
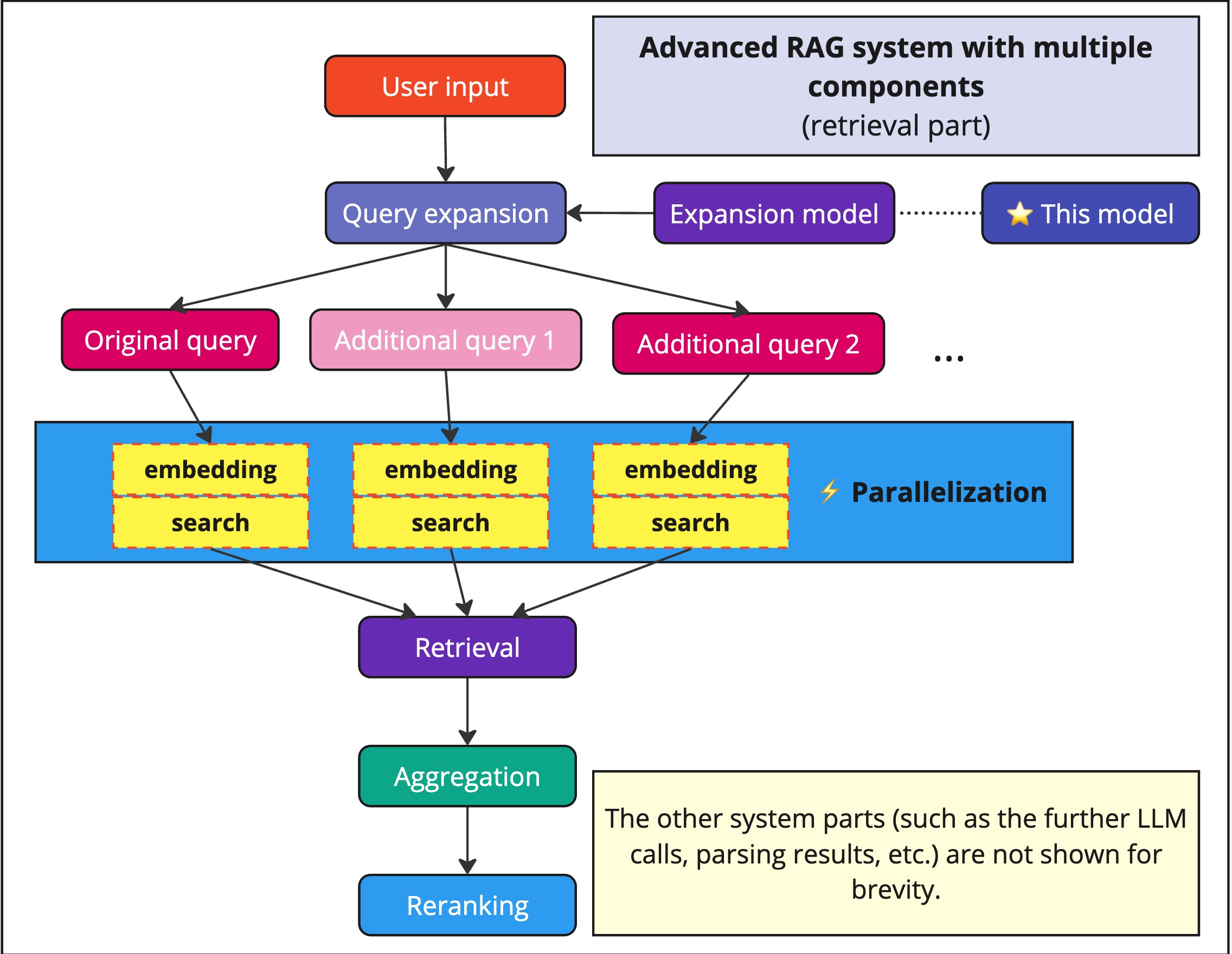
Query expansion
Collection
A collection of models along with the training dataset, designed to improve search queries and retrieval in RAG systems.
•
7 items
•
Updated
Fine-tuned Qwen2.5-7B model for generating search query expansions.
Part of a collection of query expansion models available in different architectures and sizes.
Task: Search query expansion
Base model: Qwen2.5-7B
Training data: Query Expansion Dataset
Each GGUF model is available in several quantization formats: F16, Q8_0, Q5_K_M, Q4_K_M, Q3_K_M
This model is designed for enhancing search and retrieval systems by generating semantically relevant query expansions.
It could be useful for:
from transformers import AutoModelForCausalLM, AutoTokenizer
from unsloth import FastLanguageModel
# Model configuration
MODEL_NAME = "s-emanuilov/query-expansion-Qwen2.5-7B"
MAX_SEQ_LENGTH = 2048
DTYPE = "float16"
LOAD_IN_4BIT = True
# Load model and tokenizer
model, tokenizer = FastLanguageModel.from_pretrained(
model_name=MODEL_NAME,
max_seq_length=MAX_SEQ_LENGTH,
dtype=DTYPE,
load_in_4bit=LOAD_IN_4BIT,
)
# Enable faster inference
FastLanguageModel.for_inference(model)
# Define prompt template
PROMPT_TEMPLATE = """Below is a search query. Generate relevant expansions and related terms that would help broaden and enhance the search results.
### Query:
{query}
### Expansions:
{output}"""
# Prepare input
query = "apple stock"
inputs = tokenizer(
[PROMPT_TEMPLATE.format(query=query, output="")],
return_tensors="pt"
).to("cuda")
# Generate with streaming output
from transformers import TextStreamer
streamer = TextStreamer(tokenizer)
output = model.generate(
**inputs,
streamer=streamer,
max_new_tokens=128,
)
Input: "apple stock" Expansions:
If you find my work helpful, feel free to give me a citation.