
metadata
language: vi
datasets:
- youtube-vi-13k-hours
tags:
- speech
license: cc-by-nc-4.0
Vietnamese Self-Supervised Learning Wav2Vec2 model
Model
We use wav2vec2 architecture for doing Self-Supervised learning
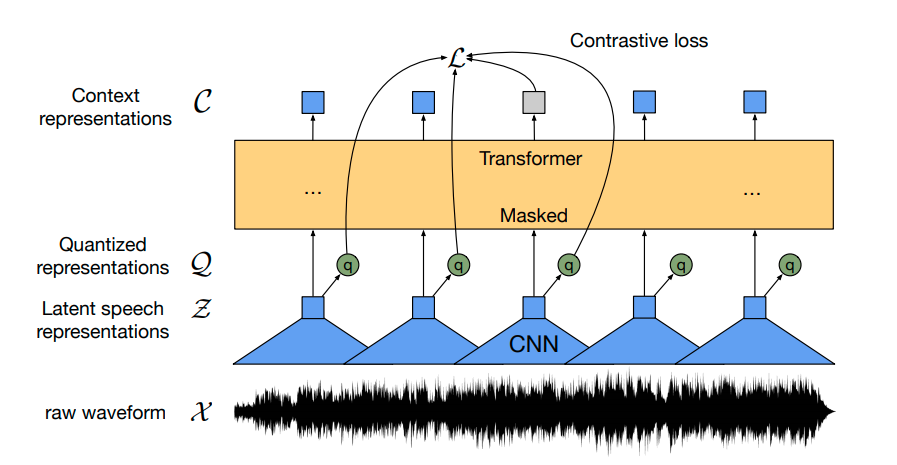
Data
Our self-supervised model is pre-trained on a massive audio set of 13k hours of Vietnamese youtube audio, which includes:
- Clean audio
- Noise audio
- Conversation
- Multi-gender and dialects
Download
We have already upload our pre-trained model to the Huggingface.
- Based version ~ 95M params
- Large version ~ 317M params
Usage
from transformers import Wav2Vec2ForPreTraining, Wav2Vec2Processor
model_name = 'nguyenvulebinh/wav2vec2-base-vi'
# model_name = 'nguyenvulebinh/wav2vec2-large-vi'
model = Wav2Vec2ForPreTraining.from_pretrained(model_name)
processor = Wav2Vec2Processor.from_pretrained(model_name)
Since our model has the same architecture as the English wav2vec2 version, you can use this notebook for more information on how to fine-tune the model.
Contact
[email protected] / [email protected]
