
repo_id
stringlengths 1
51
| file_structure
stringlengths 56
247k
| readme_content
stringlengths 0
287k
| key_code_snippets
stringlengths 1.04k
16.8M
| __index_level_0__
float64 0
7
⌀ |
|---|---|---|---|---|
large_language_model_training_playbook | {"type": "directory", "name": "large_language_model_training_playbook", "children": [{"type": "directory", "name": "architecture", "children": [{"type": "file", "name": "README.md"}]}, {"type": "directory", "name": "assets", "children": []}, {"type": "file", "name": "CODE_OF_CONDUCT.md"}, {"type": "file", "name": "CONTRIBUTING.md"}, {"type": "directory", "name": "debug", "children": [{"type": "file", "name": "NicerTrace.py"}, {"type": "file", "name": "printflock.py"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "torch-distributed-gpu-test.py"}]}, {"type": "directory", "name": "hparams", "children": [{"type": "file", "name": "README.md"}]}, {"type": "directory", "name": "instabilities", "children": [{"type": "file", "name": "README.md"}]}, {"type": "file", "name": "LICENSE"}, {"type": "directory", "name": "parallelism", "children": [{"type": "file", "name": "README.md"}]}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "resources", "children": [{"type": "file", "name": "README.md"}]}, {"type": "directory", "name": "throughput", "children": [{"type": "file", "name": "all_reduce_bench.py"}, {"type": "file", "name": "README.md"}]}]} | # How to Maximize Training Throughput
The faster you can make your model to train the sooner the model will finish training, which is important not only to being first to publish something, but also potentially saving a lot of money.
In general maximizing throughput is all about running many experiments and measuring the outcome and chosing the one that is superior.
In certain situations your modeling team may ask you to choose some hyper parameters that will be detrimental to throughput but overall beneficial for the overall model's success.
## Crucial reproducibility requirements
The most important requirements for a series of successful experiments is to be able to reproduce the experiment environment again and again while changing only one or a few setup variables.
Therefore when you try to figure out whether some change will improve performance or make it worse, you must figure out how to keep things stable.
For example, you need to find a way to prevent the network usage from fluctuations. When we were doing performance optimizations for [108B pre-BLOOM experiments](https://github.com/bigscience-workshop/bigscience/tree/master/train/tr8-104B-wide) it was close to impossible to perform, since we were on a shared internode network and the exact same setup would yield different throughput depending on how many other users used the network. It was not working. During BLOOM-176B we were given a dedicated SLURM partition with an isolated network where the only traffic was ours. Doing the performance optimization in such environment was just perfect.
## Network throughput
It's critical to understand your particular model size and framework requirements with regard to network bandwidth, throughput and latency. If you underpay for network you will end up having idle gpus and thus you wasted money and time. If you overpay for very fast network, but your gpus are slow, then again you wasted money and time.
If your network is very slow, your training is likely to be network-bound and many improvements in the training setup will not help with the improving performance.
Here is a simple all-reduce benchmark that you can use to quickly measure the throughput of your internode network:
[all_reduce_bench.py](./all_reduce_bench.py)
Usually benchmarking at least 4 nodes is recommended, but, of course, if you already have access to all the nodes you will be using during the training, benchmark using all of the nodes.
To run it on 4 nodes
```
python -m torch.distributed.run --nproc_per_node=4 all_reduce_bench.py
```
You may get results anywhere between 5Gbps and 1600Gbps (as of this writing). The minimal speed to prevent being network bound will depend on your particular training framework, but typically you'd want at least 400Gbps or higher. Though we trained BLOOM on 50Gbps.
Frameworks that shard weights and optim stages like [Deepspeed](https://github.com/microsoft/DeepSpeed) w/ ZeRO Stage-3 do a lot more traffic than frameworks like [Megatron-Deepspeed](https://github.com/bigscience-workshop/Megatron-DeepSpeed) which do tensor and pipeline parallelism in addition to data parallelism. The latter ones only send activations across and thus don't need as much bandwidth. But they are much more complicated to set up and run.
Of course, an efficient framework will overlap communications and compute, so that while one stage is fetching data, the other stage in parallel runs computations. So as long as the communication overhead is smaller than compute the network requirements are satisfied and don't have to be super fantastic.
## Checkpoint activations
Enabling checkpoint activations allows one to trade speed for memory. When this feature is activated instead of remembering the outputs of, say, transformer blocks until the backward pass is done, these outputs are dropped. This frees up huge amounts of GPU memory. But, of course, a backward pass is not possible without having the outputs of forward pass, and thus they have to be recalculated.
This, of course, can vary from model to model, but typically one pays with about 20-25% decrease in throughput, but since a huge amount of gpu memory is liberated, one can now increase the batch size per gpu and thus overall improve the effective throughput of the system.
## Vector and matrix size divisibility
### Tile and wave quantization
XXX
### Number/size of Attention heads
XXX
### Understanding TFLOPs
| {".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 efa7884290d9e8b942c61b83c03c80932b9dcf1b Hamza Amin <[email protected]> 1727369258 +0500\tclone: from https://github.com/huggingface/large_language_model_training_playbook.git\n", ".git\\refs\\heads\\main": "efa7884290d9e8b942c61b83c03c80932b9dcf1b\n"} | null |
leaderboards | {"type": "directory", "name": "leaderboards", "children": [{"type": "directory", "name": "docs", "children": [{"type": "directory", "name": "source", "children": [{"type": "directory", "name": "en", "children": [{"type": "file", "name": "index.md"}, {"type": "directory", "name": "leaderboards", "children": [{"type": "file", "name": "building_page.md"}, {"type": "file", "name": "extras.md"}, {"type": "file", "name": "finding_page.md"}, {"type": "file", "name": "intro.md"}]}, {"type": "directory", "name": "open_llm_leaderboard", "children": [{"type": "file", "name": "about.md"}, {"type": "file", "name": "archive.md"}, {"type": "file", "name": "faq.md"}, {"type": "file", "name": "normalization.md"}, {"type": "file", "name": "submitting.md"}]}, {"type": "file", "name": "_toctree.yml"}]}]}]}, {"type": "file", "name": "README.md"}]} | # Setup
```bash
pip install watchdog git+https://github.com/huggingface/doc-builder.git
```
# Build Documentation
```bash
doc-builder build leaderboard docs/source/en --build_dir build_dir --not_python_module
```
# Preview Documentation
```bash
doc-builder preview leaderboard docs/source/en/ --not_python_module
```
| {".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 ed42441704949430ddde485d9a570be279437d52 Hamza Amin <[email protected]> 1727369261 +0500\tclone: from https://github.com/huggingface/leaderboards.git\n", ".git\\refs\\heads\\main": "ed42441704949430ddde485d9a570be279437d52\n", "docs\\source\\en\\index.md": "# Leaderboards and Evaluations\n\nAs the number of open and closed source machine learning models explodes, it can be very hard to find the correct model for your project. \nThis is why we started our evaluations projects:\n- the `Open LLM Leaderboard` evaluates and ranks open source LLMs and chatbots, and provides reproducible scores separating marketing fluff from actual progress in the field.\n- `Leaderboards on the Hub` aims to gather machine learning leaderboards on the Hugging Face Hub and support evaluation creators. \n\nExplore machine learning rankings to find the best model for your use case, or build your own leaderboard, to test specific capabilities which interest you and the community!\n\n<div class=\"mt-10\">\n <div class=\"w-full flex flex-col space-y-4 md:space-y-0 md:grid md:grid-cols-3 md:gap-5\">\n <a class=\"!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg\" href=\"./leaderboards/intro\">\n <div class=\"w-full text-center bg-gradient-to-br from-green-400 to-green-500 rounded-lg py-1.5 font-semibold mb-5 text-white text-lg leading-relaxed\">Leaderboards on the Hub</div>\n <p class=\"text-gray-700\">A small introduction to all things leaderboards on the hub.</p>\n </a>\n <a class=\"!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg\" href=\"./open_llm_leaderboard/about\">\n <div class=\"w-full text-center bg-gradient-to-br from-orange-400 to-orange-500 rounded-lg py-1.5 font-semibold mb-5 text-white text-lg leading-relaxed\">Open LLM Leaderboard</div>\n <p class=\"text-gray-700\">Curious about the Open LLM Leaderboard? Start here!</p>\n </a>\n </div>\n</div>\n"} | null |
lighteval | {"type": "directory", "name": "lighteval", "children": [{"type": "file", "name": ".pre-commit-config.yaml"}, {"type": "directory", "name": "assets", "children": [{"type": "file", "name": "lighteval-doc.svg"}]}, {"type": "directory", "name": "community_tasks", "children": [{"type": "file", "name": "aimo_evals.py"}, {"type": "file", "name": "arabic_evals.py"}, {"type": "file", "name": "german_rag_evals.py"}, {"type": "file", "name": "_template.py"}]}, {"type": "directory", "name": "examples", "children": [{"type": "directory", "name": "model_configs", "children": [{"type": "file", "name": "base_model.yaml"}, {"type": "file", "name": "endpoint_model.yaml"}, {"type": "file", "name": "peft_model.yaml"}, {"type": "file", "name": "quantized_model.yaml"}, {"type": "file", "name": "tgi_model.yaml"}]}, {"type": "directory", "name": "nanotron", "children": [{"type": "file", "name": "custom_evaluation_tasks.py"}, {"type": "file", "name": "custom_task.py"}, {"type": "file", "name": "lighteval_config_override_template.yaml"}]}, {"type": "directory", "name": "tasks", "children": [{"type": "file", "name": "all_arabic_tasks.txt"}, {"type": "file", "name": "all_german_rag_evals.txt"}, {"type": "file", "name": "all_tasks.txt"}, {"type": "file", "name": "bbh.txt"}, {"type": "file", "name": "OALL_tasks.txt"}, {"type": "file", "name": "open_llm_leaderboard_tasks.txt"}, {"type": "file", "name": "recommended_set.txt"}]}]}, {"type": "file", "name": "LICENSE"}, {"type": "file", "name": "Makefile"}, {"type": "file", "name": "MANIFEST.in"}, {"type": "file", "name": "pyproject.toml"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "setup.py"}, {"type": "directory", "name": "src", "children": [{"type": "directory", "name": "lighteval", "children": [{"type": "directory", "name": "config", "children": [{"type": "file", "name": "lighteval_config.py"}]}, {"type": "file", "name": "data.py"}, {"type": "directory", "name": "logging", "children": [{"type": "file", "name": "evaluation_tracker.py"}, {"type": "file", "name": "hierarchical_logger.py"}, {"type": "file", "name": "info_loggers.py"}]}, {"type": "file", "name": "main_accelerate.py"}, {"type": "file", "name": "main_nanotron.py"}, {"type": "directory", "name": "metrics", "children": [{"type": "file", "name": "dynamic_metrics.py"}, {"type": "directory", "name": "harness_compatibility", "children": [{"type": "file", "name": "drop.py"}, {"type": "file", "name": "truthful_qa.py"}]}, {"type": "directory", "name": "imports", "children": [{"type": "file", "name": "bert_scorer.py"}, {"type": "file", "name": "data_stats_metric.py"}, {"type": "file", "name": "data_stats_utils.py"}, {"type": "file", "name": "summac.py"}]}, {"type": "file", "name": "judge_prompts.jsonl"}, {"type": "file", "name": "llm_as_judge.py"}, {"type": "file", "name": "metrics.py"}, {"type": "file", "name": "metrics_corpus.py"}, {"type": "file", "name": "metrics_sample.py"}, {"type": "file", "name": "normalizations.py"}, {"type": "file", "name": "sample_preparator.py"}, {"type": "file", "name": "stderr.py"}, {"type": "file", "name": "utils.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "models", "children": [{"type": "file", "name": "abstract_model.py"}, {"type": "file", "name": "adapter_model.py"}, {"type": "file", "name": "base_model.py"}, {"type": "file", "name": "delta_model.py"}, {"type": "file", "name": "dummy_model.py"}, {"type": "file", "name": "endpoint_model.py"}, {"type": "file", "name": "model_config.py"}, {"type": "file", "name": "model_loader.py"}, {"type": "file", "name": "model_output.py"}, {"type": "file", "name": "nanotron_model.py"}, {"type": "file", "name": "tgi_model.py"}, {"type": "file", "name": "utils.py"}, {"type": "file", "name": "vllm_model.py"}]}, {"type": "file", "name": "parsers.py"}, {"type": "file", "name": "pipeline.py"}, {"type": "directory", "name": "tasks", "children": [{"type": "file", "name": "default_prompts.py"}, {"type": "file", "name": "default_tasks.py"}, {"type": "directory", "name": "extended", "children": [{"type": "directory", "name": "ifeval", "children": [{"type": "file", "name": "instructions.py"}, {"type": "file", "name": "instructions_registry.py"}, {"type": "file", "name": "instructions_utils.py"}, {"type": "file", "name": "main.py"}]}, {"type": "directory", "name": "mt_bench", "children": [{"type": "file", "name": "main.py"}]}, {"type": "directory", "name": "tiny_benchmarks", "children": [{"type": "file", "name": "main.py"}]}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "lighteval_task.py"}, {"type": "file", "name": "prompt_manager.py"}, {"type": "file", "name": "registry.py"}, {"type": "file", "name": "requests.py"}]}, {"type": "directory", "name": "utils", "children": [{"type": "file", "name": "imports.py"}, {"type": "file", "name": "parallelism.py"}, {"type": "file", "name": "utils.py"}]}, {"type": "file", "name": "__init__.py"}, {"type": "file", "name": "__main__.py"}]}]}, {"type": "directory", "name": "tests", "children": [{"type": "file", "name": "fixtures.py"}, {"type": "directory", "name": "logging", "children": [{"type": "file", "name": "test_evaluation_tracker.py"}]}, {"type": "directory", "name": "metrics", "children": [{"type": "file", "name": "test_metric_requests.py"}, {"type": "file", "name": "test_normalizations.py"}]}, {"type": "directory", "name": "models", "children": [{"type": "file", "name": "test_abstract_mode.py"}]}, {"type": "directory", "name": "reference_scores", "children": [{"type": "file", "name": "harness_metrics.json"}, {"type": "file", "name": "harness_prompts.json"}, {"type": "file", "name": "reference_tasks.py"}, {"type": "file", "name": "reference_task_scores.py"}]}, {"type": "directory", "name": "tasks", "children": [{"type": "file", "name": "test_lighteval_task.py"}]}, {"type": "file", "name": "test_main.py"}, {"type": "file", "name": "test_unit_base_metrics.py"}, {"type": "file", "name": "test_unit_harness_metrics.py"}, {"type": "file", "name": "test_unit_harness_prompts.py"}, {"type": "file", "name": "test_unit_reorder.py"}, {"type": "file", "name": "utils.py"}, {"type": "file", "name": "__init__.py"}]}]} | <p align="center">
<br/>
<img alt="lighteval library logo" src="./assets/lighteval-doc.svg" width="376" height="59" style="max-width: 100%;">
<br/>
</p>
<p align="center">
<i>Your go-to toolkit for lightning-fast, flexible LLM evaluation, from Hugging Face's Leaderboard and Evals Team.</i>
</p>
<div align="center">
[](https://github.com/huggingface/lighteval/actions/workflows/tests.yaml?query=branch%3Amain)
[](https://github.com/huggingface/lighteval/actions/workflows/quality.yaml?query=branch%3Amain)
[](https://www.python.org/downloads/)
[](https://github.com/huggingface/lighteval/blob/main/LICENSE)
[](https://pypi.org/project/lighteval/)
</div>
---
**Documentation**: <a href="https://github.com/huggingface/lighteval/wiki" target="_blank">Lighteval's Wiki</a>
---
### Unlock the Power of LLM Evaluation with Lighteval 🚀
**Lighteval** is your all-in-one toolkit for evaluating LLMs across multiple
backends—whether it's
[transformers](https://github.com/huggingface/transformers),
[tgi](https://github.com/huggingface/text-generation-inference),
[vllm](https://github.com/vllm-project/vllm), or
[nanotron](https://github.com/huggingface/nanotron)—with
ease. Dive deep into your model’s performance by saving and exploring detailed,
sample-by-sample results to debug and see how your models stack-up.
Customization at your fingertips: letting you either browse all our existing [tasks](https://github.com/huggingface/lighteval/wiki/Available-Tasks) and [metrics](https://github.com/huggingface/lighteval/wiki/Metric-List) or effortlessly [create your own](https://github.com/huggingface/lighteval/wiki/Adding-a-Custom-Task), tailored to your needs.
Seamlessly experiment, benchmark, and store your results on the Hugging Face
Hub, S3, or locally.
## 🔑 Key Features
- **Speed**: [Use vllm as backend for fast evals](https://github.com/huggingface/lighteval/wiki/Use-VLLM-as-backend).
- **Completeness**: [Use the accelerate backend to launch any models hosted on Hugging Face](https://github.com/huggingface/lighteval/wiki/Quicktour#accelerate).
- **Seamless Storage**: [Save results in S3 or Hugging Face Datasets](https://github.com/huggingface/lighteval/wiki/Saving-and-reading-results).
- **Python API**: [Simple integration with the Python API](https://github.com/huggingface/lighteval/wiki/Using-the-Python-API).
- **Custom Tasks**: [Easily add custom tasks](https://github.com/huggingface/lighteval/wiki/Adding-a-Custom-Task).
- **Versatility**: Tons of [metrics](https://github.com/huggingface/lighteval/wiki/Metric-List) and [tasks](https://github.com/huggingface/lighteval/wiki/Available-Tasks) ready to go.
## ⚡️ Installation
```bash
pip install lighteval[accelerate]
```
Lighteval allows for many extras when installing, see [here](https://github.com/huggingface/lighteval/wiki/Installation) for a complete list.
If you want to push results to the Hugging Face Hub, add your access token as
an environment variable:
```shell
huggingface-cli login
```
## 🚀 Quickstart
Lighteval offers two main entry points for model evaluation:
* `lighteval accelerate`: evaluate models on CPU or one or more GPUs using [🤗
Accelerate](https://github.com/huggingface/accelerate).
* `lighteval nanotron`: evaluate models in distributed settings using [⚡️
Nanotron](https://github.com/huggingface/nanotron).
Here’s a quick command to evaluate using the Accelerate backend:
```shell
lighteval accelerate \
--model_args "pretrained=gpt2" \
--tasks "leaderboard|truthfulqa:mc|0|0" \
--override_batch_size 1 \
--output_dir="./evals/"
```
## 🙏 Acknowledgements
Lighteval started as an extension of the fantastic [Eleuther AI
Harness](https://github.com/EleutherAI/lm-evaluation-harness) (which powers the
[Open LLM
Leaderboard](https://huggingface.co/spaces/open-llm-leaderboard/open_llm_leaderboard))
and draws inspiration from the amazing
[HELM](https://crfm.stanford.edu/helm/latest/) framework.
While evolving Lighteval into its own standalone tool, we are grateful to the
Harness and HELM teams for their pioneering work on LLM evaluations.
## 🌟 Contributions Welcome 💙💚💛💜🧡
Got ideas? Found a bug? Want to add a
[task](https://github.com/huggingface/lighteval/wiki/Adding-a-Custom-Task) or
[metric](https://github.com/huggingface/lighteval/wiki/Adding-a-New-Metric)?
Contributions are warmly
welcomed!
## 📜 Citation
```bibtex
@misc{lighteval,
author = {Fourrier, Clémentine and Habib, Nathan and Wolf, Thomas and Tunstall, Lewis},
title = {LightEval: A lightweight framework for LLM evaluation},
year = {2023},
version = {0.5.0},
url = {https://github.com/huggingface/lighteval}
}
```
| {"setup.py": "# MIT License\n\n# Copyright (c) 2024 The HuggingFace Team\n\n# Permission is hereby granted, free of charge, to any person obtaining a copy\n# of this software and associated documentation files (the \"Software\"), to deal\n# in the Software without restriction, including without limitation the rights\n# to use, copy, modify, merge, publish, distribute, sublicense, and/or sell\n# copies of the Software, and to permit persons to whom the Software is\n# furnished to do so, subject to the following conditions:\n\n# The above copyright notice and this permission notice shall be included in all\n# copies or substantial portions of the Software.\n\n# THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR\n# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,\n# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE\n# AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER\n# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,\n# OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE\n# SOFTWARE.\n\nfrom setuptools import setup\n\n\nsetup()\n", ".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 ba2024802dfb3ced3487d498e5c5ecc00c11634f Hamza Amin <[email protected]> 1727369348 +0500\tclone: from https://github.com/huggingface/lighteval.git\n", ".git\\refs\\heads\\main": "ba2024802dfb3ced3487d498e5c5ecc00c11634f\n", "src\\lighteval\\main_accelerate.py": "# MIT License\n\n# Copyright (c) 2024 The HuggingFace Team\n\n# Permission is hereby granted, free of charge, to any person obtaining a copy\n# of this software and associated documentation files (the \"Software\"), to deal\n# in the Software without restriction, including without limitation the rights\n# to use, copy, modify, merge, publish, distribute, sublicense, and/or sell\n# copies of the Software, and to permit persons to whom the Software is\n# furnished to do so, subject to the following conditions:\n\n# The above copyright notice and this permission notice shall be included in all\n# copies or substantial portions of the Software.\n\n# THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR\n# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,\n# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE\n# AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER\n# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,\n# OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE\n# SOFTWARE.\n\nimport os\nfrom datetime import timedelta\n\nfrom lighteval.logging.evaluation_tracker import EvaluationTracker\nfrom lighteval.logging.hierarchical_logger import hlog_warn, htrack\nfrom lighteval.models.model_config import create_model_config\nfrom lighteval.pipeline import EnvConfig, ParallelismManager, Pipeline, PipelineParameters\nfrom lighteval.utils.imports import is_accelerate_available, is_tgi_available\n\n\nif not is_accelerate_available() and not is_tgi_available():\n hlog_warn(\"Using either accelerate or text-generation to run this script is advised.\")\n\nTOKEN = os.getenv(\"HF_TOKEN\")\n\nif is_accelerate_available():\n from accelerate import Accelerator, InitProcessGroupKwargs\n\n accelerator = Accelerator(kwargs_handlers=[InitProcessGroupKwargs(timeout=timedelta(seconds=3000))])\nelse:\n accelerator = None\n\n\n@htrack()\ndef main(args):\n env_config = EnvConfig(token=TOKEN, cache_dir=args.cache_dir)\n evaluation_tracker = EvaluationTracker(\n output_dir=args.output_dir,\n save_details=args.save_details,\n push_to_hub=args.push_to_hub,\n push_to_tensorboard=args.push_to_tensorboard,\n public=args.public_run,\n hub_results_org=args.results_org,\n )\n pipeline_params = PipelineParameters(\n launcher_type=ParallelismManager.ACCELERATE,\n env_config=env_config,\n job_id=args.job_id,\n dataset_loading_processes=args.dataset_loading_processes,\n custom_tasks_directory=args.custom_tasks,\n override_batch_size=args.override_batch_size,\n num_fewshot_seeds=args.num_fewshot_seeds,\n max_samples=args.max_samples,\n use_chat_template=args.use_chat_template,\n system_prompt=args.system_prompt,\n )\n\n model_config = create_model_config(\n use_chat_template=args.use_chat_template,\n override_batch_size=args.override_batch_size,\n model_args=args.model_args,\n model_config_path=args.model_config_path,\n accelerator=accelerator,\n )\n\n pipeline = Pipeline(\n tasks=args.tasks,\n pipeline_parameters=pipeline_params,\n evaluation_tracker=evaluation_tracker,\n model_config=model_config,\n )\n\n pipeline.evaluate()\n\n pipeline.show_results()\n\n results = pipeline.get_results()\n\n pipeline.save_and_push_results()\n\n return results\n", "src\\lighteval\\main_nanotron.py": "# MIT License\n\n# Copyright (c) 2024 The HuggingFace Team\n\n# Permission is hereby granted, free of charge, to any person obtaining a copy\n# of this software and associated documentation files (the \"Software\"), to deal\n# in the Software without restriction, including without limitation the rights\n# to use, copy, modify, merge, publish, distribute, sublicense, and/or sell\n# copies of the Software, and to permit persons to whom the Software is\n# furnished to do so, subject to the following conditions:\n\n# The above copyright notice and this permission notice shall be included in all\n# copies or substantial portions of the Software.\n\n# THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR\n# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,\n# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE\n# AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER\n# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,\n# OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE\n# SOFTWARE.\n\n# flake8: noqa: C901\nimport os\nfrom typing import Optional\n\nfrom lighteval.config.lighteval_config import FullNanotronConfig, LightEvalConfig\nfrom lighteval.logging.evaluation_tracker import EvaluationTracker\nfrom lighteval.logging.hierarchical_logger import htrack, htrack_block\nfrom lighteval.pipeline import ParallelismManager, Pipeline, PipelineParameters\nfrom lighteval.utils.imports import NO_NANOTRON_ERROR_MSG, is_nanotron_available\nfrom lighteval.utils.utils import EnvConfig\n\n\nif not is_nanotron_available():\n raise ImportError(NO_NANOTRON_ERROR_MSG)\n\nfrom nanotron.config import Config, get_config_from_file\n\n\nSEED = 1234\n\n\n@htrack()\ndef main(\n checkpoint_config_path: str,\n lighteval_config_path: Optional[str] = None,\n cache_dir: Optional[str] = os.getenv(\"HF_HOME\", \"/scratch\"),\n):\n env_config = EnvConfig(token=os.getenv(\"HF_TOKEN\"), cache_dir=cache_dir)\n\n with htrack_block(\"Load nanotron config\"):\n # Create nanotron config\n if not checkpoint_config_path.endswith(\".yaml\"):\n raise ValueError(\"The checkpoint path should point to a YAML file\")\n\n model_config = get_config_from_file(\n checkpoint_config_path,\n config_class=Config,\n model_config_class=None,\n skip_unused_config_keys=True,\n skip_null_keys=True,\n )\n\n # We are getting an type error, because the get_config_from_file is not correctly typed,\n lighteval_config: LightEvalConfig = get_config_from_file(lighteval_config_path, config_class=LightEvalConfig) # type: ignore\n nanotron_config = FullNanotronConfig(lighteval_config, model_config)\n\n evaluation_tracker = EvaluationTracker(\n output_dir=lighteval_config.logging.output_dir,\n hub_results_org=lighteval_config.logging.results_org,\n public=lighteval_config.logging.public_run,\n push_to_hub=lighteval_config.logging.push_to_hub,\n push_to_tensorboard=lighteval_config.logging.push_to_tensorboard,\n save_details=lighteval_config.logging.save_details,\n tensorboard_metric_prefix=lighteval_config.logging.tensorboard_metric_prefix,\n nanotron_run_info=nanotron_config.nanotron_config.general,\n )\n\n pipeline_parameters = PipelineParameters(\n launcher_type=ParallelismManager.NANOTRON,\n env_config=env_config,\n job_id=os.environ.get(\"SLURM_JOB_ID\", 0),\n nanotron_checkpoint_path=checkpoint_config_path,\n dataset_loading_processes=lighteval_config.tasks.dataset_loading_processes,\n custom_tasks_directory=lighteval_config.tasks.custom_tasks,\n override_batch_size=lighteval_config.batch_size,\n num_fewshot_seeds=1,\n max_samples=lighteval_config.tasks.max_samples,\n use_chat_template=False,\n system_prompt=None,\n )\n\n pipeline = Pipeline(\n tasks=lighteval_config.tasks.tasks,\n pipeline_parameters=pipeline_parameters,\n evaluation_tracker=evaluation_tracker,\n model_config=nanotron_config,\n )\n\n pipeline.evaluate()\n\n pipeline.show_results()\n\n pipeline.save_and_push_results()\n", "src\\lighteval\\__main__.py": "#!/usr/bin/env python\n\n# MIT License\n\n# Copyright (c) 2024 Taratra D. RAHARISON and The HuggingFace Team\n\n# Permission is hereby granted, free of charge, to any person obtaining a copy\n# of this software and associated documentation files (the \"Software\"), to deal\n# in the Software without restriction, including without limitation the rights\n# to use, copy, modify, merge, publish, distribute, sublicense, and/or sell\n# copies of the Software, and to permit persons to whom the Software is\n# furnished to do so, subject to the following conditions:\n\n# The above copyright notice and this permission notice shall be included in all\n# copies or substantial portions of the Software.\n\n# THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR\n# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,\n# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE\n# AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER\n# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,\n# OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE\n# SOFTWARE.\n\nimport argparse\nimport os\nfrom dataclasses import asdict\nfrom pprint import pformat\n\nfrom lighteval.parsers import parser_accelerate, parser_nanotron, parser_utils_tasks\nfrom lighteval.tasks.registry import Registry, taskinfo_selector\n\n\nCACHE_DIR = os.getenv(\"HF_HOME\")\n\n\ndef cli_evaluate():\n parser = argparse.ArgumentParser(description=\"CLI tool for lighteval, a lightweight framework for LLM evaluation\")\n subparsers = parser.add_subparsers(help=\"help for subcommand\", dest=\"subcommand\")\n\n # Subparser for the \"accelerate\" command\n parser_a = subparsers.add_parser(\"accelerate\", help=\"use accelerate and transformers as backend for evaluation.\")\n parser_accelerate(parser_a)\n\n # Subparser for the \"nanotron\" command\n parser_b = subparsers.add_parser(\"nanotron\", help=\"use nanotron as backend for evaluation.\")\n parser_nanotron(parser_b)\n\n # Subparser for task utils functions\n parser_c = subparsers.add_parser(\"tasks\", help=\"display information about available tasks and samples.\")\n parser_utils_tasks(parser_c)\n\n args = parser.parse_args()\n\n if args.subcommand == \"accelerate\":\n from lighteval.main_accelerate import main as main_accelerate\n\n main_accelerate(args)\n\n elif args.subcommand == \"nanotron\":\n from lighteval.main_nanotron import main as main_nanotron\n\n main_nanotron(args.checkpoint_config_path, args.lighteval_config_path, args.cache_dir)\n\n elif args.subcommand == \"tasks\":\n if args.list:\n Registry(cache_dir=\"\").print_all_tasks()\n\n if args.inspect:\n print(f\"Loading the tasks dataset to cache folder: {args.cache_dir}\")\n print(\n \"All examples will be displayed without few shot, as few shot sample construction requires loading a model and using its tokenizer. \"\n )\n # Loading task\n task_names_list, _ = taskinfo_selector(args.inspect)\n task_dict = Registry(cache_dir=args.cache_dir).get_task_dict(task_names_list)\n for name, task in task_dict.items():\n print(\"-\" * 10, name, \"-\" * 10)\n if args.show_config:\n print(\"-\" * 10, \"CONFIG\")\n task.cfg.print()\n for ix, sample in enumerate(task.eval_docs()[: int(args.num_samples)]):\n if ix == 0:\n print(\"-\" * 10, \"SAMPLES\")\n print(f\"-- sample {ix} --\")\n print(pformat(asdict(sample), indent=1))\n\n else:\n print(\"You did not provide any argument. Exiting\")\n\n\nif __name__ == \"__main__\":\n cli_evaluate()\n", "src\\lighteval\\tasks\\extended\\ifeval\\main.py": "# MIT License\n\n# Copyright (c) 2024 The HuggingFace Team\n\n# Permission is hereby granted, free of charge, to any person obtaining a copy\n# of this software and associated documentation files (the \"Software\"), to deal\n# in the Software without restriction, including without limitation the rights\n# to use, copy, modify, merge, publish, distribute, sublicense, and/or sell\n# copies of the Software, and to permit persons to whom the Software is\n# furnished to do so, subject to the following conditions:\n\n# The above copyright notice and this permission notice shall be included in all\n# copies or substantial portions of the Software.\n\n# THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR\n# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,\n# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE\n# AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER\n# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,\n# OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE\n# SOFTWARE.\n\nimport numpy as np\nfrom aenum import extend_enum\n\nimport lighteval.tasks.extended.ifeval.instructions_registry as instructions_registry\nfrom lighteval.metrics.metrics import Metrics\nfrom lighteval.metrics.utils import (\n MetricCategory,\n MetricUseCase,\n SampleLevelMetricGrouping,\n)\nfrom lighteval.tasks.lighteval_task import LightevalTaskConfig\nfrom lighteval.tasks.requests import Doc\n\n\n# Very specific task where there are no precise outputs but instead we test if the format obeys rules\ndef ifeval_prompt(line, task_name: str = None):\n return Doc(\n task_name=task_name,\n query=line[\"prompt\"],\n choices=[\"\"],\n gold_index=0,\n instruction=\"\",\n specific={\"instructions_id_list\": line[\"instruction_id_list\"], \"kwargs\": line[\"kwargs\"]},\n )\n\n\nsubmetric_names = [\n \"prompt_level_strict_acc\",\n \"inst_level_strict_acc\",\n \"prompt_level_loose_acc\",\n \"inst_level_loose_acc\",\n]\n\n\ndef ifeval_metric(predictions: list[str], formatted_doc: Doc, **kwargs) -> dict:\n response = predictions[0]\n\n # Strict instructions\n instruction_list = formatted_doc.specific[\"instructions_id_list\"]\n all_kwargs = formatted_doc.specific[\"kwargs\"]\n prompt = formatted_doc.query\n\n # Loose instructions\n r = response.split(\"\\n\")\n response_remove_first = \"\\n\".join(r[1:]).strip()\n response_remove_last = \"\\n\".join(r[:-1]).strip()\n response_remove_both = \"\\n\".join(r[1:-1]).strip()\n revised_response = response.replace(\"*\", \"\")\n revised_response_remove_first = response_remove_first.replace(\"*\", \"\")\n revised_response_remove_last = response_remove_last.replace(\"*\", \"\")\n revised_response_remove_both = response_remove_both.replace(\"*\", \"\")\n all_responses = [\n response,\n revised_response,\n response_remove_first,\n response_remove_last,\n response_remove_both,\n revised_response_remove_first,\n revised_response_remove_last,\n revised_response_remove_both,\n ]\n\n is_following_list_strict = []\n is_following_list_loose = []\n\n for index, instruction_id in enumerate(instruction_list):\n instruction_cls = instructions_registry.INSTRUCTION_DICT[instruction_id]\n instruction = instruction_cls(instruction_id)\n\n # Remove None values from kwargs to avoid unexpected keyword argument errors in build_description method.\n task_kwargs = {k: v for k, v in all_kwargs[index].items() if v}\n instruction.build_description(**task_kwargs)\n args = instruction.get_instruction_args()\n if args and \"prompt\" in args:\n instruction.build_description(prompt=prompt)\n\n # Strict\n if response.strip() and instruction.check_following(response):\n is_following_list_strict.append(True)\n else:\n is_following_list_strict.append(False)\n\n # Loose\n is_following = False\n for r in all_responses:\n if r.strip() and instruction.check_following(r):\n is_following = True\n break\n\n is_following_list_loose.append(is_following)\n\n return {\n \"prompt_level_strict_acc\": int(all(is_following_list_strict)),\n \"inst_level_strict_acc\": is_following_list_strict,\n \"prompt_level_loose_acc\": int(all(is_following_list_loose)),\n \"inst_level_loose_acc\": is_following_list_loose,\n }\n\n\ndef agg_inst_level_acc(items):\n flat_items = [item for sublist in items for item in sublist]\n inst_level_acc = sum(flat_items) / len(flat_items)\n return inst_level_acc\n\n\nifeval_metrics = SampleLevelMetricGrouping(\n metric_name=submetric_names,\n higher_is_better={n: True for n in submetric_names},\n category=MetricCategory.GENERATIVE,\n use_case=MetricUseCase.ACCURACY,\n sample_level_fn=ifeval_metric,\n corpus_level_fn={\n \"prompt_level_strict_acc\": np.mean,\n \"inst_level_strict_acc\": agg_inst_level_acc,\n \"prompt_level_loose_acc\": np.mean,\n \"inst_level_loose_acc\": agg_inst_level_acc,\n },\n)\n\n# We create the task config\nifeval = LightevalTaskConfig(\n name=\"ifeval\",\n prompt_function=ifeval_prompt,\n suite=[\"extended\"],\n hf_repo=\"google/IFEval\",\n hf_subset=\"default\",\n metric=[ifeval_metrics],\n hf_avail_splits=[\"train\"],\n evaluation_splits=[\"train\"],\n few_shots_split=\"train\",\n few_shots_select=\"random_sampling\",\n generation_size=1280,\n stop_sequence=[], # no stop sequence, will use eot token\n version=\"0.1\",\n)\n\n\nTASKS_TABLE = [ifeval]\n\nextend_enum(Metrics, \"ifeval_metric\", ifeval_metrics)\n\nif __name__ == \"__main__\":\n # Adds the metric to the metric list!\n print(t[\"name\"] for t in TASKS_TABLE)\n print(len(TASKS_TABLE))\n", "src\\lighteval\\tasks\\extended\\mt_bench\\main.py": "# MIT License\n\n# Copyright (c) 2024 The HuggingFace Team\n\n# Permission is hereby granted, free of charge, to any person obtaining a copy\n# of this software and associated documentation files (the \"Software\"), to deal\n# in the Software without restriction, including without limitation the rights\n# to use, copy, modify, merge, publish, distribute, sublicense, and/or sell\n# copies of the Software, and to permit persons to whom the Software is\n# furnished to do so, subject to the following conditions:\n\n# The above copyright notice and this permission notice shall be included in all\n# copies or substantial portions of the Software.\n\n# THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR\n# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,\n# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE\n# AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER\n# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,\n# OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE\n# SOFTWARE.\n\n# ruff: noqa: F405, F403, F401, I001\nfrom lighteval.tasks.lighteval_task import LightevalTaskConfig\nfrom lighteval.tasks.requests import Doc\nfrom lighteval.metrics.metrics import Metrics\n\n\ndef mt_bench_prompt(line, task_name: str = None):\n \"\"\"Defines how to go from a dataset line to a doc object.\n Follow examples in src/lighteval/tasks/tasks_prompt_formatting.py, or get more info\n about what this function should do in the README.\n \"\"\"\n return Doc(\n task_name=task_name,\n query=f\"{line['turns'][0]}\",\n choices=None,\n instruction=None,\n gold_index=[],\n specific={\n \"reference\": line[\"reference\"],\n \"category\": line[\"category\"],\n \"multi_turn_queries\": line[\"turns\"],\n \"id\": line[\"question_id\"],\n },\n )\n\n\ntask = LightevalTaskConfig(\n name=\"mt_bench\",\n prompt_function=mt_bench_prompt, # must be defined in the file or imported from src/lighteval/tasks/tasks_prompt_formatting.py\n suite=[\"extended\"],\n hf_repo=\"lighteval/mt-bench\",\n hf_subset=\"default\",\n hf_avail_splits=[\"train\"],\n evaluation_splits=[\"train\"],\n few_shots_split=\"\",\n few_shots_select=\"random\",\n metric=[Metrics.llm_judge_multi_turn_gpt3p5],\n generation_size=1024,\n stop_sequence=[],\n)\n\n\nTASKS_TABLE = [task]\n\nif __name__ == \"__main__\":\n print(t[\"name\"] for t in TASKS_TABLE)\n print(len(TASKS_TABLE))\n", "src\\lighteval\\tasks\\extended\\tiny_benchmarks\\main.py": "# MIT License\n\n# Copyright (c) 2024 The HuggingFace Team & Felipe Maia Polo\n\n# Permission is hereby granted, free of charge, to any person obtaining a copy\n# of this software and associated documentation files (the \"Software\"), to deal\n# in the Software without restriction, including without limitation the rights\n# to use, copy, modify, merge, publish, distribute, sublicense, and/or sell\n# copies of the Software, and to permit persons to whom the Software is\n# furnished to do so, subject to the following conditions:\n\n# The above copyright notice and this permission notice shall be included in all\n# copies or substantial portions of the Software.\n\n# THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR\n# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,\n# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE\n# AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER\n# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,\n# OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE\n# SOFTWARE.\n\n# ruff: noqa: F405, F403, F401\n\"\"\"\nSee https://github.com/felipemaiapolo/tinyBenchmarks/ for the original code.\n\nTest with `python run_evals_accelerate.py --model_args \"pretrained=EleutherAI/pythia-70m\" --tasks \"extended|tiny:winogrande|0|0,extended|tiny:gsm8k|0|0,extended|tiny:hellaswag|0|0,extended|tiny:arc|0|0,extended|tiny:truthfulqa|0|0\" --extended_tasks extended_tasks --output_dir \"./evals\"`\n\"\"\"\nimport os\nimport pathlib\nimport pickle\n\nimport numpy as np\nimport requests\nfrom aenum import extend_enum\nfrom scipy.optimize import minimize\n\nimport lighteval.tasks.default_prompts as prompt\nfrom lighteval.metrics.metrics import CorpusLevelMetricGrouping, Metrics\nfrom lighteval.metrics.metrics_sample import ExactMatches, LoglikelihoodAcc\nfrom lighteval.metrics.normalizations import gsm8k_normalizer\nfrom lighteval.metrics.utils import MetricCategory, MetricUseCase\nfrom lighteval.tasks.lighteval_task import LightevalTaskConfig\n\n\n# Utility functions\ndef sigmoid(z):\n return 1 / (1 + np.exp(-z))\n\n\ndef item_curve(theta, a, b):\n z = np.clip(a * theta - b, -30, 30).sum(axis=1)\n return sigmoid(z)\n\n\ndef fit_theta(responses_test, seen_items, A, B, theta_init=None, eps=1e-10, optimizer=\"BFGS\"):\n D = A.shape[1]\n\n # Define the negative log likelihood function\n def neg_log_like(x):\n P = item_curve(x.reshape(1, D, 1), A[:, :, seen_items], B[:, :, seen_items]).squeeze()\n log_likelihood = np.sum(\n responses_test[seen_items] * np.log(P + eps) + (1 - responses_test[seen_items]) * np.log(1 - P + eps)\n )\n return -log_likelihood\n\n # Use the minimize function to find the ability parameters that minimize the negative log likelihood\n optimal_theta = minimize(neg_log_like, np.zeros(D), method=optimizer).x[None, :, None]\n return optimal_theta\n\n\n# Evaluation function\nclass TinyCorpusAggregator:\n LEADEBRBOARD_SCENARIOS = [\"truthfulqa\", \"gsm8k\", \"winogrande\", \"arc\", \"hellaswag\"]\n BENCHS = [\"lb\", \"mmlu\"]\n METRICS = [\"irt\", \"pirt\", \"gpirt\"]\n # Not included yet:\n # - helm_lite (not avail on datasets)\n # - alpaca (needs to be added to lighteval first)\n\n def __init__(self, task: str):\n self.number_of_examples = 100\n if task not in self.LEADEBRBOARD_SCENARIOS + self.BENCHS:\n raise ValueError(f\"Bench name must be one of {','.join(self.LEADEBRBOARD_SCENARIOS + self.BENCHS)}.\")\n self.task = task\n self.scenario = \"lb\" if task in self.LEADEBRBOARD_SCENARIOS else task\n self.download()\n self.estimates = None\n self.num_samples = 0\n\n def download(self):\n # Likely to crash in // processes if we don't include the pkl\n path_dld = os.path.join(pathlib.Path(__file__).parent.resolve(), \"tinyBenchmarks.pkl\")\n # Downloading files\n if not os.path.isfile(path_dld):\n url = \"https://raw.githubusercontent.com/felipemaiapolo/tinyBenchmarks/main/tinyBenchmarks/tinyBenchmarks.pkl\"\n response = requests.get(url)\n if response.status_code == 200:\n # Write the content to a file\n with open(path_dld, \"wb\") as file:\n file.write(response.content)\n\n def compute(self, **args):\n if self.task == \"gsm8k\":\n res = ExactMatches(\n strip_strings=True, normalize_pred=gsm8k_normalizer, normalize_gold=gsm8k_normalizer\n ).compute(**args)\n return {m: res for m in self.METRICS}\n else:\n res = LoglikelihoodAcc().compute(**args)\n return {m: res for m in self.METRICS}\n\n def aggregate(self, y_input):\n if len(y_input) == self.num_samples and self.estimates is not None:\n return self.estimates[self.task]\n\n # We load the weights for the relevant examples\n with open(\"extended_tasks/tiny_benchmarks/tinyBenchmarks.pkl\", \"rb\") as handle:\n tinyBenchmarks = pickle.load(handle)\n\n seen_examples = tinyBenchmarks[self.scenario][\"seen_examples\"]\n examples_weights = tinyBenchmarks[self.scenario][\"examples_weights\"]\n irt_parameters = tinyBenchmarks[self.scenario][\"irt_parameters\"]\n A, B = irt_parameters[\"A\"], irt_parameters[\"B\"]\n optimal_lambdas = tinyBenchmarks[self.scenario][\"optimal_lambdas\"]\n scenarios_position = tinyBenchmarks[self.scenario][\"scenarios_position\"]\n subscenarios_position = tinyBenchmarks[self.scenario][\"subscenarios_position\"]\n\n N = np.max([np.max(x) for x in scenarios_position.values()]) + 1\n balance_weights = np.ones(N)\n for scenario in scenarios_position.keys():\n N_sce = len(scenarios_position[scenario])\n n_sub = len(subscenarios_position[scenario])\n for sub in subscenarios_position[scenario].keys():\n n_i = len(subscenarios_position[scenario][sub])\n balance_weights[subscenarios_position[scenario][sub]] = N_sce / (n_sub * n_i)\n\n # In case we use the big IRT model to estimate the performance of individual scenarios\n if self.task not in self.BENCHS:\n scenarios = [self.task]\n ind_scenario = (\n self.number_of_examples * ([i for i, s in enumerate(scenarios_position.keys()) if s == self.task][0])\n )\n seen_examples = seen_examples[ind_scenario : ind_scenario + self.number_of_examples]\n else:\n scenarios = list(scenarios_position.keys())\n\n # Creating vector y and estimating theta\n y = np.zeros(N)\n for i, j in enumerate(seen_examples):\n y[j] = y_input[i]\n\n # Getting estimates\n theta = fit_theta(y, seen_examples, A, B)\n estimates = {}\n unseen_examples = [i for i in range(N) if i not in seen_examples]\n\n for scenario in scenarios:\n N_sce = len(scenarios_position[scenario])\n seen_examples_sce = [s for s in seen_examples if s in scenarios_position[scenario]]\n unseen_examples_sce = [s for s in unseen_examples if s in scenarios_position[scenario]]\n\n data_part_IRTp = ((balance_weights * y)[seen_examples_sce]).mean()\n irt_part = (balance_weights * item_curve(theta.reshape(1, A.shape[1], 1), A, B))[\n 0, [unseen_examples_sce]\n ].mean()\n IRTp_lambd = self.number_of_examples / N_sce\n IRT = (examples_weights[scenario] * y[seen_examples_sce]).sum()\n IRTp = IRTp_lambd * data_part_IRTp + (1 - IRTp_lambd) * irt_part\n IRTpp = optimal_lambdas[scenario] * IRT + (1 - optimal_lambdas[scenario]) * IRTp\n\n estimates[scenario] = {}\n estimates[scenario][\"irt\"] = IRT\n estimates[scenario][\"pirt\"] = IRTp\n estimates[scenario][\"gpirt\"] = IRTpp\n\n self.num_samples = len(y_input)\n self.estimates = estimates\n\n return estimates[self.task]\n\n\n# TASK CREATION\ntask_params = [\n {\n \"name\": \"winogrande\",\n \"dataset\": \"tinyBenchmarks/tinyWinogrande\",\n \"subset\": \"winogrande_xl\",\n \"prompt\": prompt.winogrande,\n \"splits\": [\"train\", \"validation\", \"test\"],\n \"evaluation_split\": [\"validation\"],\n },\n {\n \"name\": \"arc\",\n \"dataset\": \"tinyBenchmarks/tinyAI2_arc\",\n \"subset\": \"ARC-Challenge\",\n \"prompt\": prompt.arc,\n \"splits\": [\"train\", \"validation\", \"test\"],\n \"evaluation_split\": [\"validation\"],\n },\n {\n \"name\": \"hellaswag\",\n \"dataset\": \"tinyBenchmarks/tinyHellaswag\",\n \"subset\": \"default\",\n \"prompt\": prompt.hellaswag_harness,\n \"splits\": [\"train\", \"validation\", \"test\"],\n \"evaluation_split\": [\"validation\"],\n },\n {\n \"name\": \"mmlu\",\n \"dataset\": \"tinyBenchmarks/tinyMMLU\",\n \"subset\": \"all\",\n \"prompt\": prompt.mmlu_harness,\n \"splits\": [\"validation\", \"dev\", \"test\"],\n \"evaluation_split\": [\"test\"],\n },\n {\n \"name\": \"truthfulqa\",\n \"dataset\": \"tinyBenchmarks/tinyTruthfulQA\",\n \"subset\": \"multiple_choice\",\n \"prompt\": prompt.truthful_qa_multiple_choice,\n \"splits\": [\"validation\"],\n \"evaluation_split\": [\"validation\"],\n },\n {\n \"name\": \"gsm8k\",\n \"dataset\": \"tinyBenchmarks/tinyGSM8k\",\n \"subset\": \"main\",\n \"prompt\": prompt.gsm8k,\n \"splits\": [\"train\", \"test\"],\n \"evaluation_split\": [\"test\"],\n },\n # {\n # \"name\": \"alpacaeval\",\n # \"dataset\": \"tinyBenchmarks/tinyAlpacaEval\",\n # \"subset\": \"default\"\n # },\n]\n\nTASKS_TABLE = []\nfor task in task_params:\n name = task[\"name\"]\n generation_size = None\n stop_sequence = None\n if name == \"gsm8k\":\n generation_size = 256\n stop_sequence = [\"Question:\", \"Question\"]\n task = LightevalTaskConfig(\n name=f\"tiny:{name}\",\n prompt_function=task[\"prompt\"],\n suite=[\"extended\"],\n hf_repo=task[\"dataset\"],\n hf_subset=task[\"subset\"],\n hf_avail_splits=task[\"splits\"],\n evaluation_splits=task[\"evaluation_split\"],\n few_shots_split=None,\n few_shots_select=\"random_sampling\",\n metric=[f\"tinybench_metric_{name}\"],\n generation_size=generation_size,\n stop_sequence=stop_sequence,\n )\n TASKS_TABLE.append(task)\n\n# CUSTOM METRIC\nfor task_param in task_params:\n name = task_param[\"name\"]\n if name == \"gsm8k\":\n category = MetricCategory.GENERATIVE\n use_case = MetricUseCase.MATH\n else:\n category = MetricCategory.MULTICHOICE\n use_case = MetricUseCase.ACCURACY\n\n extend_enum(\n Metrics,\n f\"tinybench_metric_{name}\",\n CorpusLevelMetricGrouping(\n metric_name=TinyCorpusAggregator.METRICS,\n higher_is_better={m: True for m in TinyCorpusAggregator.METRICS},\n sample_level_fn=TinyCorpusAggregator(name).compute,\n category=category,\n use_case=use_case,\n corpus_level_fn=TinyCorpusAggregator(name).aggregate,\n ),\n )\n\n\n# MODULE LOGIC\n# You should not need to touch this\n# Convert to dict for lighteval\nif __name__ == \"__main__\":\n print(t[\"name\"] for t in TASKS_TABLE)\n print(len(TASKS_TABLE))\n", "tests\\test_main.py": "# MIT License\n\n# Copyright (c) 2024 The HuggingFace Team\n\n# Permission is hereby granted, free of charge, to any person obtaining a copy\n# of this software and associated documentation files (the \"Software\"), to deal\n# in the Software without restriction, including without limitation the rights\n# to use, copy, modify, merge, publish, distribute, sublicense, and/or sell\n# copies of the Software, and to permit persons to whom the Software is\n# furnished to do so, subject to the following conditions:\n\n# The above copyright notice and this permission notice shall be included in all\n# copies or substantial portions of the Software.\n\n# THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR\n# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,\n# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE\n# AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER\n# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,\n# OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE\n# SOFTWARE.\n\n\"\"\"This file should be launched using `python -m pytest script_name.py`. It must stay at the same level or above as main\"\"\"\nimport os\nfrom functools import lru_cache, partial\nfrom typing import Callable, List, Literal, Tuple\n\nimport pytest\nfrom pytest import approx\n\nfrom lighteval.main_accelerate import main # noqa: E402\nfrom lighteval.parsers import parser_accelerate\nfrom tests.reference_scores.reference_task_scores import RESULTS_FULL, RESULTS_LITE # noqa: E402\nfrom tests.reference_scores.reference_tasks import ALL_SUBSETS\n\n\n# Set env var for deterministic run of models\nos.environ[\"CUBLAS_WORKSPACE_CONFIG\"] = \":4096:8\"\n\n# Set cache for github actions\nos.environ[\"HF_DATASETS_CACHE\"] = \"cache/datasets/\"\nos.environ[\"HF_HOME\"] = \"cache/models/\"\n\n# To add new models or tasks, change here\n# ! The correct results must be present in reference_task_scores\nMODELS = [\"gpt2\"]\nTASKS = ALL_SUBSETS\nFULL_TEST = os.environ.get(\"LIGHTEVAL_FULL_TEST\", False)\nModelInput = Tuple[str, str, str, str, Callable[[], dict], float]\n\n\n# Caching here to avoid re-running predictions for every single test, the size should be >= MODELS\n@lru_cache(maxsize=len(MODELS))\ndef run_model_predictions_full(model: str, tasks: tuple):\n \"\"\"Runs the full main as a black box, using the input model and tasks, on all samples without parallelism\"\"\"\n lighteval_args = [\"--model_args\", f\"pretrained={model}\", \"--tasks\", \",\".join(tasks)]\n lighteval_args += [\n \"--override_batch_size\",\n \"1\",\n \"--output_dir\",\n \"\",\n \"--dataset_loading_processes\",\n \"1\",\n \"--save_details\",\n ]\n parser = parser_accelerate()\n args = parser.parse_args(lighteval_args)\n results = main(args)\n return results\n\n\n@lru_cache(maxsize=len(MODELS))\ndef run_model_predictions_lite(model: str, tasks: tuple):\n \"\"\"Runs the full main as a black box, using the input model and tasks, on 10 samples without parallelism\"\"\"\n lighteval_args = [\"--model_args\", f\"pretrained={model}\", \"--tasks\", \",\".join(tasks)]\n lighteval_args += [\n \"--override_batch_size\",\n \"1\",\n \"--output_dir\",\n \"\",\n \"--dataset_loading_processes\",\n \"1\",\n \"--save_details\",\n ]\n lighteval_args += [\"--max_samples\", \"10\"]\n parser = parser_accelerate()\n args = parser.parse_args(lighteval_args)\n results = main(args)\n return results\n\n\ndef generate_test_parameters(tasks: List[str]) -> List[ModelInput]:\n \"\"\"Generate test parameters for all models and tasks.\"\"\"\n\n def generate_model_parameters(\n model: str, test_type: Literal[\"full\", \"lite\"], prediction_func: Callable\n ) -> List[ModelInput]:\n results = RESULTS_FULL if test_type == \"full\" else RESULTS_LITE\n return [\n (model, test_type, normalize_eval_name(eval_name), metric, prediction_func, reference)\n for eval_name in tasks\n for metric, reference in results[model][eval_name].items()\n ]\n\n parameters = []\n for model in MODELS:\n if FULL_TEST:\n # Don't call the function during collection!! Very expensive\n predictions_full = partial(run_model_predictions_full, model, tuple(tasks))\n parameters.extend(generate_model_parameters(model, \"full\", predictions_full))\n else:\n predictions_lite = partial(run_model_predictions_lite, model, tuple(tasks))\n parameters.extend(generate_model_parameters(model, \"lite\", predictions_lite))\n\n return parameters\n\n\ndef normalize_eval_name(eval_name: str) -> str:\n \"\"\"Normalize evaluation name by removing the last part if it has 4 components.\"\"\"\n parts = eval_name.split(\"|\")\n return \"|\".join(parts[:3]) if len(parts) == 4 else eval_name\n\n\n# generates the model predictions parameters at test collection time\nparameters: list[ModelInput] = generate_test_parameters(TASKS)\nids = [f\"{model_input[0]}_{model_input[1]}_{model_input[2]}_{model_input[3]}\" for model_input in parameters]\n\n\[email protected](\"model_input\", parameters, ids=ids)\ndef test_model_prediction(model_input: ModelInput):\n \"\"\"Evaluates a model on a full task - is parametrized using pytest_generate_test\"\"\"\n model_name, test_type, eval_name, metric, get_predictions, reference = model_input\n prediction = get_predictions()[\"results\"][eval_name.replace(\"|\", \":\")][metric]\n assert reference == approx(\n prediction, rel=1e-4\n ), f\"Model {model_name} on {test_type} samples, for eval {eval_name}, metric {metric} incorrect\"\n\n\nif __name__ == \"__main__\":\n parameters = generate_test_parameters(TASKS)\n print(parameters)\n"} | null |
llm-academy | {"type": "directory", "name": "llm-academy", "children": [{"type": "file", "name": "LICENSE"}, {"type": "directory", "name": "session1", "children": [{"type": "file", "name": "deep-learning.ipynb"}]}]} | {".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 4c73662ffbd1e2a3018e66f6528009b1d29919ac Hamza Amin <[email protected]> 1727369496 +0500\tclone: from https://github.com/huggingface/llm-academy.git\n", ".git\\refs\\heads\\main": "4c73662ffbd1e2a3018e66f6528009b1d29919ac\n"} | null |
|
llm-intellij | {"type": "directory", "name": "llm-intellij", "children": [{"type": "file", "name": ".qodana.yml"}, {"type": "directory", "name": ".run", "children": [{"type": "file", "name": "Run IDE with Plugin.run.xml"}, {"type": "file", "name": "Run Qodana.run.xml"}]}, {"type": "file", "name": "build.gradle.kts"}, {"type": "directory", "name": "gradle", "children": [{"type": "file", "name": "libs.versions.toml"}, {"type": "directory", "name": "wrapper", "children": [{"type": "file", "name": "gradle-wrapper.properties"}]}]}, {"type": "file", "name": "gradle.properties"}, {"type": "file", "name": "gradlew"}, {"type": "file", "name": "gradlew.bat"}, {"type": "file", "name": "LICENSE"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "settings.gradle.kts"}, {"type": "directory", "name": "src", "children": [{"type": "directory", "name": "main", "children": [{"type": "directory", "name": "kotlin", "children": [{"type": "directory", "name": "co", "children": [{"type": "directory", "name": "huggingface", "children": [{"type": "directory", "name": "llmintellij", "children": [{"type": "file", "name": "LlmLsCompletionProvider.kt"}, {"type": "file", "name": "LlmSettingsComponent.kt"}, {"type": "file", "name": "LlmSettingsConfigurable.kt"}, {"type": "file", "name": "LlmSettingsState.kt"}, {"type": "directory", "name": "lsp", "children": [{"type": "file", "name": "Completion.kt"}, {"type": "file", "name": "LlmLsGetCompletionsRequest.kt"}, {"type": "file", "name": "LlmLsLanguageServer.kt"}, {"type": "file", "name": "LlmLsLspServerDescriptor.kt"}, {"type": "file", "name": "LlmLsServerSupportProvider.kt"}]}, {"type": "file", "name": "SecretsService.kt"}]}]}]}]}, {"type": "directory", "name": "resources", "children": [{"type": "directory", "name": "META-INF", "children": [{"type": "file", "name": "plugin.xml"}, {"type": "file", "name": "pluginIcon.svg"}]}]}]}]}]} | # LLM powered development for IntelliJ
<!-- Plugin description -->
**llm-intellij** is a plugin for all things LLM. It uses [**llm-ls**](https://github.com/huggingface/llm-ls) as a backend.
> [!NOTE]
> When using the Inference API, you will probably encounter some limitations. Subscribe to the *PRO* plan to avoid getting rate limited in the free tier.
>
> https://huggingface.co/pricing#pro
## Features
### Code completion
This plugin supports "ghost-text" code completion, à la Copilot.
### Choose your model
Requests for code generation are made via an HTTP request.
You can use the Hugging Face [Inference API](https://huggingface.co/inference-api) or your own HTTP endpoint, provided it adheres to the API specified [here](https://huggingface.co/docs/api-inference/detailed_parameters#text-generation-task) or [here](https://huggingface.github.io/text-generation-inference/#/Text%20Generation%20Inference/generate).
### Always fit within the context window
The prompt sent to the model will always be sized to fit within the context window, with the number of tokens determined using [tokenizers](https://github.com/huggingface/tokenizers).
## Configuration
### Endpoint
#### With Inference API
1. Create and get your API token from here https://huggingface.co/settings/tokens.
2. Define how the plugin will read your token. For this you have multiple options, in order of precedence:
1. Set `API token = <your token>` in plugin settings
2. *(not supported yet)* You can define your `HF_HOME` environment variable and create a file containing your token at `$HF_HOME/token`
3. *(not supported yet)* Install the [huggingface-cli](https://huggingface.co/docs/huggingface_hub/quick-start) and run `huggingface-cli login` - this will prompt you to enter your token and set it at the right path
3. Choose your model on the [Hugging Face Hub](https://huggingface.co/), and set `Model = <model identifier>` in plugin settings
#### With your own HTTP endpoint
All of the above still applies, but note:
* When an API token is provided, it will be passed as a header: `Authorization: Bearer <api_token>`.
* Instead of setting a Hugging Face model identifier in `model`, set the URL for your HTTP endpoint
### Models
**llm-intellij** is assumed to be compatible with any model that generates code.
Here are some configs for popular models in JSON format that you can put in your Settings (`Cmd+,` > `LLM Settings`)
#### [Starcoder](https://huggingface.co/bigcode/starcoder)
```json
{
"tokensToClear": [
"<|endoftext|>"
],
"fim": {
"enabled": true,
"prefix": "<fim_prefix>",
"middle": "<fim_middle>",
"suffix": "<fim_suffix>"
},
"model": "bigcode/starcoder",
"context_window": 8192,
"tokenizer": {
"repository": "bigcode/starcoder"
}
}
```
> [!NOTE]
> These are the default config values
#### [CodeLlama](https://huggingface.co/codellama/CodeLlama-13b-hf)
```json
{
"tokensToClear": [
"<EOT>"
],
"fim": {
"enabled": true,
"prefix": "<PRE> ",
"middle": " <MID>",
"suffix": " <SUF>"
},
"model": "codellama/CodeLlama-13b-hf",
"context_window": 4096,
"tokenizer": {
"repository": "codellama/CodeLlama-13b-hf"
}
}
```
> [!NOTE]
> Spaces are important here
### [**llm-ls**](https://github.com/huggingface/llm-ls)
By default, **llm-ls** is installed by **llm-intellij** the first time it is loaded. The binary is downloaded from the [release page](https://github.com/huggingface/llm-ls/releases) and stored in:
```shell
"$HOME/.cache/llm_intellij/bin"
```
When developing locally or if you built your own binary because your platform is not supported, you can set the `llm-ls` > `Binary path` setting to the path of the binary.
`llm-ls` > `Version` is used only when **llm-intellij** downloads **llm-ls** from the release page.
You can also set the log level for **llm-ls** with `llm-ls` > `Log level`, which can take any of the usual `info`, `warn`, `error`, etc as a value.
The log file is located in:
```shell
"$HOME/.cache/llm_ls/llm-ls.log"
```
### Tokenizer
**llm-ls** uses [**tokenizers**](https://github.com/huggingface/tokenizers) to make sure the prompt fits the `context_window`.
To configure it, you have a few options:
* No tokenization, **llm-ls** will count the number of characters instead:
* from a local file on your disk:
* from a Hugging Face repository, **llm-ls** will attempt to download `tokenizer.json` at the root of the repository:
* from an HTTP endpoint, **llm-ls** will attempt to download a file via an HTTP GET request:
<!-- Plugin description end -->
| {".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 2972e337497cd3df9325f0c10a231693ef8ea13d Hamza Amin <[email protected]> 1727369498 +0500\tclone: from https://github.com/huggingface/llm-intellij.git\n", ".git\\refs\\heads\\main": "2972e337497cd3df9325f0c10a231693ef8ea13d\n", "gradle\\wrapper\\gradle-wrapper.properties": "distributionBase=GRADLE_USER_HOME\ndistributionPath=wrapper/dists\ndistributionUrl=https\\://services.gradle.org/distributions/gradle-8.3-bin.zip\nnetworkTimeout=10000\nvalidateDistributionUrl=true\nzipStoreBase=GRADLE_USER_HOME\nzipStorePath=wrapper/dists"} | null |
llm-ls | {"type": "directory", "name": "llm-ls", "children": [{"type": "directory", "name": ".cargo", "children": [{"type": "file", "name": "config.toml"}]}, {"type": "file", "name": "Cargo.lock"}, {"type": "file", "name": "Cargo.toml"}, {"type": "directory", "name": "crates", "children": [{"type": "directory", "name": "custom-types", "children": [{"type": "file", "name": "Cargo.toml"}, {"type": "directory", "name": "src", "children": [{"type": "file", "name": "lib.rs"}, {"type": "file", "name": "llm_ls.rs"}, {"type": "file", "name": "request.rs"}]}]}, {"type": "directory", "name": "llm-ls", "children": [{"type": "file", "name": "Cargo.toml"}, {"type": "directory", "name": "src", "children": [{"type": "file", "name": "backend.rs"}, {"type": "file", "name": "document.rs"}, {"type": "file", "name": "error.rs"}, {"type": "file", "name": "language_id.rs"}, {"type": "file", "name": "main.rs"}]}]}, {"type": "directory", "name": "lsp-client", "children": [{"type": "file", "name": "Cargo.toml"}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "src", "children": [{"type": "file", "name": "client.rs"}, {"type": "file", "name": "error.rs"}, {"type": "file", "name": "lib.rs"}, {"type": "file", "name": "msg.rs"}, {"type": "file", "name": "res_queue.rs"}, {"type": "file", "name": "server.rs"}]}]}, {"type": "directory", "name": "mock_server", "children": [{"type": "file", "name": "Cargo.toml"}, {"type": "directory", "name": "src", "children": [{"type": "file", "name": "main.rs"}]}]}, {"type": "directory", "name": "testbed", "children": [{"type": "file", "name": "Cargo.toml"}, {"type": "directory", "name": "holes", "children": [{"type": "file", "name": "async-executor-smol.json"}, {"type": "file", "name": "async-executor.json"}, {"type": "file", "name": "cached-smol.json"}, {"type": "file", "name": "cached.json"}, {"type": "file", "name": "constrandom-smol.json"}, {"type": "file", "name": "constrandom.json"}, {"type": "file", "name": "fastapi-smol.json"}, {"type": "file", "name": "fastapi.json"}, {"type": "file", "name": "helix-smol.json"}, {"type": "file", "name": "helix.json"}, {"type": "file", "name": "huggingface_hub-smol.json"}, {"type": "file", "name": "huggingface_hub.json"}, {"type": "file", "name": "io-ts-smol.json"}, {"type": "file", "name": "io-ts.json"}, {"type": "file", "name": "lance-smol.json"}, {"type": "file", "name": "lance.json"}, {"type": "file", "name": "lancedb-smol.json"}, {"type": "file", "name": "lancedb.json"}, {"type": "file", "name": "picklescan-smol.json"}, {"type": "file", "name": "picklescan.json"}, {"type": "file", "name": "simple.json"}, {"type": "file", "name": "starlette-smol.json"}, {"type": "file", "name": "starlette.json"}, {"type": "file", "name": "zod-smol.json"}, {"type": "file", "name": "zod.json"}]}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "repositories", "children": [{"type": "directory", "name": "simple", "children": [{"type": "file", "name": "Cargo.lock"}, {"type": "file", "name": "Cargo.toml"}, {"type": "directory", "name": "src", "children": [{"type": "file", "name": "main.rs"}]}]}]}, {"type": "file", "name": "repositories-ci.yaml"}, {"type": "file", "name": "repositories.yaml"}, {"type": "directory", "name": "src", "children": [{"type": "file", "name": "holes_generator.rs"}, {"type": "file", "name": "lang.rs"}, {"type": "file", "name": "main.rs"}, {"type": "file", "name": "runner.rs"}]}]}]}, {"type": "file", "name": "LICENSE"}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "xtask", "children": [{"type": "file", "name": "Cargo.toml"}, {"type": "directory", "name": "src", "children": [{"type": "file", "name": "dist.rs"}, {"type": "file", "name": "flags.rs"}, {"type": "file", "name": "main.rs"}]}]}]} | # testbed
testbed is a framework to evaluate the efficiency of the completions generated by llm-ls and the underlying model.
It works by first making holes in files, then generates completions for a given list of repositories and finally runs the associated unit tests.
The result is a table containing a line for each repository and the total with the average percentage of successful unit tests.
Here is a simplified pseudo code algorithm for testbed:
```
read the repositories file
read the holes file(s)
for each repository
for each hole
spawn a thread
setup the repository -- only once for each repository
copy files from the setup cache to a new temp dir
make the hole as specified by the file
generate completions
build the code
run the tests
print results
```
## Running testbed
Before running testbed you will need to create a repositories file. It is a YAML file containing a list of repositories to test.
It also contains the parameters to the `llm-ls/getCompletions` request.
Repositories can either be sourced from your local storage or Github.
You can check the repositories files at the root of the crate to see the full structure.
### Generating holes
Before running testbed, you will need to generate a holes file for each repository. To generate a holes file run testbed with the `-g` option. You can specify the number of holes to make with `-n <number>`. It will take the list of repositories in your YAML file and create the associated files at the defined path.
### Setup
testbed runs hole completions in parallel. It will first, and only once per repository, create a temporary directory, then copy or download the repository's source files to that location and finally run the setup commands. Then for each subsequent completion it will copy the content of the "setup directory" to a new temporary directory so that work can be parallelised.
Setup commands are useful to install dependencies.
```yaml
setup_commands:
- ["python3", ["-m", "venv", "huggingface_hub-venv"]]
- ["huggingface_hub-venv/bin/python3", ["-m", "pip", "install", ".[dev]"]]
```
### Build
Before running the tests, testbed will run a build command to check if the code is valid.
To configure the commands, you can do the following:
```yaml
build_command: huggingface_hub-venv/bin/python3
build_args: ["-m", "compileall", "-q", "."]
```
### Runners
testbed supports four test runners:
- cargo
- jest
- pytest
- vitest
To configure your runner, you have the following options:
```yaml
runner: pytest
runner_command: huggingface_hub-venv/bin/python3
runner_extra_args:
- "-k"
- "_utils_ and not _utils_cache and not _utils_http and not paginate and not git"
```
You can override the runners command with `runner_command`, which is useful when setting up dependencies in a venv.
## References
testbed was inspired by [human-eval](https://github.com/openai/human-eval) and [RepoEval](https://arxiv.org/abs/2303.12570).
| {".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 59febfea525d7930bf77e1bae85b411631d503e4 Hamza Amin <[email protected]> 1727369500 +0500\tclone: from https://github.com/huggingface/llm-ls.git\n", ".git\\refs\\heads\\main": "59febfea525d7930bf77e1bae85b411631d503e4\n", ".github\\actions\\github-release\\Dockerfile": "FROM node:slim\n\nCOPY . /action\nWORKDIR /action\n\nRUN npm install --production\n\nENTRYPOINT [\"node\", \"/action/main.js\"]\n", ".github\\actions\\github-release\\main.js": "const core = require('@actions/core');\nconst path = require(\"path\");\nconst fs = require(\"fs\");\nconst github = require('@actions/github');\nconst glob = require('glob');\n\nfunction sleep(milliseconds) {\n return new Promise(resolve => setTimeout(resolve, milliseconds));\n}\n\nasync function runOnce() {\n // Load all our inputs and env vars. Note that `getInput` reads from `INPUT_*`\n const files = core.getInput('files');\n const name = core.getInput('name');\n const token = core.getInput('token');\n const slug = process.env.GITHUB_REPOSITORY;\n const owner = slug.split('/')[0];\n const repo = slug.split('/')[1];\n const sha = process.env.HEAD_SHA;\n\n core.info(`files: ${files}`);\n core.info(`name: ${name}`);\n\n const options = {\n request: {\n timeout: 30000,\n }\n };\n const octokit = github.getOctokit(token, options);\n\n // Delete the previous release since we can't overwrite one. This may happen\n // due to retrying an upload or it may happen because we're doing the dev\n // release.\n const releases = await octokit.paginate(\"GET /repos/:owner/:repo/releases\", { owner, repo });\n for (const release of releases) {\n if (release.tag_name !== name) {\n continue;\n }\n const release_id = release.id;\n core.info(`deleting release ${release_id}`);\n await octokit.rest.repos.deleteRelease({ owner, repo, release_id });\n }\n\n // We also need to update the `dev` tag while we're at it on the `dev` branch.\n if (name == 'nightly') {\n try {\n core.info(`updating nightly tag`);\n await octokit.rest.git.updateRef({\n owner,\n repo,\n ref: 'tags/nightly',\n sha,\n force: true,\n });\n } catch (e) {\n core.error(e);\n core.info(`creating nightly tag`);\n await octokit.rest.git.createTag({\n owner,\n repo,\n tag: 'nightly',\n message: 'nightly release',\n object: sha,\n type: 'commit',\n });\n }\n }\n\n // Creates an official GitHub release for this `tag`, and if this is `dev`\n // then we know that from the previous block this should be a fresh release.\n core.info(`creating a release`);\n const release = await octokit.rest.repos.createRelease({\n owner,\n repo,\n name,\n tag_name: name,\n target_commitish: sha,\n prerelease: name === 'nightly',\n });\n const release_id = release.data.id;\n\n // Upload all the relevant assets for this release as just general blobs.\n for (const file of glob.sync(files)) {\n const size = fs.statSync(file).size;\n const name = path.basename(file);\n\n await runWithRetry(async function() {\n // We can't overwrite assets, so remove existing ones from a previous try.\n let assets = await octokit.rest.repos.listReleaseAssets({\n owner,\n repo,\n release_id\n });\n for (const asset of assets.data) {\n if (asset.name === name) {\n core.info(`delete asset ${name}`);\n const asset_id = asset.id;\n await octokit.rest.repos.deleteReleaseAsset({ owner, repo, asset_id });\n }\n }\n\n core.info(`upload ${file}`);\n const headers = { 'content-length': size, 'content-type': 'application/octet-stream' };\n const data = fs.createReadStream(file);\n await octokit.rest.repos.uploadReleaseAsset({\n data,\n headers,\n name,\n url: release.data.upload_url,\n });\n });\n }\n}\n\nasync function runWithRetry(f) {\n const retries = 10;\n const maxDelay = 4000;\n let delay = 1000;\n\n for (let i = 0; i < retries; i++) {\n try {\n await f();\n break;\n } catch (e) {\n if (i === retries - 1)\n throw e;\n\n core.error(e);\n const currentDelay = Math.round(Math.random() * delay);\n core.info(`sleeping ${currentDelay} ms`);\n await sleep(currentDelay);\n delay = Math.min(delay * 2, maxDelay);\n }\n }\n}\n\nasync function run() {\n await runWithRetry(runOnce);\n}\n\nrun().catch(err => {\n core.error(err);\n core.setFailed(err.message);\n});\n", ".github\\actions\\github-release\\package.json": "{\n \"name\": \"wasmtime-github-release\",\n \"version\": \"0.0.0\",\n \"main\": \"main.js\",\n \"dependencies\": {\n \"@actions/core\": \"^1.6\",\n \"@actions/github\": \"^5.0\",\n \"glob\": \"^7.1.5\"\n }\n}\n", "crates\\llm-ls\\src\\main.rs": "use clap::Parser;\nuse custom_types::llm_ls::{\n AcceptCompletionParams, Backend, Completion, FimParams, GetCompletionsParams,\n GetCompletionsResult, Ide, RejectCompletionParams, TokenizerConfig,\n};\nuse ropey::Rope;\nuse serde::{Deserialize, Serialize};\nuse std::collections::HashMap;\nuse std::fmt::Display;\nuse std::path::{Path, PathBuf};\nuse std::sync::Arc;\nuse std::time::{Duration, Instant, SystemTime};\nuse tokenizers::Tokenizer;\nuse tokio::io::AsyncWriteExt;\nuse tokio::net::TcpListener;\nuse tokio::sync::RwLock;\nuse tower_lsp::jsonrpc::Result as LspResult;\nuse tower_lsp::lsp_types::*;\nuse tower_lsp::{Client, LanguageServer, LspService, Server};\nuse tracing::{debug, error, info, info_span, warn, Instrument};\nuse tracing_appender::rolling;\nuse tracing_subscriber::EnvFilter;\nuse uuid::Uuid;\n\nuse crate::backend::{build_body, build_headers, parse_generations};\nuse crate::document::Document;\nuse crate::error::{internal_error, Error, Result};\n\nmod backend;\nmod document;\nmod error;\nmod language_id;\n\nconst MAX_WARNING_REPEAT: Duration = Duration::from_secs(3_600);\npub const NAME: &str = \"llm-ls\";\npub const VERSION: &str = env!(\"CARGO_PKG_VERSION\");\n\nfn get_position_idx(rope: &Rope, row: usize, col: usize) -> Result<usize> {\n Ok(rope.try_line_to_char(row)?\n + col.min(\n rope.get_line(row.min(rope.len_lines().saturating_sub(1)))\n .ok_or(Error::OutOfBoundLine(row, rope.len_lines()))?\n .len_chars()\n .saturating_sub(1),\n ))\n}\n\n#[derive(Debug, PartialEq, Eq, Serialize, Deserialize)]\nenum CompletionType {\n Empty,\n SingleLine,\n MultiLine,\n}\n\nimpl Display for CompletionType {\n fn fmt(&self, f: &mut std::fmt::Formatter<'_>) -> std::fmt::Result {\n match self {\n CompletionType::Empty => write!(f, \"empty\"),\n CompletionType::SingleLine => write!(f, \"single_line\"),\n CompletionType::MultiLine => write!(f, \"multi_line\"),\n }\n }\n}\n\nfn should_complete(document: &Document, position: Position) -> Result<CompletionType> {\n let row = position.line as usize;\n let column = position.character as usize;\n if document.text.len_chars() == 0 {\n warn!(\"Document is empty\");\n return Ok(CompletionType::Empty);\n }\n if let Some(tree) = &document.tree {\n let current_node = tree.root_node().descendant_for_point_range(\n tree_sitter::Point { row, column },\n tree_sitter::Point {\n row,\n column: column + 1,\n },\n );\n if let Some(node) = current_node {\n if node == tree.root_node() {\n return Ok(CompletionType::MultiLine);\n }\n let start = node.start_position();\n let end = node.end_position();\n let mut start_offset = get_position_idx(&document.text, start.row, start.column)?;\n let mut end_offset = get_position_idx(&document.text, end.row, end.column)? - 1;\n let start_char = document\n .text\n .get_char(start_offset.min(document.text.len_chars().saturating_sub(1)))\n .ok_or(Error::OutOfBoundIndexing(start_offset))?;\n let end_char = document\n .text\n .get_char(end_offset.min(document.text.len_chars().saturating_sub(1)))\n .ok_or(Error::OutOfBoundIndexing(end_offset))?;\n if !start_char.is_whitespace() {\n start_offset += 1;\n }\n if !end_char.is_whitespace() {\n end_offset -= 1;\n }\n if start_offset >= end_offset {\n return Ok(CompletionType::SingleLine);\n }\n let slice = document\n .text\n .get_slice(start_offset..end_offset)\n .ok_or(Error::OutOfBoundSlice(start_offset, end_offset))?;\n if slice.to_string().trim().is_empty() {\n return Ok(CompletionType::MultiLine);\n }\n }\n }\n let start_idx = document.text.try_line_to_char(row)?;\n // XXX: We treat the end of a document as a newline\n let next_char = document.text.get_char(start_idx + column).unwrap_or('\\n');\n if next_char.is_whitespace() {\n Ok(CompletionType::SingleLine)\n } else {\n Ok(CompletionType::Empty)\n }\n}\n\n#[derive(Debug, Serialize, Deserialize)]\npub struct Generation {\n generated_text: String,\n}\n\nstruct LlmService {\n cache_dir: PathBuf,\n client: Client,\n document_map: Arc<RwLock<HashMap<String, Document>>>,\n http_client: reqwest::Client,\n unsafe_http_client: reqwest::Client,\n workspace_folders: Arc<RwLock<Option<Vec<WorkspaceFolder>>>>,\n tokenizer_map: Arc<RwLock<HashMap<String, Arc<Tokenizer>>>>,\n unauthenticated_warn_at: Arc<RwLock<SystemTime>>,\n position_encoding: Arc<RwLock<document::PositionEncodingKind>>,\n}\n\nfn build_prompt(\n pos: Position,\n text: &Rope,\n fim: &FimParams,\n tokenizer: Option<Arc<Tokenizer>>,\n context_window: usize,\n) -> Result<String> {\n let t = Instant::now();\n if fim.enabled {\n let mut remaining_token_count = context_window - 3; // account for FIM tokens\n let mut before_iter = text.lines_at(pos.line as usize + 1).reversed();\n let mut after_iter = text.lines_at(pos.line as usize);\n let mut before_line = before_iter.next();\n if let Some(line) = before_line {\n let col = (pos.character as usize).clamp(0, line.len_chars());\n before_line = Some(line.slice(0..col));\n }\n let mut after_line = after_iter.next();\n if let Some(line) = after_line {\n let col = (pos.character as usize).clamp(0, line.len_chars());\n after_line = Some(line.slice(col..));\n }\n let mut before = vec![];\n let mut after = String::new();\n while before_line.is_some() || after_line.is_some() {\n if let Some(before_line) = before_line {\n let before_line = before_line.to_string();\n let tokens = if let Some(tokenizer) = tokenizer.clone() {\n tokenizer.encode(before_line.clone(), false)?.len()\n } else {\n before_line.len()\n };\n if tokens > remaining_token_count {\n break;\n }\n remaining_token_count -= tokens;\n before.push(before_line);\n }\n if let Some(after_line) = after_line {\n let after_line = after_line.to_string();\n let tokens = if let Some(tokenizer) = tokenizer.clone() {\n tokenizer.encode(after_line.clone(), false)?.len()\n } else {\n after_line.len()\n };\n if tokens > remaining_token_count {\n break;\n }\n remaining_token_count -= tokens;\n after.push_str(&after_line);\n }\n before_line = before_iter.next();\n after_line = after_iter.next();\n }\n let prompt = format!(\n \"{}{}{}{}{}\",\n fim.prefix,\n before.into_iter().rev().collect::<Vec<_>>().join(\"\"),\n fim.suffix,\n after,\n fim.middle\n );\n let time = t.elapsed().as_millis();\n info!(prompt, build_prompt_ms = time, \"built prompt in {time} ms\");\n Ok(prompt)\n } else {\n let mut remaining_token_count = context_window;\n let mut before = vec![];\n let mut first = true;\n for mut line in text.lines_at(pos.line as usize + 1).reversed() {\n if first {\n let col = (pos.character as usize).clamp(0, line.len_chars());\n line = line.slice(0..col);\n first = false;\n }\n let line = line.to_string();\n let tokens = if let Some(tokenizer) = tokenizer.clone() {\n tokenizer.encode(line.clone(), false)?.len()\n } else {\n line.len()\n };\n if tokens > remaining_token_count {\n break;\n }\n remaining_token_count -= tokens;\n before.push(line);\n }\n let prompt = before.into_iter().rev().collect::<Vec<_>>().join(\"\");\n let time = t.elapsed().as_millis();\n info!(prompt, build_prompt_ms = time, \"built prompt in {time} ms\");\n Ok(prompt)\n }\n}\n\nasync fn request_completion(\n http_client: &reqwest::Client,\n prompt: String,\n params: &GetCompletionsParams,\n) -> Result<Vec<Generation>> {\n let t = Instant::now();\n\n let json = build_body(\n ¶ms.backend,\n params.model.clone(),\n prompt,\n params.request_body.clone(),\n );\n let headers = build_headers(¶ms.backend, params.api_token.as_ref(), params.ide)?;\n let url = build_url(\n params.backend.clone(),\n ¶ms.model,\n params.disable_url_path_completion,\n );\n info!(?headers, url, \"sending request to backend\");\n debug!(?headers, body = ?json, url, \"sending request to backend\");\n let res = http_client\n .post(url)\n .json(&json)\n .headers(headers)\n .send()\n .await?;\n\n let model = ¶ms.model;\n let generations = parse_generations(¶ms.backend, res.text().await?.as_str())?;\n let time = t.elapsed().as_millis();\n info!(\n model,\n compute_generations_ms = time,\n generations = serde_json::to_string(&generations)?,\n \"{model} computed generations in {time} ms\"\n );\n Ok(generations)\n}\n\nfn format_generations(\n generations: Vec<Generation>,\n tokens_to_clear: &[String],\n completion_type: CompletionType,\n) -> Vec<Completion> {\n generations\n .into_iter()\n .map(|g| {\n let mut generated_text = g.generated_text;\n for token in tokens_to_clear {\n generated_text = generated_text.replace(token, \"\")\n }\n match completion_type {\n CompletionType::Empty => {\n warn!(\"completion type should not be empty when post processing completions\");\n Completion { generated_text }\n }\n CompletionType::SingleLine => Completion {\n generated_text: generated_text\n .split_once('\\n')\n .unwrap_or((&generated_text, \"\"))\n .0\n .to_owned(),\n },\n CompletionType::MultiLine => Completion { generated_text },\n }\n })\n .collect()\n}\n\nasync fn download_tokenizer_file(\n http_client: &reqwest::Client,\n url: &str,\n api_token: Option<&String>,\n to: impl AsRef<Path>,\n ide: Ide,\n) -> Result<()> {\n if to.as_ref().exists() {\n return Ok(());\n }\n tokio::fs::create_dir_all(to.as_ref().parent().ok_or(Error::InvalidTokenizerPath)?).await?;\n let headers = build_headers(&Backend::default(), api_token, ide)?;\n let mut file = tokio::fs::OpenOptions::new()\n .write(true)\n .create(true)\n .open(to)\n .await?;\n let http_client = http_client.clone();\n let url = url.to_owned();\n // TODO:\n // - create oneshot channel to send result of tokenizer download to display error message\n // to user?\n // - retry logic?\n tokio::spawn(async move {\n let res = match http_client.get(url).headers(headers).send().await {\n Ok(res) => res,\n Err(err) => {\n error!(\"error sending download request for the tokenzier file: {err}\");\n return;\n }\n };\n let res = match res.error_for_status() {\n Ok(res) => res,\n Err(err) => {\n error!(\"API replied with error to the tokenizer file download: {err}\");\n return;\n }\n };\n let bytes = match res.bytes().await {\n Ok(bytes) => bytes,\n Err(err) => {\n error!(\"error while streaming tokenizer file bytes: {err}\");\n return;\n }\n };\n match file.write_all(&bytes).await {\n Ok(_) => (),\n Err(err) => {\n error!(\"error writing the tokenizer file to disk: {err}\");\n }\n };\n })\n .await?;\n Ok(())\n}\n\nasync fn get_tokenizer(\n model: &str,\n tokenizer_map: &mut HashMap<String, Arc<Tokenizer>>,\n tokenizer_config: Option<&TokenizerConfig>,\n http_client: &reqwest::Client,\n cache_dir: impl AsRef<Path>,\n ide: Ide,\n) -> Result<Option<Arc<Tokenizer>>> {\n if let Some(tokenizer) = tokenizer_map.get(model) {\n return Ok(Some(tokenizer.clone()));\n }\n if let Some(config) = tokenizer_config {\n let tokenizer = match config {\n TokenizerConfig::Local { path } => match Tokenizer::from_file(path) {\n Ok(tokenizer) => Some(Arc::new(tokenizer)),\n Err(err) => {\n error!(\"error loading tokenizer from file: {err}\");\n None\n }\n },\n TokenizerConfig::HuggingFace {\n repository,\n api_token,\n } => {\n let (org, repo) = repository\n .split_once('/')\n .ok_or(Error::InvalidRepositoryId)?;\n let path = cache_dir\n .as_ref()\n .join(org)\n .join(repo)\n .join(\"tokenizer.json\");\n let url =\n format!(\"https://huggingface.co/{repository}/resolve/main/tokenizer.json\");\n download_tokenizer_file(http_client, &url, api_token.as_ref(), &path, ide).await?;\n match Tokenizer::from_file(path) {\n Ok(tokenizer) => Some(Arc::new(tokenizer)),\n Err(err) => {\n error!(\"error loading tokenizer from file: {err}\");\n None\n }\n }\n }\n TokenizerConfig::Download { url, to } => {\n download_tokenizer_file(http_client, url, None, &to, ide).await?;\n match Tokenizer::from_file(to) {\n Ok(tokenizer) => Some(Arc::new(tokenizer)),\n Err(err) => {\n error!(\"error loading tokenizer from file: {err}\");\n None\n }\n }\n }\n };\n if let Some(tokenizer) = tokenizer.clone() {\n tokenizer_map.insert(model.to_owned(), tokenizer.clone());\n }\n Ok(tokenizer)\n } else {\n Ok(None)\n }\n}\n\n// TODO: add configuration parameter to disable path auto-complete?\nfn build_url(backend: Backend, model: &str, disable_url_path_completion: bool) -> String {\n if disable_url_path_completion {\n return backend.url();\n }\n\n match backend {\n Backend::HuggingFace { url } => format!(\"{url}/models/{model}\"),\n Backend::LlamaCpp { mut url } => {\n if url.ends_with(\"/completions\") {\n url\n } else if url.ends_with('/') {\n url.push_str(\"completions\");\n url\n } else {\n url.push_str(\"/completions\");\n url\n }\n }\n Backend::Ollama { mut url } => {\n if url.ends_with(\"/api/generate\") {\n url\n } else if url.ends_with(\"/api/\") {\n url.push_str(\"generate\");\n url\n } else if url.ends_with(\"/api\") {\n url.push_str(\"/generate\");\n url\n } else if url.ends_with('/') {\n url.push_str(\"api/generate\");\n url\n } else {\n url.push_str(\"/api/generate\");\n url\n }\n }\n Backend::OpenAi { mut url } => {\n if url.ends_with(\"/v1/completions\") {\n url\n } else if url.ends_with(\"/v1/\") {\n url.push_str(\"completions\");\n url\n } else if url.ends_with(\"/v1\") {\n url.push_str(\"/completions\");\n url\n } else if url.ends_with('/') {\n url.push_str(\"v1/completions\");\n url\n } else {\n url.push_str(\"/v1/completions\");\n url\n }\n }\n Backend::Tgi { mut url } => {\n if url.ends_with(\"/generate\") {\n url\n } else if url.ends_with('/') {\n url.push_str(\"generate\");\n url\n } else {\n url.push_str(\"/generate\");\n url\n }\n }\n }\n}\n\nimpl LlmService {\n async fn get_completions(\n &self,\n params: GetCompletionsParams,\n ) -> LspResult<GetCompletionsResult> {\n let request_id = Uuid::new_v4();\n let span = info_span!(\"completion_request\", %request_id);\n\n async move {\n let document_map = self.document_map.read().await;\n\n let document =\n match document_map.get(params.text_document_position.text_document.uri.as_str()) {\n Some(doc) => doc,\n None => {\n debug!(\"failed to find document\");\n return Ok(GetCompletionsResult {\n request_id,\n completions: vec![],\n });\n }\n };\n\n info!(\n document_url = %params.text_document_position.text_document.uri,\n cursor_line = ?params.text_document_position.position.line,\n cursor_character = ?params.text_document_position.position.character,\n language_id = %document.language_id,\n model = params.model,\n backend = ?params.backend,\n ide = %params.ide,\n request_body = serde_json::to_string(¶ms.request_body).map_err(internal_error)?,\n disable_url_path_completion = params.disable_url_path_completion,\n \"received completion request\",\n );\n if params.api_token.is_none() && params.backend.is_using_inference_api() {\n let now = SystemTime::now();\n let unauthenticated_warn_at = self.unauthenticated_warn_at.read().await;\n if now.duration_since(*unauthenticated_warn_at).unwrap_or_default() > MAX_WARNING_REPEAT {\n drop(unauthenticated_warn_at);\n self.client.show_message(MessageType::WARNING, \"You are currently unauthenticated and will get rate limited. To reduce rate limiting, login with your API Token and consider subscribing to PRO: https://huggingface.co/pricing#pro\").await;\n let mut unauthenticated_warn_at = self.unauthenticated_warn_at.write().await;\n *unauthenticated_warn_at = SystemTime::now();\n }\n }\n let completion_type = should_complete(document, params.text_document_position.position)?;\n info!(%completion_type, \"completion type: {completion_type:?}\");\n if completion_type == CompletionType::Empty {\n return Ok(GetCompletionsResult { request_id, completions: vec![]});\n }\n\n let tokenizer = get_tokenizer(\n ¶ms.model,\n &mut *self.tokenizer_map.write().await,\n params.tokenizer_config.as_ref(),\n &self.http_client,\n &self.cache_dir,\n params.ide,\n )\n .await?;\n let prompt = build_prompt(\n params.text_document_position.position,\n &document.text,\n ¶ms.fim,\n tokenizer,\n params.context_window,\n )?;\n\n let http_client = if params.tls_skip_verify_insecure {\n info!(\"tls verification is disabled\");\n &self.unsafe_http_client\n } else {\n &self.http_client\n };\n let result = request_completion(\n http_client,\n prompt,\n ¶ms,\n )\n .await?;\n\n let completions = format_generations(result, ¶ms.tokens_to_clear, completion_type);\n Ok(GetCompletionsResult { request_id, completions })\n }.instrument(span).await\n }\n\n async fn accept_completion(&self, accepted: AcceptCompletionParams) -> LspResult<()> {\n info!(\n request_id = %accepted.request_id,\n accepted_position = accepted.accepted_completion,\n shown_completions = serde_json::to_string(&accepted.shown_completions).map_err(internal_error)?,\n \"accepted completion\"\n );\n Ok(())\n }\n\n async fn reject_completion(&self, rejected: RejectCompletionParams) -> LspResult<()> {\n info!(\n request_id = %rejected.request_id,\n shown_completions = serde_json::to_string(&rejected.shown_completions).map_err(internal_error)?,\n \"rejected completion\"\n );\n Ok(())\n }\n}\n\n#[tower_lsp::async_trait]\nimpl LanguageServer for LlmService {\n async fn initialize(&self, params: InitializeParams) -> LspResult<InitializeResult> {\n *self.workspace_folders.write().await = params.workspace_folders;\n let position_encoding = params\n .capabilities\n .general\n .and_then(|general_capabilities| {\n general_capabilities\n .position_encodings\n .map(TryFrom::try_from)\n })\n .unwrap_or(Ok(document::PositionEncodingKind::Utf16))?;\n\n *self.position_encoding.write().await = position_encoding;\n\n Ok(InitializeResult {\n server_info: Some(ServerInfo {\n name: \"llm-ls\".to_owned(),\n version: Some(VERSION.to_owned()),\n }),\n capabilities: ServerCapabilities {\n text_document_sync: Some(TextDocumentSyncCapability::Kind(\n TextDocumentSyncKind::INCREMENTAL,\n )),\n position_encoding: Some(position_encoding.to_lsp_type()),\n ..Default::default()\n },\n })\n }\n\n async fn initialized(&self, _: InitializedParams) {\n self.client\n .log_message(MessageType::INFO, \"llm-ls initialized\")\n .await;\n info!(\"initialized language server\");\n }\n\n async fn did_open(&self, params: DidOpenTextDocumentParams) {\n let uri = params.text_document.uri.to_string();\n if uri == \"file:///\" {\n return;\n }\n match Document::open(\n ¶ms.text_document.language_id,\n ¶ms.text_document.text,\n )\n .await\n {\n Ok(document) => {\n self.document_map\n .write()\n .await\n .insert(uri.clone(), document);\n info!(\"{uri} opened\");\n }\n Err(err) => error!(\"error opening {uri}: {err}\"),\n }\n self.client\n .log_message(MessageType::INFO, format!(\"{uri} opened\"))\n .await;\n }\n\n async fn did_change(&self, params: DidChangeTextDocumentParams) {\n let uri = params.text_document.uri.to_string();\n if uri == \"file:///\" {\n return;\n }\n if params.content_changes.is_empty() {\n return;\n }\n\n // ignore the output scheme\n if params.text_document.uri.scheme() == \"output\" {\n return;\n }\n\n let mut document_map = self.document_map.write().await;\n self.client\n .log_message(MessageType::LOG, format!(\"{uri} changed\"))\n .await;\n let doc = document_map.get_mut(&uri);\n if let Some(doc) = doc {\n for change in ¶ms.content_changes {\n match doc.apply_content_change(change, *self.position_encoding.read().await) {\n Ok(()) => info!(\"{uri} changed\"),\n Err(err) => error!(\"error when changing {uri}: {err}\"),\n }\n }\n } else {\n debug!(\"textDocument/didChange {uri}: document not found\");\n }\n }\n\n async fn did_save(&self, params: DidSaveTextDocumentParams) {\n let uri = params.text_document.uri.to_string();\n self.client\n .log_message(MessageType::INFO, format!(\"{uri} saved\"))\n .await;\n info!(\"{uri} saved\");\n }\n\n // TODO:\n // textDocument/didClose\n async fn did_close(&self, params: DidCloseTextDocumentParams) {\n let uri = params.text_document.uri.to_string();\n self.client\n .log_message(MessageType::INFO, format!(\"{uri} closed\"))\n .await;\n info!(\"{uri} closed\");\n }\n\n async fn shutdown(&self) -> LspResult<()> {\n debug!(\"shutdown\");\n Ok(())\n }\n}\n\n#[derive(Parser, Debug)]\n#[command(author, version, about, long_about = None)]\nstruct Args {\n /// Wether to use a tcp socket for data transfer\n #[arg(long = \"port\")]\n socket: Option<usize>,\n\n /// Wether to use stdio transport for data transfer, ignored because it is the default\n /// behaviour\n #[arg(short, long, default_value_t = true)]\n stdio: bool,\n}\n\n#[tokio::main]\nasync fn main() {\n let args = Args::parse();\n\n let home_dir = home::home_dir().ok_or(()).expect(\"failed to find home dir\");\n let cache_dir = home_dir.join(\".cache/llm_ls\");\n tokio::fs::create_dir_all(&cache_dir)\n .await\n .expect(\"failed to create cache dir\");\n\n let log_file = rolling::never(&cache_dir, \"llm-ls.log\");\n let builder = tracing_subscriber::fmt()\n .with_writer(log_file)\n .with_target(true)\n .with_line_number(true)\n .with_env_filter(\n EnvFilter::try_from_env(\"LLM_LOG_LEVEL\").unwrap_or_else(|_| EnvFilter::new(\"warn\")),\n );\n\n builder\n .json()\n .flatten_event(true)\n .with_current_span(false)\n .with_span_list(true)\n .init();\n\n let http_client = reqwest::Client::new();\n let unsafe_http_client = reqwest::Client::builder()\n .danger_accept_invalid_certs(true)\n .build()\n .expect(\"failed to build reqwest unsafe client\");\n\n let (service, socket) = LspService::build(|client| LlmService {\n cache_dir,\n client,\n position_encoding: Arc::new(RwLock::new(document::PositionEncodingKind::Utf16)),\n document_map: Arc::new(RwLock::new(HashMap::new())),\n http_client,\n unsafe_http_client,\n workspace_folders: Arc::new(RwLock::new(None)),\n tokenizer_map: Arc::new(RwLock::new(HashMap::new())),\n unauthenticated_warn_at: Arc::new(RwLock::new(\n SystemTime::now()\n .checked_sub(MAX_WARNING_REPEAT)\n .unwrap_or(SystemTime::now()),\n )),\n })\n .custom_method(\"llm-ls/getCompletions\", LlmService::get_completions)\n .custom_method(\"llm-ls/acceptCompletion\", LlmService::accept_completion)\n .custom_method(\"llm-ls/rejectCompletion\", LlmService::reject_completion)\n .finish();\n\n if let Some(port) = args.socket {\n let addr = format!(\"127.0.0.1:{port}\");\n let listener = TcpListener::bind(&addr)\n .await\n .unwrap_or_else(|_| panic!(\"failed to bind tcp listener to {addr}\"));\n let (stream, _) = listener\n .accept()\n .await\n .unwrap_or_else(|_| panic!(\"failed to accept new connections on {addr}\"));\n let (read, write) = tokio::io::split(stream);\n Server::new(read, write, socket).serve(service).await;\n } else {\n let (stdin, stdout) = (tokio::io::stdin(), tokio::io::stdout());\n Server::new(stdin, stdout, socket).serve(service).await;\n }\n}\n", "crates\\mock_server\\src\\main.rs": "use axum::{extract::State, http::HeaderMap, routing::post, Json, Router};\nuse serde::{Deserialize, Serialize};\nuse std::{net::SocketAddr, sync::Arc};\nuse tokio::{\n sync::Mutex,\n time::{sleep, Duration},\n};\n\n#[derive(Clone)]\nstruct AppState {\n counter: Arc<Mutex<u32>>,\n}\n\n#[derive(Deserialize, Serialize)]\nstruct GeneratedText {\n generated_text: String,\n}\n\nasync fn default(state: State<AppState>) -> Json<Vec<GeneratedText>> {\n let mut lock = state.counter.lock().await;\n *lock += 1;\n println!(\"got request {}\", lock);\n Json(vec![GeneratedText {\n generated_text: \"dummy\".to_owned(),\n }])\n}\n\nasync fn tgi(state: State<AppState>) -> Json<GeneratedText> {\n let mut lock = state.counter.lock().await;\n *lock += 1;\n Json(GeneratedText {\n generated_text: \"dummy\".to_owned(),\n })\n}\n\nasync fn log_headers(headers: HeaderMap, state: State<AppState>) -> Json<GeneratedText> {\n let mut lock = state.counter.lock().await;\n *lock += 1;\n for (name, value) in headers.iter() {\n println!(\"{lock} - {}: {}\", name, value.to_str().unwrap());\n }\n Json(GeneratedText {\n generated_text: \"dummy\".to_owned(),\n })\n}\n\nasync fn wait(state: State<AppState>) -> Json<GeneratedText> {\n let mut lock = state.counter.lock().await;\n *lock += 1;\n sleep(Duration::from_millis(200)).await;\n println!(\"waited for req {}\", lock);\n Json(GeneratedText {\n generated_text: \"dummy\".to_owned(),\n })\n}\n\n#[tokio::main]\nasync fn main() {\n let app_state = AppState {\n counter: Arc::new(Mutex::new(0)),\n };\n let app = Router::new()\n .route(\"/\", post(default))\n .route(\"/tgi\", post(tgi))\n .route(\"/headers\", post(log_headers))\n .route(\"/wait\", post(wait))\n .with_state(app_state);\n let addr: SocketAddr = format!(\"{}:{}\", \"0.0.0.0\", 4242)\n .parse()\n .expect(\"string to parse to socket addr\");\n println!(\"starting server {}:{}\", addr.ip(), addr.port(),);\n\n axum::Server::bind(&addr)\n .serve(app.into_make_service())\n .await\n .expect(\"server to start\");\n}\n", "crates\\testbed\\repositories\\simple\\src\\main.rs": "fn sum(lhs: i32, rhs: i32) -> i32 {\n lhs + rhs\n}\n\nfn sub(lhs: i32, rhs: i32) -> i32 {\n lhs - rhs\n}\n\nfn mul(lhs: i32, rhs: i32) -> i32 {\n lhs * rhs\n}\n\nfn div(lhs: i32, rhs: i32) -> i32 {\n lhs / rhs\n}\n\nfn main() {\n println!(\"42 + 42 = {}\", sum(42, 42));\n println!(\"41 - 42 = {}\", sub(41, 42));\n println!(\"42 * 42 = {}\", mul(42, 42));\n println!(\"42 / 42 = {}\", div(42, 42));\n}\n\n#[cfg(test)]\nmod tests {\n #[test]\n fn test_sum() {\n assert_eq!(42 + 42, super::sum(42, 42));\n }\n\n #[test]\n fn test_sub() {\n assert_eq!(42 - 42, super::sub(42, 42));\n assert_eq!(41 - 42, super::sub(41, 42));\n }\n\n #[test]\n fn test_mul() {\n assert_eq!(42 * 42, super::mul(42, 42));\n }\n\n #[test]\n fn test_div() {\n assert_eq!(42 / 42, super::div(42, 42));\n }\n}\n", "crates\\testbed\\src\\main.rs": "use std::{\n collections::{HashMap, VecDeque},\n fmt::Display,\n io::BufReader,\n path::{Path, PathBuf},\n process::Stdio,\n sync::Arc,\n time::Instant,\n};\n\nuse anyhow::anyhow;\nuse clap::Parser;\nuse custom_types::{\n llm_ls::{Backend, FimParams, GetCompletionsParams, Ide, TokenizerConfig},\n request::GetCompletions,\n};\nuse futures_util::{stream::FuturesUnordered, StreamExt, TryStreamExt};\nuse lang::Language;\nuse lsp_client::{client::LspClient, error::ExtractError, server::Server};\nuse lsp_types::{\n DidOpenTextDocumentParams, InitializeParams, TextDocumentIdentifier, TextDocumentItem,\n TextDocumentPositionParams,\n};\nuse ropey::Rope;\nuse runner::Runner;\nuse serde::{Deserialize, Serialize};\nuse serde_json::{Map, Value};\nuse tempfile::TempDir;\nuse tokio::{\n fs::{self, read_to_string, File, OpenOptions},\n io::{\n self, AsyncBufRead, AsyncBufReadExt, AsyncReadExt, AsyncWriteExt,\n BufReader as TokioBufReader,\n },\n join,\n process::Command,\n sync::{OnceCell, RwLock, Semaphore},\n};\nuse tokio_util::compat::FuturesAsyncReadCompatExt;\nuse tracing::{debug, error, info, info_span, warn, Instrument};\nuse tracing_subscriber::EnvFilter;\nuse url::Url;\n\nuse crate::{holes_generator::generate_holes, runner::run_test};\n\nmod holes_generator;\nmod lang;\nmod runner;\n\n/// Testbed runs llm-ls' code completion to measure its performance\n#[derive(Parser, Debug)]\n#[command(author, version, about, long_about = None)]\nstruct Args {\n /// Hugging Face Inference API Token\n #[arg(short, long)]\n api_token: Option<String>,\n\n /// Comma separated list of repos in the repositories file to run completions or holes generation for;\n /// matches on path for local repos and `owner/name` for github repos\n #[arg(short, long)]\n filter: Option<String>,\n\n /// When this is specified, holes files will be generated based on the repositories.yaml file\n #[arg(short, long, action)]\n generate_holes: bool,\n\n /// Path to the directory containing the holes files\n #[arg(short = 'H', long)]\n holes_dir_path: Option<String>,\n\n /// Number of holes to create per repository\n #[arg(short = 'n', long, default_value_t = 100)]\n holes_per_repo: usize,\n\n /// Path to llm-ls' binary\n #[arg(short, long)]\n llm_ls_bin_path: Option<String>,\n\n /// Concurrent hole completions number\n #[arg(short, long, default_value_t = 8)]\n parallel_hole_completions: usize,\n\n /// Path to the local repositories/ directory\n #[arg(short = 'R', long)]\n repos_dir_path: Option<String>,\n\n /// Path to the repositories.yaml file\n #[arg(short, long)]\n repos_file_path: Option<String>,\n}\n\n#[derive(Clone, Deserialize, Serialize)]\nstruct LocalRepo {\n path: PathBuf,\n src_path: String,\n #[serde(default)]\n exclude_paths: Vec<String>,\n}\n\n#[derive(Clone, Deserialize, Serialize)]\nstruct GithubRepo {\n owner: String,\n name: String,\n revision: String,\n #[serde(default)]\n src_path: String,\n #[serde(default)]\n exclude_paths: Vec<String>,\n}\n\n#[derive(Clone, Deserialize, Serialize)]\n#[serde(tag = \"type\")]\n#[serde(rename_all = \"lowercase\")]\nenum RepoSource {\n Local(LocalRepo),\n Github(GithubRepo),\n}\n\nimpl RepoSource {\n fn source_type(&self) -> String {\n match self {\n Self::Local { .. } => \"local\".to_owned(),\n Self::Github { .. } => \"github\".to_owned(),\n }\n }\n\n fn src_path(&self) -> String {\n match self {\n Self::Local(local) => local.src_path.clone(),\n Self::Github(github) => github.src_path.clone(),\n }\n }\n\n fn exclude_paths(&self) -> Vec<String> {\n match self {\n Self::Local(local) => local.exclude_paths.clone(),\n Self::Github(github) => github.exclude_paths.clone(),\n }\n }\n}\n\n#[derive(Clone, Deserialize, Serialize)]\nstruct Repository {\n build_command: String,\n build_args: Vec<String>,\n env: Option<Vec<String>>,\n holes_file: String,\n language: Language,\n runner: Runner,\n runner_command: Option<String>,\n runner_args: Option<Vec<String>>,\n #[serde(default)]\n runner_extra_args: Vec<String>,\n setup_commands: Option<Vec<(String, Vec<String>)>>,\n source: RepoSource,\n}\n\nimpl Repository {\n /// can panic if local path is not utf8\n fn name(&self) -> String {\n match &self.source {\n RepoSource::Local(local) => local.path.to_str().unwrap().to_owned(),\n RepoSource::Github(github) => format!(\"{}/{}\", github.owner, github.name),\n }\n }\n}\n\n#[derive(Clone, Deserialize, Serialize)]\nstruct Hole {\n cursor: lsp_types::Position,\n /// relative path of a file in the repository\n file: String,\n}\n\nimpl Hole {\n fn new(line: u32, character: u32, file: String) -> Self {\n Self {\n cursor: lsp_types::Position::new(line, character),\n file,\n }\n }\n}\n\nimpl Display for Hole {\n fn fmt(&self, f: &mut std::fmt::Formatter<'_>) -> std::fmt::Result {\n write!(\n f,\n \"{} [{}, {}]\",\n self.file, self.cursor.line, self.cursor.character\n )\n }\n}\n\n// unused for now, consider all holes as lines\n// enum HoleType {\n// Line,\n// Multiline\n// }\n\n#[derive(Clone, Deserialize, Serialize)]\nstruct RepositoriesConfig {\n context_window: usize,\n fim: FimParams,\n model: String,\n #[serde(flatten)]\n backend: Backend,\n repositories: Vec<Repository>,\n tls_skip_verify_insecure: bool,\n tokenizer_config: Option<TokenizerConfig>,\n tokens_to_clear: Vec<String>,\n request_body: Map<String, Value>,\n disable_url_path_completion: bool,\n}\n\nstruct HoleCompletionResult {\n repo_name: String,\n repo_source_type: String,\n pass_percentage: f32,\n completion_time_ms: u128,\n}\n\nimpl HoleCompletionResult {\n fn new(\n repo_name: String,\n repo_source_type: String,\n pass_percentage: f32,\n completion_time_ms: u128,\n ) -> Self {\n Self {\n repo_name,\n repo_source_type,\n pass_percentage,\n completion_time_ms,\n }\n }\n}\n\nstruct SetupCache {\n cache: HashMap<String, OnceCell<(TempDir, PathBuf)>>,\n}\n\nimpl SetupCache {\n fn new(repositories: &Vec<Repository>) -> Self {\n let mut cache = HashMap::new();\n for repo in repositories {\n cache.insert(repo.name(), OnceCell::new());\n }\n Self { cache }\n }\n\n async fn get_setup_cache(\n &self,\n repos_dir_path: PathBuf,\n repo: Repository,\n ) -> anyhow::Result<&(TempDir, PathBuf)> {\n self.cache\n .get(&repo.name())\n .ok_or(anyhow!(\n \"failed to find setup cache for repo {}\",\n repo.name()\n ))?\n .get_or_try_init(|| async move {\n let (temp_dir, repo_path) = setup_repo_dir(&repos_dir_path, &repo.source).await?;\n if let Some(commands) = &repo.setup_commands {\n run_setup(commands, &repo.env, &repo_path).await?;\n }\n Ok((temp_dir, repo_path))\n })\n .await\n }\n\n async fn create_cache_copy(\n &self,\n repos_dir_path: PathBuf,\n repo: Repository,\n ) -> anyhow::Result<TempDir> {\n let (_cached_dir, path_in_dir) = self.get_setup_cache(repos_dir_path, repo).await?;\n let temp_dir = TempDir::new()?;\n copy_dir_contents(path_in_dir, temp_dir.path()).await?;\n Ok(temp_dir)\n }\n}\n\nasync fn get_api_token(args_token: Option<String>) -> anyhow::Result<Option<String>> {\n if args_token.is_some() {\n Ok(args_token)\n } else {\n let home_dir = home::home_dir().ok_or(anyhow!(\"failed to find home dir\"))?;\n let cached_token = home_dir.join(\".cache/huggingface/token\");\n if cached_token.try_exists()? {\n let mut token = String::new();\n File::open(cached_token)\n .await?\n .read_to_string(&mut token)\n .await?;\n Ok(Some(token.trim().to_owned()))\n } else {\n Ok(None)\n }\n }\n}\n\nasync fn download_repo_from_github(\n temp_dir: &TempDir,\n repo: &GithubRepo,\n) -> anyhow::Result<PathBuf> {\n let repo_dir_name = format!(\"{}-{}\", repo.name, repo.revision);\n let archive_path = temp_dir.path().join(format!(\"{}.zip\", repo_dir_name));\n let mut archive = File::create(&archive_path).await?;\n let stream = reqwest::get(&format!(\n \"https://github.com/{}/{}/archive/{}.zip\",\n repo.owner, repo.name, repo.revision,\n ))\n .await?\n .error_for_status()?\n .bytes_stream();\n let stream = stream\n .map_err(|e| futures::io::Error::new(futures::io::ErrorKind::Other, e))\n .into_async_read();\n let mut stream = stream.compat();\n io::copy(&mut stream, &mut archive).await?;\n let archive = BufReader::new(std::fs::File::open(archive_path)?);\n zip::ZipArchive::new(archive)?.extract(temp_dir.path())?;\n Ok(temp_dir.path().join(repo_dir_name))\n}\n\nasync fn copy_dir_contents(source: &Path, dest: &Path) -> anyhow::Result<()> {\n debug!(\n \"copying files from {} to {}\",\n source.to_str().unwrap(),\n dest.to_str().unwrap()\n );\n let mut stack = VecDeque::new();\n stack.push_back((source.to_path_buf(), dest.to_path_buf()));\n while let Some((src, dst)) = stack.pop_back() {\n let mut entries = fs::read_dir(&src).await?;\n while let Some(entry) = entries.next_entry().await? {\n let entry_type = entry.file_type().await?;\n\n let src_path = entry.path();\n let dst_path = fs::canonicalize(&dst).await?.join(entry.file_name());\n\n if entry_type.is_dir() {\n fs::create_dir(&dst_path).await?;\n stack.push_back((src_path, dst_path));\n } else if entry_type.is_file() {\n fs::copy(&src_path, &dst_path).await?;\n } else if entry_type.is_symlink() {\n let link_target = fs::read_link(&src_path).await?;\n fs::symlink(link_target, dst_path.clone()).await?;\n }\n }\n }\n\n Ok(())\n}\n\nasync fn setup_repo_dir(\n repos_dir_path: &Path,\n source: &RepoSource,\n) -> anyhow::Result<(TempDir, PathBuf)> {\n match source {\n RepoSource::Local(local) => {\n debug!(\"setting up local repo: {}\", local.path.to_str().unwrap());\n let temp_dir = TempDir::new()?;\n copy_dir_contents(&repos_dir_path.join(&local.path), temp_dir.path()).await?;\n let repo_path = temp_dir.path().to_path_buf();\n Ok((temp_dir, repo_path))\n }\n RepoSource::Github(github) => {\n debug!(\"setting repo from github: {}/{}\", github.owner, github.name);\n let temp_dir = TempDir::new()?;\n let repo_path = download_repo_from_github(&temp_dir, github).await?;\n Ok((temp_dir, repo_path))\n }\n }\n}\n\nfn parse_env(env: &Option<Vec<String>>) -> anyhow::Result<Vec<(String, String)>> {\n let mut env_vars = vec![];\n if let Some(env) = env {\n for var in env {\n env_vars.push(\n var.split_once('=')\n .map(|(n, v)| (n.to_owned(), v.to_owned()))\n .ok_or(anyhow!(\"failed to split env var {var}\"))?,\n );\n }\n }\n Ok(env_vars)\n}\n\nasync fn run_setup(\n commands: &Vec<(String, Vec<String>)>,\n env: &Option<Vec<String>>,\n repo_path: impl AsRef<Path>,\n) -> anyhow::Result<()> {\n let parsed_env = parse_env(env)?;\n for command in commands {\n let mut status_cmd = Command::new(&command.0);\n for (name, value) in &parsed_env {\n status_cmd.env(name, value);\n }\n debug!(\n \"running setup command: {} {}\",\n command.0,\n command.1.join(\" \")\n );\n let mut child = status_cmd\n .args(&command.1)\n .current_dir(&repo_path)\n .stdout(Stdio::piped())\n .stderr(Stdio::piped())\n .spawn()?;\n\n if let (Some(stdout), Some(stderr)) = (child.stdout.take(), child.stderr.take()) {\n let stdout = TokioBufReader::new(stdout);\n let stderr = TokioBufReader::new(stderr);\n join!(log_lines(stdout), log_lines(stderr));\n }\n\n let status = child.wait().await?;\n if !status.success() {\n return Err(anyhow!(\n \"error running: \\\"{} {}\\\"\",\n command.0,\n command.1.join(\" \")\n ));\n }\n }\n Ok(())\n}\n\nasync fn build(\n command: &str,\n args: &Vec<String>,\n env: &Option<Vec<String>>,\n repo_path: impl AsRef<Path>,\n) -> anyhow::Result<bool> {\n let parsed_env = parse_env(env)?;\n let mut status_cmd = Command::new(command);\n for (name, value) in parsed_env {\n status_cmd.env(name, value);\n }\n debug!(\"building repo: {command} {args:?}\");\n\n let mut child = status_cmd\n .args(args)\n .current_dir(repo_path)\n .stdout(Stdio::piped())\n .stderr(Stdio::piped())\n .spawn()?;\n\n if let (Some(stdout), Some(stderr)) = (child.stdout.take(), child.stderr.take()) {\n let stdout = TokioBufReader::new(stdout);\n let stderr = TokioBufReader::new(stderr);\n join!(log_lines(stdout), log_lines(stderr));\n }\n\n let status = child.wait().await?;\n Ok(status.success())\n}\n\nasync fn log_lines<R: AsyncReadExt + AsyncBufRead + Unpin>(stdio: R) {\n let mut lines = stdio.lines();\n while let Ok(Some(log)) = lines.next_line().await {\n debug!(\"{log}\");\n }\n}\n\n#[allow(clippy::too_many_arguments)]\nasync fn complete_holes(\n hole: Hole,\n repo: Repository,\n client: Arc<LspClient>,\n file_cache: Arc<RwLock<HashMap<PathBuf, Rope>>>,\n repos_dir_path: PathBuf,\n repos_config: RepositoriesConfig,\n api_token: Option<String>,\n semaphore: Arc<Semaphore>,\n setup_cache: Arc<SetupCache>,\n) -> anyhow::Result<HoleCompletionResult> {\n let permit = semaphore.acquire_owned().await?;\n let span = info_span!(\"complete_hole\", repo_name = repo.name());\n let RepositoriesConfig {\n context_window,\n fim,\n model,\n backend,\n tls_skip_verify_insecure,\n tokenizer_config,\n tokens_to_clear,\n request_body,\n disable_url_path_completion,\n ..\n } = repos_config;\n async move {\n let tmp_dir = setup_cache\n .create_cache_copy(repos_dir_path, repo.clone())\n .await?;\n let repo_path = tmp_dir.path();\n let hole_instant = Instant::now();\n let file_path = repo_path.join(&hole.file);\n let file_path_str = file_path\n .to_str()\n .ok_or(anyhow!(\"failed to convert file to str\"))?;\n let mut file_content = if file_cache.read().await.contains_key(&file_path) {\n file_cache\n .read()\n .await\n .get(&file_path)\n .ok_or(anyhow!(\"failed to find {} in file cache\", file_path_str))?\n .to_owned()\n } else {\n let file_content = Rope::from_str(&read_to_string(&file_path).await?);\n file_cache\n .write()\n .await\n .insert(file_path.clone(), file_content.clone());\n file_content\n };\n let original_content = file_content.clone();\n let hole_start =\n file_content.line_to_char(hole.cursor.line as usize) + hole.cursor.character as usize;\n let hole_end = hole_start\n + file_content\n .line(hole.cursor.line as usize)\n .slice(hole.cursor.character as usize..)\n .len_chars()\n - 1;\n file_content.remove(hole_start..hole_end);\n\n let uri = Url::parse(&format!(\"file:/{file_path_str}\"))?;\n client.send_notification::<lsp_types::notification::DidOpenTextDocument>(\n DidOpenTextDocumentParams {\n text_document: TextDocumentItem {\n uri: uri.clone(),\n language_id: repo.language.to_string(),\n version: 0,\n text: file_content.to_string(),\n },\n },\n );\n let result = client\n .send_request::<GetCompletions>(GetCompletionsParams {\n api_token: api_token.clone(),\n context_window,\n fim: fim.clone(),\n ide: Ide::default(),\n model: model.clone(),\n backend,\n text_document_position: TextDocumentPositionParams {\n position: hole.cursor,\n text_document: TextDocumentIdentifier { uri },\n },\n tls_skip_verify_insecure,\n tokens_to_clear: tokens_to_clear.clone(),\n tokenizer_config: tokenizer_config.clone(),\n request_body: request_body.clone(),\n disable_url_path_completion,\n })\n .await?;\n\n file_content.insert(hole_start, &result.completions[0].generated_text);\n let mut file = OpenOptions::new()\n .write(true)\n .truncate(true)\n .open(&file_path)\n .await?;\n file.write_all(file_content.to_string().as_bytes()).await?;\n let test_percentage =\n if build(&repo.build_command, &repo.build_args, &repo.env, &repo_path).await? {\n run_test(\n repo.runner,\n &repo.runner_command,\n &repo.runner_args,\n &mut repo.runner_extra_args.clone(),\n &repo.env,\n repo_path,\n )\n .await?\n } else {\n 0f32\n };\n debug!(\"{} passed {}%\", hole.to_string(), test_percentage * 100f32);\n let hole_completions_result = HoleCompletionResult::new(\n repo.name(),\n repo.source.source_type(),\n test_percentage,\n hole_instant.elapsed().as_millis(),\n );\n let mut file = OpenOptions::new()\n .write(true)\n .truncate(true)\n .open(&file_path)\n .await?;\n file.write_all(original_content.to_string().as_bytes())\n .await?;\n drop(permit);\n Ok(hole_completions_result)\n }\n .instrument(span)\n .await\n}\n\n#[tokio::main]\nasync fn main() -> anyhow::Result<()> {\n tracing_subscriber::fmt()\n .with_target(true)\n .with_line_number(true)\n .with_env_filter(\n EnvFilter::try_from_env(\"LOG_LEVEL\").unwrap_or_else(|_| EnvFilter::new(\"info\")),\n )\n .init();\n\n let args = Args::parse();\n\n let api_token = get_api_token(args.api_token).await?;\n let current_dir = std::env::current_dir()?;\n let llm_ls_path = if let Some(bin_path) = args.llm_ls_bin_path {\n bin_path.into()\n } else {\n current_dir.join(\"target/release/llm-ls\")\n };\n\n let repos_dir_path = if let Some(path) = args.repos_dir_path {\n path.into()\n } else {\n current_dir.join(\"crates/testbed/repositories\")\n };\n\n let repos_file_path = if let Some(path) = args.repos_file_path {\n path.into()\n } else {\n current_dir.join(\"crates/testbed/repositories.yaml\")\n };\n\n let holes_dir_path = if let Some(path) = args.holes_dir_path {\n path.into()\n } else {\n current_dir.join(\"crates/testbed/holes\")\n };\n\n let (filter_repos, filter_list) = if let Some(filter) = args.filter {\n (true, filter.split(',').map(|s| s.to_owned()).collect())\n } else {\n (false, vec![])\n };\n\n let mut repos_file = String::new();\n File::open(&repos_file_path)\n .await?\n .read_to_string(&mut repos_file)\n .await?;\n let repos_config: RepositoriesConfig = serde_yaml::from_str(&repos_file)?;\n if args.generate_holes {\n return generate_holes(\n repos_config,\n &repos_dir_path,\n &holes_dir_path,\n args.holes_per_repo,\n filter_repos,\n filter_list,\n )\n .await;\n }\n\n debug!(\n \"initializing language server at path: {}\",\n llm_ls_path.to_str().unwrap()\n );\n let (conn, server) = Server::build().binary_path(llm_ls_path).start().await?;\n let client = Arc::new(LspClient::new(conn, server).await);\n client\n .send_request::<lsp_types::request::Initialize>(InitializeParams::default())\n .await?;\n\n let file_cache = Arc::new(RwLock::new(HashMap::new()));\n let mut passing_tests_percentage = vec![];\n\n let repositories = repos_config.repositories.clone();\n let setup_cache = Arc::new(SetupCache::new(&repositories));\n let mut handles = FuturesUnordered::new();\n let semaphore = Arc::new(Semaphore::new(args.parallel_hole_completions));\n for repo in repositories {\n if filter_repos && !filter_list.contains(&repo.name()) {\n continue;\n }\n let holes_file_path = holes_dir_path.join(&repo.holes_file);\n let mut holes = String::new();\n File::open(holes_file_path)\n .await?\n .read_to_string(&mut holes)\n .await?;\n let holes: Vec<Hole> = serde_json::from_str(&holes)?;\n info!(\"running {} hole completions\", holes.len());\n for hole in holes {\n let repo = repo.clone();\n let client = client.clone();\n let file_cache = file_cache.clone();\n let repos_dir_path = repos_dir_path.clone();\n let repos_config = repos_config.clone();\n let api_token = api_token.clone();\n let semaphore = semaphore.clone();\n let setup_cache = setup_cache.clone();\n handles.push(tokio::spawn(async move {\n complete_holes(\n hole,\n repo,\n client,\n file_cache,\n repos_dir_path,\n repos_config,\n api_token,\n semaphore,\n setup_cache,\n )\n .await\n }));\n }\n }\n\n while let Some(res) = handles.next().await {\n match res {\n Ok(Ok(res)) => passing_tests_percentage.push(res),\n Ok(Err(err)) => {\n if let Some(extract_err) = err.downcast_ref::<ExtractError>() {\n error!(\"llm-ls response error: {extract_err}\");\n } else {\n return Err(err);\n }\n }\n Err(err) => return Err(err.into()),\n }\n }\n let mut results_map: HashMap<(String, String), (u128, f32, f32)> = HashMap::new();\n for res in passing_tests_percentage {\n results_map\n .entry((res.repo_name, res.repo_source_type))\n .and_modify(|p| {\n p.0 += res.completion_time_ms;\n p.1 += res.pass_percentage;\n p.2 += 1f32;\n })\n .or_insert((res.completion_time_ms, res.pass_percentage, 1f32));\n }\n let json_result = results_map\n .iter()\n .map(|(k, v)| {\n let avg_hole_completion_time_ms = v.0 as f32 / v.2 / 1_000f32;\n let pass_percentage = v.1 / v.2 * 100f32;\n info!(\n \"{} from {} obtained {:.2}% in {:.3}s\",\n k.0, k.1, pass_percentage, avg_hole_completion_time_ms\n );\n serde_json::json!({\n \"repo_name\": k.0,\n \"source_type\": k.1,\n \"avg_hole_completion_time_ms\": format!(\"{:.3}\", avg_hole_completion_time_ms),\n \"pass_percentage\": format!(\"{:.2}\", pass_percentage),\n })\n })\n .collect::<Vec<serde_json::Value>>();\n OpenOptions::new()\n .create(true)\n .write(true)\n .truncate(true)\n .open(\"results.json\")\n .await?\n .write_all(serde_json::to_string(&json_result)?.as_bytes())\n .await?;\n\n info!(\"all tests were run, exiting\");\n client.shutdown().await?;\n match Arc::into_inner(client) {\n Some(client) => client.exit().await,\n None => warn!(\"could not send exit notification because client is referenced elsewhere\"),\n }\n Ok(())\n}\n", "xtask\\src\\main.rs": "//! See <https://github.com/matklad/cargo-xtask/>.\n//!\n//! This binary defines various auxiliary build commands, which are not\n//! expressible with just `cargo`.\n//!\n//! This binary is integrated into the `cargo` command line by using an alias in\n//! `.cargo/config`.\n\n#![warn(\n rust_2018_idioms,\n unused_lifetimes,\n semicolon_in_expressions_from_macros\n)]\n\nmod flags;\n\nmod dist;\n\nuse std::{\n env,\n path::{Path, PathBuf},\n};\nuse xshell::Shell;\n\nfn main() -> anyhow::Result<()> {\n let flags = flags::Xtask::from_env_or_exit();\n\n let sh = &Shell::new()?;\n sh.change_dir(project_root());\n\n match flags.subcommand {\n flags::XtaskCmd::Dist(cmd) => cmd.run(sh),\n }\n}\n\nfn project_root() -> PathBuf {\n Path::new(\n &env::var(\"CARGO_MANIFEST_DIR\").unwrap_or_else(|_| env!(\"CARGO_MANIFEST_DIR\").to_owned()),\n )\n .ancestors()\n .nth(1)\n .unwrap()\n .to_path_buf()\n}\n"} | null |
llm-swarm | {"type": "directory", "name": "llm-swarm", "children": [{"type": "file", "name": ".pre-commit-config.yaml"}, {"type": "directory", "name": ".vscode", "children": [{"type": "file", "name": "launch.json"}]}, {"type": "directory", "name": "examples", "children": [{"type": "file", "name": "benchmark.py"}, {"type": "directory", "name": "completions", "children": [{"type": "file", "name": "generate_completions.py"}]}, {"type": "directory", "name": "constitutional-ai", "children": [{"type": "file", "name": "constituion_grok.json"}, {"type": "file", "name": "constitution_anthropic.json"}, {"type": "directory", "name": "exps", "children": [{"type": "file", "name": "constitution_1705620057.json"}]}, {"type": "file", "name": "generate_dataset.py"}, {"type": "file", "name": "generate_system_chat.py"}, {"type": "file", "name": "README.md"}]}, {"type": "file", "name": "hello_world.py"}, {"type": "file", "name": "hello_world_vllm.py"}, {"type": "directory", "name": "openhermes-preference", "children": [{"type": "file", "name": "concat_and_push.py"}, {"type": "file", "name": "dpo_pair_rm.py"}, {"type": "file", "name": "generate.py"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}]}, {"type": "directory", "name": "self_reward", "children": [{"type": "file", "name": "generate.py"}, {"type": "file", "name": "README.md"}]}, {"type": "directory", "name": "textbooks", "children": [{"type": "file", "name": "generate_synthetic_textbooks.py"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}]}]}, {"type": "file", "name": "LICENSE"}, {"type": "directory", "name": "llm_swarm", "children": [{"type": "file", "name": "__init__.py"}, {"type": "file", "name": "__main__.py"}]}, {"type": "file", "name": "poetry.lock"}, {"type": "file", "name": "pyproject.toml"}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "static", "children": [{"type": "file", "name": "HF-Get a Pro Account-blue.svg"}]}, {"type": "directory", "name": "templates", "children": [{"type": "file", "name": "nginx.template.conf"}, {"type": "file", "name": "tgi_a100.template.slurm"}, {"type": "file", "name": "tgi_h100.template.slurm"}, {"type": "file", "name": "vllm_h100.template.slurm"}]}]} | # Guidelines
Here you can find the code used to generate large synthetic datasets like [Cosmopedia](https://huggingface.co/datasets/HuggingFaceTB/cosmopedia). You need to have a dataset containing prompts, in this case we're using [cosmopedia-100k](https://huggingface.co/datasets/HuggingFaceTB/cosmopedia-100k).
## Setup
Since we want to generate a large volume of textbooks and the generations might take a long time, we save the intermediate generations in `checkpoint_path` and track the progress and throughput with `wandb`.
```bash
pip install wandb
wandb init
```
## Generation
To run the generations on the first 2000 prompts on 2 TGI instances, you can use:
```bash
# Use --max_samples -1 to generate for the whole dataset
python ./examples/textbooks/generate_synthetic_textbooks.py \
--model mistralai/Mixtral-8x7B-Instruct-v0.1 \
--instances 2 \
--prompts_dataset "HuggingFaceTB/cosmopedia-100k" \
--prompt_column prompt \
--max_samples 2000 \
--checkpoint_path "./synthetic_data" \
--checkpoint_interval 1000
```
The output will look like this:
```
(textbooks) loubna@login-node-1:/fsx/loubna/projects/llm-swarm$ python ./examples/textbooks/generate_synthetic_textbooks.py \
--model mistralai/Mixtral-8x7B-Instruct-v0.1 \
--instances 2 \
--prompts_dataset "HuggingFaceTB/cosmopedia-100k" \
--prompt_column prompt \
--max_samples 2000 \
--checkpoint_path "./synthetic_data" \
--checkpoint_interval 1000
{'max_new_tokens': 2500, 'temperature': 0.6, 'top_p': 0.95, 'top_k': 50, 'repetition_penalty': 1.2, 'prompts_dataset': 'HuggingFaceTB/cosmopedia-100k', 'max_samples': 2000, 'start_sample': -1, 'end_sample': -1, 'seed': 42, 'prompt_column': 'prompt', 'shuffle_dataset': False, 'debug': False, 'repo_id': 'HuggingFaceTB/synthetic_data_test', 'checkpoint_path': './synthetic_data', 'checkpoint_interval': 1000, 'wandb_username': 'NAME', 'min_token_length': 150, 'push_to_hub': True, 'per_instance_max_parallel_requests': 500, 'instances': 2, 'inference_engine': 'tgi', 'model': 'mistralai/Mixtral-8x7B-Instruct-v0.1'}
Loading the first 1000 samples...
running sbatch --parsable slurm/tgi_1708388771_tgi.slurm
running sbatch --parsable slurm/tgi_1708388771_tgi.slurm
Slurm Job ID: ['2179705', '2179706']
📖 Slurm hosts path: slurm/tgi_1708388771_host_tgi.txt
✅ Done! Waiting for 2179705 to be created
📖 Slurm log path: slurm/logs/llm-swarm_2179705.out
✅ Done! Waiting for 2179706 to be created
📖 Slurm log path: slurm/logs/llm-swarm_2179706.out
✅ Done! Waiting for slurm/tgi_1708388771_host_tgi.txt to be created
obtained endpoints [MASKED_ENDPOINTS]
⢿ Waiting for [MASKED_ENDPOINTS] to be reachable
Connected to [MASKED_ENDPOINTS]
✅ Done! Waiting for [MASKED_ENDPOINTS] to be reachable
⣻ Waiting for [MASKED_ENDPOINTS] to be reachable
Connected to [MASKED_ENDPOINTS]
✅ Done! Waiting for [MASKED_ENDPOINTS] to be reachable
Endpoints running properly: ['[MASKED_ENDPOINTS]', '[MASKED_ENDPOINTS]']
✅ test generation
✅ test generation
running sudo docker run -d -p 44227:44227 --network host -v $(pwd)/slurm/tgi_1708388771_load_balancer.conf:/etc/nginx/nginx.conf nginx
running sudo docker logs b79ac41505de597196ae7825fda2ad8a60d1c66bc6a8b46038a121d8092198c9
/docker-entrypoint.sh: /docker-entrypoint.d/ is not empty, will attempt to perform configuration
/docker-entrypoint.sh: Looking for shell scripts in /docker-entrypoint.d/
/docker-entrypoint.sh: Launching /docker-entrypoint.d/10-listen-on-ipv6-by-default.sh
10-listen-on-ipv6-by-default.sh: info: Getting the checksum of /etc/nginx/conf.d/default.conf
10-listen-on-ipv6-by-default.sh: info: Enabled listen on IPv6 in /etc/nginx/conf.d/default.conf
/docker-entrypoint.sh: Sourcing /docker-entrypoint.d/15-local-resolvers.envsh
/docker-entrypoint.sh: Launching /docker-entrypoint.d/20-envsubst-on-templates.sh
/docker-entrypoint.sh: Launching /docker-entrypoint.d/30-tune-worker-processes.sh
/docker-entrypoint.sh: Configuration complete; ready for start up
🔥 endpoint ready http://localhost:44227
wandb: Currently logged in as: NAME. Use `wandb login --relogin` to force relogin
wandb: Tracking run with wandb version 0.16.3
wandb: Run data is saved locally in ./wandb/run-20240220_003007-3jlhm7lw
wandb: Run `wandb offline` to turn off syncing.
wandb: Syncing run synthetic_data_test_prompt
wandb: ⭐️ View project at https://wandb.ai/NAME/synthetic_data
wandb: 🚀 View run at https://wandb.ai/NAME/v/runs/3jlhm7lw
Will be saving at ./synthetic_data/synthetic_data_test_prompt/data
Processing chunk 0/2
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1000/1000 [02:27<00:00, 6.79it/s]
Saving the dataset (1/1 shards): 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████| 1000/1000 [00:00<00:00, 68625.21 examples/s]
💾 Checkpoint (samples 0-1000) saved at ./synthetic_data/synthetic_data_test_prompt/data/checkpoint_0.json.
Processing chunk 1/2
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1000/1000 [02:30<00:00, 6.64it/s]
Saving the dataset (1/1 shards): 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████| 1000/1000 [00:00<00:00, 82626.85 examples/s]
💾 Checkpoint (samples 1000-2000) saved at ./synthetic_data/synthetic_data_test_prompt/data/checkpoint_1000.json.
Done processing and saving all chunks 🎉! Let's get some stats and push to hub...
🏎️💨 Overall Tokens per Second: 5890.90, per instance: 2945.45
Generated 1.57M tokens
Total duration: 0.0h5min
Saving time: 0.15408611297607422s=0.0025681018829345702min
Load checkpoints...
Generating train split: 2000 examples [00:00, 13738.53 examples/s]
Filter: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 200/200 [00:00<00:00, 7032.53 examples/s]
Dataset({
features: ['prompt', 'text_token_length', 'text', 'seed_data', 'format', 'audience', 'completion', 'token_length'],
num_rows: 1999
})
📨 Pushing dataset to HuggingFaceTB/synthetic_data_test_prompt
Creating parquet from Arrow format: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 61.16ba/s]
Uploading the dataset shards: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 1.74it/s]
Dataset pushed!
1 generations failed
Creating parquet from Arrow format: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 1698.10ba/s]
Uploading the dataset shards: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 3.54it/s]
running scancel 2179729
running scancel 2179730
inference instances terminated
```
| {".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 c3249dbfd060befa36e51048b4c632dbb00eec64 Hamza Amin <[email protected]> 1727369506 +0500\tclone: from https://github.com/huggingface/llm-swarm.git\n", ".git\\refs\\heads\\main": "c3249dbfd060befa36e51048b4c632dbb00eec64\n", "examples\\openhermes-preference\\requirements.txt": "git+https://github.com/yuchenlin/LLM-Blender.git\nabsl-py\ndatasets\n", "examples\\textbooks\\requirements.txt": "datasets\npandas\npydantic\ntyro\nwonderwords", "llm_swarm\\__main__.py": "from llm_swarm import LLMSwarmConfig, LLMSwarm\nfrom transformers import HfArgumentParser\n\nparser = HfArgumentParser(LLMSwarmConfig)\nisc = parser.parse_args_into_dataclasses()[0]\nwith LLMSwarm(isc) as llm_swarm:\n while True:\n input(\"Press Enter to EXIT...\")\n break\n"} | null |
llm-vscode | {"type": "directory", "name": "llm-vscode", "children": [{"type": "file", "name": ".eslintignore"}, {"type": "file", "name": ".eslintrc.js"}, {"type": "file", "name": ".eslintrc.json"}, {"type": "file", "name": ".prettierignore"}, {"type": "file", "name": ".prettierrc.json"}, {"type": "directory", "name": ".vscode", "children": [{"type": "file", "name": "extensions.json"}, {"type": "file", "name": "launch.json"}, {"type": "file", "name": "settings.json"}, {"type": "file", "name": "tasks.json"}]}, {"type": "file", "name": ".vscodeignore"}, {"type": "file", "name": "LICENSE"}, {"type": "file", "name": "package-lock.json"}, {"type": "file", "name": "package.json"}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "src", "children": [{"type": "file", "name": "configTemplates.ts"}, {"type": "file", "name": "extension.ts"}, {"type": "directory", "name": "test", "children": [{"type": "file", "name": "runTest.ts"}, {"type": "directory", "name": "suite", "children": [{"type": "file", "name": "extension.test.ts"}, {"type": "file", "name": "index.ts"}]}]}]}, {"type": "file", "name": "tsconfig.json"}]} | # LLM powered development for VSCode
**llm-vscode** is an extension for all things LLM. It uses [**llm-ls**](https://github.com/huggingface/llm-ls) as its backend.
We also have extensions for:
* [neovim](https://github.com/huggingface/llm.nvim)
* [jupyter](https://github.com/bigcode-project/jupytercoder)
* [intellij](https://github.com/huggingface/llm-intellij)
Previously **huggingface-vscode**.
> [!NOTE]
> When using the Inference API, you will probably encounter some limitations. Subscribe to the *PRO* plan to avoid getting rate limited in the free tier.
>
> https://huggingface.co/pricing#pro
## Features
### Code completion
This plugin supports "ghost-text" code completion, à la Copilot.
### Choose your model
Requests for code generation are made via an HTTP request.
You can use the Hugging Face [Inference API](https://huggingface.co/inference-api) or your own HTTP endpoint, provided it adheres to the APIs listed in [backend](#backend).
The list of officially supported models is located in the config template section.
### Always fit within the context window
The prompt sent to the model will always be sized to fit within the context window, with the number of tokens determined using [tokenizers](https://github.com/huggingface/tokenizers).
### Code attribution
Hit `Cmd+shift+a` to check if the generated code is in [The Stack](https://huggingface.co/datasets/bigcode/the-stack).
This is a rapid first-pass attribution check using [stack.dataportraits.org](https://stack.dataportraits.org).
We check for sequences of at least 50 characters that match a Bloom filter.
This means false positives are possible and long enough surrounding context is necesssary (see the [paper](https://dataportraits.org/) for details on n-gram striding and sequence length).
[The dedicated Stack search tool](https://hf.co/spaces/bigcode/search) is a full dataset index and can be used for a complete second pass.
## Installation
Install like any other [vscode extension](https://marketplace.visualstudio.com/items?itemName=HuggingFace.huggingface-vscode).
By default, this extension uses [bigcode/starcoder](https://huggingface.co/bigcode/starcoder) & [Hugging Face Inference API](https://huggingface.co/inference-api) for the inference.
#### HF API token
You can supply your HF API token ([hf.co/settings/token](https://hf.co/settings/token)) with this command:
1. `Cmd/Ctrl+Shift+P` to open VSCode command palette
2. Type: `Llm: Login`
If you previously logged in with `huggingface-cli login` on your system the extension will read the token from disk.
## Configuration
You can check the full list of configuration settings by opening your settings page (`cmd+,`) and typing `Llm`.
### Backend
You can configure the backend to which requests will be sent. **llm-vscode** supports the following backends:
- `huggingface`: The Hugging Face Inference API (default)
- `ollama`: [Ollama](https://ollama.com)
- `openai`: any OpenAI compatible API (e.g. [llama-cpp-python](https://github.com/abetlen/llama-cpp-python))
- `tgi`: [Text Generation Inference](https://github.com/huggingface/text-generation-inference)
Let's say your current code is this:
```py
import numpy as np
import scipy as sp
{YOUR_CURSOR_POSITION}
def hello_world():
print("Hello world")
```
The request body will then look like:
```js
const inputs = `{start token}import numpy as np\nimport scipy as sp\n{end token}def hello_world():\n print("Hello world"){middle token}`
const data = { inputs, ...configuration.requestBody };
const model = configuration.modelId;
let endpoint;
switch(configuration.backend) {
// cf URL construction
let endpoint = build_url(configuration);
}
const res = await fetch(endpoint, {
body: JSON.stringify(data),
headers,
method: "POST"
});
const json = await res.json() as { generated_text: string };
```
Note that the example above is a simplified version to explain what is happening under the hood.
#### URL construction
The endpoint URL that is queried to fetch suggestions is build the following way:
- depending on the backend, it will try to append the correct path to the base URL located in the configuration (e.g. `{url}/v1/completions` for the `openai` backend)
- if no URL is set for the `huggingface` backend, it will automatically use the default URL
- it will error for other backends as there is no sensible default URL
- if you do set the **correct** path at the end of the URL it will not add it a second time as it checks if it is already present
- there is an option to disable this behavior: `llm.disableUrlPathCompletion`
### Suggestion behavior
You can tune the way the suggestions behave:
- `llm.enableAutoSuggest` lets you choose to enable or disable "suggest-as-you-type" suggestions.
- `llm.documentFilter` lets you enable suggestions only on specific files that match the pattern matching syntax you will provide. The object must be of type [`DocumentFilter | DocumentFilter[]`](https://microsoft.github.io/language-server-protocol/specifications/lsp/3.17/specification/#documentFilter):
- to match on all types of buffers: `llm.documentFilter: { pattern: "**" }`
- to match on all files in `my_project/`: `llm.documentFilter: { pattern: "/path/to/my_project/**" }`
- to match on all python and rust files: `llm.documentFilter: { pattern: "**/*.{py,rs}" }`
### Keybindings
**llm-vscode** sets two keybindings:
* you can trigger suggestions with `Cmd+shift+l` by default, which corresponds to the `editor.action.inlineSuggest.trigger` command
* [code attribution](#code-attribution) is set to `Cmd+shift+a` by default, which corresponds to the `llm.attribution` command
### [**llm-ls**](https://github.com/huggingface/llm-ls)
By default, **llm-ls** is bundled with the extension. When developing locally or if you built your own binary because your platform is not supported, you can set the `llm.lsp.binaryPath` setting to the path of the binary.
### Tokenizer
**llm-ls** uses [**tokenizers**](https://github.com/huggingface/tokenizers) to make sure the prompt fits the `context_window`.
To configure it, you have a few options:
* No tokenization, **llm-ls** will count the number of characters instead:
```json
{
"llm.tokenizer": null
}
```
* from a local file on your disk:
```json
{
"llm.tokenizer": {
"path": "/path/to/my/tokenizer.json"
}
}
```
* from a Hugging Face repository, **llm-ls** will attempt to download `tokenizer.json` at the root of the repository:
```json
{
"llm.tokenizer": {
"repository": "myusername/myrepo",
"api_token": null,
}
}
```
Note: when `api_token` is set to null, it will use the token you set with `Llm: Login` command. If you want to use a different token, you can set it here.
* from an HTTP endpoint, **llm-ls** will attempt to download a file via an HTTP GET request:
```json
{
"llm.tokenizer": {
"url": "https://my-endpoint.example.com/mytokenizer.json",
"to": "/download/path/of/mytokenizer.json"
}
}
```
### Code Llama
To test Code Llama 13B model:
1. Make sure you have the [latest version of this extension](#installing).
2. Make sure you have [supplied HF API token](#hf-api-token)
3. Open Vscode Settings (`cmd+,`) & type: `Llm: Config Template`
4. From the dropdown menu, choose `hf/codellama/CodeLlama-13b-hf`
Read more [here](https://huggingface.co/blog/codellama) about Code LLama.
### Phind and WizardCoder
To test [Phind/Phind-CodeLlama-34B-v2](https://hf.co/Phind/Phind-CodeLlama-34B-v2) and/or [WizardLM/WizardCoder-Python-34B-V1.0](https://hf.co/WizardLM/WizardCoder-Python-34B-V1.0) :
1. Make sure you have the [latest version of this extension](#installing).
2. Make sure you have [supplied HF API token](#hf-api-token)
3. Open Vscode Settings (`cmd+,`) & type: `Llm: Config Template`
4. From the dropdown menu, choose `hf/Phind/Phind-CodeLlama-34B-v2` or `hf/WizardLM/WizardCoder-Python-34B-V1.0`
Read more about Phind-CodeLlama-34B-v2 [here](https://huggingface.co/Phind/Phind-CodeLlama-34B-v2) and WizardCoder-15B-V1.0 [here](https://huggingface.co/WizardLM/WizardCoder-15B-V1.0).
## Developing
1. Clone `llm-ls`: `git clone https://github.com/huggingface/llm-ls`
2. Build `llm-ls`: `cd llm-ls && cargo build` (you can also use `cargo build --release` for a release build)
3. Clone this repo: `git clone https://github.com/huggingface/llm-vscode`
4. Install deps: `cd llm-vscode && npm ci`
5. In vscode, open `Run and Debug` side bar & click `Launch Extension`
6. In the new vscode window, set the `llm.lsp.binaryPath` setting to the path of the `llm-ls` binary you built in step 2 (e.g. `/path/to/llm-ls/target/debug/llm-ls`)
7. Close the window and restart the extension with `F5` or like in `5.`
## Community
| Repository | Description |
| --- | --- |
| [huggingface-vscode-endpoint-server](https://github.com/LucienShui/huggingface-vscode-endpoint-server) | Custom code generation endpoint for this repository |
| [llm-vscode-inference-server](https://github.com/wangcx18/llm-vscode-inference-server) | An endpoint server for efficiently serving quantized open-source LLMs for code. |
| {"package.json": "{\n \"name\": \"huggingface-vscode\",\n \"displayName\": \"llm-vscode\",\n \"description\": \"LLM powered development for VS Code\",\n \"version\": \"0.2.2\",\n \"publisher\": \"HuggingFace\",\n \"icon\": \"small_logo.png\",\n \"engines\": {\n \"vscode\": \"^1.82.0\"\n },\n \"galleryBanner\": {\n \"color\": \"#100f11\",\n \"theme\": \"dark\"\n },\n \"badges\": [\n {\n \"url\": \"https://img.shields.io/github/stars/huggingface/llm-vscode?style=social\",\n \"description\": \"Star llm-vscode on Github\",\n \"href\": \"https://github.com/huggingface/llm-vscode\"\n },\n {\n \"url\": \"https://img.shields.io/twitter/follow/huggingface?style=social\",\n \"description\": \"Follow Huggingface on Twitter\",\n \"href\": \"https://twitter.com/huggingface\"\n }\n ],\n \"homepage\": \"https://huggingface.co\",\n \"repository\": {\n \"url\": \"https://github.com/huggingface/llm-vscode.git\",\n \"type\": \"git\"\n },\n \"bugs\": {\n \"url\": \"https://github.com/huggingface/llm-vscode/issues\"\n },\n \"license\": \"Apache-2.0\",\n \"categories\": [\n \"Machine Learning\",\n \"Programming Languages\"\n ],\n \"keywords\": [\n \"code\",\n \"assistant\",\n \"ai\",\n \"llm\",\n \"development\",\n \"huggingface\"\n ],\n \"activationEvents\": [\n \"*\"\n ],\n \"main\": \"./out/extension.js\",\n \"contributes\": {\n \"commands\": [\n {\n \"command\": \"llm.afterInsert\",\n \"title\": \"Llm: After Insert\"\n },\n {\n \"command\": \"llm.login\",\n \"title\": \"Llm: Login\"\n },\n {\n \"command\": \"llm.logout\",\n \"title\": \"Llm: Logout\"\n },\n {\n \"command\": \"llm.attribution\",\n \"title\": \"Llm: Show Code Attribution\"\n }\n ],\n \"configuration\": [\n {\n \"title\": \"Llm\",\n \"properties\": {\n \"llm.requestDelay\": {\n \"type\": \"integer\",\n \"default\": 150,\n \"description\": \"Delay between requests in milliseconds\"\n },\n \"llm.enableAutoSuggest\": {\n \"type\": \"boolean\",\n \"default\": true,\n \"description\": \"Enable automatic suggestions\"\n },\n \"llm.configTemplate\": {\n \"type\": \"string\",\n \"enum\": [\n \"hf/bigcode/starcoder2-15b\",\n \"hf/codellama/CodeLlama-13b-hf\",\n \"hf/Phind/Phind-CodeLlama-34B-v2\",\n \"hf/WizardLM/WizardCoder-Python-34B-V1.0\",\n \"hf/deepseek-ai/deepseek-coder-6.7b-base\",\n \"ollama/codellama:7b\",\n \"Custom\"\n ],\n \"default\": \"hf/bigcode/starcoder2-15b\",\n \"description\": \"Choose your model template from the dropdown\"\n },\n \"llm.modelId\": {\n \"type\": \"string\",\n \"default\": \"bigcode/starcoder\",\n \"description\": \"Model id (ex: `bigcode/starcoder`), will be used to route your request to the appropriate model\"\n },\n \"llm.backend\": {\n \"type\": \"string\",\n \"enum\": [\n \"huggingface\",\n \"ollama\",\n \"openai\",\n \"tgi\"\n ],\n \"default\": \"huggingface\",\n \"description\": \"Backend used by the extension\"\n },\n \"llm.url\": {\n \"type\": [\n \"string\",\n \"null\"\n ],\n \"default\": null,\n \"description\": \"HTTP URL of the backend, when null will use the default url for the Inference API\"\n },\n \"llm.fillInTheMiddle.enabled\": {\n \"type\": \"boolean\",\n \"default\": true,\n \"description\": \"Enable fill in the middle for the current model\"\n },\n \"llm.fillInTheMiddle.prefix\": {\n \"type\": \"string\",\n \"default\": \"<fim_prefix>\",\n \"description\": \"Prefix token\"\n },\n \"llm.fillInTheMiddle.middle\": {\n \"type\": \"string\",\n \"default\": \"<fim_middle>\",\n \"description\": \"Middle token\"\n },\n \"llm.fillInTheMiddle.suffix\": {\n \"type\": \"string\",\n \"default\": \"<fim_suffix>\",\n \"description\": \"Suffix token\"\n },\n \"llm.requestBody\": {\n \"type\": \"object\",\n \"default\": {\n \"parameters\": {\n \"max_new_tokens\": 60,\n \"temperature\": 0.2,\n \"top_p\": 0.95\n }\n },\n \"description\": \"Whatever you set here will be sent as is as the HTTP POST request body to the chosen backend. Model and prompt will be added automatically.\"\n },\n \"llm.contextWindow\": {\n \"type\": \"integer\",\n \"default\": 2048,\n \"description\": \"Context window of the model\"\n },\n \"llm.tokensToClear\": {\n \"type\": \"array\",\n \"items\": {\n \"type\": \"string\"\n },\n \"default\": [\n \"<|endoftext|>\"\n ],\n \"description\": \"(Optional) Tokens that should be cleared from the resulting output. For example, in FIM mode, one usually wants to clear FIM token from resulting outout.\"\n },\n \"llm.attributionWindowSize\": {\n \"type\": \"integer\",\n \"default\": 250,\n \"description\": \"Number of characters to scan for code attribution\"\n },\n \"llm.attributionEndpoint\": {\n \"type\": \"string\",\n \"default\": \"https://stack.dataportraits.org/overlap\",\n \"description\": \"Endpoint to which attribution request will be sent to (https://stack.dataportraits.org/overlap for the stack)\"\n },\n \"llm.tlsSkipVerifyInsecure\": {\n \"type\": \"boolean\",\n \"default\": false,\n \"description\": \"Skip TLS verification for insecure connections\"\n },\n \"llm.lsp.binaryPath\": {\n \"type\": [\n \"string\",\n \"null\"\n ],\n \"default\": null,\n \"description\": \"Path to llm-ls binary, useful for debugging or when building from source\"\n },\n \"llm.lsp.port\": {\n \"type\": [\n \"number\",\n \"null\"\n ],\n \"default\": null,\n \"description\": \"When running llm-ls with `--port`, port for the llm-ls server\"\n },\n \"llm.lsp.logLevel\": {\n \"type\": \"string\",\n \"default\": \"warn\",\n \"description\": \"llm-ls log level\"\n },\n \"llm.tokenizer\": {\n \"type\": [\n \"object\",\n \"null\"\n ],\n \"default\": null,\n \"description\": \"Tokenizer configuration for the model, check out the documentation for more details\"\n },\n \"llm.documentFilter\": {\n \"type\": [\n \"object\",\n \"array\"\n ],\n \"default\": {\n \"pattern\": \"**\"\n },\n \"description\": \"Filter documents to enable suggestions for\"\n },\n \"llm.disableUrlPathCompletion\": {\n \"type\": \"boolean\",\n \"default\": false,\n \"description\": \"When setting `llm.url`, llm-ls will try to append the correct path to your URL if it doesn't end with such a path, e.g. for an OpenAI backend if it doesn't end with `/v1/completions`. Set this to `true` to disable this behavior.\"\n }\n }\n }\n ],\n \"keybindings\": [\n {\n \"key\": \"alt+shift+l\",\n \"command\": \"editor.action.inlineSuggest.trigger\"\n },\n {\n \"key\": \"cmd+shift+a\",\n \"command\": \"llm.attribution\"\n }\n ]\n },\n \"scripts\": {\n \"vscode:prepublish\": \"npm run compile\",\n \"compile\": \"tsc -p ./\",\n \"watch\": \"tsc -watch -p ./\",\n \"pretest\": \"npm run compile && npm run lint\",\n \"lint\": \"eslint src --ext ts\",\n \"test\": \"node ./out/test/runTest.js\"\n },\n \"dependencies\": {\n \"undici\": \"^6.6.2\",\n \"vscode-languageclient\": \"^9.0.1\"\n },\n \"devDependencies\": {\n \"@types/mocha\": \"^10.0.6\",\n \"@types/node\": \"16.x\",\n \"@types/vscode\": \"^1.82.0\",\n \"@typescript-eslint/eslint-plugin\": \"^6.21.0\",\n \"@typescript-eslint/parser\": \"^6.21.0\",\n \"@vscode/test-electron\": \"^2.3.9\",\n \"@vscode/vsce\": \"^2.23.0\",\n \"eslint\": \"^8.56.0\",\n \"glob\": \"^10.3.10\",\n \"mocha\": \"^10.3.0\",\n \"ovsx\": \"^0.8.3\",\n \"typescript\": \"^5.3.3\"\n }\n}\n", ".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", "src\\test\\suite\\index.ts": "import * as path from 'path';\nimport * as Mocha from 'mocha';\nimport * as glob from 'glob';\n\nexport function run(): Promise<void> {\n\t// Create the mocha test\n\tconst mocha = new Mocha({\n\t\tui: 'tdd',\n\t\tcolor: true\n\t});\n\n\tconst testsRoot = path.resolve(__dirname, '..');\n\n\treturn new Promise((c, e) => {\n\t\tconst testFiles = new glob.Glob(\"**/**.test.js\", { cwd: testsRoot });\n\t\tconst testFileStream = testFiles.stream();\n\n\t\ttestFileStream.on(\"data\", (file) => {\n\t\t\tmocha.addFile(path.resolve(testsRoot, file));\n\t\t});\n\t\ttestFileStream.on(\"error\", (err) => {\n\t\t\te(err);\n\t\t});\n\t\ttestFileStream.on(\"end\", () => {\n\t\t\ttry {\n\t\t\t\t// Run the mocha test\n\t\t\t\tmocha.run(failures => {\n\t\t\t\t\tif (failures > 0) {\n\t\t\t\t\t\te(new Error(`${failures} tests failed.`));\n\t\t\t\t\t} else {\n\t\t\t\t\t\tc();\n\t\t\t\t\t}\n\t\t\t\t});\n\t\t\t} catch (err) {\n\t\t\t\tconsole.error(err);\n\t\t\t\te(err);\n\t\t\t}\n\t\t});\n\t});\n}\n"} | null |
llm.nvim | {"type": "directory", "name": "llm.nvim", "children": [{"type": "file", "name": ".editorconfig"}, {"type": "file", "name": ".luarc.json"}, {"type": "file", "name": ".stylua.toml"}, {"type": "directory", "name": "assets", "children": []}, {"type": "file", "name": "LICENSE"}, {"type": "directory", "name": "lua", "children": [{"type": "directory", "name": "llm", "children": [{"type": "file", "name": "completion.lua"}, {"type": "file", "name": "config.lua"}, {"type": "file", "name": "init.lua"}, {"type": "file", "name": "keymaps.lua"}, {"type": "file", "name": "language_server.lua"}, {"type": "file", "name": "utils.lua"}]}]}, {"type": "file", "name": "Makefile"}, {"type": "file", "name": "neovim.yml"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "selene.toml"}]} | # LLM powered development for Neovim
**llm.nvim** is a plugin for all things LLM. It uses [**llm-ls**](https://github.com/huggingface/llm-ls) as a backend.
This project is influenced by [copilot.vim](https://github.com/github/copilot.vim) and [tabnine-nvim](https://github.com/codota/tabnine-nvim)
Formerly **hfcc.nvim**.

> [!NOTE]
> When using the Inference API, you will probably encounter some limitations. Subscribe to the *PRO* plan to avoid getting rate limited in the free tier.
>
> https://huggingface.co/pricing#pro
## Features
### Code completion
This plugin supports "ghost-text" code completion, à la Copilot.
### Choose your model
Requests for code generation are made via an HTTP request.
You can use the Hugging Face [Inference API](https://huggingface.co/inference-api) or your own HTTP endpoint, provided it adheres to the APIs listed in [backend](#backend).
### Always fit within the context window
The prompt sent to the model will always be sized to fit within the context window, with the number of tokens determined using [tokenizers](https://github.com/huggingface/tokenizers).
## Configuration
### Backend
**llm.nvim** can interface with multiple backends hosting models.
You can override the url of the backend with the `LLM_NVIM_URL` environment variable. If url is `nil`, it will default to the Inference API's [default url](https://github.com/huggingface/llm-ls/blob/8926969265990202e3b399955364cc090df389f4/crates/custom-types/src/llm_ls.rs#L8)
When `api_token` is set, it will be passed as a header: `Authorization: Bearer <api_token>`.
**llm-ls** will try to add the correct path to the url to get completions if it does not already end with said path. You can disable this behavior by setting `disable_url_path_completion` to true.
#### Inference API
##### **backend = "huggingface"**
[API](https://huggingface.co/docs/api-inference/detailed_parameters#text-generation-task)
1. Create and get your API token from here https://huggingface.co/settings/tokens.
2. Define how the plugin will read your token. For this you have multiple options, in order of precedence:
1. Pass `api_token = <your token>` in plugin opts - this is not recommended if you use a versioning tool for your configuration files
2. Set the `LLM_NVIM_HF_API_TOKEN` environment variable
3. You can define your `HF_HOME` environment variable and create a file containing your token at `$HF_HOME/token`
4. Install the [huggingface-cli](https://huggingface.co/docs/huggingface_hub/quick-start) and run `huggingface-cli login` - this will prompt you to enter your token and set it at the right path
3. Choose your model on the [Hugging Face Hub](https://huggingface.co/), and, in order of precedence, you can either:
1. Set the `LLM_NVIM_MODEL` environment variable
2. Pass `model = <model identifier>` in plugin opts
Note: the `model`'s value will be appended to the url like so : `{url}/model/{model}` as this is how we route requests to the right model.
#### [Ollama](https://ollama.com/)
##### **backend = "ollama"**
[API](https://github.com/ollama/ollama/blob/main/docs/api.md)
Refer to Ollama's documentation on how to run ollama. Here is an example configuration:
```lua
{
model = "codellama:7b",
url = "http://localhost:11434", -- llm-ls uses "/api/generate"
-- cf https://github.com/ollama/ollama/blob/main/docs/api.md#parameters
request_body = {
-- Modelfile options for the model you use
options = {
temperature = 0.2,
top_p = 0.95,
}
}
}
```
Note: `model`'s value will be added to the request body.
#### Open AI
##### **backend = "openai"**
Refer to Ollama's documentation on how to run ollama. Here is an example configuration:
```lua
{
model = "codellama",
url = "http://localhost:8000", -- llm-ls uses "/v1/completions"
-- cf https://github.com/abetlen/llama-cpp-python?tab=readme-ov-file#openai-compatible-web-server
request_body = {
temperature = 0.2,
top_p = 0.95,
}
}
```
Note: `model`'s value will be added to the request body.
#### [TGI](https://github.com/huggingface/text-generation-inference)
##### **backend = "tgi"**
[API](https://huggingface.github.io/text-generation-inference/#/Text%20Generation%20Inference/generate)
Refer to TGI's documentation on how to run TGI. Here is an example configuration:
```lua
{
model = "bigcode/starcoder",
url = "http://localhost:8080", -- llm-ls uses "/generate"
-- cf https://huggingface.github.io/text-generation-inference/#/Text%20Generation%20Inference/generate
request_body = {
parameters = {
temperature = 0.2,
top_p = 0.95,
}
}
}
```
### Models
#### [Starcoder](https://huggingface.co/bigcode/starcoder)
```lua
{
tokens_to_clear = { "<|endoftext|>" },
fim = {
enabled = true,
prefix = "<fim_prefix>",
middle = "<fim_middle>",
suffix = "<fim_suffix>",
},
model = "bigcode/starcoder",
context_window = 8192,
tokenizer = {
repository = "bigcode/starcoder",
}
}
```
> [!NOTE]
> These are the default config values
#### [CodeLlama](https://huggingface.co/codellama/CodeLlama-13b-hf)
```lua
{
tokens_to_clear = { "<EOT>" },
fim = {
enabled = true,
prefix = "<PRE> ",
middle = " <MID>",
suffix = " <SUF>",
},
model = "codellama/CodeLlama-13b-hf",
context_window = 4096,
tokenizer = {
repository = "codellama/CodeLlama-13b-hf",
}
}
```
> [!NOTE]
> Spaces are important here
### [**llm-ls**](https://github.com/huggingface/llm-ls)
By default, **llm-ls** is installed by **llm.nvim** the first time it is loaded. The binary is downloaded from the [release page](https://github.com/huggingface/llm-ls/releases) and stored in:
```lua
vim.api.nvim_call_function("stdpath", { "data" }) .. "/llm_nvim/bin"
```
When developing locally, when using mason or if you built your own binary because your platform is not supported, you can set the `lsp.bin_path` setting to the path of the binary. You can also start **llm-ls** via tcp using the `--port [PORT]` option, which is useful when using a debugger.
`lsp.version` is used only when **llm.nvim** downloads **llm-ls** from the release page.
`lsp.cmd_env` can be used to set environment variables for the **llm-ls** process.
#### Mason
You can install **llm-ls** via [mason.nvim](https://github.com/williamboman/mason.nvim). To do so, run the following command:
```vim
:MasonInstall llm-ls
```
Then reference **llm-ls**'s path in your configuration:
```lua
{
-- ...
lsp = {
bin_path = vim.api.nvim_call_function("stdpath", { "data" }) .. "/mason/bin/llm-ls",
},
-- ...
}
```
### Tokenizer
**llm-ls** uses [**tokenizers**](https://github.com/huggingface/tokenizers) to make sure the prompt fits the `context_window`.
To configure it, you have a few options:
* No tokenization, **llm-ls** will count the number of characters instead:
```lua
{
tokenizer = nil,
}
```
* from a local file on your disk:
```lua
{
tokenizer = {
path = "/path/to/my/tokenizer.json"
}
}
```
* from a Hugging Face repository, **llm-ls** will attempt to download `tokenizer.json` at the root of the repository:
```lua
{
tokenizer = {
repository = "myusername/myrepo"
api_token = nil -- optional, in case the API token used for the backend is not the same
}
}
```
* from an HTTP endpoint, **llm-ls** will attempt to download a file via an HTTP GET request:
```lua
{
tokenizer = {
url = "https://my-endpoint.example.com/mytokenizer.json",
to = "/download/path/of/mytokenizer.json"
}
}
```
### Suggestion behavior
You can tune the way the suggestions behave:
- `enable_suggestions_on_startup` lets you choose to enable or disable "suggest-as-you-type" suggestions on neovim startup. You can then toggle auto suggest with `LLMToggleAutoSuggest` (see [Commands](#commands))
- `enable_suggestions_on_files` lets you enable suggestions only on specific files that match the pattern matching syntax you will provide. It can either be a string or a list of strings, for example:
- to match on all types of buffers: `enable_suggestions_on_files: "*"`
- to match on all files in `my_project/`: `enable_suggestions_on_files: "/path/to/my_project/*"`
- to match on all python and rust files: `enable_suggestions_on_files: { "*.py", "*.rs" }`
### Commands
**llm.nvim** provides the following commands:
- `LLMToggleAutoSuggest` enables/disables automatic "suggest-as-you-type" suggestions
- `LLMSuggestion` is used to manually request a suggestion
### Package manager
#### Using [packer](https://github.com/wbthomason/packer.nvim)
```lua
require("packer").startup(function(use)
use {
'huggingface/llm.nvim',
config = function()
require('llm').setup({
-- cf Setup
})
end
}
end)
```
#### Using [lazy.nvim](https://github.com/folke/lazy.nvim)
```lua
require("lazy").setup({
{
'huggingface/llm.nvim',
opts = {
-- cf Setup
}
},
})
```
#### Using [vim-plug](https://github.com/junegunn/vim-plug)
```vim
Plug 'huggingface/llm.nvim'
```
```lua
require('llm').setup({
-- cf Setup
})
```
### Setup
```lua
local llm = require('llm')
llm.setup({
api_token = nil, -- cf Install paragraph
model = "bigcode/starcoder2-15b", -- the model ID, behavior depends on backend
backend = "huggingface", -- backend ID, "huggingface" | "ollama" | "openai" | "tgi"
url = nil, -- the http url of the backend
tokens_to_clear = { "<|endoftext|>" }, -- tokens to remove from the model's output
-- parameters that are added to the request body, values are arbitrary, you can set any field:value pair here it will be passed as is to the backend
request_body = {
parameters = {
max_new_tokens = 60,
temperature = 0.2,
top_p = 0.95,
},
},
-- set this if the model supports fill in the middle
fim = {
enabled = true,
prefix = "<fim_prefix>",
middle = "<fim_middle>",
suffix = "<fim_suffix>",
},
debounce_ms = 150,
accept_keymap = "<Tab>",
dismiss_keymap = "<S-Tab>",
tls_skip_verify_insecure = false,
-- llm-ls configuration, cf llm-ls section
lsp = {
bin_path = nil,
host = nil,
port = nil,
cmd_env = nil, -- or { LLM_LOG_LEVEL = "DEBUG" } to set the log level of llm-ls
version = "0.5.3",
},
tokenizer = nil, -- cf Tokenizer paragraph
context_window = 1024, -- max number of tokens for the context window
enable_suggestions_on_startup = true,
enable_suggestions_on_files = "*", -- pattern matching syntax to enable suggestions on specific files, either a string or a list of strings
disable_url_path_completion = false, -- cf Backend
})
```
| {".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 9832a149bdcf0709433ca9c2c3a1c87460e98d13 Hamza Amin <[email protected]> 1727369325 +0500\tclone: from https://github.com/huggingface/llm.nvim.git\n", ".git\\refs\\heads\\main": "9832a149bdcf0709433ca9c2c3a1c87460e98d13\n"} | null |
llm_training_handbook | {"type": "directory", "name": "llm_training_handbook", "children": [{"type": "file", "name": "CODE_OF_CONDUCT.md"}, {"type": "file", "name": "CONTRIBUTING.md"}, {"type": "directory", "name": "debug", "children": [{"type": "file", "name": "NicerTrace.py"}, {"type": "file", "name": "printflock.py"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "torch-distributed-gpu-test.py"}]}, {"type": "directory", "name": "dtype", "children": [{"type": "file", "name": "README.md"}]}, {"type": "directory", "name": "hparams", "children": [{"type": "file", "name": "README.md"}]}, {"type": "directory", "name": "instabilities", "children": [{"type": "file", "name": "README.md"}]}, {"type": "file", "name": "LICENSE-CC-BY-SA"}, {"type": "directory", "name": "parallelism", "children": [{"type": "file", "name": "README.md"}]}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "resources", "children": [{"type": "file", "name": "README.md"}]}, {"type": "directory", "name": "slurm", "children": [{"type": "file", "name": "cron-daily.slurm"}, {"type": "file", "name": "cron-hourly.slurm"}, {"type": "file", "name": "README.md"}]}, {"type": "directory", "name": "throughput", "children": [{"type": "file", "name": "all_reduce_bench.py"}, {"type": "file", "name": "README.md"}]}]} | # How to Maximize Training Throughput
The faster you can make your model to train the sooner the model will finish training, which is important not only to being first to publish something, but also potentially saving a lot of money.
In general maximizing throughput is all about running many experiments and measuring the outcome and chosing the one that is superior.
In certain situations your modeling team may ask you to choose some hyper parameters that will be detrimental to throughput but overall beneficial for the overall model's success.
## Crucial reproducibility requirements
The most important requirements for a series of successful experiments is to be able to reproduce the experiment environment again and again while changing only one or a few setup variables.
Therefore when you try to figure out whether some change will improve performance or make it worse, you must figure out how to keep things stable.
For example, you need to find a way to prevent the network usage from fluctuations. When we were doing performance optimizations for [108B pre-BLOOM experiments](https://github.com/bigscience-workshop/bigscience/tree/master/train/tr8-104B-wide) it was close to impossible to perform, since we were on a shared internode network and the exact same setup would yield different throughput depending on how many other users used the network. It was not working. During BLOOM-176B we were given a dedicated SLURM partition with an isolated network where the only traffic was ours. Doing the performance optimization in such environment was just perfect.
## Network throughput
It's critical to understand your particular model size and framework requirements with regard to network bandwidth, throughput and latency. If you underpay for network you will end up having idle gpus and thus you wasted money and time. If you overpay for very fast network, but your gpus are slow, then again you wasted money and time.
If your network is very slow, your training is likely to be network-bound and many improvements in the training setup will not help with the improving performance.
Here is a simple all-reduce benchmark that you can use to quickly measure the throughput of your internode network:
[all_reduce_bench.py](./all_reduce_bench.py)
Usually benchmarking at least 4 nodes is recommended, but, of course, if you already have access to all the nodes you will be using during the training, benchmark using all of the nodes.
To run it on 4 nodes
```
python -m torch.distributed.run --nproc_per_node=4 all_reduce_bench.py
```
You may get results anywhere between 5Gbps and 1600Gbps (as of this writing). The minimal speed to prevent being network bound will depend on your particular training framework, but typically you'd want at least 400Gbps or higher. Though we trained BLOOM on 50Gbps.
Frameworks that shard weights and optim stages like [Deepspeed](https://github.com/microsoft/DeepSpeed) w/ ZeRO Stage-3 do a lot more traffic than frameworks like [Megatron-Deepspeed](https://github.com/bigscience-workshop/Megatron-DeepSpeed) which do tensor and pipeline parallelism in addition to data parallelism. The latter ones only send activations across and thus don't need as much bandwidth. But they are much more complicated to set up and run.
Of course, an efficient framework will overlap communications and compute, so that while one stage is fetching data, the other stage in parallel runs computations. So as long as the communication overhead is smaller than compute the network requirements are satisfied and don't have to be super fantastic.
To get reasonable GPU throughput when training at scale (64+GPUs) with DeepSpeed ZeRO Stage 3:
1. 100Gbps is not enough
2. 200-400 Gbps is ok
3. 800-1000 Gbps is ideal
[full details](https://github.com/microsoft/DeepSpeed/issues/2928#issuecomment-1463041491)
## TFLOPs as a performance metric
Before you start optimizing the performance of your training setup you need a metric that you can use to see whether the throughput is improving or not. You can measure seconds per iteration, or iterations per second, or some other such timing, but there is a more useful metric that measures TFLOPs.
footnote: TFLOPs: Trillion FLOPs per second - [FLOPS](https://en.wikipedia.org/wiki/FLOPS)
Measuring TFLOPs is superior because without it you don't know whether you are close to the best performance that can be achieved or not. This measurement gives you an indication of how far you're from the peak performance reported by the hardware manufacturer.
In this section I will use BLOOM's training for the examplification. We use 80GB A100 NVIDIA GPUs and we trained in mixed bf16 regime. So let's look at the [A100 spec](https://www.nvidia.com/en-us/data-center/a100/) which tells us:
```
BFLOAT16 Tensor Core 312 TFLOPS
```
Therefore we now know that if we were to only run `matmul` on huge bf16 matrices without copying to and from the device we should get around 312 TFLOPs max.
Practically though, due to disk IO, communications and copying data from gpu memory to gpu computing unit overhead and because we can't do everything in bf16 and at times we have to do math in fp32 (or tf32) we can really expect about half of that. So 155 TFLOPs should be an amazing sustainable throughput for a complex hundreds of GPUs training setup.
When we first started tuning things up we were at <100 TFLOPs and a few weeks later when we launched the training we managed to get 150 TFLOPs.
The important thing to notice here is that we knew that we can't push it further by much and we knew that there was no more point to try and optimize it even more.
So a general rule of thumb - if your training set up gets about 1/2 of advertised peak performance you're doing great. Don't let it stop you though from beating this suggestion and getting even more efficient.
When calculating TFLOPs it's important to remember that the math is different if [Gradient checkpointing](#gradient-checkpointing) are enabled, since when it's activated more compute is used and it needs to be taken into an account.
for transformer models the following is an estimation formula which slightly under-reports the real TFLOPs:
TFLOPs: `model_size_in_B * 4 * 2 * seqlen * global_batch_size / (time_in_sec_per_interation * total_gpus * 1e3)`
The factor of 4 is when used with activation check-pointing, otherwise it will be 3, but for 100B+ model, activation check-pointing will always be on.
So the `3*2` is often called "model FLOPs" and `4*2` - "hardware FLOPs".
```
perl -le '$ng=64; $ms=52; $gbs=1024; $sp=127; $seqlen=2048; print $ms*4*2*$seqlen*$gbs / ( $sp * $ng * 1e3)'
```
(ng = total gpus, ms = model size in B, gbs = global batch size, sp = throughput in seconds)
same with bash env vars and broken down GBS into mbs*dp*gas (gas=pp_chunks):
```
echo "($MSIZE*4*2*SEQLEN*$MICRO_BATCH_SIZE*$DP_SIZE*$GAS)/($THROUGHPUT*$NNODES*4*1000)" | bc -l
```
The exact formula is in Equation 3 of Section 5.1 of the [Efficient Large-Scale Language Model Training on GPU Clusters Using Megatron-LM](https://arxiv.org/abs/2104.04473) paper. You can see the code [here](https://github.com/bigscience-workshop/Megatron-DeepSpeed/pull/251).
footnote: For Inference only it'd be: `24Bsh^2 + 4𝐵s^2h` floating point operations per layer
## Gradient checkpointing
This is only relevant for training.
Enabling gradient checkpointing allows one to trade speed for GPU memory. When this feature is activated instead of remembering the outputs of, say, transformer blocks until the backward pass is done, these outputs are dropped. This frees up huge amounts of GPU memory. But, of course, a backward pass is not possible without having the outputs of forward pass, and thus they have to be recalculated.
This, of course, can vary from model to model, but typically one pays with about 20-25% decrease in throughput, but since a huge amount of gpu memory is liberated, one can now increase the batch size per gpu and thus overall improve the effective throughput of the system. In some cases this allows you to double or quadruple the batch size if you were already able to do a small batch size w/o OOM.
Activation checkpointing and gradient checkpointing are 2 terms for the same methodology.
For example, in HF Transformers models you do `model.gradient_checkpointing_enable()` to activate it in your trainer or if you HF Trainer then you'd activate it with `--gradient_checkpointing 1`.
## Gradient accumulation
Depending on a situation using a large gradient accumulation can increase the throughput, even though it's only the optimizer `step` that's skipped except at the boundary of the gradient accumulation, it can be quite a significant saving. e.g. in this particular small setup I clocked 20-30% speed up:
- [A100](https://github.com/huggingface/transformers/issues/15026#issuecomment-1004592231)
- [RTX-3090](https://github.com/huggingface/transformers/issues/14608#issuecomment-1004392537)
When using Pipeline parallelism a very large Gradient Accumulation is a must to keep the [pipeline's bubble to the minimum]( https://huggingface.co/docs/transformers/main/perf_train_gpu_many#naive-model-parallelism-vertical-and-pipeline-parallelism).
## Vector and matrix size divisibility
### Tile and wave quantization
XXX
### Number/size of Attention heads
XXX
| {".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 a91b8bdc70272689db04f189802dce8fdfd21265 Hamza Amin <[email protected]> 1727369328 +0500\tclone: from https://github.com/huggingface/llm_training_handbook.git\n", ".git\\refs\\heads\\main": "a91b8bdc70272689db04f189802dce8fdfd21265\n"} | null |
local-gemma | {"type": "directory", "name": "local-gemma", "children": [{"type": "file", "name": "LICENSE"}, {"type": "directory", "name": "local_gemma", "children": [{"type": "file", "name": "attention.py"}, {"type": "file", "name": "cli.py"}, {"type": "file", "name": "modeling_local_gemma_2.py"}, {"type": "directory", "name": "utils", "children": [{"type": "file", "name": "benchmark.py"}, {"type": "file", "name": "config.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "setup.py"}]} | <p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/local-gemma-2/local_gemma.png?raw=true" width="600"/>
</p>
<h3 align="center">
<p>Run Gemma-2 locally in Python, fast!</p>
</h3>
This repository provides an easy way to run [Gemma-2](https://huggingface.co/blog/gemma2) locally directly from your CLI (or via a Python library) and fast. It is built on top of the [🤗 Transformers](https://github.com/huggingface/transformers) and [bitsandbytes](https://huggingface.co/docs/bitsandbytes/index) libraries.
It can be configured to give fully equivalent results to the original implementation, or reduce memory requirements down
to just the largest layer in the model!
> [!IMPORTANT]
> There is a new "speed" preset for running `local-gemma` on CUDA ⚡️ It makes use of torch compile for up to 6x faster generation.
> Set `--preset="speed"` when using the CLI, or pass `preset="speed"` to `from_pretrained` when using the Python API
## Installation
There are two installation flavors of `local-gemma`, which you can select depending on your use case:
<details>
<summary><b><font size="+0.5"><code>pipx</code> - Ideal for CLI</font></b></summary>
First, follow the installation steps [here](https://github.com/pypa/pipx?tab=readme-ov-file#install-pipx) to install `pipx` on your environment.
Then, run one of the commands below, depending on your machine.
#### CUDA
```sh
pipx install local-gemma"[cuda]"
```
#### MPS
```sh
pipx install local-gemma"[mps]"
```
#### CPU
```sh
pipx install local-gemma"[cpu]"
```
</details>
<details>
<summary><b><font size="+0.5"><code>pip</code> - Ideal for Python (CLI + API)</font></b></summary>
Local Gemma-2 can be installed as a hardware-specific Python package through `pip`. The only requirement is a Python
installation, details for which can be found [here](https://wiki.python.org/moin/BeginnersGuide/Download). You can
check you have a Python installed locally by running:
```sh
python3 --version
```
#### (optional) Create a new Python environment
```sh
python3 -m venv gemma-venv
source gemma-venv/bin/activate
```
#### CUDA
```sh
pip install local-gemma"[cuda]"
```
#### MPS
```sh
pip install local-gemma"[mps]"
```
#### CPU
```sh
pip install local-gemma"[cpu]"
```
</details>
<!---
<details>
<summary><b><font size="+0.5"><code>Docker</code> - Pre-prepared container</font></b></summary>
> TODO(SG): add installation
</details>
--->
## CLI Usage
You can chat with the Gemma-2 through an interactive session by calling:
```sh
local-gemma
```
> [!TIP]
> Local Gemma will check for a Hugging Face "read" token to download the model. You can follow [this guide](https://huggingface.co/docs/hub/en/security-tokens) to create a token, and pass it when prompted to log-in. If you're new to Hugging Face and never used a Gemma model, you'll also need to accept the terms at the top of [this page](https://huggingface.co/google/gemma-2-9b-it).
Alternatively, you can request a single output by passing a prompt, such as:
```sh
local-gemma "What is the capital of France?"
```
By default, this loads the [Gemma-2 9b it](https://huggingface.co/google/gemma-2-9b-it) model. To load the [2b it](https://huggingface.co/google/gemma-2-2b-it) or [27b it](https://huggingface.co/google/gemma-2-27b-it)
models, you can set the `--model` argument accordingly:
```sh
local-gemma --model 2b
```
Local Gemma-2 will automatically find the most performant preset for your hardware, trading-off speed and memory. For more
control over generation speed and memory usage, set the `--preset` argument to one of four available options:
1. exact: match the original results by maximizing accuracy
2. speed: maximize throughput through torch compile (CUDA only!)
3. memory: reducing memory through 4-bit quantization
4. memory_extreme: minimizing memory through 4-bit quantization and CPU offload
You can also control the style of the generated text through the `--mode` flag, one of "chat", "factual" or "creative":
```sh
local-gemma --model 9b --preset memory --mode factual
```
Finally, you can also pipe in other commands, which will be appended to the prompt after a `\n` separator
```sh
ls -la | local-gemma "Describe my files"
```
To see all available decoding options, call `local-gemma -h`.
## Python Usage
> [!NOTE]
> The `pipx` installation method creates its own Python environment, so you will need to use the `pip` installation method to use this library in a Python script.
Local Gemma-2 can be run locally through a Python interpreter using the familiar Transformers API. To enable a preset,
import the model class from `local_gemma` and pass the `preset` argument to `from_pretrained`. For example, the
following code-snippet loads the [Gemma-2 9b](https://huggingface.co/google/gemma-2-9b) model with the "memory" preset:
```python
from local_gemma import LocalGemma2ForCausalLM
from transformers import AutoTokenizer
model = LocalGemma2ForCausalLM.from_pretrained("google/gemma-2-9b", preset="memory")
tokenizer = AutoTokenizer.from_pretrained("google/gemma-2-9b")
model_inputs = tokenizer("The cat sat on the mat", return_attention_mask=True, return_tensors="pt")
generated_ids = model.generate(**model_inputs.to(model.device))
decoded_text = tokenizer.batch_decode(generated_ids)
```
When using an instruction-tuned model (prefixed by `-it`) for conversational use, prepare the inputs using a
chat-template. The following example loads [Gemma-2 2b it](https://huggingface.co/google/gemma-2-2b-it) model
using the "auto" preset, which automatically determines the best preset for the device:
```python
from local_gemma import LocalGemma2ForCausalLM
from transformers import AutoTokenizer
model = LocalGemma2ForCausalLM.from_pretrained("google/gemma-2-2b-it", preset="auto")
tokenizer = AutoTokenizer.from_pretrained("google/gemma-2-2b-it")
messages = [
{"role": "user", "content": "What is your favourite condiment?"},
{"role": "assistant", "content": "Well, I'm quite partial to a good squeeze of fresh lemon juice. It adds just the right amount of zesty flavour to whatever I'm cooking up in the kitchen!"},
{"role": "user", "content": "Do you have mayonnaise recipes?"}
]
model_inputs = tokenizer.apply_chat_template(messages, return_tensors="pt", return_dict=True)
generated_ids = model.generate(**model_inputs.to(model.device), max_new_tokens=1024, do_sample=True)
decoded_text = tokenizer.batch_decode(generated_ids)
```
## Presets
Local Gemma-2 provides three presets that trade-off accuracy, speed and memory. The following results highlight this
trade-off using [Gemma-2 9b](https://huggingface.co/google/gemma-2-9b) with batch size 1 on an 80GB A100 GPU:
| Mode | Performance* | Inference Speed (tok/s) | Memory (GB) |
|-------------------|--------------|-------------------------|-------------|
| exact | **73.0** | 17.2 | 18.3 |
| speed (CUDA-only) | **73.0** | **62.0** | 19.0 |
| memory | 72.1 | 13.8 | **7.3** |
| memory_extreme | 72.1 | 13.8 | **7.3** |
While an 80GB A100 places the full model on the device, only 3.7GB is required with the `memory_extreme` preset. See the
section [Preset Details](#preset-details) for details.
___
*Zero-shot results averaged over Wino, ARC Easy, Arc Challenge, PIQA, HellaSwag, MMLU, OpenBook QA.
### Preset Details
| Mode | 2b Min Memory (GB) | 9b Min Memory (GB) | 27b Min Memory (GB) | Weights dtype | CPU Offload |
|-------------------|--------------------|--------------------|---------------------|---------------|-------------|
| exact | 5.3 | 18.3 | 54.6 | bf16 | no |
| speed (CUDA-only) | 5.4 | 19.0 | 55.8 | bf16 | no |
| memory | 3.7 | 7.3 | 17.0 | int4 | no |
| memory_extreme | 1,8 | 3.7 | 4.7 | int4 | yes |
`memory_extreme` implements [CPU offloading](https://huggingface.co/docs/accelerate/en/usage_guides/big_modeling) through
[🤗 Accelerate](https://huggingface.co/docs/accelerate/en/index), reducing memory requirements down to the largest layer
in the model (which in this case is the LM head).
## Acknowledgements
Local Gemma-2 is a convenient wrapper around several open-source projects, which we thank explicitly below:
* [Transformers](https://huggingface.co/docs/transformers/en/index) for the PyTorch Gemma-2 implementation. Particularly [Arthur Zucker](https://github.com/ArthurZucker) for adding the model and the logit soft-capping fixes.
* [bitsandbytes](https://huggingface.co/docs/bitsandbytes/index) for the 4-bit optimization on CUDA.
* [quanto](https://github.com/huggingface/optimum-quanto) for the 4-bit optimization on MPS + CPU.
* [Accelerate](https://huggingface.co/docs/accelerate/en/index) for the large model loading utilities.
And last but not least, thank you to Google for the pre-trained [Gemma-2 checkpoints](https://huggingface.co/collections/google/gemma-2-release-667d6600fd5220e7b967f315), all of which you can find on the Hugging Face Hub.
| {"setup.py": "# Copyright 2024 The HuggingFace Team. All rights reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport setuptools\n\n\nDEPS = [\n \"setuptools\",\n \"torch>=2.1.1\",\n \"accelerate>=0.33.0\",\n \"transformers>=4.44.0\",\n]\n\nEXTRA_CUDA_DEPS = [\"bitsandbytes>=0.43.2\"]\nEXTRA_MPS_DEPS = [\"quanto>=0.2.0\", \"torch>=2.4.0\"]\n\nsetuptools.setup(\n name='local_gemma',\n version='0.3.0.dev0',\n author=\"The Hugging Face team\",\n packages=setuptools.find_packages(),\n entry_points={\n 'console_scripts': ['local-gemma=local_gemma.cli:main']\n },\n install_requires=DEPS,\n extras_require={\n \"cuda\": EXTRA_CUDA_DEPS,\n \"mps\": EXTRA_MPS_DEPS,\n \"cpu\": EXTRA_MPS_DEPS,\n },\n)\n", ".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 a3447f673a2446892613f2c6b9314483a0971d18 Hamza Amin <[email protected]> 1727369331 +0500\tclone: from https://github.com/huggingface/local-gemma.git\n", ".git\\refs\\heads\\main": "a3447f673a2446892613f2c6b9314483a0971d18\n"} | null |
m4-logs | {"type": "directory", "name": "m4-logs", "children": [{"type": "file", "name": "LICENSE"}, {"type": "directory", "name": "memos", "children": [{"type": "directory", "name": "images", "children": []}, {"type": "file", "name": "README.md"}]}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "tr-190-80b", "children": [{"type": "file", "name": "chronicles.md"}, {"type": "directory", "name": "images", "children": []}]}, {"type": "directory", "name": "tr_141-hanging", "children": [{"type": "file", "name": "README.md"}, {"type": "directory", "name": "tr_141_cm409xPMD01_scale_leap_of_faith_v5_num_workers_0-try3", "children": [{"type": "file", "name": "dmesg.txt"}, {"type": "file", "name": "gpu.query.0.txt"}, {"type": "file", "name": "gpu.query.1.txt"}, {"type": "file", "name": "gpu.query.all.txt"}, {"type": "file", "name": "README.md"}]}, {"type": "directory", "name": "tr_141_cm409xPMD01_scale_leap_of_faith_v5_num_workers_0-try5", "children": [{"type": "file", "name": "README.md"}]}, {"type": "directory", "name": "tr_141_cm409xPMD01_scale_leap_of_faith_v5_num_workers_02", "children": [{"type": "file", "name": "README.md"}]}, {"type": "directory", "name": "tr_141_cm409xPMD01_scale_leap_of_faith_v5_num_workers_04", "children": [{"type": "file", "name": "README.md"}]}, {"type": "directory", "name": "tr_141_cm409xPMD01_scale_leap_of_faith_v5_num_workers_06", "children": [{"type": "file", "name": "README.md"}]}]}]} | # experiment 6.1
## TLDR
like 4.1, using old deeepspeed 0.6.7+patch, but also trying low grad clip of 0.3
Run into a node failure and slurm killing the training this time.
Crash-wise is inconclusive - thinking that this was an unrelated HW problem.
But we made a huge progress 2500 iterations and 8h of run! Definitely this is much much better!
### Setup
```
cd /gpfsdswork/projects/rech/cnw/commun/experiments/stas/m4-full
bash experiments/pretraining/vloom/tr_141_cm409xPMD01_scale_leap_of_faith_v5_num_workers_06/01_launch.sh
cd /gpfsssd/scratch/rech/cnw/commun/experiments/local_experiment_dir/tr_141_cm409xPMD01_scale_leap_of_faith_v5_num_workers_06/logs
tail -f main_log.txt
```
- m4@main - no code tweaks 4a5d063212acb6f255fa91bbf824ae5fbf89bbab / Tue Jan 17 22:46:56 2023 +0100
- conda env stas-m4
- install deepspeed==0.6.7 + patch
- pt-1.12
- grad_clip: 0.3
- CUDA_LAUNCH_BLOCKING=1
- num_workers=2
- normal accumulation (really using m4@main)
(also weirdly chose to do grad_clip: 2.0 - probably tried 1.0 and made a mistake - but it looked to make no negative impact on stability)
Using Deepspeed==v0.6.7 plus this [fix](https://github.com/microsoft/DeepSpeed/pull/2642)
```
commit 78a13fbf5b0ebc25b4d47c26c9ed8d9ac02d5eae (HEAD)
Author: Samyam Rajbhandari <[email protected]>
Date: Thu Dec 22 16:50:45 2022 -0800
[zero-3] Handle forward parameter return correctly in nested cases (#2642)
Co-authored-by: Stas Bekman <[email protected]>
Co-authored-by: Olatunji Ruwase <[email protected]>
Co-authored-by: Jeff Rasley <[email protected]>
```
So specifically did:
```
source $cnw_ALL_CCFRWORK/start-m4-user
conda activate stas-m4
git clone https://github.com/microsoft/DeepSpeed DeepSpeed-v0.6.7
cd DeepSpeed-v0.6.7
pip install -e .
git checkout v0.6.7
git cherry-pick a298a43af22b9f971ff63e414887e659980889d9
```
### Investigation
a node crashed, so there was nothing we could do here - most likely a "normal" JZ hardware issue
```
iteration: 2500/500000 0% | elapsed time: 07:41:19 | per_token_loss: 3.1525 | lr: 9.990E-06 | num_tokens: 788088885 | num_images: 26284370 | num_padding: 391115 | fwd_bwd_time: 43621.8 | fwd_bwd_time_no_acc: 17.3 | image_to_text_ratio: 0.0332 | num_batches: 2500 | num_batches_in_curr_epoch: 706 | num_batches_since_training_logged: 25 | num_epochs: 1 | num_opt_steps: 2500 | z_loss: 24.6600 | per_example_loss: 15523.8 | pixel_values_sum: 1.54228E+12 | tflop_counter: 1.014E+08 | tflop_counter_no_acc: 4.055E+04 | tflops_fwd_bwd: 2.323E+03 | tflops_fwd_bwd_no_acc: 2.346E+03 | global_batch_size_current: 4096 |
** Starting validation **
Validation logs: val_per_token_loss: 3.0179 | val_per_example_loss: 14921.1 | val_num_images: 150355 | val_num_tokens: 4413196 | val_num_padding: 2292 | val_image_to_text_ratio: 0.0341 |
** Finished validation **
srun: error: Node failure on jean-zay-iam37
srun: Job step aborted: Waiting up to 62 seconds for job step to finish.
slurmstepd: error: *** STEP 1943824.0 ON jean-zay-iam17 CANCELLED AT 2023-03-06T03:17:51 DUE TO NODE FAILURE, SEE SLURMCTLD LOG FOR DETAILS ***
```
| {".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n"} | null |
making-games-with-ai-course | {"type": "directory", "name": "making-games-with-ai-course", "children": [{"type": "file", "name": "README.md"}, {"type": "directory", "name": "units", "children": [{"type": "directory", "name": "en", "children": [{"type": "directory", "name": "communication", "children": [{"type": "file", "name": "publishing-schedule.mdx"}]}, {"type": "directory", "name": "demo1", "children": [{"type": "file", "name": "conclusion.mdx"}, {"type": "file", "name": "first-game.mdx"}, {"type": "file", "name": "game-design-document.mdx"}, {"type": "file", "name": "game-idea.mdx"}, {"type": "file", "name": "introduction.mdx"}]}, {"type": "directory", "name": "unit0", "children": [{"type": "file", "name": "conclusion.mdx"}, {"type": "file", "name": "discord101.mdx"}, {"type": "file", "name": "game-demo.mdx"}, {"type": "file", "name": "how-to-get-most.mdx"}, {"type": "file", "name": "introduction.mdx"}, {"type": "file", "name": "setup.mdx"}, {"type": "file", "name": "syllabus.mdx"}, {"type": "file", "name": "who-are-we.mdx"}]}, {"type": "directory", "name": "unit1", "children": [{"type": "file", "name": "conclusion.mdx"}, {"type": "file", "name": "introduction.mdx"}, {"type": "file", "name": "local-vs-api.mdx"}, {"type": "file", "name": "make-demo.mdx"}, {"type": "file", "name": "next-steps.mdx"}, {"type": "file", "name": "sentence-similarity-explained.mdx"}, {"type": "file", "name": "what-is-hf.mdx"}]}, {"type": "directory", "name": "unit2", "children": [{"type": "file", "name": "2d-generation.mdx"}, {"type": "file", "name": "ai-voice-actors.mdx"}, {"type": "file", "name": "animation-generation.mdx"}, {"type": "file", "name": "code-assistants.mdx"}, {"type": "file", "name": "conclusion.mdx"}, {"type": "file", "name": "introduction.mdx"}, {"type": "file", "name": "music-generation.mdx"}, {"type": "file", "name": "sound-generation.mdx"}, {"type": "file", "name": "texture-generation.mdx"}]}, {"type": "directory", "name": "unit3", "children": [{"type": "file", "name": "conclusion.mdx"}, {"type": "file", "name": "customize.mdx"}, {"type": "file", "name": "demo.mdx"}, {"type": "file", "name": "introduction.mdx"}]}, {"type": "directory", "name": "unitbonus1", "children": [{"type": "file", "name": "additional-readings.mdx"}, {"type": "file", "name": "ai-and-games.mdx"}, {"type": "file", "name": "ai-gmtk.mdx"}, {"type": "file", "name": "ai-in-unity.mdx"}, {"type": "file", "name": "ai-in-unreal.mdx"}, {"type": "file", "name": "conclusion.mdx"}, {"type": "file", "name": "introduction.mdx"}]}, {"type": "file", "name": "_toctree.yml"}]}]}]} | # [Machine Learning For Games Course 🎮](https://huggingface.co/learn/ml-games-course/unit0/introduction)
<img src="https://huggingface.co/datasets/huggingface-ml-4-games-course/course-images/resolve/main/en/unit0/thumbnail.jpg" alt="Thumbnail"/>
If you like the course, don't hesitate to **⭐ star this repository. This helps us 🤗**.
This repository contains the Machine Learning for Games Course mdx files and notebooks. **The website is here** 👉 https://huggingface.co/learn/ml-games-course/unit0/introduction
- The syllabus 📚: https://huggingface.co/learn/ml-games-course/unit0/syllabus
- The course 📚: https://huggingface.co/learn/ml-games-course/unit0/introduction
Don't forget to sign up 👉 [here](http://eepurl.com/iCWDQw) (it's free)
## Citing the project
To cite this repository in publications:
```bibtex
@misc{ml-4-games-course,
author = {Simonini, Thomas},
title = {The Hugging Face Machine Learning For Games Course},
year = {2024},
publisher = {GitHub},
note = {GitHub repository},
howpublished = {\url{https://github.com/huggingface/making-games-with-ai-course}},
}
```
| {".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 cd8ee4c785de3b2b0eed371ea79ed03f884751fe Hamza Amin <[email protected]> 1727369346 +0500\tclone: from https://github.com/huggingface/making-games-with-ai-course.git\n", ".git\\refs\\heads\\main": "cd8ee4c785de3b2b0eed371ea79ed03f884751fe\n"} | null |
Mini-Python-projects | {"type": "directory", "name": "Mini-Python-projects", "children": [{"type": "directory", "name": "Library Management System", "children": [{"type": "file", "name": "Description.txt"}, {"type": "file", "name": "lib.py"}]}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "Weather Report", "children": [{"type": "file", "name": "Description.txt"}, {"type": "file", "name": "w.py"}]}]} | # Mini-Python-projects
In this repository you will find some useful mini scale projects
| {".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 131545abecc46afb7d5c1a71ba6c27a64bff9776 Hamza Amin <[email protected]> 1727376259 +0500\tclone: from https://github.com/hamza-amin-4365/Mini-Python-projects.git\n", ".git\\refs\\heads\\main": "131545abecc46afb7d5c1a71ba6c27a64bff9776\n"} | null |
ML-Agents-Training-Executables | {"type": "directory", "name": "ML-Agents-Training-Executables", "children": [{"type": "file", "name": "README.md"}]} | # ML-Agents-Training-Executables
This repo contains the Unity ML-Agents environments' executables for Windows, Mac and Linux
| {".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 2c2665cfbdfc78eadb5c25b5abb65bdfb1e4db8d Hamza Amin <[email protected]> 1727369348 +0500\tclone: from https://github.com/huggingface/ML-Agents-Training-Executables.git\n", ".git\\refs\\heads\\main": "2c2665cfbdfc78eadb5c25b5abb65bdfb1e4db8d\n"} | null |
ml-for-3d-course | {"type": "directory", "name": "ml-for-3d-course", "children": [{"type": "file", "name": "README.md"}, {"type": "directory", "name": "units", "children": [{"type": "directory", "name": "en", "children": [{"type": "directory", "name": "conclusion", "children": [{"type": "file", "name": "conclusion.mdx"}]}, {"type": "directory", "name": "unit0", "children": [{"type": "file", "name": "how-to-do-it-yourself.mdx"}, {"type": "file", "name": "introduction.mdx"}, {"type": "file", "name": "whats-going-on.mdx"}, {"type": "file", "name": "why-does-it-matter.mdx"}]}, {"type": "directory", "name": "unit1", "children": [{"type": "file", "name": "introduction.mdx"}, {"type": "file", "name": "meshes.mdx"}, {"type": "file", "name": "non-meshes.mdx"}, {"type": "file", "name": "pipelines.mdx"}]}, {"type": "directory", "name": "unit2", "children": [{"type": "file", "name": "bonus.mdx"}, {"type": "file", "name": "hands-on-1.mdx"}, {"type": "file", "name": "hands-on-2.mdx"}, {"type": "file", "name": "introduction.mdx"}, {"type": "file", "name": "pipeline.mdx"}, {"type": "file", "name": "setup.mdx"}, {"type": "file", "name": "what-is-it.mdx"}]}, {"type": "directory", "name": "unit3", "children": [{"type": "file", "name": "bonus.mdx"}, {"type": "file", "name": "hands-on.mdx"}, {"type": "file", "name": "introduction.mdx"}, {"type": "file", "name": "what-is-it.mdx"}]}, {"type": "directory", "name": "unit4", "children": [{"type": "file", "name": "hands-on.mdx"}, {"type": "file", "name": "introduction.mdx"}, {"type": "file", "name": "marching-cubes.mdx"}, {"type": "file", "name": "mesh-generation.mdx"}]}, {"type": "directory", "name": "unit5", "children": [{"type": "file", "name": "introduction.mdx"}, {"type": "file", "name": "run-in-notebook.mdx"}, {"type": "file", "name": "run-locally.mdx"}, {"type": "file", "name": "run-via-api.mdx"}, {"type": "file", "name": "walkthrough.mdx"}]}, {"type": "file", "name": "_toctree.yml"}]}]}]} | # [Machine Learning For 3D Course 🐘](https://huggingface.co/learn/ml-for-3d-course/unit0/introduction)

This repository contains the [ML for 3D Course](https://huggingface.co/learn/ml-for-3d-course/unit0/introduction) files.
Sign up [here](https://mailchi.mp/911880bcff7d/ml-for-3d-course).
## Citing
To cite this repository in publications:
```bibtex
@misc{ml-for-3d-course,
author = {Dylan Ebert},
title = {Hugging Face Machine Learning for 3D Course},
year = {2024},
publisher = {GitHub},
note = {GitHub repository},
howpublished = {\url{https://github.com/huggingface/ml-for-3d-course}},
}
```
| {".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 a6358477778ac19ef81ba8252610629c8b14cf68 Hamza Amin <[email protected]> 1727369352 +0500\tclone: from https://github.com/huggingface/ml-for-3d-course.git\n", ".git\\refs\\heads\\main": "a6358477778ac19ef81ba8252610629c8b14cf68\n"} | null |
model-evaluator | {"type": "directory", "name": "model-evaluator", "children": [{"type": "file", "name": ".env.template"}, {"type": "file", "name": "app.py"}, {"type": "file", "name": "evaluation.py"}, {"type": "directory", "name": "images", "children": []}, {"type": "file", "name": "LICENSE"}, {"type": "file", "name": "Makefile"}, {"type": "directory", "name": "notebooks", "children": [{"type": "file", "name": "flush-prediction-repos.ipynb"}]}, {"type": "file", "name": "pyproject.toml"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "run_evaluation_jobs.py"}, {"type": "file", "name": "utils.py"}]} | ---
title: Model Evaluator
emoji: 📊
colorFrom: red
colorTo: red
sdk: streamlit
sdk_version: 1.10.0
app_file: app.py
---
# Model Evaluator
> Submit evaluation jobs to AutoTrain from the Hugging Face Hub
**⚠️ This project has been archived. If you want to evaluate LLMs, checkout [this collection](https://huggingface.co/collections/clefourrier/llm-leaderboards-and-benchmarks-✨-64f99d2e11e92ca5568a7cce) of leaderboards.**
## Supported tasks
The table below shows which tasks are currently supported for evaluation in the AutoTrain backend:
| Task | Supported |
|:-----------------------------------|:---------:|
| `binary_classification` | ✅ |
| `multi_class_classification` | ✅ |
| `multi_label_classification` | ❌ |
| `entity_extraction` | ✅ |
| `extractive_question_answering` | ✅ |
| `translation` | ✅ |
| `summarization` | ✅ |
| `image_binary_classification` | ✅ |
| `image_multi_class_classification` | ✅ |
| `text_zero_shot_evaluation` | ✅ |
## Installation
To run the application locally, first clone this repository and install the dependencies as follows:
```
pip install -r requirements.txt
```
Next, copy the example file of environment variables:
```
cp .env.template .env
```
and set the `HF_TOKEN` variable with a valid API token from the [`autoevaluator`](https://huggingface.co/autoevaluator) bot user. Finally, spin up the application by running:
```
streamlit run app.py
```
## Usage
Evaluation on the Hub involves two main steps:
1. Submitting an evaluation job via the UI. This creates an AutoTrain project with `N` models for evaluation. At this stage, the dataset is also processed and prepared for evaluation.
2. Triggering the evaluation itself once the dataset is processed.
From the user perspective, only step (1) is needed since step (2) is handled by a cron job on GitHub Actions that executes the `run_evaluation_jobs.py` script every 15 minutes.
See below for details on manually triggering evaluation jobs.
### Triggering an evaluation
To evaluate the models in an AutoTrain project, run:
```
python run_evaluation_jobs.py
```
This will download the [`autoevaluate/evaluation-job-logs`](https://huggingface.co/datasets/autoevaluate/evaluation-job-logs) dataset from the Hub and check which evaluation projects are ready for evaluation (i.e. those whose dataset has been processed).
## AutoTrain configuration details
Models are evaluated by the [`autoevaluator`](https://huggingface.co/autoevaluator) bot user in AutoTrain, with the payload sent to the `AUTOTRAIN_BACKEND_API` environment variable. Evaluation projects are created and run on either the `prod` or `staging` environments. You can view the status of projects in the AutoTrain UI by navigating to one of the links below (ask internally for access to the staging UI):
| AutoTrain environment | AutoTrain UI URL | `AUTOTRAIN_BACKEND_API` |
|:---------------------:|:--------------------------------------------------------------------------------------------------------------:|:--------------------------------------------:|
| `prod` | [`https://ui.autotrain.huggingface.co/projects`](https://ui.autotrain.huggingface.co/projects) | https://api.autotrain.huggingface.co |
| `staging` | [`https://ui-staging.autotrain.huggingface.co/projects`](https://ui-staging.autotrain.huggingface.co/projects) | https://api-staging.autotrain.huggingface.co |
The current configuration for evaluation jobs running on [Spaces](https://huggingface.co/spaces/autoevaluate/model-evaluator) is:
```
AUTOTRAIN_BACKEND_API=https://api.autotrain.huggingface.co
```
To evaluate models with a _local_ instance of AutoTrain, change the environment to:
```
AUTOTRAIN_BACKEND_API=http://localhost:8000
```
### Migrating from staging to production (and vice versa)
In general, evaluation jobs should run in AutoTrain's `prod` environment, which is defined by the following environment variable:
```
AUTOTRAIN_BACKEND_API=https://api.autotrain.huggingface.co
```
However, there are times when it is necessary to run evaluation jobs in AutoTrain's `staging` environment (e.g. because a new evaluation pipeline is being deployed). In these cases the corresponding environement variable is:
```
AUTOTRAIN_BACKEND_API=https://api-staging.autotrain.huggingface.co
```
To migrate between these two environments, update the `AUTOTRAIN_BACKEND_API` in two places:
* In the [repo secrets](https://huggingface.co/spaces/autoevaluate/model-evaluator/settings) associated with the `model-evaluator` Space. This will ensure evaluation projects are created in the desired environment.
* In the [GitHub Actions secrets](https://github.com/huggingface/model-evaluator/settings/secrets/actions) associated with this repo. This will ensure that the correct evaluation jobs are approved and launched via the `run_evaluation_jobs.py` script.
| {"app.py": "import os\nimport time\nfrom pathlib import Path\n\nimport pandas as pd\nimport streamlit as st\nimport yaml\nfrom datasets import get_dataset_config_names\nfrom dotenv import load_dotenv\nfrom huggingface_hub import list_datasets\n\nfrom evaluation import filter_evaluated_models\nfrom utils import (\n AUTOTRAIN_TASK_TO_HUB_TASK,\n commit_evaluation_log,\n create_autotrain_project_name,\n format_col_mapping,\n get_compatible_models,\n get_config_metadata,\n get_dataset_card_url,\n get_key,\n get_metadata,\n http_get,\n http_post,\n)\n\nif Path(\".env\").is_file():\n load_dotenv(\".env\")\n\nHF_TOKEN = os.getenv(\"HF_TOKEN\")\nAUTOTRAIN_USERNAME = os.getenv(\"AUTOTRAIN_USERNAME\")\nAUTOTRAIN_BACKEND_API = os.getenv(\"AUTOTRAIN_BACKEND_API\")\nDATASETS_PREVIEW_API = os.getenv(\"DATASETS_PREVIEW_API\")\n\n# Put image tasks on top\nTASK_TO_ID = {\n \"image_binary_classification\": 17,\n \"image_multi_class_classification\": 18,\n \"binary_classification\": 1,\n \"multi_class_classification\": 2,\n \"natural_language_inference\": 22,\n \"entity_extraction\": 4,\n \"extractive_question_answering\": 5,\n \"translation\": 6,\n \"summarization\": 8,\n \"text_zero_shot_classification\": 23,\n}\n\nTASK_TO_DEFAULT_METRICS = {\n \"binary_classification\": [\"f1\", \"precision\", \"recall\", \"auc\", \"accuracy\"],\n \"multi_class_classification\": [\n \"f1\",\n \"precision\",\n \"recall\",\n \"accuracy\",\n ],\n \"natural_language_inference\": [\"f1\", \"precision\", \"recall\", \"auc\", \"accuracy\"],\n \"entity_extraction\": [\"precision\", \"recall\", \"f1\", \"accuracy\"],\n \"extractive_question_answering\": [\"f1\", \"exact_match\"],\n \"translation\": [\"sacrebleu\"],\n \"summarization\": [\"rouge1\", \"rouge2\", \"rougeL\", \"rougeLsum\"],\n \"image_binary_classification\": [\"f1\", \"precision\", \"recall\", \"auc\", \"accuracy\"],\n \"image_multi_class_classification\": [\n \"f1\",\n \"precision\",\n \"recall\",\n \"accuracy\",\n ],\n \"text_zero_shot_classification\": [\"accuracy\", \"loss\"],\n}\n\nAUTOTRAIN_TASK_TO_LANG = {\n \"translation\": \"en2de\",\n \"image_binary_classification\": \"unk\",\n \"image_multi_class_classification\": \"unk\",\n}\n\nAUTOTRAIN_MACHINE = {\"text_zero_shot_classification\": \"r5.16x\"}\n\n\nSUPPORTED_TASKS = list(TASK_TO_ID.keys())\n\n# Extracted from utils.get_supported_metrics\n# Hardcoded for now due to speed / caching constraints\nSUPPORTED_METRICS = [\n \"accuracy\",\n \"bertscore\",\n \"bleu\",\n \"cer\",\n \"chrf\",\n \"code_eval\",\n \"comet\",\n \"competition_math\",\n \"coval\",\n \"cuad\",\n \"exact_match\",\n \"f1\",\n \"frugalscore\",\n \"google_bleu\",\n \"mae\",\n \"mahalanobis\",\n \"matthews_correlation\",\n \"mean_iou\",\n \"meteor\",\n \"mse\",\n \"pearsonr\",\n \"perplexity\",\n \"precision\",\n \"recall\",\n \"roc_auc\",\n \"rouge\",\n \"sacrebleu\",\n \"sari\",\n \"seqeval\",\n \"spearmanr\",\n \"squad\",\n \"squad_v2\",\n \"ter\",\n \"trec_eval\",\n \"wer\",\n \"wiki_split\",\n \"xnli\",\n \"angelina-wang/directional_bias_amplification\",\n \"jordyvl/ece\",\n \"lvwerra/ai4code\",\n \"lvwerra/amex\",\n]\n\n\n#######\n# APP #\n#######\nst.title(\"Evaluation on the Hub\")\nst.warning(\n \"**\u26a0\ufe0f This project has been archived. If you want to evaluate LLMs, checkout [this collection](https://huggingface.co/collections/clefourrier/llm-leaderboards-and-benchmarks-\u2728-64f99d2e11e92ca5568a7cce) of leaderboards.**\"\n)\nst.markdown(\n \"\"\"\n Welcome to Hugging Face's automatic model evaluator \ud83d\udc4b!\n\n This application allows you to evaluate \ud83e\udd17 Transformers\n [models](https://huggingface.co/models?library=transformers&sort=downloads)\n across a wide variety of [datasets](https://huggingface.co/datasets) on the\n Hub. Please select the dataset and configuration below. The results of your\n evaluation will be displayed on the [public\n leaderboards](https://huggingface.co/spaces/autoevaluate/leaderboards). For\n more details, check out out our [blog\n post](https://huggingface.co/blog/eval-on-the-hub).\n \"\"\"\n)\n\n# all_datasets = [d.id for d in list_datasets()]\n# query_params = st.experimental_get_query_params()\n# if \"first_query_params\" not in st.session_state:\n# st.session_state.first_query_params = query_params\n# first_query_params = st.session_state.first_query_params\n# default_dataset = all_datasets[0]\n# if \"dataset\" in first_query_params:\n# if len(first_query_params[\"dataset\"]) > 0 and first_query_params[\"dataset\"][0] in all_datasets:\n# default_dataset = first_query_params[\"dataset\"][0]\n\n# selected_dataset = st.selectbox(\n# \"Select a dataset\",\n# all_datasets,\n# index=all_datasets.index(default_dataset),\n# help=\"\"\"Datasets with metadata can be evaluated with 1-click. Configure an evaluation job to add \\\n# new metadata to a dataset card.\"\"\",\n# )\n# st.experimental_set_query_params(**{\"dataset\": [selected_dataset]})\n\n# # Check if selected dataset can be streamed\n# is_valid_dataset = http_get(\n# path=\"/is-valid\",\n# domain=DATASETS_PREVIEW_API,\n# params={\"dataset\": selected_dataset},\n# ).json()\n# if is_valid_dataset[\"viewer\"] is False and is_valid_dataset[\"preview\"] is False:\n# st.error(\n# \"\"\"The dataset you selected is not currently supported. Open a \\\n# [discussion](https://huggingface.co/spaces/autoevaluate/model-evaluator/discussions) for support.\"\"\"\n# )\n\n# metadata = get_metadata(selected_dataset, token=HF_TOKEN)\n# print(f\"INFO -- Dataset metadata: {metadata}\")\n# if metadata is None:\n# st.warning(\"No evaluation metadata found. Please configure the evaluation job below.\")\n\n# with st.expander(\"Advanced configuration\"):\n# # Select task\n# selected_task = st.selectbox(\n# \"Select a task\",\n# SUPPORTED_TASKS,\n# index=SUPPORTED_TASKS.index(metadata[0][\"task_id\"]) if metadata is not None else 0,\n# help=\"\"\"Don't see your favourite task here? Open a \\\n# [discussion](https://huggingface.co/spaces/autoevaluate/model-evaluator/discussions) to request it!\"\"\",\n# )\n# # Select config\n# configs = get_dataset_config_names(selected_dataset)\n# selected_config = st.selectbox(\n# \"Select a config\",\n# configs,\n# help=\"\"\"Some datasets contain several sub-datasets, known as _configurations_. \\\n# Select one to evaluate your models on. \\\n# See the [docs](https://huggingface.co/docs/datasets/master/en/load_hub#configurations) for more details.\n# \"\"\",\n# )\n# # Some datasets have multiple metadata (one per config), so we grab the one associated with the selected config\n# config_metadata = get_config_metadata(selected_config, metadata)\n# print(f\"INFO -- Config metadata: {config_metadata}\")\n\n# # Select splits\n# splits_resp = http_get(\n# path=\"/splits\",\n# domain=DATASETS_PREVIEW_API,\n# params={\"dataset\": selected_dataset},\n# )\n# if splits_resp.status_code == 200:\n# split_names = []\n# all_splits = splits_resp.json()\n# for split in all_splits[\"splits\"]:\n# if split[\"config\"] == selected_config:\n# split_names.append(split[\"split\"])\n\n# if config_metadata is not None:\n# eval_split = config_metadata[\"splits\"].get(\"eval_split\", None)\n# else:\n# eval_split = None\n# selected_split = st.selectbox(\n# \"Select a split\",\n# split_names,\n# index=split_names.index(eval_split) if eval_split is not None else 0,\n# help=\"Be wary when evaluating models on the `train` split.\",\n# )\n\n# # Select columns\n# rows_resp = http_get(\n# path=\"/first-rows\",\n# domain=DATASETS_PREVIEW_API,\n# params={\n# \"dataset\": selected_dataset,\n# \"config\": selected_config,\n# \"split\": selected_split,\n# },\n# ).json()\n# col_names = list(pd.json_normalize(rows_resp[\"rows\"][0][\"row\"]).columns)\n\n# st.markdown(\"**Map your dataset columns**\")\n# st.markdown(\n# \"\"\"The model evaluator uses a standardised set of column names for the input examples and labels. \\\n# Please define the mapping between your dataset columns (right) and the standardised column names (left).\"\"\"\n# )\n# col1, col2 = st.columns(2)\n\n# # TODO: find a better way to layout these items\n# # TODO: need graceful way of handling dataset <--> task mismatch for datasets with metadata\n# col_mapping = {}\n# if selected_task in [\"binary_classification\", \"multi_class_classification\"]:\n# with col1:\n# st.markdown(\"`text` column\")\n# st.text(\"\")\n# st.text(\"\")\n# st.text(\"\")\n# st.text(\"\")\n# st.markdown(\"`target` column\")\n# with col2:\n# text_col = st.selectbox(\n# \"This column should contain the text to be classified\",\n# col_names,\n# index=col_names.index(get_key(config_metadata[\"col_mapping\"], \"text\"))\n# if config_metadata is not None\n# else 0,\n# )\n# target_col = st.selectbox(\n# \"This column should contain the labels associated with the text\",\n# col_names,\n# index=col_names.index(get_key(config_metadata[\"col_mapping\"], \"target\"))\n# if config_metadata is not None\n# else 0,\n# )\n# col_mapping[text_col] = \"text\"\n# col_mapping[target_col] = \"target\"\n\n# elif selected_task == \"text_zero_shot_classification\":\n# with col1:\n# st.markdown(\"`text` column\")\n# st.text(\"\")\n# st.text(\"\")\n# st.text(\"\")\n# st.text(\"\")\n# st.markdown(\"`classes` column\")\n# st.text(\"\")\n# st.text(\"\")\n# st.text(\"\")\n# st.text(\"\")\n# st.markdown(\"`target` column\")\n# with col2:\n# text_col = st.selectbox(\n# \"This column should contain the text to be classified\",\n# col_names,\n# index=col_names.index(get_key(config_metadata[\"col_mapping\"], \"text\"))\n# if config_metadata is not None\n# else 0,\n# )\n# classes_col = st.selectbox(\n# \"This column should contain the classes associated with the text\",\n# col_names,\n# index=col_names.index(get_key(config_metadata[\"col_mapping\"], \"classes\"))\n# if config_metadata is not None\n# else 0,\n# )\n# target_col = st.selectbox(\n# \"This column should contain the index of the correct class\",\n# col_names,\n# index=col_names.index(get_key(config_metadata[\"col_mapping\"], \"target\"))\n# if config_metadata is not None\n# else 0,\n# )\n# col_mapping[text_col] = \"text\"\n# col_mapping[classes_col] = \"classes\"\n# col_mapping[target_col] = \"target\"\n\n# if selected_task in [\"natural_language_inference\"]:\n# config_metadata = get_config_metadata(selected_config, metadata)\n# with col1:\n# st.markdown(\"`text1` column\")\n# st.text(\"\")\n# st.text(\"\")\n# st.text(\"\")\n# st.text(\"\")\n# st.text(\"\")\n# st.markdown(\"`text2` column\")\n# st.text(\"\")\n# st.text(\"\")\n# st.text(\"\")\n# st.text(\"\")\n# st.text(\"\")\n# st.markdown(\"`target` column\")\n# with col2:\n# text1_col = st.selectbox(\n# \"This column should contain the first text passage to be classified\",\n# col_names,\n# index=col_names.index(get_key(config_metadata[\"col_mapping\"], \"text1\"))\n# if config_metadata is not None\n# else 0,\n# )\n# text2_col = st.selectbox(\n# \"This column should contain the second text passage to be classified\",\n# col_names,\n# index=col_names.index(get_key(config_metadata[\"col_mapping\"], \"text2\"))\n# if config_metadata is not None\n# else 0,\n# )\n# target_col = st.selectbox(\n# \"This column should contain the labels associated with the text\",\n# col_names,\n# index=col_names.index(get_key(config_metadata[\"col_mapping\"], \"target\"))\n# if config_metadata is not None\n# else 0,\n# )\n# col_mapping[text1_col] = \"text1\"\n# col_mapping[text2_col] = \"text2\"\n# col_mapping[target_col] = \"target\"\n\n# elif selected_task == \"entity_extraction\":\n# with col1:\n# st.markdown(\"`tokens` column\")\n# st.text(\"\")\n# st.text(\"\")\n# st.text(\"\")\n# st.text(\"\")\n# st.markdown(\"`tags` column\")\n# with col2:\n# tokens_col = st.selectbox(\n# \"This column should contain the array of tokens to be classified\",\n# col_names,\n# index=col_names.index(get_key(config_metadata[\"col_mapping\"], \"tokens\"))\n# if config_metadata is not None\n# else 0,\n# )\n# tags_col = st.selectbox(\n# \"This column should contain the labels associated with each part of the text\",\n# col_names,\n# index=col_names.index(get_key(config_metadata[\"col_mapping\"], \"tags\"))\n# if config_metadata is not None\n# else 0,\n# )\n# col_mapping[tokens_col] = \"tokens\"\n# col_mapping[tags_col] = \"tags\"\n\n# elif selected_task == \"translation\":\n# with col1:\n# st.markdown(\"`source` column\")\n# st.text(\"\")\n# st.text(\"\")\n# st.text(\"\")\n# st.text(\"\")\n# st.markdown(\"`target` column\")\n# with col2:\n# text_col = st.selectbox(\n# \"This column should contain the text to be translated\",\n# col_names,\n# index=col_names.index(get_key(config_metadata[\"col_mapping\"], \"source\"))\n# if config_metadata is not None\n# else 0,\n# )\n# target_col = st.selectbox(\n# \"This column should contain the target translation\",\n# col_names,\n# index=col_names.index(get_key(config_metadata[\"col_mapping\"], \"target\"))\n# if config_metadata is not None\n# else 0,\n# )\n# col_mapping[text_col] = \"source\"\n# col_mapping[target_col] = \"target\"\n\n# elif selected_task == \"summarization\":\n# with col1:\n# st.markdown(\"`text` column\")\n# st.text(\"\")\n# st.text(\"\")\n# st.text(\"\")\n# st.text(\"\")\n# st.markdown(\"`target` column\")\n# with col2:\n# text_col = st.selectbox(\n# \"This column should contain the text to be summarized\",\n# col_names,\n# index=col_names.index(get_key(config_metadata[\"col_mapping\"], \"text\"))\n# if config_metadata is not None\n# else 0,\n# )\n# target_col = st.selectbox(\n# \"This column should contain the target summary\",\n# col_names,\n# index=col_names.index(get_key(config_metadata[\"col_mapping\"], \"target\"))\n# if config_metadata is not None\n# else 0,\n# )\n# col_mapping[text_col] = \"text\"\n# col_mapping[target_col] = \"target\"\n\n# elif selected_task == \"extractive_question_answering\":\n# if config_metadata is not None:\n# col_mapping = config_metadata[\"col_mapping\"]\n# # Hub YAML parser converts periods to hyphens, so we remap them here\n# col_mapping = format_col_mapping(col_mapping)\n# with col1:\n# st.markdown(\"`context` column\")\n# st.text(\"\")\n# st.text(\"\")\n# st.text(\"\")\n# st.text(\"\")\n# st.markdown(\"`question` column\")\n# st.text(\"\")\n# st.text(\"\")\n# st.text(\"\")\n# st.text(\"\")\n# st.markdown(\"`answers.text` column\")\n# st.text(\"\")\n# st.text(\"\")\n# st.text(\"\")\n# st.text(\"\")\n# st.markdown(\"`answers.answer_start` column\")\n# with col2:\n# context_col = st.selectbox(\n# \"This column should contain the question's context\",\n# col_names,\n# index=col_names.index(get_key(col_mapping, \"context\")) if config_metadata is not None else 0,\n# )\n# question_col = st.selectbox(\n# \"This column should contain the question to be answered, given the context\",\n# col_names,\n# index=col_names.index(get_key(col_mapping, \"question\")) if config_metadata is not None else 0,\n# )\n# answers_text_col = st.selectbox(\n# \"This column should contain example answers to the question, extracted from the context\",\n# col_names,\n# index=col_names.index(get_key(col_mapping, \"answers.text\")) if config_metadata is not None else 0,\n# )\n# answers_start_col = st.selectbox(\n# \"This column should contain the indices in the context of the first character of each `answers.text`\",\n# col_names,\n# index=col_names.index(get_key(col_mapping, \"answers.answer_start\"))\n# if config_metadata is not None\n# else 0,\n# )\n# col_mapping[context_col] = \"context\"\n# col_mapping[question_col] = \"question\"\n# col_mapping[answers_text_col] = \"answers.text\"\n# col_mapping[answers_start_col] = \"answers.answer_start\"\n# elif selected_task in [\"image_binary_classification\", \"image_multi_class_classification\"]:\n# with col1:\n# st.markdown(\"`image` column\")\n# st.text(\"\")\n# st.text(\"\")\n# st.text(\"\")\n# st.text(\"\")\n# st.markdown(\"`target` column\")\n# with col2:\n# image_col = st.selectbox(\n# \"This column should contain the images to be classified\",\n# col_names,\n# index=col_names.index(get_key(config_metadata[\"col_mapping\"], \"image\"))\n# if config_metadata is not None\n# else 0,\n# )\n# target_col = st.selectbox(\n# \"This column should contain the labels associated with the images\",\n# col_names,\n# index=col_names.index(get_key(config_metadata[\"col_mapping\"], \"target\"))\n# if config_metadata is not None\n# else 0,\n# )\n# col_mapping[image_col] = \"image\"\n# col_mapping[target_col] = \"target\"\n\n# # Select metrics\n# st.markdown(\"**Select metrics**\")\n# st.markdown(\"The following metrics will be computed\")\n# html_string = \" \".join(\n# [\n# '<div style=\"padding-right:5px;padding-left:5px;padding-top:5px;padding-bottom:5px;float:left\">'\n# + '<div style=\"background-color:#D3D3D3;border-radius:5px;display:inline-block;padding-right:5px;'\n# + 'padding-left:5px;color:white\">'\n# + metric\n# + \"</div></div>\"\n# for metric in TASK_TO_DEFAULT_METRICS[selected_task]\n# ]\n# )\n# st.markdown(html_string, unsafe_allow_html=True)\n# selected_metrics = st.multiselect(\n# \"(Optional) Select additional metrics\",\n# sorted(list(set(SUPPORTED_METRICS) - set(TASK_TO_DEFAULT_METRICS[selected_task]))),\n# help=\"\"\"User-selected metrics will be computed with their default arguments. \\\n# For example, `f1` will report results for binary labels. \\\n# Check out the [available metrics](https://huggingface.co/metrics) for more details.\"\"\",\n# )\n\n# with st.form(key=\"form\"):\n# compatible_models = get_compatible_models(selected_task, [selected_dataset])\n# selected_models = st.multiselect(\n# \"Select the models you wish to evaluate\",\n# compatible_models,\n# help=\"\"\"Don't see your favourite model in this list? Add the dataset and task it was trained on to the \\\n# [model card metadata.](https://huggingface.co/docs/hub/models-cards#model-card-metadata)\"\"\",\n# )\n# print(\"INFO -- Selected models before filter:\", selected_models)\n\n# hf_username = st.text_input(\"Enter your \ud83e\udd17 Hub username to be notified when the evaluation is finished\")\n\n# submit_button = st.form_submit_button(\"Evaluate models \ud83d\ude80\")\n\n# if submit_button:\n# if len(hf_username) == 0:\n# st.warning(\"No \ud83e\udd17 Hub username provided! Please enter your username and try again.\")\n# elif len(selected_models) == 0:\n# st.warning(\"\u26a0\ufe0f No models were selected for evaluation! Please select at least one model and try again.\")\n# elif len(selected_models) > 10:\n# st.warning(\"Only 10 models can be evaluated at once. Please select fewer models and try again.\")\n# else:\n# # Filter out previously evaluated models\n# selected_models = filter_evaluated_models(\n# selected_models,\n# selected_task,\n# selected_dataset,\n# selected_config,\n# selected_split,\n# selected_metrics,\n# )\n# print(\"INFO -- Selected models after filter:\", selected_models)\n# if len(selected_models) > 0:\n# project_payload = {\n# \"username\": AUTOTRAIN_USERNAME,\n# \"proj_name\": create_autotrain_project_name(selected_dataset, selected_config),\n# \"task\": TASK_TO_ID[selected_task],\n# \"config\": {\n# \"language\": AUTOTRAIN_TASK_TO_LANG[selected_task]\n# if selected_task in AUTOTRAIN_TASK_TO_LANG\n# else \"en\",\n# \"max_models\": 5,\n# \"instance\": {\n# \"provider\": \"sagemaker\" if selected_task in AUTOTRAIN_MACHINE.keys() else \"ovh\",\n# \"instance_type\": AUTOTRAIN_MACHINE[selected_task]\n# if selected_task in AUTOTRAIN_MACHINE.keys()\n# else \"p3\",\n# \"max_runtime_seconds\": 172800,\n# \"num_instances\": 1,\n# \"disk_size_gb\": 200,\n# },\n# \"evaluation\": {\n# \"metrics\": selected_metrics,\n# \"models\": selected_models,\n# \"hf_username\": hf_username,\n# },\n# },\n# }\n# print(f\"INFO -- Payload: {project_payload}\")\n# project_json_resp = http_post(\n# path=\"/projects/create\",\n# payload=project_payload,\n# token=HF_TOKEN,\n# domain=AUTOTRAIN_BACKEND_API,\n# ).json()\n# print(f\"INFO -- Project creation response: {project_json_resp}\")\n\n# if project_json_resp[\"created\"]:\n# data_payload = {\n# \"split\": 4, # use \"auto\" split choice in AutoTrain\n# \"col_mapping\": col_mapping,\n# \"load_config\": {\"max_size_bytes\": 0, \"shuffle\": False},\n# \"dataset_id\": selected_dataset,\n# \"dataset_config\": selected_config,\n# \"dataset_split\": selected_split,\n# }\n# data_json_resp = http_post(\n# path=f\"/projects/{project_json_resp['id']}/data/dataset\",\n# payload=data_payload,\n# token=HF_TOKEN,\n# domain=AUTOTRAIN_BACKEND_API,\n# ).json()\n# print(f\"INFO -- Dataset creation response: {data_json_resp}\")\n# if data_json_resp[\"download_status\"] == 1:\n# train_json_resp = http_post(\n# path=f\"/projects/{project_json_resp['id']}/data/start_processing\",\n# token=HF_TOKEN,\n# domain=AUTOTRAIN_BACKEND_API,\n# ).json()\n# # For local development we process and approve projects on-the-fly\n# if \"localhost\" in AUTOTRAIN_BACKEND_API:\n# with st.spinner(\"\u23f3 Waiting for data processing to complete ...\"):\n# is_data_processing_success = False\n# while is_data_processing_success is not True:\n# project_status = http_get(\n# path=f\"/projects/{project_json_resp['id']}\",\n# token=HF_TOKEN,\n# domain=AUTOTRAIN_BACKEND_API,\n# ).json()\n# if project_status[\"status\"] == 3:\n# is_data_processing_success = True\n# time.sleep(10)\n\n# # Approve training job\n# train_job_resp = http_post(\n# path=f\"/projects/{project_json_resp['id']}/start_training\",\n# token=HF_TOKEN,\n# domain=AUTOTRAIN_BACKEND_API,\n# ).json()\n# st.success(\"\u2705 Data processing and project approval complete - go forth and evaluate!\")\n# else:\n# # Prod/staging submissions are evaluated in a cron job via run_evaluation_jobs.py\n# print(f\"INFO -- AutoTrain job response: {train_json_resp}\")\n# if train_json_resp[\"success\"]:\n# train_eval_index = {\n# \"train-eval-index\": [\n# {\n# \"config\": selected_config,\n# \"task\": AUTOTRAIN_TASK_TO_HUB_TASK[selected_task],\n# \"task_id\": selected_task,\n# \"splits\": {\"eval_split\": selected_split},\n# \"col_mapping\": col_mapping,\n# }\n# ]\n# }\n# selected_metadata = yaml.dump(train_eval_index, sort_keys=False)\n# dataset_card_url = get_dataset_card_url(selected_dataset)\n# st.success(\"\u2705 Successfully submitted evaluation job!\")\n# st.markdown(\n# f\"\"\"\n# Evaluation can take up to 1 hour to complete, so grab a \u2615\ufe0f or \ud83c\udf75 while you wait:\n\n# * \ud83d\udd14 A [Hub pull request](https://huggingface.co/docs/hub/repositories-pull-requests-discussions) with the evaluation results will be opened for each model you selected. Check your email for notifications.\n# * \ud83d\udcca Click [here](https://hf.co/spaces/autoevaluate/leaderboards?dataset={selected_dataset}) to view the results from your submission once the Hub pull request is merged.\n# * \ud83e\udd71 Tired of configuring evaluations? Add the following metadata to the [dataset card]({dataset_card_url}) to enable 1-click evaluations:\n# \"\"\" # noqa\n# )\n# st.markdown(\n# f\"\"\"\n# ```yaml\n# {selected_metadata}\n# \"\"\"\n# )\n# print(\"INFO -- Pushing evaluation job logs to the Hub\")\n# evaluation_log = {}\n# evaluation_log[\"project_id\"] = project_json_resp[\"id\"]\n# evaluation_log[\"autotrain_env\"] = (\n# \"staging\" if \"staging\" in AUTOTRAIN_BACKEND_API else \"prod\"\n# )\n# evaluation_log[\"payload\"] = project_payload\n# evaluation_log[\"project_creation_response\"] = project_json_resp\n# evaluation_log[\"dataset_creation_response\"] = data_json_resp\n# evaluation_log[\"autotrain_job_response\"] = train_json_resp\n# commit_evaluation_log(evaluation_log, hf_access_token=HF_TOKEN)\n# else:\n# st.error(\"\ud83d\ude48 Oh no, there was an error submitting your evaluation job!\")\n# else:\n# st.warning(\"\u26a0\ufe0f No models left to evaluate! Please select other models and try again.\")\n", "requirements.txt": "huggingface_hub>=0.11\npython-dotenv\nstreamlit==1.10.0\ndatasets\nevaluate\njsonlines\ntyper\n# Dataset specific deps\npy7zr<0.19\nopenpyxl<3.1\n# Dirty bug from Google\nprotobuf<=3.20.1\n# Bug from Streamlit\naltair<5", ".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 003006a8fd779bf904dce8d7fe97b8b999d7f49e Hamza Amin <[email protected]> 1727369274 +0500\tclone: from https://github.com/huggingface/model-evaluator.git\n", ".git\\refs\\heads\\main": "003006a8fd779bf904dce8d7fe97b8b999d7f49e\n"} | null |
model_card | {"type": "directory", "name": "model_card", "children": [{"type": "file", "name": "demo.README.md"}, {"type": "file", "name": "examples.md"}, {"type": "file", "name": "LICENSE"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "template.README.md"}]} | # DEPRECATED model_card templates
Model card metadata documentation and specifications moved to https://github.com/huggingface/huggingface_hub/
The canonical documentation about model cards is now located at https://huggingface.co/docs/hub/model-repos and you can open a PR to improve the docs in the same repository https://github.com/huggingface/huggingface_hub/tree/main/docs/hub
You can also find a spec of the metadata at https://github.com/huggingface/huggingface_hub/blob/main/README.md.
| {".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n"} | null |
Mongoku | {"type": "directory", "name": "Mongoku", "children": [{"type": "file", "name": ".dockerignore"}, {"type": "directory", "name": ".vscode", "children": [{"type": "file", "name": "launch.json"}]}, {"type": "directory", "name": "app", "children": [{"type": "file", "name": ".editorconfig"}, {"type": "file", "name": "angular.json"}, {"type": "file", "name": "package-lock.json"}, {"type": "file", "name": "package.json"}, {"type": "directory", "name": "src", "children": [{"type": "directory", "name": "app", "children": [{"type": "file", "name": "app-routing.module.ts"}, {"type": "file", "name": "app.component.html"}, {"type": "file", "name": "app.component.scss"}, {"type": "file", "name": "app.component.ts"}, {"type": "file", "name": "app.module.ts"}, {"type": "directory", "name": "components", "children": [{"type": "file", "name": "components.module.ts"}, {"type": "directory", "name": "notifications", "children": [{"type": "file", "name": "notifications.component.html"}, {"type": "file", "name": "notifications.component.scss"}, {"type": "file", "name": "notifications.component.ts"}]}, {"type": "directory", "name": "panel", "children": [{"type": "file", "name": "panel.component.html"}, {"type": "file", "name": "panel.component.scss"}, {"type": "file", "name": "panel.component.ts"}]}, {"type": "directory", "name": "pretty-json", "children": [{"type": "file", "name": "pretty-json.component.html"}, {"type": "file", "name": "pretty-json.component.scss"}, {"type": "file", "name": "pretty-json.component.ts"}]}, {"type": "directory", "name": "search-box", "children": [{"type": "file", "name": "search-box.component.html"}, {"type": "file", "name": "search-box.component.scss"}, {"type": "file", "name": "search-box.component.ts"}]}]}, {"type": "directory", "name": "filters", "children": [{"type": "file", "name": "bytes.pipe.ts"}, {"type": "file", "name": "filters.module.ts"}, {"type": "file", "name": "number.pipe.ts"}, {"type": "file", "name": "server-name.pipe.ts"}]}, {"type": "directory", "name": "pages", "children": [{"type": "directory", "name": "collections", "children": [{"type": "file", "name": "collections.component.html"}, {"type": "file", "name": "collections.component.scss"}, {"type": "file", "name": "collections.component.ts"}]}, {"type": "directory", "name": "databases", "children": [{"type": "file", "name": "databases.component.html"}, {"type": "file", "name": "databases.component.scss"}, {"type": "file", "name": "databases.component.ts"}]}, {"type": "directory", "name": "document", "children": [{"type": "file", "name": "document.component.html"}, {"type": "file", "name": "document.component.scss"}, {"type": "file", "name": "document.component.ts"}]}, {"type": "directory", "name": "explore", "children": [{"type": "file", "name": "explore.component.html"}, {"type": "file", "name": "explore.component.scss"}, {"type": "file", "name": "explore.component.ts"}]}, {"type": "file", "name": "pages.module.ts"}, {"type": "directory", "name": "servers", "children": [{"type": "file", "name": "servers.component.html"}, {"type": "file", "name": "servers.component.scss"}, {"type": "file", "name": "servers.component.ts"}]}]}, {"type": "directory", "name": "services", "children": [{"type": "file", "name": "json-parser.service.ts"}, {"type": "file", "name": "mongo-db.service.ts"}, {"type": "file", "name": "notifications.service.ts"}, {"type": "file", "name": "services.module.ts"}]}]}, {"type": "directory", "name": "assets", "children": []}, {"type": "directory", "name": "environments", "children": [{"type": "file", "name": "environment.prod.ts"}, {"type": "file", "name": "environment.ts"}]}, {"type": "file", "name": "index.html"}, {"type": "file", "name": "main.ts"}, {"type": "file", "name": "polyfills.ts"}, {"type": "directory", "name": "sass", "children": [{"type": "directory", "name": "themes", "children": [{"type": "file", "name": "codemirror.scss"}, {"type": "file", "name": "dark-default.scss"}, {"type": "file", "name": "light.scss"}]}, {"type": "file", "name": "_mixins.scss"}]}, {"type": "file", "name": "styles.scss"}, {"type": "file", "name": "tsconfig.app.json"}, {"type": "file", "name": "typings.d.ts"}]}, {"type": "file", "name": "tsconfig.json"}, {"type": "file", "name": "tslint.json"}]}, {"type": "file", "name": "cli.ts"}, {"type": "file", "name": "Dockerfile"}, {"type": "directory", "name": "lib", "children": [{"type": "file", "name": "Collection.ts"}, {"type": "file", "name": "Database.ts"}, {"type": "file", "name": "Factory.ts"}, {"type": "file", "name": "HostsManager.ts"}, {"type": "file", "name": "JsonEncoder.ts"}, {"type": "file", "name": "MongoManager.ts"}, {"type": "file", "name": "ReadOnlyMiddleware.ts"}, {"type": "file", "name": "Server.ts"}, {"type": "file", "name": "Utils.ts"}]}, {"type": "file", "name": "LICENSE"}, {"type": "file", "name": "package-lock.json"}, {"type": "file", "name": "package.json"}, {"type": "directory", "name": "pm2", "children": [{"type": "file", "name": "development.json"}]}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "routes", "children": [{"type": "file", "name": "api.ts"}]}, {"type": "file", "name": "run.sh"}, {"type": "file", "name": "server.ts"}, {"type": "file", "name": "tsconfig.json"}]} | # Mongoku
MongoDB client for the web. Query your data directly from your browser. You can host it locally,
or anywhere else, for you and your team.
It scales with your data (at Hugging Face we use it on a 1TB+ cluster) and is blazing fast for all
operations, including sort/skip/limit. Built on TypeScript/Node.js/Angular.
### Demo

### Install & Run
This is the easy and recommended way of installing and running Mongoku.
```
# Install
npm install -g mongoku
# Run from your current terminal
mongoku start
```
You can also run Mongoku as a daemon, using either [PM2](https://github.com/Unitech/pm2) or
[Forever](https://github.com/foreverjs/forever).
```
mongoku start --pm2
# or
mongoku start --forever
```
### Docker
#### Using the Docker HUB image
```
docker run -d --name mongoku -p 3100:3100 huggingface/mongoku
# Run with customized default hosts
docker run -d --name mongoku -p 3100:3100 --env MONGOKU_DEFAULT_HOST="mongodb://user:[email protected]:8888" huggingface/mongoku
```
#### Build your own image
If you want to build your own docker image, just clone this repository and run the following:
```
# Build
docker build -t yournamehere/mongoku .
# Run
docker run -d --name mongoku -p 3100:3100 yournamehere/mongoku
```
### Manual Build
If you want to manually build and run mongoku, just clone this repository and run the following:
```bash
# Install the angular cli if you don't have it already
npm install -g typescript @angular/cli
npm install
# Build the front
cd app
npm install
ng build
# And the back
cd ..
tsc
# Run
node dist/server.js
```
### Configuration
You can also specify a few things using environment variables:
```
# Use some customized default hosts (Default = localhost:27017)
MONGOKU_DEFAULT_HOST="mongodb://user:password@localhost:27017;localhost:27017"
# Use another port. (Default = 3100)
MONGOKU_SERVER_PORT=8000
# Use a specific file to store hosts (Default = $HOME/.mongoku.db)
MONGOKU_DATABASE_FILE="/tmp/mongoku.db"
# Timeout before falling back to estimated documents count in ms (Default = 5000)
MONGOKU_COUNT_TIMEOUT=1000
# Read-only mode
MONGOKU_READ_ONLY_MODE=true
```
| {"Dockerfile": "FROM node:18\n\nENV UID=991 GID=991\n\nENV MONGOKU_DEFAULT_HOST=\"mongodb://localhost:27017\"\nENV MONGOKU_SERVER_PORT=3100\nENV MONGOKU_DATABASE_FILE=\"/tmp/mongoku.db\"\nENV MONGOKU_COUNT_TIMEOUT=5000\nARG READ_ONLY=false\nENV MONGOKU_READ_ONLY_MODE=$READ_ONLY\n\nRUN mkdir -p /mongoku\nWORKDIR /mongoku\n\nCOPY ./ /mongoku\n\nRUN npm install -g [email protected] @angular/cli \\\n && npm ci \\\n && cd app \\\n && npm ci \\\n && ng build --configuration production \\\n && cd .. \\\n && tsc\n\nEXPOSE 3100\n\nLABEL description=\"MongoDB client for the web. Query your data directly from your browser. You can host it locally, or anywhere else, for you and your team.\"\n\nENTRYPOINT node dist/server.js\n", "package.json": "{\n \"name\": \"mongoku\",\n \"version\": \"1.3.0\",\n \"license\": \"MIT\",\n \"author\": \"Anthony Moi <[email protected]>\",\n \"keywords\": [\n \"MongoDB\",\n \"administration\",\n \"explore\",\n \"query\"\n ],\n \"repository\": {\n \"type\": \"git\",\n \"url\": \"https://github.com/huggingface/Mongoku.git\"\n },\n \"dependencies\": {\n \"@aws-sdk/credential-providers\": \"^3.592.0\",\n \"aws4\": \"^1.13.0\",\n \"body-parser\": \"^1.19.1\",\n \"chalk\": \"^2.4.2\",\n \"commander\": \"^8.3.0\",\n \"express\": \"^4.17.2\",\n \"figlet\": \"^1.5.2\",\n \"mongodb\": \"^5.9.2\",\n \"nedb\": \"^1.8.0\"\n },\n \"devDependencies\": {\n \"@types/express\": \"^4.17.13\",\n \"@types/figlet\": \"^1.5.4\",\n \"@types/mongodb\": \"^4.0.7\",\n \"@types/nedb\": \"^1.8.12\"\n },\n \"main\": \"./dist/server.js\",\n \"scripts\": {\n \"debug-server\": \"npx tsc -w & npx nodemon --inspect=9017 ./dist/server.js\"\n },\n \"bin\": {\n \"mongoku\": \"./dist/cli.js\"\n },\n \"files\": [\n \"/dist\"\n ]\n}\n", ".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", "app\\package.json": "{\n \"name\": \"mongoku-app\",\n \"version\": \"0.0.1\",\n \"license\": \"MIT\",\n \"scripts\": {\n \"ng\": \"ng\",\n \"start\": \"ng serve\",\n \"build\": \"ng build --configuration production\",\n \"test\": \"ng test\",\n \"lint\": \"ng lint\",\n \"e2e\": \"ng e2e\"\n },\n \"private\": true,\n \"dependencies\": {\n \"@angular/animations\": \"^13.1.1\",\n \"@angular/common\": \"^13.1.1\",\n \"@angular/compiler\": \"^13.1.1\",\n \"@angular/core\": \"^13.1.1\",\n \"@angular/forms\": \"^13.1.1\",\n \"@angular/platform-browser\": \"^13.1.1\",\n \"@angular/platform-browser-dynamic\": \"^13.1.1\",\n \"@angular/router\": \"^13.1.1\",\n \"@ctrl/ngx-codemirror\": \"^5.1.1\",\n \"@ng-bootstrap/ng-bootstrap\": \"^11.0.0\",\n \"@types/esprima\": \"^4.0.3\",\n \"bootstrap\": \"4.1.3\",\n \"codemirror\": \"^5.65.0\",\n \"core-js\": \"^3.20.2\",\n \"esprima\": \"^4.0.1\",\n \"node-sass\": \"^7.0.1\",\n \"rxjs\": \"^7.5.1\",\n \"tslib\": \"^2.3.1\",\n \"zone.js\": \"^0.11.4\"\n },\n \"devDependencies\": {\n \"@angular-devkit/build-angular\": \"^13.1.2\",\n \"@angular/cli\": \"^13.1.2\",\n \"@angular/compiler-cli\": \"^13.1.1\",\n \"@angular/language-service\": \"^13.1.1\",\n \"@types/jasmine\": \"^3.10.3\",\n \"@types/jasminewd2\": \"^2.0.10\",\n \"codelyzer\": \"^6.0.2\",\n \"jasmine-core\": \"^4.0.0\",\n \"jasmine-spec-reporter\": \"^7.0.0\",\n \"karma\": \"^6.3.10\",\n \"karma-chrome-launcher\": \"^3.1.0\",\n \"karma-coverage-istanbul-reporter\": \"^3.0.3\",\n \"karma-jasmine\": \"^4.0.1\",\n \"karma-jasmine-html-reporter\": \"^1.7.0\",\n \"protractor\": \"^7.0.0\",\n \"ts-node\": \"^10.4.0\",\n \"tslint\": \"^6.1.3\",\n \"typescript\": \"^4.5.4\"\n }\n}\n", "app\\src\\index.html": "<!doctype html>\n<html lang=\"en\">\n<head>\n <meta charset=\"utf-8\">\n <title>Mongoku</title>\n <base href=\"/\">\n\n <meta name=\"viewport\" content=\"width=device-width, initial-scale=1\">\n <link rel=\"icon\" type=\"image/x-icon\" href=\"favicon.ico\">\n</head>\n<body>\n <content></content>\n</body>\n</html>\n", "app\\src\\main.ts": "import { enableProdMode } from '@angular/core';\nimport { platformBrowserDynamic } from '@angular/platform-browser-dynamic';\n\nimport { AppModule } from './app/app.module';\nimport { environment } from './environments/environment';\n\nif (environment.production) {\n enableProdMode();\n}\n\nplatformBrowserDynamic().bootstrapModule(AppModule)\n .catch(err => console.log(err));\n", "app\\src\\tsconfig.app.json": "{\n \"extends\": \"../tsconfig.json\",\n \"compilerOptions\": {\n \"outDir\": \"../out-tsc/app\",\n \"baseUrl\": \"./\",\n \"module\": \"es2015\",\n \"types\": []\n },\n \"exclude\": [\n \"test.ts\",\n \"**/*.spec.ts\"\n ]\n}\n", "app\\src\\app\\app-routing.module.ts": "import { NgModule } from '@angular/core';\nimport { RouterModule, Routes } from '@angular/router';\n\nimport { ServersComponent } from './pages/servers/servers.component';\nimport { DatabasesComponent } from './pages/databases/databases.component';\nimport { CollectionsComponent } from './pages/collections/collections.component';\nimport { ExploreComponent } from './pages/explore/explore.component';\nimport { DocumentComponent } from './pages/document/document.component';\n\nconst routes: Routes = [\n { path: 'servers/:server/databases/:database/collections/:collection/documents/:document', component: DocumentComponent },\n { path: 'servers/:server/databases/:database/collections/:collection', component: ExploreComponent },\n { path: 'servers/:server/databases/:database/collections', component: CollectionsComponent },\n { path: 'servers/:server/databases/:database', redirectTo: \"/servers/:server/databases/:database/collections\" },\n { path: 'servers/:server/databases', component: DatabasesComponent },\n { path: 'servers/:server', redirectTo: \"/servers/:server/databases\" },\n { path: 'servers', component: ServersComponent },\n { path: '', redirectTo: \"/servers\", pathMatch: 'full' }\n];\n\n@NgModule({\n imports: [ RouterModule.forRoot(routes, { enableTracing: false }) ],\n exports: [ RouterModule ]\n})\nexport class AppRoutingModule {}", "app\\src\\app\\app.component.html": "<nav class=\"navbar navbar-expand-lg navbar-dark bg-dark\">\n <a class=\"navbar-brand\" routerLink=\"/\">Mongoku</a>\n <nav aria-label=\"breadcrumb\">\n <ol class=\"breadcrumb bg-dark\">\n <li *ngFor=\"let b of breadcrumbs\" class=\"breadcrumb-item\" [class.active]=\"b.active\">\n <a *ngIf=\"b.href\" [href]=\"b.href\">{{ b.name }}</a>\n <span *ngIf=\"!b.href\">{{ b.name }}</span>\n </li>\n </ol>\n </nav>\n <button class=\"ml-auto btn btn-default btn-sm\" (click)=\"switchTheme(otherTheme)\">\n Switch to {{ otherTheme }}\n </button>\n</nav>\n\n<notifications></notifications>\n\n<div class=\"container-fluid\">\n <div class=\"row\">\n <div class=\"col-md-10 offset-md-1 col-xs-12 content\">\n <router-outlet></router-outlet>\n </div>\n </div>\n</div>\n", "app\\src\\app\\app.component.scss": ".navbar .breadcrumb {\n\tmargin-bottom: 0;\n\n\ta {\n\t\ttext-decoration: none;\n\t\tcolor: var(--text);\n\t}\n\n\t.breadcrumb-item.active {\n\t\tcolor: var(--text-darker);\n\t}\n}\n\n.navbar-brand {\n\tcolor: var(--text);\n\n\t&:hover {\n\t\tcolor: var(--text-lighter);\n\t}\n}\n\n.container-fluid .content {\n\tpadding-top: 25px;\n\tpadding-bottom: 150px;\n}\n", "app\\src\\app\\app.component.ts": "import { Component, AfterViewChecked, Renderer2, OnInit } from '@angular/core';\nimport { Router, RoutesRecognized } from '@angular/router';\n\ninterface Breadcrumb {\n href?: string;\n active: boolean;\n name: string;\n};\n\n@Component({\n selector: 'content',\n templateUrl: './app.component.html',\n styleUrls: ['./app.component.scss']\n})\nexport class AppComponent implements AfterViewChecked, OnInit {\n breadcrumbs: Breadcrumb[] = [];\n\n constructor(private route: Router, private renderer: Renderer2) { }\n\n ngOnInit() {\n const currentTheme = localStorage.getItem(\"theme\");\n if (currentTheme == this.otherTheme) {\n this.switchTheme(this.otherTheme);\n }\n }\n\n ngAfterViewChecked() {\n this.route.events.subscribe((data) => {\n if (data instanceof RoutesRecognized) {\n const params = data.state.root.firstChild.params;\n const breadcrumbs: Breadcrumb[] = [];\n\n if (params.server) {\n const server = params.server;\n breadcrumbs.push({\n name: server,\n href: `servers/${server}/databases`,\n active: false\n });\n\n if (params.database) {\n const database = params.database;\n breadcrumbs.push({\n name: database,\n href: `servers/${server}/databases/${database}/collections`,\n active: false\n });\n\n if (params.collection) {\n const collection = params.collection;\n breadcrumbs.push({\n name: collection,\n href: `servers/${server}/databases/${database}/collections/${collection}`,\n active: false\n });\n\n if (params.document) {\n const document = params.document;\n breadcrumbs.push({\n name: document,\n active: false\n });\n }\n }\n }\n }\n\n if (breadcrumbs.length > 0) {\n breadcrumbs[breadcrumbs.length - 1].href = undefined;\n breadcrumbs[breadcrumbs.length - 1].active = true;\n }\n\n this.breadcrumbs = breadcrumbs;\n }\n });\n }\n\n get otherTheme() {\n const isLight = document.body.classList.contains(\"theme-light\");\n return isLight\n ? \"Dark\"\n : \"Light\";\n }\n\n switchTheme(theme: string) {\n if (theme === \"Dark\") {\n this.renderer.removeClass(document.body, \"theme-light\");\n } else {\n this.renderer.addClass(document.body, \"theme-light\");\n }\n localStorage.setItem(\"theme\", theme);\n }\n}\n", "app\\src\\app\\app.module.ts": "import { BrowserModule } from '@angular/platform-browser';\nimport { NgModule } from '@angular/core';\nimport { NgbModule } from '@ng-bootstrap/ng-bootstrap';\n\nimport { AppComponent } from './app.component';\nimport { AppRoutingModule } from './app-routing.module';\nimport { PagesModule } from './pages/pages.module';\nimport { ComponentsModule } from './components/components.module';\nimport { FiltersModule } from './filters/filters.module';\nimport { ServicesModule } from './services/services.module';\n\n@NgModule({\n declarations: [\n AppComponent\n ],\n imports: [\n BrowserModule,\n NgbModule,\n AppRoutingModule,\n PagesModule,\n ComponentsModule,\n FiltersModule,\n ServicesModule\n ],\n providers: [],\n bootstrap: [\n AppComponent\n ]\n})\nexport class AppModule { }\n"} | null |
ms-build-mi300 | {"type": "directory", "name": "ms-build-mi300", "children": [{"type": "file", "name": "deepspeed_zero3.yaml"}, {"type": "file", "name": "local_chatbot.ipynb"}, {"type": "file", "name": "peft_fine_tune.py"}, {"type": "file", "name": "README.md"}]} | # Table of content
1. [Deploying TGI on the VM](#deploying-tgi-on-the-vm)
1. [Options to try](#options-to-try)
1. [Quantization](#quantization)
2. [Tensor parallelism](#tensor-parallelism)
3. [Speculative decoding](#speculative-decoding)
4. [Customize HIP Graph, TunableOp warmup](#customize-hip-graph-tunableop-warmup)
5. [Deploy several models on a single GPU](#deploy-several-models-on-a-single-gpu)
6. [Grammar contrained generation](#grammar-contrained-generation)
7. [Benchmarking](#benchmarking)
8. [Vision-Language models (VLM)](#vision-language-models-vlm)
2. [Model fine-tuning](#model-fine-tuning-with-transformers-and-peft)
# Deploying TGI on the VM
Access the VM through SSH using any terminal application on your system.
- IMPORTANT: Replace `<placeholders>` in the command according to printed setup instructions.
```
ssh \
-L <300#>:localhost:<300#> \
-L <888#>:localhost:<888#> \
-L <786#>:localhost:<786#> \
buildusere@<azure-vm-ip-address>
```
**Important: there are three ports to forward through ssh:**
* `300x`: TGI port.
* `888x`: jupyter notebook port.
* `786x`: gradio port.
From within the VM, please use the following Docker run command while taking note to first set the following variables according to your printout:
- For `--device=/dev/dri/renderD###` set `GPUID`
- For `--name <your-name>_tgi` set `NAME` to help identify your Docker container
```
GPUID=###
NAME=your_name
docker run --name ${NAME}_tgi --rm -it --cap-add=SYS_PTRACE --security-opt seccomp=unconfined \
--device=/dev/kfd --device=/dev/dri/renderD$GPUID --group-add video --ipc=host --shm-size 256g \
--net host -v $(pwd)/hf/hf_cache:/data \
--entrypoint "/bin/bash" \
--env PYTORCH_TUNABLEOP_ENABLED=0 \
--env HUGGING_FACE_HUB_TOKEN=$HF_READ_TOKEN \
ghcr.io/huggingface/text-generation-inference:sha-293b8125-rocm
```
From within the container in interactive mode, make sure that you have one MI300 visible:
```
rocm-smi
```
giving
```
================================================== ROCm System Management Interface ==================================================
============================================================ Concise Info ============================================================
Device Node IDs Temp Power Partitions SCLK MCLK Fan Perf PwrCap VRAM% GPU%
(DID, GUID) (Junction) (Socket) (Mem, Compute, ID)
======================================================================================================================================
0 2 0x74b5, 23674 35.0°C 132.0W NPS1, N/A, 0 132Mhz 900Mhz 0% perf_determinism 750.0W 0% 0%
======================================================================================================================================
======================================================== End of ROCm SMI Log =========================================================
```
Then, from within the container in interactive mode, TGI can be launched with:
```
text-generation-launcher \
--model-id meta-llama/Meta-Llama-3-8B-Instruct \
--num-shard 1 --port ####
```
with **the port being the one indicated on your individual instruction sheet**.
You should see a log as follow:
```
2024-05-20T17:32:40.790474Z INFO text_generation_launcher: Default `max_input_tokens` to 4095
2024-05-20T17:32:40.790512Z INFO text_generation_launcher: Default `max_total_tokens` to 4096
2024-05-20T17:32:40.790516Z INFO text_generation_launcher: Default `max_batch_prefill_tokens` to 4145
2024-05-20T17:32:40.790521Z INFO text_generation_launcher: Using default cuda graphs [1, 2, 4, 8, 16, 32]
2024-05-20T17:32:40.790658Z INFO download: text_generation_launcher: Starting download process.
2024-05-20T17:32:43.060786Z INFO text_generation_launcher: Files are already present on the host. Skipping download.
2024-05-20T17:32:43.794782Z INFO download: text_generation_launcher: Successfully downloaded weights.
2024-05-20T17:32:43.795177Z INFO shard-manager: text_generation_launcher: Starting shard rank=0
2024-05-20T17:32:46.044820Z INFO text_generation_launcher: ROCm: using Flash Attention 2 Composable Kernel implementation.
2024-05-20T17:32:46.211469Z WARN text_generation_launcher: Could not import Mamba: No module named 'mamba_ssm'
2024-05-20T17:32:49.436913Z INFO text_generation_launcher: Server started at unix:///tmp/text-generation-server-0
2024-05-20T17:32:49.502406Z INFO shard-manager: text_generation_launcher: Shard ready in 5.706223525s rank=0
2024-05-20T17:32:49.600606Z INFO text_generation_launcher: Starting Webserver
2024-05-20T17:32:49.614745Z INFO text_generation_router: router/src/main.rs:195: Using the Hugging Face API
2024-05-20T17:32:49.614784Z INFO hf_hub: /usr/local/cargo/registry/src/index.crates.io-6f17d22bba15001f/hf-hub-0.3.2/src/lib.rs:55: Token file not found "/root/.cache/huggingface/token"
2024-05-20T17:32:49.871020Z INFO text_generation_router: router/src/main.rs:474: Serving revision c4a54320a52ed5f88b7a2f84496903ea4ff07b45 of model meta-llama/Meta-Llama-3-8B-Instruct
2024-05-20T17:32:50.068073Z INFO text_generation_router: router/src/main.rs:289: Using config Some(Llama)
2024-05-20T17:32:50.071589Z INFO text_generation_router: router/src/main.rs:317: Warming up model
2024-05-20T17:32:50.592906Z INFO text_generation_launcher: PyTorch TunableOp (https://github.com/fxmarty/pytorch/tree/2.3-patched/aten/src/ATen/cuda/tunable) is enabled. The warmup may take several minutes, picking the ROCm optimal matrix multiplication kernel for the target lengths 1, 2, 4, 8, 16, 32, with typical 5-8% latency improvement for small sequence lengths. The picked GEMMs are saved in the file /data/tunableop_meta-llama-Meta-Llama-3-8B-Instruct_tp1_rank0.csv. To disable TunableOp, please launch TGI with `PYTORCH_TUNABLEOP_ENABLED=0`.
2024-05-20T17:32:50.593041Z INFO text_generation_launcher: The file /data/tunableop_meta-llama-Meta-Llama-3-8B-Instruct_tp1_rank0.csv already exists and will be reused.
2024-05-20T17:32:50.593225Z INFO text_generation_launcher: Warming up TunableOp for seqlen=1
2024-05-20T17:32:50.694955Z INFO text_generation_launcher: Warming up TunableOp for seqlen=2
2024-05-20T17:32:50.707031Z INFO text_generation_launcher: Warming up TunableOp for seqlen=4
2024-05-20T17:32:50.719015Z INFO text_generation_launcher: Warming up TunableOp for seqlen=8
2024-05-20T17:32:50.731009Z INFO text_generation_launcher: Warming up TunableOp for seqlen=16
2024-05-20T17:32:50.742969Z INFO text_generation_launcher: Warming up TunableOp for seqlen=32
2024-05-20T17:32:50.755226Z INFO text_generation_launcher: Cuda Graphs are enabled for sizes [1, 2, 4, 8, 16, 32]
2024-05-20T17:32:51.276651Z INFO text_generation_router: router/src/main.rs:354: Setting max batch total tokens to 1346240
2024-05-20T17:32:51.276675Z INFO text_generation_router: router/src/main.rs:355: Connected
2024-05-20T17:32:51.276679Z WARN text_generation_router: router/src/main.rs:369: Invalid hostname, defaulting to 0.0.0.0
```
Now, in an other terminal, ssh again into the VM **with your individual TGI, jupyter & gradio ports**:
```
ssh \
-L <300#>:localhost:<300#> \
-L <888#>:localhost:<888#> \
-L <786#>:localhost:<786#> \
buildusere@<azure-vm-ip-address>
```
Then, from within the VM, launch the jupyter container as follow, replacing `<your-name>` in the command below with your name to help identify your Docker container:
- The NAME variable will once again be used to help identify your Docker container.
```
NAME=your_name
docker run -it -u root --rm --entrypoint /bin/bash --net host \
--env HUGGING_FACE_HUB_TOKEN=$HF_READ_TOKEN \
--name ${NAME}_jnb \
jupyter/base-notebook
```
Once inside this 2nd Docker container clone the repo for this workshop
```
apt update
apt install git
git clone https://github.com/huggingface/ms-build-mi300.git
```
Finally, launch the Notebooks server while taking note to replace the `<888#>` placeholder according to your printout (should be one of 8881, 8882, ..., 8888).
- Take note of the URL supplied so can connect to Notebooks after.
```
jupyter-notebook --allow-root --port <888#>
```
You should see output that ends with something similar to:
```
[I 2024-05-19 00:38:53.523 ServerApp] Jupyter Server 2.8.0 is running at:
[I 2024-05-19 00:38:53.523 ServerApp] http://build-mi300x-vm1:8882/tree?token=9cffeac33839ab1e89e81f57dfe3be1739f4fd98729da0ad
[I 2024-05-19 00:38:53.523 ServerApp] http://127.0.0.1:8882/tree?token=9cffeac33839ab1e89e81f57dfe3be1739f4fd98729da0ad
[I 2024-05-19 00:38:53.523 ServerApp] Use Control-C to stop this server and shut down all kernels (twice to skip confirmation).
[C 2024-05-19 00:38:53.525 ServerApp]
To access the server, open this file in a browser:
file:///home/jovyan/.local/share/jupyter/runtime/jpserver-121-open.html
Or copy and paste one of these URLs:
http://build-mi300x-vm1:8882/tree?token=9cffeac33839ab1e89e81f57dfe3be1739f4fd98729da0ad
http://127.0.0.1:8882/tree?token=9cffeac33839ab1e89e81f57dfe3be1739f4fd98729da0ad
```
Now `local_chatbot.ipynb` can be used to query the model from your system through the SSH tunnel! To do so...
- Just copy and paste the provided URL into your browser (see ouput from Notebooks server)
- The format of the URL is as such: `http://127.0.0.1:####/tree?token=<unique-value-from-output>`
# Options to try
TGI's `text-generation-launcher` has many options, you can explore `text-generation-launcher --help`.
TGI's documentation can also be used as a reference: https://huggingface.co/docs/text-generation-inference
For the workshop, a few models have already been cached on the machines, and we recommend to use them:
* `meta-llama/Meta-Llama-3-8B-Instruct`
* `meta-llama/Meta-Llama-3-70B-Instruct`
* `TheBloke/Llama-2-70B-Chat-GPTQ` (GPTQ model)
* `casperhansen/llama-3-70b-instruct-awq` (AWQ model)
* `mistralai/Mistral-7B-Instruct-v0.2`
* `bigcode/starcoder2-15b-instruct-v0.1`
* `text-generation-inference/Mistral-7B-Instruct-v0.2-medusa` (with Medusa speculative decoding)
## Quantization
TGI can be used with quantized models (GPTQ, AWQ) with the option `--quantize gptq` for [quantized models](https://huggingface.co/docs/text-generation-inference/conceptual/quantization) (beware: needs to use a GPTQ model (e.g. one from https://hf.co/models?search=gptq, for example `TechxGenus/Meta-Llama-3-70B-Instruct-GPTQ`)
Example, adding to the docker command:
```
text-generation-launcher --model-id TheBloke/Llama-2-70B-Chat-GPTQ --quantize gptq --port #####
```
or
```
text-generation-launcher --model-id casperhansen/llama-3-70b-instruct-awq --quantize awq --port #####
```
## Tensor parallelism
Here we use only `--num-shard 1`, as only one GPU is available per person. But on a full node, one may use `--num-shard X` to decide how many GPUs are best to deploy a model given for example latency constraints.
Read more about tensor parallelism in TGI: https://huggingface.co/docs/text-generation-inference/conceptual/tensor_parallelism
## Speculative decoding
TGI supports **n-gram** speculation, as well as [**Medusa**](https://arxiv.org/pdf/2401.10774) speculative decoding.
In the launcher, the argument `--speculate X` allows to use speculative decoding. This argument specifies the number of input_ids to speculate on if using a medusa model, or using n-gram speculation.
Example, adding to the docker command:
```
text-generation-launcher --model-id mistralai/Mistral-7B-Instruct-v0.2 --speculate 3 --port #####
```
or with Medusa:
```
text-generation-launcher --model-id text-generation-inference/Mistral-7B-Instruct-v0.2-medusa --speculate 3 --port #####
```
(see its config: https://huggingface.co/text-generation-inference/Mistral-7B-Instruct-v0.2-medusa/blob/main/config.json)
Read more at: https://huggingface.co/docs/text-generation-inference/conceptual/speculation
Medusa implementation: https://github.com/huggingface/text-generation-inference/blob/main/server/text_generation_server/layers/medusa.py
## Customize HIP Graph, TunableOp warmup
[HIP Graphs](https://rocm.docs.amd.com/projects/HIP/en/docs-6.1.1/how-to/programming_manual.html#hip-graph) and [TunableOp](https://huggingface.co/docs/text-generation-inference/installation_amd#tunableop) are used in the warmup step to statically capture compute graphs in the decoding, and to select the best performing GEMM available implementation (from rocBLAS, hipBLASlt).
The sequence lengths for which HIP Graphs are captured can be specified with e.g. `--cuda-graphs 1,2,4,8`. `--cuda-graphs 0` can be used to disable HIP Graphs.
If necessary, TunableOp can be disabled with by passing `--env PYTORCH_TUNABLEOP_ENABLED="0"` when launcher TGI’s docker container.
## Deploy several models on a single GPU
Several models can be deployed on a single GPU. By default TGI reserves all the free GPU memory to pre-allocate the KV cache.
One can use the option `--cuda-memory-fraction` to limit the CUDA available memory used by TGI. Example: `--cuda-memory-fraction 0.5`
This is useful to deploy several different models on a single GPU.
## Vision-Language models (VLM)
Refer to: https://huggingface.co/docs/text-generation-inference/basic_tutorials/visual_language_models
## Grammar contrained generation
* [Grammar contrained generation](https://huggingface.co/docs/text-generation-inference/basic_tutorials/using_guidance#guidance): e.g. to contraint the generation to a specific format (JSON). Reference: [Guidance conceptual guide](https://huggingface.co/docs/text-generation-inference/conceptual/guidance).
```
curl localhost:3000/generate \
-X POST \
-H 'Content-Type: application/json' \
-d '{
"inputs": "I saw a puppy a cat and a raccoon during my bike ride in the park",
"parameters": {
"repetition_penalty": 1.3,
"grammar": {
"type": "json",
"value": {
"properties": {
"location": {
"type": "string"
},
"activity": {
"type": "string"
},
"animals_seen": {
"type": "integer",
"minimum": 1,
"maximum": 5
},
"animals": {
"type": "array",
"items": {
"type": "string"
}
}
},
"required": ["location", "activity", "animals_seen", "animals"]
}
}
}
}'
```
## Benchmarking
Text Generation Inference comes with its own benchmarking tool, `text-generation-benchmark`.
Usage: `text-generation-benchmark --help`
Example:
1. Launch a container with `--model-id meta-llama/Meta-Llama-3-8B-Instruct`
2. Open an other terminal in the container (`docker container ls` and then `docker exec -it container_name /bin/bash`
3. Then, run for example:
```
text-generation-benchmark --tokenizer-name meta-llama/Meta-Llama-3-8B-Instruct --sequence-length 2048 --decode-length 128 --warmups 2 --runs 10 -b 1 -b 2 -b 4 -b 8 -b 16 -b 32 -b 64
```
`text-generation-benchmark` can give results tables as:
| Parameter | Value |
|--------------------|--------------------------------------|
| Model | meta-llama/Meta-Llama-3-70B-Instruct |
| Sequence Length | 2048 |
| Decode Length | 128 |
| Top N Tokens | None |
| N Runs | 10 |
| Warmups | 2 |
| Temperature | None |
| Top K | None |
| Top P | None |
| Typical P | None |
| Repetition Penalty | None |
| Frequency Penalty | None |
| Watermark | false |
| Do Sample | false |
| Step | Batch Size | Average | Lowest | Highest | p50 | p90 | p99 |
|----------------|------------|------------|------------|------------|------------|------------|------------|
| Prefill | 1 | 345.72 ms | 342.55 ms | 348.42 ms | 345.88 ms | 348.42 ms | 348.42 ms |
| | 2 | 455.36 ms | 452.29 ms | 458.80 ms | 454.97 ms | 458.80 ms | 458.80 ms |
| | 4 | 673.80 ms | 666.73 ms | 678.06 ms | 675.55 ms | 678.06 ms | 678.06 ms |
| | 8 | 1179.98 ms | 1176.53 ms | 1185.13 ms | 1180.36 ms | 1185.13 ms | 1185.13 ms |
| | 16 | 2046.73 ms | 2036.32 ms | 2061.69 ms | 2045.36 ms | 2061.69 ms | 2061.69 ms |
| | 32 | 4313.01 ms | 4273.01 ms | 4603.97 ms | 4282.30 ms | 4603.97 ms | 4603.97 ms |
| Decode (token) | 1 | 12.38 ms | 12.02 ms | 15.06 ms | 12.08 ms | 12.12 ms | 12.12 ms |
| | 2 | 16.75 ms | 16.02 ms | 19.79 ms | 16.06 ms | 16.11 ms | 16.11 ms |
| | 4 | 17.57 ms | 16.28 ms | 19.94 ms | 18.84 ms | 16.34 ms | 16.34 ms |
| | 8 | 18.63 ms | 16.75 ms | 22.28 ms | 19.55 ms | 16.87 ms | 16.87 ms |
| | 16 | 21.83 ms | 18.94 ms | 25.53 ms | 21.99 ms | 21.98 ms | 21.98 ms |
| | 32 | 27.76 ms | 24.49 ms | 33.47 ms | 27.84 ms | 29.67 ms | 29.67 ms |
| Decode (total) | 1 | 1571.76 ms | 1526.99 ms | 1912.55 ms | 1534.09 ms | 1538.85 ms | 1538.85 ms |
| | 2 | 2127.04 ms | 2034.91 ms | 2513.82 ms | 2039.47 ms | 2046.08 ms | 2046.08 ms |
| | 4 | 2231.84 ms | 2067.17 ms | 2532.21 ms | 2393.08 ms | 2074.70 ms | 2074.70 ms |
| | 8 | 2366.38 ms | 2127.92 ms | 2829.20 ms | 2483.24 ms | 2142.88 ms | 2142.88 ms |
| | 16 | 2772.09 ms | 2405.33 ms | 3242.91 ms | 2792.36 ms | 2791.81 ms | 2791.81 ms |
| | 32 | 3525.13 ms | 3110.67 ms | 4251.15 ms | 3535.48 ms | 3767.61 ms | 3767.61 ms |
| Step | Batch Size | Average | Lowest | Highest |
|---------|------------|---------------------|--------------------|---------------------|
| Prefill | 1 | 2.89 tokens/secs | 2.87 tokens/secs | 2.92 tokens/secs |
| | 2 | 4.39 tokens/secs | 4.36 tokens/secs | 4.42 tokens/secs |
| | 4 | 5.94 tokens/secs | 5.90 tokens/secs | 6.00 tokens/secs |
| | 8 | 6.78 tokens/secs | 6.75 tokens/secs | 6.80 tokens/secs |
| | 16 | 7.82 tokens/secs | 7.76 tokens/secs | 7.86 tokens/secs |
| | 32 | 7.42 tokens/secs | 6.95 tokens/secs | 7.49 tokens/secs |
| Decode | 1 | 81.16 tokens/secs | 66.40 tokens/secs | 83.17 tokens/secs |
| | 2 | 120.14 tokens/secs | 101.04 tokens/secs | 124.82 tokens/secs |
| | 4 | 229.31 tokens/secs | 200.62 tokens/secs | 245.75 tokens/secs |
| | 8 | 433.91 tokens/secs | 359.11 tokens/secs | 477.46 tokens/secs |
| | 16 | 743.16 tokens/secs | 626.60 tokens/secs | 844.79 tokens/secs |
| | 32 | 1164.14 tokens/secs | 955.98 tokens/secs | 1306.47 tokens/secs |
## Vision-Language models (VLM)
Refer to: https://huggingface.co/docs/text-generation-inference/basic_tutorials/visual_language_models
# Model fine-tuning with Transformers and PEFT
Run TGI's container in interactive model, adding the following to `docker run`:
```
--entrypoint "/bin/bash" -v $(pwd)/ms-build-mi300:/ms-build-mi300
```
Please run:
```
pip install datasets==2.19.1 deepspeed==0.14.2 transformers==4.40.2 peft==0.10.0
apt update && apt install libaio-dev -y
```
and then:
```
HF_CACHE="/data" accelerate launch --config_file deepspeed_zero3.yaml peft_fine_tuning.py
```
| {".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 7e601094b27da30e846fcc0d98381b8ba4ee797a Hamza Amin <[email protected]> 1727369281 +0500\tclone: from https://github.com/huggingface/ms-build-mi300.git\n", ".git\\refs\\heads\\main": "7e601094b27da30e846fcc0d98381b8ba4ee797a\n"} | null |
naacl_transfer_learning_tutorial | {"type": "directory", "name": "naacl_transfer_learning_tutorial", "children": [{"type": "file", "name": "finetuning_model.py"}, {"type": "file", "name": "finetuning_train.py"}, {"type": "file", "name": "LICENCE"}, {"type": "file", "name": "pretraining_model.py"}, {"type": "file", "name": "pretraining_train.py"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "utils.py"}]} | # Code repository accompanying NAACL 2019 tutorial on "Transfer Learning in Natural Language Processing"
The tutorial was given on June 2 at NAACL 2019 in Minneapolis, MN, USA by [Sebastian Ruder](http://ruder.io/), [Matthew Peters](https://www.linkedin.com/in/petersmatthew), [Swabha Swayamdipta](http://www.cs.cmu.edu/~sswayamd/index.html) and [Thomas Wolf](http://thomwolf.io/).
Here is the [webpage](https://naacl2019.org/program/tutorials/) of NAACL tutorials for more information.
The slides for the tutorial can be found here: https://tinyurl.com/NAACLTransfer.
A Google Colab notebook with all the code for the tutorial can be found here: https://tinyurl.com/NAACLTransferColab.
The present repository can also be accessed with the following short url: https://tinyurl.com/NAACLTransferCode
## Abstract
The classic supervised machine learning paradigm is based on learning in isolation a single predictive model for a task using a single dataset. This approach requires a large number of training examples and performs best for well-defined and narrow tasks. Transfer learning refers to a set of methods that extend this approach by leveraging data from additional domains or tasks to train a model with better generalization properties.
Over the last two years, the field of Natural Language Processing (NLP) has witnessed the emergence of several transfer learning methods and architectures, which significantly improved upon the state-of-the-art on a wide range of NLP tasks.
These improvements together with the wide availability and ease of integration of these methods are reminiscent of the factors that led to the success of pretrained word embeddings and ImageNet pretraining in computer vision, and indicate that these methods will likely become a common tool in the NLP landscape as well as an important research direction.
We will present an overview of modern transfer learning methods in NLP, how models are pre-trained, what information the representations they learn capture, and review examples and case studies on how these models can be integrated and adapted in downstream NLP tasks.
## Overview
This codebase tries to present in the simplest and most compact way a few of the major Transfer Learning techniques, which have emerged over the past years. The code in this repository does not attempt to be state-of-the-art. However, effort has been made to achieve reasonable performance and with some modifications to be competitive with the current state of the art.
Special effort has been made to
- ensure the present code can be used as easily as possible, in particular by hosting pretrained models and datasets;
- keep the present codebase as compact and self-contained as possible to make it easy to manipulate and understand.
Currently the codebase comprises:
- [`pretraining_model.py`](./pretraining_model.py): a transformer model with a GPT-2-like architecture as the basic pretrained model;
- [`pretraining_train.py`](./pretraining_train.py): a pretraining script to train this model with a language modeling objective on a selection of large datasets (WikiText-103, SimpleBooks-92) using distributed training if available;
- [`finetuning_model.py`](./finetuning_model.py): several architectures based on the transformer model for fine-tuning (with a classification head on top, with adapters);
- [`finetuning_train.py`](./finetuning_train.py): a fine-tuning script to fine-tune these architectures on a classification task (IMDb).
## Installation
To use this codebase, simply clone the Github repository and install the requirements like this:
```bash
git clone https://github.com/huggingface/naacl_transfer_learning_tutorial
cd naacl_transfer_learning_tutorial
pip install -r requirements.txt
```
## Pre-training
To pre-train the transformer, run the `pretraining_train.py` script like this:
```bash
python ./pretraining_train.py
```
or using distributed training like this (for a 8 GPU server):
```bash
python -m torch.distributed.launch --nproc_per_node 8 ./pretraining_train.py
```
The pre-training script will:
- download `wikitext-103` for pre-training (default),
- instantiate a 50M parameters transformer model and train it for 50 epochs,
- log the experiements in Tensorboard and in a folder under `./runs`,
- save checkpoints in the log folder.
Pretraining to a validation perplexity of ~29 on WikiText-103 will take about 15h on 8 V100 GPUs (can be stopped earlier).
If you are interested in SOTA, there are a few reasons the validation perplexity is a bit higher than the equivalent Transformer-XL perplexity (around 24). The main reason is the use of an open vocabulary (sub-words for Bert tokenizer) instead of a closed vocabulary (see [this blog post by Sebastian Mielke](http://sjmielke.com/comparing-perplexities.htm) for some explanation)
Various pre-training options are available, you can list them with:
```bash
python ./pretraining_train.py --help
```
## Fine-tuning
To fine-tune the pre-trained transformer, run the `finetuning_train.py` script like this:
```bash
python ./finetuning_train.py --model_checkpoint PATH-TO-YOUR-PRETRAINED-MODEL-FOLDER
```
`PATH-TO-YOUR-PRETRAINED-MODEL-FOLDER` can be for instance `./runs/May17_17-47-12_my_big_server`
or using distributed training like this (for a 8 GPU server):
```bash
python -m torch.distributed.launch --nproc_per_node 8 ./finetuning_train.py --model_checkpoint PATH-TO-YOUR-PRETRAINED-MODEL-FOLDER
```
Various fine-tuning options are available, you can list them with:
```bash
python ./finetuning_train.py --help
```
| {"requirements.txt": "torch\npytorch-ignite\npytorch-pretrained-bert # for Bert tokenizer\ntensorboardX\ntensorflow # for tensorboard", ".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n"} | null |
neuralcoref-models | {"type": "directory", "name": "neuralcoref-models", "children": [{"type": "file", "name": "compatibility.json"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "shortcuts.json"}]} | # NeuralCoref models
✨ Models for the NeuralCoref coreference resolution module.
This repo is used to host the releases of models for Neuralcoref.
Please find more information on how to download, install and use the models [here](https://github.com/huggingface/neuralcoref).
| {".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n"} | null |
neuralcoref-viz | {"type": "directory", "name": "neuralcoref-viz", "children": [{"type": "directory", "name": ".vscode", "children": [{"type": "file", "name": "tasks.json"}]}, {"type": "directory", "name": "assets", "children": [{"type": "file", "name": "checkbox-off.svg"}, {"type": "file", "name": "checkbox-on.svg"}, {"type": "file", "name": "icon.svg"}, {"type": "file", "name": "icons.svg"}]}, {"type": "file", "name": "bower.json"}, {"type": "file", "name": "deploy.sh"}, {"type": "file", "name": "Gruntfile.js"}, {"type": "file", "name": "index.html"}, {"type": "directory", "name": "js-src", "children": [{"type": "file", "name": "Coref.ts"}, {"type": "file", "name": "Displacy.ts"}, {"type": "file", "name": "SvgArrow.ts"}, {"type": "file", "name": "zController.ts"}]}, {"type": "directory", "name": "less", "children": [{"type": "directory", "name": "mixins", "children": [{"type": "file", "name": "bfc.less"}, {"type": "file", "name": "clearfix.less"}, {"type": "file", "name": "size.less"}, {"type": "file", "name": "user-select.less"}]}, {"type": "file", "name": "style.less"}, {"type": "file", "name": "zDisplacy.less"}]}, {"type": "file", "name": "package-lock.json"}, {"type": "file", "name": "package.json"}, {"type": "file", "name": "tsconfig.json"}]} | {"index.html": "<!DOCTYPE html>\n<html>\n<head>\n\t<meta charset=\"utf-8\">\n\t<title>Neural Coreference \u2013 Hugging Face</title>\n\t<meta name=\"viewport\" content=\"width=device-width, initial-scale=1.0, user-scalable=no\">\n\t<link rel=\"stylesheet\" href=\"dist/style.css\">\n\t<meta property=\"og:url\" content=\"https://huggingface.co/coref/\">\n\t<meta property=\"og:image\" content=\"https://huggingface.co/coref/assets/thumbnail-large.png\">\n\t<meta property=\"fb:app_id\" content=\"1321688464574422\">\n\t<meta name=\"description\" content=\"This is a demo of Neuralcoref, our state-of-the-art neural coreference resolution system.\">\n</head>\n<body>\n\t<div class=\"header\">\n\t\t<div class=\"input-wrapper\">\n\t\t\t<form class=\"js-form\">\n\t\t\t\t<div class=\"wrapper-inner\">\n\t\t\t\t\t<div class=\"input-message-wrapper\">\n\t\t\t\t\t\t<input class=\"input-message\" type=\"text\" name=\"text\" placeholder=\"Your sentence here...\" autocomplete=\"off\" autofocus>\n\t\t\t\t\t</div>\n\t\t\t\t\t<button class=\"input-button c-input__button\">\n\t\t\t\t\t\t<svg aria-hidden=\"true\" viewBox=\"0 0 20 20\" width=\"20\" height=\"20\" fill=\"currentColor\" class=\"o-icon c-input__button__icon\">\n\t\t\t\t\t\t\t<use xmlns:xlink=\"http://www.w3.org/1999/xlink\" xlink:href=\"assets/icons.svg#icon-search\"></use>\n\t\t\t\t\t\t</svg>\n\t\t\t\t\t\t<svg aria-hidden=\"true\" viewBox=\"0 0 20 20\" width=\"20\" height=\"20\" fill=\"currentColor\" class=\"o-icon c-input__button__spinner\">\n\t\t\t\t\t\t\t<use xmlns:xlink=\"http://www.w3.org/1999/xlink\" xlink:href=\"assets/icons.svg#icon-spinner\"></use>\n\t\t\t\t\t\t</svg>\n\t\t\t\t\t</button>\n\t\t\t\t</div>\n\t\t\t</form>\n\t\t</div>\n\t\t<div class=\"menu-button js-checkbox\">\n\t\t\tDebug \n\t\t\t<img class=\"svg-checkbox js-checkbox-off\" src=\"assets/checkbox-off.svg\">\n\t\t\t<img class=\"svg-checkbox js-checkbox-on hide\" src=\"assets/checkbox-on.svg\">\n\t\t</div>\n\t\t\n\t\t<div class=\"menu-button logo\">\n\t\t\t<a target=\"_blank\" href=\"https://huggingface.co\">\n\t\t\t\t<img class=\"svg-logo\" src=\"assets/icon.svg\">\n\t\t\t</a>\n\t\t</div>\n\t</div>\n\t\n\t<div class=\"container-wrapper\">\n\t\t<svg class=\"svg-container\"></svg>\n\t\t<div class=\"container\"></div>\n\t</div>\n\t\n\t<div class=\"footer\">\n\t\t<div class=\"footline\"></div>\n\t\t<div class=\"description\">\n\t\t\t<p>This is a demo of our State-of-the-art neural coreference resolution system. \n\t\t\tThe open source code for <a target=\"_blank\" href=\"https://github.com/huggingface/neuralcoref\">Neural coref</a>, \n\t\t\tour coreference system based on neural nets and spaCy, is <a target=\"_blank\" href=\"https://github.com/huggingface/neuralcoref\">on Github</a>, \n\t\t\tand we explain in our Medium publication <a target=\"_blank\" href=\"https://medium.com/huggingface/state-of-the-art-neural-coreference-resolution-for-chatbots-3302365dcf30\">how the model works</a>\n\t\t\tand <a target=\"_blank\" href=\"https://medium.com/huggingface/how-to-train-a-neural-coreference-model-neuralcoref-2-7bb30c1abdfe\">how to train it</a>.</p>\n\t\t\t<p>In short, coreference is the fact that two or more expressions in a text \u2013 like pronouns or nouns \u2013 link to the same person or thing. \n\t\t\tIt is a classical Natural language processing task, that has seen a revival of interest in the past \n\t\t\ttwo years as several research groups applied cutting-edge deep-learning and reinforcement-learning techniques to it.\n\t\t\tIt is also one of the key building blocks to building conversational Artificial intelligences. \n\t\t\tIf you like this demo please <a target=\"_blank\" href=\"https://twitter.com/intent/tweet?url=https%3A%2F%2Fhuggingface.co%2Fcoref&via=julien_c%20%40betaworks\">tweet about it</a> \ud83d\udc4d.</p>\n\t\t\t<p><a href=\"https://twitter.com/share\" class=\"twitter-share-button\" data-show-count=\"false\" data-via=\"julien_c @betaworks\">Tweet</a><script async src=\"//platform.twitter.com/widgets.js\" charset=\"utf-8\"></script></p>\n\t\t</div>\n\t</div>\n\t\n\t<script src=\"dist/script.js\"></script>\n\t<script>\n\t(function() {\n\t\tif (window.location.hostname === 'localhost') {\n\t\t\tvar s = document.createElement('script');\n\t\t\ts.setAttribute('src', '//localhost:35729/livereload.js');\n\t\t\tdocument.body.appendChild(s);\n\t\t}\n\t})();\n\t</script>\n\t<script>\n\tif (window.location.hostname !== 'localhost') {\n\t\t(function(i,s,o,g,r,a,m){i['GoogleAnalyticsObject']=r;i[r]=i[r]||function(){\n\t\t(i[r].q=i[r].q||[]).push(arguments)},i[r].l=1*new Date();a=s.createElement(o),\n\t\tm=s.getElementsByTagName(o)[0];a.async=1;a.src=g;m.parentNode.insertBefore(a,m)\n\t\t})(window,document,'script','https://www.google-analytics.com/analytics.js','ga');\n\t\tga('create', 'UA-83738774-2', 'auto');\n\t\tga('send', 'pageview');\n\t}\n\t</script>\n</body>\n</html>", "package.json": "{\n \"name\": \"coref-viz\",\n \"version\": \"1.0.0\",\n \"description\": \"\",\n \"main\": \"Gruntfile.js\",\n \"scripts\": {\n \"test\": \"echo \\\"Error: no test specified\\\" && exit 1\"\n },\n \"author\": \"\",\n \"license\": \"ISC\",\n \"dependencies\": {\n \"grunt\": \"^1.0.1\",\n \"grunt-contrib-connect\": \"^1.0.2\",\n \"grunt-contrib-less\": \"^1.4.1\",\n \"grunt-contrib-watch\": \"^1.0.0\"\n }\n}\n", ".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n"} | null |
|
node-question-answering | {"type": "directory", "name": "node-question-answering", "children": [{"type": "file", "name": ".eslintignore"}, {"type": "file", "name": ".eslintrc.json"}, {"type": "file", "name": ".prettierrc.json"}, {"type": "file", "name": "CHANGELOG.md"}, {"type": "file", "name": "DistilBERT_to_SavedModel.ipynb"}, {"type": "file", "name": "jest.config.js"}, {"type": "file", "name": "LICENSE"}, {"type": "file", "name": "package-lock.json"}, {"type": "file", "name": "package.json"}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "scripts", "children": [{"type": "file", "name": "benchmark.js"}, {"type": "file", "name": "build.js"}, {"type": "file", "name": "cli.js"}, {"type": "file", "name": "example.js"}]}, {"type": "directory", "name": "src", "children": [{"type": "file", "name": "index.ts"}, {"type": "directory", "name": "models", "children": [{"type": "file", "name": "bert.model.ts"}, {"type": "file", "name": "distilbert.model.ts"}, {"type": "file", "name": "index.ts"}, {"type": "file", "name": "model.factory.ts"}, {"type": "file", "name": "model.ts"}, {"type": "file", "name": "roberta.model.ts"}]}, {"type": "file", "name": "qa-options.ts"}, {"type": "file", "name": "qa.test.ts"}, {"type": "file", "name": "qa.ts"}, {"type": "directory", "name": "runtimes", "children": [{"type": "file", "name": "index.ts"}, {"type": "file", "name": "remote.runtime.ts"}, {"type": "file", "name": "runtime.ts"}, {"type": "file", "name": "saved-model.runtime.ts"}, {"type": "file", "name": "saved-model.worker-thread.ts"}, {"type": "file", "name": "saved-model.worker.ts"}, {"type": "file", "name": "tfjs.runtime.ts"}, {"type": "file", "name": "worker-message.ts"}]}, {"type": "directory", "name": "tokenizers", "children": [{"type": "file", "name": "bert.tokenizer.ts"}, {"type": "file", "name": "index.ts"}, {"type": "file", "name": "roberta.tokenizer.ts"}, {"type": "file", "name": "tokenizer.factory.ts"}, {"type": "file", "name": "tokenizer.ts"}]}, {"type": "file", "name": "utils.ts"}]}, {"type": "file", "name": "tsconfig.json"}, {"type": "file", "name": "tsconfig.prod.json"}]} | # Question Answering for Node.js
[](https://www.npmjs.com/package/question-answering)
#### Production-ready Question Answering directly in Node.js, with only 3 lines of code!
This package leverages the power of the [🤗Tokenizers](https://github.com/huggingface/tokenizers) library (built with Rust) to process the input text. It then uses [TensorFlow.js](https://www.tensorflow.org/js) to run the [DistilBERT](https://arxiv.org/abs/1910.01108)-cased model fine-tuned for Question Answering (87.1 F1 score on SQuAD v1.1 dev set, compared to 88.7 for BERT-base-cased). DistilBERT is used by default, but you can use [other models](#models) available in the [🤗Transformers](https://github.com/huggingface/transformers) library in one additional line of code!
It can run models in SavedModel and TFJS formats locally, as well as [remote models](#remote-model) thanks to TensorFlow Serving.
## Installation
```bash
npm install question-answering@latest
```
## Quickstart
The following example will automatically download the default DistilBERT model in SavedModel format if not already present, along with the required vocabulary / tokenizer files. It will then run the model and return the answer to the `question`.
```typescript
import { QAClient } from "question-answering"; // When using Typescript or Babel
// const { QAClient } = require("question-answering"); // When using vanilla JS
const text = `
Super Bowl 50 was an American football game to determine the champion of the National Football League (NFL) for the 2015 season.
The American Football Conference (AFC) champion Denver Broncos defeated the National Football Conference (NFC) champion Carolina Panthers 24–10 to earn their third Super Bowl title. The game was played on February 7, 2016, at Levi's Stadium in the San Francisco Bay Area at Santa Clara, California.
As this was the 50th Super Bowl, the league emphasized the "golden anniversary" with various gold-themed initiatives, as well as temporarily suspending the tradition of naming each Super Bowl game with Roman numerals (under which the game would have been known as "Super Bowl L"), so that the logo could prominently feature the Arabic numerals 50.
`;
const question = "Who won the Super Bowl?";
const qaClient = await QAClient.fromOptions();
const answer = await qaClient.predict(question, text);
console.log(answer); // { text: 'Denver Broncos', score: 0.3 }
```
> You can also download the model and vocabulary / tokenizer files separately by [using the CLI](#cli).
## Advanced
<a name="models"></a>
### Using another model
The above example internally makes use of the default DistilBERT-cased model in the SavedModel format. The library is also compatible with any other __DistilBERT__-based model, as well as any __BERT__-based and __RoBERTa__-based models, both in SavedModel and TFJS formats. The following models are available in SavedModel format from the [Hugging Face model hub](https://huggingface.co/models) thanks to the amazing NLP community 🤗:
* [`a-ware/mobilebert-squadv2`](https://huggingface.co/a-ware/mobilebert-squadv2)
* [`a-ware/roberta-large-squadv2`](https://huggingface.co/a-ware/roberta-large-squadv2)
* [`bert-large-cased-whole-word-masking-finetuned-squad`](https://huggingface.co/bert-large-cased-whole-word-masking-finetuned-squad)
* [`bert-large-uncased-whole-word-masking-finetuned-squad`](https://huggingface.co/bert-large-uncased-whole-word-masking-finetuned-squad)
* [`deepset/bert-base-cased-squad2`](https://huggingface.co/deepset/bert-base-cased-squad2)
* [`deepset/bert-large-uncased-whole-word-masking-squad2`](https://huggingface.co/deepset/bert-large-uncased-whole-word-masking-squad2)
* [`deepset/roberta-base-squad2`](https://huggingface.co/deepset/roberta-base-squad2)
* [`distilbert-base-cased-distilled-squad`](https://huggingface.co/distilbert-base-cased-distilled-squad) (default) (also available in TFJS format)
* [`distilbert-base-uncased-distilled-squad`](https://huggingface.co/distilbert-base-uncased-distilled-squad)
* [`henryk/bert-base-multilingual-cased-finetuned-dutch-squad2`](https://huggingface.co/henryk/bert-base-multilingual-cased-finetuned-dutch-squad2)
* [`ktrapeznikov/biobert_v1.1_pubmed_squad_v2`](https://huggingface.co/ktrapeznikov/biobert_v1.1_pubmed_squad_v2)
* [`ktrapeznikov/scibert_scivocab_uncased_squad_v2`](https://huggingface.co/ktrapeznikov/scibert_scivocab_uncased_squad_v2)
* [`mrm8488/bert-base-spanish-wwm-cased-finetuned-spa-squad2-es`](https://huggingface.co/mrm8488/bert-base-spanish-wwm-cased-finetuned-spa-squad2-es)
* [`mrm8488/distill-bert-base-spanish-wwm-cased-finetuned-spa-squad2-es`](https://huggingface.co/mrm8488/distill-bert-base-spanish-wwm-cased-finetuned-spa-squad2-es)
* [`mrm8488/spanbert-finetuned-squadv2`](https://huggingface.co/mrm8488/spanbert-finetuned-squadv2)
* [`NeuML/bert-small-cord19qa`](https://huggingface.co/NeuML/bert-small-cord19qa)
* [`twmkn9/bert-base-uncased-squad2`](https://huggingface.co/twmkn9/bert-base-uncased-squad2)
To specify a model to use with the library, you need to instantiate a model class that you'll then pass to the `QAClient`:
```typescript
import { initModel, QAClient } from "question-answering"; // When using Typescript or Babel
// const { initModel, QAClient } = require("question-answering"); // When using vanilla JS
const text = ...
const question = ...
const model = await initModel({ name: "deepset/roberta-base-squad2" });
const qaClient = await QAClient.fromOptions({ model });
const answer = await qaClient.predict(question, text);
console.log(answer); // { text: 'Denver Broncos', score: 0.46 }
```
> Note that using a model [hosted on Hugging Face](https://huggingface.co/models) is not a requirement: you can use any compatible model (including any from the HF hub not already available in SavedModel or TFJS format that you converted yourself) by passing the correct local path for the model and vocabulary files in the options.
#### Using models in TFJS format
To use a TFJS model, you simply need to pass `tfjs` to the `runtime` param of `initModel` (defaults to `saved_model`):
```typescript
const model = await initModel({ name: "distilbert-base-cased-distilled-squad", runtime: RuntimeType.TFJS });
```
As with any SavedModel hosted in the HF model hub, the required files for the TFJS models will be automatically downloaded the first time. You can also download them manually [using the CLI](#cli).
<a name="remote-model"></a>
#### Using remote models with [TensorFlow Serving](https://www.tensorflow.org/tfx/guide/serving)
If your model is in the SavedModel format, you may prefer to host it on a dedicated server. Here is a simple example using [Docker](https://www.tensorflow.org/tfx/serving/docker) locally:
```bash
# Inside our project root, download DistilBERT-cased to its default `.models` location
npx question-answering download
# Download the TensorFlow Serving Docker image
docker pull tensorflow/serving
# Start TensorFlow Serving container and open the REST API port.
# Notice that in the `target` path we add a `/1`:
# this is required by TFX which is expecting the models to be "versioned"
docker run -t --rm -p 8501:8501 \
--mount type=bind,source="$(pwd)/.models/distilbert-cased/",target="/models/cased/1" \
-e MODEL_NAME=cased \
tensorflow/serving &
```
In the code, you just have to pass `remote` as `runtime` and the server endpoint as `path`:
```typescript
const model = await initModel({
name: "distilbert-base-cased-distilled-squad",
path: "http://localhost:8501/v1/models/cased",
runtime: RuntimeType.Remote
});
const qaClient = await QAClient.fromOptions({ model });
```
<a name="cli"></a>
### Downloading models with the CLI
You can choose to download the model and associated vocab file(s) manually using the CLI. For example to download the `deepset/roberta-base-squad2` model:
```bash
npx question-answering download deepset/roberta-base-squad2
```
> By default, the files are downloaded inside a `.models` directory at the root of your project; you can provide a custom directory by using the `--dir` option of the CLI. You can also use `--format tfjs` to download a model in TFJS format (if available). To check all the options of the CLI: `npx question-answering download --help`.
### Using a custom tokenizer
The `QAClient.fromOptions` params object has a `tokenizer` field which can either be a set of options relative to the tokenizer files, or an instance of a class extending the abstract [`Tokenizer`](./src/tokenizers/tokenizer.ts) class. To extend this class, you can create your own or, if you simply need to adjust some options, you can import and use the provided `initTokenizer` method, which will instantiate such a class for you.
## Performances
Thanks to [the native execution of SavedModel format](https://groups.google.com/a/tensorflow.org/d/msg/tfjs/Xtf6s1Bpkr0/7-Eqn8soAwAJ) in TFJS, the performance of such models is similar to the one using TensorFlow in Python.
Specifically, here are the results of a benchmark using `question-answering` with the default DistilBERT-cased model:
* Running entirely locally (both SavedModel and TFJS formats)
* Using a (pseudo) remote model server (i.e. local Docker with TensorFlow Serving running the SavedModel format)
* Using the Question Answering pipeline in the [🤗Transformers](https://github.com/huggingface/transformers) library.

_Shorts texts are texts between 500 and 1000 characters, long texts are between 4000 and 5000 characters. You can check the `question-answering` benchmark script [here](./scripts/benchmark.js) (the `transformers` one is equivalent). Benchmark run on a standard 2019 MacBook Pro running on macOS 10.15.2._
## Troubleshooting
### Errors when using Typescript
There is a known incompatibility in the TFJS library with some types. If you encounter errors when building your project, make sure to pass the `--skipLibCheck` flag when using the Typescript CLI, or to add `skipLibCheck: true` to your `tsconfig.json` file under `compilerOptions`. See [here](https://github.com/tensorflow/tfjs/issues/2007) for more information.
### `Tensor not referenced` when running SavedModel
Due to a [bug in TFJS](https://github.com/tensorflow/tfjs/issues/3463), the use of `@tensorflow/tfjs-node` to load or execute SavedModel models independently from the library is not recommended for now, since it could overwrite the TF backend used internally by the library. In the case where you would have to do so, make sure to require _both_ `question-answering` _and_ `@tensorflow/tfjs-node` in your code __before making any use of either of them__.
| {"package.json": "{\n \"name\": \"question-answering\",\n \"version\": \"3.0.0\",\n \"description\": \"Production-ready Question Answering directly in Node.js\",\n \"keywords\": [\n \"nlp\",\n \"question answering\",\n \"tensorflow\",\n \"distilbert\"\n ],\n \"repository\": {\n \"type\": \"git\",\n \"url\": \"git+https://github.com/huggingface/node-question-answering.git\"\n },\n \"bugs\": {\n \"url\": \"https://github.com/huggingface/node-question-answering/issues\"\n },\n \"main\": \"./dist/index.js\",\n \"types\": \"./dist/index.d.ts\",\n \"bin\": \"./cli.js\",\n \"dependencies\": {\n \"@tensorflow/tfjs-node\": \"^2.0.1\",\n \"@types/node\": \"^13.5.0\",\n \"@types/node-fetch\": \"^2.5.4\",\n \"@types/progress\": \"^2.0.3\",\n \"@types/shelljs\": \"^0.8.7\",\n \"@types/tar\": \"^4.0.3\",\n \"node-fetch\": \"^2.6.0\",\n \"progress\": \"^2.0.3\",\n \"shelljs\": \"^0.8.3\",\n \"tar\": \"^5.0.5\",\n \"tokenizers\": \"^0.7.0\",\n \"yargs\": \"^15.1.0\"\n },\n \"devDependencies\": {\n \"@types/jest\": \"^26.0.3\",\n \"@typescript-eslint/eslint-plugin\": \"^2.23.0\",\n \"@typescript-eslint/parser\": \"^2.23.0\",\n \"eslint\": \"^6.8.0\",\n \"eslint-config-prettier\": \"^6.10.0\",\n \"eslint-plugin-jest\": \"^23.6.0\",\n \"eslint-plugin-prettier\": \"^3.1.2\",\n \"eslint-plugin-simple-import-sort\": \"^5.0.0\",\n \"jest\": \"^26.1.0\",\n \"prettier\": \"^1.19.1\",\n \"ts-jest\": \"^26.1.1\",\n \"typescript\": \"^3.9.6\",\n \"yargs-interactive\": \"^3.0.0\"\n },\n \"scripts\": {\n \"dev\": \"rm -rf dist && npx tsc\",\n \"test\": \"jest\",\n \"lint\": \"eslint --fix --ext .js,.ts src scripts\",\n \"lint-check\": \"eslint --ext .js,.ts src scripts\"\n },\n \"engines\": {\n \"node\": \">=10 < 11 || >=12 <14\"\n },\n \"author\": \"Pierric Cistac <[email protected]>\",\n \"license\": \"Apache-2.0\"\n}\n", ".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", "src\\index.ts": "export * from \"./qa\";\nexport * from \"./models\";\nexport { QAOptions } from \"./qa-options\";\nexport * from \"./runtimes\";\nexport * from \"./tokenizers\";\n", "src\\models\\index.ts": "export { ModelInput, ModelInputsNames, ModelOutputNames, ModelType } from \"./model\";\nexport { initModel, ModelFactoryOptions } from \"./model.factory\";\n", "src\\runtimes\\index.ts": "export { RuntimeType } from \"./runtime\";\n", "src\\tokenizers\\index.ts": "export { Tokenizer } from \"./tokenizer\";\nexport {\n initTokenizer,\n BertTokenizerFactoryOptions,\n RobertaTokenizerFactoryOptions,\n TokenizerFactoryOptions\n} from \"./tokenizer.factory\";\n"} | null |
OBELICS | {"type": "directory", "name": "OBELICS", "children": [{"type": "directory", "name": "build_obelics", "children": [{"type": "file", "name": "01_download_warc.py"}, {"type": "file", "name": "02_bis_extract_html_get_image_urls_new_rules.py"}, {"type": "file", "name": "02_extract_html_get_image_urls.py"}, {"type": "file", "name": "02_parallel_extract_html_get_image_urls.py"}, {"type": "file", "name": "03_dl_images_create_dataset.py"}, {"type": "file", "name": "03_parallel_dl_images_create_dataset.py"}, {"type": "file", "name": "04_merge_web_docs_with_images.py"}, {"type": "file", "name": "05_filtering_web_docs.py"}, {"type": "file", "name": "06_01_create_set_image_urls_in_webdocs.py"}, {"type": "file", "name": "06_02_merge_sets_image_urls_in_webdocs.py"}, {"type": "file", "name": "06_03_remove_image_duplicates.py"}, {"type": "file", "name": "07_01_nsfw_image_filtering.py"}, {"type": "file", "name": "07_02_nsfw_image_visualization.py"}, {"type": "file", "name": "07_03_nsfw_image_removal.py"}, {"type": "file", "name": "08_01_prepare_urldedup.py"}, {"type": "file", "name": "08_02_urldedup.py"}, {"type": "file", "name": "09_01_create_web_docs_texts_only.py"}, {"type": "file", "name": "09_02_get_domain_to_positions.py"}, {"type": "file", "name": "09_03_split_domain_to_positions.py"}, {"type": "file", "name": "09_04_get_domain_to_duplicated_texts.py"}, {"type": "file", "name": "09_05_merge_domain_to_duplicated_texts_sharded.py"}, {"type": "file", "name": "09_06_line_dedup.py"}, {"type": "file", "name": "09_07_merge_web_docs_texts_only_and_rest.py"}, {"type": "file", "name": "10_final_cleaning.py"}, {"type": "file", "name": "11_01_create_set_img_urls.py"}, {"type": "file", "name": "11_02_get_docs_to_remove_by_set_img_urls_dedup.py"}, {"type": "file", "name": "11_03_set_img_urls_dedup.py"}, {"type": "file", "name": "12_01_find_opt_out_images.py"}, {"type": "file", "name": "12_02_remove_opt_out_images.py"}, {"type": "file", "name": "13_final_processing.py"}]}, {"type": "file", "name": "LICENSE"}, {"type": "directory", "name": "obelics", "children": [{"type": "directory", "name": "callers", "children": [{"type": "file", "name": "download_warc.py"}, {"type": "file", "name": "extract_html.py"}, {"type": "file", "name": "extract_web_documents.py"}, {"type": "file", "name": "filter_web_documents.py"}, {"type": "file", "name": "line_deduplicate_web_documents.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "configs", "children": [{"type": "file", "name": "config_extract_web_documents.yaml"}, {"type": "file", "name": "config_filter_web_documents.yaml"}]}, {"type": "directory", "name": "processors", "children": [{"type": "file", "name": "dom_tree_simplificator.py"}, {"type": "file", "name": "html_extractor.py"}, {"type": "file", "name": "pre_extraction_simplificator.py"}, {"type": "file", "name": "warc_downloader.py"}, {"type": "file", "name": "web_document_extractor.py"}, {"type": "file", "name": "web_document_filtering.py"}, {"type": "file", "name": "web_document_line_deduplication.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "utils", "children": [{"type": "file", "name": "filtering_utils.py"}, {"type": "file", "name": "simplification_utils.py"}, {"type": "file", "name": "tags_attributes.py"}, {"type": "file", "name": "utils.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "visualization", "children": [{"type": "directory", "name": "assets", "children": [{"type": "file", "name": "DOM_tree_viz.html"}]}, {"type": "file", "name": "choose_filtering_parameters_web_documents_node_level.py"}, {"type": "file", "name": "global_visualization.py"}, {"type": "file", "name": "web_document_and_filtering_visualization.py"}, {"type": "file", "name": "web_document_visualization.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}]} | # OBELICS
**OBELICS is an open, massive and curated collection of interleaved image-text web documents, containing 141M documents, 115B text tokens and 353M images.**
**Dataset page:** https://huggingface.co/datasets/HuggingFaceM4/OBELICS
**Visualization of OBELICS web documents:** https://huggingface.co/spaces/HuggingFaceM4/obelics_visualization
**Paper:** https://arxiv.org/abs/2306.16527
## Goal and organization of [obelics](https://github.com/huggingface/OBELICS/tree/main/obelics)
The folder [obelics](https://github.com/huggingface/OBELICS/tree/main/obelics) is aimed for:
- Download WARC files from Common Crawl dumps ([warc_downloader.py](https://github.com/huggingface/OBELICS/blob/main/obelics/processors/warc_downloader.py));
- Extract HTML files from WARC files ([html_extractor.py](https://github.com/huggingface/OBELICS/blob/main/obelics/processors/html_extractor.py));
- Simplify HTML DOM trees ([dom_tree_simplificator.py](https://github.com/huggingface/OBELICS/blob/main/obelics/processors/dom_tree_simplificator.py));
- Convert the simplified DOM trees to another structure adapted for an extraction ([pre_extraction_simplificator.py](https://github.com/huggingface/OBELICS/blob/main/obelics/processors/pre_extraction_simplificator.py));
- Perform an extraction ([web_document_extractor.py](https://github.com/huggingface/OBELICS/blob/main/obelics/processors/web_document_extractor.py));
- Perform a filtering on the extraction ([web_document_filtering.py](https://github.com/huggingface/OBELICS/blob/main/obelics/processors/web_document_filtering.py));
- Perform a line deduplication ([web_document_line_deduplication.py](https://github.com/huggingface/OBELICS/blob/main/obelics/processors/web_document_line_deduplication.py));
- Visualize the results ([visualization](https://github.com/huggingface/OBELICS/tree/main/obelics/visualization)).
The primary techniques are defined in the sub-folder [processors](https://github.com/huggingface/OBELICS/tree/main/obelics/processors), while their invocation is found in [callers](https://github.com/huggingface/OBELICS/tree/main/obelics/callers). The configs used for the extraction and the filtering of the documents are in [configs](https://github.com/huggingface/OBELICS/tree/main/obelics/configs).
We refer to our paper for details about these steps.
In [visualization](https://github.com/huggingface/OBELICS/tree/main/obelics/visualization), there are different `streamlit` visualizations:
- [global_visualization.py](https://github.com/huggingface/OBELICS/blob/main/obelics/visualization/global_visualization.py) to see original web pages and DOM trees, with our simplificated versions pre-filtering;
- [choose_filtering_parameters_web_documents_node_level.py](https://github.com/huggingface/OBELICS/blob/main/obelics/visualization/choose_filtering_parameters_web_documents_node_level.py) and [web_document_and_filtering_visualization.py](https://github.com/huggingface/OBELICS/blob/main/obelics/visualization/web_document_and_filtering_visualization.py) to see the impact of the filtering at node and document level, and help choosing the filter thresholds.
- [web_document_visualization.py](https://github.com/huggingface/OBELICS/blob/main/obelics/visualization/web_document_visualization.py) for a simple visualization of the final documents.
## Goal and organization of [build_obelics](https://github.com/huggingface/OBELICS/tree/main/build_obelics)
In the folder [build_obelics](https://github.com/huggingface/OBELICS/tree/main/build_obelics), we are giving all the scripts that were used for the creation of OBELICS, with numbers indicating the chronology.
These scripts often call methods defined in [processors](https://github.com/huggingface/OBELICS/tree/main/obelics/processors) but not only, and also define other useful methods.
## Citation
If you are using this dataset or this code, please cite
```
@misc{laurencon2023obelics,
title={OBELICS: An Open Web-Scale Filtered Dataset of Interleaved Image-Text Documents},
author={Hugo Laurençon and Lucile Saulnier and Léo Tronchon and Stas Bekman and Amanpreet Singh and Anton Lozhkov and Thomas Wang and Siddharth Karamcheti and Alexander M. Rush and Douwe Kiela and Matthieu Cord and Victor Sanh},
year={2023},
eprint={2306.16527},
archivePrefix={arXiv},
primaryClass={cs.IR}
}
```
| {"requirements.txt": "# Streamlit app\nstreamlit\npandas\njinja2~=3.0\n# Tree manipulations\nselectolax\n# Clip stuff\ntransformers\nscipy\nplotly\nkaleido\ntorch>=2.0 # for flash attention support\n# Filtering\nemoji==1.6.1\nfasttext\nsentencepiece\nhttps://github.com/kpu/kenlm/archive/master.zip\n# Tests\nhumanfriendly\n# Downloading images\nimg2dataset\n# Multiprocessing\npathos\n# Configs\nPyYAML\n# HTML extraction\nboto3\nbs4\nwarcio", ".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 c50923f346abda02aa35fb48872266ac5dc8d896 Hamza Amin <[email protected]> 1727369433 +0500\tclone: from https://github.com/huggingface/OBELICS.git\n", ".git\\refs\\heads\\main": "c50923f346abda02aa35fb48872266ac5dc8d896\n", "build_obelics\\09_02_get_domain_to_positions.py": "import json\nimport logging\nimport os\nfrom urllib.parse import urlparse\n\nfrom datasets import load_from_disk\nfrom tqdm import tqdm\n\n\nlogging.basicConfig(\n level=logging.INFO,\n format=\"%(asctime)s - %(levelname)s - %(name)s - %(message)s\",\n datefmt=\"%m/%d/%Y %H:%M:%S\",\n)\nlogger = logging.getLogger(__name__)\nlogger.setLevel(logging.INFO)\n\n\nNUM_SHARDS = 200\n\nPATH_SAVE_DISK_TMP_FILES = \"/scratch/storage_hugo/\"\n\nPATH_WEB_DOCS_S3 = (\n \"s3://m4-datasets/webdocs/web_document_dataset_filtered_imgurldedup_nsfwfiltered_urldedup_texts_only/\"\n)\nPATH_WEB_DOCS_LOCAL = os.path.join(PATH_SAVE_DISK_TMP_FILES, \"web_docs\")\n\nPATH_SAVE_DISK_LINE_DEDUP_DOMAIN_TO_POSITIONS = os.path.join(\n PATH_SAVE_DISK_TMP_FILES, \"line_dedup_domain_to_positions.json\"\n)\nPATH_SAVE_S3_LINE_DEDUP_DOMAIN_TO_POSITIONS = \"s3://m4-datasets/webdocs/line_dedup_domain_to_positions.json\"\n\n\ndef get_domain_to_positions():\n domain_to_positions = {}\n\n for idx_shard in tqdm(range(NUM_SHARDS)):\n path_subdataset = os.path.join(PATH_WEB_DOCS_LOCAL, str(idx_shard))\n sub_ds = load_from_disk(path_subdataset)\n metadata_sub_ds = sub_ds[\"general_metadata\"]\n domains = [urlparse(json.loads(meta)[\"url\"]).netloc for meta in metadata_sub_ds]\n\n new_domain_to_pos = {}\n for idx, domain in enumerate(domains):\n new_domain_to_pos[domain] = new_domain_to_pos.get(domain, []) + [idx]\n for domain in new_domain_to_pos:\n if domain not in domain_to_positions:\n domain_to_positions[domain] = {}\n domain_to_positions[domain][str(idx_shard)] = new_domain_to_pos[domain]\n\n return domain_to_positions\n\n\nif __name__ == \"__main__\":\n if os.path.exists(PATH_SAVE_DISK_TMP_FILES):\n os.system(f\"rm -r {PATH_SAVE_DISK_TMP_FILES}\")\n os.system(f\"mkdir {PATH_SAVE_DISK_TMP_FILES}\")\n\n logger.info(\"Starting downloading the web document dataset (texts only)\")\n command_sync_s3 = f\"aws s3 sync {PATH_WEB_DOCS_S3} {PATH_WEB_DOCS_LOCAL}\"\n os.system(command_sync_s3)\n os.system(command_sync_s3)\n os.system(command_sync_s3)\n logger.info(\"Finished downloading the web document dataset (texts only)\")\n\n logger.info(\"Starting creating the dictionary to go from a domain name to positions in the web document dataset\")\n domain_to_positions = get_domain_to_positions()\n logger.info(\"Finished creating the dictionary to go from a domain name to positions in the web document dataset\")\n\n logger.info(\"Starting saving the domain to positions\")\n with open(PATH_SAVE_DISK_LINE_DEDUP_DOMAIN_TO_POSITIONS, \"w\") as f:\n json.dump(domain_to_positions, f)\n\n command_sync_s3 = (\n f\"aws s3 cp {PATH_SAVE_DISK_LINE_DEDUP_DOMAIN_TO_POSITIONS} {PATH_SAVE_S3_LINE_DEDUP_DOMAIN_TO_POSITIONS}\"\n )\n os.system(command_sync_s3)\n logger.info(\"Finished saving the domain to positions\")\n\n logger.info(\"Starting deleting the tmp files\")\n os.system(f\"rm -r {PATH_SAVE_DISK_TMP_FILES}\")\n logger.info(\"Finished deleting the tmp files\")\n", "build_obelics\\09_03_split_domain_to_positions.py": "import json\nimport os\nimport random\n\nfrom tqdm import tqdm\n\n\nrandom.seed(42)\n\nNUM_SHARDS = 200\n\nPATH_LINE_DEDUP_DOMAIN_TO_POSITIONS_S3 = \"s3://m4-datasets/webdocs/line_dedup_domain_to_positions.json\"\nPATH_LINE_DEDUP_DOMAIN_TO_POSITIONS_LOCAL = \"/scratch/line_dedup_domain_to_positions.json\"\n\nPATH_SAVE_S3_LINE_DEDUP_DOMAIN_TO_POSITIONS_SHARDED = (\n \"s3://m4-datasets/webdocs/line_dedup_domain_to_positions_sharded/\"\n)\n\n\nif __name__ == \"__main__\":\n command_sync_s3 = f\"aws s3 cp {PATH_LINE_DEDUP_DOMAIN_TO_POSITIONS_S3} {PATH_LINE_DEDUP_DOMAIN_TO_POSITIONS_LOCAL}\"\n os.system(command_sync_s3)\n\n with open(PATH_LINE_DEDUP_DOMAIN_TO_POSITIONS_LOCAL) as f:\n domain_to_positions = json.load(f)\n\n keys = list(domain_to_positions.keys())\n random.shuffle(keys)\n\n sublist_size = len(keys) // NUM_SHARDS + 1\n keys_per_shard = [set(keys[i : i + sublist_size]) for i in range(0, len(keys), sublist_size)]\n\n domain_to_positions_shard = []\n\n for idx_shard in tqdm(range(NUM_SHARDS)):\n domain_to_positions_shard.append(\n {k: v for k, v in domain_to_positions.items() if k in keys_per_shard[idx_shard]}\n )\n\n with open(f\"/scratch/line_dedup_domain_to_positions_{idx_shard}.json\", \"w\") as f:\n json.dump(domain_to_positions_shard[idx_shard], f)\n\n for idx_shard in tqdm(range(NUM_SHARDS)):\n path_disk = f\"/scratch/line_dedup_domain_to_positions_{idx_shard}.json\"\n path_s3 = os.path.join(\n PATH_SAVE_S3_LINE_DEDUP_DOMAIN_TO_POSITIONS_SHARDED, str(idx_shard), \"line_dedup_domain_to_positions.json\"\n )\n command_sync_s3 = f\"aws s3 cp {path_disk} {path_s3}\"\n os.system(command_sync_s3)\n", "build_obelics\\09_04_get_domain_to_duplicated_texts.py": "import json\nimport logging\nimport os\nimport sys\n\nfrom datasets import load_from_disk\nfrom tqdm import tqdm\n\n\nlogging.basicConfig(\n level=logging.INFO,\n format=\"%(asctime)s - %(levelname)s - %(name)s - %(message)s\",\n datefmt=\"%m/%d/%Y %H:%M:%S\",\n)\nlogger = logging.getLogger(__name__)\nlogger.setLevel(logging.INFO)\n\n\nNUM_SHARDS = 200\n\nIDX_JOB = int(sys.argv[1])\nPATH_SAVE_DISK_TMP_FILES = f\"/scratch/storage_hugo_{IDX_JOB}/\"\n\nPATH_WEB_DOCS_S3 = (\n \"s3://m4-datasets/webdocs/web_document_dataset_filtered_imgurldedup_nsfwfiltered_urldedup_texts_only/\"\n)\nPATH_WEB_DOCS_LOCAL = os.path.join(PATH_SAVE_DISK_TMP_FILES, \"web_docs\")\n\nPATH_LINE_DEDUP_DOMAIN_TO_POSITIONS_S3 = (\n f\"s3://m4-datasets/webdocs/line_dedup_domain_to_positions_sharded/{IDX_JOB}/line_dedup_domain_to_positions.json\"\n)\nPATH_LINE_DEDUP_DOMAIN_TO_POSITIONS_LOCAL = os.path.join(\n PATH_SAVE_DISK_TMP_FILES, \"line_dedup_domain_to_positions.json\"\n)\n\nPATH_SAVE_DISK_LINE_DEDUP_DOMAIN_TO_DUPLICATED_TEXTS = os.path.join(\n PATH_SAVE_DISK_TMP_FILES, \"line_dedup_domain_to_duplicated_texts.json\"\n)\nPATH_SAVE_S3_LINE_DEDUP_DOMAIN_TO_DUPLICATED_TEXTS = f\"s3://m4-datasets/webdocs/line_dedup_domain_to_duplicated_texts_sharded/{IDX_JOB}/line_dedup_domain_to_duplicated_texts.json\"\n\n\ndef get_domain_to_duplicated_texts(domain_to_positions):\n shard_to_domain_to_positions = {\n str(idx_shard): {\n domain: domain_to_positions[domain][str(idx_shard)]\n for domain in domain_to_positions\n if str(idx_shard) in domain_to_positions[domain]\n }\n for idx_shard in range(NUM_SHARDS)\n }\n domain_to_duplicated_texts = {}\n\n for idx_shard in tqdm(range(NUM_SHARDS)):\n ds_shard = load_from_disk(os.path.join(PATH_WEB_DOCS_LOCAL, str(idx_shard)), keep_in_memory=True)\n\n for domain in shard_to_domain_to_positions[str(idx_shard)]:\n if domain not in domain_to_duplicated_texts:\n domain_to_duplicated_texts[domain] = {}\n\n positions = shard_to_domain_to_positions[str(idx_shard)][domain]\n\n for pos in positions:\n tot_texts = [txt for txt in ds_shard[pos][\"texts\"] if txt]\n tot_texts = [text.split(\"\\n\\n\") for text in tot_texts]\n tot_texts = [paragraph for text in tot_texts for paragraph in text]\n for text in tot_texts:\n domain_to_duplicated_texts[domain][text] = domain_to_duplicated_texts[domain].get(text, 0) + 1\n\n domain_to_duplicated_texts = {\n domain: {k: v for k, v in domain_to_duplicated_texts[domain].items() if v > 1}\n for domain in domain_to_duplicated_texts\n }\n return domain_to_duplicated_texts\n\n\nif __name__ == \"__main__\":\n if os.path.exists(PATH_SAVE_DISK_TMP_FILES):\n os.system(f\"rm -r {PATH_SAVE_DISK_TMP_FILES}\")\n os.system(f\"mkdir {PATH_SAVE_DISK_TMP_FILES}\")\n\n logger.info(\n \"Starting downloading the web document dataset (texts only) and to dictionary to go from a domain to positions\"\n )\n command_sync_s3 = f\"aws s3 sync {PATH_WEB_DOCS_S3} {PATH_WEB_DOCS_LOCAL}\"\n os.system(command_sync_s3)\n os.system(command_sync_s3)\n os.system(command_sync_s3)\n\n command_sync_s3 = f\"aws s3 cp {PATH_LINE_DEDUP_DOMAIN_TO_POSITIONS_S3} {PATH_LINE_DEDUP_DOMAIN_TO_POSITIONS_LOCAL}\"\n os.system(command_sync_s3)\n\n with open(PATH_LINE_DEDUP_DOMAIN_TO_POSITIONS_LOCAL) as f:\n domain_to_positions = json.load(f)\n logger.info(\n \"Finished downloading the web document dataset (texts only) and to dictionary to go from a domain to positions\"\n )\n\n logger.info(\"Starting finding the duplicated texts for each domain\")\n domain_to_duplicated_texts = get_domain_to_duplicated_texts(domain_to_positions)\n logger.info(\"Finished finding the duplicated texts for each domain\")\n\n logger.info(\"Starting saving the domain to duplicated texts\")\n with open(PATH_SAVE_DISK_LINE_DEDUP_DOMAIN_TO_DUPLICATED_TEXTS, \"w\") as f:\n json.dump(domain_to_duplicated_texts, f)\n\n command_sync_s3 = (\n \"aws s3 cp\"\n f\" {PATH_SAVE_DISK_LINE_DEDUP_DOMAIN_TO_DUPLICATED_TEXTS} {PATH_SAVE_S3_LINE_DEDUP_DOMAIN_TO_DUPLICATED_TEXTS}\"\n )\n os.system(command_sync_s3)\n logger.info(\"Finished saving the domain to duplicated texts\")\n\n logger.info(\"Starting deleting the tmp files\")\n os.system(f\"rm -r {PATH_SAVE_DISK_TMP_FILES}\")\n logger.info(\"Finished deleting the tmp files\")\n", "build_obelics\\09_05_merge_domain_to_duplicated_texts_sharded.py": "\"\"\"\nsrun --pty --cpus-per-task=96 bash -i\nconda activate /fsx/m4/conda/shared-m4-2023-03-10\n\"\"\"\n\n\nimport json\nimport logging\nimport os\n\nfrom tqdm import tqdm\n\n\nlogging.basicConfig(\n level=logging.INFO,\n format=\"%(asctime)s - %(levelname)s - %(name)s - %(message)s\",\n datefmt=\"%m/%d/%Y %H:%M:%S\",\n)\nlogger = logging.getLogger(__name__)\nlogger.setLevel(logging.INFO)\n\n\nNUM_SHARDS = 200\n\nPATH_LINE_DEDUP_DOMAIN_TO_DUPLICATED_TEXTS_S3 = (\n \"s3://m4-datasets/webdocs/line_dedup_domain_to_duplicated_texts_sharded/\"\n)\nPATH_LINE_DEDUP_DOMAIN_TO_DUPLICATED_TEXTS_LOCAL = \"/scratch/line_dedup_domain_to_duplicated_texts_sharded/\"\n\nPATH_SAVE_DISK_LINE_DEDUP_DOMAIN_TO_DUPLICATED_TEXTS_FULL = \"/scratch/line_dedup_domain_to_duplicated_texts.json\"\nPATH_SAVE_S3_LINE_DEDUP_DOMAIN_TO_DUPLICATED_TEXTS_FULL = (\n \"s3://m4-datasets/webdocs/line_dedup_domain_to_duplicated_texts.json\"\n)\n\nPATH_SAVE_DISK_NEW_LINE_DEDUP_DOMAIN_TO_DUPLICATED_TEXTS_FULL = (\n \"/scratch/new_line_dedup_domain_to_duplicated_texts.json\"\n)\nPATH_SAVE_S3_NEW_LINE_DEDUP_DOMAIN_TO_DUPLICATED_TEXTS_FULL = (\n \"s3://m4-datasets/webdocs/new_line_dedup_domain_to_duplicated_texts.json\"\n)\n\n\nif __name__ == \"__main__\":\n logger.info(\"Starting downloading the dictionaries to go from a domain to the associated duplicated texts\")\n command_sync_s3 = (\n \"aws s3 sync\"\n f\" {PATH_LINE_DEDUP_DOMAIN_TO_DUPLICATED_TEXTS_S3} {PATH_LINE_DEDUP_DOMAIN_TO_DUPLICATED_TEXTS_LOCAL}\"\n )\n os.system(command_sync_s3)\n os.system(command_sync_s3)\n os.system(command_sync_s3)\n logger.info(\"Finished downloading the dictionaries to go from a domain to the associated duplicated texts\")\n\n logger.info(\"Starting merging the sub dictionaries\")\n all_domain_to_duplicated_texts = []\n for idx_shard in tqdm(range(NUM_SHARDS)):\n with open(\n os.path.join(\n PATH_LINE_DEDUP_DOMAIN_TO_DUPLICATED_TEXTS_LOCAL,\n str(idx_shard),\n \"line_dedup_domain_to_duplicated_texts.json\",\n )\n ) as f:\n all_domain_to_duplicated_texts.append(json.load(f))\n\n domain_to_duplicated_texts = {\n k: v for sub_dict in tqdm(all_domain_to_duplicated_texts) for k, v in sub_dict.items()\n }\n logger.info(\"Finished merging the sub dictionaries\")\n\n logger.info(\"Starting saving the dictionary to go from a domain to the associated duplicated texts\")\n with open(PATH_SAVE_DISK_LINE_DEDUP_DOMAIN_TO_DUPLICATED_TEXTS_FULL, \"w\") as f:\n json.dump(domain_to_duplicated_texts, f)\n\n command_sync_s3 = (\n \"aws s3 cp\"\n f\" {PATH_SAVE_DISK_LINE_DEDUP_DOMAIN_TO_DUPLICATED_TEXTS_FULL} {PATH_SAVE_S3_LINE_DEDUP_DOMAIN_TO_DUPLICATED_TEXTS_FULL}\"\n )\n os.system(command_sync_s3)\n logger.info(\"Finished saving the dictionary to go from a domain to the associated duplicated texts\")\n\n # Find the strategy\n # data = {k: v for k, v in domain_to_duplicated_texts.items() if len(v) > 0}\n # keys = list(data.keys())\n # print([(idx, len(data[keys[idx]])) for idx in range(len(keys))])\n # print(\"\\n\\n\".join([k + f\"\\t{str(v)}\" for k, v in {k: v for k, v in data[keys[5258]].items() if v > 2}.items()]))\n\n logger.info(\n \"Starting making a smaller version of the dictionary, based on only what we will remove in the line\"\n \" deduplication\"\n )\n new_domain_to_duplicated_texts = {\n k: {txt: counter for txt, counter in v.items() if counter > 2}\n for k, v in tqdm(domain_to_duplicated_texts.items())\n }\n new_domain_to_duplicated_texts = {\n k: {txt: counter for txt, counter in v.items() if \"END_OF_DOCUMENT_TOKEN_TO_BE_REPLACED\" not in txt}\n for k, v in tqdm(new_domain_to_duplicated_texts.items())\n }\n new_domain_to_duplicated_texts = {k: v for k, v in new_domain_to_duplicated_texts.items() if len(v) > 0}\n logger.info(\n \"Finished making a smaller version of the dictionary, based on only what we will remove in the line\"\n \" deduplication\"\n )\n\n logger.info(\"Starting saving the new dictionary to go from a domain to the associated duplicated texts\")\n with open(PATH_SAVE_DISK_NEW_LINE_DEDUP_DOMAIN_TO_DUPLICATED_TEXTS_FULL, \"w\") as f:\n json.dump(new_domain_to_duplicated_texts, f)\n\n command_sync_s3 = (\n \"aws s3 cp\"\n f\" {PATH_SAVE_DISK_NEW_LINE_DEDUP_DOMAIN_TO_DUPLICATED_TEXTS_FULL} {PATH_SAVE_S3_NEW_LINE_DEDUP_DOMAIN_TO_DUPLICATED_TEXTS_FULL}\"\n )\n os.system(command_sync_s3)\n logger.info(\"Finished saving the new dictionary to go from a domain to the associated duplicated texts\")\n"} | null |
olm-datasets | {"type": "directory", "name": "olm-datasets", "children": [{"type": "directory", "name": "analysis_scripts", "children": [{"type": "file", "name": "duplicates.py"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "term_counts.py"}, {"type": "file", "name": "timestamp_dist.py"}, {"type": "file", "name": "url_dist.py"}]}, {"type": "file", "name": "LICENSE"}, {"type": "directory", "name": "pipeline_scripts", "children": [{"type": "directory", "name": "common_crawl", "children": [{"type": "file", "name": "apply_bigscience_filters.py"}, {"type": "file", "name": "combine_last_modified_with_text_dataset.py"}, {"type": "directory", "name": "data-preparation", "children": []}, {"type": "directory", "name": "deduplicate-text-datasets", "children": []}, {"type": "file", "name": "deduplicate.py"}, {"type": "file", "name": "download_common_crawl.py"}, {"type": "file", "name": "download_pipeline_processing_models.sh"}, {"type": "directory", "name": "experimental", "children": [{"type": "file", "name": "add_perplexity.py"}, {"type": "file", "name": "filter_for_only_updated_websites.py"}, {"type": "directory", "name": "kenlm", "children": [{"type": "file", "name": "LICENSE"}, {"type": "file", "name": "model.py"}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "wikipedia", "children": [{"type": "file", "name": "en.arpa.bin"}, {"type": "file", "name": "en.sp.vocab"}]}]}]}, {"type": "file", "name": "get_last_modified_dataset_from_wat_downloads.py"}, {"type": "file", "name": "get_text_dataset_from_wet_downloads.py"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "remove_wikipedia_urls.py"}]}, {"type": "directory", "name": "wikipedia", "children": [{"type": "file", "name": "README.md"}]}]}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}]} | Per the repository [here](https://huggingface.co/datasets/olm/wikipedia), just run this Python code. It uses all CPUs available and should take less than an hour if you have a lot of CPUs (on the order of 100).
```
from datasets import load_dataset
ds = load_dataset("olm/wikipedia", language="en", date="20220920")
ds.save_to_disk("wikipedia_en_20220920")
ds.push_to_hub("wikipedia_en_20220920")
````
The code pulls the Wikipedia snapshot for the given date and language and does all the processing required to turn it into a clean pretraining dataset. You can get the dates for the latest wikipedia snapshots here: [https://dumps.wikimedia.org/enwiki/](https://dumps.wikimedia.org/enwiki/).
| {"requirements.txt": "datasets==2.6.1\nemoji==1.7.0\nfasttext==0.9.2\nsentencepiece==0.1.97\npypi-kenlm==0.1.20220713\ntext-dedup==0.2.1\nargparse==1.4.0\ndateparser==1.1.1\nmwparserfromhell==0.6.4\nmatplotlib==3.6.2\nmultiprocess==0.70.13\n", ".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 246a98a45d1f9eda0677bedac534bdfee695bf80 Hamza Amin <[email protected]> 1727369437 +0500\tclone: from https://github.com/huggingface/olm-datasets.git\n", ".git\\refs\\heads\\main": "246a98a45d1f9eda0677bedac534bdfee695bf80\n", "pipeline_scripts\\common_crawl\\apply_bigscience_filters.py": "from datasets import load_dataset, load_from_disk\nimport argparse\nfrom subprocess import run\nfrom os import path, mkdir\nfrom shutil import rmtree\nimport sys\nimport uuid\n\nsys.path.append(\"data-preparation/preprocessing/training/01b_oscar_cleaning_and_filtering\")\nfrom filtering import DatasetFiltering\n\nparser = argparse.ArgumentParser(description=\"Applies the BigScience BLOOM filters which were used on OSCAR. They are designed to improve text quality and remove pornographic content.\")\nparser.add_argument(\"--input_dataset_name\", help=\"The name of the input dataset.\", required=True)\nparser.add_argument(\"--output_dataset_name\", help=\"The name of the output dataset.\", required=True)\nparser.add_argument(\"--lang_id\", help=\"The language id of your dataset. This is necessary because the BigScience filters use a list of language-specific pornographic words, and also language-specific hyperparameters for text quality improvement.\", required=True)\nparser.add_argument(\"--split\", default=None, help=\"The split of the dataset to apply the filters to. Not all datasets have splits, so this is not a required argument.\")\nparser.add_argument(\"--text_column\", help=\"The name of the dataset column that contains the text.\", required=True)\nparser.add_argument(\"--num_proc\", type=int, help=\"The number of processes to use.\", required=True)\nparser.add_argument(\"--push_to_hub\", action=\"store_true\", help=\"Whether to push the output dataset to the Hugging Face Hub after saving it to the disk.\")\nparser.add_argument(\"--tmp_dir\", default=\".tmp_apply_bigscience_filters\", help=\"Directory to store temporary files. It will be deleted afterwards. Defaults to .tmp_apply_bigscience_filters.\")\nparser.add_argument(\"--load_from_hub_instead_of_disk\", action=\"store_true\", help=\"Whether to pull the input dataset by name from the Hugging Face Hub. If this argument is not used, it is assumed that there is a dataset saved to the disk with the input dataset name.\")\nargs = parser.parse_args()\n\nif args.load_from_hub_instead_of_disk:\n if args.split is None:\n ds = load_dataset(args.input_dataset_name)\n else:\n ds = load_dataset(args.input_dataset_name, split=args.split)\nelse:\n if args.split is None:\n ds = load_from_disk(args.input_dataset_name)\n else:\n ds = load_from_disk(args.input_dataset_name)[args.split]\n\n# We have to do this if the text column is not named \"text\" in the dataset,\n# because DatasetFiltering assumes that the name is \"text\".\ntemp_column_name = None\nif args.text_column != \"text\":\n if \"text\" in ds.colum_names:\n temp_column_name = str(uuid.uuid4())\n ds = ds.rename_column(\"text\", temp_column_name)\n ds = ds.rename_column(args.text_column, \"text\")\n\nif path.exists(args.tmp_dir):\n run(f\"rm -r {args.tmp_dir}\", shell=True)\n\nmkdir(args.tmp_dir)\ntmp_dataset_name = path.join(args.tmp_dir, \"intermediate_bigscience_filtered_dataset\")\n\ndataset_filtering = DatasetFiltering(\n dataset=ds,\n lang_dataset_id=args.lang_id,\n path_fasttext_model=\"sp_kenlm_ft_models/lid.176.bin\",\n path_sentencepiece_model=f\"sp_kenlm_ft_models/{args.lang_id}.sp.model\",\n path_kenlm_model=f\"sp_kenlm_ft_models/{args.lang_id}.arpa.bin\",\n num_proc=args.num_proc,\n path_dir_save_dataset=tmp_dataset_name,\n)\n\ndataset_filtering.modifying_documents()\ndataset_filtering.filtering()\ndataset_filtering.save_dataset()\n\nds = load_from_disk(path.join(tmp_dataset_name, args.lang_id))\n\n# We have to do this if the text column is not named \"text\" in the dataset,\n# because DatasetFiltering assumes that the name is \"text\".\nif args.text_column != \"text\":\n ds = ds.rename_column(\"text\", args.text_column)\n if temp_column_name is not None:\n ds = ds.rename_column(temp_column_name, \"text\")\n\nds.save_to_disk(args.output_dataset_name)\nrmtree(args.tmp_dir)\n\nif args.push_to_hub:\n ds.push_to_hub(args.output_dataset_name)\n"} | null |
olm-training | {"type": "directory", "name": "olm-training", "children": [{"type": "file", "name": "chunk_and_tokenize_datasets.py"}, {"type": "file", "name": "create_tokenizer.py"}, {"type": "file", "name": "LICENSE"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "t5_data_collator.py"}, {"type": "file", "name": "train_model.py"}]} | # Online Language Modelling Training Pipeline
This repo has the code for training models and tokenizers on the olm data, but it should work with any Hugging Face dataset with text examples. You can see the models for the OLM project here: https://huggingface.co/olm. They actually get better performance than their original static counterparts.
## Creating a Tokenizer and Tokenizing Datasets
Here is an example of how to tokenize the datasets and train a tokenizer:
```bash
python create_tokenizer.py --input_dataset_names Tristan/olm-wikipedia-20221001 Tristan/olm-CC-MAIN-2022-40-sampling-ratio-0.15894621295 Tristan/olm-CC-MAIN-2022-21-sampling-ratio-0.14775510204 Tristan/olm-CC-MAIN-2022-27-sampling-ratio-0.16142697881 Tristan/olm-CC-MAIN-2022-33-sampling-ratio-0.20 --existing_tokenizer_template roberta-base --output_tokenizer_name Tristan/olm-tokenizer --text_column text --push_to_hub
python chunk_and_tokenize_datasets.py --input_dataset_names Tristan/olm-wikipedia-20221001 Tristan/olm-CC-MAIN-2022-40-sampling-ratio-0.15894621295 --input_tokenizer_name Tristan/olm-tokenizer --output_dataset_name Tristan/olm-october-2022-tokenized-512 --text_column text --num_proc 224 --push_to_hub --max_len 512
python chunk_and_tokenize_datasets.py --input_dataset_names Tristan/olm-wikipedia-20221001 Tristan/olm-CC-MAIN-2022-40-sampling-ratio-0.15894621295 --input_tokenizer_name Tristan/olm-tokenizer --output_dataset_name Tristan/olm-october-2022-tokenized-1024 --text_column text --num_proc 224 --push_to_hub --max_len 1024
```
If you just want to train a model on the existing OLM data, you may be able to skip this step, though. We already have a trained tokenizer and tokenized datasets [here](https://huggingface.co/olm)
## Training a BERT/RoBERTa model from scratch on 410B tokens (this is the 100k step option in the RoBERTa paper, which uses about the same compute as the original BERT used)
```bash
python -m torch.distributed.launch --nproc_per_node=16 train_model.py --lm_type=mlm --dataset_id=Tristan/olm-october-2022-tokenized-512 --repository_id=Tristan/olm-roberta-base-oct-2022 --tokenizer_id=Tristan/olm-tokenizer --model_config_id=roberta-base --adam_beta2=0.98 --adam_epsilon=1e-6 --adam_beta1=0.9 --warmup_steps=24000 --max_steps=100000 --per_device_train_batch_size=20 --gradient_accumulation_steps=25 --learning_rate=6e-4
```
Note that the best hyperparameters are sensitive to both model architecture and scale. We found these hyperparameters to work well for the `roberta-base` model, but they may not work as well for e.g. `roberta-large`, or another architecture entirely.
## Training a GPT2 model from scratch on 300B tokens (the number of tokens reported in the GTP3 paper)
```bash
python -m torch.distributed.launch --nproc_per_node=16 train_model.py --lm_type=clm --dataset_id=Tristan/olm-october-2022-tokenized-1024 --repository_id=Tristan/olm-gpt2-oct-2022 --tokenizer_id=Tristan/olm-tokenizer --model_config_id=gpt2 --max_steps=580000 --learning_rate=1e-3 --warmup_steps=725 --adam_beta1=0.9 --adam_beta2=0.95 --adam_epsilon=1e-7 --weight_decay=0.1 --lr_scheduler_type=cosine --per_device_train_batch_size=8 --gradient_accumulation_steps=4
```
Note that the best hyperparameters are sensitive to both model architecture and scale. We found these hyperparameters to work well for the `gpt2` model, but they may not work as well for e.g. `gpt2-large`, or another architecture entirely.
## Training a T5 model from scratch
Note that it is also possible to train T5, although we haven't tuned the hyperparameters and we aren't trainig the T5 ourselves for the OLM project. If you want to train T5, you would specify arguments like this (but please take the time to find good hyperparameters yourself!).
```bash
python -m torch.distributed.launch --nproc_per_node=16 train_model.py --lm_type=t5 --dataset_id=Tristan/olm-october-2022-tokenized-568 --repository_id=Tristan/olm-t5-small-oct-2022 --tokenizer_id=Tristan/olm-t5-tokenizer --model_config_id=t5-small --adam_beta2=0.98 --adam_epsilon=1e-6 --adam_beta1=0.9 --warmup_steps=24000 --max_steps=100000 --per_device_train_batch_size=20 --gradient_accumulation_steps=25 --learning_rate=6e-4
```
Also note:
1. If you want your T5 to have an input length of 512, you need to pass it a tokenized dataset with examples of length 568. This is because the T5 denoising pretraining objective turns several tokens into one token, so the 568 tokens will be turned into 512 tokens before they are passed into the model.
2. You should train a separate OLM tokenizer with the `create_tokenizer.py` script above, and it should be based on the T5 tokenizer template to ensure that the tokenizer has the special denoising characters (e.g., just make `--existing_tokenizer_template=t5-small`).
## DeepSpeed compatibility
Our `train_model.py` script is compatible with DeepSpeed, enabling you to train big models (which do not fit on a single GPU) accross a cluster of nodes. Just specify `--deepspeed=<path to your deepspeed config>` in the `train_model.py` arguments to use it. An example of a DeepSpeed config that you could use is [here](https://huggingface.co/docs/transformers/main_classes/deepspeed#zero3-example)
## Details on compute
To train both our OLM GPT2 and OLM BERT/RoBERTa, we use a machine with 16 40GB A100's and around 1 TB of disk space. Each model takes about 5-6 days to train with this machine.
| {"requirements.txt": "datasets==2.6.1\ntransformers==4.24.0\ntorch==1.13.0\ntensorboard==2.10.1\n", ".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 c36f916744cad4e85329ed3da525dee8b0302163 Hamza Amin <[email protected]> 1727369324 +0500\tclone: from https://github.com/huggingface/olm-training.git\n", ".git\\refs\\heads\\main": "c36f916744cad4e85329ed3da525dee8b0302163\n"} | null |
OOP-assignments | {"type": "directory", "name": "OOP-assignments", "children": [{"type": "directory", "name": "Area and volume calculator", "children": [{"type": "file", "name": "lab10t1.cpp"}, {"type": "file", "name": "ReadMe.txt"}]}, {"type": "directory", "name": "Car Rental System", "children": [{"type": "file", "name": "carRentalSystem.cpp"}]}, {"type": "directory", "name": "LMS system", "children": [{"type": "file", "name": "LMS.cpp"}, {"type": "file", "name": "readme.txt"}]}, {"type": "directory", "name": "Phone book", "children": [{"type": "file", "name": "phonebook.cpp"}]}, {"type": "file", "name": "README.md"}]} | This is the complete code for a university management system with multiple users including admin, teacher and students.
Different users have differnt controls accordingly to store and display thier data.
| {".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 4db89f80b3233f8f07de3ba1f2128104db67174d Hamza Amin <[email protected]> 1727376259 +0500\tclone: from https://github.com/hamza-amin-4365/OOP-assignments.git\n", ".git\\refs\\heads\\main": "4db89f80b3233f8f07de3ba1f2128104db67174d\n"} | null |
OOP_PSL_Auction | {"type": "directory", "name": "OOP_PSL_Auction", "children": [{"type": "directory", "name": "PSL Auction System", "children": [{"type": "file", "name": "admin.cpp"}, {"type": "file", "name": "admin.h"}, {"type": "file", "name": "allrounders.cpp"}, {"type": "file", "name": "allrounders.h"}, {"type": "file", "name": "allrounders.txt"}, {"type": "file", "name": "ATeam.cpp"}, {"type": "file", "name": "ATeam.h"}, {"type": "file", "name": "batsmen.cpp"}, {"type": "file", "name": "batsmen.h"}, {"type": "file", "name": "batsmen.txt"}, {"type": "file", "name": "bowlers.cpp"}, {"type": "file", "name": "bowlers.h"}, {"type": "file", "name": "bowlers.txt"}, {"type": "file", "name": "main.cpp"}, {"type": "file", "name": "players.cpp"}, {"type": "file", "name": "players.h"}, {"type": "file", "name": "players.txt"}, {"type": "file", "name": "teams.txt"}]}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "Sln file (visual studio)", "children": [{"type": "file", "name": "Project3.sln"}, {"type": "file", "name": "Readme.txt"}]}]} | In this file you will find folder provided with soltuion file for visual studio.
| {".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 c417f48ac84cc93a1315bfc59fd457842c78571a Hamza Amin <[email protected]> 1727376261 +0500\tclone: from https://github.com/hamza-amin-4365/OOP_PSL_Auction.git\n", ".git\\refs\\heads\\main": "c417f48ac84cc93a1315bfc59fd457842c78571a\n", "PSL Auction System\\main.cpp": "#include <iostream>\n#include <vector>\n#include <string>\n#include <fstream>\n#include <sstream>\n#include <time.h>\n#include \"admin.h\"\n\nusing namespace std;\n#define RESET \"\\033[0m\"\n#define RED \"\\033[31m\" \n#define GREEN \"\\033[32m\" \n#define YELLOW \"\\033[33m\" \n#define BLUE \"\\033[34m\" \n#define MAGENTA \"\\033[35m\" \n#define CYAN \"\\033[36m\" \n#define WHITE \"\\033[37m\" \n#define BOLD \"\\033[1m\" \n#define UNDERLINE \"\\033[4m\" \n#define BLINK \"\\033[5m\" \n#define REVERSE \"\\033[7m\" \n\nconst int NUM_TEAMS = 6;\nconst string ADMIN_USERNAME = \"admin\";\nconst string ADMIN_PASSWORD = \"password\";\n\nstruct Team {\n string name;\n string username;\n string password;\n};\n\nint get_choice() {\n int choice;\n // system(\"CLS\");\n cout << MAGENTA << BOLD << \"PSL Auction Login\" << RESET << endl;\n cout << \"Select User Type:\\n\";\n cout << \"1. Team Manager\\n\";\n cout << \"2. Admin\\n\";\n cout << \"3. Exit\\n\";\n cout << \"Enter your choice (1-3): \";\n cin >> choice;\n return choice;\n}\n\nint get_team_choice() {\n int choice;\n do {\n cout << YELLOW << BOLD << \"Team Selection\" << RESET << endl;\n cout << \"Select Team:\\n\";\n cout << \"1. Lahore Qalandars\\n\";\n cout << \"2. Karachi Kings\\n\";\n cout << \"3. Multan Sultans\\n\";\n cout << \"4. Islamabad United\\n\";\n cout << \"5. Peshawar Zalmi\\n\";\n cout << \"6. Quetta Gladiators\\n\";\n cout << \"Enter your choice (1-6): \";\n cin >> choice;\n\n // Check if the choice is outside the valid range of values\n if (choice < 1 || choice > 6) {\n cout << RED << \"Invalid choice. Please try again.\" << RESET << endl;\n }\n } while (choice < 1 || choice > 6); // Repeat if choice is outside the valid range\n\n return choice;\n }\n\nvoid team_manager_login(Team team) {\n string username, password;\n bool login_successful = false;\n while (!login_successful) {\n cout << YELLOW << BOLD << \"Team Manager Login - \" << team.name << RESET << endl;\n cout << \"Username: \";\n cin >> username;\n cout << \"Password: \";\n cin >> password;\n vector<players> playerList;\n // check if the username and password are correct\n if (username == team.username && password == team.password) {\n cout << GREEN << \"Login successful!\" << RESET << endl;\n // TODO: add code to display team manager dashboard\n login_successful = true; // set flag to exit loop\n\n // auction starts here\n int category_choice, bid_id, bid_amount;\n char contbid;\n srand(time(0));\n\n cout << \"\\t\\tPSL AUCTION HOUSE\" << endl;\n cout << \"Rules: \" << endl;\n cout << \"1. A team can have a maximum of 15 players\" << endl;\n cout << \"2. A team can have a maximum of 4 foreign players\" << endl;\n cout << \"3. The team with the maximum bid wins\" << endl;\n\n\n do {\n do {\n cout << \"\\nFrom which category do you want to bid on:\" << endl;\n cout << \"1. Batsmen\" << endl;\n cout << \"2. Bowlers\" << endl;\n cout << \"3. All-Rounders\" << endl;\n cout << \"Enter your choice (1-3): \";\n cin >> category_choice;\n } while (category_choice < 1 || category_choice > 3);\n\n batsmen bats;\n bowler bo;\n all_rounder all;\n\n switch (category_choice) {\n case 1:\n bats.displayData(\"batsmen.txt\");\n break;\n\n case 2:\n bo.displayData(\"bowlers.txt\");\n break;\n\n case 3:\n all.displayData(\"allrounders.txt\");\n break;\n\n default:\n cout << \"Incorrect input!\" << endl;\n break;\n }\n\n cout << \"Do you want to continue to Bid? (y/n): \";\n cin >> contbid;\n\n while (contbid != 'y' && contbid != 'n') {\n cout << \"Invalid input! Do you want to continue to Bid? (y/n): \";\n cin >> contbid;\n }\n\n if (contbid == 'n') {\n break;\n }\n\n cout << \"Enter the Player ID you want to bid on: \";\n cin >> bid_id;\n cin.ignore();\n\n bool found = false;\n for (const players& player : playerList) {\n if (player.getID() == bid_id) {\n found = true;\n cout << \"Player found\" << endl;\n break;\n }\n }\n if (!found) {\n cout << \"Player not found\" << endl;\n continue;\n }\n\n int randomBid, randomTeam;\n randomBid = 100000 + (rand() % 900000);\n cout << \"How much do you want to bid: \";\n cin >> bid_amount;\n cin.ignore();\n while (true) {\n if (randomBid > bid_amount) {\n cout << \"Another team has made a bid of $\" << randomBid << endl;\n cout << \"Do you wish to continue? (y/n):\";\n cin >> contbid;\n while (contbid != 'y' && contbid != 'n') {\n cout << \"Invalid input! Do you wish to continue? (y/n): \";\n cin >> contbid;\n }\n if (contbid == 'n') {\n break;\n }\n }\n else if (randomBid < bid_amount) {\n cout << \"You have won the player\" << endl;\n break;\n }\n }\n\n cout << \"Do you wish to continue bidding in another category (y/n): \";\n cin >> contbid;\n while (contbid != 'y' && contbid != 'n') {\n cout << \"Invalid input! Do you wish to continue bidding in another category (y/n): \";\n cin >> contbid;\n }\n\n } while (contbid == 'y');\n //auction ends here\n }\n else {\n cout << RED << \"Incorrect username or password. Please try again.\" << RESET << endl;\n }\n }\n }\n\nvoid admin_login() {\n string username, password;\n\n cout << YELLOW << BOLD << \"Admin Login\" << RESET << endl;\n cout << \"Username: \";\n cin >> username;\n cout << \"Password: \";\n cin >> password;\n\n // check if the username and password are correct\n if (username == ADMIN_USERNAME && password == ADMIN_PASSWORD) {\n cout << GREEN << \"Login successful!\" << RESET << endl;\n // TODO: add code to display admin dashboard\n std::vector<players> playerList; // Declare and initialize vector object\n adminMenu(playerList); // Pass vector to function\n\n \n }\n else {\n cout << RED << \"Incorrect username or password. Please try again.\" << RESET << endl;\n }\n}\n\nint main() {\n system(\"CLS\");\n // Define an array to hold information about the teams\n Team teams[NUM_TEAMS];\n // Read team information from a file\n ifstream infile(\"teams.txt\");\n \n \n string line;\n int i = 0;\n while (getline(infile, line)) {\n vector<string> fields;\n string field = \"\";\n for (char c : line) {\n if (c == ',') {\n fields.push_back(field);\n field = \"\";\n }\n else {\n field += c;\n }\n }\n fields.push_back(field);\n teams[i].name = fields[0];\n teams[i].username = fields[1];\n teams[i].password = fields[2];\n i++;\n }\n if (!infile.eof() && infile.fail()) {\n // An error occurred during the read\n cerr << \"Error: Failed to read teams.txt\" << endl;\n }\n else {\n // Read operation was successful\n cout << \"Teams successfully read from teams.txt\" << endl;\n }\n // Display the login menu and get the user's choice\n int choice;\n do {\n choice = get_choice();\n\n switch (choice) {\n case 1: // Team Manager Login\n {\n int team_choice = get_team_choice();\n team_manager_login(teams[team_choice - 1]);\n break;\n }\n case 2: // Admin Login\n admin_login();\n break;\n case 3: // Exit\n cout << RED << BOLD << \"Good bye!\" << RESET << endl;\n return 0;\n default:\n cout << RED << \"Invalid choice. Please try again.\" << RESET << endl;\n break;\n }\n\n } while (choice);\n\n return 0;\n}\n//player.getID() == bid_id"} | null |
open-muse | {"type": "directory", "name": "open-muse", "children": [{"type": "directory", "name": "benchmark", "children": [{"type": "directory", "name": "artifacts", "children": [{"type": "file", "name": "all.csv"}]}, {"type": "file", "name": "model_quality.py"}, {"type": "file", "name": "muse_chart.py"}, {"type": "file", "name": "muse_perf.py"}, {"type": "file", "name": "muse_table.py"}, {"type": "file", "name": "README.md"}]}, {"type": "file", "name": "CITATION.cff"}, {"type": "directory", "name": "configs", "children": [{"type": "file", "name": "cc12m.yaml"}, {"type": "file", "name": "cc12m_movq.yaml"}, {"type": "file", "name": "cc12m_uvit.yaml"}, {"type": "file", "name": "cc12m_uvit_clip.yaml"}, {"type": "file", "name": "cc12m_uvit_larger_paellavq_f8_clip.yaml"}, {"type": "file", "name": "cc12m_uvit_paellavq.yaml"}, {"type": "file", "name": "cc12m_uvit_paellavq_larger.yaml"}, {"type": "file", "name": "coyo700m_uvit_clip.yaml"}, {"type": "file", "name": "coyo_f8_clip_embeds.yaml"}, {"type": "file", "name": "coyo_f8_preencoded.yaml"}, {"type": "file", "name": "imagenet.yaml"}, {"type": "file", "name": "imagenet_movq.yaml"}, {"type": "file", "name": "imagenet_text2image.yaml"}, {"type": "file", "name": "imagenet_text2image_movq_conv.yaml"}, {"type": "file", "name": "laion-aesthetic-475-max-1024-joined-with-stability-metadata-laicov2_shards.yaml"}, {"type": "file", "name": "laion5plus_uvit_clip.yaml"}, {"type": "file", "name": "laiona6plus_f8_preencoded.yaml"}, {"type": "file", "name": "laiona6plus_preencod_test.yaml"}, {"type": "file", "name": "laiona6plus_prencode_random_replace.yaml"}, {"type": "file", "name": "laiona6plus_uvit_clip.yaml"}, {"type": "file", "name": "laiona6plus_uvit_clip_f8.yaml"}, {"type": "file", "name": "laiona6plus_uvit_clip_pool_embeds.yaml"}, {"type": "file", "name": "m4_shards.yaml"}, {"type": "file", "name": "research_run_512.yaml"}, {"type": "file", "name": "research_run_512_with_downsample.yaml"}, {"type": "file", "name": "research_run_512_with_downsample_finetune_on_sdxl_synthetic_data.yaml"}, {"type": "file", "name": "sdxl_synthetic_dataset_shards.yaml"}, {"type": "file", "name": "template_config.yaml"}]}, {"type": "directory", "name": "inpainting_validation", "children": [{"type": "directory", "name": "a bright jungle", "children": []}, {"type": "directory", "name": "a field in the mountains", "children": []}, {"type": "directory", "name": "a man with glasses", "children": []}, {"type": "directory", "name": "dog sitting on bench", "children": []}, {"type": "directory", "name": "person sitting on bench outside", "children": []}]}, {"type": "file", "name": "LICENSE"}, {"type": "file", "name": "Makefile"}, {"type": "directory", "name": "muse", "children": [{"type": "file", "name": "data.py"}, {"type": "file", "name": "logging.py"}, {"type": "file", "name": "lr_schedulers.py"}, {"type": "file", "name": "modeling_ema.py"}, {"type": "file", "name": "modeling_maskgit_vqgan.py"}, {"type": "file", "name": "modeling_movq.py"}, {"type": "file", "name": "modeling_paella_vq.py"}, {"type": "file", "name": "modeling_taming_vqgan.py"}, {"type": "file", "name": "modeling_transformer.py"}, {"type": "file", "name": "modeling_transformer_v2.py"}, {"type": "file", "name": "modeling_utils.py"}, {"type": "file", "name": "pipeline_muse.py"}, {"type": "file", "name": "sampling.py"}, {"type": "file", "name": "training_utils.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "pyproject.toml"}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "scripts", "children": [{"type": "file", "name": "benchmark_models.py"}, {"type": "file", "name": "calculate_fid.py"}, {"type": "file", "name": "compute_offline_ema.py"}, {"type": "file", "name": "convert_coco_to_wds.py"}, {"type": "file", "name": "convert_imagenet_to_wds.py"}, {"type": "file", "name": "convert_maskgit_vqgan.py"}, {"type": "file", "name": "gen_sdxl_synthetic_dataset.py"}, {"type": "file", "name": "log_generations_wandb.py"}, {"type": "file", "name": "log_inpainting_images.py"}, {"type": "file", "name": "pre_encode.py"}]}, {"type": "file", "name": "setup.cfg"}, {"type": "file", "name": "setup.py"}, {"type": "directory", "name": "slurm_scripts", "children": [{"type": "file", "name": "calculate_fid_coco_calculate_fid.slurm"}, {"type": "file", "name": "calculate_fid_coco_generate_images.slurm"}, {"type": "file", "name": "cc12m.slurm"}, {"type": "file", "name": "gen_sdxl_synthetic_dataset.slurm"}, {"type": "file", "name": "imagenet.slurm"}, {"type": "file", "name": "imagenet_movq_ds.slurm"}, {"type": "file", "name": "imagenet_text2image.slurm"}, {"type": "file", "name": "pre_encode_coyo.slurm"}, {"type": "file", "name": "pre_encode_laion_5.slurm"}, {"type": "file", "name": "pre_encode_laion_6.slurm"}, {"type": "file", "name": "research_run_512.slurm"}, {"type": "file", "name": "research_run_512_with_downsample.slurm"}, {"type": "file", "name": "research_run_512_with_downsample_finetune_on_sdxl_synthetic_data.slurm"}]}, {"type": "file", "name": "test.py"}, {"type": "directory", "name": "training", "children": [{"type": "file", "name": "data.py"}, {"type": "file", "name": "optimizer.py"}, {"type": "file", "name": "train_maskgit_imagenet.py"}, {"type": "file", "name": "train_muse.py"}, {"type": "file", "name": "train_vqgan.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "validation_prompts", "children": [{"type": "file", "name": "cc_validation_prompts.txt"}, {"type": "file", "name": "dalle_mini_prompts.txt"}]}]} | These are a set of script to generate performance benchmarks of open muse compared
to other models
### A100


### 4090

 | {"setup.py": "# Copyright 2023 The HuggingFace Team. All rights reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\nimport os\n\n# To use a consistent encoding\nfrom codecs import open\n\nimport setuptools\n\n_deps = [\n \"transformers==4.33\",\n \"accelerate==0.21\",\n \"einops==0.6.0\",\n \"omegaconf==2.3.0\",\n \"webdataset>=0.2.39\",\n \"datasets\",\n \"wandb\",\n \"sentencepiece\", # for T5 tokenizer\n \"plotly\",\n \"pandas\",\n]\n\n_extras_dev_deps = [\n \"black[jupyter]~=23.1\",\n \"isort>=5.5.4\",\n \"flake8>=3.8.3\",\n]\n\n\nhere = os.path.abspath(os.path.dirname(__file__))\n\nwith open(os.path.join(here, \"README.md\"), encoding=\"utf-8\") as f:\n long_description = f.read()\n\n# read version\nwith open(os.path.join(here, \"muse\", \"__init__.py\"), encoding=\"utf-8\") as f:\n for line in f:\n if line.startswith(\"__version__\"):\n version = line.split(\"=\")[1].strip().strip('\"')\n break\n else:\n raise RuntimeError(\"Unable to find version string.\")\n\nsetuptools.setup(\n name=\"muse\",\n version=version,\n description=\"The best generative model in PyTorch\",\n long_description=long_description,\n long_description_content_type=\"text/markdown\",\n packages=setuptools.find_packages(),\n install_requires=_deps,\n extras_require={\n \"dev\": [_extras_dev_deps],\n },\n)\n", ".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 64e1afe033717d795866ab8204484705cd4dc3f7 Hamza Amin <[email protected]> 1727369338 +0500\tclone: from https://github.com/huggingface/open-muse.git\n", ".git\\refs\\heads\\main": "64e1afe033717d795866ab8204484705cd4dc3f7\n"} | null |
open_asr_leaderboard | {"type": "directory", "name": "open_asr_leaderboard", "children": [{"type": "directory", "name": "ctranslate2", "children": [{"type": "file", "name": "run_eval.py"}, {"type": "file", "name": "run_whisper.sh"}]}, {"type": "directory", "name": "data", "children": []}, {"type": "file", "name": "LICENSE"}, {"type": "directory", "name": "nemo_asr", "children": [{"type": "file", "name": "run_canary.sh"}, {"type": "file", "name": "run_eval.py"}, {"type": "file", "name": "run_fast_conformer_ctc.sh"}, {"type": "file", "name": "run_fast_conformer_rnnt.sh"}]}, {"type": "directory", "name": "normalizer", "children": [{"type": "file", "name": "data_utils.py"}, {"type": "file", "name": "english_abbreviations.py"}, {"type": "file", "name": "eval_utils.py"}, {"type": "file", "name": "normalizer.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "requirements", "children": [{"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "requirements_ctranslate2.txt"}, {"type": "file", "name": "requirements_nemo.txt"}, {"type": "file", "name": "requirements_speechbrain.txt"}]}, {"type": "directory", "name": "speechbrain", "children": [{"type": "file", "name": "run_conformer.sh"}, {"type": "file", "name": "run_conformersmall.sh"}, {"type": "file", "name": "run_crdnn_rnnlm.sh"}, {"type": "file", "name": "run_crdnn_transformerlm.sh"}, {"type": "file", "name": "run_eval.py"}, {"type": "file", "name": "run_transformer_transformerlm.sh"}, {"type": "file", "name": "run_wav2vec2_commonvoice.sh"}, {"type": "file", "name": "run_wav2vec2_librispeech.sh"}]}, {"type": "directory", "name": "transformers", "children": [{"type": "file", "name": "run_data2vec.sh"}, {"type": "file", "name": "run_eval.py"}, {"type": "file", "name": "run_hubert.sh"}, {"type": "file", "name": "run_mms.sh"}, {"type": "file", "name": "run_wav2vec2.sh"}, {"type": "file", "name": "run_wav2vec2_conformer.sh"}, {"type": "file", "name": "run_whisper.sh"}]}]} | # Open ASR Leaderboard
This repository contains the code for the Open ASR Leaderboard. The leaderboard is a Gradio Space that allows users to compare the accuracy of ASR models on a variety of datasets. The leaderboard is hosted at [hf-audio/open_asr_leaderboard](https://huggingface.co/spaces/hf-audio/open_asr_leaderboard).
# Requirements
Each library has its own set of requirements. We recommend using a clean conda environment, with Python 3.10 or above.
1) Clone this repository.
2) Install PyTorch by following the instructions here: https://pytorch.org/get-started/locally/
3) Install the common requirements for all library by running `pip install -r requirements/requirements.txt`.
4) Install the requirements for each library you wish to evaluate by running `pip install -r requirements/requirements_<library_name>.txt`.
5) Connect your Hugging Face account by running `huggingface-cli login`.
**Note:** If you wish to run NeMo, the benchmark currently needs CUDA 12.6 to fix a problem in previous drivers for RNN-T inference with cooperative kernels inside conditional nodes (see here: https://github.com/NVIDIA/NeMo/pull/9869). Running `nvidia-smi` should output "CUDA Version: 12.6" or higher.
# Evaluate a model
Each library has a script `run_eval.py` that acts as the entry point for evaluating a model. The script is run by the corresponding bash script for each model that is being evaluated. The script then outputs a JSONL file containing the predictions of the model on each dataset, and summarizes the Word Error Rate (WER) and Inverse Real-Time Factor (RTFx) of the model on each dataset after completion.
To reproduce existing results:
1) Change directory into the library you wish to evaluate. For example, `cd transformers`.
2) Run the bash script for the model you wish to evaluate. For example, `bash run_wav2vec2.sh`.
**Note**: All evaluations were run using an NVIDIA A100-SXM4-80GB GPU, with NVIDIA driver 560.28.03, CUDA 12.6, and PyTorch 2.4.0. You should ensure you use the same configuration when submitting results. If you are unable to create an equivalent machine, please request one of the maintainers to run your scripts for evaluation!
# Add a new library
To add a new library for evaluation in this benchmark, please follow the steps below:
1) Fork this repository and create a new branch
2) Create a new directory for your library. For example, `mkdir transformers`.
3) Copy the template `run_eval.py` script below into your new directory. The script should be updated for the new library by making two modifications. Otherwise, please try to keep the structure of the script the same as in the template. In particular, the data loading, evaluation and manifest writing must be done in the same way as other libraries for consistency.
1) Update the model loading logic in the `main` function
2) Update the inference logic in the `benchmark` function
<details>
<summary> Template script for Transformers: </summary>
```python
import argparse
import os
import torch
from transformers import WhisperForConditionalGeneration, WhisperProcessor
import evaluate
from normalizer import data_utils
import time
from tqdm import tqdm
wer_metric = evaluate.load("wer")
def main(args):
# Load model (FILL ME!)
model = WhisperForConditionalGeneration.from_pretrained(args.model_id, torch_dtype=torch.bfloat16).to(args.device)
processor = WhisperProcessor.from_pretrained(args.model_id)
def benchmark(batch):
# Load audio inputs
audios = [audio["array"] for audio in batch["audio"]]
batch["audio_length_s"] = [len(audio) / batch["audio"][0]["sampling_rate"] for audio in audios]
minibatch_size = len(audios)
# Start timing
start_time = time.time()
# INFERENCE (FILL ME! Replacing 1-3 with steps from your library)
# 1. Pre-processing
inputs = processor(audios, sampling_rate=16_000, return_tensors="pt").to(args.device)
inputs["input_features"] = inputs["input_features"].to(torch.bfloat16)
# 2. Generation
pred_ids = model.generate(**inputs)
# 3. Post-processing
pred_text = processor.batch_decode(pred_ids, skip_special_tokens=True)
# End timing
runtime = time.time() - start_time
# normalize by minibatch size since we want the per-sample time
batch["transcription_time_s"] = minibatch_size * [runtime / minibatch_size]
# normalize transcriptions with English normalizer
batch["predictions"] = [data_utils.normalizer(pred) for pred in pred_text]
batch["references"] = batch["norm_text"]
return batch
if args.warmup_steps is not None:
warmup_dataset = data_utils.load_data(args)
warmup_dataset = data_utils.prepare_data(warmup_dataset)
num_warmup_samples = args.warmup_steps * args.batch_size
if args.streaming:
warmup_dataset = warmup_dataset.take(num_warmup_samples)
else:
warmup_dataset = warmup_dataset.select(range(min(num_warmup_samples, len(warmup_dataset))))
warmup_dataset = iter(warmup_dataset.map(benchmark, batch_size=args.batch_size, batched=True))
for _ in tqdm(warmup_dataset, desc="Warming up..."):
continue
dataset = data_utils.load_data(args)
dataset = data_utils.prepare_data(dataset)
if args.max_eval_samples is not None and args.max_eval_samples > 0:
print(f"Subsampling dataset to first {args.max_eval_samples} samples!")
if args.streaming:
dataset = dataset.take(args.max_eval_samples)
else:
dataset = dataset.select(range(min(args.max_eval_samples, len(dataset))))
dataset = dataset.map(
benchmark, batch_size=args.batch_size, batched=True, remove_columns=["audio"],
)
all_results = {
"audio_length_s": [],
"transcription_time_s": [],
"predictions": [],
"references": [],
}
result_iter = iter(dataset)
for result in tqdm(result_iter, desc="Samples..."):
for key in all_results:
all_results[key].append(result[key])
# Write manifest results (WER and RTFX)
manifest_path = data_utils.write_manifest(
all_results["references"],
all_results["predictions"],
args.model_id,
args.dataset_path,
args.dataset,
args.split,
audio_length=all_results["audio_length_s"],
transcription_time=all_results["transcription_time_s"],
)
print("Results saved at path:", os.path.abspath(manifest_path))
wer = wer_metric.compute(
references=all_results["references"], predictions=all_results["predictions"]
)
wer = round(100 * wer, 2)
rtfx = round(sum(all_results["audio_length_s"]) / sum(all_results["transcription_time_s"]), 2)
print("WER:", wer, "%", "RTFx:", rtfx)
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument(
"--model_id",
type=str,
required=True,
help="Model identifier. Should be loadable with 🤗 Transformers",
)
parser.add_argument(
"--dataset_path",
type=str,
default="esb/datasets",
help="Dataset path. By default, it is `esb/datasets`",
)
parser.add_argument(
"--dataset",
type=str,
required=True,
help="Dataset name. *E.g.* `'librispeech_asr` for the LibriSpeech ASR dataset, or `'common_voice'` for Common Voice. The full list of dataset names "
"can be found at `https://huggingface.co/datasets/esb/datasets`",
)
parser.add_argument(
"--split",
type=str,
default="test",
help="Split of the dataset. *E.g.* `'validation`' for the dev split, or `'test'` for the test split.",
)
parser.add_argument(
"--device",
type=int,
default=-1,
help="The device to run the pipeline on. -1 for CPU (default), 0 for the first GPU and so on.",
)
parser.add_argument(
"--batch_size",
type=int,
default=1,
help="Number of samples to go through each streamed batch.",
)
parser.add_argument(
"--max_eval_samples",
type=int,
default=None,
help="Number of samples to be evaluated. Put a lower number e.g. 64 for testing this script.",
)
parser.add_argument(
"--no-streaming",
dest="streaming",
action="store_false",
help="Choose whether you'd like to download the entire dataset or stream it during the evaluation.",
)
parser.add_argument(
"--warmup_steps",
type=int,
default=10,
help="Number of warm-up steps to run before launching the timed runs.",
)
args = parser.parse_args()
parser.set_defaults(streaming=False)
main(args)
```
</details>
4) Create one bash file per model type following the conversion `run_<model_type>.sh`.
- The bash script should follow the same steps as other libraries. You can copy the example for [run_whisper.sh](./transformers/run_whisper.sh) and update it to your library
- Different model sizes of the same type should share the script. For example `Wav2Vec` and `Wav2Vec2` would be two separate scripts, but different size of `Wav2Vec2` would be part of the same script.
- **Important:** for a given model, you can tune decoding hyper-parameters to maximize benchmark performance (e.g. batch size, beam size, etc.). However, you must use the **same decoding hyper-parameters** for each dataset in the benchmark. For more details, refer to the [ESB paper](https://arxiv.org/abs/2210.13352).
5) Submit a PR for your changes.
# Add a new model
To add a model from a new library for evaluation in this benchmark, you can follow the steps noted above.
To add a model from an existing library, we can simplify the steps to:
1) If the model is already supported, but of a different size, simply add the new model size to the list of models run by the corresponding bash script.
2) If the model is entirely new, create a new bash script based on others of that library and add the new model and its sizes to that script.
3) Run the evaluation script to obtain a list of predictions for the new model on each of the datasets.
4) Submit a PR for your changes.
# Citation
```bibtex
@misc{open-asr-leaderboard,
title = {Open Automatic Speech Recognition Leaderboard},
author = {Srivastav, Vaibhav and Majumdar, Somshubra and Koluguri, Nithin and Moumen, Adel and Gandhi, Sanchit and Hugging Face Team and Nvidia NeMo Team and SpeechBrain Team},
year = 2023,
publisher = {Hugging Face},
howpublished = "\\url{https://huggingface.co/spaces/huggingface.co/spaces/open-asr-leaderboard/leaderboard}"
}
```
| {".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 fe50cf007429be69c08038f7be25df01c6f2db4a Hamza Amin <[email protected]> 1727369423 +0500\tclone: from https://github.com/huggingface/open_asr_leaderboard.git\n", ".git\\refs\\heads\\main": "fe50cf007429be69c08038f7be25df01c6f2db4a\n", "requirements\\requirements.txt": "torch\ntransformers\nevaluate\ndatasets\nlibrosa\njiwer\n"} | null |
optimum | {"type": "directory", "name": "optimum", "children": [{"type": "file", "name": "CODE_OF_CONDUCT.md"}, {"type": "file", "name": "CONTRIBUTING.md"}, {"type": "directory", "name": "docs", "children": [{"type": "file", "name": "combine_docs.py"}, {"type": "file", "name": "conftest.py"}, {"type": "file", "name": "Dockerfile"}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "source", "children": [{"type": "directory", "name": "bettertransformer", "children": [{"type": "file", "name": "overview.mdx"}, {"type": "directory", "name": "tutorials", "children": [{"type": "file", "name": "contribute.mdx"}, {"type": "file", "name": "convert.mdx"}]}]}, {"type": "directory", "name": "concept_guides", "children": [{"type": "file", "name": "quantization.mdx"}]}, {"type": "directory", "name": "exporters", "children": [{"type": "directory", "name": "onnx", "children": [{"type": "file", "name": "overview.mdx"}, {"type": "directory", "name": "package_reference", "children": [{"type": "file", "name": "configuration.mdx"}, {"type": "file", "name": "export.mdx"}]}, {"type": "directory", "name": "usage_guides", "children": [{"type": "file", "name": "contribute.mdx"}, {"type": "file", "name": "export_a_model.mdx"}]}]}, {"type": "file", "name": "overview.mdx"}, {"type": "file", "name": "task_manager.mdx"}, {"type": "directory", "name": "tflite", "children": [{"type": "file", "name": "overview.mdx"}, {"type": "directory", "name": "package_reference", "children": [{"type": "file", "name": "configuration.mdx"}, {"type": "file", "name": "export.mdx"}]}, {"type": "directory", "name": "usage_guides", "children": [{"type": "file", "name": "contribute.mdx"}, {"type": "file", "name": "export_a_model.mdx"}]}]}]}, {"type": "file", "name": "index.mdx"}, {"type": "file", "name": "installation.mdx"}, {"type": "directory", "name": "llm_quantization", "children": [{"type": "directory", "name": "usage_guides", "children": [{"type": "file", "name": "quantization.mdx"}]}]}, {"type": "file", "name": "notebooks.md"}, {"type": "file", "name": "nvidia_overview.mdx"}, {"type": "directory", "name": "onnxruntime", "children": [{"type": "directory", "name": "concept_guides", "children": [{"type": "file", "name": "onnx.mdx"}]}, {"type": "file", "name": "overview.mdx"}, {"type": "directory", "name": "package_reference", "children": [{"type": "file", "name": "configuration.mdx"}, {"type": "file", "name": "modeling_ort.mdx"}, {"type": "file", "name": "optimization.mdx"}, {"type": "file", "name": "quantization.mdx"}, {"type": "file", "name": "trainer.mdx"}]}, {"type": "file", "name": "quickstart.mdx"}, {"type": "directory", "name": "usage_guides", "children": [{"type": "file", "name": "amdgpu.mdx"}, {"type": "file", "name": "gpu.mdx"}, {"type": "file", "name": "models.mdx"}, {"type": "file", "name": "optimization.mdx"}, {"type": "file", "name": "pipelines.mdx"}, {"type": "file", "name": "quantization.mdx"}, {"type": "file", "name": "trainer.mdx"}]}]}, {"type": "file", "name": "quicktour.mdx"}, {"type": "directory", "name": "torch_fx", "children": [{"type": "directory", "name": "concept_guides", "children": [{"type": "file", "name": "symbolic_tracer.mdx"}]}, {"type": "file", "name": "overview.mdx"}, {"type": "directory", "name": "package_reference", "children": [{"type": "file", "name": "optimization.mdx"}]}, {"type": "directory", "name": "usage_guides", "children": [{"type": "file", "name": "optimization.mdx"}]}]}, {"type": "directory", "name": "utils", "children": [{"type": "file", "name": "dummy_input_generators.mdx"}, {"type": "file", "name": "normalized_config.mdx"}]}, {"type": "file", "name": "_redirects.yml"}, {"type": "file", "name": "_toctree.yml"}]}]}, {"type": "directory", "name": "examples", "children": [{"type": "directory", "name": "onnxruntime", "children": [{"type": "directory", "name": "optimization", "children": [{"type": "directory", "name": "multiple-choice", "children": [{"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "run_swag.py"}]}, {"type": "directory", "name": "question-answering", "children": [{"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "run_qa.py"}, {"type": "file", "name": "trainer_qa.py"}, {"type": "file", "name": "utils_qa.py"}]}, {"type": "directory", "name": "text-classification", "children": [{"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "run_glue.py"}]}, {"type": "directory", "name": "token-classification", "children": [{"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "run_ner.py"}]}]}, {"type": "directory", "name": "quantization", "children": [{"type": "directory", "name": "image-classification", "children": [{"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "run_image_classification.py"}]}, {"type": "directory", "name": "multiple-choice", "children": [{"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "run_swag.py"}]}, {"type": "directory", "name": "question-answering", "children": [{"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "run_qa.py"}, {"type": "file", "name": "trainer_qa.py"}, {"type": "file", "name": "utils_qa.py"}]}, {"type": "directory", "name": "text-classification", "children": [{"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "run_glue.py"}]}, {"type": "directory", "name": "token-classification", "children": [{"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "run_ner.py"}]}]}, {"type": "directory", "name": "training", "children": [{"type": "directory", "name": "docker", "children": [{"type": "file", "name": "Dockerfile-ort-nightly-cu118"}, {"type": "file", "name": "Dockerfile-ort-nightly-rocm57"}, {"type": "file", "name": "Dockerfile-ort1.17.1-cu118"}]}, {"type": "directory", "name": "image-classification", "children": [{"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "run_image_classification.py"}]}, {"type": "directory", "name": "language-modeling", "children": [{"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "run_clm.py"}, {"type": "file", "name": "run_mlm.py"}]}, {"type": "directory", "name": "question-answering", "children": [{"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "run_qa.py"}, {"type": "file", "name": "trainer_qa.py"}, {"type": "file", "name": "utils_qa.py"}]}, {"type": "directory", "name": "stable-diffusion", "children": [{"type": "directory", "name": "text-to-image", "children": [{"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "train_text_to_image.py"}]}]}, {"type": "directory", "name": "summarization", "children": [{"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "run_summarization.py"}]}, {"type": "directory", "name": "text-classification", "children": [{"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "run_classification.py"}, {"type": "file", "name": "run_glue.py"}, {"type": "file", "name": "zero_stage_2.json"}]}, {"type": "directory", "name": "token-classification", "children": [{"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "run_ner.py"}]}, {"type": "directory", "name": "translation", "children": [{"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "run_translation.py"}]}]}]}]}, {"type": "file", "name": "LICENSE"}, {"type": "file", "name": "Makefile"}, {"type": "file", "name": "MANIFEST.in"}, {"type": "directory", "name": "notebooks", "children": [{"type": "file", "name": "README.md"}]}, {"type": "directory", "name": "optimum", "children": [{"type": "directory", "name": "bettertransformer", "children": [{"type": "directory", "name": "models", "children": [{"type": "file", "name": "attention.py"}, {"type": "file", "name": "base.py"}, {"type": "file", "name": "decoder_models.py"}, {"type": "file", "name": "encoder_models.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "transformation.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "commands", "children": [{"type": "file", "name": "base.py"}, {"type": "file", "name": "env.py"}, {"type": "directory", "name": "export", "children": [{"type": "file", "name": "base.py"}, {"type": "file", "name": "onnx.py"}, {"type": "file", "name": "tflite.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "optimum_cli.py"}, {"type": "directory", "name": "register", "children": [{"type": "file", "name": "README.md"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "configuration_utils.py"}, {"type": "file", "name": "conftest.py"}, {"type": "directory", "name": "exporters", "children": [{"type": "file", "name": "base.py"}, {"type": "file", "name": "error_utils.py"}, {"type": "directory", "name": "onnx", "children": [{"type": "file", "name": "base.py"}, {"type": "file", "name": "config.py"}, {"type": "file", "name": "constants.py"}, {"type": "file", "name": "convert.py"}, {"type": "file", "name": "model_configs.py"}, {"type": "file", "name": "model_patcher.py"}, {"type": "file", "name": "utils.py"}, {"type": "file", "name": "__init__.py"}, {"type": "file", "name": "__main__.py"}]}, {"type": "file", "name": "tasks.py"}, {"type": "directory", "name": "tflite", "children": [{"type": "file", "name": "base.py"}, {"type": "file", "name": "config.py"}, {"type": "file", "name": "convert.py"}, {"type": "file", "name": "model_configs.py"}, {"type": "file", "name": "__init__.py"}, {"type": "file", "name": "__main__.py"}]}, {"type": "file", "name": "utils.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "fx", "children": [{"type": "directory", "name": "optimization", "children": [{"type": "file", "name": "transformations.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "parallelization", "children": [{"type": "file", "name": "api.py"}, {"type": "file", "name": "core.py"}, {"type": "file", "name": "decomp.py"}, {"type": "directory", "name": "distributed", "children": [{"type": "file", "name": "dist_ops.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "op_registry", "children": [{"type": "file", "name": "op_handlers.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "parallel_layers", "children": [{"type": "file", "name": "embedding.py"}, {"type": "file", "name": "linear.py"}, {"type": "file", "name": "loss.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "passes.py"}, {"type": "file", "name": "utils.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "quantization", "children": [{"type": "file", "name": "functions.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "utils.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "gptq", "children": [{"type": "file", "name": "constants.py"}, {"type": "file", "name": "data.py"}, {"type": "file", "name": "eval.py"}, {"type": "file", "name": "quantizer.py"}, {"type": "file", "name": "utils.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "modeling_base.py"}, {"type": "directory", "name": "onnx", "children": [{"type": "file", "name": "configuration.py"}, {"type": "file", "name": "graph_transformations.py"}, {"type": "file", "name": "modeling_seq2seq.py"}, {"type": "file", "name": "transformations_utils.py"}, {"type": "file", "name": "utils.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "onnxruntime", "children": [{"type": "file", "name": "base.py"}, {"type": "file", "name": "configuration.py"}, {"type": "file", "name": "constants.py"}, {"type": "file", "name": "graph.py"}, {"type": "directory", "name": "io_binding", "children": [{"type": "file", "name": "io_binding_helper.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "model.py"}, {"type": "file", "name": "modeling_decoder.py"}, {"type": "file", "name": "modeling_diffusion.py"}, {"type": "file", "name": "modeling_ort.py"}, {"type": "file", "name": "modeling_seq2seq.py"}, {"type": "directory", "name": "models", "children": [{"type": "file", "name": "bloom.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "optimization.py"}, {"type": "directory", "name": "preprocessors", "children": [{"type": "directory", "name": "passes", "children": [{"type": "file", "name": "excluders.py"}, {"type": "file", "name": "fully_connected.py"}, {"type": "file", "name": "gelu.py"}, {"type": "file", "name": "layernorm.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "quantization.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "quantization.py"}, {"type": "directory", "name": "runs", "children": [{"type": "file", "name": "calibrator.py"}, {"type": "file", "name": "utils.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "subpackage", "children": [{"type": "directory", "name": "commands", "children": [{"type": "file", "name": "base.py"}, {"type": "file", "name": "optimize.py"}, {"type": "file", "name": "quantize.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "trainer.py"}, {"type": "file", "name": "trainer_seq2seq.py"}, {"type": "file", "name": "training_args.py"}, {"type": "file", "name": "training_args_seq2seq.py"}, {"type": "file", "name": "utils.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "pipelines", "children": [{"type": "directory", "name": "diffusers", "children": [{"type": "file", "name": "pipeline_latent_consistency.py"}, {"type": "file", "name": "pipeline_stable_diffusion.py"}, {"type": "file", "name": "pipeline_stable_diffusion_img2img.py"}, {"type": "file", "name": "pipeline_stable_diffusion_inpaint.py"}, {"type": "file", "name": "pipeline_stable_diffusion_xl.py"}, {"type": "file", "name": "pipeline_stable_diffusion_xl_img2img.py"}, {"type": "file", "name": "pipeline_utils.py"}, {"type": "file", "name": "watermark.py"}]}, {"type": "file", "name": "pipelines_base.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "quantization_base.py"}, {"type": "file", "name": "runs_base.py"}, {"type": "file", "name": "subpackages.py"}, {"type": "directory", "name": "utils", "children": [{"type": "file", "name": "constant.py"}, {"type": "file", "name": "doc.py"}, {"type": "file", "name": "dummy_bettertransformer_objects.py"}, {"type": "file", "name": "dummy_diffusers_objects.py"}, {"type": "file", "name": "file_utils.py"}, {"type": "file", "name": "import_utils.py"}, {"type": "file", "name": "input_generators.py"}, {"type": "file", "name": "logging.py"}, {"type": "file", "name": "modeling_utils.py"}, {"type": "file", "name": "normalized_config.py"}, {"type": "directory", "name": "preprocessing", "children": [{"type": "file", "name": "base.py"}, {"type": "file", "name": "image_classification.py"}, {"type": "file", "name": "question_answering.py"}, {"type": "file", "name": "task_processors_manager.py"}, {"type": "file", "name": "text_classification.py"}, {"type": "file", "name": "token_classification.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "runs.py"}, {"type": "file", "name": "save_utils.py"}, {"type": "file", "name": "testing_utils.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "version.py"}]}, {"type": "file", "name": "pyproject.toml"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "setup.cfg"}, {"type": "file", "name": "setup.py"}, {"type": "directory", "name": "tests", "children": [{"type": "directory", "name": "assets", "children": [{"type": "directory", "name": "hub", "children": [{"type": "file", "name": "config.json"}]}, {"type": "directory", "name": "onnx", "children": [{"type": "file", "name": "config.json"}]}]}, {"type": "directory", "name": "benchmark", "children": [{"type": "file", "name": "benchmark_bettertransformer.py"}, {"type": "file", "name": "benchmark_bettertransformer_training.py"}, {"type": "file", "name": "benchmark_bettertransformer_training_minimal.py"}, {"type": "file", "name": "benchmark_bettertransformer_vit.py"}, {"type": "file", "name": "benchmark_gptq.py"}, {"type": "file", "name": "memory_tracker.py"}, {"type": "file", "name": "profile_bettertransformer_t5.py"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "test_transformers_optimum_examples_parity.py"}]}, {"type": "directory", "name": "bettertransformer", "children": [{"type": "file", "name": "Dockerfile_bettertransformer_gpu"}, {"type": "file", "name": "testing_utils.py"}, {"type": "file", "name": "test_audio.py"}, {"type": "file", "name": "test_common.py"}, {"type": "file", "name": "test_decoder.py"}, {"type": "file", "name": "test_encoder.py"}, {"type": "file", "name": "test_encoder_decoder.py"}, {"type": "file", "name": "test_gpu.py"}, {"type": "file", "name": "test_vision.py"}]}, {"type": "directory", "name": "cli", "children": [{"type": "file", "name": "cli_with_custom_command.py"}, {"type": "file", "name": "test_cli.py"}]}, {"type": "directory", "name": "exporters", "children": [{"type": "directory", "name": "common", "children": [{"type": "file", "name": "test_tasks_manager.py"}]}, {"type": "file", "name": "Dockerfile_exporters_gpu"}, {"type": "file", "name": "exporters_utils.py"}, {"type": "directory", "name": "onnx", "children": [{"type": "file", "name": "test_exporters_onnx_cli.py"}, {"type": "file", "name": "test_onnx_config_loss.py"}, {"type": "file", "name": "test_onnx_export.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "tflite", "children": [{"type": "file", "name": "test_exporters_tflite_cli.py"}, {"type": "file", "name": "test_tflite_export.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "fx", "children": [{"type": "directory", "name": "optimization", "children": [{"type": "file", "name": "test_transformations.py"}]}, {"type": "directory", "name": "parallelization", "children": [{"type": "file", "name": "dist_utils.py"}, {"type": "file", "name": "test_tensor_parallel.py"}]}, {"type": "file", "name": "test_quantization.py"}]}, {"type": "directory", "name": "gptq", "children": [{"type": "file", "name": "test_quantization.py"}]}, {"type": "directory", "name": "onnx", "children": [{"type": "file", "name": "test_onnx_export_custom_module.py"}, {"type": "file", "name": "test_onnx_graph_transformations.py"}]}, {"type": "directory", "name": "onnxruntime", "children": [{"type": "directory", "name": "docker", "children": [{"type": "file", "name": "Dockerfile_onnxruntime_gpu"}, {"type": "file", "name": "Dockerfile_onnxruntime_trainer"}]}, {"type": "directory", "name": "ds_configs", "children": [{"type": "file", "name": "ds_config_zero_stage_1.json"}, {"type": "file", "name": "ds_config_zero_stage_2.json"}, {"type": "file", "name": "ds_config_zero_stage_3.json"}, {"type": "file", "name": "ds_config_zero_stage_inifinity.json"}]}, {"type": "file", "name": "test_diffusion.py"}, {"type": "file", "name": "test_modeling.py"}, {"type": "file", "name": "test_optimization.py"}, {"type": "file", "name": "test_quantization.py"}, {"type": "file", "name": "test_utils.py"}, {"type": "directory", "name": "training", "children": [{"type": "file", "name": "nightly_test_examples.py"}, {"type": "file", "name": "nightly_test_trainer.py"}]}, {"type": "file", "name": "utils_onnxruntime_tests.py"}]}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "run_doctest.sh"}, {"type": "file", "name": "test_configuration_utils.py"}, {"type": "file", "name": "test_modeling_base.py"}, {"type": "directory", "name": "utils", "children": [{"type": "file", "name": "documentation_tests.txt"}, {"type": "file", "name": "prepare_for_doc_test.py"}, {"type": "file", "name": "test_dummpy_input_generators.py"}, {"type": "file", "name": "test_task_processors.py"}]}, {"type": "file", "name": "__init__.py"}]}]} | # BetterTransformer benchmark
Please refer to https://medium.com/pytorch/bettertransformer-out-of-the-box-performance-for-huggingface-transformers-3fbe27d50ab2 & https://pytorch.org/blog/out-of-the-box-acceleration/ for reproduction.
# GPTQ benchmark
The results below are for AutoGPTQ 0.7.0, PyTorch 2.2.0, bitsandbytes 0.42.0, transformers 4.37.2.
Here are results obtained on a single NVIDIA A100-SXM4-80GB GPU **without act-order**. Additional benchmarks could be done in the act-order case.
From the benchmark, it appears that Exllama kernel is the best-in-class for GPTQ, although it is rather slow for larger batch sizes. The memory savings are not exactly of x4 although weights are in int4. This can be explained by the possible static buffers used by the kernels, the CUDA context (taken into account in the measurements), and the KV cache that is still in fp16.
Bitsandbytes uses the fp4 scheme, with the compute in fp16.
**Beware that exllama uses [fp16 accumulation](https://github.com/turboderp/exllamav2/blob/75f969a6d3efd28fcb521100669ba2594f3ba14c/exllamav2/exllamav2_ext/cuda/q_gemm.cu#L132-L138) for its fp16 x fp16 GEMM, while PyTorch and other kernels accumulate on fp32 for numerical accuracy purposees. This has latency implications and the comparison is therefore not apple-to-apple.**
## Prefill benchmark
The benchmark below is for a prompt length of 512, measuring only the prefill step on a single NVIDIA A100-SXM4-80GB GPU. This benchmark typically corresponds to the forward during training (to the difference that here `generate` is called, which has some overhead).
Run
```shell
# pytorch fp16
CUDA_VISIBLE_DEVICES=0 python benchmark_gptq.py --model meta-llama/Llama-2-13b-chat-hf --sweep --task text-generation --generate --prefill
# GPTQ with exllamav2 kernel (int4/fp16)
CUDA_VISIBLE_DEVICES=0 python benchmark_gptq.py --model TheBloke/Llama-2-13B-chat-GPTQ --sweep --gptq --task text-generation --use-exllama --exllama-version 2 --generate --prefill
# GPTQ with exllama kernel (int4/fp16)
CUDA_VISIBLE_DEVICES=0 python benchmark_gptq.py --model TheBloke/Llama-2-13B-chat-GPTQ --sweep -gptq --task text-generation --use-exllama --generate --prefill
# GPTQ without exllama kernel (int4/fp16)
CUDA_VISIBLE_DEVICES=0 python benchmark_gptq.py --model TheBloke/Llama-2-13B-chat-GPTQ --sweep --gptq --task text-generation --generate --prefill
# GPTQ with marlin kernel (int4/fp16)
CUDA_VISIBLE_DEVICES=0 python benchmark_gptq.py --model TheBloke/Llama-2-13B-chat-GPTQ --sweep --gptq --task text-generation --use-marlin --generate --prefill
# using bitsandbytes fp4/fp16 scheme
CUDA_VISIBLE_DEVICES=0 python benchmark_gptq.py --model meta-llama/Llama-2-13b-chat-hf --sweep --bitsandbytes --task text-generation --generate --prefill
```
### Batch size = 1
| quantization | act_order | bits | group_size | kernel | Load time (s) | Per-token latency (ms) | Throughput (tok/s) |
|--------------|-----------|------|------------|------------|---------------|------------------------|--------------------|
| None | None | None | None | None | 112.08 | 98.89 | 10.11 |
| gptq | False | 4 | 128 | cuda-old | 6.09 | 374.60 | 2.67 |
| gptq | False | 4 | 128 | exllama | 5.99 | 116.11 | 8.61 |
| gptq | False | 4 | 128 | exllama_v2 | 7.28 | 115.05 | 8.69 |
| gptq | False | 4 | 128 | marlin | 32.26 | 95.15 | 10.51 |
| bitsandbytes | None | None | None | None | 10.18 | 140.90 | 7.10 |
### Batch size = 2
| quantization | act_order | bits | group_size | kernel | Load time (s) | Per-token latency (ms) | Throughput (tok/s) |
|--------------|-----------|------|------------|------------|---------------|------------------------|--------------------|
| None | None | None | None | None | 112.08 | 183.41 | 10.90 |
| gptq | False | 4 | 128 | cuda-old | 6.09 | 458.15 | 4.37 |
| gptq | False | 4 | 128 | exllama | 5.99 | 196.50 | 10.18 |
| gptq | False | 4 | 128 | exllama_v2 | 7.28 | 195.30 | 10.24 |
| gptq | False | 4 | 128 | marlin | 32.26 | 192.18 | 10.41 |
| bitsandbytes | None | None | None | None | 10.18 | 223.30 | 8.96 |
### Batch size = 4
| quantization | act_order | bits | group_size | kernel | Load time (s) | Per-token latency (ms) | Throughput (tok/s) |
|--------------|-----------|------|------------|------------|---------------|------------------------|--------------------|
| None | None | None | None | None | 112.08 | 332.39 | 12.03 |
| gptq | False | 4 | 128 | cuda-old | 6.09 | 618.96 | 6.46 |
| gptq | False | 4 | 128 | exllama | 5.99 | 353.67 | 11.31 |
| gptq | False | 4 | 128 | exllama_v2 | 7.28 | 353.47 | 11.32 |
| gptq | False | 4 | 128 | marlin | 32.26 | 384.47 | 10.40 |
| bitsandbytes | None | None | None | None | 10.18 | 369.76 | 10.82 |
### Batch size = 8
| quantization | act_order | bits | group_size | kernel | Load time (s) | Per-token latency (ms) | Throughput (tok/s) |
|--------------|-----------|------|------------|------------|---------------|------------------------|--------------------|
| None | None | None | None | None | 112.08 | 655.58 | 12.20 |
| gptq | False | 4 | 128 | cuda-old | 6.09 | 962.64 | 8.31 |
| gptq | False | 4 | 128 | exllama | 5.99 | 687.99 | 11.63 |
| gptq | False | 4 | 128 | exllama_v2 | 7.28 | 684.68 | 11.68 |
| gptq | False | 4 | 128 | marlin | 32.26 | 760.58 | 10.52 |
| bitsandbytes | None | None | None | None | 10.18 | 689.23 | 11.61 |
### Batch size = 16
| quantization | act_order | bits | group_size | kernel | Load time (s) | Per-token latency (ms) | Throughput (tok/s) |
|--------------|-----------|------|------------|------------|---------------|------------------------|--------------------|
| None | None | None | None | None | 112.08 | 1368.83 | 11.69 |
| gptq | False | 4 | 128 | cuda-old | 6.09 | 1679.88 | 9.52 |
| gptq | False | 4 | 128 | exllama | 5.99 | 1337.64 | 11.96 |
| gptq | False | 4 | 128 | exllama_v2 | 7.28 | 1336.79 | 11.97 |
| gptq | False | 4 | 128 | marlin | 32.26 | 1515.79 | 10.56 |
| bitsandbytes | None | None | None | None | 10.18 | 1427.68 | 11.21 |
## Decode benchmark
The benchmark below is for a prefill length of 1, essentially measuring the decode step in text generation (512 tokens generated).
Run
```shell
# pytorch fp16
CUDA_VISIBLE_DEVICES=0 python benchmark_gptq.py --model meta-llama/Llama-2-13b-chat-hf --sweep --num-batches 5 --task text-generation --generate --decode
# GPTQ with exllamav2 kernel (int4/fp16)
CUDA_VISIBLE_DEVICES=0 python benchmark_gptq.py --model TheBloke/Llama-2-13B-chat-GPTQ --sweep --num-batches 5 --gptq --task text-generation --use-exllama --exllama-version 2 --generate --decode
# GPTQ with exllama kernel (int4/fp16)
CUDA_VISIBLE_DEVICES=0 python benchmark_gptq.py --model TheBloke/Llama-2-13B-chat-GPTQ --sweep --num-batches 5 --gptq --task text-generation --use-exllama --exllama-version 1 --generate --decode
# GPTQ with cuda-old kernel (int4/fp16)
CUDA_VISIBLE_DEVICES=0 python benchmark_gptq.py --model TheBloke/Llama-2-13B-chat-GPTQ --sweep --num-batches 5 --gptq --task text-generation --generate --decode
# GPTQ with marlin kernel (int4/fp16)
CUDA_VISIBLE_DEVICES=0 python benchmark_gptq.py --model TheBloke/Llama-2-13B-chat-GPTQ --sweep --num-batches 5 --gptq --task text-generation --use-marlin --generate --decode
# using bitsandbytes fp4/fp16 scheme
CUDA_VISIBLE_DEVICES=0 python benchmark_gptq.py --model meta-llama/Llama-2-13b-chat-hf --sweep --num-batches 5 --bitsandbytes --task text-generation --generate --decode
```
### Batch size = 1
| quantization | act_order | bits | group_size | kernel | Load time (s) | Per-token latency (ms) | Throughput (tok/s) |
|--------------|-----------|------|------------|------------|---------------|------------------------|--------------------|
| None | None | None | None | None | 6.64 | 30.43 | 32.86 |
| gptq | False | 4 | 128 | cuda-old | 6.03 | 42.91 | 23.30 |
| gptq | False | 4 | 128 | exllama | 6.65 | 31.68 | 31.57 |
| gptq | False | 4 | 128 | exllama_v2 | 5.86 | 31.60 | 31.64 |
| gptq | False | 4 | 128 | marlin | 31.75 | 28.96 | 34.53 |
| bitsandbytes | None | None | None | None | 9.80 | 45.06 | 22.19 |
### Batch size = 2
| quantization | act_order | bits | group_size | kernel | Load time (s) | Per-token latency (ms) | Throughput (tok/s) |
|--------------|-----------|------|------------|------------|---------------|------------------------|--------------------|
| None | None | None | None | None | 6.64 | 30.11 | 66.42 |
| gptq | False | 4 | 128 | cuda-old | 6.03 | 42.68 | 46.86 |
| gptq | False | 4 | 128 | exllama | 6.65 | 37.00 | 54.05 |
| gptq | False | 4 | 128 | exllama_v2 | 5.86 | 31.74 | 63.02 |
| gptq | False | 4 | 128 | marlin | 31.75 | 29.19 | 68.53 |
| bitsandbytes | None | None | None | None | 9.80 | 68.00 | 29.41 |
### Batch size = 4
| quantization | act_order | bits | group_size | kernel | Load time (s) | Per-token latency (ms) | Throughput (tok/s) |
|--------------|-----------|------|------------|------------|---------------|------------------------|--------------------|
| None | None | None | None | None | 6.64 | 29.76 | 134.41 |
| gptq | False | 4 | 128 | cuda-old | 6.03 | 51.43 | 77.78 |
| gptq | False | 4 | 128 | exllama | 6.65 | 55.15 | 72.53 |
| gptq | False | 4 | 128 | exllama_v2 | 5.86 | 31.58 | 126.68 |
| gptq | False | 4 | 128 | marlin | 31.75 | 29.08 | 137.56 |
| bitsandbytes | None | None | None | None | 9.80 | 70.25 | 56.94 |
### Batch size = 8
| quantization | act_order | bits | group_size | kernel | Load time (s) | Per-token latency (ms) | Throughput (tok/s) |
|--------------|-----------|------|------------|------------|---------------|------------------------|--------------------|
| None | None | None | None | None | 6.64 | 32.98 | 242.60 |
| gptq | False | 4 | 128 | cuda-old | 6.03 | 91.74 | 87.20 |
| gptq | False | 4 | 128 | exllama | 6.86 | 58.61 | 136.49 |
| gptq | False | 4 | 128 | exllama_v2 | 5.86 | 32.59 | 245.48 |
| gptq | False | 4 | 128 | marlin | 31.75 | 29.02 | 275.70 |
| bitsandbytes | None | None | None | None | 9.80 | 74.20 | 107.81 |
### Batch size = 16
| quantization | act_order | bits | group_size | kernel | Load time (s) | Per-token latency (ms) | Throughput (tok/s) |
|--------------|-----------|------|------------|------------|---------------|------------------------|--------------------|
| None | None | None | None | None | 6.64 | 40.24 | 397.61 |
| gptq | False | 4 | 128 | cuda-old | 6.03 | 171.90 | 93.08 |
| gptq | False | 4 | 128 | exllama | 6.86 | 66.37 | 241.07 |
| gptq | False | 4 | 128 | exllama_v2 | 5.86 | 48.10 | 332.61 |
| gptq | False | 4 | 128 | marlin | 31.75 | 31.71 | 504.63 |
| bitsandbytes | None | None | None | None | 9.80 | 82.29 | 194.44 |
## Perplexity benchmark results
Run
```shell
# pytorch fp16
CUDA_VISIBLE_DEVICES=0 python benchmark_gptq.py --model meta-llama/Llama-2-13b-chat-hf --task text-generation --ppl
# GPTQ with exllamav2 kernel (int4/fp16)
CUDA_VISIBLE_DEVICES=0 python benchmark_gptq.py --model TheBloke/Llama-2-13B-chat-GPTQ --revision gptq-4bit-128g-actorder_True --gptq --task text-generation --use-exllama --exllama-version 2 --ppl
# GPTQ with exllama kernel (int4/fp16)
CUDA_VISIBLE_DEVICES=0 python benchmark_gptq.py --model TheBloke/Llama-2-13B-chat-GPTQ --revision gptq-4bit-128g-actorder_True --gptq --task text-generation --use-exllama --ppl
# GPTQ without exllama kernel (int4/fp16)
CUDA_VISIBLE_DEVICES=0 python benchmark_gptq.py --model TheBloke/Llama-2-13B-chat-GPTQ --revision gptq-4bit-128g-actorder_True --gptq --task text-generation --ppl
# using bitsandbytes fp4/fp16 scheme
CUDA_VISIBLE_DEVICES=0 python benchmark_gptq.py --model meta-llama/Llama-2-13b-chat-hf ---task text-generation --bitsandbytes --ppl
```
| quantization | act_order | bits | group_size | kernel | perplexity |
|--------------|-----------|------|------------|------------------|------------|
| None | None | None | None | None | 6.61 |
| gptq | True | 4 | 128 | exllamav2 | 6.77 |
| gptq | True | 4 | 128 | exllama | 6.77 |
| gptq | True | 4 | 128 | autogptq-cuda-old| 6.77 |
| bitsandbytes | None | 4 | None | None | 6.78 | | {"setup.py": "import re\n\nfrom setuptools import find_namespace_packages, setup\n\n\n# Ensure we match the version set in src/optimum/version.py\ntry:\n filepath = \"optimum/version.py\"\n with open(filepath) as version_file:\n (__version__,) = re.findall('__version__ = \"(.*)\"', version_file.read())\nexcept Exception as error:\n assert False, \"Error: Could not open '%s' due %s\\n\" % (filepath, error)\n\n\nREQUIRED_PKGS = [\n \"coloredlogs\",\n \"sympy\",\n \"transformers[sentencepiece]>=4.29,<4.45.0\",\n \"torch>=1.11\",\n \"packaging\",\n \"numpy<2.0\", # transformers requires numpy<2.0 https://github.com/huggingface/transformers/pull/31569\n \"huggingface_hub>=0.8.0\",\n \"datasets\",\n]\n\n# TODO: unpin pytest once https://github.com/huggingface/transformers/pull/29154 is merged & released\n# pytest>=8.0.0 also fails with the transformers version pinned for exporters-tf\nTESTS_REQUIRE = [\n \"accelerate\",\n \"pytest<=8.0.0\",\n \"requests\",\n \"parameterized\",\n \"pytest-xdist\",\n \"Pillow\",\n \"sacremoses\",\n \"torchvision\",\n \"diffusers>=0.17.0\",\n \"torchaudio\",\n \"einops\",\n \"invisible-watermark\",\n \"timm\",\n \"scikit-learn\",\n \"rjieba\",\n]\n\nQUALITY_REQUIRE = [\"black~=23.1\", \"ruff==0.1.5\"]\n\nBENCHMARK_REQUIRE = [\"optuna\", \"tqdm\", \"scikit-learn\", \"seqeval\", \"torchvision\", \"evaluate>=0.2.0\"]\n\nEXTRAS_REQUIRE = {\n \"onnxruntime\": [\n \"onnx\",\n \"onnxruntime>=1.11.0\",\n \"datasets>=1.2.1\",\n \"evaluate\",\n \"protobuf>=3.20.1\",\n ],\n \"onnxruntime-gpu\": [\n \"onnx\",\n \"onnxruntime-gpu>=1.11.0\",\n \"datasets>=1.2.1\",\n \"evaluate\",\n \"protobuf>=3.20.1\",\n \"accelerate\", # ORTTrainer requires it.\n ],\n \"exporters\": [\"onnx\", \"onnxruntime\", \"timm\"],\n \"exporters-gpu\": [\"onnx\", \"onnxruntime-gpu\", \"timm\"],\n \"exporters-tf\": [\n \"tensorflow>=2.4,<=2.12.1\",\n \"tf2onnx\",\n \"onnx\",\n \"onnxruntime\",\n \"timm\",\n \"h5py\",\n \"numpy<1.24.0\",\n \"datasets<=2.16\",\n \"transformers[sentencepiece]>=4.26,<4.38\",\n ],\n \"diffusers\": [\"diffusers\"],\n \"intel\": \"optimum-intel>=1.18.0\",\n \"openvino\": \"optimum-intel[openvino]>=1.18.0\",\n \"nncf\": \"optimum-intel[nncf]>=1.18.0\",\n \"neural-compressor\": \"optimum-intel[neural-compressor]>=1.18.0\",\n \"ipex\": \"optimum-intel[ipex]>=1.18.0\",\n \"habana\": [\"optimum-habana\", \"transformers>=4.43.0,<4.44.0\"],\n \"neuron\": [\"optimum-neuron[neuron]>=0.0.20\", \"transformers>=4.36.2,<4.42.0\"],\n \"neuronx\": [\"optimum-neuron[neuronx]>=0.0.20\", \"transformers>=4.36.2,<4.42.0\"],\n \"graphcore\": \"optimum-graphcore\",\n \"furiosa\": \"optimum-furiosa\",\n \"amd\": \"optimum-amd\",\n \"quanto\": [\"optimum-quanto>=0.2.4\"],\n \"dev\": TESTS_REQUIRE + QUALITY_REQUIRE,\n \"tests\": TESTS_REQUIRE,\n \"quality\": QUALITY_REQUIRE,\n \"benchmark\": BENCHMARK_REQUIRE,\n \"doc-build\": [\"accelerate\"],\n}\n\nsetup(\n name=\"optimum\",\n version=__version__,\n description=\"Optimum Library is an extension of the Hugging Face Transformers library, providing a framework to \"\n \"integrate third-party libraries from Hardware Partners and interface with their specific \"\n \"functionality.\",\n long_description=open(\"README.md\", \"r\", encoding=\"utf-8\").read(),\n long_description_content_type=\"text/markdown\",\n classifiers=[\n \"Development Status :: 5 - Production/Stable\",\n \"License :: OSI Approved :: Apache Software License\",\n \"Intended Audience :: Developers\",\n \"Intended Audience :: Education\",\n \"Intended Audience :: Science/Research\",\n \"Operating System :: OS Independent\",\n \"Programming Language :: Python :: 3.7\",\n \"Programming Language :: Python :: 3.8\",\n \"Programming Language :: Python :: 3.9\",\n \"Topic :: Scientific/Engineering :: Artificial Intelligence\",\n ],\n keywords=\"transformers, quantization, pruning, optimization, training, inference, onnx, onnx runtime, intel, \"\n \"habana, graphcore, neural compressor, ipu, hpu\",\n url=\"https://github.com/huggingface/optimum\",\n author=\"HuggingFace Inc. Special Ops Team\",\n author_email=\"[email protected]\",\n license=\"Apache\",\n packages=find_namespace_packages(include=[\"optimum*\"]),\n install_requires=REQUIRED_PKGS,\n extras_require=EXTRAS_REQUIRE,\n python_requires=\">=3.7.0\",\n include_package_data=True,\n zip_safe=False,\n entry_points={\"console_scripts\": [\"optimum-cli=optimum.commands.optimum_cli:main\"]},\n)\n", ".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 fd638d20046a73a7221083b23c69b98445e2d321 Hamza Amin <[email protected]> 1727369439 +0500\tclone: from https://github.com/huggingface/optimum.git\n", ".git\\refs\\heads\\main": "fd638d20046a73a7221083b23c69b98445e2d321\n", ".github\\workflows\\build_main_documentation.yml": "name: Build main documentation\n\non:\n push:\n branches:\n - main\n - doc-builder*\n - v*-release\n workflow_dispatch:\n\njobs:\n build_documentation:\n runs-on: ubuntu-latest\n\n steps:\n - uses: actions/checkout@v2\n with:\n repository: 'huggingface/doc-builder'\n path: doc-builder\n\n - uses: actions/checkout@v2\n with:\n repository: 'huggingface/doc-build'\n path: doc-build\n token: ${{ secrets.HUGGINGFACE_PUSH }}\n\n - uses: actions/checkout@v2\n with:\n repository: 'huggingface/optimum'\n path: optimum\n\n - uses: actions/checkout@v2\n with:\n repository: 'huggingface/optimum-habana'\n path: optimum-habana\n\n - uses: actions/checkout@v2\n with:\n repository: 'huggingface/optimum-intel'\n path: optimum-intel\n\n - uses: actions/checkout@v2\n with:\n repository: 'huggingface/optimum-furiosa'\n path: optimum-furiosa\n\n - uses: actions/checkout@v2\n with:\n repository: 'huggingface/optimum-amd'\n path: optimum-amd\n\n - uses: actions/checkout@v2\n with:\n repository: 'huggingface/optimum-tpu'\n path: optimum-tpu\n\n - name: Free disk space\n run: |\n df -h\n sudo apt-get purge -y '^apache.*'\n sudo apt-get purge -y '^imagemagick.*'\n sudo apt-get purge -y '^dotnet.*'\n sudo apt-get purge -y '^aspnetcore.*'\n sudo apt-get purge -y 'php.*'\n sudo apt-get purge -y '^temurin.*'\n sudo apt-get purge -y '^mysql.*'\n sudo apt-get purge -y '^java.*'\n sudo apt-get purge -y '^openjdk.*'\n sudo apt-get purge -y microsoft-edge-stable google-cloud-cli azure-cli google-chrome-stable firefox powershell mono-devel\n df -h\n sudo apt-get autoremove -y >/dev/null 2>&1\n sudo apt-get clean\n df -h\n echo \"https://github.com/actions/virtual-environments/issues/709\"\n sudo rm -rf \"$AGENT_TOOLSDIRECTORY\"\n df -h\n echo \"remove big /usr/local\"\n sudo rm -rf \"/usr/local/share/boost\"\n sudo rm -rf /usr/local/lib/android >/dev/null 2>&1\n df -h\n echo \"remove /usr/share leftovers\"\n sudo rm -rf /usr/share/dotnet/sdk > /dev/null 2>&1\n sudo rm -rf /usr/share/dotnet/shared > /dev/null 2>&1\n sudo rm -rf /usr/share/swift > /dev/null 2>&1\n df -h\n echo \"remove other leftovers\"\n sudo rm -rf /var/lib/mysql > /dev/null 2>&1\n sudo rm -rf /home/runner/.dotnet > /dev/null 2>&1\n sudo rm -rf /home/runneradmin/.dotnet > /dev/null 2>&1\n sudo rm -rf /etc/skel/.dotnet > /dev/null 2>&1\n sudo rm -rf /usr/local/.ghcup > /dev/null 2>&1\n sudo rm -rf /usr/local/aws-cli > /dev/null 2>&1\n sudo rm -rf /usr/lib/heroku > /dev/null 2>&1\n sudo rm -rf /usr/local/share/chromium > /dev/null 2>&1\n df -h\n\n - name: Set environment variables\n run: |\n cd optimum\n version=`echo \"$(grep '^__version__ =' optimum/version.py | cut -d '=' -f 2- | xargs)\"`\n\n if [[ $version == *.dev0 ]]\n then\n echo \"VERSION=main\" >> $GITHUB_ENV\n else\n echo \"VERSION=v$version\" >> $GITHUB_ENV\n fi\n\n cd ..\n\n - name: Setup environment\n run: |\n pip uninstall -y doc-builder\n cd doc-builder\n git pull origin main\n pip install .\n pip install black\n cd ..\n\n - name: Make Habana documentation\n run: |\n sudo docker system prune -a -f\n cd optimum-habana\n make doc BUILD_DIR=habana-doc-build VERSION=${{ env.VERSION }}\n sudo mv habana-doc-build ../optimum\n cd ..\n\n - name: Make Intel documentation\n run: |\n sudo docker system prune -a -f\n cd optimum-intel\n make doc BUILD_DIR=intel-doc-build VERSION=${{ env.VERSION }}\n sudo mv intel-doc-build ../optimum\n cd ..\n\n - name: Make Furiosa documentation\n run: |\n cd optimum-furiosa\n pip install .\n sudo apt install software-properties-common\n sudo add-apt-repository --remove https://packages.microsoft.com/ubuntu/22.04/prod\n sudo apt update\n sudo apt install -y ca-certificates apt-transport-https gnupg\n sudo apt-key adv --keyserver keyserver.ubuntu.com --recv-key 5F03AFA423A751913F249259814F888B20B09A7E\n sudo tee -a /etc/apt/auth.conf.d/furiosa.conf > /dev/null <<EOT\n machine archive.furiosa.ai\n login ${{ secrets.FURIOSA_ACCESS_KEY }}\n password ${{ secrets.FURIOSA_SECRET_ACCESS_KEY }}\n EOT\n sudo chmod 400 /etc/apt/auth.conf.d/furiosa.conf\n sudo tee -a /etc/apt/sources.list.d/furiosa.list <<EOT\n deb [arch=amd64] https://archive.furiosa.ai/ubuntu jammy restricted\n EOT\n sudo apt update && sudo apt install -y furiosa-libnux\n doc-builder build optimum.furiosa docs/source/ --build_dir furiosa-doc-build --version pr_$PR_NUMBER --version_tag_suffix \"\" --html --clean\n mv furiosa-doc-build ../optimum\n cd ..\n\n - name: Make TPU documentation\n run: |\n sudo docker system prune -a -f\n cd optimum-tpu\n pip install -U pip\n pip install . -f https://storage.googleapis.com/libtpu-releases/index.html\n doc-builder build optimum.tpu docs/source/ --build_dir tpu-doc-build --version pr_$PR_NUMBER --version_tag_suffix \"\" --html --clean\n mv tpu-doc-build ../optimum\n cd ..\n\n - name: Make AMD documentation\n run: |\n sudo docker system prune -a -f\n cd optimum-amd\n make doc BUILD_DIR=amd-doc-build VERSION=${{ env.VERSION }}\n sudo mv amd-doc-build ../optimum\n cd ..\n\n - name: Make Optimum documentation\n run: |\n sudo docker system prune -a -f\n cd optimum\n mkdir -p optimum-doc-build/optimum && cd optimum-doc-build/optimum\n wget https://huggingface.co/datasets/hf-doc-build/doc-build/raw/main/optimum/_versions.yml\n cd ../..\n make doc BUILD_DIR=optimum-doc-build VERSION=${{ env.VERSION }} COMMIT_SHA_OPTIMUM=${{ env.VERSION }}\n cd ..\n\n - name: Combine subpackage documentation\n run: |\n cd optimum\n sudo python docs/combine_docs.py --subpackages nvidia amd intel neuron tpu habana furiosa --version ${{ env.VERSION }}\n cd ..\n\n - name: Push to repositories\n run: |\n cd optimum/optimum-doc-build\n sudo chmod -R ugo+rwx optimum\n doc-builder push optimum --doc_build_repo_id \"hf-doc-build/doc-build\" --token \"${{ secrets.HF_DOC_BUILD_PUSH }}\" --commit_msg \"Updated with commit ${{ github.sha }} See: https://github.com/huggingface/optimum/commit/${{ github.sha }}\" --n_retries 5 --upload_version_yml\n shell: bash\n", "docs\\Dockerfile": "FROM nikolaik/python-nodejs:python3.8-nodejs18\n\nARG commit_sha\nARG clone_url\n\nRUN apt -y update\nRUN python3 -m pip install --no-cache-dir --upgrade pip\nRUN python3 -m pip install --no-cache-dir git+https://github.com/huggingface/doc-builder.git\n\nRUN git clone $clone_url && cd optimum && git checkout $commit_sha\nRUN python3 -m pip install --no-cache-dir ./optimum[onnxruntime,benchmark,quality,exporters-tf,doc-build,diffusers]\n", "docs\\source\\index.mdx": "<!--Copyright 2022 The HuggingFace Team. All rights reserved.\n\nLicensed under the Apache License, Version 2.0 (the \"License\"); you may not use this file except in compliance with\nthe License. You may obtain a copy of the License at\n\nhttp://www.apache.org/licenses/LICENSE-2.0\n\nUnless required by applicable law or agreed to in writing, software distributed under the License is distributed on\nan \"AS IS\" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the\nspecific language governing permissions and limitations under the License.\n-->\n\n# \ud83e\udd17 Optimum\n\n\ud83e\udd17 Optimum is an extension of [Transformers](https://huggingface.co/docs/transformers) that provides a set of performance optimization tools to train and run models on targeted hardware with maximum efficiency.\n\nThe AI ecosystem evolves quickly, and more and more specialized hardware along with their own optimizations are emerging every day.\nAs such, Optimum enables developers to efficiently use any of these platforms with the same ease inherent to Transformers.\n\n\ud83e\udd17 Optimum is distributed as a collection of packages - check out the links below for an in-depth look at each one.\n\n\n## Hardware partners\n\nThe packages below enable you to get the best of the \ud83e\udd17 Hugging Face ecosystem on various types of devices.\n\n<div class=\"mt-10\">\n <div class=\"w-full flex flex-col space-y-4 md:space-y-0 md:grid md:grid-cols-4 md:gap-y-4 md:gap-x-5\">\n <a class=\"!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg\" href=\"https://github.com/huggingface/optimum-nvidia\"\n ><div class=\"w-full text-center bg-gradient-to-br from-green-600 to-green-600 rounded-lg py-1.5 font-semibold mb-5 text-white text-lg leading-relaxed\">NVIDIA</div>\n <p class=\"text-gray-700\">Accelerate inference with NVIDIA TensorRT-LLM on the <span class=\"underline\" onclick=\"event.preventDefault(); window.open('https://developer.nvidia.com/blog/nvidia-tensorrt-llm-supercharges-large-language-model-inference-on-nvidia-h100-gpus/', '_blank');\">NVIDIA platform</span></p>\n </a>\n <a class=\"!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg\" href=\"./amd/index\"\n ><div class=\"w-full text-center bg-gradient-to-br from-red-600 to-red-600 rounded-lg py-1.5 font-semibold mb-5 text-white text-lg leading-relaxed\">AMD</div>\n <p class=\"text-gray-700\">Enable performance optimizations for <span class=\"underline\" onclick=\"event.preventDefault(); window.open('https://www.amd.com/en/graphics/instinct-server-accelerators', '_blank');\">AMD Instinct GPUs</span> and <span class=\"underline\" onclick=\"event.preventDefault(); window.open('https://ryzenai.docs.amd.com/en/latest/index.html', '_blank');\">AMD Ryzen AI NPUs</span></p>\n </a>\n <a class=\"!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg\" href=\"./intel/index\"\n ><div class=\"w-full text-center bg-gradient-to-br from-blue-400 to-blue-500 rounded-lg py-1.5 font-semibold mb-5 text-white text-lg leading-relaxed\">Intel</div>\n <p class=\"text-gray-700\">Optimize your model to speedup inference with <span class=\"underline\" onclick=\"event.preventDefault(); window.open('https://docs.openvino.ai/latest/index.html', '_blank');\">OpenVINO</span> and <span class=\"underline\" onclick=\"event.preventDefault(); window.open('https://www.intel.com/content/www/us/en/developer/tools/oneapi/neural-compressor.html', '_blank');\">Neural Compressor</span></p>\n </a>\n <a class=\"!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg\" href=\"https://huggingface.co/docs/optimum-neuron/index\"\n ><div class=\"w-full text-center bg-gradient-to-br from-orange-400 to-orange-500 rounded-lg py-1.5 font-semibold mb-5 text-white text-lg leading-relaxed\">AWS Trainium/Inferentia</div>\n <p class=\"text-gray-700\">Accelerate your training and inference workflows with <span class=\"underline\" onclick=\"event.preventDefault(); window.open('https://aws.amazon.com/machine-learning/trainium/', '_blank');\">AWS Trainium</span> and <span class=\"underline\" onclick=\"event.preventDefault(); window.open('https://aws.amazon.com/machine-learning/inferentia/', '_blank');\">AWS Inferentia</span></p>\n </a>\n <a class=\"!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg\" href=\"https://huggingface.co/docs/optimum-tpu/index\"\n ><div class=\"w-full text-center bg-gradient-to-tr from-blue-200 to-blue-600 rounded-lg py-1.5 font-semibold mb-5 text-white text-lg leading-relaxed\">Google TPUs</div>\n <p class=\"text-gray-700\">Accelerate your training and inference workflows with <span class=\"underline\" onclick=\"event.preventDefault(); window.open('https://cloud.google.com/tpu', '_blank');\">Google TPUs</span></p>\n </a>\n <a class=\"!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg\" href=\"./habana/index\"\n ><div class=\"w-full text-center bg-gradient-to-br from-indigo-400 to-indigo-500 rounded-lg py-1.5 font-semibold mb-5 text-white text-lg leading-relaxed\">Habana</div>\n <p class=\"text-gray-700\">Maximize training throughput and efficiency with <span class=\"underline\" onclick=\"event.preventDefault(); window.open('https://docs.habana.ai/en/latest/Gaudi_Overview/Gaudi_Architecture.html', '_blank');\">Habana's Gaudi processor</span></p>\n </a>\n <a class=\"!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg\" href=\"./furiosa/index\"\n ><div class=\"w-full text-center bg-gradient-to-br from-green-400 to-green-500 rounded-lg py-1.5 font-semibold mb-5 text-white text-lg leading-relaxed\">FuriosaAI</div>\n <p class=\"text-gray-700\">Fast and efficient inference on <span class=\"underline\" onclick=\"event.preventDefault(); window.open('https://www.furiosa.ai/', '_blank');\">FuriosaAI WARBOY</span></p>\n </a>\n </div>\n</div>\n\n> [!TIP]\n> Some packages provide hardware-agnostic features (e.g. INC interface in Optimum Intel).\n\n\n## Open-source integrations\n\n\ud83e\udd17 Optimum also supports a variety of open-source frameworks to make model optimization very easy.\n\n<div class=\"mt-10\">\n <div class=\"w-full flex flex-col space-y-4 md:space-y-0 md:grid md:grid-cols-3 md:gap-y-4 md:gap-x-5\">\n <a class=\"!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg\" href=\"./onnxruntime/overview\"\n ><div class=\"w-full text-center bg-gradient-to-br from-pink-400 to-pink-500 rounded-lg py-1.5 font-semibold mb-5 text-white text-lg leading-relaxed\">ONNX Runtime</div>\n <p class=\"text-gray-700\">Apply quantization and graph optimization to accelerate Transformers models training and inference with <span class=\"underline\" onclick=\"event.preventDefault(); window.open('https://onnxruntime.ai/', '_blank');\">ONNX Runtime</span></p>\n </a>\n <a class=\"!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg\" href=\"./exporters/overview\"\n ><div class=\"w-full text-center bg-gradient-to-br from-purple-400 to-purple-500 rounded-lg py-1.5 font-semibold mb-5 text-white text-lg leading-relaxed\">Exporters</div>\n <p class=\"text-gray-700\">Export your PyTorch or TensorFlow model to different formats such as ONNX and TFLite</p>\n </a>\n <a class=\"!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg\" href=\"./bettertransformer/overview\"\n ><div class=\"w-full text-center bg-gradient-to-br from-yellow-400 to-yellow-500 rounded-lg py-1.5 font-semibold mb-5 text-white text-lg leading-relaxed\">BetterTransformer</div>\n <p class=\"text-gray-700\">A one-liner integration to use <span class=\"underline\" onclick=\"event.preventDefault(); window.open('https://pytorch.org/blog/a-better-transformer-for-fast-transformer-encoder-inference/', '_blank');\">PyTorch's BetterTransformer</span> with Transformers models</p>\n </a>\n <a class=\"!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg\" href=\"./torch_fx/overview\"\n ><div class=\"w-full text-center bg-gradient-to-br from-green-400 to-green-500 rounded-lg py-1.5 font-semibold mb-5 text-white text-lg leading-relaxed\">Torch FX</div>\n <p class=\"text-gray-700\">Create and compose custom graph transformations to optimize PyTorch Transformers models with <span class=\"underline\" onclick=\"event.preventDefault(); window.open('https://pytorch.org/docs/stable/fx.html#', '_blank');\">Torch FX</span></p>\n </a>\n </div>\n</div>\n", "examples\\onnxruntime\\optimization\\multiple-choice\\requirements.txt": "datasets >= 1.8.0\nsentencepiece != 0.1.92\nscipy\nscikit-learn\nprotobuf\ntorch >= 1.9\nonnx\nonnxruntime >= 1.9.0", "examples\\onnxruntime\\optimization\\question-answering\\requirements.txt": "datasets >= 1.8.0\ntorch >= 1.9.0\nonnx\nonnxruntime >= 1.9.0", "examples\\onnxruntime\\optimization\\text-classification\\requirements.txt": "datasets >= 1.8.0\nsentencepiece != 0.1.92\nscipy\nscikit-learn\nprotobuf\ntorch >= 1.9\nonnx\nonnxruntime >= 1.9.0", "examples\\onnxruntime\\optimization\\token-classification\\requirements.txt": "seqeval\ndatasets >= 1.18.0\ntorch >= 1.9\nonnx\nonnxruntime >= 1.9.0", "examples\\onnxruntime\\quantization\\image-classification\\requirements.txt": "torch>=1.5.0\ntorchvision>=0.6.0\ndatasets>=1.17.0\n", "examples\\onnxruntime\\quantization\\multiple-choice\\requirements.txt": "datasets >= 1.8.0\nsentencepiece != 0.1.92\nscipy\nscikit-learn\nprotobuf\ntorch >= 1.9\nonnx\nonnxruntime >= 1.9.0", "examples\\onnxruntime\\quantization\\question-answering\\requirements.txt": "datasets >= 1.8.0\ntorch >= 1.9.0\nonnx\nonnxruntime >= 1.9.0", "examples\\onnxruntime\\quantization\\text-classification\\requirements.txt": "datasets >= 1.8.0\nsentencepiece != 0.1.92\nscipy\nscikit-learn\nprotobuf\ntorch >= 1.9\nonnx\nonnxruntime >= 1.9.0", "examples\\onnxruntime\\quantization\\token-classification\\requirements.txt": "seqeval\ndatasets >= 1.8.0\ntorch >= 1.9\nonnx\nonnxruntime >= 1.9.0", "examples\\onnxruntime\\training\\docker\\Dockerfile-ort-nightly-cu118": "#!/usr/bin/env python\n# coding=utf-8\n# Copyright 2023 The HuggingFace Team All rights reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n# Use nvidia/cuda image\nFROM nvidia/cuda:11.8.0-cudnn8-devel-ubuntu20.04\nCMD nvidia-smi\n\n# Ignore interactive questions during `docker build`\nENV DEBIAN_FRONTEND noninteractive\n\n# Versions\n# available options 3.8, 3.9, 3.10, 3.11\nARG PYTHON_VERSION=3.9\nARG TORCH_CUDA_VERSION=cu118\nARG TORCH_VERSION=2.0.0\nARG TORCHVISION_VERSION=0.15.1\n\n# Bash shell\nRUN chsh -s /bin/bash\nSHELL [\"/bin/bash\", \"-c\"]\n\n# Install and update tools to minimize security vulnerabilities\nRUN apt-get update\nRUN apt-get install -y software-properties-common wget apt-utils patchelf git libprotobuf-dev protobuf-compiler cmake \\\n bzip2 ca-certificates libglib2.0-0 libxext6 libsm6 libxrender1 mercurial subversion libopenmpi-dev ffmpeg && \\\n apt-get clean\nRUN unattended-upgrade\nRUN apt-get autoremove -y\n\n# Install miniconda (comes with python 3.9 default)\nARG BUILD_USER=onnxruntimedev\nARG MINICONDA_PREFIX=/home/$BUILD_USER/miniconda3\nRUN apt-get install curl\n\nARG CONDA_URL=https://repo.anaconda.com/miniconda/Miniconda3-py37_4.9.2-Linux-x86_64.sh\nRUN curl -fSsL --insecure ${CONDA_URL} -o install-conda.sh && \\\n /bin/bash ./install-conda.sh -b -p $MINICONDA_PREFIX && \\\n $MINICONDA_PREFIX/bin/conda clean -ya && \\\n $MINICONDA_PREFIX/bin/conda install -y python=${PYTHON_VERSION}\n\nENV PATH=$MINICONDA_PREFIX/bin:${PATH}\n\nARG PYTHON_EXE=$MINICONDA_PREFIX/bin/python\n\n# (Optional) Intall test dependencies\nRUN $PYTHON_EXE -m pip install git+https://github.com/huggingface/transformers\nRUN $PYTHON_EXE -m pip install datasets accelerate evaluate coloredlogs absl-py rouge_score seqeval scipy sacrebleu nltk scikit-learn parameterized sentencepiece\nRUN $PYTHON_EXE -m pip install deepspeed mpi4py\n# RUN $PYTHON_EXE -m pip install optuna ray sigopt wandb\n\n# PyTorch\nRUN $PYTHON_EXE -m pip install onnx ninja\nRUN $PYTHON_EXE -m pip install torch==${TORCH_VERSION} torchvision==${TORCHVISION_VERSION} -f https://download.pytorch.org/whl/${TORCH_CUDA_VERSION}\n\n# ORT Module\nRUN $PYTHON_EXE -m pip install --pre onnxruntime-training -f https://download.onnxruntime.ai/onnxruntime_nightly_cu118.html\nRUN $PYTHON_EXE -m pip install torch-ort\nENV TORCH_CUDA_ARCH_LIST=\"5.2 6.0 6.1 7.0 7.5 8.0 8.6+PTX\"\nRUN $PYTHON_EXE -m pip install --upgrade protobuf==3.20.2\nRUN $PYTHON_EXE -m torch_ort.configure\n\nWORKDIR .\n\nCMD [\"/bin/bash\"]", "examples\\onnxruntime\\training\\docker\\Dockerfile-ort-nightly-rocm57": "# Use rocm image\nFROM rocm/pytorch:rocm5.7_ubuntu22.04_py3.10_pytorch_2.0.1\nCMD rocm-smi\n\n# Ignore interactive questions during `docker build`\nENV DEBIAN_FRONTEND noninteractive\n\n# Versions\n# available options 3.10\nARG PYTHON_VERSION=3.10\n\n# Bash shell\nRUN chsh -s /bin/bash\nSHELL [\"/bin/bash\", \"-c\"]\n\n# Install and update tools to minimize security vulnerabilities\nRUN apt-get update\nRUN apt-get install -y software-properties-common wget apt-utils patchelf git libprotobuf-dev protobuf-compiler cmake \\\n bzip2 ca-certificates libglib2.0-0 libxext6 libsm6 libxrender1 mercurial subversion libopenmpi-dev ffmpeg && \\\n apt-get clean\nRUN apt-get autoremove -y\n\nARG PYTHON_EXE=/opt/conda/envs/py_$PYTHON_VERSION/bin/python\n\n# (Optional) Intall test dependencies\nRUN $PYTHON_EXE -m pip install -U pip\nRUN $PYTHON_EXE -m pip install git+https://github.com/huggingface/transformers\nRUN $PYTHON_EXE -m pip install datasets accelerate evaluate coloredlogs absl-py rouge_score seqeval scipy sacrebleu nltk scikit-learn parameterized sentencepiece --no-cache-dir\nRUN $PYTHON_EXE -m pip install deepspeed --no-cache-dir\nRUN conda install -y mpi4py\n\n# PyTorch\nRUN $PYTHON_EXE -m pip install onnx ninja\n\n# ORT Module\nRUN $PYTHON_EXE -m pip install --pre onnxruntime-training -f https://download.onnxruntime.ai/onnxruntime_nightly_rocm57.html\nRUN $PYTHON_EXE -m pip install torch-ort\nRUN $PYTHON_EXE -m pip install --upgrade protobuf==3.20.2\nRUN $PYTHON_EXE -m torch_ort.configure\n\nWORKDIR .\n\nCMD [\"/bin/bash\"]", "examples\\onnxruntime\\training\\docker\\Dockerfile-ort1.17.1-cu118": "#!/usr/bin/env python\n# coding=utf-8\n# Copyright 2023 The HuggingFace Team All rights reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n# Use nvidia/cuda image\nFROM nvidia/cuda:11.8.0-cudnn8-devel-ubuntu20.04\nCMD nvidia-smi\n\n# Ignore interactive questions during `docker build`\nENV DEBIAN_FRONTEND noninteractive\n\n# Versions\nARG PYTHON_VERSION=3.10\nARG TORCH_CUDA_VERSION=cu118\nARG TORCH_VERSION=2.0.0\nARG TORCHVISION_VERSION=0.15.1\n\n# Bash shell\nRUN chsh -s /bin/bash\nSHELL [\"/bin/bash\", \"-c\"]\n\n# Install and update tools to minimize security vulnerabilities\nRUN apt-get update\nRUN apt-get install -y software-properties-common wget apt-utils patchelf git libprotobuf-dev protobuf-compiler cmake \\\n bzip2 ca-certificates libglib2.0-0 libxext6 libsm6 libxrender1 mercurial subversion libopenmpi-dev ffmpeg && \\\n apt-get clean\nRUN unattended-upgrade\nRUN apt-get autoremove -y\n\n# Install miniconda (comes with python 3.9 default)\nARG BUILD_USER=onnxruntimedev\nARG MINICONDA_PREFIX=/home/$BUILD_USER/miniconda3\nRUN apt-get install curl\n\nARG CONDA_URL=https://repo.anaconda.com/miniconda/Miniconda3-py37_4.9.2-Linux-x86_64.sh\nRUN curl -fSsL --insecure ${CONDA_URL} -o install-conda.sh && \\\n /bin/bash ./install-conda.sh -b -p $MINICONDA_PREFIX && \\\n $MINICONDA_PREFIX/bin/conda clean -ya && \\\n $MINICONDA_PREFIX/bin/conda install -y python=${PYTHON_VERSION}\n\nENV PATH=$MINICONDA_PREFIX/bin:${PATH}\n\nARG PYTHON_EXE=$MINICONDA_PREFIX/bin/python\n\n# (Optional) Intall test dependencies\nRUN $PYTHON_EXE -m pip install git+https://github.com/huggingface/transformers\nRUN $PYTHON_EXE -m pip install datasets accelerate evaluate coloredlogs absl-py rouge_score seqeval scipy sacrebleu nltk scikit-learn parameterized sentencepiece\nRUN $PYTHON_EXE -m pip install deepspeed mpi4py\n# RUN $PYTHON_EXE -m pip install optuna ray sigopt wandb\n\n# PyTorch\nRUN $PYTHON_EXE -m pip install onnx ninja\nRUN $PYTHON_EXE -m pip install torch==${TORCH_VERSION} torchvision==${TORCHVISION_VERSION} -f https://download.pytorch.org/whl/${TORCH_CUDA_VERSION}\n\n# ORT Module\nRUN $PYTHON_EXE -m pip install onnxruntime-training==1.17.1 -f https://download.onnxruntime.ai/onnxruntime_stable_cu118.html\nRUN $PYTHON_EXE -m pip install torch-ort\nENV TORCH_CUDA_ARCH_LIST=\"5.2 6.0 6.1 7.0 7.5 8.0 8.6+PTX\"\nRUN $PYTHON_EXE -m pip install --upgrade protobuf==3.20.2\nRUN $PYTHON_EXE -m torch_ort.configure\n\n# https://github.com/vllm-project/vllm/issues/1726\nRUN pip uninstall nvidia-nccl-cu12 -y\n\nWORKDIR .\n\nCMD [\"/bin/bash\"]", "examples\\onnxruntime\\training\\image-classification\\requirements.txt": "accelerate>=0.12.0\ntorch>=1.5.0\ntorchvision>=0.6.0\ndatasets>=1.17.0\nevaluate\nonnx>=1.9.0\nonnxruntime-training>=1.9.0\ntorch-ort\n", "examples\\onnxruntime\\training\\language-modeling\\requirements.txt": "datasets >= 1.8.0\nsentencepiece != 0.1.92\nscipy\nscikit-learn\nprotobuf == 3.20.2\ntorch >= 1.9.0\ntransformers>=4.16.0\nonnx>=1.9.0\nonnxruntime-training>=1.9.0\ntorch-ort\n", "examples\\onnxruntime\\training\\question-answering\\requirements.txt": "datasets >= 1.8.0\nsentencepiece != 0.1.92\nscipy\nscikit-learn\nprotobuf\ntorch >= 1.9.0\ntorch-ort\n", "examples\\onnxruntime\\training\\stable-diffusion\\text-to-image\\requirements.txt": "accelerate>=0.16.0\ntransformers>=4.25.1\ndatasets\ngit+https://github.com/huggingface/diffusers\nftfy\ntensorboard\nJinja2\n", "examples\\onnxruntime\\training\\summarization\\requirements.txt": "accelerate\nevaluate\ndatasets >= 1.8.0\nsentencepiece != 0.1.92\nscipy\nscikit-learn\nprotobuf\nrouge-score\nnltk\npy7zr\ntorch >= 1.9.0\ntorch-ort\n", "examples\\onnxruntime\\training\\text-classification\\requirements.txt": "datasets >= 1.8.0\nsentencepiece != 0.1.92\nscipy\nscikit-learn\nprotobuf\n", "examples\\onnxruntime\\training\\token-classification\\requirements.txt": "datasets >= 1.18.3\nscipy\nscikit-learn\nsentencepiece != 0.1.92\nseqeval\ntorch >= 1.8.1\nseqeval\nsentencepiece != 0.1.92\ntorch >= 1.9\ntorch-ort\n", "examples\\onnxruntime\\training\\translation\\requirements.txt": "datasets >= 1.18.0\nsentencepiece != 0.1.92\nprotobuf\nsacrebleu >= 1.4.12\npy7zr\ntorch >= 1.8", "optimum\\exporters\\onnx\\__main__.py": "# coding=utf-8\n# Copyright 2022 The HuggingFace Team. All rights reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\"\"\"Entry point to the optimum.exporters.onnx command line.\"\"\"\n\nimport argparse\nimport warnings\nfrom pathlib import Path\n\nfrom huggingface_hub.constants import HUGGINGFACE_HUB_CACHE\nfrom packaging import version\nfrom requests.exceptions import ConnectionError as RequestsConnectionError\nfrom transformers import AutoConfig, AutoTokenizer\nfrom transformers.utils import is_torch_available\n\nfrom ...commands.export.onnx import parse_args_onnx\nfrom ...configuration_utils import _transformers_version\nfrom ...utils import DEFAULT_DUMMY_SHAPES, logging\nfrom ...utils.save_utils import maybe_load_preprocessors\nfrom ..tasks import TasksManager\nfrom .constants import SDPA_ARCHS_ONNX_EXPORT_NOT_SUPPORTED\nfrom .convert import onnx_export_from_model\n\n\nif is_torch_available():\n import torch\n\nfrom typing import TYPE_CHECKING, Any, Callable, Dict, Optional, Union\n\n\nif TYPE_CHECKING:\n from .base import OnnxConfig\n\nlogger = logging.get_logger()\nlogger.setLevel(logging.INFO)\n\n\ndef main_export(\n model_name_or_path: str,\n output: Union[str, Path],\n task: str = \"auto\",\n opset: Optional[int] = None,\n device: str = \"cpu\",\n dtype: Optional[str] = None,\n fp16: Optional[bool] = False,\n optimize: Optional[str] = None,\n monolith: bool = False,\n no_post_process: bool = False,\n framework: Optional[str] = None,\n atol: Optional[float] = None,\n cache_dir: str = HUGGINGFACE_HUB_CACHE,\n trust_remote_code: bool = False,\n pad_token_id: Optional[int] = None,\n subfolder: str = \"\",\n revision: str = \"main\",\n force_download: bool = False,\n local_files_only: bool = False,\n use_auth_token: Optional[Union[bool, str]] = None,\n token: Optional[Union[bool, str]] = None,\n for_ort: bool = False,\n do_validation: bool = True,\n model_kwargs: Optional[Dict[str, Any]] = None,\n custom_onnx_configs: Optional[Dict[str, \"OnnxConfig\"]] = None,\n fn_get_submodels: Optional[Callable] = None,\n use_subprocess: bool = False,\n _variant: str = \"default\",\n library_name: Optional[str] = None,\n legacy: bool = False,\n no_dynamic_axes: bool = False,\n do_constant_folding: bool = True,\n **kwargs_shapes,\n):\n \"\"\"\n Full-suite ONNX export function, exporting **from a model ID on Hugging Face Hub or a local model repository**.\n\n Args:\n > Required parameters\n\n model_name_or_path (`str`):\n Model ID on huggingface.co or path on disk to the model repository to export. Example: `model_name_or_path=\"BAAI/bge-m3\"` or `mode_name_or_path=\"/path/to/model_folder`.\n output (`Union[str, Path]`):\n Path indicating the directory where to store the generated ONNX model.\n\n > Optional parameters\n\n task (`Optional[str]`, defaults to `None`):\n The task to export the model for. If not specified, the task will be auto-inferred based on the model. For decoder models,\n use `xxx-with-past` to export the model using past key values in the decoder.\n opset (`Optional[int]`, defaults to `None`):\n If specified, ONNX opset version to export the model with. Otherwise, the default opset for the given model architecture\n will be used.\n device (`str`, defaults to `\"cpu\"`):\n The device to use to do the export. Defaults to \"cpu\".\n fp16 (`Optional[bool]`, defaults to `\"False\"`):\n Use half precision during the export. PyTorch-only, requires `device=\"cuda\"`.\n dtype (`Optional[str]`, defaults to `None`):\n The floating point precision to use for the export. Supported options: `\"fp32\"` (float32), `\"fp16\"` (float16), `\"bf16\"` (bfloat16). Defaults to `\"fp32\"`.\n optimize (`Optional[str]`, defaults to `None`):\n Allows to run ONNX Runtime optimizations directly during the export. Some of these optimizations are specific to\n ONNX Runtime, and the resulting ONNX will not be usable with other runtime as OpenVINO or TensorRT.\n Available options: `\"O1\", \"O2\", \"O3\", \"O4\"`. Reference: [`~optimum.onnxruntime.AutoOptimizationConfig`]\n monolith (`bool`, defaults to `False`):\n Forces to export the model as a single ONNX file.\n no_post_process (`bool`, defaults to `False`):\n Allows to disable any post-processing done by default on the exported ONNX models.\n framework (`Optional[str]`, defaults to `None`):\n The framework to use for the ONNX export (`\"pt\"` or `\"tf\"`). If not provided, will attempt to automatically detect\n the framework for the checkpoint.\n atol (`Optional[float]`, defaults to `None`):\n If specified, the absolute difference tolerance when validating the model. Otherwise, the default atol for the model will be used.\n cache_dir (`Optional[str]`, defaults to `None`):\n Path indicating where to store cache. The default Hugging Face cache path will be used by default.\n trust_remote_code (`bool`, defaults to `False`):\n Allows to use custom code for the modeling hosted in the model repository. This option should only be set for repositories\n you trust and in which you have read the code, as it will execute on your local machine arbitrary code present in the\n model repository.\n pad_token_id (`Optional[int]`, defaults to `None`):\n This is needed by some models, for some tasks. If not provided, will attempt to use the tokenizer to guess it.\n subfolder (`str`, defaults to `\"\"`):\n In case the relevant files are located inside a subfolder of the model repo either locally or on huggingface.co, you can\n specify the folder name here.\n revision (`str`, defaults to `\"main\"`):\n Revision is the specific model version to use. It can be a branch name, a tag name, or a commit id.\n force_download (`bool`, defaults to `False`):\n Whether or not to force the (re-)download of the model weights and configuration files, overriding the\n cached versions if they exist.\n local_files_only (`Optional[bool]`, defaults to `False`):\n Whether or not to only look at local files (i.e., do not try to download the model).\n use_auth_token (`Optional[Union[bool,str]]`, defaults to `None`):\n Deprecated. Please use the `token` argument instead.\n token (`Optional[Union[bool,str]]`, defaults to `None`):\n The token to use as HTTP bearer authorization for remote files. If `True`, will use the token generated\n when running `huggingface-cli login` (stored in `huggingface_hub.constants.HF_TOKEN_PATH`).\n model_kwargs (`Optional[Dict[str, Any]]`, defaults to `None`):\n Experimental usage: keyword arguments to pass to the model during\n the export. This argument should be used along the `custom_onnx_configs` argument\n in case, for example, the model inputs/outputs are changed (for example, if\n `model_kwargs={\"output_attentions\": True}` is passed).\n custom_onnx_configs (`Optional[Dict[str, OnnxConfig]]`, defaults to `None`):\n Experimental usage: override the default ONNX config used for the given model. This argument may be useful for advanced users that desire a finer-grained control on the export. An example is available [here](https://huggingface.co/docs/optimum/main/en/exporters/onnx/usage_guides/export_a_model).\n fn_get_submodels (`Optional[Callable]`, defaults to `None`):\n Experimental usage: Override the default submodels that are used at the export. This is\n especially useful when exporting a custom architecture that needs to split the ONNX (e.g. encoder-decoder). If unspecified with custom models, optimum will try to use the default submodels used for the given task, with no guarantee of success.\n use_subprocess (`bool`, defaults to `False`):\n Do the ONNX exported model validation in subprocesses. This is especially useful when\n exporting on CUDA device, where ORT does not release memory at inference session\n destruction. When set to `True`, the `main_export` call should be guarded in\n `if __name__ == \"__main__\":` block.\n _variant (`str`, defaults to `default`):\n Specify the variant of the ONNX export to use.\n library_name (`Optional[str]`, defaults to `None`):\n The library of the model (`\"transformers\"` or `\"diffusers\"` or `\"timm\"` or `\"sentence_transformers\"`). If not provided, will attempt to automatically detect the library name for the checkpoint.\n legacy (`bool`, defaults to `False`):\n Disable the use of position_ids for text-generation models that require it for batched generation. Also enable to export decoder only models in three files (without + with past and the merged model). This argument is introduced for backward compatibility and will be removed in a future release of Optimum.\n no_dynamic_axes (bool, defaults to `False`):\n If True, disables the use of dynamic axes during ONNX export.\n do_constant_folding (bool, defaults to `True`):\n PyTorch-specific argument. If `True`, the PyTorch ONNX export will fold constants into adjacent nodes, if possible.\n **kwargs_shapes (`Dict`):\n Shapes to use during inference. This argument allows to override the default shapes used during the ONNX export.\n\n Example usage:\n ```python\n >>> from optimum.exporters.onnx import main_export\n\n >>> main_export(\"gpt2\", output=\"gpt2_onnx/\")\n ```\n \"\"\"\n\n if use_auth_token is not None:\n warnings.warn(\n \"The `use_auth_token` argument is deprecated and will be removed soon. Please use the `token` argument instead.\",\n FutureWarning,\n )\n if token is not None:\n raise ValueError(\"You cannot use both `use_auth_token` and `token` arguments at the same time.\")\n token = use_auth_token\n\n if fp16:\n if dtype is not None:\n raise ValueError(\n f'Both the arguments `fp16` ({fp16}) and `dtype` ({dtype}) were specified in the ONNX export, which is not supported. Please specify only `dtype`. Possible options: \"fp32\" (default), \"fp16\", \"bf16\".'\n )\n\n logger.warning(\n 'The argument `fp16` is deprecated in the ONNX export. Please use the argument `dtype=\"fp16\"` instead, or `--dtype fp16` from the command-line.'\n )\n\n dtype = \"fp16\"\n elif dtype is None:\n dtype = \"fp32\" # Defaults to float32.\n\n if optimize == \"O4\" and device != \"cuda\":\n raise ValueError(\n \"Requested O4 optimization, but this optimization requires to do the export on GPU.\"\n \" Please pass the argument `--device cuda`.\"\n )\n\n if (framework == \"tf\" and fp16) or not is_torch_available():\n raise ValueError(\"The --fp16 option is supported only for PyTorch.\")\n\n if dtype == \"fp16\" and device == \"cpu\":\n raise ValueError(\n \"FP16 export is supported only when exporting on GPU. Please pass the option `--device cuda`.\"\n )\n\n if for_ort:\n logger.warning(\n \"The option --for-ort was passed, but its behavior is now the default in the ONNX exporter\"\n \" and passing it is not required anymore.\"\n )\n\n if task in [\"stable-diffusion\", \"stable-diffusion-xl\"]:\n logger.warning(\n f\"The task `{task}` is deprecated and will be removed in a future release of Optimum. \"\n \"Please use one of the following tasks instead: `text-to-image`, `image-to-image`, `inpainting`.\"\n )\n\n original_task = task\n task = TasksManager.map_from_synonym(task)\n\n if framework is None:\n framework = TasksManager.determine_framework(\n model_name_or_path, subfolder=subfolder, revision=revision, cache_dir=cache_dir, token=token\n )\n\n if library_name is None:\n library_name = TasksManager.infer_library_from_model(\n model_name_or_path, subfolder=subfolder, revision=revision, cache_dir=cache_dir, token=token\n )\n\n torch_dtype = None\n if framework == \"pt\":\n if dtype == \"fp16\":\n torch_dtype = torch.float16\n elif dtype == \"bf16\":\n torch_dtype = torch.bfloat16\n\n if task.endswith(\"-with-past\") and monolith:\n task_non_past = task.replace(\"-with-past\", \"\")\n raise ValueError(\n f\"The task {task} is not compatible with the --monolith argument. Please either use\"\n f\" `--task {task_non_past} --monolith`, or `--task {task}` without the monolith argument.\"\n )\n\n if task == \"auto\":\n try:\n task = TasksManager.infer_task_from_model(model_name_or_path)\n except KeyError as e:\n raise KeyError(\n f\"The task could not be automatically inferred. Please provide the argument --task with the relevant task from {', '.join(TasksManager.get_all_tasks())}. Detailed error: {e}\"\n )\n except RequestsConnectionError as e:\n raise RequestsConnectionError(\n f\"The task could not be automatically inferred as this is available only for models hosted on the Hugging Face Hub. Please provide the argument --task with the relevant task from {', '.join(TasksManager.get_all_tasks())}. Detailed error: {e}\"\n )\n\n custom_architecture = False\n loading_kwargs = {}\n if library_name == \"transformers\":\n config = AutoConfig.from_pretrained(\n model_name_or_path,\n subfolder=subfolder,\n revision=revision,\n cache_dir=cache_dir,\n token=token,\n local_files_only=local_files_only,\n force_download=force_download,\n trust_remote_code=trust_remote_code,\n )\n model_type = config.model_type.replace(\"_\", \"-\")\n\n if model_type not in TasksManager._SUPPORTED_MODEL_TYPE:\n custom_architecture = True\n elif task not in TasksManager.get_supported_tasks_for_model_type(\n model_type, \"onnx\", library_name=library_name\n ):\n if original_task == \"auto\":\n autodetected_message = \" (auto-detected)\"\n else:\n autodetected_message = \"\"\n model_tasks = TasksManager.get_supported_tasks_for_model_type(\n model_type, exporter=\"onnx\", library_name=library_name\n )\n raise ValueError(\n f\"Asked to export a {model_type} model for the task {task}{autodetected_message}, but the Optimum ONNX exporter only supports the tasks {', '.join(model_tasks.keys())} for {model_type}. Please use a supported task. Please open an issue at https://github.com/huggingface/optimum/issues if you would like the task {task} to be supported in the ONNX export for {model_type}.\"\n )\n\n # TODO: Fix in Transformers so that SdpaAttention class can be exported to ONNX. `attn_implementation` is introduced in Transformers 4.36.\n if model_type in SDPA_ARCHS_ONNX_EXPORT_NOT_SUPPORTED and _transformers_version >= version.parse(\"4.35.99\"):\n loading_kwargs[\"attn_implementation\"] = \"eager\"\n\n model = TasksManager.get_model_from_task(\n task,\n model_name_or_path,\n subfolder=subfolder,\n revision=revision,\n cache_dir=cache_dir,\n token=token,\n local_files_only=local_files_only,\n force_download=force_download,\n trust_remote_code=trust_remote_code,\n framework=framework,\n torch_dtype=torch_dtype,\n device=device,\n library_name=library_name,\n **loading_kwargs,\n )\n\n needs_pad_token_id = task == \"text-classification\" and getattr(model.config, \"pad_token_id\", None) is None\n\n if needs_pad_token_id:\n if pad_token_id is not None:\n model.config.pad_token_id = pad_token_id\n else:\n tok = AutoTokenizer.from_pretrained(model_name_or_path)\n pad_token_id = getattr(tok, \"pad_token_id\", None)\n if pad_token_id is None:\n raise ValueError(\n \"Could not infer the pad token id, which is needed in this case, please provide it with the --pad_token_id argument\"\n )\n model.config.pad_token_id = pad_token_id\n\n if hasattr(model.config, \"export_model_type\"):\n model_type = model.config.export_model_type.replace(\"_\", \"-\")\n else:\n model_type = model.config.model_type.replace(\"_\", \"-\")\n\n if (\n not custom_architecture\n and library_name != \"diffusers\"\n and task + \"-with-past\"\n in TasksManager.get_supported_tasks_for_model_type(model_type, \"onnx\", library_name=library_name)\n ):\n # Make -with-past the default if --task was not explicitely specified\n if original_task == \"auto\" and not monolith:\n task = task + \"-with-past\"\n else:\n logger.info(\n f\"The task `{task}` was manually specified, and past key values will not be reused in the decoding.\"\n f\" if needed, please pass `--task {task}-with-past` to export using the past key values.\"\n )\n model.config.use_cache = False\n\n if task.endswith(\"with-past\"):\n model.config.use_cache = True\n\n if original_task == \"auto\":\n synonyms_for_task = sorted(TasksManager.synonyms_for_task(task))\n if synonyms_for_task:\n synonyms_for_task = \", \".join(synonyms_for_task)\n possible_synonyms = f\" (possible synonyms are: {synonyms_for_task})\"\n else:\n possible_synonyms = \"\"\n logger.info(f\"Automatic task detection to {task}{possible_synonyms}.\")\n\n # The preprocessors are loaded as they may be useful to export the model. Notably, some of the static input shapes may be stored in the\n # preprocessors config.\n preprocessors = maybe_load_preprocessors(\n model_name_or_path, subfolder=subfolder, trust_remote_code=trust_remote_code\n )\n\n onnx_export_from_model(\n model=model,\n output=output,\n opset=opset,\n optimize=optimize,\n monolith=monolith,\n no_post_process=no_post_process,\n atol=atol,\n do_validation=do_validation,\n model_kwargs=model_kwargs,\n custom_onnx_configs=custom_onnx_configs,\n fn_get_submodels=fn_get_submodels,\n _variant=_variant,\n legacy=legacy,\n preprocessors=preprocessors,\n device=device,\n no_dynamic_axes=no_dynamic_axes,\n task=task,\n use_subprocess=use_subprocess,\n do_constant_folding=do_constant_folding,\n **kwargs_shapes,\n )\n\n\ndef main():\n parser = argparse.ArgumentParser(\"Hugging Face Optimum ONNX exporter\")\n\n parse_args_onnx(parser)\n\n # Retrieve CLI arguments\n args = parser.parse_args()\n\n # get the shapes to be used to generate dummy inputs\n input_shapes = {}\n for input_name in DEFAULT_DUMMY_SHAPES.keys():\n input_shapes[input_name] = getattr(args, input_name)\n\n main_export(\n model_name_or_path=args.model,\n output=args.output,\n task=args.task,\n opset=args.opset,\n device=args.device,\n fp16=args.fp16,\n optimize=args.optimize,\n monolith=args.monolith,\n no_post_process=args.no_post_process,\n framework=args.framework,\n atol=args.atol,\n cache_dir=args.cache_dir,\n trust_remote_code=args.trust_remote_code,\n pad_token_id=args.pad_token_id,\n for_ort=args.for_ort,\n library_name=args.library_name,\n legacy=args.legacy,\n do_constant_folding=not args.no_constant_folding,\n **input_shapes,\n )\n\n\nif __name__ == \"__main__\":\n main()\n", "optimum\\exporters\\tflite\\__main__.py": "# coding=utf-8\n# Copyright 2023 The HuggingFace Team. All rights reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\"\"\"Entry point to the optimum.exporters.tflite command line.\"\"\"\n\nfrom argparse import ArgumentParser\n\nfrom requests.exceptions import ConnectionError as RequestsConnectionError\n\nfrom ...commands.export.tflite import parse_args_tflite\nfrom ...utils import logging\nfrom ...utils.save_utils import maybe_load_preprocessors, maybe_save_preprocessors\nfrom ..error_utils import AtolError, OutputMatchError, ShapeError\nfrom ..tasks import TasksManager\nfrom .base import TFLiteQuantizationConfig\nfrom .convert import export, validate_model_outputs\n\n\nlogger = logging.get_logger()\nlogger.setLevel(logging.INFO)\n\n\ndef main():\n parser = ArgumentParser(\"Hugging Face Optimum TensorFlow Lite exporter\")\n\n parse_args_tflite(parser)\n\n # Retrieve CLI arguments\n args = parser.parse_args()\n args.output = args.output.joinpath(\"model.tflite\")\n\n if not args.output.parent.exists():\n args.output.parent.mkdir(parents=True)\n\n # Infer the task\n task = args.task\n if task == \"auto\":\n try:\n task = TasksManager.infer_task_from_model(args.model)\n except KeyError as e:\n raise KeyError(\n \"The task could not be automatically inferred. Please provide the argument --task with the task \"\n f\"from {', '.join(TasksManager.get_all_tasks())}. Detailed error: {e}\"\n )\n except RequestsConnectionError as e:\n raise RequestsConnectionError(\n f\"The task could not be automatically inferred as this is available only for models hosted on the Hugging Face Hub. Please provide the argument --task with the relevant task from {', '.join(TasksManager.get_all_tasks())}. Detailed error: {e}\"\n )\n\n model = TasksManager.get_model_from_task(\n task, args.model, framework=\"tf\", cache_dir=args.cache_dir, trust_remote_code=args.trust_remote_code\n )\n\n tflite_config_constructor = TasksManager.get_exporter_config_constructor(\n model=model, exporter=\"tflite\", task=task, library_name=\"transformers\"\n )\n # TODO: find a cleaner way to do this.\n shapes = {name: getattr(args, name) for name in tflite_config_constructor.func.get_mandatory_axes_for_task(task)}\n tflite_config = tflite_config_constructor(model.config, **shapes)\n\n if args.atol is None:\n args.atol = tflite_config.ATOL_FOR_VALIDATION\n if isinstance(args.atol, dict):\n args.atol = args.atol[task.replace(\"-with-past\", \"\")]\n\n # Saving the model config and preprocessor as this is needed sometimes.\n model.config.save_pretrained(args.output.parent)\n maybe_save_preprocessors(args.model, args.output.parent)\n\n preprocessor = maybe_load_preprocessors(args.output.parent)\n if preprocessor:\n preprocessor = preprocessor[0]\n else:\n preprocessor = None\n\n quantization_config = None\n if args.quantize:\n quantization_config = TFLiteQuantizationConfig(\n approach=args.quantize,\n fallback_to_float=args.fallback_to_float,\n inputs_dtype=args.inputs_type,\n outputs_dtype=args.outputs_type,\n calibration_dataset_name_or_path=args.calibration_dataset,\n calibration_dataset_config_name=args.calibration_dataset_config_name,\n num_calibration_samples=args.num_calibration_samples,\n calibration_split=args.calibration_split,\n primary_key=args.primary_key,\n secondary_key=args.secondary_key,\n question_key=args.question_key,\n context_key=args.context_key,\n image_key=args.image_key,\n )\n\n tflite_inputs, tflite_outputs = export(\n model=model,\n config=tflite_config,\n output=args.output,\n task=task,\n preprocessor=preprocessor,\n quantization_config=quantization_config,\n )\n\n if args.quantize is None:\n try:\n validate_model_outputs(\n config=tflite_config,\n reference_model=model,\n tflite_model_path=args.output,\n tflite_named_outputs=tflite_config.outputs,\n atol=args.atol,\n )\n\n logger.info(\n \"The TensorFlow Lite export succeeded and the exported model was saved at: \"\n f\"{args.output.parent.as_posix()}\"\n )\n except ShapeError as e:\n raise e\n except AtolError as e:\n logger.warning(\n f\"The TensorFlow Lite export succeeded with the warning: {e}.\\n The exported model was saved at: \"\n f\"{args.output.parent.as_posix()}\"\n )\n except OutputMatchError as e:\n logger.warning(\n f\"The TensorFlow Lite export succeeded with the warning: {e}.\\n The exported model was saved at: \"\n f\"{args.output.parent.as_posix()}\"\n )\n except Exception as e:\n logger.error(\n f\"An error occured with the error message: {e}.\\n The exported model was saved at: \"\n f\"{args.output.parent.as_posix()}\"\n )\n\n\nif __name__ == \"__main__\":\n main()\n", "tests\\bettertransformer\\Dockerfile_bettertransformer_gpu": "FROM nvidia/cuda:11.7.1-cudnn8-devel-ubuntu22.04\nCMD nvidia-smi\n\n# Ignore interactive questions during `docker build`\nENV DEBIAN_FRONTEND noninteractive\n\n# Install and update tools to minimize security vulnerabilities\nRUN apt-get update\nRUN apt-get install -y software-properties-common wget apt-utils patchelf git libprotobuf-dev protobuf-compiler cmake \\\n bzip2 ca-certificates libglib2.0-0 libxext6 libsm6 libxrender1 mercurial subversion libopenmpi-dev python3-pip && \\\n apt-get clean\nRUN unattended-upgrade\nRUN apt-get autoremove -y\n\nRUN python3 -m pip install -U pip\n\nRUN pip install torch torchvision torchaudio\nRUN pip install transformers accelerate datasets\n\n# Install Optimum\nCOPY . /workspace/optimum\nRUN pip install /workspace/optimum[tests]\n\nENV RUN_SLOW=1\nWORKDIR /workspace/optimum/tests/\nCMD pytest bettertransformer/test_*.py -s --durations=0 -m gpu_test\n", "tests\\exporters\\Dockerfile_exporters_gpu": "# use version with cudnn 8.5 to match torch==1.13.1 that uses 8.5.0.96\n# has Python 3.8.10\nFROM nvcr.io/nvidia/tensorrt:22.08-py3\nCMD nvidia-smi\n\n# Ignore interactive questions during `docker build`\nENV DEBIAN_FRONTEND noninteractive\n\n# Install and update tools to minimize security vulnerabilities\nRUN apt-get update\nRUN apt-get install -y software-properties-common wget apt-utils patchelf git libprotobuf-dev protobuf-compiler cmake \\\n bzip2 ca-certificates libglib2.0-0 libxext6 libsm6 libxrender1 mercurial subversion libopenmpi-dev && \\\n apt-get clean\nRUN unattended-upgrade\nRUN apt-get autoremove -y\n\nRUN python -m pip install -U pip\n\nRUN pip install torch scipy datasets evaluate diffusers\n\nRUN pip install transformers\nRUN pip install onnxruntime-gpu\n\n# Install Optimum\nCOPY . /workspace/optimum\nRUN pip install /workspace/optimum[onnxruntime-gpu,tests,exporters-gpu]\n\nENV TEST_LEVEL=1\nENV RUN_SLOW=1\nCMD pytest exporters --durations=0 -s -vvvvv -m gpu_test\n", "tests\\onnxruntime\\docker\\Dockerfile_onnxruntime_gpu": "# use version with CUDA 11.8 and TensorRT 8.5.1.7 to match ORT 1.14 requirements\nFROM nvcr.io/nvidia/tensorrt:22.12-py3\nCMD nvidia-smi\n\n# Ignore interactive questions during `docker build`\nENV DEBIAN_FRONTEND noninteractive\n\n# Install and update tools to minimize security vulnerabilities\nRUN apt-get update\nRUN apt-get install -y software-properties-common wget apt-utils patchelf git libprotobuf-dev protobuf-compiler cmake \\\n bzip2 ca-certificates libglib2.0-0 libxext6 libsm6 libxrender1 mercurial subversion libopenmpi-dev ffmpeg && \\\n apt-get clean\nRUN unattended-upgrade\nRUN apt-get autoremove -y\n\nRUN python -m pip install -U pip\n\nRUN pip install transformers torch onnxruntime-gpu\nRUN pip install datasets evaluate diffusers scipy\n\n# Install Optimum\nCOPY . /workspace/optimum\nRUN pip install /workspace/optimum[onnxruntime-gpu,tests]\n\nENV TEST_LEVEL=1\nCMD pytest onnxruntime/test_*.py --durations=0 -s -vvvvv -m cuda_ep_test -m trt_ep_test\n", "tests\\onnxruntime\\docker\\Dockerfile_onnxruntime_trainer": "#!/usr/bin/env python\n# coding=utf-8\n# Copyright 2023 The HuggingFace Team All rights reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n# Use nvidia/cuda image\nFROM nvidia/cuda:11.8.0-cudnn8-devel-ubuntu20.04\nCMD nvidia-smi\n\n# Ignore interactive questions during `docker build`\nENV DEBIAN_FRONTEND noninteractive\n\n# Bash shell\nRUN chsh -s /bin/bash\nSHELL [\"/bin/bash\", \"-c\"]\n\n# Versions\nARG PYTHON_VERSION=3.9\nARG TORCH_CUDA_VERSION=cu118\nARG TORCH_VERSION=2.0.0\nARG TORCHVISION_VERSION=0.15.1\n\n# Install and update tools to minimize security vulnerabilities\nRUN apt-get update\nRUN apt-get install -y software-properties-common wget apt-utils patchelf git libprotobuf-dev protobuf-compiler cmake \\\n bzip2 ca-certificates libglib2.0-0 libxext6 libsm6 libxrender1 mercurial subversion libopenmpi-dev ffmpeg && \\\n apt-get clean\nRUN unattended-upgrade\nRUN apt-get autoremove -y\n\n# Install miniconda (comes with python 3.9 default)\nARG BUILD_USER=onnxruntimedev\nARG MINICONDA_PREFIX=/home/$BUILD_USER/miniconda3\nRUN apt-get install curl\n\nARG CONDA_URL=https://repo.anaconda.com/miniconda/Miniconda3-py37_4.9.2-Linux-x86_64.sh\nRUN curl -fSsL --insecure ${CONDA_URL} -o install-conda.sh && \\\n /bin/bash ./install-conda.sh -b -p $MINICONDA_PREFIX && \\\n $MINICONDA_PREFIX/bin/conda clean -ya && \\\n $MINICONDA_PREFIX/bin/conda install -y python=${PYTHON_VERSION}\n\nENV PATH=$MINICONDA_PREFIX/bin:${PATH}\n\nARG PYTHON_EXE=$MINICONDA_PREFIX/bin/python\n\n# (Optional) Intall test dependencies\nRUN $PYTHON_EXE -m pip install git+https://github.com/huggingface/transformers\nRUN $PYTHON_EXE -m pip install datasets accelerate evaluate coloredlogs absl-py rouge_score seqeval scipy sacrebleu nltk scikit-learn parameterized sentencepiece\nRUN $PYTHON_EXE -m pip install deepspeed mpi4py\n# RUN $PYTHON_EXE -m pip install optuna ray sigopt wandb\n\n# PyTorch\nRUN $PYTHON_EXE -m pip install onnx ninja\nRUN $PYTHON_EXE -m pip install torch==${TORCH_VERSION} torchvision==${TORCHVISION_VERSION} -f https://download.pytorch.org/whl/${TORCH_CUDA_VERSION}\n\n# ORT Module\nRUN $PYTHON_EXE -m pip install onnxruntime-training==1.16.3 -f https://download.onnxruntime.ai/onnxruntime_stable_cu118.html\nRUN $PYTHON_EXE -m pip install torch-ort\nENV TORCH_CUDA_ARCH_LIST=\"5.2 6.0 6.1 7.0 7.5 8.0 8.6+PTX\"\nRUN $PYTHON_EXE -m pip install --upgrade protobuf==3.20.2\nRUN $PYTHON_EXE -m torch_ort.configure\n\n# https://github.com/vllm-project/vllm/issues/1726\nRUN pip uninstall nvidia-nccl-cu12 -y\n\n# Install Optimum\nCOPY . /workspace/optimum\nRUN pip install /workspace/optimum[tests]\n\nENV TEST_LEVEL=1\nCMD RUN_SLOW=1 pytest -v -rs onnxruntime/training/nightly_test_trainer.py --durations=0\nCMD RUN_SLOW=1 pytest -v -rs onnxruntime/training/nightly_test_examples.py --durations=0"} | null |
optimum-amd | {"type": "directory", "name": "optimum-amd", "children": [{"type": "directory", "name": "benchmarks", "children": [{"type": "file", "name": "inference_pytorch_bert.yaml"}, {"type": "file", "name": "inference_pytorch_llama.yaml"}, {"type": "file", "name": "_base_.yaml"}]}, {"type": "file", "name": "conftest.py"}, {"type": "directory", "name": "docker", "children": [{"type": "directory", "name": "onnx-runtime-amd-gpu", "children": [{"type": "file", "name": "Dockerfile"}]}, {"type": "directory", "name": "transformers-pytorch-amd-cpu-zentorch", "children": [{"type": "file", "name": "Dockerfile"}]}, {"type": "directory", "name": "transformers-pytorch-amd-gpu-flash", "children": [{"type": "file", "name": "Dockerfile"}]}]}, {"type": "directory", "name": "docs", "children": [{"type": "file", "name": "Dockerfile"}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "source", "children": [{"type": "directory", "name": "amdgpu", "children": [{"type": "file", "name": "overview.mdx"}, {"type": "file", "name": "perf_hardware.mdx"}]}, {"type": "directory", "name": "brevitas", "children": [{"type": "file", "name": "api_reference.mdx"}, {"type": "file", "name": "usage_guide.mdx"}]}, {"type": "file", "name": "index.mdx"}, {"type": "file", "name": "installation.mdx"}, {"type": "directory", "name": "ryzenai", "children": [{"type": "file", "name": "overview.mdx"}, {"type": "directory", "name": "package_reference", "children": [{"type": "file", "name": "configuration.mdx"}, {"type": "file", "name": "modeling.mdx"}, {"type": "file", "name": "pipelines.mdx"}, {"type": "file", "name": "quantization.mdx"}]}, {"type": "directory", "name": "usage_guides", "children": [{"type": "file", "name": "pipelines.mdx"}, {"type": "file", "name": "quantization.mdx"}]}]}, {"type": "file", "name": "_toctree.yml"}]}]}, {"type": "directory", "name": "examples", "children": [{"type": "directory", "name": "quantization", "children": [{"type": "directory", "name": "brevitas", "children": [{"type": "file", "name": "quantize_llm.py"}, {"type": "file", "name": "README.md"}]}, {"type": "directory", "name": "ryzenai", "children": [{"type": "file", "name": "quantize_image_classification_model.py"}, {"type": "file", "name": "README.md"}]}]}]}, {"type": "file", "name": "LICENSE"}, {"type": "file", "name": "Makefile"}, {"type": "directory", "name": "notebooks", "children": [{"type": "directory", "name": "image-classification", "children": [{"type": "file", "name": "run_image_classification.ipynb"}, {"type": "file", "name": "vaip_config.json"}]}]}, {"type": "directory", "name": "optimum", "children": [{"type": "directory", "name": "amd", "children": [{"type": "directory", "name": "brevitas", "children": [{"type": "file", "name": "accelerate_utils.py"}, {"type": "file", "name": "configuration.py"}, {"type": "file", "name": "data_utils.py"}, {"type": "file", "name": "export.py"}, {"type": "file", "name": "quantizer.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "cli.py"}, {"type": "directory", "name": "ryzenai", "children": [{"type": "directory", "name": "configs", "children": [{"type": "file", "name": "vaip_config.json"}]}, {"type": "file", "name": "configuration.py"}, {"type": "file", "name": "modeling.py"}, {"type": "directory", "name": "models", "children": [{"type": "file", "name": "detection_utils.py"}, {"type": "directory", "name": "hrnet", "children": [{"type": "file", "name": "image_processing_hrnet.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "image_transforms.py"}, {"type": "directory", "name": "semanticfpn", "children": [{"type": "file", "name": "image_processing_semantic_fpn.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "yolov3", "children": [{"type": "file", "name": "image_processing_yolov3.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "yolov5", "children": [{"type": "file", "name": "image_processing_yolov5.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "yolov8", "children": [{"type": "file", "name": "image_processing_yolov8.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "yolox", "children": [{"type": "file", "name": "image_processing_yolox.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "pipelines", "children": [{"type": "file", "name": "image_classification.py"}, {"type": "file", "name": "image_segmentation.py"}, {"type": "file", "name": "object_detection.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "quantization.py"}, {"type": "file", "name": "utils.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "topology_utils.py"}, {"type": "file", "name": "version.py"}, {"type": "file", "name": "__init__.py"}]}]}, {"type": "file", "name": "pyproject.toml"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "setup.cfg"}, {"type": "file", "name": "setup.py"}, {"type": "directory", "name": "tests", "children": [{"type": "directory", "name": "brevitas", "children": [{"type": "file", "name": "testing_utils.py"}, {"type": "file", "name": "test_data.py"}, {"type": "file", "name": "test_onnx_export.py"}, {"type": "file", "name": "test_quantization.py"}]}, {"type": "directory", "name": "ryzenai", "children": [{"type": "file", "name": "operators_baseline.json"}, {"type": "file", "name": "testing_utils.py"}, {"type": "file", "name": "test_modeling.py"}, {"type": "file", "name": "test_quantization.py"}, {"type": "file", "name": "vaip_config.json"}]}, {"type": "directory", "name": "zentorch", "children": [{"type": "file", "name": "testing_utils.py"}, {"type": "file", "name": "test_sanity.py"}]}]}, {"type": "directory", "name": "utils", "children": [{"type": "directory", "name": "ryzenai", "children": [{"type": "file", "name": "generate_operators_baseline.py"}, {"type": "file", "name": "notification_service.py"}, {"type": "file", "name": "README.md"}]}]}]} | # Utilities
## Generate IPU Baseline Operators
* Setup the Ryzen testing environment.
* Run all the following command to generate the Ryzen cache for the test models.
```bash
$env:RUN_SLOW=1; pytest -m "prequantized_model_test or quant_test" .\tests\ryzenai\
```
The tests will generate the `vitisai_ep_report.json` in `ryzen_cache` folder.
* Run the below script to generate baseline operators.
```bash
python .\utils\ryzenai\generate_operators_baseline.py .\ryzen_cache\ .\tests\ryzenai\operators_baseline.json
``` | {"setup.py": "# Copyright 2023 The HuggingFace Team. All rights reserved.\n# Licensed under the MIT License.\nimport re\n\nfrom setuptools import find_namespace_packages, setup\n\n\n# Ensure we match the version set in optimum/intel/version.py\ntry:\n filepath = \"optimum/amd/version.py\"\n with open(filepath) as version_file:\n (__version__,) = re.findall('__version__ = \"(.*)\"', version_file.read())\nexcept Exception as error:\n assert False, \"Error: Could not open '%s' due %s\\n\" % (filepath, error)\n\n# ORT 1.16 is not compatible: https://github.com/Xilinx/Vitis-AI/issues/1343\nINSTALL_REQUIRE = [\"optimum\", \"transformers>=4.38\", \"onnx\", \"onnxruntime-extensions\"]\n\n# TODO: unpin pytest once https://github.com/huggingface/transformers/pull/29154 is merged & released\nTESTS_REQUIRE = [\n \"pytest<=7.4.4\",\n \"parameterized\",\n \"evaluate\",\n \"timm\",\n \"scikit-learn\",\n \"onnxruntime\",\n \"torch==2.2.1\",\n \"torchvision==0.17.1\",\n \"opencv-python\",\n \"pytest-xdist\",\n \"diffusers\",\n]\n\nQUALITY_REQUIRE = [\"black~=23.1\", \"ruff>=0.0.241,<=0.0.259\"]\n\nEXTRAS_REQUIRE = {\n \"quality\": QUALITY_REQUIRE,\n \"tests\": TESTS_REQUIRE,\n \"ryzenai\": [\"opencv-python\", \"timm\"],\n \"zentorch\": [\"torch==2.2.1\"],\n \"brevitas\": [\n \"brevitas\",\n \"torch>=2.2\",\n \"datasets>=2.17\",\n \"onnx\",\n \"onnxruntime\",\n \"accelerate>=0.30\",\n \"onnx-tool\",\n \"optimum>=1.17\",\n ],\n}\n\nsetup(\n name=\"optimum-amd\",\n version=__version__,\n description=\"Optimum Library is an extension of the Hugging Face Transformers library, providing a framework to \"\n \"integrate third-party libraries from Hardware Partners and interface with their specific \"\n \"functionality.\",\n long_description=open(\"README.md\", \"r\", encoding=\"utf-8\").read(),\n long_description_content_type=\"text/markdown\",\n classifiers=[\n \"Development Status :: 5 - Production/Stable\",\n \"License :: OSI Approved :: Apache Software License\",\n \"Intended Audience :: Developers\",\n \"Intended Audience :: Education\",\n \"Intended Audience :: Science/Research\",\n \"Operating System :: OS Independent\",\n \"Programming Language :: Python :: 3.8\",\n \"Programming Language :: Python :: 3.9\",\n \"Programming Language :: Python :: 3.10\",\n \"Programming Language :: Python :: 3.11\",\n \"Topic :: Scientific/Engineering :: Artificial Intelligence\",\n ],\n keywords=\"transformers, amd, ryzen, ipu, quantization, on-device, instinct\",\n url=\"https://github.com/huggingface/optimum-amd\",\n author=\"HuggingFace Inc. Special Ops Team\",\n author_email=\"[email protected]\",\n license=\"MIT\",\n packages=find_namespace_packages(include=[\"optimum*\"]),\n entry_points={\"console_scripts\": [\"amdrun=optimum.amd.cli:amdrun\"]},\n install_requires=INSTALL_REQUIRE,\n extras_require=EXTRAS_REQUIRE,\n package_data={\"optimum\": [\"amd/ryzenai/configs/*.json\"]},\n include_package_data=True,\n zip_safe=False,\n)\n", ".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 d0d06070225804dc6fecde00911ae38b53080123 Hamza Amin <[email protected]> 1727369444 +0500\tclone: from https://github.com/huggingface/optimum-amd.git\n", ".git\\refs\\heads\\main": "d0d06070225804dc6fecde00911ae38b53080123\n", "docker\\onnx-runtime-amd-gpu\\Dockerfile": "# Use rocm image\nFROM rocm/dev-ubuntu-22.04:6.0.2\n\n# Ignore interactive questions during `docker build`\nENV DEBIAN_FRONTEND noninteractive\n\n# Versions\n# available options 3.10\nARG PYTHON_VERSION=3.10\n\n# Bash shell\nRUN chsh -s /bin/bash\nSHELL [\"/bin/bash\", \"-c\"]\n\n# Install and update tools to minimize security vulnerabilities - are all of these really necessary?\nRUN apt-get update && apt-get install -y \\\n apt-utils \\\n bzip2 \\\n ca-certificates \\\n cmake \\\n ffmpeg \\\n git \\\n hipsparse-dev \\\n hipblas-dev \\\n hipblaslt-dev \\\n hipcub-dev \\\n hipfft-dev \\\n hiprand-dev \\\n hipsolver-dev \\\n libglib2.0-0 \\\n libopenmpi-dev \\\n libprotobuf-dev \\\n libsm6 \\\n libxext6 \\\n libxrender1 \\\n mercurial \\\n miopen-hip-dev \\\n patchelf \\\n protobuf-compiler \\\n python3 \\\n python3-dev \\\n python3-pip \\\n rccl-dev \\\n rocthrust-dev \\\n rocrand-dev \\\n rocblas-dev \\\n software-properties-common \\\n subversion \\\n wget \\\n && \\\n apt-get clean && \\\n apt-get autoremove -y\n\nRUN python3 -m pip install -U pip\nRUN python3 -m pip install cmake onnx ninja transformers --no-cache-dir\n \nRUN pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/rocm6.0 --no-cache-dir\n\n# Install ONNXRuntime from source\nRUN git clone --single-branch --branch main --recursive https://github.com/Microsoft/onnxruntime onnxruntime\n\nRUN cd onnxruntime && ./build.sh --config Release --build_wheel --allow_running_as_root --update --build --parallel --cmake_extra_defines CMAKE_HIP_ARCHITECTURES=gfx90a,gfx942 ONNXRUNTIME_VERSION=$(cat ./VERSION_NUMBER) --use_rocm --rocm_home=/opt/rocm\nRUN pip install onnxruntime/build/Linux/Release/dist/*\n\nRUN python3 -m pip install git+https://github.com/huggingface/optimum.git\n\nCMD [\"/bin/bash\"]\n", "docker\\transformers-pytorch-amd-cpu-zentorch\\Dockerfile": "# Copyright 2023 The HuggingFace Team All rights reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nARG UBUNTU_VERSION=20.04\n\nFROM ubuntu:${UBUNTU_VERSION}\n\nARG TORCH_VERSION=2.2.1\n\n# Install python and g++ compiler\nENV DEBIAN_FRONTEND noninteractive\nENV PATH=\"/home/user/.local/bin:${PATH}\"\nRUN apt-get update && apt-get install -y --no-install-recommends \\\n git \\\n ffmpeg \\\n python3.8 \\\n python3-pip \\\n python3.8-dev \\\n build-essential \\\n libjemalloc-dev && \\\n apt-get clean && \\\n rm -rf /var/lib/apt/lists/* && \\\n update-alternatives --install /usr/bin/python python /usr/bin/python3.8 1 && \\\n pip install --upgrade pip\n\n# Create a non-root user\nARG GROUP_ID\nARG USER_ID\n\nRUN addgroup --gid $GROUP_ID group\nRUN adduser --disabled-password --gecos '' --uid $USER_ID --gid $GROUP_ID user\n\nUSER user\nWORKDIR /home/user\n\n# Install PyTorch\nRUN if [ \"${TORCH_VERSION}\" = \"stable\" ]; then \\\n pip install --no-cache-dir --pre torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cpu ; \\\nelif [ \"${TORCH_VERSION}\" = \"nighly\" ]; then \\\n pip install --no-cache-dir --pre torch torchvision torchaudio --index-url https://download.pytorch.org/whl/nightly/cpu ; \\\nelse \\\n pip install --no-cache-dir torch==${TORCH_VERSION} torchvision torchaudio --index-url https://download.pytorch.org/whl/cpu ; \\\nfi\n\n# Copy and install ZenTorch wheel\nCOPY zentorch-0.1.0-cp38-cp38-manylinux2014_x86_64.whl /home/user/zentorch-0.1.0-cp38-cp38-manylinux2014_x86_64.whl\nRUN pip install --no-cache-dir /home/user/zentorch-0.1.0-cp38-cp38-manylinux2014_x86_64.whl\n", "docker\\transformers-pytorch-amd-gpu-flash\\Dockerfile": "# Copyright 2024 The HuggingFace Team. All rights reserved.\n# Licensed under the MIT License.\n\nFROM rocm/dev-ubuntu-22.04:6.0.2\n\nLABEL maintainer=\"Hugging Face\"\n\nARG DEBIAN_FRONTEND=noninteractive\n\nRUN apt-get update && apt-get install -y --no-install-recommends \\\n sudo \\\n python3.10 \\\n python3.10-dev \\\n python3-pip \\\n git \\\n libsndfile1-dev \\\n tesseract-ocr \\\n espeak-ng \\\n rocthrust-dev \\\n hipsparse-dev \\\n hipblas-dev && \\\n apt-get clean && \\\n rm -rf /var/lib/apt/lists/* && \\\n update-alternatives --install /usr/bin/python python /usr/bin/python3.10 1 && \\\n python -m pip install -U pip\n\nRUN pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/rocm6.0 --no-cache-dir\nRUN pip install -U --no-cache-dir ninja packaging git+https://github.com/facebookresearch/detectron2.git pytesseract \"itsdangerous<2.1.0\"\n\nARG FLASH_ATT_V2_COMMIT_ROCM=2554f490101742ccdc56620a938f847f61754be6\n\nRUN git clone https://github.com/ROCm/flash-attention.git flash-attention-v2 && \\\n cd flash-attention-v2 && git submodule update --init --recursive && \\\n GPU_ARCHS=\"gfx90a;gfx942\" PYTORCH_ROCM_ARCH=\"gfx90a;gfx942\" python setup.py install && \\\n cd .. && \\\n rm -rf flash-attention\n\nWORKDIR /\nRUN git clone --depth 1 --branch main https://github.com/huggingface/transformers.git && cd transformers\nRUN pip install --no-cache-dir -e ./transformers[dev-torch,testing,video]\nRUN pip uninstall -y tensorflow flax\n", "docs\\Dockerfile": "FROM python:3.10\n\nARG commit_sha\nARG clone_url\n\nRUN apt-get update && apt-get install -y \\\n python3 \\\n python3-pip \\\n git \\\n curl \\\n gnupg \\\n ffmpeg \\\n libsm6 \\\n libxext6\n\n# Need node to build doc HTML. Taken from https://stackoverflow.com/a/67491580\nRUN apt-get update && apt-get install -y \\\n software-properties-common \\\n npm\nRUN npm install [email protected] -g && \\\n npm install n -g && \\\n n latest\n\nRUN python3 -m pip install --no-cache-dir --upgrade pip\nRUN python3 -m pip install --no-cache-dir git+https://github.com/huggingface/doc-builder.git\n\nRUN git clone --depth 1 --branch v3.5 https://github.com/Xilinx/Vitis-AI.git && cd Vitis-AI/src/vai_quantizer/vai_q_onnx && sh build.sh && pip install pkgs/*.whl\n\nRUN git clone $clone_url && cd optimum-amd && git checkout $commit_sha\nRUN python3 -m pip install --no-cache-dir ./optimum-amd[brevitas,tests]\nRUN pip install onnxruntime==1.14.0\n", "docs\\source\\index.mdx": "<!--Copyright 2023 The HuggingFace Team. All rights reserved.\nLicensed under the MIT License.\n-->\n\n# \ud83e\udd17 Optimum-AMD\n\n\ud83e\udd17 Optimum-AMD is the interface between the \ud83e\udd17 Hugging Face libraries and AMD ROCm stack and AMD Ryzen AI.\n\n<div class=\"mt-10\">\n <div class=\"w-full flex flex-col space-y-4 md:space-y-0 md:grid md:grid-cols-2 md:gap-y-4 md:gap-x-5\">\n <a class=\"!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg\" href=\"./amdgpu/overview\">\n <div class=\"w-full text-center bg-gradient-to-br from-indigo-400 to-indigo-500 rounded-lg py-1.5 font-semibold mb-5 text-white text-lg leading-relaxed\">\n AMD GPU\n </div>\n <p class=\"text-gray-700\">\n In-depth guides and tools to use Hugging Face libraries efficiently on AMD GPUs.\n </p>\n </a>\n <a\n class=\"!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg\"\n href=\"./ryzenai/overview\"\n >\n <div class=\"w-full text-center bg-gradient-to-br from-purple-400 to-purple-500 rounded-lg py-1.5 font-semibold mb-5 text-white text-lg leading-relaxed\">\n Ryzen AI\n </div>\n <p class=\"text-gray-700\">Use pre-optimized models for AMD Ryzen AI NPU.</p>\n </a>\n </div>\n</div>\n"} | null |
optimum-benchmark | {"type": "directory", "name": "optimum-benchmark", "children": [{"type": "file", "name": "CONTRIBUTING.md"}, {"type": "directory", "name": "docker", "children": [{"type": "directory", "name": "cpu", "children": [{"type": "file", "name": "Dockerfile"}]}, {"type": "directory", "name": "cuda", "children": [{"type": "file", "name": "Dockerfile"}]}, {"type": "directory", "name": "cuda-ort", "children": [{"type": "file", "name": "Dockerfile"}]}, {"type": "directory", "name": "rocm", "children": [{"type": "file", "name": "Dockerfile"}]}, {"type": "directory", "name": "unroot", "children": [{"type": "file", "name": "Dockerfile"}]}]}, {"type": "directory", "name": "examples", "children": [{"type": "file", "name": "energy_star.yaml"}, {"type": "file", "name": "ipex_bert.yaml"}, {"type": "file", "name": "ipex_llama.yaml"}, {"type": "file", "name": "llama_cpp_embedding.yaml"}, {"type": "file", "name": "llama_cpp_text_generation.yaml"}, {"type": "file", "name": "neural_compressor_ptq_bert.yaml"}, {"type": "file", "name": "numactl_bert.yaml"}, {"type": "file", "name": "onnxruntime_static_quant_vit.yaml"}, {"type": "file", "name": "onnxruntime_timm.yaml"}, {"type": "file", "name": "openvino_diffusion.yaml"}, {"type": "file", "name": "openvino_static_quant_bert.yaml"}, {"type": "file", "name": "pytorch_bert.py"}, {"type": "file", "name": "pytorch_bert.yaml"}, {"type": "file", "name": "pytorch_bert_mps.yaml"}, {"type": "file", "name": "pytorch_llama.py"}, {"type": "file", "name": "pytorch_llama.yaml"}, {"type": "file", "name": "tei_bge.yaml"}, {"type": "file", "name": "tgi_llama.yaml"}, {"type": "file", "name": "trt_llama.yaml"}, {"type": "file", "name": "vllm_llama.yaml"}, {"type": "file", "name": "_base_.yaml"}]}, {"type": "file", "name": "LICENSE"}, {"type": "directory", "name": "llm_perf", "children": [{"type": "file", "name": "update_llm_perf_cpu_pytorch.py"}, {"type": "file", "name": "update_llm_perf_cuda_pytorch.py"}, {"type": "file", "name": "update_llm_perf_leaderboard.py"}, {"type": "file", "name": "utils.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "Makefile"}, {"type": "directory", "name": "optimum_benchmark", "children": [{"type": "directory", "name": "backends", "children": [{"type": "file", "name": "base.py"}, {"type": "file", "name": "config.py"}, {"type": "file", "name": "diffusers_utils.py"}, {"type": "directory", "name": "ipex", "children": [{"type": "file", "name": "backend.py"}, {"type": "file", "name": "config.py"}, {"type": "file", "name": "utils.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "llama_cpp", "children": [{"type": "file", "name": "backend.py"}, {"type": "file", "name": "config.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "llm_swarm", "children": [{"type": "file", "name": "backend.py"}, {"type": "file", "name": "config.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "neural_compressor", "children": [{"type": "file", "name": "backend.py"}, {"type": "file", "name": "config.py"}, {"type": "file", "name": "utils.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "onnxruntime", "children": [{"type": "file", "name": "backend.py"}, {"type": "file", "name": "config.py"}, {"type": "file", "name": "utils.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "openvino", "children": [{"type": "file", "name": "backend.py"}, {"type": "file", "name": "config.py"}, {"type": "file", "name": "utils.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "peft_utils.py"}, {"type": "directory", "name": "pytorch", "children": [{"type": "file", "name": "backend.py"}, {"type": "file", "name": "config.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "py_txi", "children": [{"type": "file", "name": "backend.py"}, {"type": "file", "name": "config.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "tensorrt_llm", "children": [{"type": "file", "name": "backend.py"}, {"type": "file", "name": "config.py"}, {"type": "file", "name": "utils.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "timm_utils.py"}, {"type": "directory", "name": "torch_ort", "children": [{"type": "file", "name": "backend.py"}, {"type": "file", "name": "config.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "transformers_utils.py"}, {"type": "directory", "name": "vllm", "children": [{"type": "file", "name": "backend.py"}, {"type": "file", "name": "config.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "benchmark", "children": [{"type": "file", "name": "base.py"}, {"type": "file", "name": "config.py"}, {"type": "file", "name": "report.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "cli.py"}, {"type": "directory", "name": "generators", "children": [{"type": "file", "name": "dataset_generator.py"}, {"type": "file", "name": "input_generator.py"}, {"type": "file", "name": "task_generator.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "hub_utils.py"}, {"type": "file", "name": "import_utils.py"}, {"type": "directory", "name": "launchers", "children": [{"type": "file", "name": "base.py"}, {"type": "file", "name": "config.py"}, {"type": "file", "name": "device_isolation_utils.py"}, {"type": "directory", "name": "inline", "children": [{"type": "file", "name": "config.py"}, {"type": "file", "name": "launcher.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "process", "children": [{"type": "file", "name": "config.py"}, {"type": "file", "name": "launcher.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "torchrun", "children": [{"type": "file", "name": "config.py"}, {"type": "file", "name": "launcher.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "logging_utils.py"}, {"type": "file", "name": "process_utils.py"}, {"type": "directory", "name": "profilers", "children": [{"type": "file", "name": "fx_profiler.py"}, {"type": "file", "name": "ort_profiler.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "scenarios", "children": [{"type": "file", "name": "base.py"}, {"type": "file", "name": "config.py"}, {"type": "directory", "name": "energy_star", "children": [{"type": "file", "name": "config.py"}, {"type": "file", "name": "preprocessing_utils.py"}, {"type": "file", "name": "scenario.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "inference", "children": [{"type": "file", "name": "config.py"}, {"type": "file", "name": "scenario.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "training", "children": [{"type": "file", "name": "config.py"}, {"type": "file", "name": "scenario.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "system_utils.py"}, {"type": "file", "name": "task_utils.py"}, {"type": "directory", "name": "trackers", "children": [{"type": "file", "name": "energy.py"}, {"type": "file", "name": "latency.py"}, {"type": "file", "name": "memory.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "version.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "pyproject.toml"}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "scripts", "children": [{"type": "file", "name": "install_quantization_libs.py"}, {"type": "file", "name": "total_tests_runs.py"}, {"type": "file", "name": "update_ci_badges.py"}]}, {"type": "file", "name": "setup.py"}, {"type": "directory", "name": "tests", "children": [{"type": "directory", "name": "configs", "children": [{"type": "file", "name": "cpu_inference_ipex_text_decoders.yaml"}, {"type": "file", "name": "cpu_inference_ipex_text_encoders.yaml"}, {"type": "file", "name": "cpu_inference_llama_cpp_gguf.yaml"}, {"type": "file", "name": "cpu_inference_neural_compressor_inc_quant_text_decoders.yaml"}, {"type": "file", "name": "cpu_inference_neural_compressor_inc_quant_text_encoders.yaml"}, {"type": "file", "name": "cpu_inference_onnxruntime_diffusers.yaml"}, {"type": "file", "name": "cpu_inference_onnxruntime_ort_quant.yaml"}, {"type": "file", "name": "cpu_inference_onnxruntime_text_decoders.yaml"}, {"type": "file", "name": "cpu_inference_onnxruntime_text_encoders.yaml"}, {"type": "file", "name": "cpu_inference_onnxruntime_text_encoders_decoders.yaml"}, {"type": "file", "name": "cpu_inference_onnxruntime_timm.yaml"}, {"type": "file", "name": "cpu_inference_openvino_diffusers.yaml"}, {"type": "file", "name": "cpu_inference_openvino_text_decoders.yaml"}, {"type": "file", "name": "cpu_inference_openvino_text_encoders.yaml"}, {"type": "file", "name": "cpu_inference_pytorch_diffusers.yaml"}, {"type": "file", "name": "cpu_inference_pytorch_diffusers_torch_compile.yaml"}, {"type": "file", "name": "cpu_inference_pytorch_text_decoders.yaml"}, {"type": "file", "name": "cpu_inference_pytorch_text_encoders.yaml"}, {"type": "file", "name": "cpu_inference_pytorch_text_encoders_decoders.yaml"}, {"type": "file", "name": "cpu_inference_pytorch_timm.yaml"}, {"type": "file", "name": "cpu_inference_pytorch_timm_torch_compile.yaml"}, {"type": "file", "name": "cpu_inference_py_txi_bert.yaml"}, {"type": "file", "name": "cpu_inference_py_txi_gpt2.yaml"}, {"type": "file", "name": "cpu_training_pytorch_text_decoders.yaml"}, {"type": "file", "name": "cpu_training_pytorch_text_encoders.yaml"}, {"type": "file", "name": "cuda_inference_onnxruntime_text_decoders.yaml"}, {"type": "file", "name": "cuda_inference_onnxruntime_text_encoders.yaml"}, {"type": "file", "name": "cuda_inference_pytorch_awq.yaml"}, {"type": "file", "name": "cuda_inference_pytorch_bnb.yaml"}, {"type": "file", "name": "cuda_inference_pytorch_deepspeed_inference.yaml"}, {"type": "file", "name": "cuda_inference_pytorch_device_map.yaml"}, {"type": "file", "name": "cuda_inference_pytorch_diffusers.yaml"}, {"type": "file", "name": "cuda_inference_pytorch_diffusers_torch_compile.yaml"}, {"type": "file", "name": "cuda_inference_pytorch_gptq.yaml"}, {"type": "file", "name": "cuda_inference_pytorch_text_decoders.yaml"}, {"type": "file", "name": "cuda_inference_pytorch_text_encoders.yaml"}, {"type": "file", "name": "cuda_inference_pytorch_timm.yaml"}, {"type": "file", "name": "cuda_inference_pytorch_timm_torch_compile.yaml"}, {"type": "file", "name": "cuda_inference_py_txi_bert.yaml"}, {"type": "file", "name": "cuda_inference_py_txi_gpt2.yaml"}, {"type": "file", "name": "cuda_inference_tensorrt_llm.yaml"}, {"type": "file", "name": "cuda_inference_tensorrt_llm_pp.yaml"}, {"type": "file", "name": "cuda_inference_tensorrt_llm_tp.yaml"}, {"type": "file", "name": "cuda_inference_vllm_gpt2.yaml"}, {"type": "file", "name": "cuda_inference_vllm_gpt2_pp.yaml"}, {"type": "file", "name": "cuda_inference_vllm_gpt2_tp.yaml"}, {"type": "file", "name": "cuda_training_pytorch_ddp.yaml"}, {"type": "file", "name": "cuda_training_pytorch_device_map.yaml"}, {"type": "file", "name": "cuda_training_pytorch_dp.yaml"}, {"type": "file", "name": "cuda_training_pytorch_peft.yaml"}, {"type": "file", "name": "cuda_training_pytorch_text_decoders.yaml"}, {"type": "file", "name": "cuda_training_pytorch_text_encoders.yaml"}, {"type": "file", "name": "cuda_training_torch_ort_ddp.yaml"}, {"type": "file", "name": "cuda_training_torch_ort_peft.yaml"}, {"type": "file", "name": "cuda_training_torch_ort_text_decoders.yaml"}, {"type": "file", "name": "cuda_training_torch_ort_text_encoders.yaml"}, {"type": "file", "name": "_awq_.yaml"}, {"type": "file", "name": "_base_.yaml"}, {"type": "file", "name": "_bert_.yaml"}, {"type": "file", "name": "_bloom_.yaml"}, {"type": "file", "name": "_bnb_.yaml"}, {"type": "file", "name": "_cpu_.yaml"}, {"type": "file", "name": "_cuda_.yaml"}, {"type": "file", "name": "_ddp_.yaml"}, {"type": "file", "name": "_deepspeed_inference_.yaml"}, {"type": "file", "name": "_device_isolation_.yaml"}, {"type": "file", "name": "_device_map_.yaml"}, {"type": "file", "name": "_diffusers_.yaml"}, {"type": "file", "name": "_dp_.yaml"}, {"type": "file", "name": "_gguf_.yaml"}, {"type": "file", "name": "_gpt2_.yaml"}, {"type": "file", "name": "_gptq_.yaml"}, {"type": "file", "name": "_inc_quant_.yaml"}, {"type": "file", "name": "_inference_.yaml"}, {"type": "file", "name": "_no_weights_.yaml"}, {"type": "file", "name": "_ort_quant_.yaml"}, {"type": "file", "name": "_peft_.yaml"}, {"type": "file", "name": "_serving_mode_.yaml"}, {"type": "file", "name": "_tensorrt_llm_pp_.yaml"}, {"type": "file", "name": "_tensorrt_llm_tp_.yaml"}, {"type": "file", "name": "_text_decoders_.yaml"}, {"type": "file", "name": "_text_encoders_.yaml"}, {"type": "file", "name": "_text_encoders_decoders_.yaml"}, {"type": "file", "name": "_timm_.yaml"}, {"type": "file", "name": "_torch_compile_.yaml"}, {"type": "file", "name": "_training_.yaml"}, {"type": "file", "name": "_vllm_pp_.yaml"}, {"type": "file", "name": "_vllm_tp_.yaml"}]}, {"type": "file", "name": "test_api.py"}, {"type": "file", "name": "test_cli.py"}]}]} | <p align="center"><img src="https://raw.githubusercontent.com/huggingface/optimum-benchmark/main/logo.png" alt="Optimum-Benchmark Logo" width="350" style="max-width: 100%;" /></p>
<p align="center"><q>All benchmarks are wrong, some will cost you less than others.</q></p>
<h1 align="center">Optimum-Benchmark 🏋️</h1>
[](https://pypi.org/project/optimum-benchmark/)
[](https://pypi.org/project/optimum-benchmark/)
[](https://pypi.org/project/optimum-benchmark/)
[](https://pypi.org/project/optimum-benchmark/)
[](https://pypi.org/project/optimum-benchmark/)
[](https://pypi.org/project/optimum-benchmark/)
Optimum-Benchmark is a unified [multi-backend & multi-device](#backends--devices-) utility for benchmarking [Transformers](https://github.com/huggingface/transformers), [Diffusers](https://github.com/huggingface/diffusers), [PEFT](https://github.com/huggingface/peft), [TIMM](https://github.com/huggingface/pytorch-image-models) and [Optimum](https://github.com/huggingface/optimum) libraries, along with all their supported [optimizations & quantization schemes](#backends--devices-), for [inference & training](#scenarios-), in [distributed & non-distributed settings](#launchers-), in the most correct, efficient and scalable way possible.
*News* 📰
- LlamaCpp backend for benchmarking [`llama-cpp-python`](https://github.com/abetlen/llama-cpp-python) bindings with all its supported devices 🚀
- 🥳 PyPI package is now available for installation: `pip install optimum-benchmark` 🎉 [check it out](https://pypi.org/project/optimum-benchmark/) !
- Model loading latency/memory/energy tracking for all backends in the inference scenario 🚀
- numactl support for Process and Torchrun launchers to control the NUMA nodes on which the benchmark runs.
- 4 minimal docker images (`cpu`, `cuda`, `rocm`, `cuda-ort`) in [packages](https://github.com/huggingface/optimum-benchmark/pkgs/container/optimum-benchmark) for testing, benchmarking and reproducibility 🐳
- vLLM backend for benchmarking [vLLM](https://github.com/vllm-project/vllm)'s inference engine 🚀
- Hosting the codebase of the [LLM-Perf Leaderboard](https://huggingface.co/spaces/optimum/llm-perf-leaderboard) 🥇
- Py-TXI backend for benchmarking [Py-TXI](https://github.com/IlyasMoutawwakil/py-txi/tree/main) 🚀
- Python API for running isolated and distributed benchmarks with Python scripts 🐍
- Simpler CLI interface for running benchmarks (runs and sweeps) using the Hydra 🧪
*Motivations* 🎯
- HuggingFace hardware partners wanting to know how their hardware performs compared to another hardware on the same models.
- HuggingFace ecosystem users wanting to know how their chosen model performs in terms of latency, throughput, memory usage, energy consumption, etc compared to another model.
- Benchmarking hardware & backend specific optimizations & quantization schemes that can be applied to models and improve their computational/memory/energy efficiency.
 
> \[!Note\]
> Optimum-Benchmark is a work in progress and is not yet ready for production use, but we're working hard to make it so. Please keep an eye on the project and help us improve it and make it more useful for the community. We're looking forward to your feedback and contributions. 🚀
 
## CI Status 🚦
Optimum-Benchmark is continuously and intensively tested on a variety of devices, backends, scenarios and launchers to ensure its stability with over 300 tests running on every PR (you can request more tests if you want to).
### API 📈
[](https://github.com/huggingface/optimum-benchmark/actions/workflows/test_api_cpu.yaml)
[](https://github.com/huggingface/optimum-benchmark/actions/workflows/test_api_cuda.yaml)
[](https://github.com/huggingface/optimum-benchmark/actions/workflows/test_api_misc.yaml)
[](https://github.com/huggingface/optimum-benchmark/actions/workflows/test_api_rocm.yaml)
### CLI 📈
[](https://github.com/huggingface/optimum-benchmark/actions/workflows/test_cli_cpu_ipex.yaml)
[](https://github.com/huggingface/optimum-benchmark/actions/workflows/test_cli_cpu_llama_cpp.yaml)
[](https://github.com/huggingface/optimum-benchmark/actions/workflows/test_cli_cpu_neural_compressor.yaml)
[](https://github.com/huggingface/optimum-benchmark/actions/workflows/test_cli_cpu_onnxruntime.yaml)
[](https://github.com/huggingface/optimum-benchmark/actions/workflows/test_cli_cpu_openvino.yaml)
[](https://github.com/huggingface/optimum-benchmark/actions/workflows/test_cli_cpu_pytorch.yaml)
[](https://github.com/huggingface/optimum-benchmark/actions/workflows/test_cli_cpu_py_txi.yaml)
[](https://github.com/huggingface/optimum-benchmark/actions/workflows/test_cli_cuda_onnxruntime.yaml)
[](https://github.com/huggingface/optimum-benchmark/actions/workflows/test_cli_cuda_pytorch.yaml)
[](https://github.com/huggingface/optimum-benchmark/actions/workflows/test_cli_cuda_py_txi.yaml)
[](https://github.com/huggingface/optimum-benchmark/actions/workflows/test_cli_cuda_tensorrt_llm.yaml)
[](https://github.com/huggingface/optimum-benchmark/actions/workflows/test_cli_cuda_torch_ort.yaml)
[](https://github.com/huggingface/optimum-benchmark/actions/workflows/test_cli_cuda_vllm.yaml)
[](https://github.com/huggingface/optimum-benchmark/actions/workflows/test_cli_misc.yaml)
[](https://github.com/huggingface/optimum-benchmark/actions/workflows/test_cli_rocm_pytorch.yaml)
## Quickstart 🚀
### Installation 📥
You can install the latest released version of `optimum-benchmark` on PyPI:
```bash
pip install optimum-benchmark
```
or you can install the latest version from the main branch on GitHub:
```bash
pip install git+https://github.com/huggingface/optimum-benchmark.git
```
or if you want to tinker with the code, you can clone the repository and install it in editable mode:
```bash
git clone https://github.com/huggingface/optimum-benchmark.git
cd optimum-benchmark
pip install -e .
```
<details>
<summary>Advanced install options</summary>
Depending on the backends you want to use, you can install `optimum-benchmark` with the following extras:
- PyTorch (default): `pip install optimum-benchmark`
- OpenVINO: `pip install optimum-benchmark[openvino]`
- Torch-ORT: `pip install optimum-benchmark[torch-ort]`
- OnnxRuntime: `pip install optimum-benchmark[onnxruntime]`
- TensorRT-LLM: `pip install optimum-benchmark[tensorrt-llm]`
- OnnxRuntime-GPU: `pip install optimum-benchmark[onnxruntime-gpu]`
- Neural Compressor: `pip install optimum-benchmark[neural-compressor]`
- Py-TXI: `pip install optimum-benchmark[py-txi]`
- IPEX: `pip install optimum-benchmark[ipex]`
- vLLM: `pip install optimum-benchmark[vllm]`
We also support the following extra extra dependencies:
- autoawq
- auto-gptq
- sentence-transformers
- bitsandbytes
- codecarbon
- flash-attn
- deepspeed
- diffusers
- timm
- peft
</details>
### Running benchmarks using the Python API 🧪
You can run benchmarks from the Python API, using the `Benchmark` class and its `launch` method. It takes a `BenchmarkConfig` object as input, runs the benchmark in an isolated process and returns a `BenchmarkReport` object containing the benchmark results.
Here's an example of how to run an isolated benchmark using the `pytorch` backend, `torchrun` launcher and `inference` scenario with latency and memory tracking enabled.
```python
from optimum_benchmark import Benchmark, BenchmarkConfig, TorchrunConfig, InferenceConfig, PyTorchConfig
from optimum_benchmark.logging_utils import setup_logging
setup_logging(level="INFO", handlers=["console"])
if __name__ == "__main__":
launcher_config = TorchrunConfig(nproc_per_node=2)
scenario_config = InferenceConfig(latency=True, memory=True)
backend_config = PyTorchConfig(model="gpt2", device="cuda", device_ids="0,1", no_weights=True)
benchmark_config = BenchmarkConfig(
name="pytorch_gpt2",
scenario=scenario_config,
launcher=launcher_config,
backend=backend_config,
)
benchmark_report = Benchmark.launch(benchmark_config)
# log the benchmark in terminal
benchmark_report.log() # or print(benchmark_report)
# convert artifacts to a dictionary or dataframe
benchmark_config.to_dict() # or benchmark_config.to_dataframe()
# save artifacts to disk as json or csv files
benchmark_report.save_csv("benchmark_report.csv") # or benchmark_report.save_json("benchmark_report.json")
# push artifacts to the hub
benchmark_config.push_to_hub("IlyasMoutawwakil/pytorch_gpt2") # or benchmark_config.push_to_hub("IlyasMoutawwakil/pytorch_gpt2")
# or merge them into a single artifact
benchmark = Benchmark(config=benchmark_config, report=benchmark_report)
benchmark.save_json("benchmark.json") # or benchmark.save_csv("benchmark.csv")
benchmark.push_to_hub("IlyasMoutawwakil/pytorch_gpt2")
# load artifacts from the hub
benchmark = Benchmark.from_hub("IlyasMoutawwakil/pytorch_gpt2") # or Benchmark.from_hub("IlyasMoutawwakil/pytorch_gpt2")
# or load them from disk
benchmark = Benchmark.load_json("benchmark.json") # or Benchmark.load_csv("benchmark_report.csv")
```
If you're on VSCode, you can hover over the configuration classes to see the available parameters and their descriptions. You can also see the available parameters in the [Features](#features-) section below.
### Running benchmarks using the Hydra CLI 🧪
You can also run a benchmark using the command line by specifying the configuration directory and the configuration name. Both arguments are mandatory for [`hydra`](https://hydra.cc/). `--config-dir` is the directory where the configuration files are stored and `--config-name` is the name of the configuration file without its `.yaml` extension.
```bash
optimum-benchmark --config-dir examples/ --config-name pytorch_bert
```
This will run the benchmark using the configuration in [`examples/pytorch_bert.yaml`](examples/pytorch_bert.yaml) and store the results in `runs/pytorch_bert`.
The resulting files are :
- `benchmark_config.json` which contains the configuration used for the benchmark, including the backend, launcher, scenario and the environment in which the benchmark was run.
- `benchmark_report.json` which contains a full report of the benchmark's results, like latency measurements, memory usage, energy consumption, etc.
- `benchmark.json` contains both the report and the configuration in a single file.
- `benchmark.log` contains the logs of the benchmark run.
<details>
<summary>Advanced CLI options</summary>
#### Configuration overrides 🎛️
It's easy to override the default behavior of a benchmark from the command line of an already existing configuration file. For example, to run the same benchmark on a different device, you can use the following command:
```bash
optimum-benchmark --config-dir examples/ --config-name pytorch_bert backend.model=gpt2 backend.device=cuda
```
#### Configuration sweeps 🧹
You can easily run configuration sweeps using the `--multirun` option. By default, configurations will be executed serially but other kinds of executions are supported with hydra's launcher plugins (e.g. `hydra/launcher=joblib`).
```bash
optimum-benchmark --config-dir examples --config-name pytorch_bert -m backend.device=cpu,cuda
```
### Configurations structure 📁
You can create custom and more complex configuration files following these [examples]([examples](https://github.com/IlyasMoutawwakil/optimum-benchmark-examples)). They are heavily commented to help you understand the structure of the configuration files.
</details>
## Features 🎨
`optimum-benchmark` allows you to run benchmarks with minimal configuration. A benchmark is defined by three main components:
- The launcher to use (e.g. `process`)
- The scenario to follow (e.g. `training`)
- The backend to run on (e.g. `onnxruntime`)
### Launchers 🚀
- [x] Process launcher (`launcher=process`); Launches the benchmark in an isolated process.
- [x] Torchrun launcher (`launcher=torchrun`); Launches the benchmark in multiples processes using `torch.distributed`.
- [x] Inline launcher (`launcher=inline`), not recommended for benchmarking, only for debugging purposes.
<details>
<summary>General Launcher features 🧰</summary>
- [x] Assert GPU devices (NVIDIA & AMD) isolation (`launcher.device_isolation=true`). This feature makes sure no other processes are running on the targeted GPU devices other than the benchmark. Espepecially useful when running benchmarks on shared resources.
</details>
### Scenarios 🏋
- [x] Training scenario (`scenario=training`) which benchmarks the model using the trainer class with a randomly generated dataset.
- [x] Inference scenario (`scenario=inference`) which benchmakrs the model's inference method (forward/call/generate) with randomly generated inputs.
<details>
<summary>Inference scenario features 🧰</summary>
- [x] Memory tracking (`scenario.memory=true`)
- [x] Energy and efficiency tracking (`scenario.energy=true`)
- [x] Latency and throughput tracking (`scenario.latency=true`)
- [x] Warm up runs before inference (`scenario.warmup_runs=20`)
- [x] Inputs shapes control (e.g. `scenario.input_shapes.sequence_length=128`)
- [x] Forward, Call and Generate kwargs (e.g. for an LLM `scenario.generate_kwargs.max_new_tokens=100`, for a diffusion model `scenario.call_kwargs.num_images_per_prompt=4`)
See [InferenceConfig](optimum_benchmark/scenarios/inference/config.py) for more information.
</details>
<details>
<summary>Training scenario features 🧰</summary>
- [x] Memory tracking (`scenario.memory=true`)
- [x] Energy and efficiency tracking (`scenario.energy=true`)
- [x] Latency and throughput tracking (`scenario.latency=true`)
- [x] Warm up steps before training (`scenario.warmup_steps=20`)
- [x] Dataset shapes control (e.g. `scenario.dataset_shapes.sequence_length=128`)
- [x] Training arguments control (e.g. `scenario.training_args.per_device_train_batch_size=4`)
See [TrainingConfig](optimum_benchmark/scenarios/training/config.py) for more information.
</details>
### Backends & Devices 📱
- [x] Pytorch backend for CPU (`backend=pytorch`, `backend.device=cpu`)
- [x] Pytorch backend for CUDA (`backend=pytorch`, `backend.device=cuda`, `backend.device_ids=0,1`)
- [ ] Pytorch backend for Habana Gaudi Processor (`backend=pytorch`, `backend.device=hpu`, `backend.device_ids=0,1`)
- [x] OnnxRuntime backend for CPUExecutionProvider (`backend=onnxruntime`, `backend.device=cpu`)
- [x] OnnxRuntime backend for CUDAExecutionProvider (`backend=onnxruntime`, `backend.device=cuda`)
- [x] OnnxRuntime backend for ROCMExecutionProvider (`backend=onnxruntime`, `backend.device=cuda`, `backend.provider=ROCMExecutionProvider`)
- [x] OnnxRuntime backend for TensorrtExecutionProvider (`backend=onnxruntime`, `backend.device=cuda`, `backend.provider=TensorrtExecutionProvider`)
- [x] Py-TXI backend for CPU and GPU (`backend=py-txi`, `backend.device=cpu` or `backend.device=cuda`)
- [x] Neural Compressor backend for CPU (`backend=neural-compressor`, `backend.device=cpu`)
- [x] TensorRT-LLM backend for CUDA (`backend=tensorrt-llm`, `backend.device=cuda`)
- [x] Torch-ORT backend for CUDA (`backend=torch-ort`, `backend.device=cuda`)
- [x] OpenVINO backend for CPU (`backend=openvino`, `backend.device=cpu`)
- [x] OpenVINO backend for GPU (`backend=openvino`, `backend.device=gpu`)
- [x] vLLM backend for CUDA (`backend=vllm`, `backend.device=cuda`)
- [x] vLLM backend for ROCM (`backend=vllm`, `backend.device=rocm`)
- [x] vLLM backend for CPU (`backend=vllm`, `backend.device=cpu`)
- [x] IPEX backend for CPU (`backend=ipex`, `backend.device=cpu`)
- [x] IPEX backend for XPU (`backend=ipex`, `backend.device=xpu`)
<details>
<summary>General backend features 🧰</summary>
- [x] Device selection (`backend.device=cuda`), can be `cpu`, `cuda`, `mps`, etc.
- [x] Device ids selection (`backend.device_ids=0,1`), can be a list of device ids to run the benchmark on multiple devices.
- [x] Model selection (`backend.model=gpt2`), can be a model id from the HuggingFace model hub or an **absolute path** to a model folder.
- [x] "No weights" feature, to benchmark models without downloading their weights, using randomly initialized weights (`backend.no_weights=true`)
</details>
<details>
<summary>Backend specific features 🧰</summary>
For more information on the features of each backend, you can check their respective configuration files:
- [VLLMConfig](optimum_benchmark/backends/vllm/config.py)
- [IPEXConfig](optimum_benchmark/backends/ipex/config.py)
- [OVConfig](optimum_benchmark/backends/openvino/config.py)
- [PyTXIConfig](optimum_benchmark/backends/py_txi/config.py)
- [PyTorchConfig](optimum_benchmark/backends/pytorch/config.py)
- [ORTConfig](optimum_benchmark/backends/onnxruntime/config.py)
- [TorchORTConfig](optimum_benchmark/backends/torch_ort/config.py)
- [LLMSwarmConfig](optimum_benchmark/backends/llm_swarm/config.py)
- [TRTLLMConfig](optimum_benchmark/backends/tensorrt_llm/config.py)
- [INCConfig](optimum_benchmark/backends/neural_compressor/config.py)
</details>
## Contributing 🤝
Contributions are welcome! And we're happy to help you get started. Feel free to open an issue or a pull request.
Things that we'd like to see:
- More backends (Tensorflow, TFLite, Jax, etc).
- More tests (for optimizations and quantization schemes).
- More hardware support (Habana Gaudi Processor (HPU), Apple M series, etc).
- Task evaluators for the most common tasks (would be great for output regression).
To get started, you can check the [CONTRIBUTING.md](CONTRIBUTING.md) file.
| {"setup.py": "import importlib.util\nimport os\nimport re\nimport subprocess\n\nfrom setuptools import find_packages, setup\n\n# Ensure we match the version set in src/optimum-benchmark/version.py\ntry:\n filepath = \"optimum_benchmark/version.py\"\n with open(filepath) as version_file:\n (__version__,) = re.findall('__version__ = \"(.*)\"', version_file.read())\nexcept Exception as error:\n assert False, \"Error: Could not open '%s' due %s\\n\" % (filepath, error)\n\nMIN_OPTIMUM_VERSION = \"1.18.0\"\nINSTALL_REQUIRES = [\n # HF dependencies\n \"transformers\",\n \"accelerate\",\n \"datasets\",\n # Hydra\n \"hydra-core\",\n \"omegaconf\",\n # CPU\n \"psutil\",\n # Reporting\n \"typing-extensions\",\n \"flatten_dict\",\n \"colorlog\",\n \"pandas\",\n]\n\ntry:\n subprocess.run([\"nvidia-smi\"], check=True)\n IS_NVIDIA_SYSTEM = True\nexcept Exception:\n IS_NVIDIA_SYSTEM = False\n\ntry:\n subprocess.run([\"rocm-smi\"], check=True)\n IS_ROCM_SYSTEM = True\nexcept Exception:\n IS_ROCM_SYSTEM = False\n\nUSE_CUDA = (os.environ.get(\"USE_CUDA\", None) == \"1\") or IS_NVIDIA_SYSTEM\nUSE_ROCM = (os.environ.get(\"USE_ROCM\", None) == \"1\") or IS_ROCM_SYSTEM\n\nif USE_CUDA:\n INSTALL_REQUIRES.append(\"nvidia-ml-py\")\n\nif USE_ROCM:\n PYRSMI = \"pyrsmi@git+https://github.com/ROCm/pyrsmi.git\"\n INSTALL_REQUIRES.append(PYRSMI)\n if not importlib.util.find_spec(\"amdsmi\"):\n print(\n \"ROCm GPU detected without amdsmi installed. You won't be able to run process-specific VRAM tracking. \"\n \"Please install amdsmi from https://github.com/ROCm/amdsmi to enable this feature.\"\n )\n\n\nEXTRAS_REQUIRE = {\n \"quality\": [\"ruff\"],\n \"testing\": [\"pytest\", \"hydra-joblib-launcher\"],\n # optimum backends\n \"ipex\": [f\"optimum[ipex]>={MIN_OPTIMUM_VERSION}\"],\n \"openvino\": [f\"optimum[openvino,nncf]>={MIN_OPTIMUM_VERSION}\"],\n \"onnxruntime\": [f\"optimum[onnxruntime]>={MIN_OPTIMUM_VERSION}\"],\n \"onnxruntime-gpu\": [f\"optimum[onnxruntime-gpu]>={MIN_OPTIMUM_VERSION}\"],\n \"neural-compressor\": [f\"optimum[neural-compressor]>={MIN_OPTIMUM_VERSION}\"],\n \"torch-ort\": [\"torch-ort\", \"onnxruntime-training\", f\"optimum>={MIN_OPTIMUM_VERSION}\"],\n # other backends\n \"llama-cpp\": [\"llama-cpp-python\"],\n \"llm-swarm\": [\"llm-swarm\"],\n \"py-txi\": [\"py-txi\"],\n \"vllm\": [\"vllm\"],\n # optional dependencies\n \"autoawq\": [\"autoawq\"],\n \"auto-gptq\": [\"optimum\", \"auto-gptq\"],\n \"sentence-transformers\": [\"sentence-transformers\"],\n \"bitsandbytes\": [\"bitsandbytes\"],\n \"codecarbon\": [\"codecarbon\"],\n \"flash-attn\": [\"flash-attn\"],\n \"deepspeed\": [\"deepspeed\"],\n \"diffusers\": [\"diffusers\"],\n \"timm\": [\"timm\"],\n \"peft\": [\"peft\"],\n}\n\n\nsetup(\n packages=find_packages(),\n install_requires=INSTALL_REQUIRES,\n extras_require=EXTRAS_REQUIRE,\n entry_points={\"console_scripts\": [\"optimum-benchmark=optimum_benchmark.cli:main\"]},\n description=\"Optimum-Benchmark is a unified multi-backend utility for benchmarking \"\n \"Transformers, Timm, Diffusers and Sentence-Transformers with full support of \"\n \"Optimum's hardware optimizations & quantization schemes.\",\n url=\"https://github.com/huggingface/optimum-benchmark\",\n classifiers=[\n \"Intended Audience :: Education\",\n \"Intended Audience :: Developers\",\n \"Operating System :: POSIX :: Linux\",\n \"Intended Audience :: Science/Research\",\n \"Programming Language :: Python :: 3.8\",\n \"Programming Language :: Python :: 3.9\",\n \"Programming Language :: Python :: 3.10\",\n \"License :: OSI Approved :: Apache Software License\",\n \"Topic :: Scientific/Engineering :: Artificial Intelligence\",\n ],\n keywords=\"benchmark, transformers, quantization, pruning, optimization, training, inference, onnx, onnx runtime, intel, \"\n \"habana, graphcore, neural compressor, ipex, ipu, hpu, llm-swarm, py-txi, vllm, llama-cpp, auto-gptq, autoawq, \"\n \"sentence-transformers, bitsandbytes, codecarbon, flash-attn, deepspeed, diffusers, timm, peft\",\n long_description=open(\"README.md\", \"r\", encoding=\"utf-8\").read(),\n long_description_content_type=\"text/markdown\",\n author=\"HuggingFace Inc. Special Ops Team\",\n include_package_data=True,\n name=\"optimum-benchmark\",\n version=__version__,\n license=\"Apache\",\n)\n", ".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 306b62b09358b573061bd4584566f747057b6e0f Hamza Amin <[email protected]> 1727369470 +0500\tclone: from https://github.com/huggingface/optimum-benchmark.git\n", ".git\\refs\\heads\\main": "306b62b09358b573061bd4584566f747057b6e0f\n", "docker\\cpu\\Dockerfile": "# Copyright 2023 The HuggingFace Team All rights reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nARG UBUNTU_VERSION=22.04\n\nFROM ubuntu:${UBUNTU_VERSION}\n\n# Install necessary packages\nENV DEBIAN_FRONTEND noninteractive\nENV PATH=\"/home/user/.local/bin:${PATH}\"\nRUN apt-get update && apt-get install -y --no-install-recommends \\\n sudo build-essential git bash-completion numactl \\\n python3.10 python3-pip python3.10-dev google-perftools && \\\n apt-get clean && rm -rf /var/lib/apt/lists/* && \\\n update-alternatives --install /usr/bin/python python /usr/bin/python3.10 1 && \\\n pip install --no-cache-dir --upgrade pip setuptools wheel intel-openmp\n\nENV LD_PRELOAD=\"/usr/lib/x86_64-linux-gnu/libtcmalloc_minimal.so.4:/usr/local/lib/libiomp5.so\"\n\n# Install PyTorch\nARG TORCH_VERSION=\"\"\nARG TORCH_RELEASE_TYPE=stable\n\nRUN if [ -n \"${TORCH_VERSION}\" ]; then \\\n pip install --no-cache-dir torch==${TORCH_VERSION} torchvision torchaudio --index-url https://download.pytorch.org/whl/cpu ; \\\nelif [ \"${TORCH_RELEASE_TYPE}\" = \"stable\" ]; then \\\n pip install --no-cache-dir torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cpu ; \\\nelif [ \"${TORCH_RELEASE_TYPE}\" = \"nightly\" ]; then \\\n pip install --no-cache-dir --pre torch torchvision torchaudio --index-url https://download.pytorch.org/whl/nightly/cpu ; \\\nelse \\\n echo \"Error: Invalid TORCH_RELEASE_TYPE. Must be 'stable', 'nightly', or specify a TORCH_VERSION.\" && exit 1 ; \\\nfi\n", "docker\\cuda\\Dockerfile": "# Copyright 2023 The HuggingFace Team All rights reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nARG CUDA_VERSION=12.4.1\nARG UBUNTU_VERSION=22.04\n\nFROM nvidia/cuda:${CUDA_VERSION}-cudnn-devel-ubuntu${UBUNTU_VERSION}\n\n# Install necessary packages\nENV DEBIAN_FRONTEND=noninteractive\nRUN apt-get update && apt-get install -y --no-install-recommends \\\n sudo build-essential git bash-completion \\\n python3.10 python3-pip python3.10-dev && \\\n apt-get clean && rm -rf /var/lib/apt/lists/* && \\\n update-alternatives --install /usr/bin/python python /usr/bin/python3.10 1 && \\\n pip install --no-cache-dir --upgrade pip setuptools wheel requests\n\n# Install PyTorch\nARG TORCH_VERSION=\"\"\nARG TORCH_CUDA=cu124\nARG TORCH_RELEASE_TYPE=stable\n\nRUN if [ -n \"${TORCH_VERSION}\" ]; then \\\n pip install --no-cache-dir torch==${TORCH_VERSION} torchvision torchaudio --index-url https://download.pytorch.org/whl/${TORCH_CUDA} ; \\\nelif [ \"${TORCH_RELEASE_TYPE}\" = \"stable\" ]; then \\\n pip install --no-cache-dir torch torchvision torchaudio --index-url https://download.pytorch.org/whl/${TORCH_CUDA} ; \\\nelif [ \"${TORCH_RELEASE_TYPE}\" = \"nightly\" ]; then \\\n pip install --no-cache-dir --pre torch torchvision torchaudio --index-url https://download.pytorch.org/whl/nightly/${TORCH_CUDA} ; \\\nelse \\\n echo \"Error: Invalid TORCH_RELEASE_TYPE. Must be 'stable', 'nightly', or specify a TORCH_VERSION.\" && exit 1 ; \\\nfi\n\n# Install quantization libraries from source\nENV CUDA_VERSION=12.4\nENV TORCH_CUDA_ARCH_LIST=\"6.0 7.0 7.5 8.0 8.6 9.0+PTX\"\n\nCOPY scripts/install_quantization_libs.py /internal/install_quantization_libs.py\nRUN python internal/install_quantization_libs.py --install-autogptq-from-source --install-autoawq-from-source\n", "docker\\cuda-ort\\Dockerfile": "# Copyright 2023 The HuggingFace Team All rights reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nARG CUDNN_VERSION=8\nARG CUDA_VERSION=11.8.0\nARG UBUNTU_VERSION=22.04\n\nFROM nvidia/cuda:${CUDA_VERSION}-cudnn${CUDNN_VERSION}-devel-ubuntu${UBUNTU_VERSION}\n\n# Install necessary packages\nENV DEBIAN_FRONTEND noninteractive\nRUN apt-get update && apt-get install -y --no-install-recommends \\\n sudo build-essential git bash-completion \\\n python3.10 python3-pip python3.10-dev && \\\n apt-get clean && rm -rf /var/lib/apt/lists/* && \\\n update-alternatives --install /usr/bin/python python /usr/bin/python3.10 1 && \\\n pip install --no-cache-dir --upgrade pip setuptools wheel \n\n# Install PyTorch\nARG TORCH_CUDA=cu118\nARG TORCH_VERSION=stable\n\nRUN if [ \"${TORCH_VERSION}\" = \"stable\" ]; then \\\n pip install --no-cache-dir torch torchvision torchaudio --index-url https://download.pytorch.org/whl/${TORCH_CUDA} ; \\\nelif [ \"${TORCH_VERSION}\" = \"nightly\" ]; then \\\n pip install --no-cache-dir --pre torch torchvision torchaudio --index-url https://download.pytorch.org/whl/nightly/${TORCH_CUDA} ; \\\nelse \\\n pip install --no-cache-dir torch==${TORCH_VERSION} torchvision torchaudio --index-url https://download.pytorch.org/whl/${TORCH_CUDA} ; \\\nfi\n\n# Install torch-ort and onnxruntime-training\nENV TORCH_CUDA_ARCH_LIST=\"5.0 6.0 7.0 7.5 8.0 8.6 9.0+PTX\"\n\nRUN pip install --no-cache-dir torch-ort onnxruntime-training && python -m torch_ort.configure\n", "docker\\rocm\\Dockerfile": "# Copyright 2023 The HuggingFace Team All rights reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nARG ROCM_VERSION=5.7.1\nARG UBUNTU_VERSION=22.04\n\nFROM rocm/dev-ubuntu-${UBUNTU_VERSION}:${ROCM_VERSION}\n\n# Install necessary packages\nENV PATH=\"/opt/rocm/bin:${PATH}\"\nENV DEBIAN_FRONTEND=noninteractive\nRUN apt-get update && apt-get upgrade -y && apt-get install -y --no-install-recommends \\ \n rocsparse-dev hipsparse-dev rocthrust-dev rocblas-dev hipblas-dev \\\n sudo build-essential git bash-completion \\\n python3.10 python3-pip python3.10-dev && \\\n apt-get clean && rm -rf /var/lib/apt/lists/* && \\\n update-alternatives --install /usr/bin/python python /usr/bin/python3.10 1 && \\\n pip install --no-cache-dir --upgrade pip setuptools wheel requests && \\\n cd /opt/rocm/share/amd_smi && pip install .\n\n# Install PyTorch\nARG TORCH_VERSION=\"\"\nARG TORCH_ROCM=rocm5.7\nARG TORCH_RELEASE_TYPE=stable\n\nRUN if [ -n \"${TORCH_VERSION}\" ]; then \\\n pip install --no-cache-dir torch==${TORCH_VERSION} torchvision torchaudio --index-url https://download.pytorch.org/whl/${TORCH_ROCM} ; \\\nelif [ \"${TORCH_RELEASE_TYPE}\" = \"stable\" ]; then \\\n pip install --no-cache-dir torch torchvision torchaudio --index-url https://download.pytorch.org/whl/${TORCH_ROCM} ; \\\nelif [ \"${TORCH_RELEASE_TYPE}\" = \"nightly\" ]; then \\\n pip install --no-cache-dir --pre torch torchvision torchaudio --index-url https://download.pytorch.org/whl/nightly/${TORCH_ROCM} ; \\\nelse \\\n echo \"Error: Invalid TORCH_RELEASE_TYPE. Must be 'stable', 'nightly', or specify a TORCH_VERSION.\" && exit 1 ; \\\nfi\n\n# Install quantization libraries from source\nENV ROCM_VERSION=5.7\nENV PYTORCH_ROCM_ARCH=\"gfx900;gfx906;gfx908;gfx90a;gfx1030;gfx1100\"\n\nCOPY scripts/install_quantization_libs.py /internal/install_quantization_libs.py\nRUN python internal/install_quantization_libs.py --install-autogptq-from-source --install-autoawq-from-source", "docker\\unroot\\Dockerfile": "ARG IMAGE=\"optimum-benchmark:latest\"\n\nFROM $IMAGE\n\n# Create a non-root user\nARG USER_ID\nARG GROUP_ID\nENV PATH=\"/home/user/.local/bin:${PATH}\"\n\nRUN addgroup --gid $GROUP_ID group\nRUN adduser --disabled-password --gecos '' --uid $USER_ID --gid $GROUP_ID user\n\n# For ROCm, the user needs to be in the video and render groups, check with /opt/rocm/\nRUN if [ -d /opt/rocm/ ]; then usermod -a -G video user; fi\nRUN if [ -d /opt/rocm/ ]; then usermod -a -G render user; fi\n\nUSER user\nWORKDIR /home/user\n\n"} | null |
optimum-furiosa | {"type": "directory", "name": "optimum-furiosa", "children": [{"type": "directory", "name": "docs", "children": [{"type": "file", "name": "README.md"}, {"type": "directory", "name": "source", "children": [{"type": "file", "name": "index.md"}, {"type": "file", "name": "installation.md"}, {"type": "directory", "name": "package_reference", "children": [{"type": "file", "name": "configuration.mdx"}, {"type": "file", "name": "modeling.mdx"}, {"type": "file", "name": "quantization.mdx"}]}, {"type": "directory", "name": "usage_guides", "children": [{"type": "file", "name": "models.mdx"}, {"type": "file", "name": "overview.mdx"}, {"type": "file", "name": "quantization.mdx"}]}, {"type": "file", "name": "_toctree.yml"}]}]}, {"type": "directory", "name": "examples", "children": [{"type": "directory", "name": "quantization", "children": [{"type": "directory", "name": "image-classification", "children": [{"type": "file", "name": "README.md"}, {"type": "file", "name": "run_image_classification.py"}]}]}]}, {"type": "file", "name": "LICENSE"}, {"type": "file", "name": "Makefile"}, {"type": "directory", "name": "notebooks", "children": [{"type": "file", "name": "image_classification.ipynb"}, {"type": "directory", "name": "quantization", "children": [{"type": "directory", "name": "image-classification", "children": [{"type": "file", "name": "run_image_classification.ipynb"}, {"type": "file", "name": "__init__.py"}]}]}]}, {"type": "directory", "name": "optimum", "children": [{"type": "directory", "name": "furiosa", "children": [{"type": "file", "name": "configuration.py"}, {"type": "file", "name": "modeling.py"}, {"type": "file", "name": "modeling_base.py"}, {"type": "file", "name": "quantization.py"}, {"type": "file", "name": "quantization_base.py"}, {"type": "file", "name": "utils.py"}, {"type": "file", "name": "version.py"}, {"type": "file", "name": "__init__.py"}]}]}, {"type": "file", "name": "pyproject.toml"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "setup.cfg"}, {"type": "file", "name": "setup.py"}, {"type": "directory", "name": "tests", "children": [{"type": "file", "name": "test_modeling.py"}, {"type": "file", "name": "test_quantization.py"}]}]} | <!---
Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
# Image classification
The script [`run_image_classification.py`](https://github.com/huggingface/optimum-furiosa/blob/main/examples/quantization/image_classification/run_image_classification.py) allows us to apply different quantization using [FuriosaAI SDK](https://furiosa-ai.github.io/docs/latest/en/software/quantization.html) for image classification tasks.
The following example applies quantization on a Resnet model fine-tuned on the beans classification dataset.
```bash
python run_image_classification.py \
--model_name_or_path eugenecamus/resnet-50-base-beans-demo \
--dataset_name beans \
--do_eval \
--output_dir /tmp/image_classification_resnet_beans
```
| {"setup.py": "import re\n\nfrom setuptools import find_namespace_packages, setup\n\n\n# Ensure we match the version set in optimum/furiosa/version.py\ntry:\n filepath = \"optimum/furiosa/version.py\"\n with open(filepath) as version_file:\n (__version__,) = re.findall('__version__ = \"(.*)\"', version_file.read())\nexcept Exception as error:\n assert False, \"Error: Could not open '%s' due %s\\n\" % (filepath, error)\n\nINSTALL_REQUIRE = [\n \"optimum>=1.8.0\",\n \"transformers>=4.20.0\",\n \"datasets>=1.4.0\",\n \"furiosa-optimizer\",\n \"furiosa-quantizer==0.9.0\",\n \"furiosa-quantizer-impl==0.9.1\",\n \"furiosa-sdk\",\n \"onnx>=1.12.0\",\n \"sentencepiece\",\n \"scipy\",\n]\n\nTESTS_REQUIRE = [\"pytest\", \"parameterized\", \"Pillow\", \"evaluate\", \"diffusers\", \"py-cpuinfo\"]\n\nQUALITY_REQUIRE = [\"black~=23.1\", \"ruff>=0.0.241\"]\n\nEXTRA_REQUIRE = {\n \"testing\": [\n \"filelock\",\n \"GitPython\",\n \"parameterized\",\n \"psutil\",\n \"pytest\",\n \"pytest-pythonpath\",\n \"pytest-xdist\",\n \"Pillow\",\n \"librosa\",\n \"soundfile\",\n ],\n \"quality\": QUALITY_REQUIRE,\n}\n\nsetup(\n name=\"optimum-furiosa\",\n version=__version__,\n description=\"Optimum Library is an extension of the Hugging Face Transformers library, providing a framework to \"\n \"integrate third-party libraries from Hardware Partners and interface with their specific \"\n \"functionality.\",\n long_description=open(\"README.md\", \"r\", encoding=\"utf-8\").read(),\n long_description_content_type=\"text/markdown\",\n classifiers=[\n \"Development Status :: 5 - Production/Stable\",\n \"License :: OSI Approved :: Apache Software License\",\n \"Intended Audience :: Developers\",\n \"Intended Audience :: Education\",\n \"Intended Audience :: Science/Research\",\n \"Operating System :: OS Independent\",\n \"Programming Language :: Python :: 3.7\",\n \"Programming Language :: Python :: 3.8\",\n \"Programming Language :: Python :: 3.9\",\n \"Topic :: Scientific/Engineering :: Artificial Intelligence\",\n ],\n keywords=\"transformers, quantization, pruning, knowledge distillation, optimization, training\",\n url=\"https://huggingface.co/hardware\",\n author=\"HuggingFace Inc. Special Ops Team\",\n author_email=\"[email protected]\",\n license=\"Apache\",\n packages=find_namespace_packages(include=[\"optimum*\"]),\n install_requires=INSTALL_REQUIRE,\n extras_require=EXTRA_REQUIRE,\n include_package_data=True,\n zip_safe=False,\n entry_points={\"console_scripts\": [\"optimum-cli=optimum.commands.optimum_cli:main\"]},\n)\n", ".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 5cb60e7f3b191976ceb04737dca1f374df820171 Hamza Amin <[email protected]> 1727369478 +0500\tclone: from https://github.com/huggingface/optimum-furiosa.git\n", ".git\\refs\\heads\\main": "5cb60e7f3b191976ceb04737dca1f374df820171\n", "docs\\source\\index.md": "<!---\nCopyright 2023 The HuggingFace Team. All rights reserved.\n\nLicensed under the Apache License, Version 2.0 (the \"License\");\nyou may not use this file except in compliance with the License.\nYou may obtain a copy of the License at\n\n http://www.apache.org/licenses/LICENSE-2.0\n\nUnless required by applicable law or agreed to in writing, software\ndistributed under the License is distributed on an \"AS IS\" BASIS,\nWITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\nSee the License for the specific language governing permissions and\nlimitations under the License.\n-->\n\n# \ud83e\udd17 Optimum Furiosa\n\n\ud83e\udd17 Optimum Furiosa is the interface between the \ud83e\udd17 Transformers library and Furiosa NPUs [Furiosa Warboy](https://furiosa-ai.github.io/docs/latest/en/npu/intro.html#furiosaai-warboy).\nIt provides a set of tools enabling easy model loading and inference for different downstream tasks.\n\n<div class=\"mt-10\">\n <div class=\"w-full flex flex-col space-y-4 md:space-y-0 md:grid md:grid-cols-2 md:gap-y-4 md:gap-x-5\">\n <a class=\"!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg\" href=\"./usage_guides/overview\">\n <div class=\"w-full text-center bg-gradient-to-br from-indigo-400 to-indigo-500 rounded-lg py-1.5 font-semibold mb-5 text-white text-lg leading-relaxed\">\n How-to guides\n </div>\n <p class=\"text-gray-700\">\n Practical guides to help you achieve a specific goal. Take a look at these guides to learn how to use \ud83e\udd17 Optimum\n Furiosa to solve real-world problems.\n </p>\n </a>\n <a\n class=\"!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg\"\n href=\"./package_reference/modeling\"\n >\n <div class=\"w-full text-center bg-gradient-to-br from-purple-400 to-purple-500 rounded-lg py-1.5 font-semibold mb-5 text-white text-lg leading-relaxed\">\n Reference\n </div>\n <p class=\"text-gray-700\">Technical descriptions of how the classes and methods of \ud83e\udd17 Optimum Furiosa work.</p>\n </a>\n </div>\n</div>"} | null |
optimum-graphcore | {"type": "directory", "name": "optimum-graphcore", "children": [{"type": "directory", "name": "docs", "children": [{"type": "file", "name": "Dockerfile"}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "source", "children": [{"type": "file", "name": "add_support_for_new_model.mdx"}, {"type": "file", "name": "diffusers.mdx"}, {"type": "file", "name": "index.mdx"}, {"type": "file", "name": "ipu_config.mdx"}, {"type": "file", "name": "pipelines.mdx"}, {"type": "file", "name": "quickstart.mdx"}, {"type": "file", "name": "trainer.mdx"}, {"type": "file", "name": "_toctree.yml"}]}]}, {"type": "directory", "name": "examples", "children": [{"type": "directory", "name": "audio-classification", "children": [{"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "run_audio_classification.py"}]}, {"type": "directory", "name": "image-classification", "children": [{"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "run_image_classification.py"}]}, {"type": "directory", "name": "language-modeling", "children": [{"type": "file", "name": "prepare_dataset.py"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "run_clm.py"}, {"type": "file", "name": "run_mlm.py"}, {"type": "file", "name": "run_pretraining.py"}]}, {"type": "directory", "name": "multiple-choice", "children": [{"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "run_swag.py"}]}, {"type": "directory", "name": "question-answering", "children": [{"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "run_qa.py"}, {"type": "file", "name": "run_vqa.py"}, {"type": "file", "name": "trainer_qa.py"}, {"type": "file", "name": "utils_qa.py"}]}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "speech-pretraining", "children": [{"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "run_pretraining.py"}]}, {"type": "directory", "name": "speech-recognition", "children": [{"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "run_inference_ctc.py"}, {"type": "file", "name": "run_speech_recognition_ctc.py"}, {"type": "file", "name": "run_whisper_pipeline.py"}]}, {"type": "directory", "name": "summarization", "children": [{"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "run_summarization.py"}]}, {"type": "directory", "name": "text-classification", "children": [{"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "run_glue.py"}, {"type": "file", "name": "run_xnli.py"}]}, {"type": "directory", "name": "token-classification", "children": [{"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "run_ner.py"}]}, {"type": "directory", "name": "translation", "children": [{"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "run_translation.py"}]}]}, {"type": "file", "name": "LICENSE"}, {"type": "file", "name": "Makefile"}, {"type": "file", "name": "MANIFEST.in"}, {"type": "directory", "name": "notebooks", "children": [{"type": "file", "name": "audio_classification.ipynb"}, {"type": "file", "name": "deberta-blog-notebook.ipynb"}, {"type": "file", "name": "external_model.ipynb"}, {"type": "file", "name": "flan_t5_inference.ipynb"}, {"type": "directory", "name": "images", "children": [{"type": "file", "name": "gradient-badge.svg"}]}, {"type": "file", "name": "image_classification.ipynb"}, {"type": "file", "name": "introduction_to_optimum_graphcore.ipynb"}, {"type": "file", "name": "language_modeling.ipynb"}, {"type": "file", "name": "language_modelling_from_scratch.ipynb"}, {"type": "file", "name": "managing_ipu_resources.ipynb"}, {"type": "file", "name": "mt5_translation.ipynb"}, {"type": "file", "name": "mt5_xnli.ipynb"}, {"type": "file", "name": "multiple_choice.ipynb"}, {"type": "file", "name": "name-entity-extraction.ipynb"}, {"type": "directory", "name": "packed_bert", "children": [{"type": "directory", "name": "models", "children": [{"type": "file", "name": "modeling_bert_packed.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "packedBERT_multi_label_text_classification.ipynb"}, {"type": "file", "name": "packedBERT_question_answering.ipynb"}, {"type": "file", "name": "packedBERT_single_label_text_classification.ipynb"}, {"type": "directory", "name": "pipeline", "children": [{"type": "file", "name": "packed_bert.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "utils", "children": [{"type": "directory", "name": "packing", "children": [{"type": "file", "name": "algorithms.py"}, {"type": "file", "name": "dataset_creator.py"}, {"type": "file", "name": "dataset_templates.py"}, {"type": "file", "name": "qa_utils.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "question_answering.ipynb"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "sentiment_analysis.ipynb"}, {"type": "file", "name": "squad_preprocessing.py"}, {"type": "directory", "name": "stable_diffusion", "children": [{"type": "file", "name": "image_to_image.ipynb"}, {"type": "file", "name": "inpainting.ipynb"}, {"type": "file", "name": "requirements.txt"}, {"type": "directory", "name": "sample_images", "children": []}, {"type": "directory", "name": "stable_diffusion_space", "children": [{"type": "file", "name": "app.py"}, {"type": "file", "name": "ipu_models.py"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements_app.txt"}, {"type": "file", "name": "requirements_server.txt"}, {"type": "file", "name": "server.py"}]}, {"type": "file", "name": "text_to_image.ipynb"}, {"type": "file", "name": "text_to_image_sd2.ipynb"}]}, {"type": "file", "name": "summarization.ipynb"}, {"type": "file", "name": "text_classification.ipynb"}, {"type": "directory", "name": "text_embeddings_models", "children": [{"type": "file", "name": "config.py"}, {"type": "file", "name": "text-embeddings-on-ipu.ipynb"}]}, {"type": "file", "name": "text_summarization.ipynb"}, {"type": "file", "name": "token_classification.ipynb"}, {"type": "file", "name": "translation.ipynb"}, {"type": "directory", "name": "wav2vec2", "children": [{"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "wav2vec2-fine-tuning-checkpoint.ipynb"}, {"type": "file", "name": "wav2vec2-inference-checkpoint.ipynb"}]}, {"type": "file", "name": "whisper-example.ipynb"}, {"type": "file", "name": "whisper-quantized-example.ipynb"}, {"type": "file", "name": "whisper_finetuning.ipynb"}]}, {"type": "directory", "name": "optimum", "children": [{"type": "directory", "name": "graphcore", "children": [{"type": "directory", "name": "custom_ops", "children": [{"type": "directory", "name": "group_quantize_decompress", "children": [{"type": "file", "name": "common.hpp"}, {"type": "file", "name": "group_quantize_decompress.cpp"}, {"type": "file", "name": "group_quantize_decompress.hpp"}, {"type": "file", "name": "group_quantize_decompressx.cpp"}, {"type": "file", "name": "group_quantize_decompressx.hpp"}, {"type": "file", "name": "group_quantize_decompress_codelet_v1.cpp"}]}, {"type": "directory", "name": "sdk_version_hash", "children": [{"type": "file", "name": "sdk_version_hash.py"}, {"type": "file", "name": "sdk_version_hash_lib.cpp"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "utils.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "data", "children": [{"type": "file", "name": "data_collator.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "diffusers", "children": [{"type": "directory", "name": "pipelines", "children": [{"type": "directory", "name": "stable_diffusion", "children": [{"type": "file", "name": "ipu_configs.py"}, {"type": "file", "name": "pipeline_stable_diffusion.py"}, {"type": "file", "name": "pipeline_stable_diffusion_img2img.py"}, {"type": "file", "name": "pipeline_stable_diffusion_inpaint.py"}, {"type": "file", "name": "pipeline_stable_diffusion_mixin.py"}, {"type": "file", "name": "safety_checker.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "generation", "children": [{"type": "file", "name": "attention_mixin.py"}, {"type": "file", "name": "logits_process.py"}, {"type": "file", "name": "on_device_generation.py"}, {"type": "file", "name": "utils.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "ipu_configuration.py"}, {"type": "file", "name": "modelcard.py"}, {"type": "file", "name": "modeling_utils.py"}, {"type": "directory", "name": "models", "children": [{"type": "directory", "name": "bart", "children": [{"type": "file", "name": "modeling_bart.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "bert", "children": [{"type": "file", "name": "bert_fused_attention.py"}, {"type": "file", "name": "modeling_bert.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "convnext", "children": [{"type": "file", "name": "modeling_convnext.py"}, {"type": "file", "name": "optimized_convnextlayer.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "deberta", "children": [{"type": "file", "name": "modeling_deberta.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "distilbert", "children": [{"type": "file", "name": "modeling_distilbert.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "gpt2", "children": [{"type": "file", "name": "modeling_gpt2.py"}, {"type": "file", "name": "optimized_gpt2_attn.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "groupbert", "children": [{"type": "file", "name": "groupbert_attention.py"}, {"type": "file", "name": "groupbert_convolution.py"}, {"type": "file", "name": "groupbert_ffn.py"}, {"type": "file", "name": "modeling_groupbert.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "hubert", "children": [{"type": "file", "name": "ipu_layer_drop.py"}, {"type": "file", "name": "modeling_hubert.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "lxmert", "children": [{"type": "file", "name": "modeling_lxmert.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "mpnet", "children": [{"type": "file", "name": "modeling_mpnet.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "mt5", "children": [{"type": "file", "name": "modeling_mt5.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "roberta", "children": [{"type": "file", "name": "modeling_roberta.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "t5", "children": [{"type": "file", "name": "configuration_t5.py"}, {"type": "file", "name": "modeling_t5.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "vit", "children": [{"type": "file", "name": "modeling_vit.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "wav2vec2", "children": [{"type": "file", "name": "ipu_gumbel_vector_quantizer.py"}, {"type": "file", "name": "ipu_layer_drop.py"}, {"type": "file", "name": "modeling_wav2vec2.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "whisper", "children": [{"type": "file", "name": "feature_extraction_whisper.py"}, {"type": "file", "name": "modeling_whisper.py"}, {"type": "file", "name": "processing_whisper.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "pipelines", "children": [{"type": "file", "name": "automatic_speech_recognition.py"}, {"type": "file", "name": "fill_mask.py"}, {"type": "file", "name": "text2text_generation.py"}, {"type": "file", "name": "token_classification.py"}, {"type": "file", "name": "zero_shot_classification.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "quantization", "children": [{"type": "file", "name": "group_quantize.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "trainer.py"}, {"type": "file", "name": "trainer_pt_utils.py"}, {"type": "file", "name": "trainer_seq2seq.py"}, {"type": "file", "name": "trainer_utils.py"}, {"type": "file", "name": "training_args.py"}, {"type": "file", "name": "training_args_seq2seq.py"}, {"type": "directory", "name": "utils", "children": [{"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "version.py"}, {"type": "file", "name": "__init__.py"}]}]}, {"type": "file", "name": "pyproject.toml"}, {"type": "file", "name": "pytest.ini"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "setup.cfg"}, {"type": "file", "name": "setup.py"}, {"type": "directory", "name": "tests", "children": [{"type": "file", "name": "create_diff_file_for_example.py"}, {"type": "directory", "name": "examples", "children": [{"type": "file", "name": "run_audio_classification.txt"}, {"type": "file", "name": "run_clm.txt"}, {"type": "file", "name": "run_glue.txt"}, {"type": "file", "name": "run_image_classification.txt"}, {"type": "file", "name": "run_mlm.txt"}, {"type": "file", "name": "run_ner.txt"}, {"type": "file", "name": "run_qa.txt"}, {"type": "file", "name": "run_speech_recognition_ctc.txt"}, {"type": "file", "name": "run_summarization.txt"}, {"type": "file", "name": "run_swag.txt"}, {"type": "file", "name": "run_translation.txt"}, {"type": "file", "name": "run_xnli.txt"}]}, {"type": "directory", "name": "fixtures", "children": [{"type": "directory", "name": "tests_samples", "children": [{"type": "directory", "name": "COCO", "children": []}]}]}, {"type": "directory", "name": "generation", "children": [{"type": "file", "name": "test_framework_agnostic.py"}, {"type": "file", "name": "test_utils.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "ipu_config_trainer_test.json"}, {"type": "directory", "name": "pipelines", "children": [{"type": "file", "name": "test_pipelines_audio_classification.py"}, {"type": "file", "name": "test_pipelines_automatic_speech_recognition.py"}, {"type": "file", "name": "test_pipelines_common.py"}, {"type": "file", "name": "test_pipelines_fill_mask.py"}, {"type": "file", "name": "test_pipelines_image_classification.py"}, {"type": "file", "name": "test_pipelines_question_answering.py"}, {"type": "file", "name": "test_pipelines_text_classification.py"}, {"type": "file", "name": "test_pipelines_token_classification.py"}, {"type": "file", "name": "test_pipelines_zero_shot.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "test_custom_ops.py"}, {"type": "file", "name": "test_examples.py"}, {"type": "file", "name": "test_examples_match_transformers.py"}, {"type": "file", "name": "test_ipu_configuration.py"}, {"type": "file", "name": "test_modeling_common.py"}, {"type": "file", "name": "test_modeling_utils.py"}, {"type": "file", "name": "test_pipelined_models.py"}, {"type": "file", "name": "test_trainer.py"}, {"type": "file", "name": "test_trainer_seq2seq.py"}, {"type": "file", "name": "utils.py"}, {"type": "file", "name": "__init__.py"}]}]} | # Server:
## Prerequisite
Python3.7+
## Install dependencies
```
pip install --upgrade pip
pip install wheel
pip install -r requirements_server.txt
pip install uvicorn[standard]
pip install <poptorch>.whl (not required in debug mode)
```
## Run
```
API_KEY=<secret> uvicorn server:app --host <server hostname> --port <port>
```
## Debug mode
poptorch, Poplar, torch, IPUs not needed
```
DEBUG=true API_KEY=<secret> uvicorn server:app --host <server hostname> --port <port>
```
# App:
## Install dependencies
```
pip install --upgrade pip
pip install wheel
pip install -r requirements_app.txt
```
## Run
```
IPU_BACKEND=http://<server hostname>:<port>/inference/ API_KEY=<secret> python app.py
```
Access the app via http://localhost:7860/.
| {"setup.py": "# Copyright 2021 The HuggingFace Team. All rights reserved.\n# Copyright (c) 2022 Graphcore Ltd. All rights reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport re\n\nfrom setuptools import find_namespace_packages, setup\n\n\n# Ensure we match the version set in optimum/version.py\ntry:\n filepath = \"optimum/graphcore/version.py\"\n with open(filepath) as version_file:\n (__version__,) = re.findall('__version__ = \"(.*)\"', version_file.read())\nexcept Exception as error:\n assert False, \"Error: Could not open '%s' due %s\\n\" % (filepath, error)\n\n\nINSTALL_REQUIRES = [\n \"transformers==4.29.2\",\n \"optimum==1.6.1\",\n \"diffusers[torch]==0.12.1\",\n \"cppimport==22.8.2\",\n \"peft==0.3.0\",\n \"datasets\",\n \"tokenizers\",\n \"typeguard\",\n \"sentencepiece\",\n \"scipy\",\n \"pillow\",\n]\n\nQUALITY_REQUIRES = [\n \"black~=23.1\",\n \"isort>=5.5.4\",\n \"hf-doc-builder @ git+https://github.com/huggingface/doc-builder.git\",\n \"ruff>=0.0.241,<=0.0.259\",\n]\n\nEXTRA_REQUIRE = {\n \"testing\": [\n \"filelock\",\n \"GitPython\",\n \"parameterized\",\n \"psutil\",\n \"pytest\",\n \"pytest-pythonpath\",\n \"pytest-xdist\",\n \"librosa\",\n \"soundfile\",\n ],\n \"quality\": QUALITY_REQUIRES,\n}\n\n\nsetup(\n name=\"optimum-graphcore\",\n version=__version__,\n description=\"Optimum Library is an extension of the Hugging Face Transformers library, providing a framework to \"\n \"integrate third-party libraries from Hardware Partners and interface with their specific \"\n \"functionality.\",\n long_description=open(\"README.md\", \"r\", encoding=\"utf-8\").read(),\n long_description_content_type=\"text/markdown\",\n classifiers=[\n \"Development Status :: 3 - Alpha\",\n \"License :: OSI Approved :: Apache Software License\",\n \"Intended Audience :: Developers\",\n \"Intended Audience :: Education\",\n \"Intended Audience :: Science/Research\",\n \"Operating System :: OS Independent\",\n \"Programming Language :: Python :: 3.8\",\n \"Programming Language :: Python :: 3.9\",\n \"Topic :: Scientific/Engineering :: Artificial Intelligence\",\n ],\n keywords=\"transformers, quantization, pruning, training, ipu\",\n url=\"https://huggingface.co/hardware\",\n author=\"HuggingFace Inc. Special Ops Team\",\n author_email=\"[email protected]\",\n license=\"Apache\",\n packages=find_namespace_packages(include=[\"optimum*\"]),\n install_requires=INSTALL_REQUIRES,\n extras_require=EXTRA_REQUIRE,\n include_package_data=True,\n zip_safe=False,\n package_data={\"\": [\"*.cpp\", \"*.hpp\"]}\n)\n", ".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 d415c9e17808b84afb95fbd078175161c85bcfe0 Hamza Amin <[email protected]> 1727369408 +0500\tclone: from https://github.com/huggingface/optimum-graphcore.git\n", ".git\\refs\\heads\\main": "d415c9e17808b84afb95fbd078175161c85bcfe0\n", "docs\\Dockerfile": "FROM graphcore/pytorch:3.2.0-ubuntu-20.04\n\nARG commit_sha\nARG clone_url\nARG clone_name\n\n# Need node to build doc HTML. Taken from https://stackoverflow.com/a/67491580\nRUN apt-get update && apt-get install -y \\\n git \\\n curl \\\n gnupg\nRUN curl -sL https://deb.nodesource.com/setup_18.x | bash -\nRUN apt-get -y install nodejs\nRUN npm install npm@latest -g && \\\n npm install n -g && \\\n n latest\n\nRUN git clone $clone_url && cd $clone_name && git checkout $commit_sha\nRUN python3 -m pip install --no-cache-dir --upgrade pip\nRUN cd $clone_name && python3 -m pip install --no-cache-dir .[quality]\n", "docs\\source\\index.mdx": "<!---\nCopyright 2022 The HuggingFace Team. All rights reserved.\n\nLicensed under the Apache License, Version 2.0 (the \"License\");\nyou may not use this file except in compliance with the License.\nYou may obtain a copy of the License at\n\n http://www.apache.org/licenses/LICENSE-2.0\n\nUnless required by applicable law or agreed to in writing, software\ndistributed under the License is distributed on an \"AS IS\" BASIS,\nWITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\nSee the License for the specific language governing permissions and\nlimitations under the License.\n-->\n\n\n# Optimum Graphcore\n\n\ud83e\udd17 Optimum Graphcore is the interface between the \ud83e\udd17 Transformers library and [Graphcore IPUs](https://www.graphcore.ai/products/ipu). It provides a set of tools enabling model parallelization and loading on IPUs, training and fine-tuning on all the tasks already supported by Transformers while being compatible with the Hugging Face Hub and every model available on it out of the box.\n\n## What is an Intelligence Processing Unit (IPU)?\n\nQuote from the Hugging Face [blog post](https://huggingface.co/blog/graphcore#what-is-an-intelligence-processing-unit):\n\n> IPUs are the processors that power Graphcore's IPU-POD datacenter compute systems. This new type of processor is designed to support the very specific computational requirements of AI and machine learning. Characteristics such as fine-grained parallelism, low precision arithmetic, and the ability to handle sparsity have been built into our silicon.\n\n> Instead of adopting a SIMD/SIMT architecture like GPUs, Graphcore's IPU uses a massively parallel, MIMD architecture, with ultra-high bandwidth memory placed adjacent to the processor cores, right on the silicon die.\n\n> This design delivers high performance and new levels of efficiency, whether running today's most popular models, such as BERT and EfficientNet, or exploring next-generation AI applications.\n\n## Supported models\n\nThe following model architectures and tasks are currently supported by \ud83e\udd17 Optimum Graphcore:\n\n| | Pre-Training | Masked LM | Causal LM | Seq2Seq LM (Summarization, Translation, etc) | Sequence Classification | Token Classification | Question Answering | Multiple Choice | Image Classification |\n|------------|--------------|-----------|-----------|----------------------------------------------|-------------------------|----------------------|--------------------|-----------------|----------------------|\n| BART | \u2705 | | \u274c | \u2705 | \u2705 | | \u274c | | |\n| BERT | \u2705 | \u2705 | \u274c | | \u2705 | \u2705 | \u2705 | \u2705 | |\n| ConvNeXt | \u2705 | | | | | | | | \u2705 |\n| DeBERTa | \u274c | \u274c | | | \u2705 | \u2705 | \u2705 | | |\n| DistilBERT | \u274c | \u2705 | | | \u2705 | \u2705 | \u2705 | \u2705 | |\n| GPT-2 | \u2705 | | \u2705 | | \u2705 | \u2705 | | | |\n| HuBERT | \u274c | | | | \u2705 | | | | |\n| LXMERT | \u274c | | | | | | \u2705 | | |\n| RoBERTa | \u2705 | \u2705 | \u274c | | \u2705 | \u2705 | \u2705 | \u2705 | |\n| T5 | \u2705 | | | \u2705 | | | | | |\n| ViT | \u274c | | | | | | | | \u2705 |\n| Wav2Vec2 | \u2705 | | | | | | | | |\n", "examples\\audio-classification\\requirements.txt": "--extra-index-url https://download.pytorch.org/whl/cpu\ndatasets>=1.14.0\nlibrosa\ntorchaudio==2.0.2\nscikit-learn\nevaluate\n", "examples\\image-classification\\requirements.txt": "--extra-index-url https://download.pytorch.org/whl/cpu\ntorchvision==0.15.2\ndatasets>=1.15.0\nscikit-learn==0.24.2\nevaluate\n", "examples\\language-modeling\\requirements.txt": "torch >= 1.3\ndatasets >= 1.8.0\nsentencepiece != 0.1.92\nprotobuf\nscikit-learn\nevaluate\n", "examples\\multiple-choice\\requirements.txt": "datasets\nsentencepiece != 0.1.92\nprotobuf\ntorch >= 1.3\n", "examples\\question-answering\\requirements.txt": "datasets >= 1.8.0\ntorch >= 1.3.0\nevaluate\n", "examples\\speech-pretraining\\requirements.txt": "datasets >= 1.18.0\n--extra-index-url https://download.pytorch.org/whl/cpu\ntorchaudio==2.0.2\nlibrosa\njiwer\nsoundfile\n\n", "examples\\speech-recognition\\requirements.txt": "--extra-index-url https://download.pytorch.org/whl/cpu\ntorchaudio==2.0.2\nlibrosa\njiwer\nsoundfile\nevaluate\n", "examples\\summarization\\requirements.txt": "datasets >= 1.8.0\nsentencepiece != 0.1.92\nprotobuf\nrouge-score\nnltk\npy7zr\ntorch >= 1.3\nevaluate\n", "examples\\text-classification\\requirements.txt": "datasets >= 1.8.0\nsentencepiece != 0.1.92\nscipy\nscikit-learn\nprotobuf\ntorch >= 1.3\nevaluate\n", "examples\\token-classification\\requirements.txt": "seqeval\ndatasets >= 1.8.0\nevaluate\n", "examples\\translation\\requirements.txt": "datasets >= 1.8.0\nsentencepiece != 0.1.92\nprotobuf\nsacrebleu >= 1.4.12\npy7zr\ntorch >= 1.3\nevaluate\n", "notebooks\\stable_diffusion\\requirements.txt": "optimum-graphcore==0.7\nmatplotlib\ngraphcore-cloud-tools[logger] @ git+https://github.com/graphcore/graphcore-cloud-tools\n", "notebooks\\stable_diffusion\\stable_diffusion_space\\app.py": "import os\nimport re\n\nfrom datasets import load_dataset\nfrom PIL import Image\n\nimport gradio as gr\nimport requests\n\n\n# from share_btn import community_icon_html, loading_icon_html, share_js\n\nmodel_id = \"CompVis/stable-diffusion-v1-4\"\ndevice = \"cuda\"\n\n\ndef infer(prompt: str, guidance_scale: float = 7.5):\n url = os.getenv(\"IPU_BACKEND\")\n api_key = os.getenv(\"API_KEY\")\n payload = {\"prompt\": prompt, \"guidance_scale\": guidance_scale}\n headers = {\"access_token\": api_key}\n response = requests.post(url, json=payload, headers=headers)\n response_content = response.json()\n images = []\n for image in response_content[\"images\"]:\n image_b64 = f\"data:image/jpeg;base64,{image}\"\n images.append(image_b64)\n return images, response_content[\"latency\"]\n\n\ncss = \"\"\"\n .gradio-container {\n font-family: 'IBM Plex Sans', sans-serif;\n }\n .gr-button {\n color: white;\n border-color: black;\n background: black;\n }\n input[type='range'] {\n accent-color: black;\n }\n .dark input[type='range'] {\n accent-color: #dfdfdf;\n }\n .container {\n max-width: 730px;\n margin: auto;\n padding-top: 1.5rem;\n }\n #gallery {\n min-height: 22rem;\n margin-bottom: 15px;\n margin-left: auto;\n margin-right: auto;\n border-bottom-right-radius: .5rem !important;\n border-bottom-left-radius: .5rem !important;\n }\n #gallery>div>.h-full {\n min-height: 20rem;\n }\n .details:hover {\n text-decoration: underline;\n }\n .gr-button {\n white-space: nowrap;\n }\n .gr-button:focus {\n border-color: rgb(147 197 253 / var(--tw-border-opacity));\n outline: none;\n box-shadow: var(--tw-ring-offset-shadow), var(--tw-ring-shadow), var(--tw-shadow, 0 0 #0000);\n --tw-border-opacity: 1;\n --tw-ring-offset-shadow: var(--tw-ring-inset) 0 0 0 var(--tw-ring-offset-width) var(--tw-ring-offset-color);\n --tw-ring-shadow: var(--tw-ring-inset) 0 0 0 calc(3px var(--tw-ring-offset-width)) var(--tw-ring-color);\n --tw-ring-color: rgb(191 219 254 / var(--tw-ring-opacity));\n --tw-ring-opacity: .5;\n }\n #advanced-btn {\n font-size: .7rem !important;\n line-height: 19px;\n margin-top: 12px;\n margin-bottom: 12px;\n padding: 2px 8px;\n border-radius: 14px !important;\n }\n #advanced-options {\n display: none;\n margin-bottom: 20px;\n }\n .footer {\n margin-bottom: 45px;\n margin-top: 35px;\n text-align: center;\n border-bottom: 1px solid #e5e5e5;\n }\n .footer>p {\n font-size: .8rem;\n display: inline-block;\n padding: 0 10px;\n transform: translateY(10px);\n background: white;\n }\n .dark .footer {\n border-color: #303030;\n }\n .dark .footer>p {\n background: #0b0f19;\n }\n .acknowledgments h4{\n margin: 1.25em 0 .25em 0;\n font-weight: bold;\n font-size: 115%;\n }\n #container-advanced-btns{\n display: flex;\n flex-wrap: wrap;\n justify-content: space-between;\n align-items: center;\n }\n .animate-spin {\n animation: spin 1s linear infinite;\n }\n @keyframes spin {\n from {\n transform: rotate(0deg);\n }\n to {\n transform: rotate(360deg);\n }\n }\n #share-btn-container {\n display: flex; padding-left: 0.5rem !important; padding-right: 0.5rem !important; background-color: #000000; justify-content: center; align-items: center; border-radius: 9999px !important; width: 13rem;\n }\n #share-btn {\n all: initial; color: #ffffff;font-weight: 600; cursor:pointer; font-family: 'IBM Plex Sans', sans-serif; margin-left: 0.5rem !important; padding-top: 0.25rem !important; padding-bottom: 0.25rem !important;\n }\n #share-btn * {\n all: unset;\n }\n .gr-form{\n flex: 1 1 50%; border-top-right-radius: 0; border-bottom-right-radius: 0;\n }\n #prompt-container{\n gap: 0;\n }\n\"\"\"\n\nblock = gr.Blocks(css=css)\n\nexamples = [\n [\"A high tech solarpunk utopia in the Amazon rainforest\"],\n [\"A pikachu fine dining with a view to the Eiffel Tower\"],\n [\"A mecha robot in a favela in expressionist style\"],\n [\"An insect robot preparing a delicious meal\"],\n [\"A small cabin on top of a snowy mountain in the style of Disney, artstation\"],\n]\n\n\nwith block:\n gr.HTML(\n \"\"\"\n <div style=\"text-align: center; max-width: 650px; margin: 0 auto;\">\n <div\n style=\"\n display: inline-flex;\n align-items: center;\n gap: 0.8rem;\n font-size: 1.75rem;\n \"\n >\n <svg\n width=\"0.65em\"\n height=\"0.65em\"\n viewBox=\"0 0 115 115\"\n fill=\"none\"\n xmlns=\"http://www.w3.org/2000/svg\"\n >\n <rect width=\"23\" height=\"23\" fill=\"white\"></rect>\n <rect y=\"69\" width=\"23\" height=\"23\" fill=\"white\"></rect>\n <rect x=\"23\" width=\"23\" height=\"23\" fill=\"#AEAEAE\"></rect>\n <rect x=\"23\" y=\"69\" width=\"23\" height=\"23\" fill=\"#AEAEAE\"></rect>\n <rect x=\"46\" width=\"23\" height=\"23\" fill=\"white\"></rect>\n <rect x=\"46\" y=\"69\" width=\"23\" height=\"23\" fill=\"white\"></rect>\n <rect x=\"69\" width=\"23\" height=\"23\" fill=\"black\"></rect>\n <rect x=\"69\" y=\"69\" width=\"23\" height=\"23\" fill=\"black\"></rect>\n <rect x=\"92\" width=\"23\" height=\"23\" fill=\"#D9D9D9\"></rect>\n <rect x=\"92\" y=\"69\" width=\"23\" height=\"23\" fill=\"#AEAEAE\"></rect>\n <rect x=\"115\" y=\"46\" width=\"23\" height=\"23\" fill=\"white\"></rect>\n <rect x=\"115\" y=\"115\" width=\"23\" height=\"23\" fill=\"white\"></rect>\n <rect x=\"115\" y=\"69\" width=\"23\" height=\"23\" fill=\"#D9D9D9\"></rect>\n <rect x=\"92\" y=\"46\" width=\"23\" height=\"23\" fill=\"#AEAEAE\"></rect>\n <rect x=\"92\" y=\"115\" width=\"23\" height=\"23\" fill=\"#AEAEAE\"></rect>\n <rect x=\"92\" y=\"69\" width=\"23\" height=\"23\" fill=\"white\"></rect>\n <rect x=\"69\" y=\"46\" width=\"23\" height=\"23\" fill=\"white\"></rect>\n <rect x=\"69\" y=\"115\" width=\"23\" height=\"23\" fill=\"white\"></rect>\n <rect x=\"69\" y=\"69\" width=\"23\" height=\"23\" fill=\"#D9D9D9\"></rect>\n <rect x=\"46\" y=\"46\" width=\"23\" height=\"23\" fill=\"black\"></rect>\n <rect x=\"46\" y=\"115\" width=\"23\" height=\"23\" fill=\"black\"></rect>\n <rect x=\"46\" y=\"69\" width=\"23\" height=\"23\" fill=\"black\"></rect>\n <rect x=\"23\" y=\"46\" width=\"23\" height=\"23\" fill=\"#D9D9D9\"></rect>\n <rect x=\"23\" y=\"115\" width=\"23\" height=\"23\" fill=\"#AEAEAE\"></rect>\n <rect x=\"23\" y=\"69\" width=\"23\" height=\"23\" fill=\"black\"></rect>\n </svg>\n <h1 style=\"font-weight: 900; margin-bottom: 7px;\">\n Stable Diffusion Demo\n </h1>\n </div>\n <p style=\"margin-bottom: 10px; font-size: 94%\">\n Stable Diffusion is a state of the art text-to-image model that generates\n images from text.\n </p>\n <p>\n Model by <a href=\"https://huggingface.co/runwayml\" style=\"text-decoration: underline;\" target=\"_blank\">Runway</a> and the backend is running on <a href=\"https://github.com/huggingface/optimum-graphcore\", style=\"text-decoration: underline;\" target=\"_blank\">Optimum Graphcore</a> and <a href=\"https://huggingface.co/Graphcore\" style=\"text-decoration: underline;\" target=\"_blank\">Graphcore IPUs</a>\n </p>\n </p>\n </div>\n \"\"\"\n )\n with gr.Group():\n with gr.Box():\n with gr.Row(elem_id=\"prompt-container\").style(mobile_collapse=False, equal_height=True):\n text = gr.Textbox(\n label=\"Enter your prompt\",\n show_label=False,\n max_lines=1,\n placeholder=\"Enter your prompt\",\n elem_id=\"prompt-text-input\",\n ).style(\n border=(True, False, True, True),\n rounded=(True, False, False, True),\n container=False,\n )\n btn = gr.Button(\"Generate image\").style(\n margin=False,\n rounded=(False, True, True, False),\n full_width=False,\n )\n\n gallery = gr.Gallery(label=\"Generated images\", show_label=False, elem_id=\"gallery\").style(\n grid=[1], height=\"auto\"\n )\n\n latency = gr.Textbox(label=\"Compute time (in seconds)\")\n\n with gr.Group(elem_id=\"container-advanced-btns\"):\n advanced_button = gr.Button(\"Advanced options\", elem_id=\"advanced-btn\")\n # with gr.Group(elem_id=\"share-btn-container\"):\n # community_icon = gr.HTML(community_icon_html)\n # loading_icon = gr.HTML(loading_icon_html)\n # share_button = gr.Button(\"Share to community\", elem_id=\"share-btn\")\n\n # with gr.Row(elem_id=\"advanced-options\"):\n # gr.Markdown(\"Advanced settings are temporarily unavailable\")\n # samples = gr.Slider(label=\"Images\", minimum=1, maximum=4, value=4, step=1)\n # steps = gr.Slider(label=\"Steps\", minimum=1, maximum=50, value=45, step=1)\n # scale = gr.Slider(\n # label=\"Guidance Scale\", minimum=0, maximum=50, value=7.5, step=0.1\n # )\n # seed = gr.Slider(\n # label=\"Seed\",\n # minimum=0,\n # maximum=2147483647,\n # step=1,\n # randomize=True,\n # )\n\n ex = gr.Examples(examples=examples, fn=infer, inputs=text, cache_examples=False)\n # outputs=[gallery, community_icon, loading_icon, share_button], cache_examples=False)\n ex.dataset.headers = [\"\"]\n\n text.submit(infer, inputs=text, outputs=[gallery, latency], postprocess=False)\n btn.click(infer, inputs=text, outputs=[gallery, latency], postprocess=False)\n\n advanced_button.click(\n None,\n [],\n text,\n _js=\"\"\"\n () => {\n const options = document.querySelector(\"body > gradio-app\").querySelector(\"#advanced-options\");\n options.style.display = [\"none\", \"\"].includes(options.style.display) ? \"flex\" : \"none\";\n }\"\"\",\n )\n # share_button.click(\n # None,\n # [],\n # [],\n # _js=share_js,\n # )\n gr.HTML(\n \"\"\"\n <div class=\"acknowledgments\">\n <p><h4>LICENSE</h4>\nThe model is licensed with a <a href=\"https://huggingface.co/spaces/CompVis/stable-diffusion-license\" style=\"text-decoration: underline;\" target=\"_blank\">CreativeML Open RAIL-M</a> license. The authors claim no rights on the outputs you generate, you are free to use them and are accountable for their use which must not go against the provisions set in this license. The license forbids you from sharing any content that violates any laws, produce any harm to a person, disseminate any personal information that would be meant for harm, spread misinformation and target vulnerable groups. For the full list of restrictions please <a href=\"https://huggingface.co/spaces/CompVis/stable-diffusion-license\" target=\"_blank\" style=\"text-decoration: underline;\" target=\"_blank\">read the license</a></p>\n <p><h4>Biases and content acknowledgment</h4>\n While the capabilities of image generation models are impressive, they can also reinforce or exacerbate social biases. Stable Diffusion v1 was trained on subsets of LAION-2B(en), which consists of images that are primarily limited to English descriptions. Texts and images from communities and cultures that use other languages are likely to be insufficiently accounted for. This affects the overall output of the model, as white and western cultures are often set as the default. Further, the ability of the model to generate content with non-English prompts is significantly worse than with English-language prompts.\n </div>\n \"\"\"\n )\n\nblock.queue(concurrency_count=40, max_size=20).launch(max_threads=150)\n", "notebooks\\stable_diffusion\\stable_diffusion_space\\requirements_app.txt": "datasets\ngradio\n", "notebooks\\wav2vec2\\requirements.txt": "optimum-graphcore==0.7\n--find-links https://download.pytorch.org/whl/torch_stable.html\ntorchaudio == 2.0.2+cpu\nlibrosa\njiwer\nsoundfile\ngraphcore-cloud-tools[logger] @ git+https://github.com/graphcore/graphcore-cloud-tools\n"} | null |
optimum-habana | {"type": "directory", "name": "optimum-habana", "children": [{"type": "file", "name": "conftest.py"}, {"type": "directory", "name": "docs", "children": [{"type": "file", "name": "Dockerfile"}, {"type": "directory", "name": "source", "children": [{"type": "directory", "name": "concept_guides", "children": [{"type": "file", "name": "hpu.mdx"}]}, {"type": "file", "name": "index.mdx"}, {"type": "file", "name": "installation.mdx"}, {"type": "directory", "name": "package_reference", "children": [{"type": "file", "name": "distributed_runner.mdx"}, {"type": "file", "name": "gaudi_config.mdx"}, {"type": "file", "name": "stable_diffusion_pipeline.mdx"}, {"type": "file", "name": "trainer.mdx"}]}, {"type": "file", "name": "quickstart.mdx"}, {"type": "directory", "name": "tutorials", "children": [{"type": "file", "name": "distributed.mdx"}, {"type": "file", "name": "inference.mdx"}, {"type": "file", "name": "overview.mdx"}, {"type": "file", "name": "single_hpu.mdx"}, {"type": "file", "name": "stable_diffusion.mdx"}, {"type": "file", "name": "stable_diffusion_ldm3d.mdx"}]}, {"type": "directory", "name": "usage_guides", "children": [{"type": "file", "name": "accelerate_inference.mdx"}, {"type": "file", "name": "accelerate_training.mdx"}, {"type": "file", "name": "deepspeed.mdx"}, {"type": "file", "name": "multi_node_training.mdx"}, {"type": "file", "name": "overview.mdx"}, {"type": "file", "name": "pretraining.mdx"}]}, {"type": "file", "name": "_toctree.yml"}]}]}, {"type": "directory", "name": "examples", "children": [{"type": "directory", "name": "audio-classification", "children": [{"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "run_audio_classification.py"}]}, {"type": "directory", "name": "contrastive-image-text", "children": [{"type": "file", "name": "clip_mediapipe_dataloader.py"}, {"type": "file", "name": "clip_media_pipe.py"}, {"type": "file", "name": "habana_dataloader_trainer.py"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "run_bridgetower.py"}, {"type": "file", "name": "run_clip.py"}]}, {"type": "file", "name": "gaudi_spawn.py"}, {"type": "directory", "name": "image-classification", "children": [{"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "run_image_classification.py"}, {"type": "file", "name": "run_timm_example.py"}]}, {"type": "directory", "name": "image-to-text", "children": [{"type": "directory", "name": "quantization_config", "children": [{"type": "file", "name": "act_maxabs_hw_weights_pcs_maxabs_pow2_quant.json"}, {"type": "file", "name": "maxabs_measure.json"}, {"type": "file", "name": "maxabs_measure_include_outputs.json"}, {"type": "file", "name": "maxabs_quant.json"}, {"type": "file", "name": "unit_scale_quant.json"}]}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "run_pipeline.py"}]}, {"type": "directory", "name": "kubernetes", "children": [{"type": "file", "name": "Chart.yaml"}, {"type": "directory", "name": "ci", "children": [{"type": "file", "name": "multi-card-glue-values.yaml"}, {"type": "file", "name": "multi-card-lora-clm-values.yaml"}, {"type": "file", "name": "single-card-glue-values.yaml"}, {"type": "file", "name": "single-card-lora-clm-values.yaml"}]}, {"type": "file", "name": "docker-compose.yaml"}, {"type": "file", "name": "Dockerfile"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "README.md.gotmpl"}, {"type": "file", "name": "requirements.txt"}, {"type": "directory", "name": "templates", "children": [{"type": "file", "name": "dataaccess.yaml"}, {"type": "file", "name": "gaudi-job.yaml"}, {"type": "file", "name": "pvc.yaml"}, {"type": "file", "name": "secret.yaml"}]}, {"type": "file", "name": "values.yaml"}]}, {"type": "directory", "name": "language-modeling", "children": [{"type": "file", "name": "ds_falcon_180b_z3.json"}, {"type": "file", "name": "fsdp_config.json"}, {"type": "file", "name": "llama2_ds_zero3_config.json"}, {"type": "file", "name": "ops_bf16.txt"}, {"type": "file", "name": "peft_poly_seq2seq_with_generate.py"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "run_clm.py"}, {"type": "file", "name": "run_lora_clm.py"}, {"type": "file", "name": "run_mlm.py"}, {"type": "file", "name": "run_multitask_prompt_tuning.py"}, {"type": "file", "name": "run_prompt_tuning_clm.py"}]}, {"type": "directory", "name": "multi-node-training", "children": [{"type": "directory", "name": "EFA", "children": [{"type": "file", "name": ".deepspeed_env"}, {"type": "file", "name": "Dockerfile"}]}, {"type": "directory", "name": "GaudiNIC", "children": [{"type": "file", "name": "Dockerfile"}]}, {"type": "file", "name": "hostfile"}, {"type": "file", "name": "README.md"}]}, {"type": "directory", "name": "object-detection", "children": [{"type": "file", "name": "README.md"}, {"type": "file", "name": "run_example.py"}]}, {"type": "directory", "name": "object-segementation", "children": [{"type": "file", "name": "README.md"}, {"type": "file", "name": "run_example.py"}, {"type": "file", "name": "run_example_sam.py"}]}, {"type": "directory", "name": "protein-folding", "children": [{"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "run_esmfold.py"}, {"type": "file", "name": "run_sequence_classification.py"}, {"type": "file", "name": "run_zero_shot_eval.py"}]}, {"type": "directory", "name": "question-answering", "children": [{"type": "file", "name": "fsdp_config.json"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "run_qa.py"}, {"type": "file", "name": "run_seq2seq_qa.py"}, {"type": "file", "name": "trainer_qa.py"}, {"type": "file", "name": "trainer_seq2seq_qa.py"}, {"type": "file", "name": "utils_qa.py"}]}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "sentence-transformers-training", "children": [{"type": "directory", "name": "nli", "children": [{"type": "file", "name": "ds_config.json"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "training_nli.py"}, {"type": "file", "name": "training_nli_v2.py"}, {"type": "file", "name": "training_nli_v3.py"}]}, {"type": "directory", "name": "paraphrases", "children": [{"type": "file", "name": "README.md"}, {"type": "file", "name": "training_paraphrases.py"}]}, {"type": "directory", "name": "sts", "children": [{"type": "file", "name": "ds_config.json"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "training_stsbenchmark.py"}, {"type": "file", "name": "training_stsbenchmark_continue_training.py"}]}]}, {"type": "directory", "name": "speech-recognition", "children": [{"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "run_speech_recognition_ctc.py"}, {"type": "file", "name": "run_speech_recognition_seq2seq.py"}]}, {"type": "directory", "name": "stable-diffusion", "children": [{"type": "file", "name": "depth_to_image_generation.py"}, {"type": "file", "name": "image_to_image_generation.py"}, {"type": "file", "name": "image_to_video_generation.py"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "text_to_image_generation.py"}, {"type": "directory", "name": "training", "children": [{"type": "file", "name": "media_pipe_imgdir.py"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "textual_inversion.py"}, {"type": "file", "name": "train_controlnet.py"}, {"type": "file", "name": "train_dreambooth.py"}, {"type": "file", "name": "train_dreambooth_lora_sdxl.py"}, {"type": "file", "name": "train_text_to_image_sdxl.py"}]}, {"type": "file", "name": "unconditional_image_generation.py"}]}, {"type": "directory", "name": "summarization", "children": [{"type": "file", "name": "ds_flan_t5_z3_config_bf16.json"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "run_summarization.py"}]}, {"type": "directory", "name": "table-detection", "children": [{"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "run_example.py"}]}, {"type": "directory", "name": "text-classification", "children": [{"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "run_glue.py"}]}, {"type": "directory", "name": "text-feature-extraction", "children": [{"type": "file", "name": "README.md"}, {"type": "file", "name": "run_feature_extraction.py"}]}, {"type": "directory", "name": "text-generation", "children": [{"type": "directory", "name": "quantization_config", "children": [{"type": "file", "name": "act_maxabs_pow2_weights_pcs_opt_pow2_quant.json"}, {"type": "file", "name": "maxabs_measure.json"}, {"type": "file", "name": "maxabs_measure_include_outputs.json"}, {"type": "file", "name": "maxabs_quant.json"}, {"type": "file", "name": "maxabs_quant_mixtral.json"}, {"type": "file", "name": "maxabs_quant_phi.json"}, {"type": "file", "name": "unit_scale_quant.json"}]}, {"type": "directory", "name": "quantization_tools", "children": [{"type": "file", "name": "unify_measurements.py"}]}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "requirements_lm_eval.txt"}, {"type": "file", "name": "run_generation.py"}, {"type": "file", "name": "run_lm_eval.py"}, {"type": "directory", "name": "text-generation-pipeline", "children": [{"type": "file", "name": "pipeline.py"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "run_pipeline.py"}, {"type": "file", "name": "run_pipeline_langchain.py"}]}, {"type": "file", "name": "utils.py"}]}, {"type": "directory", "name": "text-to-speech", "children": [{"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "run_pipeline.py"}]}, {"type": "directory", "name": "text-to-video", "children": [{"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "text_to_video_generation.py"}]}, {"type": "directory", "name": "translation", "children": [{"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "run_translation.py"}]}, {"type": "directory", "name": "trl", "children": [{"type": "file", "name": "ddpo.py"}, {"type": "file", "name": "dpo.py"}, {"type": "file", "name": "merge_peft_adapter.py"}, {"type": "file", "name": "ppo.py"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "reward_modeling.py"}, {"type": "file", "name": "sft.py"}]}, {"type": "directory", "name": "video-classification", "children": [{"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "run_example.py"}]}, {"type": "directory", "name": "visual-question-answering", "children": [{"type": "file", "name": "openclip_requirements.txt"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "run_openclip_vqa.py"}, {"type": "file", "name": "run_pipeline.py"}]}, {"type": "directory", "name": "zero-shot-object-detection", "children": [{"type": "file", "name": "README.md"}, {"type": "file", "name": "run_example.py"}]}]}, {"type": "file", "name": "LICENSE"}, {"type": "file", "name": "Makefile"}, {"type": "file", "name": "MANIFEST.in"}, {"type": "directory", "name": "notebooks", "children": [{"type": "file", "name": "AI_HW_Summit_2022.ipynb"}, {"type": "directory", "name": "configs", "children": [{"type": "file", "name": "deepspeed_zero_2.json"}]}]}, {"type": "directory", "name": "optimum", "children": [{"type": "directory", "name": "habana", "children": [{"type": "directory", "name": "accelerate", "children": [{"type": "file", "name": "accelerator.py"}, {"type": "file", "name": "data_loader.py"}, {"type": "file", "name": "state.py"}, {"type": "directory", "name": "utils", "children": [{"type": "file", "name": "dataclasses.py"}, {"type": "file", "name": "operations.py"}, {"type": "file", "name": "other.py"}, {"type": "file", "name": "transformer_engine.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "checkpoint_utils.py"}, {"type": "directory", "name": "diffusers", "children": [{"type": "directory", "name": "models", "children": [{"type": "file", "name": "attention_processor.py"}, {"type": "file", "name": "unet_2d.py"}, {"type": "file", "name": "unet_2d_condition.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "pipelines", "children": [{"type": "file", "name": "auto_pipeline.py"}, {"type": "directory", "name": "controlnet", "children": [{"type": "file", "name": "pipeline_controlnet.py"}]}, {"type": "directory", "name": "ddpm", "children": [{"type": "file", "name": "pipeline_ddpm.py"}]}, {"type": "file", "name": "pipeline_utils.py"}, {"type": "directory", "name": "stable_diffusion", "children": [{"type": "file", "name": "pipeline_stable_diffusion.py"}, {"type": "file", "name": "pipeline_stable_diffusion_depth2img.py"}, {"type": "file", "name": "pipeline_stable_diffusion_image_variation.py"}, {"type": "file", "name": "pipeline_stable_diffusion_img2img.py"}, {"type": "file", "name": "pipeline_stable_diffusion_inpaint.py"}, {"type": "file", "name": "pipeline_stable_diffusion_instruct_pix2pix.py"}, {"type": "file", "name": "pipeline_stable_diffusion_ldm3d.py"}, {"type": "file", "name": "pipeline_stable_diffusion_upscale.py"}]}, {"type": "directory", "name": "stable_diffusion_3", "children": [{"type": "file", "name": "pipeline_stable_diffusion_3.py"}]}, {"type": "directory", "name": "stable_diffusion_xl", "children": [{"type": "file", "name": "pipeline_stable_diffusion_xl.py"}, {"type": "file", "name": "pipeline_stable_diffusion_xl_img2img.py"}, {"type": "file", "name": "pipeline_stable_diffusion_xl_inpaint.py"}, {"type": "file", "name": "pipeline_stable_diffusion_xl_mlperf.py"}]}, {"type": "directory", "name": "stable_video_diffusion", "children": [{"type": "file", "name": "pipeline_stable_video_diffusion.py"}]}, {"type": "directory", "name": "text_to_video_synthesis", "children": [{"type": "file", "name": "pipeline_text_to_video_synth.py"}]}]}, {"type": "directory", "name": "schedulers", "children": [{"type": "file", "name": "scheduling_ddim.py"}, {"type": "file", "name": "scheduling_euler_ancestral_discrete.py"}, {"type": "file", "name": "scheduling_euler_discrete.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "distributed", "children": [{"type": "file", "name": "distributed_runner.py"}, {"type": "file", "name": "fast_ddp.py"}, {"type": "file", "name": "serialization.py"}, {"type": "file", "name": "strategy.py"}, {"type": "file", "name": "tensorparallel.py"}, {"type": "file", "name": "tp.py"}, {"type": "file", "name": "tp_wrapping.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "peft", "children": [{"type": "file", "name": "layer.py"}, {"type": "file", "name": "peft_model.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "sentence_transformers", "children": [{"type": "file", "name": "modeling_utils.py"}, {"type": "file", "name": "st_gaudi_data_collator.py"}, {"type": "file", "name": "st_gaudi_encoder.py"}, {"type": "file", "name": "st_gaudi_trainer.py"}, {"type": "file", "name": "st_gaudi_training_args.py"}, {"type": "file", "name": "st_gaudi_transformer.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "transformers", "children": [{"type": "file", "name": "gaudi_configuration.py"}, {"type": "directory", "name": "generation", "children": [{"type": "file", "name": "candidate_generator.py"}, {"type": "file", "name": "configuration_utils.py"}, {"type": "file", "name": "stopping_criteria.py"}, {"type": "file", "name": "utils.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "gradient_checkpointing.py"}, {"type": "directory", "name": "integrations", "children": [{"type": "file", "name": "deepspeed.py"}]}, {"type": "file", "name": "modeling_attn_mask_utils.py"}, {"type": "file", "name": "modeling_utils.py"}, {"type": "directory", "name": "models", "children": [{"type": "directory", "name": "albert", "children": [{"type": "file", "name": "modeling_albert.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "bart", "children": [{"type": "file", "name": "modeling_bart.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "bert", "children": [{"type": "file", "name": "modeling_bert.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "blip", "children": [{"type": "file", "name": "modeling_blip.py"}, {"type": "file", "name": "modeling_blip_text.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "bloom", "children": [{"type": "file", "name": "modeling_bloom.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "clip", "children": [{"type": "file", "name": "modeling_clip.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "codegen", "children": [{"type": "file", "name": "modeling_codegen.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "decilm", "children": [{"type": "file", "name": "configuration_decilm.py"}, {"type": "file", "name": "modeling_decilm.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "detr", "children": [{"type": "file", "name": "modeling_detr.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "esm", "children": [{"type": "file", "name": "modeling_esmfold.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "falcon", "children": [{"type": "file", "name": "modeling_falcon.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "gemma", "children": [{"type": "file", "name": "modeling_gemma.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "gpt2", "children": [{"type": "file", "name": "modeling_gpt2.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "gptj", "children": [{"type": "file", "name": "modeling_gptj.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "gpt_bigcode", "children": [{"type": "file", "name": "modeling_gpt_bigcode.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "gpt_neo", "children": [{"type": "file", "name": "modeling_gpt_neo.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "gpt_neox", "children": [{"type": "file", "name": "modeling_gpt_neox.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "llama", "children": [{"type": "file", "name": "configuration_llama.py"}, {"type": "file", "name": "modeling_llama.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "llava", "children": [{"type": "file", "name": "modeling_llava.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "llava_next", "children": [{"type": "file", "name": "modeling_llava_next.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "mamba", "children": [{"type": "file", "name": "modeling_mamba.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "mistral", "children": [{"type": "file", "name": "configuration_mistral.py"}, {"type": "file", "name": "modeling_mistral.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "mixtral", "children": [{"type": "file", "name": "configuration_mixtral.py"}, {"type": "file", "name": "modeling_mixtral.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "modeling_all_models.py"}, {"type": "directory", "name": "mpt", "children": [{"type": "file", "name": "modeling_mpt.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "opt", "children": [{"type": "file", "name": "modeling_opt.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "owlvit", "children": [{"type": "file", "name": "modeling_owlvit.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "persimmon", "children": [{"type": "file", "name": "modeling_persimmon.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "phi", "children": [{"type": "file", "name": "modeling_phi.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "qwen2", "children": [{"type": "file", "name": "modeling_qwen2.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "seamless_m4t", "children": [{"type": "file", "name": "modeling_seamless_m4t.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "speecht5", "children": [{"type": "file", "name": "modeling_speecht5.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "stablelm", "children": [{"type": "file", "name": "modeling_stablelm.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "starcoder2", "children": [{"type": "file", "name": "modeling_starcoder2.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "t5", "children": [{"type": "file", "name": "modeling_t5.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "table_transformer", "children": [{"type": "file", "name": "modeling_table_transformer.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "vision_encoder_decoder", "children": [{"type": "file", "name": "modeling_vision_encoder_decoder.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "vit", "children": [{"type": "file", "name": "modeling_vit.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "vits", "children": [{"type": "file", "name": "modeling_vits.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "wav2vec2", "children": [{"type": "file", "name": "modeling_wav2vec2.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "whisper", "children": [{"type": "file", "name": "modeling_whisper.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "trainer.py"}, {"type": "file", "name": "trainer_seq2seq.py"}, {"type": "file", "name": "trainer_utils.py"}, {"type": "file", "name": "training_args.py"}, {"type": "file", "name": "training_args_seq2seq.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "trl", "children": [{"type": "directory", "name": "models", "children": [{"type": "file", "name": "modeling_base.py"}, {"type": "file", "name": "modeling_sd_base.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "trainer", "children": [{"type": "file", "name": "ddpo_trainer.py"}, {"type": "file", "name": "dpo_config.py"}, {"type": "file", "name": "dpo_trainer.py"}, {"type": "file", "name": "ppo_config.py"}, {"type": "file", "name": "ppo_trainer.py"}, {"type": "file", "name": "reward_trainer.py"}, {"type": "file", "name": "sft_config.py"}, {"type": "file", "name": "sft_trainer.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "utils.py"}, {"type": "file", "name": "version.py"}, {"type": "file", "name": "__init__.py"}]}]}, {"type": "file", "name": "pyproject.toml"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "setup.cfg"}, {"type": "file", "name": "setup.py"}, {"type": "directory", "name": "tests", "children": [{"type": "directory", "name": "baselines", "children": [{"type": "file", "name": "albert_large_v2.json"}, {"type": "file", "name": "albert_xxlarge_v1.json"}, {"type": "file", "name": "ast_finetuned_speech_commands_v2.json"}, {"type": "file", "name": "bert_base_uncased.json"}, {"type": "file", "name": "bert_large_uncased_whole_word_masking.json"}, {"type": "file", "name": "bloom_7b1.json"}, {"type": "file", "name": "bridgetower_large_itm_mlm_itc.json"}, {"type": "file", "name": "clip_roberta.json"}, {"type": "file", "name": "CodeLlama_13b_Instruct_hf.json"}, {"type": "file", "name": "distilbert_base_uncased.json"}, {"type": "file", "name": "falcon_40b.json"}, {"type": "file", "name": "flan_t5_xxl.json"}, {"type": "file", "name": "gpt2.json"}, {"type": "file", "name": "gpt2_xl.json"}, {"type": "file", "name": "gpt_neox_20b.json"}, {"type": "file", "name": "LlamaGuard_7b.json"}, {"type": "file", "name": "llama_7b.json"}, {"type": "file", "name": "protst_esm1b_for_sequential_classification.json"}, {"type": "file", "name": "Qwen2_7B.json"}, {"type": "file", "name": "roberta_base.json"}, {"type": "file", "name": "roberta_large.json"}, {"type": "file", "name": "swin_base_patch4_window7_224_in22k.json"}, {"type": "file", "name": "t5_small.json"}, {"type": "file", "name": "vit_base_patch16_224_in21k.json"}, {"type": "file", "name": "wav2vec2_base.json"}, {"type": "file", "name": "wav2vec2_large_lv60.json"}, {"type": "file", "name": "whisper_small.json"}]}, {"type": "directory", "name": "ci", "children": [{"type": "file", "name": "albert_xxl_1x.sh"}, {"type": "file", "name": "example_diff_tests.sh"}, {"type": "file", "name": "fast_tests.sh"}, {"type": "file", "name": "fast_tests_diffusers.sh"}, {"type": "file", "name": "sentence_transformers.sh"}, {"type": "file", "name": "slow_tests_1x.sh"}, {"type": "file", "name": "slow_tests_8x.sh"}, {"type": "file", "name": "slow_tests_deepspeed.sh"}, {"type": "file", "name": "slow_tests_diffusers.sh"}, {"type": "file", "name": "slow_tests_trl.sh"}]}, {"type": "file", "name": "clip_coco_utils.py"}, {"type": "directory", "name": "configs", "children": [{"type": "file", "name": "bf16_ops.txt"}, {"type": "file", "name": "deepspeed_zero_1.json"}, {"type": "file", "name": "deepspeed_zero_2.json"}, {"type": "file", "name": "deepspeed_zero_3_gaudi1.json"}, {"type": "file", "name": "fp32_ops.txt"}, {"type": "file", "name": "gaudi_config_trainer_test.json"}]}, {"type": "file", "name": "create_diff_file_for_example.py"}, {"type": "directory", "name": "example_diff", "children": [{"type": "file", "name": "run_audio_classification.txt"}, {"type": "file", "name": "run_clip.txt"}, {"type": "file", "name": "run_clm.txt"}, {"type": "file", "name": "run_generation.txt"}, {"type": "file", "name": "run_glue.txt"}, {"type": "file", "name": "run_image_classification.txt"}, {"type": "file", "name": "run_mlm.txt"}, {"type": "file", "name": "run_qa.txt"}, {"type": "file", "name": "run_seq2seq_qa.txt"}, {"type": "file", "name": "run_speech_recognition_ctc.txt"}, {"type": "file", "name": "run_speech_recognition_seq2seq.txt"}, {"type": "file", "name": "run_summarization.txt"}, {"type": "file", "name": "run_translation.txt"}]}, {"type": "directory", "name": "resource", "children": [{"type": "file", "name": "custom_dataset.jsonl"}, {"type": "file", "name": "custom_dataset.txt"}, {"type": "directory", "name": "img", "children": []}, {"type": "file", "name": "sample_text.txt"}]}, {"type": "directory", "name": "sentence_transformers", "children": [{"type": "file", "name": "test_training_nli.py"}, {"type": "file", "name": "test_training_paraphrases.py"}, {"type": "file", "name": "test_training_stsbenchmark.py"}]}, {"type": "file", "name": "test_custom_file_input.py"}, {"type": "file", "name": "test_diffusers.py"}, {"type": "file", "name": "test_encoder_decoder.py"}, {"type": "file", "name": "test_examples.py"}, {"type": "file", "name": "test_examples_match_transformers.py"}, {"type": "file", "name": "test_feature_extraction.py"}, {"type": "file", "name": "test_fp8_examples.py"}, {"type": "file", "name": "test_fsdp_examples.py"}, {"type": "file", "name": "test_gaudi_configuration.py"}, {"type": "file", "name": "test_image_classification.py"}, {"type": "file", "name": "test_image_segmentation.py"}, {"type": "file", "name": "test_image_to_text_example.py"}, {"type": "file", "name": "test_object_detection.py"}, {"type": "file", "name": "test_object_segmentation.py"}, {"type": "file", "name": "test_openclip_vqa.py"}, {"type": "file", "name": "test_peft_inference.py"}, {"type": "file", "name": "test_pipeline.py"}, {"type": "file", "name": "test_sentence_transformers.py"}, {"type": "file", "name": "test_table_transformer.py"}, {"type": "file", "name": "test_text_generation_example.py"}, {"type": "file", "name": "test_trainer.py"}, {"type": "file", "name": "test_trainer_distributed.py"}, {"type": "file", "name": "test_trainer_seq2seq.py"}, {"type": "file", "name": "test_trl.py"}, {"type": "file", "name": "test_video_mae.py"}, {"type": "file", "name": "test_zero_shot_object_detection.py"}, {"type": "directory", "name": "transformers", "children": [{"type": "directory", "name": "tests", "children": [{"type": "directory", "name": "generation", "children": [{"type": "file", "name": "test_beam_constraints.py"}, {"type": "file", "name": "test_beam_search.py"}, {"type": "file", "name": "test_configuration_utils.py"}, {"type": "file", "name": "test_framework_agnostic.py"}, {"type": "file", "name": "test_logits_process.py"}, {"type": "file", "name": "test_stopping_criteria.py"}, {"type": "file", "name": "test_streamers.py"}, {"type": "file", "name": "test_utils.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "models", "children": [{"type": "directory", "name": "albert", "children": [{"type": "file", "name": "test_modeling_albert.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "bert", "children": [{"type": "file", "name": "test_modeling_bert.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "bridgetower", "children": [{"type": "file", "name": "test_modeling_bridgetower.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "distilbert", "children": [{"type": "file", "name": "test_modeling_distilbert.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "falcon", "children": [{"type": "file", "name": "test_modeling_falcon.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "gpt2", "children": [{"type": "file", "name": "test_modeling_gpt2.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "gptj", "children": [{"type": "file", "name": "test_modeling_gptj.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "gpt_neox", "children": [{"type": "file", "name": "test_modeling_gpt_neox.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "llama", "children": [{"type": "file", "name": "test_modeling_llama.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "mistral", "children": [{"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "mixtral", "children": [{"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "roberta", "children": [{"type": "file", "name": "test_modeling_roberta.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "swin", "children": [{"type": "file", "name": "test_modeling_swin.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "t5", "children": [{"type": "file", "name": "test_modeling_t5.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "vit", "children": [{"type": "file", "name": "test_modeling_vit.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "wav2vec2", "children": [{"type": "file", "name": "test_modeling_wav2vec2.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "test_configuration_common.py"}, {"type": "file", "name": "test_configuration_utils.py"}, {"type": "file", "name": "test_modeling_common.py"}, {"type": "directory", "name": "utils", "children": [{"type": "file", "name": "test_activations.py"}, {"type": "file", "name": "test_activations_tf.py"}, {"type": "file", "name": "test_add_new_model_like.py"}, {"type": "file", "name": "test_audio_utils.py"}, {"type": "file", "name": "test_backbone_utils.py"}, {"type": "file", "name": "test_cli.py"}, {"type": "file", "name": "test_convert_slow_tokenizer.py"}, {"type": "file", "name": "test_doc_samples.py"}, {"type": "file", "name": "test_dynamic_module_utils.py"}, {"type": "file", "name": "test_file_utils.py"}, {"type": "file", "name": "test_generic.py"}, {"type": "file", "name": "test_hf_argparser.py"}, {"type": "file", "name": "test_hub_utils.py"}, {"type": "file", "name": "test_image_processing_utils.py"}, {"type": "file", "name": "test_image_utils.py"}, {"type": "file", "name": "test_logging.py"}, {"type": "file", "name": "test_modeling_tf_core.py"}, {"type": "file", "name": "test_model_card.py"}, {"type": "file", "name": "test_model_output.py"}, {"type": "file", "name": "test_offline.py"}, {"type": "file", "name": "test_skip_decorators.py"}, {"type": "file", "name": "test_versions_utils.py"}, {"type": "file", "name": "tiny_model_summary.json"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "utils", "children": [{"type": "directory", "name": "test_module", "children": [{"type": "file", "name": "custom_configuration.py"}, {"type": "file", "name": "custom_feature_extraction.py"}, {"type": "file", "name": "custom_image_processing.py"}, {"type": "file", "name": "custom_modeling.py"}, {"type": "file", "name": "custom_pipeline.py"}, {"type": "file", "name": "custom_processing.py"}, {"type": "file", "name": "custom_tokenization.py"}, {"type": "file", "name": "custom_tokenization_fast.py"}, {"type": "file", "name": "__init__.py"}]}]}]}, {"type": "file", "name": "utils.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "text-generation-inference", "children": [{"type": "file", "name": "README.md"}]}]} | <!---
Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
# Text Generation Inference on Intel® Gaudi® AI Accelerators
Please refer to the following fork of TGI for deploying it on Habana Gaudi: https://github.com/huggingface/tgi-gaudi
| {"setup.py": "# coding=utf-8\n# Copyright 2022 The HuggingFace Inc. team.\n# Copyright (c) 2022, NVIDIA CORPORATION. All rights reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport re\n\nfrom setuptools import find_namespace_packages, setup\n\n\n# Ensure we match the version set in optimum/habana/version.py\ntry:\n filepath = \"optimum/habana/version.py\"\n with open(filepath) as version_file:\n (__version__,) = re.findall('__version__ = \"(.*)\"', version_file.read())\nexcept Exception as error:\n assert False, \"Error: Could not open '%s' due %s\\n\" % (filepath, error)\n\n\nINSTALL_REQUIRES = [\n \"transformers >= 4.43.0, < 4.44.0\",\n \"optimum\",\n \"torch\",\n \"accelerate >= 0.33.0, < 0.34.0\",\n \"diffusers == 0.29.2\",\n \"huggingface_hub >= 0.23.2\",\n \"sentence-transformers[train] == 3.0.1\",\n]\n\nTESTS_REQUIRE = [\n \"psutil\",\n \"parameterized\",\n \"GitPython\",\n \"optuna\",\n \"sentencepiece\",\n \"datasets\",\n \"timm\",\n \"safetensors\",\n \"pytest < 8.0.0\",\n \"scipy\",\n \"torchsde\",\n \"timm\",\n \"peft\",\n]\n\nQUALITY_REQUIRES = [\n \"ruff\",\n \"hf_doc_builder @ git+https://github.com/huggingface/doc-builder.git\",\n]\n\nEXTRAS_REQUIRE = {\n \"tests\": TESTS_REQUIRE,\n \"quality\": QUALITY_REQUIRES,\n}\n\nsetup(\n name=\"optimum-habana\",\n version=__version__,\n description=(\n \"Optimum Habana is the interface between the Hugging Face Transformers and Diffusers libraries and Habana's\"\n \" Gaudi processor (HPU). It provides a set of tools enabling easy model loading, training and inference on\"\n \" single- and multi-HPU settings for different downstream tasks.\"\n ),\n long_description=open(\"README.md\", \"r\", encoding=\"utf-8\").read(),\n long_description_content_type=\"text/markdown\",\n classifiers=[\n \"Development Status :: 5 - Production/Stable\",\n \"License :: OSI Approved :: Apache Software License\",\n \"Intended Audience :: Developers\",\n \"Intended Audience :: Education\",\n \"Intended Audience :: Science/Research\",\n \"Operating System :: OS Independent\",\n \"Programming Language :: Python :: 3.8\",\n \"Programming Language :: Python :: 3.9\",\n \"Topic :: Scientific/Engineering :: Artificial Intelligence\",\n ],\n keywords=\"transformers, diffusers, mixed-precision training, fine-tuning, gaudi, hpu\",\n url=\"https://huggingface.co/hardware/habana\",\n author=\"HuggingFace Inc. Special Ops Team\",\n author_email=\"[email protected]\",\n license=\"Apache\",\n packages=find_namespace_packages(include=[\"optimum*\"]),\n install_requires=INSTALL_REQUIRES,\n extras_require=EXTRAS_REQUIRE,\n include_package_data=True,\n zip_safe=False,\n)\n", ".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 29d8604518bb7e2b684d034faa79f7a8e92e8d12 Hamza Amin <[email protected]> 1727369453 +0500\tclone: from https://github.com/huggingface/optimum-habana.git\n", ".git\\refs\\heads\\main": "29d8604518bb7e2b684d034faa79f7a8e92e8d12\n", "docs\\Dockerfile": "FROM vault.habana.ai/gaudi-docker/1.17.0/ubuntu22.04/habanalabs/pytorch-installer-2.3.1:latest\n\nARG commit_sha\nARG clone_url\n\n# Need node to build doc HTML. Taken from https://stackoverflow.com/a/67491580\nRUN apt-get update && apt-get install -y \\\n software-properties-common \\\n npm\nRUN npm install n -g && \\\n n latest\n\nRUN git clone $clone_url optimum-habana && cd optimum-habana && git checkout $commit_sha\nRUN python3 -m pip install --no-cache-dir --upgrade pip\nRUN python3 -m pip install --no-cache-dir ./optimum-habana[quality]\n", "docs\\source\\index.mdx": "<!---\nCopyright 2022 The HuggingFace Team. All rights reserved.\n\nLicensed under the Apache License, Version 2.0 (the \"License\");\nyou may not use this file except in compliance with the License.\nYou may obtain a copy of the License at\n\n http://www.apache.org/licenses/LICENSE-2.0\n\nUnless required by applicable law or agreed to in writing, software\ndistributed under the License is distributed on an \"AS IS\" BASIS,\nWITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\nSee the License for the specific language governing permissions and\nlimitations under the License.\n-->\n\n\n# Optimum for Intel Gaudi\n\nOptimum for Intel Gaudi is the interface between the Transformers and Diffusers libraries and [Intel\u00ae Gaudi\u00ae AI Accelerators (HPUs)](https://docs.habana.ai/en/latest/index.html).\nIt provides a set of tools that enable easy model loading, training and inference on single- and multi-HPU settings for various downstream tasks as shown in the table below.\n\nHPUs offer fast model training and inference as well as a great price-performance ratio.\nCheck out [this blog post about BERT pre-training](https://huggingface.co/blog/pretraining-bert) and [this post benchmarking Intel Gaudi 2 with NVIDIA A100 GPUs](https://huggingface.co/blog/habana-gaudi-2-benchmark) for concrete examples.\nIf you are not familiar with HPUs, we recommend you take a look at [our conceptual guide](./concept_guides/hpu).\n\n\nThe following model architectures, tasks and device distributions have been validated for Optimum for Intel Gaudi:\n\n<Tip>\n\nIn the tables below, \u2705 means single-card, multi-card and DeepSpeed have all been validated.\n\n</Tip>\n\n- Transformers:\n\n| Architecture | Training | Inference | Tasks |\n|--------------|:--------:|:---------:|:------|\n| BERT | \u2705 | \u2705 | <li>[text classification](https://github.com/huggingface/optimum-habana/tree/main/examples/text-classification)</li><li>[question answering](https://github.com/huggingface/optimum-habana/tree/main/examples/question-answering)</li><li>[language modeling](https://github.com/huggingface/optimum-habana/tree/main/examples/language-modeling)</li><li>[text feature extraction](https://github.com/huggingface/optimum-habana/tree/main/examples/text-feature-extraction)</li> |\n| RoBERTa | \u2705 | \u2705 | <li>[question answering](https://github.com/huggingface/optimum-habana/tree/main/examples/question-answering)</li><li>[language modeling](https://github.com/huggingface/optimum-habana/tree/main/examples/language-modeling)</li> |\n| ALBERT | \u2705 | \u2705 | <li>[question answering](https://github.com/huggingface/optimum-habana/tree/main/examples/question-answering)</li><li>[language modeling](https://github.com/huggingface/optimum-habana/tree/main/examples/language-modeling)</li> |\n| DistilBERT | \u2705 | \u2705 | <li>[question answering](https://github.com/huggingface/optimum-habana/tree/main/examples/question-answering)</li><li>[language modeling](https://github.com/huggingface/optimum-habana/tree/main/examples/language-modeling)</li> |\n| GPT2 | \u2705 | \u2705 | <li>[language modeling](https://github.com/huggingface/optimum-habana/tree/main/examples/language-modeling)</li><li>[text generation](https://github.com/huggingface/optimum-habana/tree/main/examples/text-generation)</li> |\n| BLOOM(Z) | | <div style=\"text-align:left\"><li>DeepSpeed</li></div> | <li>[text generation](https://github.com/huggingface/optimum-habana/tree/main/examples/text-generation)</li> |\n| StarCoder / StarCoder2 | \u2705 | <div style=\"text-align:left\"><li>Single card</li></div> | <li>[language modeling](https://github.com/huggingface/optimum-habana/tree/main/examples/language-modeling)</li><li>[text generation](https://github.com/huggingface/optimum-habana/tree/main/examples/text-generation)</li> |\n| GPT-J | <div style=\"text-align:left\"><li>DeepSpeed</li></div> | <div style=\"text-align:left\"><li>Single card</li><li>DeepSpeed</li></div> | <li>[language modeling](https://github.com/huggingface/optimum-habana/tree/main/examples/language-modeling)</li><li>[text generation](https://github.com/huggingface/optimum-habana/tree/main/examples/text-generation)</li> |\n| GPT-Neo | | <div style=\"text-align:left\"><li>Single card</li></div> | <li>[text generation](https://github.com/huggingface/optimum-habana/tree/main/examples/text-generation)</li> |\n| GPT-NeoX | <div style=\"text-align:left\"><li>DeepSpeed</li></div> | <div style=\"text-align:left\"><li>DeepSpeed</li></div> | <li>[language modeling](https://github.com/huggingface/optimum-habana/tree/main/examples/language-modeling)</li><li>[text generation](https://github.com/huggingface/optimum-habana/tree/main/examples/text-generation)</li> |\n| OPT | | <div style=\"text-align:left\"><li>DeepSpeed</li></div> | <li>[text generation](https://github.com/huggingface/optimum-habana/tree/main/examples/text-generation)</li> |\n| Llama 2 / CodeLlama / Llama 3 / Llama Guard / Granite | \u2705 | \u2705 | <li>[language modeling](https://github.com/huggingface/optimum-habana/tree/main/examples/language-modeling)</li><li>[text generation](https://github.com/huggingface/optimum-habana/tree/main/examples/text-generation)</li><li>[question answering](https://github.com/huggingface/optimum-habana/tree/main/examples/question-answering)</li><li>[text classification](https://github.com/huggingface/optimum-habana/tree/main/examples/text-classification) (Llama Guard)</li> |\n| StableLM | | <div style=\"text-align:left\"><li>Single card</li></div> | <li>[text generation](https://github.com/huggingface/optimum-habana/tree/main/examples/text-generation)</li> |\n| Falcon | <div style=\"text-align:left\"><li>LoRA</li></div> | \u2705 | <li>[text generation](https://github.com/huggingface/optimum-habana/tree/main/examples/text-generation)</li> |\n| CodeGen | | <div style=\"text-align:left\"><li>Single card</li></div> | <li>[text generation](https://github.com/huggingface/optimum-habana/tree/main/examples/text-generation)</li> |\n| MPT | | <div style=\"text-align:left\"><li>Single card</li></div> | <li>[text generation](https://github.com/huggingface/optimum-habana/tree/main/examples/text-generation)</li> |\n| Mistral | | <div style=\"text-align:left\"><li>Single card</li></div> | <li>[text generation](https://github.com/huggingface/optimum-habana/tree/main/examples/text-generation)</li> |\n| Phi | \u2705 | <div style=\"text-align:left\"><li>Single card</li></div> | <li>[language modeling](https://github.com/huggingface/optimum-habana/tree/main/examples/language-modeling)</li><li>[text generation](https://github.com/huggingface/optimum-habana/tree/main/examples/text-generation)</li> |\n| Mixtral | | <div style=\"text-align:left\"><li>Single card</li></div> | <li>[text generation](https://github.com/huggingface/optimum-habana/tree/main/examples/text-generation)</li> |\n| Gemma | \u2705 | <div style=\"text-align:left\"><li>Single card</li></div> | <li>[language modeling](https://github.com/huggingface/optimum-habana/tree/main/examples/language-modeling)</li><li>[text generation](https://github.com/huggingface/optimum-habana/tree/main/examples/text-generation)</li> |\n| Qwen2 | <div style=\"text-align:left\"><li>Single card</li></div> | <div style=\"text-align:left\"><li>Single card</li></div> | <li>[language modeling](https://github.com/huggingface/optimum-habana/tree/main/examples/language-modeling)</li><li>[text generation](https://github.com/huggingface/optimum-habana/tree/main/examples/text-generation)</li> |\n| Persimmon | | <div style=\"text-align:left\"><li>Single card</li></div> | <li>[text generation](https://github.com/huggingface/optimum-habana/tree/main/examples/text-generation)</li> |\n| T5 / Flan T5 | \u2705 | \u2705 | <li>[summarization](https://github.com/huggingface/optimum-habana/tree/main/examples/summarization)</li><li>[translation](https://github.com/huggingface/optimum-habana/tree/main/examples/translation)</li><li>[question answering](https://github.com/huggingface/optimum-habana/tree/main/examples/question-answering#fine-tuning-t5-on-squad20)</li> |\n| BART | | <div style=\"text-align:left\"><li>Single card</li></div> | <li>[summarization](https://github.com/huggingface/optimum-habana/tree/main/examples/summarization)</li><li>[translation](https://github.com/huggingface/optimum-habana/tree/main/examples/translation)</li><li>[question answering](https://github.com/huggingface/optimum-habana/tree/main/examples/question-answering#fine-tuning-t5-on-squad20)</li> |\n| ViT | \u2705 | \u2705 | <li>[image classification](https://github.com/huggingface/optimum-habana/tree/main/examples/image-classification)</li> |\n| Swin | \u2705 | \u2705 | <li>[image classification](https://github.com/huggingface/optimum-habana/tree/main/examples/image-classification)</li> |\n| Wav2Vec2 | \u2705 | \u2705 | <li>[audio classification](https://github.com/huggingface/optimum-habana/tree/main/examples/audio-classification)</li><li>[speech recognition](https://github.com/huggingface/optimum-habana/tree/main/examples/speech-recognition)</li> |\n| Whisper | \u2705 | \u2705 | <li>[speech recognition](https://github.com/huggingface/optimum-habana/tree/main/examples/speech-recognition)</li> |\n| SpeechT5 | | <div style=\"text-align:left\"><li>Single card</li></div> | <li>[text to speech](https://github.com/huggingface/optimum-habana/tree/main/examples/text-to-speech)</li> |\n| CLIP | \u2705 | \u2705 | <li>[contrastive image-text training](https://github.com/huggingface/optimum-habana/tree/main/examples/contrastive-image-text)</li> |\n| BridgeTower | \u2705 | \u2705 | <li>[contrastive image-text training](https://github.com/huggingface/optimum-habana/tree/main/examples/contrastive-image-text)</li> |\n| ESMFold | | <div style=\"text-align:left\"><li>Single card</li></div> | <li>[protein folding](https://github.com/huggingface/optimum-habana/tree/main/examples/protein-folding)</li> |\n| Blip | | <div style=\"text-align:left\"><li>Single card</li></div> | <li>[visual question answering](https://github.com/huggingface/optimum-habana/tree/main/examples/visual-question-answering)</li><li>[image to text](https://github.com/huggingface/optimum-habana/tree/main/examples/image-to-text)</li> |\n| OWLViT | | <div style=\"text-align:left\"><li>Single card</li></div> | <li>[zero shot object detection](https://github.com/huggingface/optimum-habana/tree/main/examples/zero-shot-object-detection)</li> |\n| ClipSeg | | <div style=\"text-align:left\"><li>Single card</li></div> | <li>[object segmentation](https://github.com/huggingface/optimum-habana/tree/main/examples/object-segementation)</li> |\n| Llava / Llava-next | | <div style=\"text-align:left\"><li>Single card</li></div> | <li>[image to text](https://github.com/huggingface/optimum-habana/tree/main/examples/image-to-text)</li> |\n| SAM | | <div style=\"text-align:left\"><li>Single card</li></div> | <li>[object segmentation](https://github.com/huggingface/optimum-habana/tree/main/examples/object-segementation)</li> |\n| VideoMAE | | <div style=\"text-align:left\"><li>Single card</li></div> | <li>[Video classification](https://github.com/huggingface/optimum-habana/tree/main/examples/video-classification)</li> |\n| TableTransformer | | <div style=\"text-align:left\"><li>Single card</li></div> | <li>[table object detection](https://github.com/huggingface/optimum-habana/tree/main/examples/table-detection)</li> |\n| DETR | | <div style=\"text-align:left\"><li>Single card</li></div> | <li>[object detection](https://github.com/huggingface/optimum-habana/tree/main/examples/object-detection)</li> |\n\n- Diffusers\n\n| Architecture | Training | Inference | Tasks |\n|---------------------|:--------:|:---------:|:------|\n| Stable Diffusion | <li>[textual inversion](https://github.com/huggingface/optimum-habana/tree/main/examples/stable-diffusion/training#textual-inversion)</li><li>[ControlNet](https://github.com/huggingface/optimum-habana/tree/main/examples/stable-diffusion/training#controlnet-training)</li> | <div style=\"text-align:left\"><li>Single card</li></div> | <li>[text-to-image generation](https://github.com/huggingface/optimum-habana/tree/main/examples/stable-diffusion)</li> |\n| Stable Diffusion XL | <li>[fine-tuning](https://github.com/huggingface/optimum-habana/tree/main/examples/stable-diffusion/training#fine-tuning-for-stable-diffusion-xl)</li> | <div style=\"text-align:left\"><li>Single card</li></div> | <li>[text-to-image generation](https://github.com/huggingface/optimum-habana/tree/main/examples/stable-diffusion)</li> |\n| Stable Diffusion Depth2img | | <li>Single card</li> | <li>[depth-to-image generation](https://github.com/huggingface/optimum-habana/tree/main/examples/stable-diffusion)</li> |\n| LDM3D | | <div style=\"text-align:left\"><li>Single card</li></div> | <li>[text-to-image generation](https://github.com/huggingface/optimum-habana/tree/main/examples/stable-diffusion)</li> |\n| Text to Video | | <li>Single card</li> | <li>[text-to-video generation](https://github.com/huggingface/optimum-habana/tree/main/examples/text-to-video)</li> |\n\n- PyTorch Image Models/TIMM:\n\n| Architecture | Training | Inference | Tasks |\n|---------------------|:--------:|:---------:|:------|\n| FastViT | | <div style=\"text-align:left\"><li>Single card</li></div> | <li>[image classification](https://github.com/huggingface/optimum-habana/tree/main/examples/image-classification)</li> |\n\n- TRL:\n\n| Architecture | Training | Inference | Tasks |\n|------------------|:--------:|:--------------------:|:------|\n| Llama 2 | \u2705 | | <li>[DPO Pipeline](https://github.com/huggingface/optimum-habana/tree/main/examples/trl)</li> |\n| Llama 2 | \u2705 | | <li>[PPO Pipeline](https://github.com/huggingface/optimum-habana/tree/main/examples/trl)</li> |\n| Stable Diffusion | \u2705 | | <li>[DDPO Pipeline](https://github.com/huggingface/optimum-habana/tree/main/examples/trl)</li> |\n\n\nOther models and tasks supported by the \ud83e\udd17 Transformers and \ud83e\udd17 Diffusers library may also work.\nYou can refer to this [section](https://github.com/huggingface/optimum-habana#how-to-use-it) for using them with \ud83e\udd17 Optimum Habana.\nBesides, [this page](https://github.com/huggingface/optimum-habana/tree/main/examples) explains how to modify any [example](https://github.com/huggingface/transformers/tree/main/examples/pytorch) from the \ud83e\udd17 Transformers library to make it work with \ud83e\udd17 Optimum Habana.\n\n\n<div class=\"mt-10\">\n <div class=\"w-full flex flex-col space-y-4 md:space-y-0 md:grid md:grid-cols-2 md:gap-y-4 md:gap-x-5\">\n <a class=\"!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg\" href=\"./tutorials/overview\"\n ><div class=\"w-full text-center bg-gradient-to-br from-blue-400 to-blue-500 rounded-lg py-1.5 font-semibold mb-5 text-white text-lg leading-relaxed\">Tutorials</div>\n <p class=\"text-gray-700\">Learn the basics and become familiar with training transformers on HPUs with \ud83e\udd17 Optimum. Start here if you are using \ud83e\udd17 Optimum Habana for the first time!</p>\n </a>\n <a class=\"!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg\" href=\"./usage_guides/overview\"\n ><div class=\"w-full text-center bg-gradient-to-br from-indigo-400 to-indigo-500 rounded-lg py-1.5 font-semibold mb-5 text-white text-lg leading-relaxed\">How-to guides</div>\n <p class=\"text-gray-700\">Practical guides to help you achieve a specific goal. Take a look at these guides to learn how to use \ud83e\udd17 Optimum Habana to solve real-world problems.</p>\n </a>\n <a class=\"!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg\" href=\"./concept_guides/hpu\"\n ><div class=\"w-full text-center bg-gradient-to-br from-pink-400 to-pink-500 rounded-lg py-1.5 font-semibold mb-5 text-white text-lg leading-relaxed\">Conceptual guides</div>\n <p class=\"text-gray-700\">High-level explanations for building a better understanding of important topics such as HPUs.</p>\n </a>\n <a class=\"!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg\" href=\"./package_reference/trainer\"\n ><div class=\"w-full text-center bg-gradient-to-br from-purple-400 to-purple-500 rounded-lg py-1.5 font-semibold mb-5 text-white text-lg leading-relaxed\">Reference</div>\n <p class=\"text-gray-700\">Technical descriptions of how the Habana classes and methods of \ud83e\udd17 Optimum Habana work.</p>\n </a>\n </div>\n</div>\n", "examples\\audio-classification\\requirements.txt": "datasets>=1.14.0\nevaluate\nlibrosa\n", "examples\\contrastive-image-text\\requirements.txt": "datasets>=1.8.0\n", "examples\\image-classification\\requirements.txt": "torch>=1.5.0\ntorchvision>=0.6.0\ndatasets>=2.14.0\nevaluate\nscikit-learn\ntimm>=0.9.16", "examples\\kubernetes\\Dockerfile": "ARG GAUDI_SW_VER=1.17.0\nARG OS=ubuntu22.04\nARG TORCH_VER=2.3.1\nARG OPTIMUM_HABANA_VER=1.13.0\n\nFROM vault.habana.ai/gaudi-docker/${GAUDI_SW_VER}/${OS}/habanalabs/pytorch-installer-${TORCH_VER}:latest AS optimum-habana\n\nARG GAUDI_SW_VER\nARG OPTIMUM_HABANA_VER\n\nRUN pip install --no-cache-dir optimum-habana==${OPTIMUM_HABANA_VER} && \\\n pip install --no-cache-dir git+https://github.com/HabanaAI/DeepSpeed.git@${GAUDI_SW_VER}\n\nFROM optimum-habana AS optimum-habana-examples\n\nARG OPTIMUM_HABANA_VER\n\nWORKDIR /workspace\n\nRUN git clone https://github.com/huggingface/optimum-habana.git --single-branch --branch v${OPTIMUM_HABANA_VER}\n\nCOPY requirements.txt .\nRUN pip install -r requirements.txt\n", "examples\\kubernetes\\requirements.txt": "-r optimum-habana/examples/language-modeling/requirements.txt\n-r optimum-habana/examples/text-classification/requirements.txt\n", "examples\\language-modeling\\requirements.txt": "torch >= 1.3\ndatasets >= 2.14.0\nsentencepiece != 0.1.92\nprotobuf\nevaluate\nscikit-learn\npeft == 0.12.0\n", "examples\\multi-node-training\\EFA\\Dockerfile": "FROM vault.habana.ai/gaudi-docker/1.17.0/ubuntu22.04/habanalabs/pytorch-installer-2.3.1:latest\n\n# Installs pdsh and upgrade pip\nRUN apt-get update && apt-get install -y pdsh && \\\n python -m pip install --upgrade pip\n\n# Installs hccl_ofi_wrapper to interact with libfabric to utilize HW and networking mode (EFA)\nARG OFI_WRAPPER_WS=\"/root/hccl_ofi_wrapper\"\nRUN git clone \"https://github.com/HabanaAI/hccl_ofi_wrapper.git\" \"${OFI_WRAPPER_WS}\" && \\\n cd \"${OFI_WRAPPER_WS}\" && \\\n LIBFABRIC_ROOT=/opt/amazon/efa make\n\n# Docker ssh port setup\nRUN sed -i 's/#Port 22/Port 3022/g' /etc/ssh/sshd_config && \\\n sed -i 's/# Port 22/ Port 3022/g' /etc/ssh/ssh_config && \\\n sed -i 's/#PermitRootLogin prohibit-password/PermitRootLogin yes/' /etc/ssh/sshd_config && \\\n service ssh restart\n\n# Installs Optimum Habana and Habana's fork of DeepSpeed\nRUN pip install optimum[habana] && \\\n pip install git+https://github.com/HabanaAI/[email protected]\n\nCMD ssh-keygen -t rsa -b 4096 -N '' -f ~/.ssh/id_rsa && \\\n chmod 600 ~/.ssh/id_rsa && \\\n cat ~/.ssh/id_rsa.pub > ~/.ssh/authorized_keys && \\\n /bin/bash\n", "examples\\multi-node-training\\GaudiNIC\\Dockerfile": "FROM vault.habana.ai/gaudi-docker/1.17.0/ubuntu22.04/habanalabs/pytorch-installer-2.3.1:latest\n\n# Installs pdsh and upgrade pip\nRUN apt-get update && apt-get install -y pdsh && \\\n python -m pip install --upgrade pip\n\n# Docker ssh port setup\nRUN sed -i 's/#Port 22/Port 3022/g' /etc/ssh/sshd_config && \\\n sed -i 's/# Port 22/ Port 3022/g' /etc/ssh/ssh_config && \\\n sed -i 's/#PermitRootLogin prohibit-password/PermitRootLogin yes/' /etc/ssh/sshd_config && \\\n service ssh restart\n\n# Installs Optimum Habana and Habana's fork of DeepSpeed\nRUN pip install optimum[habana] && \\\n pip install git+https://github.com/HabanaAI/[email protected]\n\nCMD ssh-keygen -t rsa -b 4096 -N '' -f ~/.ssh/id_rsa && \\\n chmod 600 ~/.ssh/id_rsa && \\\n cat ~/.ssh/id_rsa.pub > ~/.ssh/authorized_keys && \\\n /bin/bash\n", "examples\\protein-folding\\requirements.txt": "datasets>=2.14.0\nscikit-learn\n", "examples\\question-answering\\requirements.txt": "datasets >= 2.4.0\ntorch >= 1.3.0\nevaluate\n", "examples\\speech-recognition\\requirements.txt": "datasets >= 1.18.0\nlibrosa\njiwer\nevaluate\n", "examples\\stable-diffusion\\requirements.txt": "opencv-python", "examples\\stable-diffusion\\training\\requirements.txt": "imagesize\npeft == 0.10.0\n", "examples\\summarization\\requirements.txt": "datasets >= 2.4.0\nsentencepiece != 0.1.92\nprotobuf\nrouge-score\nnltk\npy7zr\ntorch >= 1.3\nevaluate\n", "examples\\table-detection\\requirements.txt": "timm\n", "examples\\text-classification\\requirements.txt": "datasets >= 2.4.0\nsentencepiece != 0.1.92\nscipy\nscikit-learn\nprotobuf\ntorch >= 1.3\nevaluate\n", "examples\\text-generation\\requirements.txt": "datasets\npeft\n", "examples\\text-to-speech\\requirements.txt": "datasets\nsoundfile\n", "examples\\text-to-video\\requirements.txt": "opencv-python-headless\n", "examples\\translation\\requirements.txt": "datasets >= 2.4.0\nsentencepiece != 0.1.92\nprotobuf\nsacrebleu >= 1.4.12\npy7zr\ntorch >= 1.3\nevaluate\n", "examples\\trl\\requirements.txt": "trl == 0.9.6\npeft == 0.12.0\ndatasets == 2.19.2\ntyro\nevaluate\nscikit-learn\n", "examples\\video-classification\\requirements.txt": "decord\n", "examples\\visual-question-answering\\openclip_requirements.txt": "open_clip_torch==2.23.0\nmatplotlib\n\n", "optimum\\habana\\distributed\\tp_wrapping.py": "# Copyright 2024 The Foundation Model Stack Authors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n#\n# This file has been modified from its original version.\n# The original version can be found at https://github.com/foundation-model-stack/foundation-model-stack\n\nfrom torch import nn\nfrom torch.distributed.distributed_c10d import ProcessGroup\n\nfrom ..transformers.models.llama.modeling_llama import (\n GaudiLlamaAttention,\n GaudiLlamaMLP,\n TPGaudiLlamaAttention,\n TPGaudiLlamaMLP,\n)\n\n\ndef _tp_wrapped(module: nn.Module, layer: int, group: ProcessGroup):\n if hasattr(module, \"to_tp\"):\n return module.to_tp(group)\n elif isinstance(module, GaudiLlamaAttention):\n return TPGaudiLlamaAttention.import_module(module, layer, group)\n elif isinstance(module, GaudiLlamaMLP):\n return TPGaudiLlamaMLP.import_module(module, group)\n else:\n return module\n\n\ndef apply_tp(model: nn.Module, layer_idx: int, group: ProcessGroup):\n wrapped = _tp_wrapped(model, layer_idx, group)\n if wrapped is not model:\n return wrapped\n\n for name, layer in model.named_children():\n tp_layer = apply_tp(layer, layer_idx, group)\n setattr(model, name, tp_layer)\n return model\n"} | null |
optimum-intel | {"type": "directory", "name": "optimum-intel", "children": [{"type": "directory", "name": "docker", "children": [{"type": "file", "name": "Dockerfile.intel"}]}, {"type": "directory", "name": "docs", "children": [{"type": "file", "name": "Dockerfile"}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "source", "children": [{"type": "file", "name": "index.mdx"}, {"type": "file", "name": "installation.mdx"}, {"type": "directory", "name": "ipex", "children": [{"type": "file", "name": "inference.mdx"}, {"type": "file", "name": "models.mdx"}, {"type": "directory", "name": "tutorials", "children": [{"type": "file", "name": "notebooks.mdx"}]}]}, {"type": "directory", "name": "neural_compressor", "children": [{"type": "file", "name": "distributed_training.mdx"}, {"type": "file", "name": "optimization.mdx"}, {"type": "file", "name": "reference.mdx"}]}, {"type": "directory", "name": "openvino", "children": [{"type": "file", "name": "export.mdx"}, {"type": "file", "name": "inference.mdx"}, {"type": "file", "name": "models.mdx"}, {"type": "file", "name": "optimization.mdx"}, {"type": "file", "name": "reference.mdx"}, {"type": "directory", "name": "tutorials", "children": [{"type": "file", "name": "diffusers.mdx"}, {"type": "file", "name": "notebooks.mdx"}]}]}, {"type": "file", "name": "_toctree.yml"}]}]}, {"type": "directory", "name": "examples", "children": [{"type": "directory", "name": "neural_compressor", "children": [{"type": "directory", "name": "config", "children": [{"type": "file", "name": "distillation.yml"}, {"type": "file", "name": "prune.yml"}, {"type": "file", "name": "prune_pattern_lock.yml"}, {"type": "file", "name": "quantization.yml"}]}, {"type": "directory", "name": "language-modeling", "children": [{"type": "directory", "name": "config", "children": [{"type": "directory", "name": "inc", "children": [{"type": "file", "name": "quantization.yml"}]}]}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "run_clm.py"}, {"type": "file", "name": "run_mlm.py"}]}, {"type": "directory", "name": "multiple-choice", "children": [{"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "run_swag.py"}, {"type": "file", "name": "run_swag_post_training.py"}]}, {"type": "directory", "name": "optical-character-recognition", "children": [{"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "run_ocr_post_training.py"}]}, {"type": "directory", "name": "question-answering", "children": [{"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "run_qa.py"}, {"type": "file", "name": "run_qa_post_training.py"}, {"type": "file", "name": "trainer_qa.py"}, {"type": "file", "name": "utils_qa.py"}]}, {"type": "directory", "name": "summarization", "children": [{"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "run_summarization.py"}, {"type": "file", "name": "run_summarization_post_training.py"}]}, {"type": "file", "name": "test_examples.py"}, {"type": "directory", "name": "text-classification", "children": [{"type": "directory", "name": "intent-classification", "children": [{"type": "file", "name": "distillation.yml"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "run_clinc.py"}]}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "run_glue.py"}, {"type": "file", "name": "run_glue_post_training.py"}, {"type": "file", "name": "run_task_in_distributed_mode.sh"}]}, {"type": "directory", "name": "text-generation", "children": [{"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "run_generation.py"}]}, {"type": "directory", "name": "text-to-image", "children": [{"type": "directory", "name": "images", "children": []}, {"type": "file", "name": "quantization.yml"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "run_diffusion_post_training.py"}]}, {"type": "directory", "name": "textual-inversion", "children": [{"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "text2images.py"}, {"type": "file", "name": "textual_inversion.py"}]}, {"type": "directory", "name": "token-classification", "children": [{"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "run_ner.py"}, {"type": "file", "name": "run_ner_post_training.py"}]}, {"type": "directory", "name": "translation", "children": [{"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "run_translation.py"}, {"type": "file", "name": "run_translation_post_training.py"}]}]}, {"type": "directory", "name": "openvino", "children": [{"type": "directory", "name": "audio-classification", "children": [{"type": "directory", "name": "configs", "children": [{"type": "file", "name": "wav2vec2-base-jpqd.json"}, {"type": "file", "name": "wav2vec2-base-qat.json"}]}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "run_audio_classification.py"}]}, {"type": "directory", "name": "image-classification", "children": [{"type": "directory", "name": "configs", "children": [{"type": "file", "name": "swin-base-jpqd.json"}]}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "run_image_classification.py"}]}, {"type": "directory", "name": "question-answering", "children": [{"type": "directory", "name": "configs", "children": [{"type": "file", "name": "bert-base-jpqd.json"}, {"type": "file", "name": "bert-base-movement-sparsity.json"}]}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "run_qa.py"}, {"type": "file", "name": "trainer_qa.py"}, {"type": "file", "name": "utils_qa.py"}]}, {"type": "file", "name": "test_examples.py"}, {"type": "directory", "name": "text-classification", "children": [{"type": "directory", "name": "configs", "children": [{"type": "file", "name": "bert-base-jpqd.json"}]}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "run_glue.py"}]}]}]}, {"type": "file", "name": "LICENSE"}, {"type": "file", "name": "Makefile"}, {"type": "file", "name": "MANIFEST.in"}, {"type": "directory", "name": "notebooks", "children": [{"type": "directory", "name": "ipex", "children": [{"type": "file", "name": "README.md"}, {"type": "file", "name": "text_generation.ipynb"}]}, {"type": "directory", "name": "neural_compressor", "children": [{"type": "file", "name": "README.md"}]}, {"type": "directory", "name": "openvino", "children": [{"type": "file", "name": "optimum_openvino_inference.ipynb"}, {"type": "file", "name": "quantized_generation_demo.ipynb"}, {"type": "file", "name": "question_answering_quantization.ipynb"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "stable_diffusion_hybrid_quantization.ipynb"}]}, {"type": "file", "name": "README.md"}]}, {"type": "directory", "name": "optimum", "children": [{"type": "directory", "name": "commands", "children": [{"type": "directory", "name": "export", "children": [{"type": "file", "name": "openvino.py"}]}, {"type": "directory", "name": "neural_compressor", "children": [{"type": "file", "name": "base.py"}, {"type": "file", "name": "quantize.py"}]}, {"type": "directory", "name": "register", "children": [{"type": "file", "name": "register_inc.py"}, {"type": "file", "name": "register_openvino.py"}]}]}, {"type": "directory", "name": "exporters", "children": [{"type": "directory", "name": "ipex", "children": [{"type": "file", "name": "modeling_utils.py"}, {"type": "file", "name": "model_config.py"}, {"type": "file", "name": "model_patcher.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "openvino", "children": [{"type": "file", "name": "convert.py"}, {"type": "file", "name": "model_configs.py"}, {"type": "file", "name": "model_patcher.py"}, {"type": "file", "name": "stateful.py"}, {"type": "file", "name": "utils.py"}, {"type": "file", "name": "__init__.py"}, {"type": "file", "name": "__main__.py"}]}]}, {"type": "directory", "name": "intel", "children": [{"type": "directory", "name": "generation", "children": [{"type": "file", "name": "modeling.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "ipex", "children": [{"type": "file", "name": "modeling_base.py"}, {"type": "file", "name": "utils.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "neural_compressor", "children": [{"type": "file", "name": "configuration.py"}, {"type": "file", "name": "launcher.py"}, {"type": "file", "name": "modeling_base.py"}, {"type": "file", "name": "modeling_diffusion.py"}, {"type": "file", "name": "neural_coder_adaptor.py"}, {"type": "file", "name": "quantization.py"}, {"type": "file", "name": "trainer.py"}, {"type": "file", "name": "trainer_seq2seq.py"}, {"type": "file", "name": "utils.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "openvino", "children": [{"type": "file", "name": "configuration.py"}, {"type": "file", "name": "loaders.py"}, {"type": "file", "name": "modeling.py"}, {"type": "file", "name": "modeling_base.py"}, {"type": "file", "name": "modeling_base_seq2seq.py"}, {"type": "file", "name": "modeling_decoder.py"}, {"type": "file", "name": "modeling_diffusion.py"}, {"type": "file", "name": "modeling_open_clip.py"}, {"type": "file", "name": "modeling_sentence_transformers.py"}, {"type": "file", "name": "modeling_seq2seq.py"}, {"type": "file", "name": "modeling_timm.py"}, {"type": "file", "name": "quantization.py"}, {"type": "file", "name": "trainer.py"}, {"type": "file", "name": "training_args.py"}, {"type": "file", "name": "utils.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "pipelines", "children": [{"type": "file", "name": "pipeline_base.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "utils", "children": [{"type": "file", "name": "constant.py"}, {"type": "file", "name": "dummy_ipex_objects.py"}, {"type": "file", "name": "dummy_neural_compressor_and_diffusers_objects.py"}, {"type": "file", "name": "dummy_neural_compressor_objects.py"}, {"type": "file", "name": "dummy_openvino_and_diffusers_objects.py"}, {"type": "file", "name": "dummy_openvino_and_nncf_objects.py"}, {"type": "file", "name": "dummy_openvino_and_sentence_transformers_objects.py"}, {"type": "file", "name": "dummy_openvino_objects.py"}, {"type": "file", "name": "import_utils.py"}, {"type": "file", "name": "modeling_utils.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "version.py"}, {"type": "file", "name": "__init__.py"}]}]}, {"type": "file", "name": "pyproject.toml"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "setup.cfg"}, {"type": "file", "name": "setup.py"}, {"type": "directory", "name": "tests", "children": [{"type": "directory", "name": "generation", "children": [{"type": "file", "name": "test_modeling.py"}]}, {"type": "directory", "name": "ipex", "children": [{"type": "file", "name": "test_modeling.py"}, {"type": "file", "name": "test_pipelines.py"}, {"type": "file", "name": "utils_tests.py"}]}, {"type": "directory", "name": "neural_compressor", "children": [{"type": "file", "name": "test_cli.py"}, {"type": "file", "name": "test_ipex.py"}, {"type": "file", "name": "test_modeling.py"}, {"type": "file", "name": "test_optimization.py"}, {"type": "file", "name": "utils_tests.py"}]}, {"type": "directory", "name": "openvino", "children": [{"type": "file", "name": "test_diffusion.py"}, {"type": "file", "name": "test_export.py"}, {"type": "file", "name": "test_exporters_cli.py"}, {"type": "file", "name": "test_modeling.py"}, {"type": "file", "name": "test_modeling_basic.py"}, {"type": "file", "name": "test_modeling_sentence_transformers.py"}, {"type": "file", "name": "test_quantization.py"}, {"type": "file", "name": "test_training.py"}, {"type": "file", "name": "test_training_examples.py"}, {"type": "file", "name": "utils_tests.py"}]}]}]} | # 🤗 Optimum OpenVINO Notebooks
This directory contains notebooks for the OpenVINO integration in 🤗 Optimum. To
install the requirements for running all notebooks, do `pip install -r
requirements.txt`. If you do not want to install the requirements to run all the
notebooks, you can also install the requirements for a specific notebook. They
are listed at the top of each notebook file.
The notebooks have been tested with Python 3.8 and 3.10 on Ubuntu Linux.
| Notebook | Description | | |
|:----------|:-------------|:-------------|------:|
| [How to run inference with the OpenVINO](https://github.com/huggingface/optimum-intel/blob/main/notebooks/openvino/optimum_openvino_inference.ipynb) | Explains how to export your model to OpenVINO and to run inference with OpenVINO Runtime on various tasks| [](https://colab.research.google.com/github/huggingface/optimum-intel/blob/main/notebooks/openvino/optimum_openvino_inference.ipynb)| [](https://studiolab.sagemaker.aws/import/github/huggingface/optimum-intel/blob/main/notebooks/openvino/optimum_openvino_inference.ipynb)|
| [How to quantize a question answering model with OpenVINO NNCF](https://github.com/huggingface/optimum-intel/blob/main/notebooks/openvino/question_answering_quantization.ipynb) | Show how to apply post-training quantization on a question answering model using [NNCF](https://github.com/openvinotoolkit/nncf) and to accelerate inference with OpenVINO| [](https://colab.research.google.com/github/huggingface/optimum-intel/blob/main/notebooks/openvino/question_answering_quantization.ipynb)| [](https://studiolab.sagemaker.aws/import/github/huggingface/optimum-intel/blob/main/notebooks/openvino/question_answering_quantization.ipynb)|
| [How to quantize Stable Diffusion model with OpenVINO NNCF](https://github.com/huggingface/optimum-intel/blob/main/notebooks/openvino/stable_diffusion_hybrid_quantization.ipynb)| Show how to apply post-training hybrid quantization on a Stable Diffusion model using [NNCF](https://github.com/openvinotoolkit/nncf) and to accelerate inference with OpenVINO| [](https://colab.research.google.com/github/huggingface/optimum-intel/blob/main/notebooks/openvino/stable_diffusion_hybrid_quantization.ipynb)| [](https://studiolab.sagemaker.aws/import/github/huggingface/optimum-intel/blob/main/notebooks/openvino/stable_diffusion_hybrid_quantization.ipynb)| | {"setup.py": "import os\nimport re\nimport subprocess\n\nfrom setuptools import find_namespace_packages, setup\n\n\n# Ensure we match the version set in optimum/intel/version.py\ntry:\n filepath = \"optimum/intel/version.py\"\n with open(filepath) as version_file:\n (__version__,) = re.findall('__version__ = \"(.*)\"', version_file.read())\n if __version__.endswith(\".dev0\"):\n dev_version_id = \"\"\n try:\n repo_root = os.path.dirname(os.path.realpath(__file__))\n dev_version_id = (\n subprocess.check_output([\"git\", \"rev-parse\", \"--short\", \"HEAD\"], cwd=repo_root) # nosec\n .strip()\n .decode()\n )\n dev_version_id = \"+\" + dev_version_id\n except subprocess.CalledProcessError:\n pass\n __version__ = __version__ + dev_version_id\nexcept Exception as error:\n assert False, \"Error: Could not open '%s' due %s\\n\" % (filepath, error)\n\nINSTALL_REQUIRE = [\n \"torch>=1.11\",\n \"transformers>=4.36,<4.46\",\n \"optimum~=1.22\",\n \"datasets>=1.4.0\",\n \"sentencepiece\",\n \"setuptools\",\n \"scipy\",\n \"onnx\",\n]\n\nTESTS_REQUIRE = [\n \"accelerate\",\n \"pytest>=7.2.0,<8.0.0\",\n \"parameterized\",\n \"Pillow\",\n \"evaluate\",\n \"diffusers\",\n \"py-cpuinfo\",\n \"sacremoses\",\n \"torchaudio\",\n \"rjieba\",\n \"timm\",\n \"invisible-watermark>=0.2.0\",\n \"transformers_stream_generator\",\n \"einops\",\n \"tiktoken\",\n \"sentence-transformers\",\n \"open_clip_torch>=2.26.1\",\n]\n\nQUALITY_REQUIRE = [\"black~=23.1\", \"ruff==0.4.4\"]\n\nEXTRAS_REQUIRE = {\n \"neural-compressor\": [\"neural-compressor[pt]>3.0\", \"accelerate\"],\n \"openvino\": [\"openvino>=2023.3,<2024.4\", \"nncf>=2.11.0\", \"openvino-tokenizers[transformers]<2024.4\"],\n \"nncf\": [\"nncf>=2.11.0\"],\n \"ipex\": [\"intel-extension-for-pytorch\", \"transformers>=4.39,<4.45\"],\n \"diffusers\": [\"diffusers\"],\n \"quality\": QUALITY_REQUIRE,\n \"tests\": TESTS_REQUIRE,\n}\n\nsetup(\n name=\"optimum-intel\",\n version=__version__,\n description=\"Optimum Library is an extension of the Hugging Face Transformers library, providing a framework to \"\n \"integrate third-party libraries from Hardware Partners and interface with their specific \"\n \"functionality.\",\n long_description=open(\"README.md\", \"r\", encoding=\"utf-8\").read(),\n long_description_content_type=\"text/markdown\",\n classifiers=[\n \"Development Status :: 5 - Production/Stable\",\n \"License :: OSI Approved :: Apache Software License\",\n \"Intended Audience :: Developers\",\n \"Intended Audience :: Education\",\n \"Intended Audience :: Science/Research\",\n \"Operating System :: OS Independent\",\n \"Programming Language :: Python :: 3.8\",\n \"Programming Language :: Python :: 3.9\",\n \"Programming Language :: Python :: 3.10\",\n \"Programming Language :: Python :: 3.11\",\n \"Topic :: Scientific/Engineering :: Artificial Intelligence\",\n ],\n keywords=\"transformers, quantization, pruning, knowledge distillation, optimization, training\",\n url=\"https://www.intel.com\",\n author=\"HuggingFace Inc. Special Ops Team\",\n author_email=\"[email protected]\",\n license=\"Apache\",\n packages=find_namespace_packages(include=[\"optimum*\"]),\n install_requires=INSTALL_REQUIRE,\n extras_require=EXTRAS_REQUIRE,\n include_package_data=True,\n zip_safe=False,\n entry_points={\"console_scripts\": [\"optimum-cli=optimum.commands.optimum_cli:main\"]},\n)\n", ".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 d3c8ac6abe18caff836ce6898ff0fe9a902b07ca Hamza Amin <[email protected]> 1727369509 +0500\tclone: from https://github.com/huggingface/optimum-intel.git\n", ".git\\refs\\heads\\main": "d3c8ac6abe18caff836ce6898ff0fe9a902b07ca\n", ".github\\workflows\\dockerfile_sanity.yml": "name: Build and Test Docker Image\n\non:\n push:\n branches:\n - main\n paths:\n - 'docker/Dockerfile.intel'\n \n pull_request:\n branches:\n - main\n paths:\n - 'docker/Dockerfile.intel'\n\njobs:\n build_and_run:\n runs-on: ubuntu-latest\n\n steps:\n - name: Checkout code\n uses: actions/checkout@v4\n\n - name: Set up Docker Buildx\n uses: docker/setup-buildx-action@v3\n\n - name: Build and Run Docker Image\n run: |\n IMAGE_NAME=\"intel_image:latest\"\n docker build -f docker/Dockerfile.intel -t $IMAGE_NAME .\n if [ $? -ne 0 ]; then\n echo \"Docker image build failed.\"\n exit 1\n fi\n CONTAINER_ID=$(docker run -d $IMAGE_NAME tail -f /dev/null)\n if docker inspect -f '{{.State.Running}}' $CONTAINER_ID 2>/dev/null | grep -q 'true'; then\n echo \"Container is running.\"\n else\n echo \"Container failed to start.\"\n docker logs $CONTAINER_ID 2>/dev/null || echo \"No container ID found.\"\n exit 1\n fi\n docker stop $CONTAINER_ID\n docker rm $CONTAINER_ID", "docker\\Dockerfile.intel": "# syntax = docker/dockerfile:1\n# based onhttps://github.com/pytorch/pytorch/blob/master/Dockerfile\n#\n# NOTE: To build this you will need a docker version >= 19.03 and DOCKER_BUILDKIT=1\n#\n# If you do not use buildkit you are not going to have a good time\n#\n# For reference:\n# https://docs.docker.com/develop/develop-images/build_enhancements/\n\nARG BASE_IMAGE=ubuntu:22.04\nFROM ${BASE_IMAGE}\n\nRUN --mount=type=cache,id=apt-dev,target=/var/cache/apt \\\n sh -c \"apt-get update && DEBIAN_FRONTEND=noninteractive apt-get install --no-install-recommends -y \\\n ca-certificates \\\n git \\\n curl \\\n vim \\\n build-essential \\\n ccache \\\n libgoogle-perftools-dev \\\n numactl \\\n cmake \\\n libjpeg-dev \\\n pybind11-dev \\\n libpng-dev \\\n python3 \\\n python3-pip \\\n && rm -rf /var/lib/apt/lists/*\"\nRUN /usr/sbin/update-ccache-symlinks\nRUN mkdir /opt/ccache && ccache --set-config=cache_dir=/opt/ccache\n\nARG IPEX_VERSION=2.3.100\nARG PYTORCH_VERSION=2.3.1\nARG TORCHVISION_VERSION=0.18.1+cpu\nARG TORCHAUDIO_VERSION=2.3.1+cpu\n\nRUN python3 -m pip install --no-cache-dir \\\n intel-openmp \\\n torch==${PYTORCH_VERSION}+cpu \\\n torchvision==${TORCHVISION_VERSION} \\\n torchaudio==${TORCHAUDIO_VERSION} \\\n -f https://download.pytorch.org/whl/torch_stable.html && \\\n python3 -m pip install intel-extension-for-pytorch==$IPEX_VERSION && \\\n python3 -m pip install oneccl_bind_pt --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/cpu/us/ && \\\n python3 -m pip install --no-cache-dir py-libnuma\n\nARG KMP_BLOCKTIME=1\nENV KMP_BLOCKTIME=${KMP_BLOCKTIME}\nARG KMP_HW_SUBSET=1T\nENV KMP_HW_SUBSET=${KMP_HW_SUBSET}\nENV LD_PRELOAD=\"/usr/lib/x86_64-linux-gnu/libtcmalloc.so\"\n", "docs\\Dockerfile": "FROM python:3.8\n\nARG commit_sha\nARG clone_url\n\n# Need cv2 to install Intel Neural Compressor. See https://github.com/intel/neural-compressor/issues/36\nRUN apt-get update && apt-get install -y \\\n python3 \\\n python3-pip \\\n git \\\n curl \\\n gnupg \\\n ffmpeg \\\n libsm6 \\\n libxext6\n\n# Need node to build doc HTML. Taken from https://stackoverflow.com/a/67491580\nRUN apt-get update && apt-get install -y \\\n software-properties-common \\\n npm\nRUN npm install [email protected] -g && \\\n npm install n -g && \\\n n latest\n\nRUN python3 -m pip install --no-cache-dir --upgrade pip\nRUN python3 -m pip install --no-cache-dir git+https://github.com/huggingface/doc-builder.git\nRUN git clone $clone_url && cd optimum-intel && git checkout $commit_sha\nRUN python3 -m pip install --no-cache-dir ./optimum-intel[neural-compressor,openvino,diffusers,quality]\n", "docs\\source\\index.mdx": "<!---\nCopyright 2022 The HuggingFace Team. All rights reserved.\n\nLicensed under the Apache License, Version 2.0 (the \"License\");\nyou may not use this file except in compliance with the License.\nYou may obtain a copy of the License at\n\n http://www.apache.org/licenses/LICENSE-2.0\n\nUnless required by applicable law or agreed to in writing, software\ndistributed under the License is distributed on an \"AS IS\" BASIS,\nWITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\nSee the License for the specific language governing permissions and\nlimitations under the License.\n-->\n\n\n# \ud83e\udd17 Optimum Intel\n\n\ud83e\udd17 Optimum Intel is the interface between the \ud83e\udd17 Transformers and Diffusers libraries and the different tools and libraries provided by Intel to accelerate end-to-end pipelines on Intel architectures.\n\n[Intel Neural Compressor](https://www.intel.com/content/www/us/en/developer/tools/oneapi/neural-compressor.html) is an open-source library enabling the usage of the most popular compression techniques such as quantization, pruning and knowledge distillation. It supports automatic accuracy-driven tuning strategies in order for users to easily generate quantized model. The users can easily apply static, dynamic and aware-training quantization approaches while giving an expected accuracy criteria. It also supports different weight pruning techniques enabling the creation of pruned model giving a predefined sparsity target.\n\n[OpenVINO](https://docs.openvino.ai) is an open-source toolkit that enables high performance inference capabilities for Intel CPUs, GPUs, and special DL inference accelerators ([see](https://docs.openvino.ai/2024/about-openvino/compatibility-and-support/supported-devices.html) the full list of supported devices). It is supplied with a set of tools to optimize your models with compression techniques such as quantization, pruning and knowledge distillation. Optimum Intel provides a simple interface to optimize your Transformers and Diffusers models, convert them to the OpenVINO Intermediate Representation (IR) format and run inference using OpenVINO Runtime.\n\n[Intel Extension for PyTorch](https://intel.github.io/intel-extension-for-pytorch/#introduction) (IPEX) is an open-source library which provides optimizations for both eager mode and graph mode, however, compared to eager mode, graph mode in PyTorch* normally yields better performance from optimization techniques, such as operation fusion.\n\n<div class=\"mt-10\">\n <div class=\"w-full flex flex-col space-x-4 md:grid md:grid-cols-3 md:gap-x-5\">\n <a class=\"!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg\" href=\"neural_compressor/optimization\"\n ><div class=\"w-full text-center bg-gradient-to-br from-blue-400 to-blue-500 rounded-lg py-1.5 font-semibold mb-5 text-white text-lg leading-relaxed\">Neural Compressor</div>\n <p class=\"text-gray-700\">Learn how to apply compression techniques such as quantization, pruning and knowledge distillation to speed up inference.</p>\n </a>\n <a class=\"!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg\" href=\"openvino/export\"\n ><div class=\"w-full text-center bg-gradient-to-br from-purple-400 to-purple-500 rounded-lg py-1.5 font-semibold mb-5 text-white text-lg leading-relaxed\">OpenVINO</div>\n <p class=\"text-gray-700\">Learn how to run inference with OpenVINO Runtime and to apply quantization to further speed up inference.</p>\n </a>\n <a class=\"!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg\" href=\"ipex/inference\"\n ><div class=\"w-full text-center bg-gradient-to-br from-indigo-400 to-indigo-500 rounded-lg py-1.5 font-semibold mb-5 text-white text-lg leading-relaxed\">IPEX</div>\n <p class=\"text-gray-700\">Learn how to optimize your model with IPEX.</p>\n </a>\n </div>\n</div>", "examples\\neural_compressor\\language-modeling\\requirements.txt": "accelerate\ntorch >= 1.9\ndatasets >= 1.8.0\nsentencepiece != 0.1.92\nprotobuf\npeft\n", "examples\\neural_compressor\\multiple-choice\\requirements.txt": "accelerate\nsentencepiece != 0.1.92\nprotobuf\ntorch >= 1.9\n", "examples\\neural_compressor\\optical-character-recognition\\requirements.txt": "datasets >= 1.8.0\npillow\ntorch >= 1.9.0\njiwer", "examples\\neural_compressor\\question-answering\\requirements.txt": "accelerate\ndatasets >= 1.8.0\nevaluate\ntorch >= 1.9.0\n", "examples\\neural_compressor\\summarization\\requirements.txt": "accelerate\ndatasets >= 1.8.0\nsentencepiece != 0.1.92\nprotobuf\nrouge-score\nnltk\npy7zr\ntorch >= 1.9\n", "examples\\neural_compressor\\text-classification\\requirements.txt": "accelerate\ndatasets >= 1.8.0\nsentencepiece != 0.1.92\nscipy\nscikit-learn\nprotobuf\ntorch >= 1.9\n", "examples\\neural_compressor\\text-classification\\intent-classification\\requirements.txt": "datasets >= 1.8.0\nsentencepiece != 0.1.92\nscipy\nscikit-learn\nprotobuf\ntorch >= 1.9\n", "examples\\neural_compressor\\text-generation\\requirements.txt": "sentencepiece != 0.1.92\nprotobuf\ntorch >= 2.0.0\n", "examples\\neural_compressor\\text-to-image\\requirements.txt": "diffusers\naccelerate\npytorch_fid\ntorch >= 1.9\n", "examples\\neural_compressor\\textual-inversion\\requirements.txt": "diffusers\naccelerate\ntorchvision\ntransformers\nftfy\ntensorboard\nmodelcards", "examples\\neural_compressor\\token-classification\\requirements.txt": "seqeval\ndatasets >= 1.8.0\ntorch >= 1.9\n", "examples\\neural_compressor\\translation\\requirements.txt": "accelerate\ndatasets >= 1.8.0\nsentencepiece != 0.1.92\nprotobuf\nsacrebleu >= 1.4.12\npy7zr\ntorch >= 1.9", "examples\\openvino\\audio-classification\\requirements.txt": "datasets>=1.14.0,<2.20.0\nevaluate\nlibrosa\ntorchaudio\naccelerate", "examples\\openvino\\image-classification\\requirements.txt": "datasets>=1.14.0,<2.20.0\ntorch >= 1.9.0\ntorchvision>=0.6.0\nevaluate\naccelerate\n", "examples\\openvino\\question-answering\\requirements.txt": "datasets>=1.14.0,<2.20.0\ntorch >= 1.9.0\nevaluate\naccelerate\n", "examples\\openvino\\text-classification\\requirements.txt": "datasets>=1.14.0,<2.20.0\nsentencepiece != 0.1.92\nscipy\nscikit-learn\nprotobuf\ntorch >= 1.3\nevaluate\naccelerate\n", "notebooks\\openvino\\requirements.txt": "optimum-intel[openvino]\ndatasets\nevaluate[evaluator]\nipywidgets\npillow\ntorchaudio\n\n", "optimum\\exporters\\openvino\\__main__.py": "# Copyright 2022 The HuggingFace Team. All rights reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport gc\nimport logging\nimport operator\nimport warnings\nfrom functools import reduce\nfrom pathlib import Path\nfrom typing import TYPE_CHECKING, Any, Callable, Dict, Optional, Union\n\nfrom huggingface_hub.constants import HUGGINGFACE_HUB_CACHE\nfrom requests.exceptions import ConnectionError as RequestsConnectionError\nfrom transformers import AutoConfig, AutoTokenizer, PreTrainedTokenizerBase\nfrom transformers.utils import is_torch_available\n\nfrom openvino.runtime import Core, Type, save_model\nfrom optimum.exporters import TasksManager\nfrom optimum.exporters.onnx.base import OnnxConfig\nfrom optimum.exporters.onnx.constants import SDPA_ARCHS_ONNX_EXPORT_NOT_SUPPORTED\nfrom optimum.exporters.openvino.convert import export_from_model\nfrom optimum.intel.utils.import_utils import (\n is_nncf_available,\n is_openvino_tokenizers_available,\n is_openvino_version,\n is_transformers_version,\n)\nfrom optimum.intel.utils.modeling_utils import (\n _infer_library_from_model_name_or_path,\n _OpenClipForZeroShotImageClassification,\n)\nfrom optimum.utils.save_utils import maybe_load_preprocessors\n\nfrom .utils import _MAX_UNCOMPRESSED_SIZE, clear_class_registry\n\n\nif TYPE_CHECKING:\n from optimum.intel.openvino.configuration import OVConfig\n\n\nif is_torch_available():\n import torch\n\n\nlogger = logging.getLogger(__name__)\n\n\ndef infer_task(\n task,\n model_name_or_path,\n subfolder: str = \"\",\n revision: Optional[str] = None,\n cache_dir: str = HUGGINGFACE_HUB_CACHE,\n token: Optional[Union[bool, str]] = None,\n library_name: Optional[str] = None,\n):\n task = TasksManager.map_from_synonym(task)\n if task == \"auto\":\n if library_name == \"open_clip\":\n task = \"zero-shot-image-classification\"\n else:\n try:\n task = TasksManager._infer_task_from_model_name_or_path(\n model_name_or_path=model_name_or_path,\n subfolder=subfolder,\n revision=revision,\n cache_dir=cache_dir,\n token=token,\n )\n except KeyError as e:\n raise KeyError(\n f\"The task could not be automatically inferred. Please provide the argument --task with the relevant task from {', '.join(TasksManager.get_all_tasks())}. Detailed error: {e}\"\n )\n except RequestsConnectionError as e:\n raise RequestsConnectionError(\n f\"The task could not be automatically inferred as this is available only for models hosted on the Hugging Face Hub. Please provide the argument --task with the relevant task from {', '.join(TasksManager.get_all_tasks())}. Detailed error: {e}\"\n )\n return task\n\n\ndef main_export(\n model_name_or_path: str,\n output: Union[str, Path],\n task: str = \"auto\",\n device: str = \"cpu\",\n framework: Optional[str] = None,\n cache_dir: str = HUGGINGFACE_HUB_CACHE,\n trust_remote_code: bool = False,\n pad_token_id: Optional[int] = None,\n subfolder: str = \"\",\n revision: str = \"main\",\n force_download: bool = False,\n local_files_only: bool = False,\n use_auth_token: Optional[Union[bool, str]] = None,\n token: Optional[Union[bool, str]] = None,\n model_kwargs: Optional[Dict[str, Any]] = None,\n custom_export_configs: Optional[Dict[str, \"OnnxConfig\"]] = None,\n fn_get_submodels: Optional[Callable] = None,\n ov_config: \"OVConfig\" = None,\n stateful: bool = True,\n convert_tokenizer: bool = False,\n library_name: Optional[str] = None,\n model_loading_kwargs: Optional[Dict[str, Any]] = None,\n **kwargs_shapes,\n):\n \"\"\"\n Full-suite OpenVINO export.\n\n Args:\n > Required parameters\n\n model_name_or_path (`str`):\n Model ID on huggingface.co or path on disk to the model repository to export.\n output (`Union[str, Path]`):\n Path indicating the directory where to store the generated OpenVINO model.\n\n > Optional parameters\n\n task (`Optional[str]`, defaults to `None`):\n The task to export the model for. If not specified, the task will be auto-inferred based on the model. For decoder models,\n use `xxx-with-past` to export the model using past key values in the decoder.\n device (`str`, defaults to `\"cpu\"`):\n The device to use to do the export. Defaults to \"cpu\".\n framework (`Optional[str]`, defaults to `None`):\n The framework to use for the ONNX export (`\"pt\"` or `\"tf\"`). If not provided, will attempt to automatically detect\n the framework for the checkpoint.\n cache_dir (`Optional[str]`, defaults to `None`):\n Path indicating where to store cache. The default Hugging Face cache path will be used by default.\n trust_remote_code (`bool`, defaults to `False`):\n Allows to use custom code for the modeling hosted in the model repository. This option should only be set for repositories\n you trust and in which you have read the code, as it will execute on your local machine arbitrary code present in the\n model repository.\n pad_token_id (`Optional[int]`, defaults to `None`):\n This is needed by some models, for some tasks. If not provided, will attempt to use the tokenizer to guess it.\n subfolder (`str`, defaults to `\"\"`):\n In case the relevant files are located inside a subfolder of the model repo either locally or on huggingface.co, you can\n specify the folder name here.\n revision (`str`, defaults to `\"main\"`):\n Revision is the specific model version to use. It can be a branch name, a tag name, or a commit id.\n force_download (`bool`, defaults to `False`):\n Whether or not to force the (re-)download of the model weights and configuration files, overriding the\n cached versions if they exist.\n local_files_only (`Optional[bool]`, defaults to `False`):\n Whether or not to only look at local files (i.e., do not try to download the model).\n use_auth_token (Optional[Union[bool, str]], defaults to `None`):\n Deprecated. Please use `token` instead.\n token (Optional[Union[bool, str]], defaults to `None`):\n The token to use as HTTP bearer authorization for remote files. If `True`, will use the token generated\n when running `huggingface-cli login` (stored in `~/.huggingface`).\n model_kwargs (`Optional[Dict[str, Any]]`, defaults to `None`):\n Experimental usage: keyword arguments to pass to the model during\n the export. This argument should be used along the `custom_export_configs` argument\n in case, for example, the model inputs/outputs are changed (for example, if\n `model_kwargs={\"output_attentions\": True}` is passed).\n custom_export_configs (`Optional[Dict[str, OnnxConfig]]`, defaults to `None`):\n Experimental usage: override the default export config used for the given model. This argument may be useful for advanced users that desire a finer-grained control on the export. An example is available [here](https://huggingface.co/docs/optimum/main/en/exporters/onnx/usage_guides/export_a_model).\n fn_get_submodels (`Optional[Callable]`, defaults to `None`):\n Experimental usage: Override the default submodels that are used at the export. This is\n especially useful when exporting a custom architecture that needs to split the ONNX (e.g. encoder-decoder). If unspecified with custom models, optimum will try to use the default submodels used for the given task, with no guarantee of success.\n stateful (`bool`, defaults to `True`):\n Produce stateful model where all kv-cache inputs and outputs are hidden in the model and are not exposed as model inputs and outputs. Applicable only for decoder models.\n **kwargs_shapes (`Dict`):\n Shapes to use during inference. This argument allows to override the default shapes used during the ONNX export.\n\n Example usage:\n ```python\n >>> from optimum.exporters.openvino import main_export\n\n >>> main_export(\"gpt2\", output=\"gpt2_ov/\")\n ```\n \"\"\"\n\n if use_auth_token is not None:\n warnings.warn(\n \"The `use_auth_token` argument is deprecated and will be removed soon. Please use the `token` argument instead.\",\n FutureWarning,\n )\n if token is not None:\n raise ValueError(\"You cannot use both `use_auth_token` and `token` arguments at the same time.\")\n token = use_auth_token\n\n if framework is None:\n framework = TasksManager.determine_framework(\n model_name_or_path, subfolder=subfolder, revision=revision, cache_dir=cache_dir, token=token\n )\n\n if library_name is None:\n library_name = _infer_library_from_model_name_or_path(\n model_name_or_path=model_name_or_path,\n subfolder=subfolder,\n revision=revision,\n cache_dir=cache_dir,\n token=token,\n )\n if library_name == \"sentence_transformers\":\n logger.warning(\n \"Library name is not specified. There are multiple possible variants: `sentence_tenasformers`, `transformers`.\"\n \"`transformers` will be selected. If you want to load your model with the `sentence-transformers` library instead, please set --library sentence_transformers\"\n )\n library_name = \"transformers\"\n\n original_task = task\n task = infer_task(\n task,\n model_name_or_path,\n subfolder=subfolder,\n revision=revision,\n cache_dir=cache_dir,\n token=token,\n library_name=library_name,\n )\n\n do_gptq_patching = False\n custom_architecture = False\n patch_16bit = False\n loading_kwargs = model_loading_kwargs or {}\n if library_name == \"transformers\":\n config = AutoConfig.from_pretrained(\n model_name_or_path,\n subfolder=subfolder,\n revision=revision,\n cache_dir=cache_dir,\n token=token,\n local_files_only=local_files_only,\n force_download=force_download,\n trust_remote_code=trust_remote_code,\n )\n quantization_config = getattr(config, \"quantization_config\", None)\n do_gptq_patching = quantization_config and quantization_config[\"quant_method\"] == \"gptq\"\n model_type = config.model_type.replace(\"_\", \"-\")\n if model_type not in TasksManager._SUPPORTED_MODEL_TYPE:\n custom_architecture = True\n if custom_export_configs is None:\n raise ValueError(\n f\"Trying to export a {model_type} model, that is a custom or unsupported architecture, but no custom export configuration was passed as `custom_export_configs`. Please refer to https://huggingface.co/docs/optimum/main/en/exporters/onnx/usage_guides/export_a_model#custom-export-of-transformers-models for an example on how to export custom models. Please open an issue at https://github.com/huggingface/optimum-intel/issues if you would like the model type {model_type} to be supported natively in the OpenVINO export.\"\n )\n elif task not in TasksManager.get_supported_tasks_for_model_type(\n model_type, exporter=\"openvino\", library_name=library_name\n ):\n if original_task == \"auto\":\n autodetected_message = \" (auto-detected)\"\n else:\n autodetected_message = \"\"\n model_tasks = TasksManager.get_supported_tasks_for_model_type(\n model_type, exporter=\"openvino\", library_name=library_name\n )\n raise ValueError(\n f\"Asked to export a {model_type} model for the task {task}{autodetected_message}, but the Optimum OpenVINO exporter only supports the tasks {', '.join(model_tasks.keys())} for {model_type}. Please use a supported task. Please open an issue at https://github.com/huggingface/optimum/issues if you would like the task {task} to be supported in the ONNX export for {model_type}.\"\n )\n\n if is_transformers_version(\">=\", \"4.36\") and model_type in SDPA_ARCHS_ONNX_EXPORT_NOT_SUPPORTED:\n loading_kwargs[\"attn_implementation\"] = \"eager\"\n # there are some difference between remote and in library representation of past key values for some models,\n # for avoiding confusion we disable remote code for them\n if (\n trust_remote_code\n and model_type in {\"falcon\", \"mpt\", \"phi\"}\n and (\"with-past\" in task or original_task == \"auto\")\n and not custom_export_configs\n ):\n logger.warning(\n f\"Model type `{model_type}` export for task `{task}` is not supported for loading with `trust_remote_code=True`\"\n \"using default export configuration, `trust_remote_code` will be disabled. \"\n \"Please provide custom export config if you want load model with remote code.\"\n )\n trust_remote_code = False\n dtype = loading_kwargs.get(\"torch_dtype\")\n if isinstance(dtype, str):\n dtype = config.torch_dtype if dtype == \"auto\" else getattr(torch, dtype)\n\n if (\n dtype is None\n and framework == \"pt\"\n and not do_gptq_patching\n and task.startswith(\"text-generation\")\n and getattr(config, \"torch_dtype\", torch.float32) in [torch.float16, torch.bfloat16]\n ):\n if ov_config is not None and ov_config.dtype in {\"fp16\", \"fp32\"}:\n dtype = torch.float16 if ov_config.dtype == \"fp16\" else torch.float32\n elif is_openvino_version(\">=\", \"2024.2\") and config.torch_dtype == torch.float16:\n dtype = torch.float16\n elif is_openvino_version(\">=\", \"2024.3\") and config.torch_dtype == torch.bfloat16:\n dtype = torch.bfloat16\n\n if dtype is not None:\n if dtype in [torch.float16, torch.bfloat16]:\n patch_16bit = True\n loading_kwargs[\"torch_dtype\"] = dtype\n # Patch the modules to export of GPTQ models w/o GPU\n if do_gptq_patching:\n torch.set_default_dtype(torch.float32)\n orig_cuda_check = torch.cuda.is_available\n torch.cuda.is_available = lambda: True\n\n from optimum.gptq import GPTQQuantizer\n\n orig_post_init_model = GPTQQuantizer.post_init_model\n\n def post_init_model(self, model):\n from auto_gptq import exllama_set_max_input_length\n\n class StoreAttr(object):\n pass\n\n model.quantize_config = StoreAttr()\n model.quantize_config.desc_act = self.desc_act\n if self.desc_act and not self.disable_exllama and self.max_input_length is not None:\n model = exllama_set_max_input_length(model, self.max_input_length)\n return model\n\n GPTQQuantizer.post_init_model = post_init_model\n\n if library_name == \"open_clip\":\n model = _OpenClipForZeroShotImageClassification.from_pretrained(model_name_or_path, cache_dir=cache_dir)\n else:\n model = TasksManager.get_model_from_task(\n task,\n model_name_or_path,\n subfolder=subfolder,\n revision=revision,\n cache_dir=cache_dir,\n token=token,\n local_files_only=local_files_only,\n force_download=force_download,\n trust_remote_code=trust_remote_code,\n framework=framework,\n device=device,\n library_name=library_name,\n **loading_kwargs,\n )\n\n needs_pad_token_id = task == \"text-classification\" and getattr(model.config, \"pad_token_id\", None) is None\n\n if needs_pad_token_id:\n if pad_token_id is not None:\n model.config.pad_token_id = pad_token_id\n else:\n tok = AutoTokenizer.from_pretrained(model_name_or_path)\n pad_token_id = getattr(tok, \"pad_token_id\", None)\n if pad_token_id is None:\n raise ValueError(\n \"Could not infer the pad token id, which is needed in this case, please provide it with the --pad_token_id argument\"\n )\n model.config.pad_token_id = pad_token_id\n\n if hasattr(model.config, \"export_model_type\"):\n model_type = model.config.export_model_type.replace(\"_\", \"-\")\n else:\n model_type = model.config.model_type.replace(\"_\", \"-\")\n\n if (\n not custom_architecture\n and library_name != \"diffusers\"\n and task + \"-with-past\"\n in TasksManager.get_supported_tasks_for_model_type(model_type, exporter=\"openvino\", library_name=library_name)\n ):\n # Make -with-past the default if --task was not explicitely specified\n if original_task == \"auto\":\n task = task + \"-with-past\"\n else:\n logger.info(\n f\"The task `{task}` was manually specified, and past key values will not be reused in the decoding.\"\n f\" if needed, please pass `--task {task}-with-past` to export using the past key values.\"\n )\n\n if original_task == \"auto\":\n synonyms_for_task = sorted(TasksManager.synonyms_for_task(task))\n if synonyms_for_task:\n synonyms_for_task = \", \".join(synonyms_for_task)\n possible_synonyms = f\" (possible synonyms are: {synonyms_for_task})\"\n else:\n possible_synonyms = \"\"\n logger.info(f\"Automatic task detection to {task}{possible_synonyms}.\")\n\n preprocessors = maybe_load_preprocessors(\n model_name_or_path, subfolder=subfolder, trust_remote_code=trust_remote_code\n )\n\n submodel_paths = export_from_model(\n model=model,\n output=output,\n task=task,\n ov_config=ov_config,\n stateful=stateful,\n model_kwargs=model_kwargs,\n custom_export_configs=custom_export_configs,\n fn_get_submodels=fn_get_submodels,\n preprocessors=preprocessors,\n device=device,\n trust_remote_code=trust_remote_code,\n patch_16bit_model=patch_16bit,\n **kwargs_shapes,\n )\n\n if convert_tokenizer:\n maybe_convert_tokenizers(library_name, output, model, preprocessors, task=task)\n\n clear_class_registry()\n del model\n gc.collect()\n\n core = Core()\n for submodel_path in submodel_paths:\n submodel_path = Path(output) / submodel_path\n submodel = core.read_model(submodel_path)\n\n quantization_config = None\n if ov_config is None:\n num_parameters = 0\n for op in submodel.get_ops():\n if op.get_type_name() == \"Constant\" and op.get_element_type() in [Type.f16, Type.f32, Type.bf16]:\n num_parameters += reduce(operator.mul, op.shape, 1)\n if num_parameters >= _MAX_UNCOMPRESSED_SIZE:\n if is_nncf_available():\n quantization_config = {\"bits\": 8, \"sym\": False}\n logger.info(\"The model weights will be quantized to int8_asym.\")\n else:\n logger.warning(\n \"The model will be converted with no weights quantization. Quantization of the weights to int8 \"\n \"requires nncf. Please install it with `pip install nncf`\"\n )\n break\n else:\n quantization_config = ov_config.quantization_config\n if quantization_config is None:\n continue\n\n if not is_nncf_available():\n raise ImportError(\"Quantization of the weights requires nncf, please install it with `pip install nncf`\")\n\n from optimum.intel.openvino.quantization import _weight_only_quantization\n\n _weight_only_quantization(submodel, quantization_config)\n\n compressed_submodel_path = submodel_path.parent / f\"{submodel_path.stem}_compressed.xml\"\n save_model(submodel, compressed_submodel_path, compress_to_fp16=False)\n del submodel\n\n submodel_path.unlink()\n submodel_path.with_suffix(\".bin\").unlink()\n compressed_submodel_path.rename(submodel_path)\n compressed_submodel_path.with_suffix(\".bin\").rename(submodel_path.with_suffix(\".bin\"))\n\n # Unpatch modules after GPTQ export\n if do_gptq_patching:\n torch.cuda.is_available = orig_cuda_check\n GPTQQuantizer.post_init_model = orig_post_init_model\n\n\ndef maybe_convert_tokenizers(library_name: str, output: Path, model=None, preprocessors=None, task=None):\n \"\"\"\n Tries to convert tokenizers to OV format and export them to disk.\n\n Arguments:\n library_name (`str`):\n The library name.\n output (`Path`):\n Path to save converted tokenizers to.\n model (`PreTrainedModel`, *optional*, defaults to None):\n Model instance.\n preprocessors (`Iterable`, *optional*, defaults to None):\n Iterable possibly containing tokenizers to be converted.\n task (`str`, *optional*, defaults to None):\n The task to export the model for. Affects tokenizer conversion parameters.\n \"\"\"\n from optimum.exporters.openvino.convert import export_tokenizer\n\n if is_openvino_tokenizers_available():\n if library_name != \"diffusers\" and preprocessors:\n tokenizer = next(filter(lambda it: isinstance(it, PreTrainedTokenizerBase), preprocessors), None)\n if tokenizer:\n try:\n export_tokenizer(tokenizer, output, task=task)\n except Exception as exception:\n logger.warning(\n \"Could not load tokenizer using specified model ID or path. OpenVINO tokenizer/detokenizer \"\n f\"models won't be generated. Exception: {exception}\"\n )\n elif model:\n for tokenizer_name in (\"tokenizer\", \"tokenizer_2\"):\n tokenizer = getattr(model, tokenizer_name, None)\n if tokenizer:\n export_tokenizer(tokenizer, output / tokenizer_name, task=task)\n else:\n logger.warning(\"Tokenizer won't be converted.\")\n"} | null |
optimum-neuron | {"type": "directory", "name": "optimum-neuron", "children": [{"type": "directory", "name": "benchmark", "children": [{"type": "directory", "name": "text-generation", "children": [{"type": "file", "name": "benchmark.py"}, {"type": "file", "name": "gen_barcharts.py"}, {"type": "file", "name": "llama2-13b.py"}, {"type": "file", "name": "llama2-7b.py"}, {"type": "file", "name": "llama3-8b.py"}, {"type": "file", "name": "mistralv2.py"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "wiki.txt"}]}, {"type": "directory", "name": "text-generation-inference", "children": [{"type": "file", "name": "benchmark.sh"}, {"type": "file", "name": "generate_csv.py"}, {"type": "directory", "name": "llama-7b", "children": [{"type": "file", "name": ".env"}, {"type": "file", "name": "docker-compose.yaml"}, {"type": "file", "name": "nginx.conf"}, {"type": "file", "name": "tgi-results.csv"}]}, {"type": "directory", "name": "llama3-70b-inf2.48xlarge", "children": [{"type": "file", "name": ".env"}, {"type": "file", "name": "docker-compose.yaml"}, {"type": "file", "name": "tgi-results-batchsize-1.csv"}, {"type": "file", "name": "tgi-results.csv"}]}, {"type": "directory", "name": "llama3-70b-trn1.32xlarge", "children": [{"type": "file", "name": ".env"}, {"type": "file", "name": "docker-compose.yaml"}, {"type": "file", "name": "tgi-results-batchsize-1.csv"}, {"type": "file", "name": "tgi-results-batchsize-8.csv"}, {"type": "file", "name": "tgi-results.csv"}]}, {"type": "directory", "name": "llama3-8b", "children": [{"type": "file", "name": ".env"}, {"type": "file", "name": "docker-compose.yaml"}, {"type": "file", "name": "nginx.conf"}, {"type": "file", "name": "tgi-results.csv"}]}, {"type": "directory", "name": "mistral-7b", "children": [{"type": "file", "name": ".env"}, {"type": "file", "name": "docker-compose.yaml"}, {"type": "file", "name": "nginx.conf"}, {"type": "file", "name": "tgi-results.csv"}]}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "run_all.sh"}, {"type": "file", "name": "tgi_live_metrics.py"}]}]}, {"type": "directory", "name": "docs", "children": [{"type": "directory", "name": "assets", "children": [{"type": "directory", "name": "benchmarks", "children": [{"type": "directory", "name": "inferentia-llama2-13b", "children": []}, {"type": "directory", "name": "inferentia-llama2-7b", "children": []}, {"type": "directory", "name": "inferentia-llama3-8b", "children": []}, {"type": "directory", "name": "inferentia-mistral-v2", "children": []}]}, {"type": "directory", "name": "guides", "children": [{"type": "directory", "name": "models", "children": []}, {"type": "directory", "name": "setup_aws_instance", "children": []}]}]}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "source", "children": [{"type": "directory", "name": "benchmarks", "children": [{"type": "file", "name": "inferentia-llama2-13b.mdx"}, {"type": "file", "name": "inferentia-llama2-7b.mdx"}, {"type": "file", "name": "inferentia-llama3-8b.mdx"}, {"type": "file", "name": "inferentia-mistral-v2.mdx"}]}, {"type": "directory", "name": "community", "children": [{"type": "file", "name": "contributing.mdx"}]}, {"type": "file", "name": "containers.mdx"}, {"type": "directory", "name": "guides", "children": [{"type": "file", "name": "cache_system.mdx"}, {"type": "file", "name": "distributed_training.mdx"}, {"type": "file", "name": "export_model.mdx"}, {"type": "file", "name": "fine_tune.mdx"}, {"type": "file", "name": "neuronx_tgi.mdx"}, {"type": "file", "name": "pipelines.mdx"}, {"type": "file", "name": "sagemaker.mdx"}, {"type": "file", "name": "setup_aws_instance.mdx"}]}, {"type": "file", "name": "index.mdx"}, {"type": "directory", "name": "inference_tutorials", "children": [{"type": "file", "name": "llama2-13b-chatbot.mdx"}, {"type": "file", "name": "notebooks.mdx"}, {"type": "file", "name": "sentence_transformers.mdx"}, {"type": "file", "name": "stable_diffusion.mdx"}]}, {"type": "file", "name": "installation.mdx"}, {"type": "directory", "name": "package_reference", "children": [{"type": "file", "name": "distributed.mdx"}, {"type": "file", "name": "export.mdx"}, {"type": "file", "name": "modeling.mdx"}, {"type": "file", "name": "supported_models.mdx"}, {"type": "file", "name": "trainer.mdx"}]}, {"type": "file", "name": "quickstart.mdx"}, {"type": "directory", "name": "training_tutorials", "children": [{"type": "file", "name": "finetune_llm.mdx"}, {"type": "file", "name": "finetune_llm.py"}, {"type": "file", "name": "fine_tune_bert.mdx"}, {"type": "file", "name": "notebooks.mdx"}, {"type": "file", "name": "sft_lora_finetune_llm.mdx"}, {"type": "file", "name": "sft_lora_finetune_llm.py"}]}, {"type": "file", "name": "_toctree.yml"}]}]}, {"type": "directory", "name": "examples", "children": [{"type": "directory", "name": "image-classification", "children": [{"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "run_image_classification.py"}]}, {"type": "directory", "name": "language-modeling", "children": [{"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "run_clm.py"}, {"type": "file", "name": "run_mlm.py"}]}, {"type": "directory", "name": "multiple-choice", "children": [{"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "run_swag.py"}]}, {"type": "directory", "name": "question-answering", "children": [{"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "run_qa.py"}, {"type": "file", "name": "run_seq2seq_qa.py"}, {"type": "file", "name": "trainer_qa.py"}, {"type": "file", "name": "trainer_seq2seq_qa.py"}, {"type": "file", "name": "utils_qa.py"}]}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "summarization", "children": [{"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "run_summarization.py"}]}, {"type": "directory", "name": "text-classification", "children": [{"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "run_glue.py"}, {"type": "file", "name": "run_xnli.py"}]}, {"type": "directory", "name": "text-generation", "children": [{"type": "file", "name": "generation.py"}]}, {"type": "directory", "name": "token-classification", "children": [{"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "run_ner.py"}]}, {"type": "directory", "name": "translation", "children": [{"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "run_translation.py"}]}]}, {"type": "directory", "name": "infrastructure", "children": [{"type": "directory", "name": "ami", "children": [{"type": "directory", "name": "hcl2-files", "children": [{"type": "file", "name": "build.pkr.hcl"}, {"type": "file", "name": "packer.pkr.hcl"}, {"type": "file", "name": "sources.pkr.hcl"}, {"type": "file", "name": "variables.pkr.hcl"}]}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "scripts", "children": [{"type": "file", "name": "install-huggingface-libraries.sh"}, {"type": "file", "name": "validate-neuron.sh"}, {"type": "file", "name": "welcome-msg.sh"}]}]}]}, {"type": "file", "name": "LICENSE"}, {"type": "file", "name": "Makefile"}, {"type": "file", "name": "MANIFEST.in"}, {"type": "directory", "name": "notebooks", "children": [{"type": "file", "name": "README.md"}, {"type": "directory", "name": "sentence-transformers", "children": [{"type": "file", "name": "getting-started.ipynb"}]}, {"type": "directory", "name": "stable-diffusion", "children": [{"type": "file", "name": "stable-diffusion-txt2img.ipynb"}, {"type": "file", "name": "stable-diffusion-xl-txt2img.ipynb"}]}, {"type": "directory", "name": "text-classification", "children": [{"type": "file", "name": "notebook.ipynb"}, {"type": "directory", "name": "scripts", "children": [{"type": "file", "name": "train.py"}]}]}, {"type": "directory", "name": "text-generation", "children": [{"type": "file", "name": "CodeLlama-7B-Compilation.ipynb"}, {"type": "file", "name": "llama2-13b-chatbot.ipynb"}, {"type": "file", "name": "llama2-7b-fine-tuning.ipynb"}, {"type": "directory", "name": "scripts", "children": [{"type": "file", "name": "run_clm.py"}, {"type": "directory", "name": "utils", "children": [{"type": "file", "name": "pack_dataset.py"}]}]}]}]}, {"type": "directory", "name": "optimum", "children": [{"type": "directory", "name": "commands", "children": [{"type": "file", "name": "env.py"}, {"type": "directory", "name": "export", "children": [{"type": "file", "name": "neuron.py"}, {"type": "file", "name": "neuronx.py"}]}, {"type": "directory", "name": "neuron", "children": [{"type": "file", "name": "base.py"}, {"type": "file", "name": "cache.py"}, {"type": "file", "name": "subcommands.py"}]}, {"type": "directory", "name": "register", "children": [{"type": "file", "name": "register_export.py"}, {"type": "file", "name": "register_neuron.py"}]}]}, {"type": "directory", "name": "exporters", "children": [{"type": "directory", "name": "neuron", "children": [{"type": "file", "name": "base.py"}, {"type": "file", "name": "config.py"}, {"type": "file", "name": "convert.py"}, {"type": "file", "name": "model_configs.py"}, {"type": "file", "name": "model_wrappers.py"}, {"type": "file", "name": "utils.py"}, {"type": "file", "name": "__init__.py"}, {"type": "file", "name": "__main__.py"}]}]}, {"type": "directory", "name": "neuron", "children": [{"type": "directory", "name": "accelerate", "children": [{"type": "file", "name": "accelerator.py"}, {"type": "file", "name": "optimizer.py"}, {"type": "file", "name": "scheduler.py"}, {"type": "file", "name": "state.py"}, {"type": "directory", "name": "utils", "children": [{"type": "file", "name": "dataclasses.py"}, {"type": "file", "name": "misc.py"}, {"type": "file", "name": "operations.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "distributed", "children": [{"type": "file", "name": "base.py"}, {"type": "file", "name": "checkpointing.py"}, {"type": "file", "name": "decoder_models.py"}, {"type": "file", "name": "encoder_decoder_models.py"}, {"type": "file", "name": "encoder_models.py"}, {"type": "file", "name": "parallelizers_manager.py"}, {"type": "file", "name": "parallel_layers.py"}, {"type": "file", "name": "utils.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "generation", "children": [{"type": "file", "name": "logits_process.py"}, {"type": "file", "name": "token_selector.py"}, {"type": "file", "name": "utils.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "hf_argparser.py"}, {"type": "file", "name": "modeling.py"}, {"type": "file", "name": "modeling_base.py"}, {"type": "file", "name": "modeling_decoder.py"}, {"type": "file", "name": "modeling_diffusion.py"}, {"type": "file", "name": "modeling_seq2seq.py"}, {"type": "file", "name": "modeling_traced.py"}, {"type": "directory", "name": "pipelines", "children": [{"type": "directory", "name": "diffusers", "children": [{"type": "file", "name": "pipeline_controlnet.py"}, {"type": "file", "name": "pipeline_controlnet_sd_xl.py"}, {"type": "file", "name": "pipeline_latent_consistency_text2img.py"}, {"type": "file", "name": "pipeline_stable_diffusion.py"}, {"type": "file", "name": "pipeline_stable_diffusion_img2img.py"}, {"type": "file", "name": "pipeline_stable_diffusion_inpaint.py"}, {"type": "file", "name": "pipeline_stable_diffusion_instruct_pix2pix.py"}, {"type": "file", "name": "pipeline_stable_diffusion_xl.py"}, {"type": "file", "name": "pipeline_stable_diffusion_xl_img2img.py"}, {"type": "file", "name": "pipeline_stable_diffusion_xl_inpaint.py"}, {"type": "file", "name": "pipeline_utils.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "transformers", "children": [{"type": "file", "name": "base.py"}, {"type": "file", "name": "sentence_transformers.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "trainers.py"}, {"type": "file", "name": "training_args.py"}, {"type": "directory", "name": "utils", "children": [{"type": "file", "name": "argument_utils.py"}, {"type": "file", "name": "cache_utils.py"}, {"type": "file", "name": "constant.py"}, {"type": "file", "name": "deprecate_utils.py"}, {"type": "file", "name": "hub_cache_utils.py"}, {"type": "file", "name": "import_utils.py"}, {"type": "file", "name": "input_generators.py"}, {"type": "file", "name": "misc.py"}, {"type": "file", "name": "model_utils.py"}, {"type": "file", "name": "neuron_cc_wrapper"}, {"type": "file", "name": "neuron_parallel_compile.py"}, {"type": "file", "name": "optimization_utils.py"}, {"type": "file", "name": "optimum_neuron_cc_wrapper.py"}, {"type": "file", "name": "patching.py"}, {"type": "file", "name": "peft_utils.py"}, {"type": "file", "name": "require_utils.py"}, {"type": "file", "name": "runner.py"}, {"type": "file", "name": "testing_utils.py"}, {"type": "file", "name": "torch_xla_and_neuronx_initialization.py"}, {"type": "file", "name": "training_utils.py"}, {"type": "file", "name": "trl_utils.py"}, {"type": "file", "name": "version_utils.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "version.py"}, {"type": "file", "name": "__init__.py"}]}]}, {"type": "file", "name": "pyproject.toml"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "setup.cfg"}, {"type": "file", "name": "setup.py"}, {"type": "directory", "name": "tests", "children": [{"type": "directory", "name": "cache", "children": [{"type": "file", "name": "test_neuronx_cache.py"}]}, {"type": "directory", "name": "cli", "children": [{"type": "file", "name": "test_export_cli.py"}, {"type": "file", "name": "test_export_decoder_cli.py"}, {"type": "file", "name": "test_neuron_cache_cli.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "conftest.py"}, {"type": "directory", "name": "decoder", "children": [{"type": "file", "name": "conftest.py"}, {"type": "file", "name": "test_decoder_export.py"}, {"type": "file", "name": "test_decoder_generation.py"}, {"type": "file", "name": "test_decoder_hub.py"}, {"type": "file", "name": "test_decoder_pipelines.py"}, {"type": "file", "name": "test_fused_logits_warper.py"}]}, {"type": "directory", "name": "distributed", "children": [{"type": "file", "name": "test_common.py"}, {"type": "file", "name": "test_model_parallelization.py"}, {"type": "file", "name": "test_utils.py"}, {"type": "file", "name": "utils.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "distributed_utils.py"}, {"type": "directory", "name": "exporters", "children": [{"type": "file", "name": "exporters_utils.py"}, {"type": "file", "name": "test_export.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "generation", "children": [{"type": "file", "name": "conftest.py"}, {"type": "file", "name": "generation_utils.py"}, {"type": "file", "name": "test_export.py"}, {"type": "file", "name": "test_generate.py"}, {"type": "file", "name": "test_hub.py"}]}, {"type": "directory", "name": "inference", "children": [{"type": "file", "name": "inference_utils.py"}, {"type": "file", "name": "test_modeling.py"}, {"type": "file", "name": "test_stable_diffusion_pipeline.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "peft", "children": [{"type": "file", "name": "test_peft_training.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "pipelines", "children": [{"type": "file", "name": "conftest.py"}, {"type": "file", "name": "test_encoder_pipelines.py"}]}, {"type": "file", "name": "test_cache_utils.py"}, {"type": "file", "name": "test_examples.py"}, {"type": "file", "name": "test_generate.py"}, {"type": "file", "name": "test_runner.py"}, {"type": "file", "name": "test_trainers.py"}, {"type": "file", "name": "test_utils.py"}, {"type": "file", "name": "utils.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "text-generation-inference", "children": [{"type": "file", "name": "Dockerfile"}, {"type": "file", "name": "LICENSE"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "sagemaker-entrypoint.sh"}, {"type": "directory", "name": "server", "children": [{"type": "file", "name": "build-requirements.txt"}, {"type": "file", "name": "Makefile"}, {"type": "file", "name": "pyproject.toml"}, {"type": "directory", "name": "text_generation_server", "children": [{"type": "file", "name": "cli.py"}, {"type": "file", "name": "generator.py"}, {"type": "file", "name": "interceptor.py"}, {"type": "file", "name": "model.py"}, {"type": "file", "name": "server.py"}]}]}, {"type": "directory", "name": "tests", "children": [{"type": "file", "name": "conftest.py"}, {"type": "directory", "name": "fixtures", "children": [{"type": "file", "name": "model.py"}, {"type": "file", "name": "service.py"}]}, {"type": "directory", "name": "integration", "children": [{"type": "file", "name": "test_generate.py"}, {"type": "file", "name": "test_implicit_env.py"}]}, {"type": "file", "name": "pytest.ini"}, {"type": "file", "name": "requirements.txt"}, {"type": "directory", "name": "server", "children": [{"type": "file", "name": "helpers.py"}, {"type": "file", "name": "test_continuous_batching.py"}, {"type": "file", "name": "test_decode.py"}, {"type": "file", "name": "test_generator_slot.py"}, {"type": "file", "name": "test_info.py"}, {"type": "file", "name": "test_prefill.py"}]}]}, {"type": "file", "name": "tgi-entrypoint.sh"}, {"type": "file", "name": "tgi_env.py"}]}, {"type": "directory", "name": "tools", "children": [{"type": "file", "name": "auto_fill_inference_cache.py"}, {"type": "file", "name": "auto_fill_neuron_cache.py"}, {"type": "file", "name": "create_examples_from_transformers.py"}, {"type": "file", "name": "stale.py"}]}]} | # NeuronX TGI: Text-generation-inference for AWS inferentia2
NeuronX TGI is distributed as docker images for [EC2](https://github.com/huggingface/optimum-neuron/pkgs/container/neuronx-tgi) and SageMaker.
These docker images integrate:
- the AWS Neuron SDK for Inferentia2,
- the [Text Generation Inference](https://github.com/huggingface/text-generation-inference) launcher and scheduling front-end,
- a neuron specific inference server for text-generation.
## Usage
Please refer to the official [documentation](https://huggingface.co/docs/optimum-neuron/main/en/guides/neuronx_tgi).
## Build your own image
The image must be built from the top directory
```
make neuronx-tgi
```
| {"setup.py": "import re\n\nfrom setuptools import find_namespace_packages, setup\n\n\n# Ensure we match the version set in optimum/neuron/version.py\nfilepath = \"optimum/neuron/version.py\"\ntry:\n with open(filepath) as version_file:\n (__version__,) = re.findall('__version__ = \"(.*)\"', version_file.read())\nexcept Exception as error:\n assert False, \"Error: Could not open '%s' due %s\\n\" % (filepath, error)\n\n\nINSTALL_REQUIRES = [\n \"transformers == 4.43.2\",\n \"accelerate == 0.29.2\",\n \"optimum ~= 1.22.0\",\n \"huggingface_hub >= 0.20.1\",\n \"numpy>=1.22.2, <=1.25.2\",\n \"protobuf<4\",\n]\n\nTESTS_REQUIRE = [\n \"pytest <= 8.0.0\",\n \"psutil\",\n \"parameterized\",\n \"GitPython\",\n \"sentencepiece\",\n \"datasets\",\n \"sacremoses\",\n \"diffusers>=0.28.0, <0.29.0\",\n \"safetensors\",\n \"sentence-transformers >= 2.2.0\",\n \"peft\",\n \"trl\",\n \"compel\",\n \"rjieba\",\n \"soundfile\",\n \"librosa\",\n \"opencv-python-headless\",\n \"controlnet-aux\",\n \"mediapipe\",\n]\n\nQUALITY_REQUIRES = [\n \"black\",\n \"ruff\",\n \"isort\",\n \"hf_doc_builder @ git+https://github.com/huggingface/doc-builder.git\",\n]\n\nEXTRAS_REQUIRE = {\n \"tests\": TESTS_REQUIRE,\n \"quality\": QUALITY_REQUIRES,\n \"neuron\": [\n \"wheel\",\n \"torch-neuron==1.13.1.2.9.74.0\",\n \"torch==1.13.1.*\",\n \"neuron-cc[tensorflow]==1.22.0.0\",\n \"protobuf\",\n \"torchvision\",\n \"numpy==1.22.3\",\n ],\n \"neuronx\": [\n \"wheel\",\n \"neuronx-cc==2.15.128.0\",\n \"torch-neuronx==2.1.2.2.3.0\",\n \"transformers-neuronx==0.12.313\",\n \"torch==2.1.2.*\",\n \"torchvision==0.16.*\",\n \"neuronx_distributed==0.9.0\",\n \"libneuronxla==2.0.4115.0\",\n ],\n \"diffusers\": [\"diffusers>=0.28.0, <0.29.0\", \"peft\"],\n \"sentence-transformers\": [\"sentence-transformers >= 2.2.0\"],\n}\n\nsetup(\n name=\"optimum-neuron\",\n version=__version__,\n description=(\n \"Optimum Neuron is the interface between the Hugging Face Transformers and Diffusers libraries and AWS \"\n \"Trainium and Inferentia accelerators. It provides a set of tools enabling easy model loading, training and \"\n \"inference on single and multiple neuron core settings for different downstream tasks.\"\n ),\n long_description=open(\"README.md\", \"r\", encoding=\"utf-8\").read(),\n long_description_content_type=\"text/markdown\",\n classifiers=[\n \"Development Status :: 2 - Pre-Alpha\",\n \"License :: OSI Approved :: Apache Software License\",\n \"Intended Audience :: Developers\",\n \"Intended Audience :: Education\",\n \"Intended Audience :: Science/Research\",\n \"Operating System :: OS Independent\",\n \"Programming Language :: Python :: 3.8\",\n \"Programming Language :: Python :: 3.9\",\n \"Topic :: Scientific/Engineering :: Artificial Intelligence\",\n ],\n keywords=\"transformers, diffusers, mixed-precision training, fine-tuning, inference, tranium, inferentia, aws\",\n url=\"https://huggingface.co/hardware/aws\",\n author=\"HuggingFace Inc. Special Ops Team\",\n author_email=\"[email protected]\",\n license=\"Apache\",\n packages=find_namespace_packages(include=[\"optimum*\"]),\n install_requires=INSTALL_REQUIRES,\n extras_require=EXTRAS_REQUIRE,\n dependency_links=[\"https://pip.repos.neuron.amazonaws.com\"],\n include_package_data=True,\n zip_safe=False,\n entry_points={\n \"console_scripts\": [\n \"optimum-cli=optimum.commands.optimum_cli:main\",\n \"neuron_parallel_compile=optimum.neuron.utils.neuron_parallel_compile:main\",\n ]\n },\n)\n", ".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 6ba8b37181dc02ccfc1cc303347bc402f7f83c1f Hamza Amin <[email protected]> 1727369576 +0500\tclone: from https://github.com/huggingface/optimum-neuron.git\n", ".git\\refs\\heads\\main": "6ba8b37181dc02ccfc1cc303347bc402f7f83c1f\n", "docs\\source\\index.mdx": "<!---\nCopyright 2023 The HuggingFace Team. All rights reserved.\n\nLicensed under the Apache License, Version 2.0 (the \"License\");\nyou may not use this file except in compliance with the License.\nYou may obtain a copy of the License at\n\n http://www.apache.org/licenses/LICENSE-2.0\n\nUnless required by applicable law or agreed to in writing, software\ndistributed under the License is distributed on an \"AS IS\" BASIS,\nWITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\nSee the License for the specific language governing permissions and\nlimitations under the License.\n-->\n\n# \ud83e\udd17 Optimum Neuron\n\n\ud83e\udd17 Optimum Neuron is the interface between the \ud83e\udd17 Transformers library and AWS Accelerators including [AWS Trainium](https://aws.amazon.com/machine-learning/trainium/?nc1=h_ls) and [AWS Inferentia](https://aws.amazon.com/machine-learning/inferentia/?nc1=h_ls).\nIt provides a set of tools enabling easy model loading, training and inference on single- and multi-Accelerator settings for different downstream tasks.\nThe list of officially validated models and tasks is available [here](https://huggingface.co/docs/optimum-neuron/package_reference/configuration#supported-architectures).\n\n<div class=\"mt-10\">\n <div class=\"w-full flex flex-col space-y-4 md:space-y-0 md:grid md:grid-cols-2 md:gap-y-4 md:gap-x-5\">\n <a\n class=\"!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg\"\n href=\"./tutorials/fine_tune_bert\"\n >\n <div class=\"w-full text-center bg-gradient-to-br from-blue-400 to-blue-500 rounded-lg py-1.5 font-semibold mb-5 text-white text-lg leading-relaxed\">\n Tutorials\n </div>\n <p class=\"text-gray-700\">\n Learn the basics and become familiar with training & deploying transformers on AWS Trainium and AWS Inferentia.\n Start here if you are using \ud83e\udd17 Optimum Neuron for the first time!\n </p>\n </a>\n <a class=\"!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg\" href=\"./guides/setup_aws_instance\">\n <div class=\"w-full text-center bg-gradient-to-br from-indigo-400 to-indigo-500 rounded-lg py-1.5 font-semibold mb-5 text-white text-lg leading-relaxed\">\n How-to guides\n </div>\n <p class=\"text-gray-700\">\n Practical guides to help you achieve a specific goal. Take a look at these guides to learn how to use \ud83e\udd17 Optimum\n Neuron to solve real-world problems.\n </p>\n </a>\n <a\n class=\"!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg\"\n href=\"./package_reference/trainer\"\n >\n <div class=\"w-full text-center bg-gradient-to-br from-purple-400 to-purple-500 rounded-lg py-1.5 font-semibold mb-5 text-white text-lg leading-relaxed\">\n Reference\n </div>\n <p class=\"text-gray-700\">Technical descriptions of how the classes and methods of \ud83e\udd17 Optimum Neuron work.</p>\n </a>\n </div>\n</div>\n", "examples\\image-classification\\requirements.txt": "accelerate>=0.12.0\ndatasets>=1.17.0\nevaluate\nscikit-learn", "examples\\language-modeling\\requirements.txt": "accelerate >= 0.12.0\ndatasets >= 1.8.0\nsentencepiece != 0.1.92\nprotobuf\nevaluate\nscikit-learn\n", "examples\\multiple-choice\\requirements.txt": "accelerate >= 0.12.0\nsentencepiece != 0.1.92\nprotobuf\nevaluate\n", "examples\\question-answering\\requirements.txt": "accelerate >= 0.12.0\ndatasets >= 1.8.0\nevaluate", "examples\\summarization\\requirements.txt": "accelerate >= 0.12.0\ndatasets >= 1.8.0\nsentencepiece != 0.1.92\nprotobuf\nrouge-score\nnltk\npy7zr\nevaluate\n", "examples\\text-classification\\requirements.txt": "accelerate >= 0.12.0\ndatasets >= 1.8.0\nsentencepiece != 0.1.92\nscipy\nscikit-learn\nprotobuf\nevaluate", "examples\\token-classification\\requirements.txt": "accelerate >= 0.12.0\nseqeval\ndatasets >= 1.8.0\nevaluate", "examples\\translation\\requirements.txt": "accelerate >= 0.12.0\ndatasets >= 1.8.0\nsentencepiece != 0.1.92\nprotobuf\nsacrebleu >= 1.4.12\npy7zr\nevaluate", "optimum\\exporters\\neuron\\model_wrappers.py": "# coding=utf-8\n# Copyright 2023 The HuggingFace Team. All rights reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\"\"\"Model wrappers for Neuron export.\"\"\"\n\nfrom typing import TYPE_CHECKING, List, Optional\n\nimport torch\nfrom transformers.models.t5.modeling_t5 import T5LayerCrossAttention\n\n\nif TYPE_CHECKING:\n from transformers.modeling_utils import PreTrainedModel\n\n\nclass UnetNeuronWrapper(torch.nn.Module):\n def __init__(self, model, input_names: List[str]):\n super().__init__()\n self.model = model\n self.input_names = input_names\n\n def forward(self, *inputs):\n if len(inputs) != len(self.input_names):\n raise ValueError(\n f\"The model needs {len(self.input_names)} inputs: {self.input_names}.\"\n f\" But only {len(input)} inputs are passed.\"\n )\n\n ordered_inputs = dict(zip(self.input_names, inputs))\n\n added_cond_kwargs = {\n \"text_embeds\": ordered_inputs.pop(\"text_embeds\", None),\n \"time_ids\": ordered_inputs.pop(\"time_ids\", None),\n }\n sample = ordered_inputs.pop(\"sample\", None)\n timestep = ordered_inputs.pop(\"timestep\").float().expand((sample.shape[0],))\n encoder_hidden_states = ordered_inputs.pop(\"encoder_hidden_states\", None)\n\n # Re-build down_block_additional_residual\n down_block_additional_residuals = ()\n down_block_additional_residuals_names = [\n name for name in ordered_inputs.keys() if \"down_block_additional_residuals\" in name\n ]\n for name in down_block_additional_residuals_names:\n value = ordered_inputs.pop(name)\n down_block_additional_residuals += (value,)\n\n mid_block_additional_residual = ordered_inputs.pop(\"mid_block_additional_residual\", None)\n\n out_tuple = self.model(\n sample=sample,\n timestep=timestep,\n encoder_hidden_states=encoder_hidden_states,\n down_block_additional_residuals=(\n down_block_additional_residuals if down_block_additional_residuals else None\n ),\n mid_block_additional_residual=mid_block_additional_residual,\n added_cond_kwargs=added_cond_kwargs,\n return_dict=False,\n )\n\n return out_tuple\n\n\nclass ControlNetNeuronWrapper(torch.nn.Module):\n def __init__(self, model, input_names: List[str]):\n super().__init__()\n self.model = model\n self.input_names = input_names\n\n def forward(self, *inputs):\n if len(inputs) != len(self.input_names):\n raise ValueError(\n f\"The model needs {len(self.input_names)} inputs: {self.input_names}.\"\n f\" But only {len(input)} inputs are passed.\"\n )\n\n ordered_inputs = dict(zip(self.input_names, inputs))\n\n sample = ordered_inputs.pop(\"sample\", None)\n timestep = ordered_inputs.pop(\"timestep\", None)\n encoder_hidden_states = ordered_inputs.pop(\"encoder_hidden_states\", None)\n controlnet_cond = ordered_inputs.pop(\"controlnet_cond\", None)\n conditioning_scale = ordered_inputs.pop(\"conditioning_scale\", None)\n\n # Additional conditions for the Stable Diffusion XL UNet.\n added_cond_kwargs = {\n \"text_embeds\": ordered_inputs.pop(\"text_embeds\", None),\n \"time_ids\": ordered_inputs.pop(\"time_ids\", None),\n }\n\n out_tuple = self.model(\n sample=sample,\n timestep=timestep,\n encoder_hidden_states=encoder_hidden_states,\n controlnet_cond=controlnet_cond,\n conditioning_scale=conditioning_scale,\n added_cond_kwargs=added_cond_kwargs,\n guess_mode=False, # TODO: support guess mode of ControlNet\n return_dict=False,\n **ordered_inputs,\n )\n\n return out_tuple\n\n\n# Adapted from https://awsdocs-neuron.readthedocs-hosted.com/en/latest/src/examples/pytorch/torch-neuronx/t5-inference-tutorial.html\nclass T5EncoderWrapper(torch.nn.Module):\n \"\"\"Wrapper to trace the encoder and the kv cache initialization in the decoder.\"\"\"\n\n def __init__(\n self,\n model: \"PreTrainedModel\",\n num_beams: int = 1,\n device: str = \"xla\",\n tp_degree: Optional[int] = None,\n ):\n super().__init__()\n self.model = model\n self.config = model.config\n self.num_beams = num_beams\n self.device = device\n self.tp_degree = tp_degree\n\n def forward(self, input_ids, attention_mask):\n # Infer shapes\n batch_size = input_ids.shape[0]\n sequence_length = input_ids.shape[1]\n\n encoder_output = self.model.encoder(\n input_ids=input_ids, attention_mask=attention_mask, output_attentions=False, output_hidden_states=False\n )\n\n last_hidden_state = encoder_output[\"last_hidden_state\"]\n encoder_hidden_states = torch.concat(\n [tensor.unsqueeze(0).repeat(self.num_beams, 1, 1) for tensor in last_hidden_state]\n )\n\n decoder_blocks = self.model.decoder.block\n present_key_value_states_sa = []\n present_key_value_states_ca = []\n\n for block in decoder_blocks:\n # Cross attention has to be initialized with the encoder hidden state\n cross_attention: T5LayerCrossAttention = block.layer[1]\n attention = cross_attention.EncDecAttention\n\n def shape(states):\n \"\"\"projection\"\"\"\n return states.view(\n self.num_beams * batch_size, -1, self.config.num_heads, attention.key_value_proj_dim\n ).transpose(1, 2)\n\n key_states = shape(attention.k(encoder_hidden_states))\n value_states = shape(attention.v(encoder_hidden_states))\n\n # cross_attn_kv_state\n present_key_value_states_ca.append(key_states)\n present_key_value_states_ca.append(value_states)\n\n # Self attention kv states are initialized to zeros. This is done to keep the size of the kv cache tensor constant.\n # The kv cache is padded here to keep a fixed shape.\n # [key states]\n present_key_value_states_sa.append(\n torch.zeros(\n (self.num_beams * batch_size, self.config.num_heads, sequence_length - 1, self.config.d_kv),\n dtype=torch.float32,\n device=self.device,\n )\n )\n # [value states]\n present_key_value_states_sa.append(\n torch.zeros(\n (self.num_beams * batch_size, self.config.num_heads, sequence_length - 1, self.config.d_kv),\n dtype=torch.float32,\n device=self.device,\n )\n )\n\n return present_key_value_states_sa + present_key_value_states_ca\n\n\n# Adapted from https://awsdocs-neuron.readthedocs-hosted.com/en/latest/src/examples/pytorch/torch-neuronx/t5-inference-tutorial.html\nclass T5DecoderWrapper(torch.nn.Module):\n \"\"\"Wrapper to trace the decoder with past keys values with a language head.\"\"\"\n\n def __init__(\n self,\n model: \"PreTrainedModel\",\n batch_size: int,\n sequence_length: int,\n num_beams: int = 1,\n output_hidden_states: bool = False,\n output_attentions: bool = False,\n device: str = \"xla\",\n tp_degree: Optional[int] = None,\n ):\n super().__init__()\n self.model = model\n self.config = model.config\n self.batch_size = batch_size\n self.sequence_length = sequence_length\n self.num_beams = num_beams\n self.output_hidden_states = output_hidden_states\n self.output_attentions = output_attentions\n self.device = device\n self.tp_degree = tp_degree\n\n # Initialize KV cache (num_beams, n_heads, seq_length, dim_per_head)\n if device == \"cpu\":\n self.past_key_values_sa = [\n torch.ones(\n (num_beams, self.config.num_heads, self.sequence_length - 1, self.config.d_kv), dtype=torch.float32\n )\n for _ in range(self.config.num_decoder_layers * 2)\n ]\n self.past_key_values_ca = [\n torch.ones(\n (num_beams, self.config.num_heads, self.sequence_length, self.config.d_kv), dtype=torch.float32\n )\n for _ in range(self.config.num_decoder_layers * 2)\n ]\n elif device == \"xla\":\n self.past_key_values_sa = torch.nn.ParameterList(\n [\n torch.nn.Parameter(\n torch.ones(\n (\n self.batch_size * self.num_beams,\n self.config.num_heads,\n sequence_length - 1,\n self.config.d_kv,\n ),\n dtype=torch.float32,\n ),\n requires_grad=False,\n )\n for _ in range(self.config.num_decoder_layers * 2)\n ]\n )\n self.past_key_values_ca = torch.nn.ParameterList(\n [\n torch.nn.Parameter(\n torch.ones(\n (\n self.batch_size * self.num_beams,\n self.config.num_heads,\n sequence_length,\n self.config.d_kv,\n ),\n dtype=torch.float32,\n ),\n requires_grad=False,\n )\n for _ in range(self.config.num_decoder_layers * 2)\n ]\n )\n\n def update_past(self, past_key_values):\n new_past_sa = []\n new_past_ca = []\n for past_layer in past_key_values:\n new_past_layer = list(past_layer)\n for i in range(len(new_past_layer[:2])):\n new_past_layer[i] = past_layer[i][:, :, 1:]\n new_past_sa += [\n new_past_layer[:2],\n ]\n new_past_ca += [\n new_past_layer[2:],\n ]\n return new_past_sa, new_past_ca\n\n def reorder_cache(self, past_key_values, beam_idx):\n for i in range(len(past_key_values)):\n gather_index = beam_idx.view([beam_idx.shape[0], 1, 1, 1]).expand_as(past_key_values[i])\n past_key_values[i] = torch.gather(past_key_values[i], dim=0, index=gather_index)\n return past_key_values\n\n def forward(\n self,\n input_ids,\n decoder_attention_mask,\n encoder_hidden_states,\n encoder_attention_mask,\n beam_idx,\n beam_scores,\n **kwargs,\n ):\n if self.num_beams > 1:\n # We reorder the cache based on the beams selected in each iteration. Required step for beam search.\n past_key_values_sa = self.reorder_cache(self.past_key_values_sa, beam_idx)\n past_key_values_ca = self.reorder_cache(self.past_key_values_ca, beam_idx)\n else:\n # We do not need to reorder for greedy sampling\n past_key_values_sa = self.past_key_values_sa\n past_key_values_ca = self.past_key_values_ca\n\n # The cache is stored in a flatten form. We order the cache per layer before passing it to the decoder.\n # Each layer has 4 tensors, so we group by 4.\n past_key_values = [\n [*past_key_values_sa[i * 2 : i * 2 + 2], *past_key_values_ca[i * 2 : i * 2 + 2]]\n for i in range(0, int(len(past_key_values_ca) / 2))\n ]\n\n decoder_output = self.model.decoder(\n input_ids=input_ids,\n attention_mask=decoder_attention_mask,\n past_key_values=past_key_values,\n encoder_hidden_states=encoder_hidden_states,\n encoder_attention_mask=encoder_attention_mask,\n use_cache=True,\n output_attentions=self.output_attentions,\n output_hidden_states=self.output_hidden_states,\n )\n\n last_hidden_state = decoder_output[\"last_hidden_state\"]\n past_key_values = decoder_output[\"past_key_values\"]\n if self.output_hidden_states:\n decoder_hidden_states = list(\n decoder_output[\"hidden_states\"]\n ) # flatten `hidden_states` which is a tuple of tensors\n\n if self.output_attentions:\n decoder_attentions = list(\n decoder_output[\"attentions\"]\n ) # flatten `decoder_attentions` which is a tuple of tensors\n cross_attentions = list(\n decoder_output[\"cross_attentions\"]\n ) # flatten `cross_attentions` which is a tuple of tensors\n\n if self.config.tie_word_embeddings:\n # Rescale output before projecting on vocab\n # See https://github.com/tensorflow/mesh/blob/fa19d69eafc9a482aff0b59ddd96b025c0cb207d/mesh_tensorflow/transformer/transformer.py#L586\n last_hidden_state = last_hidden_state * (self.model.config.d_model**-0.5)\n\n lm_logits = self.model.lm_head(last_hidden_state)\n\n past_key_values_sa, past_key_values_ca = self.update_past(past_key_values)\n\n # We flatten the cache to a single array. This is required for the input output aliasing to work\n past_key_values_sa = [vec for kv_per_layer in past_key_values_sa for vec in kv_per_layer]\n past_key_values_ca = [vec for kv_per_layer in past_key_values_ca for vec in kv_per_layer]\n\n if self.device == \"cpu\":\n self.past_key_values_sa = past_key_values_sa\n self.past_key_values_ca = past_key_values_ca\n\n # We calculate topk inside the wrapper\n next_token_logits = lm_logits[:, -1, :]\n\n if self.num_beams > 1:\n # This section of beam search is run outside the decoder in the huggingface t5 implementation.\n # To maximize the computation within the neuron device, we move this within the wrapper\n logit_max, _ = torch.max(next_token_logits, dim=-1, keepdim=True)\n logsumexp = torch.log(torch.exp(next_token_logits - logit_max).sum(dim=-1, keepdim=True))\n next_token_scores = next_token_logits - logit_max - logsumexp\n next_token_scores = next_token_scores + beam_scores[:, None].expand_as(next_token_scores)\n\n # reshape for beam search\n vocab_size = next_token_scores.shape[-1]\n next_token_scores = next_token_scores.view(self.batch_size, self.num_beams * vocab_size)\n next_token_scores = next_token_scores * 1\n\n # Sample 2 next tokens for each beam (so we have some spare tokens and match output of beam search)\n next_token_scores, next_tokens = torch.topk(\n next_token_scores, 2 * self.num_beams, dim=1, largest=True, sorted=True\n )\n\n next_indices = torch.div(next_tokens, vocab_size, rounding_mode=\"floor\")\n next_tokens = next_tokens % vocab_size\n\n neuron_outputs = [next_token_scores, next_tokens, next_indices] + past_key_values_sa + past_key_values_ca\n\n else:\n # Greedy\n next_tokens = torch.argmax(next_token_logits, dim=-1)\n\n neuron_outputs = [next_tokens] + past_key_values_sa + past_key_values_ca\n\n if self.output_hidden_states:\n neuron_outputs += decoder_hidden_states\n\n if self.output_attentions:\n neuron_outputs += decoder_attentions\n neuron_outputs += cross_attentions\n\n return neuron_outputs\n\n\nclass SentenceTransformersTransformerNeuronWrapper(torch.nn.Module):\n def __init__(self, model, input_names: List[str]):\n super().__init__()\n self.model = model\n self.input_names = input_names\n\n def forward(self, input_ids, attention_mask):\n out_tuple = self.model({\"input_ids\": input_ids, \"attention_mask\": attention_mask})\n\n return out_tuple[\"token_embeddings\"], out_tuple[\"sentence_embedding\"]\n\n\nclass SentenceTransformersCLIPNeuronWrapper(torch.nn.Module):\n def __init__(self, model, input_names: List[str]):\n super().__init__()\n self.model = model\n self.input_names = input_names\n\n def forward(self, input_ids, pixel_values, attention_mask):\n vision_outputs = self.model[0].model.vision_model(pixel_values=pixel_values)\n image_embeds = self.model[0].model.visual_projection(vision_outputs[1])\n\n text_outputs = self.model[0].model.text_model(\n input_ids=input_ids,\n attention_mask=attention_mask,\n )\n text_embeds = self.model[0].model.text_projection(text_outputs[1])\n\n if len(self.model) > 1:\n image_embeds = self.model[1:](image_embeds)\n text_embeds = self.model[1:](text_embeds)\n\n return (text_embeds, image_embeds)\n\n\nclass NoCacheModelWrapper(torch.nn.Module):\n def __init__(self, model: \"PreTrainedModel\", input_names: List[str]):\n super().__init__()\n self.model = model\n self.input_names = input_names\n\n def forward(self, *input):\n ordered_inputs = dict(zip(self.input_names, input))\n outputs = self.model(use_cache=False, **ordered_inputs)\n\n return outputs\n", "optimum\\exporters\\neuron\\__main__.py": "# coding=utf-8\n# Copyright 2023 The HuggingFace Team. All rights reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\"\"\"Entry point to the optimum.exporters.neuron command line.\"\"\"\n\nimport argparse\nimport inspect\nimport os\nfrom argparse import ArgumentParser\nfrom pathlib import Path\nfrom typing import TYPE_CHECKING, Any, Dict, List, Optional, Union\n\nfrom requests.exceptions import ConnectionError as RequestsConnectionError\nfrom transformers import AutoConfig, AutoTokenizer, PretrainedConfig\n\nfrom ...neuron.utils import (\n DECODER_NAME,\n DIFFUSION_MODEL_CONTROLNET_NAME,\n DIFFUSION_MODEL_TEXT_ENCODER_2_NAME,\n DIFFUSION_MODEL_TEXT_ENCODER_NAME,\n DIFFUSION_MODEL_UNET_NAME,\n DIFFUSION_MODEL_VAE_DECODER_NAME,\n DIFFUSION_MODEL_VAE_ENCODER_NAME,\n ENCODER_NAME,\n NEURON_FILE_NAME,\n is_neuron_available,\n is_neuronx_available,\n)\nfrom ...neuron.utils.misc import maybe_save_preprocessors\nfrom ...neuron.utils.version_utils import (\n check_compiler_compatibility_for_stable_diffusion,\n)\nfrom ...utils import is_diffusers_available, logging\nfrom ..error_utils import AtolError, OutputMatchError, ShapeError\nfrom ..tasks import TasksManager\nfrom .base import NeuronConfig, NeuronDecoderConfig\nfrom .convert import export_models, validate_models_outputs\nfrom .model_configs import * # noqa: F403\nfrom .utils import (\n build_stable_diffusion_components_mandatory_shapes,\n check_mandatory_input_shapes,\n get_encoder_decoder_models_for_export,\n get_stable_diffusion_models_for_export,\n replace_stable_diffusion_submodels,\n)\n\n\nif is_neuron_available():\n from ...commands.export.neuron import parse_args_neuron\n\n NEURON_COMPILER = \"Neuron\"\n\n\nif is_neuronx_available():\n from ...commands.export.neuronx import parse_args_neuronx as parse_args_neuron # noqa: F811\n\n NEURON_COMPILER = \"Neuronx\"\n\nif is_diffusers_available():\n from diffusers import StableDiffusionXLPipeline\n\n\nif TYPE_CHECKING:\n from transformers import PreTrainedModel\n\n if is_diffusers_available():\n from diffusers import DiffusionPipeline, ModelMixin, StableDiffusionPipeline\n\n\nlogger = logging.get_logger()\nlogger.setLevel(logging.INFO)\n\n\ndef infer_compiler_kwargs(args: argparse.Namespace) -> Dict[str, Any]:\n # infer compiler kwargs\n auto_cast = None if args.auto_cast == \"none\" else args.auto_cast\n auto_cast_type = None if auto_cast is None else args.auto_cast_type\n compiler_kwargs = {\"auto_cast\": auto_cast, \"auto_cast_type\": auto_cast_type}\n if hasattr(args, \"disable_fast_relayout\"):\n compiler_kwargs[\"disable_fast_relayout\"] = getattr(args, \"disable_fast_relayout\")\n if hasattr(args, \"disable_fallback\"):\n compiler_kwargs[\"disable_fallback\"] = getattr(args, \"disable_fallback\")\n\n return compiler_kwargs\n\n\ndef infer_task(task: str, model_name_or_path: str) -> str:\n if task == \"auto\":\n try:\n task = TasksManager.infer_task_from_model(model_name_or_path)\n except KeyError as e:\n raise KeyError(\n \"The task could not be automatically inferred. Please provide the argument --task with the task \"\n f\"from {', '.join(TasksManager.get_all_tasks())}. Detailed error: {e}\"\n )\n except RequestsConnectionError as e:\n raise RequestsConnectionError(\n f\"The task could not be automatically inferred as this is available only for models hosted on the Hugging Face Hub. Please provide the argument --task with the relevant task from {', '.join(TasksManager.get_all_tasks())}. Detailed error: {e}\"\n )\n return task\n\n\n# This function is not applicable for diffusers / sentence transformers models\ndef get_input_shapes_and_config_class(task: str, args: argparse.Namespace) -> Dict[str, int]:\n neuron_config_constructor = get_neuron_config_class(task, args.model)\n input_args = neuron_config_constructor.func.get_input_args_for_task(task)\n input_shapes = {name: getattr(args, name) for name in input_args}\n return input_shapes, neuron_config_constructor.func\n\n\ndef get_neuron_config_class(task: str, model_id: str) -> NeuronConfig:\n config = AutoConfig.from_pretrained(model_id)\n\n model_type = config.model_type.replace(\"_\", \"-\")\n if config.is_encoder_decoder:\n model_type = model_type + \"-encoder\"\n\n neuron_config_constructor = TasksManager.get_exporter_config_constructor(\n model_type=model_type,\n exporter=\"neuron\",\n task=task,\n library_name=\"transformers\",\n )\n return neuron_config_constructor\n\n\ndef normalize_sentence_transformers_input_shapes(args: argparse.Namespace) -> Dict[str, int]:\n args = vars(args) if isinstance(args, argparse.Namespace) else args\n if \"clip\" in args.get(\"model\", \"\").lower():\n mandatory_axes = {\"text_batch_size\", \"image_batch_size\", \"sequence_length\", \"num_channels\", \"width\", \"height\"}\n else:\n mandatory_axes = {\"batch_size\", \"sequence_length\"}\n\n if not mandatory_axes.issubset(set(args.keys())):\n raise AttributeError(\n f\"Shape of {mandatory_axes} are mandatory for neuron compilation, while {mandatory_axes.difference(args.keys())} are not given.\"\n )\n mandatory_shapes = {name: args[name] for name in mandatory_axes}\n return mandatory_shapes\n\n\ndef customize_optional_outputs(args: argparse.Namespace) -> Dict[str, bool]:\n \"\"\"\n Customize optional outputs of the traced model, eg. if `output_attentions=True`, the attentions tensors will be traced.\n \"\"\"\n possible_outputs = [\"output_attentions\", \"output_hidden_states\"]\n\n customized_outputs = {}\n for name in possible_outputs:\n customized_outputs[name] = getattr(args, name, False)\n return customized_outputs\n\n\ndef parse_optlevel(args: argparse.Namespace) -> Dict[str, bool]:\n \"\"\"\n (NEURONX ONLY) Parse the level of optimization the compiler should perform. If not specified apply `O2`(the best balance between model performance and compile time).\n \"\"\"\n if is_neuronx_available():\n if args.O1:\n optlevel = \"1\"\n elif args.O2:\n optlevel = \"2\"\n elif args.O3:\n optlevel = \"3\"\n else:\n optlevel = \"2\"\n else:\n optlevel = None\n return optlevel\n\n\ndef normalize_stable_diffusion_input_shapes(\n args: argparse.Namespace,\n) -> Dict[str, Dict[str, int]]:\n args = vars(args) if isinstance(args, argparse.Namespace) else args\n mandatory_axes = set(getattr(inspect.getfullargspec(build_stable_diffusion_components_mandatory_shapes), \"args\"))\n # Remove `sequence_length` as diffusers will pad it to the max and remove number of channels.\n mandatory_axes = mandatory_axes - {\n \"sequence_length\",\n \"unet_num_channels\",\n \"vae_encoder_num_channels\",\n \"vae_decoder_num_channels\",\n \"num_images_per_prompt\", # default to 1\n }\n if not mandatory_axes.issubset(set(args.keys())):\n raise AttributeError(\n f\"Shape of {mandatory_axes} are mandatory for neuron compilation, while {mandatory_axes.difference(args.keys())} are not given.\"\n )\n mandatory_shapes = {name: args[name] for name in mandatory_axes}\n mandatory_shapes[\"num_images_per_prompt\"] = args.get(\"num_images_per_prompt\", 1)\n input_shapes = build_stable_diffusion_components_mandatory_shapes(**mandatory_shapes)\n return input_shapes\n\n\ndef infer_stable_diffusion_shapes_from_diffusers(\n input_shapes: Dict[str, Dict[str, int]],\n model: Union[\"StableDiffusionPipeline\", \"StableDiffusionXLPipeline\"],\n has_controlnets: bool,\n):\n if model.tokenizer is not None:\n sequence_length = model.tokenizer.model_max_length\n elif hasattr(model, \"tokenizer_2\") and model.tokenizer_2 is not None:\n sequence_length = model.tokenizer_2.model_max_length\n else:\n raise AttributeError(f\"Cannot infer sequence_length from {type(model)} as there is no tokenizer as attribute.\")\n unet_num_channels = model.unet.config.in_channels\n vae_encoder_num_channels = model.vae.config.in_channels\n vae_decoder_num_channels = model.vae.config.latent_channels\n vae_scale_factor = 2 ** (len(model.vae.config.block_out_channels) - 1) or 8\n height = input_shapes[\"unet\"][\"height\"]\n scaled_height = height // vae_scale_factor\n width = input_shapes[\"unet\"][\"width\"]\n scaled_width = width // vae_scale_factor\n\n input_shapes[\"text_encoder\"].update({\"sequence_length\": sequence_length})\n if hasattr(model, \"text_encoder_2\"):\n input_shapes[\"text_encoder_2\"] = input_shapes[\"text_encoder\"]\n input_shapes[\"unet\"].update(\n {\n \"sequence_length\": sequence_length,\n \"num_channels\": unet_num_channels,\n \"height\": scaled_height,\n \"width\": scaled_width,\n }\n )\n input_shapes[\"unet\"][\"vae_scale_factor\"] = vae_scale_factor\n input_shapes[\"vae_encoder\"].update({\"num_channels\": vae_encoder_num_channels, \"height\": height, \"width\": width})\n input_shapes[\"vae_decoder\"].update(\n {\"num_channels\": vae_decoder_num_channels, \"height\": scaled_height, \"width\": scaled_width}\n )\n\n # ControlNet\n if has_controlnets:\n encoder_hidden_size = model.text_encoder.config.hidden_size\n if hasattr(model, \"text_encoder_2\"):\n encoder_hidden_size += model.text_encoder_2.config.hidden_size\n input_shapes[\"controlnet\"] = {\n \"batch_size\": input_shapes[\"unet\"][\"batch_size\"],\n \"sequence_length\": sequence_length,\n \"num_channels\": unet_num_channels,\n \"height\": scaled_height,\n \"width\": scaled_width,\n \"vae_scale_factor\": vae_scale_factor,\n \"encoder_hidden_size\": encoder_hidden_size,\n }\n\n return input_shapes\n\n\ndef get_submodels_and_neuron_configs(\n model: Union[\"PreTrainedModel\", \"DiffusionPipeline\"],\n input_shapes: Dict[str, int],\n task: str,\n output: Path,\n library_name: str,\n subfolder: str = \"\",\n dynamic_batch_size: bool = False,\n model_name_or_path: Optional[Union[str, Path]] = None,\n submodels: Optional[Dict[str, Union[Path, str]]] = None,\n output_attentions: bool = False,\n output_hidden_states: bool = False,\n lora_model_ids: Optional[Union[str, List[str]]] = None,\n lora_weight_names: Optional[Union[str, List[str]]] = None,\n lora_adapter_names: Optional[Union[str, List[str]]] = None,\n lora_scales: Optional[Union[float, List[float]]] = None,\n controlnet_ids: Optional[Union[str, List[str]]] = None,\n):\n is_encoder_decoder = (\n getattr(model.config, \"is_encoder_decoder\", False) if isinstance(model.config, PretrainedConfig) else False\n )\n\n if library_name == \"diffusers\":\n # TODO: Enable optional outputs for Stable Diffusion\n if output_attentions:\n raise ValueError(f\"`output_attentions`is not supported by the {task} task yet.\")\n models_and_neuron_configs, output_model_names = _get_submodels_and_neuron_configs_for_stable_diffusion(\n model=model,\n input_shapes=input_shapes,\n output=output,\n dynamic_batch_size=dynamic_batch_size,\n submodels=submodels,\n output_hidden_states=output_hidden_states,\n lora_model_ids=lora_model_ids,\n lora_weight_names=lora_weight_names,\n lora_adapter_names=lora_adapter_names,\n lora_scales=lora_scales,\n controlnet_ids=controlnet_ids,\n )\n elif is_encoder_decoder:\n optional_outputs = {\"output_attentions\": output_attentions, \"output_hidden_states\": output_hidden_states}\n models_and_neuron_configs, output_model_names = _get_submodels_and_neuron_configs_for_encoder_decoder(\n model, input_shapes, task, output, dynamic_batch_size, model_name_or_path, **optional_outputs\n )\n else:\n # TODO: Enable optional outputs for encoders\n if output_attentions or output_hidden_states:\n raise ValueError(\n f\"`output_attentions` and `output_hidden_states` are not supported by the {task} task yet.\"\n )\n neuron_config_constructor = TasksManager.get_exporter_config_constructor(\n model=model,\n exporter=\"neuron\",\n task=task,\n library_name=library_name,\n )\n input_shapes = check_mandatory_input_shapes(neuron_config_constructor, task, input_shapes)\n neuron_config = neuron_config_constructor(model.config, dynamic_batch_size=dynamic_batch_size, **input_shapes)\n model_name = getattr(model, \"name_or_path\", None) or model_name_or_path\n model_name = model_name.split(\"/\")[-1] if model_name else model.config.model_type\n output_model_names = {model_name: \"model.neuron\"}\n models_and_neuron_configs = {model_name: (model, neuron_config)}\n maybe_save_preprocessors(model_name_or_path, output, src_subfolder=subfolder)\n return models_and_neuron_configs, output_model_names\n\n\ndef _normalize_lora_params(lora_model_ids, lora_weight_names, lora_adapter_names, lora_scales):\n if isinstance(lora_model_ids, str):\n lora_model_ids = [\n lora_model_ids,\n ]\n if isinstance(lora_weight_names, str):\n lora_weight_names = [\n lora_weight_names,\n ]\n if isinstance(lora_adapter_names, str):\n lora_adapter_names = [\n lora_adapter_names,\n ]\n if isinstance(lora_scales, float):\n lora_scales = [\n lora_scales,\n ]\n return lora_model_ids, lora_weight_names, lora_adapter_names, lora_scales\n\n\ndef _get_submodels_and_neuron_configs_for_stable_diffusion(\n model: Union[\"PreTrainedModel\", \"DiffusionPipeline\"],\n input_shapes: Dict[str, int],\n output: Path,\n dynamic_batch_size: bool = False,\n submodels: Optional[Dict[str, Union[Path, str]]] = None,\n output_hidden_states: bool = False,\n lora_model_ids: Optional[Union[str, List[str]]] = None,\n lora_weight_names: Optional[Union[str, List[str]]] = None,\n lora_adapter_names: Optional[Union[str, List[str]]] = None,\n lora_scales: Optional[Union[float, List[float]]] = None,\n controlnet_ids: Optional[Union[str, List[str]]] = None,\n):\n check_compiler_compatibility_for_stable_diffusion()\n model = replace_stable_diffusion_submodels(model, submodels)\n if is_neuron_available():\n raise RuntimeError(\n \"Stable diffusion export is not supported by neuron-cc on inf1, please use neuronx-cc on either inf2/trn1 instead.\"\n )\n input_shapes = infer_stable_diffusion_shapes_from_diffusers(\n input_shapes=input_shapes,\n model=model,\n has_controlnets=controlnet_ids is not None,\n )\n\n # Saving the model config and preprocessor as this is needed sometimes.\n model.scheduler.save_pretrained(output.joinpath(\"scheduler\"))\n if getattr(model, \"tokenizer\", None) is not None:\n model.tokenizer.save_pretrained(output.joinpath(\"tokenizer\"))\n if getattr(model, \"tokenizer_2\", None) is not None:\n model.tokenizer_2.save_pretrained(output.joinpath(\"tokenizer_2\"))\n if getattr(model, \"feature_extractor\", None) is not None:\n model.feature_extractor.save_pretrained(output.joinpath(\"feature_extractor\"))\n model.save_config(output)\n\n lora_model_ids, lora_weight_names, lora_adapter_names, lora_scales = _normalize_lora_params(\n lora_model_ids, lora_weight_names, lora_adapter_names, lora_scales\n )\n models_and_neuron_configs = get_stable_diffusion_models_for_export(\n pipeline=model,\n text_encoder_input_shapes=input_shapes[\"text_encoder\"],\n unet_input_shapes=input_shapes[\"unet\"],\n vae_encoder_input_shapes=input_shapes[\"vae_encoder\"],\n vae_decoder_input_shapes=input_shapes[\"vae_decoder\"],\n dynamic_batch_size=dynamic_batch_size,\n output_hidden_states=output_hidden_states,\n lora_model_ids=lora_model_ids,\n lora_weight_names=lora_weight_names,\n lora_adapter_names=lora_adapter_names,\n lora_scales=lora_scales,\n controlnet_ids=controlnet_ids,\n controlnet_input_shapes=input_shapes.get(\"controlnet\", None),\n )\n output_model_names = {\n DIFFUSION_MODEL_UNET_NAME: os.path.join(DIFFUSION_MODEL_UNET_NAME, NEURON_FILE_NAME),\n DIFFUSION_MODEL_VAE_ENCODER_NAME: os.path.join(DIFFUSION_MODEL_VAE_ENCODER_NAME, NEURON_FILE_NAME),\n DIFFUSION_MODEL_VAE_DECODER_NAME: os.path.join(DIFFUSION_MODEL_VAE_DECODER_NAME, NEURON_FILE_NAME),\n }\n if getattr(model, \"text_encoder\", None) is not None:\n output_model_names[DIFFUSION_MODEL_TEXT_ENCODER_NAME] = os.path.join(\n DIFFUSION_MODEL_TEXT_ENCODER_NAME, NEURON_FILE_NAME\n )\n if getattr(model, \"text_encoder_2\", None) is not None:\n output_model_names[DIFFUSION_MODEL_TEXT_ENCODER_2_NAME] = os.path.join(\n DIFFUSION_MODEL_TEXT_ENCODER_2_NAME, NEURON_FILE_NAME\n )\n\n # ControlNet models\n if controlnet_ids:\n if isinstance(controlnet_ids, str):\n controlnet_ids = [controlnet_ids]\n for idx in range(len(controlnet_ids)):\n controlnet_name = DIFFUSION_MODEL_CONTROLNET_NAME + \"_\" + str(idx)\n output_model_names[controlnet_name] = os.path.join(controlnet_name, NEURON_FILE_NAME)\n\n del model\n\n return models_and_neuron_configs, output_model_names\n\n\ndef _get_submodels_and_neuron_configs_for_encoder_decoder(\n model: \"PreTrainedModel\",\n input_shapes: Dict[str, int],\n task: str,\n output: Path,\n dynamic_batch_size: bool = False,\n model_name_or_path: Optional[Union[str, Path]] = None,\n output_attentions: bool = False,\n output_hidden_states: bool = False,\n):\n if is_neuron_available():\n raise RuntimeError(\n \"Encoder-decoder models export is not supported by neuron-cc on inf1, please use neuronx-cc on either inf2/trn1 instead.\"\n )\n\n models_and_neuron_configs = get_encoder_decoder_models_for_export(\n model=model,\n task=task,\n dynamic_batch_size=dynamic_batch_size,\n input_shapes=input_shapes,\n output_attentions=output_attentions,\n output_hidden_states=output_hidden_states,\n )\n output_model_names = {\n ENCODER_NAME: os.path.join(ENCODER_NAME, NEURON_FILE_NAME),\n DECODER_NAME: os.path.join(DECODER_NAME, NEURON_FILE_NAME),\n }\n maybe_save_preprocessors(model_name_or_path, output)\n\n return models_and_neuron_configs, output_model_names\n\n\ndef load_models_and_neuron_configs(\n model_name_or_path: str,\n output: Path,\n model: Optional[Union[\"PreTrainedModel\", \"ModelMixin\"]],\n task: str,\n dynamic_batch_size: bool,\n cache_dir: Optional[str],\n trust_remote_code: bool,\n subfolder: str,\n revision: str,\n library_name: str,\n force_download: bool,\n local_files_only: bool,\n token: Optional[Union[bool, str]],\n submodels: Optional[Dict[str, Union[Path, str]]],\n lora_model_ids: Optional[Union[str, List[str]]],\n lora_weight_names: Optional[Union[str, List[str]]],\n lora_adapter_names: Optional[Union[str, List[str]]],\n lora_scales: Optional[Union[float, List[float]]],\n controlnet_ids: Optional[Union[str, List[str]]] = None,\n output_attentions: bool = False,\n output_hidden_states: bool = False,\n **input_shapes,\n):\n model_kwargs = {\n \"task\": task,\n \"model_name_or_path\": model_name_or_path,\n \"subfolder\": subfolder,\n \"revision\": revision,\n \"cache_dir\": cache_dir,\n \"token\": token,\n \"local_files_only\": local_files_only,\n \"force_download\": force_download,\n \"trust_remote_code\": trust_remote_code,\n \"framework\": \"pt\",\n \"library_name\": library_name,\n }\n if model is None:\n model = TasksManager.get_model_from_task(**model_kwargs)\n\n models_and_neuron_configs, output_model_names = get_submodels_and_neuron_configs(\n model=model,\n input_shapes=input_shapes,\n task=task,\n library_name=library_name,\n output=output,\n subfolder=subfolder,\n dynamic_batch_size=dynamic_batch_size,\n model_name_or_path=model_name_or_path,\n submodels=submodels,\n output_attentions=output_attentions,\n output_hidden_states=output_hidden_states,\n lora_model_ids=lora_model_ids,\n lora_weight_names=lora_weight_names,\n lora_adapter_names=lora_adapter_names,\n lora_scales=lora_scales,\n controlnet_ids=controlnet_ids,\n )\n\n return models_and_neuron_configs, output_model_names\n\n\ndef main_export(\n model_name_or_path: str,\n output: Union[str, Path],\n compiler_kwargs: Dict[str, Any],\n model: Optional[Union[\"PreTrainedModel\", \"ModelMixin\"]] = None,\n task: str = \"auto\",\n dynamic_batch_size: bool = False,\n atol: Optional[float] = None,\n cache_dir: Optional[str] = None,\n disable_neuron_cache: Optional[bool] = False,\n compiler_workdir: Optional[Union[str, Path]] = None,\n inline_weights_to_neff: bool = True,\n optlevel: str = \"2\",\n trust_remote_code: bool = False,\n subfolder: str = \"\",\n revision: str = \"main\",\n force_download: bool = False,\n local_files_only: bool = False,\n token: Optional[Union[bool, str]] = None,\n do_validation: bool = True,\n submodels: Optional[Dict[str, Union[Path, str]]] = None,\n output_attentions: bool = False,\n output_hidden_states: bool = False,\n library_name: Optional[str] = None,\n lora_model_ids: Optional[Union[str, List[str]]] = None,\n lora_weight_names: Optional[Union[str, List[str]]] = None,\n lora_adapter_names: Optional[Union[str, List[str]]] = None,\n lora_scales: Optional[Union[float, List[float]]] = None,\n controlnet_ids: Optional[Union[str, List[str]]] = None,\n **input_shapes,\n):\n output = Path(output)\n if not output.parent.exists():\n output.parent.mkdir(parents=True)\n\n task = TasksManager.map_from_synonym(task)\n if library_name is None:\n library_name = TasksManager.infer_library_from_model(\n model_name_or_path, revision=revision, cache_dir=cache_dir, token=token\n )\n\n models_and_neuron_configs, output_model_names = load_models_and_neuron_configs(\n model_name_or_path=model_name_or_path,\n output=output,\n model=model,\n task=task,\n dynamic_batch_size=dynamic_batch_size,\n cache_dir=cache_dir,\n trust_remote_code=trust_remote_code,\n subfolder=subfolder,\n revision=revision,\n library_name=library_name,\n force_download=force_download,\n local_files_only=local_files_only,\n token=token,\n submodels=submodels,\n output_attentions=output_attentions,\n output_hidden_states=output_hidden_states,\n lora_model_ids=lora_model_ids,\n lora_weight_names=lora_weight_names,\n lora_adapter_names=lora_adapter_names,\n lora_scales=lora_scales,\n controlnet_ids=controlnet_ids,\n **input_shapes,\n )\n\n _, neuron_outputs = export_models(\n models_and_neuron_configs=models_and_neuron_configs,\n output_dir=output,\n disable_neuron_cache=disable_neuron_cache,\n compiler_workdir=compiler_workdir,\n inline_weights_to_neff=inline_weights_to_neff,\n optlevel=optlevel,\n output_file_names=output_model_names,\n compiler_kwargs=compiler_kwargs,\n model_name_or_path=model_name_or_path,\n )\n\n # Validate compiled model\n if do_validation is True:\n if library_name == \"diffusers\":\n # Do not validate vae encoder due to the sampling randomness\n neuron_outputs.pop(\"vae_encoder\")\n models_and_neuron_configs.pop(\"vae_encoder\", None)\n output_model_names.pop(\"vae_encoder\", None)\n\n try:\n validate_models_outputs(\n models_and_neuron_configs=models_and_neuron_configs,\n neuron_named_outputs=neuron_outputs,\n output_dir=output,\n atol=atol,\n neuron_files_subpaths=output_model_names,\n )\n\n logger.info(\n f\"The {NEURON_COMPILER} export succeeded and the exported model was saved at: \" f\"{output.as_posix()}\"\n )\n except ShapeError as e:\n raise e\n except AtolError as e:\n logger.warning(\n f\"The {NEURON_COMPILER} export succeeded with the warning: {e}.\\n The exported model was saved at: \"\n f\"{output.as_posix()}\"\n )\n except OutputMatchError as e:\n logger.warning(\n f\"The {NEURON_COMPILER} export succeeded with the warning: {e}.\\n The exported model was saved at: \"\n f\"{output.as_posix()}\"\n )\n except Exception as e:\n logger.error(\n f\"An error occured with the error message: {e}.\\n The exported model was saved at: \"\n f\"{output.as_posix()}\"\n )\n\n\ndef decoder_export(\n model_name_or_path: str,\n output: Union[str, Path],\n trust_remote_code: Optional[bool] = None,\n **kwargs,\n):\n from ...neuron import NeuronModelForCausalLM\n\n output = Path(output)\n if not output.parent.exists():\n output.parent.mkdir(parents=True)\n\n model = NeuronModelForCausalLM.from_pretrained(\n model_name_or_path, export=True, trust_remote_code=trust_remote_code, **kwargs\n )\n model.save_pretrained(output)\n try:\n tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, trust_remote_code=trust_remote_code)\n tokenizer.save_pretrained(output)\n except Exception:\n logger.warning(f\"No tokenizer found while exporting {model_name_or_path}.\")\n\n\ndef main():\n parser = ArgumentParser(f\"Hugging Face Optimum {NEURON_COMPILER} exporter\")\n\n parse_args_neuron(parser)\n\n # Retrieve CLI arguments\n args = parser.parse_args()\n\n task = infer_task(args.task, args.model)\n library_name = TasksManager.infer_library_from_model(args.model, cache_dir=args.cache_dir)\n\n if library_name == \"diffusers\":\n input_shapes = normalize_stable_diffusion_input_shapes(args)\n submodels = {\"unet\": args.unet}\n elif library_name == \"sentence_transformers\":\n input_shapes = normalize_sentence_transformers_input_shapes(args)\n submodels = None\n else:\n input_shapes, neuron_config_class = get_input_shapes_and_config_class(task, args)\n if NeuronDecoderConfig in inspect.getmro(neuron_config_class):\n # TODO: warn about ignored args:\n # dynamic_batch_size, compiler_workdir, optlevel,\n # atol, disable_validation, library_name\n decoder_export(\n model_name_or_path=args.model,\n output=args.output,\n task=task,\n cache_dir=args.cache_dir,\n trust_remote_code=args.trust_remote_code,\n subfolder=args.subfolder,\n auto_cast_type=args.auto_cast_type,\n num_cores=args.num_cores,\n **input_shapes,\n )\n return\n submodels = None\n\n disable_neuron_cache = args.disable_neuron_cache\n compiler_kwargs = infer_compiler_kwargs(args)\n optional_outputs = customize_optional_outputs(args)\n optlevel = parse_optlevel(args)\n\n main_export(\n model_name_or_path=args.model,\n output=args.output,\n compiler_kwargs=compiler_kwargs,\n task=task,\n dynamic_batch_size=args.dynamic_batch_size,\n atol=args.atol,\n cache_dir=args.cache_dir,\n disable_neuron_cache=disable_neuron_cache,\n compiler_workdir=args.compiler_workdir,\n inline_weights_to_neff=args.inline_weights_neff,\n optlevel=optlevel,\n trust_remote_code=args.trust_remote_code,\n subfolder=args.subfolder,\n do_validation=not args.disable_validation,\n submodels=submodels,\n library_name=library_name,\n lora_model_ids=getattr(args, \"lora_model_ids\", None),\n lora_weight_names=getattr(args, \"lora_weight_names\", None),\n lora_adapter_names=getattr(args, \"lora_adapter_names\", None),\n lora_scales=getattr(args, \"lora_scales\", None),\n controlnet_ids=getattr(args, \"controlnet_ids\", None),\n **optional_outputs,\n **input_shapes,\n )\n\n\nif __name__ == \"__main__\":\n main()\n", "optimum\\neuron\\utils\\neuron_cc_wrapper": "#!/usr/bin/env python3\n# -*- coding: utf-8 -*-\nimport re\nimport sys\nfrom optimum.neuron.utils.optimum_neuron_cc_wrapper import main\n\nif __name__ == '__main__':\n sys.argv[0] = re.sub(r'(-script\\.pyw|\\.exe)?$', '', sys.argv[0])\n sys.exit(main())\n", "optimum\\neuron\\utils\\optimum_neuron_cc_wrapper.py": "# coding=utf-8\n# Copyright 2024 The HuggingFace Team. All rights reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom libneuronxla.neuron_cc_wrapper import main as neuron_cc_wrapper_main\n\nfrom .cache_utils import get_hf_hub_cache_repos, get_neuron_cache_path\nfrom .hub_cache_utils import hub_neuronx_cache\n\n\ndef main():\n with hub_neuronx_cache(\"training\", cache_repo_id=get_hf_hub_cache_repos()[0], cache_dir=get_neuron_cache_path()):\n return neuron_cc_wrapper_main()\n\n\nif __name__ == \"__main__\":\n main()\n", "text-generation-inference\\Dockerfile": "# Fetch and extract the TGI sources\nFROM alpine AS tgi\nARG TGI_VERSION=2.1.1\nRUN mkdir -p /tgi\nADD https://github.com/huggingface/text-generation-inference/archive/refs/tags/v${TGI_VERSION}.tar.gz /tgi/sources.tar.gz\nRUN tar -C /tgi -xf /tgi/sources.tar.gz --strip-components=1\n\n# Build cargo components (adapted from TGI original Dockerfile)\n# Note that the build image is aligned on the same Linux version as the base image (Debian bookworm/ Ubuntu 22.04)\nFROM lukemathwalker/cargo-chef:latest-rust-1.79-bookworm AS chef\nWORKDIR /usr/src\n\nARG CARGO_REGISTRIES_CRATES_IO_PROTOCOL=sparse\n\nFROM chef AS planner\nCOPY --from=tgi /tgi/Cargo.lock Cargo.lock\nCOPY --from=tgi /tgi/Cargo.toml Cargo.toml\nCOPY --from=tgi /tgi/rust-toolchain.toml rust-toolchain.toml\nCOPY --from=tgi /tgi/proto proto\nCOPY --from=tgi /tgi/benchmark benchmark\nCOPY --from=tgi /tgi/router router\nCOPY --from=tgi /tgi/launcher launcher\nRUN cargo chef prepare --recipe-path recipe.json\n\nFROM chef AS builder\n\nRUN PROTOC_ZIP=protoc-21.12-linux-x86_64.zip && \\\n curl -OL https://github.com/protocolbuffers/protobuf/releases/download/v21.12/$PROTOC_ZIP && \\\n unzip -o $PROTOC_ZIP -d /usr/local bin/protoc && \\\n unzip -o $PROTOC_ZIP -d /usr/local 'include/*' && \\\n rm -f $PROTOC_ZIP\n\nCOPY --from=planner /usr/src/recipe.json recipe.json\nRUN cargo chef cook --release --recipe-path recipe.json\n\nCOPY --from=tgi /tgi/Cargo.lock Cargo.lock\nCOPY --from=tgi /tgi/Cargo.toml Cargo.toml\nCOPY --from=tgi /tgi/rust-toolchain.toml rust-toolchain.toml\nCOPY --from=tgi /tgi/proto proto\nCOPY --from=tgi /tgi/benchmark benchmark\nCOPY --from=tgi /tgi/router router\nCOPY --from=tgi /tgi/launcher launcher\n# Remove this line once TGI has fixed the conflict\nRUN cargo update ureq --precise 2.9.7\nRUN cargo build --release --workspace --exclude benchmark\n\n# Python base image\nFROM ubuntu:22.04 AS base\n\nRUN apt-get update -y \\\n && apt-get install -y --no-install-recommends \\\n python3-pip \\\n python3-setuptools \\\n python-is-python3 \\\n && rm -rf /var/lib/apt/lists/* \\\n && apt-get clean\nRUN pip3 --no-cache-dir install --upgrade pip\n\n# Python server build image\nFROM base AS pyserver\n\nARG VERSION\n\nRUN test -n ${VERSION:?} && apt-get update -y \\\n && apt-get install -y --no-install-recommends \\\n make \\\n python3-venv \\\n && rm -rf /var/lib/apt/lists/* \\\n && apt-get clean\n\nRUN install -d /pyserver\nWORKDIR /pyserver\nCOPY text-generation-inference/server server\nCOPY --from=tgi /tgi/proto proto\nRUN pip3 install -r server/build-requirements.txt\nRUN VERBOSE=1 BUILDDIR=/pyserver/build PROTODIR=/pyserver/proto VERSION=${VERSION} make -C server gen-server\n\n# Neuron base image (used for deployment)\nFROM base AS neuron\n\nARG VERSION\n\n# Install system prerequisites\nRUN test -n ${VERSION:?} && apt-get update -y \\\n && apt-get install -y --no-install-recommends \\\n gnupg2 \\\n wget \\\n python3-dev \\\n && rm -rf /var/lib/apt/lists/* \\\n && apt-get clean\n\nRUN echo \"deb https://apt.repos.neuron.amazonaws.com jammy main\" > /etc/apt/sources.list.d/neuron.list\nRUN wget -qO - https://apt.repos.neuron.amazonaws.com/GPG-PUB-KEY-AMAZON-AWS-NEURON.PUB | apt-key add -\n\n# Install neuronx packages\nRUN apt-get update -y \\\n && apt-get install -y --no-install-recommends \\\n aws-neuronx-dkms=2.18.12.0 \\\n aws-neuronx-collectives=2.22.26.0-17a033bc8 \\\n aws-neuronx-runtime-lib=2.22.14.0-6e27b8d5b \\\n aws-neuronx-tools=2.19.0.0 \\\n libxml2 \\\n && rm -rf /var/lib/apt/lists/* \\\n && apt-get clean\n\nENV PATH=\"/opt/bin/:/opt/aws/neuron/bin:${PATH}\"\n\nRUN pip3 install \\\n neuronx-cc==2.15.128.0 \\\n torch-neuronx==2.1.2.2.3.0 \\\n transformers-neuronx==0.12.313 \\\n libneuronxla==2.0.4115.0 \\\n --extra-index-url=https://pip.repos.neuron.amazonaws.com\n\n# Install HuggingFace packages\nRUN pip3 install \\\n hf_transfer huggingface_hub\n\n# Install optimum-neuron\nCOPY ./dist/optimum_neuron-${VERSION}.tar.gz optimum-neuron.tar.gz\nRUN pip3 install optimum-neuron.tar.gz\n\n# TGI base env\nENV HUGGINGFACE_HUB_CACHE=/data \\\n HF_HUB_ENABLE_HF_TRANSFER=1 \\\n PORT=80\n\n# Install router\nCOPY --from=builder /usr/src/target/release/text-generation-router /usr/local/bin/text-generation-router\n# Install launcher\nCOPY --from=builder /usr/src/target/release/text-generation-launcher /usr/local/bin/text-generation-launcher\n# Install python server\nCOPY --from=pyserver /pyserver/build/dist dist\nRUN pip install dist/text_generation_server*.tar.gz\n\n# AWS Sagemaker compatible image\nFROM neuron AS sagemaker\n\nCOPY text-generation-inference/sagemaker-entrypoint.sh entrypoint.sh\nRUN chmod +x entrypoint.sh\n\nENTRYPOINT [\"./entrypoint.sh\"]\n\n# Final image\nFROM neuron\nCOPY text-generation-inference/tgi-entrypoint.sh text-generation-inference/tgi_env.py /\nENTRYPOINT [\"/tgi-entrypoint.sh\"]\nCMD [\"--json-output\"]\n", "text-generation-inference\\server\\build-requirements.txt": "build\ngrpcio-tools==1.48.2\nmypy-protobuf==3.2.0\n", "text-generation-inference\\tests\\requirements.txt": "# Copyright 2023 The HuggingFace Team. All rights reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\ntext-generation >= 0.6.0\npytest >= 7.4.0\npytest-asyncio >= 0.21.1\nrequests < 2.32.0\ndocker >= 6.1.3\nLevenshtein\n"} | null |
optimum-nvidia | {"type": "directory", "name": "optimum-nvidia", "children": [{"type": "file", "name": ".dockerignore"}, {"type": "file", "name": "CONTRIBUTING.md"}, {"type": "directory", "name": "docker", "children": [{"type": "file", "name": "Dockerfile"}, {"type": "file", "name": "Dockerfile.dev"}, {"type": "file", "name": "Dockerfile.endpoint"}]}, {"type": "directory", "name": "docs", "children": [{"type": "directory", "name": "source", "children": [{"type": "file", "name": "index.md"}, {"type": "file", "name": "installation.mdx"}, {"type": "file", "name": "quantization.md"}]}]}, {"type": "directory", "name": "examples", "children": [{"type": "file", "name": "async-text-generation.py"}, {"type": "file", "name": "pipeline.py"}, {"type": "file", "name": "quantization.py"}, {"type": "file", "name": "text-generation.py"}]}, {"type": "file", "name": "LICENSE"}, {"type": "file", "name": "Makefile"}, {"type": "file", "name": "pyproject.toml"}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "scripts", "children": [{"type": "file", "name": "benchmark_pipelines.py"}]}, {"type": "file", "name": "setup.cfg"}, {"type": "file", "name": "setup.py"}, {"type": "directory", "name": "src", "children": [{"type": "directory", "name": "optimum", "children": [{"type": "directory", "name": "commands", "children": [{"type": "file", "name": "env.py"}]}, {"type": "directory", "name": "nvidia", "children": [{"type": "directory", "name": "compression", "children": [{"type": "file", "name": "modelopt.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "errors.py"}, {"type": "directory", "name": "export", "children": [{"type": "file", "name": "cli.py"}, {"type": "file", "name": "config.py"}, {"type": "file", "name": "converter.py"}, {"type": "file", "name": "workspace.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "generation", "children": [{"type": "file", "name": "logits_process.py"}]}, {"type": "file", "name": "hub.py"}, {"type": "directory", "name": "lang", "children": [{"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "logging.py"}, {"type": "directory", "name": "models", "children": [{"type": "file", "name": "auto.py"}, {"type": "file", "name": "base.py"}, {"type": "file", "name": "gemma.py"}, {"type": "file", "name": "llama.py"}, {"type": "file", "name": "mistral.py"}, {"type": "file", "name": "mixtral.py"}, {"type": "file", "name": "whisper.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "pipelines", "children": [{"type": "file", "name": "base.py"}, {"type": "file", "name": "text_generation.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "runtime.py"}, {"type": "directory", "name": "subpackage", "children": [{"type": "directory", "name": "commands", "children": [{"type": "file", "name": "env.py"}, {"type": "file", "name": "export.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "utils", "children": [{"type": "file", "name": "cli.py"}, {"type": "file", "name": "constants.py"}, {"type": "file", "name": "env.py"}, {"type": "file", "name": "hub.py"}, {"type": "file", "name": "import_utils.py"}, {"type": "file", "name": "nvml.py"}, {"type": "file", "name": "offload.py"}, {"type": "file", "name": "onnx.py"}, {"type": "file", "name": "patching.py"}, {"type": "directory", "name": "tests", "children": [{"type": "file", "name": "assertions.py"}, {"type": "file", "name": "utils.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "version.py"}, {"type": "file", "name": "__init__.py"}]}]}]}, {"type": "directory", "name": "templates", "children": [{"type": "directory", "name": "inference-endpoints", "children": [{"type": "directory", "name": "llm", "children": [{"type": "directory", "name": "1", "children": [{"type": "file", "name": "config.json"}, {"type": "file", "name": "llama_float16_tp1_rank0.engine"}]}, {"type": "file", "name": "config.pbtxt"}]}, {"type": "directory", "name": "postprocessing", "children": [{"type": "directory", "name": "1", "children": [{"type": "file", "name": "model.py"}]}, {"type": "file", "name": "config.pbtxt"}]}, {"type": "directory", "name": "preprocessing", "children": [{"type": "directory", "name": "1", "children": [{"type": "file", "name": "model.py"}]}, {"type": "file", "name": "config.pbtxt"}]}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "text-generation", "children": [{"type": "directory", "name": "1", "children": []}, {"type": "file", "name": "config.pbtxt"}]}, {"type": "directory", "name": "tokenizer", "children": [{"type": "file", "name": "special_tokens_map.json"}, {"type": "file", "name": "tokenizer.json"}, {"type": "file", "name": "tokenizer_config.json"}]}]}]}, {"type": "directory", "name": "tests", "children": [{"type": "directory", "name": "cli", "children": [{"type": "file", "name": "test_export.py"}]}, {"type": "directory", "name": "fixtures", "children": [{"type": "file", "name": "qawq_recipe.py"}, {"type": "file", "name": "qawq_recipe_no_target_recipe.py"}, {"type": "file", "name": "qfloat8_and_kv_cache_recipe.py"}]}, {"type": "directory", "name": "integration", "children": [{"type": "file", "name": "test_causal_lm.py"}, {"type": "file", "name": "utils_testing.py"}]}, {"type": "file", "name": "test_dtype.py"}, {"type": "file", "name": "test_hub.py"}]}]} | ```
/opt/tritonserver/bin/tritonserver --log-verbose=3 --exit-on-error=false --model-repo=/opt/optimum/templates/inference-endpoints/
```
| {"setup.py": "# coding=utf-8\n# Copyright 2023 The HuggingFace Inc. team. All rights reserved.\n# #\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n# #\n# http://www.apache.org/licenses/LICENSE-2.0\n# #\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\nimport re\nfrom distutils.core import setup\nfrom platform import system, machine, python_version\nfrom setuptools import find_namespace_packages\nfrom sys import version_info as pyversion\n\n# Ensure we match the version set in optimum/nvidia/version.py\nfilepath = \"src/optimum/nvidia/version.py\"\ntry:\n with open(filepath) as version_file:\n (__version__,) = re.findall('__version__ = \"(.*)\"', version_file.read())\nexcept Exception as error:\n assert False, \"Error: Could not open '%s' due %s\\n\" % (filepath, error)\n\nINSTALL_REQUIRES = [\n \"accelerate == 0.25\",\n \"datasets >= 2.14\",\n \"huggingface-hub >= 0.24\",\n \"hf-transfer==0.1.6\",\n \"mpmath == 1.3.0\",\n \"numpy >= 1.26.0\",\n \"onnx >= 1.12.0\",\n \"optimum >= 1.21.0\",\n \"setuptools\",\n \"tensorrt-llm == 0.13.0.dev2024090300\",\n \"torch>=2.3.0a,<=2.5.0a\",\n \"transformers >= 4.43.2\",\n \"pynvml\"\n]\n\nTESTS_REQUIRES = [\n \"mock\",\n \"pytest\",\n \"pytest-console-scripts\",\n \"pytest-xdist\",\n \"psutil\",\n \"parameterized\",\n \"datasets\",\n \"safetensors\",\n \"soundfile\",\n \"librosa\",\n]\n\nQUALITY_REQUIRES = [\n \"black\",\n \"ruff\",\n \"isort\",\n \"hf_doc_builder @ git+https://github.com/huggingface/doc-builder.git\",\n]\n\n\nEXTRAS_REQUIRE = {\n \"tests\": TESTS_REQUIRES,\n# \"quality\": QUALITY_REQUIRES,\n}\n\nsetup(\n name=\"optimum-nvidia\",\n version=__version__,\n description=(\n \"Optimum Nvidia is the interface between the Hugging Face Transformers and NVIDIA GPUs. \"\n \"It provides a set of tools enabling easy model loading, training and \"\n \"inference on single and multiple GPU cards for different downstream tasks.\"\n ),\n long_description=open(\"README.md\", \"r\", encoding=\"utf-8\").read(),\n long_description_content_type=\"text/markdown\",\n classifiers=[\n \"Development Status :: 2 - Pre-Alpha\",\n \"License :: OSI Approved :: Apache Software License\",\n \"Intended Audience :: Developers\",\n \"Intended Audience :: Education\",\n \"Intended Audience :: Science/Research\",\n \"Operating System :: OS Independent\",\n \"Programming Language :: Python :: 3.10\",\n \"Topic :: Scientific/Engineering :: Artificial Intelligence\",\n ],\n keywords=\"transformers, neural-network, fine-tuning, inference, nvidia, tensorrt, ampere, hopper\",\n url=\"https://huggingface.co/hardware/nvidia\",\n author=\"HuggingFace Inc. Machine Learning Optimization Team\",\n author_email=\"[email protected]\",\n license=\"Apache 2.0\",\n packages=find_namespace_packages(include=[\"optimum*\"]),\n install_requires=INSTALL_REQUIRES,\n extras_require=EXTRAS_REQUIRE,\n dependency_links=[\"https://pypi.nvidia.com\"],\n include_package_data=True,\n zip_safe=False,\n)\n", ".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 761847a2def80417684dc3485ec91176fbcb5cbc Hamza Amin <[email protected]> 1727369584 +0500\tclone: from https://github.com/huggingface/optimum-nvidia.git\n", ".git\\refs\\heads\\main": "761847a2def80417684dc3485ec91176fbcb5cbc\n", "docker\\Dockerfile": "FROM tensorrt_llm/release:latest\n\n# 75 = T4/RTX Quadro\n# 80 = A100/A30\n# 86 = A10/A40/RTX Axxx\n# 89 = L4/L40/L40s/RTX Ada/4090\n# 90 = H100/H200\n#ARG TARGET_CUDA_ARCHS=\"75-real;80-real;86-real;89-real;90-real\"\n\nCOPY . /opt/optimum-nvidia\n\n# Install dependencies\nRUN python -m pip install /opt/optimum-nvidia\n\n# Let's put our users in the examples folder\nWORKDIR /opt/optimum-nvidia/examples\n", "docker\\Dockerfile.dev": "FROM nvidia/cuda:12.3.0-devel-ubuntu22.04\n\nRUN apt-get update && \\\n apt-get -y install \\\n git \\\n python3.10 \\\n python3-pip \\\n openmpi-bin \\\n libopenmpi-dev\n\nCOPY . /opt/optimum-nvidia\nWORKDIR /opt/optimum-nvidia\n\nRUN pip install --pre --extra-index-url https://pypi.nvidia.com -e '.[quality, tests]' && \\\n pip uninstall -y optimum-nvidia && \\\n rm -rf /opt/optimum-nvidia", "docker\\Dockerfile.endpoint": "FROM nvcr.io/nvidia/tritonserver:23.10-trtllm-python-py3\n\nLABEL maintainer=\"Morgan Funtowicz <[email protected]>\"\n\nARG VCS_REF\nARG BUILD_DATE\nARG BUILD_VERSION\n\nLABEL org.label-schema.schema-version=\"1.0\"\nLABEL org.label-schema.name=\"huggingface/inference-endpoints-trtllm\"\nLABEL org.label-schema.build-date=$BUILD_DATE\nLABEL org.label-schema.version=$BUILD_VERSION\nLABEL org.label-schema.vcs-ref=$VCS_REF\nLABEL org.label-schema.vendor=\"Hugging Face Inc.\"\nLABEL org.label-schema.version=\"1.0.0\"\nLABEL org.label-schema.url=\"https://hf.co/hardware\"\nLABEL org.label-schema.vcs-url=\"https://github.com/huggingface/optimum-nvidia\"\nLABEL org.label-schema.decription=\"Hugging Face Inference Server docker image for TensorRT-LLM Inference\"\n\nENV HF_HUB_TOKEN \"\"\n\n\n# Expose (in-order) HTTP, GRPC, Metrics endpoints\nEXPOSE 8000/tcp\nEXPOSE 8001/tcp\nEXPOSE 8002/tcp\n\nWORKDIR /repository\n\n#ENTRYPOINT \"huggingface-cli login --token ${HF_HUB_TOKEN}\nCMD [\"mpirun\", \"--allow-run-as-root\", \"-n\", \"1\", \"/opt/tritonserver/bin/tritonserver\", \"--exit-on-error=false\", \"--model-repo=/repository\"]", "docs\\source\\index.md": "<!---\nCopyright 2023 The HuggingFace Team. All rights reserved.\n\nLicensed under the Apache License, Version 2.0 (the \"License\");\nyou may not use this file except in compliance with the License.\nYou may obtain a copy of the License at\n\n http://www.apache.org/licenses/LICENSE-2.0\n\nUnless required by applicable law or agreed to in writing, software\ndistributed under the License is distributed on an \"AS IS\" BASIS,\nWITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\nSee the License for the specific language governing permissions and\nlimitations under the License.\n-->\n\n# \ud83e\udd17 Optimum Nvidia\n\n\ud83e\udd17 Optimum Nvidia provides seamless integrating for [TensorRT-LLM](https://github.com/NVIDIA/TensorRT-LLM) in the Hugging Face ecosystem.\n\nWhile TensorRT-LLM provides the foundational blocks to ensure the greatest performances on NVIDIA GPUs, `optimum-nvidia` allows\nto leverage the \ud83e\udd17 to retrieve and load the weights directly inside TensorRT-LLM while maintaining a similar or identical API compared to `transformers` and others \ud83e\udd17 libraries.\n\nFor NVIDIA Tensor Cores GPUs with `float8` hardware acceleration, `optimum-nvidia` allows to run all the necessary preprocessing steps required to target this datatype along with \ndeploying the necessary technical blocks to ensure developer experience is fast and smooth for these architectures."} | null |
optimum-quanto | {"type": "directory", "name": "optimum-quanto", "children": [{"type": "directory", "name": "bench", "children": [{"type": "directory", "name": "generation", "children": [{"type": "directory", "name": "charts", "children": []}, {"type": "file", "name": "evaluate_configurations.py"}, {"type": "file", "name": "evaluate_many_models.sh"}, {"type": "file", "name": "evaluate_model.py"}, {"type": "file", "name": "gen_barchart.py"}, {"type": "directory", "name": "metrics", "children": [{"type": "file", "name": "latency.py"}, {"type": "file", "name": "perplexity.py"}, {"type": "file", "name": "prediction.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "setup", "children": [{"type": "file", "name": "awq.py"}, {"type": "file", "name": "bnb.py"}, {"type": "file", "name": "hqq.py"}, {"type": "file", "name": "quanto.py"}, {"type": "file", "name": "__init__.py"}]}]}, {"type": "directory", "name": "kernels", "children": [{"type": "file", "name": "benchmark.py"}, {"type": "file", "name": "benchmark_marlin_fp8.py"}, {"type": "file", "name": "benchmark_w4a16.py"}]}, {"type": "directory", "name": "torch_kernels", "children": [{"type": "file", "name": "README.md"}, {"type": "file", "name": "test_int_mm.py"}, {"type": "file", "name": "test_int_mm_inductor.py"}, {"type": "file", "name": "test_weight_int4pack_mm.py"}, {"type": "file", "name": "test_weight_int8pack_mm.py"}]}]}, {"type": "file", "name": "CONTRIBUTING.md"}, {"type": "directory", "name": "examples", "children": [{"type": "directory", "name": "nlp", "children": [{"type": "directory", "name": "text-classification", "children": [{"type": "directory", "name": "sst2", "children": [{"type": "file", "name": "quantize_sst2_model.py"}]}]}, {"type": "directory", "name": "text-generation", "children": [{"type": "file", "name": "quantize_causal_lm_model.py"}]}]}, {"type": "directory", "name": "speech", "children": [{"type": "directory", "name": "speech_recognition", "children": [{"type": "file", "name": "quantize_asr_model.py"}, {"type": "file", "name": "requirements.txt"}]}]}, {"type": "directory", "name": "vision", "children": [{"type": "directory", "name": "image-classification", "children": [{"type": "directory", "name": "mnist", "children": [{"type": "file", "name": "quantize_mnist_model.py"}]}, {"type": "directory", "name": "pets", "children": [{"type": "file", "name": "quantize_vit_model.py"}]}]}, {"type": "directory", "name": "object-detection", "children": [{"type": "file", "name": "quantize_owl_model.py"}]}, {"type": "directory", "name": "StableDiffusion", "children": [{"type": "file", "name": "quantize_StableDiffusion.py"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}]}, {"type": "directory", "name": "text-to-image", "children": [{"type": "file", "name": "quantize_pixart_sigma.py"}]}]}]}, {"type": "directory", "name": "external", "children": [{"type": "directory", "name": "awq", "children": [{"type": "file", "name": "conftest.py"}, {"type": "file", "name": "packing_utils.py"}, {"type": "file", "name": "pack_intweight.py"}, {"type": "file", "name": "test_awq_kernels.py"}, {"type": "file", "name": "test_awq_packing.py"}, {"type": "file", "name": "test_awq_quantize.py"}]}, {"type": "directory", "name": "smoothquant", "children": [{"type": "file", "name": "README.md"}, {"type": "file", "name": "smoothquant.py"}]}]}, {"type": "file", "name": "LICENSE"}, {"type": "file", "name": "Makefile"}, {"type": "directory", "name": "optimum", "children": [{"type": "directory", "name": "quanto", "children": [{"type": "file", "name": "calibrate.py"}, {"type": "directory", "name": "library", "children": [{"type": "directory", "name": "extensions", "children": [{"type": "directory", "name": "cpp", "children": [{"type": "file", "name": "pybind_module.cpp"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "unpack.cpp"}, {"type": "file", "name": "unpack.h"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "cuda", "children": [{"type": "directory", "name": "awq", "children": [{"type": "file", "name": "dequantize.cuh"}, {"type": "directory", "name": "v2", "children": [{"type": "file", "name": "gemm_cuda.cu"}, {"type": "file", "name": "gemm_cuda.h"}, {"type": "file", "name": "gemv_cuda.cu"}, {"type": "file", "name": "gemv_cuda.h"}, {"type": "file", "name": "semaphore.h"}]}]}, {"type": "directory", "name": "marlin", "children": [{"type": "file", "name": "COPYRIGHT"}, {"type": "file", "name": "fp8_marlin.cu"}, {"type": "file", "name": "fp8_marlin.cuh"}, {"type": "file", "name": "gptq_marlin.cuh"}, {"type": "file", "name": "gptq_marlin_dtypes.cuh"}, {"type": "file", "name": "gptq_marlin_repack.cu"}, {"type": "file", "name": "gptq_marlin_repack.cuh"}]}, {"type": "file", "name": "pybind_module.cpp"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "unpack.cu"}, {"type": "file", "name": "unpack.h"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "extension.py"}, {"type": "directory", "name": "mps", "children": [{"type": "file", "name": "pybind_module.cpp"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "unpack.h"}, {"type": "file", "name": "unpack.mm"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "ops.py"}, {"type": "directory", "name": "python", "children": [{"type": "file", "name": "README.md"}, {"type": "file", "name": "unpack.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "qbytes_mm.py"}, {"type": "file", "name": "quantize.py"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "models", "children": [{"type": "file", "name": "diffusers_models.py"}, {"type": "file", "name": "shared_dict.py"}, {"type": "file", "name": "transformers_models.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "nn", "children": [{"type": "file", "name": "qconv2d.py"}, {"type": "file", "name": "qlayernorm.py"}, {"type": "file", "name": "qlinear.py"}, {"type": "file", "name": "qmodule.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "quantize.py"}, {"type": "directory", "name": "subpackage", "children": [{"type": "directory", "name": "commands", "children": [{"type": "file", "name": "base.py"}, {"type": "file", "name": "quantize.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "tensor", "children": [{"type": "directory", "name": "activations", "children": [{"type": "file", "name": "qbytes.py"}, {"type": "file", "name": "qbytes_ops.py"}, {"type": "file", "name": "quantization.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "core.py"}, {"type": "file", "name": "function.py"}, {"type": "file", "name": "grouped.py"}, {"type": "directory", "name": "optimizers", "children": [{"type": "file", "name": "absmax_optimizer.py"}, {"type": "file", "name": "affine_optimizer.py"}, {"type": "file", "name": "hqq_optimizer.py"}, {"type": "file", "name": "max_optimizer.py"}, {"type": "file", "name": "optimizer.py"}, {"type": "file", "name": "symmetric_optimizer.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "packed.py"}, {"type": "file", "name": "qbits.py"}, {"type": "file", "name": "qbytes.py"}, {"type": "file", "name": "qtensor.py"}, {"type": "file", "name": "qtype.py"}, {"type": "directory", "name": "weights", "children": [{"type": "directory", "name": "awq", "children": [{"type": "file", "name": "packed.py"}, {"type": "file", "name": "qbits.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "marlin", "children": [{"type": "directory", "name": "fp8", "children": [{"type": "file", "name": "packed.py"}, {"type": "file", "name": "qbits.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "packing.py"}, {"type": "file", "name": "qbits.py"}, {"type": "file", "name": "qbytes.py"}, {"type": "file", "name": "quantization.py"}, {"type": "file", "name": "reordering.py"}, {"type": "directory", "name": "tinygemm", "children": [{"type": "file", "name": "packed.py"}, {"type": "file", "name": "qbits.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "__init__.py"}]}]}, {"type": "file", "name": "pyproject.toml"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "setup.sh"}, {"type": "directory", "name": "test", "children": [{"type": "directory", "name": "cli", "children": [{"type": "file", "name": "cli_helpers.py"}, {"type": "file", "name": "test_quantize_cli.py"}]}, {"type": "file", "name": "conftest.py"}, {"type": "file", "name": "helpers.py"}, {"type": "directory", "name": "library", "children": [{"type": "file", "name": "test_extensions.py"}, {"type": "file", "name": "test_mm.py"}, {"type": "file", "name": "test_quantize.py"}, {"type": "file", "name": "test_unpack.py"}]}, {"type": "directory", "name": "models", "children": [{"type": "file", "name": "conftest.py"}, {"type": "file", "name": "test_quantized_model_for_causal_lm.py"}, {"type": "file", "name": "test_quantized_model_for_pixart.py"}]}, {"type": "directory", "name": "nn", "children": [{"type": "file", "name": "test_calibrate.py"}, {"type": "file", "name": "test_qattention.py"}, {"type": "file", "name": "test_qconv2d.py"}, {"type": "file", "name": "test_qlayernorm.py"}, {"type": "file", "name": "test_qlinear.py"}, {"type": "file", "name": "test_qmodule.py"}]}, {"type": "directory", "name": "quantize", "children": [{"type": "file", "name": "test_quantize_mlp.py"}, {"type": "file", "name": "test_quantize_patterns.py"}, {"type": "file", "name": "test_requantize.py"}]}, {"type": "directory", "name": "tensor", "children": [{"type": "directory", "name": "activations", "children": [{"type": "file", "name": "test_activations_compile.py"}, {"type": "file", "name": "test_activations_dispatch.py"}, {"type": "file", "name": "test_activations_quantize.py"}]}, {"type": "directory", "name": "ops", "children": [{"type": "file", "name": "test_linear_dispatch.py"}, {"type": "file", "name": "test_mm_dispatch.py"}]}, {"type": "directory", "name": "optimizers", "children": [{"type": "file", "name": "test_hqq_optimizer.py"}]}, {"type": "file", "name": "test_absmax.py"}, {"type": "file", "name": "test_packed_tensor.py"}, {"type": "directory", "name": "weights", "children": [{"type": "directory", "name": "optimized", "children": [{"type": "file", "name": "test_awq_packed_tensor.py"}, {"type": "file", "name": "test_awq_weight_qbits_tensor.py"}, {"type": "file", "name": "test_marlin_fp8_packed_tensor.py"}, {"type": "file", "name": "test_marlin_qbytes_tensor.py"}, {"type": "file", "name": "test_tinygemm_packed_tensor.py"}, {"type": "file", "name": "test_tinygemm_weight_qbits_tensor.py"}]}, {"type": "file", "name": "test_weight_qbits_tensor.py"}, {"type": "file", "name": "test_weight_qbits_tensor_dispatch.py"}, {"type": "file", "name": "test_weight_qbits_tensor_instantiate.py"}, {"type": "file", "name": "test_weight_qbits_tensor_quantize.py"}, {"type": "file", "name": "test_weight_qbytes_tensor_backward.py"}, {"type": "file", "name": "test_weight_qbytes_tensor_dispatch.py"}, {"type": "file", "name": "test_weight_qbytes_tensor_instantiate.py"}, {"type": "file", "name": "test_weight_qbytes_tensor_quantize.py"}, {"type": "file", "name": "test_weight_qbytes_tensor_serialization.py"}]}]}]}]} | # Quanto library python/pytorch operations
This folder contains the implementations of all `quanto_py::` operations.
This namespace corresponds to the default, python-only implementations of quanto operations.
The operations are defined in `library/ops.py`.
To provide an implementation for an operation, use the following syntax:
```python
@torch.library.impl("quanto_py::unpack", "default")
def unpack(packed: torch.Tensor, bits: int) -> torch.Tensor:
...
```
The implementation **must** support all device types. This is true if it
is a composition of built-in PyTorch operators.
| {".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 5936d79f6b0c4b1cac237c4db4455c7287114d95 Hamza Amin <[email protected]> 1727369590 +0500\tclone: from https://github.com/huggingface/optimum-quanto.git\n", ".git\\refs\\heads\\main": "5936d79f6b0c4b1cac237c4db4455c7287114d95\n", "examples\\speech\\speech_recognition\\requirements.txt": "transformers\nevaluate\nlibrosa\nsoundfile\njiwer\n", "examples\\vision\\StableDiffusion\\requirements.txt": "quanto\ndiffusers\ntorch\ntransformers\naccelerate\nwandb"} | null |
optimum-tpu | {"type": "directory", "name": "optimum-tpu", "children": [{"type": "directory", "name": "docs", "children": [{"type": "directory", "name": "source", "children": [{"type": "directory", "name": "howto", "children": [{"type": "file", "name": "deploy.mdx"}, {"type": "file", "name": "overview.mdx"}, {"type": "file", "name": "serving.mdx"}]}, {"type": "file", "name": "index.mdx"}, {"type": "directory", "name": "tutorials", "children": [{"type": "file", "name": "overview.mdx"}]}, {"type": "file", "name": "_toctree.yml"}]}]}, {"type": "directory", "name": "examples", "children": [{"type": "directory", "name": "language-modeling", "children": [{"type": "file", "name": "gemma_tuning.ipynb"}, {"type": "file", "name": "llama_tuning.md"}]}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "text-generation", "children": [{"type": "file", "name": "generation.py"}]}]}, {"type": "file", "name": "install-jetstream-pt.sh"}, {"type": "file", "name": "LICENSE"}, {"type": "file", "name": "Makefile"}, {"type": "file", "name": "MANIFEST.in"}, {"type": "directory", "name": "optimum", "children": [{"type": "directory", "name": "tpu", "children": [{"type": "file", "name": "distributed_model.py"}, {"type": "file", "name": "fsdp_v2.py"}, {"type": "directory", "name": "generation", "children": [{"type": "file", "name": "logits_process.py"}, {"type": "file", "name": "token_selector.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "jetstream_pt_support.py"}, {"type": "file", "name": "model.py"}, {"type": "file", "name": "modeling.py"}, {"type": "file", "name": "modeling_gemma.py"}, {"type": "file", "name": "modeling_llama.py"}, {"type": "file", "name": "modeling_mistral.py"}, {"type": "file", "name": "static_cache_xla.py"}, {"type": "file", "name": "version.py"}, {"type": "file", "name": "xla_logger.py"}, {"type": "file", "name": "xla_model_parallel.py"}, {"type": "file", "name": "xla_mp_comm.py"}, {"type": "file", "name": "__init__.py"}]}]}, {"type": "file", "name": "pyproject.toml"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "setup.cfg"}, {"type": "directory", "name": "tests", "children": [{"type": "file", "name": "conftest.py"}, {"type": "file", "name": "test_distributed_model.py"}]}, {"type": "directory", "name": "text-generation-inference", "children": [{"type": "directory", "name": "docker", "children": [{"type": "file", "name": "Dockerfile"}, {"type": "file", "name": "entrypoint.sh"}]}, {"type": "directory", "name": "integration-tests", "children": [{"type": "file", "name": "conftest.py"}, {"type": "file", "name": "pytest.ini"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "test_gpt2.py"}]}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "server", "children": [{"type": "file", "name": "build-requirements.txt"}, {"type": "file", "name": "Makefile"}, {"type": "file", "name": "pyproject.toml"}, {"type": "directory", "name": "text_generation_server", "children": [{"type": "file", "name": "auto_generator.py"}, {"type": "file", "name": "cli.py"}, {"type": "file", "name": "generator.py"}, {"type": "file", "name": "generator_base.py"}, {"type": "file", "name": "interceptor.py"}, {"type": "directory", "name": "jetstream_pt_support", "children": [{"type": "file", "name": "compatibility.py"}, {"type": "file", "name": "engine_loader.py"}, {"type": "file", "name": "generator.py"}, {"type": "file", "name": "llama_model_exportable_hf.py"}, {"type": "file", "name": "logits_process.py"}, {"type": "file", "name": "token_selector.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "server.py"}, {"type": "file", "name": "version.py"}]}]}, {"type": "directory", "name": "tests", "children": [{"type": "file", "name": "conftest.py"}, {"type": "file", "name": "helpers.py"}, {"type": "file", "name": "test_decode.py"}, {"type": "file", "name": "test_generator_slot.py"}, {"type": "file", "name": "test_gpt2.py"}, {"type": "file", "name": "test_prefill_truncate.py"}, {"type": "file", "name": "test_warmup.py"}]}]}]} | # Text-generation-inference docker image for Pytorch/XLA
This docker image integrates into a base image:
- the [Text Generation Inference](https://github.com/huggingface/text-generation-inference) launcher and scheduling front-end,
- an XLA specific inference server for text-generation.
## Features
The basic features of the [Text Generation Inference](https://github.com/huggingface/text-generation-inference) product are supported:
- continuous batching,
- token streaming,
- greedy search and multinomial sampling using [transformers](https://huggingface.co/docs/transformers/generation_strategies#customize-text-generation).
The main differences with the standard service for CUDA and CPU backends are that:
- the service uses a single internal static batch,
- new requests are inserted in the static batch during prefill,
- the static KV cache is rebuilt entirely during prefill.
## License
This docker image is released under [HFOIL 1.0](https://github.com/huggingface/text-generation-inference/blob/bde25e62b33b05113519e5dbf75abda06a03328e/LICENSE).
HFOIL stands for Hugging Face Optimized Inference License, and it has been specifically designed for our optimized inference solutions. While the source code remains accessible, HFOIL is not a true open source license because we added a restriction: to sell a hosted or managed service built on top of TGI, we require a separate agreement.
Please refer to [this reference documentation](https://github.com/huggingface/text-generation-inference/issues/726) to see if the HFOIL 1.0 restrictions apply to your deployment.
## Deploy the service
The service is launched simply by running the tpu-tgi container with two sets of parameters:
```
docker run <system_parameters> ghcr.io/huggingface/tpu-tgi:latest <service_parameters>
```
- system parameters are used to map ports, volumes and devices between the host and the service,
- service parameters are forwarded to the `text-generation-launcher`.
### Common system parameters
Finally, you might want to export the `HF_TOKEN` if you want to access gated repository.
Here is an example of a service instantiation on a single host TPU:
```
docker run -p 8080:80 \
--net=host --privileged \
-v $(pwd)/data:/data \
-e HF_TOKEN=${HF_TOKEN} \
ghcr.io/huggingface/tpu-tgi:latest \
<service_parameters>
```
### Using a standard model from the 🤗 [HuggingFace Hub](https://huggingface.co/models)
The snippet below shows how you can deploy a service from a hub standard model:
```
docker run -p 8080:80 \
--net=host --privileged \
-v $(pwd)/data:/data \
-e HF_TOKEN=${HF_TOKEN} \
-e HF_BATCH_SIZE=1 \
-e HF_SEQUENCE_LENGTH=1024 \
ghcr.io/huggingface/tpu-tgi:latest \
--model-id mistralai/Mistral-7B-v0.1 \
--max-concurrent-requests 1 \
--max-input-length 512 \
--max-total-tokens 1024 \
--max-batch-prefill-tokens 512 \
--max-batch-total-tokens 1024
```
### Choosing service parameters
Use the following command to list the available service parameters:
```
docker run ghcr.io/huggingface/tpu-tgi --help
```
The configuration of an inference endpoint is always a compromise between throughput and latency: serving more requests in parallel will allow a higher throughput, but it will increase the latency.
The models for now work with static input dimensions `[batch_size, max_length]`.
It leads to a maximum number of tokens of `max_tokens = batch_size * max_length`.
This adds several restrictions to the following parameters:
- `--max-concurrent-requests` must be set to `batch size`,
- `--max-input-length` must be lower than `max_length`,
- `--max-total-tokens` must be set to `max_length` (it is per-request),
- `--max-batch-prefill-tokens` must be set to `batch_size * max_input_length`,
- `--max-batch-total-tokens` must be set to `max_tokens`.
### Choosing the correct batch size
As seen in the previous paragraph, model static batch size has a direct influence on the endpoint latency and throughput.
Please refer to [text-generation-inference](https://github.com/huggingface/text-generation-inference) for optimization hints.
Note that the main constraint is to be able to fit the model for the specified `batch_size` within the total device memory available
on your instance.
## Query the service
You can query the model using either the `/generate` or `/generate_stream` routes:
```
curl 127.0.0.1:8080/generate \
-X POST \
-d '{"inputs":"What is Deep Learning?","parameters":{"max_new_tokens":20}}' \
-H 'Content-Type: application/json'
```
```
curl 127.0.0.1:8080/generate_stream \
-X POST \
-d '{"inputs":"What is Deep Learning?","parameters":{"max_new_tokens":20}}' \
-H 'Content-Type: application/json'
```
## Build your own image
The image must be built from the top directory
```
make tpu-tgi
```
| {".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 01d3a42fb6c774d56b170a06a59600f747d4df3b Hamza Amin <[email protected]> 1727369593 +0500\tclone: from https://github.com/huggingface/optimum-tpu.git\n", ".git\\refs\\heads\\main": "01d3a42fb6c774d56b170a06a59600f747d4df3b\n", "docs\\source\\index.mdx": "<!---\nCopyright 2024 The HuggingFace Team. All rights reserved.\n\nLicensed under the Apache License, Version 2.0 (the \"License\");\nyou may not use this file except in compliance with the License.\nYou may obtain a copy of the License at\n\n http://www.apache.org/licenses/LICENSE-2.0\n\nUnless required by applicable law or agreed to in writing, software\ndistributed under the License is distributed on an \"AS IS\" BASIS,\nWITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\nSee the License for the specific language governing permissions and\nlimitations under the License.\n-->\n\n# \ud83e\udd17 Optimum TPU\n\nOptimum TPU provides all the necessary machinery to leverage and optimize AI workloads running on [Google Cloud TPU devices](https://cloud.google.com/tpu/docs).\n\nThe API provides the overall same user-experience as Hugging Face transformers with the minimum amount of changes required to target performance for inference.\n\nTraining support is underway, stay tuned! \ud83d\ude80\n\n\n## Installation\n\nOptimum TPU is meant to reduce as much as possible the friction in order to leverage Google Cloud TPU accelerators.\nAs such, we provide a pip installable package to make sure everyone can get easily started.\n\n### Run Cloud TPU with pip\n```bash\npip install optimum-tpu\n```\n\n### Run Cloud TPU within Docker container\n\n### PyTorch\n```bash\nexport TPUVM_IMAGE_URL=us-central1-docker.pkg.dev/tpu-pytorch-releases/docker/xla\nexport TPUVM_IMAGE_VERSION=8f1dcd5b03f993e4da5c20d17c77aff6a5f22d5455f8eb042d2e4b16ac460526\ndocker pull\ndocker run -ti --rm --privileged --network=host ${TPUVM_IMAGE_URL}@sha256:${TPUVM_IMAGE_VERSION} bash\n```\n\nFrom there you can install optimum-tpu through the pip instructions above.\n\n\n<div class=\"mt-10\">\n <div class=\"w-full flex flex-col space-y-4 md:space-y-0 md:grid md:grid-cols-2 md:gap-y-4 md:gap-x-5\">\n <a class=\"!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg\" href=\"./tutorials/overview\">\n <div class=\"w-full text-center bg-gradient-to-br from-blue-400 to-blue-500 rounded-lg py-1.5 font-semibold mb-5 text-white text-lg leading-relaxed\">\n Tutorials\n </div>\n <p class=\"text-gray-700\">\n Learn the basics and become familiar with deploying transformers on Google TPUs.\n Start here if you are using \ud83e\udd17 Optimum-TPU for the first time!\n </p>\n </a>\n <a\n class=\"!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg\"\n href=\"./howto/overview\"\n >\n <div class=\"w-full text-center bg-gradient-to-br from-indigo-400 to-indigo-500 rounded-lg py-1.5 font-semibold mb-5 text-white text-lg leading-relaxed\">\n How-to guides\n </div>\n <p class=\"text-gray-700\">\n Practical guides to help you achieve a specific goal. Take a look at these guides to learn how to use \ud83e\udd17 Optimum-TPU\n to solve real-world problems.\n </p>\n </a>\n </div>\n</div>", "text-generation-inference\\docker\\Dockerfile": "# Fetch and extract the TGI sources (TGI_VERSION is mandatory)\nFROM alpine AS tgi\nARG TGI_VERSION\nRUN test -n ${TGI_VERSION:?}\nRUN mkdir -p /tgi\nADD https://github.com/huggingface/text-generation-inference/archive/${TGI_VERSION}.tar.gz /tgi/sources.tar.gz\nRUN tar -C /tgi -xf /tgi/sources.tar.gz --strip-components=1\n\n# Build cargo components (adapted from TGI original Dockerfile)\n# Note that the build image is aligned on the same Linux version as the base image (Debian bookworm/ Ubuntu 22.04)\nFROM lukemathwalker/cargo-chef:latest-rust-1.77-bookworm AS chef\nWORKDIR /usr/src\n\nARG CARGO_REGISTRIES_CRATES_IO_PROTOCOL=sparse\n\nFROM chef as planner\nCOPY --from=tgi /tgi/Cargo.toml Cargo.toml\nCOPY --from=tgi /tgi/Cargo.lock Cargo.lock\nCOPY --from=tgi /tgi/rust-toolchain.toml rust-toolchain.toml\nCOPY --from=tgi /tgi/proto proto\nCOPY --from=tgi /tgi/benchmark benchmark\nCOPY --from=tgi /tgi/router router\nCOPY --from=tgi /tgi/launcher launcher\nRUN cargo chef prepare --recipe-path recipe.json\n\nFROM chef AS builder\n\nRUN PROTOC_ZIP=protoc-21.12-linux-x86_64.zip && \\\n curl -OL https://github.com/protocolbuffers/protobuf/releases/download/v21.12/$PROTOC_ZIP && \\\n unzip -o $PROTOC_ZIP -d /usr/local bin/protoc && \\\n unzip -o $PROTOC_ZIP -d /usr/local 'include/*' && \\\n rm -f $PROTOC_ZIP\n\nCOPY --from=planner /usr/src/recipe.json recipe.json\nRUN cargo chef cook --release --recipe-path recipe.json\n\nCOPY --from=tgi /tgi/Cargo.toml Cargo.toml\nCOPY --from=tgi /tgi/Cargo.lock Cargo.lock\nCOPY --from=tgi /tgi/rust-toolchain.toml rust-toolchain.toml\nCOPY --from=tgi /tgi/proto proto\nCOPY --from=tgi /tgi/benchmark benchmark\nCOPY --from=tgi /tgi/router router\nCOPY --from=tgi /tgi/launcher launcher\nRUN cargo build --release --workspace --exclude benchmark\n\n# Python base image\nFROM ubuntu:22.04 AS base\n\nRUN apt-get update -y \\\n && apt-get install -y --no-install-recommends \\\n python3-pip \\\n python3-setuptools \\\n python-is-python3 \\\n && rm -rf /var/lib/apt/lists/* \\\n && apt-get clean\nRUN pip3 --no-cache-dir install --upgrade pip\n\n# VERSION is a mandatory parameter\nARG VERSION\nRUN test -n ${VERSION:?}\n\n# Python server build image\nFROM base AS pyserver\n\nRUN apt-get update -y \\\n && apt-get install -y --no-install-recommends \\\n make \\\n python3-venv \\\n && rm -rf /var/lib/apt/lists/* \\\n && apt-get clean\n\nRUN install -d /pyserver\nWORKDIR /pyserver\nCOPY text-generation-inference/server server\nCOPY --from=tgi /tgi/proto proto\nRUN pip3 install -r server/build-requirements.txt\nRUN VERBOSE=1 BUILDDIR=/pyserver/build PROTODIR=/pyserver/proto VERSION=${VERSION} make -C server gen-server\n\n# TPU base image (used for deployment)\nFROM base AS tpu_base\n\nARG VERSION=${VERSION}\n\n# Install system prerequisites\nRUN apt-get update -y \\\n && apt-get install -y --no-install-recommends \\\n libpython3.10 \\\n git \\\n gnupg2 \\\n wget \\\n && rm -rf /var/lib/apt/lists/* \\\n && apt-get clean\n\n# Update pip\nRUN pip install --upgrade pip\n\n# Install HuggingFace packages\nARG TRANSFORMERS_VERSION='4.41.1'\nARG ACCELERATE_VERSION='0.27.2'\nARG SAFETENSORS_VERSION='0.4.2'\n\n# TGI base env\nENV HUGGINGFACE_HUB_CACHE=/data \\\n HF_HUB_ENABLE_HF_TRANSFER=1 \\\n PORT=80 \\\n VERSION=${VERSION}\n\nCOPY . /opt/optimum-tpu\n\n# Install requirements for optimum-tpu, then for TGI then optimum-tpu\nRUN python3 -m pip install hf_transfer safetensors==${SAFETENSORS_VERSION} && \\\n python3 -m pip install -e /opt/optimum-tpu[jetstream-pt] \\\n -f https://storage.googleapis.com/jax-releases/jax_nightly_releases.html \\\n -f https://storage.googleapis.com/jax-releases/jaxlib_nightly_releases.html \\\n -f https://storage.googleapis.com/libtpu-releases/index.html\n\n# Install router\nCOPY --from=builder /usr/src/target/release/text-generation-router /usr/local/bin/text-generation-router\n# Install launcher\nCOPY --from=builder /usr/src/target/release/text-generation-launcher /usr/local/bin/text-generation-launcher\n# Install python server\nCOPY --from=pyserver /pyserver/build/dist dist\nRUN pip install dist/text_generation_server*.tar.gz\n\n\n# TPU compatible image for Inference Endpoints\nFROM tpu_base as inference-endpoint\n\nCOPY text-generation-inference/docker/entrypoint.sh entrypoint.sh\nRUN chmod +x entrypoint.sh\n\nENTRYPOINT [\"./entrypoint.sh\"]\n\n# TPU compatible image\nFROM tpu_base\n\nENTRYPOINT [\"text-generation-launcher\"]\nCMD [\"--json-output\"]\n", "text-generation-inference\\integration-tests\\requirements.txt": "# Copyright 2023 The HuggingFace Team. All rights reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\ntext-generation >= 0.6.0\npytest >= 7.4.0\npytest-asyncio >= 0.21.1\ndocker >= 6.1.3\nLevenshtein\n", "text-generation-inference\\server\\build-requirements.txt": "build\ngrpcio-tools==1.62.1\nmypy-protobuf==3.2.0\n"} | null |
paper-style-guide | {"type": "directory", "name": "paper-style-guide", "children": [{"type": "file", "name": "README.md"}]} | # 🤗 Paper Style Guide
(Work in progress, send a PR!)
## Libraries to Know
* [booktabs](https://nhigham.com/2019/11/19/better-latex-tables-with-booktabs/)
* [natbib](https://es.overleaf.com/learn/latex/Bibliography_management_with_natbib)
* [cleveref](http://tug.ctan.org/tex-archive/macros/latex/contrib/cleveref/cleveref.pdf)
* Either [seaborn](https://seaborn.pydata.org/), plotly or [altair](https://altair-viz.github.io/) for graphs
* [algorithmicx](https://ctan.mirrors.hoobly.com/macros/latex/contrib/algorithmicx/algorithmicx.pdf)
## General
* When in doubt use sections -> Introduction, Background, Model, Training, Methods, Results, Discussion, Conclusion.
* Tables should always follow this [guide](https://people.inf.ethz.ch/markusp/teaching/guides/guide-tables.pdf)
* Tables / Figures should always float. Never inline in the text.
* When using natbib, \citet is for when the citation is a noun, and \citep is for when it is at the end.
* Captions should be short but fully self-explanatory of the columns / rows. They should not use 1st person.
* Abstracts should be 1 paragraph. When in doubt -> Context, Problem, Idea 1, Idea 2, Results.
* Section titles should be starting-caps.
* The goal of related work is not just to list papers, but to explicitly make claims as to how your work differs from each one.
* Figures should have a white background and large fonts. Do not screenshot! Generate a high-res, pdf output.
* Use present tense (almost) everywhere.
* You do not need a summary paragraph at the end of your intro.
* All empirical results must be in a table or figure.
* Methods section should not introduce new modeling. Enumerate the tasks, baselines, hyperparameters.
* Results section should not introduce new tasks or models. Summarize the tables.
* Any non-trivial notation should be introduced as early possible. Ideally background.
* 8 pages is an extremely hard limit.
* Always use \`\` '' for quotes not " ".
* Use bold sparingly. Opt for italics for new technical terms.
## Small Tips
* Turn off `\usepackage[review]{emnlp}` to `\usepackage[]{emnlp}` while editing to fix overleaf linking.
* Use `\newcommand{\todo}[1]{{\small\color{red}{\bf [*** Todo: #1]}}}` for inline comments.
## Links
* Rational Reconstruction https://web.stanford.edu/class/cs224u/readings/shieber-writing.pdf
* ICML paper blog https://icml.cc/Conferences/2002/craft.html
## Exercises
* What are the 3 contributions of the paper?
* Do my experiments convincingly prove each of these are true?
* Can I cut anything that does not satisfy these?
* Would someone who has not read a paper in 2 years understand what is happening?
| {".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 fed778ae967cacd996b75f15e1f5c203199ec052 Hamza Amin <[email protected]> 1727369354 +0500\tclone: from https://github.com/huggingface/paper-style-guide.git\n", ".git\\refs\\heads\\main": "fed778ae967cacd996b75f15e1f5c203199ec052\n"} | null |
parler-tts | {"type": "directory", "name": "parler-tts", "children": [{"type": "directory", "name": "helpers", "children": [{"type": "directory", "name": "gradio_demo", "children": [{"type": "file", "name": "app.py"}]}, {"type": "directory", "name": "model_init_scripts", "children": [{"type": "file", "name": "init_dummy_model.py"}, {"type": "file", "name": "init_dummy_model_with_encodec.py"}, {"type": "file", "name": "init_large_model.py"}, {"type": "file", "name": "init_model_600M.py"}]}, {"type": "directory", "name": "push_to_hub_scripts", "children": [{"type": "file", "name": "push_dac_to_hub.py"}, {"type": "file", "name": "push_trained_parler_tts_to_hub.py"}]}, {"type": "directory", "name": "training_configs", "children": [{"type": "file", "name": "librispeech_tts_r_300M_dummy.json"}, {"type": "file", "name": "starting_point_0.01.json"}, {"type": "file", "name": "starting_point_v1.json"}, {"type": "file", "name": "starting_point_v1_large.json"}]}]}, {"type": "file", "name": "INFERENCE.md"}, {"type": "file", "name": "LICENSE"}, {"type": "file", "name": "Makefile"}, {"type": "directory", "name": "parler_tts", "children": [{"type": "file", "name": "configuration_parler_tts.py"}, {"type": "directory", "name": "dac_wrapper", "children": [{"type": "file", "name": "configuration_dac.py"}, {"type": "file", "name": "modeling_dac.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "modeling_parler_tts.py"}, {"type": "file", "name": "streamer.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "pyproject.toml"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "setup.py"}, {"type": "directory", "name": "training", "children": [{"type": "file", "name": "arguments.py"}, {"type": "file", "name": "data.py"}, {"type": "file", "name": "eval.py"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "run_parler_tts_training.py"}, {"type": "file", "name": "utils.py"}, {"type": "file", "name": "__init__.py"}]}]} | # Training Parler-TTS
<a target="_blank" href="https://github.com/ylacombe/scripts_and_notebooks/blob/main/Finetuning_Parler_TTS_v1_on_a_single_speaker_dataset.ipynb">
<img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/>
</a>
**TL;DR:** After having followed the [installation steps](#requirements), you can reproduce the [Parler-TTS Mini v1](https://huggingface.co/parler-tts/parler-tts-mini-v1) training recipe with the following command line:
```sh
accelerate launch ./training/run_parler_tts_training.py ./helpers/training_configs/starting_point_v1.json
```
-------------
This sub-folder contains all the information to train or fine-tune your own Parler-TTS model. It consists of:
- [1. An introduction to the Parler-TTS architecture](#a-architecture)
- [2. First steps to get started](#b-getting-started)
- [3. Training guide](#c-training)
> [!IMPORTANT]
> You can also follow [this fine-tuning guide](https://github.com/ylacombe/scripts_and_notebooks/blob/main/Finetuning_Parler_TTS_v1_on_a_single_speaker_dataset.ipynb) on a mono-speaker dataset example.
## 1. Architecture
At the moment, Parler-TTS architecture is almost a carbon copy of the [MusicGen architecture](https://huggingface.co/docs/transformers/v4.39.3/en/model_doc/musicgen#model-structure) and can be decomposed into three distinct stages:
1. Text encoder: maps the text descriptions to a sequence of hidden-state representations. Parler-TTS uses a frozen text encoder initialised entirely from Flan-T5
2. Parler-TTS decoder: a language model (LM) that auto-regressively generates audio tokens (or codes) conditional on the encoder hidden-state representations
3. Audio codec: used to recover the audio waveform from the audio tokens predicted by the decoder. We use the [DAC model](https://github.com/descriptinc/descript-audio-codec) from Descript, although other codec models, such as [EnCodec](https://huggingface.co/facebook/encodec_48khz), can also be used.
Parler-TTS however introduces some small tweaks:
- The text **description** is passed through the text encoder and used in the cross-attention layers of the decoder.
- The text **prompt** is simply passed through an embedding layer and concatenated to the decoder input hidden states.
- The audio encoder used is [**DAC**](https://descript.notion.site/Descript-Audio-Codec-11389fce0ce2419891d6591a68f814d5) instead of [Encodec](https://github.com/facebookresearch/encodec), as it exhibits better quality.
## 2. Getting started
To get started, you need to follow a few steps:
1. Install the requirements.
2. Find or initialize the model you'll train on.
3. Find and/or annotate the dataset you'll train your model on.
### Requirements
The Parler-TTS code is written in [PyTorch](https://pytorch.org) and [Accelerate](https://huggingface.co/docs/accelerate/index). It uses some additional requirements, like [wandb](https://wandb.ai/), especially for logging and evaluation.
To install the package for training, you need to clone the repository from source...
```bash
git clone https://github.com/huggingface/parler-tts.git
cd parler-tts
```
... And then install the requirements:
```bash
pip install -e .[train]
```
Optionally, you can create a wandb account and login to it by following [this guide](https://docs.wandb.ai/quickstart). [`wandb`](https://docs.wandb.ai/) allows for better tracking of the experiments metrics and losses.
You also have the option to configure Accelerate by running the following command. Note that you should set the number of GPUs you wish to use for training, and also the data type (dtype) to your preferred dtype for training/inference (e.g. `bfloat16` on A100 GPUs, `float16` on V100 GPUs, etc.):
```bash
accelerate config
```
Lastly, you can link you Hugging Face account so that you can push model repositories on the Hub. This will allow you to save your trained models on the Hub so that you can share them with the community. Run the command:
```bash
git config --global credential.helper store
huggingface-cli login
```
And then enter an authentication token from https://huggingface.co/settings/tokens. Create a new token if you do not have one already. You should make sure that this token has "write" privileges.
### Initialize a model from scratch or use a pre-trained one.
Depending on your compute resources and your dataset, you need to choose between fine-tuning a pre-trained model and training a new model from scratch.
In that sense, we released a 880M checkpoint trained on 45K hours of annotated data under the repository id: [`parler-tts/parler-tts-mini-v1`](https://huggingface.co/parler-tts/parler-tts-mini-v1), that you can fine-tune for your own use-case.
You can also train you own model from scratch. You can find [here](/helpers/model_init_scripts/) examples on how to initialize a model from scratch. For example, you can initialize a dummy model with:
```sh
python helpers/model_init_scripts/init_dummy_model.py ./parler-tts-untrained-dummy --text_model "google-t5/t5-small" --audio_model "parler-tts/dac_44khZ_8kbps"
```
In the rest of this guide, and to reproduce the Parler-TTS Mini v1 training recipe, we'll use a 880M parameters model that we'll initialize with:
```sh
python helpers/model_init_scripts/init_model_600M.py ./parler-tts-untrained-600M --text_model "google/flan-t5-large" --audio_model "parler-tts/dac_44khZ_8kbps"
```
### Create or find datasets
To train your own Parler-TTS, you need datasets with 3 main features:
- speech data
- text transcription of the speech data
- conditionning text description - that you can create using [Data-Speech](https://github.com/huggingface/dataspeech), a library that allows you to annotate the speaker and utterance characteristics with natural language description.
Note that we made the choice to use description of the main speech characteristics (speaker pitch, speaking rate, level of noise, etc.) but that you are free to use any handmade or generated text description that makes sense.
To train Parler-TTS Mini v1, we used:
* A [filtered version](https://huggingface.co/datasets/parler-tts/libritts_r_filtered) of [LibriTTS-R dataset](https://huggingface.co/datasets/blabble-io/libritts_r), a 1K hours high-quality speech dataset.
* The [English subset](https://huggingface.co/datasets/parler-tts/mls_eng) of [Multilingual LibriSpeech](https://huggingface.co/datasets/facebook/multilingual_librispeech).
Both datasets have been annotated using the [Data-Speech](https://github.com/huggingface/dataspeech) recipe, respectively [here](https://huggingface.co/datasets/parler-tts/libritts-r-filtered-speaker-descriptions) and [here](https://huggingface.co/datasets/parler-tts/mls-eng-speaker-descriptions).
## 3. Training
The script [`run_parler_tts_training.py`](/training/run_parler_tts_training.py) is an end-to-end script that:
1. load dataset(s) and merge them to the annotation dataset(s) if necessary
2. pre-compute audio tokens
3. train Parler-TTS
To train Parler-TTS Mini v1, we roughly used:
```sh
accelerate launch ./training/run_parler_tts_training.py \
--model_name_or_path "./parler-tts-untrained-600M/parler-tts-untrained-600M/" \
--feature_extractor_name "parler-tts/dac_44khZ_8kbps" \
--description_tokenizer_name "google/flan-t5-large" \
--prompt_tokenizer_name "google/flan-t5-large" \
--report_to "wandb" \
--overwrite_output_dir true \
--train_dataset_name "parler-tts/libritts_r_filtered+parler-tts/libritts_r_filtered+parler-tts/libritts_r_filtered+parler-tts/mls_eng" \
--train_metadata_dataset_name "parler-tts/libritts-r-filtered-speaker-descriptions+parler-tts/libritts-r-filtered-speaker-descriptions+parler-tts/libritts-r-filtered-speaker-descriptions+parler-tts/mls-eng-speaker-descriptions" \
--train_dataset_config_name "clean+clean+other+default" \
--train_split_name "train.clean.360+train.clean.100+train.other.500+train" \
--eval_dataset_name "parler-tts/libritts_r_filtered+parler-tts/mls_eng" \
--eval_metadata_dataset_name "parler-tts/libritts-r-filtered-speaker-descriptions+parler-tts/mls-eng-speaker-descriptions" \
--eval_dataset_config_name "other+default" \
--eval_split_name "test.other+test" \
--target_audio_column_name "audio" \
--description_column_name "text_description" \
--prompt_column_name "text" \
--max_duration_in_seconds 30 \
--min_duration_in_seconds 2.0 \
--max_text_length 600 \
--add_audio_samples_to_wandb true \
--id_column_name "id" \
--preprocessing_num_workers 8 \
--do_train true \
--num_train_epochs 4 \
--gradient_accumulation_steps 6 \
--gradient_checkpointing false \
--per_device_train_batch_size 4 \
--learning_rate 0.00095 \
--adam_beta1 0.9 \
--adam_beta2 0.99 \
--weight_decay 0.01 \
--lr_scheduler_type "constant_with_warmup" \
--warmup_steps 20000 \
--logging_steps 1000 \
--freeze_text_encoder true \
--do_eval true \
--predict_with_generate true \
--include_inputs_for_metrics true \
--evaluation_strategy steps \
--eval_steps 10000 \
--save_steps 10000 \
--per_device_eval_batch_size 4 \
--audio_encoder_per_device_batch_size 24 \
--dtype "bfloat16" \
--seed 456 \
--output_dir "./output_dir_training/" \
--temporary_save_to_disk "./audio_code_tmp/" \
--save_to_disk "./tmp_dataset_audio/" \
--max_eval_samples 96 \
--dataloader_num_workers 8 \
--group_by_length true \
--attn_implementation "sdpa"
```
In particular, note how multiple training datasets, metadataset, configurations and splits can be loaded by separating the dataset arguments by + symbols:
```sh
"train_dataset_name": "parler-tts/libritts_r_filtered+parler-tts/libritts_r_filtered+parler-tts/libritts_r_filtered+parler-tts/mls_eng",
"train_metadata_dataset_name": "parler-tts/libritts-r-filtered-speaker-descriptions+parler-tts/libritts-r-filtered-speaker-descriptions+parler-tts/libritts-r-filtered-speaker-descriptions+parler-tts/mls-eng-speaker-descriptions",
"train_dataset_config_name": "clean+clean+other+default",
"train_split_name": "train.clean.360+train.clean.100+train.other.500+train",
```
Additionally, you can also write a JSON config file. Here, [starting_point_v1.json](helpers/training_configs/starting_point_v1.json) contains the exact same hyper-parameters than above and can be launched like that:
```sh
accelerate launch ./training/run_parler_tts_training.py ./helpers/training_configs/starting_point_v1.json
```
Training logs will be reported to wandb, provided that you passed `--report_to "wandb"` to the arguments.
> [!TIP]
> Starting training a new model from scratch can easily be overwhelming, so here's what training looked like for v1: [logs](https://api.wandb.ai/links/ylacombe/j7g8isjn)
Scaling to multiple GPUs using [distributed data parallelism (DDP)](https://pytorch.org/tutorials/beginner/ddp_series_theory.html) is trivial: simply run `accelerate config` and select the multi-GPU option, specifying the IDs of the GPUs you wish to use. The above script can then be run using DDP with no code changes. In our case, we used 4 nodes of 8 H100 80GB to train Parler-TTS Mini for around 1.5 days.
There are a few other noteworthy arguments:
1. `train_metadata_dataset_name` and `eval_metadata_dataset_name` specify, if necessary, the names of the dataset(s) that contain(s) the conditionning text descriptions. For example, this [dataset resulting from the Data-Speech annotation process](https://huggingface.co/datasets/parler-tts/libritts-r-filtered-speaker-descriptions) is saved without the audio column, as it's costly to write and push audio data, so it needs to be concatenated back to the original LibriTTS-R dataset.
2. As noted above, the script pre-computes audio tokens as computing audio codes is costly and only needs to be done once, since we're freezing the audio encoder. `audio_encoder_per_device_batch_size` is used to precise the per devie batch size for this pre-processing step.
3. Additionnally, when scaling up the training data and iterating on the hyper-parameters or the model architecture, we might want to avoid recomputing the audio tokens at each training run. That's why we introduced two additional parameters, `save_to_disk` and `temporary_save_to_disk` that serves as temporary buffers to save intermediary datasets. Note that processed data is made of text and audio tokens which are much more memory efficient, so the additional required space is negligible.
4. `predict_with_generate` and `add_audio_samples_to_wandb` are required to store generated audios and to compute WER and CLAP similarity.
5. `freeze_text_encoder`: which allows to freeze the text encoder, to save compute resources.
And finally, two additional comments:
1. `lr_scheduler_stype`: defines the learning rate schedule, one of `constant_with_warmup` or `cosine`. When experimenting with a training set-up or training for very few epochs, using `constant_with_warmup` is typically beneficial, since the learning rate remains high over the short training run. When performing longer training runs, using a `cosine` schedule shoud give better results.
2. `dtype`: data type (dtype) in which the model computation should be performed. Note that this only controls the dtype of the computations (forward and backward pass), and not the dtype of the parameters or optimiser states.
> [!TIP]
> Fine-tuning is as easy as modifying `model_name_or_path` to a pre-trained model.
> For example: `--model_name_or_path parler-tts/parler-tts-mini-v1`.
| {"setup.py": "# Copyright 2024 The HuggingFace Team. All rights reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport os\n\nimport setuptools\n\n\n_deps = [\n \"transformers>=4.43.0,<=4.43.3\",\n \"torch\",\n \"sentencepiece\",\n \"descript-audio-codec\",\n]\n\n_extras_dev_deps = [\n \"black~=23.1\",\n \"isort>=5.5.4\",\n \"ruff>=0.0.241,<=0.0.259\",\n]\n\n_extras_training_deps = [\n \"jiwer\",\n \"wandb\",\n \"accelerate\",\n \"evaluate\",\n \"datasets[audio]>=2.14.5\",\n]\n\nhere = os.path.abspath(os.path.dirname(__file__))\n\nwith open(os.path.join(here, \"README.md\"), encoding=\"utf-8\") as f:\n long_description = f.read()\n\n# read version\nwith open(os.path.join(here, \"parler_tts\", \"__init__.py\"), encoding=\"utf-8\") as f:\n for line in f:\n if line.startswith(\"__version__\"):\n version = line.split(\"=\")[1].strip().strip('\"')\n break\n else:\n raise RuntimeError(\"Unable to find version string.\")\n\nsetuptools.setup(\n name=\"parler_tts\",\n version=version,\n description=\"Toolkit for using and training Parler-TTS, a high-quality text-to-speech model.\",\n long_description=long_description,\n long_description_content_type=\"text/markdown\",\n packages=setuptools.find_packages(),\n install_requires=_deps,\n extras_require={\n \"dev\": _extras_dev_deps,\n \"train\": _extras_training_deps,\n },\n)\n", ".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 dcaed95e1cce6f616e3e1956f8d63f0f3f5dfe5f Hamza Amin <[email protected]> 1727369356 +0500\tclone: from https://github.com/huggingface/parler-tts.git\n", ".git\\refs\\heads\\main": "dcaed95e1cce6f616e3e1956f8d63f0f3f5dfe5f\n", "helpers\\gradio_demo\\app.py": "import gradio as gr\nimport torch\nfrom transformers import AutoFeatureExtractor, AutoTokenizer, set_seed\n\nfrom parler_tts import ParlerTTSForConditionalGeneration\n\n\ndevice = \"cuda:0\" if torch.cuda.is_available() else \"cpu\"\n\nrepo_id = \"parler-tts/parler_tts_mini_v0.1\"\n\nmodel = ParlerTTSForConditionalGeneration.from_pretrained(repo_id).to(device)\ntokenizer = AutoTokenizer.from_pretrained(repo_id)\nfeature_extractor = AutoFeatureExtractor.from_pretrained(repo_id)\n\n\nSAMPLE_RATE = feature_extractor.sampling_rate\nSEED = 41\n\ndefault_text = \"Please surprise me and speak in whatever voice you enjoy.\"\n\ntitle = \"# Parler-TTS </div>\"\n\nexamples = [\n [\n \"'This is the best time of my life, Bartley,' she said happily.\",\n \"A female speaker with a slightly low-pitched, quite monotone voice delivers her words at a slightly faster-than-average pace in a confined space with very clear audio.\",\n ],\n [\n \"Montrose also, after having experienced still more variety of good and bad fortune, threw down his arms, and retired out of the kingdom.\t\",\n \"A male speaker with a slightly high-pitched voice delivering his words at a slightly slow pace in a small, confined space with a touch of background noise and a quite monotone tone.\",\n ],\n [\n \"montrose also after having experienced still more variety of good and bad fortune threw down his arms and retired out of the kingdom\",\n \"A male speaker with a low-pitched voice delivering his words at a fast pace in a small, confined space with a lot of background noise and an animated tone.\",\n ],\n]\n\n\ndef gen_tts(text, description):\n inputs = tokenizer(description, return_tensors=\"pt\").to(device)\n prompt = tokenizer(text, return_tensors=\"pt\").to(device)\n\n set_seed(SEED)\n generation = model.generate(\n input_ids=inputs.input_ids, prompt_input_ids=prompt.input_ids, do_sample=True, temperature=1.0\n )\n audio_arr = generation.cpu().numpy().squeeze()\n\n return (SAMPLE_RATE, audio_arr)\n\n\ncss = \"\"\"\n #share-btn-container {\n display: flex;\n padding-left: 0.5rem !important;\n padding-right: 0.5rem !important;\n background-color: #000000;\n justify-content: center;\n align-items: center;\n border-radius: 9999px !important;\n width: 13rem;\n margin-top: 10px;\n margin-left: auto;\n flex: unset !important;\n }\n #share-btn {\n all: initial;\n color: #ffffff;\n font-weight: 600;\n cursor: pointer;\n font-family: 'IBM Plex Sans', sans-serif;\n margin-left: 0.5rem !important;\n padding-top: 0.25rem !important;\n padding-bottom: 0.25rem !important;\n right:0;\n }\n #share-btn * {\n all: unset !important;\n }\n #share-btn-container div:nth-child(-n+2){\n width: auto !important;\n min-height: 0px !important;\n }\n #share-btn-container .wrap {\n display: none !important;\n }\n\"\"\"\nwith gr.Blocks(css=css) as block:\n gr.Markdown(title)\n with gr.Row():\n with gr.Column():\n input_text = gr.Textbox(label=\"Input Text\", lines=2, value=default_text, elem_id=\"input_text\")\n description = gr.Textbox(label=\"Description\", lines=2, value=\"\", elem_id=\"input_description\")\n run_button = gr.Button(\"Generate Audio\", variant=\"primary\")\n with gr.Column():\n audio_out = gr.Audio(label=\"Parler-TTS generation\", type=\"numpy\", elem_id=\"audio_out\")\n\n inputs = [input_text, description]\n outputs = [audio_out]\n gr.Examples(examples=examples, fn=gen_tts, inputs=inputs, outputs=outputs, cache_examples=True)\n run_button.click(fn=gen_tts, inputs=inputs, outputs=outputs, queue=True)\n\nblock.queue()\nblock.launch(share=True)\n"} | null |
peft | {"type": "directory", "name": "peft", "children": [{"type": "file", "name": ".pre-commit-config.yaml"}, {"type": "directory", "name": "docker", "children": [{"type": "directory", "name": "peft-cpu", "children": [{"type": "file", "name": "Dockerfile"}]}, {"type": "directory", "name": "peft-gpu", "children": [{"type": "file", "name": "Dockerfile"}]}, {"type": "directory", "name": "peft-gpu-bnb-latest", "children": [{"type": "file", "name": "Dockerfile"}]}, {"type": "directory", "name": "peft-gpu-bnb-multi-source", "children": [{"type": "file", "name": "Dockerfile"}]}, {"type": "directory", "name": "peft-gpu-bnb-source", "children": [{"type": "file", "name": "Dockerfile"}]}, {"type": "file", "name": "README.md"}]}, {"type": "directory", "name": "docs", "children": [{"type": "file", "name": "Makefile"}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "source", "children": [{"type": "directory", "name": "accelerate", "children": [{"type": "file", "name": "deepspeed.md"}, {"type": "file", "name": "fsdp.md"}]}, {"type": "directory", "name": "conceptual_guides", "children": [{"type": "file", "name": "adapter.md"}, {"type": "file", "name": "ia3.md"}, {"type": "file", "name": "oft.md"}, {"type": "file", "name": "prompting.md"}]}, {"type": "directory", "name": "developer_guides", "children": [{"type": "file", "name": "checkpoint.md"}, {"type": "file", "name": "contributing.md"}, {"type": "file", "name": "custom_models.md"}, {"type": "file", "name": "lora.md"}, {"type": "file", "name": "low_level_api.md"}, {"type": "file", "name": "mixed_models.md"}, {"type": "file", "name": "model_merging.md"}, {"type": "file", "name": "quantization.md"}, {"type": "file", "name": "torch_compile.md"}, {"type": "file", "name": "troubleshooting.md"}]}, {"type": "file", "name": "index.md"}, {"type": "file", "name": "install.md"}, {"type": "directory", "name": "package_reference", "children": [{"type": "file", "name": "adalora.md"}, {"type": "file", "name": "adapter_utils.md"}, {"type": "file", "name": "auto_class.md"}, {"type": "file", "name": "boft.md"}, {"type": "file", "name": "config.md"}, {"type": "file", "name": "fourierft.md"}, {"type": "file", "name": "helpers.md"}, {"type": "file", "name": "ia3.md"}, {"type": "file", "name": "layernorm_tuning.md"}, {"type": "file", "name": "llama_adapter.md"}, {"type": "file", "name": "loha.md"}, {"type": "file", "name": "lokr.md"}, {"type": "file", "name": "lora.md"}, {"type": "file", "name": "merge_utils.md"}, {"type": "file", "name": "multitask_prompt_tuning.md"}, {"type": "file", "name": "oft.md"}, {"type": "file", "name": "peft_model.md"}, {"type": "file", "name": "peft_types.md"}, {"type": "file", "name": "poly.md"}, {"type": "file", "name": "prefix_tuning.md"}, {"type": "file", "name": "prompt_tuning.md"}, {"type": "file", "name": "p_tuning.md"}, {"type": "file", "name": "tuners.md"}, {"type": "file", "name": "vblora.md"}, {"type": "file", "name": "vera.md"}, {"type": "file", "name": "xlora.md"}]}, {"type": "file", "name": "quicktour.md"}, {"type": "directory", "name": "task_guides", "children": [{"type": "file", "name": "ia3.md"}, {"type": "file", "name": "lora_based_methods.md"}, {"type": "file", "name": "prompt_based_methods.md"}]}, {"type": "directory", "name": "tutorial", "children": [{"type": "file", "name": "peft_integrations.md"}, {"type": "file", "name": "peft_model_config.md"}]}, {"type": "file", "name": "_config.py"}, {"type": "file", "name": "_toctree.yml"}]}]}, {"type": "directory", "name": "examples", "children": [{"type": "directory", "name": "boft_controlnet", "children": [{"type": "file", "name": "boft_controlnet.md"}, {"type": "file", "name": "eval.py"}, {"type": "file", "name": "eval.sh"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "test_controlnet.py"}, {"type": "file", "name": "test_controlnet.sh"}, {"type": "file", "name": "train_controlnet.py"}, {"type": "file", "name": "train_controlnet.sh"}, {"type": "directory", "name": "utils", "children": [{"type": "file", "name": "args_loader.py"}, {"type": "file", "name": "dataset.py"}, {"type": "file", "name": "light_controlnet.py"}, {"type": "file", "name": "pipeline_controlnet.py"}, {"type": "file", "name": "tracemalloc.py"}, {"type": "file", "name": "unet_2d_condition.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "boft_dreambooth", "children": [{"type": "file", "name": "boft_dreambooth.md"}, {"type": "file", "name": "dreambooth_inference.ipynb"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "train_dreambooth.py"}, {"type": "file", "name": "train_dreambooth.sh"}, {"type": "directory", "name": "utils", "children": [{"type": "file", "name": "args_loader.py"}, {"type": "file", "name": "dataset.py"}, {"type": "file", "name": "tracemalloc.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "causal_language_modeling", "children": [{"type": "file", "name": "accelerate_ds_zero3_cpu_offload_config.yaml"}, {"type": "file", "name": "peft_ln_tuning_clm.ipynb"}, {"type": "file", "name": "peft_lora_clm_accelerate_big_model_inference.ipynb"}, {"type": "file", "name": "peft_lora_clm_accelerate_ds_zero3_offload.py"}, {"type": "file", "name": "peft_lora_clm_with_additional_tokens.ipynb"}, {"type": "file", "name": "peft_prefix_tuning_clm.ipynb"}, {"type": "file", "name": "peft_prompt_tuning_clm.ipynb"}, {"type": "file", "name": "requirements.txt"}]}, {"type": "directory", "name": "conditional_generation", "children": [{"type": "file", "name": "accelerate_ds_zero3_cpu_offload_config.yaml"}, {"type": "file", "name": "multitask_prompt_tuning.ipynb"}, {"type": "file", "name": "peft_adalora_seq2seq.py"}, {"type": "file", "name": "peft_ia3_seq2seq.ipynb"}, {"type": "file", "name": "peft_lora_seq2seq.ipynb"}, {"type": "file", "name": "peft_lora_seq2seq_accelerate_big_model_inference.ipynb"}, {"type": "file", "name": "peft_lora_seq2seq_accelerate_ds_zero3_offload.py"}, {"type": "file", "name": "peft_lora_seq2seq_accelerate_fsdp.py"}, {"type": "file", "name": "peft_prefix_tuning_seq2seq.ipynb"}, {"type": "file", "name": "peft_prompt_tuning_seq2seq.ipynb"}, {"type": "file", "name": "peft_prompt_tuning_seq2seq_with_generate.ipynb"}, {"type": "file", "name": "requirements.txt"}]}, {"type": "directory", "name": "dna_language_models", "children": [{"type": "file", "name": "dna_lm.ipynb"}]}, {"type": "directory", "name": "dora_finetuning", "children": [{"type": "file", "name": "dora_finetuning.py"}, {"type": "file", "name": "QDoRA_finetuning.ipynb"}, {"type": "file", "name": "README.md"}]}, {"type": "directory", "name": "ephemeral_gpu_offloading", "children": [{"type": "file", "name": "load_with_dora.py"}]}, {"type": "directory", "name": "feature_extraction", "children": [{"type": "file", "name": "peft_lora_embedding_semantic_search.py"}, {"type": "file", "name": "peft_lora_embedding_semantic_similarity_inference.ipynb"}, {"type": "file", "name": "requirements.txt"}]}, {"type": "directory", "name": "fp4_finetuning", "children": [{"type": "file", "name": "finetune_fp4_opt_bnb_peft.py"}]}, {"type": "directory", "name": "hra_dreambooth", "children": [{"type": "file", "name": "dreambooth_inference.ipynb"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "train_dreambooth.py"}, {"type": "file", "name": "train_dreambooth.sh"}, {"type": "directory", "name": "utils", "children": [{"type": "file", "name": "args_loader.py"}, {"type": "file", "name": "dataset.py"}, {"type": "file", "name": "tracemalloc.py"}, {"type": "file", "name": "__init__.py"}]}]}, {"type": "directory", "name": "image_classification", "children": [{"type": "file", "name": "image_classification_peft_lora.ipynb"}, {"type": "file", "name": "image_classification_timm_peft_lora.ipynb"}, {"type": "file", "name": "README.md"}]}, {"type": "directory", "name": "int8_training", "children": [{"type": "file", "name": "Finetune_flan_t5_large_bnb_peft.ipynb"}, {"type": "file", "name": "Finetune_opt_bnb_peft.ipynb"}, {"type": "file", "name": "fine_tune_blip2_int8.py"}, {"type": "file", "name": "peft_adalora_whisper_large_training.py"}, {"type": "file", "name": "peft_bnb_whisper_large_v2_training.ipynb"}, {"type": "file", "name": "run_adalora_whisper_int8.sh"}]}, {"type": "directory", "name": "loftq_finetuning", "children": [{"type": "file", "name": "LoftQ_weight_replacement.ipynb"}, {"type": "file", "name": "quantize_save_load.py"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "train_gsm8k_llama.py"}]}, {"type": "directory", "name": "lora_dreambooth", "children": [{"type": "file", "name": "colab_notebook.ipynb"}, {"type": "file", "name": "convert_kohya_ss_sd_lora_to_peft.py"}, {"type": "file", "name": "convert_peft_sd_lora_to_kohya_ss.py"}, {"type": "file", "name": "lora_dreambooth_inference.ipynb"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "train_dreambooth.py"}]}, {"type": "directory", "name": "multilayer_perceptron", "children": [{"type": "file", "name": "multilayer_perceptron_lora.ipynb"}, {"type": "file", "name": "README.md"}]}, {"type": "directory", "name": "multi_adapter_examples", "children": [{"type": "file", "name": "Lora_Merging.ipynb"}, {"type": "file", "name": "multi_adapter_weighted_inference_diffusers.ipynb"}, {"type": "file", "name": "PEFT_Multi_LoRA_Inference.ipynb"}]}, {"type": "directory", "name": "oft_dreambooth", "children": [{"type": "file", "name": "oft_dreambooth_inference.ipynb"}, {"type": "file", "name": "train_dreambooth.py"}]}, {"type": "directory", "name": "olora_finetuning", "children": [{"type": "file", "name": "olora_finetuning.py"}, {"type": "file", "name": "README.md"}]}, {"type": "directory", "name": "pissa_finetuning", "children": [{"type": "file", "name": "pissa_finetuning.py"}, {"type": "file", "name": "preprocess.py"}, {"type": "file", "name": "README.md"}]}, {"type": "directory", "name": "poly", "children": [{"type": "file", "name": "peft_poly_seq2seq_with_generate.ipynb"}]}, {"type": "directory", "name": "semantic_segmentation", "children": [{"type": "file", "name": "README.md"}, {"type": "file", "name": "semantic_segmentation_peft_lora.ipynb"}]}, {"type": "directory", "name": "sequence_classification", "children": [{"type": "file", "name": "FourierFT.ipynb"}, {"type": "file", "name": "IA3.ipynb"}, {"type": "file", "name": "LoRA.ipynb"}, {"type": "file", "name": "peft_no_lora_accelerate.py"}, {"type": "file", "name": "prefix_tuning.ipynb"}, {"type": "file", "name": "Prompt_Tuning.ipynb"}, {"type": "file", "name": "P_Tuning.ipynb"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "VBLoRA.ipynb"}, {"type": "file", "name": "VeRA.ipynb"}]}, {"type": "directory", "name": "sft", "children": [{"type": "directory", "name": "configs", "children": [{"type": "file", "name": "deepspeed_config.yaml"}, {"type": "file", "name": "deepspeed_config_z3_qlora.yaml"}, {"type": "file", "name": "fsdp_config.yaml"}, {"type": "file", "name": "fsdp_config_qlora.yaml"}]}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "requirements_colab.txt"}, {"type": "file", "name": "run_peft.sh"}, {"type": "file", "name": "run_peft_deepspeed.sh"}, {"type": "file", "name": "run_peft_fsdp.sh"}, {"type": "file", "name": "run_peft_multigpu.sh"}, {"type": "file", "name": "run_peft_qlora_deepspeed_stage3.sh"}, {"type": "file", "name": "run_peft_qlora_fsdp.sh"}, {"type": "file", "name": "run_unsloth_peft.sh"}, {"type": "file", "name": "train.py"}, {"type": "file", "name": "utils.py"}]}, {"type": "directory", "name": "stable_diffusion", "children": [{"type": "file", "name": "convert_sd_adapter_to_peft.py"}, {"type": "file", "name": "train_dreambooth.py"}]}, {"type": "directory", "name": "token_classification", "children": [{"type": "file", "name": "peft_lora_token_cls.ipynb"}, {"type": "file", "name": "requirements.txt"}]}, {"type": "directory", "name": "xlora", "children": [{"type": "file", "name": "README.md"}, {"type": "file", "name": "xlora_inference_mistralrs.py"}]}]}, {"type": "file", "name": "LICENSE"}, {"type": "file", "name": "Makefile"}, {"type": "file", "name": "pyproject.toml"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "directory", "name": "scripts", "children": [{"type": "file", "name": "launch_notebook_mp.py"}, {"type": "file", "name": "log_reports.py"}, {"type": "file", "name": "stale.py"}]}, {"type": "file", "name": "setup.py"}, {"type": "directory", "name": "src", "children": [{"type": "directory", "name": "peft", "children": [{"type": "file", "name": "auto.py"}, {"type": "file", "name": "config.py"}, {"type": "file", "name": "helpers.py"}, {"type": "file", "name": "import_utils.py"}, {"type": "file", "name": "mapping.py"}, {"type": "file", "name": "mixed_model.py"}, {"type": "directory", "name": "optimizers", "children": [{"type": "file", "name": "loraplus.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "peft_model.py"}, {"type": "file", "name": "py.typed"}, {"type": "directory", "name": "tuners", "children": [{"type": "directory", "name": "adalora", "children": [{"type": "file", "name": "bnb.py"}, {"type": "file", "name": "config.py"}, {"type": "file", "name": "gptq.py"}, {"type": "file", "name": "layer.py"}, {"type": "file", "name": "model.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "adaption_prompt", "children": [{"type": "file", "name": "config.py"}, {"type": "file", "name": "layer.py"}, {"type": "file", "name": "model.py"}, {"type": "file", "name": "utils.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "boft", "children": [{"type": "file", "name": "config.py"}, {"type": "directory", "name": "fbd", "children": [{"type": "file", "name": "fbd_cuda.cpp"}, {"type": "file", "name": "fbd_cuda_kernel.cu"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "layer.py"}, {"type": "file", "name": "model.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "fourierft", "children": [{"type": "file", "name": "config.py"}, {"type": "file", "name": "layer.py"}, {"type": "file", "name": "model.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "hra", "children": [{"type": "file", "name": "config.py"}, {"type": "file", "name": "layer.py"}, {"type": "file", "name": "model.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "ia3", "children": [{"type": "file", "name": "bnb.py"}, {"type": "file", "name": "config.py"}, {"type": "file", "name": "layer.py"}, {"type": "file", "name": "model.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "ln_tuning", "children": [{"type": "file", "name": "config.py"}, {"type": "file", "name": "layer.py"}, {"type": "file", "name": "model.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "loha", "children": [{"type": "file", "name": "config.py"}, {"type": "file", "name": "layer.py"}, {"type": "file", "name": "model.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "lokr", "children": [{"type": "file", "name": "config.py"}, {"type": "file", "name": "layer.py"}, {"type": "file", "name": "model.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "lora", "children": [{"type": "file", "name": "aqlm.py"}, {"type": "file", "name": "awq.py"}, {"type": "file", "name": "bnb.py"}, {"type": "file", "name": "config.py"}, {"type": "file", "name": "dora.py"}, {"type": "file", "name": "eetq.py"}, {"type": "file", "name": "gptq.py"}, {"type": "file", "name": "hqq.py"}, {"type": "file", "name": "layer.py"}, {"type": "file", "name": "model.py"}, {"type": "file", "name": "tp_layer.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "lycoris_utils.py"}, {"type": "directory", "name": "mixed", "children": [{"type": "file", "name": "model.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "multitask_prompt_tuning", "children": [{"type": "file", "name": "config.py"}, {"type": "file", "name": "model.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "oft", "children": [{"type": "file", "name": "config.py"}, {"type": "file", "name": "layer.py"}, {"type": "file", "name": "model.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "poly", "children": [{"type": "file", "name": "config.py"}, {"type": "file", "name": "layer.py"}, {"type": "file", "name": "model.py"}, {"type": "file", "name": "router.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "prefix_tuning", "children": [{"type": "file", "name": "config.py"}, {"type": "file", "name": "model.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "prompt_tuning", "children": [{"type": "file", "name": "config.py"}, {"type": "file", "name": "model.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "p_tuning", "children": [{"type": "file", "name": "config.py"}, {"type": "file", "name": "model.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "tuners_utils.py"}, {"type": "directory", "name": "vblora", "children": [{"type": "file", "name": "config.py"}, {"type": "file", "name": "layer.py"}, {"type": "file", "name": "model.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "vera", "children": [{"type": "file", "name": "config.py"}, {"type": "file", "name": "layer.py"}, {"type": "file", "name": "model.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "xlora", "children": [{"type": "file", "name": "classifier.py"}, {"type": "file", "name": "config.py"}, {"type": "file", "name": "layer.py"}, {"type": "file", "name": "model.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "_buffer_dict.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "utils", "children": [{"type": "file", "name": "constants.py"}, {"type": "file", "name": "integrations.py"}, {"type": "file", "name": "loftq_utils.py"}, {"type": "file", "name": "merge_utils.py"}, {"type": "file", "name": "other.py"}, {"type": "file", "name": "peft_types.py"}, {"type": "file", "name": "save_and_load.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "__init__.py"}]}]}, {"type": "directory", "name": "tests", "children": [{"type": "directory", "name": "bnb", "children": [{"type": "file", "name": "test_bnb_regression.py"}]}, {"type": "file", "name": "conftest.py"}, {"type": "directory", "name": "regression", "children": [{"type": "file", "name": "test_regression.py"}]}, {"type": "file", "name": "testing_common.py"}, {"type": "file", "name": "testing_utils.py"}, {"type": "file", "name": "test_adaption_prompt.py"}, {"type": "file", "name": "test_auto.py"}, {"type": "file", "name": "test_boft.py"}, {"type": "file", "name": "test_common_gpu.py"}, {"type": "file", "name": "test_config.py"}, {"type": "file", "name": "test_custom_models.py"}, {"type": "file", "name": "test_decoder_models.py"}, {"type": "file", "name": "test_encoder_decoder_models.py"}, {"type": "file", "name": "test_feature_extraction_models.py"}, {"type": "file", "name": "test_gpu_examples.py"}, {"type": "file", "name": "test_helpers.py"}, {"type": "file", "name": "test_hub_features.py"}, {"type": "file", "name": "test_initialization.py"}, {"type": "file", "name": "test_loraplus.py"}, {"type": "file", "name": "test_lora_megatron.py"}, {"type": "file", "name": "test_low_level_api.py"}, {"type": "file", "name": "test_mixed.py"}, {"type": "file", "name": "test_multitask_prompt_tuning.py"}, {"type": "file", "name": "test_other.py"}, {"type": "file", "name": "test_poly.py"}, {"type": "file", "name": "test_stablediffusion.py"}, {"type": "file", "name": "test_torch_compile.py"}, {"type": "file", "name": "test_tuners_utils.py"}, {"type": "file", "name": "test_vblora.py"}, {"type": "file", "name": "test_vera.py"}, {"type": "file", "name": "test_vision_models.py"}, {"type": "file", "name": "test_xlora.py"}, {"type": "file", "name": "__init__.py"}]}]} | # X-LoRA examples
## `xlora_inference_mistralrs.py`
Perform inference of an X-LoRA model using the inference engine mistral.rs.
Mistral.rs supports many base models besides Mistral, and can load models directly from saved LoRA checkpoints. Check out [adapter model docs](https://github.com/EricLBuehler/mistral.rs/blob/master/docs/ADAPTER_MODELS.md) and the [models support matrix](https://github.com/EricLBuehler/mistral.rs?tab=readme-ov-file#support-matrix).
Mistral.rs features X-LoRA support and incorporates techniques such as a dual-KV cache, continuous batching, Paged Attention, and optional non granular scalings, will allow vastly improved throughput.
Links:
- Installation: https://github.com/EricLBuehler/mistral.rs/blob/master/mistralrs-pyo3/README.md
- Runnable example: https://github.com/EricLBuehler/mistral.rs/blob/master/examples/python/xlora_zephyr.py
- Adapter model docs and making the ordering file: https://github.com/EricLBuehler/mistral.rs/blob/master/docs/ADAPTER_MODELS.md | {"requirements.txt": "accelerate\ntorch\nsafetensors\nbitsandbytes\nscipy\npeft\ntransformers\ntqdm\npackaging\npytest\nnumpy\npyyaml\ndatasets\npsutil\nsetuptools", "setup.py": "# Copyright 2023 The HuggingFace Team. All rights reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom setuptools import find_packages, setup\n\n\nVERSION = \"0.13.1.dev0\"\n\nextras = {}\nextras[\"quality\"] = [\n \"black\", # doc-builder has an implicit dependency on Black, see huggingface/doc-builder#434\n \"hf-doc-builder\",\n \"ruff~=0.6.1\",\n]\nextras[\"docs_specific\"] = [\n \"black\", # doc-builder has an implicit dependency on Black, see huggingface/doc-builder#434\n \"hf-doc-builder\",\n]\nextras[\"dev\"] = extras[\"quality\"] + extras[\"docs_specific\"]\nextras[\"test\"] = extras[\"dev\"] + [\n \"pytest\",\n \"pytest-cov\",\n \"pytest-xdist\",\n \"parameterized\",\n \"datasets\",\n \"diffusers<0.21.0\",\n \"scipy\",\n]\n\nsetup(\n name=\"peft\",\n version=VERSION,\n description=\"Parameter-Efficient Fine-Tuning (PEFT)\",\n license_files=[\"LICENSE\"],\n long_description=open(\"README.md\", encoding=\"utf-8\").read(),\n long_description_content_type=\"text/markdown\",\n keywords=\"deep learning\",\n license=\"Apache\",\n author=\"The HuggingFace team\",\n author_email=\"[email protected]\",\n url=\"https://github.com/huggingface/peft\",\n package_dir={\"\": \"src\"},\n packages=find_packages(\"src\"),\n package_data={\"peft\": [\"py.typed\", \"tuners/boft/fbd/fbd_cuda.cpp\", \"tuners/boft/fbd/fbd_cuda_kernel.cu\"]},\n entry_points={},\n python_requires=\">=3.8.0\",\n install_requires=[\n \"numpy>=1.17\",\n \"packaging>=20.0\",\n \"psutil\",\n \"pyyaml\",\n \"torch>=1.13.0\",\n \"transformers\",\n \"tqdm\",\n \"accelerate>=0.21.0\",\n \"safetensors\",\n \"huggingface_hub>=0.17.0\",\n ],\n extras_require=extras,\n classifiers=[\n \"Development Status :: 5 - Production/Stable\",\n \"Intended Audience :: Developers\",\n \"Intended Audience :: Education\",\n \"Intended Audience :: Science/Research\",\n \"License :: OSI Approved :: Apache Software License\",\n \"Operating System :: OS Independent\",\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.8\",\n \"Topic :: Scientific/Engineering :: Artificial Intelligence\",\n ],\n)\n\n# Release checklist\n# 1. Change the version in __init__.py and setup.py to the release version, e.g. from \"0.6.0.dev0\" to \"0.6.0\"\n# 2. Check if there are any deprecations that need to be addressed for this release by searching for \"# TODO\" in the code\n# 3. Commit these changes with the message: \"Release: VERSION\", create a PR and merge it.\n# 4. Add a tag in git to mark the release: \"git tag -a VERSION -m 'Adds tag VERSION for pypi' \"\n# Push the tag to git:\n# git push --tags origin main\n# It is necessary to work on the original repository, not on a fork.\n# 5. Run the following commands in the top-level directory:\n# python setup.py bdist_wheel\n# python setup.py sdist\n# Ensure that you are on the clean and up-to-date main branch (git status --untracked-files=no should not list any\n# files and show the main branch)\n# 6. Upload the package to the pypi test server first:\n# twine upload dist/* -r pypitest\n# 7. Check that you can install it in a virtualenv by running:\n# pip install -i https://testpypi.python.org/pypi --extra-index-url https://pypi.org/simple peft\n# 8. Upload the final version to actual pypi:\n# twine upload dist/* -r pypi\n# 9. Add release notes to the tag on https://github.com/huggingface/peft/releases once everything is looking hunky-dory.\n# Check the notes here: https://docs.google.com/document/d/1k-sOIfykuKjWcOIALqjhFKz4amFEp-myeJUJEzNgjoU/edit?usp=sharing\n# 10. Update the version in __init__.py, setup.py to the bumped minor version + \".dev0\" (e.g. from \"0.6.0\" to \"0.7.0.dev0\")\n", ".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 ccc350151f95a9ff95da046bae5671da75eab52f Hamza Amin <[email protected]> 1727369401 +0500\tclone: from https://github.com/huggingface/peft.git\n", ".git\\refs\\heads\\main": "ccc350151f95a9ff95da046bae5671da75eab52f\n", ".github\\workflows\\tests-main.yml": "name: tests on transformers main\n\non:\n push:\n branches: [main]\n paths-ignore:\n - 'docs/**'\n\njobs:\n tests:\n runs-on: ubuntu-latest\n steps:\n - uses: actions/checkout@v3\n - name: Set up Python 3.11\n uses: actions/setup-python@v4\n with:\n python-version: 3.11\n cache: \"pip\"\n cache-dependency-path: \"setup.py\"\n - name: Install dependencies\n run: |\n python -m pip install --upgrade pip\n # cpu version of pytorch\n pip install -U git+https://github.com/huggingface/transformers.git\n pip install -e .[test]\n - name: Test with pytest\n run: |\n make test\n - name: Post to Slack\n if: always()\n uses: huggingface/hf-workflows/.github/actions/post-slack@main\n with:\n slack_channel: ${{ secrets.SLACK_CHANNEL_ID }}\n title: \ud83e\udd17 Results of transformers main tests\n status: ${{ job.status }}\n slack_token: ${{ secrets.SLACK_CIFEEDBACK_BOT_TOKEN }}\n", "docker\\peft-cpu\\Dockerfile": "# Builds GPU docker image of PyTorch\n# Uses multi-staged approach to reduce size\n# Stage 1\n# Use base conda image to reduce time\nFROM continuumio/miniconda3:latest AS compile-image\n# Specify py version\nENV PYTHON_VERSION=3.8\n# Install apt libs - copied from https://github.com/huggingface/accelerate/blob/main/docker/accelerate-gpu/Dockerfile\nRUN apt-get update && \\\n apt-get install -y curl git wget software-properties-common git-lfs && \\\n apt-get clean && \\\n rm -rf /var/lib/apt/lists*\n\n\n# Install audio-related libraries \nRUN apt-get update && \\\n apt install -y ffmpeg\n\nRUN apt install -y libsndfile1-dev\nRUN git lfs install\n\n# Create our conda env - copied from https://github.com/huggingface/accelerate/blob/main/docker/accelerate-gpu/Dockerfile\nRUN conda create --name peft python=${PYTHON_VERSION} ipython jupyter pip\nRUN python3 -m pip install --no-cache-dir --upgrade pip\n\n# Below is copied from https://github.com/huggingface/accelerate/blob/main/docker/accelerate-gpu/Dockerfile\n# We don't install pytorch here yet since CUDA isn't available\n# instead we use the direct torch wheel\nENV PATH /opt/conda/envs/peft/bin:$PATH\n# Activate our bash shell\nRUN chsh -s /bin/bash\nSHELL [\"/bin/bash\", \"-c\"]\n# Activate the conda env and install transformers + accelerate from source\nRUN source activate peft && \\\n python3 -m pip install --no-cache-dir \\\n librosa \\\n \"soundfile>=0.12.1\" \\\n scipy \\\n git+https://github.com/huggingface/transformers \\\n git+https://github.com/huggingface/accelerate \\\n peft[test]@git+https://github.com/huggingface/peft\n\n# Install apt libs\nRUN apt-get update && \\\n apt-get install -y curl git wget && \\\n apt-get clean && \\\n rm -rf /var/lib/apt/lists*\n\nRUN echo \"source activate peft\" >> ~/.profile\n\n# Activate the virtualenv\nCMD [\"/bin/bash\"]\n", "docker\\peft-gpu\\Dockerfile": "# Builds GPU docker image of PyTorch\n# Uses multi-staged approach to reduce size\n# Stage 1\n# Use base conda image to reduce time\nFROM continuumio/miniconda3:latest AS compile-image\n# Specify py version\nENV PYTHON_VERSION=3.8\n# Install apt libs - copied from https://github.com/huggingface/accelerate/blob/main/docker/accelerate-gpu/Dockerfile\nRUN apt-get update && \\\n apt-get install -y curl git wget software-properties-common git-lfs && \\\n apt-get clean && \\\n rm -rf /var/lib/apt/lists*\n\n# Install audio-related libraries \nRUN apt-get update && \\\n apt install -y ffmpeg\n\nRUN apt install -y libsndfile1-dev\nRUN git lfs install\n\n# Create our conda env - copied from https://github.com/huggingface/accelerate/blob/main/docker/accelerate-gpu/Dockerfile\nRUN conda create --name peft python=${PYTHON_VERSION} ipython jupyter pip\nRUN python3 -m pip install --no-cache-dir --upgrade pip\n\n# Below is copied from https://github.com/huggingface/accelerate/blob/main/docker/accelerate-gpu/Dockerfile\n# We don't install pytorch here yet since CUDA isn't available\n# instead we use the direct torch wheel\nENV PATH /opt/conda/envs/peft/bin:$PATH\n# Activate our bash shell\nRUN chsh -s /bin/bash\nSHELL [\"/bin/bash\", \"-c\"]\n\n# Stage 2\nFROM nvidia/cuda:12.2.2-devel-ubuntu22.04 AS build-image\nCOPY --from=compile-image /opt/conda /opt/conda\nENV PATH /opt/conda/bin:$PATH\n\nRUN chsh -s /bin/bash\nSHELL [\"/bin/bash\", \"-c\"]\nRUN source activate peft && \\ \n python3 -m pip install --no-cache-dir bitsandbytes optimum auto-gptq\n\n# Add autoawq for quantization testing\nRUN source activate peft && \\\n python3 -m pip install --no-cache-dir https://github.com/casper-hansen/AutoAWQ/releases/download/v0.2.4/autoawq-0.2.4-cp38-cp38-linux_x86_64.whl\nRUN source activate peft && \\\n python3 -m pip install --no-cache-dir https://github.com/casper-hansen/AutoAWQ_kernels/releases/download/v0.0.6/autoawq_kernels-0.0.6-cp38-cp38-linux_x86_64.whl\n\n# Install apt libs\nRUN apt-get update && \\\n apt-get install -y curl git wget && \\\n apt-get clean && \\\n rm -rf /var/lib/apt/lists*\n\n# Add eetq for quantization testing\nRUN source activate peft && \\\n python3 -m pip install git+https://github.com/NetEase-FuXi/EETQ.git\n\n# Activate the conda env and install transformers + accelerate from source\nRUN source activate peft && \\\n python3 -m pip install -U --no-cache-dir \\\n librosa \\\n \"soundfile>=0.12.1\" \\\n scipy \\\n git+https://github.com/huggingface/transformers \\\n git+https://github.com/huggingface/accelerate \\\n peft[test]@git+https://github.com/huggingface/peft\n\n# Add aqlm for quantization testing\nRUN source activate peft && \\\n pip install aqlm[gpu]>=1.0.2\n\n# Add HQQ for quantization testing\nRUN source activate peft && \\\npip install hqq\n\nRUN source activate peft && \\ \n pip freeze | grep transformers\n\nRUN echo \"source activate peft\" >> ~/.profile\n\n# Activate the virtualenv\nCMD [\"/bin/bash\"]\n", "docker\\peft-gpu-bnb-latest\\Dockerfile": "# Builds GPU docker image of PyTorch\n# Uses multi-staged approach to reduce size\n# Stage 1\n# Use base conda image to reduce time\nFROM continuumio/miniconda3:latest AS compile-image\n# Specify py version\nENV PYTHON_VERSION=3.8\n# Install apt libs - copied from https://github.com/huggingface/accelerate/blob/main/docker/accelerate-gpu/Dockerfile\nRUN apt-get update && \\\n apt-get install -y curl git wget software-properties-common git-lfs && \\\n apt-get clean && \\\n rm -rf /var/lib/apt/lists*\n\n# Install audio-related libraries \nRUN apt-get update && \\\n apt install -y ffmpeg\n\nRUN apt install -y libsndfile1-dev\nRUN git lfs install\n\n# Create our conda env - copied from https://github.com/huggingface/accelerate/blob/main/docker/accelerate-gpu/Dockerfile\nRUN conda create --name peft python=${PYTHON_VERSION} ipython jupyter pip\nRUN python3 -m pip install --no-cache-dir --upgrade pip\n\n# Below is copied from https://github.com/huggingface/accelerate/blob/main/docker/accelerate-gpu/Dockerfile\n# We don't install pytorch here yet since CUDA isn't available\n# instead we use the direct torch wheel\nENV PATH /opt/conda/envs/peft/bin:$PATH\n# Activate our bash shell\nRUN chsh -s /bin/bash\nSHELL [\"/bin/bash\", \"-c\"]\n\n# Stage 2\nFROM nvidia/cuda:12.1.0-devel-ubuntu22.04 AS build-image\nCOPY --from=compile-image /opt/conda /opt/conda\nENV PATH /opt/conda/bin:$PATH\n\nRUN chsh -s /bin/bash\nSHELL [\"/bin/bash\", \"-c\"]\n\n# Install apt libs\nRUN apt-get update && \\\n apt-get install -y curl git wget cmake && \\\n apt-get clean && \\\n rm -rf /var/lib/apt/lists*\n\n# Activate the conda env and install transformers + accelerate from latest pypi\n# Also clone BNB and build it from source.\nRUN source activate peft && \\\n python3 -m pip install -U --no-cache-dir \\\n librosa \\\n \"soundfile>=0.12.1\" \\\n scipy \\\n transformers \\\n accelerate \\\n peft \\\n optimum \\\n auto-gptq && \\\n git clone https://github.com/TimDettmers/bitsandbytes && cd bitsandbytes && \\\n cmake -B . -DCOMPUTE_BACKEND=cuda -S . && \\\n cmake --build . && \\\n pip install -e . && \\ \n pip freeze | grep bitsandbytes\n\nRUN echo \"source activate peft\" >> ~/.profile\n\n# Activate the virtualenv\nCMD [\"/bin/bash\"]\n", "docker\\peft-gpu-bnb-multi-source\\Dockerfile": "# Builds GPU docker image of PyTorch\n# Uses multi-staged approach to reduce size\n# Stage 1\n# Use base conda image to reduce time\nFROM continuumio/miniconda3:latest AS compile-image\n# Specify py version\nENV PYTHON_VERSION=3.8\n# Install apt libs - copied from https://github.com/huggingface/accelerate/blob/main/docker/accelerate-gpu/Dockerfile\nRUN apt-get update && \\\n apt-get install -y curl git wget software-properties-common git-lfs && \\\n apt-get clean && \\\n rm -rf /var/lib/apt/lists*\n\n# Install audio-related libraries \nRUN apt-get update && \\\n apt install -y ffmpeg\n\nRUN apt install -y libsndfile1-dev\nRUN git lfs install\n\n# Create our conda env - copied from https://github.com/huggingface/accelerate/blob/main/docker/accelerate-gpu/Dockerfile\nRUN conda create --name peft python=${PYTHON_VERSION} ipython jupyter pip\nRUN python3 -m pip install --no-cache-dir --upgrade pip\n\n# Below is copied from https://github.com/huggingface/accelerate/blob/main/docker/accelerate-gpu/Dockerfile\n# We don't install pytorch here yet since CUDA isn't available\n# instead we use the direct torch wheel\nENV PATH /opt/conda/envs/peft/bin:$PATH\n# Activate our bash shell\nRUN chsh -s /bin/bash\nSHELL [\"/bin/bash\", \"-c\"]\n\n# Stage 2\nFROM nvidia/cuda:12.1.0-devel-ubuntu22.04 AS build-image\nCOPY --from=compile-image /opt/conda /opt/conda\nENV PATH /opt/conda/bin:$PATH\n\nRUN chsh -s /bin/bash\nSHELL [\"/bin/bash\", \"-c\"]\n\n# Install apt libs\nRUN apt-get update && \\\n apt-get install -y curl git wget cmake && \\\n apt-get clean && \\\n rm -rf /var/lib/apt/lists*\n\n# Activate the conda env and install transformers + accelerate from source\n# Also clone BNB and build it from source.\nRUN source activate peft && \\\n python3 -m pip install -U --no-cache-dir \\\n librosa \\\n \"soundfile>=0.12.1\" \\\n scipy \\\n git+https://github.com/huggingface/transformers \\\n git+https://github.com/huggingface/accelerate \\\n peft[test]@git+https://github.com/huggingface/peft \\\n optimum \\\n auto-gptq && \\\n git clone https://github.com/TimDettmers/bitsandbytes && cd bitsandbytes && git checkout multi-backend-refactor && \\\n cmake -B . -DCOMPUTE_BACKEND=cuda -S . && \\\n cmake --build . && \\\n pip install -e . && \\ \n pip freeze | grep bitsandbytes\n\nRUN echo \"source activate peft\" >> ~/.profile\n\n# Activate the virtualenv\nCMD [\"/bin/bash\"]\n", "docker\\peft-gpu-bnb-source\\Dockerfile": "# Builds GPU docker image of PyTorch\n# Uses multi-staged approach to reduce size\n# Stage 1\n# Use base conda image to reduce time\nFROM continuumio/miniconda3:latest AS compile-image\n# Specify py version\nENV PYTHON_VERSION=3.8\n# Install apt libs - copied from https://github.com/huggingface/accelerate/blob/main/docker/accelerate-gpu/Dockerfile\nRUN apt-get update && \\\n apt-get install -y curl git wget software-properties-common git-lfs && \\\n apt-get clean && \\\n rm -rf /var/lib/apt/lists*\n\n# Install audio-related libraries \nRUN apt-get update && \\\n apt install -y ffmpeg\n\nRUN apt install -y libsndfile1-dev\nRUN git lfs install\n\n# Create our conda env - copied from https://github.com/huggingface/accelerate/blob/main/docker/accelerate-gpu/Dockerfile\nRUN conda create --name peft python=${PYTHON_VERSION} ipython jupyter pip\nRUN python3 -m pip install --no-cache-dir --upgrade pip\n\n# Below is copied from https://github.com/huggingface/accelerate/blob/main/docker/accelerate-gpu/Dockerfile\n# We don't install pytorch here yet since CUDA isn't available\n# instead we use the direct torch wheel\nENV PATH /opt/conda/envs/peft/bin:$PATH\n# Activate our bash shell\nRUN chsh -s /bin/bash\nSHELL [\"/bin/bash\", \"-c\"]\n\n# Stage 2\nFROM nvidia/cuda:12.1.0-devel-ubuntu22.04 AS build-image\nCOPY --from=compile-image /opt/conda /opt/conda\nENV PATH /opt/conda/bin:$PATH\n\nRUN chsh -s /bin/bash\nSHELL [\"/bin/bash\", \"-c\"]\n\n# Install apt libs\nRUN apt-get update && \\\n apt-get install -y curl git wget cmake && \\\n apt-get clean && \\\n rm -rf /var/lib/apt/lists*\n\n# Activate the conda env and install transformers + accelerate from source\n# Also clone BNB and build it from source.\nRUN source activate peft && \\\n python3 -m pip install -U --no-cache-dir \\\n librosa \\\n \"soundfile>=0.12.1\" \\\n scipy \\\n git+https://github.com/huggingface/transformers \\\n git+https://github.com/huggingface/accelerate \\\n peft[test]@git+https://github.com/huggingface/peft \\\n optimum \\\n auto-gptq && \\\n git clone https://github.com/TimDettmers/bitsandbytes && cd bitsandbytes && \\\n cmake -B . -DCOMPUTE_BACKEND=cuda -S . && \\\n cmake --build . && \\\n pip install -e . && \\ \n pip freeze | grep bitsandbytes\n\nRUN echo \"source activate peft\" >> ~/.profile\n\n# Activate the virtualenv\nCMD [\"/bin/bash\"]\n", "docs\\source\\index.md": "<!--Copyright 2023 The HuggingFace Team. All rights reserved.\n\nLicensed under the Apache License, Version 2.0 (the \"License\"); you may not use this file except in compliance with\nthe License. You may obtain a copy of the License at\n\nhttp://www.apache.org/licenses/LICENSE-2.0\n\nUnless required by applicable law or agreed to in writing, software distributed under the License is distributed on\nan \"AS IS\" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the\nspecific language governing permissions and limitations under the License.\n\n\u26a0\ufe0f Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be\nrendered properly in your Markdown viewer.\n\n-->\n\n# PEFT\n\n\ud83e\udd17 PEFT (Parameter-Efficient Fine-Tuning) is a library for efficiently adapting large pretrained models to various downstream applications without fine-tuning all of a model's parameters because it is prohibitively costly. PEFT methods only fine-tune a small number of (extra) model parameters - significantly decreasing computational and storage costs - while yielding performance comparable to a fully fine-tuned model. This makes it more accessible to train and store large language models (LLMs) on consumer hardware.\n\nPEFT is integrated with the Transformers, Diffusers, and Accelerate libraries to provide a faster and easier way to load, train, and use large models for inference.\n\n<div class=\"mt-10\">\n <div class=\"w-full flex flex-col space-y-4 md:space-y-0 md:grid md:grid-cols-2 md:gap-y-4 md:gap-x-5\">\n <a class=\"!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg\" href=\"quicktour\"\n ><div class=\"w-full text-center bg-gradient-to-br from-blue-400 to-blue-500 rounded-lg py-1.5 font-semibold mb-5 text-white text-lg leading-relaxed\">Get started</div>\n <p class=\"text-gray-700\">Start here if you're new to \ud83e\udd17 PEFT to get an overview of the library's main features, and how to train a model with a PEFT method.</p>\n </a>\n <a class=\"!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg\" href=\"./task_guides/image_classification_lora\"\n ><div class=\"w-full text-center bg-gradient-to-br from-indigo-400 to-indigo-500 rounded-lg py-1.5 font-semibold mb-5 text-white text-lg leading-relaxed\">How-to guides</div>\n <p class=\"text-gray-700\">Practical guides demonstrating how to apply various PEFT methods across different types of tasks like image classification, causal language modeling, automatic speech recognition, and more. Learn how to use \ud83e\udd17 PEFT with the DeepSpeed and Fully Sharded Data Parallel scripts.</p>\n </a>\n <a class=\"!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg\" href=\"./conceptual_guides/lora\"\n ><div class=\"w-full text-center bg-gradient-to-br from-pink-400 to-pink-500 rounded-lg py-1.5 font-semibold mb-5 text-white text-lg leading-relaxed\">Conceptual guides</div>\n <p class=\"text-gray-700\">Get a better theoretical understanding of how LoRA and various soft prompting methods help reduce the number of trainable parameters to make training more efficient.</p>\n </a>\n <a class=\"!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg\" href=\"./package_reference/config\"\n ><div class=\"w-full text-center bg-gradient-to-br from-purple-400 to-purple-500 rounded-lg py-1.5 font-semibold mb-5 text-white text-lg leading-relaxed\">Reference</div>\n <p class=\"text-gray-700\">Technical descriptions of how \ud83e\udd17 PEFT classes and methods work.</p>\n </a>\n </div>\n</div>\n\n<iframe\n\tsrc=\"https://stevhliu-peft-methods.hf.space\"\n\tframeborder=\"0\"\n\twidth=\"850\"\n\theight=\"620\"\n></iframe>\n", "examples\\boft_controlnet\\requirements.txt": "datasets==2.16.1\ndiffusers==0.17.1\ntransformers==4.36.2\naccelerate==0.25.0\nwandb==0.16.1\nscikit-image==0.22.0\nopencv-python==4.9.0.80\nface-alignment==1.4.1", "examples\\boft_dreambooth\\requirements.txt": "transformers==4.36.2\naccelerate==0.25.0\nevaluate\ntqdm\ndatasets==2.16.1\ndiffusers==0.17.1\nPillow\nhuggingface_hub\nsafetensors\nnb_conda_kernels\nipykernel\nipywidgets\nwandb==0.16.1", "examples\\causal_language_modeling\\requirements.txt": "transformers\naccelerate\nevaluate\ndeepspeed\ntqdm\ndatasets", "examples\\conditional_generation\\requirements.txt": "transformers\naccelerate\nevaluate\ndeepspeed\ntqdm\ndatasets", "examples\\feature_extraction\\requirements.txt": "git+https://github.com/huggingface/peft\ngit+https://github.com/huggingface/accelerate\ngit+https://github.com/huggingface/transformers\ndatasets\nevaluate\nhnswlib\npandas\ntqdm\nhuggingface_hub\nwandb", "examples\\hra_dreambooth\\requirements.txt": "transformers==4.36.2\naccelerate==0.25.0\nevaluate\ntqdm\ndatasets==2.16.1\ndiffusers==0.17.1\nPillow\nhuggingface_hub\nsafetensors\nnb_conda_kernels\nipykernel\nipywidgets\nwandb==0.16.1", "examples\\lora_dreambooth\\requirements.txt": "transformers\naccelerate\nevaluate\ntqdm\ndatasets\ndiffusers\nPillow\ntorchvision\nhuggingface_hub\nsafetensors\nwandb", "examples\\sequence_classification\\requirements.txt": "transformers\naccelerate\nevaluate\ntqdm\ndatasets", "examples\\sft\\requirements.txt": "git+https://github.com/huggingface/transformers\ngit+https://github.com/huggingface/accelerate\ngit+https://github.com/huggingface/peft\ngit+https://github.com/huggingface/trl\ngit+https://github.com/huggingface/datatrove.git\nunsloth[conda]@git+https://github.com/unslothai/unsloth.git\ndeepspeed\nPyGithub\nflash-attn\nhuggingface-hub\nevaluate\ndatasets\nbitsandbytes\neinops\nwandb\ntensorboard\ntiktoken\npandas\nnumpy\nscipy\nmatplotlib\nsentencepiece\nnltk\nxformers\nhf_transfer", "examples\\token_classification\\requirements.txt": "transformers\naccelerate\nevaluate\ntqdm\ndatasets\nPillow\ntorchvision", "src\\peft\\mapping.py": "# Copyright 2023-present the HuggingFace Inc. team.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom __future__ import annotations\n\nimport warnings\nfrom typing import TYPE_CHECKING, Any, Optional\n\nimport torch\n\nfrom peft.tuners.xlora.model import XLoraModel\n\nfrom .config import PeftConfig\nfrom .mixed_model import PeftMixedModel\nfrom .peft_model import (\n PeftModel,\n PeftModelForCausalLM,\n PeftModelForFeatureExtraction,\n PeftModelForQuestionAnswering,\n PeftModelForSeq2SeqLM,\n PeftModelForSequenceClassification,\n PeftModelForTokenClassification,\n)\nfrom .tuners import (\n AdaLoraConfig,\n AdaLoraModel,\n AdaptionPromptConfig,\n BOFTConfig,\n BOFTModel,\n FourierFTConfig,\n FourierFTModel,\n HRAConfig,\n HRAModel,\n IA3Config,\n IA3Model,\n LNTuningConfig,\n LNTuningModel,\n LoHaConfig,\n LoHaModel,\n LoKrConfig,\n LoKrModel,\n LoraConfig,\n LoraModel,\n MultitaskPromptTuningConfig,\n OFTConfig,\n OFTModel,\n PolyConfig,\n PolyModel,\n PrefixTuningConfig,\n PromptEncoderConfig,\n PromptTuningConfig,\n VBLoRAConfig,\n VBLoRAModel,\n VeraConfig,\n VeraModel,\n XLoraConfig,\n)\nfrom .tuners.tuners_utils import BaseTuner\nfrom .utils import _prepare_prompt_learning_config\n\n\nif TYPE_CHECKING:\n from transformers import PreTrainedModel\n\n\nMODEL_TYPE_TO_PEFT_MODEL_MAPPING: dict[str, type[PeftModel]] = {\n \"SEQ_CLS\": PeftModelForSequenceClassification,\n \"SEQ_2_SEQ_LM\": PeftModelForSeq2SeqLM,\n \"CAUSAL_LM\": PeftModelForCausalLM,\n \"TOKEN_CLS\": PeftModelForTokenClassification,\n \"QUESTION_ANS\": PeftModelForQuestionAnswering,\n \"FEATURE_EXTRACTION\": PeftModelForFeatureExtraction,\n}\n\nPEFT_TYPE_TO_CONFIG_MAPPING: dict[str, type[PeftConfig]] = {\n \"ADAPTION_PROMPT\": AdaptionPromptConfig,\n \"PROMPT_TUNING\": PromptTuningConfig,\n \"PREFIX_TUNING\": PrefixTuningConfig,\n \"P_TUNING\": PromptEncoderConfig,\n \"LORA\": LoraConfig,\n \"LOHA\": LoHaConfig,\n \"LORAPLUS\": LoraConfig,\n \"LOKR\": LoKrConfig,\n \"ADALORA\": AdaLoraConfig,\n \"BOFT\": BOFTConfig,\n \"IA3\": IA3Config,\n \"MULTITASK_PROMPT_TUNING\": MultitaskPromptTuningConfig,\n \"OFT\": OFTConfig,\n \"POLY\": PolyConfig,\n \"LN_TUNING\": LNTuningConfig,\n \"VERA\": VeraConfig,\n \"FOURIERFT\": FourierFTConfig,\n \"XLORA\": XLoraConfig,\n \"HRA\": HRAConfig,\n \"VBLORA\": VBLoRAConfig,\n}\n\nPEFT_TYPE_TO_TUNER_MAPPING: dict[str, type[BaseTuner]] = {\n \"LORA\": LoraModel,\n \"LOHA\": LoHaModel,\n \"LOKR\": LoKrModel,\n \"ADALORA\": AdaLoraModel,\n \"BOFT\": BOFTModel,\n \"IA3\": IA3Model,\n \"OFT\": OFTModel,\n \"POLY\": PolyModel,\n \"LN_TUNING\": LNTuningModel,\n \"VERA\": VeraModel,\n \"FOURIERFT\": FourierFTModel,\n \"XLORA\": XLoraModel,\n \"HRA\": HRAModel,\n \"VBLORA\": VBLoRAModel,\n}\n\n\ndef get_peft_config(config_dict: dict[str, Any]) -> PeftConfig:\n \"\"\"\n Returns a Peft config object from a dictionary.\n\n Args:\n config_dict (`Dict[str, Any]`): Dictionary containing the configuration parameters.\n \"\"\"\n\n return PEFT_TYPE_TO_CONFIG_MAPPING[config_dict[\"peft_type\"]](**config_dict)\n\n\ndef get_peft_model(\n model: PreTrainedModel,\n peft_config: PeftConfig,\n adapter_name: str = \"default\",\n mixed: bool = False,\n autocast_adapter_dtype: bool = True,\n revision: Optional[str] = None,\n) -> PeftModel | PeftMixedModel:\n \"\"\"\n Returns a Peft model object from a model and a config.\n\n Args:\n model ([`transformers.PreTrainedModel`]):\n Model to be wrapped.\n peft_config ([`PeftConfig`]):\n Configuration object containing the parameters of the Peft model.\n adapter_name (`str`, `optional`, defaults to `\"default\"`):\n The name of the adapter to be injected, if not provided, the default adapter name is used (\"default\").\n mixed (`bool`, `optional`, defaults to `False`):\n Whether to allow mixing different (compatible) adapter types.\n autocast_adapter_dtype (`bool`, *optional*):\n Whether to autocast the adapter dtype. Defaults to `True`. Right now, this will only cast adapter weights\n using float16 or bfloat16 to float32, as this is typically required for stable training, and only affect\n select PEFT tuners.\n revision (`str`, `optional`, defaults to `main`):\n The revision of the base model. If this isn't set, the saved peft model will load the `main` revision for\n the base model\n \"\"\"\n model_config = BaseTuner.get_model_config(model)\n old_name = peft_config.base_model_name_or_path\n new_name = model.__dict__.get(\"name_or_path\", None)\n peft_config.base_model_name_or_path = new_name\n\n if (old_name is not None) and (old_name != new_name):\n warnings.warn(\n f\"The PEFT config's `base_model_name_or_path` was renamed from '{old_name}' to '{new_name}'. \"\n \"Please ensure that the correct base model is loaded when loading this checkpoint.\"\n )\n\n if revision is not None:\n if peft_config.revision is not None and peft_config.revision != revision:\n warnings.warn(\n f\"peft config has already set base model revision to {peft_config.revision}, overwriting with revision {revision}\"\n )\n peft_config.revision = revision\n\n if mixed:\n # note: PeftMixedModel does not support autocast_adapter_dtype, so don't pass it\n return PeftMixedModel(model, peft_config, adapter_name=adapter_name)\n\n if peft_config.task_type not in MODEL_TYPE_TO_PEFT_MODEL_MAPPING.keys() and not peft_config.is_prompt_learning:\n return PeftModel(model, peft_config, adapter_name=adapter_name, autocast_adapter_dtype=autocast_adapter_dtype)\n\n if peft_config.is_prompt_learning:\n peft_config = _prepare_prompt_learning_config(peft_config, model_config)\n return MODEL_TYPE_TO_PEFT_MODEL_MAPPING[peft_config.task_type](\n model, peft_config, adapter_name=adapter_name, autocast_adapter_dtype=autocast_adapter_dtype\n )\n\n\ndef inject_adapter_in_model(\n peft_config: PeftConfig, model: torch.nn.Module, adapter_name: str = \"default\", low_cpu_mem_usage: bool = False\n) -> torch.nn.Module:\n r\"\"\"\n A simple API to create and inject adapter in-place into a model. Currently the API does not support prompt learning\n methods and adaption prompt. Make sure to have the correct `target_names` set in the `peft_config` object. The API\n calls `get_peft_model` under the hood but would be restricted only to non-prompt learning methods.\n\n Args:\n peft_config (`PeftConfig`):\n Configuration object containing the parameters of the Peft model.\n model (`torch.nn.Module`):\n The input model where the adapter will be injected.\n adapter_name (`str`, `optional`, defaults to `\"default\"`):\n The name of the adapter to be injected, if not provided, the default adapter name is used (\"default\").\n low_cpu_mem_usage (`bool`, `optional`, defaults to `False`):\n Create empty adapter weights on meta device. Useful to speed up the loading process.\n \"\"\"\n if peft_config.is_prompt_learning or peft_config.is_adaption_prompt:\n raise ValueError(\"`create_and_replace` does not support prompt learning and adaption prompt yet.\")\n\n if peft_config.peft_type not in PEFT_TYPE_TO_TUNER_MAPPING.keys():\n raise ValueError(\n f\"`inject_adapter_in_model` does not support {peft_config.peft_type} yet. Please use `get_peft_model`.\"\n )\n\n tuner_cls = PEFT_TYPE_TO_TUNER_MAPPING[peft_config.peft_type]\n\n # By instantiating a peft model we are injecting randomly initialized LoRA layers into the model's modules.\n peft_model = tuner_cls(model, peft_config, adapter_name=adapter_name, low_cpu_mem_usage=low_cpu_mem_usage)\n\n return peft_model.model\n"} | null |
peft-pytorch-conference | {"type": "directory", "name": "peft-pytorch-conference", "children": [{"type": "directory", "name": "instruction_finetuning", "children": [{"type": "directory", "name": "dataset_generation", "children": [{"type": "file", "name": "Ad_Copy_Dataset.ipynb"}]}, {"type": "directory", "name": "training", "children": [{"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "run_peft.sh"}, {"type": "file", "name": "train.py"}, {"type": "file", "name": "utils.py"}, {"type": "file", "name": "__init__.py"}]}]}, {"type": "file", "name": "LICENSE"}, {"type": "directory", "name": "multimodal_instruction_finetuning", "children": [{"type": "file", "name": "IDEFICS_Finetuning_demo.ipynb"}]}, {"type": "directory", "name": "personal_copilot", "children": [{"type": "directory", "name": "dataset_generation", "children": [{"type": "file", "name": "clone_hf_repos.py"}, {"type": "file", "name": "prepare_dataset.py"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}]}, {"type": "directory", "name": "training", "children": [{"type": "file", "name": "fim.py"}, {"type": "file", "name": "llama_flash_attn_monkey_patch.py"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "run_peft.sh"}, {"type": "file", "name": "train.py"}]}]}, {"type": "file", "name": "README.md"}]} | {".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 57116ac4e78ae5623436cc72f478151195c195aa Hamza Amin <[email protected]> 1727369403 +0500\tclone: from https://github.com/huggingface/peft-pytorch-conference.git\n", ".git\\refs\\heads\\main": "57116ac4e78ae5623436cc72f478151195c195aa\n", "instruction_finetuning\\training\\requirements.txt": "git+https://github.com/huggingface/transformers\ngit+https://github.com/huggingface/accelerate\ngit+https://github.com/huggingface/peft\ntrl\nhuggingface-hub\nbitsandbytes\nevaluate\ndatasets\neinops\nwandb\ntiktoken", "personal_copilot\\dataset_generation\\requirements.txt": "PyGithub\ndatasets\nnbformat\npandas", "personal_copilot\\training\\requirements.txt": "git+https://github.com/huggingface/transformers\ngit+https://github.com/huggingface/accelerate\ngit+https://github.com/huggingface/peft\ntrl\nhuggingface-hub\nbitsandbytes\nevaluate\ndatasets\neinops\nwandb\ntiktoken\ndeepspeed\ntqdm\nsafetensors"} | null |
|
personas | {"type": "directory", "name": "personas", "children": [{"type": "file", "name": "README.md"}]} | # personas
Datasets for Deep learning Personas
***TL;DR:*** These are the datasets that we've used in our fun AI side project experiment, over at https://personas.huggingface.co/
We've trained seq2seq models using [DeepQA](https://github.com/Conchylicultor/DeepQA), a tensorflow implementation of "A neural conversational model" (a.k.a. the Google paper), a Deep learning based chatbot.
## Datasets used
* [Cornell Movie Dialogs](http://www.cs.cornell.edu/~cristian/Cornell_Movie-Dialogs_Corpus.html) corpus
* Supreme Court Conversation Data.
* [Ubuntu Dialogue Corpus](https://arxiv.org/abs/1506.08909) for tech-support type discussion.
* [Stack Exchange Data Dump](https://archive.org/details/stackexchange)
This is an anonymized dump of all user-contributed content on the Stack Exchange network. Each site is formatted as a separate archive consisting of XML files zipped via 7-zip using bzip2 compression. Each site archive includes Posts, Users, Votes, Comments, PostHistory and PostLinks. For complete schema information, see the included readme.txt.
Attribution: cc-by-sa 3.0
| {".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n"} | null |
pixparse | {"type": "directory", "name": "pixparse", "children": [{"type": "file", "name": "pyproject.toml"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "directory", "name": "src", "children": [{"type": "directory", "name": "pixparse", "children": [{"type": "directory", "name": "app", "children": [{"type": "file", "name": "eval.py"}, {"type": "file", "name": "train.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "data", "children": [{"type": "file", "name": "config.py"}, {"type": "file", "name": "datasets_utils.py"}, {"type": "file", "name": "loader.py"}, {"type": "file", "name": "preprocess.py"}, {"type": "file", "name": "transforms.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "framework", "children": [{"type": "file", "name": "config.py"}, {"type": "file", "name": "device.py"}, {"type": "file", "name": "eval.py"}, {"type": "file", "name": "logger.py"}, {"type": "file", "name": "monitor.py"}, {"type": "file", "name": "random.py"}, {"type": "file", "name": "task.py"}, {"type": "file", "name": "train.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "layers", "children": [{"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "models", "children": [{"type": "file", "name": "config.py"}, {"type": "directory", "name": "configs", "children": [{"type": "file", "name": "cruller_base.json"}, {"type": "file", "name": "cruller_large.json"}]}, {"type": "file", "name": "cruller.py"}, {"type": "file", "name": "image_encoder_timm.py"}, {"type": "file", "name": "text_decoder_hf.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "task", "children": [{"type": "file", "name": "task_cruller_eval_cord.py"}, {"type": "file", "name": "task_cruller_eval_docvqa.py"}, {"type": "file", "name": "task_cruller_eval_ocr.py"}, {"type": "file", "name": "task_cruller_eval_rvlcdip.py"}, {"type": "file", "name": "task_cruller_finetune_CORD.py"}, {"type": "file", "name": "task_cruller_finetune_docvqa.py"}, {"type": "file", "name": "task_cruller_finetune_RVLCDIP.py"}, {"type": "file", "name": "task_cruller_finetune_xent.py"}, {"type": "file", "name": "task_cruller_pretrain.py"}, {"type": "file", "name": "task_donut_eval_ocr.py"}, {"type": "file", "name": "task_factory.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "tokenizers", "children": [{"type": "file", "name": "config.py"}, {"type": "directory", "name": "configs", "children": [{"type": "file", "name": "tokenizer_hf.json"}]}, {"type": "file", "name": "tokenizer_hf.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "utils", "children": [{"type": "file", "name": "json_utils.py"}, {"type": "file", "name": "metrics.py"}, {"type": "file", "name": "name_utils.py"}, {"type": "file", "name": "ocr_utils.py"}, {"type": "file", "name": "s3_utils.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "version.py"}, {"type": "file", "name": "__init__.py"}]}]}]} | # Pixel Parsing (`pixparse`)
## Introduction
An open reproduction of OCR-free end-to-end document understanding models with open data.
Broadly focused on these model types:
* image encoder + text decoder w/ pixels and text tokens as input (as per Donut)
* image encoder + text decoder w/ only pixels as input (as per Pix2Struct)
* image encoder + text encoder-decoder w/ pixels and text tokens as input (as per PaLI/PaLI-X)
The training objectives and pretraining datasets will also be inspired by the associated papers above, but will mix and match. For example, we may train a Donut or PaLI-X style model with a Pix2Struct objective (masked document images w/ simplified HTML target text).
## Usage
To launch a pretraining Cruller Task on IDL data, you would need these arguments in these scopes. The task-name argument selects which task is to be run, in this case cruller_pretrain.
```bash
python -m pixparse.app.train \
--task-name cruller_pretrain \
--data.train.source "pipe:aws s3 cp s3://url-to-IDL-webdataset-shards/idl_shard-00{000..699}.tar -" \
--data.train.batch-size 8 \
--data.train.num-samples 800000 \
--data.train.num-workers 8 \
--task.model-name cruller_large \
--task.opt.clip-grad-value 1.0 \
--task.opt.clip-grad-mode norm \
--task.opt.learning-rate 3e-4 \
--task.opt.grad-accum-steps 1 \
--task.opt.betas 0.9 0.98 \
--task.dtype bfloat16 \
--task.num-intervals 30 \
--task.num-warmup-intervals 3 \
--train.checkpoint-dir <your_checkpoint_dir> \
--train.output-dir <where logs and tb files are created> \
--train.experiment awesome_experiment\
--train.tensorboard True \
--train.log-eval-data False \
--train.wandb False \
--train.log-filename out.log
```
To launch evaluation on existing checkpoints, you need to use a Cruller Eval Task, e.g. on FUNSD dataset. The task-name argument will select which task is to be run. donut_eval_ocr, for instance, runs Donut as an OCR engine on the dataset chosen and does not need external checkpoints.
```bash
python -m pixparse.app.eval \
--eval.task-name cruller_eval_ocr \
--data.eval.source "pipe:aws s3 cp s3://.../FUNSD/FUNSD-000000.tar -" \
--data.eval.num-samples 200 \
--data.eval.batch-size 16 \
--data.eval.num-workers 8 \
--model-name cruller_large_6layers \
--task.dtype bfloat16 \
--s3-bucket pixparse-exps \
--resume True
--eval.checkpoint-path 20230629-231529-model_cruller_large-lr_0.0003-b_12/checkpoints/checkpoint-29.pt \
--output-dir /fsx/pablo/
```
metrics will be saved under output_dir, with a name derived from the checkpoint used.
To finetune a pretrained pixparse model on RVLCDIP json completion:
```bash
python -m pixparse.app.train \
--task-name cruller_finetune_rvlcdip \
--data.train.source aharley/rvl_cdip \
--data.train.format hf_dataset \
--data.train.split train \
--data.train.batch-size 32 \
--data.train.num-samples 320000 \
--data.train.num-workers 8 \
--model-name cruller_base \
--task.opt.clip-grad-value 1.0 \
--task.opt.clip-grad-mode norm \
--task.opt.learning-rate 1e-4 \
--task.opt.grad-accum-steps 1 \
--task.opt.betas 0.9 0.99 \
--task.dtype bfloat16 \
--task.num-intervals \
--task.num-warmup-intervals 1 \
--train.resume True \
--train.checkpoint-path /fsx/pablo/training_pixparse/cruller_Aug11th_base_30/checkpoint-8.pt \
--train.output-checkpoint-dir /fsx/pablo/training_pixparse/ \
--train.output-dir /fsx/pablo/training_pixparse/outputs/ \
--train.tensorboard True \
--train.log-eval-data False \
--train.wandb False \
--train.log-filename out.log
```
To evaluate a model finetuned on RVLCDIP:
```bash
python -m pixparse.app.eval \
--task-name cruller_eval_rvlcdip \
--data.eval.source aharley/rvl_cdip \
--data.eval.format hf_dataset \
--data.eval.split test \
--data.eval.num-samples 40000 \
--data.eval.batch-size 16 \
--data.eval.num-workers 8 \
--model-name cruller_base \
--task.dtype bfloat16 \
--output-dir /fsx/pablo/metrics_finetune \
--eval.checkpoint-path "/fsx/pablo/training_pixparse/20230823-151033-task_cruller_finetune_rvlcdip-model_cruller_base-lr_1.0e-04-b_32/checkpoint-4.pt" \
```
This will write the accuracy metrics in metrics_finetune directory.
To finetune a model on CORD dataset:
```bash
python -m pixparse.app.train \
--task-name cruller_finetune_cord \
--data.train.source naver-clova-ix/cord-v2 \
--data.train.format hf_dataset \
--data.train.split train \
--data.train.batch-size 32 \
--data.train.num-samples 800 \
--data.train.num-workers 8 \
--model-name cruller_base \
--task.opt.clip-grad-value 1.0 \
--task.opt.clip-grad-mode norm \
--task.opt.learning-rate 3e-4 \
--task.opt.grad-accum-steps 1 \
--task.opt.betas 0.9 0.99 \
--task.opt.layer-decay 0.75 \
--task.dtype bfloat16 \
--task.num-intervals 30 \
--task.num-warmup-intervals 3 \
--train.resume True \
--train.checkpoint-path /fsx/pablo/training_pixparse/cruller_Aug11th_base_30/checkpoint-8.pt \
--train.output-checkpoint-dir /fsx/pablo/training_pixparse/ \
--train.output-dir /fsx/pablo/training_pixparse/outputs/ \
--train.tensorboard True \
--train.log-eval-data False \
--train.wandb False \
--train.log-filename out.log
```
To evaluate a model on CORD dataset:
```bash
python -m pixparse.app.eval \
--task-name cruller_eval_cord \
--data.eval.source naver-clova-ix/cord-v2 \
--data.eval.format hf_dataset \
--data.eval.split test \
--data.eval.num-samples 100 \
--data.eval.batch-size 16 \
--data.eval.num-workers 8 \
--model-name cruller_base \
--task.dtype bfloat16 \
--output-dir /fsx/pablo/metrics_finetune \
--eval.checkpoint-path /fsx/pablo/training_pixparse/20230830-133114-task_cruller_finetune_cord-model_cruller_base-lr_3.0e-05-b_8/checkpoint-29.pt \
```
## Updates
2023-06-14
* Distributed training tested in a SLURM environment w/ 16x A100 over 2 nodes.
2023-06-12
* It performs train steps on image-text datasets (objective too hard to learn anything w/o text in image)
* `python -m pixparse.app.train --train.source "/data/cc12m/cc12m-train-{0000..xxxx}.tar" --train.batch-size 8 --train.num-samples 10000000 --learning-rate 1e-4 --clip-grad-value 1.0 --clip-grad-mode norm --grad-accum-steps 4`
* Next step, trial image + ocr anno dataset
## Code Organization
Within `src/pixparse`:
* `app/` - CLI applications for training and evaluation
* `app/train.py` - main training CLI entrypoint, will attempt to keep useable across tasks
* `app/eval.py` - (TODO) main evaluation CLI entrypoint
* `app/finetune.py` - (TBD) fine-tune is handled by train.py with different args/config or separate?
* `data/` - data loaders, image and text preprocessing
* `framework/` - lightweight train & evaluation scaffolding on top of canonical PyTorch
* `layers/` - custom nn.Modules and functions for re-usable modelling components
* `models/` - modelling code with associated factory methods and helpers
* `task/` - task wrappers for various objectives (model + loss fn + pre/post-processing + optimization nuances)
* `tokenizer/` - tokenizer helpers (push into data?)
* `utils/` - misc utils that don't have a home
## Concepts & Terminology
Some terms and concepts used in this project that may be a bit unfamiliar.
### Task
A key organization concept in this project. Package the model with its loss, pre/post-processing, and optimization setup together for a given objective.
Examples of tasks conceptually:
* Pretraining a Donut style (image enc + text dec) model on supervised (OCR annotation) doc-text dataset
* Pretraining a Pix2Struct style (image enc + text dec) model w/ a dataset of webpage/screenshots and structured, simplified HTML
* Pretraining a PaLI style (image enc + text enc-dec) model w/ prefix & masked-token completion on datasets as above
* Fine-tuning any of the above pretrained models on a possibly large variety of downstream tasks
* Semi-structured doc parsing - receipt, invoice, business cards, etc.
* VQA
* Captioning
* ... and more
With the Task concept, the data pipeline exists outside the task. Samples and targets are fed into the task via the step functions. The data pipeline is coupled to the task by passing the pre-processing functions created within the task to the data pipeline on creation.
### Interval
You'll see the term 'interval' in the code, sometimes next to epoch. It's related, but an epoch means 'one complete pass of the dataset', an interval may be an epoch, but it may not. Interval is a span of training between checkpoints, ideally meaningful enough in duration to warrant evaluating and archiving each interval checkpoint.
In OpenCLIP development the term arose when using shard sampling with replacement, were the intervals between checkpoints were determined by limitations on job durations or likelihood of crashes.
| {"requirements.txt": "torch\ntimm\ntransformers\nwebdataset\nsimple-parsing", ".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 e002984025bab9fad1a3732deec838c565c79fb7 Hamza Amin <[email protected]> 1727369407 +0500\tclone: from https://github.com/huggingface/pixparse.git\n", ".git\\refs\\heads\\main": "e002984025bab9fad1a3732deec838c565c79fb7\n"} | null |
pyo3-special-method-derive | {"type": "directory", "name": "pyo3-special-method-derive", "children": [{"type": "file", "name": ".typos.toml"}, {"type": "file", "name": "Cargo.lock"}, {"type": "file", "name": "Cargo.toml"}, {"type": "file", "name": "LICENSE"}, {"type": "directory", "name": "pyo3_special_method_derive", "children": [{"type": "file", "name": "Cargo.toml"}, {"type": "directory", "name": "examples", "children": [{"type": "directory", "name": "all", "children": [{"type": "file", "name": "main.rs"}]}, {"type": "directory", "name": "dict", "children": [{"type": "file", "name": "main.rs"}]}, {"type": "directory", "name": "getattr", "children": [{"type": "file", "name": "main.rs"}]}, {"type": "directory", "name": "skips", "children": [{"type": "file", "name": "main.rs"}]}]}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "src", "children": [{"type": "file", "name": "lib.rs"}]}, {"type": "directory", "name": "tests", "children": [{"type": "file", "name": "complex_enum_formatter.rs"}, {"type": "file", "name": "dict.rs"}, {"type": "file", "name": "dict_enum.rs"}, {"type": "file", "name": "dict_enum_skipped.rs"}, {"type": "file", "name": "dict_enum_unit.rs"}, {"type": "file", "name": "dict_enum_unit_skipped.rs"}, {"type": "file", "name": "dict_skipped.rs"}, {"type": "file", "name": "dir_enum_complex.rs"}, {"type": "file", "name": "dir_enum_skip_complex.rs"}, {"type": "file", "name": "dir_enum_skip_unit.rs"}, {"type": "file", "name": "dir_skip.rs"}, {"type": "file", "name": "dir_struct.rs"}, {"type": "file", "name": "ellipsis.rs"}, {"type": "file", "name": "empty_complex_enum.rs"}, {"type": "file", "name": "enum_str_repr_skip.rs"}, {"type": "file", "name": "enum_str_repr_skip_complex.rs"}, {"type": "file", "name": "enum_str_repr_skip_str_repr.rs"}, {"type": "file", "name": "functional_enum_complex.rs"}, {"type": "file", "name": "functional_struct.rs"}, {"type": "file", "name": "functional_struct_nested.rs"}, {"type": "file", "name": "functional_struct_pub_and_attr_skip.rs"}, {"type": "file", "name": "functional_struct_pub_skip.rs"}, {"type": "file", "name": "general_skip.rs"}, {"type": "file", "name": "getattr.rs"}, {"type": "file", "name": "getattr_enum.rs"}, {"type": "file", "name": "getattr_enum_skipped.rs"}, {"type": "file", "name": "getattr_enum_skipped_unit.rs"}, {"type": "file", "name": "getattr_enum_unit.rs"}, {"type": "file", "name": "richcmp.rs"}, {"type": "file", "name": "struct_formatter.rs"}, {"type": "file", "name": "struct_str_repr_pub_skip.rs"}, {"type": "file", "name": "struct_str_repr_skip.rs"}, {"type": "file", "name": "struct_str_repr_skip_str_repr.rs"}, {"type": "file", "name": "tuple_struct_formatter.rs"}, {"type": "file", "name": "unit_enum_formatter.rs"}]}]}, {"type": "directory", "name": "pyo3_special_method_derive_example", "children": [{"type": "file", "name": "Cargo.toml"}, {"type": "file", "name": "debugging.py"}, {"type": "file", "name": "pyproject.toml"}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "src", "children": [{"type": "file", "name": "lib.rs"}]}, {"type": "file", "name": "testing.py"}]}, {"type": "directory", "name": "pyo3_special_method_derive_macro", "children": [{"type": "file", "name": "Cargo.toml"}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "src", "children": [{"type": "file", "name": "lib.rs"}, {"type": "file", "name": "str_repr.rs"}]}]}, {"type": "file", "name": "README.md"}]} | # pyo3-special-method-derive
This crate enables you to automatically derive Python dunder methods for your Rust crate using PyO3.
## Key features
- The following methods may be automatically derived on structs and enums:
- `__str__`
- `__repr__`
- `__dir__`
- `__getattr__`
- `__dict__`
- Support for structs and enums (only unit and complex enums due to a PyO3 limitation)
- Support for skipping variants or fields per derive macro with the `#[skip(...)]` attribute
- Automatically skip struct fields which are not `pub`
## Example
```rust
#[pyclass]
#[derive(Dir, Str, Repr)]
struct Person {
pub name: String,
occupation: String,
#[pyo3_smd(skip)]
pub phone_num: String,
}
```
## PyO3 feature note
To use `pyo3-special-method-derive`, you should enable the `multiple-pymethods` feature on PyO3:
```
pyo3 = { version = "0.22", features = ["multiple-pymethods"] }
``` | {".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", "pyo3_special_method_derive\\examples\\all\\main.rs": "use pyo3::pyclass;\nuse pyo3_special_method_derive::{Dir, Repr, Str};\n\n#[pyclass]\n#[derive(Str, Repr, Dir)]\nenum Tester {\n Alpha {\n x: u32,\n },\n Beta {\n x: u32,\n y: u32,\n },\n #[skip(Str, Repr, Dir)]\n Gamma {\n x: u32,\n y: u32,\n z: u32,\n },\n}\n\n#[pyclass]\n#[derive(Dir, Str, Repr)]\n#[allow(dead_code)]\nstruct Person {\n pub name: String,\n occupation: String,\n #[skip(Dir, Str, Repr)]\n pub phone_num: String,\n}\n\nfn main() {\n let person = Person {\n name: \"John Doe\".to_string(),\n occupation: \"Programmer\".to_string(),\n phone_num: \"123 456 7890\".to_string(),\n };\n assert_eq!(person.__dir__(), vec![\"name\".to_string()]);\n assert_eq!(person.__str__(), \"Person(name=\\\"John Doe\\\")\");\n\n let tester_beta = Tester::Beta { x: 123, y: 456 };\n assert_eq!(\n tester_beta.__dir__(),\n vec![\"Alpha\".to_string(), \"Beta\".to_string()]\n );\n assert_eq!(tester_beta.__str__(), \"Tester.Beta(x=123, y=456)\");\n\n let tester_gamma = Tester::Gamma {\n x: 123,\n y: 456,\n z: 789,\n };\n assert_eq!(\n tester_gamma.__dir__(),\n vec![\"Alpha\".to_string(), \"Beta\".to_string()]\n );\n assert_eq!(tester_gamma.__str__(), \"<variant skipped>\");\n}\n", "pyo3_special_method_derive\\examples\\dict\\main.rs": "use pyo3::{pyclass, types::PyAnyMethods, Python};\nuse pyo3_special_method_derive::Dict;\n\n#[pyclass]\n#[derive(Dict)]\n#[allow(dead_code)]\nstruct Person {\n pub name: String,\n pub address: String,\n location: String,\n}\n\nfn main() {\n pyo3::prepare_freethreaded_python();\n\n let res = Person {\n name: \"John Doe\".to_string(),\n address: \"Address\".to_string(),\n location: \"Earth\".to_string(),\n }\n .__dict__();\n\n let mut keys = res.keys().cloned().collect::<Vec<_>>();\n keys.sort();\n let mut values = Vec::new();\n for k in &keys {\n let v = res.get(k).unwrap();\n values.push(Python::with_gil(|py| {\n let py_any_ref = v.bind(py);\n py_any_ref.extract::<String>().unwrap()\n }));\n }\n println!(\"Keys: {keys:?} Values {values:?}\");\n}\n", "pyo3_special_method_derive\\examples\\getattr\\main.rs": "use pyo3::pyclass;\nuse pyo3_special_method_derive::Getattr;\n\n#[pyclass]\n#[derive(Getattr)]\n#[allow(dead_code)]\nstruct Person {\n pub name: String,\n pub occupation: String,\n phone_num: String,\n}\n\nfn main() {\n pyo3::prepare_freethreaded_python();\n\n let person = Person {\n name: \"John Doe\".to_string(),\n occupation: \"Programmer\".to_string(),\n phone_num: \"123 456 7890\".to_string(),\n };\n\n println!(\"{:?}\", person.__getattr__(\"name\".to_string()).unwrap());\n println!(\n \"{:?}\",\n person.__getattr__(\"phone_num\".to_string()).unwrap_err()\n );\n}\n", "pyo3_special_method_derive\\examples\\skips\\main.rs": "use pyo3::pyclass;\nuse pyo3_special_method_derive::{Dir, Repr, Str};\n\n#[pyclass]\n#[derive(Str, Repr, Dir)]\nenum Tester {\n #[skip(Str, Repr, Dir)]\n Alpha {\n x: u32,\n },\n Beta {\n x: u32,\n y: u32,\n },\n #[skip(Str, Repr, Dir)]\n Gamma {\n x: u32,\n y: u32,\n z: u32,\n },\n}\n\n#[pyclass]\n#[derive(Dir, Str, Repr)]\n#[allow(dead_code)]\nstruct Person {\n pub name: String,\n #[skip(Repr)]\n pub occupation: String,\n #[skip(Repr)]\n pub phone_num: String,\n}\n\nfn main() {\n let person = Person {\n name: \"John Doe\".to_string(),\n occupation: \"Programmer\".to_string(),\n phone_num: \"123 456 7890\".to_string(),\n };\n assert_eq!(\n person.__dir__(),\n vec![\n \"name\".to_string(),\n \"occupation\".to_string(),\n \"phone_num\".to_string()\n ]\n );\n assert_eq!(\n person.__str__(),\n \"Person(name=\\\"John Doe\\\", occupation=\\\"Programmer\\\")\"\n );\n assert_eq!(\n person.__repr__(),\n \"Person(name=\\\"John Doe\\\", phone_num=\\\"123 456 7890\\\")\"\n );\n\n let tester_beta = Tester::Beta { x: 123, y: 456 };\n assert_eq!(\n tester_beta.__dir__(),\n vec![\"Alpha\".to_string(), \"Beta\".to_string(), \"Gamma\".to_string()]\n );\n assert_eq!(tester_beta.__str__(), \"Tester.Beta(x=123, y=456)\");\n\n let tester_gamma = Tester::Gamma {\n x: 123,\n y: 456,\n z: 789,\n };\n assert_eq!(\n tester_gamma.__dir__(),\n vec![\"Alpha\".to_string(), \"Beta\".to_string(), \"Gamma\".to_string()]\n );\n assert_eq!(tester_gamma.__str__(), \"<variant skipped>\");\n\n let tester_alpha: Tester = Tester::Alpha { x: 123 };\n assert_eq!(\n tester_alpha.__dir__(),\n vec![\"Alpha\".to_string(), \"Beta\".to_string(), \"Gamma\".to_string()]\n );\n assert_eq!(tester_alpha.__repr__(), \"<variant skipped>\");\n}\n"} | null |
pytorch-openai-transformer-lm | {"type": "directory", "name": "pytorch-openai-transformer-lm", "children": [{"type": "file", "name": ".travis.yml"}, {"type": "file", "name": "analysis.py"}, {"type": "directory", "name": "assets", "children": []}, {"type": "file", "name": "datasets.py"}, {"type": "file", "name": "generate.py"}, {"type": "file", "name": "LICENSE"}, {"type": "file", "name": "loss.py"}, {"type": "file", "name": "model_pytorch.py"}, {"type": "file", "name": "opt.py"}, {"type": "file", "name": "parameters_names.json"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "text_utils.py"}, {"type": "file", "name": "train.py"}, {"type": "file", "name": "utils.py"}]} | # PyTorch implementation of OpenAI's Finetuned Transformer Language Model
This is a PyTorch implementation of the [TensorFlow code](https://github.com/openai/finetune-transformer-lm) provided with OpenAI's paper ["Improving Language Understanding by Generative Pre-Training"](https://blog.openai.com/language-unsupervised/) by Alec Radford, Karthik Narasimhan, Tim Salimans and Ilya Sutskever.
This implementation comprises **a script to load in the PyTorch model the weights pre-trained by the authors** with the TensorFlow implementation.

The model classes and loading script are located in [model_pytorch.py](model_pytorch.py).
The names of the modules in the PyTorch model follow the names of the Variable in the TensorFlow implementation. This implementation tries to follow the original code as closely as possible to minimize the discrepancies.
This implementation thus also comprises a modified Adam optimization algorithm as used in OpenAI's paper with:
- fixed weights decay following the work of [Loshchilov et al.](https://arxiv.org/abs/1711.05101), and
- scheduled learning rate as [commonly used for Transformers](http://nlp.seas.harvard.edu/2018/04/03/attention.html#optimizer).
## Requirements
To use the model it-self by importing [model_pytorch.py](model_pytorch.py), you just need:
- PyTorch (version >=0.4)
To run the classifier training script in [train.py](train.py) you will need in addition:
- tqdm
- sklearn
- spacy
- ftfy
- pandas
You can download the weights of the OpenAI pre-trained version by cloning [Alec Radford's repo](https://github.com/openai/finetune-transformer-lm) and placing the `model` folder containing the pre-trained weights in the present repo.
## Using the pre-trained model as a Transformer Language Model
The model can be used as a transformer language model with OpenAI's pre-trained weights as follow:
```python
from model_pytorch import TransformerModel, load_openai_pretrained_model, DEFAULT_CONFIG
args = DEFAULT_CONFIG
model = TransformerModel(args)
load_openai_pretrained_model(model)
```
This model generates Transformer's hidden states. You can use the `LMHead` class in [model_pytorch.py](model_pytorch.py) to add a decoder tied with the weights of the encoder and get a full language model. You can also use the `ClfHead` class in [model_pytorch.py](model_pytorch.py) to add a classifier on top of the transformer and get a classifier as described in OpenAI's publication. (see an example of both in the `__main__` function of [train.py](train.py))
To use the positional encoder of the transformer, you should encode your dataset using the `encode_dataset()` function of [utils.py](utils.py). Please refer to the beginning of the `__main__` function in [train.py](train.py) to see how to properly define the vocabulary and encode your dataset.
## Fine-tuning the pre-trained model on a classification task
This model can also be integrated in a classifier as detailed in [OpenAI's paper](https://blog.openai.com/language-unsupervised/). An example of fine-tuning on the ROCStories Cloze task is included with the training code in [train.py](train.py)
The ROCStories dataset can be downloaded from the associated [website](http://cs.rochester.edu/nlp/rocstories/).
As with the [TensorFlow code](https://github.com/openai/finetune-transformer-lm), this code implements the ROCStories Cloze Test result reported in the paper which can be reproduced by running:
```bash
python -m spacy download en
python train.py --dataset rocstories --desc rocstories --submit --analysis --data_dir [path to data here]
```
#### First experiments on the ROCStories test set
Finetuning the PyTorch model for 3 Epochs on ROCStories takes 10 minutes to run on a single NVidia K-80.
The single run test accuracy of this PyTorch version is 85.84%, while the authors reports a median accuracy with the TensorFlow code of 85.8% and the paper reports a best single run accuracy of 86.5%.
The authors implementations uses 8 GPU and can thus accomodate a batch of 64 samples while the present implementation is single GPU and is in consequence limited to 20 instances on a K80 for memory reasons. In our test, increasing the batch size from 8 to 20 samples increased the test accuracy by 2.5 points. A better accuracy may be obtained by using a multi-GPU setting (not tried yet).
The previous SOTA on the ROCStories dataset is 77.6% ("Hidden Coherence Model" of Chaturvedi et al. published in "Story Comprehension for Predicting What Happens Next" EMNLP 2017, which is a very nice paper too!)
| {".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n"} | null |
pytorch-pretrained-BigGAN | {"type": "directory", "name": "pytorch-pretrained-BigGAN", "children": [{"type": "directory", "name": "assets", "children": []}, {"type": "file", "name": "full_requirements.txt"}, {"type": "file", "name": "LICENSE"}, {"type": "file", "name": "MANIFEST.in"}, {"type": "directory", "name": "pytorch_pretrained_biggan", "children": [{"type": "file", "name": "config.py"}, {"type": "file", "name": "convert_tf_to_pytorch.py"}, {"type": "file", "name": "file_utils.py"}, {"type": "file", "name": "model.py"}, {"type": "file", "name": "utils.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "directory", "name": "scripts", "children": [{"type": "file", "name": "convert_tf_hub_models.sh"}, {"type": "file", "name": "download_tf_hub_models.sh"}]}, {"type": "file", "name": "setup.py"}]} | # PyTorch pretrained BigGAN
An op-for-op PyTorch reimplementation of DeepMind's BigGAN model with the pre-trained weights from DeepMind.
## Introduction
This repository contains an op-for-op PyTorch reimplementation of DeepMind's BigGAN that was released with the paper [Large Scale GAN Training for High Fidelity Natural Image Synthesis](https://openreview.net/forum?id=B1xsqj09Fm) by Andrew Brock, Jeff Donahue and Karen Simonyan.
This PyTorch implementation of BigGAN is provided with the [pretrained 128x128, 256x256 and 512x512 models by DeepMind](https://tfhub.dev/deepmind/biggan-deep-128/1). We also provide the scripts used to download and convert these models from the TensorFlow Hub models.
This reimplementation was done from the raw computation graph of the Tensorflow version and behave similarly to the TensorFlow version (variance of the output difference of the order of 1e-5).
This implementation currently only contains the generator as the weights of the discriminator were not released (although the structure of the discriminator is very similar to the generator so it could be added pretty easily. Tell me if you want to do a PR on that, I would be happy to help.)
## Installation
This repo was tested on Python 3.6 and PyTorch 1.0.1
PyTorch pretrained BigGAN can be installed from pip as follows:
```bash
pip install pytorch-pretrained-biggan
```
If you simply want to play with the GAN this should be enough.
If you want to use the conversion scripts and the imagenet utilities, additional requirements are needed, in particular TensorFlow and NLTK. To install all the requirements please use the `full_requirements.txt` file:
```bash
git clone https://github.com/huggingface/pytorch-pretrained-BigGAN.git
cd pytorch-pretrained-BigGAN
pip install -r full_requirements.txt
```
## Models
This repository provide direct and simple access to the pretrained "deep" versions of BigGAN for 128, 256 and 512 pixels resolutions as described in the [associated publication](https://openreview.net/forum?id=B1xsqj09Fm).
Here are some details on the models:
- `BigGAN-deep-128`: a 50.4M parameters model generating 128x128 pixels images, the model dump weights 201 MB,
- `BigGAN-deep-256`: a 55.9M parameters model generating 256x256 pixels images, the model dump weights 224 MB,
- `BigGAN-deep-512`: a 56.2M parameters model generating 512x512 pixels images, the model dump weights 225 MB.
Please refer to Appendix B of the paper for details on the architectures.
All models comprise pre-computed batch norm statistics for 51 truncation values between 0 and 1 (see Appendix C.1 in the paper for details).
## Usage
Here is a quick-start example using `BigGAN` with a pre-trained model.
See the [doc section](#doc) below for details on these classes and methods.
```python
import torch
from pytorch_pretrained_biggan import (BigGAN, one_hot_from_names, truncated_noise_sample,
save_as_images, display_in_terminal)
# OPTIONAL: if you want to have more information on what's happening, activate the logger as follows
import logging
logging.basicConfig(level=logging.INFO)
# Load pre-trained model tokenizer (vocabulary)
model = BigGAN.from_pretrained('biggan-deep-256')
# Prepare a input
truncation = 0.4
class_vector = one_hot_from_names(['soap bubble', 'coffee', 'mushroom'], batch_size=3)
noise_vector = truncated_noise_sample(truncation=truncation, batch_size=3)
# All in tensors
noise_vector = torch.from_numpy(noise_vector)
class_vector = torch.from_numpy(class_vector)
# If you have a GPU, put everything on cuda
noise_vector = noise_vector.to('cuda')
class_vector = class_vector.to('cuda')
model.to('cuda')
# Generate an image
with torch.no_grad():
output = model(noise_vector, class_vector, truncation)
# If you have a GPU put back on CPU
output = output.to('cpu')
# If you have a sixtel compatible terminal you can display the images in the terminal
# (see https://github.com/saitoha/libsixel for details)
display_in_terminal(output)
# Save results as png images
save_as_images(output)
```



## Doc
### Loading DeepMind's pre-trained weights
To load one of DeepMind's pre-trained models, instantiate a `BigGAN` model with `from_pretrained()` as:
```python
model = BigGAN.from_pretrained(PRE_TRAINED_MODEL_NAME_OR_PATH, cache_dir=None)
```
where
- `PRE_TRAINED_MODEL_NAME_OR_PATH` is either:
- the shortcut name of a Google AI's or OpenAI's pre-trained model selected in the list:
- `biggan-deep-128`: 12-layer, 768-hidden, 12-heads, 110M parameters
- `biggan-deep-256`: 24-layer, 1024-hidden, 16-heads, 340M parameters
- `biggan-deep-512`: 12-layer, 768-hidden, 12-heads , 110M parameters
- a path or url to a pretrained model archive containing:
- `config.json`: a configuration file for the model, and
- `pytorch_model.bin` a PyTorch dump of a pre-trained instance of `BigGAN` (saved with the usual `torch.save()`).
If `PRE_TRAINED_MODEL_NAME_OR_PATH` is a shortcut name, the pre-trained weights will be downloaded from AWS S3 (see the links [here](pytorch_pretrained_biggan/model.py)) and stored in a cache folder to avoid future download (the cache folder can be found at `~/.pytorch_pretrained_biggan/`).
- `cache_dir` can be an optional path to a specific directory to download and cache the pre-trained model weights.
### Configuration
`BigGANConfig` is a class to store and load BigGAN configurations. It's defined in [`config.py`](./pytorch_pretrained_biggan/config.py).
Here are some details on the attributes:
- `output_dim`: output resolution of the GAN (128, 256 or 512) for the pre-trained models,
- `z_dim`: size of the noise vector (128 for the pre-trained models).
- `class_embed_dim`: size of the class embedding vectors (128 for the pre-trained models).
- `channel_width`: size of each channel (128 for the pre-trained models).
- `num_classes`: number of classes in the training dataset, like imagenet (1000 for the pre-trained models).
- `layers`: A list of layers definition. Each definition for a layer is a triple of [up-sample in the layer ? (bool), number of input channels (int), number of output channels (int)]
- `attention_layer_position`: Position of the self-attention layer in the layer hierarchy (8 for the pre-trained models).
- `eps`: epsilon value to use for spectral and batch normalization layers (1e-4 for the pre-trained models).
- `n_stats`: number of pre-computed statistics for the batch normalization layers associated to various truncation values between 0 and 1 (51 for the pre-trained models).
### Model
`BigGAN` is a PyTorch model (`torch.nn.Module`) of BigGAN defined in [`model.py`](./pytorch_pretrained_biggan/model.py). This model comprises the class embeddings (a linear layer) and the generator with a series of convolutions and conditional batch norms. The discriminator is currently not implemented since pre-trained weights have not been released for it.
The inputs and output are **identical to the TensorFlow model inputs and outputs**.
We detail them here.
`BigGAN` takes as *inputs*:
- `z`: a torch.FloatTensor of shape [batch_size, config.z_dim] with noise sampled from a truncated normal distribution, and
- `class_label`: an optional torch.LongTensor of shape [batch_size, sequence_length] with the token types indices selected in [0, 1]. Type 0 corresponds to a `sentence A` and type 1 corresponds to a `sentence B` token (see BERT paper for more details).
- `truncation`: a float between 0 (not comprised) and 1. The truncation of the truncated normal used for creating the noise vector. This truncation value is used to selecte between a set of pre-computed statistics (means and variances) for the batch norm layers.
`BigGAN` *outputs* an array of shape [batch_size, 3, resolution, resolution] where resolution is 128, 256 or 512 depending of the model:
### Utilities: Images, Noise, Imagenet classes
We provide a few utility method to use the model. They are defined in [`utils.py`](./pytorch_pretrained_biggan/utils.py).
Here are some details on these methods:
- `truncated_noise_sample(batch_size=1, dim_z=128, truncation=1., seed=None)`:
Create a truncated noise vector.
- Params:
- batch_size: batch size.
- dim_z: dimension of z
- truncation: truncation value to use
- seed: seed for the random generator
- Output:
array of shape (batch_size, dim_z)
- `convert_to_images(obj)`:
Convert an output tensor from BigGAN in a list of images.
- Params:
- obj: tensor or numpy array of shape (batch_size, channels, height, width)
- Output:
- list of Pillow Images of size (height, width)
- `save_as_images(obj, file_name='output')`:
Convert and save an output tensor from BigGAN in a list of saved images.
- Params:
- obj: tensor or numpy array of shape (batch_size, channels, height, width)
- file_name: path and beggingin of filename to save.
Images will be saved as `file_name_{image_number}.png`
- `display_in_terminal(obj)`:
Convert and display an output tensor from BigGAN in the terminal. This function use `libsixel` and will only work in a libsixel-compatible terminal. Please refer to https://github.com/saitoha/libsixel for more details.
- Params:
- obj: tensor or numpy array of shape (batch_size, channels, height, width)
- file_name: path and beggingin of filename to save.
Images will be saved as `file_name_{image_number}.png`
- `one_hot_from_int(int_or_list, batch_size=1)`:
Create a one-hot vector from a class index or a list of class indices.
- Params:
- int_or_list: int, or list of int, of the imagenet classes (between 0 and 999)
- batch_size: batch size.
- If int_or_list is an int create a batch of identical classes.
- If int_or_list is a list, we should have `len(int_or_list) == batch_size`
- Output:
- array of shape (batch_size, 1000)
- `one_hot_from_names(class_name, batch_size=1)`:
Create a one-hot vector from the name of an imagenet class ('tennis ball', 'daisy', ...). We use NLTK's wordnet search to try to find the relevant synset of ImageNet and take the first one. If we can't find it direcly, we look at the hyponyms and hypernyms of the class name.
- Params:
- class_name: string containing the name of an imagenet object.
- Output:
- array of shape (batch_size, 1000)
## Download and conversion scripts
Scripts to download and convert the TensorFlow models from TensorFlow Hub are provided in [./scripts](./scripts/).
The scripts can be used directly as:
```bash
./scripts/download_tf_hub_models.sh
./scripts/convert_tf_hub_models.sh
```
| {"full_requirements.txt": "tensorflow\ntensorflow-hub\nPillow\nnltk\nlibsixel-python", "requirements.txt": "# PyTorch\ntorch>=0.4.1\n# progress bars in model download and training scripts\ntqdm\n# Accessing files from S3 directly.\nboto3\n# Used for downloading models over HTTP\nrequests", "setup.py": "\"\"\"\nSimple check list from AllenNLP repo: https://github.com/allenai/allennlp/blob/master/setup.py\n\nTo create the package for pypi.\n\n1. Change the version in __init__.py and setup.py.\n\n2. Commit these changes with the message: \"Release: VERSION\"\n\n3. Add a tag in git to mark the release: \"git tag VERSION -m'Adds tag VERSION for pypi' \"\n Push the tag to git: git push --tags origin master\n\n4. Build both the sources and the wheel. Do not change anything in setup.py between\n creating the wheel and the source distribution (obviously).\n\n For the wheel, run: \"python setup.py bdist_wheel\" in the top level allennlp directory.\n (this will build a wheel for the python version you use to build it - make sure you use python 3.x).\n\n For the sources, run: \"python setup.py sdist\"\n You should now have a /dist directory with both .whl and .tar.gz source versions of allennlp.\n\n5. Check that everything looks correct by uploading the package to the pypi test server:\n\n twine upload dist/* -r pypitest\n (pypi suggest using twine as other methods upload files via plaintext.)\n\n Check that you can install it in a virtualenv by running:\n pip install -i https://testpypi.python.org/pypi allennlp\n\n6. Upload the final version to actual pypi:\n twine upload dist/* -r pypi\n\n7. Copy the release notes from RELEASE.md to the tag in github once everything is looking hunky-dory.\n\n\"\"\"\nfrom io import open\nfrom setuptools import find_packages, setup\n\nsetup(\n name=\"pytorch_pretrained_biggan\",\n version=\"0.1.0\",\n author=\"Thomas Wolf\",\n author_email=\"[email protected]\",\n description=\"PyTorch version of DeepMind's BigGAN model with pre-trained models\",\n long_description=open(\"README.md\", \"r\", encoding='utf-8').read(),\n long_description_content_type=\"text/markdown\",\n keywords='BIGGAN GAN deep learning google deepmind',\n license='Apache',\n url=\"https://github.com/huggingface/pytorch-pretrained-BigGAN\",\n packages=find_packages(exclude=[\"*.tests\", \"*.tests.*\",\n \"tests.*\", \"tests\"]),\n install_requires=['torch>=0.4.1',\n 'numpy',\n 'boto3',\n 'requests',\n 'tqdm'],\n tests_require=['pytest'],\n entry_points={\n 'console_scripts': [\n \"pytorch_pretrained_biggan=pytorch_pretrained_biggan.convert_tf_to_pytorch:main\",\n ]\n },\n classifiers=[\n 'Intended Audience :: Science/Research',\n 'License :: OSI Approved :: Apache Software License',\n 'Programming Language :: Python :: 3',\n 'Topic :: Scientific/Engineering :: Artificial Intelligence',\n ],\n)\n", ".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n"} | null |
pytorch_block_sparse | {"type": "directory", "name": "pytorch_block_sparse", "children": [{"type": "directory", "name": "doc", "children": [{"type": "file", "name": "DevNotes.md"}, {"type": "directory", "name": "notebooks", "children": [{"type": "directory", "name": "01_how_to_train_sparse", "children": [{"type": "file", "name": "01_how_to_train_sparse.ipynb"}]}, {"type": "file", "name": "Beyond Layered Networks.ipynb"}, {"type": "file", "name": "ModelSparsification.ipynb"}]}, {"type": "file", "name": "Troubleshooting.md"}]}, {"type": "file", "name": "LICENSE.TXT"}, {"type": "file", "name": "MANIFEST.in"}, {"type": "directory", "name": "pytorch_block_sparse", "children": [{"type": "file", "name": "block_sparse.py"}, {"type": "file", "name": "block_sparse_linear.py"}, {"type": "directory", "name": "cutlass", "children": [{"type": "directory", "name": "gemm", "children": [{"type": "file", "name": "block_loader.h"}, {"type": "file", "name": "block_loader_congruous_dp1.h"}, {"type": "file", "name": "block_loader_congruous_dp1_prune_sparse.h"}, {"type": "file", "name": "block_loader_crosswise.h"}, {"type": "file", "name": "block_loader_crosswise_prune_dense.h"}, {"type": "file", "name": "block_task.h"}, {"type": "file", "name": "block_task_back.h"}, {"type": "file", "name": "block_task_back_full.h"}, {"type": "file", "name": "dispatch.h"}, {"type": "file", "name": "dispatch_back.h"}, {"type": "file", "name": "dispatch_back_full.h"}, {"type": "file", "name": "dispatch_policies.h"}, {"type": "file", "name": "dp_accummulate.h"}, {"type": "file", "name": "epilogue_function.h"}, {"type": "file", "name": "grid_raster.h"}, {"type": "file", "name": "grid_raster_sparse.h"}, {"type": "file", "name": "k_split_control.h"}, {"type": "file", "name": "thread_accumulator.h"}]}, {"type": "directory", "name": "util", "children": [{"type": "file", "name": "debug.h"}, {"type": "file", "name": "device_introspection.h"}, {"type": "file", "name": "io_intrinsics.h"}, {"type": "file", "name": "math.h"}, {"type": "file", "name": "matrix_transform.h"}, {"type": "file", "name": "nv_std.h"}, {"type": "file", "name": "printable.h"}, {"type": "file", "name": "util.h"}]}]}, {"type": "directory", "name": "native", "children": [{"type": "file", "name": "block_sparse_cutlass_kernel.cu"}, {"type": "file", "name": "block_sparse_cutlass_kernel_back.cu"}, {"type": "file", "name": "block_sparse_native.cpp"}, {"type": "file", "name": "cutlass_dispatch.h"}, {"type": "file", "name": "cutlass_dispatch_back.h"}]}, {"type": "file", "name": "sparse_optimizer.py"}, {"type": "directory", "name": "tests", "children": [{"type": "directory", "name": "data", "children": [{"type": "file", "name": "merges.txt"}, {"type": "file", "name": "oscar.eo.small.txt"}, {"type": "file", "name": "vocab.json"}]}, {"type": "file", "name": "test_basic.py"}, {"type": "file", "name": "test_data_parallel.py"}, {"type": "file", "name": "test_emulate.py"}, {"type": "file", "name": "test_integration.py"}, {"type": "file", "name": "test_linear_nn.py"}, {"type": "file", "name": "test_matmul.py"}, {"type": "file", "name": "test_matmul_back.py"}, {"type": "file", "name": "test_replace.py"}, {"type": "file", "name": "test_save.py"}, {"type": "file", "name": "test_sparse_optimizer.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "util.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "setup.cfg"}, {"type": "file", "name": "setup.py"}]} | # Fast Block Sparse Matrices for Pytorch
This PyTorch extension provides a **drop-in replacement** for torch.nn.Linear using **block sparse matrices** instead of dense ones.
It enables very easy experimentation with sparse matrices since you can directly replace Linear layers in your model with sparse ones.
## Motivation
The goal of this library is to show that **sparse matrices can be used in neural networks**, instead of dense ones, without significantly altering the precision.
This is great news as sparse matrices unlock savings in both space and compute: a **50% sparse matrix** will use **only 50% memory**, and theoretically will use only 50% of computation.
In this library we make use of Cutlass to improve the CUDA performances versus a naive implementation.
However, due to the very optimized nature of cuBLAS based torch.nn.Linear, the current version of the library is still slower, by roughly a factor of 2 (this may be improved in the future).
In the present stage of the library, the performances for sparse matrices are roughly a factor of 2 slower than their optimized dense counterpart (we hope to improve this in the future). However, the performance gain of using sparse matrices grows with the sparsity, so a **75% sparse matrix** is roughly **2x** faster than the dense equivalent.
This is a huge improvement on PyTorch sparse matrices: their current implementation is an order of magnitude slower than the dense one.
Combined with other methods like distillation and quantization this allow to obtain networks which are both smaller and faster!
## Original code
This work is based on the [cutlass tilesparse](https://github.com/YulhwaKim/cutlass_tilesparse) proof of concept by [Yulhwa Kim](https://github.com/YulhwaKim).
It is using C++ CUDA templates for block-sparse matrix multiplication based on [CUTLASS](https://developer.nvidia.com/blog/cutlass-linear-algebra-cuda/).
## Basic usage
You can use the BlockSparseLinear drop in replacement for torch.nn.Linear in your own model:
```python
# from torch.nn import Linear
from pytorch_block_sparse import BlockSparseLinear
...
# self.fc = nn.Linear(1024, 256)
self.fc = BlockSparseLinear(1024, 256, density=0.1)
```
## Advanced usage: converting whole models
Or you can use a utility called BlockSparseModelPatcher to modify easily an existing model before training it. (you will need to train it from scratch rather than sparsifying a pre-trained model).
Here is an example with a Roberta Model from Hugging Face ([full example](doc/notebooks/ModelSparsification.ipynb))
```python
from pytorch_block_sparse import BlockSparseModelPatcher
# Create a model patcher
mp = BlockSparseModelPatcher()
# Selecting some layers to sparsify.
# This is the "artful" part, as some parts are more prone to be sparsified, other may impact model precision too much.
# Match layers using regexp (we escape the ., just because, it's more correct, but it does not change anything here)
# the [0-9]+ match any layer number.
# We setup a density of 0.5 on these layers, you can test other layers / densities .
mp.add_pattern("roberta\.encoder\.layer\.[0-9]+\.intermediate\.dense", {"density":0.5})
mp.add_pattern("roberta\.encoder\.layer\.[0-9]+\.output\.dense", {"density":0.5})
mp.add_pattern("roberta\.encoder\.layer\.[0-9]+\.attention\.output\.dense", {"density":0.5})
mp.patch_model(model)
print(f"Final model parameters count={model.num_parameters()}")
# => 68 million parameters instead of 84 million parameters (embeddings are taking a lof of space in Roberta)
```
You can use the provided [notebook](doc/notebooks/01_how_to_train_sparse/01_how_to_train_sparse.ipynb) to train a partially sparse Roberta.
## Performance
It's notoriously hard to approach cuBLAS performance with custom CUDA kernels.
OpenAI kernels for example make ample use of assembly language to achieve a good performance.
The promise of Cutlass was to provide tools that abstract the different parts of CUDA kernels using smart C++ templates.
This allows the `pytorch_block_sparse` library to achieve roughly 50% of cuBLAS performance:
depending on the exact matrix computation, it achieves 40% to 55% of the cuBLAS performance on large matrices
(which is the case when using large batch x sequence sizes in Transformers for example).
Practically, this means that a Transformer with BlockSparseLinear with a 50% sparsity is as fast as the dense version.
This may be improved in next releases, especially when newer version of Cutlass are used.
## Related work
OpenAI announced in January 2020 that their very advanced (and complex) TensorFlow code [would be ported](https://openai.com/blog/openai-pytorch/) to PyTorch.
Unfortunately this has not happened yet.
Google and Stanford June 2020 paper [Sparse GPU Kernels for Deep Learning](https://arxiv.org/abs/2006.10901) is promising too, as the code should be released at some time.
This would be even more general, as the sparsity pattern is not constrained, and the performance looks very good, with some smart ad hoc optimizations.
## Future work
- Implement some paper methods (and provide new ones) to optimize the sparse pattern during training, while doing the classic parameter optimization using backprop. The basic idea is to remove some smaller magnitude weights (or blocks of weights) at some positions and try other ones.
- [Movement Pruning: Adaptive Sparsity by Fine-Tuning](https://arxiv.org/abs/2005.07683)
- [Sparse Networks from Scratch: Faster Training without Losing Performance](https://arxiv.org/abs/1907.04840)
- [Structured Pruning of Large Language Models](https://arxiv.org/abs/1910.04732)
- [Learning Sparse Neural Networks through L0 Regularization](https://arxiv.org/abs/1712.01312), )
- Upgrade to the latest CUTLASS version to optimize speed for the latest architectures (using Tensor Cores for example)
- Use the new Ampere 50% sparse pattern within blocks themselves: more information on the [Hugging Face Blog](https://medium.com/huggingface/sparse-neural-networks-2-n-gpu-performance-b8bc9ce950fc).
## Installation
You can just use pip:
```
pip install pytorch-block-sparse
```
Or from source, clone this git repository, and in the root directory just execute:
```
python setup.py install
```
# Development Notes
You will find them [here](doc/DevNotes.md)
| {"setup.py": "import os\n\nimport torch\nfrom setuptools import setup\nfrom torch.utils.cpp_extension import BuildExtension, CUDAExtension\n\nrootdir = os.path.dirname(os.path.realpath(__file__))\n\nversion = \"0.1.2\"\n\next_modules = []\n\nif torch.cuda.is_available():\n ext = CUDAExtension(\n \"block_sparse_native\",\n [\n \"pytorch_block_sparse/native/block_sparse_native.cpp\",\n \"pytorch_block_sparse/native/block_sparse_cutlass_kernel_back.cu\",\n \"pytorch_block_sparse/native/block_sparse_cutlass_kernel.cu\",\n ],\n extra_compile_args=[\"-I\", \"%s/pytorch_block_sparse\" % rootdir],\n )\n ext_modules = [ext]\nelse:\n print(\"WARNING: torch cuda seems unavailable, emulated features only will be available.\")\n\nsetup(\n name=\"pytorch_block_sparse\",\n version=version,\n description=\"PyTorch extension for fast block sparse matrices computation,\"\n \" drop in replacement for torch.nn.Linear.\",\n long_description=\"pytorch_block_sparse is a PyTorch extension for fast block sparse matrices computation,\"\n \" drop in replacement for torch.nn.Linear\",\n classifiers=[\n \"Development Status :: 4 - Beta\",\n \"License :: OSI Approved :: BSD License\",\n \"Programming Language :: Python :: 3.0\",\n ],\n keywords=\"PyTorch,sparse,matrices,machine learning\",\n url=\"https://github.com/huggingface/pytorch_block_sparse\",\n author=\"Fran\u00e7ois Lagunas\",\n author_email=\"[email protected]\",\n download_url=f\"https://test.pypi.org/project/pytorch-block-sparse/{version}/\",\n license='BSD 3-Clause \"New\" or \"Revised\" License',\n packages=[\"pytorch_block_sparse\"],\n install_requires=[],\n include_package_data=True,\n zip_safe=False,\n ext_modules=ext_modules,\n cmdclass={\"build_ext\": BuildExtension},\n)\n", ".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n"} | null |
rasa_hmtl | {"type": "directory", "name": "rasa_hmtl", "children": [{"type": "directory", "name": ".vscode", "children": [{"type": "file", "name": "settings.json"}]}, {"type": "file", "name": "rasa_hmtl.py"}, {"type": "file", "name": "README.md"}]} | # RASA wrapper for HMTL (Hierarchical Multi-Task Learning)
## 🌊 A State-of-the-Art neural network model for several NLP tasks based on PyTorch and AllenNLP
---
```
@article{sanh2018hmtl,
title={A Hierarchical Multi-task Approach for Learning Embeddings from Semantic Tasks},
author={Sanh, Victor and Wolf, Thomas and Ruder, Sebastian},
journal={arXiv preprint arXiv:1811.06031},
year={2018}
}
```
⚠ Work in progress, this has not been thoroughly tested. ⚠
Main repo: https://github.com/huggingface/hmtl
Demo: https://huggingface.co/hmtl/
This code sample demonstrates how to use `rasa_nlu`'s `Component` mechanism to integrate the tasks results from `HMTL`:
- Named Entity Recoginition
- Entity Mention Detection
- Relation Extraction
- Coreference Resolution
| {".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n"} | null |
ratchet | {"type": "directory", "name": "ratchet", "children": [{"type": "directory", "name": ".cargo", "children": [{"type": "file", "name": "config.toml"}]}, {"type": "directory", "name": ".config", "children": [{"type": "file", "name": "nextest.toml"}]}, {"type": "file", "name": "ARCHITECTURE.md"}, {"type": "file", "name": "Cargo.toml"}, {"type": "directory", "name": "config", "children": [{"type": "file", "name": "webdriver-linux.json"}, {"type": "file", "name": "webdriver-macos.json"}, {"type": "file", "name": "webdriver-win.json"}]}, {"type": "file", "name": "CONTRIBUTING.md"}, {"type": "directory", "name": "crates", "children": [{"type": "directory", "name": "ratchet-cli", "children": [{"type": "file", "name": "Cargo.toml"}, {"type": "directory", "name": "src", "children": [{"type": "directory", "name": "bin", "children": [{"type": "file", "name": "cli.rs"}]}, {"type": "file", "name": "lib.rs"}]}]}, {"type": "directory", "name": "ratchet-core", "children": [{"type": "file", "name": "Cargo.toml"}, {"type": "directory", "name": "src", "children": [{"type": "file", "name": "compiled_op.rs"}, {"type": "directory", "name": "cpu", "children": [{"type": "file", "name": "gemm.rs"}, {"type": "file", "name": "mod.rs"}]}, {"type": "file", "name": "device.rs"}, {"type": "directory", "name": "dtype", "children": [{"type": "file", "name": "blocks.rs"}, {"type": "file", "name": "mod.rs"}]}, {"type": "file", "name": "enforcer.rs"}, {"type": "file", "name": "executable.rs"}, {"type": "directory", "name": "gpu", "children": [{"type": "file", "name": "align.rs"}, {"type": "directory", "name": "buffer_allocator", "children": [{"type": "file", "name": "allocator.rs"}, {"type": "file", "name": "mod.rs"}, {"type": "file", "name": "tensor_usage_record.rs"}]}, {"type": "file", "name": "device.rs"}, {"type": "file", "name": "mod.rs"}, {"type": "directory", "name": "pools", "children": [{"type": "file", "name": "bind_group_layout_pool.rs"}, {"type": "file", "name": "bind_group_pool.rs"}, {"type": "file", "name": "buffer_pool.rs"}, {"type": "file", "name": "dynamic_resource_pool.rs"}, {"type": "file", "name": "kernel_module_pool.rs"}, {"type": "file", "name": "mod.rs"}, {"type": "file", "name": "pipeline_layout_pool.rs"}, {"type": "file", "name": "pipeline_pool.rs"}, {"type": "file", "name": "static_resource_pool.rs"}]}, {"type": "file", "name": "profiler.rs"}, {"type": "file", "name": "uniform.rs"}, {"type": "directory", "name": "wgsl", "children": [{"type": "file", "name": "access_granularity.rs"}, {"type": "file", "name": "dtype.rs"}, {"type": "file", "name": "kernel.rs"}, {"type": "file", "name": "kernel_binding.rs"}, {"type": "file", "name": "kernel_builder.rs"}, {"type": "file", "name": "mod.rs"}]}, {"type": "file", "name": "workload.rs"}]}, {"type": "file", "name": "lib.rs"}, {"type": "file", "name": "ndarray_ext.rs"}, {"type": "file", "name": "op.rs"}, {"type": "directory", "name": "ops", "children": [{"type": "file", "name": "binary.rs"}, {"type": "file", "name": "cache.rs"}, {"type": "file", "name": "cast.rs"}, {"type": "file", "name": "concat.rs"}, {"type": "file", "name": "conv.rs"}, {"type": "file", "name": "index_write.rs"}, {"type": "directory", "name": "matmul", "children": [{"type": "file", "name": "gemm.rs"}, {"type": "file", "name": "mod.rs"}, {"type": "file", "name": "quantized.rs"}, {"type": "file", "name": "subgroup_gemv.rs"}, {"type": "file", "name": "workgroup_gemv.rs"}]}, {"type": "file", "name": "mod.rs"}, {"type": "directory", "name": "norm", "children": [{"type": "file", "name": "groupnorm.rs"}, {"type": "file", "name": "mod.rs"}]}, {"type": "directory", "name": "reindex", "children": [{"type": "file", "name": "broadcast.rs"}, {"type": "file", "name": "mod.rs"}, {"type": "file", "name": "permute.rs"}, {"type": "file", "name": "slice.rs"}]}, {"type": "file", "name": "rope.rs"}, {"type": "file", "name": "select.rs"}, {"type": "file", "name": "softmax.rs"}, {"type": "file", "name": "unary.rs"}, {"type": "file", "name": "view.rs"}]}, {"type": "file", "name": "plot.rs"}, {"type": "file", "name": "quant.rs"}, {"type": "file", "name": "shape.rs"}, {"type": "directory", "name": "storage", "children": [{"type": "file", "name": "cpu_buffer.rs"}, {"type": "file", "name": "gpu_buffer.rs"}, {"type": "file", "name": "mod.rs"}]}, {"type": "file", "name": "strides.rs"}, {"type": "file", "name": "tensor.rs"}, {"type": "file", "name": "tensor_id.rs"}]}, {"type": "directory", "name": "tests", "children": [{"type": "file", "name": "attn_tests.rs"}]}]}, {"type": "directory", "name": "ratchet-hub", "children": [{"type": "file", "name": "Cargo.toml"}, {"type": "directory", "name": "src", "children": [{"type": "file", "name": "lib.rs"}, {"type": "file", "name": "util.rs"}]}]}, {"type": "directory", "name": "ratchet-loader", "children": [{"type": "file", "name": "Cargo.toml"}, {"type": "directory", "name": "src", "children": [{"type": "file", "name": "error.rs"}, {"type": "directory", "name": "gguf", "children": [{"type": "file", "name": "dtype.rs"}, {"type": "file", "name": "gguf.rs"}, {"type": "file", "name": "mod.rs"}, {"type": "file", "name": "utils.rs"}]}, {"type": "file", "name": "k_quants.rs"}, {"type": "file", "name": "lib.rs"}]}, {"type": "directory", "name": "test-data", "children": [{"type": "file", "name": "nano-llama-q4k.gguf"}]}]}, {"type": "directory", "name": "ratchet-macros", "children": [{"type": "file", "name": "Cargo.toml"}, {"type": "directory", "name": "src", "children": [{"type": "file", "name": "lib.rs"}, {"type": "file", "name": "wgsl_metadata.rs"}]}]}, {"type": "directory", "name": "ratchet-models", "children": [{"type": "file", "name": "Cargo.toml"}, {"type": "directory", "name": "src", "children": [{"type": "file", "name": "lib.rs"}, {"type": "directory", "name": "moondream", "children": [{"type": "file", "name": "generate.rs"}, {"type": "file", "name": "mlp.rs"}, {"type": "file", "name": "mod.rs"}, {"type": "file", "name": "model.rs"}, {"type": "file", "name": "text_model.rs"}, {"type": "file", "name": "vision_encoder.rs"}]}, {"type": "directory", "name": "phi2", "children": [{"type": "file", "name": "attn.rs"}, {"type": "file", "name": "generate.rs"}, {"type": "file", "name": "mlp.rs"}, {"type": "file", "name": "mod.rs"}, {"type": "file", "name": "model.rs"}]}, {"type": "directory", "name": "phi3", "children": [{"type": "file", "name": "attn.rs"}, {"type": "file", "name": "generate.rs"}, {"type": "file", "name": "mlp.rs"}, {"type": "file", "name": "mod.rs"}, {"type": "file", "name": "model.rs"}]}, {"type": "file", "name": "registry.rs"}, {"type": "file", "name": "token_stream.rs"}, {"type": "directory", "name": "whisper", "children": [{"type": "file", "name": "config.rs"}, {"type": "file", "name": "decoder.rs"}, {"type": "file", "name": "encoder.rs"}, {"type": "directory", "name": "logit_mutators", "children": [{"type": "file", "name": "mod.rs"}, {"type": "file", "name": "timestamp_rules.rs"}]}, {"type": "file", "name": "mha.rs"}, {"type": "file", "name": "mlp.rs"}, {"type": "file", "name": "mod.rs"}, {"type": "file", "name": "model.rs"}, {"type": "file", "name": "options.rs"}, {"type": "file", "name": "residual_block.rs"}, {"type": "directory", "name": "samplers", "children": [{"type": "file", "name": "greedy.rs"}, {"type": "file", "name": "mod.rs"}]}, {"type": "file", "name": "spectrogram.rs"}, {"type": "file", "name": "task.rs"}, {"type": "file", "name": "tokenizer.rs"}, {"type": "file", "name": "transcribe.rs"}, {"type": "file", "name": "transcript.rs"}]}]}, {"type": "directory", "name": "tests", "children": [{"type": "file", "name": "whisper.rs"}]}, {"type": "file", "name": "webdriver.json"}]}, {"type": "directory", "name": "ratchet-nn", "children": [{"type": "file", "name": "Cargo.toml"}, {"type": "directory", "name": "src", "children": [{"type": "file", "name": "embedding.rs"}, {"type": "file", "name": "groupnorm.rs"}, {"type": "file", "name": "kv_cache.rs"}, {"type": "file", "name": "lib.rs"}, {"type": "file", "name": "linear.rs"}, {"type": "file", "name": "norm.rs"}, {"type": "file", "name": "rope.rs"}]}]}, {"type": "directory", "name": "ratchet-web", "children": [{"type": "file", "name": "Cargo.toml"}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "src", "children": [{"type": "file", "name": "db.rs"}, {"type": "file", "name": "lib.rs"}, {"type": "file", "name": "model.rs"}]}]}]}, {"type": "directory", "name": "examples", "children": [{"type": "directory", "name": "ratchet-moondream", "children": [{"type": "file", "name": "package-lock.json"}, {"type": "file", "name": "package.json"}, {"type": "directory", "name": "public", "children": [{"type": "file", "name": "index.html"}, {"type": "file", "name": "manifest.json"}, {"type": "file", "name": "robots.txt"}]}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "src", "children": [{"type": "file", "name": "App.css"}, {"type": "file", "name": "App.js"}, {"type": "file", "name": "index.css"}, {"type": "file", "name": "index.js"}]}]}, {"type": "directory", "name": "ratchet-phi", "children": [{"type": "file", "name": "next.config.mjs"}, {"type": "file", "name": "package.json"}, {"type": "file", "name": "postcss.config.js"}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "src", "children": [{"type": "directory", "name": "app", "children": [{"type": "directory", "name": "components", "children": [{"type": "file", "name": "progressBar.tsx"}, {"type": "file", "name": "warningModal.tsx"}, {"type": "file", "name": "WebGPUModal.tsx"}]}, {"type": "file", "name": "favicon.ico"}, {"type": "file", "name": "globals.css"}, {"type": "file", "name": "layout.tsx"}, {"type": "file", "name": "page.module.css"}, {"type": "file", "name": "page.tsx"}]}]}, {"type": "file", "name": "tailwind.config.js"}, {"type": "file", "name": "tsconfig.json"}]}, {"type": "directory", "name": "ratchet-whisper", "children": [{"type": "file", "name": "next.config.mjs"}, {"type": "file", "name": "package.json"}, {"type": "file", "name": "postcss.config.js"}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "src", "children": [{"type": "directory", "name": "app", "children": [{"type": "file", "name": "audio.ts"}, {"type": "directory", "name": "components", "children": [{"type": "file", "name": "configModal.tsx"}, {"type": "file", "name": "languageDropdown.tsx"}, {"type": "file", "name": "micButton.tsx"}, {"type": "file", "name": "modelSelector.tsx"}, {"type": "file", "name": "progressBar.tsx"}, {"type": "file", "name": "suppressSelector.tsx"}, {"type": "file", "name": "taskSelector.tsx"}, {"type": "file", "name": "WebGPUModal.tsx"}]}, {"type": "file", "name": "favicon.ico"}, {"type": "file", "name": "globals.css"}, {"type": "file", "name": "layout.tsx"}, {"type": "file", "name": "page.module.css"}, {"type": "file", "name": "page.tsx"}]}]}, {"type": "file", "name": "tailwind.config.js"}, {"type": "file", "name": "tsconfig.json"}]}]}, {"type": "file", "name": "justfile"}, {"type": "file", "name": "LICENSE"}, {"type": "file", "name": "package.json"}, {"type": "file", "name": "pnpm-lock.yaml"}, {"type": "file", "name": "pnpm-workspace.yaml"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "rust-toolchain.toml"}, {"type": "directory", "name": "scripts", "children": [{"type": "file", "name": "phi3.py"}, {"type": "file", "name": "understanding_matmul.py"}]}]} | This is a [Next.js](https://nextjs.org/) project bootstrapped with [`create-next-app`](https://github.com/vercel/next.js/tree/canary/packages/create-next-app).
## Getting Started
First, run the development server:
```bash
npm run dev
# or
yarn dev
# or
pnpm dev
# or
bun dev
```
Open [http://localhost:3000](http://localhost:3000) with your browser to see the result.
You can start editing the page by modifying `app/page.tsx`. The page auto-updates as you edit the file.
This project uses [`next/font`](https://nextjs.org/docs/basic-features/font-optimization) to automatically optimize and load Inter, a custom Google Font.
## Learn More
To learn more about Next.js, take a look at the following resources:
- [Next.js Documentation](https://nextjs.org/docs) - learn about Next.js features and API.
- [Learn Next.js](https://nextjs.org/learn) - an interactive Next.js tutorial.
You can check out [the Next.js GitHub repository](https://github.com/vercel/next.js/) - your feedback and contributions are welcome!
## Deploy on Vercel
The easiest way to deploy your Next.js app is to use the [Vercel Platform](https://vercel.com/new?utm_medium=default-template&filter=next.js&utm_source=create-next-app&utm_campaign=create-next-app-readme) from the creators of Next.js.
Check out our [Next.js deployment documentation](https://nextjs.org/docs/deployment) for more details.
| {"package.json": "{\n \"name\": \"ratchet-repo\",\n \"version\": \"0.0.0\",\n \"packageManager\": \"[email protected]\",\n \"private\": true,\n \"devDependencies\": {\n \"pkg-pr-new\": \"0.0.15\",\n \"wasm-pack\": \"0.12.1\"\n }\n}\n", "requirements.txt": "--extra-index-url https://download.pytorch.org/whl/cpu\nnumpy==1.24.3\ntorch==2.3.0\nrequests==2.26.0\nmlx==0.9.1; sys_platform == 'darwin'\ngit+https://github.com/FL33TW00D/whisper.git@feature/reference#egg=openai-whisper\ngguf==0.6.0\n", ".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", "crates\\ratchet-core\\src\\ops\\index_write.rs": "use derive_new::new;\nuse encase::ShaderType;\nuse half::f16;\nuse inline_wgsl::wgsl;\nuse ratchet_macros::WgslMetadata;\n\nuse crate::{\n gpu::BindGroupLayoutDescriptor, rvec, Array, BindingMode, BuiltIn, DType, GPUOperation, Kernel,\n KernelElement, KernelRenderable, KernelSource, OpGuards, Operation, OperationError, RVec,\n Scalar, Shape, StorageView, Strides, Tensor, Vec2, Vec4, WgslKernelBuilder, WgslPrimitive,\n WorkgroupSize, Workload,\n};\n\n#[derive(new, Debug, Clone)]\npub struct IndexWrite {\n dst: Tensor,\n src: Tensor,\n write_start: RVec<usize>,\n}\n\nimpl IndexWrite {}\n\n#[derive(Debug, derive_new::new, ShaderType, WgslMetadata)]\npub struct IndexWriteMeta {\n dst_strides: glam::UVec4,\n src_numel: u32,\n write_start: glam::UVec4,\n}\n\nimpl OpGuards for IndexWrite {\n fn check_shapes(&self) {}\n\n fn check_dtypes(&self) {}\n}\n\nimpl Operation for IndexWrite {\n fn name(&self) -> &'static str {\n \"IndexWrite\"\n }\n\n fn compute_view(&self) -> Result<StorageView, OperationError> {\n Ok(self.dst.storage_view().clone())\n }\n\n fn srcs(&self) -> RVec<&Tensor> {\n rvec![&self.dst, &self.src]\n }\n\n fn supports_inplace(&self) -> bool {\n true\n }\n}\n\nimpl GPUOperation for IndexWrite {\n type KernelEnum = IndexWriteKernels;\n\n fn select_kernel(&self) -> Self::KernelEnum {\n IndexWriteKernels::Standard(self.clone())\n }\n}\n\npub enum IndexWriteKernels {\n Standard(IndexWrite),\n}\n\nimpl KernelRenderable for IndexWriteKernels {\n fn register_bindings<P: WgslPrimitive>(\n &self,\n builder: &mut WgslKernelBuilder,\n _: bool,\n ) -> Result<(), OperationError> {\n let arr = Array::<P>::default();\n builder.register_storage(\"D\", BindingMode::ReadWrite, arr);\n builder.register_storage(\"S\", BindingMode::ReadOnly, arr);\n builder.register_uniform();\n Ok(())\n }\n\n fn render<P: WgslPrimitive>(\n &self,\n inplace: bool,\n dst: &Tensor,\n workgroup_size: &WorkgroupSize,\n ) -> Result<KernelSource, OperationError> {\n let device = dst.device().try_gpu()?;\n let mut kernel_builder = WgslKernelBuilder::new(\n workgroup_size.clone(),\n rvec![\n BuiltIn::LocalInvocationIndex,\n BuiltIn::NumWorkgroups,\n BuiltIn::WorkgroupId,\n ],\n device.compute_features().clone(),\n );\n self.register_bindings::<P>(&mut kernel_builder, inplace)?;\n\n kernel_builder.render_metadata(&self.metadata(dst, &self.kernel_element(dst))?);\n kernel_builder.write_index_to_offset();\n\n kernel_builder.write_main(wgsl! {\n let x_offset = workgroup_id.x * 64u;\n let thread_offset = (workgroup_id.y * num_workgroups.x * 64u) + x_offset + local_invocation_index;\n if (thread_offset >= metadata.src_numel) {\n return;\n }\n let offset_index = ndIndexToOffset(metadata.write_start, metadata.dst_strides);\n D[offset_index + thread_offset] = S[thread_offset];\n });\n\n Ok(kernel_builder.build()?)\n }\n}\n\nimpl Kernel for IndexWriteKernels {\n type Metadata = IndexWriteMeta;\n\n fn storage_bind_group_layout(\n &self,\n inplace: bool,\n ) -> Result<BindGroupLayoutDescriptor, OperationError> {\n if !inplace {\n panic!(\"IndexWrite only supports inplace operation\");\n }\n Ok(BindGroupLayoutDescriptor::binary_inplace())\n }\n\n fn kernel_name(&self) -> String {\n match self {\n IndexWriteKernels::Standard(_) => \"index_write\".to_string(),\n }\n }\n\n fn metadata(&self, dst: &Tensor, _: &KernelElement) -> Result<Self::Metadata, OperationError> {\n let IndexWriteKernels::Standard(inner) = self;\n let padder = |mut shape: Shape| {\n shape.left_pad_to(1, 4);\n let strides = Strides::from(&shape);\n (shape, strides)\n };\n let (_, dst_strides) = padder(dst.shape().clone());\n let (src_shape, _) = padder(inner.src.shape().clone());\n\n let mut start = [0u32; 4];\n let offset = 4 - inner.write_start.len();\n for (i, &s) in inner.write_start.iter().enumerate() {\n start[i + offset] = s as u32;\n }\n\n Ok(IndexWriteMeta {\n dst_strides: glam::UVec4::from(&dst_strides),\n src_numel: src_shape.numel() as u32,\n write_start: start.into(),\n })\n }\n\n fn calculate_dispatch(&self, _: &Tensor) -> Result<Workload, OperationError> {\n let IndexWriteKernels::Standard(inner) = self;\n Ok(Workload::std(\n inner.src.shape().numel(),\n KernelElement::Scalar,\n ))\n }\n\n fn kernel_element(&self, _: &Tensor) -> KernelElement {\n KernelElement::Scalar\n }\n\n fn build_kernel(\n &self,\n inplace: bool,\n dst: &Tensor,\n workgroup_size: &WorkgroupSize,\n ) -> Result<KernelSource, OperationError> {\n let kernel_element = self.kernel_element(dst);\n let IndexWriteKernels::Standard(inner) = self;\n match (inner.src.dt(), &kernel_element) {\n (DType::F32, KernelElement::Scalar) => {\n self.render::<Scalar<f32>>(inplace, dst, workgroup_size)\n }\n (DType::F32, KernelElement::Vec2) => {\n self.render::<Vec2<f32>>(inplace, dst, workgroup_size)\n }\n (DType::F32, KernelElement::Vec4) => {\n self.render::<Vec4<f32>>(inplace, dst, workgroup_size)\n }\n (DType::F16, KernelElement::Scalar) => {\n self.render::<Scalar<f16>>(inplace, dst, workgroup_size)\n }\n (DType::F16, KernelElement::Vec2) => {\n self.render::<Vec2<f16>>(inplace, dst, workgroup_size)\n }\n (DType::F16, KernelElement::Vec4) => {\n self.render::<Vec4<f16>>(inplace, dst, workgroup_size)\n }\n _ => Err(OperationError::CompileError(format!(\n \"Unsupported dtype {:?} or kernel element {:?}\",\n inner.src.dt(),\n kernel_element\n ))),\n }\n }\n}\n\n#[cfg(test)]\nmod tests {\n use crate::{rvec, shape, Device, DeviceRequest, Tensor};\n\n #[test]\n fn test_index_write() {\n let device = Device::request_device(DeviceRequest::GPU).unwrap();\n\n let dst = Tensor::from_data(vec![1., 2., 3., 4., 5., 6.], shape![3, 2], device.clone());\n let src = Tensor::from_data(vec![7., 8.], shape![1, 2], device.clone());\n let write_start = rvec![2, 0];\n let b = dst\n .index_write(src, write_start)\n .unwrap()\n .resolve()\n .unwrap();\n\n let result = b.to(&Device::CPU).unwrap();\n\n let ground_truth =\n Tensor::from_data(vec![1., 2., 3., 4., 7., 8.], shape![3, 2], Device::CPU);\n println!(\"result: {:?}\", result);\n println!(\"ground_truth: {:?}\", ground_truth);\n ground_truth.all_close(&result, 1e-8, 1e-8).unwrap();\n }\n}\n", "examples\\ratchet-moondream\\package.json": "{\n \"name\": \"ratchet-moondream\",\n \"version\": \"0.1.0\",\n \"private\": true,\n \"dependencies\": {\n \"@emotion/react\": \"^11.11.4\",\n \"@emotion/styled\": \"^11.11.5\",\n \"@mui/icons-material\": \"^5.15.19\",\n \"@mui/material\": \"^5.15.19\",\n \"@ratchet-ml/ratchet-web\": \"file:../../target/pkg/ratchet-web\",\n \"react\": \"^18.3.1\",\n \"react-dom\": \"^18.3.1\",\n \"react-scripts\": \"5.0.1\",\n \"web-vitals\": \"^2.1.4\"\n },\n \"scripts\": {\n \"start\": \"react-scripts start\",\n \"build\": \"react-scripts build\",\n \"test\": \"react-scripts test\",\n \"eject\": \"react-scripts eject\"\n },\n \"eslintConfig\": {\n \"extends\": [\n \"react-app\",\n \"react-app/jest\"\n ]\n },\n \"browserslist\": {\n \"production\": [\n \">0.2%\",\n \"not dead\",\n \"not op_mini all\"\n ],\n \"development\": [\n \"last 1 chrome version\",\n \"last 1 firefox version\",\n \"last 1 safari version\"\n ]\n },\n \"devDependencies\": {\n \"prettier\": \"3.3.1\"\n }\n}\n", "examples\\ratchet-moondream\\public\\index.html": "<!doctype html>\n<html lang=\"en\">\n <head>\n <meta charset=\"utf-8\" />\n <meta name=\"viewport\" content=\"width=device-width, initial-scale=1\" />\n <meta name=\"theme-color\" content=\"#000000\" />\n <meta\n name=\"description\"\n content=\"Web site created using create-react-app\"\n />\n <title>Ratchet Moondream</title>\n </head>\n <body>\n <noscript>You need to enable JavaScript to run this app.</noscript>\n <div id=\"root\"></div>\n <!--\n This HTML file is a template.\n If you open it directly in the browser, you will see an empty page.\n\n You can add webfonts, meta tags, or analytics to this file.\n The build step will place the bundled scripts into the <body> tag.\n\n To begin the development, run `npm start` or `yarn start`.\n To create a production bundle, use `npm run build` or `yarn build`.\n -->\n </body>\n</html>\n", "examples\\ratchet-moondream\\src\\App.css": ".App {\n text-align: center;\n}\n\n.App-logo {\n height: 40vmin;\n pointer-events: none;\n}\n\n@media (prefers-reduced-motion: no-preference) {\n .App-logo {\n animation: App-logo-spin infinite 20s linear;\n }\n}\n\n.App-header {\n background-color: #282c34;\n min-height: 100vh;\n display: flex;\n flex-direction: column;\n align-items: center;\n justify-content: center;\n font-size: calc(10px + 2vmin);\n color: white;\n}\n\n.App-link {\n color: #61dafb;\n}\n\n@keyframes App-logo-spin {\n from {\n transform: rotate(0deg);\n }\n to {\n transform: rotate(360deg);\n }\n}\n", "examples\\ratchet-moondream\\src\\App.js": "import \"./App.css\";\nimport { Model, Quantization, default as init } from \"@ratchet-ml/ratchet-web\";\nimport { styled } from \"@mui/material/styles\";\nimport { useState, useEffect } from \"react\";\nimport {\n LinearProgress,\n TextField,\n Button,\n Container,\n Card,\n CardMedia,\n Stack,\n Box,\n Dialog,\n DialogActions,\n DialogContentText,\n DialogTitle,\n DialogContent,\n Typography,\n CardActions,\n InputAdornment,\n IconButton,\n} from \"@mui/material\";\nimport SendIcon from \"@mui/icons-material/Send\";\n\nconst VisuallyHiddenInput = styled(\"input\")({\n clip: \"rect(0 0 0 0)\",\n clipPath: \"inset(50%)\",\n height: 1,\n overflow: \"hidden\",\n position: \"absolute\",\n bottom: 0,\n left: 0,\n whiteSpace: \"nowrap\",\n width: 1,\n});\n\nfunction App() {\n const [question, setQuestion] = useState(\"\");\n const [generatedText, setGeneratedText] = useState(\"\");\n const [image, setImage] = useState(new Uint8Array());\n const [progress, setProgress] = useState(0);\n const [isLoading, setIsLoading] = useState(true);\n const [accepted, setAccepted] = useState(false);\n const [isSupportedBrowser, setIsSupportedBrowser] = useState(true);\n const [ratchetDBExists, setRatchetDBExists] = useState(false);\n const [model, setModel] = useState(null);\n const [isRunning, setIsRunning] = useState(false);\n\n useEffect(() => {\n (async () => {\n await init();\n setRatchetDBExists(\n (await window.indexedDB.databases())\n .map((db) => db.name)\n .includes(\"ratchet\"),\n );\n await setImage(\n new Uint8Array(\n await (\n await fetch(\n \"https://raw.githubusercontent.com/vikhyat/moondream/main/assets/demo-1.jpg\",\n )\n ).arrayBuffer(),\n ),\n );\n })();\n }, []);\n\n async function loadModel() {\n setAccepted(true);\n setProgress(2);\n setModel(\n await Model.load(\"Moondream\", Quantization.Q8_0, (p) => setProgress(p)),\n );\n setProgress(100);\n setIsLoading(false);\n }\n\n async function runModel() {\n if (!model || isRunning) {\n return;\n }\n\n setGeneratedText(\"\");\n\n let cb = (s) => {\n setGeneratedText((prevText) => {\n return prevText + s;\n });\n };\n\n setIsRunning(true);\n await model.run({ question: question, image_bytes: image, callback: cb });\n setIsRunning(false);\n }\n\n async function handleUpload(e) {\n if (e.target.files.length == 0) {\n return;\n }\n setImage(new Uint8Array(await e.target.files[0].arrayBuffer()));\n }\n\n async function keypress(e) {\n if (e.key === \"Enter\") {\n runModel();\n e.preventDefault();\n }\n }\n\n async function deleteWeights() {\n setAccepted(false);\n setProgress(0);\n setModel(null);\n await window.indexedDB.deleteDatabase(\"ratchet\");\n setIsLoading(true);\n }\n\n return (\n <div className=\"App\">\n <Container maxWidth=\"sm\" sx={{ marginTop: \"50px\" }}>\n <Dialog\n open={isSupportedBrowser && !accepted}\n aria-labelledby=\"alert-dialog-title\"\n aria-describedby=\"alert-dialog-description\"\n >\n <DialogTitle id=\"alert-dialog-title\">\n {navigator.gpu ? \"Load Model\" : \"Unsupported Browser\"}\n </DialogTitle>\n <DialogContent>\n <DialogContentText id=\"alert-dialog-description\">\n {navigator.gpu\n ? \"This app requires downloading a 2.2GB model which may take a few minutes. If the model has been previously downloaded, it will be loaded from cache.\"\n : \"This app requires a browser that supports webgpu\"}\n </DialogContentText>\n </DialogContent>\n {navigator.gpu ? (\n <DialogActions>\n <Button onClick={() => loadModel()} autoFocus>\n Load Model\n </Button>\n </DialogActions>\n ) : (\n <></>\n )}\n </Dialog>\n <Stack spacing={2}>\n <Box sx={{ justifyContent: \"center\", display: \"flex\" }}>\n <Typography>\n Moondream by{\" \"}\n <a href=\"https://github.com/vikhyat/moondream\">Vikhyat</a> running\n on WebGpu via{\" \"}\n <a href=\"https://github.com/huggingface/ratchet\">Ratchet</a>\n </Typography>\n </Box>\n <Box sx={{ justifyContent: \"center\", display: \"flex\" }}>\n <Card>\n <CardMedia\n sx={{ maxWidth: 377, maxHeight: 377 }}\n component=\"img\"\n image={URL.createObjectURL(new Blob([image]))}\n />\n <CardActions sx={{ justifyContent: \"center\", display: \"flex\" }}>\n <Button\n component=\"label\"\n role={undefined}\n disabled={isLoading}\n size=\"small\"\n variant=\"contained\"\n >\n Change Image\n <VisuallyHiddenInput\n type=\"file\"\n accept=\"image/png, image/jpeg\"\n onInput={handleUpload}\n />\n </Button>\n <Button\n component=\"label\"\n role={undefined}\n variant=\"contained\"\n size=\"small\"\n disabled={isLoading}\n sx={{backgroundColor: \"#e57373\"}}\n onClick={() => deleteWeights()}\n >\n Delete Weights\n </Button>\n </CardActions>\n </Card>\n </Box>\n <Box>\n <TextField\n fullWidth\n disabled={isLoading}\n label=\"Question\"\n variant=\"outlined\"\n onChange={(e) => setQuestion(e.target.value)}\n onKeyDown={keypress}\n InputProps={{\n endAdornment: (\n <InputAdornment position=\"end\">\n <IconButton disabled={isLoading || isRunning}>\n <SendIcon\n color=\"primary\"\n disabled={isLoading || isRunning}\n onClick={runModel}\n />\n </IconButton>\n </InputAdornment>\n ),\n }}\n />\n </Box>\n <div>\n <LinearProgress variant=\"determinate\" value={progress} />\n </div>\n {isLoading && progress < 99 ? (\n <Box sx={{ justifyContent: \"center\", display: \"flex\" }}>\n <Typography>Downloading Weights...</Typography>\n </Box>\n ) : (\n <></>\n )}\n {isLoading && progress > 99 ? (\n <Box sx={{ justifyContent: \"center\", display: \"flex\" }}>\n <Typography>Preparing Weights...</Typography>\n </Box>\n ) : (\n <></>\n )}\n <div>\n <Typography>{generatedText}</Typography>\n </div>\n </Stack>\n </Container>\n </div>\n );\n}\n\nexport default App;\n", "examples\\ratchet-moondream\\src\\index.css": "body {\n margin: 0;\n font-family: -apple-system, BlinkMacSystemFont, \"Segoe UI\", \"Roboto\", \"Oxygen\",\n \"Ubuntu\", \"Cantarell\", \"Fira Sans\", \"Droid Sans\", \"Helvetica Neue\",\n sans-serif;\n -webkit-font-smoothing: antialiased;\n -moz-osx-font-smoothing: grayscale;\n}\n\ncode {\n font-family: source-code-pro, Menlo, Monaco, Consolas, \"Courier New\",\n monospace;\n}\n", "examples\\ratchet-moondream\\src\\index.js": "import React from \"react\";\nimport ReactDOM from \"react-dom/client\";\nimport \"./index.css\";\nimport App from \"./App\";\n\nconst root = ReactDOM.createRoot(document.getElementById(\"root\"));\nroot.render(\n <React.StrictMode>\n <App />\n </React.StrictMode>,\n);\n", "examples\\ratchet-phi\\package.json": "{\n \"name\": \"ratchet-phi\",\n \"version\": \"0.1.0\",\n \"private\": true,\n \"scripts\": {\n \"dev\": \"next dev\",\n \"build\": \"next build\",\n \"start\": \"next start\",\n \"lint\": \"next lint\"\n },\n \"dependencies\": {\n \"@ffmpeg/ffmpeg\": \"0.12.6\",\n \"@ffmpeg/util\": \"^0.12.1\",\n \"@ratchet-ml/ratchet-web\": \"link:../../target/pkg/ratchet-web\",\n \"fix-webm-duration\": \"^1.0.5\",\n \"next\": \"14.1.0\",\n \"react\": \"^18.2.0\",\n \"react-dom\": \"^18.2.0\",\n \"react-hot-toast\": \"^2.4.1\",\n \"react-responsive-modal\": \"^6.4.2\"\n },\n \"devDependencies\": {\n \"@types/node\": \"^20.11.24\",\n \"@types/react\": \"^18.2.61\",\n \"@types/react-dom\": \"^18.2.19\",\n \"autoprefixer\": \"^10.4.18\",\n \"postcss\": \"^8.4.35\",\n \"tailwindcss\": \"^3.4.1\",\n \"typescript\": \"^5.3.3\"\n }\n}\n", "examples\\ratchet-whisper\\package.json": "{\n \"name\": \"ratchet-whisper\",\n \"version\": \"0.1.0\",\n \"private\": true,\n \"scripts\": {\n \"dev\": \"next dev\",\n \"build\": \"next build\",\n \"start\": \"next start\",\n \"lint\": \"next lint\"\n },\n \"dependencies\": {\n \"@ffmpeg/ffmpeg\": \"0.12.6\",\n \"@ffmpeg/util\": \"^0.12.1\",\n \"@ratchet-ml/ratchet-web\": \"link:../../target/pkg/ratchet-web\",\n \"fix-webm-duration\": \"^1.0.5\",\n \"next\": \"14.1.0\",\n \"react\": \"^18.2.0\",\n \"react-dom\": \"^18.2.0\",\n \"react-hot-toast\": \"^2.4.1\",\n \"react-responsive-modal\": \"^6.4.2\"\n },\n \"devDependencies\": {\n \"@types/node\": \"^20.11.24\",\n \"@types/react\": \"^18.2.61\",\n \"@types/react-dom\": \"^18.2.19\",\n \"autoprefixer\": \"^10.4.18\",\n \"postcss\": \"^8.4.35\",\n \"tailwindcss\": \"^3.4.1\",\n \"typescript\": \"^5.3.3\"\n }\n}\n"} | null |
readme-generator | {"type": "directory", "name": "readme-generator", "children": [{"type": "file", "name": "LICENSE"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "directory", "name": "scripts", "children": [{"type": "file", "name": "app.py"}, {"type": "file", "name": "gemini.py"}, {"type": "file", "name": "mistral.py"}]}, {"type": "directory", "name": "src", "children": [{"type": "directory", "name": "data", "children": [{"type": "file", "name": "parallel_clone_repos.py"}, {"type": "file", "name": "prepare_dataset.py"}, {"type": "file", "name": "push_to_hub.py"}, {"type": "file", "name": "requirements.txt"}]}, {"type": "directory", "name": "data_collection", "children": [{"type": "file", "name": "github_scraper.py"}, {"type": "file", "name": "github_utils.py"}, {"type": "file", "name": "repo_data.json"}]}, {"type": "directory", "name": "model", "children": [{"type": "file", "name": "dummy.py"}]}]}]} | # README Generator
## Overview
The README Generator is a Python application designed to automatically generate comprehensive `README.md` files for GitHub repositories. It utilizes advanced language models (GPT-4o-mini and Gemini) to analyze repository contents and produce well-structured documentation, including project descriptions, installation instructions, and usage guidelines.
## Features
- **Automatic Cloning**: Clones any specified GitHub repository to a temporary directory for analysis.
- **Content Analysis**: Reads the contents of important files in the repository to gather relevant information.
- **README Generation**: Uses state-of-the-art AI models to generate a detailed `README.md` file based on the repository's content.
- **Multi-Model Support**: Integrates with multiple AI models (OpenAI GPT-4o-mini and Google Gemini) for enhanced versatility.
- **Logging**: Provides informative logging for tracking the progress and troubleshooting potential issues.
## Files
- `app.py`: The main application file that handles user input, repository cloning, content reading, and README generation using GPT-4o.
- `gemini.py`: A variant that uses the Gemini API to generate concise README files with rate limit handling.
- `mistral.py`: Another variant that leverages Hugging Face's Mixtral model for generating README files.
- `LICENSE`: The MIT License under which this project is distributed.
## Installation
To run the README Generator, follow these steps:
1. **Clone the Repository**:
```bash
git clone https://github.com/hamza-amin-4365/readme-generator.git
cd readme-generator
```
2. **Set Up Environment**:
- Ensure you have Python 3.7 or later installed.
- Install the required packages:
```bash
pip install -r requirements.txt
```
3. **Set Up API Keys**:
- Create a `.env` file in the root directory of the project with the following content:
```plaintext
OPENAI_API_KEY=your_openai_api_key
GEMINI_API_KEY=your_gemini_api_key
huggingfacehub_api_token=your_huggingfacehub_token
```
## Usage
1. **Run the Application**:
To generate a `README.md` for a specific GitHub repository, run:
```bash
python app.py
```
or for the Gemini version:
```bash
python gemini.py <repository_url>
```
2. **Input the Repository URL**:
When prompted, enter the URL of the GitHub repository you want to analyze.
3. **Generated README**:
After successful execution, a `README.md` file will be created in the current directory with the generated content.
## Logging
The application uses the built-in `logging` module to provide insights into its operation. You can adjust the logging level in the source code if you wish to see more or less detail.
## License
This project is licensed under the MIT License. See the `LICENSE` file for more details.
## Contributing
Contributions are welcome! Please feel free to open issues or submit pull requests for any improvements or additional features.
## Disclaimer and future work
This readme file was generated by one of the scripts written here. This also serve as the demo for you, how your readme file will look like. Don't input the repos having very large amount of code because you have a token limit in APIs. In future we shall be using fine-tuned models to exclude the need of paid APIs and use generative ai techniques to handle large amount of code bases. If you want to contribute you're very welcome to do so.
## Acknowledgments
This project utilizes the following libraries and APIs:
- [LangChain](https://langchain.com/) for AI-driven generation.
- [GitPython](https://gitpython.readthedocs.io/en/stable/) for Git repository interactions.
- [dotenv](https://pypi.org/project/python-dotenv/) for environment variable management.
## Contact
For questions or feedback, please contact [Hamza Amin](mailto:[email protected]).
| {"requirements.txt": "gitpython\npython-dotenv\ngoogle-api-python-client\nlangchain_openai\nlangchain\nhuggingface_hub", ".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 f39845cab9e1620181e6ab1f8a8283a9e812ce45 Hamza Amin <[email protected]> 1727376261 +0500\tclone: from https://github.com/hamza-amin-4365/readme-generator.git\n", ".git\\refs\\heads\\main": "f39845cab9e1620181e6ab1f8a8283a9e812ce45\n", "scripts\\app.py": "# !!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!\n# This script has the highest accuracy in making readme files. When you run this script it will make a directory \n# called temp_repo and clone the repository in it. Make sure to delete that before using this script again.\n\nimport os\nimport git\nimport shutil\nfrom langchain_openai import ChatOpenAI\nfrom langchain.schema import HumanMessage, SystemMessage\nfrom dotenv import load_dotenv\n\n\nload_dotenv()\nos.environ['OPENAI_API_KEY'] = os.getenv('OPENAI_API_KEY')\nllm = ChatOpenAI(model_name='gpt-4o-mini')\n\n\ndef CloneRepository(repo_url, local_path):\n \"\"\"Clone the given repository to the specified local path.\"\"\"\n if os.path.exists(local_path):\n shutil.rmtree(local_path) \n git.Repo.clone_from(repo_url, local_path)\n\ndef ReadRepositoryContents(repo_path):\n \"\"\"Read the contents of all files in the repository.\"\"\"\n contents = []\n for root, _, files in os.walk(repo_path):\n for file in files:\n if file.startswith('.') or file == 'README.md':\n continue\n file_path = os.path.join(root, file)\n with open(file_path, 'r', encoding='utf-8', errors='ignore') as f:\n contents.append(f\"File: {file_path}\\n\\n{f.read()}\\n\\n\")\n return '\\n'.join(contents)\n\ndef GenerateReadme(repo_contents):\n \"\"\"Generate a README file using GPT-4o-mini.\"\"\"\n prompt = f\"Based on the following repository contents, generate a comprehensive README.md file:\\n\\n{repo_contents}\\n\\nREADME.md:\"\n \n messages = [\n SystemMessage(content=\"You are a helpful assistant that generates README files for GitHub repositories.\"),\n HumanMessage(content=prompt)\n ]\n \n response = llm.invoke(messages)\n \n return response.content.strip()\n\ndef main():\n repo_url = input(\"Enter the GitHub repository URL: \")\n local_path = \"./temp_repo\"\n \n try:\n CloneRepository(repo_url, local_path)\n \n repo_contents = ReadRepositoryContents(local_path)\n \n readme_content = GenerateReadme(repo_contents)\n \n with open(\"README.md\", \"w\") as f:\n f.write(readme_content)\n \n print(\"README.md has been generated successfully!\")\n \n finally:\n shutil.rmtree(local_path, ignore_errors=True)\n\nif __name__ == \"__main__\":\n main()", "src\\data\\requirements.txt": "datasets\nnbformat\npandas\npygithub"} | null |
RL-model-card-template | {"type": "directory", "name": "RL-model-card-template", "children": [{"type": "file", "name": "model-card-v1.md"}, {"type": "file", "name": "README.md"}]} | # RL-model-card-template
Model card template
| {".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 7fc7a9e5f6c6508cc0f3d148447319cbe0861acc Hamza Amin <[email protected]> 1727369549 +0500\tclone: from https://github.com/huggingface/RL-model-card-template.git\n", ".git\\refs\\heads\\main": "7fc7a9e5f6c6508cc0f3d148447319cbe0861acc\n"} | null |
rlhf-interface | {"type": "directory", "name": "rlhf-interface", "children": [{"type": "file", "name": ".env.example"}, {"type": "file", "name": "app.py"}, {"type": "file", "name": "collect.py"}, {"type": "file", "name": "config.py.example"}, {"type": "file", "name": "Makefile"}, {"type": "directory", "name": "prompt_templates", "children": [{"type": "file", "name": "openai_chatgpt.json"}]}, {"type": "file", "name": "qualification_answers.xml"}, {"type": "file", "name": "qualification_questions.xml"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "utils.py"}]} | ---
title: RLHF
emoji: 🏢
colorFrom: red
colorTo: gray
sdk: gradio
sdk_version: 3.1
app_file: app.py
pinned: false
---
An RLHF interface for data collection with [Amazon Mechanical Turk](https://www.mturk.com) and Gradio.
## Instructions for someone to use for their own project
### Install dependencies
First, create a Python virtual environment and install the project's dependencies as follows:
```bash
python -m pip install -r requirements.txt
```
### Setting up the Space
1. Clone this repo and deploy it on your own Hugging Face space.
2. Add the following secrets to your space:
- `HF_TOKEN`: One of your Hugging Face tokens.
- `DATASET_REPO_URL`: The url to an empty dataset that you created the hub. It
can be a private or public dataset.
- `FORCE_PUSH`: "yes"
When you run this space on mturk and when people visit your space on
huggingface.co, the app will use your token to automatically store new HITs
in your dataset. Setting `FORCE_PUSH` to "yes" ensures that your repo will
force push changes to the dataset during data collection. Otherwise,
accidental manual changes to your dataset could result in your space getting
merge conflicts as it automatically tries to push the dataset to the hub. For
local development, add these three keys to a `.env` file, and consider setting
`FORCE_PUSH` to "no".
To launch the Space locally, run:
```bash
python app.py
```
The app will then be available at a local address, such as http://127.0.0.1:7860
### Running data collection*
1. On your local repo that you pulled, create a copy of `config.py.example`,
just called `config.py`. Now, put keys from your AWS account in `config.py`.
These keys should be for an AWS account that has the
AmazonMechanicalTurkFullAccess permission. You also need to
create an mturk requestor account associated with your AWS account.
2. Run `python collect.py` locally.
### Profit
Now, you should be watching hits come into your Hugging Face dataset
automatically!
### Tips and tricks
- Use caution while doing local development of your space and
simultaneously running it on mturk. Consider setting `FORCE_PUSH` to "no" in
your local `.env` file.
- huggingface spaces have limited computational resources and memory. If you
run too many HITs and/or assignments at once, then you could encounter issues.
You could also encounter issues if you are trying to create a dataset that is
very large. Check the log of your space for any errors that could be happening.
| {"app.py": "# Basic example for doing model-in-the-loop dynamic adversarial data collection\n# using Gradio Blocks.\nimport json\nimport os\nimport threading\nimport time\nimport uuid\nfrom concurrent.futures import ThreadPoolExecutor\nfrom pathlib import Path\nfrom typing import List\nfrom urllib.parse import parse_qs\n\nimport gradio as gr\nfrom dotenv import load_dotenv\nfrom huggingface_hub import Repository\nfrom langchain import ConversationChain\nfrom langchain.chains.conversation.memory import ConversationBufferMemory\nfrom langchain.llms import HuggingFaceHub\nfrom langchain.prompts import load_prompt\n\nfrom utils import force_git_push\n\n\ndef generate_respone(chatbot: ConversationChain, input: str) -> str:\n \"\"\"Generates a response for a `langchain` chatbot.\"\"\"\n return chatbot.predict(input=input)\n\n\ndef generate_responses(chatbots: List[ConversationChain], inputs: List[str]) -> List[str]:\n \"\"\"Generates parallel responses for a list of `langchain` chatbots.\"\"\"\n results = []\n with ThreadPoolExecutor(max_workers=100) as executor:\n for result in executor.map(generate_respone, chatbots, inputs):\n results.append(result)\n return results\n\n\n# These variables are for storing the MTurk HITs in a Hugging Face dataset.\nif Path(\".env\").is_file():\n load_dotenv(\".env\")\nDATASET_REPO_URL = os.getenv(\"DATASET_REPO_URL\")\nFORCE_PUSH = os.getenv(\"FORCE_PUSH\")\nHF_TOKEN = os.getenv(\"HF_TOKEN\")\nPROMPT_TEMPLATES = Path(\"prompt_templates\")\n\nDATA_FILENAME = \"data.jsonl\"\nDATA_FILE = os.path.join(\"data\", DATA_FILENAME)\nrepo = Repository(local_dir=\"data\", clone_from=DATASET_REPO_URL, use_auth_token=HF_TOKEN)\n\nTOTAL_CNT = 3 # How many user inputs per HIT\n\n# This function pushes the HIT data written in data.jsonl to our Hugging Face\n# dataset every minute. Adjust the frequency to suit your needs.\nPUSH_FREQUENCY = 60\n\n\ndef asynchronous_push(f_stop):\n if repo.is_repo_clean():\n print(\"Repo currently clean. Ignoring push_to_hub\")\n else:\n repo.git_add(auto_lfs_track=True)\n repo.git_commit(\"Auto commit by space\")\n if FORCE_PUSH == \"yes\":\n force_git_push(repo)\n else:\n repo.git_push()\n if not f_stop.is_set():\n # call again in 60 seconds\n threading.Timer(PUSH_FREQUENCY, asynchronous_push, [f_stop]).start()\n\n\nf_stop = threading.Event()\nasynchronous_push(f_stop)\n\n# Now let's run the app!\nprompt = load_prompt(PROMPT_TEMPLATES / \"openai_chatgpt.json\")\n\n# TODO: update this list with better, instruction-trained models\nMODEL_IDS = [\"google/flan-t5-xl\", \"bigscience/T0_3B\", \"EleutherAI/gpt-j-6B\"]\nchatbots = []\n\nfor model_id in MODEL_IDS:\n chatbots.append(\n ConversationChain(\n llm=HuggingFaceHub(\n repo_id=model_id,\n model_kwargs={\"temperature\": 1},\n huggingfacehub_api_token=HF_TOKEN,\n ),\n prompt=prompt,\n verbose=False,\n memory=ConversationBufferMemory(ai_prefix=\"Assistant\"),\n )\n )\n\n\nmodel_id2model = {chatbot.llm.repo_id: chatbot for chatbot in chatbots}\n\ndemo = gr.Blocks()\n\nwith demo:\n dummy = gr.Textbox(visible=False) # dummy for passing assignmentId\n\n # We keep track of state as a JSON\n state_dict = {\n \"conversation_id\": str(uuid.uuid4()),\n \"assignmentId\": \"\",\n \"cnt\": 0,\n \"data\": [],\n \"past_user_inputs\": [],\n \"generated_responses\": [],\n }\n for idx in range(len(chatbots)):\n state_dict[f\"response_{idx+1}\"] = \"\"\n state = gr.JSON(state_dict, visible=False)\n\n gr.Markdown(\"# Talk to the assistant\")\n\n state_display = gr.Markdown(f\"Your messages: 0/{TOTAL_CNT}\")\n\n # Generate model prediction\n def _predict(txt, state):\n start = time.time()\n responses = generate_responses(chatbots, [txt] * len(chatbots))\n print(f\"Time taken to generate {len(chatbots)} responses : {time.time() - start:.2f} seconds\")\n\n response2model_id = {}\n for chatbot, response in zip(chatbots, responses):\n response2model_id[response] = chatbot.llm.repo_id\n\n state[\"cnt\"] += 1\n\n new_state_md = f\"Inputs remaining in HIT: {state['cnt']}/{TOTAL_CNT}\"\n\n metadata = {\"cnt\": state[\"cnt\"], \"text\": txt}\n for idx, response in enumerate(responses):\n metadata[f\"response_{idx + 1}\"] = response\n\n metadata[\"response2model_id\"] = response2model_id\n\n state[\"data\"].append(metadata)\n state[\"past_user_inputs\"].append(txt)\n\n past_conversation_string = \"<br />\".join(\n [\n \"<br />\".join([\"Human \ud83d\ude03: \" + user_input, \"Assistant \ud83e\udd16: \" + model_response])\n for user_input, model_response in zip(state[\"past_user_inputs\"], state[\"generated_responses\"] + [\"\"])\n ]\n )\n return (\n gr.update(visible=False),\n gr.update(visible=True),\n gr.update(visible=True, choices=responses, interactive=True, value=responses[0]),\n gr.update(value=past_conversation_string),\n state,\n gr.update(visible=False),\n gr.update(visible=False),\n gr.update(visible=False),\n new_state_md,\n dummy,\n )\n\n def _select_response(selected_response, state, dummy):\n done = state[\"cnt\"] == TOTAL_CNT\n state[\"generated_responses\"].append(selected_response)\n state[\"data\"][-1][\"selected_response\"] = selected_response\n state[\"data\"][-1][\"selected_model\"] = state[\"data\"][-1][\"response2model_id\"][selected_response]\n if state[\"cnt\"] == TOTAL_CNT:\n # Write the HIT data to our local dataset because the worker has\n # submitted everything now.\n with open(DATA_FILE, \"a\") as jsonlfile:\n json_data_with_assignment_id = [\n json.dumps(\n dict(\n {\"assignmentId\": state[\"assignmentId\"], \"conversation_id\": state[\"conversation_id\"]},\n **datum,\n )\n )\n for datum in state[\"data\"]\n ]\n jsonlfile.write(\"\\n\".join(json_data_with_assignment_id) + \"\\n\")\n toggle_example_submit = gr.update(visible=not done)\n past_conversation_string = \"<br />\".join(\n [\n \"<br />\".join([\"\ud83d\ude03: \" + user_input, \"\ud83e\udd16: \" + model_response])\n for user_input, model_response in zip(state[\"past_user_inputs\"], state[\"generated_responses\"])\n ]\n )\n query = parse_qs(dummy[1:])\n if \"assignmentId\" in query and query[\"assignmentId\"][0] != \"ASSIGNMENT_ID_NOT_AVAILABLE\":\n # It seems that someone is using this app on mturk. We need to\n # store the assignmentId in the state before submit_hit_button\n # is clicked. We can do this here in _predict. We need to save the\n # assignmentId so that the turker can get credit for their HIT.\n state[\"assignmentId\"] = query[\"assignmentId\"][0]\n toggle_final_submit = gr.update(visible=done)\n toggle_final_submit_preview = gr.update(visible=False)\n else:\n toggle_final_submit_preview = gr.update(visible=done)\n toggle_final_submit = gr.update(visible=False)\n\n if done:\n # Wipe the memory completely because we will be starting a new hit soon.\n for chatbot in chatbots:\n chatbot.memory = ConversationBufferMemory(ai_prefix=\"Assistant\")\n else:\n # Sync all of the model's memories with the conversation path that\n # was actually taken.\n for chatbot in chatbots:\n chatbot.memory = model_id2model[state[\"data\"][-1][\"response2model_id\"][selected_response]].memory\n\n text_input = gr.update(visible=False) if done else gr.update(visible=True)\n return (\n gr.update(visible=False),\n gr.update(visible=True),\n text_input,\n gr.update(visible=False),\n state,\n gr.update(value=past_conversation_string),\n toggle_example_submit,\n toggle_final_submit,\n toggle_final_submit_preview,\n dummy,\n )\n\n # Input fields\n past_conversation = gr.Markdown()\n text_input = gr.Textbox(placeholder=\"Enter a statement\", show_label=False)\n select_response = gr.Radio(\n choices=[None, None], visible=False, label=\"Choose the most helpful and honest response\"\n )\n select_response_button = gr.Button(\"Select Response\", visible=False)\n with gr.Column() as example_submit:\n submit_ex_button = gr.Button(\"Submit\")\n with gr.Column(visible=False) as final_submit:\n submit_hit_button = gr.Button(\"Submit HIT\")\n with gr.Column(visible=False) as final_submit_preview:\n submit_hit_button_preview = gr.Button(\n \"Submit Work (preview mode; no MTurk HIT credit, but your examples will still be stored)\"\n )\n\n # Button event handlers\n get_window_location_search_js = \"\"\"\n function(select_response, state, dummy) {\n return [select_response, state, window.location.search];\n }\n \"\"\"\n\n select_response_button.click(\n _select_response,\n inputs=[select_response, state, dummy],\n outputs=[\n select_response,\n example_submit,\n text_input,\n select_response_button,\n state,\n past_conversation,\n example_submit,\n final_submit,\n final_submit_preview,\n dummy,\n ],\n _js=get_window_location_search_js,\n )\n\n submit_ex_button.click(\n _predict,\n inputs=[text_input, state],\n outputs=[\n text_input,\n select_response_button,\n select_response,\n past_conversation,\n state,\n example_submit,\n final_submit,\n final_submit_preview,\n state_display,\n ],\n )\n\n post_hit_js = \"\"\"\n function(state) {\n // If there is an assignmentId, then the submitter is on mturk\n // and has accepted the HIT. So, we need to submit their HIT.\n const form = document.createElement('form');\n form.action = 'https://workersandbox.mturk.com/mturk/externalSubmit';\n form.method = 'post';\n for (const key in state) {\n const hiddenField = document.createElement('input');\n hiddenField.type = 'hidden';\n hiddenField.name = key;\n hiddenField.value = state[key];\n form.appendChild(hiddenField);\n };\n document.body.appendChild(form);\n form.submit();\n return state;\n }\n \"\"\"\n\n submit_hit_button.click(\n lambda state: state,\n inputs=[state],\n outputs=[state],\n _js=post_hit_js,\n )\n\n refresh_app_js = \"\"\"\n function(state) {\n // The following line here loads the app again so the user can\n // enter in another preview-mode \"HIT\".\n window.location.href = window.location.href;\n return state;\n }\n \"\"\"\n\n submit_hit_button_preview.click(\n lambda state: state,\n inputs=[state],\n outputs=[state],\n _js=refresh_app_js,\n )\n\ndemo.launch()\n", "requirements.txt": "boto3==1.24.32\nboto==2.49.0\nhuggingface_hub==0.8.1\npython-dotenv==0.20.0\nlangchain==0.0.74\n", ".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 3e289fc7d8af1b986b540c00125a2178caa4d384 Hamza Amin <[email protected]> 1727369412 +0500\tclone: from https://github.com/huggingface/rlhf-interface.git\n", ".git\\refs\\heads\\main": "3e289fc7d8af1b986b540c00125a2178caa4d384\n"} | null |
roots-search-tool | {"type": "directory", "name": "roots-search-tool", "children": [{"type": "file", "name": "Makefile"}, {"type": "directory", "name": "notebooks", "children": [{"type": "file", "name": "draft_roots_en_exploration.ipynb"}, {"type": "file", "name": "mongodb_exploration.ipynb"}, {"type": "file", "name": "pyserini_exploration.ipynb"}, {"type": "file", "name": "roots_1e_exploration.ipynb"}, {"type": "file", "name": "roots_en_exploration.ipynb"}]}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "directory", "name": "scripts", "children": [{"type": "file", "name": "populate_mongodb.py"}, {"type": "file", "name": "preprocessing.py"}, {"type": "file", "name": "retrieve_pyserini.py"}, {"type": "file", "name": "save_datasets.py"}, {"type": "file", "name": "summarize_datasets.py"}, {"type": "file", "name": "utils.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "web", "children": [{"type": "file", "name": "bigscience_pii_detect_redact.py"}, {"type": "file", "name": "em_server.py"}, {"type": "file", "name": "sample_query.py"}, {"type": "file", "name": "server.py"}]}]} | # roots-search-tool
Scripts supporting the development and serving the Roots Search Tool - https://hf.co/spaces/bigscience-data/roots-search
| {"requirements.txt": "datasets\nfaiss-cpu\nfasttext\nhuggingface_hub\npyserini\nregex\ntorch\n", ".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 487fbe15cdb6a99399854eedf18fac522b4f1088 Hamza Amin <[email protected]> 1727369414 +0500\tclone: from https://github.com/huggingface/roots-search-tool.git\n", ".git\\refs\\heads\\main": "487fbe15cdb6a99399854eedf18fac522b4f1088\n"} | null |
safetensors | {"type": "directory", "name": "safetensors", "children": [{"type": "file", "name": ".dockerignore"}, {"type": "file", "name": ".pre-commit-config.yaml"}, {"type": "directory", "name": "attacks", "children": [{"type": "file", "name": "numpy_dos_create.py"}, {"type": "file", "name": "numpy_dos_get_pwned.py"}, {"type": "file", "name": "paddle_ace_create.py"}, {"type": "file", "name": "paddle_ace_get_pwned.py"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "safetensors_abuse_attempt_1.py"}, {"type": "file", "name": "safetensors_abuse_attempt_2.py"}, {"type": "file", "name": "safetensors_abuse_attempt_3.py"}, {"type": "file", "name": "tf_ace_create.py"}, {"type": "file", "name": "tf_ace_get_pwned.py"}, {"type": "file", "name": "tf_safe_ace_create.py"}, {"type": "file", "name": "tf_safe_ace_get_pwned.py"}, {"type": "file", "name": "torch_ace_create.py"}, {"type": "file", "name": "torch_ace_get_pwned.py"}, {"type": "file", "name": "torch_dos_create.py"}, {"type": "file", "name": "torch_dos_get_pwned.py"}]}, {"type": "directory", "name": "bindings", "children": [{"type": "directory", "name": "python", "children": [{"type": "directory", "name": "benches", "children": [{"type": "file", "name": "test_flax.py"}, {"type": "file", "name": "test_mlx.py"}, {"type": "file", "name": "test_paddle.py"}, {"type": "file", "name": "test_pt.py"}, {"type": "file", "name": "test_tf.py"}]}, {"type": "file", "name": "Cargo.toml"}, {"type": "file", "name": "convert.py"}, {"type": "file", "name": "convert_all.py"}, {"type": "file", "name": "fuzz.py"}, {"type": "file", "name": "Makefile"}, {"type": "file", "name": "MANIFEST.in"}, {"type": "file", "name": "pyproject.toml"}, {"type": "directory", "name": "py_src", "children": [{"type": "directory", "name": "safetensors", "children": [{"type": "file", "name": "flax.py"}, {"type": "file", "name": "mlx.py"}, {"type": "file", "name": "numpy.py"}, {"type": "file", "name": "paddle.py"}, {"type": "file", "name": "py.typed"}, {"type": "file", "name": "tensorflow.py"}, {"type": "file", "name": "torch.py"}, {"type": "file", "name": "__init__.py"}, {"type": "file", "name": "__init__.pyi"}]}]}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "setup.cfg"}, {"type": "directory", "name": "src", "children": [{"type": "file", "name": "lib.rs"}]}, {"type": "file", "name": "stub.py"}, {"type": "directory", "name": "tests", "children": [{"type": "directory", "name": "data", "children": [{"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "test_flax_comparison.py"}, {"type": "file", "name": "test_mlx_comparison.py"}, {"type": "file", "name": "test_paddle_comparison.py"}, {"type": "file", "name": "test_pt_comparison.py"}, {"type": "file", "name": "test_pt_model.py"}, {"type": "file", "name": "test_simple.py"}, {"type": "file", "name": "test_tf_comparison.py"}]}]}]}, {"type": "file", "name": "codecov.yaml"}, {"type": "file", "name": "codecov.yml"}, {"type": "file", "name": "Dockerfile.s390x.test"}, {"type": "directory", "name": "docs", "children": [{"type": "file", "name": "safetensors.schema.json"}, {"type": "directory", "name": "source", "children": [{"type": "directory", "name": "api", "children": [{"type": "file", "name": "flax.mdx"}, {"type": "file", "name": "numpy.mdx"}, {"type": "file", "name": "paddle.mdx"}, {"type": "file", "name": "tensorflow.mdx"}, {"type": "file", "name": "torch.mdx"}]}, {"type": "file", "name": "convert-weights.md"}, {"type": "file", "name": "index.mdx"}, {"type": "file", "name": "metadata_parsing.mdx"}, {"type": "file", "name": "speed.mdx"}, {"type": "file", "name": "torch_shared_tensors.mdx"}, {"type": "file", "name": "_toctree.yml"}]}]}, {"type": "file", "name": "LICENSE"}, {"type": "file", "name": "Makefile"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "RELEASE.md"}, {"type": "directory", "name": "safetensors", "children": [{"type": "directory", "name": "benches", "children": [{"type": "file", "name": "benchmark.rs"}]}, {"type": "file", "name": "Cargo.toml"}, {"type": "directory", "name": "fuzz", "children": [{"type": "file", "name": "Cargo.toml"}, {"type": "directory", "name": "fuzz_targets", "children": [{"type": "file", "name": "fuzz_target_1.rs"}]}]}, {"type": "file", "name": "LICENSE"}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "src", "children": [{"type": "file", "name": "lib.rs"}, {"type": "file", "name": "slice.rs"}, {"type": "file", "name": "tensor.rs"}]}]}]} | ../README.md | {"Dockerfile.s390x.test": "FROM s390x/python\nRUN wget https://repo.anaconda.com/miniconda/Miniconda3-py311_23.5.2-0-Linux-s390x.sh \\\n && bash Miniconda3-py311_23.5.2-0-Linux-s390x.sh -b \\\n && rm -f Miniconda3-py311_23.5.2-0-Linux-s390x.sh\nRUN curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | bash -s -- -y\nRUN /root/miniconda3/bin/conda install pytorch cpuonly -c pytorch -y\nWORKDIR /safetensors/\nRUN /root/miniconda3/bin/pip install -U pip pytest\n# RUN /root/miniconda3/bin/pip install -U huggingface_hub\n# RUN /root/miniconda3/bin/python -c 'from huggingface_hub import hf_hub_download; filename = hf_hub_download(\"roberta-base\", \"model.safetensors\")'\nCOPY . .\nSHELL [\"/bin/bash\", \"-c\"]\nWORKDIR /safetensors/bindings/python/\nRUN source /root/.cargo/env && /root/miniconda3/bin/pip install -e .\nRUN /root/miniconda3/bin/pytest -sv tests/test_pt_* tests/test_simple.py\n# RUN /root/miniconda3/bin/python -c 'from huggingface_hub import hf_hub_download; filename = hf_hub_download(\"roberta-base\", \"model.safetensors\"); from safetensors.torch import load_file; weights = load_file(filename); assert weights[\"roberta.embeddings.position_embeddings.weight\"][0][0].abs().item() > 1e-10'\nENTRYPOINT /bin/bash\n", ".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 5db3b92c76ba293a0715b916c16b113c0b3551e9 Hamza Amin <[email protected]> 1727369420 +0500\tclone: from https://github.com/huggingface/safetensors.git\n", ".git\\refs\\heads\\main": "5db3b92c76ba293a0715b916c16b113c0b3551e9\n", "docs\\source\\index.mdx": "<!-- DISABLE-FRONTMATTER-SECTIONS -->\n\n<div class=\"flex justify-center\">\n <img class=\"block dark:hidden\" src=\"https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/safetensors/safetensors-logo-light.svg\"/>\n <img class=\"hidden dark:block\" src=\"https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/safetensors/safetensors-logo-dark.svg\"/>\n</div>\n\n# Safetensors\n\nSafetensors is a new simple format for storing tensors safely (as opposed to pickle) and that is still fast (zero-copy). Safetensors is really [fast \ud83d\ude80](./speed).\n\n## Installation\n\nwith pip:\n```\npip install safetensors\n```\n\nwith conda:\n```\nconda install -c huggingface safetensors\n```\n\n## Usage\n\n### Load tensors\n\n```python\nfrom safetensors import safe_open\n\ntensors = {}\nwith safe_open(\"model.safetensors\", framework=\"pt\", device=0) as f:\n for k in f.keys():\n tensors[k] = f.get_tensor(k)\n```\n\nLoading only part of the tensors (interesting when running on multiple GPU)\n\n```python\nfrom safetensors import safe_open\n\ntensors = {}\nwith safe_open(\"model.safetensors\", framework=\"pt\", device=0) as f:\n tensor_slice = f.get_slice(\"embedding\")\n vocab_size, hidden_dim = tensor_slice.get_shape()\n tensor = tensor_slice[:, :hidden_dim]\n```\n\n### Save tensors\n\n```python\nimport torch\nfrom safetensors.torch import save_file\n\ntensors = {\n \"embedding\": torch.zeros((2, 2)),\n \"attention\": torch.zeros((2, 3))\n}\nsave_file(tensors, \"model.safetensors\")\n```\n\n## Format\n\nLet's say you have safetensors file named `model.safetensors`, then `model.safetensors` will have the following internal format:\n\n<div class=\"flex justify-center\">\n <img src=\"https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/safetensors/safetensors-format.svg\"/>\n</div>\n\n## Featured Projects\n\nSafetensors is being used widely at leading AI enterprises, such as [Hugging Face](https://huggingface.co/), [EleutherAI](https://www.eleuther.ai/),\u00a0and\u00a0[StabilityAI](https://stability.ai/). Here is a non-exhaustive list of projects that are using safetensors:\n\n* [huggingface/transformers](https://github.com/huggingface/transformers)\n* [ml-explore/mlx](https://github.com/ml-explore/mlx)\n* [huggingface/candle](https://github.com/huggingface/candle)\n* [AUTOMATIC1111/stable-diffusion-webui](https://github.com/AUTOMATIC1111/stable-diffusion-webui)\n* [Llama-cpp](https://github.com/ggerganov/llama.cpp/blob/e6a46b0ed1884c77267dc70693183e3b7164e0e0/convert.py#L537)\n* [microsoft/TaskMatrix](https://github.com/microsoft/TaskMatrix)\n* [hpcaitech/ColossalAI](https://github.com/hpcaitech/ColossalAI)\n* [huggingface/pytorch-image-models](https://github.com/huggingface/pytorch-image-models)\n* [CivitAI](https://civitai.com/)\n* [huggingface/diffusers](https://github.com/huggingface/diffusers)\n* [coreylowman/dfdx](https://github.com/coreylowman/dfdx)\n* [invoke-ai/InvokeAI](https://github.com/invoke-ai/InvokeAI)\n* [oobabooga/text-generation-webui](https://github.com/oobabooga/text-generation-webui)\n* [Sanster/lama-cleaner](https://github.com/Sanster/lama-cleaner)\n* [PaddlePaddle/PaddleNLP](https://github.com/PaddlePaddle/PaddleNLP)\n* [AIGC-Audio/AudioGPT](https://github.com/AIGC-Audio/AudioGPT)\n* [brycedrennan/imaginAIry](https://github.com/brycedrennan/imaginAIry)\n* [comfyanonymous/ComfyUI](https://github.com/comfyanonymous/ComfyUI)\n* [LianjiaTech/BELLE](https://github.com/LianjiaTech/BELLE)\n* [alvarobartt/safejax](https://github.com/alvarobartt/safejax)\n* [MaartenGr/BERTopic](https://github.com/MaartenGr/BERTopic)\n"} | null |
semver-release-action | {"type": "directory", "name": "semver-release-action", "children": [{"type": "file", "name": ".eslintrc.cjs"}, {"type": "file", "name": ".releaserc.json"}, {"type": "file", "name": "action.yml"}, {"type": "file", "name": "Dockerfile"}, {"type": "file", "name": "LICENSE"}, {"type": "file", "name": "package-lock.json"}, {"type": "file", "name": "package.json"}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "src", "children": [{"type": "file", "name": "index.js"}]}]} | <h1 style="text-align: center; border-bottom: none;">📦🚀 semver-release-action</h1>
<h3 style="text-align: center">Github Action to release projects using <a href="https://github.com/semantic-release/semantic-release">Semantic Release</a>.</h3>
<p style="text-align: center">
<a href="https://github.com/huggingface/semver-release-action/releases">
<img alt="Latest release" src="https://img.shields.io/github/v/release/huggingface/semver-release-action?label=Release">
</a>
<a href="https://opensource.org/licenses/Apache-2.0">
<img alt="License" src="https://img.shields.io/badge/License-Apache_2.0-yellow.svg">
</a>
</p>
# Usage
This github action automates the whole package release workflow including: determining the next version number, generating the release notes, and publishing the package.
```yaml
name: Release project
on:
workflow_dispatch:
jobs:
release:
name: Release
runs-on: ubuntu-latest
steps:
- name: Checkout repository
uses: actions/checkout@v3
- name: Release
uses: huggingface/semver-release-action@latest
```
## Inputs parameters
### branches
The branches on which releases should happen. By default semantic-release will release:
See : https://github.com/semantic-release/semantic-release/blob/master/docs/usage/configuration.md#branches
```yaml
- name: Helm Publish Action
uses: huggingface/helm-publish-action@latest
with:
branches: ["main"]
```
### dryRun
The objective of the dry-run mode is to get a preview of the pending release. Dry-run mode skips the following steps: prepare, publish, addChannel, success and fail.
In addition to this it prints the next version and release notes to the console.
```yaml
- name: Helm Publish Action
uses: huggingface/helm-publish-action@latest
with:
dryRun: true
```
### commitAnalyzerPluginOpts
JSON Options to pass to commit analyzer plugins. See : https://github.com/semantic-release/commit-analyzer#options
```yaml
- name: Helm Publish Action
uses: huggingface/helm-publish-action@latest
with:
commitAnalyzerPluginOpts: {...}
```
## Outputs
### tag
Tag as tag-prefix + version, example: v1.2.3
### version
New version or current version if not released, example: 1.2.3
### changelog
Changelog of the new version
### released
True if new version was released | {"Dockerfile": "FROM node:18.9.1\n\nWORKDIR /workspace\n\nCOPY ./package.json ./package-lock.json ./\nRUN npm ci --omit=dev\n\nCOPY src/index.js .\nENTRYPOINT [\"node\", \"/workspace/index.js\"]\n", "package.json": "{\n \"name\": \"semver-release-action\",\n \"version\": \"1.0.0\",\n \"description\": \"Github action to release project using semantic versioning\",\n \"main\": \"src/index.js\",\n \"scripts\": {\n \"lint\": \"eslint\",\n \"test\": \"echo \\\"Error: no test specified\\\" && exit 1\"\n },\n \"repository\": {\n \"type\": \"git\",\n \"url\": \"git+https://github.com/huggingface/semver-release-action.git\"\n },\n \"keywords\": [\n \"github\",\n \"release\",\n \"semantic\",\n \"version\"\n ],\n \"author\": \"huggingface\",\n \"license\": \"Apache-2.0\",\n \"bugs\": {\n \"url\": \"https://github.com/huggingface/semver-release-action/issues\"\n },\n \"homepage\": \"https://github.com/huggingface/semver-release-action#readme\",\n \"type\": \"module\",\n \"dependencies\": {\n \"@actions/core\": \"^1.10.0\",\n \"@semantic-release/commit-analyzer\": \"^12.0.0\",\n \"@semantic-release/exec\": \"^6.0.3\",\n \"@semantic-release/github\": \"^10.0.3\",\n \"@semantic-release/release-notes-generator\": \"^13.0.0\",\n \"semantic-release\": \"^23.0.8\"\n },\n \"devDependencies\": {\n \"eslint\": \"^8.38.0\",\n \"eslint-config-standard\": \"^17.0.0\",\n \"eslint-plugin-import\": \"^2.27.5\",\n \"eslint-plugin-n\": \"^15.7.0\",\n \"eslint-plugin-promise\": \"^6.1.1\"\n }\n}\n", ".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 0a2970a99000efa01e3a9b9de0136b5ccc67ca31 Hamza Amin <[email protected]> 1727369528 +0500\tclone: from https://github.com/huggingface/semver-release-action.git\n", ".git\\refs\\heads\\main": "0a2970a99000efa01e3a9b9de0136b5ccc67ca31\n", "src\\index.js": "import core from '@actions/core';\nimport semanticRelease from 'semantic-release';\nimport process from 'node:process';\n\nasync function main() {\n const dryRun = core.getInput('dryRun') ? core.getBooleanInput('dryRun') : false;\n const branches = core.getInput('branches') ? JSON.parse(core.getInput('branches')) : ['main'];\n const commitAnalyzerPluginOpts = core.getInput('commitAnalyzerPluginOpts') ? JSON.parse(core.getInput('commitAnalyzerPluginOpts')) : null;\n\n try {\n core.debug(`Start execution with following env var : ${JSON.stringify(process.env)}`);\n\n const result = await semanticRelease(\n {\n dryRun,\n branches,\n plugins: [\n '@semantic-release/commit-analyzer', commitAnalyzerPluginOpts || {},\n '@semantic-release/release-notes-generator',\n '@semantic-release/github',\n ]\n },\n {\n // Run semantic-release from `/path/to/git/repo/root` without having to change local process `cwd` with `process.chdir()`\n // cwd: '/Volumes/Data/workspace/huggingface/private-hub-package'\n cwd: '/github/workspace'\n // Pass the variable `MY_ENV_VAR` to semantic-release without having to modify the local `process.env`\n // env: { ...process.env, MY_ENV_VAR: \"MY_ENV_VAR_VALUE\" },\n }\n );\n\n if (result) {\n core.debug(`semantic result : ${result}`);\n const { nextRelease } = result;\n\n core.setOutput('released', dryRun !== true);\n core.setOutput('tag', nextRelease.gitTag);\n core.setOutput('version', nextRelease.version);\n core.setOutput('changelog', nextRelease.notes);\n } else {\n core.setOutput('released', false);\n core.info('No release published.');\n }\n } catch (err) {\n core.error(`The automated release failed with ${err}`);\n core.setFailed(`The automated release failed with ${err}`);\n }\n}\n\nmain();\n"} | null |
sharp-transformers | {"type": "directory", "name": "sharp-transformers", "children": [{"type": "file", "name": "LICENSE"}, {"type": "file", "name": "package.json"}, {"type": "file", "name": "package.json.meta"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "README.md.meta"}, {"type": "directory", "name": "Runtime", "children": [{"type": "file", "name": "HuggingFace.SharpTransformers.asmdef"}, {"type": "file", "name": "HuggingFace.SharpTransformers.asmdef.meta"}, {"type": "directory", "name": "Tokenizers", "children": [{"type": "directory", "name": "Decoders", "children": [{"type": "file", "name": "Decoders.cs"}, {"type": "file", "name": "Decoders.cs.meta"}]}, {"type": "file", "name": "Decoders.meta"}, {"type": "directory", "name": "Normalizers", "children": [{"type": "file", "name": "Normalizers.cs"}, {"type": "file", "name": "Normalizers.cs.meta"}, {"type": "file", "name": "NormalizersUtils.cs"}, {"type": "file", "name": "NormalizersUtils.cs.meta"}]}, {"type": "file", "name": "Normalizers.meta"}, {"type": "directory", "name": "PostProcessors", "children": [{"type": "file", "name": "PostProcessors.cs"}, {"type": "file", "name": "PostProcessors.cs.meta"}]}, {"type": "file", "name": "PostProcessors.meta"}, {"type": "directory", "name": "PreTokenizers", "children": [{"type": "file", "name": "PreTokenizers.cs"}, {"type": "file", "name": "PreTokenizers.cs.meta"}]}, {"type": "file", "name": "PreTokenizers.meta"}, {"type": "directory", "name": "Tokenizers", "children": [{"type": "file", "name": "Tokenizers.cs"}, {"type": "file", "name": "Tokenizers.cs.meta"}, {"type": "file", "name": "TokenizersUtils.cs"}, {"type": "file", "name": "TokenizersUtils.cs.meta"}]}, {"type": "file", "name": "Tokenizers.meta"}]}, {"type": "file", "name": "Tokenizers.meta"}]}, {"type": "file", "name": "Runtime.meta"}]} | fileFormatVersion: 2
guid: b0ec1865350d9eb4e8f442d1d2d6a24c
TextScriptImporter:
externalObjects: {}
userData:
assetBundleName:
assetBundleVariant:
| {"package.json": "{\n \"name\": \"com.huggingface.sharp-transformers\",\n \"displayName\": \"Hugging Face Sharp Transformers\",\n \"version\": \"0.0.1\",\n \"unity\": \"2020.3\",\n \"description\": \"A Unity plugin for using Transformers models in Unity.\",\n \"keywords\": [\"huggingface\", \"llm\", \"AI\"],\n \"author\": {\n \"name\": \"Thomas Simonini\",\n \"email\": \"[email protected]\",\n \"url\": \"https://github.com/huggingface/sharp-transformers\"\n },\n \"dependencies\": {\n \"com.unity.nuget.newtonsoft-json\": \"3.2.1\"\n }\n}", "package.json.meta": "fileFormatVersion: 2\nguid: 5d09fabafa75bd14aba7b139d2379b45\nTextScriptImporter:\n externalObjects: {}\n userData: \n assetBundleName: \n assetBundleVariant: \n", ".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 577bfe23c286a605f58d328ea991aa4d4d06f4c8 Hamza Amin <[email protected]> 1727369613 +0500\tclone: from https://github.com/huggingface/sharp-transformers.git\n", ".git\\refs\\heads\\main": "577bfe23c286a605f58d328ea991aa4d4d06f4c8\n"} | null |
simulate | {"type": "directory", "name": "simulate", "children": [{"type": "file", "name": "CMakeLists.txt"}, {"type": "file", "name": "CODE_OF_CONDUCT.md"}, {"type": "file", "name": "CONTRIBUTING.md"}, {"type": "directory", "name": "docs", "children": [{"type": "file", "name": "README.md"}, {"type": "directory", "name": "source", "children": [{"type": "directory", "name": "api", "children": [{"type": "file", "name": "actors.mdx"}, {"type": "file", "name": "actuators.mdx"}, {"type": "file", "name": "joints.mdx"}, {"type": "file", "name": "lights.mdx"}, {"type": "file", "name": "objects.mdx"}, {"type": "file", "name": "physics.mdx"}, {"type": "file", "name": "reward_functions.mdx"}, {"type": "file", "name": "rl_env.mdx"}, {"type": "file", "name": "scenes.mdx"}, {"type": "file", "name": "sensors.mdx"}]}, {"type": "directory", "name": "assets", "children": []}, {"type": "directory", "name": "conceptual", "children": [{"type": "file", "name": "backends.mdx"}, {"type": "file", "name": "gltf.mdx"}, {"type": "file", "name": "philosophy.mdx"}]}, {"type": "directory", "name": "howto", "children": [{"type": "file", "name": "map_pools.mdx"}, {"type": "file", "name": "plugins.mdx"}, {"type": "file", "name": "rl.mdx"}, {"type": "file", "name": "run_on_gcp.mdx"}, {"type": "file", "name": "sample_factory.mdx"}]}, {"type": "file", "name": "index.mdx"}, {"type": "file", "name": "installation.mdx"}, {"type": "file", "name": "quicktour.mdx"}, {"type": "directory", "name": "tutorials", "children": [{"type": "file", "name": "creating_a_scene.mdx"}, {"type": "file", "name": "interaction.mdx"}, {"type": "file", "name": "running_the_simulation.mdx"}]}, {"type": "file", "name": "_toctree.yml"}]}]}, {"type": "directory", "name": "examples", "children": [{"type": "directory", "name": "advanced", "children": [{"type": "file", "name": "cartpole.py"}, {"type": "file", "name": "doors_plugin.py"}, {"type": "file", "name": "lunar_lander.py"}, {"type": "file", "name": "mountaincar.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "basic", "children": [{"type": "file", "name": "create_and_save.py"}, {"type": "file", "name": "objects.py"}, {"type": "file", "name": "simple_physics.py"}, {"type": "file", "name": "structured_grid_test.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "intermediate", "children": [{"type": "file", "name": "multi_agent_playground.py"}, {"type": "file", "name": "playground.py"}, {"type": "file", "name": "procgen_grid.py"}, {"type": "file", "name": "reward_functions.py"}, {"type": "file", "name": "tmaze.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "notebooks", "children": [{"type": "file", "name": "quick_tour.ipynb"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "rl", "children": [{"type": "file", "name": "sb3_basic_maze.py"}, {"type": "file", "name": "sb3_collectables.py"}, {"type": "file", "name": "sb3_move_boxes.py"}, {"type": "file", "name": "sb3_multiprocess.py"}, {"type": "file", "name": "sb3_procgen.py"}, {"type": "file", "name": "sb3_visual_reward.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "robot.py"}, {"type": "file", "name": "shapenet.py"}, {"type": "directory", "name": "under_construction", "children": [{"type": "file", "name": "advanced_physics.py"}, {"type": "file", "name": "maze2d.py"}, {"type": "file", "name": "maze2denvs.py"}, {"type": "file", "name": "pendulum.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "under_the_hood", "children": [{"type": "file", "name": "blender_example.py"}, {"type": "file", "name": "echo_gltf.py"}, {"type": "file", "name": "gltf_loading_test.py"}, {"type": "file", "name": "godot_example.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "integrations", "children": [{"type": "directory", "name": "Blender", "children": [{"type": "file", "name": "README.md"}, {"type": "directory", "name": "simulate_blender", "children": [{"type": "file", "name": "client.py"}, {"type": "file", "name": "simenv_op.py"}, {"type": "file", "name": "simenv_pnl.py"}, {"type": "file", "name": "simulator.py"}, {"type": "file", "name": "__init__.py"}]}]}, {"type": "directory", "name": "Godot", "children": [{"type": "file", "name": "README.md"}, {"type": "directory", "name": "simulate_godot", "children": [{"type": "file", "name": "icon.png.import"}, {"type": "file", "name": "project.godot"}, {"type": "directory", "name": "Scenes", "children": [{"type": "file", "name": "scene.tscn"}]}, {"type": "directory", "name": "Simulate", "children": [{"type": "directory", "name": "Bridge", "children": [{"type": "file", "name": "client.gd"}, {"type": "file", "name": "command.gd"}]}, {"type": "directory", "name": "Commands", "children": [{"type": "file", "name": "close.gd"}, {"type": "file", "name": "initialize.gd"}, {"type": "file", "name": "reset.gd"}, {"type": "file", "name": "step.gd"}]}, {"type": "file", "name": "debug_camera.gd"}, {"type": "directory", "name": "GLTF", "children": [{"type": "file", "name": "gltf_enums.gd"}, {"type": "file", "name": "hf_actuator.gd"}, {"type": "file", "name": "hf_articulation_body.gd"}, {"type": "file", "name": "hf_collider.gd"}, {"type": "file", "name": "hf_extensions.gd"}, {"type": "file", "name": "hf_physic_material.gd"}, {"type": "file", "name": "hf_raycast_sensor.gd"}, {"type": "file", "name": "hf_reward_function.gd"}, {"type": "file", "name": "hf_rigid_body.gd"}, {"type": "file", "name": "hf_state_sensor.gd"}]}, {"type": "file", "name": "render_camera.gd"}, {"type": "directory", "name": "RLAgents", "children": [{"type": "file", "name": "agent.gd"}, {"type": "file", "name": "agent_manager.gd"}, {"type": "file", "name": "reward_function.gd"}, {"type": "file", "name": "rl_action.gd"}]}, {"type": "file", "name": "simulation_node.gd"}, {"type": "file", "name": "simulator.gd"}]}]}]}, {"type": "directory", "name": "Unity", "children": [{"type": "file", "name": "README.md"}, {"type": "directory", "name": "simulate-unity", "children": [{"type": "directory", "name": "Assets", "children": [{"type": "file", "name": "GLTF.meta"}, {"type": "directory", "name": "MountainCar", "children": [{"type": "file", "name": "Cart.cs"}, {"type": "file", "name": "Cart.cs.meta"}, {"type": "file", "name": "MountainCar.asmdef"}, {"type": "file", "name": "MountainCar.asmdef.meta"}, {"type": "file", "name": "MountainCarPlugin.cs"}, {"type": "file", "name": "MountainCarPlugin.cs.meta"}]}, {"type": "file", "name": "MountainCar.meta"}, {"type": "directory", "name": "Plugins", "children": [{"type": "directory", "name": "Doors", "children": [{"type": "file", "name": "src.zip.meta"}]}, {"type": "file", "name": "Doors.meta"}]}, {"type": "file", "name": "Plugins.meta"}, {"type": "directory", "name": "Resources", "children": [{"type": "file", "name": "DefaultEmissive.mat"}, {"type": "file", "name": "DefaultEmissive.mat.meta"}, {"type": "file", "name": "DefaultLit.mat"}, {"type": "file", "name": "DefaultLit.mat.meta"}, {"type": "file", "name": "Plugins.meta"}, {"type": "directory", "name": "Singletons", "children": [{"type": "file", "name": "Client.asset"}, {"type": "file", "name": "Client.asset.meta"}]}, {"type": "file", "name": "Singletons.meta"}]}, {"type": "file", "name": "Resources.meta"}, {"type": "directory", "name": "Scenes", "children": [{"type": "directory", "name": "SampleScene", "children": [{"type": "file", "name": "PostProcessing Profile.asset"}, {"type": "file", "name": "PostProcessing Profile.asset.meta"}]}, {"type": "file", "name": "SampleScene.meta"}, {"type": "file", "name": "SampleScene.unity"}, {"type": "file", "name": "SampleScene.unity.meta"}, {"type": "file", "name": "URPAsset.asset"}, {"type": "file", "name": "URPAsset.asset.meta"}, {"type": "file", "name": "URPAsset_Renderer.asset"}, {"type": "file", "name": "URPAsset_Renderer.asset.meta"}, {"type": "file", "name": "URPGlobalSettings.asset"}, {"type": "file", "name": "URPGlobalSettings.asset.meta"}]}, {"type": "file", "name": "Scenes.meta"}, {"type": "directory", "name": "Simulate", "children": [{"type": "directory", "name": "Editor", "children": [{"type": "file", "name": "GLBImporterEditor.cs"}, {"type": "file", "name": "GLBImporterEditor.cs.meta"}, {"type": "file", "name": "GLTFAssetUtility.cs"}, {"type": "file", "name": "GLTFAssetUtility.cs.meta"}, {"type": "file", "name": "GLTFImporterEditor.cs"}, {"type": "file", "name": "GLTFImporterEditor.cs.meta"}, {"type": "file", "name": "SimEnvEditor.asmdef"}, {"type": "file", "name": "SimEnvEditor.asmdef.meta"}]}, {"type": "file", "name": "Editor.meta"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "README.md.meta"}, {"type": "directory", "name": "Runtime", "children": [{"type": "directory", "name": "Bridge", "children": [{"type": "file", "name": "Client.cs"}, {"type": "file", "name": "Client.cs.meta"}, {"type": "file", "name": "Close.cs"}, {"type": "file", "name": "Close.cs.meta"}, {"type": "file", "name": "Initialize.cs"}, {"type": "file", "name": "Initialize.cs.meta"}, {"type": "file", "name": "Reset.cs"}, {"type": "file", "name": "Reset.cs.meta"}, {"type": "file", "name": "Step.cs"}, {"type": "file", "name": "Step.cs.meta"}, {"type": "file", "name": "TestEchoGLTF.cs"}, {"type": "file", "name": "TestEchoGLTF.cs.meta"}]}, {"type": "file", "name": "Bridge.meta"}, {"type": "directory", "name": "GLTF", "children": [{"type": "file", "name": "AnimationSettings.cs"}, {"type": "file", "name": "AnimationSettings.cs.meta"}, {"type": "file", "name": "BufferedBinaryReader.cs"}, {"type": "file", "name": "BufferedBinaryReader.cs.meta"}, {"type": "directory", "name": "Converters", "children": [{"type": "file", "name": "ColorConverter.cs"}, {"type": "file", "name": "ColorConverter.cs.meta"}, {"type": "file", "name": "EnumConverter.cs"}, {"type": "file", "name": "EnumConverter.cs.meta"}, {"type": "file", "name": "Matrix4x4Converter.cs"}, {"type": "file", "name": "Matrix4x4Converter.cs.meta"}, {"type": "file", "name": "QuaternionConverter.cs"}, {"type": "file", "name": "QuaternionConverter.cs.meta"}, {"type": "file", "name": "TranslationConverter.cs"}, {"type": "file", "name": "TranslationConverter.cs.meta"}, {"type": "file", "name": "Vector2Converter.cs"}, {"type": "file", "name": "Vector2Converter.cs.meta"}, {"type": "file", "name": "Vector3Converter.cs"}, {"type": "file", "name": "Vector3Converter.cs.meta"}]}, {"type": "file", "name": "Converters.meta"}, {"type": "file", "name": "Enums.cs"}, {"type": "file", "name": "Enums.cs.meta"}, {"type": "file", "name": "Exporter.cs"}, {"type": "file", "name": "Exporter.cs.meta"}, {"type": "file", "name": "GLTFAccessor.cs"}, {"type": "file", "name": "GLTFAccessor.cs.meta"}, {"type": "file", "name": "GLTFAnimation.cs"}, {"type": "file", "name": "GLTFAnimation.cs.meta"}, {"type": "file", "name": "GLTFAsset.cs"}, {"type": "file", "name": "GLTFAsset.cs.meta"}, {"type": "file", "name": "GLTFBuffer.cs"}, {"type": "file", "name": "GLTFBuffer.cs.meta"}, {"type": "file", "name": "GLTFBufferView.cs"}, {"type": "file", "name": "GLTFBufferView.cs.meta"}, {"type": "file", "name": "GLTFCamera.cs"}, {"type": "file", "name": "GLTFCamera.cs.meta"}, {"type": "file", "name": "GLTFExtensions.cs"}, {"type": "file", "name": "GLTFExtensions.cs.meta"}, {"type": "file", "name": "GLTFImage.cs"}, {"type": "file", "name": "GLTFImage.cs.meta"}, {"type": "file", "name": "GLTFMaterial.cs"}, {"type": "file", "name": "GLTFMaterial.cs.meta"}, {"type": "file", "name": "GLTFMesh.cs"}, {"type": "file", "name": "GLTFMesh.cs.meta"}, {"type": "file", "name": "GLTFNode.cs"}, {"type": "file", "name": "GLTFNode.cs.meta"}, {"type": "file", "name": "GLTFObject.cs"}, {"type": "file", "name": "GLTFObject.cs.meta"}, {"type": "file", "name": "GLTFPrimitive.cs"}, {"type": "file", "name": "GLTFPrimitive.cs.meta"}, {"type": "file", "name": "GLTFScene.cs"}, {"type": "file", "name": "GLTFScene.cs.meta"}, {"type": "file", "name": "GLTFSkin.cs"}, {"type": "file", "name": "GLTFSkin.cs.meta"}, {"type": "file", "name": "GLTFTexture.cs"}, {"type": "file", "name": "GLTFTexture.cs.meta"}, {"type": "file", "name": "HF_actuators.cs"}, {"type": "file", "name": "HF_actuators.cs.meta"}, {"type": "file", "name": "HF_articulation_bodies.cs"}, {"type": "file", "name": "HF_articulation_bodies.cs.meta"}, {"type": "file", "name": "HF_colliders.cs"}, {"type": "file", "name": "HF_colliders.cs.meta"}, {"type": "file", "name": "HF_physic_materials.cs"}, {"type": "file", "name": "HF_physic_materials.cs.meta"}, {"type": "file", "name": "HF_raycast_sensors.cs"}, {"type": "file", "name": "HF_raycast_sensors.cs.meta"}, {"type": "file", "name": "HF_reward_functions.cs"}, {"type": "file", "name": "HF_reward_functions.cs.meta"}, {"type": "file", "name": "HF_rigid_bodies.cs"}, {"type": "file", "name": "HF_rigid_bodies.cs.meta"}, {"type": "file", "name": "HF_state_sensors.cs"}, {"type": "file", "name": "HF_state_sensors.cs.meta"}, {"type": "file", "name": "Importer.cs"}, {"type": "file", "name": "Importer.cs.meta"}, {"type": "file", "name": "ImportSettings.cs"}, {"type": "file", "name": "ImportSettings.cs.meta"}, {"type": "file", "name": "KHR_lights_punctual.cs"}, {"type": "file", "name": "KHR_lights_punctual.cs.meta"}, {"type": "file", "name": "KHR_texture_transform.cs"}, {"type": "file", "name": "KHR_texture_transform.cs.meta"}]}, {"type": "file", "name": "GLTF.meta"}, {"type": "directory", "name": "Helpers", "children": [{"type": "file", "name": "Extensions.cs"}, {"type": "file", "name": "Extensions.cs.meta"}, {"type": "file", "name": "Singleton.cs"}, {"type": "file", "name": "Singleton.cs.meta"}]}, {"type": "file", "name": "Helpers.meta"}, {"type": "file", "name": "Node.cs"}, {"type": "file", "name": "Node.cs.meta"}, {"type": "directory", "name": "Plugins", "children": [{"type": "file", "name": "ICommand.cs"}, {"type": "file", "name": "ICommand.cs.meta"}, {"type": "file", "name": "IGLTFExtension.cs"}, {"type": "file", "name": "IGLTFExtension.cs.meta"}, {"type": "file", "name": "IPlugin.cs"}, {"type": "file", "name": "IPlugin.cs.meta"}, {"type": "file", "name": "PluginBase.cs"}, {"type": "file", "name": "PluginBase.cs.meta"}]}, {"type": "file", "name": "Plugins.meta"}, {"type": "file", "name": "RenderCamera.cs"}, {"type": "file", "name": "RenderCamera.cs.meta"}, {"type": "directory", "name": "RLActors", "children": [{"type": "file", "name": "Actions.cs"}, {"type": "file", "name": "Actions.cs.meta"}, {"type": "file", "name": "Actor.cs"}, {"type": "file", "name": "Actor.cs.meta"}, {"type": "file", "name": "Map.cs"}, {"type": "file", "name": "Map.cs.meta"}, {"type": "file", "name": "MapPool.cs"}, {"type": "file", "name": "MapPool.cs.meta"}, {"type": "file", "name": "RewardFunction.cs"}, {"type": "file", "name": "RewardFunction.cs.meta"}, {"type": "file", "name": "RLPlugin.cs"}, {"type": "file", "name": "RLPlugin.cs.meta"}, {"type": "directory", "name": "Sensors", "children": [{"type": "file", "name": "CameraSensor.cs"}, {"type": "file", "name": "CameraSensor.cs.meta"}, {"type": "file", "name": "ISensors.cs"}, {"type": "file", "name": "ISensors.cs.meta"}, {"type": "file", "name": "JsonHelper.cs"}, {"type": "file", "name": "JsonHelper.cs.meta"}, {"type": "file", "name": "RaycastSensor.cs"}, {"type": "file", "name": "RaycastSensor.cs.meta"}, {"type": "file", "name": "StateSensor.cs"}, {"type": "file", "name": "StateSensor.cs.meta"}]}, {"type": "file", "name": "Sensors.meta"}, {"type": "file", "name": "SimEnv.RLAgents.asmdef"}, {"type": "file", "name": "SimEnv.RLAgents.asmdef.meta"}]}, {"type": "file", "name": "RLActors.meta"}, {"type": "file", "name": "Simulate.asmdef"}, {"type": "file", "name": "Simulate.asmdef.meta"}, {"type": "directory", "name": "Simulation", "children": [{"type": "file", "name": "Config.cs"}, {"type": "file", "name": "Config.cs.meta"}, {"type": "file", "name": "EventData.cs"}, {"type": "file", "name": "EventData.cs.meta"}]}, {"type": "file", "name": "Simulation.meta"}, {"type": "file", "name": "Simulator.cs"}, {"type": "file", "name": "Simulator.cs.meta"}, {"type": "directory", "name": "Tests", "children": [{"type": "directory", "name": "EditMode", "children": [{"type": "file", "name": "EditMode.asmdef"}, {"type": "file", "name": "EditMode.asmdef.meta"}, {"type": "file", "name": "TestRewardFunctions.cs"}, {"type": "file", "name": "TestRewardFunctions.cs.meta"}]}, {"type": "file", "name": "EditMode.meta"}, {"type": "directory", "name": "PlayMode", "children": [{"type": "file", "name": "PlayMode.asmdef"}, {"type": "file", "name": "PlayMode.asmdef.meta"}, {"type": "file", "name": "TestRewardFunctions.cs"}, {"type": "file", "name": "TestRewardFunctions.cs.meta"}]}, {"type": "file", "name": "PlayMode.meta"}]}, {"type": "file", "name": "Tests.meta"}, {"type": "directory", "name": "Utils", "children": [{"type": "file", "name": "DebugCam.cs"}, {"type": "file", "name": "DebugCam.cs.meta"}]}, {"type": "file", "name": "Utils.meta"}]}, {"type": "file", "name": "Runtime.meta"}]}, {"type": "file", "name": "Simulate.meta"}, {"type": "file", "name": "StreamingAssets.meta"}, {"type": "directory", "name": "Tests", "children": [{"type": "file", "name": "Tests.asmdef"}, {"type": "file", "name": "Tests.asmdef.meta"}]}, {"type": "file", "name": "Tests.meta"}]}, {"type": "directory", "name": "Packages", "children": [{"type": "file", "name": "manifest.json"}, {"type": "file", "name": "packages-lock.json"}]}, {"type": "directory", "name": "ProjectSettings", "children": [{"type": "file", "name": "AudioManager.asset"}, {"type": "file", "name": "boot.config"}, {"type": "file", "name": "BurstAotSettings_StandaloneLinux64.json"}, {"type": "file", "name": "BurstAotSettings_StandaloneOSX.json"}, {"type": "file", "name": "BurstAotSettings_StandaloneWindows.json"}, {"type": "file", "name": "BurstAotSettings_WebGL 2.json"}, {"type": "file", "name": "BurstAotSettings_WebGL.json"}, {"type": "file", "name": "ClusterInputManager.asset"}, {"type": "file", "name": "CommonBurstAotSettings.json"}, {"type": "file", "name": "DynamicsManager.asset"}, {"type": "file", "name": "EditorBuildSettings.asset"}, {"type": "file", "name": "EditorSettings.asset"}, {"type": "file", "name": "GraphicsSettings.asset"}, {"type": "file", "name": "InputManager.asset"}, {"type": "file", "name": "MemorySettings.asset"}, {"type": "file", "name": "NavMeshAreas.asset"}, {"type": "file", "name": "PackageManagerSettings.asset"}, {"type": "directory", "name": "Packages", "children": [{"type": "directory", "name": "com.unity.testtools.codecoverage", "children": [{"type": "file", "name": "Settings.json"}]}]}, {"type": "file", "name": "Physics2DSettings.asset"}, {"type": "file", "name": "PresetManager.asset"}, {"type": "file", "name": "ProjectSettings.asset"}, {"type": "file", "name": "ProjectVersion.txt"}, {"type": "file", "name": "QualitySettings.asset"}, {"type": "file", "name": "SceneTemplateSettings.json"}, {"type": "file", "name": "ShaderGraphSettings 2.asset"}, {"type": "file", "name": "ShaderGraphSettings 3.asset"}, {"type": "file", "name": "ShaderGraphSettings 4.asset"}, {"type": "file", "name": "ShaderGraphSettings.asset"}, {"type": "file", "name": "TagManager.asset"}, {"type": "file", "name": "TimeManager.asset"}, {"type": "file", "name": "UnityConnectSettings.asset"}, {"type": "file", "name": "URPProjectSettings.asset"}, {"type": "file", "name": "VersionControlSettings.asset"}, {"type": "file", "name": "VFXManager.asset"}, {"type": "file", "name": "XRSettings.asset"}]}]}, {"type": "directory", "name": "tests", "children": [{"type": "file", "name": "conftest.py"}, {"type": "file", "name": "test_action_add_force.py"}, {"type": "file", "name": "test_action_add_torque.py"}, {"type": "file", "name": "test_action_change_position.py"}, {"type": "file", "name": "test_action_metadata.py"}, {"type": "file", "name": "__init__.py"}]}]}]}, {"type": "file", "name": "LICENSE"}, {"type": "file", "name": "Makefile"}, {"type": "file", "name": "MANIFEST.in"}, {"type": "file", "name": "pyproject.toml"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "SECURITY.md"}, {"type": "file", "name": "setup.cfg"}, {"type": "file", "name": "setup.py"}, {"type": "directory", "name": "src", "children": [{"type": "directory", "name": "simulate", "children": [{"type": "directory", "name": "assets", "children": [{"type": "file", "name": "action_mapping.py"}, {"type": "file", "name": "actors.py"}, {"type": "file", "name": "actuator.py"}, {"type": "directory", "name": "anytree", "children": [{"type": "file", "name": "abstractiter.py"}, {"type": "file", "name": "exceptions.py"}, {"type": "file", "name": "nodemixin.py"}, {"type": "file", "name": "preorderiter.py"}, {"type": "file", "name": "render.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "articulation_body.py"}, {"type": "file", "name": "asset.py"}, {"type": "file", "name": "camera.py"}, {"type": "file", "name": "collider.py"}, {"type": "directory", "name": "gltflib", "children": [{"type": "directory", "name": "enums", "children": [{"type": "file", "name": "accessor_type.py"}, {"type": "file", "name": "alpha_mode.py"}, {"type": "file", "name": "animation_target_path.py"}, {"type": "file", "name": "buffer_target.py"}, {"type": "file", "name": "camera_type.py"}, {"type": "file", "name": "component_type.py"}, {"type": "file", "name": "interpolation.py"}, {"type": "file", "name": "primitive_mode.py"}, {"type": "file", "name": "rigidbody_constraints.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "gltf.py"}, {"type": "file", "name": "gltf_resource.py"}, {"type": "directory", "name": "models", "children": [{"type": "file", "name": "accessor.py"}, {"type": "file", "name": "animation.py"}, {"type": "file", "name": "animation_sampler.py"}, {"type": "file", "name": "asset.py"}, {"type": "file", "name": "attributes.py"}, {"type": "file", "name": "base_model.py"}, {"type": "file", "name": "buffer.py"}, {"type": "file", "name": "buffer_view.py"}, {"type": "file", "name": "camera.py"}, {"type": "file", "name": "channel.py"}, {"type": "directory", "name": "extensions", "children": [{"type": "file", "name": "khr_lights_ponctual.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "gltf_model.py"}, {"type": "file", "name": "image.py"}, {"type": "file", "name": "material.py"}, {"type": "file", "name": "mesh.py"}, {"type": "file", "name": "named_base_model.py"}, {"type": "file", "name": "node.py"}, {"type": "file", "name": "normal_texture_info.py"}, {"type": "file", "name": "occlusion_texture_info.py"}, {"type": "file", "name": "orthographic_camera_info.py"}, {"type": "file", "name": "pbr_metallic_roughness.py"}, {"type": "file", "name": "perspective_camera_info.py"}, {"type": "file", "name": "primitive.py"}, {"type": "file", "name": "sampler.py"}, {"type": "file", "name": "scene.py"}, {"type": "file", "name": "skin.py"}, {"type": "file", "name": "sparse.py"}, {"type": "file", "name": "sparse_indices.py"}, {"type": "file", "name": "sparse_values.py"}, {"type": "file", "name": "target.py"}, {"type": "file", "name": "texture.py"}, {"type": "file", "name": "texture_info.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "utils", "children": [{"type": "file", "name": "data_utils.py"}, {"type": "file", "name": "file_utils.py"}, {"type": "file", "name": "json_utils.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "__init__.py"}, {"type": "file", "name": "__version__.py"}]}, {"type": "file", "name": "gltf_export.py"}, {"type": "file", "name": "gltf_extension.py"}, {"type": "file", "name": "gltf_import.py"}, {"type": "file", "name": "light.py"}, {"type": "file", "name": "material.py"}, {"type": "file", "name": "object.py"}, {"type": "file", "name": "physic_material.py"}, {"type": "directory", "name": "procgen", "children": [{"type": "file", "name": "constants.py"}, {"type": "directory", "name": "prims", "children": [{"type": "file", "name": "build_map.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "wfc", "children": [{"type": "file", "name": "build_map.py"}, {"type": "file", "name": "wfc_utils.py"}, {"type": "file", "name": "wfc_wrapping.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "reward_functions.py"}, {"type": "file", "name": "rigid_body.py"}, {"type": "file", "name": "sensors.py"}, {"type": "directory", "name": "spaces", "children": [{"type": "file", "name": "box.py"}, {"type": "file", "name": "dict.py"}, {"type": "file", "name": "discrete.py"}, {"type": "file", "name": "multi_binary.py"}, {"type": "file", "name": "multi_discrete.py"}, {"type": "file", "name": "seeding.py"}, {"type": "file", "name": "space.py"}, {"type": "file", "name": "tuple.py"}, {"type": "file", "name": "utils.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "utils.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "config.py"}, {"type": "directory", "name": "engine", "children": [{"type": "file", "name": "blender_engine.py"}, {"type": "file", "name": "engine.py"}, {"type": "file", "name": "godot_engine.py"}, {"type": "file", "name": "notebook_engine.py"}, {"type": "file", "name": "pyvista_engine.py"}, {"type": "file", "name": "unity_engine.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "rl", "children": [{"type": "file", "name": "multi_proc_rl_env.py"}, {"type": "file", "name": "parallel_rl_env.py"}, {"type": "file", "name": "rl_env.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "scene.py"}, {"type": "directory", "name": "utils", "children": [{"type": "file", "name": "imports.py"}, {"type": "file", "name": "logging.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "__init__.py"}]}]}, {"type": "directory", "name": "tests", "children": [{"type": "file", "name": "conftest.py"}, {"type": "directory", "name": "test_assets", "children": [{"type": "directory", "name": "fixtures", "children": []}, {"type": "file", "name": "test_actor.py"}, {"type": "file", "name": "test_asset.py"}, {"type": "file", "name": "test_camera.py"}, {"type": "file", "name": "test_collider.py"}, {"type": "file", "name": "test_controller.py"}, {"type": "file", "name": "test_gltf.py"}, {"type": "file", "name": "test_light.py"}, {"type": "file", "name": "test_material.py"}, {"type": "file", "name": "test_object.py"}, {"type": "file", "name": "test_reward.py"}, {"type": "file", "name": "test_rigidbody_component.py"}, {"type": "file", "name": "test_sensor.py"}, {"type": "file", "name": "test_utils.py"}, {"type": "file", "name": "test_wfc_wrapping.py"}]}, {"type": "directory", "name": "test_engine", "children": [{"type": "file", "name": "test_pyvista.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "test_gltflib", "children": [{"type": "directory", "name": "e2e", "children": [{"type": "file", "name": "test_roundtrip.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "samples", "children": [{"type": "directory", "name": "custom", "children": [{"type": "directory", "name": "BadEncoding", "children": [{"type": "directory", "name": "glb", "children": []}, {"type": "directory", "name": "gltf", "children": []}]}, {"type": "directory", "name": "Corrupt", "children": []}, {"type": "directory", "name": "EmptyChunk", "children": []}, {"type": "directory", "name": "External", "children": []}, {"type": "directory", "name": "Minimal", "children": []}, {"type": "directory", "name": "MultipleChunks", "children": []}]}]}, {"type": "directory", "name": "unit", "children": [{"type": "file", "name": "test_gltf.py"}, {"type": "file", "name": "test_gltf_model.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "util.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "test_rl", "children": [{"type": "directory", "name": "test_wrappers", "children": [{"type": "file", "name": "create_env.py"}, {"type": "file", "name": "test_parallel_simenv.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "test_scene.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "third-party", "children": [{"type": "file", "name": "CMakeLists.txt"}, {"type": "directory", "name": "fastwfc", "children": [{"type": "directory", "name": "cmake", "children": [{"type": "file", "name": "fastwfcTargets.cmake.in"}]}, {"type": "file", "name": "CMakeLists.txt"}, {"type": "file", "name": "fastwfc_py.cpp"}, {"type": "directory", "name": "include", "children": [{"type": "directory", "name": "fastwfc", "children": [{"type": "file", "name": "direction.hpp"}, {"type": "file", "name": "overlapping_wfc.hpp"}, {"type": "file", "name": "propagator.hpp"}, {"type": "file", "name": "run_wfc.hpp"}, {"type": "file", "name": "tiling_wfc.hpp"}, {"type": "directory", "name": "utils", "children": [{"type": "file", "name": "array2D.hpp"}, {"type": "file", "name": "array3D.hpp"}]}, {"type": "file", "name": "wave.hpp"}, {"type": "file", "name": "wfc.hpp"}]}]}, {"type": "file", "name": "Makefile"}, {"type": "directory", "name": "src", "children": [{"type": "file", "name": "propagator.cpp"}, {"type": "file", "name": "run_wfc.cpp"}, {"type": "file", "name": "wave.cpp"}, {"type": "file", "name": "wfc.cpp"}]}]}, {"type": "directory", "name": "vhacd", "children": [{"type": "directory", "name": "cmake", "children": [{"type": "file", "name": "vhacdConfig.cmake.in"}, {"type": "file", "name": "vhacdTargets.cmake.in"}]}, {"type": "file", "name": "CMakeLists.txt"}, {"type": "directory", "name": "include", "children": [{"type": "directory", "name": "vhacd", "children": [{"type": "file", "name": "VHACD.h"}]}]}, {"type": "file", "name": "Makefile"}, {"type": "file", "name": "vhacd_py.cpp"}]}]}]} | # Tests examples taken from the original great gltflib
Find the great gltflib by Lukas Shawford here: https://github.com/lukas-shawford/gltflib
| {"setup.py": "# Lint as: python3\n\"\"\" HuggingFace/simulate is an open library of simulation and synthetic environments.\n\nNote:\n\n VERSION needs to be formatted following the MAJOR.MINOR.PATCH convention\n (we need to follow this convention to be able to retrieve versioned scripts)\n\nSimple check list for release from AllenNLP repo: https://github.com/allenai/allennlp/blob/main/setup.py\n\nTo create the package for pypi.\n\n0. Prerequisites:\n - Dependencies:\n - twine: \"pip install twine\"\n - Create an account in (and join the 'simulate' project):\n - PyPI: https://pypi.org/\n - Test PyPI: https://test.pypi.org/\n\n1. Change the version in:\n - __init__.py\n - setup.py\n\n2. Commit these changes: \"git commit -m 'Release: VERSION'\"\n\n3. Add a tag in git to mark the release: \"git tag VERSION -m 'Add tag VERSION for pypi'\"\n Push the tag to remote: git push --tags origin main\n\n4. Build both the sources and the wheel. Do not change anything in setup.py between\n creating the wheel and the source distribution (obviously).\n\n First, delete any \"build\" directory that may exist from previous builds.\n\n For the wheel, run: \"python setup.py bdist_wheel\" in the top level directory.\n (this will build a wheel for the python version you use to build it).\n\n For the sources, run: \"python setup.py sdist\"\n You should now have a /dist directory with both .whl and .tar.gz source versions.\n\n5. Check that everything looks correct by uploading the package to the pypi test server:\n\n twine upload dist/* -r pypitest --repository-url=https://test.pypi.org/legacy/\n\n Check that you can install it in a virtualenv/notebook by running:\n pip install -i https://testpypi.python.org/pypi simulate\n\n6. Upload the final version to actual pypi:\n twine upload dist/* -r pypi\n\n7. Fill release notes in the tag in GitHub once everything is looking hunky-dory.\n\n8. Change the version in __init__.py and setup.py to X.X.X+1.dev0 (e.g. VERSION=1.18.3 -> 1.18.4.dev0).\n Then push the change with a message 'set dev version'\n\"\"\"\nfrom skbuild import setup\n\nimport numpy as np\nfrom glob import glob\n\n# Available at setup time due to pyproject.toml\n# from pybind11.setup_helpers import Pybind11Extension, build_ext\n\nfrom setuptools import find_packages\nimport sys\n\n__version__ = \"0.1.3.dev0\" # expected format is one of x.y.z.dev0, or x.y.z.rc1 or x.y.z (no to dashes, yes to dots)\n\nREQUIRED_PKGS = [\n \"dataclasses_json\", # For GLTF export/imports\n \"numpy>=1.18\", # We use numpy>=1.17 to have np.random.Generator\n \"vtk>=9.0\", # Pyvista doesn't always install vtk, so we do it here\n \"pyvista>=0.35\", # For mesh creation and edition and simple vizualization\n \"huggingface_hub>=0.10\", # For sharing objects, environments & trained RL policies\n 'pybind11>=2.10.0', # For compiling extensions pybind11\n 'scikit-build>=0.5', # For compiling extensions\n]\n\nRL_REQUIRE = [\n \"gym==0.21.0\", # For RL action spaces and API\n]\nSB3_REQUIRE = [\n \"gym==0.21.0\", # For RL action spaces and API\n \"stable-baselines3\"\n]\n\nDEV_REQUIRE = [\n \"gym==0.21.0\", # For RL action spaces and API\n \"stable-baselines3\", # For training with SB3\n\n # For background vizualization capabilities (could be optional - note than some Qt backend can have GPL license)\n \"pyvistaqt\",\n \"pyqt5\", # You can also use PySide2, PyQt6 or PySide6 (see https://github.com/spyder-ide/qtpy#requirements)\n]\n\nTESTS_REQUIRE = [\n \"pytest\",\n \"pytest-xdist\",\n\n \"gym\", # For RL action spaces and API\n \"stable-baselines3\", # For training with SB3\n]\n\nDOCS_REQUIRE = [\n \"s3fs\"\n]\n\nQUALITY_REQUIRE = [\"black[jupyter]~=22.0\", \"flake8>=3.8.3\", \"isort>=5.0.0\", \"pyyaml>=5.3.1\"]\n\nEXTRAS_REQUIRE = {\n \"rl\": RL_REQUIRE,\n \"sb3\": SB3_REQUIRE,\n \"dev\": DEV_REQUIRE + TESTS_REQUIRE + QUALITY_REQUIRE,\n \"test\": TESTS_REQUIRE,\n \"quality\": QUALITY_REQUIRE,\n \"docs\": DOCS_REQUIRE,\n}\n\nif sys.platform == 'darwin':\n extra_compile_args = [\"-std=c++11\"]\n extra_link_args = [\"-std=c++11\"]\n\nelse:\n extra_compile_args = []\n extra_link_args = []\n\n\nsetup(\n name=\"simulate\",\n version=__version__,\n description=\"HuggingFace community-driven open-source library of simulation environments\",\n long_description=open(\"README.md\", encoding=\"utf-8\").read(),\n long_description_content_type=\"text/markdown\",\n author=\"HuggingFace Inc.\",\n author_email=\"[email protected]\",\n url=\"https://github.com/huggingface/simulate\",\n download_url=\"https://github.com/huggingface/simulate/tags\",\n license=\"Apache 2.0\",\n package_dir={\"\": \"src\"},\n packages=find_packages(\"src\"),\n include_package_data=True,\n package_data={'simulate': ['src/simulate/engine/*.zip']},\n install_requires=REQUIRED_PKGS,\n extras_require=EXTRAS_REQUIRE,\n classifiers=[\n \"Development Status :: 5 - Production/Stable\",\n \"Intended Audience :: Developers\",\n \"Intended Audience :: Education\",\n \"Intended Audience :: Science/Research\",\n \"License :: OSI Approved :: Apache Software License\",\n \"Operating System :: OS Independent\",\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.8\",\n \"Programming Language :: Python :: 3.9\",\n \"Programming Language :: Python :: 3.10\",\n \"Topic :: Scientific/Engineering :: Artificial Intelligence\",\n ],\n keywords=\"simulation environments synthetic data datasets machine learning\",\n zip_safe=False, # Required for mypy to find the py.typed file\n python_requires=\">=3.8\",\n include_dirs=[np.get_include()],\n cmake_install_dir='src/simulate',\n)\n\n# When building extension modules `cmake_install_dir` should always be set to the\n# location of the package you are building extension modules for.\n# Specifying the installation directory in the CMakeLists subtley breaks the relative\n# paths in the helloTargets.cmake file to all of the library components.\n", ".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 1a7832e46bd4702490e223612a528b586fb36eb1 Hamza Amin <[email protected]> 1727369459 +0500\tclone: from https://github.com/huggingface/simulate.git\n", ".git\\refs\\heads\\main": "1a7832e46bd4702490e223612a528b586fb36eb1\n", "docs\\source\\index.mdx": "<!--Copyright 2022 The HuggingFace Team. All rights reserved.\n\nLicensed under the Apache License, Version 2.0 (the \"License\"); you may not use this file except in compliance with\nthe License. You may obtain a copy of the License at\n\nhttp://www.apache.org/licenses/LICENSE-2.0\n\nUnless required by applicable law or agreed to in writing, software distributed under the License is distributed on\nan \"AS IS\" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the\nspecific language governing permissions and limitations under the License.\n-->\n<p align=\"center\">\n <br>\n <img class=\"!m-0 !border-0 !dark:border-0 !shadow-none !max-w-lg w-[800]\" src=\"https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/simulate/simulate_library.png\"/>\n <br>\n</p>\n\n# \ud83e\udd17 Simulate\n\n\ud83e\udd17 Simulate is a library for easily creating and sharing simulation environments for intelligent agents (e.g. reinforcement learning) or snythetic data generation.\n\n<div class=\"mt-10\">\n <div class=\"w-full flex flex-col space-y-4 md:space-y-0 md:grid md:grid-cols-2 md:gap-y-4 md:gap-x-5\">\n <a class=\"!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg\" href=\"./tutorials/creating_a_scene\"\n ><div class=\"w-full text-center bg-gradient-to-br from-blue-400 to-blue-500 rounded-lg py-1.5 font-semibold mb-5 text-white text-lg leading-relaxed\">Tutorials</div>\n <p class=\"text-gray-700\">Start here if you're a beginner. This section will help you gain the basic skills you need to start using the library.</p>\n </a>\n <a class=\"!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg\" href=\"./howto/rl\"\n ><div class=\"w-full text-center bg-gradient-to-br from-indigo-400 to-indigo-500 rounded-lg py-1.5 font-semibold mb-5 text-white text-lg leading-relaxed\">How-to guides</div>\n <p class=\"text-gray-700\">Practical guides to help you achieve specific goals, such as training a reinforcement learning agent, or building custom plugins.</p>\n </a>\n <a class=\"!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg\" href=\"./conceptual/philosophy\"\n ><div class=\"w-full text-center bg-gradient-to-br from-pink-400 to-pink-500 rounded-lg py-1.5 font-semibold mb-5 text-white text-lg leading-relaxed\">Conceptual guides</div>\n <p class=\"text-gray-700\">More discussion and explanation of the underlying concepts and ideas behind \ud83e\udd17 Simulate.</p>\n </a>\n <a class=\"!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg\" href=\"./api/scenes\"\n ><div class=\"w-full text-center bg-gradient-to-br from-purple-400 to-purple-500 rounded-lg py-1.5 font-semibold mb-5 text-white text-lg leading-relaxed\">API</div>\n <p class=\"text-gray-700\">Technical descriptions of how \ud83e\udd17 Simulate classes and methods work.</p>\n </a>\n </div>\n</div>", "integrations\\Unity\\simulate-unity\\Assets\\Simulate\\Runtime\\RLActors\\MapPool.cs": "using System.Collections;\nusing System.Collections.Generic;\nusing UnityEngine;\n\nnamespace Simulate.RlAgents {\n public class MapPool : IEnumerable<Map> {\n Queue<Map> pool;\n\n public MapPool() {\n pool = new Queue<Map>();\n }\n\n public void Push(Map map) {\n Debug.Assert(!pool.Contains(map));\n map.SetActive(false);\n pool.Enqueue(map);\n }\n\n public Map Request() {\n if (pool.Count == 0) {\n Debug.LogWarning(\"Pool empty\");\n return null;\n }\n Map map = pool.Dequeue();\n map.SetActive(true);\n return map;\n }\n\n public void Clear() {\n pool.Clear();\n }\n\n public IEnumerator<Map> GetEnumerator() {\n return pool.GetEnumerator();\n }\n\n IEnumerator IEnumerable.GetEnumerator() {\n return GetEnumerator();\n }\n }\n}", "integrations\\Unity\\simulate-unity\\Assets\\Simulate\\Runtime\\RLActors\\MapPool.cs.meta": "fileFormatVersion: 2\nguid: 314769c7ec80df142bd21bfd9d2ca5cb\nMonoImporter:\n externalObjects: {}\n serializedVersion: 2\n defaultReferences: []\n executionOrder: 0\n icon: {instanceID: 0}\n userData: \n assetBundleName: \n assetBundleVariant: \n", "src\\simulate\\assets\\action_mapping.py": "# Copyright 2022 The HuggingFace Authors.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n# Lint as: python3\n\"\"\" Some mapping from Discrete and Box Spaces to physics actions.\"\"\"\nfrom dataclasses import dataclass\nfrom typing import List, Optional\n\n\nALLOWED_PHYSICAL_ACTION_TYPES = [\n \"add_force\",\n \"add_torque\",\n \"add_force_at_position\",\n \"change_position\",\n \"change_rotation\",\n \"do_nothing\",\n \"set_position\",\n \"set_rotation\",\n]\n\n\n@dataclass\nclass ActionMapping:\n \"\"\"\n Map a RL agent action to an actor physical action\n\n The conversion is as follows\n (where X is the RL input action and Y the physics engine action e.g. force, torque, position):\n Y = Y + (X - offset) * amplitude\n For discrete action we assume X = 1.0 so that amplitude can be used to define the discrete value to apply.\n\n \"max_velocity_threshold\" can be used to limit the max resulting velocity or angular velocity\n after the action was applied :\n - max final velocity for \"add_force\" actions (in m/s) \u2013\n only apply the action if the current velocity is below this value\n - max angular velocity for \"add_torque\" actions (in rad/s) -\n only apply the action if the current angular velocity is below this value\n Long discussion on Unity here: https://forum.unity.com/threads/terminal-velocity.34667/\n\n Args:\n action (`str`):\n The physical action to be mapped to. A string selected in:\n - \"add_force\": apply a force to the object (at the center of mass)\n The force is given in Newton if is_impulse is False and in Newton*second if is_impulse is True.\n If is_impulse is False:\n - the value can be considered as applied during the duration of the time step\n (controlled by the frame rate)\n - changing the frame rate will change the force applied at each step but will lead to the same\n result over a given total duration.\n If is_impulse is True:\n - the force can be considered as a velocity change applied instantaneously at the step\n - changing the frame rate will not change the force applied at each step but will lead to the\n different result over a given total duration.\n (see https://docs.unity3d.com/ScriptReference/Rigidbody.AddForce.html)\n (see https://docs.unity3d.com/ScriptReference/Rigidbody.AddRelativeForce.html)\n - \"add_torque\": add a torque to the object\n (see https://docs.unity3d.com/ScriptReference/Rigidbody.AddTorque.html)\n (see https://docs.unity3d.com/ScriptReference/Rigidbody.AddRelativeTorque.html)\n - \"add_force_at_position\": add a force to the object at a position in the object's local coordinate system\n (see https://docs.unity3d.com/ScriptReference/Rigidbody.AddForceAtPosition.html)\n - \"change_position\": teleport the object along an axis\n (see https://docs.unity3d.com/ScriptReference/Rigidbody.MovePosition.html)\n - \"change_rotation\": teleport the object around an axis\n (see https://docs.unity3d.com/ScriptReference/Rigidbody.MoveRotation.html)\n - \"do_nothing\": step the environment with no external input.\n - \"set_position\": teleport the object's position to 'position'\n (see https://docs.unity3d.com/ScriptReference/Rigidbody.MovePosition.html)\n - \"set_rotation\": teleport the object's rotation to 'rotation'\n (see https://docs.unity3d.com/ScriptReference/Rigidbody.MoveRotation.html)\n amplitude (`float`, *optional*, defaults to `1.0`):\n The amplitude of the action to be applied (see below for details)\n offset (`float`, *optional*, defaults to `0.0`):\n The offset of the action to be applied (see below for details)\n axis (`List[float]`):\n The axis of the action to be applied along or around.\n TODO -- shape for forces\n TODO -- shape for torques\n position (`List[float]`):\n The position of the action.\n In the case of the \"add_force_at_position\" action, this is the position of the force.\n In the case of the set_position, this is the position to set the object to.\n use_local_coordinates (`bool`, *optional*, defaults to `True`):\n Whether to use the local/relative coordinates of the object.\n is_impulse (`bool`, *optional*, defaults to `False`):\n Whether to apply the action as an impulse or a force.\n max_velocity_threshold (`float`, *optional*, defaults to `None`):\n When we apply a force/torque, only apply if the velocity is below this value.\n \"\"\"\n\n action: str\n amplitude: float = 1.0\n offset: float = 0.0\n axis: Optional[List[float]] = None\n position: Optional[List[float]] = None\n use_local_coordinates: bool = True\n is_impulse: bool = False\n max_velocity_threshold: Optional[float] = None\n\n def __post_init__(self):\n if self.action not in ALLOWED_PHYSICAL_ACTION_TYPES:\n raise ValueError(f\"{self.action} is not a valid physical action type\")\n", "src\\simulate\\assets\\procgen\\wfc\\wfc_wrapping.py": "\"\"\"Python wrapper for constructors of C++ classes.\"\"\"\n\nfrom typing import Any, List, Optional, Tuple\n\nimport numpy as np\n\nfrom ....utils import is_fastwfc_available\n\n\nif is_fastwfc_available():\n from simulate._fastwfc import IdPair, Neighbor, PyTile, run_wfc\n\n\ndef build_wfc_neighbor(left: str, right: str, left_or: int = 0, right_or: int = 0) -> Any:\n \"\"\"\n Builds neighbors.\n \"\"\"\n return Neighbor(left=left, left_or=left_or, right=right, right_or=right_or)\n\n\ndef build_tile(tile: List, name: str, symmetry: str = \"L\", weight: int = 1, size: int = 0):\n if size == 0:\n size = np.sqrt(len(tile))\n\n for i in range(len(tile)):\n tile[i] = IdPair(uid=tile[i], rotation=0, reflected=0)\n\n return PyTile(size=size, tile=tile, name=name, symmetry=symmetry, weight=weight)\n\n\ndef build_wfc_tile(tile: List[int], name: str, symmetry: str = \"L\", weight: int = 1, size: int = 0) -> np.ndarray:\n \"\"\"\n Builds tiles.\n \"\"\"\n return build_tile(\n size=size, tile=tile, name=bytes(name, \"UTF_8\"), symmetry=bytes(symmetry, \"UTF_8\"), weight=weight\n )\n\n\ndef transform_to_id_pair(uid, rotation=0, reflected=0):\n return IdPair(uid, rotation, reflected)\n\n\ndef preprocess_tiles(\n tiles: np.ndarray, symmetries: Optional[np.ndarray] = None, weights: Optional[np.ndarray] = None\n) -> Tuple[list, dict, dict, tuple]:\n n_tiles, tile_w, tile_h = tiles.shape\n tile_shape = tile_w, tile_h\n\n if symmetries is None:\n symmetries = [\"L\"] * n_tiles\n\n if weights is None:\n weights = [1] * n_tiles\n\n tiles = [tuple(map(tuple, tile)) for tile in tiles]\n\n idx_to_tile = {i: tiles[i] for i in range(n_tiles)}\n tile_to_idx = {tiles[i]: i for i in range(n_tiles)}\n\n converted_tiles = [\n build_wfc_tile(\n size=1,\n tile=[i],\n name=str(i),\n symmetry=symmetries[i],\n weight=weights[i],\n )\n for i in range(n_tiles)\n ]\n\n return converted_tiles, idx_to_tile, tile_to_idx, tile_shape\n\n\ndef preprocess_neighbors(neighbors: np.ndarray, tile_to_idx: dict) -> list:\n \"\"\"\n Preprocesses tiles.\n \"\"\"\n preprocessed_neighbors = []\n\n for neighbor in neighbors:\n preprocessed_neighbor = (\n str(tile_to_idx[tuple(map(tuple, neighbor[0]))]),\n str(tile_to_idx[tuple(map(tuple, neighbor[1]))]),\n *neighbor[2:],\n )\n\n preprocessed_neighbors.append(build_wfc_neighbor(*preprocessed_neighbor))\n\n return preprocessed_neighbors\n\n\ndef preprocess_tiles_and_neighbors(\n tiles: np.ndarray,\n neighbors: np.ndarray,\n symmetries: Optional[np.ndarray] = None,\n weights: Optional[np.ndarray] = None,\n) -> Tuple[list, list, dict, tuple]:\n \"\"\"\n Preprocesses tiles.\n \"\"\"\n converted_tiles, idx_to_tile, tile_to_idx, tile_shape = preprocess_tiles(tiles, symmetries, weights)\n converted_neighbors = preprocess_neighbors(neighbors, tile_to_idx)\n\n return converted_tiles, converted_neighbors, idx_to_tile, tile_shape\n\n\ndef preprocess_input_img(input_img: np.ndarray) -> Tuple[list, dict, tuple]:\n \"\"\"\n Preprocesses input image by extracting the tiles.\n \"\"\"\n w, h, tile_w, tile_h = input_img.shape\n tile_shape = tile_w, tile_h\n input_img = np.reshape(input_img, (-1, tile_w, tile_h))\n tuple_input_img = [tuple(map(tuple, tile)) for tile in input_img]\n\n tile_to_idx = {}\n idx_to_tile = {}\n\n counter = 0\n for i in range(w * h):\n if tuple_input_img[i] not in tile_to_idx:\n tile_to_idx[tuple_input_img[i]] = counter\n idx_to_tile[counter] = input_img[i]\n counter += 1\n\n converted_input_img = [transform_to_id_pair(tile_to_idx[tile]) for tile in tuple_input_img]\n\n return converted_input_img, idx_to_tile, tile_shape\n\n\ndef get_tiles_back(\n gen_map: np.ndarray, tile_conversion: dict, nb_samples: int, width: int, height: int, tile_shape: tuple\n) -> np.ndarray:\n \"\"\"\n Returns tiles back.\n \"\"\"\n gen_map = np.reshape(gen_map, (nb_samples * width * height, 3))\n converted_map = []\n\n for i in range(nb_samples * width * height):\n # Rotate and reflect single tiles / patterns\n converted_tile = np.rot90(tile_conversion[gen_map[i][0]], gen_map[i][1])\n if gen_map[i][2] == 1:\n converted_tile = np.fliplr(converted_tile)\n converted_map.append(converted_tile)\n\n return np.reshape(np.array(converted_map), (nb_samples, width, height, *tile_shape))\n\n\ndef apply_wfc(\n width: int,\n height: int,\n input_img: Optional[np.ndarray] = None,\n tiles: Optional[np.ndarray] = None,\n neighbors: Optional[np.ndarray] = None,\n periodic_output: bool = True,\n N: int = 3,\n periodic_input: bool = False,\n ground: bool = False,\n nb_samples: int = 1,\n symmetry: int = 8,\n seed: int = 0,\n verbose: bool = False,\n nb_tries: int = 100,\n symmetries: Optional[np.ndarray] = None,\n weights: Optional[np.ndarray] = None,\n) -> Optional[np.ndarray]:\n if (tiles is not None and neighbors is not None) or input_img is not None:\n if input_img is not None:\n input_width, input_height = input_img.shape[:2]\n input_img, tile_conversion, tile_shape = preprocess_input_img(input_img)\n sample_type = 1\n\n else:\n input_width, input_height = 0, 0\n tiles, neighbors, tile_conversion, tile_shape = preprocess_tiles_and_neighbors(\n tiles, neighbors, symmetries, weights\n )\n sample_type = 0\n\n if tiles is None:\n tiles = []\n if neighbors is None:\n neighbors = []\n if input_img is None:\n input_img = []\n\n gen_map = run_wfc(\n seed=seed,\n width=width,\n height=height,\n sample_type=sample_type,\n input_img=input_img,\n input_width=input_width,\n input_height=input_height,\n periodic_output=periodic_output,\n N=N,\n periodic_input=periodic_input,\n ground=ground,\n nb_samples=nb_samples,\n symmetry=symmetry,\n verbose=verbose,\n nb_tries=nb_tries,\n tiles=tiles,\n neighbors=neighbors,\n )\n\n gen_map = get_tiles_back(gen_map, tile_conversion, nb_samples, width, height, tile_shape)\n return gen_map\n\n else:\n raise ValueError(\"Either input_img or tiles and neighbors must be provided.\")\n", "tests\\test_assets\\test_wfc_wrapping.py": "\"\"\"Tests of WFC wrapping functions.\"\"\"\n\nimport unittest\n\nimport numpy as np\n\nfrom simulate.assets.procgen.wfc.wfc_wrapping import (\n apply_wfc,\n preprocess_input_img,\n preprocess_tiles,\n preprocess_tiles_and_neighbors,\n)\n\n\nclass TestTilesNeighbors(unittest.TestCase):\n def __init__(self, *args, **kwargs):\n super().__init__(*args, **kwargs)\n\n self.tiles = np.array([[[0, 1], [1, 0]], [[2, 0], [0, 1]], [[0, 3], [0, 0]], [[0, 0], [0, 0]]])\n self.neighbors = [\n (self.tiles[0], self.tiles[1], 0, 1),\n (self.tiles[0], self.tiles[2], 1, 0),\n (self.tiles[0], self.tiles[3]),\n (self.tiles[1], self.tiles[2], 2, 2),\n (self.tiles[1], self.tiles[3]),\n (self.tiles[2], self.tiles[3]),\n ]\n\n def test_create_tiles(self):\n tuple_tiles = [tuple(map(tuple, tile)) for tile in self.tiles]\n\n preprocessed_tiles, idx_to_tile, tile_to_idx, tile_shape = preprocess_tiles(self.tiles)\n self.assertTrue(np.all([idx_to_tile[i] == self.tiles[i] for i in range(len(self.tiles))]))\n self.assertTrue(np.all([tile_to_idx[tuple_tiles[i]] == i for i in range(len(self.tiles))]))\n self.assertTrue(tile_shape == (2, 2))\n\n def test_create_tiles_neighbors(self):\n tiles, neighbors, idx_to_tile, tile_shape = preprocess_tiles_and_neighbors(self.tiles, self.neighbors)\n left_values = [\"0\", \"0\", \"0\", \"1\", \"1\", \"2\"]\n right_values = [\"1\", \"2\", \"3\", \"2\", \"3\", \"3\"]\n left_or_values = [0, 1, 0, 2, 0, 0]\n right_or_values = [1, 0, 0, 2, 0, 0]\n\n self.assertTrue(np.all([neighbors[i].left == left_values[i] for i in range(len(self.neighbors))]))\n self.assertTrue(np.all([neighbors[i].right == right_values[i] for i in range(len(self.neighbors))]))\n self.assertTrue(np.all([neighbors[i].left_or == left_or_values[i] for i in range(len(self.neighbors))]))\n self.assertTrue(np.all([neighbors[i].right_or == right_or_values[i] for i in range(len(self.neighbors))]))\n self.assertTrue(tile_shape == (2, 2))\n\n def test_apply_wfc_tiles(self):\n tiles = np.array([[[0, 0], [0, 0]], [[2, 0], [0, 1]]])\n neighbors = [\n (tiles[0], tiles[0]),\n (tiles[1], tiles[1]),\n (tiles[0], tiles[1]),\n ]\n\n width, height = 3, 3\n seed = np.random.randint(2**32)\n nb_samples = 1\n tile_shape = (2, 2)\n\n output = apply_wfc(\n width=width,\n height=height,\n periodic_output=False,\n seed=seed,\n verbose=False,\n tiles=tiles,\n neighbors=neighbors,\n nb_samples=nb_samples,\n )\n\n self.assertTrue(output.shape == (nb_samples, width, height, *tile_shape))\n\n\nclass TestSampleMap(unittest.TestCase):\n def __init__(self, *args, **kwargs):\n super().__init__(*args, **kwargs)\n self.y = np.array(\n [\n [[[0, 0], [0, 0]], [[0, 0], [0, 0]], [[0, 0], [0, 0]], [[0, 0], [0, 0]]],\n [[[0, 0], [0, 0]], [[0, 2], [0, 0]], [[1, 0], [0, 0]], [[1, 0], [0, 0]]],\n [[[0, 0], [0, 0]], [[0, 0], [0, 0]], [[2, 0], [0, 0]], [[2, 0], [0, 0]]],\n ]\n )\n\n def test_sample_map(self):\n tuple_y = [tuple(map(tuple, tile)) for tile in np.reshape(self.y, (-1, 2, 2))]\n single_tiles = [tuple_y[0], tuple_y[5], tuple_y[6], tuple_y[10]]\n\n n_idxs = 4\n\n converted_input_img, idx_to_tile, tile_shape = preprocess_input_img(self.y)\n\n self.assertTrue(np.all([idx_to_tile[i] == single_tiles[i] for i in range(n_idxs)]))\n self.assertTrue(tile_shape == (2, 2))\n\n def test_apply_wfc_sample_map(self):\n width, height = 3, 3\n seed = np.random.randint(2**32)\n nb_samples = 1\n tile_shape = (2, 2)\n\n output = apply_wfc(\n width=width,\n height=height,\n periodic_output=False,\n seed=seed,\n input_img=self.y,\n verbose=False,\n nb_samples=nb_samples,\n )\n\n self.assertTrue(output.shape == (nb_samples, width, height, *tile_shape))\n\n\nif __name__ == \"__main__\":\n unittest.main()\n", "third-party\\fastwfc\\include\\fastwfc\\overlapping_wfc.hpp": "#ifndef FAST_WFC_OVERLAPPING_WFC_HPP_\n#define FAST_WFC_OVERLAPPING_WFC_HPP_\n\n#include <vector>\n#include <algorithm>\n#include <unordered_map>\n\n#include \"utils/array2D.hpp\"\n#include \"wfc.hpp\"\n\n/**\n * Options needed to use the overlapping wfc.\n */\nstruct OverlappingWFCOptions {\n bool periodic_input; // True if the input is toric.\n bool periodic_output; // True if the output is toric.\n unsigned out_height; // The height of the output in pixels.\n unsigned out_width; // The width of the output in pixels.\n unsigned symmetry; // The number of symmetries (the order is defined in wfc).\n bool ground; // True if the ground needs to be set (see init_ground).\n unsigned pattern_size; // The width and height in pixel of the patterns.\n\n /**\n * Get the wave height given these options.\n */\n unsigned get_wave_height() const noexcept {\n return periodic_output ? out_height : out_height - pattern_size + 1;\n }\n\n /**\n * Get the wave width given these options.\n */\n unsigned get_wave_width() const noexcept {\n return periodic_output ? out_width : out_width - pattern_size + 1;\n }\n};\n\n/**\n * Class generating a new image with the overlapping WFC algorithm.\n */\ntemplate <typename T> class OverlappingWFC {\n\nprivate:\n /**\n * The input image. T is usually a color.\n */\n Array2D<T> input;\n\n /**\n * Options needed by the algorithm.\n */\n OverlappingWFCOptions options;\n\n /**\n * The array of the different patterns extracted from the input.\n */\n std::vector<Array2D<T>> patterns;\n\n /**\n * The underlying generic WFC algorithm.\n */\n WFC wfc;\n\n /**\n * Constructor initializing the wfc.\n * This constructor is called by the other constructors.\n * This is necessary in order to initialize wfc only once.\n */\n OverlappingWFC(\n const Array2D<T> &input, const OverlappingWFCOptions &options,\n const int &seed,\n const std::pair<std::vector<Array2D<T>>, std::vector<double>> &patterns,\n const std::vector<std::array<std::vector<unsigned>, 4>>\n &propagator) noexcept\n : input(input), options(options), patterns(patterns.first),\n wfc(options.periodic_output, seed, patterns.second, propagator,\n options.get_wave_height(), options.get_wave_width()) {\n // If necessary, the ground is set.\n if (options.ground) {\n init_ground(wfc, input, patterns.first, options);\n }\n }\n\n /**\n * Constructor used only to call the other constructor with more computed\n * parameters.\n */\n OverlappingWFC(const Array2D<T> &input, const OverlappingWFCOptions &options,\n const int &seed,\n const std::pair<std::vector<Array2D<T>>, std::vector<double>>\n &patterns) noexcept\n : OverlappingWFC(input, options, seed, patterns,\n generate_compatible(patterns.first)) {}\n\n /**\n * Init the ground of the output image.\n * The lowest middle pattern is used as a floor (and ceiling when the input is\n * toric) and is placed at the lowest possible pattern position in the output\n * image, on all its width. The pattern cannot be used at any other place in\n * the output image.\n */\n void init_ground(WFC &wfc, const Array2D<T> &input,\n const std::vector<Array2D<T>> &patterns,\n const OverlappingWFCOptions &options) noexcept {\n unsigned ground_pattern_id =\n get_ground_pattern_id(input, patterns, options);\n\n // Place the pattern in the ground.\n for (unsigned j = 0; j < options.get_wave_width(); j++) {\n set_pattern(ground_pattern_id, options.get_wave_height() - 1, j);\n }\n\n // Remove the pattern from the other positions.\n for (unsigned i = 0; i < options.get_wave_height() - 1; i++) {\n for (unsigned j = 0; j < options.get_wave_width(); j++) {\n wfc.remove_wave_pattern(i, j, ground_pattern_id);\n }\n }\n\n // Propagate the information with wfc.\n wfc.propagate();\n }\n\n /**\n * Return the id of the lowest middle pattern.\n */\n static unsigned\n get_ground_pattern_id(const Array2D<T> &input,\n const std::vector<Array2D<T>> &patterns,\n const OverlappingWFCOptions &options) noexcept {\n // Get the pattern.\n Array2D<T> ground_pattern =\n input.get_sub_array(input.height - 1, input.width / 2,\n options.pattern_size, options.pattern_size);\n\n // Retrieve the id of the pattern.\n for (unsigned i = 0; i < patterns.size(); i++) {\n if (ground_pattern == patterns[i]) {\n return i;\n }\n }\n\n // The pattern exists.\n assert(false);\n return 0;\n }\n\n /**\n * Return the list of patterns, as well as their probabilities of apparition.\n */\n static std::pair<std::vector<Array2D<T>>, std::vector<double>>\n get_patterns(const Array2D<T> &input,\n const OverlappingWFCOptions &options) noexcept {\n std::unordered_map<Array2D<T>, unsigned> patterns_id;\n std::vector<Array2D<T>> patterns;\n\n // The number of time a pattern is seen in the input image.\n std::vector<double> patterns_weight;\n\n std::vector<Array2D<T>> symmetries(\n 8, Array2D<T>(options.pattern_size, options.pattern_size));\n unsigned max_i = options.periodic_input\n ? input.height\n : input.height - options.pattern_size + 1;\n unsigned max_j = options.periodic_input\n ? input.width\n : input.width - options.pattern_size + 1;\n\n for (unsigned i = 0; i < max_i; i++) {\n for (unsigned j = 0; j < max_j; j++) {\n // Compute the symmetries of every pattern in the image.\n symmetries[0].data =\n input\n .get_sub_array(i, j, options.pattern_size, options.pattern_size)\n .data;\n symmetries[1].data = symmetries[0].reflected().data;\n symmetries[2].data = symmetries[0].rotated().data;\n symmetries[3].data = symmetries[2].reflected().data;\n symmetries[4].data = symmetries[2].rotated().data;\n symmetries[5].data = symmetries[4].reflected().data;\n symmetries[6].data = symmetries[4].rotated().data;\n symmetries[7].data = symmetries[6].reflected().data;\n\n // The number of symmetries in the option class define which symetries\n // will be used.\n for (unsigned k = 0; k < options.symmetry; k++) {\n auto res = patterns_id.insert(\n std::make_pair(symmetries[k], patterns.size()));\n\n // If the pattern already exist, we just have to increase its number\n // of appearance.\n if (!res.second) {\n patterns_weight[res.first->second] += 1;\n } else {\n patterns.push_back(symmetries[k]);\n patterns_weight.push_back(1);\n }\n }\n }\n }\n\n return {patterns, patterns_weight};\n }\n\n /**\n * Return true if the pattern1 is compatible with pattern2\n * when pattern2 is at a distance (dy,dx) from pattern1.\n */\n static bool agrees(const Array2D<T> &pattern1, const Array2D<T> &pattern2,\n int dy, int dx) noexcept {\n unsigned xmin = dx < 0 ? 0 : dx;\n unsigned xmax = dx < 0 ? dx + pattern2.width : pattern1.width;\n unsigned ymin = dy < 0 ? 0 : dy;\n unsigned ymax = dy < 0 ? dy + pattern2.height : pattern1.width;\n\n // Iterate on every pixel contained in the intersection of the two pattern.\n for (unsigned y = ymin; y < ymax; y++) {\n for (unsigned x = xmin; x < xmax; x++) {\n // Check if the color is the same in the two patterns in that pixel.\n if (pattern1.get(y, x) != pattern2.get(y - dy, x - dx)) {\n return false;\n }\n }\n }\n return true;\n }\n\n /**\n * Precompute the function agrees(pattern1, pattern2, dy, dx).\n * If agrees(pattern1, pattern2, dy, dx), then compatible[pattern1][direction]\n * contains pattern2, where direction is the direction defined by (dy, dx)\n * (see direction.hpp).\n */\n static std::vector<std::array<std::vector<unsigned>, 4>>\n generate_compatible(const std::vector<Array2D<T>> &patterns) noexcept {\n std::vector<std::array<std::vector<unsigned>, 4>> compatible =\n std::vector<std::array<std::vector<unsigned>, 4>>(patterns.size());\n\n // Iterate on every dy, dx, pattern1 and pattern2\n for (unsigned pattern1 = 0; pattern1 < patterns.size(); pattern1++) {\n for (unsigned direction = 0; direction < 4; direction++) {\n for (unsigned pattern2 = 0; pattern2 < patterns.size(); pattern2++) {\n if (agrees(patterns[pattern1], patterns[pattern2],\n directions_y[direction], directions_x[direction])) {\n compatible[pattern1][direction].push_back(pattern2);\n }\n }\n }\n }\n\n return compatible;\n }\n\n /**\n * Transform a 2D array containing the patterns id to a 2D array containing\n * the pixels.\n */\n Array2D<T> to_image(const Array2D<unsigned> &output_patterns) const noexcept {\n Array2D<T> output = Array2D<T>(options.out_height, options.out_width);\n\n if (options.periodic_output) {\n for (unsigned y = 0; y < options.get_wave_height(); y++) {\n for (unsigned x = 0; x < options.get_wave_width(); x++) {\n output.get(y, x) = patterns[output_patterns.get(y, x)].get(0, 0);\n }\n }\n } else {\n for (unsigned y = 0; y < options.get_wave_height(); y++) {\n for (unsigned x = 0; x < options.get_wave_width(); x++) {\n output.get(y, x) = patterns[output_patterns.get(y, x)].get(0, 0);\n }\n }\n for (unsigned y = 0; y < options.get_wave_height(); y++) {\n const Array2D<T> &pattern =\n patterns[output_patterns.get(y, options.get_wave_width() - 1)];\n for (unsigned dx = 1; dx < options.pattern_size; dx++) {\n output.get(y, options.get_wave_width() - 1 + dx) = pattern.get(0, dx);\n }\n }\n for (unsigned x = 0; x < options.get_wave_width(); x++) {\n const Array2D<T> &pattern =\n patterns[output_patterns.get(options.get_wave_height() - 1, x)];\n for (unsigned dy = 1; dy < options.pattern_size; dy++) {\n output.get(options.get_wave_height() - 1 + dy, x) =\n pattern.get(dy, 0);\n }\n }\n const Array2D<T> &pattern = patterns[output_patterns.get(\n options.get_wave_height() - 1, options.get_wave_width() - 1)];\n for (unsigned dy = 1; dy < options.pattern_size; dy++) {\n for (unsigned dx = 1; dx < options.pattern_size; dx++) {\n output.get(options.get_wave_height() - 1 + dy,\n options.get_wave_width() - 1 + dx) = pattern.get(dy, dx);\n }\n }\n }\n\n return output;\n }\n\n std::optional<unsigned> get_pattern_id(const Array2D<T> &pattern) {\n unsigned* pattern_id = std::find(patterns.begin(), patterns.end(), pattern);\n\n if (pattern_id != patterns.end()) {\n return *pattern_id;\n }\n\n return std::nullopt;\n }\n\n /**\n * Set the pattern at a specific position, given its pattern id\n * pattern_id needs to be a valid pattern id, and i and j needs to be in the wave range\n */\n void set_pattern(unsigned pattern_id, unsigned i, unsigned j) noexcept {\n for (unsigned p = 0; p < patterns.size(); p++) {\n if (pattern_id != p) {\n wfc.remove_wave_pattern(i, j, p);\n }\n }\n }\n\npublic:\n /**\n * The constructor used by the user.\n */\n OverlappingWFC(const Array2D<T> &input, const OverlappingWFCOptions &options,\n int seed) noexcept\n : OverlappingWFC(input, options, seed, get_patterns(input, options)) {}\n\n /**\n * Set the pattern at a specific position.\n * Returns false if the given pattern does not exist, or if the\n * coordinates are not in the wave\n */\n bool set_pattern(const Array2D<T>& pattern, unsigned i, unsigned j) noexcept {\n auto pattern_id = get_pattern_id(pattern);\n\n if (pattern_id == std::nullopt || i >= options.get_wave_height() || j >= options.get_wave_width()) {\n return false;\n }\n\n set_pattern(pattern_id, i, j);\n return true;\n }\n\n /**\n * Run the WFC algorithm, and return the result if the algorithm succeeded.\n */\n std::optional<Array2D<T>> run() noexcept {\n std::optional<Array2D<unsigned>> result = wfc.run();\n if (result.has_value()) {\n return to_image(*result);\n }\n return std::nullopt;\n }\n};\n\n#endif // FAST_WFC_WFC_HPP_\n"} | null |
snapchat-lens-api | {"type": "directory", "name": "snapchat-lens-api", "children": [{"type": "file", "name": "package.json"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "snapchat-lens-api.d.ts"}]} | ## Snapchat Lens API
Snapchat Lenses include a scripting library for creating rich interactive experiences. With scripts, Lenses can respond to touch input, play animation and audio, modify Scene Objects, etc.
Snapchat provides a Javascript interpreter and exposes a number of variables and classes, which are documented in the [official API documentation](https://lensstudio.snapchat.com/api/).
> This type definition builds upon the official API, which it re-packages in a format that's easy to consume by production-grade applications.
### Install using npm
```
npm i snapchat-lens-api
```
If you're using Typescript in your build process, add the following to your `tsconfig.json`:
```
"types": [ "./node_modules/snapchat-lens-api" ]
```
### Feedback
Any feedback? Please open an issue.
<p style="text-align: center" align="center">
<img src="https://raw.githubusercontent.com/huggingface/snapchat-lens-api/master/logo.png">
</p>
| {"package.json": "{\n \"name\": \"snapchat-lens-api\",\n \"version\": \"1.2.0\",\n \"description\": \"Type definitions for Snapchat Lenses scripting\",\n \"types\": \"./snapchat-lens-api.d.ts\",\n \"dependencies\": {},\n \"devDependencies\": {},\n \"scripts\": {\n \"test\": \"echo \\\"Error: no test specified\\\" && exit 1\"\n },\n \"repository\": {\n \"type\": \"git\",\n \"url\": \"git+https://github.com/huggingface/snapchat-lens-api.git\"\n },\n \"keywords\": [\n \"snapchat\",\n \"lenses\",\n \"snap\",\n \"lens\",\n \"studio\"\n ],\n \"author\": \"Julien Chaumond\",\n \"license\": \"ISC\",\n \"bugs\": {\n \"url\": \"https://github.com/huggingface/snapchat-lens-api/issues\"\n },\n \"homepage\": \"https://github.com/huggingface/snapchat-lens-api#readme\"\n}\n", ".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n"} | null |
Snowball-Target | {"type": "directory", "name": "Snowball-Target", "children": [{"type": "file", "name": "README.md"}]} | # Snowball Target ⛄
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit7/snowballtarget.gif" alt="Snowball Target"/>
SnowballTarget is an environment we created at Hugging Face using assets from [Kay Lousberg](https://www.kaylousberg.com/) **where you train an agent called Julien the bear 🐻 that learns to hit targets with snowballs**.
You can learn **to train this agent using Deep Reinforcement Learning** 👉 [with this tutorial](https://huggingface.co/learn/deep-rl-course/unit5/introduction).
| {".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 1bc2647d32c4f83dbfacf53af57cb5e44896386a Hamza Amin <[email protected]> 1727369465 +0500\tclone: from https://github.com/huggingface/Snowball-Target.git\n", ".git\\refs\\heads\\main": "1bc2647d32c4f83dbfacf53af57cb5e44896386a\n"} | null |
speech-to-speech | {"type": "directory", "name": "speech-to-speech", "children": [{"type": "file", "name": ".dockerignore"}, {"type": "directory", "name": "arguments_classes", "children": [{"type": "file", "name": "chat_tts_arguments.py"}, {"type": "file", "name": "language_model_arguments.py"}, {"type": "file", "name": "melo_tts_arguments.py"}, {"type": "file", "name": "mlx_language_model_arguments.py"}, {"type": "file", "name": "module_arguments.py"}, {"type": "file", "name": "open_api_language_model_arguments.py"}, {"type": "file", "name": "paraformer_stt_arguments.py"}, {"type": "file", "name": "parler_tts_arguments.py"}, {"type": "file", "name": "socket_receiver_arguments.py"}, {"type": "file", "name": "socket_sender_arguments.py"}, {"type": "file", "name": "vad_arguments.py"}, {"type": "file", "name": "whisper_stt_arguments.py"}]}, {"type": "file", "name": "baseHandler.py"}, {"type": "directory", "name": "connections", "children": [{"type": "file", "name": "local_audio_streamer.py"}, {"type": "file", "name": "socket_receiver.py"}, {"type": "file", "name": "socket_sender.py"}]}, {"type": "file", "name": "docker-compose.yml"}, {"type": "file", "name": "Dockerfile"}, {"type": "file", "name": "Dockerfile.arm64"}, {"type": "file", "name": "LICENSE"}, {"type": "file", "name": "listen_and_play.py"}, {"type": "directory", "name": "LLM", "children": [{"type": "file", "name": "chat.py"}, {"type": "file", "name": "language_model.py"}, {"type": "file", "name": "mlx_language_model.py"}, {"type": "file", "name": "openai_api_language_model.py"}]}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "requirements_mac.txt"}, {"type": "file", "name": "s2s_pipeline.py"}, {"type": "directory", "name": "STT", "children": [{"type": "file", "name": "lightning_whisper_mlx_handler.py"}, {"type": "file", "name": "paraformer_handler.py"}, {"type": "file", "name": "whisper_stt_handler.py"}]}, {"type": "directory", "name": "TTS", "children": [{"type": "file", "name": "chatTTS_handler.py"}, {"type": "file", "name": "melo_handler.py"}, {"type": "file", "name": "parler_handler.py"}]}, {"type": "directory", "name": "utils", "children": [{"type": "file", "name": "thread_manager.py"}, {"type": "file", "name": "utils.py"}]}, {"type": "directory", "name": "VAD", "children": [{"type": "file", "name": "vad_handler.py"}, {"type": "file", "name": "vad_iterator.py"}]}]} | <div align="center">
<div> </div>
<img src="logo.png" width="600"/>
</div>
# Speech To Speech: an effort for an open-sourced and modular GPT4-o
## 📖 Quick Index
* [Approach](#approach)
- [Structure](#structure)
- [Modularity](#modularity)
* [Setup](#setup)
* [Usage](#usage)
- [Docker Server approach](#docker-server)
- [Server/Client approach](#serverclient-approach)
- [Local approach](#local-approach-running-on-mac)
* [Command-line usage](#command-line-usage)
- [Model parameters](#model-parameters)
- [Generation parameters](#generation-parameters)
- [Notable parameters](#notable-parameters)
## Approach
### Structure
This repository implements a speech-to-speech cascaded pipeline consisting of the following parts:
1. **Voice Activity Detection (VAD)**
2. **Speech to Text (STT)**
3. **Language Model (LM)**
4. **Text to Speech (TTS)**
### Modularity
The pipeline provides a fully open and modular approach, with a focus on leveraging models available through the Transformers library on the Hugging Face hub. The code is designed for easy modification, and we already support device-specific and external library implementations:
**VAD**
- [Silero VAD v5](https://github.com/snakers4/silero-vad)
**STT**
- Any [Whisper](https://huggingface.co/docs/transformers/en/model_doc/whisper) model checkpoint on the Hugging Face Hub through Transformers 🤗, including [whisper-large-v3](https://huggingface.co/openai/whisper-large-v3) and [distil-large-v3](https://huggingface.co/distil-whisper/distil-large-v3)
- [Lightning Whisper MLX](https://github.com/mustafaaljadery/lightning-whisper-mlx?tab=readme-ov-file#lightning-whisper-mlx)
- [Paraformer - FunASR](https://github.com/modelscope/FunASR)
**LLM**
- Any instruction-following model on the [Hugging Face Hub](https://huggingface.co/models?pipeline_tag=text-generation&sort=trending) via Transformers 🤗
- [mlx-lm](https://github.com/ml-explore/mlx-examples/blob/main/llms/README.md)
- [OpenAI API](https://platform.openai.com/docs/quickstart)
**TTS**
- [Parler-TTS](https://github.com/huggingface/parler-tts) 🤗
- [MeloTTS](https://github.com/myshell-ai/MeloTTS)
- [ChatTTS](https://github.com/2noise/ChatTTS?tab=readme-ov-file)
## Setup
Clone the repository:
```bash
git clone https://github.com/huggingface/speech-to-speech.git
cd speech-to-speech
```
Install the required dependencies using [uv](https://github.com/astral-sh/uv):
```bash
uv pip install -r requirements.txt
```
For Mac users, use the `requirements_mac.txt` file instead:
```bash
uv pip install -r requirements_mac.txt
```
If you want to use Melo TTS, you also need to run:
```bash
python -m unidic download
```
## Usage
The pipeline can be run in two ways:
- **Server/Client approach**: Models run on a server, and audio input/output are streamed from a client.
- **Local approach**: Runs locally.
### Recommanded setup
### Server/Client Approach
1. Run the pipeline on the server:
```bash
python s2s_pipeline.py --recv_host 0.0.0.0 --send_host 0.0.0.0
```
2. Run the client locally to handle microphone input and receive generated audio:
```bash
python listen_and_play.py --host <IP address of your server>
```
### Local Approach (Mac)
1. For optimal settings on Mac:
```bash
python s2s_pipeline.py --local_mac_optimal_settings
```
This setting:
- Adds `--device mps` to use MPS for all models.
- Sets LightningWhisperMLX for STT
- Sets MLX LM for language model
- Sets MeloTTS for TTS
### Docker Server
#### Install the NVIDIA Container Toolkit
https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/latest/install-guide.html
#### Start the docker container
```docker compose up```
### Recommended usage with Cuda
Leverage Torch Compile for Whisper and Parler-TTS. **The usage of Parler-TTS allows for audio output streaming, futher reducing the overeall latency** 🚀:
```bash
python s2s_pipeline.py \
--lm_model_name microsoft/Phi-3-mini-4k-instruct \
--stt_compile_mode reduce-overhead \
--tts_compile_mode default \
--recv_host 0.0.0.0 \
--send_host 0.0.0.0
```
For the moment, modes capturing CUDA Graphs are not compatible with streaming Parler-TTS (`reduce-overhead`, `max-autotune`).
### Multi-language Support
The pipeline currently supports English, French, Spanish, Chinese, Japanese, and Korean.
Two use cases are considered:
- **Single-language conversation**: Enforce the language setting using the `--language` flag, specifying the target language code (default is 'en').
- **Language switching**: Set `--language` to 'auto'. In this case, Whisper detects the language for each spoken prompt, and the LLM is prompted with "`Please reply to my message in ...`" to ensure the response is in the detected language.
Please note that you must use STT and LLM checkpoints compatible with the target language(s). For the STT part, Parler-TTS is not yet multilingual (though that feature is coming soon! 🤗). In the meantime, you should use Melo (which supports English, French, Spanish, Chinese, Japanese, and Korean) or Chat-TTS.
#### With the server version:
For automatic language detection:
```bash
python s2s_pipeline.py \
--stt_model_name large-v3 \
--language auto \
--mlx_lm_model_name mlx-community/Meta-Llama-3.1-8B-Instruct \
```
Or for one language in particular, chinese in this example
```bash
python s2s_pipeline.py \
--stt_model_name large-v3 \
--language zh \
--mlx_lm_model_name mlx-community/Meta-Llama-3.1-8B-Instruct \
```
#### Local Mac Setup
For automatic language detection:
```bash
python s2s_pipeline.py \
--local_mac_optimal_settings \
--device mps \
--stt_model_name large-v3 \
--language auto \
--mlx_lm_model_name mlx-community/Meta-Llama-3.1-8B-Instruct-4bit \
```
Or for one language in particular, chinese in this example
```bash
python s2s_pipeline.py \
--local_mac_optimal_settings \
--device mps \
--stt_model_name large-v3 \
--language zh \
--mlx_lm_model_name mlx-community/Meta-Llama-3.1-8B-Instruct-4bit \
```
## Command-line Usage
> **_NOTE:_** References for all the CLI arguments can be found directly in the [arguments classes](https://github.com/huggingface/speech-to-speech/tree/d5e460721e578fef286c7b64e68ad6a57a25cf1b/arguments_classes) or by running `python s2s_pipeline.py -h`.
### Module level Parameters
See [ModuleArguments](https://github.com/huggingface/speech-to-speech/blob/d5e460721e578fef286c7b64e68ad6a57a25cf1b/arguments_classes/module_arguments.py) class. Allows to set:
- a common `--device` (if one wants each part to run on the same device)
- `--mode` `local` or `server`
- chosen STT implementation
- chosen LM implementation
- chose TTS implementation
- logging level
### VAD parameters
See [VADHandlerArguments](https://github.com/huggingface/speech-to-speech/blob/d5e460721e578fef286c7b64e68ad6a57a25cf1b/arguments_classes/vad_arguments.py) class. Notably:
- `--thresh`: Threshold value to trigger voice activity detection.
- `--min_speech_ms`: Minimum duration of detected voice activity to be considered speech.
- `--min_silence_ms`: Minimum length of silence intervals for segmenting speech, balancing sentence cutting and latency reduction.
### STT, LM and TTS parameters
`model_name`, `torch_dtype`, and `device` are exposed for each implementation of the Speech to Text, Language Model, and Text to Speech. Specify the targeted pipeline part with the corresponding prefix (e.g. `stt`, `lm` or `tts`, check the implementations' [arguments classes](https://github.com/huggingface/speech-to-speech/tree/d5e460721e578fef286c7b64e68ad6a57a25cf1b/arguments_classes) for more details).
For example:
```bash
--lm_model_name google/gemma-2b-it
```
### Generation parameters
Other generation parameters of the model's generate method can be set using the part's prefix + `_gen_`, e.g., `--stt_gen_max_new_tokens 128`. These parameters can be added to the pipeline part's arguments class if not already exposed.
## Citations
### Silero VAD
```bibtex
@misc{Silero VAD,
author = {Silero Team},
title = {Silero VAD: pre-trained enterprise-grade Voice Activity Detector (VAD), Number Detector and Language Classifier},
year = {2021},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/snakers4/silero-vad}},
commit = {insert_some_commit_here},
email = {[email protected]}
}
```
### Distil-Whisper
```bibtex
@misc{gandhi2023distilwhisper,
title={Distil-Whisper: Robust Knowledge Distillation via Large-Scale Pseudo Labelling},
author={Sanchit Gandhi and Patrick von Platen and Alexander M. Rush},
year={2023},
eprint={2311.00430},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
### Parler-TTS
```bibtex
@misc{lacombe-etal-2024-parler-tts,
author = {Yoach Lacombe and Vaibhav Srivastav and Sanchit Gandhi},
title = {Parler-TTS},
year = {2024},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/huggingface/parler-tts}}
}
```
| {"docker-compose.yml": "---\nservices:\n\n pipeline:\n build:\n context: .\n dockerfile: ${DOCKERFILE:-Dockerfile}\n command: \n - python3 \n - s2s_pipeline.py \n - --recv_host \n - 0.0.0.0 \n - --send_host \n - 0.0.0.0 \n - --lm_model_name \n - microsoft/Phi-3-mini-4k-instruct \n - --init_chat_role \n - system\n - --init_chat_prompt\n - \"You are a helpful assistant\"\n - --stt_compile_mode \n - reduce-overhead \n - --tts_compile_mode \n - default\n expose:\n - 12345/tcp\n - 12346/tcp\n ports:\n - 12345:12345/tcp\n - 12346:12346/tcp\n volumes:\n - ./cache/:/root/.cache/\n - ./s2s_pipeline.py:/usr/src/app/s2s_pipeline.py\n deploy:\n resources:\n reservations:\n devices:\n - driver: nvidia\n device_ids: ['0']\n capabilities: [gpu]\n", "Dockerfile": "FROM pytorch/pytorch:2.4.0-cuda12.1-cudnn9-devel\n\nENV PYTHONUNBUFFERED 1\n\nWORKDIR /usr/src/app\n\n# Install packages\nRUN apt-get update && apt-get install -y git && rm -rf /var/lib/apt/lists/*\n\nCOPY requirements.txt ./\nRUN pip install --no-cache-dir -r requirements.txt\n\nCOPY . .\n", "Dockerfile.arm64": "FROM nvcr.io/nvidia/l4t-pytorch:r35.2.1-pth2.0-py3\n\nENV PYTHONUNBUFFERED 1\n\nWORKDIR /usr/src/app\n\n# Install packages\nRUN apt-get update && apt-get install -y git && rm -rf /var/lib/apt/lists/*\n\nCOPY requirements.txt ./\nRUN pip install --no-cache-dir -r requirements.txt\n\nCOPY . .", "requirements.txt": "nltk==3.9.1\nparler_tts @ git+https://github.com/huggingface/parler-tts.git\nmelotts @ git+https://github.com/andimarafioti/MeloTTS.git#egg=MeloTTS # made a copy of MeloTTS to have compatible versions of transformers\ntorch==2.4.0\nsounddevice==0.5.0\nChatTTS>=0.1.1\nfunasr>=1.1.6\nmodelscope>=1.17.1\ndeepfilternet>=0.5.6\nopenai>=1.40.1", ".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 725184a8141f332b210a0598543ced3db6ca3900 Hamza Amin <[email protected]> 1727369468 +0500\tclone: from https://github.com/huggingface/speech-to-speech.git\n", ".git\\refs\\heads\\main": "725184a8141f332b210a0598543ced3db6ca3900\n"} | null |
speechbox | {"type": "directory", "name": "speechbox", "children": [{"type": "file", "name": "CODE_OF_CONDUCT.md"}, {"type": "file", "name": "CONTRIBUTING.md"}, {"type": "directory", "name": "examples", "children": [{"type": "file", "name": "restore.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "LICENSE"}, {"type": "file", "name": "Makefile"}, {"type": "file", "name": "pyproject.toml"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "setup.py"}, {"type": "directory", "name": "src", "children": [{"type": "directory", "name": "speechbox", "children": [{"type": "file", "name": "dependency_versions_table.py"}, {"type": "file", "name": "diarize.py"}, {"type": "file", "name": "restore.py"}, {"type": "directory", "name": "utils", "children": [{"type": "file", "name": "dummy_transformers_and_accelerate_and_scipy_objects.py"}, {"type": "file", "name": "dummy_transformers_and_torchaudio_and_pyannote_objects.py"}, {"type": "file", "name": "dummy_transformers_objects.py"}, {"type": "file", "name": "import_utils.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "__init__.py"}]}]}, {"type": "directory", "name": "utils", "children": [{"type": "file", "name": "check_dummies.py"}]}]} | <p align="center">
<a href="https://github.com/huggingface/speechbox/releases">
<img alt="GitHub release" src="https://img.shields.io/github/release/huggingface/speechbox.svg">
</a>
<a href="CODE_OF_CONDUCT.md">
<img alt="Contributor Covenant" src="https://img.shields.io/badge/Contributor%20Covenant-2.0-4baaaa.svg">
</a>
</p>
🚨🚨 **Important:** This package is not actively maintained. If you are interested in maintaining this repo, please open an issue so that we can contact you 🚨🚨
🤗 Speechbox offers a set of speech processing tools, such as punctuation restoration.
# Installation
With `pip` (official package)
```bash
pip install speechbox
```
# Contributing
We ❤️ contributions from the open-source community!
If you want to contribute to this library, please check out our [Contribution guide](https://github.com/huggingface/speechbox/blob/main/CONTRIBUTING.md).
You can look out for [issues](https://github.com/huggingface/speechbox/issues) you'd like to tackle to contribute to the library.
- See [Good first issues](https://github.com/huggingface/speechbox/issues?q=is%3Aopen+is%3Aissue+label%3A%22good+first+issue%22) for general opportunities to contribute
- See [New Task](https://github.com/huggingface/speechbox/labels/New%20Task) for more advanced contributions. Make sure to have read the [Philosophy guide](https://github.com/huggingface/speechbox/blob/main/CONTRIBUTING.md#philosophy) to succesfully add a new task.
Also, say 👋 in our public Discord channel <a href="https://discord.gg/G7tWnz98XR"><img alt="Join us on Discord" src="https://img.shields.io/discord/823813159592001537?color=5865F2&logo=discord&logoColor=white"></a> under **ML for Audio and Speech**. We discuss the new trends about machine learning methods for speech, help each other with contributions, personal projects or
just hang out ☕.
# Tasks
| Task | Description | Author |
|-|-|-|
| [Punctuation Restoration](#punctuation-restoration) | Punctuation restoration allows one to predict capitalized words as well as punctuation by using [Whisper](https://huggingface.co/models?other=whisper). | [Patrick von Platen](https://github.com/patrickvonplaten) |
| [ASR With Speaker Diarization](#asr-with-speaker-diarization) | Transcribe long audio files, such as meeting recordings, with speaker information (who spoke when) and the transcribed text. | [Sanchit Gandhi](https://github.com/sanchit-gandhi) |
## Punctuation Restoration
Punctuation restoration relies on the premise that [Whisper](https://huggingface.co/models?other=whisper) can understand universal speech. The model is forced to predict the passed words,
but is allowed to capitalized letters, remove or add blank spaces as well as add punctuation.
Punctuation is simply defined as the offial Python [string.Punctuation](https://docs.python.org/3/library/string.html#string.punctuation) characters.
**Note**: For now this package has only been tested with:
- [openai/whisper-tiny.en](https://huggingface.co/openai/whisper-tiny.en)
- [openai/whisper-base.en](https://huggingface.co/openai/whisper-base.en)
- [openai/whisper-small.en](https://huggingface.co/openai/whisper-small.en)
- [openai/whisper-medium.en](https://huggingface.co/openai/whisper-medium.en)
and **only** on some 80 audio samples of [patrickvonplaten/librispeech_asr_dummy](https://huggingface.co/datasets/patrickvonplaten/librispeech_asr_dummy).
See some transcribed results [here](https://huggingface.co/datasets?other=speechbox_punc).
### Web Demo
If you want to try out the punctuation restoration, you can try out the following 🚀 Spaces:
[](https://huggingface.co/spaces/speechbox/whisper-restore-punctuation)
### Example
In order to use the punctuation restoration task, you need to install [Transformers](https://github.com/huggingface/transformers):
```
pip install --upgrade transformers
```
For this example, we will additionally make use of [datasets](https://github.com/huggingface/datasets) to load a sample audio file:
```
pip install --upgrade datasets
```
Now we stream a single audio sample, load the punctuation restoring class with ["openai/whisper-tiny.en"](https://huggingface.co/openai/whisper-tiny.en) and add punctuation to the transcription.
```python
from speechbox import PunctuationRestorer
from datasets import load_dataset
streamed_dataset = load_dataset("librispeech_asr", "clean", split="validation", streaming=True)
# get first sample
sample = next(iter(streamed_dataset))
# print out normalized transcript
print(sample["text"])
# => "HE WAS IN A FEVERED STATE OF MIND OWING TO THE BLIGHT HIS WIFE'S ACTION THREATENED TO CAST UPON HIS ENTIRE FUTURE"
# load the restoring class
restorer = PunctuationRestorer.from_pretrained("openai/whisper-tiny.en")
restorer.to("cuda")
restored_text, log_probs = restorer(sample["audio"]["array"], sample["text"], sampling_rate=sample["audio"]["sampling_rate"], num_beams=1)
print("Restored text:\n", restored_text)
```
See [examples/restore](https://github.com/huggingface/speechbox/blob/main/examples/restore.py) for more information.
## ASR With Speaker Diarization
Given an unlabelled audio segment, a speaker diarization model is used to predict "who spoke when". These speaker
predictions are paired with the output of a speech recognition system (e.g. Whisper) to give speaker-labelled
transcriptions.
The combined ASR + Diarization pipeline can be applied directly to long audio samples, such as meeting recordings, to
give fully annotated meeting transcriptions.
### Web Demo
If you want to try out the ASR + Diarization pipeline, you can try out the following Space:
[](https://huggingface.co/spaces/speechbox/whisper-speaker-diarization)
### Example
In order to use the ASR + Diarization pipeline, you need to install 🤗 [Transformers](https://github.com/huggingface/transformers)
and [pyannote.audio](https://github.com/pyannote/pyannote-audio):
```
pip install --upgrade transformers pyannote.audio
```
For this example, we will additionally make use of 🤗 [Datasets](https://github.com/huggingface/datasets) to load a sample audio file:
```
pip install --upgrade datasets
```
Now we stream a single audio sample, pass it to the ASR + Diarization pipeline, and return the speaker-segmented transcription:
```python
import torch
from speechbox import ASRDiarizationPipeline
from datasets import load_dataset
device = "cuda:0" if torch.cuda.is_available() else "cpu"
pipeline = ASRDiarizationPipeline.from_pretrained("openai/whisper-tiny", device=device)
# load dataset of concatenated LibriSpeech samples
concatenated_librispeech = load_dataset("sanchit-gandhi/concatenated_librispeech", split="train", streaming=True)
# get first sample
sample = next(iter(concatenated_librispeech))
out = pipeline(sample["audio"])
print(out)
```
| {"setup.py": "# Copyright 2023 The HuggingFace Team. All rights reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"\nSimple check list from AllenNLP repo: https://github.com/allenai/allennlp/blob/main/setup.py\n\nTo create the package for pypi.\n\n1. Run `make pre-release` (or `make pre-patch` for a patch release) then run `make fix-copies` to fix the index of the\n documentation.\n\n If releasing on a special branch, copy the updated README.md on the main branch for your the commit you will make\n for the post-release and run `make fix-copies` on the main branch as well.\n\n2. Run Tests for Amazon Sagemaker. The documentation is located in `./tests/sagemaker/README.md`, otherwise @philschmid.\n\n3. Unpin specific versions from setup.py that use a git install.\n\n4. Checkout the release branch (v<RELEASE>-release, for example v4.19-release), and commit these changes with the\n message: \"Release: <RELEASE>\" and push.\n\n5. Wait for the tests on main to be completed and be green (otherwise revert and fix bugs)\n\n6. Add a tag in git to mark the release: \"git tag v<RELEASE> -m 'Adds tag v<RELEASE> for pypi' \"\n Push the tag to git: git push --tags origin v<RELEASE>-release\n\n7. Build both the sources and the wheel. Do not change anything in setup.py between\n creating the wheel and the source distribution (obviously).\n\n For the wheel, run: \"python setup.py bdist_wheel\" in the top level directory.\n (this will build a wheel for the python version you use to build it).\n\n For the sources, run: \"python setup.py sdist\"\n You should now have a /dist directory with both .whl and .tar.gz source versions.\n\n8. Check that everything looks correct by uploading the package to the pypi test server:\n\n twine upload dist/* -r pypitest\n (pypi suggest using twine as other methods upload files via plaintext.)\n You may have to specify the repository url, use the following command then:\n twine upload dist/* -r pypitest --repository-url=https://test.pypi.org/legacy/\n\n Check that you can install it in a virtualenv by running:\n pip install -i https://testpypi.python.org/pypi diffusers\n\n Check you can run the following commands:\n python -c \"from diffusers import pipeline; classifier = pipeline('text-classification'); print(classifier('What a nice release'))\"\n python -c \"from diffusers import *\"\n\n9. Upload the final version to actual pypi:\n twine upload dist/* -r pypi\n\n10. Copy the release notes from RELEASE.md to the tag in github once everything is looking hunky-dory.\n\n11. Run `make post-release` (or, for a patch release, `make post-patch`). If you were on a branch for the release,\n you need to go back to main before executing this.\n\"\"\"\n\nimport os\nimport re\nfrom distutils.core import Command\n\nfrom setuptools import find_packages, setup\n\n\n# IMPORTANT:\n# 1. all dependencies should be listed here with their version requirements if any\n# 2. once modified, run: `make deps_table_update` to update src/diffusers/dependency_versions_table.py\n_deps = [\n \"accelerate>=0.14.0\",\n \"torch>=1.9\",\n \"transformers>=4.24.0\",\n \"black==22.8\",\n \"isort>=5.5.4\",\n \"flake8>=3.8.3\",\n \"numpy\",\n \"filelock\",\n \"importlib_metadata\",\n \"datasets>=2.7.0\",\n \"torchaudio\",\n \"pyannote.audio\",\n]\n\n# this is a lookup table with items like:\n#\n# tokenizers: \"huggingface-hub==0.8.0\"\n# packaging: \"packaging\"\n#\n# some of the values are versioned whereas others aren't.\ndeps = {b: a for a, b in (re.findall(r\"^(([^!=<>~]+)(?:[!=<>~].*)?$)\", x)[0] for x in _deps)}\n\n# since we save this data in src/diffusers/dependency_versions_table.py it can be easily accessed from\n# anywhere. If you need to quickly access the data from this table in a shell, you can do so easily with:\n#\n# python -c 'import sys; from diffusers.dependency_versions_table import deps; \\\n# print(\" \".join([ deps[x] for x in sys.argv[1:]]))' tokenizers datasets\n#\n# Just pass the desired package names to that script as it's shown with 2 packages above.\n#\n# If diffusers is not yet installed and the work is done from the cloned repo remember to add `PYTHONPATH=src` to the script above\n#\n# You can then feed this for example to `pip`:\n#\n# pip install -U $(python -c 'import sys; from diffusers.dependency_versions_table import deps; \\\n# print(\" \".join([ deps[x] for x in sys.argv[1:]]))' tokenizers datasets)\n#\n\n\ndef deps_list(*pkgs):\n return [deps[pkg] for pkg in pkgs]\n\n\nclass DepsTableUpdateCommand(Command):\n \"\"\"\n A custom distutils command that updates the dependency table.\n usage: python setup.py deps_table_update\n \"\"\"\n\n description = \"build runtime dependency table\"\n user_options = [\n # format: (long option, short option, description).\n (\"dep-table-update\", None, \"updates src/diffusers/dependency_versions_table.py\"),\n ]\n\n def initialize_options(self):\n pass\n\n def finalize_options(self):\n pass\n\n def run(self):\n entries = \"\\n\".join([f' \"{k}\": \"{v}\",' for k, v in deps.items()])\n content = [\n \"# THIS FILE HAS BEEN AUTOGENERATED. To update:\",\n \"# 1. modify the `_deps` dict in setup.py\",\n \"# 2. run `make deps_table_update``\",\n \"deps = {\",\n entries,\n \"}\",\n \"\",\n ]\n target = \"src/speechbox/dependency_versions_table.py\"\n print(f\"updating {target}\")\n with open(target, \"w\", encoding=\"utf-8\", newline=\"\\n\") as f:\n f.write(\"\\n\".join(content))\n\n\nextras = {}\n\n\nextras = {}\nextras[\"quality\"] = deps_list(\"black\", \"isort\", \"flake8\")\n\n\nextras[\"dev\"] = extras[\"quality\"] + deps_list(\"transformers\", \"accelerate\", \"datasets\", \"torchaudio\", \"pyannote.audio\")\n\n\ninstall_requires = [\n deps[\"torch\"],\n deps[\"importlib_metadata\"],\n deps[\"filelock\"],\n deps[\"numpy\"],\n]\n\nsetup(\n name=\"speechbox\",\n version=\"0.2.1\", # expected format is one of x.y.z.dev0, or x.y.z.rc1 or x.y.z (no to dashes, yes to dots)\n description=\"Speechbox\",\n long_description=open(\"README.md\", \"r\", encoding=\"utf-8\").read(),\n long_description_content_type=\"text/markdown\",\n keywords=\"deep learning\",\n license=\"Apache\",\n author=\"The HuggingFace team\",\n author_email=\"[email protected]\",\n url=\"https://github.com/huggingface/speechbox\",\n package_dir={\"\": \"src\"},\n packages=find_packages(\"src\"),\n include_package_data=True,\n python_requires=\">=3.7.0\",\n install_requires=install_requires,\n extras_require=extras,\n classifiers=[\n \"Development Status :: 5 - Production/Stable\",\n \"Intended Audience :: Developers\",\n \"Intended Audience :: Education\",\n \"Intended Audience :: Science/Research\",\n \"License :: OSI Approved :: Apache Software License\",\n \"Operating System :: OS Independent\",\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.7\",\n \"Programming Language :: Python :: 3.8\",\n \"Programming Language :: Python :: 3.9\",\n \"Topic :: Scientific/Engineering :: Artificial Intelligence\",\n ],\n cmdclass={\"deps_table_update\": DepsTableUpdateCommand},\n)\n\n# Release checklist\n# 1. Change the version in __init__.py and setup.py.\n# 2. Commit these changes with the message: \"Release: Release\"\n# 3. Add a tag in git to mark the release: \"git tag RELEASE -m 'Adds tag RELEASE for pypi' \"\n# Push the tag to git: git push --tags origin main\n# 4. Run the following commands in the top-level directory:\n# python setup.py bdist_wheel\n# python setup.py sdist\n# 5. Upload the package to the pypi test server first:\n# twine upload dist/* -r pypitest\n# twine upload dist/* -r pypitest --repository-url=https://test.pypi.org/legacy/\n# 6. Check that you can install it in a virtualenv by running:\n# pip install -i https://testpypi.python.org/pypi diffusers\n# diffusers env\n# diffusers test\n# 7. Upload the final version to actual pypi:\n# twine upload dist/* -r pypi\n# 8. Add release notes to the tag in github once everything is looking hunky-dory.\n# 9. Update the version in __init__.py, setup.py to the new version \"-dev\" and push to master\n", ".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 e7339dc021c8aa3047f824fb5c24b5b2c8197a76 Hamza Amin <[email protected]> 1727369470 +0500\tclone: from https://github.com/huggingface/speechbox.git\n", ".git\\refs\\heads\\main": "e7339dc021c8aa3047f824fb5c24b5b2c8197a76\n"} | null |
spm_precompiled | {"type": "directory", "name": "spm_precompiled", "children": [{"type": "file", "name": "Cargo.toml"}, {"type": "file", "name": "LICENSE"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "README.tpl"}, {"type": "directory", "name": "src", "children": [{"type": "file", "name": "lib.rs"}, {"type": "file", "name": "tests.rs"}]}, {"type": "file", "name": "test.json"}]} | 
[](https://crates.io/crates/spm_precompiled)
[](https://docs.rs/spm_precompiled)
# {{crate}}
{{readme}}
| {".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n"} | null |
swift-chat | {"type": "directory", "name": "swift-chat", "children": [{"type": "file", "name": "LICENSE"}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "SwiftChat", "children": [{"type": "directory", "name": "Assets.xcassets", "children": [{"type": "directory", "name": "AccentColor.colorset", "children": [{"type": "file", "name": "Contents.json"}]}, {"type": "directory", "name": "AppIcon.appiconset", "children": [{"type": "file", "name": "Contents.json"}]}, {"type": "file", "name": "Contents.json"}]}, {"type": "file", "name": "ContentView.swift"}, {"type": "file", "name": "ControlView.swift"}, {"type": "file", "name": "ModelLoader.swift"}, {"type": "directory", "name": "Preview Content", "children": [{"type": "directory", "name": "Preview Assets.xcassets", "children": [{"type": "file", "name": "Contents.json"}]}]}, {"type": "file", "name": "StatusView.swift"}, {"type": "file", "name": "SwiftChat.entitlements"}, {"type": "file", "name": "SwiftChatApp.swift"}]}, {"type": "directory", "name": "SwiftChatTests", "children": [{"type": "file", "name": "SwiftChatTests.swift"}]}, {"type": "directory", "name": "SwiftChatUITests", "children": [{"type": "file", "name": "SwiftChatUITests.swift"}, {"type": "file", "name": "SwiftChatUITestsLaunchTests.swift"}]}]} | # Swift Chat and Language Model Tester
This is a small app that shows how to integrate [`swift-transformers`](https://github.com/huggingface/swift-transformers) in a Swift app.

## Features and Roadmap
Please, refer to the [`swift-transformers` repo](https://github.com/huggingface/swift-transformers).
## License
[Apache 2](LICENSE).
| {".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 7e9c33255f9801e8d59cf5ebbb5793a23c9d136e Hamza Amin <[email protected]> 1727369477 +0500\tclone: from https://github.com/huggingface/swift-chat.git\n", ".git\\refs\\heads\\main": "7e9c33255f9801e8d59cf5ebbb5793a23c9d136e\n", "SwiftChat\\SwiftChatApp.swift": "//\n// SwiftChatApp.swift\n// SwiftChat\n//\n// Created by Pedro Cuenca on 3/5/23.\n//\n\nimport SwiftUI\n\n@main\nstruct SwiftChatApp: App {\n @State private var clearTriggered = false\n\n var body: some Scene {\n WindowGroup {\n ContentView(clearTriggered: $clearTriggered)\n }\n .commands {\n CommandGroup(after: .pasteboard) {\n Button(action: {\n print(\"clear\")\n self.clearTriggered.toggle()\n }) {\n Text(\"Clear Output\")\n }\n .keyboardShortcut(.delete, modifiers: [.command])\n }\n }\n }\n}\n"} | null |
swift-coreml-diffusers | {"type": "directory", "name": "swift-coreml-diffusers", "children": [{"type": "directory", "name": "config", "children": [{"type": "file", "name": "common.xcconfig"}, {"type": "file", "name": "debug.xcconfig"}]}, {"type": "directory", "name": "Diffusion", "children": [{"type": "directory", "name": "Assets.xcassets", "children": [{"type": "directory", "name": "AccentColor.colorset", "children": [{"type": "file", "name": "Contents.json"}]}, {"type": "directory", "name": "AppIcon.appiconset", "children": [{"type": "file", "name": "Contents.json"}]}, {"type": "file", "name": "Contents.json"}, {"type": "directory", "name": "placeholder.imageset", "children": [{"type": "file", "name": "Contents.json"}]}]}, {"type": "directory", "name": "Common", "children": [{"type": "file", "name": "DiffusionImage.swift"}, {"type": "file", "name": "Downloader.swift"}, {"type": "file", "name": "ModelInfo.swift"}, {"type": "directory", "name": "Pipeline", "children": [{"type": "file", "name": "Pipeline.swift"}, {"type": "file", "name": "PipelineLoader.swift"}]}, {"type": "file", "name": "State.swift"}, {"type": "file", "name": "Utils.swift"}, {"type": "directory", "name": "Views", "children": [{"type": "file", "name": "PromptTextField.swift"}]}]}, {"type": "file", "name": "Diffusion.entitlements"}, {"type": "file", "name": "DiffusionApp.swift"}, {"type": "file", "name": "DiffusionImage+iOS.swift"}, {"type": "file", "name": "Info.plist"}, {"type": "directory", "name": "Preview Content", "children": [{"type": "directory", "name": "Preview Assets.xcassets", "children": [{"type": "file", "name": "Contents.json"}]}]}, {"type": "file", "name": "Utils_iOS.swift"}, {"type": "directory", "name": "Views", "children": [{"type": "file", "name": "Loading.swift"}, {"type": "file", "name": "TextToImage.swift"}]}]}, {"type": "directory", "name": "Diffusion-macOS", "children": [{"type": "file", "name": "Capabilities.swift"}, {"type": "file", "name": "ContentView.swift"}, {"type": "file", "name": "ControlsView.swift"}, {"type": "file", "name": "DiffusionImage+macOS.swift"}, {"type": "file", "name": "Diffusion_macOS.entitlements"}, {"type": "file", "name": "Diffusion_macOSApp.swift"}, {"type": "file", "name": "GeneratedImageView.swift"}, {"type": "file", "name": "HelpContent.swift"}, {"type": "file", "name": "Info.plist"}, {"type": "directory", "name": "Preview Content", "children": [{"type": "directory", "name": "Preview Assets.xcassets", "children": [{"type": "file", "name": "Contents.json"}]}]}, {"type": "file", "name": "StatusView.swift"}, {"type": "file", "name": "Utils_macOS.swift"}]}, {"type": "directory", "name": "DiffusionTests", "children": [{"type": "file", "name": "DiffusionTests.swift"}]}, {"type": "directory", "name": "DiffusionUITests", "children": [{"type": "file", "name": "DiffusionUITests.swift"}, {"type": "file", "name": "DiffusionUITestsLaunchTests.swift"}]}, {"type": "file", "name": "LICENSE"}, {"type": "file", "name": "README.md"}]} | # Swift Core ML Diffusers 🧨
This is a native app that shows how to integrate Apple's [Core ML Stable Diffusion implementation](https://github.com/apple/ml-stable-diffusion) in a native Swift UI application. The Core ML port is a simplification of the Stable Diffusion implementation from the [diffusers library](https://github.com/huggingface/diffusers). This application can be used for faster iteration, or as sample code for any use cases.
This is what the app looks like on macOS:

On first launch, the application downloads a zipped archive with a Core ML version of Stability AI's Stable Diffusion v2 base, from [this location in the Hugging Face Hub](https://huggingface.co/pcuenq/coreml-stable-diffusion-2-base/tree/main). This process takes a while, as several GB of data have to be downloaded and unarchived.
For faster inference, we use a very fast scheduler: [DPM-Solver++](https://github.com/LuChengTHU/dpm-solver), that we ported to Swift from our [diffusers DPMSolverMultistepScheduler implementation](https://github.com/huggingface/diffusers/blob/main/src/diffusers/schedulers/scheduling_dpmsolver_multistep.py).
The app supports models quantized with `coremltools` version 7 or better. This requires macOS 14 or iOS/iPadOS 17.
## Compatibility and Performance
- macOS Ventura 13.1, iOS/iPadOS 16.2, Xcode 14.2.
- Performance (after the initial generation, which is slower)
* ~8s in macOS on MacBook Pro M1 Max (64 GB). Model: Stable Diffusion v2-base, ORIGINAL attention implementation, running on CPU + GPU.
* 23 ~ 30s on iPhone 13 Pro. Model: Stable Diffusion v2-base, SPLIT_EINSUM attention, CPU + Neural Engine, memory reduction enabled.
See [this post](https://huggingface.co/blog/fast-mac-diffusers) and [this issue](https://github.com/huggingface/swift-coreml-diffusers/issues/31) for additional performance figures.
Quantized models run faster, but they require macOS Ventura 14, or iOS/iPadOS 17.
The application will try to guess the best hardware to run models on. You can override this setting using the `Advanced` section in the controls sidebar.
## How to Run
The easiest way to test the app on macOS is by [downloading it from the Mac App Store](https://apps.apple.com/app/diffusers/id1666309574).
## How to Build
You need [Xcode](https://developer.apple.com/xcode/) to build the app. When you clone the repo, please update `common.xcconfig` with your development team identifier. Code signing is required to run on iOS, but it's currently disabled for macOS.
## Known Issues
Performance on iPhone is somewhat erratic, sometimes it's ~20x slower and the phone heats up. This happens because the model could not be scheduled to run on the Neural Engine and everything happens in the CPU. We have not been able to determine the reasons for this problem. If you observe the same, here are some recommendations:
- Detach from Xcode
- Kill apps you are not using.
- Let the iPhone cool down before repeating the test.
- Reboot your device.
## Next Steps
- Allow additional models to be downloaded from the Hub.
| {".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 a561fae8b47707efa68f70e2fa1fea5ab4462ab9 Hamza Amin <[email protected]> 1727369491 +0500\tclone: from https://github.com/huggingface/swift-coreml-diffusers.git\n", ".git\\refs\\heads\\main": "a561fae8b47707efa68f70e2fa1fea5ab4462ab9\n", "Diffusion\\DiffusionApp.swift": "//\n// DiffusionApp.swift\n// Diffusion\n//\n// Created by Pedro Cuenca on December 2022.\n// See LICENSE at https://github.com/huggingface/swift-coreml-diffusers/LICENSE\n//\n\nimport SwiftUI\n\n@main\nstruct DiffusionApp: App {\n var body: some Scene {\n WindowGroup {\n LoadingView()\n }\n }\n}\n\nlet runningOnMac = ProcessInfo.processInfo.isMacCatalystApp\nlet deviceHas6GBOrMore = ProcessInfo.processInfo.physicalMemory > 5910000000 // Reported by iOS 17 beta (21A5319a) on iPhone 13 Pro: 5917753344\nlet deviceHas8GBOrMore = ProcessInfo.processInfo.physicalMemory > 7900000000 // Reported by iOS 17.0.2 on iPhone 15 Pro Max: 8021032960\n\nlet deviceSupportsQuantization = {\n if #available(iOS 17, *) {\n true\n } else {\n false\n }\n}()\n", "Diffusion-macOS\\Diffusion_macOSApp.swift": "//\n// Diffusion_macOSApp.swift\n// Diffusion-macOS\n//\n// Created by Cyril Zakka on 1/12/23.\n// See LICENSE at https://github.com/huggingface/swift-coreml-diffusers/LICENSE\n//\n\nimport SwiftUI\n\n@main\nstruct Diffusion_macOSApp: App {\n var body: some Scene {\n WindowGroup {\n ContentView()\n }\n }\n}\n"} | null |
swift-coreml-transformers | {"type": "directory", "name": "swift-coreml-transformers", "children": [{"type": "directory", "name": "CoreMLBert", "children": [{"type": "file", "name": "AppDelegate.swift"}, {"type": "directory", "name": "Assets.xcassets", "children": [{"type": "directory", "name": "AppIcon.appiconset", "children": [{"type": "file", "name": "Contents.json"}]}, {"type": "file", "name": "Contents.json"}, {"type": "directory", "name": "shuffle.imageset", "children": [{"type": "file", "name": "Contents.json"}]}]}, {"type": "directory", "name": "Base.lproj", "children": [{"type": "file", "name": "LaunchScreen.storyboard"}, {"type": "file", "name": "Main.storyboard"}]}, {"type": "file", "name": "Info.plist"}, {"type": "file", "name": "LoaderView.swift"}, {"type": "file", "name": "SceneDelegate.swift"}, {"type": "file", "name": "ViewController.swift"}]}, {"type": "directory", "name": "CoreMLBertTests", "children": [{"type": "file", "name": "BertForQATests.swift"}, {"type": "file", "name": "BertTokenizerTests.swift"}, {"type": "file", "name": "DistilbertForQATests.swift"}, {"type": "file", "name": "Info.plist"}]}, {"type": "directory", "name": "CoreMLGPT2", "children": [{"type": "file", "name": "AppDelegate.swift"}, {"type": "directory", "name": "Assets.xcassets", "children": [{"type": "directory", "name": "AppIcon.appiconset", "children": [{"type": "file", "name": "Contents.json"}]}, {"type": "file", "name": "Contents.json"}, {"type": "directory", "name": "shuffle.imageset", "children": [{"type": "file", "name": "Contents.json"}]}]}, {"type": "directory", "name": "Base.lproj", "children": [{"type": "file", "name": "LaunchScreen.storyboard"}, {"type": "file", "name": "Main.storyboard"}]}, {"type": "file", "name": "Info.plist"}, {"type": "file", "name": "SceneDelegate.swift"}, {"type": "file", "name": "ViewController.swift"}]}, {"type": "directory", "name": "CoreMLGPT2Tests", "children": [{"type": "file", "name": "CoreMLGPT2Tests.swift"}, {"type": "file", "name": "Info.plist"}, {"type": "file", "name": "MultiArrayUtilsTests.swift"}]}, {"type": "file", "name": "LICENSE"}, {"type": "directory", "name": "media", "children": []}, {"type": "directory", "name": "model_generation", "children": [{"type": "file", "name": "distilbert-onnx-coreml.py"}, {"type": "file", "name": "distilbert-performance.md"}, {"type": "file", "name": "distilbert-validate.py"}, {"type": "file", "name": "gpt2.py"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "utils.py"}]}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "Resources", "children": [{"type": "file", "name": "basic_tokenized_questions.json"}, {"type": "file", "name": "dev-v1.1.json"}, {"type": "file", "name": "encoded_tokens.json"}, {"type": "file", "name": "gpt2-merges.txt"}, {"type": "file", "name": "gpt2-vocab.json"}, {"type": "file", "name": "question_tokens.json"}, {"type": "file", "name": "tokenized_questions.json"}, {"type": "file", "name": "vocab.txt"}]}, {"type": "directory", "name": "Sources", "children": [{"type": "file", "name": "BertForQuestionAnswering.swift"}, {"type": "file", "name": "BertTokenizer.swift"}, {"type": "file", "name": "GPT2.swift"}, {"type": "file", "name": "GPT2ByteEncoder.swift"}, {"type": "file", "name": "GPT2Tokenizer.swift"}, {"type": "file", "name": "Math.swift"}, {"type": "file", "name": "MLMultiArray+Utils.swift"}, {"type": "file", "name": "SquadDataset.swift"}, {"type": "file", "name": "Utils.swift"}]}]} | # This repo is not actively maintained and has been archived. For an in-development replacement, please head over to [swift-transformers](https://github.com/huggingface/swift-transformers)!
# Swift Core ML implementations of Transformers: GPT-2, DistilGPT-2, BERT, DistilBERT, more coming soon!
This repository contains:
- For **BERT** and **DistilBERT**:
- pretrained [Google BERT](https://github.com/google-research/bert) and [Hugging Face DistilBERT](https://arxiv.org/abs/1910.01108) models fine-tuned for Question answering on the SQuAD dataset.
- Swift implementations of the [BERT tokenizer](https://github.com/huggingface/swift-coreml-transformers/blob/master/Sources/BertTokenizer.swift) (`BasicTokenizer` and `WordpieceTokenizer`) and SQuAD dataset parsing utilities.
- A neat demo question answering app.
- For **GPT-2** and **DistilGPT-2**:
- a [conversion script](https://github.com/huggingface/swift-coreml-transformers/blob/master/model_generation/gpt2.py) from PyTorch trained GPT-2 models (see our [`transformers`](https://github.com/huggingface/transformers) repo) to CoreML models.
- The [GPT-2 generation model](https://github.com/huggingface/swift-coreml-transformers/blob/master/Sources/GPT2.swift) itself, including decoding strategies (greedy and TopK are currently implemented) and GPT-2 Byte-pair encoder and decoder.
- A neat demo app showcasing on-device text generation.
# 🦄 GPT-2 and DistilGPT-2
Unleash the full power of text generation with GPT-2 on device!!
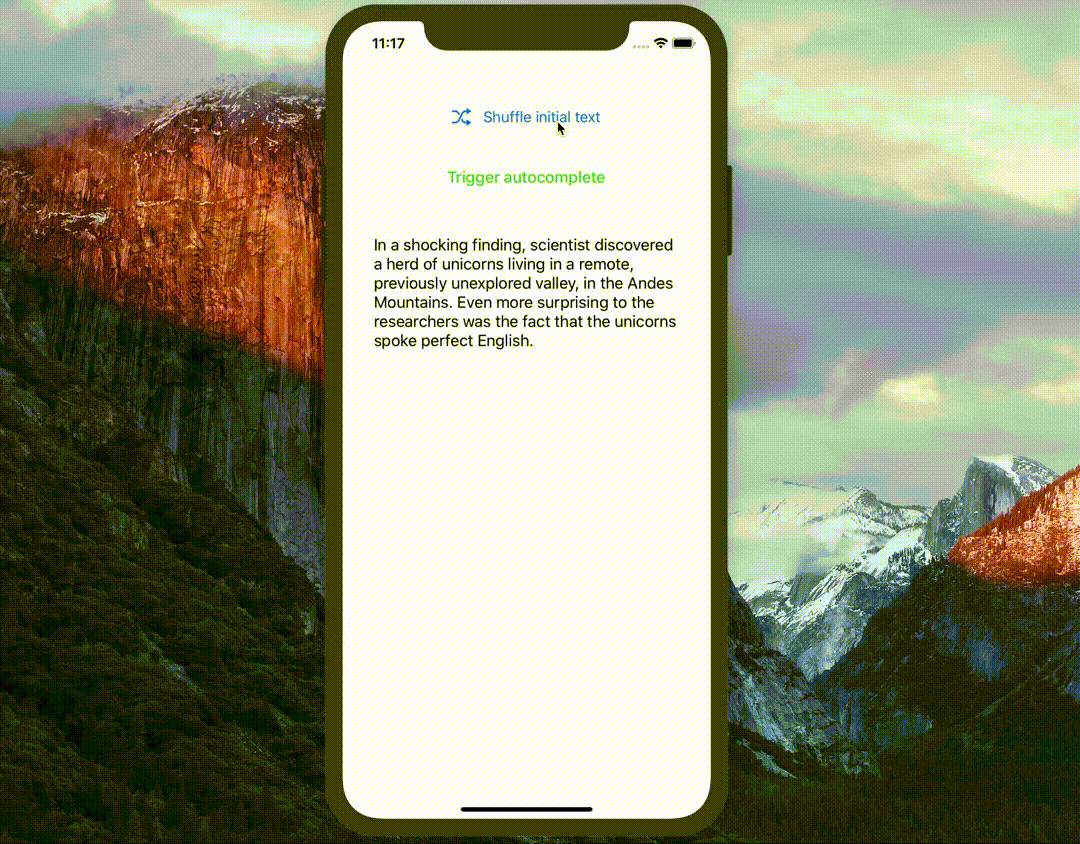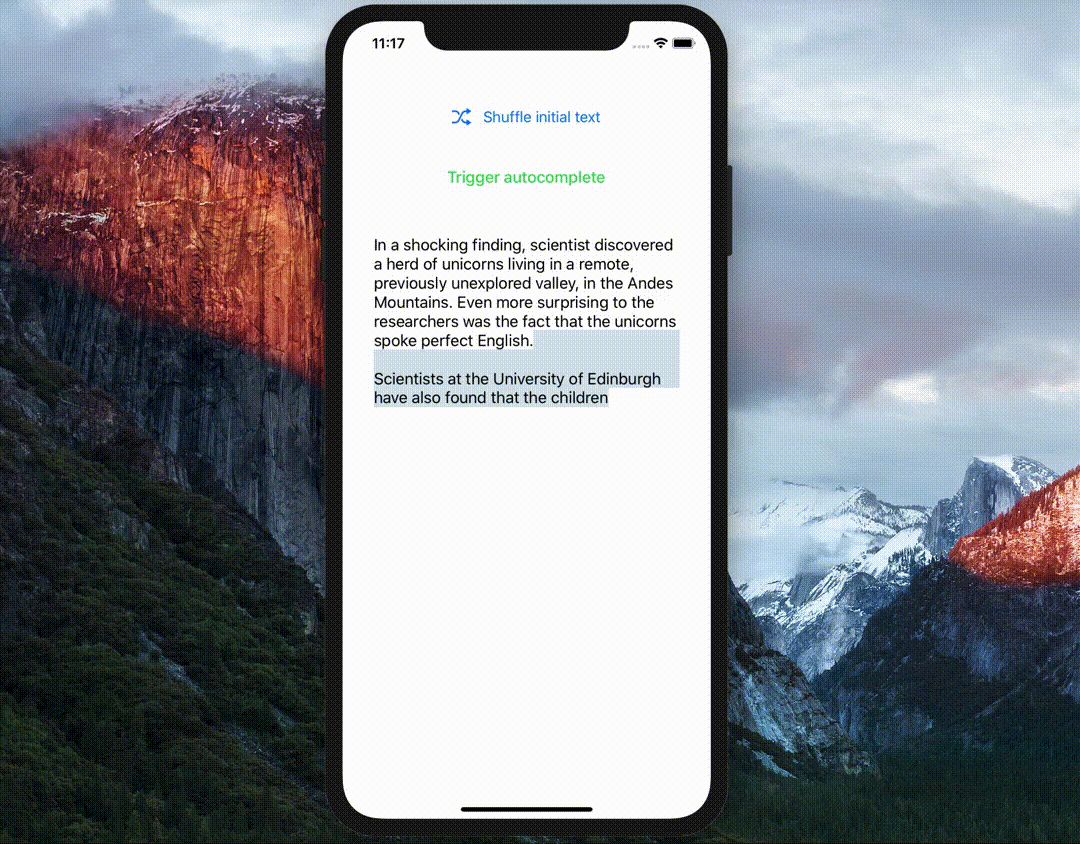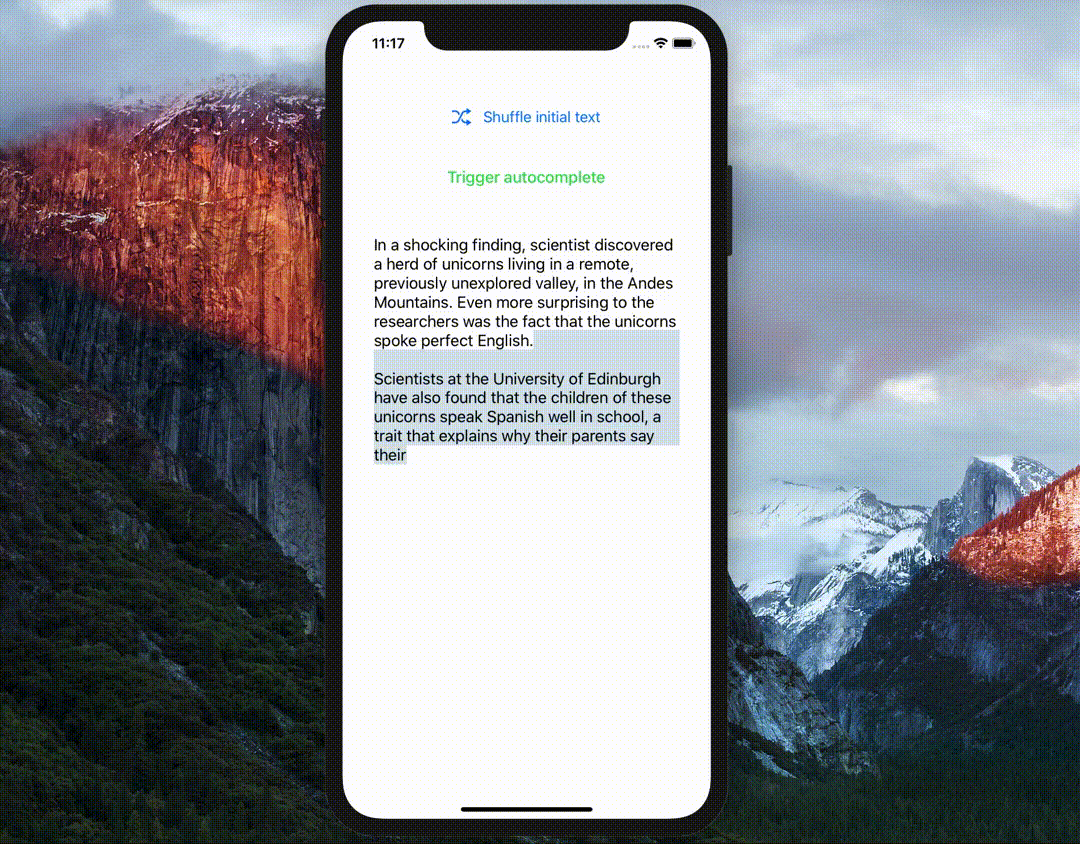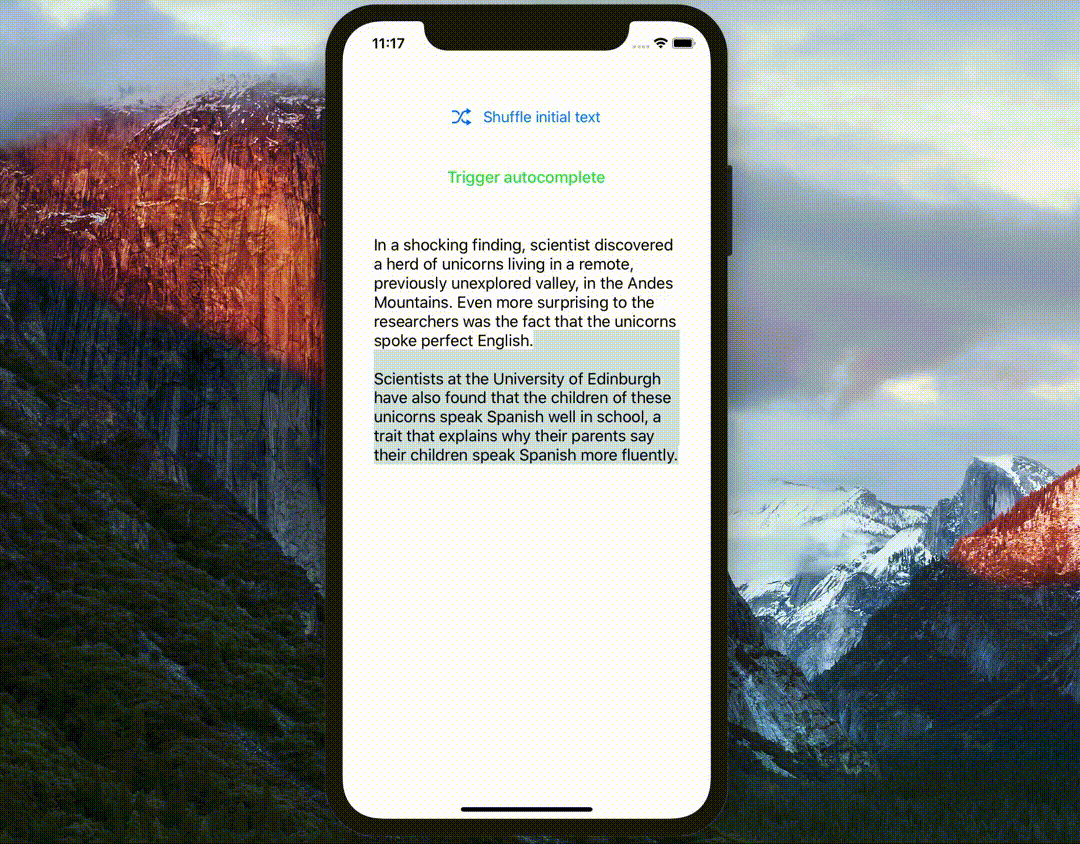
# 🐸 BERT and DistilBERT
The `BERTSQUADFP16` Core ML model was packaged by Apple and is linked from the [main ML models page](https://developer.apple.com/machine-learning/models/#text). It was demoed at WWDC 2019 as part of the Core ML 3 launch.
The `DistilBERT` Core ML models were converted from [`🤗/transformers`](https://github.com/huggingface/transformers) exports using the scripts in this repo.

## 🦄 Demo Time 🔥
Apple demo at WWDC 2019

full video [here](https://developer.apple.com/videos/play/wwdc2019/704)
## BERT Architecture (wwdc slide)
## Notes
We use `git-lfs` to store large model files and it is required to obtain some of the files the app needs to run.
See how to install `git-lfs`on the [installation page](https://git-lfs.github.com/)
| {".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", "CoreMLBert\\AppDelegate.swift": "//\n// AppDelegate.swift\n// CoreMLBert\n//\n// Created by Julien Chaumond on 27/06/2019.\n// Copyright \u00a9 2019 Hugging Face. All rights reserved.\n//\n\nimport UIKit\n\n@UIApplicationMain\nclass AppDelegate: UIResponder, UIApplicationDelegate {\n\n\n\n func application(_ application: UIApplication, didFinishLaunchingWithOptions launchOptions: [UIApplication.LaunchOptionsKey: Any]?) -> Bool {\n // Override point for customization after application launch.\n return true\n }\n\n func applicationWillTerminate(_ application: UIApplication) {\n // Called when the application is about to terminate. Save data if appropriate. See also applicationDidEnterBackground:.\n }\n\n // MARK: UISceneSession Lifecycle\n\n func application(_ application: UIApplication, configurationForConnecting connectingSceneSession: UISceneSession, options: UIScene.ConnectionOptions) -> UISceneConfiguration {\n // Called when a new scene session is being created.\n // Use this method to select a configuration to create the new scene with.\n return UISceneConfiguration(name: \"Default Configuration\", sessionRole: connectingSceneSession.role)\n }\n\n func application(_ application: UIApplication, didDiscardSceneSessions sceneSessions: Set<UISceneSession>) {\n // Called when the user discards a scene session.\n // If any sessions were discarded while the application was not running, this will be called shortly after application:didFinishLaunchingWithOptions.\n // Use this method to release any resources that were specific to the discarded scenes, as they will not return.\n }\n\n\n}\n\n", "CoreMLBert\\Base.lproj\\Main.storyboard": "<?xml version=\"1.0\" encoding=\"UTF-8\"?>\n<document type=\"com.apple.InterfaceBuilder3.CocoaTouch.Storyboard.XIB\" version=\"3.0\" toolsVersion=\"14810.12\" targetRuntime=\"iOS.CocoaTouch\" propertyAccessControl=\"none\" useAutolayout=\"YES\" useTraitCollections=\"YES\" useSafeAreas=\"YES\" colorMatched=\"YES\" initialViewController=\"BYZ-38-t0r\">\n <device id=\"retina6_1\" orientation=\"portrait\" appearance=\"light\"/>\n <dependencies>\n <plugIn identifier=\"com.apple.InterfaceBuilder.IBCocoaTouchPlugin\" version=\"14766.15\"/>\n <capability name=\"Safe area layout guides\" minToolsVersion=\"9.0\"/>\n <capability name=\"documents saved in the Xcode 8 format\" minToolsVersion=\"8.0\"/>\n <capability name=\"iOS 13.0 system colors\" minToolsVersion=\"11.0\"/>\n </dependencies>\n <scenes>\n <!--View Controller-->\n <scene sceneID=\"tne-QT-ifu\">\n <objects>\n <viewController id=\"BYZ-38-t0r\" customClass=\"ViewController\" customModule=\"CoreMLBert\" customModuleProvider=\"target\" sceneMemberID=\"viewController\">\n <view key=\"view\" contentMode=\"scaleToFill\" id=\"8bC-Xf-vdC\">\n <rect key=\"frame\" x=\"0.0\" y=\"0.0\" width=\"414\" height=\"896\"/>\n <autoresizingMask key=\"autoresizingMask\" widthSizable=\"YES\" heightSizable=\"YES\"/>\n <subviews>\n <stackView opaque=\"NO\" contentMode=\"scaleToFill\" spacing=\"13\" translatesAutoresizingMaskIntoConstraints=\"NO\" id=\"uLd-ff-Y26\" userLabel=\"Main Button\">\n <rect key=\"frame\" x=\"98.5\" y=\"84\" width=\"217\" height=\"30\"/>\n <subviews>\n <imageView clipsSubviews=\"YES\" userInteractionEnabled=\"NO\" contentMode=\"scaleAspectFit\" horizontalHuggingPriority=\"251\" verticalHuggingPriority=\"251\" image=\"shuffle\" translatesAutoresizingMaskIntoConstraints=\"NO\" id=\"qwo-CD-cds\">\n <rect key=\"frame\" x=\"0.0\" y=\"0.0\" width=\"22\" height=\"30\"/>\n </imageView>\n <button opaque=\"NO\" contentMode=\"scaleToFill\" contentHorizontalAlignment=\"center\" contentVerticalAlignment=\"center\" buttonType=\"roundedRect\" lineBreakMode=\"middleTruncation\" translatesAutoresizingMaskIntoConstraints=\"NO\" id=\"CDX-gO-HMp\">\n <rect key=\"frame\" x=\"35\" y=\"0.0\" width=\"182\" height=\"30\"/>\n <state key=\"normal\" title=\"Shuffle subject & question\"/>\n </button>\n </subviews>\n </stackView>\n <label opaque=\"NO\" userInteractionEnabled=\"NO\" contentMode=\"left\" horizontalHuggingPriority=\"251\" verticalHuggingPriority=\"251\" text=\"Subject\" textAlignment=\"natural\" lineBreakMode=\"tailTruncation\" baselineAdjustment=\"alignBaselines\" adjustsFontSizeToFit=\"NO\" translatesAutoresizingMaskIntoConstraints=\"NO\" id=\"UiS-Wk-aYr\">\n <rect key=\"frame\" x=\"30\" y=\"144\" width=\"354\" height=\"20.5\"/>\n <fontDescription key=\"fontDescription\" type=\"system\" pointSize=\"17\"/>\n <nil key=\"textColor\"/>\n <nil key=\"highlightedColor\"/>\n </label>\n <textView clipsSubviews=\"YES\" multipleTouchEnabled=\"YES\" contentMode=\"scaleToFill\" textAlignment=\"natural\" translatesAutoresizingMaskIntoConstraints=\"NO\" id=\"sdv-s8-Rs2\">\n <rect key=\"frame\" x=\"30\" y=\"184.5\" width=\"354\" height=\"220\"/>\n <color key=\"backgroundColor\" xcode11CocoaTouchSystemColor=\"systemBackgroundColor\" cocoaTouchSystemColor=\"whiteColor\"/>\n <constraints>\n <constraint firstAttribute=\"height\" constant=\"220\" id=\"hsf-UP-aKg\"/>\n </constraints>\n <string key=\"text\">Lorem ipsum dolor sit er elit lamet, consectetaur cillium adipisicing pecu, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum. Nam liber te conscient to factor tum poen legum odioque civiuda.</string>\n <color key=\"textColor\" xcode11CocoaTouchSystemColor=\"labelColor\" cocoaTouchSystemColor=\"darkTextColor\"/>\n <fontDescription key=\"fontDescription\" type=\"system\" pointSize=\"14\"/>\n <textInputTraits key=\"textInputTraits\" autocapitalizationType=\"sentences\"/>\n </textView>\n <label opaque=\"NO\" userInteractionEnabled=\"NO\" contentMode=\"left\" horizontalHuggingPriority=\"251\" verticalHuggingPriority=\"251\" text=\"Question\" textAlignment=\"natural\" lineBreakMode=\"tailTruncation\" baselineAdjustment=\"alignBaselines\" adjustsFontSizeToFit=\"NO\" translatesAutoresizingMaskIntoConstraints=\"NO\" id=\"Wec-Xd-ci9\">\n <rect key=\"frame\" x=\"30\" y=\"434.5\" width=\"354\" height=\"20.5\"/>\n <fontDescription key=\"fontDescription\" type=\"system\" pointSize=\"17\"/>\n <nil key=\"textColor\"/>\n <nil key=\"highlightedColor\"/>\n </label>\n <textView clipsSubviews=\"YES\" multipleTouchEnabled=\"YES\" contentMode=\"scaleToFill\" textAlignment=\"natural\" translatesAutoresizingMaskIntoConstraints=\"NO\" id=\"Xbl-h3-7B5\">\n <rect key=\"frame\" x=\"30\" y=\"475\" width=\"354\" height=\"140\"/>\n <color key=\"backgroundColor\" xcode11CocoaTouchSystemColor=\"systemBackgroundColor\" cocoaTouchSystemColor=\"whiteColor\"/>\n <constraints>\n <constraint firstAttribute=\"height\" constant=\"140\" id=\"cLq-93-KUo\"/>\n </constraints>\n <string key=\"text\">Lorem ipsum dolor sit er elit lamet, consectetaur cillium adipisicing pecu, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum. Nam liber te conscient to factor tum poen legum odioque civiuda.</string>\n <color key=\"textColor\" xcode11CocoaTouchSystemColor=\"labelColor\" cocoaTouchSystemColor=\"darkTextColor\"/>\n <fontDescription key=\"fontDescription\" type=\"system\" pointSize=\"14\"/>\n <textInputTraits key=\"textInputTraits\" autocapitalizationType=\"sentences\"/>\n </textView>\n <button opaque=\"NO\" contentMode=\"scaleToFill\" contentHorizontalAlignment=\"center\" contentVerticalAlignment=\"center\" buttonType=\"roundedRect\" lineBreakMode=\"middleTruncation\" translatesAutoresizingMaskIntoConstraints=\"NO\" id=\"vV9-0K-bM4\">\n <rect key=\"frame\" x=\"30\" y=\"639\" width=\"354\" height=\"30\"/>\n <state key=\"normal\" title=\"Answer question\"/>\n </button>\n <label opaque=\"NO\" userInteractionEnabled=\"NO\" contentMode=\"left\" horizontalHuggingPriority=\"251\" verticalHuggingPriority=\"251\" text=\"Answer\" textAlignment=\"center\" lineBreakMode=\"tailTruncation\" numberOfLines=\"0\" baselineAdjustment=\"alignBaselines\" adjustsFontSizeToFit=\"NO\" translatesAutoresizingMaskIntoConstraints=\"NO\" id=\"06d-sR-ORJ\">\n <rect key=\"frame\" x=\"30\" y=\"689\" width=\"354\" height=\"27.5\"/>\n <fontDescription key=\"fontDescription\" type=\"system\" weight=\"medium\" pointSize=\"23\"/>\n <color key=\"textColor\" cocoaTouchSystemColor=\"systemGreenColor\"/>\n <nil key=\"highlightedColor\"/>\n </label>\n </subviews>\n <color key=\"backgroundColor\" xcode11CocoaTouchSystemColor=\"systemBackgroundColor\" cocoaTouchSystemColor=\"whiteColor\"/>\n <constraints>\n <constraint firstItem=\"6Tk-OE-BBY\" firstAttribute=\"trailing\" secondItem=\"06d-sR-ORJ\" secondAttribute=\"trailing\" constant=\"30\" id=\"0ef-qn-mVN\"/>\n <constraint firstItem=\"uLd-ff-Y26\" firstAttribute=\"centerX\" secondItem=\"8bC-Xf-vdC\" secondAttribute=\"centerX\" id=\"3bT-g8-KpV\"/>\n <constraint firstItem=\"Xbl-h3-7B5\" firstAttribute=\"leading\" secondItem=\"6Tk-OE-BBY\" secondAttribute=\"leading\" constant=\"30\" id=\"5Q0-9o-pu2\"/>\n <constraint firstItem=\"6Tk-OE-BBY\" firstAttribute=\"trailing\" secondItem=\"vV9-0K-bM4\" secondAttribute=\"trailing\" constant=\"30\" id=\"AKt-AV-qEe\"/>\n <constraint firstItem=\"Wec-Xd-ci9\" firstAttribute=\"leading\" secondItem=\"6Tk-OE-BBY\" secondAttribute=\"leading\" constant=\"30\" id=\"Atb-vL-40W\"/>\n <constraint firstItem=\"vV9-0K-bM4\" firstAttribute=\"top\" secondItem=\"Xbl-h3-7B5\" secondAttribute=\"bottom\" constant=\"24\" id=\"E0y-49-dnU\"/>\n <constraint firstItem=\"vV9-0K-bM4\" firstAttribute=\"leading\" secondItem=\"6Tk-OE-BBY\" secondAttribute=\"leading\" constant=\"30\" id=\"Egf-sb-EKB\"/>\n <constraint firstItem=\"sdv-s8-Rs2\" firstAttribute=\"top\" secondItem=\"UiS-Wk-aYr\" secondAttribute=\"bottom\" constant=\"20\" id=\"I2f-Zf-fKE\"/>\n <constraint firstItem=\"06d-sR-ORJ\" firstAttribute=\"top\" secondItem=\"vV9-0K-bM4\" secondAttribute=\"bottom\" constant=\"20\" id=\"JLw-zY-Jkh\"/>\n <constraint firstItem=\"6Tk-OE-BBY\" firstAttribute=\"trailing\" secondItem=\"sdv-s8-Rs2\" secondAttribute=\"trailing\" constant=\"30\" id=\"LaL-TE-wJk\"/>\n <constraint firstItem=\"uLd-ff-Y26\" firstAttribute=\"top\" secondItem=\"6Tk-OE-BBY\" secondAttribute=\"top\" constant=\"40\" id=\"Ti2-Cg-jmb\"/>\n <constraint firstItem=\"UiS-Wk-aYr\" firstAttribute=\"top\" secondItem=\"uLd-ff-Y26\" secondAttribute=\"bottom\" constant=\"30\" id=\"dD8-wx-p86\"/>\n <constraint firstItem=\"Xbl-h3-7B5\" firstAttribute=\"top\" secondItem=\"Wec-Xd-ci9\" secondAttribute=\"bottom\" constant=\"20\" id=\"fXD-gy-Pye\"/>\n <constraint firstItem=\"sdv-s8-Rs2\" firstAttribute=\"leading\" secondItem=\"6Tk-OE-BBY\" secondAttribute=\"leading\" constant=\"30\" id=\"fpl-0l-7aF\"/>\n <constraint firstItem=\"6Tk-OE-BBY\" firstAttribute=\"trailing\" secondItem=\"Wec-Xd-ci9\" secondAttribute=\"trailing\" constant=\"30\" id=\"h53-xd-Yqc\"/>\n <constraint firstItem=\"UiS-Wk-aYr\" firstAttribute=\"leading\" secondItem=\"6Tk-OE-BBY\" secondAttribute=\"leading\" constant=\"30\" id=\"hTp-Pw-GvU\"/>\n <constraint firstItem=\"06d-sR-ORJ\" firstAttribute=\"leading\" secondItem=\"6Tk-OE-BBY\" secondAttribute=\"leading\" constant=\"30\" id=\"hYZ-6c-kui\"/>\n <constraint firstItem=\"6Tk-OE-BBY\" firstAttribute=\"trailing\" secondItem=\"Xbl-h3-7B5\" secondAttribute=\"trailing\" constant=\"30\" id=\"oVl-kZ-hEh\"/>\n <constraint firstItem=\"6Tk-OE-BBY\" firstAttribute=\"trailing\" secondItem=\"UiS-Wk-aYr\" secondAttribute=\"trailing\" constant=\"30\" id=\"ukn-92-QZ2\"/>\n <constraint firstItem=\"Wec-Xd-ci9\" firstAttribute=\"top\" secondItem=\"sdv-s8-Rs2\" secondAttribute=\"bottom\" constant=\"30\" id=\"xgn-0Y-TLX\"/>\n </constraints>\n <viewLayoutGuide key=\"safeArea\" id=\"6Tk-OE-BBY\"/>\n </view>\n <connections>\n <outlet property=\"answerBtn\" destination=\"vV9-0K-bM4\" id=\"4xD-Tp-VOZ\"/>\n <outlet property=\"answerLabel\" destination=\"06d-sR-ORJ\" id=\"XHP-vn-FT7\"/>\n <outlet property=\"questionField\" destination=\"Xbl-h3-7B5\" id=\"IGe-9e-YZv\"/>\n <outlet property=\"shuffleBtn\" destination=\"CDX-gO-HMp\" id=\"sl7-Hd-ChZ\"/>\n <outlet property=\"subjectField\" destination=\"sdv-s8-Rs2\" id=\"tao-04-9sy\"/>\n </connections>\n </viewController>\n <placeholder placeholderIdentifier=\"IBFirstResponder\" id=\"dkx-z0-nzr\" sceneMemberID=\"firstResponder\"/>\n </objects>\n <point key=\"canvasLocation\" x=\"140.57971014492756\" y=\"138.61607142857142\"/>\n </scene>\n </scenes>\n <resources>\n <image name=\"shuffle\" width=\"22\" height=\"20\"/>\n </resources>\n</document>\n", "CoreMLGPT2\\AppDelegate.swift": "//\n// AppDelegate.swift\n// CoreMLGPT2\n//\n// Created by Julien Chaumond on 18/07/2019.\n// Copyright \u00a9 2019 Hugging Face. All rights reserved.\n//\n\nimport UIKit\n\n@UIApplicationMain\nclass AppDelegate: UIResponder, UIApplicationDelegate {\n\n\n\n func application(_ application: UIApplication, didFinishLaunchingWithOptions launchOptions: [UIApplication.LaunchOptionsKey: Any]?) -> Bool {\n // Override point for customization after application launch.\n return true\n }\n\n func applicationWillTerminate(_ application: UIApplication) {\n // Called when the application is about to terminate. Save data if appropriate. See also applicationDidEnterBackground:.\n }\n\n // MARK: UISceneSession Lifecycle\n\n func application(_ application: UIApplication, configurationForConnecting connectingSceneSession: UISceneSession, options: UIScene.ConnectionOptions) -> UISceneConfiguration {\n // Called when a new scene session is being created.\n // Use this method to select a configuration to create the new scene with.\n return UISceneConfiguration(name: \"Default Configuration\", sessionRole: connectingSceneSession.role)\n }\n\n func application(_ application: UIApplication, didDiscardSceneSessions sceneSessions: Set<UISceneSession>) {\n // Called when the user discards a scene session.\n // If any sessions were discarded while the application was not running, this will be called shortly after application:didFinishLaunchingWithOptions.\n // Use this method to release any resources that were specific to the discarded scenes, as they will not return.\n }\n\n\n}\n\n", "CoreMLGPT2\\Base.lproj\\Main.storyboard": "<?xml version=\"1.0\" encoding=\"UTF-8\"?>\n<document type=\"com.apple.InterfaceBuilder3.CocoaTouch.Storyboard.XIB\" version=\"3.0\" toolsVersion=\"19162\" targetRuntime=\"iOS.CocoaTouch\" propertyAccessControl=\"none\" useAutolayout=\"YES\" useTraitCollections=\"YES\" useSafeAreas=\"YES\" colorMatched=\"YES\" initialViewController=\"BYZ-38-t0r\">\n <device id=\"retina6_1\" orientation=\"portrait\" appearance=\"light\"/>\n <dependencies>\n <deployment identifier=\"iOS\"/>\n <plugIn identifier=\"com.apple.InterfaceBuilder.IBCocoaTouchPlugin\" version=\"19144\"/>\n <capability name=\"Safe area layout guides\" minToolsVersion=\"9.0\"/>\n <capability name=\"System colors in document resources\" minToolsVersion=\"11.0\"/>\n <capability name=\"documents saved in the Xcode 8 format\" minToolsVersion=\"8.0\"/>\n </dependencies>\n <scenes>\n <!--View Controller-->\n <scene sceneID=\"tne-QT-ifu\">\n <objects>\n <viewController id=\"BYZ-38-t0r\" customClass=\"ViewController\" customModule=\"CoreMLGPT2\" customModuleProvider=\"target\" sceneMemberID=\"viewController\">\n <view key=\"view\" contentMode=\"scaleToFill\" id=\"8bC-Xf-vdC\">\n <rect key=\"frame\" x=\"0.0\" y=\"0.0\" width=\"414\" height=\"896\"/>\n <autoresizingMask key=\"autoresizingMask\" widthSizable=\"YES\" heightSizable=\"YES\"/>\n <subviews>\n <label opaque=\"NO\" userInteractionEnabled=\"NO\" contentMode=\"left\" horizontalHuggingPriority=\"251\" verticalHuggingPriority=\"251\" text=\"2.8\" textAlignment=\"center\" lineBreakMode=\"tailTruncation\" baselineAdjustment=\"alignBaselines\" adjustsFontSizeToFit=\"NO\" translatesAutoresizingMaskIntoConstraints=\"NO\" id=\"VKb-B1-hjK\">\n <rect key=\"frame\" x=\"143\" y=\"68\" width=\"128\" height=\"107.5\"/>\n <fontDescription key=\"fontDescription\" type=\"system\" weight=\"medium\" pointSize=\"90\"/>\n <nil key=\"highlightedColor\"/>\n </label>\n <stackView opaque=\"NO\" contentMode=\"scaleToFill\" spacing=\"13\" translatesAutoresizingMaskIntoConstraints=\"NO\" id=\"v6A-rK-I0u\" userLabel=\"Main Button\">\n <rect key=\"frame\" x=\"120\" y=\"249\" width=\"174\" height=\"34\"/>\n <subviews>\n <imageView clipsSubviews=\"YES\" userInteractionEnabled=\"NO\" contentMode=\"scaleAspectFit\" horizontalHuggingPriority=\"251\" verticalHuggingPriority=\"251\" image=\"shuffle\" translatesAutoresizingMaskIntoConstraints=\"NO\" id=\"eeI-ON-KFt\">\n <rect key=\"frame\" x=\"0.0\" y=\"0.0\" width=\"22\" height=\"34\"/>\n </imageView>\n <button opaque=\"NO\" contentMode=\"scaleToFill\" contentHorizontalAlignment=\"center\" contentVerticalAlignment=\"center\" buttonType=\"system\" lineBreakMode=\"middleTruncation\" translatesAutoresizingMaskIntoConstraints=\"NO\" id=\"H1r-WV-vYz\">\n <rect key=\"frame\" x=\"35\" y=\"0.0\" width=\"139\" height=\"34\"/>\n <fontDescription key=\"fontDescription\" type=\"system\" pointSize=\"18\"/>\n <state key=\"normal\" title=\"Shuffle initial text\"/>\n </button>\n </subviews>\n </stackView>\n <button opaque=\"NO\" contentMode=\"scaleToFill\" contentHorizontalAlignment=\"center\" contentVerticalAlignment=\"center\" buttonType=\"system\" lineBreakMode=\"middleTruncation\" translatesAutoresizingMaskIntoConstraints=\"NO\" id=\"BaR-B6-OfK\">\n <rect key=\"frame\" x=\"118\" y=\"293\" width=\"178\" height=\"34\"/>\n <fontDescription key=\"fontDescription\" type=\"system\" weight=\"medium\" pointSize=\"18\"/>\n <state key=\"normal\" title=\"Trigger autocomplete\">\n <color key=\"titleColor\" red=\"0.20392156859999999\" green=\"0.78039215689999997\" blue=\"0.34901960780000002\" alpha=\"1\" colorSpace=\"custom\" customColorSpace=\"sRGB\"/>\n </state>\n </button>\n <textView clipsSubviews=\"YES\" multipleTouchEnabled=\"YES\" contentMode=\"scaleToFill\" textAlignment=\"natural\" translatesAutoresizingMaskIntoConstraints=\"NO\" id=\"N8U-8n-h72\">\n <rect key=\"frame\" x=\"30\" y=\"367\" width=\"354\" height=\"455\"/>\n <color key=\"backgroundColor\" white=\"0.0\" alpha=\"0.0\" colorSpace=\"custom\" customColorSpace=\"genericGamma22GrayColorSpace\"/>\n <string key=\"text\">Lorem ipsum dolor sit er elit lamet, consectetaur cillium adipisicing pecu, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum. Nam liber te conscient to factor tum poen legum odioque civiuda.</string>\n <color key=\"textColor\" systemColor=\"labelColor\"/>\n <fontDescription key=\"fontDescription\" type=\"system\" pointSize=\"18\"/>\n <textInputTraits key=\"textInputTraits\" autocapitalizationType=\"sentences\"/>\n </textView>\n <label opaque=\"NO\" userInteractionEnabled=\"NO\" contentMode=\"left\" horizontalHuggingPriority=\"251\" verticalHuggingPriority=\"251\" text=\"Tokens per sec\" textAlignment=\"natural\" lineBreakMode=\"tailTruncation\" baselineAdjustment=\"alignBaselines\" adjustsFontSizeToFit=\"NO\" translatesAutoresizingMaskIntoConstraints=\"NO\" id=\"0t2-Mi-2DR\">\n <rect key=\"frame\" x=\"145\" y=\"177.5\" width=\"124\" height=\"21.5\"/>\n <fontDescription key=\"fontDescription\" type=\"system\" weight=\"medium\" pointSize=\"18\"/>\n <nil key=\"textColor\"/>\n <nil key=\"highlightedColor\"/>\n </label>\n </subviews>\n <viewLayoutGuide key=\"safeArea\" id=\"6Tk-OE-BBY\"/>\n <color key=\"backgroundColor\" systemColor=\"systemBackgroundColor\"/>\n <constraints>\n <constraint firstItem=\"v6A-rK-I0u\" firstAttribute=\"centerX\" secondItem=\"8bC-Xf-vdC\" secondAttribute=\"centerX\" id=\"7o4-EI-CUO\"/>\n <constraint firstItem=\"N8U-8n-h72\" firstAttribute=\"centerX\" secondItem=\"8bC-Xf-vdC\" secondAttribute=\"centerX\" id=\"8kJ-18-0e2\"/>\n <constraint firstItem=\"0t2-Mi-2DR\" firstAttribute=\"centerX\" secondItem=\"8bC-Xf-vdC\" secondAttribute=\"centerX\" id=\"Fka-Hp-hfD\"/>\n <constraint firstItem=\"v6A-rK-I0u\" firstAttribute=\"top\" secondItem=\"0t2-Mi-2DR\" secondAttribute=\"bottom\" constant=\"50\" id=\"JgA-Hi-tXs\"/>\n <constraint firstItem=\"6Tk-OE-BBY\" firstAttribute=\"bottom\" secondItem=\"N8U-8n-h72\" secondAttribute=\"bottom\" constant=\"40\" id=\"N2O-4H-8vQ\"/>\n <constraint firstItem=\"VKb-B1-hjK\" firstAttribute=\"centerX\" secondItem=\"8bC-Xf-vdC\" secondAttribute=\"centerX\" id=\"PYU-0S-CrL\"/>\n <constraint firstItem=\"0t2-Mi-2DR\" firstAttribute=\"top\" secondItem=\"VKb-B1-hjK\" secondAttribute=\"bottom\" constant=\"2\" id=\"TKF-2M-BWW\"/>\n <constraint firstItem=\"N8U-8n-h72\" firstAttribute=\"top\" secondItem=\"BaR-B6-OfK\" secondAttribute=\"bottom\" constant=\"40\" id=\"YCL-ka-fkT\"/>\n <constraint firstItem=\"6Tk-OE-BBY\" firstAttribute=\"trailing\" secondItem=\"N8U-8n-h72\" secondAttribute=\"trailing\" constant=\"30\" id=\"daw-NK-Uqf\"/>\n <constraint firstItem=\"N8U-8n-h72\" firstAttribute=\"leading\" secondItem=\"6Tk-OE-BBY\" secondAttribute=\"leading\" constant=\"30\" id=\"e5S-8a-AOf\"/>\n <constraint firstItem=\"0t2-Mi-2DR\" firstAttribute=\"centerX\" secondItem=\"8bC-Xf-vdC\" secondAttribute=\"centerX\" id=\"fBA-3T-8ca\"/>\n <constraint firstItem=\"VKb-B1-hjK\" firstAttribute=\"top\" secondItem=\"6Tk-OE-BBY\" secondAttribute=\"top\" constant=\"24\" id=\"hW4-k5-uUj\"/>\n <constraint firstItem=\"BaR-B6-OfK\" firstAttribute=\"centerX\" secondItem=\"8bC-Xf-vdC\" secondAttribute=\"centerX\" id=\"j7a-cg-Pp5\"/>\n <constraint firstItem=\"BaR-B6-OfK\" firstAttribute=\"top\" secondItem=\"v6A-rK-I0u\" secondAttribute=\"bottom\" constant=\"10\" id=\"t9B-Ji-T0d\"/>\n </constraints>\n </view>\n <connections>\n <outlet property=\"shuffleBtn\" destination=\"H1r-WV-vYz\" id=\"30f-9L-Gro\"/>\n <outlet property=\"speedLabel\" destination=\"VKb-B1-hjK\" id=\"Y1E-qW-sDt\"/>\n <outlet property=\"textView\" destination=\"N8U-8n-h72\" id=\"cTg-zl-9t0\"/>\n <outlet property=\"triggerBtn\" destination=\"BaR-B6-OfK\" id=\"bhy-tR-L9a\"/>\n </connections>\n </viewController>\n <placeholder placeholderIdentifier=\"IBFirstResponder\" id=\"dkx-z0-nzr\" sceneMemberID=\"firstResponder\"/>\n </objects>\n <point key=\"canvasLocation\" x=\"141\" y=\"129\"/>\n </scene>\n </scenes>\n <resources>\n <image name=\"shuffle\" width=\"22\" height=\"20\"/>\n <systemColor name=\"labelColor\">\n <color white=\"0.0\" alpha=\"1\" colorSpace=\"custom\" customColorSpace=\"genericGamma22GrayColorSpace\"/>\n </systemColor>\n <systemColor name=\"systemBackgroundColor\">\n <color white=\"1\" alpha=\"1\" colorSpace=\"custom\" customColorSpace=\"genericGamma22GrayColorSpace\"/>\n </systemColor>\n </resources>\n</document>\n", "model_generation\\requirements.txt": "transformers==2.0.0\ncoremltools==3.0\nonnx-coreml==1.0\n"} | null |
swift-transformers | {"type": "directory", "name": "swift-transformers", "children": [{"type": "file", "name": ".spi.yml"}, {"type": "file", "name": "LICENSE"}, {"type": "file", "name": "Package.swift"}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "Sources", "children": [{"type": "directory", "name": "Generation", "children": [{"type": "file", "name": "Generation.swift"}, {"type": "file", "name": "GenerationConfig.swift"}]}, {"type": "directory", "name": "Hub", "children": [{"type": "file", "name": "Downloader.swift"}, {"type": "directory", "name": "FallbackConfigs", "children": [{"type": "file", "name": "gpt2_tokenizer_config.json"}, {"type": "file", "name": "t5_tokenizer_config.json"}]}, {"type": "file", "name": "Hub.swift"}, {"type": "file", "name": "HubApi.swift"}]}, {"type": "directory", "name": "HubCLI", "children": [{"type": "file", "name": "HubCLI.swift"}]}, {"type": "directory", "name": "Models", "children": [{"type": "file", "name": "LanguageModel.swift"}, {"type": "file", "name": "LanguageModelTypes.swift"}]}, {"type": "directory", "name": "TensorUtils", "children": [{"type": "directory", "name": "LogitsWarper", "children": [{"type": "file", "name": "LogitsProcessor.swift"}, {"type": "file", "name": "LogitsWarper.swift"}, {"type": "file", "name": "RepetitionPenaltyWarper.swift"}, {"type": "file", "name": "TemperatureLogitsWarper.swift"}, {"type": "file", "name": "TopKLogitsWarper.swift"}, {"type": "file", "name": "TopPLogitsWarper.swift"}]}, {"type": "file", "name": "Math.swift"}, {"type": "file", "name": "MLMultiArray+Utils.swift"}, {"type": "file", "name": "MLShapedArray+Utils.swift"}]}, {"type": "directory", "name": "Tokenizers", "children": [{"type": "file", "name": "BertTokenizer.swift"}, {"type": "file", "name": "BPETokenizer.swift"}, {"type": "file", "name": "ByteEncoder.swift"}, {"type": "file", "name": "Decoder.swift"}, {"type": "file", "name": "Normalizer.swift"}, {"type": "file", "name": "PostProcessor.swift"}, {"type": "file", "name": "PreTokenizer.swift"}, {"type": "file", "name": "Tokenizer.swift"}, {"type": "file", "name": "TokenLattice.swift"}, {"type": "file", "name": "Trie.swift"}, {"type": "file", "name": "UnigramTokenizer.swift"}, {"type": "file", "name": "Utils.swift"}]}, {"type": "directory", "name": "TransformersCLI", "children": [{"type": "file", "name": "main.swift"}]}]}, {"type": "directory", "name": "Tests", "children": [{"type": "directory", "name": "HubTests", "children": [{"type": "file", "name": "HubApiTests.swift"}, {"type": "file", "name": "HubTests.swift"}]}, {"type": "directory", "name": "NormalizerTests", "children": [{"type": "file", "name": "NormalizerTests.swift"}]}, {"type": "directory", "name": "PostProcessorTests", "children": [{"type": "file", "name": "PostProcessorTests.swift"}]}, {"type": "directory", "name": "PreTokenizerTests", "children": [{"type": "file", "name": "PreTokenizerTests.swift"}]}, {"type": "directory", "name": "TensorUtilsTests", "children": [{"type": "file", "name": "LogitsWarperTests.swift"}, {"type": "file", "name": "TensorUtilsTests.swift"}, {"type": "file", "name": "TestUtils.swift"}]}, {"type": "directory", "name": "TokenizersTests", "children": [{"type": "file", "name": "AddedTokensTests.swift"}, {"type": "file", "name": "BertTokenizerTests.swift"}, {"type": "file", "name": "DecoderTests.swift"}, {"type": "file", "name": "FactoryTests.swift"}, {"type": "directory", "name": "Resources", "children": [{"type": "file", "name": "basic_tokenized_questions.json"}, {"type": "file", "name": "dev-v1.1.json"}, {"type": "file", "name": "falcon_encoded.json"}, {"type": "file", "name": "gemma_encoded.json"}, {"type": "file", "name": "gpt2_encoded_tokens.json"}, {"type": "file", "name": "llama_3.2_encoded.json"}, {"type": "file", "name": "llama_encoded.json"}, {"type": "file", "name": "question_tokens.json"}, {"type": "file", "name": "t5_base_encoded.json"}, {"type": "file", "name": "tokenized_questions.json"}, {"type": "file", "name": "tokenizer_tests.json"}, {"type": "file", "name": "whisper_large_v2_encoded.json"}, {"type": "file", "name": "whisper_tiny_en_encoded.json"}]}, {"type": "file", "name": "SplitTests.swift"}, {"type": "file", "name": "SquadDataset.swift"}, {"type": "file", "name": "TokenizerTests.swift"}, {"type": "file", "name": "TrieTests.swift"}, {"type": "directory", "name": "Vocabs", "children": [{"type": "file", "name": "bert-vocab.txt"}]}]}]}]} | # `swift-transformers`
[](https://github.com/huggingface/swift-transformers/actions/workflows/unit-tests.yml)
[](https://swiftpackageindex.com/huggingface/swift-transformers)
[](https://swiftpackageindex.com/huggingface/swift-transformers)
This is a collection of utilities to help adopt language models in Swift apps. It tries to follow the Python `transformers` API and abstractions whenever possible, but it also aims to provide an idiomatic Swift interface and does not assume prior familiarity with [`transformers`](https://github.com/huggingface/transformers) or [`tokenizers`](https://github.com/huggingface/tokenizers).
## Rationale and Overview
Please, check [our post](https://huggingface.co/blog/swift-coreml-llm).
## Modules
- `Tokenizers`. Utilities to convert text to tokens and back. Follows the abstractions in [`tokenizers`](https://github.com/huggingface/tokenizers) and [`transformers.js`](https://github.com/xenova/transformers.js). Usage example:
```swift
import Tokenizers
func testTokenizer() async throws {
let tokenizer = try await AutoTokenizer.from(pretrained: "pcuenq/Llama-2-7b-chat-coreml")
let inputIds = tokenizer("Today she took a train to the West")
assert(inputIds == [1, 20628, 1183, 3614, 263, 7945, 304, 278, 3122])
}
```
However, you don't usually need to tokenize the input text yourself - the [`Generation` code](https://github.com/huggingface/swift-transformers/blob/17d4bfae3598482fc7ecf1a621aa77ab586d379a/Sources/Generation/Generation.swift#L82) will take care of it.
- `Hub`. Utilities to download configuration files from the Hub, used to instantiate tokenizers and learn about language model characteristics.
- `Generation`. Algorithms for text generation. Currently supported ones are greedy search and top-k sampling.
- `Models`. Language model abstraction over a Core ML package.
## Supported Models
This package has been tested with autoregressive language models such as:
- GPT, GPT-Neox, GPT-J.
- SantaCoder.
- StarCoder.
- Falcon.
- Llama 2.
Encoder-decoder models such as T5 and Flan are currently _not supported_. They are high up in our [priority list](#roadmap).
## Other Tools
- [`swift-chat`](https://github.com/huggingface/swift-chat), a simple app demonstrating how to use this package.
- [`exporters`](https://github.com/huggingface/exporters), a Core ML conversion package for transformers models, based on Apple's [`coremltools`](https://github.com/apple/coremltools).
- [`transformers-to-coreml`](https://huggingface.co/spaces/coreml-projects/transformers-to-coreml), a no-code Core ML conversion tool built on `exporters`.
## SwiftPM
To use `swift-transformers` with SwiftPM, you can add this to your `Package.swift`:
```swift
dependencies: [
.package(url: "https://github.com/huggingface/swift-transformers", from: "0.1.5")
]
```
And then, add the Transformers library as a dependency to your target:
```
targets: [
.target(
name: "YourTargetName",
dependencies: [
.product(name: "Transformers", package: "swift-transformers")
]
)
]
```
## <a name="roadmap"></a> Roadmap / To Do
- [ ] Tokenizers: download from the Hub, port from [`tokenizers`](https://github.com/huggingface/tokenizers)
- [x] BPE family
- [x] Fix Falcon, broken while porting BPE
- [x] Improve tests, add edge cases, see https://github.com/xenova/transformers.js/blob/27920d84831e323275b38f0b5186644b7936e1a2/tests/generate_tests.py#L24
- [x] Include fallback `tokenizer_config.json` for known architectures whose models don't have a configuration in the Hub (GPT2)
- [ ] Port other tokenizer types: Unigram, WordPiece
- [ ] [`exporters`](https://github.com/huggingface/exporters) – Core ML conversion tool.
- [x] Allow max sequence length to be specified.
- [ ] Allow discrete shapes
- [x] Return `logits` from converted Core ML model
- [x] Use `coremltools` @ `main` for latest fixes. In particular, [this merged PR](https://github.com/apple/coremltools/pull/1915) makes it easier to use recent versions of transformers.
- [ ] Generation
- [ ] Nucleus sampling (we currently have greedy and top-k sampling)
- [ ] Use [new `top-k` implementation in `Accelerate`](https://developer.apple.com/documentation/accelerate/bnns#4164142).
- [ ] Support discrete shapes in the underlying Core ML model by selecting the smallest sequence length larger than the input.
- [ ] Optimization: cache past key-values.
- [ ] Encoder-decoder models (T5)
- [ ] [Demo app](https://github.com/huggingface/swift-chat)
- [ ] Allow system prompt to be specified.
- [ ] How to define a system prompt template?
- [ ] Test a code model (to stretch system prompt definition)
## License
[Apache 2](LICENSE).
| {".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 0f2306713d48a75b862026ebb291926793773f52 Hamza Amin <[email protected]> 1727373213 +0500\tclone: from https://github.com/huggingface/swift-transformers.git\n", ".git\\refs\\heads\\main": "0f2306713d48a75b862026ebb291926793773f52\n", "Sources\\TransformersCLI\\main.swift": "import ArgumentParser\nimport CoreML\nimport Foundation\n\nimport Models\nimport Generation\n\n@available(iOS 16.2, macOS 13.1, *)\nstruct TransformersCLI: ParsableCommand {\n static let configuration = CommandConfiguration(\n abstract: \"Run text generation on a Core ML language model\",\n version: \"0.0.1\"\n )\n\n @Argument(help: \"Input text\")\n var prompt: String\n\n @Argument(help: \"Path to Core ML mlpackage model\")\n var modelPath: String = \"./model.mlpackage\"\n\n @Option(help: \"Maximum amount of tokens the model should generate\")\n var maxLength: Int = 50\n\n @Option(help: \"Compute units to load model with {all,cpuOnly,cpuAndGPU,cpuAndNeuralEngine}\")\n var computeUnits: ComputeUnits = .cpuAndGPU\n \n func generate(model: LanguageModel, config: GenerationConfig, prompt: String, printOutput: Bool = true) {\n let semaphore = DispatchSemaphore(value: 0)\n Task.init { [config] in\n defer { semaphore.signal() }\n var tokensReceived = 0\n var previousIndex: String.Index? = nil\n let begin = Date()\n do {\n try await model.generate(config: config, prompt: prompt) { inProgressGeneration in\n tokensReceived += 1\n let response = inProgressGeneration.replacingOccurrences(of: \"\\\\n\", with: \"\\n\")\n if printOutput {\n print(response[(previousIndex ?? response.startIndex)...], terminator: \"\")\n fflush(stdout)\n }\n previousIndex = response.endIndex\n }\n let completionTime = Date().timeIntervalSince(begin)\n let tps = Double(tokensReceived) / completionTime\n if printOutput {\n print(\"\")\n print(\"\\(tps.formatted(\"%.2f\")) tokens/s, total time: \\(completionTime.formatted(\"%.2f\"))s\")\n }\n } catch {\n print(\"Error \\(error)\")\n }\n }\n semaphore.wait()\n }\n\n func compile(at url: URL) throws -> URL {\n #if os(watchOS)\n fatalError(\"Model compilation is not supported on watchOS\")\n #else\n if url.pathExtension == \"mlmodelc\" { return url }\n print(\"Compiling model \\(url)\")\n return try MLModel.compileModel(at: url)\n #endif\n }\n\n func run() throws {\n let url = URL(filePath: modelPath)\n let compiledURL = try compile(at: url)\n print(\"Loading model \\(compiledURL)\")\n let model = try LanguageModel.loadCompiled(url: compiledURL, computeUnits: computeUnits.asMLComputeUnits)\n \n // Using greedy generation for now\n var config = model.defaultGenerationConfig\n config.doSample = false\n config.maxNewTokens = maxLength\n \n print(\"Warming up...\")\n generate(model: model, config: config, prompt: prompt, printOutput: false)\n \n print(\"Generating\")\n generate(model: model, config: config, prompt: prompt)\n }\n}\n\n@available(iOS 16.2, macOS 13.1, *)\nenum ComputeUnits: String, ExpressibleByArgument, CaseIterable {\n case all, cpuAndGPU, cpuOnly, cpuAndNeuralEngine\n var asMLComputeUnits: MLComputeUnits {\n switch self {\n case .all: return .all\n case .cpuAndGPU: return .cpuAndGPU\n case .cpuOnly: return .cpuOnly\n case .cpuAndNeuralEngine: return .cpuAndNeuralEngine\n }\n }\n}\n\nif #available(iOS 16.2, macOS 13.1, *) {\n TransformersCLI.main()\n} else {\n print(\"Unsupported OS\")\n}\n\nextension Double {\n func formatted(_ format: String) -> String {\n return String(format: \"\\(format)\", self)\n }\n}\n"} | null |
tailscale-action | {"type": "directory", "name": "tailscale-action", "children": [{"type": "file", "name": "action.yaml"}, {"type": "file", "name": "LICENSE"}, {"type": "file", "name": "README.md"}]} | # tailscale-action
Hugging Face Github action to connect to tailscale (Based from https://github.com/tailscale/github-action)
You can use this github action for 2 differents use cases :
- Access to internal shared ressources (like registry)
- Log in SSH on the runner in order to debug the workflow
In the first case, you can also configure Tailscale to automatically start SSH server in case of job failure
# Access to internal shared ressources (like registry)
Ask for the TAILSCALE_AUTHKEY secret and add this step to your workflow.
```yaml
- name: Tailscale
uses: huggingface/tailscale-action@main
with:
authkey: ${{ secrets.TAILSCALE_AUTHKEY }}
```
You can configure This Tailscale Action to run dynamically an SSH server on your runner if a step failed, or if you started your job with debug mode.
In this case, you have to add 2 inputs for slack notification and add a "wait" step at the end of your job
```yaml
- name: Tailscale
uses: huggingface/tailscale-action@main
with:
authkey: ${{ secrets.TAILSCALE_AUTHKEY }}
slackChannel: ${{ secrets.SLACK_CIFEEDBACK_CHANNEL }}
slackToken: ${{ secrets.SLACK_CIFEEDBACK_BOT_TOKEN }}
```
```yaml
- name: Tailscale Wait
if: ${{ failure() || runner.debug == '1' }}
uses: huggingface/tailscale-action@main
with:
waitForSSH: true
```
# Log in SSH on the runner in order to debug the workflow
- Add this step at the end of your job (`TAILSCALE_SSH_AUTHKEY`, `SLACK_CIFEEDBACK_CHANNEL`, `SLACK_CIFEEDBACK_BOT_TOKEN` already available on all repos)
- Re-Run your Job with `Enable debug logging` on the github popup
- Join the slack channel #github-runners, you will receive a slack message.
```yaml
- name: Tailscale Wait
if: ${{ failure() || runner.debug == '1' }}
uses: huggingface/tailscale-action@main
with:
waitForSSH: true
authkey: ${{ secrets.TAILSCALE_SSH_AUTHKEY }}
slackChannel: ${{ secrets.SLACK_CIFEEDBACK_CHANNEL }}
slackToken: ${{ secrets.SLACK_CIFEEDBACK_BOT_TOKEN }}
```
**WARNING : if you have a workflow with a lot of jobs, don't run your workflow with `Enable debug logging`**
Tooltip : If you want to connect to the runner at the start of your workflow, to be able to debug during steps
- add the Tailscale action Step at the start of your job
- Add the Tailscale Wait action at the end
```yaml
- name: Tailscale
uses: huggingface/tailscale-action@main
with:
authkey: ${{ secrets.TAILSCALE_SSH_AUTHKEY }}
slackChannel: ${{ secrets.SLACK_CIFEEDBACK_CHANNEL }}
slackToken: ${{ secrets.SLACK_CIFEEDBACK_BOT_TOKEN }}
.....
- name: Tailscale Wait
if: ${{ failure() || runner.debug == '1' }}
uses: huggingface/tailscale-action@main
with:
waitForSSH: true
```
## Others options
- `sshTimeout` : by default Tailscale is waiting 5 minutes before terminating the job. You can increase this time.
| {".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 4a1c425681a21306610f2ae6b7ec2f0263323e56 Hamza Amin <[email protected]> 1727373215 +0500\tclone: from https://github.com/huggingface/tailscale-action.git\n", ".git\\refs\\heads\\main": "4a1c425681a21306610f2ae6b7ec2f0263323e56\n"} | null |
temp-tailscale-action | {"type": "directory", "name": "temp-tailscale-action", "children": [{"type": "file", "name": "action.yaml"}]} | {".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 8c35f3ef336619478175c3742d515e1be6e2e086 Hamza Amin <[email protected]> 1727373216 +0500\tclone: from https://github.com/huggingface/temp-tailscale-action.git\n", ".git\\refs\\heads\\main": "8c35f3ef336619478175c3742d515e1be6e2e086\n"} | null |
|
test-actions | {"type": "directory", "name": "test-actions", "children": []} | {".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 a9bb027eaa66458a587526ad75244eafa5bdb7f9 Hamza Amin <[email protected]> 1727373218 +0500\tclone: from https://github.com/huggingface/test-actions.git\n", ".git\\refs\\heads\\main": "a9bb027eaa66458a587526ad75244eafa5bdb7f9\n"} | null |
|
test_gh_secret | {"type": "directory", "name": "test_gh_secret", "children": [{"type": "file", "name": "README.md"}]} | testing github actions
| {".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 62e2f3a1213576d0481c221e50d174b82c01d355 Hamza Amin <[email protected]> 1727373219 +0500\tclone: from https://github.com/huggingface/test_gh_secret.git\n", ".git\\refs\\heads\\main": "62e2f3a1213576d0481c221e50d174b82c01d355\n"} | null |
text-clustering | {"type": "directory", "name": "text-clustering", "children": [{"type": "directory", "name": "examples", "children": [{"type": "file", "name": "README.md"}]}, {"type": "file", "name": "LICENSE"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "run_pipeline.py"}, {"type": "directory", "name": "src", "children": [{"type": "file", "name": "plot_utils.py"}, {"type": "file", "name": "text_clustering.py"}]}]} | # Examples
## Cosmopedia experiments: clustering of web samples
Here you can find the commands we used during the selection of web samples for [Cosmopedia](https://huggingface.co/datasets/HuggingFaceTB/cosmopedia) prompts.
Our goal was to find the topics in random web samples and their educational score. The topics were used in the creation of prompts for synthetic data generation and helped us understand the range of domains covered. Initially, we clustered **100,000 samples**, yielding **145 clusters**. Then we assigned **15 million samples** to these clusters using the inference mode of `text-clustering`; however, half of them did not fit into any cluster and were excluded from prompt creation.
For illustration, we will use [AutoMathText](https://huggingface.co/datasets/math-ai/AutoMathText) here. In Cosmopedia we used samples from a web dataset like [RefineWeb](https://huggingface.co/datasets/tiiuae/falcon-refinedweb).
We will run the clustering using `topic_mode` single with educational scores. This pipeline clusters files and prompts an LLM (by default [Mixtral-8x7B-Instruct-v0.1](https://huggingface.co/mistralai/Mixtral-8x7B-Instruct-v0.1)) to find the topic of each cluster and give it an educational score. We plot the distribution of samples over topics and the distribution of the educational score and save the plots in the `save_load_path` folder.
```bash
python run_pipeline.py --mode run \
--save_load_path './web_samples_100k' \
--input_dataset math-ai/AutoMathText \
--data_subset "web-0.70-to-1.00" \
--input_content text \
--n_samples 100000 \
--build_hf_ds \
--topic_mode single_topic \
--dbscan_eps 0.08 \
--dbscan_min_samples 50
```
This detects 213 clusters that you can visualize in this [plot](https://huggingface.co/datasets/HuggingFaceTB/miscellaneous/blob/main/AMT_plots/topics_distpng.png) along with the [educational scores](https://huggingface.co/datasets/HuggingFaceTB/miscellaneous/blob/main/AMT_plots/educational_score.png) which is very high for this AutoMathText dataset.
When using general web datasets, you might want to filter out files with a lower quality by discarding clusters with a low educational score (e.g. Explicit Adult Content). You can check this [demo](https://huggingface.co/spaces/HuggingFaceTB/inspect_clusters_free_topics) for an example.
<div align="center">
<img src="https://huggingface.co/datasets/HuggingFaceTB/miscellaneous/resolve/main/AMT_plots/topics_distpng.png" alt="clusters" width="1000" height="700">
<p>The clusters of AutoMathText</p>
</div>
| {".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 7815f8b37d91b75cf160ed3f0ec8550c0b58cabb Hamza Amin <[email protected]> 1727369484 +0500\tclone: from https://github.com/huggingface/text-clustering.git\n", ".git\\refs\\heads\\main": "7815f8b37d91b75cf160ed3f0ec8550c0b58cabb\n"} | null |
text-embeddings-inference | {"type": "directory", "name": "text-embeddings-inference", "children": [{"type": "directory", "name": ".cargo", "children": [{"type": "file", "name": "config.toml"}]}, {"type": "file", "name": ".dockerignore"}, {"type": "file", "name": ".pre-commit-config.yaml"}, {"type": "directory", "name": "assets", "children": []}, {"type": "directory", "name": "backends", "children": [{"type": "directory", "name": "candle", "children": [{"type": "file", "name": "build.rs"}, {"type": "file", "name": "Cargo.toml"}, {"type": "directory", "name": "src", "children": [{"type": "file", "name": "alibi.rs"}, {"type": "file", "name": "compute_cap.rs"}, {"type": "file", "name": "flash_attn.rs"}, {"type": "directory", "name": "layers", "children": [{"type": "file", "name": "cublaslt.rs"}, {"type": "file", "name": "layer_norm.rs"}, {"type": "file", "name": "linear.rs"}, {"type": "file", "name": "mod.rs"}, {"type": "file", "name": "rms_norm.rs"}]}, {"type": "file", "name": "lib.rs"}, {"type": "directory", "name": "models", "children": [{"type": "file", "name": "bert.rs"}, {"type": "file", "name": "distilbert.rs"}, {"type": "file", "name": "flash_bert.rs"}, {"type": "file", "name": "flash_distilbert.rs"}, {"type": "file", "name": "flash_gte.rs"}, {"type": "file", "name": "flash_jina.rs"}, {"type": "file", "name": "flash_jina_code.rs"}, {"type": "file", "name": "flash_mistral.rs"}, {"type": "file", "name": "flash_nomic.rs"}, {"type": "file", "name": "flash_qwen2.rs"}, {"type": "file", "name": "gte.rs"}, {"type": "file", "name": "jina.rs"}, {"type": "file", "name": "jina_code.rs"}, {"type": "file", "name": "mistral.rs"}, {"type": "file", "name": "mod.rs"}, {"type": "file", "name": "nomic.rs"}, {"type": "file", "name": "qwen2.rs"}]}]}, {"type": "directory", "name": "tests", "children": [{"type": "file", "name": "common.rs"}, {"type": "directory", "name": "snapshots", "children": [{"type": "file", "name": "test_bert__bert_classification_single.snap"}, {"type": "file", "name": "test_bert__emotions_batch.snap"}, {"type": "file", "name": "test_bert__emotions_single.snap"}, {"type": "file", "name": "test_bert__mini_batch.snap"}, {"type": "file", "name": "test_bert__mini_batch_pooled.snap"}, {"type": "file", "name": "test_bert__mini_batch_raw.snap"}, {"type": "file", "name": "test_bert__mini_single.snap"}, {"type": "file", "name": "test_bert__mini_single_pooled.snap"}, {"type": "file", "name": "test_bert__mini_single_raw.snap"}, {"type": "file", "name": "test_flash_bert__bert_classification_single.snap"}, {"type": "file", "name": "test_flash_bert__emotions_batch.snap"}, {"type": "file", "name": "test_flash_bert__emotions_single.snap"}, {"type": "file", "name": "test_flash_bert__mini_batch.snap"}, {"type": "file", "name": "test_flash_bert__mini_batch_pooled.snap"}, {"type": "file", "name": "test_flash_bert__mini_batch_raw.snap"}, {"type": "file", "name": "test_flash_bert__mini_single.snap"}, {"type": "file", "name": "test_flash_bert__mini_single_pooled.snap"}, {"type": "file", "name": "test_flash_bert__mini_single_raw.snap"}, {"type": "file", "name": "test_flash_gte__gte_batch.snap"}, {"type": "file", "name": "test_flash_gte__gte_single.snap"}, {"type": "file", "name": "test_flash_jina_code__jina_code_batch.snap"}, {"type": "file", "name": "test_flash_jina_code__jina_code_single.snap"}, {"type": "file", "name": "test_flash_jina__jina_batch.snap"}, {"type": "file", "name": "test_flash_jina__jina_single.snap"}, {"type": "file", "name": "test_flash_mistral__mistral_batch.snap"}, {"type": "file", "name": "test_flash_mistral__mistral_single.snap"}, {"type": "file", "name": "test_flash_nomic__nomic_batch.snap"}, {"type": "file", "name": "test_flash_nomic__nomic_single.snap"}, {"type": "file", "name": "test_flash_qwen2__qwen2_batch.snap"}, {"type": "file", "name": "test_flash_qwen2__qwen2_single.snap"}, {"type": "file", "name": "test_jina_code__jina_code_batch.snap"}, {"type": "file", "name": "test_jina_code__jina_code_single.snap"}, {"type": "file", "name": "test_jina__jina_batch.snap"}, {"type": "file", "name": "test_jina__jina_single.snap"}, {"type": "file", "name": "test_nomic__nomic_batch.snap"}, {"type": "file", "name": "test_nomic__nomic_single.snap"}]}, {"type": "file", "name": "test_bert.rs"}, {"type": "file", "name": "test_flash_bert.rs"}, {"type": "file", "name": "test_flash_gte.rs"}, {"type": "file", "name": "test_flash_jina.rs"}, {"type": "file", "name": "test_flash_jina_code.rs"}, {"type": "file", "name": "test_flash_mistral.rs"}, {"type": "file", "name": "test_flash_nomic.rs"}, {"type": "file", "name": "test_flash_qwen2.rs"}, {"type": "file", "name": "test_jina.rs"}, {"type": "file", "name": "test_jina_code.rs"}, {"type": "file", "name": "test_nomic.rs"}]}]}, {"type": "file", "name": "Cargo.toml"}, {"type": "directory", "name": "core", "children": [{"type": "file", "name": "Cargo.toml"}, {"type": "directory", "name": "src", "children": [{"type": "file", "name": "lib.rs"}]}]}, {"type": "directory", "name": "grpc-client", "children": [{"type": "file", "name": "build.rs"}, {"type": "file", "name": "Cargo.toml"}, {"type": "directory", "name": "src", "children": [{"type": "file", "name": "client.rs"}, {"type": "file", "name": "lib.rs"}, {"type": "directory", "name": "pb", "children": []}]}]}, {"type": "directory", "name": "grpc-metadata", "children": [{"type": "file", "name": "Cargo.toml"}, {"type": "directory", "name": "src", "children": [{"type": "file", "name": "lib.rs"}]}]}, {"type": "directory", "name": "ort", "children": [{"type": "file", "name": "Cargo.toml"}, {"type": "directory", "name": "src", "children": [{"type": "file", "name": "lib.rs"}]}]}, {"type": "directory", "name": "proto", "children": [{"type": "file", "name": "embed.proto"}]}, {"type": "directory", "name": "python", "children": [{"type": "file", "name": "Cargo.toml"}, {"type": "directory", "name": "server", "children": [{"type": "file", "name": "Makefile"}, {"type": "file", "name": "Makefile-flash-att"}, {"type": "file", "name": "Makefile-flash-att-v2"}, {"type": "file", "name": "poetry.lock"}, {"type": "file", "name": "pyproject.toml"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "directory", "name": "text_embeddings_server", "children": [{"type": "file", "name": "cli.py"}, {"type": "directory", "name": "models", "children": [{"type": "file", "name": "default_model.py"}, {"type": "file", "name": "flash_bert.py"}, {"type": "file", "name": "model.py"}, {"type": "file", "name": "types.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "pb", "children": []}, {"type": "file", "name": "server.py"}, {"type": "directory", "name": "utils", "children": [{"type": "file", "name": "flash_attn.py"}, {"type": "file", "name": "interceptor.py"}, {"type": "file", "name": "tracing.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "__init__.py"}]}]}, {"type": "directory", "name": "src", "children": [{"type": "file", "name": "lib.rs"}, {"type": "file", "name": "logging.rs"}, {"type": "file", "name": "management.rs"}]}]}, {"type": "directory", "name": "src", "children": [{"type": "file", "name": "dtype.rs"}, {"type": "file", "name": "lib.rs"}]}]}, {"type": "file", "name": "Cargo.lock"}, {"type": "file", "name": "Cargo.toml"}, {"type": "file", "name": "CODE_OF_CONDUCT.md"}, {"type": "file", "name": "CONTRIBUTING.md"}, {"type": "directory", "name": "core", "children": [{"type": "file", "name": "Cargo.toml"}, {"type": "directory", "name": "src", "children": [{"type": "file", "name": "download.rs"}, {"type": "file", "name": "infer.rs"}, {"type": "file", "name": "lib.rs"}, {"type": "file", "name": "queue.rs"}, {"type": "file", "name": "tokenization.rs"}]}]}, {"type": "file", "name": "cuda-all-entrypoint.sh"}, {"type": "file", "name": "Dockerfile"}, {"type": "file", "name": "Dockerfile-cuda"}, {"type": "file", "name": "Dockerfile-cuda-all"}, {"type": "directory", "name": "docs", "children": [{"type": "file", "name": "index.html"}, {"type": "file", "name": "openapi.json"}, {"type": "directory", "name": "source", "children": [{"type": "directory", "name": "en", "children": [{"type": "file", "name": "cli_arguments.md"}, {"type": "file", "name": "custom_container.md"}, {"type": "file", "name": "examples.md"}, {"type": "file", "name": "index.md"}, {"type": "file", "name": "local_cpu.md"}, {"type": "file", "name": "local_gpu.md"}, {"type": "file", "name": "local_metal.md"}, {"type": "file", "name": "private_models.md"}, {"type": "file", "name": "quick_tour.md"}, {"type": "file", "name": "supported_models.md"}, {"type": "file", "name": "_toctree.yml"}]}]}]}, {"type": "file", "name": "LICENSE"}, {"type": "directory", "name": "load_tests", "children": [{"type": "file", "name": "load.js"}, {"type": "file", "name": "load_grpc.js"}, {"type": "file", "name": "load_grpc_stream.js"}]}, {"type": "file", "name": "Makefile"}, {"type": "directory", "name": "proto", "children": [{"type": "file", "name": "tei.proto"}]}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "router", "children": [{"type": "file", "name": "build.rs"}, {"type": "file", "name": "Cargo.toml"}, {"type": "directory", "name": "src", "children": [{"type": "directory", "name": "grpc", "children": [{"type": "file", "name": "mod.rs"}, {"type": "directory", "name": "pb", "children": []}, {"type": "file", "name": "server.rs"}]}, {"type": "directory", "name": "http", "children": [{"type": "file", "name": "mod.rs"}, {"type": "file", "name": "server.rs"}, {"type": "file", "name": "types.rs"}]}, {"type": "file", "name": "lib.rs"}, {"type": "file", "name": "logging.rs"}, {"type": "file", "name": "main.rs"}, {"type": "file", "name": "prometheus.rs"}, {"type": "file", "name": "shutdown.rs"}]}, {"type": "directory", "name": "tests", "children": [{"type": "file", "name": "common.rs"}, {"type": "directory", "name": "snapshots", "children": [{"type": "file", "name": "test_http_embed__embeddings_batch.snap"}, {"type": "file", "name": "test_http_embed__embeddings_raw.snap"}, {"type": "file", "name": "test_http_embed__embeddings_single.snap"}, {"type": "file", "name": "test_http_predict__predictions_batch.snap"}, {"type": "file", "name": "test_http_predict__predictions_single.snap"}, {"type": "file", "name": "test_http_rerank__ranks.snap"}]}, {"type": "file", "name": "test_http_embed.rs"}, {"type": "file", "name": "test_http_predict.rs"}, {"type": "file", "name": "test_http_rerank.rs"}]}]}, {"type": "file", "name": "rust-toolchain.toml"}, {"type": "file", "name": "sagemaker-entrypoint-cuda-all.sh"}, {"type": "file", "name": "sagemaker-entrypoint.sh"}]} | # Text Embeddings Inference Python gRPC Server
A Python gRPC server for Text Embeddings Inference
## Install
```shell
make install
```
## Run
```shell
make run-dev
```
| {"Dockerfile": "FROM lukemathwalker/cargo-chef:latest-rust-1.75-bookworm AS chef\nWORKDIR /usr/src\n\nENV SCCACHE=0.5.4\nENV RUSTC_WRAPPER=/usr/local/bin/sccache\n\n# Donwload, configure sccache\nRUN curl -fsSL https://github.com/mozilla/sccache/releases/download/v$SCCACHE/sccache-v$SCCACHE-x86_64-unknown-linux-musl.tar.gz | tar -xzv --strip-components=1 -C /usr/local/bin sccache-v$SCCACHE-x86_64-unknown-linux-musl/sccache && \\\n chmod +x /usr/local/bin/sccache\n\nFROM chef AS planner\n\nCOPY backends backends\nCOPY core core\nCOPY router router\nCOPY Cargo.toml ./\nCOPY Cargo.lock ./\n\nRUN cargo chef prepare --recipe-path recipe.json\n\nFROM chef AS builder\n\nARG GIT_SHA\nARG DOCKER_LABEL\n\n# sccache specific variables\nARG ACTIONS_CACHE_URL\nARG ACTIONS_RUNTIME_TOKEN\nARG SCCACHE_GHA_ENABLED\n\nCOPY --from=planner /usr/src/recipe.json recipe.json\n\nRUN cargo chef cook --release --features ort --no-default-features --recipe-path recipe.json && sccache -s\n\nCOPY backends backends\nCOPY core core\nCOPY router router\nCOPY Cargo.toml ./\nCOPY Cargo.lock ./\n\nFROM builder AS http-builder\n\nRUN cargo build --release --bin text-embeddings-router -F ort -F http --no-default-features && sccache -s\n\nFROM builder AS grpc-builder\n\nRUN PROTOC_ZIP=protoc-21.12-linux-x86_64.zip && \\\n curl -OL https://github.com/protocolbuffers/protobuf/releases/download/v21.12/$PROTOC_ZIP && \\\n unzip -o $PROTOC_ZIP -d /usr/local bin/protoc && \\\n unzip -o $PROTOC_ZIP -d /usr/local 'include/*' && \\\n rm -f $PROTOC_ZIP\n\nCOPY proto proto\n\nRUN cargo build --release --bin text-embeddings-router -F grpc -F ort --no-default-features && sccache -s\n\nFROM debian:bookworm-slim AS base\n\nENV HUGGINGFACE_HUB_CACHE=/data \\\n PORT=80\n\nRUN apt-get update && DEBIAN_FRONTEND=noninteractive apt-get install -y --no-install-recommends \\\n ca-certificates \\\n libssl-dev \\\n curl \\\n && rm -rf /var/lib/apt/lists/*\n\n\nFROM base AS grpc\n\nCOPY --from=grpc-builder /usr/src/target/release/text-embeddings-router /usr/local/bin/text-embeddings-router\n\nENTRYPOINT [\"text-embeddings-router\"]\nCMD [\"--json-output\"]\n\nFROM base AS http\n\nCOPY --from=http-builder /usr/src/target/release/text-embeddings-router /usr/local/bin/text-embeddings-router\n\n# Amazon SageMaker compatible image\nFROM http AS sagemaker\nCOPY --chmod=775 sagemaker-entrypoint.sh entrypoint.sh\n\nENTRYPOINT [\"./entrypoint.sh\"]\n\n# Default image\nFROM http\n\nENTRYPOINT [\"text-embeddings-router\"]\nCMD [\"--json-output\"]\n", "Dockerfile-cuda": "FROM nvidia/cuda:12.2.0-devel-ubuntu22.04 AS base-builder\n\nENV SCCACHE=0.5.4\nENV RUSTC_WRAPPER=/usr/local/bin/sccache\nENV PATH=\"/root/.cargo/bin:${PATH}\"\n\nRUN apt-get update && DEBIAN_FRONTEND=noninteractive apt-get install -y --no-install-recommends \\\n curl \\\n libssl-dev \\\n pkg-config \\\n && rm -rf /var/lib/apt/lists/*\n\n# Donwload and configure sccache\nRUN curl -fsSL https://github.com/mozilla/sccache/releases/download/v$SCCACHE/sccache-v$SCCACHE-x86_64-unknown-linux-musl.tar.gz | tar -xzv --strip-components=1 -C /usr/local/bin sccache-v$SCCACHE-x86_64-unknown-linux-musl/sccache && \\\n chmod +x /usr/local/bin/sccache\n\nRUN curl https://sh.rustup.rs -sSf | bash -s -- -y\nRUN cargo install cargo-chef --locked\n\nFROM base-builder AS planner\n\nWORKDIR /usr/src\n\nCOPY backends backends\nCOPY core core\nCOPY router router\nCOPY Cargo.toml ./\nCOPY Cargo.lock ./\n\nRUN cargo chef prepare --recipe-path recipe.json\n\nFROM base-builder AS builder\n\nARG CUDA_COMPUTE_CAP=80\nARG GIT_SHA\nARG DOCKER_LABEL\n\n# Limit parallelism\nARG RAYON_NUM_THREADS\nARG CARGO_BUILD_JOBS\nARG CARGO_BUILD_INCREMENTAL\n\n# sccache specific variables\nARG ACTIONS_CACHE_URL\nARG ACTIONS_RUNTIME_TOKEN\nARG SCCACHE_GHA_ENABLED\n\nWORKDIR /usr/src\n\nRUN if [ ${CUDA_COMPUTE_CAP} -ge 75 -a ${CUDA_COMPUTE_CAP} -lt 80 ]; \\\n then \\\n nvprune --generate-code code=sm_${CUDA_COMPUTE_CAP} /usr/local/cuda/lib64/libcublas_static.a -o /usr/local/cuda/lib64/libcublas_static.a; \\\n elif [ ${CUDA_COMPUTE_CAP} -ge 80 -a ${CUDA_COMPUTE_CAP} -lt 90 ]; \\\n then \\\n nvprune --generate-code code=sm_80 --generate-code code=sm_${CUDA_COMPUTE_CAP} /usr/local/cuda/lib64/libcublas_static.a -o /usr/local/cuda/lib64/libcublas_static.a; \\\n elif [ ${CUDA_COMPUTE_CAP} -eq 90 ]; \\\n then \\\n nvprune --generate-code code=sm_90 /usr/local/cuda/lib64/libcublas_static.a -o /usr/local/cuda/lib64/libcublas_static.a; \\\n else \\\n echo \"cuda compute cap ${CUDA_COMPUTE_CAP} is not supported\"; exit 1; \\\n fi;\n\nCOPY --from=planner /usr/src/recipe.json recipe.json\n\nRUN if [ ${CUDA_COMPUTE_CAP} -ge 75 -a ${CUDA_COMPUTE_CAP} -lt 80 ]; \\\n then \\\n cargo chef cook --release --features candle-cuda-turing --features static-linking --no-default-features --recipe-path recipe.json && sccache -s; \\\n else \\\n cargo chef cook --release --features candle-cuda --features static-linking --no-default-features --recipe-path recipe.json && sccache -s; \\\n fi;\n\nCOPY backends backends\nCOPY core core\nCOPY router router\nCOPY Cargo.toml ./\nCOPY Cargo.lock ./\n\nFROM builder AS http-builder\n\nRUN if [ ${CUDA_COMPUTE_CAP} -ge 75 -a ${CUDA_COMPUTE_CAP} -lt 80 ]; \\\n then \\\n cargo build --release --bin text-embeddings-router -F candle-cuda-turing -F static-linking -F http --no-default-features && sccache -s; \\\n else \\\n cargo build --release --bin text-embeddings-router -F candle-cuda -F static-linking -F http --no-default-features && sccache -s; \\\n fi;\n\nFROM builder AS grpc-builder\n\nRUN apt-get update && DEBIAN_FRONTEND=noninteractive apt-get install -y --no-install-recommends \\\n unzip \\\n && rm -rf /var/lib/apt/lists/*\n\nRUN PROTOC_ZIP=protoc-21.12-linux-x86_64.zip && \\\n curl -OL https://github.com/protocolbuffers/protobuf/releases/download/v21.12/$PROTOC_ZIP && \\\n unzip -o $PROTOC_ZIP -d /usr/local bin/protoc && \\\n unzip -o $PROTOC_ZIP -d /usr/local 'include/*' && \\\n rm -f $PROTOC_ZIP\n\nCOPY proto proto\n\nRUN if [ ${CUDA_COMPUTE_CAP} -ge 75 -a ${CUDA_COMPUTE_CAP} -lt 80 ]; \\\n then \\\n cargo build --release --bin text-embeddings-router -F candle-cuda-turing -F static-linking -F grpc --no-default-features && sccache -s; \\\n else \\\n cargo build --release --bin text-embeddings-router -F candle-cuda -F static-linking -F grpc --no-default-features && sccache -s; \\\n fi;\n\nFROM nvidia/cuda:12.2.0-base-ubuntu22.04 AS base\n\nARG DEFAULT_USE_FLASH_ATTENTION=True\n\nENV HUGGINGFACE_HUB_CACHE=/data \\\n PORT=80 \\\n USE_FLASH_ATTENTION=$DEFAULT_USE_FLASH_ATTENTION\n\nRUN apt-get update && DEBIAN_FRONTEND=noninteractive apt-get install -y --no-install-recommends \\\n ca-certificates \\\n libssl-dev \\\n curl \\\n && rm -rf /var/lib/apt/lists/*\n\nFROM base AS grpc\n\nCOPY --from=grpc-builder /usr/src/target/release/text-embeddings-router /usr/local/bin/text-embeddings-router\n\nENTRYPOINT [\"text-embeddings-router\"]\nCMD [\"--json-output\"]\n\nFROM base\n\nCOPY --from=http-builder /usr/src/target/release/text-embeddings-router /usr/local/bin/text-embeddings-router\n\nENTRYPOINT [\"text-embeddings-router\"]\nCMD [\"--json-output\"]\n", "Dockerfile-cuda-all": "FROM nvidia/cuda:12.2.0-devel-ubuntu22.04 AS base-builder\n\nENV SCCACHE=0.5.4\nENV RUSTC_WRAPPER=/usr/local/bin/sccache\nENV PATH=\"/root/.cargo/bin:${PATH}\"\n\nRUN apt-get update && DEBIAN_FRONTEND=noninteractive apt-get install -y --no-install-recommends \\\n curl \\\n libssl-dev \\\n pkg-config \\\n && rm -rf /var/lib/apt/lists/*\n\n# Donwload and configure sccache\nRUN curl -fsSL https://github.com/mozilla/sccache/releases/download/v$SCCACHE/sccache-v$SCCACHE-x86_64-unknown-linux-musl.tar.gz | tar -xzv --strip-components=1 -C /usr/local/bin sccache-v$SCCACHE-x86_64-unknown-linux-musl/sccache && \\\n chmod +x /usr/local/bin/sccache\n\nRUN curl https://sh.rustup.rs -sSf | bash -s -- -y\nRUN cargo install cargo-chef --locked\n\nFROM base-builder AS planner\n\nWORKDIR /usr/src\n\nCOPY backends backends\nCOPY core core\nCOPY router router\nCOPY Cargo.toml ./\nCOPY Cargo.lock ./\n\nRUN cargo chef prepare --recipe-path recipe.json\n\nFROM base-builder AS builder\n\nARG GIT_SHA\nARG DOCKER_LABEL\nARG VERTEX=\"false\"\n\n# sccache specific variables\nARG ACTIONS_CACHE_URL\nARG ACTIONS_RUNTIME_TOKEN\nARG SCCACHE_GHA_ENABLED\n\n# Limit parallelism\nARG RAYON_NUM_THREADS=4\nARG CARGO_BUILD_JOBS\nARG CARGO_BUILD_INCREMENTAL\n\nWORKDIR /usr/src\n\nCOPY --from=planner /usr/src/recipe.json recipe.json\n\nRUN if [ $VERTEX = \"true\" ]; \\\n then \\\n cargo chef cook --release --features google --recipe-path recipe.json && sccache -s; \\\n else \\\n cargo chef cook --release --recipe-path recipe.json && sccache -s; \\\n fi;\n\nRUN if [ $VERTEX = \"true\" ]; \\\n then \\\n CUDA_COMPUTE_CAP=75 cargo chef cook --release --features google --features candle-cuda-turing --recipe-path recipe.json && sccache -s; \\\n else \\\n CUDA_COMPUTE_CAP=75 cargo chef cook --release --features candle-cuda-turing --recipe-path recipe.json && sccache -s; \\\n fi;\n\nRUN if [ $VERTEX = \"true\" ]; \\\n then \\\n CUDA_COMPUTE_CAP=80 cargo chef cook --release --features google --features candle-cuda --recipe-path recipe.json && sccache -s; \\\n else \\\n CUDA_COMPUTE_CAP=80 cargo chef cook --release --features candle-cuda --recipe-path recipe.json && sccache -s; \\\n fi;\n\nRUN if [ $VERTEX = \"true\" ]; \\\n then \\\n CUDA_COMPUTE_CAP=90 cargo chef cook --release --features google --features candle-cuda --recipe-path recipe.json && sccache -s; \\\n else \\\n CUDA_COMPUTE_CAP=90 cargo chef cook --release --features candle-cuda --recipe-path recipe.json && sccache -s; \\\n fi;\n\nCOPY backends backends\nCOPY core core\nCOPY router router\nCOPY Cargo.toml ./\nCOPY Cargo.lock ./\n\nRUN if [ $VERTEX = \"true\" ]; \\\n then \\\n CUDA_COMPUTE_CAP=75 cargo build --release --bin text-embeddings-router -F candle-cuda-turing -F google && sccache -s; \\\n else \\\n CUDA_COMPUTE_CAP=75 cargo build --release --bin text-embeddings-router -F candle-cuda-turing && sccache -s; \\\n fi;\n\nRUN mv /usr/src/target/release/text-embeddings-router /usr/src/target/release/text-embeddings-router-75\n\nRUN if [ $VERTEX = \"true\" ]; \\\n then \\\n CUDA_COMPUTE_CAP=80 cargo build --release --bin text-embeddings-router -F candle-cuda -F google && sccache -s; \\\n else \\\n CUDA_COMPUTE_CAP=80 cargo build --release --bin text-embeddings-router -F candle-cuda && sccache -s; \\\n fi;\n\nRUN mv /usr/src/target/release/text-embeddings-router /usr/src/target/release/text-embeddings-router-80\n\nRUN if [ $VERTEX = \"true\" ]; \\\n then \\\n CUDA_COMPUTE_CAP=90 cargo build --release --bin text-embeddings-router -F candle-cuda -F google && sccache -s; \\\n else \\\n CUDA_COMPUTE_CAP=90 cargo build --release --bin text-embeddings-router -F candle-cuda && sccache -s; \\\n fi;\n\nRUN mv /usr/src/target/release/text-embeddings-router /usr/src/target/release/text-embeddings-router-90\n\nFROM nvidia/cuda:12.2.0-runtime-ubuntu22.04 AS base\n\nARG DEFAULT_USE_FLASH_ATTENTION=True\n\nENV HUGGINGFACE_HUB_CACHE=/data \\\n PORT=80 \\\n USE_FLASH_ATTENTION=$DEFAULT_USE_FLASH_ATTENTION\n\nRUN apt-get update && DEBIAN_FRONTEND=noninteractive apt-get install -y --no-install-recommends \\\n ca-certificates \\\n libssl-dev \\\n curl \\\n && rm -rf /var/lib/apt/lists/*\n\nCOPY --from=builder /usr/src/target/release/text-embeddings-router-75 /usr/local/bin/text-embeddings-router-75\nCOPY --from=builder /usr/src/target/release/text-embeddings-router-80 /usr/local/bin/text-embeddings-router-80\nCOPY --from=builder /usr/src/target/release/text-embeddings-router-90 /usr/local/bin/text-embeddings-router-90\n\n# Amazon SageMaker compatible image\nFROM base AS sagemaker\n\nCOPY --chmod=775 sagemaker-entrypoint-cuda-all.sh entrypoint.sh\n\nENTRYPOINT [\"./entrypoint.sh\"]\n\n# Default image\nFROM base\n\nCOPY --chmod=775 cuda-all-entrypoint.sh entrypoint.sh\n\nENTRYPOINT [\"./entrypoint.sh\"]\nCMD [\"--json-output\"]\n", ".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 416efe19f2ad687a3461ae453c32003be0892749 Hamza Amin <[email protected]> 1727369490 +0500\tclone: from https://github.com/huggingface/text-embeddings-inference.git\n", ".git\\refs\\heads\\main": "416efe19f2ad687a3461ae453c32003be0892749\n", "backends\\python\\server\\requirements.txt": "backoff==2.2.1 ; python_version >= \"3.9\" and python_version < \"3.13\"\ncertifi==2023.7.22 ; python_version >= \"3.9\" and python_version < \"3.13\"\ncharset-normalizer==3.2.0 ; python_version >= \"3.9\" and python_version < \"3.13\"\nclick==8.1.7 ; python_version >= \"3.9\" and python_version < \"3.13\"\ncolorama==0.4.6 ; python_version >= \"3.9\" and python_version < \"3.13\" and (sys_platform == \"win32\" or platform_system == \"Windows\")\ndeprecated==1.2.14 ; python_version >= \"3.9\" and python_version < \"3.13\"\nfilelock==3.12.3 ; python_version >= \"3.9\" and python_version < \"3.13\"\nfsspec==2023.9.0 ; python_version >= \"3.9\" and python_version < \"3.13\"\ngoogleapis-common-protos==1.60.0 ; python_version >= \"3.9\" and python_version < \"3.13\"\ngrpc-interceptor==0.15.3 ; python_version >= \"3.9\" and python_version < \"3.13\"\ngrpcio-reflection==1.58.0 ; python_version >= \"3.9\" and python_version < \"3.13\"\ngrpcio-status==1.58.0 ; python_version >= \"3.9\" and python_version < \"3.13\"\ngrpcio==1.58.0 ; python_version >= \"3.9\" and python_version < \"3.13\"\nhuggingface-hub==0.16.4 ; python_version >= \"3.9\" and python_version < \"3.13\"\nidna==3.4 ; python_version >= \"3.9\" and python_version < \"3.13\"\njinja2==3.1.2 ; python_version >= \"3.9\" and python_version < \"3.13\"\nloguru==0.6.0 ; python_version >= \"3.9\" and python_version < \"3.13\"\nmarkupsafe==2.1.3 ; python_version >= \"3.9\" and python_version < \"3.13\"\nmpmath==1.3.0 ; python_version >= \"3.9\" and python_version < \"3.13\"\nnetworkx==3.1 ; python_version >= \"3.9\" and python_version < \"3.13\"\nopentelemetry-api==1.15.0 ; python_version >= \"3.9\" and python_version < \"3.13\"\nopentelemetry-exporter-otlp-proto-grpc==1.15.0 ; python_version >= \"3.9\" and python_version < \"3.13\"\nopentelemetry-exporter-otlp-proto-http==1.15.0 ; python_version >= \"3.9\" and python_version < \"3.13\"\nopentelemetry-exporter-otlp==1.15.0 ; python_version >= \"3.9\" and python_version < \"3.13\"\nopentelemetry-instrumentation-grpc==0.36b0 ; python_version >= \"3.9\" and python_version < \"3.13\"\nopentelemetry-instrumentation==0.36b0 ; python_version >= \"3.9\" and python_version < \"3.13\"\nopentelemetry-proto==1.15.0 ; python_version >= \"3.9\" and python_version < \"3.13\"\nopentelemetry-sdk==1.15.0 ; python_version >= \"3.9\" and python_version < \"3.13\"\nopentelemetry-semantic-conventions==0.36b0 ; python_version >= \"3.9\" and python_version < \"3.13\"\npackaging==23.1 ; python_version >= \"3.9\" and python_version < \"3.13\"\nprotobuf==4.24.3 ; python_version >= \"3.9\" and python_version < \"3.13\"\npyyaml==6.0.1 ; python_version >= \"3.9\" and python_version < \"3.13\"\nrequests==2.31.0 ; python_version >= \"3.9\" and python_version < \"3.13\"\nsafetensors==0.3.3 ; python_version >= \"3.9\" and python_version < \"3.13\"\nsetuptools==68.2.0 ; python_version >= \"3.9\" and python_version < \"3.13\"\nsympy==1.12 ; python_version >= \"3.9\" and python_version < \"3.13\"\ntorch==2.0.1 ; python_version >= \"3.9\" and python_version < \"3.13\"\ntqdm==4.66.1 ; python_version >= \"3.9\" and python_version < \"3.13\"\ntyper==0.6.1 ; python_version >= \"3.9\" and python_version < \"3.13\"\ntyping-extensions==4.7.1 ; python_version >= \"3.9\" and python_version < \"3.13\"\nurllib3==2.0.4 ; python_version >= \"3.9\" and python_version < \"3.13\"\nwin32-setctime==1.1.0 ; python_version >= \"3.9\" and python_version < \"3.13\" and sys_platform == \"win32\"\nwrapt==1.15.0 ; python_version >= \"3.9\" and python_version < \"3.13\"\n", "docs\\index.html": "<html>\n <head>\n <!-- Load the latest Swagger UI code and style from npm using unpkg.com -->\n <script src=\"https://unpkg.com/swagger-ui-dist@3/swagger-ui-bundle.js\"></script>\n <link rel=\"stylesheet\" type=\"text/css\" href=\"https://unpkg.com/swagger-ui-dist@3/swagger-ui.css\"/>\n <title>Text Embeddings Inference API</title>\n </head>\n <body>\n <div id=\"swagger-ui\"></div> <!-- Div to hold the UI component -->\n <script>\n window.onload = function () {\n // Begin Swagger UI call region\n const ui = SwaggerUIBundle({\n url: \"openapi.json\", //Location of Open API spec in the repo\n dom_id: '#swagger-ui',\n deepLinking: true,\n supportedSubmitMethods: [],\n presets: [\n SwaggerUIBundle.presets.apis,\n SwaggerUIBundle.SwaggerUIStandalonePreset\n ],\n plugins: [\n SwaggerUIBundle.plugins.DownloadUrl\n ],\n })\n window.ui = ui\n }\n </script>\n </body>\n</html>\n", "docs\\source\\en\\index.md": "<!--Copyright 2023 The HuggingFace Team. All rights reserved.\n\nLicensed under the Apache License, Version 2.0 (the \"License\"); you may not use this file except in compliance with\nthe License. You may obtain a copy of the License at\n\nhttp://www.apache.org/licenses/LICENSE-2.0\n\nUnless required by applicable law or agreed to in writing, software distributed under the License is distributed on\nan \"AS IS\" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the\nspecific language governing permissions and limitations under the License.\n\n\u26a0\ufe0f Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be\nrendered properly in your Markdown viewer.\n\n-->\n\n# Text Embeddings Inference\n\nText Embeddings Inference (TEI) is a comprehensive toolkit designed for efficient deployment and serving of open source\ntext embeddings models. It enables high-performance extraction for the most popular models, including FlagEmbedding, Ember, GTE, and E5.\n\nTEI offers multiple features tailored to optimize the deployment process and enhance overall performance.\n\n**Key Features:**\n\n* **Streamlined Deployment:** TEI eliminates the need for a model graph compilation step for an easier deployment process.\n* **Efficient Resource Utilization:** Benefit from small Docker images and rapid boot times, allowing for true serverless capabilities.\n* **Dynamic Batching:** TEI incorporates token-based dynamic batching thus optimizing resource utilization during inference.\n* **Optimized Inference:** TEI leverages [Flash Attention](https://github.com/HazyResearch/flash-attention), [Candle](https://github.com/huggingface/candle), and [cuBLASLt](https://docs.nvidia.com/cuda/cublas/#using-the-cublaslt-api) by using optimized transformers code for inference.\n* **Safetensors weight loading:** TEI loads [Safetensors](https://github.com/huggingface/safetensors) weights for faster boot times.\n* **Production-Ready:** TEI supports distributed tracing through Open Telemetry and exports Prometheus metrics.\n\n**Benchmarks**\n\nBenchmark for [BAAI/bge-base-en-v1.5](https://hf.co/BAAI/bge-large-en-v1.5) on an NVIDIA A10 with a sequence length of 512 tokens:\n\n<p>\n <img src=\"https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/tei/bs1-lat.png\" width=\"400\" alt=\"Latency comparison for batch size of 1\" />\n <img src=\"https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/tei/bs1-tp.png\" width=\"400\" alt=\"Throughput comparison for batch size of 1\"/>\n</p>\n<p>\n <img src=\"https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/tei/bs32-lat.png\" width=\"400\" alt=\"Latency comparison for batch size of 32\"/>\n <img src=\"https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/tei/bs32-tp.png\" width=\"400\" alt=\"Throughput comparison for batch size of 32\" />\n</p>\n\n**Getting Started:**\n\nTo start using TEI, check the [Quick Tour](quick_tour) guide.\n", "router\\src\\main.rs": "use anyhow::Result;\nuse clap::Parser;\nuse opentelemetry::global;\nuse text_embeddings_backend::DType;\nuse veil::Redact;\n\n#[cfg(not(target_os = \"linux\"))]\n#[global_allocator]\nstatic GLOBAL: mimalloc::MiMalloc = mimalloc::MiMalloc;\n\n/// App Configuration\n#[derive(Parser, Redact)]\n#[clap(author, version, about, long_about = None)]\nstruct Args {\n /// The name of the model to load.\n /// Can be a MODEL_ID as listed on <https://hf.co/models> like\n /// `BAAI/bge-large-en-v1.5`.\n /// Or it can be a local directory containing the necessary files\n /// as saved by `save_pretrained(...)` methods of transformers\n #[clap(default_value = \"BAAI/bge-large-en-v1.5\", long, env)]\n #[redact(partial)]\n model_id: String,\n\n /// The actual revision of the model if you're referring to a model\n /// on the hub. You can use a specific commit id or a branch like `refs/pr/2`.\n #[clap(long, env)]\n revision: Option<String>,\n\n /// Optionally control the number of tokenizer workers used for payload tokenization, validation\n /// and truncation.\n /// Default to the number of CPU cores on the machine.\n #[clap(long, env)]\n tokenization_workers: Option<usize>,\n\n /// The dtype to be forced upon the model.\n #[clap(long, env, value_enum)]\n dtype: Option<DType>,\n\n /// Optionally control the pooling method for embedding models.\n ///\n /// If `pooling` is not set, the pooling configuration will be parsed from the\n /// model `1_Pooling/config.json` configuration.\n ///\n /// If `pooling` is set, it will override the model pooling configuration\n #[clap(long, env, value_enum)]\n pooling: Option<text_embeddings_backend::Pool>,\n\n /// The maximum amount of concurrent requests for this particular deployment.\n /// Having a low limit will refuse clients requests instead of having them\n /// wait for too long and is usually good to handle backpressure correctly.\n #[clap(default_value = \"512\", long, env)]\n max_concurrent_requests: usize,\n\n /// **IMPORTANT** This is one critical control to allow maximum usage\n /// of the available hardware.\n ///\n /// This represents the total amount of potential tokens within a batch.\n ///\n /// For `max_batch_tokens=1000`, you could fit `10` queries of `total_tokens=100`\n /// or a single query of `1000` tokens.\n ///\n /// Overall this number should be the largest possible until the model is compute bound.\n /// Since the actual memory overhead depends on the model implementation,\n /// text-embeddings-inference cannot infer this number automatically.\n #[clap(default_value = \"16384\", long, env)]\n max_batch_tokens: usize,\n\n /// Optionally control the maximum number of individual requests in a batch\n #[clap(long, env)]\n max_batch_requests: Option<usize>,\n\n /// Control the maximum number of inputs that a client can send in a single request\n #[clap(default_value = \"32\", long, env)]\n max_client_batch_size: usize,\n\n /// Automatically truncate inputs that are longer than the maximum supported size\n ///\n /// Unused for gRPC servers\n #[clap(long, env)]\n auto_truncate: bool,\n\n /// The name of the prompt that should be used by default for encoding. If not set, no prompt\n /// will be applied.\n ///\n /// Must be a key in the `sentence-transformers` configuration `prompts` dictionary.\n ///\n /// For example if ``default_prompt_name`` is \"query\" and the ``prompts`` is {\"query\": \"query: \", ...},\n /// then the sentence \"What is the capital of France?\" will be encoded as\n /// \"query: What is the capital of France?\" because the prompt text will be prepended before\n /// any text to encode.\n ///\n /// The argument '--default-prompt-name <DEFAULT_PROMPT_NAME>' cannot be used with\n /// '--default-prompt <DEFAULT_PROMPT>`\n #[clap(long, env, conflicts_with = \"default_prompt\")]\n default_prompt_name: Option<String>,\n\n /// The prompt that should be used by default for encoding. If not set, no prompt\n /// will be applied.\n ///\n /// For example if ``default_prompt`` is \"query: \" then the sentence \"What is the capital of\n /// France?\" will be encoded as \"query: What is the capital of France?\" because the prompt\n /// text will be prepended before any text to encode.\n ///\n /// The argument '--default-prompt <DEFAULT_PROMPT>' cannot be used with\n /// '--default-prompt-name <DEFAULT_PROMPT_NAME>`\n #[clap(long, env, conflicts_with = \"default_prompt_name\")]\n default_prompt: Option<String>,\n\n /// Your HuggingFace hub token\n #[clap(long, env)]\n #[redact(partial)]\n hf_api_token: Option<String>,\n\n /// The IP address to listen on\n #[clap(default_value = \"0.0.0.0\", long, env)]\n hostname: String,\n\n /// The port to listen on.\n #[clap(default_value = \"3000\", long, short, env)]\n port: u16,\n\n /// The name of the unix socket some text-embeddings-inference backends will use as they\n /// communicate internally with gRPC.\n #[clap(default_value = \"/tmp/text-embeddings-inference-server\", long, env)]\n uds_path: String,\n\n /// The location of the huggingface hub cache.\n /// Used to override the location if you want to provide a mounted disk for instance\n #[clap(long, env)]\n huggingface_hub_cache: Option<String>,\n\n /// Payload size limit in bytes\n ///\n /// Default is 2MB\n #[clap(default_value = \"2000000\", long, env)]\n payload_limit: usize,\n\n /// Set an api key for request authorization.\n ///\n /// By default the server responds to every request. With an api key set, the requests must have the Authorization header set with the api key as Bearer token.\n #[clap(long, env)]\n api_key: Option<String>,\n\n /// Outputs the logs in JSON format (useful for telemetry)\n #[clap(long, env)]\n json_output: bool,\n\n /// The grpc endpoint for opentelemetry. Telemetry is sent to this endpoint as OTLP over gRPC.\n /// e.g. `http://localhost:4317`\n #[clap(long, env)]\n otlp_endpoint: Option<String>,\n\n /// The service name for opentelemetry.\n /// e.g. `text-embeddings-inference.server`\n #[clap(default_value = \"text-embeddings-inference.server\", long, env)]\n otlp_service_name: String,\n\n /// Unused for gRPC servers\n #[clap(long, env)]\n cors_allow_origin: Option<Vec<String>>,\n}\n\n#[tokio::main]\nasync fn main() -> Result<()> {\n // Pattern match configuration\n let args: Args = Args::parse();\n\n // Initialize logging and telemetry\n let global_tracer = text_embeddings_router::init_logging(\n args.otlp_endpoint.as_ref(),\n args.otlp_service_name.clone(),\n args.json_output,\n );\n\n tracing::info!(\"{args:?}\");\n\n // Hack to trim pages regularly\n // see: https://www.algolia.com/blog/engineering/when-allocators-are-hoarding-your-precious-memory/\n // and: https://github.com/huggingface/text-embeddings-inference/issues/156\n #[cfg(target_os = \"linux\")]\n tokio::spawn(async move {\n use tokio::time::Duration;\n loop {\n tokio::time::sleep(Duration::from_millis(100)).await;\n unsafe {\n libc::malloc_trim(0);\n }\n }\n });\n\n text_embeddings_router::run(\n args.model_id,\n args.revision,\n args.tokenization_workers,\n args.dtype,\n args.pooling,\n args.max_concurrent_requests,\n args.max_batch_tokens,\n args.max_batch_requests,\n args.max_client_batch_size,\n args.auto_truncate,\n args.default_prompt,\n args.default_prompt_name,\n args.hf_api_token,\n Some(args.hostname),\n args.port,\n Some(args.uds_path),\n args.huggingface_hub_cache,\n args.payload_limit,\n args.api_key,\n args.otlp_endpoint,\n args.otlp_service_name,\n args.cors_allow_origin,\n )\n .await?;\n\n if global_tracer {\n // Shutdown tracer\n global::shutdown_tracer_provider();\n }\n Ok(())\n}\n"} | null |
text-generation-inference | {"type": "directory", "name": "text-generation-inference", "children": [{"type": "directory", "name": ".devcontainer", "children": [{"type": "file", "name": "devcontainer.json"}, {"type": "file", "name": "Dockerfile.trtllm"}]}, {"type": "file", "name": ".dockerignore"}, {"type": "file", "name": ".pre-commit-config.yaml"}, {"type": "file", "name": ".redocly.lint-ignore.yaml"}, {"type": "directory", "name": "assets", "children": [{"type": "file", "name": "tgi_grafana.json"}]}, {"type": "directory", "name": "backends", "children": [{"type": "directory", "name": "client", "children": [{"type": "file", "name": "build.rs"}, {"type": "file", "name": "Cargo.toml"}, {"type": "directory", "name": "src", "children": [{"type": "file", "name": "lib.rs"}, {"type": "directory", "name": "v2", "children": [{"type": "file", "name": "client.rs"}, {"type": "file", "name": "mod.rs"}, {"type": "file", "name": "sharded_client.rs"}]}, {"type": "directory", "name": "v3", "children": [{"type": "file", "name": "client.rs"}, {"type": "file", "name": "mod.rs"}, {"type": "file", "name": "sharded_client.rs"}]}]}]}, {"type": "directory", "name": "grpc-metadata", "children": [{"type": "file", "name": "Cargo.toml"}, {"type": "directory", "name": "src", "children": [{"type": "file", "name": "lib.rs"}]}]}, {"type": "directory", "name": "trtllm", "children": [{"type": "file", "name": "build.rs"}, {"type": "file", "name": "Cargo.toml"}, {"type": "directory", "name": "cmake", "children": [{"type": "file", "name": "fmt.cmake"}, {"type": "file", "name": "json.cmake"}, {"type": "file", "name": "spdlog.cmake"}, {"type": "file", "name": "trtllm.cmake"}, {"type": "directory", "name": "utils", "children": [{"type": "file", "name": "detect_cuda_arch.cu"}]}]}, {"type": "file", "name": "CMakeLists.txt"}, {"type": "file", "name": "Dockerfile"}, {"type": "directory", "name": "include", "children": [{"type": "file", "name": "backend.h"}, {"type": "file", "name": "ffi.h"}, {"type": "file", "name": "hardware.h"}]}, {"type": "directory", "name": "lib", "children": [{"type": "file", "name": "backend.cpp"}]}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "scripts", "children": [{"type": "file", "name": "install_tensorrt.sh"}]}, {"type": "directory", "name": "src", "children": [{"type": "file", "name": "backend.rs"}, {"type": "file", "name": "errors.rs"}, {"type": "file", "name": "ffi.cpp"}, {"type": "file", "name": "lib.rs"}, {"type": "file", "name": "main.rs"}]}, {"type": "directory", "name": "tests", "children": [{"type": "file", "name": "infer_test.cpp"}]}]}, {"type": "directory", "name": "v2", "children": [{"type": "file", "name": "build.rs"}, {"type": "file", "name": "Cargo.toml"}, {"type": "directory", "name": "src", "children": [{"type": "file", "name": "backend.rs"}, {"type": "directory", "name": "client", "children": [{"type": "file", "name": "grpc_client.rs"}, {"type": "file", "name": "mod.rs"}, {"type": "file", "name": "sharded_client.rs"}]}, {"type": "file", "name": "lib.rs"}, {"type": "file", "name": "main.rs"}, {"type": "file", "name": "queue.rs"}]}]}, {"type": "directory", "name": "v3", "children": [{"type": "directory", "name": "benches", "children": [{"type": "file", "name": "prefix_cache.rs"}]}, {"type": "file", "name": "build.rs"}, {"type": "file", "name": "Cargo.toml"}, {"type": "directory", "name": "src", "children": [{"type": "file", "name": "backend.rs"}, {"type": "file", "name": "block_allocator.rs"}, {"type": "directory", "name": "client", "children": [{"type": "file", "name": "grpc_client.rs"}, {"type": "file", "name": "mod.rs"}, {"type": "file", "name": "sharded_client.rs"}]}, {"type": "file", "name": "lib.rs"}, {"type": "file", "name": "main.rs"}, {"type": "file", "name": "queue.rs"}, {"type": "file", "name": "radix.rs"}]}]}]}, {"type": "directory", "name": "benchmark", "children": [{"type": "file", "name": "Cargo.toml"}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "src", "children": [{"type": "file", "name": "app.rs"}, {"type": "file", "name": "event.rs"}, {"type": "file", "name": "generation.rs"}, {"type": "file", "name": "lib.rs"}, {"type": "file", "name": "main.rs"}, {"type": "file", "name": "table.rs"}, {"type": "file", "name": "utils.rs"}]}]}, {"type": "file", "name": "Cargo.lock"}, {"type": "file", "name": "Cargo.toml"}, {"type": "directory", "name": "clients", "children": [{"type": "directory", "name": "python", "children": [{"type": "file", "name": "Makefile"}, {"type": "file", "name": "poetry.lock"}, {"type": "file", "name": "pyproject.toml"}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "tests", "children": [{"type": "file", "name": "conftest.py"}, {"type": "file", "name": "test_client.py"}, {"type": "file", "name": "test_errors.py"}, {"type": "file", "name": "test_inference_api.py"}, {"type": "file", "name": "test_types.py"}]}, {"type": "directory", "name": "text_generation", "children": [{"type": "file", "name": "client.py"}, {"type": "file", "name": "errors.py"}, {"type": "file", "name": "inference_api.py"}, {"type": "file", "name": "types.py"}, {"type": "file", "name": "__init__.py"}]}]}]}, {"type": "file", "name": "CODE_OF_CONDUCT.md"}, {"type": "file", "name": "CONTRIBUTING.md"}, {"type": "file", "name": "Dockerfile"}, {"type": "file", "name": "Dockerfile.trtllm"}, {"type": "file", "name": "Dockerfile_amd"}, {"type": "file", "name": "Dockerfile_intel"}, {"type": "directory", "name": "docs", "children": [{"type": "file", "name": "index.html"}, {"type": "file", "name": "openapi.json"}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "source", "children": [{"type": "file", "name": "architecture.md"}, {"type": "directory", "name": "basic_tutorials", "children": [{"type": "file", "name": "consuming_tgi.md"}, {"type": "file", "name": "gated_model_access.md"}, {"type": "file", "name": "monitoring.md"}, {"type": "file", "name": "non_core_models.md"}, {"type": "file", "name": "preparing_model.md"}, {"type": "file", "name": "safety.md"}, {"type": "file", "name": "train_medusa.md"}, {"type": "file", "name": "using_cli.md"}, {"type": "file", "name": "using_guidance.md"}, {"type": "file", "name": "visual_language_models.md"}]}, {"type": "directory", "name": "conceptual", "children": [{"type": "file", "name": "external.md"}, {"type": "file", "name": "flash_attention.md"}, {"type": "file", "name": "guidance.md"}, {"type": "file", "name": "lora.md"}, {"type": "file", "name": "paged_attention.md"}, {"type": "file", "name": "quantization.md"}, {"type": "file", "name": "safetensors.md"}, {"type": "file", "name": "speculation.md"}, {"type": "file", "name": "streaming.md"}, {"type": "file", "name": "tensor_parallelism.md"}]}, {"type": "file", "name": "index.md"}, {"type": "file", "name": "installation.md"}, {"type": "file", "name": "installation_amd.md"}, {"type": "file", "name": "installation_gaudi.md"}, {"type": "file", "name": "installation_inferentia.md"}, {"type": "file", "name": "installation_intel.md"}, {"type": "file", "name": "installation_nvidia.md"}, {"type": "file", "name": "quicktour.md"}, {"type": "directory", "name": "reference", "children": [{"type": "file", "name": "api_reference.md"}, {"type": "file", "name": "launcher.md"}, {"type": "file", "name": "metrics.md"}]}, {"type": "file", "name": "supported_models.md"}, {"type": "file", "name": "usage_statistics.md"}, {"type": "file", "name": "_toctree.yml"}]}]}, {"type": "file", "name": "flake.lock"}, {"type": "file", "name": "flake.nix"}, {"type": "directory", "name": "integration-tests", "children": [{"type": "file", "name": "conftest.py"}, {"type": "directory", "name": "images", "children": []}, {"type": "directory", "name": "models", "children": [{"type": "file", "name": "test_bloom_560m.py"}, {"type": "file", "name": "test_bloom_560m_sharded.py"}, {"type": "file", "name": "test_chat_llama.py"}, {"type": "file", "name": "test_completion_prompts.py"}, {"type": "file", "name": "test_flash_awq.py"}, {"type": "file", "name": "test_flash_awq_sharded.py"}, {"type": "file", "name": "test_flash_deepseek_v2.py"}, {"type": "file", "name": "test_flash_falcon.py"}, {"type": "file", "name": "test_flash_gemma.py"}, {"type": "file", "name": "test_flash_gemma2.py"}, {"type": "file", "name": "test_flash_gemma_gptq.py"}, {"type": "file", "name": "test_flash_gpt2.py"}, {"type": "file", "name": "test_flash_grammar_llama.py"}, {"type": "file", "name": "test_flash_llama.py"}, {"type": "file", "name": "test_flash_llama_exl2.py"}, {"type": "file", "name": "test_flash_llama_fp8.py"}, {"type": "file", "name": "test_flash_llama_gptq.py"}, {"type": "file", "name": "test_flash_llama_marlin.py"}, {"type": "file", "name": "test_flash_llama_marlin_24.py"}, {"type": "file", "name": "test_flash_llama_prefix.py"}, {"type": "file", "name": "test_flash_llama_prefix_flashdecoding.py"}, {"type": "file", "name": "test_flash_medusa.py"}, {"type": "file", "name": "test_flash_mistral.py"}, {"type": "file", "name": "test_flash_mixtral.py"}, {"type": "file", "name": "test_flash_neox.py"}, {"type": "file", "name": "test_flash_neox_sharded.py"}, {"type": "file", "name": "test_flash_pali_gemma.py"}, {"type": "file", "name": "test_flash_phi.py"}, {"type": "file", "name": "test_flash_qwen2.py"}, {"type": "file", "name": "test_flash_santacoder.py"}, {"type": "file", "name": "test_flash_starcoder.py"}, {"type": "file", "name": "test_flash_starcoder2.py"}, {"type": "file", "name": "test_flash_starcoder_gptq.py"}, {"type": "file", "name": "test_grammar_llama.py"}, {"type": "file", "name": "test_grammar_response_format_llama.py"}, {"type": "file", "name": "test_idefics.py"}, {"type": "file", "name": "test_idefics2.py"}, {"type": "file", "name": "test_llava_next.py"}, {"type": "file", "name": "test_lora_mistral.py"}, {"type": "file", "name": "test_mamba.py"}, {"type": "file", "name": "test_mpt.py"}, {"type": "file", "name": "test_mt0_base.py"}, {"type": "file", "name": "test_neox.py"}, {"type": "file", "name": "test_neox_sharded.py"}, {"type": "file", "name": "test_opt.py"}, {"type": "file", "name": "test_t5_sharded.py"}, {"type": "file", "name": "test_tools_llama.py"}, {"type": "directory", "name": "__snapshots__", "children": [{"type": "directory", "name": "test_bloom_560m", "children": [{"type": "file", "name": "test_bloom_560m.json"}, {"type": "file", "name": "test_bloom_560m_all_params.json"}, {"type": "file", "name": "test_bloom_560m_load.json"}]}, {"type": "directory", "name": "test_bloom_560m_sharded", "children": [{"type": "file", "name": "test_bloom_560m_sharded.json"}, {"type": "file", "name": "test_bloom_560m_sharded_load.json"}]}, {"type": "directory", "name": "test_chat_llama", "children": [{"type": "file", "name": "test_flash_llama_simple.json"}]}, {"type": "directory", "name": "test_completion_prompts", "children": [{"type": "file", "name": "test_flash_llama_completion_many_prompts.json"}, {"type": "file", "name": "test_flash_llama_completion_many_prompts_stream.json"}, {"type": "file", "name": "test_flash_llama_completion_single_prompt.json"}, {"type": "file", "name": "test_flash_llama_completion_stream_usage.json"}]}, {"type": "directory", "name": "test_flash_awq", "children": [{"type": "file", "name": "test_flash_llama_awq.json"}, {"type": "file", "name": "test_flash_llama_awq_all_params.json"}, {"type": "file", "name": "test_flash_llama_awq_load.json"}]}, {"type": "directory", "name": "test_flash_awq_sharded", "children": [{"type": "file", "name": "test_flash_llama_awq_load_sharded.json"}, {"type": "file", "name": "test_flash_llama_awq_sharded.json"}]}, {"type": "directory", "name": "test_flash_deepseek_v2", "children": [{"type": "file", "name": "test_flash_deepseek_v2.json"}, {"type": "file", "name": "test_flash_deepseek_v2_all_params.json"}, {"type": "file", "name": "test_flash_deepseek_v2_load.json"}]}, {"type": "directory", "name": "test_flash_falcon", "children": [{"type": "file", "name": "test_flash_falcon.json"}, {"type": "file", "name": "test_flash_falcon_all_params.json"}, {"type": "file", "name": "test_flash_falcon_load.json"}]}, {"type": "directory", "name": "test_flash_gemma", "children": [{"type": "file", "name": "test_flash_gemma.json"}, {"type": "file", "name": "test_flash_gemma_all_params.json"}, {"type": "file", "name": "test_flash_gemma_load.json"}]}, {"type": "directory", "name": "test_flash_gemma2", "children": [{"type": "file", "name": "test_flash_gemma2.json"}, {"type": "file", "name": "test_flash_gemma2_load.json"}]}, {"type": "directory", "name": "test_flash_gemma_gptq", "children": [{"type": "file", "name": "test_flash_gemma_gptq.json"}, {"type": "file", "name": "test_flash_gemma_gptq_all_params.json"}, {"type": "file", "name": "test_flash_gemma_gptq_load.json"}]}, {"type": "directory", "name": "test_flash_gpt2", "children": [{"type": "file", "name": "test_flash_gpt2.json"}, {"type": "file", "name": "test_flash_gpt2_load.json"}]}, {"type": "directory", "name": "test_flash_grammar_llama", "children": [{"type": "file", "name": "test_flash_llama_grammar.json"}, {"type": "file", "name": "test_flash_llama_grammar_json.json"}, {"type": "file", "name": "test_flash_llama_grammar_load.json"}, {"type": "file", "name": "test_flash_llama_grammar_regex.json"}, {"type": "file", "name": "test_flash_llama_grammar_single_load_instance.json"}]}, {"type": "directory", "name": "test_flash_llama", "children": [{"type": "file", "name": "test_flash_llama.json"}, {"type": "file", "name": "test_flash_llama_all_params.json"}, {"type": "file", "name": "test_flash_llama_load.json"}]}, {"type": "directory", "name": "test_flash_llama_exl2", "children": [{"type": "file", "name": "test_flash_llama_exl2.json"}, {"type": "file", "name": "test_flash_llama_exl2_all_params.json"}, {"type": "file", "name": "test_flash_llama_exl2_load.json"}]}, {"type": "directory", "name": "test_flash_llama_fp8", "children": [{"type": "file", "name": "test_flash_llama_fp8.json"}, {"type": "file", "name": "test_flash_llama_fp8_all_params.json"}, {"type": "file", "name": "test_flash_llama_fp8_load.json"}]}, {"type": "directory", "name": "test_flash_llama_gptq", "children": [{"type": "file", "name": "test_flash_llama_gptq.json"}, {"type": "file", "name": "test_flash_llama_gptq_all_params.json"}, {"type": "file", "name": "test_flash_llama_gptq_load.json"}]}, {"type": "directory", "name": "test_flash_llama_marlin", "children": [{"type": "file", "name": "test_flash_llama_marlin.json"}, {"type": "file", "name": "test_flash_llama_marlin_all_params.json"}, {"type": "file", "name": "test_flash_llama_marlin_load.json"}]}, {"type": "directory", "name": "test_flash_llama_marlin_24", "children": [{"type": "file", "name": "test_flash_llama_marlin.json"}, {"type": "file", "name": "test_flash_llama_marlin24_all_params.json"}, {"type": "file", "name": "test_flash_llama_marlin24_load.json"}]}, {"type": "directory", "name": "test_flash_llama_prefix", "children": [{"type": "file", "name": "test_flash_llama_load.json"}]}, {"type": "directory", "name": "test_flash_llama_prefix_flashdecoding", "children": [{"type": "file", "name": "test_flash_llama_flashdecoding.json"}]}, {"type": "directory", "name": "test_flash_medusa", "children": [{"type": "file", "name": "test_flash_medusa_all_params.json"}, {"type": "file", "name": "test_flash_medusa_load.json"}, {"type": "file", "name": "test_flash_medusa_simple.json"}]}, {"type": "directory", "name": "test_flash_mistral", "children": [{"type": "file", "name": "test_flash_mistral.json"}, {"type": "file", "name": "test_flash_mistral_all_params.json"}, {"type": "file", "name": "test_flash_mistral_load.json"}]}, {"type": "directory", "name": "test_flash_mixtral", "children": [{"type": "file", "name": "test_flash_mixtral.json"}, {"type": "file", "name": "test_flash_mixtral_all_params.json"}, {"type": "file", "name": "test_flash_mixtral_load.json"}]}, {"type": "directory", "name": "test_flash_neox", "children": [{"type": "file", "name": "test_flash_neox.json"}, {"type": "file", "name": "test_flash_neox_load.json"}]}, {"type": "directory", "name": "test_flash_neox_sharded", "children": [{"type": "file", "name": "test_flash_neox.json"}, {"type": "file", "name": "test_flash_neox_load.json"}]}, {"type": "directory", "name": "test_flash_pali_gemma", "children": [{"type": "file", "name": "test_flash_pali_gemma.json"}, {"type": "file", "name": "test_flash_pali_gemma_two_images.json"}]}, {"type": "directory", "name": "test_flash_phi", "children": [{"type": "file", "name": "test_flash_phi.json"}, {"type": "file", "name": "test_flash_phi_all_params.json"}, {"type": "file", "name": "test_flash_phi_load.json"}]}, {"type": "directory", "name": "test_flash_qwen2", "children": [{"type": "file", "name": "test_flash_qwen2.json"}, {"type": "file", "name": "test_flash_qwen2_all_params.json"}, {"type": "file", "name": "test_flash_qwen2_load.json"}]}, {"type": "directory", "name": "test_flash_santacoder", "children": [{"type": "file", "name": "test_flash_santacoder.json"}, {"type": "file", "name": "test_flash_santacoder_load.json"}]}, {"type": "directory", "name": "test_flash_starcoder", "children": [{"type": "file", "name": "test_flash_starcoder.json"}, {"type": "file", "name": "test_flash_starcoder_default_params.json"}, {"type": "file", "name": "test_flash_starcoder_load.json"}]}, {"type": "directory", "name": "test_flash_starcoder2", "children": [{"type": "file", "name": "test_flash_starcoder2.json"}, {"type": "file", "name": "test_flash_starcoder2_default_params.json"}, {"type": "file", "name": "test_flash_starcoder2_load.json"}]}, {"type": "directory", "name": "test_flash_starcoder_gptq", "children": [{"type": "file", "name": "test_flash_starcoder_gptq.json"}, {"type": "file", "name": "test_flash_starcoder_gptq_default_params.json"}, {"type": "file", "name": "test_flash_starcoder_gptq_load.json"}]}, {"type": "directory", "name": "test_grammar_llama", "children": [{"type": "file", "name": "test_non_flash_llama_grammar_json.json"}]}, {"type": "directory", "name": "test_grammar_response_format_llama", "children": [{"type": "file", "name": "test_grammar_response_format_llama_json.json"}]}, {"type": "directory", "name": "test_idefics", "children": [{"type": "file", "name": "test_idefics.json"}, {"type": "file", "name": "test_idefics_load.json"}, {"type": "file", "name": "test_idefics_two_images.json"}]}, {"type": "directory", "name": "test_idefics2", "children": [{"type": "file", "name": "test_flash_idefics2_next_all_params.json"}, {"type": "file", "name": "test_flash_idefics2_next_load.json"}, {"type": "file", "name": "test_flash_idefics2_next_simple.json"}, {"type": "file", "name": "test_flash_idefics2_two_images.json"}]}, {"type": "directory", "name": "test_llava_next", "children": [{"type": "file", "name": "test_flash_llava_next_all_params.json"}, {"type": "file", "name": "test_flash_llava_next_load.json"}, {"type": "file", "name": "test_flash_llava_next_simple.json"}]}, {"type": "directory", "name": "test_lora_mistral", "children": [{"type": "file", "name": "test_lora_mistral_without_adapter.json"}, {"type": "file", "name": "test_lora_mistral_without_customer_support_adapter.json"}, {"type": "file", "name": "test_lora_mistral_with_customer_support_adapter.json"}, {"type": "file", "name": "test_lora_mistral_with_dbpedia_adapter.json"}]}, {"type": "directory", "name": "test_mamba", "children": [{"type": "file", "name": "test_mamba.json"}, {"type": "file", "name": "test_mamba_all_params.json"}, {"type": "file", "name": "test_mamba_load.json"}]}, {"type": "directory", "name": "test_mpt", "children": [{"type": "file", "name": "test_mpt.json"}, {"type": "file", "name": "test_mpt_load.json"}]}, {"type": "directory", "name": "test_mt0_base", "children": [{"type": "file", "name": "test_mt0_base.json"}, {"type": "file", "name": "test_mt0_base_all_params.json"}, {"type": "file", "name": "test_mt0_base_load.json"}]}, {"type": "directory", "name": "test_neox", "children": [{"type": "file", "name": "test_neox.json"}, {"type": "file", "name": "test_neox_load.json"}]}, {"type": "directory", "name": "test_neox_sharded", "children": [{"type": "file", "name": "test_neox.json"}, {"type": "file", "name": "test_neox_load.json"}]}, {"type": "directory", "name": "test_server_gptq_quantized", "children": [{"type": "file", "name": "test_server_gptq_quantized.json"}, {"type": "file", "name": "test_server_gptq_quantized_all_params.json"}, {"type": "file", "name": "test_server_gptq_quantized_load.json"}]}, {"type": "directory", "name": "test_t5_sharded", "children": [{"type": "file", "name": "test_t5_sharded.json"}, {"type": "file", "name": "test_t5_sharded_load.json"}]}, {"type": "directory", "name": "test_tools_llama", "children": [{"type": "file", "name": "test_flash_llama_grammar_tools.json"}, {"type": "file", "name": "test_flash_llama_grammar_tools_auto.json"}, {"type": "file", "name": "test_flash_llama_grammar_tools_choice.json"}, {"type": "file", "name": "test_flash_llama_grammar_tools_insufficient_information.json"}, {"type": "file", "name": "test_flash_llama_grammar_tools_stream.json"}]}]}]}, {"type": "file", "name": "poetry.lock"}, {"type": "file", "name": "pyproject.toml"}, {"type": "file", "name": "pytest.ini"}, {"type": "file", "name": "requirements.txt"}]}, {"type": "directory", "name": "launcher", "children": [{"type": "file", "name": "build.rs"}, {"type": "file", "name": "Cargo.toml"}, {"type": "directory", "name": "src", "children": [{"type": "file", "name": "env_runtime.rs"}, {"type": "file", "name": "main.rs"}]}]}, {"type": "file", "name": "LICENSE"}, {"type": "directory", "name": "load_tests", "children": [{"type": "file", "name": "common.js"}, {"type": "file", "name": "filter.py"}, {"type": "file", "name": "Makefile"}, {"type": "file", "name": "orca.py"}]}, {"type": "file", "name": "Makefile"}, {"type": "directory", "name": "nix", "children": [{"type": "file", "name": "client.nix"}, {"type": "file", "name": "crate-overrides.nix"}, {"type": "file", "name": "server.nix"}]}, {"type": "directory", "name": "proto", "children": [{"type": "file", "name": "generate.proto"}, {"type": "directory", "name": "v3", "children": [{"type": "file", "name": "generate.proto"}]}]}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "router", "children": [{"type": "file", "name": "build.rs"}, {"type": "file", "name": "Cargo.toml"}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "src", "children": [{"type": "file", "name": "config.rs"}, {"type": "directory", "name": "infer", "children": [{"type": "file", "name": "chat_template.rs"}, {"type": "file", "name": "mod.rs"}, {"type": "file", "name": "tool_grammar.rs"}]}, {"type": "file", "name": "kserve.rs"}, {"type": "file", "name": "lib.rs"}, {"type": "file", "name": "logging.rs"}, {"type": "file", "name": "main.rs.back"}, {"type": "file", "name": "server.rs"}, {"type": "file", "name": "usage_stats.rs"}, {"type": "file", "name": "validation.rs"}, {"type": "file", "name": "vertex.rs"}]}]}, {"type": "file", "name": "rust-toolchain.toml"}, {"type": "file", "name": "sagemaker-entrypoint.sh"}, {"type": "directory", "name": "server", "children": [{"type": "directory", "name": "custom_kernels", "children": [{"type": "directory", "name": "custom_kernels", "children": [{"type": "file", "name": "fused_attention_cuda.cu"}, {"type": "file", "name": "fused_bloom_attention_cuda.cu"}]}, {"type": "file", "name": "setup.py"}]}, {"type": "directory", "name": "exllamav2_kernels", "children": [{"type": "directory", "name": "exllamav2_kernels", "children": [{"type": "file", "name": "config.h"}, {"type": "directory", "name": "cpp", "children": [{"type": "file", "name": "util.h"}]}, {"type": "directory", "name": "cuda", "children": [{"type": "file", "name": "compat.cuh"}, {"type": "file", "name": "matrix_view.cuh"}, {"type": "directory", "name": "quant", "children": [{"type": "file", "name": "qdq_2.cuh"}, {"type": "file", "name": "qdq_3.cuh"}, {"type": "file", "name": "qdq_4.cuh"}, {"type": "file", "name": "qdq_5.cuh"}, {"type": "file", "name": "qdq_6.cuh"}, {"type": "file", "name": "qdq_8.cuh"}, {"type": "file", "name": "qdq_util.cuh"}]}, {"type": "file", "name": "q_gemm.cu"}, {"type": "file", "name": "q_gemm.cuh"}, {"type": "file", "name": "q_gemm_kernel.cuh"}, {"type": "file", "name": "q_gemm_kernel_gptq.cuh"}, {"type": "file", "name": "q_matrix.cu"}, {"type": "file", "name": "q_matrix.cuh"}, {"type": "file", "name": "util.cuh"}]}, {"type": "file", "name": "ext.cpp"}]}, {"type": "file", "name": "setup.py"}]}, {"type": "directory", "name": "exllama_kernels", "children": [{"type": "directory", "name": "exllama_kernels", "children": [{"type": "file", "name": "cuda_buffers.cu"}, {"type": "file", "name": "cuda_buffers.cuh"}, {"type": "directory", "name": "cuda_func", "children": [{"type": "file", "name": "column_remap.cu"}, {"type": "file", "name": "column_remap.cuh"}, {"type": "file", "name": "q4_matmul.cu"}, {"type": "file", "name": "q4_matmul.cuh"}, {"type": "file", "name": "q4_matrix.cu"}, {"type": "file", "name": "q4_matrix.cuh"}]}, {"type": "file", "name": "cu_compat.cuh"}, {"type": "file", "name": "exllama_ext.cpp"}, {"type": "file", "name": "hip_compat.cuh"}, {"type": "file", "name": "matrix.cuh"}, {"type": "file", "name": "tuning.h"}, {"type": "file", "name": "util.cuh"}]}, {"type": "file", "name": "setup.py"}]}, {"type": "file", "name": "Makefile"}, {"type": "file", "name": "Makefile-awq"}, {"type": "file", "name": "Makefile-eetq"}, {"type": "file", "name": "Makefile-exllamav2"}, {"type": "file", "name": "Makefile-fbgemm"}, {"type": "file", "name": "Makefile-flash-att"}, {"type": "file", "name": "Makefile-flash-att-v2"}, {"type": "file", "name": "Makefile-flashinfer"}, {"type": "file", "name": "Makefile-lorax-punica"}, {"type": "file", "name": "Makefile-selective-scan"}, {"type": "file", "name": "Makefile-vllm"}, {"type": "file", "name": "poetry.lock"}, {"type": "file", "name": "pyproject.toml"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements_cuda.txt"}, {"type": "file", "name": "requirements_intel.txt"}, {"type": "file", "name": "requirements_rocm.txt"}, {"type": "directory", "name": "tests", "children": [{"type": "file", "name": "conftest.py"}, {"type": "directory", "name": "models", "children": [{"type": "file", "name": "test_bloom.py"}, {"type": "file", "name": "test_causal_lm.py"}, {"type": "file", "name": "test_model.py"}, {"type": "file", "name": "test_santacoder.py"}, {"type": "file", "name": "test_seq2seq_lm.py"}]}, {"type": "directory", "name": "utils", "children": [{"type": "file", "name": "test_adapter.py"}, {"type": "file", "name": "test_convert.py"}, {"type": "file", "name": "test_hub.py"}, {"type": "file", "name": "test_layers.py"}, {"type": "file", "name": "test_tokens.py"}, {"type": "file", "name": "test_watermark.py"}, {"type": "file", "name": "test_weights.py"}]}]}, {"type": "directory", "name": "text_generation_server", "children": [{"type": "directory", "name": "adapters", "children": [{"type": "file", "name": "config.py"}, {"type": "file", "name": "lora.py"}, {"type": "file", "name": "weights.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "cache.py"}, {"type": "file", "name": "cli.py"}, {"type": "file", "name": "interceptor.py"}, {"type": "directory", "name": "layers", "children": [{"type": "directory", "name": "attention", "children": [{"type": "file", "name": "common.py"}, {"type": "file", "name": "cuda.py"}, {"type": "file", "name": "flashinfer.py"}, {"type": "file", "name": "flash_attn_triton.py"}, {"type": "file", "name": "ipex.py"}, {"type": "file", "name": "rocm.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "awq", "children": [{"type": "file", "name": "conversion_utils.py"}, {"type": "directory", "name": "quantize", "children": [{"type": "file", "name": "qmodule.py"}]}]}, {"type": "file", "name": "bnb.py"}, {"type": "file", "name": "conv.py"}, {"type": "file", "name": "eetq.py"}, {"type": "file", "name": "exl2.py"}, {"type": "file", "name": "fp8.py"}, {"type": "directory", "name": "gptq", "children": [{"type": "file", "name": "custom_autotune.py"}, {"type": "file", "name": "exllama.py"}, {"type": "file", "name": "exllamav2.py"}, {"type": "file", "name": "quantize.py"}, {"type": "file", "name": "quant_linear.py"}, {"type": "file", "name": "utils.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "layernorm.py"}, {"type": "file", "name": "linear.py"}, {"type": "file", "name": "lora.py"}, {"type": "directory", "name": "marlin", "children": [{"type": "file", "name": "fp8.py"}, {"type": "file", "name": "gptq.py"}, {"type": "file", "name": "marlin.py"}, {"type": "file", "name": "util.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "medusa.py"}, {"type": "file", "name": "mlp.py"}, {"type": "directory", "name": "moe", "children": [{"type": "file", "name": "unquantized.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "rotary.py"}, {"type": "file", "name": "speculative.py"}, {"type": "file", "name": "tensor_parallel.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "models", "children": [{"type": "file", "name": "bloom.py"}, {"type": "file", "name": "causal_lm.py"}, {"type": "directory", "name": "custom_modeling", "children": [{"type": "file", "name": "bloom_modeling.py"}, {"type": "file", "name": "clip.py"}, {"type": "file", "name": "flash_cohere_modeling.py"}, {"type": "file", "name": "flash_dbrx_modeling.py"}, {"type": "file", "name": "flash_deepseek_v2_modeling.py"}, {"type": "file", "name": "flash_gemma2_modeling.py"}, {"type": "file", "name": "flash_gemma_modeling.py"}, {"type": "file", "name": "flash_gpt2_modeling.py"}, {"type": "file", "name": "flash_gptj_modeling.py"}, {"type": "file", "name": "flash_llama_modeling.py"}, {"type": "file", "name": "flash_mistral_modeling.py"}, {"type": "file", "name": "flash_mixtral_modeling.py"}, {"type": "file", "name": "flash_neox_modeling.py"}, {"type": "file", "name": "flash_pali_gemma_modeling.py"}, {"type": "file", "name": "flash_phi_modeling.py"}, {"type": "file", "name": "flash_qwen2_modeling.py"}, {"type": "file", "name": "flash_rw_modeling.py"}, {"type": "file", "name": "flash_santacoder_modeling.py"}, {"type": "file", "name": "flash_starcoder2_modeling.py"}, {"type": "file", "name": "idefics2.py"}, {"type": "file", "name": "idefics_config.py"}, {"type": "file", "name": "idefics_image_processing.py"}, {"type": "file", "name": "idefics_modeling.py"}, {"type": "file", "name": "idefics_perceiver.py"}, {"type": "file", "name": "idefics_processing.py"}, {"type": "file", "name": "idefics_vision.py"}, {"type": "file", "name": "llava_next.py"}, {"type": "file", "name": "mamba_modeling.py"}, {"type": "file", "name": "mpt_modeling.py"}, {"type": "file", "name": "neox_modeling.py"}, {"type": "file", "name": "opt_modeling.py"}, {"type": "file", "name": "phi_modeling.py"}, {"type": "file", "name": "siglip.py"}, {"type": "file", "name": "t5_modeling.py"}, {"type": "file", "name": "vlm.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "flash_causal_lm.py"}, {"type": "file", "name": "galactica.py"}, {"type": "file", "name": "globals.py"}, {"type": "file", "name": "idefics.py"}, {"type": "file", "name": "idefics_causal_lm.py"}, {"type": "file", "name": "mamba.py"}, {"type": "file", "name": "model.py"}, {"type": "file", "name": "pali_gemma.py"}, {"type": "file", "name": "seq2seq_lm.py"}, {"type": "file", "name": "types.py"}, {"type": "file", "name": "vlm_causal_lm.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "pb", "children": []}, {"type": "file", "name": "server.py"}, {"type": "file", "name": "tracing.py"}, {"type": "directory", "name": "utils", "children": [{"type": "file", "name": "adapter.py"}, {"type": "file", "name": "chunks.py"}, {"type": "file", "name": "convert.py"}, {"type": "file", "name": "dist.py"}, {"type": "file", "name": "hub.py"}, {"type": "file", "name": "import_utils.py"}, {"type": "file", "name": "log.py"}, {"type": "file", "name": "logits_process.py"}, {"type": "directory", "name": "merges", "children": [{"type": "file", "name": "strategies.py"}, {"type": "file", "name": "utils.py"}]}, {"type": "file", "name": "peft.py"}, {"type": "file", "name": "quantization.py"}, {"type": "file", "name": "segments.py"}, {"type": "file", "name": "sgmv.py"}, {"type": "file", "name": "speculate.py"}, {"type": "file", "name": "tokens.py"}, {"type": "file", "name": "watermark.py"}, {"type": "file", "name": "weights.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "__init__.py"}]}]}, {"type": "file", "name": "tgi-entrypoint.sh"}, {"type": "file", "name": "update_doc.py"}]} | # Text Generation Inference Python gRPC Server
A Python gRPC server for Text Generation Inference
## Install
```shell
make install
```
## Run
```shell
make run-dev
```
| {"Dockerfile": "# Rust builder\nFROM lukemathwalker/cargo-chef:latest-rust-1.80 AS chef\nWORKDIR /usr/src\n\nARG CARGO_REGISTRIES_CRATES_IO_PROTOCOL=sparse\n\nFROM chef AS planner\nCOPY Cargo.lock Cargo.lock\nCOPY Cargo.toml Cargo.toml\nCOPY rust-toolchain.toml rust-toolchain.toml\nCOPY proto proto\nCOPY benchmark benchmark\nCOPY router router\nCOPY backends backends\nCOPY launcher launcher\n\nRUN cargo chef prepare --recipe-path recipe.json\n\nFROM chef AS builder\n\nRUN apt-get update && DEBIAN_FRONTEND=noninteractive apt-get install -y --no-install-recommends \\\n python3.11-dev\nRUN PROTOC_ZIP=protoc-21.12-linux-x86_64.zip && \\\n curl -OL https://github.com/protocolbuffers/protobuf/releases/download/v21.12/$PROTOC_ZIP && \\\n unzip -o $PROTOC_ZIP -d /usr/local bin/protoc && \\\n unzip -o $PROTOC_ZIP -d /usr/local 'include/*' && \\\n rm -f $PROTOC_ZIP\n\nCOPY --from=planner /usr/src/recipe.json recipe.json\nRUN cargo chef cook --profile release-opt --recipe-path recipe.json\n\nARG GIT_SHA\nARG DOCKER_LABEL\n\nCOPY Cargo.toml Cargo.toml\nCOPY rust-toolchain.toml rust-toolchain.toml\nCOPY proto proto\nCOPY benchmark benchmark\nCOPY router router\nCOPY backends backends\nCOPY launcher launcher\nRUN cargo build --profile release-opt\n\n# Python builder\n# Adapted from: https://github.com/pytorch/pytorch/blob/master/Dockerfile\nFROM nvidia/cuda:12.4.1-devel-ubuntu22.04 AS pytorch-install\n\n# NOTE: When updating PyTorch version, beware to remove `pip install nvidia-nccl-cu12==2.22.3` below in the Dockerfile. Context: https://github.com/huggingface/text-generation-inference/pull/2099\nARG PYTORCH_VERSION=2.4.0\n\nARG PYTHON_VERSION=3.11\n# Keep in sync with `server/pyproject.toml\nARG CUDA_VERSION=12.4\nARG MAMBA_VERSION=24.3.0-0\nARG CUDA_CHANNEL=nvidia\nARG INSTALL_CHANNEL=pytorch\n# Automatically set by buildx\nARG TARGETPLATFORM\n\nENV PATH /opt/conda/bin:$PATH\n\nRUN apt-get update && DEBIAN_FRONTEND=noninteractive apt-get install -y --no-install-recommends \\\n build-essential \\\n ca-certificates \\\n ccache \\\n curl \\\n git && \\\n rm -rf /var/lib/apt/lists/*\n\n# Install conda\n# translating Docker's TARGETPLATFORM into mamba arches\nRUN case ${TARGETPLATFORM} in \\\n \"linux/arm64\") MAMBA_ARCH=aarch64 ;; \\\n *) MAMBA_ARCH=x86_64 ;; \\\n esac && \\\n curl -fsSL -v -o ~/mambaforge.sh -O \"https://github.com/conda-forge/miniforge/releases/download/${MAMBA_VERSION}/Mambaforge-${MAMBA_VERSION}-Linux-${MAMBA_ARCH}.sh\"\nRUN chmod +x ~/mambaforge.sh && \\\n bash ~/mambaforge.sh -b -p /opt/conda && \\\n rm ~/mambaforge.sh\n\n# Install pytorch\n# On arm64 we exit with an error code\nRUN case ${TARGETPLATFORM} in \\\n \"linux/arm64\") exit 1 ;; \\\n *) /opt/conda/bin/conda update -y conda && \\\n /opt/conda/bin/conda install -c \"${INSTALL_CHANNEL}\" -c \"${CUDA_CHANNEL}\" -y \"python=${PYTHON_VERSION}\" \"pytorch=$PYTORCH_VERSION\" \"pytorch-cuda=$(echo $CUDA_VERSION | cut -d'.' -f 1-2)\" ;; \\\n esac && \\\n /opt/conda/bin/conda clean -ya\n\n# CUDA kernels builder image\nFROM pytorch-install AS kernel-builder\n\nARG MAX_JOBS=8\nENV TORCH_CUDA_ARCH_LIST=\"8.0;8.6;9.0+PTX\"\n\nRUN apt-get update && DEBIAN_FRONTEND=noninteractive apt-get install -y --no-install-recommends \\\n ninja-build cmake \\\n && rm -rf /var/lib/apt/lists/*\n\n# Build Flash Attention CUDA kernels\nFROM kernel-builder AS flash-att-builder\n\nWORKDIR /usr/src\n\nCOPY server/Makefile-flash-att Makefile\n\n# Build specific version of flash attention\nRUN make build-flash-attention\n\n# Build Flash Attention v2 CUDA kernels\nFROM kernel-builder AS flash-att-v2-builder\n\nWORKDIR /usr/src\n\nCOPY server/Makefile-flash-att-v2 Makefile\n\n# Build specific version of flash attention v2\nRUN make build-flash-attention-v2-cuda\n\n# Build Transformers exllama kernels\nFROM kernel-builder AS exllama-kernels-builder\nWORKDIR /usr/src\nCOPY server/exllama_kernels/ .\n\nRUN python setup.py build\n\n# Build Transformers exllama kernels\nFROM kernel-builder AS exllamav2-kernels-builder\nWORKDIR /usr/src\nCOPY server/Makefile-exllamav2/ Makefile\n\n# Build specific version of transformers\nRUN make build-exllamav2\n\n# Build Transformers awq kernels\nFROM kernel-builder AS awq-kernels-builder\nWORKDIR /usr/src\nCOPY server/Makefile-awq Makefile\n# Build specific version of transformers\nRUN make build-awq\n\n# Build eetq kernels\nFROM kernel-builder AS eetq-kernels-builder\nWORKDIR /usr/src\nCOPY server/Makefile-eetq Makefile\n# Build specific version of transformers\nRUN make build-eetq\n\n# Build Lorax Punica kernels\nFROM kernel-builder AS lorax-punica-builder\nWORKDIR /usr/src\nCOPY server/Makefile-lorax-punica Makefile\n# Build specific version of transformers\nRUN TORCH_CUDA_ARCH_LIST=\"8.0;8.6+PTX\" make build-lorax-punica\n\n# Build Transformers CUDA kernels\nFROM kernel-builder AS custom-kernels-builder\nWORKDIR /usr/src\nCOPY server/custom_kernels/ .\n# Build specific version of transformers\nRUN python setup.py build\n\n# Build FBGEMM CUDA kernels\nFROM kernel-builder AS fbgemm-builder\n\nWORKDIR /usr/src\n\nCOPY server/Makefile-fbgemm Makefile\n\nRUN make build-fbgemm\n\n# Build vllm CUDA kernels\nFROM kernel-builder AS vllm-builder\n\nWORKDIR /usr/src\n\nENV TORCH_CUDA_ARCH_LIST=\"7.0 7.5 8.0 8.6 8.9 9.0+PTX\"\n\nCOPY server/Makefile-vllm Makefile\n\n# Build specific version of vllm\nRUN make build-vllm-cuda\n\n# Build mamba kernels\nFROM kernel-builder AS mamba-builder\nWORKDIR /usr/src\nCOPY server/Makefile-selective-scan Makefile\nRUN make build-all\n\n# Build flashinfer\nFROM kernel-builder AS flashinfer-builder\nWORKDIR /usr/src\nCOPY server/Makefile-flashinfer Makefile\nRUN make install-flashinfer\n\n# Text Generation Inference base image\nFROM nvidia/cuda:12.1.0-base-ubuntu22.04 AS base\n\n# Conda env\nENV PATH=/opt/conda/bin:$PATH \\\n CONDA_PREFIX=/opt/conda\n\n# Text Generation Inference base env\nENV HF_HOME=/data \\\n HF_HUB_ENABLE_HF_TRANSFER=1 \\\n PORT=80\n\nWORKDIR /usr/src\n\nRUN apt-get update && DEBIAN_FRONTEND=noninteractive apt-get install -y --no-install-recommends \\\n libssl-dev \\\n ca-certificates \\\n make \\\n curl \\\n git \\\n && rm -rf /var/lib/apt/lists/*\n\n# Copy conda with PyTorch installed\nCOPY --from=pytorch-install /opt/conda /opt/conda\n\n# Copy build artifacts from flash attention builder\nCOPY --from=flash-att-builder /usr/src/flash-attention/build/lib.linux-x86_64-cpython-311 /opt/conda/lib/python3.11/site-packages\nCOPY --from=flash-att-builder /usr/src/flash-attention/csrc/layer_norm/build/lib.linux-x86_64-cpython-311 /opt/conda/lib/python3.11/site-packages\nCOPY --from=flash-att-builder /usr/src/flash-attention/csrc/rotary/build/lib.linux-x86_64-cpython-311 /opt/conda/lib/python3.11/site-packages\n\n# Copy build artifacts from flash attention v2 builder\nCOPY --from=flash-att-v2-builder /opt/conda/lib/python3.11/site-packages/flash_attn_2_cuda.cpython-311-x86_64-linux-gnu.so /opt/conda/lib/python3.11/site-packages\n\n# Copy build artifacts from custom kernels builder\nCOPY --from=custom-kernels-builder /usr/src/build/lib.linux-x86_64-cpython-311 /opt/conda/lib/python3.11/site-packages\n# Copy build artifacts from exllama kernels builder\nCOPY --from=exllama-kernels-builder /usr/src/build/lib.linux-x86_64-cpython-311 /opt/conda/lib/python3.11/site-packages\n# Copy build artifacts from exllamav2 kernels builder\nCOPY --from=exllamav2-kernels-builder /usr/src/exllamav2/build/lib.linux-x86_64-cpython-311 /opt/conda/lib/python3.11/site-packages\n# Copy build artifacts from awq kernels builder\nCOPY --from=awq-kernels-builder /usr/src/llm-awq/awq/kernels/build/lib.linux-x86_64-cpython-311 /opt/conda/lib/python3.11/site-packages\n# Copy build artifacts from eetq kernels builder\nCOPY --from=eetq-kernels-builder /usr/src/eetq/build/lib.linux-x86_64-cpython-311 /opt/conda/lib/python3.11/site-packages\n# Copy build artifacts from lorax punica kernels builder\nCOPY --from=lorax-punica-builder /usr/src/lorax-punica/server/punica_kernels/build/lib.linux-x86_64-cpython-311 /opt/conda/lib/python3.11/site-packages\n# Copy build artifacts from fbgemm builder\nCOPY --from=fbgemm-builder /usr/src/fbgemm/fbgemm_gpu/_skbuild/linux-x86_64-3.11/cmake-install /opt/conda/lib/python3.11/site-packages\n# Copy build artifacts from vllm builder\nCOPY --from=vllm-builder /usr/src/vllm/build/lib.linux-x86_64-cpython-311 /opt/conda/lib/python3.11/site-packages\n# Copy build artifacts from mamba builder\nCOPY --from=mamba-builder /usr/src/mamba/build/lib.linux-x86_64-cpython-311/ /opt/conda/lib/python3.11/site-packages\nCOPY --from=mamba-builder /usr/src/causal-conv1d/build/lib.linux-x86_64-cpython-311/ /opt/conda/lib/python3.11/site-packages\nCOPY --from=flashinfer-builder /opt/conda/lib/python3.11/site-packages/flashinfer/ /opt/conda/lib/python3.11/site-packages/flashinfer/\n\n# Install flash-attention dependencies\nRUN pip install einops --no-cache-dir\n\n# Install server\nCOPY proto proto\nCOPY server server\nCOPY server/Makefile server/Makefile\nRUN cd server && \\\n make gen-server && \\\n pip install -r requirements_cuda.txt && \\\n pip install \".[bnb, accelerate, marlin, moe, quantize, peft, outlines]\" --no-cache-dir && \\\n pip install nvidia-nccl-cu12==2.22.3\n\nENV LD_PRELOAD=/opt/conda/lib/python3.11/site-packages/nvidia/nccl/lib/libnccl.so.2\n# Required to find libpython within the rust binaries\nENV LD_LIBRARY_PATH=\"$LD_LIBRARY_PATH:/opt/conda/lib/\"\n# This is needed because exl2 tries to load flash-attn\n# And fails with our builds.\nENV EXLLAMA_NO_FLASH_ATTN=1\n\n# Deps before the binaries\n# The binaries change on every build given we burn the SHA into them\n# The deps change less often.\nRUN apt-get update && DEBIAN_FRONTEND=noninteractive apt-get install -y --no-install-recommends \\\n build-essential \\\n g++ \\\n && rm -rf /var/lib/apt/lists/*\n\n# Install benchmarker\nCOPY --from=builder /usr/src/target/release-opt/text-generation-benchmark /usr/local/bin/text-generation-benchmark\n# Install router\nCOPY --from=builder /usr/src/target/release-opt/text-generation-router /usr/local/bin/text-generation-router\n# Install launcher\nCOPY --from=builder /usr/src/target/release-opt/text-generation-launcher /usr/local/bin/text-generation-launcher\n\n\n# AWS Sagemaker compatible image\nFROM base AS sagemaker\n\nCOPY sagemaker-entrypoint.sh entrypoint.sh\nRUN chmod +x entrypoint.sh\n\nENTRYPOINT [\"./entrypoint.sh\"]\n\n# Final image\nFROM base\n\nCOPY ./tgi-entrypoint.sh /tgi-entrypoint.sh\nRUN chmod +x /tgi-entrypoint.sh\n\nENTRYPOINT [\"/tgi-entrypoint.sh\"]\n# CMD [\"--json-output\"]\n", "Dockerfile.trtllm": "# All the tooling for CUDA\nFROM nvidia/cuda:12.4.1-cudnn-devel-ubuntu22.04 AS cuda-builder\n\nWORKDIR /usr/src/tgi/backends/trtllm\nRUN apt update && apt install -y cmake git git-lfs gcc g++ ninja-build libopenmpi-dev python3-dev python3-pip wget\n\nCOPY . /usr/src/tgi\nRUN chmod +x scripts/install_tensorrt.sh && scripts/install_tensorrt.sh\nRUN cmake -G Ninja -B build -DTRT_LIB_DIR=/usr/local/tensorrt/lib -DTRT_INCLUDE_DIR=/usr/local/tensorrt/include .\nRUN cmake --build build --parallel -t tgi_trtllm_backend_impl\n\n# All the tooling for Rust\nFROM lukemathwalker/cargo-chef:latest-rust-1.79 AS chef\nWORKDIR /usr/src\n\n# Include CUDA related libraries and tools to the Rust based image\nCOPY --from=cuda-builder /usr/local/cuda /usr/local/cuda\nCOPY --from=cuda-builder /usr/local/tensorrt /usr/local/tensorrt\nCOPY --from=cuda-builder /usr/src/tgi/backends/trtllm/build /usr/local/tgi/trtllm/build\nENV PATH=/usr/local/cuda/bin:$PATH\nENV LD_LIBRARY_PATH=/usr/local/tensorrt/lib:$LD_LIBRARY_PATH\n\nRUN apt update && apt install -y cmake git gcc g++ ninja-build libopenmpi3\n", "Dockerfile_amd": "# Rust builder\nFROM lukemathwalker/cargo-chef:latest-rust-1.80 AS chef\nWORKDIR /usr/src\n\nARG CARGO_REGISTRIES_CRATES_IO_PROTOCOL=sparse\n\nFROM chef AS planner\nCOPY Cargo.lock Cargo.lock\nCOPY Cargo.toml Cargo.toml\nCOPY rust-toolchain.toml rust-toolchain.toml\nCOPY proto proto\nCOPY benchmark benchmark\nCOPY router router\nCOPY backends backends\nCOPY launcher launcher\nRUN cargo chef prepare --recipe-path recipe.json\n\nFROM chef AS builder\n\nRUN apt-get update && DEBIAN_FRONTEND=noninteractive apt-get install -y --no-install-recommends \\\n python3.11-dev\nRUN PROTOC_ZIP=protoc-21.12-linux-x86_64.zip && \\\n curl -OL https://github.com/protocolbuffers/protobuf/releases/download/v21.12/$PROTOC_ZIP && \\\n unzip -o $PROTOC_ZIP -d /usr/local bin/protoc && \\\n unzip -o $PROTOC_ZIP -d /usr/local 'include/*' && \\\n rm -f $PROTOC_ZIP\n\nCOPY --from=planner /usr/src/recipe.json recipe.json\nRUN cargo chef cook --profile release-opt --recipe-path recipe.json\n\nARG GIT_SHA\nARG DOCKER_LABEL\n\nCOPY Cargo.toml Cargo.toml\nCOPY rust-toolchain.toml rust-toolchain.toml\nCOPY proto proto\nCOPY benchmark benchmark\nCOPY router router\nCOPY backends backends\nCOPY launcher launcher\nRUN cargo build --profile release-opt\n\n# Text Generation Inference base image for RoCm\nFROM rocm/dev-ubuntu-22.04:6.1.1_hip_update AS base\n\nRUN apt-get update && DEBIAN_FRONTEND=noninteractive apt-get install -y --no-install-recommends \\\n build-essential \\\n ca-certificates \\\n ccache \\\n curl \\\n git \\\n make \\\n libssl-dev \\\n g++ \\\n # Needed to build VLLM & flash.\n rocthrust-dev \\\n hipsparse-dev \\\n hipblas-dev \\\n hipblaslt-dev \\\n rocblas-dev \\\n hiprand-dev \\\n rocrand-dev \\\n miopen-hip-dev \\\n hipfft-dev \\\n hipcub-dev \\\n hipsolver-dev \\\n rccl-dev \\\n cmake \\\n python3.11-dev && \\\n rm -rf /var/lib/apt/lists/*\n\n# Keep in sync with `server/pyproject.toml\nARG MAMBA_VERSION=23.1.0-1\nARG PYTORCH_VERSION='2.3.0'\nARG ROCM_VERSION='6.0.2'\nARG PYTHON_VERSION='3.11.10'\n# Automatically set by buildx\nARG TARGETPLATFORM\nENV PATH /opt/conda/bin:$PATH\n\n# TGI seem to require libssl.so.1.1 instead of libssl.so.3 so we can't use ubuntu 22.04. Ubuntu 20.04 has python==3.8, and TGI requires python>=3.9, hence the need for miniconda.\n# Install mamba\n# translating Docker's TARGETPLATFORM into mamba arches\nRUN case ${TARGETPLATFORM} in \\\n \"linux/arm64\") MAMBA_ARCH=aarch64 ;; \\\n *) MAMBA_ARCH=x86_64 ;; \\\n esac && \\\n curl -fsSL -v -o ~/mambaforge.sh -O \"https://github.com/conda-forge/miniforge/releases/download/${MAMBA_VERSION}/Mambaforge-${MAMBA_VERSION}-Linux-${MAMBA_ARCH}.sh\"\nRUN chmod +x ~/mambaforge.sh && \\\n bash ~/mambaforge.sh -b -p /opt/conda && \\\n mamba init && \\\n rm ~/mambaforge.sh\n\n# RUN conda install intel::mkl-static intel::mkl-include\n# Install pytorch\n# On arm64 we exit with an error code\nRUN case ${TARGETPLATFORM} in \\\n \"linux/arm64\") exit 1 ;; \\\n *) /opt/conda/bin/conda update -y conda && \\\n /opt/conda/bin/conda install -y \"python=${PYTHON_VERSION}\" ;; \\\n esac && \\\n /opt/conda/bin/conda clean -ya\n# Install flash-attention, torch dependencies\nRUN pip install numpy einops ninja --no-cache-dir\n\nRUN pip uninstall -y triton && \\\n git clone --depth 1 --single-branch https://github.com/ROCm/triton.git && \\\n cd triton/python && \\\n pip install .\n\nRUN git clone --depth 1 --recursive --single-branch --branch 2.3-patched https://github.com/fxmarty/pytorch.git pytorch && cd pytorch && pip install -r requirements.txt --no-cache-dir\n\nARG _GLIBCXX_USE_CXX11_ABI=\"1\"\nARG CMAKE_PREFIX_PATH=\"/opt/conda\"\nARG PYTORCH_ROCM_ARCH=\"gfx90a;gfx942\"\nARG BUILD_CAFFE2=\"0\" \\\n BUILD_CAFFE2_OPS=\"0\" \\\n USE_CUDA=\"0\" \\\n USE_ROCM=\"1\" \\\n BUILD_TEST=\"0\" \\\n USE_FBGEMM=\"0\" \\\n USE_NNPACK=\"0\" \\\n USE_QNNPACK=\"0\" \\\n USE_XNNPACK=\"0\" \\\n USE_FLASH_ATTENTION=\"1\" \\\n USE_MEM_EFF_ATTENTION=\"0\"\n\nRUN cd pytorch && python tools/amd_build/build_amd.py && python setup.py install\n\n# Set AS recommended: https://github.com/ROCm/triton/wiki/A-script-to-set-program-execution-environment-in-ROCm\nENV HIP_FORCE_DEV_KERNARG=1\n\n# On MI250 and MI300, performances for flash with Triton FA are slightly better than CK.\n# However, Triton requires a tunning for each prompt length, which is prohibitive.\nENV ROCM_USE_FLASH_ATTN_V2_TRITON=0\n\nFROM base AS kernel-builder\n\n# # Build vllm kernels\nFROM kernel-builder AS vllm-builder\nWORKDIR /usr/src\n\nCOPY server/Makefile-vllm Makefile\n\n# Build specific version of vllm\nRUN make build-vllm-rocm\n\n# Build Flash Attention v2 kernels\nFROM kernel-builder AS flash-att-v2-builder\nWORKDIR /usr/src\n\nCOPY server/Makefile-flash-att-v2 Makefile\n\n# Build specific version of flash attention v2\nRUN make build-flash-attention-v2-rocm\n\n# Build Transformers CUDA kernels (gpt-neox and bloom)\nFROM kernel-builder AS custom-kernels-builder\nWORKDIR /usr/src\nCOPY server/custom_kernels/ .\nRUN python setup.py build\n\n# Build exllama kernels\nFROM kernel-builder AS exllama-kernels-builder\nWORKDIR /usr/src\nCOPY server/exllama_kernels/ .\n\nRUN python setup.py build\n\n# Build exllama v2 kernels\nFROM kernel-builder AS exllamav2-kernels-builder\nWORKDIR /usr/src\nCOPY server/exllamav2_kernels/ .\n\nRUN python setup.py build\n\nFROM base AS base-copy\n\n# Text Generation Inference base env\nENV HF_HOME=/data \\\n HF_HUB_ENABLE_HF_TRANSFER=1 \\\n PORT=80\n\n# Copy builds artifacts from vllm builder\nCOPY --from=vllm-builder /usr/src/vllm/build/lib.linux-x86_64-cpython-311 /opt/conda/lib/python3.11/site-packages\n\n# Copy build artifacts from flash attention v2 builder\nCOPY --from=flash-att-v2-builder /usr/src/flash-attention-v2/build/lib.linux-x86_64-cpython-311 /opt/conda/lib/python3.11/site-packages\n\n# Copy build artifacts from custom kernels builder\nCOPY --from=custom-kernels-builder /usr/src/build/lib.linux-x86_64-cpython-311 /opt/conda/lib/python3.11/site-packages\n\n# Copy build artifacts from exllama kernels builder\nCOPY --from=exllama-kernels-builder /usr/src/build/lib.linux-x86_64-cpython-311 /opt/conda/lib/python3.11/site-packages\n\n# Copy build artifacts from exllamav2 kernels builder\nCOPY --from=exllamav2-kernels-builder /usr/src/build/lib.linux-x86_64-cpython-311 /opt/conda/lib/python3.11/site-packages\n\n# Install server\nCOPY proto proto\nCOPY server server\nCOPY server/Makefile server/Makefile\nRUN cd server && \\\n make gen-server && \\\n pip install -r requirements_rocm.txt && \\\n pip install \".[accelerate, peft, outlines]\" --no-cache-dir\n\n# Install benchmarker\nCOPY --from=builder /usr/src/target/release-opt/text-generation-benchmark /usr/local/bin/text-generation-benchmark\n# Install router\nCOPY --from=builder /usr/src/target/release-opt/text-generation-router /usr/local/bin/text-generation-router\n# Install launcher\nCOPY --from=builder /usr/src/target/release-opt/text-generation-launcher /usr/local/bin/text-generation-launcher\nENV LD_LIBRARY_PATH=\"$LD_LIBRARY_PATH:/opt/conda/lib/\"\n\n# AWS Sagemaker compatible image\nFROM base AS sagemaker\n\nCOPY sagemaker-entrypoint.sh entrypoint.sh\nRUN chmod +x entrypoint.sh\n\nENTRYPOINT [\"./entrypoint.sh\"]\n\n# Final image\nFROM base-copy\n\nCOPY ./tgi-entrypoint.sh /tgi-entrypoint.sh\nRUN chmod +x /tgi-entrypoint.sh\n\nENTRYPOINT [\"/tgi-entrypoint.sh\"]\nCMD [\"--json-output\"]\n", "Dockerfile_intel": "ARG PLATFORM=xpu\n\nFROM lukemathwalker/cargo-chef:latest-rust-1.80 AS chef\nWORKDIR /usr/src\n\nARG CARGO_REGISTRIES_CRATES_IO_PROTOCOL=sparse\n\nFROM chef AS planner\nCOPY Cargo.lock Cargo.lock\nCOPY Cargo.toml Cargo.toml\nCOPY rust-toolchain.toml rust-toolchain.toml\nCOPY proto proto\nCOPY benchmark benchmark\nCOPY router router\nCOPY backends backends\nCOPY launcher launcher\nRUN cargo chef prepare --recipe-path recipe.json\n\nFROM chef AS builder\n\nRUN apt-get update && DEBIAN_FRONTEND=noninteractive apt-get install -y --no-install-recommends \\\n python3.11-dev\nRUN PROTOC_ZIP=protoc-21.12-linux-x86_64.zip && \\\n curl -OL https://github.com/protocolbuffers/protobuf/releases/download/v21.12/$PROTOC_ZIP && \\\n unzip -o $PROTOC_ZIP -d /usr/local bin/protoc && \\\n unzip -o $PROTOC_ZIP -d /usr/local 'include/*' && \\\n rm -f $PROTOC_ZIP\n\nCOPY --from=planner /usr/src/recipe.json recipe.json\nRUN cargo chef cook --profile release-opt --recipe-path recipe.json\n\nARG GIT_SHA\nARG DOCKER_LABEL\n\nCOPY Cargo.toml Cargo.toml\nCOPY rust-toolchain.toml rust-toolchain.toml\nCOPY proto proto\nCOPY benchmark benchmark\nCOPY router router\nCOPY backends backends\nCOPY launcher launcher\nRUN cargo build --profile release-opt\n\n\n# Text Generation Inference base image for Intel\n\nFROM intel/intel-extension-for-pytorch:2.3.110-xpu AS xpu\n\nUSER root\n\nARG MAMBA_VERSION=23.1.0-1\nARG PYTHON_VERSION='3.11.10'\n# Automatically set by buildx\nARG TARGETPLATFORM\nENV PATH /opt/conda/bin:$PATH\n\n# TGI seem to require libssl.so.1.1 instead of libssl.so.3 so we can't use ubuntu 22.04. Ubuntu 20.04 has python==3.8, and TGI requires python>=3.9, hence the need for miniconda.\n# Install mamba\n# translating Docker's TARGETPLATFORM into mamba arches\nRUN case ${TARGETPLATFORM} in \\\n \"linux/arm64\") MAMBA_ARCH=aarch64 ;; \\\n *) MAMBA_ARCH=x86_64 ;; \\\n esac && \\\n curl -fsSL -v -o ~/mambaforge.sh -O \"https://github.com/conda-forge/miniforge/releases/download/${MAMBA_VERSION}/Mambaforge-${MAMBA_VERSION}-Linux-${MAMBA_ARCH}.sh\"\nRUN chmod +x ~/mambaforge.sh && \\\n bash ~/mambaforge.sh -b -p /opt/conda && \\\n rm ~/mambaforge.sh\n\nRUN case ${TARGETPLATFORM} in \\\n \"linux/arm64\") exit 1 ;; \\\n *) /opt/conda/bin/conda update -y conda && \\\n /opt/conda/bin/conda install -y \"python=${PYTHON_VERSION}\" ;; \\\n esac && \\\n /opt/conda/bin/conda clean -ya\n\n# libssl.so.1.1 is not installed on Ubuntu 22.04 by default, install it\nRUN wget http://nz2.archive.ubuntu.com/ubuntu/pool/main/o/openssl/libssl1.1_1.1.1f-1ubuntu2_amd64.deb && \\\n dpkg -i ./libssl1.1_1.1.1f-1ubuntu2_amd64.deb\n\nRUN wget -qO - https://repositories.intel.com/gpu/intel-graphics.key | gpg --dearmor | tee /usr/share/keyrings/intel-graphics.gpg > /dev/null\n\nRUN wget -O- https://apt.repos.intel.com/intel-gpg-keys/GPG-PUB-KEY-INTEL-SW-PRODUCTS.PUB \\\n| gpg --dearmor | tee /usr/share/keyrings/oneapi-archive-keyring.gpg > /dev/null && echo \"deb [signed-by=/usr/share/keyrings/oneapi-archive-keyring.gpg] https://apt.repos.intel.com/oneapi all main\" | tee /etc/apt/sources.list.d/oneAPI.list\n\nRUN apt-get update && DEBIAN_FRONTEND=noninteractive apt install -y intel-basekit xpu-smi cmake ninja-build pciutils\n\n# Text Generation Inference base env\nENV HF_HOME=/data \\\n HF_HUB_ENABLE_HF_TRANSFER=1 \\\n PORT=80\n\n\nWORKDIR /usr/src\nRUN pip install torch==2.3.1+cxx11.abi torchvision==0.18.1+cxx11.abi torchaudio==2.3.1+cxx11.abi intel-extension-for-pytorch==2.3.110+xpu oneccl_bind_pt==2.3.100+xpu --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/ --no-cache-dir\n\n# Install server\nCOPY proto proto\nCOPY server server\nCOPY server/Makefile server/Makefile\nRUN cd server && \\\n make gen-server && \\\n pip install -r requirements_intel.txt && \\\n pip install \".[accelerate, peft, outlines]\" --no-cache-dir\n\nENV CCL_ROOT=/opt/intel/oneapi/ccl/latest\nENV I_MPI_ROOT=/opt/intel/oneapi/mpi/latest\nENV FI_PROVIDER_PATH=/opt/intel/oneapi/mpi/latest/opt/mpi/libfabric/lib/prov:/usr/lib/x86_64-linux-gnu/libfabric\nENV LIBRARY_PATH=/opt/intel/oneapi/mpi/latest/lib:/opt/intel/oneapi/ccl/latest/lib/:/opt/intel/oneapi/mkl/latest/lib/:/opt/intel/oneapi/compiler/latest/lib\nENV LD_LIBRARY_PATH=/opt/intel/oneapi/ccl/latest/lib/:/opt/intel/oneapi/mpi/latest/opt/mpi/libfabric/lib:/opt/intel/oneapi/mpi/latest/lib:/opt/intel/oneapi/mkl/latest/lib:/opt/intel/oneapi/compiler/latest/opt/compiler/lib:/opt/intel/oneapi/compiler/latest/lib:/opt/intel/oneapi/lib:/opt/intel/oneapi/lib/intel64:/opt/conda/lib\nENV PATH=/opt/conda/bin:/opt/intel/oneapi/mpi/latest/opt/mpi/libfabric/bin:/opt/intel/oneapi/mpi/latest/bin:/opt/intel/oneapi/mpi/latest/opt/mpi/libfabric/bin:/opt/intel/oneapi/mkl/latest/bin/:/opt/intel/oneapi/compiler/latest/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin\nENV CCL_ZE_IPC_EXCHANGE=sockets\nENV CMAKE_PREFIX_PATH=/opt/intel/oneapi/mkl/latest/lib/cmake:/opt/intel/oneapi/compiler/latest\nENV CPATH=/opt/intel/oneapi/mpi/latest/include:/opt/intel/oneapi/ccl/latest/include:/opt/intel/oneapi/mkl/latest/include\n\n# Install benchmarker\nCOPY --from=builder /usr/src/target/release-opt/text-generation-benchmark /usr/local/bin/text-generation-benchmark\n# Install router\nCOPY --from=builder /usr/src/target/release-opt/text-generation-router /usr/local/bin/text-generation-router\n# Install launcher\nCOPY --from=builder /usr/src/target/release-opt/text-generation-launcher /usr/local/bin/text-generation-launcher\n\n\n# Text Generation Inference base image for Intel-cpu\nFROM ubuntu:22.04 AS cpu\n\nRUN apt-get update && DEBIAN_FRONTEND=noninteractive apt-get install -y --no-install-recommends \\\n curl \\\n ca-certificates \\\n make \\\n g++ \\\n git \\\n wget \\\n cmake \\\n libnuma-dev\n\nENV HUGGINGFACE_HUB_CACHE=/data \\\n HF_HUB_ENABLE_HF_TRANSFER=1 \\\n PORT=80\n\nARG MAMBA_VERSION=23.1.0-1\nARG PYTHON_VERSION='3.11.10'\n# Automatically set by buildx\nARG TARGETPLATFORM\nENV PATH /opt/conda/bin:$PATH\n\n# TGI seem to require libssl.so.1.1 instead of libssl.so.3 so we can't use ubuntu 22.04. Ubuntu 20.04 has python==3.8, and TGI requires python>=3.9, hence the need for miniconda.\n# Install mamba\n# translating Docker's TARGETPLATFORM into mamba arches\nRUN case ${TARGETPLATFORM} in \\\n \"linux/arm64\") MAMBA_ARCH=aarch64 ;; \\\n *) MAMBA_ARCH=x86_64 ;; \\\n esac && \\\n curl -fsSL -v -o ~/mambaforge.sh -O \"https://github.com/conda-forge/miniforge/releases/download/${MAMBA_VERSION}/Mambaforge-${MAMBA_VERSION}-Linux-${MAMBA_ARCH}.sh\"\nRUN chmod +x ~/mambaforge.sh && \\\n bash ~/mambaforge.sh -b -p /opt/conda && \\\n rm ~/mambaforge.sh\n\nRUN case ${TARGETPLATFORM} in \\\n \"linux/arm64\") exit 1 ;; \\\n *) /opt/conda/bin/conda update -y conda && \\\n /opt/conda/bin/conda install -y \"python=${PYTHON_VERSION}\" ;; \\\n esac && \\\n /opt/conda/bin/conda clean -ya\n\nRUN conda install -c conda-forge gperftools mkl\n\nRUN pip install https://download.pytorch.org/whl/nightly/cpu/torch-2.4.0.dev20240612%2Bcpu-cp311-cp311-linux_x86_64.whl\nRUN pip install https://download.pytorch.org/whl/nightly/cpu/torchvision-0.19.0.dev20240612%2Bcpu-cp311-cp311-linux_x86_64.whl\nRUN pip install https://download.pytorch.org/whl/nightly/cpu/torchaudio-2.4.0.dev20240612%2Bcpu-cp311-cp311-linux_x86_64.whl\nRUN pip install triton py-libnuma\n\nWORKDIR /usr/src\n\nRUN git clone https://github.com/intel/intel-extension-for-pytorch && cd intel-extension-for-pytorch && git checkout eda7a7c42df6f9a64e0de9c2b69304ee02f2c32a\n\nRUN git clone https://github.com/intel/torch-ccl.git && cd torch-ccl && git checkout ccl_torch_dev_0131\n\nRUN cd intel-extension-for-pytorch && git submodule sync && git submodule update --init --recursive && python setup.py install\n\nRUN cd torch-ccl && git submodule sync && git submodule update --init --recursive && pip install .\n\nENV LD_PRELOAD=/opt/conda/lib/libtcmalloc.so\nENV CCL_ROOT=/opt/conda/lib/python3.11/site-packages/oneccl_bindings_for_pytorch\nENV I_MPI_ROOT=/opt/conda/lib/python3.11/site-packages/oneccl_bindings_for_pytorch\nENV FI_PROVIDER_PATH=/opt/conda/lib/python3.11/site-packages/oneccl_bindings_for_pytorch/opt/mpi/libfabric/lib/prov:/usr/lib64/libfabric\nENV LD_LIBRARY_PATH=/opt/conda/lib/python3.11/site-packages/oneccl_bindings_for_pytorch/opt/mpi/libfabric/lib:/opt/conda/lib/python3.11/site-packages/oneccl_bindings_for_pytorch/lib\nENV LD_LIBRARY_PATH=\"$LD_LIBRARY_PATH:/opt/conda/lib/\"\n\n# Install server\nCOPY proto proto\nCOPY server server\nCOPY server/Makefile server/Makefile\nRUN cd server && \\\n make gen-server && \\\n pip install -r requirements_intel.txt && \\\n pip install \".[accelerate, peft, outlines]\" --no-cache-dir\n\n# Install benchmarker\nCOPY --from=builder /usr/src/target/release-opt/text-generation-benchmark /usr/local/bin/text-generation-benchmark\n# Install router\nCOPY --from=builder /usr/src/target/release-opt/text-generation-router /usr/local/bin/text-generation-router\n# Install launcher\nCOPY --from=builder /usr/src/target/release-opt/text-generation-launcher /usr/local/bin/text-generation-launcher\n\nFROM ${PLATFORM} AS final\nENV ATTENTION=paged\nENV USE_PREFIX_CACHING=0\nENV CUDA_GRAPHS=0\nENTRYPOINT [\"text-generation-launcher\"]\nCMD [\"--json-output\"]\n", ".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 0aa66d693a85faed268be50ab8e662cf5516be30 Hamza Amin <[email protected]> 1727369563 +0500\tclone: from https://github.com/huggingface/text-generation-inference.git\n", ".git\\refs\\heads\\main": "0aa66d693a85faed268be50ab8e662cf5516be30\n", "backends\\trtllm\\Dockerfile": "ARG CUDA_ARCH_LIST=\"75-real;80-real;86-real;89-real;90-real\"\nARG OMPI_VERSION=\"4.1.6\"\n\n# Build dependencies resolver stage\nFROM lukemathwalker/cargo-chef:latest AS chef\nWORKDIR /usr/src/text-generation-inference/backends/trtllm\n\nFROM chef AS planner\nCOPY . .\nRUN cargo chef prepare --recipe-path recipe.json\n\n# CUDA dependent dependencies resolver stage\nFROM nvidia/cuda:12.5.1-cudnn-devel-ubuntu22.04 AS cuda-builder\n\nRUN --mount=type=cache,target=/var/cache/apt,sharing=locked \\\n --mount=type=cache,target=/var/lib/apt,sharing=locked \\\n apt update && apt install -y \\\n build-essential \\\n cmake \\\n curl \\\n gcc \\\n g++ \\\n git \\\n git-lfs \\\n libssl-dev \\\n ninja-build \\\n pkg-config \\\n python3 \\\n python3-setuptools \\\n tar \\\n wget\n\nENV TGI_INSTALL_PREFIX=/usr/local/tgi\nENV TENSORRT_INSTALL_PREFIX=/usr/local/tensorrt\n\n# Install OpenMPI\nFROM cuda-builder AS mpi-builder\nARG OMPI_VERSION\n\nENV OMPI_TARBALL_FILENAME=\"openmpi-$OMPI_VERSION.tar.bz2\"\nRUN wget \"https://download.open-mpi.org/release/open-mpi/v4.1/$OMPI_TARBALL_FILENAME\" -P /opt/src && \\\n mkdir /usr/src/mpi && \\\n tar -xf \"/opt/src/$OMPI_TARBALL_FILENAME\" -C /usr/src/mpi --strip-components=1 && \\\n cd /usr/src/mpi && \\\n ./configure --prefix=/usr/local/mpi --with-cuda=/usr/local/cuda && \\\n make -j all && \\\n make install && \\\n rm -rf \"/opt/src/$OMPI_TARBALL_FILENAME\"\n\n# Install TensorRT\nFROM cuda-builder AS trt-builder\nCOPY backends/trtllm/scripts/install_tensorrt.sh /opt/install_tensorrt.sh\nRUN chmod +x /opt/install_tensorrt.sh && \\\n /opt/install_tensorrt.sh\n\n# Build Backend\nFROM cuda-builder AS tgi-builder\nWORKDIR /usr/src/text-generation-inference\n\n# Install Rust\nRUN curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | bash -s -- -y && \\\n chmod -R a+w /root/.rustup && \\\n chmod -R a+w /root/.cargo\n\nENV PATH=\"/root/.cargo/bin:$PATH\"\nRUN cargo install cargo-chef\n\n# Cache dependencies\nCOPY --from=planner /usr/src/text-generation-inference/backends/trtllm/recipe.json .\nRUN cargo chef cook --release --recipe-path recipe.json\n\n# Build actual TGI\nARG CUDA_ARCH_LIST\nENV CMAKE_PREFIX_PATH=\"/usr/local/mpi:/usr/local/tensorrt:$CMAKE_PREFIX_PATH\"\nENV LD_LIBRARY_PATH=\"/usr/local/mpi/lib:$LD_LIBRARY_PATH\"\nENV PKG_CONFIG_PATH=\"/usr/local/mpi/lib/pkgconfig:$PKG_CONFIG_PATH\"\n\nCOPY . .\nCOPY --from=trt-builder /usr/local/tensorrt /usr/local/tensorrt\nCOPY --from=mpi-builder /usr/local/mpi /usr/local/mpi\nRUN mkdir $TGI_INSTALL_PREFIX && mkdir \"$TGI_INSTALL_PREFIX/include\" && mkdir \"$TGI_INSTALL_PREFIX/lib\" && \\\n cd backends/trtllm && \\\n CMAKE_INSTALL_PREFIX=$TGI_INSTALL_PREFIX cargo build --release\n\nFROM nvidia/cuda:12.5.1-cudnn-runtime-ubuntu22.04 AS runtime\nWORKDIR /usr/local/tgi/bin\n\nENV LD_LIBRARY_PATH=\"/usr/local/tgi/lib:/usr/local/tensorrt/lib:/usr/local/cuda/lib64/stubs:$LD_LIBRARY_PATH\"\n\nCOPY --from=mpi-builder /usr/local/mpi /usr/local/mpi\nCOPY --from=trt-builder /usr/local/tensorrt /usr/local/tensorrt\nCOPY --from=tgi-builder /usr/local/tgi /usr/local/tgi\nCOPY --from=tgi-builder /usr/src/text-generation-inference/target/release/text-generation-backends-trtllm /usr/local/tgi/bin/text-generation-launcher\n\nFROM runtime\n\nLABEL co.huggingface.vendor=\"Hugging Face Inc.\"\nLABEL org.opencontainers.image.authors=\"[email protected]\"\n\nENTRYPOINT [\"./text-generation-launcher\"]\nCMD [\"--executor-worker\", \"/usr/local/tgi/bin/executorWorker\"]\n", "backends\\trtllm\\src\\main.rs": "use clap::Parser;\nuse std::collections::HashMap;\nuse std::path::PathBuf;\nuse text_generation_backends_trtllm::errors::TensorRtLlmBackendError;\nuse text_generation_backends_trtllm::TensorRtLlmBackend;\nuse text_generation_router::server;\nuse tokenizers::{FromPretrainedParameters, Tokenizer};\n\n/// App Configuration\n#[derive(Parser, Debug)]\n#[clap(author, version, about, long_about = None)]\nstruct Args {\n #[clap(default_value = \"128\", long, env)]\n max_concurrent_requests: usize,\n #[clap(default_value = \"2\", long, env)]\n max_best_of: usize,\n #[clap(default_value = \"4\", long, env)]\n max_stop_sequences: usize,\n #[clap(default_value = \"5\", long, env)]\n max_top_n_tokens: u32,\n #[clap(default_value = \"1024\", long, env)]\n max_input_tokens: usize,\n #[clap(default_value = \"2048\", long, env)]\n max_total_tokens: usize,\n #[clap(default_value = \"4096\", long, env)]\n max_batch_prefill_tokens: u32,\n #[clap(long, env)]\n max_batch_total_tokens: Option<u32>,\n #[clap(default_value = \"0.0.0.0\", long, env)]\n hostname: String,\n #[clap(default_value = \"3000\", long, short, env)]\n port: u16,\n #[clap(long, env, required = true)]\n tokenizer_name: String,\n #[clap(long, env)]\n tokenizer_config_path: Option<String>,\n #[clap(long, env)]\n revision: Option<String>,\n #[clap(long, env)]\n model_id: String,\n #[clap(default_value = \"2\", long, env)]\n validation_workers: usize,\n #[clap(long, env)]\n json_output: bool,\n #[clap(long, env)]\n otlp_endpoint: Option<String>,\n #[clap(default_value = \"text-generation-inference.router\", long, env)]\n otlp_service_name: String,\n #[clap(long, env)]\n cors_allow_origin: Option<Vec<String>>,\n #[clap(long, env, default_value_t = false)]\n messages_api_enabled: bool,\n #[clap(default_value = \"4\", long, env)]\n max_client_batch_size: usize,\n #[clap(long, env)]\n auth_token: Option<String>,\n #[clap(long, env, help = \"Path to the TensorRT-LLM Orchestrator worker\")]\n executor_worker: PathBuf,\n}\n\n#[tokio::main]\nasync fn main() -> Result<(), TensorRtLlmBackendError> {\n // Get args\n let args = Args::parse();\n // Pattern match configuration\n let Args {\n max_concurrent_requests,\n max_best_of,\n max_stop_sequences,\n max_top_n_tokens,\n max_input_tokens,\n max_total_tokens,\n max_batch_prefill_tokens,\n max_batch_total_tokens,\n hostname,\n port,\n tokenizer_name,\n tokenizer_config_path,\n revision,\n model_id,\n validation_workers,\n json_output,\n otlp_endpoint,\n otlp_service_name,\n cors_allow_origin,\n messages_api_enabled,\n max_client_batch_size,\n auth_token,\n executor_worker,\n } = args;\n\n // Launch Tokio runtime\n text_generation_router::logging::init_logging(otlp_endpoint, otlp_service_name, json_output);\n\n // Validate args\n if max_input_tokens >= max_total_tokens {\n return Err(TensorRtLlmBackendError::ArgumentValidation(\n \"`max_input_tokens` must be < `max_total_tokens`\".to_string(),\n ));\n }\n if max_input_tokens as u32 > max_batch_prefill_tokens {\n return Err(TensorRtLlmBackendError::ArgumentValidation(format!(\"`max_batch_prefill_tokens` must be >= `max_input_tokens`. Given: {max_batch_prefill_tokens} and {max_input_tokens}\")));\n }\n\n if validation_workers == 0 {\n return Err(TensorRtLlmBackendError::ArgumentValidation(\n \"`validation_workers` must be > 0\".to_string(),\n ));\n }\n\n if let Some(ref max_batch_total_tokens) = max_batch_total_tokens {\n if max_batch_prefill_tokens > *max_batch_total_tokens {\n return Err(TensorRtLlmBackendError::ArgumentValidation(format!(\"`max_batch_prefill_tokens` must be <= `max_batch_total_tokens`. Given: {max_batch_prefill_tokens} and {max_batch_total_tokens}\")));\n }\n if max_total_tokens as u32 > *max_batch_total_tokens {\n return Err(TensorRtLlmBackendError::ArgumentValidation(format!(\"`max_total_tokens` must be <= `max_batch_total_tokens`. Given: {max_total_tokens} and {max_batch_total_tokens}\")));\n }\n }\n\n if !executor_worker.exists() {\n return Err(TensorRtLlmBackendError::ArgumentValidation(format!(\n \"`executor_work` specified path doesn't exists: {}\",\n executor_worker.display()\n )));\n }\n\n // Run server\n let tokenizer = Tokenizer::from_pretrained(\n tokenizer_name.clone(),\n Some(FromPretrainedParameters {\n revision: revision.clone().unwrap_or(String::from(\"main\")),\n user_agent: HashMap::new(),\n auth_token,\n }),\n )\n .map_err(|e| TensorRtLlmBackendError::Tokenizer(e.to_string()))?;\n\n let backend = TensorRtLlmBackend::new(tokenizer, model_id, executor_worker)?;\n server::run(\n backend,\n max_concurrent_requests,\n max_best_of,\n max_stop_sequences,\n max_top_n_tokens,\n max_input_tokens,\n max_total_tokens,\n validation_workers,\n None,\n tokenizer_name,\n tokenizer_config_path,\n revision,\n hostname,\n port,\n cors_allow_origin,\n false,\n None,\n None,\n messages_api_enabled,\n true,\n max_client_batch_size,\n false,\n false,\n )\n .await?;\n Ok(())\n}\n", "backends\\v2\\src\\main.rs": "use clap::{Parser, Subcommand};\nuse text_generation_router::{server, usage_stats};\nuse text_generation_router_v2::{connect_backend, V2Error};\nuse thiserror::Error;\n\n/// App Configuration\n#[derive(Parser, Debug)]\n#[clap(author, version, about, long_about = None)]\nstruct Args {\n #[command(subcommand)]\n command: Option<Commands>,\n\n #[clap(default_value = \"128\", long, env)]\n max_concurrent_requests: usize,\n #[clap(default_value = \"2\", long, env)]\n max_best_of: usize,\n #[clap(default_value = \"4\", long, env)]\n max_stop_sequences: usize,\n #[clap(default_value = \"5\", long, env)]\n max_top_n_tokens: u32,\n #[clap(default_value = \"1024\", long, env)]\n max_input_tokens: usize,\n #[clap(default_value = \"2048\", long, env)]\n max_total_tokens: usize,\n #[clap(default_value = \"1.2\", long, env)]\n waiting_served_ratio: f32,\n #[clap(default_value = \"4096\", long, env)]\n max_batch_prefill_tokens: u32,\n #[clap(long, env)]\n max_batch_total_tokens: Option<u32>,\n #[clap(default_value = \"20\", long, env)]\n max_waiting_tokens: usize,\n #[clap(long, env)]\n max_batch_size: Option<usize>,\n #[clap(default_value = \"0.0.0.0\", long, env)]\n hostname: String,\n #[clap(default_value = \"3000\", long, short, env)]\n port: u16,\n #[clap(default_value = \"/tmp/text-generation-server-0\", long, env)]\n master_shard_uds_path: String,\n #[clap(default_value = \"bigscience/bloom\", long, env)]\n tokenizer_name: String,\n #[clap(long, env)]\n tokenizer_config_path: Option<String>,\n #[clap(long, env)]\n revision: Option<String>,\n #[clap(default_value = \"2\", long, env)]\n validation_workers: usize,\n #[clap(long, env)]\n api_key: Option<String>,\n #[clap(long, env)]\n json_output: bool,\n #[clap(long, env)]\n otlp_endpoint: Option<String>,\n #[clap(default_value = \"text-generation-inference.router\", long, env)]\n otlp_service_name: String,\n #[clap(long, env)]\n cors_allow_origin: Option<Vec<String>>,\n #[clap(long, env)]\n ngrok: bool,\n #[clap(long, env)]\n ngrok_authtoken: Option<String>,\n #[clap(long, env)]\n ngrok_edge: Option<String>,\n #[clap(long, env, default_value_t = false)]\n messages_api_enabled: bool,\n #[clap(long, env, default_value_t = false)]\n disable_grammar_support: bool,\n #[clap(default_value = \"4\", long, env)]\n max_client_batch_size: usize,\n #[clap(default_value = \"on\", long, env)]\n usage_stats: usage_stats::UsageStatsLevel,\n}\n\n#[derive(Debug, Subcommand)]\nenum Commands {\n PrintSchema,\n}\n\n#[tokio::main]\nasync fn main() -> Result<(), RouterError> {\n // Get args\n let args = Args::parse();\n // Pattern match configuration\n let Args {\n command,\n max_concurrent_requests,\n max_best_of,\n max_stop_sequences,\n max_top_n_tokens,\n max_input_tokens,\n max_total_tokens,\n waiting_served_ratio,\n max_batch_prefill_tokens,\n max_batch_total_tokens,\n max_waiting_tokens,\n max_batch_size,\n hostname,\n port,\n master_shard_uds_path,\n tokenizer_name,\n tokenizer_config_path,\n revision,\n validation_workers,\n api_key,\n json_output,\n otlp_endpoint,\n otlp_service_name,\n cors_allow_origin,\n ngrok,\n ngrok_authtoken,\n ngrok_edge,\n messages_api_enabled,\n disable_grammar_support,\n max_client_batch_size,\n usage_stats,\n } = args;\n\n if let Some(Commands::PrintSchema) = command {\n use utoipa::OpenApi;\n let api_doc = text_generation_router::server::ApiDoc::openapi();\n let api_doc = serde_json::to_string_pretty(&api_doc).unwrap();\n println!(\"{}\", api_doc);\n std::process::exit(0);\n };\n text_generation_router::logging::init_logging(otlp_endpoint, otlp_service_name, json_output);\n\n // Validate args\n if max_input_tokens >= max_total_tokens {\n return Err(RouterError::ArgumentValidation(\n \"`max_input_tokens` must be < `max_total_tokens`\".to_string(),\n ));\n }\n if max_input_tokens as u32 > max_batch_prefill_tokens {\n return Err(RouterError::ArgumentValidation(format!(\"`max_batch_prefill_tokens` must be >= `max_input_tokens`. Given: {max_batch_prefill_tokens} and {max_input_tokens}\")));\n }\n\n if validation_workers == 0 {\n return Err(RouterError::ArgumentValidation(\n \"`validation_workers` must be > 0\".to_string(),\n ));\n }\n\n if let Some(ref max_batch_total_tokens) = max_batch_total_tokens {\n if max_batch_prefill_tokens > *max_batch_total_tokens {\n return Err(RouterError::ArgumentValidation(format!(\"`max_batch_prefill_tokens` must be <= `max_batch_total_tokens`. Given: {max_batch_prefill_tokens} and {max_batch_total_tokens}\")));\n }\n if max_total_tokens as u32 > *max_batch_total_tokens {\n return Err(RouterError::ArgumentValidation(format!(\"`max_total_tokens` must be <= `max_batch_total_tokens`. Given: {max_total_tokens} and {max_batch_total_tokens}\")));\n }\n }\n\n if let Some(max_batch_size) = max_batch_size {\n if max_batch_size == 0 {\n return Err(RouterError::ArgumentValidation(\n \"`max_batch_size` must be > 0\".to_string(),\n ));\n }\n }\n\n let (backend, _backend_info) = connect_backend(\n max_input_tokens,\n max_total_tokens,\n master_shard_uds_path,\n waiting_served_ratio,\n max_batch_prefill_tokens,\n max_batch_total_tokens,\n max_waiting_tokens,\n max_batch_size,\n )\n .await?;\n\n // Run server\n server::run(\n backend,\n max_concurrent_requests,\n max_best_of,\n max_stop_sequences,\n max_top_n_tokens,\n max_input_tokens,\n max_total_tokens,\n validation_workers,\n api_key,\n tokenizer_name,\n tokenizer_config_path,\n revision,\n hostname,\n port,\n cors_allow_origin,\n ngrok,\n ngrok_authtoken,\n ngrok_edge,\n messages_api_enabled,\n disable_grammar_support,\n max_client_batch_size,\n usage_stats,\n )\n .await?;\n Ok(())\n}\n\n#[derive(Debug, Error)]\nenum RouterError {\n #[error(\"Argument validation error: {0}\")]\n ArgumentValidation(String),\n #[error(\"Backend failed: {0}\")]\n Backend(#[from] V2Error),\n #[error(\"WebServer error: {0}\")]\n WebServer(#[from] server::WebServerError),\n #[error(\"Tokio runtime failed to start: {0}\")]\n Tokio(#[from] std::io::Error),\n}\n", "backends\\v3\\src\\main.rs": "use clap::{Parser, Subcommand};\nuse text_generation_router::{server, usage_stats};\nuse text_generation_router_v3::{connect_backend, V3Error};\nuse thiserror::Error;\n\n/// App Configuration\n#[derive(Parser, Debug)]\n#[clap(author, version, about, long_about = None)]\nstruct Args {\n #[command(subcommand)]\n command: Option<Commands>,\n\n #[clap(default_value = \"128\", long, env)]\n max_concurrent_requests: usize,\n #[clap(default_value = \"2\", long, env)]\n max_best_of: usize,\n #[clap(default_value = \"4\", long, env)]\n max_stop_sequences: usize,\n #[clap(default_value = \"5\", long, env)]\n max_top_n_tokens: u32,\n #[clap(default_value = \"1024\", long, env)]\n max_input_tokens: usize,\n #[clap(default_value = \"2048\", long, env)]\n max_total_tokens: usize,\n #[clap(default_value = \"1.2\", long, env)]\n waiting_served_ratio: f32,\n #[clap(default_value = \"4096\", long, env)]\n max_batch_prefill_tokens: u32,\n #[clap(long, env)]\n max_batch_total_tokens: Option<u32>,\n #[clap(default_value = \"20\", long, env)]\n max_waiting_tokens: usize,\n #[clap(long, env)]\n max_batch_size: Option<usize>,\n #[clap(default_value = \"0.0.0.0\", long, env)]\n hostname: String,\n #[clap(default_value = \"3000\", long, short, env)]\n port: u16,\n #[clap(default_value = \"/tmp/text-generation-server-0\", long, env)]\n master_shard_uds_path: String,\n #[clap(default_value = \"bigscience/bloom\", long, env)]\n tokenizer_name: String,\n #[clap(long, env)]\n tokenizer_config_path: Option<String>,\n #[clap(long, env)]\n revision: Option<String>,\n #[clap(default_value = \"2\", long, env)]\n validation_workers: usize,\n #[clap(long, env)]\n api_key: Option<String>,\n #[clap(long, env)]\n json_output: bool,\n #[clap(long, env)]\n otlp_endpoint: Option<String>,\n #[clap(default_value = \"text-generation-inference.router\", long, env)]\n otlp_service_name: String,\n #[clap(long, env)]\n cors_allow_origin: Option<Vec<String>>,\n #[clap(long, env)]\n ngrok: bool,\n #[clap(long, env)]\n ngrok_authtoken: Option<String>,\n #[clap(long, env)]\n ngrok_edge: Option<String>,\n #[clap(long, env, default_value_t = false)]\n messages_api_enabled: bool,\n #[clap(long, env, default_value_t = false)]\n disable_grammar_support: bool,\n #[clap(default_value = \"4\", long, env)]\n max_client_batch_size: usize,\n #[clap(default_value = \"on\", long, env)]\n usage_stats: usage_stats::UsageStatsLevel,\n}\n\n#[derive(Debug, Subcommand)]\nenum Commands {\n PrintSchema,\n}\n\n#[tokio::main]\nasync fn main() -> Result<(), RouterError> {\n // Get args\n let args = Args::parse();\n // Pattern match configuration\n let Args {\n command,\n max_concurrent_requests,\n max_best_of,\n max_stop_sequences,\n max_top_n_tokens,\n max_input_tokens,\n max_total_tokens,\n waiting_served_ratio,\n max_batch_prefill_tokens,\n max_batch_total_tokens,\n max_waiting_tokens,\n max_batch_size,\n hostname,\n port,\n master_shard_uds_path,\n tokenizer_name,\n tokenizer_config_path,\n revision,\n validation_workers,\n api_key,\n json_output,\n otlp_endpoint,\n otlp_service_name,\n cors_allow_origin,\n ngrok,\n ngrok_authtoken,\n ngrok_edge,\n messages_api_enabled,\n disable_grammar_support,\n max_client_batch_size,\n usage_stats,\n } = args;\n\n if let Some(Commands::PrintSchema) = command {\n use utoipa::OpenApi;\n let api_doc = text_generation_router::server::ApiDoc::openapi();\n let api_doc = serde_json::to_string_pretty(&api_doc).unwrap();\n println!(\"{}\", api_doc);\n std::process::exit(0);\n };\n text_generation_router::logging::init_logging(otlp_endpoint, otlp_service_name, json_output);\n\n // Validate args\n if max_input_tokens >= max_total_tokens {\n return Err(RouterError::ArgumentValidation(\n \"`max_input_tokens` must be < `max_total_tokens`\".to_string(),\n ));\n }\n if max_input_tokens as u32 > max_batch_prefill_tokens {\n return Err(RouterError::ArgumentValidation(format!(\"`max_batch_prefill_tokens` must be >= `max_input_tokens`. Given: {max_batch_prefill_tokens} and {max_input_tokens}\")));\n }\n\n if validation_workers == 0 {\n return Err(RouterError::ArgumentValidation(\n \"`validation_workers` must be > 0\".to_string(),\n ));\n }\n\n if let Some(ref max_batch_total_tokens) = max_batch_total_tokens {\n if max_batch_prefill_tokens > *max_batch_total_tokens {\n return Err(RouterError::ArgumentValidation(format!(\"`max_batch_prefill_tokens` must be <= `max_batch_total_tokens`. Given: {max_batch_prefill_tokens} and {max_batch_total_tokens}\")));\n }\n if max_total_tokens as u32 > *max_batch_total_tokens {\n return Err(RouterError::ArgumentValidation(format!(\"`max_total_tokens` must be <= `max_batch_total_tokens`. Given: {max_total_tokens} and {max_batch_total_tokens}\")));\n }\n }\n\n if let Some(max_batch_size) = max_batch_size {\n if max_batch_size == 0 {\n return Err(RouterError::ArgumentValidation(\n \"`max_batch_size` must be > 0\".to_string(),\n ));\n }\n }\n\n let (backend, _backend_info) = connect_backend(\n max_input_tokens,\n max_total_tokens,\n master_shard_uds_path,\n waiting_served_ratio,\n max_batch_prefill_tokens,\n max_batch_total_tokens,\n max_waiting_tokens,\n max_batch_size,\n )\n .await?;\n\n // Run server\n server::run(\n backend,\n max_concurrent_requests,\n max_best_of,\n max_stop_sequences,\n max_top_n_tokens,\n max_input_tokens,\n max_total_tokens,\n validation_workers,\n api_key,\n tokenizer_name,\n tokenizer_config_path,\n revision,\n hostname,\n port,\n cors_allow_origin,\n ngrok,\n ngrok_authtoken,\n ngrok_edge,\n messages_api_enabled,\n disable_grammar_support,\n max_client_batch_size,\n usage_stats,\n )\n .await?;\n Ok(())\n}\n\n#[derive(Debug, Error)]\nenum RouterError {\n #[error(\"Argument validation error: {0}\")]\n ArgumentValidation(String),\n #[error(\"Backend failed: {0}\")]\n Backend(#[from] V3Error),\n #[error(\"WebServer error: {0}\")]\n WebServer(#[from] server::WebServerError),\n #[error(\"Tokio runtime failed to start: {0}\")]\n Tokio(#[from] std::io::Error),\n}\n", "benchmark\\src\\app.rs": "/// Inspired by https://github.com/hatoo/oha/blob/bb989ea3cd77727e7743e7daa60a19894bb5e901/src/monitor.rs\nuse crate::generation::{Decode, Message, Prefill};\nuse ratatui::crossterm::event::{KeyCode, KeyEvent, KeyModifiers};\nuse ratatui::layout::{Alignment, Constraint, Direction, Layout};\nuse ratatui::style::{Color, Modifier, Style};\nuse ratatui::text::{Line, Span};\nuse ratatui::widgets::{\n Axis, BarChart, Block, Borders, Chart, Dataset, Gauge, GraphType, Paragraph, Tabs,\n};\nuse ratatui::{symbols, Frame};\nuse text_generation_client::ClientError;\nuse tokio::sync::mpsc;\n\n/// TUI powered App\npub(crate) struct App {\n pub(crate) running: bool,\n pub(crate) data: Data,\n completed_runs: Vec<usize>,\n completed_batch: usize,\n current_batch: usize,\n current_tab: usize,\n touched_tab: bool,\n zoom: bool,\n is_error: bool,\n tokenizer_name: String,\n sequence_length: u32,\n decode_length: u32,\n n_run: usize,\n receiver: mpsc::Receiver<Result<Message, ClientError>>,\n}\n\nimpl App {\n pub(crate) fn new(\n receiver: mpsc::Receiver<Result<Message, ClientError>>,\n tokenizer_name: String,\n sequence_length: u32,\n decode_length: u32,\n n_run: usize,\n batch_size: Vec<u32>,\n ) -> Self {\n let current_tab = 0;\n\n let completed_runs: Vec<usize> = (0..batch_size.len()).map(|_| 0).collect();\n let completed_batch = 0;\n let current_batch = 0;\n let is_error = false;\n\n let data = Data::new(n_run, batch_size);\n\n Self {\n running: true,\n data,\n completed_runs,\n completed_batch,\n current_batch,\n current_tab,\n touched_tab: false,\n zoom: false,\n is_error,\n tokenizer_name,\n sequence_length,\n decode_length,\n n_run,\n receiver,\n }\n }\n\n /// Handle crossterm key events\n pub(crate) fn handle_key_event(&mut self, key_event: KeyEvent) {\n match key_event {\n // Increase and wrap tab\n KeyEvent {\n code: KeyCode::Right,\n ..\n }\n | KeyEvent {\n code: KeyCode::Tab, ..\n } => {\n self.touched_tab = true;\n self.current_tab = (self.current_tab + 1) % self.data.batch_size.len();\n }\n // Decrease and wrap tab\n KeyEvent {\n code: KeyCode::Left,\n ..\n } => {\n self.touched_tab = true;\n if self.current_tab > 0 {\n self.current_tab -= 1;\n } else {\n self.current_tab = self.data.batch_size.len() - 1;\n }\n }\n // Zoom on throughput/latency fig\n KeyEvent {\n code: KeyCode::Char('+'),\n ..\n } => {\n self.zoom = true;\n }\n // Unzoom on throughput/latency fig\n KeyEvent {\n code: KeyCode::Char('-'),\n ..\n } => {\n self.zoom = false;\n }\n // Quit\n KeyEvent {\n code: KeyCode::Char('q'),\n ..\n }\n | KeyEvent {\n code: KeyCode::Char('c'),\n modifiers: KeyModifiers::CONTROL,\n ..\n } => {\n self.running = false;\n }\n _ => (),\n }\n }\n\n /// Get all pending messages from generation task\n pub(crate) fn tick(&mut self) {\n while let Ok(message) = self.receiver.try_recv() {\n match message {\n Ok(message) => match message {\n Message::Prefill(step) => self.data.push_prefill(step, self.current_batch),\n Message::Decode(step) => self.data.push_decode(step, self.current_batch),\n Message::EndRun => {\n self.completed_runs[self.current_batch] += 1;\n }\n Message::EndBatch => {\n self.data.end_batch(self.current_batch);\n self.completed_batch += 1;\n\n if self.current_batch < self.data.batch_size.len() - 1 {\n // Only go to next tab if the user never touched the tab keys\n if !self.touched_tab {\n self.current_tab += 1;\n }\n\n self.current_batch += 1;\n }\n }\n Message::Warmup => {}\n },\n Err(_) => self.is_error = true,\n }\n }\n }\n\n /// Render frame\n pub fn render(&mut self, f: &mut Frame) {\n let batch_progress =\n (self.completed_batch as f64 / self.data.batch_size.len() as f64).clamp(0.0, 1.0);\n let run_progress =\n (self.completed_runs[self.current_batch] as f64 / self.n_run as f64).clamp(0.0, 1.0);\n\n // Vertical layout\n let row5 = Layout::default()\n .direction(Direction::Vertical)\n .constraints(\n [\n Constraint::Length(1),\n Constraint::Length(3),\n Constraint::Length(3),\n Constraint::Length(13),\n Constraint::Min(10),\n ]\n .as_ref(),\n )\n .split(f.area());\n\n // Top row horizontal layout\n let top = Layout::default()\n .direction(Direction::Horizontal)\n .constraints([Constraint::Percentage(50), Constraint::Percentage(50)].as_ref())\n .split(row5[2]);\n\n // Mid row horizontal layout\n let mid = Layout::default()\n .direction(Direction::Horizontal)\n .constraints(\n [\n Constraint::Percentage(25),\n Constraint::Percentage(25),\n Constraint::Percentage(25),\n Constraint::Percentage(25),\n ]\n .as_ref(),\n )\n .split(row5[3]);\n\n // Left mid row vertical layout\n let prefill_text = Layout::default()\n .direction(Direction::Vertical)\n .constraints([Constraint::Length(8), Constraint::Length(5)].as_ref())\n .split(mid[0]);\n\n // Right mid row vertical layout\n let decode_text = Layout::default()\n .direction(Direction::Vertical)\n .constraints([Constraint::Length(8), Constraint::Length(5)].as_ref())\n .split(mid[2]);\n let decode_text_latency = Layout::default()\n .direction(Direction::Horizontal)\n .constraints([Constraint::Percentage(50), Constraint::Percentage(50)].as_ref())\n .split(decode_text[0]);\n\n // Bottom row horizontal layout\n let bottom = Layout::default()\n .direction(Direction::Horizontal)\n .constraints([Constraint::Percentage(50), Constraint::Percentage(50)].as_ref())\n .split(row5[4]);\n\n // Title\n let title = Block::default()\n .borders(Borders::NONE)\n .title(format!(\n \"Model: {} | Sequence Length: {} | Decode Length: {}\",\n self.tokenizer_name, self.sequence_length, self.decode_length\n ))\n .style(\n Style::default()\n .add_modifier(Modifier::BOLD)\n .fg(Color::White),\n );\n f.render_widget(title, row5[0]);\n\n // Helper\n let helper = Block::default()\n .borders(Borders::NONE)\n .title(\"<- | tab | ->: change batch tab | q / CTRL + c: quit | +/-: zoom\")\n .title_alignment(Alignment::Right)\n .style(Style::default().fg(Color::White));\n f.render_widget(helper, row5[0]);\n\n // Batch tabs\n let titles: Vec<Line> = self\n .data\n .batch_size\n .iter()\n .map(|b| {\n Line::from(vec![Span::styled(\n format!(\"Batch: {b}\"),\n Style::default().fg(Color::White),\n )])\n })\n .collect();\n let tabs = Tabs::new(titles)\n .block(Block::default().borders(Borders::ALL).title(\"Tabs\"))\n .select(self.current_tab)\n .style(Style::default().fg(Color::LightCyan))\n .highlight_style(\n Style::default()\n .add_modifier(Modifier::BOLD)\n .bg(Color::Black),\n );\n f.render_widget(tabs, row5[1]);\n\n // Total progress bar\n let color = if self.is_error {\n Color::Red\n } else {\n Color::LightGreen\n };\n let batch_gauge = progress_gauge(\n \"Total Progress\",\n format!(\"{} / {}\", self.completed_batch, self.data.batch_size.len()),\n batch_progress,\n color,\n );\n f.render_widget(batch_gauge, top[0]);\n\n // Batch progress Bar\n let color = if self.is_error {\n Color::Red\n } else {\n Color::LightBlue\n };\n let run_gauge = progress_gauge(\n \"Batch Progress\",\n format!(\n \"{} / {}\",\n self.completed_runs[self.current_batch], self.n_run\n ),\n run_progress,\n color,\n );\n f.render_widget(run_gauge, top[1]);\n\n // Prefill text infos\n let prefill_latency_block = latency_paragraph(\n &mut self.data.prefill_latencies[self.current_tab],\n \"Prefill\",\n );\n let prefill_throughput_block =\n throughput_paragraph(&self.data.prefill_throughputs[self.current_tab], \"Prefill\");\n\n f.render_widget(prefill_latency_block, prefill_text[0]);\n f.render_widget(prefill_throughput_block, prefill_text[1]);\n\n // Prefill latency histogram\n let histo_width = 7;\n let bins = if mid[1].width < 2 {\n 0\n } else {\n (mid[1].width as usize - 2) / (histo_width + 1)\n }\n .max(2);\n\n let histo_data =\n latency_histogram_data(&self.data.prefill_latencies[self.current_tab], bins);\n let histo_data_str: Vec<(&str, u64)> =\n histo_data.iter().map(|(l, v)| (l.as_str(), *v)).collect();\n let prefill_histogram =\n latency_histogram(&histo_data_str, \"Prefill\").bar_width(histo_width as u16);\n f.render_widget(prefill_histogram, mid[1]);\n\n // Decode text info\n let decode_latency_block = latency_paragraph(\n &mut self.data.decode_latencies[self.current_tab],\n \"Decode Total\",\n );\n let decode_token_latency_block = latency_paragraph(\n &mut self.data.decode_token_latencies[self.current_tab],\n \"Decode Token\",\n );\n let decode_throughput_block =\n throughput_paragraph(&self.data.decode_throughputs[self.current_tab], \"Decode\");\n f.render_widget(decode_latency_block, decode_text_latency[0]);\n f.render_widget(decode_token_latency_block, decode_text_latency[1]);\n f.render_widget(decode_throughput_block, decode_text[1]);\n\n // Decode latency histogram\n let histo_data =\n latency_histogram_data(&self.data.decode_latencies[self.current_tab], bins);\n let histo_data_str: Vec<(&str, u64)> =\n histo_data.iter().map(|(l, v)| (l.as_str(), *v)).collect();\n let decode_histogram =\n latency_histogram(&histo_data_str, \"Decode\").bar_width(histo_width as u16);\n f.render_widget(decode_histogram, mid[3]);\n\n // Prefill latency/throughput chart\n let prefill_latency_throughput_chart = latency_throughput_chart(\n &self.data.prefill_batch_latency_throughput,\n &self.data.batch_size,\n self.zoom,\n \"Prefill\",\n );\n f.render_widget(prefill_latency_throughput_chart, bottom[0]);\n\n // Decode latency/throughput chart\n let decode_latency_throughput_chart = latency_throughput_chart(\n &self.data.decode_batch_latency_throughput,\n &self.data.batch_size,\n self.zoom,\n \"Decode\",\n );\n f.render_widget(decode_latency_throughput_chart, bottom[1]);\n }\n}\n\n/// App internal data struct\npub(crate) struct Data {\n pub(crate) batch_size: Vec<u32>,\n pub(crate) prefill_latencies: Vec<Vec<f64>>,\n pub(crate) prefill_throughputs: Vec<Vec<f64>>,\n pub(crate) decode_latencies: Vec<Vec<f64>>,\n pub(crate) decode_token_latencies: Vec<Vec<f64>>,\n pub(crate) decode_throughputs: Vec<Vec<f64>>,\n pub(crate) prefill_batch_latency_throughput: Vec<(f64, f64)>,\n pub(crate) decode_batch_latency_throughput: Vec<(f64, f64)>,\n}\n\nimpl Data {\n fn new(n_run: usize, batch_size: Vec<u32>) -> Self {\n let prefill_latencies: Vec<Vec<f64>> = (0..batch_size.len())\n .map(|_| Vec::with_capacity(n_run))\n .collect();\n let prefill_throughputs: Vec<Vec<f64>> = prefill_latencies.clone();\n\n let decode_latencies: Vec<Vec<f64>> = prefill_latencies.clone();\n let decode_token_latencies: Vec<Vec<f64>> = decode_latencies.clone();\n let decode_throughputs: Vec<Vec<f64>> = prefill_throughputs.clone();\n\n let prefill_batch_latency_throughput: Vec<(f64, f64)> =\n Vec::with_capacity(batch_size.len());\n let decode_batch_latency_throughput: Vec<(f64, f64)> =\n prefill_batch_latency_throughput.clone();\n\n Self {\n batch_size,\n prefill_latencies,\n prefill_throughputs,\n decode_latencies,\n decode_token_latencies,\n decode_throughputs,\n prefill_batch_latency_throughput,\n decode_batch_latency_throughput,\n }\n }\n\n fn push_prefill(&mut self, prefill: Prefill, batch_idx: usize) {\n let latency = prefill.latency.as_micros() as f64 / 1000.0;\n self.prefill_latencies[batch_idx].push(latency);\n self.prefill_throughputs[batch_idx].push(prefill.throughput);\n }\n\n fn push_decode(&mut self, decode: Decode, batch_idx: usize) {\n let latency = decode.latency.as_micros() as f64 / 1000.0;\n let token_latency = decode.token_latency.as_micros() as f64 / 1000.0;\n self.decode_latencies[batch_idx].push(latency);\n self.decode_token_latencies[batch_idx].push(token_latency);\n self.decode_throughputs[batch_idx].push(decode.throughput);\n }\n\n fn end_batch(&mut self, batch_idx: usize) {\n self.prefill_batch_latency_throughput.push((\n self.prefill_latencies[batch_idx].iter().sum::<f64>()\n / self.prefill_latencies[batch_idx].len() as f64,\n self.prefill_throughputs[batch_idx].iter().sum::<f64>()\n / self.prefill_throughputs[batch_idx].len() as f64,\n ));\n self.decode_batch_latency_throughput.push((\n self.decode_latencies[batch_idx].iter().sum::<f64>()\n / self.decode_latencies[batch_idx].len() as f64,\n self.decode_throughputs[batch_idx].iter().sum::<f64>()\n / self.decode_throughputs[batch_idx].len() as f64,\n ));\n }\n}\n\n/// Progress bar\nfn progress_gauge(title: &str, label: String, progress: f64, color: Color) -> Gauge {\n Gauge::default()\n .block(Block::default().title(title).borders(Borders::ALL))\n .gauge_style(Style::default().fg(color))\n .label(Span::raw(label))\n .ratio(progress)\n}\n\n/// Throughput paragraph\nfn throughput_paragraph<'a>(throughput: &[f64], name: &'static str) -> Paragraph<'a> {\n // Throughput average/high/low texts\n let throughput_texts = statis_spans(throughput, \"tokens/secs\");\n\n // Throughput block\n Paragraph::new(throughput_texts).block(\n Block::default()\n .title(Span::raw(format!(\"{name} Throughput\")))\n .borders(Borders::ALL),\n )\n}\n\n/// Latency paragraph\nfn latency_paragraph<'a>(latency: &mut [f64], name: &'static str) -> Paragraph<'a> {\n // Latency average/high/low texts\n let mut latency_texts = statis_spans(latency, \"ms\");\n\n // Sort latency for percentiles\n float_ord::sort(latency);\n let latency_percentiles = crate::utils::percentiles(latency, &[50, 90, 99]);\n\n // Latency p50/p90/p99 texts\n let colors = [Color::LightGreen, Color::LightYellow, Color::LightRed];\n for (i, (name, value)) in latency_percentiles.iter().enumerate() {\n let span = Line::from(vec![Span::styled(\n format!(\"{name}: {value:.2} ms\"),\n Style::default().fg(colors[i]),\n )]);\n latency_texts.push(span);\n }\n\n Paragraph::new(latency_texts).block(\n Block::default()\n .title(Span::raw(format!(\"{name} Latency\")))\n .borders(Borders::ALL),\n )\n}\n\n/// Average/High/Low spans\nfn statis_spans<'a>(data: &[f64], unit: &'static str) -> Vec<Line<'a>> {\n vec![\n Line::from(vec![Span::styled(\n format!(\n \"Average: {:.2} {unit}\",\n data.iter().sum::<f64>() / data.len() as f64\n ),\n Style::default().fg(Color::LightBlue),\n )]),\n Line::from(vec![Span::styled(\n format!(\n \"Lowest: {:.2} {unit}\",\n data.iter()\n .min_by(|a, b| a.total_cmp(b))\n .unwrap_or(&f64::NAN)\n ),\n Style::default().fg(Color::Reset),\n )]),\n Line::from(vec![Span::styled(\n format!(\n \"Highest: {:.2} {unit}\",\n data.iter()\n .max_by(|a, b| a.total_cmp(b))\n .unwrap_or(&f64::NAN)\n ),\n Style::default().fg(Color::Reset),\n )]),\n ]\n}\n\n/// Latency histogram data\nfn latency_histogram_data(latency: &[f64], bins: usize) -> Vec<(String, u64)> {\n let histo_data: Vec<(String, u64)> = {\n let histo = crate::utils::histogram(latency, bins);\n histo\n .into_iter()\n .map(|(label, v)| (format!(\"{label:.2}\"), v as u64))\n .collect()\n };\n\n histo_data\n}\n\n/// Latency Histogram\nfn latency_histogram<'a>(\n histo_data_str: &'a Vec<(&'a str, u64)>,\n name: &'static str,\n) -> BarChart<'a> {\n BarChart::default()\n .block(\n Block::default()\n .title(format!(\"{name} latency histogram\"))\n .style(Style::default().fg(Color::LightYellow).bg(Color::Reset))\n .borders(Borders::ALL),\n )\n .data(histo_data_str.as_slice())\n}\n\n/// Latency/Throughput chart\nfn latency_throughput_chart<'a>(\n latency_throughput: &'a [(f64, f64)],\n batch_sizes: &'a [u32],\n zoom: bool,\n name: &'static str,\n) -> Chart<'a> {\n let latency_iter = latency_throughput.iter().map(|(l, _)| l);\n let throughput_iter = latency_throughput.iter().map(|(_, t)| t);\n\n // Get extreme values\n let min_latency: f64 = *latency_iter\n .clone()\n .min_by(|a, b| a.total_cmp(b))\n .unwrap_or(&f64::NAN);\n let max_latency: f64 = *latency_iter\n .max_by(|a, b| a.total_cmp(b))\n .unwrap_or(&f64::NAN);\n let min_throughput: f64 = *throughput_iter\n .clone()\n .min_by(|a, b| a.total_cmp(b))\n .unwrap_or(&f64::NAN);\n let max_throughput: f64 = *throughput_iter\n .max_by(|a, b| a.total_cmp(b))\n .unwrap_or(&f64::NAN);\n\n // Char min max values\n let min_x = if zoom {\n ((min_latency - 0.05 * min_latency) / 100.0).floor() * 100.0\n } else {\n 0.0\n };\n let max_x = ((max_latency + 0.05 * max_latency) / 100.0).ceil() * 100.0;\n let step_x = (max_x - min_x) / 4.0;\n\n // Chart min max values\n let min_y = if zoom {\n ((min_throughput - 0.05 * min_throughput) / 100.0).floor() * 100.0\n } else {\n 0.0\n };\n let max_y = ((max_throughput + 0.05 * max_throughput) / 100.0).ceil() * 100.0;\n let step_y = (max_y - min_y) / 4.0;\n\n // Labels\n let mut x_labels = vec![Span::styled(\n format!(\"{min_x:.2}\"),\n Style::default()\n .add_modifier(Modifier::BOLD)\n .fg(Color::Gray)\n .bg(Color::Reset),\n )];\n for i in 0..3 {\n x_labels.push(Span::styled(\n format!(\"{:.2}\", min_x + ((i + 1) as f64 * step_x)),\n Style::default().fg(Color::Gray).bg(Color::Reset),\n ));\n }\n x_labels.push(Span::styled(\n format!(\"{max_x:.2}\"),\n Style::default()\n .add_modifier(Modifier::BOLD)\n .fg(Color::Gray)\n .bg(Color::Reset),\n ));\n\n // Labels\n let mut y_labels = vec![Span::styled(\n format!(\"{min_y:.2}\"),\n Style::default()\n .add_modifier(Modifier::BOLD)\n .fg(Color::Gray)\n .bg(Color::Reset),\n )];\n for i in 0..3 {\n y_labels.push(Span::styled(\n format!(\"{:.2}\", min_y + ((i + 1) as f64 * step_y)),\n Style::default().fg(Color::Gray).bg(Color::Reset),\n ));\n }\n y_labels.push(Span::styled(\n format!(\"{max_y:.2}\"),\n Style::default()\n .add_modifier(Modifier::BOLD)\n .fg(Color::Gray)\n .bg(Color::Reset),\n ));\n\n // Chart dataset\n let colors = color_vec();\n let datasets: Vec<Dataset> = (0..latency_throughput.len())\n .map(|i| {\n let color_idx = i % colors.len();\n\n Dataset::default()\n .name(batch_sizes[i].to_string())\n .marker(symbols::Marker::Block)\n .style(Style::default().fg(colors[color_idx]))\n .graph_type(GraphType::Scatter)\n .data(&latency_throughput[i..(i + 1)])\n })\n .collect();\n\n // Chart\n Chart::new(datasets)\n .style(Style::default().fg(Color::Cyan).bg(Color::Reset))\n .block(\n Block::default()\n .title(Span::styled(\n format!(\"{name} throughput over latency\"),\n Style::default().fg(Color::Gray).bg(Color::Reset),\n ))\n .borders(Borders::ALL),\n )\n .x_axis(\n Axis::default()\n .title(\"ms\")\n .style(Style::default().fg(Color::Gray).bg(Color::Reset))\n .labels(x_labels)\n .bounds([min_x, max_x]),\n )\n .y_axis(\n Axis::default()\n .title(\"tokens/secs\")\n .style(Style::default().fg(Color::Gray).bg(Color::Reset))\n .labels(y_labels)\n .bounds([min_y, max_y]),\n )\n}\n\n// Colors for latency/throughput chart\nfn color_vec() -> Vec<Color> {\n vec![\n Color::Red,\n Color::Green,\n Color::Yellow,\n Color::Blue,\n Color::Magenta,\n Color::Cyan,\n Color::Gray,\n Color::DarkGray,\n Color::LightRed,\n Color::LightGreen,\n Color::LightYellow,\n Color::LightBlue,\n Color::LightMagenta,\n Color::LightCyan,\n ]\n}\n", "benchmark\\src\\main.rs": "/// Text Generation Inference benchmarking tool\n///\n/// Inspired by the great Oha app: https://github.com/hatoo/oha\n/// and: https://github.com/orhun/rust-tui-template\nuse clap::Parser;\nuse std::path::Path;\nuse text_generation_client::v3::ShardedClient;\nuse tokenizers::{FromPretrainedParameters, Tokenizer};\nuse tracing_subscriber::layer::SubscriberExt;\nuse tracing_subscriber::util::SubscriberInitExt;\nuse tracing_subscriber::EnvFilter;\n\n/// App Configuration\n#[derive(Parser, Debug)]\n#[clap(author, version, about, long_about = None)]\nstruct Args {\n /// The name of the tokenizer (as in model_id on the huggingface hub, or local path).\n #[clap(short, long, env)]\n tokenizer_name: String,\n\n /// The revision to use for the tokenizer if on the hub.\n #[clap(default_value = \"main\", long, env)]\n revision: String,\n\n /// The various batch sizes to benchmark for, the idea is to get enough\n /// batching to start seeing increased latency, this usually means you're\n /// moving from memory bound (usual as BS=1) to compute bound, and this is\n /// a sweet spot for the maximum batch size for the model under test\n #[clap(short, long)]\n batch_size: Option<Vec<u32>>,\n\n /// This is the initial prompt sent to the text-generation-server length\n /// in token. Longer prompt will slow down the benchmark. Usually the\n /// latency grows somewhat linearly with this for the prefill step.\n ///\n /// Most importantly, the prefill step is usually not the one dominating\n /// your runtime, so it's ok to keep it short.\n #[clap(default_value = \"10\", short, long, env)]\n sequence_length: u32,\n\n /// This is how many tokens will be generated by the server and averaged out\n /// to give the `decode` latency. This is the *critical* number you want to optimize for\n /// LLM spend most of their time doing decoding.\n ///\n /// Decode latency is usually quite stable.\n #[clap(default_value = \"8\", short, long, env)]\n decode_length: u32,\n\n ///How many runs should we average from\n #[clap(default_value = \"10\", short, long, env)]\n runs: usize,\n\n /// Number of warmup cycles\n #[clap(default_value = \"1\", short, long, env)]\n warmups: usize,\n\n /// The location of the grpc socket. This benchmark tool bypasses the router\n /// completely and directly talks to the gRPC processes\n #[clap(default_value = \"/tmp/text-generation-server-0\", short, long, env)]\n master_shard_uds_path: String,\n\n /// Generation parameter in case you want to specifically test/debug particular\n /// decoding strategies, for full doc refer to the `text-generation-server`\n #[clap(long, env)]\n temperature: Option<f32>,\n\n /// Generation parameter in case you want to specifically test/debug particular\n /// decoding strategies, for full doc refer to the `text-generation-server`\n #[clap(long, env)]\n top_k: Option<u32>,\n\n /// Generation parameter in case you want to specifically test/debug particular\n /// decoding strategies, for full doc refer to the `text-generation-server`\n #[clap(long, env)]\n top_p: Option<f32>,\n\n /// Generation parameter in case you want to specifically test/debug particular\n /// decoding strategies, for full doc refer to the `text-generation-server`\n #[clap(long, env)]\n typical_p: Option<f32>,\n\n /// Generation parameter in case you want to specifically test/debug particular\n /// decoding strategies, for full doc refer to the `text-generation-server`\n #[clap(long, env)]\n repetition_penalty: Option<f32>,\n\n /// Generation parameter in case you want to specifically test/debug particular\n /// decoding strategies, for full doc refer to the `text-generation-server`\n #[clap(long, env)]\n frequency_penalty: Option<f32>,\n\n /// Generation parameter in case you want to specifically test/debug particular\n /// decoding strategies, for full doc refer to the `text-generation-server`\n #[clap(long, env)]\n watermark: bool,\n\n /// Generation parameter in case you want to specifically test/debug particular\n /// decoding strategies, for full doc refer to the `text-generation-server`\n #[clap(long, env)]\n do_sample: bool,\n\n /// Generation parameter in case you want to specifically test/debug particular\n /// decoding strategies, for full doc refer to the `text-generation-server`\n #[clap(long, env)]\n top_n_tokens: Option<u32>,\n}\n\nfn main() -> Result<(), Box<dyn std::error::Error>> {\n init_logging();\n\n // Get args\n let args = Args::parse();\n // Pattern match configuration\n let Args {\n tokenizer_name,\n revision,\n batch_size,\n sequence_length,\n decode_length,\n runs,\n warmups,\n temperature,\n top_k,\n top_p,\n typical_p,\n repetition_penalty,\n frequency_penalty,\n watermark,\n do_sample,\n master_shard_uds_path,\n top_n_tokens,\n } = args;\n\n let batch_size = batch_size.unwrap_or(vec![1, 2, 4, 8, 16, 32]);\n\n // Tokenizer instance\n // This will only be used to validate payloads\n tracing::info!(\"Loading tokenizer\");\n let local_path = Path::new(&tokenizer_name);\n let tokenizer =\n if local_path.exists() && local_path.is_dir() && local_path.join(\"tokenizer.json\").exists()\n {\n // Load local tokenizer\n tracing::info!(\"Found local tokenizer\");\n Tokenizer::from_file(local_path.join(\"tokenizer.json\")).unwrap()\n } else {\n tracing::info!(\"Downloading tokenizer\");\n\n // Parse Huggingface hub token\n let auth_token = std::env::var(\"HF_TOKEN\")\n .or_else(|_| std::env::var(\"HUGGING_FACE_HUB_TOKEN\"))\n .ok();\n\n // Download and instantiate tokenizer\n // We need to download it outside of the Tokio runtime\n let params = FromPretrainedParameters {\n revision,\n auth_token,\n ..Default::default()\n };\n Tokenizer::from_pretrained(tokenizer_name.clone(), Some(params)).unwrap()\n };\n tracing::info!(\"Tokenizer loaded\");\n\n // Launch Tokio runtime\n tokio::runtime::Builder::new_multi_thread()\n .enable_all()\n .build()\n .unwrap()\n .block_on(async {\n // Instantiate sharded client from the master unix socket\n tracing::info!(\"Connect to model server\");\n let mut sharded_client = ShardedClient::connect_uds(master_shard_uds_path)\n .await\n .expect(\"Could not connect to server\");\n // Clear the cache; useful if the webserver rebooted\n sharded_client\n .clear_cache(None)\n .await\n .expect(\"Unable to clear cache\");\n tracing::info!(\"Connected\");\n\n // Run app\n text_generation_benchmark::run(\n tokenizer_name,\n tokenizer,\n batch_size,\n sequence_length,\n decode_length,\n top_n_tokens,\n runs,\n warmups,\n temperature,\n top_k,\n top_p,\n typical_p,\n repetition_penalty,\n frequency_penalty,\n watermark,\n do_sample,\n sharded_client,\n )\n .await\n .unwrap();\n });\n Ok(())\n}\n\n/// Init logging using LOG_LEVEL\nfn init_logging() {\n // STDOUT/STDERR layer\n let fmt_layer = tracing_subscriber::fmt::layer()\n .with_file(true)\n .with_line_number(true);\n\n // Filter events with LOG_LEVEL\n let env_filter =\n EnvFilter::try_from_env(\"LOG_LEVEL\").unwrap_or_else(|_| EnvFilter::new(\"info\"));\n\n tracing_subscriber::registry()\n .with(env_filter)\n .with(fmt_layer)\n .init();\n}\n", "docs\\index.html": "<html>\n <head>\n <!-- Load the latest Swagger UI code and style from npm using unpkg.com -->\n <script src=\"https://unpkg.com/swagger-ui-dist@3/swagger-ui-bundle.js\"></script>\n <link rel=\"stylesheet\" type=\"text/css\" href=\"https://unpkg.com/swagger-ui-dist@3/swagger-ui.css\"/>\n <title>Text Generation Inference API</title>\n </head>\n <body>\n <div id=\"swagger-ui\"></div> <!-- Div to hold the UI component -->\n <script>\n window.onload = function () {\n // Begin Swagger UI call region\n const ui = SwaggerUIBundle({\n url: \"openapi.json\", //Location of Open API spec in the repo\n dom_id: '#swagger-ui',\n deepLinking: true,\n supportedSubmitMethods: [],\n presets: [\n SwaggerUIBundle.presets.apis,\n SwaggerUIBundle.SwaggerUIStandalonePreset\n ],\n plugins: [\n SwaggerUIBundle.plugins.DownloadUrl\n ],\n })\n window.ui = ui\n }\n </script>\n </body>\n</html>\n", "docs\\source\\index.md": "# Text Generation Inference\n\nText Generation Inference (TGI) is a toolkit for deploying and serving Large Language Models (LLMs). TGI enables high-performance text generation for the most popular open-source LLMs, including Llama, Falcon, StarCoder, BLOOM, GPT-NeoX, and T5.\n\n\n\nText Generation Inference implements many optimizations and features, such as:\n\n- Simple launcher to serve most popular LLMs\n- Production ready (distributed tracing with Open Telemetry, Prometheus metrics)\n- Tensor Parallelism for faster inference on multiple GPUs\n- Token streaming using Server-Sent Events (SSE)\n- Continuous batching of incoming requests for increased total throughput\n- Optimized transformers code for inference using [Flash Attention](https://github.com/HazyResearch/flash-attention) and [Paged Attention](https://github.com/vllm-project/vllm) on the most popular architectures\n- Quantization with [bitsandbytes](https://github.com/TimDettmers/bitsandbytes) and [GPT-Q](https://arxiv.org/abs/2210.17323)\n- [Safetensors](https://github.com/huggingface/safetensors) weight loading\n- Watermarking with [A Watermark for Large Language Models](https://arxiv.org/abs/2301.10226)\n- Logits warper (temperature scaling, top-p, top-k, repetition penalty)\n- Stop sequences\n- Log probabilities\n- Fine-tuning Support: Utilize fine-tuned models for specific tasks to achieve higher accuracy and performance.\n- [Guidance](../conceptual/guidance): Enable function calling and tool-use by forcing the model to generate structured outputs based on your own predefined output schemas.\n\nText Generation Inference is used in production by multiple projects, such as:\n\n- [Hugging Chat](https://github.com/huggingface/chat-ui), an open-source interface for open-access models, such as Open Assistant and Llama\n- [OpenAssistant](https://open-assistant.io/), an open-source community effort to train LLMs in the open\n- [nat.dev](http://nat.dev/), a playground to explore and compare LLMs.\n", "integration-tests\\requirements.txt": "aiohappyeyeballs==2.4.0 ; python_version >= \"3.10\" and python_version < \"3.13\"\naiohttp==3.10.5 ; python_version >= \"3.10\" and python_version < \"3.13\"\naiosignal==1.3.1 ; python_version >= \"3.10\" and python_version < \"3.13\"\nannotated-types==0.7.0 ; python_version >= \"3.10\" and python_version < \"3.13\"\nasync-timeout==4.0.3 ; python_version >= \"3.10\" and python_version < \"3.11\"\nattrs==24.2.0 ; python_version >= \"3.10\" and python_version < \"3.13\"\ncertifi==2024.8.30 ; python_version >= \"3.10\" and python_version < \"3.13\"\ncharset-normalizer==3.3.2 ; python_version >= \"3.10\" and python_version < \"3.13\"\ncolorama==0.4.6 ; python_version >= \"3.10\" and python_version < \"3.13\" and (sys_platform == \"win32\" or platform_system == \"Windows\")\ndocker==7.1.0 ; python_version >= \"3.10\" and python_version < \"3.13\"\nexceptiongroup==1.2.2 ; python_version >= \"3.10\" and python_version < \"3.11\"\nfilelock==3.16.0 ; python_version >= \"3.10\" and python_version < \"3.13\"\nfrozenlist==1.4.1 ; python_version >= \"3.10\" and python_version < \"3.13\"\nfsspec==2024.9.0 ; python_version >= \"3.10\" and python_version < \"3.13\"\nhuggingface-hub==0.24.6 ; python_version >= \"3.10\" and python_version < \"3.13\"\nidna==3.8 ; python_version >= \"3.10\" and python_version < \"3.13\"\niniconfig==2.0.0 ; python_version >= \"3.10\" and python_version < \"3.13\"\nmultidict==6.1.0 ; python_version >= \"3.10\" and python_version < \"3.13\"\nnumpy==1.26.4 ; python_version >= \"3.10\" and python_version < \"3.13\"\npackaging==24.1 ; python_version >= \"3.10\" and python_version < \"3.13\"\npluggy==1.5.0 ; python_version >= \"3.10\" and python_version < \"3.13\"\npydantic-core==2.23.3 ; python_version >= \"3.10\" and python_version < \"3.13\"\npydantic==2.9.1 ; python_version >= \"3.10\" and python_version < \"3.13\"\npytest-asyncio==0.21.2 ; python_version >= \"3.10\" and python_version < \"3.13\"\npytest==7.4.4 ; python_version >= \"3.10\" and python_version < \"3.13\"\npywin32==306 ; python_version >= \"3.10\" and python_version < \"3.13\" and sys_platform == \"win32\"\npyyaml==6.0.2 ; python_version >= \"3.10\" and python_version < \"3.13\"\nrequests==2.32.3 ; python_version >= \"3.10\" and python_version < \"3.13\"\nsyrupy==4.7.1 ; python_version >= \"3.10\" and python_version < \"3.13\"\ntext-generation==0.6.1 ; python_version >= \"3.10\" and python_version < \"3.13\"\ntomli==2.0.1 ; python_version >= \"3.10\" and python_version < \"3.11\"\ntqdm==4.66.5 ; python_version >= \"3.10\" and python_version < \"3.13\"\ntyping-extensions==4.12.2 ; python_version >= \"3.10\" and python_version < \"3.13\"\nurllib3==2.2.2 ; python_version >= \"3.10\" and python_version < \"3.13\"\nyarl==1.11.1 ; python_version >= \"3.10\" and python_version < \"3.13\"\n", "launcher\\src\\main.rs": "use clap::{Parser, ValueEnum};\nuse hf_hub::{\n api::sync::{Api, ApiBuilder},\n Repo, RepoType,\n};\nuse nix::sys::signal::{self, Signal};\nuse nix::unistd::Pid;\nuse serde::Deserialize;\nuse std::env;\nuse std::ffi::OsString;\nuse std::io::{BufRead, BufReader};\nuse std::os::unix::process::{CommandExt, ExitStatusExt};\nuse std::path::Path;\nuse std::process::{Child, Command, ExitStatus, Stdio};\nuse std::sync::atomic::{AtomicBool, Ordering};\nuse std::sync::mpsc::TryRecvError;\nuse std::sync::{mpsc, Arc};\nuse std::thread;\nuse std::thread::sleep;\nuse std::time::{Duration, Instant};\nuse std::{\n fs, io,\n io::{Read, Write},\n};\nuse thiserror::Error;\nuse tracing_subscriber::{filter::LevelFilter, EnvFilter};\n\nmod env_runtime;\n\nfn get_config(\n model_id: &str,\n revision: &Option<String>,\n) -> Result<Config, Box<dyn std::error::Error>> {\n let mut path = std::path::Path::new(model_id).to_path_buf();\n let model_id = model_id.to_string();\n let filename = if !path.exists() {\n // Assume it's a hub id\n\n let api = if let Ok(token) = std::env::var(\"HF_TOKEN\") {\n // env variable has precedence over on file token.\n ApiBuilder::new().with_token(Some(token)).build()?\n } else {\n Api::new()?\n };\n let repo = if let Some(ref revision) = revision {\n api.repo(Repo::with_revision(\n model_id,\n RepoType::Model,\n revision.to_string(),\n ))\n } else {\n api.model(model_id)\n };\n repo.get(\"config.json\")?\n } else {\n path.push(\"config.json\");\n path\n };\n\n let content = std::fs::read_to_string(filename)?;\n let config: RawConfig = serde_json::from_str(&content)?;\n\n let config: Config = config.into();\n Ok(config)\n}\n\nfn resolve_attention(config: &Option<Config>, lora_adapters: &Option<String>) -> (String, String) {\n let mut prefix_caching: Option<String> = std::env::var(\"USE_PREFIX_CACHING\").ok();\n let mut attention: Option<String> = std::env::var(\"ATTENTION\").ok();\n if let Some(config) = config {\n if prefix_caching.is_none() {\n if config.vision_config.is_some() {\n tracing::info!(\"Disabling prefix caching because of VLM model\");\n prefix_caching = Some(\"0\".to_string());\n } else if config.is_encoder_decoder {\n tracing::info!(\"Disabling prefix caching because of seq2seq model\");\n prefix_caching = Some(\"0\".to_string());\n }\n }\n match config.head_dim {\n Some(h) if h == 64 || h == 128 || h == 256 => {\n if lora_adapters.is_some() && prefix_caching.is_none() {\n tracing::info!(\"Disabling prefix caching because of lora adapters\");\n prefix_caching = Some(\"0\".to_string());\n }\n match config.model_type.as_deref() {\n Some(\"gemma2\") | Some(\"falcon\") | Some(\"deepseek_v2\") => {\n // Required because gemma2 needs bfloat16 which is not supported by\n // flashinfer ?\n if attention.is_none() {\n tracing::info!(\n \"Forcing flash decoding because model {} requires it\",\n config.model_type.as_ref().unwrap()\n );\n attention = Some(\"flashdecoding\".to_string());\n }\n }\n Some(\"t5\") => {}\n _ => {}\n }\n }\n _ => {\n if attention.is_none() {\n tracing::info!(\"Forcing flash decoding because head dim is not supported by flashinfer, also disabling prefix caching\");\n attention = Some(\"flashdecoding\".to_string());\n }\n if prefix_caching.is_none() {\n prefix_caching = Some(\"0\".to_string());\n }\n }\n }\n }\n let prefix_caching = prefix_caching.unwrap_or(\"true\".to_string());\n let attention = attention.unwrap_or(\"flashinfer\".to_string());\n (prefix_caching, attention)\n}\n\n#[derive(Deserialize)]\nstruct RawConfig {\n max_position_embeddings: Option<usize>,\n n_positions: Option<usize>,\n model_type: Option<String>,\n max_seq_len: Option<usize>,\n quantization_config: Option<QuantizationConfig>,\n n_embd: Option<usize>,\n hidden_size: Option<usize>,\n num_attention_heads: Option<usize>,\n head_dim: Option<usize>,\n vision_config: Option<VisionConfig>,\n is_encoder_decoder: Option<bool>,\n}\n\n#[derive(Deserialize)]\nstruct QuantizationConfig {\n quant_method: Option<Quantization>,\n}\n\n#[derive(Deserialize)]\nstruct VisionConfig {}\n\n#[derive(Deserialize)]\nstruct Config {\n max_position_embeddings: Option<usize>,\n quantize: Option<Quantization>,\n head_dim: Option<usize>,\n model_type: Option<String>,\n vision_config: Option<VisionConfig>,\n is_encoder_decoder: bool,\n}\n\nimpl From<RawConfig> for Config {\n fn from(other: RawConfig) -> Self {\n let max_position_embeddings = other\n .max_position_embeddings\n .or(other.max_seq_len)\n .or(other.n_positions);\n let quantize = other.quantization_config.and_then(|q| q.quant_method);\n let head_dim = other.head_dim.or_else(|| {\n match (other.hidden_size, other.n_embd, other.num_attention_heads) {\n (Some(hidden_size), _, Some(num_attention_heads))\n if hidden_size % num_attention_heads == 0 =>\n {\n Some(hidden_size / num_attention_heads)\n }\n // Legacy\n (_, Some(hidden_size), Some(num_attention_heads))\n if hidden_size % num_attention_heads == 0 =>\n {\n Some(hidden_size / num_attention_heads)\n }\n _ => None,\n }\n });\n let model_type = other.model_type;\n let vision_config = other.vision_config;\n let is_encoder_decoder = other.is_encoder_decoder.unwrap_or(false);\n Config {\n max_position_embeddings,\n quantize,\n head_dim,\n model_type,\n vision_config,\n is_encoder_decoder,\n }\n }\n}\n\n#[derive(Clone, Copy, Debug, ValueEnum, Deserialize)]\n#[serde(rename_all = \"kebab-case\")]\nenum Quantization {\n /// 4 bit quantization. Requires a specific AWQ quantized model:\n /// <https://hf.co/models?search=awq>.\n /// Should replace GPTQ models wherever possible because of the better latency\n Awq,\n /// 8 bit quantization, doesn't require specific model.\n /// Should be a drop-in replacement to bitsandbytes with much better performance.\n /// Kernels are from <https://github.com/NetEase-FuXi/EETQ.git>\n Eetq,\n /// Variable bit quantization. Requires a specific EXL2 quantized model:\n /// <https://hf.co/models?search=exl2>. Requires exllama2 kernels and does\n /// not support tensor parallelism (num_shard > 1).\n Exl2,\n /// 4 bit quantization. Requires a specific GTPQ quantized model: <https://hf.co/models?search=gptq>.\n /// text-generation-inference will use exllama (faster) kernels wherever possible, and use\n /// triton kernel (wider support) when it's not.\n /// AWQ has faster kernels.\n Gptq,\n /// 4 bit quantization. Requires a specific Marlin quantized model: <https://hf.co/models?search=marlin>.\n Marlin,\n /// Bitsandbytes 8bit. Can be applied on any model, will cut the memory requirement in half,\n /// but it is known that the model will be much slower to run than the native f16.\n // #[deprecated(\n // since = \"1.1.0\",\n // note = \"Use `eetq` instead, which provides better latencies overall and is drop-in in most cases\"\n // )]\n Bitsandbytes,\n /// Bitsandbytes 4bit. Can be applied on any model, will cut the memory requirement by 4x,\n /// but it is known that the model will be much slower to run than the native f16.\n BitsandbytesNf4,\n /// Bitsandbytes 4bit. nf4 should be preferred in most cases but maybe this one has better\n /// perplexity performance for you model\n BitsandbytesFp4,\n /// [FP8](https://developer.nvidia.com/blog/nvidia-arm-and-intel-publish-fp8-specification-for-standardization-as-an-interchange-format-for-ai/) (e4m3) works on H100 and above\n /// This dtype has native ops should be the fastest if available.\n /// This is currently not the fastest because of local unpacking + padding to satisfy matrix\n /// multiplication limitations.\n Fp8,\n}\n\nimpl std::fmt::Display for Quantization {\n fn fmt(&self, f: &mut std::fmt::Formatter<'_>) -> std::fmt::Result {\n // To keep in track with `server`.\n match self {\n #[allow(deprecated)]\n // Use `eetq` instead, which provides better latencies overall and is drop-in in most cases\n Quantization::Bitsandbytes => {\n write!(f, \"bitsandbytes\")\n }\n Quantization::BitsandbytesNf4 => {\n write!(f, \"bitsandbytes-nf4\")\n }\n Quantization::BitsandbytesFp4 => {\n write!(f, \"bitsandbytes-fp4\")\n }\n Quantization::Exl2 => {\n write!(f, \"exl2\")\n }\n Quantization::Gptq => {\n write!(f, \"gptq\")\n }\n Quantization::Marlin => {\n write!(f, \"marlin\")\n }\n Quantization::Awq => {\n write!(f, \"awq\")\n }\n Quantization::Eetq => {\n write!(f, \"eetq\")\n }\n Quantization::Fp8 => {\n write!(f, \"fp8\")\n }\n }\n }\n}\n\n#[derive(Clone, Copy, Debug, ValueEnum)]\nenum Dtype {\n Float16,\n #[clap(name = \"bfloat16\")]\n BFloat16,\n}\n\nimpl std::fmt::Display for Dtype {\n fn fmt(&self, f: &mut std::fmt::Formatter<'_>) -> std::fmt::Result {\n // To keep in track with `server`.\n match self {\n Dtype::Float16 => {\n write!(f, \"float16\")\n }\n Dtype::BFloat16 => {\n write!(f, \"bfloat16\")\n }\n }\n }\n}\n\n#[derive(Clone, Copy, Debug, ValueEnum)]\nenum RopeScaling {\n Linear,\n Dynamic,\n}\n\nimpl std::fmt::Display for RopeScaling {\n fn fmt(&self, f: &mut std::fmt::Formatter<'_>) -> std::fmt::Result {\n // To keep in track with `server`.\n match self {\n RopeScaling::Linear => {\n write!(f, \"linear\")\n }\n RopeScaling::Dynamic => {\n write!(f, \"dynamic\")\n }\n }\n }\n}\n\n#[derive(Clone, Copy, Debug, ValueEnum)]\npub enum UsageStatsLevel {\n /// Default option, usage statistics are collected anonymously\n On,\n /// Disables all collection of usage statistics\n Off,\n /// Doesn't send the error stack trace or error type, but allows sending a crash event\n NoStack,\n}\n\nimpl std::fmt::Display for UsageStatsLevel {\n fn fmt(&self, f: &mut std::fmt::Formatter<'_>) -> std::fmt::Result {\n // To keep in track with `server`.\n match self {\n UsageStatsLevel::On => {\n write!(f, \"on\")\n }\n UsageStatsLevel::Off => {\n write!(f, \"off\")\n }\n UsageStatsLevel::NoStack => {\n write!(f, \"no-stack\")\n }\n }\n }\n}\n\n/// App Configuration\n#[derive(Parser, Debug)]\n#[clap(author, version, about, long_about = None)]\nstruct Args {\n /// The name of the model to load.\n /// Can be a MODEL_ID as listed on <https://hf.co/models> like\n /// `gpt2` or `OpenAssistant/oasst-sft-1-pythia-12b`.\n /// Or it can be a local directory containing the necessary files\n /// as saved by `save_pretrained(...)` methods of transformers\n #[clap(default_value = \"bigscience/bloom-560m\", long, env)]\n model_id: String,\n\n /// The actual revision of the model if you're referring to a model\n /// on the hub. You can use a specific commit id or a branch like `refs/pr/2`.\n #[clap(long, env)]\n revision: Option<String>,\n\n /// The number of tokenizer workers used for payload validation and truncation inside the\n /// router.\n #[clap(default_value = \"2\", long, env)]\n validation_workers: usize,\n\n /// Whether to shard the model across multiple GPUs\n /// By default text-generation-inference will use all available GPUs to run\n /// the model. Setting it to `false` deactivates `num_shard`.\n #[clap(long, env)]\n sharded: Option<bool>,\n\n /// The number of shards to use if you don't want to use all GPUs on a given machine.\n /// You can use `CUDA_VISIBLE_DEVICES=0,1 text-generation-launcher... --num_shard 2`\n /// and `CUDA_VISIBLE_DEVICES=2,3 text-generation-launcher... --num_shard 2` to\n /// launch 2 copies with 2 shard each on a given machine with 4 GPUs for instance.\n #[clap(long, env)]\n num_shard: Option<usize>,\n\n /// Quantization method to use for the model. It is not necessary to specify this option\n /// for pre-quantized models, since the quantization method is read from the model\n /// configuration.\n ///\n /// Marlin kernels will be used automatically for GPTQ/AWQ models.\n #[clap(long, env, value_enum)]\n quantize: Option<Quantization>,\n\n /// The number of input_ids to speculate on\n /// If using a medusa model, the heads will be picked up automatically\n /// Other wise, it will use n-gram speculation which is relatively free\n /// in terms of compute, but the speedup heavily depends on the task.\n #[clap(long, env)]\n speculate: Option<usize>,\n\n /// The dtype to be forced upon the model. This option cannot be used with `--quantize`.\n #[clap(long, env, value_enum)]\n dtype: Option<Dtype>,\n\n /// Whether you want to execute hub modelling code. Explicitly passing a `revision` is\n /// encouraged when loading a model with custom code to ensure no malicious code has been\n /// contributed in a newer revision.\n #[clap(long, env, value_enum)]\n trust_remote_code: bool,\n\n /// The maximum amount of concurrent requests for this particular deployment.\n /// Having a low limit will refuse clients requests instead of having them\n /// wait for too long and is usually good to handle backpressure correctly.\n #[clap(default_value = \"128\", long, env)]\n max_concurrent_requests: usize,\n\n /// This is the maximum allowed value for clients to set `best_of`.\n /// Best of makes `n` generations at the same time, and return the best\n /// in terms of overall log probability over the entire generated sequence\n #[clap(default_value = \"2\", long, env)]\n max_best_of: usize,\n\n /// This is the maximum allowed value for clients to set `stop_sequences`.\n /// Stop sequences are used to allow the model to stop on more than just\n /// the EOS token, and enable more complex \"prompting\" where users can preprompt\n /// the model in a specific way and define their \"own\" stop token aligned with\n /// their prompt.\n #[clap(default_value = \"4\", long, env)]\n max_stop_sequences: usize,\n\n /// This is the maximum allowed value for clients to set `top_n_tokens`.\n /// `top_n_tokens` is used to return information about the the `n` most likely\n /// tokens at each generation step, instead of just the sampled token. This\n /// information can be used for downstream tasks like for classification or\n /// ranking.\n #[clap(default_value = \"5\", long, env)]\n max_top_n_tokens: u32,\n\n /// This is the maximum allowed input length (expressed in number of tokens)\n /// for users. The larger this value, the longer prompt users can send which\n /// can impact the overall memory required to handle the load.\n /// Please note that some models have a finite range of sequence they can handle.\n /// Default to min(max_position_embeddings - 1, 4095)\n #[clap(long, env)]\n max_input_tokens: Option<usize>,\n\n /// Legacy version of [`Args::max_input_tokens`].\n #[clap(long, env)]\n max_input_length: Option<usize>,\n\n /// This is the most important value to set as it defines the \"memory budget\"\n /// of running clients requests.\n /// Clients will send input sequences and ask to generate `max_new_tokens`\n /// on top. with a value of `1512` users can send either a prompt of\n /// `1000` and ask for `512` new tokens, or send a prompt of `1` and ask for\n /// `1511` max_new_tokens.\n /// The larger this value, the larger amount each request will be in your RAM\n /// and the less effective batching can be.\n /// Default to min(max_position_embeddings, 4096)\n #[clap(long, env)]\n max_total_tokens: Option<usize>,\n\n /// This represents the ratio of waiting queries vs running queries where\n /// you want to start considering pausing the running queries to include the waiting\n /// ones into the same batch.\n /// `waiting_served_ratio=1.2` Means when 12 queries are waiting and there's\n /// only 10 queries left in the current batch we check if we can fit those 12\n /// waiting queries into the batching strategy, and if yes, then batching happens\n /// delaying the 10 running queries by a `prefill` run.\n ///\n /// This setting is only applied if there is room in the batch\n /// as defined by `max_batch_total_tokens`.\n #[clap(default_value = \"0.3\", long, env)]\n waiting_served_ratio: f32,\n\n /// Limits the number of tokens for the prefill operation.\n /// Since this operation take the most memory and is compute bound, it is interesting\n /// to limit the number of requests that can be sent.\n /// Default to `max_input_tokens + 50` to give a bit of room.\n #[clap(long, env)]\n max_batch_prefill_tokens: Option<u32>,\n\n /// **IMPORTANT** This is one critical control to allow maximum usage\n /// of the available hardware.\n ///\n /// This represents the total amount of potential tokens within a batch.\n /// When using padding (not recommended) this would be equivalent of\n /// `batch_size` * `max_total_tokens`.\n ///\n /// However in the non-padded (flash attention) version this can be much finer.\n ///\n /// For `max_batch_total_tokens=1000`, you could fit `10` queries of `total_tokens=100`\n /// or a single query of `1000` tokens.\n ///\n /// Overall this number should be the largest possible amount that fits the\n /// remaining memory (after the model is loaded). Since the actual memory overhead\n /// depends on other parameters like if you're using quantization, flash attention\n /// or the model implementation, text-generation-inference cannot infer this number\n /// automatically.\n #[clap(long, env)]\n max_batch_total_tokens: Option<u32>,\n\n /// This setting defines how many tokens can be passed before forcing the waiting\n /// queries to be put on the batch (if the size of the batch allows for it).\n /// New queries require 1 `prefill` forward, which is different from `decode`\n /// and therefore you need to pause the running batch in order to run `prefill`\n /// to create the correct values for the waiting queries to be able to join the batch.\n ///\n /// With a value too small, queries will always \"steal\" the compute to run `prefill`\n /// and running queries will be delayed by a lot.\n ///\n /// With a value too big, waiting queries could wait for a very long time\n /// before being allowed a slot in the running batch. If your server is busy\n /// that means that requests that could run in ~2s on an empty server could\n /// end up running in ~20s because the query had to wait for 18s.\n ///\n /// This number is expressed in number of tokens to make it a bit more\n /// \"model\" agnostic, but what should really matter is the overall latency\n /// for end users.\n #[clap(default_value = \"20\", long, env)]\n max_waiting_tokens: usize,\n\n /// Enforce a maximum number of requests per batch\n /// Specific flag for hardware targets that do not support unpadded inference\n #[clap(long, env)]\n max_batch_size: Option<usize>,\n\n /// Specify the batch sizes to compute cuda graphs for.\n /// Use \"0\" to disable.\n /// Default = \"1,2,4,8,16,32\"\n #[clap(long, env, value_delimiter = ',')]\n cuda_graphs: Option<Vec<usize>>,\n\n /// The IP address to listen on\n #[clap(default_value = \"0.0.0.0\", long, env)]\n hostname: String,\n\n /// The port to listen on.\n #[clap(default_value = \"3000\", long, short, env)]\n port: u16,\n\n /// The name of the socket for gRPC communication between the webserver\n /// and the shards.\n #[clap(default_value = \"/tmp/text-generation-server\", long, env)]\n shard_uds_path: String,\n\n /// The address the master shard will listen on. (setting used by torch distributed)\n #[clap(default_value = \"localhost\", long, env)]\n master_addr: String,\n\n /// The address the master port will listen on. (setting used by torch distributed)\n #[clap(default_value = \"29500\", long, env)]\n master_port: usize,\n\n /// The location of the huggingface hub cache.\n /// Used to override the location if you want to provide a mounted disk for instance\n #[clap(long, env)]\n huggingface_hub_cache: Option<String>,\n\n /// The location of the huggingface hub cache.\n /// Used to override the location if you want to provide a mounted disk for instance\n #[clap(long, env)]\n weights_cache_override: Option<String>,\n\n /// For some models (like bloom), text-generation-inference implemented custom\n /// cuda kernels to speed up inference. Those kernels were only tested on A100.\n /// Use this flag to disable them if you're running on different hardware and\n /// encounter issues.\n #[clap(long, env)]\n disable_custom_kernels: bool,\n\n /// Limit the CUDA available memory.\n /// The allowed value equals the total visible memory multiplied by cuda-memory-fraction.\n #[clap(default_value = \"1.0\", long, env)]\n cuda_memory_fraction: f32,\n\n /// Rope scaling will only be used for RoPE models\n /// and allow rescaling the position rotary to accomodate for\n /// larger prompts.\n ///\n /// Goes together with `rope_factor`.\n ///\n /// `--rope-factor 2.0` gives linear scaling with a factor of 2.0\n /// `--rope-scaling dynamic` gives dynamic scaling with a factor of 1.0\n /// `--rope-scaling linear` gives linear scaling with a factor of 1.0 (Nothing will be changed\n /// basically)\n ///\n /// `--rope-scaling linear --rope-factor` fully describes the scaling you want\n #[clap(long, env)]\n rope_scaling: Option<RopeScaling>,\n\n /// Rope scaling will only be used for RoPE models\n /// See `rope_scaling`\n #[clap(long, env)]\n rope_factor: Option<f32>,\n\n /// Outputs the logs in JSON format (useful for telemetry)\n #[clap(long, env)]\n json_output: bool,\n\n #[clap(long, env)]\n otlp_endpoint: Option<String>,\n\n #[clap(default_value = \"text-generation-inference.router\", long, env)]\n otlp_service_name: String,\n\n #[clap(long, env)]\n cors_allow_origin: Vec<String>,\n\n #[clap(long, env)]\n api_key: Option<String>,\n\n #[clap(long, env)]\n watermark_gamma: Option<f32>,\n #[clap(long, env)]\n watermark_delta: Option<f32>,\n\n /// Enable ngrok tunneling\n #[clap(long, env)]\n ngrok: bool,\n\n /// ngrok authentication token\n #[clap(long, env)]\n ngrok_authtoken: Option<String>,\n\n /// ngrok edge\n #[clap(long, env)]\n ngrok_edge: Option<String>,\n\n /// The path to the tokenizer config file. This path is used to load the tokenizer configuration which may\n /// include a `chat_template`. If not provided, the default config will be used from the model hub.\n #[clap(long, env)]\n tokenizer_config_path: Option<String>,\n\n /// Disable outlines grammar constrained generation.\n /// This is a feature that allows you to generate text that follows a specific grammar.\n #[clap(long, env)]\n disable_grammar_support: bool,\n\n /// Display a lot of information about your runtime environment\n #[clap(long, short, action)]\n env: bool,\n\n /// Control the maximum number of inputs that a client can send in a single request\n #[clap(default_value = \"4\", long, env)]\n max_client_batch_size: usize,\n\n /// Lora Adapters a list of adapter ids i.e. `repo/adapter1,repo/adapter2` to load during\n /// startup that will be available to callers via the `adapter_id` field in a request.\n #[clap(long, env)]\n lora_adapters: Option<String>,\n\n /// Control if anonymous usage stats are collected.\n /// Options are \"on\", \"off\" and \"no-stack\"\n /// Defaul is on.\n #[clap(default_value = \"on\", long, env)]\n usage_stats: UsageStatsLevel,\n}\n\n#[derive(Debug)]\nenum ShardStatus {\n Ready,\n Failed(usize),\n}\n\n#[allow(clippy::too_many_arguments)]\nfn shard_manager(\n model_id: String,\n revision: Option<String>,\n quantize: Option<Quantization>,\n speculate: Option<usize>,\n dtype: Option<Dtype>,\n trust_remote_code: bool,\n uds_path: String,\n rank: usize,\n world_size: usize,\n master_addr: String,\n master_port: usize,\n huggingface_hub_cache: Option<String>,\n weights_cache_override: Option<String>,\n disable_custom_kernels: bool,\n watermark_gamma: Option<f32>,\n watermark_delta: Option<f32>,\n cuda_graphs: Vec<usize>,\n cuda_memory_fraction: f32,\n rope_scaling: Option<RopeScaling>,\n rope_factor: Option<f32>,\n max_total_tokens: usize,\n max_batch_size: Option<usize>,\n max_input_tokens: usize,\n lora_adapters: Option<String>,\n otlp_endpoint: Option<String>,\n otlp_service_name: String,\n log_level: LevelFilter,\n status_sender: mpsc::Sender<ShardStatus>,\n shutdown: Arc<AtomicBool>,\n _shutdown_sender: mpsc::Sender<()>,\n) {\n // Enter shard-manager tracing span\n let _span = tracing::span!(tracing::Level::INFO, \"shard-manager\", rank = rank).entered();\n\n // Get UDS path\n let uds_string = format!(\"{uds_path}-{rank}\");\n let uds = Path::new(&uds_string);\n // Clean previous runs\n if uds.exists() {\n fs::remove_file(uds).unwrap();\n }\n\n // Process args\n let mut shard_args = vec![\n \"serve\".to_string(),\n model_id,\n \"--uds-path\".to_string(),\n uds_path,\n \"--logger-level\".to_string(),\n log_level.to_string().to_uppercase(),\n \"--json-output\".to_string(),\n ];\n\n // Activate trust remote code\n if trust_remote_code {\n shard_args.push(\"--trust-remote-code\".to_string());\n }\n\n // Activate tensor parallelism\n if world_size > 1 {\n shard_args.push(\"--sharded\".to_string());\n }\n\n if let Some(quantize) = quantize {\n shard_args.push(\"--quantize\".to_string());\n shard_args.push(quantize.to_string())\n }\n\n if let Some(speculate) = speculate {\n shard_args.push(\"--speculate\".to_string());\n shard_args.push(speculate.to_string())\n }\n\n if let Some(dtype) = dtype {\n shard_args.push(\"--dtype\".to_string());\n shard_args.push(dtype.to_string())\n }\n\n // Model optional revision\n if let Some(revision) = revision {\n shard_args.push(\"--revision\".to_string());\n shard_args.push(revision)\n }\n\n let rope = match (rope_scaling, rope_factor) {\n (None, None) => None,\n (Some(scaling), None) => Some((scaling, 1.0)),\n (Some(scaling), Some(factor)) => Some((scaling, factor)),\n (None, Some(factor)) => Some((RopeScaling::Linear, factor)),\n };\n\n // OpenTelemetry Endpoint\n if let Some(otlp_endpoint) = otlp_endpoint {\n shard_args.push(\"--otlp-endpoint\".to_string());\n shard_args.push(otlp_endpoint);\n }\n\n // OpenTelemetry Service Name\n shard_args.push(\"--otlp-service-name\".to_string());\n shard_args.push(otlp_service_name);\n\n // In case we use sliding window, we may ignore the sliding in flash for some backends depending on the parameter.\n shard_args.push(\"--max-input-tokens\".to_string());\n shard_args.push(max_input_tokens.to_string());\n\n // Copy current process env\n let mut envs: Vec<(OsString, OsString)> = env::vars_os().collect();\n\n // Remove LOG_LEVEL if present\n envs.retain(|(name, _)| name != \"LOG_LEVEL\");\n\n // Torch Distributed Env vars\n envs.push((\"RANK\".into(), rank.to_string().into()));\n envs.push((\"WORLD_SIZE\".into(), world_size.to_string().into()));\n envs.push((\"MASTER_ADDR\".into(), master_addr.into()));\n envs.push((\"MASTER_PORT\".into(), master_port.to_string().into()));\n envs.push((\"TORCH_NCCL_AVOID_RECORD_STREAMS\".into(), \"1\".into()));\n\n // CUDA memory fraction\n envs.push((\n \"CUDA_MEMORY_FRACTION\".into(),\n cuda_memory_fraction.to_string().into(),\n ));\n\n // Safetensors load fast\n envs.push((\"SAFETENSORS_FAST_GPU\".into(), \"1\".into()));\n\n // Disable progress bar\n envs.push((\"HF_HUB_DISABLE_PROGRESS_BARS\".into(), \"1\".into()));\n\n // Enable hf transfer for insane download speeds\n let enable_hf_transfer = env::var(\"HF_HUB_ENABLE_HF_TRANSFER\").unwrap_or(\"1\".to_string());\n envs.push((\n \"HF_HUB_ENABLE_HF_TRANSFER\".into(),\n enable_hf_transfer.into(),\n ));\n\n // Parse Inference API token\n if let Ok(api_token) = env::var(\"HF_API_TOKEN\") {\n envs.push((\"HF_TOKEN\".into(), api_token.into()))\n };\n\n // Detect rope scaling\n // Sending as env instead of CLI args to not bloat everything\n // those only can be used by RoPE models, so passing information around\n // for all models will complexify code unnecessarily\n if let Some((scaling, factor)) = rope {\n envs.push((\"ROPE_SCALING\".into(), scaling.to_string().into()));\n envs.push((\"ROPE_FACTOR\".into(), factor.to_string().into()));\n }\n\n envs.push((\n \"MAX_TOTAL_TOKENS\".into(),\n max_total_tokens.to_string().into(),\n ));\n if let Some(max_batch_size) = max_batch_size {\n envs.push((\"MAX_BATCH_SIZE\".into(), max_batch_size.to_string().into()));\n }\n\n // Lora Adapters\n if let Some(lora_adapters) = lora_adapters {\n envs.push((\"LORA_ADAPTERS\".into(), lora_adapters.into()));\n }\n\n // If huggingface_hub_cache is some, pass it to the shard\n // Useful when running inside a docker container\n if let Some(huggingface_hub_cache) = huggingface_hub_cache {\n envs.push((\"HUGGINGFACE_HUB_CACHE\".into(), huggingface_hub_cache.into()));\n };\n\n // If weights_cache_override is some, pass it to the shard\n // Useful when running inside a HuggingFace Inference Endpoint\n if let Some(weights_cache_override) = weights_cache_override {\n envs.push((\n \"WEIGHTS_CACHE_OVERRIDE\".into(),\n weights_cache_override.into(),\n ));\n };\n\n // Enable experimental support for cuda graphs\n if !cuda_graphs.is_empty() {\n envs.push((\n \"CUDA_GRAPHS\".into(),\n cuda_graphs\n .into_iter()\n .map(|c| c.to_string())\n .collect::<Vec<_>>()\n .join(\",\")\n .into(),\n ));\n }\n\n // If disable_custom_kernels is true, pass it to the shard as an env var\n if disable_custom_kernels {\n envs.push((\"DISABLE_CUSTOM_KERNELS\".into(), \"True\".into()))\n }\n\n // Watermark Gamma\n if let Some(watermark_gamma) = watermark_gamma {\n envs.push((\"WATERMARK_GAMMA\".into(), watermark_gamma.to_string().into()))\n }\n\n // Watermark Delta\n if let Some(watermark_delta) = watermark_delta {\n envs.push((\"WATERMARK_DELTA\".into(), watermark_delta.to_string().into()))\n }\n\n // Start process\n tracing::info!(\"Starting shard\");\n let mut p = match Command::new(\"text-generation-server\")\n .args(shard_args)\n .env_clear()\n .envs(envs)\n .stdin(Stdio::piped())\n .stdout(Stdio::piped())\n .stderr(Stdio::piped())\n .process_group(0)\n .spawn()\n {\n Ok(p) => p,\n Err(err) => {\n if err.kind() == io::ErrorKind::NotFound {\n tracing::error!(\"text-generation-server not found in PATH\");\n tracing::error!(\"Please install it with `make install-server`\")\n }\n {\n tracing::error!(\"{}\", err);\n }\n\n status_sender.send(ShardStatus::Failed(rank)).unwrap();\n return;\n }\n };\n\n // Redirect STDOUT to the console\n let mut pstdin = p.stdin.take().unwrap();\n let shard_stdout_reader = BufReader::new(p.stdout.take().unwrap());\n let shard_stderr_reader = BufReader::new(p.stderr.take().unwrap());\n\n //stdout tracing thread\n thread::spawn(move || {\n log_lines(shard_stdout_reader);\n });\n // We read stderr in another thread as it seems that lines() can block in some cases\n let (err_sender, err_receiver) = mpsc::channel();\n thread::spawn(move || {\n for line in shard_stderr_reader.lines().map_while(Result::ok) {\n err_sender.send(line).unwrap_or(());\n }\n });\n // We read stdin in another thread as it seems that lines() can block in some cases\n thread::spawn(move || {\n let mut stdin = io::stdin(); // We get `Stdin` here.\n loop {\n let mut buffer = vec![0; 4096];\n if let Ok(n) = stdin.read(&mut buffer) {\n if n > 0 {\n let _ = pstdin.write_all(&buffer[..n]);\n }\n }\n }\n });\n\n let mut ready = false;\n let start_time = Instant::now();\n let mut wait_time = Instant::now();\n loop {\n // Process exited\n if let Some(exit_status) = p.try_wait().unwrap() {\n let mut err = String::new();\n while let Ok(line) = err_receiver.recv_timeout(Duration::from_millis(10)) {\n err = err + \"\\n\" + &line;\n }\n\n tracing::error!(\"Shard complete standard error output:\\n{err}\");\n\n if let Some(signal) = exit_status.signal() {\n tracing::error!(\"Shard process was signaled to shutdown with signal {signal}\");\n }\n\n status_sender.send(ShardStatus::Failed(rank)).unwrap();\n return;\n }\n\n // We received a shutdown signal\n if shutdown.load(Ordering::SeqCst) {\n terminate(\"shard\", p, Duration::from_secs(90)).unwrap();\n return;\n }\n\n // Shard is ready\n if uds.exists() && !ready {\n tracing::info!(\"Shard ready in {:?}\", start_time.elapsed());\n status_sender.send(ShardStatus::Ready).unwrap();\n ready = true;\n } else if !ready && wait_time.elapsed() > Duration::from_secs(10) {\n tracing::info!(\"Waiting for shard to be ready...\");\n wait_time = Instant::now();\n }\n sleep(Duration::from_millis(100));\n }\n}\n\nfn shutdown_shards(shutdown: Arc<AtomicBool>, shutdown_receiver: &mpsc::Receiver<()>) {\n tracing::info!(\"Shutting down shards\");\n // Update shutdown value to true\n // This will be picked up by the shard manager\n shutdown.store(true, Ordering::SeqCst);\n\n // Wait for shards to shutdown\n // This will block till all shutdown_sender are dropped\n let _ = shutdown_receiver.recv();\n}\n\nfn num_cuda_devices() -> Option<usize> {\n let devices = match env::var(\"CUDA_VISIBLE_DEVICES\") {\n Ok(devices) => devices,\n Err(_) => match env::var(\"NVIDIA_VISIBLE_DEVICES\") {\n Ok(devices) => devices,\n Err(_) => env::var(\"ZE_AFFINITY_MASK\").ok()?,\n },\n };\n let n_devices = devices.split(',').count();\n Some(n_devices)\n}\n\n#[derive(Deserialize)]\n#[serde(rename_all = \"UPPERCASE\")]\nenum PythonLogLevelEnum {\n Trace,\n Debug,\n Info,\n Success,\n Warning,\n Error,\n Critical,\n}\n\n#[derive(Deserialize)]\nstruct PythonLogLevel {\n name: PythonLogLevelEnum,\n}\n\n#[derive(Deserialize)]\nstruct PythonLogRecord {\n level: PythonLogLevel,\n}\n\n#[derive(Deserialize)]\nstruct PythonLogMessage {\n text: String,\n record: PythonLogRecord,\n}\n\nimpl PythonLogMessage {\n fn trace(&self) {\n match self.record.level.name {\n PythonLogLevelEnum::Trace => tracing::trace!(\"{}\", self.text.trim_end()),\n PythonLogLevelEnum::Debug => tracing::debug!(\"{}\", self.text.trim_end()),\n PythonLogLevelEnum::Info => tracing::info!(\"{}\", self.text.trim_end()),\n PythonLogLevelEnum::Success => tracing::info!(\"{}\", self.text.trim_end()),\n PythonLogLevelEnum::Warning => tracing::warn!(\"{}\", self.text.trim_end()),\n PythonLogLevelEnum::Error => tracing::error!(\"{}\", self.text.trim_end()),\n PythonLogLevelEnum::Critical => tracing::error!(\"{}\", self.text.trim_end()),\n }\n }\n}\n\nimpl TryFrom<&[u8]> for PythonLogMessage {\n type Error = serde_json::Error;\n\n fn try_from(value: &[u8]) -> Result<Self, Self::Error> {\n serde_json::from_slice::<Self>(value)\n }\n}\n\nfn log_lines<R: Sized + Read>(mut bufread: BufReader<R>) {\n let mut buffer = vec![0u8; 8 * 4096];\n let mut stdout = std::io::stdout();\n loop {\n let n = bufread.read(&mut buffer);\n if let Ok(n) = n {\n if n > 0 {\n let mut lines = buffer[..n].split(|i| *i == b'\\n').peekable();\n while let Some(line) = lines.next() {\n match PythonLogMessage::try_from(line) {\n Ok(log) => log.trace(),\n // For interactive debugging ?\n Err(_) => {\n if LevelFilter::current() >= tracing::Level::DEBUG {\n stdout.write_all(line).unwrap();\n if lines.peek().is_some() {\n stdout.write_all(b\"\\n\").unwrap();\n }\n stdout.flush().unwrap();\n }\n }\n }\n }\n }\n }\n }\n}\n\nfn find_num_shards(\n sharded: Option<bool>,\n num_shard: Option<usize>,\n) -> Result<usize, LauncherError> {\n // get the number of shards given `sharded` and `num_shard`\n let num_shard = match (sharded, num_shard) {\n (Some(true), None) => {\n // try to default to the number of available GPUs\n tracing::info!(\"Parsing num_shard from CUDA_VISIBLE_DEVICES/NVIDIA_VISIBLE_DEVICES/ZE_AFFINITY_MASK\");\n let n_devices = num_cuda_devices()\n .expect(\"--num-shard and CUDA_VISIBLE_DEVICES/NVIDIA_VISIBLE_DEVICES/ZE_AFFINITY_MASK are not set\");\n if n_devices <= 1 {\n return Err(LauncherError::NotEnoughCUDADevices(format!(\n \"`sharded` is true but only found {n_devices} CUDA devices\"\n )));\n }\n n_devices\n }\n (Some(true), Some(num_shard)) => {\n // we can't have only one shard while sharded\n if num_shard <= 1 {\n return Err(LauncherError::ArgumentValidation(\n \"`sharded` is true but `num_shard` <= 1\".to_string(),\n ));\n }\n num_shard\n }\n (Some(false), Some(num_shard)) => num_shard,\n (Some(false), None) => 1,\n (None, None) => num_cuda_devices().unwrap_or(1),\n (None, Some(num_shard)) => num_shard,\n };\n if num_shard < 1 {\n return Err(LauncherError::ArgumentValidation(\n \"`num_shard` cannot be < 1\".to_string(),\n ));\n }\n Ok(num_shard)\n}\n\n#[derive(Debug, Error)]\nenum LauncherError {\n #[error(\"Invalid argument: {0}\")]\n ArgumentValidation(String),\n #[error(\"not enough cuda devices: {0}\")]\n NotEnoughCUDADevices(String),\n #[error(\"Download error\")]\n DownloadError,\n #[error(\"Shard cannot start\")]\n ShardCannotStart,\n #[error(\"Shard disconnected\")]\n ShardDisconnected,\n #[error(\"Shard failed\")]\n ShardFailed,\n #[error(\"Webserver failed\")]\n WebserverFailed,\n #[error(\"Webserver cannot start\")]\n WebserverCannotStart,\n}\n\nfn download_convert_model(\n model_id: &str,\n revision: Option<&str>,\n trust_remote_code: bool,\n huggingface_hub_cache: Option<&str>,\n weights_cache_override: Option<&str>,\n running: Arc<AtomicBool>,\n) -> Result<(), LauncherError> {\n // Enter download tracing span\n let _span = tracing::span!(tracing::Level::INFO, \"download\").entered();\n\n let mut download_args = vec![\n \"download-weights\".to_string(),\n model_id.to_string(),\n \"--extension\".to_string(),\n \".safetensors\".to_string(),\n \"--logger-level\".to_string(),\n \"INFO\".to_string(),\n \"--json-output\".to_string(),\n ];\n\n // Model optional revision\n if let Some(revision) = &revision {\n download_args.push(\"--revision\".to_string());\n download_args.push(revision.to_string())\n }\n\n // Trust remote code for automatic peft fusion\n if trust_remote_code {\n download_args.push(\"--trust-remote-code\".to_string());\n }\n\n // Copy current process env\n let mut envs: Vec<(OsString, OsString)> = env::vars_os().collect();\n\n // Remove LOG_LEVEL if present\n envs.retain(|(name, _)| name != \"LOG_LEVEL\");\n\n // Disable progress bar\n envs.push((\"HF_HUB_DISABLE_PROGRESS_BARS\".into(), \"1\".into()));\n\n // If huggingface_hub_cache is set, pass it to the download process\n // Useful when running inside a docker container\n if let Some(ref huggingface_hub_cache) = huggingface_hub_cache {\n envs.push((\"HUGGINGFACE_HUB_CACHE\".into(), huggingface_hub_cache.into()));\n };\n\n // Enable hf transfer for insane download speeds\n let enable_hf_transfer = env::var(\"HF_HUB_ENABLE_HF_TRANSFER\").unwrap_or(\"1\".to_string());\n envs.push((\n \"HF_HUB_ENABLE_HF_TRANSFER\".into(),\n enable_hf_transfer.into(),\n ));\n\n // Parse Inference API token\n if let Ok(api_token) = env::var(\"HF_API_TOKEN\") {\n envs.push((\"HF_TOKEN\".into(), api_token.into()))\n };\n\n // If args.weights_cache_override is some, pass it to the download process\n // Useful when running inside a HuggingFace Inference Endpoint\n if let Some(weights_cache_override) = &weights_cache_override {\n envs.push((\n \"WEIGHTS_CACHE_OVERRIDE\".into(),\n weights_cache_override.into(),\n ));\n };\n\n // Start process\n tracing::info!(\"Starting check and download process for {model_id}\");\n let mut download_process = match Command::new(\"text-generation-server\")\n .args(download_args)\n .env_clear()\n .envs(envs)\n .stdout(Stdio::piped())\n .stderr(Stdio::piped())\n .process_group(0)\n .spawn()\n {\n Ok(p) => p,\n Err(err) => {\n if err.kind() == io::ErrorKind::NotFound {\n tracing::error!(\"text-generation-server not found in PATH\");\n tracing::error!(\"Please install it with `make install-server`\")\n } else {\n tracing::error!(\"{}\", err);\n }\n\n return Err(LauncherError::DownloadError);\n }\n };\n\n let download_stdout = BufReader::new(download_process.stdout.take().unwrap());\n\n thread::spawn(move || {\n log_lines(download_stdout);\n });\n\n let download_stderr = BufReader::new(download_process.stderr.take().unwrap());\n\n // We read stderr in another thread as it seems that lines() can block in some cases\n let (err_sender, err_receiver) = mpsc::channel();\n thread::spawn(move || {\n for line in download_stderr.lines().map_while(Result::ok) {\n err_sender.send(line).unwrap_or(());\n }\n });\n\n loop {\n if let Some(status) = download_process.try_wait().unwrap() {\n if status.success() {\n tracing::info!(\"Successfully downloaded weights for {model_id}\");\n break;\n }\n\n let mut err = String::new();\n while let Ok(line) = err_receiver.recv_timeout(Duration::from_millis(10)) {\n err = err + \"\\n\" + &line;\n }\n\n if let Some(signal) = status.signal() {\n tracing::error!(\n \"Download process was signaled to shutdown with signal {signal}: {err}\"\n );\n } else {\n tracing::error!(\"Download encountered an error: {err}\");\n }\n\n return Err(LauncherError::DownloadError);\n }\n if !running.load(Ordering::SeqCst) {\n terminate(\"download\", download_process, Duration::from_secs(10)).unwrap();\n return Ok(());\n }\n sleep(Duration::from_millis(100));\n }\n Ok(())\n}\n\n#[allow(clippy::too_many_arguments)]\nfn spawn_shards(\n num_shard: usize,\n args: &Args,\n cuda_graphs: Vec<usize>,\n max_total_tokens: usize,\n max_input_tokens: usize,\n quantize: Option<Quantization>,\n max_log_level: LevelFilter,\n shutdown: Arc<AtomicBool>,\n shutdown_receiver: &mpsc::Receiver<()>,\n shutdown_sender: mpsc::Sender<()>,\n status_receiver: &mpsc::Receiver<ShardStatus>,\n status_sender: mpsc::Sender<ShardStatus>,\n running: Arc<AtomicBool>,\n) -> Result<(), LauncherError> {\n // Start shard processes\n for rank in 0..num_shard {\n let model_id = args.model_id.clone();\n let revision = args.revision.clone();\n let uds_path = args.shard_uds_path.clone();\n let master_addr = args.master_addr.clone();\n let huggingface_hub_cache = args.huggingface_hub_cache.clone();\n let weights_cache_override = args.weights_cache_override.clone();\n let status_sender = status_sender.clone();\n let shutdown = shutdown.clone();\n let shutdown_sender = shutdown_sender.clone();\n let otlp_endpoint = args.otlp_endpoint.clone();\n let otlp_service_name = args.otlp_service_name.clone();\n let speculate = args.speculate;\n let dtype = args.dtype;\n let trust_remote_code = args.trust_remote_code;\n let master_port = args.master_port;\n let disable_custom_kernels = args.disable_custom_kernels;\n let watermark_gamma = args.watermark_gamma;\n let watermark_delta = args.watermark_delta;\n let cuda_graphs_clone = cuda_graphs.clone();\n let cuda_memory_fraction = args.cuda_memory_fraction;\n let rope_scaling = args.rope_scaling;\n let rope_factor = args.rope_factor;\n let max_batch_size = args.max_batch_size;\n let lora_adapters = args.lora_adapters.clone();\n thread::spawn(move || {\n shard_manager(\n model_id,\n revision,\n quantize,\n speculate,\n dtype,\n trust_remote_code,\n uds_path,\n rank,\n num_shard,\n master_addr,\n master_port,\n huggingface_hub_cache,\n weights_cache_override,\n disable_custom_kernels,\n watermark_gamma,\n watermark_delta,\n cuda_graphs_clone,\n cuda_memory_fraction,\n rope_scaling,\n rope_factor,\n max_total_tokens,\n max_batch_size,\n max_input_tokens,\n lora_adapters,\n otlp_endpoint,\n otlp_service_name,\n max_log_level,\n status_sender,\n shutdown,\n shutdown_sender,\n )\n });\n }\n drop(shutdown_sender);\n\n // Wait for shard to start\n let mut shard_ready = 0;\n while running.load(Ordering::SeqCst) {\n match status_receiver.try_recv() {\n Ok(ShardStatus::Ready) => {\n shard_ready += 1;\n if shard_ready == num_shard {\n break;\n }\n }\n Err(TryRecvError::Empty) => {\n sleep(Duration::from_millis(100));\n }\n Ok(ShardStatus::Failed(rank)) => {\n tracing::error!(\"Shard {rank} failed to start\");\n shutdown_shards(shutdown, shutdown_receiver);\n return Err(LauncherError::ShardCannotStart);\n }\n Err(TryRecvError::Disconnected) => {\n tracing::error!(\"Shard status channel disconnected\");\n shutdown_shards(shutdown, shutdown_receiver);\n return Err(LauncherError::ShardDisconnected);\n }\n }\n }\n Ok(())\n}\n\nfn compute_type(num_shard: usize) -> Option<String> {\n let output = Command::new(\"nvidia-smi\")\n .args([\"--query-gpu=gpu_name\", \"--format=csv\"])\n .output()\n .ok()?;\n let output = String::from_utf8(output.stdout).ok()?;\n let fullname = output.split('\\n').nth(1)?;\n let cardname = fullname.replace(' ', \"-\").to_lowercase();\n let compute_type = format!(\"{num_shard}-{cardname}\");\n Some(compute_type)\n}\n\nfn spawn_webserver(\n num_shard: usize,\n args: Args,\n max_input_tokens: usize,\n max_total_tokens: usize,\n max_batch_prefill_tokens: u32,\n shutdown: Arc<AtomicBool>,\n shutdown_receiver: &mpsc::Receiver<()>,\n) -> Result<Child, LauncherError> {\n // All shard started\n // Start webserver\n tracing::info!(\"Starting Webserver\");\n let mut router_args = vec![\n \"--max-client-batch-size\".to_string(),\n args.max_client_batch_size.to_string(),\n \"--max-concurrent-requests\".to_string(),\n args.max_concurrent_requests.to_string(),\n \"--max-best-of\".to_string(),\n args.max_best_of.to_string(),\n \"--max-stop-sequences\".to_string(),\n args.max_stop_sequences.to_string(),\n \"--max-top-n-tokens\".to_string(),\n args.max_top_n_tokens.to_string(),\n \"--max-input-tokens\".to_string(),\n max_input_tokens.to_string(),\n \"--max-total-tokens\".to_string(),\n max_total_tokens.to_string(),\n \"--max-batch-prefill-tokens\".to_string(),\n max_batch_prefill_tokens.to_string(),\n \"--waiting-served-ratio\".to_string(),\n args.waiting_served_ratio.to_string(),\n \"--max-waiting-tokens\".to_string(),\n args.max_waiting_tokens.to_string(),\n \"--validation-workers\".to_string(),\n args.validation_workers.to_string(),\n \"--hostname\".to_string(),\n args.hostname.to_string(),\n \"--port\".to_string(),\n args.port.to_string(),\n \"--master-shard-uds-path\".to_string(),\n format!(\"{}-0\", args.shard_uds_path),\n \"--tokenizer-name\".to_string(),\n args.model_id,\n ];\n\n // Pass usage stats flags to router\n router_args.push(\"--usage-stats\".to_string());\n router_args.push(args.usage_stats.to_string());\n\n // Grammar support\n if args.disable_grammar_support {\n router_args.push(\"--disable-grammar-support\".to_string());\n }\n\n // Tokenizer config path\n if let Some(ref tokenizer_config_path) = args.tokenizer_config_path {\n router_args.push(\"--tokenizer-config-path\".to_string());\n router_args.push(tokenizer_config_path.to_string());\n }\n\n // Model optional max batch total tokens\n if let Some(max_batch_total_tokens) = args.max_batch_total_tokens {\n router_args.push(\"--max-batch-total-tokens\".to_string());\n router_args.push(max_batch_total_tokens.to_string());\n }\n\n // Router optional max batch size\n if let Some(max_batch_size) = args.max_batch_size {\n router_args.push(\"--max-batch-size\".to_string());\n router_args.push(max_batch_size.to_string());\n }\n\n // Model optional revision\n if let Some(ref revision) = args.revision {\n router_args.push(\"--revision\".to_string());\n router_args.push(revision.to_string())\n }\n\n if args.json_output {\n router_args.push(\"--json-output\".to_string());\n }\n\n // OpenTelemetry\n if let Some(otlp_endpoint) = args.otlp_endpoint {\n router_args.push(\"--otlp-endpoint\".to_string());\n router_args.push(otlp_endpoint);\n }\n\n // OpenTelemetry\n let otlp_service_name = args.otlp_service_name;\n router_args.push(\"--otlp-service-name\".to_string());\n router_args.push(otlp_service_name);\n\n // CORS origins\n for origin in args.cors_allow_origin.into_iter() {\n router_args.push(\"--cors-allow-origin\".to_string());\n router_args.push(origin);\n }\n\n // API Key\n if let Some(api_key) = args.api_key {\n router_args.push(\"--api-key\".to_string());\n router_args.push(api_key);\n }\n // Ngrok\n if args.ngrok {\n router_args.push(\"--ngrok\".to_string());\n router_args.push(\"--ngrok-authtoken\".to_string());\n router_args.push(args.ngrok_authtoken.unwrap());\n router_args.push(\"--ngrok-edge\".to_string());\n router_args.push(args.ngrok_edge.unwrap());\n }\n\n // Copy current process env\n let mut envs: Vec<(OsString, OsString)> = env::vars_os().collect();\n\n // Parse Inference API token\n if let Ok(api_token) = env::var(\"HF_API_TOKEN\") {\n envs.push((\"HF_TOKEN\".into(), api_token.into()))\n };\n\n // Parse Compute type\n if let Ok(compute_type) = env::var(\"COMPUTE_TYPE\") {\n envs.push((\"COMPUTE_TYPE\".into(), compute_type.into()))\n } else if let Some(compute_type) = compute_type(num_shard) {\n envs.push((\"COMPUTE_TYPE\".into(), compute_type.into()))\n }\n\n let mut webserver = match Command::new(\"text-generation-router\")\n .args(router_args)\n .envs(envs)\n .stdout(Stdio::piped())\n .stderr(Stdio::piped())\n .process_group(0)\n .spawn()\n {\n Ok(p) => p,\n Err(err) => {\n tracing::error!(\"Failed to start webserver: {}\", err);\n if err.kind() == io::ErrorKind::NotFound {\n tracing::error!(\"text-generation-router not found in PATH\");\n tracing::error!(\"Please install it with `make install-router`\")\n } else {\n tracing::error!(\"{}\", err);\n }\n\n shutdown_shards(shutdown, shutdown_receiver);\n return Err(LauncherError::WebserverCannotStart);\n }\n };\n\n // Redirect STDOUT and STDERR to the console\n let webserver_stdout = webserver.stdout.take().unwrap();\n let webserver_stderr = webserver.stderr.take().unwrap();\n\n thread::spawn(move || {\n let stdout = BufReader::new(webserver_stdout);\n let stderr = BufReader::new(webserver_stderr);\n for line in stdout.lines() {\n println!(\"{}\", line.unwrap());\n }\n for line in stderr.lines() {\n println!(\"{}\", line.unwrap());\n }\n });\n Ok(webserver)\n}\n\nfn terminate(process_name: &str, mut process: Child, timeout: Duration) -> io::Result<ExitStatus> {\n tracing::info!(\"Terminating {process_name}\");\n\n let terminate_time = Instant::now();\n signal::kill(Pid::from_raw(process.id() as i32), Signal::SIGTERM).unwrap();\n\n tracing::info!(\"Waiting for {process_name} to gracefully shutdown\");\n while terminate_time.elapsed() < timeout {\n if let Some(status) = process.try_wait()? {\n tracing::info!(\"{process_name} terminated\");\n return Ok(status);\n }\n sleep(Duration::from_millis(100));\n }\n tracing::info!(\"Killing {process_name}\");\n\n process.kill()?;\n let exit_status = process.wait()?;\n\n tracing::info!(\"{process_name} killed\");\n Ok(exit_status)\n}\n\nfn main() -> Result<(), LauncherError> {\n // Pattern match configuration\n let args: Args = Args::parse();\n\n // Filter events with LOG_LEVEL\n let varname = \"LOG_LEVEL\";\n let env_filter = if let Ok(log_level) = std::env::var(varname) {\n // Override to avoid simple logs to be spammed with tokio level informations\n let log_level = match &log_level[..] {\n \"warn\" => \"text_generation_launcher=warn,text_generation_router=warn\",\n \"info\" => \"text_generation_launcher=info,text_generation_router=info\",\n \"debug\" => \"text_generation_launcher=debug,text_generation_router=debug\",\n log_level => log_level,\n };\n EnvFilter::builder()\n .with_default_directive(LevelFilter::INFO.into())\n .parse_lossy(log_level)\n } else {\n EnvFilter::new(\"info\")\n };\n let max_log_level = env_filter.max_level_hint().unwrap_or(LevelFilter::INFO);\n\n if args.json_output {\n tracing_subscriber::fmt()\n .with_env_filter(env_filter)\n .json()\n .init();\n } else {\n tracing_subscriber::fmt()\n .with_env_filter(env_filter)\n .compact()\n .init();\n }\n\n if args.env {\n let env_runtime = env_runtime::Env::new();\n tracing::info!(\"{}\", env_runtime);\n }\n\n tracing::info!(\"{:#?}\", args);\n\n let config: Option<Config> = get_config(&args.model_id, &args.revision).ok();\n let quantize = config.as_ref().and_then(|c| c.quantize);\n // Quantization usually means you're even more RAM constrained.\n let max_default = 4096;\n\n let max_position_embeddings = if let Some(config) = &config {\n if let Some(max_position_embeddings) = config.max_position_embeddings {\n if max_position_embeddings > max_default {\n let max = max_position_embeddings;\n if args.max_input_tokens.is_none()\n && args.max_total_tokens.is_none()\n && args.max_batch_prefill_tokens.is_none()\n {\n tracing::info!(\"Model supports up to {max} but tgi will now set its default to {max_default} instead. This is to save VRAM by refusing large prompts in order to allow more users on the same hardware. You can increase that size using `--max-batch-prefill-tokens={} --max-total-tokens={max} --max-input-tokens={}`.\", max + 50, max - 1);\n }\n max_default\n } else {\n max_position_embeddings\n }\n } else {\n max_default\n }\n } else {\n max_default\n };\n let (prefix_caching, attention) = resolve_attention(&config, &args.lora_adapters);\n tracing::info!(\"Using attention {attention} - Prefix caching {prefix_caching}\");\n std::env::set_var(\"USE_PREFIX_CACHING\", prefix_caching);\n std::env::set_var(\"ATTENTION\", attention);\n\n let max_input_tokens = {\n match (args.max_input_tokens, args.max_input_length) {\n (Some(max_input_tokens), Some(max_input_length)) => {\n return Err(LauncherError::ArgumentValidation(\n format!(\"Both `max_input_tokens` ({max_input_tokens}) and `max_input_length` ({max_input_length}) are set. Please define only `max_input_tokens` as `max_input_length is deprecated for naming consistency.\",\n )));\n }\n (Some(max_input_tokens), None) | (None, Some(max_input_tokens)) => max_input_tokens,\n (None, None) => {\n let value = max_position_embeddings - 1;\n tracing::info!(\"Default `max_input_tokens` to {value}\");\n value\n }\n }\n };\n let max_total_tokens = {\n match args.max_total_tokens {\n Some(max_total_tokens) => max_total_tokens,\n None => {\n let value = max_position_embeddings;\n tracing::info!(\"Default `max_total_tokens` to {value}\");\n value\n }\n }\n };\n let max_batch_prefill_tokens = {\n match args.max_batch_prefill_tokens {\n Some(max_batch_prefill_tokens) => max_batch_prefill_tokens,\n None => {\n let value: u32 = if let Some(max_batch_size) = args.max_batch_size {\n max_batch_size * max_input_tokens\n } else {\n // Adding some edge in order to account for potential block_size alignement\n // issue.\n max_input_tokens + 50\n } as u32;\n tracing::info!(\"Default `max_batch_prefill_tokens` to {value}\");\n value\n }\n }\n };\n\n // Validate args\n if max_input_tokens >= max_total_tokens {\n return Err(LauncherError::ArgumentValidation(\n \"`max_input_tokens must be < `max_total_tokens`\".to_string(),\n ));\n }\n if max_input_tokens as u32 > max_batch_prefill_tokens {\n return Err(LauncherError::ArgumentValidation(format!(\n \"`max_batch_prefill_tokens` must be >= `max_input_tokens`. Given: {} and {}\",\n max_batch_prefill_tokens, max_input_tokens\n )));\n }\n\n if matches!(args.quantize, Some(Quantization::Bitsandbytes)) {\n tracing::warn!(\"Bitsandbytes is deprecated, use `eetq` instead, which provides better latencies overall and is drop-in in most cases.\");\n }\n let quantize = args.quantize.or(quantize);\n let cuda_graphs = match (&args.cuda_graphs, &quantize) {\n (Some(cuda_graphs), _) => cuda_graphs.iter().cloned().filter(|&c| c > 0).collect(),\n #[allow(deprecated)]\n (\n None,\n Some(\n Quantization::Bitsandbytes\n | Quantization::BitsandbytesNf4\n | Quantization::BitsandbytesFp4,\n ),\n ) => {\n tracing::warn!(\"Bitsandbytes doesn't work with cuda graphs, deactivating them\");\n vec![]\n }\n (None, Some(Quantization::Exl2)) => {\n tracing::warn!(\"Exl2 doesn't work with cuda graphs, deactivating them\");\n vec![]\n }\n _ => {\n let cuda_graphs = vec![1, 2, 4, 8, 16, 32];\n tracing::info!(\"Using default cuda graphs {cuda_graphs:?}\");\n cuda_graphs\n }\n };\n\n if args.validation_workers == 0 {\n return Err(LauncherError::ArgumentValidation(\n \"`validation_workers` must be > 0\".to_string(),\n ));\n }\n if args.trust_remote_code {\n tracing::warn!(\n \"`trust_remote_code` is set. Trusting that model `{}` do not contain malicious code.\",\n args.model_id\n );\n }\n\n let num_shard = find_num_shards(args.sharded, args.num_shard)?;\n if num_shard > 1 {\n if matches!(args.quantize, Some(Quantization::Exl2)) {\n return Err(LauncherError::ArgumentValidation(\n \"Sharding is currently not supported with `exl2` quantization\".into(),\n ));\n }\n tracing::info!(\"Sharding model on {num_shard} processes\");\n }\n\n if let Some(ref max_batch_total_tokens) = args.max_batch_total_tokens {\n if max_batch_prefill_tokens > *max_batch_total_tokens {\n return Err(LauncherError::ArgumentValidation(format!(\n \"`max_batch_prefill_tokens` must be <= `max_batch_total_tokens`. Given: {} and {}\",\n max_batch_prefill_tokens, max_batch_total_tokens\n )));\n }\n if max_total_tokens as u32 > *max_batch_total_tokens {\n return Err(LauncherError::ArgumentValidation(format!(\n \"`max_total_tokens` must be <= `max_batch_total_tokens`. Given: {} and {}\",\n max_total_tokens, max_batch_total_tokens\n )));\n }\n }\n\n if args.ngrok {\n if args.ngrok_authtoken.is_none() {\n return Err(LauncherError::ArgumentValidation(\n \"`ngrok-authtoken` must be set when using ngrok tunneling\".to_string(),\n ));\n }\n\n if args.ngrok_edge.is_none() {\n return Err(LauncherError::ArgumentValidation(\n \"`ngrok-edge` must be set when using ngrok tunneling\".to_string(),\n ));\n }\n }\n\n // Signal handler\n let running = Arc::new(AtomicBool::new(true));\n let r = running.clone();\n ctrlc::set_handler(move || {\n r.store(false, Ordering::SeqCst);\n })\n .expect(\"Error setting Ctrl-C handler\");\n\n // Download and convert model weights\n download_convert_model(\n &args.model_id,\n args.revision.as_deref(),\n args.trust_remote_code,\n args.huggingface_hub_cache.as_deref(),\n args.weights_cache_override.as_deref(),\n running.clone(),\n )?;\n\n // Download and convert lora adapters if any\n if let Some(lora_adapters) = &args.lora_adapters {\n for adapter in lora_adapters.split(',') {\n // skip download if a path is provided\n if adapter.contains('=') {\n continue;\n }\n download_convert_model(\n adapter,\n None,\n args.trust_remote_code,\n args.huggingface_hub_cache.as_deref(),\n args.weights_cache_override.as_deref(),\n running.clone(),\n )?;\n }\n }\n\n if !running.load(Ordering::SeqCst) {\n // Launcher was asked to stop\n return Ok(());\n }\n\n // Shared shutdown bool\n let shutdown = Arc::new(AtomicBool::new(false));\n // Shared shutdown channel\n // When shutting down, the main thread will wait for all senders to be dropped\n let (shutdown_sender, shutdown_receiver) = mpsc::channel();\n\n // Shared channel to track shard status\n let (status_sender, status_receiver) = mpsc::channel();\n\n spawn_shards(\n num_shard,\n &args,\n cuda_graphs,\n max_total_tokens,\n max_input_tokens,\n quantize,\n max_log_level,\n shutdown.clone(),\n &shutdown_receiver,\n shutdown_sender,\n &status_receiver,\n status_sender,\n running.clone(),\n )?;\n\n // We might have received a termination signal\n if !running.load(Ordering::SeqCst) {\n shutdown_shards(shutdown, &shutdown_receiver);\n return Ok(());\n }\n\n let mut webserver = spawn_webserver(\n num_shard,\n args,\n max_input_tokens,\n max_total_tokens,\n max_batch_prefill_tokens,\n shutdown.clone(),\n &shutdown_receiver,\n )\n .inspect_err(|_| {\n shutdown_shards(shutdown.clone(), &shutdown_receiver);\n })?;\n\n // Default exit code\n let mut exit_code = Ok(());\n\n while running.load(Ordering::SeqCst) {\n if let Ok(ShardStatus::Failed(rank)) = status_receiver.try_recv() {\n tracing::error!(\"Shard {rank} crashed\");\n exit_code = Err(LauncherError::ShardFailed);\n break;\n };\n\n match webserver.try_wait().unwrap() {\n Some(_) => {\n tracing::error!(\"Webserver Crashed\");\n shutdown_shards(shutdown, &shutdown_receiver);\n return Err(LauncherError::WebserverFailed);\n }\n None => {\n sleep(Duration::from_millis(100));\n }\n };\n }\n\n // Graceful termination\n terminate(\"webserver\", webserver, Duration::from_secs(90)).unwrap();\n shutdown_shards(shutdown, &shutdown_receiver);\n\n exit_code\n}\n", "router\\src\\main.rs.back": "use axum::http::HeaderValue;\nuse clap::Parser;\nuse clap::Subcommand;\nuse hf_hub::api::tokio::{Api, ApiBuilder, ApiRepo};\nuse hf_hub::{Cache, Repo, RepoType};\nuse opentelemetry::sdk::propagation::TraceContextPropagator;\nuse opentelemetry::sdk::trace;\nuse opentelemetry::sdk::trace::Sampler;\nuse opentelemetry::sdk::Resource;\nuse opentelemetry::{global, KeyValue};\nuse opentelemetry_otlp::WithExportConfig;\nuse std::fs::File;\nuse std::io::BufReader;\nuse std::net::{IpAddr, Ipv4Addr, SocketAddr};\nuse std::path::{Path, PathBuf};\nuse text_generation_router::config::Config;\nuse text_generation_router::usage_stats;\nuse text_generation_router::{\n server, HubModelInfo, HubPreprocessorConfig, HubProcessorConfig, HubTokenizerConfig,\n};\nuse thiserror::Error;\nuse tokenizers::{processors::template::TemplateProcessing, Tokenizer};\nuse tower_http::cors::AllowOrigin;\nuse tracing_subscriber::layer::SubscriberExt;\nuse tracing_subscriber::util::SubscriberInitExt;\nuse tracing_subscriber::{filter::LevelFilter, EnvFilter, Layer};\n\n/// App Configuration\n#[derive(Parser, Debug)]\n#[clap(author, version, about, long_about = None)]\nstruct Args {\n #[command(subcommand)]\n command: Option<Commands>,\n\n #[clap(default_value = \"128\", long, env)]\n max_concurrent_requests: usize,\n #[clap(default_value = \"2\", long, env)]\n max_best_of: usize,\n #[clap(default_value = \"4\", long, env)]\n max_stop_sequences: usize,\n #[clap(default_value = \"5\", long, env)]\n max_top_n_tokens: u32,\n #[clap(default_value = \"1024\", long, env)]\n max_input_tokens: usize,\n #[clap(default_value = \"2048\", long, env)]\n max_total_tokens: usize,\n #[clap(default_value = \"1.2\", long, env)]\n waiting_served_ratio: f32,\n #[clap(default_value = \"4096\", long, env)]\n max_batch_prefill_tokens: u32,\n #[clap(long, env)]\n max_batch_total_tokens: Option<u32>,\n #[clap(default_value = \"20\", long, env)]\n max_waiting_tokens: usize,\n #[clap(long, env)]\n max_batch_size: Option<usize>,\n #[clap(default_value = \"0.0.0.0\", long, env)]\n hostname: String,\n #[clap(default_value = \"3000\", long, short, env)]\n port: u16,\n #[clap(default_value = \"/tmp/text-generation-server-0\", long, env)]\n master_shard_uds_path: String,\n #[clap(default_value = \"bigscience/bloom\", long, env)]\n tokenizer_name: String,\n #[clap(long, env)]\n tokenizer_config_path: Option<String>,\n #[clap(long, env)]\n revision: Option<String>,\n #[clap(default_value = \"2\", long, env)]\n validation_workers: usize,\n #[clap(long, env)]\n json_output: bool,\n #[clap(long, env)]\n otlp_endpoint: Option<String>,\n #[clap(default_value = \"text-generation-inference.router\", long, env)]\n otlp_service_name: String,\n #[clap(long, env)]\n cors_allow_origin: Option<Vec<String>>,\n #[clap(long, env)]\n api_key: Option<String>,\n #[clap(long, env)]\n ngrok: bool,\n #[clap(long, env)]\n ngrok_authtoken: Option<String>,\n #[clap(long, env)]\n ngrok_edge: Option<String>,\n #[clap(long, env, default_value_t = false)]\n messages_api_enabled: bool,\n #[clap(long, env, default_value_t = false)]\n disable_grammar_support: bool,\n #[clap(default_value = \"4\", long, env)]\n max_client_batch_size: usize,\n #[clap(long, env, default_value_t)]\n disable_usage_stats: bool,\n #[clap(long, env, default_value_t)]\n disable_crash_reports: bool,\n}\n\n#[derive(Debug, Subcommand)]\nenum Commands {\n PrintSchema,\n}\n\n#[tokio::main]\nasync fn main() -> Result<(), RouterError> {\n let args = Args::parse();\n\n // Pattern match configuration\n let Args {\n max_concurrent_requests,\n max_best_of,\n max_stop_sequences,\n max_top_n_tokens,\n max_input_tokens,\n max_total_tokens,\n waiting_served_ratio,\n max_batch_prefill_tokens,\n max_batch_total_tokens,\n max_waiting_tokens,\n max_batch_size,\n hostname,\n port,\n master_shard_uds_path,\n tokenizer_name,\n tokenizer_config_path,\n revision,\n validation_workers,\n json_output,\n otlp_endpoint,\n otlp_service_name,\n cors_allow_origin,\n api_key,\n ngrok,\n ngrok_authtoken,\n ngrok_edge,\n messages_api_enabled,\n disable_grammar_support,\n max_client_batch_size,\n disable_usage_stats,\n disable_crash_reports,\n command,\n } = args;\n\n let print_schema_command = match command {\n Some(Commands::PrintSchema) => true,\n None => {\n // only init logging if we are not running the print schema command\n init_logging(otlp_endpoint, otlp_service_name, json_output);\n false\n }\n };\n\n // Validate args\n if max_input_tokens >= max_total_tokens {\n return Err(RouterError::ArgumentValidation(\n \"`max_input_tokens` must be < `max_total_tokens`\".to_string(),\n ));\n }\n if max_input_tokens as u32 > max_batch_prefill_tokens {\n return Err(RouterError::ArgumentValidation(format!(\"`max_batch_prefill_tokens` must be >= `max_input_tokens`. Given: {max_batch_prefill_tokens} and {max_input_tokens}\")));\n }\n\n if validation_workers == 0 {\n return Err(RouterError::ArgumentValidation(\n \"`validation_workers` must be > 0\".to_string(),\n ));\n }\n\n if let Some(ref max_batch_total_tokens) = max_batch_total_tokens {\n if max_batch_prefill_tokens > *max_batch_total_tokens {\n return Err(RouterError::ArgumentValidation(format!(\"`max_batch_prefill_tokens` must be <= `max_batch_total_tokens`. Given: {max_batch_prefill_tokens} and {max_batch_total_tokens}\")));\n }\n if max_total_tokens as u32 > *max_batch_total_tokens {\n return Err(RouterError::ArgumentValidation(format!(\"`max_total_tokens` must be <= `max_batch_total_tokens`. Given: {max_total_tokens} and {max_batch_total_tokens}\")));\n }\n }\n\n // CORS allowed origins\n // map to go inside the option and then map to parse from String to HeaderValue\n // Finally, convert to AllowOrigin\n let cors_allow_origin: Option<AllowOrigin> = cors_allow_origin.map(|cors_allow_origin| {\n AllowOrigin::list(\n cors_allow_origin\n .iter()\n .map(|origin| origin.parse::<HeaderValue>().unwrap()),\n )\n });\n\n // Parse Huggingface hub token\n let authorization_token = std::env::var(\"HF_TOKEN\")\n .or_else(|_| std::env::var(\"HUGGING_FACE_HUB_TOKEN\"))\n .ok();\n\n // Tokenizer instance\n // This will only be used to validate payloads\n let local_path = Path::new(&tokenizer_name);\n\n // Shared API builder initialization\n let api_builder = || {\n let mut builder = ApiBuilder::new()\n .with_progress(false)\n .with_token(authorization_token);\n\n if let Ok(cache_dir) = std::env::var(\"HUGGINGFACE_HUB_CACHE\") {\n builder = builder.with_cache_dir(cache_dir.into());\n }\n\n builder\n };\n\n // Decide if we need to use the API based on the revision and local path\n let use_api = revision.is_some() || !local_path.exists() || !local_path.is_dir();\n\n // Initialize API if needed\n #[derive(Clone)]\n enum Type {\n Api(Api),\n Cache(Cache),\n None,\n }\n let api = if use_api {\n if std::env::var(\"HF_HUB_OFFLINE\") == Ok(\"1\".to_string()) {\n let cache = std::env::var(\"HUGGINGFACE_HUB_CACHE\")\n .map_err(|_| ())\n .map(|cache_dir| Cache::new(cache_dir.into()))\n .unwrap_or_else(|_| Cache::default());\n\n tracing::warn!(\"Offline mode active using cache defaults\");\n Type::Cache(cache)\n } else {\n tracing::info!(\"Using the Hugging Face API\");\n match api_builder().build() {\n Ok(api) => Type::Api(api),\n Err(_) => {\n tracing::warn!(\"Unable to build the Hugging Face API\");\n Type::None\n }\n }\n }\n } else {\n Type::None\n };\n\n // Load tokenizer and model info\n let (\n tokenizer_filename,\n config_filename,\n tokenizer_config_filename,\n preprocessor_config_filename,\n processor_config_filename,\n model_info,\n ) = match api {\n Type::None => (\n Some(local_path.join(\"tokenizer.json\")),\n Some(local_path.join(\"config.json\")),\n Some(local_path.join(\"tokenizer_config.json\")),\n Some(local_path.join(\"preprocessor_config.json\")),\n Some(local_path.join(\"processor_config.json\")),\n None,\n ),\n Type::Api(api) => {\n let api_repo = api.repo(Repo::with_revision(\n tokenizer_name.to_string(),\n RepoType::Model,\n revision.clone().unwrap_or_else(|| \"main\".to_string()),\n ));\n\n let tokenizer_filename = match api_repo.get(\"tokenizer.json\").await {\n Ok(tokenizer_filename) => Some(tokenizer_filename),\n Err(_) => get_base_tokenizer(&api, &api_repo).await,\n };\n let config_filename = api_repo.get(\"config.json\").await.ok();\n let tokenizer_config_filename = api_repo.get(\"tokenizer_config.json\").await.ok();\n let preprocessor_config_filename = api_repo.get(\"preprocessor_config.json\").await.ok();\n let processor_config_filename = api_repo.get(\"processor_config.json\").await.ok();\n\n let model_info = if let Some(model_info) = get_model_info(&api_repo).await {\n Some(model_info)\n } else {\n tracing::warn!(\"Could not retrieve model info from the Hugging Face hub.\");\n None\n };\n (\n tokenizer_filename,\n config_filename,\n tokenizer_config_filename,\n preprocessor_config_filename,\n processor_config_filename,\n model_info,\n )\n }\n Type::Cache(cache) => {\n let repo = cache.repo(Repo::with_revision(\n tokenizer_name.to_string(),\n RepoType::Model,\n revision.clone().unwrap_or_else(|| \"main\".to_string()),\n ));\n (\n repo.get(\"tokenizer.json\"),\n repo.get(\"config.json\"),\n repo.get(\"tokenizer_config.json\"),\n repo.get(\"preprocessor_config.json\"),\n repo.get(\"processor_config.json\"),\n None,\n )\n }\n };\n let config: Option<Config> = config_filename.and_then(|filename| {\n std::fs::read_to_string(filename)\n .ok()\n .as_ref()\n .and_then(|c| {\n let config: Result<Config, _> = serde_json::from_str(c);\n if let Err(err) = &config {\n tracing::warn!(\"Could not parse config {err:?}\");\n }\n config.ok()\n })\n });\n let model_info = model_info.unwrap_or_else(|| HubModelInfo {\n model_id: tokenizer_name.to_string(),\n sha: None,\n pipeline_tag: None,\n });\n\n // Read the JSON contents of the file as an instance of 'HubTokenizerConfig'.\n let tokenizer_config: Option<HubTokenizerConfig> = if let Some(filename) = tokenizer_config_path\n {\n HubTokenizerConfig::from_file(filename)\n } else {\n tokenizer_config_filename.and_then(HubTokenizerConfig::from_file)\n };\n let tokenizer_config = tokenizer_config.unwrap_or_else(|| {\n tracing::warn!(\"Could not find tokenizer config locally and no API specified\");\n HubTokenizerConfig::default()\n });\n let tokenizer_class = tokenizer_config.tokenizer_class.clone();\n\n let tokenizer: Option<Tokenizer> = tokenizer_filename.and_then(|filename| {\n let mut tokenizer = Tokenizer::from_file(filename).ok();\n if let Some(tokenizer) = &mut tokenizer {\n if let Some(class) = &tokenizer_config.tokenizer_class {\n if class == \"LlamaTokenizer\" || class == \"LlamaTokenizerFast\"{\n if let Ok(post_processor) = create_post_processor(tokenizer, &tokenizer_config) {\n tracing::info!(\"Overriding LlamaTokenizer with TemplateProcessing to follow python override defined in https://github.com/huggingface/transformers/blob/4aa17d00690b7f82c95bb2949ea57e22c35b4336/src/transformers/models/llama/tokenization_llama_fast.py#L203-L205\");\n tokenizer.with_post_processor(post_processor);\n }\n }\n }\n }\n tokenizer\n });\n\n let preprocessor_config =\n preprocessor_config_filename.and_then(HubPreprocessorConfig::from_file);\n let processor_config = processor_config_filename\n .and_then(HubProcessorConfig::from_file)\n .unwrap_or_default();\n\n tracing::info!(\"Using config {config:?}\");\n if tokenizer.is_none() {\n tracing::warn!(\"Could not find a fast tokenizer implementation for {tokenizer_name}\");\n tracing::warn!(\"Rust input length validation and truncation is disabled\");\n }\n\n // if pipeline-tag == text-generation we default to return_full_text = true\n let compat_return_full_text = match &model_info.pipeline_tag {\n None => {\n tracing::warn!(\"no pipeline tag found for model {tokenizer_name}\");\n true\n }\n Some(pipeline_tag) => pipeline_tag.as_str() == \"text-generation\",\n };\n\n // Determine the server port based on the feature and environment variable.\n let port = if cfg!(feature = \"google\") {\n std::env::var(\"AIP_HTTP_PORT\")\n .map(|aip_http_port| aip_http_port.parse::<u16>().unwrap_or(port))\n .unwrap_or(port)\n } else {\n port\n };\n\n let addr = match hostname.parse() {\n Ok(ip) => SocketAddr::new(ip, port),\n Err(_) => {\n tracing::warn!(\"Invalid hostname, defaulting to 0.0.0.0\");\n SocketAddr::new(IpAddr::V4(Ipv4Addr::new(0, 0, 0, 0)), port)\n }\n };\n\n // Only send usage stats when TGI is run in container and the function returns Some\n let is_container = matches!(usage_stats::is_container(), Ok(true));\n\n let user_agent = if !disable_usage_stats && is_container {\n let reduced_args = usage_stats::Args::new(\n config.clone(),\n tokenizer_class,\n max_concurrent_requests,\n max_best_of,\n max_stop_sequences,\n max_top_n_tokens,\n max_input_tokens,\n max_total_tokens,\n waiting_served_ratio,\n max_batch_prefill_tokens,\n max_batch_total_tokens,\n max_waiting_tokens,\n max_batch_size,\n revision,\n validation_workers,\n messages_api_enabled,\n disable_grammar_support,\n max_client_batch_size,\n disable_usage_stats,\n disable_crash_reports,\n );\n Some(usage_stats::UserAgent::new(reduced_args))\n } else {\n None\n };\n\n if let Some(ref ua) = user_agent {\n let start_event =\n usage_stats::UsageStatsEvent::new(ua.clone(), usage_stats::EventType::Start, None);\n tokio::spawn(async move {\n start_event.send().await;\n });\n };\n\n // Run server\n let result = server::run(\n master_shard_uds_path,\n model_info,\n compat_return_full_text,\n max_concurrent_requests,\n max_best_of,\n max_stop_sequences,\n max_top_n_tokens,\n max_input_tokens,\n max_total_tokens,\n waiting_served_ratio,\n max_batch_prefill_tokens,\n max_batch_total_tokens,\n max_waiting_tokens,\n max_batch_size,\n tokenizer,\n config,\n validation_workers,\n addr,\n cors_allow_origin,\n api_key,\n ngrok,\n ngrok_authtoken,\n ngrok_edge,\n tokenizer_config,\n preprocessor_config,\n processor_config,\n messages_api_enabled,\n disable_grammar_support,\n max_client_batch_size,\n print_schema_command,\n )\n .await;\n\n match result {\n Ok(_) => {\n if let Some(ref ua) = user_agent {\n let stop_event = usage_stats::UsageStatsEvent::new(\n ua.clone(),\n usage_stats::EventType::Stop,\n None,\n );\n stop_event.send().await;\n };\n Ok(())\n }\n Err(e) => {\n if let Some(ref ua) = user_agent {\n if !disable_crash_reports {\n let error_event = usage_stats::UsageStatsEvent::new(\n ua.clone(),\n usage_stats::EventType::Error,\n Some(e.to_string()),\n );\n error_event.send().await;\n } else {\n let unknow_error_event = usage_stats::UsageStatsEvent::new(\n ua.clone(),\n usage_stats::EventType::Error,\n Some(\"unknow_error\".to_string()),\n );\n unknow_error_event.send().await;\n }\n };\n Err(RouterError::WebServer(e))\n }\n }\n}\n\n/// Init logging using env variables LOG_LEVEL and LOG_FORMAT:\n/// - otlp_endpoint is an optional URL to an Open Telemetry collector\n/// - otlp_service_name service name to appear in APM\n/// - LOG_LEVEL may be TRACE, DEBUG, INFO, WARN or ERROR (default to INFO)\n/// - LOG_FORMAT may be TEXT or JSON (default to TEXT)\n/// - LOG_COLORIZE may be \"false\" or \"true\" (default to \"true\" or ansi supported platforms)\nfn init_logging(otlp_endpoint: Option<String>, otlp_service_name: String, json_output: bool) {\n let mut layers = Vec::new();\n\n // STDOUT/STDERR layer\n let ansi = std::env::var(\"LOG_COLORIZE\") != Ok(\"1\".to_string());\n let fmt_layer = tracing_subscriber::fmt::layer()\n .with_file(true)\n .with_ansi(ansi)\n .with_line_number(true);\n\n let fmt_layer = match json_output {\n true => fmt_layer.json().flatten_event(true).boxed(),\n false => fmt_layer.boxed(),\n };\n layers.push(fmt_layer);\n\n // OpenTelemetry tracing layer\n if let Some(otlp_endpoint) = otlp_endpoint {\n global::set_text_map_propagator(TraceContextPropagator::new());\n\n let tracer = opentelemetry_otlp::new_pipeline()\n .tracing()\n .with_exporter(\n opentelemetry_otlp::new_exporter()\n .tonic()\n .with_endpoint(otlp_endpoint),\n )\n .with_trace_config(\n trace::config()\n .with_resource(Resource::new(vec![KeyValue::new(\n \"service.name\",\n otlp_service_name,\n )]))\n .with_sampler(Sampler::AlwaysOn),\n )\n .install_batch(opentelemetry::runtime::Tokio);\n\n if let Ok(tracer) = tracer {\n layers.push(tracing_opentelemetry::layer().with_tracer(tracer).boxed());\n init_tracing_opentelemetry::init_propagator().unwrap();\n };\n }\n\n // Filter events with LOG_LEVEL\n let varname = \"LOG_LEVEL\";\n let env_filter = if let Ok(log_level) = std::env::var(varname) {\n // Override to avoid simple logs to be spammed with tokio level informations\n let log_level = match &log_level[..] {\n \"warn\" => \"text_generation_launcher=warn,text_generation_router=warn\",\n \"info\" => \"text_generation_launcher=info,text_generation_router=info\",\n \"debug\" => \"text_generation_launcher=debug,text_generation_router=debug\",\n log_level => log_level,\n };\n EnvFilter::builder()\n .with_default_directive(LevelFilter::INFO.into())\n .parse_lossy(log_level)\n } else {\n EnvFilter::new(\"info\")\n };\n\n tracing_subscriber::registry()\n .with(env_filter)\n .with(layers)\n .init();\n}\n\n/// get model info from the Huggingface Hub\npub async fn get_model_info(api: &ApiRepo) -> Option<HubModelInfo> {\n let response = api.info_request().send().await.ok()?;\n\n if response.status().is_success() {\n let hub_model_info: HubModelInfo =\n serde_json::from_str(&response.text().await.ok()?).ok()?;\n if let Some(sha) = &hub_model_info.sha {\n tracing::info!(\n \"Serving revision {sha} of model {}\",\n hub_model_info.model_id\n );\n }\n Some(hub_model_info)\n } else {\n None\n }\n}\n\n/// get base tokenizer\npub async fn get_base_tokenizer(api: &Api, api_repo: &ApiRepo) -> Option<PathBuf> {\n let config_filename = api_repo.get(\"config.json\").await.ok()?;\n\n // Open the file in read-only mode with buffer.\n let file = File::open(config_filename).ok()?;\n let reader = BufReader::new(file);\n\n // Read the JSON contents of the file as an instance of `User`.\n let config: serde_json::Value = serde_json::from_reader(reader).ok()?;\n\n if let Some(serde_json::Value::String(base_model_id)) = config.get(\"base_model_name_or_path\") {\n let api_base_repo = api.repo(Repo::with_revision(\n base_model_id.to_string(),\n RepoType::Model,\n \"main\".to_string(),\n ));\n\n api_base_repo.get(\"tokenizer.json\").await.ok()\n } else {\n None\n }\n}\n\n/// get tokenizer_config from the Huggingface Hub\npub async fn get_tokenizer_config(api_repo: &ApiRepo) -> Option<HubTokenizerConfig> {\n let tokenizer_config_filename = api_repo.get(\"tokenizer_config.json\").await.ok()?;\n\n // Open the file in read-only mode with buffer.\n let file = File::open(tokenizer_config_filename).ok()?;\n let reader = BufReader::new(file);\n\n // Read the JSON contents of the file as an instance of 'HubTokenizerConfig'.\n let tokenizer_config: HubTokenizerConfig = serde_json::from_reader(reader)\n .map_err(|e| {\n tracing::warn!(\"Unable to parse tokenizer config: {}\", e);\n e\n })\n .ok()?;\n\n Some(tokenizer_config)\n}\n\n/// Create a post_processor for the LlamaTokenizer\npub fn create_post_processor(\n tokenizer: &Tokenizer,\n tokenizer_config: &HubTokenizerConfig,\n) -> Result<TemplateProcessing, tokenizers::processors::template::TemplateProcessingBuilderError> {\n let add_bos_token = tokenizer_config.add_bos_token.unwrap_or(true);\n let add_eos_token = tokenizer_config.add_eos_token.unwrap_or(false);\n\n let bos_token = tokenizer_config.bos_token.as_ref();\n let eos_token = tokenizer_config.eos_token.as_ref();\n\n if add_bos_token && bos_token.is_none() {\n panic!(\"add_bos_token = true but bos_token is None\");\n }\n\n if add_eos_token && eos_token.is_none() {\n panic!(\"add_eos_token = true but eos_token is None\");\n }\n\n let mut single = Vec::new();\n let mut pair = Vec::new();\n let mut special_tokens = Vec::new();\n\n if add_bos_token {\n if let Some(bos) = bos_token {\n let bos_token_id = tokenizer\n .token_to_id(bos.as_str())\n .expect(\"Should have found the bos token id\");\n special_tokens.push((bos.as_str(), bos_token_id));\n single.push(format!(\"{}:0\", bos.as_str()));\n pair.push(format!(\"{}:0\", bos.as_str()));\n }\n }\n\n single.push(\"$A:0\".to_string());\n pair.push(\"$A:0\".to_string());\n\n if add_eos_token {\n if let Some(eos) = eos_token {\n let eos_token_id = tokenizer\n .token_to_id(eos.as_str())\n .expect(\"Should have found the eos token id\");\n special_tokens.push((eos.as_str(), eos_token_id));\n single.push(format!(\"{}:0\", eos.as_str()));\n pair.push(format!(\"{}:0\", eos.as_str()));\n }\n }\n\n if add_bos_token {\n if let Some(bos) = bos_token {\n pair.push(format!(\"{}:1\", bos.as_str()));\n }\n }\n\n pair.push(\"$B:1\".to_string());\n\n if add_eos_token {\n if let Some(eos) = eos_token {\n pair.push(format!(\"{}:1\", eos.as_str()));\n }\n }\n\n let post_processor = TemplateProcessing::builder()\n .try_single(single)?\n .try_pair(pair)?\n .special_tokens(special_tokens)\n .build()?;\n\n Ok(post_processor)\n}\n\n#[derive(Debug, Error)]\nenum RouterError {\n #[error(\"Argument validation error: {0}\")]\n ArgumentValidation(String),\n #[error(\"WebServer error: {0}\")]\n WebServer(#[from] server::WebServerError),\n #[error(\"Tokio runtime failed to start: {0}\")]\n Tokio(#[from] std::io::Error),\n}\n\n#[cfg(test)]\nmod tests {\n use super::*;\n use text_generation_router::TokenizerConfigToken;\n\n #[test]\n fn test_create_post_processor() {\n let tokenizer_config = HubTokenizerConfig {\n add_bos_token: None,\n add_eos_token: None,\n bos_token: Some(TokenizerConfigToken::String(\"<s>\".to_string())),\n eos_token: Some(TokenizerConfigToken::String(\"</s>\".to_string())),\n chat_template: None,\n tokenizer_class: None,\n completion_template: None,\n };\n\n let tokenizer =\n Tokenizer::from_pretrained(\"TinyLlama/TinyLlama-1.1B-Chat-v1.0\", None).unwrap();\n let post_processor = create_post_processor(&tokenizer, &tokenizer_config).unwrap();\n\n let expected = TemplateProcessing::builder()\n .try_single(\"<s>:0 $A:0\")\n .unwrap()\n .try_pair(\"<s>:0 $A:0 <s>:1 $B:1\")\n .unwrap()\n .special_tokens(vec![(\"<s>\".to_string(), 1)])\n .build()\n .unwrap();\n\n assert_eq!(post_processor, expected);\n }\n}\n", "server\\custom_kernels\\setup.py": "from setuptools import setup\nfrom torch.utils.cpp_extension import BuildExtension, CUDAExtension\n\nextra_compile_args = [\"-std=c++17\"]\n\nsetup(\n name=\"custom_kernels\",\n ext_modules=[\n CUDAExtension(\n name=\"custom_kernels.fused_bloom_attention_cuda\",\n sources=[\"custom_kernels/fused_bloom_attention_cuda.cu\"],\n extra_compile_args=extra_compile_args,\n ),\n CUDAExtension(\n name=\"custom_kernels.fused_attention_cuda\",\n sources=[\"custom_kernels/fused_attention_cuda.cu\"],\n extra_compile_args=extra_compile_args,\n ),\n ],\n cmdclass={\"build_ext\": BuildExtension},\n)\n", "server\\exllamav2_kernels\\setup.py": "from setuptools import setup\nfrom torch.utils.cpp_extension import BuildExtension, CUDAExtension\nimport torch\n\nextra_cuda_cflags = [\"-lineinfo\", \"-O3\"]\n\nif torch.version.hip:\n extra_cuda_cflags += [\"-DHIPBLAS_USE_HIP_HALF\"]\n\nextra_compile_args = {\n \"nvcc\": extra_cuda_cflags,\n}\n\nsetup(\n name=\"exllamav2_kernels\",\n ext_modules=[\n CUDAExtension(\n name=\"exllamav2_kernels\",\n sources=[\n \"exllamav2_kernels/ext.cpp\",\n \"exllamav2_kernels/cuda/q_matrix.cu\",\n \"exllamav2_kernels/cuda/q_gemm.cu\",\n ],\n extra_compile_args=extra_compile_args,\n )\n ],\n cmdclass={\"build_ext\": BuildExtension},\n)\n", "server\\exllama_kernels\\setup.py": "from setuptools import setup\nfrom torch.utils.cpp_extension import BuildExtension, CUDAExtension\n\nsetup(\n name=\"exllama_kernels\",\n ext_modules=[\n CUDAExtension(\n name=\"exllama_kernels\",\n sources=[\n \"exllama_kernels/exllama_ext.cpp\",\n \"exllama_kernels/cuda_buffers.cu\",\n \"exllama_kernels/cuda_func/column_remap.cu\",\n \"exllama_kernels/cuda_func/q4_matmul.cu\",\n \"exllama_kernels/cuda_func/q4_matrix.cu\",\n ],\n )\n ],\n cmdclass={\"build_ext\": BuildExtension},\n)\n"} | null |
text-generation-inference-nix | {"type": "directory", "name": "text-generation-inference-nix", "children": [{"type": "file", "name": "default.nix"}, {"type": "file", "name": "flake.lock"}, {"type": "file", "name": "flake.nix"}, {"type": "file", "name": "overlay.nix"}, {"type": "directory", "name": "pkgs", "children": [{"type": "directory", "name": "python-modules", "children": [{"type": "directory", "name": "awq-inference-engine", "children": [{"type": "file", "name": "default.nix"}]}, {"type": "directory", "name": "causal-conv1d", "children": [{"type": "file", "name": "default.nix"}]}, {"type": "directory", "name": "eetq", "children": [{"type": "file", "name": "default.nix"}]}, {"type": "directory", "name": "exllamav2", "children": [{"type": "file", "name": "default.nix"}]}, {"type": "directory", "name": "fbgemm-gpu", "children": [{"type": "file", "name": "default.nix"}]}, {"type": "directory", "name": "flash-attn", "children": [{"type": "file", "name": "default.nix"}]}, {"type": "directory", "name": "flash-attn-layer-norm", "children": [{"type": "file", "name": "default.nix"}]}, {"type": "directory", "name": "flash-attn-rotary", "children": [{"type": "file", "name": "default.nix"}]}, {"type": "directory", "name": "flash-attn-v1", "children": [{"type": "file", "name": "default.nix"}]}, {"type": "directory", "name": "flashinfer", "children": [{"type": "file", "name": "default.nix"}, {"type": "file", "name": "include-cstdint.diff"}]}, {"type": "directory", "name": "hf-transfer", "children": [{"type": "file", "name": "default.nix"}]}, {"type": "directory", "name": "mamba-ssm", "children": [{"type": "file", "name": "default.nix"}]}, {"type": "directory", "name": "marlin-kernels", "children": [{"type": "file", "name": "default.nix"}]}, {"type": "directory", "name": "moe-kernels", "children": [{"type": "file", "name": "default.nix"}]}, {"type": "directory", "name": "punica-kernels", "children": [{"type": "file", "name": "default.nix"}, {"type": "file", "name": "fix-asm-output-operand-modifiers.diff"}, {"type": "file", "name": "include-cstdint.diff"}]}, {"type": "directory", "name": "torch", "children": [{"type": "file", "name": "default.nix"}, {"type": "file", "name": "fix-cmake-cuda-toolkit.patch"}, {"type": "file", "name": "mkl-rpath.patch"}, {"type": "file", "name": "passthrough-python-lib-rel-path.patch"}, {"type": "file", "name": "prefetch.sh"}, {"type": "file", "name": "pthreadpool-disable-gcd.diff"}, {"type": "file", "name": "pytorch-pr-108847.patch"}]}, {"type": "directory", "name": "vllm", "children": [{"type": "file", "name": "0001-setup.py-don-t-ask-for-hipcc-version.patch"}, {"type": "file", "name": "0002-setup.py-nix-support-respect-cmakeFlags.patch"}, {"type": "file", "name": "default.nix"}]}]}]}, {"type": "file", "name": "README.md"}]} | ## Text Generation Inference Flake
This Nix flake packages dependencies of Text Generation Inference.
| {".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 1d42c4125ebafb87707118168995675cc5050b9d Hamza Amin <[email protected]> 1727369566 +0500\tclone: from https://github.com/huggingface/text-generation-inference-nix.git\n", ".git\\refs\\heads\\main": "1d42c4125ebafb87707118168995675cc5050b9d\n", "pkgs\\python-modules\\vllm\\0001-setup.py-don-t-ask-for-hipcc-version.patch": "From f6a7748bee79fc2e1898968fef844daacfa7860b Mon Sep 17 00:00:00 2001\nFrom: SomeoneSerge <[email protected]>\nDate: Wed, 31 Jul 2024 12:02:53 +0000\nSubject: [PATCH 1/2] setup.py: don't ask for hipcc --version\n\n---\n setup.py | 1 +\n 1 file changed, 1 insertion(+)\n\ndiff --git a/setup.py b/setup.py\nindex 72ef26f1..01e006f9 100644\n--- a/setup.py\n+++ b/setup.py\n@@ -279,6 +279,7 @@ def _install_punica() -> bool:\n \n \n def get_hipcc_rocm_version():\n+ return \"0.0\" # `hipcc --version` misbehaves (\"unresolved paths\") inside the nix sandbox\n # Run the hipcc --version command\n result = subprocess.run(['hipcc', '--version'],\n stdout=subprocess.PIPE,\n-- \n2.45.1\n\n", "pkgs\\python-modules\\vllm\\0002-setup.py-nix-support-respect-cmakeFlags.patch": "From 10b7e8330bdba319a4162cceb8e5dd4280215b04 Mon Sep 17 00:00:00 2001\nFrom: SomeoneSerge <[email protected]>\nDate: Wed, 31 Jul 2024 12:06:15 +0000\nSubject: [PATCH 2/2] setup.py: nix-support (respect cmakeFlags)\n\n---\n setup.py | 10 ++++++++++\n 1 file changed, 10 insertions(+)\n\ndiff --git a/setup.py b/setup.py\nindex 01e006f9..14762146 100644\n--- a/setup.py\n+++ b/setup.py\n@@ -15,6 +15,15 @@ from setuptools import Extension, find_packages, setup\n from setuptools.command.build_ext import build_ext\n from torch.utils.cpp_extension import CUDA_HOME\n \n+import os\n+import json\n+\n+if \"NIX_ATTRS_JSON_FILE\" in os.environ:\n+ with open(os.environ[\"NIX_ATTRS_JSON_FILE\"], \"r\") as f:\n+ NIX_ATTRS = json.load(f)\n+else:\n+ NIX_ATTRS = { \"cmakeFlags\": os.environ.get(\"cmakeFlags\", \"\").split() }\n+\n \n def load_module_from_path(module_name, path):\n spec = importlib.util.spec_from_file_location(module_name, path)\n@@ -159,6 +168,7 @@ class cmake_build_ext(build_ext):\n '-DCMAKE_LIBRARY_OUTPUT_DIRECTORY={}'.format(outdir),\n '-DCMAKE_ARCHIVE_OUTPUT_DIRECTORY={}'.format(self.build_temp),\n '-DVLLM_TARGET_DEVICE={}'.format(VLLM_TARGET_DEVICE),\n+ *NIX_ATTRS[\"cmakeFlags\"],\n ]\n \n verbose = envs.VERBOSE\n-- \n2.45.1\n\n"} | null |
that_is_good_data | {"type": "directory", "name": "that_is_good_data", "children": [{"type": "file", "name": "CONTRIBUTING.md"}, {"type": "file", "name": "dataset_issues.md"}, {"type": "file", "name": "LICENSE"}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "reported_issues", "children": [{"type": "file", "name": "DROP.csv"}, {"type": "file", "name": "ETHOS.csv"}, {"type": "file", "name": "MKQA.csv"}, {"type": "file", "name": "PAWS-X.csv"}, {"type": "file", "name": "XNLI.csv"}, {"type": "file", "name": "XSum.csv"}]}, {"type": "file", "name": "sample_issues.md"}]} | # That is good data
Did you ever have the frustrating experience of looking at the evaluation results of your NLP model, and realising that some of your model mistakes are in fact mistakes in the evaluation data?
You are not the only one.
In fact, you are likely not even the only one who observed that particular mistake in the data!
**Many people discover mistakes in commonly used evaluation datasets, but there is no real protocol to report and correct those mistakes** -- until now.
In this repository, we provide a venue to make sure that mistakes in evaluation datasets are recorded and eventually corrected (depending on the place of the data, of course) and -- importantly -- that they are visible to future researchers using datasets, in one place.
Go directly to the list of recorded [issues with individual sample](sample_issues.md) or the reported [entire dataset issues](dataset_issues.md).
## Table of contents
- [What kind of issues can I report?](https://github.com/huggingface/that_is_good_data#what-kind-of-issues-can-i-report)
- [How do I report issues?](https://github.com/huggingface/that_is_good_data#how-do-i-report-issues-with-evaluation-datasets)
- [Reporting issues with individual examples](https://github.com/huggingface/that_is_good_data#reporting-issues-with-individual-examples-in-evaluation-datasets)
- [Reporting entire dataset issues](https://github.com/huggingface/that_is_good_data#reporting-entire-dataset-issues)
- [Helping out](https://github.com/huggingface/that_is_good_data#helping-out)
## What kind of issues can I report?
At the moment, we keep track of two types of dataset issues:
- **Issues with individual examples** (e.g. the input sentence is ambiguous wrt the label, the input is incomprehensible, the label is incorrect or it is not clear why it should be preferred over another label). While we first start with collecting these examples, our eventual aim is to make sure they also get *corrected* or removed from the dataset in question.
- Known (and published) issues/problems that pertain to datasets as a whole (e.g. strong correlation between labels and lexical items, strong contamination in commonly used training corpora). Depending on what a dataset is used for, biases may not always be problematic, but it is nevertheless always good to be aware of them.
For the moment, we collect individual mistakes in a series of spreadsheets, that can be found on the [individual sample issues](sample_issues.md) page.
If a dataset is not listed on this page this implies no errors have been reported for it yet (in this repository).
Issues with entire datasets are recorded on the [entire dataset issues page](dataset_issues.md) in this repository.
If a dataset is not listed on this page, it means we have not received any input on biases in these datasets.
## How do I report issues with evaluation datasets?
For the time being, there are two options for contributing issues/mistakes/biases to this dataset:
- Create an issue on this repository
- Fill in [this form](https://forms.gle/CjhzTsRVQCVghHgC6)
Below, you can find what information you should provide, depending on what kind of issue your contribution reports.
### Reporting issues with individual examples in evaluation datasets
To report a mistake in a dataset, fill out [this form](https://forms.gle/CjhzTsRVQCVghHgC6), or create an issue on this repository with the following information:
- The dataset name
- A link to the source of the dataset, with a commit sha (or other kind of time stamp). If the dataset is available on [HuggingFace datasets](https://huggingface.co/datasets), provide the HuggingFace link.
- The index of the example that contains a mistake -- if the dataset is available on HuggingFace, you can directly link to the example (e.g. [https://huggingface.co/datasets/cais/mmlu/viewer/professional_psychology/validation?row=8])
- The example itself or the relevant parts of the example (if there is a lot of text), written out
- A description of the issue with the example
- For multilingual datasets: Which language(s) are affected
- Whether and how the issue could be fixed (optional)
- Whether you'd like to receive public credit for detecting the mistake in this repository
We will review reported issues on a rolling basis and incorporate them in the repository, crediting you if you wish.
If you found these issues by checking a larger batch, we welcome it if you also provide the number of examples you checked and/or the id's of the examples you *didn't* find any issues with.
If you'd like to report more than one mistake but (understandably) don't feel like filing multiple issues or filling out the form multiple times, please reach out to us at <[email protected]>.
You can, for instance, provide us a spreadsheet that contains the information above for all examples you'd like to report.
### Reporting entire dataset issues
Also biases or issues with entire datasets beyond individual examples can be submitted through github issues, or through the [form](https://forms.gle/CjhzTsRVQCVghHgC6) linked above.
Because we cannot confirm these biases ourselves, we require that there is peer-reviewed paper that exposes the bias.
If you'd like to report an issue with a dataset, please report:
- The dataset name
- A link to the source of the dataset, with a commit sha (or other kind of time stamp). If the dataset is available on [HuggingFace datasets](https://huggingface.co/datasets), provide the HuggingFace link.
- A short description of the issue
- A link to the publication that exposes the issue
- Whether and how the issue could be fixed (optional)
- Whether you'd like to receive public credit for detecting the mistake in this repository
## Helping out
Interested in helping out?
Apart from reporting issues with datasets, we are also looking for people that can help out with validating reported issues, especially for languages that we cannot judge ourselves!
For more information, check the [contributions file](CONTRIBUTING.md)
## Initiators of this initiative
This initiative was set up by [Dieuwke Hupkes](https://dieuwkehupkes.nl), [Xenia Ohmer](https://xeniaohmer.github.io/), [Thomas Wolf](https://thomwolf.io/) and [Adina Williams](https://scholar.google.com/citations?user=MUtbKt0AAAAJ&hl=en).
| {".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 b060267155b94194d386168d02ce1f0ce9d1ff25 Hamza Amin <[email protected]> 1727369632 +0500\tclone: from https://github.com/huggingface/that_is_good_data.git\n", ".git\\refs\\heads\\main": "b060267155b94194d386168d02ce1f0ce9d1ff25\n"} | null |
tokenizers | {"type": "directory", "name": "tokenizers", "children": [{"type": "directory", "name": "bindings", "children": [{"type": "directory", "name": "node", "children": [{"type": "directory", "name": ".cargo", "children": [{"type": "file", "name": "config.toml"}]}, {"type": "file", "name": ".editorconfig"}, {"type": "file", "name": ".eslintrc.yml"}, {"type": "file", "name": ".prettierignore"}, {"type": "file", "name": ".taplo.toml"}, {"type": "directory", "name": ".yarn", "children": [{"type": "directory", "name": "releases", "children": [{"type": "file", "name": "yarn-3.5.1.cjs"}]}]}, {"type": "file", "name": ".yarnrc.yml"}, {"type": "file", "name": "build.rs"}, {"type": "file", "name": "Cargo.toml"}, {"type": "directory", "name": "examples", "children": [{"type": "directory", "name": "documentation", "children": [{"type": "file", "name": "pipeline.test.ts"}, {"type": "file", "name": "quicktour.test.ts"}]}]}, {"type": "file", "name": "index.d.ts"}, {"type": "file", "name": "index.js"}, {"type": "file", "name": "jest.config.js"}, {"type": "directory", "name": "lib", "children": [{"type": "directory", "name": "bindings", "children": [{"type": "file", "name": "decoders.test.ts"}, {"type": "file", "name": "encoding.test.ts"}, {"type": "file", "name": "models.test.ts"}, {"type": "file", "name": "normalizers.test.ts"}, {"type": "file", "name": "post-processors.test.ts"}, {"type": "file", "name": "pre-tokenizers.test.ts"}, {"type": "file", "name": "tokenizer.test.ts"}, {"type": "file", "name": "utils.test.ts"}, {"type": "directory", "name": "__mocks__", "children": [{"type": "file", "name": "merges.txt"}, {"type": "file", "name": "vocab.json"}, {"type": "file", "name": "vocab.txt"}]}]}]}, {"type": "file", "name": "LICENSE"}, {"type": "file", "name": "Makefile"}, {"type": "directory", "name": "npm", "children": [{"type": "directory", "name": "android-arm-eabi", "children": [{"type": "file", "name": "package.json"}, {"type": "file", "name": "README.md"}]}, {"type": "directory", "name": "android-arm64", "children": [{"type": "file", "name": "package.json"}, {"type": "file", "name": "README.md"}]}, {"type": "directory", "name": "darwin-arm64", "children": [{"type": "file", "name": "package.json"}, {"type": "file", "name": "README.md"}]}, {"type": "directory", "name": "darwin-x64", "children": [{"type": "file", "name": "package.json"}, {"type": "file", "name": "README.md"}]}, {"type": "directory", "name": "freebsd-x64", "children": [{"type": "file", "name": "package.json"}, {"type": "file", "name": "README.md"}]}, {"type": "directory", "name": "linux-arm-gnueabihf", "children": [{"type": "file", "name": "package.json"}, {"type": "file", "name": "README.md"}]}, {"type": "directory", "name": "linux-arm64-gnu", "children": [{"type": "file", "name": "package.json"}, {"type": "file", "name": "README.md"}]}, {"type": "directory", "name": "linux-arm64-musl", "children": [{"type": "file", "name": "package.json"}, {"type": "file", "name": "README.md"}]}, {"type": "directory", "name": "linux-x64-gnu", "children": [{"type": "file", "name": "package.json"}, {"type": "file", "name": "README.md"}]}, {"type": "directory", "name": "linux-x64-musl", "children": [{"type": "file", "name": "package.json"}, {"type": "file", "name": "README.md"}]}, {"type": "directory", "name": "win32-arm64-msvc", "children": [{"type": "file", "name": "package.json"}, {"type": "file", "name": "README.md"}]}, {"type": "directory", "name": "win32-ia32-msvc", "children": [{"type": "file", "name": "package.json"}, {"type": "file", "name": "README.md"}]}, {"type": "directory", "name": "win32-x64-msvc", "children": [{"type": "file", "name": "package.json"}, {"type": "file", "name": "README.md"}]}]}, {"type": "file", "name": "package.json"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "rustfmt.toml"}, {"type": "directory", "name": "src", "children": [{"type": "file", "name": "arc_rwlock_serde.rs"}, {"type": "file", "name": "decoders.rs"}, {"type": "file", "name": "encoding.rs"}, {"type": "file", "name": "lib.rs"}, {"type": "file", "name": "models.rs"}, {"type": "file", "name": "normalizers.rs"}, {"type": "file", "name": "pre_tokenizers.rs"}, {"type": "file", "name": "processors.rs"}, {"type": "directory", "name": "tasks", "children": [{"type": "file", "name": "mod.rs"}, {"type": "file", "name": "models.rs"}, {"type": "file", "name": "tokenizer.rs"}]}, {"type": "file", "name": "tokenizer.rs"}, {"type": "file", "name": "trainers.rs"}, {"type": "file", "name": "utils.rs"}]}, {"type": "file", "name": "tsconfig.json"}, {"type": "file", "name": "types.ts"}, {"type": "file", "name": "yarn.lock"}]}, {"type": "directory", "name": "python", "children": [{"type": "directory", "name": ".cargo", "children": [{"type": "file", "name": "config.toml"}]}, {"type": "directory", "name": "benches", "children": [{"type": "file", "name": "test_tiktoken.py"}]}, {"type": "file", "name": "Cargo.toml"}, {"type": "file", "name": "CHANGELOG.md"}, {"type": "file", "name": "conftest.py"}, {"type": "directory", "name": "examples", "children": [{"type": "file", "name": "custom_components.py"}, {"type": "file", "name": "example.py"}, {"type": "file", "name": "train_bert_wordpiece.py"}, {"type": "file", "name": "train_bytelevel_bpe.py"}, {"type": "file", "name": "train_with_datasets.py"}, {"type": "file", "name": "using_the_visualizer.ipynb"}]}, {"type": "file", "name": "Makefile"}, {"type": "file", "name": "MANIFEST.in"}, {"type": "file", "name": "pyproject.toml"}, {"type": "directory", "name": "py_src", "children": [{"type": "directory", "name": "tokenizers", "children": [{"type": "directory", "name": "decoders", "children": [{"type": "file", "name": "__init__.py"}, {"type": "file", "name": "__init__.pyi"}]}, {"type": "directory", "name": "implementations", "children": [{"type": "file", "name": "base_tokenizer.py"}, {"type": "file", "name": "bert_wordpiece.py"}, {"type": "file", "name": "byte_level_bpe.py"}, {"type": "file", "name": "char_level_bpe.py"}, {"type": "file", "name": "sentencepiece_bpe.py"}, {"type": "file", "name": "sentencepiece_unigram.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "models", "children": [{"type": "file", "name": "__init__.py"}, {"type": "file", "name": "__init__.pyi"}]}, {"type": "directory", "name": "normalizers", "children": [{"type": "file", "name": "__init__.py"}, {"type": "file", "name": "__init__.pyi"}]}, {"type": "directory", "name": "pre_tokenizers", "children": [{"type": "file", "name": "__init__.py"}, {"type": "file", "name": "__init__.pyi"}]}, {"type": "directory", "name": "processors", "children": [{"type": "file", "name": "__init__.py"}, {"type": "file", "name": "__init__.pyi"}]}, {"type": "directory", "name": "tools", "children": [{"type": "file", "name": "visualizer-styles.css"}, {"type": "file", "name": "visualizer.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "trainers", "children": [{"type": "file", "name": "__init__.py"}, {"type": "file", "name": "__init__.pyi"}]}, {"type": "file", "name": "__init__.py"}, {"type": "file", "name": "__init__.pyi"}]}]}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "rust-toolchain"}, {"type": "directory", "name": "scripts", "children": [{"type": "file", "name": "convert.py"}, {"type": "file", "name": "sentencepiece_extractor.py"}, {"type": "file", "name": "spm_parity_check.py"}]}, {"type": "file", "name": "setup.cfg"}, {"type": "directory", "name": "src", "children": [{"type": "file", "name": "decoders.rs"}, {"type": "file", "name": "encoding.rs"}, {"type": "file", "name": "error.rs"}, {"type": "file", "name": "lib.rs"}, {"type": "file", "name": "models.rs"}, {"type": "file", "name": "normalizers.rs"}, {"type": "file", "name": "pre_tokenizers.rs"}, {"type": "file", "name": "processors.rs"}, {"type": "file", "name": "token.rs"}, {"type": "file", "name": "tokenizer.rs"}, {"type": "file", "name": "trainers.rs"}, {"type": "directory", "name": "utils", "children": [{"type": "file", "name": "iterators.rs"}, {"type": "file", "name": "mod.rs"}, {"type": "file", "name": "normalization.rs"}, {"type": "file", "name": "pretokenization.rs"}, {"type": "file", "name": "regex.rs"}, {"type": "file", "name": "serde_pyo3.rs"}]}]}, {"type": "file", "name": "stub.py"}, {"type": "file", "name": "test.txt"}, {"type": "directory", "name": "tests", "children": [{"type": "directory", "name": "bindings", "children": [{"type": "file", "name": "test_decoders.py"}, {"type": "file", "name": "test_encoding.py"}, {"type": "file", "name": "test_models.py"}, {"type": "file", "name": "test_normalizers.py"}, {"type": "file", "name": "test_pre_tokenizers.py"}, {"type": "file", "name": "test_processors.py"}, {"type": "file", "name": "test_tokenizer.py"}, {"type": "file", "name": "test_trainers.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "documentation", "children": [{"type": "file", "name": "test_pipeline.py"}, {"type": "file", "name": "test_quicktour.py"}, {"type": "file", "name": "test_tutorial_train_from_iterators.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "implementations", "children": [{"type": "file", "name": "test_base_tokenizer.py"}, {"type": "file", "name": "test_bert_wordpiece.py"}, {"type": "file", "name": "test_byte_level_bpe.py"}, {"type": "file", "name": "test_char_bpe.py"}, {"type": "file", "name": "test_sentencepiece.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "test_serialization.py"}, {"type": "file", "name": "utils.py"}, {"type": "file", "name": "__init__.py"}]}]}]}, {"type": "file", "name": "CITATION.cff"}, {"type": "directory", "name": "docs", "children": [{"type": "file", "name": "Makefile"}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "source", "children": [{"type": "directory", "name": "api", "children": [{"type": "file", "name": "node.inc"}, {"type": "file", "name": "python.inc"}, {"type": "file", "name": "reference.rst"}, {"type": "file", "name": "rust.inc"}]}, {"type": "file", "name": "components.rst"}, {"type": "file", "name": "conf.py"}, {"type": "file", "name": "entities.inc"}, {"type": "file", "name": "index.rst"}, {"type": "directory", "name": "installation", "children": [{"type": "file", "name": "main.rst"}, {"type": "file", "name": "node.inc"}, {"type": "file", "name": "python.inc"}, {"type": "file", "name": "rust.inc"}]}, {"type": "file", "name": "pipeline.rst"}, {"type": "file", "name": "quicktour.rst"}, {"type": "directory", "name": "tutorials", "children": [{"type": "directory", "name": "python", "children": [{"type": "file", "name": "training_from_memory.rst"}]}]}, {"type": "directory", "name": "_ext", "children": [{"type": "file", "name": "entities.py"}, {"type": "file", "name": "rust_doc.py"}, {"type": "file", "name": "toctree_tags.py"}]}, {"type": "directory", "name": "_static", "children": [{"type": "directory", "name": "css", "children": [{"type": "file", "name": "code-snippets.css"}, {"type": "file", "name": "huggingface.css"}]}, {"type": "directory", "name": "js", "children": [{"type": "file", "name": "custom.js"}]}]}]}, {"type": "directory", "name": "source-doc-builder", "children": [{"type": "directory", "name": "api", "children": [{"type": "file", "name": "added-tokens.mdx"}, {"type": "file", "name": "decoders.mdx"}, {"type": "file", "name": "encode-inputs.mdx"}, {"type": "file", "name": "encoding.mdx"}, {"type": "file", "name": "input-sequences.mdx"}, {"type": "file", "name": "models.mdx"}, {"type": "file", "name": "normalizers.mdx"}, {"type": "file", "name": "post-processors.mdx"}, {"type": "file", "name": "pre-tokenizers.mdx"}, {"type": "file", "name": "tokenizer.mdx"}, {"type": "file", "name": "trainers.mdx"}, {"type": "file", "name": "visualizer.mdx"}]}, {"type": "file", "name": "components.mdx"}, {"type": "file", "name": "index.mdx"}, {"type": "file", "name": "installation.mdx"}, {"type": "file", "name": "pipeline.mdx"}, {"type": "file", "name": "quicktour.mdx"}, {"type": "file", "name": "training_from_memory.mdx"}, {"type": "file", "name": "_toctree.yml"}]}]}, {"type": "file", "name": "LICENSE"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "RELEASE.md"}, {"type": "directory", "name": "tokenizers", "children": [{"type": "directory", "name": "benches", "children": [{"type": "file", "name": "bert_benchmark.rs"}, {"type": "file", "name": "bpe_benchmark.rs"}, {"type": "directory", "name": "common", "children": [{"type": "file", "name": "mod.rs"}]}, {"type": "file", "name": "layout_benchmark.rs"}, {"type": "file", "name": "llama3.rs"}, {"type": "file", "name": "unigram_benchmark.rs"}]}, {"type": "file", "name": "Cargo.toml"}, {"type": "file", "name": "CHANGELOG.md"}, {"type": "directory", "name": "examples", "children": [{"type": "file", "name": "encode_batch.rs"}, {"type": "file", "name": "serialization.rs"}, {"type": "directory", "name": "unstable_wasm", "children": [{"type": "file", "name": "Cargo.toml"}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "src", "children": [{"type": "file", "name": "lib.rs"}, {"type": "file", "name": "utils.rs"}]}, {"type": "directory", "name": "tests", "children": [{"type": "file", "name": "web.rs"}]}, {"type": "directory", "name": "www", "children": [{"type": "directory", "name": ".bin", "children": [{"type": "file", "name": "create-wasm-app.js"}]}, {"type": "file", "name": ".travis.yml"}, {"type": "file", "name": "bootstrap.js"}, {"type": "file", "name": "index.html"}, {"type": "file", "name": "index.js"}, {"type": "file", "name": "LICENSE-APACHE"}, {"type": "file", "name": "LICENSE-MIT"}, {"type": "file", "name": "package-lock.json"}, {"type": "file", "name": "package.json"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "webpack.config.js"}]}]}]}, {"type": "file", "name": "LICENSE"}, {"type": "file", "name": "Makefile"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "README.tpl"}, {"type": "file", "name": "rust-toolchain"}, {"type": "directory", "name": "src", "children": [{"type": "directory", "name": "decoders", "children": [{"type": "file", "name": "bpe.rs"}, {"type": "file", "name": "byte_fallback.rs"}, {"type": "file", "name": "ctc.rs"}, {"type": "file", "name": "fuse.rs"}, {"type": "file", "name": "mod.rs"}, {"type": "file", "name": "sequence.rs"}, {"type": "file", "name": "strip.rs"}, {"type": "file", "name": "wordpiece.rs"}]}, {"type": "file", "name": "lib.rs"}, {"type": "directory", "name": "models", "children": [{"type": "directory", "name": "bpe", "children": [{"type": "file", "name": "mod.rs"}, {"type": "file", "name": "model.rs"}, {"type": "file", "name": "serialization.rs"}, {"type": "file", "name": "trainer.rs"}, {"type": "file", "name": "word.rs"}]}, {"type": "file", "name": "mod.rs"}, {"type": "directory", "name": "unigram", "children": [{"type": "file", "name": "lattice.rs"}, {"type": "file", "name": "mod.rs"}, {"type": "file", "name": "model.rs"}, {"type": "file", "name": "serialization.rs"}, {"type": "file", "name": "trainer.rs"}, {"type": "file", "name": "trie.rs"}]}, {"type": "directory", "name": "wordlevel", "children": [{"type": "file", "name": "mod.rs"}, {"type": "file", "name": "serialization.rs"}, {"type": "file", "name": "trainer.rs"}]}, {"type": "directory", "name": "wordpiece", "children": [{"type": "file", "name": "mod.rs"}, {"type": "file", "name": "serialization.rs"}, {"type": "file", "name": "trainer.rs"}]}]}, {"type": "directory", "name": "normalizers", "children": [{"type": "file", "name": "bert.rs"}, {"type": "file", "name": "byte_level.rs"}, {"type": "file", "name": "mod.rs"}, {"type": "file", "name": "precompiled.rs"}, {"type": "file", "name": "prepend.rs"}, {"type": "file", "name": "replace.rs"}, {"type": "file", "name": "strip.rs"}, {"type": "file", "name": "unicode.rs"}, {"type": "file", "name": "utils.rs"}]}, {"type": "directory", "name": "pre_tokenizers", "children": [{"type": "file", "name": "bert.rs"}, {"type": "file", "name": "byte_level.rs"}, {"type": "file", "name": "delimiter.rs"}, {"type": "file", "name": "digits.rs"}, {"type": "file", "name": "metaspace.rs"}, {"type": "file", "name": "mod.rs"}, {"type": "file", "name": "punctuation.rs"}, {"type": "file", "name": "sequence.rs"}, {"type": "file", "name": "split.rs"}, {"type": "directory", "name": "unicode_scripts", "children": [{"type": "file", "name": "mod.rs"}, {"type": "file", "name": "pre_tokenizer.rs"}, {"type": "file", "name": "scripts.rs"}]}, {"type": "file", "name": "whitespace.rs"}]}, {"type": "directory", "name": "processors", "children": [{"type": "file", "name": "bert.rs"}, {"type": "file", "name": "mod.rs"}, {"type": "file", "name": "roberta.rs"}, {"type": "file", "name": "sequence.rs"}, {"type": "file", "name": "template.rs"}]}, {"type": "directory", "name": "tokenizer", "children": [{"type": "file", "name": "added_vocabulary.rs"}, {"type": "file", "name": "encoding.rs"}, {"type": "file", "name": "mod.rs"}, {"type": "file", "name": "normalizer.rs"}, {"type": "file", "name": "pattern.rs"}, {"type": "file", "name": "pre_tokenizer.rs"}, {"type": "file", "name": "serialization.rs"}]}, {"type": "directory", "name": "utils", "children": [{"type": "file", "name": "cache.rs"}, {"type": "file", "name": "fancy.rs"}, {"type": "file", "name": "from_pretrained.rs"}, {"type": "file", "name": "iter.rs"}, {"type": "file", "name": "mod.rs"}, {"type": "file", "name": "onig.rs"}, {"type": "file", "name": "padding.rs"}, {"type": "file", "name": "parallelism.rs"}, {"type": "file", "name": "progress.rs"}, {"type": "file", "name": "truncation.rs"}]}]}, {"type": "directory", "name": "tests", "children": [{"type": "file", "name": "added_tokens.rs"}, {"type": "directory", "name": "common", "children": [{"type": "file", "name": "mod.rs"}]}, {"type": "file", "name": "documentation.rs"}, {"type": "file", "name": "from_pretrained.rs"}, {"type": "file", "name": "offsets.rs"}, {"type": "file", "name": "serialization.rs"}, {"type": "file", "name": "training.rs"}, {"type": "file", "name": "unigram.rs"}]}]}]} | <div align="center">
<h1><code>create-wasm-app</code></h1>
<strong>An <code>npm init</code> template for kick starting a project that uses NPM packages containing Rust-generated WebAssembly and bundles them with Webpack.</strong>
<p>
<a href="https://travis-ci.org/rustwasm/create-wasm-app"><img src="https://img.shields.io/travis/rustwasm/create-wasm-app.svg?style=flat-square" alt="Build Status" /></a>
</p>
<h3>
<a href="#usage">Usage</a>
<span> | </span>
<a href="https://discordapp.com/channels/442252698964721669/443151097398296587">Chat</a>
</h3>
<sub>Built with 🦀🕸 by <a href="https://rustwasm.github.io/">The Rust and WebAssembly Working Group</a></sub>
</div>
## About
This template is designed for depending on NPM packages that contain
Rust-generated WebAssembly and using them to create a Website.
* Want to create an NPM package with Rust and WebAssembly? [Check out
`wasm-pack-template`.](https://github.com/rustwasm/wasm-pack-template)
* Want to make a monorepo-style Website without publishing to NPM? Check out
[`rust-webpack-template`](https://github.com/rustwasm/rust-webpack-template)
and/or
[`rust-parcel-template`](https://github.com/rustwasm/rust-parcel-template).
## 🚴 Usage
```
npm init wasm-app
```
## 🔋 Batteries Included
- `.gitignore`: ignores `node_modules`
- `LICENSE-APACHE` and `LICENSE-MIT`: most Rust projects are licensed this way, so these are included for you
- `README.md`: the file you are reading now!
- `index.html`: a bare bones html document that includes the webpack bundle
- `index.js`: example js file with a comment showing how to import and use a wasm pkg
- `package.json` and `package-lock.json`:
- pulls in devDependencies for using webpack:
- [`webpack`](https://www.npmjs.com/package/webpack)
- [`webpack-cli`](https://www.npmjs.com/package/webpack-cli)
- [`webpack-dev-server`](https://www.npmjs.com/package/webpack-dev-server)
- defines a `start` script to run `webpack-dev-server`
- `webpack.config.js`: configuration file for bundling your js with webpack
## License
Licensed under either of
* Apache License, Version 2.0, ([LICENSE-APACHE](LICENSE-APACHE) or http://www.apache.org/licenses/LICENSE-2.0)
* MIT license ([LICENSE-MIT](LICENSE-MIT) or http://opensource.org/licenses/MIT)
at your option.
### Contribution
Unless you explicitly state otherwise, any contribution intentionally
submitted for inclusion in the work by you, as defined in the Apache-2.0
license, shall be dual licensed as above, without any additional terms or
conditions.
| {".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 14a07b06e4a8bd8f80d884419ae4630f5a3d8098 Hamza Amin <[email protected]> 1727369642 +0500\tclone: from https://github.com/huggingface/tokenizers.git\n", ".git\\refs\\heads\\main": "14a07b06e4a8bd8f80d884419ae4630f5a3d8098\n", "bindings\\node\\index.d.ts": "/* tslint:disable */\n/* eslint-disable */\n\n/* auto-generated by NAPI-RS */\n\nexport function bpeDecoder(suffix?: string | undefined | null): Decoder\nexport function byteFallbackDecoder(): Decoder\nexport function ctcDecoder(\n padToken?: string = '<pad>',\n wordDelimiterToken?: string | undefined | null,\n cleanup?: boolean | undefined | null,\n): Decoder\nexport function fuseDecoder(): Decoder\nexport function metaspaceDecoder(\n replacement?: string = '\u2581',\n prependScheme?: prepend_scheme = 'always',\n split?: split = true,\n): Decoder\nexport function replaceDecoder(pattern: string, content: string): Decoder\nexport function sequenceDecoder(decoders: Array<Decoder>): Decoder\nexport function stripDecoder(content: string, left: number, right: number): Decoder\nexport function wordPieceDecoder(prefix?: string = '##', cleanup?: bool = true): Decoder\nexport const enum TruncationDirection {\n Left = 'Left',\n Right = 'Right',\n}\nexport const enum TruncationStrategy {\n LongestFirst = 'LongestFirst',\n OnlyFirst = 'OnlyFirst',\n OnlySecond = 'OnlySecond',\n}\nexport interface BpeOptions {\n cacheCapacity?: number\n dropout?: number\n unkToken?: string\n continuingSubwordPrefix?: string\n endOfWordSuffix?: string\n fuseUnk?: boolean\n byteFallback?: boolean\n}\nexport interface WordPieceOptions {\n unkToken?: string\n continuingSubwordPrefix?: string\n maxInputCharsPerWord?: number\n}\nexport interface WordLevelOptions {\n unkToken?: string\n}\nexport interface UnigramOptions {\n unkId?: number\n byteFallback?: boolean\n}\nexport function prependNormalizer(prepend: string): Normalizer\nexport function stripAccentsNormalizer(): Normalizer\nexport interface BertNormalizerOptions {\n cleanText?: boolean\n handleChineseChars?: boolean\n stripAccents?: boolean\n lowercase?: boolean\n}\n/**\n * bert_normalizer(options?: {\n * cleanText?: bool = true,\n * handleChineseChars?: bool = true,\n * stripAccents?: bool = true,\n * lowercase?: bool = true\n * })\n */\nexport function bertNormalizer(options?: BertNormalizerOptions | undefined | null): Normalizer\nexport function nfdNormalizer(): Normalizer\nexport function nfkdNormalizer(): Normalizer\nexport function nfcNormalizer(): Normalizer\nexport function nfkcNormalizer(): Normalizer\nexport function stripNormalizer(left?: boolean | undefined | null, right?: boolean | undefined | null): Normalizer\nexport function sequenceNormalizer(normalizers: Array<Normalizer>): Normalizer\nexport function lowercase(): Normalizer\nexport function replace(pattern: string, content: string): Normalizer\nexport function nmt(): Normalizer\nexport function precompiled(bytes: Array<number>): Normalizer\nexport const enum JsSplitDelimiterBehavior {\n Removed = 'Removed',\n Isolated = 'Isolated',\n MergedWithPrevious = 'MergedWithPrevious',\n MergedWithNext = 'MergedWithNext',\n Contiguous = 'Contiguous',\n}\n/** byte_level(addPrefixSpace: bool = true, useRegex: bool = true) */\nexport function byteLevelPreTokenizer(\n addPrefixSpace?: boolean | undefined | null,\n useRegex?: boolean | undefined | null,\n): PreTokenizer\nexport function byteLevelAlphabet(): Array<string>\nexport function whitespacePreTokenizer(): PreTokenizer\nexport function whitespaceSplitPreTokenizer(): PreTokenizer\nexport function bertPreTokenizer(): PreTokenizer\nexport function metaspacePreTokenizer(\n replacement?: string = '\u2581',\n prependScheme?: prepend_scheme = 'always',\n split?: split = true,\n): PreTokenizer\nexport function splitPreTokenizer(pattern: string, behavior: string, invert?: boolean | undefined | null): PreTokenizer\nexport function punctuationPreTokenizer(behavior?: string | undefined | null): PreTokenizer\nexport function sequencePreTokenizer(preTokenizers: Array<PreTokenizer>): PreTokenizer\nexport function charDelimiterSplit(delimiter: string): PreTokenizer\nexport function digitsPreTokenizer(individualDigits?: boolean | undefined | null): PreTokenizer\nexport function bertProcessing(sep: [string, number], cls: [string, number]): Processor\nexport function robertaProcessing(\n sep: [string, number],\n cls: [string, number],\n trimOffsets?: boolean | undefined | null,\n addPrefixSpace?: boolean | undefined | null,\n): Processor\nexport function byteLevelProcessing(trimOffsets?: boolean | undefined | null): Processor\nexport function templateProcessing(\n single: string,\n pair?: string | undefined | null,\n specialTokens?: Array<[string, number]> | undefined | null,\n): Processor\nexport function sequenceProcessing(processors: Array<Processor>): Processor\nexport const enum PaddingDirection {\n Left = 0,\n Right = 1,\n}\nexport interface PaddingOptions {\n maxLength?: number\n direction?: string | PaddingDirection\n padToMultipleOf?: number\n padId?: number\n padTypeId?: number\n padToken?: string\n}\nexport interface EncodeOptions {\n isPretokenized?: boolean\n addSpecialTokens?: boolean\n}\nexport interface TruncationOptions {\n maxLength?: number\n strategy?: TruncationStrategy\n direction?: string | TruncationDirection\n stride?: number\n}\nexport interface AddedTokenOptions {\n singleWord?: boolean\n leftStrip?: boolean\n rightStrip?: boolean\n normalized?: boolean\n}\nexport interface JsFromPretrainedParameters {\n revision?: string\n authToken?: string\n}\nexport function slice(s: string, beginIndex?: number | undefined | null, endIndex?: number | undefined | null): string\nexport function mergeEncodings(encodings: Array<Encoding>, growingOffsets?: boolean | undefined | null): Encoding\n/** Decoder */\nexport class Decoder {\n decode(tokens: Array<string>): string\n}\nexport type JsEncoding = Encoding\nexport class Encoding {\n constructor()\n getLength(): number\n getNSequences(): number\n getIds(): Array<number>\n getTypeIds(): Array<number>\n getAttentionMask(): Array<number>\n getSpecialTokensMask(): Array<number>\n getTokens(): Array<string>\n getOffsets(): Array<Array<number>>\n getWordIds(): Array<number | undefined | null>\n charToToken(pos: number, seqId?: number | undefined | null): number | null\n charToWord(pos: number, seqId?: number | undefined | null): number | null\n pad(length: number, options?: PaddingOptions | undefined | null): void\n truncate(\n length: number,\n stride?: number | undefined | null,\n direction?: string | TruncationDirection | undefined | null,\n ): void\n wordToTokens(word: number, seqId?: number | undefined | null): [number, number] | null | undefined\n wordToChars(word: number, seqId?: number | undefined | null): [number, number] | null | undefined\n tokenToChars(token: number): [number, [number, number]] | null | undefined\n tokenToWord(token: number): number | null\n getOverflowing(): Array<Encoding>\n getSequenceIds(): Array<number | undefined | null>\n tokenToSequence(token: number): number | null\n}\nexport class Model {}\nexport type Bpe = BPE\nexport class BPE {\n static empty(): Model\n static init(vocab: Vocab, merges: Merges, options?: BpeOptions | undefined | null): Model\n static fromFile(vocab: string, merges: string, options?: BpeOptions | undefined | null): Promise<Model>\n}\nexport class WordPiece {\n static init(vocab: Vocab, options?: WordPieceOptions | undefined | null): Model\n static empty(): WordPiece\n static fromFile(vocab: string, options?: WordPieceOptions | undefined | null): Promise<Model>\n}\nexport class WordLevel {\n static init(vocab: Vocab, options?: WordLevelOptions | undefined | null): Model\n static empty(): WordLevel\n static fromFile(vocab: string, options?: WordLevelOptions | undefined | null): Promise<Model>\n}\nexport class Unigram {\n static init(vocab: Array<[string, number]>, options?: UnigramOptions | undefined | null): Model\n static empty(): Model\n}\n/** Normalizer */\nexport class Normalizer {\n normalizeString(sequence: string): string\n}\n/** PreTokenizers */\nexport class PreTokenizer {\n preTokenizeString(sequence: string): [string, [number, number]][]\n}\nexport class Processor {}\nexport class AddedToken {\n constructor(token: string, isSpecial: boolean, options?: AddedTokenOptions | undefined | null)\n getContent(): string\n}\nexport class Tokenizer {\n constructor(model: Model)\n setPreTokenizer(preTokenizer: PreTokenizer): void\n setDecoder(decoder: Decoder): void\n setModel(model: Model): void\n setPostProcessor(postProcessor: Processor): void\n setNormalizer(normalizer: Normalizer): void\n save(path: string, pretty?: boolean | undefined | null): void\n addAddedTokens(tokens: Array<AddedToken>): number\n addTokens(tokens: Array<string>): number\n encode(\n sentence: InputSequence,\n pair?: InputSequence | null,\n encodeOptions?: EncodeOptions | undefined | null,\n ): Promise<JsEncoding>\n encodeBatch(sentences: EncodeInput[], encodeOptions?: EncodeOptions | undefined | null): Promise<JsEncoding[]>\n decode(ids: Array<number>, skipSpecialTokens: boolean): Promise<string>\n decodeBatch(ids: Array<Array<number>>, skipSpecialTokens: boolean): Promise<string[]>\n static fromString(s: string): Tokenizer\n static fromFile(file: string): Tokenizer\n addSpecialTokens(tokens: Array<string>): void\n setTruncation(maxLength: number, options?: TruncationOptions | undefined | null): void\n disableTruncation(): void\n setPadding(options?: PaddingOptions | undefined | null): void\n disablePadding(): void\n getDecoder(): Decoder | null\n getNormalizer(): Normalizer | null\n getPreTokenizer(): PreTokenizer | null\n getPostProcessor(): Processor | null\n getVocab(withAddedTokens?: boolean | undefined | null): Record<string, number>\n getVocabSize(withAddedTokens?: boolean | undefined | null): number\n idToToken(id: number): string | null\n tokenToId(token: string): number | null\n train(files: Array<string>): void\n runningTasks(): number\n postProcess(\n encoding: Encoding,\n pair?: Encoding | undefined | null,\n addSpecialTokens?: boolean | undefined | null,\n ): Encoding\n}\nexport class Trainer {}\n", "bindings\\node\\index.js": "/* tslint:disable */\n/* eslint-disable */\n/* prettier-ignore */\n\n/* auto-generated by NAPI-RS */\n\nconst { existsSync, readFileSync } = require('fs')\nconst { join } = require('path')\n\nconst { platform, arch } = process\n\nlet nativeBinding = null\nlet localFileExisted = false\nlet loadError = null\n\nfunction isMusl() {\n // For Node 10\n if (!process.report || typeof process.report.getReport !== 'function') {\n try {\n const lddPath = require('child_process').execSync('which ldd').toString().trim()\n return readFileSync(lddPath, 'utf8').includes('musl')\n } catch (e) {\n return true\n }\n } else {\n const { glibcVersionRuntime } = process.report.getReport().header\n return !glibcVersionRuntime\n }\n}\n\nswitch (platform) {\n case 'android':\n switch (arch) {\n case 'arm64':\n localFileExisted = existsSync(join(__dirname, 'tokenizers.android-arm64.node'))\n try {\n if (localFileExisted) {\n nativeBinding = require('./tokenizers.android-arm64.node')\n } else {\n nativeBinding = require('tokenizers-android-arm64')\n }\n } catch (e) {\n loadError = e\n }\n break\n case 'arm':\n localFileExisted = existsSync(join(__dirname, 'tokenizers.android-arm-eabi.node'))\n try {\n if (localFileExisted) {\n nativeBinding = require('./tokenizers.android-arm-eabi.node')\n } else {\n nativeBinding = require('tokenizers-android-arm-eabi')\n }\n } catch (e) {\n loadError = e\n }\n break\n default:\n throw new Error(`Unsupported architecture on Android ${arch}`)\n }\n break\n case 'win32':\n switch (arch) {\n case 'x64':\n localFileExisted = existsSync(join(__dirname, 'tokenizers.win32-x64-msvc.node'))\n try {\n if (localFileExisted) {\n nativeBinding = require('./tokenizers.win32-x64-msvc.node')\n } else {\n nativeBinding = require('tokenizers-win32-x64-msvc')\n }\n } catch (e) {\n loadError = e\n }\n break\n case 'ia32':\n localFileExisted = existsSync(join(__dirname, 'tokenizers.win32-ia32-msvc.node'))\n try {\n if (localFileExisted) {\n nativeBinding = require('./tokenizers.win32-ia32-msvc.node')\n } else {\n nativeBinding = require('tokenizers-win32-ia32-msvc')\n }\n } catch (e) {\n loadError = e\n }\n break\n case 'arm64':\n localFileExisted = existsSync(join(__dirname, 'tokenizers.win32-arm64-msvc.node'))\n try {\n if (localFileExisted) {\n nativeBinding = require('./tokenizers.win32-arm64-msvc.node')\n } else {\n nativeBinding = require('tokenizers-win32-arm64-msvc')\n }\n } catch (e) {\n loadError = e\n }\n break\n default:\n throw new Error(`Unsupported architecture on Windows: ${arch}`)\n }\n break\n case 'darwin':\n localFileExisted = existsSync(join(__dirname, 'tokenizers.darwin-universal.node'))\n try {\n if (localFileExisted) {\n nativeBinding = require('./tokenizers.darwin-universal.node')\n } else {\n nativeBinding = require('tokenizers-darwin-universal')\n }\n break\n } catch {}\n switch (arch) {\n case 'x64':\n localFileExisted = existsSync(join(__dirname, 'tokenizers.darwin-x64.node'))\n try {\n if (localFileExisted) {\n nativeBinding = require('./tokenizers.darwin-x64.node')\n } else {\n nativeBinding = require('tokenizers-darwin-x64')\n }\n } catch (e) {\n loadError = e\n }\n break\n case 'arm64':\n localFileExisted = existsSync(join(__dirname, 'tokenizers.darwin-arm64.node'))\n try {\n if (localFileExisted) {\n nativeBinding = require('./tokenizers.darwin-arm64.node')\n } else {\n nativeBinding = require('tokenizers-darwin-arm64')\n }\n } catch (e) {\n loadError = e\n }\n break\n default:\n throw new Error(`Unsupported architecture on macOS: ${arch}`)\n }\n break\n case 'freebsd':\n if (arch !== 'x64') {\n throw new Error(`Unsupported architecture on FreeBSD: ${arch}`)\n }\n localFileExisted = existsSync(join(__dirname, 'tokenizers.freebsd-x64.node'))\n try {\n if (localFileExisted) {\n nativeBinding = require('./tokenizers.freebsd-x64.node')\n } else {\n nativeBinding = require('tokenizers-freebsd-x64')\n }\n } catch (e) {\n loadError = e\n }\n break\n case 'linux':\n switch (arch) {\n case 'x64':\n if (isMusl()) {\n localFileExisted = existsSync(join(__dirname, 'tokenizers.linux-x64-musl.node'))\n try {\n if (localFileExisted) {\n nativeBinding = require('./tokenizers.linux-x64-musl.node')\n } else {\n nativeBinding = require('tokenizers-linux-x64-musl')\n }\n } catch (e) {\n loadError = e\n }\n } else {\n localFileExisted = existsSync(join(__dirname, 'tokenizers.linux-x64-gnu.node'))\n try {\n if (localFileExisted) {\n nativeBinding = require('./tokenizers.linux-x64-gnu.node')\n } else {\n nativeBinding = require('tokenizers-linux-x64-gnu')\n }\n } catch (e) {\n loadError = e\n }\n }\n break\n case 'arm64':\n if (isMusl()) {\n localFileExisted = existsSync(join(__dirname, 'tokenizers.linux-arm64-musl.node'))\n try {\n if (localFileExisted) {\n nativeBinding = require('./tokenizers.linux-arm64-musl.node')\n } else {\n nativeBinding = require('tokenizers-linux-arm64-musl')\n }\n } catch (e) {\n loadError = e\n }\n } else {\n localFileExisted = existsSync(join(__dirname, 'tokenizers.linux-arm64-gnu.node'))\n try {\n if (localFileExisted) {\n nativeBinding = require('./tokenizers.linux-arm64-gnu.node')\n } else {\n nativeBinding = require('tokenizers-linux-arm64-gnu')\n }\n } catch (e) {\n loadError = e\n }\n }\n break\n case 'arm':\n localFileExisted = existsSync(join(__dirname, 'tokenizers.linux-arm-gnueabihf.node'))\n try {\n if (localFileExisted) {\n nativeBinding = require('./tokenizers.linux-arm-gnueabihf.node')\n } else {\n nativeBinding = require('tokenizers-linux-arm-gnueabihf')\n }\n } catch (e) {\n loadError = e\n }\n break\n case 'riscv64':\n if (isMusl()) {\n localFileExisted = existsSync(join(__dirname, 'tokenizers.linux-riscv64-musl.node'))\n try {\n if (localFileExisted) {\n nativeBinding = require('./tokenizers.linux-riscv64-musl.node')\n } else {\n nativeBinding = require('tokenizers-linux-riscv64-musl')\n }\n } catch (e) {\n loadError = e\n }\n } else {\n localFileExisted = existsSync(join(__dirname, 'tokenizers.linux-riscv64-gnu.node'))\n try {\n if (localFileExisted) {\n nativeBinding = require('./tokenizers.linux-riscv64-gnu.node')\n } else {\n nativeBinding = require('tokenizers-linux-riscv64-gnu')\n }\n } catch (e) {\n loadError = e\n }\n }\n break\n case 's390x':\n localFileExisted = existsSync(join(__dirname, 'tokenizers.linux-s390x-gnu.node'))\n try {\n if (localFileExisted) {\n nativeBinding = require('./tokenizers.linux-s390x-gnu.node')\n } else {\n nativeBinding = require('tokenizers-linux-s390x-gnu')\n }\n } catch (e) {\n loadError = e\n }\n break\n default:\n throw new Error(`Unsupported architecture on Linux: ${arch}`)\n }\n break\n default:\n throw new Error(`Unsupported OS: ${platform}, architecture: ${arch}`)\n}\n\nif (!nativeBinding) {\n if (loadError) {\n throw loadError\n }\n throw new Error(`Failed to load native binding`)\n}\n\nconst {\n Decoder,\n bpeDecoder,\n byteFallbackDecoder,\n ctcDecoder,\n fuseDecoder,\n metaspaceDecoder,\n replaceDecoder,\n sequenceDecoder,\n stripDecoder,\n wordPieceDecoder,\n Encoding,\n TruncationDirection,\n TruncationStrategy,\n Model,\n BPE,\n WordPiece,\n WordLevel,\n Unigram,\n Normalizer,\n prependNormalizer,\n stripAccentsNormalizer,\n bertNormalizer,\n nfdNormalizer,\n nfkdNormalizer,\n nfcNormalizer,\n nfkcNormalizer,\n stripNormalizer,\n sequenceNormalizer,\n lowercase,\n replace,\n nmt,\n precompiled,\n JsSplitDelimiterBehavior,\n PreTokenizer,\n byteLevelPreTokenizer,\n byteLevelAlphabet,\n whitespacePreTokenizer,\n whitespaceSplitPreTokenizer,\n bertPreTokenizer,\n metaspacePreTokenizer,\n splitPreTokenizer,\n punctuationPreTokenizer,\n sequencePreTokenizer,\n charDelimiterSplit,\n digitsPreTokenizer,\n Processor,\n bertProcessing,\n robertaProcessing,\n byteLevelProcessing,\n templateProcessing,\n sequenceProcessing,\n PaddingDirection,\n AddedToken,\n Tokenizer,\n Trainer,\n slice,\n mergeEncodings,\n} = nativeBinding\n\nmodule.exports.Decoder = Decoder\nmodule.exports.bpeDecoder = bpeDecoder\nmodule.exports.byteFallbackDecoder = byteFallbackDecoder\nmodule.exports.ctcDecoder = ctcDecoder\nmodule.exports.fuseDecoder = fuseDecoder\nmodule.exports.metaspaceDecoder = metaspaceDecoder\nmodule.exports.replaceDecoder = replaceDecoder\nmodule.exports.sequenceDecoder = sequenceDecoder\nmodule.exports.stripDecoder = stripDecoder\nmodule.exports.wordPieceDecoder = wordPieceDecoder\nmodule.exports.Encoding = Encoding\nmodule.exports.TruncationDirection = TruncationDirection\nmodule.exports.TruncationStrategy = TruncationStrategy\nmodule.exports.Model = Model\nmodule.exports.BPE = BPE\nmodule.exports.WordPiece = WordPiece\nmodule.exports.WordLevel = WordLevel\nmodule.exports.Unigram = Unigram\nmodule.exports.Normalizer = Normalizer\nmodule.exports.prependNormalizer = prependNormalizer\nmodule.exports.stripAccentsNormalizer = stripAccentsNormalizer\nmodule.exports.bertNormalizer = bertNormalizer\nmodule.exports.nfdNormalizer = nfdNormalizer\nmodule.exports.nfkdNormalizer = nfkdNormalizer\nmodule.exports.nfcNormalizer = nfcNormalizer\nmodule.exports.nfkcNormalizer = nfkcNormalizer\nmodule.exports.stripNormalizer = stripNormalizer\nmodule.exports.sequenceNormalizer = sequenceNormalizer\nmodule.exports.lowercase = lowercase\nmodule.exports.replace = replace\nmodule.exports.nmt = nmt\nmodule.exports.precompiled = precompiled\nmodule.exports.JsSplitDelimiterBehavior = JsSplitDelimiterBehavior\nmodule.exports.PreTokenizer = PreTokenizer\nmodule.exports.byteLevelPreTokenizer = byteLevelPreTokenizer\nmodule.exports.byteLevelAlphabet = byteLevelAlphabet\nmodule.exports.whitespacePreTokenizer = whitespacePreTokenizer\nmodule.exports.whitespaceSplitPreTokenizer = whitespaceSplitPreTokenizer\nmodule.exports.bertPreTokenizer = bertPreTokenizer\nmodule.exports.metaspacePreTokenizer = metaspacePreTokenizer\nmodule.exports.splitPreTokenizer = splitPreTokenizer\nmodule.exports.punctuationPreTokenizer = punctuationPreTokenizer\nmodule.exports.sequencePreTokenizer = sequencePreTokenizer\nmodule.exports.charDelimiterSplit = charDelimiterSplit\nmodule.exports.digitsPreTokenizer = digitsPreTokenizer\nmodule.exports.Processor = Processor\nmodule.exports.bertProcessing = bertProcessing\nmodule.exports.robertaProcessing = robertaProcessing\nmodule.exports.byteLevelProcessing = byteLevelProcessing\nmodule.exports.templateProcessing = templateProcessing\nmodule.exports.sequenceProcessing = sequenceProcessing\nmodule.exports.PaddingDirection = PaddingDirection\nmodule.exports.AddedToken = AddedToken\nmodule.exports.Tokenizer = Tokenizer\nmodule.exports.Trainer = Trainer\nmodule.exports.slice = slice\nmodule.exports.mergeEncodings = mergeEncodings\n", "bindings\\node\\package.json": "{\n \"name\": \"tokenizers\",\n \"version\": \"0.15.3-dev0\",\n \"repository\": {\n \"type\": \"git\",\n \"url\": \"git+https://github.com/huggingface/tokenizers.git\"\n },\n \"bugs\": {\n \"url\": \"https://github.com/huggingface/tokenizers/issues\"\n },\n \"homepage\": \"https://github.com/huggingface/tokenizers/tree/master/bindings/node\",\n \"author\": \"Anthony MOI <[email protected]>\",\n \"license\": \"Apache-2.0\",\n \"description\": \"Provides an implementation of today's most used tokenizers, with a focus on performances and versatility.\",\n \"files\": [\n \"index.d.ts\",\n \"index.js\"\n ],\n \"napi\": {\n \"name\": \"tokenizers\",\n \"triples\": {\n \"defaults\": true,\n \"additional\": [\n \"x86_64-unknown-linux-musl\",\n \"aarch64-unknown-linux-gnu\",\n \"i686-pc-windows-msvc\",\n \"armv7-unknown-linux-gnueabihf\",\n \"aarch64-apple-darwin\",\n \"aarch64-linux-android\",\n \"x86_64-unknown-freebsd\",\n \"aarch64-unknown-linux-musl\",\n \"aarch64-pc-windows-msvc\",\n \"armv7-linux-androideabi\"\n ]\n }\n },\n \"engines\": {\n \"node\": \">= 10\"\n },\n \"publishConfig\": {\n \"registry\": \"https://registry.npmjs.org/\",\n \"access\": \"public\"\n },\n \"scripts\": {\n \"artifacts\": \"napi artifacts\",\n \"bench\": \"node -r @swc-node/register benchmark/bench.ts\",\n \"build\": \"napi build --platform --release --pipe \\\"prettier -w\\\"\",\n \"build:debug\": \"napi build --platform --pipe \\\"prettier -w\\\"\",\n \"format\": \"run-p format:prettier format:rs format:toml\",\n \"format:prettier\": \"prettier . -w\",\n \"format:toml\": \"taplo format\",\n \"format:rs\": \"cargo fmt\",\n \"lint\": \"eslint . -c ./.eslintrc.yml\",\n \"prepublishOnly\": \"napi prepublish -t npm\",\n \"test\": \"jest\",\n \"version\": \"napi version\"\n },\n \"devDependencies\": {\n \"@napi-rs/cli\": \"^2.14.6\",\n \"@swc-node/register\": \"^1.5.5\",\n \"@swc/core\": \"^1.3.32\",\n \"@taplo/cli\": \"^0.5.2\",\n \"@types/jest\": \"^29.5.1\",\n \"@typescript-eslint/eslint-plugin\": \"^5.50.0\",\n \"@typescript-eslint/parser\": \"^5.50.0\",\n \"ava\": \"^5.1.1\",\n \"benny\": \"^3.7.1\",\n \"chalk\": \"^5.2.0\",\n \"eslint\": \"^8.33.0\",\n \"eslint-config-prettier\": \"^8.6.0\",\n \"eslint-plugin-import\": \"^2.27.5\",\n \"eslint-plugin-prettier\": \"^4.2.1\",\n \"husky\": \"^8.0.3\",\n \"jest\": \"^29.5.0\",\n \"lint-staged\": \"^13.1.0\",\n \"npm-run-all\": \"^4.1.5\",\n \"prettier\": \"^2.8.3\",\n \"ts-jest\": \"^29.1.0\",\n \"typescript\": \"^5.0.0\"\n },\n \"lint-staged\": {\n \"*.@(js|ts|tsx)\": [\n \"eslint -c .eslintrc.yml --fix\"\n ],\n \"*.@(js|ts|tsx|yml|yaml|md|json)\": [\n \"prettier --write\"\n ],\n \"*.toml\": [\n \"taplo format\"\n ]\n },\n \"ava\": {\n \"require\": [\n \"@swc-node/register\"\n ],\n \"extensions\": [\n \"ts\"\n ],\n \"timeout\": \"2m\",\n \"workerThreads\": false,\n \"environmentVariables\": {\n \"TS_NODE_PROJECT\": \"./tsconfig.json\"\n }\n },\n \"prettier\": {\n \"printWidth\": 120,\n \"semi\": false,\n \"trailingComma\": \"all\",\n \"singleQuote\": true,\n \"arrowParens\": \"always\"\n },\n \"packageManager\": \"[email protected]\"\n}\n", "bindings\\node\\npm\\android-arm-eabi\\package.json": "{\n \"name\": \"tokenizers-android-arm-eabi\",\n \"version\": \"0.13.4-rc1\",\n \"os\": [\n \"android\"\n ],\n \"cpu\": [\n \"arm\"\n ],\n \"main\": \"tokenizers.android-arm-eabi.node\",\n \"files\": [\n \"tokenizers.android-arm-eabi.node\"\n ],\n \"description\": \"Tokenizers platform specific bindings\",\n \"keywords\": [\n \"napi-rs\",\n \"NAPI\",\n \"N-API\",\n \"Rust\",\n \"node-addon\",\n \"node-addon-api\"\n ],\n \"license\": \"MIT\",\n \"engines\": {\n \"node\": \">= 10\"\n },\n \"publishConfig\": {\n \"registry\": \"https://registry.npmjs.org/\",\n \"access\": \"public\"\n },\n \"repository\": \"tokenizers\"\n}", "bindings\\node\\npm\\android-arm64\\package.json": "{\n \"name\": \"tokenizers-android-arm64\",\n \"version\": \"0.13.4-rc1\",\n \"os\": [\n \"android\"\n ],\n \"cpu\": [\n \"arm64\"\n ],\n \"main\": \"tokenizers.android-arm64.node\",\n \"files\": [\n \"tokenizers.android-arm64.node\"\n ],\n \"description\": \"Tokenizers platform specific bindings\",\n \"keywords\": [\n \"napi-rs\",\n \"NAPI\",\n \"N-API\",\n \"Rust\",\n \"node-addon\",\n \"node-addon-api\"\n ],\n \"license\": \"MIT\",\n \"engines\": {\n \"node\": \">= 10\"\n },\n \"publishConfig\": {\n \"registry\": \"https://registry.npmjs.org/\",\n \"access\": \"public\"\n },\n \"repository\": \"tokenizers\"\n}", "bindings\\node\\npm\\darwin-arm64\\package.json": "{\n \"name\": \"tokenizers-darwin-arm64\",\n \"version\": \"0.13.4-rc1\",\n \"os\": [\n \"darwin\"\n ],\n \"cpu\": [\n \"arm64\"\n ],\n \"main\": \"tokenizers.darwin-arm64.node\",\n \"files\": [\n \"tokenizers.darwin-arm64.node\"\n ],\n \"description\": \"Tokenizers platform specific bindings\",\n \"keywords\": [\n \"napi-rs\",\n \"NAPI\",\n \"N-API\",\n \"Rust\",\n \"node-addon\",\n \"node-addon-api\"\n ],\n \"license\": \"MIT\",\n \"engines\": {\n \"node\": \">= 10\"\n },\n \"publishConfig\": {\n \"registry\": \"https://registry.npmjs.org/\",\n \"access\": \"public\"\n },\n \"repository\": \"tokenizers\"\n}", "bindings\\node\\npm\\darwin-x64\\package.json": "{\n \"name\": \"tokenizers-darwin-x64\",\n \"version\": \"0.13.4-rc1\",\n \"os\": [\n \"darwin\"\n ],\n \"cpu\": [\n \"x64\"\n ],\n \"main\": \"tokenizers.darwin-x64.node\",\n \"files\": [\n \"tokenizers.darwin-x64.node\"\n ],\n \"description\": \"Tokenizers platform specific bindings\",\n \"keywords\": [\n \"napi-rs\",\n \"NAPI\",\n \"N-API\",\n \"Rust\",\n \"node-addon\",\n \"node-addon-api\"\n ],\n \"license\": \"MIT\",\n \"engines\": {\n \"node\": \">= 10\"\n },\n \"publishConfig\": {\n \"registry\": \"https://registry.npmjs.org/\",\n \"access\": \"public\"\n },\n \"repository\": \"tokenizers\"\n}", "bindings\\node\\npm\\freebsd-x64\\package.json": "{\n \"name\": \"tokenizers-freebsd-x64\",\n \"version\": \"0.13.4-rc1\",\n \"os\": [\n \"freebsd\"\n ],\n \"cpu\": [\n \"x64\"\n ],\n \"main\": \"tokenizers.freebsd-x64.node\",\n \"files\": [\n \"tokenizers.freebsd-x64.node\"\n ],\n \"description\": \"Tokenizers platform specific bindings\",\n \"keywords\": [\n \"napi-rs\",\n \"NAPI\",\n \"N-API\",\n \"Rust\",\n \"node-addon\",\n \"node-addon-api\"\n ],\n \"license\": \"MIT\",\n \"engines\": {\n \"node\": \">= 10\"\n },\n \"publishConfig\": {\n \"registry\": \"https://registry.npmjs.org/\",\n \"access\": \"public\"\n },\n \"repository\": \"tokenizers\"\n}", "bindings\\node\\npm\\linux-arm-gnueabihf\\package.json": "{\n \"name\": \"tokenizers-linux-arm-gnueabihf\",\n \"version\": \"0.13.4-rc1\",\n \"os\": [\n \"linux\"\n ],\n \"cpu\": [\n \"arm\"\n ],\n \"main\": \"tokenizers.linux-arm-gnueabihf.node\",\n \"files\": [\n \"tokenizers.linux-arm-gnueabihf.node\"\n ],\n \"description\": \"Tokenizers platform specific bindings\",\n \"keywords\": [\n \"napi-rs\",\n \"NAPI\",\n \"N-API\",\n \"Rust\",\n \"node-addon\",\n \"node-addon-api\"\n ],\n \"license\": \"MIT\",\n \"engines\": {\n \"node\": \">= 10\"\n },\n \"publishConfig\": {\n \"registry\": \"https://registry.npmjs.org/\",\n \"access\": \"public\"\n },\n \"repository\": \"tokenizers\"\n}", "bindings\\node\\npm\\linux-arm64-gnu\\package.json": "{\n \"name\": \"tokenizers-linux-arm64-gnu\",\n \"version\": \"0.13.4-rc1\",\n \"os\": [\n \"linux\"\n ],\n \"cpu\": [\n \"arm64\"\n ],\n \"main\": \"tokenizers.linux-arm64-gnu.node\",\n \"files\": [\n \"tokenizers.linux-arm64-gnu.node\"\n ],\n \"description\": \"Tokenizers platform specific bindings\",\n \"keywords\": [\n \"napi-rs\",\n \"NAPI\",\n \"N-API\",\n \"Rust\",\n \"node-addon\",\n \"node-addon-api\"\n ],\n \"license\": \"MIT\",\n \"engines\": {\n \"node\": \">= 10\"\n },\n \"publishConfig\": {\n \"registry\": \"https://registry.npmjs.org/\",\n \"access\": \"public\"\n },\n \"repository\": \"tokenizers\",\n \"libc\": [\n \"glibc\"\n ]\n}", "bindings\\node\\npm\\linux-arm64-musl\\package.json": "{\n \"name\": \"tokenizers-linux-arm64-musl\",\n \"version\": \"0.13.4-rc1\",\n \"os\": [\n \"linux\"\n ],\n \"cpu\": [\n \"arm64\"\n ],\n \"main\": \"tokenizers.linux-arm64-musl.node\",\n \"files\": [\n \"tokenizers.linux-arm64-musl.node\"\n ],\n \"description\": \"Tokenizers platform specific bindings\",\n \"keywords\": [\n \"napi-rs\",\n \"NAPI\",\n \"N-API\",\n \"Rust\",\n \"node-addon\",\n \"node-addon-api\"\n ],\n \"license\": \"MIT\",\n \"engines\": {\n \"node\": \">= 10\"\n },\n \"publishConfig\": {\n \"registry\": \"https://registry.npmjs.org/\",\n \"access\": \"public\"\n },\n \"repository\": \"tokenizers\",\n \"libc\": [\n \"musl\"\n ]\n}", "bindings\\node\\npm\\linux-x64-gnu\\package.json": "{\n \"name\": \"tokenizers-linux-x64-gnu\",\n \"version\": \"0.13.4-rc1\",\n \"os\": [\n \"linux\"\n ],\n \"cpu\": [\n \"x64\"\n ],\n \"main\": \"tokenizers.linux-x64-gnu.node\",\n \"files\": [\n \"tokenizers.linux-x64-gnu.node\"\n ],\n \"description\": \"Tokenizers platform specific bindings\",\n \"keywords\": [\n \"napi-rs\",\n \"NAPI\",\n \"N-API\",\n \"Rust\",\n \"node-addon\",\n \"node-addon-api\"\n ],\n \"license\": \"MIT\",\n \"engines\": {\n \"node\": \">= 10\"\n },\n \"publishConfig\": {\n \"registry\": \"https://registry.npmjs.org/\",\n \"access\": \"public\"\n },\n \"repository\": \"tokenizers\",\n \"libc\": [\n \"glibc\"\n ]\n}", "bindings\\node\\npm\\linux-x64-musl\\package.json": "{\n \"name\": \"tokenizers-linux-x64-musl\",\n \"version\": \"0.13.4-rc1\",\n \"os\": [\n \"linux\"\n ],\n \"cpu\": [\n \"x64\"\n ],\n \"main\": \"tokenizers.linux-x64-musl.node\",\n \"files\": [\n \"tokenizers.linux-x64-musl.node\"\n ],\n \"description\": \"Tokenizers platform specific bindings\",\n \"keywords\": [\n \"napi-rs\",\n \"NAPI\",\n \"N-API\",\n \"Rust\",\n \"node-addon\",\n \"node-addon-api\"\n ],\n \"license\": \"MIT\",\n \"engines\": {\n \"node\": \">= 10\"\n },\n \"publishConfig\": {\n \"registry\": \"https://registry.npmjs.org/\",\n \"access\": \"public\"\n },\n \"repository\": \"tokenizers\",\n \"libc\": [\n \"musl\"\n ]\n}", "bindings\\node\\npm\\win32-arm64-msvc\\package.json": "{\n \"name\": \"tokenizers-win32-arm64-msvc\",\n \"version\": \"0.13.4-rc1\",\n \"os\": [\n \"win32\"\n ],\n \"cpu\": [\n \"arm64\"\n ],\n \"main\": \"tokenizers.win32-arm64-msvc.node\",\n \"files\": [\n \"tokenizers.win32-arm64-msvc.node\"\n ],\n \"description\": \"Tokenizers platform specific bindings\",\n \"keywords\": [\n \"napi-rs\",\n \"NAPI\",\n \"N-API\",\n \"Rust\",\n \"node-addon\",\n \"node-addon-api\"\n ],\n \"license\": \"MIT\",\n \"engines\": {\n \"node\": \">= 10\"\n },\n \"publishConfig\": {\n \"registry\": \"https://registry.npmjs.org/\",\n \"access\": \"public\"\n },\n \"repository\": \"tokenizers\"\n}", "bindings\\node\\npm\\win32-ia32-msvc\\package.json": "{\n \"name\": \"tokenizers-win32-ia32-msvc\",\n \"version\": \"0.13.4-rc1\",\n \"os\": [\n \"win32\"\n ],\n \"cpu\": [\n \"ia32\"\n ],\n \"main\": \"tokenizers.win32-ia32-msvc.node\",\n \"files\": [\n \"tokenizers.win32-ia32-msvc.node\"\n ],\n \"description\": \"Tokenizers platform specific bindings\",\n \"keywords\": [\n \"napi-rs\",\n \"NAPI\",\n \"N-API\",\n \"Rust\",\n \"node-addon\",\n \"node-addon-api\"\n ],\n \"license\": \"MIT\",\n \"engines\": {\n \"node\": \">= 10\"\n },\n \"publishConfig\": {\n \"registry\": \"https://registry.npmjs.org/\",\n \"access\": \"public\"\n },\n \"repository\": \"tokenizers\"\n}", "bindings\\node\\npm\\win32-x64-msvc\\package.json": "{\n \"name\": \"tokenizers-win32-x64-msvc\",\n \"version\": \"0.13.4-rc1\",\n \"os\": [\n \"win32\"\n ],\n \"cpu\": [\n \"x64\"\n ],\n \"main\": \"tokenizers.win32-x64-msvc.node\",\n \"files\": [\n \"tokenizers.win32-x64-msvc.node\"\n ],\n \"description\": \"Tokenizers platform specific bindings\",\n \"keywords\": [\n \"napi-rs\",\n \"NAPI\",\n \"N-API\",\n \"Rust\",\n \"node-addon\",\n \"node-addon-api\"\n ],\n \"license\": \"MIT\",\n \"engines\": {\n \"node\": \">= 10\"\n },\n \"publishConfig\": {\n \"registry\": \"https://registry.npmjs.org/\",\n \"access\": \"public\"\n },\n \"repository\": \"tokenizers\"\n}", "docs\\source\\index.rst": "Tokenizers\n====================================================================================================\n\nFast State-of-the-art tokenizers, optimized for both research and production\n\n`\ud83e\udd17 Tokenizers`_ provides an implementation of today's most used tokenizers, with\na focus on performance and versatility. These tokenizers are also used in\n`\ud83e\udd17 Transformers`_.\n\n.. _\ud83e\udd17 Tokenizers: https://github.com/huggingface/tokenizers\n.. _\ud83e\udd17 Transformers: https://github.com/huggingface/transformers\n\nMain features:\n----------------------------------------------------------------------------------------------------\n\n - Train new vocabularies and tokenize, using today's most used tokenizers.\n - Extremely fast (both training and tokenization), thanks to the Rust implementation. Takes\n less than 20 seconds to tokenize a GB of text on a server's CPU.\n - Easy to use, but also extremely versatile.\n - Designed for both research and production.\n - Full alignment tracking. Even with destructive normalization, it's always possible to get\n the part of the original sentence that corresponds to any token.\n - Does all the pre-processing: Truncation, Padding, add the special tokens your model needs.\n\n\n.. toctree::\n :maxdepth: 2\n :caption: Getting Started\n\n quicktour\n installation/main\n pipeline\n components\n\n.. toctree-tags::\n :maxdepth: 3\n :caption: Using \ud83e\udd17 Tokenizers\n :glob:\n\n :python:tutorials/python/*\n\n.. toctree::\n :maxdepth: 3\n :caption: API Reference\n\n api/reference\n\n.. include:: entities.inc\n", "docs\\source\\installation\\main.rst": "Installation\n====================================================================================================\n\n.. only:: python\n\n .. include:: python.inc\n\n.. only:: rust\n\n .. include:: rust.inc\n\n.. only:: node\n\n .. include:: node.inc\n\n", "docs\\source-doc-builder\\index.mdx": "<!-- DISABLE-FRONTMATTER-SECTIONS -->\n\n# Tokenizers\n\nFast State-of-the-art tokenizers, optimized for both research and\nproduction\n\n[\ud83e\udd17 Tokenizers](https://github.com/huggingface/tokenizers) provides an\nimplementation of today's most used tokenizers, with a focus on\nperformance and versatility. These tokenizers are also used in [\ud83e\udd17 Transformers](https://github.com/huggingface/transformers).\n\n# Main features:\n\n- Train new vocabularies and tokenize, using today's most used tokenizers.\n- Extremely fast (both training and tokenization), thanks to the Rust implementation. Takes less than 20 seconds to tokenize a GB of text on a server's CPU.\n- Easy to use, but also extremely versatile.\n- Designed for both research and production.\n- Full alignment tracking. Even with destructive normalization, it's always possible to get the part of the original sentence that corresponds to any token.\n- Does all the pre-processing: Truncation, Padding, add the special tokens your model needs.\n", "tokenizers\\examples\\unstable_wasm\\www\\index.html": "<!DOCTYPE html>\n<html>\n <head>\n <meta charset=\"utf-8\">\n <title>Hello wasm-pack!</title>\n </head>\n <body>\n <noscript>This page contains webassembly and javascript content, please enable javascript in your browser.</noscript>\n <script src=\"./bootstrap.js\"></script>\n </body>\n</html>\n", "tokenizers\\examples\\unstable_wasm\\www\\index.js": "import * as wasm from \"unstable_wasm\";\n\nconsole.log(wasm.tokenize(\"ab\"));\nconsole.log(wasm.tokenize(\"abc\"));\n", "tokenizers\\examples\\unstable_wasm\\www\\package.json": "{\n \"name\": \"create-wasm-app\",\n \"version\": \"0.1.0\",\n \"description\": \"create an app to consume rust-generated wasm packages\",\n \"main\": \"index.js\",\n \"bin\": {\n \"create-wasm-app\": \".bin/create-wasm-app.js\"\n },\n \"scripts\": {\n \"build\": \"webpack --config webpack.config.js\",\n \"start\": \"NODE_OPTIONS=--openssl-legacy-provider webpack-dev-server\"\n },\n \"repository\": {\n \"type\": \"git\",\n \"url\": \"git+https://github.com/rustwasm/create-wasm-app.git\"\n },\n \"keywords\": [\"webassembly\", \"wasm\", \"rust\", \"webpack\"],\n \"author\": \"Ashley Williams <[email protected]>\",\n \"license\": \"(MIT OR Apache-2.0)\",\n \"bugs\": {\n \"url\": \"https://github.com/rustwasm/create-wasm-app/issues\"\n },\n \"homepage\": \"https://github.com/rustwasm/create-wasm-app#readme\",\n \"devDependencies\": {\n \"copy-webpack-plugin\": \"^11.0.0\",\n \"webpack\": \"^5.75.0\",\n \"webpack-cli\": \"^5.0.1\",\n \"webpack-dev-server\": \"^4.10.0\"\n },\n \"dependencies\": {\n \"unstable_wasm\": \"file:../pkg\"\n }\n}\n", "tokenizers\\examples\\unstable_wasm\\www\\.bin\\create-wasm-app.js": "#!/usr/bin/env node\n\nconst { spawn } = require(\"child_process\");\nconst fs = require(\"fs\");\n\nlet folderName = '.';\n\nif (process.argv.length >= 3) {\n folderName = process.argv[2];\n if (!fs.existsSync(folderName)) {\n fs.mkdirSync(folderName);\n }\n}\n\nconst clone = spawn(\"git\", [\"clone\", \"https://github.com/rustwasm/create-wasm-app.git\", folderName]);\n\nclone.on(\"close\", code => {\n if (code !== 0) {\n console.error(\"cloning the template failed!\")\n process.exit(code);\n } else {\n console.log(\"\ud83e\udd80 Rust + \ud83d\udd78 Wasm = \u2764\");\n }\n});\n"} | null |
torchMoji | {"type": "directory", "name": "torchMoji", "children": [{"type": "file", "name": ".travis.yml"}, {"type": "directory", "name": "data", "children": [{"type": "file", "name": "emoji_codes.json"}, {"type": "directory", "name": "filtering", "children": [{"type": "file", "name": "wanted_emojis.csv"}]}, {"type": "directory", "name": "kaggle-insults", "children": []}, {"type": "directory", "name": "Olympic", "children": []}, {"type": "directory", "name": "PsychExp", "children": []}, {"type": "directory", "name": "SCv1", "children": []}, {"type": "directory", "name": "SCv2-GEN", "children": []}, {"type": "directory", "name": "SE0714", "children": []}, {"type": "directory", "name": "SS-Twitter", "children": []}, {"type": "directory", "name": "SS-Youtube", "children": []}]}, {"type": "directory", "name": "examples", "children": [{"type": "file", "name": "create_twitter_vocab.py"}, {"type": "file", "name": "dataset_split.py"}, {"type": "file", "name": "encode_texts.py"}, {"type": "file", "name": "example_helper.py"}, {"type": "file", "name": "finetune_insults_chain-thaw.py"}, {"type": "file", "name": "finetune_semeval_class-avg_f1.py"}, {"type": "file", "name": "finetune_youtube_last.py"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "score_texts_emojis.py"}, {"type": "file", "name": "text_emojize.py"}, {"type": "file", "name": "tokenize_dataset.py"}, {"type": "file", "name": "vocab_extension.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "LICENSE"}, {"type": "directory", "name": "model", "children": [{"type": "file", "name": "vocabulary.json"}]}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "scripts", "children": [{"type": "file", "name": "analyze_all_results.py"}, {"type": "file", "name": "analyze_results.py"}, {"type": "file", "name": "calculate_coverages.py"}, {"type": "file", "name": "convert_all_datasets.py"}, {"type": "file", "name": "download_weights.py"}, {"type": "file", "name": "finetune_dataset.py"}, {"type": "directory", "name": "results", "children": []}]}, {"type": "file", "name": "setup.py"}, {"type": "directory", "name": "tests", "children": [{"type": "file", "name": "test_finetuning.py"}, {"type": "file", "name": "test_helper.py"}, {"type": "file", "name": "test_sentence_tokenizer.py"}, {"type": "file", "name": "test_tokenizer.py"}, {"type": "file", "name": "test_word_generator.py"}]}, {"type": "directory", "name": "torchmoji", "children": [{"type": "file", "name": "attlayer.py"}, {"type": "file", "name": "class_avg_finetuning.py"}, {"type": "file", "name": "create_vocab.py"}, {"type": "file", "name": "filter_input.py"}, {"type": "file", "name": "filter_utils.py"}, {"type": "file", "name": "finetuning.py"}, {"type": "file", "name": "global_variables.py"}, {"type": "file", "name": "lstm.py"}, {"type": "file", "name": "model_def.py"}, {"type": "file", "name": "sentence_tokenizer.py"}, {"type": "file", "name": "tokenizer.py"}, {"type": "file", "name": "word_generator.py"}, {"type": "file", "name": "__init__.py"}]}]} | # torchMoji examples
## Initialization
[create_twitter_vocab.py](create_twitter_vocab.py)
Create a new vocabulary from a tsv file.
[tokenize_dataset.py](tokenize_dataset.py)
Tokenize a given dataset using the prebuilt vocabulary.
[vocab_extension.py](vocab_extension.py)
Extend the given vocabulary using dataset-specific words.
[dataset_split.py](dataset_split.py)
Split a given dataset into training, validation and testing.
## Use pretrained model/architecture
[score_texts_emojis.py](score_texts_emojis.py)
Use torchMoji to score texts for emoji distribution.
[text_emojize.py](text_emojize.py)
Use torchMoji to output emoji visualization from a single text input (mapped from `emoji_overview.png`)
```sh
python examples/text_emojize.py --text "I love mom's cooking\!"
# => I love mom's cooking! 😋 😍 💓 💛 ❤
```
[encode_texts.py](encode_texts.py)
Use torchMoji to encode the text into 2304-dimensional feature vectors for further modeling/analysis.
## Transfer learning
[finetune_youtube_last.py](finetune_youtube_last.py)
Finetune the model on the SS-Youtube dataset using the 'last' method.
[finetune_insults_chain-thaw.py](finetune_insults_chain-thaw.py)
Finetune the model on the Kaggle insults dataset (from blog post) using the 'chain-thaw' method.
[finetune_semeval_class-avg_f1.py](finetune_semeval_class-avg_f1.py)
Finetune the model on the SemeEval emotion dataset using the 'full' method and evaluate using the class average F1 metric.
| {"setup.py": "from setuptools import setup\n\nsetup(\n name='torchmoji',\n version='1.0',\n packages=['torchmoji'],\n description='torchMoji',\n include_package_data=True,\n install_requires=[\n 'emoji==0.4.5',\n 'numpy==1.13.1',\n 'scipy==0.19.1',\n 'scikit-learn==0.19.0',\n 'text-unidecode==1.0',\n ],\n)\n", ".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n"} | null |
transfer-learning-conv-ai | {"type": "directory", "name": "transfer-learning-conv-ai", "children": [{"type": "file", "name": "convai_evaluation.py"}, {"type": "file", "name": "Dockerfile"}, {"type": "file", "name": "example_entry.py"}, {"type": "file", "name": "interact.py"}, {"type": "file", "name": "LICENCE"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "test_special_tokens.py"}, {"type": "file", "name": "train.py"}, {"type": "file", "name": "utils.py"}]} | # 🦄 Building a State-of-the-Art Conversational AI with Transfer Learning
The present repo contains the code accompanying the blog post [🦄 How to build a State-of-the-Art Conversational AI with Transfer Learning](https://medium.com/@Thomwolf/how-to-build-a-state-of-the-art-conversational-ai-with-transfer-learning-2d818ac26313).
This code is a clean and commented code base with training and testing scripts that can be used to train a dialog agent leveraging transfer Learning from an OpenAI GPT and GPT-2 Transformer language model.
This codebase can be used to reproduce the results of HuggingFace's participation to NeurIPS 2018 dialog competition [ConvAI2](http://convai.io/) which was state-of-the-art on the automatic metrics. The 3k+ lines of competition code was distilled in about 250 lines of training code with distributed & FP16 options to form the present repository.
This model can be trained in about one hour on a 8 V100 cloud instance (currently costs about $25) and a pre-trained model is also made available.
## Installation
To install and use the training and inference scripts please clone the repo and install the requirements:
```bash
git clone https://github.com/huggingface/transfer-learning-conv-ai
cd transfer-learning-conv-ai
pip install -r requirements.txt
python -m spacy download en
```
## Installation with Docker
To install using docker please build the self-contained image:
```bash
docker build -t convai .
```
_Note: Make sure your Docker setup allocates enough memory to building the container. Building with the default of 1.75GB will fail due to large Pytorch wheel._
You can then enter the image
```bash
ip-192-168-22-157:transfer-learning-conv-ai loretoparisi$ docker run --rm -it convai bash
root@91e241bb823e:/# ls
Dockerfile README.md boot dev home lib media models proc root sbin sys train.py utils.py
LICENCE bin convai_evaluation.py etc interact.py lib64 mnt opt requirements.txt run srv tmp usr var
```
You can then run the `interact.py` script on the pretrained model:
```bash
python3 interact.py --model models/
```
## Pretrained model
We make a pretrained and fine-tuned model available on our S3 [here](https://s3.amazonaws.com/models.huggingface.co/transfer-learning-chatbot/finetuned_chatbot_gpt.tar.gz). The easiest way to download and use this model is just to run the `interact.py` script to talk with the model. Without any argument, this script will automatically download and cache our model.
## Using the training script
The training script can be used in single GPU or multi GPU settings:
```bash
python ./train.py # Single GPU training
python -m torch.distributed.launch --nproc_per_node=8 ./train.py # Training on 8 GPUs
```
The training script accept several arguments to tweak the training:
Argument | Type | Default value | Description
---------|------|---------------|------------
dataset_path | `str` | `""` | Path or url of the dataset. If empty download from S3.
dataset_cache | `str` | `'./dataset_cache.bin'` | Path or url of the dataset cache
model | `str` | `"openai-gpt"` | Path, url or short name of the model
num_candidates | `int` | `2` | Number of candidates for training
max_history | `int` | `2` | Number of previous exchanges to keep in history
train_batch_size | `int` | `4` | Batch size for training
valid_batch_size | `int` | `4` | Batch size for validation
gradient_accumulation_steps | `int` | `8` | Accumulate gradients on several steps
lr | `float` | `6.25e-5` | Learning rate
lm_coef | `float` | `1.0` | LM loss coefficient
mc_coef | `float` | `1.0` | Multiple-choice loss coefficient
max_norm | `float` | `1.0` | Clipping gradient norm
n_epochs | `int` | `3` | Number of training epochs
personality_permutations | `int` | `1` | Number of permutations of personality sentences
device | `str` | `"cuda" if torch.cuda.is_available() else "cpu"` | Device (cuda or cpu)
fp16 | `str` | `""` | Set to O0, O1, O2 or O3 for fp16 training (see apex documentation)
local_rank | `int` | `-1` | Local rank for distributed training (-1: not distributed)
Here is how to reproduce our results on a server with 8 V100 GPUs (adapt number of nodes and batch sizes to your configuration):
```bash
python -m torch.distributed.launch --nproc_per_node=8 ./train.py --gradient_accumulation_steps=4 --lm_coef=2.0 --max_history=2 --n_epochs=1 --num_candidates=4 --personality_permutations=2 --train_batch_size=2 --valid_batch_size=2
```
This model should give a Hits@1 over 79, perplexity of 20.5 and F1 of 16.5 using the convai2 evaluation script (see below).
These numbers are slightly lower than the number we obtained in the ConvAI2 competition. Here is what you can tweak to reach the same results:
- in the ConvAI2 competition we also used tweaked position emebddings so that the history of the dialog always start at with the same embeddings. This is easy to add with pytorch-transformers and should improve the hits@1 metric.
- in the ConvAI2 competition we used a beam search decoder. While the results are better in term of f1 metric, our feeling is that the human experience is less compelling with beam search versus the nucleus sampling detector which is provided in the present repository.
## Using the interaction script
The training script saves all the experiments and checkpoints in a sub-folder named with the timestamp of the experiment in the `./runs` folder of the repository base folder.
You can then use the interactive script to interact with the model simply by pointing to this folder.
Here is an example command line to run the interactive script:
```bash
python ./interact.py --model_checkpoint ./data/Apr17_13-31-38_thunder/ # run the interactive script with a training checkpoint
python ./interact.py # run the interactive script with the finetuned model on our S3
```
The fine-tuned model will gives FINAL Hits@1: 0.715
The interactive script accept a few arguments to tweak the decoding algorithm:
Argument | Type | Default value | Description
---------|------|---------------|------------
dataset_path | `str` | `""` | Path or url of the dataset. If empty download from S3.
dataset_cache | `str` | `'./dataset_cache.bin'` | Path or url of the dataset cache
model | `str` | `"openai-gpt"` | Path, url or short name of the model
max_history | `int` | `2` | Number of previous utterances to keep in history
device | `str` | `cuda` if `torch.cuda.is_available()` else `cpu` | Device (cuda or cpu)
no_sample | action `store_true` | Set to use greedy decoding instead of sampling
max_length | `int` | `20` | Maximum length of the output utterances
min_length | `int` | `1` | Minimum length of the output utterances
seed | `int` | `42` | Seed
temperature | `int` | `0.7` | Sampling softmax temperature
top_k | `int` | `0` | Filter top-k tokens before sampling (`<=0`: no filtering)
top_p | `float` | `0.9` | Nucleus filtering (top-p) before sampling (`<=0.0`: no filtering)
## Running ConvAI2 evaluation scripts
To run the evaluation scripts of the ConvAI2 challenge, you first need to install `ParlAI` in the repo base folder like this:
```bash
git clone https://github.com/facebookresearch/ParlAI.git
cd ParlAI
python setup.py develop
```
You can then run the evaluation script from `ParlAI` base folder:
```bash
cd ParlAI
python ../convai_evaluation.py --eval_type hits@1 # to download and evaluate our fine-tuned model on hits@1 metric
python ../convai_evaluation.py --eval_type hits@1 --model_checkpoint ./data/Apr17_13-31-38_thunder/ # to evaluate a training checkpoint on hits@1 metric
```
The evaluation script accept a few arguments to select the evaluation metric and tweak the decoding algorithm:
Argument | Type | Default value | Description
---------|------|---------------|------------
eval_type | `str` | `"hits@1"` | Evaluate the model on `hits@1`, `ppl` or `f1` metric on the ConvAI2 validation dataset
model | `str` | `"openai-gpt"` | Path, url or short name of the model
max_history | `int` | `2` | Number of previous utterances to keep in history
device | `str` | `cuda` if `torch.cuda.is_available()` else `cpu` | Device (cuda or cpu)
no_sample | action `store_true` | Set to use greedy decoding instead of sampling
max_length | `int` | `20` | Maximum length of the output utterances
min_length | `int` | `1` | Minimum length of the output utterances
seed | `int` | `42` | Seed
temperature | `int` | `0.7` | Sampling softmax temperature
top_k | `int` | `0` | Filter top-k tokens before sampling (`<=0`: no filtering)
top_p | `float` | `0.9` | Nucleus filtering (top-p) before sampling (`<=0.0`: no filtering)
## Data Format
see `example_entry.py`, and the comment at the top.
## Citation
If you use this code in your research, you can cite our NeurIPS CAI workshop [paper](http://arxiv.org/abs/1901.08149):
```bash
@article{DBLP:journals/corr/abs-1901-08149,
author = {Thomas Wolf and
Victor Sanh and
Julien Chaumond and
Clement Delangue},
title = {TransferTransfo: {A} Transfer Learning Approach for Neural Network
Based Conversational Agents},
journal = {CoRR},
volume = {abs/1901.08149},
year = {2019},
url = {http://arxiv.org/abs/1901.08149},
archivePrefix = {arXiv},
eprint = {1901.08149},
timestamp = {Sat, 02 Feb 2019 16:56:00 +0100},
biburl = {https://dblp.org/rec/bib/journals/corr/abs-1901-08149},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
| {"Dockerfile": "FROM ubuntu:18.04\n\nMAINTAINER Loreto Parisi [email protected]\n\n######################################## BASE SYSTEM\n# set noninteractive installation\nARG DEBIAN_FRONTEND=noninteractive\nRUN apt-get update && apt-get install -y apt-utils\nRUN apt-get install -y --no-install-recommends \\\n build-essential \\\n pkg-config \\\n tzdata \\\n curl\n\n######################################## PYTHON3\nRUN apt-get install -y \\\n python3 \\\n python3-pip\n\n# set local timezone\nRUN ln -fs /usr/share/zoneinfo/America/New_York /etc/localtime && \\\n dpkg-reconfigure --frontend noninteractive tzdata\n\n# transfer-learning-conv-ai\nENV PYTHONPATH /usr/local/lib/python3.6 \nCOPY . ./\nCOPY requirements.txt /tmp/requirements.txt\nRUN pip3 install -r /tmp/requirements.txt\n\n# model zoo\nRUN mkdir models && \\\n curl https://s3.amazonaws.com/models.huggingface.co/transfer-learning-chatbot/finetuned_chatbot_gpt.tar.gz > models/finetuned_chatbot_gpt.tar.gz && \\\n cd models/ && \\\n tar -xvzf finetuned_chatbot_gpt.tar.gz && \\\n rm finetuned_chatbot_gpt.tar.gz\n \nCMD [\"bash\"]", "requirements.txt": "torch\npytorch-ignite\ntransformers==2.5.1\ntensorboardX==1.8\ntensorflow # for tensorboardX\nspacy\n", ".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n"} | null |
transformers-bloom-inference | {"type": "directory", "name": "transformers-bloom-inference", "children": [{"type": "file", "name": ".pre-commit-config.yaml"}, {"type": "directory", "name": "assets", "children": []}, {"type": "directory", "name": "bloom-inference-scripts", "children": [{"type": "file", "name": "bloom-accelerate-inference.py"}, {"type": "file", "name": "bloom-ds-inference.py"}, {"type": "file", "name": "bloom-ds-zero-inference.py"}, {"type": "file", "name": "README.md"}]}, {"type": "file", "name": "Dockerfile"}, {"type": "directory", "name": "inference_server", "children": [{"type": "file", "name": "benchmark.py"}, {"type": "file", "name": "cli.py"}, {"type": "file", "name": "constants.py"}, {"type": "file", "name": "download_model.py"}, {"type": "directory", "name": "models", "children": [{"type": "file", "name": "ds_inference.py"}, {"type": "file", "name": "ds_zero.py"}, {"type": "file", "name": "hf_accelerate.py"}, {"type": "file", "name": "hf_cpu.py"}, {"type": "file", "name": "model.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "model_handler", "children": [{"type": "file", "name": "deployment.py"}, {"type": "directory", "name": "grpc_utils", "children": [{"type": "file", "name": "generation_server.py"}, {"type": "directory", "name": "pb", "children": [{"type": "file", "name": "generation_pb2.py"}, {"type": "file", "name": "generation_pb2_grpc.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "proto", "children": [{"type": "file", "name": "generation.proto"}]}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "launch.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "server.py"}, {"type": "directory", "name": "utils", "children": [{"type": "file", "name": "requests.py"}, {"type": "file", "name": "utils.py"}, {"type": "file", "name": "__init__.py"}]}]}, {"type": "file", "name": "LICENSE"}, {"type": "file", "name": "Makefile"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "server_request.py"}, {"type": "file", "name": "setup.cfg"}, {"type": "directory", "name": "static", "children": [{"type": "directory", "name": "css", "children": [{"type": "file", "name": "style.css"}]}, {"type": "directory", "name": "js", "children": [{"type": "file", "name": "index.js"}]}]}, {"type": "directory", "name": "templates", "children": [{"type": "file", "name": "index.html"}]}, {"type": "file", "name": "ui.py"}]} | # Inference scripts for BLOOM
## BLOOM Inference solutions
Here are some benchmark resuls on JeanZay's 8x80GB A100 node w/ 512GB of CPU memory:
All benchmarks are doing greedy generation of 100 token outputs:
```
Generate args {'max_length': 100, 'do_sample': False}
```
The input prompt is comprised of just a few tokens.
Throughput in msecs on 8x80GB gpus:
| project \ bs | 1 | 8 | 16 | 32 | 64 | 128 | 256 | 512 |
| :---------------- | :----- | :---- | :---- | :---- | :--- | :--- | :--- | :--- |
| accelerate bf16 | 230.38 | 31.78 | 17.84 | 10.89 | oom | | | |
| accelerate int8 | 286.56 | 40.92 | 22.65 | 13.27 | oom | | | |
| ds-inference fp16 | 44.02 | 5.70 | 3.01 | 1.68 | 1.00 | 0.69 | oom | |
| ds-inference int8 | 89.09 | 11.44 | 5.88 | 3.09 | 1.71 | 1.02 | 0.71 | oom |
| ds-zero bf16 | 283 | 34.88 | oom | | | | | |
note: Since Deepspeed-ZeRO can process multiple generate streams in parallel its throughput can be further divided by 8 or 16, depending on whether 8 or 16 gpus were used during the generate. and, of course, it means that it can process a bs of 64 in the case of 8x80 A100 (the table above).
Start to ready to generate in secs (mainly loading and data preparation time):
| project | |
| :---------------------- | :--- |
| accelerate | 121 |
| ds-inference shard-int8 | 61 |
| ds-inference shard-fp16 | 60 |
| ds-inference unsharded | 662 |
| ds-zero | 462 |
Now let's look at the power of quantized int8-based models provided by [Deepspeed-Inference](https://www.deepspeed.ai/tutorials/inference-tutorial/) and [BitsNBytes](https://github.com/TimDettmers/bitsandbytes), as it requires only half the original GPU memory of inference in bfloat16 or float16.
Throughput in msecs 4x80GB A100:
| project \ bs | 1 | 8 | 16 | 32 | 64 | 128 |
| :---------------- | :----- | :---- | :---- | :---- | :--- | :--- |
| accelerate int8 | 284.15 | 40.14 | 21.97 | oom | | |
| ds-inference int8 | 156.51 | 20.11 | 10.38 | 5.50 | 2.96 | oom |
To get the benchmark results simply add `--benchmark` to any of these 3 scripts discussed below.
## Deepspeed-Inference
Deepspeed-Inference uses Tensor-Parallelism and efficient fused CUDA kernels:
https://www.deepspeed.ai/tutorials/inference-tutorial/
### Setup
```
pip install deepspeed>=0.7.3
```
### Run
1. the fastest approach is to use a tp-pre-sharded checkpoint that takes only ~1min to load, as compared to 10min for non-presharded bloom checkpoint
```
deepspeed --num_gpus 8 bloom-inference-scripts/bloom-ds-inference.py --name microsoft/bloom-deepspeed-inference-fp16
```
1a.
if you want to run the original bloom checkpoint, which once loaded will run at the same throughput as the previous solution, but the loading will take 10-20min:
```
deepspeed --num_gpus 8 bloom-inference-scripts/bloom-ds-inference.py --name bigscience/bloom
```
2a. The 8bit quantized version requires you to have only half the GPU memory of the normal half precision version:
```
deepspeed --num_gpus 8 bloom-inference-scripts/bloom-ds-inference.py --name microsoft/bloom-deepspeed-inference-int8 --dtype int8
```
Here we used `microsoft/bloom-deepspeed-inference-int8` and also told the script to run in `int8`.
And of course, just 4x80GB A100 gpus is now sufficient:
```
deepspeed --num_gpus 4 bloom-inference-scripts/bloom-ds-inference.py --name microsoft/bloom-deepspeed-inference-int8 --dtype int8
```
## HF Accelerate
HF Accelerate can use naive Pipeline Parallelism to load a huge model over multiple GPUs:
https://github.com/huggingface/accelerate
### Setup
```
pip install transformers>=4.21.3 accelerate>=0.12.0
```
### Run
```
python bloom-inference-scripts/bloom-accelerate-inference.py --name bigscience/bloom --batch_size 1 --benchmark 2>&1 | tee bloom-accelerate-inference_bs=1.txt
```
To activate the 8bit quantized solution first install `bitsnbytes`:
```
pip install bitsandbytes
```
and then add `--dtype int8` to the previous command line:
```
python bloom-inference-scripts/bloom-accelerate-inference.py --name bigscience/bloom --dtype int8 --batch_size 1 --benchmark 2>&1 | tee bloom-int8-accelerate-inference_bs=1.txt
```
if you have more than 4 GPUs you can tell it to use only 4 with:
```
CUDA_VISIBLE_DEVICES=0,1,2,3 python bloom-inference-scripts/bloom-accelerate-inference.py --name bigscience/bloom --dtype int8 --batch_size 1 --benchmark 2>&1 | tee bloom-int8-accelerate-inference_bs=1.txt
```
## Deepspeed ZeRO-Inference
[Deepspeed ZeRO](https://www.deepspeed.ai/tutorials/zero/) uses a magical sharding approach which can take almost any model and scale it across a few or hundreds of GPUs.
### Setup
```
pip install deepspeed
```
### Run
Note that the script currently runs the same inputs on all GPUs, but you can run a different stream on each GPU, and get `n_gpu` times faster throughput. You can't do that with Deepspeed-Inference.
```
deepspeed --num_gpus 8 bloom-inference-scripts/bloom-ds-zero-inference.py --name bigscience/bloom --batch_size 1 --benchmark 2>&1 | tee bloom-ds-zero-inference_bs=1.txt
```
Please remember that with ZeRO the user can generate multiple unique streams at the same time - and thus the overall performance should be throughput in secs/token divided by number of participating gpus - so 8x to 16x faster depending on whether 8 or 16 gpus were used!
You can also try the offloading solutions with just one small GPU, which will take a long time to run, but if you don't have 8 huge GPUs this is as good as it gets.
CPU-Offload (1x gpus):
```
deepspeed --num_gpus 1 bloom-inference-scripts/bloom-ds-zero-inference.py --name bigscience/bloom --batch_size 8 --cpu_offload --benchmark 2>&1 | tee bloom-ds-zero-inference-cpu_offload_bs=8.txt
```
NVMe-Offload (1x gpus):
```
deepspeed --num_gpus 1 bloom-inference-scripts/bloom-ds-zero-inference.py --name bigscience/bloom --batch_size 8 --nvme_offload_path=/path/to/nvme_offload --benchmark 2>&1 | tee bloom-ds-zero-inference-nvme_offload_bs=8.txt
```
make sure to adjust `/path/to/nvme_offload` to somewhere you have ~400GB of free memory on a fast NVMe drive.
## Support
If you run into things not working or have other questions please open an Issue in the corresponding backend:
- [Accelerate](https://github.com/huggingface/accelerate/issues)
- [Deepspeed-Inference](https://github.com/microsoft/DeepSpeed/issues)
- [Deepspeed-ZeRO](https://github.com/microsoft/DeepSpeed/issues)
If there a specific issue with one of the scripts and not the backend only then please open an Issue here and tag [@stas00](https://github.com/stas00).
| {"Dockerfile": "FROM nvidia/cuda:11.6.1-devel-ubi8 as base\n\nRUN dnf install -y --disableplugin=subscription-manager make git && dnf clean all --disableplugin=subscription-manager\n\n# taken form pytorch's dockerfile\nRUN curl -L -o ./miniconda.sh -O https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh && \\\n chmod +x ./miniconda.sh && \\\n ./miniconda.sh -b -p /opt/conda && \\\n rm ./miniconda.sh\n\nENV PYTHON_VERSION=3.9 \\\n PATH=/opt/conda/envs/inference/bin:/opt/conda/bin:${PATH}\n\n# create conda env\nRUN conda create -n inference python=${PYTHON_VERSION} pip -y\n\n# change shell to activate env\nSHELL [\"conda\", \"run\", \"-n\", \"inference\", \"/bin/bash\", \"-c\"]\n\nFROM base as conda\n\n# update conda\nRUN conda update -n base -c defaults conda -y\n# cmake\nRUN conda install -c anaconda cmake -y\n\n# necessary stuff\nRUN pip install torch==1.12.1+cu116 --extra-index-url https://download.pytorch.org/whl/cu116 \\\n transformers==4.26.1 \\\n deepspeed==0.7.6 \\\n accelerate==0.16.0 \\\n gunicorn==20.1.0 \\\n flask \\\n flask_api \\\n fastapi==0.89.1 \\\n uvicorn==0.19.0 \\\n jinja2==3.1.2 \\\n pydantic==1.10.2 \\\n huggingface_hub==0.12.1 \\\n\tgrpcio-tools==1.50.0 \\\n --no-cache-dir\n\n# clean conda env\nRUN conda clean -ya\n\n# change this as you like \ud83e\udd17\nENV TRANSFORMERS_CACHE=/cos/HF_cache \\\n HUGGINGFACE_HUB_CACHE=${TRANSFORMERS_CACHE}\n\nFROM conda as app\n\nWORKDIR /src\nRUN chmod -R g+w /src\n\nRUN mkdir /.cache && \\\n chmod -R g+w /.cache\n\nENV PORT=5000 \\\n UI_PORT=5001\nEXPOSE ${PORT}\nEXPOSE ${UI_PORT}\n\nCMD git clone https://github.com/huggingface/transformers-bloom-inference.git && \\\n cd transformers-bloom-inference && \\\n # install grpc and compile protos\n make gen-proto && \\\n make bloom-560m\n", ".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 7bea3526d8270b4aeeefecc57d7d7d638e2bbe0e Hamza Amin <[email protected]> 1727369570 +0500\tclone: from https://github.com/huggingface/transformers-bloom-inference.git\n", ".git\\refs\\heads\\main": "7bea3526d8270b4aeeefecc57d7d7d638e2bbe0e\n", "static\\js\\index.js": "const textGenInput = document.getElementById('text-input');\nconst clickButton = document.getElementById('submit-button');\n\nconst temperatureSlider = document.getElementById('temperature-slider');\nconst temperatureTextBox = document.getElementById('temperature-textbox')\n\nconst top_pSlider = document.getElementById('top_p-slider');\nconst top_pTextBox = document.getElementById('top_p-textbox');\n\nconst top_kSlider = document.getElementById('top_k-slider');\nconst top_kTextBox = document.getElementById('top_k-textbox');\n\nconst repetition_penaltySlider = document.getElementById('repetition_penalty-slider');\nconst repetition_penaltyTextBox = document.getElementById('repetition_penalty-textbox');\n\nconst max_new_tokensInput = document.getElementById('max-new-tokens-input');\n\nconst textLogOutput = document.getElementById('log-output');\n\nfunction get_temperature() {\n return parseFloat(temperatureSlider.value);\n}\n\ntemperatureSlider.addEventListener('input', async (event) => {\n temperatureTextBox.innerHTML = \"temperature = \" + get_temperature();\n});\n\nfunction get_top_p() {\n return parseFloat(top_pSlider.value);\n}\n\ntop_pSlider.addEventListener('input', async (event) => {\n top_pTextBox.innerHTML = \"top_p = \" + get_top_p();\n});\n\nfunction get_top_k() {\n return parseInt(top_kSlider.value);\n}\n\ntop_kSlider.addEventListener('input', async (event) => {\n top_kTextBox.innerHTML = \"top_k = \" + get_top_k();\n});\n\nfunction get_repetition_penalty() {\n return parseFloat(repetition_penaltySlider.value);\n}\n\nrepetition_penaltySlider.addEventListener('input', async (event) => {\n repetition_penaltyTextBox.innerHTML = \"repetition_penalty = \" + get_repetition_penalty();\n});\n\nfunction get_max_new_tokens() {\n return parseInt(max_new_tokensInput.value);\n}\n\nclickButton.addEventListener('click', async (event) => {\n clickButton.textContent = 'Processing'\n clickButton.disabled = true;\n\n var jsonPayload = {\n text: [textGenInput.value],\n temperature: get_temperature(),\n top_k: get_top_k(),\n top_p: get_top_p(),\n max_new_tokens: get_max_new_tokens(),\n repetition_penalty: get_repetition_penalty(),\n do_sample: true,\n remove_input_from_output: true\n };\n\n if (jsonPayload.temperature == 0) {\n jsonPayload.do_sample = false;\n }\n\n console.log(jsonPayload);\n\n $.ajax({\n url: '/generate/',\n type: 'POST',\n contentType: \"application/json; charset=utf-8\",\n data: JSON.stringify(jsonPayload),\n headers: { 'Access-Control-Allow-Origin': '*' },\n success: function (response) {\n var input_text = textGenInput.value;\n\n if (\"text\" in response) {\n if (response.is_encoder_decoder) {\n textLogOutput.value = response.text[0] + '\\n\\n';\n } else {\n textGenInput.value = input_text + response.text[0];\n textLogOutput.value = '';\n }\n\n textLogOutput.value += 'total_time_taken = ' + response.total_time_taken + \"\\n\";\n textLogOutput.value += 'num_generated_tokens = ' + response.num_generated_tokens + \"\\n\";\n textLogOutput.style.backgroundColor = \"lightblue\";\n } else {\n textLogOutput.value = 'total_time_taken = ' + response.total_time_taken + \"\\n\";\n textLogOutput.value += 'error: ' + response.message;\n textLogOutput.style.backgroundColor = \"#D65235\";\n }\n\n clickButton.textContent = 'Submit';\n clickButton.disabled = false;\n },\n error: function (error) {\n console.log(JSON.stringify(error, null, 2));\n clickButton.textContent = 'Submit'\n clickButton.disabled = false;\n }\n });\n});\n", "templates\\index.html": "<!DOCTYPE html>\n<html lang=\"en\">\n\n<head>\n <meta charset=\"UTF-8\" />\n <meta name=\"viewport\" content=\"width=device-width, initial-scale=1.0\" />\n <title>Large Models Playground</title>\n <link href=\"{{ url_for('static', path='css/style.css') }}\" rel=\"stylesheet\">\n <script type=\"module\" src=\"{{ url_for('static', path='js/index.js') }}\"></script>\n <script src=\"https://ajax.googleapis.com/ajax/libs/jquery/3.6.0/jquery.min.js\"></script>\n</head>\n\n<body>\n <div id=\"left-column\">\n <textarea placeholder=\"Input Prompt\" id=\"text-input\" style=\"color: black; background-color: white;\"\n rows=\"47\"></textarea>\n </div>\n\n <div id=\"right-column\">\n <div>\n <textbox id=\"temperature-textbox\">\n temperature = 1\n </textbox>\n <input type=\"range\" min=\"0\" max=\"1\" value=\"1\" step=\"0.01\" class=\"slider\" id=\"temperature-slider\">\n </div>\n\n <div>\n <textbox id=\"top_k-textbox\">\n top_k = 50\n </textbox>\n <input type=\"range\" min=\"1\" max=\"100\" value=\"50\" class=\"slider\" id=\"top_k-slider\">\n </div>\n\n <div>\n <textbox id=\"top_p-textbox\">\n top_p = 1\n </textbox>\n <input type=\"range\" min=\"0\" max=\"1\" step=\"0.01\" value=\"1\" class=\"slider\" id=\"top_p-slider\">\n </div>\n\n <div>\n <textbox style=\"float: left;\">\n max_new_tokens =\n </textbox>\n <input type=\"text\" value=\"40\" id=\"max-new-tokens-input\">\n </div>\n\n <div>\n <textbox id=\"repetition_penalty-textbox\">\n repetition_penalty = 1\n </textbox>\n <input type=\"range\" min=\"1\" max=\"3\" step=\"0.01\" value=\"1\" class=\"slider\" id=\"repetition_penalty-slider\">\n </div>\n\n <button id=\"submit-button\" style=\"margin-top: 10px;\">Submit</button>\n\n <div style=\"margin-top: 10px;\">\n <textarea id=\"log-output\" rows=\"40\" style=\"color: black; background-color: lightblue;\" readonly></textarea>\n </div>\n </div>\n</body>\n\n</html>\n"} | null |
transformers.js-examples | {"type": "directory", "name": "transformers.js-examples", "children": [{"type": "file", "name": ".prettierrc"}, {"type": "directory", "name": ".scripts", "children": [{"type": "file", "name": "build.js"}, {"type": "file", "name": "update.js"}]}, {"type": "directory", "name": "bun", "children": [{"type": "file", "name": "bun.lockb"}, {"type": "file", "name": "index.ts"}, {"type": "file", "name": "package.json"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "tsconfig.json"}]}, {"type": "file", "name": "LICENSE"}, {"type": "directory", "name": "node-cjs", "children": [{"type": "file", "name": "index.js"}, {"type": "file", "name": "package-lock.json"}, {"type": "file", "name": "package.json"}, {"type": "file", "name": "README.md"}]}, {"type": "directory", "name": "node-esm", "children": [{"type": "file", "name": "index.js"}, {"type": "file", "name": "package-lock.json"}, {"type": "file", "name": "package.json"}, {"type": "file", "name": "README.md"}]}, {"type": "file", "name": "package-lock.json"}, {"type": "file", "name": "package.json"}, {"type": "directory", "name": "pglite-semantic-search", "children": [{"type": "file", "name": "eslint.config.js"}, {"type": "file", "name": "index.html"}, {"type": "file", "name": "package-lock.json"}, {"type": "file", "name": "package.json"}, {"type": "file", "name": "postcss.config.js"}, {"type": "directory", "name": "public", "children": [{"type": "file", "name": "vite.svg"}]}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "src", "children": [{"type": "file", "name": "App.jsx"}, {"type": "file", "name": "globals.css"}, {"type": "file", "name": "main.jsx"}, {"type": "directory", "name": "utils", "children": [{"type": "file", "name": "db.js"}]}, {"type": "file", "name": "worker.js"}]}, {"type": "file", "name": "tailwind.config.js"}, {"type": "file", "name": "vite.config.js"}]}, {"type": "directory", "name": "phi-3.5-webgpu", "children": [{"type": "file", "name": "eslint.config.js"}, {"type": "file", "name": "index.html"}, {"type": "file", "name": "package-lock.json"}, {"type": "file", "name": "package.json"}, {"type": "file", "name": "postcss.config.js"}, {"type": "directory", "name": "public", "children": []}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "src", "children": [{"type": "file", "name": "App.jsx"}, {"type": "directory", "name": "components", "children": [{"type": "file", "name": "Chat.css"}, {"type": "file", "name": "Chat.jsx"}, {"type": "directory", "name": "icons", "children": [{"type": "file", "name": "ArrowRightIcon.jsx"}, {"type": "file", "name": "BotIcon.jsx"}, {"type": "file", "name": "StopIcon.jsx"}, {"type": "file", "name": "UserIcon.jsx"}]}, {"type": "file", "name": "Progress.jsx"}]}, {"type": "file", "name": "index.css"}, {"type": "file", "name": "main.jsx"}, {"type": "file", "name": "worker.js"}]}, {"type": "file", "name": "tailwind.config.js"}, {"type": "file", "name": "vite.config.js"}]}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "remove-background-webgpu", "children": [{"type": "file", "name": "eslint.config.js"}, {"type": "file", "name": "index.html"}, {"type": "file", "name": "package-lock.json"}, {"type": "file", "name": "package.json"}, {"type": "file", "name": "postcss.config.js"}, {"type": "directory", "name": "public", "children": []}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "src", "children": [{"type": "file", "name": "App.jsx"}, {"type": "file", "name": "index.css"}, {"type": "file", "name": "main.jsx"}]}, {"type": "file", "name": "tailwind.config.js"}, {"type": "file", "name": "vite.config.js"}]}, {"type": "directory", "name": "sapiens-node", "children": [{"type": "directory", "name": "assets", "children": []}, {"type": "file", "name": "index.js"}, {"type": "file", "name": "package-lock.json"}, {"type": "file", "name": "package.json"}, {"type": "file", "name": "README.md"}]}, {"type": "directory", "name": "segment-anything-webgpu", "children": [{"type": "file", "name": "index.css"}, {"type": "file", "name": "index.html"}, {"type": "file", "name": "index.js"}, {"type": "file", "name": "README.md"}]}, {"type": "directory", "name": "smollm-webgpu", "children": [{"type": "file", "name": "eslint.config.js"}, {"type": "file", "name": "index.html"}, {"type": "file", "name": "package-lock.json"}, {"type": "file", "name": "package.json"}, {"type": "file", "name": "postcss.config.js"}, {"type": "directory", "name": "public", "children": []}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "src", "children": [{"type": "file", "name": "App.jsx"}, {"type": "directory", "name": "components", "children": [{"type": "file", "name": "Chat.css"}, {"type": "file", "name": "Chat.jsx"}, {"type": "directory", "name": "icons", "children": [{"type": "file", "name": "ArrowRightIcon.jsx"}, {"type": "file", "name": "BotIcon.jsx"}, {"type": "file", "name": "StopIcon.jsx"}, {"type": "file", "name": "UserIcon.jsx"}]}, {"type": "file", "name": "Progress.jsx"}]}, {"type": "file", "name": "index.css"}, {"type": "file", "name": "main.jsx"}, {"type": "file", "name": "worker.js"}]}, {"type": "file", "name": "tailwind.config.js"}, {"type": "file", "name": "vite.config.js"}]}]} | ---
title: SmolLM WebGPU
emoji: 🤏
colorFrom: blue
colorTo: indigo
sdk: static
pinned: false
license: apache-2.0
models:
- HuggingFaceTB/SmolLM-360M-Instruct
short_description: A powerful AI chatbot that runs locally in your browser
thumbnail: https://huggingface.co/spaces/webml-community/smollm-webgpu/resolve/main/banner.png
---
# SmolLM WebGPU
A simple React + Vite application for running [SmolLM-360M-Instruct](https://huggingface.co/HuggingFaceTB/SmolLM-360M-Instruct), a powerful small language model, locally in the browser using Transformers.js and WebGPU-acceleration.
## Getting Started
Follow the steps below to set up and run the application.
### 1. Clone the Repository
Clone the examples repository from GitHub:
```sh
git clone https://github.com/huggingface/transformers.js-examples.git
```
### 2. Navigate to the Project Directory
Change your working directory to the `smollm-webgpu` folder:
```sh
cd transformers.js-examples/smollm-webgpu
```
### 3. Install Dependencies
Install the necessary dependencies using npm:
```sh
npm i
```
### 4. Run the Development Server
Start the development server:
```sh
npm run dev
```
The application should now be running locally. Open your browser and go to `http://localhost:5173` to see it in action.
| {"package.json": "{\n \"name\": \"transformers.js-examples\",\n \"version\": \"1.0.0\",\n \"description\": \"A collection of [\ud83e\udd17 Transformers.js](https://huggingface.co/docs/transformers.js) demos and example applications.\",\n \"type\": \"module\",\n \"scripts\": {\n \"update\": \"node .scripts/update.js\",\n \"build\": \"node .scripts/build.js\",\n \"format\": \"prettier --write .\"\n },\n \"keywords\": [\n \"transformers\",\n \"transformers.js\",\n \"hugging face\",\n \"huggingface\",\n \"machine learning\",\n \"ai\"\n ],\n \"author\": \"Hugging Face\",\n \"license\": \"Apache-2.0\",\n \"devDependencies\": {\n \"prettier\": \"3.3.3\"\n }\n}\n", ".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 7f1857fb66ff8067d95eacc64a670faf20e9ae52 Hamza Amin <[email protected]> 1727369584 +0500\tclone: from https://github.com/huggingface/transformers.js-examples.git\n", ".git\\refs\\heads\\main": "7f1857fb66ff8067d95eacc64a670faf20e9ae52\n", "bun\\index.ts": "import { pipeline } from \"@huggingface/transformers\";\n\n// Create a feature-extraction pipeline\nconst extractor = await pipeline(\n \"feature-extraction\",\n \"Xenova/all-MiniLM-L6-v2\",\n);\n\n// Compute sentence embeddings\nconst sentences = [\"Hello world\", \"This is an example sentence\"];\nconst output = await extractor(sentences, { pooling: \"mean\", normalize: true });\nconsole.log(output.tolist());\n// [\n// [ -0.03172111138701439, 0.04395204409956932, 0.00014728980022482574, ... ],\n// [ 0.0646488294005394, 0.0715673640370369, 0.05925070866942406, ... ]\n// ]\n", "bun\\package.json": "{\n \"name\": \"bun\",\n \"module\": \"index.ts\",\n \"type\": \"module\",\n \"devDependencies\": {\n \"@types/bun\": \"latest\"\n },\n \"peerDependencies\": {\n \"typescript\": \"^5.0.0\"\n },\n \"dependencies\": {\n \"@huggingface/transformers\": \"3.0.0-alpha.13\"\n }\n}\n", "node-cjs\\index.js": "const { pipeline } = require(\"@huggingface/transformers\");\n\nasync function main() {\n const classifier = await pipeline(\"text-classification\");\n const result = await classifier(\"I love Transformers.js!\");\n console.log(result); // [{ label: 'POSITIVE', score: 0.9997673034667969 }]\n}\nmain();\n", "node-cjs\\package.json": "{\n \"name\": \"node-cjs\",\n \"version\": \"1.0.0\",\n \"main\": \"index.js\",\n \"author\": \"Hugging Face\",\n \"license\": \"Apache-2.0\",\n \"description\": \"\",\n \"dependencies\": {\n \"@huggingface/transformers\": \"3.0.0-alpha.13\"\n }\n}\n", "node-esm\\index.js": "import { pipeline } from \"@huggingface/transformers\";\n\nconst classifier = await pipeline(\"text-classification\");\nconst result = await classifier(\"I love Transformers.js!\");\nconsole.log(result); // [{ label: 'POSITIVE', score: 0.9997673034667969 }]\n", "node-esm\\package.json": "{\n \"name\": \"node-esm\",\n \"version\": \"1.0.0\",\n \"main\": \"index.js\",\n \"type\": \"module\",\n \"author\": \"Hugging Face\",\n \"license\": \"Apache-2.0\",\n \"description\": \"\",\n \"dependencies\": {\n \"@huggingface/transformers\": \"3.0.0-alpha.13\"\n }\n}\n", "pglite-semantic-search\\index.html": "<!doctype html>\n<html lang=\"en\">\n <head>\n <meta charset=\"UTF-8\" />\n <link rel=\"icon\" type=\"image/svg+xml\" href=\"/vite.svg\" />\n <meta name=\"viewport\" content=\"width=device-width, initial-scale=1.0\" />\n <title>Browser Vector Search</title>\n </head>\n <body>\n <div id=\"root\"></div>\n <script type=\"module\" src=\"/src/main.jsx\"></script>\n </body>\n</html>\n", "pglite-semantic-search\\package.json": "{\n \"name\": \"browser-vector-search-vite\",\n \"private\": true,\n \"version\": \"0.0.0\",\n \"type\": \"module\",\n \"scripts\": {\n \"dev\": \"vite\",\n \"build\": \"vite build\",\n \"lint\": \"eslint .\",\n \"preview\": \"vite preview\"\n },\n \"dependencies\": {\n \"@electric-sql/pglite\": \"0.2.0\",\n \"@huggingface/transformers\": \"3.0.0-alpha.13\",\n \"react\": \"^18.3.1\",\n \"react-dom\": \"^18.3.1\"\n },\n \"devDependencies\": {\n \"@eslint/js\": \"^9.8.0\",\n \"@types/react\": \"^18.3.3\",\n \"@types/react-dom\": \"^18.3.0\",\n \"@vitejs/plugin-react\": \"^4.3.1\",\n \"autoprefixer\": \"^10.4.20\",\n \"eslint\": \"^9.8.0\",\n \"eslint-plugin-react\": \"^7.35.0\",\n \"eslint-plugin-react-hooks\": \"^5.1.0-rc.0\",\n \"eslint-plugin-react-refresh\": \"^0.4.9\",\n \"globals\": \"^15.9.0\",\n \"postcss\": \"^8.4.41\",\n \"tailwindcss\": \"^3.4.10\",\n \"vite\": \"^5.4.0\"\n }\n}\n", "pglite-semantic-search\\src\\App.jsx": "import { getDB, initSchema, countRows, seedDb, search } from \"./utils/db\";\nimport { useState, useEffect, useRef, useCallback } from \"react\";\n\nexport default function App() {\n // Keep track of the classification result and the model loading status.\n const [input, setInput] = useState(\"\");\n const [content, setContent] = useState([]);\n const [result, setResult] = useState(null);\n const [ready, setReady] = useState(null);\n const initailizing = useRef(false);\n\n // Create a reference to the worker object.\n const worker = useRef(null);\n\n // Set up DB\n const db = useRef(null);\n useEffect(() => {\n const setup = async () => {\n initailizing.current = true;\n db.current = await getDB();\n await initSchema(db.current);\n let count = await countRows(db.current, \"embeddings\");\n console.log(`Found ${count} rows`);\n if (count === 0) {\n await seedDb(db.current);\n count = await countRows(db.current, \"embeddings\");\n console.log(`Seeded ${count} rows`);\n }\n // Get Items\n const items = await db.current.query(\"SELECT content FROM embeddings\");\n setContent(items.rows.map((x) => x.content));\n };\n if (!db.current && !initailizing.current) {\n setup();\n }\n }, []);\n\n // We use the `useEffect` hook to set up the worker as soon as the `App` component is mounted.\n useEffect(() => {\n if (!worker.current) {\n // Create the worker if it does not yet exist.\n worker.current = new Worker(new URL(\"./worker.js\", import.meta.url), {\n type: \"module\",\n });\n }\n\n // Create a callback function for messages from the worker thread.\n const onMessageReceived = async (e) => {\n switch (e.data.status) {\n case \"initiate\":\n setReady(false);\n break;\n case \"ready\":\n setReady(true);\n break;\n case \"complete\":\n // Cosine similarity search in pgvector\n const searchResults = await search(db.current, e.data.embedding);\n console.log({ searchResults });\n setResult(searchResults.map((x) => x.content));\n break;\n }\n };\n\n // Attach the callback function as an event listener.\n worker.current.addEventListener(\"message\", onMessageReceived);\n\n // Define a cleanup function for when the component is unmounted.\n return () =>\n worker.current.removeEventListener(\"message\", onMessageReceived);\n });\n\n const classify = useCallback((text) => {\n if (worker.current) {\n worker.current.postMessage({ text });\n }\n }, []);\n return (\n <main className=\"flex min-h-screen flex-col items-center justify-center p-12\">\n <h1 className=\"text-5xl font-bold mb-2 text-center\">Transformers.js</h1>\n <h2 className=\"text-2xl mb-4 text-center\">\n 100% in-browser Semantic Search with{\" \"}\n <a\n className=\"underline\"\n href=\"https://huggingface.co/docs/transformers.js\"\n >\n Transformers.js\n </a>\n {\", \"}\n <a className=\"underline\" href=\"https://github.com/electric-sql/pglite\">\n PGlite\n </a>{\" \"}\n {\" + \"}\n <a className=\"underline\" href=\"https://github.com/pgvector/pgvector\">\n pgvector!\n </a>\n </h2>\n <p className=\"text-center\">Items in database:</p>\n <pre className=\"bg-gray-100 p-2 mb-4 rounded\">\n {JSON.stringify(content)}\n </pre>\n <form\n onSubmit={(e) => {\n e.preventDefault();\n classify(input);\n }}\n >\n <input\n type=\"text\"\n className=\"w-full max-w-xs p-2 border border-gray-300 rounded mb-4\"\n placeholder=\"Enter text here\"\n onInput={(e) => {\n setResult([]);\n setInput(e.target.value);\n }}\n />\n <button\n type=\"submit\"\n className=\"bg-blue-500 text-white p-2 mb-4 rounded w-full max-w-xs\"\n >\n Semantic Search\n </button>\n </form>\n\n {ready !== null && (\n <>\n <p className=\"text-center\">Similarity Search results:</p>\n <pre className=\"bg-gray-100 p-2 rounded\">\n {!ready || !result ? \"Loading...\" : JSON.stringify(result)}\n </pre>\n </>\n )}\n </main>\n );\n}\n", "pglite-semantic-search\\src\\main.jsx": "import { StrictMode } from \"react\";\nimport { createRoot } from \"react-dom/client\";\nimport App from \"./App.jsx\";\nimport \"./globals.css\";\n\ncreateRoot(document.getElementById(\"root\")).render(\n <StrictMode>\n <App />\n </StrictMode>,\n);\n", "phi-3.5-webgpu\\index.html": "<!doctype html>\n<html lang=\"en\">\n <head>\n <meta charset=\"UTF-8\" />\n <link rel=\"icon\" type=\"image/png\" href=\"/logo.png\" />\n <meta name=\"viewport\" content=\"width=device-width, initial-scale=1.0\" />\n <title>Phi-3.5 WebGPU</title>\n </head>\n\n <body>\n <div id=\"root\"></div>\n\n <script>\n window.MathJax = {\n tex: {\n inlineMath: [\n [\"$\", \"$\"],\n [\"\\\\(\", \"\\\\)\"],\n ],\n },\n svg: {\n fontCache: \"global\",\n },\n };\n </script>\n <script\n id=\"MathJax-script\"\n src=\"https://cdn.jsdelivr.net/npm/mathjax@3/es5/tex-mml-chtml.js\"\n ></script>\n <script type=\"module\" src=\"/src/main.jsx\"></script>\n </body>\n</html>\n", "phi-3.5-webgpu\\package.json": "{\n \"name\": \"phi-3.5-webgpu\",\n \"private\": true,\n \"version\": \"0.0.0\",\n \"type\": \"module\",\n \"scripts\": {\n \"dev\": \"vite\",\n \"build\": \"vite build\",\n \"lint\": \"eslint .\",\n \"preview\": \"vite preview\"\n },\n \"dependencies\": {\n \"@huggingface/transformers\": \"3.0.0-alpha.13\",\n \"dompurify\": \"^3.1.2\",\n \"marked\": \"^12.0.2\",\n \"react\": \"^18.3.1\",\n \"react-dom\": \"^18.3.1\"\n },\n \"devDependencies\": {\n \"@eslint/js\": \"^9.9.0\",\n \"@types/react\": \"^18.3.3\",\n \"@types/react-dom\": \"^18.3.0\",\n \"@vitejs/plugin-react\": \"^4.3.1\",\n \"autoprefixer\": \"^10.4.20\",\n \"eslint\": \"^9.9.0\",\n \"eslint-plugin-react\": \"^7.35.0\",\n \"eslint-plugin-react-hooks\": \"^5.1.0-rc.0\",\n \"eslint-plugin-react-refresh\": \"^0.4.9\",\n \"globals\": \"^15.9.0\",\n \"postcss\": \"^8.4.41\",\n \"tailwindcss\": \"^3.4.10\",\n \"vite\": \"^5.4.1\"\n }\n}\n", "phi-3.5-webgpu\\src\\App.jsx": "import { useEffect, useState, useRef } from \"react\";\n\nimport Chat from \"./components/Chat\";\nimport ArrowRightIcon from \"./components/icons/ArrowRightIcon\";\nimport StopIcon from \"./components/icons/StopIcon\";\nimport Progress from \"./components/Progress\";\n\nconst IS_WEBGPU_AVAILABLE = !!navigator.gpu;\nconst STICKY_SCROLL_THRESHOLD = 120;\nconst EXAMPLES = [\n \"Give me some tips to improve my time management skills.\",\n \"What is the difference between AI and ML?\",\n \"Write python code to compute the nth fibonacci number.\",\n];\n\nfunction App() {\n // Create a reference to the worker object.\n const worker = useRef(null);\n\n const textareaRef = useRef(null);\n const chatContainerRef = useRef(null);\n\n // Model loading and progress\n const [status, setStatus] = useState(null);\n const [error, setError] = useState(null);\n const [loadingMessage, setLoadingMessage] = useState(\"\");\n const [progressItems, setProgressItems] = useState([]);\n const [isRunning, setIsRunning] = useState(false);\n\n // Inputs and outputs\n const [input, setInput] = useState(\"\");\n const [messages, setMessages] = useState([]);\n const [tps, setTps] = useState(null);\n const [numTokens, setNumTokens] = useState(null);\n\n function onEnter(message) {\n setMessages((prev) => [...prev, { role: \"user\", content: message }]);\n setTps(null);\n setIsRunning(true);\n setInput(\"\");\n }\n\n function onInterrupt() {\n // NOTE: We do not set isRunning to false here because the worker\n // will send a 'complete' message when it is done.\n worker.current.postMessage({ type: \"interrupt\" });\n }\n\n useEffect(() => {\n resizeInput();\n }, [input]);\n\n function resizeInput() {\n if (!textareaRef.current) return;\n\n const target = textareaRef.current;\n target.style.height = \"auto\";\n const newHeight = Math.min(Math.max(target.scrollHeight, 24), 200);\n target.style.height = `${newHeight}px`;\n }\n\n // We use the `useEffect` hook to setup the worker as soon as the `App` component is mounted.\n useEffect(() => {\n // Create the worker if it does not yet exist.\n if (!worker.current) {\n worker.current = new Worker(new URL(\"./worker.js\", import.meta.url), {\n type: \"module\",\n });\n worker.current.postMessage({ type: \"check\" }); // Do a feature check\n }\n\n // Create a callback function for messages from the worker thread.\n const onMessageReceived = (e) => {\n switch (e.data.status) {\n case \"loading\":\n // Model file start load: add a new progress item to the list.\n setStatus(\"loading\");\n setLoadingMessage(e.data.data);\n break;\n\n case \"initiate\":\n setProgressItems((prev) => [...prev, e.data]);\n break;\n\n case \"progress\":\n // Model file progress: update one of the progress items.\n setProgressItems((prev) =>\n prev.map((item) => {\n if (item.file === e.data.file) {\n return { ...item, ...e.data };\n }\n return item;\n }),\n );\n break;\n\n case \"done\":\n // Model file loaded: remove the progress item from the list.\n setProgressItems((prev) =>\n prev.filter((item) => item.file !== e.data.file),\n );\n break;\n\n case \"ready\":\n // Pipeline ready: the worker is ready to accept messages.\n setStatus(\"ready\");\n break;\n\n case \"start\":\n {\n // Start generation\n setMessages((prev) => [\n ...prev,\n { role: \"assistant\", content: \"\" },\n ]);\n }\n break;\n\n case \"update\":\n {\n // Generation update: update the output text.\n // Parse messages\n const { output, tps, numTokens } = e.data;\n setTps(tps);\n setNumTokens(numTokens);\n setMessages((prev) => {\n const cloned = [...prev];\n const last = cloned.at(-1);\n cloned[cloned.length - 1] = {\n ...last,\n content: last.content + output,\n };\n return cloned;\n });\n }\n break;\n\n case \"complete\":\n // Generation complete: re-enable the \"Generate\" button\n setIsRunning(false);\n break;\n\n case \"error\":\n setError(e.data.data);\n break;\n }\n };\n\n const onErrorReceived = (e) => {\n console.error(\"Worker error:\", e);\n };\n\n // Attach the callback function as an event listener.\n worker.current.addEventListener(\"message\", onMessageReceived);\n worker.current.addEventListener(\"error\", onErrorReceived);\n\n // Define a cleanup function for when the component is unmounted.\n return () => {\n worker.current.removeEventListener(\"message\", onMessageReceived);\n worker.current.removeEventListener(\"error\", onErrorReceived);\n };\n }, []);\n\n // Send the messages to the worker thread whenever the `messages` state changes.\n useEffect(() => {\n if (messages.filter((x) => x.role === \"user\").length === 0) {\n // No user messages yet: do nothing.\n return;\n }\n if (messages.at(-1).role === \"assistant\") {\n // Do not update if the last message is from the assistant\n return;\n }\n setTps(null);\n worker.current.postMessage({ type: \"generate\", data: messages });\n }, [messages, isRunning]);\n\n useEffect(() => {\n if (!chatContainerRef.current || !isRunning) return;\n const element = chatContainerRef.current;\n if (\n element.scrollHeight - element.scrollTop - element.clientHeight <\n STICKY_SCROLL_THRESHOLD\n ) {\n element.scrollTop = element.scrollHeight;\n }\n }, [messages, isRunning]);\n\n return IS_WEBGPU_AVAILABLE ? (\n <div className=\"flex flex-col h-screen mx-auto items justify-end text-gray-800 dark:text-gray-200 bg-white dark:bg-gray-900\">\n {status === null && messages.length === 0 && (\n <div className=\"h-full overflow-auto scrollbar-thin flex justify-center items-center flex-col relative\">\n <div className=\"flex flex-col items-center mb-1 max-w-[300px] text-center\">\n <img\n src=\"logo.png\"\n width=\"85%\"\n height=\"auto\"\n className=\"block\"\n ></img>\n <h1 className=\"text-4xl font-bold mb-1\">Phi-3.5 WebGPU</h1>\n <h2 className=\"font-semibold\">\n A private and powerful AI chatbot\n <br />\n that runs locally in your browser.\n </h2>\n </div>\n\n <div className=\"flex flex-col items-center px-4\">\n <p className=\"max-w-[514px] mb-4\">\n <br />\n You are about to load{\" \"}\n <a\n href=\"onnx-community/Phi-3.5-mini-instruct-onnx-web\"\n target=\"_blank\"\n rel=\"noreferrer\"\n className=\"font-medium underline\"\n >\n Phi-3.5-mini-instruct\n </a>\n , a 3.82 billion parameter LLM that is optimized for inference on\n the web. Once downloaded, the model (2.3 GB) will be cached\n and reused when you revisit the page.\n <br />\n <br />\n Everything runs directly in your browser using{\" \"}\n <a\n href=\"https://huggingface.co/docs/transformers.js\"\n target=\"_blank\"\n rel=\"noreferrer\"\n className=\"underline\"\n >\n \ud83e\udd17 Transformers.js\n </a>{\" \"}\n and ONNX Runtime Web, meaning your conversations aren't sent\n to a server. You can even disconnect from the internet after the\n model has loaded!\n <br />\n Want to learn more? Check out the demo's source code on{\" \"}\n <a\n href=\"https://github.com/huggingface/transformers.js-examples/tree/main/phi-3.5-webgpu\"\n target=\"_blank\"\n rel=\"noreferrer\"\n className=\"underline\"\n >\n GitHub\n </a>\n !\n </p>\n\n {error && (\n <div className=\"text-red-500 text-center mb-2\">\n <p className=\"mb-1\">\n Unable to load model due to the following error:\n </p>\n <p className=\"text-sm\">{error}</p>\n </div>\n )}\n\n <button\n className=\"border px-4 py-2 rounded-lg bg-blue-400 text-white hover:bg-blue-500 disabled:bg-blue-100 disabled:cursor-not-allowed select-none\"\n onClick={() => {\n worker.current.postMessage({ type: \"load\" });\n setStatus(\"loading\");\n }}\n disabled={status !== null || error !== null}\n >\n Load model\n </button>\n </div>\n </div>\n )}\n {status === \"loading\" && (\n <>\n <div className=\"w-full max-w-[500px] text-left mx-auto p-4 bottom-0 mt-auto\">\n <p className=\"text-center mb-1\">{loadingMessage}</p>\n {progressItems.map(({ file, progress, total }, i) => (\n <Progress\n key={i}\n text={file}\n percentage={progress}\n total={total}\n />\n ))}\n </div>\n </>\n )}\n\n {status === \"ready\" && (\n <div\n ref={chatContainerRef}\n className=\"overflow-y-auto scrollbar-thin w-full flex flex-col items-center h-full\"\n >\n <Chat messages={messages} />\n {messages.length === 0 && (\n <div>\n {EXAMPLES.map((msg, i) => (\n <div\n key={i}\n className=\"m-1 border dark:border-gray-600 rounded-md p-2 bg-gray-100 dark:bg-gray-700 cursor-pointer\"\n onClick={() => onEnter(msg)}\n >\n {msg}\n </div>\n ))}\n </div>\n )}\n <p className=\"text-center text-sm min-h-6 text-gray-500 dark:text-gray-300\">\n {tps && messages.length > 0 && (\n <>\n {!isRunning && (\n <span>\n Generated {numTokens} tokens in{\" \"}\n {(numTokens / tps).toFixed(2)} seconds (\n </span>\n )}\n {\n <>\n <span className=\"font-medium text-center mr-1 text-black dark:text-white\">\n {tps.toFixed(2)}\n </span>\n <span className=\"text-gray-500 dark:text-gray-300\">\n tokens/second\n </span>\n </>\n }\n {!isRunning && (\n <>\n <span className=\"mr-1\">).</span>\n <span\n className=\"underline cursor-pointer\"\n onClick={() => {\n worker.current.postMessage({ type: \"reset\" });\n setMessages([]);\n }}\n >\n Reset\n </span>\n </>\n )}\n </>\n )}\n </p>\n </div>\n )}\n\n <div className=\"mt-2 border dark:bg-gray-700 rounded-lg w-[600px] max-w-[80%] max-h-[200px] mx-auto relative mb-3 flex\">\n <textarea\n ref={textareaRef}\n className=\"scrollbar-thin w-[550px] dark:bg-gray-700 px-3 py-4 rounded-lg bg-transparent border-none outline-none text-gray-800 disabled:text-gray-400 dark:text-gray-200 placeholder-gray-500 dark:placeholder-gray-400 disabled:placeholder-gray-200 resize-none disabled:cursor-not-allowed\"\n placeholder=\"Type your message...\"\n type=\"text\"\n rows={1}\n value={input}\n disabled={status !== \"ready\"}\n title={status === \"ready\" ? \"Model is ready\" : \"Model not loaded yet\"}\n onKeyDown={(e) => {\n if (\n input.length > 0 &&\n !isRunning &&\n e.key === \"Enter\" &&\n !e.shiftKey\n ) {\n e.preventDefault(); // Prevent default behavior of Enter key\n onEnter(input);\n }\n }}\n onInput={(e) => setInput(e.target.value)}\n />\n {isRunning ? (\n <div className=\"cursor-pointer\" onClick={onInterrupt}>\n <StopIcon className=\"h-8 w-8 p-1 rounded-md text-gray-800 dark:text-gray-100 absolute right-3 bottom-3\" />\n </div>\n ) : input.length > 0 ? (\n <div className=\"cursor-pointer\" onClick={() => onEnter(input)}>\n <ArrowRightIcon\n className={`h-8 w-8 p-1 bg-gray-800 dark:bg-gray-100 text-white dark:text-black rounded-md absolute right-3 bottom-3`}\n />\n </div>\n ) : (\n <div>\n <ArrowRightIcon\n className={`h-8 w-8 p-1 bg-gray-200 dark:bg-gray-600 text-gray-50 dark:text-gray-800 rounded-md absolute right-3 bottom-3`}\n />\n </div>\n )}\n </div>\n\n <p className=\"text-xs text-gray-400 text-center mb-3\">\n Disclaimer: Generated content may be inaccurate or false.\n </p>\n </div>\n ) : (\n <div className=\"fixed w-screen h-screen bg-black z-10 bg-opacity-[92%] text-white text-2xl font-semibold flex justify-center items-center text-center\">\n WebGPU is not supported\n <br />\n by this browser :(\n </div>\n );\n}\n\nexport default App;\n", "phi-3.5-webgpu\\src\\index.css": "@tailwind base;\n@tailwind components;\n@tailwind utilities;\n\n@layer utilities {\n .scrollbar-thin::-webkit-scrollbar {\n @apply w-2;\n }\n\n .scrollbar-thin::-webkit-scrollbar-track {\n @apply rounded-full bg-gray-100 dark:bg-gray-700;\n }\n\n .scrollbar-thin::-webkit-scrollbar-thumb {\n @apply rounded-full bg-gray-300 dark:bg-gray-600;\n }\n\n .scrollbar-thin::-webkit-scrollbar-thumb:hover {\n @apply bg-gray-500;\n }\n\n .animation-delay-200 {\n animation-delay: 200ms;\n }\n .animation-delay-400 {\n animation-delay: 400ms;\n }\n\n .overflow-wrap-anywhere {\n overflow-wrap: anywhere;\n }\n}\n", "phi-3.5-webgpu\\src\\main.jsx": "import React from \"react\";\nimport ReactDOM from \"react-dom/client\";\nimport App from \"./App.jsx\";\nimport \"./index.css\";\n\nReactDOM.createRoot(document.getElementById(\"root\")).render(\n <React.StrictMode>\n <App />\n </React.StrictMode>,\n);\n", "remove-background-webgpu\\index.html": "<!doctype html>\n<html lang=\"en\">\n <head>\n <meta charset=\"UTF-8\" />\n <meta name=\"viewport\" content=\"width=device-width, initial-scale=1.0\" />\n <title>Remove Background WebGPU</title>\n </head>\n <body>\n <div id=\"root\"></div>\n <script type=\"module\" src=\"/src/main.jsx\"></script>\n </body>\n</html>\n", "remove-background-webgpu\\package.json": "{\n \"name\": \"remove-background-webgpu\",\n \"private\": true,\n \"version\": \"0.0.0\",\n \"type\": \"module\",\n \"scripts\": {\n \"dev\": \"vite\",\n \"build\": \"vite build\",\n \"lint\": \"eslint .\",\n \"preview\": \"vite preview\"\n },\n \"dependencies\": {\n \"@huggingface/transformers\": \"3.0.0-alpha.13\",\n \"file-saver\": \"^2.0.5\",\n \"jszip\": \"^3.10.1\",\n \"react\": \"^18.3.1\",\n \"react-dom\": \"^18.3.1\",\n \"react-dropzone\": \"^14.2.3\"\n },\n \"devDependencies\": {\n \"@eslint/js\": \"^9.9.0\",\n \"@types/react\": \"^18.3.3\",\n \"@types/react-dom\": \"^18.3.0\",\n \"@vitejs/plugin-react\": \"^4.3.1\",\n \"autoprefixer\": \"^10.4.20\",\n \"eslint\": \"^9.9.0\",\n \"eslint-plugin-react\": \"^7.35.0\",\n \"eslint-plugin-react-hooks\": \"^5.1.0-rc.0\",\n \"eslint-plugin-react-refresh\": \"^0.4.9\",\n \"globals\": \"^15.9.0\",\n \"postcss\": \"^8.4.41\",\n \"tailwindcss\": \"^3.4.10\",\n \"vite\": \"^5.4.1\"\n }\n}\n", "remove-background-webgpu\\src\\App.jsx": "import { useState, useCallback, useEffect, useRef } from \"react\";\nimport { useDropzone } from \"react-dropzone\";\nimport {\n env,\n AutoModel,\n AutoProcessor,\n RawImage,\n} from \"@huggingface/transformers\";\n\nimport JSZip from \"jszip\";\nimport { saveAs } from \"file-saver\";\n\nexport default function App() {\n const [images, setImages] = useState([]);\n const [processedImages, setProcessedImages] = useState([]);\n const [isProcessing, setIsProcessing] = useState(false);\n const [isDownloadReady, setIsDownloadReady] = useState(false);\n const [isLoading, setIsLoading] = useState(true);\n const [error, setError] = useState(null);\n\n const modelRef = useRef(null);\n const processorRef = useRef(null);\n\n useEffect(() => {\n (async () => {\n try {\n if (!navigator.gpu) {\n throw new Error(\"WebGPU is not supported in this browser.\");\n }\n const model_id = \"Xenova/modnet\";\n env.backends.onnx.wasm.proxy = false;\n modelRef.current ??= await AutoModel.from_pretrained(model_id, {\n device: \"webgpu\",\n });\n processorRef.current ??= await AutoProcessor.from_pretrained(model_id);\n } catch (err) {\n setError(err);\n }\n setIsLoading(false);\n })();\n }, []);\n\n const onDrop = useCallback((acceptedFiles) => {\n setImages((prevImages) => [\n ...prevImages,\n ...acceptedFiles.map((file) => URL.createObjectURL(file)),\n ]);\n }, []);\n\n const {\n getRootProps,\n getInputProps,\n isDragActive,\n isDragAccept,\n isDragReject,\n } = useDropzone({\n onDrop,\n accept: {\n \"image/*\": [\".jpeg\", \".jpg\", \".png\"],\n },\n });\n\n const removeImage = (index) => {\n setImages((prevImages) => prevImages.filter((_, i) => i !== index));\n setProcessedImages((prevProcessed) =>\n prevProcessed.filter((_, i) => i !== index),\n );\n };\n\n const processImages = async () => {\n setIsProcessing(true);\n setProcessedImages([]);\n\n const model = modelRef.current;\n const processor = processorRef.current;\n\n for (let i = 0; i < images.length; ++i) {\n // Load image\n const img = await RawImage.fromURL(images[i]);\n\n // Pre-process image\n const { pixel_values } = await processor(img);\n\n // Predict alpha matte\n const { output } = await model({ input: pixel_values });\n\n const maskData = (\n await RawImage.fromTensor(output[0].mul(255).to(\"uint8\")).resize(\n img.width,\n img.height,\n )\n ).data;\n\n // Create new canvas\n const canvas = document.createElement(\"canvas\");\n canvas.width = img.width;\n canvas.height = img.height;\n const ctx = canvas.getContext(\"2d\");\n\n // Draw original image output to canvas\n ctx.drawImage(img.toCanvas(), 0, 0);\n\n // Update alpha channel\n const pixelData = ctx.getImageData(0, 0, img.width, img.height);\n for (let i = 0; i < maskData.length; ++i) {\n pixelData.data[4 * i + 3] = maskData[i];\n }\n ctx.putImageData(pixelData, 0, 0);\n setProcessedImages((prevProcessed) => [\n ...prevProcessed,\n canvas.toDataURL(\"image/png\"),\n ]);\n }\n\n setIsProcessing(false);\n setIsDownloadReady(true);\n };\n\n const downloadAsZip = async () => {\n const zip = new JSZip();\n const promises = images.map(\n (image, i) =>\n new Promise((resolve) => {\n const canvas = document.createElement(\"canvas\");\n const ctx = canvas.getContext(\"2d\");\n\n const img = new Image();\n img.src = processedImages[i] || image;\n\n img.onload = () => {\n canvas.width = img.width;\n canvas.height = img.height;\n ctx.drawImage(img, 0, 0);\n canvas.toBlob((blob) => {\n if (blob) {\n zip.file(`image-${i + 1}.png`, blob);\n }\n resolve(null);\n }, \"image/png\");\n };\n }),\n );\n\n await Promise.all(promises);\n\n const content = await zip.generateAsync({ type: \"blob\" });\n saveAs(content, \"images.zip\");\n };\n\n const clearAll = () => {\n setImages([]);\n setProcessedImages([]);\n setIsDownloadReady(false);\n };\n\n const copyToClipboard = async (url) => {\n try {\n // Fetch the image from the URL and convert it to a Blob\n const response = await fetch(url);\n const blob = await response.blob();\n\n // Create a clipboard item with the image blob\n const clipboardItem = new ClipboardItem({ [blob.type]: blob });\n\n // Write the clipboard item to the clipboard\n await navigator.clipboard.write([clipboardItem]);\n\n console.log(\"Image copied to clipboard\");\n } catch (err) {\n console.error(\"Failed to copy image: \", err);\n }\n };\n\n const downloadImage = (url) => {\n const link = document.createElement(\"a\");\n link.href = url;\n link.download = \"image.png\";\n document.body.appendChild(link);\n link.click();\n document.body.removeChild(link);\n };\n\n if (error) {\n return (\n <div className=\"min-h-screen bg-black text-white flex items-center justify-center\">\n <div className=\"text-center\">\n <h2 className=\"text-4xl mb-2\">ERROR</h2>\n <p className=\"text-xl max-w-[500px]\">{error.message}</p>\n </div>\n </div>\n );\n }\n\n if (isLoading) {\n return (\n <div className=\"min-h-screen bg-black text-white flex items-center justify-center\">\n <div className=\"text-center\">\n <div className=\"inline-block animate-spin rounded-full h-8 w-8 border-t-2 border-b-2 border-white mb-4\"></div>\n <p className=\"text-lg\">Loading background removal model...</p>\n </div>\n </div>\n );\n }\n\n return (\n <div className=\"min-h-screen bg-black text-white p-8\">\n <div className=\"max-w-4xl mx-auto\">\n <h1 className=\"text-4xl font-bold mb-2 text-center\">\n Remove Background WebGPU\n </h1>\n <h2 className=\"text-lg font-semibold mb-2 text-center\">\n In-browser background removal, powered by{\" \"}\n <a\n className=\"underline\"\n target=\"_blank\"\n href=\"https://github.com/xenova/transformers.js\"\n >\n \ud83e\udd17 Transformers.js\n </a>\n </h2>\n <div className=\"flex justify-center mb-8 gap-8\">\n <a\n className=\"underline\"\n target=\"_blank\"\n href=\"https://github.com/huggingface/transformers.js-examples/blob/main/LICENSE\"\n >\n License (Apache 2.0)\n </a>\n <a\n className=\"underline\"\n target=\"_blank\"\n href=\"https://huggingface.co/Xenova/modnet\"\n >\n Model (MODNet)\n </a>\n <a\n className=\"underline\"\n target=\"_blank\"\n href=\"https://github.com/huggingface/transformers.js-examples/tree/main/remove-background-webgpu/\"\n >\n Code (GitHub)\n </a>\n </div>\n <div\n {...getRootProps()}\n className={`p-8 mb-8 border-2 border-dashed rounded-lg text-center cursor-pointer transition-colors duration-300 ease-in-out\n ${isDragAccept ? \"border-green-500 bg-green-900/20\" : \"\"}\n ${isDragReject ? \"border-red-500 bg-red-900/20\" : \"\"}\n ${isDragActive ? \"border-blue-500 bg-blue-900/20\" : \"border-gray-700 hover:border-blue-500 hover:bg-blue-900/10\"}\n `}\n >\n <input {...getInputProps()} className=\"hidden\" />\n <p className=\"text-lg mb-2\">\n {isDragActive\n ? \"Drop the images here...\"\n : \"Drag and drop some images here\"}\n </p>\n <p className=\"text-sm text-gray-400\">or click to select files</p>\n </div>\n <div className=\"flex flex-col items-center gap-4 mb-8\">\n <button\n onClick={processImages}\n disabled={isProcessing || images.length === 0}\n className=\"px-6 py-3 bg-blue-600 text-white rounded-md hover:bg-blue-700 focus:outline-none focus:ring-2 focus:ring-blue-500 focus:ring-offset-2 focus:ring-offset-black disabled:bg-gray-700 disabled:cursor-not-allowed transition-colors duration-200 text-lg font-semibold\"\n >\n {isProcessing ? \"Processing...\" : \"Process\"}\n </button>\n <div className=\"flex gap-4\">\n <button\n onClick={downloadAsZip}\n disabled={!isDownloadReady}\n className=\"px-3 py-1 bg-green-600 text-white rounded-md hover:bg-green-700 focus:outline-none focus:ring-2 focus:ring-green-500 focus:ring-offset-2 focus:ring-offset-black disabled:bg-gray-700 disabled:cursor-not-allowed transition-colors duration-200 text-sm\"\n >\n Download as ZIP\n </button>\n <button\n onClick={clearAll}\n className=\"px-3 py-1 bg-red-600 text-white rounded-md hover:bg-red-700 focus:outline-none focus:ring-2 focus:ring-red-500 focus:ring-offset-2 focus:ring-offset-black transition-colors duration-200 text-sm\"\n >\n Clear All\n </button>\n </div>\n </div>\n <div className=\"grid grid-cols-2 md:grid-cols-3 lg:grid-cols-4 gap-6\">\n {images.map((src, index) => (\n <div key={index} className=\"relative group\">\n <img\n src={processedImages[index] || src}\n alt={`Image ${index + 1}`}\n className=\"rounded-lg object-cover w-full h-48\"\n />\n {processedImages[index] && (\n <div className=\"absolute inset-0 bg-black bg-opacity-70 opacity-0 group-hover:opacity-100 transition-opacity duration-300 rounded-lg flex items-center justify-center\">\n <button\n onClick={() =>\n copyToClipboard(processedImages[index] || src)\n }\n className=\"mx-2 px-3 py-1 bg-white text-gray-900 rounded-md hover:bg-gray-200 transition-colors duration-200 text-sm\"\n aria-label={`Copy image ${index + 1} to clipboard`}\n >\n Copy\n </button>\n <button\n onClick={() => downloadImage(processedImages[index] || src)}\n className=\"mx-2 px-3 py-1 bg-white text-gray-900 rounded-md hover:bg-gray-200 transition-colors duration-200 text-sm\"\n aria-label={`Download image ${index + 1}`}\n >\n Download\n </button>\n </div>\n )}\n <button\n onClick={() => removeImage(index)}\n className=\"absolute top-2 right-2 bg-black bg-opacity-50 text-white w-6 h-6 rounded-full flex items-center justify-center opacity-0 group-hover:opacity-100 transition-opacity duration-300 hover:bg-opacity-70\"\n aria-label={`Remove image ${index + 1}`}\n >\n ✕\n </button>\n </div>\n ))}\n </div>\n </div>\n </div>\n );\n}\n", "remove-background-webgpu\\src\\index.css": "@tailwind base;\n@tailwind components;\n@tailwind utilities;\n", "remove-background-webgpu\\src\\main.jsx": "import { StrictMode } from \"react\";\nimport { createRoot } from \"react-dom/client\";\nimport App from \"./App.jsx\";\nimport \"./index.css\";\n\ncreateRoot(document.getElementById(\"root\")).render(\n <StrictMode>\n <App />\n </StrictMode>,\n);\n", "sapiens-node\\index.js": "import {\n AutoProcessor,\n SapiensForSemanticSegmentation,\n SapiensForDepthEstimation,\n SapiensForNormalEstimation,\n RawImage,\n interpolate_4d,\n} from \"@huggingface/transformers\";\n\n// Load segmentation, depth, and normal estimation models\nconst segment = await SapiensForSemanticSegmentation.from_pretrained(\n \"onnx-community/sapiens-seg-0.3b\",\n { dtype: \"q8\" },\n);\nconst depth = await SapiensForDepthEstimation.from_pretrained(\n \"onnx-community/sapiens-depth-0.3b\",\n { dtype: \"q4\" },\n);\nconst normal = await SapiensForNormalEstimation.from_pretrained(\n \"onnx-community/sapiens-normal-0.3b\",\n { dtype: \"q4\" },\n);\n\n// Load processor\nconst processor = await AutoProcessor.from_pretrained(\n \"onnx-community/sapiens-seg-0.3b\",\n);\n\n// Read and prepare image\nconst image = await RawImage.read(\"./assets/image.jpg\");\nconst inputs = await processor(image);\n\n// Run segmentation model\nconsole.time(\"segmentation\");\nconst segmentation_outputs = await segment(inputs); // [1, 28, 512, 384]\nconsole.timeEnd(\"segmentation\");\nconst { segmentation } =\n processor.feature_extractor.post_process_semantic_segmentation(\n segmentation_outputs,\n inputs.original_sizes,\n )[0];\n\n// Run depth estimation model\nconsole.time(\"depth\");\nconst { predicted_depth } = await depth(inputs); // [1, 1, 1024, 768]\nconsole.timeEnd(\"depth\");\n\n// Run normal estimation model\nconsole.time(\"normal\");\nconst { predicted_normal } = await normal(inputs); // [1, 3, 512, 384]\nconsole.timeEnd(\"normal\");\n\nconsole.time(\"post-processing\");\n\n// Resize predicted depth and normal maps to the original image size\nconst size = [image.height, image.width];\nconst depth_map = await interpolate_4d(predicted_depth, { size });\nconst normal_map = await interpolate_4d(predicted_normal, { size });\n\n// Use the segmentation mask to remove the background\nconst stride = size[0] * size[1];\nconst depth_map_data = depth_map.data;\nconst normal_map_data = normal_map.data;\nlet minDepth = Infinity;\nlet maxDepth = -Infinity;\nlet maxAbsNormal = -Infinity;\nfor (let i = 0; i < depth_map_data.length; ++i) {\n if (segmentation.data[i] === 0) {\n // Background\n depth_map_data[i] = Infinity;\n\n for (let j = 0; j < 3; ++j) {\n normal_map_data[j * stride + i] = -Infinity;\n }\n } else {\n // Foreground\n minDepth = Math.min(minDepth, depth_map_data[i]);\n maxDepth = Math.max(maxDepth, depth_map_data[i]);\n for (let j = 0; j < 3; ++j) {\n maxAbsNormal = Math.max(\n maxAbsNormal,\n Math.abs(normal_map_data[j * stride + i]),\n );\n }\n }\n}\n\n// Normalize the depth map to [0, 1]\nconst depth_tensor = depth_map\n .sub_(minDepth)\n .div_(-(maxDepth - minDepth)) // Flip for visualization purposes\n .add_(1)\n .clamp_(0, 1)\n .mul_(255)\n .round_()\n .to(\"uint8\");\n\nconst normal_tensor = normal_map\n .div_(maxAbsNormal)\n .clamp_(-1, 1)\n .add_(1)\n .mul_(255 / 2)\n .round_()\n .to(\"uint8\");\n\nconsole.timeEnd(\"post-processing\");\n\nconst depth_image = RawImage.fromTensor(depth_tensor[0]);\ndepth_image.save(\"assets/depth.png\");\n\nconst normal_image = RawImage.fromTensor(normal_tensor[0]);\nnormal_image.save(\"assets/normal.png\");\n", "sapiens-node\\package.json": "{\n \"name\": \"sapiens-node\",\n \"version\": \"1.0.0\",\n \"main\": \"index.js\",\n \"type\": \"module\",\n \"scripts\": {\n \"test\": \"echo \\\"Error: no test specified\\\" && exit 1\"\n },\n \"keywords\": [],\n \"author\": \"\",\n \"license\": \"ISC\",\n \"description\": \"\",\n \"dependencies\": {\n \"@huggingface/transformers\": \"3.0.0-alpha.13\"\n }\n}\n", "segment-anything-webgpu\\index.css": "* {\n box-sizing: border-box;\n padding: 0;\n margin: 0;\n font-family: sans-serif;\n}\n\nhtml,\nbody {\n height: 100%;\n}\n\nbody {\n padding: 16px 32px;\n}\n\nbody,\n#container,\n#upload-button {\n display: flex;\n flex-direction: column;\n justify-content: center;\n align-items: center;\n}\n\nh1,\nh3 {\n text-align: center;\n}\n\n#container {\n position: relative;\n width: 640px;\n height: 420px;\n max-width: 100%;\n max-height: 100%;\n border: 2px dashed #d1d5db;\n border-radius: 0.75rem;\n overflow: hidden;\n cursor: pointer;\n margin-top: 1rem;\n background-size: 100% 100%;\n background-position: center;\n background-repeat: no-repeat;\n}\n\n#mask-output {\n position: absolute;\n width: 100%;\n height: 100%;\n pointer-events: none;\n}\n\n#upload-button {\n gap: 0.4rem;\n font-size: 18px;\n cursor: pointer;\n opacity: 0.2;\n}\n\n#upload {\n display: none;\n}\n\nsvg {\n pointer-events: none;\n}\n\n#example {\n font-size: 14px;\n text-decoration: underline;\n cursor: pointer;\n pointer-events: none;\n}\n\n#example:hover {\n color: #2563eb;\n}\n\ncanvas {\n position: absolute;\n width: 100%;\n height: 100%;\n opacity: 0.6;\n}\n\n#status {\n min-height: 16px;\n margin: 8px 0;\n}\n\n.icon {\n height: 16px;\n width: 16px;\n position: absolute;\n transform: translate(-50%, -50%);\n}\n\n#controls > button {\n padding: 6px 12px;\n background-color: #3498db;\n color: white;\n border: 1px solid #2980b9;\n border-radius: 5px;\n cursor: pointer;\n font-size: 16px;\n}\n\n#controls > button:disabled {\n background-color: #d1d5db;\n color: #6b7280;\n border: 1px solid #9ca3af;\n cursor: not-allowed;\n}\n\n#information {\n margin-top: 0.25rem;\n font-size: 15px;\n}\n", "segment-anything-webgpu\\index.html": "<!doctype html>\n<html lang=\"en\">\n <head>\n <meta charset=\"UTF-8\" />\n <link rel=\"stylesheet\" href=\"index.css\" />\n\n <meta name=\"viewport\" content=\"width=device-width, initial-scale=1.0\" />\n <title>Segment Anything WebGPU | Transformers.js</title>\n </head>\n\n <body>\n <h1>Segment Anything WebGPU</h1>\n <h3>\n In-browser image segmentation w/\n <a href=\"https://hf.co/docs/transformers.js\" target=\"_blank\"\n >\ud83e\udd17 Transformers.js</a\n >\n </h3>\n <div id=\"container\">\n <label id=\"upload-button\" for=\"upload\">\n <svg\n width=\"25\"\n height=\"25\"\n viewBox=\"0 0 25 25\"\n fill=\"none\"\n xmlns=\"http://www.w3.org/2000/svg\"\n >\n <path\n fill=\"#000\"\n d=\"M3.5 24.3a3 3 0 0 1-1.9-.8c-.5-.5-.8-1.2-.8-1.9V2.9c0-.7.3-1.3.8-1.9.6-.5 1.2-.7 2-.7h18.6c.7 0 1.3.2 1.9.7.5.6.7 1.2.7 2v18.6c0 .7-.2 1.4-.7 1.9a3 3 0 0 1-2 .8H3.6Zm0-2.7h18.7V2.9H3.5v18.7Zm2.7-2.7h13.3c.3 0 .5 0 .6-.3v-.7l-3.7-5a.6.6 0 0 0-.6-.2c-.2 0-.4 0-.5.3l-3.5 4.6-2.4-3.3a.6.6 0 0 0-.6-.3c-.2 0-.4.1-.5.3l-2.7 3.6c-.1.2-.2.4 0 .7.1.2.3.3.6.3Z\"\n ></path>\n </svg>\n Click to upload image\n <label id=\"example\">(or try example)</label>\n </label>\n <image id=\"image\"></image>\n <canvas id=\"mask-output\"></canvas>\n </div>\n <label id=\"status\"></label>\n <div id=\"controls\">\n <button id=\"reset-image\">Reset image</button>\n <button id=\"clear-points\">Clear points</button>\n <button id=\"cut-mask\" disabled>Cut mask</button>\n </div>\n <p id=\"information\">\n Left click = positive points, right click = negative points.\n </p>\n <input id=\"upload\" type=\"file\" accept=\"image/*\" disabled />\n\n <div style=\"display: none\">\n <!-- Preload star and cross images to avoid lag on first click -->\n <img\n id=\"star-icon\"\n class=\"icon\"\n src=\"https://huggingface.co/datasets/Xenova/transformers.js-docs/resolve/main/star-icon.png\"\n />\n <img\n id=\"cross-icon\"\n class=\"icon\"\n src=\"https://huggingface.co/datasets/Xenova/transformers.js-docs/resolve/main/cross-icon.png\"\n />\n </div>\n <script src=\"index.js\" type=\"module\"></script>\n </body>\n</html>\n", "segment-anything-webgpu\\index.js": "import {\n SamModel,\n AutoProcessor,\n RawImage,\n Tensor,\n} from \"https://cdn.jsdelivr.net/npm/@huggingface/[email protected]\";\n\n// Reference the elements we will use\nconst statusLabel = document.getElementById(\"status\");\nconst fileUpload = document.getElementById(\"upload\");\nconst imageContainer = document.getElementById(\"container\");\nconst example = document.getElementById(\"example\");\nconst uploadButton = document.getElementById(\"upload-button\");\nconst resetButton = document.getElementById(\"reset-image\");\nconst clearButton = document.getElementById(\"clear-points\");\nconst cutButton = document.getElementById(\"cut-mask\");\nconst starIcon = document.getElementById(\"star-icon\");\nconst crossIcon = document.getElementById(\"cross-icon\");\nconst maskCanvas = document.getElementById(\"mask-output\");\nconst maskContext = maskCanvas.getContext(\"2d\");\n\nconst EXAMPLE_URL =\n \"https://huggingface.co/datasets/Xenova/transformers.js-docs/resolve/main/corgi.jpg\";\n\n// State variables\nlet isEncoding = false;\nlet isDecoding = false;\nlet decodePending = false;\nlet lastPoints = null;\nlet isMultiMaskMode = false;\nlet imageInput = null;\nlet imageProcessed = null;\nlet imageEmbeddings = null;\n\nasync function decode() {\n // Only proceed if we are not already decoding\n if (isDecoding) {\n decodePending = true;\n return;\n }\n isDecoding = true;\n\n // Prepare inputs for decoding\n const reshaped = imageProcessed.reshaped_input_sizes[0];\n const points = lastPoints\n .map((x) => [x.position[0] * reshaped[1], x.position[1] * reshaped[0]])\n .flat(Infinity);\n const labels = lastPoints.map((x) => BigInt(x.label)).flat(Infinity);\n\n const num_points = lastPoints.length;\n const input_points = new Tensor(\"float32\", points, [1, 1, num_points, 2]);\n const input_labels = new Tensor(\"int64\", labels, [1, 1, num_points]);\n\n // Generate the mask\n const { pred_masks, iou_scores } = await model({\n ...imageEmbeddings,\n input_points,\n input_labels,\n });\n\n // Post-process the mask\n const masks = await processor.post_process_masks(\n pred_masks,\n imageProcessed.original_sizes,\n imageProcessed.reshaped_input_sizes,\n );\n\n isDecoding = false;\n\n updateMaskOverlay(RawImage.fromTensor(masks[0][0]), iou_scores.data);\n\n // Check if another decode is pending\n if (decodePending) {\n decodePending = false;\n decode();\n }\n}\n\nfunction updateMaskOverlay(mask, scores) {\n // Update canvas dimensions (if different)\n if (maskCanvas.width !== mask.width || maskCanvas.height !== mask.height) {\n maskCanvas.width = mask.width;\n maskCanvas.height = mask.height;\n }\n\n // Allocate buffer for pixel data\n const imageData = maskContext.createImageData(\n maskCanvas.width,\n maskCanvas.height,\n );\n\n // Select best mask\n const numMasks = scores.length; // 3\n let bestIndex = 0;\n for (let i = 1; i < numMasks; ++i) {\n if (scores[i] > scores[bestIndex]) {\n bestIndex = i;\n }\n }\n statusLabel.textContent = `Segment score: ${scores[bestIndex].toFixed(2)}`;\n\n // Fill mask with colour\n const pixelData = imageData.data;\n for (let i = 0; i < pixelData.length; ++i) {\n if (mask.data[numMasks * i + bestIndex] === 1) {\n const offset = 4 * i;\n pixelData[offset] = 0; // red\n pixelData[offset + 1] = 114; // green\n pixelData[offset + 2] = 189; // blue\n pixelData[offset + 3] = 255; // alpha\n }\n }\n\n // Draw image data to context\n maskContext.putImageData(imageData, 0, 0);\n}\n\nfunction clearPointsAndMask() {\n // Reset state\n isMultiMaskMode = false;\n lastPoints = null;\n\n // Remove points from previous mask (if any)\n document.querySelectorAll(\".icon\").forEach((e) => e.remove());\n\n // Disable cut button\n cutButton.disabled = true;\n\n // Reset mask canvas\n maskContext.clearRect(0, 0, maskCanvas.width, maskCanvas.height);\n}\nclearButton.addEventListener(\"click\", clearPointsAndMask);\n\nresetButton.addEventListener(\"click\", () => {\n // Reset the state\n imageInput = null;\n imageProcessed = null;\n imageEmbeddings = null;\n isEncoding = false;\n isDecoding = false;\n\n // Clear points and mask (if present)\n clearPointsAndMask();\n\n // Update UI\n cutButton.disabled = true;\n imageContainer.style.backgroundImage = \"none\";\n uploadButton.style.display = \"flex\";\n statusLabel.textContent = \"Ready\";\n});\n\nasync function encode(url) {\n if (isEncoding) return;\n isEncoding = true;\n statusLabel.textContent = \"Extracting image embedding...\";\n\n imageInput = await RawImage.fromURL(url);\n\n // Update UI\n imageContainer.style.backgroundImage = `url(${url})`;\n uploadButton.style.display = \"none\";\n cutButton.disabled = true;\n\n // Recompute image embeddings\n imageProcessed = await processor(imageInput);\n imageEmbeddings = await model.get_image_embeddings(imageProcessed);\n\n statusLabel.textContent = \"Embedding extracted!\";\n isEncoding = false;\n}\n\n// Handle file selection\nfileUpload.addEventListener(\"change\", function (e) {\n const file = e.target.files[0];\n if (!file) return;\n\n const reader = new FileReader();\n\n // Set up a callback when the file is loaded\n reader.onload = (e2) => encode(e2.target.result);\n\n reader.readAsDataURL(file);\n});\n\nexample.addEventListener(\"click\", (e) => {\n e.preventDefault();\n encode(EXAMPLE_URL);\n});\n\n// Attach hover event to image container\nimageContainer.addEventListener(\"mousedown\", (e) => {\n if (e.button !== 0 && e.button !== 2) {\n return; // Ignore other buttons\n }\n if (!imageEmbeddings) {\n return; // Ignore if not encoded yet\n }\n if (!isMultiMaskMode) {\n lastPoints = [];\n isMultiMaskMode = true;\n cutButton.disabled = false;\n }\n\n const point = getPoint(e);\n lastPoints.push(point);\n\n // add icon\n const icon = (point.label === 1 ? starIcon : crossIcon).cloneNode();\n icon.style.left = `${point.position[0] * 100}%`;\n icon.style.top = `${point.position[1] * 100}%`;\n imageContainer.appendChild(icon);\n\n // Run decode\n decode();\n});\n\n// Clamp a value inside a range [min, max]\nfunction clamp(x, min = 0, max = 1) {\n return Math.max(Math.min(x, max), min);\n}\n\nfunction getPoint(e) {\n // Get bounding box\n const bb = imageContainer.getBoundingClientRect();\n\n // Get the mouse coordinates relative to the container\n const mouseX = clamp((e.clientX - bb.left) / bb.width);\n const mouseY = clamp((e.clientY - bb.top) / bb.height);\n\n return {\n position: [mouseX, mouseY],\n label:\n e.button === 2 // right click\n ? 0 // negative prompt\n : 1, // positive prompt\n };\n}\n\n// Do not show context menu on right click\nimageContainer.addEventListener(\"contextmenu\", (e) => e.preventDefault());\n\n// Attach hover event to image container\nimageContainer.addEventListener(\"mousemove\", (e) => {\n if (!imageEmbeddings || isMultiMaskMode) {\n // Ignore mousemove events if the image is not encoded yet,\n // or we are in multi-mask mode\n return;\n }\n lastPoints = [getPoint(e)];\n\n decode();\n});\n\n// Handle cut button click\ncutButton.addEventListener(\"click\", async () => {\n const [w, h] = [maskCanvas.width, maskCanvas.height];\n\n // Get the mask pixel data (and use this as a buffer)\n const maskImageData = maskContext.getImageData(0, 0, w, h);\n\n // Create a new canvas to hold the cut-out\n const cutCanvas = new OffscreenCanvas(w, h);\n const cutContext = cutCanvas.getContext(\"2d\");\n\n // Copy the image pixel data to the cut canvas\n const maskPixelData = maskImageData.data;\n const imagePixelData = imageInput.data;\n for (let i = 0; i < w * h; ++i) {\n const sourceOffset = 3 * i; // RGB\n const targetOffset = 4 * i; // RGBA\n\n if (maskPixelData[targetOffset + 3] > 0) {\n // Only copy opaque pixels\n for (let j = 0; j < 3; ++j) {\n maskPixelData[targetOffset + j] = imagePixelData[sourceOffset + j];\n }\n }\n }\n cutContext.putImageData(maskImageData, 0, 0);\n\n // Download image\n const link = document.createElement(\"a\");\n link.download = \"image.png\";\n link.href = URL.createObjectURL(await cutCanvas.convertToBlob());\n link.click();\n link.remove();\n});\n\nconst model_id = \"Xenova/slimsam-77-uniform\";\nstatusLabel.textContent = \"Loading model...\";\nconst model = await SamModel.from_pretrained(model_id, {\n dtype: \"fp16\", // or \"fp32\"\n device: \"webgpu\",\n});\nconst processor = await AutoProcessor.from_pretrained(model_id);\nstatusLabel.textContent = \"Ready\";\n\n// Enable the user interface\nfileUpload.disabled = false;\nuploadButton.style.opacity = 1;\nexample.style.pointerEvents = \"auto\";\n", "smollm-webgpu\\index.html": "<!doctype html>\n<html lang=\"en\">\n <head>\n <meta charset=\"UTF-8\" />\n <link rel=\"icon\" type=\"image/png\" href=\"/logo.png\" />\n <meta name=\"viewport\" content=\"width=device-width, initial-scale=1.0\" />\n <title>SmolLM WebGPU</title>\n </head>\n\n <body>\n <div id=\"root\"></div>\n\n <script>\n window.MathJax = {\n tex: {\n inlineMath: [\n [\"$\", \"$\"],\n [\"\\\\(\", \"\\\\)\"],\n ],\n },\n svg: {\n fontCache: \"global\",\n },\n };\n </script>\n <script\n id=\"MathJax-script\"\n src=\"https://cdn.jsdelivr.net/npm/mathjax@3/es5/tex-mml-chtml.js\"\n ></script>\n <script type=\"module\" src=\"/src/main.jsx\"></script>\n </body>\n</html>\n", "smollm-webgpu\\package.json": "{\n \"name\": \"smollm-webgpu\",\n \"private\": true,\n \"version\": \"0.0.0\",\n \"type\": \"module\",\n \"scripts\": {\n \"dev\": \"vite\",\n \"build\": \"vite build\",\n \"lint\": \"eslint .\",\n \"preview\": \"vite preview\"\n },\n \"dependencies\": {\n \"@huggingface/transformers\": \"3.0.0-alpha.13\",\n \"dompurify\": \"^3.1.2\",\n \"marked\": \"^12.0.2\",\n \"react\": \"^18.3.1\",\n \"react-dom\": \"^18.3.1\"\n },\n \"devDependencies\": {\n \"@eslint/js\": \"^9.9.0\",\n \"@types/react\": \"^18.3.3\",\n \"@types/react-dom\": \"^18.3.0\",\n \"@vitejs/plugin-react\": \"^4.3.1\",\n \"autoprefixer\": \"^10.4.20\",\n \"eslint\": \"^9.9.0\",\n \"eslint-plugin-react\": \"^7.35.0\",\n \"eslint-plugin-react-hooks\": \"^5.1.0-rc.0\",\n \"eslint-plugin-react-refresh\": \"^0.4.9\",\n \"globals\": \"^15.9.0\",\n \"postcss\": \"^8.4.41\",\n \"tailwindcss\": \"^3.4.10\",\n \"vite\": \"^5.4.1\"\n }\n}\n", "smollm-webgpu\\src\\App.jsx": "import { useEffect, useState, useRef } from \"react\";\n\nimport Chat from \"./components/Chat\";\nimport ArrowRightIcon from \"./components/icons/ArrowRightIcon\";\nimport StopIcon from \"./components/icons/StopIcon\";\nimport Progress from \"./components/Progress\";\n\nconst IS_WEBGPU_AVAILABLE = !!navigator.gpu;\nconst STICKY_SCROLL_THRESHOLD = 120;\nconst EXAMPLES = [\n \"Give me some tips to improve my time management skills.\",\n \"What is the difference between AI and ML?\",\n \"Write python code to compute the nth fibonacci number.\",\n];\n\nfunction App() {\n // Create a reference to the worker object.\n const worker = useRef(null);\n\n const textareaRef = useRef(null);\n const chatContainerRef = useRef(null);\n\n // Model loading and progress\n const [status, setStatus] = useState(null);\n const [error, setError] = useState(null);\n const [loadingMessage, setLoadingMessage] = useState(\"\");\n const [progressItems, setProgressItems] = useState([]);\n const [isRunning, setIsRunning] = useState(false);\n\n // Inputs and outputs\n const [input, setInput] = useState(\"\");\n const [messages, setMessages] = useState([]);\n const [tps, setTps] = useState(null);\n const [numTokens, setNumTokens] = useState(null);\n\n function onEnter(message) {\n setMessages((prev) => [...prev, { role: \"user\", content: message }]);\n setTps(null);\n setIsRunning(true);\n setInput(\"\");\n }\n\n function onInterrupt() {\n // NOTE: We do not set isRunning to false here because the worker\n // will send a 'complete' message when it is done.\n worker.current.postMessage({ type: \"interrupt\" });\n }\n\n useEffect(() => {\n resizeInput();\n }, [input]);\n\n function resizeInput() {\n if (!textareaRef.current) return;\n\n const target = textareaRef.current;\n target.style.height = \"auto\";\n const newHeight = Math.min(Math.max(target.scrollHeight, 24), 200);\n target.style.height = `${newHeight}px`;\n }\n\n // We use the `useEffect` hook to setup the worker as soon as the `App` component is mounted.\n useEffect(() => {\n // Create the worker if it does not yet exist.\n if (!worker.current) {\n worker.current = new Worker(new URL(\"./worker.js\", import.meta.url), {\n type: \"module\",\n });\n worker.current.postMessage({ type: \"check\" }); // Do a feature check\n }\n\n // Create a callback function for messages from the worker thread.\n const onMessageReceived = (e) => {\n switch (e.data.status) {\n case \"loading\":\n // Model file start load: add a new progress item to the list.\n setStatus(\"loading\");\n setLoadingMessage(e.data.data);\n break;\n\n case \"initiate\":\n setProgressItems((prev) => [...prev, e.data]);\n break;\n\n case \"progress\":\n // Model file progress: update one of the progress items.\n setProgressItems((prev) =>\n prev.map((item) => {\n if (item.file === e.data.file) {\n return { ...item, ...e.data };\n }\n return item;\n }),\n );\n break;\n\n case \"done\":\n // Model file loaded: remove the progress item from the list.\n setProgressItems((prev) =>\n prev.filter((item) => item.file !== e.data.file),\n );\n break;\n\n case \"ready\":\n // Pipeline ready: the worker is ready to accept messages.\n setStatus(\"ready\");\n break;\n\n case \"start\":\n {\n // Start generation\n setMessages((prev) => [\n ...prev,\n { role: \"assistant\", content: \"\" },\n ]);\n }\n break;\n\n case \"update\":\n {\n // Generation update: update the output text.\n // Parse messages\n const { output, tps, numTokens } = e.data;\n setTps(tps);\n setNumTokens(numTokens);\n setMessages((prev) => {\n const cloned = [...prev];\n const last = cloned.at(-1);\n cloned[cloned.length - 1] = {\n ...last,\n content: last.content + output,\n };\n return cloned;\n });\n }\n break;\n\n case \"complete\":\n // Generation complete: re-enable the \"Generate\" button\n setIsRunning(false);\n break;\n\n case \"error\":\n setError(e.data.data);\n break;\n }\n };\n\n const onErrorReceived = (e) => {\n console.error(\"Worker error:\", e);\n };\n\n // Attach the callback function as an event listener.\n worker.current.addEventListener(\"message\", onMessageReceived);\n worker.current.addEventListener(\"error\", onErrorReceived);\n\n // Define a cleanup function for when the component is unmounted.\n return () => {\n worker.current.removeEventListener(\"message\", onMessageReceived);\n worker.current.removeEventListener(\"error\", onErrorReceived);\n };\n }, []);\n\n // Send the messages to the worker thread whenever the `messages` state changes.\n useEffect(() => {\n if (messages.filter((x) => x.role === \"user\").length === 0) {\n // No user messages yet: do nothing.\n return;\n }\n if (messages.at(-1).role === \"assistant\") {\n // Do not update if the last message is from the assistant\n return;\n }\n setTps(null);\n worker.current.postMessage({ type: \"generate\", data: messages });\n }, [messages, isRunning]);\n\n useEffect(() => {\n if (!chatContainerRef.current || !isRunning) return;\n const element = chatContainerRef.current;\n if (\n element.scrollHeight - element.scrollTop - element.clientHeight <\n STICKY_SCROLL_THRESHOLD\n ) {\n element.scrollTop = element.scrollHeight;\n }\n }, [messages, isRunning]);\n\n return IS_WEBGPU_AVAILABLE ? (\n <div className=\"flex flex-col h-screen mx-auto items justify-end text-gray-800 dark:text-gray-200 bg-white dark:bg-gray-900\">\n {status === null && messages.length === 0 && (\n <div className=\"h-full overflow-auto scrollbar-thin flex justify-center items-center flex-col relative\">\n <div className=\"flex flex-col items-center mb-1 max-w-[300px] text-center\">\n <img\n src=\"logo.png\"\n width=\"85%\"\n height=\"auto\"\n className=\"block\"\n ></img>\n <h1 className=\"text-4xl font-bold mb-1\">SmolLM WebGPU</h1>\n <h2 className=\"font-semibold\">\n A blazingly fast and powerful AI chatbot that runs locally in your\n browser.\n </h2>\n </div>\n\n <div className=\"flex flex-col items-center px-4\">\n <p className=\"max-w-[480px] mb-4\">\n <br />\n You are about to load{\" \"}\n <a\n href=\"https://huggingface.co/HuggingFaceTB/SmolLM-360M-Instruct\"\n target=\"_blank\"\n rel=\"noreferrer\"\n className=\"font-medium underline\"\n >\n SmolLM-360M-Instruct\n </a>\n , a 360M parameter LLM optimized for in-browser inference.\n Everything runs entirely in your browser with{\" \"}\n <a\n href=\"https://huggingface.co/docs/transformers.js\"\n target=\"_blank\"\n rel=\"noreferrer\"\n className=\"underline\"\n >\n \ud83e\udd17 Transformers.js\n </a>{\" \"}\n and ONNX Runtime Web, meaning no data is sent to a server. Once\n loaded, it can even be used offline. The source code for the demo\n is available on{\" \"}\n <a\n href=\"https://github.com/huggingface/transformers.js-examples/tree/main/smollm-webgpu\"\n target=\"_blank\"\n rel=\"noreferrer\"\n className=\"font-medium underline\"\n >\n GitHub\n </a>\n .\n <br />\n <br />\n <em>Disclaimer:</em> This model handles general knowledge,\n creative writing, and basic Python. It is English-only and may\n struggle with arithmetic, editing, and complex reasoning.\n </p>\n\n {error && (\n <div className=\"text-red-500 text-center mb-2\">\n <p className=\"mb-1\">\n Unable to load model due to the following error:\n </p>\n <p className=\"text-sm\">{error}</p>\n </div>\n )}\n\n <button\n className=\"border px-4 py-2 rounded-lg bg-blue-400 text-white hover:bg-blue-500 disabled:bg-blue-100 disabled:cursor-not-allowed select-none\"\n onClick={() => {\n worker.current.postMessage({ type: \"load\" });\n setStatus(\"loading\");\n }}\n disabled={status !== null || error !== null}\n >\n Load model\n </button>\n </div>\n </div>\n )}\n {status === \"loading\" && (\n <>\n <div className=\"w-full max-w-[500px] text-left mx-auto p-4 bottom-0 mt-auto\">\n <p className=\"text-center mb-1\">{loadingMessage}</p>\n {progressItems.map(({ file, progress, total }, i) => (\n <Progress\n key={i}\n text={file}\n percentage={progress}\n total={total}\n />\n ))}\n </div>\n </>\n )}\n\n {status === \"ready\" && (\n <div\n ref={chatContainerRef}\n className=\"overflow-y-auto scrollbar-thin w-full flex flex-col items-center h-full\"\n >\n <Chat messages={messages} />\n {messages.length === 0 && (\n <div>\n {EXAMPLES.map((msg, i) => (\n <div\n key={i}\n className=\"m-1 border dark:border-gray-600 rounded-md p-2 bg-gray-100 dark:bg-gray-700 cursor-pointer\"\n onClick={() => onEnter(msg)}\n >\n {msg}\n </div>\n ))}\n </div>\n )}\n <p className=\"text-center text-sm min-h-6 text-gray-500 dark:text-gray-300\">\n {tps && messages.length > 0 && (\n <>\n {!isRunning && (\n <span>\n Generated {numTokens} tokens in{\" \"}\n {(numTokens / tps).toFixed(2)} seconds (\n </span>\n )}\n {\n <>\n <span className=\"font-medium text-center mr-1 text-black dark:text-white\">\n {tps.toFixed(2)}\n </span>\n <span className=\"text-gray-500 dark:text-gray-300\">\n tokens/second\n </span>\n </>\n }\n {!isRunning && (\n <>\n <span className=\"mr-1\">).</span>\n <span\n className=\"underline cursor-pointer\"\n onClick={() => {\n worker.current.postMessage({ type: \"reset\" });\n setMessages([]);\n }}\n >\n Reset\n </span>\n </>\n )}\n </>\n )}\n </p>\n </div>\n )}\n\n <div className=\"mt-2 border dark:bg-gray-700 rounded-lg w-[600px] max-w-[80%] max-h-[200px] mx-auto relative mb-3 flex\">\n <textarea\n ref={textareaRef}\n className=\"scrollbar-thin w-[550px] dark:bg-gray-700 px-3 py-4 rounded-lg bg-transparent border-none outline-none text-gray-800 disabled:text-gray-400 dark:text-gray-200 placeholder-gray-500 dark:placeholder-gray-400 disabled:placeholder-gray-200 resize-none disabled:cursor-not-allowed\"\n placeholder=\"Type your message...\"\n type=\"text\"\n rows={1}\n value={input}\n disabled={status !== \"ready\"}\n title={status === \"ready\" ? \"Model is ready\" : \"Model not loaded yet\"}\n onKeyDown={(e) => {\n if (\n input.length > 0 &&\n !isRunning &&\n e.key === \"Enter\" &&\n !e.shiftKey\n ) {\n e.preventDefault(); // Prevent default behavior of Enter key\n onEnter(input);\n }\n }}\n onInput={(e) => setInput(e.target.value)}\n />\n {isRunning ? (\n <div className=\"cursor-pointer\" onClick={onInterrupt}>\n <StopIcon className=\"h-8 w-8 p-1 rounded-md text-gray-800 dark:text-gray-100 absolute right-3 bottom-3\" />\n </div>\n ) : input.length > 0 ? (\n <div className=\"cursor-pointer\" onClick={() => onEnter(input)}>\n <ArrowRightIcon\n className={`h-8 w-8 p-1 bg-gray-800 dark:bg-gray-100 text-white dark:text-black rounded-md absolute right-3 bottom-3`}\n />\n </div>\n ) : (\n <div>\n <ArrowRightIcon\n className={`h-8 w-8 p-1 bg-gray-200 dark:bg-gray-600 text-gray-50 dark:text-gray-800 rounded-md absolute right-3 bottom-3`}\n />\n </div>\n )}\n </div>\n\n <p className=\"text-xs text-gray-400 text-center mb-3\">\n Disclaimer: Generated content may be inaccurate or false.\n </p>\n </div>\n ) : (\n <div className=\"fixed w-screen h-screen bg-black z-10 bg-opacity-[92%] text-white text-2xl font-semibold flex justify-center items-center text-center\">\n WebGPU is not supported\n <br />\n by this browser :(\n </div>\n );\n}\n\nexport default App;\n", "smollm-webgpu\\src\\index.css": "@tailwind base;\n@tailwind components;\n@tailwind utilities;\n\n@layer utilities {\n .scrollbar-thin::-webkit-scrollbar {\n @apply w-2;\n }\n\n .scrollbar-thin::-webkit-scrollbar-track {\n @apply rounded-full bg-gray-100 dark:bg-gray-700;\n }\n\n .scrollbar-thin::-webkit-scrollbar-thumb {\n @apply rounded-full bg-gray-300 dark:bg-gray-600;\n }\n\n .scrollbar-thin::-webkit-scrollbar-thumb:hover {\n @apply bg-gray-500;\n }\n\n .animation-delay-200 {\n animation-delay: 200ms;\n }\n .animation-delay-400 {\n animation-delay: 400ms;\n }\n\n .overflow-wrap-anywhere {\n overflow-wrap: anywhere;\n }\n}\n", "smollm-webgpu\\src\\main.jsx": "import React from \"react\";\nimport ReactDOM from \"react-dom/client\";\nimport App from \"./App.jsx\";\nimport \"./index.css\";\n\nReactDOM.createRoot(document.getElementById(\"root\")).render(\n <React.StrictMode>\n <App />\n </React.StrictMode>,\n);\n"} | null |
transformers_bloom_parallel | {"type": "directory", "name": "transformers_bloom_parallel", "children": [{"type": "file", "name": "generate.py"}, {"type": "file", "name": "LICENSE"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "server.py"}, {"type": "file", "name": "utils.py"}]} | # BLOOM parallel test
## DIRTY solution
install `transformers` branch: `thomas/dirty_bloom_tp`
```
pip -e git+https://github.com/huggingface/transformers.git@thomas/add_custom_kernels#egg=transformers
```
Alternatively,
For the custom kernel:
```
git clone https://github.com/huggingface/transformers.git
cd transformers
git checkout thomas/add_custom_kernels
python setup.py build_ext --inplace # Might have to edit `setup.py` to remove the torch import
pip install -e .
```
### RUN
This will require `redis` to be installed on the machine.
Redis is the easiest way to communicate through pubsub to all the various processes without causing too much issues for NCCL
or the webserver threading/circuit breaking model.
```
python -m torch.distributed.run --nproc_per_node=8 generate.py --name bigscience/bloom --max-input-tokens=1000 --save-path=/data/models/
```
```
python server.py
```
### USE
```
curl -X POST -d '{"inputs": "This is a test", "parameters": {"max_new_tokens": 20, "temperature": 0.4}}' http://localhost:8000/generate -H "content-type: application/json"
```
| {"requirements.txt": "-e git+https://github.com/huggingface/transformers.git@thomas/add_custom_kernels#egg=transformers\nsafetensors==0.2.1\nredis==4.3.4\ntorch==1.12.0+cu116 -f https://download.pytorch.org/whl/cu116/torch_stable.html\n", ".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 8ef174830e89019bbe098e824f6f05f22258a126 Hamza Amin <[email protected]> 1727369589 +0500\tclone: from https://github.com/huggingface/transformers_bloom_parallel.git\n", ".git\\refs\\heads\\main": "8ef174830e89019bbe098e824f6f05f22258a126\n"} | null |
trl | {"type": "directory", "name": "trl", "children": [{"type": "file", "name": ".pre-commit-config.yaml"}, {"type": "file", "name": "CITATION.cff"}, {"type": "file", "name": "CODE_OF_CONDUCT.md"}, {"type": "directory", "name": "commands", "children": [{"type": "file", "name": "run_dpo.sh"}, {"type": "file", "name": "run_sft.sh"}]}, {"type": "file", "name": "CONTRIBUTING.md"}, {"type": "directory", "name": "docker", "children": [{"type": "directory", "name": "trl-latest-gpu", "children": [{"type": "file", "name": "Dockerfile"}]}, {"type": "directory", "name": "trl-source-gpu", "children": [{"type": "file", "name": "Dockerfile"}]}]}, {"type": "directory", "name": "docs", "children": [{"type": "directory", "name": "source", "children": [{"type": "file", "name": "alignprop_trainer.mdx"}, {"type": "file", "name": "bco_trainer.mdx"}, {"type": "file", "name": "best_of_n.mdx"}, {"type": "file", "name": "callbacks.mdx"}, {"type": "file", "name": "clis.mdx"}, {"type": "file", "name": "cpo_trainer.mdx"}, {"type": "file", "name": "customization.mdx"}, {"type": "file", "name": "dataset_formats.mdx"}, {"type": "file", "name": "data_utils.mdx"}, {"type": "file", "name": "ddpo_trainer.mdx"}, {"type": "file", "name": "detoxifying_a_lm.mdx"}, {"type": "file", "name": "dpo_trainer.mdx"}, {"type": "file", "name": "example_overview.md"}, {"type": "file", "name": "gkd_trainer.md"}, {"type": "file", "name": "how_to_train.md"}, {"type": "file", "name": "index.mdx"}, {"type": "file", "name": "installation.mdx"}, {"type": "file", "name": "iterative_sft_trainer.mdx"}, {"type": "file", "name": "judges.mdx"}, {"type": "file", "name": "kto_trainer.mdx"}, {"type": "file", "name": "learning_tools.mdx"}, {"type": "file", "name": "logging.mdx"}, {"type": "file", "name": "lora_tuning_peft.mdx"}, {"type": "file", "name": "models.mdx"}, {"type": "file", "name": "multi_adapter_rl.mdx"}, {"type": "file", "name": "nash_md_trainer.md"}, {"type": "file", "name": "online_dpo_trainer.md"}, {"type": "file", "name": "orpo_trainer.md"}, {"type": "file", "name": "ppov2_trainer.md"}, {"type": "file", "name": "ppo_trainer.mdx"}, {"type": "file", "name": "quickstart.mdx"}, {"type": "file", "name": "reward_trainer.mdx"}, {"type": "file", "name": "rloo_trainer.md"}, {"type": "file", "name": "sentiment_tuning.mdx"}, {"type": "file", "name": "sft_trainer.mdx"}, {"type": "file", "name": "text_environments.md"}, {"type": "file", "name": "use_model.md"}, {"type": "file", "name": "using_llama_models.mdx"}, {"type": "file", "name": "xpo_trainer.mdx"}, {"type": "file", "name": "_toctree.yml"}]}]}, {"type": "directory", "name": "examples", "children": [{"type": "directory", "name": "accelerate_configs", "children": [{"type": "file", "name": "deepspeed_zero1.yaml"}, {"type": "file", "name": "deepspeed_zero2.yaml"}, {"type": "file", "name": "deepspeed_zero3.yaml"}, {"type": "file", "name": "fsdp_qlora.yaml"}, {"type": "file", "name": "multi_gpu.yaml"}, {"type": "file", "name": "single_gpu.yaml"}]}, {"type": "directory", "name": "cli_configs", "children": [{"type": "file", "name": "example_config.yaml"}]}, {"type": "directory", "name": "datasets", "children": [{"type": "file", "name": "hh-rlhf-helpful-base.py"}, {"type": "file", "name": "lm-human-preferences-descriptiveness.py"}, {"type": "file", "name": "lm-human-preferences-sentiment.py"}, {"type": "file", "name": "tldr.py"}, {"type": "file", "name": "tldr_preference.py"}, {"type": "file", "name": "tokenize_ds.py"}, {"type": "file", "name": "ultrafeedback-prompt.py"}, {"type": "file", "name": "ultrafeedback.py"}, {"type": "file", "name": "zen.py"}]}, {"type": "file", "name": "hello_world.py"}, {"type": "directory", "name": "notebooks", "children": [{"type": "file", "name": "best_of_n.ipynb"}, {"type": "file", "name": "gpt2-sentiment-control.ipynb"}, {"type": "file", "name": "gpt2-sentiment.ipynb"}, {"type": "file", "name": "README.md"}]}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "research_projects", "children": [{"type": "file", "name": "README.md"}, {"type": "directory", "name": "stack_llama", "children": [{"type": "directory", "name": "scripts", "children": [{"type": "file", "name": "merge_peft_adapter.py"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "reward_modeling.py"}, {"type": "file", "name": "rl_training.py"}, {"type": "file", "name": "supervised_finetuning.py"}]}]}, {"type": "directory", "name": "stack_llama_2", "children": [{"type": "directory", "name": "scripts", "children": [{"type": "file", "name": "dpo_llama2.py"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "sft_llama2.py"}]}]}, {"type": "directory", "name": "tools", "children": [{"type": "file", "name": "calculator.py"}, {"type": "file", "name": "python_interpreter.py"}, {"type": "file", "name": "triviaqa.py"}]}, {"type": "directory", "name": "toxicity", "children": [{"type": "file", "name": "README.md"}, {"type": "directory", "name": "scripts", "children": [{"type": "file", "name": "evaluate-toxicity.py"}, {"type": "file", "name": "gpt-j-6b-toxicity.py"}]}]}]}, {"type": "directory", "name": "scripts", "children": [{"type": "file", "name": "alignprop.py"}, {"type": "file", "name": "bco.py"}, {"type": "file", "name": "chat.py"}, {"type": "directory", "name": "config", "children": [{"type": "file", "name": "default_chat_config.yaml"}]}, {"type": "file", "name": "cpo.py"}, {"type": "file", "name": "ddpo.py"}, {"type": "file", "name": "dpo.py"}, {"type": "file", "name": "dpo_online.py"}, {"type": "file", "name": "dpo_visual.py"}, {"type": "directory", "name": "evals", "children": [{"type": "file", "name": "judge_tldr.py"}]}, {"type": "file", "name": "gkd.py"}, {"type": "file", "name": "kto.py"}, {"type": "file", "name": "nash_md.py"}, {"type": "file", "name": "orpo.py"}, {"type": "directory", "name": "ppo", "children": [{"type": "file", "name": "ppo.py"}, {"type": "file", "name": "ppo_tldr.py"}]}, {"type": "file", "name": "ppo.py"}, {"type": "file", "name": "ppo_multi_adapter.py"}, {"type": "file", "name": "reward_modeling.py"}, {"type": "directory", "name": "rloo", "children": [{"type": "file", "name": "rloo.py"}, {"type": "file", "name": "rloo_tldr.py"}]}, {"type": "file", "name": "sft.py"}, {"type": "file", "name": "sft_vlm.py"}, {"type": "file", "name": "xpo.py"}]}]}, {"type": "file", "name": "LICENSE"}, {"type": "file", "name": "Makefile"}, {"type": "file", "name": "MANIFEST.in"}, {"type": "file", "name": "pyproject.toml"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "directory", "name": "scripts", "children": [{"type": "file", "name": "add_copyrights.py"}, {"type": "file", "name": "log_example_reports.py"}, {"type": "file", "name": "log_reports.py"}, {"type": "file", "name": "stale.py"}]}, {"type": "file", "name": "setup.cfg"}, {"type": "file", "name": "setup.py"}, {"type": "directory", "name": "tests", "children": [{"type": "directory", "name": "slow", "children": [{"type": "file", "name": "testing_constants.py"}, {"type": "file", "name": "test_dpo_slow.py"}, {"type": "file", "name": "test_sft_slow.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "testing_constants.py"}, {"type": "file", "name": "testing_utils.py"}, {"type": "file", "name": "test_alignprop_trainer.py"}, {"type": "file", "name": "test_bco_trainer.py"}, {"type": "file", "name": "test_best_of_n_sampler.py"}, {"type": "file", "name": "test_callbacks.py"}, {"type": "file", "name": "test_cli.py"}, {"type": "file", "name": "test_core.py"}, {"type": "file", "name": "test_cpo_trainer.py"}, {"type": "file", "name": "test_dataset_formatting.py"}, {"type": "file", "name": "test_data_collator_completion_only.py"}, {"type": "file", "name": "test_data_utils.py"}, {"type": "file", "name": "test_ddpo_trainer.py"}, {"type": "file", "name": "test_dpo_trainer.py"}, {"type": "file", "name": "test_e2e.py"}, {"type": "file", "name": "test_environments.py"}, {"type": "file", "name": "test_gkd_trainer.py"}, {"type": "file", "name": "test_iterative_sft_trainer.py"}, {"type": "file", "name": "test_judges.py"}, {"type": "file", "name": "test_kto_trainer.py"}, {"type": "file", "name": "test_modeling_geometric_mixture_wrapper.py"}, {"type": "file", "name": "test_modeling_value_head.py"}, {"type": "file", "name": "test_nash_md_trainer.py"}, {"type": "file", "name": "test_no_peft.py"}, {"type": "file", "name": "test_online_dpo_trainer.py"}, {"type": "file", "name": "test_orpo_trainer.py"}, {"type": "file", "name": "test_peft_models.py"}, {"type": "file", "name": "test_ppov2_trainer.py"}, {"type": "file", "name": "test_ppo_trainer.py"}, {"type": "file", "name": "test_reward_trainer.py"}, {"type": "file", "name": "test_rich_progress_callback.py"}, {"type": "file", "name": "test_rloo_trainer.py"}, {"type": "file", "name": "test_sft_trainer.py"}, {"type": "file", "name": "test_trainers_args.py"}, {"type": "file", "name": "test_utils.py"}, {"type": "file", "name": "test_xpo_trainer.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "trl", "children": [{"type": "directory", "name": "commands", "children": [{"type": "file", "name": "cli.py"}, {"type": "file", "name": "cli_utils.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "core.py"}, {"type": "file", "name": "data_utils.py"}, {"type": "directory", "name": "environment", "children": [{"type": "file", "name": "base_environment.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "env_utils.py"}, {"type": "directory", "name": "extras", "children": [{"type": "file", "name": "best_of_n_sampler.py"}, {"type": "file", "name": "dataset_formatting.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "import_utils.py"}, {"type": "directory", "name": "models", "children": [{"type": "file", "name": "auxiliary_modules.py"}, {"type": "file", "name": "modeling_base.py"}, {"type": "file", "name": "modeling_sd_base.py"}, {"type": "file", "name": "modeling_value_head.py"}, {"type": "file", "name": "sd_utils.py"}, {"type": "file", "name": "utils.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "trainer", "children": [{"type": "file", "name": "alignprop_config.py"}, {"type": "file", "name": "alignprop_trainer.py"}, {"type": "file", "name": "base.py"}, {"type": "file", "name": "bco_config.py"}, {"type": "file", "name": "bco_trainer.py"}, {"type": "file", "name": "callbacks.py"}, {"type": "file", "name": "cpo_config.py"}, {"type": "file", "name": "cpo_trainer.py"}, {"type": "file", "name": "ddpo_config.py"}, {"type": "file", "name": "ddpo_trainer.py"}, {"type": "file", "name": "dpo_config.py"}, {"type": "file", "name": "dpo_trainer.py"}, {"type": "file", "name": "gkd_config.py"}, {"type": "file", "name": "gkd_trainer.py"}, {"type": "file", "name": "iterative_sft_trainer.py"}, {"type": "file", "name": "judges.py"}, {"type": "file", "name": "kto_config.py"}, {"type": "file", "name": "kto_trainer.py"}, {"type": "file", "name": "model_config.py"}, {"type": "file", "name": "nash_md_config.py"}, {"type": "file", "name": "nash_md_trainer.py"}, {"type": "file", "name": "online_dpo_config.py"}, {"type": "file", "name": "online_dpo_trainer.py"}, {"type": "file", "name": "orpo_config.py"}, {"type": "file", "name": "orpo_trainer.py"}, {"type": "file", "name": "ppov2_config.py"}, {"type": "file", "name": "ppov2_trainer.py"}, {"type": "file", "name": "ppo_config.py"}, {"type": "file", "name": "ppo_trainer.py"}, {"type": "file", "name": "reward_config.py"}, {"type": "file", "name": "reward_trainer.py"}, {"type": "file", "name": "rloo_config.py"}, {"type": "file", "name": "rloo_trainer.py"}, {"type": "file", "name": "sft_config.py"}, {"type": "file", "name": "sft_trainer.py"}, {"type": "file", "name": "utils.py"}, {"type": "file", "name": "xpo_config.py"}, {"type": "file", "name": "xpo_trainer.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "__init__.py"}]}]} | # De-detoxifying language models
To run this code, do the following:
```shell
ACCELERATE_LOG_LEVEL=info accelerate launch --config_file {CONFIG} examples/research_projects/toxicity/scripts/gpt-j-6b-toxicity.py --log_with wandb
```
| {"requirements.txt": "datasets>=1.17.0\ntorch>=1.4.0\ntqdm\ntransformers>=4.40.0\naccelerate\npeft>=0.3.0\ntyro>=0.5.7", "setup.py": "# Copyright 2024 The HuggingFace Inc. team. All rights reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"trl is an open library for RL with transformer models.\n\nNote:\n\n VERSION needs to be formatted following the MAJOR.MINOR.PATCH convention\n (we need to follow this convention to be able to retrieve versioned scripts)\n\nSimple check list for release from AllenNLP repo: https://github.com/allenai/allennlp/blob/master/setup.py\n\nTo create the package for pypi.\n\n0. Prerequisites:\n - Dependencies:\n - twine: \"pip install twine\"\n - Create an account in (and join the 'trl' project):\n - PyPI: https://pypi.org/\n - Test PyPI: https://test.pypi.org/\n\n1. Change the version in:\n - __init__.py\n - setup.py\n\n2. Commit these changes: \"git commit -m 'Release: VERSION'\"\n\n3. Add a tag in git to mark the release: \"git tag VERSION -m 'Add tag VERSION for pypi'\"\n Push the tag to remote: git push --tags origin main\n\n4. Build both the sources and the wheel. Do not change anything in setup.py between\n creating the wheel and the source distribution (obviously).\n\n First, delete any \"build\" directory that may exist from previous builds.\n\n For the wheel, run: \"python setup.py bdist_wheel\" in the top level directory.\n (this will build a wheel for the python version you use to build it).\n\n For the sources, run: \"python setup.py sdist\"\n You should now have a /dist directory with both .whl and .tar.gz source versions.\n\n5. Check that everything looks correct by uploading the package to the pypi test server:\n\n twine upload dist/* -r pypitest --repository-url=https://test.pypi.org/legacy/\n\n Check that you can install it in a virtualenv/notebook by running:\n pip install huggingface_hub fsspec aiohttp\n pip install -U tqdm\n pip install -i https://testpypi.python.org/pypi evaluate\n\n6. Upload the final version to actual pypi:\n twine upload dist/* -r pypi\n\n7. Fill release notes in the tag in github once everything is looking hunky-dory.\n\n8. Change the version in __init__.py and setup.py to X.X.X+1.dev0 (e.g. VERSION=1.18.3 -> 1.18.4.dev0).\n Then push the change with a message 'set dev version'\n\"\"\"\n\nimport os\n\nfrom setuptools import find_packages, setup\n\n\n__version__ = \"0.12.0.dev0\" # expected format is one of x.y.z.dev0, or x.y.z.rc1 or x.y.z (no to dashes, yes to dots)\n\nREQUIRED_PKGS = [\n \"torch>=1.4.0\",\n \"transformers>=4.40.0\",\n \"numpy>=1.18.2;platform_system!='Windows'\",\n \"numpy<2;platform_system=='Windows'\",\n \"accelerate\",\n \"datasets\",\n \"tyro>=0.5.11\",\n]\nEXTRAS = {\n \"test\": [\n \"parameterized\",\n \"peft>=0.8.0\",\n \"pytest\",\n \"pytest-xdist\",\n \"pytest-cov\",\n \"pytest-xdist\",\n \"scikit-learn\",\n \"Pillow\",\n \"pytest-rerunfailures\",\n \"llm-blender>=0.0.2\",\n ],\n \"peft\": [\"peft>=0.8.0\"],\n \"liger\": [\"liger-kernel>=0.2.1\"],\n \"diffusers\": [\"diffusers>=0.18.0\"],\n \"deepspeed\": [\"deepspeed>=0.14.4\"],\n \"quantization\": [\"bitsandbytes<=0.41.1\"],\n \"llm_judge\": [\"openai>=1.23.2\", \"llm-blender>=0.0.2\"],\n}\nEXTRAS[\"dev\"] = []\nfor reqs in EXTRAS.values():\n EXTRAS[\"dev\"].extend(reqs)\n\ntry:\n file_path = os.path.dirname(os.path.abspath(__file__))\n os.symlink(os.path.join(file_path, \"examples/scripts\"), os.path.join(file_path, \"trl/commands/scripts\"))\n\n setup(\n name=\"trl\",\n license=\"Apache 2.0\",\n classifiers=[\n \"Development Status :: 2 - Pre-Alpha\",\n \"Intended Audience :: Developers\",\n \"Intended Audience :: Science/Research\",\n \"License :: OSI Approved :: Apache Software License\",\n \"Natural Language :: English\",\n \"Operating System :: OS Independent\",\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.9\",\n \"Programming Language :: Python :: 3.10\",\n \"Programming Language :: Python :: 3.11\",\n ],\n url=\"https://github.com/huggingface/trl\",\n entry_points={\n \"console_scripts\": [\"trl=trl.commands.cli:main\"],\n },\n include_package_data=True,\n package_data={\"trl\": [\"commands/scripts/config/*\", \"commands/scripts/*\"]},\n packages=find_packages(exclude={\"tests\"}),\n install_requires=REQUIRED_PKGS,\n extras_require=EXTRAS,\n python_requires=\">=3.7\",\n long_description=open(\"README.md\", encoding=\"utf-8\").read(),\n long_description_content_type=\"text/markdown\",\n zip_safe=False,\n version=__version__,\n description=\"Train transformer language models with reinforcement learning.\",\n keywords=\"ppo, transformers, huggingface, gpt2, language modeling, rlhf\",\n author=\"Leandro von Werra\",\n author_email=\"[email protected]\",\n )\nfinally:\n os.unlink(os.path.join(file_path, \"trl/commands/scripts\"))\n", ".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 9af4734178d4436a8dc98a069042eedd2ccf178f Hamza Amin <[email protected]> 1727369615 +0500\tclone: from https://github.com/huggingface/trl.git\n", ".git\\refs\\heads\\main": "9af4734178d4436a8dc98a069042eedd2ccf178f\n", ".github\\workflows\\tests-main.yml": "name: tests on transformers PEFT main\n\non:\n push:\n branches: [ main ]\n\nenv:\n CI_SLACK_CHANNEL: ${{ secrets.CI_PUSH_MAIN_CHANNEL }}\n\njobs:\n tests:\n strategy:\n matrix:\n python-version: ['3.9', '3.10', '3.11']\n os: ['ubuntu-latest', 'windows-latest']\n fail-fast: false\n runs-on: ${{ matrix.os }}\n steps:\n - uses: actions/checkout@v4\n - name: Set up Python ${{ matrix.python-version }}\n uses: actions/setup-python@v5\n with:\n python-version: ${{ matrix.python-version }}\n cache: \"pip\"\n cache-dependency-path: |\n setup.py\n requirements.txt\n - name: Install dependencies\n run: |\n python -m pip install --upgrade pip\n # install PEFT & transformers from source\n pip install -U git+https://github.com/huggingface/peft.git\n pip install -U git+https://github.com/huggingface/transformers.git\n # cpu version of pytorch\n pip install \".[test, diffusers]\"\n - name: Test with pytest\n run: |\n make test\n - name: Post to Slack\n if: always()\n uses: huggingface/hf-workflows/.github/actions/post-slack@main\n with:\n slack_channel: ${{ env.CI_SLACK_CHANNEL }}\n title: \ud83e\udd17 Results of the TRL CI on transformers/PEFT main\n status: ${{ job.status }}\n slack_token: ${{ secrets.SLACK_CIFEEDBACK_BOT_TOKEN }}\n", "docker\\trl-latest-gpu\\Dockerfile": "# Builds GPU docker image of PyTorch\n# Uses multi-staged approach to reduce size\n# Stage 1\n# Use base conda image to reduce time\nFROM continuumio/miniconda3:latest AS compile-image\n# Specify py version\nENV PYTHON_VERSION=3.10\n# Install apt libs - copied from https://github.com/huggingface/accelerate/blob/main/docker/accelerate-gpu/Dockerfile\nRUN apt-get update && \\\n apt-get install -y curl git wget software-properties-common git-lfs && \\\n apt-get clean && \\\n rm -rf /var/lib/apt/lists*\n\n# Install audio-related libraries \nRUN apt-get update && \\\n apt install -y ffmpeg\n\nRUN apt install -y libsndfile1-dev\nRUN git lfs install\n\n# Create our conda env - copied from https://github.com/huggingface/accelerate/blob/main/docker/accelerate-gpu/Dockerfile\nRUN conda create --name trl python=${PYTHON_VERSION} ipython jupyter pip\nRUN python3 -m pip install --no-cache-dir --upgrade pip\n\n# Below is copied from https://github.com/huggingface/accelerate/blob/main/docker/accelerate-gpu/Dockerfile\n# We don't install pytorch here yet since CUDA isn't available\n# instead we use the direct torch wheel\nENV PATH /opt/conda/envs/trl/bin:$PATH\n# Activate our bash shell\nRUN chsh -s /bin/bash\nSHELL [\"/bin/bash\", \"-c\"]\n\n# Stage 2\nFROM nvidia/cuda:12.2.2-devel-ubuntu22.04 AS build-image\nCOPY --from=compile-image /opt/conda /opt/conda\nENV PATH /opt/conda/bin:$PATH\n\nRUN chsh -s /bin/bash\nSHELL [\"/bin/bash\", \"-c\"]\nRUN source activate trl && \\ \n python3 -m pip install --no-cache-dir bitsandbytes optimum auto-gptq\n\n# Install apt libs\nRUN apt-get update && \\\n apt-get install -y curl git wget && \\\n apt-get clean && \\\n rm -rf /var/lib/apt/lists*\n\n# Activate the conda env and install transformers + accelerate from source\nRUN source activate trl && \\\n python3 -m pip install -U --no-cache-dir \\\n librosa \\\n \"soundfile>=0.12.1\" \\\n scipy \\\n transformers \\\n accelerate \\\n peft \\\n trl[test]@git+https://github.com/huggingface/trl\n\nRUN source activate trl && \\ \n pip freeze | grep trl\n\nRUN echo \"source activate trl\" >> ~/.profile\n\n# Activate the virtualenv\nCMD [\"/bin/bash\"]", "docker\\trl-source-gpu\\Dockerfile": "# Builds GPU docker image of PyTorch\n# Uses multi-staged approach to reduce size\n# Stage 1\n# Use base conda image to reduce time\nFROM continuumio/miniconda3:latest AS compile-image\n# Specify py version\nENV PYTHON_VERSION=3.10\n# Install apt libs - copied from https://github.com/huggingface/accelerate/blob/main/docker/accelerate-gpu/Dockerfile\nRUN apt-get update && \\\n apt-get install -y curl git wget software-properties-common git-lfs && \\\n apt-get clean && \\\n rm -rf /var/lib/apt/lists*\n\n# Install audio-related libraries \nRUN apt-get update && \\\n apt install -y ffmpeg\n\nRUN apt install -y libsndfile1-dev\nRUN git lfs install\n\n# Create our conda env - copied from https://github.com/huggingface/accelerate/blob/main/docker/accelerate-gpu/Dockerfile\nRUN conda create --name trl python=${PYTHON_VERSION} ipython jupyter pip\nRUN python3 -m pip install --no-cache-dir --upgrade pip\n\n# Below is copied from https://github.com/huggingface/accelerate/blob/main/docker/accelerate-gpu/Dockerfile\n# We don't install pytorch here yet since CUDA isn't available\n# instead we use the direct torch wheel\nENV PATH /opt/conda/envs/trl/bin:$PATH\n# Activate our bash shell\nRUN chsh -s /bin/bash\nSHELL [\"/bin/bash\", \"-c\"]\n\n# Stage 2\nFROM nvidia/cuda:12.2.2-devel-ubuntu22.04 AS build-image\nCOPY --from=compile-image /opt/conda /opt/conda\nENV PATH /opt/conda/bin:$PATH\n\nRUN chsh -s /bin/bash\nSHELL [\"/bin/bash\", \"-c\"]\nRUN source activate trl && \\ \n python3 -m pip install --no-cache-dir bitsandbytes optimum auto-gptq\n\n# Install apt libs\nRUN apt-get update && \\\n apt-get install -y curl git wget && \\\n apt-get clean && \\\n rm -rf /var/lib/apt/lists*\n\n# Activate the conda env and install transformers + accelerate from source\nRUN source activate trl && \\\n python3 -m pip install -U --no-cache-dir \\\n librosa \\\n \"soundfile>=0.12.1\" \\\n scipy \\\n git+https://github.com/huggingface/transformers \\\n git+https://github.com/huggingface/accelerate \\\n git+https://github.com/huggingface/peft \\\n trl[test]@git+https://github.com/huggingface/trl\n\nRUN source activate trl && \\ \n pip freeze | grep transformers\n\nRUN echo \"source activate trl\" >> ~/.profile\n\n# Activate the virtualenv\nCMD [\"/bin/bash\"]", "docs\\source\\index.mdx": "<div style=\"text-align: center\">\n<img src=\"https://huggingface.co/datasets/trl-internal-testing/example-images/resolve/main/images/trl_banner_dark.png\">\n</div>\n\n# TRL - Transformer Reinforcement Learning\n\nTRL is a full stack library where we provide a set of tools to train transformer language models with Reinforcement Learning, from the Supervised Fine-tuning step (SFT), Reward Modeling step (RM) to the Proximal Policy Optimization (PPO) step. \nThe library is integrated with \ud83e\udd17 [transformers](https://github.com/huggingface/transformers).\n\n<div style=\"text-align: center\">\n<img src=\"https://huggingface.co/datasets/trl-internal-testing/example-images/resolve/main/images/TRL-readme.png\">\n</div>\n\nCheck the appropriate sections of the documentation depending on your needs:\n\n## API documentation\n\n- [Model Classes](models): *A brief overview of what each public model class does.*\n- [`SFTTrainer`](sft_trainer): *Supervise Fine-tune your model easily with `SFTTrainer`*\n- [`RewardTrainer`](reward_trainer): *Train easily your reward model using `RewardTrainer`.*\n- [`PPOTrainer`](ppo_trainer): *Further fine-tune the supervised fine-tuned model using PPO algorithm*\n- [Best-of-N Sampling](best-of-n): *Use best of n sampling as an alternative way to sample predictions from your active model*\n- [`DPOTrainer`](dpo_trainer): *Direct Preference Optimization training using `DPOTrainer`.*\n- [`TextEnvironment`](text_environments): *Text environment to train your model using tools with RL.*\n\n## Examples\n\n- [Sentiment Tuning](sentiment_tuning): *Fine tune your model to generate positive movie contents*\n- [Training with PEFT](lora_tuning_peft): *Memory efficient RLHF training using adapters with PEFT*\n- [Detoxifying LLMs](detoxifying_a_lm): *Detoxify your language model through RLHF*\n- [StackLlama](using_llama_models): *End-to-end RLHF training of a Llama model on Stack exchange dataset*\n- [Learning with Tools](learning_tools): *Walkthrough of using `TextEnvironments`*\n- [Multi-Adapter Training](multi_adapter_rl): *Use a single base model and multiple adapters for memory efficient end-to-end training*\n\n\n## Blog posts\n\n<div class=\"mt-10\">\n <div class=\"w-full flex flex-col space-y-4 md:space-y-0 md:grid md:grid-cols-2 md:gap-y-4 md:gap-x-5\">\n <a class=\"!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg\" href=\"https://huggingface.co/blog/dpo_vlm\">\n <img src=\"https://raw.githubusercontent.com/huggingface/blog/main/assets/dpo_vlm/thumbnail.png\" alt=\"thumbnail\">\n <p class=\"text-gray-700\">Preference Optimization for Vision Language Models with TRL</p>\n </a>\n <a class=\"!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg\" href=\"https://huggingface.co/blog/rlhf\">\n <img src=\"https://raw.githubusercontent.com/huggingface/blog/main/assets/120_rlhf/thumbnail.png\" alt=\"thumbnail\">\n <p class=\"text-gray-700\">Illustrating Reinforcement Learning from Human Feedback</p>\n </a>\n <a class=\"!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg\" href=\"https://huggingface.co/blog/trl-peft\">\n <img src=\"https://github.com/huggingface/blog/blob/main/assets/133_trl_peft/thumbnail.png?raw=true\" alt=\"thumbnail\">\n <p class=\"text-gray-700\">Fine-tuning 20B LLMs with RLHF on a 24GB consumer GPU</p>\n </a>\n <a class=\"!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg\" href=\"https://huggingface.co/blog/stackllama\">\n <img src=\"https://github.com/huggingface/blog/blob/main/assets/138_stackllama/thumbnail.png?raw=true\" alt=\"thumbnail\">\n <p class=\"text-gray-700\">StackLLaMA: A hands-on guide to train LLaMA with RLHF</p>\n </a>\n <a class=\"!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg\" href=\"https://huggingface.co/blog/dpo-trl\">\n <img src=\"https://github.com/huggingface/blog/blob/main/assets/157_dpo_trl/dpo_thumbnail.png?raw=true\" alt=\"thumbnail\">\n <p class=\"text-gray-700\">Fine-tune Llama 2 with DPO</p>\n </a>\n <a class=\"!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg\" href=\"https://huggingface.co/blog/trl-ddpo\">\n <img src=\"https://github.com/huggingface/blog/blob/main/assets/166_trl_ddpo/thumbnail.png?raw=true\" alt=\"thumbnail\">\n <p class=\"text-gray-700\">Finetune Stable Diffusion Models with DDPO via TRL</p>\n </a>\n </div>\n</div>\n", "examples\\research_projects\\stack_llama_2\\scripts\\requirements.txt": "transformers\ntrl\npeft\naccelerate\ndatasets\nbitsandbytes\nwandb\n", "tests\\test_modeling_geometric_mixture_wrapper.py": "# Copyright 2024 The HuggingFace Team. All rights reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\nimport unittest\n\nimport torch\nfrom transformers import AutoModelForCausalLM, GenerationConfig\n\nfrom trl.models.modeling_base import GeometricMixtureWrapper, create_reference_model\n\n\nclass TestGeometricMixtureWrapper(unittest.TestCase):\n def setUp(self):\n self.model = AutoModelForCausalLM.from_pretrained(\"gpt2\")\n self.ref_model = create_reference_model(self.model)\n self.generation_config = GenerationConfig.from_pretrained(\"gpt2\")\n self.mixture_coef = 0.5\n self.wrapper = GeometricMixtureWrapper(\n self.model, self.ref_model, self.generation_config, mixture_coef=self.mixture_coef\n )\n\n def test_forward(self):\n input_ids = torch.tensor([[1, 2, 3, 4, 5]])\n attention_mask = torch.ones_like(input_ids)\n\n output = self.wrapper(input_ids=input_ids, attention_mask=attention_mask)\n\n self.assertIsNotNone(output)\n self.assertTrue(hasattr(output, \"logits\"))\n self.assertEqual(output.logits.shape, (1, 5, self.model.config.vocab_size))\n\n def test_mixture_coefficient(self):\n input_ids = torch.tensor([[1, 2, 3, 4, 5]])\n attention_mask = torch.ones_like(input_ids)\n\n with torch.no_grad():\n model_output = self.model(input_ids=input_ids, attention_mask=attention_mask)\n ref_model_output = self.ref_model(input_ids=input_ids, attention_mask=attention_mask)\n wrapper_output = self.wrapper(input_ids=input_ids, attention_mask=attention_mask)\n\n expected_logits = torch.nn.functional.log_softmax(\n self.mixture_coef * ref_model_output.logits + (1 - self.mixture_coef) * model_output.logits, dim=-1\n )\n\n self.assertTrue(torch.allclose(wrapper_output.logits, expected_logits, atol=1e-5))\n\n def test_prepare_inputs_for_generation(self):\n input_ids = torch.tensor([[1, 2, 3, 4, 5]])\n attention_mask = torch.ones_like(input_ids)\n\n inputs = self.wrapper.prepare_inputs_for_generation(input_ids, attention_mask=attention_mask, use_cache=True)\n\n self.assertIn(\"input_ids\", inputs)\n self.assertIn(\"attention_mask\", inputs)\n self.assertFalse(inputs.get(\"use_cache\", False))\n"} | null |
tune | {"type": "directory", "name": "tune", "children": [{"type": "file", "name": ".dockerignore"}, {"type": "directory", "name": "configs", "children": [{"type": "directory", "name": "backend", "children": [{"type": "file", "name": "ort.yaml"}, {"type": "file", "name": "pytorch.yaml"}, {"type": "file", "name": "tensorflow.yaml"}, {"type": "file", "name": "tensorflow_graph.yaml"}, {"type": "file", "name": "torchscript.yaml"}]}, {"type": "file", "name": "benchmark.yaml"}]}, {"type": "file", "name": "consolidate.py"}, {"type": "directory", "name": "docker", "children": [{"type": "file", "name": ".tf_configure.bazelrc"}, {"type": "file", "name": "Dockerfile"}, {"type": "file", "name": "Dockerfile.compile"}, {"type": "file", "name": "oneAPI.repo"}]}, {"type": "file", "name": "intel-requirements.txt"}, {"type": "file", "name": "launcher.py"}, {"type": "file", "name": "LICENSE"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "requirements.txt"}, {"type": "directory", "name": "src", "children": [{"type": "directory", "name": "backends", "children": [{"type": "file", "name": "ort.py"}, {"type": "file", "name": "pytorch.py"}, {"type": "file", "name": "tensorflow.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "benchmark.py"}, {"type": "file", "name": "config.py"}, {"type": "file", "name": "main.py"}, {"type": "file", "name": "reports.py"}, {"type": "directory", "name": "utils", "children": [{"type": "file", "name": "cpu.py"}, {"type": "file", "name": "env.py"}, {"type": "file", "name": "__init__.py"}]}]}]} | ## Transformers performance & evaluation framework
The benchmarking repository provides an easy and flexible testbed to generate, run and save multiple configurations
in order to compare Transformers based Neural Network models.
The overall benchmarking project leverages the Hydra framework from Facebook AI & Research which is able to generate
all the given sweeps through configurations files. Currently, we provide benchmarks for 5 Deep Learning frameworks
among the most used:
- PyTorch (Eager mode)
- TorchScript (Static Graph mode)
- TensorFlow 2 (Eager mode)
- TensorFlow 2 Graph (Static Graph mode)
- ONNX Runtime for Inference (Static Graph mode + Graph Optimizations)
The repository is divided into 2 principal sections:
- `config/` stores all the configuration files for the supported backends.
- `backends/` stores the actual logic to generate textual inputs and execute a forward pass for the targeted backend.
## Getting Started
**Instructions presented here have been tested on Ubuntu 20.04**
```bash
apt update && apt -y install python3 python3-pip python3-dev libnuma-dev
cd <repo/path>
pip install -r requirements.txt
```
## Benchmarking framework
### How to use this repository to benchmark with a specific configuration
Hydra, the configuration framework used in this project, provides a simple command-line interface to specify and
override the configuration to be run.
For instance, in order to run a benchmark for ONNX Runtime on CPU with:
- **Backend = ORT**
- **Model = bert-base-cased**
- **Device = CPU**
- **Batch Size = 1**
- **Sequence Length = 32**
```bash
python3 src/main.py model=bert-base-cased sequence_length=32 backend=ort device=cpu
```
### Automatically let Hydra generate all the permutations to cover multiple configurations
Hydra integrates a very powerful sweep generation utility which is exposed through the `--multirun` command-line flag
when invoking the benchmark script.
For instance, in order to run a benchmark for PyTorch on CPU with the following specs:
- **Model = bert-base-cased**
- **Device = CPU**
- **Batch Size = 1**
- **Sequence Length = 128**
```bash
python3 src/main.py model=bert-base-cased batch_size=1 sequence_length=128 backend=pytorch device=cpu
```
### Overridable configuration properties
- `backend`: Specify the backend(s) to use to run the benchmark `{"pytorch", "torchscript", "tensorflow", "xla", "ort"}`
- `device`: Specify on which device to run the benchmark `{"cpu", "cuda"}`
- `precision`: Specify the model's parameters data format. For now, only supports `float32` (_i.e. full precision_)
- `num_threads`: Number of threads to use for intra-operation (`-1` Detect the number of CPU cores and use this value)
- `num_interops_threads`: Number of threads to use for inter-operation (`-1` Detect the number of CPU cores and use this value)
- `warmup_runs`: Number of warmup forward to execute before recording any benchmarking results. (Especially useful to preallocate memory buffers).
- `benchmark_duration`: Duration (in seconds) of the benchmark in an attempt to do as many forward calls as possible within the specified duration. These runs are executed after `warmup_runs`.
## Backend specific configuration properties
Framework exposes different features which can be enabled to tune the execution of the model on the underlying hardware.
In this repository we expose some of them, essentially the most common ones.
### PyTorch
- `use_torchscript` Boolean indicating if the runtime should trace the eager model to produce an optimized version.
This value is `False` when using backend `pytorch` and `True` when using backend `torchscript`
### TensorFlow
- `use_xla` Boolean indicating if the model should be wrapped around `tf.function(jit_compile=True)` in order to compile the underlying graph through XLA.
This value is `False` when using backend `tensorflow_graph` and can be enabled by config file or cmd line.
### ONNX Runtime (ORT)
- `opset` Integer setting which version of the ONNX Opset specification to use when exporting the model
- `graph_optimisation_level` Which level of optimization to apply with ONNX Runtime when loading the model. Possible values are:
- `ORT_DISABLE_ALL` Use the raw ONNX graph without any further optimization.
- `ORT_ENABLE_BASIC` Use basic graph optimizations which are not platform dependant.
- `ORT_ENABLE_EXTENDED` Use more advanced technics *(might include platform dependant optimizations)*.
- `ORT_ENABLE_ALL` Enable all the possible optimizations *(might include platform dependant optimizations)*.
- `execution_mode` Mode to execute the ONNX Graph. Can be either:
- `ORT_SEQUENTIAL` Execute the graph sequentially, without looking for subgraph to execute in parallel.
- `ORT_PARALLEL` Execute the graph potentially in parallel, looking for non-dependant subgraphs which can be run simultaneously.
## Launch utility tool
The benchmarking comes with a launcher tool highly inspired by [the one made available by Intel](https://github.com/intel/intel-extension-for-pytorch/blob/master/intel_pytorch_extension_py/launch.py).
The launcher tool helps you handle all the lower bits to configure experiments and get the best out of the platform you have.
More precisely, it will be able to configure the following elements:
- Linux transparent huge pages mechanism
- CPU cores affinity for OpenMP threads on NUMA platforms
- Memory affinity for OpenMP threads on NUMA platforms
- OpenMP configurations (KMP_AFFINITY, KMP_BLOCKTIME, OMP_NUM_THREADS, OMP_MAX_ACTIVE_LEVELS, etc.)
- Change at runtime the OpenMP library to be used (GNU / Intel)
- Change the memory allocation library to be used (std, tcmalloc, jemalloc)
- Setup multi-instances inference (multi independent models executing in parallel) with per-instance CPU core/memory affinity
The launcher script `launcher.py` is located at the root of transformers-benchmarks folder.
You can run `python launcher.py --help` to get all the tuning options available.
## Ready to use CLI command
### Benchmarking out of the box configuration for multiple backends
```shell
--multirun model=bert-base-cased backend=pytorch,torchscript,tensorflow,xla,ort
```
### Tuning the number of intra/inter ops for parallel sections (OMP_NUM_THREADS, MKL_NUM_THREADS, etc.)
```shell
--multirun model=bert-base-cased batch_size=1 sequence_length=32 backend.num_threads=2,4,8 backend.num_interops_threads=2,4,8
```
### Tuning OpenMP thread affinity
```shell
python launcher.py --kmp_affinity=<value_here> -- src/main.py model=bert-base-cased batch_size=1 sequence_length=32 ...
```
### Tuning number of model instances (multi-instance setup) along with intra/inter ops for parallel sections
```shell
python launcher.py --ninstances=4 -- src/main.py model=bert-base-cased batch_size=1 sequence_length=32 ...
```
### Tuning allocation library
```shell
export TCMALLOC_LIBRARY_PATH=</path/to/tcmalloc/libtcmalloc.so>
python launcher.py --enable_tcmalloc -- src/main.py model=bert-base-cased batch_size=1 sequence_length=32 ...
```
### Tuning OpenMP implementation
```shell
export INTEL_OPENMP_LIBRARY_PATH=</path/to/intel/openmp/libomp.so>
python launcher.py --enable_iomp -- src/main.py model=bert-base-cased batch_size=1 sequence_length=32 ...
```
### Enabling Transparent Huge Page
```shell
python launcher.py --enable_thp -- src/main.py model=bert-base-cased batch_size=1 sequence_length=32 ...
```
## Hydra FAQ
## Executing dry-run to highlight configuration
```shell
python launcher.py --enable_tcmalloc --enable_iomp --ninstances=2 -- src/main.py --info config model=bert-base-cased batch_size=16 sequence_length=512
```
| {"intel-requirements.txt": "omegaconf>=2.1.0dev20\nhydra-core>=1.1.0.dev5\ntorch\nintel-tensorflow\nonnxruntime\npsutil\npandas\nrich\ntransformers\nmultiprocess\nsympy", "requirements.txt": "omegaconf>=2.1.0dev20\nhydra-core>=1.1.0.dev5\ntorch\ntensorflow\nonnxruntime\npsutil\npandas\nrich\ntransformers\nmultiprocess\nsympy\n", ".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 90873d1097e46063018584783348e74fa4a20f37 Hamza Amin <[email protected]> 1727369511 +0500\tclone: from https://github.com/huggingface/tune.git\n", ".git\\refs\\heads\\main": "90873d1097e46063018584783348e74fa4a20f37\n", "docker\\Dockerfile": "FROM ubuntu:20.04\n\nARG TRANSFORMERS_VERSION=4.1.1\nARG PYTORCH_VERSION=1.7.1\nARG TENSORFLOW_VERSION=2.4.0\nARG ONNXRUNTIME_VERSION=1.6.0\nARG MKL_THREADING_LIBRARY=OMP\n\nRUN apt update && \\\n apt install -y \\\n git \\\n python3 \\\n python3-pip && \\\n rm -rf /var/lib/apt/lists/*\n\n# PyTorch\nRUN python3 -m pip install torch==1.7.1+cpu -f https://download.pytorch.org/whl/torch_stable.html\n\n# TensorFlow\nRUN python3 -m pip install tensorflow\n\n# ONNX Runtime\nRUN python3 -m pip install onnxruntime\n\nCOPY . /opt/intel-benchmarks\n\nWORKDIR /opt/intel-benchmarks\nRUN python3 -m pip install -r requirements.txt\n\n", "docker\\Dockerfile.compile": "FROM nvidia/cuda:11.2.0-cudnn8-devel-ubuntu20.04 as builder\n\nARG TRANSFORMERS_VERSION=4.5.0\nARG PYTORCH_VERSION=1.8.1\nARG TENSORFLOW_VERSION=2.4.1\nARG MKL_THREADING_LIBRARY=OMP\nARG CUDA_ARCH_LIST=7.0;7.5;8.0;8.6+PTX\n\n# Ensure tzdata is set\nENV TZ=America/New_York\nRUN ln -snf /usr/share/zoneinfo/$TZ /etc/localtime && echo $TZ > /etc/timezone\n\nRUN apt update && \\\n apt install -y \\\n curl \\\n cmake \\\n make \\\n ninja-build \\\n git \\\n gpg-agent \\\n wget \\\n python3 \\\n python3-dev \\\n python3-pip\n\n# Install oneAPI repo\nRUN wget https://apt.repos.intel.com/intel-gpg-keys/GPG-PUB-KEY-INTEL-SW-PRODUCTS.PUB && \\\n apt-key add GPG-PUB-KEY-INTEL-SW-PRODUCTS.PUB && \\\n rm GPG-PUB-KEY-INTEL-SW-PRODUCTS.PUB && \\\n echo \"deb https://apt.repos.intel.com/oneapi all main\" | tee /etc/apt/sources.list.d/oneAPI.list\n\nRUN apt update && apt install -y \\\n intel-oneapi-mkl-devel \\\n intel-oneapi-runtime-openmp && \\\n rm -rf /var/lib/apt/lists/*\n\nENV LD_LIBRARY_PATH='/opt/intel/oneapi/tbb/latest/env/lib/intel64/gcc4.8:/opt/intel/oneapi/mkl/latest/lib/intel64'\nENV LIBRARY_PATH='/opt/intel/oneapi/tbb/latest/lib/intel64/gcc4.8:/opt/intel/oneapi/mkl/latest/lib/intel64'\nENV MKLROOT='/opt/intel/oneapi/mkl/latest'\n\n# Create a folder to store all the compiled binaries\nENV FRAMEWORK_BINARIES_FOLDER /opt/bin\nRUN mkdir ${FRAMEWORK_BINARIES_FOLDER}\n\n# Bazel for TensorFlow\nENV BAZEL_VERSION 4.0.0\nRUN cd \"/usr/bin\" && curl -fLO https://releases.bazel.build/${BAZEL_VERSION}/release/bazel-${BAZEL_VERSION}-linux-x86_64 && \\\n chmod +x bazel-${BAZEL_VERSION}-linux-x86_64 && \\\n mv bazel-${BAZEL_VERSION}-linux-x86_64 bazel && \\\n ln -s /usr/bin/python3 /usr/bin/python\n\n# Enable MKL to be found by the compilation process\nENV PATH=/opt/intel/oneapi/mkl/latest/include:$PATH\nENV CMAKE_PREFIX_PATH=/opt/intel/oneapi/mkl/latest/lib/intel64:$CMAKE_PREFIX_PATH\nENV CMAKE_INCLUDE_PATH=/opt/intel/oneapi/mkl/latest/include:$PATH:$CMAKE_INCLUDE_PATH\n\n# TODO: Merge with above when ready\nENV BUILD_CAFFE2_OPS=OFF \\\n BUILD_CAFFE2=OFF \\\n BUILD_TEST=OFF \\\n USE_CUDA=ON \\\n USE_OPENCV=OFF \\\n USE_FFMPEG=OFF \\\n USE_LEVELDB=OFF \\\n USE_KINETO=OFF \\\n USE_REDIS=OFF \\\n USE_DISTRIBUTED=OFF \\\n USE_QNNPACK=ON \\\n USE_FBGEMM=ON \\\n USE_NNPACK=ON \\\n USE_MKLDNN=ON \\\n BLAS=MKL \\\n MKLDNN_CPU_RUNTIME=$MKL_THREADING_LIBRARY \\\n TORCH_CUDA_ARCH_LIST=$CUDA_ARCH_LIST\n\n# PyTorch\nRUN git clone https://github.com/pytorch/pytorch /opt/pytorch && \\\n cd /opt/pytorch && \\\n git checkout v${PYTORCH_VERSION} && \\\n git submodule update --init --recursive && \\\n python3 -m pip install -r requirements.txt && \\\n python3 setup.py bdist_wheel && \\\n ls dist/ | grep -i \".whl\" | xargs -I % sh -c 'cp /opt/pytorch/dist/% ${FRAMEWORK_BINARIES_FOLDER}/'\n\n\n\n# TensorFlow\nRUN git clone https://github.com/tensorflow/tensorflow /opt/tensorflow && \\\n cd /opt/tensorflow && \\\n git checkout v${TENSORFLOW_VERSION}\n\nCOPY docker/.tf_configure.bazelrc /opt/tensorflow/.tf_configure.bazelrc\nRUN cd /opt/tensorflow && \\\n python3 -m pip install -U --user pip numpy wheel && \\\n python3 -m pip install -U --user keras_preprocessing --no-deps && \\\n bazel build \\\n --config=cuda \\\n --config=v2 \\\n --config=opt \\\n --config=mkl \\\n --config=numa \\\n --config=noaws \\\n --config=nogcp \\\n --config=nohdfs \\\n --config=nonccl \\\n //tensorflow/tools/pip_package:build_pip_package\n\nRUN cd /opt/tensorflow && \\\n ./bazel-bin/tensorflow/tools/pip_package/build_pip_package /tmp/tensorflow_pkg && \\\n ls /tmp/tensorflow_pkg | grep -i \".whl\" | xargs -I % sh -c 'cp /tmp/tensorflow_pkg/% ${FRAMEWORK_BINARIES_FOLDER}/'\n\n\n# ONNX Runtime\nRUN git clone https://github.com/microsoft/onnxruntime opt/onnxruntime && \\\n cd /opt/onnxruntime && \\\n ./build.sh --config=Release --parallel --cmake_generator=Ninja --enable_pybind --build_wheel --enable_lto --use_openmp --skip_tests --skip_onnx_tests && \\\n ls /opt/onnxruntime/build/Linux/Release/dist/ | grep -i \".whl\" | xargs -I % sh -c 'cp /opt/onnxruntime/build/Linux/Release/dist/% ${FRAMEWORK_BINARIES_FOLDER}/'\n\nFROM nvidia/cuda:11.2.0-cudnn8-runtime-ubuntu20.04\n\nRUN apt update && \\\n apt install -y \\\n python3 \\\n python3-pip \\\n numactl \\\n libtcmalloc-minimal4 \\\n wget\n\n# Install oneAPI repo\nRUN wget https://apt.repos.intel.com/intel-gpg-keys/GPG-PUB-KEY-INTEL-SW-PRODUCTS.PUB && \\\n apt-key add GPG-PUB-KEY-INTEL-SW-PRODUCTS.PUB && \\\n rm GPG-PUB-KEY-INTEL-SW-PRODUCTS.PUB && \\\n echo \"deb https://apt.repos.intel.com/oneapi all main\" | tee /etc/apt/sources.list.d/oneAPI.list\n\nRUN apt update && apt install -y \\\n intel-oneapi-mkl \\\n intel-oneapi-runtime-openmp && \\\n rm -rf /var/lib/apt/lists/*\n\nENV LD_LIBRARY_PATH='/usr/local/cuda/compat:/opt/intel/oneapi/tbb/latest/env/lib/intel64/gcc4.8:/opt/intel/oneapi/mkl/latest/lib/intel64'\nENV LIBRARY_PATH='/opt/intel/oneapi/tbb/latest/lib/intel64/gcc4.8:/opt/intel/oneapi/mkl/latest/lib/intel64'\nENV MKLROOT='/opt/intel/oneapi/mkl/latest'\n\n# Copy\nCOPY --from=builder /opt/bin /opt\n\n# Install frameworks\nRUN ls /opt/*whl | xargs python3 -m pip install\n\n# Copy tune\nCOPY . /opt/tune\n\nWORKDIR /opt/tune\nRUN python3 -m pip install -r requirements.txt\n\nWORKDIR /opt/tune\nRUN python3 -m pip install -r requirements.txt", "src\\main.py": "# Copyright 2021 Hugging Face Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\nfrom logging import getLogger\nfrom typing import Type, get_args, Union\n\nimport hydra\nimport numpy as np\nfrom hydra.core.config_store import ConfigStore\nfrom hydra.experimental import compose\nfrom hydra.utils import get_class\nfrom omegaconf import OmegaConf, DictConfig\n\nfrom backends import Backend, BackendConfig\nfrom backends.ort import OnnxRuntimeConfig\nfrom backends.pytorch import PyTorchConfig\nfrom backends.tensorflow import TensorflowConfig\nfrom config import BenchmarkConfig\n\n\n# Register resolvers\nOmegaConf.register_new_resolver(\"pytorch_version\", PyTorchConfig.version)\nOmegaConf.register_new_resolver(\"tensorflow_version\", TensorflowConfig.version)\nOmegaConf.register_new_resolver(\"ort_version\", OnnxRuntimeConfig.version)\n\n# Register configurations\ncs = ConfigStore.instance()\ncs.store(name=\"benchmark\", node=BenchmarkConfig)\ncs.store(group=\"backend\", name=\"pytorch_backend\", node=PyTorchConfig)\ncs.store(group=\"backend\", name=\"torchscript_backend\", node=PyTorchConfig)\ncs.store(group=\"backend\", name=\"tensorflow_backend\", node=TensorflowConfig)\ncs.store(group=\"backend\", name=\"tensorflow_graph_backend\", node=TensorflowConfig)\ncs.store(group=\"backend\", name=\"ort_backend\", node=OnnxRuntimeConfig)\n\n\nLOGGER = getLogger(\"benchmark\")\n\n\ndef get_overrided_backend_config(original_config: Union[DictConfig, BackendConfig], override: str) -> DictConfig:\n # Copy the initial config and pop the backend\n update_config = original_config.copy()\n OmegaConf.set_struct(update_config, False)\n update_config.pop(\"backend\")\n\n # Retrieve the original backend factory\n backend_factory: Type[Backend] = get_class(original_config.backend._target_)\n\n # Compose the two configs (reference <- original @backend==config.reference)\n reference_config = compose(config_name=\"benchmark\", overrides=[f\"backend={override}\"])\n reference_config.merge_with(update_config)\n reference_backend_factory: Type[Backend] = get_class(reference_config.backend._target_)\n\n # Retrieve each original & reference BackendConfig instance type\n reference_backend_config_type: Type[BackendConfig] = get_args(reference_backend_factory.__orig_bases__[0])[0]\n original_backend_config_type: Type[BackendConfig] = get_args(backend_factory.__orig_bases__[0])[0]\n\n # Filter out to rely only on the common subset of supported config elements\n reference_backend_keys = reference_backend_config_type.supported_keys()\n original_backend_keys = original_backend_config_type.supported_keys()\n\n # (A - B) union (A inter B)\n overlapping_backend_config_keys = \\\n (reference_backend_keys.intersection(original_backend_keys)) - {\"name\", \"_target_\", \"version\"}\n\n LOGGER.debug(f\"Keys to override from original config in the new one: {overlapping_backend_config_keys}\")\n\n # Get a masked configuration copy\n original_overlapping_backend_config = OmegaConf.masked_copy(\n original_config,\n list(overlapping_backend_config_keys)\n )\n\n # Override the properties\n reference_config[\"backend\"].merge_with(original_overlapping_backend_config)\n\n return reference_config\n\n\[email protected](config_path=\"../configs\", config_name=\"benchmark\")\ndef run(config: BenchmarkConfig) -> None:\n # We need to allocate the reference backend (used to compare backend output against)\n if config.reference is not None and config.reference != config.backend:\n LOGGER.info(f\"Using {config.reference} as reference backend\")\n reference_config = get_overrided_backend_config(config, override=config.reference)\n else:\n reference_config = None\n\n # Allocate requested target backend\n backend_factory: Type[Backend] = get_class(config.backend._target_)\n backend = backend_factory.allocate(config)\n\n # Run benchmark and reference\n benchmark, outputs = backend.execute(config, is_reference=False)\n backend.clean(config)\n\n if reference_config is not None:\n reference_backend_factory = get_class(reference_config.backend._target_)\n reference_backend = reference_backend_factory.allocate(reference_config)\n _, ref_outputs = reference_backend.execute(reference_config, is_reference=True)\n\n # Record the outputs to compare with the target backend\n benchmark.record_outputs(outputs, ref_outputs)\n reference_backend.clean(reference_config)\n\n LOGGER.info(\n f\"Reference backend ({config.reference}) against target backend ({config.backend.name})\"\n f\" absolute difference:\"\n f\" {np.mean(benchmark.outputs_diff)} (+/- {np.std(benchmark.outputs_diff)})\"\n f\" over {len(benchmark.outputs_diff)} sample(s)\"\n )\n\n # Save the resolved config\n OmegaConf.save(config, \".hydra/config.yaml\", resolve=True)\n\n df = benchmark.to_pandas()\n df.to_csv(\"results.csv\", index_label=\"id\")\n\n\nif __name__ == '__main__':\n run()\n"} | null |
unity-api | {"type": "directory", "name": "unity-api", "children": [{"type": "directory", "name": "Editor", "children": [{"type": "file", "name": "APIConfigUpdater.cs"}, {"type": "file", "name": "APIConfigUpdater.cs.meta"}, {"type": "file", "name": "HuggingFaceAPI.Editor.asmdef"}, {"type": "file", "name": "HuggingFaceAPI.Editor.asmdef.meta"}, {"type": "file", "name": "HuggingFaceAPIWizard.cs"}, {"type": "file", "name": "HuggingFaceAPIWizard.cs.meta"}]}, {"type": "file", "name": "Editor.meta"}, {"type": "directory", "name": "Examples", "children": [{"type": "directory", "name": "Fonts", "children": [{"type": "file", "name": "Roboto-Regular SDF.asset"}, {"type": "file", "name": "Roboto-Regular SDF.asset.meta"}, {"type": "file", "name": "Roboto-Regular.ttf.meta"}]}, {"type": "file", "name": "Fonts.meta"}, {"type": "directory", "name": "Scenes", "children": [{"type": "file", "name": "ConversationExample.unity"}, {"type": "file", "name": "ConversationExample.unity.meta"}, {"type": "file", "name": "SpeechRecognitionExample.unity"}, {"type": "file", "name": "SpeechRecognitionExample.unity.meta"}, {"type": "file", "name": "TextToImageExample.unity"}, {"type": "file", "name": "TextToImageExample.unity.meta"}]}, {"type": "file", "name": "Scenes.meta"}, {"type": "directory", "name": "Scripts", "children": [{"type": "file", "name": "ConversationExample.cs"}, {"type": "file", "name": "ConversationExample.cs.meta"}, {"type": "file", "name": "SpeechRecognitionExample.cs"}, {"type": "file", "name": "SpeechRecognitionExample.cs.meta"}, {"type": "file", "name": "TextToImageExample.cs"}, {"type": "file", "name": "TextToImageExample.cs.meta"}]}, {"type": "file", "name": "Scripts.meta"}, {"type": "directory", "name": "Sounds", "children": [{"type": "file", "name": "tutorial.wav.meta"}]}, {"type": "file", "name": "Sounds.meta"}]}, {"type": "file", "name": "Examples.meta"}, {"type": "file", "name": "LICENSE"}, {"type": "file", "name": "LICENSE.meta"}, {"type": "file", "name": "package.json"}, {"type": "file", "name": "package.json.meta"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "README.md.meta"}, {"type": "file", "name": "README.pdf.meta"}, {"type": "directory", "name": "Runtime", "children": [{"type": "file", "name": "HuggingFaceAPI.asmdef"}, {"type": "file", "name": "HuggingFaceAPI.asmdef.meta"}, {"type": "directory", "name": "Implementations", "children": [{"type": "file", "name": "APIClient.cs"}, {"type": "file", "name": "APIClient.cs.meta"}, {"type": "file", "name": "APIConfig.cs"}, {"type": "file", "name": "APIConfig.cs.meta"}, {"type": "file", "name": "ByteArrayPayload.cs"}, {"type": "file", "name": "ByteArrayPayload.cs.meta"}, {"type": "file", "name": "HuggingFaceAPI.cs"}, {"type": "file", "name": "HuggingFaceAPI.cs.meta"}, {"type": "file", "name": "JObjectPayload.cs"}, {"type": "file", "name": "JObjectPayload.cs.meta"}, {"type": "directory", "name": "Tasks", "children": [{"type": "file", "name": "AutomaticSpeechRecognitionTask.cs"}, {"type": "file", "name": "AutomaticSpeechRecognitionTask.cs.meta"}, {"type": "file", "name": "ConversationTask.cs"}, {"type": "file", "name": "ConversationTask.cs.meta"}, {"type": "file", "name": "QuestionAnsweringTask.cs"}, {"type": "file", "name": "QuestionAnsweringTask.cs.meta"}, {"type": "file", "name": "SentenceSimilarityTask.cs"}, {"type": "file", "name": "SentenceSimilarityTask.cs.meta"}, {"type": "file", "name": "SummarizationTask.cs"}, {"type": "file", "name": "SummarizationTask.cs.meta"}, {"type": "file", "name": "TaskBase.cs"}, {"type": "file", "name": "TaskBase.cs.meta"}, {"type": "file", "name": "TextClassificationTask.cs"}, {"type": "file", "name": "TextClassificationTask.cs.meta"}, {"type": "file", "name": "TextGenerationTask.cs"}, {"type": "file", "name": "TextGenerationTask.cs.meta"}, {"type": "file", "name": "TextToImageTask.cs"}, {"type": "file", "name": "TextToImageTask.cs.meta"}, {"type": "file", "name": "TranslationTask.cs"}, {"type": "file", "name": "TranslationTask.cs.meta"}, {"type": "file", "name": "ZeroShotTextClassificationTask.cs"}, {"type": "file", "name": "ZeroShotTextClassificationTask.cs.meta"}]}, {"type": "file", "name": "Tasks.meta"}]}, {"type": "file", "name": "Implementations.meta"}, {"type": "directory", "name": "Interfaces", "children": [{"type": "file", "name": "IAPIClient.cs"}, {"type": "file", "name": "IAPIClient.cs.meta"}, {"type": "file", "name": "IAPIConfig.cs"}, {"type": "file", "name": "IAPIConfig.cs.meta"}, {"type": "file", "name": "IJObjectPayload.cs"}, {"type": "file", "name": "IJObjectPayload.cs.meta"}, {"type": "file", "name": "IPayload.cs"}, {"type": "file", "name": "IPayload.cs.meta"}, {"type": "file", "name": "ITask.cs"}, {"type": "file", "name": "ITask.cs.meta"}]}, {"type": "file", "name": "Interfaces.meta"}, {"type": "directory", "name": "Utilities", "children": [{"type": "file", "name": "Classification.cs"}, {"type": "file", "name": "Classification.cs.meta"}, {"type": "file", "name": "Conversation.cs"}, {"type": "file", "name": "Conversation.cs.meta"}, {"type": "file", "name": "Extensions.cs"}, {"type": "file", "name": "Extensions.cs.meta"}, {"type": "file", "name": "QuestionAnsweringResponse.cs"}, {"type": "file", "name": "QuestionAnsweringResponse.cs.meta"}, {"type": "file", "name": "SentenceSimilarity.cs"}, {"type": "file", "name": "SentenceSimilarity.cs.meta"}, {"type": "file", "name": "TaskEndpoint.cs"}, {"type": "file", "name": "TaskEndpoint.cs.meta"}, {"type": "file", "name": "TextClassificationResponse.cs"}, {"type": "file", "name": "TextClassificationResponse.cs.meta"}, {"type": "file", "name": "ZeroShotTextClassificationInput.cs"}, {"type": "file", "name": "ZeroShotTextClassificationInput.cs.meta"}, {"type": "file", "name": "ZeroShotTextClassificationResponse.cs"}, {"type": "file", "name": "ZeroShotTextClassificationResponse.cs.meta"}]}, {"type": "file", "name": "Utilities.meta"}]}, {"type": "file", "name": "Runtime.meta"}]} | fileFormatVersion: 2
guid: 5cc81ea56e0259445968a7a5e657014b
DefaultImporter:
externalObjects: {}
userData:
assetBundleName:
assetBundleVariant:
| {"package.json": "{\n \"name\": \"com.huggingface.api\",\n \"displayName\": \"Hugging Face API\",\n \"version\": \"0.8.0\",\n \"unity\": \"2020.3\",\n \"description\": \"A Unity plugin for making API calls to the Hugging Face API.\",\n \"keywords\": [\"huggingface\", \"api\", \"chatbot\"],\n \"author\": {\n \"name\": \"Dylan Ebert\",\n \"email\": \"[email protected]\",\n \"url\": \"https://github.com/huggingface/unity-api\"\n },\n \"dependencies\": {\n \"com.unity.textmeshpro\": \"3.0.6\",\n \"com.unity.nuget.newtonsoft-json\": \"3.0.1\"\n }\n}\n", "package.json.meta": "fileFormatVersion: 2\nguid: 63645684cef6426418305f4f6130d7ad\nTextScriptImporter:\n externalObjects: {}\n userData: \n assetBundleName: \n assetBundleVariant: \n", ".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 8d0231780ead66aba3ad5ad3373158d5de0bc533 Hamza Amin <[email protected]> 1727369515 +0500\tclone: from https://github.com/huggingface/unity-api.git\n", ".git\\refs\\heads\\main": "8d0231780ead66aba3ad5ad3373158d5de0bc533\n"} | null |
Unity-MLAgents-LoadFromHub-Assets | {"type": "directory", "name": "Unity-MLAgents-LoadFromHub-Assets", "children": [{"type": "file", "name": "README.md"}]} | # Unity MLAgents x 🤗 : Load from Hub
This repository contains prefabs, scripts, and UI elements for your Unity project, allowing you to **easily load ML-Agents models from the Hugging Face Hub using the Hugging Face Hub API**.
## Provided Versions
- `LoadOneModelFromHub-v2`: When you want to load one model (single agent environments like Huggy).
## How Does It Look? 👀
### LoadOneModelFromHub
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/notebooks/unit-bonus1/load-huggy.jpg" alt="Huggy Example"/>
| {".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 21f4e31cad1e2456e811a9393a2779f50170dcca Hamza Amin <[email protected]> 1727369518 +0500\tclone: from https://github.com/huggingface/Unity-MLAgents-LoadFromHub-Assets.git\n", ".git\\refs\\heads\\main": "21f4e31cad1e2456e811a9393a2779f50170dcca\n"} | null |
Unity-WebGL-template-for-Hugging-Face-Spaces | {"type": "directory", "name": "Unity-WebGL-template-for-Hugging-Face-Spaces", "children": [{"type": "directory", "name": "assets", "children": [{"type": "directory", "name": "images", "children": []}]}, {"type": "file", "name": "readme.md"}]} | # Hugging Face Unity WebGL Template for Spaces
This WebGL template allows you to build and publish your demo on [Hugging Face Spaces](https://huggingface.co/spaces).
<img src="./assets/images/webgl.jpg" alt="Snowball Fight"/>
This template is based on the work of [greggman](https://greggman.github.io/better-unity-webgl-template/)
## Instructions
- Download the Unity Package and place it into your project.
- In `Edit> Project Settings > Player`, in the WebGL tab under *Resolution and Presentation* pick "Hugging Face" template. <img src="./assets/images/screenshot.jpg" alt="Snowball Fight"/>
- You can change the loading logo in `Assets/WebGLTemplates/Hugging Face/logo.png`
| {".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n"} | null |
.github | {"type": "directory", "name": ".github", "children": []} | # .github
| {".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 39bf8ee9042c9c9e024fe4a08dfd8be2a2dfa49b Hamza Amin <[email protected]> 1728220004 +0500\tclone: from https://github.com/Netflix/.github.git\n", ".git\\refs\\heads\\main": "39bf8ee9042c9c9e024fe4a08dfd8be2a2dfa49b\n"} | null |
aegisthus | {"type": "directory", "name": "aegisthus", "children": [{"type": "directory", "name": "aegisthus-core", "children": [{"type": "directory", "name": "src", "children": [{"type": "directory", "name": "main", "children": [{"type": "directory", "name": "java", "children": [{"type": "directory", "name": "com", "children": [{"type": "directory", "name": "netflix", "children": [{"type": "directory", "name": "aegisthus", "children": [{"type": "directory", "name": "tools", "children": [{"type": "file", "name": "AegisthusSerializer.java"}, {"type": "file", "name": "ChainedPathFilter.java"}, {"type": "file", "name": "DirectoryWalker.java"}, {"type": "file", "name": "StorageHelper.java"}, {"type": "file", "name": "Utils.java"}]}]}]}]}, {"type": "directory", "name": "org", "children": [{"type": "directory", "name": "xerial", "children": [{"type": "directory", "name": "snappy", "children": [{"type": "file", "name": "SnappyInputStream2.java"}]}]}]}]}]}, {"type": "directory", "name": "test", "children": [{"type": "directory", "name": "java", "children": [{"type": "directory", "name": "com", "children": [{"type": "directory", "name": "netflix", "children": [{"type": "directory", "name": "aegisthus", "children": [{"type": "directory", "name": "tools", "children": [{"type": "file", "name": "AegisthusSerializerTest.java"}]}]}]}]}]}]}]}]}, {"type": "directory", "name": "aegisthus-distcp", "children": [{"type": "directory", "name": "src", "children": [{"type": "directory", "name": "main", "children": [{"type": "directory", "name": "java", "children": [{"type": "directory", "name": "com", "children": [{"type": "directory", "name": "netflix", "children": [{"type": "directory", "name": "hadoop", "children": [{"type": "directory", "name": "output", "children": [{"type": "file", "name": "CleanOutputCommitter.java"}, {"type": "file", "name": "CleanOutputFormat.java"}]}]}]}]}, {"type": "file", "name": "Distcp.java"}]}]}]}]}, {"type": "directory", "name": "aegisthus-hadoop", "children": [{"type": "directory", "name": "src", "children": [{"type": "directory", "name": "main", "children": [{"type": "directory", "name": "java", "children": [{"type": "directory", "name": "com", "children": [{"type": "directory", "name": "netflix", "children": [{"type": "directory", "name": "aegisthus", "children": [{"type": "directory", "name": "input", "children": [{"type": "file", "name": "AegisthusCombinedInputFormat.java"}, {"type": "file", "name": "AegisthusInputFormat.java"}, {"type": "directory", "name": "readers", "children": [{"type": "file", "name": "CombineSSTableReader.java"}, {"type": "file", "name": "SSTableRecordReader.java"}]}, {"type": "directory", "name": "splits", "children": [{"type": "file", "name": "AegCombinedSplit.java"}, {"type": "file", "name": "AegCompressedSplit.java"}, {"type": "file", "name": "AegSplit.java"}]}]}, {"type": "directory", "name": "io", "children": [{"type": "directory", "name": "sstable", "children": [{"type": "directory", "name": "compression", "children": [{"type": "file", "name": "CompressionInputStream.java"}, {"type": "file", "name": "CompressionMetadata.java"}]}, {"type": "file", "name": "IndexDatabaseScanner.java"}, {"type": "file", "name": "SSTableColumnScanner.java"}]}, {"type": "directory", "name": "writable", "children": [{"type": "file", "name": "AegisthusKey.java"}, {"type": "file", "name": "AegisthusKeyGroupingComparator.java"}, {"type": "file", "name": "AegisthusKeyMapper.java"}, {"type": "file", "name": "AegisthusKeyPartitioner.java"}, {"type": "file", "name": "AegisthusKeySortingComparator.java"}, {"type": "file", "name": "AtomWritable.java"}, {"type": "file", "name": "RowWritable.java"}]}]}, {"type": "directory", "name": "mapreduce", "children": [{"type": "file", "name": "CassSSTableReducer.java"}]}, {"type": "directory", "name": "output", "children": [{"type": "file", "name": "CustomFileNameFileOutputFormat.java"}, {"type": "file", "name": "JsonOutputFormat.java"}, {"type": "file", "name": "SSTableOutputFormat.java"}]}, {"type": "directory", "name": "util", "children": [{"type": "file", "name": "CFMetadataUtility.java"}, {"type": "file", "name": "JobKiller.java"}, {"type": "file", "name": "ObservableToIterator.java"}]}]}, {"type": "file", "name": "Aegisthus.java"}]}]}, {"type": "directory", "name": "org", "children": [{"type": "directory", "name": "coursera", "children": [{"type": "directory", "name": "mapreducer", "children": [{"type": "file", "name": "CQLMapper.java"}]}, {"type": "file", "name": "SSTableExport.java"}]}]}]}]}, {"type": "directory", "name": "test", "children": [{"type": "directory", "name": "groovy", "children": [{"type": "file", "name": "AegisthusIntegrationTest.groovy"}]}, {"type": "directory", "name": "resources", "children": [{"type": "directory", "name": "testdata", "children": [{"type": "directory", "name": "1.2.18", "children": [{"type": "directory", "name": "randomtable", "children": [{"type": "directory", "name": "aeg_json_output", "children": [{"type": "file", "name": "aeg-00000"}]}, {"type": "directory", "name": "input", "children": [{"type": "directory", "name": "b22fc624d00501e2150087fadb82ea0742fc7f796a051cfe80939c2d0d0cbd07", "children": [{"type": "directory", "name": "testdata", "children": []}]}]}]}]}]}]}]}]}]}, {"type": "file", "name": "CHANGELOG.md"}, {"type": "file", "name": "LICENSE"}, {"type": "file", "name": "OSSMETADATA"}, {"type": "file", "name": "README.md"}]} | Aegisthus
=========
STATUS
------
Aegisthus has been archived and will receive no further updates.
OVERVIEW
--------
A Bulk Data Pipeline out of Cassandra. Aegisthus implements a reader for the
SSTable format and provides a map/reduce program to create a compacted snapshot
of the data contained in a column family.
BUILDING
--------
Aegisthus is built via Gradle (http://www.gradle.org). To build from the command line:
./gradlew build
RUNNING
-------
Please [see the wiki](https://github.com/Netflix/aegisthus/wiki) or checkout the scripts
directory to use our sstable2json wrapper for individual sstables.
TESTING
-------
To run the included tests from the command line:
./gradlew build
ENHANCEMENTS
------------
* Reading
* Commit log readers
* Code to do this previously existed in Aegisthus but was removed in commit [35a05e3f](https://github.com/Netflix/aegisthus/commit/35a05e3fd02a016e61ea6ec833c5dbbf22feceac).
* Split compressed input files
* Currently compressed input files are only handled by a single mapper. See the [discussion in issue #9](https://github.com/Netflix/aegisthus/issues/9). The relevant section of code is in [getSSTableSplitsForFile in AegisthusInputFormat](https://github.com/Netflix/aegisthus/blob/1343de5b389c5a846d8509102078e3ca0680bedf/aegisthus-hadoop/src/main/java/com/netflix/aegisthus/input/AegisthusInputFormat.java#L74).
* Add CQL support
* This way the user doesn't have to add the key and column types as job parameters. Perhaps we will do this by requiring the table schema like SSTableExporter does.
* Writing
* Add an option to snappy compress output.
* Add an output format for easier downstream processing.
* See discussion on issue [#36](https://github.com/Netflix/aegisthus/issues/36).
* Add a pivot format
* Create an output format that contains a column per row. This can be used to support very large rows without having to have all of the columns in memory at one time.
* Packaging
* Publish Aegisthus to Maven Central
* Publish Shaded/Shadowed/FatJar version of Aegisthus as well
LICENSE
--------
Copyright 2013 Netflix, Inc.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
| {".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", "aegisthus-core\\src\\main\\java\\org\\xerial\\snappy\\SnappyInputStream2.java": "/*--------------------------------------------------------------------------\n * Copyright 2011 Taro L. Saito\n *\n * Licensed under the Apache License, Version 2.0 (the \"License\");\n * you may not use this file except in compliance with the License.\n * You may obtain a copy of the License at\n *\n * http://www.apache.org/licenses/LICENSE-2.0\n *\n * Unless required by applicable law or agreed to in writing, software\n * distributed under the License is distributed on an \"AS IS\" BASIS,\n * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n * See the License for the specific language governing permissions and\n * limitations under the License.\n *--------------------------------------------------------------------------*/\n//--------------------------------------\n// XerialJ\n//\n// SnappyInputStream.java\n// Since: 2011/03/31 20:14:56\n//\n// $URL$\n// $Author$\n//--------------------------------------\npackage org.xerial.snappy;\n\nimport java.io.ByteArrayInputStream;\nimport java.io.IOException;\nimport java.io.InputStream;\n\n\n/**\n * This is included because a patch I put in upstream isn't installed on EMR...\n */\n/**\n * A stream filter for reading data compressed by {@link SnappyOutputStream}.\n * \n * \n * @author leo\n * \n */\npublic class SnappyInputStream2 extends InputStream\n{\n private boolean finishedReading = false;\n protected final InputStream in;\n\n private byte[] compressed;\n private byte[] uncompressed;\n private int uncompressedCursor = 0;\n private int uncompressedLimit = 0;\n\n private byte[] chunkSizeBuf = new byte[4];\n\n /**\n * Create a filter for reading compressed data as a uncompressed stream\n * \n * @param input\n * @throws IOException\n */\n public SnappyInputStream2(InputStream input) throws IOException {\n this.in = input;\n readHeader();\n }\n\n /**\n * Close the stream\n */\n /* (non-Javadoc)\n * @see java.io.InputStream#close()\n */\n @Override\n public void close() throws IOException {\n compressed = null;\n uncompressed = null;\n if (in != null)\n in.close();\n }\n\n protected void readHeader() throws IOException {\n byte[] header = new byte[SnappyCodec.headerSize()];\n int readBytes = 0;\n while (readBytes < header.length) {\n int ret = in.read(header, readBytes, header.length - readBytes);\n if (ret == -1)\n break;\n readBytes += ret;\n }\n\n // Quick test of the header \n if (readBytes < header.length || header[0] != SnappyCodec.MAGIC_HEADER[0]) {\n // do the default uncompression\n readFully(header, readBytes);\n return;\n }\n\n SnappyCodec codec = SnappyCodec.readHeader(new ByteArrayInputStream(header));\n if (codec.isValidMagicHeader()) {\n // The input data is compressed by SnappyOutputStream\n if (codec.version < SnappyCodec.MINIMUM_COMPATIBLE_VERSION) {\n throw new IOException(String.format(\n \"compressed with imcompatible codec version %d. At least version %d is required\",\n codec.version, SnappyCodec.MINIMUM_COMPATIBLE_VERSION));\n }\n }\n else {\n // (probably) compressed by Snappy.compress(byte[])\n readFully(header, readBytes);\n return;\n }\n }\n\n protected void readFully(byte[] fragment, int fragmentLength) throws IOException {\n // read the entire input data to the buffer \n compressed = new byte[Math.max(8 * 1024, fragmentLength)]; // 8K\n System.arraycopy(fragment, 0, compressed, 0, fragmentLength);\n int cursor = fragmentLength;\n for (int readBytes = 0; (readBytes = in.read(compressed, cursor, compressed.length - cursor)) != -1;) {\n cursor += readBytes;\n if (cursor >= compressed.length) {\n byte[] newBuf = new byte[(compressed.length * 2)];\n System.arraycopy(compressed, 0, newBuf, 0, compressed.length);\n compressed = newBuf;\n }\n }\n\n finishedReading = true;\n\n // Uncompress\n int uncompressedLength = Snappy.uncompressedLength(compressed, 0, cursor);\n uncompressed = new byte[uncompressedLength];\n Snappy.uncompress(compressed, 0, cursor, uncompressed, 0);\n this.uncompressedCursor = 0;\n this.uncompressedLimit = uncompressedLength;\n\n }\n\n /**\n * Reads up to len bytes of data from the input stream into an array of\n * bytes.\n */\n /* (non-Javadoc)\n * @see java.io.InputStream#read(byte[], int, int)\n */\n @Override\n public int read(byte[] b, int off, int len) throws IOException {\n return rawRead(b, off, len);\n }\n\n /**\n * Read uncompressed data into the specified array\n * \n * @param array\n * @param byteOffset\n * @param byteLength\n * @return written bytes\n * @throws IOException\n */\n public int rawRead(Object array, int byteOffset, int byteLength) throws IOException {\n int writtenBytes = 0;\n for (; writtenBytes < byteLength;) {\n if (uncompressedCursor >= uncompressedLimit) {\n if (hasNextChunk())\n continue;\n else {\n return writtenBytes == 0 ? -1 : writtenBytes;\n }\n }\n int bytesToWrite = Math.min(uncompressedLimit - uncompressedCursor, byteLength - writtenBytes);\n Snappy.arrayCopy(uncompressed, uncompressedCursor, bytesToWrite, array, byteOffset + writtenBytes);\n writtenBytes += bytesToWrite;\n uncompressedCursor += bytesToWrite;\n }\n\n return writtenBytes;\n }\n\n /**\n * Read long array from the stream\n * \n * @param d\n * input\n * @param off\n * offset\n * @param len\n * the number of long elements to read\n * @return the total number of bytes read into the buffer, or -1 if there is\n * no more data because the end of the stream has been reached.\n * @throws IOException\n */\n public int read(long[] d, int off, int len) throws IOException {\n return rawRead(d, off * 8, len * 8);\n }\n\n /**\n * Read long array from the stream\n * \n * @param d\n * @return the total number of bytes read into the buffer, or -1 if there is\n * no more data because the end of the stream has been reached.\n * @throws IOException\n */\n public int read(long[] d) throws IOException {\n return read(d, 0, d.length);\n }\n\n /**\n * Read double array from the stream\n * \n * @param d\n * input\n * @param off\n * offset\n * @param len\n * the number of double elements to read\n * @return the total number of bytes read into the buffer, or -1 if there is\n * no more data because the end of the stream has been reached.\n * @throws IOException\n */\n public int read(double[] d, int off, int len) throws IOException {\n return rawRead(d, off * 8, len * 8);\n }\n\n /**\n * Read double array from the stream\n * \n * @param d\n * @return the total number of bytes read into the buffer, or -1 if there is\n * no more data because the end of the stream has been reached.\n * @throws IOException\n */\n public int read(double[] d) throws IOException {\n return read(d, 0, d.length);\n }\n\n /**\n * Read int array from the stream\n * \n * @param d\n * @return the total number of bytes read into the buffer, or -1 if there is\n * no more data because the end of the stream has been reached.\n * @throws IOException\n */\n public int read(int[] d) throws IOException {\n return read(d, 0, d.length);\n }\n\n /**\n * Read int array from the stream\n * \n * @param d\n * input\n * @param off\n * offset\n * @param len\n * the number of int elements to read\n * @return the total number of bytes read into the buffer, or -1 if there is\n * no more data because the end of the stream has been reached.\n * @throws IOException\n */\n public int read(int[] d, int off, int len) throws IOException {\n return rawRead(d, off * 4, len * 4);\n }\n\n /**\n * Read float array from the stream\n * \n * @param d\n * input\n * @param off\n * offset\n * @param len\n * the number of float elements to read\n * @return the total number of bytes read into the buffer, or -1 if there is\n * no more data because the end of the stream has been reached.\n * @throws IOException\n */\n public int read(float[] d, int off, int len) throws IOException {\n return rawRead(d, off * 4, len * 4);\n }\n\n /**\n * Read float array from the stream\n * \n * @param d\n * @return the total number of bytes read into the buffer, or -1 if there is\n * no more data because the end of the stream has been reached.\n * @throws IOException\n */\n public int read(float[] d) throws IOException {\n return read(d, 0, d.length);\n }\n\n /**\n * Read short array from the stream\n * \n * @param d\n * input\n * @param off\n * offset\n * @param len\n * the number of short elements to read\n * @return the total number of bytes read into the buffer, or -1 if there is\n * no more data because the end of the stream has been reached.\n * @throws IOException\n */\n public int read(short[] d, int off, int len) throws IOException {\n return rawRead(d, off * 2, len * 2);\n }\n\n /**\n * Read short array from the stream\n * \n * @param d\n * @return the total number of bytes read into the buffer, or -1 if there is\n * no more data because the end of the stream has been reached.\n * @throws IOException\n */\n public int read(short[] d) throws IOException {\n return read(d, 0, d.length);\n }\n\n protected boolean hasNextChunk() throws IOException {\n if (finishedReading)\n return false;\n\n uncompressedCursor = 0;\n uncompressedLimit = 0;\n\n int readBytes = 0;\n while (readBytes < 4) {\n int ret = in.read(chunkSizeBuf, readBytes, 4 - readBytes);\n if (ret == -1) {\n finishedReading = true;\n return false;\n }\n readBytes += ret;\n }\n int chunkSize = SnappyOutputStream.readInt(chunkSizeBuf, 0);\n // extend the compressed data buffer size\n if (compressed == null || chunkSize > compressed.length) {\n compressed = new byte[chunkSize];\n }\n readBytes = 0;\n while (readBytes < chunkSize) {\n int ret = in.read(compressed, readBytes, chunkSize - readBytes);\n if (ret == -1)\n break;\n readBytes += ret;\n }\n if (readBytes < chunkSize) {\n throw new IOException(\"failed to read chunk\");\n }\n try {\n int uncompressedLength = Snappy.uncompressedLength(compressed, 0, chunkSize);\n if (uncompressed == null || uncompressedLength > uncompressed.length) {\n uncompressed = new byte[uncompressedLength];\n }\n int actualUncompressedLength = Snappy.uncompress(compressed, 0, chunkSize, uncompressed, 0);\n if (uncompressedLength != actualUncompressedLength) {\n throw new IOException(\"invalid uncompressed byte size\");\n }\n uncompressedLimit = actualUncompressedLength;\n }\n catch (IOException e) {\n throw new IOException(\"failed to uncompress the chunk: \" + e.getMessage());\n }\n\n return true;\n }\n\n /**\n * Reads the next byte of uncompressed data from the input stream. The value\n * byte is returned as an int in the range 0 to 255. If no byte is available\n * because the end of the stream has been reached, the value -1 is returned.\n * This method blocks until input data is available, the end of the stream\n * is detected, or an exception is thrown.\n */\n /* (non-Javadoc)\n * @see java.io.InputStream#read()\n */\n @Override\n public int read() throws IOException {\n if (uncompressedCursor < uncompressedLimit) {\n return uncompressed[uncompressedCursor++] & 0xFF;\n }\n else {\n if (hasNextChunk())\n return read();\n else\n return -1;\n }\n }\n\n}", "aegisthus-hadoop\\src\\main\\java\\com\\netflix\\aegisthus\\io\\sstable\\IndexDatabaseScanner.java": "/**\n * Copyright 2013 Netflix, Inc.\n *\n * Licensed under the Apache License, Version 2.0 (the \"License\");\n * you may not use this file except in compliance with the License.\n * You may obtain a copy of the License at\n *\n * http://www.apache.org/licenses/LICENSE-2.0\n *\n * Unless required by applicable law or agreed to in writing, software\n * distributed under the License is distributed on an \"AS IS\" BASIS,\n * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n * See the License for the specific language governing permissions and\n * limitations under the License.\n */\npackage com.netflix.aegisthus.io.sstable;\n\nimport org.apache.cassandra.io.util.FileUtils;\nimport org.apache.commons.io.input.CountingInputStream;\n\nimport javax.annotation.Nonnull;\nimport java.io.Closeable;\nimport java.io.DataInputStream;\nimport java.io.IOError;\nimport java.io.IOException;\nimport java.io.InputStream;\nimport java.util.Iterator;\n\n/**\n * This class reads an SSTable index file and returns the offset for each key.\n */\npublic class IndexDatabaseScanner implements Iterator<IndexDatabaseScanner.OffsetInfo>, Closeable {\n private final CountingInputStream countingInputStream;\n private final DataInputStream input;\n\n public IndexDatabaseScanner(@Nonnull InputStream is) {\n this.countingInputStream = new CountingInputStream(is);\n this.input = new DataInputStream(this.countingInputStream);\n }\n\n @Override\n public void close() {\n try {\n input.close();\n } catch (IOException ignored) {\n }\n }\n\n @Override\n public boolean hasNext() {\n try {\n return input.available() != 0;\n } catch (IOException e) {\n throw new IOError(e);\n }\n }\n\n @Override\n @Nonnull\n public OffsetInfo next() {\n try {\n long indexOffset = countingInputStream.getByteCount();\n int keysize = input.readUnsignedShort();\n input.skipBytes(keysize);\n Long dataOffset = input.readLong();\n skipPromotedIndexes();\n return new OffsetInfo(dataOffset, indexOffset);\n } catch (IOException e) {\n throw new IOError(e);\n }\n }\n\n @Override\n public void remove() {\n throw new UnsupportedOperationException();\n }\n\n void skipPromotedIndexes() throws IOException {\n int size = input.readInt();\n if (size <= 0) {\n return;\n }\n\n FileUtils.skipBytesFully(input, size);\n }\n\n public static class OffsetInfo {\n private final long dataFileOffset;\n private final long indexFileOffset;\n\n public OffsetInfo(long dataFileOffset, long indexFileOffset) {\n this.dataFileOffset = dataFileOffset;\n this.indexFileOffset = indexFileOffset;\n }\n\n public long getDataFileOffset() {\n return dataFileOffset;\n }\n\n @SuppressWarnings(\"unused\")\n public long getIndexFileOffset() {\n return indexFileOffset;\n }\n }\n}\n", "aegisthus-hadoop\\src\\main\\java\\com\\netflix\\aegisthus\\io\\writable\\AegisthusKeyMapper.java": "package com.netflix.aegisthus.io.writable;\n\nimport org.apache.hadoop.mapreduce.Mapper;\n\nimport java.io.IOException;\n\npublic class AegisthusKeyMapper extends Mapper<AegisthusKey, AtomWritable, AegisthusKey, AtomWritable> {\n @Override\n protected void map(AegisthusKey key, AtomWritable value, Context context)\n throws IOException, InterruptedException {\n context.write(key, value);\n }\n}\n", "aegisthus-hadoop\\src\\main\\java\\org\\coursera\\mapreducer\\CQLMapper.java": "package org.coursera.mapreducer;\n\nimport com.netflix.aegisthus.io.writable.AegisthusKey;\nimport com.netflix.aegisthus.io.writable.AtomWritable;\nimport com.netflix.aegisthus.util.CFMetadataUtility;\nimport org.apache.avro.Schema;\nimport org.apache.avro.generic.GenericData;\nimport org.apache.avro.generic.GenericRecord;\nimport org.apache.avro.mapred.AvroKey;\nimport org.apache.avro.mapreduce.AvroJob;\nimport org.apache.cassandra.config.CFMetaData;\nimport org.apache.cassandra.cql3.CFDefinition;\nimport org.apache.cassandra.cql3.statements.ColumnGroupMap;\nimport org.apache.cassandra.db.Column;\nimport org.apache.cassandra.db.OnDiskAtom;\nimport org.apache.cassandra.db.marshal.*;\nimport org.apache.cassandra.utils.ByteBufferUtil;\nimport org.apache.hadoop.io.IntWritable;\nimport org.apache.hadoop.io.NullWritable;\nimport org.apache.hadoop.io.WritableComparable;\nimport org.apache.hadoop.mapreduce.Mapper;\nimport org.slf4j.Logger;\nimport org.slf4j.LoggerFactory;\nimport java.io.IOException;\nimport java.nio.ByteBuffer;\nimport java.sql.Timestamp;\nimport java.util.Date;\nimport java.util.UUID;\n\npublic class CQLMapper extends Mapper<AegisthusKey, AtomWritable, AvroKey<GenericRecord>, NullWritable> {\n private static final Logger LOG = LoggerFactory.getLogger(CQLMapper.class);\n\n ColumnGroupMap.Builder cgmBuilder;\n CFMetaData cfMetaData;\n CFDefinition cfDef;\n ByteBuffer currentKey;\n\n Schema avroSchema;\n\n @Override protected void setup(\n Context context)\n throws IOException, InterruptedException {\n avroSchema = AvroJob.getOutputKeySchema(context.getConfiguration());\n\n cfMetaData = CFMetadataUtility.initializeCfMetaData(context.getConfiguration());\n cfDef = cfMetaData.getCfDef();\n initBuilder();\n\n /* This exporter assumes tables are composite, which should be true of all current schemas */\n if (!cfDef.isComposite) throw new RuntimeException(\"Only can export composite CQL table schemas.\");\n }\n\n @Override protected void map(AegisthusKey key, AtomWritable value,\n Context context)\n throws IOException, InterruptedException {\n if (currentKey == null) {\n currentKey = key.getKey();\n } else if (!currentKey.equals(key.getKey())) {\n flushCgm(context);\n currentKey = key.getKey();\n }\n\n OnDiskAtom atom = value.getAtom();\n if (atom == null) {\n LOG.warn(\"Got null atom for key {}.\", cfMetaData.getKeyValidator().compose(key.getKey()));\n return;\n }\n\n if (atom instanceof Column) {\n cgmBuilder.add((Column) atom);\n } else {\n LOG.error(\"Non-colum atom. {} {}\", atom.getClass(), atom);\n throw new IllegalArgumentException(\"Got a non-column Atom.\");\n }\n }\n\n @Override protected void cleanup(\n Context context)\n throws IOException, InterruptedException {\n super.cleanup(context);\n\n if (currentKey != null) {\n flushCgm(context);\n }\n }\n\n private void initBuilder() {\n // TODO: we might need to make \"current\" time configurable to avoid wrongly expiring data when trying to backfill.\n cgmBuilder = new ColumnGroupMap.Builder((CompositeType) cfMetaData.comparator,\n cfDef.hasCollections, System.currentTimeMillis());\n }\n\n private void flushCgm(Context context) throws IOException, InterruptedException {\n if (cgmBuilder.isEmpty())\n return;\n\n ByteBuffer[] keyComponents =\n cfDef.hasCompositeKey\n ? ((CompositeType) cfMetaData.getKeyValidator()).split(currentKey)\n : new ByteBuffer[] { currentKey };\n\n ColumnGroupMap staticGroup = ColumnGroupMap.EMPTY;\n if (!cgmBuilder.isEmpty() && cgmBuilder.firstGroup().isStatic) {\n staticGroup = cgmBuilder.firstGroup();\n cgmBuilder.discardFirst();\n\n // Special case: if there are no rows, but only the static values, just flush the static values.\n if (cgmBuilder.isEmpty()) {\n handleGroup(context, ColumnGroupMap.EMPTY, keyComponents, staticGroup);\n }\n }\n\n for (ColumnGroupMap group : cgmBuilder.groups()) {\n handleGroup(context, group, keyComponents, staticGroup);\n }\n\n initBuilder();\n currentKey = null;\n }\n\n private void handleGroup(Context context, ColumnGroupMap group, ByteBuffer[] keyComponents, ColumnGroupMap staticGroup)\n throws IOException, InterruptedException {\n GenericRecord record = new GenericData.Record(avroSchema);\n\n // write out partition keys\n for (CFDefinition.Name name : cfDef.partitionKeys()) {\n addCqlValueToRecord(record, name, keyComponents[name.position]);\n }\n\n // write out clustering columns\n for (CFDefinition.Name name : cfDef.clusteringColumns()) {\n addCqlValueToRecord(record, name, group.getKeyComponent(name.position));\n }\n\n // regular columns\n for (CFDefinition.Name name : cfDef.regularColumns()) {\n addValue(record, name, group);\n }\n\n // static columns\n for (CFDefinition.Name name : cfDef.staticColumns()) {\n addValue(record, name, staticGroup);\n }\n\n context.write(new AvroKey(record), NullWritable.get());\n }\n\n /* adapted from org.apache.cassandra.cql3.statements.SelectStatement.addValue */\n private void addValue(GenericRecord record, CFDefinition.Name name, ColumnGroupMap group) {\n if (name.type.isCollection()) {\n // TODO(danchia): support collections\n throw new RuntimeException(\"Collections not supported yet.\");\n } else {\n Column c = group.getSimple(name.name.key);\n addCqlValueToRecord(record, name, (c == null) ? null : c.value());\n }\n }\n\n private void addCqlValueToRecord(GenericRecord record, CFDefinition.Name name, ByteBuffer value) {\n if (value == null) {\n record.put(name.name.toString(), null);\n return;\n }\n\n AbstractType<?> type = name.type;\n Object valueDeserialized = type.compose(value);\n\n AbstractType<?> baseType = (type instanceof ReversedType<?>)\n ? ((ReversedType<?>) type).baseType\n : type;\n\n /* special case some unsupported CQL3 types to Hive types. */\n if (baseType instanceof UUIDType || baseType instanceof TimeUUIDType) {\n valueDeserialized = ((UUID) valueDeserialized).toString();\n } else if (baseType instanceof BytesType) {\n ByteBuffer buffer = (ByteBuffer) valueDeserialized;\n byte[] data = new byte[buffer.remaining()];\n buffer.get(data);\n\n valueDeserialized = data;\n } else if (baseType instanceof TimestampType) {\n Date date = (Date) valueDeserialized;\n valueDeserialized = date.getTime();\n }\n\n //LOG.info(\"Setting {} type {} to class {}\", name.name.toString(), type, valueDeserialized.getClass());\n\n record.put(name.name.toString(), valueDeserialized);\n }\n}\n"} | null |
af_tsa | {"type": "directory", "name": "af_tsa", "children": [{"type": "directory", "name": ".buildkite", "children": [{"type": "file", "name": "pipeline.yml"}]}, {"type": "file", "name": ".clang-format"}, {"type": "directory", "name": "client", "children": [{"type": "file", "name": "client.c"}, {"type": "file", "name": "meson.build"}]}, {"type": "directory", "name": "hacks", "children": [{"type": "file", "name": "Dockerfile"}]}, {"type": "file", "name": "LICENSE"}, {"type": "file", "name": "Makefile"}, {"type": "file", "name": "mkdkms.sh"}, {"type": "file", "name": "mkpostInstall.sh"}, {"type": "file", "name": "mkpreRemove.sh"}, {"type": "file", "name": "nfpm.jsonnet"}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "src", "children": [{"type": "file", "name": "af_tsa3.c"}, {"type": "directory", "name": "include", "children": [{"type": "directory", "name": "uapi", "children": [{"type": "file", "name": "af_tsa.h"}]}]}, {"type": "file", "name": "Kbuild"}]}]} | # AF_TSA
af_tsa is a kernel module that's meant to allow for a TCP or UDP socket that can be
swapped out. Specifically, the swap it allows is for you to move the underlying "real socket"
from one network namespace to another. It does this by just wrapping the underlying socket.
# Development
## Building
To build the kernel module:
```
make kbuild
```
## Testing
To test the module (once loaded):
```
cd client
meson build
ninja -C build
sudo ./build/client
```
# Installation
The only supported platform is Ubuntu Bionic running a 5.10+ kernel.
```
curl -s https://packagecloud.io/install/repositories/netflix/titus/script.deb.sh | sudo bash
apt-get install -y aftsa-multi
```
## Caveats
af_tsa might have concurrency problems.
We try to mitigate this by being clever about our GC, and making sure we come to a stop point before GCing an sk.
The problem comes in when we swap the underlying sk.
We can't do an af_kcm kind of thing - because we'll all of the built-in kernel setsockopts (since those directly modify struct sock, and there's no way to make them cascade).
| {".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 279e0ce9c6c5d4c62c88b750fc6ad8383a730ef0 Hamza Amin <[email protected]> 1728220018 +0500\tclone: from https://github.com/Netflix/af_tsa.git\n", ".git\\refs\\heads\\main": "279e0ce9c6c5d4c62c88b750fc6ad8383a730ef0\n", "hacks\\Dockerfile": "FROM ubuntu:bionic\nRUN apt-get update && apt-get install -y dkms linux-kernel-headers git wget\nRUN wget https://github.com/goreleaser/nfpm/releases/download/v2.7.1/nfpm_amd64.deb && dpkg -i nfpm_amd64.deb && rm nfpm_amd64.deb\nRUN wget https://github.com/google/go-jsonnet/releases/download/v0.17.0/jsonnetfmt-go_0.17.0_linux_amd64.deb https://github.com/google/go-jsonnet/releases/download/v0.17.0/jsonnet-go_0.17.0_linux_amd64.deb && \\\n\tdpkg -i jsonnet-go_0.17.0_linux_amd64.deb jsonnetfmt-go_0.17.0_linux_amd64.deb && \\\n\trm jsonnetfmt-go_0.17.0_linux_amd64.deb jsonnet-go_0.17.0_linux_amd64.deb\n"} | null |
aminator | {"type": "directory", "name": "aminator", "children": [{"type": "directory", "name": "aminator", "children": [{"type": "file", "name": "cli.py"}, {"type": "file", "name": "config.py"}, {"type": "file", "name": "core.py"}, {"type": "directory", "name": "default_conf", "children": [{"type": "file", "name": "aminator.yml"}, {"type": "file", "name": "environments.yml"}, {"type": "file", "name": "logging.yml"}]}, {"type": "file", "name": "environment.py"}, {"type": "file", "name": "exceptions.py"}, {"type": "directory", "name": "plugins", "children": [{"type": "file", "name": "base.py"}, {"type": "directory", "name": "blockdevice", "children": [{"type": "file", "name": "base.py"}, {"type": "directory", "name": "default_conf", "children": [{"type": "file", "name": "aminator.plugins.blockdevice.linux.yml"}, {"type": "file", "name": "aminator.plugins.blockdevice.null.yml"}]}, {"type": "file", "name": "linux.py"}, {"type": "file", "name": "manager.py"}, {"type": "file", "name": "null.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "cloud", "children": [{"type": "file", "name": "base.py"}, {"type": "directory", "name": "default_conf", "children": [{"type": "file", "name": "aminator.plugins.cloud.ec2.yml"}]}, {"type": "file", "name": "ec2.py"}, {"type": "file", "name": "manager.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "distro", "children": [{"type": "file", "name": "base.py"}, {"type": "file", "name": "debian.py"}, {"type": "directory", "name": "default_conf", "children": [{"type": "file", "name": "aminator.plugins.distro.debian.yml"}, {"type": "file", "name": "aminator.plugins.distro.redhat.yml"}]}, {"type": "file", "name": "linux.py"}, {"type": "file", "name": "manager.py"}, {"type": "file", "name": "redhat.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "finalizer", "children": [{"type": "file", "name": "base.py"}, {"type": "directory", "name": "default_conf", "children": [{"type": "file", "name": "aminator.plugins.finalizer.tagging_ebs.yml"}, {"type": "file", "name": "aminator.plugins.finalizer.tagging_s3.yml"}]}, {"type": "file", "name": "manager.py"}, {"type": "file", "name": "tagging_base.py"}, {"type": "file", "name": "tagging_ebs.py"}, {"type": "file", "name": "tagging_s3.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "manager.py"}, {"type": "directory", "name": "metrics", "children": [{"type": "file", "name": "base.py"}, {"type": "directory", "name": "default_conf", "children": [{"type": "file", "name": "aminator.plugins.metrics.logger.yml"}]}, {"type": "file", "name": "logger.py"}, {"type": "file", "name": "manager.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "provisioner", "children": [{"type": "file", "name": "apt.py"}, {"type": "file", "name": "aptitude.py"}, {"type": "file", "name": "base.py"}, {"type": "directory", "name": "default_conf", "children": [{"type": "file", "name": "aminator.plugins.provisioner.apt.yml"}, {"type": "file", "name": "aminator.plugins.provisioner.aptitude.yml"}, {"type": "file", "name": "aminator.plugins.provisioner.yum.yml"}]}, {"type": "file", "name": "manager.py"}, {"type": "file", "name": "yum.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "volume", "children": [{"type": "file", "name": "base.py"}, {"type": "directory", "name": "default_conf", "children": [{"type": "file", "name": "aminator.plugins.volume.linux.yml"}]}, {"type": "file", "name": "linux.py"}, {"type": "file", "name": "manager.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "__init__.py"}]}, {"type": "directory", "name": "util", "children": [{"type": "file", "name": "linux.py"}, {"type": "file", "name": "metrics.py"}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "__init__.py"}]}, {"type": "file", "name": "CONTRIBUTING.md"}, {"type": "directory", "name": "docs", "children": [{"type": "file", "name": "conf.py"}, {"type": "file", "name": "index.rst"}, {"type": "file", "name": "make.bat"}, {"type": "file", "name": "Makefile"}]}, {"type": "file", "name": "GNUmakefile"}, {"type": "file", "name": "LICENSE.txt"}, {"type": "file", "name": "MANIFEST.in"}, {"type": "file", "name": "OSSMETADATA"}, {"type": "file", "name": "pylintrc"}, {"type": "file", "name": "README.rst"}, {"type": "file", "name": "requirements-locked.txt"}, {"type": "file", "name": "requirements.txt"}, {"type": "file", "name": "setup.cfg"}, {"type": "file", "name": "setup.py"}, {"type": "directory", "name": "tests", "children": [{"type": "file", "name": "TestAptProvisionerPlugin.py"}, {"type": "file", "name": "test_chef_node.json"}, {"type": "file", "name": "test_yum_provisioner_plugin.py"}, {"type": "file", "name": "util.py"}, {"type": "file", "name": "yum_test.yml"}, {"type": "file", "name": "__init__.py"}]}]} | aminator - Easily create application-specific custom AMIs
=========================================
Aminator creates a custom AMI from just:
* A base ami ID
* A link to a deb or rpm package that installs your application.
This is useful for many AWS workflows, particularly ones that take advantage of auto-scaling groups.
Requirements
------------
* Python 2.7 (Python 3.x support not yet available)
* Linux or UNIX cloud instance (EC2 currently supported)
Installation
------------
Clone this repository and run:
.. code-block:: bash
# python setup.py install
*or*
.. code-block:: bash
# pip install git+https://github.com/Netflix/aminator.git#egg=aminator
Usage
-----
::
usage: aminate [-h] [-e ENVIRONMENT] [--version] [--debug] [-n NAME]
[-s SUFFIX] [-c CREATOR] (-b BASE_AMI_NAME | -B BASE_AMI_ID)
[--ec2-region REGION] [--boto-secure] [--boto-debug]
package
positional arguments:
package package to aminate. A string resolvable by the native
package manager or a file system path or http url to
the package file.
optional arguments:
-h, --help show this help message and exit
-e ENVIRONMENT, --environment ENVIRONMENT
The environment configuration for amination
--version show program's version number and exit
--debug Verbose debugging output
AMI Tagging and Naming:
Tagging and naming options for the resultant AMI
-n NAME, --name NAME name of resultant AMI (default package_name-version-
release-arch-yyyymmddHHMM-ebs
-s SUFFIX, --suffix SUFFIX
suffix of ami name, (default yyyymmddHHMM)
-c CREATOR, --creator CREATOR
The user who is aminating. The resultant AMI will
receive a creator tag w/ this user
Base AMI:
EITHER AMI id OR name, not both!
-b BASE_AMI_NAME, --base-ami-name BASE_AMI_NAME
The name of the base AMI used in provisioning
-B BASE_AMI_ID, --base-ami-id BASE_AMI_ID
The id of the base AMI used in provisioning
EC2 Options:
EC2 Connection Information
--ec2-region REGION EC2 region (default: us-east-1)
--boto-secure Connect via https
--boto-debug Boto debug output
Details
-------
The rough amination workflow:
#. Create a volume from the snapshot of the base AMI
#. Attach and mount the volume
#. Chroot into mounted volume
#. Provision application onto mounted volume using rpm or deb package
#. Unmount the volume and create a snapshot
#. Register the snapshot as an AMI
Support
-------
* `Aminator Google Group <http://groups.google.com/group/Aminator>`_
Documentation
-------------
See the `aminator wiki <https://github.com/Netflix/aminator/wiki>`_ for documentation
License
-------
Copyright 2013 Netflix, Inc.
Licensed under the Apache License, Version 2.0 (the “License”); you may not use this file except in compliance with the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an “AS IS” BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License.
| {"requirements.txt": "boto>=2.7\nboto3>=1.4.4\nbunch\ndecorator\nlogutils\npyyaml\nrequests\nstevedore\nsimplejson\ndill\n\n", "setup.py": "#\n#\n# Copyright 2013 Netflix, Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n#\n#\n\nimport setuptools\n\nsetuptools.setup(setup_requires=['pbr'], pbr=True)\n", ".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", "docs\\index.rst": ".. aminator documentation master file, created by\n sphinx-quickstart on Thu Mar 14 18:38:34 2013.\n You can adapt this file completely to your liking, but it should at least\n contain the root `toctree` directive.\n\nWelcome to aminator's documentation!\n====================================\n\nContents:\n\n.. toctree::\n :maxdepth: 2\n\n\n\nIndices and tables\n==================\n\n* :ref:`genindex`\n* :ref:`modindex`\n* :ref:`search`\n\n"} | null |
astyanax | {"type": "directory", "name": "astyanax", "children": [{"type": "directory", "name": "astyanax", "children": [{"type": "file", "name": "build.gradle"}]}, {"type": "directory", "name": "astyanax-cassandra", "children": [{"type": "file", "name": "build.gradle"}, {"type": "directory", "name": "src", "children": [{"type": "directory", "name": "main", "children": [{"type": "directory", "name": "java", "children": [{"type": "directory", "name": "com", "children": [{"type": "directory", "name": "netflix", "children": [{"type": "directory", "name": "astyanax", "children": [{"type": "file", "name": "AbstractColumnListMutation.java"}, {"type": "file", "name": "AstyanaxConfiguration.java"}, {"type": "file", "name": "AstyanaxContext.java"}, {"type": "file", "name": "AstyanaxTypeFactory.java"}, {"type": "file", "name": "CassandraOperationCategory.java"}, {"type": "file", "name": "CassandraOperationTracer.java"}, {"type": "file", "name": "CassandraOperationType.java"}, {"type": "file", "name": "Cluster.java"}, {"type": "file", "name": "ColumnListMutation.java"}, {"type": "file", "name": "ColumnMutation.java"}, {"type": "directory", "name": "cql", "children": [{"type": "file", "name": "CqlPreparedStatement.java"}, {"type": "file", "name": "CqlSchema.java"}, {"type": "file", "name": "CqlStatement.java"}, {"type": "file", "name": "CqlStatementResult.java"}]}, {"type": "directory", "name": "ddl", "children": [{"type": "file", "name": "ColumnDefinition.java"}, {"type": "file", "name": "ColumnFamilyDefinition.java"}, {"type": "file", "name": "FieldMetadata.java"}, {"type": "directory", "name": "impl", "children": [{"type": "file", "name": "SchemaChangeResponseImpl.java"}]}, {"type": "file", "name": "KeyspaceDefinition.java"}, {"type": "file", "name": "SchemaChangeResult.java"}]}, {"type": "directory", "name": "impl", "children": [{"type": "file", "name": "AckingQueue.java"}, {"type": "file", "name": "AstyanaxCheckpointManager.java"}, {"type": "file", "name": "AstyanaxConfigurationImpl.java"}, {"type": "file", "name": "NoOpWriteAheadLog.java"}, {"type": "file", "name": "PreparedIndexExpressionImpl.java"}, {"type": "file", "name": "RingDescribeHostSupplier.java"}]}, {"type": "file", "name": "Keyspace.java"}, {"type": "file", "name": "KeyspaceTracerFactory.java"}, {"type": "directory", "name": "mapping", "children": [{"type": "file", "name": "AnnotationSet.java"}, {"type": "file", "name": "Coercions.java"}, {"type": "file", "name": "Column.java"}, {"type": "file", "name": "DefaultAnnotationSet.java"}, {"type": "file", "name": "Id.java"}, {"type": "file", "name": "Mapping.java"}, {"type": "file", "name": "MappingCache.java"}, {"type": "file", "name": "MappingUtil.java"}]}, {"type": "directory", "name": "model", "children": [{"type": "file", "name": "AbstractColumnImpl.java"}, {"type": "file", "name": "AbstractColumnList.java"}, {"type": "file", "name": "AbstractComposite.java"}, {"type": "file", "name": "ByteBufferRange.java"}, {"type": "file", "name": "Column.java"}, {"type": "file", "name": "ColumnFamily.java"}, {"type": "file", "name": "ColumnList.java"}, {"type": "file", "name": "ColumnMap.java"}, {"type": "file", "name": "ColumnPath.java"}, {"type": "file", "name": "ColumnSlice.java"}, {"type": "file", "name": "ColumnType.java"}, {"type": "file", "name": "Composite.java"}, {"type": "file", "name": "CompositeBuilder.java"}, {"type": "file", "name": "CompositeBuilderImpl.java"}, {"type": "file", "name": "CompositeParser.java"}, {"type": "file", "name": "CompositeParserImpl.java"}, {"type": "file", "name": "Composites.java"}, {"type": "file", "name": "ConsistencyLevel.java"}, {"type": "file", "name": "CqlResult.java"}, {"type": "file", "name": "DynamicComposite.java"}, {"type": "file", "name": "Equality.java"}, {"type": "file", "name": "KeySlice.java"}, {"type": "file", "name": "OrderedColumnMap.java"}, {"type": "file", "name": "RangeEndpoint.java"}, {"type": "file", "name": "Row.java"}, {"type": "file", "name": "Rows.java"}]}, {"type": "file", "name": "MultiMutationBatchManager.java"}, {"type": "file", "name": "MutationBatch.java"}, {"type": "file", "name": "MutationBatchManager.java"}, {"type": "directory", "name": "partitioner", "children": [{"type": "file", "name": "BigInteger127Partitioner.java"}, {"type": "file", "name": "BOP20Partitioner.java"}, {"type": "file", "name": "LongBOPPartitioner.java"}, {"type": "file", "name": "Murmur3Partitioner.java"}, {"type": "file", "name": "OrderedBigIntegerPartitioner.java"}]}, {"type": "directory", "name": "query", "children": [{"type": "file", "name": "AbstractPreparedCqlQuery.java"}, {"type": "file", "name": "AllRowsQuery.java"}, {"type": "file", "name": "CheckpointManager.java"}, {"type": "file", "name": "ColumnCountQuery.java"}, {"type": "file", "name": "ColumnFamilyQuery.java"}, {"type": "file", "name": "ColumnPredicate.java"}, {"type": "file", "name": "ColumnQuery.java"}, {"type": "file", "name": "CqlQuery.java"}, {"type": "file", "name": "IndexColumnExpression.java"}, {"type": "file", "name": "IndexOperationExpression.java"}, {"type": "file", "name": "IndexOperator.java"}, {"type": "file", "name": "IndexQuery.java"}, {"type": "file", "name": "IndexValueExpression.java"}, {"type": "file", "name": "PreparedCqlQuery.java"}, {"type": "file", "name": "PreparedIndexColumnExpression.java"}, {"type": "file", "name": "PreparedIndexExpression.java"}, {"type": "file", "name": "PreparedIndexOperationExpression.java"}, {"type": "file", "name": "PreparedIndexValueExpression.java"}, {"type": "file", "name": "RowQuery.java"}, {"type": "file", "name": "RowSliceColumnCountQuery.java"}, {"type": "file", "name": "RowSliceQuery.java"}]}, {"type": "file", "name": "RowCallback.java"}, {"type": "file", "name": "RowCopier.java"}, {"type": "file", "name": "Serializer.java"}, {"type": "file", "name": "SerializerPackage.java"}, {"type": "directory", "name": "serializers", "children": [{"type": "file", "name": "AbstractSerializer.java"}, {"type": "file", "name": "AnnotatedCompositeSerializer.java"}, {"type": "file", "name": "AsciiSerializer.java"}, {"type": "file", "name": "BigDecimalSerializer.java"}, {"type": "file", "name": "BigIntegerSerializer.java"}, {"type": "file", "name": "BooleanSerializer.java"}, {"type": "file", "name": "ByteBufferOutputStream.java"}, {"type": "file", "name": "ByteBufferSerializer.java"}, {"type": "file", "name": "BytesArraySerializer.java"}, {"type": "file", "name": "ByteSerializer.java"}, {"type": "file", "name": "CharSerializer.java"}, {"type": "file", "name": "ComparatorType.java"}, {"type": "file", "name": "CompositeRangeBuilder.java"}, {"type": "file", "name": "CompositeSerializer.java"}, {"type": "file", "name": "DateSerializer.java"}, {"type": "file", "name": "DoubleSerializer.java"}, {"type": "file", "name": "DynamicCompositeSerializer.java"}, {"type": "file", "name": "FloatSerializer.java"}, {"type": "file", "name": "GzipStringSerializer.java"}, {"type": "file", "name": "Int32Serializer.java"}, {"type": "file", "name": "IntegerSerializer.java"}, {"type": "file", "name": "JacksonSerializer.java"}, {"type": "file", "name": "JaxbSerializer.java"}, {"type": "file", "name": "ListSerializer.java"}, {"type": "file", "name": "LongSerializer.java"}, {"type": "file", "name": "MapSerializer.java"}, {"type": "file", "name": "ObjectSerializer.java"}, {"type": "file", "name": "PrefixedSerializer.java"}, {"type": "file", "name": "ReversedSerializer.java"}, {"type": "file", "name": "SerializerPackageImpl.java"}, {"type": "file", "name": "SerializerTypeInferer.java"}, {"type": "file", "name": "SetSerializer.java"}, {"type": "file", "name": "ShortSerializer.java"}, {"type": "file", "name": "SnappyStringSerializer.java"}, {"type": "file", "name": "SpecificCompositeSerializer.java"}, {"type": "file", "name": "SpecificReversedSerializer.java"}, {"type": "file", "name": "StringSerializer.java"}, {"type": "file", "name": "TimeUUIDSerializer.java"}, {"type": "file", "name": "TypeInferringSerializer.java"}, {"type": "file", "name": "UnknownComparatorException.java"}, {"type": "file", "name": "UUIDSerializer.java"}]}, {"type": "directory", "name": "shaded", "children": [{"type": "directory", "name": "org", "children": [{"type": "directory", "name": "apache", "children": [{"type": "directory", "name": "cassandra", "children": [{"type": "directory", "name": "db", "children": [{"type": "directory", "name": "marshal", "children": [{"type": "file", "name": "ShadedTypeParser.java"}]}]}]}]}]}]}, {"type": "directory", "name": "shallows", "children": [{"type": "file", "name": "EmptyCheckpointManager.java"}, {"type": "file", "name": "EmptyColumn.java"}, {"type": "file", "name": "EmptyColumnList.java"}, {"type": "file", "name": "EmptyKeyspaceTracer.java"}, {"type": "file", "name": "EmptyKeyspaceTracerFactory.java"}, {"type": "file", "name": "EmptyRowsImpl.java"}]}, {"type": "file", "name": "ThreadLocalMutationBatchManager.java"}, {"type": "directory", "name": "util", "children": [{"type": "file", "name": "BlockingAckingQueue.java"}, {"type": "file", "name": "ByteBufferRangeImpl.java"}, {"type": "file", "name": "ColumnarRecordWriter.java"}, {"type": "file", "name": "CsvColumnReader.java"}, {"type": "file", "name": "CsvRecordReader.java"}, {"type": "file", "name": "CsvRowsWriter.java"}, {"type": "file", "name": "JsonRowsWriter.java"}, {"type": "file", "name": "MutationBatchExecutorWithQueue.java"}, {"type": "file", "name": "RangeBuilder.java"}, {"type": "file", "name": "RecordReader.java"}, {"type": "file", "name": "RecordWriter.java"}, {"type": "file", "name": "RowsWriter.java"}, {"type": "file", "name": "WriteAheadMutationBatchExecutor.java"}]}, {"type": "file", "name": "WriteAheadEntry.java"}, {"type": "file", "name": "WriteAheadLog.java"}]}]}]}]}]}]}]}, {"type": "directory", "name": "astyanax-cassandra-all-shaded", "children": [{"type": "file", "name": "build.gradle"}]}, {"type": "directory", "name": "astyanax-contrib", "children": [{"type": "file", "name": "build.gradle"}, {"type": "directory", "name": "src", "children": [{"type": "directory", "name": "main", "children": [{"type": "directory", "name": "java", "children": [{"type": "directory", "name": "com", "children": [{"type": "directory", "name": "netflix", "children": [{"type": "directory", "name": "astyanax", "children": [{"type": "directory", "name": "contrib", "children": [{"type": "directory", "name": "dualwrites", "children": [{"type": "file", "name": "AsyncFailedWritesLogger.java"}, {"type": "file", "name": "BestEffortSecondaryWriteStrategy.java"}, {"type": "file", "name": "CassBasedFailedWritesLogger.java"}, {"type": "file", "name": "DualKeyspaceMetadata.java"}, {"type": "file", "name": "DualWritesColumnListMutation.java"}, {"type": "file", "name": "DualWritesColumnMutation.java"}, {"type": "file", "name": "DualWritesCqlPreparedStatement.java"}, {"type": "file", "name": "DualWritesCqlStatement.java"}, {"type": "file", "name": "DualWritesDemo.java"}, {"type": "file", "name": "DualWritesKeyspace.java"}, {"type": "file", "name": "DualWritesMutationBatch.java"}, {"type": "file", "name": "DualWritesStrategy.java"}, {"type": "file", "name": "DualWritesUpdateListener.java"}, {"type": "file", "name": "FailedWritesLogger.java"}, {"type": "file", "name": "LogBasedFailedWritesLogger.java"}, {"type": "file", "name": "WriteMetadata.java"}]}, {"type": "directory", "name": "eureka", "children": [{"type": "file", "name": "EurekaBasedHostSupplier.java"}]}, {"type": "directory", "name": "valve", "children": [{"type": "file", "name": "RollingTimeWindowValve.java"}, {"type": "file", "name": "TimeWindowValve.java"}]}]}]}]}]}]}]}]}]}, {"type": "directory", "name": "astyanax-core", "children": [{"type": "file", "name": "build.gradle"}, {"type": "directory", "name": "src", "children": [{"type": "directory", "name": "main", "children": [{"type": "directory", "name": "java", "children": [{"type": "directory", "name": "com", "children": [{"type": "directory", "name": "netflix", "children": [{"type": "directory", "name": "astyanax", "children": [{"type": "directory", "name": "annotations", "children": [{"type": "file", "name": "Component.java"}]}, {"type": "file", "name": "AuthenticationCredentials.java"}, {"type": "directory", "name": "clock", "children": [{"type": "file", "name": "ClockType.java"}, {"type": "file", "name": "ConstantClock.java"}, {"type": "file", "name": "MicrosecondsAsyncClock.java"}, {"type": "file", "name": "MicrosecondsClock.java"}, {"type": "file", "name": "MicrosecondsSyncClock.java"}, {"type": "file", "name": "MillisecondsClock.java"}]}, {"type": "file", "name": "Clock.java"}, {"type": "directory", "name": "connectionpool", "children": [{"type": "file", "name": "BadHostDetector.java"}, {"type": "file", "name": "Connection.java"}, {"type": "file", "name": "ConnectionContext.java"}, {"type": "file", "name": "ConnectionFactory.java"}, {"type": "file", "name": "ConnectionPool.java"}, {"type": "file", "name": "ConnectionPoolConfiguration.java"}, {"type": "file", "name": "ConnectionPoolMonitor.java"}, {"type": "file", "name": "ConnectionPoolProxy.java"}, {"type": "directory", "name": "exceptions", "children": [{"type": "file", "name": "AuthenticationException.java"}, {"type": "file", "name": "BadConfigurationException.java"}, {"type": "file", "name": "BadRequestException.java"}, {"type": "file", "name": "ConnectionAbortedException.java"}, {"type": "file", "name": "ConnectionException.java"}, {"type": "file", "name": "HostDownException.java"}, {"type": "file", "name": "InterruptedOperationException.java"}, {"type": "file", "name": "IsDeadConnectionException.java"}, {"type": "file", "name": "IsRetryableException.java"}, {"type": "file", "name": "IsTimeoutException.java"}, {"type": "file", "name": "MaxConnsPerHostReachedException.java"}, {"type": "file", "name": "NoAvailableHostsException.java"}, {"type": "file", "name": "NotFoundException.java"}, {"type": "file", "name": "OperationException.java"}, {"type": "file", "name": "OperationTimeoutException.java"}, {"type": "file", "name": "PoolTimeoutException.java"}, {"type": "file", "name": "SchemaDisagreementException.java"}, {"type": "file", "name": "SerializationException.java"}, {"type": "file", "name": "ThriftStateException.java"}, {"type": "file", "name": "ThrottledException.java"}, {"type": "file", "name": "TimeoutException.java"}, {"type": "file", "name": "TokenRangeOfflineException.java"}, {"type": "file", "name": "TransportException.java"}, {"type": "file", "name": "UnknownException.java"}, {"type": "file", "name": "WalException.java"}]}, {"type": "file", "name": "ExecuteWithFailover.java"}, {"type": "file", "name": "Host.java"}, {"type": "file", "name": "HostConnectionPool.java"}, {"type": "file", "name": "HostStats.java"}, {"type": "directory", "name": "impl", "children": [{"type": "file", "name": "AbstractExecuteWithFailoverImpl.java"}, {"type": "file", "name": "AbstractExecutionImpl.java"}, {"type": "file", "name": "AbstractHostPartitionConnectionPool.java"}, {"type": "file", "name": "AbstractLatencyScoreStrategyImpl.java"}, {"type": "file", "name": "AbstractOperationFilter.java"}, {"type": "file", "name": "AbstractTopology.java"}, {"type": "file", "name": "BadHostDetectorImpl.java"}, {"type": "file", "name": "BagOfConnectionsConnectionPoolImpl.java"}, {"type": "file", "name": "ConnectionPoolConfigurationImpl.java"}, {"type": "file", "name": "ConnectionPoolMBeanManager.java"}, {"type": "file", "name": "ConnectionPoolType.java"}, {"type": "file", "name": "CountingConnectionPoolMonitor.java"}, {"type": "file", "name": "EmaLatencyScoreStrategyImpl.java"}, {"type": "file", "name": "ExponentialRetryBackoffStrategy.java"}, {"type": "file", "name": "FixedRetryBackoffStrategy.java"}, {"type": "file", "name": "HostConnectionPoolPartition.java"}, {"type": "file", "name": "HostSelectorStrategy.java"}, {"type": "file", "name": "HostStats.java"}, {"type": "file", "name": "LeastOutstandingExecuteWithFailover.java"}, {"type": "file", "name": "NodeDiscoveryImpl.java"}, {"type": "file", "name": "NodeDiscoveryMonitorManager.java"}, {"type": "file", "name": "OldHostSupplierAdapter.java"}, {"type": "file", "name": "OperationFilterFactoryList.java"}, {"type": "file", "name": "OperationResultImpl.java"}, {"type": "file", "name": "RoundRobinConnectionPoolImpl.java"}, {"type": "file", "name": "RoundRobinExecuteWithFailover.java"}, {"type": "file", "name": "SimpleAuthenticationCredentials.java"}, {"type": "file", "name": "SimpleHostConnectionPool.java"}, {"type": "file", "name": "SimpleRateLimiterImpl.java"}, {"type": "file", "name": "Slf4jConnectionPoolMonitorImpl.java"}, {"type": "file", "name": "SmaLatencyScoreStrategyImpl.java"}, {"type": "file", "name": "TokenAwareConnectionPoolImpl.java"}, {"type": "file", "name": "TokenHostConnectionPoolPartition.java"}, {"type": "file", "name": "TokenPartitionedTopology.java"}, {"type": "file", "name": "TokenRangeImpl.java"}, {"type": "file", "name": "Topology.java"}]}, {"type": "file", "name": "JmxConnectionPoolMonitor.java"}, {"type": "file", "name": "JmxConnectionPoolMonitorMBean.java"}, {"type": "file", "name": "LatencyScoreStrategy.java"}, {"type": "file", "name": "LatencyScoreStrategyType.java"}, {"type": "file", "name": "NodeDiscovery.java"}, {"type": "file", "name": "NodeDiscoveryMonitor.java"}, {"type": "file", "name": "NodeDiscoveryMonitorMBean.java"}, {"type": "file", "name": "NodeDiscoveryType.java"}, {"type": "file", "name": "Operation.java"}, {"type": "file", "name": "OperationFilterFactory.java"}, {"type": "file", "name": "OperationResult.java"}, {"type": "file", "name": "RateLimiter.java"}, {"type": "file", "name": "RetryBackoffStrategy.java"}, {"type": "file", "name": "SSLConnectionContext.java"}, {"type": "file", "name": "TokenRange.java"}]}, {"type": "file", "name": "ExceptionCallback.java"}, {"type": "file", "name": "Execution.java"}, {"type": "directory", "name": "impl", "children": [{"type": "file", "name": "FilteringHostSupplier.java"}]}, {"type": "directory", "name": "partitioner", "children": [{"type": "file", "name": "Partitioner.java"}]}, {"type": "directory", "name": "retry", "children": [{"type": "file", "name": "BoundedExponentialBackoff.java"}, {"type": "file", "name": "ConstantBackoff.java"}, {"type": "file", "name": "ExponentialBackoff.java"}, {"type": "file", "name": "IndefiniteRetry.java"}, {"type": "file", "name": "RetryNTimes.java"}, {"type": "file", "name": "RetryPolicy.java"}, {"type": "file", "name": "RunOnce.java"}, {"type": "file", "name": "RunOnceRetryPolicyFactory.java"}, {"type": "file", "name": "SleepingRetryPolicy.java"}]}, {"type": "directory", "name": "shallows", "children": [{"type": "file", "name": "EmptyBadHostDetectorImpl.java"}, {"type": "file", "name": "EmptyConnectionPoolMonitor.java"}, {"type": "file", "name": "EmptyIterator.java"}, {"type": "file", "name": "EmptyLatencyScoreStrategyImpl.java"}, {"type": "file", "name": "EmptyNodeDiscoveryImpl.java"}, {"type": "file", "name": "EmptyOperationFilterFactory.java"}, {"type": "file", "name": "EmptyOperationTracer.java"}, {"type": "file", "name": "EmptyPartitioner.java"}]}, {"type": "directory", "name": "test", "children": [{"type": "file", "name": "IncreasingRateSupplier.java"}, {"type": "file", "name": "ProbabalisticFunction.java"}, {"type": "file", "name": "SessionEvent.java"}, {"type": "file", "name": "TestClient.java"}, {"type": "file", "name": "TestCompositeType.java"}, {"type": "file", "name": "TestCompositeType2.java"}, {"type": "file", "name": "TestConnectionFactory.java"}, {"type": "file", "name": "TestConnectionPool.java"}, {"type": "file", "name": "TestDriver.java"}, {"type": "file", "name": "TestHostConnectionPool.java"}, {"type": "file", "name": "TestHostType.java"}, {"type": "file", "name": "TestOperation.java"}, {"type": "file", "name": "TestTokenRange.java"}]}, {"type": "directory", "name": "tracing", "children": [{"type": "file", "name": "AstyanaxContext.java"}, {"type": "file", "name": "OperationTracer.java"}]}, {"type": "directory", "name": "util", "children": [{"type": "file", "name": "BarrierCallableDecorator.java"}, {"type": "file", "name": "BlockingConcurrentWindowCounter.java"}, {"type": "file", "name": "Callables.java"}, {"type": "file", "name": "TimeUUIDUtils.java"}, {"type": "file", "name": "TokenGenerator.java"}]}]}]}]}]}]}]}]}, {"type": "directory", "name": "astyanax-cql", "children": [{"type": "file", "name": "build.gradle"}, {"type": "directory", "name": "src", "children": [{"type": "directory", "name": "main", "children": [{"type": "directory", "name": "java", "children": [{"type": "directory", "name": "com", "children": [{"type": "directory", "name": "netflix", "children": [{"type": "directory", "name": "astyanax", "children": [{"type": "directory", "name": "cql", "children": [{"type": "file", "name": "ConsistencyLevelMapping.java"}, {"type": "file", "name": "CqlAbstractExecutionImpl.java"}, {"type": "file", "name": "CqlClusterImpl.java"}, {"type": "file", "name": "CqlFamilyFactory.java"}, {"type": "file", "name": "CqlKeyspaceImpl.java"}, {"type": "file", "name": "CqlOperationResultImpl.java"}, {"type": "file", "name": "CqlRingDescriber.java"}, {"type": "file", "name": "CqlSchemaVersionReader.java"}, {"type": "directory", "name": "direct", "children": [{"type": "file", "name": "DirectCqlPreparedStatement.java"}, {"type": "file", "name": "DirectCqlStatement.java"}, {"type": "file", "name": "DirectCqlStatementResultImpl.java"}]}, {"type": "file", "name": "JavaDriverConfigBridge.java"}, {"type": "file", "name": "JavaDriverConfigBuilder.java"}, {"type": "file", "name": "JavaDriverConnectionPoolConfigurationImpl.java"}, {"type": "file", "name": "JavaDriverConnectionPoolMonitorImpl.java"}, {"type": "directory", "name": "reads", "children": [{"type": "file", "name": "CFColumnQueryGen.java"}, {"type": "file", "name": "CFRowKeysQueryGen.java"}, {"type": "file", "name": "CFRowQueryGen.java"}, {"type": "file", "name": "CFRowRangeQueryGen.java"}, {"type": "file", "name": "CFRowSliceQueryGen.java"}, {"type": "file", "name": "CqlAllRowsQueryImpl.java"}, {"type": "file", "name": "CqlColumnCountQueryImpl.java"}, {"type": "file", "name": "CqlColumnFamilyQueryImpl.java"}, {"type": "file", "name": "CqlColumnQueryImpl.java"}, {"type": "file", "name": "CqlRowCopier.java"}, {"type": "file", "name": "CqlRowQueryImpl.java"}, {"type": "file", "name": "CqlRowSliceColumnCountQueryImpl.java"}, {"type": "file", "name": "CqlRowSliceQueryImpl.java"}, {"type": "file", "name": "DirectCqlQueryImpl.java"}, {"type": "file", "name": "FlatTableRowQueryGen.java"}, {"type": "file", "name": "FlatTableRowSliceQueryGen.java"}, {"type": "directory", "name": "model", "children": [{"type": "file", "name": "CqlColumnImpl.java"}, {"type": "file", "name": "CqlColumnListImpl.java"}, {"type": "file", "name": "CqlColumnSlice.java"}, {"type": "file", "name": "CqlRangeBuilder.java"}, {"type": "file", "name": "CqlRangeImpl.java"}, {"type": "file", "name": "CqlRowImpl.java"}, {"type": "file", "name": "CqlRowListImpl.java"}, {"type": "file", "name": "CqlRowListIterator.java"}, {"type": "file", "name": "CqlRowSlice.java"}, {"type": "file", "name": "DirectCqlResult.java"}]}, {"type": "file", "name": "QueryGenCache.java"}]}, {"type": "directory", "name": "retrypolicies", "children": [{"type": "file", "name": "ChangeConsistencyLevelRetryPolicy.java"}, {"type": "file", "name": "JavaDriverBasedRetryPolicy.java"}]}, {"type": "directory", "name": "schema", "children": [{"type": "file", "name": "CqlColumnDefinitionImpl.java"}, {"type": "file", "name": "CqlColumnFamilyDefinitionImpl.java"}, {"type": "file", "name": "CqlKeyspaceDefinitionImpl.java"}]}, {"type": "directory", "name": "util", "children": [{"type": "file", "name": "AsyncOperationResult.java"}, {"type": "file", "name": "CFQueryContext.java"}, {"type": "file", "name": "ConsistencyLevelTransform.java"}, {"type": "file", "name": "CqlTypeMapping.java"}, {"type": "file", "name": "DataTypeMapping.java"}]}, {"type": "directory", "name": "writes", "children": [{"type": "file", "name": "AbstractColumnListMutationImpl.java"}, {"type": "file", "name": "AbstractMutationBatchImpl.java"}, {"type": "file", "name": "BatchedStatements.java"}, {"type": "file", "name": "CFMutationQueryGen.java"}, {"type": "file", "name": "CqlColumnListMutationImpl.java"}, {"type": "file", "name": "CqlColumnMutationImpl.java"}, {"type": "file", "name": "CqlMutationBatchImpl.java"}, {"type": "file", "name": "CqlStyleMutationQuery.java"}, {"type": "file", "name": "MutationQueries.java"}, {"type": "file", "name": "StatementCache.java"}]}]}]}]}]}]}]}]}]}, {"type": "directory", "name": "astyanax-entity-mapper", "children": [{"type": "file", "name": "build.gradle"}, {"type": "directory", "name": "src", "children": [{"type": "directory", "name": "main", "children": [{"type": "directory", "name": "java", "children": [{"type": "directory", "name": "com", "children": [{"type": "directory", "name": "netflix", "children": [{"type": "directory", "name": "astyanax", "children": [{"type": "directory", "name": "entitystore", "children": [{"type": "file", "name": "AbstractColumnMapper.java"}, {"type": "file", "name": "ColumnMapper.java"}, {"type": "file", "name": "CompositeColumnEntityMapper.java"}, {"type": "file", "name": "CompositeColumnMapper.java"}, {"type": "file", "name": "CompositeEntityManager.java"}, {"type": "file", "name": "CompositeEntityMapper.java"}, {"type": "file", "name": "DefaultEntityManager.java"}, {"type": "file", "name": "EntityManager.java"}, {"type": "file", "name": "EntityMapper.java"}, {"type": "file", "name": "FieldMapper.java"}, {"type": "file", "name": "LeafColumnMapper.java"}, {"type": "file", "name": "LifecycleEvents.java"}, {"type": "file", "name": "MapColumnMapper.java"}, {"type": "file", "name": "MappingUtils.java"}, {"type": "file", "name": "NativeQuery.java"}, {"type": "file", "name": "Serializer.java"}, {"type": "file", "name": "SetColumnMapper.java"}, {"type": "file", "name": "SimpleCompositeBuilder.java"}, {"type": "file", "name": "TTL.java"}]}]}]}]}]}]}]}]}, {"type": "directory", "name": "astyanax-examples", "children": [{"type": "file", "name": "build.gradle"}, {"type": "directory", "name": "src", "children": [{"type": "directory", "name": "main", "children": [{"type": "directory", "name": "java", "children": [{"type": "directory", "name": "com", "children": [{"type": "directory", "name": "netflix", "children": [{"type": "directory", "name": "astyanax", "children": [{"type": "directory", "name": "examples", "children": [{"type": "file", "name": "AstClient.java"}, {"type": "file", "name": "AstCQLClient.java"}, {"type": "file", "name": "ModelConstants.java"}]}]}]}]}]}, {"type": "directory", "name": "resources", "children": [{"type": "file", "name": "log4j.xml"}]}]}]}]}, {"type": "directory", "name": "astyanax-queue", "children": [{"type": "file", "name": "build.gradle"}, {"type": "directory", "name": "src", "children": [{"type": "directory", "name": "main", "children": [{"type": "directory", "name": "java", "children": [{"type": "directory", "name": "com", "children": [{"type": "directory", "name": "netflix", "children": [{"type": "directory", "name": "astyanax", "children": [{"type": "directory", "name": "recipes", "children": [{"type": "directory", "name": "queue", "children": [{"type": "file", "name": "BaseQueueHook.java"}, {"type": "file", "name": "CountingQueueStats.java"}, {"type": "file", "name": "DuplicateMessageException.java"}, {"type": "file", "name": "KeyExistsException.java"}, {"type": "file", "name": "Message.java"}, {"type": "file", "name": "MessageConsumer.java"}, {"type": "file", "name": "MessageConsumerImpl.java"}, {"type": "file", "name": "MessageContext.java"}, {"type": "file", "name": "MessageHandlerFactory.java"}, {"type": "file", "name": "MessageHistory.java"}, {"type": "file", "name": "MessageMetadataEntry.java"}, {"type": "file", "name": "MessageMetadataEntryType.java"}, {"type": "file", "name": "MessageProducer.java"}, {"type": "file", "name": "MessageQueue.java"}, {"type": "file", "name": "MessageQueueDispatcher.java"}, {"type": "file", "name": "MessageQueueEntry.java"}, {"type": "file", "name": "MessageQueueEntryState.java"}, {"type": "file", "name": "MessageQueueEntryType.java"}, {"type": "file", "name": "MessageQueueException.java"}, {"type": "file", "name": "MessageQueueHooks.java"}, {"type": "file", "name": "MessageQueueManager.java"}, {"type": "file", "name": "MessageQueueMetadata.java"}, {"type": "file", "name": "MessageQueueSettings.java"}, {"type": "file", "name": "MessageQueueShard.java"}, {"type": "file", "name": "MessageQueueShardStats.java"}, {"type": "file", "name": "MessageQueueStats.java"}, {"type": "file", "name": "MessageStatus.java"}, {"type": "file", "name": "SendMessageResponse.java"}, {"type": "directory", "name": "shard", "children": [{"type": "file", "name": "KeyModShardPolicy.java"}, {"type": "file", "name": "ModShardPolicy.java"}, {"type": "file", "name": "NoModShardingPolicy.java"}, {"type": "file", "name": "ShardReaderPolicy.java"}, {"type": "file", "name": "TimeModShardPolicy.java"}, {"type": "file", "name": "TimePartitionedShardReaderPolicy.java"}]}, {"type": "file", "name": "ShardedDistributedMessageQueue.java"}, {"type": "file", "name": "ShardLock.java"}, {"type": "file", "name": "ShardLockManager.java"}, {"type": "file", "name": "SimpleMessageHandlerFactory.java"}, {"type": "directory", "name": "triggers", "children": [{"type": "file", "name": "AbstractTrigger.java"}, {"type": "file", "name": "RepeatingTrigger.java"}, {"type": "file", "name": "RunOnceTrigger.java"}, {"type": "file", "name": "Trigger.java"}]}]}]}]}]}]}]}]}]}]}, {"type": "directory", "name": "astyanax-recipes", "children": [{"type": "file", "name": "build.gradle"}, {"type": "directory", "name": "src", "children": [{"type": "directory", "name": "main", "children": [{"type": "directory", "name": "java", "children": [{"type": "directory", "name": "com", "children": [{"type": "directory", "name": "netflix", "children": [{"type": "directory", "name": "astyanax", "children": [{"type": "directory", "name": "recipes", "children": [{"type": "file", "name": "Callback.java"}, {"type": "file", "name": "ConstantSupplier.java"}, {"type": "file", "name": "DistributedMergeSort.java"}, {"type": "directory", "name": "functions", "children": [{"type": "file", "name": "ColumnCounterFunction.java"}, {"type": "file", "name": "RowCopierFunction.java"}, {"type": "file", "name": "RowCounterFunction.java"}, {"type": "file", "name": "TraceFunction.java"}]}, {"type": "directory", "name": "locks", "children": [{"type": "file", "name": "BusyLockException.java"}, {"type": "file", "name": "ColumnPrefixDistributedRowLock.java"}, {"type": "file", "name": "DistributedRowLock.java"}, {"type": "file", "name": "LockColumnStrategy.java"}, {"type": "file", "name": "OneStepDistributedRowLock.java"}, {"type": "file", "name": "StaleLockException.java"}, {"type": "file", "name": "StringRowLockColumnStrategy.java"}]}, {"type": "directory", "name": "reader", "children": [{"type": "file", "name": "AllRowsReader.java"}]}, {"type": "file", "name": "ReverseIndexQuery.java"}, {"type": "file", "name": "Shards.java"}, {"type": "directory", "name": "storage", "children": [{"type": "file", "name": "AutoAllocatingLinkedBlockingQueue.java"}, {"type": "file", "name": "CassandraChunkedStorageProvider.java"}, {"type": "file", "name": "ChunkedStorage.java"}, {"type": "file", "name": "ChunkedStorageProvider.java"}, {"type": "file", "name": "NoOpObjectReadCallback.java"}, {"type": "file", "name": "NoOpObjectWriteCallback.java"}, {"type": "file", "name": "ObjectDeleter.java"}, {"type": "file", "name": "ObjectDirectoryLister.java"}, {"type": "file", "name": "ObjectInfoReader.java"}, {"type": "file", "name": "ObjectMetadata.java"}, {"type": "file", "name": "ObjectReadCallback.java"}, {"type": "file", "name": "ObjectReader.java"}, {"type": "file", "name": "ObjectWriteCallback.java"}, {"type": "file", "name": "ObjectWriter.java"}]}, {"type": "directory", "name": "uniqueness", "children": [{"type": "file", "name": "ColumnPrefixUniquenessConstraint.java"}, {"type": "file", "name": "DedicatedMultiRowUniquenessConstraint.java"}, {"type": "file", "name": "MultiRowUniquenessConstraint.java"}, {"type": "file", "name": "NotUniqueException.java"}, {"type": "file", "name": "RowUniquenessConstraint.java"}, {"type": "file", "name": "UniquenessConstraint.java"}]}, {"type": "file", "name": "UniquenessConstraint.java"}, {"type": "file", "name": "UniquenessConstraintViolationMonitor.java"}, {"type": "file", "name": "UniquenessConstraintWithPrefix.java"}, {"type": "file", "name": "UUIDStringSupplier.java"}]}]}]}]}]}]}]}]}, {"type": "directory", "name": "astyanax-test", "children": [{"type": "file", "name": "build.gradle"}, {"type": "directory", "name": "src", "children": [{"type": "directory", "name": "main", "children": [{"type": "directory", "name": "java", "children": [{"type": "directory", "name": "com", "children": [{"type": "directory", "name": "netflix", "children": [{"type": "directory", "name": "astyanax", "children": [{"type": "directory", "name": "cql", "children": [{"type": "directory", "name": "test", "children": [{"type": "file", "name": "AllRowsQueryTest.java"}, {"type": "file", "name": "CFStandardTests.java"}, {"type": "file", "name": "ClickStreamTests.java"}, {"type": "file", "name": "ColumnCountQueryTests.java"}, {"type": "file", "name": "ColumnTimestampAndTTLTests.java"}, {"type": "file", "name": "CompositeColumnTests.java"}, {"type": "file", "name": "CompositeKeyTests.java"}, {"type": "file", "name": "CounterColumnTests.java"}, {"type": "file", "name": "DirectCqlTests.java"}, {"type": "directory", "name": "entitymapper", "children": [{"type": "file", "name": "EntityMapperTests.java"}]}, {"type": "file", "name": "KeyspaceTests.java"}, {"type": "file", "name": "LongColumnPaginationTests.java"}, {"type": "file", "name": "MockCompositeTypeTests.java"}, {"type": "file", "name": "PreparedStatementTests.java"}, {"type": "directory", "name": "recipes", "children": [{"type": "file", "name": "AllRowsReaderTest.java"}, {"type": "file", "name": "ChunkedObjectStoreTest.java"}, {"type": "file", "name": "ColumnPrefixDistributedLockTest.java"}, {"type": "file", "name": "ColumnPrefixUniquenessConstraintTest.java"}]}, {"type": "file", "name": "RingDescribeTests.java"}, {"type": "file", "name": "RowCopierTests.java"}, {"type": "file", "name": "RowSliceRowRangeQueryTests.java"}, {"type": "file", "name": "RowUniquenessConstraintTest.java"}, {"type": "file", "name": "SchemaTests.java"}, {"type": "file", "name": "SerializerPackageTests.java"}, {"type": "file", "name": "SingleColumnMutationTests.java"}, {"type": "file", "name": "SingleRowColumnPaginationTests.java"}, {"type": "file", "name": "SingleRowColumnRangeQueryTests.java"}, {"type": "file", "name": "SingleRowQueryTests.java"}, {"type": "file", "name": "StaticColumnFamilyTests.java"}, {"type": "file", "name": "TimeUUIDTests.java"}, {"type": "directory", "name": "utils", "children": [{"type": "file", "name": "AstyanaxContextFactory.java"}, {"type": "file", "name": "ClusterConfiguration.java"}, {"type": "file", "name": "ReadTests.java"}, {"type": "file", "name": "TestUtils.java"}]}]}]}, {"type": "directory", "name": "test", "children": [{"type": "file", "name": "EmbeddedCassandra.java"}]}]}]}]}]}, {"type": "directory", "name": "resources", "children": [{"type": "file", "name": "cassandra-template.yaml"}, {"type": "file", "name": "cassandra2-template.yaml"}]}]}, {"type": "directory", "name": "test", "children": [{"type": "directory", "name": "java", "children": [{"type": "directory", "name": "com", "children": [{"type": "directory", "name": "netflix", "children": [{"type": "directory", "name": "astyanax", "children": [{"type": "directory", "name": "connectionpool", "children": [{"type": "directory", "name": "impl", "children": [{"type": "file", "name": "BagConnectionPoolImplTest.java"}, {"type": "file", "name": "BaseConnectionPoolTest.java"}, {"type": "file", "name": "HostConnectionPoolPartitionTest.java"}, {"type": "file", "name": "RingDescribeNodeAutoDiscoveryImplTest.java"}, {"type": "file", "name": "RoundRobinConnectionPoolImplTest.java"}, {"type": "file", "name": "SimpleHostConnectionPoolTest.java"}, {"type": "file", "name": "Stress.java"}, {"type": "file", "name": "StressSimpleHostConnectionPoolImpl.java"}, {"type": "file", "name": "TokenAwareConnectionPoolTest.java"}]}]}, {"type": "directory", "name": "contrib", "children": [{"type": "directory", "name": "valve", "children": [{"type": "file", "name": "MultiThreadTestControl.java"}, {"type": "file", "name": "RollingTimeWindowValveTest.java"}, {"type": "file", "name": "TimeWindowValveTest.java"}]}]}, {"type": "directory", "name": "entitystore", "children": [{"type": "file", "name": "CompositeEntityManagerTest.java"}, {"type": "file", "name": "DefaultEntityManagerNullableTest.java"}, {"type": "file", "name": "DefaultEntityManagerTest.java"}, {"type": "file", "name": "DefaultEntityManagerTtlTest.java"}, {"type": "file", "name": "DoubleIdColumnEntity.java"}, {"type": "file", "name": "EntityMapperTest.java"}, {"type": "file", "name": "NullableEntity.java"}, {"type": "file", "name": "SampleEntity.java"}, {"type": "file", "name": "SimpleEntity.java"}]}, {"type": "directory", "name": "impl", "children": [{"type": "file", "name": "FilteringHostSupplierTest.java"}, {"type": "file", "name": "RingDescribeHostSupplierTest.java"}]}, {"type": "directory", "name": "mapping", "children": [{"type": "file", "name": "FakeKeyspaceBean.java"}, {"type": "file", "name": "TestMapping.java"}]}, {"type": "directory", "name": "model", "children": [{"type": "file", "name": "CompositeTest.java"}, {"type": "file", "name": "DynamicCompositeTest.java"}]}, {"type": "directory", "name": "partitioner", "children": [{"type": "file", "name": "PartitionerTest.java"}]}, {"type": "directory", "name": "query", "children": [{"type": "file", "name": "PreparedQueryTests.java"}]}, {"type": "directory", "name": "recipes", "children": [{"type": "file", "name": "ChunkedObjectRecipeTest.java"}, {"type": "file", "name": "LockRecipeTest.java"}, {"type": "file", "name": "MiscUnitTest.java"}, {"type": "file", "name": "ReverseIndexQueryTest.java"}, {"type": "file", "name": "UniquenessConstraintTest.java"}]}, {"type": "directory", "name": "retry", "children": [{"type": "file", "name": "BoundedExponentialBackoffTest.java"}, {"type": "file", "name": "ExponentialBackoffTest.java"}]}, {"type": "directory", "name": "serializers", "children": [{"type": "file", "name": "AnnotatedCompositeSerializerTest.java"}, {"type": "file", "name": "SerializerPackageImplTest.java"}, {"type": "file", "name": "SerializersTest.java"}]}, {"type": "directory", "name": "test", "children": [{"type": "file", "name": "TestConstants.java"}, {"type": "file", "name": "TestKeyspace.java"}, {"type": "file", "name": "TokenTestOperation.java"}]}, {"type": "directory", "name": "thrift", "children": [{"type": "file", "name": "CqlTest.java"}, {"type": "file", "name": "HelloWorldFunction.java"}, {"type": "file", "name": "MockCompositeType.java"}, {"type": "file", "name": "QueueTest.java"}, {"type": "file", "name": "ThriftClusterImplTest.java"}, {"type": "file", "name": "ThriftKeyspaceAllRowsTest.java"}, {"type": "file", "name": "ThriftKeyspaceImplTest.java"}]}, {"type": "directory", "name": "util", "children": [{"type": "file", "name": "ExecuteWithRetryTest.java"}, {"type": "file", "name": "RateLimiterTest.java"}, {"type": "file", "name": "SingletonEmbeddedCassandra.java"}, {"type": "file", "name": "TimeUUIDTest.java"}]}]}]}]}]}, {"type": "directory", "name": "resources", "children": [{"type": "file", "name": "simplelogger.properties"}]}]}]}]}, {"type": "directory", "name": "astyanax-thrift", "children": [{"type": "file", "name": "build.gradle"}, {"type": "directory", "name": "src", "children": [{"type": "directory", "name": "main", "children": [{"type": "directory", "name": "java", "children": [{"type": "directory", "name": "com", "children": [{"type": "directory", "name": "netflix", "children": [{"type": "directory", "name": "astyanax", "children": [{"type": "directory", "name": "thrift", "children": [{"type": "file", "name": "AbstractIndexQueryImpl.java"}, {"type": "file", "name": "AbstractKeyspaceOperationImpl.java"}, {"type": "file", "name": "AbstractOperationImpl.java"}, {"type": "file", "name": "AbstractRowQueryImpl.java"}, {"type": "file", "name": "AbstractRowSliceQueryImpl.java"}, {"type": "file", "name": "AbstractThriftColumnMutationImpl.java"}, {"type": "file", "name": "AbstractThriftCqlPreparedStatement.java"}, {"type": "file", "name": "AbstractThriftCqlQuery.java"}, {"type": "file", "name": "AbstractThriftMutationBatchImpl.java"}, {"type": "directory", "name": "ddl", "children": [{"type": "file", "name": "ThriftColumnDefinitionImpl.java"}, {"type": "file", "name": "ThriftColumnFamilyDefinitionImpl.java"}, {"type": "file", "name": "ThriftKeyspaceDefinitionImpl.java"}]}, {"type": "directory", "name": "model", "children": [{"type": "file", "name": "ThriftColumnImpl.java"}, {"type": "file", "name": "ThriftColumnListImpl.java"}, {"type": "file", "name": "ThriftColumnOrSuperColumnListImpl.java"}, {"type": "file", "name": "ThriftCounterColumnImpl.java"}, {"type": "file", "name": "ThriftCounterColumnListImpl.java"}, {"type": "file", "name": "ThriftCounterSuperColumnImpl.java"}, {"type": "file", "name": "ThriftCounterSuperColumnMutationImpl.java"}, {"type": "file", "name": "ThriftCqlResultImpl.java"}, {"type": "file", "name": "ThriftCqlRowsImpl.java"}, {"type": "file", "name": "ThriftRowImpl.java"}, {"type": "file", "name": "ThriftRowsListImpl.java"}, {"type": "file", "name": "ThriftRowsSliceImpl.java"}, {"type": "file", "name": "ThriftSuperColumnImpl.java"}]}, {"type": "file", "name": "ThriftAllRowsImpl.java"}, {"type": "file", "name": "ThriftAllRowsQueryImpl.java"}, {"type": "file", "name": "ThriftClusterImpl.java"}, {"type": "file", "name": "ThriftColumnFamilyMutationImpl.java"}, {"type": "file", "name": "ThriftColumnFamilyQueryImpl.java"}, {"type": "file", "name": "ThriftConverter.java"}, {"type": "file", "name": "ThriftCql2Factory.java"}, {"type": "file", "name": "ThriftCql3Factory.java"}, {"type": "file", "name": "ThriftCql3Query.java"}, {"type": "file", "name": "ThriftCql3Statement.java"}, {"type": "file", "name": "ThriftCqlFactory.java"}, {"type": "file", "name": "ThriftCqlFactoryResolver.java"}, {"type": "file", "name": "ThriftCqlQuery.java"}, {"type": "file", "name": "ThriftCqlSchema.java"}, {"type": "file", "name": "ThriftCqlStatement.java"}, {"type": "file", "name": "ThriftCqlStatementResult.java"}, {"type": "file", "name": "ThriftFamilyFactory.java"}, {"type": "file", "name": "ThriftKeyspaceImpl.java"}, {"type": "file", "name": "ThriftSuperColumnMutationImpl.java"}, {"type": "file", "name": "ThriftSyncConnectionFactoryImpl.java"}, {"type": "file", "name": "ThriftTypes.java"}, {"type": "file", "name": "ThriftUtils.java"}]}]}]}]}]}]}]}]}, {"type": "file", "name": "build.gradle"}, {"type": "file", "name": "CHANGELOG.md"}, {"type": "directory", "name": "codequality", "children": [{"type": "file", "name": "checkstyle.xml"}]}, {"type": "file", "name": "dependency-versions.gradle"}, {"type": "directory", "name": "gradle", "children": [{"type": "directory", "name": "wrapper", "children": [{"type": "file", "name": "gradle-wrapper.properties"}]}]}, {"type": "file", "name": "gradle.properties"}, {"type": "file", "name": "gradlew"}, {"type": "file", "name": "gradlew.bat"}, {"type": "file", "name": "index.html"}, {"type": "file", "name": "LICENSE.txt"}, {"type": "file", "name": "NOTICE.txt"}, {"type": "file", "name": "OSSMETADATA"}, {"type": "file", "name": "Readme.markdown"}, {"type": "file", "name": "README.txt"}, {"type": "file", "name": "settings.gradle"}]} | Astyanax is a high level Java client for Apache Cassandra.
Apache Cassandra is a highly available column oriented database: http://cassandra.apache.org
Astyanax was the son of Hector in greek mythology.
http://en.wikipedia.org/wiki/Astyanax
http://en.wikipedia.org/wiki/Cassandra
Astyanax is currently in use at Netflix. Issues generally are fixed as quickly as possbile and releases done frequently.
Some features provided by this client:
o high level, simple object oriented interface to cassandra
o failover behavior on the client side
o Connection pool abstraction. Implementation of a round robin connection pool.
o Monitoring abstraction to get event notification from the connection pool
o complete encapsulation of the underlying Thrift API and structs
o automatic retry of downed hosts
o automatic discovery of additional hosts in the cluster
o suspension of hosts for a short period of time after several timeouts
o annotations to simplify use of composite columns
Detailed documentation of Astyanax features and usage can be found on the wiki:
https://github.com/Netflix/astyanax/wiki
The work was initially inspired by https://github.com/hector-client/hector.
| {"index.html": "<!DOCTYPE html>\n<!--\n ~ Copyright 2013 Netflix, Inc.\n ~\n ~ Licensed under the Apache License, Version 2.0 (the \"License\");\n ~ you may not use this file except in compliance with the License.\n ~ You may obtain a copy of the License at\n ~\n ~ http://www.apache.org/licenses/LICENSE-2.0\n ~\n ~ Unless required by applicable law or agreed to in writing, software\n ~ distributed under the License is distributed on an \"AS IS\" BASIS,\n ~ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n ~ See the License for the specific language governing permissions and\n ~ limitations under the License.\n -->\n\n<html>\n<head>\n <meta charset='utf-8'>\n\n <title>Netflix/astyanax @ GitHub</title>\n\n <style type=\"text/css\">\n body {\n margin-top: 1.0em;\n background-color: #B9090B;\n font-family: Helvetica, Arial, FreeSans, san-serif;\n color: #ffffff;\n }\n #container {\n margin: 0 auto;\n width: 700px;\n }\n h1 { font-size: 3.8em; color: #46f6f4; margin-bottom: 3px; }\n h1 .small { font-size: 0.4em; }\n h1 a { text-decoration: none }\n h2 { font-size: 1.5em; color: #46f6f4; }\n h3 { text-align: center; color: #46f6f4; }\n a { color: #46f6f4; }\n .description { font-size: 1.2em; margin-bottom: 30px; margin-top: 30px; font-style: italic;}\n .download { float: right; }\n pre { background: #000; color: #fff; padding: 15px;}\n hr { border: 0; width: 80%; border-bottom: 1px solid #aaa}\n .footer { text-align:center; padding-top:30px; font-style: italic; }\n </style>\n</head>\n\n<body>\n <a href=\"https://github.com/Netflix/astyanax\"><img style=\"position: absolute; top: 0; right: 0; border: 0;\" src=\"http://s3.amazonaws.com/github/ribbons/forkme_right_darkblue_121621.png\" alt=\"Fork me on GitHub\" /></a>\n\n <div id=\"container\">\n\n <div class=\"download\">\n <a href=\"https://github.com/Netflix/astyanax/zipball/master\">\n <img border=\"0\" width=\"90\" src=\"https://github.com/images/modules/download/zip.png\"></a>\n <a href=\"https://github.com/Netflix/astyanax/tarball/master\">\n <img border=\"0\" width=\"90\" src=\"https://github.com/images/modules/download/tar.png\"></a>\n </div>\n\n <h1><a href=\"https://github.com/Netflix/astyanax\">astyanax</a>\n <span class=\"small\">by <a href=\"https://github.com/Netflix\">Netflix</a></span></h1>\n\n <div class=\"description\">\n Cassandra Java Client \n </div>\n\n \n <p>Astyanax is a high level Java client for Apache Cassandra. Astyanax provides a connection pool as well as common best practices recipes on top of the cassandra thrift api. </p>\n \n <h2>Install</h2>\n <p>Get the binaries from Maven Central:\n\n<pre>\n<dependency>\n <groupId>com.netflix.astyanax</groupId>\n <artifactId>astyanax</artifactId>\n <version>version-number</version>\n</dependency>\n</pre>\n\n \n <h2>License</h2>\n <p>Apache 2.0</p>\n \n\n \n <h2>Authors</h2>\n <p>Eran Landau ([email protected])\n<br/></p>\n \n\n \n <h2>Contact</h2>\n <p>Netflix, Inc. ([email protected])\n<br/> </p>\n \n\n <h2>Download</h2>\n <p>\n You can download this project in either\n <a href=\"https://github.com/Netflix/astyanax/zipball/master\">zip</a> or\n <a href=\"https://github.com/Netflix/astyanax/tarball/master\">tar formats.</a>\n </p>\n <p>You can also clone the project with <a href=\"http://git-scm.com\">Git</a>\n by running:\n <pre>$ git clone git://github.com/Netflix/elandau</pre>\n </p>\n\n <div class=\"footer\">\n get the source code on GitHub : <a href=\"https://github.com/Netflix/astyanax\">Netflix/astyanax</a>\n </div>\n\n </div>\n\n</body>\n</html>", ".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", "astyanax-cassandra\\src\\main\\java\\com\\netflix\\astyanax\\impl\\PreparedIndexExpressionImpl.java": "/*******************************************************************************\n * Copyright 2011 Netflix\n * \n * Licensed under the Apache License, Version 2.0 (the \"License\");\n * you may not use this file except in compliance with the License.\n * You may obtain a copy of the License at\n * \n * http://www.apache.org/licenses/LICENSE-2.0\n * \n * Unless required by applicable law or agreed to in writing, software\n * distributed under the License is distributed on an \"AS IS\" BASIS,\n * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n * See the License for the specific language governing permissions and\n * limitations under the License.\n ******************************************************************************/\npackage com.netflix.astyanax.impl;\n\nimport java.nio.ByteBuffer;\nimport java.util.Date;\nimport java.util.UUID;\n\nimport com.netflix.astyanax.Serializer;\nimport com.netflix.astyanax.query.IndexOperator;\nimport com.netflix.astyanax.query.PreparedIndexExpression;\nimport com.netflix.astyanax.query.PreparedIndexValueExpression;\nimport com.netflix.astyanax.query.PreparedIndexOperationExpression;\nimport com.netflix.astyanax.serializers.BooleanSerializer;\nimport com.netflix.astyanax.serializers.ByteBufferSerializer;\nimport com.netflix.astyanax.serializers.BytesArraySerializer;\nimport com.netflix.astyanax.serializers.DateSerializer;\nimport com.netflix.astyanax.serializers.DoubleSerializer;\nimport com.netflix.astyanax.serializers.IntegerSerializer;\nimport com.netflix.astyanax.serializers.LongSerializer;\nimport com.netflix.astyanax.serializers.StringSerializer;\nimport com.netflix.astyanax.serializers.UUIDSerializer;\n\npublic class PreparedIndexExpressionImpl<K, C> implements PreparedIndexExpression<K, C>,\n PreparedIndexOperationExpression<K, C>, PreparedIndexValueExpression<K, C> {\n private ByteBuffer value;\n private ByteBuffer column;\n private IndexOperator operator;\n private final Serializer<C> columnSerializer;\n\n public PreparedIndexExpressionImpl(Serializer<C> columnSerializer) {\n this.columnSerializer = columnSerializer;\n }\n\n @Override\n public PreparedIndexOperationExpression<K, C> whereColumn(C columnName) {\n column = columnSerializer.toByteBuffer(columnName);\n return this;\n }\n\n @Override\n public ByteBuffer getColumn() {\n return column;\n }\n\n @Override\n public ByteBuffer getValue() {\n return value;\n }\n\n @Override\n public IndexOperator getOperator() {\n return operator;\n }\n\n @Override\n public PreparedIndexValueExpression<K, C> equals() {\n operator = IndexOperator.EQ;\n return this;\n }\n\n @Override\n public PreparedIndexValueExpression<K, C> greaterThan() {\n operator = IndexOperator.GT;\n return this;\n }\n\n @Override\n public PreparedIndexValueExpression<K, C> lessThan() {\n operator = IndexOperator.LT;\n return this;\n }\n\n @Override\n public PreparedIndexValueExpression<K, C> greaterThanEquals() {\n operator = IndexOperator.GTE;\n return this;\n }\n\n @Override\n public PreparedIndexValueExpression<K, C> lessThanEquals() {\n operator = IndexOperator.LTE;\n return this;\n }\n\n @Override\n public PreparedIndexExpression<K, C> value(String value) {\n this.value = StringSerializer.get().toByteBuffer(value);\n return this;\n }\n\n @Override\n public PreparedIndexExpression<K, C> value(long value) {\n this.value = LongSerializer.get().toByteBuffer(value);\n return this;\n }\n\n @Override\n public PreparedIndexExpression<K, C> value(int value) {\n this.value = IntegerSerializer.get().toByteBuffer(value);\n return this;\n }\n\n @Override\n public PreparedIndexExpression<K, C> value(boolean value) {\n this.value = BooleanSerializer.get().toByteBuffer(value);\n return this;\n }\n\n @Override\n public PreparedIndexExpression<K, C> value(Date value) {\n this.value = DateSerializer.get().toByteBuffer(value);\n return this;\n }\n\n @Override\n public PreparedIndexExpression<K, C> value(byte[] value) {\n this.value = BytesArraySerializer.get().toByteBuffer(value);\n return this;\n }\n\n @Override\n public PreparedIndexExpression<K, C> value(ByteBuffer value) {\n this.value = ByteBufferSerializer.get().toByteBuffer(value);\n return this;\n }\n\n @Override\n public PreparedIndexExpression<K, C> value(double value) {\n this.value = DoubleSerializer.get().toByteBuffer(value);\n return this;\n }\n\n @Override\n public PreparedIndexExpression<K, C> value(UUID value) {\n this.value = UUIDSerializer.get().toByteBuffer(value);\n return this;\n }\n\n @Override\n public <V> PreparedIndexExpression<K, C> value(V value, Serializer<V> valueSerializer) {\n this.value = valueSerializer.toByteBuffer(value);\n return this;\n }\n\n}\n", "astyanax-cassandra\\src\\main\\java\\com\\netflix\\astyanax\\mapping\\Mapping.java": "/*******************************************************************************\n * Copyright 2011 Netflix\n * \n * Licensed under the Apache License, Version 2.0 (the \"License\");\n * you may not use this file except in compliance with the License.\n * You may obtain a copy of the License at\n * \n * http://www.apache.org/licenses/LICENSE-2.0\n * \n * Unless required by applicable law or agreed to in writing, software\n * distributed under the License is distributed on an \"AS IS\" BASIS,\n * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n * See the License for the specific language governing permissions and\n * limitations under the License.\n ******************************************************************************/\npackage com.netflix.astyanax.mapping;\n\nimport com.google.common.base.Preconditions;\nimport com.google.common.collect.ImmutableMap;\nimport com.google.common.collect.Lists;\nimport com.google.common.collect.Sets;\nimport com.netflix.astyanax.ColumnListMutation;\nimport com.netflix.astyanax.model.ColumnList;\nimport com.netflix.astyanax.model.Row;\nimport com.netflix.astyanax.model.Rows;\n\nimport java.lang.annotation.Annotation;\nimport java.lang.reflect.Field;\nimport java.util.ArrayList;\nimport java.util.Collection;\nimport java.util.List;\nimport java.util.Set;\nimport java.util.concurrent.atomic.AtomicBoolean;\n\n/**\n * <p>\n * Utility for doing object/relational mapping between bean-like instances and\n * Cassandra\n * </p>\n * <p/>\n * <p>\n * The mapper stores values in Cassandra and maps in/out to native types. Column\n * names must be strings. Annotate your bean with {@link Id} and {@link Column}.\n * Or, provide an {@link AnnotationSet} that defines IDs and Columns in your\n * bean.\n * \n * @deprecated please use DefaultEntityManager instead\n */\n@Deprecated\n@SuppressWarnings({ \"SuspiciousMethodCalls\" })\npublic class Mapping<T> {\n private final ImmutableMap<String, Field> fields;\n private final String idFieldName;\n private final Class<T> clazz;\n\n /**\n * If the ID column does not have a Column annotation, this column name is\n * used\n */\n public static final String DEFAULT_ID_COLUMN_NAME = \"ID\";\n\n /**\n * Convenience for allocation a mapping object\n * \n * @param clazz\n * clazz type to map\n * @return mapper\n */\n public static <T> Mapping<T> make(Class<T> clazz, boolean includeParentFields) {\n return new Mapping<T>(clazz, new DefaultAnnotationSet(), includeParentFields);\n }\n\n public static <T> Mapping<T> make(Class<T> clazz) {\n return new Mapping<T>(clazz, new DefaultAnnotationSet(), false);\n\t}\n\n /**\n * Convenience for allocation a mapping object\n * \n * @param clazz\n * clazz type to map\n * @param annotationSet\n * annotations to use when analyzing a bean\n * @return mapper\n */\n public static <T> Mapping<T> make(Class<T> clazz, AnnotationSet<?, ?> annotationSet, boolean includeParentFields) {\n return new Mapping<T>(clazz, annotationSet, includeParentFields);\n }\n\n public static <T> Mapping<T> make(Class<T> clazz, AnnotationSet<?, ?> annotationSet) {\n\t\treturn new Mapping(clazz, annotationSet, false);\t\t\n\t}\n\t\n /**\n * @param clazz\n * clazz type to map\n */\n public Mapping(Class<T> clazz, boolean includeParentFields) {\n this(clazz, new DefaultAnnotationSet(), includeParentFields);\n }\n\n public Mapping(Class<T> clazz) {\n\t\tthis(clazz, new DefaultAnnotationSet(), false);\t\t\n\t}\n\t\n /**\n * @param clazz\n * clazz type to map\n * @param annotationSet\n * annotations to use when analyzing a bean\n */\n public Mapping(Class<T> clazz, AnnotationSet<?, ?> annotationSet, boolean includeParentFields) {\n this.clazz = clazz;\n\n String localKeyFieldName = null;\n ImmutableMap.Builder<String, Field> builder = ImmutableMap.builder();\n\n AtomicBoolean isKey = new AtomicBoolean();\n Set<String> usedNames = Sets.newHashSet();\n\n\t\tList<Field> allFields = getFields(clazz, includeParentFields);\n for (Field field : allFields) {\n String name = mapField(field, annotationSet, builder, usedNames, isKey);\n if (isKey.get()) {\n Preconditions.checkArgument(localKeyFieldName == null);\n localKeyFieldName = name;\n }\n }\n\n Preconditions.checkNotNull(localKeyFieldName);\n\n fields = builder.build();\n idFieldName = localKeyFieldName;\n }\n\n public Mapping(Class<T> clazz, AnnotationSet<?, ?> annotationSet) {\n\t\tthis(clazz, annotationSet, false);\n\t}\n\n\tprivate List<Field> getFields(Class clazz, boolean recursuvely) {\n\t\tList<Field> allFields = new ArrayList<Field>();\n\t\tif (clazz.getDeclaredFields() != null && clazz.getDeclaredFields().length > 0) {\n\t\t\tfor (Field field : clazz.getDeclaredFields()) {\n\t\t\t\tallFields.add(field);\n\t\t\t}\n\t\t\tif (recursuvely && clazz.getSuperclass() != null) {\n\t\t\t\tallFields.addAll(getFields(clazz.getSuperclass(), true));\n\t\t\t}\n\t\t}\n\t\treturn allFields;\n\t}\n\n /**\n * Return the value for the ID/Key column from the given instance\n * \n * @param instance\n * the instance\n * @param valueClass\n * type of the value (must match the actual native type in the\n * instance's class)\n * @return value\n */\n public <V> V getIdValue(T instance, Class<V> valueClass) {\n return getColumnValue(instance, idFieldName, valueClass);\n }\n\n /**\n * Return the value for the given column from the given instance\n * \n * @param instance\n * the instance\n * @param columnName\n * name of the column (must match a corresponding annotated field\n * in the instance's class)\n * @param valueClass\n * type of the value (must match the actual native type in the\n * instance's class)\n * @return value\n */\n public <V> V getColumnValue(T instance, String columnName,\n Class<V> valueClass) {\n Field field = fields.get(columnName);\n if (field == null) {\n throw new IllegalArgumentException(\"Column not found: \"\n + columnName);\n }\n try {\n return valueClass.cast(field.get(instance));\n } catch (IllegalAccessException e) {\n throw new RuntimeException(e); // should never get here\n }\n }\n\n /**\n * Set the value for the ID/Key column for the given instance\n * \n * @param instance\n * the instance\n * @param value\n * The value (must match the actual native type in the instance's\n * class)\n */\n public <V> void setIdValue(T instance, V value) {\n setColumnValue(instance, idFieldName, value);\n }\n\n /**\n * Set the value for the given column for the given instance\n * \n * @param instance\n * the instance\n * @param columnName\n * name of the column (must match a corresponding annotated field\n * in the instance's class)\n * @param value\n * The value (must match the actual native type in the instance's\n * class)\n */\n public <V> void setColumnValue(T instance, String columnName, V value) {\n Field field = fields.get(columnName);\n if (field == null) {\n throw new IllegalArgumentException(\"Column not found: \"\n + columnName);\n }\n try {\n field.set(instance, value);\n } catch (IllegalAccessException e) {\n throw new RuntimeException(e); // should never get here\n }\n }\n\n /**\n * Map a bean to a column mutation. i.e. set the columns in the mutation to\n * the corresponding values from the instance\n * \n * @param instance\n * instance\n * @param mutation\n * mutation\n */\n public void fillMutation(T instance, ColumnListMutation<String> mutation) {\n for (String fieldName : getNames()) {\n Coercions.setColumnMutationFromField(instance, fields.get(fieldName), fieldName, mutation);\n }\n }\n\n /**\n * Allocate a new instance and populate it with the values from the given\n * column list\n * \n * @param columns\n * column list\n * @return the allocated instance\n * @throws IllegalAccessException\n * if a new instance could not be instantiated\n * @throws InstantiationException\n * if a new instance could not be instantiated\n */\n public T newInstance(ColumnList<String> columns)\n throws IllegalAccessException, InstantiationException {\n return initInstance(clazz.newInstance(), columns);\n }\n\n /**\n * Populate the given instance with the values from the given column list\n * \n * @param instance\n * instance\n * @param columns\n * column this\n * @return instance (as a convenience for chaining)\n */\n public T initInstance(T instance, ColumnList<String> columns) {\n for (com.netflix.astyanax.model.Column<String> column : columns) {\n Field field = fields.get(column.getName());\n if (field != null) { // otherwise it may be a column that was\n // removed, etc.\n Coercions.setFieldFromColumn(instance, field, column);\n }\n }\n return instance;\n }\n\n /**\n * Load a set of rows into new instances populated with values from the\n * column lists\n * \n * @param rows\n * the rows\n * @return list of new instances\n * @throws IllegalAccessException\n * if a new instance could not be instantiated\n * @throws InstantiationException\n * if a new instance could not be instantiated\n */\n public List<T> getAll(Rows<?, String> rows) throws InstantiationException,\n IllegalAccessException {\n List<T> list = Lists.newArrayList();\n for (Row<?, String> row : rows) {\n if (!row.getColumns().isEmpty()) {\n list.add(newInstance(row.getColumns()));\n }\n }\n return list;\n }\n\n /**\n * Return the set of column names discovered from the bean class\n * \n * @return column names\n */\n public Collection<String> getNames() {\n return fields.keySet();\n }\n\n Class<?> getIdFieldClass() {\n return fields.get(idFieldName).getType();\n }\n\n private <ID extends Annotation, COLUMN extends Annotation> String mapField(\n Field field, AnnotationSet<ID, COLUMN> annotationSet,\n ImmutableMap.Builder<String, Field> builder, Set<String> usedNames,\n AtomicBoolean isKey) {\n String mappingName = null;\n\n ID idAnnotation = field.getAnnotation(annotationSet.getIdAnnotation());\n COLUMN columnAnnotation = field.getAnnotation(annotationSet\n .getColumnAnnotation());\n\n if ((idAnnotation != null) && (columnAnnotation != null)) {\n throw new IllegalStateException(\n \"A field cannot be marked as both an ID and a Column: \"\n + field.getName());\n }\n\n if (idAnnotation != null) {\n mappingName = annotationSet.getIdName(field, idAnnotation);\n isKey.set(true);\n } else {\n isKey.set(false);\n }\n\n if ((columnAnnotation != null)) {\n mappingName = annotationSet.getColumnName(field, columnAnnotation);\n }\n\n if (mappingName != null) {\n Preconditions.checkArgument(\n !usedNames.contains(mappingName.toLowerCase()), mappingName\n + \" has already been used for this column family\");\n usedNames.add(mappingName.toLowerCase());\n\n field.setAccessible(true);\n builder.put(mappingName, field);\n }\n\n return mappingName;\n }\n}\n", "astyanax-cassandra\\src\\main\\java\\com\\netflix\\astyanax\\mapping\\MappingCache.java": "/*******************************************************************************\n * Copyright 2011 Netflix\n * \n * Licensed under the Apache License, Version 2.0 (the \"License\");\n * you may not use this file except in compliance with the License.\n * You may obtain a copy of the License at\n * \n * http://www.apache.org/licenses/LICENSE-2.0\n * \n * Unless required by applicable law or agreed to in writing, software\n * distributed under the License is distributed on an \"AS IS\" BASIS,\n * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n * See the License for the specific language governing permissions and\n * limitations under the License.\n ******************************************************************************/\npackage com.netflix.astyanax.mapping;\n\nimport com.google.common.collect.Maps;\n\nimport java.util.Map;\n\n/**\n * Utility to cache mappers. There's a small performance hit to reflect on a\n * bean. This cache, re-uses mappers for a given bean\n */\npublic class MappingCache {\n private final Map<Class<?>, Mapping<?>> cache = Maps.newConcurrentMap();\n\n /**\n * Return a new or cached mapper\n * \n * @param clazz\n * class for the mapper\n * @return mapper\n */\n public <T> Mapping<T> getMapping(Class<T> clazz, boolean includeParentFields) {\n return getMapping(clazz, new DefaultAnnotationSet(), includeParentFields);\n }\n\n public <T> Mapping<T> getMapping(Class<T> clazz) {\n\t\treturn getMapping(clazz, false);\t\t\n\t}\n\n /**\n * Return a new or cached mapper\n * \n * @param clazz\n * class for the mapper\n * @param annotationSet\n * annotation set for the mapper\n * @return mapper\n */\n @SuppressWarnings({ \"unchecked\" })\n public <T> Mapping<T> getMapping(Class<T> clazz,\n AnnotationSet<?, ?> annotationSet, boolean includeParentFields) {\n Mapping<T> mapping = (Mapping<T>) cache.get(clazz); // cast is safe as\n // this instance is\n // the one adding to\n // the map\n if (mapping == null) {\n // multiple threads can get here but that's OK\n mapping = new Mapping<T>(clazz, annotationSet, includeParentFields);\n cache.put(clazz, mapping);\n }\n\n return mapping;\n }\n\n public <T> Mapping<T> getMapping(Class<T> clazz, AnnotationSet<?, ?> annotationSet) {\n\t\treturn getMapping(clazz, annotationSet, false);\n\t}\n}\n", "astyanax-cassandra\\src\\main\\java\\com\\netflix\\astyanax\\mapping\\MappingUtil.java": "/*******************************************************************************\n * Copyright 2011 Netflix\n * \n * Licensed under the Apache License, Version 2.0 (the \"License\");\n * you may not use this file except in compliance with the License.\n * You may obtain a copy of the License at\n * \n * http://www.apache.org/licenses/LICENSE-2.0\n * \n * Unless required by applicable law or agreed to in writing, software\n * distributed under the License is distributed on an \"AS IS\" BASIS,\n * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n * See the License for the specific language governing permissions and\n * limitations under the License.\n ******************************************************************************/\npackage com.netflix.astyanax.mapping;\n\nimport com.netflix.astyanax.ColumnListMutation;\nimport com.netflix.astyanax.Keyspace;\nimport com.netflix.astyanax.MutationBatch;\nimport com.netflix.astyanax.model.ColumnFamily;\nimport com.netflix.astyanax.model.ColumnList;\nimport com.netflix.astyanax.model.Rows;\n\nimport java.util.List;\n\n/**\n * Higher level mapping functions. Methods that behave similar to a Map.\n * \n * @deprecated please use DefaultEntityManager\n */\n@Deprecated\npublic class MappingUtil {\n private final Keyspace keyspace;\n private final MappingCache cache;\n private final AnnotationSet<?, ?> annotationSet;\n\n /**\n * @param keyspace\n * keyspace to use\n */\n public MappingUtil(Keyspace keyspace) {\n this(keyspace, null, null);\n }\n\n /**\n * @param keyspace\n * keyspace to use\n * @param annotationSet\n * annotation set to use\n */\n public MappingUtil(Keyspace keyspace, AnnotationSet<?, ?> annotationSet) {\n this(keyspace, null, annotationSet);\n }\n\n /**\n * @param keyspace\n * keyspace to use\n * @param cache\n * cache to use\n */\n public MappingUtil(Keyspace keyspace, MappingCache cache) {\n this(keyspace, cache, null);\n }\n\n /**\n * @param keyspace\n * keyspace to use\n * @param cache\n * cache to use\n * @param annotationSet\n * annotation set to use\n */\n public MappingUtil(Keyspace keyspace, MappingCache cache,\n AnnotationSet<?, ?> annotationSet) {\n this.keyspace = keyspace;\n this.cache = cache;\n this.annotationSet = (annotationSet != null) ? annotationSet\n : new DefaultAnnotationSet();\n }\n\n /**\n * Remove the given item\n * \n * @param columnFamily\n * column family of the item\n * @param item\n * the item to remove\n * @throws Exception\n * errors\n */\n public <T, K> void remove(ColumnFamily<K, String> columnFamily, T item)\n throws Exception {\n @SuppressWarnings({ \"unchecked\" })\n Class<T> clazz = (Class<T>) item.getClass();\n Mapping<T> mapping = getMapping(clazz);\n @SuppressWarnings({ \"unchecked\" })\n Class<K> idFieldClass = (Class<K>) mapping.getIdFieldClass(); // safe -\n // after\n // erasure,\n // this is\n // all\n // just\n // Class\n // anyway\n\n MutationBatch mutationBatch = keyspace.prepareMutationBatch();\n mutationBatch.withRow(columnFamily,\n mapping.getIdValue(item, idFieldClass)).delete();\n mutationBatch.execute();\n }\n\n /**\n * Add/update the given item\n * \n * @param columnFamily\n * column family of the item\n * @param item\n * the item to add/update\n * @throws Exception\n * errors\n */\n public <T, K> void put(ColumnFamily<K, String> columnFamily, T item)\n throws Exception {\n @SuppressWarnings({ \"unchecked\" })\n Class<T> clazz = (Class<T>) item.getClass();\n Mapping<T> mapping = getMapping(clazz);\n @SuppressWarnings({ \"unchecked\" })\n Class<K> idFieldClass = (Class<K>) mapping.getIdFieldClass(); // safe -\n // after\n // erasure,\n // this is\n // all\n // just\n // Class\n // anyway\n\n MutationBatch mutationBatch = keyspace.prepareMutationBatch();\n ColumnListMutation<String> columnListMutation = mutationBatch.withRow(\n columnFamily, mapping.getIdValue(item, idFieldClass));\n mapping.fillMutation(item, columnListMutation);\n\n mutationBatch.execute();\n }\n\n /**\n * Get the specified item by its key/id\n * \n * @param columnFamily\n * column family of the item\n * @param id\n * id/key of the item\n * @param itemClass\n * item's class\n * @return new instance with the item's columns propagated\n * @throws Exception\n * errors\n */\n public <T, K> T get(ColumnFamily<K, String> columnFamily, K id,\n Class<T> itemClass) throws Exception {\n Mapping<T> mapping = getMapping(itemClass);\n ColumnList<String> result = keyspace.prepareQuery(columnFamily)\n .getKey(id).execute().getResult();\n return mapping.newInstance(result);\n }\n\n /**\n * Get all rows of the specified item\n * \n * @param columnFamily\n * column family of the item\n * @param itemClass\n * item's class\n * @return new instances with the item's columns propagated\n * @throws Exception\n * errors\n */\n public <T, K> List<T> getAll(ColumnFamily<K, String> columnFamily,\n Class<T> itemClass) throws Exception {\n Mapping<T> mapping = getMapping(itemClass);\n Rows<K, String> result = keyspace.prepareQuery(columnFamily)\n .getAllRows().execute().getResult();\n return mapping.getAll(result);\n }\n\n /**\n * Return the mapping instance for the given class\n * \n * @param clazz\n * the class\n * @return mapping instance (new or from cache)\n */\n public <T> Mapping<T> getMapping(Class<T> clazz) {\n return (cache != null) ? cache.getMapping(clazz, annotationSet)\n : new Mapping<T>(clazz, annotationSet);\n }\n}\n", "astyanax-cassandra\\src\\main\\java\\com\\netflix\\astyanax\\query\\IndexColumnExpression.java": "/*******************************************************************************\n * Copyright 2011 Netflix\n * \n * Licensed under the Apache License, Version 2.0 (the \"License\");\n * you may not use this file except in compliance with the License.\n * You may obtain a copy of the License at\n * \n * http://www.apache.org/licenses/LICENSE-2.0\n * \n * Unless required by applicable law or agreed to in writing, software\n * distributed under the License is distributed on an \"AS IS\" BASIS,\n * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n * See the License for the specific language governing permissions and\n * limitations under the License.\n ******************************************************************************/\npackage com.netflix.astyanax.query;\n\npublic interface IndexColumnExpression<K, C> {\n /**\n * Set the column part of the expression\n * \n * @param columnName\n * @return\n */\n IndexOperationExpression<K, C> whereColumn(C columnName);\n\n}\n", "astyanax-cassandra\\src\\main\\java\\com\\netflix\\astyanax\\query\\IndexOperationExpression.java": "/*******************************************************************************\n * Copyright 2011 Netflix\n * \n * Licensed under the Apache License, Version 2.0 (the \"License\");\n * you may not use this file except in compliance with the License.\n * You may obtain a copy of the License at\n * \n * http://www.apache.org/licenses/LICENSE-2.0\n * \n * Unless required by applicable law or agreed to in writing, software\n * distributed under the License is distributed on an \"AS IS\" BASIS,\n * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n * See the License for the specific language governing permissions and\n * limitations under the License.\n ******************************************************************************/\npackage com.netflix.astyanax.query;\n\npublic interface IndexOperationExpression<K, C> {\n IndexValueExpression<K, C> equals();\n\n IndexValueExpression<K, C> greaterThan();\n\n IndexValueExpression<K, C> lessThan();\n\n IndexValueExpression<K, C> greaterThanEquals();\n\n IndexValueExpression<K, C> lessThanEquals();\n\n}\n", "astyanax-cassandra\\src\\main\\java\\com\\netflix\\astyanax\\query\\IndexOperator.java": "/**\n * Copyright 2013 Netflix, Inc.\n *\n * Licensed under the Apache License, Version 2.0 (the \"License\");\n * you may not use this file except in compliance with the License.\n * You may obtain a copy of the License at\n *\n * http://www.apache.org/licenses/LICENSE-2.0\n *\n * Unless required by applicable law or agreed to in writing, software\n * distributed under the License is distributed on an \"AS IS\" BASIS,\n * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n * See the License for the specific language governing permissions and\n * limitations under the License.\n */\npackage com.netflix.astyanax.query;\n\npublic enum IndexOperator {\n GT, LT, GTE, LTE, EQ\n}\n", "astyanax-cassandra\\src\\main\\java\\com\\netflix\\astyanax\\query\\IndexQuery.java": "/*******************************************************************************\n * Copyright 2011 Netflix\n * \n * Licensed under the Apache License, Version 2.0 (the \"License\");\n * you may not use this file except in compliance with the License.\n * You may obtain a copy of the License at\n * \n * http://www.apache.org/licenses/LICENSE-2.0\n * \n * Unless required by applicable law or agreed to in writing, software\n * distributed under the License is distributed on an \"AS IS\" BASIS,\n * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n * See the License for the specific language governing permissions and\n * limitations under the License.\n ******************************************************************************/\npackage com.netflix.astyanax.query;\n\nimport java.nio.ByteBuffer;\nimport java.util.Collection;\n\nimport com.netflix.astyanax.Execution;\nimport com.netflix.astyanax.model.ByteBufferRange;\nimport com.netflix.astyanax.model.ColumnSlice;\nimport com.netflix.astyanax.model.Rows;\n\npublic interface IndexQuery<K, C> extends Execution<Rows<K, C>> {\n /**\n * Limit the number of rows in the response\n * \n * @param count\n * @deprecated Use setRowLimit instead\n */\n @Deprecated\n IndexQuery<K, C> setLimit(int count);\n\n /**\n * Limits the number of rows returned\n * \n * @param count\n */\n IndexQuery<K, C> setRowLimit(int count);\n\n /**\n * @param key\n */\n IndexQuery<K, C> setStartKey(K key);\n\n /**\n * Add an expression (EQ, GT, GTE, LT, LTE) to the clause. Expressions are\n * inherently ANDed\n */\n IndexColumnExpression<K, C> addExpression();\n\n /**\n * Add a set of prepare index expressions.\n * \n * @param expressions\n */\n IndexQuery<K, C> addPreparedExpressions(Collection<PreparedIndexExpression<K, C>> expressions);\n\n /**\n * Specify a non-contiguous set of columns to retrieve.\n * \n * @param columns\n */\n IndexQuery<K, C> withColumnSlice(C... columns);\n\n /**\n * Specify a non-contiguous set of columns to retrieve.\n * \n * @param columns\n */\n IndexQuery<K, C> withColumnSlice(Collection<C> columns);\n\n /**\n * Use this when your application caches the column slice.\n * \n * @param slice\n */\n IndexQuery<K, C> withColumnSlice(ColumnSlice<C> columns);\n\n /**\n * Specify a range of columns to return.\n * \n * @param startColumn\n * First column in the range\n * @param endColumn\n * Last column in the range\n * @param reversed\n * True if the order should be reversed. Note that for reversed,\n * startColumn should be greater than endColumn.\n * @param count\n * Maximum number of columns to return (similar to SQL LIMIT)\n */\n IndexQuery<K, C> withColumnRange(C startColumn, C endColumn, boolean reversed, int count);\n\n /**\n * Specify a range and provide pre-constructed start and end columns. Use\n * this with Composite columns\n * \n * @param startColumn\n * @param endColumn\n * @param reversed\n * @param count\n */\n IndexQuery<K, C> withColumnRange(ByteBuffer startColumn, ByteBuffer endColumn, boolean reversed, int count);\n\n /**\n * Specify a range of composite columns. Use this in conjunction with the\n * AnnotatedCompositeSerializer.buildRange().\n * \n * @param range\n */\n IndexQuery<K, C> withColumnRange(ByteBufferRange range);\n\n /**\n * @deprecated autoPaginateRows()\n */\n IndexQuery<K, C> setIsPaginating();\n\n /**\n * Automatically sets the next start key so that the next call to execute\n * will fetch the next block of rows\n */\n IndexQuery<K, C> autoPaginateRows(boolean autoPaginate);\n\n}\n", "astyanax-cassandra\\src\\main\\java\\com\\netflix\\astyanax\\query\\IndexValueExpression.java": "/*******************************************************************************\n * Copyright 2011 Netflix\n * \n * Licensed under the Apache License, Version 2.0 (the \"License\");\n * you may not use this file except in compliance with the License.\n * You may obtain a copy of the License at\n * \n * http://www.apache.org/licenses/LICENSE-2.0\n * \n * Unless required by applicable law or agreed to in writing, software\n * distributed under the License is distributed on an \"AS IS\" BASIS,\n * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n * See the License for the specific language governing permissions and\n * limitations under the License.\n ******************************************************************************/\npackage com.netflix.astyanax.query;\n\nimport java.nio.ByteBuffer;\nimport java.util.Date;\nimport java.util.UUID;\n\nimport com.netflix.astyanax.Serializer;\n\npublic interface IndexValueExpression<K, C> {\n\n IndexQuery<K, C> value(String value);\n\n IndexQuery<K, C> value(long value);\n\n IndexQuery<K, C> value(int value);\n\n IndexQuery<K, C> value(boolean value);\n\n IndexQuery<K, C> value(Date value);\n\n IndexQuery<K, C> value(byte[] value);\n\n IndexQuery<K, C> value(ByteBuffer value);\n\n IndexQuery<K, C> value(double value);\n\n IndexQuery<K, C> value(UUID value);\n\n <V> IndexQuery<K, C> value(V value, Serializer<V> valueSerializer);\n}\n", "astyanax-cassandra\\src\\main\\java\\com\\netflix\\astyanax\\query\\PreparedIndexColumnExpression.java": "/**\n * Copyright 2013 Netflix, Inc.\n *\n * Licensed under the Apache License, Version 2.0 (the \"License\");\n * you may not use this file except in compliance with the License.\n * You may obtain a copy of the License at\n *\n * http://www.apache.org/licenses/LICENSE-2.0\n *\n * Unless required by applicable law or agreed to in writing, software\n * distributed under the License is distributed on an \"AS IS\" BASIS,\n * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n * See the License for the specific language governing permissions and\n * limitations under the License.\n */\npackage com.netflix.astyanax.query;\n\npublic interface PreparedIndexColumnExpression<K, C> {\n /**\n * Set the column part of the expression\n * \n * @param columnName\n * @return\n */\n PreparedIndexOperationExpression<K, C> whereColumn(C columnName);\n}\n", "astyanax-cassandra\\src\\main\\java\\com\\netflix\\astyanax\\query\\PreparedIndexExpression.java": "/**\n * Copyright 2013 Netflix, Inc.\n *\n * Licensed under the Apache License, Version 2.0 (the \"License\");\n * you may not use this file except in compliance with the License.\n * You may obtain a copy of the License at\n *\n * http://www.apache.org/licenses/LICENSE-2.0\n *\n * Unless required by applicable law or agreed to in writing, software\n * distributed under the License is distributed on an \"AS IS\" BASIS,\n * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n * See the License for the specific language governing permissions and\n * limitations under the License.\n */\npackage com.netflix.astyanax.query;\n\nimport java.nio.ByteBuffer;\n\npublic interface PreparedIndexExpression<K, C> extends PreparedIndexColumnExpression<K, C> {\n public ByteBuffer getColumn();\n\n public ByteBuffer getValue();\n\n public IndexOperator getOperator();\n}\n", "astyanax-cassandra\\src\\main\\java\\com\\netflix\\astyanax\\query\\PreparedIndexOperationExpression.java": "/**\n * Copyright 2013 Netflix, Inc.\n *\n * Licensed under the Apache License, Version 2.0 (the \"License\");\n * you may not use this file except in compliance with the License.\n * You may obtain a copy of the License at\n *\n * http://www.apache.org/licenses/LICENSE-2.0\n *\n * Unless required by applicable law or agreed to in writing, software\n * distributed under the License is distributed on an \"AS IS\" BASIS,\n * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n * See the License for the specific language governing permissions and\n * limitations under the License.\n */\npackage com.netflix.astyanax.query;\n\npublic interface PreparedIndexOperationExpression<K, C> {\n PreparedIndexValueExpression<K, C> equals();\n\n PreparedIndexValueExpression<K, C> greaterThan();\n\n PreparedIndexValueExpression<K, C> lessThan();\n\n PreparedIndexValueExpression<K, C> greaterThanEquals();\n\n PreparedIndexValueExpression<K, C> lessThanEquals();\n\n}\n", "astyanax-cassandra\\src\\main\\java\\com\\netflix\\astyanax\\query\\PreparedIndexValueExpression.java": "/**\n * Copyright 2013 Netflix, Inc.\n *\n * Licensed under the Apache License, Version 2.0 (the \"License\");\n * you may not use this file except in compliance with the License.\n * You may obtain a copy of the License at\n *\n * http://www.apache.org/licenses/LICENSE-2.0\n *\n * Unless required by applicable law or agreed to in writing, software\n * distributed under the License is distributed on an \"AS IS\" BASIS,\n * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n * See the License for the specific language governing permissions and\n * limitations under the License.\n */\npackage com.netflix.astyanax.query;\n\nimport java.nio.ByteBuffer;\nimport java.util.Date;\nimport java.util.UUID;\n\nimport com.netflix.astyanax.Serializer;\n\npublic interface PreparedIndexValueExpression<K, C> {\n\n PreparedIndexExpression<K, C> value(String value);\n\n PreparedIndexExpression<K, C> value(long value);\n\n PreparedIndexExpression<K, C> value(int value);\n\n PreparedIndexExpression<K, C> value(boolean value);\n\n PreparedIndexExpression<K, C> value(Date value);\n\n PreparedIndexExpression<K, C> value(byte[] value);\n\n PreparedIndexExpression<K, C> value(ByteBuffer value);\n\n PreparedIndexExpression<K, C> value(double value);\n\n PreparedIndexExpression<K, C> value(UUID value);\n\n <V> PreparedIndexExpression<K, C> value(V value, Serializer<V> valueSerializer);\n\n}\n", "astyanax-cassandra\\src\\main\\java\\com\\netflix\\astyanax\\serializers\\SnappyStringSerializer.java": "/**\n * Copyright 2013 Netflix, Inc.\n *\n * Licensed under the Apache License, Version 2.0 (the \"License\");\n * you may not use this file except in compliance with the License.\n * You may obtain a copy of the License at\n *\n * http://www.apache.org/licenses/LICENSE-2.0\n *\n * Unless required by applicable law or agreed to in writing, software\n * distributed under the License is distributed on an \"AS IS\" BASIS,\n * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n * See the License for the specific language governing permissions and\n * limitations under the License.\n */\npackage com.netflix.astyanax.serializers;\n\nimport java.io.ByteArrayInputStream;\nimport java.io.ByteArrayOutputStream;\nimport java.io.IOException;\nimport java.nio.ByteBuffer;\n\nimport com.netflix.astyanax.shaded.org.apache.cassandra.db.marshal.UTF8Type;\nimport org.apache.commons.codec.binary.StringUtils;\nimport org.xerial.snappy.SnappyInputStream;\nimport org.xerial.snappy.SnappyOutputStream;\n\npublic class SnappyStringSerializer extends AbstractSerializer<String> {\n\n private static final SnappyStringSerializer instance = new SnappyStringSerializer();\n\n public static SnappyStringSerializer get() {\n return instance;\n }\n\n @Override\n public ByteBuffer toByteBuffer(String obj) {\n if (obj == null) {\n return null;\n }\n \n ByteArrayOutputStream out = new ByteArrayOutputStream();\n SnappyOutputStream snappy;\n try {\n snappy = new SnappyOutputStream(out);\n snappy.write(StringUtils.getBytesUtf8(obj));\n snappy.close();\n return ByteBuffer.wrap(out.toByteArray());\n } catch (IOException e) {\n throw new RuntimeException(\"Error compressing column data\", e);\n } \n }\n\n @Override\n public String fromByteBuffer(ByteBuffer byteBuffer) {\n if (byteBuffer == null) {\n return null;\n }\n \n SnappyInputStream snappy = null;\n ByteArrayOutputStream baos = null;\n try {\n ByteBuffer dup = byteBuffer.duplicate();\n snappy = new SnappyInputStream(\n new ByteArrayInputStream(dup.array(), 0,\n dup.limit()));\n \n baos = new ByteArrayOutputStream();\n for (int value = 0; value != -1;) {\n value = snappy.read();\n if (value != -1) {\n baos.write(value);\n }\n }\n snappy.close();\n baos.close();\n return StringUtils.newStringUtf8(baos.toByteArray());\n } catch (IOException e) {\n throw new RuntimeException(\"Error decompressing column data\", e);\n } finally {\n if (snappy != null) {\n try {\n snappy.close();\n } catch (IOException e) {\n }\n }\n if (baos != null) {\n try {\n baos.close();\n } catch (IOException e) {\n }\n }\n }\n }\n\n @Override\n public ComparatorType getComparatorType() {\n return ComparatorType.BYTESTYPE;\n }\n\n @Override\n public ByteBuffer fromString(String str) {\n return UTF8Type.instance.fromString(str);\n }\n\n @Override\n public String getString(ByteBuffer byteBuffer) {\n return UTF8Type.instance.getString(byteBuffer);\n }\n}\n", "astyanax-cql\\src\\main\\java\\com\\netflix\\astyanax\\cql\\ConsistencyLevelMapping.java": "/**\n * Copyright 2013 Netflix, Inc.\n *\n * Licensed under the Apache License, Version 2.0 (the \"License\");\n * you may not use this file except in compliance with the License.\n * You may obtain a copy of the License at\n *\n * http://www.apache.org/licenses/LICENSE-2.0\n *\n * Unless required by applicable law or agreed to in writing, software\n * distributed under the License is distributed on an \"AS IS\" BASIS,\n * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n * See the License for the specific language governing permissions and\n * limitations under the License.\n */\npackage com.netflix.astyanax.cql;\n\nimport com.netflix.astyanax.model.ConsistencyLevel;\n\n/**\n * Helper class for translating Astyanax consistency level to java driver consistency level\n * \n * @author poberai\n */\npublic class ConsistencyLevelMapping {\n\n\tpublic static com.datastax.driver.core.ConsistencyLevel getCL(ConsistencyLevel cl) {\n\t\t\n\t\tswitch (cl) {\n\t\t\n\t\tcase CL_ONE:\n\t\t\treturn com.datastax.driver.core.ConsistencyLevel.ONE;\n\t\tcase CL_TWO:\n\t\t\treturn com.datastax.driver.core.ConsistencyLevel.TWO;\n\t\tcase CL_THREE:\n\t\t\treturn com.datastax.driver.core.ConsistencyLevel.THREE;\n\t\tcase CL_QUORUM:\n\t\t\treturn com.datastax.driver.core.ConsistencyLevel.QUORUM;\n\t\tcase CL_LOCAL_QUORUM:\n\t\t\treturn com.datastax.driver.core.ConsistencyLevel.LOCAL_QUORUM;\n\t\tcase CL_EACH_QUORUM:\n\t\t\treturn com.datastax.driver.core.ConsistencyLevel.EACH_QUORUM;\n\t\tcase CL_ALL:\n\t\t\treturn com.datastax.driver.core.ConsistencyLevel.ALL;\n\t\tcase CL_ANY:\n\t\t\treturn com.datastax.driver.core.ConsistencyLevel.ANY;\n\t\tdefault:\n\t\t\tthrow new RuntimeException(\"CL Level not recognized: \" + cl.name());\n\t\t}\n\t}\n}\n", "astyanax-cql\\src\\main\\java\\com\\netflix\\astyanax\\cql\\util\\CqlTypeMapping.java": "/**\n * Copyright 2013 Netflix, Inc.\n *\n * Licensed under the Apache License, Version 2.0 (the \"License\");\n * you may not use this file except in compliance with the License.\n * You may obtain a copy of the License at\n *\n * http://www.apache.org/licenses/LICENSE-2.0\n *\n * Unless required by applicable law or agreed to in writing, software\n * distributed under the License is distributed on an \"AS IS\" BASIS,\n * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n * See the License for the specific language governing permissions and\n * limitations under the License.\n */\npackage com.netflix.astyanax.cql.util;\n\nimport java.util.HashMap;\nimport java.util.List;\nimport java.util.Map;\n\nimport org.apache.commons.lang.NotImplementedException;\n\nimport com.datastax.driver.core.Row;\nimport com.netflix.astyanax.Serializer;\nimport com.netflix.astyanax.cql.schema.CqlColumnFamilyDefinitionImpl;\nimport com.netflix.astyanax.ddl.ColumnDefinition;\nimport com.netflix.astyanax.model.ColumnFamily;\nimport com.netflix.astyanax.serializers.AnnotatedCompositeSerializer;\nimport com.netflix.astyanax.serializers.AnnotatedCompositeSerializer.ComponentSerializer;\nimport com.netflix.astyanax.serializers.ComparatorType;\n\n/**\n * Helpful utility that maps the different data types and helps translate to and from Astyanax and java driver objects.\n * \n * @author poberai\n *\n */\npublic class CqlTypeMapping {\n\n\tprivate static Map<String, String> comparatorToCql3Type = new HashMap<String, String>();\n\tprivate static Map<String, ComparatorType> cqlToComparatorType = new HashMap<String, ComparatorType>();\n\t\t\n\tstatic {\n\t\tinitComparatorTypeMap();\n\t}\n\t\t\n\tprivate static void initComparatorTypeMap() {\n\t\t\n\t\tMap<ComparatorType, String> tmpMap = new HashMap<ComparatorType, String>();\n\n\t\ttmpMap.put(ComparatorType.ASCIITYPE, \"ASCII\");\n\t\ttmpMap.put(ComparatorType.BYTESTYPE, \"BLOB\"); \n\t\ttmpMap.put(ComparatorType.BOOLEANTYPE, \"BOOLEAN\"); \n\t\ttmpMap.put(ComparatorType.COUNTERTYPE, \"COUNTER\"); \n\t\ttmpMap.put(ComparatorType.DECIMALTYPE, \"DECIMAL\");\n\t\ttmpMap.put(ComparatorType.DOUBLETYPE, \"DOUBLE\"); \n\t\ttmpMap.put(ComparatorType.FLOATTYPE, \"FLOAT\"); \n\t\ttmpMap.put(ComparatorType.LONGTYPE, \"BIGINT\");\n\t\ttmpMap.put(ComparatorType.INT32TYPE, \"INT\");\n\t\ttmpMap.put(ComparatorType.UTF8TYPE, \"TEXT\"); \n\t\ttmpMap.put(ComparatorType.DATETYPE, \"TIMESTAMP\");\n\t\ttmpMap.put(ComparatorType.UUIDTYPE, \"UUID\"); \n\t\ttmpMap.put(ComparatorType.INTEGERTYPE, \"VARINT\"); \n\t\ttmpMap.put(ComparatorType.TIMEUUIDTYPE, \"TIMEUUID\"); \n\t\t\n\t\tfor (ComparatorType cType : tmpMap.keySet()) {\n\t\t\t\n\t\t\tString value = tmpMap.get(cType);\n\t\t\t\n\t\t\tcomparatorToCql3Type.put(cType.getClassName(), value);\n\t\t\tcomparatorToCql3Type.put(cType.getTypeName(), value);\n\t\t\t\n\t\t\tcqlToComparatorType.put(value, cType);\n\t\t}\n\t}\n\t\n\tpublic static ComparatorType getComparatorFromCqlType(String cqlTypeString) {\n\t\tComparatorType value = cqlToComparatorType.get(cqlTypeString);\n\t\tif (value == null) {\n\t\t\tthrow new RuntimeException(\"Unrecognized cql type: \" + cqlTypeString);\n\t\t}\n\t\treturn value;\n\t}\n\t\n\t\n\tpublic static String getCqlTypeFromComparator(String comparatorString) {\n\t\tString value = comparatorToCql3Type.get(comparatorString);\n\t\tif (value == null) {\n\t\t\tthrow new RuntimeException(\"Could not find comparator type string: \" + comparatorString);\n\t\t}\n\t\treturn value;\n\t}\n\t\n\tprivate static <T> Object getDynamicColumn(Row row, Serializer<T> serializer, String columnName, ColumnFamily<?,?> cf) {\n\t\t\n\t\tComparatorType comparatorType = serializer.getComparatorType();\n\t\t\n\t\tswitch(comparatorType) {\n\n\t\tcase ASCIITYPE:\n\t\t\treturn row.getString(columnName);\n\t\tcase BYTESTYPE:\n\t\t\treturn row.getBytes(columnName);\n\t\tcase INTEGERTYPE:\n\t\t\treturn row.getInt(columnName);\n\t\tcase INT32TYPE:\n\t\t\treturn row.getInt(columnName);\n\t\tcase DECIMALTYPE:\n\t\t\treturn row.getFloat(columnName);\n\t\tcase LEXICALUUIDTYPE:\n\t\t\treturn row.getUUID(columnName);\n\t\tcase LOCALBYPARTITIONERTYPE:\n\t\t return row.getBytes(columnName);\n\t\tcase LONGTYPE:\n\t\t return row.getLong(columnName);\n\t\tcase TIMEUUIDTYPE:\n\t\t return row.getUUID(columnName);\n\t\tcase UTF8TYPE:\n\t\t return row.getString(columnName);\n\t\tcase COMPOSITETYPE:\n\t\t\treturn getCompositeColumn(row, (AnnotatedCompositeSerializer<?>) serializer, cf);\n\t\tcase DYNAMICCOMPOSITETYPE:\n\t\t\tthrow new NotImplementedException();\n\t\tcase UUIDTYPE:\n\t\t return row.getUUID(columnName);\n\t\tcase COUNTERTYPE:\n\t\t return row.getLong(columnName);\n\t\tcase DOUBLETYPE:\n\t\t return row.getDouble(columnName);\n\t\tcase FLOATTYPE:\n\t\t return row.getFloat(columnName);\n\t\tcase BOOLEANTYPE:\n\t\t return row.getBool(columnName);\n\t\tcase DATETYPE:\n\t\t return row.getDate(columnName);\n\t\t \n\t\tdefault:\n\t\t\tthrow new RuntimeException(\"Could not recognize comparator type: \" + comparatorType.getTypeName());\n\t\t}\n\t}\n\t\n\tpublic static <T> Object getDynamicColumn(Row row, Serializer<T> serializer, int columnIndex, ColumnFamily<?,?> cf) {\n\t\t\n\t\tComparatorType comparatorType = serializer.getComparatorType();\n\t\t\n\t\tswitch(comparatorType) {\n\n\t\tcase ASCIITYPE:\n\t\t\treturn row.getString(columnIndex);\n\t\tcase BYTESTYPE:\n\t\t\treturn row.getBytes(columnIndex);\n\t\tcase INTEGERTYPE:\n\t\t\treturn row.getInt(columnIndex);\n\t\tcase INT32TYPE:\n\t\t\treturn row.getInt(columnIndex);\n\t\tcase DECIMALTYPE:\n\t\t\treturn row.getFloat(columnIndex);\n\t\tcase LEXICALUUIDTYPE:\n\t\t\treturn row.getUUID(columnIndex);\n\t\tcase LOCALBYPARTITIONERTYPE:\n\t\t return row.getBytes(columnIndex);\n\t\tcase LONGTYPE:\n\t\t return row.getLong(columnIndex);\n\t\tcase TIMEUUIDTYPE:\n\t\t return row.getUUID(columnIndex);\n\t\tcase UTF8TYPE:\n\t\t return row.getString(columnIndex);\n\t\tcase COMPOSITETYPE:\n\t\t\treturn getCompositeColumn(row, (AnnotatedCompositeSerializer<?>) serializer, cf);\n\t\tcase DYNAMICCOMPOSITETYPE:\n\t\t\tthrow new NotImplementedException();\n\t\tcase UUIDTYPE:\n\t\t return row.getUUID(columnIndex);\n\t\tcase COUNTERTYPE:\n\t\t return row.getLong(columnIndex);\n\t\tcase DOUBLETYPE:\n\t\t return row.getDouble(columnIndex);\n\t\tcase FLOATTYPE:\n\t\t return row.getFloat(columnIndex);\n\t\tcase BOOLEANTYPE:\n\t\t return row.getBool(columnIndex);\n\t\tcase DATETYPE:\n\t\t return row.getDate(columnIndex);\n\t\t \n\t\tdefault:\n\t\t\tthrow new RuntimeException(\"Could not recognize comparator type: \" + comparatorType.getTypeName());\n\t\t}\n\t}\n\t\n\t\n\tprivate static Object getCompositeColumn(Row row, AnnotatedCompositeSerializer<?> compositeSerializer, ColumnFamily<?,?> cf) {\n\t\t\n\t\tClass<?> clazz = compositeSerializer.getClazz();\n\t\t\n\t\tObject obj = null;\n\t\ttry {\n\t\t\tobj = clazz.newInstance();\n\t\t} catch (Exception e) {\n\t\t\tthrow new RuntimeException(e);\n\t\t}\n\t\t\n\t\tCqlColumnFamilyDefinitionImpl cfDef = (CqlColumnFamilyDefinitionImpl) cf.getColumnFamilyDefinition();\n\t\tList<ColumnDefinition> cluseringKeyList = cfDef.getClusteringKeyColumnDefinitionList();\n\t\t\n\t\tint componentIndex = 0;\n\t\tfor (ComponentSerializer<?> component : compositeSerializer.getComponents()) {\n\t\t\t\n\t\t\tObject value = getDynamicColumn(row, component.getSerializer(), cluseringKeyList.get(componentIndex).getName(), cf);\n\t\t\ttry {\n\t\t\t\tcomponent.setFieldValueDirectly(obj, value);\n\t\t\t\tcomponentIndex++;\n\t\t\t} catch (Exception e) {\n\t\t\t\tthrow new RuntimeException(e);\n\t\t\t}\n\t\t}\n\t\treturn obj;\n\t}\n}\n", "astyanax-cql\\src\\main\\java\\com\\netflix\\astyanax\\cql\\util\\DataTypeMapping.java": "/**\n * Copyright 2013 Netflix, Inc.\n *\n * Licensed under the Apache License, Version 2.0 (the \"License\");\n * you may not use this file except in compliance with the License.\n * You may obtain a copy of the License at\n *\n * http://www.apache.org/licenses/LICENSE-2.0\n *\n * Unless required by applicable law or agreed to in writing, software\n * distributed under the License is distributed on an \"AS IS\" BASIS,\n * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n * See the License for the specific language governing permissions and\n * limitations under the License.\n */\npackage com.netflix.astyanax.cql.util;\n\nimport com.datastax.driver.core.DataType;\nimport com.datastax.driver.core.Row;\n\npublic class DataTypeMapping {\n\n\tpublic static <T> Object getDynamicColumn(Row row, String columnName, DataType dataType) {\n\t\t\n\t\tswitch(dataType.getName()) {\n\n\t\tcase ASCII:\n\t\t return row.getString(columnName);\n\t\tcase BIGINT:\n\t\t return row.getLong(columnName);\n\t\tcase BLOB:\n\t\t return row.getBytes(columnName);\n\t\tcase BOOLEAN:\n\t\t return row.getBool(columnName);\n\t\tcase COUNTER:\n\t\t return row.getLong(columnName);\n\t\tcase DECIMAL:\n\t\t return row.getDecimal(columnName);\n\t\tcase DOUBLE:\n\t\t return row.getDouble(columnName);\n\t\tcase FLOAT:\n\t\t return row.getFloat(columnName);\n\t\tcase INET:\n\t\t return row.getInet(columnName);\n\t\tcase INT:\n\t\t return row.getInt(columnName);\n\t\tcase TEXT:\n\t\t return row.getString(columnName);\n\t\tcase TIMESTAMP:\n\t\t return row.getDate(columnName);\n\t\tcase UUID:\n\t\t return row.getUUID(columnName);\n\t\tcase VARCHAR:\n\t\t return row.getString(columnName);\n\t\tcase VARINT:\n\t\t return row.getLong(columnName);\n\t\tcase TIMEUUID:\n\t\t return row.getUUID(columnName);\n\t\tcase LIST:\n\t\t throw new UnsupportedOperationException(\"Collection objects not supported for column: \" + columnName);\n\t\tcase SET:\n\t\t throw new UnsupportedOperationException(\"Collection objects not supported for column: \" + columnName);\n\t\tcase MAP:\n\t\t\treturn row.getMap(columnName, Object.class, Object.class);\n\t\t //throw new UnsupportedOperationException(\"Collection objects not supported for column: \" + columnName);\n\t\tcase CUSTOM:\n\t\t throw new UnsupportedOperationException(\"Collection objects not supported for column: \" + columnName);\n\t\t \n\t\tdefault:\n\t\t throw new UnsupportedOperationException(\"Unrecognized object for column: \" + columnName);\n\t\t}\n\t}\n\n}\n", "astyanax-entity-mapper\\src\\main\\java\\com\\netflix\\astyanax\\entitystore\\AbstractColumnMapper.java": "/**\n * Copyright 2013 Netflix, Inc.\n *\n * Licensed under the Apache License, Version 2.0 (the \"License\");\n * you may not use this file except in compliance with the License.\n * You may obtain a copy of the License at\n *\n * http://www.apache.org/licenses/LICENSE-2.0\n *\n * Unless required by applicable law or agreed to in writing, software\n * distributed under the License is distributed on an \"AS IS\" BASIS,\n * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n * See the License for the specific language governing permissions and\n * limitations under the License.\n */\npackage com.netflix.astyanax.entitystore;\n\nimport java.lang.reflect.Field;\n\nimport javax.persistence.Column;\n\npublic abstract class AbstractColumnMapper implements ColumnMapper {\n protected final Field field;\n protected final Column columnAnnotation;\n protected final String columnName;\n \n public AbstractColumnMapper(Field field) {\n this.field = field;\n this.columnAnnotation = field.getAnnotation(Column.class);\n \n\t\t// use field name if annotation name is not set\n\t\tString name = columnAnnotation.name().isEmpty() ? field.getName() : columnAnnotation.name();\n\t\t\n\t\t// dot is a reserved char as separator\n\t\tif(name.indexOf(\".\") >= 0)\n\t\t\tthrow new IllegalArgumentException(\"illegal column name containing reserved dot (.) char: \" + name);\n\t\t\n this.columnName = name;\n\t}\n\n public Field getField() {\n return this.field;\n }\n}\n", "astyanax-entity-mapper\\src\\main\\java\\com\\netflix\\astyanax\\entitystore\\ColumnMapper.java": "/**\n * Copyright 2013 Netflix, Inc.\n *\n * Licensed under the Apache License, Version 2.0 (the \"License\");\n * you may not use this file except in compliance with the License.\n * You may obtain a copy of the License at\n *\n * http://www.apache.org/licenses/LICENSE-2.0\n *\n * Unless required by applicable law or agreed to in writing, software\n * distributed under the License is distributed on an \"AS IS\" BASIS,\n * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n * See the License for the specific language governing permissions and\n * limitations under the License.\n */\npackage com.netflix.astyanax.entitystore;\n\nimport java.lang.reflect.Field;\nimport java.util.Iterator;\n\nimport com.netflix.astyanax.ColumnListMutation;\nimport com.netflix.astyanax.model.Column;\n\npublic interface ColumnMapper {\n\t\n\tpublic String getColumnName();\n\n\t/**\n\t * @return true if set, false if skipped due to null value for nullable field\n\t * @throws IllegalArgumentException if value is null and field is NOT nullable\n\t */\n\tpublic boolean fillMutationBatch(Object entity, ColumnListMutation<String> clm, String prefix) throws Exception;\n\t\n\t/**\n\t * @return true if set, false if skipped due to non-existent column for nullable field\n\t * @throws IllegalArgumentException if value is null and field is NOT nullable\n\t */\n\tpublic boolean setField(Object entity, Iterator<String> name, Column<String> column) throws Exception;\n\t\n\t/**\n\t * Perform a validation step either before persisting or after loading \n\t * @throws Exception\n\t */\n\tpublic void validate(Object entity) throws Exception;\n\t\n\t/**\n\t * Return the field associated with this mapper\n\t */\n\tpublic Field getField();\n}\n", "astyanax-entity-mapper\\src\\main\\java\\com\\netflix\\astyanax\\entitystore\\CompositeColumnEntityMapper.java": "/**\n * Copyright 2013 Netflix, Inc.\n *\n * Licensed under the Apache License, Version 2.0 (the \"License\");\n * you may not use this file except in compliance with the License.\n * You may obtain a copy of the License at\n *\n * http://www.apache.org/licenses/LICENSE-2.0\n *\n * Unless required by applicable law or agreed to in writing, software\n * distributed under the License is distributed on an \"AS IS\" BASIS,\n * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n * See the License for the specific language governing permissions and\n * limitations under the License.\n */\npackage com.netflix.astyanax.entitystore;\n\nimport java.lang.reflect.Field;\nimport java.lang.reflect.ParameterizedType;\nimport java.nio.ByteBuffer;\nimport java.util.Collection;\nimport java.util.Iterator;\nimport java.util.List;\nimport java.util.Set;\n\nimport javax.persistence.Column;\nimport javax.persistence.PersistenceException;\n\nimport org.apache.commons.lang.StringUtils;\n\nimport com.google.common.base.Function;\nimport com.google.common.base.Preconditions;\nimport com.google.common.collect.ArrayListMultimap;\nimport com.google.common.collect.Collections2;\nimport com.google.common.collect.Lists;\nimport com.google.common.collect.Sets;\nimport com.netflix.astyanax.ColumnListMutation;\nimport com.netflix.astyanax.model.ColumnList;\nimport com.netflix.astyanax.model.Equality;\nimport com.netflix.astyanax.query.ColumnPredicate;\n\n/**\n * Mapper from a CompositeType to an embedded entity. The composite entity is expected\n * to have an @Id annotation for each composite component and a @Column annotation for\n * the value.\n * \n * @author elandau\n *\n */\npublic class CompositeColumnEntityMapper {\n /**\n * Class of embedded entity\n */\n private final Class<?> clazz;\n \n /**\n * List of serializers for the composite parts\n */\n private List<FieldMapper<?>> components = Lists.newArrayList();\n \n /**\n * List of valid (i.e. existing) column names\n */\n private Set<String> validNames = Sets.newHashSet();\n \n /**\n * Mapper for the value part of the entity\n */\n private FieldMapper<?> valueMapper;\n \n /**\n * Largest buffer size\n */\n private int bufferSize = 64;\n \n /**\n * Parent field\n */\n private final Field containerField;\n \n public CompositeColumnEntityMapper(Field field) {\n \n ParameterizedType containerEntityType = (ParameterizedType) field.getGenericType();\n \n this.clazz = (Class<?>) containerEntityType.getActualTypeArguments()[0];\n this.containerField = field;\n this.containerField.setAccessible(true);\n Field[] declaredFields = clazz.getDeclaredFields();\n for (Field f : declaredFields) {\n // The value\n Column columnAnnotation = f.getAnnotation(Column.class);\n if ((columnAnnotation != null)) {\n f.setAccessible(true);\n FieldMapper fieldMapper = new FieldMapper(f);\n components.add(fieldMapper);\n validNames.add(fieldMapper.getName());\n }\n }\n \n // Last one is always treated as the 'value'\n valueMapper = components.remove(components.size() - 1);\n }\n \n /**\n * Iterate through the list and create a column for each element\n * @param clm\n * @param entity\n * @throws IllegalArgumentException\n * @throws IllegalAccessException\n */\n public void fillMutationBatch(ColumnListMutation<ByteBuffer> clm, Object entity) throws IllegalArgumentException, IllegalAccessException {\n List<?> list = (List<?>) containerField.get(entity);\n if (list != null) {\n for (Object element : list) {\n fillColumnMutation(clm, element);\n }\n }\n }\n \n public void fillMutationBatchForDelete(ColumnListMutation<ByteBuffer> clm, Object entity) throws IllegalArgumentException, IllegalAccessException {\n List<?> list = (List<?>) containerField.get(entity);\n if (list == null) {\n clm.delete();\n }\n else {\n for (Object element : list) {\n clm.deleteColumn(toColumnName(element));\n }\n }\n }\n \n /**\n * Add a column based on the provided entity\n * \n * @param clm\n * @param entity\n */\n public void fillColumnMutation(ColumnListMutation<ByteBuffer> clm, Object entity) {\n try {\n ByteBuffer columnName = toColumnName(entity);\n ByteBuffer value = valueMapper.toByteBuffer(entity);\n \n clm.putColumn(columnName, value);\n } catch(Exception e) {\n throw new PersistenceException(\"failed to fill mutation batch\", e);\n }\n }\n \n /**\n * Return the column name byte buffer for this entity\n * \n * @param obj\n * @return\n */\n public ByteBuffer toColumnName(Object obj) {\n SimpleCompositeBuilder composite = new SimpleCompositeBuilder(bufferSize, Equality.EQUAL);\n\n // Iterate through each component and add to a CompositeType structure\n for (FieldMapper<?> mapper : components) {\n try {\n composite.addWithoutControl(mapper.toByteBuffer(obj));\n }\n catch (Exception e) {\n throw new RuntimeException(e);\n }\n }\n return composite.get();\n }\n \n /**\n * Set the collection field using the provided column list of embedded entities\n * @param entity\n * @param name\n * @param column\n * @return\n * @throws Exception\n */\n public boolean setField(Object entity, ColumnList<ByteBuffer> columns) throws Exception {\n List<Object> list = getOrCreateField(entity);\n \n // Iterate through columns and add embedded entities to the list\n for (com.netflix.astyanax.model.Column<ByteBuffer> c : columns) {\n list.add(fromColumn(c));\n }\n \n return true;\n }\n \n public boolean setFieldFromCql(Object entity, ColumnList<ByteBuffer> columns) throws Exception {\n List<Object> list = getOrCreateField(entity);\n \n // Iterate through columns and add embedded entities to the list\n// for (com.netflix.astyanax.model.Column<ByteBuffer> c : columns) {\n list.add(fromCqlColumns(columns));\n// }\n \n return true;\n }\n \n private List<Object> getOrCreateField(Object entity) throws IllegalArgumentException, IllegalAccessException {\n // Get or create the list field\n List<Object> list = (List<Object>) containerField.get(entity);\n if (list == null) {\n list = Lists.newArrayList();\n containerField.set(entity, list);\n }\n return list;\n }\n \n /**\n * Return an object from the column\n * \n * @param cl\n * @return\n */\n public Object fromColumn(com.netflix.astyanax.model.Column<ByteBuffer> c) {\n try {\n // Allocate a new entity\n Object entity = clazz.newInstance();\n \n setEntityFieldsFromColumnName(entity, c.getRawName().duplicate());\n \n valueMapper.setField(entity, c.getByteBufferValue().duplicate());\n return entity;\n } catch(Exception e) {\n throw new PersistenceException(\"failed to construct entity\", e);\n }\n }\n \n public Object fromCqlColumns(com.netflix.astyanax.model.ColumnList<ByteBuffer> c) {\n try {\n // Allocate a new entity\n Object entity = clazz.newInstance();\n \n Iterator<com.netflix.astyanax.model.Column<ByteBuffer>> columnIter = c.iterator();\n columnIter.next();\n \n for (FieldMapper<?> component : components) {\n component.setField(entity, columnIter.next().getByteBufferValue());\n }\n \n valueMapper.setField(entity, columnIter.next().getByteBufferValue());\n return entity;\n } catch(Exception e) {\n throw new PersistenceException(\"failed to construct entity\", e);\n }\n }\n \n /**\n * \n * @param entity\n * @param columnName\n * @throws IllegalArgumentException\n * @throws IllegalAccessException\n */\n public void setEntityFieldsFromColumnName(Object entity, ByteBuffer columnName) throws IllegalArgumentException, IllegalAccessException {\n // Iterate through components in order and set fields\n for (FieldMapper<?> component : components) {\n ByteBuffer data = getWithShortLength(columnName);\n if (data != null) {\n if (data.remaining() > 0) {\n component.setField(entity, data);\n }\n byte end_of_component = columnName.get();\n if (end_of_component != Equality.EQUAL.toByte()) {\n throw new RuntimeException(\"Invalid composite column. Expected END_OF_COMPONENT.\");\n }\n }\n else {\n throw new RuntimeException(\"Missing component data in composite type\");\n }\n }\n }\n\n /**\n * Return the cassandra comparator type for this composite structure\n * @return\n */\n public String getComparatorType() {\n StringBuilder sb = new StringBuilder();\n sb.append(\"CompositeType(\");\n sb.append(StringUtils.join(\n Collections2.transform(components, new Function<FieldMapper<?>, String>() {\n public String apply(FieldMapper<?> input) {\n return input.serializer.getComparatorType().getClassName();\n }\n }),\n \",\"));\n sb.append(\")\");\n return sb.toString();\n }\n\n \n public static int getShortLength(ByteBuffer bb) {\n int length = (bb.get() & 0xFF) << 8;\n return length | (bb.get() & 0xFF);\n }\n\n public static ByteBuffer getWithShortLength(ByteBuffer bb) {\n int length = getShortLength(bb);\n return getBytes(bb, length);\n }\n\n public static ByteBuffer getBytes(ByteBuffer bb, int length) {\n ByteBuffer copy = bb.duplicate();\n copy.limit(copy.position() + length);\n bb.position(bb.position() + length);\n return copy;\n }\n\n public String getValueType() {\n return valueMapper.getSerializer().getComparatorType().getClassName();\n }\n\n public ByteBuffer[] getQueryEndpoints(Collection<ColumnPredicate> predicates) {\n // Convert to multimap for easy lookup\n ArrayListMultimap<Object, ColumnPredicate> lookup = ArrayListMultimap.create();\n for (ColumnPredicate predicate : predicates) {\n Preconditions.checkArgument(validNames.contains(predicate.getName()), \"Field '\" + predicate.getName() + \"' does not exist in the entity \" + clazz.getCanonicalName());\n lookup.put(predicate.getName(), predicate);\n }\n \n SimpleCompositeBuilder start = new SimpleCompositeBuilder(bufferSize, Equality.GREATER_THAN_EQUALS);\n SimpleCompositeBuilder end = new SimpleCompositeBuilder(bufferSize, Equality.LESS_THAN_EQUALS);\n\n // Iterate through components in order while applying predicate to 'start' and 'end'\n for (FieldMapper<?> mapper : components) {\n for (ColumnPredicate p : lookup.get(mapper.getName())) {\n applyPredicate(mapper, start, end, p);\n }\n }\n \n return new ByteBuffer[]{start.get(), end.get()};\n }\n \n private void applyPredicate(FieldMapper<?> mapper, SimpleCompositeBuilder start, SimpleCompositeBuilder end, ColumnPredicate predicate) {\n ByteBuffer bb = mapper.valueToByteBuffer(predicate.getValue());\n \n switch (predicate.getOp()) {\n case EQUAL:\n start.addWithoutControl(bb);\n end.addWithoutControl(bb);\n break;\n case GREATER_THAN:\n case GREATER_THAN_EQUALS:\n if (mapper.isAscending())\n start.add(bb, predicate.getOp());\n else \n end.add(bb, predicate.getOp());\n break;\n case LESS_THAN:\n case LESS_THAN_EQUALS:\n if (mapper.isAscending())\n end.add(bb, predicate.getOp());\n else \n start.add(bb, predicate.getOp());\n break;\n }\n }\n}\n", "astyanax-entity-mapper\\src\\main\\java\\com\\netflix\\astyanax\\entitystore\\CompositeColumnMapper.java": "/**\n * Copyright 2013 Netflix, Inc.\n *\n * Licensed under the Apache License, Version 2.0 (the \"License\");\n * you may not use this file except in compliance with the License.\n * You may obtain a copy of the License at\n *\n * http://www.apache.org/licenses/LICENSE-2.0\n *\n * Unless required by applicable law or agreed to in writing, software\n * distributed under the License is distributed on an \"AS IS\" BASIS,\n * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n * See the License for the specific language governing permissions and\n * limitations under the License.\n */\npackage com.netflix.astyanax.entitystore;\n\nimport java.lang.reflect.Field;\nimport java.util.Iterator;\nimport java.util.List;\nimport java.util.Map;\nimport java.util.Set;\n\nimport javax.persistence.Column;\nimport javax.persistence.Entity;\n\nimport com.google.common.base.Preconditions;\nimport com.google.common.collect.Lists;\nimport com.google.common.collect.Maps;\nimport com.google.common.collect.Sets;\nimport com.netflix.astyanax.ColumnListMutation;\n\nclass CompositeColumnMapper extends AbstractColumnMapper {\n\tprivate final Class<?> clazz;\n\tprivate final Map<String, ColumnMapper> columnList;\n\tprivate final List<ColumnMapper> nonNullableFields;\n\t\n\tCompositeColumnMapper(final Field field) {\n\t super(field);\n\t\tthis.clazz = field.getType();\n\t\t// clazz should be annotated with @Entity\n\t\tEntity entityAnnotation = clazz.getAnnotation(Entity.class);\n\t\tif(entityAnnotation == null)\n\t\t\tthrow new IllegalArgumentException(\"class is NOT annotated with @javax.persistence.Entity: \" + clazz.getName());\n\n\t\tcolumnList = Maps.newHashMapWithExpectedSize(clazz.getDeclaredFields().length);\n\t\tnonNullableFields = Lists.newArrayList();\n\t\t\n\t\tSet<String> usedColumnNames = Sets.newHashSet();\n\t\tfor (Field childField : clazz.getDeclaredFields()) {\n\t\t\t// extract @Column annotated fields\n\t\t\tColumn annotation = childField.getAnnotation(Column.class);\n\t\t\tif ((annotation != null)) {\n\t\t\t\tchildField.setAccessible(true);\n\t\t\t\tColumnMapper columnMapper = null;\n\t\t\t\tEntity compositeAnnotation = childField.getType().getAnnotation(Entity.class);\n\t\t\t\tif(compositeAnnotation == null) {\n\t\t\t\t\tcolumnMapper = new LeafColumnMapper(childField);\n\t\t\t\t} else {\n\t\t\t\t\tcolumnMapper = new CompositeColumnMapper(childField);\n\t\t\t\t}\n\t\t\t\tPreconditions.checkArgument(!usedColumnNames.contains(columnMapper.getColumnName().toLowerCase()), \n\t\t\t\t\t\tString.format(\"duplicate case-insensitive column name: %s\", columnMapper.getColumnName()));\n\t\t\t\tcolumnList.put(columnMapper.getColumnName(), columnMapper);\n\t\t\t\tusedColumnNames.add(columnMapper.getColumnName().toLowerCase());\n\t\t\t\t\n\t if (!annotation.nullable()) {\n\t nonNullableFields.add(columnMapper);\n\t }\n\t\t\t}\n\t\t}\n\t}\n\n\t@Override\n\tpublic String toString() {\n\t\treturn String.format(\"CompositeColumnMapper(%s)\", clazz);\n\t}\n\n\t@Override\n\tpublic String getColumnName() {\n\t\treturn columnName;\n\t}\n\n\t@Override\n\tpublic boolean fillMutationBatch(Object entity, ColumnListMutation<String> clm, String prefix) throws Exception {\n\t\tObject childEntity = field.get(entity);\n\t\tif(childEntity == null) {\n\t\t\tif(columnAnnotation.nullable()) {\n\t\t\t\treturn false; // skip. cannot write null column\n\t\t\t} else {\n\t\t\t\tthrow new IllegalArgumentException(\"cannot write non-nullable column with null value: \" + columnName);\n\t\t\t}\n\t\t}\n\t\t\n\t\tprefix += getColumnName() + \".\";\n\t\tboolean hasNonNullChildField = false;\n\t\tfor (ColumnMapper mapper : columnList.values()) {\n\t\t\tboolean childFilled = mapper.fillMutationBatch(childEntity, clm, prefix);\n\t\t\tif(childFilled)\n\t\t\t\thasNonNullChildField = true;\n\t\t}\n\t\treturn hasNonNullChildField;\n\t}\n\n @Override\n public boolean setField(Object entity, Iterator<String> name, com.netflix.astyanax.model.Column<String> column) throws Exception {\n Object childEntity = field.get(entity);\n if (childEntity == null) {\n childEntity = clazz.newInstance();\n field.set(entity, childEntity);\n }\n \n ColumnMapper mapper = this.columnList.get(name.next());\n if (mapper == null)\n return false;\n \n return mapper.setField(childEntity, name, column);\n }\n\n @Override\n public void validate(Object entity) throws Exception {\n Object objForThisField = field.get(entity);\n if (objForThisField == null) {\n if (!columnAnnotation.nullable())\n throw new IllegalArgumentException(\"cannot find non-nullable column: \" + columnName);\n }\n else {\n for (ColumnMapper childField : this.nonNullableFields) {\n childField.validate(objForThisField);\n }\n }\n }\n\n}\n", "astyanax-entity-mapper\\src\\main\\java\\com\\netflix\\astyanax\\entitystore\\CompositeEntityMapper.java": "/**\n * Copyright 2013 Netflix, Inc.\n *\n * Licensed under the Apache License, Version 2.0 (the \"License\");\n * you may not use this file except in compliance with the License.\n * You may obtain a copy of the License at\n *\n * http://www.apache.org/licenses/LICENSE-2.0\n *\n * Unless required by applicable law or agreed to in writing, software\n * distributed under the License is distributed on an \"AS IS\" BASIS,\n * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n * See the License for the specific language governing permissions and\n * limitations under the License.\n */\npackage com.netflix.astyanax.entitystore;\n\nimport java.lang.reflect.Field;\nimport java.lang.reflect.InvocationTargetException;\nimport java.lang.reflect.Method;\nimport java.nio.ByteBuffer;\nimport java.util.Collection;\nimport java.util.Iterator;\nimport java.util.List;\nimport java.util.Set;\n\nimport javax.persistence.Column;\nimport javax.persistence.Entity;\nimport javax.persistence.Id;\nimport javax.persistence.PersistenceException;\n\nimport org.apache.commons.lang.StringUtils;\n\nimport com.google.common.annotations.VisibleForTesting;\nimport com.google.common.base.Function;\nimport com.google.common.base.Preconditions;\nimport com.google.common.collect.ArrayListMultimap;\nimport com.google.common.collect.Collections2;\nimport com.google.common.collect.Iterables;\nimport com.google.common.collect.Lists;\nimport com.google.common.collect.Sets;\nimport com.netflix.astyanax.ColumnListMutation;\nimport com.netflix.astyanax.MutationBatch;\nimport com.netflix.astyanax.model.ColumnFamily;\nimport com.netflix.astyanax.model.ColumnList;\nimport com.netflix.astyanax.model.Equality;\nimport com.netflix.astyanax.query.ColumnPredicate;\n\n/**\n * The composite entity mapper maps a Pojo to a composite column structure where\n * the row key represents the Pojo ID, each @Column is a component of the composite\n * and the final @Column is the column value.\n * @Column for the value.\n * \n * @author elandau\n *\n * @param <T>\n * @param <K>\n */\npublic class CompositeEntityMapper<T, K> {\n\n /**\n * Entity class\n */\n private final Class<T> clazz;\n \n /**\n * Default ttl\n */\n private final Integer ttl;\n \n /**\n * TTL supplier method\n */\n private final Method ttlMethod;\n \n /**\n * ID Field (same as row key)\n */\n final FieldMapper<?> idMapper;\n \n /**\n * TODO\n */\n private final String entityName;\n\n /**\n * List of serializers for the composite parts\n */\n private List<FieldMapper<?>> components = Lists.newArrayList();\n \n /**\n * List of valid (i.e. existing) column names\n */\n private Set<String> validNames = Sets.newHashSet();\n\n /**\n * Mapper for the value part of the entity\n */\n private FieldMapper<?> valueMapper;\n \n /**\n * Largest buffer size\n */\n private int bufferSize = 64;\n\n /**\n * \n * @param clazz\n * @param prefix \n * @throws IllegalArgumentException \n * if clazz is NOT annotated with @Entity\n * if column name contains illegal char (like dot)\n */\n public CompositeEntityMapper(Class<T> clazz, Integer ttl, ByteBuffer prefix) {\n this.clazz = clazz;\n \n // clazz should be annotated with @Entity\n Entity entityAnnotation = clazz.getAnnotation(Entity.class);\n if(entityAnnotation == null)\n throw new IllegalArgumentException(\"class is NOT annotated with @javax.persistence.Entity: \" + clazz.getName());\n \n entityName = MappingUtils.getEntityName(entityAnnotation, clazz);\n \n // TTL value from constructor or class-level annotation\n Integer tmpTtlValue = ttl;\n if(tmpTtlValue == null) {\n // constructor value has higher priority\n // try @TTL annotation at entity/class level.\n // it doesn't make sense to support @TTL annotation at individual column level.\n TTL ttlAnnotation = clazz.getAnnotation(TTL.class);\n if(ttlAnnotation != null) {\n int ttlAnnotationValue = ttlAnnotation.value();\n Preconditions.checkState(ttlAnnotationValue > 0, \"cannot define non-positive value for TTL annotation at class level: \" + ttlAnnotationValue);\n tmpTtlValue = ttlAnnotationValue;\n }\n }\n this.ttl = tmpTtlValue;\n\n // TTL method\n Method tmpTtlMethod = null;\n for (Method method : this.clazz.getDeclaredMethods()) {\n if (method.isAnnotationPresent(TTL.class)) {\n Preconditions.checkState(tmpTtlMethod == null, \"Duplicate TTL method annotation on \" + method.getName());\n tmpTtlMethod = method;\n tmpTtlMethod.setAccessible(true);\n }\n }\n this.ttlMethod = tmpTtlMethod;\n\n Field[] declaredFields = clazz.getDeclaredFields();\n FieldMapper tempIdMapper = null;\n CompositeColumnEntityMapper tempEmbeddedEntityMapper = null;\n for (Field field : declaredFields) {\n // Should only have one id field and it should map to the row key\n Id idAnnotation = field.getAnnotation(Id.class);\n if(idAnnotation != null) {\n Preconditions.checkArgument(tempIdMapper == null, \"there are multiple fields with @Id annotation\");\n field.setAccessible(true);\n tempIdMapper = new FieldMapper(field, prefix);\n }\n \n // Composite part or the value\n Column columnAnnotation = field.getAnnotation(Column.class);\n if (columnAnnotation != null) {\n field.setAccessible(true);\n FieldMapper fieldMapper = new FieldMapper(field);\n components.add(fieldMapper);\n validNames.add(fieldMapper.getName());\n }\n }\n \n Preconditions.checkNotNull(tempIdMapper, \"there are no field with @Id annotation\");\n idMapper = tempIdMapper;\n \n Preconditions.checkNotNull(components.size() > 2, \"there should be at least 2 component columns and a value\");\n \n // Last one is always treated as the 'value'\n valueMapper = components.remove(components.size() - 1);\n }\n\n void fillMutationBatch(MutationBatch mb, ColumnFamily<K, ByteBuffer> columnFamily, T entity) {\n try {\n @SuppressWarnings(\"unchecked\")\n ColumnListMutation<ByteBuffer> clm = mb.withRow(columnFamily, (K)idMapper.getValue(entity));\n clm.setDefaultTtl(getTtl(entity));\n try {\n ByteBuffer columnName = toColumnName(entity);\n ByteBuffer value = valueMapper.toByteBuffer(entity);\n clm.putColumn(columnName, value);\n } catch(Exception e) {\n throw new PersistenceException(\"failed to fill mutation batch\", e);\n }\n\n } catch(Exception e) {\n throw new PersistenceException(\"failed to fill mutation batch\", e);\n }\n }\n \n void fillMutationBatchForDelete(MutationBatch mb, ColumnFamily<K, ByteBuffer> columnFamily, T entity) {\n try {\n @SuppressWarnings(\"unchecked\")\n ColumnListMutation<ByteBuffer> clm = mb.withRow(columnFamily, (K)idMapper.getValue(entity));\n clm.deleteColumn(toColumnName(entity));\n } catch(Exception e) {\n throw new PersistenceException(\"failed to fill mutation batch\", e);\n }\n }\n \n private Integer getTtl(T entity) throws IllegalArgumentException, IllegalAccessException, InvocationTargetException {\n Integer retTtl = this.ttl;\n // TTL method has higher priority\n if(ttlMethod != null) {\n Object retobj = ttlMethod.invoke(entity);\n retTtl = (Integer) retobj;\n }\n return retTtl;\n }\n \n /**\n * Return the column name byte buffer for this entity\n * \n * @param obj\n * @return\n */\n private ByteBuffer toColumnName(Object obj) {\n SimpleCompositeBuilder composite = new SimpleCompositeBuilder(bufferSize, Equality.EQUAL);\n\n // Iterate through each component and add to a CompositeType structure\n for (FieldMapper<?> mapper : components) {\n try {\n composite.addWithoutControl(mapper.toByteBuffer(obj));\n }\n catch (Exception e) {\n throw new RuntimeException(e);\n }\n }\n return composite.get();\n }\n \n /**\n * Construct an entity object from a row key and column list.\n * \n * @param id\n * @param cl\n * @return\n */\n T constructEntity(K id, com.netflix.astyanax.model.Column<ByteBuffer> column) {\n try {\n // First, construct the parent class and give it an id\n T entity = clazz.newInstance();\n idMapper.setValue(entity, id);\n setEntityFieldsFromColumnName(entity, column.getRawName().duplicate());\n valueMapper.setField(entity, column.getByteBufferValue().duplicate());\n return entity;\n } catch(Exception e) {\n throw new PersistenceException(\"failed to construct entity\", e);\n }\n }\n \n T constructEntityFromCql(ColumnList<ByteBuffer> cl) {\n try {\n T entity = clazz.newInstance();\n \n // First, construct the parent class and give it an id\n K id = (K) idMapper.fromByteBuffer(Iterables.getFirst(cl, null).getByteBufferValue());\n idMapper.setValue(entity, id);\n \n Iterator<com.netflix.astyanax.model.Column<ByteBuffer>> columnIter = cl.iterator();\n columnIter.next();\n \n for (FieldMapper<?> component : components) {\n component.setField(entity, columnIter.next().getByteBufferValue());\n }\n \n valueMapper.setField(entity, columnIter.next().getByteBufferValue());\n return entity;\n } catch(Exception e) {\n throw new PersistenceException(\"failed to construct entity\", e);\n }\n }\n \n @SuppressWarnings(\"unchecked\")\n public K getEntityId(T entity) throws Exception {\n return (K)idMapper.getValue(entity);\n }\n \n @VisibleForTesting\n Field getId() {\n return idMapper.field;\n }\n \n public String getEntityName() {\n return entityName;\n }\n \n @Override\n public String toString() {\n return String.format(\"EntityMapper(%s)\", clazz);\n }\n\n public String getKeyType() {\n return idMapper.getSerializer().getComparatorType().getTypeName();\n }\n\n /**\n * Return an object from the column\n * \n * @param cl\n * @return\n */\n Object fromColumn(K id, com.netflix.astyanax.model.Column<ByteBuffer> c) {\n try {\n // Allocate a new entity\n Object entity = clazz.newInstance();\n \n idMapper.setValue(entity, id);\n setEntityFieldsFromColumnName(entity, c.getRawName().duplicate());\n valueMapper.setField(entity, c.getByteBufferValue().duplicate());\n return entity;\n } catch(Exception e) {\n throw new PersistenceException(\"failed to construct entity\", e);\n }\n }\n \n /**\n * \n * @param entity\n * @param columnName\n * @throws IllegalArgumentException\n * @throws IllegalAccessException\n */\n void setEntityFieldsFromColumnName(Object entity, ByteBuffer columnName) throws IllegalArgumentException, IllegalAccessException {\n // Iterate through components in order and set fields\n for (FieldMapper<?> component : components) {\n ByteBuffer data = getWithShortLength(columnName);\n if (data != null) {\n if (data.remaining() > 0) {\n component.setField(entity, data);\n }\n byte end_of_component = columnName.get();\n if (end_of_component != Equality.EQUAL.toByte()) {\n throw new RuntimeException(\"Invalid composite column. Expected END_OF_COMPONENT.\");\n }\n }\n else {\n throw new RuntimeException(\"Missing component data in composite type\");\n }\n }\n }\n\n /**\n * Return the cassandra comparator type for this composite structure\n * @return\n */\n public String getComparatorType() {\n StringBuilder sb = new StringBuilder();\n sb.append(\"CompositeType(\");\n sb.append(StringUtils.join(\n Collections2.transform(components, new Function<FieldMapper<?>, String>() {\n public String apply(FieldMapper<?> input) {\n return input.serializer.getComparatorType().getTypeName();\n }\n }),\n \",\"));\n sb.append(\")\");\n return sb.toString();\n }\n\n \n public static int getShortLength(ByteBuffer bb) {\n int length = (bb.get() & 0xFF) << 8;\n return length | (bb.get() & 0xFF);\n }\n\n public static ByteBuffer getWithShortLength(ByteBuffer bb) {\n int length = getShortLength(bb);\n return getBytes(bb, length);\n }\n\n public static ByteBuffer getBytes(ByteBuffer bb, int length) {\n ByteBuffer copy = bb.duplicate();\n copy.limit(copy.position() + length);\n bb.position(bb.position() + length);\n return copy;\n }\n\n String getValueType() {\n return valueMapper.getSerializer().getComparatorType().getTypeName();\n }\n\n ByteBuffer[] getQueryEndpoints(Collection<ColumnPredicate> predicates) {\n // Convert to multimap for easy lookup\n ArrayListMultimap<Object, ColumnPredicate> lookup = ArrayListMultimap.create();\n for (ColumnPredicate predicate : predicates) {\n Preconditions.checkArgument(validNames.contains(predicate.getName()), \"Field '\" + predicate.getName() + \"' does not exist in the entity \" + clazz.getCanonicalName());\n lookup.put(predicate.getName(), predicate);\n }\n \n SimpleCompositeBuilder start = new SimpleCompositeBuilder(bufferSize, Equality.GREATER_THAN_EQUALS);\n SimpleCompositeBuilder end = new SimpleCompositeBuilder(bufferSize, Equality.LESS_THAN_EQUALS);\n\n // Iterate through components in order while applying predicate to 'start' and 'end'\n for (FieldMapper<?> mapper : components) {\n for (ColumnPredicate p : lookup.get(mapper.getName())) {\n try {\n applyPredicate(mapper, start, end, p);\n }\n catch (Exception e) {\n throw new RuntimeException(String.format(\"Failed to serialize predicate '%s'\", p.toString()), e);\n }\n }\n }\n \n return new ByteBuffer[]{start.get(), end.get()};\n }\n \n void applyPredicate(FieldMapper<?> mapper, SimpleCompositeBuilder start, SimpleCompositeBuilder end, ColumnPredicate predicate) {\n ByteBuffer bb = mapper.valueToByteBuffer(predicate.getValue());\n \n switch (predicate.getOp()) {\n case EQUAL:\n start.addWithoutControl(bb);\n end.addWithoutControl(bb);\n break;\n case GREATER_THAN:\n case GREATER_THAN_EQUALS:\n if (mapper.isAscending())\n start.add(bb, predicate.getOp());\n else \n end.add(bb, predicate.getOp());\n break;\n case LESS_THAN:\n case LESS_THAN_EQUALS:\n if (mapper.isAscending())\n end.add(bb, predicate.getOp());\n else \n start.add(bb, predicate.getOp());\n break;\n }\n }\n}\n", "astyanax-entity-mapper\\src\\main\\java\\com\\netflix\\astyanax\\entitystore\\EntityMapper.java": "/**\n * Copyright 2013 Netflix, Inc.\n *\n * Licensed under the Apache License, Version 2.0 (the \"License\");\n * you may not use this file except in compliance with the License.\n * You may obtain a copy of the License at\n *\n * http://www.apache.org/licenses/LICENSE-2.0\n *\n * Unless required by applicable law or agreed to in writing, software\n * distributed under the License is distributed on an \"AS IS\" BASIS,\n * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n * See the License for the specific language governing permissions and\n * limitations under the License.\n */\npackage com.netflix.astyanax.entitystore;\n\nimport java.lang.reflect.Field;\nimport java.lang.reflect.InvocationTargetException;\nimport java.lang.reflect.Method;\nimport java.util.Collection;\nimport java.util.Iterator;\nimport java.util.List;\nimport java.util.Map;\nimport java.util.Set;\n\nimport javax.persistence.Column;\nimport javax.persistence.Entity;\nimport javax.persistence.Id;\nimport javax.persistence.PersistenceException;\n\nimport org.apache.commons.lang.StringUtils;\n\nimport com.google.common.annotations.VisibleForTesting;\nimport com.google.common.base.Preconditions;\nimport com.google.common.collect.Lists;\nimport com.google.common.collect.Maps;\nimport com.google.common.collect.Sets;\nimport com.netflix.astyanax.ColumnListMutation;\nimport com.netflix.astyanax.MutationBatch;\nimport com.netflix.astyanax.model.ColumnFamily;\nimport com.netflix.astyanax.model.ColumnList;\n\n/**\n * utility class to map btw root Entity and cassandra data model\n * @param <T> entity type \n * @param <K> rowKey type\n */\npublic class EntityMapper<T, K> {\n\n\tprivate final Class<T> clazz;\n\tprivate final Integer ttl;\n\tprivate final Method ttlMethod;\n\tprivate final Field idField;\n\tprivate final Map<String, ColumnMapper> columnList;\n\tprivate final ColumnMapper uniqueColumn;\n\tprivate final String entityName;\n\t\n\t/**\n\t * \n\t * @param clazz\n\t * @throws IllegalArgumentException \n\t * \t\tif clazz is NOT annotated with @Entity\n\t * \t\tif column name contains illegal char (like dot)\n\t */\n\tpublic EntityMapper(Class<T> clazz, Integer ttl) {\n\t\tthis.clazz = clazz;\n\t\t\n\t\t// clazz should be annotated with @Entity\n\t\tEntity entityAnnotation = clazz.getAnnotation(Entity.class);\n\t\tif(entityAnnotation == null)\n\t\t\tthrow new IllegalArgumentException(\"class is NOT annotated with @javax.persistence.Entity: \" + clazz.getName());\n\t\t\n\t\tentityName = MappingUtils.getEntityName(entityAnnotation, clazz);\n\t\t\n\t\t// TTL value from constructor or class-level annotation\n\t\tInteger tmpTtlValue = ttl;\n\t\tif(tmpTtlValue == null) {\n\t\t\t// constructor value has higher priority\n\t\t\t// try @TTL annotation at entity/class level.\n\t\t\t// it doesn't make sense to support @TTL annotation at individual column level.\n\t\t\tTTL ttlAnnotation = clazz.getAnnotation(TTL.class);\n\t\t\tif(ttlAnnotation != null) {\n\t\t\t\tint ttlAnnotationValue = ttlAnnotation.value();\n\t\t\t\tPreconditions.checkState(ttlAnnotationValue > 0, \"cannot define non-positive value for TTL annotation at class level: \" + ttlAnnotationValue);\n\t\t\t\ttmpTtlValue = ttlAnnotationValue;\n\t\t\t}\n\t\t}\n\t\tthis.ttl = tmpTtlValue;\n\n\t\t// TTL method\n\t\tMethod tmpTtlMethod = null;\n\t\tfor (Method method : this.clazz.getDeclaredMethods()) {\n\t\t\tif (method.isAnnotationPresent(TTL.class)) {\n\t\t\t\tPreconditions.checkState(tmpTtlMethod == null, \"Duplicate TTL method annotation on \" + method.getName());\n\t\t\t\ttmpTtlMethod = method;\n\t\t\t\ttmpTtlMethod.setAccessible(true);\n\t\t\t}\n\t\t}\n\t\tthis.ttlMethod = tmpTtlMethod;\n\n\t\tField[] declaredFields = clazz.getDeclaredFields();\n\t\tcolumnList = Maps.newHashMapWithExpectedSize(declaredFields.length);\n\t\tSet<String> usedColumnNames = Sets.newHashSet();\n\t\tField tmpIdField = null;\n\t\tColumnMapper tempUniqueMapper = null;\n\t\tfor (Field field : declaredFields) {\n\t\t\tId idAnnotation = field.getAnnotation(Id.class);\n\t\t\tif(idAnnotation != null) {\n\t\t\t\tPreconditions.checkArgument(tmpIdField == null, \"there are multiple fields with @Id annotation\");\n\t\t\t\tfield.setAccessible(true);\n\t\t\t\ttmpIdField = field;\n\t\t\t}\n\t\t\tColumn columnAnnotation = field.getAnnotation(Column.class);\n\t\t\tif ((columnAnnotation != null)) {\n\t\t\t\tfield.setAccessible(true);\n\t\t\t\tColumnMapper columnMapper = null;\n\t\t\t\tEntity compositeAnnotation = field.getType().getAnnotation(Entity.class);\n\t\t\t if (Map.class.isAssignableFrom(field.getType())) {\n columnMapper = new MapColumnMapper(field);\n } else if (Set.class.isAssignableFrom(field.getType())) {\n columnMapper = new SetColumnMapper(field);\n } else if(compositeAnnotation == null) {\n if (columnAnnotation.unique()) {\n Preconditions.checkArgument(tempUniqueMapper == null, \"can't have multiple unique columns '\" + field.getName() + \"'\");\n tempUniqueMapper = new LeafColumnMapper(field);\n }\n else {\n columnMapper = new LeafColumnMapper(field);\n }\n\t\t\t\t} else {\n\t columnMapper = new CompositeColumnMapper(field);\n\t\t\t\t}\n\t\t\t\tPreconditions.checkArgument(!usedColumnNames.contains(columnMapper.getColumnName()), \n\t\t\t\t\t\tString.format(\"duplicate case-insensitive column name: %s\", columnMapper.getColumnName().toLowerCase()));\n\t\t\t\tcolumnList.put(columnMapper.getColumnName(), columnMapper);\n\t\t\t\tusedColumnNames.add(columnMapper.getColumnName().toLowerCase());\n\t\t\t}\n\t\t}\n\t\tPreconditions.checkNotNull(tmpIdField, \"there are no field with @Id annotation\");\n\t\t//Preconditions.checkArgument(tmpIdField.getClass().equals(K.getClass()), String.format(\"@Id field type (%s) doesn't match generic type K (%s)\", tmpIdField.getClass(), K.getClass()));\n\t\tidField = tmpIdField;\n\t\tuniqueColumn = tempUniqueMapper;\n\t}\n\n public void fillMutationBatch(MutationBatch mb, ColumnFamily<K, String> columnFamily, T entity) {\n\t\ttry {\n\t\t\t@SuppressWarnings(\"unchecked\")\n\t\t\tK rowKey = (K) idField.get(entity);\n\t\t\tColumnListMutation<String> clm = mb.withRow(columnFamily, rowKey);\n\t\t\tclm.setDefaultTtl(getTtl(entity));\n\t\t\t\n\t\t\tfor (ColumnMapper mapper : columnList.values()) {\n\t\t\t\tmapper.fillMutationBatch(entity, clm, \"\");\n\t\t\t}\n\t\t} catch(Exception e) {\n\t\t\tthrow new PersistenceException(\"failed to fill mutation batch\", e);\n\t\t}\n\t}\n \n private Integer getTtl(T entity) throws IllegalArgumentException, IllegalAccessException, InvocationTargetException {\n \tInteger retTtl = this.ttl;\n \t// TTL method has higher priority\n \tif(ttlMethod != null) {\n \t\tObject retobj = ttlMethod.invoke(entity);\n \t\tretTtl = (Integer) retobj;\n \t}\n \treturn retTtl;\n }\n\n\tpublic T constructEntity(K id, ColumnList<String> cl) {\n\t\ttry {\n\t\t T entity = clazz.newInstance();\n\t\t\tidField.set(entity, id);\n\t\t\t\n\t\t\tfor (com.netflix.astyanax.model.Column<String> column : cl) {\n\t\t\t List<String> name = Lists.newArrayList(StringUtils.split(column.getName(), \".\"));\n\t\t\t setField(entity, name.iterator(), column);\n\t\t\t}\n\t\t\t\n\t\t\tfor (ColumnMapper column : columnList.values()) {\n\t\t\t column.validate(entity);\n\t\t\t}\n\t\t\treturn entity;\n\t\t} catch(Exception e) {\n\t\t\tthrow new PersistenceException(\"failed to construct entity\", e);\n\t\t}\n\t}\n\t\n\tvoid setField(T entity, Iterator<String> name, com.netflix.astyanax.model.Column<String> column) throws Exception {\n\t String fieldName = name.next();\n\t ColumnMapper mapper = this.columnList.get(fieldName);\n if (mapper != null)\n mapper.setField(entity, name, column);\n\t}\n\t\n\t@SuppressWarnings(\"unchecked\")\n\tpublic K getEntityId(T entity) throws Exception {\n\t return (K)idField.get(entity);\n\t}\n\t\n\t@VisibleForTesting\n\tField getId() {\n\t\treturn idField;\n\t}\n\t\n\t@VisibleForTesting\n\tCollection<ColumnMapper> getColumnList() {\n\t\treturn columnList.values();\n\t}\n\n\tpublic String getEntityName() {\n\t return entityName;\n\t}\n\t\n\t@Override\n\tpublic String toString() {\n\t\treturn String.format(\"EntityMapper(%s)\", clazz);\n\t}\n}\n", "astyanax-entity-mapper\\src\\main\\java\\com\\netflix\\astyanax\\entitystore\\FieldMapper.java": "/**\n * Copyright 2013 Netflix, Inc.\n *\n * Licensed under the Apache License, Version 2.0 (the \"License\");\n * you may not use this file except in compliance with the License.\n * You may obtain a copy of the License at\n *\n * http://www.apache.org/licenses/LICENSE-2.0\n *\n * Unless required by applicable law or agreed to in writing, software\n * distributed under the License is distributed on an \"AS IS\" BASIS,\n * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n * See the License for the specific language governing permissions and\n * limitations under the License.\n */\npackage com.netflix.astyanax.entitystore;\n\nimport java.lang.reflect.Field;\nimport java.nio.ByteBuffer;\n\nimport javax.persistence.Column;\nimport javax.persistence.OrderBy;\n\nimport com.netflix.astyanax.Serializer;\nimport com.netflix.astyanax.serializers.PrefixedSerializer;\nimport com.netflix.astyanax.serializers.ByteBufferSerializer;\n\n/**\n * Mapper from a field to a ByteBuffer\n * @author elandau\n *\n * @param <T>\n */\npublic class FieldMapper<T> {\n final Serializer<T> serializer;\n final Field field;\n final String name;\n final boolean reversed;\n\n enum Order {\n ASC,\n DESC,\n }\n \n public FieldMapper(final Field field) {\n this(field, null);\n }\n \n public FieldMapper(final Field field, ByteBuffer prefix) {\n \n if (prefix != null) {\n this.serializer = new PrefixedSerializer<ByteBuffer, T>(prefix, ByteBufferSerializer.get(), (Serializer<T>) MappingUtils.getSerializerForField(field));\n }\n else {\n this.serializer = (Serializer<T>) MappingUtils.getSerializerForField(field);\n }\n this.field = field;\n \n Column columnAnnotation = field.getAnnotation(Column.class);\n if (columnAnnotation == null || columnAnnotation.name().isEmpty()) {\n name = field.getName();\n }\n else {\n name = columnAnnotation.name();\n }\n \n OrderBy orderByAnnotation = field.getAnnotation(OrderBy.class);\n if (orderByAnnotation == null) {\n reversed = false;\n }\n else {\n Order order = Order.valueOf(orderByAnnotation.value());\n reversed = (order == Order.DESC);\n }\n }\n\n public Serializer<?> getSerializer() {\n return serializer;\n }\n \n public ByteBuffer toByteBuffer(Object entity) throws IllegalArgumentException, IllegalAccessException {\n return serializer.toByteBuffer(getValue(entity));\n }\n \n public T fromByteBuffer(ByteBuffer buffer) {\n return serializer.fromByteBuffer(buffer);\n }\n \n public T getValue(Object entity) throws IllegalArgumentException, IllegalAccessException {\n return (T)field.get(entity);\n }\n \n public ByteBuffer valueToByteBuffer(Object value) {\n return serializer.toByteBuffer((T)value);\n }\n \n public void setValue(Object entity, Object value) throws IllegalArgumentException, IllegalAccessException {\n field.set(entity, value);\n }\n \n public void setField(Object entity, ByteBuffer buffer) throws IllegalArgumentException, IllegalAccessException {\n field.set(entity, fromByteBuffer(buffer));\n }\n\n public boolean isAscending() {\n return reversed == false;\n }\n \n public boolean isDescending() {\n return reversed == true;\n }\n \n public String getName() {\n return name;\n }\n}\n", "astyanax-entity-mapper\\src\\main\\java\\com\\netflix\\astyanax\\entitystore\\LeafColumnMapper.java": "/**\n * Copyright 2013 Netflix, Inc.\n *\n * Licensed under the Apache License, Version 2.0 (the \"License\");\n * you may not use this file except in compliance with the License.\n * You may obtain a copy of the License at\n *\n * http://www.apache.org/licenses/LICENSE-2.0\n *\n * Unless required by applicable law or agreed to in writing, software\n * distributed under the License is distributed on an \"AS IS\" BASIS,\n * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n * See the License for the specific language governing permissions and\n * limitations under the License.\n */\npackage com.netflix.astyanax.entitystore;\n\nimport java.lang.reflect.Field;\nimport java.util.Iterator;\n\nimport com.netflix.astyanax.ColumnListMutation;\nimport com.netflix.astyanax.Serializer;\n\nclass LeafColumnMapper extends AbstractColumnMapper {\n\t\n\tprivate final Serializer<?> serializer;\n\n\tLeafColumnMapper(final Field field) {\n\t super(field);\n\t\tthis.serializer = MappingUtils.getSerializerForField(field);\n\t}\n\n\t@Override\n\tpublic String getColumnName() {\n\t\treturn columnName;\n\t}\n\t\n\tSerializer<?> getSerializer() {\n\t return serializer;\n\t}\n\t\n\t@SuppressWarnings(\"unchecked\")\n\t@Override\n\tpublic boolean fillMutationBatch(Object entity, ColumnListMutation<String> clm, String prefix) throws Exception {\n\t\tObject value = field.get(entity);\n\t\tif(value == null) {\n\t\t\tif(columnAnnotation.nullable())\n\t\t\t\treturn false; // skip\n\t\t\telse\n\t\t\t\tthrow new IllegalArgumentException(\"cannot write non-nullable column with null value: \" + columnName);\n\t\t}\n\t\t@SuppressWarnings(\"rawtypes\")\n\t\tfinal Serializer valueSerializer = serializer;\n\t\t// TODO: suppress the unchecked raw type now.\n\t\t// we have to use the raw type to avoid compiling error\n\t\tclm.putColumn(prefix + columnName, value, valueSerializer, null);\n\t\treturn true;\n\t}\n\t\n @Override\n public boolean setField(Object entity, Iterator<String> name, com.netflix.astyanax.model.Column<String> column) throws Exception {\n if (name.hasNext()) \n return false;\n final Object fieldValue = column.getValue(serializer);\n field.set(entity, fieldValue);\n return true;\n }\n\n @Override\n public void validate(Object entity) throws Exception {\n if (field.get(entity) == null && !columnAnnotation.nullable())\n throw new IllegalArgumentException(\"cannot find non-nullable column: \" + columnName);\n }\n}\n", "astyanax-entity-mapper\\src\\main\\java\\com\\netflix\\astyanax\\entitystore\\MapColumnMapper.java": "/**\n * Copyright 2013 Netflix, Inc.\n *\n * Licensed under the Apache License, Version 2.0 (the \"License\");\n * you may not use this file except in compliance with the License.\n * You may obtain a copy of the License at\n *\n * http://www.apache.org/licenses/LICENSE-2.0\n *\n * Unless required by applicable law or agreed to in writing, software\n * distributed under the License is distributed on an \"AS IS\" BASIS,\n * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n * See the License for the specific language governing permissions and\n * limitations under the License.\n */\npackage com.netflix.astyanax.entitystore;\n\nimport java.lang.reflect.Field;\nimport java.lang.reflect.ParameterizedType;\nimport java.util.Iterator;\nimport java.util.Map;\nimport java.util.Map.Entry;\n\nimport com.google.common.collect.Maps;\nimport com.netflix.astyanax.ColumnListMutation;\nimport com.netflix.astyanax.Serializer;\nimport com.netflix.astyanax.serializers.SerializerTypeInferer;\n\npublic class MapColumnMapper extends AbstractColumnMapper {\n private final Class<?> keyClazz;\n private final Class<?> valueClazz;\n private final Serializer<?> keySerializer;\n private final Serializer<Object> valueSerializer;\n\n public MapColumnMapper(Field field) {\n super(field);\n \n ParameterizedType stringListType = (ParameterizedType) field.getGenericType();\n this.keyClazz = (Class<?>) stringListType.getActualTypeArguments()[0];\n this.keySerializer = SerializerTypeInferer.getSerializer(this.keyClazz);\n\n this.valueClazz = (Class<?>) stringListType.getActualTypeArguments()[1];\n this.valueSerializer = SerializerTypeInferer.getSerializer(this.valueClazz);\n }\n\n @Override\n public String getColumnName() {\n return this.columnName;\n }\n\n @Override\n public boolean fillMutationBatch(Object entity, ColumnListMutation<String> clm, String prefix) throws Exception {\n Map<?, ?> map = (Map<?, ?>) field.get(entity);\n if (map == null) {\n if (columnAnnotation.nullable())\n return false; // skip\n else\n throw new IllegalArgumentException(\"cannot write non-nullable column with null value: \" + columnName);\n }\n \n for (Entry<?, ?> entry : map.entrySet()) {\n clm.putColumn(prefix + columnName + \".\" + entry.getKey().toString(), entry.getValue(), valueSerializer, null);\n }\n return true;\n }\n \n @Override\n public boolean setField(Object entity, Iterator<String> name, com.netflix.astyanax.model.Column<String> column) throws Exception {\n Map<Object, Object> map = (Map<Object, Object>) field.get(entity);\n if (map == null) {\n map = Maps.newLinkedHashMap();\n field.set(entity, map);\n }\n \n String key = name.next();\n if (name.hasNext())\n return false;\n map.put(keySerializer.fromByteBuffer(keySerializer.fromString(key)),\n valueSerializer.fromByteBuffer(column.getByteBufferValue()));\n return true;\n }\n\n @Override\n public void validate(Object entity) throws Exception {\n // TODO Auto-generated method stub\n }\n\n}\n", "astyanax-entity-mapper\\src\\main\\java\\com\\netflix\\astyanax\\entitystore\\MappingUtils.java": "/**\n * Copyright 2013 Netflix, Inc.\n *\n * Licensed under the Apache License, Version 2.0 (the \"License\");\n * you may not use this file except in compliance with the License.\n * You may obtain a copy of the License at\n *\n * http://www.apache.org/licenses/LICENSE-2.0\n *\n * Unless required by applicable law or agreed to in writing, software\n * distributed under the License is distributed on an \"AS IS\" BASIS,\n * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n * See the License for the specific language governing permissions and\n * limitations under the License.\n */\npackage com.netflix.astyanax.entitystore;\n\nimport java.lang.reflect.Field;\nimport java.lang.reflect.Method;\n\nimport javax.persistence.Entity;\n\nimport org.apache.commons.lang.StringUtils;\n\nimport com.netflix.astyanax.serializers.SerializerTypeInferer;\n\npublic class MappingUtils {\n static com.netflix.astyanax.Serializer<?> getSerializerForField(Field field) {\n com.netflix.astyanax.Serializer<?> serializer = null;\n // check if there is explicit @Serializer annotation first\n Serializer serializerAnnotation = field.getAnnotation(Serializer.class);\n if(serializerAnnotation != null) {\n final Class<?> serializerClazz = serializerAnnotation.value();\n // check type\n if(!(com.netflix.astyanax.Serializer.class.isAssignableFrom(serializerClazz)))\n throw new RuntimeException(\"annotated serializer class is not a subclass of com.netflix.astyanax.Serializer. \" + serializerClazz.getCanonicalName());\n // invoke public static get() method\n try {\n Method getInstanceMethod = serializerClazz.getMethod(\"get\");\n serializer = (com.netflix.astyanax.Serializer<?>) getInstanceMethod.invoke(null);\n } catch(Exception e) {\n throw new RuntimeException(\"Failed to get or invoke public static get() method\", e);\n }\n } else {\n // otherwise automatically infer the Serializer type from field object type\n serializer = SerializerTypeInferer.getSerializer(field.getType());\n }\n return serializer;\n }\n\n static String getEntityName(Entity entityAnnotation, Class<?> clazz) {\n String name = entityAnnotation.name();\n if (name == null || name.isEmpty()) \n return StringUtils.substringAfterLast(clazz.getName(), \".\").toLowerCase();\n else\n return name;\n }\n\n\n}\n", "astyanax-entity-mapper\\src\\main\\java\\com\\netflix\\astyanax\\entitystore\\SetColumnMapper.java": "/**\n * Copyright 2013 Netflix, Inc.\n *\n * Licensed under the Apache License, Version 2.0 (the \"License\");\n * you may not use this file except in compliance with the License.\n * You may obtain a copy of the License at\n *\n * http://www.apache.org/licenses/LICENSE-2.0\n *\n * Unless required by applicable law or agreed to in writing, software\n * distributed under the License is distributed on an \"AS IS\" BASIS,\n * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n * See the License for the specific language governing permissions and\n * limitations under the License.\n */\npackage com.netflix.astyanax.entitystore;\n\nimport java.lang.reflect.Field;\nimport java.lang.reflect.ParameterizedType;\nimport java.util.Iterator;\nimport java.util.Set;\n\nimport com.google.common.collect.Sets;\nimport com.netflix.astyanax.ColumnListMutation;\nimport com.netflix.astyanax.Serializer;\nimport com.netflix.astyanax.serializers.SerializerTypeInferer;\n\n/**\n * \n * <field>.<key>\n * @author elandau\n *\n */\npublic class SetColumnMapper extends AbstractColumnMapper {\n private final Class<?> clazz;\n private final Serializer<?> serializer;\n\n public SetColumnMapper(Field field) {\n super(field);\n \n ParameterizedType stringListType = (ParameterizedType) field.getGenericType();\n this.clazz = (Class<?>) stringListType.getActualTypeArguments()[0];\n this.serializer = SerializerTypeInferer.getSerializer(this.clazz);\n }\n\n @Override\n public String getColumnName() {\n return this.columnName;\n }\n\n @Override\n public boolean fillMutationBatch(Object entity, ColumnListMutation<String> clm, String prefix) throws Exception {\n Set<?> set = (Set<?>) field.get(entity);\n if(set == null) {\n if(columnAnnotation.nullable())\n return false; // skip\n else\n throw new IllegalArgumentException(\"cannot write non-nullable column with null value: \" + columnName);\n }\n \n for (Object entry : set) {\n clm.putEmptyColumn(prefix + columnName + \".\" + entry.toString(), null);\n }\n return true;\n }\n \n @Override\n public boolean setField(Object entity, Iterator<String> name, com.netflix.astyanax.model.Column<String> column) throws Exception {\n Set<Object> set = (Set<Object>) field.get(entity);\n if (set == null) {\n set = Sets.newHashSet();\n field.set(entity, set);\n }\n \n String value = name.next();\n if (name.hasNext())\n return false;\n set.add(serializer.fromByteBuffer(serializer.fromString(value)));\n return true;\n }\n\n @Override\n public void validate(Object entity) throws Exception {\n // TODO Auto-generated method stub\n \n }\n}\n", "astyanax-recipes\\src\\main\\java\\com\\netflix\\astyanax\\recipes\\ReverseIndexQuery.java": "/**\n * Copyright 2013 Netflix, Inc.\n *\n * Licensed under the Apache License, Version 2.0 (the \"License\");\n * you may not use this file except in compliance with the License.\n * You may obtain a copy of the License at\n *\n * http://www.apache.org/licenses/LICENSE-2.0\n *\n * Unless required by applicable law or agreed to in writing, software\n * distributed under the License is distributed on an \"AS IS\" BASIS,\n * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n * See the License for the specific language governing permissions and\n * limitations under the License.\n */\npackage com.netflix.astyanax.recipes;\n\nimport java.nio.ByteBuffer;\nimport java.util.Collection;\nimport java.util.List;\nimport java.util.concurrent.CountDownLatch;\nimport java.util.concurrent.ExecutorService;\nimport java.util.concurrent.Executors;\nimport java.util.concurrent.TimeUnit;\nimport java.util.concurrent.atomic.AtomicLong;\n\nimport com.google.common.base.Function;\nimport com.google.common.collect.Lists;\nimport com.google.common.util.concurrent.ThreadFactoryBuilder;\nimport com.netflix.astyanax.Keyspace;\nimport com.netflix.astyanax.Serializer;\nimport com.netflix.astyanax.connectionpool.OperationResult;\nimport com.netflix.astyanax.connectionpool.exceptions.ConnectionException;\nimport com.netflix.astyanax.model.Column;\nimport com.netflix.astyanax.model.ColumnFamily;\nimport com.netflix.astyanax.model.ColumnList;\nimport com.netflix.astyanax.model.ColumnSlice;\nimport com.netflix.astyanax.model.CompositeParser;\nimport com.netflix.astyanax.model.Composites;\nimport com.netflix.astyanax.model.ConsistencyLevel;\nimport com.netflix.astyanax.model.Row;\nimport com.netflix.astyanax.model.Rows;\nimport com.netflix.astyanax.retry.RetryPolicy;\nimport com.netflix.astyanax.retry.RunOnce;\nimport com.netflix.astyanax.serializers.ByteBufferSerializer;\nimport com.netflix.astyanax.util.RangeBuilder;\n\n/**\n * Performs a search on a reverse index and fetches all the matching rows\n * \n * CFData:K C=V1 C=V2\n * \n * CFIndex: V1:K\n * \n * <h3>Data and Index column family</h3> The CFData column family has key of\n * type K and fields or columns of type C. Each column may have a different\n * value type. The CFIndex column family is a sorted index by one of the value\n * types V. The column names in the reverse index are a composite of the value\n * type V and the CFData rowkey type K (V:K).\n * \n * @author elandau\n * \n * @param <K>\n * Key type for data table\n * @param <C>\n * Column name type for data table\n * @param <V>\n * Value type being indexed\n */\npublic class ReverseIndexQuery<K, C, V> {\n\n public static <K, C, V> ReverseIndexQuery<K, C, V> newQuery(Keyspace ks, ColumnFamily<K, C> cf, String indexCf,\n Serializer<V> valSerializer) {\n return new ReverseIndexQuery<K, C, V>(ks, cf, indexCf, valSerializer);\n }\n\n public static <K, C, V> ReverseIndexQuery<K, C, V> newQuery(Keyspace ks, ColumnFamily<K, C> cf, ColumnFamily<ByteBuffer, ByteBuffer> indexCf,\n Serializer<V> valSerializer) {\n return new ReverseIndexQuery<K, C, V>(ks, cf, indexCf, valSerializer);\n }\n\n public static interface IndexEntryCallback<K, V> {\n boolean handleEntry(K key, V value, ByteBuffer meta);\n }\n\n private final Keyspace ks;\n private final ColumnFamily<K, C> cfData;\n private final Serializer<V> valSerializer;\n private Collection<ByteBuffer> shardKeys;\n private final ColumnFamily<ByteBuffer, ByteBuffer> cfIndex;\n private ExecutorService executor;\n private V startValue;\n private V endValue;\n private int keyLimit = 100;\n private int columnLimit = 1000;\n private int shardColumnLimit = 0;\n private final AtomicLong pendingTasks = new AtomicLong();\n private Function<Row<K, C>, Void> callback;\n private IndexEntryCallback<K, V> indexCallback;\n private ConsistencyLevel consistencyLevel = ConsistencyLevel.CL_ONE;\n private RetryPolicy retry = RunOnce.get();\n private Collection<C> columnSlice;\n private CountDownLatch latch = new CountDownLatch(1);\n\n public ReverseIndexQuery(Keyspace ks, ColumnFamily<K, C> cfData, String indexCf, Serializer<V> valSerializer) {\n this.ks = ks;\n this.cfData = cfData;\n this.valSerializer = valSerializer;\n this.startValue = null;\n this.endValue = null;\n this.cfIndex = ColumnFamily.newColumnFamily(indexCf, ByteBufferSerializer.get(), ByteBufferSerializer.get());\n }\n\n public ReverseIndexQuery(Keyspace ks, ColumnFamily<K, C> cfData, ColumnFamily<ByteBuffer, ByteBuffer> indexCf, Serializer<V> valSerializer) {\n this.ks = ks;\n this.cfData = cfData;\n this.valSerializer = valSerializer;\n this.startValue = null;\n this.endValue = null;\n this.cfIndex = indexCf;\n }\n\n public ReverseIndexQuery<K, C, V> useExecutor(ExecutorService executor) {\n this.executor = executor;\n return this;\n }\n\n public ReverseIndexQuery<K, C, V> useRetryPolicy(RetryPolicy retry) {\n this.retry = retry;\n return this;\n }\n\n public ReverseIndexQuery<K, C, V> withIndexShards(Collection<ByteBuffer> shardKeys) {\n this.shardKeys = shardKeys;\n return this;\n }\n\n public ReverseIndexQuery<K, C, V> fromIndexValue(V startValue) {\n this.startValue = startValue;\n return this;\n }\n\n public ReverseIndexQuery<K, C, V> toIndexValue(V endValue) {\n this.endValue = endValue;\n return this;\n }\n\n public ReverseIndexQuery<K, C, V> forEach(Function<Row<K, C>, Void> callback) {\n this.callback = callback;\n return this;\n }\n\n public ReverseIndexQuery<K, C, V> forEachIndexEntry(IndexEntryCallback<K, V> callback) {\n this.indexCallback = callback;\n return this;\n }\n\n public ReverseIndexQuery<K, C, V> withConsistencyLevel(ConsistencyLevel consistencyLevel) {\n this.consistencyLevel = consistencyLevel;\n return this;\n }\n\n public ReverseIndexQuery<K, C, V> withColumnSlice(Collection<C> columnSlice) {\n this.columnSlice = columnSlice;\n return this;\n }\n\n /**\n * Set the number shard keys to fetch for the first query\n * \n * @param size\n * @return\n */\n public ReverseIndexQuery<K, C, V> setShardBlockSize(int size) {\n this.keyLimit = size;\n return this;\n }\n\n /**\n * Set the number columns to read from each shard when paginating.\n * \n * @param size\n * @return\n */\n public ReverseIndexQuery<K, C, V> setShardPageSize(int size) {\n this.columnLimit = size;\n return this;\n }\n\n public ReverseIndexQuery<K, C, V> setShardNextPageSize(int size) {\n this.shardColumnLimit = size;\n return this;\n }\n\n public abstract class Task implements Runnable {\n public Task() {\n pendingTasks.incrementAndGet();\n executor.submit(this);\n }\n\n @Override\n public final void run() {\n try {\n internalRun();\n }\n catch (Throwable t) {\n }\n\n if (pendingTasks.decrementAndGet() == 0)\n latch.countDown();\n }\n\n protected abstract void internalRun();\n }\n\n public void execute() {\n if (executor == null)\n executor = Executors.newFixedThreadPool(5, new ThreadFactoryBuilder().setDaemon(true).build());\n\n // Break up the shards into batches\n List<ByteBuffer> batch = Lists.newArrayListWithCapacity(keyLimit);\n for (ByteBuffer shard : shardKeys) {\n batch.add(shard);\n if (batch.size() == keyLimit) {\n fetchFirstIndexBatch(batch);\n batch = Lists.newArrayListWithCapacity(keyLimit);\n }\n }\n if (!batch.isEmpty()) {\n fetchFirstIndexBatch(batch);\n }\n\n if (pendingTasks.get() > 0) {\n try {\n latch.await(1000, TimeUnit.MINUTES);\n }\n catch (InterruptedException e) {\n Thread.currentThread().interrupt();\n }\n }\n }\n\n private void fetchFirstIndexBatch(final Collection<ByteBuffer> keys) {\n new Task() {\n @Override\n protected void internalRun() {\n // Get the first range in the index\n \tRangeBuilder range = new RangeBuilder();\n if (startValue != null) {\n range.setStart(Composites.newCompositeBuilder().greaterThanEquals().add(startValue, valSerializer)\n .build());\n }\n if (endValue != null) {\n range.setEnd(Composites.newCompositeBuilder().lessThanEquals().add(endValue, valSerializer).build());\n }\n\n // Read the index shards\n OperationResult<Rows<ByteBuffer, ByteBuffer>> result = null;\n try {\n result = ks.prepareQuery(cfIndex).setConsistencyLevel(consistencyLevel).withRetryPolicy(retry)\n .getKeySlice(keys).withColumnRange(range.setLimit(columnLimit).build()).execute();\n }\n catch (ConnectionException e) {\n e.printStackTrace();\n return;\n }\n\n // Read the actual data rows in batches\n List<K> batch = Lists.newArrayListWithCapacity(keyLimit);\n for (Row<ByteBuffer, ByteBuffer> row : result.getResult()) {\n if (!row.getColumns().isEmpty()) {\n V lastValue = null;\n for (Column<ByteBuffer> column : row.getColumns()) {\n CompositeParser parser = Composites.newCompositeParser(column.getName());\n lastValue = parser.read(valSerializer);\n K key = parser.read(cfData.getKeySerializer());\n\n if (indexCallback != null) {\n if (!indexCallback.handleEntry(key, lastValue, column.getByteBufferValue())) {\n continue;\n }\n }\n\n if (callback != null) {\n batch.add(key);\n\n if (batch.size() == keyLimit) {\n fetchDataBatch(batch);\n batch = Lists.newArrayListWithCapacity(keyLimit);\n }\n }\n }\n\n if (row.getColumns().size() == columnLimit) {\n paginateIndexShard(row.getKey(), lastValue);\n }\n }\n }\n if (!batch.isEmpty()) {\n fetchDataBatch(batch);\n }\n }\n };\n }\n\n private void paginateIndexShard(final ByteBuffer shard, final V value) {\n new Task() {\n @Override\n protected void internalRun() {\n V nextValue = value;\n ColumnList<ByteBuffer> result = null;\n List<K> batch = Lists.newArrayListWithCapacity(keyLimit);\n\n int pageSize = shardColumnLimit;\n if (pageSize == 0)\n pageSize = columnLimit;\n\n do {\n // Get the first range in the index\n RangeBuilder range = new RangeBuilder().setStart(Composites.newCompositeBuilder()\n .greaterThanEquals().addBytes(valSerializer.getNext(valSerializer.toByteBuffer(nextValue)))\n .build());\n if (endValue != null) {\n range.setEnd(Composites.newCompositeBuilder().lessThanEquals().add(endValue, valSerializer)\n .build());\n }\n\n // Read the index shards\n try {\n result = ks.prepareQuery(cfIndex).setConsistencyLevel(consistencyLevel).withRetryPolicy(retry)\n .getKey(shard).withColumnRange(range.setLimit(pageSize).build()).execute().getResult();\n }\n catch (ConnectionException e) {\n e.printStackTrace();\n return;\n }\n\n // Read the actual data rows in batches\n for (Column<ByteBuffer> column : result) {\n CompositeParser parser = Composites.newCompositeParser(column.getName());\n nextValue = parser.read(valSerializer);\n K key = parser.read(cfData.getKeySerializer());\n\n if (indexCallback != null) {\n if (!indexCallback.handleEntry(key, nextValue, column.getByteBufferValue())) {\n continue;\n }\n }\n\n if (callback != null) {\n batch.add(key);\n\n if (batch.size() == keyLimit) {\n fetchDataBatch(batch);\n batch = Lists.newArrayListWithCapacity(keyLimit);\n }\n }\n }\n } while (result != null && result.size() == pageSize);\n\n if (!batch.isEmpty()) {\n fetchDataBatch(batch);\n }\n }\n };\n }\n\n private void fetchDataBatch(final Collection<K> keys) {\n new Task() {\n @Override\n protected void internalRun() {\n try {\n OperationResult<Rows<K, C>> result = ks.prepareQuery(cfData).withRetryPolicy(retry)\n .setConsistencyLevel(consistencyLevel).getKeySlice(keys)\n .withColumnSlice(new ColumnSlice<C>(columnSlice)).execute();\n\n for (Row<K, C> row : result.getResult()) {\n callback.apply(row);\n }\n }\n catch (ConnectionException e) {\n e.printStackTrace();\n }\n }\n };\n }\n}\n", "astyanax-test\\src\\main\\java\\com\\netflix\\astyanax\\cql\\test\\entitymapper\\EntityMapperTests.java": "/**\n * Copyright 2013 Netflix, Inc.\n *\n * Licensed under the Apache License, Version 2.0 (the \"License\");\n * you may not use this file except in compliance with the License.\n * You may obtain a copy of the License at\n *\n * http://www.apache.org/licenses/LICENSE-2.0\n *\n * Unless required by applicable law or agreed to in writing, software\n * distributed under the License is distributed on an \"AS IS\" BASIS,\n * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n * See the License for the specific language governing permissions and\n * limitations under the License.\n */\npackage com.netflix.astyanax.cql.test.entitymapper;\n\nimport java.util.ArrayList;\nimport java.util.List;\n\nimport javax.persistence.Column;\nimport javax.persistence.Entity;\nimport javax.persistence.Id;\n\nimport junit.framework.Assert;\n\nimport org.junit.AfterClass;\nimport org.junit.BeforeClass;\nimport org.junit.Test;\n\nimport com.netflix.astyanax.cql.test.KeyspaceTests;\nimport com.netflix.astyanax.cql.test.entitymapper.EntityMapperTests.SampleTestCompositeEntity.InnerEntity;\nimport com.netflix.astyanax.entitystore.DefaultEntityManager;\nimport com.netflix.astyanax.entitystore.EntityManager;\nimport com.netflix.astyanax.model.ColumnFamily;\nimport com.netflix.astyanax.serializers.StringSerializer;\n\npublic class EntityMapperTests extends KeyspaceTests {\n\t\n private static ColumnFamily<String, String> CF_SAMPLE_TEST_ENTITY = ColumnFamily\n .newColumnFamily(\n \"sampletestentity\", \n StringSerializer.get(),\n StringSerializer.get());\n\n\tprivate static EntityManager<SampleTestEntity, String> entityManager;\n\tprivate static EntityManager<SampleTestCompositeEntity, String> compositeEntityManager;\n\n @BeforeClass\n\tpublic static void init() throws Exception {\n\t\tinitContext();\n\t\tkeyspace.createColumnFamily(CF_SAMPLE_TEST_ENTITY, null);\n\t\t\n \tCF_SAMPLE_TEST_ENTITY.describe(keyspace);\n \t\n \tentityManager = \n \t\tnew DefaultEntityManager.Builder<SampleTestEntity, String>()\n \t\t.withEntityType(SampleTestEntity.class)\n \t\t.withKeyspace(keyspace)\n \t\t.withColumnFamily(CF_SAMPLE_TEST_ENTITY)\n \t\t.build();\n\n \tcompositeEntityManager = \n \t\tnew DefaultEntityManager.Builder<SampleTestCompositeEntity, String>()\n \t\t.withEntityType(SampleTestCompositeEntity.class)\n \t\t.withKeyspace(keyspace)\n \t\t.withColumnFamily(CF_SAMPLE_TEST_ENTITY)\n \t\t.build();\n }\n\n @AfterClass\n\tpublic static void tearDown() throws Exception {\n \tkeyspace.dropColumnFamily(CF_SAMPLE_TEST_ENTITY);\n\t}\n \n \n @Test\n public void testSimpleEntityCRUD() throws Exception {\n \t\n \tfinal String ID = \"testSimpleEntityCRUD\";\n \t\n \tfinal SampleTestEntity testEntity = new SampleTestEntity();\n \t\n \ttestEntity.id = ID;\n \ttestEntity.testInt = 1;\n \ttestEntity.testLong = 2L;\n \ttestEntity.testString = \"testString1\";\n \ttestEntity.testDouble = 3.0;\n \ttestEntity.testFloat = 4.0f; \n \ttestEntity.testBoolean = true;\n \t\n \t// PUT\n \tentityManager.put(testEntity);\n \t\n \t// GET\n \tSampleTestEntity getEntity = entityManager.get(ID);\n \tAssert.assertNotNull(getEntity);\n \tAssert.assertTrue(testEntity.equals(getEntity));\n \t\n \t// DELETE\n \tentityManager.delete(ID);\n \tgetEntity = entityManager.get(ID);\n \tAssert.assertNull(getEntity);\n }\n\n @Test\n public void testSimpleEntityList() throws Exception {\n \t\n \tList<SampleTestEntity> entities = new ArrayList<SampleTestEntity>();\n \tList<String> ids = new ArrayList<String>();\n \t\n \tint entityCount = 11;\n \t\n \tfor (int i=0; i<entityCount; i++) {\n \t\t\n \tSampleTestEntity testEntity = new SampleTestEntity();\n \t\n \ttestEntity.id = \"id\" + i;\n \ttestEntity.testInt = i;\n \ttestEntity.testLong = i;\n \ttestEntity.testString = \"testString\" + i;\n \ttestEntity.testDouble = i;\n \ttestEntity.testFloat = i; \n \ttestEntity.testBoolean = true;\n \t\n \tentities.add(testEntity);\n \tids.add(\"id\" + i);\n \t}\n \t\n \t// PUT COLLECTION\n \tentityManager.put(entities);\n \t\n \t// GET\n \tList<SampleTestEntity> getEntities = entityManager.get(ids);\n \tAssert.assertTrue(entityCount == getEntities.size());\n \t\n \tint count = 0;\n \tfor (SampleTestEntity e : getEntities) {\n \t\tAssert.assertTrue(count == e.testInt);\n \t\tAssert.assertTrue(count == e.testLong);\n \t\tAssert.assertTrue((\"testString\" + count).equals(e.testString));\n \t\tcount++;\n \t}\n \t\n \t// DELETE\n \tentityManager.delete(ids);\n \t\n \t// GET AFTER DELETE\n \tgetEntities = entityManager.get(ids);\n \tAssert.assertTrue(0 == getEntities.size());\n }\n\n @Test\n public void testGetAll() throws Exception {\n \t\n \tList<SampleTestEntity> entities = new ArrayList<SampleTestEntity>();\n \tList<String> ids = new ArrayList<String>();\n \t\n \tint entityCount = 11;\n \t\n \tfor (int i=0; i<entityCount; i++) {\n \t\t\n \tSampleTestEntity testEntity = new SampleTestEntity();\n \t\n \ttestEntity.id = \"id\" + i;\n \ttestEntity.testInt = i;\n \ttestEntity.testLong = i;\n \ttestEntity.testString = \"testString\" + i;\n \ttestEntity.testDouble = i;\n \ttestEntity.testFloat = i; \n \ttestEntity.testBoolean = true;\n \t\n \tentities.add(testEntity);\n \tids.add(\"id\" + i);\n \t}\n \t\n \t// PUT COLLECTION\n \tentityManager.put(entities);\n \t\n \tList<SampleTestEntity> getEntities = entityManager.getAll();\n \tAssert.assertTrue(entityCount == getEntities.size());\n \tfor (SampleTestEntity e : getEntities) {\n \t\tString id = e.id;\n \t\tint i = Integer.parseInt(id.substring(\"id\".length()));\n \t\tAssert.assertTrue(i == e.testInt);\n \t\tAssert.assertTrue(i == e.testLong);\n \t\tAssert.assertTrue((\"testString\" + i).equals(e.testString));\n \t}\n \t\n \t// DELETE\n \tentityManager.delete(ids);\n \t// GET AFTER DELETE\n \tgetEntities = entityManager.getAll();\n \tAssert.assertTrue(0 == getEntities.size());\n }\n\n @Test\n public void testCompositeEntityCRUD() throws Exception {\n \t\n \tfinal String ID = \"testCompositeEntityCRUD\";\n\n \tfinal SampleTestCompositeEntity testEntity = new SampleTestCompositeEntity();\n \t\n \ttestEntity.id = ID;\n \ttestEntity.testInt = 1;\n \ttestEntity.testLong = 2L;\n \ttestEntity.testString = \"testString1\";\n \ttestEntity.testDouble = 3.0;\n \ttestEntity.testFloat = 4.0f; \n \ttestEntity.testBoolean = true;\n \t\n \ttestEntity.inner = new InnerEntity();\n \ttestEntity.inner.testInnerInt = 11;\n \ttestEntity.inner.testInnerLong = 22L;\n \ttestEntity.inner.testInnerString = \"testInnserString1\";\n \t\n \t// PUT\n \tcompositeEntityManager.put(testEntity);\n \t\n \t// GET\n \tSampleTestCompositeEntity getEntity = compositeEntityManager.get(ID);\n \tSystem.out.println(getEntity);\n \tAssert.assertNotNull(getEntity);\n \tAssert.assertTrue(testEntity.equals(getEntity));\n \t\n \t// DELETE\n \tentityManager.delete(ID);\n \tgetEntity = compositeEntityManager.get(ID);\n \tAssert.assertNull(getEntity);\n }\n\n @Entity\n public static class SampleTestEntity {\n \t\n \t@Id\n \tprivate String id;\n \t\n \t@Column(name=\"integer\")\n \tprivate int testInt; \n \t@Column(name=\"long\")\n \tprivate long testLong;\n \t@Column(name=\"string\")\n \tprivate String testString; \n \t@Column(name=\"float\")\n \tprivate float testFloat;\n \t@Column(name=\"double\")\n \tprivate double testDouble;\n \t@Column(name=\"boolean\")\n \tprivate boolean testBoolean;\n \t\n \tpublic SampleTestEntity() {\n \t\t\n \t}\n \t\n\t\t@Override\n\t\tpublic String toString() {\n\t\t\treturn \"SampleTestEntity [\\nid=\" + id + \"\\ntestInt=\" + testInt\n\t\t\t\t\t+ \"\\ntestLong=\" + testLong + \"\\ntestString=\" + testString\n\t\t\t\t\t+ \"\\ntestFloat=\" + testFloat + \"\\ntestDouble=\" + testDouble\n\t\t\t\t\t+ \"\\ntestBoolean=\" + testBoolean + \"]\";\n\t\t}\n\n\t\t@Override\n\t\tpublic int hashCode() {\n\t\t\tfinal int prime = 31;\n\t\t\tint result = 1;\n\t\t\tresult = prime * result + ((id == null) ? 0 : id.hashCode());\n\t\t\tresult = prime * result + (testBoolean ? 1231 : 1237);\n\t\t\tlong temp;\n\t\t\ttemp = Double.doubleToLongBits(testDouble);\n\t\t\tresult = prime * result + (int) (temp ^ (temp >>> 32));\n\t\t\tresult = prime * result + Float.floatToIntBits(testFloat);\n\t\t\tresult = prime * result + testInt;\n\t\t\tresult = prime * result + (int) (testLong ^ (testLong >>> 32));\n\t\t\tresult = prime * result + ((testString == null) ? 0 : testString.hashCode());\n\t\t\treturn result;\n\t\t}\n\n\t\t@Override\n\t\tpublic boolean equals(Object obj) {\n\t\t\t\n\t\t\tif (this == obj) return true;\n\t\t\tif (obj == null) return false;\n\t\t\tif (getClass() != obj.getClass()) return false;\n\t\t\t\n\t\t\tSampleTestEntity other = (SampleTestEntity) obj;\n\t\t\tboolean equal = true;\n\n\t\t\tequal &= (id != null) ? id.equals(other.id) : other.id == null;\n\t\t\tequal &= testInt == other.testInt;\n\t\t\tequal &= testLong == other.testLong;\n\t\t\tequal &= testBoolean == other.testBoolean;\n\t\t\tequal &= (testString != null) ? testString.equals(other.testString) : other.testString == null;\n\t\t\tequal &= (Double.doubleToLongBits(testDouble) == Double.doubleToLongBits(other.testDouble));\n\t\t\tequal &= (Float.floatToIntBits(testFloat) == Float.floatToIntBits(other.testFloat));\n\t\t\t\n\t\t\treturn equal;\n\t\t}\n }\n \n @Entity\n public static class SampleTestCompositeEntity {\n \t\n \t@Id\n \tprivate String id;\n \t\n \t@Column(name=\"integer\")\n \tprivate int testInt; \n \t@Column(name=\"long\")\n \tprivate long testLong;\n \t@Column(name=\"string\")\n \tprivate String testString; \n \t@Column(name=\"float\")\n \tprivate float testFloat;\n \t@Column(name=\"double\")\n \tprivate double testDouble;\n \t@Column(name=\"boolean\")\n \tprivate boolean testBoolean;\n \t\n \t@Entity\n \tpublic static class InnerEntity {\n \t\t\n \t@Column(name=\"inner_integer\")\n \tprivate int testInnerInt; \n \t@Column(name=\"inner_long\")\n \tprivate long testInnerLong;\n \t@Column(name=\"inner_string\")\n \tprivate String testInnerString; \n \t\n \t\t@Override\n \t\tpublic String toString() {\n \t\t\treturn \"InnerEntity [\\ninnerInt=\" + testInnerInt\n \t\t\t\t\t+ \"\\ninnerLong=\" + testInnerLong + \"\\ninnerString=\" + testInnerString + \"]\";\n \t\t}\n\n \t\t@Override\n \t\tpublic int hashCode() {\n \t\t\tfinal int prime = 31;\n \t\t\tint result = 1;\n \t\t\tresult = prime * result + testInnerInt;\n \t\t\tresult = prime * result + (int) (testInnerLong ^ (testInnerLong >>> 32));\n \t\t\tresult = prime * result + ((testInnerString == null) ? 0 : testInnerString.hashCode());\n \t\t\treturn result;\n \t\t}\n\n \t\t@Override\n \t\tpublic boolean equals(Object obj) {\n \t\t\t\n \t\t\tif (this == obj) return true;\n \t\t\tif (obj == null) return false;\n \t\t\tif (getClass() != obj.getClass()) return false;\n \t\t\t\n \t\t\tInnerEntity other = (InnerEntity) obj;\n \t\t\tboolean equal = true;\n \t\t\tequal &= testInnerInt == other.testInnerInt;\n \t\t\tequal &= testInnerLong == other.testInnerLong;\n \t\t\tequal &= (testInnerString != null) ? testInnerString.equals(other.testInnerString) : other.testInnerString == null;\n \t\t\treturn equal;\n \t\t}\n\n \t}\n \t\n \t@Column(name=\"inner\")\n \tprivate InnerEntity inner; \n \t\n \tpublic SampleTestCompositeEntity() {\n \t\t\n \t}\n \t\n\t\t@Override\n\t\tpublic String toString() {\n\t\t\treturn \"SampleTestEntity [\\nid=\" + id + \"\\ntestInt=\" + testInt\n\t\t\t\t\t+ \"\\ntestLong=\" + testLong + \"\\ntestString=\" + testString\n\t\t\t\t\t+ \"\\ntestFloat=\" + testFloat + \"\\ntestDouble=\" + testDouble\n\t\t\t\t\t+ \"\\ntestBoolean=\" + testBoolean \n\t\t\t\t\t+ \"\\ninner = \" + inner.toString() + \"]\";\n\t\t}\n\n\t\t@Override\n\t\tpublic int hashCode() {\n\t\t\tfinal int prime = 31;\n\t\t\tint result = 1;\n\t\t\tresult = prime * result + ((id == null) ? 0 : id.hashCode());\n\t\t\tresult = prime * result + (testBoolean ? 1231 : 1237);\n\t\t\tlong temp;\n\t\t\ttemp = Double.doubleToLongBits(testDouble);\n\t\t\tresult = prime * result + (int) (temp ^ (temp >>> 32));\n\t\t\tresult = prime * result + Float.floatToIntBits(testFloat);\n\t\t\tresult = prime * result + testInt;\n\t\t\tresult = prime * result + (int) (testLong ^ (testLong >>> 32));\n\t\t\tresult = prime * result + ((testString == null) ? 0 : testString.hashCode());\n\t\t\tresult = prime * result + ((inner == null) ? 0 : inner.hashCode());\n\t\t\treturn result;\n\t\t}\n\n\t\t@Override\n\t\tpublic boolean equals(Object obj) {\n\t\t\t\n\t\t\tif (this == obj) return true;\n\t\t\tif (obj == null) return false;\n\t\t\tif (getClass() != obj.getClass()) return false;\n\t\t\t\n\t\t\tSampleTestCompositeEntity other = (SampleTestCompositeEntity) obj;\n\t\t\tboolean equal = true;\n\n\t\t\tequal &= (id != null) ? id.equals(other.id) : other.id == null;\n\t\t\tequal &= testInt == other.testInt;\n\t\t\tequal &= testLong == other.testLong;\n\t\t\tequal &= testBoolean == other.testBoolean;\n\t\t\tequal &= (testString != null) ? testString.equals(other.testString) : other.testString == null;\n\t\t\tequal &= (Double.doubleToLongBits(testDouble) == Double.doubleToLongBits(other.testDouble));\n\t\t\tequal &= (Float.floatToIntBits(testFloat) == Float.floatToIntBits(other.testFloat));\n\t\t\tequal &= (inner != null) ? inner.equals(other.inner) : other.inner == null;\n\t\t\t\n\t\t\treturn equal;\n\t\t}\n }\n}\n", "astyanax-test\\src\\test\\java\\com\\netflix\\astyanax\\entitystore\\EntityMapperTest.java": "package com.netflix.astyanax.entitystore;\n\nimport java.lang.reflect.Field;\nimport java.util.Collection;\n\nimport javax.persistence.Column;\nimport javax.persistence.Entity;\nimport javax.persistence.Id;\n\nimport junit.framework.Assert;\n\nimport org.junit.Test;\n\npublic class EntityMapperTest {\n\n\t@Test\n\tpublic void basic() {\n\t\tEntityMapper<SampleEntity, String> entityMapper = new EntityMapper<SampleEntity, String>(SampleEntity.class, null);\n\n\t\t// test id field\n\t\tField idField = entityMapper.getId();\n\t\tAssert.assertEquals(\"id\", idField.getName());\n\n\t\t// test column number\n\t\tCollection<ColumnMapper> cols = entityMapper.getColumnList();\n\t\tSystem.out.println(cols);\n\t\t// 19 simple + 1 nested Bar\n\t\tAssert.assertEquals(24, cols.size());\n\n\t\t// test field without explicit column name\n\t\t// simple field name is used\n\t\tboolean foundUUID = false;\n\t\tboolean founduuid = false;\n\t\tfor(ColumnMapper mapper: cols) {\n\t\t\tif(mapper.getColumnName().equals(\"UUID\"))\n\t\t\t\tfoundUUID = true;\n\t\t\tif(mapper.getColumnName().equals(\"uuid\"))\n\t\t\t\tfounduuid = true;\n\t\t}\n\t\tAssert.assertFalse(foundUUID);\n\t\tAssert.assertTrue(founduuid);\n\t}\n\n\t@Test(expected = IllegalArgumentException.class) \n\tpublic void missingEntityAnnotation() {\n\t\tnew EntityMapper<String, String>(String.class, null);\n\t}\n\n\t@Entity\n\tprivate static class InvalidColumnNameEntity {\n\t\t@SuppressWarnings(\"unused\")\n\t\t@Id\n\t\tprivate String id;\n\n\t\t@SuppressWarnings(\"unused\")\n\t\t@Column(name=\"LONG.PRIMITIVE\")\n\t\tprivate long longPrimitive;\n\t}\n\n\t@Test(expected = IllegalArgumentException.class) \n\tpublic void invalidColumnName() {\n\t\tnew EntityMapper<InvalidColumnNameEntity, String>(InvalidColumnNameEntity.class, null);\n\t}\n\n\t@Test\n\tpublic void doubleIdColumnAnnotation() {\n\t\tEntityMapper<DoubleIdColumnEntity, String> entityMapper = new EntityMapper<DoubleIdColumnEntity, String>(DoubleIdColumnEntity.class, null);\n\n\t\t// test id field\n\t\tField idField = entityMapper.getId();\n\t\tAssert.assertEquals(\"id\", idField.getName());\n\n\t\t// test column number\n\t\tCollection<ColumnMapper> cols = entityMapper.getColumnList();\n\t\tSystem.out.println(cols);\n\t\t// 3 cols: id, num, str\n\t\tAssert.assertEquals(3, cols.size());\n\t}\n}\n", "astyanax-test\\src\\test\\java\\com\\netflix\\astyanax\\mapping\\TestMapping.java": "package com.netflix.astyanax.mapping;\n\nimport junit.framework.Assert;\nimport org.junit.Test;\n\npublic class TestMapping {\n @Test\n public void testKeyspaceAnnotations() {\n FakeKeyspaceBean override = new FakeKeyspaceBean();\n override.setId(\"1\");\n override.setCountry(\"USA\");\n override.setCountryStatus(2);\n override.setCreateTS(12345678L);\n override.setExpirationTS(87654321L);\n override.setLastUpdateTS(24681357L);\n override.setType(\"thing\");\n override.setUpdatedBy(\"John Galt\");\n override.setByteArray(\"Some Bytes\".getBytes());\n\n Mapping<FakeKeyspaceBean> mapping = Mapping\n .make(FakeKeyspaceBean.class);\n\n Assert.assertEquals(mapping.getIdValue(override, String.class),\n override.getId());\n Assert.assertEquals(\n mapping.getColumnValue(override, \"PK\", String.class),\n override.getId());\n Assert.assertEquals(mapping.getColumnValue(override,\n \"COUNTRY_OVERRIDE\", String.class), override.getCountry());\n Assert.assertEquals(mapping.getColumnValue(override,\n \"COUNTRY_STATUS_OVERRIDE\", Integer.class), override\n .getCountryStatus());\n Assert.assertEquals(\n mapping.getColumnValue(override, \"CREATE_TS\", Long.class),\n override.getCreateTS());\n Assert.assertEquals(\n mapping.getColumnValue(override, \"EXP_TS\", Long.class),\n override.getExpirationTS());\n Assert.assertEquals(\n mapping.getColumnValue(override, \"LAST_UPDATE_TS\", Long.class),\n override.getLastUpdateTS());\n Assert.assertEquals(mapping.getColumnValue(override,\n \"OVERRIDE_BY_TYPE\", String.class), override.getType());\n Assert.assertEquals(\n mapping.getColumnValue(override, \"UPDATED_BY\", String.class),\n override.getUpdatedBy());\n Assert.assertEquals(\n mapping.getColumnValue(override, \"BYTE_ARRAY\", byte[].class),\n override.getByteArray());\n\n FakeKeyspaceBean copy = new FakeKeyspaceBean();\n for (String fieldName : mapping.getNames()) {\n mapping.setColumnValue(copy, fieldName,\n mapping.getColumnValue(override, fieldName, Object.class));\n }\n\n Assert.assertEquals(copy.getId(), override.getId());\n Assert.assertEquals(copy.getCountry(), override.getCountry());\n Assert.assertEquals(copy.getCountryStatus(),\n override.getCountryStatus());\n Assert.assertEquals(copy.getCreateTS(), override.getCreateTS());\n Assert.assertEquals(copy.getExpirationTS(), override.getExpirationTS());\n Assert.assertEquals(copy.getLastUpdateTS(), override.getLastUpdateTS());\n Assert.assertEquals(copy.getType(), override.getType());\n Assert.assertEquals(copy.getUpdatedBy(), override.getUpdatedBy());\n Assert.assertEquals(copy.getByteArray(), override.getByteArray());\n }\n\n @Test\n public void testCache() {\n MappingCache cache = new MappingCache();\n\n Mapping<FakeKeyspaceBean> keyspaceBeanMapping1 = cache\n .getMapping(FakeKeyspaceBean.class);\n Mapping<FakeKeyspaceBean> keyspaceBeanMapping2 = cache\n .getMapping(FakeKeyspaceBean.class);\n\n Assert.assertSame(keyspaceBeanMapping1, keyspaceBeanMapping2);\n }\n}\n", "astyanax-test\\src\\test\\java\\com\\netflix\\astyanax\\recipes\\ReverseIndexQueryTest.java": "package com.netflix.astyanax.recipes;\n\nimport java.nio.ByteBuffer;\nimport java.util.Arrays;\nimport java.util.HashMap;\nimport java.util.Map;\nimport java.util.concurrent.atomic.AtomicLong;\n\nimport junit.framework.Assert;\n\nimport org.junit.AfterClass;\nimport org.junit.BeforeClass;\nimport org.junit.Test;\nimport org.slf4j.Logger;\nimport org.slf4j.LoggerFactory;\n\nimport com.google.common.base.Function;\nimport com.netflix.astyanax.AstyanaxContext;\nimport com.netflix.astyanax.Cluster;\nimport com.netflix.astyanax.Keyspace;\nimport com.netflix.astyanax.MutationBatch;\nimport com.netflix.astyanax.Serializer;\nimport com.netflix.astyanax.annotations.Component;\nimport com.netflix.astyanax.connectionpool.NodeDiscoveryType;\nimport com.netflix.astyanax.connectionpool.exceptions.ConnectionException;\nimport com.netflix.astyanax.connectionpool.impl.ConnectionPoolConfigurationImpl;\nimport com.netflix.astyanax.connectionpool.impl.CountingConnectionPoolMonitor;\nimport com.netflix.astyanax.ddl.KeyspaceDefinition;\nimport com.netflix.astyanax.impl.AstyanaxConfigurationImpl;\nimport com.netflix.astyanax.model.Column;\nimport com.netflix.astyanax.model.ColumnFamily;\nimport com.netflix.astyanax.model.Row;\nimport com.netflix.astyanax.recipes.ReverseIndexQuery.IndexEntryCallback;\nimport com.netflix.astyanax.serializers.AnnotatedCompositeSerializer;\nimport com.netflix.astyanax.serializers.LongSerializer;\nimport com.netflix.astyanax.serializers.StringSerializer;\nimport com.netflix.astyanax.thrift.ThriftFamilyFactory;\n\npublic class ReverseIndexQueryTest {\n\n private static Logger LOG = LoggerFactory.getLogger(ReverseIndexQueryTest.class);\n\n private static AstyanaxContext<Cluster> clusterContext;\n\n private static final String TEST_CLUSTER_NAME = \"TestCluster\";\n private static final String TEST_KEYSPACE_NAME = \"ReverseIndexTest\";\n private static final String TEST_DATA_CF = \"Data\";\n private static final String TEST_INDEX_CF = \"Index\";\n\n private static final boolean TEST_INIT_KEYSPACE = true;\n private static final long ROW_COUNT = 1000;\n private static final int SHARD_COUNT = 11;\n\n public static final String SEEDS = \"localhost:7102\";\n\n private static ColumnFamily<Long, String> CF_DATA = ColumnFamily\n .newColumnFamily(TEST_DATA_CF, LongSerializer.get(),\n StringSerializer.get());\n\n private static class IndexEntry {\n @Component(ordinal = 0)\n Long value;\n @Component(ordinal = 1)\n Long key;\n\n public IndexEntry(Long value, Long key) {\n this.value = value;\n this.key = key;\n }\n }\n\n private static Serializer<IndexEntry> indexEntitySerializer = new AnnotatedCompositeSerializer<IndexEntry>(\n IndexEntry.class);\n\n private static ColumnFamily<String, IndexEntry> CF_INDEX = ColumnFamily\n .newColumnFamily(TEST_INDEX_CF, StringSerializer.get(),\n indexEntitySerializer);\n\n @BeforeClass\n public static void setup() throws Exception {\n clusterContext = new AstyanaxContext.Builder()\n .forCluster(TEST_CLUSTER_NAME)\n .withAstyanaxConfiguration(\n new AstyanaxConfigurationImpl()\n .setDiscoveryType(NodeDiscoveryType.NONE))\n .withConnectionPoolConfiguration(\n new ConnectionPoolConfigurationImpl(TEST_CLUSTER_NAME)\n .setMaxConnsPerHost(1).setSeeds(SEEDS))\n .withConnectionPoolMonitor(new CountingConnectionPoolMonitor())\n .buildCluster(ThriftFamilyFactory.getInstance());\n\n clusterContext.start();\n\n if (TEST_INIT_KEYSPACE) {\n Cluster cluster = clusterContext.getEntity();\n try {\n LOG.info(\"Dropping keyspace: \" + TEST_KEYSPACE_NAME);\n cluster.dropKeyspace(TEST_KEYSPACE_NAME);\n Thread.sleep(10000);\n } catch (ConnectionException e) {\n LOG.warn(e.getMessage());\n }\n\n Map<String, String> stratOptions = new HashMap<String, String>();\n stratOptions.put(\"replication_factor\", \"3\");\n\n try {\n LOG.info(\"Creating keyspace: \" + TEST_KEYSPACE_NAME);\n\n KeyspaceDefinition ksDef = cluster.makeKeyspaceDefinition();\n\n ksDef.setName(TEST_KEYSPACE_NAME)\n .setStrategyOptions(stratOptions)\n .setStrategyClass(\"SimpleStrategy\")\n .addColumnFamily(\n cluster.makeColumnFamilyDefinition()\n .setName(CF_DATA.getName())\n .setComparatorType(\"UTF8Type\")\n // .setKeyValidationClass(\"LongType\")\n // .setDefaultValidationClass(\"BytesType\")\n )\n .addColumnFamily(\n cluster.makeColumnFamilyDefinition()\n .setName(CF_INDEX.getName())\n .setComparatorType(\n \"CompositeType(LongType, LongType)\")\n .setDefaultValidationClass(\"BytesType\"));\n cluster.addKeyspace(ksDef);\n Thread.sleep(2000);\n populateKeyspace();\n } catch (ConnectionException e) {\n LOG.error(e.getMessage());\n }\n }\n }\n\n @AfterClass\n public static void teardown() {\n if (clusterContext != null)\n clusterContext.shutdown();\n }\n\n public static void populateKeyspace() throws Exception {\n LOG.info(\"Ppoulating keyspace: \" + TEST_KEYSPACE_NAME);\n\n Keyspace keyspace = clusterContext.getEntity().getKeyspace(\n TEST_KEYSPACE_NAME);\n\n try {\n // CF_Users :\n // 1 :\n // 'A' : 1,\n // 'B' : 2,\n //\n // CF_Index :\n // 'B_Shard1':\n // 2:1 : null\n // 3:2 : null\n //\n\n MutationBatch m = keyspace.prepareMutationBatch();\n\n for (long row = 0; row < ROW_COUNT; row++) {\n long value = row * 100;\n m.withRow(CF_DATA, row).putColumn(\"A\", \"ABC\", null)\n .putColumn(\"B\", \"DEF\", null);\n m.withRow(CF_INDEX, \"B_\" + (row % SHARD_COUNT)).putColumn(\n new IndexEntry(value, row), row, null);\n }\n\n // System.out.println(m);\n m.execute();\n } catch (Exception e) {\n LOG.error(e.getMessage());\n Assert.fail();\n }\n }\n\n @Test\n public void testReverseIndex() throws Exception{\n LOG.info(\"Starting\");\n final AtomicLong counter = new AtomicLong();\n\n Keyspace keyspace = clusterContext.getEntity().getKeyspace(TEST_KEYSPACE_NAME);\n ReverseIndexQuery\n .newQuery(keyspace, CF_DATA, CF_INDEX.getName(),\n LongSerializer.get())\n .fromIndexValue(100L)\n .toIndexValue(10000L)\n .withIndexShards(\n new Shards.StringShardBuilder().setPrefix(\"B_\")\n .setShardCount(SHARD_COUNT).build())\n .withColumnSlice(Arrays.asList(\"A\"))\n .forEach(new Function<Row<Long, String>, Void>() {\n @Override\n public Void apply(Row<Long, String> row) {\n StringBuilder sb = new StringBuilder();\n for (Column<String> column : row.getColumns()) {\n sb.append(column.getName()).append(\", \");\n }\n counter.incrementAndGet();\n LOG.info(\"Row: \" + row.getKey() + \" Columns: \"\n + sb.toString());\n return null;\n }\n }).forEachIndexEntry(new IndexEntryCallback<Long, Long>() {\n @Override\n public boolean handleEntry(Long key, Long value,\n ByteBuffer meta) {\n LOG.info(\"Row : \" + key + \" IndexValue: \" + value\n + \" Meta: \"\n + LongSerializer.get().fromByteBuffer(meta));\n if (key % 2 == 1)\n return false;\n return true;\n }\n }).execute();\n\n LOG.info(\"Read \" + counter.get() + \" rows\");\n }\n\n}\n", "astyanax-thrift\\src\\main\\java\\com\\netflix\\astyanax\\thrift\\AbstractIndexQueryImpl.java": "/*******************************************************************************\n * Copyright 2011 Netflix\n * \n * Licensed under the Apache License, Version 2.0 (the \"License\");\n * you may not use this file except in compliance with the License.\n * You may obtain a copy of the License at\n * \n * http://www.apache.org/licenses/LICENSE-2.0\n * \n * Unless required by applicable law or agreed to in writing, software\n * distributed under the License is distributed on an \"AS IS\" BASIS,\n * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n * See the License for the specific language governing permissions and\n * limitations under the License.\n ******************************************************************************/\npackage com.netflix.astyanax.thrift;\n\nimport java.nio.ByteBuffer;\nimport java.util.Arrays;\nimport java.util.Collection;\nimport java.util.Date;\nimport java.util.UUID;\n\nimport org.apache.cassandra.thrift.IndexOperator;\nimport org.apache.cassandra.thrift.SlicePredicate;\nimport org.apache.cassandra.thrift.SliceRange;\n\nimport com.netflix.astyanax.Serializer;\nimport com.netflix.astyanax.model.ByteBufferRange;\nimport com.netflix.astyanax.model.ColumnFamily;\nimport com.netflix.astyanax.model.ColumnSlice;\nimport com.netflix.astyanax.query.IndexColumnExpression;\nimport com.netflix.astyanax.query.IndexOperationExpression;\nimport com.netflix.astyanax.query.IndexQuery;\nimport com.netflix.astyanax.query.IndexValueExpression;\nimport com.netflix.astyanax.query.PreparedIndexExpression;\nimport com.netflix.astyanax.serializers.BooleanSerializer;\nimport com.netflix.astyanax.serializers.ByteBufferSerializer;\nimport com.netflix.astyanax.serializers.BytesArraySerializer;\nimport com.netflix.astyanax.serializers.DateSerializer;\nimport com.netflix.astyanax.serializers.DoubleSerializer;\nimport com.netflix.astyanax.serializers.IntegerSerializer;\nimport com.netflix.astyanax.serializers.LongSerializer;\nimport com.netflix.astyanax.serializers.StringSerializer;\nimport com.netflix.astyanax.serializers.UUIDSerializer;\n\npublic abstract class AbstractIndexQueryImpl<K, C> implements IndexQuery<K, C> {\n protected final org.apache.cassandra.thrift.IndexClause indexClause = new org.apache.cassandra.thrift.IndexClause();\n protected SlicePredicate predicate = new SlicePredicate().setSlice_range(ThriftUtils.createAllInclusiveSliceRange());\n protected boolean isPaginating = false;\n protected boolean paginateNoMore = false;\n protected boolean firstPage = true;\n protected ColumnFamily<K, C> columnFamily;\n\n public AbstractIndexQueryImpl(ColumnFamily<K, C> columnFamily) {\n this.columnFamily = columnFamily;\n indexClause.setStart_key(ByteBuffer.allocate(0));\n }\n\n @Override\n public IndexQuery<K, C> withColumnSlice(C... columns) {\n if (columns != null) {\n predicate.setColumn_names(columnFamily.getColumnSerializer().toBytesList(Arrays.asList(columns)))\n .setSlice_rangeIsSet(false);\n }\n return this;\n }\n\n @Override\n public IndexQuery<K, C> withColumnSlice(Collection<C> columns) {\n if (columns != null)\n predicate.setColumn_names(columnFamily.getColumnSerializer().toBytesList(columns)).setSlice_rangeIsSet(\n false);\n return this;\n }\n\n @Override\n public IndexQuery<K, C> withColumnSlice(ColumnSlice<C> slice) {\n if (slice.getColumns() != null) {\n predicate.setColumn_names(columnFamily.getColumnSerializer().toBytesList(slice.getColumns()))\n .setSlice_rangeIsSet(false);\n }\n else {\n predicate.setSlice_range(ThriftUtils.createSliceRange(columnFamily.getColumnSerializer(),\n slice.getStartColumn(), slice.getEndColumn(), slice.getReversed(), slice.getLimit()));\n }\n return this;\n }\n\n @Override\n public IndexQuery<K, C> withColumnRange(C startColumn, C endColumn, boolean reversed, int count) {\n predicate.setSlice_range(ThriftUtils.createSliceRange(columnFamily.getColumnSerializer(), startColumn,\n endColumn, reversed, count));\n return this;\n }\n\n @Override\n public IndexQuery<K, C> withColumnRange(ByteBufferRange range) {\n predicate.setSlice_range(new SliceRange().setStart(range.getStart()).setFinish(range.getEnd())\n .setCount(range.getLimit()).setReversed(range.isReversed()));\n return this;\n }\n\n @Override\n public IndexQuery<K, C> withColumnRange(ByteBuffer startColumn, ByteBuffer endColumn, boolean reversed, int count) {\n predicate.setSlice_range(new SliceRange(startColumn, endColumn, reversed, count));\n return this;\n }\n\n @Override\n public IndexQuery<K, C> setLimit(int count) {\n return setRowLimit(count);\n }\n\n @Override\n public IndexQuery<K, C> setRowLimit(int count) {\n indexClause.setCount(count);\n return this;\n }\n\n @Override\n public IndexQuery<K, C> setStartKey(K key) {\n indexClause.setStart_key(columnFamily.getKeySerializer().toByteBuffer(key));\n return this;\n }\n\n protected void setNextStartKey(ByteBuffer byteBuffer) {\n indexClause.setStart_key(byteBuffer);\n if (firstPage) {\n firstPage = false;\n if (indexClause.getCount() != Integer.MAX_VALUE)\n indexClause.setCount(indexClause.getCount() + 1);\n }\n }\n\n private IndexQuery<K, C> getThisQuery() {\n return this;\n }\n\n static interface IndexExpression<K, C> extends IndexColumnExpression<K, C>, IndexOperationExpression<K, C>,\n IndexValueExpression<K, C> {\n\n }\n\n public IndexQuery<K, C> addPreparedExpressions(Collection<PreparedIndexExpression<K, C>> expressions) {\n for (PreparedIndexExpression<K, C> expression : expressions) {\n org.apache.cassandra.thrift.IndexExpression expr = new org.apache.cassandra.thrift.IndexExpression()\n .setColumn_name(expression.getColumn().duplicate()).setValue(expression.getValue().duplicate());\n switch (expression.getOperator()) {\n case EQ:\n expr.setOp(IndexOperator.EQ);\n break;\n case LT:\n expr.setOp(IndexOperator.LT);\n break;\n case GT:\n expr.setOp(IndexOperator.GT);\n break;\n case GTE:\n expr.setOp(IndexOperator.GTE);\n break;\n case LTE:\n expr.setOp(IndexOperator.LTE);\n break;\n default:\n throw new RuntimeException(\"Invalid operator type: \" + expression.getOperator().name());\n }\n indexClause.addToExpressions(expr);\n }\n return this;\n }\n\n @Override\n public IndexColumnExpression<K, C> addExpression() {\n return new IndexExpression<K, C>() {\n private final org.apache.cassandra.thrift.IndexExpression internalExpression = new org.apache.cassandra.thrift.IndexExpression();\n\n @Override\n public IndexOperationExpression<K, C> whereColumn(C columnName) {\n internalExpression.setColumn_name(columnFamily.getColumnSerializer().toBytes(columnName));\n return this;\n }\n\n @Override\n public IndexValueExpression<K, C> equals() {\n internalExpression.setOp(IndexOperator.EQ);\n return this;\n }\n\n @Override\n public IndexValueExpression<K, C> greaterThan() {\n internalExpression.setOp(IndexOperator.GT);\n return this;\n }\n\n @Override\n public IndexValueExpression<K, C> lessThan() {\n internalExpression.setOp(IndexOperator.LT);\n return this;\n }\n\n @Override\n public IndexValueExpression<K, C> greaterThanEquals() {\n internalExpression.setOp(IndexOperator.GTE);\n return this;\n }\n\n @Override\n public IndexValueExpression<K, C> lessThanEquals() {\n internalExpression.setOp(IndexOperator.LTE);\n return this;\n }\n\n @Override\n public IndexQuery<K, C> value(String value) {\n internalExpression.setValue(StringSerializer.get().toBytes(value));\n indexClause.addToExpressions(internalExpression);\n return getThisQuery();\n }\n\n @Override\n public IndexQuery<K, C> value(long value) {\n internalExpression.setValue(LongSerializer.get().toBytes(value));\n indexClause.addToExpressions(internalExpression);\n return getThisQuery();\n }\n\n @Override\n public IndexQuery<K, C> value(int value) {\n internalExpression.setValue(IntegerSerializer.get().toBytes(value));\n indexClause.addToExpressions(internalExpression);\n return getThisQuery();\n }\n\n @Override\n public IndexQuery<K, C> value(boolean value) {\n internalExpression.setValue(BooleanSerializer.get().toBytes(value));\n indexClause.addToExpressions(internalExpression);\n return getThisQuery();\n }\n\n @Override\n public IndexQuery<K, C> value(Date value) {\n internalExpression.setValue(DateSerializer.get().toBytes(value));\n indexClause.addToExpressions(internalExpression);\n return getThisQuery();\n }\n\n @Override\n public IndexQuery<K, C> value(byte[] value) {\n internalExpression.setValue(BytesArraySerializer.get().toBytes(value));\n indexClause.addToExpressions(internalExpression);\n return getThisQuery();\n }\n\n @Override\n public IndexQuery<K, C> value(ByteBuffer value) {\n internalExpression.setValue(ByteBufferSerializer.get().toBytes(value));\n indexClause.addToExpressions(internalExpression);\n return getThisQuery();\n }\n\n @Override\n public IndexQuery<K, C> value(double value) {\n internalExpression.setValue(DoubleSerializer.get().toBytes(value));\n indexClause.addToExpressions(internalExpression);\n return getThisQuery();\n }\n\n @Override\n public IndexQuery<K, C> value(UUID value) {\n internalExpression.setValue(UUIDSerializer.get().toBytes(value));\n indexClause.addToExpressions(internalExpression);\n return getThisQuery();\n }\n\n @Override\n public <V> IndexQuery<K, C> value(V value, Serializer<V> valueSerializer) {\n internalExpression.setValue(valueSerializer.toBytes(value));\n indexClause.addToExpressions(internalExpression);\n return getThisQuery();\n }\n };\n }\n\n @Override\n public IndexQuery<K, C> setIsPaginating() {\n return autoPaginateRows(true);\n }\n\n @Override\n public IndexQuery<K, C> autoPaginateRows(boolean autoPaginate) {\n this.isPaginating = autoPaginate;\n return this;\n }\n\n}\n", "gradle\\wrapper\\gradle-wrapper.properties": "distributionBase=GRADLE_USER_HOME\ndistributionPath=wrapper/dists\ndistributionUrl=https\\://services.gradle.org/distributions/gradle-6.8.3-bin.zip\nzipStoreBase=GRADLE_USER_HOME\nzipStorePath=wrapper/dists\n"} | null |
aws-autoscaling | {"type": "directory", "name": "aws-autoscaling", "children": [{"type": "file", "name": "OSSMETADATA"}, {"type": "file", "name": "README.textile"}, {"type": "directory", "name": "scripts", "children": [{"type": "file", "name": "scale-down.sh"}, {"type": "file", "name": "scale-up.sh"}]}]} | Tools for using auto scaling and documentation related to best practices. | {".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n"} | null |
awsobjectmapper | {"type": "directory", "name": "awsobjectmapper", "children": [{"type": "directory", "name": "awsobjectmapper", "children": [{"type": "directory", "name": "src", "children": [{"type": "directory", "name": "main", "children": [{"type": "directory", "name": "java", "children": [{"type": "directory", "name": "com", "children": [{"type": "directory", "name": "netflix", "children": [{"type": "directory", "name": "awsobjectmapper", "children": [{"type": "file", "name": "package-info.java"}]}]}]}]}]}, {"type": "directory", "name": "test", "children": [{"type": "directory", "name": "java", "children": [{"type": "directory", "name": "com", "children": [{"type": "directory", "name": "netflix", "children": [{"type": "directory", "name": "awsobjectmapper", "children": [{"type": "file", "name": "AmazonObjectMapperTest.java"}]}]}]}]}, {"type": "directory", "name": "resources", "children": [{"type": "file", "name": "recordSet.json"}]}]}]}]}, {"type": "file", "name": "build.gradle"}, {"type": "directory", "name": "buildSrc", "children": [{"type": "file", "name": "build.gradle"}, {"type": "directory", "name": "src", "children": [{"type": "directory", "name": "main", "children": [{"type": "directory", "name": "groovy", "children": [{"type": "file", "name": "AwsMixinGenerator.groovy"}]}]}]}]}, {"type": "directory", "name": "codequality", "children": [{"type": "file", "name": "checkstyle.xml"}, {"type": "file", "name": "HEADER"}]}, {"type": "directory", "name": "gradle", "children": [{"type": "directory", "name": "wrapper", "children": [{"type": "file", "name": "gradle-wrapper.properties"}]}]}, {"type": "file", "name": "gradle.properties"}, {"type": "file", "name": "gradlew"}, {"type": "file", "name": "LICENSE.txt"}, {"type": "file", "name": "OSSMETADATA"}, {"type": "file", "name": "README.md"}, {"type": "file", "name": "settings.gradle"}]} |
[](https://travis-ci.org/Netflix/AWSObjectMapper/builds)
# AWS ObjectMapper
Mapper that can be used with jackson to convert AWS model objects to/from json.
| {".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n", ".git\\logs\\refs\\heads\\main": "0000000000000000000000000000000000000000 1e71df6f18d764cf2764eb7147cc951c1411e8db Hamza Amin <[email protected]> 1728220209 +0500\tclone: from https://github.com/Netflix/awsobjectmapper.git\n", ".git\\refs\\heads\\main": "1e71df6f18d764cf2764eb7147cc951c1411e8db\n", "awsobjectmapper\\src\\test\\java\\com\\netflix\\awsobjectmapper\\AmazonObjectMapperTest.java": "/**\n * Copyright 2014 Netflix, Inc.\n *\n * Licensed under the Apache License, Version 2.0 (the \"License\");\n * you may not use this file except in compliance with the License.\n * You may obtain a copy of the License at\n *\n * http://www.apache.org/licenses/LICENSE-2.0\n *\n * Unless required by applicable law or agreed to in writing, software\n * distributed under the License is distributed on an \"AS IS\" BASIS,\n * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n * See the License for the specific language governing permissions and\n * limitations under the License.\n */\npackage com.netflix.awsobjectmapper;\n\nimport com.amazonaws.services.ecs.model.VersionInfo;\nimport com.fasterxml.jackson.databind.ObjectMapper;\nimport com.google.common.reflect.ClassPath;\nimport com.google.common.io.Resources;\n\nimport org.jeasy.random.EasyRandom;\nimport org.jeasy.random.EasyRandomParameters;\n\nimport com.amazonaws.services.route53.model.ResourceRecordSet;\n\nimport java.lang.reflect.Field;\nimport java.util.Set;\nimport java.util.function.Predicate;\n\nimport org.junit.Assert;\nimport org.junit.Test;\nimport org.junit.runner.RunWith;\nimport org.junit.runners.JUnit4;\n\n@RunWith(JUnit4.class)\npublic class AmazonObjectMapperTest {\n\n private boolean hasEmptyConstructor(Class<?> c) {\n try {\n c.getConstructor(); // Throws if no match\n return true;\n } catch (Exception e) {\n return false;\n }\n }\n\n private boolean isModelClass(Class<?> c) {\n boolean skip = false;\n\n // Skip package and exception classes\n final String simpleName = c.getSimpleName();\n skip = simpleName == \"package-info\" || simpleName.endsWith(\"Exception\");\n\n // Ignore transform classes\n skip = skip || c.getName().contains(\".transform.\");\n\n // Ignore interfaces\n skip = skip || c.isInterface();\n\n // Must have an empty constructor\n skip = skip || !hasEmptyConstructor(c);\n\n return !skip;\n }\n\n @Test\n public void mapRandomAwsObjects() throws Exception {\n final ObjectMapper mapper = new ObjectMapper();\n AmazonObjectMapperConfigurer.configure(mapper);\n final EasyRandomParameters parameters = new EasyRandomParameters()\n .ignoreRandomizationErrors(true)\n .excludeField(excludedFields())\n .excludeType(excludedTypes())\n .collectionSizeRange(1, 3);\n final EasyRandom easyRandom = new EasyRandom(parameters);\n final Set<ClassPath.ClassInfo> classes = ClassPath\n .from(getClass().getClassLoader())\n .getTopLevelClassesRecursive(\"com.amazonaws\");\n for (ClassPath.ClassInfo cinfo : classes) {\n if (cinfo.getName().contains(\".model.\")\n && !cinfo.getSimpleName().startsWith(\"GetConsole\")\n && !cinfo.getName().contains(\".s3.model.\")) { // TODO: problem with CORSRule\n final Class<?> c = cinfo.load();\n if (isModelClass(c)) {\n Object obj = easyRandom.nextObject(c);\n String j1 = mapper.writeValueAsString(obj);\n Object d1 = mapper.readValue(j1, c);\n String j2 = mapper.writeValueAsString(d1);\n Assert.assertEquals(j1, j2);\n }\n }\n }\n }\n\n private Predicate<Field> excludedFields() {\n return field -> field.getType().equals(com.amazonaws.ResponseMetadata.class) ||\n field.getType().equals(com.amazonaws.http.SdkHttpMetadata.class);\n }\n\n private Predicate<Class<?>> excludedTypes() {\n return type -> type.getSuperclass().equals(com.amazonaws.AmazonWebServiceRequest.class) ||\n type.equals(com.amazonaws.services.simplesystemsmanagement.model.InventoryAggregator.class);\n }\n\n @Test\n @SuppressWarnings(\"deprecation\")\n public void testDeprecatedMapper() throws Exception {\n final AmazonObjectMapper mapper = new AmazonObjectMapper();\n final EasyRandom easyRandom = new EasyRandom();\n Object obj = easyRandom.nextObject(VersionInfo.class);\n String j1 = mapper.writeValueAsString(obj);\n Object d1 = mapper.readValue(j1, VersionInfo.class);\n String j2 = mapper.writeValueAsString(d1);\n Assert.assertEquals(j1, j2);\n }\n\n @Test\n public void namingStrategy() throws Exception {\n final ObjectMapper mapper = new ObjectMapper();\n AmazonObjectMapperConfigurer.configure(mapper);\n byte[] json = Resources.toByteArray(Resources.getResource(\"recordSet.json\"));\n ResourceRecordSet recordSet = mapper.readValue(json, ResourceRecordSet.class);\n Assert.assertEquals(60L, (long) recordSet.getTTL());\n }\n}\n", "gradle\\wrapper\\gradle-wrapper.properties": "distributionBase=GRADLE_USER_HOME\ndistributionPath=wrapper/dists\ndistributionUrl=https\\://services.gradle.org/distributions/gradle-6.8.3-bin.zip\nzipStoreBase=GRADLE_USER_HOME\nzipStorePath=wrapper/dists\n"} | null |
batch_request_api | {"type": "directory", "name": "batch_request_api", "children": [{"type": "file", "name": ".rspec"}, {"type": "file", "name": "batch_request_api.gemspec"}, {"type": "directory", "name": "config", "children": [{"type": "file", "name": "routes.rb"}]}, {"type": "directory", "name": "docs", "children": [{"type": "file", "name": "expected_middleware_payload.md"}, {"type": "file", "name": "sample_parallel_controller.md"}, {"type": "file", "name": "talent_create.json"}, {"type": "file", "name": "talent_update.json"}]}, {"type": "file", "name": "Gemfile"}, {"type": "directory", "name": "lib", "children": [{"type": "directory", "name": "batch_request_api", "children": [{"type": "file", "name": "batch_parallel.rb"}, {"type": "file", "name": "batch_sequential.rb"}, {"type": "file", "name": "batch_util.rb"}, {"type": "file", "name": "configuration.rb"}, {"type": "file", "name": "engine.rb"}, {"type": "file", "name": "middleware.rb"}, {"type": "file", "name": "railtie.rb"}, {"type": "file", "name": "version.rb"}]}, {"type": "file", "name": "batch_request_api.rb"}]}, {"type": "file", "name": "LICENSE"}, {"type": "file", "name": "OSSMETADATA"}, {"type": "file", "name": "Rakefile"}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "spec", "children": [{"type": "file", "name": "batch_parallel_spec.rb"}, {"type": "file", "name": "batch_util_spec.rb"}, {"type": "directory", "name": "mocks", "children": [{"type": "file", "name": "movie_mock.json"}]}, {"type": "file", "name": "spec_helper.rb"}]}]} | # batch_request_api
[]()
Rails middleware gem to achieve Batch creates, updates and deletes.
* Customizable middleware
* Batch create, update and delete records sequentially or in parallel
### Installation
Add this line to your application's Gemfile:
```ruby
gem 'batch_request_api'
```
Or install it yourself as:
$ gem install batch_request_api
### Overview
After installing the gem, you get the middleware which will intercept requests to the following urls.
* batch_sequential ```(/api/v1/batch_sequential)```
* batch_parallel ```(/api/v1/batch_parallel)```
To use custom URLs, add a configuration block to your app initialization. Example:
```ruby
BatchRequestApi.configure do |config|
config.batch_sequential_paths = ['/api/v1/batch_sequential']
config.batch_parallel_paths = ['/api/v1/batch_parallel']
end
```
API endpoint can be disabled by setting the path to a falsy value (`nil`/`false`).
### Sequential Usage
This is the simplest way to implement batch. One network request to ```/api/v1/batch_sequential``` containing the batched payload will work with a regular rails controller.
### Parallel Usage
This requires your controller to iterate and apply a transaction. One network request to ```/api/v1/batch_parallel``` containing the batched payload will need a code similar to this [sample](https://github.com/Netflix/batch_request_api/blob/master/docs/sample_parallel_controller.md).
The batch request payload is available on the controller using ``` params['json'] ```
### Batch Client
* [Ember Addon](https://github.com/Netflix/ember-batch-request) (Ideal)
* [Ruby Client](https://github.com/Netflix/batch_request_client)
We expect that you will probably use the [Ember Add on](https://github.com/Netflix/ember-batch-request) with this gem to make the batch request and receive a response.
If not, no worries we have built a [sample Ruby Client](https://github.com/Netflix/batch_request_client) for that reason.
Here are the sample payloads that the middleware expects for [create/update/delete](https://github.com/Netflix/batch_request_api/blob/master/docs/expected_middleware_payload.md).
The ruby client constructs the format for create action.
### Batch Request Payload:
```javascript
"requests": [
{
"method": "POST",
"url": "/api/v1/movies",
"body": { }, { }
}
]
}
```
### Batch Request Response:
```ruby
[
{"status"=>200, "headers"=>{}, "response"=>{}},
{"status"=>200, "headers"=>{}, "response"=>{}}
]
```
### Contributing
If you would like to contribute, you can fork the project, edit, and make a pull request.
| {".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n"} | null |
batch_request_client | {"type": "directory", "name": "batch_request_client", "children": [{"type": "file", "name": "batch_request_client.gemspec"}, {"type": "directory", "name": "docs", "children": [{"type": "file", "name": "sample_request.md"}]}, {"type": "file", "name": "Gemfile"}, {"type": "directory", "name": "lib", "children": [{"type": "directory", "name": "batch_request_client", "children": [{"type": "file", "name": "batch_util.rb"}, {"type": "file", "name": "version.rb"}]}, {"type": "file", "name": "batch_request_client.rb"}]}, {"type": "file", "name": "LICENSE"}, {"type": "file", "name": "OSSMETADATA"}, {"type": "file", "name": "Rakefile"}, {"type": "file", "name": "README.md"}, {"type": "directory", "name": "test", "children": [{"type": "directory", "name": "batch_request_client", "children": [{"type": "file", "name": "batch_util_test.rb"}]}, {"type": "file", "name": "batch_request_client_test.rb"}, {"type": "file", "name": "test_helper.rb"}]}]} | # BatchRequestClient
[]()
Ruby Client to create batch payload for use with [Batch Request API Middleware](https://github.com/Netflix/batch_request_api)
## Installation
Add this line to your application's Gemfile:
```ruby
gem 'batch_request_client'
```
Or install it yourself as:
```bash
$ gem install batch_request_client
```
## Usage
``` ruby
BatchRequestClient.create(payload, url)
```
## Arguments
* payload - Array of models.
* url - Complete route.
## Example:
``` ruby
BatchRequestClient.create(payload, 'http://localhost:3000/talents', :parallel)
```
Default is sequential operation, if you want parallel, you can pass ```:parallel``` in the list of arguments.
## Coming Soon
Update and Delete is still TODO, since we focussed on the [Ember Addon](https://github.com/Netflix/ember-batch-request) that handles update and delete from UI.
## Contributing
If you would like to contribute, you can fork the project, edit, and make a pull request.
| {".git\\hooks\\applypatch-msg.sample": "#!/bin/sh\n#\n# An example hook script to check the commit log message taken by\n# applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit. The hook is\n# allowed to edit the commit message file.\n#\n# To enable this hook, rename this file to \"applypatch-msg\".\n\n. git-sh-setup\ncommitmsg=\"$(git rev-parse --git-path hooks/commit-msg)\"\ntest -x \"$commitmsg\" && exec \"$commitmsg\" ${1+\"$@\"}\n:\n", ".git\\hooks\\pre-applypatch.sample": "#!/bin/sh\n#\n# An example hook script to verify what is about to be committed\n# by applypatch from an e-mail message.\n#\n# The hook should exit with non-zero status after issuing an\n# appropriate message if it wants to stop the commit.\n#\n# To enable this hook, rename this file to \"pre-applypatch\".\n\n. git-sh-setup\nprecommit=\"$(git rev-parse --git-path hooks/pre-commit)\"\ntest -x \"$precommit\" && exec \"$precommit\" ${1+\"$@\"}\n:\n"} | null |