicon.svg"}, {"type": "file", "name": "icon.svg"}, {"type": "file", "name": "logo.svg"}, {"type": "file", "name": "manifest.json"}]}]}, {"type": "file", "name": "svelte.config.js"}, {"type": "file", "name": "tailwind.config.cjs"}, {"type": "file", "name": "tsconfig.json"}, {"type": "file", "name": "vite.config.ts"}]} | ---
title: chat-ui
emoji: 🔥
colorFrom: purple
colorTo: purple
sdk: docker
pinned: false
license: apache-2.0
base_path: /chat
app_port: 3000
failure_strategy: rollback
load_balancing_strategy: random
---
# Chat UI
**Find the docs at [hf.co/docs/chat-ui](https://huggingface.co/docs/chat-ui/index).**

A chat interface using open source models, eg OpenAssistant or Llama. It is a SvelteKit app and it powers the [HuggingChat app on hf.co/chat](https://huggingface.co/chat).
0. [Quickstart](#quickstart)
1. [No Setup Deploy](#no-setup-deploy)
2. [Setup](#setup)
3. [Launch](#launch)
4. [Web Search](#web-search)
5. [Text Embedding Models](#text-embedding-models)
6. [Extra parameters](#extra-parameters)
7. [Common issues](#common-issues)
8. [Deploying to a HF Space](#deploying-to-a-hf-space)
9. [Building](#building)
## Quickstart
You can quickly start a locally running chat-ui & LLM text-generation server thanks to chat-ui's [llama.cpp server support](https://huggingface.co/docs/chat-ui/configuration/models/providers/llamacpp).
**Step 1 (Start llama.cpp server):**
Install llama.cpp w/ brew (for Mac):
```bash
# install llama.cpp
brew install llama.cpp
```
or [build directly from the source](https://github.com/ggerganov/llama.cpp/blob/master/docs/build.md) for your target device:
```
git clone https://github.com/ggerganov/llama.cpp && cd llama.cpp && make
```
Next, start the server with the [LLM of your choice](https://huggingface.co/models?library=gguf):
```bash
# start llama.cpp server (using hf.co/microsoft/Phi-3-mini-4k-instruct-gguf as an example)
llama-server --hf-repo microsoft/Phi-3-mini-4k-instruct-gguf --hf-file Phi-3-mini-4k-instruct-q4.gguf -c 4096
```
A local LLaMA.cpp HTTP Server will start on `http://localhost:8080`. Read more [here](https://huggingface.co/docs/chat-ui/configuration/models/providers/llamacpp).
**Step 2 (tell chat-ui to use local llama.cpp server):**
Add the following to your `.env.local`:
```ini
MODELS=`[
{
"name": "Local microsoft/Phi-3-mini-4k-instruct-gguf",
"tokenizer": "microsoft/Phi-3-mini-4k-instruct-gguf",
"preprompt": "",
"chatPromptTemplate": "<s>{{preprompt}}{{#each messages}}{{#ifUser}}<|user|>\n{{content}}<|end|>\n<|assistant|>\n{{/ifUser}}{{#ifAssistant}}{{content}}<|end|>\n{{/ifAssistant}}{{/each}}",
"parameters": {
"stop": ["<|end|>", "<|endoftext|>", "<|assistant|>"],
"temperature": 0.7,
"max_new_tokens": 1024,
"truncate": 3071
},
"endpoints": [{
"type" : "llamacpp",
"baseURL": "http://localhost:8080"
}],
},
]`
```
Read more [here](https://huggingface.co/docs/chat-ui/configuration/models/providers/llamacpp).
**Step 3 (make sure you have MongoDb running locally):**
```bash
docker run -d -p 27017:27017 --name mongo-chatui mongo:latest
```
Read more [here](#database).
**Step 4 (start chat-ui):**
```bash
git clone https://github.com/huggingface/chat-ui
cd chat-ui
npm install
npm run dev -- --open
```
Read more [here](#launch).
<img class="hidden dark:block" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/chat-ui/llamacpp-dark.png" height="auto"/>
## No Setup Deploy
If you don't want to configure, setup, and launch your own Chat UI yourself, you can use this option as a fast deploy alternative.
You can deploy your own customized Chat UI instance with any supported [LLM](https://huggingface.co/models?pipeline_tag=text-generation&sort=trending) of your choice on [Hugging Face Spaces](https://huggingface.co/spaces). To do so, use the chat-ui template [available here](https://huggingface.co/new-space?template=huggingchat/chat-ui-template).
Set `HF_TOKEN` in [Space secrets](https://huggingface.co/docs/hub/spaces-overview#managing-secrets-and-environment-variables) to deploy a model with gated access or a model in a private repository. It's also compatible with [Inference for PROs](https://huggingface.co/blog/inference-pro) curated list of powerful models with higher rate limits. Make sure to create your personal token first in your [User Access Tokens settings](https://huggingface.co/settings/tokens).
Read the full tutorial [here](https://huggingface.co/docs/hub/spaces-sdks-docker-chatui#chatui-on-spaces).
## Setup
The default config for Chat UI is stored in the `.env` file. You will need to override some values to get Chat UI to run locally. This is done in `.env.local`.
Start by creating a `.env.local` file in the root of the repository. The bare minimum config you need to get Chat UI to run locally is the following:
```env
MONGODB_URL=<the URL to your MongoDB instance>
HF_TOKEN=<your access token>
```
### Database
The chat history is stored in a MongoDB instance, and having a DB instance available is needed for Chat UI to work.
You can use a local MongoDB instance. The easiest way is to spin one up using docker:
```bash
docker run -d -p 27017:27017 --name mongo-chatui mongo:latest
```
In which case the url of your DB will be `MONGODB_URL=mongodb://localhost:27017`.
Alternatively, you can use a [free MongoDB Atlas](https://www.mongodb.com/pricing) instance for this, Chat UI should fit comfortably within their free tier. After which you can set the `MONGODB_URL` variable in `.env.local` to match your instance.
### Hugging Face Access Token
If you use a remote inference endpoint, you will need a Hugging Face access token to run Chat UI locally. You can get one from [your Hugging Face profile](https://huggingface.co/settings/tokens).
## Launch
After you're done with the `.env.local` file you can run Chat UI locally with:
```bash
npm install
npm run dev
```
## Web Search
Chat UI features a powerful Web Search feature. It works by:
1. Generating an appropriate search query from the user prompt.
2. Performing web search and extracting content from webpages.
3. Creating embeddings from texts using a text embedding model.
4. From these embeddings, find the ones that are closest to the user query using a vector similarity search. Specifically, we use `inner product` distance.
5. Get the corresponding texts to those closest embeddings and perform [Retrieval-Augmented Generation](https://huggingface.co/papers/2005.11401) (i.e. expand user prompt by adding those texts so that an LLM can use this information).
## Text Embedding Models
By default (for backward compatibility), when `TEXT_EMBEDDING_MODELS` environment variable is not defined, [transformers.js](https://huggingface.co/docs/transformers.js) embedding models will be used for embedding tasks, specifically, [Xenova/gte-small](https://huggingface.co/Xenova/gte-small) model.
You can customize the embedding model by setting `TEXT_EMBEDDING_MODELS` in your `.env.local` file. For example:
```env
TEXT_EMBEDDING_MODELS = `[
{
"name": "Xenova/gte-small",
"displayName": "Xenova/gte-small",
"description": "locally running embedding",
"chunkCharLength": 512,
"endpoints": [
{"type": "transformersjs"}
]
},
{
"name": "intfloat/e5-base-v2",
"displayName": "intfloat/e5-base-v2",
"description": "hosted embedding model",
"chunkCharLength": 768,
"preQuery": "query: ", # See https://huggingface.co/intfloat/e5-base-v2#faq
"prePassage": "passage: ", # See https://huggingface.co/intfloat/e5-base-v2#faq
"endpoints": [
{
"type": "tei",
"url": "http://127.0.0.1:8080/",
"authorization": "TOKEN_TYPE TOKEN" // optional authorization field. Example: "Basic VVNFUjpQQVNT"
}
]
}
]`
```
The required fields are `name`, `chunkCharLength` and `endpoints`.
Supported text embedding backends are: [`transformers.js`](https://huggingface.co/docs/transformers.js), [`TEI`](https://github.com/huggingface/text-embeddings-inference) and [`OpenAI`](https://platform.openai.com/docs/guides/embeddings). `transformers.js` models run locally as part of `chat-ui`, whereas `TEI` models run in a different environment & accessed through an API endpoint. `openai` models are accessed through the [OpenAI API](https://platform.openai.com/docs/guides/embeddings).
When more than one embedding models are supplied in `.env.local` file, the first will be used by default, and the others will only be used on LLM's which configured `embeddingModel` to the name of the model.
## Extra parameters
### OpenID connect
The login feature is disabled by default and users are attributed a unique ID based on their browser. But if you want to use OpenID to authenticate your users, you can add the following to your `.env.local` file:
```env
OPENID_CONFIG=`{
PROVIDER_URL: "<your OIDC issuer>",
CLIENT_ID: "<your OIDC client ID>",
CLIENT_SECRET: "<your OIDC client secret>",
SCOPES: "openid profile",
TOLERANCE: // optional
RESOURCE: // optional
}`
```
These variables will enable the openID sign-in modal for users.
### Trusted header authentication
You can set the env variable `TRUSTED_EMAIL_HEADER` to point to the header that contains the user's email address. This will allow you to authenticate users from the header. This setup is usually combined with a proxy that will be in front of chat-ui and will handle the auth and set the header.
> [!WARNING]
> Make sure to only allow requests to chat-ui through your proxy which handles authentication, otherwise users could authenticate as anyone by setting the header manually! Only set this up if you understand the implications and know how to do it correctly.
Here is a list of header names for common auth providers:
- Tailscale Serve: `Tailscale-User-Login`
- Cloudflare Access: `Cf-Access-Authenticated-User-Email`
- oauth2-proxy: `X-Forwarded-Email`
### Theming
You can use a few environment variables to customize the look and feel of chat-ui. These are by default:
```env
PUBLIC_APP_NAME=ChatUI
PUBLIC_APP_ASSETS=chatui
PUBLIC_APP_COLOR=blue
PUBLIC_APP_DESCRIPTION="Making the community's best AI chat models available to everyone."
PUBLIC_APP_DATA_SHARING=
PUBLIC_APP_DISCLAIMER=
```
- `PUBLIC_APP_NAME` The name used as a title throughout the app.
- `PUBLIC_APP_ASSETS` Is used to find logos & favicons in `static/$PUBLIC_APP_ASSETS`, current options are `chatui` and `huggingchat`.
- `PUBLIC_APP_COLOR` Can be any of the [tailwind colors](https://tailwindcss.com/docs/customizing-colors#default-color-palette).
- `PUBLIC_APP_DATA_SHARING` Can be set to 1 to add a toggle in the user settings that lets your users opt-in to data sharing with models creator.
- `PUBLIC_APP_DISCLAIMER` If set to 1, we show a disclaimer about generated outputs on login.
### Web Search config
You can enable the web search through an API by adding `YDC_API_KEY` ([docs.you.com](https://docs.you.com)) or `SERPER_API_KEY` ([serper.dev](https://serper.dev/)) or `SERPAPI_KEY` ([serpapi.com](https://serpapi.com/)) or `SERPSTACK_API_KEY` ([serpstack.com](https://serpstack.com/)) or `SEARCHAPI_KEY` ([searchapi.io](https://www.searchapi.io/)) to your `.env.local`.
You can also simply enable the local google websearch by setting `USE_LOCAL_WEBSEARCH=true` in your `.env.local` or specify a SearXNG instance by adding the query URL to `SEARXNG_QUERY_URL`.
You can enable javascript when parsing webpages to improve compatibility with `WEBSEARCH_JAVASCRIPT=true` at the cost of increased CPU usage. You'll want at least 4 cores when enabling.
### Custom models
You can customize the parameters passed to the model or even use a new model by updating the `MODELS` variable in your `.env.local`. The default one can be found in `.env` and looks like this :
```env
MODELS=`[
{
"name": "mistralai/Mistral-7B-Instruct-v0.2",
"displayName": "mistralai/Mistral-7B-Instruct-v0.2",
"description": "Mistral 7B is a new Apache 2.0 model, released by Mistral AI that outperforms Llama2 13B in benchmarks.",
"websiteUrl": "https://mistral.ai/news/announcing-mistral-7b/",
"preprompt": "",
"chatPromptTemplate" : "<s>{{#each messages}}{{#ifUser}}[INST] {{#if @first}}{{#if @root.preprompt}}{{@root.preprompt}}\n{{/if}}{{/if}}{{content}} [/INST]{{/ifUser}}{{#ifAssistant}}{{content}}</s>{{/ifAssistant}}{{/each}}",
"parameters": {
"temperature": 0.3,
"top_p": 0.95,
"repetition_penalty": 1.2,
"top_k": 50,
"truncate": 3072,
"max_new_tokens": 1024,
"stop": ["</s>"]
},
"promptExamples": [
{
"title": "Write an email from bullet list",
"prompt": "As a restaurant owner, write a professional email to the supplier to get these products every week: \n\n- Wine (x10)\n- Eggs (x24)\n- Bread (x12)"
}, {
"title": "Code a snake game",
"prompt": "Code a basic snake game in python, give explanations for each step."
}, {
"title": "Assist in a task",
"prompt": "How do I make a delicious lemon cheesecake?"
}
]
}
]`
```
You can change things like the parameters, or customize the preprompt to better suit your needs. You can also add more models by adding more objects to the array, with different preprompts for example.
#### chatPromptTemplate
When querying the model for a chat response, the `chatPromptTemplate` template is used. `messages` is an array of chat messages, it has the format `[{ content: string }, ...]`. To identify if a message is a user message or an assistant message the `ifUser` and `ifAssistant` block helpers can be used.
The following is the default `chatPromptTemplate`, although newlines and indentiation have been added for readability. You can find the prompts used in production for HuggingChat [here](https://github.com/huggingface/chat-ui/blob/main/PROMPTS.md).
```prompt
{{preprompt}}
{{#each messages}}
{{#ifUser}}{{@root.userMessageToken}}{{content}}{{@root.userMessageEndToken}}{{/ifUser}}
{{#ifAssistant}}{{@root.assistantMessageToken}}{{content}}{{@root.assistantMessageEndToken}}{{/ifAssistant}}
{{/each}}
{{assistantMessageToken}}
```
#### Multi modal model
We currently support [IDEFICS](https://huggingface.co/blog/idefics) (hosted on TGI), OpenAI and Claude 3 as multimodal models. You can enable it by setting `multimodal: true` in your `MODELS` configuration. For IDEFICS, you must have a [PRO HF Api token](https://huggingface.co/settings/tokens). For OpenAI, see the [OpenAI section](#OpenAI). For Anthropic, see the [Anthropic section](#anthropic).
```env
{
"name": "HuggingFaceM4/idefics-80b-instruct",
"multimodal" : true,
"description": "IDEFICS is the new multimodal model by Hugging Face.",
"preprompt": "",
"chatPromptTemplate" : "{{#each messages}}{{#ifUser}}User: {{content}}{{/ifUser}}<end_of_utterance>\nAssistant: {{#ifAssistant}}{{content}}\n{{/ifAssistant}}{{/each}}",
"parameters": {
"temperature": 0.1,
"top_p": 0.95,
"repetition_penalty": 1.2,
"top_k": 12,
"truncate": 1000,
"max_new_tokens": 1024,
"stop": ["<end_of_utterance>", "User:", "\nUser:"]
}
}
```
#### Running your own models using a custom endpoint
If you want to, instead of hitting models on the Hugging Face Inference API, you can run your own models locally.
A good option is to hit a [text-generation-inference](https://github.com/huggingface/text-generation-inference) endpoint. This is what is done in the official [Chat UI Spaces Docker template](https://huggingface.co/new-space?template=huggingchat/chat-ui-template) for instance: both this app and a text-generation-inference server run inside the same container.
To do this, you can add your own endpoints to the `MODELS` variable in `.env.local`, by adding an `"endpoints"` key for each model in `MODELS`.
```env
{
// rest of the model config here
"endpoints": [{
"type" : "tgi",
"url": "https://HOST:PORT",
}]
}
```
If `endpoints` are left unspecified, ChatUI will look for the model on the hosted Hugging Face inference API using the model name.
##### OpenAI API compatible models
Chat UI can be used with any API server that supports OpenAI API compatibility, for example [text-generation-webui](https://github.com/oobabooga/text-generation-webui/tree/main/extensions/openai), [LocalAI](https://github.com/go-skynet/LocalAI), [FastChat](https://github.com/lm-sys/FastChat/blob/main/docs/openai_api.md), [llama-cpp-python](https://github.com/abetlen/llama-cpp-python), and [ialacol](https://github.com/chenhunghan/ialacol) and [vllm](https://docs.vllm.ai/en/latest/serving/openai_compatible_server.html).
The following example config makes Chat UI works with [text-generation-webui](https://github.com/oobabooga/text-generation-webui/tree/main/extensions/openai), the `endpoint.baseUrl` is the url of the OpenAI API compatible server, this overrides the baseUrl to be used by OpenAI instance. The `endpoint.completion` determine which endpoint to be used, default is `chat_completions` which uses `v1/chat/completions`, change to `endpoint.completion` to `completions` to use the `v1/completions` endpoint.
Parameters not supported by OpenAI (e.g., top_k, repetition_penalty, etc.) must be set in the extraBody of endpoints. Be aware that setting them in parameters will cause them to be omitted.
```
MODELS=`[
{
"name": "text-generation-webui",
"id": "text-generation-webui",
"parameters": {
"temperature": 0.9,
"top_p": 0.95,
"max_new_tokens": 1024,
"stop": []
},
"endpoints": [{
"type" : "openai",
"baseURL": "http://localhost:8000/v1",
"extraBody": {
"repetition_penalty": 1.2,
"top_k": 50,
"truncate": 1000
}
}]
}
]`
```
The `openai` type includes official OpenAI models. You can add, for example, GPT4/GPT3.5 as a "openai" model:
```
OPENAI_API_KEY=#your openai api key here
MODELS=`[{
"name": "gpt-4",
"displayName": "GPT 4",
"endpoints" : [{
"type": "openai"
}]
},
{
"name": "gpt-3.5-turbo",
"displayName": "GPT 3.5 Turbo",
"endpoints" : [{
"type": "openai"
}]
}]`
```
You may also consume any model provider that provides compatible OpenAI API endpoint. For example, you may self-host [Portkey](https://github.com/Portkey-AI/gateway) gateway and experiment with Claude or GPTs offered by Azure OpenAI. Example for Claude from Anthropic:
```
MODELS=`[{
"name": "claude-2.1",
"displayName": "Claude 2.1",
"description": "Anthropic has been founded by former OpenAI researchers...",
"parameters": {
"temperature": 0.5,
"max_new_tokens": 4096,
},
"endpoints": [
{
"type": "openai",
"baseURL": "https://gateway.example.com/v1",
"defaultHeaders": {
"x-portkey-config": '{"provider":"anthropic","api_key":"sk-ant-abc...xyz"}'
}
}
]
}]`
```
Example for GPT 4 deployed on Azure OpenAI:
```
MODELS=`[{
"id": "gpt-4-1106-preview",
"name": "gpt-4-1106-preview",
"displayName": "gpt-4-1106-preview",
"parameters": {
"temperature": 0.5,
"max_new_tokens": 4096,
},
"endpoints": [
{
"type": "openai",
"baseURL": "https://{resource-name}.openai.azure.com/openai/deployments/{deployment-id}",
"defaultHeaders": {
"api-key": "{api-key}"
},
"defaultQuery": {
"api-version": "2023-05-15"
}
}
]
}]`
```
Or try Mistral from [Deepinfra](https://deepinfra.com/mistralai/Mistral-7B-Instruct-v0.1/api?example=openai-http):
> Note, apiKey can either be set custom per endpoint, or globally using `OPENAI_API_KEY` variable.
```
MODELS=`[{
"name": "mistral-7b",
"displayName": "Mistral 7B",
"description": "A 7B dense Transformer, fast-deployed and easily customisable. Small, yet powerful for a variety of use cases. Supports English and code, and a 8k context window.",
"parameters": {
"temperature": 0.5,
"max_new_tokens": 4096,
},
"endpoints": [
{
"type": "openai",
"baseURL": "https://api.deepinfra.com/v1/openai",
"apiKey": "abc...xyz"
}
]
}]`
```
##### Llama.cpp API server
chat-ui also supports the llama.cpp API server directly without the need for an adapter. You can do this using the `llamacpp` endpoint type.
If you want to run Chat UI with llama.cpp, you can do the following, using [microsoft/Phi-3-mini-4k-instruct-gguf](https://huggingface.co/microsoft/Phi-3-mini-4k-instruct-gguf) as an example model:
```bash
# install llama.cpp
brew install llama.cpp
# start llama.cpp server
llama-server --hf-repo microsoft/Phi-3-mini-4k-instruct-gguf --hf-file Phi-3-mini-4k-instruct-q4.gguf -c 4096
```
```env
MODELS=`[
{
"name": "Local Zephyr",
"chatPromptTemplate": "<|system|>\n{{preprompt}}</s>\n{{#each messages}}{{#ifUser}}<|user|>\n{{content}}</s>\n<|assistant|>\n{{/ifUser}}{{#ifAssistant}}{{content}}</s>\n{{/ifAssistant}}{{/each}}",
"parameters": {
"temperature": 0.1,
"top_p": 0.95,
"repetition_penalty": 1.2,
"top_k": 50,
"truncate": 1000,
"max_new_tokens": 2048,
"stop": ["</s>"]
},
"endpoints": [
{
"url": "http://127.0.0.1:8080",
"type": "llamacpp"
}
]
}
]`
```
Start chat-ui with `npm run dev` and you should be able to chat with Zephyr locally.
#### Ollama
We also support the Ollama inference server. Spin up a model with
```cli
ollama run mistral
```
Then specify the endpoints like so:
```env
MODELS=`[
{
"name": "Ollama Mistral",
"chatPromptTemplate": "<s>{{#each messages}}{{#ifUser}}[INST] {{#if @first}}{{#if @root.preprompt}}{{@root.preprompt}}\n{{/if}}{{/if}} {{content}} [/INST]{{/ifUser}}{{#ifAssistant}}{{content}}</s> {{/ifAssistant}}{{/each}}",
"parameters": {
"temperature": 0.1,
"top_p": 0.95,
"repetition_penalty": 1.2,
"top_k": 50,
"truncate": 3072,
"max_new_tokens": 1024,
"stop": ["</s>"]
},
"endpoints": [
{
"type": "ollama",
"url" : "http://127.0.0.1:11434",
"ollamaName" : "mistral"
}
]
}
]`
```
#### Anthropic
We also support Anthropic models (including multimodal ones via `multmodal: true`) through the official SDK. You may provide your API key via the `ANTHROPIC_API_KEY` env variable, or alternatively, through the `endpoints.apiKey` as per the following example.
```
MODELS=`[
{
"name": "claude-3-haiku-20240307",
"displayName": "Claude 3 Haiku",
"description": "Fastest and most compact model for near-instant responsiveness",
"multimodal": true,
"parameters": {
"max_new_tokens": 4096,
},
"endpoints": [
{
"type": "anthropic",
// optionals
"apiKey": "sk-ant-...",
"baseURL": "https://api.anthropic.com",
"defaultHeaders": {},
"defaultQuery": {}
}
]
},
{
"name": "claude-3-sonnet-20240229",
"displayName": "Claude 3 Sonnet",
"description": "Ideal balance of intelligence and speed",
"multimodal": true,
"parameters": {
"max_new_tokens": 4096,
},
"endpoints": [
{
"type": "anthropic",
// optionals
"apiKey": "sk-ant-...",
"baseURL": "https://api.anthropic.com",
"defaultHeaders": {},
"defaultQuery": {}
}
]
},
{
"name": "claude-3-opus-20240229",
"displayName": "Claude 3 Opus",
"description": "Most powerful model for highly complex tasks",
"multimodal": true,
"parameters": {
"max_new_tokens": 4096
},
"endpoints": [
{
"type": "anthropic",
// optionals
"apiKey": "sk-ant-...",
"baseURL": "https://api.anthropic.com",
"defaultHeaders": {},
"defaultQuery": {}
}
]
}
]`
```
We also support using Anthropic models running on Vertex AI. Authentication is done using Google Application Default Credentials. Project ID can be provided through the `endpoints.projectId` as per the following example:
```
MODELS=`[
{
"name": "claude-3-sonnet@20240229",
"displayName": "Claude 3 Sonnet",
"description": "Ideal balance of intelligence and speed",
"multimodal": true,
"parameters": {
"max_new_tokens": 4096,
},
"endpoints": [
{
"type": "anthropic-vertex",
"region": "us-central1",
"projectId": "gcp-project-id",
// optionals
"defaultHeaders": {},
"defaultQuery": {}
}
]
},
{
"name": "claude-3-haiku@20240307",
"displayName": "Claude 3 Haiku",
"description": "Fastest, most compact model for near-instant responsiveness",
"multimodal": true,
"parameters": {
"max_new_tokens": 4096
},
"endpoints": [
{
"type": "anthropic-vertex",
"region": "us-central1",
"projectId": "gcp-project-id",
// optionals
"defaultHeaders": {},
"defaultQuery": {}
}
]
}
]`
```
#### Amazon
You can also specify your Amazon SageMaker instance as an endpoint for chat-ui. The config goes like this:
```env
"endpoints": [
{
"type" : "aws",
"service" : "sagemaker"
"url": "",
"accessKey": "",
"secretKey" : "",
"sessionToken": "",
"region": "",
"weight": 1
}
]
```
You can also set `"service" : "lambda"` to use a lambda instance.
You can get the `accessKey` and `secretKey` from your AWS user, under programmatic access.
#### Cloudflare Workers AI
You can also use Cloudflare Workers AI to run your own models with serverless inference.
You will need to have a Cloudflare account, then get your [account ID](https://developers.cloudflare.com/fundamentals/setup/find-account-and-zone-ids/) as well as your [API token](https://developers.cloudflare.com/workers-ai/get-started/rest-api/#1-get-an-api-token) for Workers AI.
You can either specify them directly in your `.env.local` using the `CLOUDFLARE_ACCOUNT_ID` and `CLOUDFLARE_API_TOKEN` variables, or you can set them directly in the endpoint config.
You can find the list of models available on Cloudflare [here](https://developers.cloudflare.com/workers-ai/models/#text-generation).
```env
{
"name" : "nousresearch/hermes-2-pro-mistral-7b",
"tokenizer": "nousresearch/hermes-2-pro-mistral-7b",
"parameters": {
"stop": ["<|im_end|>"]
},
"endpoints" : [
{
"type" : "cloudflare"
<!-- optionally specify these
"accountId": "your-account-id",
"authToken": "your-api-token"
-->
}
]
}
```
#### Cohere
You can also use Cohere to run their models directly from chat-ui. You will need to have a Cohere account, then get your [API token](https://dashboard.cohere.com/api-keys). You can either specify it directly in your `.env.local` using the `COHERE_API_TOKEN` variable, or you can set it in the endpoint config.
Here is an example of a Cohere model config. You can set which model you want to use by setting the `id` field to the model name.
```env
{
"name" : "CohereForAI/c4ai-command-r-v01",
"id": "command-r",
"description": "C4AI Command-R is a research release of a 35 billion parameter highly performant generative model",
"endpoints": [
{
"type": "cohere",
<!-- optionally specify these, or use COHERE_API_TOKEN
"apiKey": "your-api-token"
-->
}
]
}
```
##### Google Vertex models
Chat UI can connect to the google Vertex API endpoints ([List of supported models](https://cloud.google.com/vertex-ai/generative-ai/docs/learn/models)).
To enable:
1. [Select](https://console.cloud.google.com/project) or [create](https://cloud.google.com/resource-manager/docs/creating-managing-projects#creating_a_project) a Google Cloud project.
1. [Enable billing for your project](https://cloud.google.com/billing/docs/how-to/modify-project).
1. [Enable the Vertex AI API](https://console.cloud.google.com/flows/enableapi?apiid=aiplatform.googleapis.com).
1. [Set up authentication with a service account](https://cloud.google.com/docs/authentication/getting-started)
so you can access the API from your local workstation.
The service account credentials file can be imported as an environmental variable:
```env
GOOGLE_APPLICATION_CREDENTIALS = clientid.json
```
Make sure your docker container has access to the file and the variable is correctly set.
Afterwards Google Vertex endpoints can be configured as following:
```
MODELS=`[
//...
{
"name": "gemini-1.5-pro",
"displayName": "Vertex Gemini Pro 1.5",
"multimodal": true,
"endpoints" : [{
"type": "vertex",
"project": "abc-xyz",
"location": "europe-west3",
"model": "gemini-1.5-pro-preview-0409", // model-name
// Optional
"safetyThreshold": "BLOCK_MEDIUM_AND_ABOVE",
"apiEndpoint": "", // alternative api endpoint url,
"tools": [{
"googleSearchRetrieval": {
"disableAttribution": true
}
}],
"multimodal": {
"image": {
"supportedMimeTypes": ["image/png", "image/jpeg", "image/webp"],
"preferredMimeType": "image/png",
"maxSizeInMB": 5,
"maxWidth": 2000,
"maxHeight": 1000;
}
}
}]
},
]`
```
##### LangServe
LangChain applications that are deployed using LangServe can be called with the following config:
```
MODELS=`[
//...
{
"name": "summarization-chain", //model-name
"endpoints" : [{
"type": "langserve",
"url" : "http://127.0.0.1:8100",
}]
},
]`
```
### Custom endpoint authorization
#### Basic and Bearer
Custom endpoints may require authorization, depending on how you configure them. Authentication will usually be set either with `Basic` or `Bearer`.
For `Basic` we will need to generate a base64 encoding of the username and password.
`echo -n "USER:PASS" | base64`
> VVNFUjpQQVNT
For `Bearer` you can use a token, which can be grabbed from [here](https://huggingface.co/settings/tokens).
You can then add the generated information and the `authorization` parameter to your `.env.local`.
```env
"endpoints": [
{
"url": "https://HOST:PORT",
"authorization": "Basic VVNFUjpQQVNT",
}
]
```
Please note that if `HF_TOKEN` is also set or not empty, it will take precedence.
#### Models hosted on multiple custom endpoints
If the model being hosted will be available on multiple servers/instances add the `weight` parameter to your `.env.local`. The `weight` will be used to determine the probability of requesting a particular endpoint.
```env
"endpoints": [
{
"url": "https://HOST:PORT",
"weight": 1
},
{
"url": "https://HOST:PORT",
"weight": 2
}
...
]
```
#### Client Certificate Authentication (mTLS)
Custom endpoints may require client certificate authentication, depending on how you configure them. To enable mTLS between Chat UI and your custom endpoint, you will need to set the `USE_CLIENT_CERTIFICATE` to `true`, and add the `CERT_PATH` and `KEY_PATH` parameters to your `.env.local`. These parameters should point to the location of the certificate and key files on your local machine. The certificate and key files should be in PEM format. The key file can be encrypted with a passphrase, in which case you will also need to add the `CLIENT_KEY_PASSWORD` parameter to your `.env.local`.
If you're using a certificate signed by a private CA, you will also need to add the `CA_PATH` parameter to your `.env.local`. This parameter should point to the location of the CA certificate file on your local machine.
If you're using a self-signed certificate, e.g. for testing or development purposes, you can set the `REJECT_UNAUTHORIZED` parameter to `false` in your `.env.local`. This will disable certificate validation, and allow Chat UI to connect to your custom endpoint.
#### Specific Embedding Model
A model can use any of the embedding models defined in `.env.local`, (currently used when web searching),
by default it will use the first embedding model, but it can be changed with the field `embeddingModel`:
```env
TEXT_EMBEDDING_MODELS = `[
{
"name": "Xenova/gte-small",
"chunkCharLength": 512,
"endpoints": [
{"type": "transformersjs"}
]
},
{
"name": "intfloat/e5-base-v2",
"chunkCharLength": 768,
"endpoints": [
{"type": "tei", "url": "http://127.0.0.1:8080/", "authorization": "Basic VVNFUjpQQVNT"},
{"type": "tei", "url": "http://127.0.0.1:8081/"}
]
}
]`
MODELS=`[
{
"name": "Ollama Mistral",
"chatPromptTemplate": "...",
"embeddingModel": "intfloat/e5-base-v2"
"parameters": {
...
},
"endpoints": [
...
]
}
]`
```
## Common issues
### 403:You don't have access to this conversation
Most likely you are running chat-ui over HTTP. The recommended option is to setup something like NGINX to handle HTTPS and proxy the requests to chat-ui. If you really need to run over HTTP you can add `ALLOW_INSECURE_COOKIES=true` to your `.env.local`.
Make sure to set your `PUBLIC_ORIGIN` in your `.env.local` to the correct URL as well.
## Deploying to a HF Space
Create a `DOTENV_LOCAL` secret to your HF space with the content of your .env.local, and they will be picked up automatically when you run.
## Building
To create a production version of your app:
```bash
npm run build
```
You can preview the production build with `npm run preview`.
> To deploy your app, you may need to install an [adapter](https://kit.svelte.dev/docs/adapters) for your target environment.
## Config changes for HuggingChat
The config file for HuggingChat is stored in the `chart/env/prod.yaml` file. It is the source of truth for the environment variables used for our CI/CD pipeline. For HuggingChat, as we need to customize the app color, as well as the base path, we build a custom docker image. You can find the workflow here.
> [!TIP]
> If you want to make changes to the model config used in production for HuggingChat, you should do so against `chart/env/prod.yaml`.
### Running a copy of HuggingChat locally
If you want to run an exact copy of HuggingChat locally, you will need to do the following first:
1. Create an [OAuth App on the hub](https://huggingface.co/settings/applications/new) with `openid profile email` permissions. Make sure to set the callback URL to something like `http://localhost:5173/chat/login/callback` which matches the right path for your local instance.
2. Create a [HF Token](https://huggingface.co/settings/tokens) with your Hugging Face account. You will need a Pro account to be able to access some of the larger models available through HuggingChat.
3. Create a free account with [serper.dev](https://serper.dev/) (you will get 2500 free search queries)
4. Run an instance of mongoDB, however you want. (Local or remote)
You can then create a new `.env.SECRET_CONFIG` file with the following content
```env
MONGODB_URL=<link to your mongo DB from step 4>
HF_TOKEN=<your HF token from step 2>
OPENID_CONFIG=`{
PROVIDER_URL: "https://huggingface.co",
CLIENT_ID: "<your client ID from step 1>",
CLIENT_SECRET: "<your client secret from step 1>",
}`
SERPER_API_KEY=<your serper API key from step 3>
MESSAGES_BEFORE_LOGIN=<can be any numerical value, or set to 0 to require login>
```
You can then run `npm run updateLocalEnv` in the root of chat-ui. This will create a `.env.local` file which combines the `chart/env/prod.yaml` and the `.env.SECRET_CONFIG` file. You can then run `npm run dev` to start your local instance of HuggingChat.
### Populate database
> [!WARNING]
> The `MONGODB_URL` used for this script will be fetched from `.env.local`. Make sure it's correct! The command runs directly on the database.
You can populate the database using faker data using the `populate` script:
```bash
npm run populate <flags here>
```
At least one flag must be specified, the following flags are available:
- `reset` - resets the database
- `all` - populates all tables
- `users` - populates the users table
- `settings` - populates the settings table for existing users
- `assistants` - populates the assistants table for existing users
- `conversations` - populates the conversations table for existing users
For example, you could use it like so:
```bash
npm run populate reset
```
to clear out the database. Then login in the app to create your user and run the following command:
```bash
npm run populate users settings assistants conversations
```
to populate the database with fake data, including fake conversations and assistants for your user.
| {"Dockerfile": "# syntax=docker/dockerfile:1\n# read the doc: https://huggingface.co/docs/hub/spaces-sdks-docker\n# you will also find guides on how best to write your Dockerfile\nARG INCLUDE_DB=false\n\n# stage that install the dependencies\nFROM node:20 AS builder-production\n\nWORKDIR /app\n\nCOPY --link --chown=1000 package-lock.json package.json ./\nRUN --mount=type=cache,target=/app/.npm \\\n npm set cache /app/.npm && \\\n npm ci --omit=dev\n\nFROM builder-production AS builder\n\nARG APP_BASE=\nARG PUBLIC_APP_COLOR=blue\nENV BODY_SIZE_LIMIT=15728640\n\nRUN --mount=type=cache,target=/app/.npm \\\n npm set cache /app/.npm && \\\n npm ci\n\nCOPY --link --chown=1000 . .\n\nRUN npm run build\n\n# mongo image\nFROM mongo:latest AS mongo\n\n# image to be used if INCLUDE_DB is false\nFROM node:20-slim AS local_db_false\n\n# image to be used if INCLUDE_DB is true\nFROM node:20-slim AS local_db_true\n\nRUN apt-get update\nRUN apt-get install gnupg curl -y\n# copy mongo from the other stage\nCOPY --from=mongo /usr/bin/mongo* /usr/bin/\n\nENV MONGODB_URL=mongodb://localhost:27017\nRUN mkdir -p /data/db\nRUN chown -R 1000:1000 /data/db\n\n# final image\nFROM local_db_${INCLUDE_DB} AS final\n\n# build arg to determine if the database should be included\nARG INCLUDE_DB=false\nENV INCLUDE_DB=${INCLUDE_DB}\n\n# svelte requires APP_BASE at build time so it must be passed as a build arg\nARG APP_BASE=\n# tailwind requires the primary theme to be known at build time so it must be passed as a build arg\nARG PUBLIC_APP_COLOR=blue\nENV BODY_SIZE_LIMIT=15728640\n\n# install dotenv-cli\nRUN npm install -g dotenv-cli\n\n# switch to a user that works for spaces\nRUN userdel -r node\nRUN useradd -m -u 1000 user\nUSER user\n\nENV HOME=/home/user \\\n\tPATH=/home/user/.local/bin:$PATH\n\nWORKDIR /app\n\n# add a .env.local if the user doesn't bind a volume to it\nRUN touch /app/.env.local\n\n# get the default config, the entrypoint script and the server script\nCOPY --chown=1000 package.json /app/package.json\nCOPY --chown=1000 .env /app/.env\nCOPY --chown=1000 entrypoint.sh /app/entrypoint.sh\nCOPY --chown=1000 gcp-*.json /app/\n\n#import the build & dependencies\nCOPY --from=builder --chown=1000 /app/build /app/build\nCOPY --from=builder --chown=1000 /app/node_modules /app/node_modules\n\nRUN npx playwright install\n\nUSER root\nRUN npx playwright install-deps\nUSER user\n\nRUN chmod +x /app/entrypoint.sh\n\nCMD [\"/bin/bash\", \"-c\", \"/app/entrypoint.sh\"]\n", "package.json": "{\n\t\"name\": \"chat-ui\",\n\t\"version\": \"0.9.2\",\n\t\"private\": true,\n\t\"packageManager\": \"[email protected]\",\n\t\"scripts\": {\n\t\t\"dev\": \"vite dev\",\n\t\t\"build\": \"vite build\",\n\t\t\"preview\": \"vite preview\",\n\t\t\"check\": \"svelte-kit sync && svelte-check --tsconfig ./tsconfig.json\",\n\t\t\"check:watch\": \"svelte-kit sync && svelte-check --tsconfig ./tsconfig.json --watch\",\n\t\t\"lint\": \"prettier --plugin-search-dir . --check . && eslint .\",\n\t\t\"format\": \"prettier --plugin-search-dir . --write .\",\n\t\t\"test\": \"vitest\",\n\t\t\"updateLocalEnv\": \"node --loader ts-node/esm scripts/updateLocalEnv.ts\",\n\t\t\"populate\": \"vite-node --options.transformMode.ssr='/.*/' scripts/populate.ts\",\n\t\t\"prepare\": \"husky\"\n\t},\n\t\"devDependencies\": {\n\t\t\"@faker-js/faker\": \"^8.4.1\",\n\t\t\"@iconify-json/carbon\": \"^1.1.16\",\n\t\t\"@iconify-json/eos-icons\": \"^1.1.6\",\n\t\t\"@sveltejs/adapter-node\": \"^5.2.0\",\n\t\t\"@sveltejs/kit\": \"^2.5.20\",\n\t\t\"@tailwindcss/typography\": \"^0.5.9\",\n\t\t\"@types/dompurify\": \"^3.0.5\",\n\t\t\"@types/express\": \"^4.17.21\",\n\t\t\"@types/js-yaml\": \"^4.0.9\",\n\t\t\"@types/jsdom\": \"^21.1.1\",\n\t\t\"@types/jsonpath\": \"^0.2.4\",\n\t\t\"@types/minimist\": \"^1.2.5\",\n\t\t\"@types/node\": \"^22.1.0\",\n\t\t\"@types/parquetjs\": \"^0.10.3\",\n\t\t\"@types/sbd\": \"^1.0.5\",\n\t\t\"@types/uuid\": \"^9.0.8\",\n\t\t\"@typescript-eslint/eslint-plugin\": \"^6.x\",\n\t\t\"@typescript-eslint/parser\": \"^6.x\",\n\t\t\"dompurify\": \"^3.1.6\",\n\t\t\"eslint\": \"^8.28.0\",\n\t\t\"eslint-config-prettier\": \"^8.5.0\",\n\t\t\"eslint-plugin-svelte\": \"^2.30.0\",\n\t\t\"isomorphic-dompurify\": \"^2.13.0\",\n\t\t\"js-yaml\": \"^4.1.0\",\n\t\t\"minimist\": \"^1.2.8\",\n\t\t\"prettier\": \"^2.8.0\",\n\t\t\"prettier-plugin-svelte\": \"^2.10.1\",\n\t\t\"prettier-plugin-tailwindcss\": \"^0.2.7\",\n\t\t\"prom-client\": \"^15.1.2\",\n\t\t\"svelte\": \"^4.2.19\",\n\t\t\"svelte-check\": \"^3.8.5\",\n\t\t\"ts-node\": \"^10.9.1\",\n\t\t\"tslib\": \"^2.4.1\",\n\t\t\"typescript\": \"^5.0.0\",\n\t\t\"unplugin-icons\": \"^0.16.1\",\n\t\t\"vite\": \"^5.3.5\",\n\t\t\"vite-node\": \"^1.3.1\",\n\t\t\"vitest\": \"^0.31.0\"\n\t},\n\t\"type\": \"module\",\n\t\"dependencies\": {\n\t\t\"@aws-sdk/credential-providers\": \"^3.592.0\",\n\t\t\"@cliqz/adblocker-playwright\": \"^1.27.2\",\n\t\t\"@gradio/client\": \"^1.1.1\",\n\t\t\"@huggingface/hub\": \"^0.5.1\",\n\t\t\"@huggingface/inference\": \"^2.7.0\",\n\t\t\"@huggingface/transformers\": \"^3.0.0-alpha.6\",\n\t\t\"@iconify-json/bi\": \"^1.1.21\",\n\t\t\"@playwright/browser-chromium\": \"^1.43.1\",\n\t\t\"@resvg/resvg-js\": \"^2.6.2\",\n\t\t\"autoprefixer\": \"^10.4.14\",\n\t\t\"aws-sigv4-fetch\": \"^4.0.1\",\n\t\t\"aws4\": \"^1.13.0\",\n\t\t\"browser-image-resizer\": \"^2.4.1\",\n\t\t\"date-fns\": \"^2.29.3\",\n\t\t\"dotenv\": \"^16.0.3\",\n\t\t\"express\": \"^4.21.0\",\n\t\t\"file-type\": \"^19.4.1\",\n\t\t\"google-auth-library\": \"^9.13.0\",\n\t\t\"handlebars\": \"^4.7.8\",\n\t\t\"highlight.js\": \"^11.7.0\",\n\t\t\"husky\": \"^9.0.11\",\n\t\t\"image-size\": \"^1.0.2\",\n\t\t\"ip-address\": \"^9.0.5\",\n\t\t\"jose\": \"^5.3.0\",\n\t\t\"jsdom\": \"^22.0.0\",\n\t\t\"json5\": \"^2.2.3\",\n\t\t\"jsonpath\": \"^1.1.1\",\n\t\t\"lint-staged\": \"^15.2.7\",\n\t\t\"marked\": \"^12.0.1\",\n\t\t\"marked-katex-extension\": \"^5.0.1\",\n\t\t\"mongodb\": \"^5.8.0\",\n\t\t\"nanoid\": \"^4.0.2\",\n\t\t\"openid-client\": \"^5.4.2\",\n\t\t\"parquetjs\": \"^0.11.2\",\n\t\t\"pino\": \"^9.0.0\",\n\t\t\"pino-pretty\": \"^11.0.0\",\n\t\t\"playwright\": \"^1.44.1\",\n\t\t\"postcss\": \"^8.4.31\",\n\t\t\"saslprep\": \"^1.0.3\",\n\t\t\"satori\": \"^0.10.11\",\n\t\t\"satori-html\": \"^0.3.2\",\n\t\t\"sbd\": \"^1.0.19\",\n\t\t\"serpapi\": \"^1.1.1\",\n\t\t\"sharp\": \"^0.33.4\",\n\t\t\"tailwind-scrollbar\": \"^3.0.0\",\n\t\t\"tailwindcss\": \"^3.4.0\",\n\t\t\"uuid\": \"^10.0.0\",\n\t\t\"zod\": \"^3.22.3\"\n\t},\n\t\"optionalDependencies\": {\n\t\t\"@aws-sdk/client-bedrock-runtime\": \"^3.631.0\",\n\t\t\"@anthropic-ai/sdk\": \"^0.25.0\",\n\t\t\"@anthropic-ai/vertex-sdk\": \"^0.4.1\",\n\t\t\"@google-cloud/vertexai\": \"^1.1.0\",\n\t\t\"@google/generative-ai\": \"^0.14.1\",\n\t\t\"aws4fetch\": \"^1.0.17\",\n\t\t\"cohere-ai\": \"^7.9.0\",\n\t\t\"openai\": \"^4.44.0\"\n\t}\n}\n", ".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 7be4d8a285e4683b5d8a2d4fdaf9106ccd635be1 Hamza Amin <[email protected]> 1727369064 +0500\tclone: from https://github.com/huggingface/chat-ui.git\n", ".git\\refs\\heads\\main": "7be4d8a285e4683b5d8a2d4fdaf9106ccd635be1\n", "docs\\source\\index.md": "# \ud83e\udd17 Chat UI\n\nOpen source chat interface with support for tools, web search, multimodal and many API providers. The app uses MongoDB and SvelteKit behind the scenes. Try the live version of the app called [HuggingChat on hf.co/chat](https://huggingface.co/chat) or [setup your own instance](./installation/spaces).\n\n\ud83d\udd27 **[Tools](./configuration/models/tools)**: Function calling with custom tools and support for [Zero GPU spaces](https://huggingface.co/spaces/enzostvs/zero-gpu-spaces)\n\n\ud83d\udd0d **[Web Search](./configuration/web-search)**: Automated web search, scraping and RAG for all models\n\n\ud83d\udc19 **[Multimodal](./configuration/models/multimodal)**: Accepts image file uploads on supported providers\n\n\ud83d\udc64 **[OpenID](./configuration/open-id)**: Optionally setup OpenID for user authentication\n\n<div class=\"flex gap-x-4\">\n\n<div>\nTools\n<div class=\"flex justify-center\">\n<img class=\"block dark:hidden\" src=\"https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/chat-ui/tools-light.png\" height=\"auto\"/>\n<img class=\"hidden dark:block\" src=\"https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/chat-ui/tools-dark.png\" height=\"auto\"/>\n</div>\n</div>\n\n<div>\nWeb Search\n<div class=\"flex justify-center\">\n<img class=\"block dark:hidden\" src=\"https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/chat-ui/websearch-light.png\" height=\"auto\"/>\n<img class=\"hidden dark:block\" src=\"https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/chat-ui/websearch-dark.png\" height=\"auto\"/>\n</div>\n</div>\n\n</div>\n\n## Quickstart\n\nYou can quickly have a locally running chat-ui & LLM text-generation server thanks to chat-ui's [llama.cpp server support](https://huggingface.co/docs/chat-ui/configuration/models/providers/llamacpp).\n\n**Step 1 (Start llama.cpp server):**\n\n```bash\n# install llama.cpp\nbrew install llama.cpp\n# start llama.cpp server (using hf.co/microsoft/Phi-3-mini-4k-instruct-gguf as an example)\nllama-server --hf-repo microsoft/Phi-3-mini-4k-instruct-gguf --hf-file Phi-3-mini-4k-instruct-q4.gguf -c 4096\n```\n\nA local LLaMA.cpp HTTP Server will start on `http://localhost:8080`. Read more [here](https://huggingface.co/docs/chat-ui/configuration/models/providers/llamacpp).\n\n**Step 2 (tell chat-ui to use local llama.cpp server):**\n\nAdd the following to your `.env.local`:\n\n```ini\nMODELS=`[\n {\n \"name\": \"Local microsoft/Phi-3-mini-4k-instruct-gguf\",\n \"tokenizer\": \"microsoft/Phi-3-mini-4k-instruct-gguf\",\n \"preprompt\": \"\",\n \"chatPromptTemplate\": \"<s>{{preprompt}}{{#each messages}}{{#ifUser}}<|user|>\\n{{content}}<|end|>\\n<|assistant|>\\n{{/ifUser}}{{#ifAssistant}}{{content}}<|end|>\\n{{/ifAssistant}}{{/each}}\",\n \"parameters\": {\n \"stop\": [\"<|end|>\", \"<|endoftext|>\", \"<|assistant|>\"],\n \"temperature\": 0.7,\n \"max_new_tokens\": 1024,\n \"truncate\": 3071\n },\n \"endpoints\": [{\n \"type\" : \"llamacpp\",\n \"baseURL\": \"http://localhost:8080\"\n }],\n },\n]`\n```\n\nRead more [here](https://huggingface.co/docs/chat-ui/configuration/models/providers/llamacpp).\n\n**Step 3 (make sure you have MongoDb running locally):**\n\n```bash\ndocker run -d -p 27017:27017 --name mongo-chatui mongo:latest\n```\n\nRead more [here](https://github.com/huggingface/chat-ui?tab=Readme-ov-file#database).\n\n**Step 4 (start chat-ui):**\n\n```bash\ngit clone https://github.com/huggingface/chat-ui\ncd chat-ui\nnpm install\nnpm run dev -- --open\n```\n\nRead more [here](https://github.com/huggingface/chat-ui?tab=readme-ov-file#launch).\n\n<div class=\"flex justify-center\">\n<img class=\"block dark:hidden\" src=\"https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/chat-ui/llamacpp-light.png\" height=\"auto\"/>\n<img class=\"hidden dark:block\" src=\"https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/chat-ui/llamacpp-dark.png\" height=\"auto\"/>\n</div>\n", "src\\app.d.ts": "/// <reference types=\"@sveltejs/kit\" />\n/// <reference types=\"unplugin-icons/types/svelte\" />\n\nimport type { User } from \"$lib/types/User\";\n\n// See https://kit.svelte.dev/docs/types#app\n// for information about these interfaces\ndeclare global {\n\tnamespace App {\n\t\t// interface Error {}\n\t\tinterface Locals {\n\t\t\tsessionId: string;\n\t\t\tuser?: User & { logoutDisabled?: boolean };\n\t\t}\n\n\t\tinterface Error {\n\t\t\tmessage: string;\n\t\t\terrorId?: ReturnType<typeof crypto.randomUUID>;\n\t\t}\n\t\t// interface PageData {}\n\t\t// interface Platform {}\n\t}\n}\n\nexport {};\n", "src\\app.html": "<!DOCTYPE html>\n<html lang=\"en\" class=\"h-full\">\n\t<head>\n\t\t<meta charset=\"utf-8\" />\n\t\t<meta name=\"viewport\" content=\"width=device-width, initial-scale=1, user-scalable=no\" />\n\t\t<meta name=\"theme-color\" content=\"rgb(249, 250, 251)\" />\n\t\t<script>\n\t\t\tif (\n\t\t\t\tlocalStorage.theme === \"dark\" ||\n\t\t\t\t(!(\"theme\" in localStorage) && window.matchMedia(\"(prefers-color-scheme: dark)\").matches)\n\t\t\t) {\n\t\t\t\tdocument.documentElement.classList.add(\"dark\");\n\t\t\t\tdocument\n\t\t\t\t\t.querySelector('meta[name=\"theme-color\"]')\n\t\t\t\t\t.setAttribute(\"content\", \"rgb(26, 36, 50)\");\n\t\t\t}\n\n\t\t\t// For some reason, Sveltekit doesn't let us load env variables from .env here, so we load it from hooks.server.ts\n\t\t\twindow.gaId = \"%gaId%\";\n\t\t</script>\n\t\t%sveltekit.head%\n\t</head>\n\t<body data-sveltekit-preload-data=\"hover\" class=\"h-full dark:bg-gray-900\">\n\t\t<div id=\"app\" class=\"contents h-full\">%sveltekit.body%</div>\n\n\t\t<!-- Google Tag Manager -->\n\t\t<script>\n\t\t\tif (window.gaId) {\n\t\t\t\tconst script = document.createElement(\"script\");\n\t\t\t\tscript.src = \"https://www.googletagmanager.com/gtag/js?id=\" + window.gaId;\n\t\t\t\tscript.async = true;\n\t\t\t\tdocument.head.appendChild(script);\n\n\t\t\t\twindow.dataLayer = window.dataLayer || [];\n\t\t\t\tfunction gtag() {\n\t\t\t\t\tdataLayer.push(arguments);\n\t\t\t\t}\n\t\t\t\tgtag(\"js\", new Date());\n\t\t\t\t/// ^ See https://developers.google.com/tag-platform/gtagjs/install\n\t\t\t\tgtag(\"config\", window.gaId);\n\t\t\t\tgtag(\"consent\", \"default\", { ad_storage: \"denied\", analytics_storage: \"denied\" });\n\t\t\t\t/// ^ See https://developers.google.com/tag-platform/gtagjs/reference#consent\n\t\t\t\t/// TODO: ask the user for their consent and update this with gtag('consent', 'update')\n\t\t\t}\n\t\t</script>\n\t</body>\n</html>\n", "src\\lib\\migrations\\routines\\index.ts": "import type { ObjectId } from \"mongodb\";\n\nimport updateSearchAssistant from \"./01-update-search-assistants\";\nimport updateAssistantsModels from \"./02-update-assistants-models\";\nimport type { Database } from \"$lib/server/database\";\nimport addToolsToSettings from \"./03-add-tools-in-settings\";\nimport updateMessageUpdates from \"./04-update-message-updates\";\nimport updateMessageFiles from \"./05-update-message-files\";\nimport trimMessageUpdates from \"./06-trim-message-updates\";\nimport resetTools from \"./07-reset-tools-in-settings\";\n\nexport interface Migration {\n\t_id: ObjectId;\n\tname: string;\n\tup: (client: Database) => Promise<boolean>;\n\tdown?: (client: Database) => Promise<boolean>;\n\trunForFreshInstall?: \"only\" | \"never\"; // leave unspecified to run for both\n\trunForHuggingChat?: \"only\" | \"never\"; // leave unspecified to run for both\n\trunEveryTime?: boolean;\n}\n\nexport const migrations: Migration[] = [\n\tupdateSearchAssistant,\n\tupdateAssistantsModels,\n\taddToolsToSettings,\n\tupdateMessageUpdates,\n\tupdateMessageFiles,\n\ttrimMessageUpdates,\n\tresetTools,\n];\n", "src\\lib\\server\\textGeneration\\index.ts": "import { runWebSearch } from \"$lib/server/websearch/runWebSearch\";\nimport { preprocessMessages } from \"../endpoints/preprocessMessages\";\n\nimport { generateTitleForConversation } from \"./title\";\nimport {\n\tassistantHasDynamicPrompt,\n\tassistantHasWebSearch,\n\tgetAssistantById,\n\tprocessPreprompt,\n} from \"./assistant\";\nimport { getTools, runTools } from \"./tools\";\nimport type { WebSearch } from \"$lib/types/WebSearch\";\nimport {\n\ttype MessageUpdate,\n\tMessageUpdateType,\n\tMessageUpdateStatus,\n} from \"$lib/types/MessageUpdate\";\nimport { generate } from \"./generate\";\nimport { mergeAsyncGenerators } from \"$lib/utils/mergeAsyncGenerators\";\nimport type { TextGenerationContext } from \"./types\";\nimport type { ToolResult } from \"$lib/types/Tool\";\nimport { toolHasName } from \"../tools/utils\";\n\nasync function* keepAlive(done: AbortSignal): AsyncGenerator<MessageUpdate, undefined, undefined> {\n\twhile (!done.aborted) {\n\t\tyield {\n\t\t\ttype: MessageUpdateType.Status,\n\t\t\tstatus: MessageUpdateStatus.KeepAlive,\n\t\t};\n\t\tawait new Promise((resolve) => setTimeout(resolve, 100));\n\t}\n}\n\nexport async function* textGeneration(ctx: TextGenerationContext) {\n\tconst done = new AbortController();\n\n\tconst titleGen = generateTitleForConversation(ctx.conv);\n\tconst textGen = textGenerationWithoutTitle(ctx, done);\n\tconst keepAliveGen = keepAlive(done.signal);\n\n\t// keep alive until textGen is done\n\n\tyield* mergeAsyncGenerators([titleGen, textGen, keepAliveGen]);\n}\n\nasync function* textGenerationWithoutTitle(\n\tctx: TextGenerationContext,\n\tdone: AbortController\n): AsyncGenerator<MessageUpdate, undefined, undefined> {\n\tyield {\n\t\ttype: MessageUpdateType.Status,\n\t\tstatus: MessageUpdateStatus.Started,\n\t};\n\n\tctx.assistant ??= await getAssistantById(ctx.conv.assistantId);\n\tconst { model, conv, messages, assistant, isContinue, webSearch, toolsPreference } = ctx;\n\tconst convId = conv._id;\n\n\tlet webSearchResult: WebSearch | undefined;\n\n\t// run websearch if:\n\t// - it's not continuing a previous message\n\t// - AND the model doesn't support tools and websearch is selected\n\t// - OR the assistant has websearch enabled (no tools for assistants for now)\n\tif (!isContinue && ((webSearch && !conv.assistantId) || assistantHasWebSearch(assistant))) {\n\t\twebSearchResult = yield* runWebSearch(conv, messages, assistant?.rag);\n\t}\n\n\tlet preprompt = conv.preprompt;\n\tif (assistantHasDynamicPrompt(assistant) && preprompt) {\n\t\tpreprompt = await processPreprompt(preprompt);\n\t\tif (messages[0].from === \"system\") messages[0].content = preprompt;\n\t}\n\n\tlet toolResults: ToolResult[] = [];\n\n\tif (model.tools) {\n\t\tconst tools = await getTools(toolsPreference, ctx.assistant);\n\t\tconst toolCallsRequired = tools.some((tool) => !toolHasName(\"directly_answer\", tool));\n\t\tif (toolCallsRequired) toolResults = yield* runTools(ctx, tools, preprompt);\n\t}\n\n\tconst processedMessages = await preprocessMessages(messages, webSearchResult, convId);\n\tyield* generate({ ...ctx, messages: processedMessages }, toolResults, preprompt);\n\tdone.abort();\n}\n", "src\\lib\\server\\tools\\index.ts": "import { MessageUpdateType } from \"$lib/types/MessageUpdate\";\nimport {\n\tToolColor,\n\tToolIcon,\n\tToolOutputComponents,\n\ttype BackendCall,\n\ttype BaseTool,\n\ttype ConfigTool,\n\ttype ToolInput,\n} from \"$lib/types/Tool\";\nimport type { TextGenerationContext } from \"../textGeneration/types\";\n\nimport { z } from \"zod\";\nimport JSON5 from \"json5\";\nimport { env } from \"$env/dynamic/private\";\n\nimport jp from \"jsonpath\";\nimport calculator from \"./calculator\";\nimport directlyAnswer from \"./directlyAnswer\";\nimport fetchUrl from \"./web/url\";\nimport websearch from \"./web/search\";\nimport { callSpace, getIpToken } from \"./utils\";\nimport { uploadFile } from \"../files/uploadFile\";\nimport type { MessageFile } from \"$lib/types/Message\";\nimport { sha256 } from \"$lib/utils/sha256\";\nimport { ObjectId } from \"mongodb\";\nimport { isValidOutputComponent, ToolOutputPaths } from \"./outputs\";\nimport { downloadFile } from \"../files/downloadFile\";\nimport { fileTypeFromBlob } from \"file-type\";\n\nexport type BackendToolContext = Pick<\n\tTextGenerationContext,\n\t\"conv\" | \"messages\" | \"assistant\" | \"ip\" | \"username\"\n> & { preprompt?: string };\n\nconst IOType = z.union([z.literal(\"str\"), z.literal(\"int\"), z.literal(\"float\"), z.literal(\"bool\")]);\n\nconst toolInputBaseSchema = z.union([\n\tz.object({\n\t\tname: z.string().min(1).max(80),\n\t\tdescription: z.string().max(200).optional(),\n\t\tparamType: z.literal(\"required\"),\n\t}),\n\tz.object({\n\t\tname: z.string().min(1).max(80),\n\t\tdescription: z.string().max(200).optional(),\n\t\tparamType: z.literal(\"optional\"),\n\t\tdefault: z\n\t\t\t.union([z.string().max(300), z.number(), z.boolean(), z.undefined()])\n\t\t\t.transform((val) => (val === undefined ? \"\" : val)),\n\t}),\n\tz.object({\n\t\tname: z.string().min(1).max(80),\n\t\tparamType: z.literal(\"fixed\"),\n\t\tvalue: z\n\t\t\t.union([z.string().max(300), z.number(), z.boolean(), z.undefined()])\n\t\t\t.transform((val) => (val === undefined ? \"\" : val)),\n\t}),\n]);\n\nconst toolInputSchema = toolInputBaseSchema.and(\n\tz.object({ type: IOType }).or(\n\t\tz.object({\n\t\t\ttype: z.literal(\"file\"),\n\t\t\tmimeTypes: z.string().min(1),\n\t\t})\n\t)\n);\n\nexport const editableToolSchema = z\n\t.object({\n\t\tname: z\n\t\t\t.string()\n\t\t\t.regex(/^[a-zA-Z_][a-zA-Z0-9_]*$/) // only allow letters, numbers, and underscores, and start with a letter or underscore\n\t\t\t.min(1)\n\t\t\t.max(40),\n\t\t// only allow huggingface spaces either through namespace or direct URLs\n\t\tbaseUrl: z.union([\n\t\t\tz.string().regex(/^[^/]+\\/[^/]+$/),\n\t\t\tz\n\t\t\t\t.string()\n\t\t\t\t.regex(/^https:\\/\\/huggingface\\.co\\/spaces\\/[a-zA-Z0-9-]+\\/[a-zA-Z0-9-]+$/)\n\t\t\t\t.transform((url) => url.split(\"/\").slice(-2).join(\"/\")),\n\t\t]),\n\t\tendpoint: z.string().min(1).max(100),\n\t\tinputs: z.array(toolInputSchema),\n\t\toutputComponent: z.string().min(1).max(100),\n\t\tshowOutput: z.boolean(),\n\t\tdisplayName: z.string().min(1).max(40),\n\t\tcolor: ToolColor,\n\t\ticon: ToolIcon,\n\t\tdescription: z.string().min(1).max(100),\n\t})\n\t.transform((tool) => ({\n\t\t...tool,\n\t\toutputComponentIdx: parseInt(tool.outputComponent.split(\";\")[0]),\n\t\toutputComponent: ToolOutputComponents.parse(tool.outputComponent.split(\";\")[1]),\n\t}));\nexport const configTools = z\n\t.array(\n\t\tz\n\t\t\t.object({\n\t\t\t\tname: z.string(),\n\t\t\t\tdescription: z.string(),\n\t\t\t\tendpoint: z.union([z.string(), z.null()]),\n\t\t\t\tinputs: z.array(toolInputSchema),\n\t\t\t\toutputComponent: ToolOutputComponents.or(z.null()),\n\t\t\t\toutputComponentIdx: z.number().int().default(0),\n\t\t\t\tshowOutput: z.boolean(),\n\t\t\t\t_id: z\n\t\t\t\t\t.string()\n\t\t\t\t\t.length(24)\n\t\t\t\t\t.regex(/^[0-9a-fA-F]{24}$/)\n\t\t\t\t\t.transform((val) => new ObjectId(val)),\n\t\t\t\tbaseUrl: z.string().optional(),\n\t\t\t\tdisplayName: z.string(),\n\t\t\t\tcolor: ToolColor,\n\t\t\t\ticon: ToolIcon,\n\t\t\t\tisOnByDefault: z.optional(z.literal(true)),\n\t\t\t\tisLocked: z.optional(z.literal(true)),\n\t\t\t\tisHidden: z.optional(z.literal(true)),\n\t\t\t})\n\t\t\t.transform((val) => ({\n\t\t\t\ttype: \"config\" as const,\n\t\t\t\t...val,\n\t\t\t\tcall: getCallMethod(val),\n\t\t\t}))\n\t)\n\t// add the extra hardcoded tools\n\t.transform((val) => [...val, calculator, directlyAnswer, fetchUrl, websearch]);\n\nexport function getCallMethod(tool: Omit<BaseTool, \"call\">): BackendCall {\n\treturn async function* (params, ctx, uuid) {\n\t\tif (\n\t\t\ttool.endpoint === null ||\n\t\t\t!tool.baseUrl ||\n\t\t\t!tool.outputComponent ||\n\t\t\ttool.outputComponentIdx === null\n\t\t) {\n\t\t\tthrow new Error(`Tool function ${tool.name} has no endpoint`);\n\t\t}\n\n\t\tconst ipToken = await getIpToken(ctx.ip, ctx.username);\n\n\t\tfunction coerceInput(value: unknown, type: ToolInput[\"type\"]) {\n\t\t\tconst valueStr = String(value);\n\t\t\tswitch (type) {\n\t\t\t\tcase \"str\":\n\t\t\t\t\treturn valueStr;\n\t\t\t\tcase \"int\":\n\t\t\t\t\treturn parseInt(valueStr);\n\t\t\t\tcase \"float\":\n\t\t\t\t\treturn parseFloat(valueStr);\n\t\t\t\tcase \"bool\":\n\t\t\t\t\treturn valueStr === \"true\";\n\t\t\t\tdefault:\n\t\t\t\t\tthrow new Error(`Unsupported type ${type}`);\n\t\t\t}\n\t\t}\n\t\tconst inputs = tool.inputs.map(async (input) => {\n\t\t\tif (input.type === \"file\" && input.paramType !== \"required\") {\n\t\t\t\tthrow new Error(\"File inputs are always required and cannot be optional or fixed\");\n\t\t\t}\n\n\t\t\tif (input.paramType === \"fixed\") {\n\t\t\t\treturn coerceInput(input.value, input.type);\n\t\t\t} else if (input.paramType === \"optional\") {\n\t\t\t\treturn coerceInput(params[input.name] ?? input.default, input.type);\n\t\t\t} else if (input.paramType === \"required\") {\n\t\t\t\tif (params[input.name] === undefined) {\n\t\t\t\t\tthrow new Error(`Missing required input ${input.name}`);\n\t\t\t\t}\n\n\t\t\t\tif (input.type === \"file\") {\n\t\t\t\t\t// todo: parse file here !\n\t\t\t\t\t// structure is {input|output}-{msgIdx}-{fileIdx}-{filename}\n\n\t\t\t\t\tconst filename = params[input.name];\n\n\t\t\t\t\tif (!filename || typeof filename !== \"string\") {\n\t\t\t\t\t\tthrow new Error(`Filename is not a string`);\n\t\t\t\t\t}\n\n\t\t\t\t\tconst messages = ctx.messages;\n\n\t\t\t\t\tconst msgIdx = parseInt(filename.split(\"_\")[1]);\n\t\t\t\t\tconst fileIdx = parseInt(filename.split(\"_\")[2]);\n\n\t\t\t\t\tif (Number.isNaN(msgIdx) || Number.isNaN(fileIdx)) {\n\t\t\t\t\t\tthrow Error(`Message index or file index is missing`);\n\t\t\t\t\t}\n\n\t\t\t\t\tif (msgIdx >= messages.length) {\n\t\t\t\t\t\tthrow Error(`Message index ${msgIdx} is out of bounds`);\n\t\t\t\t\t}\n\n\t\t\t\t\tconst file = messages[msgIdx].files?.[fileIdx];\n\n\t\t\t\t\tif (!file) {\n\t\t\t\t\t\tthrow Error(`File index ${fileIdx} is out of bounds`);\n\t\t\t\t\t}\n\n\t\t\t\t\tconst blob = await downloadFile(file.value, ctx.conv._id)\n\t\t\t\t\t\t.then((file) => fetch(`data:${file.mime};base64,${file.value}`))\n\t\t\t\t\t\t.then((res) => res.blob())\n\t\t\t\t\t\t.catch((err) => {\n\t\t\t\t\t\t\tthrow Error(\"Failed to download file\", { cause: err });\n\t\t\t\t\t\t});\n\n\t\t\t\t\treturn blob;\n\t\t\t\t} else {\n\t\t\t\t\treturn coerceInput(params[input.name], input.type);\n\t\t\t\t}\n\t\t\t}\n\t\t});\n\n\t\tconst outputs = yield* callSpace(\n\t\t\ttool.baseUrl,\n\t\t\ttool.endpoint,\n\t\t\tawait Promise.all(inputs),\n\t\t\tipToken,\n\t\t\tuuid\n\t\t);\n\n\t\tif (!isValidOutputComponent(tool.outputComponent)) {\n\t\t\tthrow new Error(`Tool output component is not defined`);\n\t\t}\n\n\t\tconst { type, path } = ToolOutputPaths[tool.outputComponent];\n\n\t\tif (!path || !type) {\n\t\t\tthrow new Error(`Tool output type ${tool.outputComponent} is not supported`);\n\t\t}\n\n\t\tconst files: MessageFile[] = [];\n\n\t\tconst toolOutputs: Array<Record<string, string>> = [];\n\n\t\tif (outputs.length <= tool.outputComponentIdx) {\n\t\t\tthrow new Error(`Tool output component index is out of bounds`);\n\t\t}\n\n\t\t// if its not an object, return directly\n\t\tif (\n\t\t\toutputs[tool.outputComponentIdx] !== undefined &&\n\t\t\ttypeof outputs[tool.outputComponentIdx] !== \"object\"\n\t\t) {\n\t\t\treturn {\n\t\t\t\toutputs: [{ [tool.name + \"-0\"]: outputs[tool.outputComponentIdx] }],\n\t\t\t\tdisplay: tool.showOutput,\n\t\t\t};\n\t\t}\n\n\t\tawait Promise.all(\n\t\t\tjp\n\t\t\t\t.query(outputs[tool.outputComponentIdx], path)\n\t\t\t\t.map(async (output: string | string[], idx) => {\n\t\t\t\t\tconst arrayedOutput = Array.isArray(output) ? output : [output];\n\t\t\t\t\tif (type === \"file\") {\n\t\t\t\t\t\t// output files are actually URLs\n\n\t\t\t\t\t\tawait Promise.all(\n\t\t\t\t\t\t\tarrayedOutput.map(async (output, idx) => {\n\t\t\t\t\t\t\t\tawait fetch(output)\n\t\t\t\t\t\t\t\t\t.then((res) => res.blob())\n\t\t\t\t\t\t\t\t\t.then(async (blob) => {\n\t\t\t\t\t\t\t\t\t\tconst { ext, mime } = (await fileTypeFromBlob(blob)) ?? { ext: \"octet-stream\" };\n\n\t\t\t\t\t\t\t\t\t\treturn new File(\n\t\t\t\t\t\t\t\t\t\t\t[blob],\n\t\t\t\t\t\t\t\t\t\t\t`${idx}-${await sha256(JSON.stringify(params))}.${ext}`,\n\t\t\t\t\t\t\t\t\t\t\t{\n\t\t\t\t\t\t\t\t\t\t\t\ttype: mime,\n\t\t\t\t\t\t\t\t\t\t\t}\n\t\t\t\t\t\t\t\t\t\t);\n\t\t\t\t\t\t\t\t\t})\n\t\t\t\t\t\t\t\t\t.then((file) => uploadFile(file, ctx.conv))\n\t\t\t\t\t\t\t\t\t.then((file) => files.push(file));\n\t\t\t\t\t\t\t})\n\t\t\t\t\t\t);\n\n\t\t\t\t\t\ttoolOutputs.push({\n\t\t\t\t\t\t\t[tool.name +\n\t\t\t\t\t\t\t\"-\" +\n\t\t\t\t\t\t\tidx.toString()]: `Only and always answer: 'I used the tool ${tool.displayName}, here is the result.' Don't add anything else.`,\n\t\t\t\t\t\t});\n\t\t\t\t\t} else {\n\t\t\t\t\t\tfor (const output of arrayedOutput) {\n\t\t\t\t\t\t\ttoolOutputs.push({\n\t\t\t\t\t\t\t\t[tool.name + \"-\" + idx.toString()]: output,\n\t\t\t\t\t\t\t});\n\t\t\t\t\t\t}\n\t\t\t\t\t}\n\t\t\t\t})\n\t\t);\n\n\t\tfor (const file of files) {\n\t\t\tyield {\n\t\t\t\ttype: MessageUpdateType.File,\n\t\t\t\tname: file.name,\n\t\t\t\tsha: file.value,\n\t\t\t\tmime: file.mime,\n\t\t\t};\n\t\t}\n\n\t\treturn { outputs: toolOutputs, display: tool.showOutput };\n\t};\n}\n\nexport const toolFromConfigs = configTools.parse(JSON5.parse(env.TOOLS)) satisfies ConfigTool[];\n", "src\\styles\\main.css": "@import \"./highlight-js.css\";\n\n@tailwind base;\n@tailwind components;\n@tailwind utilities;\n\n@layer components {\n\t.btn {\n\t\t@apply inline-flex flex-shrink-0 cursor-pointer select-none items-center justify-center whitespace-nowrap outline-none transition-all focus:ring disabled:cursor-default;\n\t}\n}\n\n@layer utilities {\n\t.scrollbar-custom {\n\t\t@apply scrollbar-thin scrollbar-track-transparent scrollbar-thumb-black/10 scrollbar-thumb-rounded-full scrollbar-w-1 hover:scrollbar-thumb-black/20 dark:scrollbar-thumb-white/10 dark:hover:scrollbar-thumb-white/20;\n\t}\n}\n"} | null |
chat-ui-android | {"type": "directory", "name": "chat-ui-android", "children": [{"type": "directory", "name": "app", "children": [{"type": "file", "name": "build.gradle.kts"}, {"type": "file", "name": "proguard-rules.pro"}, {"type": "directory", "name": "src", "children": [{"type": "directory", "name": "main", "children": [{"type": "file", "name": "AndroidManifest.xml"}, {"type": "directory", "name": "java", "children": [{"type": "directory", "name": "co", "children": [{"type": "directory", "name": "huggingface", "children": [{"type": "directory", "name": "chat_ui_android", "children": [{"type": "file", "name": "MainActivity.kt"}]}]}]}]}, {"type": "directory", "name": "res", "children": [{"type": "directory", "name": "drawable", "children": [{"type": "file", "name": "ic_launcher_foreground.xml"}]}, {"type": "directory", "name": "layout", "children": [{"type": "file", "name": "activity_main.xml"}, {"type": "file", "name": "content_main.xml"}]}, {"type": "directory", "name": "mipmap-anydpi-v26", "children": [{"type": "file", "name": "ic_launcher.xml"}, {"type": "file", "name": "ic_launcher_round.xml"}]}, {"type": "directory", "name": "mipmap-hdpi", "children": []}, {"type": "directory", "name": "mipmap-ldpi", "children": []}, {"type": "directory", "name": "mipmap-mdpi", "children": []}, {"type": "directory", "name": "mipmap-xhdpi", "children": []}, {"type": "directory", "name": "mipmap-xxhdpi", "children": []}, {"type": "directory", "name": "mipmap-xxxhdpi", "children": []}, {"type": "directory", "name": "values", "children": [{"type": "file", "name": "colors.xml"}, {"type": "file", "name": "dimens.xml"}, {"type": "file", "name": "strings.xml"}, {"type": "file", "name": "themes.xml"}]}, {"type": "directory", "name": "values-land", "children": [{"type": "file", "name": "dimens.xml"}]}, {"type": "directory", "name": "values-night", "children": [{"type": "file", "name": "themes.xml"}]}, {"type": "directory", "name": "values-v23", "children": [{"type": "file", "name": "themes.xml"}]}, {"type": "directory", "name": "values-w1240dp", "children": [{"type": "file", "name": "dimens.xml"}]}, {"type": "directory", "name": "values-w600dp", "children": [{"type": "file", "name": "dimens.xml"}]}, {"type": "directory", "name": "xml", "children": [{"type": "file", "name": "backup_rules.xml"}, {"type": "file", "name": "data_extraction_rules.xml"}, {"type": "file", "name": "file_paths.xml"}]}]}]}]}]}, {"type": "file", "name": "build.gradle.kts"}, {"type": "directory", "name": "gradle", "children": [{"type": "file", "name": "libs.versions.toml"}, {"type": "directory", "name": "wrapper", "children": [{"type": "file", "name": "gradle-wrapper.properties"}]}]}, {"type": "file", "name": "gradle.properties"}, {"type": "file", "name": "gradlew"}, {"type": "file", "name": "gradlew.bat"}, {"type": "file", "name": "LICENSE"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "settings.gradle.kts"}]} | # HuggingChat Android Client
## Open-Source Android Client for HuggingChat
------------------------------------------
A native Android client that wrap HuggingChat into a native android Webview, built with love and open-sourced under the Apache-2.0 license.
### Getting Started
---------------
1. Clone the repository: `git clone https://github.com/your-username/huggingchat-android-client.git`
2. Import the project into Android Studio
3. Run Gradle Sync Project: File -> Sync Project with Gradle Files
4. Build and run the app on your Android device or emulator
### License
-------
This project is licensed under the Apache-2.0 license. See [LICENSE](LICENSE) for more information. | {".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 fb3ac37ff7271e4855d65c4c5cb3897fac13aa04 Hamza Amin <[email protected]> 1727369067 +0500\tclone: from https://github.com/huggingface/chat-ui-android.git\n", ".git\\refs\\heads\\main": "fb3ac37ff7271e4855d65c4c5cb3897fac13aa04\n", "app\\src\\main\\java\\co\\huggingface\\chat_ui_android\\MainActivity.kt": "package co.huggingface.chat_ui_android\n\nimport android.content.Intent\nimport android.net.Uri\nimport android.os.Bundle\nimport androidx.appcompat.app.AppCompatActivity\nimport android.webkit.WebView\nimport android.webkit.WebViewClient\nimport androidx.activity.enableEdgeToEdge\nimport android.view.KeyEvent\nimport android.webkit.ValueCallback\nimport android.webkit.WebChromeClient\n\nclass MainActivity : AppCompatActivity() {\n\n private lateinit var webView: WebView\n private var fileUploadCallback: ValueCallback<Array<Uri>>? = null\n private lateinit var currentPhotoUri: Uri\n\n companion object {\n private const val FILE_CHOOSER_REQUEST_CODE = 1\n }\n\n override fun onCreate(savedInstanceState: Bundle?) {\n enableEdgeToEdge()\n super.onCreate(savedInstanceState)\n setContentView(R.layout.activity_main)\n webView = findViewById(R.id.webview)\n webView.settings.setJavaScriptEnabled(true)\n\n webView.webViewClient = object : WebViewClient() {\n override fun shouldOverrideUrlLoading(view: WebView?, url: String?): Boolean {\n url?.let {\n if (it.contains(\"huggingface.co/chat\")\n || it.contains(\"huggingface.co/oauth\")\n || it.contains(\"huggingface.co/login\")\n || it.contains(\"huggingface.co/authorize\")\n ) {\n view?.loadUrl(it)\n return false\n } else {\n val browserIntent = Intent(Intent.ACTION_VIEW, Uri.parse(it))\n startActivity(browserIntent)\n }\n }\n return true\n }\n }\n\n webView.getSettings()\n .setUserAgentString(BuildConfig.APPLICATION_ID + \"/\" + BuildConfig.VERSION_NAME + \" \" + webView.settings.userAgentString);\n\n webView.webChromeClient = object : WebChromeClient() {\n override fun onShowFileChooser(\n webView: WebView?,\n filePathCallback: ValueCallback<Array<Uri>>?,\n fileChooserParams: FileChooserParams?\n ): Boolean {\n fileUploadCallback?.onReceiveValue(null)\n fileUploadCallback = filePathCallback\n\n // Use file picker\n val intent = Intent(Intent.ACTION_GET_CONTENT)\n intent.addCategory(Intent.CATEGORY_OPENABLE)\n intent.type = \"*/*\"\n val chooserIntent = Intent.createChooser(intent, \"Choose File\")\n startActivityForResult(chooserIntent, FILE_CHOOSER_REQUEST_CODE)\n\n return true\n }\n }\n\n webView.loadUrl(\"https://huggingface.co/chat\")\n }\n\n override fun onKeyDown(keyCode: Int, event: KeyEvent?): Boolean {\n if (keyCode == KeyEvent.KEYCODE_BACK && webView.canGoBack()) {\n webView.goBack()\n return true\n }\n return super.onKeyDown(keyCode, event)\n }\n\n override fun onActivityResult(requestCode: Int, resultCode: Int, data: Intent?) {\n if (requestCode == FILE_CHOOSER_REQUEST_CODE) {\n if (fileUploadCallback == null) {\n super.onActivityResult(requestCode, resultCode, data)\n return\n }\n\n val results: Array<Uri>? = when {\n resultCode == RESULT_OK && data?.data != null -> arrayOf(data.data!!)\n resultCode == RESULT_OK -> arrayOf(currentPhotoUri)\n else -> null\n }\n\n fileUploadCallback?.onReceiveValue(results)\n fileUploadCallback = null\n } else {\n super.onActivityResult(requestCode, resultCode, data)\n }\n }\n}\n", "app\\src\\main\\res\\layout\\activity_main.xml": "<?xml version=\"1.0\" encoding=\"utf-8\"?>\n<androidx.coordinatorlayout.widget.CoordinatorLayout xmlns:android=\"http://schemas.android.com/apk/res/android\"\n xmlns:app=\"http://schemas.android.com/apk/res-auto\"\n xmlns:tools=\"http://schemas.android.com/tools\"\n android:layout_width=\"match_parent\"\n android:layout_height=\"match_parent\"\n android:fitsSystemWindows=\"true\"\n tools:context=\".MainActivity\">\n\n <include layout=\"@layout/content_main\" />\n\n</androidx.coordinatorlayout.widget.CoordinatorLayout>", "app\\src\\main\\res\\layout\\content_main.xml": "<?xml version=\"1.0\" encoding=\"utf-8\"?>\n<androidx.constraintlayout.widget.ConstraintLayout xmlns:android=\"http://schemas.android.com/apk/res/android\"\n xmlns:app=\"http://schemas.android.com/apk/res-auto\"\n xmlns:tools=\"http://schemas.android.com/tools\"\n android:layout_width=\"match_parent\"\n android:layout_height=\"match_parent\"\n app:layout_behavior=\"@string/appbar_scrolling_view_behavior\">\n\n <WebView\n android:id=\"@+id/webview\"\n android:layout_width=\"match_parent\"\n android:layout_height=\"match_parent\"\n tools:layout_editor_absoluteX=\"0dp\"\n tools:layout_editor_absoluteY=\"0dp\" />\n\n</androidx.constraintlayout.widget.ConstraintLayout>", "gradle\\wrapper\\gradle-wrapper.properties": "#Tue Jun 11 13:26:48 CEST 2024\ndistributionBase=GRADLE_USER_HOME\ndistributionPath=wrapper/dists\ndistributionUrl=https\\://services.gradle.org/distributions/gradle-8.6-bin.zip\nzipStoreBase=GRADLE_USER_HOME\nzipStorePath=wrapper/dists\n"} | null |
Chat-with-sql | {"type": "directory", "name": "Chat-with-sql", "children": [{"type": "file", "name": "app.db"}, {"type": "file", "name": "app.py"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "testdb.db"}]} | # CHAT with SQLite Streamlit App with Foreign Keys
## Table of Content
- [Overview](#overview)
- [Motivation](#motivation)
- [Technical Aspect](#technical-aspect)
- [Installation And Run](#installation-and-run)
- [Directory Tree](#directory-tree)
- [To Do](#to-do)
- [Bug / Feature Request](#bug---feature-request)
- [Technologies Used](#technologies-used)
- [Credits](#credits)
## Overview
This project is a Streamlit application that allows users to upload multiple CSV files and create a SQLite database with tables corresponding to each CSV file. The application also handles foreign key relationships between the tables based on common integer columns found in the CSV files and it allows you to query your database in natural language.
## Motivation
The motivation behind this project was to provide a user-friendly way to convert CSV data into a SQLite database, while also automatically handling foreign key relationships between the tables. This can be useful for data analysis, querying, and integration with other applications that work with SQLite databases.
## Technical Aspect
The application uses the following technologies and libraries:
- **Streamlit**: A Python library for building interactive web applications.
- **Pandas**: A popular data manipulation and analysis library for Python.
- **SQLite3**: A Python library for working with SQLite databases.
- **LangChain**: A framework for building applications with large language models (LLMs).
- **HuggingFace Endpoint**: An LLM provided by HuggingFace for natural language processing tasks.
The application follows these steps:
1. Allow the user to upload multiple CSV files through the Streamlit interface.
2. Read the CSV files into Pandas DataFrames.
3. Analyze the DataFrames to find potential foreign key relationships based on common integer columns.
4. Create a SQLite database and tables corresponding to each CSV file, with foreign key constraints based on the detected relationships.
5. Provide an interface for the user to ask questions about the data.
6. Use the LangChain framework and the HuggingFace LLM to generate SQL queries based on the user's questions.
7. Execute the generated SQL queries on the SQLite database and display the results to the user.
## Installation And Run
1. Clone the repository or download the source code.
2. Install the required packages by running the following command:
```bash
pip install -r requirements.txt
```
3. Set up your HuggingFace API token by creating a .env file in the project directory and adding the following line:
```bash
huggingfacehub_api_token=YOUR_API_TOKEN
```
4. Run the Streamlit app with the following command:
```bash
streamlit run app.py
```
Directory Tree
```bash
│ app.py
│ README.md
│ requirements.txt
└───data
# CSV files will be stored here
```
## To Do
Implement support for handling more complex data types in CSV files.
Improve the foreign key detection algorithm for better accuracy.
Add support for creating indexes on columns.
## Bug / Feature Request
If you find a bug or have a feature request, please open an issue here.
## Technologies Used
<img target="_blank" src="https://streamlit.io/images/brand/streamlit-mark-color.png" width=200>
<img target="_blank" src="https://pandas.pydata.org/static/img/pandas.svg" width=200>
<img target="_blank" src="https://www.sqlite.org/images/sqlite370_banner.gif" width=200>
<img target="_blank" src="https://huggingface.co/front/assets/huggingface_logo-noborder.svg" width=200>
## Credits
HuggingFace
LangChain
| {"app.py": "import streamlit as st\nimport pandas as pd\nimport sqlite3\nimport os\nimport logging\nfrom langchain_community.utilities import SQLDatabase\nfrom langchain_community.llms import HuggingFaceEndpoint\nfrom langchain_experimental.sql.base import SQLDatabaseChain\nfrom langchain.chains import create_sql_query_chain\nfrom langchain_community.tools.sql_database.tool import QuerySQLDataBaseTool\nfrom langchain_core.prompts import PromptTemplate\nfrom langchain_core.output_parsers import StrOutputParser\nfrom langchain_core.runnables import RunnablePassthrough\nfrom operator import itemgetter\nfrom dotenv import load_dotenv\n\nload_dotenv()\n\n# Set up logging\nlogging.basicConfig(level=logging.INFO)\nlogger = logging.getLogger()\n\n# Create or connect to a SQLite database\nconn = sqlite3.connect('app.db')\nc = conn.cursor()\n\ndef create_table_with_fk(table_name, df, foreign_keys):\n try:\n columns = ', '.join([f'\"{column}\" TEXT' if df[column].dtype == 'object' else f'\"{column}\" {df[column].dtype}' for column in df.columns])\n \n foreign_key_constraints = ', '.join([f'FOREIGN KEY (\"{fk}\") REFERENCES \"{ref_table}\" (\"{fk}\")' for fk, ref_table in foreign_keys.items()])\n create_table_sql = f'CREATE TABLE \"{table_name}\" ({columns}{\", \" + foreign_key_constraints if foreign_key_constraints else \"\"})'\n\n c.execute(create_table_sql)\n conn.commit()\n logger.info(f\"Table {table_name} created in the database with foreign keys!\")\n df.to_sql(table_name, conn, if_exists='append', index=False, method='multi')\n except Exception as e:\n logger.error(f\"Error creating table {table_name}: {e}\")\n\n# Function to find potential foreign keys\ndef find_potential_foreign_keys(df_list, uploaded_files):\n foreign_keys = {}\n for i, df1 in enumerate(df_list):\n for j, df2 in enumerate(df_list):\n if i != j:\n common_columns = set(df1.columns).intersection(df2.columns)\n for column in common_columns:\n if df1[column].dtype == 'int64' and df2[column].dtype == 'int64':\n foreign_keys[column] = os.path.splitext(uploaded_files[j].name)[0]\n return foreign_keys\n\n# Streamlit app\ndef main():\n st.title('CSV to SQLite Streamlit App with Foreign Keys')\n \n uploaded_files = st.file_uploader(\"Choose CSV files\", accept_multiple_files=True)\n if uploaded_files:\n if len(uploaded_files) > 5:\n st.error(\"You can upload no more than 5 CSV files.\")\n else:\n df_list = [pd.read_csv(uploaded_file) for uploaded_file in uploaded_files]\n foreign_keys = find_potential_foreign_keys(df_list, uploaded_files)\n for uploaded_file, df in zip(uploaded_files, df_list):\n table_name = os.path.splitext(uploaded_file.name)[0]\n create_table_with_fk(table_name, df, foreign_keys)\n st.success(\"Database created successfully!\")\n\n # Language model setup\n api_key = os.getenv(\"huggingfacehub_api_token\")\n llm = HuggingFaceEndpoint(\n huggingfacehub_api_token=api_key,\n repo_id = \"mistralai/Mistral-7B-Instruct-v0.2\",\n temperature=0.5,\n model_kwargs={\"max_length\": 20}\n )\n\n # Connect to the new database\n db = SQLDatabase.from_uri(\"sqlite:///app.db\", sample_rows_in_table_info=3)\n\n prompt_template = '''\n Given an input question, first create a syntactically correct SQLite query to run, then look at the results of the query and return the answer to the input question.\n Unless the user specifies in the question a specific number of examples to obtain, query for at most 10 results using the LIMIT clause as per SQLite. You can order the results to return the most informative data in the database.\n Never query for all columns from a table. You must query only the columns that are needed to answer the question. Wrap each column name in double quotes (\") to denote them as delimited identifiers.\n Pay attention to use only the column names you can see in the tables below. Be careful to not query for columns that do not exist. Also, pay attention to which column is in which table.\n Pay attention to user question, think like the user is dumb but you are not if the user do not enters specific details about the question it is your duty to generate syntactically correct query and do not through errors you get from database instead simply say please provide more details about the question you asked.\n Pay attention to use date('now') function to get the current date, if the question involves \"today\".\n\n Question: Question here\n SQLQuery: SQL Query to run\n SQLResult: Result of the SQLQuery\n Answer: Final answer here\n\n Only use the following tables:\n {table_info}\n\n Question: {input}\n '''\n PROMPT = PromptTemplate.from_template(prompt_template, variables=['input'])\n\n sql_db_chain = SQLDatabaseChain.from_llm(llm=llm, db=db, verbose=True, prompt=PROMPT)\n st.subheader(\"Ask Questions about the Data\")\n user_question = st.text_input(\"Enter your question:\")\n if user_question:\n try:\n logger.info(f\"User question: {user_question}\")\n response = sql_db_chain.invoke(user_question)\n answer = response['result']\n st.write(answer)\n except Exception as e:\n st.error(f\"Error processing the question: {e}\")\n\n\nif __name__ == \"__main__\":\n main()\n", "requirements.txt": "streamlit==1.14.0\npandas==1.5.2\nlangchain-community==0.0.18\nlangchain-experimental==0.0.14\nlangchain-core==0.0.65\npython-dotenv==0.21.0\n", ".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n"} | null |
chug | {"type": "directory", "name": "chug", "children": [{"type": "file", "name": "LICENSE"}, {"type": "file", "name": "pyproject.toml"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "directory", "name": "src", "children": [{"type": "directory", "name": "chug", "children": [{"type": "directory", "name": "app", "children": [{"type": "file", "name": "test.py"}]}, {"type": "directory", "name": "common", "children": [{"type": "file", "name": "collate.py"}, {"type": "file", "name": "config.py"}, {"type": "file", "name": "random.py"}, {"type": "file", "name": "task_config.py"}, {"type": "file", "name": "types.py"}, {"type": "file", "name": "urls.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "doc", "children": [{"type": "file", "name": "constants.py"}, {"type": "file", "name": "doc_processor.py"}, {"type": "file", "name": "doc_read_processor.py"}, {"type": "file", "name": "doc_vqa_processor.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "hfds", "children": [{"type": "file", "name": "collate.py"}, {"type": "file", "name": "loader.py"}, {"type": "file", "name": "wrappers.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "image", "children": [{"type": "file", "name": "build_transforms_doc.py"}, {"type": "file", "name": "build_transforms_image.py"}, {"type": "file", "name": "transforms_alb.py"}, {"type": "file", "name": "transforms_factory.py"}, {"type": "file", "name": "transforms_torch.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "loader.py"}, {"type": "directory", "name": "task_pipeline", "children": [{"type": "file", "name": "pipeline_doc_read.py"}, {"type": "file", "name": "pipeline_doc_vqa.py"}, {"type": "file", "name": "pipeline_factory.py"}, {"type": "file", "name": "pipeline_gtparse.py"}, {"type": "file", "name": "pipeline_image_text.py"}, {"type": "file", "name": "pipeline_manual.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "text", "children": [{"type": "file", "name": "tokenization.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "version.py"}, {"type": "directory", "name": "wds", "children": [{"type": "file", "name": "dataset_info.py"}, {"type": "file", "name": "decode.py"}, {"type": "file", "name": "filters.py"}, {"type": "file", "name": "helpers.py"}, {"type": "file", "name": "loader.py"}, {"type": "file", "name": "pipeline.py"}, {"type": "file", "name": "shardlists.py"}, {"type": "file", "name": "tariterators.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "__init__.py"}]}]} | # Chugging Data
A library to help w/ efficient training for multi-modal data. Initially focused on image & document + text tasks.
`chug` currently leverages `webdataset` and Hugging Face `datasets`.
`webdataset` tar files and dataset pipelines are preferred for scalable pretraining.
Hugging Face `datasets` are supported and work great for exploration, validation, and fine-tune use cases.
`chug` provides on the fly PDF decoding and rendering via either pypdfium2 (https://github.com/pypdfium2-team/pypdfium2) as a default, or fitz/pymupdf (https://github.com/pymupdf/PyMuPDF) if your use case is okay with their AGPL-3.0 license. `fitz` support must be manually enabled. The pdf handling is implemented at the webdataset level, so you can plug it in to other webdataset pipelines. This enables large scale sharded streaming of native .pdf files without needing to pre-render to .png/.tiff, etc.
## Status
This library is still a WIP, consider this an alpha release (pre announcement). Major features should be working, the library has been tested with several PDF datasets we will shortly make public. However, do expect there will still be breaking changes, lots of improvements, etc.
`pip install --pre chug` will install the current dev version.
### TODOs
### Nearish
* Cleanup and refinement, codebase will change
* Documentation & unit-tests
* Support reading of info .json/.yaml files for automatic shard info resolution for webdatasets (like timm)
### Mediumish
* Option to output bbox annotations for lines (or word + word output) for tasks that leverage layout
* Unified preprocessor functions for combined image + text tokenization (img+text token interleaving, etc.)
* Image token (patch) packing ala NaViT. Online bin packing based algorithms integrated with image preprocessing and pipeline.
### Longish
* Increase range of task pipelines for other tasks, modelling needs
* Support additional modalities & targets (video, audio, detection/dense pixel targets, image/video/audio targets)
* Explore alternatives to .tar shards (array_record, arrow, etc)
## Design
### Submodule Hierarchy
The library has been designed so that functions, classes at different levels can be used independently.
If one wants to build a loader & pipeline with JSON/YAML serializable configs, use the top-level `chug.create_loader()` in `chug/loader.py`. Depending on dataset sources, one can easily switch this between webdataset, HF datasets (in the future, other sources).
Bypassing the highest level, one can also call `build_pipeline_*` methods in `task_pipeline` and then call `create_loader_wds` with a full array of args for `wds` only use cases.
If one doesn't want to use `chug` loaders and pipelines at all, `image`, `text`, and `wds` (especially decoder) functionality may be useful in other projects.
#### Library modules (highest to lowest level)
The dependencies of modules within the library are intended to follow the hierarchy below. e.g. doc depends on wds, but wds should never depend on doc.
```
app
|
loader (chug/loader.py)
|
task_pipeline
|
doc
|
wds, hfds, image, text
|
common
```
### Submodules
#### `common`
Configs, structures (dataclasses) for general use across the library
#### `wds`
Webdataset (`wds` for short) specific code. Extensions and alterations of webdataset functionality to fit covered use case and improve robustness.
All data pipelines in `chug` currently leverage `wds` pipelines, even when not using `wds` datasets.
Document oriented decoding (pdf decoder) is present in `chug/wds/decode.py`, it can be used with any webdataset pipeline as a decoder. e.g. `wds.decode(chug.wds.DecodeDoc('pill'), 'pill')`
#### `hfds`
Hugging Face `datasets` support. A minimal wrapper that allows `datasets` to be used with chug processing pipelines.
The processing pipelines remain webdataset based when using `datasets`, they are invoked by a custom collate class.
#### `image`
Image processing, `torchvision` and `albumentations` based transform building code. A mix of generic image (imagenet, simclr) transforms and document specific transforms, including an implementation of `albumentations` based `nougat` transforms.
#### `text`
Text processing, tokenization code.
#### `doc`
Document processing code. Currently focused on processors that apply image/pdf decoders and process document OCR or VQA annotations.
#### `task_pipeline`
Task specific pipelines, where dataset formats meet modelling needs.
Inputs to task pipelines are sample dictionaries based on the dataset form, they are decoded and then processed into outputs that match model input requirements.
Task specific pipelines that handle the data <--> model input interface are inserted into an encompassing data pipeline which handles shard lists, shuffle, wrapping, distributed worker, splitting, batching, etc.
#### `chug.loader`
This lone top-level file includes the main factory methods for creating loaders w/ associated pipelines from config dataclasses.
#### `app`
Most applications using `chug` will exist outside of the lib in training libraries, etc. Some builtin utility / exploration apps will be included here.
## Concepts
WIP
## Datasets
Datasets that work well with this library can be found on the Hugging Face Hub under the `pixparse` organization (https://huggingface.co/pixparse).
We'll add links to other noteworthy datasets that can be used as we become aware of them.
## Usage / Examples
### Document Reading, Training w/ IDL
```python
import chug
img_cfg = chug.ImageInputCfg(size=(1024, 768), transform_type='doc_better')
img_fn = chug.create_image_preprocessor(input_cfg=img_cfg, is_training=True)
txt_fn = chug.create_text_preprocessor(
'naver-clova-ix/donut-base',
prompt_end_token='<s_idl>',
task_start_token='<s_idl>', # NOTE needs to be added to tokenizer
)
task_cfg = chug.DataTaskDocReadCfg(
image_process_fn=img_fn,
text_process_fn=txt_fn,
page_sampling='random',
error_handler='dump_and_reraise',
)
data_cfg = chug.DataCfg(
source='pipe:curl -s -f -L https://huggingface.co/datasets/pixparse/idl-wds/resolve/main/idl-train-0{0000..2999}.tar',
batch_size=8,
num_samples=3144726,
format='wds',
)
lb = chug.create_loader(
data_cfg,
task_cfg,
is_training=True,
)
ii = iter(lb)
sample = next(ii)
```
### Document Reading, Exploring IDL
```python
import chug
task_cfg = chug.DataTaskDocReadCfg(page_sampling='all')
data_cfg = chug.DataCfg(
source='pixparse/idl-wds',
split='train',
batch_size=None,
format='hfids',
num_workers=0,
)
lb = chug.create_loader(
data_cfg,
task_cfg,
)
ii = iter(lb)
sample = next(ii)
```
### Document Reading, Training with PDFA
```python
import chug
img_cfg = chug.ImageInputCfg(size=(1024, 768), transform_type='doc_nougat')
img_fn = chug.create_image_preprocessor(input_cfg=img_cfg, is_training=True)
txt_fn = chug.create_text_preprocessor(
'naver-clova-ix/donut-base',
prompt_end_token='<s_pdfa>',
task_start_token='<s_pdfa>', # NOTE needs to be added to tokenizer
)
task_cfg = chug.DataTaskDocReadCfg(
image_process_fn=img_fn,
text_process_fn=txt_fn,
page_sampling='random',
)
data_cfg = chug.DataCfg(
source='pipe:curl -s -f -L https://huggingface.co/datasets/pixparse/pdfa-english-train/resolve/main/pdfa-eng-train-{000000..005000}.tar',
batch_size=8,
num_samples=1000000, # FIXME replace with actual
format='wds',
)
lb = chug.create_loader(
data_cfg,
task_cfg,
is_training=True,
)
ii = iter(lb)
sample = next(ii)
```
### Document Reading, Exploring PDFA
```python
import chug
task_cfg = chug.DataTaskDocReadCfg(
page_sampling='all',
)
data_cfg = chug.DataCfg(
source='pixparse/pdfa-eng-wds',
split='train',
batch_size=None,
format='hfids',
num_workers=0,
)
lb = chug.create_loader(
data_cfg,
task_cfg,
)
ii = iter(lb)
sample = next(ii)
```
### Image + Text
### Training
```python
import chug
import transformers
from functools import partial
img_cfg = chug.ImageInputCfg(size=(512, 512), transform_type='image_timm')
img_fn = chug.create_image_preprocessor(input_cfg=img_cfg, is_training=True)
tokenizer = transformers.AutoTokenizer.from_pretrained('laion/CLIP-ViT-H-14-laion2B-s32B-b79K')
txt_fn = partial(chug.tokenize, max_length=1000, tokenizer=tokenizer)
task_cfg = chug.DataTaskImageTextCfg(
image_process_fn=img_fn,
text_process_fn=txt_fn,
)
data_cfg = chug.DataCfg(
source='pipe:curl -s -f -L https://huggingface.co/datasets/pixparse/cc12m-wds/resolve/main/cc12m-train-{0000..2175}.tar',
batch_size=8,
num_samples=10968539,
format='wds',
)
lb = chug.create_loader(
data_cfg,
task_cfg,
is_training=True,
)
ii = iter(lb)
sample = next(ii)
```
### Document VQA
#### Training, Fine-tuning
```python
import chug
from chug.task_pipeline import create_task_pipeline
img_cfg = chug.ImageInputCfg(size=(1024, 768), transform_type='doc_basic')
img_fn = chug.create_image_preprocessor(img_cfg, is_training=True)
txt_fn = chug.create_text_preprocessor(
'naver-clova-ix/donut-base-finetuned-docvqa',
prompt_end_token='<s_answer>',
task_start_token='<s_docvqa>',
)
task_cfg = chug.DataTaskDocVqaCfg(
image_process_fn=img_fn,
text_process_fn=txt_fn,
)
data_cfg = chug.DataCfg(
source='pipe:curl -s -f -L https://huggingface.co/datasets/pixparse/docvqa-wds/resolve/main/docvqa-train-{000..383}.tar',
batch_size=8,
format='wds',
num_samples=39463,
)
lb = chug.create_loader(
data_cfg,
task_cfg,
is_training=True,
)
ii = iter(lb)
sample = next(ii)
```
#### Exploration
```python
import chug
from chug.task_pipeline import create_task_pipeline
task_cfg = chug.DataTaskDocVqaCfg(
question_prefix='Question: ',
question_suffix='',
answer_prefix='Answer: ',
answer_suffix=''
)
data_cfg = chug.DataCfg(
source='pixparse/docvqa-single-page-questions',
split='validation',
batch_size=None,
format='hfids',
num_workers=0,
)
lb = chug.create_loader(
data_cfg,
task_cfg
)
ii = iter(lb)
sample = next(ii)
```
## Acknowledgement
`chug` evolve from the `webdataset` datapipeline used successfully in the [OpenCLIP](https://github.com/mlfoundations/open_clip) project. Thanks to all the contributors in that project. Future work will likely involve closing the loop and leveraging `chug` in OpenCLIP for increased capability.
The image/document augmentations in `chug` rely on a number of external influences. Our document oriented `doc_better` torchvision augmentations are influenced by `nougat`, and the `doc_nougat` is a direct adaptation of the [`albumentations`](https://albumentations.ai/) + `cv2` document pipeline in [`nougat`](https://github.com/facebookresearch/nougat). Several image augmentations leverage existing work in the `timm` library.
Also, big thanks to the maintainers of [`webdataset`](https://github.com/webdataset/webdataset) and Hugging Face [`datasets`](https://github.com/huggingface/datasets).
| {"requirements.txt": "torch\ntimm\nwebdataset\ndatasets\npypdfium2\nsimple_parsing", ".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 0068000564c7a481af065779cf26ad04defe4c2a Hamza Amin <[email protected]> 1727369038 +0500\tclone: from https://github.com/huggingface/chug.git\n", ".git\\refs\\heads\\main": "0068000564c7a481af065779cf26ad04defe4c2a\n", "src\\chug\\hfds\\wrappers.py": "from torch.utils.data import Dataset, IterableDataset\n\nfrom chug.common import SharedCount\n\nclass SafeDataset(Dataset):\n \"\"\"\n This is a Dataset wrapped by a try/except in the __getitem__ in case\n the hfds datasets used have errors/corrupt data.\n \"\"\"\n\n def __init__(self, original_dataset, max_retry=10):\n self.ds = original_dataset\n self.max_retry = max_retry\n\n def __len__(self):\n return len(self.ds)\n\n def __getitem__(self, idx):\n err = None\n for try_idx in range(self.max_retry):\n try:\n item = self.ds[idx + try_idx]\n return item\n except Exception as e:\n err = e\n continue\n raise err\n\n\n\nclass WrappedIterableDataset(IterableDataset):\n \"\"\"\n \"\"\"\n\n def __init__(self, original_dataset, interval_count=None, max_retry=10):\n self.ds = original_dataset\n self.max_retry = max_retry\n self.interval_count = interval_count\n\n def set_interval_count(self, interval_count):\n if isinstance(self.interval_count, SharedCount):\n self.interval_count.set_value(interval_count)\n else:\n self.interval_count = interval_count\n\n def __iter__(self):\n if isinstance(self.interval_count, SharedCount):\n interval_count = self.interval_count.get_value()\n else:\n interval_count = self.interval_count\n self.ds.set_epoch(interval_count)\n for sample in self.ds:\n yield sample\n"} | null |
collaborative-training-auth | {"type": "directory", "name": "collaborative-training-auth", "children": [{"type": "directory", "name": "backend", "children": [{"type": "file", "name": ".env.template"}, {"type": "file", "name": "alembic.ini"}, {"type": "directory", "name": "app", "children": [{"type": "directory", "name": "api", "children": [{"type": "directory", "name": "dependencies", "children": [{"type": "file", "name": "crypto.py"}, {"type": "file", "name": "database.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "routes", "children": [{"type": "file", "name": "experiments.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "server.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "core", "children": [{"type": "file", "name": "config.py"}, {"type": "file", "name": "tasks.py"}]}, {"type": "directory", "name": "db", "children": [{"type": "directory", "name": "migrations", "children": [{"type": "file", "name": "env.py"}, {"type": "file", "name": "script.py.mako"}, {"type": "directory", "name": "versions", "children": [{"type": "file", "name": "1ff5763812c1_create_collaborator.py"}, {"type": "file", "name": "2dc2179b353f_create_main_tables.py"}, {"type": "file", "name": "97659da4900e_create_experiments_table.py"}, {"type": "file", "name": "a7841c3b04d0_drop_everything.py"}, {"type": "file", "name": "abc051ececd5_add_coordinator_ip_and_port.py"}, {"type": "file", "name": "ba788d7c81bf_add_keys.py"}]}]}, {"type": "file", "name": "models.py"}, {"type": "directory", "name": "repositories", "children": [{"type": "file", "name": "base.py"}, {"type": "file", "name": "experiments.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "tasks.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "models", "children": [{"type": "file", "name": "core.py"}, {"type": "file", "name": "experiment.py"}, {"type": "file", "name": "experiment_join.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "services", "children": [{"type": "file", "name": "authentication.py"}, {"type": "file", "name": "__init__.py"}]}]}, {"type": "file", "name": "Dockerfile"}, {"type": "file", "name": "Makefile"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "setup.cfg"}, {"type": "directory", "name": "tests", "children": [{"type": "file", "name": "conftest.py"}, {"type": "file", "name": "test_authentication.py"}, {"type": "file", "name": "test_experiments.py"}, {"type": "file", "name": "__init__.py"}]}]}, {"type": "file", "name": "docker-compose.yml"}, {"type": "file", "name": "LICENSE"}, {"type": "file", "name": "README.md"}]} | # Collaborative Hub Training Authentication API
Collaborative Hub Training Authentication API server-side machinery
## Overview
This is the server application that manages the authentication of peers in a collaborative training.
This API allows moderators of collaborative trainings to create and manage experiences which includes the allow listing
of hugging face users. This API also delivers passes to Hugging Face users who would like to join a collaborative training
More details in this [issue](https://github.com/learning-at-home/hivemind/issues/253)
API with fastapi & postgres database
## Developer guide
### Requirements for local development
- Python 3.8
- Docker (& docker-compose)
### Getting Started
Create an `.env` file in the `backend` folder. You can use the template in the `.env.template` file as inspiration.
Build & launch services with this command
```Bash
docker-compose up --build
```
Once your service is running, you can consult the documentation by copy-pasting this address in your search engine: `http://0.0.0.0:8000/docs#/`
### Test
Run tests
```Bash
docker-compose up -d --build
docker exec collaborative-training-auth_server_1 pytest -v
```
| {"docker-compose.yml": "##\n## Copyright (c) 2021 the Hugging Face team.\n##\n## Licensed under the Apache License, Version 2.0 (the \"License\");\n## you may not use this file except in compliance with the License.\n## You may obtain a copy of the License at\n##\n## http://www.apache.org/licenses/LICENSE-2.0\n##\n## Unless required by applicable law or agreed to in writing, software\n## distributed under the License is distributed on an \"AS IS\" BASIS,\n## WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n## See the License for the specific language governing permissions and\n## limitations under the License.##\nversion: \"3.8\"\nservices:\n server:\n build:\n context: ./backend\n dockerfile: Dockerfile\n restart: always\n volumes:\n - ./backend/:/backend/\n command: uvicorn app.api.server:app --reload --workers 1 --host 0.0.0.0 --port 8000\n env_file:\n - ./backend/.env\n ports:\n - 8000:8000\n depends_on:\n - db\n db:\n image: postgres:13-alpine\n restart: always\n volumes:\n - postgres_data:/var/lib/postgresql/data/\n env_file:\n - ./backend/.env\n ports:\n - 5432:5432\nvolumes:\n postgres_data:\n", ".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 aae4ee030002610949ee72f65345a8d1746fcd30 Hamza Amin <[email protected]> 1727369040 +0500\tclone: from https://github.com/huggingface/collaborative-training-auth.git\n", ".git\\refs\\heads\\main": "aae4ee030002610949ee72f65345a8d1746fcd30\n", "backend\\Dockerfile": "##\n## Copyright (c) 2021 the Hugging Face team.\n##\n## Licensed under the Apache License, Version 2.0 (the \"License\");\n## you may not use this file except in compliance with the License.\n## You may obtain a copy of the License at\n##\n## http://www.apache.org/licenses/LICENSE-2.0\n##\n## Unless required by applicable law or agreed to in writing, software\n## distributed under the License is distributed on an \"AS IS\" BASIS,\n## WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n## See the License for the specific language governing permissions and\n## limitations under the License.##\nFROM python:3.8-slim-buster\nWORKDIR /backend\nENV PYTHONDONTWRITEBYTECODE 1\nENV PYTHONBUFFERED 1\n# install system dependencies\nRUN apt-get update \\\n && apt-get -y install netcat gcc postgresql \\\n && apt-get clean\n# install python dependencies\nRUN pip install --upgrade pip\nCOPY ./requirements.txt /backend/requirements.txt\nRUN pip install -r requirements.txt\nCOPY . /backend", "backend\\requirements.txt": "# app\nfastapi>=0.65.2\nuvicorn>=0.11.7\npydantic>=1.6.2\nemail-validator==1.1.1\n\n#auth\nrequests\ncryptography==3.4.6\n\n# db\ndatabases[postgresql]==0.4.2\nSQLAlchemy==1.3.16\nalembic==1.4.2\npsycopg2-binary==2.8.6\nsqlalchemy-utils\n\n# dev\npytest==6.2.1\npytest-asyncio==0.14.0\nhttpx==0.16.1\nasgi-lifespan==1.0.1\nblack\nisort\nflake8\npytest-cov", "backend\\app\\db\\migrations\\versions\\2dc2179b353f_create_main_tables.py": "#\n# Copyright (c) 2021 the Hugging Face team.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.#\n\"\"\"create_main_tables\nRevision ID: 2dc2179b353f\nRevises: \nCreate Date: 2021-04-28 07:54:49.181680\n\"\"\" # noqa\nfrom typing import Tuple\n\nimport sqlalchemy as sa\nfrom alembic import op\n\n\n# revision identifiers, used by Alembic\nrevision = \"2dc2179b353f\"\ndown_revision = None\nbranch_labels = None\ndepends_on = None\n\n\ndef create_updated_at_trigger() -> None:\n op.execute(\n \"\"\"\n CREATE OR REPLACE FUNCTION update_updated_at_column()\n RETURNS TRIGGER AS\n $$\n BEGIN\n NEW.updated_at = now();\n RETURN NEW;\n END;\n $$ language 'plpgsql';\n \"\"\"\n )\n\n\ndef timestamps(indexed: bool = False) -> Tuple[sa.Column, sa.Column]:\n return (\n sa.Column(\n \"created_at\",\n sa.TIMESTAMP(timezone=True),\n server_default=sa.func.now(),\n nullable=False,\n index=indexed,\n ),\n sa.Column(\n \"updated_at\",\n sa.TIMESTAMP(timezone=True),\n server_default=sa.func.now(),\n nullable=False,\n index=indexed,\n ),\n )\n\n\ndef create_experiments_table() -> None:\n op.create_table(\n \"experiments\",\n sa.Column(\"id\", sa.Integer, primary_key=True),\n sa.Column(\"name\", sa.Text, nullable=False, index=True),\n sa.Column(\"owner\", sa.Text, nullable=False, index=True),\n *timestamps(),\n )\n op.execute(\n \"\"\"\n CREATE TRIGGER update_experiments_modtime\n BEFORE UPDATE\n ON experiments\n FOR EACH ROW\n EXECUTE PROCEDURE update_updated_at_column();\n \"\"\"\n )\n\n\ndef create_whitelist_table() -> None:\n op.create_table(\n \"whitelist\",\n sa.Column(\"id\", sa.Integer, primary_key=True),\n sa.Column(\"experiment_id\", sa.Integer, nullable=False, index=True),\n sa.Column(\"user_id\", sa.Integer, nullable=False, index=False),\n *timestamps(),\n )\n op.execute(\n \"\"\"\n CREATE TRIGGER update_whitelist_modtime\n BEFORE UPDATE\n ON whitelist\n FOR EACH ROW\n EXECUTE PROCEDURE update_updated_at_column();\n \"\"\"\n )\n\n\ndef create_users_table() -> None:\n op.create_table(\n \"users\",\n sa.Column(\"id\", sa.Integer, primary_key=True),\n sa.Column(\"username\", sa.Text, unique=True, nullable=True, index=True),\n *timestamps(),\n )\n op.execute(\n \"\"\"\n CREATE TRIGGER update_user_modtime\n BEFORE UPDATE\n ON users\n FOR EACH ROW\n EXECUTE PROCEDURE update_updated_at_column();\n \"\"\"\n )\n\n\ndef upgrade() -> None:\n create_updated_at_trigger()\n create_experiments_table()\n create_whitelist_table()\n create_users_table()\n\n\ndef downgrade() -> None:\n op.drop_table(\"users\")\n op.drop_table(\"experiments\")\n op.drop_table(\"whitelist\")\n op.execute(\"DROP FUNCTION update_updated_at_column\")\n"} | null |
competitions | {"type": "directory", "name": "competitions", "children": [{"type": "file", "name": ".dockerignore"}, {"type": "file", "name": ".env.example"}, {"type": "directory", "name": "competitions", "children": [{"type": "file", "name": "api.py"}, {"type": "file", "name": "app.py"}, {"type": "directory", "name": "cli", "children": [{"type": "file", "name": "competitions.py"}, {"type": "file", "name": "create.py"}, {"type": "file", "name": "run.py"}, {"type": "file", "name": "submit.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "compute_metrics.py"}, {"type": "file", "name": "create.py"}, {"type": "file", "name": "download.py"}, {"type": "file", "name": "enums.py"}, {"type": "file", "name": "errors.py"}, {"type": "file", "name": "evaluate.py"}, {"type": "file", "name": "info.py"}, {"type": "file", "name": "leaderboard.py"}, {"type": "file", "name": "oauth.py"}, {"type": "file", "name": "params.py"}, {"type": "file", "name": "runner.py"}, {"type": "directory", "name": "static", "children": [{"type": "file", "name": ".keep"}]}, {"type": "file", "name": "submissions.py"}, {"type": "directory", "name": "templates", "children": [{"type": "file", "name": "index.html"}]}, {"type": "directory", "name": "tests", "children": [{"type": "file", "name": "test_dummy.py"}]}, {"type": "file", "name": "text.py"}, {"type": "file", "name": "utils.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "Dockerfile"}, {"type": "directory", "name": "docs", "children": [{"type": "directory", "name": "source", "children": [{"type": "file", "name": "competition_repo.mdx"}, {"type": "file", "name": "competition_space.mdx"}, {"type": "file", "name": "create_competition.mdx"}, {"type": "file", "name": "custom_metric.mdx"}, {"type": "file", "name": "index.mdx"}, {"type": "file", "name": "leaderboard.mdx"}, {"type": "file", "name": "pricing.mdx"}, {"type": "file", "name": "submit.mdx"}, {"type": "file", "name": "teams.mdx"}, {"type": "file", "name": "_toctree.yml"}]}]}, {"type": "directory", "name": "examples", "children": [{"type": "file", "name": "generate_fake_submissions.py"}]}, {"type": "file", "name": "LICENSE"}, {"type": "file", "name": "Makefile"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "requirements_docker.txt"}, {"type": "file", "name": "sandbox.c"}, {"type": "file", "name": "setup.cfg"}, {"type": "file", "name": "setup.py"}]} | # Competitions
Create a machine learning competition for your organization, friends or the world!
## Getting Started
There are two types of competitions you can create:
- generic: a competition where you provide the data and the participants provide the predictions as a CSV file. all the test data is always available to the participants.
- script: a competition where you provide the data and the participants provide the code that generates the predictions. test data can be hidden from the participants.
## Costs
Creating a competition is free. However, you will need to pay for the compute resources used to run the competition. The cost of the compute resources depends the type of competition you create.
- generic: generic competitions are free to run. you can, however, upgrade the compute to cpu-basic to speed up the metric calculation and reduce the waiting time for the participants.
- script: script competitions require a compute resource to run the participant's code. you can choose between a variety of cpu and gpu instances (T4, A10g and even A100). the cost of the compute resource is charged per hour.
For information on the cost of the compute resources, please see the [pricing page](https://huggingface.co/docs/hub/spaces-overview#hardware-resources).
## Visibility
You can choose to make your competition public or private. Public competitions are visible to everyone and anyone can participate. Private competitions are only visible to the people you invite!
## How to create a competition?
Please read the [docs](https://huggingface.co/docs/competitions) to learn how to create a competition. | {"Dockerfile": "FROM nvidia/cuda:12.1.1-cudnn8-runtime-ubuntu22.04\n\nENV DEBIAN_FRONTEND=noninteractive \\\n TZ=UTC \\\n HF_HUB_ENABLE_HF_TRANSFER=1\n\nENV PATH=\"${HOME}/miniconda3/bin:${PATH}\"\nARG PATH=\"${HOME}/miniconda3/bin:${PATH}\"\n\nRUN mkdir -p /tmp/model && \\\n chown -R 1000:1000 /tmp/model && \\\n mkdir -p /tmp/data && \\\n chown -R 1000:1000 /tmp/data\n\nRUN apt-get update && \\\n apt-get upgrade -y && \\\n apt-get install -y \\\n build-essential \\\n cmake \\\n curl \\\n ca-certificates \\\n gcc \\\n git \\\n locales \\\n net-tools \\\n wget \\\n libpq-dev \\\n libsndfile1-dev \\\n git \\\n git-lfs \\\n libgl1 \\\n unzip \\\n openjdk-11-jre-headless \\\n libseccomp-dev \\\n && rm -rf /var/lib/apt/lists/* && \\\n apt-get clean\n\nRUN curl -s https://packagecloud.io/install/repositories/github/git-lfs/script.deb.sh | bash && \\\n git lfs install\n\nWORKDIR /app\n\nRUN mkdir -p /app/.cache\nENV HF_HOME=\"/app/.cache\"\nRUN chown -R 1000:1000 /app\nUSER 1000\nENV HOME=/app\n\nENV PYTHONPATH=$HOME/app \\\n PYTHONUNBUFFERED=1 \\\n GRADIO_ALLOW_FLAGGING=never \\\n GRADIO_NUM_PORTS=1 \\\n GRADIO_SERVER_NAME=0.0.0.0 \\\n GRADIO_THEME=huggingface \\\n SYSTEM=spaces\n\n\nRUN wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh \\\n && sh Miniconda3-latest-Linux-x86_64.sh -b -p /app/miniconda \\\n && rm -f Miniconda3-latest-Linux-x86_64.sh\nENV PATH /app/miniconda/bin:$PATH\n\nRUN conda create -p /app/env -y python=3.10\n\nSHELL [\"conda\", \"run\",\"--no-capture-output\", \"-p\",\"/app/env\", \"/bin/bash\", \"-c\"]\n\nRUN conda install pytorch torchvision torchaudio pytorch-cuda=12.1 -c pytorch -c nvidia && \\\n conda clean -ya && \\\n conda install -c \"nvidia/label/cuda-12.1.0\" cuda-nvcc && conda clean -ya\n\nCOPY --chown=1000:1000 . /app/\nRUN make sandbox\n\n# give permissions to run sandbox\nRUN chmod +x /app/sandbox\n\nENV PATH=\"/app:${PATH}\"\n\nRUN pip install -U pip\nRUN pip install -e .\nRUN pip install -r requirements_docker.txt", "requirements.txt": "# essentials\nfastapi==0.111.0\njoblib==1.4.2\nloguru==0.7.2\npandas==2.2.2\nhuggingface_hub==0.24.6\ntabulate==0.9.0\nmarkdown==3.6\npsutil==6.0.0\npython-multipart==0.0.9\nuvicorn==0.30.1\npy7zr==0.21.1\npydantic==2.8.2\ngradio==4.37.2\nauthlib==1.3.1\nitsdangerous==2.2.0\nhf-transfer\n", "setup.py": "# coding=utf-8\n# Copyright 2022 Hugging Face Inc\n#\n# Lint as: python3\n# pylint: enable=line-too-long\n\"\"\"Hugging Face Competitions\n\"\"\"\nimport os\n\nfrom setuptools import find_packages, setup\n\n\nthis_directory = os.path.abspath(os.path.dirname(__file__))\nwith open(os.path.join(this_directory, \"README.md\"), encoding=\"utf-8\") as f:\n LONG_DESCRIPTION = f.read()\n\nQUALITY_REQUIRE = [\n \"black~=23.0\",\n \"isort==5.13.2\",\n \"flake8==7.0.0\",\n \"mypy==1.8.0\",\n]\n\nTEST_REQUIRE = [\"pytest\", \"pytest-cov\"]\n\nEXTRAS_REQUIRE = {\n \"dev\": QUALITY_REQUIRE,\n \"quality\": QUALITY_REQUIRE,\n \"test\": QUALITY_REQUIRE + TEST_REQUIRE,\n \"docs\": QUALITY_REQUIRE + TEST_REQUIRE + [\"hf-doc-builder\"],\n}\n\nwith open(\"requirements.txt\", encoding=\"utf-8\") as f:\n INSTALL_REQUIRES = f.read().splitlines()\n\nsetup(\n name=\"competitions\",\n description=\"Hugging Face Competitions\",\n long_description=LONG_DESCRIPTION,\n author=\"HuggingFace Inc.\",\n url=\"https://github.com/huggingface/competitions\",\n download_url=\"https://github.com/huggingface/competitions/tags\",\n packages=find_packages(\".\"),\n entry_points={\"console_scripts\": [\"competitions=competitions.cli.competitions:main\"]},\n install_requires=INSTALL_REQUIRES,\n extras_require=EXTRAS_REQUIRE,\n python_requires=\">=3.10\",\n license=\"Apache 2.0\",\n classifiers=[\n \"Intended Audience :: Developers\",\n \"Intended Audience :: Education\",\n \"Intended Audience :: Science/Research\",\n \"License :: OSI Approved :: Apache Software License\",\n \"Operating System :: OS Independent\",\n \"Programming Language :: Python :: 3.10\",\n \"Topic :: Scientific/Engineering :: Artificial Intelligence\",\n ],\n keywords=\"huggingface competitions machine learning ai nlp tabular\",\n data_files=[\n (\n \"templates\",\n [\n \"competitions/templates/index.html\",\n ],\n ),\n ],\n include_package_data=True,\n)\n", ".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 5174fae09fbca33324fa73f1532775d7a7d1d367 Hamza Amin <[email protected]> 1727369105 +0500\tclone: from https://github.com/huggingface/competitions.git\n", ".git\\refs\\heads\\main": "5174fae09fbca33324fa73f1532775d7a7d1d367\n", "competitions\\app.py": "import datetime\nimport os\nimport threading\nimport time\n\nfrom fastapi import Depends, FastAPI, File, Form, HTTPException, Request, UploadFile\nfrom fastapi.responses import HTMLResponse, JSONResponse\nfrom fastapi.staticfiles import StaticFiles\nfrom fastapi.templating import Jinja2Templates\nfrom huggingface_hub import hf_hub_download\nfrom huggingface_hub.utils import disable_progress_bars\nfrom huggingface_hub.utils._errors import EntryNotFoundError\nfrom loguru import logger\nfrom pydantic import BaseModel\n\nfrom competitions import __version__, utils\nfrom competitions.errors import AuthenticationError\nfrom competitions.info import CompetitionInfo\nfrom competitions.leaderboard import Leaderboard\nfrom competitions.oauth import attach_oauth\nfrom competitions.runner import JobRunner\nfrom competitions.submissions import Submissions\nfrom competitions.text import SUBMISSION_SELECTION_TEXT, SUBMISSION_TEXT\n\n\nHF_TOKEN = os.environ.get(\"HF_TOKEN\", None)\nBASE_DIR = os.path.dirname(os.path.abspath(__file__))\nCOMPETITION_ID = os.environ.get(\"COMPETITION_ID\")\nOUTPUT_PATH = os.environ.get(\"OUTPUT_PATH\", \"/tmp/model\")\nSTART_DATE = os.environ.get(\"START_DATE\", \"2000-12-31\")\nDISABLE_PUBLIC_LB = int(os.environ.get(\"DISABLE_PUBLIC_LB\", 0))\n\ndisable_progress_bars()\n\ntry:\n REQUIREMENTS_FNAME = hf_hub_download(\n repo_id=COMPETITION_ID,\n filename=\"requirements.txt\",\n token=HF_TOKEN,\n repo_type=\"dataset\",\n )\nexcept EntryNotFoundError:\n REQUIREMENTS_FNAME = None\n\nif REQUIREMENTS_FNAME:\n logger.info(\"Uninstalling and installing requirements\")\n utils.uninstall_requirements(REQUIREMENTS_FNAME)\n utils.install_requirements(REQUIREMENTS_FNAME)\n\n\nclass LeaderboardRequest(BaseModel):\n lb: str\n\n\nclass UpdateSelectedSubmissionsRequest(BaseModel):\n submission_ids: str\n\n\nclass UpdateTeamNameRequest(BaseModel):\n new_team_name: str\n\n\ndef run_job_runner():\n job_runner = JobRunner(\n competition_id=COMPETITION_ID,\n token=HF_TOKEN,\n output_path=OUTPUT_PATH,\n )\n job_runner.run()\n\n\ndef start_job_runner_thread():\n thread = threading.Thread(target=run_job_runner)\n # thread.daemon = True\n thread.start()\n return thread\n\n\ndef watchdog(job_runner_thread):\n while True:\n if not job_runner_thread.is_alive():\n logger.warning(\"Job runner thread stopped. Restarting...\")\n job_runner_thread = start_job_runner_thread()\n time.sleep(10)\n\n\njob_runner_thread = start_job_runner_thread()\nwatchdog_thread = threading.Thread(target=watchdog, args=(job_runner_thread,))\nwatchdog_thread.daemon = True\nwatchdog_thread.start()\n\n\napp = FastAPI()\nattach_oauth(app)\n\nstatic_path = os.path.join(BASE_DIR, \"static\")\napp.mount(\"/static\", StaticFiles(directory=static_path), name=\"static\")\ntemplates_path = os.path.join(BASE_DIR, \"templates\")\ntemplates = Jinja2Templates(directory=templates_path)\n\n\[email protected](\"/\", response_class=HTMLResponse)\nasync def read_form(request: Request):\n \"\"\"\n This function is used to render the HTML file\n :param request:\n :return:\n \"\"\"\n if HF_TOKEN is None:\n return HTTPException(status_code=500, detail=\"HF_TOKEN is not set.\")\n competition_info = CompetitionInfo(competition_id=COMPETITION_ID, autotrain_token=HF_TOKEN)\n context = {\n \"request\": request,\n \"logo\": competition_info.logo_url,\n \"competition_type\": competition_info.competition_type,\n \"version\": __version__,\n \"rules_available\": competition_info.rules is not None,\n }\n return templates.TemplateResponse(\"index.html\", context)\n\n\[email protected](\"/login_status\", response_class=JSONResponse)\nasync def use_oauth(request: Request, user_token: str = Depends(utils.user_authentication)):\n if user_token:\n return {\"response\": 2}\n return {\"response\": 1}\n\n\[email protected](\"/logout\", response_class=HTMLResponse)\nasync def user_logout(request: Request):\n \"\"\"Endpoint that logs out the user (e.g. delete cookie session).\"\"\"\n\n if \"oauth_info\" in request.session:\n request.session.pop(\"oauth_info\", None)\n\n competition_info = CompetitionInfo(competition_id=COMPETITION_ID, autotrain_token=HF_TOKEN)\n context = {\n \"request\": request,\n \"logo\": competition_info.logo_url,\n \"competition_type\": competition_info.competition_type,\n \"__version__\": __version__,\n \"rules_available\": competition_info.rules is not None,\n }\n\n return templates.TemplateResponse(\"index.html\", context)\n\n\[email protected](\"/competition_info\", response_class=JSONResponse)\nasync def get_comp_info(request: Request):\n competition_info = CompetitionInfo(competition_id=COMPETITION_ID, autotrain_token=HF_TOKEN)\n info = competition_info.competition_desc\n resp = {\"response\": info}\n return resp\n\n\[email protected](\"/dataset_info\", response_class=JSONResponse)\nasync def get_dataset_info(request: Request):\n competition_info = CompetitionInfo(competition_id=COMPETITION_ID, autotrain_token=HF_TOKEN)\n info = competition_info.dataset_desc\n resp = {\"response\": info}\n return resp\n\n\[email protected](\"/rules\", response_class=JSONResponse)\nasync def get_rules(request: Request):\n competition_info = CompetitionInfo(competition_id=COMPETITION_ID, autotrain_token=HF_TOKEN)\n if competition_info.rules is not None:\n return {\"response\": competition_info.rules}\n return {\"response\": \"No rules available.\"}\n\n\[email protected](\"/submission_info\", response_class=JSONResponse)\nasync def get_submission_info(request: Request):\n competition_info = CompetitionInfo(competition_id=COMPETITION_ID, autotrain_token=HF_TOKEN)\n info = competition_info.submission_desc\n resp = {\"response\": info}\n return resp\n\n\[email protected](\"/leaderboard\", response_class=JSONResponse)\nasync def fetch_leaderboard(\n request: Request, body: LeaderboardRequest, user_token: str = Depends(utils.user_authentication)\n):\n lb = body.lb\n\n comp_org = COMPETITION_ID.split(\"/\")[0]\n if user_token is not None:\n is_user_admin = utils.is_user_admin(user_token, comp_org)\n else:\n is_user_admin = False\n\n if DISABLE_PUBLIC_LB == 1 and lb == \"public\" and not is_user_admin:\n return {\"response\": \"Public leaderboard is disabled by the competition host.\"}\n\n competition_info = CompetitionInfo(competition_id=COMPETITION_ID, autotrain_token=HF_TOKEN)\n leaderboard = Leaderboard(\n end_date=competition_info.end_date,\n eval_higher_is_better=competition_info.eval_higher_is_better,\n max_selected_submissions=competition_info.selection_limit,\n competition_id=COMPETITION_ID,\n token=HF_TOKEN,\n scoring_metric=competition_info.scoring_metric,\n )\n if lb == \"private\":\n current_utc_time = datetime.datetime.now()\n if current_utc_time < competition_info.end_date and not is_user_admin:\n return {\"response\": f\"Private leaderboard will be available on {competition_info.end_date} UTC.\"}\n df = leaderboard.fetch(private=lb == \"private\")\n\n if len(df) == 0:\n return {\"response\": \"No teams yet. Why not make a submission?\"}\n resp = {\"response\": df.to_markdown(index=False)}\n return resp\n\n\[email protected](\"/my_submissions\", response_class=JSONResponse)\nasync def my_submissions(request: Request, user_token: str = Depends(utils.user_authentication)):\n competition_info = CompetitionInfo(competition_id=COMPETITION_ID, autotrain_token=HF_TOKEN)\n if user_token is None:\n return {\n \"response\": {\n \"submissions\": \"\",\n \"submission_text\": SUBMISSION_TEXT.format(competition_info.submission_limit),\n \"error\": \"**Invalid token. Please login.**\",\n \"team_name\": \"\",\n }\n }\n sub = Submissions(\n end_date=competition_info.end_date,\n submission_limit=competition_info.submission_limit,\n competition_id=COMPETITION_ID,\n token=HF_TOKEN,\n competition_type=competition_info.competition_type,\n hardware=competition_info.hardware,\n )\n try:\n subs = sub.my_submissions(user_token)\n except AuthenticationError:\n return {\n \"response\": {\n \"submissions\": \"\",\n \"submission_text\": SUBMISSION_TEXT.format(competition_info.submission_limit),\n \"error\": \"**Invalid token. Please login.**\",\n \"team_name\": \"\",\n }\n }\n subs = subs.to_dict(orient=\"records\")\n error = \"\"\n if len(subs) == 0:\n error = \"**You have not made any submissions yet.**\"\n subs = \"\"\n submission_text = SUBMISSION_TEXT.format(competition_info.submission_limit)\n submission_selection_text = SUBMISSION_SELECTION_TEXT.format(competition_info.selection_limit)\n\n team_name = utils.get_team_name(user_token, COMPETITION_ID, HF_TOKEN)\n\n resp = {\n \"response\": {\n \"submissions\": subs,\n \"submission_text\": submission_text + submission_selection_text,\n \"error\": error,\n \"team_name\": team_name,\n }\n }\n return resp\n\n\[email protected](\"/new_submission\", response_class=JSONResponse)\nasync def new_submission(\n request: Request,\n submission_file: UploadFile = File(None),\n hub_model: str = Form(...),\n submission_comment: str = Form(None),\n user_token: str = Depends(utils.user_authentication),\n):\n if submission_comment is None:\n submission_comment = \"\"\n\n if user_token is None:\n return {\"response\": \"Invalid token\"}\n\n todays_date = datetime.datetime.now()\n start_date = datetime.datetime.strptime(START_DATE, \"%Y-%m-%d\")\n if todays_date < start_date:\n comp_org = COMPETITION_ID.split(\"/\")[0]\n if not utils.is_user_admin(user_token, comp_org):\n return {\"response\": \"Competition has not started yet!\"}\n\n competition_info = CompetitionInfo(competition_id=COMPETITION_ID, autotrain_token=HF_TOKEN)\n sub = Submissions(\n end_date=competition_info.end_date,\n submission_limit=competition_info.submission_limit,\n competition_id=COMPETITION_ID,\n token=HF_TOKEN,\n competition_type=competition_info.competition_type,\n hardware=competition_info.hardware,\n )\n try:\n if competition_info.competition_type == \"generic\":\n resp = sub.new_submission(user_token, submission_file, submission_comment)\n return {\"response\": f\"Success! You have {resp} submissions remaining today.\"}\n if competition_info.competition_type == \"script\":\n resp = sub.new_submission(user_token, hub_model, submission_comment)\n return {\"response\": f\"Success! You have {resp} submissions remaining today.\"}\n except AuthenticationError:\n return {\"response\": \"Invalid token\"}\n return {\"response\": \"Invalid competition type\"}\n\n\[email protected](\"/update_selected_submissions\", response_class=JSONResponse)\ndef update_selected_submissions(\n request: Request, body: UpdateSelectedSubmissionsRequest, user_token: str = Depends(utils.user_authentication)\n):\n submission_ids = body.submission_ids\n\n if user_token is None:\n return {\"success\": False, \"error\": \"Invalid token, please login.\"}\n\n competition_info = CompetitionInfo(competition_id=COMPETITION_ID, autotrain_token=HF_TOKEN)\n sub = Submissions(\n end_date=competition_info.end_date,\n submission_limit=competition_info.submission_limit,\n competition_id=COMPETITION_ID,\n token=HF_TOKEN,\n competition_type=competition_info.competition_type,\n hardware=competition_info.hardware,\n )\n submission_ids = submission_ids.split(\",\")\n submission_ids = [s.strip() for s in submission_ids]\n if len(submission_ids) > competition_info.selection_limit:\n return {\n \"success\": False,\n \"error\": f\"Please select at most {competition_info.selection_limit} submissions.\",\n }\n sub.update_selected_submissions(user_token=user_token, selected_submission_ids=submission_ids)\n return {\"success\": True, \"error\": \"\"}\n\n\[email protected](\"/update_team_name\", response_class=JSONResponse)\ndef update_team_name(\n request: Request, body: UpdateTeamNameRequest, user_token: str = Depends(utils.user_authentication)\n):\n new_team_name = body.new_team_name\n\n if user_token is None:\n return {\"success\": False, \"error\": \"Invalid token\"}\n\n if str(new_team_name).strip() == \"\":\n return {\"success\": False, \"error\": \"Team name cannot be empty.\"}\n\n try:\n utils.update_team_name(user_token, new_team_name, COMPETITION_ID, HF_TOKEN)\n return {\"success\": True, \"error\": \"\"}\n except Exception as e:\n return {\"success\": False, \"error\": str(e)}\n\n\[email protected](\"/admin/comp_info\", response_class=JSONResponse)\nasync def admin_comp_info(request: Request, user_token: str = Depends(utils.user_authentication)):\n comp_org = COMPETITION_ID.split(\"/\")[0]\n user_is_admin = utils.is_user_admin(user_token, comp_org)\n if not user_is_admin:\n return {\"response\": \"You are not an admin.\"}, 403\n\n competition_info = CompetitionInfo(competition_id=COMPETITION_ID, autotrain_token=HF_TOKEN)\n\n markdowns = {\n \"competition_desc\": competition_info.competition_desc,\n \"rules\": competition_info.rules,\n \"submission_desc\": competition_info.submission_desc,\n \"dataset_desc\": competition_info.dataset_desc,\n }\n if markdowns[\"rules\"] is None:\n markdowns[\"rules\"] = \"No rules available.\"\n\n config = {\n \"SUBMISSION_LIMIT\": competition_info.submission_limit,\n \"SELECTION_LIMIT\": competition_info.selection_limit,\n \"END_DATE\": competition_info.end_date.strftime(\"%Y-%m-%d\"),\n \"EVAL_HIGHER_IS_BETTER\": competition_info.eval_higher_is_better,\n \"SUBMISSION_COLUMNS\": competition_info.submission_columns_raw,\n \"SUBMISSION_ID_COLUMN\": competition_info.submission_id_col,\n \"LOGO\": competition_info.logo_url,\n \"COMPETITION_TYPE\": competition_info.competition_type,\n \"EVAL_METRIC\": competition_info.metric,\n \"SUBMISSION_ROWS\": competition_info.submission_rows,\n \"TIME_LIMIT\": competition_info.time_limit,\n \"DATASET\": competition_info.dataset,\n \"SUBMISSION_FILENAMES\": competition_info.submission_filenames,\n \"SCORING_METRIC\": competition_info.scoring_metric,\n \"HARDWARE\": competition_info.hardware,\n }\n\n return {\"response\": {\"config\": config, \"markdowns\": markdowns}}\n\n\[email protected](\"/admin/update_comp_info\", response_class=JSONResponse)\nasync def update_comp_info(request: Request, user_token: str = Depends(utils.user_authentication)):\n comp_org = COMPETITION_ID.split(\"/\")[0]\n user_is_admin = utils.is_user_admin(user_token, comp_org)\n if not user_is_admin:\n return {\"response\": \"You are not an admin.\"}, 403\n\n competition_info = CompetitionInfo(competition_id=COMPETITION_ID, autotrain_token=HF_TOKEN)\n\n data = await request.json()\n config = data[\"config\"]\n markdowns = data[\"markdowns\"]\n\n valid_keys = [\n \"SUBMISSION_LIMIT\",\n \"SELECTION_LIMIT\",\n \"END_DATE\",\n \"EVAL_HIGHER_IS_BETTER\",\n \"SUBMISSION_COLUMNS\",\n \"SUBMISSION_ID_COLUMN\",\n \"LOGO\",\n \"COMPETITION_TYPE\",\n \"EVAL_METRIC\",\n \"SUBMISSION_ROWS\",\n \"TIME_LIMIT\",\n \"DATASET\",\n \"SUBMISSION_FILENAMES\",\n \"SCORING_METRIC\",\n \"HARDWARE\",\n ]\n\n for key in config:\n if key not in valid_keys:\n return {\"success\": False, \"error\": f\"Invalid key: {key}\"}\n\n try:\n competition_info.update_competition_info(config, markdowns, HF_TOKEN)\n except Exception as e:\n logger.error(e)\n return {\"success\": False}, 500\n\n return {\"success\": True}\n", "competitions\\templates\\index.html": "<!doctype html>\n<html>\n\n<head>\n <meta charset=\"UTF-8\">\n <meta name=\"viewport\" content=\"width=device-width, initial-scale=1.0\">\n <script src=\"https://cdn.jsdelivr.net/npm/marked/marked.min.js\"></script>\n <script src=\"https://cdn.tailwindcss.com?plugins=forms,typography,aspect-ratio,line-clamp\"></script>\n <link rel=\"stylesheet\" href=\"https://cdnjs.cloudflare.com/ajax/libs/font-awesome/5.15.3/css/all.min.css\">\n <link href=\"https://cdnjs.cloudflare.com/ajax/libs/flowbite/2.2.1/flowbite.min.css\" rel=\"stylesheet\" />\n <script>\n document.addEventListener('DOMContentLoaded', function () {\n function showSubmissionModal() {\n const modal = document.getElementById('submission-modal');\n modal.classList.add('flex');\n modal.classList.remove('hidden');\n }\n\n function hideSubmissionModal() {\n const modal = document.getElementById('submission-modal');\n modal.classList.remove('flex');\n modal.classList.add('hidden');\n }\n\n function addTargetBlankToLinks() {\n const content = document.getElementById('content');\n const links = content.getElementsByTagName('a');\n\n for (let i = 0; i < links.length; i++) {\n if (!links[i].hasAttribute('target')) {\n links[i].setAttribute('target', '_blank');\n }\n }\n }\n\n function fetchAndDisplayCompetitionInfo() {\n const articleLoadingSpinner = document.getElementById('articleLoadingSpinner');\n articleLoadingSpinner.classList.remove('hidden');\n fetch('/competition_info')\n .then(response => {\n if (!response.ok) {\n throw new Error('Network response was not ok');\n }\n return response.json(); // Parse the JSON response\n })\n .then(data => {\n // Populate the 'content' div with the HTML from the response\n const contentDiv = document.getElementById('content');\n contentDiv.style.display = 'block';\n contentDiv.innerHTML = marked.parse(data.response);\n addTargetBlankToLinks();\n articleLoadingSpinner.classList.add('hidden');\n })\n .catch(error => {\n console.error('There has been a problem with your fetch operation:', error);\n articleLoadingSpinner.classList.add('hidden');\n });\n }\n\n function fetchAndDisplayDatasetInfo() {\n const articleLoadingSpinner = document.getElementById('articleLoadingSpinner');\n articleLoadingSpinner.classList.remove('hidden');\n fetch('/dataset_info')\n .then(response => {\n if (!response.ok) {\n throw new Error('Network response was not ok');\n }\n return response.json(); // Parse the JSON response\n })\n .then(data => {\n // Populate the 'content' div with the HTML from the response\n const contentDiv = document.getElementById('content');\n contentDiv.innerHTML = marked.parse(data.response);\n addTargetBlankToLinks();\n articleLoadingSpinner.classList.add('hidden');\n })\n .catch(error => {\n console.error('There has been a problem with your fetch operation:', error);\n articleLoadingSpinner.classList.add('hidden');\n });\n }\n function fetchAndDisplayLeaderboard(leaderboardType) {\n const articleLoadingSpinner = document.getElementById('articleLoadingSpinner');\n articleLoadingSpinner.classList.remove('hidden');\n\n const payload = {\n lb: leaderboardType,\n };\n\n fetch('/leaderboard', {\n method: 'POST',\n headers: {\n 'Content-Type': 'application/json'\n },\n body: JSON.stringify(payload)\n })\n .then(response => {\n if (!response.ok) {\n throw new Error('Network response was not ok');\n }\n return response.json();\n })\n .then(data => {\n const contentDiv = document.getElementById('content');\n contentDiv.innerHTML = marked.parse(data.response);\n articleLoadingSpinner.classList.add('hidden');\n })\n .catch(error => {\n console.error('There has been a problem with your fetch operation:', error);\n articleLoadingSpinner.classList.add('hidden');\n });\n }\n\n function fetchAndDisplayPublicLeaderboard() {\n fetchAndDisplayLeaderboard('public');\n }\n\n function fetchAndDisplayPrivateLeaderboard() {\n fetchAndDisplayLeaderboard('private');\n }\n\n function fetchAndDisplaySubmissions() {\n const apiEndpoint = '/my_submissions';\n const articleLoadingSpinner = document.getElementById('articleLoadingSpinner');\n articleLoadingSpinner.classList.remove('hidden');\n\n const requestOptions = {\n method: 'POST',\n headers: {\n 'Content-Type': 'application/json',\n }\n };\n\n fetch(apiEndpoint, requestOptions)\n .then(response => {\n if (!response.ok) {\n throw new Error('Network response was not ok');\n }\n return response.json();\n })\n .then(data => {\n const contentDiv = document.getElementById('content');\n // console.log(data.response.submissions);\n // contentDiv.innerHTML = marked.parse(data.response.submission_text) + data.response.submissions;\n if (data.response.submissions && data.response.submissions.length > 0 && data.response.error.length == 0) {\n // Start building the table HTML\n let tableHTML = `\n <div class=\"flex items-center\">\n <input type=\"text\" name=\"team_name\" id=\"team_name\" class=\"mt-1 mb-1 block me-2\" value=\"${data.response.team_name}\">\n <button id=\"updateTeamNameButton\" type=\"button\" class=\"confirm text-white bg-green-600 hover:bg-green-800 focus:ring-4 focus:outline-none focus:ring-green-300 font-medium rounded-lg text-sm inline-flex items-center px-5 py-2.5 text-center me-2\">Update Team Name</button>\n </div>`;\n tableHTML += '<table border=\"1\"><tr><th>Datetime</th><th>Submission ID</th><th>Public Score</th><th>Submission Comment</th><th>Selected</th><th>Status</th></tr>';\n\n // Iterate over each submission and add it to the table\n data.response.submissions.forEach(submission => {\n tableHTML += `<tr>\n <td>${submission.datetime}</td>\n <td>${submission.submission_id}</td>\n <td>${submission.public_score}</td>\n <td>${submission.submission_comment}</td>\n <td><input type=\"checkbox\" name=\"selectedSubmissions\" value=\"${submission.submission_id}\" ${submission.selected ? 'checked' : ''}></td>\n <td>${submission.status}</td>\n </tr>`;\n });\n\n // Close the table HTML and set it as the content\n tableHTML += '</table>';\n tableHTML += '<button id=\"updateSelectedSubmissionsButton\" type=\"button\" class=\"confirm text-white bg-green-600 hover:bg-green-800 focus:ring-4 focus:outline-none focus:ring-green-300 font-medium rounded-lg text-sm inline-flex items-center px-5 py-2.5 text-center me-2\">Update Selected Submissions</button>';\n // add a text field which displays team name and a button to update team name\n contentDiv.innerHTML = marked.parse(data.response.submission_text) + tableHTML;\n document.getElementById('updateSelectedSubmissionsButton').addEventListener('click', function () {\n updateSelectedSubmissions();\n });\n document.getElementById('updateTeamNameButton').addEventListener('click', function () {\n updateTeamName();\n });\n } else {\n // Display message if there are no submissions\n contentDiv.innerHTML = marked.parse(data.response.submission_text) + marked.parse(data.response.error);\n }\n articleLoadingSpinner.classList.add('hidden');\n })\n .catch(error => {\n console.error('There was a problem with the fetch operation:', error);\n articleLoadingSpinner.classList.add('hidden');\n });\n }\n\n function fetchAndDisplaySubmissionInfo() {\n const articleLoadingSpinner = document.getElementById('articleLoadingSpinner');\n articleLoadingSpinner.classList.remove('hidden');\n fetch('/submission_info')\n .then(response => {\n if (!response.ok) {\n throw new Error('Network response was not ok');\n }\n return response.json(); // Parse the JSON response\n })\n .then(data => {\n // Populate the 'content' div with the HTML from the response\n const contentDiv = document.getElementById('content');\n contentDiv.innerHTML = marked.parse(data.response);\n addTargetBlankToLinks();\n articleLoadingSpinner.classList.add('hidden');\n })\n .catch(error => {\n console.error('There has been a problem with your fetch operation:', error);\n articleLoadingSpinner.classList.add('hidden');\n });\n }\n\n function fetchAndDisplayTeamInfo() {\n const apiEndpoint = '/team_info';\n const articleLoadingSpinner = document.getElementById('articleLoadingSpinner');\n articleLoadingSpinner.classList.remove('hidden');\n\n const requestOptions = {\n method: 'POST',\n headers: {\n 'Content-Type': 'application/json',\n }\n };\n fetch(apiEndpoint, requestOptions)\n .then(response => {\n if (!response.ok) {\n throw new Error('Network response was not ok');\n }\n return response.json(); // Parse the JSON response\n })\n .then(data => {\n // Populate the 'content' div with the HTML from the response\n const contentDiv = document.getElementById('content');\n if (data.team_exists) {\n contentHTML = \"<h2>Team</h2>\";\n contentHTML += \"<p>\" + data.team_name + \"</p>\";\n contentDiv.innerHTML = marked.parse(contentHTML);\n } else {\n contentDiv.innerHTML = marked.parse(data.response);\n }\n contentDiv.innerHTML = marked.parse(data.response);\n articleLoadingSpinner.classList.add('hidden');\n })\n .catch(error => {\n console.error('There has been a problem with your fetch operation:', error);\n articleLoadingSpinner.classList.add('hidden');\n });\n }\n\n function fetchAndDisplayRules() {\n const articleLoadingSpinner = document.getElementById('articleLoadingSpinner');\n articleLoadingSpinner.classList.remove('hidden');\n fetch('/rules')\n .then(response => {\n if (!response.ok) {\n throw new Error('Network response was not ok');\n }\n return response.json(); // Parse the JSON response\n })\n .then(data => {\n // Populate the 'content' div with the HTML from the response\n const contentDiv = document.getElementById('content');\n contentDiv.innerHTML = marked.parse(data.response);\n addTargetBlankToLinks();\n articleLoadingSpinner.classList.add('hidden');\n })\n .catch(error => {\n console.error('There has been a problem with your fetch operation:', error);\n articleLoadingSpinner.classList.add('hidden');\n });\n }\n\n const homeLink = document.getElementById('home');\n const datasetLink = document.getElementById('dataset');\n const publicLBLink = document.getElementById('public_lb');\n const privateLBLink = document.getElementById('private_lb');\n const newSubmission = document.getElementById('new_submission');\n const mySubmissions = document.getElementById('my_submissions');\n const submissionInfo = document.getElementById('submission_info');\n const rulesLink = document.getElementById('rules');\n\n // Add a click event listener to the 'Home' link\n homeLink.addEventListener('click', function (event) {\n event.preventDefault(); // Prevent the default link behavior\n fetchAndDisplayCompetitionInfo(); // Fetch and display info on click\n });\n\n datasetLink.addEventListener('click', function (event) {\n event.preventDefault(); // Prevent the default link behavior\n fetchAndDisplayDatasetInfo(); // Fetch and display info on click\n });\n\n publicLBLink.addEventListener('click', function (event) {\n event.preventDefault(); // Prevent the default link behavior\n fetchAndDisplayPublicLeaderboard(); // Fetch and display info on click\n });\n\n privateLBLink.addEventListener('click', function (event) {\n event.preventDefault(); // Prevent the default link behavior\n fetchAndDisplayPrivateLeaderboard(); // Fetch and display info on click\n });\n\n newSubmission.addEventListener('click', function (event) {\n event.preventDefault(); // Prevent the default link behavior\n showSubmissionModal(); // Fetch and display info on click\n });\n mySubmissions.addEventListener('click', function (event) {\n event.preventDefault(); // Prevent the default link behavior\n fetchAndDisplaySubmissions(); // Fetch and display info on click\n });\n submissionInfo.addEventListener('click', function (event) {\n event.preventDefault(); // Prevent the default link behavior\n fetchAndDisplaySubmissionInfo(); // Fetch and display info on click\n });\n rulesLink.addEventListener('click', function (event) {\n event.preventDefault(); // Prevent the default link behavior\n fetchAndDisplayRules(); // Fetch and display info on click\n });\n\n\n // Fetch and display info when the page loads\n fetchAndDisplayCompetitionInfo();\n\n document.querySelector('#submission-modal .cancel').addEventListener('click', function () {\n hideSubmissionModal();\n });\n });\n\n </script>\n\n <script>\n function makeApiRequest(url, callback) {\n var xhr = new XMLHttpRequest();\n xhr.open(\"GET\", url, true);\n xhr.onreadystatechange = function () {\n if (xhr.readyState === 4 && xhr.status === 200) {\n var response = JSON.parse(xhr.responseText);\n callback(response.response);\n }\n };\n xhr.send();\n }\n\n function checkOAuth() {\n var url = \"/login_status\";\n makeApiRequest(url, function (response) {\n if (response === 1) {\n document.getElementById(\"loginButton\").style.display = \"block\";\n document.getElementById(\"logoutButton\").style.display = \"none\";\n } else if (response === 2) {\n document.getElementById(\"loginButton\").style.display = \"none\";\n document.getElementById(\"logoutButton\").style.display = \"block\";\n }\n });\n }\n window.onload = checkOAuth;\n </script>\n</head>\n\n<body class=\"flex h-screen\">\n <!-- Sidebar -->\n <aside id=\"sidebar-multi-level-sidebar\"\n class=\"fixed top-0 left-0 z-40 w-64 h-screen transition-transform -translate-x-full sm:translate-x-0\"\n aria-label=\"Sidebar\">\n <div class=\"h-full px-3 py-4 overflow-y-auto\">\n <ul class=\"space-y-2 font-medium\">\n <li>\n <a href=\"#\" id=\"home\"\n class=\"flex items-center p-2 text-gray-900 rounded-lg hover:bg-gray-100 group\">\n <svg class=\"w-5 h-5 text-gray-500 transition duration-75 group-hover:text-gray-900\"\n viewBox=\"0 0 22 21\" xmlns=\"http://www.w3.org/2000/svg\" fill=\"currentColor\">\n <path d=\"M1,10 L11,1 L21,10 L21,20 L1,20 Z\" /> <!-- House structure -->\n <path d=\"M6,20 L6,14 L16,14 L16,20\" /> <!-- Door -->\n </svg>\n\n <span class=\"ms-3\">Home</span>\n </a>\n </li>\n <li>\n <a href=\"#\" id=\"dataset\"\n class=\"flex items-center p-2 text-gray-900 rounded-lg hover:bg-gray-100 group\">\n <svg class=\"flex-shrink-0 w-5 h-5 text-gray-500 transition duration-75 group-hover:text-gray-900\"\n aria-hidden=\"true\" xmlns=\"http://www.w3.org/2000/svg\" fill=\"currentColor\"\n viewBox=\"0 0 18 18\">\n <path\n d=\"M6.143 0H1.857A1.857 1.857 0 0 0 0 1.857v4.286C0 7.169.831 8 1.857 8h4.286A1.857 1.857 0 0 0 8 6.143V1.857A1.857 1.857 0 0 0 6.143 0Zm10 0h-4.286A1.857 1.857 0 0 0 10 1.857v4.286C10 7.169 10.831 8 11.857 8h4.286A1.857 1.857 0 0 0 18 6.143V1.857A1.857 1.857 0 0 0 16.143 0Zm-10 10H1.857A1.857 1.857 0 0 0 0 11.857v4.286C0 17.169.831 18 1.857 18h4.286A1.857 1.857 0 0 0 8 16.143v-4.286A1.857 1.857 0 0 0 6.143 10Zm10 0h-4.286A1.857 1.857 0 0 0 10 11.857v4.286c0 1.026.831 1.857 1.857 1.857h4.286A1.857 1.857 0 0 0 18 16.143v-4.286A1.857 1.857 0 0 0 16.143 10Z\" />\n </svg>\n <span class=\"flex-1 ms-3 whitespace-nowrap\">Dataset</span>\n </a>\n </li>\n {% if rules_available %}\n <li>\n <a href=\"#\" id=\"rules\"\n class=\"flex items-center p-2 text-gray-900 rounded-lg hover:bg-gray-100 group\">\n <svg class=\"flex-shrink-0 w-5 h-5 text-gray-500 transition duration-75 group-hover:text-gray-900\"\n aria-hidden=\"true\" xmlns=\"http://www.w3.org/2000/svg\" fill=\"currentColor\"\n viewBox=\"0 0 24 24\">\n <path\n d=\"M3 0h18v2H3V0zm0 4h18v2H3V4zm0 4h18v2H3V8zm0 4h18v2H3v-2zm0 4h18v2H3v-2zm0 4h18v2H3v-2z\" />\n </svg>\n <span class=\"flex-1 ms-3 whitespace-nowrap\">Rules</span>\n </a>\n </li>\n {% else %}\n <span id=\"rules\"></span>\n {% endif %}\n <li>\n <button type=\"button\"\n class=\"flex items-center w-full p-2 text-base text-gray-900 transition duration-75 rounded-lg group hover:bg-gray-100\"\n aria-controls=\"lb-dropdown\" data-collapse-toggle=\"lb-dropdown\">\n <svg class=\"flex-shrink-0 w-5 h-5 text-gray-500 transition duration-75 group-hover:text-gray-900\"\n aria-hidden=\"true\" xmlns=\"http://www.w3.org/2000/svg\" fill=\"currentColor\"\n viewBox=\"0 0 18 21\">\n <path d=\"M2,4 L20,4 L20,16 L2,16 Z\" />\n <path d=\"M6,17 L16,17 L16,18 L6,18 Z\" />\n </svg>\n <span class=\"flex-1 ms-3 text-left rtl:text-right whitespace-nowrap\">Leaderboard</span>\n <svg class=\"w-3 h-3\" aria-hidden=\"true\" xmlns=\"http://www.w3.org/2000/svg\" fill=\"none\"\n viewBox=\"0 0 10 6\">\n <path stroke=\"currentColor\" stroke-linecap=\"round\" stroke-linejoin=\"round\" stroke-width=\"2\"\n d=\"m1 1 4 4 4-4\" />\n </svg>\n </button>\n <ul id=\"lb-dropdown\" class=\"py-2 space-y-2\">\n <li>\n <a href=\"#\" id=\"public_lb\"\n class=\"flex items-center w-full p-2 text-gray-900 transition duration-75 rounded-lg pl-11 group hover:bg-gray-100\">Public</a>\n </li>\n <li>\n <a href=\"#\" id=\"private_lb\"\n class=\"flex items-center w-full p-2 text-gray-900 transition duration-75 rounded-lg pl-11 group hover:bg-gray-100\">Private</a>\n </li>\n </ul>\n </li>\n <li>\n <button type=\"button\"\n class=\"flex items-center w-full p-2 text-base text-gray-900 transition duration-75 rounded-lg group hover:bg-gray-100\"\n aria-controls=\"submissions-dropdown\" data-collapse-toggle=\"submissions-dropdown\">\n <svg class=\"flex-shrink-0 w-5 h-5 text-gray-500 transition duration-75 group-hover:text-gray-900\"\n aria-hidden=\"true\" xmlns=\"http://www.w3.org/2000/svg\" fill=\"currentColor\"\n viewBox=\"0 0 20 20\">\n <path d=\"M5 5V.13a2.96 2.96 0 0 0-1.293.749L.879 3.707A2.96 2.96 0 0 0 .13 5H5Z\" />\n <path\n d=\"M6.737 11.061a2.961 2.961 0 0 1 .81-1.515l6.117-6.116A4.839 4.839 0 0 1 16 2.141V2a1.97 1.97 0 0 0-1.933-2H7v5a2 2 0 0 1-2 2H0v11a1.969 1.969 0 0 0 1.933 2h12.134A1.97 1.97 0 0 0 16 18v-3.093l-1.546 1.546c-.413.413-.94.695-1.513.81l-3.4.679a2.947 2.947 0 0 1-1.85-.227 2.96 2.96 0 0 1-1.635-3.257l.681-3.397Z\" />\n <path\n d=\"M8.961 16a.93.93 0 0 0 .189-.019l3.4-.679a.961.961 0 0 0 .49-.263l6.118-6.117a2.884 2.884 0 0 0-4.079-4.078l-6.117 6.117a.96.96 0 0 0-.263.491l-.679 3.4A.961.961 0 0 0 8.961 16Zm7.477-9.8a.958.958 0 0 1 .68-.281.961.961 0 0 1 .682 1.644l-.315.315-1.36-1.36.313-.318Zm-5.911 5.911 4.236-4.236 1.359 1.359-4.236 4.237-1.7.339.341-1.699Z\" />\n </svg>\n <span class=\"flex-1 ms-3 text-left rtl:text-right whitespace-nowrap\">Submissions</span>\n <svg class=\"w-3 h-3\" aria-hidden=\"true\" xmlns=\"http://www.w3.org/2000/svg\" fill=\"none\"\n viewBox=\"0 0 10 6\">\n <path stroke=\"currentColor\" stroke-linecap=\"round\" stroke-linejoin=\"round\" stroke-width=\"2\"\n d=\"m1 1 4 4 4-4\" />\n </svg>\n </button>\n <ul id=\"submissions-dropdown\" class=\"py-2 space-y-2\">\n <li>\n <a href=\"#\" id=\"submission_info\"\n class=\"flex items-center w-full p-2 text-gray-900 transition duration-75 rounded-lg pl-11 group hover:bg-gray-100\">Submission\n information</a>\n </li>\n <li>\n <a href=\"#\" id=\"my_submissions\"\n class=\"flex items-center w-full p-2 text-gray-900 transition duration-75 rounded-lg pl-11 group hover:bg-gray-100\">My\n submissions</a>\n </li>\n <li>\n <a href=\"#\" id=\"new_submission\"\n class=\"flex items-center w-full p-2 text-gray-900 transition duration-75 rounded-lg pl-11 group hover:bg-gray-100\">New\n submission</a>\n </li>\n </ul>\n </li>\n <li>\n <a href=\"#\" id=\"admin\"\n class=\"flex items-center p-2 text-gray-900 rounded-lg hover:bg-gray-100 group\">\n <svg class=\"flex-shrink-0 w-5 h-5 text-gray-500 transition duration-75 group-hover:text-gray-900\"\n aria-hidden=\"true\" xmlns=\"http://www.w3.org/2000/svg\" fill=\"currentColor\"\n viewBox=\"0 0 24 24\">\n <path\n d=\"M12 15.5c-1.93 0-3.5-1.57-3.5-3.5s1.57-3.5 3.5-3.5 3.5 1.57 3.5 3.5-1.57 3.5-3.5 3.5zm7.43-3.5c.04-.33.07-.66.07-1s-.03-.67-.07-1l2.11-1.65c.19-.15.23-.42.12-.63l-2-3.46c-.11-.21-.35-.3-.57-.24l-2.49 1c-.52-.4-1.08-.73-1.69-.98l-.38-2.65C14.57 2.18 14.3 2 14 2h-4c-.3 0-.57.18-.64.45L8.98 5.1c-.61.25-1.17.58-1.69.98l-2.49-1c-.22-.06-.46.03-.57.24l-2 3.46c-.11.21-.07.48.12.63l2.11 1.65c-.04.33-.07.66-.07 1s.03.67.07 1L2.46 14.1c-.19.15-.23.42-.12.63l2 3.46c.11.21.35.3.57.24l2.49-1c.52.4 1.08.73 1.69.98l.38 2.65c.07.27.34.45.64.45h4c.3 0 .57-.18.64-.45l.38-2.65c.61-.25 1.17-.58 1.69-.98l2.49 1c.22.06.46-.03.57-.24l2-3.46c.11-.21.07-.48-.12-.63l-2.11-1.65zM12 17c-2.76 0-5-2.24-5-5s2.24-5 5-5 5 2.24 5 5-2.24 5-5 5z\" />\n </svg>\n <span class=\"flex-1 ms-3 whitespace-nowrap\">Admin</span>\n </a>\n </li>\n <li id=\"loginButton\" style=\"display: none;\">\n <a href=\"/login/huggingface\"\n class=\"flex justify-center items-center bg-blue-400 hover:bg-blue-600 text-white text-center font-bold py-2 px-4 rounded transition duration-200 ease-in-out\">\n Login with Hugging Face\n </a>\n </li>\n <li id=\"logoutButton\" style=\"display: none;\">\n <a href=\"/logout\"\n class=\"flex justify-center items-center bg-red-400 hover:bg-red-600 text-white text-center font-bold py-2 px-4 rounded transition duration-200 ease-in-out\">\n Logout\n </a>\n </li>\n </ul>\n\n <footer>\n <div class=\"w-full mx-auto max-w-screen-xl p-4 md:flex md:items-center md:justify-between\">\n <span class=\"text-sm text-gray-500 sm:text-center\">Powered by <a\n href=\"https://github.com/huggingface/competitions\" target=\"_blank\"\n class=\"hover:underline\">Hugging Face\n Competitions</a>\n </span>\n </div>\n <div class=\"text-center\">\n <span class=\"text-xs text-gray-400\">{{version}}\n </span>\n </div>\n </footer>\n </div>\n </aside>\n <div class=\"p-1 sm:ml-64\">\n <img src={{logo}} alt=\"Competition logo\">\n <hr class=\"mt-3 mb-2\">\n <div id=\"articleLoadingSpinner\" role=\"status\"\n class=\"hidden absolute -translate-x-1/2 -translate-y-1/2 top-2/4 left-1/2\">\n <div class=\"animate-spin rounded-full h-32 w-32 border-b-2 border-gray-900\"></div>\n <span class=\"sr-only\">Loading...</span>\n </div>\n <article class=\"prose w-full mx-auto max-w-screen-xl p-4 md:flex md:items-center md:justify-between\"\n id=\"content\">\n </article>\n </div>\n <div id=\"submission-modal\" tabindex=\"-1\"\n class=\"hidden overflow-y-auto overflow-x-hidden fixed top-0 right-0 left-0 z-50 justify-center items-center w-full md:inset-0 h-[calc(100%-1rem)] max-h-full\">\n <div id=\"loadingSpinner\" role=\"status\"\n class=\"hidden absolute -translate-x-1/2 -translate-y-1/2 top-2/4 left-1/2\">\n <div class=\"animate-spin rounded-full h-32 w-32 border-b-2 border-gray-900\"></div>\n <span class=\"sr-only\">Loading...</span>\n </div>\n <div class=\"form-container max-w-5xl mx-auto mt-3 p-6 shadow-2xl bg-white\">\n <p class=\"text-lg font-medium text-gray-900\">New Submission</p>\n <form action=\"#\" method=\"post\" class=\"gap-2\" enctype=\"multipart/form-data\">\n {% if competition_type == 'generic' %}\n <div class=\"form-group\">\n <label class=\"block mb-2 text-sm font-medium text-gray-900\" for=\"submission_file\">Upload\n file</label>\n <input\n class=\"block w-full text-sm text-gray-900 border border-gray-300 rounded-lg cursor-pointer bg-gray-50 focus:outline-none \"\n id=\"submission_file\" type=\"file\" name=\"submission_file\">\n </div>\n {% endif %}\n {% if competition_type == 'script' %}\n <div class=\"form-group\">\n <label for=\"hub_model\" class=\"text-sm font-medium text-gray-700\">Hub model\n </label>\n <input type=\"text\" name=\"hub_model\" id=\"hub_model\"\n class=\"mt-1 block w-full border border-gray-300 px-3 py-1.5 bg-white rounded-md shadow-sm focus:outline-none focus:ring-indigo-500 focus:border-indigo-500\"\n placeholder=\"username/my-model\">\n </div>\n {% endif %}\n <div class=\"form-group mt-2\">\n <label for=\"submission_comment\" class=\"text-sm font-medium text-gray-700\">Submission description\n (optional)\n </label>\n <textarea id=\"submission_comment\" name=\"submission_comment\" rows=\"5\"\n class=\"p-2.5 w-full text-sm text-gray-900\" placeholder=\" \"></textarea>\n </div>\n <div class=\"form-actions mt-6\">\n <button data-modal-hide=\"submission-modal\" type=\"button\"\n class=\"confirm text-white bg-green-600 hover:bg-green-800 focus:ring-4 focus:outline-none focus:ring-green-300font-medium rounded-lg text-sm inline-flex items-center px-5 py-2.5 text-center me-2\">\n Submit\n </button>\n <button data-modal-hide=\"submission-modal\" type=\"button\"\n class=\"cancel text-white bg-red-600 hover:bg-red-100 focus:ring-4 focus:outline-none focus:ring-red-200 rounded-lg border border-red-200 text-sm font-medium px-5 py-2.5 hover:text-red-900 focus:z-10\">Cancel</button>\n </div>\n </form>\n <hr class=\"mt-3\">\n <div id=\"error-message\" style=\"color: red;\"></div>\n <div id=\"success-message\" style=\"color: green;\"></div>\n </div>\n </div>\n <div id=\"admin-modal\" tabindex=\"-1\"\n class=\"hidden fixed inset-0 z-40 flex items-center justify-center w-full h-full bg-black bg-opacity-50\">\n <div id=\"adminLoadingSpinner\" role=\"status\"\n class=\"hidden fixed inset-0 z-50 flex items-center justify-center bg-black bg-opacity-50\">\n <div class=\"animate-spin rounded-full h-32 w-32 border-b-2 border-gray-900\"></div>\n <span class=\"sr-only\">Loading...</span>\n </div>\n <div class=\"relative w-full max-w-5xl p-4\">\n <div class=\"relative bg-white rounded-lg shadow-2xl\">\n <button type=\"button\"\n class=\"absolute top-3 right-3 text-gray-400 bg-transparent hover:bg-gray-200 hover:text-gray-900 rounded-lg text-sm w-8 h-8 inline-flex justify-center items-center\"\n data-modal-hide=\"admin-modal\">\n <svg class=\"w-4 h-4\" aria-hidden=\"true\" xmlns=\"http://www.w3.org/2000/svg\" fill=\"none\"\n viewBox=\"0 0 14 14\">\n <path stroke=\"currentColor\" stroke-linecap=\"round\" stroke-linejoin=\"round\" stroke-width=\"2\"\n d=\"m1 1 6 6m0 0 6 6M7 7l6-6M7 7l-6 6\" />\n </svg>\n <span class=\"sr-only\">Close</span>\n </button>\n <div class=\"p-6 md:p-8 text-center\">\n <h3 class=\"mb-5 text-lg font-medium text-gray-900\">Admin</h3>\n <div class=\"tabs\">\n <ul class=\"flex border-b\">\n <li class=\"mr-1\">\n <a class=\"tab bg-white inline-block py-2 px-4 text-blue-500 hover:text-blue-800 font-semibold\"\n href=\"#config\">Config</a>\n </li>\n <li class=\"mr-1\">\n <a class=\"tab bg-white inline-block py-2 px-4 text-blue-500 hover:text-blue-800 font-semibold\"\n href=\"#competition-desc\">Competition Desc</a>\n </li>\n <li class=\"mr-1\">\n <a class=\"tab bg-white inline-block py-2 px-4 text-blue-500 hover:text-blue-800 font-semibold\"\n href=\"#dataset-desc\">Dataset Desc</a>\n </li>\n <li class=\"mr-1\">\n <a class=\"tab bg-white inline-block py-2 px-4 text-blue-500 hover:text-blue-800 font-semibold\"\n href=\"#submission-desc\">Submission Desc</a>\n </li>\n <li class=\"mr-1\">\n <a class=\"tab bg-white inline-block py-2 px-4 text-blue-500 hover:text-blue-800 font-semibold\"\n href=\"#rules-desc\">Rules</a>\n </li>\n </ul>\n </div>\n <div id=\"tab-contents\"\n class=\"text-xs font-normal text-left overflow-y-auto max-h-[calc(100vh-400px)] border-t border-gray-200 pt-4\">\n <div id=\"config\">\n <textarea id=\"config-textarea\" class=\"w-full h-64 p-2 border rounded\">Loading..</textarea>\n <p class=\"text-xs text-gray-500\">Note: The config should be a valid JSON object. To learn\n details about entries, click <a\n href=\"https://huggingface.co/docs/competitions/competition_repo#confjson\"\n target=\"_blank\">here</a>.\n </p>\n </div>\n <div id=\"competition-desc\" class=\"hidden\">\n <textarea id=\"competition-desc-textarea\"\n class=\"w-full h-64 p-2 border rounded\">Loading..</textarea>\n </div>\n <div id=\"dataset-desc\" class=\"hidden\">\n <textarea id=\"dataset-desc-textarea\"\n class=\"w-full h-64 p-2 border rounded\">Loading..</textarea>\n </div>\n <div id=\"submission-desc\" class=\"hidden\">\n <textarea id=\"submission-desc-textarea\"\n class=\"w-full h-64 p-2 border rounded\">Loading..</textarea>\n </div>\n <div id=\"rules-desc\" class=\"hidden\">\n <textarea id=\"rules-desc-textarea\"\n class=\"w-full h-64 p-2 border rounded\">Loading..</textarea>\n </div>\n </div>\n <button id=\"save-button\" class=\"mt-4 px-4 py-2 bg-blue-500 text-white rounded hover:bg-blue-700\">\n Save\n </button>\n </div>\n </div>\n </div>\n </div>\n <script src=\"https://cdnjs.cloudflare.com/ajax/libs/flowbite/2.2.1/flowbite.min.js\"></script>\n <script>\n document.addEventListener(\"DOMContentLoaded\", function () {\n const content = document.getElementById('content');\n const links = content.getElementsByTagName('a');\n\n for (let i = 0; i < links.length; i++) {\n if (!links[i].hasAttribute('target')) {\n links[i].setAttribute('target', '_blank');\n }\n }\n });\n </script>\n</body>\n\n<script>\n document.addEventListener(\"DOMContentLoaded\", function () {\n document.querySelectorAll('.tabs a').forEach(tab => {\n tab.addEventListener('click', event => {\n event.preventDefault();\n document.querySelectorAll('.tabs a').forEach(t => t.classList.remove('active'));\n tab.classList.add('active');\n\n document.querySelectorAll('#tab-contents > div').forEach(content => content.classList.add('hidden'));\n const selectedTab = document.querySelector(tab.getAttribute('href'));\n selectedTab.classList.remove('hidden');\n });\n });\n\n async function fetchAdminCompInfo() {\n const adminLoadingSpinner = document.getElementById('adminLoadingSpinner');\n adminLoadingSpinner.classList.remove('hidden');\n try {\n const response = await fetch(\"/admin/comp_info\", {\n method: \"POST\",\n headers: {\n \"Content-Type\": \"application/json\"\n }\n });\n const data = await response.json();\n if (response.ok) {\n populateAdminModal(data.response);\n } else {\n alert(data.response || \"Failed to fetch competition info\");\n }\n } catch (error) {\n console.error(\"Error fetching admin competition info:\", error);\n alert(\"An error occurred while fetching competition info.\");\n } finally {\n adminLoadingSpinner.classList.add('hidden');\n }\n }\n\n function populateAdminModal(data) {\n document.getElementById(\"config-textarea\").value = JSON.stringify(data.config, null, 2);\n document.getElementById(\"competition-desc-textarea\").value = data.markdowns[\"competition_desc\"] || \"\";\n document.getElementById(\"dataset-desc-textarea\").value = data.markdowns[\"dataset_desc\"] || \"\";\n document.getElementById(\"submission-desc-textarea\").value = data.markdowns[\"submission_desc\"] || \"\";\n document.getElementById(\"rules-desc-textarea\").value = data.markdowns[\"rules\"] || \"No rules available.\";\n }\n\n document.querySelectorAll(\".tab\").forEach(tab => {\n tab.addEventListener(\"click\", function (event) {\n event.preventDefault();\n const targetId = this.getAttribute(\"href\").substring(1);\n\n document.querySelectorAll(\"#tab-contents > div\").forEach(content => {\n content.classList.add(\"hidden\");\n });\n document.getElementById(targetId).classList.remove(\"hidden\");\n\n document.querySelectorAll(\".tab\").forEach(t => {\n t.classList.remove(\"text-blue-800\");\n t.classList.add(\"text-blue-500\");\n });\n this.classList.remove(\"text-blue-500\");\n this.classList.add(\"text-blue-800\");\n });\n });\n\n document.getElementById(\"admin\").addEventListener(\"click\", function () {\n document.getElementById(\"admin-modal\").classList.remove(\"hidden\");\n fetchAdminCompInfo();\n });\n\n document.querySelector(\"[data-modal-hide='admin-modal']\").addEventListener(\"click\", function () {\n document.getElementById(\"admin-modal\").classList.add(\"hidden\");\n });\n\n document.getElementById(\"save-button\").addEventListener(\"click\", async function () {\n const adminLoadingSpinner = document.getElementById('adminLoadingSpinner');\n adminLoadingSpinner.classList.remove('hidden');\n\n const config = document.getElementById(\"config-textarea\").value;\n const competitionDesc = document.getElementById(\"competition-desc-textarea\").value;\n const datasetDesc = document.getElementById(\"dataset-desc-textarea\").value;\n const submissionDesc = document.getElementById(\"submission-desc-textarea\").value;\n const rulesDesc = document.getElementById(\"rules-desc-textarea\").value;\n\n const data = {\n config: JSON.parse(config),\n markdowns: {\n competition_desc: competitionDesc,\n dataset_desc: datasetDesc,\n submission_desc: submissionDesc,\n rules: rulesDesc\n }\n };\n\n try {\n const response = await fetch(\"/admin/update_comp_info\", {\n method: \"POST\",\n headers: {\n \"Content-Type\": \"application/json\"\n },\n body: JSON.stringify(data)\n });\n const result = await response.json();\n if (response.ok) {\n alert(result.response || \"Successfully updated competition info\");\n } else {\n alert(result.response || \"Failed to update competition info\");\n }\n } catch (error) {\n console.error(\"Error updating competition info:\", error);\n alert(\"An error occurred while updating competition info.\");\n } finally {\n adminLoadingSpinner.classList.add('hidden');\n }\n });\n\n });\n</script>\n\n<script>\n document.addEventListener('DOMContentLoaded', function () {\n document.querySelector('.confirm').addEventListener('click', function (event) {\n event.preventDefault();\n document.getElementById('error-message').textContent = '';\n document.getElementById('success-message').textContent = '';\n const loadingSpinner = document.getElementById('loadingSpinner');\n loadingSpinner.classList.remove('hidden');\n\n var formData = new FormData();\n var competitionType = '{{ competition_type }}';\n\n if (competitionType === 'generic') {\n var submissionFile = document.getElementById('submission_file').files[0];\n formData.append('submission_file', submissionFile);\n formData.append('hub_model', 'None');\n } else if (competitionType === 'script') {\n var hubModel = document.getElementById('hub_model').value;\n if (!hubModel) {\n alert('Hub model is required.');\n return;\n }\n formData.append('hub_model', hubModel);\n } else {\n alert('Invalid competition type.');\n return;\n }\n\n var submissionComment = document.getElementById('submission_comment').value;\n formData.append('submission_comment', submissionComment);\n\n fetch('/new_submission', {\n method: 'POST',\n body: formData\n })\n .then(response => response.json())\n .then(data => {\n loadingSpinner.classList.add('hidden');\n document.getElementById('success-message').textContent = data.response;\n\n })\n .catch((error) => {\n console.error('Error:', error);\n loadingSpinner.classList.add('hidden');\n document.getElementById('error-message').textContent = error;\n });\n });\n });\n</script>\n\n<script>\n function updateSelectedSubmissions() {\n const selectedSubmissions = document.querySelectorAll('input[name=\"selectedSubmissions\"]:checked');\n const articleLoadingSpinner = document.getElementById('articleLoadingSpinner');\n articleLoadingSpinner.classList.remove('hidden');\n let selectedSubmissionIds = [];\n selectedSubmissions.forEach((submission) => {\n selectedSubmissionIds.push(submission.value);\n });\n\n const updateEndpoint = '/update_selected_submissions';\n const requestOptions = {\n method: 'POST',\n headers: {\n 'Content-Type': 'application/json',\n },\n body: JSON.stringify({\n \"submission_ids\": selectedSubmissionIds.join(',')\n })\n };\n\n fetch(updateEndpoint, requestOptions)\n .then(response => {\n if (!response.ok) {\n throw new Error('Network response was not ok');\n }\n return response.json();\n })\n .then(data => {\n if (data.success) {\n // Optionally, display a success message or handle accordingly\n console.log('Update successful');\n articleLoadingSpinner.classList.add('hidden');\n } else {\n // Handle failure case\n console.log('Update failed');\n articleLoadingSpinner.classList.add('hidden');\n alert(data.error);\n }\n // Refresh submissions display\n fetchAndDisplaySubmissions();\n })\n .catch(error => {\n console.error('There was a problem with the fetch operation for updating:', error);\n });\n }\n</script>\n\n<script>\n function updateTeamName() {\n const teamName = document.getElementById('team_name').value;\n const articleLoadingSpinner = document.getElementById('articleLoadingSpinner');\n articleLoadingSpinner.classList.remove('hidden');\n\n const updateEndpoint = '/update_team_name';\n const requestOptions = {\n method: 'POST',\n headers: {\n 'Content-Type': 'application/json',\n },\n body: JSON.stringify({\n \"new_team_name\": teamName\n })\n };\n\n fetch(updateEndpoint, requestOptions)\n .then(response => {\n if (!response.ok) {\n throw new Error('Network response was not ok');\n }\n return response.json();\n })\n .then(data => {\n if (data.success) {\n // Optionally, display a success message or handle accordingly\n console.log('Update successful');\n articleLoadingSpinner.classList.add('hidden');\n } else {\n // Handle failure case\n console.log('Update failed');\n articleLoadingSpinner.classList.add('hidden');\n alert(data.error);\n }\n // Refresh submissions display\n fetchAndDisplaySubmissions();\n })\n .catch(error => {\n console.error('There was a problem with the fetch operation for updating:', error);\n });\n }\n</script>\n\n<script>\n function showAdminModal() {\n const modal = document.getElementById('admin-modal');\n modal.classList.add('flex');\n modal.classList.remove('hidden');\n }\n\n function hideAdminModal() {\n const modal = document.getElementById('admin-modal');\n modal.classList.remove('flex');\n modal.classList.add('hidden');\n }\n\n document.querySelector('#admin').addEventListener('click', function () {\n showAdminModal();\n });\n\n document.querySelector('[data-modal-hide=\"admin-modal\"]').addEventListener('click', function () {\n hideAdminModal();\n });\n</script>\n\n</html>", "docs\\source\\index.mdx": "# Competitions\n\nCreate a machine learning competition for your organization, friends or the world!\n\n\n\n## Supported competition types\n\nThere are two types of competitions you can create:\n\n- generic: a competition where you provide the data and the participants provide the predictions as a CSV file. all the test data is always available to the participants.\n\n- script: a competition where you provide the data and the participants provide the code that generates the predictions. test data can be hidden from the participants.\n\nYou can choose to make your competition public or private. Public competitions are visible to everyone and anyone can participate. Private competitions are only visible to the people you invite!\n\n## Why choose Hugging Face Competitions?\n\n- you can create totally private competitions that are only visible to the people you invite.\n\n- generic competition can be hosted for free.\n\n- script competitions have a variety of compute options to choose from: CPU, T4, A10g & even A100.\n\n- you have full control over the data you want to use for your competition.\n\n- its open source!\n\n\n## Issues / feature requests\n\nSomething missing? Found a bug? Please open an issue on this [GitHub repository](https://github.com/huggingface/competitions) and we'll fix it as soon as possible!\n\nTo host competition on hf.co/competitions, please contact us at autotrain [at] huggingface [dot] co"} | null |
controlnet_aux | {"type": "directory", "name": "controlnet_aux", "children": [{"type": "file", "name": "LICENSE.txt"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "setup.py"}, {"type": "directory", "name": "src", "children": [{"type": "directory", "name": "controlnet_aux", "children": [{"type": "directory", "name": "anyline", "children": [{"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "canny", "children": [{"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "dwpose", "children": [{"type": "directory", "name": "dwpose_config", "children": [{"type": "file", "name": "dwpose-l_384x288.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "util.py"}, {"type": "file", "name": "wholebody.py"}, {"type": "directory", "name": "yolox_config", "children": [{"type": "file", "name": "yolox_l_8xb8-300e_coco.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "hed", "children": [{"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "leres", "children": [{"type": "directory", "name": "leres", "children": [{"type": "file", "name": "depthmap.py"}, {"type": "file", "name": "LICENSE"}, {"type": "file", "name": "multi_depth_model_woauxi.py"}, {"type": "file", "name": "network_auxi.py"}, {"type": "file", "name": "net_tools.py"}, {"type": "file", "name": "Resnet.py"}, {"type": "file", "name": "Resnext_torch.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "pix2pix", "children": [{"type": "file", "name": "LICENSE"}, {"type": "directory", "name": "models", "children": [{"type": "file", "name": "base_model.py"}, {"type": "file", "name": "base_model_hg.py"}, {"type": "file", "name": "networks.py"}, {"type": "file", "name": "pix2pix4depth_model.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "options", "children": [{"type": "file", "name": "base_options.py"}, {"type": "file", "name": "test_options.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "util", "children": [{"type": "file", "name": "util.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "lineart", "children": [{"type": "file", "name": "LICENSE"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "lineart_anime", "children": [{"type": "file", "name": "LICENSE"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "lineart_standard", "children": [{"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "mediapipe_face", "children": [{"type": "file", "name": "mediapipe_face_common.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "midas", "children": [{"type": "file", "name": "api.py"}, {"type": "file", "name": "LICENSE"}, {"type": "directory", "name": "midas", "children": [{"type": "file", "name": "base_model.py"}, {"type": "file", "name": "blocks.py"}, {"type": "file", "name": "dpt_depth.py"}, {"type": "file", "name": "midas_net.py"}, {"type": "file", "name": "midas_net_custom.py"}, {"type": "file", "name": "transforms.py"}, {"type": "file", "name": "vit.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "utils.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "mlsd", "children": [{"type": "file", "name": "LICENSE"}, {"type": "directory", "name": "models", "children": [{"type": "file", "name": "mbv2_mlsd_large.py"}, {"type": "file", "name": "mbv2_mlsd_tiny.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "utils.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "normalbae", "children": [{"type": "file", "name": "LICENSE"}, {"type": "directory", "name": "nets", "children": [{"type": "file", "name": "baseline.py"}, {"type": "file", "name": "NNET.py"}, {"type": "directory", "name": "submodules", "children": [{"type": "file", "name": "decoder.py"}, {"type": "directory", "name": "efficientnet_repo", "children": [{"type": "file", "name": "BENCHMARK.md"}, {"type": "file", "name": "caffe2_benchmark.py"}, {"type": "file", "name": "caffe2_validate.py"}, {"type": "directory", "name": "geffnet", "children": [{"type": "directory", "name": "activations", "children": [{"type": "file", "name": "activations.py"}, {"type": "file", "name": "activations_jit.py"}, {"type": "file", "name": "activations_me.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "config.py"}, {"type": "file", "name": "conv2d_layers.py"}, {"type": "file", "name": "efficientnet_builder.py"}, {"type": "file", "name": "gen_efficientnet.py"}, {"type": "file", "name": "helpers.py"}, {"type": "file", "name": "mobilenetv3.py"}, {"type": "file", "name": "model_factory.py"}, {"type": "file", "name": "version.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "hubconf.py"}, {"type": "file", "name": "LICENSE"}, {"type": "file", "name": "onnx_export.py"}, {"type": "file", "name": "onnx_optimize.py"}, {"type": "file", "name": "onnx_to_caffe.py"}, {"type": "file", "name": "onnx_validate.py"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "setup.py"}, {"type": "file", "name": "utils.py"}, {"type": "file", "name": "validate.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "encoder.py"}, {"type": "file", "name": "submodules.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "open_pose", "children": [{"type": "file", "name": "body.py"}, {"type": "file", "name": "face.py"}, {"type": "file", "name": "hand.py"}, {"type": "file", "name": "LICENSE"}, {"type": "file", "name": "model.py"}, {"type": "file", "name": "util.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "pidi", "children": [{"type": "file", "name": "LICENSE"}, {"type": "file", "name": "model.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "processor.py"}, {"type": "directory", "name": "segment_anything", "children": [{"type": "file", "name": "automatic_mask_generator.py"}, {"type": "file", "name": "build_sam.py"}, {"type": "directory", "name": "modeling", "children": [{"type": "file", "name": "common.py"}, {"type": "file", "name": "image_encoder.py"}, {"type": "file", "name": "mask_decoder.py"}, {"type": "file", "name": "prompt_encoder.py"}, {"type": "file", "name": "sam.py"}, {"type": "file", "name": "tiny_vit_sam.py"}, {"type": "file", "name": "transformer.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "predictor.py"}, {"type": "directory", "name": "utils", "children": [{"type": "file", "name": "amg.py"}, {"type": "file", "name": "onnx.py"}, {"type": "file", "name": "transforms.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "shuffle", "children": [{"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "teed", "children": [{"type": "file", "name": "Fsmish.py"}, {"type": "file", "name": "LICENSE.txt"}, {"type": "file", "name": "ted.py"}, {"type": "file", "name": "Xsmish.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "tests", "children": [{"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "test_processor.py"}, {"type": "file", "name": "test_processor_pytest.py"}]}, {"type": "file", "name": "util.py"}, {"type": "directory", "name": "zoe", "children": [{"type": "file", "name": "LICENSE"}, {"type": "directory", "name": "zoedepth", "children": [{"type": "directory", "name": "models", "children": [{"type": "directory", "name": "base_models", "children": [{"type": "file", "name": "midas.py"}, {"type": "directory", "name": "midas_repo", "children": [{"type": "file", "name": "hubconf.py"}, {"type": "file", "name": "LICENSE"}, {"type": "directory", "name": "midas", "children": [{"type": "directory", "name": "backbones", "children": [{"type": "file", "name": "beit.py"}, {"type": "file", "name": "levit.py"}, {"type": "file", "name": "next_vit.py"}, {"type": "file", "name": "swin.py"}, {"type": "file", "name": "swin2.py"}, {"type": "file", "name": "swin_common.py"}, {"type": "file", "name": "utils.py"}, {"type": "file", "name": "vit.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "base_model.py"}, {"type": "file", "name": "blocks.py"}, {"type": "file", "name": "dpt_depth.py"}, {"type": "file", "name": "midas_net.py"}, {"type": "file", "name": "midas_net_custom.py"}, {"type": "file", "name": "model_loader.py"}, {"type": "file", "name": "transforms.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "builder.py"}, {"type": "file", "name": "depth_model.py"}, {"type": "directory", "name": "layers", "children": [{"type": "file", "name": "attractor.py"}, {"type": "file", "name": "dist_layers.py"}, {"type": "file", "name": "localbins_layers.py"}, {"type": "file", "name": "patch_transformer.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "model_io.py"}, {"type": "directory", "name": "zoedepth", "children": [{"type": "file", "name": "config_zoedepth.json"}, {"type": "file", "name": "config_zoedepth_kitti.json"}, {"type": "file", "name": "zoedepth_v1.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "zoedepth_nk", "children": [{"type": "file", "name": "config_zoedepth_nk.json"}, {"type": "file", "name": "zoedepth_nk_v1.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "utils", "children": [{"type": "file", "name": "arg_utils.py"}, {"type": "file", "name": "config.py"}, {"type": "directory", "name": "easydict", "children": [{"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "__init__.py"}]}]}, {"type": "directory", "name": "tests", "children": [{"type": "file", "name": "test_controlnet_aux.py"}]}]} | ## Towards Robust Monocular Depth Estimation: Mixing Datasets for Zero-shot Cross-dataset Transfer
This repository contains code to compute depth from a single image. It accompanies our [paper](https://arxiv.org/abs/1907.01341v3):
>Towards Robust Monocular Depth Estimation: Mixing Datasets for Zero-shot Cross-dataset Transfer
René Ranftl, Katrin Lasinger, David Hafner, Konrad Schindler, Vladlen Koltun
and our [preprint](https://arxiv.org/abs/2103.13413):
> Vision Transformers for Dense Prediction
> René Ranftl, Alexey Bochkovskiy, Vladlen Koltun
MiDaS was trained on up to 12 datasets (ReDWeb, DIML, Movies, MegaDepth, WSVD, TartanAir, HRWSI, ApolloScape, BlendedMVS, IRS, KITTI, NYU Depth V2) with
multi-objective optimization.
The original model that was trained on 5 datasets (`MIX 5` in the paper) can be found [here](https://github.com/isl-org/MiDaS/releases/tag/v2).
The figure below shows an overview of the different MiDaS models; the bubble size scales with number of parameters.

### Setup
1) Pick one or more models and download the corresponding weights to the `weights` folder:
MiDaS 3.1
- For highest quality: [dpt_beit_large_512](https://github.com/isl-org/MiDaS/releases/download/v3_1/dpt_beit_large_512.pt)
- For moderately less quality, but better speed-performance trade-off: [dpt_swin2_large_384](https://github.com/isl-org/MiDaS/releases/download/v3_1/dpt_swin2_large_384.pt)
- For embedded devices: [dpt_swin2_tiny_256](https://github.com/isl-org/MiDaS/releases/download/v3_1/dpt_swin2_tiny_256.pt), [dpt_levit_224](https://github.com/isl-org/MiDaS/releases/download/v3_1/dpt_levit_224.pt)
- For inference on Intel CPUs, OpenVINO may be used for the small legacy model: openvino_midas_v21_small [.xml](https://github.com/isl-org/MiDaS/releases/download/v3_1/openvino_midas_v21_small_256.xml), [.bin](https://github.com/isl-org/MiDaS/releases/download/v3_1/openvino_midas_v21_small_256.bin)
MiDaS 3.0: Legacy transformer models [dpt_large_384](https://github.com/isl-org/MiDaS/releases/download/v3/dpt_large_384.pt) and [dpt_hybrid_384](https://github.com/isl-org/MiDaS/releases/download/v3/dpt_hybrid_384.pt)
MiDaS 2.1: Legacy convolutional models [midas_v21_384](https://github.com/isl-org/MiDaS/releases/download/v2_1/midas_v21_384.pt) and [midas_v21_small_256](https://github.com/isl-org/MiDaS/releases/download/v2_1/midas_v21_small_256.pt)
1) Set up dependencies:
```shell
conda env create -f environment.yaml
conda activate midas-py310
```
#### optional
For the Next-ViT model, execute
```shell
git submodule add https://github.com/isl-org/Next-ViT midas/external/next_vit
```
For the OpenVINO model, install
```shell
pip install openvino
```
### Usage
1) Place one or more input images in the folder `input`.
2) Run the model with
```shell
python run.py --model_type <model_type> --input_path input --output_path output
```
where ```<model_type>``` is chosen from [dpt_beit_large_512](#model_type), [dpt_beit_large_384](#model_type),
[dpt_beit_base_384](#model_type), [dpt_swin2_large_384](#model_type), [dpt_swin2_base_384](#model_type),
[dpt_swin2_tiny_256](#model_type), [dpt_swin_large_384](#model_type), [dpt_next_vit_large_384](#model_type),
[dpt_levit_224](#model_type), [dpt_large_384](#model_type), [dpt_hybrid_384](#model_type),
[midas_v21_384](#model_type), [midas_v21_small_256](#model_type), [openvino_midas_v21_small_256](#model_type).
3) The resulting depth maps are written to the `output` folder.
#### optional
1) By default, the inference resizes the height of input images to the size of a model to fit into the encoder. This
size is given by the numbers in the model names of the [accuracy table](#accuracy). Some models do not only support a single
inference height but a range of different heights. Feel free to explore different heights by appending the extra
command line argument `--height`. Unsupported height values will throw an error. Note that using this argument may
decrease the model accuracy.
2) By default, the inference keeps the aspect ratio of input images when feeding them into the encoder if this is
supported by a model (all models except for Swin, Swin2, LeViT). In order to resize to a square resolution,
disregarding the aspect ratio while preserving the height, use the command line argument `--square`.
#### via Camera
If you want the input images to be grabbed from the camera and shown in a window, leave the input and output paths
away and choose a model type as shown above:
```shell
python run.py --model_type <model_type> --side
```
The argument `--side` is optional and causes both the input RGB image and the output depth map to be shown
side-by-side for comparison.
#### via Docker
1) Make sure you have installed Docker and the
[NVIDIA Docker runtime](https://github.com/NVIDIA/nvidia-docker/wiki/Installation-\(Native-GPU-Support\)).
2) Build the Docker image:
```shell
docker build -t midas .
```
3) Run inference:
```shell
docker run --rm --gpus all -v $PWD/input:/opt/MiDaS/input -v $PWD/output:/opt/MiDaS/output -v $PWD/weights:/opt/MiDaS/weights midas
```
This command passes through all of your NVIDIA GPUs to the container, mounts the
`input` and `output` directories and then runs the inference.
#### via PyTorch Hub
The pretrained model is also available on [PyTorch Hub](https://pytorch.org/hub/intelisl_midas_v2/)
#### via TensorFlow or ONNX
See [README](https://github.com/isl-org/MiDaS/tree/master/tf) in the `tf` subdirectory.
Currently only supports MiDaS v2.1.
#### via Mobile (iOS / Android)
See [README](https://github.com/isl-org/MiDaS/tree/master/mobile) in the `mobile` subdirectory.
#### via ROS1 (Robot Operating System)
See [README](https://github.com/isl-org/MiDaS/tree/master/ros) in the `ros` subdirectory.
Currently only supports MiDaS v2.1. DPT-based models to be added.
### Accuracy
We provide a **zero-shot error** $\epsilon_d$ which is evaluated for 6 different datasets
(see [paper](https://arxiv.org/abs/1907.01341v3)). **Lower error values are better**.
$\color{green}{\textsf{Overall model quality is represented by the improvement}}$ ([Imp.](#improvement)) with respect to
MiDaS 3.0 DPT<sub>L-384</sub>. The models are grouped by the height used for inference, whereas the square training resolution is given by
the numbers in the model names. The table also shows the **number of parameters** (in millions) and the
**frames per second** for inference at the training resolution (for GPU RTX 3090):
| MiDaS Model | DIW </br><sup>WHDR</sup> | Eth3d </br><sup>AbsRel</sup> | Sintel </br><sup>AbsRel</sup> | TUM </br><sup>δ1</sup> | KITTI </br><sup>δ1</sup> | NYUv2 </br><sup>δ1</sup> | $\color{green}{\textsf{Imp.}}$ </br><sup>%</sup> | Par.</br><sup>M</sup> | FPS</br><sup> </sup> |
|-----------------------------------------------------------------------------------------------------------------------|-------------------------:|-----------------------------:|------------------------------:|-------------------------:|-------------------------:|-------------------------:|-------------------------------------------------:|----------------------:|--------------------------:|
| **Inference height 512** | | | | | | | | | |
| [v3.1 BEiT<sub>L-512</sub>](https://github.com/isl-org/MiDaS/releases/download/v3_1/dpt_beit_large_512.pt) | 0.1137 | 0.0659 | 0.2366 | **6.13** | 11.56* | **1.86*** | $\color{green}{\textsf{19}}$ | **345** | **5.7** |
| [v3.1 BEiT<sub>L-512</sub>](https://github.com/isl-org/MiDaS/releases/download/v3_1/dpt_beit_large_512.pt)$\tiny{\square}$ | **0.1121** | **0.0614** | **0.2090** | 6.46 | **5.00*** | 1.90* | $\color{green}{\textsf{34}}$ | **345** | **5.7** |
| | | | | | | | | | |
| **Inference height 384** | | | | | | | | | |
| [v3.1 BEiT<sub>L-512</sub>](https://github.com/isl-org/MiDaS/releases/download/v3_1/dpt_beit_large_512.pt) | 0.1245 | 0.0681 | **0.2176** | **6.13** | 6.28* | **2.16*** | $\color{green}{\textsf{28}}$ | 345 | 12 |
| [v3.1 Swin2<sub>L-384</sub>](https://github.com/isl-org/MiDaS/releases/download/v3_1/dpt_swin2_large_384.pt)$\tiny{\square}$ | 0.1106 | 0.0732 | 0.2442 | 8.87 | **5.84*** | 2.92* | $\color{green}{\textsf{22}}$ | 213 | 41 |
| [v3.1 Swin2<sub>B-384</sub>](https://github.com/isl-org/MiDaS/releases/download/v3_1/dpt_swin2_base_384.pt)$\tiny{\square}$ | 0.1095 | 0.0790 | 0.2404 | 8.93 | 5.97* | 3.28* | $\color{green}{\textsf{22}}$ | 102 | 39 |
| [v3.1 Swin<sub>L-384</sub>](https://github.com/isl-org/MiDaS/releases/download/v3_1/dpt_swin_large_384.pt)$\tiny{\square}$ | 0.1126 | 0.0853 | 0.2428 | 8.74 | 6.60* | 3.34* | $\color{green}{\textsf{17}}$ | 213 | 49 |
| [v3.1 BEiT<sub>L-384</sub>](https://github.com/isl-org/MiDaS/releases/download/v3_1/dpt_beit_large_384.pt) | 0.1239 | **0.0667** | 0.2545 | 7.17 | 9.84* | 2.21* | $\color{green}{\textsf{17}}$ | 344 | 13 |
| [v3.1 Next-ViT<sub>L-384</sub>](https://github.com/isl-org/MiDaS/releases/download/v3_1/dpt_next_vit_large_384.pt) | **0.1031** | 0.0954 | 0.2295 | 9.21 | 6.89* | 3.47* | $\color{green}{\textsf{16}}$ | **72** | 30 |
| [v3.1 BEiT<sub>B-384</sub>](https://github.com/isl-org/MiDaS/releases/download/v3_1/dpt_beit_base_384.pt) | 0.1159 | 0.0967 | 0.2901 | 9.88 | 26.60* | 3.91* | $\color{green}{\textsf{-31}}$ | 112 | 31 |
| [v3.0 DPT<sub>L-384</sub>](https://github.com/isl-org/MiDaS/releases/download/v3/dpt_large_384.pt) | 0.1082 | 0.0888 | 0.2697 | 9.97 | 8.46 | 8.32 | $\color{green}{\textsf{0}}$ | 344 | **61** |
| [v3.0 DPT<sub>H-384</sub>](https://github.com/isl-org/MiDaS/releases/download/v3/dpt_hybrid_384.pt) | 0.1106 | 0.0934 | 0.2741 | 10.89 | 11.56 | 8.69 | $\color{green}{\textsf{-10}}$ | 123 | 50 |
| [v2.1 Large<sub>384</sub>](https://github.com/isl-org/MiDaS/releases/download/v2_1/midas_v21_384.pt) | 0.1295 | 0.1155 | 0.3285 | 12.51 | 16.08 | 8.71 | $\color{green}{\textsf{-32}}$ | 105 | 47 |
| | | | | | | | | | |
| **Inference height 256** | | | | | | | | | |
| [v3.1 Swin2<sub>T-256</sub>](https://github.com/isl-org/MiDaS/releases/download/v3_1/dpt_swin2_tiny_256.pt)$\tiny{\square}$ | **0.1211** | **0.1106** | **0.2868** | **13.43** | **10.13*** | **5.55*** | $\color{green}{\textsf{-11}}$ | 42 | 64 |
| [v2.1 Small<sub>256</sub>](https://github.com/isl-org/MiDaS/releases/download/v2_1/midas_v21_small_256.pt) | 0.1344 | 0.1344 | 0.3370 | 14.53 | 29.27 | 13.43 | $\color{green}{\textsf{-76}}$ | **21** | **90** |
| | | | | | | | | | |
| **Inference height 224** | | | | | | | | | |
| [v3.1 LeViT<sub>224</sub>](https://github.com/isl-org/MiDaS/releases/download/v3_1/dpt_levit_224.pt)$\tiny{\square}$ | **0.1314** | **0.1206** | **0.3148** | **18.21** | **15.27*** | **8.64*** | $\color{green}{\textsf{-40}}$ | **51** | **73** |
* No zero-shot error, because models are also trained on KITTI and NYU Depth V2\
$\square$ Validation performed at **square resolution**, either because the transformer encoder backbone of a model
does not support non-square resolutions (Swin, Swin2, LeViT) or for comparison with these models. All other
validations keep the aspect ratio. A difference in resolution limits the comparability of the zero-shot error and the
improvement, because these quantities are averages over the pixels of an image and do not take into account the
advantage of more details due to a higher resolution.\
Best values per column and same validation height in bold
#### Improvement
The improvement in the above table is defined as the relative zero-shot error with respect to MiDaS v3.0
DPT<sub>L-384</sub> and averaging over the datasets. So, if $\epsilon_d$ is the zero-shot error for dataset $d$, then
the $\color{green}{\textsf{improvement}}$ is given by $100(1-(1/6)\sum_d\epsilon_d/\epsilon_{d,\rm{DPT_{L-384}}})$%.
Note that the improvements of 10% for MiDaS v2.0 → v2.1 and 21% for MiDaS v2.1 → v3.0 are not visible from the
improvement column (Imp.) in the table but would require an evaluation with respect to MiDaS v2.1 Large<sub>384</sub>
and v2.0 Large<sub>384</sub> respectively instead of v3.0 DPT<sub>L-384</sub>.
### Depth map comparison
Zoom in for better visibility

### Speed on Camera Feed
Test configuration
- Windows 10
- 11th Gen Intel Core i7-1185G7 3.00GHz
- 16GB RAM
- Camera resolution 640x480
- openvino_midas_v21_small_256
Speed: 22 FPS
### Changelog
* [Dec 2022] Released MiDaS v3.1:
- New models based on 5 different types of transformers ([BEiT](https://arxiv.org/pdf/2106.08254.pdf), [Swin2](https://arxiv.org/pdf/2111.09883.pdf), [Swin](https://arxiv.org/pdf/2103.14030.pdf), [Next-ViT](https://arxiv.org/pdf/2207.05501.pdf), [LeViT](https://arxiv.org/pdf/2104.01136.pdf))
- Training datasets extended from 10 to 12, including also KITTI and NYU Depth V2 using [BTS](https://github.com/cleinc/bts) split
- Best model, BEiT<sub>Large 512</sub>, with resolution 512x512, is on average about [28% more accurate](#Accuracy) than MiDaS v3.0
- Integrated live depth estimation from camera feed
* [Sep 2021] Integrated to [Huggingface Spaces](https://huggingface.co/spaces) with [Gradio](https://github.com/gradio-app/gradio). See [Gradio Web Demo](https://huggingface.co/spaces/akhaliq/DPT-Large).
* [Apr 2021] Released MiDaS v3.0:
- New models based on [Dense Prediction Transformers](https://arxiv.org/abs/2103.13413) are on average [21% more accurate](#Accuracy) than MiDaS v2.1
- Additional models can be found [here](https://github.com/isl-org/DPT)
* [Nov 2020] Released MiDaS v2.1:
- New model that was trained on 10 datasets and is on average about [10% more accurate](#Accuracy) than [MiDaS v2.0](https://github.com/isl-org/MiDaS/releases/tag/v2)
- New light-weight model that achieves [real-time performance](https://github.com/isl-org/MiDaS/tree/master/mobile) on mobile platforms.
- Sample applications for [iOS](https://github.com/isl-org/MiDaS/tree/master/mobile/ios) and [Android](https://github.com/isl-org/MiDaS/tree/master/mobile/android)
- [ROS package](https://github.com/isl-org/MiDaS/tree/master/ros) for easy deployment on robots
* [Jul 2020] Added TensorFlow and ONNX code. Added [online demo](http://35.202.76.57/).
* [Dec 2019] Released new version of MiDaS - the new model is significantly more accurate and robust
* [Jul 2019] Initial release of MiDaS ([Link](https://github.com/isl-org/MiDaS/releases/tag/v1))
### Citation
Please cite our paper if you use this code or any of the models:
```
@ARTICLE {Ranftl2022,
author = "Ren\'{e} Ranftl and Katrin Lasinger and David Hafner and Konrad Schindler and Vladlen Koltun",
title = "Towards Robust Monocular Depth Estimation: Mixing Datasets for Zero-Shot Cross-Dataset Transfer",
journal = "IEEE Transactions on Pattern Analysis and Machine Intelligence",
year = "2022",
volume = "44",
number = "3"
}
```
If you use a DPT-based model, please also cite:
```
@article{Ranftl2021,
author = {Ren\'{e} Ranftl and Alexey Bochkovskiy and Vladlen Koltun},
title = {Vision Transformers for Dense Prediction},
journal = {ICCV},
year = {2021},
}
```
### Acknowledgements
Our work builds on and uses code from [timm](https://github.com/rwightman/pytorch-image-models) and [Next-ViT](https://github.com/bytedance/Next-ViT).
We'd like to thank the authors for making these libraries available.
### License
MIT License
| {"setup.py": "# Copyright 2023 The HuggingFace Team. All rights reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"\nSimple check list from AllenNLP repo: https://github.com/allenai/allennlp/blob/main/setup.py\n\nTo create the package for pypi.\n\n1. Run `make pre-release` (or `make pre-patch` for a patch release) then run `make fix-copies` to fix the index of the\n documentation.\n\n If releasing on a special branch, copy the updated README.md on the main branch for your the commit you will make\n for the post-release and run `make fix-copies` on the main branch as well.\n\n2. Run Tests for Amazon Sagemaker. The documentation is located in `./tests/sagemaker/README.md`, otherwise @philschmid.\n\n3. Unpin specific versions from setup.py that use a git install.\n\n4. Checkout the release branch (v<RELEASE>-release, for example v4.19-release), and commit these changes with the\n message: \"Release: <RELEASE>\" and push.\n\n5. Wait for the tests on main to be completed and be green (otherwise revert and fix bugs)\n\n6. Add a tag in git to mark the release: \"git tag v<RELEASE> -m 'Adds tag v<RELEASE> for pypi' \"\n Push the tag to git: git push --tags origin v<RELEASE>-release\n\n7. Build both the sources and the wheel. Do not change anything in setup.py between\n creating the wheel and the source distribution (obviously).\n\n For the wheel, run: \"python setup.py bdist_wheel\" in the top level directory.\n (this will build a wheel for the python version you use to build it).\n\n For the sources, run: \"python setup.py sdist\"\n You should now have a /dist directory with both .whl and .tar.gz source versions.\n\n8. Check that everything looks correct by uploading the package to the pypi test server:\n\n twine upload dist/* -r pypitest\n (pypi suggest using twine as other methods upload files via plaintext.)\n You may have to specify the repository url, use the following command then:\n twine upload dist/* -r pypitest --repository-url=https://test.pypi.org/legacy/\n\n Check that you can install it in a virtualenv by running:\n pip install -i https://testpypi.python.org/pypi diffusers\n\n Check you can run the following commands:\n python -c \"from diffusers import pipeline; classifier = pipeline('text-classification'); print(classifier('What a nice release'))\"\n python -c \"from diffusers import *\"\n\n9. Upload the final version to actual pypi:\n twine upload dist/* -r pypi\n\n10. Copy the release notes from RELEASE.md to the tag in github once everything is looking hunky-dory.\n\n11. Run `make post-release` (or, for a patch release, `make post-patch`). If you were on a branch for the release,\n you need to go back to main before executing this.\n\"\"\"\n\nimport os\nimport re\nfrom distutils.core import Command\n\nfrom setuptools import find_packages, setup\n\n# IMPORTANT:\n# 1. all dependencies should be listed here with their version requirements if any\n# 2. once modified, run: `make deps_table_update` to update src/diffusers/dependency_versions_table.py\n_deps = [\n \"Pillow\",\n \"torch\",\n \"numpy\",\n \"filelock\",\n \"importlib_metadata\",\n \"opencv-python-headless\",\n \"scipy\",\n \"huggingface_hub\",\n \"einops\",\n \"timm<=0.6.7\",\n \"torchvision\",\n \"scikit-image\",\n]\n\n# this is a lookup table with items like:\n#\n# tokenizers: \"huggingface-hub==0.8.0\"\n# packaging: \"packaging\"\n#\n# some of the values are versioned whereas others aren't.\ndeps = {\n b: a for a, b in (re.findall(r\"^(([^!=<>~]+)(?:[!=<>~].*)?$)\", x)[0] for x in _deps)\n}\n\n# since we save this data in src/diffusers/dependency_versions_table.py it can be easily accessed from\n# anywhere. If you need to quickly access the data from this table in a shell, you can do so easily with:\n#\n# python -c 'import sys; from diffusers.dependency_versions_table import deps; \\\n# print(\" \".join([ deps[x] for x in sys.argv[1:]]))' tokenizers datasets\n#\n# Just pass the desired package names to that script as it's shown with 2 packages above.\n#\n# If diffusers is not yet installed and the work is done from the cloned repo remember to add `PYTHONPATH=src` to the script above\n#\n# You can then feed this for example to `pip`:\n#\n# pip install -U $(python -c 'import sys; from diffusers.dependency_versions_table import deps; \\\n# print(\" \".join([ deps[x] for x in sys.argv[1:]]))' tokenizers datasets)\n#\n\n\ndef deps_list(*pkgs):\n return [deps[pkg] for pkg in pkgs]\n\n\nclass DepsTableUpdateCommand(Command):\n \"\"\"\n A custom distutils command that updates the dependency table.\n usage: python setup.py deps_table_update\n \"\"\"\n\n description = \"build runtime dependency table\"\n user_options = [\n # format: (long option, short option, description).\n (\n \"dep-table-update\",\n None,\n \"updates src/diffusers/dependency_versions_table.py\",\n ),\n ]\n\n def initialize_options(self):\n pass\n\n def finalize_options(self):\n pass\n\n def run(self):\n entries = \"\\n\".join([f' \"{k}\": \"{v}\",' for k, v in deps.items()])\n content = [\n \"# THIS FILE HAS BEEN AUTOGENERATED. To update:\",\n \"# 1. modify the `_deps` dict in setup.py\",\n \"# 2. run `make deps_table_update``\",\n \"deps = {\",\n entries,\n \"}\",\n \"\",\n ]\n target = \"src/controlnet_aux/dependency_versions_table.py\"\n print(f\"updating {target}\")\n with open(target, \"w\", encoding=\"utf-8\", newline=\"\\n\") as f:\n f.write(\"\\n\".join(content))\n\n\nextras = {}\n\ninstall_requires = [\n deps[\"torch\"],\n deps[\"importlib_metadata\"],\n deps[\"huggingface_hub\"],\n deps[\"scipy\"],\n deps[\"opencv-python-headless\"],\n deps[\"filelock\"],\n deps[\"numpy\"],\n deps[\"Pillow\"],\n deps[\"einops\"],\n deps[\"torchvision\"],\n deps[\"timm\"],\n deps[\"scikit-image\"],\n]\n\nsetup(\n name=\"controlnet_aux\",\n version=\"0.0.9\", # expected format is one of x.y.z.dev0, or x.y.z.rc1 or x.y.z (no to dashes, yes to dots)\n description=\"Auxillary models for controlnet\",\n long_description=open(\"README.md\", \"r\", encoding=\"utf-8\").read(),\n long_description_content_type=\"text/markdown\",\n keywords=\"deep learning\",\n license=\"Apache\",\n author=\"The HuggingFace team\",\n author_email=\"[email protected]\",\n url=\"https://github.com/patrickvonplaten/controlnet_aux\",\n package_dir={\"\": \"src\"},\n packages=find_packages(\"src\"),\n include_package_data=True,\n python_requires=\">=3.7.0\",\n install_requires=install_requires,\n extras_require=extras,\n classifiers=[\n \"Development Status :: 5 - Production/Stable\",\n \"Intended Audience :: Developers\",\n \"Intended Audience :: Education\",\n \"Intended Audience :: Science/Research\",\n \"License :: OSI Approved :: Apache Software License\",\n \"Operating System :: OS Independent\",\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.7\",\n \"Programming Language :: Python :: 3.8\",\n \"Programming Language :: Python :: 3.9\",\n \"Topic :: Scientific/Engineering :: Artificial Intelligence\",\n ],\n cmdclass={\"deps_table_update\": DepsTableUpdateCommand},\n package_data={'controlnet_aux' : ['zoe/zoedepth/models/zoedepth/*.json', 'zoe/zoedepth/models/zoedepth_nk/*.json']}\n)\n\n# Release checklist\n# 1. Change the version in __init__.py and setup.py.\n# 2. Commit these changes with the message: \"Release: Release\"\n# 3. Add a tag in git to mark the release: \"git tag RELEASE -m 'Adds tag RELEASE for pypi' \"\n# Push the tag to git: git push --tags origin main\n# 4. Run the following commands in the top-level directory:\n# python setup.py bdist_wheel\n# python setup.py sdist\n# 5. Upload the package to the pypi test server first:\n# twine upload dist/* -r pypitest\n# twine upload dist/* -r pypitest --repository-url=https://test.pypi.org/legacy/\n# 6. Check that you can install it in a virtualenv by running:\n# pip install -i https://testpypi.python.org/pypi diffusers\n# diffusers env\n# diffusers test\n# 7. Upload the final version to actual pypi:\n# twine upload dist/* -r pypi\n# 8. Add release notes to the tag in github once everything is looking hunky-dory.\n# 9. Update the version in __init__.py, setup.py to the new version \"-dev\" and push to master\n", ".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", "src\\controlnet_aux\\normalbae\\nets\\submodules\\efficientnet_repo\\requirements.txt": "torch>=1.2.0\ntorchvision>=0.4.0\n", "src\\controlnet_aux\\normalbae\\nets\\submodules\\efficientnet_repo\\setup.py": "\"\"\" Setup\n\"\"\"\nfrom setuptools import setup, find_packages\nfrom codecs import open\nfrom os import path\n\nhere = path.abspath(path.dirname(__file__))\n\n# Get the long description from the README file\nwith open(path.join(here, 'README.md'), encoding='utf-8') as f:\n long_description = f.read()\n\nexec(open('geffnet/version.py').read())\nsetup(\n name='geffnet',\n version=__version__,\n description='(Generic) EfficientNets for PyTorch',\n long_description=long_description,\n long_description_content_type='text/markdown',\n url='https://github.com/rwightman/gen-efficientnet-pytorch',\n author='Ross Wightman',\n author_email='[email protected]',\n classifiers=[\n # How mature is this project? Common values are\n # 3 - Alpha\n # 4 - Beta\n # 5 - Production/Stable\n 'Development Status :: 3 - Alpha',\n 'Intended Audience :: Education',\n 'Intended Audience :: Science/Research',\n 'License :: OSI Approved :: Apache Software License',\n 'Programming Language :: Python :: 3.6',\n 'Programming Language :: Python :: 3.7',\n 'Programming Language :: Python :: 3.8',\n 'Topic :: Scientific/Engineering',\n 'Topic :: Scientific/Engineering :: Artificial Intelligence',\n 'Topic :: Software Development',\n 'Topic :: Software Development :: Libraries',\n 'Topic :: Software Development :: Libraries :: Python Modules',\n ],\n\n # Note that this is a string of words separated by whitespace, not a list.\n keywords='pytorch pretrained models efficientnet mixnet mobilenetv3 mnasnet',\n packages=find_packages(exclude=['data']),\n install_requires=['torch >= 1.4', 'torchvision'],\n python_requires='>=3.6',\n)\n"} | null |
coreml-examples | {"type": "directory", "name": "coreml-examples", "children": [{"type": "directory", "name": "depth-anything-example", "children": [{"type": "directory", "name": "Common", "children": [{"type": "file", "name": "CoreImageExtensions.swift"}]}, {"type": "directory", "name": "DepthApp", "children": [{"type": "directory", "name": "Assets.xcassets", "children": [{"type": "directory", "name": "AccentColor.colorset", "children": [{"type": "file", "name": "Contents.json"}]}, {"type": "directory", "name": "AppIcon.appiconset", "children": [{"type": "file", "name": "Contents.json"}]}, {"type": "file", "name": "Contents.json"}]}, {"type": "file", "name": "Camera.swift"}, {"type": "file", "name": "CameraView.swift"}, {"type": "file", "name": "DataModel.swift"}, {"type": "file", "name": "DepthApp.entitlements"}, {"type": "file", "name": "DepthApp.swift"}, {"type": "file", "name": "DepthView.swift"}, {"type": "directory", "name": "models", "children": [{"type": "file", "name": ".keep"}]}, {"type": "directory", "name": "Preview Content", "children": [{"type": "directory", "name": "Preview Assets.xcassets", "children": [{"type": "file", "name": "Contents.json"}]}]}, {"type": "file", "name": "ViewfinderView.swift"}]}, {"type": "directory", "name": "DepthCLI", "children": [{"type": "file", "name": "MainCommand.swift"}]}, {"type": "file", "name": "README.md"}]}, {"type": "directory", "name": "FastViTSample", "children": [{"type": "directory", "name": "FastViTSample", "children": [{"type": "directory", "name": "Assets.xcassets", "children": [{"type": "directory", "name": "AccentColor.colorset", "children": [{"type": "file", "name": "Contents.json"}]}, {"type": "directory", "name": "AppIcon.appiconset", "children": [{"type": "file", "name": "Contents.json"}]}, {"type": "file", "name": "Contents.json"}]}, {"type": "file", "name": "Camera.swift"}, {"type": "file", "name": "CameraView.swift"}, {"type": "file", "name": "CoreImageExtensions.swift"}, {"type": "file", "name": "DataModel.swift"}, {"type": "file", "name": "FastViTApp.swift"}, {"type": "file", "name": "FastViTSample.entitlements"}, {"type": "directory", "name": "models", "children": [{"type": "file", "name": ".keep"}]}, {"type": "directory", "name": "Preview Content", "children": [{"type": "directory", "name": "Preview Assets.xcassets", "children": [{"type": "file", "name": "Contents.json"}]}]}, {"type": "file", "name": "ViewfinderView.swift"}]}, {"type": "file", "name": "README.md"}]}, {"type": "file", "name": "LICENSE"}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "SemanticSegmentationSample", "children": [{"type": "directory", "name": "Common", "children": [{"type": "file", "name": "CoreImageExtensions.swift"}, {"type": "file", "name": "PostProcessing.swift"}, {"type": "file", "name": "SemanticMapToColor.metal"}, {"type": "file", "name": "SemanticMapToImage.swift"}]}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "SemanticSegmentationCLI", "children": [{"type": "file", "name": "MainCommand.swift"}]}, {"type": "directory", "name": "SemanticSegmentationSample", "children": [{"type": "directory", "name": "Assets.xcassets", "children": [{"type": "directory", "name": "AccentColor.colorset", "children": [{"type": "file", "name": "Contents.json"}]}, {"type": "directory", "name": "AppIcon.appiconset", "children": [{"type": "file", "name": "Contents.json"}]}, {"type": "file", "name": "Contents.json"}]}, {"type": "file", "name": "Camera.swift"}, {"type": "file", "name": "CameraView.swift"}, {"type": "file", "name": "DataModel.swift"}, {"type": "directory", "name": "Preview Content", "children": [{"type": "directory", "name": "Preview Assets.xcassets", "children": [{"type": "file", "name": "Contents.json"}]}]}, {"type": "file", "name": "SegmentationView.swift"}, {"type": "file", "name": "SemanticSegmentationSample.entitlements"}, {"type": "file", "name": "SemanticSegmentationSampleApp.swift"}, {"type": "file", "name": "ViewfinderView.swift"}]}]}, {"type": "directory", "name": "tutorials", "children": [{"type": "file", "name": "depth-anything-coreml-guide.ipynb"}, {"type": "directory", "name": "images", "children": []}]}]} | # Semantic Segmentation Sample with DETR
This sample demonstrates the use of [DETR](https://huggingface.co/facebook/detr-resnet-50) converted to Core ML. It allows semantic segmentation on iOS devices, where each pixel in an image is classified according to the most probable category it belongs to.
We leverage [coremltools](https://github.com/apple/coremltools) for model conversion and compression. You can read more about it [here](https://apple.github.io/coremltools/docs-guides/source/opt-palettization-api.html).
## Instructions
1. [Download DETRResnet50SemanticSegmentationF16.mlpackage](#download) from the Hugging Face Hub and place it inside the `models` folder of the project.
2. Open `SemanticSegmentationSample.xcodeproj` in Xcode.
3. Build & run the project!
DEtection TRansformer (DETR) was introduced in the paper [End-to-End Object Detection with Transformers](https://arxiv.org/abs/2005.12872) by Carion et al. and first released in [this repository](https://github.com/facebookresearch/detr).
## Download
Core ML packages are available in [apple/coreml-detr-semantic-segmentation](https://huggingface.co/apple/coreml-detr-semantic-segmentation).
Install `huggingface-cli`
```bash
brew install huggingface-cli
```
Download `DETRResnet50SemanticSegmentationF16.mlpackage` to the `models` directory:
```bash
huggingface-cli download \
--local-dir models --local-dir-use-symlinks False \
apple/coreml-detr-semantic-segmentation \
--include "DETRResnet50SemanticSegmentationF16.mlpackage/*"
```
To download all the model versions, including quantized ones, skip the `--include` argument.
| {".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 fa8aae50fc09f4b0fe9a742c4988d6896997b17c Hamza Amin <[email protected]> 1727369197 +0500\tclone: from https://github.com/huggingface/coreml-examples.git\n", ".git\\refs\\heads\\main": "fa8aae50fc09f4b0fe9a742c4988d6896997b17c\n", "depth-anything-example\\DepthApp\\DepthApp.entitlements": "<?xml version=\"1.0\" encoding=\"UTF-8\"?>\n<!DOCTYPE plist PUBLIC \"-//Apple//DTD PLIST 1.0//EN\" \"http://www.apple.com/DTDs/PropertyList-1.0.dtd\">\n<plist version=\"1.0\">\n<dict>\n\t<key>com.apple.security.app-sandbox</key>\n\t<true/>\n\t<key>com.apple.security.device.camera</key>\n\t<true/>\n\t<key>com.apple.security.files.user-selected.read-only</key>\n\t<true/>\n</dict>\n</plist>\n", "depth-anything-example\\DepthApp\\DepthApp.swift": "import SwiftUI\n\n@main\nstruct CameraApp: App {\n init() {\n UINavigationBar.applyCustomAppearance()\n }\n\n var body: some Scene {\n WindowGroup {\n CameraView()\n }\n }\n}\n\nfileprivate extension UINavigationBar {\n static func applyCustomAppearance() {\n let appearance = UINavigationBarAppearance()\n appearance.backgroundEffect = UIBlurEffect(style: .systemUltraThinMaterial)\n UINavigationBar.appearance().standardAppearance = appearance\n UINavigationBar.appearance().compactAppearance = appearance\n UINavigationBar.appearance().scrollEdgeAppearance = appearance\n }\n}\n", "depth-anything-example\\DepthCLI\\MainCommand.swift": "import ArgumentParser\nimport CoreImage\nimport CoreML\nimport ImageIO\nimport UniformTypeIdentifiers\n\nlet targetSize = CGSize(width: 686, height: 518)\nlet context = CIContext()\n\n@main\nstruct MainCommand: AsyncParsableCommand {\n static let configuration = CommandConfiguration(\n commandName: \"depth\",\n abstract: \"Performs depth estimation on an image.\"\n )\n\n @Option(name: .shortAndLong, help: \"Depth model package file.\")\n var model: String\n\n @Option(name: .shortAndLong, help: \"The input image file.\")\n var input: String\n\n @Option(name: .shortAndLong, help: \"The output image file.\")\n var output: String\n\n mutating func run() async throws {\n // Compile and load the model\n let config = MLModelConfiguration()\n config.computeUnits = .cpuAndGPU\n let compiledURL = try await MLModel.compileModel(at: URL(filePath: model))\n let model = try MLModel(contentsOf: compiledURL, configuration: config)\n\n // Load the input image\n guard let inputImage = CIImage(contentsOf: URL(filePath: input)) else {\n print(\"Failed to load image.\")\n throw ExitCode(EXIT_FAILURE)\n }\n print(\"Original image size \\(inputImage.extent)\")\n\n // Resize the image to match the model's expected input\n let resizedImage = inputImage.resized(to: targetSize)\n\n // Convert to a pixel buffer\n guard let pixelBuffer = context.render(resizedImage, pixelFormat: kCVPixelFormatType_32ARGB) else {\n print(\"Failed to create a pixel buffer.\")\n throw ExitCode(EXIT_FAILURE)\n }\n\n // Execute the model\n let clock = ContinuousClock()\n let start = clock.now\n let featureProvider = try MLDictionaryFeatureProvider(dictionary: [\"image\": pixelBuffer])\n let result = try await model.prediction(from: featureProvider)\n guard let outputPixelBuffer = result.featureValue(for: \"depth\")?.imageBufferValue else {\n print(\"The model did not return a 'depth' feature with an image.\")\n throw ExitCode(EXIT_FAILURE)\n }\n let duration = clock.now - start\n print(\"Model inference took \\(duration.formatted(.units(allowed: [.seconds, .milliseconds])))\")\n\n // Undo the scale to match the original image size\n var outputImage = CIImage(cvPixelBuffer: outputPixelBuffer)\n outputImage = outputImage.resized(to: CGSize(width: inputImage.extent.width, height: inputImage.extent.height))\n\n // Save the depth image\n context.writePNG(outputImage, to: URL(filePath: output))\n }\n}\n", "depth-anything-example\\DepthSample.xcodeproj\\xcshareddata\\xcschemes\\DepthApp.xcscheme": "<?xml version=\"1.0\" encoding=\"UTF-8\"?>\n<Scheme\n LastUpgradeVersion = \"1600\"\n version = \"1.7\">\n <BuildAction\n parallelizeBuildables = \"YES\"\n buildImplicitDependencies = \"YES\"\n buildArchitectures = \"Automatic\">\n <BuildActionEntries>\n <BuildActionEntry\n buildForTesting = \"YES\"\n buildForRunning = \"YES\"\n buildForProfiling = \"YES\"\n buildForArchiving = \"YES\"\n buildForAnalyzing = \"YES\">\n <BuildableReference\n BuildableIdentifier = \"primary\"\n BlueprintIdentifier = \"D8C8947C2BE931A10043DB71\"\n BuildableName = \"DepthApp.app\"\n BlueprintName = \"DepthApp\"\n ReferencedContainer = \"container:DepthSample.xcodeproj\">\n </BuildableReference>\n </BuildActionEntry>\n </BuildActionEntries>\n </BuildAction>\n <TestAction\n buildConfiguration = \"Debug\"\n selectedDebuggerIdentifier = \"Xcode.DebuggerFoundation.Debugger.LLDB\"\n selectedLauncherIdentifier = \"Xcode.DebuggerFoundation.Launcher.LLDB\"\n shouldUseLaunchSchemeArgsEnv = \"YES\"\n shouldAutocreateTestPlan = \"YES\">\n </TestAction>\n <LaunchAction\n buildConfiguration = \"Debug\"\n selectedDebuggerIdentifier = \"Xcode.DebuggerFoundation.Debugger.LLDB\"\n selectedLauncherIdentifier = \"Xcode.DebuggerFoundation.Launcher.LLDB\"\n launchStyle = \"0\"\n useCustomWorkingDirectory = \"NO\"\n ignoresPersistentStateOnLaunch = \"NO\"\n debugDocumentVersioning = \"YES\"\n debugServiceExtension = \"internal\"\n allowLocationSimulation = \"YES\">\n <BuildableProductRunnable\n runnableDebuggingMode = \"0\">\n <BuildableReference\n BuildableIdentifier = \"primary\"\n BlueprintIdentifier = \"D8C8947C2BE931A10043DB71\"\n BuildableName = \"DepthApp.app\"\n BlueprintName = \"DepthApp\"\n ReferencedContainer = \"container:DepthSample.xcodeproj\">\n </BuildableReference>\n </BuildableProductRunnable>\n </LaunchAction>\n <ProfileAction\n buildConfiguration = \"Release\"\n shouldUseLaunchSchemeArgsEnv = \"YES\"\n savedToolIdentifier = \"\"\n useCustomWorkingDirectory = \"NO\"\n debugDocumentVersioning = \"YES\">\n <BuildableProductRunnable\n runnableDebuggingMode = \"0\">\n <BuildableReference\n BuildableIdentifier = \"primary\"\n BlueprintIdentifier = \"D8C8947C2BE931A10043DB71\"\n BuildableName = \"DepthApp.app\"\n BlueprintName = \"DepthApp\"\n ReferencedContainer = \"container:DepthSample.xcodeproj\">\n </BuildableReference>\n </BuildableProductRunnable>\n </ProfileAction>\n <AnalyzeAction\n buildConfiguration = \"Debug\">\n </AnalyzeAction>\n <ArchiveAction\n buildConfiguration = \"Release\"\n revealArchiveInOrganizer = \"YES\">\n </ArchiveAction>\n <InstallAction\n buildConfiguration = \"Release\">\n </InstallAction>\n</Scheme>\n", "FastViTSample\\FastViTSample\\FastViTApp.swift": "import SwiftUI\n\n@main\nstruct CameraApp: App {\n init() {\n UINavigationBar.applyCustomAppearance()\n }\n\n var body: some Scene {\n WindowGroup {\n CameraView()\n }\n }\n}\n\nfileprivate extension UINavigationBar {\n static func applyCustomAppearance() {\n let appearance = UINavigationBarAppearance()\n appearance.backgroundEffect = UIBlurEffect(style: .systemUltraThinMaterial)\n UINavigationBar.appearance().standardAppearance = appearance\n UINavigationBar.appearance().compactAppearance = appearance\n UINavigationBar.appearance().scrollEdgeAppearance = appearance\n }\n}\n", "SemanticSegmentationSample\\SemanticSegmentationCLI\\MainCommand.swift": "import ArgumentParser\nimport CoreImage\nimport CoreML\nimport ImageIO\nimport UniformTypeIdentifiers\n\nlet targetSize = CGSize(width: 448, height: 448)\nlet context = CIContext()\n\n@main\nstruct MainCommand: AsyncParsableCommand {\n static let configuration = CommandConfiguration(\n commandName: \"semantic\",\n abstract: \"Performs semantic segmentation on an image.\"\n )\n\n @Option(name: .shortAndLong, help: \"Semantic segmentation model package file.\")\n var model: String\n\n @Option(name: .shortAndLong, help: \"The input image file.\")\n var input: String\n\n @Option(name: .shortAndLong, help: \"The output PNG image file, showing the segmentation map overlaid on top of the original image.\")\n var output: String\n \n @Option(name: [.long, .customShort(\"k\")], help: \"The output file name for the segmentation mask.\")\n var mask: String? = nil\n\n mutating func run() async throws {\n // Compile and load the model\n let config = MLModelConfiguration()\n config.computeUnits = .cpuAndGPU\n let compiledURL = try await MLModel.compileModel(at: URL(filePath: model))\n let model = try MLModel(contentsOf: compiledURL, configuration: config)\n let postProcessor = try DETRPostProcessor(model: model)\n\n // Load the input image\n guard let inputImage = CIImage(contentsOf: URL(filePath: input)) else {\n print(\"Failed to load image.\")\n throw ExitCode(EXIT_FAILURE)\n }\n print(\"Original image size \\(inputImage.extent)\")\n\n // Resize the image to match the model's expected input\n let resizedImage = inputImage.resized(to: targetSize)\n\n // Convert to a pixel buffer\n guard let pixelBuffer = context.render(resizedImage, pixelFormat: kCVPixelFormatType_32ARGB) else {\n print(\"Failed to create pixel buffer for input image.\")\n throw ExitCode(EXIT_FAILURE)\n }\n\n // Execute the model\n let clock = ContinuousClock()\n let start = clock.now\n let featureProvider = try MLDictionaryFeatureProvider(dictionary: [\"image\": pixelBuffer])\n let result = try await model.prediction(from: featureProvider)\n guard let semanticPredictions = result.featureValue(for: \"semanticPredictions\")?.shapedArrayValue(of: Int32.self) else {\n print(\"The model did not return a 'semanticPredictions' output feature.\")\n throw ExitCode(EXIT_FAILURE)\n }\n let duration = clock.now - start\n print(\"Model inference took \\(duration.formatted(.units(allowed: [.seconds, .milliseconds])))\")\n\n guard let semanticImage = try? postProcessor.semanticImage(semanticPredictions: semanticPredictions) else {\n print(\"Error post-processing semanticPredictions\")\n throw ExitCode(EXIT_FAILURE)\n }\n\n // Undo the scale to match the original image size\n // TODO: Bilinear?\n let outputImage = semanticImage.resized(to: CGSize(width: inputImage.extent.width, height: inputImage.extent.height))\n // Save mask if we need to\n if let mask = mask {\n context.writePNG(outputImage, to: URL(filePath: mask))\n }\n\n // Display mask over original\n guard let outputImage = outputImage.withAlpha(0.5)?.composited(over: inputImage) else {\n print(\"Failed to blend mask.\")\n throw ExitCode(EXIT_FAILURE)\n }\n context.writePNG(outputImage, to: URL(filePath: output))\n }\n}\n", "SemanticSegmentationSample\\SemanticSegmentationSample\\SemanticSegmentationSampleApp.swift": "import SwiftUI\n\n@main\nstruct CameraApp: App {\n init() {\n UINavigationBar.applyCustomAppearance()\n }\n\n var body: some Scene {\n WindowGroup {\n CameraView()\n }\n }\n}\n\nfileprivate extension UINavigationBar {\n static func applyCustomAppearance() {\n let appearance = UINavigationBarAppearance()\n appearance.backgroundEffect = UIBlurEffect(style: .systemUltraThinMaterial)\n UINavigationBar.appearance().standardAppearance = appearance\n UINavigationBar.appearance().compactAppearance = appearance\n UINavigationBar.appearance().scrollEdgeAppearance = appearance\n }\n}\n"} | null |
cosmopedia | {"type": "directory", "name": "cosmopedia", "children": [{"type": "directory", "name": "classification", "children": [{"type": "file", "name": "README.md"}, {"type": "file", "name": "run_edu_bert.py"}, {"type": "file", "name": "run_edu_bert.slurm"}, {"type": "file", "name": "train_edu_bert.py"}, {"type": "file", "name": "train_edu_bert.slurm"}]}, {"type": "directory", "name": "decontamination", "children": [{"type": "file", "name": "decontaminate.py"}, {"type": "file", "name": "README.md"}]}, {"type": "directory", "name": "deduplication", "children": [{"type": "file", "name": "deduplicate_dataset.py"}, {"type": "file", "name": "README.md"}]}, {"type": "directory", "name": "evaluation", "children": [{"type": "file", "name": "eval.slurm"}, {"type": "file", "name": "lighteval_tasks.py"}, {"type": "file", "name": "README.md"}]}, {"type": "directory", "name": "fulltext_search", "children": [{"type": "file", "name": "index_docs.py"}, {"type": "file", "name": "index_docs.slurm"}, {"type": "file", "name": "manticore.conf"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "search_sharded.py"}, {"type": "file", "name": "search_sharded.slurm"}]}, {"type": "directory", "name": "generation", "children": [{"type": "file", "name": "boilerplate_cleanup.py"}, {"type": "file", "name": "llm_swarm_script.py"}, {"type": "file", "name": "README.md"}]}, {"type": "file", "name": "LICENSE"}, {"type": "directory", "name": "plots", "children": []}, {"type": "directory", "name": "prompts", "children": [{"type": "directory", "name": "auto_math_text", "children": [{"type": "file", "name": "build_science_prompts.py"}, {"type": "file", "name": "README.md"}]}, {"type": "directory", "name": "khanacademy", "children": [{"type": "file", "name": "generate_textbooks.py"}, {"type": "directory", "name": "khan_dl", "children": [{"type": "file", "name": "khan_dl.py"}, {"type": "file", "name": "main.py"}, {"type": "file", "name": "requirements.txt"}]}, {"type": "file", "name": "README.md"}]}, {"type": "directory", "name": "openstax", "children": [{"type": "file", "name": "build_openstax_prompts.py"}, {"type": "file", "name": "README.md"}]}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "stanford", "children": [{"type": "file", "name": "1_scraper.ipynb"}, {"type": "file", "name": "2_generate_course_outlines.ipynb"}, {"type": "file", "name": "README.md"}]}, {"type": "directory", "name": "stories", "children": [{"type": "file", "name": "build_openhermes_stories_prompts.py"}, {"type": "file", "name": "build_ultrachat_stories_prompts.py"}, {"type": "file", "name": "filter_openhermes.py"}, {"type": "file", "name": "README.md"}]}, {"type": "directory", "name": "web_samples", "children": [{"type": "file", "name": "build_web_prompts.py"}, {"type": "file", "name": "filter_and_classify_clusters.py"}, {"type": "file", "name": "README.md"}]}, {"type": "directory", "name": "wikihow", "children": [{"type": "file", "name": "README.md"}, {"type": "file", "name": "wikihowcom-20231012-titles.txt"}]}]}, {"type": "file", "name": "README.md"}]} | # Synthetic WikiHow articles from scraped WikiHow titles
You can find the list fo WikiHow titles we scraped in `wikihowcom-20231012-titles.txt`.
An updated list of wikihow titles can be extracted using https://github.com/mediawiki-client-tools/mediawiki-dump-generator
[TODO] Add code for updated prompts of Cosmopedia | {".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 6d646fbedc372cd51958af6d9781a5bad7ce4b4c Hamza Amin <[email protected]> 1727369068 +0500\tclone: from https://github.com/huggingface/cosmopedia.git\n", ".git\\refs\\heads\\main": "6d646fbedc372cd51958af6d9781a5bad7ce4b4c\n", "fulltext_search\\index_docs.py": "import json\nimport time\nimport sys\nimport random\n\nimport requests\nfrom datasets import load_dataset\n\n\ndef insert_batch(batch):\n ndjson = \"\"\n\n index_name = f\"fineweb{random.randint(0, 63)}\"\n\n for text, _id, url, language_score, token_count in zip(\n batch[\"text\"],\n batch[\"id\"],\n batch[\"url\"],\n batch[\"language_score\"],\n batch[\"token_count\"],\n ):\n doc = {\n \"insert\": {\n \"index\": index_name,\n \"_id\": _id.split(\":\")[-1].strip(\">\"),\n \"doc\": {\n \"content\": text,\n \"fw_id\": _id.split(\":\")[-1].strip(\">\"),\n \"url\": url,\n \"language_score\": language_score,\n \"token_count\": token_count,\n },\n }\n }\n ndjson += json.dumps(doc) + \"\\n\"\n\n response = None\n while response is None:\n try:\n response = requests.post(\n \"http://127.0.0.1:9308/bulk\",\n headers={\"Content-Type\": \"application/x-ndjson\"},\n data=ndjson,\n )\n except requests.exceptions.ConnectionError as e:\n print(e, file=sys.stderr)\n time.sleep(1)\n pass\n\n return {\"response\": [response.status_code]}\n\n\ndef main():\n sql_url = \"http://127.0.0.1:9308/sql?mode=raw\"\n\n print(\"Removing table\", file=sys.stderr)\n while True:\n try:\n requests.post(sql_url, data={\"query\": \"drop table if exists fineweb\"})\n break\n except requests.exceptions.ConnectionError as e:\n print(e, file=sys.stderr)\n time.sleep(5)\n pass\n\n print(\"Creating table\", file=sys.stderr)\n for i in range(64):\n response = requests.post(\n sql_url, data={\"query\": f\"drop table if exists fineweb{i}\"}\n )\n print(response.text, file=sys.stderr)\n local_query = f\"create table fineweb{i}(content text, fw_id string, url string, language_score float, token_count int) charset_table='non_cjk' stopwords='en' morphology='stem_en'\"\n response = requests.post(sql_url, data={\"query\": local_query})\n print(response.text, file=sys.stderr)\n\n distributed_query = \"create table fineweb type='distributed'\"\n for i in range(64):\n distributed_query += f\" local='fineweb{i}'\"\n response = requests.post(sql_url, data={\"query\": distributed_query})\n print(response.text, file=sys.stderr)\n\n for dump in [\"CC-MAIN-2024-10\", \"CC-MAIN-2023-50\"]:\n print(\"Loading dataset\", file=sys.stderr)\n dataset = load_dataset(\n \"HuggingFaceFW/fineweb\",\n dump,\n split=\"train\",\n num_proc=64,\n cache_dir=\"/scratch/cosmo/.cache\",\n )\n dataset = dataset.select_columns(\n [\"text\", \"id\", \"url\", \"language_score\", \"token_count\"]\n )\n dataset = dataset.map(\n insert_batch,\n batched=True,\n batch_size=10000,\n remove_columns=[\"text\", \"id\", \"url\", \"language_score\", \"token_count\"],\n num_proc=64,\n )\n for _ in dataset:\n pass\n\n time.sleep(30)\n for i in range(64):\n print(f\"Optimizing table fineweb{i}\", file=sys.stderr)\n response = requests.post(\n sql_url,\n data={\"query\": f\"FLUSH TABLE fineweb{i}\"},\n timeout=600,\n )\n print(response.text, file=sys.stderr)\n response = requests.post(\n sql_url,\n data={\"query\": f\"OPTIMIZE TABLE fineweb{i} OPTION cutoff=16, sync=1\"},\n timeout=600,\n )\n print(response.text, file=sys.stderr)\n response = requests.post(\n sql_url,\n data={\"query\": f\"FREEZE fineweb{i}\"},\n timeout=600,\n )\n print(response.text, file=sys.stderr)\n\n response = requests.post(\n \"http://127.0.0.1:9308/search\",\n data='{\"index\":\"fineweb\",\"query\":{\"match\":{\"*\":\"hello world\"}}}',\n )\n print(response.text, file=sys.stderr)\n\n # print(\"Backing up the index\", file=sys.stderr)\n # time.sleep(30)\n # response = requests.post(\n # sql_url,\n # data={\"query\": \"BACKUP TO /tmp/backups\"},\n # )\n # print(response.text, file=sys.stderr)\n\n\nif __name__ == \"__main__\":\n main()\n", "fulltext_search\\index_docs.slurm": "#!/bin/bash\n#SBATCH --job-name=index_fineweb\n#SBATCH --partition hopper-prod\n#SBATCH --nodes=1\n#SBATCH --ntasks-per-node=1\n#SBATCH --cpus-per-task=96\n#SBATCH --mem-per-cpu=20G\n#SBATCH -o %x_%j.out\n#SBATCH -e %x_%j.err\n#SBATCH --time=7-00:00:00\n\nset -x -e\nsource ~/.bashrc\nsource \"$CONDA_PREFIX/etc/profile.d/conda.sh\"\nsource activate pyspark\n\nulimit -n 99999\n\nmkdir -p /scratch/cosmo/manticore_idx\nrm -rf /scratch/cosmo/manticore_idx/*\nsrun --container-image='manticoresearch/manticore:6.2.12' \\\n --container-env=EXTRA=1 \\\n --container-mounts=\"/scratch/cosmo/manticore_idx:/var/lib/manticore:z,$(pwd)/manticore.conf:/etc/manticoresearch/manticore.conf\" \\\n --no-container-mount-home \\\n --qos high \\\n /bin/bash -c 'mkdir -p /var/run/manticore && chown manticore:manticore /var/run/manticore && mkdir -p /var/run/mysqld && chown manticore:manticore /var/run/mysqld && export EXTRA=1 && source /entrypoint.sh && docker_setup_env && /entrypoint.sh searchd -c /etc/manticoresearch/manticore.conf --nodetach' &\n\npython index_docs.py\n\nsleep 1000\n\nrclone copy -P --transfers 32 /scratch/cosmo/manticore_idx/ s3:cosmopedia-data/manticore_idx/CC-MAIN-2024-10-2023-50/\n\nsleep 1000000000", "prompts\\khanacademy\\khan_dl\\main.py": "# Adapted from https://github.com/rand-net/khan-dl\n\nimport json\nimport logging.handlers\n\nfrom tqdm import tqdm\n\nfrom khan_dl import *\nimport argparse\nimport sys\nfrom art import tprint\n\n__version__ = \"1.2.8\"\n\n\ndef set_log_level(args):\n if not args.verbose:\n logging.basicConfig(level=logging.ERROR)\n elif int(args.verbose) == 1:\n logging.basicConfig(level=logging.WARNING)\n elif int(args.verbose) == 2:\n logging.basicConfig(level=logging.INFO)\n elif int(args.verbose) >= 3:\n logging.basicConfig(level=logging.DEBUG)\n\n\ndef main(argv=None):\n argv = sys.argv if argv is None else argv\n argparser = argparse.ArgumentParser()\n argparser.add_argument(\n \"-i\",\n \"--interactive\",\n help=\"Enter Interactive Course Selection Mode\",\n dest=\"interactive_prompt\",\n action=\"store_true\",\n )\n argparser.add_argument(\n \"-c\",\n \"--course_url\",\n help=\"Enter Course URL\",\n )\n\n argparser.add_argument(\n \"-a\",\n \"--all\",\n help=\"Download all Courses from all Domains\",\n action=\"store_true\",\n )\n\n argparser.add_argument(\n \"-v\",\n \"--verbose\",\n help=\"Verbose Levels of log. 1 = Warning; 2 = Info; 3 = Debug\",\n )\n\n args = argparser.parse_args()\n\n if args.interactive_prompt:\n set_log_level(args)\n tprint(\"KHAN-DL\")\n khan_down = KhanDL()\n khan_down.download_course_interactive()\n\n elif args.course_url:\n set_log_level(args)\n tprint(\"KHAN-DL\")\n print(\"Looking up \" + args.course_url + \"...\")\n selected_course_url = args.course_url\n khan_down = KhanDL()\n khan_down.download_course_given(selected_course_url)\n\n elif args.all:\n set_log_level(args)\n tprint(\"KHAN-DL\")\n khan_down = KhanDL()\n all_course_urls = khan_down.get_all_courses()\n courses = [khan_down.download_course_given(course_url) for course_url in tqdm(all_course_urls)]\n with open(\"khan_courses.json\", \"w\") as outfile:\n outfile.write(json.dumps(courses, indent=4))\n\n\nif __name__ == \"__main__\":\n main()\n", "prompts\\khanacademy\\khan_dl\\requirements.txt": "art==5.5\nbeautifulsoup4==4.11.1\ncertifi==2021.10.8\ncharset-normalizer==2.0.12\nidna==3.3\nlxml==4.8.0\nprompt-toolkit==3.0.29\nrequests==2.27.1\nsoupsieve==2.3.2.post1\nurllib3==1.26.9\nwcwidth==0.2.5\nyt-dlp==2022.5.18\ntqdm>=4.66.2"} | null |
data-is-better-together | {"type": "directory", "name": "data-is-better-together", "children": [{"type": "directory", "name": "community-efforts", "children": [{"type": "directory", "name": "prompt_ranking", "children": [{"type": "directory", "name": "assets", "children": []}, {"type": "file", "name": "README.md"}]}, {"type": "directory", "name": "prompt_translation", "children": [{"type": "file", "name": "01_setup_prompt_translation_space.ipynb"}, {"type": "file", "name": "02_upload_prompt_translation_data.ipynb"}, {"type": "file", "name": "03_create_dashboard.ipynb"}, {"type": "directory", "name": "dashboard_template", "children": [{"type": "file", "name": "app.py"}, {"type": "file", "name": "dumpy.py"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}]}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.in"}, {"type": "file", "name": "Translation_with_distilabel_gpt_4_turbo.ipynb"}]}]}, {"type": "directory", "name": "cookbook-efforts", "children": [{"type": "directory", "name": "domain-specific-datasets", "children": [{"type": "directory", "name": "assets", "children": []}, {"type": "directory", "name": "distilabel_pipelines", "children": [{"type": "file", "name": "domain_expert_pipeline.py"}, {"type": "file", "name": "requirements.txt"}]}, {"type": "directory", "name": "parent_app", "children": [{"type": "file", "name": "app.py"}, {"type": "file", "name": "hub.py"}, {"type": "directory", "name": "pages", "children": [{"type": "file", "name": "\ud83e\uddd1\u200d\ud83c\udf3e Domain Data Grower.py"}]}, {"type": "file", "name": "project_config.json"}, {"type": "file", "name": "seed_data.json"}]}, {"type": "directory", "name": "project_app", "children": [{"type": "directory", "name": ".streamlit", "children": [{"type": "file", "name": "config.toml"}]}, {"type": "file", "name": "app.py"}, {"type": "file", "name": "DATASET_README_BASE.md"}, {"type": "file", "name": "defaults.py"}, {"type": "file", "name": "hub.py"}, {"type": "file", "name": "infer.py"}, {"type": "directory", "name": "pages", "children": [{"type": "file", "name": "2_\ud83d\udc69\ud83c\udffc\u200d\ud83d\udd2c Describe Domain.py"}, {"type": "file", "name": "3_\ud83c\udf31 Generate Dataset.py"}, {"type": "file", "name": "4_\ud83d\udd0d Review Generated Data.py"}]}, {"type": "file", "name": "pipeline.yaml"}, {"type": "file", "name": "project_config.json"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "seed_data.json"}, {"type": "file", "name": "utils.py"}]}, {"type": "file", "name": "README.md"}]}, {"type": "directory", "name": "dpo-orpo-preference", "children": [{"type": "file", "name": "00_datasets_exploration.ipynb"}, {"type": "file", "name": "01_data_prep.ipynb"}, {"type": "file", "name": "02_load_from_argilla.ipynb"}, {"type": "directory", "name": "assets", "children": [{"type": "file", "name": "banner.webp"}]}, {"type": "file", "name": "aya_dpo_gen.py"}, {"type": "file", "name": "custom_preference_to_argilla.py"}, {"type": "directory", "name": "examples", "children": [{"type": "directory", "name": "en", "children": [{"type": "file", "name": "01_en_data_prep.ipynb"}, {"type": "file", "name": "aya_en_dpo_gen.py"}, {"type": "file", "name": "custom_preference_to_argilla.py"}]}]}, {"type": "file", "name": "instructions.md"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.in"}, {"type": "file", "name": "requirements.txt"}]}, {"type": "directory", "name": "kto-preference", "children": [{"type": "file", "name": "01_create_preference_task.ipynb"}, {"type": "directory", "name": "assets", "children": [{"type": "file", "name": "b822ac33-a10e-4da7-a36a-682b96d1fe0e.webp"}]}, {"type": "file", "name": "preference_gen.py"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.in"}, {"type": "file", "name": "requirements.txt"}]}]}, {"type": "file", "name": "README.md"}]} | <p align="center">
<img src="assets/b822ac33-a10e-4da7-a36a-682b96d1fe0e.webp" width="500px"/>
</p>
# KTO Dataset Project
The KTO Dataset Project aims to create more preference data according to the KTO format. With the provided tools, the community will be able to easily generate a KTO dataset in any language or domain they are interested in. This type of preference data is easier to collect than others like DPO, and can be used to train models to better align with human preferences. By following two simple steps, you will be able to create your KTO dataset.
## What is the goal of this project?
The goal of this project is to create more KTO datasets for different languages or domains. This will help the community to train models that better align with human preferences. The project will provide the tools and resources to easily generate a KTO dataset.
### Why do we need more KTO datasets?
<details>
<summary><strong>What is a preference dataset?</strong></summary>
Preference tuning is a step often performed when creating a chat/instruction following model with the goal of more closely aligning the model's outputs with the "human preferences" (or more accurately one set of human preferences). Often this is done through some form of reinforcement learning. Increasingly instead of having a separate reward model, we can use a preference dataset to directly train the model. Two prominent approaches to this are:
- Direct Preference Optimization (DPO)
- Kahneman-Tversky Optimisation (KTO)
We won't dive into all of the technical details here but instead focus on what the data for both of these approaches look like. The overall steps are something like this:
- Have some prompts
- Generate responses to these prompts
- Rank/rate the responses to the prompts
We'll use the example of haiku here but this could be any kind of text generation task.
</details>
<details>
<summary><strong>What is the difference between DPO vs KTO?</strong></summary>
Whilst both DPO and KTO are methods for preference tuning (and sound like things that would be shouted at the end of a street fighter level), they differ in the kinds of data they require. DPO requires a preference dataset where we have two sets of responses with one "chosen" and one "rejected". We can take a look at a screenshot from a dataset server of a DPO dataset below:

As you can see, we have one column containing "chosen" responses and another containing "rejected" responses. This is the kind of data we would need for DPO. How would we collect this data once we have our candidate haiku responses? If we want to stick to using human feedback rather than a judge LM we would need to indicate their preferences between different haiku.
There are different ways we could do this. We could ask humans to rate the haiku on a scale of 1-5, we could ask them to pick their favorite haiku from a set of 5, we could ask them to rank the haiku from best to worst etc. One disadvantage of DPO is that generating this kind of data from humans is quite cognitively demanding. It can be hard to compare two things and say which one is better and even with an optimized interface, it can be quite time-consuming. This is where KTO can provide an alternative.
In contrast to DPO, KTO doesn't require two candidate responses i.e. "chosen" and "rejected". Instead, it can rely on a simple binary preference i.e. 👍👎. This is arguably much easier for an annotator to create.
</details><br>
As we know, preference data is crucial for training models that better align with human preferences. However, collecting this DPO-formatted data can be time-consuming and expensive. This is where KTO datasets come in. KTO datasets are easier to collect than DPO datasets as they only require a prompt-response dataset with binary preference i.e. 👍👎. By creating more KTO datasets, we aim to improve our models more simply.
<details open>
<summary><strong>Why should we generate responses to prompts?</strong></summary>
We could of course collect all of our preferences data by hand i.e. we could write a prompt like: "Write a recipe for banana bread" and then write two sets of responses one which we prefer over the other. However, this is time-consuming and not scalable. Instead, we can use a model to generate responses to our prompts and then use human feedback to determine which response we prefer. In our case, we can ask different LLMs to write haiku based on a prompt and then ask humans to rate the haiku.

</details>
## How can you contribute?
As part of Data Is Better Together, we're supporting the community in generating more KTO datasets for different languages or the domains they are interested in. If you would like to help, you can follow the steps below to generate a KTO dataset. There are already many communities working together on the Hugging Face Discord server, so you can also join the server to collaborate with others on this project 🤗.
## Project Overview
Here we will walk through a simple example of how you might create a KTO dataset using synthetic data and human feedback. We will use haiku as our example but this could be any kind of text generation task.
### 1. Prerequisites
* A 🤗 Hugging Face account: We'll extensively use the Hugging Face Hub both to generate our data via hosted model APIs and to share our generated datasets. You can sign up for a Hugging Face account [here](https://huggingface.co/join).
* For the workflow we describe here, we assume you already have a dataset of prompts. This [notebook](https://github.com/davanstrien/haiku-dpo/blob/main/01_generate_haiku_prompts.ipynb) shows how you could generate a dataset of haiku prompts. This approach could be adapted to any kind of text-generation task. The [instruction generation](https://distilabel.argilla.io/latest/tutorials/create-a-math-preference-dataset/#instruction-generation) section of this Distilabel tutorial provides a good overview of how you might generate a dataset of prompts for a different kind of text generation task.
### 2. Produce generations with various open models
We will use [Distilabel](https://github.com/argilla-io/distilabel) to generate our haiku responses based on our initial prompt dataset. To generate the dataset, we will use the following models:
- [NousResearch/Nous-Hermes-2-Yi-34B](https://huggingface.co/NousResearch/Nous-Hermes-2-Yi-34B)
- [mistralai/Mistral-7B-Instruct-v0.2](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.2)
- [llama/Llama-2-70b-chat-hf](https://huggingface.co/llama/Llama-2-70b-chat-hf)
However, you could swap these out for other models depending on your goals, budget, the domain you are working in etc.
You will find the code to generate the haiku responses in [preference_gen.py](preference_gen.py).
#### Hosted Model APIs
We can use Hugging Face's free inference API to generate our haiku responses. This is a great way to get started with generating synthetic data. You can find more information on the supported models and how to use the API [here](https://huggingface.co/blog/inference-pro#supported-models).
One of our models, "NousResearch/Nous-Hermes-2-Yi-34B" is hosted using [Inference Endpoints](https://huggingface.co/inference-endpoints/dedicated) instead. In the code, this part is commented out so it should be possible to run the code without needing to set up dedicated inference endpoints.
> [!WARNING]
> If you have local GPUs available, you can also adapt this approach using other [inference frameworks](https://distilabel.argilla.io/latest/components-gallery/llms/) such as Ollama or vLLM.
#### The dataset produced
A single row from the dataset produced by this code looks like this:
```python
{
"input": "Can you compose a haiku about the serenity of mountain peaks?",
"generation_model": [
"mistralai/Mistral-7B-Instruct-v0.2",
"meta-llama/Llama-2-70b-chat-hf",
"NousResearch/Nous-Hermes-2-Yi-34B",
],
"generation_prompt": [
"<s>[INST] <<SYS>>\nYou are a poet specialising in creating Haiku. \nYour haiku consist of three lines, with five syllables in the first line, seven in the second, and five in the third.\nBeyond being technically correct, your haiku should also be beautiful and meaningful. \nYou respond only with a haiku. You do not add anything else to your responses. \n\n<</SYS>>\n\nCan you compose a haiku about the serenity of mountain peaks? [/INST]",
"<s>[INST] <<SYS>>\nYou are a poet specialising in creating Haiku. \nYour haiku consist of three lines, with five syllables in the first line, seven in the second, and five in the third.\nBeyond being technically correct, your haiku should also be beautiful and meaningful. \nYou respond only with a haiku. You do not add anything else to your responses. \n\n<</SYS>>\n\nCan you compose a haiku about the serenity of mountain peaks? [/INST]",
"<|im_start|>system\nYou are a poet specialising in creating Haiku. \nYour haiku consist of three lines, with five syllables in the first line, seven in the second, and five in the third.\nBeyond being technically correct, your haiku should also be beautiful and meaningful. \nYou respond only with a haiku. You do not add anything else to your responses. \n\n<|im_end|>\n<|im_start|>user\nCan you compose a haiku about the serenity of mountain peaks?<|im_end|>\n<|im_start|>assistant\n",
],
"raw_generation_responses": [
" Peaceful summit rests,\nSky's reflection in still lake,\nSilence whispers on.",
" Snow-capped peaks rise high\nSilent, majestic, and serene\nNature's peaceful throne",
"Mountain peaks, serene\nPeaceful silence, whispers breeze\nNature's tranquil song",
],
"generations": [
" Peaceful summit rests,\nSky's reflection in still lake,\nSilence whispers on.",
" Snow-capped peaks rise high\nSilent, majestic, and serene\nNature's peaceful throne",
"Mountain peaks, serene\nPeaceful silence, whispers breeze\nNature's tranquil song",
],
}
```
As you can hopefully see, we have a single prompt and three haiku responses. We also have the model that generated each haiku response. This kind of data could be used to generate both a DPO and KTO dataset. We will focus on KTO here.
### I'm GPU-poor, can I still get involved?
Yes! The example scripts in this repository use Hugging Face Inference Endpoints for the inference component. This means you can run the scripts on your local machine without needing a GPU. We can provide you with GPU grants to run the `distilabel` script if you need them. Please reach out to us on the Hugging Face Discord server if you need a GPU grant. **Note**: We will want to ensure that you have a plan for how you will use the GPU grant before providing it, in particular, we'll want to see that you have set up an Argilla Space for your project already and have already done some work to identify the language you want to work on and the models you want to use.
## 3. Create a preference dataset annotation Space in Argilla hosted on Spaces with HF authentication
Hugging Face Spaces offer a simple way to host ML demo apps directly on your profile or your organization’s profile. [Argilla](https://argilla.io/) is a powerful data annotation tool that is integrated strongly with Hugging Face Spaces and other parts of the Hugging Face ecosystem.

The [create_preference_task.ipynb](01_create_preference_task.ipynb) notebook shows how you could create a preference dataset annotation Argilla Space that anyone with a Hugging Face account can contribute to. This is a great way to collect human feedback on your synthetic data.
This will create a task that looks like this:

## Next steps
The current notebooks and code currently only show how to generate the synthetic data and create a preference dataset annotation Space. The next steps would be to collect human feedback on the synthetic data and then use this to train a model. We will cover this in a future notebook. | {".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 0685967b99dcd10ad124645797084b1dbcbe8bea Hamza Amin <[email protected]> 1727369160 +0500\tclone: from https://github.com/huggingface/data-is-better-together.git\n", ".git\\refs\\heads\\main": "0685967b99dcd10ad124645797084b1dbcbe8bea\n", "community-efforts\\prompt_translation\\dashboard_template\\app.py": "from apscheduler.schedulers.background import BackgroundScheduler\nimport datetime\nimport os\nfrom typing import Dict, Tuple\nfrom uuid import UUID\n\nimport altair as alt\nimport argilla as rg\nfrom argilla.feedback import FeedbackDataset\nfrom argilla.client.feedback.dataset.remote.dataset import RemoteFeedbackDataset\nfrom huggingface_hub import restart_space\nimport gradio as gr\nimport pandas as pd\n\n\"\"\"\nThis is the main file for the dashboard application. It contains the main function and the functions to obtain the data and create the charts.\nIt's designed as a template to recreate the dashboard for the prompt translation project of any language. \n\nTo create a new dashboard, you need several environment variables, that you can easily set in the HuggingFace Space that you are using to host the dashboard:\n\n- HF_TOKEN: Token with write access from your Hugging Face account: https://huggingface.co/settings/tokens\n- SOURCE_DATASET: The dataset id of the source dataset\n- SOURCE_WORKSPACE: The workspace id of the source dataset\n- TARGET_RECORDS: The number of records that you have as a target to annotate. We usually set this to 500.\n- ARGILLA_API_URL: Link to the Huggingface Space where the annotation effort is being hosted. For example, the Spanish one is https://somosnlp-dibt-prompt-translation-for-es.hf.space/\n- ARGILLA_API_KEY: The API key to access the Huggingface Space. Please, write this as a secret in the Huggingface Space configuration.\n\"\"\"\n\n# Translation of legends and titles\nANNOTATED = \"Annotations\"\nNUMBER_ANNOTATED = \"Total Annotations\"\nPENDING = \"Pending\"\n\nNUMBER_ANNOTATORS = \"Number of annotators\"\nNAME = \"Username\"\nNUMBER_ANNOTATIONS = \"Number of annotations\"\n\nCATEGORY = \"Category\"\n\n\ndef restart() -> None:\n \"\"\"\n This function restarts the space where the dashboard is hosted.\n \"\"\"\n\n # Update Space name with your Space information\n gr.Info(\"Restarting space at \" + str(datetime.datetime.now()))\n restart_space(\n \"ignacioct/TryingRestartDashboard\",\n token=os.getenv(\"HF_TOKEN\"),\n # factory_reboot=True,\n )\n\n\ndef obtain_source_target_datasets() -> (\n Tuple[\n FeedbackDataset | RemoteFeedbackDataset, FeedbackDataset | RemoteFeedbackDataset\n ]\n):\n \"\"\"\n This function returns the source and target datasets to be used in the application.\n\n Returns:\n A tuple with the source and target datasets. The source dataset is filtered by the response status 'pending'.\n\n \"\"\"\n\n # Obtain the public dataset and see how many pending records are there\n source_dataset = rg.FeedbackDataset.from_argilla(\n os.getenv(\"SOURCE_DATASET\"), workspace=os.getenv(\"SOURCE_WORKSPACE\")\n )\n filtered_source_dataset = source_dataset.filter_by(response_status=[\"pending\"])\n\n # Obtain a list of users from the private workspace\n # target_dataset = rg.FeedbackDataset.from_argilla(\n # os.getenv(\"RESULTS_DATASET\"), workspace=os.getenv(\"RESULTS_WORKSPACE\")\n # )\n\n target_dataset = source_dataset.filter_by(response_status=[\"submitted\"])\n\n return filtered_source_dataset, target_dataset\n\n\ndef get_user_annotations_dictionary(\n dataset: FeedbackDataset | RemoteFeedbackDataset,\n) -> Dict[str, int]:\n \"\"\"\n This function returns a dictionary with the username as the key and the number of annotations as the value.\n\n Args:\n dataset: The dataset to be analyzed.\n Returns:\n A dictionary with the username as the key and the number of annotations as the value.\n \"\"\"\n output = {}\n for record in dataset:\n for response in record.responses:\n if str(response.user_id) not in output.keys():\n output[str(response.user_id)] = 1\n else:\n output[str(response.user_id)] += 1\n\n # Changing the name of the keys, from the id to the username\n for key in list(output.keys()):\n output[rg.User.from_id(UUID(key)).username] = output.pop(key)\n\n return output\n\n\ndef donut_chart_total() -> alt.Chart:\n \"\"\"\n This function returns a donut chart with the progress of the total annotations.\n Counts each record that has been annotated at least once.\n\n Returns:\n An altair chart with the donut chart.\n \"\"\"\n\n # Load your data\n annotated_records = len(target_dataset)\n pending_records = int(os.getenv(\"TARGET_RECORDS\")) - annotated_records\n\n # Prepare data for the donut chart\n source = pd.DataFrame(\n {\n \"values\": [annotated_records, pending_records],\n \"category\": [ANNOTATED, PENDING],\n \"colors\": [\n \"#4682b4\",\n \"#e68c39\",\n ], # Blue for Completed, Orange for Remaining\n }\n )\n\n domain = source[\"category\"].tolist()\n range_ = source[\"colors\"].tolist()\n\n base = alt.Chart(source).encode(\n theta=alt.Theta(\"values:Q\", stack=True),\n radius=alt.Radius(\n \"values\", scale=alt.Scale(type=\"sqrt\", zero=True, rangeMin=20)\n ),\n color=alt.Color(\n field=\"category\",\n type=\"nominal\",\n scale=alt.Scale(domain=domain, range=range_),\n legend=alt.Legend(title=CATEGORY),\n ),\n )\n\n c1 = base.mark_arc(innerRadius=20, stroke=\"#fff\")\n\n c2 = base.mark_text(radiusOffset=20).encode(text=\"values:Q\")\n\n chart = c1 + c2\n\n return chart\n\n\ndef kpi_chart_remaining() -> alt.Chart:\n \"\"\"\n This function returns a KPI chart with the remaining amount of records to be annotated.\n Returns:\n An altair chart with the KPI chart.\n \"\"\"\n\n pending_records = int(os.getenv(\"TARGET_RECORDS\")) - len(target_dataset)\n # Assuming you have a DataFrame with user data, create a sample DataFrame\n data = pd.DataFrame({\"Category\": [PENDING], \"Value\": [pending_records]})\n\n # Create Altair chart\n chart = (\n alt.Chart(data)\n .mark_text(fontSize=100, align=\"center\", baseline=\"middle\", color=\"#e68b39\")\n .encode(text=\"Value:N\")\n .properties(title=PENDING, width=250, height=200)\n )\n\n return chart\n\n\ndef kpi_chart_submitted() -> alt.Chart:\n \"\"\"\n This function returns a KPI chart with the total amount of records that have been annotated.\n Returns:\n An altair chart with the KPI chart.\n \"\"\"\n\n total = len(target_dataset)\n\n # Assuming you have a DataFrame with user data, create a sample DataFrame\n data = pd.DataFrame({\"Category\": [NUMBER_ANNOTATED], \"Value\": [total]})\n\n # Create Altair chart\n chart = (\n alt.Chart(data)\n .mark_text(fontSize=100, align=\"center\", baseline=\"middle\", color=\"steelblue\")\n .encode(text=\"Value:N\")\n .properties(title=NUMBER_ANNOTATED, width=250, height=200)\n )\n\n return chart\n\n\ndef kpi_chart_total_annotators() -> alt.Chart:\n \"\"\"\n This function returns a KPI chart with the total amount of annotators.\n\n Returns:\n An altair chart with the KPI chart.\n \"\"\"\n\n # Obtain the total amount of annotators\n total_annotators = len(user_ids_annotations)\n\n # Assuming you have a DataFrame with user data, create a sample DataFrame\n data = pd.DataFrame({\"Category\": [NUMBER_ANNOTATORS], \"Value\": [total_annotators]})\n\n # Create Altair chart\n chart = (\n alt.Chart(data)\n .mark_text(fontSize=100, align=\"center\", baseline=\"middle\", color=\"steelblue\")\n .encode(text=\"Value:N\")\n .properties(title=NUMBER_ANNOTATORS, width=250, height=200)\n )\n\n return chart\n\n\ndef render_hub_user_link(hub_id: str) -> str:\n \"\"\"\n This function returns a link to the user's profile on Hugging Face.\n\n Args:\n hub_id: The user's id on Hugging Face.\n\n Returns:\n A string with the link to the user's profile on Hugging Face.\n \"\"\"\n link = f\"https://huggingface.co/{hub_id}\"\n return f'<a target=\"_blank\" href=\"{link}\" style=\"color: var(--link-text-color); text-decoration: underline;text-decoration-style: dotted;\">{hub_id}</a>'\n\n\ndef obtain_top_users(user_ids_annotations: Dict[str, int], N: int = 50) -> pd.DataFrame:\n \"\"\"\n This function returns the top N users with the most annotations.\n\n Args:\n user_ids_annotations: A dictionary with the user ids as the key and the number of annotations as the value.\n\n Returns:\n A pandas dataframe with the top N users with the most annotations.\n \"\"\"\n\n dataframe = pd.DataFrame(\n user_ids_annotations.items(), columns=[NAME, NUMBER_ANNOTATIONS]\n )\n dataframe[NAME] = dataframe[NAME].apply(render_hub_user_link)\n dataframe = dataframe.sort_values(by=NUMBER_ANNOTATIONS, ascending=False)\n return dataframe.head(N)\n\n\ndef fetch_data() -> None:\n \"\"\"\n This function fetches the data from the source and target datasets and updates the global variables.\n \"\"\"\n\n print(f\"Starting to fetch data: {datetime.datetime.now()}\")\n\n global source_dataset, target_dataset, user_ids_annotations, annotated, remaining, percentage_completed, top_dataframe\n source_dataset, target_dataset = obtain_source_target_datasets()\n user_ids_annotations = get_user_annotations_dictionary(target_dataset)\n\n annotated = len(target_dataset)\n remaining = int(os.getenv(\"TARGET_RECORDS\")) - annotated\n percentage_completed = round(\n (annotated / int(os.getenv(\"TARGET_RECORDS\"))) * 100, 1\n )\n\n # Print the current date and time\n print(f\"Data fetched: {datetime.datetime.now()}\")\n\n\ndef get_top(N=50) -> pd.DataFrame:\n \"\"\"\n This function returns the top N users with the most annotations.\n\n Args:\n N: The number of users to be returned. 50 by default\n\n Returns:\n A pandas dataframe with the top N users with the most annotations.\n \"\"\"\n\n return obtain_top_users(user_ids_annotations, N=N)\n\n\ndef main() -> None:\n\n # Connect to the space with rg.init()\n rg.init(\n api_url=os.getenv(\"ARGILLA_API_URL\"),\n api_key=os.getenv(\"ARGILLA_API_KEY\"),\n )\n\n # Fetch the data initially\n fetch_data()\n\n # To avoid the orange border for the Gradio elements that are in constant loading\n css = \"\"\"\n .generating {\n border: none;\n }\n \"\"\"\n\n with gr.Blocks(css=css, delete_cache=(300, 300)) as demo:\n gr.Markdown(\n \"\"\"\n # \ud83c\udf0d [YOUR LANGUAGE] - Multilingual Prompt Evaluation Project\n\n Hugging Face and @argilla are developing [Multilingual Prompt Evaluation Project](https://github.com/huggingface/data-is-better-together/tree/main/prompt_translation) project. It is an open multilingual benchmark for evaluating language models, and of course, also for [YOUR LANGUAGE].\n\n ## The goal is to translate 500 Prompts\n And as always: data is needed for that! The community selected the best 500 prompts that will form the benchmark. In English, of course.\n **That's why we need your help**: if we all translate the 500 prompts, we can add [YOUR LANGUAGE] to the leaderboard.\n\n ## How to participate\n Participating is easy. Go to the [annotation space][add a link to your annotation dataset], log in or create a Hugging Face account, and you can start working.\n Thanks in advance! Oh, and we'll give you a little push: GPT4 has already prepared a translation suggestion for you.\n \"\"\"\n )\n\n gr.Markdown(\n f\"\"\"\n ## \ud83d\ude80 Current Progress\n This is what we've achieved so far!\n \"\"\"\n )\n with gr.Row():\n\n kpi_submitted_plot = gr.Plot(label=\"Plot\")\n demo.load(\n kpi_chart_submitted,\n inputs=[],\n outputs=[kpi_submitted_plot],\n )\n\n kpi_remaining_plot = gr.Plot(label=\"Plot\")\n demo.load(\n kpi_chart_remaining,\n inputs=[],\n outputs=[kpi_remaining_plot],\n )\n\n donut_total_plot = gr.Plot(label=\"Plot\")\n demo.load(\n donut_chart_total,\n inputs=[],\n outputs=[donut_total_plot],\n )\n\n gr.Markdown(\n \"\"\"\n ## \ud83d\udc7e Hall of Fame\n Here you can see the top contributors and the number of annotations they have made.\n \"\"\"\n )\n\n with gr.Row():\n\n kpi_hall_plot = gr.Plot(label=\"Plot\")\n demo.load(kpi_chart_total_annotators, inputs=[], outputs=[kpi_hall_plot])\n\n top_df_plot = gr.Dataframe(\n headers=[NAME, NUMBER_ANNOTATIONS],\n datatype=[\n \"markdown\",\n \"number\",\n ],\n row_count=50,\n col_count=(2, \"fixed\"),\n interactive=False,\n )\n demo.load(get_top, None, [top_df_plot])\n\n # Manage background refresh\n scheduler = BackgroundScheduler()\n _ = scheduler.add_job(restart, \"interval\", minutes=30)\n scheduler.start()\n\n # Launch the Gradio interface\n demo.launch()\n\n\nif __name__ == \"__main__\":\n main()\n", "community-efforts\\prompt_translation\\dashboard_template\\requirements.txt": "aiofiles==23.2.1\naltair==5.2.0\nannotated-types==0.6.0\nanyio==4.2.0\napscheduler==3.10.4\nargilla==1.23.0\nattrs==23.2.0\nbackoff==2.2.1\ncertifi==2024.2.2\ncharset-normalizer==3.3.2\nclick==8.1.7\ncolorama==0.4.6\ncontourpy==1.2.0\ncycler==0.12.1\nDeprecated==1.2.14\nexceptiongroup==1.2.0\nfastapi==0.109.2\nffmpy==0.3.1\nfilelock==3.13.1\nfonttools==4.48.1\nfsspec==2024.2.0\ngradio==4.17.0\ngradio_client==0.9.0\nh11==0.14.0\nhttpcore==1.0.2\nhttpx==0.26.0\nhuggingface-hub==0.20.3\nidna==3.6\nimportlib-resources==6.1.1\nJinja2==3.1.3\njsonschema==4.21.1\njsonschema-specifications==2023.12.1\nkiwisolver==1.4.5\nmarkdown-it-py==3.0.0\nMarkupSafe==2.1.5\nmatplotlib==3.8.2\nmdurl==0.1.2\nmonotonic==1.6\nnumpy==1.23.5\norjson==3.9.13\npackaging==23.2\npandas==1.5.3\npillow==10.2.0\npydantic==2.6.1\npydantic_core==2.16.2\npydub==0.25.1\nPygments==2.17.2\npyparsing==3.1.1\npython-dateutil==2.8.2\npython-multipart==0.0.7\npytz==2024.1\nPyYAML==6.0.1\nreferencing==0.33.0\nrequests==2.31.0\nrich==13.7.0\nrpds-py==0.17.1\nruff==0.2.1\nsemantic-version==2.10.0\nshellingham==1.5.4\nsix==1.16.0\nsniffio==1.3.0\nstarlette==0.36.3\ntomlkit==0.12.0\ntoolz==0.12.1\ntqdm==4.66.1\ntyper==0.9.0\ntyping_extensions==4.9.0\nurllib3==2.2.0\nuvicorn==0.27.0.post1\nvega-datasets==0.9.0\nwebsockets==11.0.3\nwrapt==1.14.1\n", "cookbook-efforts\\domain-specific-datasets\\distilabel_pipelines\\domain_expert_pipeline.py": "import json\nfrom typing import Any, Dict\n\nimport argilla as rg\nfrom distilabel.llms import InferenceEndpointsLLM\nfrom distilabel.pipeline import Pipeline\nfrom distilabel.steps import (\n LoadDataFromDicts,\n TextGenerationToArgilla,\n ExpandColumns,\n)\nfrom distilabel.steps.tasks import (\n TextGeneration,\n SelfInstruct,\n)\nfrom distilabel.steps.tasks.typing import ChatType\nfrom huggingface_hub import hf_hub_download\n\n\n################################################################################\n# Define custom Argilla Dataset\n################################################################################\n\n\ndef create_argilla_dataset(\n api_url: str,\n api_key: str,\n dataset_name: str,\n workspace: str,\n):\n \"\"\"Create a dataset in Argilla.\"\"\"\n\n rg.init(api_url, api_key)\n rg_dataset = rg.FeedbackDataset(\n fields=[\n rg.TextField(name=\"id\", title=\"id\"), # type: ignore\n rg.TextField(name=\"instruction\", title=\"instruction\"), # type: ignore\n rg.TextField(name=\"generation\", title=\"generation\"), # type: ignore\n ],\n questions=[\n rg.LabelQuestion( # type: ignore\n name=\"quality\",\n title=f\"What's the quality of the generation for the given instruction?\",\n labels={\"bad\": \"\ud83d\udc4e\", \"good\": \"\ud83d\udc4d\"},\n ),\n rg.TextQuestion(\n name=\"improved_instruction\",\n title=\"How would you improve the instruction?\",\n required=False,\n ),\n rg.TextQuestion(\n name=\"improved_response\",\n title=\"How would you improve the response?\",\n required=False,\n ),\n ],\n )\n try:\n rg_dataset.push_to_argilla(name=dataset_name, workspace=workspace)\n except RuntimeError as e:\n print(f\"Failed to create the dataset in Argilla: {e} Moving on...\")\n\n\n################################################################################\n# Define out custom step for the domain expert\n################################################################################\n\n\nclass DomainExpert(TextGeneration):\n \"\"\"A customized task to generate text as a domain expert in the domain of farming and agriculture.\"\"\"\n\n system_prompt: str\n template: str = \"\"\"This is the the instruction: {instruction}\"\"\"\n\n def format_input(self, input: Dict[str, Any]) -> \"ChatType\":\n return [\n {\n \"role\": \"system\",\n \"content\": self.system_prompt,\n },\n {\n \"role\": \"user\",\n \"content\": self.template.format(**input),\n },\n ]\n\n\n################################################################################\n# Main script to run the pipeline\n################################################################################\n\n\nif __name__ == \"__main__\":\n import os\n import json\n import sys\n\n # get some args\n repo_id = sys.argv[1]\n\n # Get super secret tokens\n\n hub_token = os.environ.get(\"HF_TOKEN\")\n argilla_api_key = os.environ.get(\"ARGILLA_API_KEY\", \"owner.apikey\")\n\n # load pipeline parameters\n\n with open(\n hf_hub_download(\n repo_id=repo_id, filename=\"pipeline_params.json\", repo_type=\"dataset\"\n ),\n \"r\",\n ) as f:\n params = json.load(f)\n\n argilla_api_url = params.get(\"argilla_api_url\")\n argilla_dataset_name = params.get(\"argilla_dataset_name\")\n self_instruct_base_url = params.get(\"self_instruct_base_url\")\n domain_expert_base_url = params.get(\"domain_expert_base_url\")\n self_intruct_num_generations = params.get(\"self_instruct_num_generations\", 2)\n domain_expert_num_generations = params.get(\"domain_expert_num_generations\", 2)\n self_instruct_temperature = params.get(\"self_instruct_temperature\", 0.9)\n domain_expert_temperature = params.get(\"domain_expert_temperature\", 0.9)\n self_instruct_max_new_tokens = params.get(\"self_instruct_max_new_tokens\", 2048)\n domain_expert_max_new_tokens = params.get(\"domain_expert_max_new_tokens\", 2048)\n\n if not all(\n [\n argilla_api_url,\n argilla_dataset_name,\n self_instruct_base_url,\n domain_expert_base_url,\n ]\n ):\n raise ValueError(\"Some of the pipeline parameters are missing\")\n\n # collect our seed prompts defined in the space\n\n with open(\n hf_hub_download(\n repo_id=repo_id, filename=\"seed_data.json\", repo_type=\"dataset\"\n ),\n \"r\",\n ) as f:\n seed_data = json.load(f)\n\n application_instruction = seed_data.get(\"application_instruction\")\n domain_expert_prompt = seed_data.get(\"domain_expert_prompt\")\n domain_name = seed_data.get(\"domain\")\n terms = seed_data.get(\"seed_terms\")\n\n # Create the Argilla dataset\n\n create_argilla_dataset(\n api_url=argilla_api_url,\n api_key=argilla_api_key,\n dataset_name=argilla_dataset_name,\n workspace=\"admin\",\n )\n\n # Define the distilabel pipeline\n\n with Pipeline(domain_name) as pipeline:\n load_data = LoadDataFromDicts(\n name=\"load_data\",\n batch_size=64,\n data=[{\"input\": term} for term in terms],\n )\n\n self_instruct = SelfInstruct(\n name=\"self_instruct\",\n num_instructions=self_intruct_num_generations,\n input_batch_size=8,\n llm=InferenceEndpointsLLM(\n api_key=hub_token,\n base_url=self_instruct_base_url,\n ),\n application_description=application_instruction,\n )\n\n expand_columns = ExpandColumns(\n name=\"expand_columns\",\n columns=[\"instructions\"],\n output_mappings={\"instructions\": \"instruction\"},\n )\n\n domain_expert = DomainExpert(\n name=\"domain_expert\",\n llm=InferenceEndpointsLLM(\n api_key=hub_token,\n base_url=domain_expert_base_url,\n ),\n input_batch_size=8,\n num_generations=domain_expert_num_generations,\n system_prompt=domain_expert_prompt,\n )\n\n # Push the generated dataset to Argilla\n to_argilla = TextGenerationToArgilla(\n name=\"to_argilla\",\n dataset_workspace=\"admin\",\n )\n\n # Connect up the pipeline\n\n load_data.connect(self_instruct)\n self_instruct.connect(expand_columns)\n expand_columns.connect(domain_expert)\n domain_expert.connect(to_argilla)\n\n # Run the pipeline\n\n pipeline.run(\n parameters={\n \"self_instruct\": {\n \"llm\": {\n \"generation_kwargs\": {\n \"max_new_tokens\": self_instruct_max_new_tokens,\n \"temperature\": self_instruct_temperature,\n },\n }\n },\n \"domain_expert\": {\n \"llm\": {\n \"generation_kwargs\": {\n \"max_new_tokens\": self_instruct_max_new_tokens,\n \"temperature\": domain_expert_temperature,\n },\n }\n },\n \"to_argilla\": {\n \"dataset_name\": argilla_dataset_name,\n \"api_key\": argilla_api_key,\n \"api_url\": argilla_api_url,\n },\n },\n use_cache=False,\n )\n", "cookbook-efforts\\domain-specific-datasets\\distilabel_pipelines\\requirements.txt": "datasets\npython_dotenv\nstreamlit\nhuggingface_hub\nargilla\ngit+https://github.com/argilla-io/distilabel.git", "cookbook-efforts\\domain-specific-datasets\\parent_app\\app.py": "import time\n\nfrom hub import (\n setup_dataset_on_hub,\n duplicate_space_on_hub,\n add_project_config_to_space_repo,\n)\n\nimport streamlit as st\n\n\n# Constants\n# Written here to avoid defaults.py\nDEFAULT_DOMAIN = \"farming\"\n\nst.set_page_config(\n \"Domain Data Grower\", page_icon=\"\ud83e\uddd1\u200d\ud83c\udf3e\", initial_sidebar_state=\"collapsed\"\n)\n\nst.header(\"\ud83e\uddd1\u200d\ud83c\udf3e Domain Data Grower\")\nst.divider()\n\nst.sidebar.link_button(\n \"\ud83e\udd17 Get your Hub Token\", \"https://huggingface.co/settings/tokens\"\n)\n\n################################################################################\n# APP MARKDOWN\n################################################################################\n\nst.header(\"\ud83c\udf31 Create a domain specific dataset\")\n\nst.markdown(\n \"\"\"This space will set up your domain specific dataset project. It will \ncreate the resources that you need to build a dataset. Those resources include: \n \n- A dataset repository on the Hub\n- Another space to define expert domain and run generation pipelines \n\nFor a complete overview of the project. Check out the README \n\"\"\"\n)\n\nst.page_link(\n \"pages/\ud83e\uddd1\u200d\ud83c\udf3e Domain Data Grower.py\",\n label=\"Domain Data Grower\",\n icon=\"\ud83e\uddd1\u200d\ud83c\udf3e\",\n)\n\n################################################################################\n# CONFIGURATION\n################################################################################\n\nst.subheader(\"\ud83c\udf3e Project Configuration\")\n\nproject_name = st.text_input(\"Project Name\", DEFAULT_DOMAIN)\nhub_username = st.text_input(\"Hub Username\", \"argilla\")\nhub_token = st.text_input(\"Hub Token\", type=\"password\")\nprivate_selector = st.checkbox(\"Private Space\", value=False)\n\nif st.button(\"\ud83e\udd17 Setup Project Resources\"):\n repo_id = f\"{hub_username}/{project_name}\"\n\n setup_dataset_on_hub(\n repo_id=repo_id,\n hub_token=hub_token,\n )\n\n st.success(\n f\"Dataset seed created and pushed to the Hub. Check it out [here](https://huggingface.co/datasets/{hub_username}/{project_name}). Hold on the repo_id: {repo_id}, we will need it in the next steps.\"\n )\n\n space_name = f\"{project_name}_config_space\"\n\n duplicate_space_on_hub(\n source_repo=\"argilla/domain-specific-datasets-template\",\n target_repo=space_name,\n hub_token=hub_token,\n private=private_selector,\n )\n\n st.success(\n f\"Configuration Space created. Check it out [here](https://huggingface.co/spaces/{hub_username}/{space_name}).\"\n )\n\n argilla_name = f\"{project_name}_argilla_space\"\n\n duplicate_space_on_hub(\n source_repo=\"argilla/argilla-template-space\",\n target_repo=argilla_name,\n hub_token=hub_token,\n private=private_selector,\n )\n\n st.success(\n f\"Argilla Space created. Check it out [here](https://huggingface.co/spaces/{hub_username}/{argilla_name}).\"\n )\n\n seconds = 5\n\n with st.spinner(f\"Adding project configuration to spaces in {seconds} seconds\"):\n time.sleep(seconds)\n add_project_config_to_space_repo(\n dataset_repo_id=repo_id,\n hub_token=hub_token,\n project_name=project_name,\n argilla_space_repo_id=f\"{hub_username}/{argilla_name}\",\n project_space_repo_id=f\"{hub_username}/{space_name}\",\n )\n\n st.subheader(\"\ud83d\udc62 Next Steps\")\n\n st.write(\"Go to you project specific space!\")\n\n st.link_button(\n \"\ud83e\uddd1\u200d\ud83c\udf3e Open Configuration Space\",\n f\"https://huggingface.co/spaces/{hub_username}/{space_name}\",\n )\n", "cookbook-efforts\\domain-specific-datasets\\parent_app\\pages\\\ud83e\uddd1\u200d\ud83c\udf3e Domain Data Grower.py": "import streamlit as st\nimport requests\n\n\nreadme_location = \"https://raw.githubusercontent.com/huggingface/data-is-better-together/51f29e67165d8277d9f9d1e4be60869f4b705a08/domain-specific-datasets/README.md\"\n\n\ndef open_markdown_file(url):\n response = requests.get(url)\n return response.text\n\n\nreadme = open_markdown_file(readme_location)\n\nst.markdown(readme)\n", "cookbook-efforts\\domain-specific-datasets\\project_app\\app.py": "import streamlit as st\n\nfrom defaults import (\n PROJECT_NAME,\n ARGILLA_SPACE_REPO_ID,\n DATASET_REPO_ID,\n ARGILLA_URL,\n PROJECT_SPACE_REPO_ID,\n DIBT_PARENT_APP_URL,\n)\nfrom utils import project_sidebar\n\nst.set_page_config(\"Domain Data Grower\", page_icon=\"\ud83e\uddd1\u200d\ud83c\udf3e\")\n\nproject_sidebar()\n\nif PROJECT_NAME == \"DEFAULT_DOMAIN\":\n st.warning(\n \"Please set up the project configuration in the parent app before proceeding.\"\n )\n st.stop()\n\n\nst.header(\"\ud83e\uddd1\u200d\ud83c\udf3e Domain Data Grower\")\nst.divider()\n\nst.markdown(\n \"\"\"\n## \ud83c\udf31 Create a dataset seed for aligning models to a specific domain\n\nThis app helps you create a dataset seed for building diverse domain-specific datasets for aligning models.\nAlignment datasets are used to fine-tune models to a specific domain or task, but as yet, there's a shortage of diverse datasets for this purpose.\n\"\"\"\n)\nst.markdown(\n \"\"\"\n## \ud83d\ude9c How it works\n\nYou can create a dataset seed by defining the domain expertise, perspectives, topics, and examples for your domain-specific dataset. \nThe dataset seed is then used to generate synthetic data for training a language model.\n\n\"\"\"\n)\nst.markdown(\n \"\"\"\n## \ud83d\uddfa\ufe0f The process\n\n### Step 1: ~~Setup the project~~\n\n~~Define the project details, including the project name, domain, and API credentials. Create Dataset Repo on the Hub.~~\n\"\"\"\n)\nst.link_button(\"\ud83d\ude80 ~~Setup Project via the parent app~~\", DIBT_PARENT_APP_URL)\n\nst.markdown(\n \"\"\"\n### Step 2: Describe the Domain\n\nDefine the domain expertise, perspectives, topics, and examples for your domain-specific dataset. \nYou can collaborate with domain experts to define the domain expertise and perspectives.\n\"\"\"\n)\n\nst.page_link(\n \"pages/2_\ud83d\udc69\ud83c\udffc\u200d\ud83d\udd2c Describe Domain.py\",\n label=\"Describe Domain\",\n icon=\"\ud83d\udc69\ud83c\udffc\u200d\ud83d\udd2c\",\n)\n\nst.markdown(\n \"\"\"\n### Step 3: Generate Synthetic Data\n\nUse distilabel to generate synthetic data for your domain-specific dataset. \nYou can run the pipeline locally or in this space to generate synthetic data.\n\"\"\"\n)\n\nst.page_link(\n \"pages/3_\ud83c\udf31 Generate Dataset.py\",\n label=\"Generate Dataset\",\n icon=\"\ud83c\udf31\",\n)\n\nst.markdown(\n \"\"\"\n### Step 4: Review the Dataset\n\nUse Argilla to review the generated synthetic data and provide feedback on the quality of the data.\n\n\n\"\"\"\n)\nst.link_button(\"\ud83d\udd0d Review the dataset in Argilla\", ARGILLA_URL)\n", "cookbook-efforts\\domain-specific-datasets\\project_app\\requirements.txt": "datasets\npython_dotenv\nstreamlit\nhuggingface_hub\nargilla", "cookbook-efforts\\domain-specific-datasets\\project_app\\pages\\2_\ud83d\udc69\ud83c\udffc\u200d\ud83d\udd2c Describe Domain.py": "import json\n\nimport streamlit as st\n\nfrom hub import push_dataset_to_hub, pull_seed_data_from_repo\nfrom infer import query\nfrom defaults import (\n N_PERSPECTIVES,\n N_TOPICS,\n SEED_DATA_PATH,\n PIPELINE_PATH,\n DATASET_REPO_ID,\n)\nfrom utils import project_sidebar, create_seed_terms, create_application_instruction\n\n\nst.set_page_config(\n page_title=\"Domain Data Grower\",\n page_icon=\"\ud83e\uddd1\u200d\ud83c\udf3e\",\n)\nproject_sidebar()\n\n\n################################################################################\n# HEADER\n################################################################################\n\nst.header(\"\ud83e\uddd1\u200d\ud83c\udf3e Domain Data Grower\")\nst.divider()\nst.subheader(\n \"Step 2. Define the specific domain that you want to generate synthetic data for.\",\n)\nst.write(\n \"Define the project details, including the project name, domain, and API credentials\"\n)\n\n\n################################################################################\n# LOAD EXISTING DOMAIN DATA\n################################################################################\n\nDATASET_REPO_ID = (\n f\"{st.session_state['hub_username']}/{st.session_state['project_name']}\"\n)\nSEED_DATA = pull_seed_data_from_repo(\n DATASET_REPO_ID, hub_token=st.session_state[\"hub_token\"]\n)\nDEFAULT_DOMAIN = SEED_DATA.get(\"domain\", \"\")\nDEFAULT_PERSPECTIVES = SEED_DATA.get(\"perspectives\", [\"\"])\nDEFAULT_TOPICS = SEED_DATA.get(\"topics\", [\"\"])\nDEFAULT_EXAMPLES = SEED_DATA.get(\"examples\", [{\"question\": \"\", \"answer\": \"\"}])\nDEFAULT_SYSTEM_PROMPT = SEED_DATA.get(\"domain_expert_prompt\", \"\")\n\n################################################################################\n# Domain Expert Section\n################################################################################\n\n(\n tab_domain_expert,\n tab_domain_perspectives,\n tab_domain_topics,\n tab_examples,\n tab_raw_seed,\n) = st.tabs(\n tabs=[\n \"\ud83d\udc69\ud83c\udffc\u200d\ud83d\udd2c Domain Expert\",\n \"\ud83d\udd0d Domain Perspectives\",\n \"\ud83d\udd78\ufe0f Domain Topics\",\n \"\ud83d\udcda Examples\",\n \"\ud83c\udf31 Raw Seed Data\",\n ]\n)\n\nwith tab_domain_expert:\n st.text(\"Define the domain expertise that you want to train a language model\")\n st.info(\n \"A domain expert is a person who is an expert in a particular field or area. For example, a domain expert in farming would be someone who has extensive knowledge and experience in farming and agriculture.\"\n )\n\n domain = st.text_input(\"Domain Name\", DEFAULT_DOMAIN)\n\n domain_expert_prompt = st.text_area(\n label=\"Domain Expert Definition\",\n value=DEFAULT_SYSTEM_PROMPT,\n height=200,\n )\n\n################################################################################\n# Domain Perspectives\n################################################################################\n\nwith tab_domain_perspectives:\n st.text(\"Define the different perspectives from which the domain can be viewed\")\n st.info(\n \"\"\"\n Perspectives are different viewpoints or angles from which a domain can be viewed. \n For example, the domain of farming can be viewed from the perspective of a commercial \n farmer or an independent family farmer.\"\"\"\n )\n\n perspectives = st.session_state.get(\n \"perspectives\",\n [DEFAULT_PERSPECTIVES[0]],\n )\n perspectives_container = st.container()\n\n perspectives = [\n perspectives_container.text_input(\n f\"Domain Perspective {i + 1}\", value=perspective\n )\n for i, perspective in enumerate(perspectives)\n ]\n\n if st.button(\"Add Perspective\", key=\"add_perspective\"):\n n = len(perspectives)\n perspectives.append(\n perspectives_container.text_input(f\"Domain Perspective {n + 1}\", value=\"\")\n )\n\n st.session_state[\"perspectives\"] = perspectives\n\n\n################################################################################\n# Domain Topics\n################################################################################\n\nwith tab_domain_topics:\n st.text(\"Define the main themes or subjects that are relevant to the domain\")\n st.info(\n \"\"\"Topics are the main themes or subjects that are relevant to the domain. For example, the domain of farming can have topics like soil health, crop rotation, or livestock management.\"\"\"\n )\n topics = st.session_state.get(\n \"topics\",\n [DEFAULT_TOPICS[0]],\n )\n topics_container = st.container()\n topics = [\n topics_container.text_input(f\"Domain Topic {i + 1}\", value=topic)\n for i, topic in enumerate(topics)\n ]\n\n if st.button(\"Add Topic\", key=\"add_topic\"):\n n = len(topics)\n topics.append(topics_container.text_input(f\"Domain Topics {n + 1}\", value=\"\"))\n\n st.session_state[\"topics\"] = topics\n\n\n################################################################################\n# Examples Section\n################################################################################\n\nwith tab_examples:\n st.text(\n \"Add high-quality questions and answers that can be used to generate synthetic data\"\n )\n st.info(\n \"\"\"\n Examples are high-quality questions and answers that can be used to generate \n synthetic data for the domain. These examples will be used to train the language model\n to generate questions and answers.\n \"\"\"\n )\n\n examples = st.session_state.get(\n \"examples\",\n [\n {\n \"question\": \"\",\n \"answer\": \"\",\n }\n ],\n )\n\n for n, example in enumerate(examples, 1):\n question = example[\"question\"]\n answer = example[\"answer\"]\n examples_container = st.container()\n question_column, answer_column = examples_container.columns(2)\n\n if st.button(f\"Generate Answer {n}\"):\n if st.session_state[\"hub_token\"] is None:\n st.error(\"Please provide a Hub token to generate answers\")\n else:\n answer = query(question, st.session_state[\"hub_token\"])\n with question_column:\n question = st.text_area(f\"Question {n}\", value=question)\n\n with answer_column:\n answer = st.text_area(f\"Answer {n}\", value=answer)\n examples[n - 1] = {\"question\": question, \"answer\": answer}\n st.session_state[\"examples\"] = examples\n st.divider()\n\n if st.button(\"Add Example\"):\n examples.append({\"question\": \"\", \"answer\": \"\"})\n st.session_state[\"examples\"] = examples\n st.rerun()\n\n################################################################################\n# Save Domain Data\n################################################################################\n\nperspectives = list(filter(None, perspectives))\ntopics = list(filter(None, topics))\n\ndomain_data = {\n \"domain\": domain,\n \"perspectives\": perspectives,\n \"topics\": topics,\n \"examples\": examples,\n \"domain_expert_prompt\": domain_expert_prompt,\n \"application_instruction\": create_application_instruction(domain, examples),\n \"seed_terms\": create_seed_terms(topics, perspectives),\n}\n\nwith open(SEED_DATA_PATH, \"w\") as f:\n json.dump(domain_data, f, indent=2)\n\nwith tab_raw_seed:\n st.code(json.dumps(domain_data, indent=2), language=\"json\", line_numbers=True)\n\n################################################################################\n# Setup Dataset on the Hub\n################################################################################\n\nst.divider()\n\n\nif st.button(\"\ud83e\udd17 Push Dataset Seed\") and all(\n (\n domain,\n domain_expert_prompt,\n perspectives,\n topics,\n examples,\n )\n):\n if all(\n (\n st.session_state.get(\"project_name\"),\n st.session_state.get(\"hub_username\"),\n st.session_state.get(\"hub_token\"),\n )\n ):\n project_name = st.session_state[\"project_name\"]\n hub_username = st.session_state[\"hub_username\"]\n hub_token = st.session_state[\"hub_token\"]\n else:\n st.error(\n \"Please create a dataset repo on the Hub before pushing the dataset seed\"\n )\n st.stop()\n\n push_dataset_to_hub(\n domain_seed_data_path=SEED_DATA_PATH,\n project_name=project_name,\n domain=domain,\n hub_username=hub_username,\n hub_token=hub_token,\n pipeline_path=PIPELINE_PATH,\n )\n\n st.success(\n f\"Dataset seed created and pushed to the Hub. Check it out [here](https://huggingface.co/datasets/{hub_username}/{project_name})\"\n )\n\n st.write(\"You can now move on to runnning your distilabel pipeline.\")\n\n st.page_link(\n page=\"pages/3_\ud83c\udf31 Generate Dataset.py\",\n label=\"Generate Dataset\",\n icon=\"\ud83c\udf31\",\n )\n\nelse:\n st.info(\n \"Please fill in all the required domain fields to push the dataset seed to the Hub\"\n )\n", "cookbook-efforts\\dpo-orpo-preference\\requirements.txt": "# This file was autogenerated by uv via the following command:\n# uv pip compile requirements.in -o requirements.txt\naiohttp==3.9.5\n # via\n # datasets\n # fsspec\naiosignal==1.3.1\n # via aiohttp\nannotated-types==0.6.0\n # via pydantic\nanyio==4.3.0\n # via httpx\nappnope==0.1.4\n # via ipykernel\nargilla==1.27.0\nasttokens==2.4.1\n # via stack-data\nattrs==23.2.0\n # via aiohttp\nbackoff==2.2.1\n # via argilla\ncertifi==2024.2.2\n # via\n # httpcore\n # httpx\n # requests\ncharset-normalizer==3.3.2\n # via requests\nclick==8.1.7\n # via typer\ncomm==0.2.2\n # via\n # ipykernel\n # ipywidgets\ndatasets==2.19.0\n # via distilabel\ndebugpy==1.8.1\n # via ipykernel\ndecorator==5.1.1\n # via ipython\ndeprecated==1.2.14\n # via argilla\ndill==0.3.8\n # via\n # datasets\n # multiprocess\ndistilabel==1.0.3\nexecuting==2.0.1\n # via stack-data\nfilelock==3.14.0\n # via\n # datasets\n # huggingface-hub\n # transformers\nfrozenlist==1.4.1\n # via\n # aiohttp\n # aiosignal\nfsspec==2024.3.1\n # via\n # datasets\n # huggingface-hub\nh11==0.14.0\n # via httpcore\nhttpcore==1.0.5\n # via httpx\nhttpx==0.26.0\n # via\n # argilla\n # distilabel\nhuggingface-hub==0.23.0\n # via\n # datasets\n # tokenizers\n # transformers\nidna==3.7\n # via\n # anyio\n # httpx\n # requests\n # yarl\nipykernel==6.29.4\nipython==8.24.0\n # via\n # ipykernel\n # ipywidgets\nipywidgets==8.1.2\njedi==0.19.1\n # via ipython\njinja2==3.1.3\n # via distilabel\njupyter-client==8.6.1\n # via ipykernel\njupyter-core==5.7.2\n # via\n # ipykernel\n # jupyter-client\njupyterlab-widgets==3.0.10\n # via ipywidgets\nmarkdown-it-py==3.0.0\n # via rich\nmarkupsafe==2.1.5\n # via jinja2\nmatplotlib-inline==0.1.7\n # via\n # ipykernel\n # ipython\nmdurl==0.1.2\n # via markdown-it-py\nmonotonic==1.6\n # via argilla\nmultidict==6.0.5\n # via\n # aiohttp\n # yarl\nmultiprocess==0.70.16\n # via\n # datasets\n # distilabel\nnest-asyncio==1.6.0\n # via\n # distilabel\n # ipykernel\nnetworkx==3.3\n # via distilabel\nnumpy==1.23.5\n # via\n # argilla\n # datasets\n # pandas\n # pyarrow\n # scipy\n # transformers\npackaging==24.0\n # via\n # argilla\n # datasets\n # huggingface-hub\n # ipykernel\n # transformers\npandas==2.2.2\n # via\n # argilla\n # datasets\nparso==0.8.4\n # via jedi\npexpect==4.9.0\n # via ipython\nplatformdirs==4.2.1\n # via jupyter-core\nprompt-toolkit==3.0.43\n # via ipython\npsutil==5.9.8\n # via ipykernel\nptyprocess==0.7.0\n # via pexpect\npure-eval==0.2.2\n # via stack-data\npyarrow==16.0.0\n # via datasets\npyarrow-hotfix==0.6\n # via datasets\npydantic==2.7.1\n # via\n # argilla\n # distilabel\npydantic-core==2.18.2\n # via pydantic\npygments==2.17.2\n # via\n # ipython\n # rich\npython-dateutil==2.9.0.post0\n # via\n # jupyter-client\n # pandas\npython-dotenv==1.0.1\npytz==2024.1\n # via pandas\npyyaml==6.0.1\n # via\n # datasets\n # huggingface-hub\n # transformers\npyzmq==26.0.3\n # via\n # ipykernel\n # jupyter-client\nregex==2024.4.28\n # via transformers\nrequests==2.31.0\n # via\n # datasets\n # huggingface-hub\n # transformers\nrich==13.7.1\n # via\n # argilla\n # distilabel\nsafetensors==0.4.3\n # via transformers\nscipy==1.13.0\n # via distilabel\nsix==1.16.0\n # via\n # asttokens\n # python-dateutil\nsniffio==1.3.1\n # via\n # anyio\n # httpx\nstack-data==0.6.3\n # via ipython\ntblib==3.0.0\n # via distilabel\ntokenizers==0.19.1\n # via transformers\ntornado==6.4\n # via\n # ipykernel\n # jupyter-client\ntqdm==4.66.4\n # via\n # argilla\n # datasets\n # huggingface-hub\n # transformers\ntraitlets==5.14.3\n # via\n # comm\n # ipykernel\n # ipython\n # ipywidgets\n # jupyter-client\n # jupyter-core\n # matplotlib-inline\ntransformers==4.40.1\ntyper==0.9.4\n # via\n # argilla\n # distilabel\ntyping-extensions==4.11.0\n # via\n # huggingface-hub\n # ipython\n # pydantic\n # pydantic-core\n # typer\ntzdata==2024.1\n # via pandas\nurllib3==2.2.1\n # via requests\nwcwidth==0.2.13\n # via prompt-toolkit\nwidgetsnbextension==4.0.10\n # via ipywidgets\nwrapt==1.14.1\n # via\n # argilla\n # deprecated\nxxhash==3.4.1\n # via datasets\nyarl==1.9.4\n # via aiohttp\n", "cookbook-efforts\\kto-preference\\requirements.txt": "# This file was autogenerated by uv via the following command:\n# uv pip compile requirements.in -o requirements.txt\naiohttp==3.9.3\n # via\n # datasets\n # fsspec\naiosignal==1.3.1\n # via aiohttp\nannotated-types==0.6.0\n # via pydantic\nanyio==4.3.0\n # via httpx\nargilla==1.25.0\nasttokens==2.4.1\n # via stack-data\nattrs==23.2.0\n # via aiohttp\nbackoff==2.2.1\n # via argilla\ncertifi==2024.2.2\n # via\n # httpcore\n # httpx\n # requests\ncharset-normalizer==3.3.2\n # via requests\nclick==8.1.7\n # via\n # nltk\n # typer\ncomm==0.2.2\n # via ipywidgets\ndatasets==2.18.0\n # via distilabel\ndecorator==5.1.1\n # via ipython\ndeprecated==1.2.14\n # via argilla\ndill==0.3.8\n # via\n # datasets\n # multiprocess\ndistilabel==0.6.0\nexecuting==2.0.1\n # via stack-data\nfilelock==3.13.1\n # via\n # datasets\n # huggingface-hub\nfrozenlist==1.4.1\n # via\n # aiohttp\n # aiosignal\nfsspec==2024.2.0\n # via\n # datasets\n # huggingface-hub\nh11==0.14.0\n # via httpcore\nhttpcore==1.0.4\n # via httpx\nhttpx==0.26.0\n # via argilla\nhuggingface-hub==0.21.4\n # via\n # datasets\n # distilabel\nidna==3.6\n # via\n # anyio\n # httpx\n # requests\n # yarl\nipython==8.22.2\n # via ipywidgets\nipywidgets==8.1.2\njedi==0.19.1\n # via ipython\njinja2==3.1.3\n # via distilabel\njoblib==1.3.2\n # via nltk\njupyterlab-widgets==3.0.10\n # via ipywidgets\nmarkdown-it-py==3.0.0\n # via rich\nmarkupsafe==2.1.5\n # via jinja2\nmatplotlib-inline==0.1.6\n # via ipython\nmdurl==0.1.2\n # via markdown-it-py\nmonotonic==1.6\n # via argilla\nmultidict==6.0.5\n # via\n # aiohttp\n # yarl\nmultiprocess==0.70.16\n # via\n # datasets\n # distilabel\nnltk==3.8.1\n # via argilla\nnumpy==1.23.5\n # via\n # argilla\n # datasets\n # pandas\n # pyarrow\npackaging==24.0\n # via\n # argilla\n # datasets\n # huggingface-hub\npandas==2.2.1\n # via\n # argilla\n # datasets\nparso==0.8.3\n # via jedi\npexpect==4.9.0\n # via ipython\nprompt-toolkit==3.0.43\n # via ipython\nptyprocess==0.7.0\n # via pexpect\npure-eval==0.2.2\n # via stack-data\npyarrow==15.0.1\n # via datasets\npyarrow-hotfix==0.6\n # via datasets\npydantic==2.6.4\n # via argilla\npydantic-core==2.16.3\n # via pydantic\npygments==2.17.2\n # via\n # ipython\n # rich\npython-dateutil==2.9.0.post0\n # via pandas\npython-dotenv==1.0.1\npytz==2024.1\n # via pandas\npyyaml==6.0.1\n # via\n # datasets\n # huggingface-hub\nregex==2023.12.25\n # via nltk\nrequests==2.31.0\n # via\n # datasets\n # huggingface-hub\nrich==13.7.1\n # via\n # argilla\n # distilabel\nsix==1.16.0\n # via\n # asttokens\n # python-dateutil\nsniffio==1.3.1\n # via\n # anyio\n # httpx\nstack-data==0.6.3\n # via ipython\ntenacity==8.2.3\n # via distilabel\ntqdm==4.66.2\n # via\n # argilla\n # datasets\n # huggingface-hub\n # nltk\ntraitlets==5.14.2\n # via\n # comm\n # ipython\n # ipywidgets\n # matplotlib-inline\ntyper==0.9.0\n # via argilla\ntyping-extensions==4.10.0\n # via\n # huggingface-hub\n # pydantic\n # pydantic-core\n # typer\ntzdata==2024.1\n # via pandas\nurllib3==2.2.1\n # via requests\nwcwidth==0.2.13\n # via prompt-toolkit\nwidgetsnbextension==4.0.10\n # via ipywidgets\nwrapt==1.14.1\n # via\n # argilla\n # deprecated\nxxhash==3.4.1\n # via datasets\nyarl==1.9.4\n # via aiohttp\n"} | null |
datasets-tagging | {"type": "directory", "name": "datasets-tagging", "children": [{"type": "file", "name": "apputils.py"}, {"type": "file", "name": "build_docker_image.sh"}, {"type": "file", "name": "build_metadata_file.py"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "tagging_app.py"}]} | ---
title: Datasets Tagging
emoji: 🤗
colorFrom: pink
colorTo: blue
sdk: streamlit
app_file: tagging_app.py
pinned: false
---
## ⚠️ This repo is now directly maintained in the Space repo at https://huggingface.co/spaces/huggingface/datasets-tagging ⚠️
You can clone it from there with `git clone https://huggingface.co/spaces/huggingface/datasets-tagging`.
You can open Pull requests & Discussions in the repo too: https://huggingface.co/spaces/huggingface/datasets-tagging/discussions.
# 🤗 Datasets Tagging
A Streamlit app to add structured tags to a dataset card.
Available online [here!](https://huggingface.co/spaces/huggingface/datasets-tagging)
1. `pip install -r requirements.txt`
2. `./build_metadata_file.py` will build an up-to-date metadata file from the `datasets/` repo (clones it locally)
3. `streamlit run tagging_app.py`
This will give you a `localhost` link you can click to open in your browser.
The app initialization on the first run takes a few minutes, subsequent runs are faster.
Make sure to hit the `Done? Save to File!` button in the right column when you're done tagging a config!
| {"apputils.py": "from typing import Dict, List\n\n\ndef new_state() -> Dict[str, List]:\n return {\n \"task_categories\": [],\n \"task_ids\": [],\n \"multilinguality\": [],\n \"languages\": [],\n \"language_creators\": [],\n \"annotations_creators\": [],\n \"source_datasets\": [],\n \"size_categories\": [],\n \"licenses\": [],\n \"pretty_name\": None,\n }\n", "requirements.txt": "pyyaml\ndatasets==1.9.0\nstreamlit>=0.88.0\nlangcodes[data]\n", "tagging_app.py": "import json\nimport logging\nfrom pathlib import Path\nfrom typing import Callable, Dict, List, Tuple\n\nimport langcodes as lc\nimport streamlit as st\nimport yaml\nfrom datasets.utils.metadata import (\n DatasetMetadata,\n known_creators,\n known_licenses,\n known_multilingualities,\n known_size_categories,\n known_task_ids,\n)\n\nfrom apputils import new_state\n\nst.set_page_config(\n page_title=\"HF Dataset Tagging App\",\n page_icon=\"https://huggingface.co/front/assets/huggingface_logo.svg\",\n layout=\"wide\",\n initial_sidebar_state=\"auto\",\n)\n\n# XXX: restyling errors as streamlit does not respect whitespaces on `st.error` and doesn't scroll horizontally, which\n# generally makes things easier when reading error reports\nst.markdown(\n \"\"\"\n<style>\n div[role=alert] { overflow-x: scroll}\n div.stAlert p { white-space: pre }\n</style>\n\"\"\",\n unsafe_allow_html=True,\n)\n\n########################\n## Helper functions\n########################\n\n\ndef load_ds_datas() -> Dict[str, Dict[str, Dict]]:\n metada_exports = sorted(\n [f for f in Path.cwd().iterdir() if f.name.startswith(\"metadata_\")],\n key=lambda f: f.lstat().st_mtime,\n reverse=True,\n )\n if len(metada_exports) == 0:\n raise ValueError(\"need to run ./build_metada_file.py at least once\")\n with metada_exports[0].open() as fi:\n logging.info(f\"loaded {metada_exports[0]}\")\n return json.load(fi)\n\n\ndef split_known(vals: List[str], okset: List[str]) -> Tuple[List[str], List[str]]:\n if vals is None:\n return [], []\n return [v for v in vals if v in okset], [v for v in vals if v not in okset]\n\n\ndef multiselect(\n w: st.delta_generator.DeltaGenerator,\n title: str,\n markdown: str,\n values: List[str],\n valid_set: List[str],\n format_func: Callable = str,\n):\n valid_values, invalid_values = split_known(values, valid_set)\n w.markdown(f\"#### {title}\")\n if len(invalid_values) > 0:\n w.markdown(\"Found the following invalid values:\")\n w.error(invalid_values)\n return w.multiselect(markdown, valid_set, default=valid_values, format_func=format_func)\n\n\ndef validate_dict(w: st.delta_generator.DeltaGenerator, state_dict: Dict):\n try:\n DatasetMetadata(**state_dict)\n w.markdown(\"\u2705 This is a valid tagset! \ud83e\udd17\")\n except Exception as e:\n w.markdown(\"\u274c This is an invalid tagset, here are the errors in it:\")\n w.error(e)\n\n\ndef map_num_examples_to_size_categories(n: int) -> str:\n if n <= 0:\n size_cat = \"unknown\"\n elif n < 1000:\n size_cat = \"n<1K\"\n elif n < 10000:\n size_cat = \"1K<n<10K\"\n elif n < 100000:\n size_cat = \"10K<n<100K\"\n elif n < 1000000:\n size_cat = \"100K<n<1M\"\n elif n < 10000000:\n size_cat = \"1M<n<10M\"\n elif n < 100000000:\n size_cat = \"10M<n<100M\"\n elif n < 1000000000:\n size_cat = \"100M<n<1B\"\n elif n < 10000000000:\n size_cat = \"1B<n<10B\"\n elif n < 100000000000:\n size_cat = \"10B<n<100B\"\n elif n < 1000000000000:\n size_cat = \"100B<n<1T\"\n else:\n size_cat = \"n>1T\"\n return size_cat\n\n\ndef is_state_empty(state: Dict[str, List]) -> bool:\n return sum(len(v) if v is not None else 0 for v in state.values()) == 0\n\n\nstate = new_state()\ndatasets_md = load_ds_datas()\ndataset_ids = list(datasets_md.keys())\ndataset_id_to_metadata = {name: mds[\"metadata\"] for name, mds in datasets_md.items()}\ndataset_id_to_infos = {name: mds[\"infos\"] for name, mds in datasets_md.items()}\n\n\n########################\n## Dataset selection\n########################\n\n\nst.sidebar.markdown(\n \"\"\"\n# HuggingFace Dataset Tagger\n\nThis app aims to make it easier to add structured tags to the datasets present in the library.\n\n\"\"\"\n)\n\n\nqueryparams = st.experimental_get_query_params()\npreload = queryparams.get(\"preload_dataset\", list())\npreloaded_id = None\ninitial_state = None\ninitial_infos, initial_info_cfg = None, None\ndataset_selector_index = 0\n\nif len(preload) == 1 and preload[0] in dataset_ids:\n preloaded_id, *_ = preload\n initial_state = dataset_id_to_metadata.get(preloaded_id)\n initial_infos = dataset_id_to_infos.get(preloaded_id)\n initial_info_cfg = next(iter(initial_infos)) if initial_infos is not None else None # pick first available config\n state = initial_state or new_state()\n dataset_selector_index = dataset_ids.index(preloaded_id)\n\npreloaded_id = st.sidebar.selectbox(\n label=\"Choose dataset to load tag set from\", options=dataset_ids, index=dataset_selector_index\n)\n\nleftbtn, rightbtn = st.sidebar.columns(2)\nif leftbtn.button(\"pre-load\"):\n initial_state = dataset_id_to_metadata[preloaded_id]\n initial_infos = dataset_id_to_infos[preloaded_id]\n initial_info_cfg = next(iter(initial_infos)) # pick first available config\n state = initial_state or new_state()\n st.experimental_set_query_params(preload_dataset=preloaded_id)\nif not is_state_empty(state):\n if rightbtn.button(\"flush state\"):\n state = new_state()\n initial_state = None\n preloaded_id = None\n st.experimental_set_query_params()\n\nif preloaded_id is not None and initial_state is not None:\n st.sidebar.markdown(\n f\"\"\"\n---\nThe current base tagset is [`{preloaded_id}`](https://huggingface.co/datasets/{preloaded_id})\n\"\"\"\n )\n validate_dict(st.sidebar, initial_state)\n st.sidebar.markdown(\n f\"\"\"\nHere is the matching yaml block:\n\n```yaml\n{yaml.dump(initial_state)}\n```\n\"\"\"\n )\n\n\nleftcol, _, rightcol = st.columns([12, 1, 12])\n\n#\n# DATASET NAME\n#\nleftcol.markdown(\"### Dataset name\")\nstate[\"pretty_name\"] = leftcol.text_area(\n \"Pick a nice descriptive name for the dataset\",\n)\n\n\n\n#\n# TASKS\n#\nleftcol.markdown(\"### Supported tasks\")\nstate[\"task_categories\"] = multiselect(\n leftcol,\n \"Task category\",\n \"What categories of task does the dataset support?\",\n values=state[\"task_categories\"],\n valid_set=list(known_task_ids.keys()),\n format_func=lambda tg: f\"{tg}: {known_task_ids[tg]['description']}\",\n)\ntask_specifics = []\nfor task_category in state[\"task_categories\"]:\n specs = multiselect(\n leftcol,\n f\"Specific _{task_category}_ tasks\",\n f\"What specific tasks does the dataset support?\",\n values=[ts for ts in (state[\"task_ids\"] or []) if ts in known_task_ids[task_category][\"options\"]],\n valid_set=known_task_ids[task_category][\"options\"],\n )\n if \"other\" in specs:\n other_task = leftcol.text_input(\n \"You selected 'other' task. Please enter a short hyphen-separated description for the task:\",\n value=\"my-task-description\",\n )\n leftcol.write(f\"Registering {task_category}-other-{other_task} task\")\n specs[specs.index(\"other\")] = f\"{task_category}-other-{other_task}\"\n task_specifics += specs\nstate[\"task_ids\"] = task_specifics\n\n\n#\n# LANGUAGES\n#\nleftcol.markdown(\"### Languages\")\nstate[\"multilinguality\"] = multiselect(\n leftcol,\n \"Monolingual?\",\n \"Does the dataset contain more than one language?\",\n values=state[\"multilinguality\"],\n valid_set=list(known_multilingualities.keys()),\n format_func=lambda m: f\"{m} : {known_multilingualities[m]}\",\n)\n\nif \"other\" in state[\"multilinguality\"]:\n other_multilinguality = leftcol.text_input(\n \"You selected 'other' type of multilinguality. Please enter a short hyphen-separated description:\",\n value=\"my-multilinguality\",\n )\n leftcol.write(f\"Registering other-{other_multilinguality} multilinguality\")\n state[\"multilinguality\"][state[\"multilinguality\"].index(\"other\")] = f\"other-{other_multilinguality}\"\n\nvalid_values, invalid_values = list(), list()\nfor langtag in state[\"languages\"]:\n try:\n lc.get(langtag)\n valid_values.append(langtag)\n except:\n invalid_values.append(langtag)\nleftcol.markdown(\"#### Languages\")\nif len(invalid_values) > 0:\n leftcol.markdown(\"Found the following invalid values:\")\n leftcol.error(invalid_values)\n\nlangtags = leftcol.text_area(\n \"What languages are represented in the dataset? expected format is BCP47 tags separated for ';' e.g. 'en-US;fr-FR'\",\n value=\";\".join(valid_values),\n)\nstate[\"languages\"] = langtags.strip().split(\";\") if langtags.strip() != \"\" else []\n\n\n#\n# DATASET CREATORS & ORIGINS\n#\nleftcol.markdown(\"### Dataset creators\")\nstate[\"language_creators\"] = multiselect(\n leftcol,\n \"Data origin\",\n \"Where does the text in the dataset come from?\",\n values=state[\"language_creators\"],\n valid_set=known_creators[\"language\"],\n)\nstate[\"annotations_creators\"] = multiselect(\n leftcol,\n \"Annotations origin\",\n \"Where do the annotations in the dataset come from?\",\n values=state[\"annotations_creators\"],\n valid_set=known_creators[\"annotations\"],\n)\n\n\n#\n# LICENSES\n#\nstate[\"licenses\"] = multiselect(\n leftcol,\n \"Licenses\",\n \"What licenses is the dataset under?\",\n valid_set=list(known_licenses.keys()),\n values=state[\"licenses\"],\n format_func=lambda l: f\"{l} : {known_licenses[l]}\",\n)\nif \"other\" in state[\"licenses\"]:\n other_license = st.text_input(\n \"You selected 'other' type of license. Please enter a short hyphen-separated description:\",\n value=\"my-license\",\n )\n st.write(f\"Registering other-{other_license} license\")\n state[\"licenses\"][state[\"licenses\"].index(\"other\")] = f\"other-{other_license}\"\n\n\n#\n# LINK TO SUPPORTED DATASETS\n#\npre_select_ext_a = []\nif \"original\" in state[\"source_datasets\"]:\n pre_select_ext_a += [\"original\"]\nif any([p.startswith(\"extended\") for p in state[\"source_datasets\"]]):\n pre_select_ext_a += [\"extended\"]\nstate[\"source_datasets\"] = multiselect(\n leftcol,\n \"Relations to existing work\",\n \"Does the dataset contain original data and/or was it extended from other datasets?\",\n values=pre_select_ext_a,\n valid_set=[\"original\", \"extended\"],\n)\n\nif \"extended\" in state[\"source_datasets\"]:\n pre_select_ext_b = [p.split(\"|\")[1] for p in state[\"source_datasets\"] if p.startswith(\"extended|\")]\n extended_sources = multiselect(\n leftcol,\n \"Linked datasets\",\n \"Which other datasets does this one use data from?\",\n values=pre_select_ext_b,\n valid_set=dataset_ids + [\"other\"],\n )\n # flush placeholder\n state[\"source_datasets\"].remove(\"extended\")\n state[\"source_datasets\"] += [f\"extended|{src}\" for src in extended_sources]\n\n\n#\n# SIZE CATEGORY\n#\nleftcol.markdown(\"### Size category\")\nlogging.info(initial_infos[initial_info_cfg][\"splits\"] if initial_infos is not None else 0)\ninitial_num_examples = (\n sum([dct.get(\"num_examples\", 0) for _split, dct in initial_infos[initial_info_cfg].get(\"splits\", dict()).items()])\n if initial_infos is not None\n else -1\n)\ninitial_size_cats = map_num_examples_to_size_categories(initial_num_examples)\nleftcol.markdown(f\"Computed size category from automatically generated dataset info to: `{initial_size_cats}`\")\ncurrent_size_cats = state.get(\"size_categories\") or [\"unknown\"]\nok, nonok = split_known(current_size_cats, known_size_categories)\nif len(nonok) > 0:\n leftcol.markdown(f\"**Found bad codes in existing tagset**:\\n{nonok}\")\nelse:\n state[\"size_categories\"] = [initial_size_cats]\n\n\n########################\n## Show results\n########################\n\nrightcol.markdown(\n f\"\"\"\n### Finalized tag set\n\n\"\"\"\n)\nif is_state_empty(state):\n rightcol.markdown(\"\u274c This is an invalid tagset: it's empty!\")\nelse:\n validate_dict(rightcol, state)\n\n\nrightcol.markdown(\n f\"\"\"\n\n```yaml\n{yaml.dump(state)}\n```\n---\n#### Arbitrary yaml validator\n\nThis is a standalone tool, it is useful to check for errors on an existing tagset or modifying directly the text rather than the UI on the left.\n\"\"\",\n)\n\nyamlblock = rightcol.text_area(\"Input your yaml here\")\nif yamlblock.strip() != \"\":\n inputdict = yaml.safe_load(yamlblock)\n validate_dict(rightcol, inputdict)\n", ".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 491835238883a36ae7d1d2da4b07e44b0a071c2f Hamza Amin <[email protected]> 1727369041 +0500\tclone: from https://github.com/huggingface/datasets-tagging.git\n", ".git\\refs\\heads\\main": "491835238883a36ae7d1d2da4b07e44b0a071c2f\n"} | null |
datasets-viewer | {"type": "directory", "name": "datasets-viewer", "children": [{"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "run.py"}]} | # Hugging Face Datasets Viewer
Viewer for the Hugging Face datasets library.
<img src="viewer.png" />
```
streamlit run run.py
```
or if you want to view local files
```
streamlit run run.py <absolutepath to datasets/datasets/>
```
| {"requirements.txt": "datasets\nstreamlit\npandas>=1.2.4,<1.3\npyyaml\n", ".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n"} | null |
dataspeech | {"type": "directory", "name": "dataspeech", "children": [{"type": "directory", "name": "dataspeech", "children": [{"type": "directory", "name": "cpu_enrichments", "children": [{"type": "file", "name": "rate.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "gpu_enrichments", "children": [{"type": "file", "name": "pitch.py"}, {"type": "file", "name": "snr_and_reverb.py"}, {"type": "file", "name": "squim.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "examples", "children": [{"type": "directory", "name": "prompt_creation", "children": [{"type": "file", "name": "run_prompt_creation_10k.sh"}, {"type": "file", "name": "run_prompt_creation_1k.sh"}, {"type": "file", "name": "run_prompt_creation_1k_with_speaker_consistency.sh"}, {"type": "file", "name": "run_prompt_creation_45k.sh"}, {"type": "file", "name": "run_prompt_creation_dummy.sh"}, {"type": "file", "name": "run_prompt_creation_jenny.sh"}, {"type": "file", "name": "speaker_ids_to_names.json"}]}, {"type": "directory", "name": "prompt_creation_llm_swarm", "children": [{"type": "file", "name": "nginx.template.conf"}, {"type": "file", "name": "run_prompt_creation_10k.sh"}, {"type": "file", "name": "run_prompt_creation_1k.sh"}, {"type": "file", "name": "run_prompt_creation_dummy.sh"}, {"type": "file", "name": "run_prompt_creation_full_mls.sh"}, {"type": "file", "name": "tgi_h100.template.slurm"}]}, {"type": "directory", "name": "tagging", "children": [{"type": "file", "name": "run_main_10k.sh"}, {"type": "file", "name": "run_main_1k.sh"}, {"type": "file", "name": "run_main_45k.sh"}, {"type": "file", "name": "run_main_dummy.sh"}]}, {"type": "directory", "name": "tags_to_annotations", "children": [{"type": "file", "name": "run_metadata_to_text_10k.sh"}, {"type": "file", "name": "run_metadata_to_text_10k_v02.sh"}, {"type": "file", "name": "run_metadata_to_text_for_finetuning.sh"}, {"type": "file", "name": "v01_bin_edges.json"}, {"type": "file", "name": "v01_text_bins.json"}, {"type": "file", "name": "v02_bin_edges.json"}, {"type": "file", "name": "v02_text_bins.json"}]}]}, {"type": "file", "name": "LICENSE"}, {"type": "file", "name": "main.py"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "directory", "name": "scripts", "children": [{"type": "file", "name": "filter_audio_separation.py"}, {"type": "file", "name": "merge_audio_to_metadata.py"}, {"type": "file", "name": "metadata_to_text.py"}, {"type": "directory", "name": "per_dataset_script", "children": [{"type": "file", "name": "add_gender_to_libritts_r.py"}, {"type": "file", "name": "add_gender_to_MLS.py"}, {"type": "file", "name": "clean_libritts_r.py"}]}, {"type": "file", "name": "run_prompt_creation.py"}, {"type": "file", "name": "run_prompt_creation_llm_swarm.py"}]}]} | # Data-Speech
Data-Speech is a suite of utility scripts designed to tag speech datasets.
Its aim is to provide a simple, clean codebase for applying audio transformations (or annotations) that may be requested as part of the development of speech-based AI models, such as text-to-speech engines.
Its primary use is to reproduce the annotation method from Dan Lyth and Simon King's research paper [Natural language guidance of high-fidelity text-to-speech with synthetic annotations](https://arxiv.org/abs/2402.01912), that labels various speaker characteristics with natural language descriptions.
Applying these tools allows us to prepare and release tagged versions of [LibriTTS-R](https://huggingface.co/datasets/parler-tts/libritts-r-filtered-speaker-descriptions), and of [the English version of MLS](https://huggingface.co/datasets/parler-tts/mls-eng-speaker-descriptions).
This repository is designed to accompany the [Parler-TTS library](https://github.com/huggingface/parler-tts), which contains the inference and training code for Parler-TTS, a new family of high-quality text-to-speech models.
---------
## 📖 Quick Index
* [Requirements](#set-up)
* [Annotating datasets to fine-tune Parler-TTS](#annotating-datasets-to-fine-tune-parler-tts)
* [Annotating datasets from scratch](#annotating-datasets-from-scratch)
* [Using Data-Speech to filter your speech datasets](#using-data-speech-to-filter-your-speech-datasets)
* [❓ FAQ](#faq)
* [Logs](#logs)
## Set-up
You first need to clone this repository before installing requirements.
```sh
git clone [email protected]:huggingface/dataspeech.git
cd dataspeech
pip install -r requirements.txt
```
## Annotating datasets to fine-tune Parler-TTS
In the following examples, we'll load 30 hours of audio data from the [Jenny TTS dataset](https://github.com/dioco-group/jenny-tts-dataset), a high-quality mono-speaker TTS dataset, from an Irish female speaker named Jenny.
The aim here is to create an annotated version of Jenny TTS, in order to fine-tune the [Parler-TTS v1 checkpoint](https://huggingface.co/parler-tts/parler-tts-mini-v1) on this dataset.
Thanks to a [script similar to what's described in the FAQ](#how-do-i-use-datasets-that-i-have-with-this-repository), we've uploaded the dataset to the HuggingFace hub, under the name [reach-vb/jenny_tts_dataset](https://huggingface.co/datasets/reach-vb/jenny_tts_dataset).
Feel free to follow the link above to listen to some samples of the Jenny TTS dataset thanks to the hub viewer.
> [!IMPORTANT]
> Refer to the section [Annotating datasets from scratch](#annotating-datasets-from-scratch) for more detailed explanations of what's going on under-the-hood.
We'll:
1. Annotate the Jenny dataset with continuous variables that measures the speech characteristics
2. Map those annotations to text bins that characterize the speech characteristics.
3. Create natural language descriptions from those text bins
### 1. Annotate the Jenny dataset
We'll use [`main.py`](main.py) to get the following continuous variables:
- Speaking rate `(nb_phonemes / utterance_length)`
- Scale-Invariant Signal-to-Distortion Ratio (SI-SDR)
- Reverberation
- Speech monotony
```sh
python main.py "reach-vb/jenny_tts_dataset" \
--configuration "default" \
--text_column_name "transcription" \
--audio_column_name "audio" \
--cpu_num_workers 8 \
--rename_column \
--repo_id "jenny-tts-tags-v1" \
--apply_squim_quality_estimation
```
Note that the script will be faster if you have GPUs at your disposal. It will automatically scale-up to every GPUs available in your environnement.
The resulting dataset will be pushed to the HuggingFace hub under your HuggingFace handle. Mine was pushed to [ylacombe/jenny-tts-tags-v1](https://huggingface.co/datasets/ylacombe/jenny-tts-tags-v1).
### 2. Map annotations to text bins
Since the ultimate goal here is to fine-tune the [Parler-TTS v1 checkpoint](https://huggingface.co/parler-tts/parler-tts-mini-v1) on the Jenny dataset, we want to stay consistent with the text bins of the datasets on which the latter model was trained.
This is easy to do thanks to the following command:
```sh
python ./scripts/metadata_to_text.py \
"ylacombe/jenny-tts-tags-v1" \
--repo_id "jenny-tts-tags-v1" \
--configuration "default" \
--cpu_num_workers "8" \
--path_to_bin_edges "./examples/tags_to_annotations/v02_bin_edges.json" \
--path_to_text_bins "./examples/tags_to_annotations/v02_text_bins.json" \
--avoid_pitch_computation \
--apply_squim_quality_estimation
```
Thanks to [`v02_bin_edges.json`](/examples/tags_to_annotations/v02_bin_edges.json), we don't need to recompute bins from scratch and the above script takes a few seconds.
The resulting dataset will be pushed to the HuggingFace hub under your HuggingFace handle. Mine was push to [ylacombe/jenny-tts-tags-v1](https://huggingface.co/datasets/ylacombe/jenny-tts-tags-v1).
You can notice that text bins such as `slightly slowly`, `very monotone` have been added to the samples.
### 3. Create natural language descriptions from those text bins
Now that we have text bins associated to the Jenny dataset, the next step is to create natural language descriptions out of the few created features.
Here, we decided to create prompts that use the name `Jenny`, prompts that'll look like the following:
`In a very expressive voice, Jenny pronounces her words incredibly slowly. There's some background noise in this room with a bit of echo.'`
This step generally demands more resources and times and should use one or many GPUs.
[`run_prompt_creation_jenny.sh`](examples/prompt_creation/run_prompt_creation_jenny.sh) indicates how to run it on the Jenny dataset:
```sh
python ./scripts/run_prompt_creation.py \
--speaker_name "Jenny" \
--is_single_speaker \
--is_new_speaker_prompt \
--dataset_name "ylacombe/jenny-tts-tags-v1" \
--dataset_config_name "default" \
--model_name_or_path "mistralai/Mistral-7B-Instruct-v0.2" \
--per_device_eval_batch_size 128 \
--attn_implementation "sdpa" \
--output_dir "./tmp_jenny" \
--load_in_4bit \
--push_to_hub \
--hub_dataset_id "jenny-tts-tagged-v1" \
--preprocessing_num_workers 24 \
--dataloader_num_workers 24
```
As usual, we precise the dataset name and configuration we want to annotate. `model_name_or_path` should point to a `transformers` model for prompt annotation. You can find a list of such models [here](https://huggingface.co/models?pipeline_tag=text-generation&library=transformers&sort=trending). Here, we used a version of Mistral's 7B model.
> [!NOTE]
> If you want to use this on a multi-speaker dataset, you'll have to adapt the logic of the script. First, you need to remove the `--is_single_speaker` and `--speaker_name "Jenny"` flags.
>
> Then, there's two cases:
> 1. In case you want to associate names to some speakers, you need to pass the speaker id column name, and a JSON file which maps the speaker ids to these names. For example, `--speaker_id_column "speaker_id" --speaker_ids_to_name_json ./examples/prompt_creation/speaker_ids_to_names.json`. Feel free to take a look at [speaker_ids_to_names.json](examples/prompt_creation/speaker_ids_to_names.json) to get inspiration.
> 2. In case you don't want to associate names to speakers, you don't have to do anything else.
## Annotating datasets from scratch
In the following examples, we'll load 1,000 hours of labelled audio data from the [LibriTTS-R dataset](https://huggingface.co/datasets/blabble-io/libritts_r) and add annotations using the dataspeech library. The resulting dataset is complete with discrete annotation tags, as well as a coherent audio
description of the spoken audio characteristics.
There are 3 steps to be completed in order to generate annotations:
1. [Annotate the speech dataset](#predict-annotations) to get the following continuous variables:
- Speaking rate `(nb_phonemes / utterance_length)`
- Scale-Invariant Signal-to-Distortion Ratio (SI-SDR)
- Reverberation
- Speech monotony
2. [Map the previous annotations categorical to discrete keywords bins](#map-continuous-annotations-to-key-words)
3. [Create natural language descriptions from a set of keywords](#generate-natural-language-descriptions)
### 1. Predict annotations
For the time being, [`main.py`](main.py) can be used to generate speaking rate, SNR, reverberation, PESQ, SI-SDR and pitch estimation.
To use it, you need a dataset from the [datasets](https://huggingface.co/docs/datasets/v2.17.0/en/index) library, either locally or on the [hub](https://huggingface.co/datasets).
```sh
python main.py "blabble-io/libritts_r" \
--configuration "dev" \
--output_dir ./tmp_libritts_r_dev/ \
--text_column_name "text_normalized" \
--audio_column_name "audio" \
--cpu_num_workers 8 \
--rename_column \
--apply_squim_quality_estimation
```
Here, we've used 8 processes for operations that don't use GPUs, namely to compute the speaking rate. If GPUs were present in the environnement, the operations that can be computed on GPUs - namely pitch, SNR and reverberation estimation - will use every GPUs available in the environnement.
You can learn more about the arguments you can pass to `main.py` by passing:
```sh
python main.py --help
```
In [`/examples/tagging/run_main_1k.sh`](/examples/tagging/run_main_1k.sh), we scaled up the initial command line to the whole dataset. Note that we've used the `repo_id` argument to push the dataset to the hub, resulting in [this dataset](https://huggingface.co/datasets/ylacombe/libritts-r-text-tags-v3).
The dataset viewer gives an idea of what has been done, namely:
- new columns were added:
- `utterance_pitch_std`: Gives a measure of the standard deviation of pitch in the utterance.
- `utterance_pitch_mean`: Gives a measure of average pitch in the utterance.
- `snr`: Speech-to-noise ratio
- `c50`: Reverberation estimation
- `speaking_rate`
- `phonemes`: which was used to compute the speaking rate
- `pesq` and `si-sdr`: which measure intelligibility and a proxy of noise, as indicated [here](https://pytorch.org/audio/main/tutorials/squim_tutorial.html)
- the audio column was removed - this is especially useful when dealing with big datasets, as writing and pushing audio data can become a bottleneck.

### 2. Map continuous annotations to key-words
The next step is to map the continuous annotations from the previous steps to key-words. To do so, continous annotations are mapped to categorical bins that are then associated to key-words. For example, the speaking rate can be associated to 7 text bins which are: `"very slowly", "quite slowly", "slightly slowly", "moderate speed", "slightly fast", "quite fast", "very fast"`.
[`scripts/metadata_to_text.py`](/scripts/metadata_to_text.py) computes bins on aggregated statistics from multiple datasets:
- A speaker's pitch is calculated by averaging the pitches across its voice clips. The computed pitch estimator is then compared to speakers of the same gender to derive the pitch keyword of the speaker(very high-pitched to very low-pitched).
- The rest of the keywords are derived by [computing histograms](https://numpy.org/doc/stable/reference/generated/numpy.histogram.html) of the continuous variables over all training samples, from which the extreme values have been eliminated, and associating a keyword with each bin.
```sh
python ./scripts/metadata_to_text.py "ylacombe/libritts-r-text-tags-v3+ylacombe/libritts-r-text-tags-v3" \
--configuration "clean+other" \
--output_dir "./tmp_tts_clean+./tmp_tts_other" \
--cpu_num_workers "8" \
--leading_split_for_bins "train" \
--plot_directory "./plots/" \
--path_to_text_bins "./examples/tags_to_annotations/v02_text_bins.json" \
--apply_squim_quality_estimation \
```
Note how we've been able to pass different datasets with different configurations by separating the relevant arguments with `"+"`.
By passing `--repo_id parler-tts/libritts-r-tags-and-text+parler-tts/libritts-r-tags-and-text`, we pushed the resulting dataset to [this hub repository](https://huggingface.co/datasets/parler-tts/libritts-r-tags-and-text).
Note that this step is a bit more subtle than the previous one, as we generally want to collect a wide variety of speech data to compute accurate key-words.
Indeed, some datasets, such as LibriTTS-R, collect data from only one or a few sources; for LibriTTS-R, these are audiobooks, and the process of collecting or processing the data can result in homogeneous data that has little variation. In the case of LibriTTS-R, the data has been cleaned to have little noise, little reverberation, and the audiobooks collected leaves little variety in intonation.
You can learn more about the arguments you can pass to `main.py` by passing:
```sh
python main.py --help
```
### 3. Generate natural language descriptions
Now that we have text bins associated to our datasets, the next step is to create natural language descriptions. To
achieve this, we pass the discrete features to an LLM, and have it generate a natural language description. This step
generally demands more resources and times and should use one or many GPUs. It can be performed in one of two ways:
1. Using the [Accelerate](https://huggingface.co/docs/accelerate/index)-based script, [`scripts/run_prompt_creation.py`](/scripts/run_prompt_creation.py), or
2. Using the [TGI](https://huggingface.co/docs/text-generation-inference/en/index)-based script, [`scripts/run_prompt_creation_llm_swarm.py`](/scripts/run_prompt_creation_llm_swarm.py)
We recommend you first try the Accelerate script, since it makes no assumptions about the GPU hardware available and is
thus easier to run. Should you need faster inference, you can switch to the TGI script, which assumes you have a SLURM
cluster with Docker support.
### 3.1 Accelerate Inference
[`scripts/run_prompt_creation.py`](/scripts/run_prompt_creation.py) relies on [`accelerate`](https://huggingface.co/docs/accelerate/index) and [`transformers`](https://huggingface.co/docs/transformers/index) to generate natural language descriptions from LLMs.
[`examples/prompt_creation/run_prompt_creation_1k.sh`](examples/prompt_creation/run_prompt_creation_1k.sh) indicates how to run it on LibriTTS-R
with 8 GPUs in half-precision:
```sh
accelerate launch --multi_gpu --mixed_precision=fp16 --num_processes=8 run_prompt_creation.py \
--dataset_name "parler-tts/libritts-r-tags-and-text" \
--dataset_config_name "clean" \
--model_name_or_path "meta-llama/Meta-Llama-3-8B-Instruct" \
--per_device_eval_batch_size 64 \
--attn_implementation "sdpa" \
--torch_compile \
--dataloader_num_workers 4 \
--output_dir "./" \
--load_in_4bit \
--push_to_hub \
--hub_dataset_id "parler-tts/libritts-r-tags-and-text-generated" \
--is_new_speaker_prompt \
```
As usual, we define the dataset name and configuration we want to annotate. `model_name_or_path` should point to a `transformers` model for prompt annotation. You can find a list of such models [here](https://huggingface.co/models?pipeline_tag=text-generation&library=transformers&sort=trending). Here, we used an instruction-tuned version of Meta's LLaMA-3 8B model. Should you use LLaMA or Gemma, you can enable torch compile with the flag `--torch_compile` for up to 1.5x faster inference.
The folder [`examples/prompt_creation/`](examples/prompt_creation/) contains more examples.
In particular, (`run_prompt_creation_1k_with_speaker_consistency.sh`)[examples/prompt_creation/run_prompt_creation_1k_with_speaker_consistency.sh] adapts the previous example but introduces speaker consistency. Here, "speaker consistency" simply means associating certain speakers with specific names. In this case, all descriptions linked to these speakers will specify their names, rather than generating anonymous descriptions.
> [!TIP]
> Scripts from this library can also be used as a starting point for applying other models to other datasets from the [datasets library](https://huggingface.co/docs/datasets/v2.17.0/en/index) in a large-scale settings.
>
> For example, `scripts/run_prompt_creation.py` can be adapted to perform large-scaled inference using other LLMs and prompts.
### 3.2 TGI Inference
[`scripts/run_prompt_creation_llm_swarm.py`](/scripts/run_prompt_creation_llm_swarm.py) relies on [TGI](https://huggingface.co/docs/text-generation-inference/en/index)
and [LLM-Swarm](https://github.com/huggingface/llm-swarm/tree/main) to generate descriptions from an LLM endpoint.
Compared to the Accelerate script, it uses continuous-batching, which improves throughput by up to 1.5x. It requires one
extra dependency, LLM-Swarm:
```sh
pip install git+https://github.com/huggingface/llm-swarm.git
```
[`examples/prompt_creation_llm_swarm/run_prompt_creation_1k.sh`](examples/prompt_creation_llm_swarm/run_prompt_creation_1k.sh) indicates how to run it on LibriTTS-R
with 1 TGI instance:
```sh
python run_prompt_creation_llm_swarm.py \
--dataset_name "stable-speech/libritts-r-tags-and-text" \
--dataset_config_name "clean" \
--model_name_or_path "mistralai/Mistral-7B-Instruct-v0.2" \
--num_instances "1" \
--output_dir "./" \
--push_to_hub \
--hub_dataset_id "parler-tts/libritts-r-tags-and-text-generated"
```
Note that the script relies on the SLURM file [`examples/prompt_creation_llm_swarm/tgi_h100.template.slurm`](examples/prompt_creation_llm_swarm/tgi_h100.template.slurm),
which is a template configuration for the Hugging Face H100 cluster. You can update the config based on your cluster.
### To conclude
In the [`/examples`](/examples/) folder, we applied this recipe to both [MLS Eng](https://huggingface.co/datasets/parler-tts/mls-eng-speaker-descriptions) and [LibriTTS-R](https://huggingface.co/datasets/parler-tts/libritts-r-filtered-speaker-descriptions). The resulting datasets were used to train [Parler-TTS](https://github.com/huggingface/parler-tts), a new text-to-speech model.
This recipe is both scalable and easily modifiable and will hopefully help the TTS research community explore new ways of conditionning speech synthesis.
## Using Data-Speech to filter your speech datasets
While the rest of the README explains how to use this repository to create text descriptions of speech utterances, Data-Speech can also be used to perform filtering on speech datasets.
For example, you can
1. Use the [`Predict annotations`](#1-predict-annotations) step to predict SNR and reverberation.
2. Filter your data sets to retain only the most qualitative samples.
You could also, to give more examples, filter on a certain pitch level (e.g only low-pitched voices), or a certain speech rate (e.g only fast speech).
## FAQ
### What kind of datasets do I need?
We rely on the [`datasets`](https://huggingface.co/docs/datasets/v2.17.0/en/index) library, which is optimized for speed and efficiency, and is deeply integrated with the [HuggingFace Hub](https://huggingface.co/datasets) which allows easy sharing and loading.
In order to use this repository, you need a speech dataset from [`datasets`](https://huggingface.co/docs/datasets/v2.17.0/en/index) with at least one audio column and a text transcription column. Additionally, you also need a gender and a speaker id column, especially if you want to compute pitch.
### How do I use datasets that I have with this repository?
If you have a local dataset, and want to create a dataset from [`datasets`](https://huggingface.co/docs/datasets/v2.17.0/en/index) to use Data-Speech, you can use the following recipes or refer to the [`dataset` docs](https://huggingface.co/docs/datasets/v2.17.0/en/index) for more complex use-cases.
1. You first need to create a csv file that contains the **full paths** to the audio. The column name for those audio files could be for example `audio`, but you can use whatever you want. You also need a column with the transcriptions of the audio, this column can be named `transcript` but you can use whatever you want.
2. Once you have this csv file, you can load it to a dataset like this:
```python
from datasets import DatasetDict
dataset = DatasetDict.from_csv({"train": PATH_TO_CSV_FILE})
```
3. You then need to convert the audio column name to [`Audio`](https://huggingface.co/docs/datasets/v2.19.0/en/package_reference/main_classes#datasets.Audio) so that `datasets` understand that it deals with audio files.
```python
from datasets import Audio
dataset = dataset.cast_column("audio", Audio())
```
4. You can then [push the dataset to the hub](https://huggingface.co/docs/datasets/v2.19.0/en/package_reference/main_classes#datasets.DatasetDict.push_to_hub):
```python
dataset.push_to_hub(REPO_ID)
```
Note that you can make the dataset private by passing [`private=True`](https://huggingface.co/docs/datasets/v2.19.0/en/package_reference/main_classes#datasets.DatasetDict.push_to_hub.private) to the [`push_to_hub`](https://huggingface.co/docs/datasets/v2.19.0/en/package_reference/main_classes#datasets.DatasetDict.push_to_hub) method. Find other possible arguments [here](https://huggingface.co/docs/datasets/v2.19.0/en/package_reference/main_classes#datasets.DatasetDict.push_to_hub).
When using Data-Speech, you can then use `REPO_ID` (replace this by the name you want here and above) as the dataset name.
## Logs
* [August 2024]: Updated version of Data-Speech, suited for Parler-TTS v1
* New measures: Pesq and SI-SDR, the latter being used for better noise estimation
* Improved prompts
* Prompt creation can deal with speaker consistency and accents
* [April 2024]: Release of the first version of Data-Speech
## Acknowledgements
This library builds on top of a number of open-source giants, to whom we'd like to extend our warmest thanks for providing these tools!
Special thanks to:
- Dan Lyth and Simon King, from Stability AI and Edinburgh University respectively, for publishing such a promising and clear research paper: [Natural language guidance of high-fidelity text-to-speech with synthetic annotations](https://arxiv.org/abs/2402.01912).
- and the many libraries used, namely [datasets](https://huggingface.co/docs/datasets/v2.17.0/en/index), [brouhaha](https://github.com/marianne-m/brouhaha-vad/blob/main/README.md), [penn](https://github.com/interactiveaudiolab/penn/blob/master/README.md), [g2p](https://github.com/Kyubyong/g2p), [accelerate](https://huggingface.co/docs/accelerate/en/index) and [transformers](https://huggingface.co/docs/transformers/index).
## Citation
If you found this repository useful, please consider citing this work and also the original Stability AI paper:
```
@misc{lacombe-etal-2024-dataspeech,
author = {Yoach Lacombe and Vaibhav Srivastav and Sanchit Gandhi},
title = {Data-Speech},
year = {2024},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/ylacombe/dataspeech}}
}
```
```
@misc{lyth2024natural,
title={Natural language guidance of high-fidelity text-to-speech with synthetic annotations},
author={Dan Lyth and Simon King},
year={2024},
eprint={2402.01912},
archivePrefix={arXiv},
primaryClass={cs.SD}
}
```
### TODOs
- [ ] Accent classification training script
- [ ] Accent classification inference script
- [x] Better speaking rate estimation with long silence removal
- [x] Better SNR estimation with other SNR models
- [ ] Add more annotation categories
- [ ] Multilingual speaking rate estimation
- [ ] (long term) Benchmark for best audio dataset format
- [ ] (long term) Compatibility with streaming
| {"main.py": "from datasets import load_dataset, Audio\nfrom multiprocess import set_start_method\nfrom dataspeech import rate_apply, pitch_apply, snr_apply, squim_apply\nimport torch\nimport argparse\n\n\nif __name__ == \"__main__\":\n set_start_method(\"spawn\")\n parser = argparse.ArgumentParser()\n \n \n parser.add_argument(\"dataset_name\", type=str, help=\"Path or name of the dataset. See: https://huggingface.co/docs/datasets/v2.17.0/en/package_reference/loading_methods#datasets.load_dataset.path\")\n parser.add_argument(\"--configuration\", default=None, type=str, help=\"Dataset configuration to use, if necessary.\")\n parser.add_argument(\"--output_dir\", default=None, type=str, help=\"If specified, save the dataset on disk with this path.\")\n parser.add_argument(\"--repo_id\", default=None, type=str, help=\"If specified, push the dataset to the hub.\")\n parser.add_argument(\"--audio_column_name\", default=\"audio\", type=str, help=\"Column name of the audio column to be enriched.\")\n parser.add_argument(\"--text_column_name\", default=\"text\", type=str, help=\"Text column name.\")\n parser.add_argument(\"--rename_column\", action=\"store_true\", help=\"If activated, rename audio and text column names to 'audio' and 'text'. Useful if you want to merge datasets afterwards.\")\n parser.add_argument(\"--cpu_num_workers\", default=1, type=int, help=\"Number of CPU workers for transformations that don't use GPUs or if no GPU are available.\")\n parser.add_argument(\"--cpu_writer_batch_size\", default=1000, type=int, help=\"writer_batch_size for transformations that don't use GPUs. See: https://huggingface.co/docs/datasets/v2.17.0/en/package_reference/main_classes#datasets.Dataset.map.writer_batch_size\")\n parser.add_argument(\"--batch_size\", default=2, type=int, help=\"This parameters specify how many samples are passed by workers for operations that are using GPUs.\")\n parser.add_argument(\"--penn_batch_size\", default=4096, type=int, help=\"Pitch estimation chunks audio into smaller pieces and processes them in batch. This specify the batch size. If you are using a gpu, pick a batch size that doesn't cause memory errors.\")\n parser.add_argument(\"--num_workers_per_gpu_for_pitch\", default=1, type=int, help=\"Number of workers per GPU for the pitch estimation if GPUs are available. Defaults to 1 if some are avaiable. Useful if you want multiple processes per GPUs to maximise GPU usage.\")\n parser.add_argument(\"--num_workers_per_gpu_for_snr\", default=1, type=int, help=\"Number of workers per GPU for the SNR and reverberation estimation if GPUs are available. Defaults to 1 if some are avaiable. Useful if you want multiple processes per GPUs to maximise GPU usage.\")\n parser.add_argument(\"--apply_squim_quality_estimation\", action=\"store_true\", help=\"If set, will also use torchaudio-squim estimation (SI-SNR, STOI and PESQ).\")\n parser.add_argument(\"--num_workers_per_gpu_for_squim\", default=1, type=int, help=\"Number of workers per GPU for the SI-SNR, STOI and PESQ estimation if GPUs are available. Defaults to 1 if some are avaiable. Useful if you want multiple processes per GPUs to maximise GPU usage.\")\n\n\n args = parser.parse_args()\n \n if args.configuration:\n dataset = load_dataset(args.dataset_name, args.configuration, num_proc=args.cpu_num_workers,)\n else:\n dataset = load_dataset(args.dataset_name, num_proc=args.cpu_num_workers,)\n \n audio_column_name = \"audio\" if args.rename_column else args.audio_column_name\n text_column_name = \"text\" if args.rename_column else args.text_column_name\n if args.rename_column:\n dataset = dataset.rename_columns({args.audio_column_name: \"audio\", args.text_column_name: \"text\"})\n \n\n if args.apply_squim_quality_estimation:\n print(\"Compute SI-SDR, PESQ, STOI\")\n squim_dataset = dataset.map(\n squim_apply,\n batched=True,\n batch_size=args.batch_size,\n with_rank=True if torch.cuda.device_count()>0 else False,\n num_proc=torch.cuda.device_count()*args.num_workers_per_gpu_for_squim if torch.cuda.device_count()>0 else args.cpu_num_workers,\n remove_columns=[audio_column_name], # tricks to avoid rewritting audio\n fn_kwargs={\"audio_column_name\": audio_column_name,},\n )\n\n print(\"Compute pitch\")\n pitch_dataset = dataset.cast_column(audio_column_name, Audio(sampling_rate=16_000)).map(\n pitch_apply,\n batched=True,\n batch_size=args.batch_size,\n with_rank=True if torch.cuda.device_count()>0 else False,\n num_proc=torch.cuda.device_count()*args.num_workers_per_gpu_for_pitch if torch.cuda.device_count()>0 else args.cpu_num_workers,\n remove_columns=[audio_column_name], # tricks to avoid rewritting audio\n fn_kwargs={\"audio_column_name\": audio_column_name, \"penn_batch_size\": args.penn_batch_size},\n )\n\n print(\"Compute snr and reverb\")\n snr_dataset = dataset.map(\n snr_apply,\n batched=True,\n batch_size=args.batch_size,\n with_rank=True if torch.cuda.device_count()>0 else False,\n num_proc=torch.cuda.device_count()*args.num_workers_per_gpu_for_snr if torch.cuda.device_count()>0 else args.cpu_num_workers,\n remove_columns=[audio_column_name], # tricks to avoid rewritting audio\n fn_kwargs={\"audio_column_name\": audio_column_name},\n )\n \n print(\"Compute speaking rate\")\n if \"speech_duration\" in snr_dataset[next(iter(snr_dataset.keys()))].features: \n rate_dataset = snr_dataset.map(\n rate_apply,\n with_rank=False,\n num_proc=args.cpu_num_workers,\n writer_batch_size= args.cpu_writer_batch_size,\n fn_kwargs={\"audio_column_name\": audio_column_name, \"text_column_name\": text_column_name},\n )\n else:\n rate_dataset = dataset.map(\n rate_apply,\n with_rank=False,\n num_proc=args.cpu_num_workers,\n writer_batch_size= args.cpu_writer_batch_size,\n remove_columns=[audio_column_name], # tricks to avoid rewritting audio\n fn_kwargs={\"audio_column_name\": audio_column_name, \"text_column_name\": text_column_name},\n )\n \n for split in dataset.keys():\n dataset[split] = pitch_dataset[split].add_column(\"snr\", snr_dataset[split][\"snr\"]).add_column(\"c50\", snr_dataset[split][\"c50\"])\n if \"speech_duration\" in snr_dataset[split]:\n dataset[split] = dataset[split].add_column(\"speech_duration\", snr_dataset[split][\"speech_duration\"])\n dataset[split] = dataset[split].add_column(\"speaking_rate\", rate_dataset[split][\"speaking_rate\"]).add_column(\"phonemes\", rate_dataset[split][\"phonemes\"])\n if args.apply_squim_quality_estimation:\n dataset[split] = dataset[split].add_column(\"stoi\", squim_dataset[split][\"stoi\"]).add_column(\"si-sdr\", squim_dataset[split][\"sdr\"]).add_column(\"pesq\", squim_dataset[split][\"pesq\"])\n \n if args.output_dir:\n print(\"Saving to disk...\")\n dataset.save_to_disk(args.output_dir)\n if args.repo_id:\n print(\"Pushing to the hub...\")\n if args.configuration:\n dataset.push_to_hub(args.repo_id, args.configuration)\n else:\n dataset.push_to_hub(args.repo_id)\n \n", "requirements.txt": "datasets[audio]\nhttps://github.com/marianne-m/brouhaha-vad/archive/main.zip\npenn\ng2p\ndemucs\ntransformers\naccelerate\nbitsandbytes", ".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 aecbcfde51bfcada69b1983ae46b24bf2fe545a0 Hamza Amin <[email protected]> 1727369047 +0500\tclone: from https://github.com/huggingface/dataspeech.git\n", ".git\\refs\\heads\\main": "aecbcfde51bfcada69b1983ae46b24bf2fe545a0\n", "examples\\tagging\\run_main_10k.sh": "#!/usr/bin/env bash\n\npython main.py \"blabble-io/libritts_r\" \\\n --configuration \"clean\" \\\n --output_dir ./tmp_libritts_r_clean/ \\\n --text_column_name \"text_normalized\" \\\n --audio_column_name \"audio\" \\\n --cpu_num_workers 32 \\\n --num_workers_per_gpu 4 \\\n --rename_column \\\n --repo_id \"ylacombe/libritts_r_tags\"\\\n\npython main.py \"blabble-io/libritts_r\" \\\n --configuration \"other\" \\\n --output_dir ./tmp_libritts_r_other/ \\\n --text_column_name \"text_normalized\" \\\n --audio_column_name \"audio\" \\\n --cpu_num_workers 32 \\\n --num_workers_per_gpu 4 \\\n --rename_column \\\n --repo_id \"ylacombe/libritts_r_tags\"\\\n\npython main.py \"parler-tts/mls_eng_10k\" \\\n --output_dir ./tmp_mls_eng_10k/ \\\n --text_column_name \"transcript\" \\\n --audio_column_name \"audio\" \\\n --cpu_num_workers 32 \\\n --num_workers_per_gpu 4 \\\n --rename_column \\\n --repo_id \"ylacombe/mls_eng_10k_tags\"\\", "examples\\tagging\\run_main_1k.sh": "#!/usr/bin/env bash\n\npython main.py \"blabble-io/libritts_r\" \\\n --configuration \"clean\" \\\n --output_dir ./tmp_libritts_r_clean/ \\\n --text_column_name \"text_normalized\" \\\n --audio_column_name \"audio\" \\\n --cpu_num_workers 32 \\\n --num_workers_per_gpu 4 \\\n --rename_column \\\n --repo_id \"ylacombe/libritts-r-text-tags-v3\"\\\n --apply_squim_quality_estimation \\\n\n\npython main.py \"blabble-io/libritts_r\" \\\n --configuration \"other\" \\\n --output_dir ./tmp_libritts_r_other/ \\\n --text_column_name \"text_normalized\" \\\n --audio_column_name \"audio\" \\\n --cpu_num_workers 32 \\\n --num_workers_per_gpu 4 \\\n --rename_column \\\n --repo_id \"ylacombe/libritts-r-text-tags-v3\"\\\n --apply_squim_quality_estimation \\\n\n", "examples\\tagging\\run_main_45k.sh": "#!/usr/bin/env bash\n\npython main.py \"blabble-io/libritts_r\" \\\n --configuration \"clean\" \\\n --output_dir ./tmp_libritts_r_clean/ \\\n --text_column_name \"text_normalized\" \\\n --audio_column_name \"audio\" \\\n --cpu_num_workers 32 \\\n --num_workers_per_gpu 4 \\\n --rename_column \\\n --repo_id \"ylacombe/libritts-r-text-tags-v3\"\\\n --apply_squim_quality_estimation \\\n\n\npython main.py \"blabble-io/libritts_r\" \\\n --configuration \"other\" \\\n --output_dir ./tmp_libritts_r_other/ \\\n --text_column_name \"text_normalized\" \\\n --audio_column_name \"audio\" \\\n --cpu_num_workers 32 \\\n --num_workers_per_gpu 4 \\\n --rename_column \\\n --repo_id \"ylacombe/libritts-r-text-tags-v3\"\\\n --apply_squim_quality_estimation \\\n\npython main.py \"parler-tts/mls_eng\" \\\n --output_dir ./tmp_mls_eng/ \\\n --text_column_name \"transcript\" \\\n --audio_column_name \"audio\" \\\n --cpu_num_workers 32 \\\n --num_workers_per_gpu 4 \\\n --rename_column \\\n --repo_id \"ylacombe/mls-eng-tags-v4\"\\\n --apply_squim_quality_estimation \\\n", "examples\\tagging\\run_main_dummy.sh": "#!/usr/bin/env bash\n\npython main.py \"blabble-io/libritts_r\" \\\n --configuration \"dev\" \\\n --output_dir ./tmp_libritts_r_dev/ \\\n --text_column_name \"text_normalized\" \\\n --audio_column_name \"audio\" \\\n --cpu_num_workers 8 \\\n --num_workers_per_gpu 4 \\\n --rename_column \\"} | null |
diffusion-fast | {"type": "directory", "name": "diffusion-fast", "children": [{"type": "file", "name": "Dockerfile"}, {"type": "directory", "name": "experiment-scripts", "children": [{"type": "file", "name": "run_pixart.sh"}, {"type": "file", "name": "run_sd.sh"}, {"type": "file", "name": "run_sd_cpu.sh"}]}, {"type": "file", "name": "LICENSE"}, {"type": "file", "name": "Makefile"}, {"type": "file", "name": "prepare_results.py"}, {"type": "file", "name": "pyproject.toml"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "run_benchmark.py"}, {"type": "file", "name": "run_benchmark_pixart.py"}, {"type": "file", "name": "run_profile.py"}, {"type": "directory", "name": "utils", "children": [{"type": "file", "name": "benchmarking_utils.py"}, {"type": "file", "name": "pipeline_utils.py"}, {"type": "file", "name": "pipeline_utils_pixart.py"}]}]} | # Diffusion, fast
Repository for the blog post: [**Accelerating Generative AI Part III: Diffusion, Fast**](https://pytorch.org/blog/accelerating-generative-ai-3/). You can find a run down of the techniques on the [🤗 Diffusers website](https://huggingface.co/docs/diffusers/main/en/tutorials/fast_diffusion) too.
<div align="center">
<img src="https://huggingface.co/datasets/sayakpaul/sample-datasets/resolve/main/final-results-diffusion-fast/SDXL%2C_Batch_Size%3A_1%2C_Steps%3A_30.png" width=500>
</div><br>
Summary of the optimizations:
* Running with the bfloat16 precision
* `scaled_dot_product_attention` (SDPA)
* `torch.compile`
* Combining q,k,v projections for attention computation
* Dynamic int8 quantization
These techniques are fairly generalizable to other pipelines too, as we show below.
Table of contents:
* [Setup](#setup-🛠️)
* [Running benchmarking experiments](#running-a-benchmarking-experiment-🏎️)
* [Code](#improvements-progressively-📈-📊)
* [Results from other pipelines](#results-from-other-pipelines-🌋)
## Setup 🛠️
We rely on pure PyTorch for the optimizations. You can refer to the [Dockerfile](./Dockerfile) to get the complete development environment setup.
For hardware, we used an 80GB 400W A100 GPU with its memory clock set to the maximum rate (1593 in our case).
Meanwhile, these optimizations (BFloat16, SDPA, torch.compile, Combining q,k,v projections) can run on CPU platforms as well, and bring 4x latency improvement to Stable Diffusion XL (SDXL) on 4th Gen Intel® Xeon® Scalable processors.
## Running a benchmarking experiment 🏎️
[`run_benchmark.py`](./run_benchmark.py) is the main script for benchmarking the different optimization techniques. After an experiment has been done, you should expect to see two files:
* A `.csv` file with all the benchmarking numbers.
* A `.jpeg` image file corresponding to the experiment.
Refer to the [`experiment-scripts/run_sd.sh`](./experiment-scripts/run_sd.sh) for some reference experiment commands.
**Notes on running PixArt-Alpha experiments**:
* Use the [`run_experiment_pixart.py`](./run_benchmark_pixart.py) for this.
* Uninstall the current installation of `diffusers` and re-install it again like so: `pip install git+https://github.com/huggingface/diffusers@fuse-projections-pixart`.
* Refer to the [`experiment-scripts/run_pixart.sh`](./experiment-scripts/run_pixart.sh) script for some reference experiment commands.
_(Support for PixArt-Alpha is experimental.)_
You can use the [`prepare_results.py`](./prepare_results.py) script to generate a consolidated CSV file and a plot to visualize the results from it. This is best used after you have run a couple of benchmarking experiments already and have their corresponding CSV files.
The script also supports CPU platforms, you can refer to the [`experiment-scripts/run_sd_cpu.sh`](./experiment-scripts/run_sd_cpu.sh) for some reference experiment commands.
To run the script, you need the following dependencies:
* pandas
* matplotlib
* seaborn
## Improvements, progressively 📈 📊
<details>
<summary>Baseline</summary>
```python
from diffusers import StableDiffusionXLPipeline
# Load the pipeline in full-precision and place its model components on CUDA.
pipe = StableDiffusionXLPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0"
).to("cuda")
# Run the attention ops without efficiency.
pipe.unet.set_default_attn_processor()
pipe.vae.set_default_attn_processor()
prompt = "Astronaut in a jungle, cold color palette, muted colors, detailed, 8k"
image = pipe(prompt, num_inference_steps=30).images[0]
```
With this, we're at:
<div align="center">
<img src="https://huggingface.co/datasets/sayakpaul/sample-datasets/resolve/main/progressive-acceleration-sdxl/SDXL%2C_Batch_Size%3A_1%2C_Steps%3A_30_0.png" width=500>
</div>
</details>
<details>
<summary>Bfloat16</summary>
```python
from diffusers import StableDiffusionXLPipeline
import torch
pipe = StableDiffusionXLPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.bfloat16
).to("cuda")
# Run the attention ops without efficiency.
pipe.unet.set_default_attn_processor()
pipe.vae.set_default_attn_processor()
prompt = "Astronaut in a jungle, cold color palette, muted colors, detailed, 8k"
image = pipe(prompt, num_inference_steps=30).images[0]
```
<div align="center">
<img src="https://huggingface.co/datasets/sayakpaul/sample-datasets/resolve/main/progressive-acceleration-sdxl/SDXL%2C_Batch_Size%3A_1%2C_Steps%3A_30_1.png" width=500>
</div>
> 💡 We later ran the experiments in float16 and found out that the recent versions of `torchao` do not incur numerical problems from float16.
</details>
<details>
<summary>scaled_dot_product_attention</summary>
```python
from diffusers import StableDiffusionXLPipeline
import torch
pipe = StableDiffusionXLPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.bfloat16
).to("cuda")
prompt = "Astronaut in a jungle, cold color palette, muted colors, detailed, 8k"
image = pipe(prompt, num_inference_steps=30).images[0]
```
<div align="center">
<img src="https://huggingface.co/datasets/sayakpaul/sample-datasets/resolve/main/progressive-acceleration-sdxl/SDXL%2C_Batch_Size%3A_1%2C_Steps%3A_30_2.png" width=500>
</div>
</details>
<details>
<summary>torch.compile</summary><br>
First, configure some compiler flags:
```python
from diffusers import StableDiffusionXLPipeline
import torch
# Set the following compiler flags to make things go brrr.
torch._inductor.config.conv_1x1_as_mm = True
torch._inductor.config.coordinate_descent_tuning = True
torch._inductor.config.epilogue_fusion = False
torch._inductor.config.coordinate_descent_check_all_directions = True
```
Then load the pipeline:
```python
pipe = StableDiffusionXLPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.bfloat16
).to("cuda")
```
Compile and perform inference:
```python
# Compile the UNet and VAE.
pipe.unet.to(memory_format=torch.channels_last)
pipe.vae.to(memory_format=torch.channels_last)
pipe.unet = torch.compile(pipe.unet, mode="max-autotune", fullgraph=True)
pipe.vae.decode = torch.compile(pipe.vae.decode, mode="max-autotune", fullgraph=True)
prompt = "Astronaut in a jungle, cold color palette, muted colors, detailed, 8k"
# First call to `pipe` will be slow, subsequent ones will be faster.
image = pipe(prompt, num_inference_steps=30).images[0]
```
<div align="center">
<img src="https://huggingface.co/datasets/sayakpaul/sample-datasets/resolve/main/progressive-acceleration-sdxl/SDXL%2C_Batch_Size%3A_1%2C_Steps%3A_30_3.png" width=500>
</div>
</details>
<details>
<summary>Combining attention projection matrices</summary><br>
```python
from diffusers import StableDiffusionXLPipeline
import torch
# Configure the compiler flags.
torch._inductor.config.conv_1x1_as_mm = True
torch._inductor.config.coordinate_descent_tuning = True
torch._inductor.config.epilogue_fusion = False
torch._inductor.config.coordinate_descent_check_all_directions = True
pipe = StableDiffusionXLPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.bfloat16
).to("cuda")
# Combine attention projection matrices.
pipe.fuse_qkv_projections()
# Compile the UNet and VAE.
pipe.unet.to(memory_format=torch.channels_last)
pipe.vae.to(memory_format=torch.channels_last)
pipe.unet = torch.compile(pipe.unet, mode="max-autotune", fullgraph=True)
pipe.vae.decode = torch.compile(pipe.vae.decode, mode="max-autotune", fullgraph=True)
prompt = "Astronaut in a jungle, cold color palette, muted colors, detailed, 8k"
# First call to `pipe` will be slow, subsequent ones will be faster.
image = pipe(prompt, num_inference_steps=30).images[0]
```
<div align="center">
<img src="https://huggingface.co/datasets/sayakpaul/sample-datasets/resolve/main/progressive-acceleration-sdxl/SDXL%2C_Batch_Size%3A_1%2C_Steps%3A_30_4.png" width=500>
</div>
</details>
<details>
<summary>Dynamic quantization</summary><br>
Start by setting the compiler flags (this time, we have two new):
```python
from diffusers import StableDiffusionXLPipeline
import torch
from torchao.quantization import apply_dynamic_quant, swap_conv2d_1x1_to_linear
# Compiler flags. There are two new.
torch._inductor.config.conv_1x1_as_mm = True
torch._inductor.config.coordinate_descent_tuning = True
torch._inductor.config.epilogue_fusion = False
torch._inductor.config.coordinate_descent_check_all_directions = True
torch._inductor.config.force_fuse_int_mm_with_mul = True
torch._inductor.config.use_mixed_mm = True
```
Then write the filtering functions to apply dynamic quantization:
```python
def dynamic_quant_filter_fn(mod, *args):
return (
isinstance(mod, torch.nn.Linear)
and mod.in_features > 16
and (mod.in_features, mod.out_features)
not in [
(1280, 640),
(1920, 1280),
(1920, 640),
(2048, 1280),
(2048, 2560),
(2560, 1280),
(256, 128),
(2816, 1280),
(320, 640),
(512, 1536),
(512, 256),
(512, 512),
(640, 1280),
(640, 1920),
(640, 320),
(640, 5120),
(640, 640),
(960, 320),
(960, 640),
]
)
def conv_filter_fn(mod, *args):
return (
isinstance(mod, torch.nn.Conv2d) and mod.kernel_size == (1, 1) and 128 in [mod.in_channels, mod.out_channels]
)
```
Then we're rwady for inference:
```python
pipe = StableDiffusionXLPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.bfloat16
).to("cuda")
# Combine attention projection matrices.
pipe.fuse_qkv_projections()
# Change the memory layout.
pipe.unet.to(memory_format=torch.channels_last)
pipe.vae.to(memory_format=torch.channels_last)
# Swap the pointwise convs with linears.
swap_conv2d_1x1_to_linear(pipe.unet, conv_filter_fn)
swap_conv2d_1x1_to_linear(pipe.vae, conv_filter_fn)
# Apply dynamic quantization.
apply_dynamic_quant(pipe.unet, dynamic_quant_filter_fn)
apply_dynamic_quant(pipe.vae, dynamic_quant_filter_fn)
# Compile.
pipe.unet = torch.compile(pipe.unet, mode="max-autotune", fullgraph=True)
pipe.vae.decode = torch.compile(pipe.vae.decode, mode="max-autotune", fullgraph=True)
prompt = "Astronaut in a jungle, cold color palette, muted colors, detailed, 8k"
image = pipe(prompt, num_inference_steps=30).images[0]
```
<div align="center">
<img src="https://huggingface.co/datasets/sayakpaul/sample-datasets/resolve/main/progressive-acceleration-sdxl/SDXL%2C_Batch_Size%3A_1%2C_Steps%3A_30_5.png" width=500>
</div>
</details>
## Results from other pipelines 🌋
<details>
<summary>SSD-1B</summary>
<div align="center">
<img src="https://huggingface.co/datasets/sayakpaul/sample-datasets/resolve/main/final-results-diffusion-fast/SSD-1B%2C_Batch_Size%3A_1%2C_Steps%3A_30.png" width=500>
<br><sup><a href="https://huggingface.co/segmind/SSD-1B">segmind/SSD-1B</a></sup>
</div>
</details>
<details>
<summary>SD v1-5</summary>
<div align="center">
<img src="https://huggingface.co/datasets/sayakpaul/sample-datasets/resolve/main/final-results-diffusion-fast/SD_v1-5%2C_Batch_Size%3A_1%2C_Steps%3A_30.png" width=500>
<br><sup><a href="https://huggingface.co/runwayml/stable-diffusion-v1-5">runwayml/stable-diffusion-v1-5</a></sup>
</div>
</details>
<details>
<summary>Pixart-Alpha</summary>
<div align="center">
<img src="https://huggingface.co/datasets/sayakpaul/sample-datasets/resolve/main/final-results-diffusion-fast/PixArt-%24%5Calpha%24%2C_Batch_Size%3A_1%2C_Steps%3A_30.png" width=500>
<br><sup><a href="https://huggingface.co/PixArt-alpha/PixArt-XL-2-1024-MS">PixArt-alpha/PixArt-XL-2-1024-MS</a></sup>
</div>
</details>
| {"Dockerfile": "FROM nvidia/cuda:12.1.0-runtime-ubuntu20.04\n\nENV DEBIAN_FRONTEND=noninteractive\n\nRUN apt update && \\\n apt install -y bash \\\n build-essential \\\n git \\\n git-lfs \\\n curl \\\n ca-certificates \\\n libsndfile1-dev \\\n libgl1 \\\n python3.8 \\\n python3-pip \\\n python3.8-venv && \\\n rm -rf /var/lib/apt/lists\n\nRUN python3 -m venv /opt/venv\nENV PATH=\"/opt/venv/bin:$PATH\"\n\nRUN python3 -m pip install --no-cache-dir --upgrade pip && \\\n python3 -m pip install --no-cache-dir --pre torch==2.3.0.dev20231218+cu121 --index-url https://download.pytorch.org/whl/nightly/cu121 && \\\n python3 -m pip install --no-cache-dir \\\n accelerate \\\n transformers \\\n peft \n\nRUN python3 -m pip install --no-cache-dir diffusers==0.25.0\nRUN python3 -m pip install --no-cache-dir git+https://github.com/pytorch-labs/ao@54bcd5a10d0abbe7b0c045052029257099f83fd9\n\nCMD [\"/bin/bash\"]", ".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 f4fa861422d9819226eb2ceac247c85c3547130d Hamza Amin <[email protected]> 1727369039 +0500\tclone: from https://github.com/huggingface/diffusion-fast.git\n", ".git\\refs\\heads\\main": "f4fa861422d9819226eb2ceac247c85c3547130d\n"} | null |
disaggregators | {"type": "directory", "name": "disaggregators", "children": [{"type": "file", "name": "conftest.py"}, {"type": "file", "name": "LICENSE"}, {"type": "file", "name": "Makefile"}, {"type": "file", "name": "noxfile.py"}, {"type": "file", "name": "pyproject.toml"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "setup.cfg"}, {"type": "file", "name": "setup.py"}, {"type": "directory", "name": "src", "children": [{"type": "directory", "name": "disaggregators", "children": [{"type": "directory", "name": "disaggregation_modules", "children": [{"type": "directory", "name": "age", "children": [{"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "continent", "children": [{"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "disaggregation_module.py"}, {"type": "directory", "name": "gender", "children": [{"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "pronoun", "children": [{"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "religion", "children": [{"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "disaggregator.py"}, {"type": "file", "name": "__init__.py"}]}]}, {"type": "directory", "name": "tests", "children": [{"type": "directory", "name": "disaggregation_modules", "children": [{"type": "file", "name": "test_age.py"}, {"type": "file", "name": "test_continent.py"}, {"type": "file", "name": "test_gender.py"}, {"type": "file", "name": "test_pronoun.py"}, {"type": "file", "name": "test_religion.py"}]}, {"type": "directory", "name": "integration", "children": [{"type": "file", "name": "test_disaggregation.py"}]}, {"type": "file", "name": "test_disaggregation_module.py"}, {"type": "file", "name": "test_disaggregator.py"}, {"type": "file", "name": "__init__.py"}]}]} | <p align="center">
<br>
<img alt="Hugging Face Disaggregators" src="https://user-images.githubusercontent.com/6765188/206785111-b7724be3-6460-4092-9561-9fc2cd522320.png" width="400"/>
<br>
<p>
<p align="center">
<a href="https://huggingface.co/spaces/society-ethics/disaggregators">
<img alt="GitHub" src="https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face%20Spaces-Demo-blue">
</a>
<a href="https://github.com/huggingface/transformers/releases">
<img alt="GitHub release" src="https://img.shields.io/github/release/huggingface/disaggregators.svg">
</a>
</p>
> ⚠️ Please note: This library is in early development, and the disaggregation modules that are included are proofs of concept that are _not_ production-ready. Additionally, all APIs are subject to breaking changes any time before a 1.0.0 release. Rigorously tested versions of the included modules will be released in the future, so stay tuned. [We'd love your feedback in the meantime!](https://github.com/huggingface/disaggregators/discussions/23)
The `disaggregators` library allows you to easily add new features to your datasets to enable disaggregated data exploration and disaggregated model evaluation. `disaggregators` is preloaded with disaggregation modules for text data, with image modules coming soon!
This library is intended to be used with [🤗 Datasets](https://github.com/huggingface/datasets), but should work with any other "mappable" interface to a dataset.
## Requirements and Installation
`disaggregators` has been tested on Python 3.8, 3.9, and 3.10.
`pip install disaggregators` will fetch the latest release from PyPI.
Note that some disaggregation modules require extra dependencies such as SpaCy modules, which may need to be installed manually. If these dependencies aren't installed, `disaggregators` will inform you about how to install them.
To install directly from this GitHub repo, use the following command:
```shell
pip install git+https://github.com/huggingface/disaggregators.git
```
## Usage
You will likely want to use 🤗 Datasets with `disaggregators`.
```shell
pip install datasets
```
The snippet below loads the IMDB dataset from the Hugging Face Hub, and initializes a disaggregator for "pronoun" that will run on the IMDB dataset's "text" column. If you would like to run multiple disaggregations, you can pass a list to the `Disaggregator` constructor (e.g. `Disaggregator(["pronoun", "sentiment"], column="text")`). We then use the 🤗 Datasets `map` method to apply the disaggregation to the dataset.
```python
from disaggregators import Disaggregator
from datasets import load_dataset
dataset = load_dataset("imdb", split="train")
disaggregator = Disaggregator("pronoun", column="text")
ds = dataset.map(disaggregator) # New boolean columns are added for she/her, he/him, and they/them
```
The resulting dataset can now be used for data exploration and disaggregated model evaluation.
You can also run disaggregations on Pandas DataFrames with `.apply` and `.merge`:
```python
from disaggregators import Disaggregator
import pandas as pd
df = pd.DataFrame({"text": ["They went to the park."]})
disaggregator = Disaggregator("pronoun", column="text")
new_cols = df.apply(disaggregator, axis=1)
df = pd.merge(df, pd.json_normalize(new_cols), left_index=True, right_index=True)
```
### Available Disaggregation Modules
The following modules are currently available:
- `"age"`
- `"gender"`
- `"pronoun"`
- `"religion"`
- `"continent"`
Note that `disaggregators` is in active development, and that these (and future) modules are subject to changing interfaces and implementations at any time before a `1.0.0` release. Each module provides its own method for overriding the default configuration, with the general interface documented below.
### Module Configurations
Modules may make certain variables and functionality configurable. If you'd like to configure a module, import the module, its labels, and its config class. Then, override the labels and set the configuration as needed while instantiating the module. Once instantiated, you can pass the module to the `Disaggregator`. The example below shows this with the `Age` module.
```python
from disaggregators import Disaggregator
from disaggregators.disaggregation_modules.age import Age, AgeLabels, AgeConfig
class MeSHAgeLabels(AgeLabels):
INFANT = "infant"
CHILD_PRESCHOOL = "child_preschool"
CHILD = "child"
ADOLESCENT = "adolescent"
ADULT = "adult"
MIDDLE_AGED = "middle_aged"
AGED = "aged"
AGED_80_OVER = "aged_80_over"
age = Age(
config=AgeConfig(
labels=MeSHAgeLabels,
ages=[list(MeSHAgeLabels)],
breakpoints=[0, 2, 5, 12, 18, 44, 64, 79]
),
column="question"
)
disaggregator = Disaggregator([age, "gender"], column="question")
```
### Custom Modules
Custom modules can be created by extending the `CustomDisaggregator`. All custom modules must have `labels` and a `module_id`, and must implement a `__call__` method.
```python
from disaggregators import Disaggregator, DisaggregationModuleLabels, CustomDisaggregator
class TabsSpacesLabels(DisaggregationModuleLabels):
TABS = "tabs"
SPACES = "spaces"
class TabsSpaces(CustomDisaggregator):
module_id = "tabs_spaces"
labels = TabsSpacesLabels
def __call__(self, row, *args, **kwargs):
if "\t" in row[self.column]:
return {self.labels.TABS: True, self.labels.SPACES: False}
else:
return {self.labels.TABS: False, self.labels.SPACES: True}
disaggregator = Disaggregator(TabsSpaces, column="text")
```
## Development
Development requirements can be installed with `pip install .[dev]`. See the `Makefile` for useful targets, such as code quality and test running.
To run tests locally across multiple Python versions (3.8, 3.9, and 3.10), ensure that you have all the Python versions available and then run `nox -r`. Note that this is quite slow, so it's only worth doing to double-check your code before you open a Pull Request.
## Contact
Nima Boscarino – `nima <at> huggingface <dot> co`
| {"setup.py": "# Lint as: python3\n\"\"\" HuggingFace/Disaggregators is an open library for disaggregating datasets.\n\nNote:\n\n VERSION needs to be formatted following the MAJOR.MINOR.PATCH convention\n\nSimple check list for release from AllenNLP repo: https://github.com/allenai/allennlp/blob/master/setup.py\n\nTo create the package for pypi.\n\n0. Prerequisites:\n - Dependencies:\n - twine: \"pip install twine\"\n - Create an account in (and join the 'disaggregators' project):\n - PyPI: https://pypi.org/\n - Test PyPI: https://test.pypi.org/\n\n1. Change the version in:\n - __init__.py\n - setup.py\n\n2. Commit these changes: \"git commit -m 'Release: VERSION'\"\n\n3. Add a tag in git to mark the release: \"git tag VERSION -m 'Add tag VERSION for pypi'\"\n Push the tag to remote: git push --tags origin main\n\n4. Build both the sources and the wheel. Do not change anything in setup.py between\n creating the wheel and the source distribution (obviously).\n\n First, delete any \"build\" directory that may exist from previous builds.\n\n For the wheel, run: \"python setup.py bdist_wheel\" in the top level directory.\n (this will build a wheel for the python version you use to build it).\n\n For the sources, run: \"python setup.py sdist\"\n You should now have a /dist directory with both .whl and .tar.gz source versions.\n\n5. Check that everything looks correct by uploading the package to the pypi test server:\n\n twine upload dist/* -r pypitest --repository-url=https://test.pypi.org/legacy/\n\n Check that you can install it in a virtualenv/notebook by running:\n pip install -i https://testpypi.python.org/pypi disaggregators\n\n6. Upload the final version to actual pypi:\n twine upload dist/* -r pypi\n\n7. Fill release notes in the tag in GitHub once everything is looking hunky-dory.\n\n8. Change the version in __init__.py and setup.py to X.X.X+1.dev0 (e.g. VERSION=1.18.3 -> 1.18.4.dev0).\n Then push the change with a message 'set dev version'\n\"\"\"\n\nfrom setuptools import find_packages, setup\n\n\nREQUIRED_PKGS = [\n # Utilities from PyPA to e.g., compare versions\n \"packaging\",\n \"spacy\",\n \"datasets\",\n \"aenum>=3.1.11\",\n \"sentence-transformers>=2.2.2\",\n \"geograpy3\",\n \"nltk\",\n \"requests\",\n]\n\nTESTS_REQUIRE = [\n # test dependencies\n \"pytest\",\n \"pytest-datadir\",\n \"pytest-xdist\",\n \"pytest-mock\",\n \"nox\",\n \"pandas\",\n]\n\nQUALITY_REQUIRE = [\"black~=22.0\", \"flake8>=3.8.3\", \"isort>=5.0.0\", \"pyyaml>=5.3.1\"]\n\n\nEXTRAS_REQUIRE = {\n \"dev\": TESTS_REQUIRE + QUALITY_REQUIRE,\n \"tests\": TESTS_REQUIRE,\n \"quality\": QUALITY_REQUIRE,\n}\n\nsetup(\n name=\"disaggregators\",\n version=\"0.1.3.dev0\", # expected format is one of x.y.z.dev0, or x.y.z.rc1 or x.y.z (no to dashes, yes to dots)\n description=\"HuggingFace community-driven open-source library for dataset disaggregation\",\n long_description=open(\"README.md\", encoding=\"utf-8\").read(),\n long_description_content_type=\"text/markdown\",\n author=\"HuggingFace Inc.\",\n author_email=\"[email protected]\",\n url=\"https://github.com/NimaBoscarino/disaggregators\",\n download_url=\"https://github.com/NimaBoscarino/disaggregators/tags\",\n license=\"Apache 2.0\",\n package_dir={\"\": \"src\"},\n packages=find_packages(\"src\"),\n install_requires=REQUIRED_PKGS,\n extras_require=EXTRAS_REQUIRE,\n python_requires=\">=3.7.0\",\n classifiers=[\n \"Development Status :: 1 - Planning\",\n \"Intended Audience :: Developers\",\n \"Intended Audience :: Education\",\n \"Intended Audience :: Science/Research\",\n \"License :: OSI Approved :: Apache Software License\",\n \"Operating System :: OS Independent\",\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.8\",\n \"Programming Language :: Python :: 3.9\",\n \"Programming Language :: Python :: 3.10\",\n \"Topic :: Scientific/Engineering :: Artificial Intelligence\",\n ],\n keywords=\"machine learning evaluate evaluation disaggregation\",\n zip_safe=False, # Required for mypy to find the py.typed file\n)\n", ".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 b8ea3170b119e6768812874b71367b8932db0d37 Hamza Amin <[email protected]> 1727369112 +0500\tclone: from https://github.com/huggingface/disaggregators.git\n", ".git\\refs\\heads\\main": "b8ea3170b119e6768812874b71367b8932db0d37\n"} | null |
discord-bots | {"type": "directory", "name": "discord-bots", "children": [{"type": "directory", "name": "codellama", "children": [{"type": "file", "name": "codellama.py"}]}, {"type": "directory", "name": "deepfloydif", "children": [{"type": "file", "name": "deepfloydif.py"}]}, {"type": "directory", "name": "falcon180b", "children": [{"type": "file", "name": "falcon180b.py"}]}, {"type": "directory", "name": "legacy", "children": [{"type": "file", "name": "audioldm2"}, {"type": "file", "name": "musicgen.py"}]}, {"type": "file", "name": "Makefile"}, {"type": "file", "name": "pyproject.toml"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "directory", "name": "wuerstchen", "children": [{"type": "file", "name": "wuerstchen.py"}]}]} | # Our bots 🤖
| Bot | Code Link | Invite Link |
| -------- | -------- | -------- |
| CodeLlama 13B | [Code](https://huggingface.co/spaces/huggingface-projects/codellama-bot) | [Invite Bot](https://discord.com/api/oauth2/authorize?client_id=1152238037355474964&permissions=309237647360&scope=bot) |
| DeepFloydIF | [Code](https://huggingface.co/spaces/huggingface-projects/deepfloydif-bot) | [Invite Bot](https://discord.com/api/oauth2/authorize?client_id=1154395078735953930&permissions=51200&scope=bot) |
| Falcon 180B | [Code](https://huggingface.co/spaces/huggingface-projects/falcon180b-bot) | [Invite Bot](https://discord.com/api/oauth2/authorize?client_id=1155169841276260546&permissions=326417516544&scope=bot) |
| Wuerstchen | [Code](https://huggingface.co/spaces/huggingface-projects/wuerstchen-bot) | [Invite Bot](https://discord.com/api/oauth2/authorize?client_id=1155489509518098565&permissions=51200&scope=bot) |
| AudioLDM 2 | [Code](https://huggingface.co/spaces/huggingface-projects/AudioLDM2-bot)| - |
| MusicGen | [Code](https://huggingface.co/spaces/huggingface-projects/MusicGen-bot) | - |
# TLDR: How do our bots work ❓
- We run the bots inside a free-tier [Space](https://huggingface.co/new-space?sdk=gradio), which acts as a server.
- We use Gradio apps as APIs to use them in our bots
### Building blocks of a Discord Bot 🤖
1. Create an [application](https://discord.com/developers/applications)
2. Create a Hugging Face [Space](https://huggingface.co/new-space?sdk=gradio)
3. Add [commands](https://huggingface.co/spaces/huggingface-projects/huggingbots/blob/main/app.py)
After that, we'll have a working discord bot. So how do we spice it up with machine learning?
### Using ML demos in your bot 🧠
- Almost any [Gradio](https://github.com/gradio-app/gradio/tree/main/client/python) app can be [used as an API](https://www.gradio.app/guides/sharing-your-app#api-page)! This means we can query most Spaces on the Hugging Face Hub and use them in our discord bots.

Here's an extremely simplified example 💻:
```python
from gradio_client import Client
musicgen = Client("huggingface-projects/transformers-musicgen", hf_token=os.getenv("HF_TOKEN"))
# call this function when we use a command + prompt
async def music_create(ctx, prompt):
# run_in_executor for the blocking function
loop = asyncio.get_running_loop()
job = await loop.run_in_executor(None, music_create_job, prompt)
# extract what we want from the outputs
video = job.outputs()[0][0]
# send what we want to discord
await thread.send(video_file)
# submit as a Gradio job; this makes retrieving outputs simpler
def music_create_job(prompt):
# pass prompt and other parameters if necessary
job = musicgen.submit(prompt, api_name="/predict")
return job
```
In summary, we:
1. Use a command and specify a prompt ("piano music", for example)
2. Query a specific Gradio Space as an API, and send it our prompt
3. Retrieve the results once done and post them to discord
🎉 And voila! 🎉
For further explorations (depending on your needs), we can recommend checking these out 🧐:
- Events in discord bots (to automate some behavior)
- Handling concurrency (important if you're making many concurrent requests at once)
- UI (discord buttons, interactive fields) (can add a lot of functionality)
| {"requirements.txt": "discord.py\ngradio\n", ".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 efb8fc72eb6f012e660358d7599143e17a8043e6 Hamza Amin <[email protected]> 1727369114 +0500\tclone: from https://github.com/huggingface/discord-bots.git\n", ".git\\refs\\heads\\main": "efb8fc72eb6f012e660358d7599143e17a8043e6\n"} | null |
distil-whisper | {"type": "directory", "name": "distil-whisper", "children": [{"type": "file", "name": "LICENSE"}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "training", "children": [{"type": "file", "name": "create_student_model.py"}, {"type": "directory", "name": "flax", "children": [{"type": "directory", "name": "conversion_scripts", "children": [{"type": "file", "name": "run_convert_distilled_train_state_to_hf.sh"}]}, {"type": "file", "name": "convert_train_state_to_hf.py"}, {"type": "file", "name": "create_student_model.py"}, {"type": "directory", "name": "distillation_scripts", "children": [{"type": "file", "name": "run_32_2_pt.sh"}, {"type": "file", "name": "run_bs_sweep.yaml"}, {"type": "file", "name": "run_dataset_sweep.yaml"}, {"type": "file", "name": "run_decoder_sweep.yaml"}, {"type": "file", "name": "run_distillation_12_2_timestamped.sh"}, {"type": "file", "name": "run_distillation_15s_context.sh"}, {"type": "file", "name": "run_distillation_16_2.sh"}, {"type": "file", "name": "run_distillation_24_2.sh"}, {"type": "file", "name": "run_distillation_24_2_timestamped.sh"}, {"type": "file", "name": "run_distillation_32_2.sh"}, {"type": "file", "name": "run_distillation_32_2_by_samples.sh"}, {"type": "file", "name": "run_distillation_32_2_gpu.sh"}, {"type": "file", "name": "run_distillation_32_2_timestamped.sh"}, {"type": "file", "name": "run_distillation_large_32_2_gpu_timestamped.sh"}, {"type": "file", "name": "run_distillation_objective.yaml"}, {"type": "file", "name": "run_dropout_sweep.yaml"}, {"type": "file", "name": "run_librispeech.sh"}, {"type": "file", "name": "run_librispeech_dummy_pt.sh"}, {"type": "file", "name": "run_librispeech_streaming_dummy.sh"}, {"type": "file", "name": "run_lr_sweep.yaml"}, {"type": "file", "name": "run_mse_sweep.yaml"}, {"type": "file", "name": "run_timestamp_sweep.yaml"}, {"type": "file", "name": "run_wer_sweep.yaml"}]}, {"type": "directory", "name": "distil_whisper", "children": [{"type": "file", "name": "layers.py"}, {"type": "file", "name": "modeling_flax_whisper.py"}, {"type": "file", "name": "partitioner.py"}, {"type": "file", "name": "pipeline.py"}, {"type": "file", "name": "train_state.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "evaluation_scripts", "children": [{"type": "file", "name": "run_baselines.sh"}, {"type": "file", "name": "run_distilled.sh"}, {"type": "file", "name": "run_distilled_16_2.sh"}, {"type": "file", "name": "run_librispeech_eval_dummy.sh"}, {"type": "directory", "name": "test", "children": [{"type": "file", "name": "run_baselines.sh"}, {"type": "file", "name": "run_baselines_pt.sh"}, {"type": "file", "name": "run_distilled.sh"}]}]}, {"type": "directory", "name": "finetuning_scripts", "children": [{"type": "file", "name": "run_librispeech.sh"}, {"type": "file", "name": "run_librispeech_dummy.sh"}, {"type": "file", "name": "run_librispeech_eval.sh"}, {"type": "file", "name": "run_librispeech_eval_dummy.sh"}, {"type": "file", "name": "run_librispeech_sweep.yaml"}]}, {"type": "directory", "name": "initialisation_scripts", "children": [{"type": "file", "name": "run_large_32_2_init.sh"}, {"type": "file", "name": "run_medium_24_2_init.sh"}, {"type": "file", "name": "run_small_12_2_init.sh"}, {"type": "file", "name": "run_tiny_2_1_init.sh"}, {"type": "file", "name": "run_tiny_2_1_init_pt.sh"}]}, {"type": "directory", "name": "latency_scripts", "children": [{"type": "file", "name": "run_speculative.sh"}, {"type": "file", "name": "run_speed.sh"}, {"type": "file", "name": "run_speed_longform.sh"}, {"type": "file", "name": "run_trial.sh"}]}, {"type": "file", "name": "LICENSE"}, {"type": "directory", "name": "long_form_transcription_scripts", "children": [{"type": "file", "name": "run_chunk_length_s_sweep.yaml"}, {"type": "file", "name": "run_eval_with_pipeline.sh"}, {"type": "file", "name": "run_length_penalty_sweep.yaml"}, {"type": "file", "name": "run_tedlium_long_form.sh"}, {"type": "file", "name": "run_tedlium_long_form_dummy.sh"}, {"type": "file", "name": "run_tedlium_long_form_timestamps.sh"}, {"type": "file", "name": "run_top_k_temperature_sweep.yaml"}, {"type": "directory", "name": "test", "children": [{"type": "file", "name": "run_baselines.sh"}, {"type": "file", "name": "run_baselines_pt.sh"}, {"type": "file", "name": "run_distilled.sh"}]}]}, {"type": "file", "name": "Makefile"}, {"type": "directory", "name": "noise_evaluation_scripts", "children": [{"type": "file", "name": "run_baselines.sh"}, {"type": "file", "name": "run_baselines_pt.sh"}, {"type": "file", "name": "run_distilled.sh"}, {"type": "directory", "name": "test", "children": [{"type": "file", "name": "run_baselines.sh"}, {"type": "file", "name": "run_distilled.sh"}]}]}, {"type": "directory", "name": "pseudo_labelling_scripts", "children": [{"type": "file", "name": "run_librispeech_pseudo_labelling.sh"}, {"type": "file", "name": "run_librispeech_pseudo_labelling_dummy.sh"}, {"type": "file", "name": "run_pseudo_labelling.sh"}, {"type": "file", "name": "run_pseudo_labelling_2.sh"}, {"type": "file", "name": "run_pseudo_labelling_dummy_pt.sh"}, {"type": "file", "name": "run_pseudo_labelling_token_ids.sh"}, {"type": "file", "name": "run_pseudo_labelling_token_ids_2.sh"}]}, {"type": "file", "name": "pyproject.toml"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "run_distillation.py"}, {"type": "file", "name": "run_eval.py"}, {"type": "file", "name": "run_finetuning.py"}, {"type": "file", "name": "run_long_form_transcription.py"}, {"type": "file", "name": "run_orig_longform.sh"}, {"type": "file", "name": "run_pseudo_labelling_pt.py"}, {"type": "file", "name": "run_pt_long_form_transcription.py"}, {"type": "file", "name": "run_speculative_decoding.py"}, {"type": "file", "name": "run_speed.sh"}, {"type": "file", "name": "run_speed_pt.py"}, {"type": "file", "name": "setup.py"}, {"type": "file", "name": "tpu_connect.sh"}]}, {"type": "file", "name": "Makefile"}, {"type": "file", "name": "pyproject.toml"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "run_distillation.py"}, {"type": "file", "name": "run_eval.py"}, {"type": "file", "name": "run_pseudo_labelling.py"}, {"type": "file", "name": "setup.py"}]}]} | ## Reproducing Distil-Whisper
This sub-folder contains all the training and inference scripts to reproduce the Distil-Whisper project. Distil-Whisper
is written in JAX to leverage the fast training and inference speed offered by TPU v4 hardware. However, it also works
efficiently on GPU hardware without any additional code changes.
Reproducing the Distil-Whisper project requires four stages to be completed in successive order:
1. [Pseudo-labelling](#pseudo-labelling)
2. [Initialisation](#initialisation)
3. [Training](#training)
4. [Evaluation](#evaluation)
This README is partitioned according to the four stages. Each section provides a minimal example for running the
scripts used in the project. The final scripts used to train the model are referenced in-line.
It is worth noting that the experiments performed in JAX/Flax have been on English ASR only. For multilingual training code,
the [PyTorch Training Code](../README.md) can easily be used, facilitating anyone to run Whisper distillation on a language of their choice.
## Requirements
Distil-Whisper is written in Python, JAX and Flax, and heavily leverages the Flax Whisper implementation in
[🤗 Transformers](https://github.com/huggingface/transformers). The instructions for installing the package are as follows:
1. Install JAX from the [official instructions](https://github.com/google/jax#installation), ensuring you install the correct version for your hardware (GPU or TPU).
2. Install the `distil_whisper` package by cloning the repository and performing an editable installation:
```bash
git clone https://github.com/huggingface/distil-whisper.git
cd distil-whisper/training/flax
pip install -e .
```
## Pseudo-Labelling
Pseudo-labelling is the process of generating target text predictions for the input audio data using the teacher model.
The generated text labels then replace the ground truth text labels when performing distillation. The rationale for
using pseudo-labels instead of ground truth labels is to circumvent the issue of inconsistent transcription formatting
across datasets.
The python script [`run_pseudo_labelling.py`](run_pseudo_labelling.py) is a flexible inference script that can be used
to generate pseudo-labels under a range of settings, including using both greedy and beam-search. It is also compatible
with [🤗 Datasets](https://github.com/huggingface/datasets) *streaming mode*, allowing users to load massive audio
datasets with **no disk space requirements**. For more information on streaming mode, the reader is referred to the
blog post: [A Complete Guide to Audio Datasets](https://huggingface.co/blog/audio-datasets#streaming-mode-the-silver-bullet).
The following script demonstrates how to pseudo-label the [LibriSpeech 960h](https://huggingface.co/datasets/librispeech_asr)
dataset with greedy sampling and streaming mode:
```bash
#!/usr/bin/env bash
python run_pseudo_labelling.py \
--model_name_or_path "openai/whisper-large-v2" \
--dataset_name "librispeech_asr" \
--dataset_config_name "all" \
--data_split_name "train.clean.100+train.clean.360+train.other.500" \
--text_column_name "text" \
--output_dir "./transcriptions" \
--per_device_eval_batch_size 16 \
--max_label_length 256 \
--dtype "bfloat16" \
--report_to "wandb" \
--dataloader_num_workers 16 \
--streaming \
--push_to_hub \
--generation_num_beams 1 # for greedy, set >1 for beam
```
The script will save the generated pseudo-labels alongside the file ids to the output directory `output_dir`. Adding the
`--push_to_hub` argument uploads the generated pseudo-labels to the Hugging Face Hub on save.
The directory [`pseudo_labelling_scripts`](pseudo_labelling_scripts) contains a collection of bash scripts for
pseudo-labelling all 10 audio datasets used in the project. The datasets with the Whisper generated transcriptions
can be found on the Hugging Face Hub under the [Distil Whisper organisation](https://huggingface.co/datasets?sort=trending&search=distil-whisper%2F).
They can be re-used should you wish to bypass the data labelling stage of the reproduction.
<!--- TODO(SG): Combine PS with source audio to create dataset --->
## Initialisation
The script [`create_student_model.py`](create_student_model.py) can be used to initialise a small student model
from a large teacher model. When initialising a student model with fewer layers than the teacher model, the student is
initialised by copying maximally spaced layers from the teacher, as per the [DistilBart](https://arxiv.org/abs/2010.13002)
recommendations.
The following command demonstrates how to initialise a student model from the [large-v2](https://huggingface.co/openai/whisper-large-v2)
checkpoint, with all 32 encoder layer and 2 decoder layers. The 2 student decoder layers are copied from teacher layers
1 and 32 respectively, as the maximally spaced layers.
```bash
#!/usr/bin/env bash
python create_student_model.py \
--teacher_checkpoint "openai/whisper-large-v2" \
--encoder_layers 32 \
--decoder_layers 2 \
--save_dir "./large-32-2" \
--push_to_hub
```
## Training
The script [`run_distillation.py`](run_distillation.py) is an end-to-end script for loading multiple
datasets, a student model, a teacher model, and performing teacher-student distillation. It uses the loss formulation
from [DistilBart](https://arxiv.org/abs/2010.13002), which is a combination of a cross-entropy, KL-divergence and
mean-square error (MSE) loss:
https://github.com/huggingface/distil-whisper/blob/4dd831543e6c40b1159f1ec951db7f4fe0e86850/run_distillation.py#L1725
The weight assigned to the MSE loss is configurable. The others are fixed to the values from the DistilBART paper.
The following command takes the LibriSpeech 960h dataset that was pseudo-labelled in the first stage and trains the
2-layer decoder model intialised in the previous step. Note that multiple training datasets and splits can be loaded
by separating the dataset arguments by `+` symbols. Thus, the script generalises to any number of training datasets.
```bash
#!/usr/bin/env bash
python3 run_distillation.py \
--model_name_or_path "./large-32-2" \
--teacher_model_name_or_path "openai/whisper-large-v2" \
--train_dataset_name "librispeech_asr+librispeech_asr+librispeech_asr" \
--train_dataset_config_name "all+all+all" \
--train_split_name "train.clean.100+train.clean.360+train.other.500" \
--train_dataset_samples "100+360+500" \
--eval_dataset_name "librispeech_asr" \
--eval_dataset_config_name "all" \
--eval_split_name "validation.clean" \
--eval_steps 5000 \
--save_steps 5000 \
--warmup_steps 500 \
--learning_rate 0.0001 \
--lr_scheduler_type "constant_with_warmup" \
--logging_steps 25 \
--save_total_limit 1 \
--max_steps 20000 \
--wer_threshold 10 \
--per_device_train_batch_size 64 \
--per_device_eval_batch_size 64 \
--dataloader_num_workers 16 \
--dtype "bfloat16" \
--output_dir "./" \
--do_train \
--do_eval \
--use_scan \
--gradient_checkpointing \
--overwrite_output_dir \
--predict_with_generate \
--freeze_encoder \
--streaming \
--use_auth_token \
--push_to_hub
```
The above training script will take approximately 20 hours to complete on a TPU v4-8 and yield a final WER of 2.3%.
Training logs will be reported to TensorBoard and WandB, provided the relevant packages are available. An example of a
saved checkpoint pushed to the Hugging Face Hub can be found here: [large-32-2](https://huggingface.co/distil-whisper/large-32-2).
There are a few noteworthy arguments that can be configured to give optimal training performance:
* `train_dataset_samples`: defines the number of training samples in each dataset. Used to calculate the sampling probabilities in the dataloader. A good starting point is setting the samples to the number of hours of audio data in each split. A more refined strategy is setting it to the number of training samples in each split, however this might require downloading the dataset offline to compute these statistics.
* `wer_threshold`: sets the WER threshold between the normalised pseudo-labels and normalised ground truth labels. Any samples with WER > `wer_threshold` are discarded from the training data. This is beneficial to avoid training the student model on pseudo-labels where Whisper hallucinated or got the predictions grossly wrong.
* `freeze_encoder`: whether to freeze the entire encoder of the student model during training. Beneficial when the student encoder is copied exactly from the teacher encoder. In this case, the encoder hidden-states from the teacher model are re-used for the student model. Stopping the gradient computation through the encoder and sharing the encoder hidden-states provides a significant memory saving, and can enable up to 2x batch sizes.
* `dtype`: data type (dtype) in which the model computation should be performed. Note that this only controls the dtype of the computations (forward and backward pass), and not the dtype of the parameters or optimiser states.
The Distil Whisper project extends the above script to train on a combined dataset formed from 12 open-source ASR datasets,
totalling 22k hours and over 50k speakers. Template scripts to run training on this composite dataset can be found
in the directory [`distillation_scripts`](distillation_scripts).
## Evaluation
There are two types of evaluation performed in Distil-Whisper:
1. Short form: evaluation on audio samples less than 30s in duration. Examples include typical ASR test sets, such as the LibriSpeech validation set.
2. Long form: evaluation on audio samples longer than 30s in duration. Examples include entire TED talks or earnings calls.
Both forms of evaluation are performed using the *word-error rate (WER)* metric.
### Short Form
The script [`run_eval.py`](run_eval.py) can be used to evaluate a trained student model over multiple validation sets.
The following example demonstrates how to evaluate the student model trained in the previous step on the LibriSpeech
`validation.clean` and `validation.other` dev sets. Again, it leverages streaming mode to bypass the need to download
the data offline:
```bash
#!/usr/bin/env bash
python run_eval.py \
--model_name_or_path "./large-32-2" \
--dataset_name "librispeech_asr+librispeech_asr" \
--dataset_config_name "all+all" \
--dataset_split_name "validation.clean+validation.other" \
--output_dir "./large-32-2" \
--per_device_eval_batch_size 64 \
--dtype "bfloat16" \
--dataloader_num_workers 16 \
--report_to "wandb" \
--streaming \
--predict_with_generate
```
### Long Form
Long form evaluation runs on the premise that a single long audio file can be *chunked* into smaller segments and
inferred in parallel. The resulting transcriptions are then joined at the boundaries to give the final text prediction.
A small overlap (or *stride*) is used between adjacent segments to ensure a continuous transcription across chunks.
This style of chunked inference is performed using the [`FlaxWhisperPipeline`](https://github.com/huggingface/distil-whisper/blob/6426022e3b3a0a498b4150a636b54e2e3898bf1a/distil_whisper/pipeline.py#L61)
class, which is heavily inspired from [Whisper JAX](https://github.com/sanchit-gandhi/whisper-jax/tree/main#pipeline-usage).
The script [`run_long_form_transcription.py`](run_long_form_transcription.py) can be used to evaluate the trained
student model on an arbitrary number of long-form evaluation sets. The following script demonstrates how to evaluate
the example student model on two such test sets, [Earnings 21](https://huggingface.co/datasets/distil-whisper/earnings21)
and [Earnings 22](https://huggingface.co/datasets/distil-whisper/earnings22):
```bash
#!/usr/bin/env bash
python run_long_form_transcription.py \
--model_name_or_path "./large-32-2" \
--dataset_name "distil-whisper/earnings21+distil-whisper/earnings22" \
--dataset_config_name "default+default" \
--dataset_split_name "test+test+test+test" \
--text_column_name "transcription+transcription" \
--output_dir "./large-32-2" \
--per_device_eval_batch_size 64 \
--chunk_length_s 15 \
--dtype "bfloat16" \
--report_to "wandb" \
--streaming
```
The argument `chunk_length_s` controls the length of the chunked audio samples. It should be set to match the typical
length of audio the student model was trained on. If unsure about what value of `chunk_length_s` is optimal for your case,
it is recommended to run a *sweep* over all possible values. A template script for running a [WandB sweep](https://docs.wandb.ai/guides/sweeps)
can be found under [`run_chunk_length_s_sweep.yaml`](long_form_transcription_scripts/run_chunk_length_s_sweep.yaml).
### 1. Pseudo Labelling
#### Greedy vs Beam
We found there to be little-to-no difference in the downstream performance of the distilled model after pseudo labelling
using either greedy or beam-search. We attribute this to the minimal difference in performance of the pre-trained Whisper
model under greedy and beam-search decoding, giving pseudo-labelled transcriptions of similar quality. We encourage
users to generate pseudo-labels using greedy decoding given it runs significantly faster. Beam search is only advised if
the pre-trained model is hallucinating significantly on the audio inputs, in which case it helps reduce the frequency and
severity of hallucinations. If using beam search, the number of beams can be kept low: even 2 beams helps reduce the
amount of hallucinations significantly.
#### Timestamps
Whisper is trained on a timestamp prediction task as part of the pre-training set-up. Here, a fixed proportion of the
pre-training data includes sequence-level *timestamps* as part of the transcription labels:
```bash
<|0.00|> Hey, this is a test transcription. <|3.42|>
```
Timestamp prediction is useful for enriching the transcriptions with timing information for downstream tasks, such as
aligning the Whisper transcription with the output of a speaker diarization system, and also reduces the frequency of
hallucinations.
The pseudo-labelling scrip [`run_pseudo_labelling.py`](run_pseudo_labelling.py) can be extended to predict timestamp
information in the audio data by appending the `--return_timestamps` flag to the launch command. The timestamped labelled
data can be passed to the training script in exactly the same way as the non-timestamped version, and the pre-processing
function will take care of encoding the timestamps and appending the required task tokens.
#### Previous Context
Whisper is also pre-trained on a prompting task, where the transcription for the preceding utterance is fed as context
to the current one:
```bash
<|startofprev|> This is the previous context from the preceding utterance.<|startoftranscript|> And this is the current utterance.<|endoftranscript|>
```
Annotating the transcriptions with previous context labels is only possible for datasets where we have consecutive files
and unique speaker ids, since we need to ensure segment `i` directly follows on from segment `i-1` if we use it as the
prompt.
As per the Whisper paper, we mask out the loss over the previous context tokens. At inference time, we can replace the
previous context with a “prompt” to encourage the model to generate text in the style of the prompt (i.e. for specific
named entities, or styles of transcription)
## Acknowledgements
* 🤗 Hugging Face Transformers for the base Whisper implementation
* Google's [TPU Research Cloud (TRC)](https://sites.research.google/trc/about/) programme for their generous provision of Cloud TPUs
| {".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 9422916d714bde70ea9d88e13c56f877ced1e76b Hamza Amin <[email protected]> 1727369119 +0500\tclone: from https://github.com/huggingface/distil-whisper.git\n", ".git\\refs\\heads\\main": "9422916d714bde70ea9d88e13c56f877ced1e76b\n", "training\\setup.py": "# Copyright 2023 The HuggingFace Team. All rights reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\nimport os\n\nimport setuptools\n\n_deps = [\n \"torch>=1.10\",\n \"transformers>=4.35.1\",\n \"datasets[audio]>=2.14.7\",\n \"accelerate>=0.24.1\",\n \"jiwer\",\n \"evaluate>=0.4.1\",\n \"wandb\",\n \"tensorboard\",\n \"nltk\",\n]\n\n_extras_dev_deps = [\n \"ruff==0.1.5\",\n]\n\nhere = os.path.abspath(os.path.dirname(__file__))\n\nwith open(os.path.join(here, \"README.md\"), encoding=\"utf-8\") as f:\n long_description = f.read()\n\nsetuptools.setup(\n name=\"distil_whisper\",\n description=\"Toolkit for distilling OpenAI's Whisper model.\",\n long_description=long_description,\n long_description_content_type=\"text/markdown\",\n packages=setuptools.find_packages(),\n install_requires=_deps,\n extras_require={\n \"dev\": [_extras_dev_deps],\n },\n)\n\n", "training\\flax\\requirements.txt": "torch>=1.7\ntransformers\ndatasets[audio]\njiwer\nevaluate>=0.3.0\n", "training\\flax\\setup.py": "# Copyright 2023 The HuggingFace Team. All rights reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\nimport os\n\nimport setuptools\n\n\n_deps = [\n \"transformers>=4.34.0\",\n \"datasets[audio]>=2.14.5\",\n \"jax>=0.4.13\",\n \"flax>=0.7.2\",\n \"optax\",\n \"evaluate\",\n \"jiwer\",\n \"torch\",\n \"torchdata\",\n \"tokenizers\",\n]\n\n_extras_dev_deps = [\n \"black~=23.1\",\n \"isort>=5.5.4\",\n \"ruff>=0.0.241,<=0.0.259\",\n]\n\nhere = os.path.abspath(os.path.dirname(__file__))\n\nwith open(os.path.join(here, \"README.md\"), encoding=\"utf-8\") as f:\n long_description = f.read()\n\n# read version\nwith open(os.path.join(here, \"distil_whisper\", \"__init__.py\"), encoding=\"utf-8\") as f:\n for line in f:\n if line.startswith(\"__version__\"):\n version = line.split(\"=\")[1].strip().strip('\"')\n break\n else:\n raise RuntimeError(\"Unable to find version string.\")\n\nsetuptools.setup(\n name=\"distil_whisper\",\n version=version,\n description=\"Toolkit for distilling OpenAI's Whisper model.\",\n long_description=long_description,\n long_description_content_type=\"text/markdown\",\n packages=setuptools.find_packages(),\n install_requires=_deps,\n extras_require={\n \"dev\": [_extras_dev_deps],\n },\n)\n"} | null |
distill-bloom-deepspeed | {"type": "directory", "name": "distill-bloom-deepspeed", "children": [{"type": "directory", "name": "distill_bloom", "children": [{"type": "directory", "name": "arguments", "children": [{"type": "file", "name": "arguments.py"}, {"type": "file", "name": "logging.py"}]}, {"type": "directory", "name": "dataset", "children": [{"type": "file", "name": "dataloader.py"}, {"type": "file", "name": "get_dataset.py"}, {"type": "file", "name": "gpt_dataset.py"}, {"type": "file", "name": "indexed_dataset.py"}, {"type": "directory", "name": "megatron", "children": [{"type": "file", "name": "helpers.cpp"}, {"type": "file", "name": "Makefile"}, {"type": "directory", "name": "mpu", "children": [{"type": "file", "name": "cross_entropy.py"}, {"type": "file", "name": "data.py"}, {"type": "file", "name": "initialize.py"}, {"type": "file", "name": "layers.py"}, {"type": "file", "name": "mappings.py"}, {"type": "file", "name": "random.py"}, {"type": "directory", "name": "tests", "children": [{"type": "file", "name": "commons.py"}, {"type": "file", "name": "test_cross_entropy.py"}, {"type": "file", "name": "test_data.py"}, {"type": "file", "name": "test_initialize.py"}, {"type": "file", "name": "test_layers.py"}, {"type": "file", "name": "test_random.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "utils.py"}, {"type": "file", "name": "__init__.py"}]}]}, {"type": "file", "name": "utils.py"}]}, {"type": "file", "name": "init_wrapper.py"}, {"type": "file", "name": "teacher-inference-script.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "Makefile"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "teacher-inference-script.py"}, {"type": "file", "name": "test_dataset.py"}]} | # distill-bloom-deepspeed
Teacher - student distillation using DeepSpeed.
This repository is partially based from [BLOOM DeepSpeed repository](https://github.com/huggingface/transformers-bloom-inference/tree/main/bloom-inference-scripts). We follow the same setup as the repository above
## Setup
```pip install transformers huggingface_hub==0.9.0```
```pip install deepspeed>=0.7.3```
## Install teacher checkpoints
Install the DeepSpeed teacher checkpoints from [here]() to perform fast loading as described [here](https://github.com/huggingface/transformers-bloom-inference/tree/main/bloom-inference-scripts#run). Download them locally and follow the instructions below to run the training.
### Teacher inference
We highly recommend to install the teacher and student weights locally, therefore to not have to re-install the weights again.
After installing the teacher weights, run the following command to perform inference on the teacher model.
```
deepspeed --num_gpus NUM_GPUS teacher-inference-script.py --teacher-model-path[PATH_TO_BLOOM] --train-weighted-split-paths-path [PATH_TO_DATA] --train-iters [TRAIN_ITERS] --global-batch-size [GLOBAL_BATCH_SIZE] --eval-iters [EVAL_ITERS] --seq-length [SEQ_LEN]
```
#### Processing the dataset
##### Download the dataset
Here we use the dataset used to train the BLOOM model, that is available on Jean Zay. First, download the dataset that is available on a S3 bucket. The raw dataset consist of 1.6TB of numpy arrays. If you want to train our your custom dataset, please build your own dataloader structure.
##### Get the splits
For now we recommend to get the splits by running the following command.
```
export DATAPATH=[PATH_TO_DATASET]
git clone https://github.com/bigscience-workshop/bigscience.git
cd bigscience/
python data/catalogue/load_ratios_meg_ds_format.py --dataset-ratios-path ./data/catalogue/training_dataset_ratios_merged_nigercongo_v3.json --split train --output-meg-ds-ratio-file $DATAPATH/train.txt
python data/catalogue/load_ratios_meg_ds_format.py --dataset-ratios-path ./data/catalogue/training_dataset_ratios_merged_nigercongo_v3.json --split val --output-meg-ds-ratio-file $DATAPATH/val.txt
```
##### Test the data loading script
```
deepspeed --num_gpus 8 test.py --train-weighted-split-paths-path $DATAPATH/train.txt --train-iters 200 --global-batch-size 64 --eval-iters 20 --seq-length 2048
```
This test should output the lenght of the combined dataset as well as the total number of epochs.
#### Training
One the dataset is ready, we can start training the student model.
## Roadmap
- [ ] Add support for teacher inference
- [ ] Add support for student inference
- [ ] Add support for communicating teacher logits to student node
- [ ] Add support for student training (Ds-Zero)
- [ ] Add support for distributed training (`hostfile`)
- [x] Add support for loading Jean-Zay dataset
- [ ] Add support for loading custom dataset
| {".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 cf6f75ee7e14bef4d26c9bbd12b289a912a80172 Hamza Amin <[email protected]> 1727369121 +0500\tclone: from https://github.com/huggingface/distill-bloom-deepspeed.git\n", ".git\\refs\\heads\\main": "cf6f75ee7e14bef4d26c9bbd12b289a912a80172\n", "distill_bloom\\init_wrapper.py": "import io, json\nfrom pathlib import Path\n\nimport torch\nimport torch.distributed as dist\n\nfrom transformers.models.bloom.modeling_bloom import BloomBlock as BloomBlock\n\nclass DeepSpeedInitWrapper(object):\n r\"\"\"\n This is a wrapper around DeepSpeed inference / training script initialisation. \n It is used to initialise the DeepSpeed engine and load the necessary variables\n to correctly load the model and run inference.\n\n Args:\n args (:obj:`argparse.Namespace`):\n The parsed arguments from the command line. This contains all the arguments for \n training and inference. The `model_path` argument is used to load the model from\n the specified path. \n \"\"\"\n def __init__(self, args):\n r\"\"\"\n We need to store the rank of the current process since `write_checkpoints` is \n called only on rank 0.\n \"\"\"\n self.rank = dist.get_rank()\n self.checkpoints_json = \"checkpoints.json\"\n self.repo_root = args.teacher_model_path\n self.infer_dtype = \"float16\"\n \n def init_deepspeed_inference(self):\n r\"\"\"\n This function is a wrapper around the first lines that are called inside \n https://github.com/huggingface/transformers-bloom-inference/blob/main/bloom-inference-scripts/bloom-ds-inference.py \n \"\"\"\n tp_presharded_models = [\n \"microsoft/bloom-deepspeed-inference-int8\",\n \"microsoft/bloom-deepspeed-inference-fp16\",\n ]\n tp_presharded_mode = True if self.repo_root in tp_presharded_models else False\n \n\n # use one of these args to `init_inference`\n # 1. injection_policy is the slower version, but it's plain pytorch so it'll always work\n # 2. replace_with_kernel_inject is the faster one (fast fused kernels)\n kernel_inject = True\n # kernel_inject = False\n\n if kernel_inject:\n # XXX: for now ds-inference only works with fp16\n self.dtype = torch.float16\n else:\n self.dtype = torch.bfloat16\n\n if kernel_inject:\n self.kwargs = dict(replace_with_kernel_inject=True)\n else:\n self.kwargs = dict(\n injection_policy={BloomBlock: (\"self_attention.dense\", \"mlp.dense_4h_to_h\")}\n )\n\n if tp_presharded_mode:\n # tp presharded repos come with their own checkpoints config file\n checkpoints_json = os.path.join(self.repo_root, \"ds_inference_config.json\")\n else:\n # for normal bloom repo we need to write the checkpoints config file\n if self.rank == 0:\n write_checkponts_json(self.repo_root , self.rank, self.checkpoints_json)\n # dist.barrier()\n\ndef print_rank0(*msg, rank=0):\n if rank != 0:\n return\n print(*msg)\n\n\ndef get_checkpoint_files(model_name_or_path, rank=0,revision=None, force_offline=True):\n if not force_offline:\n # checks if online or not\n if is_offline_mode():\n print_rank0(\"Offline mode: forcing local_files_only=True\", rank)\n local_files_only = True\n else:\n local_files_only = False\n\n # loads files from hub\n cached_repo_dir = snapshot_download(\n model_name_or_path,\n allow_patterns=[\"*\"],\n local_files_only=True,\n revision=revision,\n )\n else:\n cached_repo_dir = model_name_or_path\n\n # extensions: .bin | .pt\n # creates a list of paths from all downloaded files in cache dir\n file_list = [\n str(entry)\n for entry in Path(cached_repo_dir).rglob(\"*.[bp][it][n]\")\n if entry.is_file()\n ]\n return file_list\n\n\ndef write_checkponts_json(model_name, rank=0, checkpoints_json=\"checkpoints.json\"):\n with io.open(checkpoints_json, \"w\", encoding=\"utf-8\") as f:\n # checkpoint_files = glob.glob(f\"{checkpoint_dir}/*bin\")\n checkpoint_files = get_checkpoint_files(model_name, rank)\n\n # print(\"Checkpoint files:\", checkpoint_files)\n\n data = {\"type\": \"BLOOM\", \"checkpoints\": checkpoint_files, \"version\": 1.0}\n\n json.dump(data, f)\n\n", "distill_bloom\\dataset\\indexed_dataset.py": "# Copyright (c) Facebook, Inc. and its affiliates.\n#\n# This source code is licensed under the MIT license found in the\n# LICENSE file in the root directory of this source tree.\n\n\n# copied from fairseq/fairseq/data/indexed_dataset.py\n# Removed IndexedRawTextDataset since it relied on Fairseq dictionary\n# other slight modifications to remove fairseq dependencies\n# Added document index to index file and made it accessible.\n# An empty sentence no longer separates documents.\n\nimport os\nimport shutil\nimport stat\nimport struct\nfrom functools import lru_cache\nfrom itertools import accumulate\n\nimport numpy as np\nimport torch\n\n\ndef best_fitting_dtype(vocab_size=None):\n if vocab_size is not None and vocab_size < 65500:\n return np.uint16\n else:\n return np.int32\n\n\ndef get_available_dataset_impl():\n return [\"lazy\", \"cached\", \"mmap\"]\n\n\ndef infer_dataset_impl(path):\n if IndexedDataset.exists(path):\n with open(index_file_path(path), \"rb\") as f:\n magic = f.read(8)\n if magic == IndexedDataset._HDR_MAGIC:\n return \"cached\"\n elif magic == MMapIndexedDataset.Index._HDR_MAGIC[:8]:\n return \"mmap\"\n else:\n return None\n else:\n print(f\"Dataset does not exist: {path}\")\n print(\n \"Path should be a basename that both .idx and .bin can be appended to get\"\n \" full filenames.\"\n )\n return None\n\n\ndef make_builder(out_file, impl, dtype=None):\n if impl == \"mmap\":\n assert dtype is not None\n return MMapIndexedDatasetBuilder(out_file, dtype=dtype)\n else:\n assert dtype is None\n return IndexedDatasetBuilder(out_file)\n\n\ndef make_dataset(path, impl, skip_warmup=False):\n if not IndexedDataset.exists(path):\n print(f\"Dataset does not exist: {path}\")\n print(\n \"Path should be a basename that both .idx and .bin can be appended to get\"\n \" full filenames.\"\n )\n return None\n if impl == \"infer\":\n impl = infer_dataset_impl(path)\n if impl == \"lazy\" and IndexedDataset.exists(path):\n return IndexedDataset(path)\n elif impl == \"cached\" and IndexedDataset.exists(path):\n return IndexedCachedDataset(path)\n elif impl == \"mmap\" and MMapIndexedDataset.exists(path):\n return MMapIndexedDataset(path, skip_warmup)\n print(f\"Unknown dataset implementation: {impl}\")\n return None\n\n\ndef dataset_exists(path, impl):\n if impl == \"mmap\":\n return MMapIndexedDataset.exists(path)\n else:\n return IndexedDataset.exists(path)\n\n\ndef read_longs(f, n):\n a = np.empty(n, dtype=np.int64)\n f.readinto(a)\n return a\n\n\ndef write_longs(f, a):\n f.write(np.array(a, dtype=np.int64))\n\n\ndtypes = {\n 1: np.uint8,\n 2: np.int8,\n 3: np.int16,\n 4: np.int32,\n 5: np.int64,\n 6: np.float,\n 7: np.double,\n 8: np.uint16,\n}\n\n\ndef code(dtype):\n for k in dtypes.keys():\n if dtypes[k] == dtype:\n return k\n raise ValueError(dtype)\n\n\ndef index_file_path(prefix_path):\n return prefix_path + \".idx\"\n\n\ndef data_file_path(prefix_path):\n return prefix_path + \".bin\"\n\n\ndef create_doc_idx(sizes):\n doc_idx = [0]\n for i, s in enumerate(sizes):\n if s == 0:\n doc_idx.append(i + 1)\n return doc_idx\n\n\nclass IndexedDataset(torch.utils.data.Dataset):\n \"\"\"Loader for IndexedDataset\"\"\"\n\n _HDR_MAGIC = b\"TNTIDX\\x00\\x00\"\n\n def __init__(self, path):\n super().__init__()\n self.path = path\n self.data_file = None\n self.read_index(path)\n\n def read_index(self, path):\n with open(index_file_path(path), \"rb\") as f:\n magic = f.read(8)\n print(magic, self._HDR_MAGIC)\n assert magic == self._HDR_MAGIC, (\n \"Index file doesn't match expected format. \"\n \"Make sure that --dataset-impl is configured properly.\"\n )\n version = f.read(8)\n assert struct.unpack(\"<Q\", version) == (1,)\n code, self.element_size = struct.unpack(\"<QQ\", f.read(16))\n self.dtype = dtypes[code]\n self._len, self.s = struct.unpack(\"<QQ\", f.read(16))\n self.doc_count = struct.unpack(\"<Q\", f.read(8))\n self.dim_offsets = read_longs(f, self._len + 1)\n self.data_offsets = read_longs(f, self._len + 1)\n self.sizes = read_longs(f, self.s)\n self.doc_idx = read_longs(f, self.doc_count)\n\n def read_data(self, path):\n self.data_file = open(data_file_path(path), \"rb\", buffering=0)\n\n def check_index(self, i):\n if i < 0 or i >= self._len:\n raise IndexError(\"index out of range\")\n\n def __del__(self):\n if self.data_file:\n self.data_file.close()\n\n # @lru_cache(maxsize=8)\n def __getitem__(self, idx):\n if not self.data_file:\n self.read_data(self.path)\n if isinstance(idx, int):\n i = idx\n self.check_index(i)\n tensor_size = self.sizes[self.dim_offsets[i] : self.dim_offsets[i + 1]]\n a = np.empty(tensor_size, dtype=self.dtype)\n self.data_file.seek(self.data_offsets[i] * self.element_size)\n self.data_file.readinto(a)\n return a\n elif isinstance(idx, slice):\n start, stop, step = idx.indices(len(self))\n if step != 1:\n raise ValueError(\"Slices into indexed_dataset must be contiguous\")\n sizes = self.sizes[self.dim_offsets[start] : self.dim_offsets[stop]]\n size = sum(sizes)\n a = np.empty(size, dtype=self.dtype)\n self.data_file.seek(self.data_offsets[start] * self.element_size)\n self.data_file.readinto(a)\n offsets = list(accumulate(sizes))\n sents = np.split(a, offsets[:-1])\n return sents\n\n def __len__(self):\n return self._len\n\n def num_tokens(self, index):\n return self.sizes[index]\n\n def size(self, index):\n return self.sizes[index]\n\n @staticmethod\n def exists(path):\n return os.path.exists(index_file_path(path)) and os.path.exists(\n data_file_path(path)\n )\n\n @property\n def supports_prefetch(self):\n return False # avoid prefetching to save memory\n\n\nclass IndexedCachedDataset(IndexedDataset):\n def __init__(self, path):\n super().__init__(path)\n self.cache = None\n self.cache_index = {}\n\n @property\n def supports_prefetch(self):\n return True\n\n def prefetch(self, indices):\n if all(i in self.cache_index for i in indices):\n return\n if not self.data_file:\n self.read_data(self.path)\n indices = sorted(set(indices))\n total_size = 0\n for i in indices:\n total_size += self.data_offsets[i + 1] - self.data_offsets[i]\n self.cache = np.empty(total_size, dtype=self.dtype)\n ptx = 0\n self.cache_index.clear()\n for i in indices:\n self.cache_index[i] = ptx\n size = self.data_offsets[i + 1] - self.data_offsets[i]\n a = self.cache[ptx : ptx + size]\n self.data_file.seek(self.data_offsets[i] * self.element_size)\n self.data_file.readinto(a)\n ptx += size\n if self.data_file:\n # close and delete data file after prefetch so we can pickle\n self.data_file.close()\n self.data_file = None\n\n # @lru_cache(maxsize=8)\n def __getitem__(self, idx):\n if isinstance(idx, int):\n i = idx\n self.check_index(i)\n tensor_size = self.sizes[self.dim_offsets[i] : self.dim_offsets[i + 1]]\n a = np.empty(tensor_size, dtype=self.dtype)\n ptx = self.cache_index[i]\n np.copyto(a, self.cache[ptx : ptx + a.size])\n return a\n elif isinstance(idx, slice):\n # Hack just to make this work, can optimizer later if necessary\n sents = []\n for i in range(*idx.indices(len(self))):\n sents.append(self[i])\n return sents\n\n\nclass IndexedDatasetBuilder(object):\n element_sizes = {\n np.uint8: 1,\n np.int8: 1,\n np.uint16: 2,\n np.int16: 2,\n np.int32: 4,\n np.int64: 8,\n np.float: 4,\n np.double: 8,\n }\n\n @staticmethod\n def write_header(fout, dtype, numdata, numsize, numdoc):\n \"\"\"Writes header for cached indexed dataset to given file handle, return number of bytes written.\n \"\"\"\n startpos = fout.tell()\n\n fout.write(IndexedDataset._HDR_MAGIC)\n fout.write(struct.pack(\"<Q\", 1))\n fout.write(struct.pack(\"<Q\", code(dtype)))\n fout.write(struct.pack(\"<Q\", IndexedDatasetBuilder.element_sizes[dtype]))\n fout.write(struct.pack(\"<Q\", numdata - 1))\n fout.write(struct.pack(\"<Q\", numsize))\n fout.write(struct.pack(\"<Q\", numdoc))\n\n endpos = fout.tell()\n return endpos - startpos\n\n def __init__(self, out_file, dtype=np.int32):\n self.out_file = open(out_file, \"wb\")\n self.dtype = dtype\n self.data_offsets = [0]\n self.dim_offsets = [0]\n self.sizes = []\n self.element_size = self.element_sizes[self.dtype]\n self.doc_idx = [0]\n\n def add_item(self, tensor):\n bytes = self.out_file.write(np.array(tensor.numpy(), dtype=self.dtype))\n self.data_offsets.append(self.data_offsets[-1] + bytes / self.element_size)\n for s in tensor.size():\n self.sizes.append(s)\n self.dim_offsets.append(self.dim_offsets[-1] + len(tensor.size()))\n\n def end_document(self):\n self.doc_idx.append(len(self.sizes))\n\n def merge_file_(self, another_file):\n index = IndexedDataset(another_file)\n assert index.dtype == self.dtype\n\n doc_offset = len(self.sizes)\n\n begin = self.data_offsets[-1]\n for data_offset in index.data_offsets[1:]:\n self.data_offsets.append(begin + data_offset)\n self.sizes.extend(index.sizes)\n begin = self.dim_offsets[-1]\n for dim_offset in index.dim_offsets[1:]:\n self.dim_offsets.append(begin + dim_offset)\n self.doc_idx.extend((doc_offset + index.doc_idx)[1:])\n\n with open(data_file_path(another_file), \"rb\") as f:\n while True:\n data = f.read(1024)\n if data:\n self.out_file.write(data)\n else:\n break\n\n def finalize(self, index_file):\n self.out_file.close()\n index = open(index_file, \"wb\")\n IndexedDatasetBuilder.write_header(\n index,\n self.dtype,\n len(self.data_offsets),\n len(self.sizes),\n len(self.doc_idx),\n )\n write_longs(index, self.dim_offsets)\n write_longs(index, self.data_offsets)\n write_longs(index, self.sizes)\n write_longs(index, self.doc_idx)\n index.close()\n\n\ndef _warmup_mmap_file(path):\n with open(path, \"rb\") as stream:\n while stream.read(100 * 1024 * 1024):\n pass\n\n\ndef exscan_from_cumsum_(arr):\n # given an array holding the result of an inclusive scan (cumsum),\n # convert to an exclusive scan (shift to the right)\n # [10, 30, 35, 50] --> [0, 10, 30, 35]\n if arr.size > 1:\n arr[1:] = arr[:-1]\n if arr.size > 0:\n arr[0] = 0\n\n\ndef get_pointers_with_total(sizes, elemsize, dtype):\n \"\"\"Return a numpy array of type np.dtype giving the byte offsets.\n\n Multiplies values in the sizes array by elemsize (bytes),\n and then computes an exclusive scan to get byte offsets.\n Returns the total number of bytes as second item in a tuple.\n \"\"\"\n\n # scale values in sizes array by elemsize to get sizes in bytes\n pointers = np.array(sizes, dtype=dtype)\n pointers *= elemsize\n np.cumsum(pointers, axis=0, out=pointers)\n\n # get total number of bytes from all sizes (last element)\n bytes_last = pointers[-1] if len(sizes) > 0 else 0\n\n # convert to byte offsets\n exscan_from_cumsum_(pointers)\n\n return pointers, bytes_last\n\n\nclass MMapIndexedDataset(torch.utils.data.Dataset):\n class Index(object):\n _HDR_MAGIC = b\"MMIDIDX\\x00\\x00\"\n\n @staticmethod\n def write_header(fout, dtype, numsizes, numdocs):\n \"\"\"Writes header for mmap indexed dataset to given file handle, return number of bytes written.\n \"\"\"\n startpos = fout.tell()\n\n fout.write(MMapIndexedDataset.Index._HDR_MAGIC)\n fout.write(struct.pack(\"<Q\", 1))\n fout.write(struct.pack(\"<B\", code(dtype)))\n fout.write(struct.pack(\"<Q\", numsizes))\n fout.write(struct.pack(\"<Q\", numdocs))\n\n endpos = fout.tell()\n return endpos - startpos\n\n @classmethod\n def writer(cls, path, dtype):\n class _Writer(object):\n def __enter__(self):\n self._file = open(path, \"wb\")\n return self\n\n @staticmethod\n def _get_pointers(sizes, npdtype):\n \"\"\"Return a numpy array of byte offsets given a list of sizes.\n\n Multiplies values in the sizes array by dtype size (bytes),\n and then computes an exclusive scan to get byte offsets.\n \"\"\"\n\n # compute element sizes in bytes\n pointers, _ = get_pointers_with_total(\n sizes, dtype().itemsize, npdtype\n )\n return pointers\n\n def write(self, sizes, doc_idx):\n MMapIndexedDataset.Index.write_header(\n self._file, dtype, len(sizes), len(doc_idx)\n )\n\n sizes32 = np.array(sizes, dtype=np.int32)\n self._file.write(sizes32.tobytes(order=\"C\"))\n del sizes32\n\n pointers = self._get_pointers(sizes, np.int64)\n self._file.write(pointers.tobytes(order=\"C\"))\n del pointers\n\n doc_idx = np.array(doc_idx, dtype=np.int64)\n self._file.write(doc_idx.tobytes(order=\"C\"))\n\n def __exit__(self, exc_type, exc_val, exc_tb):\n self._file.close()\n\n return _Writer()\n\n def __init__(self, path, skip_warmup=False):\n with open(path, \"rb\") as stream:\n magic_test = stream.read(9)\n assert self._HDR_MAGIC == magic_test, (\n \"Index file doesn't match expected format. \"\n \"Make sure that --dataset-impl is configured properly.\"\n )\n version = struct.unpack(\"<Q\", stream.read(8))\n assert (1,) == version\n\n (dtype_code,) = struct.unpack(\"<B\", stream.read(1))\n self._dtype = dtypes[dtype_code]\n self._dtype_size = self._dtype().itemsize\n\n self._len = struct.unpack(\"<Q\", stream.read(8))[0]\n self._doc_count = struct.unpack(\"<Q\", stream.read(8))[0]\n offset = stream.tell()\n\n if not skip_warmup:\n _warmup_mmap_file(path)\n\n self._bin_buffer_mmap = np.memmap(path, mode=\"r\", order=\"C\")\n self._bin_buffer = memoryview(self._bin_buffer_mmap)\n print(\" reading sizes...\")\n self._sizes = np.frombuffer(\n self._bin_buffer, dtype=np.int32, count=self._len, offset=offset\n )\n print(\" reading pointers...\")\n self._pointers = np.frombuffer(\n self._bin_buffer,\n dtype=np.int64,\n count=self._len,\n offset=offset + self._sizes.nbytes,\n )\n print(\" reading document index...\")\n self._doc_idx = np.frombuffer(\n self._bin_buffer,\n dtype=np.int64,\n count=self._doc_count,\n offset=offset + self._sizes.nbytes + self._pointers.nbytes,\n )\n\n def __del__(self):\n self._bin_buffer_mmap._mmap.close()\n del self._bin_buffer_mmap\n\n @property\n def dtype(self):\n return self._dtype\n\n @property\n def sizes(self):\n return self._sizes\n\n @property\n def doc_idx(self):\n return self._doc_idx\n\n @lru_cache(maxsize=8)\n def __getitem__(self, i):\n return self._pointers[i], self._sizes[i]\n\n def __len__(self):\n return self._len\n\n def __init__(self, path, skip_warmup=False):\n super().__init__()\n\n self._path = None\n self._index = None\n self._bin_buffer = None\n\n self._do_init(path, skip_warmup)\n\n def __getstate__(self):\n return self._path\n\n def __setstate__(self, state):\n self._do_init(state)\n\n def _do_init(self, path, skip_warmup):\n self._path = path\n self._index = self.Index(index_file_path(self._path), skip_warmup)\n\n if not skip_warmup:\n print(\" warming up data mmap file...\")\n _warmup_mmap_file(data_file_path(self._path))\n print(\" creating numpy buffer of mmap...\")\n self._bin_buffer_mmap = np.memmap(\n data_file_path(self._path), mode=\"r\", order=\"C\"\n )\n print(\" creating memory view of numpy buffer...\")\n self._bin_buffer = memoryview(self._bin_buffer_mmap)\n\n def __del__(self):\n self._bin_buffer_mmap._mmap.close()\n del self._bin_buffer_mmap\n del self._index\n\n def __len__(self):\n return len(self._index)\n\n # @lru_cache(maxsize=8)\n def __getitem__(self, idx):\n if isinstance(idx, int):\n ptr, size = self._index[idx]\n np_array = np.frombuffer(\n self._bin_buffer, dtype=self._index.dtype, count=size, offset=ptr\n )\n return np_array\n elif isinstance(idx, slice):\n start, stop, step = idx.indices(len(self))\n if step != 1:\n raise ValueError(\"Slices into indexed_dataset must be contiguous\")\n ptr = self._index._pointers[start]\n sizes = self._index._sizes[idx]\n offsets = list(accumulate(sizes))\n total_size = sum(sizes)\n np_array = np.frombuffer(\n self._bin_buffer, dtype=self._index.dtype, count=total_size, offset=ptr\n )\n sents = np.split(np_array, offsets[:-1])\n return sents\n\n def get(self, idx, offset=0, length=None):\n \"\"\"Retrieves a single item from the dataset with the option to only\n return a portion of the item.\n\n get(idx) is the same as [idx] but get() does not support slicing.\n \"\"\"\n ptr, size = self._index[idx]\n if length is None:\n length = size - offset\n ptr += offset * np.dtype(self._index.dtype).itemsize\n np_array = np.frombuffer(\n self._bin_buffer, dtype=self._index.dtype, count=length, offset=ptr\n )\n return np_array\n\n @property\n def sizes(self):\n return self._index.sizes\n\n def size(self, index):\n return self._index.sizes[index]\n\n @property\n def doc_idx(self):\n return self._index.doc_idx\n\n def get_doc_idx(self):\n return self._index._doc_idx\n\n def set_doc_idx(self, doc_idx_):\n self._index._doc_idx = doc_idx_\n\n @property\n def supports_prefetch(self):\n return False\n\n @staticmethod\n def exists(path):\n return os.path.exists(index_file_path(path)) and os.path.exists(\n data_file_path(path)\n )\n\n @property\n def dtype(self):\n return self._index.dtype\n\n\nclass MMapIndexedDatasetBuilder(object):\n def __init__(self, out_file, dtype=np.int64):\n self._data_file = open(out_file, \"wb\")\n self._dtype = dtype\n self._sizes = []\n self._doc_idx = [0]\n\n def add_item(self, tensor):\n np_array = np.array(tensor.numpy(), dtype=self._dtype)\n self._data_file.write(np_array.tobytes(order=\"C\"))\n self._sizes.append(np_array.size)\n\n def end_document(self):\n self._doc_idx.append(len(self._sizes))\n\n def merge_file_(self, another_file):\n # Concatenate index\n index = MMapIndexedDataset.Index(index_file_path(another_file))\n assert index.dtype == self._dtype\n\n total_len = len(index.sizes) + len(self._sizes)\n print(\n f\" concat {another_file} size={len(index.sizes)} for a total size of\"\n f\" {total_len}\"\n )\n\n offset = len(self._sizes)\n self._sizes.extend(index.sizes)\n self._doc_idx.extend((offset + index.doc_idx)[1:])\n\n # Concatenate data\n with open(data_file_path(another_file), \"rb\") as f:\n shutil.copyfileobj(f, self._data_file)\n\n def finalize(self, index_file):\n self._data_file.close()\n\n with MMapIndexedDataset.Index.writer(index_file, self._dtype) as index:\n index.write(self._sizes, self._doc_idx)\n\n\n# To merge a set of binary files, one can simply concatenate them in order.\n# We stat each binary file to determine its size, execute a scan to compute\n# the byte offset where the calling rank should write its data, seek to proper\n# spot, and copy each file.\ndef gather_files_dist_bin(outfile, filelist, distctx):\n \"\"\"Concatenate binary files in filelist into a new file given by outfile\"\"\"\n # lookup size of each of our binary files\n filesizes = [os.stat(data_file_path(f))[stat.ST_SIZE] for f in filelist]\n\n # compute total bytes of the merged file and the offset\n # at which this rank will write data from its files\n numbytes = sum(filesizes)\n count = distctx.sum(numbytes)\n offset = distctx.exscan(numbytes)\n\n # We first write to a temporary file name. We rename to the final name\n # if successful or delete the temporary file if not.\n # This way if the final name appears, the user knows it's a valid file.\n finalname = data_file_path(outfile)\n finalnametmp = finalname + \".tmp\"\n\n # First delete the final file if it already exists\n distctx.remove(finalname)\n\n # Catch I/O errors from any process\n err = None\n try:\n # Create shared output file and pre-truncate to its final size.\n with distctx.open(finalnametmp, truncate=count) as fout:\n # Seek to appropriate starting offset in the merged file.\n fout.seek(offset)\n\n # Copy in contents of each of our files.\n for f in filelist:\n with open(data_file_path(f), \"rb\") as fsrc:\n shutil.copyfileobj(fsrc, fout)\n\n except Exception as e:\n err = e\n\n # Check that all ranks wrote successfully.\n # This will raise an exception all on ranks if we detect\n # an exception on any rank.\n distctx.allraise_if(err)\n\n # Everyone wrote their part successfully.\n # Rename the temporary file to the final file.\n distctx.rename(finalnametmp, finalname)\n\n\ndef write_list_at_offset(fout, file_offset, vals, shift, elem_offset, dtype):\n \"\"\"Write list of vals to fout starting at an offset given by file_offset, elem_offset, and dtype.\n\n Copies list of values in vals to a numpy array of type dtype.\n Adds a constant shift value to all elements.\n Writes the numpy array to the file handle at given offset and scaled by size of the datatype.\n offset = file_offset + elem_offset * dtype().itemsize\n\n Parameters\n ----------\n fout : file handle\n Open file handle to which to write list of vals\n file_offset : int\n Byte offset within the file where the global list starts\n vals : list[int]\n List of values to be written\n shift : int\n Value to add to each element in vals before writing (use 0 for no change)\n elem_offset : int\n Zero-based element index where vals starts within the global list.\n This value is scaled by dtype().itemsize to convert to a corresponding byte offset.\n dtype : np.dtype\n numpy datatype to be used when writing the list to the file\n \"\"\"\n\n # Make a copy of the vals list using the requested datatype.\n npvals = np.array(vals, dtype=dtype)\n\n # Shift values in the list by a constant value.\n npvals += shift\n\n # Seek to proper offset for this rank and write\n # values into file, stored as given datatype.\n fout.seek(file_offset + elem_offset * dtype().itemsize)\n fout.write(npvals.tobytes(order=\"C\"))\n\n\ndef gather_files_dist_check_dtype(filelist, dtype_rank_consistent, dtype_code, distctx):\n # Verify that no rank has found an inconsistent value in its own set of files.\n # This includes an allreduce to verify that dtype_rank_consistent is True everywhere.\n distctx.allassert(\n dtype_rank_consistent, \"Some rank found inconsistent dtype values\"\n )\n\n # Verify that at least one rank found a dtype value.\n # Because of the bcast, the the value of first_dtype_code is the same on all ranks.\n first_dtype_code = distctx.bcast_first(dtype_code)\n assert (\n first_dtype_code is not None\n ), \"Failed to find a dtype value in any index file\"\n\n # Verify that the dtype is consistent on all ranks, if a rank has a dtype value.\n distctx.allassert(\n dtype_code == first_dtype_code or dtype_code is None,\n \"Different dtype values detected in index files\",\n )\n\n # return the dtype\n return dtypes[first_dtype_code]\n\n\ndef gather_files_dist_idx_cached(outfile, filelist, distctx):\n # Read each index file and append items to our lists\n sizes = []\n data_offsets = [0]\n dim_offsets = [0]\n doc_idx = [0]\n dtype_rank_consistent = (\n True # whether this rank identifies inconsistent dtype values in its files\n )\n dtype_value = None # the current dtype code to compare against, if any\n for f in filelist:\n # read index file for this file\n index = IndexedDataset(f)\n\n # append its size, data, dim, and doc entries to our lists\n doc_offset = len(sizes)\n sizes.extend(index.sizes)\n data_offsets.extend(index.data_offsets[1:] + data_offsets[-1])\n dim_offsets.extend(index.dim_offsets[1:] + dim_offsets[-1])\n doc_idx.extend(index.doc_idx[1:] + doc_offset)\n\n # check that the dtype in this index matches the dtype in our other files\n dtype_code = code(index.dtype)\n if dtype_value is None:\n dtype_value = dtype_code\n if dtype_value != dtype_code:\n dtype_rank_consistent = False\n\n # Check that we have consistent dtypes in all files from all ranks,\n # and return the dtype being used.\n dtype = gather_files_dist_check_dtype(\n filelist, dtype_rank_consistent, dtype_value, distctx\n )\n\n # Capture the last value in the data array before we delete any items.\n # Note this may be zero on any rank that has no items,\n # but zero is the correct value in that case.\n # We use this last value to compute a shift value that\n # is later be added to each element in our data list.\n data_shift = distctx.exscan(data_offsets[-1])\n\n # Drop the zero entry from the lists that start with\n # a \"0\" value unless we're rank 0.\n if distctx.rank != 0:\n del data_offsets[0]\n del dim_offsets[0]\n del doc_idx[0]\n\n # Compute total number of entires in data, size, dim,\n # and doc_idx lists across all ranks. Also compute the offset\n # of the calling rank for each list considering the number\n # of entries for all ranks before the calling rank.\n numdata = len(data_offsets)\n numsize = len(sizes)\n numdim = len(dim_offsets)\n numdoc = len(doc_idx)\n\n global_data_count = distctx.sum(numdata)\n global_size_count = distctx.sum(numsize)\n global_dim_count = distctx.sum(numdim)\n global_doc_count = distctx.sum(numdoc)\n\n global_data_offset = distctx.exscan(numdata)\n global_size_offset = distctx.exscan(numsize)\n global_dim_offset = distctx.exscan(numdim)\n global_doc_offset = distctx.exscan(numdoc)\n\n # We first write to a temporary file name. We rename to the final name\n # if successful or delete the temporary file if not.\n # This way if the final name appears, the user knows it's a valid file.\n finalname = index_file_path(outfile)\n finalnametmp = finalname + \".tmp\"\n\n # First delete the final file if it already exists\n distctx.remove(finalname)\n\n # Catch and I/O errors to later determine whether all ranks wrote successfully.\n err = None\n try:\n # Create shared output file\n with distctx.open(finalnametmp) as fout:\n # Have rank 0 write the file header\n file_offset = 0\n if distctx.rank == 0:\n try:\n file_offset = fout.tell()\n file_offset += IndexedDatasetBuilder.write_header(\n fout,\n dtype,\n global_data_count,\n global_size_count,\n global_doc_count,\n )\n except Exception as e:\n err = e\n distctx.allraise_if(err)\n\n # Broadcast current file position from rank 0.\n file_offset = distctx.bcast(file_offset, root=0)\n\n # The dimension list records the offset within\n # the sizes list for each sentence.\n # We shift our dimension index values to account for the number of size values\n # that come before the calling rank which is in global_size_offset.\n write_list_at_offset(\n fout,\n file_offset,\n dim_offsets,\n global_size_offset,\n global_dim_offset,\n np.int64,\n )\n file_offset += global_dim_count * np.int64().itemsize\n\n # The data index records the element offset to the start of each\n # sentence within the binary data file. Note that this is an\n # element offset, not a byte offset. Each element is pyhsically stored\n # in the data file as dtype().itemsize bytes.\n # We shift the data index values according to the number of elements that\n # come before the calling rank, which is stored in data_shift.\n write_list_at_offset(\n fout,\n file_offset,\n data_offsets,\n data_shift,\n global_data_offset,\n np.int64,\n )\n file_offset += global_data_count * np.int64().itemsize\n\n # Each sentence is stored as a tensor.\n # The tensor for each sentence can be multidimensional.\n # The number of tensor dimensions per sentence is variable,\n # and the size of each dimension of a sentence is arbitrary.\n # The size list records a flattened list of the sizes\n # for each dimension of a sentence.\n # No shift value is needed.\n write_list_at_offset(\n fout, file_offset, sizes, 0, global_size_offset, np.int64\n )\n file_offset += global_size_count * np.int64().itemsize\n\n # The document index records the offset within the sizes\n # array for the first sentence of each document.\n # We shift the document index values for number of size values that\n # come before the calling rank which is in global_size_offset.\n write_list_at_offset(\n fout,\n file_offset,\n doc_idx,\n global_size_offset,\n global_doc_offset,\n np.int64,\n )\n file_offset += global_doc_count * np.int64().itemsize\n\n except Exception as e:\n # if we encounter any exception while writing, store it for later\n err = e\n\n # Check that all ranks wrote successfully\n distctx.allraise_if(err)\n\n # Everyone wrote their part successfully.\n # Rename the temporary file to the final file.\n distctx.rename(finalnametmp, finalname)\n\n\ndef gather_files_dist_idx_mmap(outfile, filelist, distctx):\n # Read each index file and append items to the size and doc_idx lists\n sizes = []\n doc_idx = [0]\n dtype_rank_consistent = (\n True # whether rank identifies inconsistent dtype values in its files\n )\n dtype_value = None # the current dtype code to compare against, if any\n for f in filelist:\n # read index file for this file\n index = MMapIndexedDataset.Index(index_file_path(f))\n\n # append its size and doc entries to our lists\n docs_offset = len(sizes)\n sizes.extend(index.sizes)\n doc_idx.extend(index.doc_idx[1:] + docs_offset)\n\n # check that the dtype in this index matches the dtype in our other files\n dtype_code = code(index.dtype)\n if dtype_value is None:\n dtype_value = dtype_code\n if dtype_value != dtype_code:\n dtype_rank_consistent = False\n\n # Check that we have consistent dtypes in all files from all ranks,\n # and return the dtype being used.\n dtype = gather_files_dist_check_dtype(\n filelist, dtype_rank_consistent, dtype_value, distctx\n )\n\n # Drop the zero entry from the lists that start with\n # a \"0\" value unless we're rank 0\n if distctx.rank != 0:\n del doc_idx[0]\n\n # Compute total number of size and document index\n # values across all ranks. Also compute the offset\n # of the calling rank for each value considering\n # the values of sizes/docs for all ranks before the\n # calling rank.\n numsizes = len(sizes)\n numdocs = len(doc_idx)\n\n global_size_count = distctx.sum(numsizes)\n global_docs_count = distctx.sum(numdocs)\n\n global_size_offset = distctx.exscan(numsizes)\n global_docs_offset = distctx.exscan(numdocs)\n\n # Compute local byte offsets for each of our sentences given\n # the token count and byte size of the vocab dtype.\n pointers, pointers_bytes = get_pointers_with_total(\n sizes, dtype().itemsize, np.int64\n )\n\n # Determine total number of bytes for all sentences on ranks\n # before the calling rank.\n pointer_offset = distctx.exscan(pointers_bytes)\n\n # We first write to a temporary file name. We rename to the final name\n # if successful or delete the temporary file if not.\n # This way if the final name appears, the user knows it's a valid file.\n finalname = index_file_path(outfile)\n finalnametmp = finalname + \".tmp\"\n\n # First delete the final file if it already exists\n distctx.remove(finalname)\n\n # Catch and I/O errors to later determine whether all ranks wrote successfully.\n err = None\n try:\n # Create shared output file\n with distctx.open(finalnametmp) as fout:\n # Have rank 0 write the file header\n file_offset = 0\n if distctx.rank == 0:\n try:\n file_offset = fout.tell()\n file_offset += MMapIndexedDataset.Index.write_header(\n fout, dtype, global_size_count, global_docs_count\n )\n except Exception as e:\n err = e\n distctx.allraise_if(err)\n\n # Broadcast current file position from rank 0.\n file_offset = distctx.bcast(file_offset, root=0)\n\n # The list of size values from each rank are\n # concatenated and stored as int32.\n write_list_at_offset(\n fout, file_offset, sizes, 0, global_size_offset, np.int32\n )\n file_offset += global_size_count * np.int32().itemsize\n\n # The pointer values store the byte offset to each sentence when in memory.\n # A sentence has a variable number of tokens, given by\n # its corresponding entry in the size array. Each token\n # of a sentence is stored in units of type dtype, which consumes\n # dtype().itemsize bytes (often a standard type that is just\n # large enough to represent all elements of the vocabulary).\n # Since the pointers array is the same length as the sizes array,\n # we use global_size_offset and global_size_count to position\n # within the file for writing the pointer values.\n write_list_at_offset(\n fout,\n file_offset,\n pointers,\n pointer_offset,\n global_size_offset,\n np.int64,\n )\n file_offset += global_size_count * np.int64().itemsize\n\n # The document index points to the position in the sizes\n # array for the starting sentence of each document.\n # A variable number of sentences can be in each document.\n # We shift the document index for number of sentences that\n # come before the calling rank which is in global_size_offset.\n write_list_at_offset(\n fout,\n file_offset,\n doc_idx,\n global_size_offset,\n global_docs_offset,\n np.int64,\n )\n file_offset += global_docs_count * np.int64().itemsize\n\n except Exception as e:\n # if we encounter any exception while writing, store it for later\n err = e\n\n # Check that all ranks wrote successfully\n distctx.allraise_if(err)\n\n # Everyone wrote their part successfully.\n # Rename the temporary file to the final file.\n distctx.rename(finalnametmp, finalname)\n\n\n# Verify that all files in filelist are of the same index type.\n# Returns the identified type {cached, mmap} as a string.\ndef gather_files_dist_check_impltype(filelist, distctx):\n # Sanity check for typos in file names.\n # Check that a data file exists for each of our files.\n all_files_exist = all([os.path.exists(data_file_path(f)) for f in filelist])\n\n # Check that all ranks have all of their files.\n distctx.allassert(all_files_exist, \"Some rank is missing its input file\")\n\n # map type string to an integer for easier bcast, use 0 for unknown\n implmap = {\"cached\": 1, \"mmap\": 2}\n\n # check that all files in filelist are of the same type\n sametype = True\n ourtype = None\n for f in filelist:\n # read header of index file to determine its type\n impl = infer_dataset_impl(f)\n implval = implmap[impl] if impl in implmap else 0\n\n # check that the type matches our other files\n if ourtype is None:\n ourtype = implval\n if ourtype != implval:\n sametype = False\n\n # Check that all ranks have the same type,\n # and that there is no unknown type.\n # This checks that:\n # - all of our own files (if any) are of the same type AND\n # - either we have no files or the type of our files match the broadcast type AND\n # - the broadcast type is of a known type: {cached, mmap}\n bcasttype = distctx.bcast_first(ourtype)\n matchtype = (\n sametype and (ourtype is None or ourtype == bcasttype) and bcasttype != 0\n )\n distctx.allassert(matchtype, \"Cannot merge dataset files of different types\")\n\n # map back to return index string name\n for key in implmap.keys():\n if implmap[key] == bcasttype:\n return key\n\n # raise exception if key for bcasttype was not found\n raise UnreachableCode\n\n\ndef gather_files_dist(filemain, filelist, distctx):\n \"\"\"Collectively merge files into a new output file specified in filemain.\n\n Each rank contributes a distinct list of zero or more files in filelist,\n and each rank directly merges its set of files into filemain.\n It is allowed for the input files in filelist to only be readable from the calling process.\n In particular, the input files specified by the calling process may be in storage\n that only the calling process can access, like /dev/shm or a node-local SSD.\n The output file in filemain should be in a location that is writable by all processes.\n\n NOTE: This uses parallel writes to a shared file to achieve high write bandwidth.\n To do so, this implementation seeks beyond the end of the file to write at different\n offsets from different processes via the seek() method on a python file handle.\n The behavior of seek() is not well documented, but it seems to map to fseek()/lseek(),\n and it works as desired on POSIX-compliant file systems like Lustre and GPFS.\"\"\"\n\n # Check that at least one input file is listed\n filecount = distctx.sum(len(filelist))\n assert filecount > 0, \"All ranks have no input files to merge\"\n\n # Check that files are all of the same index type\n indexstr = gather_files_dist_check_impltype(filelist, distctx)\n\n # Concatenate the data files\n gather_files_dist_bin(filemain, filelist, distctx)\n\n # Combine index files into a single index file\n if indexstr == \"cached\":\n gather_files_dist_idx_cached(filemain, filelist, distctx)\n elif indexstr == \"mmap\":\n gather_files_dist_idx_mmap(filemain, filelist, distctx)\n\n\ndef get_start_end(count, rank, numranks):\n \"\"\"Return (start, end) index values for calling rank to evenly divide count items among numranks.\n\n Example usage:\n start, end = get_start_end(len(itemlist), distctx.rank, distctx.numranks)\n sublist = itemlist[start:end]\n\n Parameters\n ----------\n count : int\n Total number of items to be divided\n rank : int\n Rank of the calling process, within range of [0, numranks)\n numranks : int\n Number of ranks by which to divide count items\n\n Returns\n ----------\n (start, end) : tuple(int)\n Start and end index values that define the [start, end) range for rank\n \"\"\"\n num, remainder = divmod(count, numranks)\n if rank < remainder:\n start = (num + 1) * rank\n end = start + num + 1\n else:\n start = (num + 1) * remainder + num * (rank - remainder)\n end = start + num\n return start, end\n\n\ndef merge_files_dist(filemain, filelist, distctx):\n \"\"\"Merge list of indexed datasets into a single indexed dataset named in filemain.\n\n Given a list of indexed datasets in filelist, and the set of processes defined\n by the distributed environment in distctx, collectively merge files into\n a new, single output indexed dataset named in filemain. This overwrites filemain\n if it already exists. It does not delete the input datasets in filelist. The input\n parameters filemain and filelist must be identical on all calling processes,\n and all processes in distctx must call this method collectively.\n It requires that all ranks be able to read any file in filelist, and all\n ranks must be able to write to the single output file named in filemain.\"\"\"\n\n # TODO: if file sizes vary significantly, it might be better to consider\n # file size when splitting the list to different ranks.\n\n # evenly divide list of files among ranks\n start, end = get_start_end(len(filelist), distctx.rank, distctx.numranks)\n sublist = filelist[start:end]\n\n # delegate merge to gather implementation\n return gather_files_dist(filemain, sublist, distctx)\n", "distill_bloom\\dataset\\megatron\\mpu\\mappings.py": "# coding=utf-8\n# Copyright (c) 2020, NVIDIA CORPORATION. All rights reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport torch\n\nfrom .initialize import (get_tensor_model_parallel_group,\n get_tensor_model_parallel_rank,\n get_tensor_model_parallel_world_size)\nfrom .utils import split_tensor_along_last_dim\n\n\ndef _reduce(input_):\n \"\"\"All-reduce the the input tensor across model parallel group.\"\"\"\n\n # Bypass the function if we are using only 1 GPU.\n if get_tensor_model_parallel_world_size() == 1:\n return input_\n\n # All-reduce.\n torch.distributed.all_reduce(input_, group=get_tensor_model_parallel_group())\n\n return input_\n\n\ndef _split(input_):\n \"\"\"Split the tensor along its last dimension and keep the\n corresponding slice.\"\"\"\n\n world_size = get_tensor_model_parallel_world_size()\n # Bypass the function if we are using only 1 GPU.\n if world_size == 1:\n return input_\n\n # Split along last dimension.\n input_list = split_tensor_along_last_dim(input_, world_size)\n\n # Note: torch.split does not create contiguous tensors by default.\n rank = get_tensor_model_parallel_rank()\n output = input_list[rank].contiguous()\n\n return output\n\n\ndef _gather(input_):\n \"\"\"Gather tensors and concatinate along the last dimension.\"\"\"\n\n world_size = get_tensor_model_parallel_world_size()\n # Bypass the function if we are using only 1 GPU.\n if world_size == 1:\n return input_\n\n # Size and dimension.\n last_dim = input_.dim() - 1\n rank = get_tensor_model_parallel_rank()\n\n tensor_list = [torch.empty_like(input_) for _ in range(world_size)]\n tensor_list[rank] = input_\n torch.distributed.all_gather(\n tensor_list, input_, group=get_tensor_model_parallel_group()\n )\n\n # Note: torch.cat already creates a contiguous tensor.\n output = torch.cat(tensor_list, dim=last_dim).contiguous()\n\n return output\n\n\nclass _CopyToModelParallelRegion(torch.autograd.Function):\n \"\"\"Pass the input to the model parallel region.\"\"\"\n\n @staticmethod\n def symbolic(graph, input_):\n return input_\n\n @staticmethod\n def forward(ctx, input_):\n return input_\n\n @staticmethod\n def backward(ctx, grad_output):\n return _reduce(grad_output)\n\n\nclass _ReduceFromModelParallelRegion(torch.autograd.Function):\n \"\"\"All-reduce the input from the model parallel region.\"\"\"\n\n @staticmethod\n def symbolic(graph, input_):\n return _reduce(input_)\n\n @staticmethod\n def forward(ctx, input_):\n return _reduce(input_)\n\n @staticmethod\n def backward(ctx, grad_output):\n return grad_output\n\n\nclass _ScatterToModelParallelRegion(torch.autograd.Function):\n \"\"\"Split the input and keep only the corresponding chuck to the rank.\"\"\"\n\n @staticmethod\n def symbolic(graph, input_):\n return _split(input_)\n\n @staticmethod\n def forward(ctx, input_):\n return _split(input_)\n\n @staticmethod\n def backward(ctx, grad_output):\n return _gather(grad_output)\n\n\nclass _GatherFromModelParallelRegion(torch.autograd.Function):\n \"\"\"Gather the input from model parallel region and concatinate.\"\"\"\n\n @staticmethod\n def symbolic(graph, input_):\n return _gather(input_)\n\n @staticmethod\n def forward(ctx, input_):\n return _gather(input_)\n\n @staticmethod\n def backward(ctx, grad_output):\n return _split(grad_output)\n\n\n# -----------------\n# Helper functions.\n# -----------------\n\n\ndef copy_to_tensor_model_parallel_region(input_):\n return _CopyToModelParallelRegion.apply(input_)\n\n\ndef reduce_from_tensor_model_parallel_region(input_):\n return _ReduceFromModelParallelRegion.apply(input_)\n\n\ndef scatter_to_tensor_model_parallel_region(input_):\n return _ScatterToModelParallelRegion.apply(input_)\n\n\ndef gather_from_tensor_model_parallel_region(input_):\n return _GatherFromModelParallelRegion.apply(input_)\n"} | null |
distribution-v2 | {"type": "directory", "name": "distribution-v2", "children": []} | {".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 baa88eb5993ce01b3941e4e6aa8d8cd8f9b0fc14 Hamza Amin <[email protected]> 1727369123 +0500\tclone: from https://github.com/huggingface/distribution-v2.git\n", ".git\\refs\\heads\\main": "baa88eb5993ce01b3941e4e6aa8d8cd8f9b0fc14\n", ".github\\workflows\\main.yml": "on: # yamllint disable-line rule:truthy\n workflow_dispatch:\n\nname: Copy Distribution\njobs:\n copy:\n name: Copy to registry\n runs-on: ubuntu-latest\n steps:\n - name: Login to GitHub Container Registry\n uses: docker/login-action@v3\n with:\n registry: ghcr.io\n username: ${{ github.actor }}\n password: ${{ secrets.GITHUB_TOKEN }}\n - name: Update values\n run: |\n docker pull rtrompier/distribution:v2-sha-extension\n docker tag rtrompier/distribution:v2-sha-extension ghcr.io/huggingface/distribution-v2/distribution:v2-sha-extension\n docker push ghcr.io/huggingface/distribution-v2/distribution:v2-sha-extension\n"} | null |
|
docmatix | {"type": "directory", "name": "docmatix", "children": [{"type": "directory", "name": "analysis", "children": [{"type": "file", "name": "count_words_in_dataset.py"}, {"type": "file", "name": "plot.py"}]}, {"type": "directory", "name": "clean_and_create", "children": [{"type": "file", "name": "generate_dataset.sh"}, {"type": "file", "name": "load_data.py"}, {"type": "file", "name": "single_job.sh"}]}, {"type": "directory", "name": "create_only_with_pdfs", "children": [{"type": "file", "name": "generate_dataset.sh"}, {"type": "file", "name": "load_data.py"}, {"type": "file", "name": "single_job.sh"}, {"type": "file", "name": "upload_data.py"}]}, {"type": "directory", "name": "florence_2_dataset", "children": [{"type": "file", "name": "create_florence_2_dataset.py"}]}, {"type": "directory", "name": "generation", "children": [{"type": "file", "name": "base_prompts.py"}, {"type": "file", "name": "llm_swarm_script.py"}]}, {"type": "file", "name": "LICENSE"}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "zero_shot_exp", "children": [{"type": "file", "name": "zero_shot.py"}]}]} | # Docmatix
Docmatix is a comprehensive dataset designed for Document Visual Question Answering (DocVQA). It provides a robust collection of document images paired with corresponding questions and answers to facilitate research and development in the field of visual question answering on document images.

## This repository
This repository includes all the code used to generate Docmatix.
## Dataset
The dataset includes:
- A variety of document images.
- Question-answer pairs for each document.
- Annotations to facilitate training and evaluation of DocVQA models.
## License
This project is licensed under the MIT License. See the LICENSE file for details. | {".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 4bb0872340257ff79cf0321ea51f2ac7c9cd6542 Hamza Amin <[email protected]> 1727369263 +0500\tclone: from https://github.com/huggingface/docmatix.git\n", ".git\\refs\\heads\\main": "4bb0872340257ff79cf0321ea51f2ac7c9cd6542\n"} | null |
education-toolkit | {"type": "directory", "name": "education-toolkit", "children": [{"type": "file", "name": "01_huggingface-hub-tour.md"}, {"type": "file", "name": "02_ml-demos-with-gradio.ipynb"}, {"type": "file", "name": "03_getting-started-with-transformers.ipynb"}, {"type": "directory", "name": "images", "children": []}, {"type": "file", "name": "LICENSE"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "TRANSLATING.md"}, {"type": "directory", "name": "tutorials", "children": [{"type": "directory", "name": "ES", "children": [{"type": "file", "name": "01_tour_hub_de_huggingface.md"}, {"type": "file", "name": "02_ml-demos-con-gradio.ipynb"}, {"type": "file", "name": "03_Primeros_pasos_con_Transformers.ipynb"}, {"type": "file", "name": "README.md"}]}, {"type": "directory", "name": "FR", "children": [{"type": "file", "name": "01_huggingface-hub-tour.md"}, {"type": "file", "name": "02_ml-demos-avec-gradio.ipynb"}, {"type": "file", "name": "03_d\u00e9buter-avec-les-transformers.ipynb"}, {"type": "file", "name": "README.md"}]}, {"type": "directory", "name": "HE", "children": [{"type": "file", "name": "README.md"}]}, {"type": "directory", "name": "IT", "children": [{"type": "file", "name": "01_huggingface-hub-tour.md"}, {"type": "file", "name": "02_ml-demos-with-gradio.ipynb"}, {"type": "file", "name": "03_getting-started-with-transformers.ipynb"}, {"type": "file", "name": "README.md"}]}, {"type": "directory", "name": "JA", "children": [{"type": "file", "name": "README.md"}]}, {"type": "directory", "name": "KO", "children": [{"type": "file", "name": "01_huggingface-hub-tour.md"}, {"type": "file", "name": "README.md"}]}, {"type": "directory", "name": "PT", "children": [{"type": "file", "name": "README.md"}]}, {"type": "directory", "name": "TR", "children": [{"type": "file", "name": "01_huggingface-hub-tour.md"}, {"type": "file", "name": "02_ml-demos-with-gradio.ipynb"}, {"type": "file", "name": "03_getting-started-with-transformers.ipynb"}, {"type": "file", "name": "README.md"}]}, {"type": "directory", "name": "VI", "children": [{"type": "file", "name": "01_kh\u00e1m-ph\u00e1-huggingface-hub.md"}, {"type": "file", "name": "02_demos-v\u1edbi-gradio.ipynb"}, {"type": "file", "name": "03_kh\u1edfi-\u0111\u1ed9ng-c\u00f9ng-transformers.ipynb"}, {"type": "file", "name": "README.md"}]}]}]} | # 🤗 Bộ Công cụ Giáo dục
<aside>
👋 **Chào mừng các bạn!**
Chúng tôi đã tập hợp một bộ công cụ mà bất kỳ ai cũng có thể sử dụng để dễ dàng chuẩn bị cho các hội thảo, sự kiện, bài tập về nhà, hoặc lớp học. Nội dung hoàn toàn độc lập có thể dễ dàng kết hợp với các tài liệu khác. Nội dung này hoàn toàn **miễn phí** và sử dụng các công nghệ Mã nguồn mở nổi tiếng (`transformers`, `gradio`, v.v.).
Ngoài các bài hướng dẫn, chúng tôi cũng chia sẻ các tài nguyên khác giúp đi sâu hơn về Học máy hoặc giúp hỗ trợ thiết kế nội dung.
</aside>
Bạn muốn tìm các bài hướng dẫn ở ngôn ngữ khác? Bạn có thể tìm thấy tất cả các bản dịch tại [đây!](https://github.com/huggingface/education-toolkit#-translations)
## **Danh mục hướng dẫn**
### 1️⃣ Khám phá Hugging Face Hub
> Trong bài hướng dẫn này, bạn có thể:
>
> - Khám phá hơn 30,000 mô hình được chia sẻ trong Hub.
> - Tìm hiểu các phương pháp hiệu quả để tìm đúng mô hình và bộ dữ liệu cho bài toán của riêng bạn.
> - Tìm hiểu cách đóng góp và cộng tác trong quy trình xây dựng mô hình Học máy của bạn.
>
> **_Thời lượng: 20-40 phút_**
>
> 👉 [bấm vào đây để truy cập bài hướng dẫn](https://github.com/huggingface/education-toolkit/blob/main/01_huggingface-hub-tour.md) hoặc 👩🏫 [bài giảng](https://docs.google.com/presentation/d/1zQqpFTcpNLV7haj2Inw2qKHq8DjfZEaiObW1ZkLvPWM/edit?usp=sharing).
### 2️⃣ Xây dựng và lưu trữ bản thử nghiệm (demo) Học máy với Gradio và Hugging Face
> Trong bài hướng dẫn này, bạn có thể:
>
> - Khám phá các bản thử nghiệm Học máy do cộng đồng tạo ra.
> - Xây dựng bản thử nghiệm nhanh cho mô hình Học máy với Python sử dụng thư viện `gradio`.
> - Lưu trữ các bản thử nghiệm miễn phí trên Hugging Face Spaces.
> - Thêm bản thử nghiệm của bạn vào Hugging Face để phục vụ cho lớp học hoặc hội nghị của bạn.
>
> **_Thời lượng: 20-40 phút_**
>
> 👉 [bấm vào đây để truy cập bài hướng dẫn](https://colab.research.google.com/github/huggingface/education-toolkit/blob/main/02_ml-demos-with-gradio.ipynb) hoặc 👩🏫 [bài giảng](https://docs.google.com/presentation/d/14EU_xjtINXtpidWLnUvfcEpmxN46ORS-PLpwfUf8C1I/edit?usp=sharing).
### 3️⃣ Khởi động cùng Transformers
> Trong bài hướng dẫn này, bạn có thể nắm được:
>
> - Mạng nơ-ron Transformer có thể được sử dụng để giải quyết một loạt các tác vụ trong Xử lý Ngôn ngữ Tự nhiên và hơn thế nữa.
> - Học chuyển giao tri thức cho phép ta điều chỉnh Transformers phù hợp với các tác vụ cụ thể.
> - Có thể sử dụng hàm `pipeline()` của thư viện `transformers` để luận suy với các mô hình từ [Hugging Face Hub](https://huggingface.co/models).
>
> Bài hướng dẫn này dựa trên phần đầu tiên trong cuốn sách *[Natural Language Processing with Transformers](https://transformersbook.com/)* từ O'Reilly của chúng tôi - các bạn có thể tham khảo thêm nội dung cuốn sách nếu muốn tìm hiểu sâu hơn về chủ đề này!
>
> **_Thời lượng: 30-45 phút_**
>
> 👉 [bấm vào đây để truy cập bài hướng dẫn](https://colab.research.google.com/github/huggingface/education-toolkit/blob/main/03_getting-started-with-transformers.ipynb).
## **Hướng dẫn giảng dạy: Khám phá 🤗 Hub & Gradio**
Trong video này, Nate và Lewis cung cấp cho các bạn một cái nhìn tổng quan về Transformers và học chuyển giao, cũng như những nỗ lực và các công cụ khoa học mở của Hugging Face cho phép mọi người cộng tác trong các dự án Học máy.
[](http://www.youtube.com/watch?v=k8sHYMeDitQ "Khám phá Hugging Face Hub & Hướng dẫn thực hành Gradio")
## **Các tài nguyên khác để bạn tìm hiểu theo cách của bạn!**
### **🤗 Khoá học Xử lý Ngôn ngữ Tự nhiên**
Chúng tôi cung cấp một khóa học (miễn phí và không có quảng cáo) về Xử lý Ngôn ngữ Tự nhiên (NLP) sử dụng các thư viện từ hệ sinh thái **[Hugging Face](https://huggingface.co/)**.
👉 [bấm vào đây để truy cập 🤗 Khoá học](https://huggingface.co/course/chapter1/1).
<aside>
💡 Khóa học này:
- Yêu cầu có kiến thức tốt về Python.
- Nên tìm hiểu sau khi đã hoàn thành một khóa nhập môn về Học sâu, chẳng hạn như **[Practical Deep Learning for Coders](https://course.fast.ai/)** của **[fast.ai](https://www.fast.ai/)** hoặc một trong những chương trình được phát triển bởi **[DeepLearning.AI](https://www.deeplearning.ai/)**.
- Không yêu cầu biết trước các kiến thức về **[PyTorch](https://pytorch.org/)** hoặc **[TensorFlow](https://www.tensorflow.org/)**, mặc dù quen thuộc với một số kiến thức này sẽ hữu ích.
</aside>
### **🤗 Khoá học về Gradio**
Chúng tôi cung cấp một khóa học (miễn phí và không có quảng cáo) hướng dẫn bạn cách tạo các bản thử nghiệm cho mô hình Học máy của bạn sử dụng các thư viện từ hệ sinh thái **[Hugging Face](https://huggingface.co/)**.
👉 [bấm vào đây để truy cập 🤗 Khoá học](https://huggingface.co/course/chapter9/1).
<aside>
💡 Khóa học này:
- Mục tiêu hướng đến cho phép các nhà phát triển Học máy dễ dàng trình bày thành quả của họ cho nhiều đối tượng, bao gồm các nhóm không chuyên về kỹ thuật hoặc khách hàng, các nhà nghiên cứu để họ dễ dàng tái tạo các mô hình và hành vi Học máy hơn, cũng như người dùng cuối để họ dễ dàng xác định và gỡ lỗi cho mô hình, và hơn thế nữa!
</aside>
### **🤗 Khoá học về Học Tăng cường**
Chúng tôi cung cấp một khóa học (miễn phí và không có quảng cáo) về Học Tăng cường sâu sử dụng các thư viện từ hệ sinh thái **[Hugging Face](https://huggingface.co/)**.
👉 [bấm vào đây để truy cập 🤗 Khoá học](https://github.com/huggingface/deep-rl-class).
<aside>
💡 Khóa học này:
- Tìm hiểu Học Tăng cường sâu về cả mặt lý thuyết và thực hành.
- Học cách sử dụng các thư viện Học Tăng cường sâu nổi tiếng.
- Huấn luyện máy trong môi trường độc nhất.
- Phát hành lên Hugging Face Hub các máy đã được huấn luyện của bạn chỉ với một dòng mã nguồn, và hơn thế nữa!
</aside>
### **Các tài liệu giáo dục về Sentence Transformers**
Chúng tôi cung cấp một số hướng dẫn về một trong những thư viện mạnh mẽ nhất dành cho các ứng dụng trong công nghiệp và học thuật, đó là [Sentence Transformers](https://huggingface.co/sentence-transformers). [Sentence Transformers](https://huggingface.co/sentence-transformers) cho phép bạn tạo ra các biểu diễn tân tiến nhất từ hình ảnh và văn bản một cách miễn phí.
<aside>
💡 Chúng tôi khuyến khích các bạn nên làm theo các hướng dẫn theo thứ tự dưới đây:
- Giới thiệu về cách làm việc với các phép biểu diễn bằng cách sử dụng Inference API và thư viện 🤗 Datasets ([link](https://t.co/gcqqilyJYn)).
- Hướng dẫn có tương tác về Tìm kiếm theo Ngữ nghĩa ([link](https://t.co/lboHZKmygR)).
- Chia sẻ và tải các mô hình Sentence Transformers từ Hub([link](https://www.sbert.net/docs/hugging_face.html)).
- Hướng dẫn bắt đầu với dự án sử dụng Sentence Transformers của bạn ([link](https://t.co/BDTP6XoATu)).
- Mô hình Sentence Transformers cùng các liên kết tới Hub ([link](https://huggingface.co/sentence-transformers)).
### **🤗 Các đầu sách**
<img alt="book-cover" height=200 src="images/book_cover.jpg" id="book-cover"/>
Phát hành tháng Hai, 2022
Từ các chuyên gia tại Hugging Face, hãy tìm hiểu tất cả mọi thứ về Transformers và các ứng dụng của chúng cho một loạt các tác vụ NLP.
👉 [bấm vào đây để truy cập trang web của cuốn sách](https://transformersbook.com/).
<aside>
💡 Cuốn sách này:
- Được viết cho các nhà Khoa học dữ liệu và kỹ sư Học máy, những người có thể đã nghe nói về những đột phá gần đây liên quan đến Transformers, nhưng thiếu hướng dẫn chuyên sâu để giúp họ điều chỉnh các mô hình này cho các trường hợp sử dụng của riêng họ.
- Giả sử rằng bạn đã có một số kinh nghiệm thực tế với các mô hình huấn luyện trên GPU.
- Không yêu cầu biết trước các kiến thức về **[PyTorch](https://pytorch.org/)** hoặc **[TensorFlow](https://www.tensorflow.org/)**, mặc dù quen thuộc với một số kiến thức này sẽ hữu ích.
</aside>
### **🤗 Classrooms**
Classrooms cung cấp cho giáo viên và học sinh không gian làm việc cộng tác chuyên dụng để tận dụng tài nguyên của Hugging Face một cách mạnh mẽ hơn so với người dùng thông thường.
👉 [bấm vào đây để tạo 🤗 Classrooms miễn phí](https://huggingface.co/classrooms).
<aside>
💡 Từ Classrooms, bạn có thể:
- **Trao quyền cho sinh viên của bạn tiếp cận với những tài nguyên tối tân:** xây dựng các ứng dụng Học máy với Hugging Face và cộng tác với sinh viên của bạn một cách dễ dàng trên tất cả các bộ dữ liệu, các mô hình, và các bản thử nghiệm Học máy lưu trữ trong không gian classroom của bạn.
- **Cho phép sinh viên của bạn truy cập phi giới hạn vào các công cụ Học máy hiện đại:** tải các bộ dữ liệu, các mô hình và các bản thử nghiệm miễn phí. Huấn luyện, tinh chỉnh, thử nghiệm, và triển khai, sau đó chia sẻ các mô hình và bản thử nghiệm với lớp học hoặc cộng đồng, tất cả đều được lưu trữ miễn phí.
- **Hưởng lợi từ các tài nguyên tính toán nâng cao miễn phí** ví dụ như quyền truy cập tới Accelerated Inference API. [bấm vào đây để cải thiện Classroom của bạn](https://docs.google.com/forms/d/e/1FAIpQLSfQ22dZHmsh-vHpjboLwcyMJvEC5kpKX8k9N_ihM_lyGgcXHA/viewform).
</aside>
### **🤗 Sự kiện và Tin tức Giáo dục**
- [SỰ KIỆN] ngày **09/08**: ML Demo.cratization tour ở Colombia lúc 6 giờ chiều (giờ địa phương). [Đăng kí tại đây](https://docs.google.com/forms/d/e/1FAIpQLScmQHvi_qN790MEao1hFgZbfnGZ32sdTuT_12T6Uud1hd50Jw/viewform?usp=sf_link)
- [SỰ KIỆN] ngày **15/08**: ML Demo.cratization tour ở Singapore lúc 9 giờ sáng (giờ địa phương). [Đăng kí tại đây](https://docs.google.com/forms/d/e/1FAIpQLSflZx4zbzlIwCHlyOptS_bBps7g2oeYbte56117_8Ohrv6v5Q/viewform?usp=sf_link)
- [SỰ KIỆN] ngày **17/08**: ML Demo.cratization tour ỏ Ghana lúc 3 giờ chiều (giờ địa phương). [Đăng kí tại đây](https://docs.google.com/forms/d/e/1FAIpQLSdU_M_Om7kZHjtisFTcH88TcfTn8pACeqPUXPyJglSTTUDhfQ/viewform?usp=sf_link)
- [SỰ KIỆN] ngày **08/09**: ML Demo.cratization tour ỏ Argentina lúc 2 giờ chiều (giờ địa phương). [Đăng kí tại đây](https://docs.google.com/forms/d/e/1FAIpQLSfeD1C5W_YQxrGAm1pPHpccglqimm-Ot56RZwW-WQHWUOjxPA/viewform?usp=sf_link)
- [SỰ KIỆN] ngày **14/09**: ML Demo.cratization tour ỏ Canada lúc 6 tối (giờ miền Đông). [Đăng kí tại đây](https://docs.google.com/forms/d/e/1FAIpQLSeEBSBVLQGsGJkW2suo3FYexvlkelurcweA2sSLMFTUTBy3Og/viewform?usp=sf_link)
## 🌎 Các bản dịch
| Ngôn ngữ | Nguồn | Người đóng góp |
|:----------------:|:-----------------------------------------------------------------------------------------------:|---------------------------------------------------------------------------------------------|
| Tiếng Ý | [ `tutorials/IT` ](https://github.com/huggingface/education-toolkit/tree/main/tutorials/IT) | @[MorenoLaQuatra](https://github.com/MorenoLaQuatra) |
| Tiếng Tây Ban Nha | [ `tutorials/ES` ]( https://github.com/huggingface/education-toolkit/tree/main/tutorials/ES ) | @[Fabioburgos](https://github.com/Fabioburgos) |
| Tiếng Thổ Nhĩ Kỳ | [ `tutorials/TR` ]( https://github.com/huggingface/education-toolkit/tree/main/tutorials/TR ) | @[emrecgty](https://github.com/emrecgty/) @[farukozderim](https://github.com/FarukOzderim/) |
| Tiếng Pháp (WIP) | [ `tutorials/FR` ](https://github.com/huggingface/education-toolkit/tree/main/tutorials/FR) | @[g0bel1n](https://github.com/g0bel1n) @[lbourdois](https://github.com/lbourdois) |
| Tiếng Do Thái (WIP) | [ `tutorials/HE` ](https://github.com/huggingface/education-toolkit/tree/main/tutorials/IW) | @[omer-dor](https://github.com/omer-dor) |
| Tiếng Nhật (WIP) | [ `tutorials/JA` ]( https://github.com/huggingface/education-toolkit/tree/main/tutorials/JA ) | @[Wataru-Nakata](https://github.com/Wataru-Nakata) |
| Tiếng Hàn (WIP) | [ `tutorials/KO` ]( https://github.com/huggingface/education-toolkit/tree/main/tutorials/KO ) | @[oikosohn](https://github.com/oikosohn) @[eunseojo](https://github.com/oikosohn) |
| Tiếng Bồ Đào Nha (WIP) | [ `tutorials/PT` ]( https://github.com/huggingface/education-toolkit/tree/main/tutorials/PT ) | @[johnnv1](https://github.com/johnnv1/) |
| Tiếng Việt | [ `tutorials/VI` ]( https://github.com/huggingface/education-toolkit/tree/main/tutorials/VI ) | @[honghanhh](https://github.com/honghanhh) |
Nếu bạn muốn dịch các phần hướng dẫn này sang ngôn ngữ của mình, hãy xem hướng dẫn [DỊCH](https://github.com/huggingface/education-toolkit/blob/main/TRANSLATING.md) của chúng tôi.
<aside>
✉️ Mọi thắc mắc vui lòng liên hệ [email protected]!
</aside>
| {"requirements.txt": "transformers[torch,sentencepiece]\njupyter\ngradio\nstreamlit\n", ".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 e0339f873e614671c442759017bd2eacac6dd2c5 Hamza Amin <[email protected]> 1727369268 +0500\tclone: from https://github.com/huggingface/education-toolkit.git\n", ".git\\refs\\heads\\main": "e0339f873e614671c442759017bd2eacac6dd2c5\n"} | null |
efficient_scripts | {"type": "directory", "name": "efficient_scripts", "children": [{"type": "file", "name": "change_config.py"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "upload_a_new_repo.py"}]} | # Efficient_scripts
Collection of scripts that should make your life easier when working with the HF model hub.
## change_config.py
This script can be used to change a parameter of multiple config files.
In the beginning the script should be run without `--do_upload` to make sure the changed
configs can be checked locally before uploading them to the respective git repos, *e.g.*:
```bash
./change_config.py --search_key patrickvonplaten/t5-tiny-ra --key max_length --value 10
```
Having checked that the configs look as expected locally, one can upload them
to the repective git repos by adding `--do_upload`. Adding the `--rf` arg force deletes previously cloned
model repos.
```bash
./change_config.py --search_key patrickvonplaten/t5-tiny-ra --key max_length --value 10 --rf --upload
```
## upload_a_new_repo.py
This script can be used to quickly create a new repo.
```bash
./upload_a_new_repo.py --user patrickvonplaten --pw 12345678 --org google --model mt5-small
```
| {".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 af037b486bb49bc8f2ff442c43e94a426a49aee0 Hamza Amin <[email protected]> 1727369270 +0500\tclone: from https://github.com/huggingface/efficient_scripts.git\n", ".git\\refs\\heads\\main": "af037b486bb49bc8f2ff442c43e94a426a49aee0\n"} | null |
EnergyStarAI | {"type": "directory", "name": "EnergyStarAI", "children": [{"type": "file", "name": "check_h100.py"}, {"type": "file", "name": "Dockerfile"}, {"type": "file", "name": "entrypoint.sh"}, {"type": "file", "name": "LICENSE"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}]} | # EnergyStarAI
A repository for the AI Energy Star Project, aiming to establish energy efficiency ratings for AI models.
> [!NOTE]
> This is still a work in progress.
## Hardware
The Dockerfile provided in this repository is made to be used on NVIDIA H100 GPUs.
If you would like to run benchmarks on other types of hardware, we invite you to take a look at [these configuration examples](https://github.com/huggingface/optimum-benchmark/tree/energy_star_dev/examples/energy_star) that can be run directly with [Optimum Benchmark](https://github.com/huggingface/optimum-benchmark/tree/energy_star_dev).
## Usage
You can build the Docker image with:
```
docker build -t energy_star .
```
Then you can run your benchmark with:
```
docker run --gpus all --shm-size 1g energy_star --config-name my_task
```
where `my_task` is the name of a task with a configuration here: https://github.com/huggingface/optimum-benchmark/tree/energy_star_dev/examples/energy_star
You can override the value of a field in a configuration as explained here: https://github.com/huggingface/optimum-benchmark/tree/energy_star_dev?tab=readme-ov-file#configuration-overrides-%EF%B8%8F
| {"Dockerfile": "FROM nvidia/cuda:12.2.0-devel-ubuntu22.04\n\nARG PYTORCH_VERSION=2.4.0\nARG PYTHON_VERSION=3.9\nARG CUDA_VERSION=12.1\nARG MAMBA_VERSION=24.3.0-0\nARG CUDA_CHANNEL=nvidia\nARG INSTALL_CHANNEL=pytorch\n# Automatically set by buildx\nARG TARGETPLATFORM\n\nENV PATH=/opt/conda/bin:$PATH\n\nRUN apt-get update && DEBIAN_FRONTEND=noninteractive apt-get install -y --no-install-recommends \\\n build-essential \\\n ca-certificates \\\n ccache \\\n curl \\\n git && \\\n rm -rf /var/lib/apt/lists/*\n\n# Install conda\n# translating Docker's TARGETPLATFORM into mamba arches\nRUN case ${TARGETPLATFORM} in \\\n \"linux/arm64\") MAMBA_ARCH=aarch64 ;; \\\n *) MAMBA_ARCH=x86_64 ;; \\\n esac && \\\n curl -fsSL -v -o ~/mambaforge.sh -O \"https://github.com/conda-forge/miniforge/releases/download/${MAMBA_VERSION}/Mambaforge-${MAMBA_VERSION}-Linux-${MAMBA_ARCH}.sh\"\nRUN chmod +x ~/mambaforge.sh && \\\n bash ~/mambaforge.sh -b -p /opt/conda && \\\n rm ~/mambaforge.sh\n\n# Install pytorch\n# On arm64 we exit with an error code\nRUN case ${TARGETPLATFORM} in \\\n \"linux/arm64\") exit 1 ;; \\\n *) /opt/conda/bin/conda update -y conda && \\\n /opt/conda/bin/conda install -c \"${INSTALL_CHANNEL}\" -c \"${CUDA_CHANNEL}\" -y \"python=${PYTHON_VERSION}\" \"pytorch=$PYTORCH_VERSION\" \"pytorch-cuda=$(echo $CUDA_VERSION | cut -d'.' -f 1-2)\" ;; \\\n esac && \\\n /opt/conda/bin/conda clean -ya\n\nCOPY requirements.txt requirements.txt\nRUN pip install -r requirements.txt\n\nRUN git clone -b energy_star_dev https://github.com/huggingface/optimum-benchmark.git /optimum-benchmark && cd optimum-benchmark && pip install -e .\n\nCOPY ./check_h100.py /check_h100.py\nCOPY ./entrypoint.sh /entrypoint.sh\nRUN chmod +x /entrypoint.sh\n\nENTRYPOINT [\"/entrypoint.sh\"]\n", "requirements.txt": "accelerate==0.33.0\ncodecarbon==2.5.1\ndatasets==2.20.0\ndiffusers==0.30.0\nhuggingface-hub==0.24.5\nlibrosa==0.10.1\nomegaconf==2.3.0\n# optimum-benchmark @ git+https://github.com/huggingface/optimum-benchmark@energy_star_dev\ntorch==2.4.0\ntransformers==4.44.0\n", ".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 6ecb83b2a2bc2e52928e9b93dc62b261818375d4 Hamza Amin <[email protected]> 1727369271 +0500\tclone: from https://github.com/huggingface/EnergyStarAI.git\n", ".git\\refs\\heads\\main": "6ecb83b2a2bc2e52928e9b93dc62b261818375d4\n"} | null |
ethics-education | {"type": "directory", "name": "ethics-education", "children": [{"type": "directory", "name": "course", "children": [{"type": "file", "name": "README.md"}]}, {"type": "directory", "name": "explainers", "children": [{"type": "file", "name": "README.md"}]}, {"type": "file", "name": "README.md"}]} | Help needed! Please visit the GitHub issues for this repo to contribute 🤗 | {".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 06c1546a1175e2ebf9c04390fdcfedb9371e2547 Hamza Amin <[email protected]> 1727369126 +0500\tclone: from https://github.com/huggingface/ethics-education.git\n", ".git\\refs\\heads\\main": "06c1546a1175e2ebf9c04390fdcfedb9371e2547\n"} | null |
ethics-scripts | {"type": "directory", "name": "ethics-scripts", "children": [{"type": "directory", "name": "async_api_scrapes", "children": [{"type": "file", "name": "prepare_dataset.py"}, {"type": "file", "name": "Results.md"}, {"type": "file", "name": "run.py"}]}, {"type": "directory", "name": "delete_spaces_batch", "children": [{"type": "file", "name": "run.py"}]}, {"type": "directory", "name": "featured_spaces_likes", "children": [{"type": "file", "name": "run.py"}, {"type": "file", "name": "spaces.csv"}, {"type": "file", "name": "spaces_with_likes.csv"}]}, {"type": "directory", "name": "model_scraping", "children": [{"type": "directory", "name": "cards", "children": [{"type": "file", "name": "albert-base-v2.md"}, {"type": "file", "name": "bert-base-cased.md"}, {"type": "file", "name": "bert-base-multilingual-cased.md"}, {"type": "file", "name": "bert-base-uncased.md"}, {"type": "file", "name": "cl-tohoku___bert-base-japanese-whole-word-masking.md"}, {"type": "file", "name": "distilbert-base-cased-distilled-squad.md"}, {"type": "file", "name": "distilbert-base-uncased-finetuned-sst-2-english.md"}, {"type": "file", "name": "distilbert-base-uncased.md"}, {"type": "file", "name": "distilroberta-base.md"}, {"type": "file", "name": "emilyalsentzer___Bio_ClinicalBERT.md"}, {"type": "file", "name": "facebook___bart-large-mnli.md"}, {"type": "file", "name": "google___electra-base-discriminator.md"}, {"type": "file", "name": "gpt2.md"}, {"type": "file", "name": "Helsinki-NLP___opus-mt-en-es.md"}, {"type": "file", "name": "jonatasgrosman___wav2vec2-large-xlsr-53-english.md"}, {"type": "file", "name": "microsoft___layoutlmv3-base.md"}, {"type": "file", "name": "openai___clip-vit-base-patch32.md"}, {"type": "file", "name": "openai___clip-vit-large-patch14.md"}, {"type": "file", "name": "philschmid___bart-large-cnn-samsum.md"}, {"type": "file", "name": "prajjwal1___bert-tiny.md"}, {"type": "file", "name": "roberta-base.md"}, {"type": "file", "name": "roberta-large.md"}, {"type": "file", "name": "runwayml___stable-diffusion-v1-5.md"}, {"type": "file", "name": "sentence-transformers___all-MiniLM-L6-v2.md"}, {"type": "file", "name": "StanfordAIMI___stanford-deidentifier-base.md"}, {"type": "file", "name": "t5-base.md"}, {"type": "file", "name": "t5-small.md"}, {"type": "file", "name": "xlm-roberta-base.md"}, {"type": "file", "name": "xlm-roberta-large.md"}, {"type": "file", "name": "yiyanghkust___finbert-tone.md"}]}, {"type": "file", "name": "run.py"}]}, {"type": "file", "name": "requirements.txt"}]} | {"requirements.txt": "aiolimiter\naiohttp\ndatasets\n", ".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 7993020a54ac28be6f24043c8aa95627bb87e658 Hamza Amin <[email protected]> 1727369131 +0500\tclone: from https://github.com/huggingface/ethics-scripts.git\n", ".git\\refs\\heads\\main": "7993020a54ac28be6f24043c8aa95627bb87e658\n"} | null |
|
evaluate | {"type": "directory", "name": "evaluate", "children": [{"type": "file", "name": "additional-tests-requirements.txt"}, {"type": "file", "name": "AUTHORS"}, {"type": "file", "name": "CODE_OF_CONDUCT.md"}, {"type": "directory", "name": "comparisons", "children": [{"type": "directory", "name": "exact_match", "children": [{"type": "file", "name": "app.py"}, {"type": "file", "name": "exact_match.py"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}]}, {"type": "directory", "name": "mcnemar", "children": [{"type": "file", "name": "app.py"}, {"type": "file", "name": "mcnemar.py"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}]}, {"type": "directory", "name": "wilcoxon", "children": [{"type": "file", "name": "app.py"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "wilcoxon.py"}]}]}, {"type": "file", "name": "CONTRIBUTING.md"}, {"type": "directory", "name": "docs", "children": [{"type": "file", "name": "README.md"}, {"type": "directory", "name": "source", "children": [{"type": "file", "name": "a_quick_tour.mdx"}, {"type": "file", "name": "base_evaluator.mdx"}, {"type": "file", "name": "choosing_a_metric.mdx"}, {"type": "file", "name": "considerations.mdx"}, {"type": "file", "name": "creating_and_sharing.mdx"}, {"type": "file", "name": "custom_evaluator.mdx"}, {"type": "file", "name": "evaluation_suite.mdx"}, {"type": "file", "name": "index.mdx"}, {"type": "file", "name": "installation.mdx"}, {"type": "file", "name": "keras_integrations.md"}, {"type": "directory", "name": "package_reference", "children": [{"type": "file", "name": "evaluator_classes.mdx"}, {"type": "file", "name": "hub_methods.mdx"}, {"type": "file", "name": "loading_methods.mdx"}, {"type": "file", "name": "logging_methods.mdx"}, {"type": "file", "name": "main_classes.mdx"}, {"type": "file", "name": "saving_methods.mdx"}, {"type": "file", "name": "visualization_methods.mdx"}]}, {"type": "file", "name": "sklearn_integrations.mdx"}, {"type": "file", "name": "transformers_integrations.mdx"}, {"type": "file", "name": "types_of_evaluations.mdx"}, {"type": "file", "name": "_toctree.yml"}]}]}, {"type": "file", "name": "LICENSE"}, {"type": "file", "name": "Makefile"}, {"type": "directory", "name": "measurements", "children": [{"type": "directory", "name": "honest", "children": [{"type": "file", "name": "app.py"}, {"type": "file", "name": "honest.py"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}]}, {"type": "directory", "name": "label_distribution", "children": [{"type": "file", "name": "app.py"}, {"type": "file", "name": "label_distribution.py"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}]}, {"type": "directory", "name": "perplexity", "children": [{"type": "file", "name": "app.py"}, {"type": "file", "name": "perplexity.py"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}]}, {"type": "directory", "name": "regard", "children": [{"type": "file", "name": "app.py"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "regard.py"}, {"type": "file", "name": "requirements.txt"}]}, {"type": "directory", "name": "text_duplicates", "children": [{"type": "file", "name": "app.py"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "text_duplicates.py"}]}, {"type": "directory", "name": "toxicity", "children": [{"type": "file", "name": "app.py"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "toxicity.py"}]}, {"type": "directory", "name": "word_count", "children": [{"type": "file", "name": "app.py"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "word_count.py"}]}, {"type": "directory", "name": "word_length", "children": [{"type": "file", "name": "app.py"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "word_length.py"}]}]}, {"type": "directory", "name": "metrics", "children": [{"type": "directory", "name": "accuracy", "children": [{"type": "file", "name": "accuracy.py"}, {"type": "file", "name": "app.py"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}]}, {"type": "directory", "name": "bertscore", "children": [{"type": "file", "name": "app.py"}, {"type": "file", "name": "bertscore.py"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}]}, {"type": "directory", "name": "bleu", "children": [{"type": "file", "name": "app.py"}, {"type": "file", "name": "bleu.py"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "tokenizer_13a.py"}]}, {"type": "directory", "name": "bleurt", "children": [{"type": "file", "name": "app.py"}, {"type": "file", "name": "bleurt.py"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}]}, {"type": "directory", "name": "brier_score", "children": [{"type": "file", "name": "app.py"}, {"type": "file", "name": "brier_score.py"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}]}, {"type": "directory", "name": "cer", "children": [{"type": "file", "name": "app.py"}, {"type": "file", "name": "cer.py"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "test_cer.py"}]}, {"type": "directory", "name": "character", "children": [{"type": "file", "name": "app.py"}, {"type": "file", "name": "character.py"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}]}, {"type": "directory", "name": "charcut_mt", "children": [{"type": "file", "name": "app.py"}, {"type": "file", "name": "charcut_mt.py"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}]}, {"type": "directory", "name": "chrf", "children": [{"type": "file", "name": "app.py"}, {"type": "file", "name": "chrf.py"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}]}, {"type": "directory", "name": "code_eval", "children": [{"type": "file", "name": "app.py"}, {"type": "file", "name": "code_eval.py"}, {"type": "file", "name": "execute.py"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}]}, {"type": "directory", "name": "comet", "children": [{"type": "file", "name": "app.py"}, {"type": "file", "name": "comet.py"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}]}, {"type": "directory", "name": "competition_math", "children": [{"type": "file", "name": "app.py"}, {"type": "file", "name": "competition_math.py"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}]}, {"type": "directory", "name": "confusion_matrix", "children": [{"type": "file", "name": "app.py"}, {"type": "file", "name": "confusion_matrix.py"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}]}, {"type": "directory", "name": "coval", "children": [{"type": "file", "name": "app.py"}, {"type": "file", "name": "coval.py"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}]}, {"type": "directory", "name": "cuad", "children": [{"type": "file", "name": "app.py"}, {"type": "file", "name": "compute_score.py"}, {"type": "file", "name": "cuad.py"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}]}, {"type": "directory", "name": "exact_match", "children": [{"type": "file", "name": "app.py"}, {"type": "file", "name": "exact_match.py"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}]}, {"type": "directory", "name": "f1", "children": [{"type": "file", "name": "app.py"}, {"type": "file", "name": "f1.py"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}]}, {"type": "directory", "name": "frugalscore", "children": [{"type": "file", "name": "app.py"}, {"type": "file", "name": "frugalscore.py"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}]}, {"type": "directory", "name": "glue", "children": [{"type": "file", "name": "app.py"}, {"type": "file", "name": "glue.py"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}]}, {"type": "directory", "name": "google_bleu", "children": [{"type": "file", "name": "app.py"}, {"type": "file", "name": "google_bleu.py"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "tokenizer_13a.py"}]}, {"type": "directory", "name": "indic_glue", "children": [{"type": "file", "name": "app.py"}, {"type": "file", "name": "indic_glue.py"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}]}, {"type": "directory", "name": "mae", "children": [{"type": "file", "name": "app.py"}, {"type": "file", "name": "mae.py"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}]}, {"type": "directory", "name": "mahalanobis", "children": [{"type": "file", "name": "app.py"}, {"type": "file", "name": "mahalanobis.py"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}]}, {"type": "directory", "name": "mape", "children": [{"type": "file", "name": "app.py"}, {"type": "file", "name": "mape.py"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}]}, {"type": "directory", "name": "mase", "children": [{"type": "file", "name": "app.py"}, {"type": "file", "name": "mase.py"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}]}, {"type": "directory", "name": "matthews_correlation", "children": [{"type": "file", "name": "app.py"}, {"type": "file", "name": "matthews_correlation.py"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}]}, {"type": "directory", "name": "mauve", "children": [{"type": "file", "name": "app.py"}, {"type": "file", "name": "mauve.py"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}]}, {"type": "directory", "name": "mean_iou", "children": [{"type": "file", "name": "app.py"}, {"type": "file", "name": "mean_iou.py"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}]}, {"type": "directory", "name": "meteor", "children": [{"type": "file", "name": "app.py"}, {"type": "file", "name": "meteor.py"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}]}, {"type": "directory", "name": "mse", "children": [{"type": "file", "name": "app.py"}, {"type": "file", "name": "mse.py"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}]}, {"type": "directory", "name": "nist_mt", "children": [{"type": "file", "name": "app.py"}, {"type": "file", "name": "nist_mt.py"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "tests.py"}]}, {"type": "directory", "name": "pearsonr", "children": [{"type": "file", "name": "app.py"}, {"type": "file", "name": "pearsonr.py"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}]}, {"type": "directory", "name": "perplexity", "children": [{"type": "file", "name": "app.py"}, {"type": "file", "name": "perplexity.py"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}]}, {"type": "directory", "name": "poseval", "children": [{"type": "file", "name": "app.py"}, {"type": "file", "name": "poseval.py"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}]}, {"type": "directory", "name": "precision", "children": [{"type": "file", "name": "app.py"}, {"type": "file", "name": "precision.py"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}]}, {"type": "directory", "name": "recall", "children": [{"type": "file", "name": "app.py"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "recall.py"}, {"type": "file", "name": "requirements.txt"}]}, {"type": "directory", "name": "rl_reliability", "children": [{"type": "file", "name": "app.py"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "rl_reliability.py"}]}, {"type": "directory", "name": "roc_auc", "children": [{"type": "file", "name": "app.py"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "roc_auc.py"}]}, {"type": "directory", "name": "rouge", "children": [{"type": "file", "name": "app.py"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "rouge.py"}]}, {"type": "directory", "name": "r_squared", "children": [{"type": "file", "name": "app.py"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "r_squared.py"}]}, {"type": "directory", "name": "sacrebleu", "children": [{"type": "file", "name": "app.py"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "sacrebleu.py"}]}, {"type": "directory", "name": "sari", "children": [{"type": "file", "name": "app.py"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "sari.py"}]}, {"type": "directory", "name": "seqeval", "children": [{"type": "file", "name": "app.py"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "seqeval.py"}]}, {"type": "directory", "name": "smape", "children": [{"type": "file", "name": "app.py"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "smape.py"}]}, {"type": "directory", "name": "spearmanr", "children": [{"type": "file", "name": "app.py"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "spearmanr.py"}]}, {"type": "directory", "name": "squad", "children": [{"type": "file", "name": "app.py"}, {"type": "file", "name": "compute_score.py"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "squad.py"}]}, {"type": "directory", "name": "squad_v2", "children": [{"type": "file", "name": "app.py"}, {"type": "file", "name": "compute_score.py"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "squad_v2.py"}]}, {"type": "directory", "name": "super_glue", "children": [{"type": "file", "name": "app.py"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "record_evaluation.py"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "super_glue.py"}]}, {"type": "directory", "name": "ter", "children": [{"type": "file", "name": "app.py"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "ter.py"}]}, {"type": "directory", "name": "trec_eval", "children": [{"type": "file", "name": "app.py"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "trec_eval.py"}]}, {"type": "directory", "name": "wer", "children": [{"type": "file", "name": "app.py"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "wer.py"}]}, {"type": "directory", "name": "wiki_split", "children": [{"type": "file", "name": "app.py"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "wiki_split.py"}]}, {"type": "directory", "name": "xnli", "children": [{"type": "file", "name": "app.py"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "xnli.py"}]}, {"type": "directory", "name": "xtreme_s", "children": [{"type": "file", "name": "app.py"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "xtreme_s.py"}]}]}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "setup.cfg"}, {"type": "file", "name": "setup.py"}, {"type": "directory", "name": "src", "children": [{"type": "directory", "name": "evaluate", "children": [{"type": "directory", "name": "commands", "children": [{"type": "file", "name": "evaluate_cli.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "config.py"}, {"type": "directory", "name": "evaluation_suite", "children": [{"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "evaluator", "children": [{"type": "file", "name": "audio_classification.py"}, {"type": "file", "name": "automatic_speech_recognition.py"}, {"type": "file", "name": "base.py"}, {"type": "file", "name": "image_classification.py"}, {"type": "file", "name": "question_answering.py"}, {"type": "file", "name": "text2text_generation.py"}, {"type": "file", "name": "text_classification.py"}, {"type": "file", "name": "text_generation.py"}, {"type": "file", "name": "token_classification.py"}, {"type": "file", "name": "utils.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "hub.py"}, {"type": "file", "name": "info.py"}, {"type": "file", "name": "inspect.py"}, {"type": "file", "name": "loading.py"}, {"type": "file", "name": "module.py"}, {"type": "file", "name": "naming.py"}, {"type": "file", "name": "saving.py"}, {"type": "directory", "name": "utils", "children": [{"type": "file", "name": "file_utils.py"}, {"type": "file", "name": "gradio.py"}, {"type": "file", "name": "logging.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "visualization.py"}, {"type": "file", "name": "__init__.py"}]}]}, {"type": "directory", "name": "templates", "children": [{"type": "file", "name": "cookiecutter.json"}, {"type": "directory", "name": "{{ cookiecutter.module_slug }}", "children": [{"type": "file", "name": "app.py"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "tests.py"}, {"type": "file", "name": "{{ cookiecutter.module_slug }}.py"}]}]}, {"type": "directory", "name": "tests", "children": [{"type": "file", "name": "conftest.py"}, {"type": "file", "name": "test_evaluation_suite.py"}, {"type": "file", "name": "test_evaluator.py"}, {"type": "file", "name": "test_file_utils.py"}, {"type": "file", "name": "test_hub.py"}, {"type": "file", "name": "test_load.py"}, {"type": "file", "name": "test_metric.py"}, {"type": "file", "name": "test_metric_common.py"}, {"type": "file", "name": "test_save.py"}, {"type": "file", "name": "test_trainer_evaluator_parity.py"}, {"type": "file", "name": "test_viz.py"}, {"type": "file", "name": "utils.py"}, {"type": "file", "name": "__init__.py"}]}]} | ---
title: {{ cookiecutter.module_name }}
datasets:
- {{ cookiecutter.dataset_name }}
tags:
- evaluate
- {{ cookiecutter.module_type }}
description: "TODO: add a description here"
sdk: gradio
sdk_version: 3.19.1
app_file: app.py
pinned: false
---
# {{ cookiecutter.module_type|capitalize }} Card for {{ cookiecutter.module_name }}
***Module Card Instructions:*** *Fill out the following subsections. Feel free to take a look at existing {{ cookiecutter.module_type }} cards if you'd like examples.*
## {{ cookiecutter.module_type|capitalize }} Description
*Give a brief overview of this {{ cookiecutter.module_type }}, including what task(s) it is usually used for, if any.*
## How to Use
*Give general statement of how to use the {{ cookiecutter.module_type }}*
*Provide simplest possible example for using the {{ cookiecutter.module_type }}*
### Inputs
*List all input arguments in the format below*
- **input_field** *(type): Definition of input, with explanation if necessary. State any default value(s).*
### Output Values
*Explain what this {{ cookiecutter.module_type }} outputs and provide an example of what the {{ cookiecutter.module_type }} output looks like. Modules should return a dictionary with one or multiple key-value pairs, e.g. {"bleu" : 6.02}*
*State the range of possible values that the {{ cookiecutter.module_type }}'s output can take, as well as what in that range is considered good. For example: "This {{ cookiecutter.module_type }} can take on any value between 0 and 100, inclusive. Higher scores are better."*
#### Values from Popular Papers
*Give examples, preferrably with links to leaderboards or publications, to papers that have reported this {{ cookiecutter.module_type }}, along with the values they have reported.*
### Examples
*Give code examples of the {{ cookiecutter.module_type }} being used. Try to include examples that clear up any potential ambiguity left from the {{ cookiecutter.module_type }} description above. If possible, provide a range of examples that show both typical and atypical results, as well as examples where a variety of input parameters are passed.*
## Limitations and Bias
*Note any known limitations or biases that the {{ cookiecutter.module_type }} has, with links and references if possible.*
## Citation
*Cite the source where this {{ cookiecutter.module_type }} was introduced.*
## Further References
*Add any useful further references.*
| {"additional-tests-requirements.txt": "unbabel-comet>=1.0.0;python_version>'3.6'\ngit+https://github.com/google-research/bleurt.git\ngit+https://github.com/ns-moosavi/coval.git\ngit+https://github.com/hendrycks/math.git\ngit+https://github.com/google-research/rl-reliability-metrics\ngin-config", "setup.py": "# Lint as: python3\n\"\"\" HuggingFace/Evaluate is an open library for evaluation.\n\nNote:\n\n VERSION needs to be formatted following the MAJOR.MINOR.PATCH convention\n (we need to follow this convention to be able to retrieve versioned scripts)\n\nTo create the package for pypi.\n\n1. Open a PR and change the version in:\n - __init__.py\n - setup.py\n Then merge the PR once it's approved.\n\n3. Add a tag \"vVERSION\" (e.g. v0.4.1) in git to mark the release : \"git tag vVERSION -m 'Add tag vVERSION for pypi'\"\n Push the tag to remote: git push --tags origin main\n Then verify that the 'Python release' CI job runs and succeeds.\n\n4. Fill release notes in the tag in github once everything is looking hunky-dory.\n\n5. Open a PR to change the version in __init__.py and setup.py to X.X.X+1.dev0 (e.g. VERSION=0.4.1 -> 0.4.2.dev0).\n Then merge the PR once it's approved.\n\"\"\"\n\nimport os\n\nfrom setuptools import find_packages, setup\n\n\nREQUIRED_PKGS = [\n # We need datasets as a backend\n \"datasets>=2.0.0\",\n # We use numpy>=1.17 to have np.random.Generator (Dataset shuffling)\n \"numpy>=1.17\",\n # For smart caching dataset processing\n \"dill\",\n # For performance gains with apache arrow\n \"pandas\",\n # for downloading datasets over HTTPS\n \"requests>=2.19.0\",\n # progress bars in download and scripts\n \"tqdm>=4.62.1\",\n # for fast hashing\n \"xxhash\",\n # for better multiprocessing\n \"multiprocess\",\n # to get metadata of optional dependencies such as torch or tensorflow for Python versions that don't have it\n \"importlib_metadata;python_version<'3.8'\",\n # to save datasets locally or on any filesystem\n # minimum 2021.05.0 to have the AbstractArchiveFileSystem\n \"fsspec[http]>=2021.05.0\",\n # To get datasets from the Datasets Hub on huggingface.co\n \"huggingface-hub>=0.7.0\",\n # Utilities from PyPA to e.g., compare versions\n \"packaging\",\n]\n\nTEMPLATE_REQUIRE = [\n # to populate metric template\n \"cookiecutter\",\n # for the gradio widget\n \"gradio>=3.0.0\"\n]\n\nEVALUATOR_REQUIRE = [\n \"transformers\",\n # for bootstrap computations in Evaluator\n \"scipy>=1.7.1\",\n]\n\nTESTS_REQUIRE = [\n # test dependencies\n \"absl-py\",\n \"charcut>=1.1.1\", # for charcut_mt\n \"cer>=1.2.0\", # for characTER\n \"nltk\", # for NIST and probably others\n \"pytest\",\n \"pytest-datadir\",\n \"pytest-xdist\",\n # optional dependencies\n \"numpy<2.0.0\", # tensorflow requires numpy < 2\n \"tensorflow>=2.3,!=2.6.0,!=2.6.1, <=2.10\",\n \"torch\",\n # metrics dependencies\n \"accelerate\", # for frugalscore (calls transformers' Trainer)\n \"bert_score>=0.3.6\",\n \"rouge_score>=0.1.2\",\n \"sacrebleu\",\n \"sacremoses\",\n \"scipy>=1.10.0\",\n \"seqeval\",\n \"scikit-learn\",\n \"jiwer\",\n \"sentencepiece\", # for bleurt\n \"transformers\", # for evaluator\n \"mauve-text\",\n \"trectools\",\n # to speed up pip backtracking\n \"toml>=0.10.1\",\n \"requests_file>=1.5.1\",\n \"tldextract>=3.1.0\",\n \"texttable>=1.6.3\",\n \"unidecode>=1.3.4\",\n \"Werkzeug>=1.0.1\",\n \"six~=1.15.0\",\n]\n\nQUALITY_REQUIRE = [\"black~=22.0\", \"flake8>=3.8.3\", \"isort>=5.0.0\", \"pyyaml>=5.3.1\"]\n\n\nEXTRAS_REQUIRE = {\n \"tensorflow\": [\"tensorflow>=2.2.0,!=2.6.0,!=2.6.1\"],\n \"tensorflow_gpu\": [\"tensorflow-gpu>=2.2.0,!=2.6.0,!=2.6.1\"],\n \"torch\": [\"torch\"],\n \"dev\": TESTS_REQUIRE + QUALITY_REQUIRE,\n \"tests\": TESTS_REQUIRE,\n \"quality\": QUALITY_REQUIRE,\n \"docs\": [\n # Might need to add doc-builder and some specific deps in the future\n \"s3fs\",\n ],\n \"template\": TEMPLATE_REQUIRE,\n \"evaluator\": EVALUATOR_REQUIRE\n}\n\nsetup(\n name=\"evaluate\",\n version=\"0.4.4.dev0\", # expected format is one of x.y.z.dev0, or x.y.z.rc1 or x.y.z (no to dashes, yes to dots)\n description=\"HuggingFace community-driven open-source library of evaluation\",\n long_description=open(\"README.md\", encoding=\"utf-8\").read(),\n long_description_content_type=\"text/markdown\",\n author=\"HuggingFace Inc.\",\n author_email=\"[email protected]\",\n url=\"https://github.com/huggingface/evaluate\",\n download_url=\"https://github.com/huggingface/evaluate/tags\",\n license=\"Apache 2.0\",\n package_dir={\"\": \"src\"},\n packages=find_packages(\"src\"),\n entry_points={\"console_scripts\": [\"evaluate-cli=evaluate.commands.evaluate_cli:main\"]},\n install_requires=REQUIRED_PKGS,\n extras_require=EXTRAS_REQUIRE,\n python_requires=\">=3.8.0\",\n classifiers=[\n \"Development Status :: 5 - Production/Stable\",\n \"Intended Audience :: Developers\",\n \"Intended Audience :: Education\",\n \"Intended Audience :: Science/Research\",\n \"License :: OSI Approved :: Apache Software License\",\n \"Operating System :: OS Independent\",\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.8\",\n \"Programming Language :: Python :: 3.9\",\n \"Programming Language :: Python :: 3.10\",\n \"Topic :: Scientific/Engineering :: Artificial Intelligence\",\n ],\n keywords=\"metrics machine learning evaluate evaluation\",\n zip_safe=False, # Required for mypy to find the py.typed file\n)\n", ".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 55f1bc6e072b05c2d9db1589a07e20f38902b1ec Hamza Amin <[email protected]> 1727369147 +0500\tclone: from https://github.com/huggingface/evaluate.git\n", ".git\\refs\\heads\\main": "55f1bc6e072b05c2d9db1589a07e20f38902b1ec\n", ".github\\hub\\requirements.txt": "huggingface_hub", "comparisons\\exact_match\\app.py": "import evaluate\nfrom evaluate.utils import launch_gradio_widget\n\n\nmodule = evaluate.load(\"exact_match\", module_type=\"comparison\")\nlaunch_gradio_widget(module)\n", "comparisons\\exact_match\\requirements.txt": "git+https://github.com/huggingface/evaluate@{COMMIT_PLACEHOLDER}\nscipy", "comparisons\\mcnemar\\app.py": "import evaluate\nfrom evaluate.utils import launch_gradio_widget\n\n\nmodule = evaluate.load(\"mcnemar\", module_type=\"comparison\")\nlaunch_gradio_widget(module)\n", "comparisons\\mcnemar\\requirements.txt": "git+https://github.com/huggingface/evaluate@{COMMIT_PLACEHOLDER}\nscipy", "comparisons\\wilcoxon\\app.py": "import evaluate\nfrom evaluate.utils import launch_gradio_widget\n\n\nmodule = evaluate.load(\"wilcoxon\", module_type=\"comparison\")\nlaunch_gradio_widget(module)\n", "comparisons\\wilcoxon\\requirements.txt": "git+https://github.com/huggingface/evaluate@a45df1eb9996eec64ec3282ebe554061cb366388\ndatasets~=2.0\nscipy\n", "docs\\source\\index.mdx": "<p align=\"center\">\n <br>\n <img src=\"https://huggingface.co/datasets/evaluate/media/resolve/main/evaluate-banner.png\" width=\"400\"/>\n <br>\n</p>\n\n# \ud83e\udd17 Evaluate\n\nA library for easily evaluating machine learning models and datasets.\n\nWith a single line of code, you get access to dozens of evaluation methods for different domains (NLP, Computer Vision, Reinforcement Learning, and more!). Be it on your local machine or in a distributed training setup, you can evaluate your models in a consistent and reproducible way! \n\nVisit the \ud83e\udd17 Evaluate [organization](https://huggingface.co/evaluate-metric) for a full list of available metrics. Each metric has a dedicated Space with an interactive demo for how to use the metric, and a documentation card detailing the metrics limitations and usage.\n\n> **Tip:** For more recent evaluation approaches, for example for evaluating LLMs, we recommend our newer and more actively maintained library [LightEval](https://github.com/huggingface/lighteval).\n\n<div class=\"mt-10\">\n <div class=\"w-full flex flex-col space-y-4 md:space-y-0 md:grid md:grid-cols-2 md:gap-y-4 md:gap-x-5\">\n <a class=\"!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg\" href=\"./installation\"\n ><div class=\"w-full text-center bg-gradient-to-br from-blue-400 to-blue-500 rounded-lg py-1.5 font-semibold mb-5 text-white text-lg leading-relaxed\">Tutorials</div>\n <p class=\"text-gray-700\">Learn the basics and become familiar with loading, computing, and saving with \ud83e\udd17 Evaluate. Start here if you are using \ud83e\udd17 Evaluate for the first time!</p>\n </a>\n <a class=\"!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg\" href=\"./choosing_a_metric\"\n ><div class=\"w-full text-center bg-gradient-to-br from-indigo-400 to-indigo-500 rounded-lg py-1.5 font-semibold mb-5 text-white text-lg leading-relaxed\">How-to guides</div>\n <p class=\"text-gray-700\">Practical guides to help you achieve a specific goal. Take a look at these guides to learn how to use \ud83e\udd17 Evaluate to solve real-world problems.</p>\n </a>\n <a class=\"!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg\" href=\"./types_of_evaluations\"\n ><div class=\"w-full text-center bg-gradient-to-br from-pink-400 to-pink-500 rounded-lg py-1.5 font-semibold mb-5 text-white text-lg leading-relaxed\">Conceptual guides</div>\n <p class=\"text-gray-700\">High-level explanations for building a better understanding of important topics such as considerations going into evaluating a model or dataset and the difference between metrics, measurements, and comparisons.</p>\n </a>\n <a class=\"!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg\" href=\"./package_reference/main_classes\"\n ><div class=\"w-full text-center bg-gradient-to-br from-purple-400 to-purple-500 rounded-lg py-1.5 font-semibold mb-5 text-white text-lg leading-relaxed\">Reference</div>\n <p class=\"text-gray-700\">Technical descriptions of how \ud83e\udd17 Evaluate classes and methods work.</p>\n </a>\n </div>\n</div>\n", "docs\\source\\package_reference\\main_classes.mdx": "# Main classes\n\n## EvaluationModuleInfo\n\nThe base class `EvaluationModuleInfo` implements a the logic for the subclasses `MetricInfo`, `ComparisonInfo`, and `MeasurementInfo`.\n\n[[autodoc]] evaluate.EvaluationModuleInfo\n\n[[autodoc]] evaluate.MetricInfo\n\n[[autodoc]] evaluate.ComparisonInfo\n\n[[autodoc]] evaluate.MeasurementInfo\n\n## EvaluationModule\n\nThe base class `EvaluationModule` implements a the logic for the subclasses `Metric`, `Comparison`, and `Measurement`.\n\n[[autodoc]] evaluate.EvaluationModule\n\n[[autodoc]] evaluate.Metric\n\n[[autodoc]] evaluate.Comparison\n\n[[autodoc]] evaluate.Measurement\n\n## CombinedEvaluations\n\nThe `combine` function allows to combine multiple `EvaluationModule`s into a single `CombinedEvaluations`.\n\n[[autodoc]] evaluate.combine\n\n[[autodoc]] CombinedEvaluations\n", "measurements\\honest\\app.py": "import evaluate\nfrom evaluate.utils import launch_gradio_widget\n\n\nmodule = evaluate.load(\"honest\", \"en\")\nlaunch_gradio_widget(module)\n", "measurements\\honest\\requirements.txt": "git+https://github.com/huggingface/evaluate@{COMMIT_PLACEHOLDER}\ntransformers\nunidecode==1.3.4\ntorch\n", "measurements\\label_distribution\\app.py": "import evaluate\nfrom evaluate.utils import launch_gradio_widget\n\n\nmodule = evaluate.load(\"label_distribution\", module_type=\"measurement\")\nlaunch_gradio_widget(module)\n", "measurements\\label_distribution\\requirements.txt": "git+https://github.com/huggingface/evaluate@{COMMIT_PLACEHOLDER}\nscipy\n", "measurements\\perplexity\\app.py": "import evaluate\nfrom evaluate.utils import launch_gradio_widget\n\n\nmodule = evaluate.load(\"perplexity\", module_type=\"measurement\")\nlaunch_gradio_widget(module)\n", "measurements\\perplexity\\requirements.txt": "git+https://github.com/huggingface/evaluate@{COMMIT_PLACEHOLDER}\ntorch\ntransformers", "measurements\\regard\\app.py": "import evaluate\nfrom evaluate.utils import launch_gradio_widget\n\n\nmodule = evaluate.load(\"regard\")\nlaunch_gradio_widget(module)\n", "measurements\\regard\\requirements.txt": "git+https://github.com/huggingface/evaluate.git@{COMMIT_PLACEHOLDER}\ntransformers\ntorch\n", "measurements\\text_duplicates\\app.py": "import evaluate\nfrom evaluate.utils import launch_gradio_widget\n\n\nmodule = evaluate.load(\"text_duplicates\")\nlaunch_gradio_widget(module)\n", "measurements\\text_duplicates\\requirements.txt": "git+https://github.com/huggingface/evaluate.git@{COMMIT_PLACEHOLDER}\n", "measurements\\toxicity\\app.py": "import evaluate\nfrom evaluate.utils import launch_gradio_widget\n\n\nmodule = evaluate.load(\"toxicity\")\nlaunch_gradio_widget(module)\n", "measurements\\toxicity\\requirements.txt": "git+https://github.com/huggingface/evaluate@{COMMIT_PLACEHOLDER}\ntransformers\ntorch\n", "measurements\\word_count\\app.py": "import evaluate\nfrom evaluate.utils import launch_gradio_widget\n\n\nmodule = evaluate.load(\"word_count\")\nlaunch_gradio_widget(module)\n", "measurements\\word_count\\requirements.txt": "git+https://github.com/huggingface/evaluate.git@{COMMIT_PLACEHOLDER}\nscikit-learn~=0.0\n", "measurements\\word_length\\app.py": "import evaluate\nfrom evaluate.utils import launch_gradio_widget\n\n\nmodule = evaluate.load(\"word_length\", module_type=\"measurement\")\nlaunch_gradio_widget(module)\n", "measurements\\word_length\\requirements.txt": "git+https://github.com/huggingface/evaluate.git@{COMMIT_PLACEHOLDER}\nnltk~=3.7\n", "metrics\\accuracy\\app.py": "import evaluate\nfrom evaluate.utils import launch_gradio_widget\n\n\nmodule = evaluate.load(\"accuracy\")\nlaunch_gradio_widget(module)\n", "metrics\\accuracy\\requirements.txt": "git+https://github.com/huggingface/evaluate@{COMMIT_PLACEHOLDER}\nscikit-learn", "metrics\\bertscore\\app.py": "import evaluate\nfrom evaluate.utils import launch_gradio_widget\n\n\nmodule = evaluate.load(\"bertscore\")\nlaunch_gradio_widget(module)\n", "metrics\\bertscore\\requirements.txt": "git+https://github.com/huggingface/evaluate@{COMMIT_PLACEHOLDER}\nbert_score", "metrics\\bleu\\app.py": "import evaluate\nfrom evaluate.utils import launch_gradio_widget\n\n\nmodule = evaluate.load(\"bleu\")\nlaunch_gradio_widget(module)\n", "metrics\\bleu\\requirements.txt": "git+https://github.com/huggingface/evaluate@{COMMIT_PLACEHOLDER}", "metrics\\bleurt\\app.py": "import sys\n\nimport evaluate\nfrom evaluate.utils import launch_gradio_widget\n\n\nsys.path = [p for p in sys.path if p != \"/home/user/app\"]\nmodule = evaluate.load(\"bleurt\")\nsys.path = [\"/home/user/app\"] + sys.path\n\nlaunch_gradio_widget(module)\n", "metrics\\bleurt\\requirements.txt": "git+https://github.com/huggingface/evaluate@{COMMIT_PLACEHOLDER}\ngit+https://github.com/google-research/bleurt.git", "metrics\\brier_score\\app.py": "import evaluate\nfrom evaluate.utils import launch_gradio_widget\n\n\nmodule = evaluate.load(\"brier_score\")\nlaunch_gradio_widget(module)\n", "metrics\\brier_score\\requirements.txt": "git+https://github.com/huggingface/evaluate@{COMMIT_PLACEHOLDER}\nscikit-learn", "metrics\\cer\\app.py": "import evaluate\nfrom evaluate.utils import launch_gradio_widget\n\n\nmodule = evaluate.load(\"cer\")\nlaunch_gradio_widget(module)\n", "metrics\\cer\\requirements.txt": "git+https://github.com/huggingface/evaluate@{COMMIT_PLACEHOLDER}\njiwer", "metrics\\character\\app.py": "import evaluate\nfrom evaluate.utils import launch_gradio_widget\n\n\nmodule = evaluate.load(\"character\")\nlaunch_gradio_widget(module)\n", "metrics\\character\\requirements.txt": "git+https://github.com/huggingface/evaluate@{COMMIT_PLACEHOLDER}\ncer>=1.2.0\n", "metrics\\charcut_mt\\app.py": "import evaluate\nfrom evaluate.utils import launch_gradio_widget\n\n\nmodule = evaluate.load(\"charcut_mt\")\nlaunch_gradio_widget(module)\n", "metrics\\charcut_mt\\requirements.txt": "git+https://github.com/huggingface/evaluate@{COMMIT_PLACEHOLDER}\ncharcut>=1.1.1\n", "metrics\\chrf\\app.py": "import evaluate\nfrom evaluate.utils import launch_gradio_widget\n\n\nmodule = evaluate.load(\"chrf\")\nlaunch_gradio_widget(module)\n", "metrics\\chrf\\requirements.txt": "git+https://github.com/huggingface/evaluate@{COMMIT_PLACEHOLDER}\nsacrebleu", "metrics\\code_eval\\app.py": "import evaluate\nfrom evaluate.utils import launch_gradio_widget\n\n\nmodule = evaluate.load(\"code_eval\")\nlaunch_gradio_widget(module)\n", "metrics\\code_eval\\requirements.txt": "git+https://github.com/huggingface/evaluate@{COMMIT_PLACEHOLDER}", "metrics\\comet\\app.py": "import sys\n\nimport evaluate\nfrom evaluate.utils import launch_gradio_widget\n\n\nsys.path = [p for p in sys.path if p != \"/home/user/app\"]\nmodule = evaluate.load(\"comet\")\nsys.path = [\"/home/user/app\"] + sys.path\n\nlaunch_gradio_widget(module)\n", "metrics\\comet\\requirements.txt": "git+https://github.com/huggingface/evaluate@{COMMIT_PLACEHOLDER}\nunbabel-comet\ntorch", "metrics\\competition_math\\app.py": "import evaluate\nfrom evaluate.utils import launch_gradio_widget\n\n\nmodule = evaluate.load(\"competition_math\")\nlaunch_gradio_widget(module)\n", "metrics\\competition_math\\requirements.txt": "git+https://github.com/huggingface/evaluate@{COMMIT_PLACEHOLDER}\ngit+https://github.com/hendrycks/math.git", "metrics\\confusion_matrix\\app.py": "import evaluate\nfrom evaluate.utils import launch_gradio_widget\n\n\nmodule = evaluate.load(\"confusion_matrix\")\nlaunch_gradio_widget(module)\n", "metrics\\confusion_matrix\\requirements.txt": "git+https://github.com/huggingface/evaluate@{COMMIT_PLACEHOLDER}\nscikit-learn", "metrics\\coval\\app.py": "import sys\n\nimport evaluate\nfrom evaluate.utils import launch_gradio_widget\n\n\nsys.path = [p for p in sys.path if p != \"/home/user/app\"]\nmodule = evaluate.load(\"coval\")\nsys.path = [\"/home/user/app\"] + sys.path\n\nlaunch_gradio_widget(module)\n", "metrics\\coval\\requirements.txt": "git+https://github.com/huggingface/evaluate@{COMMIT_PLACEHOLDER}\ngit+https://github.com/ns-moosavi/coval.git", "metrics\\cuad\\app.py": "import evaluate\nfrom evaluate.utils import launch_gradio_widget\n\n\nmodule = evaluate.load(\"cuad\")\nlaunch_gradio_widget(module)\n", "metrics\\cuad\\requirements.txt": "git+https://github.com/huggingface/evaluate@{COMMIT_PLACEHOLDER}", "metrics\\exact_match\\app.py": "import evaluate\nfrom evaluate.utils import launch_gradio_widget\n\n\nmodule = evaluate.load(\"exact_match\")\nlaunch_gradio_widget(module)\n", "metrics\\exact_match\\requirements.txt": "git+https://github.com/huggingface/evaluate@{COMMIT_PLACEHOLDER}", "metrics\\f1\\app.py": "import evaluate\nfrom evaluate.utils import launch_gradio_widget\n\n\nmodule = evaluate.load(\"f1\")\nlaunch_gradio_widget(module)\n", "metrics\\f1\\requirements.txt": "git+https://github.com/huggingface/evaluate@{COMMIT_PLACEHOLDER}\nscikit-learn", "metrics\\frugalscore\\app.py": "import evaluate\nfrom evaluate.utils import launch_gradio_widget\n\n\nmodule = evaluate.load(\"frugalscore\")\nlaunch_gradio_widget(module)\n", "metrics\\frugalscore\\requirements.txt": "git+https://github.com/huggingface/evaluate@{COMMIT_PLACEHOLDER}\ntorch\ntransformers", "metrics\\glue\\app.py": "import evaluate\nfrom evaluate.utils import launch_gradio_widget\n\n\nmodule = evaluate.load(\"glue\", \"sst2\")\nlaunch_gradio_widget(module)\n", "metrics\\glue\\requirements.txt": "git+https://github.com/huggingface/evaluate@{COMMIT_PLACEHOLDER}\nscipy\nscikit-learn", "metrics\\google_bleu\\app.py": "import evaluate\nfrom evaluate.utils import launch_gradio_widget\n\n\nmodule = evaluate.load(\"google_bleu\")\nlaunch_gradio_widget(module)\n", "metrics\\google_bleu\\requirements.txt": "git+https://github.com/huggingface/evaluate@{COMMIT_PLACEHOLDER}\nnltk", "metrics\\indic_glue\\app.py": "import evaluate\nfrom evaluate.utils import launch_gradio_widget\n\n\nmodule = evaluate.load(\"indic_glue\", \"wnli\")\nlaunch_gradio_widget(module)\n", "metrics\\indic_glue\\requirements.txt": "git+https://github.com/huggingface/evaluate@{COMMIT_PLACEHOLDER}\nscipy\nscikit-learn", "metrics\\mae\\app.py": "import evaluate\nfrom evaluate.utils import launch_gradio_widget\n\n\nmodule = evaluate.load(\"mae\")\nlaunch_gradio_widget(module)\n", "metrics\\mae\\requirements.txt": "git+https://github.com/huggingface/evaluate@{COMMIT_PLACEHOLDER}\nscikit-learn", "metrics\\mahalanobis\\app.py": "import evaluate\nfrom evaluate.utils import launch_gradio_widget\n\n\nmodule = evaluate.load(\"mahalanobis\")\nlaunch_gradio_widget(module)\n", "metrics\\mahalanobis\\requirements.txt": "git+https://github.com/huggingface/evaluate@{COMMIT_PLACEHOLDER}", "metrics\\mape\\app.py": "import evaluate\nfrom evaluate.utils import launch_gradio_widget\n\n\nmodule = evaluate.load(\"mape\")\nlaunch_gradio_widget(module)\n", "metrics\\mape\\requirements.txt": "git+https://github.com/huggingface/evaluate@{COMMIT_PLACEHOLDER}\nscikit-learn\n", "metrics\\mase\\app.py": "import evaluate\nfrom evaluate.utils import launch_gradio_widget\n\n\nmodule = evaluate.load(\"mase\")\nlaunch_gradio_widget(module)\n", "metrics\\mase\\requirements.txt": "git+https://github.com/huggingface/evaluate@{COMMIT_PLACEHOLDER}\nscikit-learn\n", "metrics\\matthews_correlation\\app.py": "import evaluate\nfrom evaluate.utils import launch_gradio_widget\n\n\nmodule = evaluate.load(\"matthews_correlation\")\nlaunch_gradio_widget(module)\n", "metrics\\matthews_correlation\\requirements.txt": "git+https://github.com/huggingface/evaluate@{COMMIT_PLACEHOLDER}\nscikit-learn", "metrics\\mauve\\app.py": "import sys\n\nimport evaluate\nfrom evaluate.utils import launch_gradio_widget\n\n\nsys.path = [p for p in sys.path if p != \"/home/user/app\"]\nmodule = evaluate.load(\"mauve\")\nsys.path = [\"/home/user/app\"] + sys.path\n\nlaunch_gradio_widget(module)\n", "metrics\\mauve\\requirements.txt": "git+https://github.com/huggingface/evaluate@{COMMIT_PLACEHOLDER}\nfaiss-cpu\nscikit-learn\nmauve-text", "metrics\\mean_iou\\app.py": "import evaluate\nfrom evaluate.utils import launch_gradio_widget\n\n\nmodule = evaluate.load(\"mean_iou\")\nlaunch_gradio_widget(module)\n", "metrics\\mean_iou\\requirements.txt": "git+https://github.com/huggingface/evaluate@{COMMIT_PLACEHOLDER}", "metrics\\meteor\\app.py": "import evaluate\nfrom evaluate.utils import launch_gradio_widget\n\n\nmodule = evaluate.load(\"meteor\")\nlaunch_gradio_widget(module)\n", "metrics\\meteor\\requirements.txt": "git+https://github.com/huggingface/evaluate@{COMMIT_PLACEHOLDER}\nnltk", "metrics\\mse\\app.py": "import evaluate\nfrom evaluate.utils import launch_gradio_widget\n\n\nmodule = evaluate.load(\"mse\")\nlaunch_gradio_widget(module)\n", "metrics\\mse\\requirements.txt": "git+https://github.com/huggingface/evaluate@{COMMIT_PLACEHOLDER}\nscikit-learn", "metrics\\nist_mt\\app.py": "import evaluate\nfrom evaluate.utils import launch_gradio_widget\n\n\nmodule = evaluate.load(\"nist_mt\")\nlaunch_gradio_widget(module)\n", "metrics\\nist_mt\\requirements.txt": "git+https://github.com/huggingface/evaluate@{COMMIT_PLACEHOLDER}\nnltk\n", "metrics\\pearsonr\\app.py": "import evaluate\nfrom evaluate.utils import launch_gradio_widget\n\n\nmodule = evaluate.load(\"pearsonr\")\nlaunch_gradio_widget(module)\n", "metrics\\pearsonr\\requirements.txt": "git+https://github.com/huggingface/evaluate@{COMMIT_PLACEHOLDER}\nscipy", "metrics\\perplexity\\app.py": "import evaluate\nfrom evaluate.utils import launch_gradio_widget\n\n\nmodule = evaluate.load(\"perplexity\", module_type=\"metric\")\nlaunch_gradio_widget(module)\n", "metrics\\perplexity\\requirements.txt": "git+https://github.com/huggingface/evaluate@{COMMIT_PLACEHOLDER}\ntorch\ntorch\ntransformers", "metrics\\poseval\\app.py": "import evaluate\nfrom evaluate.utils import launch_gradio_widget\n\n\nmodule = evaluate.load(\"poseval\")\n\nlaunch_gradio_widget(module)\n", "metrics\\poseval\\requirements.txt": "git+https://github.com/huggingface/evaluate@{COMMIT_PLACEHOLDER}\nscikit-learn", "metrics\\precision\\app.py": "import evaluate\nfrom evaluate.utils import launch_gradio_widget\n\n\nmodule = evaluate.load(\"precision\")\nlaunch_gradio_widget(module)\n", "metrics\\precision\\requirements.txt": "git+https://github.com/huggingface/evaluate@{COMMIT_PLACEHOLDER}\nscikit-learn", "metrics\\recall\\app.py": "import evaluate\nfrom evaluate.utils import launch_gradio_widget\n\n\nmodule = evaluate.load(\"recall\")\nlaunch_gradio_widget(module)\n", "metrics\\recall\\requirements.txt": "git+https://github.com/huggingface/evaluate@{COMMIT_PLACEHOLDER}\nscikit-learn", "metrics\\rl_reliability\\app.py": "import evaluate\nfrom evaluate.utils import launch_gradio_widget\n\n\nmodule = evaluate.load(\"rl_reliability\", \"online\")\nlaunch_gradio_widget(module)\n", "metrics\\rl_reliability\\requirements.txt": "git+https://github.com/huggingface/evaluate@{COMMIT_PLACEHOLDER}\ngit+https://github.com/google-research/rl-reliability-metrics\nscipy\ntensorflow\ngin-config", "metrics\\roc_auc\\app.py": "import evaluate\nfrom evaluate.utils import launch_gradio_widget\n\n\nmodule = evaluate.load(\"roc_auc\")\nlaunch_gradio_widget(module)\n", "metrics\\roc_auc\\requirements.txt": "git+https://github.com/huggingface/evaluate@{COMMIT_PLACEHOLDER}\nscikit-learn", "metrics\\rouge\\app.py": "import evaluate\nfrom evaluate.utils import launch_gradio_widget\n\n\nmodule = evaluate.load(\"rouge\")\nlaunch_gradio_widget(module)\n", "metrics\\rouge\\requirements.txt": "git+https://github.com/huggingface/evaluate@{COMMIT_PLACEHOLDER}\nabsl-py\nnltk\nrouge_score>=0.1.2", "metrics\\r_squared\\app.py": "import evaluate\nfrom evaluate.utils import launch_gradio_widget\n\n\nmodule = evaluate.load(\"r_squared\")\nlaunch_gradio_widget(module)\n", "metrics\\r_squared\\requirements.txt": "git+https://github.com/huggingface/evaluate@{COMMIT_PLACEHOLDER}\n", "metrics\\sacrebleu\\app.py": "import sys\n\nimport evaluate\nfrom evaluate.utils import launch_gradio_widget\n\n\nsys.path = [p for p in sys.path if p != \"/home/user/app\"]\nmodule = evaluate.load(\"sacrebleu\")\nsys.path = [\"/home/user/app\"] + sys.path\n\nlaunch_gradio_widget(module)\n", "metrics\\sacrebleu\\requirements.txt": "git+https://github.com/huggingface/evaluate@{COMMIT_PLACEHOLDER}\nsacrebleu", "metrics\\sari\\app.py": "import evaluate\nfrom evaluate.utils import launch_gradio_widget\n\n\nmodule = evaluate.load(\"sari\")\nlaunch_gradio_widget(module)\n", "metrics\\sari\\requirements.txt": "git+https://github.com/huggingface/evaluate@{COMMIT_PLACEHOLDER}\nsacrebleu\nsacremoses", "metrics\\seqeval\\app.py": "import sys\n\nimport evaluate\nfrom evaluate.utils import launch_gradio_widget\n\n\nsys.path = [p for p in sys.path if p != \"/home/user/app\"]\nmodule = evaluate.load(\"seqeval\")\nsys.path = [\"/home/user/app\"] + sys.path\n\nlaunch_gradio_widget(module)\n", "metrics\\seqeval\\requirements.txt": "git+https://github.com/huggingface/evaluate@{COMMIT_PLACEHOLDER}\nseqeval", "metrics\\smape\\app.py": "import evaluate\nfrom evaluate.utils import launch_gradio_widget\n\n\nmodule = evaluate.load(\"smape\")\nlaunch_gradio_widget(module)\n", "metrics\\smape\\requirements.txt": "git+https://github.com/huggingface/evaluate@{COMMIT_PLACEHOLDER}\nscikit-learn\n", "metrics\\spearmanr\\app.py": "import evaluate\nfrom evaluate.utils import launch_gradio_widget\n\n\nmodule = evaluate.load(\"spearmanr\")\nlaunch_gradio_widget(module)\n", "metrics\\spearmanr\\requirements.txt": "git+https://github.com/huggingface/evaluate@{COMMIT_PLACEHOLDER}\nscipy", "metrics\\squad\\app.py": "import evaluate\nfrom evaluate.utils import launch_gradio_widget\n\n\nmodule = evaluate.load(\"squad\")\nlaunch_gradio_widget(module)\n", "metrics\\squad\\requirements.txt": "git+https://github.com/huggingface/evaluate@{COMMIT_PLACEHOLDER}", "metrics\\squad_v2\\app.py": "import evaluate\nfrom evaluate.utils import launch_gradio_widget\n\n\nmodule = evaluate.load(\"squad_v2\")\nlaunch_gradio_widget(module)\n", "metrics\\squad_v2\\requirements.txt": "git+https://github.com/huggingface/evaluate@{COMMIT_PLACEHOLDER}", "metrics\\super_glue\\app.py": "import evaluate\nfrom evaluate.utils import launch_gradio_widget\n\n\nmodule = evaluate.load(\"super_glue\", \"copa\")\nlaunch_gradio_widget(module)\n", "metrics\\super_glue\\requirements.txt": "git+https://github.com/huggingface/evaluate@{COMMIT_PLACEHOLDER}\nscikit-learn", "metrics\\ter\\app.py": "import evaluate\nfrom evaluate.utils import launch_gradio_widget\n\n\nmodule = evaluate.load(\"ter\")\nlaunch_gradio_widget(module)\n", "metrics\\ter\\requirements.txt": "git+https://github.com/huggingface/evaluate@{COMMIT_PLACEHOLDER}\nsacrebleu", "metrics\\trec_eval\\app.py": "import evaluate\nfrom evaluate.utils import launch_gradio_widget\n\n\nmodule = evaluate.load(\"trec_eval\")\nlaunch_gradio_widget(module)\n", "metrics\\trec_eval\\requirements.txt": "git+https://github.com/huggingface/evaluate@{COMMIT_PLACEHOLDER}\ntrectools", "metrics\\wer\\app.py": "import evaluate\nfrom evaluate.utils import launch_gradio_widget\n\n\nmodule = evaluate.load(\"wer\")\nlaunch_gradio_widget(module)\n", "metrics\\wer\\requirements.txt": "git+https://github.com/huggingface/evaluate@{COMMIT_PLACEHOLDER}\njiwer", "metrics\\wiki_split\\app.py": "import evaluate\nfrom evaluate.utils import launch_gradio_widget\n\n\nmodule = evaluate.load(\"wiki_split\")\nlaunch_gradio_widget(module)\n", "metrics\\wiki_split\\requirements.txt": "git+https://github.com/huggingface/evaluate@{COMMIT_PLACEHOLDER}\nsacrebleu\nsacremoses", "metrics\\xnli\\app.py": "import evaluate\nfrom evaluate.utils import launch_gradio_widget\n\n\nmodule = evaluate.load(\"xnli\")\nlaunch_gradio_widget(module)\n", "metrics\\xnli\\requirements.txt": "git+https://github.com/huggingface/evaluate@{COMMIT_PLACEHOLDER}", "metrics\\xtreme_s\\app.py": "import evaluate\nfrom evaluate.utils import launch_gradio_widget\n\n\nmodule = evaluate.load(\"xtreme_s\", \"mls\")\nlaunch_gradio_widget(module)\n", "metrics\\xtreme_s\\requirements.txt": "git+https://github.com/huggingface/evaluate@{COMMIT_PLACEHOLDER}\nscikit-learn", "templates\\{{ cookiecutter.module_slug }}\\app.py": "import evaluate\nfrom evaluate.utils import launch_gradio_widget\n\n\nmodule = evaluate.load(\"{{ cookiecutter.namespace }}/{{ cookiecutter.module_slug }}\")\nlaunch_gradio_widget(module)", "templates\\{{ cookiecutter.module_slug }}\\requirements.txt": "git+https://github.com/huggingface/evaluate@main"} | null |
exporters | {"type": "directory", "name": "exporters", "children": [{"type": "file", "name": "DESIGN_NOTES.md"}, {"type": "file", "name": "LICENSE"}, {"type": "file", "name": "MODELS.md"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "setup.py"}, {"type": "directory", "name": "src", "children": [{"type": "directory", "name": "exporters", "children": [{"type": "directory", "name": "coreml", "children": [{"type": "file", "name": "config.py"}, {"type": "file", "name": "convert.py"}, {"type": "file", "name": "features.py"}, {"type": "file", "name": "models.py"}, {"type": "file", "name": "validate.py"}, {"type": "file", "name": "__init__.py"}, {"type": "file", "name": "__main__.py"}]}, {"type": "directory", "name": "utils", "children": [{"type": "file", "name": "logging.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "__init__.py"}]}]}, {"type": "directory", "name": "tests", "children": [{"type": "file", "name": "testing_utils.py"}, {"type": "file", "name": "test_coreml.py"}, {"type": "file", "name": "__init__.py"}]}]} | <!---
Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
# 🤗 Exporters
👷 **WORK IN PROGRESS** 👷
This package lets you export 🤗 Transformers models to Core ML.
> For converting models to TFLite, we recommend using [Optimum](https://huggingface.co/docs/optimum/exporters/tflite/usage_guides/export_a_model).
## When to use 🤗 Exporters
🤗 Transformers models are implemented in PyTorch, TensorFlow, or JAX. However, for deployment you might want to use a different framework such as Core ML. This library makes it easy to convert Transformers models to this format.
The aim of the Exporters package is to be more convenient than writing your own conversion script with *coremltools* and to be tightly integrated with the 🤗 Transformers library and the Hugging Face Hub.
For an even more convenient approach, `Exporters` powers a [no-code transformers to Core ML conversion Space](https://huggingface.co/spaces/huggingface-projects/transformers-to-coreml). You can try it out without installing anything to check whether the model you are interested in can be converted. If conversion succeeds, the converted Core ML weights will be pushed to the Hub. For additional flexibility and details about the conversion process, please read on.
Note: Keep in mind that Transformer models are usually quite large and are not always suitable for use on mobile devices. It might be a good idea to [optimize the model for inference](https://github.com/huggingface/optimum) first using 🤗 Optimum.
## Installation
Clone this repo:
```bash
$ git clone https://github.com/huggingface/exporters.git
```
Install it as a Python package:
```bash
$ cd exporters
$ pip install -e .
```
All done!
Note: The Core ML exporter can be used from Linux but macOS is recommended.
## Core ML
[Core ML](https://developer.apple.com/machine-learning/core-ml/) is Apple's software library for fast on-device model inference with neural networks and other types of machine learning models. It can be used on macOS, iOS, tvOS, and watchOS, and is optimized for using the CPU, GPU, and Apple Neural Engine. Although the Core ML framework is proprietary, the Core ML file format is an open format.
The Core ML exporter uses [coremltools](https://coremltools.readme.io/docs) to perform the conversion from PyTorch or TensorFlow to Core ML.
The `exporters.coreml` package enables you to convert model checkpoints to a Core ML model by leveraging configuration objects. These configuration objects come ready-made for a number of model architectures, and are designed to be easily extendable to other architectures.
Ready-made configurations include the following architectures:
- BEiT
- BERT
- ConvNeXT
- CTRL
- CvT
- DistilBERT
- DistilGPT2
- GPT2
- LeViT
- MobileBERT
- MobileViT
- SegFormer
- SqueezeBERT
- Vision Transformer (ViT)
- YOLOS
<!-- TODO: automatically generate this list -->
[See here](MODELS.md) for a complete list of supported models.
### Exporting a model to Core ML
<!--
To export a 🤗 Transformers model to Core ML, you'll first need to install some extra dependencies:
``bash
pip install transformers[coreml]
``
The `transformers.coreml` package can then be used as a Python module:
-->
The `exporters.coreml` package can be used as a Python module from the command line. To export a checkpoint using a ready-made configuration, do the following:
```bash
python -m exporters.coreml --model=distilbert-base-uncased exported/
```
This exports a Core ML version of the checkpoint defined by the `--model` argument. In this example it is `distilbert-base-uncased`, but it can be any checkpoint on the Hugging Face Hub or one that's stored locally.
The resulting Core ML file will be saved to the `exported` directory as `Model.mlpackage`. Instead of a directory you can specify a filename, such as `DistilBERT.mlpackage`.
It's normal for the conversion process to output many warning messages and other logging information. You can safely ignore these. If all went well, the export should conclude with the following logs:
```bash
Validating Core ML model...
-[✓] Core ML model output names match reference model ({'last_hidden_state'})
- Validating Core ML model output "last_hidden_state":
-[✓] (1, 128, 768) matches (1, 128, 768)
-[✓] all values close (atol: 0.0001)
All good, model saved at: exported/Model.mlpackage
```
Note: While it is possible to export models to Core ML on Linux, the validation step will only be performed on Mac, as it requires the Core ML framework to run the model.
The resulting file is `Model.mlpackage`. This file can be added to an Xcode project and be loaded into a macOS or iOS app.
The exported Core ML models use the **mlpackage** format with the **ML Program** model type. This format was introduced in 2021 and requires at least iOS 15, macOS 12.0, and Xcode 13. We prefer to use this format as it is the future of Core ML. The Core ML exporter can also make models in the older `.mlmodel` format, but this is not recommended.
The process is identical for TensorFlow checkpoints on the Hub. For example, you can export a pure TensorFlow checkpoint from the [Keras organization](https://huggingface.co/keras-io) as follows:
```bash
python -m exporters.coreml --model=keras-io/transformers-qa exported/
```
To export a model that's stored locally, you'll need to have the model's weights and tokenizer files stored in a directory. For example, we can load and save a checkpoint as follows:
```python
>>> from transformers import AutoTokenizer, AutoModelForSequenceClassification
>>> # Load tokenizer and PyTorch weights form the Hub
>>> tokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased")
>>> pt_model = AutoModelForSequenceClassification.from_pretrained("distilbert-base-uncased")
>>> # Save to disk
>>> tokenizer.save_pretrained("local-pt-checkpoint")
>>> pt_model.save_pretrained("local-pt-checkpoint")
```
Once the checkpoint is saved, you can export it to Core ML by pointing the `--model` argument to the directory holding the checkpoint files:
```bash
python -m exporters.coreml --model=local-pt-checkpoint exported/
```
<!--
TODO: also TFAutoModel example
-->
### Selecting features for different model topologies
Each ready-made configuration comes with a set of _features_ that enable you to export models for different types of topologies or tasks. As shown in the table below, each feature is associated with a different auto class:
| Feature | Auto Class |
| -------------------------------------------- | ------------------------------------ |
| `default`, `default-with-past` | `AutoModel` |
| `causal-lm`, `causal-lm-with-past` | `AutoModelForCausalLM` |
| `ctc` | `AutoModelForCTC` |
| `image-classification` | `AutoModelForImageClassification` |
| `masked-im` | `AutoModelForMaskedImageModeling` |
| `masked-lm` | `AutoModelForMaskedLM` |
| `multiple-choice` | `AutoModelForMultipleChoice` |
| `next-sentence-prediction` | `AutoModelForNextSentencePrediction` |
| `object-detection` | `AutoModelForObjectDetection` |
| `question-answering` | `AutoModelForQuestionAnswering` |
| `semantic-segmentation` | `AutoModelForSemanticSegmentation` |
| `seq2seq-lm`, `seq2seq-lm-with-past` | `AutoModelForSeq2SeqLM` |
| `sequence-classification` | `AutoModelForSequenceClassification` |
| `speech-seq2seq`, `speech-seq2seq-with-past` | `AutoModelForSpeechSeq2Seq` |
| `token-classification` | `AutoModelForTokenClassification` |
For each configuration, you can find the list of supported features via the `FeaturesManager`. For example, for DistilBERT we have:
```python
>>> from exporters.coreml.features import FeaturesManager
>>> distilbert_features = list(FeaturesManager.get_supported_features_for_model_type("distilbert").keys())
>>> print(distilbert_features)
['default', 'masked-lm', 'multiple-choice', 'question-answering', 'sequence-classification', 'token-classification']
```
You can then pass one of these features to the `--feature` argument in the `exporters.coreml` package. For example, to export a text-classification model we can pick a fine-tuned model from the Hub and run:
```bash
python -m exporters.coreml --model=distilbert-base-uncased-finetuned-sst-2-english \
--feature=sequence-classification exported/
```
which will display the following logs:
```bash
Validating Core ML model...
- Core ML model is classifier, validating output
-[✓] predicted class NEGATIVE matches NEGATIVE
-[✓] number of classes 2 matches 2
-[✓] all values close (atol: 0.0001)
All good, model saved at: exported/Model.mlpackage
```
Notice that in this case, the exported model is a Core ML classifier, which predicts the highest scoring class name in addition to a dictionary of probabilities, instead of the `last_hidden_state` we saw with the `distilbert-base-uncased` checkpoint earlier. This is expected since the fine-tuned model has a sequence classification head.
<Tip>
The features that have a `with-past` suffix (e.g. `causal-lm-with-past`) correspond to model topologies with precomputed hidden states (key and values in the attention blocks) that can be used for fast autoregressive decoding.
</Tip>
### Configuring the export options
To see the full list of possible options, run the following from the command line:
```bash
python -m exporters.coreml --help
```
Exporting a model requires at least these arguments:
- `-m <model>`: The model ID from the Hugging Face Hub, or a local path to load the model from.
- `--feature <task>`: The task the model should perform, for example `"image-classification"`. See the table above for possible task names.
- `<output>`: The path where to store the generated Core ML model.
The output path can be a folder, in which case the file will be named `Model.mlpackage`, or you can also specify the filename directly.
Additional arguments that can be provided:
- `--preprocessor <value>`: Which type of preprocessor to use. `auto` tries to automatically detect it. Possible values are: `auto` (the default), `tokenizer`, `feature_extractor`, `processor`.
- `--atol <number>`: The absolute difference tolerence used when validating the model. The default value is 1e-4.
- `--quantize <value>`: Whether to quantize the model weights. The possible quantization options are: `float32` for no quantization (the default) or `float16` for 16-bit floating point.
- `--compute_units <value>`: Whether to optimize the model for CPU, GPU, and/or Neural Engine. Possible values are: `all` (the default), `cpu_and_gpu`, `cpu_only`, `cpu_and_ne`.
### Using the exported model
Using the exported model in an app is just like using any other Core ML model. After adding the model to Xcode, it will auto-generate a Swift class that lets you make predictions from within the app.
Depending on the chosen export options, you may still need to preprocess or postprocess the input and output tensors.
For image inputs, there is no need to perform any preprocessing as the Core ML model will already normalize the pixels. For classifier models, the Core ML model will output the predictions as a dictionary of probabilities. For other models, you might need to do more work.
Core ML does not have the concept of a tokenizer and so text models will still require manual tokenization of the input data. [Here is an example](https://github.com/huggingface/swift-coreml-transformers) of how to perform tokenization in Swift.
### Overriding default choices in the configuration object
An important goal of Core ML is to make it easy to use the models inside apps. Where possible, the Core ML exporter will add extra operations to the model, so that you do not have to do your own pre- and postprocessing.
In particular,
- Image models will automatically perform pixel normalization as part of the model. You do not need to preprocess the image yourself, except potentially resizing or cropping it.
- For classification models, a softmax layer is added and the labels are included in the model file. Core ML makes a distinction between classifier models and other types of neural networks. For a model that outputs a single classification prediction per input example, Core ML makes it so that the model predicts the winning class label and a dictionary of probabilities instead of a raw logits tensor. Where possible, the exporter uses this special classifier model type.
- Other models predict logits but do not fit into Core ML's definition of a classifier, such as the `token-classificaton` task that outputs a prediction for each token in the sequence. Here, the exporter also adds a softmax to convert the logits into probabilities. The label names are added to the model's metadata. Core ML ignores these label names but they can be retrieved by writing a few lines of Swift code.
- A `semantic-segmentation` model will upsample the output image to the original spatial dimensions and apply an argmax to obtain the predicted class label indices. It does not automatically apply a softmax.
The Core ML exporter makes these choices because they are the settings you're most likely to need. To override any of the above defaults, you must create a subclass of the configuration object, and then export the model to Core ML by writing a short Python program.
Example: To prevent the MobileViT semantic segmentation model from upsampling the output image, you would create a subclass of `MobileViTCoreMLConfig` and override the `outputs` property to set `do_upsample` to False. Other options you can set for this output are `do_argmax` and `do_softmax`.
```python
from collections import OrderedDict
from exporters.coreml.models import MobileViTCoreMLConfig
from exporters.coreml.config import OutputDescription
class MyCoreMLConfig(MobileViTCoreMLConfig):
@property
def outputs(self) -> OrderedDict[str, OutputDescription]:
return OrderedDict(
[
(
"logits",
OutputDescription(
"classLabels",
"Classification scores for each pixel",
do_softmax=True,
do_upsample=False,
do_argmax=False,
)
),
]
)
config = MyCoreMLConfig(model.config, "semantic-segmentation")
```
Here you can also change the name of the output from `classLabels` to something else, or fill in the output description ("Classification scores for each pixel").
It is also possible to change the properties of the model inputs. For example, for text models the default sequence length is between 1 and 128 tokens. To set the input sequence length on a DistilBERT model to a fixed length of 32 tokens, you could override the config object as follows:
```python
from collections import OrderedDict
from exporters.coreml.models import DistilBertCoreMLConfig
from exporters.coreml.config import InputDescription
class MyCoreMLConfig(DistilBertCoreMLConfig):
@property
def inputs(self) -> OrderedDict[str, InputDescription]:
input_descs = super().inputs
input_descs["input_ids"].sequence_length = 32
return input_descs
config = MyCoreMLConfig(model.config, "text-classification")
```
Using a fixed sequence length generally outputs a simpler, and possibly faster, Core ML model. However, for many models the input needs to have a flexible length. In that case, specify a tuple for `sequence_length` to set the (min, max) lengths. Use (1, -1) to have no upper limit on the sequence length. (Note: if `sequence_length` is set to a fixed value, then the batch size is fixed to 1.)
To find out what input and output options are available for the model you're interested in, create its `CoreMLConfig` object and examine the `config.inputs` and `config.outputs` properties.
Not all inputs or outputs are always required: For text models, you may remove the `attention_mask` input. Without this input, the attention mask is always assumed to be filled with ones (no padding). However, if the task requires a `token_type_ids` input, there must also be an `attention_mask` input.
Removing inputs and/or outputs is accomplished by making a subclass of `CoreMLConfig` and overriding the `inputs` and `outputs` properties.
By default, a model is generated in the ML Program format. By overriding the `use_legacy_format` property to return `True`, the older NeuralNetwork format will be used. This is not recommended and only exists as a workaround for models that fail to convert to the ML Program format.
Once you have the modified `config` instance, you can use it to export the model following the instructions from the section "Exporting the model" below.
Not everything is described by the configuration objects. The behavior of the converted model is also determined by the model's tokenizer or feature extractor. For example, to use a different input image size, you'd create the feature extractor with different resizing or cropping settings and use that during the conversion instead of the default feature extractor.
### Exporting a model for an unsupported architecture
If you wish to export a model whose architecture is not natively supported by the library, there are three main steps to follow:
1. Implement a custom Core ML configuration.
2. Export the model to Core ML.
3. Validate the outputs of the PyTorch and exported models.
In this section, we'll look at how DistilBERT was implemented to show what's involved with each step.
#### Implementing a custom Core ML configuration
TODO: didn't write this section yet because the implementation is not done yet
Let’s start with the configuration object. We provide an abstract classes that you should inherit from, `CoreMLConfig`.
```python
from exporters.coreml import CoreMLConfig
```
TODO: stuff to cover here:
- `modality` property
- how to implement custom ops + link to coremltools documentation on this topic
- decoder models (`use_past`) and encoder-decoder models (`seq2seq`)
#### Exporting the model
Once you have implemented the Core ML configuration, the next step is to export the model. Here we can use the `export()` function provided by the `exporters.coreml` package. This function expects the Core ML configuration, along with the base model and tokenizer (for text models) or feature extractor (for vision models):
```python
from transformers import AutoConfig, AutoModelForSequenceClassification, AutoTokenizer
from exporters.coreml import export
from exporters.coreml.models import DistilBertCoreMLConfig
model_ckpt = "distilbert-base-uncased"
base_model = AutoModelForSequenceClassification.from_pretrained(model_ckpt, torchscript=True)
preprocessor = AutoTokenizer.from_pretrained(model_ckpt)
coreml_config = DistilBertCoreMLConfig(base_model.config, task="text-classification")
mlmodel = export(preprocessor, base_model, coreml_config)
```
Note: For the best results, pass the argument `torchscript=True` to `from_pretrained` when loading the model. This allows the model to configure itself for PyTorch tracing, which is needed for the Core ML conversion.
Additional options that can be passed into `export()`:
- `quantize`: Use `"float32"` for no quantization (the default), `"float16"` to quantize the weights to 16-bit floats.
- `compute_units`: Whether to optimize the model for CPU, GPU, and/or Neural Engine. Defaults to `coremltools.ComputeUnit.ALL`.
To export the model with precomputed hidden states (key and values in the attention blocks) for fast autoregressive decoding, pass the argument `use_past=True` when creating the `CoreMLConfig` object.
It is normal for the Core ML exporter to print out a lot of warning and information messages. In particular, you might see messages such as these:
> TracerWarning: Converting a tensor to a Python boolean might cause the trace to be incorrect. We can't record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs!
Those messages are to be expected and are a normal part of the conversion process. If there is a real problem, the converter will throw an error.
If the export succeeded, the return value from `export()` is a `coremltools.models.MLModel` object. Write `print(mlmodel)` to examine the Core ML model's inputs, outputs, and metadata.
Optionally fill in the model's metadata:
```python
mlmodel.short_description = "Your awesome model"
mlmodel.author = "Your name"
mlmodel.license = "Fill in the copyright information here"
mlmodel.version = "1.0"
```
Finally, save the model. You can open the resulting **mlpackage** file in Xcode and examine it there.
```python
mlmodel.save("DistilBert.mlpackage")
```
Note: If the configuration object used returns `True` from `use_legacy_format`, the model can be saved as `ModelName.mlmodel` instead of `.mlpackage`.
#### Exporting a decoder model
Decoder-based models can use a `past_key_values` input that ontains pre-computed hidden-states (key and values in the self-attention blocks), which allows for much faster sequential decoding. This feature is enabled by passing `use_cache=True` to the Transformer model.
To enable this feature with the Core ML exporter, set the `use_past=True` argument when creating the `CoreMLConfig` object:
```python
coreml_config = CTRLCoreMLConfig(base_model.config, task="text-generation", use_past=True)
# or:
coreml_config = CTRLCoreMLConfig.with_past(base_model.config, task="text-generation")
```
This adds multiple new inputs and outputs to the model with names such as `past_key_values_0_key`, `past_key_values_0_value`, ... (inputs) and `present_key_values_0_key`, `present_key_values_0_value`, ... (outputs).
Enabling this option makes the model less convenient to use, since you will have to keep track of many additional tensors, but it does make inference much faster on sequences.
The Transformers model must be loaded with `is_decoder=True`, for example:
```python
base_model = BigBirdForCausalLM.from_pretrained("google/bigbird-roberta-base", torchscript=True, is_decoder=True)
```
TODO: Example of how to use this in Core ML. The `past_key_values` tensors will grow larger over time. The `attention_mask` tensor must have the size of `past_key_values` plus new `input_ids`.
#### Exporting an encoder-decoder model
TODO: properly write this section
You'll need to export the model as two separate Core ML models: the encoder and the decoder.
Export the model like so:
```python
coreml_config = TODOCoreMLConfig(base_model.config, task="text2text-generation", seq2seq="encoder")
encoder_mlmodel = export(preprocessor, base_model.get_encoder(), coreml_config)
coreml_config = TODOCoreMLConfig(base_model.config, task="text2text-generation", seq2seq="decoder")
decoder_mlmodel = export(preprocessor, base_model, coreml_config)
```
When the `seq2seq` option is used, the sequence length in the Core ML model is always unbounded. The `sequence_length` specified in the configuration object is ignored.
This can also be combined with `use_past=True`. TODO: explain how to use this.
#### Validating the model outputs
The final step is to validate that the outputs from the base and exported model agree within some absolute tolerance. You can use the `validate_model_outputs()` function provided by the `exporters.coreml` package as follows.
First enable logging:
```python
from exporters.utils import logging
logger = logging.get_logger("exporters.coreml")
logger.setLevel(logging.INFO)
```
Then validate the model:
```python
from exporters.coreml import validate_model_outputs
validate_model_outputs(
coreml_config, preprocessor, base_model, mlmodel, coreml_config.atol_for_validation
)
```
Note: `validate_model_outputs` only works on Mac computers, as it depends on the Core ML framework to make predictions with the model.
This function uses the `CoreMLConfig.generate_dummy_inputs()` method to generate inputs for the base and exported model, and the absolute tolerance can be defined in the configuration. We generally find numerical agreement in the 1e-6 to 1e-4 range, although anything smaller than 1e-3 is likely to be OK.
If validation fails with an error such as the following, it doesn't necessarily mean the model is broken:
> ValueError: Output values do not match between reference model and Core ML exported model: Got max absolute difference of: 0.12345
The comparison is done using an absolute difference value, which in this example is 0.12345. That is much larger than the default tolerance value of 1e-4, hence the reported error. However, the magnitude of the activations also matters. For a model whose activations are on the order of 1e+3, a maximum absolute difference of 0.12345 would usually be acceptable.
If validation fails with this error and you're not entirely sure if this is a true problem, call `mlmodel.predict()` on a dummy input tensor and look at the largest absolute magnitude in the output tensor.
### Contributing a new configuration to 🤗 Transformers
We are looking to expand the set of ready-made configurations and welcome contributions from the community! If you would like to contribute your addition to the library, you will need to:
* Implement the Core ML configuration in the `models.py` file
* Include the model architecture and corresponding features in [`~coreml.features.FeatureManager`]
* Add your model architecture to the tests in `test_coreml.py`
### Troubleshooting: What if Core ML Exporters doesn't work for your model?
It's possible that the model you wish to export fails to convert using Core ML Exporters or even when you try to use `coremltools` directly. When running these automated conversion tools, it's quite possible the conversion bails out with an inscrutable error message. Or, the conversion may appear to succeed but the model does not work or produces incorrect outputs.
The most common reasons for conversion errors are:
- You provided incorrect arguments to the converter. The `task` argument should match the chosen model architecture. For example, the `"feature-extraction"` task should only be used with models of type `AutoModel`, not `AutoModelForXYZ`. Additionally, the `seq2seq` argument is required to tell apart encoder-decoder type models from encoder-only or decoder-only models. Passing invalid choices for these arguments may give an error during the conversion process or it may create a model that works but does the wrong thing.
- The model performs an operation that is not supported by Core ML or coremltools. It's also possible coremltools has a bug or can't handle particularly complex models.
If the Core ML export fails due to the latter, you have a couple of options:
1. Implement the missing operator in the `CoreMLConfig`'s `patch_pytorch_ops()` function.
2. Fix the original model. This requires a deep understanding of how the model works and is not trivial. However, sometimes the fix is to hardcode certain values rather than letting PyTorch or TensorFlow calculate them from the shapes of tensors.
3. Fix coremltools. It is sometimes possible to hack coremltools so that it ignores the issue.
4. Forget about automated conversion and [build the model from scratch using MIL](https://coremltools.readme.io/docs/model-intermediate-language). This is the intermediate language that coremltools uses internally to represent models. It's similar in many ways to PyTorch.
5. Submit an issue and we'll see what we can do. 😀
### Known issues
The Core ML exporter writes models in the **mlpackage** format. Unfortunately, for some models the generated ML Program is incorrect, in which case it's recommended to convert the model to the older NeuralNetwork format by setting the configuration object's `use_legacy_format` property to `True`. On certain hardware, the older format may also run more efficiently. If you're not sure which one to use, export the model twice and compare the two versions.
Known models that need to be exported with `use_legacy_format=True` are: GPT2, DistilGPT2.
Using flexible input sequence length with GPT2 or GPT-Neo causes the converter to be extremely slow and allocate over 200 GB of RAM. This is clearly a bug in coremltools or the Core ML framework, as the allocated memory is never used (the computer won't start swapping). After many minutes, the conversion does succeed, but the model may not be 100% correct. Loading the model afterwards takes a very long time and makes similar memory allocations. Likewise for making predictions. While theoretically the conversion succeeds (if you have enough patience), the model is not really usable like this.
## Pushing the model to the Hugging Face Hub
The [Hugging Face Hub](https://huggingface.co) can also host your Core ML models. You can use the [`huggingface_hub` package](https://huggingface.co/docs/huggingface_hub/main/en/index) to upload the converted model to the Hub from Python.
First log in to your Hugging Face account account with the following command:
```bash
huggingface-cli login
```
Once you are logged in, save the **mlpackage** to the Hub as follows:
```python
from huggingface_hub import Repository
with Repository(
"<model name>", clone_from="https://huggingface.co/<user>/<model name>",
use_auth_token=True).commit(commit_message="add Core ML model"):
mlmodel.save("<model name>.mlpackage")
```
Make sure to replace `<model name>` with the name of the model and `<user>` with your Hugging Face username.
| {"setup.py": "from setuptools import setup, find_packages\n\nsetup(\n name=\"exporters\",\n version=\"0.0.1\",\n description=\"Core ML exporter for Hugging Face Transformers\",\n long_description=\"\",\n author=\"The HuggingFace team\",\n author_email=\"[email protected]\",\n url=\"https://github.com/huggingface/exporters\",\n package_dir={\"\": \"src\"},\n packages=find_packages(\"src\"),\n include_package_data=True,\n python_requires=\">=3.8.0\",\n install_requires=[\n \"transformers >= 4.30.0\",\n \"coremltools >= 7\",\n ],\n classifiers=[\n ],\n license=\"Apache\",\n)\n", ".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 7a545974275c7af167a2fa4e16c4574359f2acec Hamza Amin <[email protected]> 1727369151 +0500\tclone: from https://github.com/huggingface/exporters.git\n", ".git\\refs\\heads\\main": "7a545974275c7af167a2fa4e16c4574359f2acec\n", "src\\exporters\\coreml\\__main__.py": "# coding=utf-8\n# Copyright 2021-2022 The HuggingFace Team. All rights reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport warnings\n\nfrom argparse import ArgumentParser\nfrom pathlib import Path\n\nfrom coremltools import ComputeUnit\nfrom coremltools.models import MLModel\nfrom coremltools.models.utils import _is_macos, _macos_version\n\nfrom transformers.models.auto import AutoFeatureExtractor, AutoProcessor, AutoTokenizer\nfrom transformers.onnx.utils import get_preprocessor\n\nfrom .convert import export\nfrom .features import FeaturesManager\nfrom .validate import validate_model_outputs\nfrom ..utils import logging\n\n\ndef convert_model(preprocessor, model, model_coreml_config, args, use_past=False, seq2seq=None):\n coreml_config = model_coreml_config(model.config, use_past=use_past, seq2seq=seq2seq)\n\n compute_units = ComputeUnit.ALL\n if args.compute_units == \"cpu_and_gpu\":\n compute_units = ComputeUnit.CPU_AND_GPU\n elif args.compute_units == \"cpu_only\":\n compute_units = ComputeUnit.CPU_ONLY\n elif args.compute_units == \"cpu_and_ne\":\n compute_units = ComputeUnit.CPU_AND_NE\n\n mlmodel = export(\n preprocessor,\n model,\n coreml_config,\n quantize=args.quantize,\n compute_units=compute_units,\n )\n\n filename = args.output\n if seq2seq == \"encoder\":\n filename = filename.parent / (\"encoder_\" + filename.name)\n elif seq2seq == \"decoder\":\n filename = filename.parent / (\"decoder_\" + filename.name)\n filename = filename.as_posix()\n\n mlmodel.save(filename)\n\n if args.atol is None:\n args.atol = coreml_config.atol_for_validation\n\n if not _is_macos() or _macos_version() < (12, 0):\n logger.info(\"Skipping model validation, requires macOS 12.0 or later\")\n else:\n # Run validation on CPU\n mlmodel = MLModel(filename, compute_units=ComputeUnit.CPU_ONLY)\n validate_model_outputs(coreml_config, preprocessor, model, mlmodel, args.atol)\n\n logger.info(f\"All good, model saved at: {filename}\")\n\n\ndef main():\n parser = ArgumentParser(\"Hugging Face Transformers Core ML exporter\")\n parser.add_argument(\n \"-m\", \"--model\", type=str, required=True, help=\"Model ID on huggingface.co or path on disk to load model from.\"\n )\n parser.add_argument(\n \"--feature\",\n choices=list(FeaturesManager.AVAILABLE_FEATURES_INCLUDING_LEGACY),\n default=\"feature-extraction\",\n help=\"The type of features to export the model with.\",\n )\n parser.add_argument(\n \"--atol\", type=float, default=None, help=\"Absolute difference tolerence when validating the model.\"\n )\n parser.add_argument(\n \"--use_past\", action=\"store_true\", help=\"Export the model with precomputed hidden states (key and values in the attention blocks) for fast autoregressive decoding.\"\n )\n parser.add_argument(\n \"--framework\", type=str, choices=[\"pt\", \"tf\"], default=\"pt\", help=\"The framework to use for the Core ML export.\"\n )\n parser.add_argument(\n \"--quantize\", type=str, choices=[\"float32\", \"float16\"], default=\"float16\", help=\"Quantization option for the model weights.\"\n )\n parser.add_argument(\n \"--compute_units\", type=str, choices=[\"all\", \"cpu_and_gpu\", \"cpu_only\", \"cpu_and_ne\"], default=\"all\", help=\"Optimize the model for CPU, GPU, and/or Neural Engine.\"\n )\n # parser.add_argument(\"--cache_dir\", type=str, default=None, help=\"Path indicating where to store cache.\")\n parser.add_argument(\n \"--preprocessor\",\n type=str,\n choices=[\"auto\", \"tokenizer\", \"feature_extractor\", \"processor\"],\n default=\"auto\",\n help=\"Which type of preprocessor to use. 'auto' tries to automatically detect it.\",\n )\n parser.add_argument(\"output\", type=Path, help=\"Path indicating where to store generated Core ML model.\")\n\n args = parser.parse_args()\n\n if (not args.output.is_file()) and (args.output.suffix not in [\".mlpackage\", \".mlmodel\"]):\n args.output = args.output.joinpath(\"Model.mlpackage\")\n if not args.output.parent.exists():\n args.output.parent.mkdir(parents=True)\n\n # Instantiate the appropriate preprocessor\n if args.preprocessor == \"auto\":\n preprocessor = get_preprocessor(args.model)\n elif args.preprocessor == \"tokenizer\":\n preprocessor = AutoTokenizer.from_pretrained(args.model)\n elif args.preprocessor == \"feature_extractor\":\n preprocessor = AutoFeatureExtractor.from_pretrained(args.model)\n elif args.preprocessor == \"processor\":\n preprocessor = AutoProcessor.from_pretrained(args.model)\n else:\n raise ValueError(f\"Unknown preprocessor type '{args.preprocessor}'\")\n \n # Support legacy task names in CLI only\n feature = args.feature\n args.feature = FeaturesManager.map_from_synonym(args.feature)\n if feature != args.feature:\n deprecation_message = f\"Feature '{feature}' is deprecated, please use '{args.feature}' instead.\"\n warnings.warn(deprecation_message, FutureWarning)\n\n # Allocate the model\n model = FeaturesManager.get_model_from_feature(\n args.feature, args.model, framework=args.framework, #cache_dir=args.cache_dir\n )\n model_kind, model_coreml_config = FeaturesManager.check_supported_model_or_raise(model, feature=args.feature)\n\n if args.feature in [\"text2text-generation\", \"speech-seq2seq\"]:\n logger.info(f\"Converting encoder model...\")\n\n convert_model(\n preprocessor,\n model,\n model_coreml_config,\n args,\n use_past=False,\n seq2seq=\"encoder\"\n )\n\n logger.info(f\"Converting decoder model...\")\n\n convert_model(\n preprocessor,\n model,\n model_coreml_config,\n args,\n use_past=args.use_past,\n seq2seq=\"decoder\"\n )\n else:\n convert_model(\n preprocessor,\n model,\n model_coreml_config,\n args,\n use_past=args.use_past,\n )\n\n\nif __name__ == \"__main__\":\n logger = logging.get_logger(\"exporters.coreml\") # pylint: disable=invalid-name\n logger.setLevel(logging.INFO)\n main()\n"} | null |
fineVideo | {"type": "directory", "name": "fineVideo", "children": [{"type": "directory", "name": "contentannotation", "children": [{"type": "file", "name": "gemini_prompt.txt"}, {"type": "file", "name": "video2annotation.py"}]}, {"type": "directory", "name": "contentselection", "children": [{"type": "file", "name": "content_taxonomy.json"}, {"type": "file", "name": "oracle.py"}]}, {"type": "directory", "name": "dynamicfilters", "children": [{"type": "directory", "name": "videodynamismfiltering", "children": [{"type": "file", "name": "check_static.py"}, {"type": "file", "name": "Dockerfile"}]}, {"type": "file", "name": "worddensityfiltering.py"}]}, {"type": "directory", "name": "finealignment", "children": [{"type": "file", "name": "video_alignment.py"}]}, {"type": "directory", "name": "rawdataset", "children": [{"type": "file", "name": "filter-yt-commons.py"}, {"type": "directory", "name": "ytdlps3", "children": [{"type": "file", "name": "Dockerfile"}, {"type": "file", "name": "download_and_upload.py"}]}]}, {"type": "file", "name": "readme.md"}, {"type": "directory", "name": "videocategorization", "children": [{"type": "file", "name": "content_taxonomy.json"}, {"type": "file", "name": "create_prompts.py"}, {"type": "file", "name": "launchTGI-Slurm.sh"}, {"type": "file", "name": "tgi_inference_client.py"}]}]} | 
## Introduction
We recently released [FineVideo](https://huggingface.co/spaces/HuggingFaceFV/FineVideo-Explorer), a dataset with 43k+ videos/3.4k hours annotated with rich descriptions, narrative details scene splits and QA pairs.
We cannot be more excited about the response of the community! If you have not seen FineVideo yet, take a look at it through the [dataset explorer page](https://huggingface.co/spaces/HuggingFaceFV/FineVideo-Explorer)

If you are interested in more technical details about the pipeline, we invite you to take a look at our [blog post](https://huggingface.co/).
## Content of the repository
This repository contains the code that we used in FineVideo to gather videos and annotate them. Those scripts cover all the different steps in the pipeline below.

The scripts are grouped in folders and each folder represent one or more steps of the pipeline:
```
├── rawdataset
│ ├── filter-yt-commons.py
│ └── ytdlps3
│ ├── Dockerfile
│ └── download_and_upload.py
├── dynamicfilters
│ ├── videodynamismfiltering
│ │ ├── Dockerfile
│ │ └── check_static.py
│ └── worddensityfiltering.py
├── videocategorization
│ ├── content_taxonomy.json
│ ├── create_prompts.py
│ ├── launchTGI-Slurm.sh
│ └── tgi_inference_client.py
├── contentselection
│ ├── content_taxonomy.json
│ └── oracle.py
├── contentannotation
│ ├── gemini_prompt.txt
│ └── video2annotation.py
├── finealignment
└── video_alignment.py
```
Given the size of the content to scan and/or annotate, all the parts that require scalability are implemented as docker containers that can be launched in a distributed way or prepared to split a list of work in chunks and process specific chunks of it so that you can launch multiple instances of the same script to parallelize.
For example:
* video download `ytdlps3` and video dynamism filtering `videodynamismfiltering` are packaged as Docker containers.
* video id gathering for the raw dataset `filter-yt-commons.py`, content selection `oracle.py` or word density filtering `worddensityfiltering.py` are scripts that process all the content at once
* content annotation `video2annotation.py`, video categorization `tgi_inference_client.py` & `create_prompts.py` and video-metadata alignment `video_alignment.py` are prepared to process chunks of a queue so that you can launch multiple instances of the same script. | {".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 b961b6ade22910d041aa75451afa94e454bca372 Hamza Amin <[email protected]> 1727369184 +0500\tclone: from https://github.com/huggingface/fineVideo.git\n", ".git\\refs\\heads\\main": "b961b6ade22910d041aa75451afa94e454bca372\n", "dynamicfilters\\videodynamismfiltering\\Dockerfile": "# Use the official Python image with necessary packages\nFROM python:3.9-slim\n\n# Install ffmpeg and other dependencies\nRUN apt-get update && \\\n apt-get install -y ffmpeg && \\\n apt-get clean && \\\n rm -rf /var/lib/apt/lists/*\n\n# Set the working directory\nWORKDIR /app\n\n# Copy the Python script into the container\nCOPY check_static.py .\n\n# Install Python dependencies\nRUN pip install boto3 ffmpeg-python\n\n# Command to run the script\nCMD [\"python\", \"check_static.py\"]\n", "rawdataset\\ytdlps3\\Dockerfile": "FROM python:3.9-slim\n\nENV PYTHONDONTWRITEBYTECODE 1\nENV PYTHONUNBUFFERED 1\n\n# Install required packages\nRUN apt-get update && apt-get install -y \\\n wget \\\n ffmpeg \\\n && apt-get clean\n\n# Install yt-dlp (a fork of youtube-dl with more features and better maintenance)\nRUN pip install yt-dlp boto3\n\n# Create a directory for the application\nWORKDIR /app\n\n# Copy the script into the Docker image\nCOPY download_and_upload.py /app/download_and_upload.py\n\n# Set the entry point to the script\nENTRYPOINT [\"python\", \"/app/download_and_upload.py\"]\n"} | null |
frp | {"type": "directory", "name": "frp", "children": [{"type": "file", "name": ".golangci.yml"}, {"type": "file", "name": ".goreleaser.yml"}, {"type": "directory", "name": "assets", "children": [{"type": "file", "name": "assets.go"}, {"type": "directory", "name": "frpc", "children": [{"type": "file", "name": "embed.go"}, {"type": "directory", "name": "static", "children": [{"type": "file", "name": "535877f50039c0cb49a6196a5b7517cd.woff"}, {"type": "file", "name": "favicon.ico"}, {"type": "file", "name": "index.html"}, {"type": "file", "name": "manifest.js"}, {"type": "file", "name": "vendor.js"}]}]}, {"type": "directory", "name": "frps", "children": [{"type": "file", "name": "embed.go"}, {"type": "directory", "name": "static", "children": [{"type": "file", "name": "535877f50039c0cb49a6196a5b7517cd.woff"}, {"type": "file", "name": "favicon.ico"}, {"type": "file", "name": "index.html"}, {"type": "file", "name": "manifest.js"}, {"type": "file", "name": "vendor.js"}]}]}]}, {"type": "directory", "name": "client", "children": [{"type": "file", "name": "admin.go"}, {"type": "file", "name": "admin_api.go"}, {"type": "file", "name": "control.go"}, {"type": "directory", "name": "event", "children": [{"type": "file", "name": "event.go"}]}, {"type": "directory", "name": "health", "children": [{"type": "file", "name": "health.go"}]}, {"type": "directory", "name": "proxy", "children": [{"type": "file", "name": "proxy.go"}, {"type": "file", "name": "proxy_manager.go"}, {"type": "file", "name": "proxy_wrapper.go"}]}, {"type": "file", "name": "service.go"}, {"type": "file", "name": "visitor.go"}, {"type": "file", "name": "visitor_manager.go"}]}, {"type": "directory", "name": "cmd", "children": [{"type": "directory", "name": "frpc", "children": [{"type": "file", "name": "main.go"}, {"type": "directory", "name": "sub", "children": [{"type": "file", "name": "http.go"}, {"type": "file", "name": "https.go"}, {"type": "file", "name": "reload.go"}, {"type": "file", "name": "root.go"}, {"type": "file", "name": "status.go"}, {"type": "file", "name": "stcp.go"}, {"type": "file", "name": "sudp.go"}, {"type": "file", "name": "tcp.go"}, {"type": "file", "name": "tcpmux.go"}, {"type": "file", "name": "udp.go"}, {"type": "file", "name": "verify.go"}, {"type": "file", "name": "xtcp.go"}]}]}, {"type": "directory", "name": "frps", "children": [{"type": "file", "name": "main.go"}, {"type": "file", "name": "root.go"}, {"type": "file", "name": "verify.go"}]}]}, {"type": "directory", "name": "conf", "children": [{"type": "file", "name": "frpc.ini"}, {"type": "file", "name": "frpc_full.ini"}, {"type": "file", "name": "frps.ini"}, {"type": "file", "name": "frps_full.ini"}]}, {"type": "directory", "name": "doc", "children": [{"type": "directory", "name": "pic", "children": []}, {"type": "file", "name": "server_plugin.md"}]}, {"type": "directory", "name": "dockerfiles", "children": [{"type": "file", "name": "Dockerfile-for-frpc"}, {"type": "file", "name": "Dockerfile-for-frps"}]}, {"type": "file", "name": "go.mod"}, {"type": "file", "name": "go.sum"}, {"type": "directory", "name": "hack", "children": [{"type": "file", "name": "run-e2e.sh"}]}, {"type": "file", "name": "LICENSE"}, {"type": "file", "name": "Makefile"}, {"type": "file", "name": "Makefile.cross-compiles"}, {"type": "file", "name": "package.sh"}, {"type": "directory", "name": "pkg", "children": [{"type": "directory", "name": "auth", "children": [{"type": "file", "name": "auth.go"}, {"type": "file", "name": "oidc.go"}, {"type": "file", "name": "token.go"}]}, {"type": "directory", "name": "config", "children": [{"type": "file", "name": "client.go"}, {"type": "file", "name": "client_test.go"}, {"type": "file", "name": "parse.go"}, {"type": "file", "name": "proxy.go"}, {"type": "file", "name": "proxy_test.go"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "server.go"}, {"type": "file", "name": "server_test.go"}, {"type": "file", "name": "types.go"}, {"type": "file", "name": "types_test.go"}, {"type": "file", "name": "utils.go"}, {"type": "file", "name": "value.go"}, {"type": "file", "name": "visitor.go"}, {"type": "file", "name": "visitor_test.go"}]}, {"type": "directory", "name": "consts", "children": [{"type": "file", "name": "consts.go"}]}, {"type": "directory", "name": "errors", "children": [{"type": "file", "name": "errors.go"}]}, {"type": "directory", "name": "metrics", "children": [{"type": "directory", "name": "aggregate", "children": [{"type": "file", "name": "server.go"}]}, {"type": "directory", "name": "mem", "children": [{"type": "file", "name": "server.go"}, {"type": "file", "name": "types.go"}]}, {"type": "file", "name": "metrics.go"}, {"type": "directory", "name": "prometheus", "children": [{"type": "file", "name": "server.go"}]}]}, {"type": "directory", "name": "msg", "children": [{"type": "file", "name": "ctl.go"}, {"type": "file", "name": "msg.go"}]}, {"type": "directory", "name": "nathole", "children": [{"type": "file", "name": "nathole.go"}]}, {"type": "directory", "name": "plugin", "children": [{"type": "directory", "name": "client", "children": [{"type": "file", "name": "http2https.go"}, {"type": "file", "name": "https2http.go"}, {"type": "file", "name": "https2https.go"}, {"type": "file", "name": "http_proxy.go"}, {"type": "file", "name": "plugin.go"}, {"type": "file", "name": "socks5.go"}, {"type": "file", "name": "static_file.go"}, {"type": "file", "name": "unix_domain_socket.go"}]}, {"type": "directory", "name": "server", "children": [{"type": "file", "name": "http.go"}, {"type": "file", "name": "manager.go"}, {"type": "file", "name": "plugin.go"}, {"type": "file", "name": "tracer.go"}, {"type": "file", "name": "types.go"}]}]}, {"type": "directory", "name": "proto", "children": [{"type": "directory", "name": "udp", "children": [{"type": "file", "name": "udp.go"}, {"type": "file", "name": "udp_test.go"}]}]}, {"type": "directory", "name": "transport", "children": [{"type": "file", "name": "tls.go"}]}, {"type": "directory", "name": "util", "children": [{"type": "directory", "name": "limit", "children": [{"type": "file", "name": "reader.go"}, {"type": "file", "name": "writer.go"}]}, {"type": "directory", "name": "log", "children": [{"type": "file", "name": "log.go"}]}, {"type": "directory", "name": "metric", "children": [{"type": "file", "name": "counter.go"}, {"type": "file", "name": "counter_test.go"}, {"type": "file", "name": "date_counter.go"}, {"type": "file", "name": "date_counter_test.go"}, {"type": "file", "name": "metrics.go"}]}, {"type": "directory", "name": "net", "children": [{"type": "file", "name": "conn.go"}, {"type": "file", "name": "dial.go"}, {"type": "file", "name": "http.go"}, {"type": "file", "name": "kcp.go"}, {"type": "file", "name": "listener.go"}, {"type": "file", "name": "tls.go"}, {"type": "file", "name": "udp.go"}, {"type": "file", "name": "websocket.go"}]}, {"type": "directory", "name": "tcpmux", "children": [{"type": "file", "name": "httpconnect.go"}]}, {"type": "directory", "name": "util", "children": [{"type": "file", "name": "http.go"}, {"type": "file", "name": "util.go"}, {"type": "file", "name": "util_test.go"}]}, {"type": "directory", "name": "version", "children": [{"type": "file", "name": "version.go"}, {"type": "file", "name": "version_test.go"}]}, {"type": "directory", "name": "vhost", "children": [{"type": "file", "name": "http.go"}, {"type": "file", "name": "https.go"}, {"type": "file", "name": "https_test.go"}, {"type": "file", "name": "resource.go"}, {"type": "file", "name": "router.go"}, {"type": "file", "name": "vhost.go"}]}, {"type": "directory", "name": "xlog", "children": [{"type": "file", "name": "ctx.go"}, {"type": "file", "name": "xlog.go"}]}]}]}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "scripts", "children": [{"type": "file", "name": "404.html"}, {"type": "file", "name": "build.sh"}, {"type": "file", "name": "frps.ini"}, {"type": "file", "name": "frps_tls.ini"}, {"type": "file", "name": "start.sh"}, {"type": "file", "name": "test.py"}]}, {"type": "directory", "name": "server", "children": [{"type": "file", "name": "control.go"}, {"type": "directory", "name": "controller", "children": [{"type": "file", "name": "resource.go"}]}, {"type": "file", "name": "dashboard.go"}, {"type": "file", "name": "dashboard_api.go"}, {"type": "directory", "name": "group", "children": [{"type": "file", "name": "group.go"}, {"type": "file", "name": "http.go"}, {"type": "file", "name": "tcp.go"}, {"type": "file", "name": "tcpmux.go"}]}, {"type": "directory", "name": "metrics", "children": [{"type": "file", "name": "metrics.go"}]}, {"type": "directory", "name": "ports", "children": [{"type": "file", "name": "ports.go"}]}, {"type": "directory", "name": "proxy", "children": [{"type": "file", "name": "http.go"}, {"type": "file", "name": "https.go"}, {"type": "file", "name": "proxy.go"}, {"type": "file", "name": "stcp.go"}, {"type": "file", "name": "sudp.go"}, {"type": "file", "name": "tcp.go"}, {"type": "file", "name": "tcpmux.go"}, {"type": "file", "name": "udp.go"}, {"type": "file", "name": "xtcp.go"}]}, {"type": "file", "name": "service.go"}, {"type": "directory", "name": "visitor", "children": [{"type": "file", "name": "visitor.go"}]}]}, {"type": "directory", "name": "test", "children": [{"type": "directory", "name": "e2e", "children": [{"type": "directory", "name": "basic", "children": [{"type": "file", "name": "basic.go"}, {"type": "file", "name": "client.go"}, {"type": "file", "name": "client_server.go"}, {"type": "file", "name": "cmd.go"}, {"type": "file", "name": "config.go"}, {"type": "file", "name": "http.go"}, {"type": "file", "name": "server.go"}]}, {"type": "file", "name": "e2e.go"}, {"type": "file", "name": "e2e_test.go"}, {"type": "file", "name": "examples.go"}, {"type": "directory", "name": "features", "children": [{"type": "file", "name": "bandwidth_limit.go"}, {"type": "file", "name": "chaos.go"}, {"type": "file", "name": "group.go"}, {"type": "file", "name": "heartbeat.go"}, {"type": "file", "name": "monitor.go"}, {"type": "file", "name": "real_ip.go"}]}, {"type": "directory", "name": "framework", "children": [{"type": "file", "name": "cleanup.go"}, {"type": "file", "name": "client.go"}, {"type": "directory", "name": "consts", "children": [{"type": "file", "name": "consts.go"}]}, {"type": "file", "name": "expect.go"}, {"type": "file", "name": "framework.go"}, {"type": "directory", "name": "ginkgowrapper", "children": [{"type": "file", "name": "wrapper.go"}]}, {"type": "file", "name": "log.go"}, {"type": "file", "name": "mockservers.go"}, {"type": "file", "name": "process.go"}, {"type": "file", "name": "request.go"}, {"type": "file", "name": "test_context.go"}, {"type": "file", "name": "util.go"}]}, {"type": "directory", "name": "mock", "children": [{"type": "directory", "name": "server", "children": [{"type": "directory", "name": "httpserver", "children": [{"type": "file", "name": "server.go"}]}, {"type": "file", "name": "interface.go"}, {"type": "directory", "name": "streamserver", "children": [{"type": "file", "name": "server.go"}]}]}]}, {"type": "directory", "name": "pkg", "children": [{"type": "directory", "name": "cert", "children": [{"type": "file", "name": "generator.go"}, {"type": "file", "name": "selfsigned.go"}]}, {"type": "directory", "name": "port", "children": [{"type": "file", "name": "port.go"}, {"type": "file", "name": "util.go"}]}, {"type": "directory", "name": "process", "children": [{"type": "file", "name": "process.go"}]}, {"type": "directory", "name": "request", "children": [{"type": "file", "name": "request.go"}]}, {"type": "directory", "name": "rpc", "children": [{"type": "file", "name": "rpc.go"}]}, {"type": "directory", "name": "sdk", "children": [{"type": "directory", "name": "client", "children": [{"type": "file", "name": "client.go"}]}]}, {"type": "directory", "name": "utils", "children": [{"type": "file", "name": "utils.go"}]}]}, {"type": "directory", "name": "plugin", "children": [{"type": "file", "name": "client.go"}, {"type": "file", "name": "server.go"}, {"type": "file", "name": "utils.go"}]}, {"type": "file", "name": "suites.go"}]}]}, {"type": "directory", "name": "web", "children": [{"type": "directory", "name": "frpc", "children": [{"type": "file", "name": ".babelrc"}, {"type": "file", "name": "Makefile"}, {"type": "file", "name": "package.json"}, {"type": "file", "name": "postcss.config.js"}, {"type": "directory", "name": "src", "children": [{"type": "file", "name": "App.vue"}, {"type": "directory", "name": "assets", "children": [{"type": "file", "name": "favicon.ico"}]}, {"type": "directory", "name": "components", "children": [{"type": "file", "name": "Configure.vue"}, {"type": "file", "name": "Overview.vue"}]}, {"type": "file", "name": "index.html"}, {"type": "file", "name": "main.js"}, {"type": "directory", "name": "router", "children": [{"type": "file", "name": "index.js"}]}, {"type": "directory", "name": "utils", "children": [{"type": "directory", "name": "less", "children": [{"type": "file", "name": "custom.less"}]}, {"type": "file", "name": "status.js"}]}]}, {"type": "file", "name": "webpack.config.js"}, {"type": "file", "name": "yarn.lock"}]}, {"type": "directory", "name": "frps", "children": [{"type": "file", "name": ".babelrc"}, {"type": "file", "name": "Makefile"}, {"type": "file", "name": "package.json"}, {"type": "file", "name": "postcss.config.js"}, {"type": "directory", "name": "src", "children": [{"type": "file", "name": "App.vue"}, {"type": "directory", "name": "assets", "children": [{"type": "file", "name": "favicon.ico"}]}, {"type": "directory", "name": "components", "children": [{"type": "file", "name": "Overview.vue"}, {"type": "file", "name": "ProxiesHttp.vue"}, {"type": "file", "name": "ProxiesHttps.vue"}, {"type": "file", "name": "ProxiesStcp.vue"}, {"type": "file", "name": "ProxiesSudp.vue"}, {"type": "file", "name": "ProxiesTcp.vue"}, {"type": "file", "name": "ProxiesUdp.vue"}, {"type": "file", "name": "Traffic.vue"}]}, {"type": "file", "name": "index.html"}, {"type": "file", "name": "main.js"}, {"type": "directory", "name": "router", "children": [{"type": "file", "name": "index.js"}]}, {"type": "directory", "name": "utils", "children": [{"type": "file", "name": "chart.js"}, {"type": "directory", "name": "less", "children": [{"type": "file", "name": "custom.less"}]}, {"type": "file", "name": "proxy.js"}]}]}, {"type": "file", "name": "webpack.config.js"}, {"type": "file", "name": "yarn.lock"}]}]}]} | So far, there is no mature Go project that does well in parsing `*.ini` files.
By comparison, we have selected an open source project: `https://github.com/go-ini/ini`.
This library helped us solve most of the key-value matching, but there are still some problems, such as not supporting parsing `map`.
We add our own logic on the basis of this library. In the current situationwhich, we need to complete the entire `Unmarshal` in two steps:
* Step#1, use `go-ini` to complete the basic parameter matching;
* Step#2, parse our custom parameters to realize parsing special structure, like `map`, `array`.
Some of the keywords in `tag`(like inline, extends, etc.) may be different from standard libraries such as `json` and `protobuf` in Go. For details, please refer to the library documentation: https://ini.unknwon.io/docs/intro. | {".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", "assets\\frpc\\static\\index.html": "<!doctype html> <html lang=en> <head> <meta charset=utf-8> <title>frp client admin UI</title> <link rel=\"shortcut icon\" href=\"favicon.ico\"></head> <body> <div id=app></div> <script type=\"text/javascript\" src=\"manifest.js?5d5774096cf5c1b4d5af\"></script><script type=\"text/javascript\" src=\"vendor.js?dc42700731a508d39009\"></script></body> </html> ", "assets\\frps\\static\\index.html": "<!doctype html> <html lang=en> <head> <meta charset=utf-8> <title>frps dashboard</title> <link rel=\"shortcut icon\" href=\"favicon.ico\"></head> <body> <div id=app></div> <script type=\"text/javascript\" src=\"manifest.js?5d154ba4c6b342d8c0c3\"></script><script type=\"text/javascript\" src=\"vendor.js?ddbd1f69fb6e67be4b78\"></script></body> </html> ", "client\\proxy\\proxy_wrapper.go": "package proxy\n\nimport (\n\t\"context\"\n\t\"fmt\"\n\t\"net\"\n\t\"sync\"\n\t\"sync/atomic\"\n\t\"time\"\n\n\t\"github.com/fatedier/golib/errors\"\n\n\t\"github.com/fatedier/frp/client/event\"\n\t\"github.com/fatedier/frp/client/health\"\n\t\"github.com/fatedier/frp/pkg/config\"\n\t\"github.com/fatedier/frp/pkg/msg\"\n\t\"github.com/fatedier/frp/pkg/util/xlog\"\n)\n\nconst (\n\tProxyPhaseNew = \"new\"\n\tProxyPhaseWaitStart = \"wait start\"\n\tProxyPhaseStartErr = \"start error\"\n\tProxyPhaseRunning = \"running\"\n\tProxyPhaseCheckFailed = \"check failed\"\n\tProxyPhaseClosed = \"closed\"\n)\n\nvar (\n\tstatusCheckInterval = 3 * time.Second\n\twaitResponseTimeout = 20 * time.Second\n\tstartErrTimeout = 30 * time.Second\n)\n\ntype WorkingStatus struct {\n\tName string `json:\"name\"`\n\tType string `json:\"type\"`\n\tPhase string `json:\"status\"`\n\tErr string `json:\"err\"`\n\tCfg config.ProxyConf `json:\"cfg\"`\n\n\t// Got from server.\n\tRemoteAddr string `json:\"remote_addr\"`\n}\n\ntype Wrapper struct {\n\tWorkingStatus\n\n\t// underlying proxy\n\tpxy Proxy\n\n\t// if ProxyConf has healcheck config\n\t// monitor will watch if it is alive\n\tmonitor *health.Monitor\n\n\t// event handler\n\thandler event.Handler\n\n\thealth uint32\n\tlastSendStartMsg time.Time\n\tlastStartErr time.Time\n\tcloseCh chan struct{}\n\thealthNotifyCh chan struct{}\n\tmu sync.RWMutex\n\n\txl *xlog.Logger\n\tctx context.Context\n}\n\nfunc NewWrapper(ctx context.Context, cfg config.ProxyConf, clientCfg config.ClientCommonConf, eventHandler event.Handler, serverUDPPort int) *Wrapper {\n\tbaseInfo := cfg.GetBaseInfo()\n\txl := xlog.FromContextSafe(ctx).Spawn().AppendPrefix(baseInfo.ProxyName)\n\tpw := &Wrapper{\n\t\tWorkingStatus: WorkingStatus{\n\t\t\tName: baseInfo.ProxyName,\n\t\t\tType: baseInfo.ProxyType,\n\t\t\tPhase: ProxyPhaseNew,\n\t\t\tCfg: cfg,\n\t\t},\n\t\tcloseCh: make(chan struct{}),\n\t\thealthNotifyCh: make(chan struct{}),\n\t\thandler: eventHandler,\n\t\txl: xl,\n\t\tctx: xlog.NewContext(ctx, xl),\n\t}\n\n\tif baseInfo.HealthCheckType != \"\" {\n\t\tpw.health = 1 // means failed\n\t\tpw.monitor = health.NewMonitor(pw.ctx, baseInfo.HealthCheckType, baseInfo.HealthCheckIntervalS,\n\t\t\tbaseInfo.HealthCheckTimeoutS, baseInfo.HealthCheckMaxFailed, baseInfo.HealthCheckAddr,\n\t\t\tbaseInfo.HealthCheckURL, pw.statusNormalCallback, pw.statusFailedCallback)\n\t\txl.Trace(\"enable health check monitor\")\n\t}\n\n\tpw.pxy = NewProxy(pw.ctx, pw.Cfg, clientCfg, serverUDPPort)\n\treturn pw\n}\n\nfunc (pw *Wrapper) SetRunningStatus(remoteAddr string, respErr string) error {\n\tpw.mu.Lock()\n\tdefer pw.mu.Unlock()\n\tif pw.Phase != ProxyPhaseWaitStart {\n\t\treturn fmt.Errorf(\"status not wait start, ignore start message\")\n\t}\n\n\tpw.RemoteAddr = remoteAddr\n\tif respErr != \"\" {\n\t\tpw.Phase = ProxyPhaseStartErr\n\t\tpw.Err = respErr\n\t\tpw.lastStartErr = time.Now()\n\t\treturn fmt.Errorf(pw.Err)\n\t}\n\n\tif err := pw.pxy.Run(); err != nil {\n\t\tpw.close()\n\t\tpw.Phase = ProxyPhaseStartErr\n\t\tpw.Err = err.Error()\n\t\tpw.lastStartErr = time.Now()\n\t\treturn err\n\t}\n\n\tpw.Phase = ProxyPhaseRunning\n\tpw.Err = \"\"\n\treturn nil\n}\n\nfunc (pw *Wrapper) Start() {\n\tgo pw.checkWorker()\n\tif pw.monitor != nil {\n\t\tgo pw.monitor.Start()\n\t}\n}\n\nfunc (pw *Wrapper) Stop() {\n\tpw.mu.Lock()\n\tdefer pw.mu.Unlock()\n\tclose(pw.closeCh)\n\tclose(pw.healthNotifyCh)\n\tpw.pxy.Close()\n\tif pw.monitor != nil {\n\t\tpw.monitor.Stop()\n\t}\n\tpw.Phase = ProxyPhaseClosed\n\tpw.close()\n}\n\nfunc (pw *Wrapper) close() {\n\t_ = pw.handler(&event.CloseProxyPayload{\n\t\tCloseProxyMsg: &msg.CloseProxy{\n\t\t\tProxyName: pw.Name,\n\t\t},\n\t})\n}\n\nfunc (pw *Wrapper) checkWorker() {\n\txl := pw.xl\n\tif pw.monitor != nil {\n\t\t// let monitor do check request first\n\t\ttime.Sleep(500 * time.Millisecond)\n\t}\n\tfor {\n\t\t// check proxy status\n\t\tnow := time.Now()\n\t\tif atomic.LoadUint32(&pw.health) == 0 {\n\t\t\tpw.mu.Lock()\n\t\t\tif pw.Phase == ProxyPhaseNew ||\n\t\t\t\tpw.Phase == ProxyPhaseCheckFailed ||\n\t\t\t\t(pw.Phase == ProxyPhaseWaitStart && now.After(pw.lastSendStartMsg.Add(waitResponseTimeout))) ||\n\t\t\t\t(pw.Phase == ProxyPhaseStartErr && now.After(pw.lastStartErr.Add(startErrTimeout))) {\n\n\t\t\t\txl.Trace(\"change status from [%s] to [%s]\", pw.Phase, ProxyPhaseWaitStart)\n\t\t\t\tpw.Phase = ProxyPhaseWaitStart\n\n\t\t\t\tvar newProxyMsg msg.NewProxy\n\t\t\t\tpw.Cfg.MarshalToMsg(&newProxyMsg)\n\t\t\t\tpw.lastSendStartMsg = now\n\t\t\t\t_ = pw.handler(&event.StartProxyPayload{\n\t\t\t\t\tNewProxyMsg: &newProxyMsg,\n\t\t\t\t})\n\t\t\t}\n\t\t\tpw.mu.Unlock()\n\t\t} else {\n\t\t\tpw.mu.Lock()\n\t\t\tif pw.Phase == ProxyPhaseRunning || pw.Phase == ProxyPhaseWaitStart {\n\t\t\t\tpw.close()\n\t\t\t\txl.Trace(\"change status from [%s] to [%s]\", pw.Phase, ProxyPhaseCheckFailed)\n\t\t\t\tpw.Phase = ProxyPhaseCheckFailed\n\t\t\t}\n\t\t\tpw.mu.Unlock()\n\t\t}\n\n\t\tselect {\n\t\tcase <-pw.closeCh:\n\t\t\treturn\n\t\tcase <-time.After(statusCheckInterval):\n\t\tcase <-pw.healthNotifyCh:\n\t\t}\n\t}\n}\n\nfunc (pw *Wrapper) statusNormalCallback() {\n\txl := pw.xl\n\tatomic.StoreUint32(&pw.health, 0)\n\t_ = errors.PanicToError(func() {\n\t\tselect {\n\t\tcase pw.healthNotifyCh <- struct{}{}:\n\t\tdefault:\n\t\t}\n\t})\n\txl.Info(\"health check success\")\n}\n\nfunc (pw *Wrapper) statusFailedCallback() {\n\txl := pw.xl\n\tatomic.StoreUint32(&pw.health, 1)\n\t_ = errors.PanicToError(func() {\n\t\tselect {\n\t\tcase pw.healthNotifyCh <- struct{}{}:\n\t\tdefault:\n\t\t}\n\t})\n\txl.Info(\"health check failed\")\n}\n\nfunc (pw *Wrapper) InWorkConn(workConn net.Conn, m *msg.StartWorkConn) {\n\txl := pw.xl\n\tpw.mu.RLock()\n\tpxy := pw.pxy\n\tpw.mu.RUnlock()\n\tif pxy != nil && pw.Phase == ProxyPhaseRunning {\n\t\txl.Debug(\"start a new work connection, localAddr: %s remoteAddr: %s\", workConn.LocalAddr().String(), workConn.RemoteAddr().String())\n\t\tgo pxy.InWorkConn(workConn, m)\n\t} else {\n\t\tworkConn.Close()\n\t}\n}\n\nfunc (pw *Wrapper) GetStatus() *WorkingStatus {\n\tpw.mu.RLock()\n\tdefer pw.mu.RUnlock()\n\tps := &WorkingStatus{\n\t\tName: pw.Name,\n\t\tType: pw.Type,\n\t\tPhase: pw.Phase,\n\t\tErr: pw.Err,\n\t\tCfg: pw.Cfg,\n\t\tRemoteAddr: pw.RemoteAddr,\n\t}\n\treturn ps\n}\n", "cmd\\frpc\\main.go": "// Copyright 2016 fatedier, [email protected]\n//\n// Licensed under the Apache License, Version 2.0 (the \"License\");\n// you may not use this file except in compliance with the License.\n// You may obtain a copy of the License at\n//\n// http://www.apache.org/licenses/LICENSE-2.0\n//\n// Unless required by applicable law or agreed to in writing, software\n// distributed under the License is distributed on an \"AS IS\" BASIS,\n// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n// See the License for the specific language governing permissions and\n// limitations under the License.\n\npackage main\n\nimport (\n\t_ \"github.com/fatedier/frp/assets/frpc\"\n\t\"github.com/fatedier/frp/cmd/frpc/sub\"\n)\n\nfunc main() {\n\tsub.Execute()\n}\n", "cmd\\frps\\main.go": "// Copyright 2018 fatedier, [email protected]\n//\n// Licensed under the Apache License, Version 2.0 (the \"License\");\n// you may not use this file except in compliance with the License.\n// You may obtain a copy of the License at\n//\n// http://www.apache.org/licenses/LICENSE-2.0\n//\n// Unless required by applicable law or agreed to in writing, software\n// distributed under the License is distributed on an \"AS IS\" BASIS,\n// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n// See the License for the specific language governing permissions and\n// limitations under the License.\n\npackage main\n\nimport (\n\t\"math/rand\"\n\t\"time\"\n\n\t\"github.com/fatedier/golib/crypto\"\n\n\t_ \"github.com/fatedier/frp/assets/frps\"\n\t_ \"github.com/fatedier/frp/pkg/metrics\"\n)\n\nfunc main() {\n\tcrypto.DefaultSalt = \"frp\"\n\trand.Seed(time.Now().UnixNano())\n\n\tExecute()\n}\n", "dockerfiles\\Dockerfile-for-frpc": "FROM golang:1.19 AS building\n\nCOPY . /building\nWORKDIR /building\n\nRUN make frpc\n\nFROM alpine:3\n\nCOPY --from=building /building/bin/frpc /usr/bin/frpc\n\nENTRYPOINT [\"/usr/bin/frpc\"]\n", "dockerfiles\\Dockerfile-for-frps": "FROM golang:1.19 AS building\n\nCOPY . /building\nWORKDIR /building\n\nRUN make frps\n\nFROM alpine:3\n\nCOPY --from=building /building/bin/frps /usr/bin/frps\n\nRUN apk add curl\n\nHEALTHCHECK --interval=1m --timeout=30s --retries=3 CMD curl --fail http://localhost:7001/healthz || exit 1\n\nENTRYPOINT [\"/usr/bin/frps\"]\n", "pkg\\plugin\\client\\unix_domain_socket.go": "// Copyright 2017 fatedier, [email protected]\n//\n// Licensed under the Apache License, Version 2.0 (the \"License\");\n// you may not use this file except in compliance with the License.\n// You may obtain a copy of the License at\n//\n// http://www.apache.org/licenses/LICENSE-2.0\n//\n// Unless required by applicable law or agreed to in writing, software\n// distributed under the License is distributed on an \"AS IS\" BASIS,\n// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n// See the License for the specific language governing permissions and\n// limitations under the License.\n\npackage plugin\n\nimport (\n\t\"fmt\"\n\t\"io\"\n\t\"net\"\n\n\tfrpIo \"github.com/fatedier/golib/io\"\n)\n\nconst PluginUnixDomainSocket = \"unix_domain_socket\"\n\nfunc init() {\n\tRegister(PluginUnixDomainSocket, NewUnixDomainSocketPlugin)\n}\n\ntype UnixDomainSocketPlugin struct {\n\tUnixAddr *net.UnixAddr\n}\n\nfunc NewUnixDomainSocketPlugin(params map[string]string) (p Plugin, err error) {\n\tunixPath, ok := params[\"plugin_unix_path\"]\n\tif !ok {\n\t\terr = fmt.Errorf(\"plugin_unix_path not found\")\n\t\treturn\n\t}\n\n\tunixAddr, errRet := net.ResolveUnixAddr(\"unix\", unixPath)\n\tif errRet != nil {\n\t\terr = errRet\n\t\treturn\n\t}\n\n\tp = &UnixDomainSocketPlugin{\n\t\tUnixAddr: unixAddr,\n\t}\n\treturn\n}\n\nfunc (uds *UnixDomainSocketPlugin) Handle(conn io.ReadWriteCloser, realConn net.Conn, extraBufToLocal []byte) {\n\tlocalConn, err := net.DialUnix(\"unix\", nil, uds.UnixAddr)\n\tif err != nil {\n\t\treturn\n\t}\n\tif len(extraBufToLocal) > 0 {\n\t\tif _, err := localConn.Write(extraBufToLocal); err != nil {\n\t\t\treturn\n\t\t}\n\t}\n\n\tfrpIo.Join(localConn, conn)\n}\n\nfunc (uds *UnixDomainSocketPlugin) Name() string {\n\treturn PluginUnixDomainSocket\n}\n\nfunc (uds *UnixDomainSocketPlugin) Close() error {\n\treturn nil\n}\n", "test\\e2e\\framework\\ginkgowrapper\\wrapper.go": "// Package ginkgowrapper wraps Ginkgo Fail and Skip functions to panic\n// with structured data instead of a constant string.\npackage ginkgowrapper\n\nimport (\n\t\"bufio\"\n\t\"bytes\"\n\t\"regexp\"\n\t\"runtime\"\n\t\"runtime/debug\"\n\t\"strings\"\n\n\t\"github.com/onsi/ginkgo\"\n)\n\n// FailurePanic is the value that will be panicked from Fail.\ntype FailurePanic struct {\n\tMessage string // The failure message passed to Fail\n\tFilename string // The filename that is the source of the failure\n\tLine int // The line number of the filename that is the source of the failure\n\tFullStackTrace string // A full stack trace starting at the source of the failure\n}\n\n// String makes FailurePanic look like the old Ginkgo panic when printed.\nfunc (FailurePanic) String() string { return ginkgo.GINKGO_PANIC }\n\n// Fail wraps ginkgo.Fail so that it panics with more useful\n// information about the failure. This function will panic with a\n// FailurePanic.\nfunc Fail(message string, callerSkip ...int) {\n\tskip := 1\n\tif len(callerSkip) > 0 {\n\t\tskip += callerSkip[0]\n\t}\n\n\t_, file, line, _ := runtime.Caller(skip)\n\tfp := FailurePanic{\n\t\tMessage: message,\n\t\tFilename: file,\n\t\tLine: line,\n\t\tFullStackTrace: pruneStack(skip),\n\t}\n\n\tdefer func() {\n\t\te := recover()\n\t\tif e != nil {\n\t\t\tpanic(fp)\n\t\t}\n\t}()\n\n\tginkgo.Fail(message, skip)\n}\n\n// ginkgo adds a lot of test running infrastructure to the stack, so\n// we filter those out\nvar stackSkipPattern = regexp.MustCompile(`onsi/ginkgo`)\n\nfunc pruneStack(skip int) string {\n\tskip += 2 // one for pruneStack and one for debug.Stack\n\tstack := debug.Stack()\n\tscanner := bufio.NewScanner(bytes.NewBuffer(stack))\n\tvar prunedStack []string\n\n\t// skip the top of the stack\n\tfor i := 0; i < 2*skip+1; i++ {\n\t\tscanner.Scan()\n\t}\n\n\tfor scanner.Scan() {\n\t\tif stackSkipPattern.Match(scanner.Bytes()) {\n\t\t\tscanner.Scan() // these come in pairs\n\t\t} else {\n\t\t\tprunedStack = append(prunedStack, scanner.Text())\n\t\t\tscanner.Scan() // these come in pairs\n\t\t\tprunedStack = append(prunedStack, scanner.Text())\n\t\t}\n\t}\n\n\treturn strings.Join(prunedStack, \"\\n\")\n}\n", "web\\frpc\\package.json": "{\n \"name\": \"frpc-web\",\n \"description\": \"An admin web ui for frp client.\",\n \"author\": \"fatedier\",\n \"private\": true,\n \"scripts\": {\n \"dev\": \"webpack-dev-server -d --inline --hot --env.dev\",\n \"build\": \"rimraf dist && webpack -p --progress --hide-modules\"\n },\n \"dependencies\": {\n \"element-ui\": \"^2.5.3\",\n \"vue\": \"^2.5.22\",\n \"vue-resource\": \"^1.5.1\",\n \"vue-router\": \"^3.0.2\",\n \"whatwg-fetch\": \"^3.0.0\"\n },\n \"engines\": {\n \"node\": \">=6\"\n },\n \"devDependencies\": {\n \"autoprefixer\": \"^9.4.7\",\n \"babel-core\": \"^6.26.3\",\n \"babel-eslint\": \"^10.0.1\",\n \"babel-loader\": \"^7.1.5\",\n \"babel-plugin-component\": \"^1.1.1\",\n \"babel-preset-es2015\": \"^6.24.1\",\n \"css-loader\": \"^2.1.0\",\n \"eslint\": \"^5.12.1\",\n \"eslint-config-enough\": \"^0.3.4\",\n \"eslint-loader\": \"^2.1.1\",\n \"file-loader\": \"^3.0.1\",\n \"html-loader\": \"^0.5.5\",\n \"html-webpack-plugin\": \"^2.24.1\",\n \"less\": \"^3.9.0\",\n \"less-loader\": \"^4.1.0\",\n \"postcss-loader\": \"^3.0.0\",\n \"rimraf\": \"^2.6.3\",\n \"style-loader\": \"^0.23.1\",\n \"url-loader\": \"^1.1.2\",\n \"vue-loader\": \"^15.6.2\",\n \"vue-template-compiler\": \"^2.5.22\",\n \"webpack\": \"^2.7.0\",\n \"webpack-cli\": \"^3.2.1\",\n \"webpack-dev-server\": \"^3.1.14\"\n }\n}\n", "web\\frpc\\src\\App.vue": "<template>\n <div id=\"app\">\n <header class=\"grid-content header-color\">\n <el-row>\n <a class=\"brand\" href=\"#\">frp client</a>\n </el-row>\n </header>\n <section>\n <el-row>\n <el-col id=\"side-nav\" :xs=\"24\" :md=\"4\">\n <el-menu default-active=\"1\" mode=\"vertical\" theme=\"light\" router=\"false\" @select=\"handleSelect\">\n <el-menu-item index=\"/\">Overview</el-menu-item>\n <el-menu-item index=\"/configure\">Configure</el-menu-item>\n <el-menu-item index=\"\">Help</el-menu-item>\n </el-menu>\n\t\t\t\t</el-col>\n\n\t\t\t\t<el-col :xs=\"24\" :md=\"20\">\n <div id=\"content\">\n <router-view></router-view>\n </div>\n\t\t\t\t</el-col>\n\t\t</el-row>\n\t</section>\n\t<footer></footer>\n</div>\n</template>\n\n<script>\n export default {\n methods: {\n handleSelect(key, path) {\n if (key == '') {\n window.open(\"https://github.com/fatedier/frp\")\n }\n }\n }\n }\n</script>\n\n<style>\n body {\n background-color: #fafafa;\n margin: 0px;\n font-family: -apple-system,BlinkMacSystemFont,Helvetica Neue,sans-serif;\n }\n \n header {\n width: 100%;\n height: 60px;\n }\n \n .header-color {\n background: #58B7FF;\n }\n \n #content {\n margin-top: 20px;\n padding-right: 40px;\n }\n \n .brand {\n color: #fff;\n background-color: transparent;\n margin-left: 20px;\n float: left;\n line-height: 25px;\n font-size: 25px;\n padding: 15px 15px;\n height: 30px;\n text-decoration: none;\n }\n</style>\n", "web\\frpc\\src\\index.html": "<!DOCTYPE html>\n<html lang=\"en\">\n\n<head>\n <meta charset=\"utf-8\">\n <title>frp client admin UI</title>\n</head>\n\n<body>\n <div id=\"app\"></div>\n <!--<script src=\"https://code.jquery.com/jquery-3.2.0.min.js\"></script>-->\n <!--<script src=\"//cdn.bootcss.com/echarts/3.4.0/echarts.min.js\"></script>-->\n</body>\n\n</html>\n", "web\\frpc\\src\\main.js": "import Vue from 'vue'\n// import ElementUI from 'element-ui'\nimport {\n Button,\n Form,\n FormItem,\n Row,\n Col,\n Table,\n TableColumn,\n Menu,\n MenuItem,\n MessageBox,\n Message,\n Input\n} from 'element-ui'\nimport lang from 'element-ui/lib/locale/lang/en'\nimport locale from 'element-ui/lib/locale'\nimport 'element-ui/lib/theme-chalk/index.css'\nimport './utils/less/custom.less'\n\nimport App from './App.vue'\nimport router from './router'\nimport 'whatwg-fetch'\n\nlocale.use(lang)\n\nVue.use(Button)\nVue.use(Form)\nVue.use(FormItem)\nVue.use(Row)\nVue.use(Col)\nVue.use(Table)\nVue.use(TableColumn)\nVue.use(Menu)\nVue.use(MenuItem)\nVue.use(Input)\n\nVue.prototype.$msgbox = MessageBox;\nVue.prototype.$confirm = MessageBox.confirm\nVue.prototype.$message = Message\n\n//Vue.use(ElementUI)\n\nVue.config.productionTip = false\n\nnew Vue({\n el: '#app',\n router,\n template: '<App/>',\n components: { App }\n})\n", "web\\frpc\\src\\router\\index.js": "import Vue from 'vue'\nimport Router from 'vue-router'\nimport Overview from '../components/Overview.vue'\nimport Configure from '../components/Configure.vue'\n\nVue.use(Router)\n\nexport default new Router({\n routes: [{\n path: '/',\n name: 'Overview',\n component: Overview\n },{\n path: '/configure',\n name: 'Configure',\n component: Configure,\n }]\n})\n", "web\\frps\\package.json": "{\n \"name\": \"frps-dashboard\",\n \"description\": \"A dashboard for frp server.\",\n \"author\": \"fatedier\",\n \"private\": true,\n \"scripts\": {\n \"dev\": \"webpack-dev-server -d --inline --hot --env.dev\",\n \"build\": \"rimraf dist && webpack -p --progress --hide-modules\"\n },\n \"dependencies\": {\n \"bootstrap\": \"^3.3.7\",\n \"echarts\": \"^3.5.0\",\n \"element-ui\": \"^2.3.8\",\n \"humanize-plus\": \"^1.8.2\",\n \"vue\": \"^2.5.16\",\n \"vue-resource\": \"^1.2.1\",\n \"vue-router\": \"^2.3.0\",\n \"whatwg-fetch\": \"^2.0.3\"\n },\n \"engines\": {\n \"node\": \">=6\"\n },\n \"devDependencies\": {\n \"autoprefixer\": \"^6.6.0\",\n \"babel-core\": \"^6.21.0\",\n \"babel-eslint\": \"^7.1.1\",\n \"babel-loader\": \"^6.4.0\",\n \"babel-plugin-component\": \"^1.1.1\",\n \"babel-preset-es2015\": \"^6.13.2\",\n \"css-loader\": \"^0.27.0\",\n \"eslint\": \"^3.12.2\",\n \"eslint-config-enough\": \"^0.2.2\",\n \"eslint-loader\": \"^1.6.3\",\n \"file-loader\": \"^0.10.1\",\n \"html-loader\": \"^0.4.5\",\n \"html-webpack-plugin\": \"^2.24.1\",\n \"less\": \"^3.0.4\",\n \"less-loader\": \"^4.1.0\",\n \"postcss-loader\": \"^1.3.3\",\n \"rimraf\": \"^2.5.4\",\n \"style-loader\": \"^0.13.2\",\n \"url-loader\": \"^1.0.1\",\n \"vue-loader\": \"^15.0.10\",\n \"vue-template-compiler\": \"^2.1.8\",\n \"webpack\": \"^2.2.0-rc.4\",\n \"webpack-dev-server\": \"^3.1.4\"\n }\n}\n", "web\\frps\\src\\App.vue": "<template>\n <div id=\"app\">\n <header class=\"grid-content header-color\">\n <el-row>\n <a class=\"brand\" href=\"#\">frp</a>\n </el-row>\n </header>\n <section>\n <el-row>\n <el-col id=\"side-nav\" :xs=\"24\" :md=\"4\">\n <el-menu default-active=\"1\" mode=\"vertical\" theme=\"light\" router=\"false\" @select=\"handleSelect\">\n <el-menu-item index=\"/\">Overview</el-menu-item>\n <el-submenu index=\"/proxies\">\n <template slot=\"title\">Proxies</template>\n <el-menu-item index=\"/proxies/tcp\">TCP</el-menu-item>\n <el-menu-item index=\"/proxies/udp\">UDP</el-menu-item>\n <el-menu-item index=\"/proxies/http\">HTTP</el-menu-item>\n <el-menu-item index=\"/proxies/https\">HTTPS</el-menu-item>\n <el-menu-item index=\"/proxies/stcp\">STCP</el-menu-item>\n <el-menu-item index=\"/proxies/sudp\">SUDP</el-menu-item>\n </el-submenu>\n <el-menu-item index=\"\">Help</el-menu-item>\n </el-menu>\n\t\t\t\t</el-col>\n\n\t\t\t\t<el-col :xs=\"24\" :md=\"20\">\n <div id=\"content\">\n <router-view></router-view>\n </div>\n\t\t\t\t</el-col>\n\t\t</el-row>\n\t</section>\n\t<footer></footer>\n</div>\n</template>\n\n<script>\n export default {\n methods: {\n handleSelect(key, path) {\n if (key == '') {\n window.open(\"https://github.com/fatedier/frp\")\n }\n }\n }\n }\n</script>\n\n<style>\n body {\n background-color: #fafafa;\n margin: 0px;\n font-family: -apple-system,BlinkMacSystemFont,Helvetica Neue,sans-serif;\n }\n \n header {\n width: 100%;\n height: 60px;\n }\n \n .header-color {\n background: #58B7FF;\n }\n \n #content {\n margin-top: 20px;\n padding-right: 40px;\n }\n \n .brand {\n color: #fff;\n background-color: transparent;\n margin-left: 20px;\n float: left;\n line-height: 25px;\n font-size: 25px;\n padding: 15px 15px;\n height: 30px;\n text-decoration: none;\n }\n</style>\n", "web\\frps\\src\\index.html": "<!DOCTYPE html>\n<html lang=\"en\">\n\n<head>\n <meta charset=\"utf-8\">\n <title>frps dashboard</title>\n</head>\n\n<body>\n <div id=\"app\"></div>\n <!--<script src=\"https://code.jquery.com/jquery-3.2.0.min.js\"></script>-->\n <!--<script src=\"//cdn.bootcss.com/echarts/3.4.0/echarts.min.js\"></script>-->\n</body>\n\n</html>\n", "web\\frps\\src\\main.js": "import Vue from 'vue'\n//import ElementUI from 'element-ui'\nimport {\n Button,\n Form,\n FormItem,\n Row,\n Col,\n Table,\n TableColumn,\n Popover,\n Menu,\n Submenu,\n MenuItem,\n Tag\n} from 'element-ui'\nimport lang from 'element-ui/lib/locale/lang/en'\nimport locale from 'element-ui/lib/locale'\nimport 'element-ui/lib/theme-chalk/index.css'\nimport './utils/less/custom.less'\n\nimport App from './App.vue'\nimport router from './router'\nimport 'whatwg-fetch'\n\nlocale.use(lang)\n\nVue.use(Button)\nVue.use(Form)\nVue.use(FormItem)\nVue.use(Row)\nVue.use(Col)\nVue.use(Table)\nVue.use(TableColumn)\nVue.use(Popover)\nVue.use(Menu)\nVue.use(Submenu)\nVue.use(MenuItem)\nVue.use(Tag)\n\nVue.config.productionTip = false\n\nnew Vue({\n el: '#app',\n router,\n template: '<App/>',\n components: { App }\n})\n", "web\\frps\\src\\router\\index.js": "import Vue from 'vue'\nimport Router from 'vue-router'\nimport Overview from '../components/Overview.vue'\nimport ProxiesTcp from '../components/ProxiesTcp.vue'\nimport ProxiesUdp from '../components/ProxiesUdp.vue'\nimport ProxiesHttp from '../components/ProxiesHttp.vue'\nimport ProxiesHttps from '../components/ProxiesHttps.vue'\nimport ProxiesStcp from '../components/ProxiesStcp.vue'\nimport ProxiesSudp from '../components/ProxiesSudp.vue'\n\nVue.use(Router)\n\nexport default new Router({\n routes: [{\n path: '/',\n name: 'Overview',\n component: Overview\n }, {\n path: '/proxies/tcp',\n name: 'ProxiesTcp',\n component: ProxiesTcp\n }, {\n path: '/proxies/udp',\n name: 'ProxiesUdp',\n component: ProxiesUdp\n }, {\n path: '/proxies/http',\n name: 'ProxiesHttp',\n component: ProxiesHttp\n }, {\n path: '/proxies/https',\n name: 'ProxiesHttps',\n component: ProxiesHttps\n }, {\n path: '/proxies/stcp',\n name: 'ProxiesStcp',\n component: ProxiesStcp\n }, {\n path: '/proxies/sudp',\n name: 'ProxiesSudp',\n component: ProxiesSudp\n }]\n})\n"} | null |
fuego | {"type": "directory", "name": "fuego", "children": [{"type": "directory", "name": "examples", "children": [{"type": "file", "name": "fuego_demo.ipynb"}, {"type": "directory", "name": "github_runner_app", "children": [{"type": "file", "name": "app.py"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "style.css"}]}, {"type": "directory", "name": "pytorch_vae_github", "children": [{"type": "file", "name": "fuego_run.py"}]}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "run_all.sh"}, {"type": "directory", "name": "simple_example", "children": [{"type": "file", "name": "fuego_run.py"}, {"type": "file", "name": "run.py"}]}, {"type": "directory", "name": "simple_example_with_requirements", "children": [{"type": "file", "name": "fuego_run.py"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "run.py"}]}, {"type": "directory", "name": "transformers_github", "children": [{"type": "file", "name": "fuego_run.py"}]}]}, {"type": "file", "name": "LICENSE"}, {"type": "file", "name": "Makefile"}, {"type": "file", "name": "pyproject.toml"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "setup.py"}, {"type": "directory", "name": "src", "children": [{"type": "directory", "name": "fuego", "children": [{"type": "file", "name": "runtime.py"}, {"type": "file", "name": "run_on_spaces.py"}, {"type": "file", "name": "__init__.py"}]}]}]} | # Examples
See each example subdirectory's `fuego_run.py` for details. | {"setup.py": "from setuptools import find_packages, setup\n\n\ndef get_version() -> str:\n rel_path = \"src/fuego/__init__.py\"\n with open(rel_path, \"r\") as fp:\n for line in fp.read().splitlines():\n if line.startswith(\"__version__\"):\n delim = '\"' if '\"' in line else \"'\"\n return line.split(delim)[1]\n raise RuntimeError(\"Unable to find version string.\")\n\n\nrequirements = [\n \"fire\",\n \"huggingface_hub>=0.12.0\",\n \"GitPython\",\n]\n\nextras = {}\nextras[\"quality\"] = [\"black~=23.1\", \"ruff>=0.0.241\"]\n\nsetup(\n name=\"fuego\",\n description=\"Fuego\",\n long_description=open(\"README.md\", \"r\", encoding=\"utf-8\").read(),\n long_description_content_type=\"text/markdown\",\n url=\"https://github.com/huggingface/fuego\",\n version=get_version(),\n author=\"Nathan Raw\",\n author_email=\"[email protected]\",\n license=\"Apache\",\n install_requires=requirements,\n extras_require=extras,\n package_dir={\"\": \"src\"},\n packages=find_packages(\"src\"),\n entry_points={\"console_scripts\": [\"fuego=fuego.run_on_spaces:cli_run\"]},\n)\n", ".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 67eaf55db3315bdd34795bdec8b935f5301232d6 Hamza Amin <[email protected]> 1727369275 +0500\tclone: from https://github.com/huggingface/fuego.git\n", ".git\\refs\\heads\\main": "67eaf55db3315bdd34795bdec8b935f5301232d6\n", "examples\\github_runner_app\\app.py": "# Gradio app to run fuego.github_run() on Hugging Face Spaces\n# Hosted at https://hf.co/nateraw/fuego\nimport gradio as gr\nimport yaml\n\nimport fuego\n\n\ndef fuego_github_run_wrapper(\n token,\n github_repo_id,\n github_repo_branch,\n script,\n requirements_file,\n extra_requirements,\n script_args,\n output_dirs,\n private,\n delete_space_on_completion,\n downgrade_hardware_on_completion,\n space_hardware,\n):\n if not token.strip():\n return gr.update(\n value=\"\"\"## token with write access is required. Get one from <a href=\"https://hf.co/settings/tokens\" target=\"_blank\">here</a>\"\"\",\n visible=True,\n )\n\n if script_args.strip():\n script_args = yaml.safe_load(script_args)\n\n if not requirements_file.strip():\n requirements_file = None\n\n if extra_requirements.strip():\n extra_requirements = [x.strip() for x in extra_requirements.split(\"\\n\")]\n else:\n extra_requirements = None\n\n if output_dirs.strip():\n output_dirs = [x.strip() for x in output_dirs.split(\",\")]\n\n github_repo_id = github_repo_id.strip()\n if not github_repo_id:\n return gr.update(value=\"## GitHub repo ID is required\", visible=True)\n\n script = script.strip()\n if not script:\n return gr.update(value=\"## script is required\", visible=True)\n\n github_repo_branch = github_repo_branch.strip()\n if not github_repo_branch:\n return gr.update(\"## github repo branch is required\", visible=True)\n\n space_url, dataset_url = fuego.github_run(\n github_repo_id.strip(),\n script.strip(),\n requirements_file,\n github_repo_branch,\n space_hardware=space_hardware,\n private=private,\n delete_space_on_completion=delete_space_on_completion,\n downgrade_hardware_on_completion=downgrade_hardware_on_completion,\n space_output_dirs=output_dirs,\n extra_requirements=extra_requirements,\n token=token,\n **script_args,\n )\n output_message = f\"\"\"\n ## Job launched successfully! \ud83d\ude80\n - <a href=\"{space_url}\" target=\"_blank\">Link to Space</a>\n - <a href=\"{dataset_url}\" target=\"_blank\">Link to Dataset</a>\n \"\"\"\n return gr.update(value=output_message, visible=True)\n\n\ndescription = \"\"\"\nThis app lets you run scripts from GitHub on Spaces, using any hardware you'd like. Just point to a repo, the script you'd like to run, the dependencies to install, and any args to pass to your script, and watch it go. \ud83d\ude0e\n\nIt uses \ud83d\udd25[fuego](https://github.com/huggingface/fuego)\ud83d\udd25 under the hood to launch your script in one line of Python code. Give the repo a \u2b50\ufe0f if you think its \ud83d\udd25.\n\n**Note: You'll need a Hugging Face token with write access, which you can get from [here](https://hf.co/settings/tokens)**\n\"\"\"\n\nadditional_info = \"\"\"\n## Pricing\n\nRuns using this tool are **free** as long as you use `cpu-basic` hardware. \ud83d\udd25\n\n**See pricing for accelerated hardware (anything other than `cpu-basic`) [here](https://hf.co/pricing#spaces)**\n\n## What this space does:\n 1. Spins up 2 new HF repos for you: a \"runner\" space repo and an \"output\" dataset repo.\n 2. Uploads your code to the space, as well as some wrapper code that invokes your script.\n 3. Runs your code on the space via the wrapper. Logs should show up in the space.\n 4. When the script is done, it takes anything saved to the `output_dirs` and uploads the files within to the output dataset repo\n 5. Deletes the space (or downgrades, or just leaves on). Depends on your choice of `delete_space_on_completion` and `downgrade_hardware_on_completion`.\n\n## FAQ\n\n- If your space ends up having a \"no application file\" issue, you may need to \"factory reset\" the space. You can do this from the settings page of the space.\n\"\"\"\n\noutput_message = gr.Markdown(\"\", visible=False)\n\nwith gr.Blocks(css=\"style.css\") as demo:\n gr.Markdown(\"# \ud83d\udd25Fuego\ud83d\udd25 GitHub Script Runner\")\n gr.Markdown(description)\n with gr.Accordion(\"\ud83d\udc40 More Details (Hardware Pricing, How it Works, and FAQ)\", open=False):\n gr.Markdown(additional_info)\n\n with gr.Row():\n token = gr.Textbox(lines=1, label=\"Hugging Face token with write access\", type=\"password\")\n\n with gr.Row():\n with gr.Column():\n with gr.Box():\n gr.Markdown(\"What script would you like to run? Also, what are its dependencies?\")\n github_repo_id = gr.Textbox(lines=1, label=\"GitHub repo ID (ex. huggingface/fuego)\")\n github_repo_branch = gr.Textbox(\n lines=1, label=\"Branch of GitHub repo (ex. main)\", value=\"main\", interactive=True\n )\n script = gr.Textbox(lines=1, label=\"Path to python script in the GitHub repo\")\n requirements_file = gr.Textbox(lines=1, label=\"Path to pip requirements file in the repo\")\n extra_requirements = gr.Textbox(\n lines=5,\n label=\"Any extra pip requirements to your script, just as you would write them in requirements.txt\",\n )\n with gr.Column():\n with gr.Box():\n gr.Markdown(\"How should we run your script?\")\n script_args = gr.Textbox(lines=10, label=\"Script args to your python file. Input here as YAML.\")\n spaces_output_dirs = gr.Textbox(\n lines=1,\n label=\"Name of output directory to save assets to from within your script. Use commas if you have multiple.\",\n value=\"./outputs, ./logs\",\n )\n private = gr.Checkbox(False, label=\"Should space/dataset be made as private repos?\")\n delete_space_on_completion = gr.Checkbox(True, label=\"Delete the space on completion?\")\n downgrade_hardware_on_completion = gr.Checkbox(\n True,\n label=\"Downgrade hardware of the space on completion? Only applicable if not deleting on completion.\",\n )\n with gr.Row():\n with gr.Column():\n spaces_hardware = gr.Dropdown(\n [\"cpu-basic\", \"cpu-upgrade\", \"t4-small\", \"t4-medium\", \"a10g-small\", \"a10g-large\", \"a100-large\"],\n label=\"Spaces Hardware\",\n value=\"cpu-basic\",\n interactive=True,\n )\n spaces_hardware_msg = gr.Markdown(\n \"\"\"\n \ud83d\udd34 **The hardware you chose is not free, and you will be charged for it** \ud83d\udd34\n\n If you want to run your script for free, please choose `cpu-basic` as your hardware.\n \"\"\",\n visible=False,\n )\n spaces_hardware.change(\n lambda x: gr.update(visible=True) if x != \"cpu-basic\" else gr.update(visible=False),\n inputs=[spaces_hardware],\n outputs=[spaces_hardware_msg],\n )\n\n with gr.Row():\n with gr.Accordion(\"\ud83d\udc40 Examples\", open=False):\n gr.Examples(\n [\n [\n \"pytorch/examples\",\n \"main\",\n \"vae/main.py\",\n \"vae/requirements.txt\",\n \"\",\n \"epochs: 3\",\n \"./results\",\n False,\n True,\n True,\n \"cpu-basic\",\n ],\n [\n \"huggingface/transformers\",\n \"main\",\n \"examples/pytorch/text-classification/run_glue.py\",\n \"examples/pytorch/text-classification/requirements.txt\",\n \"tensorboard\\ngit+https://github.com/huggingface/transformers@main#egg=transformers\",\n \"model_name_or_path: bert-base-cased\\ntask_name: mrpc\\ndo_train: True\\ndo_eval: True\\nmax_seq_length: 128\\nper_device_train_batch_size: 32\\nlearning_rate: 2e-5\\nnum_train_epochs: 3\\noutput_dir: ./outputs\\nlogging_dir: ./logs\\nlogging_steps: 20\\nreport_to: tensorboard\",\n \"./outputs,./logs\",\n False,\n True,\n True,\n \"cpu-basic\",\n ],\n ],\n inputs=[\n github_repo_id,\n github_repo_branch,\n script,\n requirements_file,\n extra_requirements,\n script_args,\n spaces_output_dirs,\n private,\n delete_space_on_completion,\n downgrade_hardware_on_completion,\n spaces_hardware,\n ],\n outputs=[\n github_repo_id,\n github_repo_branch,\n script,\n requirements_file,\n extra_requirements,\n script_args,\n spaces_output_dirs,\n private,\n delete_space_on_completion,\n downgrade_hardware_on_completion,\n spaces_hardware,\n ],\n cache_examples=False,\n )\n\n with gr.Row():\n submit = gr.Button(\"Submit\")\n reset_btn = gr.Button(\"Reset fields\")\n\n with gr.Row():\n output_message.render()\n\n submit.click(\n fuego_github_run_wrapper,\n inputs=[\n token,\n github_repo_id,\n github_repo_branch,\n script,\n requirements_file,\n extra_requirements,\n script_args,\n spaces_output_dirs,\n private,\n delete_space_on_completion,\n downgrade_hardware_on_completion,\n spaces_hardware,\n ],\n outputs=[output_message],\n )\n\n def reset_fields():\n return {\n output_message: gr.update(value=\"\", visible=False),\n github_repo_id: gr.update(value=\"\"),\n github_repo_branch: gr.update(value=\"main\"),\n script: gr.update(value=\"\"),\n requirements_file: gr.update(value=\"\"),\n extra_requirements: gr.update(value=\"\"),\n script_args: gr.update(value=\"\"),\n spaces_output_dirs: gr.update(value=\"./outputs, ./logs\"),\n private: gr.update(value=False),\n delete_space_on_completion: gr.update(value=True),\n downgrade_hardware_on_completion: gr.update(value=True),\n spaces_hardware: gr.update(value=\"cpu-basic\"),\n }\n\n reset_btn.click(\n reset_fields,\n outputs=[\n output_message,\n github_repo_id,\n github_repo_branch,\n script,\n requirements_file,\n extra_requirements,\n script_args,\n spaces_output_dirs,\n private,\n delete_space_on_completion,\n downgrade_hardware_on_completion,\n spaces_hardware,\n ],\n )\n\nif __name__ == \"__main__\":\n demo.launch(debug=True)\n", "examples\\github_runner_app\\requirements.txt": "gradio\nPyYAML\nfuego==0.0.8\n", "examples\\simple_example_with_requirements\\requirements.txt": "fire==0.5.0"} | null |
gaia | {"type": "directory", "name": "gaia", "children": [{"type": "directory", "name": "indexes", "children": []}, {"type": "directory", "name": "notebooks", "children": [{"type": "file", "name": "00-indexing.ipynb"}, {"type": "file", "name": "01-tokenization.ipynb"}, {"type": "file", "name": "02-searching.ipynb"}, {"type": "file", "name": "03-analysis.ipynb"}]}, {"type": "directory", "name": "preprocessing", "children": [{"type": "file", "name": "preprocessing.py"}]}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "directory", "name": "shards", "children": []}, {"type": "directory", "name": "web", "children": [{"type": "file", "name": "bigscience_pii_detect_redact.py"}, {"type": "file", "name": "gaia_server.py"}, {"type": "file", "name": "sample_query.py"}]}]} | # gaia
Hugging Face and Pyserini interoperability
| {"requirements.txt": "datasets\ntorch\ntokenizers\npyserini\nfaiss-cpu\njupyterlab\nnltk\nipywidgets", ".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 547e84a5ec059f15dc163f35ee2ccb5d60f4c620 Hamza Amin <[email protected]> 1727369161 +0500\tclone: from https://github.com/huggingface/gaia.git\n", ".git\\refs\\heads\\main": "547e84a5ec059f15dc163f35ee2ccb5d60f4c620\n", "notebooks\\00-indexing.ipynb": "import os\nimport json\nimport pprint\n\nfrom tqdm.notebook import tqdm\n\nfrom pyserini.index.lucene import LuceneIndexer, IndexReader\nfrom pyserini.pyclass import autoclass\n\nfrom datasets import load_dataset, Dataset\nfrom datasets.utils.py_utils import convert_file_size_to_int\ndset = load_dataset(\"imdb\", split=\"train\")\ndset\ndset = dset.add_column(\"id\", [str(i) for i in range(len(dset))])\ndset = dset.rename_column(\"text\", \"contents\")\ndset = dset.select_columns([\"id\", \"contents\"])\ndset\npprint.pprint(dset[0])\nshard_dir = f\"../shards/imdb\"\nmax_shard_size = convert_file_size_to_int(\"10MB\")\ndataset_nbytes = dset.data.nbytes\nnum_shards = int(dataset_nbytes / max_shard_size) + 1\nnum_shards = max(num_shards, 1)\nprint(f\"Sharding into {num_shards} JSONL files.\")\nos.makedirs(shard_dir, exist_ok=True)\nfor shard_index in tqdm(range(num_shards)):\n shard = dset.shard(num_shards=num_shards, index=shard_index, contiguous=True)\n shard.to_json(\n f\"{shard_dir}/docs-{shard_index:03d}.jsonl\", orient=\"records\", lines=True\n )\nJIndexCollection = autoclass(\"io.anserini.index.IndexCollection\")\nindexing_args = [\n \"-input\",\n shard_dir,\n \"-index\",\n \"../indexes/imdb\",\n \"-collection\",\n \"JsonCollection\",\n \"-threads\",\n \"28\",\n \"-language\",\n \"en\",\n \"-storePositions\",\n \"-storeDocvectors\",\n \"-storeContents\",\n]\n%%time\nJIndexCollection.main(indexing_args)\ndset_streaming = load_dataset(\"imdb\", split=\"train\", streaming=True)\ndset_streaming\nstreaming_indexer = LuceneIndexer(\"../indexes/imdb-streaming\", threads=28)\n%%time\nfor i, row in tqdm(enumerate(dset_streaming)):\n streaming_indexer.add_doc_dict({\"contents\": row[\"text\"], \"id\": str(i)})\nstreaming_indexer.close()\ndset_streaming = load_dataset(\"imdb\", split=\"train\", streaming=True)\nbatched_streaming_indexer = LuceneIndexer(\n \"../indexes/imdb-streaming-batched\", threads=28\n)\n%%time\nbatch_size = 1000\nbatch = []\n\nfor i, row in tqdm(enumerate(dset_streaming)):\n batch.append({\"contents\": row[\"text\"], \"id\": str(i)})\n if len(batch) >= batch_size:\n batched_streaming_indexer.add_batch_dict(batch)\n batch = []\n\nif len(batch) >= batch_size:\n batched_streaming_indexer.add_batch_dict(batch)\n\nbatched_streaming_indexer.close()\n%%time\nstreaming_indexer = LuceneIndexer(\"../indexes/imdb-streaming\", threads=28)\nfor i, row in tqdm(enumerate(dset)):\n streaming_indexer.add_doc_dict(row)\nstreaming_indexer.close()\n%%time\nbatched_streaming_indexer = LuceneIndexer(\n \"../indexes/imdb-streaming-batched\", threads=28\n)\nbatch_size = 1000\nbatch = []\n\nfor i, row in tqdm(enumerate(dset)):\n batch.append(row)\n if len(batch) >= batch_size:\n batched_streaming_indexer.add_batch_dict(batch)\n batch = []\n\nif len(batch) >= batch_size:\n batched_streaming_indexer.add_batch_dict(batch)\n\nbatched_streaming_indexer.close()\n"} | null |
GameZone | {"type": "directory", "name": "GameZone", "children": [{"type": "directory", "name": "Number guessing game", "children": [{"type": "file", "name": "file2.py"}]}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "Tic tac toe", "children": [{"type": "file", "name": "file.py"}]}]} | # GameZone
A collection of games
| {".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 c6a26c6131249f54b727428e34606faaca9388f3 Hamza Amin <[email protected]> 1727376260 +0500\tclone: from https://github.com/hamza-amin-4365/GameZone.git\n", ".git\\refs\\heads\\main": "c6a26c6131249f54b727428e34606faaca9388f3\n"} | null |
gguf-jinja-analysis | {"type": "directory", "name": "gguf-jinja-analysis", "children": [{"type": "file", "name": "Cargo.lock"}, {"type": "file", "name": "Cargo.toml"}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "src", "children": [{"type": "file", "name": "main.rs"}]}]} | # `.gguf` chat template exploit analysis
### Overview
This analysis examines the vulnerability in GGUF models related to the [recently disclosed CVE](https://github.com/abetlen/llama-cpp-python/security/advisories/GHSA-56xg-wfcc-g829) affecting jinja2's template rendering mechanism in llama-cpp-python. The goal is to identify any dangerous implementations of this template in publicly available GGUF models.
### Background
Each GGUF model can include a chat template, which utilizes jinja2 templating to format the prompt. This template resides in the file's header metadata. A potential security risk arises when this template is not rendered in a sandboxed environment, leading to possible arbitrary code execution.
### Analysis Methodology
The analysis was conducted using a *blazingly fast* Rust script that retrieves and processes a large number of GGUF files. Specifically, the script emits an HTTP request with a RANGE header to fetch only the relevant bytes of the GGUF file, containing the header & the chat template.
Two evaluation methods were employed:
- Dynamic Analysis: Executing the chat template in a jinja2.sandbox.SandboxedEnvironment to observe its behavior.
- Static Analysis: Scanning the chat templates for suspicious strings collected from various sources on the web.
### Results
Out of over 116,000 GGUF models analyzed, only one dangerous model was identified: [@retr0reg](https://x.com/retr0reg)'s exploit. Approximately 70 models were flagged as suspicious during the static analysis, but further inspection revealed no additional threats. It is worth noting that about 40% of the models (approximately 46,000) included a chat template, highlighting the potential impact of this vulnerability.
### Recommendations
- Update llama-cpp-python to the latest version to address the disclosed CVE.
- Exercise caution when loading weights or models from unknown or untrusted sources.
| {".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 8e4ce84c981cba94d327398db8add7322b89ffdf Hamza Amin <[email protected]> 1727369164 +0500\tclone: from https://github.com/huggingface/gguf-jinja-analysis.git\n", ".git\\refs\\heads\\main": "8e4ce84c981cba94d327398db8add7322b89ffdf\n", "src\\main.rs": "use std::sync::Arc;\n\nuse anyhow::anyhow;\nuse bytes::{BufMut, BytesMut};\nuse futures::stream::FuturesUnordered;\nuse gguf::{GGUFHeader, GGUFMetadata, GGUFMetadataValue};\nuse indicatif::ProgressBar;\nuse pyo3::{\n types::{PyAnyMethods, PyTypeMethods},\n PyResult, Python,\n};\nuse reqwest::{\n header::{LINK, RANGE},\n IntoUrl, StatusCode,\n};\nuse serde::Deserialize;\nuse tokio::{sync::Semaphore, time::Instant};\nuse tracing::{debug, info, info_span, Instrument};\n\nconst DANGER_LIST: [&str; 6] = [\n \"__\",\n \"\\\\x5f\\\\x5f\",\n \"attr\",\n \"__class__\",\n \"__base__\",\n \"__subclasses__\",\n];\n// Default to 10 Mib\nconst HEADER_CHUNK_LENGTH: usize = 10_485_760;\nconst MAX_CONCURRENT_CHECKS: usize = 128;\nconst WARNING_THRESHOLD: usize = 104_857_600;\n\n#[derive(Deserialize)]\nstruct Sibling {\n rfilename: String,\n}\n\n#[derive(Deserialize)]\nstruct SiblingsList {\n _id: String,\n id: String,\n siblings: Vec<Sibling>,\n}\n\nenum StaticCheckStatus {\n Innocuous,\n Suspicious,\n}\n\nfn static_check(chat_template: &str) -> StaticCheckStatus {\n if DANGER_LIST.iter().any(|expr| chat_template.contains(expr)) {\n info!(\"potentially malicious chat template:\\n{chat_template}\");\n StaticCheckStatus::Suspicious\n } else {\n StaticCheckStatus::Innocuous\n }\n}\n\nfn get_key_value(key: &str, metadata: &[GGUFMetadata]) -> Option<(String, GGUFMetadataValue)> {\n for kv in metadata {\n if kv.key == key {\n return Some((kv.key.clone(), kv.value.clone()));\n }\n }\n\n None\n}\n\nstruct SecurityError(bool);\n\nasync fn run_jinja_template(chat_template: String) -> anyhow::Result<SecurityError> {\n tokio::task::spawn_blocking(|| {\n let py_res: PyResult<bool> = Python::with_gil(|py| {\n let jinja2_sandbox = py.import_bound(\"jinja2.sandbox\")?;\n let sandboxed_env = jinja2_sandbox.getattr(\"SandboxedEnvironment\")?.call0()?;\n let template = sandboxed_env.call_method1(\"from_string\", (chat_template,))?;\n let rendered = template.call_method1(\"render\", ());\n match rendered {\n Ok(_) => (),\n Err(err) => {\n let r#type = err.get_type_bound(py);\n if r#type.name()? == \"SecurityError\" {\n return Ok(true);\n }\n }\n }\n\n Ok(false)\n });\n\n Ok(SecurityError(py_res?))\n })\n .await?\n}\n\nasync fn build_repo_list(\n client: &reqwest::Client,\n url: impl IntoUrl,\n) -> anyhow::Result<Vec<SiblingsList>> {\n let mut response = client.get(url).send().await?.error_for_status()?;\n let mut siblings_list: Vec<SiblingsList> = vec![];\n loop {\n let next_link = response\n .headers()\n .get(LINK)\n .and_then(|v| v.to_str().ok())\n .and_then(|v| parse_link_header::parse(v).ok())\n .and_then(|mut links| links.remove(&Some(\"next\".to_owned())))\n .map(|link| link.uri.clone());\n\n siblings_list.extend(response.json::<Vec<SiblingsList>>().await?);\n if let Some(link) = next_link {\n response = client.get(link).send().await?.error_for_status()?;\n } else {\n break;\n }\n }\n\n Ok(siblings_list)\n}\n\nasync fn fetch_file_header(\n client: &reqwest::Client,\n url: impl IntoUrl,\n) -> anyhow::Result<Option<GGUFHeader>> {\n let mut bytes = BytesMut::with_capacity(HEADER_CHUNK_LENGTH);\n let range = format!(\"bytes=0-{HEADER_CHUNK_LENGTH}\");\n let url = url.into_url()?;\n let response = client\n .get(url.clone())\n .header(RANGE, range)\n .send()\n .await?\n .error_for_status()?;\n bytes.put(response.bytes().await?);\n let mut header = match GGUFHeader::read(&bytes).map_err(|e| anyhow!(e)) {\n Ok(header) => header,\n Err(err) => {\n debug!(\"failed to parse header: {err}\");\n return Ok(None);\n }\n };\n let mut start = HEADER_CHUNK_LENGTH + 1;\n let mut stop = start + HEADER_CHUNK_LENGTH;\n while header.is_none() {\n let range = format!(\"bytes={start}-{stop}\");\n let response = match client\n .get(url.clone())\n .header(RANGE, range)\n .send()\n .await?\n .error_for_status()\n {\n Ok(res) => res,\n Err(err) => {\n if err.status() == Some(StatusCode::RANGE_NOT_SATISFIABLE) {\n debug!(\"failed to parse header after downloading full file\");\n return Ok(None);\n } else {\n return Err(anyhow::Error::from(err));\n }\n }\n };\n bytes.put(response.bytes().await?);\n header = match GGUFHeader::read(&bytes).map_err(|e| anyhow!(e)) {\n Ok(header) => header,\n Err(err) => {\n debug!(\"failed to parse header: {err}\");\n return Ok(None);\n }\n };\n if stop > WARNING_THRESHOLD {\n debug!(\"downloaded over {WARNING_THRESHOLD} bytes for file, skipping\");\n return Ok(None);\n }\n start += stop + 1;\n stop += start + HEADER_CHUNK_LENGTH;\n }\n\n Ok(header)\n}\n\nstruct Stats {\n no_chat_template: bool,\n parse_header_failure: bool,\n security_error: bool,\n static_check_status: StaticCheckStatus,\n}\n\nimpl Stats {\n fn no_chat_template() -> Self {\n Self {\n no_chat_template: true,\n parse_header_failure: false,\n security_error: false,\n static_check_status: StaticCheckStatus::Innocuous,\n }\n }\n\n fn parse_header_failure() -> Self {\n Self {\n no_chat_template: false,\n parse_header_failure: true,\n security_error: false,\n static_check_status: StaticCheckStatus::Innocuous,\n }\n }\n\n fn verify_result(security_error: bool, static_check_status: StaticCheckStatus) -> Self {\n Self {\n no_chat_template: false,\n parse_header_failure: false,\n security_error,\n static_check_status,\n }\n }\n}\n\nasync fn verify_file(\n client: reqwest::Client,\n file: Sibling,\n repo_id: String,\n semaphore: Arc<Semaphore>,\n stats_collector_tx: tokio::sync::mpsc::Sender<Stats>,\n) -> anyhow::Result<()> {\n // let full_instant = Instant::now();\n let permit = semaphore.acquire_owned().await?;\n let url = format!(\n \"https://huggingface.co/{}/resolve/main/{}\",\n repo_id, file.rfilename\n );\n // let fetch_header_inst = Instant::now();\n let header = match fetch_file_header(&client, url).await? {\n Some(header) => header,\n None => {\n // info!(\n // \"fetch_header took: {}s\",\n // fetch_header_inst.elapsed().as_secs()\n // );\n stats_collector_tx\n .send(Stats::parse_header_failure())\n .await?;\n return Ok(());\n }\n };\n // info!(\n // \"fetch_header took: {}s\",\n // fetch_header_inst.elapsed().as_secs()\n // );\n let value = match get_key_value(\"tokenizer.chat_template\", &header.metadata) {\n Some((_, v)) => v,\n None => {\n stats_collector_tx.send(Stats::no_chat_template()).await?;\n return Ok(());\n }\n };\n if let GGUFMetadataValue::String(value) = value {\n // let static_check_inst = Instant::now();\n let static_check_status = static_check(&value);\n // info!(\n // \"static_check took: {}s\",\n // static_check_inst.elapsed().as_secs()\n // );\n // let run_jinja_inst = Instant::now();\n let security_error = run_jinja_template(value).await?.0;\n // info!(\n // \"run_jinja_template took: {}s\",\n // run_jinja_inst.elapsed().as_secs()\n // );\n if security_error {\n info!(\"Security Error was caught when running chat template\");\n }\n stats_collector_tx\n .send(Stats::verify_result(security_error, static_check_status))\n .await?;\n drop(permit);\n // info!(\"verify_file took: {}s\", full_instant.elapsed().as_secs());\n Ok(())\n } else {\n drop(permit);\n // info!(\"verify_file took: {}s\", full_instant.elapsed().as_secs());\n Err(anyhow!(\n \"invalid 'tokenizer.chat_template' value, got: {:?}\",\n value\n ))\n }\n}\n\nfn print_report(\n no_chat_template: usize,\n parse_header_failures: usize,\n sandbox_run_suspicious_files: usize,\n static_scan_suspicious_files: usize,\n current_total: u64,\n) {\n info!(\"{no_chat_template} out of {current_total} gguf files were missing a chat_template\");\n info!(\"failed to parse headers for {parse_header_failures} out of {current_total} gguf files\");\n info!(\"{sandbox_run_suspicious_files} out of {current_total} gguf files triggered a SecurityError in jinja2 sandbox environment\");\n info!(\"{static_scan_suspicious_files} out of {current_total} gguf files were flagged as suspicious by static scan\");\n\n info!(\"total # of processed files: {current_total}\");\n}\n\n#[tokio::main]\nasync fn main() -> anyhow::Result<()> {\n let builder = tracing_subscriber::fmt()\n .with_target(true)\n .with_line_number(true);\n\n builder\n // .json()\n // .flatten_event(true)\n // .with_current_span(false)\n // .with_span_list(true)\n .init();\n\n let client = reqwest::Client::new();\n let repo_list_url = \"https://huggingface.co/api/models?filter=gguf&expand[]=siblings\";\n\n let instant = Instant::now();\n let repos_list = build_repo_list(&client, repo_list_url).await?;\n info!(\"build repo list in {}s\", instant.elapsed().as_secs());\n\n info!(\"repos_list len: {}\", repos_list.len());\n\n let (stats_collector_tx, mut stats_collector_rx) = tokio::sync::mpsc::channel(512);\n let mut total_gguf_files = 0;\n let semaphore = Arc::new(Semaphore::new(MAX_CONCURRENT_CHECKS));\n let handles = FuturesUnordered::new();\n for repo in repos_list {\n for file in repo.siblings {\n if file.rfilename.ends_with(\".gguf\") {\n total_gguf_files += 1;\n\n let span = info_span!(\n \"file verification\",\n repo_id = repo.id,\n revision = \"main\",\n filename = file.rfilename\n );\n let client = client.clone();\n let repo_id = repo.id.clone();\n let semaphore = semaphore.clone();\n let stats_collector_tx = stats_collector_tx.clone();\n handles.push(tokio::spawn(\n verify_file(client, file, repo_id, semaphore, stats_collector_tx)\n .instrument(span),\n ));\n }\n }\n }\n\n drop(stats_collector_tx);\n let mut no_chat_template = 0;\n let mut parse_header_failures = 0;\n let mut sandbox_run_suspicious_files = 0;\n let mut static_scan_suspicious_files = 0;\n let bar = ProgressBar::new(total_gguf_files);\n let mut done_scans = 0;\n let ten_percent = total_gguf_files / 10;\n let mut display_stats_thresh = ten_percent;\n while let Some(stats) = stats_collector_rx.recv().await {\n if stats.no_chat_template {\n no_chat_template += 1;\n }\n if stats.parse_header_failure {\n parse_header_failures += 1;\n }\n if stats.security_error {\n sandbox_run_suspicious_files += 1;\n }\n if matches!(stats.static_check_status, StaticCheckStatus::Suspicious) {\n static_scan_suspicious_files += 1;\n }\n done_scans += 1;\n bar.inc(1);\n if done_scans >= display_stats_thresh {\n print_report(\n no_chat_template,\n parse_header_failures,\n sandbox_run_suspicious_files,\n static_scan_suspicious_files,\n total_gguf_files,\n );\n display_stats_thresh += ten_percent;\n }\n }\n\n futures::future::join_all(handles)\n .await\n .into_iter()\n .flatten()\n .collect::<anyhow::Result<()>>()?;\n\n Ok(())\n}\n\n#[cfg(test)]\nmod tests {\n use super::*;\n\n #[tokio::test]\n async fn test_static_malicious() {\n let chat_template = r#\"{% for x in ().__class__.__base__.__subclasses__() %}{% if \"warning\" in x.__name__ %}{{x()._module.__builtins__['__import__']('os').popen(\"touch /tmp/retr0reg\")}}{%endif%}{% endfor %}\"#;\n assert!(matches!(\n static_check(chat_template),\n StaticCheckStatus::Suspicious\n ));\n }\n\n #[tokio::test]\n async fn test_sandbox_malicious() {\n let chat_template = r#\"{% for x in ().__class__.__base__.__subclasses__() %}{% if \"warning\" in x.__name__ %}{{x()._module.__builtins__['__import__']('os').popen(\"touch /tmp/retr0reg\")}}{%endif%}{% endfor %}\"#;\n assert!(matches!(\n run_jinja_template(chat_template.to_owned()).await,\n Ok(SecurityError(true))\n ));\n }\n\n // XXX: this test does not assert anything because [`verify_file`]'s return type is `()`\n // #[tokio::test]\n // async fn test_known_repo() -> anyhow::Result<()> {\n // let client = reqwest::Client::new();\n // let file = Sibling {\n // rfilename: \"retr0reg.gguf\".to_owned(),\n // };\n // let repo_id = String::from(\"Retr0REG/Whats-up-gguf\");\n // let semaphore = Arc::new(Semaphore::new(1));\n // assert!(matches!(\n // verify_file(client, file, repo_id, semaphore).await?,\n // ()\n // ));\n //\n // Ok(())\n // }\n}\n"} | null |
gsplat.js | {"type": "directory", "name": "gsplat.js", "children": [{"type": "file", "name": ".eslintrc.json"}, {"type": "file", "name": ".prettierrc"}, {"type": "file", "name": "compile_wasm.sh"}, {"type": "directory", "name": "examples", "children": [{"type": "directory", "name": "4d", "children": [{"type": "file", "name": "index.html"}, {"type": "file", "name": "package-lock.json"}, {"type": "file", "name": "package.json"}, {"type": "directory", "name": "src", "children": [{"type": "file", "name": "main.ts"}, {"type": "file", "name": "vite-env.d.ts"}]}, {"type": "file", "name": "style.css"}, {"type": "file", "name": "tsconfig.json"}]}, {"type": "directory", "name": "camera-updates", "children": [{"type": "file", "name": "index.html"}, {"type": "file", "name": "package-lock.json"}, {"type": "file", "name": "package.json"}, {"type": "directory", "name": "src", "children": [{"type": "file", "name": "main.ts"}, {"type": "file", "name": "vite-env.d.ts"}]}, {"type": "file", "name": "style.css"}, {"type": "file", "name": "tsconfig.json"}]}, {"type": "directory", "name": "editor", "children": [{"type": "file", "name": "index.html"}, {"type": "file", "name": "package-lock.json"}, {"type": "file", "name": "package.json"}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "src", "children": [{"type": "file", "name": "Action.ts"}, {"type": "file", "name": "Controls.ts"}, {"type": "file", "name": "DefaultMode.ts"}, {"type": "file", "name": "Engine.ts"}, {"type": "file", "name": "GrabMode.ts"}, {"type": "file", "name": "InputHandler.ts"}, {"type": "file", "name": "InputMode.ts"}, {"type": "file", "name": "KeyboardManager.ts"}, {"type": "file", "name": "main.ts"}, {"type": "file", "name": "ModeManager.ts"}, {"type": "file", "name": "MouseManager.ts"}, {"type": "file", "name": "MoveAction.ts"}, {"type": "file", "name": "OrbitControls.ts"}, {"type": "directory", "name": "programs", "children": [{"type": "file", "name": "AxisProgram.ts"}, {"type": "file", "name": "GridProgram.ts"}]}, {"type": "file", "name": "RotateAction.ts"}, {"type": "file", "name": "RotateMode.ts"}, {"type": "file", "name": "ScaleAction.ts"}, {"type": "file", "name": "ScaleMode.ts"}, {"type": "file", "name": "SelectionManager.ts"}, {"type": "file", "name": "UndoManager.ts"}, {"type": "file", "name": "vite-env.d.ts"}]}, {"type": "file", "name": "style.css"}, {"type": "file", "name": "tsconfig.json"}]}, {"type": "directory", "name": "file-loader", "children": [{"type": "file", "name": "index.html"}, {"type": "file", "name": "package-lock.json"}, {"type": "file", "name": "package.json"}, {"type": "directory", "name": "src", "children": [{"type": "file", "name": "main.ts"}, {"type": "file", "name": "vite-env.d.ts"}]}, {"type": "file", "name": "tsconfig.json"}]}, {"type": "directory", "name": "fps", "children": [{"type": "file", "name": "index.html"}, {"type": "file", "name": "package-lock.json"}, {"type": "file", "name": "package.json"}, {"type": "directory", "name": "src", "children": [{"type": "file", "name": "main.ts"}, {"type": "file", "name": "vite-env.d.ts"}]}, {"type": "file", "name": "style.css"}, {"type": "file", "name": "tsconfig.json"}]}, {"type": "directory", "name": "ply-converter", "children": [{"type": "file", "name": "index.html"}, {"type": "file", "name": "package-lock.json"}, {"type": "file", "name": "package.json"}, {"type": "directory", "name": "src", "children": [{"type": "file", "name": "main.ts"}, {"type": "file", "name": "vite-env.d.ts"}]}, {"type": "file", "name": "style.css"}, {"type": "file", "name": "tsconfig.json"}]}, {"type": "directory", "name": "scene-transformations", "children": [{"type": "file", "name": "index.html"}, {"type": "file", "name": "package-lock.json"}, {"type": "file", "name": "package.json"}, {"type": "directory", "name": "src", "children": [{"type": "file", "name": "main.ts"}, {"type": "file", "name": "vite-env.d.ts"}]}, {"type": "file", "name": "style.css"}, {"type": "file", "name": "tsconfig.json"}]}, {"type": "directory", "name": "simple-server", "children": [{"type": "file", "name": "index.html"}, {"type": "file", "name": "package-lock.json"}, {"type": "file", "name": "package.json"}, {"type": "directory", "name": "src", "children": [{"type": "file", "name": "main.ts"}, {"type": "file", "name": "vite-env.d.ts"}]}, {"type": "file", "name": "style.css"}, {"type": "file", "name": "tsconfig.json"}]}, {"type": "directory", "name": "vanilla-js", "children": [{"type": "file", "name": "index.html"}, {"type": "file", "name": "index.js"}, {"type": "file", "name": "style.css"}]}]}, {"type": "file", "name": "jest.config.js"}, {"type": "file", "name": "LICENSE"}, {"type": "file", "name": "package-lock.json"}, {"type": "file", "name": "package.json"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "rollup.config.js"}, {"type": "directory", "name": "src", "children": [{"type": "directory", "name": "cameras", "children": [{"type": "file", "name": "Camera.ts"}, {"type": "file", "name": "CameraData.ts"}]}, {"type": "directory", "name": "controls", "children": [{"type": "file", "name": "FPSControls.ts"}, {"type": "file", "name": "OrbitControls.ts"}]}, {"type": "directory", "name": "core", "children": [{"type": "file", "name": "Object3D.ts"}, {"type": "file", "name": "Scene.ts"}]}, {"type": "file", "name": "custom.d.ts"}, {"type": "directory", "name": "events", "children": [{"type": "file", "name": "EventDispatcher.ts"}, {"type": "file", "name": "Events.ts"}]}, {"type": "file", "name": "index.ts"}, {"type": "directory", "name": "loaders", "children": [{"type": "file", "name": "Loader.ts"}, {"type": "file", "name": "PLYLoader.ts"}, {"type": "file", "name": "SplatvLoader.ts"}]}, {"type": "directory", "name": "math", "children": [{"type": "file", "name": "Box3.ts"}, {"type": "file", "name": "BVH.ts"}, {"type": "file", "name": "Color32.ts"}, {"type": "file", "name": "Matrix3.ts"}, {"type": "file", "name": "Matrix4.ts"}, {"type": "file", "name": "Plane.ts"}, {"type": "file", "name": "Quaternion.ts"}, {"type": "file", "name": "Vector3.ts"}, {"type": "file", "name": "Vector4.ts"}]}, {"type": "directory", "name": "renderers", "children": [{"type": "directory", "name": "webgl", "children": [{"type": "directory", "name": "passes", "children": [{"type": "file", "name": "FadeInPass.ts"}, {"type": "file", "name": "ShaderPass.ts"}]}, {"type": "directory", "name": "programs", "children": [{"type": "file", "name": "RenderProgram.ts"}, {"type": "file", "name": "ShaderProgram.ts"}, {"type": "file", "name": "VideoRenderProgram.ts"}]}, {"type": "directory", "name": "utils", "children": [{"type": "file", "name": "DataWorker.ts"}, {"type": "file", "name": "IntersectionTester.ts"}, {"type": "file", "name": "RenderData.ts"}, {"type": "file", "name": "SortWorker.ts"}]}]}, {"type": "file", "name": "WebGLRenderer.ts"}]}, {"type": "directory", "name": "splats", "children": [{"type": "file", "name": "Splat.ts"}, {"type": "file", "name": "SplatData.ts"}, {"type": "file", "name": "Splatv.ts"}, {"type": "file", "name": "SplatvData.ts"}]}, {"type": "directory", "name": "utils", "children": [{"type": "file", "name": "Converter.ts"}, {"type": "file", "name": "LoaderUtils.ts"}]}, {"type": "directory", "name": "wasm", "children": [{"type": "file", "name": "data.d.ts"}, {"type": "file", "name": "data.js"}, {"type": "file", "name": "sort.d.ts"}, {"type": "file", "name": "sort.js"}]}]}, {"type": "file", "name": "tsconfig.json"}, {"type": "directory", "name": "wasm", "children": [{"type": "file", "name": "data.cpp"}, {"type": "file", "name": "sort.cpp"}]}]} | # gsplat.js editor
This simple editor showcases the realtime editing capabilities of gsplat.js.
## Usage
- Import gaussian splatting objects from a file (`.ply` or `.splat`) by dragging and dropping them into the editor window.
- Download splats as a `.splat` file by clicking the download button in the top right corner.s
- If an object is selected, only that object will be downloaded. Otherwise, all objects will be combined and downloaded.
- Use the controls below to edit the splats.
## Controls
### Camera
- `Middle Mouse` - Orbit camera
- `Shift + Middle Mouse` - Pan camera
- `Scroll Wheel` - Zoom camera
### Editing
- `Left Mouse` - Select an object / confirm action
- `Right Mouse` - Cancel action
- `G` - Grab selected object
- `R` - Rotate selected object
- `S` - Scale selected object
- `X` - Delete selected object / lock to X axis
- `Y` - Lock to Y axis
- `Z` - Lock to Z axis
| {"package.json": "{\n \"name\": \"gsplat\",\n \"version\": \"1.2.4\",\n \"description\": \"JavaScript Gaussian Splatting library\",\n \"main\": \"dist/index.js\",\n \"types\": \"dist/index.d.ts\",\n \"type\": \"module\",\n \"scripts\": {\n \"build:wasm\": \"sh ./compile_wasm.sh\",\n \"copy:wasm\": \"ncp ./src/wasm ./dist/wasm\",\n \"build\": \"npm run build:wasm && rollup -c && npm run copy:wasm\",\n \"test\": \"jest --passWithNoTests\",\n \"lint\": \"eslint \\\"src/**/*.ts\\\" \\\"examples/**/*.ts\\\"\",\n \"format\": \"prettier --write \\\"src/**/*.ts\\\" \\\"examples/**/*.ts\\\"\"\n },\n \"repository\": {\n \"type\": \"git\",\n \"url\": \"git+https://github.com/dylanebert/splat.js.git\"\n },\n \"keywords\": [\n \"gsplat\",\n \"gaussian splatting\",\n \"javascript\",\n \"3d\",\n \"webgl\"\n ],\n \"author\": \"dylanebert\",\n \"license\": \"MIT\",\n \"bugs\": {\n \"url\": \"https://github.com/dylanebert/splat.js/issues\"\n },\n \"homepage\": \"https://github.com/dylanebert/splat.js#readme\",\n \"devDependencies\": {\n \"@jest/globals\": \"^29.7.0\",\n \"@rollup/plugin-commonjs\": \"^25.0.7\",\n \"@rollup/plugin-node-resolve\": \"^15.2.3\",\n \"@rollup/plugin-replace\": \"^5.0.5\",\n \"@rollup/plugin-terser\": \"^0.4.4\",\n \"@rollup/plugin-typescript\": \"^11.1.5\",\n \"@types/jest\": \"^29.5.8\",\n \"@types/node\": \"^20.8.10\",\n \"@typescript-eslint/eslint-plugin\": \"^6.9.1\",\n \"@typescript-eslint/parser\": \"^6.9.1\",\n \"eslint\": \"^8.52.0\",\n \"eslint-config-prettier\": \"^9.0.0\",\n \"eslint-plugin-prettier\": \"^5.0.1\",\n \"jest\": \"^29.7.0\",\n \"ncp\": \"^2.0.0\",\n \"prettier\": \"^3.0.3\",\n \"rollup\": \"^4.3.0\",\n \"rollup-plugin-web-worker-loader\": \"^1.6.1\",\n \"ts-jest\": \"^29.1.1\",\n \"typescript\": \"^5.2.2\"\n },\n \"files\": [\n \"dist/**/*\"\n ]\n}\n", ".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 d6df8ec0b8ac3683438cb99fec308e56ca7b14a9 Hamza Amin <[email protected]> 1727369247 +0500\tclone: from https://github.com/huggingface/gsplat.js.git\n", ".git\\refs\\heads\\main": "d6df8ec0b8ac3683438cb99fec308e56ca7b14a9\n", "examples\\4d\\index.html": "<!doctype html>\n<html lang=\"en\">\n <head>\n <meta charset=\"UTF-8\" />\n <link rel=\"stylesheet\" href=\"style.css\" />\n <meta name=\"viewport\" content=\"width=device-width, initial-scale=1.0\" />\n <title>gsplat.js - Viewer Demo</title>\n </head>\n <body>\n <div id=\"progress-container\">\n <dialog open id=\"progress-dialog\">\n <p>\n <label for=\"progress-indicator\">Loading scene...</label>\n </p>\n <progress max=\"100\" id=\"progress-indicator\"></progress>\n </dialog>\n </div>\n\n <canvas id=\"canvas\"></canvas>\n <script type=\"module\" src=\"/src/main.ts\"></script>\n </body>\n</html>\n", "examples\\4d\\package.json": "{\n \"name\": \"simple-server\",\n \"private\": true,\n \"version\": \"0.0.0\",\n \"type\": \"module\",\n \"scripts\": {\n \"dev\": \"vite\",\n \"build\": \"tsc && vite build\",\n \"preview\": \"vite preview\"\n },\n \"devDependencies\": {\n \"typescript\": \"^5.0.2\",\n \"vite\": \"^4.4.5\"\n }\n}\n", "examples\\4d\\src\\main.ts": "import * as SPLAT from \"gsplat\";\n\nconst canvas = document.getElementById(\"canvas\") as HTMLCanvasElement;\nconst progressDialog = document.getElementById(\"progress-dialog\") as HTMLDialogElement;\nconst progressIndicator = document.getElementById(\"progress-indicator\") as HTMLProgressElement;\n\nconst renderer = new SPLAT.WebGLRenderer(canvas);\nrenderer.addProgram(new SPLAT.VideoRenderProgram(renderer));\n\nconst scene = new SPLAT.Scene();\nconst camera = new SPLAT.Camera();\nconst controls = new SPLAT.OrbitControls(camera, canvas);\n\nlet loading = false;\n\nasync function selectFile(file: File) {\n if (loading) return;\n loading = true;\n // Check if .splatv file\n if (file.name.endsWith(\".splatv\")) {\n scene.reset();\n progressDialog.showModal();\n await SPLAT.SplatvLoader.LoadFromFileAsync(file, scene, camera, (progress: number) => {\n progressIndicator.value = progress * 100;\n });\n progressDialog.close();\n }\n loading = false;\n}\n\nasync function main() {\n const url = \"https://huggingface.co/datasets/dylanebert/3dgs/resolve/main/4d/flame/flame.splatv\";\n await SPLAT.SplatvLoader.LoadAsync(url, scene, camera, (progress) => (progressIndicator.value = progress * 100));\n controls.setCameraTarget(camera.position.add(camera.forward.multiply(5)));\n progressDialog.close();\n\n const handleResize = () => {\n renderer.setSize(canvas.clientWidth, canvas.clientHeight);\n };\n\n const frame = () => {\n controls.update();\n renderer.render(scene, camera);\n\n requestAnimationFrame(frame);\n };\n\n handleResize();\n window.addEventListener(\"resize\", handleResize);\n\n requestAnimationFrame(frame);\n\n // Listen for file drops\n document.addEventListener(\"drop\", (e) => {\n e.preventDefault();\n e.stopPropagation();\n\n if (e.dataTransfer != null) {\n scene.reset();\n selectFile(e.dataTransfer.files[0]);\n }\n });\n}\n\nmain();\n", "examples\\camera-updates\\index.html": "<!doctype html>\n<html lang=\"en\">\n <head>\n <meta charset=\"UTF-8\" />\n <link rel=\"stylesheet\" href=\"style.css\" />\n <meta name=\"viewport\" content=\"width=device-width, initial-scale=1.0\" />\n <title>gsplat.js - Camera Updates</title>\n </head>\n <body>\n <div id=\"progress-container\">\n <dialog open id=\"progress-dialog\">\n <p>\n <label for=\"progress-indicator\">Loading scene...</label>\n </p>\n <progress max=\"100\" id=\"progress-indicator\"></progress>\n </dialog>\n </div>\n\n <canvas id=\"canvas\"></canvas>\n <script type=\"module\" src=\"/src/main.ts\"></script>\n </body>\n</html>\n", "examples\\camera-updates\\package.json": "{\n \"name\": \"camera-updates\",\n \"private\": true,\n \"version\": \"0.0.0\",\n \"type\": \"module\",\n \"scripts\": {\n \"dev\": \"vite\",\n \"build\": \"tsc && vite build\",\n \"preview\": \"vite preview\"\n },\n \"devDependencies\": {\n \"typescript\": \"^5.0.2\",\n \"vite\": \"^4.4.5\"\n },\n \"dependencies\": {\n \"gsplat\": \"^0.2.4\"\n }\n}\n", "examples\\camera-updates\\src\\main.ts": "import * as SPLAT from \"gsplat\";\n\nconst canvas = document.getElementById(\"canvas\") as HTMLCanvasElement;\nconst progressDialog = document.getElementById(\"progress-dialog\") as HTMLDialogElement;\nconst progressIndicator = document.getElementById(\"progress-indicator\") as HTMLProgressElement;\n\nconst renderer = new SPLAT.WebGLRenderer(canvas);\nconst scene = new SPLAT.Scene();\nconst camera = new SPLAT.Camera();\nconst controls = new SPLAT.OrbitControls(camera, canvas);\n\nasync function main() {\n const url = \"https://huggingface.co/datasets/dylanebert/3dgs/resolve/main/bonsai/bonsai-7k.splat\";\n await SPLAT.Loader.LoadAsync(url, scene, (progress) => (progressIndicator.value = progress * 100));\n progressDialog.close();\n\n const handleResize = () => {\n renderer.setSize(canvas.clientWidth, canvas.clientHeight);\n };\n\n const frame = () => {\n controls.update();\n renderer.render(scene, camera);\n\n requestAnimationFrame(frame);\n };\n\n const onKeyDown = (event: KeyboardEvent) => {\n // Use i, j, k, l to move the camera around\n let translation = new SPLAT.Vector3();\n if (event.key === \"j\") {\n translation = translation.add(new SPLAT.Vector3(-1, 0, 0));\n }\n if (event.key === \"l\") {\n translation = translation.add(new SPLAT.Vector3(1, 0, 0));\n }\n if (event.key === \"i\") {\n translation = translation.add(new SPLAT.Vector3(0, 0, 1));\n }\n if (event.key === \"k\") {\n translation = translation.add(new SPLAT.Vector3(0, 0, -1));\n }\n camera.position = camera.position.add(translation);\n\n // Use u to set a random look target near the origin\n if (event.key === \"u\") {\n const target = new SPLAT.Vector3(Math.random() - 0.5, Math.random() - 0.5, Math.random() - 0.5);\n controls.setCameraTarget(target);\n }\n\n // Use space to reset the camera\n if (event.key === \" \") {\n camera.position = new SPLAT.Vector3();\n camera.rotation = new SPLAT.Quaternion();\n }\n };\n\n handleResize();\n window.addEventListener(\"resize\", handleResize);\n window.addEventListener(\"keydown\", onKeyDown);\n\n requestAnimationFrame(frame);\n}\n\nmain();\n", "examples\\editor\\index.html": "<!DOCTYPE html>\n<html lang=\"en\">\n <head>\n <meta charset=\"UTF-8\" />\n <link rel=\"stylesheet\" href=\"style.css\" />\n <link rel=\"stylesheet\" href=\"https://cdnjs.cloudflare.com/ajax/libs/font-awesome/5.15.4/css/all.min.css\" />\n <meta name=\"viewport\" content=\"width=device-width, initial-scale=1.0\" />\n <title>gsplat.js - Editor Demo</title>\n </head>\n <body>\n <div id=\"progress-container\">\n <dialog open id=\"progress-dialog\">\n <p>\n <label for=\"progress-indicator\">Loading scene...</label>\n </p>\n <progress max=\"100\" id=\"progress-indicator\"></progress>\n </dialog>\n </div>\n\n <button id=\"upload-button\" class=\"tool-button\" title=\"Import Splat\">\n <svg xmlns=\"http://www.w3.org/2000/svg\" width=\"18\" height=\"18\" viewBox=\"0 0 32 32\">\n <path fill=\"#ddd\" d=\"M28 19H14.83l2.58-2.59L16 15l-5 5l5 5l1.41-1.41L14.83 21H28z\" />\n <path\n fill=\"#ddd\"\n d=\"M24 14v-4a1 1 0 0 0-.29-.71l-7-7A1 1 0 0 0 16 2H6a2 2 0 0 0-2 2v24a2 2 0 0 0 2 2h16a2 2 0 0 0 2-2v-2h-2v2H6V4h8v6a2 2 0 0 0 2 2h6v2Zm-8-4V4.41L21.59 10Z\"\n />\n </svg>\n </button>\n\n <div id=\"upload-modal\" class=\"modal\">\n <div class=\"modal-content\">\n <span id=\"upload-modal-close\" class=\"close\">×</span>\n <p>Import Splat</p>\n <hr class=\"divider\" />\n <div class=\"modal-section\">\n <p>Upload a file</p>\n <input type=\"file\" id=\"file-input\" accept=\".splat,.ply\" />\n <label for=\"file-input\" id=\"file-input-label\">Choose File</label>\n </div>\n <div class=\"modal-section\">\n <p>Or enter a URL</p>\n <input\n type=\"text\"\n id=\"url-input\"\n placeholder=\"https://huggingface.co/datasets/dylanebert/3dgs/resolve/main/bonsai/bonsai-7k-mini.splat\"\n />\n <button id=\"upload-submit\" class=\"submit\">Import</button>\n </div>\n <div class=\"modal-section\">\n <p id=\"upload-error\"></p>\n </div>\n </div>\n </div>\n\n <div id=\"download-modal\" class=\"modal\">\n <div class=\"modal-content\">\n <span id=\"download-modal-close\" class=\"close\">×</span>\n <p>Export Splat</p>\n <hr class=\"divider\" />\n <div class=\"modal-section\">\n <div id=\"format-select\">\n <p>Select format</p>\n <div>\n <input type=\"radio\" id=\"splat\" name=\"format\" value=\"splat\" checked />\n <label for=\"splat\">.splat</label>\n </div>\n <div>\n <input type=\"radio\" id=\"ply\" name=\"format\" value=\"ply\" />\n <label for=\"ply\">.ply</label>\n </div>\n </div>\n </div>\n <div class=\"modal-section\">\n <button id=\"download-submit\" class=\"submit\">Export</button>\n </div>\n </div>\n </div>\n\n <button id=\"download-button\" class=\"tool-button\" title=\"Export Splat\">\n <svg xmlns=\"http://www.w3.org/2000/svg\" width=\"18\" height=\"18\" viewBox=\"0 0 32 32\">\n <path\n fill=\"#ddd\"\n d=\"M26 24v4H6v-4H4v4a2 2 0 0 0 2 2h20a2 2 0 0 0 2-2v-4zm0-10l-1.41-1.41L17 20.17V2h-2v18.17l-7.59-7.58L6 14l10 10z\"\n />\n </svg>\n </button>\n\n <button id=\"controls-display-button\" class=\"tool-button active\" title=\"Show/Hide Controls\">\n <svg xmlns=\"http://www.w3.org/2000/svg\" width=\"18\" height=\"18\" viewBox=\"0 0 32 32\">\n <path\n fill=\"#ddd\"\n d=\"M16 2a14 14 0 1 0 14 14A14 14 0 0 0 16 2m0 26a12 12 0 1 1 12-12a12 12 0 0 1-12 12\"\n />\n <circle cx=\"16\" cy=\"23.5\" r=\"1.5\" fill=\"#ddd\" />\n <path\n fill=\"#ddd\"\n d=\"M17 8h-1.5a4.49 4.49 0 0 0-4.5 4.5v.5h2v-.5a2.5 2.5 0 0 1 2.5-2.5H17a2.5 2.5 0 0 1 0 5h-2v4.5h2V17a4.5 4.5 0 0 0 0-9\"\n />\n </svg>\n </button>\n\n <div id=\"controls-display\" class=\"active\">\n <p>Controls</p>\n <hr class=\"divider\" />\n <p>Camera</p>\n <div class=\"control-item\">\n <p class=\"control-name\">Orbit</p>\n <p class=\"control-icon\">MMB / Alt + LMB</p>\n </div>\n <div class=\"control-item\">\n <p class=\"control-name\">Pan</p>\n <p class=\"control-icon\">Shift + MMB / Alt + RMB</p>\n </div>\n <div class=\"control-item\">\n <p class=\"control-name\">Zoom</p>\n <p class=\"control-icon\">Scroll</p>\n </div>\n <hr class=\"divider\" />\n <p>Actions</p>\n <div class=\"control-item\">\n <p class=\"control-name\">Select</p>\n <p class=\"control-icon\">LMB</p>\n </div>\n <div class=\"control-item\">\n <p class=\"control-name\">Grab</p>\n <p class=\"control-icon\">G</p>\n </div>\n <div class=\"control-item\">\n <p class=\"control-name\">Rotate</p>\n <p class=\"control-icon\">R</p>\n </div>\n <div class=\"control-item\">\n <p class=\"control-name\">Scale</p>\n <p class=\"control-icon\">S</p>\n </div>\n <div class=\"control-item\">\n <p class=\"control-name\">Delete</p>\n <p class=\"control-icon\">X</p>\n </div>\n <hr class=\"divider\" />\n <p>During Action</p>\n <div class=\"control-item\">\n <p class=\"control-name\">Confirm Action</p>\n <p class=\"control-icon\">LMB</p>\n </div>\n <div class=\"control-item\">\n <p class=\"control-name\">Cancel Action</p>\n <p class=\"control-icon\">RMB</p>\n </div>\n <div class=\"control-item\">\n <p class=\"control-name\">Lock X Axis</p>\n <p class=\"control-icon\">X</p>\n </div>\n <div class=\"control-item\">\n <p class=\"control-name\">Lock Y Axis</p>\n <p class=\"control-icon\">Y</p>\n </div>\n <div class=\"control-item\">\n <p class=\"control-name\">Lock Z Axis</p>\n <p class=\"control-icon\">Z</p>\n </div>\n <hr class=\"divider\" />\n <div class=\"control-item\">\n <p class=\"control-name\">Undo</p>\n <p class=\"control-icon\">Ctrl + Z</p>\n </div>\n <div id=\"about\">Click here to learn more</div>\n </div>\n\n <canvas id=\"canvas\"> </canvas>\n <script type=\"module\" src=\"/src/main.ts\"></script>\n </body>\n</html>\n", "examples\\editor\\package.json": "{\n \"name\": \"editor\",\n \"private\": true,\n \"version\": \"0.0.0\",\n \"type\": \"module\",\n \"scripts\": {\n \"dev\": \"vite\",\n \"build\": \"tsc && vite build\",\n \"preview\": \"vite preview\",\n \"start\": \"serve dist\"\n },\n \"devDependencies\": {\n \"serve\": \"^14.2.1\",\n \"typescript\": \"^5.2.2\",\n \"vite\": \"^5.0.0\"\n },\n \"dependencies\": {\n \"gsplat\": \"^1.0.6\"\n }\n}\n", "examples\\editor\\src\\main.ts": "import * as SPLAT from \"gsplat\";\nimport { Engine } from \"./Engine\";\nimport { SelectionManager } from \"./SelectionManager\";\n\nconst canvas = document.getElementById(\"canvas\") as HTMLCanvasElement;\nconst progressDialog = document.getElementById(\"progress-dialog\") as HTMLDialogElement;\nconst progressIndicator = document.getElementById(\"progress-indicator\") as HTMLProgressElement;\nconst uploadButton = document.getElementById(\"upload-button\") as HTMLButtonElement;\nconst downloadButton = document.getElementById(\"download-button\") as HTMLButtonElement;\nconst controlsDisplayButton = document.getElementById(\"controls-display-button\") as HTMLButtonElement;\nconst controlsDisplay = document.getElementById(\"controls-display\") as HTMLDivElement;\nconst uploadModal = document.getElementById(\"upload-modal\") as HTMLDialogElement;\nconst uploadModalClose = document.getElementById(\"upload-modal-close\") as HTMLButtonElement;\nconst downloadModal = document.getElementById(\"download-modal\") as HTMLDialogElement;\nconst downloadModalClose = document.getElementById(\"download-modal-close\") as HTMLButtonElement;\nconst fileInput = document.getElementById(\"file-input\") as HTMLInputElement;\nconst urlInput = document.getElementById(\"url-input\") as HTMLInputElement;\nconst uploadSubmit = document.getElementById(\"upload-submit\") as HTMLButtonElement;\nconst uploadError = document.getElementById(\"upload-error\") as HTMLDivElement;\nconst downloadSubmit = document.getElementById(\"download-submit\") as HTMLButtonElement;\nconst learnMoreButton = document.getElementById(\"about\") as HTMLButtonElement;\nconst splatRadio = document.getElementById(\"splat\") as HTMLInputElement;\nconst plyRadio = document.getElementById(\"ply\") as HTMLInputElement;\n\nconst engine = new Engine(canvas);\n\nlet loading = false;\nasync function selectFile(file: File) {\n if (loading) return;\n SelectionManager.selectedSplat = null;\n loading = true;\n if (file.name.endsWith(\".splat\")) {\n uploadModal.style.display = \"none\";\n progressDialog.showModal();\n await SPLAT.Loader.LoadFromFileAsync(file, engine.scene, (progress: number) => {\n progressIndicator.value = progress * 100;\n });\n progressDialog.close();\n } else if (file.name.endsWith(\".ply\")) {\n const format = \"\";\n // const format = \"polycam\"; // Uncomment to load a Polycam PLY file\n uploadModal.style.display = \"none\";\n progressDialog.showModal();\n await SPLAT.PLYLoader.LoadFromFileAsync(\n file,\n engine.scene,\n (progress: number) => {\n progressIndicator.value = progress * 100;\n },\n format,\n );\n progressDialog.close();\n } else {\n uploadError.style.display = \"block\";\n uploadError.innerText = `Invalid file type: ${file.name}`;\n }\n loading = false;\n}\n\nasync function main() {\n const url = \"https://huggingface.co/datasets/dylanebert/3dgs/resolve/main/bonsai/bonsai-7k-mini.splat\";\n await SPLAT.Loader.LoadAsync(url, engine.scene, (progress) => (progressIndicator.value = progress * 100));\n progressDialog.close();\n engine.renderer.backgroundColor = new SPLAT.Color32(64, 64, 64, 255);\n\n const handleResize = () => {\n engine.renderer.setSize(canvas.clientWidth, canvas.clientHeight);\n };\n\n const frame = () => {\n engine.update();\n\n requestAnimationFrame(frame);\n };\n\n handleResize();\n window.addEventListener(\"resize\", handleResize);\n\n requestAnimationFrame(frame);\n\n document.addEventListener(\"drop\", (e) => {\n e.preventDefault();\n e.stopPropagation();\n\n if (e.dataTransfer != null) {\n selectFile(e.dataTransfer.files[0]);\n }\n });\n\n uploadButton.addEventListener(\"click\", () => {\n uploadModal.style.display = \"block\";\n });\n\n uploadModalClose.addEventListener(\"click\", () => {\n uploadModal.style.display = \"none\";\n });\n\n downloadButton.addEventListener(\"click\", () => {\n downloadModal.style.display = \"block\";\n });\n\n downloadModalClose.addEventListener(\"click\", () => {\n downloadModal.style.display = \"none\";\n });\n\n controlsDisplayButton.addEventListener(\"click\", () => {\n controlsDisplayButton.classList.toggle(\"active\");\n controlsDisplay.classList.toggle(\"active\");\n });\n\n fileInput.addEventListener(\"change\", () => {\n if (fileInput.files != null) {\n selectFile(fileInput.files[0]);\n }\n });\n\n uploadSubmit.addEventListener(\"click\", async () => {\n let url = urlInput.value;\n if (url === \"\") {\n url = urlInput.placeholder;\n }\n if (url.endsWith(\".splat\")) {\n uploadModal.style.display = \"none\";\n progressDialog.showModal();\n await SPLAT.Loader.LoadAsync(url, engine.scene, (progress) => (progressIndicator.value = progress * 100));\n progressDialog.close();\n } else if (url.endsWith(\".ply\")) {\n uploadModal.style.display = \"none\";\n progressDialog.showModal();\n await SPLAT.PLYLoader.LoadAsync(\n url,\n engine.scene,\n (progress) => (progressIndicator.value = progress * 100),\n );\n progressDialog.close();\n } else {\n uploadError.style.display = \"block\";\n uploadError.innerText = `Invalid file type: ${url}`;\n return;\n }\n });\n\n downloadSubmit.addEventListener(\"click\", () => {\n let format;\n if (splatRadio.checked) {\n format = \"splat\";\n } else if (plyRadio.checked) {\n format = \"ply\";\n } else {\n throw new Error(\"Unknown format\");\n }\n const filename = \"model.\" + format;\n\n if (SelectionManager.selectedSplat !== null) {\n SelectionManager.selectedSplat.saveToFile(filename, format);\n } else {\n engine.scene.saveToFile(filename, format);\n }\n });\n\n learnMoreButton.addEventListener(\"click\", () => {\n window.open(\"https://huggingface.co/spaces/dylanebert/gsplat-editor/discussions/1\", \"_blank\");\n });\n\n window.addEventListener(\"click\", () => {\n window.focus();\n });\n}\n\nmain();\n", "examples\\file-loader\\index.html": "<!doctype html>\n<html lang=\"en\">\n <head>\n <meta charset=\"UTF-8\" />\n <meta name=\"viewport\" content=\"width=device-width, initial-scale=1.0\" />\n <title>gsplat.js - File Loader</title>\n </head>\n <body>\n <div id=\"app\"></div>\n <script type=\"module\" src=\"/src/main.ts\"></script>\n </body>\n</html>\n", "examples\\file-loader\\package.json": "{\n \"name\": \"file-loader\",\n \"private\": true,\n \"version\": \"0.0.0\",\n \"type\": \"module\",\n \"scripts\": {\n \"dev\": \"vite\",\n \"build\": \"tsc && vite build\",\n \"preview\": \"vite preview\"\n },\n \"devDependencies\": {\n \"typescript\": \"^5.0.2\",\n \"vite\": \"^4.4.5\"\n }\n}\n", "examples\\file-loader\\src\\main.ts": "import * as SPLAT from \"gsplat\";\n\nconst renderer = new SPLAT.WebGLRenderer();\nconst scene = new SPLAT.Scene();\nconst camera = new SPLAT.Camera();\nconst controls = new SPLAT.OrbitControls(camera, renderer.canvas);\n\nlet loading = false;\n\nasync function selectFile(file: File) {\n if (loading) return;\n loading = true;\n // Check if .splat file\n if (file.name.endsWith(\".splat\")) {\n await SPLAT.Loader.LoadFromFileAsync(file, scene, (progress: number) => {\n console.log(\"Loading SPLAT file: \" + progress);\n });\n } else if (file.name.endsWith(\".ply\")) {\n const format = \"\";\n // const format = \"polycam\"; // Uncomment to load a Polycam PLY file\n await SPLAT.PLYLoader.LoadFromFileAsync(\n file,\n scene,\n (progress: number) => {\n console.log(\"Loading PLY file: \" + progress);\n },\n format,\n );\n }\n loading = false;\n}\n\nasync function main() {\n // Load a placeholder scene\n const url = \"https://huggingface.co/datasets/dylanebert/3dgs/resolve/main/bonsai/bonsai-7k.splat\";\n await SPLAT.Loader.LoadAsync(url, scene, () => {});\n\n // Render loop\n const frame = () => {\n controls.update();\n renderer.render(scene, camera);\n\n requestAnimationFrame(frame);\n };\n\n requestAnimationFrame(frame);\n\n // Listen for file drops\n document.addEventListener(\"drop\", (e) => {\n e.preventDefault();\n e.stopPropagation();\n\n if (e.dataTransfer != null) {\n scene.reset();\n selectFile(e.dataTransfer.files[0]);\n }\n });\n}\n\nmain();\n", "examples\\fps\\index.html": "<!doctype html>\n<html lang=\"en\">\n <head>\n <meta charset=\"UTF-8\" />\n <link rel=\"stylesheet\" href=\"style.css\" />\n <meta name=\"viewport\" content=\"width=device-width, initial-scale=1.0\" />\n <title>gsplat.js - FPS Demo</title>\n </head>\n <body>\n <div id=\"progress-container\">\n <dialog open id=\"progress-dialog\">\n <p>\n <label for=\"progress-indicator\">Loading scene...</label>\n </p>\n <progress max=\"100\" id=\"progress-indicator\"></progress>\n </dialog>\n </div>\n\n <canvas id=\"canvas\"></canvas>\n <script type=\"module\" src=\"/src/main.ts\"></script>\n </body>\n</html>\n", "examples\\fps\\package.json": "{\n \"name\": \"simple-server\",\n \"private\": true,\n \"version\": \"0.0.0\",\n \"type\": \"module\",\n \"scripts\": {\n \"dev\": \"vite\",\n \"build\": \"tsc && vite build\",\n \"preview\": \"vite preview\"\n },\n \"devDependencies\": {\n \"typescript\": \"^5.0.2\",\n \"vite\": \"^4.4.5\"\n }\n}\n", "examples\\fps\\src\\main.ts": "import * as SPLAT from \"gsplat\";\n\nconst canvas = document.getElementById(\"canvas\") as HTMLCanvasElement;\nconst progressDialog = document.getElementById(\"progress-dialog\") as HTMLDialogElement;\nconst progressIndicator = document.getElementById(\"progress-indicator\") as HTMLProgressElement;\n\nconst renderer = new SPLAT.WebGLRenderer(canvas);\nconst scene = new SPLAT.Scene();\nconst camera = new SPLAT.Camera();\ncamera.position = new SPLAT.Vector3(0, -1.5, -5);\nconst controls = new SPLAT.FPSControls(camera, canvas);\n\nasync function main() {\n const url = \"https://huggingface.co/datasets/dylanebert/3dgs/resolve/main/bicycle/bicycle-7k-mini.splat\";\n await SPLAT.Loader.LoadAsync(url, scene, (progress) => (progressIndicator.value = progress * 100));\n progressDialog.close();\n\n const handleResize = () => {\n renderer.setSize(canvas.clientWidth, canvas.clientHeight);\n };\n\n const frame = () => {\n controls.update();\n renderer.render(scene, camera);\n\n requestAnimationFrame(frame);\n };\n\n handleResize();\n window.addEventListener(\"resize\", handleResize);\n\n requestAnimationFrame(frame);\n}\n\nmain();\n", "examples\\ply-converter\\index.html": "<!doctype html>\n<html lang=\"en\">\n <head>\n <meta charset=\"UTF-8\" />\n <link rel=\"stylesheet\" href=\"style.css\" />\n <meta name=\"viewport\" content=\"width=device-width, initial-scale=1.0\" />\n <title>gsplat.js - PLY Converter</title>\n </head>\n <body>\n <div id=\"progress-container\">\n <dialog open id=\"progress-dialog\">\n <p>\n <label for=\"progress-indicator\">Loading PLY file...</label>\n </p>\n <progress max=\"100\" id=\"progress-indicator\"></progress>\n </dialog>\n </div>\n\n <canvas id=\"canvas\"></canvas>\n <script type=\"module\" src=\"/src/main.ts\"></script>\n </body>\n</html>\n", "examples\\ply-converter\\package.json": "{\n \"name\": \"ply-converter\",\n \"private\": true,\n \"version\": \"0.0.0\",\n \"type\": \"module\",\n \"scripts\": {\n \"dev\": \"vite\",\n \"build\": \"tsc && vite build\",\n \"preview\": \"vite preview\"\n },\n \"devDependencies\": {\n \"typescript\": \"^5.0.2\",\n \"vite\": \"^4.4.5\"\n }\n}\n", "examples\\ply-converter\\src\\main.ts": "import * as SPLAT from \"gsplat\";\n\nconst canvas = document.getElementById(\"canvas\") as HTMLCanvasElement;\nconst progressDialog = document.getElementById(\"progress-dialog\") as HTMLDialogElement;\nconst progressIndicator = document.getElementById(\"progress-indicator\") as HTMLProgressElement;\n\nconst renderer = new SPLAT.WebGLRenderer(canvas);\nconst scene = new SPLAT.Scene();\nconst camera = new SPLAT.Camera();\nconst controls = new SPLAT.OrbitControls(camera, canvas);\n\nconst format = \"\";\n// const format = \"polycam\"; // Uncomment to use polycam format\n\nasync function main() {\n // Load and convert ply from url\n const url =\n \"https://huggingface.co/datasets/dylanebert/3dgs/resolve/main/bonsai/point_cloud/iteration_7000/point_cloud.ply\";\n await SPLAT.PLYLoader.LoadAsync(url, scene, (progress) => (progressIndicator.value = progress * 100), format);\n progressDialog.close();\n scene.saveToFile(\"bonsai.splat\");\n\n // Alternatively, uncomment below to convert from splat to ply\n // NOTE: Data like SH coefficients will be lost when converting ply -> splat -> ply\n /* const url = \"https://huggingface.co/datasets/dylanebert/3dgs/resolve/main/bonsai/bonsai-7k-mini.splat\";\n await SPLAT.Loader.LoadAsync(url, scene, (progress) => (progressIndicator.value = progress * 100));\n progressDialog.close();\n scene.saveToFile(\"bonsai-7k-mini.ply\", \"ply\"); */\n\n // Render loop\n const frame = () => {\n controls.update();\n renderer.render(scene, camera);\n\n requestAnimationFrame(frame);\n };\n\n requestAnimationFrame(frame);\n\n // Alternatively, load and convert ply from file\n let loading = false;\n const selectFile = async (file: File) => {\n if (loading) return;\n loading = true;\n if (file.name.endsWith(\".splat\")) {\n await SPLAT.Loader.LoadFromFileAsync(file, scene, (progress: number) => {\n progressIndicator.value = progress * 100;\n });\n } else if (file.name.endsWith(\".ply\")) {\n await SPLAT.PLYLoader.LoadFromFileAsync(\n file,\n scene,\n (progress: number) => {\n progressIndicator.value = progress * 100;\n },\n format,\n );\n }\n scene.saveToFile(file.name.replace(\".ply\", \".splat\"));\n loading = false;\n };\n\n document.addEventListener(\"drop\", (e) => {\n e.preventDefault();\n e.stopPropagation();\n\n if (e.dataTransfer != null && e.dataTransfer.files.length > 0) {\n selectFile(e.dataTransfer.files[0]);\n }\n });\n}\n\nmain();\n", "examples\\scene-transformations\\index.html": "<!doctype html>\n<html lang=\"en\">\n <head>\n <meta charset=\"UTF-8\" />\n <link rel=\"stylesheet\" href=\"style.css\" />\n <meta name=\"viewport\" content=\"width=device-width, initial-scale=1.0\" />\n <title>gsplat.js - Scene Transformations</title>\n </head>\n <body>\n <div id=\"progress-container\">\n <dialog open id=\"progress-dialog\">\n <p>\n <label for=\"progress-indicator\">Loading scene...</label>\n </p>\n <progress max=\"100\" id=\"progress-indicator\"></progress>\n </dialog>\n </div>\n\n <canvas id=\"canvas\"></canvas>\n <script type=\"module\" src=\"/src/main.ts\"></script>\n </body>\n</html>\n", "examples\\scene-transformations\\package.json": "{\n \"name\": \"scene-transformations\",\n \"private\": true,\n \"version\": \"0.0.0\",\n \"type\": \"module\",\n \"scripts\": {\n \"dev\": \"vite\",\n \"build\": \"tsc && vite build\",\n \"preview\": \"vite preview\"\n },\n \"devDependencies\": {\n \"typescript\": \"^5.0.2\",\n \"vite\": \"^4.4.5\"\n }\n}\n", "examples\\scene-transformations\\src\\main.ts": "import * as SPLAT from \"gsplat\";\n\nconst canvas = document.getElementById(\"canvas\") as HTMLCanvasElement;\nconst progressDialog = document.getElementById(\"progress-dialog\") as HTMLDialogElement;\nconst progressIndicator = document.getElementById(\"progress-indicator\") as HTMLProgressElement;\n\nconst renderer = new SPLAT.WebGLRenderer(canvas);\nconst scene = new SPLAT.Scene();\nconst camera = new SPLAT.Camera();\nconst controls = new SPLAT.OrbitControls(camera, canvas, 0.5, 0.5, 5);\n\nasync function main() {\n // Load the scene\n const name = \"bonsai\";\n const url = `https://huggingface.co/datasets/dylanebert/3dgs/resolve/main/${name}/${name}-7k.splat`;\n const splat = await SPLAT.Loader.LoadAsync(url, scene, (progress) => (progressIndicator.value = progress * 100));\n progressDialog.close();\n\n // Transform it\n const rotation = new SPLAT.Vector3(0, 0, 0);\n const translation = new SPLAT.Vector3(-0.2, 0.2, 0);\n const scaling = new SPLAT.Vector3(1.5, 1.5, 1.5);\n splat.rotation = SPLAT.Quaternion.FromEuler(rotation);\n splat.position = translation;\n splat.scale = scaling;\n splat.applyPosition();\n splat.applyRotation();\n splat.applyScale();\n\n const handleResize = () => {\n renderer.setSize(canvas.clientWidth, canvas.clientHeight);\n };\n\n const frame = () => {\n controls.update();\n renderer.render(scene, camera);\n\n requestAnimationFrame(frame);\n };\n\n const onKeyDown = (e: KeyboardEvent) => {\n if (e.key === \"PageUp\") {\n splat.scale = new SPLAT.Vector3(1.1, 1.1, 1.1);\n splat.applyScale();\n } else if (e.key === \"PageDown\") {\n splat.scale = new SPLAT.Vector3(0.9, 0.9, 0.9);\n splat.applyScale();\n }\n };\n\n handleResize();\n window.addEventListener(\"resize\", handleResize);\n window.addEventListener(\"keydown\", onKeyDown);\n\n requestAnimationFrame(frame);\n}\n\nmain();\n", "examples\\simple-server\\index.html": "<!doctype html>\n<html lang=\"en\">\n <head>\n <meta charset=\"UTF-8\" />\n <link rel=\"stylesheet\" href=\"style.css\" />\n <meta name=\"viewport\" content=\"width=device-width, initial-scale=1.0\" />\n <title>gsplat.js - Viewer Demo</title>\n </head>\n <body>\n <div id=\"progress-container\">\n <dialog open id=\"progress-dialog\">\n <p>\n <label for=\"progress-indicator\">Loading scene...</label>\n </p>\n <progress max=\"100\" id=\"progress-indicator\"></progress>\n </dialog>\n </div>\n\n <canvas id=\"canvas\"></canvas>\n <script type=\"module\" src=\"/src/main.ts\"></script>\n </body>\n</html>\n", "examples\\simple-server\\package.json": "{\n \"name\": \"simple-server\",\n \"private\": true,\n \"version\": \"0.0.0\",\n \"type\": \"module\",\n \"scripts\": {\n \"dev\": \"vite\",\n \"build\": \"tsc && vite build\",\n \"preview\": \"vite preview\"\n },\n \"devDependencies\": {\n \"typescript\": \"^5.0.2\",\n \"vite\": \"^4.4.5\"\n }\n}\n", "examples\\simple-server\\src\\main.ts": "import * as SPLAT from \"gsplat\";\n\nconst canvas = document.getElementById(\"canvas\") as HTMLCanvasElement;\nconst progressDialog = document.getElementById(\"progress-dialog\") as HTMLDialogElement;\nconst progressIndicator = document.getElementById(\"progress-indicator\") as HTMLProgressElement;\n\nconst renderer = new SPLAT.WebGLRenderer(canvas);\nconst scene = new SPLAT.Scene();\nconst camera = new SPLAT.Camera();\nconst controls = new SPLAT.OrbitControls(camera, canvas);\n\nasync function main() {\n const url = \"https://huggingface.co/datasets/dylanebert/3dgs/resolve/main/bonsai/bonsai-7k-mini.splat\";\n await SPLAT.Loader.LoadAsync(url, scene, (progress) => (progressIndicator.value = progress * 100));\n progressDialog.close();\n\n const handleResize = () => {\n renderer.setSize(canvas.clientWidth, canvas.clientHeight);\n };\n\n const frame = () => {\n controls.update();\n renderer.render(scene, camera);\n\n requestAnimationFrame(frame);\n };\n\n handleResize();\n window.addEventListener(\"resize\", handleResize);\n\n requestAnimationFrame(frame);\n}\n\nmain();\n", "examples\\vanilla-js\\index.html": "<!doctype html>\n<html lang=\"en\">\n <head>\n <meta charset=\"utf-8\" />\n <link rel=\"stylesheet\" href=\"style.css\" />\n <meta name=\"viewport\" content=\"width=device-width, initial-scale=1\" />\n <title>gsplat.js - Viewer Demo</title>\n </head>\n\n <body>\n <div id=\"progress-container\">\n <dialog open id=\"progress-dialog\">\n <p>\n <label for=\"progress-indicator\">Loading scene...</label>\n </p>\n <progress max=\"100\" id=\"progress-indicator\"></progress>\n </dialog>\n </div>\n\n <canvas id=\"canvas\"></canvas>\n <script src=\"index.js\" type=\"module\"></script>\n </body>\n</html>\n", "examples\\vanilla-js\\index.js": "import * as SPLAT from \"https://cdn.jsdelivr.net/npm/gsplat@latest\";\n\nconst canvas = document.getElementById(\"canvas\");\nconst progressDialog = document.getElementById(\"progress-dialog\");\nconst progressIndicator = document.getElementById(\"progress-indicator\");\n\nconst renderer = new SPLAT.WebGLRenderer(canvas);\nconst scene = new SPLAT.Scene();\nconst camera = new SPLAT.Camera();\nconst controls = new SPLAT.OrbitControls(camera, canvas);\n\nasync function main() {\n const url = \"https://huggingface.co/datasets/dylanebert/3dgs/resolve/main/bonsai/bonsai-7k-mini.splat\";\n await SPLAT.Loader.LoadAsync(url, scene, (progress) => (progressIndicator.value = progress * 100));\n progressDialog.close();\n\n const handleResize = () => {\n renderer.setSize(canvas.clientWidth, canvas.clientHeight);\n };\n\n const frame = () => {\n controls.update();\n renderer.render(scene, camera);\n\n requestAnimationFrame(frame);\n };\n\n handleResize();\n window.addEventListener(\"resize\", handleResize);\n\n requestAnimationFrame(frame);\n}\n\nmain();\n", "src\\index.ts": "export { Object3D } from \"./core/Object3D\";\nexport { SplatData } from \"./splats/SplatData\";\nexport { SplatvData } from \"./splats/SplatvData\";\nexport { Splat } from \"./splats/Splat\";\nexport { Splatv } from \"./splats/Splatv\";\nexport { CameraData } from \"./cameras/CameraData\";\nexport { Camera } from \"./cameras/Camera\";\nexport { Scene } from \"./core/Scene\";\nexport { Loader } from \"./loaders/Loader\";\nexport { PLYLoader } from \"./loaders/PLYLoader\";\nexport { SplatvLoader } from \"./loaders/SplatvLoader\";\nexport { WebGLRenderer } from \"./renderers/WebGLRenderer\";\nexport { OrbitControls } from \"./controls/OrbitControls\";\nexport { FPSControls } from \"./controls/FPSControls\";\nexport { Quaternion } from \"./math/Quaternion\";\nexport { Vector3 } from \"./math/Vector3\";\nexport { Vector4 } from \"./math/Vector4\";\nexport { Matrix4 } from \"./math/Matrix4\";\nexport { Matrix3 } from \"./math/Matrix3\";\nexport { Color32 } from \"./math/Color32\";\nexport { Plane } from \"./math/Plane\";\nexport { ShaderPass } from \"./renderers/webgl/passes/ShaderPass\";\nexport { FadeInPass } from \"./renderers/webgl/passes/FadeInPass\";\nexport { RenderData } from \"./renderers/webgl/utils/RenderData\";\nexport { ShaderProgram } from \"./renderers/webgl/programs/ShaderProgram\";\nexport { RenderProgram } from \"./renderers/webgl/programs/RenderProgram\";\nexport { VideoRenderProgram } from \"./renderers/webgl/programs/VideoRenderProgram\";\nexport { IntersectionTester } from \"./renderers/webgl/utils/IntersectionTester\";\n"} | null |
gym-aloha | {"type": "directory", "name": "gym-aloha", "children": [{"type": "file", "name": ".pre-commit-config.yaml"}, {"type": "file", "name": "example.py"}, {"type": "directory", "name": "gym_aloha", "children": [{"type": "directory", "name": "assets", "children": [{"type": "file", "name": "bimanual_viperx_end_effector_insertion.xml"}, {"type": "file", "name": "bimanual_viperx_end_effector_transfer_cube.xml"}, {"type": "file", "name": "bimanual_viperx_insertion.xml"}, {"type": "file", "name": "bimanual_viperx_transfer_cube.xml"}, {"type": "file", "name": "scene.xml"}, {"type": "file", "name": "tabletop.stl"}, {"type": "file", "name": "vx300s_10_custom_finger_left.stl"}, {"type": "file", "name": "vx300s_10_custom_finger_right.stl"}, {"type": "file", "name": "vx300s_10_gripper_finger.stl"}, {"type": "file", "name": "vx300s_11_ar_tag.stl"}, {"type": "file", "name": "vx300s_1_base.stl"}, {"type": "file", "name": "vx300s_2_shoulder.stl"}, {"type": "file", "name": "vx300s_3_upper_arm.stl"}, {"type": "file", "name": "vx300s_4_upper_forearm.stl"}, {"type": "file", "name": "vx300s_5_lower_forearm.stl"}, {"type": "file", "name": "vx300s_6_wrist.stl"}, {"type": "file", "name": "vx300s_7_gripper.stl"}, {"type": "file", "name": "vx300s_8_gripper_prop.stl"}, {"type": "file", "name": "vx300s_9_gripper_bar.stl"}, {"type": "file", "name": "vx300s_dependencies.xml"}, {"type": "file", "name": "vx300s_left.xml"}, {"type": "file", "name": "vx300s_right.xml"}]}, {"type": "file", "name": "constants.py"}, {"type": "file", "name": "env.py"}, {"type": "directory", "name": "tasks", "children": [{"type": "file", "name": "sim.py"}, {"type": "file", "name": "sim_end_effector.py"}]}, {"type": "file", "name": "utils.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "LICENSE"}, {"type": "file", "name": "poetry.lock"}, {"type": "file", "name": "pyproject.toml"}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "tests", "children": [{"type": "file", "name": "test_env.py"}]}]} | # gym-aloha
A gym environment for ALOHA
<img src="http://remicadene.com/assets/gif/aloha_act.gif" width="50%" alt="ACT policy on ALOHA env"/>
## Installation
Create a virtual environment with Python 3.10 and activate it, e.g. with [`miniconda`](https://docs.anaconda.com/free/miniconda/index.html):
```bash
conda create -y -n aloha python=3.10 && conda activate aloha
```
Install gym-aloha:
```bash
pip install gym-aloha
```
## Quickstart
```python
# example.py
import imageio
import gymnasium as gym
import numpy as np
import gym_aloha
env = gym.make("gym_aloha/AlohaInsertion-v0")
observation, info = env.reset()
frames = []
for _ in range(1000):
action = env.action_space.sample()
observation, reward, terminated, truncated, info = env.step(action)
image = env.render()
frames.append(image)
if terminated or truncated:
observation, info = env.reset()
env.close()
imageio.mimsave("example.mp4", np.stack(frames), fps=25)
```
## Description
Aloha environment.
Two tasks are available:
- TransferCubeTask: The right arm needs to first pick up the red cube lying on the table, then place it inside the gripper of the other arm.
- InsertionTask: The left and right arms need to pick up the socket and peg respectively, and then insert in mid-air so the peg touches the “pins” inside the socket.
### Action Space
The action space consists of continuous values for each arm and gripper, resulting in a 14-dimensional vector:
- Six values for each arm's joint positions (absolute values).
- One value for each gripper's position, normalized between 0 (closed) and 1 (open).
### Observation Space
Observations are provided as a dictionary with the following keys:
- `qpos` and `qvel`: Position and velocity data for the arms and grippers.
- `images`: Camera feeds from different angles.
- `env_state`: Additional environment state information, such as positions of the peg and sockets.
### Rewards
- TransferCubeTask:
- 1 point for holding the box with the right gripper.
- 2 points if the box is lifted with the right gripper.
- 3 points for transferring the box to the left gripper.
- 4 points for a successful transfer without touching the table.
- InsertionTask:
- 1 point for touching both the peg and a socket with the grippers.
- 2 points for grasping both without dropping them.
- 3 points if the peg is aligned with and touching the socket.
- 4 points for successful insertion of the peg into the socket.
### Success Criteria
Achieving the maximum reward of 4 points.
### Starting State
The arms and the items (block, peg, socket) start at a random position and angle.
### Arguments
```python
>>> import gymnasium as gym
>>> import gym_aloha
>>> env = gym.make("gym_aloha/AlohaInsertion-v0", obs_type="pixels", render_mode="rgb_array")
>>> env
<TimeLimit<OrderEnforcing<PassiveEnvChecker<AlohaEnv<gym_aloha/AlohaInsertion-v0>>>>>
```
* `obs_type`: (str) The observation type. Can be either `pixels` or `pixels_agent_pos`. Default is `pixels`.
* `render_mode`: (str) The rendering mode. Only `rgb_array` is supported for now.
* `observation_width`: (int) The width of the observed image. Default is `640`.
* `observation_height`: (int) The height of the observed image. Default is `480`.
* `visualization_width`: (int) The width of the visualized image. Default is `640`.
* `visualization_height`: (int) The height of the visualized image. Default is `480`.
## Contribute
Instead of using `pip` directly, we use `poetry` for development purposes to easily track our dependencies.
If you don't have it already, follow the [instructions](https://python-poetry.org/docs/#installation) to install it.
Install the project with dev dependencies:
```bash
poetry install --all-extras
```
### Follow our style
```bash
# install pre-commit hooks
pre-commit install
# apply style and linter checks on staged files
pre-commit
```
## Acknowledgment
gym-aloha is adapted from [ALOHA](https://tonyzhaozh.github.io/aloha/)
| {".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 be0aa0cead54a650f30cb21fa9bd6b0b49153a70 Hamza Amin <[email protected]> 1727369249 +0500\tclone: from https://github.com/huggingface/gym-aloha.git\n", ".git\\refs\\heads\\main": "be0aa0cead54a650f30cb21fa9bd6b0b49153a70\n"} | null |
gym-pusht | {"type": "directory", "name": "gym-pusht", "children": [{"type": "file", "name": ".pre-commit-config.yaml"}, {"type": "file", "name": "example.py"}, {"type": "directory", "name": "gym_pusht", "children": [{"type": "directory", "name": "envs", "children": [{"type": "file", "name": "pusht.py"}, {"type": "file", "name": "pymunk_override.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "LICENSE"}, {"type": "file", "name": "poetry.lock"}, {"type": "file", "name": "pyproject.toml"}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "tests", "children": [{"type": "file", "name": "test_env.py"}]}]} | # gym-pusht
A gymnasium environment PushT.
<img src="http://remicadene.com/assets/gif/pusht_diffusion.gif" width="50%" alt="Diffusion policy on PushT env"/>
## Installation
Create a virtual environment with Python 3.10 and activate it, e.g. with [`miniconda`](https://docs.anaconda.com/free/miniconda/index.html):
```bash
conda create -y -n pusht python=3.10 && conda activate pusht
```
Install gym-pusht:
```bash
pip install gym-pusht
```
## Quick start
```python
# example.py
import gymnasium as gym
import gym_pusht
env = gym.make("gym_pusht/PushT-v0", render_mode="human")
observation, info = env.reset()
for _ in range(1000):
action = env.action_space.sample()
observation, reward, terminated, truncated, info = env.step(action)
image = env.render()
if terminated or truncated:
observation, info = env.reset()
env.close()
```
## Description
PushT environment.
The goal of the agent is to push the block to the goal zone. The agent is a circle and the block is a tee shape.
### Action Space
The action space is continuous and consists of two values: [x, y]. The values are in the range [0, 512] and
represent the target position of the agent.
### Observation Space
If `obs_type` is set to `state`, the observation space is a 5-dimensional vector representing the state of the
environment: [agent_x, agent_y, block_x, block_y, block_angle]. The values are in the range [0, 512] for the agent
and block positions and [0, 2*pi] for the block angle.
If `obs_type` is set to `environment_state_agent_pos` the observation space is a dictionary with:
- `environment_state`: 16-dimensional vector representing the keypoint locations of the T (in [x0, y0, x1, y1, ...]
format). The values are in the range [0, 512].
- `agent_pos`: A 2-dimensional vector representing the position of the robot end-effector.
If `obs_type` is set to `pixels`, the observation space is a 96x96 RGB image of the environment.
### Rewards
The reward is the coverage of the block in the goal zone. The reward is 1.0 if the block is fully in the goal zone.
### Success Criteria
The environment is considered solved if the block is at least 95% in the goal zone.
### Starting State
The agent starts at a random position and the block starts at a random position and angle.
### Episode Termination
The episode terminates when the block is at least 95% in the goal zone.
### Arguments
```python
>>> import gymnasium as gym
>>> import gym_pusht
>>> env = gym.make("gym_pusht/PushT-v0", obs_type="state", render_mode="rgb_array")
>>> env
<TimeLimit<OrderEnforcing<PassiveEnvChecker<PushTEnv<gym_pusht/PushT-v0>>>>>
```
* `obs_type`: (str) The observation type. Can be either `state`, `environment_state_agent_pos`, `pixels` or `pixels_agent_pos`. Default is `state`.
* `block_cog`: (tuple) The center of gravity of the block if different from the center of mass. Default is `None`.
* `damping`: (float) The damping factor of the environment if different from 0. Default is `None`.
* `render_mode`: (str) The rendering mode. Can be either `human` or `rgb_array`. Default is `rgb_array`.
* `observation_width`: (int) The width of the observed image. Default is `96`.
* `observation_height`: (int) The height of the observed image. Default is `96`.
* `visualization_width`: (int) The width of the visualized image. Default is `680`.
* `visualization_height`: (int) The height of the visualized image. Default is `680`.
### Reset Arguments
Passing the option `options["reset_to_state"]` will reset the environment to a specific state.
> [!WARNING]
> For legacy compatibility, the inner functioning has been preserved, and the state set is not the same as the
> the one passed in the argument.
```python
>>> import gymnasium as gym
>>> import gym_pusht
>>> env = gym.make("gym_pusht/PushT-v0")
>>> state, _ = env.reset(options={"reset_to_state": [0.0, 10.0, 20.0, 30.0, 1.0]})
>>> state
array([ 0. , 10. , 57.866196, 50.686398, 1. ],
dtype=float32)
```
## Version History
* v0: Original version
## References
* TODO:
## Contribute
Instead of using `pip` directly, we use `poetry` for development purposes to easily track our dependencies.
If you don't have it already, follow the [instructions](https://python-poetry.org/docs/#installation) to install it.
Install the project with dev dependencies:
```bash
poetry install --all-extras
```
### Follow our style
```bash
# install pre-commit hooks
pre-commit install
# apply style and linter checks on staged files
pre-commit
```
## Acknowledgment
gym-pusht is adapted from [Diffusion Policy](https://diffusion-policy.cs.columbia.edu/)
| {".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 5e2489be9ff99ed9cd47b6c653dda3b7aa844d24 Hamza Amin <[email protected]> 1727369251 +0500\tclone: from https://github.com/huggingface/gym-pusht.git\n", ".git\\refs\\heads\\main": "5e2489be9ff99ed9cd47b6c653dda3b7aa844d24\n"} | null |
gym-xarm | {"type": "directory", "name": "gym-xarm", "children": [{"type": "file", "name": ".pre-commit-config.yaml"}, {"type": "file", "name": "example.py"}, {"type": "directory", "name": "gym_xarm", "children": [{"type": "directory", "name": "tasks", "children": [{"type": "directory", "name": "assets", "children": [{"type": "file", "name": "lift.xml"}, {"type": "directory", "name": "mesh", "children": [{"type": "file", "name": "base_link.stl"}, {"type": "file", "name": "block_inner.stl"}, {"type": "file", "name": "block_inner2.stl"}, {"type": "file", "name": "block_outer.stl"}, {"type": "file", "name": "left_finger.stl"}, {"type": "file", "name": "left_inner_knuckle.stl"}, {"type": "file", "name": "left_outer_knuckle.stl"}, {"type": "file", "name": "link1.stl"}, {"type": "file", "name": "link2.stl"}, {"type": "file", "name": "link3.stl"}, {"type": "file", "name": "link4.stl"}, {"type": "file", "name": "link5.stl"}, {"type": "file", "name": "link6.stl"}, {"type": "file", "name": "link7.stl"}, {"type": "file", "name": "link_base.stl"}, {"type": "file", "name": "right_finger.stl"}, {"type": "file", "name": "right_inner_knuckle.stl"}, {"type": "file", "name": "right_outer_knuckle.stl"}]}, {"type": "file", "name": "peg_in_box.xml"}, {"type": "file", "name": "push.xml"}, {"type": "file", "name": "reach.xml"}, {"type": "file", "name": "shared.xml"}, {"type": "file", "name": "xarm.xml"}]}, {"type": "file", "name": "base.py"}, {"type": "file", "name": "lift.py"}, {"type": "file", "name": "mocap.py"}, {"type": "file", "name": "peg_in_box.py"}, {"type": "file", "name": "push.py"}, {"type": "file", "name": "reach.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "LICENSE"}, {"type": "file", "name": "poetry.lock"}, {"type": "file", "name": "pyproject.toml"}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "tests", "children": [{"type": "file", "name": "test_env.py"}]}]} | # gym-xarm
A gym environment for xArm
<td><img src="http://remicadene.com/assets/gif/simxarm_tdmpc.gif" width="50%" alt="TDMPC policy on xArm env"/></td>
## Installation
Create a virtual environment with Python 3.10 and activate it, e.g. with [`miniconda`](https://docs.anaconda.com/free/miniconda/index.html):
```bash
conda create -y -n xarm python=3.10 && conda activate xarm
```
Install gym-xarm:
```bash
pip install gym-xarm
```
## Quickstart
```python
# example.py
import gymnasium as gym
import gym_xarm
env = gym.make("gym_xarm/XarmLift-v0", render_mode="human")
observation, info = env.reset()
for _ in range(1000):
action = env.action_space.sample()
observation, reward, terminated, truncated, info = env.step(action)
image = env.render()
if terminated or truncated:
observation, info = env.reset()
env.close()
```
To use this [example](./example.py) with `render_mode="human"`, you should set the environment variable `export MUJOCO_GL=glfw` or simply run
```bash
MUJOCO_GL=glfw python example.py
```
## Description for `Lift` task
The goal of the agent is to lift the block above a height threshold. The agent is an xArm robot arm and the block is a cube.
### Action Space
The action space is continuous and consists of four values [x, y, z, w]:
- [x, y, z] represent the position of the end effector
- [w] represents the gripper control
### Observation Space
Observation space is dependent on the value set to `obs_type`:
- `"state"`: observations contain agent and object state vectors only (no rendering)
- `"pixels"`: observations contains rendered image only (no state vectors)
- `"pixels_agent_pos"`: contains rendered image and agent state vector
## Contribute
Instead of using `pip` directly, we use `poetry` for development purposes to easily track our dependencies.
If you don't have it already, follow the [instructions](https://python-poetry.org/docs/#installation) to install it.
Install the project with dev dependencies:
```bash
poetry install --all-extras
```
### Follow our style
```bash
# install pre-commit hooks
pre-commit install
# apply style and linter checks on staged files
pre-commit
```
## Acknowledgment
gym-xarm is adapted from [FOWM](https://www.yunhaifeng.com/FOWM/) and is based on work by [Nicklas Hansen](https://nicklashansen.github.io/), [Yanjie Ze](https://yanjieze.com/), [Rishabh Jangir](https://jangirrishabh.github.io/), [Mohit Jain](https://natsu6767.github.io/), and [Sambaran Ghosal](https://github.com/SambaranRepo) as part of the following publications:
* [Self-Supervised Policy Adaptation During Deployment](https://arxiv.org/abs/2007.04309)
* [Generalization in Reinforcement Learning by Soft Data Augmentation](https://arxiv.org/abs/2011.13389)
* [Stabilizing Deep Q-Learning with ConvNets and Vision Transformers under Data Augmentation](https://arxiv.org/abs/2107.00644)
* [Look Closer: Bridging Egocentric and Third-Person Views with Transformers for Robotic Manipulation](https://arxiv.org/abs/2201.07779)
* [Visual Reinforcement Learning with Self-Supervised 3D Representations](https://arxiv.org/abs/2210.07241)
| {".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 254aa0af94d41396877ab542da0ae62875c8d34a Hamza Amin <[email protected]> 1727369255 +0500\tclone: from https://github.com/huggingface/gym-xarm.git\n", ".git\\refs\\heads\\main": "254aa0af94d41396877ab542da0ae62875c8d34a\n"} | null |
hamza-amin-4365 | {"type": "directory", "name": "hamza-amin-4365", "children": [{"type": "directory", "name": "assets", "children": []}, {"type": "file", "name": "README.md"}]} | <div align="center">
<h1 style="display: inline-block">Hi 👋, I'm Hamza Amin</h1>
</div>
<!--- snake -->
<!--h2 without bottom border-->
<div id="user-content-toc">
<ul align="center">
<h2 style="display: inline-block">🤖 Programming is a journey, and confusion is just a milestone!</h2>
</ul>
</div>
- 📈 Enhancing my skills in data science, machine learning, deep learning, and computer vision
- 📚 Currently delving into Generative AI, Advanced Computer Vision, Cloud Computing, and data analytics
- 🤝 Searching for open-source projects to contribute to and expand my experience. Let's collaborate! 🚀
- 📫 Check me out on [LinkedIn](https://linkedin.com/in/hamza-amin-9a457124a)
- 📫 Check me out on [Kaggle](https://www.kaggle.com/tommas4365)

<!--- stats & Trophy (start) -->
<p align="center">
<!--- GitHub Profile Summary Cards (start) -->
<table align="center">
<tr border="none">
<td width="50%" align="center">
<!-- Overall Stats Card -->
<img align="center" src="http://github-profile-summary-cards.vercel.app/api/cards/stats?username=hamza-amin-4365&theme=gruvbox" />
<!-- Language Stats -->
<img align="center" src="http://github-profile-summary-cards.vercel.app/api/cards/repos-per-language?username=hamza-amin-4365&theme=gruvbox" />
</td>
<td width="50%" align="center">
<!-- Streak Stats -->
<img align="center" src="https://github-readme-streak-stats.herokuapp.com/?user=hamza-amin-4365&theme=dark&hide_border=false" />
</td>
</tr>
</table>
<!--- GitHub Profile Summary Cards (end) -->
<!--- trophy (start) -->
<div align=center>
<a href="https://github.com/ryo-ma/github-profile-trophy" title="Go to Source">
<img align="center" width=84% src="https://github-profile-trophy.vercel.app/?username=hamza-amin-4365&theme=radical&row=1&column=7&margin-h=15&margin-w=5&no-bg=true" alt="TROPHY" />
</a>
</div>
<!--- trophy (end) -->
</p>
<!--- stats (end) -->
<!--h1 without bottom border-->
<div id="user-content-toc">
<ul align="center">
<summary><h2 style="display: inline-block">Technologies That I Know👨🏻💻</h2></summary>
</ul>
</div>
<!--tech stack icons-->
<p align="center">
<a href="https://skillicons.dev">
<img src="https://skillicons.dev/icons?i=git,py,discord,github,html,linux,azure,postgres,sqlite,cpp,vscode,opencv,tensorflow&perline=14" />
</a>
</p>
<!-- Connect with me -->
<!--h2 without bottom border-->
<div id="user-content-toc">
<ul align="center">
<summary><h2 style="display: inline-block">Connect With Me🤝</h2></summary>
</ul>
</div>
<!--icons and links-->
<p align="center">
<a href="https://linkedin.com/in/hamza-amin-9a457124a" target="blank"><img align="center" src="https://user-images.githubusercontent.com/88904952/234979284-68c11d7f-1acc-4f0c-ac78-044e1037d7b0.png" alt="linkedin" height="50" width="50" /></a>
<a href="https://twitter.com/hamza_amin65" target="blank"><img align="center" src="https://user-images.githubusercontent.com/88904952/234980676-61bfb021-ecc8-48f7-88e6-34c1b06c4a58.png" alt="twitter" height="50" width="50" /></a>
<a href="https://www.instagram.com/hamza_amin4365?igsh=NGNlYmtpYnU2NDhs" target="blank"><img align="center" src="https://user-images.githubusercontent.com/88904952/234981169-2dd1e58f-4b7e-468c-8213-034ba62156c3.png" alt="instagram" height="50" width="50" /></a>
</p>
| {".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 57b1a8091e7dbd6442f527bb148c3ab0181b1002 Hamza Amin <[email protected]> 1727376260 +0500\tclone: from https://github.com/hamza-amin-4365/hamza-amin-4365.git\n", ".git\\refs\\heads\\main": "57b1a8091e7dbd6442f527bb148c3ab0181b1002\n"} | null |
helm-common | {"type": "directory", "name": "helm-common", "children": [{"type": "directory", "name": "charts", "children": [{"type": "directory", "name": "common", "children": [{"type": "file", "name": ".helmignore"}, {"type": "file", "name": "Chart.yaml"}, {"type": "directory", "name": "templates", "children": [{"type": "file", "name": "_helpers.tpl"}, {"type": "file", "name": "_images.tpl"}, {"type": "file", "name": "_ingress.tpl"}, {"type": "file", "name": "_labels.tpl"}, {"type": "file", "name": "_tplvalues.tpl"}]}]}, {"type": "directory", "name": "unit-tests", "children": [{"type": "file", "name": ".helmignore"}, {"type": "file", "name": "Chart.lock"}, {"type": "file", "name": "Chart.yaml"}, {"type": "directory", "name": "templates", "children": [{"type": "file", "name": "deployment.yaml"}, {"type": "file", "name": "_helpers.yaml"}]}, {"type": "directory", "name": "tests", "children": [{"type": "file", "name": "deployment_test.yaml"}, {"type": "file", "name": "test-values.yaml"}]}, {"type": "file", "name": "values.yaml"}]}]}, {"type": "file", "name": "LICENSE"}, {"type": "file", "name": "README.md"}]} | # Hugging Face Common Helm Chart
[](https://github.com/huggingface/helm-publish-action/releases)
[](https://opensource.org/licenses/Apache-2.0)

Helm Chart containing Hugging Face common functions
## Usage
### How to install
Add this chart to your chart dependencies.
```
apiVersion: v2
name: my-chart
description: Your Helm chart description
icon: https://huggingface.co/front/assets/huggingface_logo-noborder.svg
type: application
version: 1.0.0
appVersion: "latest"
dependencies:
- name: common
version: x.x.x
repository: https://HUGGINGFACE_PRIVATE_REGISTRY/chartrepo/charts
```
or if your project is open-source :
```
apiVersion: v2
name: my-chart
description: Your Helm chart description
icon: https://huggingface.co/front/assets/huggingface_logo-noborder.svg
type: application
version: 1.0.0
appVersion: "latest"
dependencies:
- name: common
version: x.x.x
repository: oci://ghcr.io/huggingface/helm-common
```
### Docker images management
#### Use a public docker image
To use a public docker image (on docker hub).
**`values.yaml`**
```yaml
global:
huggingface:
imageRegistry: ""
imagePullSecrets: []
images:
pullPolicy: IfNotPresent
nginx:
useGlobalRegistry: false
repository: nginx
tag: "1.22"
```
**`_helpers.yaml`**
```yaml
{{- define "nginx.image" -}}
{{ include "hf.common.images.image" (dict "imageRoot" .Values.images.nginx "global" .Values.global.huggingface) | quote }}
{{- end -}}
```
**`deployment.yaml`**
```yaml
...
containers:
- name: ...
image: {{ include "nginx.image" . }}
...
```
The common function will generate : `image: "nginx:1.22"`
#### Use a public docker image on specific repository (docker hub)
To use a public docker image (on docker hub).
**`values.yaml`**
```yaml
global:
huggingface:
imageRegistry: ""
imagePullSecrets: []
images:
pullPolicy: IfNotPresent
admin:
registry: huggingface
useGlobalRegistry: false
repository: datasets-server
tag: sha-27ad2f7
```
**`_helpers.yaml`**
```yaml
{{- define "admin.image" -}}
{{ include "hf.common.images.image" (dict "imageRoot" .Values.images.admin "global" .Values.global.huggingface) | quote }}
{{- end -}}
```
**`deployment.yaml`**
```yaml
...
containers:
- name: ...
image: {{ include "admin.image" . }}
...
```
The common function will generate : `image: "huggingface/datasets-server:sha-27ad2f7"`
#### Use a docker image from private registry (with global registry)
To use a docker image from a global private registry.
A global registry is usefull to avoid duplicate your registry for all your images.
**`values.yaml`**
```yaml
global:
huggingface:
imageRegistry: "my-registry.com"
imagePullSecrets: []
images:
pullPolicy: IfNotPresent
app:
repository: project/app
tag: 1.0.0
```
**`_helpers.yaml`**
```yaml
{{- define "app.image" -}}
{{ include "hf.common.images.image" (dict "imageRoot" .Values.images.app "global" .Values.global.huggingface) | quote }}
{{- end -}}
```
**`deployment.yaml`**
```yaml
...
containers:
- name: ...
image: {{ include "app.image" . }}
...
```
The common function will generate : `image: "my-registry.com/project/app:1.0.0"`
#### Use a docker image from private registry (without global registry)
To use a docker image for a specific private private registry (not global).
**`values.yaml`**
```yaml
global:
huggingface:
imageRegistry: "my-registry.com"
imagePullSecrets: []
images:
pullPolicy: IfNotPresent
app:
registry: my-other-registry.com
repository: project/app
tag: 1.0.0
```
**`_helpers.yaml`**
```yaml
{{- define "app.image" -}}
{{ include "hf.common.images.image" (dict "imageRoot" .Values.images.app "global" .Values.global.huggingface) | quote }}
{{- end -}}
```
**`deployment.yaml`**
```yaml
...
containers:
- name: ...
image: {{ include "app.image" . }}
...
```
The common function will generate : `image: "my-other-registry.com/project/app:1.0.0"`
### Pull Secret management
If your registry is private, you will need an imagePullSecret to allow your cluster to pull the docker image.
You can set it globally to avoid duplicate.
**`values.yaml`**
```yaml
global:
huggingface:
imageRegistry: "my-registry.com"
imagePullSecrets: [myregcred]
images:
pullPolicy: IfNotPresent
app:
repository: project/app
tag: 1.0.0
```
**`_helpers.yaml`**
```yaml
{{- define "app.image" -}}
{{ include "hf.common.images.image" (dict "imageRoot" .Values.images.app "global" .Values.global.huggingface) | quote }}
{{- end -}}
{{- define "app.imagePullSecrets" -}}
{{- include "hf.common.images.renderPullSecrets" (dict "images" (list .Values.images) "context" $) -}}
{{- end -}}
```
**`deployment.yaml`**
```yaml
...
spec:
{{- include "app.imagePullSecrets" . | nindent 6 }}
containers:
- name: app
image: {{ include "app.image" . }}
imagePullPolicy: {{ .Values.images.pullPolicy }}
...
```
The common function will generate :
```yaml
...
spec:
imagePullSecrets:
- name: regcred
containers:
- name: proxy
image: "my-registry.com/project/app:1.0.0"
imagePullPolicy: IfNotPresent
...
```
### Labels management
Use the common function to generate your resource labels.
**`_helpers.yaml`**
```yaml
{{- define "yourComp.selectorLabels" -}}
{{ include "hf.labels.commons" . }}
app.kubernetes.io/component: your-component-name
{{- end }}
```
**`deployment.yaml`**
```yaml
apiVersion: apps/v1
kind: Deployment
metadata:
labels: {{- include "yourComp.selectorLabels" . | nindent 4 }}
```
## Credits
This charts is inspired from [Bitnami](https://github.com/bitnami/charts) common functions.
## License
Copyright © 2023 HuggingFace
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License.
You may obtain a copy of the License at
<http://www.apache.org/licenses/LICENSE-2.0>
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and limitations under the License.
| {".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 c0b439224efd4d8d43703432c8cfbc629fff341d Hamza Amin <[email protected]> 1727369175 +0500\tclone: from https://github.com/huggingface/helm-common.git\n", ".git\\refs\\heads\\main": "c0b439224efd4d8d43703432c8cfbc629fff341d\n"} | null |
helm-publish-action | {"type": "directory", "name": "helm-publish-action", "children": [{"type": "file", "name": "action.yml"}, {"type": "file", "name": "LICENSE"}, {"type": "file", "name": "README.md"}]} | # HELM PUBLISH ACTION
[](https://github.com/huggingface/helm-publish-action/releases)
[](https://opensource.org/licenses/Apache-2.0)
Github Action to simplify Helm Chart publish into a registry.
# Usage
See [action.yml](action.yml)
```yaml
- name: Helm Publish Action
uses: huggingface/helm-publish-action@latest
with:
workingDirectory: charts
repository: https://registry.your-domain.com
username: ${{ secrets.REGISTRY_USERNAME }}
password: ${{ secrets.REGISTRY_PASSWORD }}
beforeHook: cd subcharts/my-sub-chart && helm dependencies update
```
### Use Tailscale VPN
If your registry is only accessible on a private network, and you use Tailscale, you can pass your tailscale Key to the action.
```yaml
- name: Helm Publish Action
uses: huggingface/helm-publish-action@latest
with:
tailscaleKey: ${{ secrets.TAILSCALE_AUTHKEY }}
```
### Before hook
If you need to execute a command before to publish, pass it via `beforeHook` argument.
This hook is usefully if you have subchart inside your Chart and you want update it before to publish your parent chart.
```yaml
- name: Helm Publish Action
uses: huggingface/helm-publish-action@latest
with:
beforeHook: cd subcharts/my-sub-chart && helm dependencies update
```
| {".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 f8e5375b77d55ac66f2d02d727e08924c3b67ac1 Hamza Amin <[email protected]> 1727369177 +0500\tclone: from https://github.com/huggingface/helm-publish-action.git\n", ".git\\refs\\heads\\main": "f8e5375b77d55ac66f2d02d727e08924c3b67ac1\n"} | null |
hf-endpoints-documentation | {"type": "directory", "name": "hf-endpoints-documentation", "children": [{"type": "directory", "name": "assets", "children": [{"type": "directory", "name": "access_ui", "children": []}]}, {"type": "directory", "name": "docs", "children": [{"type": "directory", "name": "source", "children": [{"type": "file", "name": "api_reference.mdx"}, {"type": "file", "name": "autoscaling.mdx"}, {"type": "file", "name": "faq.mdx"}, {"type": "directory", "name": "guides", "children": [{"type": "file", "name": "access.mdx"}, {"type": "file", "name": "advanced.mdx"}, {"type": "file", "name": "change_organization.mdx"}, {"type": "file", "name": "create_endpoint.mdx"}, {"type": "file", "name": "custom_container.mdx"}, {"type": "file", "name": "custom_dependencies.mdx"}, {"type": "file", "name": "custom_handler.mdx"}, {"type": "file", "name": "logs.mdx"}, {"type": "file", "name": "metrics.mdx"}, {"type": "file", "name": "pause_endpoint.mdx"}, {"type": "file", "name": "private_link.mdx"}, {"type": "file", "name": "test_endpoint.mdx"}, {"type": "file", "name": "update_endpoint.mdx"}]}, {"type": "file", "name": "index.mdx"}, {"type": "directory", "name": "others", "children": [{"type": "file", "name": "container_types.mdx"}, {"type": "file", "name": "runtime.mdx"}, {"type": "file", "name": "serialization.mdx"}]}, {"type": "file", "name": "pricing.mdx"}, {"type": "file", "name": "security.mdx"}, {"type": "file", "name": "support.mdx"}, {"type": "file", "name": "supported_tasks.mdx"}, {"type": "file", "name": "_toctree.yml"}]}]}, {"type": "file", "name": "env.json"}, {"type": "file", "name": "README.md"}]} | # Hugging Face Inference Endpoints documentation
## Setup
```bash
pip install hf-doc-builder==0.4.0 watchdog --upgrade
```
## Local Development
```bash
doc-builder preview endpoints docs/source/ --not_python_module
```
## Build Docs
```bash
doc-builder build endpoints docs/source/ --build_dir build/ --not_python_module
```
## Add assets/Images
Adding images/assets is only possible through `https://` links meaning you need to use `https://raw.githubusercontent.com/huggingface/hf-endpoints-documentation/main/assets/` prefix.
example
```bash
<img src="https://raw.githubusercontent.com/huggingface/hf-endpoints-documentation/main/assets/0_login.png" alt="Login" />
```
## Generate API Reference
1. Copy openapi spec from `https://api.endpoints.huggingface.cloud/api-doc/openapi.json`
2. create markdown `widdershins --environment env.json openapi.json -o myOutput.md`
3. copy into `api_reference.mdx`
| {".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 3c6909b6636d4351237fd4149c96ba462036363a Hamza Amin <[email protected]> 1727369203 +0500\tclone: from https://github.com/huggingface/hf-endpoints-documentation.git\n", ".git\\refs\\heads\\main": "3c6909b6636d4351237fd4149c96ba462036363a\n", "docs\\source\\index.mdx": "# Inference Endpoints\n\nInference Endpoints offers a secure production solution to easily deploy any Transformers, Sentence-Transformers and Diffusers models from the Hub on dedicated and autoscaling infrastructure managed by Hugging Face.\n\nA Hugging Face Endpoint is built from a [Hugging Face Model Repository](https://huggingface.co/models). When an Endpoint is created, the service creates image artifacts that are either built from the model you select or a custom-provided container image. The image artifacts are completely decoupled from the Hugging Face Hub source repositories to ensure the highest security and reliability levels.\n\nInference Endpoints support all of the [Transformers, Sentence-Transformers and Diffusers tasks](/docs/inference-endpoints/supported_tasks) as well as [custom tasks](/docs/inference-endpoints/guides/custom_handler) not supported by Transformers yet like speaker diarization and diffusion.\n\nIn addition, Inference Endpoints gives you the option to use a custom container image managed on an external service, for instance, [Docker Hub](https://hub.docker.com/), [AWS ECR](https://aws.amazon.com/ecr/?nc1=h_ls), [Azure ACR](https://azure.microsoft.com/de-de/services/container-registry/), or [Google GCR](https://cloud.google.com/container-registry?hl=de). \n\n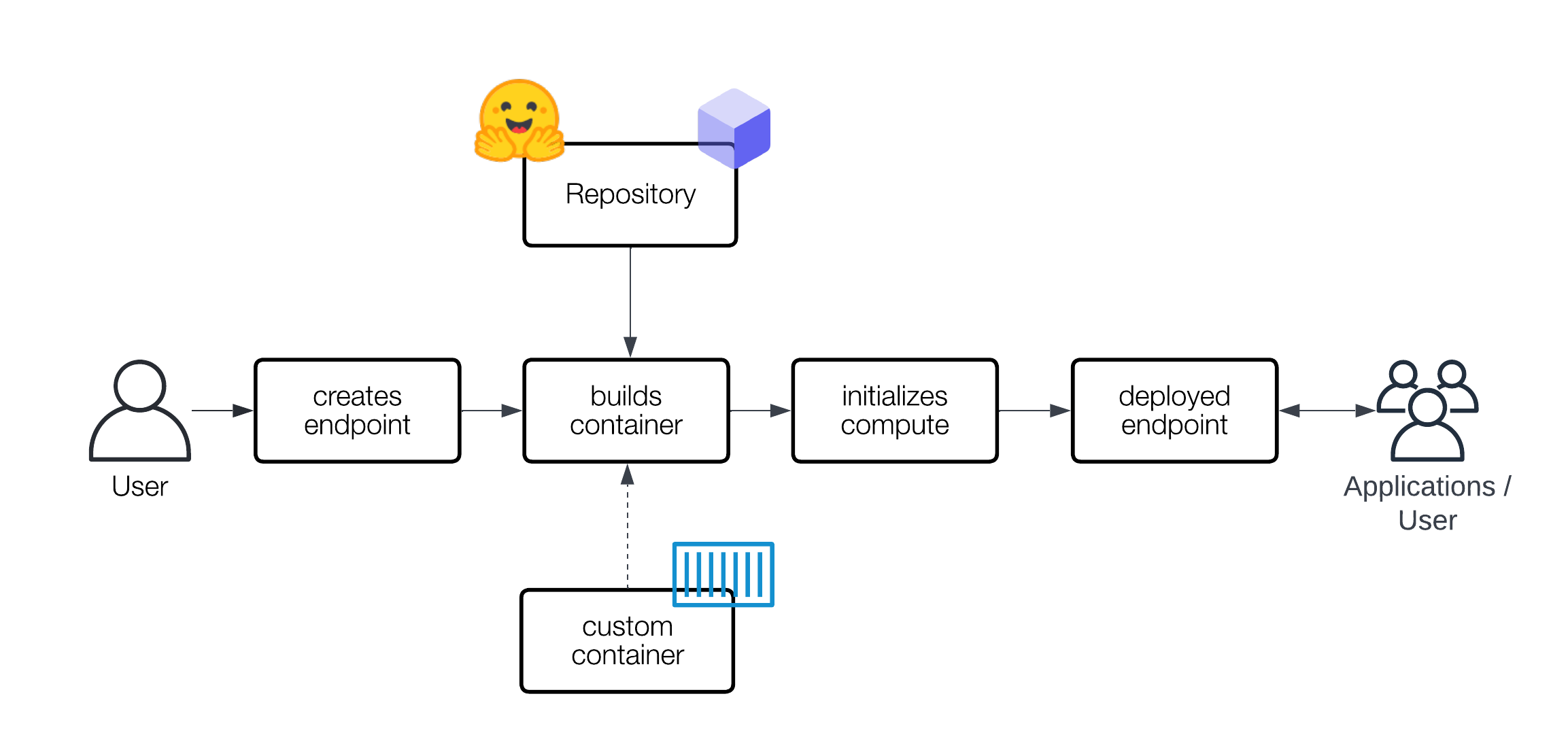\n\n## Documentation and Examples\n\n* [Security & Compliance](/docs/inference-endpoints/security)\n* [Supported Transformers Task](/docs/inference-endpoints/supported_tasks)\n* [API Reference](/docs/inference-endpoints/api_reference)\n* [Autoscaling](/docs/inference-endpoints/autoscaling)\n* [FAQ](/docs/inference-endpoints/faq)\n* [Help & Support](/docs/inference-endpoints/support)\n\n### Guides\n\n* [Access the solution (UI)](/docs/inference-endpoints/guides/access)\n* [Create your first Endpoint](/docs/inference-endpoints/guides/create_endpoint)\n* [Send Requests to Endpoints](/docs/inference-endpoints/guides/test_endpoint)\n* [Update your Endpoint](/docs/inference-endpoints/guides/update_endpoint)\n* [Advanced Setup (Instance Types, Auto Scaling, Versioning)](/docs/inference-endpoints/guides/advanced)\n* [Create a Private Endpoint with AWS PrivateLink](/docs/inference-endpoints/guides/private_link)\n* [Add custom Dependencies](/docs/inference-endpoints/guides/custom_dependencies)\n* [Create custom Inference Handler](/docs/inference-endpoints/guides/custom_handler)\n* [Use a custom Container Image](/docs/inference-endpoints/guides/custom_container)\n* [Access and read Logs](/docs/inference-endpoints/guides/logs)\n* [Access and view Metrics](/docs/inference-endpoints/guides/metrics)\n* [Change Organization or Account](/docs/inference-endpoints/guides/change_organization)\n\n### Others\n\n* [Inference Endpoints Versions](/docs/inference-endpoints/others/runtime)\n* [Serialization & Deserialization for Requests](/docs/inference-endpoints/others/serialization)\n"} | null |
hf-endpoints-emulator | {"type": "directory", "name": "hf-endpoints-emulator", "children": [{"type": "directory", "name": "examples", "children": [{"type": "file", "name": "my_handler.py"}, {"type": "file", "name": "test.py"}]}, {"type": "file", "name": "LICENSE"}, {"type": "file", "name": "makefile"}, {"type": "file", "name": "pyproject.toml"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "setup.cfg"}, {"type": "file", "name": "setup.py"}, {"type": "directory", "name": "src", "children": [{"type": "directory", "name": "hf_endpoints_emulator", "children": [{"type": "file", "name": "cli.py"}, {"type": "file", "name": "emulator.py"}, {"type": "file", "name": "serializer_deserializer.py"}, {"type": "file", "name": "__init__.py"}]}]}]} | # Emulator for Custom Handlers for Inference Endpoints
🤗 Inference Endpoints offers a secure production solution to easily deploy any 🤗 Transformers and Sentence-Transformers models from the Hub on dedicated and autoscaling infrastructure managed by Hugging Face.
🤗 Inference Endpoints support all of the 🤗 Transformers and Sentence-Transformers tasks as well as custom tasks not supported by 🤗 Transformers yet like speaker diarization and diffusion.
The `hf-endpoints-emulator` package provides a simple way to test your custom handlers locally before deploying them to Inference Endpoints. It is also useful for debugging your custom handlers.
The package provides a `hf-endpoints-emulator` command line tool that can be used to run your custom handlers locally. It also provides a `hf_endpoint_emulator` Python package that can be used to run your custom handlers locally from Python.
## Installation
```bash
pip install hf-endpoints-emulator
```
## Usage
You can check the `examples/` directory for examples on how to use the `hf-endpoints-emulator` package.
### Command Line
```bash
hf-endpoints-emulator --handler <handler>
```
This will start a web server that will run your custom handler. The web server will be accessible at `http://localhost:5000`. You can then send requests to the web server to test your custom handler.
**curl**
```bash
curl --request POST \
--url http://localhost/:5000 \
--header 'Content-Type: application/json' \
--data '{
"inputs": "I like you."
}'
```
**python**
```python
import requests
url = "http://localhost:5000/"
payload = {"inputs": "test"}
headers = {"Content-Type": "application/json"}
response = requests.request("POST", url, json=payload, headers=headers)
print(response.json())
```
## Python pacakge
```python
from hf_endpoints_emulator.emulator import emulate
emulate(handler_path="examples/my_handler.py", port=5000)
``` | {"setup.py": "from setuptools import find_packages, setup\n\n# We don't declare our dependency on transformers here because we build with\n# different packages for different variants\n\nVERSION = \"0.1.1\"\n\n\n# Ubuntu packages\n# libsndfile1-dev: torchaudio requires the development version of the libsndfile package which can be installed via a system package manager. On Ubuntu it can be installed as follows: apt install libsndfile1-dev\n# ffmpeg: ffmpeg is required for audio processing. On Ubuntu it can be installed as follows: apt install ffmpeg\n# libavcodec-extra : libavcodec-extra inculdes additional codecs for ffmpeg\n\ninstall_requires = [\n # transformers\n \"Pillow\",\n \"starlette\",\n \"uvicorn\",\n \"typer[all]\",\n]\n\nextras = {}\n\n# test and quality\nextras[\"test\"] = [\n \"pytest\",\n \"pytest-xdist\",\n \"parameterized\",\n \"psutil\",\n \"datasets\",\n \"pytest-sugar\",\n \"mock==2.0.0\",\n \"docker\",\n \"requests\",\n]\nextras[\"quality\"] = [\n \"black\",\n \"isort\",\n \"flake8\",\n]\n\n\nsetup(\n name=\"hf-endpoints-emulator\",\n version=VERSION,\n author=\"HuggingFace\",\n description=\"Emulator for Custom Handlers for Inference Endpoints\",\n long_description=open(\"README.md\", \"r\", encoding=\"utf-8\").read(),\n long_description_content_type=\"text/markdown\",\n keywords=\"NLP deep-learning transformer pytorch tensorflow BERT GPT GPT-2\",\n url=\"https://huggingface.co/inference-endpoints\",\n package_dir={\"\": \"src\"},\n packages=find_packages(where=\"src\"),\n install_requires=install_requires,\n extras_require=extras,\n entry_points={\"console_scripts\": \"hf-endpoints-emulator=hf_endpoints_emulator.cli:app\"},\n python_requires=\">=3.8.0\",\n license=\"MIT\",\n classifiers=[\n \"Development Status :: 5 - Production/Stable\",\n \"Intended Audience :: Developers\",\n \"Intended Audience :: Education\",\n \"Intended Audience :: Science/Research\",\n \"License :: OSI Approved :: Apache Software License\",\n \"Operating System :: OS Independent\",\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.9\",\n \"Topic :: Scientific/Engineering :: Artificial Intelligence\",\n ],\n)\n", ".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 f26e9e2afad0bbaa0034d3817d0ccc7d319fad44 Hamza Amin <[email protected]> 1727369205 +0500\tclone: from https://github.com/huggingface/hf-endpoints-emulator.git\n", ".git\\refs\\heads\\main": "f26e9e2afad0bbaa0034d3817d0ccc7d319fad44\n"} | null |
hf-hub | {"type": "directory", "name": "hf-hub", "children": [{"type": "file", "name": ".pre-commit-config.yaml"}, {"type": "file", "name": "Cargo.toml"}, {"type": "directory", "name": "examples", "children": [{"type": "file", "name": "download.rs"}]}, {"type": "file", "name": "flake.lock"}, {"type": "file", "name": "flake.nix"}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "src", "children": [{"type": "directory", "name": "api", "children": [{"type": "file", "name": "mod.rs"}, {"type": "file", "name": "sync.rs"}, {"type": "file", "name": "tokio.rs"}]}, {"type": "file", "name": "lib.rs"}]}]} | This crates aims to emulate and be compatible with the
[huggingface_hub](https://github.com/huggingface/huggingface_hub/) python package.
compatible means the Api should reuse the same files skipping downloads if
they are already present and whenever this crate downloads or modifies this cache
it should be consistent with [huggingface_hub](https://github.com/huggingface/huggingface_hub/)
At this time only a limited subset of the functionality is present, the goal is to add new
features over time. We are currently treating this as an internel/external tool, meaning
we will are currently modifying everything at will for out internal needs. This will eventually
stabilize as it matures to accomodate most of our needs.
If you're interested in using this, you're welcome to do it but be warned about potential changing grounds.
If you want to contribute, you are more than welcome.
However allowing new features or creating new features might be denied by lack of maintainability
time. We're focusing on what we currently internally need. Hopefully that subset is already interesting
to more users.
# How to use
Add the dependency
```bash
cargo add hf-hub # --features tokio
```
`tokio` feature will enable an async (and potentially faster) API.
Use the crate:
```rust
use hf_hub::api::sync::Api;
let api = Api::new().unwrap();
let repo = api.model("bert-base-uncased".to_string());
let _filename = repo.get("config.json").unwrap();
// filename is now the local location within hf cache of the config.json file
```
# SSL/TLS
When using the [`ureq`](https://github.com/algesten/ureq) feature, you will always use its default TLS backend which is [rustls](https://github.com/rustls/rustls).
When using [`tokio`](https://github.com/tokio-rs/tokio), by default `default-tls` will be enabled, which means OpenSSL. If you want/need to use rustls, disable the default features and use `rustls-tls` in conjunction with `tokio`.
| {".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 a66bdcf2f2664a55ab3a1415184c7aebd8ac4ed5 Hamza Amin <[email protected]> 1727369208 +0500\tclone: from https://github.com/huggingface/hf-hub.git\n", ".git\\refs\\heads\\main": "a66bdcf2f2664a55ab3a1415184c7aebd8ac4ed5\n"} | null |
hf-rocm-benchmark | {"type": "directory", "name": "hf-rocm-benchmark", "children": [{"type": "file", "name": "deepspeed_zero3.yml"}, {"type": "file", "name": "LICENSE"}, {"type": "file", "name": "peft_fine_tuning.py"}, {"type": "file", "name": "README.md"}]} | ## TGI benchmark
TGI benchmark with TP=8 can be reproduced as follow on MI250 and MI300:
```
docker run --rm -it --cap-add=SYS_PTRACE --security-opt seccomp=unconfined \
--device=/dev/kfd --device=/dev/dri --group-add video --ipc=host --shm-size 256g \
--net host -v $(pwd)/hf_cache:/data -e HUGGING_FACE_HUB_TOKEN=$HF_READ_TOKEN \
ghcr.io/huggingface/text-generation-inference:sha-293b8125-rocm \
--model-id meta-llama/Meta-Llama-3-70B-Instruct --num-shard 8
```
Then, a second shell needs to be open in TGI's server container:
```
docker container ls
docker exec -it container_name /bin/bash
```
From the second shell:
```
huggingface-cli login --token your_hf_read_token
text-generation-benchmark --tokenizer-name meta-llama/Meta-Llama-3-70B-Instruct \
--sequence-length 2048 --decode-length 128 --warmups 2 --runs 10 \
-b 1 -b 2 -b 4 -b 8 -b 16 -b 32 -b 64
```
Once the benchmark is finished, one can press Ctrl+C in the benchmark shell and should find a markdown table summarizing prefill and decode latency, as well as throughput.
Note: TGI's tool `text-generation-benchmark` tends to OOM, which does not reflect the real memory limit of the benchmarked GPUs. For reference: https://github.com/huggingface/text-generation-inference/issues/1831, https://github.com/huggingface/text-generation-inference/issues/1286
Note: Once released, we recommend to use the image `ghcr.io/huggingface/text-generation-inference:2.1-rocm` instead of `ghcr.io/huggingface/text-generation-inference:sha-293b8125-rocm`. TGI on ROCm can also be built from source using [this dockerfile](https://github.com/huggingface/text-generation-inference/blob/main/Dockerfile_amd).
### Recommended setup
We recommend setting on the host ([reference](https://huggingface.co/docs/optimum/main/en/amd/amdgpu/perf_hardware#numa-nodes)):
```
sudo sh -c "/usr/bin/echo 0 > /proc/sys/kernel/numa_balancing"
sudo rocm-smi --setperfdeterminism 1900
```
More details: https://github.com/ROCm/triton/wiki/A-script-to-set-program-execution-environment-in-ROCm
| {".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 eb18b6c9a53ed360907aed6806144b5ba227a233 Hamza Amin <[email protected]> 1727369211 +0500\tclone: from https://github.com/huggingface/hf-rocm-benchmark.git\n", ".git\\refs\\heads\\main": "eb18b6c9a53ed360907aed6806144b5ba227a233\n"} | null |
hf-workflows | {"type": "directory", "name": "hf-workflows", "children": [{"type": "file", "name": "README.md"}]} | # hf-workflows | {".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 1e5ae0c6ae6772df5ca482b3b3d71ad697d40c48 Hamza Amin <[email protected]> 1727369213 +0500\tclone: from https://github.com/huggingface/hf-workflows.git\n", ".git\\refs\\heads\\main": "1e5ae0c6ae6772df5ca482b3b3d71ad697d40c48\n"} | null |
hfapi | {"type": "directory", "name": "hfapi", "children": [{"type": "file", "name": "batch_throttle.py"}, {"type": "file", "name": "example.py"}, {"type": "directory", "name": "hfapi", "children": [{"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "LICENSE"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "setup.py"}]} | <p align="center">
<img src="https://huggingface.co/front/assets/huggingface_logo.svg" width="200" />
# HF API
Beta API client for Hugging Face Inference API. Directly call any model available in the Model Hub https://huggingface.co/models.
See example inference widget on https://huggingface.co/distilbert-base-uncased.
Client also takes an option api key for authorized access. These are available on your huggingface profile.
```
pip install git+https://github.com/huggingface/hfapi/
```
```python
import hfapi
client = hfapi.Client()
```
## Question Answering
```python
client.question_answering("Where does she live?", "She lives in Berlin.")
```
> {'score': 0.9375529668751711, 'start': 13, 'end': 19, 'answer': 'Berlin.'}
## Text Generation
```python
client.text_generation("My name is Julien and I like to ", model="gpt2")
```
> [{'generated_text': "My name is Julien and I like to \xa0play guitar, rock, record record, I can't thi
nk of a more unique band, I feel like i'm really connected, I always want to work and im passionate, thi
s feels like the"}]
## Summarization
```python
client.summarization("The tower is 324 metres (1,063 ft) tall, about the same height as an 81-storey building, and the tallest structure in Paris. Its base is square, measuring 125 metres (410 ft) on each side. During its construction, the Eiffel Tower surpassed the Washington Monument to become the tallest man-made structure in the world, a title it held for 41 years until the Chrysler Building in New York City was finished in 1930. It was the first structure to reach a height of 300 metres. Due to the addition of a broadcasting aerial at the top of the tower in 1957, it is now taller than the Chrysler Building by 5.2 metres (17 ft). Excluding transmitters, the Eiffel Tower is the second tallest free-standing structure in France after the Millau Viaduct.")
```
> [{'summary_text': ' The Eiffel Tower in Paris has officially opened its doors to the public.'}]
## Mask Filling
```python
client.fill_mask("Paris is the [MASK] of France."))
```
> [{'sequence': '[CLS] paris is the capital of france. [SEP]', 'score': 0.9815465807914734, 'token': 3007, 'token_str': 'capital'}, {'sequence': '[CLS] paris is the birthplace of france. [SEP]', 'score': 0.00334245921112597, 'token': 14508, 'token_str': 'birthplace'}, {'sequence': '[CLS] paris is the northernmost of france. [SEP]', 'score': 0.001044721808284521, 'token': 22037, 'token_str': 'northernmost'}, {'sequence': '[CLS] paris is the centre of france. [SEP]', 'score': 0.001004318823106587, 'token': 2803, 'token_str': 'centre'}, {'sequence': '[CLS] paris is the southernmost of france. [SEP]', 'score': 0.0007803254993632436, 'token': 21787, 'token_str': 'southernmost'}]
## Text Classification
```python
client.text_classification("I hated the movie!")
```
> [[{'label': 'NEGATIVE', 'score': 0.9996837973594666}, {'label': 'POSITIVE', 'score': 0.0003162133798468858}]]
## Token Classification
```python
client.token_classification("My name is Sarah and I live in London")
```
> [{'entity_group': 'B-PER', 'score': 0.9985478520393372, 'word': 'Sarah'}, {'entity_group': 'B-LOC', 'score': 0.999621570110321, 'word': 'London'}]
| {"setup.py": "#!/usr/bin/env python\n\n\nfrom distutils.core import setup\n\nsetup(name='HF API',\n version='0.1',\n description='Hugging Face Python API',\n packages=['hfapi']\n)\n", ".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n"} | null |
hffs | {"type": "directory", "name": "hffs", "children": [{"type": "file", "name": "CODE_OF_CONDUCT.md"}, {"type": "file", "name": "CONTRIBUTING.md"}, {"type": "file", "name": "LICENSE"}, {"type": "file", "name": "Makefile"}, {"type": "file", "name": "pyproject.toml"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "setup.cfg"}, {"type": "file", "name": "setup.py"}, {"type": "directory", "name": "src", "children": [{"type": "directory", "name": "hffs", "children": [{"type": "file", "name": "fs.py"}, {"type": "file", "name": "__init__.py"}]}]}, {"type": "directory", "name": "tests", "children": [{"type": "file", "name": "test_fs.py"}]}]} | > **Warning**
> `hffs` is no longer maintained. Please use `huggingface_hub`'s [FileSystem API](https://huggingface.co/docs/huggingface_hub/main/en/guides/hf_file_system) instead.
# `hffs`
`hffs` builds on [`huggingface_hub`](https://github.com/huggingface/huggingface_hub) and [`fsspec`](https://github.com/fsspec/filesystem_spec) to provide a convenient Python filesystem interface to 🤗 Hub.
## Basic usage
Locate and read a file from a 🤗 Hub repo:
```python
>>> import hffs
>>> fs = hffs.HfFileSystem()
>>> fs.ls("datasets/my-username/my-dataset-repo", detail=False)
['datasets/my-username/my-dataset-repo/.gitattributes', 'datasets/my-username/my-dataset-repo/my-file.txt']
>>> with fs.open("datasets/my-username/my-dataset-repo/my-file.txt", "r") as f:
... f.read()
'Hello, world'
```
Write a file to the repo:
```python
>>> with fs.open("datasets/my-username/my-dataset-repo/my-file-new.txt", "w") as f:
... f.write("Hello, world1")
... f.write("Hello, world2")
>>> fs.exists("datasets/my-username/my-dataset-repo/my-file-new.txt")
True
>>> fs.du("datasets/my-username/my-dataset-repo/my-file-new.txt")
26
```
Instantiation via `fsspec`:
```python
>>> import fsspec
>>> # Instantiate a `hffs.HfFileSystem` object
>>> fs = fsspec.filesystem("hf")
>>> fs.ls("my-username/my-model-repo")
['my-username/my-model-repo/.gitattributes', 'my-username/my-model-repo/config.json', 'my-username/my-model-repo/pytorch_model.bin']
>>> # Instantiate a `hffs.HfFileSystem` object and write a file to it
>>> with fsspec.open("hf://datasets/my-username/my-dataset-repo/my-file-new.txt"):
... f.write("Hello, world1")
... f.write("Hello, world2")
```
> **Note**: To be recognized as a `hffs` URL, the URL path passed to [`fsspec.open`](https://filesystem-spec.readthedocs.io/en/latest/api.html?highlight=open#fsspec.open) must adhere to the following scheme:
> ```
> hf://[<repo_type_prefix>]<repo_id>/<path/in/repo>
> ```
The prefix for datasets is "datasets/", the prefix for spaces is "spaces/" and models don't need a prefix in the URL.
## Installation
```bash
pip install hffs
```
## Usage examples
* [`pandas`](https://pandas.pydata.org/pandas-docs/stable/user_guide/io.html#reading-writing-remote-files)/[`dask`](https://docs.dask.org/en/stable/how-to/connect-to-remote-data.html)
```python
>>> import pandas as pd
>>> # Read a remote CSV file into a dataframe
>>> df = pd.read_csv("hf://datasets/my-username/my-dataset-repo/train.csv")
>>> # Write a dataframe to a remote CSV file
>>> df.to_csv("hf://datasets/my-username/my-dataset-repo/test.csv")
```
* [`datasets`](https://huggingface.co/docs/datasets/filesystems#load-and-save-your-datasets-using-your-cloud-storage-filesystem)
```python
>>> import datasets
>>> # Export a (large) dataset to a repo
>>> output_dir = "hf://datasets/my-username/my-dataset-repo"
>>> builder = datasets.load_dataset_builder("path/to/local/loading_script/loading_script.py")
>>> builder.download_and_prepare(output_dir, file_format="parquet")
>>> # Stream the dataset from the repo
>>> dset = datasets.load_dataset("my-username/my-dataset-repo", split="train", streaming=True)
>>> # Process the examples
>>> for ex in dset:
... ...
```
* [`zarr`](https://zarr.readthedocs.io/en/stable/tutorial.html#io-with-fsspec)
```python
>>> import numpy as np
>>> import zarr
>>> embeddings = np.random.randn(50000, 1000).astype("float32")
>>> # Write an array to a repo acting as a remote zarr store
>>> with zarr.open_group("hf://my-username/my-model-repo/array-store", mode="w") as root:
... foo = root.create_group("embeddings")
... foobar = foo.zeros('experiment_0', shape=(50000, 1000), chunks=(10000, 1000), dtype='f4')
... foobar[:] = embeddings
>>> # Read from a remote zarr store
>>> with zarr.open_group("hf://my-username/my-model-repo/array-store", mode="r") as root:
... first_row = root["embeddings/experiment_0"][0]
```
* [`duckdb`](https://duckdb.org/docs/guides/python/filesystems)
```python
>>> import hffs
>>> import duckdb
>>> fs = hffs.HfFileSystem()
>>> duckdb.register_filesystem(fs)
>>> # Query a remote file and get the result as a dataframe
>>> df = duckdb.query("SELECT * FROM 'hf://datasets/my-username/my-dataset-repo/data.parquet' LIMIT 10").df()
```
## Authentication
To write to your repositories or access your private repositories; you can login by running
```bash
huggingface-cli login
```
Or pass a token (from your [HF settings](https://huggingface.co/settings/tokens)) to
```python
>>> import hffs
>>> fs = hffs.HfFileSystem(token=token)
```
or as `storage_options`:
```python
>>> storage_options = {"token": token}
>>> df = pd.read_csv("hf://datasets/my-username/my-dataset-repo/train.csv", storage_options=storage_options)
```
| {"setup.py": "# Lint as: python3\n\"\"\"HuggingFace Filesystem is an interface to huggingface.co repositories.\n\nNote:\n\n VERSION needs to be formatted following the MAJOR.MINOR.PATCH convention\n (we need to follow this convention to be able to retrieve versioned scripts)\n\nSimple check list for release from AllenNLP repo: https://github.com/allenai/allennlp/blob/master/setup.py\n\nSteps to make a release:\n\n0. Prerequisites:\n - Dependencies:\n - twine: `pip install twine`\n - Create an account in (and join the 'hffs' project):\n - PyPI: https://pypi.org/\n - Test PyPI: https://test.pypi.org/\n\n1. Create the release branch from main branch:\n ```\n git checkout main\n git pull upstream main\n git checkout -b release-VERSION\n ```\n2. Change the version to the release VERSION in:\n - __init__.py\n - setup.py\n\n3. Commit these changes, push and create a Pull Request:\n ```\n git add -u\n git commit -m \"Release: VERSION\"\n git push upstream release-VERSION\n ```\n - Go to: https://github.com/huggingface/hffs/pull/new/release\n - Create pull request\n\n4. From your local release branch, build both the sources and the wheel. Do not change anything in setup.py between\n creating the wheel and the source distribution (obviously).\n - First, delete any building directories that may exist from previous builds:\n - build\n - dist\n - From the top level directory, build the wheel and the sources:\n ```\n python setup.py bdist_wheel\n python setup.py sdist\n ```\n - You should now have a /dist directory with both .whl and .tar.gz source versions.\n\n5. Check that everything looks correct by uploading the package to the test PyPI server:\n ```\n twine upload dist/* -r pypitest --repository-url=https://test.pypi.org/legacy/\n ```\n Check that you can install it in a virtualenv/notebook by running:\n ```\n pip install huggingface_hub fsspec aiohttp\n pip install -U tqdm\n pip install -i https://testpypi.python.org/pypi hffs\n ```\n\n6. Upload the final version to the actual PyPI:\n ```\n twine upload dist/* -r pypi\n ```\n\n7. Make the release on GitHub once everything is looking hunky-dory:\n - Merge the release Pull Request\n - Create a new release: https://github.com/huggingface/hffs/releases/new\n - Choose a tag: Introduce the new VERSION as tag, that will be created when you publish the release\n - Create new tag VERSION on publish\n - Release title: Introduce the new VERSION as well\n - Describe the release\n - Use \"Generate release notes\" button for automatic generation\n - Publish release\n\n8. Set the dev version\n - Create the dev-version branch from the main branch:\n ```\n git checkout main\n git pull upstream main\n git branch -D dev-version\n git checkout -b dev-version\n ```\n - Change the version to X.X.X+1.dev0 (e.g. VERSION=1.18.3 -> 1.18.4.dev0) in:\n - __init__.py\n - setup.py\n - Commit these changes, push and create a Pull Request:\n ```\n git add -u\n git commit -m \"Set dev version\"\n git push upstream dev-version\n ```\n - Go to: https://github.com/huggingface/hffs/pull/new/dev-version\n - Create pull request\n - Merge the dev version Pull Request\n\"\"\"\n\n\nfrom setuptools import find_packages, setup\n\n\nREQUIRED_PKGS = [\n \"fsspec\",\n \"requests\",\n \"huggingface_hub>=0.13.0\",\n]\n\n\nTESTS_REQUIRE = [\n \"pytest\",\n]\n\n\nQUALITY_REQUIRE = [\"black~=23.1\", \"ruff>=0.0.241\"]\n\n\nEXTRAS_REQUIRE = {\n \"dev\": TESTS_REQUIRE + QUALITY_REQUIRE,\n \"tests\": TESTS_REQUIRE,\n \"quality\": QUALITY_REQUIRE,\n}\n\nsetup(\n name=\"hffs\",\n version=\"0.0.1.dev0\", # expected format is one of x.y.z.dev0, or x.y.z.rc1 or x.y.z (no to dashes, yes to dots)\n description=\"Filesystem interface over huggingface.co repositories\",\n long_description=open(\"README.md\", encoding=\"utf-8\").read(),\n long_description_content_type=\"text/markdown\",\n author=\"HuggingFace Inc.\",\n author_email=\"[email protected]\",\n url=\"https://github.com/huggingface/hffs\",\n download_url=\"https://github.com/huggingface/hffs/tags\",\n license=\"Apache 2.0\",\n package_dir={\"\": \"src\"},\n packages=find_packages(\"src\"),\n python_requires=\">=3.7.0\",\n install_requires=REQUIRED_PKGS,\n extras_require=EXTRAS_REQUIRE,\n classifiers=[\n \"Development Status :: 5 - Production/Stable\",\n \"Intended Audience :: Developers\",\n \"Intended Audience :: Education\",\n \"Intended Audience :: Science/Research\",\n \"License :: OSI Approved :: Apache Software License\",\n \"Operating System :: OS Independent\",\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.7\",\n \"Programming Language :: Python :: 3.8\",\n \"Programming Language :: Python :: 3.9\",\n \"Programming Language :: Python :: 3.10\",\n \"Topic :: Scientific/Engineering :: Artificial Intelligence\",\n ],\n keywords=\"models datasets machine learning huggingface filesystem\",\n zip_safe=False, # Required for mypy to find the py.typed file\n)\n", ".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 ebdd09da437cb1bc7ec09d15bbc593dc79855333 Hamza Amin <[email protected]> 1727369200 +0500\tclone: from https://github.com/huggingface/hffs.git\n", ".git\\refs\\heads\\main": "ebdd09da437cb1bc7ec09d15bbc593dc79855333\n"} | null |
hf_benchmarks | {"type": "directory", "name": "hf_benchmarks", "children": [{"type": "file", "name": ".env.example"}, {"type": "directory", "name": "benchmarks", "children": [{"type": "directory", "name": "dummy", "children": [{"type": "file", "name": "evaluation.py"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "gem", "children": [{"type": "file", "name": "evaluation.py"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "generic_competition", "children": [{"type": "file", "name": "evaluation.py"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "raft", "children": [{"type": "file", "name": "evaluation.py"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "registration.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "data", "children": []}, {"type": "file", "name": "LICENSE"}, {"type": "file", "name": "Makefile"}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "scripts", "children": [{"type": "file", "name": "run_evaluation.py"}, {"type": "file", "name": "run_evaluation_dummy.py"}, {"type": "file", "name": "run_gem_scoring.py"}, {"type": "file", "name": "submission_table.py"}]}, {"type": "file", "name": "setup.cfg"}, {"type": "file", "name": "setup.py"}, {"type": "directory", "name": "src", "children": [{"type": "directory", "name": "hf_benchmarks", "children": [{"type": "file", "name": "file_utils.py"}, {"type": "file", "name": "hub.py"}, {"type": "file", "name": "schemas.py"}, {"type": "file", "name": "__init__.py"}]}]}, {"type": "directory", "name": "tests", "children": [{"type": "file", "name": "testing_utils.py"}, {"type": "file", "name": "test_dummy_benchmark.py"}, {"type": "file", "name": "test_evaluate.py"}, {"type": "file", "name": "test_hub.py"}, {"type": "file", "name": "__init__.py"}]}]} | # Hugging Face Benchmarks
## AutoTrain configuration details
Benchmarks are evaluated by AutoTrain, with the payload sent to the `AUTOTRAIN_BACKEND_API` environment variable. The current configuration for the hosted benchmarks is shown in the table below.
| Benchmark | Backend API |
|:---------:|:----------------------------------------------:|
| RAFT | `https://api.autotrain.huggingface.co` |
| GEM | `https://api.autotrain.huggingface.co` |
| {"setup.py": "# Lint as: python3\n\"\"\" Hugging Face Benchmarks is an open-source library for evaluating machine learning benchmarks.\n\nNote:\n\n VERSION needs to be formatted following the MAJOR.MINOR.PATCH convention\n (we need to follow this convention to be able to retrieve versioned scripts)\n\nSimple check list for release from AllenNLP repo: https://github.com/allenai/allennlp/blob/master/setup.py\n\nTo create the package for pypi.\n\n1. Change the version in __init__.py, setup.py as well as docs/source/conf.py.\n\n2. Commit these changes with the message: \"Release: VERSION\"\n\n3. Add a tag in git to mark the release: \"git tag VERSION -m'Adds tag VERSION for pypi' \"\n Push the tag to git: git push --tags origin master\n\n4. Build both the sources and the wheel. Do not change anything in setup.py between\n creating the wheel and the source distribution (obviously).\n\n For the wheel, run: \"python setup.py bdist_wheel\" in the top level directory.\n (this will build a wheel for the python version you use to build it).\n\n For the sources, run: \"python setup.py sdist\"\n You should now have a /dist directory with both .whl and .tar.gz source versions.\n\n5. Check that everything looks correct by uploading the package to the pypi test server:\n\n twine upload dist/* -r pypitest\n (pypi suggest using twine as other methods upload files via plaintext.)\n You may have to specify the repository url, use the following command then:\n twine upload dist/* -r pypitest --repository-url=https://test.pypi.org/legacy/\n\n Check that you can install it in a virtualenv by running:\n pip install -i https://testpypi.python.org/pypi datasets\n\n6. Upload the final version to actual pypi:\n twine upload dist/* -r pypi\n\n7. Fill release notes in the tag in github once everything is looking hunky-dory.\n\n8. Update the documentation commit in .circleci/deploy.sh for the accurate documentation to be displayed\n Update the version mapping in docs/source/_static/js/custom.js with utils/release.py,\n and set version to X.X.X+1.dev0 (e.g. 1.8.0 -> 1.8.1.dev0) in setup.py and __init__.py\n\n\"\"\"\n\nfrom pathlib import Path\n\nfrom setuptools import find_packages, setup\n\n\nDOCLINES = __doc__.split(\"\\n\")\n\n# We must upper bound the datasets version to match that in the AutoTrain backend\nREQUIRED_PKGS = [\n \"datasets<=2.2\",\n \"typer>=0.3.2\",\n \"click==8.0\",\n \"python-dotenv>=0.18.0\",\n \"evaluate==0.1.2\",\n \"scikit-learn==1.1.1\",\n \"huggingface-hub==0.10.1\",\n]\n\nQUALITY_REQUIRE = [\"black\", \"flake8\", \"isort\", \"pyyaml>=5.3.1\", \"mypy\", \"types-requests\"]\n\nTESTS_REQUIRE = [\"pytest\", \"pytest-cov\"]\n\nEXTRAS_REQUIRE = {\"quality\": QUALITY_REQUIRE, \"tests\": TESTS_REQUIRE}\n\n\ndef combine_requirements(base_keys):\n return list(set(k for v in base_keys for k in EXTRAS_REQUIRE[v]))\n\n\nEXTRAS_REQUIRE[\"dev\"] = combine_requirements([k for k in EXTRAS_REQUIRE])\nEXTRAS_REQUIRE[\"cron\"] = [\"requests\"]\n\nbenchmark_dependencies = list(Path(\"benchmarks/\").glob(\"**/requirements.txt\"))\nfor benchmark in benchmark_dependencies:\n with open(benchmark, \"r\") as f:\n deps = f.read().splitlines()\n EXTRAS_REQUIRE[benchmark.parent.name] = deps\n\nsetup(\n name=\"hf_benchmarks\",\n version=\"0.0.1\",\n description=DOCLINES[0],\n long_description=\"\\n\".join(DOCLINES[2:]),\n author=\"HuggingFace Inc.\",\n author_email=\"[email protected]\",\n url=\"https://github.com/huggingface/hf_benchmarks\",\n download_url=\"https://github.com/huggingface/hf_benchmarks/tags\",\n license=\"Apache 2.0\",\n package_dir={\"\": \"src\"},\n packages=find_packages(\"src\"),\n install_requires=REQUIRED_PKGS,\n extras_require=EXTRAS_REQUIRE,\n classifiers=[\n \"Development Status :: 1 - Planning\",\n \"Intended Audience :: Developers\",\n \"Intended Audience :: Education\",\n \"Intended Audience :: Science/Research\",\n \"License :: OSI Approved :: Apache Software License\",\n \"Operating System :: OS Independent\",\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.8\",\n \"Programming Language :: Python :: 3.9\",\n \"Topic :: Scientific/Engineering :: Artificial Intelligence\",\n ],\n keywords=\"machine learning benchmarks evaluation metrics\",\n zip_safe=False, # Required for mypy to find the py.typed file\n)\n", ".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 48044301c356f1118bcd43a8dfca379493ec22ed Hamza Amin <[email protected]> 1727369203 +0500\tclone: from https://github.com/huggingface/hf_benchmarks.git\n", ".git\\refs\\heads\\main": "48044301c356f1118bcd43a8dfca379493ec22ed\n", "benchmarks\\dummy\\requirements.txt": "scikit-learn>=0.24.2\ndatasets<=2.2\nevaluate==0.1.2", "benchmarks\\gem\\requirements.txt": "datasets==1.17.0 # DO NOT CHANGE!\ngem-metrics @ git+https://github.com/GEM-benchmark/GEM-metrics.git", "benchmarks\\generic_competition\\requirements.txt": "scikit-learn>=0.24.2", "benchmarks\\raft\\requirements.txt": "scikit-learn>=0.24.2"} | null |
hf_transfer | {"type": "directory", "name": "hf_transfer", "children": [{"type": "file", "name": "Cargo.lock"}, {"type": "file", "name": "Cargo.toml"}, {"type": "directory", "name": "examples", "children": [{"type": "file", "name": "upload_to_s3.py"}]}, {"type": "file", "name": "LICENSE"}, {"type": "file", "name": "pyproject.toml"}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "src", "children": [{"type": "file", "name": "lib.rs"}]}]} | # HF Transfer
Speed up file transfers with the Hub.
# DISCLAIMER
This library is a power user tool, to go beyond `~500MB/s` on very high bandwidth
network, where Python cannot cap out the available bandwidth.
This is *not* meant to be a general usability tool.
It purposefully lacks progressbars and comes generally as-is.
Please file issues *only* if there's an issue on the underlying downloaded file.
## Contributing
```sh
python3 -m venv ~/.venv/hf_transfer
source ~/.venv/hf_transfer/bin/activate
pip install maturin
maturin develop
```
### `huggingface_hub`
If you are working on changes with `huggingface_hub`
```sh
git clone [email protected]:huggingface/huggingface_hub.git
# git clone https://github.com/huggingface/huggingface_hub.git
cd huggingface_hub
python3 -m pip install -e ".[quality]"
```
You can use the following test script:
```py
import os
# os.environ["HF_ENDPOINT"] = "http://localhost:5564"
os.environ["HF_HUB_ENABLE_HF_TRANSFER"] = "1"
from huggingface_hub import HfApi, logging
logging.set_verbosity_debug()
hf = HfApi()
hf.upload_file(path_or_fileobj="/path/to/my/repo/some_file", path_in_repo="some_file", repo_id="my/repo", repo_type="model")
```
| {".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 a1feb83ea64fe431801689b842f4d3ff61f06fa7 Hamza Amin <[email protected]> 1727369206 +0500\tclone: from https://github.com/huggingface/hf_transfer.git\n", ".git\\refs\\heads\\main": "a1feb83ea64fe431801689b842f4d3ff61f06fa7\n"} | null |
hmtl | {"type": "directory", "name": "hmtl", "children": [{"type": "directory", "name": "configs", "children": [{"type": "file", "name": "coref_ace.json"}, {"type": "file", "name": "coref_conll.json"}, {"type": "file", "name": "emd.json"}, {"type": "file", "name": "emd_coref_ace.json"}, {"type": "file", "name": "emd_relation.json"}, {"type": "file", "name": "hmtl_coref_ace.json"}, {"type": "file", "name": "hmtl_coref_conll.json"}, {"type": "file", "name": "ner.json"}, {"type": "file", "name": "ner_emd.json"}, {"type": "file", "name": "ner_emd_coref_ace.json"}, {"type": "file", "name": "ner_emd_relation.json"}, {"type": "file", "name": "relation.json"}]}, {"type": "directory", "name": "demo", "children": [{"type": "file", "name": "hmtlPredictor.py"}, {"type": "directory", "name": "model_dumps", "children": [{"type": "directory", "name": "conll_full_elmo", "children": [{"type": "file", "name": "config.json"}, {"type": "directory", "name": "vocabulary", "children": [{"type": "file", "name": "ace_mention_labels.txt"}, {"type": "file", "name": "ner_ontonotes_labels.txt"}, {"type": "file", "name": "non_padded_namespaces.txt"}, {"type": "file", "name": "relation_ace_labels.txt"}, {"type": "file", "name": "tokens.txt"}, {"type": "file", "name": "token_characters.txt"}]}, {"type": "file", "name": "weights.th"}]}, {"type": "directory", "name": "conll_medium_elmo", "children": [{"type": "file", "name": "config.json"}, {"type": "directory", "name": "vocabulary", "children": [{"type": "file", "name": "ace_mention_labels.txt"}, {"type": "file", "name": "ner_ontonotes_labels.txt"}, {"type": "file", "name": "non_padded_namespaces.txt"}, {"type": "file", "name": "relation_ace_labels.txt"}, {"type": "file", "name": "tokens.txt"}, {"type": "file", "name": "token_characters.txt"}]}, {"type": "file", "name": "weights.th"}]}, {"type": "directory", "name": "conll_small_elmo", "children": [{"type": "file", "name": "config.json"}, {"type": "directory", "name": "vocabulary", "children": [{"type": "file", "name": "ace_mention_labels.txt"}, {"type": "file", "name": "ner_ontonotes_labels.txt"}, {"type": "file", "name": "non_padded_namespaces.txt"}, {"type": "file", "name": "relation_ace_labels.txt"}, {"type": "file", "name": "tokens.txt"}, {"type": "file", "name": "token_characters.txt"}]}, {"type": "file", "name": "weights.th"}]}]}, {"type": "file", "name": "predictionFormatter.py"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "server.py"}, {"type": "directory", "name": "web", "children": [{"type": "directory", "name": "assets", "children": [{"type": "file", "name": "checkbox-off.svg"}, {"type": "file", "name": "checkbox-on.svg"}, {"type": "file", "name": "icon.svg"}, {"type": "file", "name": "icons.svg"}, {"type": "file", "name": "link.svg"}]}, {"type": "file", "name": "bower.json"}, {"type": "file", "name": "deploy.sh"}, {"type": "file", "name": "Gruntfile.js"}, {"type": "file", "name": "index.html"}, {"type": "directory", "name": "js-src", "children": [{"type": "file", "name": "Displacy.ts"}, {"type": "file", "name": "HuggingNlp.ts"}, {"type": "file", "name": "SvgArrow.ts"}, {"type": "file", "name": "Utils.ts"}, {"type": "file", "name": "zController.ts"}]}, {"type": "directory", "name": "less", "children": [{"type": "directory", "name": "mixins", "children": [{"type": "file", "name": "bfc.less"}, {"type": "file", "name": "clearfix.less"}, {"type": "file", "name": "size.less"}, {"type": "file", "name": "user-select.less"}]}, {"type": "file", "name": "style.less"}, {"type": "file", "name": "zDisplacy.less"}]}, {"type": "file", "name": "package-lock.json"}, {"type": "file", "name": "package.json"}, {"type": "file", "name": "tsconfig.json"}]}]}, {"type": "file", "name": "evaluate.py"}, {"type": "file", "name": "fine_tune.py"}, {"type": "directory", "name": "hmtl", "children": [{"type": "directory", "name": "common", "children": [{"type": "file", "name": "util.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "dataset_readers", "children": [{"type": "file", "name": "coref_ace.py"}, {"type": "directory", "name": "dataset_utils", "children": [{"type": "file", "name": "ace.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "mention_ace.py"}, {"type": "file", "name": "ner_ontonotes.py"}, {"type": "file", "name": "relation_ace.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "models", "children": [{"type": "file", "name": "coref_custom.py"}, {"type": "file", "name": "hmtl.py"}, {"type": "file", "name": "layerCoref.py"}, {"type": "file", "name": "layerEmdCoref.py"}, {"type": "file", "name": "layerEmdRelation.py"}, {"type": "file", "name": "layerNer.py"}, {"type": "file", "name": "layerNerEmd.py"}, {"type": "file", "name": "layerNerEmdCoref.py"}, {"type": "file", "name": "layerNerEmdRelation.py"}, {"type": "file", "name": "layerRelation.py"}, {"type": "file", "name": "relation_extraction.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "modules", "children": [{"type": "directory", "name": "seq2seq_encoders", "children": [{"type": "file", "name": "stacked_gru.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "text_field_embedders", "children": [{"type": "file", "name": "shortcut_connect_text_field_embedder.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "tasks", "children": [{"type": "file", "name": "task.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "training", "children": [{"type": "directory", "name": "metrics", "children": [{"type": "file", "name": "conll_coref_full_scores.py"}, {"type": "file", "name": "relation_f1_measure.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "multi_task_trainer.py"}, {"type": "file", "name": "sampler_multi_task_trainer.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "html_senteval.py"}, {"type": "file", "name": "LICENSE"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "directory", "name": "scripts", "children": [{"type": "file", "name": "data_setup.sh"}, {"type": "file", "name": "machine_setup.sh"}]}, {"type": "directory", "name": "SentEval", "children": []}, {"type": "file", "name": "train.py"}]} | # 🎮 Demo: HMTL (Hierarchical Multi-Task Learning model)
## Introduction
This is a demonstration of our NLP system: HMTL is a neural model for resolving four fundamental tasks in NLP, namely *Named Entity Recognition*, *Entity Mention Detection*, *Relation Extraction* and *Coreference Resolution* using multi-task learning.
For a brief introduction to multi-task learning, you can refer to [our blog post](https://medium.com/p/b4e1d5c3faf). Each of the four tasks considered is detailed in the following section.
The web interface for the demo can be found [here](https://huggingface.co/hmtl/) for you to try and play with it. HMTL comes with the web visualization client if you prefer to run on your local machine. The demo (and the released weights) are for English.
<img src="https://github.com/huggingface/hmtl/blob/master/demo/HMTL_demo.png" alt="HMTL Demo" width="900"/>
## Setup
The [web demo](https://huggingface.co/hmtl/) is based on Python 3.6 and [AllenNLP](https://github.com/allenai/allennlp).
The easiest way to setup a clean and working environment with the necessary dependencies is to refer to the setup section in the [parent folder](https://github.com/huggingface/hmtl#dependecies-and-installation).
A few supplementary dependecies are listed in `requirements.txt` and are required to run the demo.
We also release three pre-trained HMTL models on English corporas. The three models essentially differ by the size of the ELMo embeddings used and thus the size of the model. The bigger the model, the higher the performance:
| Model Name | NER (F1) | EMD (F1) | RE (F1) | CR(F1) | Description |
| --- | --- | --- | --- | --- | --- |
| conll_small_elmo | 85.73 | 83.51 | 58.40 | 62.85 | Small version of ELMo |
| conll_medium_elmo | 86.41 | 84.02 | 58.78 | 61.62 | Medium version of ELMo |
| conll_full_elmo _(default model)_ | 86.40 | 85.59 | 61.37 | 62.26 | Original version of ELMo |
To download the pre-trained models, please install [git lfs](https://git-lfs.github.com/) and do a `git lfs pull`. The weights of the model will be saved in the `model_dumps` folder.
## Description of the tasks
### Named Entity Recognition (NER)
_Named Entity Recognition_ aims at identifying and clasifying named entities (real-world object, such as persons, locations, etc. that can be denoted with a proper name).
[Homer Simpson]<sub>PERS</sub> lives in [Springfield]<sub>LOC</sub> with his wife and kids.
HMTL is trained on OntoNotes 5.0 and can recognized various types (18) of named entities: _PERSON_, _NORP_, _FAC_, _ORG_, _GPE_, _LOC_, etc.
### Entity Mention Detection (EMD)
_Entity Mention Detection_ aims at identifying and clasifying entity mentions (real-world object, such as persons, locations, etc. that are not necessarily denoted with a proper name).
[The men]<sub>PERS</sub> held on [the sinking vessel]<sub>VEH</sub> until [the ship]<sub>VEH</sub> was able to reach them from [Corsica]<sub>LOC</sub>.
HMTL can recognized different types of mentions: _PER_, _GPE_, _ORG_, _FAC_, _LOC_, _WEA_ and _VEH_.
### Relation Extraction (RE)
_Relation extraction_ aims at extracting the semantic relations between the mentions.
The different types of relation detectec by HMTL are the following:
| Shortname | Full Name | Description | Example |
| --- | --- | -- | -- |
| ART | Artifact | User-Owner-Inventor-Manufacturer | {Leonard de Vinci painted the Joconde., ARG1 = Leonard de Vinci, ARG2 = Joconde} |
| GEN-AFF | Gen-Affiliation | Citizen-Resident-Religion-Ethnicity, Org-Location | {The people of Iraq., ARG1 = The people, ARG2 = Iraq} |
| ORG-AFF | Org-Affiliation | Employment, Founder, Ownership, Student-Alum, Sports-Affiliation, Investor-Shareholder, Membership | {Martin Geisler, ITV News, Safwan southern Iraq., ARG1 = Martin Geisler, ARG2 = ITV News} |
| PART-WHOLE | Part-whole | Artifact, Geographical, Subsidiary | {They could safeguard the fields in Iraq., ARG1 = the fields, ARG2 = Iraq} |
| PER-SOC | Person-social | Business, Family, Lasting-Personal | {Sean Flyn, son the famous actor Errol Flynn, ARG1 = son, ARG2 = Errol Flynn} |
| PHYS | Physical | Located, Near | {The two journalists worked from the hotel., ARG1 = the two journalists, ARG2 = the hotel} |
For more details, please refer to the [dataset release notes](https://pdfs.semanticscholar.org/3a9b/136ca1ab91592df36f148ef16095f74d009e.pdf).
### Coreference Resolution (CR)
In a text, two or more expressions can link to the same person or thing in the worl. _Coreference Resolution_ aims at finding the coreferent spans and cluster them.
[My mom]<sub>1</sub> tasted [the cake]<sub>2</sub>. [She]<sub>1</sub> liked [it]<sub>2</sub>.
## Using HMTL as a server
HTML can be used as a REST API. A simple example of server script is provided as an example in [server.py](https://github.com/huggingface/hmtl/blob/master/demo/server.py).
To launch a specific model (please make sure to be in a environment with all the dependencies before: `source .env/bin/activate`):
```bash
gunicorn -b:8000 'server:build_app(model_name="<model_name>")'
```
or simply launching the default (full) model:
```bash
gunicorn -b:8000 'server:build_app()'
```
You can then call then the model with the following command: `curl http://localhost:8000/jmd/?text=Barack%20Obama%20is%20the%20former%20president.`.
| {"requirements.txt": "alabaster==0.7.12\nallennlp==0.7.0\nasn1crypto==0.24.0\natomicwrites==1.2.1\nattrs==18.2.0\naws-xray-sdk==0.95\nawscli==1.16.38\nBabel==2.6.0\nbiscuits==0.1.1\nboto==2.49.0\nboto3==1.9.28\nbotocore==1.12.28\ncertifi==2018.10.15\ncffi==1.11.2\nchardet==3.0.4\nClick==7.0\ncolorama==0.3.9\nconllu==0.11\ncookies==2.2.1\ncryptography==2.3.1\ncymem==2.0.2\ncytoolz==0.9.0.1\ndill==0.2.8.2\ndocker==3.5.1\ndocker-pycreds==0.3.0\ndocutils==0.14\necdsa==0.13\neditdistance==0.5.2\nhttps://github.com/explosion/spacy-models/releases/download/en_core_web_sm-2.0.0/en_core_web_sm-2.0.0.tar.gz\nflaky==3.4.0\nFlask==0.12.4\nFlask-Cors==3.0.3\nftfy==5.5.0\nfuture==0.16.0\ngevent==1.3.6\ngreenlet==0.4.15\nh5py==2.8.0\nidna==2.7\nimagesize==1.1.0\nItsDangerous==1.1.0\nJinja2==2.10\njmespath==0.9.3\njsondiff==1.1.1\njsonnet==0.10.0\njsonpickle==1.0\nMarkupSafe==1.0\nmock==2.0.0\nmore-itertools==4.3.0\nmoto==1.3.4\nmsgpack==0.5.6\nmsgpack-numpy==0.4.3.2\nmurmurhash==1.0.1\nnltk==3.3\nnumpy==1.15.2\nnumpydoc==0.8.0\noverrides==1.9\npackaging==18.0\nparsimonious==0.8.0\npbr==5.0.0\nplac==0.9.6\npluggy==0.8.0\npreshed==2.0.1\nprotobuf==3.6.1\npy==1.7.0\npyaml==17.12.1\npyasn1==0.4.4\npycparser==2.19\npycryptodome==3.6.6\nPygments==2.7.4\npyparsing==2.2.2\npytest==3.9.1\npytest-pythonpath==0.7.3\npython-dateutil==2.7.3\npython-jose==2.0.2\npytz==2017.3\nPyYAML==3.13\nregex==2018.1.10\nrequests==2.20.0\nresponses==0.10.1\nrsa==3.4.2\ns3transfer==0.1.13\nscikit-learn==0.20.0\nscipy==1.1.0\nsix==1.11.0\nsnowballstemmer==1.2.1\nspacy==2.0.16\nSphinx==1.8.1\nsphinxcontrib-websupport==1.1.0\nsqlparse==0.2.4\ntensorboardX==1.2\nthinc==6.12.0\ntoolz==0.9.0\ntorch==0.4.1\ntqdm==4.28.1\nujson==1.35\nUnidecode==1.0.22\nurllib3==1.24\nwcwidth==0.1.7\nwebsocket-client==0.53.0\nWerkzeug==0.14.1\nwrapt==1.10.11\nxmltodict==0.11.0\n", ".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", "demo\\requirements.txt": "emoji==0.5.1\nfalcon==1.4.1\ngunicorn==19.9.0\npython-mimeparse==1.6.0\nstatsd==3.3.0\n", "demo\\web\\index.html": "<!DOCTYPE html>\n<html>\n<head>\n\t<meta charset=\"utf-8\">\n\t<title>HMTL for NLP</title>\n\t<meta name=\"viewport\" content=\"width=device-width, initial-scale=1.0, user-scalable=no\">\n\t<link rel=\"stylesheet\" href=\"dist/style.css\">\n\t<meta property=\"og:url\" content=\"https://huggingface.co/hmtl/\">\n\t<meta property=\"og:image\" content=\"https://huggingface.co/hmtl/assets/thumbnail-hmtl.png\">\n\t<meta property=\"fb:app_id\" content=\"1321688464574422\">\n\t<meta name=\"description\" content=\"This is a demo of HMTL for NLP, our new NLP multi-task model that reaches or beats SotA on 4 distinct NLP tasks.\">\n</head>\n<body>\n\t<div class=\"navbar\">\n\t\t<a target=\"_blank\" href=\"https://huggingface.co\">\n\t\t\t<img class=\"svg-logo\" src=\"assets/icon.svg\">\n\t\t</a>\n\t\t<div class=\"title-wrapper\">\n\t\t\t<div class=\"title\">HMTL for NLP</div>\n\t\t\t<div class=\"link\">\n\t\t\t\t<a target=\"_blank\" href=\"https://github.com/huggingface/hmtl\">GitHub</a>\n\t\t\t</div>\n\t\t</div>\n\t</div>\n\t<div class=\"header\">\n\t\t<div class=\"input-wrapper\">\n\t\t\t<form class=\"js-form\">\n\t\t\t\t<div class=\"wrapper-inner\">\n\t\t\t\t\t<div class=\"input-message-wrapper\">\n\t\t\t\t\t\t<input class=\"input-message\" type=\"text\" name=\"text\" placeholder=\"Your sentence here...\" autocomplete=\"off\" autofocus>\n\t\t\t\t\t</div>\n\t\t\t\t\t<button class=\"input-button c-input__button\">\n\t\t\t\t\t\t<svg aria-hidden=\"true\" viewBox=\"0 0 20 20\" width=\"20\" height=\"20\" fill=\"currentColor\" class=\"o-icon c-input__button__icon\">\n\t\t\t\t\t\t\t<use xmlns:xlink=\"http://www.w3.org/1999/xlink\" xlink:href=\"assets/icons.svg#icon-search\"></use>\n\t\t\t\t\t\t</svg>\n\t\t\t\t\t\t<svg aria-hidden=\"true\" viewBox=\"0 0 20 20\" width=\"20\" height=\"20\" fill=\"currentColor\" class=\"o-icon c-input__button__spinner\">\n\t\t\t\t\t\t\t<use xmlns:xlink=\"http://www.w3.org/1999/xlink\" xlink:href=\"assets/icons.svg#icon-spinner\"></use>\n\t\t\t\t\t\t</svg>\n\t\t\t\t\t</button>\n\t\t\t\t</div>\n\t\t\t</form>\n\t\t</div>\n\t</div>\n\t\n\t<div class=\"tasks\">\n\t\t<div class=\"task ner\" id=\"ner\">\n\t\t\t<div class=\"hairline\"></div>\n\t\t\t<div class=\"title\">\n\t\t\t\t<div class=\"title-inner\">Named Entity Recognition</div>\n\t\t\t\t<a href=\"#ner\">\n\t\t\t\t\t<svg aria-hidden=\"true\" viewBox=\"0 0 16 16\" width=\"16\" height=\"16\" fill=\"currentColor\" class=\"svg-link\">\n\t\t\t\t\t\t<use xmlns:xlink=\"http://www.w3.org/1999/xlink\" xlink:href=\"assets/link.svg#icon-link\"></use>\n\t\t\t\t\t</svg>\n\t\t\t\t</a>\n\t\t\t</div>\n\t\t\t<div class=\"container-wrapper\">\n\t\t\t\t<svg class=\"svg-container\"></svg>\n\t\t\t\t<div class=\"container\"></div>\n\t\t\t</div>\n\t\t</div>\n\t\t\n\t\t<div class=\"task emd\" id=\"emd\">\n\t\t\t<div class=\"hairline\"></div>\n\t\t\t<div class=\"title\">\n\t\t\t\t<div class=\"title-inner\">Entity Mention Detection</div>\n\t\t\t\t<a href=\"#emd\">\n\t\t\t\t\t<svg aria-hidden=\"true\" viewBox=\"0 0 16 16\" width=\"16\" height=\"16\" fill=\"currentColor\" class=\"svg-link\">\n\t\t\t\t\t\t<use xmlns:xlink=\"http://www.w3.org/1999/xlink\" xlink:href=\"assets/link.svg#icon-link\"></use>\n\t\t\t\t\t</svg>\n\t\t\t\t</a>\n\t\t\t</div>\n\t\t\t<div class=\"container-wrapper\">\n\t\t\t\t<svg class=\"svg-container\"></svg>\n\t\t\t\t<div class=\"container\"></div>\n\t\t\t</div>\n\t\t</div>\n\t\t\n\t\t<div class=\"task relex\" id=\"relex\">\n\t\t\t<div class=\"hairline\"></div>\n\t\t\t<div class=\"title\">\n\t\t\t\t<div class=\"title-inner\">Relation Extraction</div>\n\t\t\t\t<a href=\"#relex\">\n\t\t\t\t\t<svg aria-hidden=\"true\" viewBox=\"0 0 16 16\" width=\"16\" height=\"16\" fill=\"currentColor\" class=\"svg-link\">\n\t\t\t\t\t\t<use xmlns:xlink=\"http://www.w3.org/1999/xlink\" xlink:href=\"assets/link.svg#icon-link\"></use>\n\t\t\t\t\t</svg>\n\t\t\t\t</a>\n\t\t\t</div>\n\t\t\t<div class=\"container-wrapper\">\n\t\t\t\t<svg class=\"svg-container\"></svg>\n\t\t\t\t<div class=\"container\"></div>\n\t\t\t</div>\n\t\t</div>\n\t\t\n\t\t<div class=\"task coref\" id=\"coref\">\n\t\t\t<div class=\"hairline\"></div>\n\t\t\t<div class=\"title\">\n\t\t\t\t<div class=\"title-inner\">Coreference Resolution</div>\n\t\t\t\t<a href=\"#coref\">\n\t\t\t\t\t<svg aria-hidden=\"true\" viewBox=\"0 0 16 16\" width=\"16\" height=\"16\" fill=\"currentColor\" class=\"svg-link\">\n\t\t\t\t\t\t<use xmlns:xlink=\"http://www.w3.org/1999/xlink\" xlink:href=\"assets/link.svg#icon-link\"></use>\n\t\t\t\t\t</svg>\n\t\t\t\t</a>\n\t\t\t</div>\n\t\t\t<div class=\"container-wrapper\">\n\t\t\t\t<svg class=\"svg-container\"></svg>\n\t\t\t\t<div class=\"container\"></div>\n\t\t\t</div>\n\t\t</div>\n\t</div>\n\t\n\t\n\t<div class=\"footer\">\n\t\t<div class=\"footline\"></div>\n\t\t<div class=\"description\">\n\t\t\t<p>\n\t\t\t\tCompare with <a target=\"_blank\" class=\"js-corenlp\" href=\"http://corenlp.run/#text=\">CoreNLP\u2019s results</a> on the same query. \n\t\t\t\tOr compare with spaCy\u2019s <a target=\"_blank\" class=\"js-displacy\" href=\"https://explosion.ai/demos/displacy-ent?text=\">displaCy results</a> on entity recognition.\n\t\t\t</p>\n\t\t\t<p>\n\t\t\t\tThis is a demo of HMTL for NLP, our new NLP multi-task model that reaches or beats the state-of-the-art on 4 distinct NLP tasks. \n\t\t\t\tThe model combines Named Entity Recognition, Entity Mention Detection, Relation Extraction and Coreference Resolution. \n\t\t\t\tThese 4 tasks are all fundamentals for NLP and NLU applications such as conversational agents. \n\t\t\t\tMoreover, these 4 tasks can benefit each other when trained together in a multi-task learning framework, a recent trend in NLP which has been driving a lot of top-notch research.\n\t\t\t</p>\n\t\t\t<p>\n\t\t\t\tOur implementation is based on the <a target=\"_blank\" href=\"https://allennlp.org\">AllenNLP library</a> \n\t\t\t\tfrom the <a target=\"_blank\" href=\"https://allenai.org\">Allen Institute for Artificial Intelligence</a>, and makes use of the ELMo embeddings. \n\t\t\t\t<!--If you are interested in learning more about the model, we explain in a Medium blogpost the core components of the model and opensource the training code.-->\n\t\t\t\tIf you like this demo, please share it and <a target=\"_blank\" href=\"https://twitter.com/intent/tweet?url=https%3A%2F%2Fhuggingface.co%2Fhmtl&via=SanhEstPasMoi%20%40Thom_Wolf%20%40seb_ruder%20%40julien_c%20%40huggingface\">tweet about it</a> \ud83d\udc9b!\n\t\t\t</p>\n\t\t\t<p><a href=\"https://twitter.com/share\" class=\"twitter-share-button\" data-show-count=\"false\" data-via=\"SanhEstPasMoi @Thom_Wolf @seb_ruder @julien_c @huggingface\">Tweet</a><script async src=\"//platform.twitter.com/widgets.js\" charset=\"utf-8\"></script></p>\n\t\t</div>\n\t</div>\n\t\n\t<script src=\"dist/script.js\"></script>\n\t<script>\n\t(function() {\n\t\tif (window.location.hostname === 'localhost') {\n\t\t\tvar s = document.createElement('script');\n\t\t\ts.setAttribute('src', '//localhost:35729/livereload.js');\n\t\t\tdocument.body.appendChild(s);\n\t\t}\n\t})();\n\t</script>\n\t<script>\n\tif (window.location.hostname !== 'localhost') {\n\t\t(function(i,s,o,g,r,a,m){i['GoogleAnalyticsObject']=r;i[r]=i[r]||function(){\n\t\t(i[r].q=i[r].q||[]).push(arguments)},i[r].l=1*new Date();a=s.createElement(o),\n\t\tm=s.getElementsByTagName(o)[0];a.async=1;a.src=g;m.parentNode.insertBefore(a,m)\n\t\t})(window,document,'script','https://www.google-analytics.com/analytics.js','ga');\n\t\tga('create', 'UA-83738774-2', 'auto');\n\t\tga('send', 'pageview');\n\t}\n\t</script>\n</body>\n</html>", "demo\\web\\package.json": "{\n \"name\": \"hmtl-web\",\n \"version\": \"1.0.0\",\n \"description\": \"\",\n \"main\": \"Gruntfile.js\",\n \"scripts\": {\n \"test\": \"echo \\\"Error: no test specified\\\" && exit 1\"\n },\n \"author\": \"\",\n \"license\": \"ISC\",\n \"dependencies\": {\n \"grunt\": \"^1.0.3\",\n \"grunt-contrib-connect\": \"^2.0.0\",\n \"grunt-contrib-less\": \"^2.0.0\",\n \"grunt-contrib-watch\": \"^1.1.0\"\n }\n}\n"} | null |
hub-docs | {"type": "directory", "name": "hub-docs", "children": [{"type": "file", "name": "datasetcard.md"}, {"type": "directory", "name": "docs", "children": [{"type": "directory", "name": "api-inference", "children": [{"type": "file", "name": "getting-started.md"}, {"type": "file", "name": "index.md"}, {"type": "file", "name": "parameters.md"}, {"type": "file", "name": "rate-limits.md"}, {"type": "file", "name": "security.md"}, {"type": "file", "name": "supported-models.md"}, {"type": "directory", "name": "tasks", "children": [{"type": "file", "name": "audio-classification.md"}, {"type": "file", "name": "automatic-speech-recognition.md"}, {"type": "file", "name": "chat-completion.md"}, {"type": "file", "name": "feature-extraction.md"}, {"type": "file", "name": "fill-mask.md"}, {"type": "file", "name": "image-classification.md"}, {"type": "file", "name": "image-segmentation.md"}, {"type": "file", "name": "image-to-image.md"}, {"type": "file", "name": "object-detection.md"}, {"type": "file", "name": "question-answering.md"}, {"type": "file", "name": "summarization.md"}, {"type": "file", "name": "table-question-answering.md"}, {"type": "file", "name": "text-classification.md"}, {"type": "file", "name": "text-generation.md"}, {"type": "file", "name": "text-to-image.md"}, {"type": "file", "name": "token-classification.md"}, {"type": "file", "name": "translation.md"}, {"type": "file", "name": "zero-shot-classification.md"}]}, {"type": "file", "name": "_redirects.yml"}, {"type": "file", "name": "_toctree.yml"}]}, {"type": "directory", "name": "hub", "children": [{"type": "file", "name": "adapters.md"}, {"type": "file", "name": "advanced-compute-options.md"}, {"type": "file", "name": "allennlp.md"}, {"type": "file", "name": "api.md"}, {"type": "file", "name": "asteroid.md"}, {"type": "file", "name": "audit-logs.md"}, {"type": "file", "name": "bertopic.md"}, {"type": "file", "name": "billing.md"}, {"type": "file", "name": "collections.md"}, {"type": "file", "name": "datasets-adding.md"}, {"type": "file", "name": "datasets-argilla.md"}, {"type": "file", "name": "datasets-audio.md"}, {"type": "file", "name": "datasets-cards.md"}, {"type": "file", "name": "datasets-dask.md"}, {"type": "file", "name": "datasets-data-files-configuration.md"}, {"type": "file", "name": "datasets-distilabel.md"}, {"type": "file", "name": "datasets-download-stats.md"}, {"type": "file", "name": "datasets-downloading.md"}, {"type": "file", "name": "datasets-duckdb-auth.md"}, {"type": "file", "name": "datasets-duckdb-combine-and-export.md"}, {"type": "file", "name": "datasets-duckdb-select.md"}, {"type": "file", "name": "datasets-duckdb-sql.md"}, {"type": "file", "name": "datasets-duckdb-vector-similarity-search.md"}, {"type": "file", "name": "datasets-duckdb.md"}, {"type": "file", "name": "datasets-fiftyone.md"}, {"type": "file", "name": "datasets-file-names-and-splits.md"}, {"type": "file", "name": "datasets-gated.md"}, {"type": "file", "name": "datasets-image.md"}, {"type": "file", "name": "datasets-libraries.md"}, {"type": "file", "name": "datasets-manual-configuration.md"}, {"type": "file", "name": "datasets-overview.md"}, {"type": "file", "name": "datasets-pandas.md"}, {"type": "file", "name": "datasets-polars-auth.md"}, {"type": "file", "name": "datasets-polars-file-formats.md"}, {"type": "file", "name": "datasets-polars-operations.md"}, {"type": "file", "name": "datasets-polars-optimizations.md"}, {"type": "file", "name": "datasets-polars.md"}, {"type": "file", "name": "datasets-spark.md"}, {"type": "file", "name": "datasets-usage.md"}, {"type": "file", "name": "datasets-viewer-configure.md"}, {"type": "file", "name": "datasets-viewer-embed.md"}, {"type": "file", "name": "datasets-viewer.md"}, {"type": "file", "name": "datasets-webdataset.md"}, {"type": "file", "name": "datasets.md"}, {"type": "file", "name": "diffusers.md"}, {"type": "file", "name": "doi.md"}, {"type": "file", "name": "enterprise-hub-datasets.md"}, {"type": "file", "name": "enterprise-hub-resource-groups.md"}, {"type": "file", "name": "enterprise-hub-tokens-management.md"}, {"type": "file", "name": "enterprise-hub.md"}, {"type": "file", "name": "enterprise-sso.md"}, {"type": "file", "name": "espnet.md"}, {"type": "file", "name": "fastai.md"}, {"type": "file", "name": "flair.md"}, {"type": "file", "name": "gguf-gpt4all.md"}, {"type": "file", "name": "gguf-llamacpp.md"}, {"type": "file", "name": "gguf.md"}, {"type": "file", "name": "index.md"}, {"type": "file", "name": "keras.md"}, {"type": "file", "name": "ml-agents.md"}, {"type": "file", "name": "mlx-image.md"}, {"type": "file", "name": "mlx.md"}, {"type": "file", "name": "model-card-annotated.md"}, {"type": "file", "name": "model-card-appendix.md"}, {"type": "file", "name": "model-card-guidebook.md"}, {"type": "file", "name": "model-card-landscape-analysis.md"}, {"type": "file", "name": "model-cards-co2.md"}, {"type": "file", "name": "model-cards-components.md"}, {"type": "file", "name": "model-cards-user-studies.md"}, {"type": "file", "name": "model-cards.md"}, {"type": "file", "name": "models-adding-libraries.md"}, {"type": "file", "name": "models-advanced.md"}, {"type": "file", "name": "models-download-stats.md"}, {"type": "file", "name": "models-downloading.md"}, {"type": "file", "name": "models-faq.md"}, {"type": "file", "name": "models-gated.md"}, {"type": "file", "name": "models-inference.md"}, {"type": "file", "name": "models-libraries.md"}, {"type": "file", "name": "models-tasks.md"}, {"type": "file", "name": "models-the-hub.md"}, {"type": "file", "name": "models-uploading.md"}, {"type": "file", "name": "models-widgets-examples.md"}, {"type": "file", "name": "models-widgets.md"}, {"type": "file", "name": "models.md"}, {"type": "file", "name": "moderation.md"}, {"type": "file", "name": "notebooks.md"}, {"type": "file", "name": "notifications.md"}, {"type": "file", "name": "oauth.md"}, {"type": "file", "name": "open_clip.md"}, {"type": "file", "name": "organizations-cards.md"}, {"type": "file", "name": "organizations-managing.md"}, {"type": "file", "name": "organizations-security.md"}, {"type": "file", "name": "organizations.md"}, {"type": "file", "name": "other.md"}, {"type": "file", "name": "paddlenlp.md"}, {"type": "file", "name": "paper-pages.md"}, {"type": "file", "name": "peft.md"}, {"type": "file", "name": "repositories-getting-started.md"}, {"type": "file", "name": "repositories-licenses.md"}, {"type": "file", "name": "repositories-next-steps.md"}, {"type": "file", "name": "repositories-pull-requests-discussions.md"}, {"type": "file", "name": "repositories-recommendations.md"}, {"type": "file", "name": "repositories-settings.md"}, {"type": "file", "name": "repositories.md"}, {"type": "file", "name": "rl-baselines3-zoo.md"}, {"type": "file", "name": "sample-factory.md"}, {"type": "file", "name": "search.md"}, {"type": "file", "name": "security-2fa.md"}, {"type": "file", "name": "security-git-ssh.md"}, {"type": "file", "name": "security-gpg.md"}, {"type": "file", "name": "security-malware.md"}, {"type": "file", "name": "security-pickle.md"}, {"type": "file", "name": "security-resource-groups.md"}, {"type": "file", "name": "security-secrets.md"}, {"type": "file", "name": "security-sso-azure-oidc.md"}, {"type": "file", "name": "security-sso-azure-saml.md"}, {"type": "file", "name": "security-sso-okta-oidc.md"}, {"type": "file", "name": "security-sso-okta-saml.md"}, {"type": "file", "name": "security-sso.md"}, {"type": "file", "name": "security-tokens.md"}, {"type": "file", "name": "security.md"}, {"type": "file", "name": "sentence-transformers.md"}, {"type": "file", "name": "setfit.md"}, {"type": "file", "name": "spaces-add-to-arxiv.md"}, {"type": "file", "name": "spaces-advanced.md"}, {"type": "file", "name": "spaces-changelog.md"}, {"type": "file", "name": "spaces-circleci.md"}, {"type": "file", "name": "spaces-config-reference.md"}, {"type": "file", "name": "spaces-cookie-limitations.md"}, {"type": "file", "name": "spaces-dependencies.md"}, {"type": "file", "name": "spaces-embed.md"}, {"type": "file", "name": "spaces-github-actions.md"}, {"type": "file", "name": "spaces-gpus.md"}, {"type": "file", "name": "spaces-handle-url-parameters.md"}, {"type": "file", "name": "spaces-more-ways-to-create.md"}, {"type": "file", "name": "spaces-oauth.md"}, {"type": "file", "name": "spaces-organization-cards.md"}, {"type": "file", "name": "spaces-overview.md"}, {"type": "file", "name": "spaces-run-with-docker.md"}, {"type": "file", "name": "spaces-sdks-docker-aim.md"}, {"type": "file", "name": "spaces-sdks-docker-argilla.md"}, {"type": "file", "name": "spaces-sdks-docker-chatui.md"}, {"type": "file", "name": "spaces-sdks-docker-examples.md"}, {"type": "file", "name": "spaces-sdks-docker-first-demo.md"}, {"type": "file", "name": "spaces-sdks-docker-giskard.md"}, {"type": "file", "name": "spaces-sdks-docker-jupyter.md"}, {"type": "file", "name": "spaces-sdks-docker-label-studio.md"}, {"type": "file", "name": "spaces-sdks-docker-livebook.md"}, {"type": "file", "name": "spaces-sdks-docker-panel.md"}, {"type": "file", "name": "spaces-sdks-docker-shiny.md"}, {"type": "file", "name": "spaces-sdks-docker-tabby.md"}, {"type": "file", "name": "spaces-sdks-docker-zenml.md"}, {"type": "file", "name": "spaces-sdks-docker.md"}, {"type": "file", "name": "spaces-sdks-gradio.md"}, {"type": "file", "name": "spaces-sdks-python.md"}, {"type": "file", "name": "spaces-sdks-static.md"}, {"type": "file", "name": "spaces-sdks-streamlit.md"}, {"type": "file", "name": "spaces-settings.md"}, {"type": "file", "name": "spaces-storage.md"}, {"type": "file", "name": "spaces-using-opencv.md"}, {"type": "file", "name": "spaces.md"}, {"type": "file", "name": "spacy.md"}, {"type": "file", "name": "span_marker.md"}, {"type": "file", "name": "speechbrain.md"}, {"type": "file", "name": "stable-baselines3.md"}, {"type": "file", "name": "stanza.md"}, {"type": "file", "name": "storage-regions.md"}, {"type": "file", "name": "tensorboard.md"}, {"type": "file", "name": "tf-keras.md"}, {"type": "file", "name": "timm.md"}, {"type": "file", "name": "transformers-js.md"}, {"type": "file", "name": "transformers.md"}, {"type": "file", "name": "unity-sentis.md"}, {"type": "file", "name": "webhooks-guide-auto-retrain.md"}, {"type": "file", "name": "webhooks-guide-discussion-bot.md"}, {"type": "file", "name": "webhooks-guide-metadata-review.md"}, {"type": "file", "name": "webhooks.md"}, {"type": "file", "name": "_config.py"}, {"type": "file", "name": "_redirects.yml"}, {"type": "file", "name": "_toctree.yml"}]}, {"type": "directory", "name": "sagemaker", "children": [{"type": "file", "name": "getting-started.md"}, {"type": "file", "name": "index.md"}, {"type": "file", "name": "inference.md"}, {"type": "file", "name": "reference.md"}, {"type": "file", "name": "train.md"}, {"type": "file", "name": "_toctree.yml"}]}, {"type": "file", "name": "TODOs.md"}]}, {"type": "directory", "name": "hacktoberfest_challenges", "children": [{"type": "file", "name": "datasets_without_language.csv"}, {"type": "file", "name": "datasets_without_language.md"}, {"type": "file", "name": "model_license_other.csv"}, {"type": "file", "name": "model_license_other.md"}, {"type": "file", "name": "model_no_license.csv"}, {"type": "file", "name": "model_no_license.md"}]}, {"type": "file", "name": "LICENSE"}, {"type": "file", "name": "modelcard.md"}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "scripts", "children": [{"type": "directory", "name": "api-inference", "children": [{"type": "file", "name": ".prettierignore"}, {"type": "file", "name": "package.json"}, {"type": "file", "name": "pnpm-lock.yaml"}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "scripts", "children": [{"type": "file", "name": "generate.ts"}]}, {"type": "directory", "name": "templates", "children": [{"type": "directory", "name": "common", "children": [{"type": "file", "name": "page-header.handlebars"}, {"type": "file", "name": "snippets-template.handlebars"}, {"type": "file", "name": "specs-headers.handlebars"}, {"type": "file", "name": "specs-output.handlebars"}, {"type": "file", "name": "specs-payload.handlebars"}]}, {"type": "directory", "name": "task", "children": [{"type": "file", "name": "audio-classification.handlebars"}, {"type": "file", "name": "automatic-speech-recognition.handlebars"}, {"type": "file", "name": "chat-completion.handlebars"}, {"type": "file", "name": "feature-extraction.handlebars"}, {"type": "file", "name": "fill-mask.handlebars"}, {"type": "file", "name": "image-classification.handlebars"}, {"type": "file", "name": "image-segmentation.handlebars"}, {"type": "file", "name": "image-to-image.handlebars"}, {"type": "file", "name": "object-detection.handlebars"}, {"type": "file", "name": "question-answering.handlebars"}, {"type": "file", "name": "summarization.handlebars"}, {"type": "file", "name": "table-question-answering.handlebars"}, {"type": "file", "name": "text-classification.handlebars"}, {"type": "file", "name": "text-generation.handlebars"}, {"type": "file", "name": "text-to-image.handlebars"}, {"type": "file", "name": "token-classification.handlebars"}, {"type": "file", "name": "translation.handlebars"}, {"type": "file", "name": "zero-shot-classification.handlebars"}]}]}, {"type": "file", "name": "tsconfig.json"}]}]}]} | Install dependencies.
```sh
pnpm install
```
Generate documentation.
```sh
pnpm run generate
``` | {".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 f675826175c5804bbb5b4b9ddafaf68e83274024 Hamza Amin <[email protected]> 1727370231 +0500\tclone: from https://github.com/huggingface/hub-docs.git\n", ".git\\refs\\heads\\main": "f675826175c5804bbb5b4b9ddafaf68e83274024\n", "docs\\api-inference\\index.md": "# Serverless Inference API\n\n**Instant Access to thousands of ML Models for Fast Prototyping**\n\nExplore the most popular models for text, image, speech, and more \u2014 all with a simple API request. Build, test, and experiment without worrying about infrastructure or setup.\n\n---\n\n## Why use the Inference API?\n\nThe Serverless Inference API offers a fast and free way to explore thousands of models for a variety of tasks. Whether you're prototyping a new application or experimenting with ML capabilities, this API gives you instant access to high-performing models across multiple domains:\n\n* **Text Generation:** Including large language models and tool-calling prompts, generate and experiment with high-quality responses.\n* **Image Generation:** Easily create customized images, including LoRAs for your own styles.\n* **Document Embeddings:** Build search and retrieval systems with SOTA embeddings.\n* **Classical AI Tasks:** Ready-to-use models for text classification, image classification, speech recognition, and more.\n\n\u26a1 **Fast and Free to Get Started**: The Inference API is free with higher rate limits for PRO users. For production needs, explore [Inference Endpoints](https://ui.endpoints.huggingface.co/) for dedicated resources, autoscaling, advanced security features, and more.\n\n---\n\n## Key Benefits\n\n- \ud83d\ude80 **Instant Prototyping:** Access powerful models without setup.\n- \ud83c\udfaf **Diverse Use Cases:** One API for text, image, and beyond.\n- \ud83d\udd27 **Developer-Friendly:** Simple requests, fast responses.\n\n---\n\n## Main Features\n\n* Leverage over 800,000+ models from different open-source libraries (transformers, sentence transformers, adapter transformers, diffusers, timm, etc.).\n* Use models for a variety of tasks, including text generation, image generation, document embeddings, NER, summarization, image classification, and more.\n* Accelerate your prototyping by using GPU-powered models.\n* Run very large models that are challenging to deploy in production.\n* Production-grade platform without the hassle: built-in automatic scaling, load balancing and caching.\n\n---\n\n## Contents\n\nThe documentation is organized into two sections:\n\n* **Getting Started** Learn the basics of how to use the Inference API.\n* **API Reference** Dive into task-specific settings and parameters.\n\n---\n\n## Looking for custom support from the Hugging Face team?\n\n<a target=\"_blank\" href=\"https://huggingface.co/support\">\n <img alt=\"HuggingFace Expert Acceleration Program\" src=\"https://cdn-media.huggingface.co/marketing/transformers/new-support-improved.png\" style=\"max-width: 600px; border: 1px solid #eee; border-radius: 4px; box-shadow: 0 1px 2px 0 rgba(0, 0, 0, 0.05);\">\n</a><br>\n", "docs\\hub\\index.md": "# Hugging Face Hub documentation\n\nThe Hugging Face Hub is a platform with over 900k models, 200k datasets, and 300k demo apps (Spaces), all open source and publicly available, in an online platform where people can easily collaborate and build ML together. The Hub works as a central place where anyone can explore, experiment, collaborate, and build technology with Machine Learning. Are you ready to join the path towards open source Machine Learning? \ud83e\udd17\n\n<div class=\"grid grid-cols-1 gap-4 sm:grid-cols-2 lg:grid-cols-3 md:mt-10\">\n\n<div class=\"group flex flex-col space-y-2 rounded-xl border border-orange-100 bg-gradient-to-br from-orange-50 dark:bg-none px-6 py-4 transition-colors hover:shadow dark:border-orange-700\">\n<div class=\"flex items-center py-0.5 text-lg font-semibold text-orange-600 dark:text-gray-400 mb-1\">\n <svg class=\"shrink-0 mr-1.5 text-orange-500\" xmlns=\"http://www.w3.org/2000/svg\" xmlns:xlink=\"http://www.w3.org/1999/xlink\" aria-hidden=\"true\" focusable=\"false\" role=\"img\" width=\"1em\" height=\"1em\" preserveAspectRatio=\"xMidYMid meet\" viewBox=\"0 0 24 24\"><path fill=\"currentColor\" d=\"M2.6 10.59L8.38 4.8l1.69 1.7c-.24.85.15 1.78.93 2.23v5.54c-.6.34-1 .99-1 1.73a2 2 0 0 0 2 2a2 2 0 0 0 2-2c0-.74-.4-1.39-1-1.73V9.41l2.07 2.09c-.07.15-.07.32-.07.5a2 2 0 0 0 2 2a2 2 0 0 0 2-2a2 2 0 0 0-2-2c-.18 0-.35 0-.5.07L13.93 7.5a1.98 1.98 0 0 0-1.15-2.34c-.43-.16-.88-.2-1.28-.09L9.8 3.38l.79-.78c.78-.79 2.04-.79 2.82 0l7.99 7.99c.79.78.79 2.04 0 2.82l-7.99 7.99c-.78.79-2.04.79-2.82 0L2.6 13.41c-.79-.78-.79-2.04 0-2.82Z\"></path></svg>Repositories</div>\n<a class=\"transform !no-underline transition-colors hover:translate-x-px hover:text-gray-700\" href=\"./repositories\">Introduction</a>\n<a class=\"transform !no-underline transition-colors hover:translate-x-px hover:text-gray-700\" href=\"./repositories-getting-started\">Getting Started</a>\n<a class=\"transform !no-underline transition-colors hover:translate-x-px hover:text-gray-700\" href=\"./repositories-settings\">Repository Settings</a>\n<a class=\"transform !no-underline transition-colors hover:translate-x-px hover:text-gray-700\" href=\"./repositories-pull-requests-discussions\">Pull requests and Discussions</a>\n<a class=\"transform !no-underline transition-colors hover:translate-x-px hover:text-gray-700\" href=\"./notifications\">Notifications</a>\n<a class=\"transform !no-underline transition-colors hover:translate-x-px hover:text-gray-700\" href=\"./collections\">Collections</a>\n<a class=\"transform !no-underline transition-colors hover:translate-x-px hover:text-gray-700\" href=\"./webhooks\">Webhooks</a>\n<a class=\"transform !no-underline transition-colors hover:translate-x-px hover:text-gray-700\" href=\"./repositories-next-steps\">Next Steps</a>\n<a class=\"transform !no-underline transition-colors hover:translate-x-px hover:text-gray-700\" href=\"./repositories-licenses\">Licenses</a>\n</div>\n\n<div class=\"group flex flex-col space-y-2 rounded-xl border border-indigo-100 bg-gradient-to-br from-indigo-50 dark:bg-none px-6 py-4 transition-colors hover:shadow dark:border-indigo-700\">\n<div class=\"flex items-center py-0.5 text-lg font-semibold text-indigo-600 dark:text-gray-400 mb-1\">\n <svg class=\"shrink-0 mr-1.5 text-indigo-500\" xmlns=\"http://www.w3.org/2000/svg\" xmlns:xlink=\"http://www.w3.org/1999/xlink\" aria-hidden=\"true\" focusable=\"false\" role=\"img\" width=\"1em\" height=\"1em\" preserveAspectRatio=\"xMidYMid meet\" viewBox=\"0 0 24 24\"><path class=\"uim-quaternary\" d=\"M20.23 7.24L12 12L3.77 7.24a1.98 1.98 0 0 1 .7-.71L11 2.76c.62-.35 1.38-.35 2 0l6.53 3.77c.29.173.531.418.7.71z\" opacity=\".25\" fill=\"currentColor\"></path><path class=\"uim-tertiary\" d=\"M12 12v9.5a2.09 2.09 0 0 1-.91-.21L4.5 17.48a2.003 2.003 0 0 1-1-1.73v-7.5a2.06 2.06 0 0 1 .27-1.01L12 12z\" opacity=\".5\" fill=\"currentColor\"></path><path class=\"uim-primary\" d=\"M20.5 8.25v7.5a2.003 2.003 0 0 1-1 1.73l-6.62 3.82c-.275.13-.576.198-.88.2V12l8.23-4.76c.175.308.268.656.27 1.01z\" fill=\"currentColor\"></path></svg> Models</div>\n<a class=\"!no-underline hover:opacity-60 transform transition-colors hover:translate-x-px\" href=\"./models\">Introduction</a>\n<a class=\"!no-underline hover:opacity-60 transform transition-colors hover:translate-x-px\" href=\"./models-the-hub\">The Model Hub</a>\n<a class=\"!no-underline hover:opacity-60 transform transition-colors hover:translate-x-px\" href=\"./model-cards\">Model Cards</a>\n<a class=\"!no-underline hover:opacity-60 transform transition-colors hover:translate-x-px\" href=\"./models-gated\">Gated Models</a>\n<a class=\"!no-underline hover:opacity-60 transform transition-colors hover:translate-x-px\" href=\"./models-uploading\">Uploading Models</a>\n<a class=\"!no-underline hover:opacity-60 transform transition-colors hover:translate-x-px\" href=\"./models-downloading\">Downloading Models</a>\n<a class=\"!no-underline hover:opacity-60 transform transition-colors hover:translate-x-px\" href=\"./models-libraries\">Libraries</a>\n<a class=\"!no-underline hover:opacity-60 transform transition-colors hover:translate-x-px\" href=\"./models-tasks\">Tasks</a>\n<a class=\"!no-underline hover:opacity-60 transform transition-colors hover:translate-x-px\" href=\"./models-widgets\">Widgets</a>\n<a class=\"!no-underline hover:opacity-60 transform transition-colors hover:translate-x-px\" href=\"./models-inference\">Inference API</a>\n<a class=\"!no-underline hover:opacity-60 transform transition-colors hover:translate-x-px\" href=\"./models-download-stats\">Download Stats</a>\n</div>\n\n<div class=\"group flex flex-col space-y-2 rounded-xl border border-red-100 bg-gradient-to-br from-red-50 dark:bg-none px-6 py-4 transition-colors hover:shadow dark:border-red-700\">\n<div class=\"flex items-center py-0.5 text-lg font-semibold text-red-600 dark:text-gray-400 mb-1\">\n<svg class=\"shrink-0 mr-1.5 text-red-400\" xmlns=\"http://www.w3.org/2000/svg\" xmlns:xlink=\"http://www.w3.org/1999/xlink\" aria-hidden=\"true\" focusable=\"false\" role=\"img\" width=\"1em\" height=\"1em\" preserveAspectRatio=\"xMidYMid meet\" viewBox=\"0 0 25 25\"><ellipse cx=\"12.5\" cy=\"5\" fill=\"currentColor\" fill-opacity=\"0.25\" rx=\"7.5\" ry=\"2\"></ellipse><path d=\"M12.5 15C16.6421 15 20 14.1046 20 13V20C20 21.1046 16.6421 22 12.5 22C8.35786 22 5 21.1046 5 20V13C5 14.1046 8.35786 15 12.5 15Z\" fill=\"currentColor\" opacity=\"0.5\"></path><path d=\"M12.5 7C16.6421 7 20 6.10457 20 5V11.5C20 12.6046 16.6421 13.5 12.5 13.5C8.35786 13.5 5 12.6046 5 11.5V5C5 6.10457 8.35786 7 12.5 7Z\" fill=\"currentColor\" opacity=\"0.5\"></path><path d=\"M5.23628 12C5.08204 12.1598 5 12.8273 5 13C5 14.1046 8.35786 15 12.5 15C16.6421 15 20 14.1046 20 13C20 12.8273 19.918 12.1598 19.7637 12C18.9311 12.8626 15.9947 13.5 12.5 13.5C9.0053 13.5 6.06886 12.8626 5.23628 12Z\" fill=\"currentColor\"></path></svg> Datasets</div>\n<a class=\"!no-underline hover:opacity-60 transform transition-colors hover:translate-x-px\" href=\"./datasets\">Introduction</a>\n<a class=\"!no-underline hover:opacity-60 transform transition-colors hover:translate-x-px\" href=\"./datasets-overview\">Datasets Overview</a>\n<a class=\"!no-underline hover:opacity-60 transform transition-colors hover:translate-x-px\" href=\"./datasets-cards\">Dataset Cards</a>\n<a class=\"!no-underline hover:opacity-60 transform transition-colors hover:translate-x-px\" href=\"./datasets-gated\">Gated Datasets</a>\n<a class=\"!no-underline hover:opacity-60 transform transition-colors hover:translate-x-px\" href=\"./datasets-adding\">Uploading Datasets</a>\n<a class=\"!no-underline hover:opacity-60 transform transition-colors hover:translate-x-px\" href=\"./datasets-downloading\">Downloading Datasets</a>\n<a class=\"!no-underline hover:opacity-60 transform transition-colors hover:translate-x-px\" href=\"./datasets-libraries\">Libraries</a>\n<a class=\"!no-underline hover:opacity-60 transform transition-colors hover:translate-x-px\" href=\"./datasets-viewer\">Dataset Viewer</a>\n<a class=\"!no-underline hover:opacity-60 transform transition-colors hover:translate-x-px\" href=\"./datasets-download-stats\">Download Stats</a>\n<a class=\"!no-underline hover:opacity-60 transform transition-colors hover:translate-x-px\" href=\"./datasets-data-files-configuration\">Data files Configuration</a>\n</div>\n\n<div class=\"group flex flex-col space-y-2 rounded-xl border border-blue-100 bg-gradient-to-br from-blue-50 dark:bg-none px-6 py-4 transition-colors hover:shadow dark:border-blue-700\">\n<div class=\"flex items-center py-0.5 text-lg font-semibold text-blue-600 dark:text-gray-400 mb-1\">\n<svg class=\"shrink-0 mr-1.5 text-blue-500\" xmlns=\"http://www.w3.org/2000/svg\" xmlns:xlink=\"http://www.w3.org/1999/xlink\" aria-hidden=\"true\" focusable=\"false\" role=\"img\" width=\"1em\" height=\"1em\" viewBox=\"0 0 25 25\"><path opacity=\".5\" d=\"M6.016 14.674v4.31h4.31v-4.31h-4.31ZM14.674 14.674v4.31h4.31v-4.31h-4.31ZM6.016 6.016v4.31h4.31v-4.31h-4.31Z\" fill=\"currentColor\"></path><path opacity=\".75\" fill-rule=\"evenodd\" clip-rule=\"evenodd\" d=\"M3 4.914C3 3.857 3.857 3 4.914 3h6.514c.884 0 1.628.6 1.848 1.414a5.171 5.171 0 0 1 7.31 7.31c.815.22 1.414.964 1.414 1.848v6.514A1.914 1.914 0 0 1 20.086 22H4.914A1.914 1.914 0 0 1 3 20.086V4.914Zm3.016 1.102v4.31h4.31v-4.31h-4.31Zm0 12.968v-4.31h4.31v4.31h-4.31Zm8.658 0v-4.31h4.31v4.31h-4.31Zm0-10.813a2.155 2.155 0 1 1 4.31 0 2.155 2.155 0 0 1-4.31 0Z\" fill=\"currentColor\"></path><path opacity=\".25\" d=\"M16.829 6.016a2.155 2.155 0 1 0 0 4.31 2.155 2.155 0 0 0 0-4.31Z\" fill=\"currentColor\"></path></svg> Spaces</div>\n<a class=\"!no-underline hover:opacity-60 transform transition-colors hover:translate-x-px\" href=\"./spaces\">Introduction</a>\n<a class=\"!no-underline hover:opacity-60 transform transition-colors hover:translate-x-px\" href=\"./spaces-overview\">Spaces Overview</a>\n<a class=\"!no-underline hover:opacity-60 transform transition-colors hover:translate-x-px\" href=\"./spaces-sdks-gradio\">Gradio Spaces</a>\n<a class=\"!no-underline hover:opacity-60 transform transition-colors hover:translate-x-px\" href=\"./spaces-sdks-streamlit\">Streamlit Spaces</a>\n<a class=\"!no-underline hover:opacity-60 transform transition-colors hover:translate-x-px\" href=\"./spaces-sdks-static\">Static HTML Spaces</a>\n<a class=\"!no-underline hover:opacity-60 transform transition-colors hover:translate-x-px\" href=\"./spaces-sdks-docker\">Docker Spaces</a>\n<a class=\"!no-underline hover:opacity-60 transform transition-colors hover:translate-x-px\" href=\"./spaces-embed\">Embed your Space</a>\n<a class=\"!no-underline hover:opacity-60 transform transition-colors hover:translate-x-px\" href=\"./spaces-run-with-docker\">Run with Docker</a>\n<a class=\"!no-underline hover:opacity-60 transform transition-colors hover:translate-x-px\" href=\"./spaces-config-reference\">Reference</a>\n<a class=\"!no-underline hover:opacity-60 transform transition-colors hover:translate-x-px\" href=\"./spaces-changelog\">Changelog</a>\n<a class=\"!no-underline hover:opacity-60 transform transition-colors hover:translate-x-px\" href=\"./spaces-advanced\">Advanced Topics</a>\n<a class=\"!no-underline hover:opacity-60 transform transition-colors hover:translate-x-px\" href=\"./spaces-oauth\">Sign in with HF</a>\n</div>\n\n<div class=\"group flex flex-col space-y-2 rounded-xl border border-green-100 bg-gradient-to-br from-green-50 dark:bg-none px-6 py-4 transition-colors hover:shadow dark:border-green-700\">\n<div class=\"flex items-center py-0.5 text-lg font-semibold text-green-600 dark:text-gray-400 mb-1\">\n<svg class=\"shrink-0 mr-1.5 text-green-500\" xmlns=\"http://www.w3.org/2000/svg\" xmlns:xlink=\"http://www.w3.org/1999/xlink\" aria-hidden=\"true\" focusable=\"false\" role=\"img\" width=\"1em\" height=\"1em\" viewBox=\"0 0 24 24\"><path fill=\"currentColor\" stroke=\"currentColor\" d=\"M8.892 21.854a6.25 6.25 0 0 1-4.42-10.67l7.955-7.955a4.5 4.5 0 0 1 6.364 6.364l-6.895 6.894a2.816 2.816 0 0 1-3.89 0a2.75 2.75 0 0 1 .002-3.888l5.126-5.127a1 1 0 1 1 1.414 1.414l-5.126 5.127a.75.75 0 0 0 0 1.06a.768.768 0 0 0 1.06 0l6.895-6.894a2.503 2.503 0 0 0 0-3.535a2.56 2.56 0 0 0-3.536 0l-7.955 7.955a4.25 4.25 0 1 0 6.01 6.01l6.188-6.187a1 1 0 1 1 1.414 1.414l-6.187 6.186a6.206 6.206 0 0 1-4.42 1.832z\"></path></svg> Other</div>\n<a class=\"!no-underline hover:opacity-60 transform transition-colors hover:translate-x-px\" href=\"./organizations\">Organizations</a>\n<a class=\"!no-underline hover:opacity-60 transform transition-colors hover:translate-x-px\" href=\"./enterprise-hub\">Enterprise Hub</a>\n<a class=\"!no-underline hover:opacity-60 transform transition-colors hover:translate-x-px\" href=\"./billing\">Billing</a>\n<a class=\"!no-underline hover:opacity-60 transform transition-colors hover:translate-x-px\" href=\"./security\">Security</a>\n<a class=\"!no-underline hover:opacity-60 transform transition-colors hover:translate-x-px\" href=\"./moderation\">Moderation</a>\n<a class=\"!no-underline hover:opacity-60 transform transition-colors hover:translate-x-px\" href=\"./paper-pages\">Paper Pages</a>\n<a class=\"!no-underline hover:opacity-60 transform transition-colors hover:translate-x-px\" href=\"./search\">Search</a>\n<a class=\"!no-underline hover:opacity-60 transform transition-colors hover:translate-x-px\" href=\"./doi\">Digital Object Identifier (DOI)</a>\n<a class=\"!no-underline hover:opacity-60 transform transition-colors hover:translate-x-px\" href=\"./api\">Hub API Endpoints</a>\n<a class=\"!no-underline hover:opacity-60 transform transition-colors hover:translate-x-px\" href=\"./oauth\">Sign in with HF</a>\n<a class=\"!no-underline hover:opacity-60 transform transition-colors hover:translate-x-px\" href=\"https://huggingface.co/code-of-conduct\">Contributor Code of Conduct</a>\n<a class=\"!no-underline hover:opacity-60 transform transition-colors hover:translate-x-px\" href=\"https://huggingface.co/content-guidelines\">Content Guidelines</a>\n</div>\n\n</div>\n\n## What's the Hugging Face Hub?\n\nWe are helping the community work together towards the goal of advancing Machine Learning \ud83d\udd25.\n\nThe Hugging Face Hub is a platform with over 900k models, 200k datasets, and 300k demos in which people can easily collaborate in their ML workflows. The Hub works as a central place where anyone can share, explore, discover, and experiment with open-source Machine Learning.\n\nNo single company, including the Tech Titans, will be able to \u201csolve AI\u201d by themselves \u2013 the only way we'll achieve this is by sharing knowledge and resources in a community-centric approach. We are building the largest open-source collection of models, datasets, and demos on the Hugging Face Hub to democratize and advance ML for everyone \ud83d\ude80.\n\nWe encourage you to read the [Code of Conduct](https://huggingface.co/code-of-conduct) and the [Content Guidelines](https://huggingface.co/content-guidelines) to familiarize yourself with the values that we expect our community members to uphold \ud83e\udd17.\n\n## What can you find on the Hub?\n\nThe Hugging Face Hub hosts Git-based repositories, which are version-controlled buckets that can contain all your files. \ud83d\udcbe\n\nOn it, you'll be able to upload and discover...\n\n- Models, _hosting the latest state-of-the-art models for NLP, vision, and audio tasks_\n- Datasets, _featuring a wide variety of data for different domains and modalities_..\n- Spaces, _interactive apps for demonstrating ML models directly in your browser_.\n\nThe Hub offers **versioning, commit history, diffs, branches, and over a dozen library integrations**! You can learn more about the features that all repositories share in the [**Repositories documentation**](./repositories).\n\n## Models\n\nYou can discover and use dozens of thousands of open-source ML models shared by the community. To promote responsible model usage and development, model repos are equipped with [Model Cards](./model-cards) to inform users of each model's limitations and biases. Additional [metadata](./model-cards#model-card-metadata) about info such as their tasks, languages, and evaluation results can be included, with training metrics charts even added if the repository contains [TensorBoard traces](./tensorboard). It's also easy to add an [**inference widget**](./models-widgets) to your model, allowing anyone to play with the model directly in the browser! For programmatic access, a serverless API is provided to [**instantly serve your model**](./models-inference).\n\nTo upload models to the Hub, or download models and integrate them into your work, explore the [**Models documentation**](./models). You can also choose from [**over a dozen libraries**](./models-libraries) such as \ud83e\udd17 Transformers, Asteroid, and ESPnet that support the Hub.\n\n## Datasets\n\nThe Hub is home to over 200k datasets in more than 8k languages that can be used for a broad range of tasks across NLP, Computer Vision, and Audio. The Hub makes it simple to find, download, and upload datasets. Datasets are accompanied by extensive documentation in the form of [**Dataset Cards**](./datasets-cards) and [**Dataset Viewer**](./datasets-viewer) to let you explore the data directly in your browser. While many datasets are public, [**organizations**](./organizations) and individuals can create private datasets to comply with licensing or privacy issues. You can learn more about [**Datasets here on Hugging Face Hub documentation**](./datasets-overview).\n\nThe [\ud83e\udd17 `datasets`](https://huggingface.co/docs/datasets/index) library allows you to programmatically interact with the datasets, so you can easily use datasets from the Hub in your projects. With a single line of code, you can access the datasets; even if they are so large they don't fit in your computer, you can use streaming to efficiently access the data.\n\n## Spaces\n\n[Spaces](https://huggingface.co/spaces) is a simple way to host ML demo apps on the Hub. They allow you to build your ML portfolio, showcase your projects at conferences or to stakeholders, and work collaboratively with other people in the ML ecosystem.\n\nWe currently support two awesome Python SDKs (**[Gradio](https://gradio.app/)** and **[Streamlit](https://streamlit.io/)**) that let you build cool apps in a matter of minutes. Users can also create static Spaces which are simple HTML/CSS/JavaScript page within a Space.\n\nAfter you've explored a few Spaces (take a look at our [Space of the Week!](https://huggingface.co/spaces)), dive into the [**Spaces documentation**](./spaces-overview) to learn all about how you can create your own Space. You'll also be able to upgrade your Space to run on a GPU or other accelerated hardware. \u26a1\ufe0f\n\n## Organizations\n\nCompanies, universities and non-profits are an essential part of the Hugging Face community! The Hub offers [**Organizations**](./organizations), which can be used to group accounts and manage datasets, models, and Spaces. Educators can also create collaborative organizations for students using [Hugging Face for Classrooms](https://huggingface.co/classrooms). An organization's repositories will be featured on the organization\u2019s page and every member of the organization will have the ability to contribute to the repository. In addition to conveniently grouping all of an organization's work, the Hub allows admins to set roles to [**control access to repositories**](./organizations-security), and manage their organization's [payment method and billing info](https://huggingface.co/pricing). Machine Learning is more fun when collaborating! \ud83d\udd25\n\n[Explore existing organizations](https://huggingface.co/organizations), create a new organization [here](https://huggingface.co/organizations/new), and then visit the [**Organizations documentation**](./organizations) to learn more.\n\n## Security\n\nThe Hugging Face Hub supports security and access control features to give you the peace of mind that your code, models, and data are safe. Visit the [**Security**](./security) section in these docs to learn about:\n\n- User Access Tokens\n- Access Control for Organizations\n- Signing commits with GPG\n- Malware scanning\n\n<img width=\"150\" src=\"https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/security-soc-1.jpg\">\n", "docs\\hub\\model-card-appendix.md": "# Appendix\n\n## Appendix A: User Study\n_Full text responses to key questions_\n\n### How would you define model cards?\n\n***Insight: Respondents had generally similar views of what model cards are: documentation focused on issues like training, use cases, and bias/limitations***\n\n* Model cards are model descriptions, both of how they were trained, their use cases, and potential biases and limitations\n* Documents describing the essential features of a model in order for the reader/user to understand the artefact he/she has in front, the background/training, how it can be used, and its technical/ethical limitations.\n* They serve as a living artefact of models to document them. Model cards contain information that go from a high level description of what the specific model can be used to, to limitations, biases, metrics, and much more. They are used primarily to understand what the model does.\n* Model cards are to models what GitHub READMEs are to GitHub projects. It tells people all the information they need to know about the model. If you don't write one, nobody will use your model.\n* From what I understand, a model card uses certain benchmarks (geography, culture, sex, etc) to define both a model's usability and limitations. It's essentially a model's 'nutrition facts label' that can show how a model was created and educates others on its reusability.\n* Model cards are the metadata and documentation about the model, everything I need to know to use the model properly: info about the model, what paper introduced it, what dataset was it trained on or fine-tuned on, whom does it belong to, are there known risks and limitations with this model, any useful technical info.\n* IMO model cards are a brief presentation of a model which includes:\n * short summary of the architectural particularities of the model\n * describing the data it was trained on\n * what is the performance on reference datasets (accuracy and speed metrics if possible)\n * limitations\n * how to use it in the context of the Transformers library\n * source (original article, Github repo,...)\n* Easily accessible documentation that any background can read and learn about critical model components and social impact\n\n\n### What do you like about model cards?\n\n* They are interesting to teach people about new models\n* As a non-technical guy, the possibility of getting to know the model, to understand the basics of it, it's an opportunity for the author to disclose its innovation in a transparent & explainable (i.e. trustworthy) way.\n* I like interactive model cards with visuals and widgets that allow me to try the model without running any code.\n* What I like about good model cards is that you can find all the information you need about that particular model.\n* Model cards are revolutionary to the world of AI ethics. It's one of the first tangible steps in mitigating/educating on biases in machine learning. They foster greater awareness and accountability!\n* Structured, exhaustive, the more info the better.\n* It helps to get an understanding of what the model is good (or bad) at.\n* Conciseness and accessibility\n\n\n### What do you dislike about model cards?\n\n* Might get to technical and/or dense\n* <mark >They contain lots of information for different audiences (researchers, engineers, non engineers), so it's difficult to explore model cards with an intended use cases.</mark> \n * [NOTE: this comment could be addressed with toggle views for different audiences]\n* <mark >Good ones are time consuming to create. They are hard to test to make sure the information is up to date. Often times, model cards are formatted completely differently - so you have to sort of figure out how that certain individual has structured theirs.</mark> \n * [NOTE: this comment helps demonstrate the value of a standardized format and automation tools to make it easier to create model cards]\n* Without the help of the community to pitch in supplemental evals, model cards might be subject to inherent biases that the developer might not be aware of. It's early days for them, but without more thorough evaluations, a model card's information might be too limited.\n* <mark > Empty model cards. No license information - customers need that info and generally don't have it.</mark> \n* They are usually either too concise or too verbose.\n* writing them lol bless you\n\n### Other key new insights\n\n* Model cards are best filled out when done by people with different roles: Technical specifications can generally only be filled out by the developers; ethical considerations throughout are generally best informed by people who tend to work on ethical issues.\n* Model users care a lot about licences -- specifically, whether a model can legally be used for a specific task.\n\n\n## Appendix B: Landscape Analysis\n_Overview of the state of model documentation in Machine Learning_\n\n### MODEL CARD EXAMPLES\nExamples of model cards and closely-related variants include: \n\n* Google Cloud: [Face Detection](https://modelcards.withgoogle.com/face-detection), [Object Detection](https://modelcards.withgoogle.com/object-detection)\n* Google Research: [ML Kit Vision Models](https://developers.google.com/s/results/ml-kit?q=%22Model%20Card%22), [Face Detection](https://sites.google.com/view/perception-cv4arvr/blazeface), [Conversation AI](https://github.com/conversationai/perspectiveapi/tree/main/model-cards)\n* OpenAI: [GPT-3](https://github.com/openai/gpt-3/blob/master/model-card.md), [GPT-2](https://github.com/openai/gpt-2/blob/master/model_card.md), [DALL-E dVAE](https://github.com/openai/DALL-E/blob/master/model_card.md), [CLIP](https://github.com/openai/CLIP-featurevis/blob/master/model-card.md)\n* [NVIDIA Model Cards](https://catalog.ngc.nvidia.com/models?filters=&orderBy=weightPopularASC&query=)\n* [Salesforce Model Cards](https://blog.salesforceairesearch.com/model-cards-for-ai-model-transparency/)\n* [Allen AI Model Cards](https://github.com/allenai/allennlp-models/tree/main/allennlp_models/modelcards)\n* [Co:here AI Model Cards](https://docs.cohere.ai/responsible-use/)\n* [Duke PULSE Model Card](https://arxiv.org/pdf/2003.03808.pdf)\n* [Stanford Dynasent](https://github.com/cgpotts/dynasent/blob/main/dynasent_modelcard.md)\n* [GEM Model Cards](https://gem-benchmark.com/model_cards)\n* Parl.AI: [Parl.AI sample model cards](https://github.com/facebookresearch/ParlAI/tree/main/docs/sample_model_cards), [BlenderBot 2.0 2.7B](https://github.com/facebookresearch/ParlAI/blob/main/parlai/zoo/blenderbot2/model_card.md)\n* [Perspective API Model Cards](https://github.com/conversationai/perspectiveapi/tree/main/model-cards)\n* See https://github.com/ivylee/model-cards-and-datasheets for more examples!\n\n### MODEL CARDS FOR LARGE LANGUAGE MODELS\nLarge language models are often released with associated documentation. Large language models that have an associated model card (or related documentation tool) include: \n\n\n* [Big Science BLOOM model card](https://huggingface.co/bigscience/bloom)\n* [GPT-2 Model Card](https://github.com/openai/gpt-2/blob/master/model_card.md) \n* [GPT-3 Model Card](https://github.com/openai/gpt-3/blob/master/model-card.md)\n* [DALL-E 2 Preview System Card](https://github.com/openai/dalle-2-preview/blob/main/system-card.md)\n* [OPT-175B model card](https://arxiv.org/pdf/2205.01068.pdf)\n\n### MODEL CARD GENERATION TOOLS\nTools for programmatically or interactively generating model cards include: \n\n* [Salesforce Model Card Creation](https://help.salesforce.com/s/articleView?id=release-notes.rn_bi_edd_model_card.htm&type=5&release=232)\n* [TensorFlow Model Card Toolkit](https://ai.googleblog.com/2020/07/introducing-model-card-toolkit-for.html)\n * [Python library](https://pypi.org/project/model-card-toolkit/)\n* [GSA / US Census Bureau Collaboration on Model Card Generator](https://bias.xd.gov/resources/model-card-generator/)\n* [Parl.AI Auto Generation Tool](https://parl.ai/docs/tutorial_model_cards.html)\n* [VerifyML Model Card Generation Web Tool](https://www.verifyml.com)\n* [RMarkdown Template for Model Card as part of vetiver package](https://cran.r-project.org/web/packages/vetiver/vignettes/model-card.html)\n* [Databaseline ML Cards toolkit](https://databaseline.tech/ml-cards/)\n\n### MODEL CARD EDUCATIONAL TOOLS\nTools for understanding model cards and understanding how to create model cards include: \n\n* [Hugging Face Hub docs](https://huggingface.co/course/chapter4/4?fw=pt)\n* [Perspective API](https://developers.perspectiveapi.com/s/about-the-api-model-cards)\n* [Kaggle](https://www.kaggle.com/code/var0101/model-cards/tutorial)\n* [Code.org](https://studio.code.org/s/aiml-2021/lessons/8)\n* [UNICEF](https://unicef.github.io/inventory/data/model-card/)\n\n---\n\n**Please cite as:**\nOzoani, Ezi and Gerchick, Marissa and Mitchell, Margaret. Model Card Guidebook. Hugging Face, 2022. https://huggingface.co/docs/hub/en/model-card-guidebook \n\n", "docs\\sagemaker\\index.md": "# Hugging Face on Amazon SageMaker\n\n\n\n## Deep Learning Containers\n\nDeep Learning Containers (DLCs) are Docker images pre-installed with deep learning frameworks and libraries such as \ud83e\udd17 Transformers, \ud83e\udd17 Datasets, and \ud83e\udd17 Tokenizers. The DLCs allow you to start training models immediately, skipping the complicated process of building and optimizing your training environments from scratch. Our DLCs are thoroughly tested and optimized for deep learning environments, requiring no configuration or maintenance on your part. In particular, the Hugging Face Inference DLC comes with a pre-written serving stack which drastically lowers the technical bar of deep learning serving.\n\nOur DLCs are available everywhere [Amazon SageMaker](https://aws.amazon.com/sagemaker/) is [available](https://aws.amazon.com/about-aws/global-infrastructure/regional-product-services/). While it is possible to use the DLCs without the SageMaker Python SDK, there are many advantages to using SageMaker to train your model:\n\n- Cost-effective: Training instances are only live for the duration of your job. Once your job is complete, the training cluster stops, and you won't be billed anymore. SageMaker also supports [Spot instances]((https://docs.aws.amazon.com/sagemaker/latest/dg/model-managed-spot-training.html)), which can reduce costs up to 90%.\n- Built-in automation: SageMaker automatically stores training metadata and logs in a serverless managed metastore and fully manages I/O operations with S3 for your datasets, checkpoints, and model artifacts.\n- Multiple security mechanisms: SageMaker offers [encryption at rest](https://docs.aws.amazon.com/sagemaker/latest/dg/encryption-at-rest-nbi.html), [in transit](https://docs.aws.amazon.com/sagemaker/latest/dg/encryption-in-transit.html), [Virtual Private Cloud](https://docs.aws.amazon.com/sagemaker/latest/dg/interface-vpc-endpoint.html) connectivity, and [Identity and Access Management](https://docs.aws.amazon.com/sagemaker/latest/dg/security_iam_service-with-iam.html) to secure your data and code.\n\nHugging Face DLCs are open source and licensed under Apache 2.0. Feel free to reach out on our [community forum](https://discuss.huggingface.co/c/sagemaker/17) if you have any questions. For premium support, our [Expert Acceleration Program](https://huggingface.co/support) gives you direct dedicated support from our team.\n\n## Features & benefits \ud83d\udd25\n\nHugging Face DLCs make it easier than ever to train Transformer models in SageMaker. Here is why you should consider using Hugging Face DLCs to train and deploy your next machine learning models:\n\n**One command is all you need**\n\nWith the new Hugging Face DLCs, train cutting-edge Transformers-based NLP models in a single line of code. Choose from multiple DLC variants, each one optimized for TensorFlow and PyTorch, single-GPU, single-node multi-GPU, and multi-node clusters.\n\n**Accelerate machine learning from science to production**\n\nIn addition to Hugging Face DLCs, we created a first-class Hugging Face extension for the SageMaker Python SDK to accelerate data science teams, reducing the time required to set up and run experiments from days to minutes.\n\nYou can use the Hugging Face DLCs with SageMaker's automatic model tuning to optimize your training hyperparameters and increase the accuracy of your models.\n\nDeploy your trained models for inference with just one more line of code or select any of the 10,000+ publicly available models from the [model Hub](https://huggingface.co/models) and deploy them with SageMaker.\n\nEasily track and compare your experiments and training artifacts in SageMaker Studio's web-based integrated development environment (IDE).\n\n**Built-in performance**\n\nHugging Face DLCs feature built-in performance optimizations for PyTorch and TensorFlow to train NLP models faster. The DLCs also give you the flexibility to choose a training infrastructure that best aligns with the price/performance ratio for your workload.\n\nThe Hugging Face Training DLCs are fully integrated with SageMaker distributed training libraries to train models faster than ever, using the latest generation of instances available on Amazon Elastic Compute Cloud.\n\nHugging Face Inference DLCs provide you with production-ready endpoints that scale quickly with your AWS environment, built-in monitoring, and a ton of enterprise features. \n\n---\n\n## Resources, Documentation & Samples \ud83d\udcc4\n\nTake a look at our published blog posts, videos, documentation, sample notebooks and scripts for additional help and more context about Hugging Face DLCs on SageMaker.\n\n### Blogs and videos\n\n- [AWS: Embracing natural language processing with Hugging Face](https://aws.amazon.com/de/blogs/opensource/embracing-natural-language-processing-with-hugging-face/)\n- [Deploy Hugging Face models easily with Amazon SageMaker](https://huggingface.co/blog/deploy-hugging-face-models-easily-with-amazon-sagemaker)\n- [AWS and Hugging Face collaborate to simplify and accelerate adoption of natural language processing models](https://aws.amazon.com/blogs/machine-learning/aws-and-hugging-face-collaborate-to-simplify-and-accelerate-adoption-of-natural-language-processing-models/)\n- [Walkthrough: End-to-End Text Classification](https://youtu.be/ok3hetb42gU)\n- [Working with Hugging Face models on Amazon SageMaker](https://youtu.be/leyrCgLAGjMn)\n- [Distributed Training: Train BART/T5 for Summarization using \ud83e\udd17 Transformers and Amazon SageMaker](https://huggingface.co/blog/sagemaker-distributed-training-seq2seq)\n- [Deploy a Hugging Face Transformers Model from S3 to Amazon SageMaker](https://youtu.be/pfBGgSGnYLs)\n- [Deploy a Hugging Face Transformers Model from the Model Hub to Amazon SageMaker](https://youtu.be/l9QZuazbzWM)\n\n### Documentation\n\n- [Run training on Amazon SageMaker](/docs/sagemaker/train)\n- [Deploy models to Amazon SageMaker](/docs/sagemaker/inference)\n- [Reference](/docs/sagemaker/reference)\n- [Amazon SageMaker documentation for Hugging Face](https://docs.aws.amazon.com/sagemaker/latest/dg/hugging-face.html)\n- [Python SDK SageMaker documentation for Hugging Face](https://sagemaker.readthedocs.io/en/stable/frameworks/huggingface/index.html)\n- [Deep Learning Container](https://github.com/aws/deep-learning-containers/blob/master/available_images.md#huggingface-training-containers)\n- [SageMaker's Distributed Data Parallel Library](https://docs.aws.amazon.com/sagemaker/latest/dg/data-parallel.html)\n- [SageMaker's Distributed Model Parallel Library](https://docs.aws.amazon.com/sagemaker/latest/dg/model-parallel.html)\n\n### Sample notebooks\n\n- [All notebooks](https://github.com/huggingface/notebooks/tree/master/sagemaker)\n- [Getting Started with Pytorch](https://github.com/huggingface/notebooks/blob/main/sagemaker/01_getting_started_pytorch/sagemaker-notebook.ipynb)\n- [Getting Started with Tensorflow](https://github.com/huggingface/notebooks/blob/main/sagemaker/02_getting_started_tensorflow/sagemaker-notebook.ipynb)\n- [Distributed Training Data Parallelism](https://github.com/huggingface/notebooks/blob/main/sagemaker/03_distributed_training_data_parallelism/sagemaker-notebook.ipynb)\n- [Distributed Training Model Parallelism](https://github.com/huggingface/notebooks/blob/main/sagemaker/04_distributed_training_model_parallelism/sagemaker-notebook.ipynb)\n- [Spot Instances and continue training](https://github.com/huggingface/notebooks/blob/main/sagemaker/05_spot_instances/sagemaker-notebook.ipynb)\n- [SageMaker Metrics](https://github.com/huggingface/notebooks/blob/main/sagemaker/06_sagemaker_metrics/sagemaker-notebook.ipynb)\n- [Distributed Training Data Parallelism Tensorflow](https://github.com/huggingface/notebooks/blob/main/sagemaker/07_tensorflow_distributed_training_data_parallelism/sagemaker-notebook.ipynb)\n- [Distributed Training Summarization](https://github.com/huggingface/notebooks/blob/main/sagemaker/08_distributed_summarization_bart_t5/sagemaker-notebook.ipynb)\n- [Image Classification with Vision Transformer](https://github.com/huggingface/notebooks/blob/main/sagemaker/09_image_classification_vision_transformer/sagemaker-notebook.ipynb)\n- [Deploy one of the 10 000+ Hugging Face Transformers to Amazon SageMaker for Inference](https://github.com/huggingface/notebooks/blob/main/sagemaker/11_deploy_model_from_hf_hub/deploy_transformer_model_from_hf_hub.ipynb)\n- [Deploy a Hugging Face Transformer model from S3 to SageMaker for inference](https://github.com/huggingface/notebooks/blob/main/sagemaker/10_deploy_model_from_s3/deploy_transformer_model_from_s3.ipynb)\n", "scripts\\api-inference\\package.json": "{\n \"name\": \"api-inference-generator\",\n \"version\": \"1.0.0\",\n \"description\": \"\",\n \"main\": \"index.js\",\n \"type\": \"module\",\n \"scripts\": {\n \"format\": \"prettier --write .\",\n \"format:check\": \"prettier --check .\",\n \"generate\": \"tsx scripts/generate.ts\"\n },\n \"keywords\": [],\n \"author\": \"\",\n \"license\": \"ISC\",\n \"dependencies\": {\n \"@huggingface/tasks\": \"^0.11.11\",\n \"@types/node\": \"^22.5.0\",\n \"handlebars\": \"^4.7.8\",\n \"node\": \"^20.17.0\",\n \"prettier\": \"^3.3.3\",\n \"ts-node\": \"^10.9.2\",\n \"tsx\": \"^4.17.0\",\n \"type-fest\": \"^4.25.0\",\n \"typescript\": \"^5.5.4\"\n }\n}\n"} | null |
hub-js-utils | {"type": "directory", "name": "hub-js-utils", "children": [{"type": "file", "name": "share-canvas.js"}]} | {".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 f900881a289aff63e0b6f765ac959d69817f31a7 Hamza Amin <[email protected]> 1727370233 +0500\tclone: from https://github.com/huggingface/hub-js-utils.git\n", ".git\\refs\\heads\\main": "f900881a289aff63e0b6f765ac959d69817f31a7\n"} | null |
|
huggingface-inference-toolkit | {"type": "directory", "name": "huggingface-inference-toolkit", "children": [{"type": "file", "name": ".dockerignore"}, {"type": "directory", "name": "dockerfiles", "children": [{"type": "directory", "name": "pytorch", "children": [{"type": "file", "name": "Dockerfile"}, {"type": "file", "name": "Dockerfile.inf2"}]}]}, {"type": "file", "name": "LICENSE"}, {"type": "file", "name": "makefile"}, {"type": "file", "name": "MANIFEST.in"}, {"type": "file", "name": "pyproject.toml"}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "scripts", "children": [{"type": "file", "name": "entrypoint.sh"}]}, {"type": "file", "name": "setup.cfg"}, {"type": "file", "name": "setup.py"}, {"type": "directory", "name": "src", "children": [{"type": "directory", "name": "huggingface_inference_toolkit", "children": [{"type": "file", "name": "async_utils.py"}, {"type": "file", "name": "const.py"}, {"type": "file", "name": "diffusers_utils.py"}, {"type": "file", "name": "env_utils.py"}, {"type": "file", "name": "handler.py"}, {"type": "file", "name": "logging.py"}, {"type": "file", "name": "optimum_utils.py"}, {"type": "file", "name": "sentence_transformers_utils.py"}, {"type": "directory", "name": "serialization", "children": [{"type": "file", "name": "audio_utils.py"}, {"type": "file", "name": "base.py"}, {"type": "file", "name": "image_utils.py"}, {"type": "file", "name": "json_utils.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "utils.py"}, {"type": "file", "name": "vertex_ai_utils.py"}, {"type": "file", "name": "webservice_starlette.py"}, {"type": "file", "name": "__init__.py"}]}]}, {"type": "directory", "name": "tests", "children": [{"type": "directory", "name": "integ", "children": [{"type": "file", "name": "config.py"}, {"type": "file", "name": "conftest.py"}, {"type": "file", "name": "helpers.py"}, {"type": "file", "name": "test_pytorch_local_cpu.py"}, {"type": "file", "name": "test_pytorch_local_gpu.py"}, {"type": "file", "name": "test_pytorch_local_inf2.py"}, {"type": "file", "name": "test_pytorch_remote_cpu.py"}, {"type": "file", "name": "test_pytorch_remote_gpu.py"}, {"type": "file", "name": "utils.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "resources", "children": [{"type": "directory", "name": "audio", "children": [{"type": "file", "name": "sample.amr"}, {"type": "file", "name": "sample.m4a"}]}, {"type": "directory", "name": "custom_handler", "children": [{"type": "file", "name": "custom_utils.py"}, {"type": "file", "name": "pipeline.py"}]}, {"type": "directory", "name": "image", "children": [{"type": "file", "name": "tiger.bmp"}, {"type": "file", "name": "tiger.tiff"}, {"type": "file", "name": "tiger.webp"}]}]}, {"type": "directory", "name": "unit", "children": [{"type": "file", "name": "conftest.py"}, {"type": "file", "name": "test_const.py"}, {"type": "file", "name": "test_diffusers.py"}, {"type": "file", "name": "test_handler.py"}, {"type": "file", "name": "test_optimum_utils.py"}, {"type": "file", "name": "test_sentence_transformers.py"}, {"type": "file", "name": "test_serializer.py"}, {"type": "file", "name": "test_utils.py"}, {"type": "file", "name": "test_vertex_ai_utils.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "__init__.py"}]}]} | <img src="https://huggingface.co/front/assets/huggingface_logo.svg" width="100"/>
# Hugging Face Inference Toolkit
Hugging Face Inference Toolkit is for serving 🤗 Transformers models in containers. This library provides default pre-processing, prediction, and postprocessing for Transformers, diffusers, and Sentence Transformers. It is also possible to define a custom `handler.py` for customization. The Toolkit is built to work with the [Hugging Face Hub](https://huggingface.co/models) and is used as the "default" option in [Inference Endpoints](https://ui.endpoints.huggingface.co/)
## 💻 Getting Started with Hugging Face Inference Toolkit
- Clone the repository `git clone https://github.com/huggingface/huggingface-inference-toolkit`
- Install the dependencies in dev mode `pip install -e ".[torch,st,diffusers,test,quality]"`
- If you develop on AWS Inferentia2 install with `pip install -e ".[inf2,test,quality]" --upgrade`
- If you develop on Google Cloud install with `pip install -e ".[torch,st,diffusers,google,test,quality]"`
- Unit Testing: `make unit-test`
- Integration testing: `make integ-test`
### Local run
```bash
mkdir tmp2/
HF_MODEL_ID=hf-internal-testing/tiny-random-distilbert HF_MODEL_DIR=tmp2 HF_TASK=text-classification uvicorn src.huggingface_inference_toolkit.webservice_starlette:app --port 5000
```
### Container
1. build the preferred container for either CPU or GPU for PyTorch.
_CPU Images_
```bash
make inference-pytorch-cpu
```
_GPU Images_
```bash
make inference-pytorch-gpu
```
2. Run the container and provide either environment variables to the HUB model you want to use or mount a volume to the container, where your model is stored.
```bash
docker run -ti -p 5000:5000 -e HF_MODEL_ID=distilbert-base-uncased-distilled-squad -e HF_TASK=question-answering integration-test-pytorch:cpu
docker run -ti -p 5000:5000 --gpus all -e HF_MODEL_ID=nlpconnect/vit-gpt2-image-captioning -e HF_TASK=image-to-text integration-test-pytorch:gpu
docker run -ti -p 5000:5000 --gpus all -e HF_MODEL_ID=echarlaix/tiny-random-stable-diffusion-xl -e HF_TASK=text-to-image integration-test-pytorch:gpu
docker run -ti -p 5000:5000 --gpus all -e HF_MODEL_ID=stabilityai/stable-diffusion-xl-base-1.0 -e HF_TASK=text-to-image integration-test-pytorch:gpu
docker run -ti -p 5000:5000 -e HF_MODEL_DIR=/repository -v $(pwd)/distilbert-base-uncased-emotion:/repository integration-test-pytorch:cpu
```
3. Send request. The API schema is the same as from the [inference API](https://huggingface.co/docs/api-inference/detailed_parameters)
```bash
curl --request POST \
--url http://localhost:5000 \
--header 'Content-Type: application/json' \
--data '{
"inputs": {
"question": "What is used for inference?",
"context": "My Name is Philipp and I live in Nuremberg. This model is used with sagemaker for inference."
}
}'
```
### Custom Handler and dependency support
The Hugging Face Inference Toolkit allows user to provide a custom inference through a `handler.py` file which is located in the repository.
For an example check [philschmid/custom-pipeline-text-classification](https://huggingface.co/philschmid/custom-pipeline-text-classification):
```bash
model.tar.gz/
|- pytorch_model.bin
|- ....
|- handler.py
|- requirements.txt
```
In this example, `pytroch_model.bin` is the model file saved from training, `handler.py` is the custom inference handler, and `requirements.txt` is a requirements file to add additional dependencies.
The custom module can override the following methods:
### Vertex AI Support
The Hugging Face Inference Toolkit is also supported on Vertex AI, based on [Custom container requirements for prediction](https://cloud.google.com/vertex-ai/docs/predictions/custom-container-requirements). [Environment variables set by Vertex AI](https://cloud.google.com/vertex-ai/docs/predictions/custom-container-requirements#aip-variables) are automatically detected and used by the toolkit.
#### Local run with HF_MODEL_ID and HF_TASK
Start Hugging Face Inference Toolkit with the following environment variables.
```bash
mkdir tmp2/
AIP_MODE=PREDICTION AIP_PORT=8080 AIP_PREDICT_ROUTE=/pred AIP_HEALTH_ROUTE=/h HF_MODEL_DIR=tmp2 HF_MODEL_ID=distilbert/distilbert-base-uncased-finetuned-sst-2-english HF_TASK=text-classification uvicorn src.huggingface_inference_toolkit.webservice_starlette:app --port 8080
```
Send request
```bash
curl --request POST \
--url http://localhost:8080/pred \
--header 'Content-Type: application/json' \
--data '{
"instances": ["I love this product", "I hate this product"],
"parameters": { "top_k": 2 }
}'
```
#### Container run with HF_MODEL_ID and HF_TASK
1. build the preferred container for either CPU or GPU for PyTorch o.
```bash
docker build -t vertex -f dockerfiles/pytorch/Dockerfile -t vertex-test-pytorch:gpu .
```
2. Run the container and provide either environment variables to the HUB model you want to use or mount a volume to the container, where your model is stored.
```bash
docker run -ti -p 8080:8080 -e AIP_MODE=PREDICTION -e AIP_HTTP_PORT=8080 -e AIP_PREDICT_ROUTE=/pred -e AIP_HEALTH_ROUTE=/h -e HF_MODEL_ID=distilbert/distilbert-base-uncased-finetuned-sst-2-english -e HF_TASK=text-classification vertex-test-pytorch:gpu
```
3. Send request
```bash
curl --request POST \
--url http://localhost:8080/pred \
--header 'Content-Type: application/json' \
--data '{
"instances": ["I love this product", "I hate this product"],
"parameters": { "top_k": 2 }
}'
```
### AWS Inferentia2 Support
The Hugging Face Inference Toolkit provides support for deploying Hugging Face on AWS Inferentia2. To deploy a model on Inferentia2 you have 3 options:
- Provide `HF_MODEL_ID`, the model repo id on huggingface.co which contains the compiled model under `.neuron` format e.g. `optimum/bge-base-en-v1.5-neuronx`
- Provide the `HF_OPTIMUM_BATCH_SIZE` and `HF_OPTIMUM_SEQUENCE_LENGTH` environment variables to compile the model on the fly, e.g. `HF_OPTIMUM_BATCH_SIZE=1 HF_OPTIMUM_SEQUENCE_LENGTH=128`
- Include `neuron` dictionary in the [config.json](https://huggingface.co/optimum/tiny_random_bert_neuron/blob/main/config.json) file in the model archive, e.g. `neuron: {"static_batch_size": 1, "static_sequence_length": 128}`
The currently supported tasks can be found [here](https://huggingface.co/docs/optimum-neuron/en/package_reference/supported_models). If you plan to deploy an LLM, we recommend taking a look at [Neuronx TGI](https://huggingface.co/blog/text-generation-inference-on-inferentia2), which is purposly build for LLMs.
#### Local run with HF_MODEL_ID and HF_TASK
Start Hugging Face Inference Toolkit with the following environment variables.
_Note: You need to run this on an Inferentia2 instance._
- transformers `text-classification` with `HF_OPTIMUM_BATCH_SIZE` and `HF_OPTIMUM_SEQUENCE_LENGTH`
```bash
mkdir tmp2/
HF_MODEL_ID="distilbert/distilbert-base-uncased-finetuned-sst-2-english" HF_TASK="text-classification" HF_OPTIMUM_BATCH_SIZE=1 HF_OPTIMUM_SEQUENCE_LENGTH=128 HF_MODEL_DIR=tmp2 uvicorn src.huggingface_inference_toolkit.webservice_starlette:app --port 5000
```
- sentence transformers `feature-extration` with `HF_OPTIMUM_BATCH_SIZE` and `HF_OPTIMUM_SEQUENCE_LENGTH`
```bash
HF_MODEL_ID="sentence-transformers/all-MiniLM-L6-v2" HF_TASK="feature-extraction" HF_OPTIMUM_BATCH_SIZE=1 HF_OPTIMUM_SEQUENCE_LENGTH=128 HF_MODEL_DIR=tmp2 uvicorn src.huggingface_inference_toolkit.webservice_starlette:app --port 5000
```
Send request
```bash
curl --request POST \
--url http://localhost:5000 \
--header 'Content-Type: application/json' \
--data '{
"inputs": "Wow, this is such a great product. I love it!"
}'
```
#### Container run with HF_MODEL_ID and HF_TASK
1. build the preferred container for either CPU or GPU for PyTorch o.
```bash
make inference-pytorch-inf2
```
2. Run the container and provide either environment variables to the HUB model you want to use or mount a volume to the container, where your model is stored.
```bash
docker run -ti -p 5000:5000 -e HF_MODEL_ID="distilbert/distilbert-base-uncased-finetuned-sst-2-english" -e HF_TASK="text-classification" -e HF_OPTIMUM_BATCH_SIZE=1 -e HF_OPTIMUM_SEQUENCE_LENGTH=128 --device=/dev/neuron0 integration-test-pytorch:inf2
```
3. Send request
```bash
curl --request POST \
--url http://localhost:5000 \
--header 'Content-Type: application/json' \
--data '{
"inputs": "Wow, this is such a great product. I love it!",
"parameters": { "top_k": 2 }
}'
```
---
## 🛠️ Environment variables
The Hugging Face Inference Toolkit implements various additional environment variables to simplify your deployment experience. A full list of environment variables is given below. All potential environment variables can be found in [const.py](src/huggingface_inference_toolkit/const.py)
### `HF_MODEL_DIR`
The `HF_MODEL_DIR` environment variable defines the directory where your model is stored or will be stored.
If `HF_MODEL_ID` is not set the toolkit expects a the model artifact at this directory. This value should be set to the value where you mount your model artifacts.
If `HF_MODEL_ID` is set the toolkit and the directory where `HF_MODEL_DIR` is pointing to is empty. The toolkit will download the model from the Hub to this directory.
The default value is `/opt/huggingface/model`
```bash
HF_MODEL_ID="/opt/mymodel"
```
### `HF_TASK`
The `HF_TASK` environment variable defines the task for the used Transformers pipeline or Sentence Transformers. A full list of tasks can be find in [supported & tested task section](#supported--tested-tasks)
```bash
HF_TASK="question-answering"
```
### `HF_MODEL_ID`
The `HF_MODEL_ID` environment variable defines the model id, which will be automatically loaded from [huggingface.co/models](https://huggingface.co/models) when starting the container.
```bash
HF_MODEL_ID="distilbert-base-uncased-finetuned-sst-2-english"
```
### `HF_REVISION`
The `HF_REVISION` is an extension to `HF_MODEL_ID` and allows you to define/pin a revision of the model to make sure you always load the same model on your SageMaker Endpoint.
```bash
HF_REVISION="03b4d196c19d0a73c7e0322684e97db1ec397613"
```
### `HF_HUB_TOKEN`
The `HF_HUB_TOKEN` environment variable defines the your Hugging Face authorization token. The `HF_HUB_TOKEN` is used as a HTTP bearer authorization for remote files, like private models. You can find your token at your [settings page](https://huggingface.co/settings/token).
```bash
HF_HUB_TOKEN="api_XXXXXXXXXXXXXXXXXXXXXXXXXXXXX"
```
### `HF_TRUST_REMOTE_CODE`
The `HF_TRUST_REMOTE_CODE` environment variable defines whether to trust remote code. This flag is already used for community defined inference code, and is therefore quite representative of the level of confidence you are giving the model providers when loading models from the Hugging Face Hub. The default value is `"0"`; set it to `"1"` to trust remote code.
```bash
HF_TRUST_REMOTE_CODE="0"
```
### `HF_FRAMEWORK`
The `HF_FRAMEWORK` environment variable defines the base deep learning framework used in the container. This is important when loading large models from the Hugguing Face Hub to avoid extra file downloads.
```bash
HF_FRAMEWORK="pytorch"
```
#### `HF_OPTIMUM_BATCH_SIZE`
The `HF_OPTIMUM_BATCH_SIZE` environment variable defines the batch size, which is used when compiling the model to Neuron. The default value is `1`. Not required when model is already converted.
```bash
HF_OPTIMUM_BATCH_SIZE="1"
```
#### `HF_OPTIMUM_SEQUENCE_LENGTH`
The `HF_OPTIMUM_SEQUENCE_LENGTH` environment variable defines the sequence length, which is used when compiling the model to Neuron. There is no default value. Not required when model is already converted.
```bash
HF_OPTIMUM_SEQUENCE_LENGTH="128"
```
---
## ⚙ Supported Front-Ends
- [x] Starlette (HF Endpoints)
- [x] Starlette (Vertex AI)
- [ ] Starlette (Azure ML)
- [ ] Starlette (SageMaker)
## 📜 License
This project is licensed under the Apache-2.0 License.
| {"setup.py": "from __future__ import absolute_import\n\nfrom setuptools import find_packages, setup\n\n# We don't declare our dependency on transformers here because we build with\n# different packages for different variants\n\nVERSION = \"0.5.0\"\n\n# Ubuntu packages\n# libsndfile1-dev: torchaudio requires the development version of the libsndfile package which can be installed via a system package manager. On Ubuntu it can be installed as follows: apt install libsndfile1-dev\n# ffmpeg: ffmpeg is required for audio processing. On Ubuntu it can be installed as follows: apt install ffmpeg\n# libavcodec-extra : libavcodec-extra includes additional codecs for ffmpeg\n\ninstall_requires = [\n \"transformers[sklearn,sentencepiece,audio,vision,sentencepiece]==4.44.0\",\n \"huggingface_hub[hf_transfer]==0.24.5\",\n # vision\n \"Pillow\",\n \"librosa\",\n # speech + torchaudio\n \"pyctcdecode>=0.3.0\",\n \"phonemizer\",\n \"ffmpeg\",\n # web api\n \"starlette\",\n \"uvicorn\",\n \"pandas\",\n \"orjson\",\n]\n\nextras = {}\n\nextras[\"st\"] = [\"sentence_transformers==2.7.0\"]\nextras[\"diffusers\"] = [\"diffusers==0.30.0\", \"accelerate==0.33.0\"]\n# Includes `peft` as PEFT requires `torch` so having `peft` as a core dependency\n# means that `torch` will be installed even if the `torch` extra is not specified.\nextras[\"torch\"] = [\"torch==2.2.2\", \"torchvision\", \"torchaudio\", \"peft==0.12.0\"]\nextras[\"test\"] = [\n \"pytest==7.2.1\",\n \"pytest-xdist\",\n \"parameterized\",\n \"psutil\",\n \"datasets\",\n \"pytest-sugar\",\n \"mock==2.0.0\",\n \"docker\",\n \"requests\",\n \"tenacity\",\n]\nextras[\"quality\"] = [\"isort\", \"ruff\"]\nextras[\"inf2\"] = [\"optimum-neuron\"]\nextras[\"google\"] = [\"google-cloud-storage\", \"crcmod==1.7\"]\n\nsetup(\n name=\"huggingface-inference-toolkit\",\n version=VERSION,\n author=\"Hugging Face\",\n description=\"Hugging Face Inference Toolkit is for serving \ud83e\udd17 Transformers models in containers.\",\n url=\"\",\n package_dir={\"\": \"src\"},\n packages=find_packages(where=\"src\"),\n install_requires=install_requires,\n extras_require=extras,\n entry_points={\n \"console_scripts\": \"serve=sagemaker_huggingface_inference_toolkit.serving:main\"\n },\n python_requires=\">=3.8\",\n license=\"Apache License 2.0\",\n classifiers=[\n \"Development Status :: 5 - Production/Stable\",\n \"Intended Audience :: Developers\",\n \"Intended Audience :: Education\",\n \"Intended Audience :: Science/Research\",\n \"License :: OSI Approved :: Apache Software License\",\n \"Operating System :: OS Independent\",\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.8\",\n \"Programming Language :: Python :: 3.9\",\n \"Programming Language :: Python :: 3.10\",\n \"Programming Language :: Python :: 3.11\",\n \"Programming Language :: Python :: 3.12\",\n \"Topic :: Scientific/Engineering :: Artificial Intelligence\",\n ],\n)\n", ".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 ee550bf848aa63b9a83075e0717af8323bb469df Hamza Amin <[email protected]> 1727369207 +0500\tclone: from https://github.com/huggingface/huggingface-inference-toolkit.git\n", ".git\\refs\\heads\\main": "ee550bf848aa63b9a83075e0717af8323bb469df\n", "dockerfiles\\pytorch\\Dockerfile": "ARG BASE_IMAGE=nvidia/cuda:12.1.0-devel-ubuntu22.04\n\nFROM $BASE_IMAGE as base \nSHELL [\"/bin/bash\", \"-c\"]\n\nLABEL maintainer=\"Hugging Face\"\n\nENV DEBIAN_FRONTEND=noninteractive\n\nWORKDIR /app\n\nRUN apt-get update && \\\n apt-get install software-properties-common -y && \\\n add-apt-repository ppa:deadsnakes/ppa && \\\n apt-get -y upgrade --only-upgrade systemd openssl cryptsetup && \\\n apt-get install -y \\\n build-essential \\\n bzip2 \\\n curl \\\n git \\\n git-lfs \\\n tar \\\n gcc \\\n g++ \\\n cmake \\\n libprotobuf-dev \\\n protobuf-compiler \\\n python3-dev \\\n python3-pip \\\n python3.11 \\\n libsndfile1-dev \\\n ffmpeg \\\n && apt-get clean autoremove --yes \\\n && rm -rf /var/lib/{apt,dpkg,cache,log}\n\n# Copying only necessary files as filtered by .dockerignore\nCOPY . .\n\n# install wheel and setuptools\nRUN pip install --no-cache-dir --upgrade pip \".[torch,st,diffusers]\"\n\n# copy application\nCOPY src/huggingface_inference_toolkit huggingface_inference_toolkit\nCOPY src/huggingface_inference_toolkit/webservice_starlette.py webservice_starlette.py\n\n# copy entrypoint and change permissions\nCOPY --chmod=0755 scripts/entrypoint.sh entrypoint.sh\n\nENTRYPOINT [\"bash\", \"-c\", \"./entrypoint.sh\"]\n\nFROM base AS vertex\n\n# Install `google` extra for Vertex AI compatibility\nRUN pip install --no-cache-dir --upgrade \".[google]\"\n", "dockerfiles\\pytorch\\Dockerfile.inf2": "# Build based on https://github.com/aws/deep-learning-containers/blob/master/huggingface/pytorch/inference/docker/2.1/py3/sdk2.18.0/Dockerfile.neuronx\nFROM ubuntu:20.04 as base\n\nLABEL maintainer=\"Hugging Face\"\n\nARG PYTHON=python3.10\nARG PYTHON_VERSION=3.10.12\nARG MAMBA_VERSION=23.1.0-4\n\n# Neuron SDK components version numbers\nARG NEURONX_FRAMEWORK_VERSION=2.1.2.2.1.0\nARG NEURONX_DISTRIBUTED_VERSION=0.7.0\nARG NEURONX_CC_VERSION=2.13.66.0\nARG NEURONX_TRANSFORMERS_VERSION=0.10.0.21\nARG NEURONX_COLLECTIVES_LIB_VERSION=2.20.22.0-c101c322e\nARG NEURONX_RUNTIME_LIB_VERSION=2.20.22.0-1b3ca6425\nARG NEURONX_TOOLS_VERSION=2.17.1.0\n\n# HF ARGS\nARG OPTIMUM_NEURON_VERSION=0.0.23\n\n# See http://bugs.python.org/issue19846\nENV LANG C.UTF-8\nENV LD_LIBRARY_PATH /opt/aws/neuron/lib:/lib/x86_64-linux-gnu:/opt/conda/lib/:$LD_LIBRARY_PATH\nENV PATH /opt/conda/bin:/opt/aws/neuron/bin:$PATH\n\nRUN apt-get update \\\n && apt-get upgrade -y \\\n && apt-get install -y --no-install-recommends software-properties-common \\\n && add-apt-repository ppa:openjdk-r/ppa \\\n && apt-get update \\\n && apt-get install -y --no-install-recommends \\\n build-essential \\\n apt-transport-https \\\n ca-certificates \\\n cmake \\\n curl \\\n emacs \\\n git \\\n jq \\\n libgl1-mesa-glx \\\n libsm6 \\\n libxext6 \\\n libxrender-dev \\\n openjdk-11-jdk \\\n vim \\\n wget \\\n unzip \\\n zlib1g-dev \\\n libcap-dev \\\n gpg-agent \\\n && rm -rf /var/lib/apt/lists/* \\\n && rm -rf /tmp/tmp* \\\n && apt-get clean\n\nRUN echo \"deb https://apt.repos.neuron.amazonaws.com focal main\" > /etc/apt/sources.list.d/neuron.list\nRUN wget -qO - https://apt.repos.neuron.amazonaws.com/GPG-PUB-KEY-AMAZON-AWS-NEURON.PUB | apt-key add -\n\n# Install Neuronx tools\nRUN apt-get update \\\n && apt-get install -y \\\n aws-neuronx-tools=$NEURONX_TOOLS_VERSION \\\n aws-neuronx-collectives=$NEURONX_COLLECTIVES_LIB_VERSION \\\n aws-neuronx-runtime-lib=$NEURONX_RUNTIME_LIB_VERSION \\\n && rm -rf /var/lib/apt/lists/* \\\n && rm -rf /tmp/tmp* \\\n && apt-get clean\n\n# https://github.com/docker-library/openjdk/issues/261 https://github.com/docker-library/openjdk/pull/263/files\nRUN keytool -importkeystore -srckeystore /etc/ssl/certs/java/cacerts -destkeystore /etc/ssl/certs/java/cacerts.jks -deststoretype JKS -srcstorepass changeit -deststorepass changeit -noprompt; \\\n mv /etc/ssl/certs/java/cacerts.jks /etc/ssl/certs/java/cacerts; \\\n /var/lib/dpkg/info/ca-certificates-java.postinst configure;\n\nRUN curl -L -o ~/mambaforge.sh https://github.com/conda-forge/miniforge/releases/download/${MAMBA_VERSION}/Mambaforge-${MAMBA_VERSION}-Linux-x86_64.sh \\\n && chmod +x ~/mambaforge.sh \\\n && ~/mambaforge.sh -b -p /opt/conda \\\n && rm ~/mambaforge.sh \\\n && /opt/conda/bin/conda update -y conda \\\n && /opt/conda/bin/conda install -c conda-forge -y \\\n python=$PYTHON_VERSION \\\n pyopenssl \\\n cython \\\n mkl-include \\\n mkl \\\n botocore \\\n parso \\\n scipy \\\n typing \\\n # Below 2 are included in miniconda base, but not mamba so need to install\n conda-content-trust \\\n charset-normalizer \\\n && /opt/conda/bin/conda update -y conda \\\n && /opt/conda/bin/conda clean -ya\n\nRUN conda install -c conda-forge \\\n scikit-learn \\\n h5py \\\n requests \\\n && conda clean -ya \\\n && pip install --upgrade pip --trusted-host pypi.org --trusted-host files.pythonhosted.org \\\n && ln -s /opt/conda/bin/pip /usr/local/bin/pip3 \\\n && pip install --no-cache-dir \"protobuf>=3.18.3,<4\" setuptools==69.5.1 packaging\n\nWORKDIR /\n\n# install Hugging Face libraries and its dependencies\nRUN pip install --extra-index-url https://pip.repos.neuron.amazonaws.com --no-cache-dir optimum-neuron[neuronx]==${OPTIMUM_NEURON_VERSION} \\\n && pip install --no-deps --no-cache-dir -U torchvision==0.16.*\n\n\nCOPY . .\n# install wheel and setuptools\nRUN pip install --no-cache-dir -U pip \".[st]\"\n\n# copy application\nCOPY src/huggingface_inference_toolkit huggingface_inference_toolkit\nCOPY src/huggingface_inference_toolkit/webservice_starlette.py webservice_starlette.py\n\n# copy entrypoint and change permissions\nCOPY --chmod=0755 scripts/entrypoint.sh entrypoint.sh\n\nENTRYPOINT [\"bash\", \"-c\", \"./entrypoint.sh\"]\n"} | null |
huggingface-llama-recipes | {"type": "directory", "name": "huggingface-llama-recipes", "children": [{"type": "file", "name": "4bit_bnb.ipynb"}, {"type": "file", "name": "8bit_bnb.ipynb"}, {"type": "directory", "name": "assets", "children": []}, {"type": "file", "name": "assisted_decoding.py"}, {"type": "file", "name": "assisted_decoding_70B_3B.ipynb"}, {"type": "file", "name": "assisted_decoding_8B_1B.ipynb"}, {"type": "file", "name": "awq.ipynb"}, {"type": "file", "name": "awq_generation.py"}, {"type": "file", "name": "deepspeed_zero3.yaml"}, {"type": "file", "name": "fp8-405B.ipynb"}, {"type": "file", "name": "gptq_generation.py"}, {"type": "file", "name": "inference-api.ipynb"}, {"type": "file", "name": "Llama-Vision FT.ipynb"}, {"type": "file", "name": "peft_finetuning.py"}, {"type": "file", "name": "prompt_guard.ipynb"}, {"type": "file", "name": "prompt_reuse.py"}, {"type": "file", "name": "qlora_405B.slurm"}, {"type": "file", "name": "quantized_cache.py"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "sft_vlm.py"}, {"type": "file", "name": "synthetic-data-with-llama.ipynb"}, {"type": "file", "name": "torch_compile.py"}, {"type": "file", "name": "torch_compile_with_torchao.ipynb"}]} | # Hugging Face Llama Recipes
🤗🦙Welcome! This repository contains minimal recipes to get started with Llama 3.1 quickly.
* To get an overview of Llama 3.1, please visit [Hugging Face announcement blog post](https://huggingface.co/blog/llama31).
* For more advanced end-to-end use cases with open ML, please visit the [Open Source AI Cookbook](https://huggingface.co/learn/cookbook/index).
This repository is WIP so that you might see considerable changes in the coming days.
_Note: To use Llama 3.1, you need to accept the license and request permission to access the models. Please, visit [any of the Hugging Face repos](https://huggingface.co/meta-llama/Meta-Llama-3.1-8B-Instruct) and submit your request. You only need to do this once, you'll get access to all the repos if your request is approved._
## Local Inference
Would you like to run inference of the Llama 3.1 models locally? So do we! The memory requirements depend on the model size and the precision of the weights. Here's a table showing the approximate memory needed for different configurations:
<table>
<tr>
<td><strong>Model Size</strong>
</td>
<td><strong>FP16</strong>
</td>
<td><strong>FP8</strong>
</td>
<td><strong>INT4 (AWQ/GPTQ/bnb)</strong>
</td>
</tr>
<tr>
<td>8B
</td>
<td>16 GB
</td>
<td>8 GB
</td>
<td>4 GB
</td>
</tr>
<tr>
<td>70B
</td>
<td>140 GB
</td>
<td>70 GB
</td>
<td>35 GB
</td>
</tr>
<tr>
<td>405B
</td>
<td>810 GB
</td>
<td>405 GB
</td>
<td>203 GB
</td>
</tr>
</table>
_Note: These are estimated values and may vary based on specific implementation details and optimizations._
Here are some notebooks to help you started:
* Run Llama 8B in free Google Colab in half precision
* [Run Llama 8B in 8-bits with bitsandbytes](./8bit_bnb.ipynb)
* [Run Llama 8B in 4-bits with bitsandbytes](./4bit_bnb.ipynb)
* [Run Llama 8B with AWQ & fused ops](./awq.ipynb)
* [Run Llama 3.1 405B FP8](./fp8-405B.ipynb)
* [Run Llama 3.1 405B quantized to INT4 with AWQ](./awq_generation.py)
* [Run Llama 3.1 405B quantized to INT4 with GPTQ](./gptq_generation.py)
* [Run assisted decoding with Llama 405B and Llama 8B](./assisted_decoding.py)
* [Accelerate your inference using torch.compile](./torch_compile.py)
* [Accelerate your inference using torch.compile and 4-bit quantization with torchao](./torch_compile_with_torchao.ipynb)
* Execute some Llama-generated Python code
* Use tools with Llama!
## API inference
Are these models too large for you to run at home? Would you like to experiment with Llama 405B? Try out the following examples!
* [Use the Inference API for PRO users](./inference-api.ipynb)
* Use a dedicated Inference Endpoint
## Llama Guard and Prompt Guard
In addition to the generative models, Meta released two new models: Llama Guard 3 and Prompt Guard. Prompt Guard is a small classifier that detects jailbreaks and prompt injections. Llama Guard 3 is a safeguard model that can classify LLM inputs and generations. Learn how to use them as done in the following notebooks:
* [Detecting jailbreaks and prompt injection with Prompt Guard](./prompt_guard.ipynb)
* Using Llama Guard for Guardrailing
## Advanced use cases
* [How to fine-tune Llama 3.1 8B on consumer GPU with PEFT and QLoRA with bitsandbytes](./peft_finetuning.py)
* [Generate synthetic data with `distilabel`](./synthetic-data-with-llama.ipynb)
* Do assisted decoding with a large and a small model
* Build a ML demo using Gradio
| {".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 13fac397a37061dc3c3debf8f8131a4e18fd8b95 Hamza Amin <[email protected]> 1727369211 +0500\tclone: from https://github.com/huggingface/huggingface-llama-recipes.git\n", ".git\\refs\\heads\\main": "13fac397a37061dc3c3debf8f8131a4e18fd8b95\n"} | null |
huggingface-sagemaker-snowflake-example | {"type": "directory", "name": "huggingface-sagemaker-snowflake-example", "children": [{"type": "directory", "name": "assets", "children": []}, {"type": "directory", "name": "aws-infrastructure", "children": [{"type": "file", "name": "app.py"}, {"type": "file", "name": "cdk.json"}, {"type": "directory", "name": "huggingface_sagemaker", "children": [{"type": "file", "name": "config.py"}, {"type": "file", "name": "huggingface_stack.py"}, {"type": "file", "name": "sagemaker_endpoint.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "lambda_src", "children": [{"type": "file", "name": "handler.py"}]}, {"type": "file", "name": "requirements.txt"}]}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "tweet_data.csv"}]} | # Tutorial: Use Hugging Face Transformers with Snowflake External Functions
This repository contains code and instructions on how to integrate Hugging Face Transformers with Snowflake using External Functions. Below you can find an architectural overview of the solution.

# Tutorial
## 0. Prequisition
1. Running Snowflake Warehose. Get started [here](https://signup.snowflake.com/?utm_cta=trial-en-www-homepage-top-right-nav-ss-evg&_ga=2.4253299.1747282503.1647350425-2028784425.1644849379)
2. Database with data, e.g. [tweet_data](tweet_data.csv)
* [YT: Load CSV data to create a new table in Snowflake](https://www.youtube.com/watch?v=GfCBhZK3X7w&ab_channel=KahanDataSolutions)
# 1. Deploy Hugging Face endpoint with Amazon API Gateway on Amazon SageMaker
TODO: Add API Gateway policy
We are going to use AWS CDK to deploy your Hugging Face Transformers to Amazon SageMaker and create the AWS API Gateway to connect to Snowflake and our SageMaker endpoint.
Install the cdk required dependencies. Make your you have the [cdk](https://docs.aws.amazon.com/cdk/latest/guide/getting_started.html#getting_started_install) installed.
```bash
pip3 install -r aws-infrastructure/requirements.txt
```
Change directory int to `aws-infrastructure/`
```bash
cd aws-infrastructure/
```
[Bootstrap](https://docs.aws.amazon.com/cdk/latest/guide/bootstrapping.html) your application in the cloud.
```bash
cdk bootstrap \
-c model="distilbert-base-uncased-finetuned-sst-2-english" \
-c task="text-classification"
```
Deploy your Hugging Face Transformer model to Amazon SageMaker
```bash
cdk deploy \
-c model="distilbert-base-uncased-finetuned-sst-2-english" \
-c task="text-classification"
```
Test your endpoint with `curl`:
```bash
curl --request POST \
--url {HuggingfaceSagemakerEndpoint.hfapigwEndpointE75D67B4} \
--header 'Content-Type: application/json' \
--data '{
"inputs": "Hugging Face, the winner of VentureBeat’s Innovation in Natural Language Process/Understanding Award for 2021, is looking to level the playing field. The team, launched by Clément Delangue and Julien Chaumond in 2016, was recognized for its work in democratizing NLP, the global market value for which is expected to hit $35.1 billion by 2026. This week, Google’s former head of Ethical AI Margaret Mitchell joined the team."
}'
```
You should see the following response: `[{"label":"POSITIVE","score":0.9970797896385193}]`
# 2. Create API Integration in snowflake
Open a new Worksheet in the Snowflake Web Console and create a new API Integration. Therefore we need our API Gateway endpoint and the `snowflake_role` arn. Change the Values in the snippet below and then execute.
```sql
CREATE OR REPLACE API INTEGRATION huggingface
API_PROVIDER = aws_api_gateway
API_AWS_ROLE_ARN = 'arn:aws:iam::{YOUR-ACCOUNT-ID}:role/snowflake_role'
API_ALLOWED_PREFIXES = ('{HuggingfaceSagemakerEndpoint.hfapigwEndpointE75D67B4}')
ENABLED = TRUE
;
```

# 3. Update IAM role (different CDK) project
Before we can create and use our external function we need to authorize Snowflake to assume our `snowflake_role` to access our API Gateway. To do this we need to extracte the `API_AWS_IAM_USER_ARN` and `API_AWS_EXTERNAL_ID` from out Snowflake API integration.
Therefore we need to run the following snippet in our snowflake web console:
```sql
describe integration huggingface;
```
Then copy the `API_AWS_IAM_USER_ARN` and `API_AWS_EXTERNAL_ID`.

To authorize snowflake we need to manually adjust the trust relationship for our `snowflake_role`. Go to the AWS Management Console IAM Service. Search for the `snoflake_role` and click on the `Edit trust policy` button on the "Trust Relationships" tab.

Replace `API_AWS_IAM_USER_ARN` and `API_AWS_EXTERNAL_ID` from the snippet below with your values and click "update policy".
```bash
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"AWS": "{API_AWS_IAM_USER_ARN}"
},
"Action": "sts:AssumeRole",
"Condition": {"StringEquals": {"sts:ExternalId": "{API_AWS_EXTERNAL_ID}"}}
}
]
}
```
# 4. Create External Function
After we have enabled the trust relationship between Snowflake and our `snowflake_role` we can create our external function. Replace the `{HuggingfaceSagemakerEndpoint.hfapigwEndpointE75D67B4}` value with your API Gateway endpoint and then execute the following snippet in Snowflake.
```bash
CREATE OR REPLACE external function huggingface_function(v varchar)
returns variant
api_integration = huggingface
as '{HuggingfaceSagemakerEndpoint.hfapigwEndpointE75D67B4}';
```

# 5. Run External function on data
Now we can use our external function to run our model on our data. Replace `HUGGINGFACE_TEST.PUBLIC.TWEETS` and `inputs` with your database and column.
```sql
select huggingface_function(inputs) from HUGGINGFACE_TEST.PUBLIC.TWEETS limit 100
```
the result look the similar to this

# Resources
* [Snowflake: External Functions YT](https://www.youtube.com/watch?v=qangh4oM_zs&ab_channel=SnowflakeInc.)
* [Snowflake: External Functions Docs](https://docs.snowflake.com/en/sql-reference/external-functions-creating-aws-ui.html)
* [Snowflake: API Gateway policy](https://docs.snowflake.com/en/sql-reference/external-functions-creating-aws-common-api-integration-proxy-link.html) | {".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 73f8323cfbe06a2d5ab6f93f3e56746fdbc1c678 Hamza Amin <[email protected]> 1727369220 +0500\tclone: from https://github.com/huggingface/huggingface-sagemaker-snowflake-example.git\n", ".git\\refs\\heads\\main": "73f8323cfbe06a2d5ab6f93f3e56746fdbc1c678\n", "aws-infrastructure\\app.py": "#!/usr/bin/env python3\nimport os\n\n# For consistency with TypeScript code, `cdk` is the preferred import name for\n# the CDK's core module. The following line also imports it as `core` for use\n# with examples from the CDK Developer's Guide, which are in the process of\n# being updated to use `cdk`. You may delete this import if you don't need it.\nfrom aws_cdk import core as cdk\n\nfrom huggingface_sagemaker.huggingface_stack import HuggingfaceSagemaker\n\n# Environment\n# CDK_DEFAULT_ACCOUNT and CDK_DEFAULT_REGION are set based on the\n# AWS profile specified using the --profile option.\nmy_environment = cdk.Environment(account=os.environ[\"CDK_DEFAULT_ACCOUNT\"], region=os.environ[\"CDK_DEFAULT_REGION\"])\n\n\napp = cdk.App()\nsagemaker = HuggingfaceSagemaker(app, \"HuggingfaceSagemakerEndpoint\", env=my_environment)\n\napp.synth()\n", "aws-infrastructure\\requirements.txt": "aws_cdk.aws_sagemaker>=1.123.0\naws_cdk.aws_iam>=1.123.0\naws-cdk.core>=1.123.0\naws-cdk.aws-lambda>=1.123.0\naws-cdk.aws-apigateway>=1.123.0\n"} | null |
huggingface.js | {"type": "directory", "name": "huggingface.js", "children": [{"type": "file", "name": ".editorconfig"}, {"type": "file", "name": ".eslintrc.cjs"}, {"type": "file", "name": ".npmrc"}, {"type": "file", "name": ".prettierignore"}, {"type": "file", "name": ".prettierrc"}, {"type": "directory", "name": ".vscode", "children": [{"type": "file", "name": "extensions.json"}, {"type": "file", "name": "settings.json"}]}, {"type": "file", "name": "CODEOWNERS"}, {"type": "file", "name": "CONTRIBUTING.md"}, {"type": "directory", "name": "docs", "children": [{"type": "file", "name": "_toctree.yml"}]}, {"type": "directory", "name": "e2e", "children": [{"type": "directory", "name": "deno", "children": [{"type": "file", "name": "index.ts"}]}, {"type": "file", "name": "mock-registry-config.yaml"}, {"type": "directory", "name": "svelte", "children": [{"type": "file", "name": ".npmrc"}, {"type": "file", "name": "package.json"}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "src", "children": [{"type": "file", "name": "app.d.ts"}, {"type": "file", "name": "app.html"}, {"type": "directory", "name": "routes", "children": [{"type": "file", "name": "+page.svelte"}]}, {"type": "file", "name": "test.spec.ts"}]}, {"type": "directory", "name": "static", "children": []}, {"type": "file", "name": "svelte.config.js"}, {"type": "file", "name": "tsconfig.json"}, {"type": "file", "name": "vite.config.ts"}]}, {"type": "directory", "name": "ts", "children": [{"type": "file", "name": "package.json"}, {"type": "directory", "name": "src", "children": [{"type": "file", "name": "index.ts"}]}, {"type": "file", "name": "tsconfig.json"}]}, {"type": "directory", "name": "yarn", "children": [{"type": "file", "name": "package.json"}]}]}, {"type": "file", "name": "LICENSE"}, {"type": "file", "name": "package.json"}, {"type": "directory", "name": "packages", "children": [{"type": "directory", "name": "agents", "children": [{"type": "file", "name": ".eslintignore"}, {"type": "file", "name": ".prettierignore"}, {"type": "file", "name": "index.ts"}, {"type": "file", "name": "LICENSE"}, {"type": "file", "name": "package.json"}, {"type": "file", "name": "pnpm-lock.yaml"}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "src", "children": [{"type": "file", "name": "HfAgent.ts"}, {"type": "file", "name": "index.ts"}, {"type": "directory", "name": "lib", "children": [{"type": "file", "name": "evalBuilder.ts"}, {"type": "file", "name": "examples.ts"}, {"type": "file", "name": "generateCode.ts"}, {"type": "file", "name": "promptGeneration.ts"}]}, {"type": "directory", "name": "llms", "children": [{"type": "file", "name": "index.ts"}, {"type": "file", "name": "LLMHF.ts"}]}, {"type": "directory", "name": "tools", "children": [{"type": "file", "name": "imageToText.ts"}, {"type": "file", "name": "index.ts"}, {"type": "file", "name": "message.ts"}, {"type": "file", "name": "speechToText.ts"}, {"type": "file", "name": "textToImage.ts"}, {"type": "file", "name": "textToSpeech.ts"}]}, {"type": "file", "name": "types.d.ts"}]}, {"type": "directory", "name": "test", "children": [{"type": "file", "name": "HfAgent.spec.ts"}, {"type": "file", "name": "vitest.d.ts"}]}, {"type": "file", "name": "tsconfig.json"}, {"type": "file", "name": "tsup.config.ts"}, {"type": "file", "name": "vitest-browser.config.mts"}]}, {"type": "directory", "name": "doc-internal", "children": [{"type": "file", "name": ".prettierignore"}, {"type": "file", "name": "fix-cdn-versions.ts"}, {"type": "file", "name": "fix-md-headinghashlinks.ts"}, {"type": "file", "name": "fix-md-links.ts"}, {"type": "file", "name": "package.json"}, {"type": "file", "name": "pnpm-lock.yaml"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "tsconfig.json"}, {"type": "file", "name": "update-toc.ts"}]}, {"type": "directory", "name": "gguf", "children": [{"type": "file", "name": ".eslintignore"}, {"type": "file", "name": ".prettierignore"}, {"type": "file", "name": "package.json"}, {"type": "file", "name": "pnpm-lock.yaml"}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "scripts", "children": [{"type": "file", "name": "generate-llm.ts"}]}, {"type": "directory", "name": "src", "children": [{"type": "file", "name": "gguf.spec.ts"}, {"type": "file", "name": "gguf.ts"}, {"type": "file", "name": "index.ts"}, {"type": "file", "name": "quant-descriptions.ts"}, {"type": "file", "name": "transformer-llm.ts"}, {"type": "file", "name": "types.spec.ts"}, {"type": "file", "name": "types.ts"}, {"type": "directory", "name": "utils", "children": [{"type": "file", "name": "FileBlob.ts"}, {"type": "file", "name": "isBackend.ts"}, {"type": "file", "name": "promisesQueue.ts"}]}]}, {"type": "file", "name": "tsconfig.json"}, {"type": "file", "name": "tsup.config.ts"}]}, {"type": "directory", "name": "hub", "children": [{"type": "file", "name": ".eslintignore"}, {"type": "file", "name": ".prettierignore"}, {"type": "file", "name": "index.ts"}, {"type": "file", "name": "LICENSE"}, {"type": "file", "name": "package.json"}, {"type": "file", "name": "pnpm-lock.yaml"}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "src", "children": [{"type": "file", "name": "consts.ts"}, {"type": "file", "name": "error.ts"}, {"type": "file", "name": "index.ts"}, {"type": "directory", "name": "lib", "children": [{"type": "file", "name": "cache-management.spec.ts"}, {"type": "file", "name": "cache-management.ts"}, {"type": "file", "name": "commit.spec.ts"}, {"type": "file", "name": "commit.ts"}, {"type": "file", "name": "count-commits.spec.ts"}, {"type": "file", "name": "count-commits.ts"}, {"type": "file", "name": "create-repo.spec.ts"}, {"type": "file", "name": "create-repo.ts"}, {"type": "file", "name": "delete-file.spec.ts"}, {"type": "file", "name": "delete-file.ts"}, {"type": "file", "name": "delete-files.spec.ts"}, {"type": "file", "name": "delete-files.ts"}, {"type": "file", "name": "delete-repo.ts"}, {"type": "file", "name": "download-file.ts"}, {"type": "file", "name": "file-download-info.spec.ts"}, {"type": "file", "name": "file-download-info.ts"}, {"type": "file", "name": "file-exists.spec.ts"}, {"type": "file", "name": "file-exists.ts"}, {"type": "file", "name": "index.ts"}, {"type": "file", "name": "list-commits.spec.ts"}, {"type": "file", "name": "list-commits.ts"}, {"type": "file", "name": "list-datasets.spec.ts"}, {"type": "file", "name": "list-datasets.ts"}, {"type": "file", "name": "list-files.spec.ts"}, {"type": "file", "name": "list-files.ts"}, {"type": "file", "name": "list-models.spec.ts"}, {"type": "file", "name": "list-models.ts"}, {"type": "file", "name": "list-spaces.spec.ts"}, {"type": "file", "name": "list-spaces.ts"}, {"type": "file", "name": "oauth-handle-redirect.ts"}, {"type": "file", "name": "oauth-login-url.ts"}, {"type": "file", "name": "parse-safetensors-metadata.spec.ts"}, {"type": "file", "name": "parse-safetensors-metadata.ts"}, {"type": "file", "name": "upload-file.spec.ts"}, {"type": "file", "name": "upload-file.ts"}, {"type": "file", "name": "upload-files-with-progress.spec.ts"}, {"type": "file", "name": "upload-files-with-progress.ts"}, {"type": "file", "name": "upload-files.spec.ts"}, {"type": "file", "name": "upload-files.ts"}, {"type": "file", "name": "who-am-i.spec.ts"}, {"type": "file", "name": "who-am-i.ts"}]}, {"type": "directory", "name": "test", "children": [{"type": "file", "name": "consts.ts"}]}, {"type": "directory", "name": "types", "children": [{"type": "directory", "name": "api", "children": [{"type": "file", "name": "api-commit.ts"}, {"type": "file", "name": "api-create-repo.ts"}, {"type": "file", "name": "api-dataset.ts"}, {"type": "file", "name": "api-index-tree.ts"}, {"type": "file", "name": "api-model.ts"}, {"type": "file", "name": "api-space.ts"}, {"type": "file", "name": "api-who-am-i.ts"}]}, {"type": "file", "name": "public.ts"}]}, {"type": "directory", "name": "utils", "children": [{"type": "file", "name": "base64FromBytes.ts"}, {"type": "file", "name": "checkCredentials.ts"}, {"type": "file", "name": "chunk.ts"}, {"type": "file", "name": "createBlob.ts"}, {"type": "file", "name": "eventToGenerator.spec.ts"}, {"type": "file", "name": "eventToGenerator.ts"}, {"type": "file", "name": "FileBlob.spec.ts"}, {"type": "file", "name": "FileBlob.ts"}, {"type": "file", "name": "hexFromBytes.ts"}, {"type": "file", "name": "insecureRandomString.ts"}, {"type": "file", "name": "isBackend.ts"}, {"type": "file", "name": "isFrontend.ts"}, {"type": "file", "name": "omit.ts"}, {"type": "file", "name": "parseLinkHeader.ts"}, {"type": "file", "name": "pick.ts"}, {"type": "file", "name": "promisesQueue.spec.ts"}, {"type": "file", "name": "promisesQueue.ts"}, {"type": "file", "name": "promisesQueueStreaming.ts"}, {"type": "file", "name": "range.ts"}, {"type": "file", "name": "sha256-node.ts"}, {"type": "file", "name": "sha256.spec.ts"}, {"type": "file", "name": "sha256.ts"}, {"type": "file", "name": "sum.ts"}, {"type": "file", "name": "toRepoId.ts"}, {"type": "file", "name": "typedEntries.ts"}, {"type": "file", "name": "typedInclude.ts"}, {"type": "file", "name": "WebBlob.spec.ts"}, {"type": "file", "name": "WebBlob.ts"}]}, {"type": "directory", "name": "vendor", "children": [{"type": "directory", "name": "hash-wasm", "children": [{"type": "file", "name": "build.sh"}, {"type": "file", "name": "sha256-wrapper.ts"}, {"type": "file", "name": "sha256.c"}, {"type": "file", "name": "sha256.d.ts"}, {"type": "file", "name": "sha256.js"}]}, {"type": "directory", "name": "type-fest", "children": [{"type": "file", "name": "basic.ts"}, {"type": "file", "name": "entries.ts"}, {"type": "file", "name": "entry.ts"}, {"type": "file", "name": "except.ts"}, {"type": "file", "name": "is-equal.ts"}, {"type": "file", "name": "set-required.ts"}, {"type": "file", "name": "simplify.ts"}]}]}]}, {"type": "file", "name": "tsconfig.json"}, {"type": "file", "name": "tsup.config.ts"}, {"type": "file", "name": "vitest-browser.config.mts"}]}, {"type": "directory", "name": "inference", "children": [{"type": "file", "name": ".eslintignore"}, {"type": "file", "name": ".prettierignore"}, {"type": "file", "name": "LICENSE"}, {"type": "file", "name": "package.json"}, {"type": "file", "name": "pnpm-lock.yaml"}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "scripts", "children": [{"type": "file", "name": "generate-dts.ts"}]}, {"type": "directory", "name": "src", "children": [{"type": "file", "name": "HfInference.ts"}, {"type": "file", "name": "index.ts"}, {"type": "directory", "name": "lib", "children": [{"type": "file", "name": "getDefaultTask.ts"}, {"type": "file", "name": "InferenceOutputError.ts"}, {"type": "file", "name": "isUrl.ts"}, {"type": "file", "name": "makeRequestOptions.ts"}]}, {"type": "directory", "name": "tasks", "children": [{"type": "directory", "name": "audio", "children": [{"type": "file", "name": "audioClassification.ts"}, {"type": "file", "name": "audioToAudio.ts"}, {"type": "file", "name": "automaticSpeechRecognition.ts"}, {"type": "file", "name": "textToSpeech.ts"}]}, {"type": "directory", "name": "custom", "children": [{"type": "file", "name": "request.ts"}, {"type": "file", "name": "streamingRequest.ts"}]}, {"type": "directory", "name": "cv", "children": [{"type": "file", "name": "imageClassification.ts"}, {"type": "file", "name": "imageSegmentation.ts"}, {"type": "file", "name": "imageToImage.ts"}, {"type": "file", "name": "imageToText.ts"}, {"type": "file", "name": "objectDetection.ts"}, {"type": "file", "name": "textToImage.ts"}, {"type": "file", "name": "zeroShotImageClassification.ts"}]}, {"type": "file", "name": "index.ts"}, {"type": "directory", "name": "multimodal", "children": [{"type": "file", "name": "documentQuestionAnswering.ts"}, {"type": "file", "name": "visualQuestionAnswering.ts"}]}, {"type": "directory", "name": "nlp", "children": [{"type": "file", "name": "chatCompletion.ts"}, {"type": "file", "name": "chatCompletionStream.ts"}, {"type": "file", "name": "featureExtraction.ts"}, {"type": "file", "name": "fillMask.ts"}, {"type": "file", "name": "questionAnswering.ts"}, {"type": "file", "name": "sentenceSimilarity.ts"}, {"type": "file", "name": "summarization.ts"}, {"type": "file", "name": "tableQuestionAnswering.ts"}, {"type": "file", "name": "textClassification.ts"}, {"type": "file", "name": "textGeneration.ts"}, {"type": "file", "name": "textGenerationStream.ts"}, {"type": "file", "name": "tokenClassification.ts"}, {"type": "file", "name": "translation.ts"}, {"type": "file", "name": "zeroShotClassification.ts"}]}, {"type": "directory", "name": "tabular", "children": [{"type": "file", "name": "tabularClassification.ts"}, {"type": "file", "name": "tabularRegression.ts"}]}]}, {"type": "file", "name": "types.ts"}, {"type": "directory", "name": "utils", "children": [{"type": "file", "name": "base64FromBytes.ts"}, {"type": "file", "name": "distributive-omit.ts"}, {"type": "file", "name": "isBackend.ts"}, {"type": "file", "name": "isFrontend.ts"}, {"type": "file", "name": "omit.ts"}, {"type": "file", "name": "pick.ts"}, {"type": "file", "name": "toArray.ts"}, {"type": "file", "name": "typedInclude.ts"}]}, {"type": "directory", "name": "vendor", "children": [{"type": "directory", "name": "fetch-event-source", "children": [{"type": "file", "name": "parse.spec.ts"}, {"type": "file", "name": "parse.ts"}]}]}]}, {"type": "directory", "name": "test", "children": [{"type": "file", "name": "expect-closeto.ts"}, {"type": "file", "name": "global.d.ts"}, {"type": "file", "name": "HfInference.spec.ts"}, {"type": "file", "name": "tapes.json"}, {"type": "file", "name": "test-files.ts"}, {"type": "file", "name": "vcr.ts"}, {"type": "file", "name": "vitest.d.ts"}]}, {"type": "file", "name": "tsconfig.json"}, {"type": "file", "name": "vitest.config.mts"}]}, {"type": "directory", "name": "jinja", "children": [{"type": "file", "name": ".eslintignore"}, {"type": "file", "name": "package.json"}, {"type": "file", "name": "pnpm-lock.yaml"}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "src", "children": [{"type": "file", "name": "ast.ts"}, {"type": "file", "name": "index.ts"}, {"type": "file", "name": "lexer.ts"}, {"type": "file", "name": "parser.ts"}, {"type": "file", "name": "runtime.ts"}, {"type": "file", "name": "utils.ts"}]}, {"type": "directory", "name": "test", "children": [{"type": "file", "name": "e2e.test.js"}, {"type": "file", "name": "interpreter.test.js"}, {"type": "file", "name": "templates.test.js"}, {"type": "file", "name": "utils.test.js"}]}, {"type": "file", "name": "tsconfig.json"}, {"type": "file", "name": "vite.config.js"}, {"type": "file", "name": "vitest.config.ts"}]}, {"type": "directory", "name": "languages", "children": [{"type": "file", "name": ".prettierignore"}, {"type": "file", "name": "package.json"}, {"type": "file", "name": "pnpm-lock.yaml"}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "src", "children": [{"type": "file", "name": "index.ts"}, {"type": "file", "name": "language.spec.ts"}, {"type": "file", "name": "language.ts"}, {"type": "file", "name": "languages_iso_639_1.ts"}, {"type": "file", "name": "languages_iso_639_3.ts"}, {"type": "file", "name": "types.d.ts"}, {"type": "file", "name": "wikiLink.spec.ts"}, {"type": "file", "name": "wikiLink.ts"}]}, {"type": "file", "name": "tsconfig.json"}]}, {"type": "directory", "name": "space-header", "children": [{"type": "file", "name": ".eslintignore"}, {"type": "file", "name": ".prettierignore"}, {"type": "file", "name": "index.ts"}, {"type": "file", "name": "package.json"}, {"type": "file", "name": "pnpm-lock.yaml"}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "src", "children": [{"type": "directory", "name": "header", "children": [{"type": "directory", "name": "components", "children": [{"type": "file", "name": "box.ts"}, {"type": "directory", "name": "collapse", "children": [{"type": "file", "name": "arrow.ts"}, {"type": "file", "name": "index.ts"}]}, {"type": "directory", "name": "content", "children": [{"type": "file", "name": "avatar.ts"}, {"type": "file", "name": "index.ts"}, {"type": "file", "name": "namespace.ts"}, {"type": "file", "name": "separation.ts"}, {"type": "file", "name": "username.ts"}]}, {"type": "directory", "name": "like", "children": [{"type": "file", "name": "count.ts"}, {"type": "file", "name": "heart.ts"}, {"type": "file", "name": "index.ts"}]}]}, {"type": "file", "name": "create.ts"}]}, {"type": "file", "name": "index.ts"}, {"type": "file", "name": "inject.ts"}, {"type": "file", "name": "inject_fonts.ts"}, {"type": "file", "name": "type.ts"}, {"type": "directory", "name": "utils", "children": [{"type": "file", "name": "check_avatar.ts"}, {"type": "file", "name": "get_space.ts"}]}]}, {"type": "file", "name": "tsconfig.json"}, {"type": "file", "name": "tsup.config.d.ts"}, {"type": "file", "name": "tsup.config.ts"}]}, {"type": "directory", "name": "tasks", "children": [{"type": "file", "name": ".eslintignore"}, {"type": "file", "name": ".prettierignore"}, {"type": "file", "name": "LICENSE"}, {"type": "file", "name": "package.json"}, {"type": "file", "name": "pnpm-lock.yaml"}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "scripts", "children": [{"type": "file", "name": "inference-codegen.ts"}, {"type": "file", "name": "inference-tei-import.ts"}, {"type": "file", "name": "inference-tgi-import.ts"}]}, {"type": "directory", "name": "src", "children": [{"type": "file", "name": "dataset-libraries.ts"}, {"type": "file", "name": "default-widget-inputs.ts"}, {"type": "file", "name": "hardware.ts"}, {"type": "file", "name": "index.ts"}, {"type": "file", "name": "library-to-tasks.ts"}, {"type": "file", "name": "local-apps.ts"}, {"type": "file", "name": "model-data.ts"}, {"type": "file", "name": "model-libraries-downloads.ts"}, {"type": "file", "name": "model-libraries-snippets.ts"}, {"type": "file", "name": "model-libraries.ts"}, {"type": "file", "name": "pipelines.ts"}, {"type": "directory", "name": "snippets", "children": [{"type": "file", "name": "curl.ts"}, {"type": "file", "name": "index.ts"}, {"type": "file", "name": "inputs.ts"}, {"type": "file", "name": "js.ts"}, {"type": "file", "name": "python.ts"}, {"type": "file", "name": "types.ts"}]}, {"type": "directory", "name": "tasks", "children": [{"type": "directory", "name": "audio-classification", "children": [{"type": "file", "name": "about.md"}, {"type": "file", "name": "data.ts"}, {"type": "file", "name": "inference.ts"}, {"type": "directory", "name": "spec", "children": [{"type": "file", "name": "input.json"}, {"type": "file", "name": "output.json"}]}]}, {"type": "directory", "name": "audio-to-audio", "children": [{"type": "file", "name": "about.md"}, {"type": "file", "name": "data.ts"}]}, {"type": "directory", "name": "automatic-speech-recognition", "children": [{"type": "file", "name": "about.md"}, {"type": "file", "name": "data.ts"}, {"type": "file", "name": "inference.ts"}, {"type": "directory", "name": "spec", "children": [{"type": "file", "name": "input.json"}, {"type": "file", "name": "output.json"}]}]}, {"type": "directory", "name": "chat-completion", "children": [{"type": "file", "name": "inference.ts"}, {"type": "directory", "name": "spec", "children": [{"type": "file", "name": "input.json"}, {"type": "file", "name": "output.json"}, {"type": "file", "name": "stream_output.json"}]}]}, {"type": "file", "name": "common-definitions.json"}, {"type": "directory", "name": "depth-estimation", "children": [{"type": "file", "name": "about.md"}, {"type": "file", "name": "data.ts"}, {"type": "file", "name": "inference.ts"}, {"type": "directory", "name": "spec", "children": [{"type": "file", "name": "input.json"}, {"type": "file", "name": "output.json"}]}]}, {"type": "directory", "name": "document-question-answering", "children": [{"type": "file", "name": "about.md"}, {"type": "file", "name": "data.ts"}, {"type": "file", "name": "inference.ts"}, {"type": "directory", "name": "spec", "children": [{"type": "file", "name": "input.json"}, {"type": "file", "name": "output.json"}]}]}, {"type": "directory", "name": "feature-extraction", "children": [{"type": "file", "name": "about.md"}, {"type": "file", "name": "data.ts"}, {"type": "file", "name": "inference.ts"}, {"type": "directory", "name": "spec", "children": [{"type": "file", "name": "input.json"}, {"type": "file", "name": "output.json"}]}]}, {"type": "directory", "name": "fill-mask", "children": [{"type": "file", "name": "about.md"}, {"type": "file", "name": "data.ts"}, {"type": "file", "name": "inference.ts"}, {"type": "directory", "name": "spec", "children": [{"type": "file", "name": "input.json"}, {"type": "file", "name": "output.json"}]}]}, {"type": "directory", "name": "image-classification", "children": [{"type": "file", "name": "about.md"}, {"type": "file", "name": "data.ts"}, {"type": "file", "name": "inference.ts"}, {"type": "directory", "name": "spec", "children": [{"type": "file", "name": "input.json"}, {"type": "file", "name": "output.json"}]}]}, {"type": "directory", "name": "image-feature-extraction", "children": [{"type": "file", "name": "about.md"}, {"type": "file", "name": "data.ts"}]}, {"type": "directory", "name": "image-segmentation", "children": [{"type": "file", "name": "about.md"}, {"type": "file", "name": "data.ts"}, {"type": "file", "name": "inference.ts"}, {"type": "directory", "name": "spec", "children": [{"type": "file", "name": "input.json"}, {"type": "file", "name": "output.json"}]}]}, {"type": "directory", "name": "image-text-to-text", "children": [{"type": "file", "name": "about.md"}, {"type": "file", "name": "data.ts"}]}, {"type": "directory", "name": "image-to-3d", "children": [{"type": "file", "name": "about.md"}, {"type": "file", "name": "data.ts"}]}, {"type": "directory", "name": "image-to-image", "children": [{"type": "file", "name": "about.md"}, {"type": "file", "name": "data.ts"}, {"type": "file", "name": "inference.ts"}, {"type": "directory", "name": "spec", "children": [{"type": "file", "name": "input.json"}, {"type": "file", "name": "output.json"}]}]}, {"type": "directory", "name": "image-to-text", "children": [{"type": "file", "name": "about.md"}, {"type": "file", "name": "data.ts"}, {"type": "file", "name": "inference.ts"}, {"type": "directory", "name": "spec", "children": [{"type": "file", "name": "input.json"}, {"type": "file", "name": "output.json"}]}]}, {"type": "file", "name": "index.ts"}, {"type": "directory", "name": "keypoint-detection", "children": [{"type": "file", "name": "about.md"}, {"type": "file", "name": "data.ts"}]}, {"type": "directory", "name": "mask-generation", "children": [{"type": "file", "name": "about.md"}, {"type": "file", "name": "data.ts"}]}, {"type": "directory", "name": "object-detection", "children": [{"type": "file", "name": "about.md"}, {"type": "file", "name": "data.ts"}, {"type": "file", "name": "inference.ts"}, {"type": "directory", "name": "spec", "children": [{"type": "file", "name": "input.json"}, {"type": "file", "name": "output.json"}]}]}, {"type": "directory", "name": "placeholder", "children": [{"type": "file", "name": "about.md"}, {"type": "file", "name": "data.ts"}, {"type": "directory", "name": "spec", "children": [{"type": "file", "name": "input.json"}, {"type": "file", "name": "output.json"}]}]}, {"type": "directory", "name": "question-answering", "children": [{"type": "file", "name": "about.md"}, {"type": "file", "name": "data.ts"}, {"type": "file", "name": "inference.ts"}, {"type": "directory", "name": "spec", "children": [{"type": "file", "name": "input.json"}, {"type": "file", "name": "output.json"}]}]}, {"type": "directory", "name": "reinforcement-learning", "children": [{"type": "file", "name": "about.md"}, {"type": "file", "name": "data.ts"}]}, {"type": "directory", "name": "sentence-similarity", "children": [{"type": "file", "name": "about.md"}, {"type": "file", "name": "data.ts"}, {"type": "file", "name": "inference.ts"}, {"type": "directory", "name": "spec", "children": [{"type": "file", "name": "input.json"}, {"type": "file", "name": "output.json"}]}]}, {"type": "directory", "name": "summarization", "children": [{"type": "file", "name": "about.md"}, {"type": "file", "name": "data.ts"}, {"type": "file", "name": "inference.ts"}, {"type": "directory", "name": "spec", "children": [{"type": "file", "name": "input.json"}, {"type": "file", "name": "output.json"}]}]}, {"type": "directory", "name": "table-question-answering", "children": [{"type": "file", "name": "about.md"}, {"type": "file", "name": "data.ts"}, {"type": "file", "name": "inference.ts"}, {"type": "directory", "name": "spec", "children": [{"type": "file", "name": "input.json"}, {"type": "file", "name": "output.json"}]}]}, {"type": "directory", "name": "tabular-classification", "children": [{"type": "file", "name": "about.md"}, {"type": "file", "name": "data.ts"}]}, {"type": "directory", "name": "tabular-regression", "children": [{"type": "file", "name": "about.md"}, {"type": "file", "name": "data.ts"}]}, {"type": "directory", "name": "text-classification", "children": [{"type": "file", "name": "about.md"}, {"type": "file", "name": "data.ts"}, {"type": "file", "name": "inference.ts"}, {"type": "directory", "name": "spec", "children": [{"type": "file", "name": "input.json"}, {"type": "file", "name": "output.json"}]}]}, {"type": "directory", "name": "text-generation", "children": [{"type": "file", "name": "about.md"}, {"type": "file", "name": "data.ts"}, {"type": "file", "name": "inference.ts"}, {"type": "directory", "name": "spec", "children": [{"type": "file", "name": "input.json"}, {"type": "file", "name": "output.json"}, {"type": "file", "name": "stream_output.json"}]}]}, {"type": "directory", "name": "text-to-3d", "children": [{"type": "file", "name": "about.md"}, {"type": "file", "name": "data.ts"}]}, {"type": "directory", "name": "text-to-audio", "children": [{"type": "file", "name": "inference.ts"}, {"type": "directory", "name": "spec", "children": [{"type": "file", "name": "input.json"}, {"type": "file", "name": "output.json"}]}]}, {"type": "directory", "name": "text-to-image", "children": [{"type": "file", "name": "about.md"}, {"type": "file", "name": "data.ts"}, {"type": "file", "name": "inference.ts"}, {"type": "directory", "name": "spec", "children": [{"type": "file", "name": "input.json"}, {"type": "file", "name": "output.json"}]}]}, {"type": "directory", "name": "text-to-speech", "children": [{"type": "file", "name": "about.md"}, {"type": "file", "name": "data.ts"}, {"type": "file", "name": "inference.ts"}, {"type": "directory", "name": "spec", "children": [{"type": "file", "name": "input.json"}, {"type": "file", "name": "output.json"}]}]}, {"type": "directory", "name": "text-to-video", "children": [{"type": "file", "name": "about.md"}, {"type": "file", "name": "data.ts"}]}, {"type": "directory", "name": "text2text-generation", "children": [{"type": "file", "name": "inference.ts"}, {"type": "directory", "name": "spec", "children": [{"type": "file", "name": "input.json"}, {"type": "file", "name": "output.json"}]}]}, {"type": "directory", "name": "token-classification", "children": [{"type": "file", "name": "about.md"}, {"type": "file", "name": "data.ts"}, {"type": "file", "name": "inference.ts"}, {"type": "directory", "name": "spec", "children": [{"type": "file", "name": "input.json"}, {"type": "file", "name": "output.json"}]}]}, {"type": "directory", "name": "translation", "children": [{"type": "file", "name": "about.md"}, {"type": "file", "name": "data.ts"}, {"type": "file", "name": "inference.ts"}, {"type": "directory", "name": "spec", "children": [{"type": "file", "name": "input.json"}, {"type": "file", "name": "output.json"}]}]}, {"type": "directory", "name": "unconditional-image-generation", "children": [{"type": "file", "name": "about.md"}, {"type": "file", "name": "data.ts"}]}, {"type": "directory", "name": "video-classification", "children": [{"type": "file", "name": "about.md"}, {"type": "file", "name": "data.ts"}, {"type": "file", "name": "inference.ts"}, {"type": "directory", "name": "spec", "children": [{"type": "file", "name": "input.json"}, {"type": "file", "name": "output.json"}]}]}, {"type": "directory", "name": "video-text-to-text", "children": [{"type": "file", "name": "about.md"}, {"type": "file", "name": "data.ts"}]}, {"type": "directory", "name": "visual-question-answering", "children": [{"type": "file", "name": "about.md"}, {"type": "file", "name": "data.ts"}, {"type": "file", "name": "inference.ts"}, {"type": "directory", "name": "spec", "children": [{"type": "file", "name": "input.json"}, {"type": "file", "name": "output.json"}]}]}, {"type": "directory", "name": "zero-shot-classification", "children": [{"type": "file", "name": "about.md"}, {"type": "file", "name": "data.ts"}, {"type": "file", "name": "inference.ts"}, {"type": "directory", "name": "spec", "children": [{"type": "file", "name": "input.json"}, {"type": "file", "name": "output.json"}]}]}, {"type": "directory", "name": "zero-shot-image-classification", "children": [{"type": "file", "name": "about.md"}, {"type": "file", "name": "data.ts"}, {"type": "file", "name": "inference.ts"}, {"type": "directory", "name": "spec", "children": [{"type": "file", "name": "input.json"}, {"type": "file", "name": "output.json"}]}]}, {"type": "directory", "name": "zero-shot-object-detection", "children": [{"type": "file", "name": "about.md"}, {"type": "file", "name": "data.ts"}, {"type": "file", "name": "inference.ts"}, {"type": "directory", "name": "spec", "children": [{"type": "file", "name": "input.json"}, {"type": "file", "name": "output.json"}]}]}]}, {"type": "file", "name": "tokenizer-data.ts"}, {"type": "file", "name": "widget-example.ts"}]}, {"type": "file", "name": "tsconfig.json"}]}, {"type": "directory", "name": "widgets", "children": [{"type": "file", "name": ".eslintignore"}, {"type": "file", "name": ".prettierignore"}, {"type": "file", "name": "package.json"}, {"type": "file", "name": "pnpm-lock.yaml"}, {"type": "file", "name": "postcss.config.js"}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "src", "children": [{"type": "file", "name": "additional-svelte-typings.d.ts"}, {"type": "file", "name": "app.d.ts"}, {"type": "file", "name": "app.html"}, {"type": "file", "name": "hooks.server.ts"}, {"type": "directory", "name": "lib", "children": [{"type": "directory", "name": "components", "children": [{"type": "directory", "name": "DemoThemeSwitcher", "children": [{"type": "file", "name": "DemoThemeSwitcher.svelte"}]}, {"type": "directory", "name": "Icons", "children": [{"type": "file", "name": "IconAnyToAny.svelte"}, {"type": "file", "name": "IconAudioClassification.svelte"}, {"type": "file", "name": "IconAudioToAudio.svelte"}, {"type": "file", "name": "IconAutomaticSpeechRecognition.svelte"}, {"type": "file", "name": "IconAzureML.svelte"}, {"type": "file", "name": "IconCaretDown.svelte"}, {"type": "file", "name": "IconCaretDownV2.svelte"}, {"type": "file", "name": "IconCode.svelte"}, {"type": "file", "name": "IconConversational.svelte"}, {"type": "file", "name": "IconCross.svelte"}, {"type": "file", "name": "IconDepthEstimation.svelte"}, {"type": "file", "name": "IconDocumentQuestionAnswering.svelte"}, {"type": "file", "name": "IconFeatureExtraction.svelte"}, {"type": "file", "name": "IconFile.svelte"}, {"type": "file", "name": "IconFillMask.svelte"}, {"type": "file", "name": "IconGraphML.svelte"}, {"type": "file", "name": "IconHuggingFace.svelte"}, {"type": "file", "name": "IconImageAndTextToText.svelte"}, {"type": "file", "name": "IconImageClassification.svelte"}, {"type": "file", "name": "IconImageFeatureExtraction.svelte"}, {"type": "file", "name": "IconImageSegmentation.svelte"}, {"type": "file", "name": "IconImageTo3D.svelte"}, {"type": "file", "name": "IconImageToImage.svelte"}, {"type": "file", "name": "IconImageToText.svelte"}, {"type": "file", "name": "IconImageToVideo.svelte"}, {"type": "file", "name": "IconInfo.svelte"}, {"type": "file", "name": "IconKeypointDetection.svelte"}, {"type": "file", "name": "IconLightning.svelte"}, {"type": "file", "name": "IconMagicWand.svelte"}, {"type": "file", "name": "IconMaskGeneration.svelte"}, {"type": "file", "name": "IconMaximize.svelte"}, {"type": "file", "name": "IconMicrophone.svelte"}, {"type": "file", "name": "IconObjectDetection.svelte"}, {"type": "file", "name": "IconQuestionAnswering.svelte"}, {"type": "file", "name": "IconRefresh.svelte"}, {"type": "file", "name": "IconReinforcementLearning.svelte"}, {"type": "file", "name": "IconRobotics.svelte"}, {"type": "file", "name": "IconRow.svelte"}, {"type": "file", "name": "IconSentenceSimilarity.svelte"}, {"type": "file", "name": "IconSpin.svelte"}, {"type": "file", "name": "IconSummarization.svelte"}, {"type": "file", "name": "IconTableQuestionAnswering.svelte"}, {"type": "file", "name": "IconTabularClassification.svelte"}, {"type": "file", "name": "IconTabularRegression.svelte"}, {"type": "file", "name": "IconText2textGeneration.svelte"}, {"type": "file", "name": "IconTextClassification.svelte"}, {"type": "file", "name": "IconTextGeneration.svelte"}, {"type": "file", "name": "IconTextTo3D.svelte"}, {"type": "file", "name": "IconTextToImage.svelte"}, {"type": "file", "name": "IconTextToSpeech.svelte"}, {"type": "file", "name": "IconTextToVideo.svelte"}, {"type": "file", "name": "IconTokenClassification.svelte"}, {"type": "file", "name": "IconTranslation.svelte"}, {"type": "file", "name": "IconUnconditionalImageGeneration.svelte"}, {"type": "file", "name": "IconVideoClassification.svelte"}, {"type": "file", "name": "IconVideoTextToText.svelte"}, {"type": "file", "name": "IconVoiceActivityDetection.svelte"}, {"type": "file", "name": "IconZeroShotClassification.svelte"}, {"type": "file", "name": "IconZeroShotObjectDetection.svelte"}]}, {"type": "directory", "name": "InferenceWidget", "children": [{"type": "file", "name": "InferenceWidget.svelte"}, {"type": "directory", "name": "shared", "children": [{"type": "file", "name": "consts.ts"}, {"type": "file", "name": "helpers.ts"}, {"type": "file", "name": "inputValidation.ts"}, {"type": "file", "name": "outputValidation.ts"}, {"type": "file", "name": "types.ts"}, {"type": "directory", "name": "WidgetAddSentenceBtn", "children": [{"type": "file", "name": "WidgetAddSentenceBtn.svelte"}]}, {"type": "directory", "name": "WidgetAudioTrack", "children": [{"type": "file", "name": "WidgetAudioTrack.svelte"}]}, {"type": "directory", "name": "WidgetBloomDecoding", "children": [{"type": "file", "name": "WidgetBloomDecoding.svelte"}]}, {"type": "directory", "name": "WidgetCheckbox", "children": [{"type": "file", "name": "WidgetCheckbox.svelte"}]}, {"type": "directory", "name": "WidgetDropzone", "children": [{"type": "file", "name": "WidgetDropzone.svelte"}]}, {"type": "directory", "name": "WidgetExamples", "children": [{"type": "file", "name": "WidgetExamples.svelte"}, {"type": "file", "name": "WidgetExamplesGroup.svelte"}]}, {"type": "directory", "name": "WidgetFileInput", "children": [{"type": "file", "name": "WidgetFileInput.svelte"}]}, {"type": "directory", "name": "WidgetFooter", "children": [{"type": "file", "name": "WidgetFooter.svelte"}]}, {"type": "directory", "name": "WidgetHeader", "children": [{"type": "file", "name": "WidgetHeader.svelte"}]}, {"type": "directory", "name": "WidgetInfo", "children": [{"type": "file", "name": "WidgetInfo.svelte"}]}, {"type": "directory", "name": "WidgetLabel", "children": [{"type": "file", "name": "WidgetLabel.svelte"}]}, {"type": "directory", "name": "WidgetModelLoading", "children": [{"type": "file", "name": "WidgetModelLoading.svelte"}]}, {"type": "directory", "name": "WidgetOuputConvoBubble", "children": [{"type": "file", "name": "WidgetOutputConvoBubble.svelte"}]}, {"type": "directory", "name": "WidgetOutputChart", "children": [{"type": "file", "name": "WidgetOutputChart.svelte"}]}, {"type": "directory", "name": "WidgetOutputConvo", "children": [{"type": "file", "name": "WidgetOutputConvo.svelte"}]}, {"type": "directory", "name": "WidgetOutputTableQA", "children": [{"type": "file", "name": "WidgetOutputTableQA.svelte"}]}, {"type": "directory", "name": "WidgetOutputText", "children": [{"type": "file", "name": "WidgetOutputText.svelte"}]}, {"type": "directory", "name": "WidgetOutputTokens", "children": [{"type": "file", "name": "WidgetOutputTokens.svelte"}]}, {"type": "directory", "name": "WidgetQuickInput", "children": [{"type": "file", "name": "WidgetQuickInput.svelte"}]}, {"type": "directory", "name": "WidgetRadio", "children": [{"type": "file", "name": "WidgetRadio.svelte"}]}, {"type": "directory", "name": "WidgetRealtimeRecorder", "children": [{"type": "file", "name": "Recorder.ts"}, {"type": "file", "name": "WidgetRealtimeRecorder.svelte"}]}, {"type": "directory", "name": "WidgetRecorder", "children": [{"type": "file", "name": "Recorder.ts"}, {"type": "file", "name": "WidgetRecorder.svelte"}]}, {"type": "directory", "name": "WidgetShortcutRunLabel", "children": [{"type": "file", "name": "WidgetShortcutRunLabel.svelte"}]}, {"type": "directory", "name": "WidgetState", "children": [{"type": "file", "name": "WidgetState.svelte"}]}, {"type": "directory", "name": "WidgetSubmitBtn", "children": [{"type": "file", "name": "WidgetSubmitBtn.svelte"}]}, {"type": "directory", "name": "WidgetTableInput", "children": [{"type": "file", "name": "WidgetTableInput.svelte"}]}, {"type": "directory", "name": "WidgetTextarea", "children": [{"type": "file", "name": "WidgetTextarea.svelte"}]}, {"type": "directory", "name": "WidgetTextInput", "children": [{"type": "file", "name": "WidgetTextInput.svelte"}]}, {"type": "directory", "name": "WidgetTimer", "children": [{"type": "file", "name": "WidgetTimer.svelte"}]}, {"type": "directory", "name": "WidgetWrapper", "children": [{"type": "file", "name": "WidgetWrapper.svelte"}]}]}, {"type": "file", "name": "stores.ts"}, {"type": "directory", "name": "widgets", "children": [{"type": "directory", "name": "AudioClassificationWidget", "children": [{"type": "file", "name": "AudioClassificationWidget.svelte"}]}, {"type": "directory", "name": "AudioToAudioWidget", "children": [{"type": "file", "name": "AudioToAudioWidget.svelte"}]}, {"type": "directory", "name": "AutomaticSpeechRecognitionWidget", "children": [{"type": "file", "name": "AutomaticSpeechRecognitionWidget.svelte"}]}, {"type": "directory", "name": "ConversationalWidget", "children": [{"type": "file", "name": "ConversationalWidget.svelte"}]}, {"type": "directory", "name": "FeatureExtractionWidget", "children": [{"type": "file", "name": "DataTable.ts"}, {"type": "file", "name": "FeatureExtractionWidget.svelte"}]}, {"type": "directory", "name": "FillMaskWidget", "children": [{"type": "file", "name": "FillMaskWidget.svelte"}]}, {"type": "directory", "name": "ImageClassificationWidget", "children": [{"type": "file", "name": "ImageClassificationWidget.svelte"}]}, {"type": "directory", "name": "ImageSegmentationWidget", "children": [{"type": "file", "name": "Canvas.svelte"}, {"type": "file", "name": "ImageSegmentationWidget.svelte"}]}, {"type": "directory", "name": "ImageToImageWidget", "children": [{"type": "file", "name": "ImageToImageWidget.svelte"}]}, {"type": "directory", "name": "ImageToTextWidget", "children": [{"type": "file", "name": "ImageToTextWidget.svelte"}]}, {"type": "directory", "name": "ObjectDetectionWidget", "children": [{"type": "file", "name": "ObjectDetectionWidget.svelte"}, {"type": "file", "name": "SvgBoundingBoxes.svelte"}]}, {"type": "directory", "name": "QuestionAnsweringWidget", "children": [{"type": "file", "name": "QuestionAnsweringWidget.svelte"}]}, {"type": "directory", "name": "ReinforcementLearningWidget", "children": [{"type": "file", "name": "ReinforcementLearningWidget.svelte"}]}, {"type": "directory", "name": "SentenceSimilarityWidget", "children": [{"type": "file", "name": "SentenceSimilarityWidget.svelte"}]}, {"type": "directory", "name": "SummarizationWidget", "children": [{"type": "file", "name": "SummarizationWidget.svelte"}]}, {"type": "directory", "name": "TableQuestionAnsweringWidget", "children": [{"type": "file", "name": "TableQuestionAnsweringWidget.svelte"}]}, {"type": "directory", "name": "TabularDataWidget", "children": [{"type": "file", "name": "TabularDataWidget.svelte"}]}, {"type": "directory", "name": "TextGenerationWidget", "children": [{"type": "file", "name": "TextGenerationWidget.svelte"}]}, {"type": "directory", "name": "TextToImageWidget", "children": [{"type": "file", "name": "TextToImageWidget.svelte"}]}, {"type": "directory", "name": "TextToSpeechWidget", "children": [{"type": "file", "name": "TextToSpeechWidget.svelte"}]}, {"type": "directory", "name": "TokenClassificationWidget", "children": [{"type": "file", "name": "TokenClassificationWidget.svelte"}]}, {"type": "directory", "name": "VisualQuestionAnsweringWidget", "children": [{"type": "file", "name": "VisualQuestionAnsweringWidget.svelte"}]}, {"type": "directory", "name": "ZeroShotClassificationWidget", "children": [{"type": "file", "name": "ZeroShotClassificationWidget.svelte"}]}, {"type": "directory", "name": "ZeroShotImageClassificationWidget", "children": [{"type": "file", "name": "ZeroShotImageClassificationWidget.svelte"}]}]}]}, {"type": "directory", "name": "LogInPopover", "children": [{"type": "file", "name": "LogInPopover.svelte"}]}, {"type": "directory", "name": "PipelineIcon", "children": [{"type": "file", "name": "PipelineIcon.svelte"}]}, {"type": "directory", "name": "PipelineTag", "children": [{"type": "file", "name": "PipelineTag.svelte"}]}, {"type": "directory", "name": "Popover", "children": [{"type": "file", "name": "Popover.svelte"}]}]}, {"type": "file", "name": "index.ts"}, {"type": "directory", "name": "utils", "children": [{"type": "file", "name": "ViewUtils.ts"}]}]}, {"type": "directory", "name": "routes", "children": [{"type": "file", "name": "+layout.server.ts"}, {"type": "file", "name": "+layout.svelte"}, {"type": "file", "name": "+page.svelte"}, {"type": "directory", "name": "[...model]", "children": [{"type": "file", "name": "+page.svelte"}, {"type": "file", "name": "+page.ts"}]}]}, {"type": "file", "name": "tailwind.css"}]}, {"type": "directory", "name": "static", "children": [{"type": "file", "name": "audioProcessor.js"}]}, {"type": "file", "name": "svelte.config.js"}, {"type": "file", "name": "tailwind.config.cjs"}, {"type": "file", "name": "tsconfig.json"}, {"type": "file", "name": "vite.config.ts"}]}]}, {"type": "file", "name": "pnpm-lock.yaml"}, {"type": "file", "name": "pnpm-workspace.yaml"}, {"type": "file", "name": "README.md"}]} | # Huggingface Widgets
**Note: this package is no longer maintained.**
Open-source version of the inference widgets from huggingface.co
> Built with Svelte and SvelteKit
**Demo page:** https://huggingface.co/spaces/huggingfacejs/inference-widgets
## Publishing
Because `@huggingface/widgets` depends on `@huggingface/tasks`, you need to publish `@huggingface/tasks` first, and then `@huggingface/widgets`. There should be a CI check to prevent publishing `@huggingface/widgets` if `@huggingface/tasks` hasn't been published yet.
## Demo
You can run the demo locally:
```console
pnpm install
pnpm dev --open
```
If you are submitting a PR, make sure that you run `format` & `lint` before submitting the PR:
```console
pnpm format
pnpm lint
```
If you want to try the "Sign-in with HF" feature locally, you will need to https://huggingface.co/settings/applications/new an OAuth application with `"openid"`, `"profile"` and `"inference-api"` scopes and `http://localhost:5173/auth/callback/huggingface` as the redirect URL.
Then you can create a `.env.local` file with the following content:
```env
OAUTH_CLIENT_ID=...
OAUTH_CLIENT_SECRET=...
```
If you want to try the "Sign-in with HF" feature in a Space, you can just duplicate https://huggingface.co/spaces/huggingfacejs/inference-widgets, it should work out of the box thanks to the metadata in the `README.md` file.
## Testing for moon (for huggingface admins)
```console
pnpm i
pnpm build
```
And then inside moon, run the following command for both `server` & `front`:
```console
npm i --save @huggingface/widgets@<relative path to huggingface.js/packages/widgets>
```
| {"package.json": "{\n\t\"private\": true,\n\t\"name\": \"@huggingface/root\",\n\t\"license\": \"MIT\",\n\t\"packageManager\": \"[email protected]\",\n\t\"scripts\": {\n\t\t\"lint\": \"eslint --quiet --fix --ext .cjs,.ts .eslintrc.cjs\",\n\t\t\"lint:check\": \"eslint --ext .cjs,.ts .eslintrc.cjs\",\n\t\t\"format\": \"prettier --write package.json .prettierrc .vscode .eslintrc.cjs e2e .github *.md\",\n\t\t\"format:check\": \"prettier --check package.json .prettierrc .vscode .eslintrc.cjs .github *.md\"\n\t},\n\t\"devDependencies\": {\n\t\t\"@typescript-eslint/eslint-plugin\": \"^7.2.0\",\n\t\t\"@typescript-eslint/parser\": \"^7.2.0\",\n\t\t\"@vitest/browser\": \"^0.34.6\",\n\t\t\"eslint\": \"^8.57.0\",\n\t\t\"eslint-config-prettier\": \"^9.0.0\",\n\t\t\"eslint-plugin-prettier\": \"^4.2.1\",\n\t\t\"eslint-plugin-svelte\": \"^2.30.0\",\n\t\t\"npm-run-all\": \"^4.1.5\",\n\t\t\"prettier\": \"^3.1.0\",\n\t\t\"prettier-plugin-svelte\": \"^3.1.2\",\n\t\t\"semver\": \"^7.5.0\",\n\t\t\"tsup\": \"^6.7.0\",\n\t\t\"tsx\": \"^4.7.0\",\n\t\t\"typescript\": \"^5.4.2\",\n\t\t\"vite\": \"^5.0.2\",\n\t\t\"vitest\": \"^0.34.6\",\n\t\t\"webdriverio\": \"^8.6.7\"\n\t}\n}\n", ".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 fae585340d11fb4f7f034387e19e275134e8d882 Hamza Amin <[email protected]> 1727369237 +0500\tclone: from https://github.com/huggingface/huggingface.js.git\n", ".git\\refs\\heads\\main": "fae585340d11fb4f7f034387e19e275134e8d882\n", "e2e\\deno\\index.ts": "import { HfInference } from \"npm:@huggingface/inference@*\";\nimport { whoAmI, listFiles } from \"npm:@huggingface/hub@*\";\n\nconst info = await whoAmI({ credentials: { accessToken: \"hf_hub.js\" }, hubUrl: \"https://hub-ci.huggingface.co\" });\nconsole.log(info);\n\nfor await (const file of listFiles({ credentials: { accessToken: \"hf_hub.js\" }, repo: \"gpt2\" })) {\n\tconsole.log(file);\n}\n\nconst token = Deno.env.get(\"HF_TOKEN\");\nif (token) {\n\tconst hf = new HfInference(token);\n\n\tconst tokenInfo = await whoAmI({ credentials: { accessToken: token } });\n\tconsole.log(tokenInfo);\n\n\tconst sum = await hf.summarization({\n\t\tmodel: \"facebook/bart-large-cnn\",\n\t\tinputs:\n\t\t\t\"The tower is 324 metres (1,063 ft) tall, about the same height as an 81-storey building, and the tallest structure in Paris. Its base is square, measuring 125 metres (410 ft) on each side. During its construction, the Eiffel Tower surpassed the Washington Monument to become the tallest man-made structure in the world, a title it held for 41 years until the Chrysler Building in New York City was finished in 1930.\",\n\t\tparameters: {\n\t\t\tmax_length: 100,\n\t\t},\n\t});\n\n\tconsole.log(sum);\n}\n", "e2e\\svelte\\package.json": "{\n\t\"name\": \"myapp\",\n\t\"version\": \"0.0.1\",\n\t\"private\": true,\n\t\"packageManager\": \"[email protected]\",\n\t\"scripts\": {\n\t\t\"dev\": \"vite dev\",\n\t\t\"build\": \"vite build\",\n\t\t\"preview\": \"vite preview\",\n\t\t\"check\": \"svelte-kit sync && svelte-check --tsconfig ./tsconfig.json\",\n\t\t\"check:watch\": \"svelte-kit sync && svelte-check --tsconfig ./tsconfig.json --watch\",\n\t\t\"test:browser\": \"vitest run --browser.name=chrome --browser.headless\"\n\t},\n\t\"devDependencies\": {\n\t\t\"@sveltejs/adapter-auto\": \"^3.2.0\",\n\t\t\"@sveltejs/kit\": \"^2.5.9\",\n\t\t\"@sveltejs/vite-plugin-svelte\": \"^3.0.0\",\n\t\t\"@vitest/browser\": \"^1.6.0\",\n\t\t\"svelte\": \"^4.2.17\",\n\t\t\"svelte-check\": \"^3.0.1\",\n\t\t\"tslib\": \"^2.4.1\",\n\t\t\"typescript\": \"^5.0.0\",\n\t\t\"vite\": \"^5.2.11\",\n\t\t\"vitest\": \"^1.6.0\"\n\t},\n\t\"type\": \"module\",\n\t\"dependencies\": {\n\t\t\"@huggingface/hub\": \"*\",\n\t\t\"@huggingface/inference\": \"*\"\n\t}\n}\n", "e2e\\svelte\\src\\app.d.ts": "// See https://kit.svelte.dev/docs/types#app\n// for information about these interfaces\ndeclare global {\n\tnamespace App {\n\t\t// interface Error {}\n\t\t// interface Locals {}\n\t\t// interface PageData {}\n\t\t// interface Platform {}\n\t}\n}\n\nexport {};\n", "e2e\\svelte\\src\\app.html": "<!doctype html>\n<html lang=\"en\">\n\t<head>\n\t\t<meta charset=\"utf-8\" />\n\t\t<link rel=\"icon\" href=\"%sveltekit.assets%/favicon.png\" />\n\t\t<meta name=\"viewport\" content=\"width=device-width\" />\n\t\t%sveltekit.head%\n\t</head>\n\t<body data-sveltekit-preload-data=\"hover\">\n\t\t<div style=\"display: contents\">%sveltekit.body%</div>\n\t</body>\n</html>\n", "e2e\\ts\\package.json": "{\n\t\"name\": \"ts\",\n\t\"version\": \"1.0.0\",\n\t\"description\": \"\",\n\t\"main\": \"index.js\",\n\t\"scripts\": {\n\t\t\"start\": \"tsc && node ./dist/index.js\"\n\t},\n\t\"keywords\": [],\n\t\"author\": \"\",\n\t\"license\": \"ISC\",\n\t\"devDependencies\": {\n\t\t\"@types/node\": \"^18.16.1\",\n\t\t\"typescript\": \"^5.0.4\"\n\t},\n\t\"dependencies\": {\n\t\t\"@huggingface/inference\": \"*\",\n\t\t\"@huggingface/hub\": \"*\"\n\t}\n}\n", "e2e\\ts\\src\\index.ts": "import { HfInference } from \"@huggingface/inference\";\nimport { whoAmI } from \"@huggingface/hub\";\n\nconst hfToken = process.env.token;\n\nconst hf = new HfInference(hfToken);\n\n(async () => {\n\tconst info = await whoAmI({ credentials: { accessToken: \"hf_hub.js\" }, hubUrl: \"https://hub-ci.huggingface.co\" });\n\tconsole.log(info);\n\n\tif (hfToken) {\n\t\tconst sum = await hf.summarization({\n\t\t\tmodel: \"facebook/bart-large-cnn\",\n\t\t\tinputs:\n\t\t\t\t\"The tower is 324 metres (1,063 ft) tall, about the same height as an 81-storey building, and the tallest structure in Paris. Its base is square, measuring 125 metres (410 ft) on each side. During its construction, the Eiffel Tower surpassed the Washington Monument to become the tallest man-made structure in the world, a title it held for 41 years until the Chrysler Building in New York City was finished in 1930.\",\n\t\t\tparameters: {\n\t\t\t\tmax_length: 100,\n\t\t\t},\n\t\t});\n\n\t\tconsole.log(sum);\n\t}\n})();\n", "e2e\\yarn\\package.json": "{\n\t\"name\": \"yarn\",\n\t\"version\": \"1.0.0\",\n\t\"main\": \"index.js\",\n\t\"license\": \"MIT\",\n\t\"dependencies\": {\n\t\t\"@huggingface/inference\": \"*\",\n\t\t\"@huggingface/hub\": \"*\"\n\t}\n}\n", "packages\\agents\\index.ts": "export * from \"./src\";\n", "packages\\agents\\package.json": "{\n\t\"name\": \"@huggingface/agents\",\n\t\"packageManager\": \"[email protected]\",\n\t\"version\": \"0.0.5\",\n\t\"description\": \"Multi-modal agents using Hugging Face's models\",\n\t\"repository\": \"https://github.com/huggingface/huggingface.js.git\",\n\t\"publishConfig\": {\n\t\t\"access\": \"public\"\n\t},\n\t\"main\": \"./dist/index.js\",\n\t\"module\": \"./dist/index.mjs\",\n\t\"types\": \"./dist/index.d.ts\",\n\t\"exports\": {\n\t\t\".\": {\n\t\t\t\"types\": \"./dist/index.d.ts\",\n\t\t\t\"require\": \"./dist/index.js\",\n\t\t\t\"import\": \"./dist/index.mjs\"\n\t\t}\n\t},\n\t\"browser\": {\n\t\t\"./dist/index.js\": \"./dist/browser/index.js\",\n\t\t\"./dist/index.mjs\": \"./dist/browser/index.mjs\"\n\t},\n\t\"engines\": {\n\t\t\"node\": \">=18\"\n\t},\n\t\"source\": \"index.ts\",\n\t\"scripts\": {\n\t\t\"lint\": \"eslint --quiet --fix --ext .cjs,.ts .\",\n\t\t\"lint:check\": \"eslint --ext .cjs,.ts .\",\n\t\t\"format\": \"prettier --write .\",\n\t\t\"format:check\": \"prettier --check .\",\n\t\t\"prepublishOnly\": \"pnpm run build\",\n\t\t\"build\": \"tsup && tsc --emitDeclarationOnly --declaration\",\n\t\t\"test\": \"vitest run\",\n\t\t\"test:browser\": \"vitest run --browser.name=chrome --browser.headless --config vitest-browser.config.mts\",\n\t\t\"check\": \"tsc\"\n\t},\n\t\"files\": [\n\t\t\"src\",\n\t\t\"dist\",\n\t\t\"index.ts\",\n\t\t\"tsconfig.json\"\n\t],\n\t\"keywords\": [\n\t\t\"huggingface\",\n\t\t\"agents\",\n\t\t\"api\",\n\t\t\"client\",\n\t\t\"hugging\",\n\t\t\"face\"\n\t],\n\t\"author\": \"Hugging Face\",\n\t\"license\": \"MIT\",\n\t\"devDependencies\": {\n\t\t\"@types/node\": \"^18.13.0\"\n\t},\n\t\"dependencies\": {\n\t\t\"@huggingface/inference\": \"^2.6.1\"\n\t}\n}\n", "packages\\agents\\src\\index.ts": "export { HfAgent } from \"./HfAgent\";\nexport * from \"./tools\";\nexport * from \"./llms\";\n", "packages\\agents\\src\\llms\\index.ts": "export { LLMFromHub, LLMFromEndpoint } from \"./LLMHF\";\n", "packages\\agents\\src\\tools\\index.ts": "import { textToImageTool } from \"./textToImage\";\nimport { imageToTextTool } from \"./imageToText\";\nimport { textToSpeechTool } from \"./textToSpeech\";\nimport { speechToTextTool } from \"./speechToText\";\nimport type { Tool } from \"../types\";\n\nexport const defaultTools: Array<Tool> = [textToImageTool, imageToTextTool, textToSpeechTool, speechToTextTool];\n\nexport { textToImageTool } from \"./textToImage\";\nexport { imageToTextTool } from \"./imageToText\";\nexport { textToSpeechTool } from \"./textToSpeech\";\nexport { speechToTextTool } from \"./speechToText\";\n", "packages\\doc-internal\\package.json": "{\n\t\"name\": \"@huggingface/doc-internal\",\n\t\"packageManager\": \"[email protected]\",\n\t\"version\": \"1.0.0\",\n\t\"description\": \"Package to generate doc for other @huggingface packages\",\n\t\"private\": true,\n\t\"scripts\": {\n\t\t\"start\": \"pnpm run fix-cdn-versions && pnpm run doc-hub && pnpm run doc-inference && pnpm run doc-agents && pnpm run doc-space-header && pnpm run doc-gguf && cp ../../README.md ../../docs/index.md && pnpm run update-toc && pnpm run fix-md-links && pnpm run fix-md-headinghashlinks\",\n\t\t\"lint\": \"eslint --quiet --fix --ext .cjs,.ts .\",\n\t\t\"lint:check\": \"eslint --ext .cjs,.ts .\",\n\t\t\"format\": \"prettier --write .\",\n\t\t\"format:check\": \"prettier --check .\",\n\t\t\"doc-hub\": \"typedoc --tsconfig ../hub/tsconfig.json --githubPages false --plugin typedoc-plugin-markdown --out ../../docs/hub --hideBreadcrumbs --hideInPageTOC --sourceLinkTemplate https://github.com/huggingface/huggingface.js/blob/main/{path}#L{line} ../hub/index.ts\",\n\t\t\"doc-inference\": \"typedoc --tsconfig ../inference/tsconfig.json --githubPages false --plugin typedoc-plugin-markdown --out ../../docs/inference --hideBreadcrumbs --hideInPageTOC --sourceLinkTemplate https://github.com/huggingface/huggingface.js/blob/main/{path}#L{line} ../inference/src/index.ts\",\n\t\t\"doc-agents\": \"typedoc --tsconfig ../agents/tsconfig.json --githubPages false --plugin typedoc-plugin-markdown --out ../../docs/agents --hideBreadcrumbs --hideInPageTOC --sourceLinkTemplate https://github.com/huggingface/huggingface.js/blob/main/{path}#L{line} ../agents/src/index.ts\",\n\t\t\"doc-gguf\": \"mkdir -p ../../docs/gguf && cp ../../packages/gguf/README.md ../../docs/gguf/README.md\",\n\t\t\"doc-space-header\": \"mkdir -p ../../docs/space-header && cp ../../packages/space-header/README.md ../../docs/space-header/README.md\",\n\t\t\"update-toc\": \"tsx update-toc.ts\",\n\t\t\"fix-cdn-versions\": \"tsx fix-cdn-versions.ts\",\n\t\t\"fix-md-links\": \"tsx fix-md-links.ts\",\n\t\t\"fix-md-headinghashlinks\": \"tsx fix-md-headinghashlinks.ts\"\n\t},\n\t\"type\": \"module\",\n\t\"license\": \"MIT\",\n\t\"devDependencies\": {\n\t\t\"@types/node\": \"^18.14.5\",\n\t\t\"typedoc\": \"^0.25.12\",\n\t\t\"typedoc-plugin-markdown\": \"^3.17.1\"\n\t},\n\t\"dependencies\": {\n\t\t\"glob\": \"^9.2.1\",\n\t\t\"yaml\": \"^2.2.2\"\n\t}\n}\n", "packages\\gguf\\package.json": "{\n\t\"name\": \"@huggingface/gguf\",\n\t\"packageManager\": \"[email protected]\",\n\t\"version\": \"0.1.10\",\n\t\"description\": \"a GGUF parser that works on remotely hosted files\",\n\t\"repository\": \"https://github.com/huggingface/huggingface.js.git\",\n\t\"publishConfig\": {\n\t\t\"access\": \"public\"\n\t},\n\t\"main\": \"./dist/index.js\",\n\t\"module\": \"./dist/index.mjs\",\n\t\"types\": \"./dist/index.d.ts\",\n\t\"exports\": {\n\t\t\".\": {\n\t\t\t\"types\": \"./dist/index.d.ts\",\n\t\t\t\"require\": \"./dist/index.js\",\n\t\t\t\"import\": \"./dist/index.mjs\"\n\t\t}\n\t},\n\t\"browser\": {\n\t\t\"./src/utils/FileBlob.ts\": false,\n\t\t\"./dist/index.js\": \"./dist/browser/index.js\",\n\t\t\"./dist/index.mjs\": \"./dist/browser/index.mjs\"\n\t},\n\t\"engines\": {\n\t\t\"node\": \">=20\"\n\t},\n\t\"source\": \"index.ts\",\n\t\"scripts\": {\n\t\t\"lint\": \"eslint --quiet --fix --ext .cjs,.ts .\",\n\t\t\"lint:check\": \"eslint --ext .cjs,.ts .\",\n\t\t\"format\": \"prettier --write .\",\n\t\t\"format:check\": \"prettier --check .\",\n\t\t\"prepublishOnly\": \"pnpm run build\",\n\t\t\"build\": \"tsup src/index.ts --format cjs,esm --clean && tsc --emitDeclarationOnly --declaration\",\n\t\t\"build:llm\": \"tsx scripts/generate-llm.ts && pnpm run format\",\n\t\t\"test\": \"vitest run\",\n\t\t\"check\": \"tsc\"\n\t},\n\t\"files\": [\n\t\t\"dist\",\n\t\t\"src\",\n\t\t\"tsconfig.json\"\n\t],\n\t\"keywords\": [\n\t\t\"huggingface\",\n\t\t\"hub\",\n\t\t\"gguf\"\n\t],\n\t\"author\": \"Hugging Face\",\n\t\"license\": \"MIT\",\n\t\"devDependencies\": {\n\t\t\"@types/node\": \"^20.12.8\"\n\t}\n}\n", "packages\\gguf\\src\\index.ts": "export * from \"./gguf\";\n", "packages\\hub\\index.ts": "export * from \"./src\";\n", "packages\\hub\\package.json": "{\n\t\"name\": \"@huggingface/hub\",\n\t\"packageManager\": \"[email protected]\",\n\t\"version\": \"0.17.0\",\n\t\"description\": \"Utilities to interact with the Hugging Face hub\",\n\t\"repository\": \"https://github.com/huggingface/huggingface.js.git\",\n\t\"publishConfig\": {\n\t\t\"access\": \"public\"\n\t},\n\t\"main\": \"./dist/index.js\",\n\t\"module\": \"./dist/index.mjs\",\n\t\"types\": \"./dist/index.d.ts\",\n\t\"exports\": {\n\t\t\".\": {\n\t\t\t\"types\": \"./dist/index.d.ts\",\n\t\t\t\"require\": \"./dist/index.js\",\n\t\t\t\"import\": \"./dist/index.mjs\"\n\t\t}\n\t},\n\t\"browser\": {\n\t\t\"./src/utils/sha256-node.ts\": false,\n\t\t\"./src/utils/FileBlob.ts\": false,\n\t\t\"./src/lib/cache-management.ts\": false,\n\t\t\"./dist/index.js\": \"./dist/browser/index.js\",\n\t\t\"./dist/index.mjs\": \"./dist/browser/index.mjs\"\n\t},\n\t\"engines\": {\n\t\t\"node\": \">=18\"\n\t},\n\t\"source\": \"index.ts\",\n\t\"scripts\": {\n\t\t\"lint\": \"eslint --quiet --fix --ext .cjs,.ts .\",\n\t\t\"lint:check\": \"eslint --ext .cjs,.ts .\",\n\t\t\"format\": \"prettier --write .\",\n\t\t\"format:check\": \"prettier --check .\",\n\t\t\"prepublishOnly\": \"pnpm run build\",\n\t\t\"build\": \"tsup && tsc --emitDeclarationOnly --declaration\",\n\t\t\"prepare\": \"pnpm run build\",\n\t\t\"test\": \"vitest run\",\n\t\t\"test:browser\": \"vitest run --browser.name=chrome --browser.headless --config vitest-browser.config.mts\",\n\t\t\"check\": \"tsc\"\n\t},\n\t\"files\": [\n\t\t\"src\",\n\t\t\"dist\",\n\t\t\"index.ts\",\n\t\t\"tsconfig.json\"\n\t],\n\t\"keywords\": [\n\t\t\"huggingface\",\n\t\t\"hub\",\n\t\t\"api\",\n\t\t\"client\",\n\t\t\"hugging\",\n\t\t\"face\"\n\t],\n\t\"author\": \"Hugging Face\",\n\t\"license\": \"MIT\",\n\t\"devDependencies\": {\n\t\t\"@types/node\": \"^20.11.28\"\n\t},\n\t\"dependencies\": {\n\t\t\"@huggingface/tasks\": \"workspace:^\"\n\t}\n}\n", "packages\\hub\\src\\index.ts": "export * from \"./lib\";\n// Typescript 5 will add 'export type *'\nexport type {\n\tAccessToken,\n\tAccessTokenRole,\n\tAuthType,\n\tCredentials,\n\tPipelineType,\n\tRepoDesignation,\n\tRepoFullName,\n\tRepoId,\n\tRepoType,\n\tSpaceHardwareFlavor,\n\tSpaceResourceConfig,\n\tSpaceResourceRequirement,\n\tSpaceRuntime,\n\tSpaceSdk,\n\tSpaceStage,\n} from \"./types/public\";\nexport { HubApiError, InvalidApiResponseFormatError } from \"./error\";\n/**\n * Only exported for E2Es convenience\n */\nexport { sha256 as __internal_sha256 } from \"./utils/sha256\";\n", "packages\\hub\\src\\lib\\index.ts": "export * from \"./cache-management\";\nexport * from \"./commit\";\nexport * from \"./count-commits\";\nexport * from \"./create-repo\";\nexport * from \"./delete-file\";\nexport * from \"./delete-files\";\nexport * from \"./delete-repo\";\nexport * from \"./download-file\";\nexport * from \"./file-download-info\";\nexport * from \"./file-exists\";\nexport * from \"./list-commits\";\nexport * from \"./list-datasets\";\nexport * from \"./list-files\";\nexport * from \"./list-models\";\nexport * from \"./list-spaces\";\nexport * from \"./oauth-handle-redirect\";\nexport * from \"./oauth-login-url\";\nexport * from \"./parse-safetensors-metadata\";\nexport * from \"./upload-file\";\nexport * from \"./upload-files\";\nexport * from \"./upload-files-with-progress\";\nexport * from \"./who-am-i\";\n", "packages\\hub\\src\\types\\api\\api-index-tree.ts": "export interface ApiIndexTreeEntry {\n\ttype: \"file\" | \"directory\" | \"unknown\";\n\tsize: number;\n\tpath: string;\n\toid: string;\n\tlfs?: {\n\t\toid: string;\n\t\tsize: number;\n\t\t/** Size of the raw pointer file, 100~200 bytes */\n\t\tpointerSize: number;\n\t};\n\tlastCommit?: {\n\t\tdate: string;\n\t\tid: string;\n\t\ttitle: string;\n\t};\n\tsecurity?: ApiFileScanResult;\n}\n\nexport interface ApiFileScanResult {\n\t/** namespaced by repo type (models/, datasets/, spaces/) */\n\trepositoryId: string;\n\tblobId: string;\n\tname: string;\n\tsafe: boolean;\n\tavScan?: ApiAVScan;\n\tpickleImportScan?: ApiPickleImportScan;\n}\n\ninterface ApiAVScan {\n\tvirusFound: boolean;\n\tvirusNames?: string[];\n}\n\ntype ApiSafetyLevel = \"innocuous\" | \"suspicious\" | \"dangerous\";\n\ninterface ApiPickleImport {\n\tmodule: string;\n\tname: string;\n\tsafety: ApiSafetyLevel;\n}\n\ninterface ApiPickleImportScan {\n\thighestSafetyLevel: ApiSafetyLevel;\n\timports: ApiPickleImport[];\n}\n", "packages\\hub\\src\\vendor\\hash-wasm\\sha256-wrapper.ts": "import WasmModule from \"./sha256\";\n\nexport async function createSHA256(isInsideWorker = false): Promise<{\n\tinit(): void;\n\tupdate(data: Uint8Array): void;\n\tdigest(method: \"hex\"): string;\n}> {\n\tconst BUFFER_MAX_SIZE = 8 * 1024 * 1024;\n\tconst wasm: Awaited<ReturnType<typeof WasmModule>> = isInsideWorker\n\t\t? // @ts-expect-error WasmModule will be populated inside self object\n\t\t await self[\"SHA256WasmModule\"]()\n\t\t: await WasmModule();\n\tconst heap = wasm.HEAPU8.subarray(wasm._GetBufferPtr());\n\treturn {\n\t\tinit() {\n\t\t\twasm._Hash_Init(256);\n\t\t},\n\t\tupdate(data: Uint8Array) {\n\t\t\tlet byteUsed = 0;\n\t\t\twhile (byteUsed < data.byteLength) {\n\t\t\t\tconst bytesLeft = data.byteLength - byteUsed;\n\t\t\t\tconst length = Math.min(bytesLeft, BUFFER_MAX_SIZE);\n\t\t\t\theap.set(data.subarray(byteUsed, byteUsed + length));\n\t\t\t\twasm._Hash_Update(length);\n\t\t\t\tbyteUsed += length;\n\t\t\t}\n\t\t},\n\t\tdigest(method: \"hex\") {\n\t\t\tif (method !== \"hex\") {\n\t\t\t\tthrow new Error(\"Only digest hex is supported\");\n\t\t\t}\n\t\t\twasm._Hash_Final();\n\t\t\tconst result = Array.from(heap.slice(0, 32));\n\t\t\treturn result.map((b) => b.toString(16).padStart(2, \"0\")).join(\"\");\n\t\t},\n\t};\n}\n\nexport function createSHA256WorkerCode(): string {\n\treturn `\n\t\tself.addEventListener('message', async (event) => {\n const { file } = event.data;\n const sha256 = await self.createSHA256(true);\n sha256.init();\n const reader = file.stream().getReader();\n const total = file.size;\n let bytesDone = 0;\n while (true) {\n const { done, value } = await reader.read();\n if (done) {\n break;\n }\n sha256.update(value);\n bytesDone += value.length;\n postMessage({ progress: bytesDone / total });\n }\n postMessage({ sha256: sha256.digest('hex') });\n });\n self.SHA256WasmModule = ${WasmModule.toString()};\n self.createSHA256 = ${createSHA256.toString()};\n `;\n}\n", "packages\\inference\\package.json": "{\n\t\"name\": \"@huggingface/inference\",\n\t\"version\": \"2.8.0\",\n\t\"packageManager\": \"[email protected]\",\n\t\"license\": \"MIT\",\n\t\"author\": \"Tim Mikeladze <[email protected]>\",\n\t\"description\": \"Typescript wrapper for the Hugging Face Inference Endpoints & Inference API\",\n\t\"repository\": {\n\t\t\"type\": \"git\",\n\t\t\"url\": \"https://github.com/huggingface/huggingface.js.git\"\n\t},\n\t\"publishConfig\": {\n\t\t\"access\": \"public\"\n\t},\n\t\"keywords\": [\n\t\t\"hugging face\",\n\t\t\"hugging face typescript\",\n\t\t\"huggingface\",\n\t\t\"huggingface-inference-api\",\n\t\t\"huggingface-inference-api-typescript\",\n\t\t\"inference\",\n\t\t\"ai\"\n\t],\n\t\"engines\": {\n\t\t\"node\": \">=18\"\n\t},\n\t\"files\": [\n\t\t\"dist\",\n\t\t\"src\"\n\t],\n\t\"source\": \"src/index.ts\",\n\t\"types\": \"./dist/src/index.d.ts\",\n\t\"main\": \"./dist/index.cjs\",\n\t\"module\": \"./dist/index.js\",\n\t\"exports\": {\n\t\t\"types\": \"./dist/src/index.d.ts\",\n\t\t\"require\": \"./dist/index.cjs\",\n\t\t\"import\": \"./dist/index.js\"\n\t},\n\t\"type\": \"module\",\n\t\"scripts\": {\n\t\t\"build\": \"tsup src/index.ts --format cjs,esm --clean && tsc --emitDeclarationOnly --declaration\",\n\t\t\"dts\": \"tsx scripts/generate-dts.ts && tsc --noEmit dist/index.d.ts\",\n\t\t\"lint\": \"eslint --quiet --fix --ext .cjs,.ts .\",\n\t\t\"lint:check\": \"eslint --ext .cjs,.ts .\",\n\t\t\"format\": \"prettier --write .\",\n\t\t\"format:check\": \"prettier --check .\",\n\t\t\"prepare\": \"pnpm run build\",\n\t\t\"prepublishOnly\": \"pnpm run build\",\n\t\t\"test\": \"vitest run --config vitest.config.mts\",\n\t\t\"test:browser\": \"vitest run --browser.name=chrome --browser.headless --config vitest.config.mts\",\n\t\t\"check\": \"tsc\"\n\t},\n\t\"dependencies\": {\n\t\t\"@huggingface/tasks\": \"workspace:^\"\n\t},\n\t\"devDependencies\": {\n\t\t\"@types/node\": \"18.13.0\"\n\t},\n\t\"resolutions\": {}\n}\n", "packages\\inference\\src\\index.ts": "export { HfInference, HfInferenceEndpoint } from \"./HfInference\";\nexport { InferenceOutputError } from \"./lib/InferenceOutputError\";\nexport * from \"./types\";\nexport * from \"./tasks\";\n", "packages\\inference\\src\\tasks\\index.ts": "// Custom tasks with arbitrary inputs and outputs\nexport * from \"./custom/request\";\nexport * from \"./custom/streamingRequest\";\n\n// Audio tasks\nexport * from \"./audio/audioClassification\";\nexport * from \"./audio/automaticSpeechRecognition\";\nexport * from \"./audio/textToSpeech\";\nexport * from \"./audio/audioToAudio\";\n\n// Computer Vision tasks\nexport * from \"./cv/imageClassification\";\nexport * from \"./cv/imageSegmentation\";\nexport * from \"./cv/imageToText\";\nexport * from \"./cv/objectDetection\";\nexport * from \"./cv/textToImage\";\nexport * from \"./cv/imageToImage\";\nexport * from \"./cv/zeroShotImageClassification\";\n\n// Natural Language Processing tasks\nexport * from \"./nlp/featureExtraction\";\nexport * from \"./nlp/fillMask\";\nexport * from \"./nlp/questionAnswering\";\nexport * from \"./nlp/sentenceSimilarity\";\nexport * from \"./nlp/summarization\";\nexport * from \"./nlp/tableQuestionAnswering\";\nexport * from \"./nlp/textClassification\";\nexport * from \"./nlp/textGeneration\";\nexport * from \"./nlp/textGenerationStream\";\nexport * from \"./nlp/tokenClassification\";\nexport * from \"./nlp/translation\";\nexport * from \"./nlp/zeroShotClassification\";\nexport * from \"./nlp/chatCompletion\";\nexport * from \"./nlp/chatCompletionStream\";\n\n// Multimodal tasks\nexport * from \"./multimodal/documentQuestionAnswering\";\nexport * from \"./multimodal/visualQuestionAnswering\";\n\n// Tabular tasks\nexport * from \"./tabular/tabularRegression\";\nexport * from \"./tabular/tabularClassification\";\n", "packages\\jinja\\package.json": "{\n\t\"name\": \"@huggingface/jinja\",\n\t\"packageManager\": \"[email protected]\",\n\t\"version\": \"0.3.1\",\n\t\"description\": \"A minimalistic JavaScript implementation of the Jinja templating engine, specifically designed for parsing and rendering ML chat templates.\",\n\t\"repository\": \"https://github.com/huggingface/huggingface.js.git\",\n\t\"publishConfig\": {\n\t\t\"access\": \"public\"\n\t},\n\t\"type\": \"module\",\n\t\"main\": \"./dist/index.cjs\",\n\t\"module\": \"./dist/index.js\",\n\t\"types\": \"./dist/index.d.ts\",\n\t\"exports\": {\n\t\t\".\": {\n\t\t\t\"types\": \"./dist/index.d.ts\",\n\t\t\t\"require\": \"./dist/index.cjs\",\n\t\t\t\"import\": \"./dist/index.js\"\n\t\t}\n\t},\n\t\"engines\": {\n\t\t\"node\": \">=18\"\n\t},\n\t\"source\": \"src/index.ts\",\n\t\"scripts\": {\n\t\t\"lint\": \"eslint --quiet --fix --ext .cjs,.ts .\",\n\t\t\"lint:check\": \"eslint --ext .cjs,.ts .\",\n\t\t\"format\": \"prettier --write .\",\n\t\t\"format:check\": \"prettier --check .\",\n\t\t\"prepublishOnly\": \"pnpm run build\",\n\t\t\"prepare\": \"pnpm run build\",\n\t\t\"build\": \"tsup src/index.ts --format cjs,esm --clean && tsc --emitDeclarationOnly --declaration\",\n\t\t\"test\": \"vitest run\",\n\t\t\"test:browser\": \"vitest run --browser.name=chrome --browser.headless\",\n\t\t\"check\": \"tsc\"\n\t},\n\t\"files\": [\n\t\t\"src\",\n\t\t\"dist\",\n\t\t\"README.md\",\n\t\t\"tsconfig.json\"\n\t],\n\t\"keywords\": [\n\t\t\"huggingface\",\n\t\t\"jinja\",\n\t\t\"templates\",\n\t\t\"hugging\",\n\t\t\"face\"\n\t],\n\t\"author\": \"Hugging Face\",\n\t\"license\": \"MIT\",\n\t\"devDependencies\": {\n\t\t\"typescript\": \"^5.3.2\",\n\t\t\"@huggingface/hub\": \"workspace:^\",\n\t\t\"@xenova/transformers\": \"^2.9.0\"\n\t}\n}\n", "packages\\jinja\\src\\index.ts": "/**\n * @file Jinja templating engine\n *\n * A minimalistic JavaScript reimplementation of the [Jinja](https://github.com/pallets/jinja) templating engine,\n * to support the chat templates. Special thanks to [Tyler Laceby](https://github.com/tlaceby) for his amazing\n * [\"Guide to Interpreters\"](https://github.com/tlaceby/guide-to-interpreters-series) tutorial series,\n * which provided the basis for this implementation.\n *\n * See the [Transformers documentation](https://huggingface.co/docs/transformers/main/en/chat_templating) for more information.\n *\n * @module index\n */\nimport { tokenize } from \"./lexer\";\nimport { parse } from \"./parser\";\nimport { Environment, Interpreter } from \"./runtime\";\nimport type { Program } from \"./ast\";\nimport type { StringValue } from \"./runtime\";\nimport { range } from \"./utils\";\n\nexport class Template {\n\tparsed: Program;\n\n\t/**\n\t * @param {string} template The template string\n\t */\n\tconstructor(template: string) {\n\t\tconst tokens = tokenize(template, {\n\t\t\tlstrip_blocks: true,\n\t\t\ttrim_blocks: true,\n\t\t});\n\t\tthis.parsed = parse(tokens);\n\t}\n\n\trender(items: Record<string, unknown>): string {\n\t\t// Create a new environment for this template\n\t\tconst env = new Environment();\n\n\t\t// Declare global variables\n\t\tenv.set(\"false\", false);\n\t\tenv.set(\"true\", true);\n\t\tenv.set(\"raise_exception\", (args: string) => {\n\t\t\tthrow new Error(args);\n\t\t});\n\t\tenv.set(\"range\", range);\n\n\t\t// Add user-defined variables\n\t\tfor (const [key, value] of Object.entries(items)) {\n\t\t\tenv.set(key, value);\n\t\t}\n\n\t\tconst interpreter = new Interpreter(env);\n\n\t\tconst result = interpreter.run(this.parsed) as StringValue;\n\t\treturn result.value;\n\t}\n}\n\nexport { Environment, Interpreter, tokenize, parse };\n", "packages\\languages\\package.json": "{\n\t\"name\": \"@huggingface/languages\",\n\t\"packageManager\": \"[email protected]\",\n\t\"version\": \"1.0.0\",\n\t\"description\": \"List of ISO-639 languages used in the Hub\",\n\t\"repository\": \"https://github.com/huggingface/huggingface.js.git\",\n\t\"publishConfig\": {\n\t\t\"access\": \"public\"\n\t},\n\t\"main\": \"./dist/index.js\",\n\t\"module\": \"./dist/index.mjs\",\n\t\"types\": \"./dist/index.d.ts\",\n\t\"exports\": {\n\t\t\".\": {\n\t\t\t\"types\": \"./dist/index.d.ts\",\n\t\t\t\"require\": \"./dist/index.js\",\n\t\t\t\"import\": \"./dist/index.mjs\"\n\t\t}\n\t},\n\t\"source\": \"index.ts\",\n\t\"scripts\": {\n\t\t\"lint\": \"eslint --quiet --fix --ext .cjs,.ts .\",\n\t\t\"lint:check\": \"eslint --ext .cjs,.ts .\",\n\t\t\"format\": \"prettier --write .\",\n\t\t\"format:check\": \"prettier --check .\",\n\t\t\"prepublishOnly\": \"pnpm run build\",\n\t\t\"build\": \"tsup src/index.ts --format cjs,esm --clean && tsc --emitDeclarationOnly --declaration\",\n\t\t\"test\": \"vitest run\",\n\t\t\"check\": \"tsc\"\n\t},\n\t\"files\": [\n\t\t\"dist\",\n\t\t\"src\",\n\t\t\"tsconfig.json\"\n\t],\n\t\"keywords\": [\n\t\t\"huggingface\",\n\t\t\"hub\",\n\t\t\"languages\"\n\t],\n\t\"author\": \"Hugging Face\",\n\t\"license\": \"MIT\",\n\t\"devDependencies\": {}\n}\n", "packages\\languages\\src\\index.ts": "export type { Language } from \"./types\";\nexport { language } from \"./language\";\nexport { wikiLink } from \"./wikiLink\";\nexport { LANGUAGES_ISO_639_1 } from \"./languages_iso_639_1\";\nexport { LANGUAGES_ISO_639_3 } from \"./languages_iso_639_3\";\n", "packages\\space-header\\index.ts": "export * from \"./src\";\n", "packages\\space-header\\package.json": "{\n\t\"name\": \"@huggingface/space-header\",\n\t\"version\": \"1.0.4\",\n\t\"packageManager\": \"[email protected]\",\n\t\"description\": \"Use the Space mini_header outside Hugging Face\",\n\t\"repository\": \"https://github.com/huggingface/huggingface.js.git\",\n\t\"publishConfig\": {\n\t\t\"access\": \"public\"\n\t},\n\t\"main\": \"./dist/index.js\",\n\t\"module\": \"./dist/index.mjs\",\n\t\"types\": \"./dist/index.d.ts\",\n\t\"exports\": {\n\t\t\".\": {\n\t\t\t\"types\": \"./dist/index.d.ts\",\n\t\t\t\"require\": \"./dist/index.js\",\n\t\t\t\"import\": \"./dist/index.mjs\"\n\t\t}\n\t},\n\t\"browser\": {\n\t\t\"./dist/index.js\": \"./dist/browser/index.js\",\n\t\t\"./dist/index.mjs\": \"./dist/browser/index.mjs\"\n\t},\n\t\"scripts\": {\n\t\t\"build\": \"tsup && tsc --emitDeclarationOnly --declaration\",\n\t\t\"lint\": \"eslint --quiet --fix --ext .cjs,.ts .\",\n\t\t\"lint:check\": \"eslint --ext .cjs,.ts .\",\n\t\t\"format\": \"prettier --write .\",\n\t\t\"format:check\": \"prettier --check .\",\n\t\t\"prepublishOnly\": \"pnpm run build\"\n\t},\n\t\"keywords\": [\n\t\t\"huggingface\",\n\t\t\"spaces\",\n\t\t\"space-header\"\n\t],\n\t\"files\": [\n\t\t\"src\",\n\t\t\"dist\",\n\t\t\"index.ts\",\n\t\t\"tsconfig.json\"\n\t],\n\t\"author\": \"Hugging Face\",\n\t\"license\": \"MIT\",\n\t\"devDependencies\": {\n\t\t\"tsup\": \"^8.1.0\",\n\t\t\"typescript\": \"^5.4.5\"\n\t}\n}\n", "packages\\space-header\\src\\index.ts": "import type { Options, Space, Header } from \"./type\";\n\nimport { inject_fonts } from \"./inject_fonts\";\n\nimport { create } from \"./header/create\";\nimport { check_avatar } from \"./utils/check_avatar\";\nimport { get_space } from \"./utils/get_space\";\nimport { inject } from \"./inject\";\n\nasync function main(initialSpace: string | Space, options?: Options) {\n\tif (window === undefined) return console.error(\"Please run this script in a browser environment\");\n\t// Don't run on huggingface.co to avoid duplicate headers\n\tconst has_huggingface_ancestor = Object.values(\n\t\twindow.location?.ancestorOrigins ?? {\n\t\t\t0: window.document.referrer,\n\t\t}\n\t).some((origin) => new URL(origin)?.origin === \"https://huggingface.co\");\n\tif (has_huggingface_ancestor) return;\n\n\tinject_fonts();\n\n\tlet space;\n\n\tif (typeof initialSpace === \"string\") {\n\t\tspace = await get_space(initialSpace);\n\t\tif (space === null) return console.error(\"Space not found\");\n\t} else {\n\t\tspace = initialSpace;\n\t}\n\n\tconst [user, org] = await Promise.all([check_avatar(space.author, \"user\"), check_avatar(space.author, \"org\")]);\n\tspace.type = user ? \"user\" : org ? \"org\" : \"unknown\";\n\n\tconst mini_header_element = create(space as Space);\n\tinject(mini_header_element, options);\n\n\treturn {\n\t\telement: mini_header_element,\n\t};\n}\n\nexport const init = (space: string | Space, options?: Options): Promise<Header | void> => main(space, options);\n", "packages\\space-header\\src\\header\\components\\collapse\\index.ts": "import type { Space } from \"../../../type\";\nimport { ArrowCollapse } from \"./arrow\";\n\nexport const Collapse = (space: Space, callback: () => void): HTMLDivElement | SVGElement => {\n\tconst box = document.createElement(\"div\");\n\n\tbox.setAttribute(\"id\", \"space-header__collapse\");\n\n\tbox.style.display = \"flex\";\n\tbox.style.flexDirection = \"row\";\n\tbox.style.alignItems = \"center\";\n\tbox.style.justifyContent = \"center\";\n\tbox.style.fontSize = \"16px\";\n\tbox.style.paddingLeft = \"10px\";\n\tbox.style.paddingRight = \"10px\";\n\tbox.style.height = \"40px\";\n\tbox.style.cursor = \"pointer\";\n\tbox.style.color = \"#40546e\";\n\tbox.style.transitionDuration = \"0.1s\";\n\tbox.style.transitionProperty = \"all\";\n\tbox.style.transitionTimingFunction = \"ease-in-out\";\n\n\tbox.appendChild(ArrowCollapse());\n\n\tbox.addEventListener(\"click\", (e) => {\n\t\te.preventDefault();\n\t\te.stopPropagation();\n\t\tcallback();\n\t});\n\n\tbox.addEventListener(\"mouseenter\", () => {\n\t\tbox.style.color = \"#213551\";\n\t});\n\tbox.addEventListener(\"mouseleave\", () => {\n\t\tbox.style.color = \"#40546e\";\n\t});\n\n\treturn box;\n};\n", "packages\\space-header\\src\\header\\components\\content\\index.ts": "import type { Space } from \"../../../type\";\nimport { Like } from \"../like\";\nimport { Avatar } from \"./avatar\";\nimport { Namespace } from \"./namespace\";\nimport { Separation } from \"./separation\";\nimport { Username } from \"./username\";\n\nexport const Content = (space: Space): HTMLDivElement => {\n\tconst content = document.createElement(\"div\");\n\tcontent.style.display = \"flex\";\n\tcontent.style.flexDirection = \"row\";\n\tcontent.style.alignItems = \"center\";\n\tcontent.style.justifyContent = \"center\";\n\tcontent.style.borderRight = \"1px solid #e5e7eb\";\n\tcontent.style.paddingRight = \"12px\";\n\tcontent.style.height = \"40px\";\n\n\tif (space.type !== \"unknown\") {\n\t\tcontent.appendChild(Avatar(space.author, space.type));\n\t}\n\tcontent.appendChild(Username(space.author));\n\tcontent.appendChild(Separation());\n\tcontent.appendChild(Namespace(space.id));\n\tcontent.appendChild(Like(space));\n\n\treturn content;\n};\n", "packages\\space-header\\src\\header\\components\\like\\index.ts": "import type { Space } from \"../../../type\";\nimport { Count } from \"./count\";\nimport { Heart } from \"./heart\";\n\nexport const Like = (space: Space): HTMLAnchorElement => {\n\tconst box = document.createElement(\"a\");\n\n\tbox.setAttribute(\"href\", `https://huggingface.co/spaces/${space.id}`);\n\tbox.setAttribute(\"rel\", \"noopener noreferrer\");\n\tbox.setAttribute(\"target\", \"_blank\");\n\n\tbox.style.border = \"1px solid #e5e7eb\";\n\tbox.style.borderRadius = \"6px\";\n\tbox.style.display = \"flex\";\n\tbox.style.flexDirection = \"row\";\n\tbox.style.alignItems = \"center\";\n\tbox.style.margin = \"0 0 0 12px\";\n\tbox.style.fontSize = \"14px\";\n\tbox.style.paddingLeft = \"4px\";\n\tbox.style.textDecoration = \"none\";\n\n\tbox.appendChild(Heart());\n\tbox.appendChild(Count(space.likes));\n\n\treturn box;\n};\n", "packages\\tasks\\package.json": "{\n\t\"name\": \"@huggingface/tasks\",\n\t\"packageManager\": \"[email protected]\",\n\t\"version\": \"0.12.9\",\n\t\"description\": \"List of ML tasks for huggingface.co/tasks\",\n\t\"repository\": \"https://github.com/huggingface/huggingface.js.git\",\n\t\"publishConfig\": {\n\t\t\"access\": \"public\"\n\t},\n\t\"main\": \"./dist/index.cjs\",\n\t\"module\": \"./dist/index.js\",\n\t\"types\": \"./dist/src/index.d.ts\",\n\t\"exports\": {\n\t\t\".\": {\n\t\t\t\"types\": \"./dist/src/index.d.ts\",\n\t\t\t\"require\": \"./dist/index.cjs\",\n\t\t\t\"import\": \"./dist/index.js\"\n\t\t}\n\t},\n\t\"source\": \"src/index.ts\",\n\t\"scripts\": {\n\t\t\"lint\": \"eslint --quiet --fix --ext .cjs,.ts .\",\n\t\t\"lint:check\": \"eslint --ext .cjs,.ts .\",\n\t\t\"format\": \"prettier --write .\",\n\t\t\"format:check\": \"prettier --check .\",\n\t\t\"prepublishOnly\": \"pnpm run inference-codegen && git diff --name-only --exit-code src && pnpm run build\",\n\t\t\"build\": \"tsup src/index.ts --format cjs,esm --clean && tsc --emitDeclarationOnly --declaration\",\n\t\t\"watch:export\": \"tsup src/index.ts --format cjs,esm --watch\",\n\t\t\"watch:types\": \"tsc --emitDeclarationOnly --declaration --watch\",\n\t\t\"watch\": \"npm-run-all --parallel watch:export watch:types\",\n\t\t\"prepare\": \"pnpm run build\",\n\t\t\"check\": \"tsc\",\n\t\t\"inference-codegen\": \"tsx scripts/inference-codegen.ts && prettier --write src/tasks/*/inference.ts\",\n\t\t\"inference-tgi-import\": \"tsx scripts/inference-tgi-import.ts && prettier --write src/tasks/text-generation/spec/*.json && prettier --write src/tasks/chat-completion/spec/*.json\",\n\t\t\"inference-tei-import\": \"tsx scripts/inference-tei-import.ts && prettier --write src/tasks/feature-extraction/spec/*.json\"\n\t},\n\t\"type\": \"module\",\n\t\"files\": [\n\t\t\"dist\",\n\t\t\"src\",\n\t\t\"tsconfig.json\"\n\t],\n\t\"keywords\": [\n\t\t\"huggingface\",\n\t\t\"hub\",\n\t\t\"languages\"\n\t],\n\t\"author\": \"Hugging Face\",\n\t\"license\": \"MIT\",\n\t\"devDependencies\": {\n\t\t\"@types/node\": \"^20.11.5\",\n\t\t\"quicktype-core\": \"https://github.com/huggingface/quicktype/raw/pack-18.0.17/packages/quicktype-core/quicktype-core-18.0.17.tgz\",\n\t\t\"type-fest\": \"^3.13.1\"\n\t}\n}\n", "packages\\tasks\\src\\index.ts": "export { LIBRARY_TASK_MAPPING } from \"./library-to-tasks\";\nexport { MAPPING_DEFAULT_WIDGET } from \"./default-widget-inputs\";\nexport type { TaskData, TaskDemo, TaskDemoEntry, ExampleRepo } from \"./tasks\";\nexport * from \"./tasks\";\nexport {\n\tPIPELINE_DATA,\n\tPIPELINE_TYPES,\n\ttype WidgetType,\n\ttype PipelineType,\n\ttype PipelineData,\n\ttype Modality,\n\tMODALITIES,\n\tMODALITY_LABELS,\n\tSUBTASK_TYPES,\n\tPIPELINE_TYPES_SET,\n} from \"./pipelines\";\nexport { ALL_DISPLAY_MODEL_LIBRARY_KEYS, ALL_MODEL_LIBRARY_KEYS, MODEL_LIBRARIES_UI_ELEMENTS } from \"./model-libraries\";\nexport type { LibraryUiElement, ModelLibraryKey } from \"./model-libraries\";\nexport type { ModelData, TransformersInfo } from \"./model-data\";\nexport type { AddedToken, SpecialTokensMap, TokenizerConfig } from \"./tokenizer-data\";\nexport type {\n\tWidgetExample,\n\tWidgetExampleAttribute,\n\tWidgetExampleAssetAndPromptInput,\n\tWidgetExampleAssetAndTextInput,\n\tWidgetExampleAssetAndZeroShotInput,\n\tWidgetExampleAssetInput,\n\tWidgetExampleChatInput,\n\tWidgetExampleSentenceSimilarityInput,\n\tWidgetExampleStructuredDataInput,\n\tWidgetExampleTableDataInput,\n\tWidgetExampleTextAndContextInput,\n\tWidgetExampleTextAndTableInput,\n\tWidgetExampleTextInput,\n\tWidgetExampleZeroShotTextInput,\n\tWidgetExampleOutput,\n\tWidgetExampleOutputUrl,\n\tWidgetExampleOutputLabels,\n\tWidgetExampleOutputAnswerScore,\n\tWidgetExampleOutputText,\n} from \"./widget-example\";\nexport { SPECIAL_TOKENS_ATTRIBUTES } from \"./tokenizer-data\";\n\nimport * as snippets from \"./snippets\";\nexport { snippets };\n\nexport { SKUS, DEFAULT_MEMORY_OPTIONS } from \"./hardware\";\nexport type { HardwareSpec, SkuType } from \"./hardware\";\nexport { LOCAL_APPS } from \"./local-apps\";\nexport type { LocalApp, LocalAppKey, LocalAppSnippet } from \"./local-apps\";\n\nexport { DATASET_LIBRARIES_UI_ELEMENTS } from \"./dataset-libraries\";\nexport type { DatasetLibraryUiElement, DatasetLibraryKey } from \"./dataset-libraries\";\n", "packages\\tasks\\src\\local-apps.ts": "import type { ModelData } from \"./model-data\";\nimport type { PipelineType } from \"./pipelines\";\n\nexport interface LocalAppSnippet {\n\t/**\n\t * Title of the snippet\n\t */\n\ttitle: string;\n\t/**\n\t * Optional setup guide\n\t */\n\tsetup?: string;\n\t/**\n\t * Content (or command) to be run\n\t */\n\tcontent: string;\n}\n\n/**\n * Elements configurable by a local app.\n */\nexport type LocalApp = {\n\t/**\n\t * Name that appears in buttons\n\t */\n\tprettyLabel: string;\n\t/**\n\t * Link to get more info about a local app (website etc)\n\t */\n\tdocsUrl: string;\n\t/**\n\t * main category of app\n\t */\n\tmainTask: PipelineType;\n\t/**\n\t * Whether to display a pill \"macOS-only\"\n\t */\n\tmacOSOnly?: boolean;\n\n\tcomingSoon?: boolean;\n\t/**\n\t * IMPORTANT: function to figure out whether to display the button on a model page's main \"Use this model\" dropdown.\n\t */\n\tdisplayOnModelPage: (model: ModelData) => boolean;\n} & (\n\t| {\n\t\t\t/**\n\t\t\t * If the app supports deeplink, URL to open.\n\t\t\t */\n\t\t\tdeeplink: (model: ModelData, filepath?: string) => URL;\n\t }\n\t| {\n\t\t\t/**\n\t\t\t * And if not (mostly llama.cpp), snippet to copy/paste in your terminal\n\t\t\t * Support the placeholder {{GGUF_FILE}} that will be replaced by the gguf file path or the list of available files.\n\t\t\t */\n\t\t\tsnippet: (model: ModelData, filepath?: string) => string | string[] | LocalAppSnippet | LocalAppSnippet[];\n\t }\n);\n\nfunction isGgufModel(model: ModelData): boolean {\n\treturn model.tags.includes(\"gguf\");\n}\n\nfunction isAwqModel(model: ModelData): boolean {\n\treturn model.config?.quantization_config?.quant_method === \"awq\";\n}\n\nfunction isGptqModel(model: ModelData): boolean {\n\treturn model.config?.quantization_config?.quant_method === \"gptq\";\n}\n\nfunction isAqlmModel(model: ModelData): boolean {\n\treturn model.config?.quantization_config?.quant_method === \"aqlm\";\n}\n\nfunction isMarlinModel(model: ModelData): boolean {\n\treturn model.config?.quantization_config?.quant_method === \"marlin\";\n}\n\nfunction isTransformersModel(model: ModelData): boolean {\n\treturn model.tags.includes(\"transformers\");\n}\n\nfunction isLlamaCppGgufModel(model: ModelData) {\n\treturn !!model.gguf?.context_length;\n}\n\nconst snippetLlamacpp = (model: ModelData, filepath?: string): LocalAppSnippet[] => {\n\tconst command = (binary: string) =>\n\t\t[\n\t\t\t\"# Load and run the model:\",\n\t\t\t`${binary} \\\\`,\n\t\t\t` --hf-repo \"${model.id}\" \\\\`,\n\t\t\t` --hf-file ${filepath ?? \"{{GGUF_FILE}}\"} \\\\`,\n\t\t\t' -p \"You are a helpful assistant\" \\\\',\n\t\t\t\" --conversation\",\n\t\t].join(\"\\n\");\n\treturn [\n\t\t{\n\t\t\ttitle: \"Install from brew\",\n\t\t\tsetup: \"brew install llama.cpp\",\n\t\t\tcontent: command(\"llama-cli\"),\n\t\t},\n\t\t{\n\t\t\ttitle: \"Use pre-built binary\",\n\t\t\tsetup: [\n\t\t\t\t// prettier-ignore\n\t\t\t\t\"# Download pre-built binary from:\",\n\t\t\t\t\"# https://github.com/ggerganov/llama.cpp/releases\",\n\t\t\t].join(\"\\n\"),\n\t\t\tcontent: command(\"./llama-cli\"),\n\t\t},\n\t\t{\n\t\t\ttitle: \"Build from source code\",\n\t\t\tsetup: [\n\t\t\t\t\"git clone https://github.com/ggerganov/llama.cpp.git\",\n\t\t\t\t\"cd llama.cpp\",\n\t\t\t\t\"LLAMA_CURL=1 make llama-cli\",\n\t\t\t].join(\"\\n\"),\n\t\t\tcontent: command(\"./llama-cli\"),\n\t\t},\n\t];\n};\n\nconst snippetLocalAI = (model: ModelData, filepath?: string): LocalAppSnippet[] => {\n\tconst command = (binary: string) =>\n\t\t[\"# Load and run the model:\", `${binary} huggingface://${model.id}/${filepath ?? \"{{GGUF_FILE}}\"}`].join(\"\\n\");\n\treturn [\n\t\t{\n\t\t\ttitle: \"Install from binary\",\n\t\t\tsetup: \"curl https://localai.io/install.sh | sh\",\n\t\t\tcontent: command(\"local-ai run\"),\n\t\t},\n\t\t{\n\t\t\ttitle: \"Use Docker images\",\n\t\t\tsetup: [\n\t\t\t\t// prettier-ignore\n\t\t\t\t\"# Pull the image:\",\n\t\t\t\t\"docker pull localai/localai:latest-cpu\",\n\t\t\t].join(\"\\n\"),\n\t\t\tcontent: command(\n\t\t\t\t\"docker run -p 8080:8080 --name localai -v $PWD/models:/build/models localai/localai:latest-cpu\"\n\t\t\t),\n\t\t},\n\t];\n};\n\nconst snippetVllm = (model: ModelData): LocalAppSnippet[] => {\n\tconst runCommand = [\n\t\t\"\",\n\t\t\"# Call the server using curl:\",\n\t\t`curl -X POST \"http://localhost:8000/v1/chat/completions\" \\\\ `,\n\t\t`\t-H \"Content-Type: application/json\" \\\\ `,\n\t\t`\t--data '{`,\n\t\t`\t\t\"model\": \"${model.id}\"`,\n\t\t`\t\t\"messages\": [`,\n\t\t`\t\t\t{\"role\": \"user\", \"content\": \"Hello!\"}`,\n\t\t`\t\t]`,\n\t\t`\t}'`,\n\t];\n\treturn [\n\t\t{\n\t\t\ttitle: \"Install from pip\",\n\t\t\tsetup: [\"# Install vLLM from pip:\", \"pip install vllm\"].join(\"\\n\"),\n\t\t\tcontent: [\"# Load and run the model:\", `vllm serve \"${model.id}\"`, ...runCommand].join(\"\\n\"),\n\t\t},\n\t\t{\n\t\t\ttitle: \"Use Docker images\",\n\t\t\tsetup: [\n\t\t\t\t\"# Deploy with docker on Linux:\",\n\t\t\t\t`docker run --runtime nvidia --gpus all \\\\`,\n\t\t\t\t`\t--name my_vllm_container \\\\`,\n\t\t\t\t`\t-v ~/.cache/huggingface:/root/.cache/huggingface \\\\`,\n\t\t\t\t` \t--env \"HUGGING_FACE_HUB_TOKEN=<secret>\" \\\\`,\n\t\t\t\t`\t-p 8000:8000 \\\\`,\n\t\t\t\t`\t--ipc=host \\\\`,\n\t\t\t\t`\tvllm/vllm-openai:latest \\\\`,\n\t\t\t\t`\t--model ${model.id}`,\n\t\t\t].join(\"\\n\"),\n\t\t\tcontent: [\n\t\t\t\t\"# Load and run the model:\",\n\t\t\t\t`docker exec -it my_vllm_container bash -c \"vllm serve ${model.id}\"`,\n\t\t\t\t...runCommand,\n\t\t\t].join(\"\\n\"),\n\t\t},\n\t];\n};\n\n/**\n * Add your new local app here.\n *\n * This is open to new suggestions and awesome upcoming apps.\n *\n * /!\\ IMPORTANT\n *\n * If possible, you need to support deeplinks and be as cross-platform as possible.\n *\n * Ping the HF team if we can help with anything!\n */\nexport const LOCAL_APPS = {\n\t\"llama.cpp\": {\n\t\tprettyLabel: \"llama.cpp\",\n\t\tdocsUrl: \"https://github.com/ggerganov/llama.cpp\",\n\t\tmainTask: \"text-generation\",\n\t\tdisplayOnModelPage: isLlamaCppGgufModel,\n\t\tsnippet: snippetLlamacpp,\n\t},\n\tvllm: {\n\t\tprettyLabel: \"vLLM\",\n\t\tdocsUrl: \"https://docs.vllm.ai\",\n\t\tmainTask: \"text-generation\",\n\t\tdisplayOnModelPage: (model: ModelData) =>\n\t\t\tisAwqModel(model) ||\n\t\t\tisGptqModel(model) ||\n\t\t\tisAqlmModel(model) ||\n\t\t\tisMarlinModel(model) ||\n\t\t\tisGgufModel(model) ||\n\t\t\tisTransformersModel(model),\n\t\tsnippet: snippetVllm,\n\t},\n\tlmstudio: {\n\t\tprettyLabel: \"LM Studio\",\n\t\tdocsUrl: \"https://lmstudio.ai\",\n\t\tmainTask: \"text-generation\",\n\t\tdisplayOnModelPage: isLlamaCppGgufModel,\n\t\tdeeplink: (model, filepath) =>\n\t\t\tnew URL(`lmstudio://open_from_hf?model=${model.id}${filepath ? `&file=${filepath}` : \"\"}`),\n\t},\n\tlocalai: {\n\t\tprettyLabel: \"LocalAI\",\n\t\tdocsUrl: \"https://github.com/mudler/LocalAI\",\n\t\tmainTask: \"text-generation\",\n\t\tdisplayOnModelPage: isLlamaCppGgufModel,\n\t\tsnippet: snippetLocalAI,\n\t},\n\tjan: {\n\t\tprettyLabel: \"Jan\",\n\t\tdocsUrl: \"https://jan.ai\",\n\t\tmainTask: \"text-generation\",\n\t\tdisplayOnModelPage: isLlamaCppGgufModel,\n\t\tdeeplink: (model) => new URL(`jan://models/huggingface/${model.id}`),\n\t},\n\tbackyard: {\n\t\tprettyLabel: \"Backyard AI\",\n\t\tdocsUrl: \"https://backyard.ai\",\n\t\tmainTask: \"text-generation\",\n\t\tdisplayOnModelPage: isLlamaCppGgufModel,\n\t\tdeeplink: (model) => new URL(`https://backyard.ai/hf/model/${model.id}`),\n\t},\n\tsanctum: {\n\t\tprettyLabel: \"Sanctum\",\n\t\tdocsUrl: \"https://sanctum.ai\",\n\t\tmainTask: \"text-generation\",\n\t\tdisplayOnModelPage: isLlamaCppGgufModel,\n\t\tdeeplink: (model) => new URL(`sanctum://open_from_hf?model=${model.id}`),\n\t},\n\tjellybox: {\n\t\tprettyLabel: \"Jellybox\",\n\t\tdocsUrl: \"https://jellybox.com\",\n\t\tmainTask: \"text-generation\",\n\t\tdisplayOnModelPage: (model) =>\n\t\t\tisLlamaCppGgufModel(model) ||\n\t\t\t(model.library_name === \"diffusers\" &&\n\t\t\t\tmodel.tags.includes(\"safetensors\") &&\n\t\t\t\t(model.pipeline_tag === \"text-to-image\" || model.tags.includes(\"lora\"))),\n\t\tdeeplink: (model) => {\n\t\t\tif (isLlamaCppGgufModel(model)) {\n\t\t\t\treturn new URL(`jellybox://llm/models/huggingface/LLM/${model.id}`);\n\t\t\t} else if (model.tags.includes(\"lora\")) {\n\t\t\t\treturn new URL(`jellybox://image/models/huggingface/ImageLora/${model.id}`);\n\t\t\t} else {\n\t\t\t\treturn new URL(`jellybox://image/models/huggingface/Image/${model.id}`);\n\t\t\t}\n\t\t},\n\t},\n\tmsty: {\n\t\tprettyLabel: \"Msty\",\n\t\tdocsUrl: \"https://msty.app\",\n\t\tmainTask: \"text-generation\",\n\t\tdisplayOnModelPage: isLlamaCppGgufModel,\n\t\tdeeplink: (model) => new URL(`msty://models/search/hf/${model.id}`),\n\t},\n\trecursechat: {\n\t\tprettyLabel: \"RecurseChat\",\n\t\tdocsUrl: \"https://recurse.chat\",\n\t\tmainTask: \"text-generation\",\n\t\tmacOSOnly: true,\n\t\tdisplayOnModelPage: isLlamaCppGgufModel,\n\t\tdeeplink: (model) => new URL(`recursechat://new-hf-gguf-model?hf-model-id=${model.id}`),\n\t},\n\tdrawthings: {\n\t\tprettyLabel: \"Draw Things\",\n\t\tdocsUrl: \"https://drawthings.ai\",\n\t\tmainTask: \"text-to-image\",\n\t\tmacOSOnly: true,\n\t\tdisplayOnModelPage: (model) =>\n\t\t\tmodel.library_name === \"diffusers\" && (model.pipeline_tag === \"text-to-image\" || model.tags.includes(\"lora\")),\n\t\tdeeplink: (model) => {\n\t\t\tif (model.tags.includes(\"lora\")) {\n\t\t\t\treturn new URL(`https://drawthings.ai/import/diffusers/pipeline.load_lora_weights?repo_id=${model.id}`);\n\t\t\t} else {\n\t\t\t\treturn new URL(`https://drawthings.ai/import/diffusers/pipeline.from_pretrained?repo_id=${model.id}`);\n\t\t\t}\n\t\t},\n\t},\n\tdiffusionbee: {\n\t\tprettyLabel: \"DiffusionBee\",\n\t\tdocsUrl: \"https://diffusionbee.com\",\n\t\tmainTask: \"text-to-image\",\n\t\tmacOSOnly: true,\n\t\tdisplayOnModelPage: (model) => model.library_name === \"diffusers\" && model.pipeline_tag === \"text-to-image\",\n\t\tdeeplink: (model) => new URL(`https://diffusionbee.com/huggingface_import?model_id=${model.id}`),\n\t},\n\tjoyfusion: {\n\t\tprettyLabel: \"JoyFusion\",\n\t\tdocsUrl: \"https://joyfusion.app\",\n\t\tmainTask: \"text-to-image\",\n\t\tmacOSOnly: true,\n\t\tdisplayOnModelPage: (model) =>\n\t\t\tmodel.tags.includes(\"coreml\") && model.tags.includes(\"joyfusion\") && model.pipeline_tag === \"text-to-image\",\n\t\tdeeplink: (model) => new URL(`https://joyfusion.app/import_from_hf?repo_id=${model.id}`),\n\t},\n\tinvoke: {\n\t\tprettyLabel: \"Invoke\",\n\t\tdocsUrl: \"https://github.com/invoke-ai/InvokeAI\",\n\t\tmainTask: \"text-to-image\",\n\t\tdisplayOnModelPage: (model) => model.library_name === \"diffusers\" && model.pipeline_tag === \"text-to-image\",\n\t\tdeeplink: (model) => new URL(`https://models.invoke.ai/huggingface/${model.id}`),\n\t},\n} satisfies Record<string, LocalApp>;\n\nexport type LocalAppKey = keyof typeof LOCAL_APPS;\n", "packages\\tasks\\src\\snippets\\index.ts": "import * as inputs from \"./inputs\";\nimport * as curl from \"./curl\";\nimport * as python from \"./python\";\nimport * as js from \"./js\";\n\nexport { inputs, curl, python, js };\n", "packages\\tasks\\src\\tasks\\index.ts": "import type { PipelineType } from \"../pipelines\";\nimport { PIPELINE_DATA } from \"../pipelines\";\n\nimport audioClassification from \"./audio-classification/data\";\nimport audioToAudio from \"./audio-to-audio/data\";\nimport automaticSpeechRecognition from \"./automatic-speech-recognition/data\";\nimport documentQuestionAnswering from \"./document-question-answering/data\";\nimport featureExtraction from \"./feature-extraction/data\";\nimport fillMask from \"./fill-mask/data\";\nimport imageClassification from \"./image-classification/data\";\nimport imageFeatureExtraction from \"./image-feature-extraction/data\";\nimport imageToImage from \"./image-to-image/data\";\nimport imageToText from \"./image-to-text/data\";\nimport imageTextToText from \"./image-text-to-text/data\";\nimport imageSegmentation from \"./image-segmentation/data\";\nimport maskGeneration from \"./mask-generation/data\";\nimport objectDetection from \"./object-detection/data\";\nimport depthEstimation from \"./depth-estimation/data\";\nimport placeholder from \"./placeholder/data\";\nimport reinforcementLearning from \"./reinforcement-learning/data\";\nimport questionAnswering from \"./question-answering/data\";\nimport sentenceSimilarity from \"./sentence-similarity/data\";\nimport summarization from \"./summarization/data\";\nimport tableQuestionAnswering from \"./table-question-answering/data\";\nimport tabularClassification from \"./tabular-classification/data\";\nimport tabularRegression from \"./tabular-regression/data\";\nimport textToImage from \"./text-to-image/data\";\nimport textToSpeech from \"./text-to-speech/data\";\nimport tokenClassification from \"./token-classification/data\";\nimport translation from \"./translation/data\";\nimport textClassification from \"./text-classification/data\";\nimport textGeneration from \"./text-generation/data\";\nimport textToVideo from \"./text-to-video/data\";\nimport unconditionalImageGeneration from \"./unconditional-image-generation/data\";\nimport videoClassification from \"./video-classification/data\";\nimport visualQuestionAnswering from \"./visual-question-answering/data\";\nimport zeroShotClassification from \"./zero-shot-classification/data\";\nimport zeroShotImageClassification from \"./zero-shot-image-classification/data\";\nimport zeroShotObjectDetection from \"./zero-shot-object-detection/data\";\nimport imageTo3D from \"./image-to-3d/data\";\nimport textTo3D from \"./text-to-3d/data\";\nimport keypointDetection from \"./keypoint-detection/data\";\n\nexport type * from \"./audio-classification/inference\";\nexport type * from \"./automatic-speech-recognition/inference\";\nexport type {\n\tChatCompletionInput,\n\tChatCompletionInputMessage,\n\tChatCompletionOutput,\n\tChatCompletionOutputComplete,\n\tChatCompletionOutputMessage,\n\tChatCompletionStreamOutput,\n\tChatCompletionStreamOutputChoice,\n\tChatCompletionStreamOutputDelta,\n} from \"./chat-completion/inference\";\nexport type * from \"./document-question-answering/inference\";\nexport type * from \"./feature-extraction/inference\";\nexport type * from \"./fill-mask/inference\";\nexport type {\n\tImageClassificationInput,\n\tImageClassificationOutput,\n\tImageClassificationOutputElement,\n\tImageClassificationParameters,\n} from \"./image-classification/inference\";\nexport type * from \"./image-to-image/inference\";\nexport type { ImageToTextInput, ImageToTextOutput, ImageToTextParameters } from \"./image-to-text/inference\";\nexport type * from \"./image-segmentation/inference\";\nexport type * from \"./object-detection/inference\";\nexport type * from \"./depth-estimation/inference\";\nexport type * from \"./question-answering/inference\";\nexport type * from \"./sentence-similarity/inference\";\nexport type * from \"./summarization/inference\";\nexport type * from \"./table-question-answering/inference\";\nexport type { TextToImageInput, TextToImageOutput, TextToImageParameters } from \"./text-to-image/inference\";\nexport type { TextToSpeechParameters, TextToSpeechInput, TextToSpeechOutput } from \"./text-to-speech/inference\";\nexport type * from \"./token-classification/inference\";\nexport type { TranslationInput, TranslationOutput } from \"./translation/inference\";\nexport type {\n\tClassificationOutputTransform,\n\tTextClassificationInput,\n\tTextClassificationOutput,\n\tTextClassificationOutputElement,\n\tTextClassificationParameters,\n} from \"./text-classification/inference\";\nexport type {\n\tTextGenerationOutputFinishReason,\n\tTextGenerationOutputPrefillToken,\n\tTextGenerationInput,\n\tTextGenerationOutput,\n\tTextGenerationOutputDetails,\n\tTextGenerationInputGenerateParameters,\n\tTextGenerationOutputBestOfSequence,\n\tTextGenerationOutputToken,\n\tTextGenerationStreamOutputStreamDetails,\n\tTextGenerationStreamOutput,\n} from \"./text-generation/inference\";\nexport type * from \"./video-classification/inference\";\nexport type * from \"./visual-question-answering/inference\";\nexport type * from \"./zero-shot-classification/inference\";\nexport type * from \"./zero-shot-image-classification/inference\";\nexport type {\n\tBoundingBox,\n\tZeroShotObjectDetectionInput,\n\tZeroShotObjectDetectionInputData,\n\tZeroShotObjectDetectionOutput,\n\tZeroShotObjectDetectionOutputElement,\n} from \"./zero-shot-object-detection/inference\";\n\nimport type { ModelLibraryKey } from \"../model-libraries\";\n\n/**\n * Model libraries compatible with each ML task\n */\nexport const TASKS_MODEL_LIBRARIES: Record<PipelineType, ModelLibraryKey[]> = {\n\t\"audio-classification\": [\"speechbrain\", \"transformers\", \"transformers.js\"],\n\t\"audio-to-audio\": [\"asteroid\", \"fairseq\", \"speechbrain\"],\n\t\"automatic-speech-recognition\": [\"espnet\", \"nemo\", \"speechbrain\", \"transformers\", \"transformers.js\"],\n\t\"depth-estimation\": [\"transformers\", \"transformers.js\"],\n\t\"document-question-answering\": [\"transformers\", \"transformers.js\"],\n\t\"feature-extraction\": [\"sentence-transformers\", \"transformers\", \"transformers.js\"],\n\t\"fill-mask\": [\"transformers\", \"transformers.js\"],\n\t\"graph-ml\": [\"transformers\"],\n\t\"image-classification\": [\"keras\", \"timm\", \"transformers\", \"transformers.js\"],\n\t\"image-feature-extraction\": [\"timm\", \"transformers\"],\n\t\"image-segmentation\": [\"transformers\", \"transformers.js\"],\n\t\"image-text-to-text\": [\"transformers\"],\n\t\"image-to-image\": [\"diffusers\", \"transformers\", \"transformers.js\"],\n\t\"image-to-text\": [\"transformers\", \"transformers.js\"],\n\t\"image-to-video\": [\"diffusers\"],\n\t\"keypoint-detection\": [\"transformers\"],\n\t\"video-classification\": [\"transformers\"],\n\t\"mask-generation\": [\"transformers\"],\n\t\"multiple-choice\": [\"transformers\"],\n\t\"object-detection\": [\"transformers\", \"transformers.js\"],\n\tother: [],\n\t\"question-answering\": [\"adapter-transformers\", \"allennlp\", \"transformers\", \"transformers.js\"],\n\trobotics: [],\n\t\"reinforcement-learning\": [\"transformers\", \"stable-baselines3\", \"ml-agents\", \"sample-factory\"],\n\t\"sentence-similarity\": [\"sentence-transformers\", \"spacy\", \"transformers.js\"],\n\tsummarization: [\"transformers\", \"transformers.js\"],\n\t\"table-question-answering\": [\"transformers\"],\n\t\"table-to-text\": [\"transformers\"],\n\t\"tabular-classification\": [\"sklearn\"],\n\t\"tabular-regression\": [\"sklearn\"],\n\t\"tabular-to-text\": [\"transformers\"],\n\t\"text-classification\": [\"adapter-transformers\", \"setfit\", \"spacy\", \"transformers\", \"transformers.js\"],\n\t\"text-generation\": [\"transformers\", \"transformers.js\"],\n\t\"text-retrieval\": [],\n\t\"text-to-image\": [\"diffusers\"],\n\t\"text-to-speech\": [\"espnet\", \"tensorflowtts\", \"transformers\", \"transformers.js\"],\n\t\"text-to-audio\": [\"transformers\", \"transformers.js\"],\n\t\"text-to-video\": [\"diffusers\"],\n\t\"text2text-generation\": [\"transformers\", \"transformers.js\"],\n\t\"time-series-forecasting\": [],\n\t\"token-classification\": [\n\t\t\"adapter-transformers\",\n\t\t\"flair\",\n\t\t\"spacy\",\n\t\t\"span-marker\",\n\t\t\"stanza\",\n\t\t\"transformers\",\n\t\t\"transformers.js\",\n\t],\n\ttranslation: [\"transformers\", \"transformers.js\"],\n\t\"unconditional-image-generation\": [\"diffusers\"],\n\t\"video-text-to-text\": [\"transformers\"],\n\t\"visual-question-answering\": [\"transformers\", \"transformers.js\"],\n\t\"voice-activity-detection\": [],\n\t\"zero-shot-classification\": [\"transformers\", \"transformers.js\"],\n\t\"zero-shot-image-classification\": [\"transformers\", \"transformers.js\"],\n\t\"zero-shot-object-detection\": [\"transformers\", \"transformers.js\"],\n\t\"text-to-3d\": [\"diffusers\"],\n\t\"image-to-3d\": [\"diffusers\"],\n\t\"any-to-any\": [\"transformers\"],\n};\n\n/**\n * Return the whole TaskData object for a certain task.\n * If the partialTaskData argument is left undefined,\n * the default placholder data will be used.\n */\nfunction getData(type: PipelineType, partialTaskData: TaskDataCustom = placeholder): TaskData {\n\treturn {\n\t\t...partialTaskData,\n\t\tid: type,\n\t\tlabel: PIPELINE_DATA[type].name,\n\t\tlibraries: TASKS_MODEL_LIBRARIES[type],\n\t};\n}\n\n// To make comparisons easier, task order is the same as in const.ts\n// Tasks set to undefined won't have an associated task page.\n// Tasks that call getData() without the second argument will\n// have a \"placeholder\" page.\nexport const TASKS_DATA: Record<PipelineType, TaskData | undefined> = {\n\t\"any-to-any\": getData(\"any-to-any\", placeholder),\n\t\"audio-classification\": getData(\"audio-classification\", audioClassification),\n\t\"audio-to-audio\": getData(\"audio-to-audio\", audioToAudio),\n\t\"automatic-speech-recognition\": getData(\"automatic-speech-recognition\", automaticSpeechRecognition),\n\t\"depth-estimation\": getData(\"depth-estimation\", depthEstimation),\n\t\"document-question-answering\": getData(\"document-question-answering\", documentQuestionAnswering),\n\t\"feature-extraction\": getData(\"feature-extraction\", featureExtraction),\n\t\"fill-mask\": getData(\"fill-mask\", fillMask),\n\t\"graph-ml\": undefined,\n\t\"image-classification\": getData(\"image-classification\", imageClassification),\n\t\"image-feature-extraction\": getData(\"image-feature-extraction\", imageFeatureExtraction),\n\t\"image-segmentation\": getData(\"image-segmentation\", imageSegmentation),\n\t\"image-to-image\": getData(\"image-to-image\", imageToImage),\n\t\"image-text-to-text\": getData(\"image-text-to-text\", imageTextToText),\n\t\"image-to-text\": getData(\"image-to-text\", imageToText),\n\t\"image-to-video\": undefined,\n\t\"keypoint-detection\": getData(\"keypoint-detection\", keypointDetection),\n\t\"mask-generation\": getData(\"mask-generation\", maskGeneration),\n\t\"multiple-choice\": undefined,\n\t\"object-detection\": getData(\"object-detection\", objectDetection),\n\t\"video-classification\": getData(\"video-classification\", videoClassification),\n\tother: undefined,\n\t\"question-answering\": getData(\"question-answering\", questionAnswering),\n\t\"reinforcement-learning\": getData(\"reinforcement-learning\", reinforcementLearning),\n\trobotics: undefined,\n\t\"sentence-similarity\": getData(\"sentence-similarity\", sentenceSimilarity),\n\tsummarization: getData(\"summarization\", summarization),\n\t\"table-question-answering\": getData(\"table-question-answering\", tableQuestionAnswering),\n\t\"table-to-text\": undefined,\n\t\"tabular-classification\": getData(\"tabular-classification\", tabularClassification),\n\t\"tabular-regression\": getData(\"tabular-regression\", tabularRegression),\n\t\"tabular-to-text\": undefined,\n\t\"text-classification\": getData(\"text-classification\", textClassification),\n\t\"text-generation\": getData(\"text-generation\", textGeneration),\n\t\"text-retrieval\": undefined,\n\t\"text-to-image\": getData(\"text-to-image\", textToImage),\n\t\"text-to-speech\": getData(\"text-to-speech\", textToSpeech),\n\t\"text-to-audio\": undefined,\n\t\"text-to-video\": getData(\"text-to-video\", textToVideo),\n\t\"text2text-generation\": undefined,\n\t\"time-series-forecasting\": undefined,\n\t\"token-classification\": getData(\"token-classification\", tokenClassification),\n\ttranslation: getData(\"translation\", translation),\n\t\"unconditional-image-generation\": getData(\"unconditional-image-generation\", unconditionalImageGeneration),\n\t\"video-text-to-text\": getData(\"video-text-to-text\", placeholder),\n\t\"visual-question-answering\": getData(\"visual-question-answering\", visualQuestionAnswering),\n\t\"voice-activity-detection\": undefined,\n\t\"zero-shot-classification\": getData(\"zero-shot-classification\", zeroShotClassification),\n\t\"zero-shot-image-classification\": getData(\"zero-shot-image-classification\", zeroShotImageClassification),\n\t\"zero-shot-object-detection\": getData(\"zero-shot-object-detection\", zeroShotObjectDetection),\n\t\"text-to-3d\": getData(\"text-to-3d\", textTo3D),\n\t\"image-to-3d\": getData(\"image-to-3d\", imageTo3D),\n} as const;\n\nexport interface ExampleRepo {\n\tdescription: string;\n\tid: string;\n}\n\nexport type TaskDemoEntry =\n\t| {\n\t\t\tfilename: string;\n\t\t\ttype: \"audio\";\n\t }\n\t| {\n\t\t\tdata: Array<{\n\t\t\t\tlabel: string;\n\t\t\t\tscore: number;\n\t\t\t}>;\n\t\t\ttype: \"chart\";\n\t }\n\t| {\n\t\t\tfilename: string;\n\t\t\ttype: \"img\";\n\t }\n\t| {\n\t\t\ttable: string[][];\n\t\t\ttype: \"tabular\";\n\t }\n\t| {\n\t\t\tcontent: string;\n\t\t\tlabel: string;\n\t\t\ttype: \"text\";\n\t }\n\t| {\n\t\t\ttext: string;\n\t\t\ttokens: Array<{\n\t\t\t\tend: number;\n\t\t\t\tstart: number;\n\t\t\t\ttype: string;\n\t\t\t}>;\n\t\t\ttype: \"text-with-tokens\";\n\t };\n\nexport interface TaskDemo {\n\tinputs: TaskDemoEntry[];\n\toutputs: TaskDemoEntry[];\n}\n\nexport interface TaskData {\n\tdatasets: ExampleRepo[];\n\tdemo: TaskDemo;\n\tid: PipelineType;\n\tcanonicalId?: PipelineType;\n\tisPlaceholder?: boolean;\n\tlabel: string;\n\tlibraries: ModelLibraryKey[];\n\tmetrics: ExampleRepo[];\n\tmodels: ExampleRepo[];\n\tspaces: ExampleRepo[];\n\tsummary: string;\n\twidgetModels: string[];\n\tyoutubeId?: string;\n}\n\nexport type TaskDataCustom = Omit<TaskData, \"id\" | \"label\" | \"libraries\">;\n", "packages\\widgets\\package.json": "{\n\t\"name\": \"@huggingface/widgets\",\n\t\"packageManager\": \"[email protected]\",\n\t\"version\": \"0.2.12\",\n\t\"publishConfig\": {\n\t\t\"access\": \"public\"\n\t},\n\t\"scripts\": {\n\t\t\"dev\": \"vite dev --mode app\",\n\t\t\"build\": \"vite build --mode app && vite build --mode lib && vite build --mode lib --ssr && npm run package\",\n\t\t\"preview\": \"vite preview --mode app\",\n\t\t\"package\": \"publint\",\n\t\t\"prepublishOnly\": \"npm run build\",\n\t\t\"check\": \"svelte-check --tsconfig ./tsconfig.json src,static\",\n\t\t\"check:watch\": \"svelte-check --tsconfig ./tsconfig.json --watch src,static\",\n\t\t\"lint\": \"eslint --quiet --fix --ext .cjs,.ts .\",\n\t\t\"lint:check\": \"eslint --ext .cjs,.ts .\",\n\t\t\"format\": \"prettier --write .\",\n\t\t\"format:check\": \"prettier --check .\"\n\t},\n\t\"type\": \"module\",\n\t\"module\": \"./dist/server/index.js\",\n\t\"main\": \"./dist/server/index.cjs\",\n\t\"types\": \"./dist/client/index.d.ts\",\n\t\"source\": \"src/lib/index.ts\",\n\t\"exports\": {\n\t\t\".\": {\n\t\t\t\"types\": \"./dist/client/index.d.ts\",\n\t\t\t\"node\": {\n\t\t\t\t\"require\": \"./dist/server/index.cjs\",\n\t\t\t\t\"import\": \"./dist/server/index.js\"\n\t\t\t},\n\t\t\t\"browser\": {\n\t\t\t\t\"import\": \"./dist/client/index.js\",\n\t\t\t\t\"require\": \"./dist/client/index.cjs\"\n\t\t\t},\n\t\t\t\"svelte\": \"./src/lib/index.ts\"\n\t\t}\n\t},\n\t\"files\": [\n\t\t\"dist\",\n\t\t\"src\",\n\t\t\"!dist/**/*.test.*\",\n\t\t\"!dist/**/*.spec.*\",\n\t\t\"static/audioProcessor.js\"\n\t],\n\t\"dependencies\": {\n\t\t\"@huggingface/inference\": \"workspace:^\",\n\t\t\"@huggingface/tasks\": \"workspace:^\",\n\t\t\"marked\": \"^12.0.2\"\n\t},\n\t\"peerDependencies\": {\n\t\t\"svelte\": \"^3.59.2\"\n\t},\n\t\"devDependencies\": {\n\t\t\"@auth/core\": \"^0.18.3\",\n\t\t\"@auth/sveltekit\": \"^0.3.14\",\n\t\t\"@fontsource/ibm-plex-mono\": \"^5.0.8\",\n\t\t\"@fontsource/source-sans-pro\": \"^5.0.8\",\n\t\t\"@sveltejs/adapter-node\": \"^1.3.1\",\n\t\t\"@sveltejs/kit\": \"^1.27.4\",\n\t\t\"@sveltejs/package\": \"^2.0.0\",\n\t\t\"@sveltejs/vite-plugin-svelte\": \"2.5.3\",\n\t\t\"@tailwindcss/forms\": \"^0.5.7\",\n\t\t\"@types/node\": \"20\",\n\t\t\"autoprefixer\": \"^10.4.16\",\n\t\t\"postcss\": \"^8.4.31\",\n\t\t\"publint\": \"^0.1.9\",\n\t\t\"svelte\": \"^3.59.2\",\n\t\t\"svelte-check\": \"^3.6.0\",\n\t\t\"svelte-preprocess\": \"^5.1.1\",\n\t\t\"tailwindcss\": \"^3.4.1\",\n\t\t\"tslib\": \"^2.4.1\",\n\t\t\"vite\": \"^4.5.0\",\n\t\t\"vite-plugin-dts\": \"^3.6.4\"\n\t}\n}\n", "packages\\widgets\\src\\app.d.ts": "// See https://kit.svelte.dev/docs/types#app\n// for information about these interfaces\ndeclare global {\n\tnamespace App {\n\t\t// interface Error {}\n\t\t// interface Locals {}\n\t\t// interface PageData {}\n\t\t// interface Platform {}\n\t}\n\n\texport interface Session {\n\t\taccess_token?: string;\n\t}\n}\n\ndeclare module \"@auth/core/types\" {\n\texport interface Session {\n\t\taccess_token?: string;\n\t}\n\n\texport interface User {\n\t\tusername: string;\n\t}\n}\n\nexport {};\n", "packages\\widgets\\src\\app.html": "<!doctype html>\n<html lang=\"en\">\n\t<head>\n\t\t<meta charset=\"utf-8\" />\n\t\t<link rel=\"icon\" href=\"%sveltekit.assets%/favicon.png\" />\n\t\t<meta name=\"viewport\" content=\"width=device-width, initial-scale=1\" />\n\t\t%sveltekit.head%\n\t</head>\n\t<body data-sveltekit-preload-data=\"hover\">\n\t\t<div>%sveltekit.body%</div>\n\t</body>\n</html>\n", "packages\\widgets\\src\\lib\\index.ts": "import InferenceWidget from \"./components/InferenceWidget/InferenceWidget.svelte\";\nimport WidgetOutputChart from \"./components/InferenceWidget/shared/WidgetOutputChart/WidgetOutputChart.svelte\";\nimport WidgetOutputTokens from \"./components/InferenceWidget/shared/WidgetOutputTokens/WidgetOutputTokens.svelte\";\nimport PipelineIcon from \"./components/PipelineIcon/PipelineIcon.svelte\";\nimport { modelLoadStates } from \"./components/InferenceWidget/stores.js\";\n\nexport { InferenceWidget, WidgetOutputChart, WidgetOutputTokens, modelLoadStates, PipelineIcon };\n", "packages\\widgets\\src\\lib\\components\\InferenceWidget\\shared\\WidgetWrapper\\WidgetWrapper.svelte": "<script lang=\"ts\" generics=\"TWidgetExample extends WidgetExample\">\n\timport { InferenceDisplayability } from \"@huggingface/tasks\";\n\timport type { WidgetExample } from \"@huggingface/tasks\";\n\timport type { WidgetProps } from \"../types.js\";\n\n\timport { onMount } from \"svelte\";\n\n\timport WidgetFooter from \"../WidgetFooter/WidgetFooter.svelte\";\n\timport WidgetHeader from \"../WidgetHeader/WidgetHeader.svelte\";\n\timport WidgetInfo from \"../WidgetInfo/WidgetInfo.svelte\";\n\timport IconCross from \"../../..//Icons/IconCross.svelte\";\n\timport { getModelLoadInfo } from \"../../..//InferenceWidget/shared/helpers.js\";\n\timport { modelLoadStates, widgetStates, updateWidgetState } from \"../../stores.js\";\n\n\texport let apiUrl: string;\n\texport let model: WidgetProps[\"model\"];\n\texport let includeCredentials: WidgetProps[\"includeCredentials\"];\n\n\t$: isMaximized = $widgetStates?.[model.id]?.isMaximized;\n\n\tconst isDisabled = model.inference !== InferenceDisplayability.Yes && model.pipeline_tag !== \"reinforcement-learning\";\n\tupdateWidgetState(model.id, \"isDisabled\", isDisabled);\n\n\tonMount(() => {\n\t\t(async () => {\n\t\t\tif (model.inference !== InferenceDisplayability.Yes) {\n\t\t\t\treturn;\n\t\t\t}\n\n\t\t\tconst modelLoadInfo = await getModelLoadInfo(apiUrl, model.id, includeCredentials);\n\t\t\t$modelLoadStates[model.id] = modelLoadInfo;\n\n\t\t\tif (modelLoadInfo?.state === \"TooBig\") {\n\t\t\t\tupdateWidgetState(model.id, \"isDisabled\", true);\n\t\t\t}\n\t\t})();\n\t});\n</script>\n\n{#if $widgetStates?.[model.id]?.noInference}\n\t<WidgetHeader {model} noTitle={true} />\n\t<WidgetInfo {model} />\n{:else if $modelLoadStates[model.id] || model.inference !== InferenceDisplayability.Yes}\n\t<form\n\t\tclass=\"flex w-full max-w-full flex-col\n\t{isMaximized ? 'fixed inset-0 z-20 bg-white p-12' : ''}\"\n\t>\n\t\t{#if isMaximized}\n\t\t\t<button class=\"absolute right-12 top-6\" on:click={() => updateWidgetState(model.id, \"isMaximized\", false)}>\n\t\t\t\t<IconCross classNames=\"text-xl text-gray-500 hover:text-black\" />\n\t\t\t</button>\n\t\t{/if}\n\t\t<slot {WidgetInfo} {WidgetHeader} {WidgetFooter} />\n\t</form>\n{/if}\n"} | null |
huggingface_sb3 | {"type": "directory", "name": "huggingface_sb3", "children": [{"type": "directory", "name": "huggingface_sb3", "children": [{"type": "file", "name": "load_from_hub.py"}, {"type": "file", "name": "naming_schemes.py"}, {"type": "file", "name": "push_to_hub.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "Makefile"}, {"type": "directory", "name": "notebooks", "children": [{"type": "file", "name": "sb3_huggingface.ipynb"}, {"type": "file", "name": "Stable_Baselines_3_x_Hugging_Face_\ud83e\udd17_tutorial.ipynb"}]}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "setup.cfg"}, {"type": "file", "name": "setup.py"}, {"type": "directory", "name": "tests", "children": [{"type": "file", "name": "test_load_from_hub.py"}, {"type": "file", "name": "test_naming_scheme.py"}, {"type": "file", "name": "test_push_to_hub.py"}, {"type": "file", "name": "__init__.py"}]}]} | # Hugging Face 🤗 x Stable-baselines3 v3.0
A library to load and upload Stable-baselines3 models from the Hub with Gymnasium and Gymnasium compatible environments.
⚠️ If you use Gym, you need to install `huggingface_sb3==2.3.1`
## Installation
### With pip
```
pip install huggingface-sb3
```
## Examples
We wrote a tutorial on how to use 🤗 Hub and Stable-Baselines3 [here](https://colab.research.google.com/github/huggingface/deep-rl-class/blob/master/notebooks/unit1/unit1.ipynb)
If you use **Colab or a Virtual/Screenless Machine**, you can check Case 3 and Case 4.
### Case 1: I want to download a model from the Hub
```python
import gymnasium as gym
from huggingface_sb3 import load_from_hub
from stable_baselines3 import PPO
from stable_baselines3.common.evaluation import evaluate_policy
# Retrieve the model from the hub
## repo_id = id of the model repository from the Hugging Face Hub (repo_id = {organization}/{repo_name})
## filename = name of the model zip file from the repository
checkpoint = load_from_hub(
repo_id="sb3/demo-hf-CartPole-v1",
filename="ppo-CartPole-v1.zip",
)
model = PPO.load(checkpoint)
# Evaluate the agent and watch it
eval_env = gym.make("CartPole-v1")
mean_reward, std_reward = evaluate_policy(
model, eval_env, render=False, n_eval_episodes=5, deterministic=True, warn=False
)
print(f"mean_reward={mean_reward:.2f} +/- {std_reward}")
```
### Case 2: I trained an agent and want to upload it to the Hub
With `package_to_hub()` **we'll save, evaluate, generate a model card and record a replay video of your agent before pushing the repo to the hub**.
It currently **works for Gym and Atari environments**. If you use another environment, you should use `push_to_hub()` instead.
First you need to be logged in to Hugging Face:
- If you're using Colab/Jupyter Notebooks:
```python
from huggingface_hub import login
login()
```
- Else:
```
huggingface-cli login
```
For more details about authentication, check out [this guide](https://huggingface.co/docs/huggingface_hub/quick-start#authentication).
Then
**With `package_to_hub()`**:
```python
import gymnasium as gym
from stable_baselines3 import PPO
from stable_baselines3.common.env_util import make_vec_env
from huggingface_sb3 import package_to_hub
# Create the environment
env_id = "LunarLander-v2"
env = make_vec_env(env_id, n_envs=1)
# Create the evaluation env
eval_env = make_vec_env(env_id, n_envs=1)
# Instantiate the agent
model = PPO("MlpPolicy", env, verbose=1)
# Train the agent
model.learn(total_timesteps=int(5000))
# This method save, evaluate, generate a model card and record a replay video of your agent before pushing the repo to the hub
package_to_hub(model=model,
model_name="ppo-LunarLander-v2",
model_architecture="PPO",
env_id=env_id,
eval_env=eval_env,
repo_id="ThomasSimonini/ppo-LunarLander-v2",
commit_message="Test commit")
```
**With `push_to_hub()`**:
Push to hub only **push a file to the Hub**, if you want to save, evaluate, generate a model card and record a replay video of your agent before pushing the repo to the hub, use `package_to_hub()`
```python
import gymnasium as gym
from stable_baselines3 import PPO
from stable_baselines3.common.env_util import make_vec_env
from huggingface_sb3 import push_to_hub
# Create the environment
env_id = "LunarLander-v2"
env = make_vec_env(env_id, n_envs=1)
# Instantiate the agent
model = PPO("MlpPolicy", env, verbose=1)
# Train it for 10000 timesteps
model.learn(total_timesteps=10_000)
# Save the model
model.save("ppo-LunarLander-v2")
# Push this saved model .zip file to the hf repo
# If this repo does not exists it will be created
## repo_id = id of the model repository from the Hugging Face Hub (repo_id = {organization}/{repo_name})
## filename: the name of the file == "name" inside model.save("ppo-LunarLander-v2")
push_to_hub(
repo_id="ThomasSimonini/ppo-LunarLander-v2",
filename="ppo-LunarLander-v2.zip",
commit_message="Added LunarLander-v2 model trained with PPO",
)
```
### Case 3: I use Google Colab with Classic Control/Box2D Gym Environments
- You can use xvbf (virtual screen)
```
!apt-get install -y xvfb python-opengl > /dev/null 2>&1
```
- Just put your code inside a python file and run
```
!xvfb-run -s "-screen 0 1400x900x24" <your_python_file>
```
### Case 4: I use a Virtual/Remote Machine
- You can use xvbf (virtual screen)
```
xvfb-run -s "-screen 0 1400x900x24" <your_python_file>
```
### Case 5: I want to automate upload/download from the Hub
If you want to upload or download models for many environments, you might want to
automate this process.
It makes sense to adhere to a fixed naming scheme for models and repositories.
You will run into trouble when your environment names contain slashes.
Therefore, we provide some helper classes:
```python
import gymnasium as gym
from huggingface_sb3.naming_schemes import EnvironmentName, ModelName, ModelRepoId
env_name = EnvironmentName("seals/Walker2d-v0")
model_name = ModelName("ppo", env_name)
repo_id = ModelRepoId("YourOrganization", model_name)
# prints 'seals-Walker2d-v0'. Notice how the slash is removed so you can use it to
# construct file paths if you like.
print(env_name)
# you can still access the original gym id if needed
env = gym.make(env_name.gym_id)
# prints `ppo-seals-Walker2d-v0`
print(model_name)
# prints: `ppo-seals-Walker2d-v0.zip`.
# This is where `model.save(model_name)` will place the model file
print(model_name.filename)
# prints: `YourOrganization/ppo-seals-Walker2d-v0`
print(repo_id)
```
| {"setup.py": "from setuptools import setup\n\ninstall_requires = [\n \"huggingface_hub>=0.21\",\n \"pyyaml~=6.0\",\n \"wasabi\",\n \"numpy<2.0\",\n \"cloudpickle>=1.6\",\n \"stable-baselines3\",\n \"moviepy\",\n]\n\nextras = {}\n\nextras[\"quality\"] = [\n \"black~=22.0\",\n \"isort>=5.5.4\",\n \"flake8>=3.8.3\",\n]\n\nextras[\"test\"] = [\"pytest\", \"gymnasium[classic-control]\"]\n\nextras[\"dev\"] = extras[\"quality\"] + extras[\"test\"]\n\nsetup(\n name=\"huggingface_sb3\",\n version=\"3.1\",\n packages=[\"huggingface_sb3\"],\n url=\"https://github.com/huggingface/huggingface_sb3\",\n license=\"Apache\",\n author=\"Thomas Simonini, Omar Sanseviero and Hugging Face Team\",\n author_email=\"[email protected]\",\n description=\"Additional code for Stable-baselines3 to load and upload models from the Hub.\",\n install_requires=install_requires,\n extras_require=extras,\n long_description=open(\"README.md\", \"r\", encoding=\"utf-8\").read(),\n long_description_content_type=\"text/markdown\",\n keywords=\"reinforcement learning deep reinforcement learning RL\",\n)\n", ".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 e54d3cf51f5d082bed01e385fc906455183ae88c Hamza Amin <[email protected]> 1727369320 +0500\tclone: from https://github.com/huggingface/huggingface_sb3.git\n", ".git\\refs\\heads\\main": "e54d3cf51f5d082bed01e385fc906455183ae88c\n"} | null |
huggingface_tianshou | {"type": "directory", "name": "huggingface_tianshou", "children": [{"type": "file", "name": "README.md"}]} | # huggingface_tianshou
Additional code for Tianshou to load and upload models from the Hub.
| {".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 fc2964223f28d5bc8ea3608e167fb9c84b6073db Hamza Amin <[email protected]> 1727369322 +0500\tclone: from https://github.com/huggingface/huggingface_tianshou.git\n", ".git\\refs\\heads\\main": "fc2964223f28d5bc8ea3608e167fb9c84b6073db\n"} | null |
Huggy | {"type": "directory", "name": "Huggy", "children": [{"type": "file", "name": "README.md"}]} | # Huggy 🐶
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/notebooks/unit-bonus1/huggy.jpg" alt="Huggy"/>
Huggy is a Unity ML-Agents environment showcasing a dog mastering stick-catching through deep reinforcement learning.
You can **play with him in your browser** 👉 [here](https://huggingface.co/spaces/ThomasSimonini/Huggy)
You can **learn to train Huggy using Deep Reinforcement Learning** 👉 [with this tutorial](https://huggingface.co/learn/deep-rl-course/unitbonus1/introduction)
## Aknowledgments
Huggy is a Deep Reinforcement Learning environment made by Hugging Face and based on [Puppo the Corgi](https://blog.unity.com/technology/puppo-the-corgi-cuteness-overload-with-the-unity-ml-agents-toolkit), a project by the Unity MLAgents team. This environment was created using the Unity game engine and MLAgents. **ML-Agents is a toolkit for the game engine from Unity that allows us to create environments using Unity or use pre-made environments to train our agents**.
| {".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 0235c299a13308520f14185ca5db31ff3e4aeee4 Hamza Amin <[email protected]> 1727369215 +0500\tclone: from https://github.com/huggingface/Huggy.git\n", ".git\\refs\\heads\\main": "0235c299a13308520f14185ca5db31ff3e4aeee4\n"} | null |
instruction-tuned-sd | {"type": "directory", "name": "instruction-tuned-sd", "children": [{"type": "directory", "name": "data_preparation", "children": [{"type": "file", "name": "export_to_hub.py"}, {"type": "file", "name": "generate_dataset.py"}, {"type": "file", "name": "image_utils.py"}, {"type": "file", "name": "instructions.txt"}, {"type": "file", "name": "model_utils.py"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "finetune_instruct_pix2pix.py"}, {"type": "file", "name": "LICENSE"}, {"type": "file", "name": "Makefile"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "train_instruct_pix2pix.py"}, {"type": "directory", "name": "validation", "children": [{"type": "file", "name": "compare_models.py"}, {"type": "file", "name": "data_utils.py"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "__init__.py"}]}]} | This directory provides utilities to visually compare the results of different models:
* [sayakpaul/whitebox-cartoonizer](https://hf.co/sayakpaul/whitebox-cartoonizer) (TensorFlow)
* [instruction-tuning-vision/instruction-tuned-cartoonizer](https://hf.co/sayakpaul/instruction-tuning-vision/instruction-tuned-cartoonizer) (Diffusers)
* [timbrooks/instruct-pix2pix](https://hf.co/sayakpaul/timbrooks/instruct-pix2pix) (Diffusers)
We use the `validation` split of ImageNette for the validation purpose. Launch the following script to cartoonize 10 different samples with a specific model:
```bash
python compare_models.py --model_id sayakpaul/whitebox-cartoonizer --max_num_samples 10
```
For the Diffusers' compatible models, you can additionally specify the following options:
* prompt
* num_inference_steps
* image_guidance_scale
* guidance_scale
After the samples have been generated, they should be serialized in the following structure:
```bash
├── comparison-sayakpaul
│ └── whitebox-cartoonizer
│ ├── 0 -- class label
│ │ └── 55f8f5846192691faa2f603b0c92f27fd8599fc7 -- original image hash
│ │ └── tf_image.png -- cartoonized image
│ ├── 1
│ │ ├── b8bfb2ec1a9af348ade8f467ac99e0af0fa0e937
│ │ │ └── tf_image.png
│ │ └── d23da1e9d9c39b17dacb66ddb52f290049a774a5
│ │ └── tf_image.png
│ ├── 2
│ │ └── 7e25076bd693e10ad04e3c41aa29a3258e3d0ecd
│ │ └── tf_image.png
│ ├── 3
│ │ ├── 1c43c5c5f7350b59d0c0607fd9357ed9e1b55e46
│ │ │ └── tf_image.png
│ │ └── cd4ca63c3d7913b1473937618c157c1919465930
│ │ └── tf_image.png
│ ├── 6
│ │ ├── 220b6c136d47e81b186d337e0bdd064c67532e4e
│ │ │ └── tf_image.png
│ │ └── f80589219ae2b913677ea9417962d4ab75f08c2f
│ │ └── tf_image.png
│ └── 7
│ ├── 4f33183189589bb171ba9489b898e5edbac25dfe
│ │ └── tf_image.png
│ └── 519863ade478d26b467e08dc5fb4353a6316833c
│ └── tf_image.png
```
For you use a Diffusers' compatible model then it would look like so:
```bash
├── comparison-instruction-tuning-vision
│ └── instruction-tuned-cartoonizer
│ ├── 0
│ │ └── 55f8f5846192691faa2f603b0c92f27fd8599fc7
│ │ └── steps@[email protected]@7.0.png
│ ├── 1
│ │ ├── b8bfb2ec1a9af348ade8f467ac99e0af0fa0e937
│ │ │ └── steps@[email protected]@7.0.png
│ │ └── d23da1e9d9c39b17dacb66ddb52f290049a774a5
│ │ └── steps@[email protected]@7.0.png
│ ├── 2
│ │ └── 7e25076bd693e10ad04e3c41aa29a3258e3d0ecd
│ │ └── steps@[email protected]@7.0.png
│ ├── 3
│ │ ├── 1c43c5c5f7350b59d0c0607fd9357ed9e1b55e46
│ │ │ └── steps@[email protected]@7.0.png
│ │ └── cd4ca63c3d7913b1473937618c157c1919465930
│ │ └── steps@[email protected]@7.0.png
│ ├── 6
│ │ ├── 220b6c136d47e81b186d337e0bdd064c67532e4e
│ │ │ └── steps@[email protected]@7.0.png
│ │ └── f80589219ae2b913677ea9417962d4ab75f08c2f
│ │ └── steps@[email protected]@7.0.png
│ └── 7
│ ├── 4f33183189589bb171ba9489b898e5edbac25dfe
│ │ └── steps@[email protected]@7.0.png
│ └── 519863ade478d26b467e08dc5fb4353a6316833c
│ └── steps@[email protected]@7.0.png
```
| {"requirements.txt": "torchvision\naccelerate\ndiffusers\ntransformers\nnumpy\ndatasets\nwandb\nblack~=23.1\nisort>=5.5.4\nruff>=0.0.241,<=0.0.259", ".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 2be8f490013895c5fbe9b21385bd5739671d3117 Hamza Amin <[email protected]> 1727369216 +0500\tclone: from https://github.com/huggingface/instruction-tuned-sd.git\n", ".git\\refs\\heads\\main": "2be8f490013895c5fbe9b21385bd5739671d3117\n", "data_preparation\\requirements.txt": "tensorflow\ntensorflow_datasets==4.6.0\ndatasets \nhuggingface_hub\nnumpy\nPillow\nopencv-python\nprotobuf==3.20.*", "validation\\requirements.txt": "tensorflow\ntensorflow_datasets==4.6.0\ndatasets \nhuggingface_hub\nnumpy\nPillow\nopencv-python\ntorch==1.13.1\ntorchvision==0.14.1"} | null |
Intelligent-word-correction-using-NLP | {"type": "directory", "name": "Intelligent-word-correction-using-NLP", "children": [{"type": "file", "name": "app.py"}, {"type": "file", "name": "index.html"}, {"type": "file", "name": "Oxford English Dictionary.txt"}, {"type": "file", "name": "README.md"}]} | # Word Suggester
## Description
This web application suggests similar words based on a given input word. It calculates similarity using the Jaccard distance and returns the top five most similar words ordered by similarity and probability.
## Features
- Calculates word similarity using the Jaccard distance
- Uses a large vocabulary of words from the Oxford English Dictionary
- Considers both similarity and probability in ranking suggestions
- Easy-to-use web interface
## Installation & Usage
1. Clone the repository: `git clone https:https://github.com/hamza-amin-4365/Intelligent-word-correction-using-NLP`
2. Install the required Python libraries: `pip install -r requirements.txt`
3. Run the application: `python app.py runserver`
4. Visit `http://localhost:5000/` in a web browser
5. Enter a word in the search box and click "Suggest"
## License
This project is licensed under the MIT License.
| {"app.py": "# importing main libraries\nfrom flask import Flask, render_template,request\nimport numpy as np\nimport pandas as pd\nimport textdistance\nfrom collections import Counter\nimport re\n\n\napp = Flask(__name__)\n\n# File opening and cleaning our txt file\nwords = []\nwith open('Oxford English Dictionary.txt', 'r', encoding='utf-8') as f:\n data = f.read().lower()\n words = re.findall('\\w+', data)\n words += words\n\n\n# Make vocabulary\nV = set(words) # gives unique words\n\n#build frequency of all words\nwords_freq_dict = Counter(words)\n\n\n# RELATIVE FREQUENCY OF WORDS\n# Now we want to get probability of occurance of each word, this equals relative frequency\n# the formula is:\n# probability(word) = Frequency(word)/Total words\ntotal_words_freq = sum(words_freq_dict.values()) # sum of all total words\nprobs = {}\nfor k in words_freq_dict.keys():\n probs[k] = words_freq_dict[k] / total_words_freq\n\n\[email protected]('/')\ndef index():\n return render_template('index.html', suggestions=None)\n\n\n# FINDING SIMILAR WORDS\n# Now we will sort similar words according to Jaccard distance fr by calculating 2 grams Q of the words. \n# Next, we will return 5 most similar words ordered by similarity and probability.\n# Jaccard distance measures the dissimilarity b/w two sets by comparing their intersection and union \[email protected]('/suggest', methods=['POST'])\ndef suggest():\n keyword = request.form['keyword'].lower()\n if keyword:\n similarities = [1 - textdistance.Jaccard(qval=2).distance(v, keyword) for v in words_freq_dict.keys()]\n df = pd.DataFrame.from_dict(probs, orient='index').reset_index()\n df.columns = ['Word', 'Prob']\n df['Similarity'] = similarities\n # Filter words with similarity greater than 0\n df = df[df['Similarity'] > 0]\n suggestions = df.sort_values(['Similarity', 'Prob'], ascending=False)[['Word', 'Similarity']]\n suggestions_list = suggestions.to_dict('records') # Convert DataFrame to list of dictionaries\n return render_template('index.html', suggestions=suggestions_list)\n\nif __name__ == '__main__':\n app.run(debug=True)", "index.html": "<!DOCTYPE html>\n<html lang=\"en\">\n<head>\n <meta charset=\"UTF-8\">\n <meta name=\"viewport\" content=\"width=device-width, initial-scale=1.0\">\n <title>Autocorrect System</title>\n <link rel=\"stylesheet\" href=\"https://stackpath.bootstrapcdn.com/bootstrap/4.5.2/css/bootstrap.min.css\">\n</head>\n<body style=\"background: #bcc499;\">\n\n <div class=\"container mt-5\">\n <div class=\"jumbotron\">\n <h1 class=\"display-4\">AutoSuggest and Autocorrect System</h1>\n <p class=\"lead\">Enhance your writing with intelligent suggestions.</p>\n </div>\n\n <form method=\"POST\" action=\"/suggest\" class=\"mt-4\">\n <div class=\"form-group\">\n <label for=\"keyword\">Enter a word:</label>\n <input type=\"text\" class=\"form-control\" id=\"keyword\" name=\"keyword\" required>\n </div>\n <button type=\"submit\" class=\"btn btn-primary\">Get Suggestions</button>\n </form>\n\n <div id=\"suggestions\" class=\"mt-4\">\n {% if suggestions %}\n <div class=\"card\">\n <div class=\"card-header\">\n <h5 class=\"mb-0\">Suggestions</h5>\n </div>\n <div class=\"card-body\">\n <table class=\"table table-bordered\">\n <thead class=\"thead-dark\">\n <tr>\n <th>Suggested Word</th>\n <th>Similarity</th>\n </tr>\n </thead>\n <tbody>\n {% for suggestion in suggestions %}\n <tr>\n <td>{{ suggestion['Word'] }}</td>\n <td>{{ suggestion['Similarity'] }}</td>\n </tr>\n {% endfor %}\n </tbody>\n </table>\n </div>\n </div>\n {% endif %}\n </div>\n </div>\n\n</body>\n</html>\n", ".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 84096da83b4c8d540a8ae2ef5737e90fbdcbd71b Hamza Amin <[email protected]> 1727376290 +0500\tclone: from https://github.com/hamza-amin-4365/Intelligent-word-correction-using-NLP.git\n", ".git\\refs\\heads\\main": "84096da83b4c8d540a8ae2ef5737e90fbdcbd71b\n"} | null |
jat | {"type": "directory", "name": "jat", "children": [{"type": "directory", "name": "data", "children": [{"type": "directory", "name": "conceptual_captions", "children": [{"type": "file", "name": "generate_conceptual_caption.py"}]}, {"type": "directory", "name": "envs", "children": [{"type": "directory", "name": "atari", "children": [{"type": "file", "name": "create_atari_57_dataset.sh"}, {"type": "file", "name": "create_atari_dataset.py"}, {"type": "file", "name": "generate_random_score.py"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}]}, {"type": "directory", "name": "babyai", "children": [{"type": "file", "name": "bot_agent.py"}, {"type": "file", "name": "create_babyai_dataset.py"}, {"type": "file", "name": "create_babyai_dataset.slurm"}, {"type": "file", "name": "generate_random_score.py"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}]}, {"type": "file", "name": "download_expert_scores.py"}, {"type": "directory", "name": "metaworld", "children": [{"type": "file", "name": "generate_dataset.py"}, {"type": "file", "name": "generate_dataset_all.sh"}, {"type": "file", "name": "generate_random_score.py"}, {"type": "file", "name": "push.py"}, {"type": "file", "name": "push_all.sh"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "train.py"}, {"type": "file", "name": "train_all.sh"}]}, {"type": "directory", "name": "mujoco", "children": [{"type": "file", "name": "create_mujoco_dataset.py"}, {"type": "file", "name": "create_mujoco_dataset.sh"}, {"type": "file", "name": "generate_random_score.py"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}]}]}, {"type": "file", "name": "GUIDELINES.md"}, {"type": "directory", "name": "ok-vqa", "children": [{"type": "file", "name": "ok-vqa.py"}, {"type": "file", "name": "requirements.txt"}]}, {"type": "file", "name": "to_hub.py"}]}, {"type": "directory", "name": "examples", "children": [{"type": "file", "name": "load_dataset.py"}]}, {"type": "directory", "name": "jat", "children": [{"type": "file", "name": "configuration_jat.py"}, {"type": "directory", "name": "eval", "children": [{"type": "directory", "name": "rl", "children": [{"type": "file", "name": "core.py"}, {"type": "file", "name": "scores_dict.json"}, {"type": "file", "name": "wrappers.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "modeling_jat.py"}, {"type": "file", "name": "processing_jat.py"}, {"type": "file", "name": "utils.py"}, {"type": "file", "name": "utils_interleave_datasets.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "LICENSE"}, {"type": "file", "name": "Makefile"}, {"type": "file", "name": "pyproject.toml"}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "scripts", "children": [{"type": "file", "name": "download_all_datasets.py"}, {"type": "file", "name": "eval_jat.py"}, {"type": "file", "name": "generate_config_jat.py"}, {"type": "file", "name": "tokenize_stream.py"}, {"type": "file", "name": "train_jat.py"}, {"type": "file", "name": "train_jat_tokenized.py"}]}, {"type": "file", "name": "setup.cfg"}, {"type": "file", "name": "setup.py"}, {"type": "directory", "name": "templates", "children": [{"type": "file", "name": "model_card.md"}]}, {"type": "directory", "name": "tests", "children": [{"type": "directory", "name": "jat", "children": [{"type": "directory", "name": "rl", "children": [{"type": "file", "name": "test_core.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "test_modeling_jat.py"}, {"type": "file", "name": "test_processing_jat.py"}]}, {"type": "file", "name": "__init__.py"}]}]} | # How to create the Mujoco dataset and push it to the hub
1. Install the jat lib from the root dir `pip install .[dev]`
2. install the additional dependencies for generating the atari dataset. `pip install -r requirements.txt`
3. python -m sample_factory.huggingface.load_from_hub -r edbeeching/atari_2B_atari_pong_1111 -d train_dir
4. For a single env run `python create_atari_dataset.py --env=atari_pong --experiment=atari_2B_atari_pong_1111 --train_dir=train_dir --push_to_hub --hf_repository=edbeeching/prj_jat_dataset_atari_2B_atari_pong_1111 --max_num_frames=100000 --no_render`
| {"setup.py": "# Lint as: python3\n\"\"\" HuggingFace/jat is an open library the training of Jack of All Trades (JAT) agents.\n\nNote:\n\n VERSION needs to be formatted following the MAJOR.MINOR.PATCH convention\n (we need to follow this convention to be able to retrieve versioned scripts)\n\nSimple check list for release from AllenNLP repo: https://github.com/allenai/allennlp/blob/main/setup.py\n\nTo create the package for pypi.\n\n0. Prerequisites:\n - Dependencies:\n - twine: \"pip install twine\"\n - Create an account in (and join the 'simulate' project):\n - PyPI: https://pypi.org/\n - Test PyPI: https://test.pypi.org/\n\n1. Change the version in:\n - __init__.py\n - setup.py\n\n2. Commit these changes: \"git commit -m 'Release: VERSION'\"\n\n3. Add a tag in git to mark the release: \"git tag VERSION -m 'Add tag VERSION for pypi'\"\n Push the tag to remote: git push --tags origin main\n\n4. Build both the sources and the wheel. Do not change anything in setup.py between\n creating the wheel and the source distribution (obviously).\n\n First, delete any \"build\" directory that may exist from previous builds.\n\n For the wheel, run: \"python setup.py bdist_wheel\" in the top level directory.\n (this will build a wheel for the python version you use to build it).\n\n For the sources, run: \"python setup.py sdist\"\n You should now have a /dist directory with both .whl and .tar.gz source versions.\n\n5. Check that everything looks correct by uploading the package to the pypi test server:\n\n twine upload dist/* -r pypitest --repository-url=https://test.pypi.org/legacy/\n\n Check that you can install it in a virtualenv/notebook by running:\n pip install -i https://testpypi.python.org/pypi simulate\n\n6. Upload the final version to actual pypi:\n twine upload dist/* -r pypi\n\n7. Fill release notes in the tag in GitHub once everything is looking hunky-dory.\n\n8. Change the version in __init__.py and setup.py to X.X.X+1.dev0 (e.g. VERSION=1.18.3 -> 1.18.4.dev0).\n Then push the change with a message 'set dev version'\n\"\"\"\n# from skbuild import setup\nfrom distutils.core import setup\n\nfrom setuptools import find_packages\n\n\n__version__ = \"0.0.1.dev0\" # expected format is one of x.y.z.dev0, or x.y.z.rc1 or x.y.z (no to dashes, yes to dots)\n\nREQUIRED_PKGS = [\n \"accelerate>=0.25.0\",\n \"datasets>=2.15.0\",\n \"gymnasium==0.29.1\", # For RL action spaces and API\n \"huggingface_hub>=0.10\", # For sharing objects, environments & trained RL policies\n \"numpy\",\n \"opencv-python\",\n \"torch>=2.1.1\",\n \"torchvision\",\n \"transformers>=4.36.1\",\n \"wandb\",\n]\n\nEVAL_REQUIRE = [\n \"free-mujoco-py\",\n \"gymnasium[accept-rom-license,atari,mujoco]\",\n \"metaworld @ git+https://github.com/qgallouedec/[email protected]_register\",\n \"minigrid\",\n \"rliable\",\n]\nTRAIN_REQUIRE = []\n\n\nTESTS_REQUIRE = [\n \"pytest-xdist\",\n \"pytest\",\n]\nQUALITY_REQUIRE = [\"black[jupyter]~=22.0\", \"ruff\", \"pyyaml>=5.3.1\"]\n\nEXTRAS_REQUIRE = {\n \"train\": TRAIN_REQUIRE,\n \"dev\": TRAIN_REQUIRE + EVAL_REQUIRE + TESTS_REQUIRE + QUALITY_REQUIRE,\n \"test\": TESTS_REQUIRE + EVAL_REQUIRE,\n \"eval\": EVAL_REQUIRE,\n}\n\n\nsetup(\n name=\"jat\",\n version=__version__,\n description=\"is an open library for the training of Jack of All Trades (JAT) agents.\",\n long_description=open(\"README.md\", encoding=\"utf-8\").read(),\n long_description_content_type=\"text/markdown\",\n author=\"HuggingFace Inc.\",\n author_email=\"[email protected]\",\n url=\"https://github.com/huggingface/jat\",\n download_url=\"https://github.com/huggingface/jat/tags\",\n license=\"Apache 2.0\",\n package_dir={\"\": \".\"},\n packages=find_packages(where=\".\", include=\"jat*\"),\n install_requires=REQUIRED_PKGS,\n extras_require=EXTRAS_REQUIRE,\n classifiers=[\n \"Development Status :: 5 - Production/Stable\",\n \"Intended Audience :: Developers\",\n \"Intended Audience :: Education\",\n \"Intended Audience :: Science/Research\",\n \"License :: OSI Approved :: Apache Software License\",\n \"Operating System :: OS Independent\",\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.8\",\n \"Programming Language :: Python :: 3.9\",\n \"Programming Language :: Python :: 3.10\",\n \"Topic :: Scientific/Engineering :: Artificial Intelligence\",\n ],\n keywords=\"simulation environments machine learning reinforcement learning deep learning\",\n zip_safe=False, # Required for mypy to find the py.typed file\n python_requires=\">=3.8\",\n)\n\n# When building extension modules `cmake_install_dir` should always be set to the\n# location of the package you are building extension modules for.\n# Specifying the installation directory in the CMakeLists subtley breaks the relative\n# paths in the helloTargets.cmake file to all of the library components.\n", ".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 e8a1964ce827aa866f7caeedf7d8ec12738e02d5 Hamza Amin <[email protected]> 1727369220 +0500\tclone: from https://github.com/huggingface/jat.git\n", ".git\\refs\\heads\\main": "e8a1964ce827aa866f7caeedf7d8ec12738e02d5\n", "data\\envs\\atari\\requirements.txt": "sample-factory[atari,envpool]\nshimmy", "data\\envs\\babyai\\requirements.txt": "minigrid\nnumpy==1.23.1", "data\\envs\\metaworld\\requirements.txt": "sample-factory\ngit+https://github.com/qgallouedec/[email protected]_register", "data\\envs\\mujoco\\requirements.txt": "sample-factory[mujoco,envpool]", "data\\ok-vqa\\requirements.txt": "Pillow==9.5.0", "jat\\eval\\rl\\wrappers.py": "from typing import Any, Dict, Tuple\n\nimport gymnasium as gym\nimport numpy as np\nfrom PIL import Image, ImageDraw, ImageFont\n\n\nclass NoopResetEnv(gym.Wrapper):\n \"\"\"\n Sample initial states by taking random number of no-ops on reset. No-op is assumed to be action 0.\n\n Adapted from Stable-Baselines3.\n\n Args:\n env (`gym.Env`):\n The environment to wrap.\n noop_max (`int`):\n The maximum number of no-ops to perform.\n \"\"\"\n\n def __init__(self, env: gym.Env, noop_max: int = 30) -> None:\n super().__init__(env)\n self.noop_max = noop_max\n self.noop_action = 0\n assert env.unwrapped.get_action_meanings()[self.noop_action] == \"NOOP\"\n\n def reset(self, **kwargs) -> Tuple[np.ndarray, Dict]:\n self.env.reset(**kwargs)\n noops = self.unwrapped.np_random.integers(1, self.noop_max + 1)\n for _ in range(noops):\n observation, reward, terminated, truncated, info = self.env.step(self.noop_action)\n if terminated | truncated:\n observation, info = self.env.reset(**kwargs)\n return observation, info\n\n\nclass FireResetEnv(gym.Wrapper):\n \"\"\"\n Take FIRE action on reset for environments that are fixed until firing.\n\n Adapted from Stable-Baselines3.\n\n Args:\n env (`gym.Env`):\n The environment to wrap.\n \"\"\"\n\n def __init__(self, env: gym.Env) -> None:\n super().__init__(env)\n assert env.unwrapped.get_action_meanings()[1] == \"FIRE\"\n assert len(env.unwrapped.get_action_meanings()) >= 3\n\n def reset(self, **kwargs) -> Tuple[np.ndarray, Dict]:\n self.env.reset(**kwargs)\n observation, reward, terminated, truncated, info = self.env.step(1)\n if terminated | truncated:\n self.env.reset(**kwargs)\n observation, reward, terminated, truncated, info = self.env.step(2)\n if terminated | truncated:\n observation, info = self.env.reset(**kwargs)\n return observation, info\n\n\nclass EpisodicLifeEnv(gym.Wrapper):\n \"\"\"\n Make end-of-life == end-of-episode, but only reset on true game over (lives exhausted).\n Done by DeepMind for the DQN and co. since it helps value estimation.\n This way all states are still reachable even though lives are episodic,\n and the learner need not know about any of this behind-the-scenes.\n\n Adapted from Stable-Baselines3.\n\n Args:\n env (`gym.Env`):\n The environment to wrap.\n \"\"\"\n\n def __init__(self, env: gym.Env) -> None:\n super().__init__(env)\n self.lives = 0\n self.inner_game_over = True\n\n def step(self, action: int):\n observation, reward, terminated, truncated, info = self.env.step(action)\n self.inner_game_over = terminated | truncated\n # Check current lives, make loss of life terminal, then update lives to handle bonus lives.\n lives = self.env.unwrapped.ale.lives()\n if 0 < lives < self.lives:\n # For Qbert sometimes we stay in lives == 0 condtion for a few frames\n # so its important to keep lives > 0, so that we only reset once\n # the environment advertises done.\n terminated = True\n self.lives = lives\n return observation, reward, terminated, truncated, info\n\n def reset(self, **kwargs) -> Tuple[np.ndarray, Dict]:\n if self.inner_game_over:\n observation, info = self.env.reset(**kwargs)\n else:\n # No-op step to advance from terminal/lost life state\n observation, reward, terminated, truncated, info = self.env.step(0)\n self.lives = self.env.unwrapped.ale.lives()\n return observation, info\n\n\nclass MaxAndSkipEnv(gym.Wrapper):\n \"\"\"\n Return only every ``skip``-th frame (frameskipping).\n\n Adapted from Stable-Baselines3.\n\n Args:\n env (`gym.Env`):\n The environment to wrap.\n skip (`int`):\n The number of frames to skip.\n \"\"\"\n\n def __init__(self, env: gym.Env, skip: int = 4) -> None:\n super().__init__(env)\n # Most recent raw observations (for max pooling across time steps)\n self._obs_buffer = np.zeros((2,) + env.observation_space.shape, dtype=env.observation_space.dtype)\n self.skip = skip\n\n def step(self, action: int):\n \"\"\"\n Step the environment with the given action\n Repeat action, sum reward, and max over last observations.\n :param action: the action\n :return: observation, reward, terminated, truncated, information\n \"\"\"\n total_reward = 0.0\n info = {}\n terminated = truncated = False\n for i in range(self.skip):\n obs, reward, terminated, truncated, info = self.env.step(action)\n if i == self.skip - 2:\n self._obs_buffer[0] = obs\n if i == self.skip - 1:\n self._obs_buffer[1] = obs\n total_reward += reward\n if terminated | truncated:\n break\n # Note that the observation on the done=True frame doesn't matter\n max_frame = self._obs_buffer.max(axis=0)\n\n return max_frame, total_reward, terminated, truncated, info\n\n\nclass ClipRewardEnv(gym.RewardWrapper):\n \"\"\"\n Clips the reward to {+1, 0, -1} by its sign.\n\n Adapted from Stable-Baselines3.\n\n Args:\n env (`gym.Env`):\n The environment to wrap.\n \"\"\"\n\n def reward(self, reward: float) -> float:\n return np.sign(reward)\n\n\nclass NumpyObsWrapper(gym.ObservationWrapper):\n \"\"\"\n RL algorithm generally expects numpy arrays or Tensors as observations. Atari envs for example return\n LazyFrames which need to be converted to numpy arrays before we actually use them.\n \"\"\"\n\n def observation(self, observation: Any) -> np.ndarray:\n return np.array(observation)\n\n\nclass RenderMission(gym.Wrapper):\n \"\"\"\n Wrapper to add mission in the RGB rendering for BabyAI.\n \"\"\"\n\n @staticmethod\n def add_text_to_image(image, text, position=(10, 5), font_size=20, text_color=(255, 255, 255)):\n \"\"\"\n Add text to an RGB image represented as a NumPy array and return the modified image as a NumPy array.\n\n Args:\n image (numpy.ndarray): The input RGB image as a NumPy array.\n text (str): The text to be added to the image.\n position (tuple): The (x, y) coordinates of the top-left corner of the text.\n font_size (int): The font size for the text.\n text_color (tuple): The RGB color code for the text color.\n\n Returns:\n numpy.ndarray: The modified RGB image as a NumPy array.\n \"\"\"\n # Convert the input NumPy array to a PIL Image\n image = Image.fromarray(np.uint8(image))\n\n # Create a drawing context on the image\n draw = ImageDraw.Draw(image)\n\n # Use the default font\n font = ImageFont.load_default().font_variant(size=font_size)\n\n # Add the text to the image\n draw.text(position, text, fill=text_color, font=font)\n\n # Convert the modified image back to a NumPy array\n modified_image_np = np.array(image)\n\n return modified_image_np\n\n def render(self):\n img = super().render()\n if img is not None:\n img = self.add_text_to_image(img, self.mission)\n return img\n"} | null |
khipu_workshop | {"type": "directory", "name": "khipu_workshop", "children": [{"type": "file", "name": "notebook.ipynb"}, {"type": "file", "name": "README.md"}]} | # khipu_workshop | {".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 918b92bc0cc5717aceceafa92cc2ad53724f69a1 Hamza Amin <[email protected]> 1727369255 +0500\tclone: from https://github.com/huggingface/khipu_workshop.git\n", ".git\\refs\\heads\\main": "918b92bc0cc5717aceceafa92cc2ad53724f69a1\n"} | null |
knockknock | {"type": "directory", "name": "knockknock", "children": [{"type": "directory", "name": "knockknock", "children": [{"type": "file", "name": "chime_sender.py"}, {"type": "file", "name": "desktop_sender.py"}, {"type": "file", "name": "dingtalk_sender.py"}, {"type": "file", "name": "discord_sender.py"}, {"type": "file", "name": "email_sender.py"}, {"type": "file", "name": "matrix_sender.py"}, {"type": "file", "name": "rocketchat_sender.py"}, {"type": "file", "name": "slack_sender.py"}, {"type": "file", "name": "sms_sender.py"}, {"type": "file", "name": "teams_sender.py"}, {"type": "file", "name": "telegram_sender.py"}, {"type": "directory", "name": "tests", "children": [{"type": "file", "name": "test_senders.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "wechat_sender.py"}, {"type": "file", "name": "__init__.py"}, {"type": "file", "name": "__main__.py"}]}, {"type": "file", "name": "LICENSE"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "setup.py"}]} | # Knock Knock
[](#python) [](https://pepy.tech/project/knockknock) [](https://pepy.tech/project/knockknock/month) [](https://github.com/huggingface/knockknock/stargazers/)
A small library to get a notification when your training is complete or when it crashes during the process with two additional lines of code.
When training deep learning models, it is common to use early stopping. Apart from a rough estimate, it is difficult to predict when the training will finish. Thus, it can be interesting to set up automatic notifications for your training. It is also interesting to be notified when your training crashes in the middle of the process for unexpected reasons.
## Installation
Install with `pip` or equivalent.
```bash
pip install knockknock
```
This code has only been tested with Python >= 3.6.
## Usage
The library is designed to be used in a seamless way, with minimal code modification: you only need to add a decorator on top your main function call. The return value (if there is one) is also reported in the notification.
There are currently *twelve* ways to setup notifications:
| Platform | External Contributors |
| :-----------------------------------: | :---------------------------------------------------------------------------------------: |
| [email](#email) | - |
| [Slack](#slack) | - |
| [Telegram](#telegram) | - |
| [Microsoft Teams](#microsoft-teams) | [@noklam](https://github.com/noklam) |
| [Text Message](<#text-message-(sms)>) | [@abhishekkrthakur](https://github.com/abhishekkrthakur) |
| [Discord](#discord) | [@watkinsm](https://github.com/watkinsm) |
| [Desktop](#desktop-notification) | [@atakanyenel](https://github.com/atakanyenel) [@eyalmazuz](https://github.com/eyalmazuz) |
| [Matrix](#matrix) | [@jcklie](https://github.com/jcklie) |
| [Amazon Chime](#amazon-chime) | [@prabhakar267](https://github.com/prabhakar267) |
| [DingTalk](#dingtalk) | [@wuutiing](https://github.com/wuutiing) |
| [RocketChat](#rocketchat) | [@radao](https://github.com/radao) |
| [WeChat Work](#wechat-work) | [@jcyk](https://github.com/jcyk) |
### Email
The service relies on [Yagmail](https://github.com/kootenpv/yagmail) a GMAIL/SMTP client. You'll need a gmail email address to use it (you can setup one [here](https://accounts.google.com), it's free). I recommend creating a new one (rather than your usual one) since you'll have to modify the account's security settings to allow the Python library to access it by [Turning on less secure apps](https://devanswers.co/allow-less-secure-apps-access-gmail-account/).
#### Python
```python
from knockknock import email_sender
@email_sender(recipient_emails=["<[email protected]>", "<[email protected]>"], sender_email="<grandma'[email protected]>")
def train_your_nicest_model(your_nicest_parameters):
import time
time.sleep(10000)
return {'loss': 0.9} # Optional return value
```
#### Command-line
```bash
knockknock email \
--recipient-emails <[email protected]>,<[email protected]> \
--sender-email <grandma'[email protected]> \
sleep 10
```
If `sender_email` is not specified, then the first email in `recipient_emails` will be used as the sender's email.
Note that launching this will asks you for the sender's email password. It will be safely stored in the system keyring service through the [`keyring` Python library](https://pypi.org/project/keyring/).
### Slack
Similarly, you can also use Slack to get notifications. You'll have to get your Slack room [webhook URL](https://api.slack.com/incoming-webhooks#create_a_webhook) and optionally your [user id](https://api.slack.com/methods/users.identity) (if you want to tag yourself or someone else).
#### Python
```python
from knockknock import slack_sender
webhook_url = "<webhook_url_to_your_slack_room>"
@slack_sender(webhook_url=webhook_url, channel="<your_favorite_slack_channel>")
def train_your_nicest_model(your_nicest_parameters):
import time
time.sleep(10000)
return {'loss': 0.9} # Optional return value
```
You can also specify an optional argument to tag specific people: `user_mentions=[<your_slack_id>, <grandma's_slack_id>]`.
#### Command-line
```bash
knockknock slack \
--webhook-url <webhook_url_to_your_slack_room> \
--channel <your_favorite_slack_channel> \
sleep 10
```
You can also specify an optional argument to tag specific people: `--user-mentions <your_slack_id>,<grandma's_slack_id>`.
### Telegram
You can also use Telegram Messenger to get notifications. You'll first have to create your own notification bot by following the three steps provided by Telegram [here](https://core.telegram.org/bots#6-botfather) and save your API access `TOKEN`.
Telegram bots are shy and can't send the first message so you'll have to do the first step. By sending the first message, you'll be able to get the `chat_id` required (identification of your messaging room) by visiting `https://api.telegram.org/bot<YourBOTToken>/getUpdates` and get the `int` under the key `message['chat']['id']`.
#### Python
```python
from knockknock import telegram_sender
CHAT_ID: int = <your_messaging_room_id>
@telegram_sender(token="<your_api_token>", chat_id=CHAT_ID)
def train_your_nicest_model(your_nicest_parameters):
import time
time.sleep(10000)
return {'loss': 0.9} # Optional return value
```
#### Command-line
```bash
knockknock telegram \
--token <your_api_token> \
--chat-id <your_messaging_room_id> \
sleep 10
```
### Microsoft Teams
Thanks to [@noklam](https://github.com/noklam), you can also use Microsoft Teams to get notifications. You'll have to get your Team Channel [webhook URL](https://docs.microsoft.com/en-us/microsoftteams/platform/concepts/connectors/connectors-using).
#### Python
```python
from knockknock import teams_sender
@teams_sender(token="<webhook_url_to_your_teams_channel>")
def train_your_nicest_model(your_nicest_parameters):
import time
time.sleep(10)
return {'loss': 0.9} # Optional return value
```
#### Command-line
```bash
knockknock teams \
--webhook-url <webhook_url_to_your_teams_channel> \
sleep 10
```
You can also specify an optional argument to tag specific people: `user_mentions=[<your_teams_id>, <grandma's_teams_id>]`.
### Text Message (SMS)
Thanks to [@abhishekkrthakur](https://github.com/abhishekkrthakur), you can use Twilio to send text message notifications. You'll have to setup a [Twilio](www.twilio.com) account [here](https://www.twilio.com/try-twilio), which is paid service with competitive prices: for instance in the US, getting a new number and sending one text message through this service respectively cost $1.00 and $0.0075. You'll need to get (a) a phone number, (b) your [account SID](https://www.twilio.com/docs/glossary/what-is-a-sid) and (c) your [authentification token](https://www.twilio.com/docs/iam/access-tokens). Some detail [here](https://www.twilio.com/docs/iam/api/account).
#### Python
```python
from knockknock import sms_sender
ACCOUNT_SID: str = "<your_account_sid>"
AUTH_TOKEN: str = "<your_auth_token>"
@sms_sender(account_sid=ACCOUNT_SID, auth_token=AUTH_TOKEN, recipient_number="<recipient's_number>", sender_number="<sender's_number>")
def train_your_nicest_model(your_nicest_parameters):
import time
time.sleep(10)
return {'loss': 0.9} # Optional return value
```
#### Command-line
```bash
knockknock sms \
--account-sid <your_account_sid> \
--auth-token <your_account_auth_token> \
--recipient-number <recipient_number> \
--sender-number <sender_number>
sleep 10
```
### Discord
Thanks to [@watkinsm](https://github.com/watkinsm), you can also use Discord to get notifications. You'll just have to get your Discord channel's [webhook URL](https://support.discordapp.com/hc/en-us/articles/228383668-Intro-to-Webhooks).
#### Python
```python
from knockknock import discord_sender
webhook_url = "<webhook_url_to_your_discord_channel>"
@discord_sender(webhook_url=webhook_url)
def train_your_nicest_model(your_nicest_parameters):
import time
time.sleep(10000)
return {'loss': 0.9} # Optional return value
```
#### Command-line
```bash
knockknock discord \
--webhook-url <webhook_url_to_your_discord_channel> \
sleep 10
```
### Desktop Notification
You can also get notified from a desktop notification. It is currently only available for MacOS and Linux and Windows 10.
For Linux it uses the nofity-send command which uses libnotify, In order to use libnotify, you have to install a notification server. Cinnamon, Deepin, Enlightenment, GNOME, GNOME Flashback and KDE Plasma use their own implementations to display notifications. In other desktop environments, the notification server needs to be launched using your WM's/DE's "autostart" option.
#### Python
```python
from knockknock import desktop_sender
@desktop_sender(title="Knockknock Desktop Notifier")
def train_your_nicest_model(your_nicest_parameters):
import time
time.sleep(10000)
return {"loss": 0.9}
```
#### Command Line
```bash
knockknock desktop \
--title 'Knockknock Desktop Notifier' \
sleep 2
```
### Matrix
Thanks to [@jcklie](https://github.com/jcklie), you can send notifications via [Matrix](https://matrix.org/). The homeserver is the
server on which your user that will send messages is registered. Do not forget the schema for the URL (`http` or `https`).
You'll have to get the access token for a bot or your own user. The easiest way to obtain it is to look into Riot looking
in the riot settings, `Help & About`, down the bottom is: `Access Token:<click to reveal>`. You also need to specify a
room alias to which messages are sent. To obtain the alias in Riot, create a room you want to use, then open the room
settings under `Room Addresses` and add an alias.
#### Python
```python
from knockknock import matrix_sender
HOMESERVER = "<url_to_your_home_server>" # e.g. https://matrix.org
TOKEN = "<your_auth_token>" # e.g. WiTyGizlr8ntvBXdFfZLctyY
ROOM = "<room_alias" # e.g. #knockknock:matrix.org
@matrix_sender(homeserver=HOMESERVER, token=TOKEN, room=ROOM)
def train_your_nicest_model(your_nicest_parameters):
import time
time.sleep(10000)
return {'loss': 0.9} # Optional return value
```
#### Command-line
```bash
knockknock matrix \
--homeserver <homeserver> \
--token <token> \
--room <room> \
sleep 10
```
### Amazon Chime
Thanks to [@prabhakar267](https://github.com/prabhakar267), you can also use Amazon Chime to get notifications. You'll have to get your Chime room [webhook URL](https://docs.aws.amazon.com/chime/latest/dg/webhooks.html).
#### Python
```python
from knockknock import chime_sender
@chime_sender(webhook_url="<webhook_url_to_your_chime_room>")
def train_your_nicest_model(your_nicest_parameters):
import time
time.sleep(10)
return {'loss': 0.9} # Optional return value
```
#### Command-line
```bash
knockknock chime \
--webhook-url <webhook_url_to_your_chime_room> \
sleep 10
```
You can also specify an optional argument to tag specific people: `user_mentions=[<your_alias>, <grandma's_alias>]`.
### DingTalk
DingTalk is now supported thanks to [@wuutiing](https://github.com/wuutiing). Given DingTalk chatroom robot's webhook url and secret/keywords(at least one of them are set when creating a chatroom robot), your notifications will be sent to reach any one in that chatroom.
#### Python
```python
from knockknock import dingtalk_sender
webhook_url = "<webhook_url_to_your_dingtalk_chatroom_robot>"
@dingtalk_sender(webhook_url=webhook_url, secret="<your_robot_secret_if_set>", keywords=["<list_of_keywords_if_set>"])
def train_your_nicest_model(your_nicest_parameters):
import time
time.sleep(10000)
return {'loss': 0.9} # Optional return value
```
#### Command-line
```bash
knockknock dingtalk \
--webhook-url <webhook_url_to_your_dingtalk_chatroom_robot> \
--secret <your_robot_secret_if_set> \
sleep 10
```
You can also specify an optional argument to at specific people: `user_mentions=["<list_of_phonenumbers_who_you_want_to_tag>"]`.
### RocketChat
You can use [RocketChat](https://rocket.chat/) to get notifications. You'll need the following before you can post notifications:
- a RocketChat server e.g. rocketchat.yourcompany.com
- a RocketChat user id (you'll be able to view your user id when you create a personal access token in the next step)
- a RocketChat personal access token ([create one as per this guide](https://rocket.chat/docs/developer-guides/rest-api/personal-access-tokens/))
- a RocketChat channel
#### Python
```python
from knockknock import rocketchat_sender
@rocketchat_sender(
rocketchat_server_url="<url_to_your_rocketchat_server>",
rocketchat_user_id="<your_rocketchat_user_id>",
rocketchat_auth_token="<your_rocketchat_auth_token>",
channel="<channel_name>")
def train_your_nicest_model(your_nicest_parameters):
import time
time.sleep(10000)
return {'loss': 0.9} # Optional return value
```
You can also specify two optional arguments:
- to tag specific users: `user_mentions=[<your_user_name>, <grandma's_user_name>]`
- to use an alias for the notification: `alias="My Alias"`
#### Command-line
```bash
knockknock rocketchat \
--rocketchat-server-url <url_to_your_rocketchat_server> \
--rocketchat-user-id <your_rocketchat_user_id> \
--rocketchat-auth-token <your_rocketchat_auth_token> \
--channel <channel_name> \
sleep 10
```
### WeChat Work
WeChat Work is now supported thanks to [@jcyk](https://github.com/jcyk). Given WeChat Work chatroom robot's webhook url, your notifications will be sent to reach anyone in that chatroom.
#### Python
```python
from knockknock import wechat_sender
webhook_url = "<webhook_url_to_your_wechat_work_chatroom_robot>"
@wechat_sender(webhook_url=webhook_url)
def train_your_nicest_model(your_nicest_parameters):
import time
time.sleep(10000)
return {'loss': 0.9} # Optional return value
```
#### Command-line
```bash
knockknock wechat \
--webhook-url <webhook_url_to_your_wechat_work_chatroom_robot> \
sleep 10
```
You can also specify an optional argument to tag specific people: `user-mentions=["<list_of_userids_you_want_to_tag>"]` and/or `user-mentions-mobile=["<list_of_phonenumbers_you_want_to_tag>"]`.
## Note on distributed training
When using distributed training, a GPU is bound to its process using the local rank variable. Since knockknock works at the process level, if you are using 8 GPUs, you would get 8 notifications at the beginning and 8 notifications at the end... To circumvent that, except for errors, only the master process is allowed to send notifications so that you receive only one notification at the beginning and one notification at the end.
**Note:** _In PyTorch, the launch of `torch.distributed.launch` sets up a RANK environment variable for each process (see [here](https://github.com/pytorch/pytorch/blob/master/torch/distributed/launch.py#L211)). This is used to detect the master process, and for now, the only simple way I came up with. Unfortunately, this is not intended to be general for all platforms but I would happily discuss smarter/better ways to handle distributed training in an issue/PR._
| {"setup.py": "from setuptools import setup, find_packages\nfrom io import open\n\nsetup(\n name='knockknock',\n version='0.1.8.1',\n description='Be notified when your training is complete with only two additional lines of code',\n long_description=open('README.md', 'r', encoding='utf-8').read(),\n long_description_content_type='text/markdown',\n url='http://github.com/huggingface/knockknock',\n author='Victor SANH',\n author_email='[email protected]',\n license='MIT',\n packages=find_packages(),\n entry_points={\n 'console_scripts': [\n 'knockknock = knockknock.__main__:main'\n ]\n },\n zip_safe=False,\n python_requires='>=3.6',\n install_requires=[\n 'yagmail>=0.11.214',\n 'keyring',\n 'matrix_client',\n 'python-telegram-bot',\n 'requests',\n 'twilio',\n ],\n classifiers=[\n 'Intended Audience :: Science/Research',\n 'Development Status :: 3 - Alpha',\n 'License :: OSI Approved :: MIT License',\n 'Programming Language :: Python :: 3.6',\n 'Topic :: Scientific/Engineering :: Artificial Intelligence',\n ]\n)\n", ".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", "knockknock\\__main__.py": "import argparse\nimport subprocess\n\nfrom knockknock import (chime_sender,\n desktop_sender,\n dingtalk_sender,\n discord_sender,\n email_sender,\n matrix_sender,\n rocketchat_sender,\n slack_sender,\n sms_sender,\n teams_sender,\n telegram_sender,\n wechat_sender,)\n\ndef main():\n parser = argparse.ArgumentParser(\n description=\"KnockKnock - Be notified when your training is complete.\")\n parser.add_argument(\"--verbose\", required=False, action=\"store_true\",\n help=\"Show full command in notification.\")\n subparsers = parser.add_subparsers()\n\n # Chime\n chime_parser = subparsers.add_parser(\n name=\"chime\", description=\"Send a Chime message before and after function \" +\n \"execution, with start and end status (successfully or crashed).\")\n chime_parser.add_argument(\n \"--webhook-url\", type=str, required=True,\n help=\"The webhook URL to access your chime room.\")\n chime_parser.add_argument(\n \"--user-mentions\", type=lambda s: s.split(\",\"), required=False, default=[],\n help=\"Optional user alias or full email address to notify, as comma separated list.\")\n chime_parser.set_defaults(sender_func=chime_sender)\n\n # Desktop\n desktop_parser = subparsers.add_parser(\n name=\"desktop\", description=\"Send a desktop notification before and after function \" +\n \"execution, with start and end status (successfully or crashed).\")\n desktop_parser.add_argument(\"--title\", type=str, required=False,\n help=\"The title of the notification, default to knockknock\")\n desktop_parser.set_defaults(sender_func=desktop_sender)\n\n # Discord\n discord_parser = subparsers.add_parser(\n name=\"discord\", description=\"Send a Discord message before and after function \" +\n \"execution, with start and end status (sucessfully or crashed).\")\n discord_parser.add_argument(\n \"--webhook-url\", type=str, required=True,\n help=\"The webhook URL to access your Discord server/channel.\")\n discord_parser.set_defaults(sender_func=discord_sender)\n\n # Email\n email_parser = subparsers.add_parser(\n name=\"email\", description=\"Send an email before and after function \" +\n \"execution, with start and end status (sucessfully or crashed).\")\n email_parser.add_argument(\n \"--recipient-emails\", type=lambda s: s.split(\",\"), required=True,\n help=\"The email addresses to notify, as comma separated list.\")\n email_parser.add_argument(\n \"--sender-email\", type=str, required=False,\n help=\"The email adress to send the messages.\" +\n \"(default: use the same address as the first email in `recipient-emails`)\")\n email_parser.set_defaults(sender_func=email_sender)\n\n # Slack\n slack_parser = subparsers.add_parser(\n name=\"slack\", description=\"Send a Slack message before and after function \" +\n \"execution, with start and end status (sucessfully or crashed).\")\n slack_parser.add_argument(\n \"--webhook-url\", type=str, required=True,\n help=\"The webhook URL to access your slack room.\")\n slack_parser.add_argument(\n \"--channel\", type=str, required=True, help=\"The slack room to log.\")\n slack_parser.add_argument(\n \"--user-mentions\", type=lambda s: s.split(\",\"), required=False, default=[],\n help=\"Optional user ids to notify, as comma seperated list.\")\n slack_parser.set_defaults(sender_func=slack_sender)\n\n # DingTalk\n dingtalk_parser = subparsers.add_parser(\n name=\"dingtalk\", description=\"Send a dingtalk message before and after function \" +\n \"execution, with start and end status (sucessfully or crashed).\")\n dingtalk_parser.add_argument(\n \"--webhook-url\", type=str, required=True,\n help=\"The webhook URL to access your dingtalk chatroom\")\n dingtalk_parser.add_argument(\n \"--user-mentions\", type=lambda s: s.split(\",\"), required=False, default=[],\n help=\"Optional user's phone number to notify, as comma seperated list.\")\n dingtalk_parser.add_argument(\n \"--secret\", type=str, required=False, default='',\n help=\"Optional the dingtalk chatroom robot's secret\")\n dingtalk_parser.add_argument(\n \"--keywords\", type=lambda s: s.split(\",\"), required=False, default=[],\n help=\"Optional accepted keywords set in dingtalk chatroom robot\")\n dingtalk_parser.set_defaults(sender_func=dingtalk_sender)\n\n # Telegram\n telegram_parser = subparsers.add_parser(\n name=\"telegram\", description=\"Send a Telegram message before and after \" +\n \"function execution, with start and end status (sucessfully or crashed).\")\n telegram_parser.add_argument(\n \"--token\", type=str, required=True,\n help=\"The API access TOKEN required to use the Telegram API.\")\n telegram_parser.add_argument(\n \"--chat-id\", type=int, required=True,\n help=\"Your chat room id with your notification BOT.\")\n telegram_parser.set_defaults(sender_func=telegram_sender)\n\n # Teams\n teams_parser = subparsers.add_parser(\n name=\"teams\", description=\"Send a teams message before and after function \" +\n \"execution, with start and end status (sucessfully or crashed).\")\n teams_parser.add_argument(\n \"--webhook-url\", type=str, required=True,\n help=\"The webhook URL to access your teams channel.\")\n teams_parser.add_argument(\n \"--user-mentions\", type=lambda s: s.split(\",\"), required=False, default=[],\n help=\"Optional user ids to notify, as comma seperated list.\")\n teams_parser.set_defaults(sender_func=teams_sender)\n\n # SMS\n sms_parser = subparsers.add_parser(\n name=\"sms\", description=\"Send an SMS using the Twilio API\")\n sms_parser.add_argument(\n \"--account-sid\", type=str, required=True,\n help=\"The account SID to access your Twilio account.\")\n sms_parser.add_argument(\n \"--auth-token\", type=str, required=True,\n help=\"The authentication token to access your Twilio account.\")\n sms_parser.add_argument(\n \"--recipient-number\", type=str, required=True,\n help=\"The phone number of the recipient.\")\n sms_parser.add_argument(\n \"--sender-number\", type=str, required=True,\n help=\"The phone number of the sender (Twilio number).\")\n sms_parser.set_defaults(sender_func=sms_sender)\n\n # Matrix\n matrix_parser = subparsers.add_parser(\n name=\"matrix\", description=\"Send a Matrix message before and after \" +\n \"function execution, with start and end status (sucessfully or crashed).\")\n matrix_parser.add_argument(\n \"--homeserver\", type=str, required=True,\n help=\"The homeserver address which was used to register the BOT.\")\n matrix_parser.add_argument(\n \"--token\", type=str, required=True,\n help=\"The access TOKEN of the user that will send the messages.\")\n matrix_parser.add_argument(\n \"--room\", type=str, required=True,\n help=\"The alias of the room to which messages will be send by the BOT.\")\n matrix_parser.set_defaults(sender_func=matrix_sender)\n\n # RocketChat\n rocketchat_parser = subparsers.add_parser(\n name=\"rocketchat\", description=\"Send a RocketChat message before and after function \" +\n \"execution, with start and end status (sucessfully or crashed).\")\n rocketchat_parser.add_argument(\n \"--rocketchat-server-url\", type=str, required=True,\n help=\"The RocketChat server URL.\")\n rocketchat_parser.add_argument(\n \"--rocketchat-user-id\", type=str, required=True,\n help=\"The RocketChat user id to post messages with (you'll be able to view your user id when you create a personal access token).\")\n rocketchat_parser.add_argument(\n \"--rocketchat-auth-token\", type=str, required=True,\n help=\"The RocketChat personal access token.\" +\n \"Visit https://rocket.chat/docs/developer-guides/rest-api/personal-access-tokens/ for more details.\")\n rocketchat_parser.add_argument(\n \"--channel\", type=str, required=True, help=\"The RocketChat channel to log.\")\n rocketchat_parser.add_argument(\n \"--user-mentions\", type=lambda s: s.split(\",\"), required=False, default=[],\n help=\"Optional user names to notify, as comma seperated list.\")\n rocketchat_parser.add_argument(\n \"--alias\", type=str, required=False, default=\"\", help=\"Optional alias to use for the notification.\")\n rocketchat_parser.set_defaults(sender_func=rocketchat_sender)\n\n # WeChat Work\n wechat_parser = subparsers.add_parser(\n name=\"wechat\", description=\"Send a WeChat Work message before and after function \" +\n \"execution, with start and end status (sucessfully or crashed).\")\n wechat_parser.add_argument(\n \"--webhook-url\", type=str, required=True,\n help=\"The webhook URL to access your wechat_work chatroom\")\n wechat_parser.add_argument(\n \"--user-mentions\", type=lambda s: s.split(\",\"), required=False, default=[],\n help=\"Optional userids to notify (use '@all' for all group members), as comma seperated list.\")\n wechat_parser.add_argument(\n \"--user-mentions-mobile\", type=lambda s: s.split(\",\"), required=False, default=[],\n help=\"Optional user phone numbers to notify (use '@all' for all group members), as comma seperated list.\")\n wechat_parser.set_defaults(sender_func=wechat_sender)\n\n args, remaining_args = parser.parse_known_args()\n args = vars(args)\n\n sender_func = args.pop(\"sender_func\", None)\n\n if sender_func is None:\n parser.print_help()\n exit(1)\n\n verbose = args.pop(\"verbose\")\n\n def run_func(): return subprocess.run(remaining_args, check=True)\n run_func.__name__ = \" \".join(\n remaining_args) if verbose else remaining_args[0]\n\n sender_func(**args)(run_func)()\n\n\nif __name__ == \"__main__\":\n main()\n"} | null |
Langchain-Series | {"type": "directory", "name": "Langchain-Series", "children": [{"type": "file", "name": "chatBot.py"}, {"type": "file", "name": "coder.py"}, {"type": "file", "name": "imageProcessing.py"}, {"type": "file", "name": "imageRetriever.py"}, {"type": "file", "name": "LICENSE"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "tavilyDdg.py"}, {"type": "file", "name": "usage.py"}, {"type": "file", "name": "vectorStore.py"}, {"type": "file", "name": "wikiDdgAgent.py"}]} | # AI Assistant Repository
This repository contains a collection of Python scripts that implement various AI functionalities, including a chatbot powered by Wikipedia and DuckDuckGo search, a code generation and testing AI, image processing with caption generation, and an image retrieval system. The project utilizes the Langchain framework, Hugging Face models, and various APIs for information retrieval and image processing.
## Features
1. **Chatbot Application (`chatBot.py`)**:
- An interactive AI tutor that answers questions by searching Wikipedia and DuckDuckGo.
- Integrates real-time text generation using Hugging Face models.
2. **Code Generation and Testing (`coder.py`)**:
- An AI agent that can generate Python code based on user prompts.
- Includes functionality to create test functions for the generated code and run tests to check correctness.
3. **Image Processing and Captioning (`imageProcessing.py`)**:
- Generates detailed captions for input images using Google's Gemini API.
- Downloads images from the web based on user queries.
4. **Image Retrieval (`imageRetriever.py`)**:
- A simple image downloader that retrieves images from Bing based on specified keywords.
5. **Vector Store and Retrieval (`vectorStore.py`)**:
- Implements a vector store to manage and retrieve documents using embeddings from Hugging Face.
- Supports question-answering functionality over the stored documents.
6. **Agents for Information Retrieval (`tavilyDdg.py`, `wikiDdgAgent.py`)**:
- Define agents that utilize Tavily and DuckDuckGo or Wikipedia for answering questions.
- These agents are designed to assist users in retrieving high-quality information.
## Installation
To set up the project, follow these steps:
1. **Clone the repository**:
```bash
git clone https://github.com/hamza-amin-4365/Langchain-Series.git
cd Langchain-Series
```
2. **Install the required packages**:
Ensure you have Python installed (preferably Python 3.7 or higher). You can create a virtual environment and install dependencies using pip:
```bash
python -m venv venv
source venv/bin/activate # On Windows use `venv\Scripts\activate`
pip install -r requirements.txt
```
3. **Set up environment variables**:
Create a `.env` file in the root directory of the project and add the following variables:
```bash
huggingfacehub_api_token=YOUR_HUGGINGFACE_API_TOKEN
Gemin_api_key=YOUR_GOOGLE_GENERATIVE_AI_API_KEY
TAVILY_API_KEY=YOUR_TAVILY_API_KEY
```
4. **Run the applications**:
- For the Chatbot:
```bash
streamlit run chatBot.py
```
- For the Code Generator:
```bash
python coder.py
```
- For Image Processing:
```bash
python usage.py # Adjust the usage as necessary based on your needs
```
- For Image Retrieval:
```bash
python imageRetriever.py
```
## Usage
- **Chatbot**: Ask questions related to various subjects, and the AI will respond with a combination of Wikipedia and DuckDuckGo results.
- **Code Generation**: Provide a description of what you want to achieve, and the AI will generate the corresponding Python code.
- **Image Processing**: Supply an image, and the AI will generate a descriptive caption for it.
- **Image Retrieval**: Enter a keyword to download related images from Bing.
## Contributing
Contributions are welcome! If you have suggestions or improvements, please feel free to submit a pull request. Make sure to follow the coding standards and include tests for your changes.
## License
This project is licensed under the MIT License. See the [LICENSE](LICENSE) file for more details.
---
This README provides an overview of the capabilities and functionality of the AI Assistant repository. For further details about each script, please refer to the respective source files.
| {"requirements.txt": "langchain\nlangchain_community\nhuggingface_hub\nduckduckgo_search\nstreamlit\npython-dotenv\npytest\npython-tavily\ntransformers\nunittest", ".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 d19525fead29b19b9d7c8c523295701bf4b8230b Hamza Amin <[email protected]> 1727376260 +0500\tclone: from https://github.com/hamza-amin-4365/Langchain-Series.git\n", ".git\\refs\\heads\\main": "d19525fead29b19b9d7c8c523295701bf4b8230b\n"} | null |