

license: mit
datasets:
- HuggingFaceFW/fineweb-edu
- bigcode/the-stack-v2
- mlfoundations/dclm-baseline-1.0
- math-ai/AutoMathText
- gair-prox/open-web-math-pro
- RUC-AIBOX/long_form_thought_data_5k
- internlm/Lean-Workbook
- internlm/Lean-Github
- deepseek-ai/DeepSeek-Prover-V1
- ScalableMath/Lean-STaR-base
- ScalableMath/Lean-STaR-plus
- ScalableMath/Lean-CoT-base
- ScalableMath/Lean-CoT-plus
- opencsg/chinese-fineweb-edu
- liwu/MNBVC
- vikp/textbook_quality_programming
- HuggingFaceTB/smollm-corpus
- OpenCoder-LLM/opc-annealing-corpus
- OpenCoder-LLM/opc-sft-stage1
- OpenCoder-LLM/opc-sft-stage2
- XinyaoHu/AMPS_mathematica
- deepmind/math_dataset
- mrfakename/basic-math-10m
- microsoft/orca-math-word-problems-200k
- AI-MO/NuminaMath-CoT
- HuggingFaceTB/cosmopedia
- MU-NLPC/Calc-ape210k
- manu/project_gutenberg
- storytracer/LoC-PD-Books
- allenai/dolma
language:
- en
- zh
中文 | English
YuLan-Mini: An Open Data-efficient Language Model

YuLan-Mini is a lightweight language model with 2.4 billion parameters. It achieves performance comparable to industry-leading models trained on significantly more data, despite being pre-trained on only 1.08T tokens. The model excels particularly in the domains of mathematics and code. To facilitate reproducibility, we will open-source the relevant pre-training resources.
Model Downloads 🔗
Model weights will be uploaded after final preparations.
| Model | Context Length | SFT |
|---|---|---|
| YuLan-Mini (Recommended) | 28K | ❎ |
| YuLan-Mini-2.4B-4K | 4K | ❎ |
| YuLan-Mini-Instruct | Comming soon | ✅ |
Features 🌟
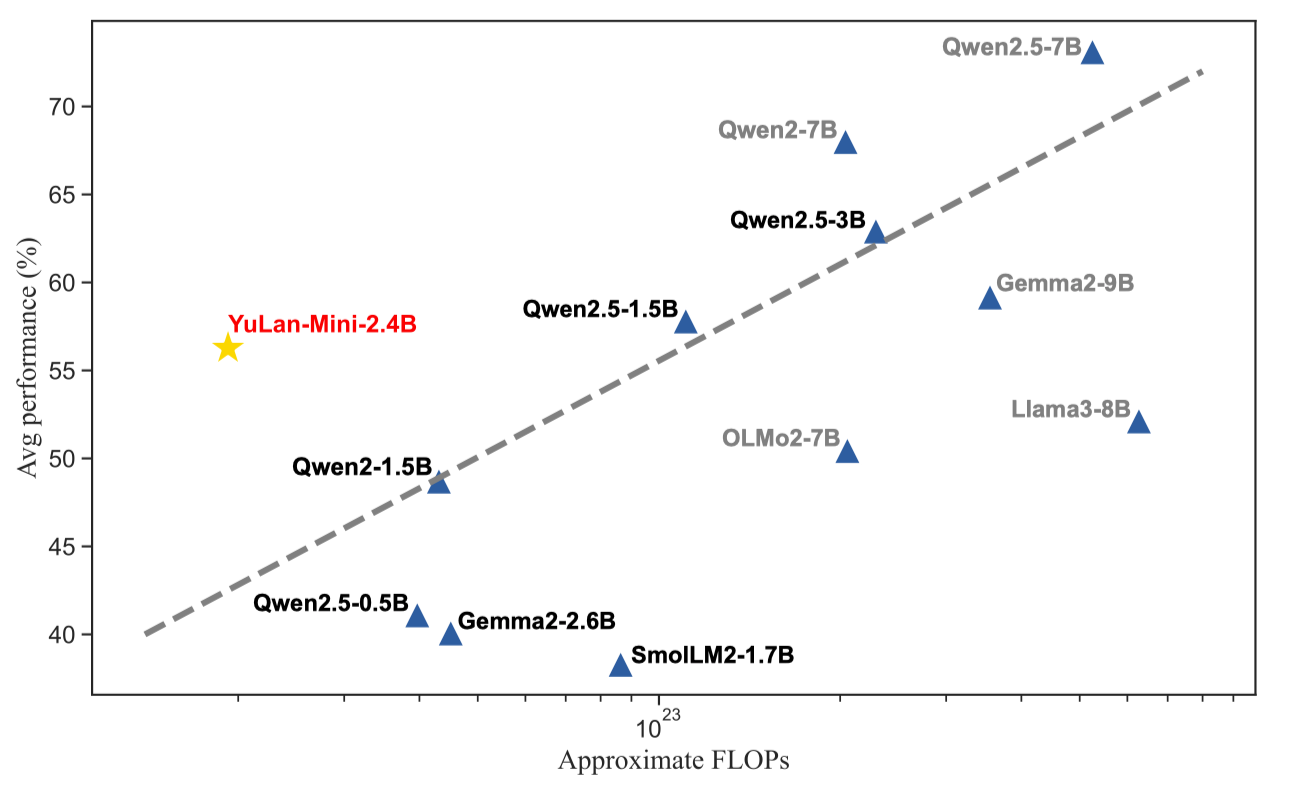
Our pre-training methodology improves training efficiency through three key innovations:
- an elaborately designed data pipeline that combines data cleaning with data schedule strategies;
- a systematic optimization method that can effectively mitigate training instability;
- an effective annealing approach that integrate targeted data selection and long context training.
Behchmarks 🌟
| Models | Model Size | # Train Tokens | Context Length | MATH 500 | GSM 8K | Human Eval | MBPP | RACE Middle | RACE High | RULER |
|---|---|---|---|---|---|---|---|---|---|---|
| MiniCPM | 2.6B | 1.06T | 4K | 15.00 | 53.83 | 50.00* | 47.31 | 56.61 | 44.27 | N/A |
| Qwen-2 | 1.5B | 7T | 128K | 22.60 | 46.90* | 34.80* | 46.90* | 55.77 | 43.69 | 60.16 |
| Qwen2.5 | 0.5B | 18T | 128K | 23.60 | 41.60* | 30.50* | 39.30* | 52.36 | 40.31 | 49.23 |
| Qwen2.5 | 1.5B | 18T | 128K | 45.40 | 68.50* | 37.20* | 60.20* | 58.77 | 44.33 | 68.26 |
| Gemma2 | 2.6B | 2T | 8K | 18.30* | 30.30* | 19.50* | 42.10* | - | - | N/A |
| StableLM2 | 1.7B | 2T | 4K | - | 20.62 | 8.50* | 17.50 | 56.33 | 45.06 | N/A |
| SmolLM2 | 1.7B | 11T | 8K | 11.80 | - | 23.35 | 45.00 | 55.77 | 43.06 | N/A |
| Llama3.2 | 3.2B | 9T | 128K | 7.40 | - | 29.30 | 49.70 | 55.29 | 43.34 | 77.06 |
| YuLan-Mini | 2.4B | 1.04T | 4K | 32.60 | 66.65 | 61.60 | 66.70 | 55.71 | 43.58 | N/A |
| YuLan-Mini | 2.4B | 1.08T | 28K | 37.80 | 68.46 | 64.00 | 65.90 | 57.18 | 44.57 | 51.48 |
| Models | LAMBADA | MMLU | CMMLU | CEval | HellaSwag | WinoGrande | StoryCloze | ARC-e | ARC-c |
|---|---|---|---|---|---|---|---|---|---|
| MiniCPM-2.6B | 61.91 | 53.37 | 48.97 | 48.24 | 67.92 | 65.74 | 78.51 | 55.51 | 43.86 |
| Qwen2-1.5B | 64.68 | 55.90 | 70.76 | 71.94 | 66.11 | 66.14 | 77.60 | 62.21 | 42.92 |
| Qwen2.5-0.5B | 52.00 | 47.50 | 52.17 | 54.27 | 50.54 | 55.88 | 71.67 | 56.10 | 39.51 |
| Qwen2.5-1.5B | 62.12 | 60.71 | 67.82 | 69.05 | 67.18 | 64.48 | 76.80 | 71.51 | 53.41 |
| Gemma2-2.6B | - | 52.20* | - | 28.00* | 74.60* | 71.50* | - | - | 55.70* |
| StableLM2-1.7B | 66.15 | 40.37 | 29.29 | 26.99 | 69.79 | 64.64 | 78.56 | 54.00 | 40.78 |
| SmolLM2-1.7B | 67.42 | 51.91 | 33.46 | 35.10 | 72.96 | 67.40 | 79.32 | 44.82 | 35.49 |
| Llama3.2-3B | 69.08 | 63.40 | 44.44 | 44.49 | 75.62 | 67.48 | 76.80 | 70.12 | 48.81 |
| YuLan-Mini | 64.72 | 51.79 | 48.35 | 51.47 | 68.65 | 67.09 | 76.37 | 69.87 | 50.51 |
| YuLan-Mini | 65.67 | 49.10 | 45.45 | 48.23 | 67.22 | 67.24 | 75.89 | 67.47 | 49.32 |
Pre-Training Resources 🔧
To enhance research transparency and reproducibility, we are open-sourcing relevant pre-training resources:
1. Pre-training and Evaluation Code
The pre-training and evaluation code will be released in a future update.
2. Intermediate Stage Checkpoints
The intermediate stage checkpoints are released in YuLan-Mini.3. Optimizer States Before Annealing
Optimizer states before annealing will be released in a future update.
4. The Used Open-Source Datasets

6. Synthetic Data
Data cleaning and synthesis pipeline:

The synthetic data we are using is released in YuLan-Mini-Datasets
7. Intermediate Optimizer States
Intermediate optimizer states will be released in a future update.
Quick Start 💻
Below is a simple example for inference using Huggingface:
Huggingface Inference Example
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
# Load model and tokenizer
tokenizer = AutoTokenizer.from_pretrained("yulan-team/YuLan-Mini")
model = AutoModelForCausalLM.from_pretrained("yulan-team/YuLan-Mini", torch_dtype=torch.bfloat16)
# Input text
input_text = "Renmin University of China is"
inputs = tokenizer(input_text, return_tensors="pt")
# Completion
output = model.generate(inputs["input_ids"], max_new_tokens=100)
print(tokenizer.decode(output[0], skip_special_tokens=True))
vLLM Serve Example
vllm serve yulan-team/YuLan-Mini --dtype bfloat16
License
- The code in this repository is released under the MIT License.
- Policies regarding the use of model weights, intermediate optimizer states, and training data will be announced in future updates.
- Limitations: Despite our efforts to mitigate safety concerns and encourage the generation of ethical and lawful text, the probabilistic nature of language models may still lead to unexpected outputs. For instance, responses might contain bias, discrimination, or other harmful content. Please refrain from disseminating such content. We are not liable for any consequences arising from the spread of harmful information.
Citation
If you find YuLan-Mini helpful for your research or development, please cite our technical report:
@misc{hu2024yulanmini,
title={YuLan-Mini: An Open Data-efficient Language Model},
author={Yiwen Hu and Huatong Song and Jia Deng and Jiapeng Wang and Jie Chen and Kun Zhou and Yutao Zhu and Jinhao Jiang and Zican Dong and Wayne Xin Zhao and Ji-Rong Wen},
year={2024},
eprint={2412.17743},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2412.17743},
}